mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
commit
97d92d8e17
@ -0,0 +1,143 @@
|
||||
Cloud Commander:一个有控制台和编辑器的 Web 文件管理器
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Cloud Commander** 是一个基于 web 的文件管理程序,它允许你通过任何计算机、移动端或平板电脑的浏览器查看、访问或管理系统文件或文件夹。它有两个简单而又经典的面板,并且会像你设备的显示尺寸一样自动转换大小。它也拥有两款内置的叫做 **Dword** 和 **Edward** 的文本编辑器,它们支持语法高亮,并带有一个支持系统命令行的控制台。因此,您可以随时随地编辑文件。Cloud Commander 服务器是一款在 Linux、Windows、Mac OS X 运行的跨平台应用,而且该应用客户端可以在任何一款浏览器上运行。它是用 **JavaScript/Node.Js** 写的,并使用 **MIT** 许可证。
|
||||
|
||||
在这个简易教程中,让我们看一看如何在 Ubuntu 18.04 LTS 服务器上安装 Cloud Commander。
|
||||
|
||||
### 前提条件
|
||||
|
||||
像我之前提到的,是用 Node.js 写的。所以为了安装 Cloud Commander,我们需要首先安装 Node.js。要执行安装,参考下面的指南。
|
||||
|
||||
- [如何在 Linux 上安装 Node.js](https://www.ostechnix.com/install-node-js-linux/)
|
||||
|
||||
### 安装 Cloud Commander
|
||||
|
||||
在安装 Node.js 之后,运行下列命令安装 Cloud Commander:
|
||||
|
||||
```
|
||||
$ npm i cloudcmd -g
|
||||
```
|
||||
|
||||
祝贺!Cloud Commander 已经安装好了。让我们往下继续看看 Cloud Commander 的基本使用。
|
||||
|
||||
### 开始使用 Cloud Commander
|
||||
|
||||
运行以下命令启动 Cloud Commander:
|
||||
|
||||
```
|
||||
$ cloudcmd
|
||||
```
|
||||
|
||||
**输出示例:**
|
||||
|
||||
```
|
||||
url: http://localhost:8000
|
||||
```
|
||||
|
||||
现在,打开你的浏览器并转到链接:`http://localhost:8000` 或 `http://IP-address:8000`。
|
||||
|
||||
从现在开始,您可以直接在本地系统或远程系统或移动设备,平板电脑等Web浏览器中创建,删除,查看,管理文件或文件夹。
|
||||
|
||||
![][2]
|
||||
|
||||
如你所见上面的截图,Clouder Commander 有两个面板,十个热键 (`F1` 到 `F10`),还有控制台。
|
||||
|
||||
每个热键执行的都是一个任务。
|
||||
|
||||
* `F1` – 帮助
|
||||
* `F2` – 重命名文件/文件夹
|
||||
* `F3` – 查看文件/文件夹
|
||||
* `F4` – 编辑文件
|
||||
* `F5` – 复制文件/文件夹
|
||||
* `F6` – 移动文件/文件夹
|
||||
* `F7` – 创建新目录
|
||||
* `F8` – 删除文件/文件夹
|
||||
* `F9` – 打开菜单
|
||||
* `F10` – 打开设置
|
||||
|
||||
#### Cloud Commmander 控制台
|
||||
|
||||
点击控制台图标。这即将打开系统默认的命令行界面。
|
||||
|
||||
![][3]
|
||||
|
||||
在此控制台中,您可以执行各种管理任务,例如安装软件包、删除软件包、更新系统等。您甚至可以关闭或重新引导系统。 因此,Cloud Commander 不仅仅是一个文件管理器,还具有远程管理工具的功能。
|
||||
|
||||
#### 创建文件/文件夹
|
||||
|
||||
要创建新的文件或文件夹就右键单击任意空位置并找到 “New - >File or Directory”。
|
||||
|
||||
![][4]
|
||||
|
||||
#### 查看文件
|
||||
|
||||
你可以查看图片,查看音视频文件。
|
||||
|
||||
![][5]
|
||||
|
||||
#### 上传文件
|
||||
|
||||
另一个很酷的特性是我们可以从任何系统或设备简单地上传一个文件到 Cloud Commander 系统。
|
||||
|
||||
要上传文件,右键单击 Cloud Commander 面板的任意空白处,并且单击“Upload”选项。
|
||||
|
||||
![][6]
|
||||
|
||||
选择你想要上传的文件。
|
||||
|
||||
另外,你也可以上传来自像 Google 云盘、Dropbox、Amazon 云盘、Facebook、Twitter、Gmail、GitHub、Picasa、Instagram 还有很多的云服务上的文件。
|
||||
|
||||
要从云端上传文件, 右键单击面板的任意空白处,并且右键单击面板任意空白处并选择“Upload from Cloud”。
|
||||
|
||||
![][7]
|
||||
|
||||
选择任意一个你选择的网络服务,例如谷歌云盘。点击“Connect to Google drive”按钮。
|
||||
|
||||
![][8]
|
||||
|
||||
下一步,用 Cloud Commander 验证你的谷歌云端硬盘,从谷歌云端硬盘选择文件并点击“Upload”。
|
||||
|
||||
![][9]
|
||||
|
||||
#### 更新 Cloud Commander
|
||||
|
||||
要更新到最新的可用版本,执行下面的命令:
|
||||
|
||||
```
|
||||
$ npm update cloudcmd -g
|
||||
```
|
||||
|
||||
#### 总结
|
||||
|
||||
据我测试,它运行很好。在我的 Ubuntu 服务器测试期间,我没有遇到任何问题。此外,Cloud Commander 不仅是基于 Web 的文件管理器,还可以充当执行大多数 Linux 管理任务的远程管理工具。 您可以创建文件/文件夹、重命名、删除、编辑和查看它们。此外,您可以像在终端中在本地系统中那样安装、更新、升级和删除任何软件包。当然,您甚至可以从 Cloud Commander 控制台本身关闭或重启系统。 还有什么需要的吗? 尝试一下,你会发现它很有用。
|
||||
|
||||
目前为止就这样吧。 我将很快在这里发表另一篇有趣的文章。 在此之前,请继续关注我们。
|
||||
|
||||
祝贺!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/cloud-commander-a-web-file-manager-with-console-and-editor/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuzheng1998](https://github.com/fuzheng1998)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-Google-Chrome_006-4.jpg
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-Google-Chrome_007-2.jpg
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-commander-file-folder-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_008-1.jpg
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2016/05/cloud-commander-upload-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2016/05/upload-from-cloud-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_009-2.jpg
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_010-1.jpg
|
||||
@ -1,4 +1,4 @@
|
||||
Trash-Cli : Linux 上的命令行回收站工具
|
||||
Trash-Cli:Linux 上的命令行回收站工具
|
||||
======
|
||||
|
||||
相信每个人都对<ruby>回收站<rt>trashcan</rt></ruby>很熟悉,因为无论是对 Linux 用户,还是 Windows 用户,或者 Mac 用户来说,它都很常见。当你删除一个文件或目录的时候,该文件或目录会被移动到回收站中。
|
||||
@ -33,31 +33,27 @@ $ sudo apt install trash-cli
|
||||
|
||||
```
|
||||
$ sudo yum install trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 Fedora 用户,使用 [dnf][6] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo dnf install trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 Arch Linux 用户,使用 [pacman][7] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo pacman -S trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 openSUSE 用户,使用 [zypper][8] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo zypper in trash-cli
|
||||
|
||||
```
|
||||
|
||||
如果你的发行版中没有提供 Trash-Cli 的安装包,那么你也可以使用 pip 来安装。为了能够安装 python 包,你的系统中应该会有 pip 包管理器。
|
||||
如果你的发行版中没有提供 Trash-Cli 的安装包,那么你也可以使用 `pip` 来安装。为了能够安装 python 包,你的系统中应该会有 `pip` 包管理器。
|
||||
|
||||
```
|
||||
$ sudo pip install trash-cli
|
||||
@ -66,7 +62,6 @@ Collecting trash-cli
|
||||
Installing collected packages: trash-cli
|
||||
Running setup.py bdist_wheel for trash-cli ... done
|
||||
Successfully installed trash-cli-0.17.1.14
|
||||
|
||||
```
|
||||
|
||||
### 如何使用 Trash-Cli
|
||||
@ -81,7 +76,7 @@ Trash-Cli 的使用不难,因为它提供了一个很简单的语法。Trash-C
|
||||
|
||||
下面,让我们通过一些例子来试验一下。
|
||||
|
||||
1)删除文件和目录:在这个例子中,我们通过运行下面这个命令,将 2g.txt 这一文件和 magi 这一文件夹移动到回收站中。
|
||||
1) 删除文件和目录:在这个例子中,我们通过运行下面这个命令,将 `2g.txt` 这一文件和 `magi` 这一文件夹移动到回收站中。
|
||||
|
||||
```
|
||||
$ trash-put 2g.txt magi
|
||||
@ -89,7 +84,7 @@ $ trash-put 2g.txt magi
|
||||
|
||||
和你在文件管理器中看到的一样。
|
||||
|
||||
2)列出被删除了的文件和目录:为了查看被删除了的文件和目录,你需要运行下面这个命令。之后,你可以在输出中看到被删除文件和目录的详细信息,比如名字、删除日期和时间,以及文件路径。
|
||||
2) 列出被删除了的文件和目录:为了查看被删除了的文件和目录,你需要运行下面这个命令。之后,你可以在输出中看到被删除文件和目录的详细信息,比如名字、删除日期和时间,以及文件路径。
|
||||
|
||||
```
|
||||
$ trash-list
|
||||
@ -97,7 +92,7 @@ $ trash-list
|
||||
2017-10-01 01:40:50 /home/magi/magi/magi
|
||||
```
|
||||
|
||||
3)从回收站中恢复文件或目录:任何时候,你都可以通过运行下面这个命令来恢复文件和目录。它将会询问你来选择你想要恢复的文件或目录。在这个例子中,我打算恢复 2g.txt 文件,所以我的选择是 0 。
|
||||
3) 从回收站中恢复文件或目录:任何时候,你都可以通过运行下面这个命令来恢复文件和目录。它将会询问你来选择你想要恢复的文件或目录。在这个例子中,我打算恢复 `2g.txt` 文件,所以我的选择是 `0` 。
|
||||
|
||||
```
|
||||
$ trash-restore
|
||||
@ -106,7 +101,7 @@ $ trash-restore
|
||||
What file to restore [0..1]: 0
|
||||
```
|
||||
|
||||
4)从回收站中删除文件:如果你想删除回收站中的特定文件,那么可以运行下面这个命令。在这个例子中,我将删除 magi 目录。
|
||||
4) 从回收站中删除文件:如果你想删除回收站中的特定文件,那么可以运行下面这个命令。在这个例子中,我将删除 `magi` 目录。
|
||||
|
||||
```
|
||||
$ trash-rm magi
|
||||
@ -118,11 +113,10 @@ $ trash-rm magi
|
||||
$ trash-empty
|
||||
```
|
||||
|
||||
6)删除超过 X 天的垃圾文件:或者,你可以通过运行下面这个命令来删除回收站中超过 X 天的文件。在这个例子中,我将删除回收站中超过 10 天的项目。
|
||||
6)删除超过 X 天的垃圾文件:或者,你可以通过运行下面这个命令来删除回收站中超过 X 天的文件。在这个例子中,我将删除回收站中超过 `10` 天的项目。
|
||||
|
||||
```
|
||||
$ trash-empty 10
|
||||
|
||||
```
|
||||
|
||||
Trash-Cli 可以工作的很好,但是如果你想尝试它的一些替代品,那么你也可以试一试 [gvfs-trash][9] 和 [autotrash][10] 。
|
||||
@ -133,7 +127,7 @@ via: https://www.2daygeek.com/trash-cli-command-line-trashcan-linux-system/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
132
published/20171124 How do groups work on Linux.md
Normal file
132
published/20171124 How do groups work on Linux.md
Normal file
@ -0,0 +1,132 @@
|
||||
“用户组”在 Linux 上到底是怎么工作的?
|
||||
========
|
||||
|
||||
嗨!就在上周,我还自认为对 Linux 上的用户和组的工作机制了如指掌。我认为它们的关系是这样的:
|
||||
|
||||
1. 每个进程都属于一个用户(比如用户 `julia`)
|
||||
2. 当这个进程试图读取一个被某个组所拥有的文件时, Linux 会
|
||||
a. 先检查用户`julia` 是否有权限访问文件。(LCTT 译注:此处应该是指检查文件的所有者是否就是 `julia`)
|
||||
b. 检查 `julia` 属于哪些组,并进一步检查在这些组里是否有某个组拥有这个文件或者有权限访问这个文件。
|
||||
3. 如果上述 a、b 任一为真(或者“其它”位设为有权限访问),那么这个进程就有权限访问这个文件。
|
||||
|
||||
比如说,如果一个进程被用户 `julia` 拥有并且 `julia` 在`awesome` 组,那么这个进程就能访问下面这个文件。
|
||||
|
||||
```
|
||||
r--r--r-- 1 root awesome 6872 Sep 24 11:09 file.txt
|
||||
```
|
||||
|
||||
然而上述的机制我并没有考虑得非常清楚,如果你硬要我阐述清楚,我会说进程可能会在**运行时**去检查 `/etc/group` 文件里是否有某些组拥有当前的用户。
|
||||
|
||||
### 然而这并不是 Linux 里“组”的工作机制
|
||||
|
||||
我在上个星期的工作中发现了一件有趣的事,事实证明我前面的理解错了,我对组的工作机制的描述并不准确。特别是 Linux **并不会**在进程每次试图访问一个文件时就去检查这个进程的用户属于哪些组。
|
||||
|
||||
我在读了《[Linux 编程接口][1]》这本书的第九章(“进程资格”)后才恍然大悟(这本书真是太棒了),这才是组真正的工作方式!我意识到之前我并没有真正理解用户和组是怎么工作的,我信心满满的尝试了下面的内容并且验证到底发生了什么,事实证明现在我的理解才是对的。
|
||||
|
||||
### 用户和组权限检查是怎么完成的
|
||||
|
||||
现在这些关键的知识在我看来非常简单! 这本书的第九章上来就告诉我如下事实:用户和组 ID 是**进程的属性**,它们是:
|
||||
|
||||
* 真实用户 ID 和组 ID;
|
||||
* 有效用户 ID 和组 ID;
|
||||
* 保存的 set-user-ID 和保存的 set-group-ID;
|
||||
* 文件系统用户 ID 和组 ID(特定于 Linux);
|
||||
* 补充的组 ID;
|
||||
|
||||
这说明 Linux **实际上**检查一个进程能否访问一个文件所做的组检查是这样的:
|
||||
|
||||
* 检查一个进程的组 ID 和补充组 ID(这些 ID 就在进程的属性里,**并不是**实时在 `/etc/group` 里查找这些 ID)
|
||||
* 检查要访问的文件的访问属性里的组设置
|
||||
* 确定进程对文件是否有权限访问(LCTT 译注:即文件的组是否是以上的组之一)
|
||||
|
||||
通常当访问控制的时候使用的是**有效**用户/组 ID,而不是**真实**用户/组 ID。技术上来说当访问一个文件时使用的是**文件系统**的 ID,它们通常和有效用户/组 ID 一样。(LCTT 译注:这句话针对 Linux 而言。)
|
||||
|
||||
### 将一个用户加入一个组并不会将一个已存在的进程(的用户)加入那个组
|
||||
|
||||
下面是一个有趣的例子:如果我创建了一个新的组:`panda` 组并且将我自己(`bork`)加入到这个组,然后运行 `groups` 来检查我是否在这个组里:结果是我(`bork`)竟然不在这个组?!
|
||||
|
||||
```
|
||||
bork@kiwi~> sudo addgroup panda
|
||||
Adding group `panda' (GID 1001) ...
|
||||
Done.
|
||||
bork@kiwi~> sudo adduser bork panda
|
||||
Adding user `bork' to group `panda' ...
|
||||
Adding user bork to group panda
|
||||
Done.
|
||||
bork@kiwi~> groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd
|
||||
|
||||
```
|
||||
|
||||
`panda` 并不在上面的组里!为了再次确定我们的发现,让我们建一个文件,这个文件被 `panda` 组拥有,看看我能否访问它。
|
||||
|
||||
```
|
||||
$ touch panda-file.txt
|
||||
$ sudo chown root:panda panda-file.txt
|
||||
$ sudo chmod 660 panda-file.txt
|
||||
$ cat panda-file.txt
|
||||
cat: panda-file.txt: Permission denied
|
||||
```
|
||||
|
||||
好吧,确定了,我(`bork`)无法访问 `panda-file.txt`。这一点都不让人吃惊,我的命令解释器并没有将 `panda` 组作为补充组 ID,运行 `adduser bork panda` 并不会改变这一点。
|
||||
|
||||
### 那进程一开始是怎么得到用户的组的呢?
|
||||
|
||||
这真是个非常令人困惑的问题,对吗?如果进程会将组的信息预置到进程的属性里面,进程在初始化的时候怎么取到组的呢?很明显你无法给你自己指定更多的组(否则就会和 Linux 访问控制的初衷相违背了……)
|
||||
|
||||
有一点还是很清楚的:一个新的进程是怎么从我的命令行解释器(`/bash/fish`)里被**执行**而得到它的组的。(新的)进程将拥有我的用户 ID(`bork`),并且进程属性里还有很多组 ID。从我的命令解释器里执行的所有进程是从这个命令解释器里 `fork()` 而来的,所以这个新进程得到了和命令解释器同样的组。
|
||||
|
||||
因此一定存在一个“第一个”进程来把你的组设置到进程属性里,而所有由此进程而衍生的进程将都设置这些组。而那个“第一个”进程就是你的<ruby>登录程序<rt>login shell</rt></ruby>,在我的笔记本电脑上,它是由 `login` 程序(`/bin/login`)实例化而来。登录程序以 root 身份运行,然后调用了一个 C 的库函数 —— `initgroups` 来设置你的进程的组(具体来说是通过读取 `/etc/group` 文件),因为登录程序是以 root 运行的,所以它能设置你的进程的组。
|
||||
|
||||
### 让我们再登录一次
|
||||
|
||||
好了!假如说我们正处于一个登录程序中,而我又想刷新我的进程的组设置,从我们前面所学到的进程是怎么初始化组 ID 的,我应该可以通过再次运行登录程序来刷新我的进程组并启动一个新的登录命令!
|
||||
|
||||
让我们试试下边的方法:
|
||||
|
||||
```
|
||||
$ sudo login bork
|
||||
$ groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd panda
|
||||
$ cat panda-file.txt # it works! I can access the file owned by `panda` now!
|
||||
```
|
||||
|
||||
当然,成功了!现在由登录程序衍生的程序的用户是组 `panda` 的一部分了!太棒了!这并不会影响我其他的已经在运行的登录程序(及其子进程),如果我真的希望“所有的”进程都能对 `panda` 组有访问权限。我必须完全的重启我的登录会话,这意味着我必须退出我的窗口管理器然后再重新登录。(LCTT 译注:即更新进程树的树根进程,这里是窗口管理器进程。)
|
||||
|
||||
### newgrp 命令
|
||||
|
||||
在 Twitter 上有人告诉我如果只是想启动一个刷新了组信息的命令解释器的话,你可以使用 `newgrp`(LCTT 译注:不启动新的命令解释器),如下:
|
||||
|
||||
```
|
||||
sudo addgroup panda
|
||||
sudo adduser bork panda
|
||||
newgrp panda # starts a new shell, and you don't have to be root to run it!
|
||||
```
|
||||
|
||||
你也可以用 `sg panda bash` 来完成同样的效果,这个命令能启动一个`bash` 登录程序,而这个程序就有 `panda` 组。
|
||||
|
||||
### seduid 将设置有效用户 ID
|
||||
|
||||
其实我一直对一个进程如何以 `setuid root` 的权限来运行意味着什么有点似是而非。现在我知道了,事实上所发生的是:`setuid` 设置了
|
||||
“有效用户 ID”! 如果我(`julia`)运行了一个 `setuid root` 的进程( 比如 `passwd`),那么进程的**真实**用户 ID 将为 `julia`,而**有效**用户 ID 将被设置为 `root`。
|
||||
|
||||
`passwd` 需要以 root 权限来运行,但是它能看到进程的真实用户 ID 是 `julia` ,是 `julia` 启动了这个进程,`passwd` 会阻止这个进程修改除了 `julia` 之外的用户密码。
|
||||
|
||||
### 就是这些了!
|
||||
|
||||
在《[Linux 编程接口][1]》这本书里有很多 Linux 上一些功能的罕见使用方法以及 Linux 上所有的事物到底是怎么运行的详细解释,这里我就不一一展开了。那本书棒极了,我上面所说的都在该书的第九章,这章在 1300 页的书里只占了 17 页。
|
||||
|
||||
我最爱这本书的一点是我只用读 17 页关于用户和组是怎么工作的内容,而这区区 17 页就能做到内容完备、详实有用。我不用读完所有的 1300 页书就能得到有用的东西,太棒了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/20/groups/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[DavidChen](https://github.com/DavidChenLiang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://man7.org/tlpi/
|
||||
@ -1,29 +1,28 @@
|
||||
|
||||
我从编程面试中学到的
|
||||
============================================================
|
||||
|
||||
======
|
||||
|
||||

|
||||
聊聊白板编程面试
|
||||
|
||||
在2017年,我参加了[Grace Hopper Celebration][1]‘计算机行业中的女性’这一活动。这个活动是这类科技活动中最大的一个。共有17,000名女性IT工作者参加。
|
||||
*聊聊白板编程面试*
|
||||
|
||||
这个会议有个大型的配套招聘会,会上有招聘公司来面试会议参加者。有些人甚至现场拿到offer。我在现场晃荡了一下,注意到一些应聘者看上去非常紧张忧虑。我还隐隐听到应聘者之间的谈话,其中一些人谈到在面试中做的并不好。
|
||||
在 2017 年,我参加了 ‘计算机行业中的女性’ 的[Grace Hopper 庆祝活动][1]。这个活动是这类科技活动中最大的一个。共有 17,000 名女性IT工作者参加。
|
||||
|
||||
我走近我听到谈话的那群人并和她们聊了起来并给了一些面试上的小建议。我想我的建议还是比较偏基本的,如“(在面试时)一开始给出个能工作的解决方案也还说的过去”之类的,但是当她们听到我的一些其他的建议时还是颇为吃惊。
|
||||
这个会议有个大型的配套招聘会,会上有招聘公司来面试会议参加者。有些人甚至现场拿到 offer。我在现场晃荡了一下,注意到一些应聘者看上去非常紧张忧虑。我还隐隐听到应聘者之间的谈话,其中一些人谈到在面试中做的并不好。
|
||||
|
||||
为了能更多的帮到像她们一样的白面面试者,我收集了一些过去对我有用的小点子,这些小点子我已经发表在了[prodcast episode][2]上。它们也是这篇文章的主题。
|
||||
我走近我听到谈话的那群人并和她们聊了起来并给了一些面试上的小建议。我想我的建议还是比较偏基本的,如“(在面试时)一开始给出个能工作的解决方案也还说的过去”之类的,但是当她们听到我的一些其他的建议时还是颇为吃惊。
|
||||
|
||||
为了能更多的帮到像她们一样的小白面试者,我收集了一些过去对我有用的小点子,这些小点子我已经发表在了 [prodcast episode][2] 上。它们也是这篇文章的主题。
|
||||
|
||||
为了实习生职位和全职工作,我做过很多次的面试。当我还在大学主修计算机科学时,学校每个秋季学期都有招聘会,第一轮招聘会在校园里举行。(我在第一和最后一轮都搞砸过。)不过,每次面试后,我都会反思哪些方面我能做的更好,我还会和朋友们做模拟面试,这样我就能从他们那儿得到更多的面试反馈。
|
||||
|
||||
不管我们怎么样找工作: 工作中介,网络,或者学校招聘,他们的招聘流程中都会涉及到技术面试:
|
||||
不管我们怎么样找工作: 工作中介、网络,或者学校招聘,他们的招聘流程中都会涉及到技术面试:
|
||||
|
||||
近年来,我注意到了一些新的不同的面试形式出现了:
|
||||
|
||||
* 与招聘方的一位工程师结对编程
|
||||
* 网络在线测试及在线编码
|
||||
* 白板编程(LCTT译者注: 这种形式应该不新了)
|
||||
|
||||
* 白板编程(LCTT 译注: 这种形式应该不新了)
|
||||
|
||||
我将重点谈谈白板面试,这种形式我经历的最多。我有过很多次面试,有些挺不错的,有些被我搞砸了。
|
||||
|
||||
@ -31,7 +30,7 @@
|
||||
|
||||
首先,我想回顾一下我做的不好的地方。知错能改,善莫大焉。
|
||||
|
||||
当面试者提出一个要我解决的问题时, 我立即马上立刻开始在白板上写代码,_什么都不问。_
|
||||
当面试者提出一个要我解决的问题时, 我立即马上立刻开始在白板上写代码,_什么都不问。_
|
||||
|
||||
这里我犯了两个错误:
|
||||
|
||||
@ -41,7 +40,7 @@
|
||||
|
||||
#### 只会默默思考,不去记录想法或和面试官沟通
|
||||
|
||||
在面试中,很多时候我也会傻傻站在那思考,什么都不写。我和一个朋友模拟面试的时候,他告诉我因为他曾经和我一起工作过所以他知道我在思考,但是如果他是个陌生的面试官的话,他会觉得要么我正站在那冥思苦想,毫无头绪。不要急匆匆的直奔解题而去是很重要的。花点时间多想想各种解题的可能性。有时候面试官会乐意和你一起探索解题的步骤。不管怎样,这就是在一家公司开工作会议的的普遍方式,大家各抒己见,一起讨论如何解决问题。
|
||||
在面试中,很多时候我也会傻傻站在那思考,什么都不写。我和一个朋友模拟面试的时候,他告诉我因为他曾经和我一起工作过所以他知道我在思考,但是如果他是个陌生的面试官的话,他会觉得我正站在那冥思苦想,毫无头绪。不要急匆匆的直奔解题而去是很重要的。花点时间多想想各种解题的可能性。有时候面试官会乐意和你一起探索解题的步骤。不管怎样,这就是在一家公司开工作会议的的普遍方式,大家各抒己见,一起讨论如何解决问题。
|
||||
|
||||
### 想到一个解题方法
|
||||
|
||||
@ -50,30 +49,27 @@
|
||||
这是对我管用的步骤:
|
||||
|
||||
1. 头脑风暴
|
||||
|
||||
2. 写代码
|
||||
|
||||
3. 处理错误路径
|
||||
|
||||
4. 测试
|
||||
|
||||
#### 1\. 头脑风暴
|
||||
#### 1、 头脑风暴
|
||||
|
||||
对我来说,我会首先通过一些例子来视觉化我要解决的问题。比如说如果这个问题和数据结构中的树有关,我就会从树底层的空节点开始思考,如何处理一个节点的情况呢?两个节点呢?三个节点呢?这能帮助你从具体例子里抽象出你的解决方案。
|
||||
|
||||
在白板上先写下你的算法要做的事情列表。这样做,你往往能在开始写代码前就发现bug和缺陷(不过你可得掌握好时间)。我犯过的一个错误是我花了过多的时间在澄清问题和头脑风暴上,最后几乎没有留下时间给我写代码。你的面试官可能没有机会看你在白板上写下代码,这可太糟了。你可以带块手表,或者房间有钟的话,你也可以抬头看看时间。有些时候面试者会提醒你你已经得到了所有的信息(这时你就不要再问别的了),'我想我们已经把所有需要的信息都澄清了,让我们写代码实现吧'
|
||||
在白板上先写下你的算法要做的事情列表。这样做,你往往能在开始写代码前就发现 bug 和缺陷(不过你可得掌握好时间)。我犯过的一个错误是我花了过多的时间在澄清问题和头脑风暴上,最后几乎没有留下时间给我写代码。你的面试官可能没有机会看你在白板上写下代码,这可太糟了。你可以带块手表,或者房间有钟的话,你也可以抬头看看时间。有些时候面试者会提醒你你已经得到了所有的信息(这时你就不要再问别的了),“我想我们已经把所有需要的信息都澄清了,让我们写代码实现吧”。
|
||||
|
||||
#### 2\. 开始写代码,一气呵成
|
||||
#### 2、 开始写代码,一气呵成
|
||||
|
||||
如果你还没有得到问题的完美解决方法,从最原始的解法开始总的可以的。当你在向面试官解释最显而易见的解法时,你要想想怎么去完善它,并指明这种做法是最原始,未加优化的。(请熟悉算法中的O()的概念,这对面试非常有用。)在向面试者提交前请仔细检查你的解决方案两三遍。面试者有时会给你些提示, ‘还有更好的方法吗?’,这句话的意思是面试官提示你有更优化的解决方案。
|
||||
如果你还没有得到问题的完美解决方法,从最原始的解法开始总是可以的。当你在向面试官解释最显而易见的解法时,你要想想怎么去完善它,并指明这种做法是最原始的,未加优化的。(请熟悉算法中的 `O()` 的概念,这对面试非常有用。)在向面试者提交前请仔细检查你的解决方案两三遍。面试者有时会给你些提示, “还有更好的方法吗?”,这句话的意思是面试官提示你有更优化的解决方案。
|
||||
|
||||
#### 3\. 错误处理
|
||||
#### 3、 错误处理
|
||||
|
||||
当你在编码时,对你想做错误处理的代码行做个注释。当面试者说,'很好,这里你想到了错误处理。你想怎么处理呢?抛出异常还是返回错误码?',这将给你个机会去引出关于代码质量的一番讨论。当然,这种地方提出几个就够了。有时,面试者为了节省编码的时间,会告诉你可以假设外界输入的参数都已经通过了校验。不管怎样,你都要展现你对错误处理和编码质量的重要性的认识。
|
||||
当你在编码时,对你想做错误处理的代码行做个注释。当面试者说,“很好,这里你想到了错误处理。你想怎么处理呢?抛出异常还是返回错误码?”,这将给你个机会去引出关于代码质量的一番讨论。当然,这种地方提出几个就够了。有时,面试者为了节省编码的时间,会告诉你可以假设外界输入的参数都已经通过了校验。不管怎样,你都要展现你对错误处理和编码质量的重要性的认识。
|
||||
|
||||
#### 4\. 测试
|
||||
#### 4、 测试
|
||||
|
||||
在编码完成后,用你在前面头脑风暴中写的用例来在你脑子里“跑”一下你的代码,确定万无一失。例如你可以说,‘让我用前面写下的树的例子来跑一下我的代码,如果是一个节点是什么结果,如果是两个节点是什么结果。。。’
|
||||
在编码完成后,用你在前面头脑风暴中写的用例来在你脑子里“跑”一下你的代码,确定万无一失。例如你可以说,“让我用前面写下的树的例子来跑一下我的代码,如果是一个节点是什么结果,如果是两个节点是什么结果……”
|
||||
|
||||
在你结束之后,面试者有时会问你你将会怎么测试你的代码,你会涉及什么样的测试用例。我建议你用下面不同的分类来组织你的错误用例:
|
||||
|
||||
@ -83,7 +79,7 @@
|
||||
2. 错误用例
|
||||
3. 期望的正常用例
|
||||
|
||||
对于性能测试,要考虑极端数量下的情况。例如,如果问题是关于列表的,你可以说你将会使用一个非常大的列表以及的非常小的列表来测试。如果和数字有关,你将会测试系统中的最大整数和最小整数。我建议读一些有关软件测试的书来得到更多的知识。在这个领域我最喜欢的书是[How We Test Software at Microsoft][3]。
|
||||
对于性能测试,要考虑极端数量下的情况。例如,如果问题是关于列表的,你可以说你将会使用一个非常大的列表以及的非常小的列表来测试。如果和数字有关,你将会测试系统中的最大整数和最小整数。我建议读一些有关软件测试的书来得到更多的知识。在这个领域我最喜欢的书是 《[我们在微软如何测试软件][3]》。
|
||||
|
||||
对于错误用例,想一下什么是期望的错误情况并一一写下。
|
||||
|
||||
@ -91,50 +87,45 @@
|
||||
|
||||
### “你还有什么要问我的吗?”
|
||||
|
||||
面试最后总是会留几分钟给你问问题。我建议你在面试前写下你想问的问题。千万别说,‘我没什么问题了’,就算你觉得面试砸了或者你对这间公司不怎么感兴趣,你总有些东西可以问问。你甚至可以问面试者他最喜欢自己的工作什么,最讨厌自己的工作什么。或者你可以问问面试官的工作具体是什么,在用什么技术和实践。不要因为觉得自己在面试中做的不好而心灰意冷,不想问什么问题。
|
||||
面试最后总是会留几分钟给你问问题。我建议你在面试前写下你想问的问题。千万别说,“我没什么问题了”,就算你觉得面试砸了或者你对这间公司不怎么感兴趣,你总有些东西可以问问。你甚至可以问面试者他最喜欢自己的工作什么,最讨厌自己的工作什么。或者你可以问问面试官的工作具体是什么,在用什么技术和实践。不要因为觉得自己在面试中做的不好而心灰意冷,不想问什么问题。
|
||||
|
||||
### 申请一份工作
|
||||
|
||||
|
||||
关于找工作申请工作,有人曾经告诉我,你应该去找你真正有激情工作的地方。去找一家你喜欢的公司,或者你喜欢使用的产品,看看你能不能去那儿工作。
|
||||
关于找工作和申请工作,有人曾经告诉我,你应该去找你真正有激情工作的地方。去找一家你喜欢的公司,或者你喜欢使用的产品,看看你能不能去那儿工作。
|
||||
|
||||
我个人并不推荐你用上述的方法去找工作。你会排除很多很好的公司,特别是你是在找实习工作或者入门级的职位时。
|
||||
|
||||
你也可以集中在其他的一些目标上。如:我想从这个工作里得到哪方面的更多经验?这个工作是关于云计算?Web开发?或是人工智能?当在招聘会上与招聘公司沟通是,看看他们的工作单位有没有在这些领域的。你可能会在一家并非在你的想去公司列表上的公司(或非盈利机构)里找到你想找的职位。
|
||||
你也可以集中在其他的一些目标上。如:我想从这个工作里得到哪方面的更多经验?这个工作是关于云计算?Web 开发?或是人工智能?当在招聘会上与招聘公司沟通时,看看他们的工作单位有没有在这些领域的。你可能会在一家并非在你的想去公司列表上的公司(或非盈利机构)里找到你想找的职位。
|
||||
|
||||
#### 换组
|
||||
|
||||
在这家公司里的第一个组里呆了一年半以后,我觉得是时候去探索一下不同的东西了。我找到了一个我喜欢的组并进行了4轮面试。结果我搞砸了。
|
||||
|
||||
|
||||
我什么都没有准备,甚至都没在白板上练练手。我当时的逻辑是,如果我都已经在一家公司干了快2年了,我还需要练什么?我完全错了,我在接下去的白板面试中跌跌撞撞。我的板书写得太小,而且因为没有从最左上角开始写代码,我的代码大大超出了一个白板的空间,这些都导致了白板面试失败。
|
||||
在这家公司里的第一个组里呆了一年半以后,我觉得是时候去探索一下不同的东西了。我找到了一个我喜欢的组并进行了 4 轮面试。结果我搞砸了。
|
||||
|
||||
我什么都没有准备,甚至都没在白板上练练手。我当时的逻辑是,如果我都已经在一家公司干了快 2 年了,我还需要练什么?我完全错了,我在接下去的白板面试中跌跌撞撞。我的板书写得太小,而且因为没有从最左上角开始写代码,我的代码大大超出了一个白板的空间,这些都导致了白板面试失败。
|
||||
|
||||
我在面试前也没有刷过数据结构和算法题。如果我做了的话,我将会在面试中更有信心。就算你已经在一家公司担任了软件工程师,在你去另外一个组面试前,我强烈建议你在一块白板上演练一下如何写代码。
|
||||
|
||||
对于换项目组这件事,如果你是在公司内部换组的话,事先能同那个组的人非正式聊聊会很有帮助。对于这一点,我发现几乎每个人都很乐于和你一起吃个午饭。人一般都会在中午有空,约不到人或者别人正好有会议冲突的风险会很低。这是一种非正式的途径来了解你想去的组正在干什么,以及这个组成员个性是怎么样的。相信我,你能从一次午餐中得到很多信息,这可会对你的正式面试帮助不小。
|
||||
|
||||
对于换项目组这件事,如果你是在公司内部换组的话,事先能同那个组的人非正式聊聊会很有帮助。对于这一点,我发现几乎每个人都很乐于和你一起吃个午饭。人一般都会在中午有空,约不到人或者别人正好有会议冲突的风险会很低。这是一种非正式的途径来了解你想去的组正在干什么,以及这个组成员个性是怎么样的。相信我, 你能从一次午餐中得到很多信息,这可会对你的正式面试帮助不小。
|
||||
非常重要的一点是,你在面试一个特定的组时,就算你在面试中做的很好,因为文化不契合的原因,你也很可能拿不到 offer。这也是为什么我一开始就想去见见组里不同的人的原因(有时这也不太可能),我希望你不要被一次拒绝所击倒,请保持开放的心态,选择新的机会,并多多练习。
|
||||
|
||||
|
||||
非常重要的一点是,你在面试一个特定的组时,就算你在面试中做的很好,因为文化不契合的原因,你也很可能拿不到offer。这也是为什么我一开始就想去见见组里不同的人的原因(有时这也不太可能),我希望你不要被一次拒绝所击倒,请保持开放的心态,选择新的机会,并多多练习。
|
||||
|
||||
|
||||
以上内容来自["Programming interviews"][4] 章节,选自 [The Women in Tech Show: Technical Interviews with Prominent Women in Tech][5]
|
||||
以上内容选自 《[The Women in Tech Show: Technical Interviews with Prominent Women in Tech][5]》的 “[编程面试][4]”章节,
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
微软研究院Software Engineer II, www.thewomenintechshow.com站长,所有观点都只代表本人意见。
|
||||
微软研究院 Software Engineer II, www.thewomenintechshow.com 站长,所有观点都只代表本人意见。
|
||||
|
||||
------------
|
||||
|
||||
via: https://medium.freecodecamp.org/what-i-learned-from-programming-interviews-29ba49c9b851
|
||||
|
||||
作者:[Edaena Salinas ][a]
|
||||
译者:DavidChenLiang (https://github.com/DavidChenLiang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Edaena Salinas][a]
|
||||
译者:[DavidChenLiang](https://github.com/DavidChenLiang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,65 +1,58 @@
|
||||
你没听说过的 Go 语言惊人优点
|
||||
============================================================
|
||||
=========
|
||||
|
||||

|
||||
|
||||
来自 [https://github.com/ashleymcnamara/gophers][1] 的图稿
|
||||
*来自 [https://github.com/ashleymcnamara/gophers][1] 的图稿*
|
||||
|
||||
在这篇文章中,我将讨论为什么你需要尝试一下 Go,以及应该从哪里学起。
|
||||
在这篇文章中,我将讨论为什么你需要尝试一下 Go 语言,以及应该从哪里学起。
|
||||
|
||||
Golang 是可能是最近几年里你经常听人说起的编程语言。尽管它在 2009 年已经发布,但它最近才开始流行起来。
|
||||
Go 语言是可能是最近几年里你经常听人说起的编程语言。尽管它在 2009 年已经发布了,但它最近才开始流行起来。
|
||||
|
||||
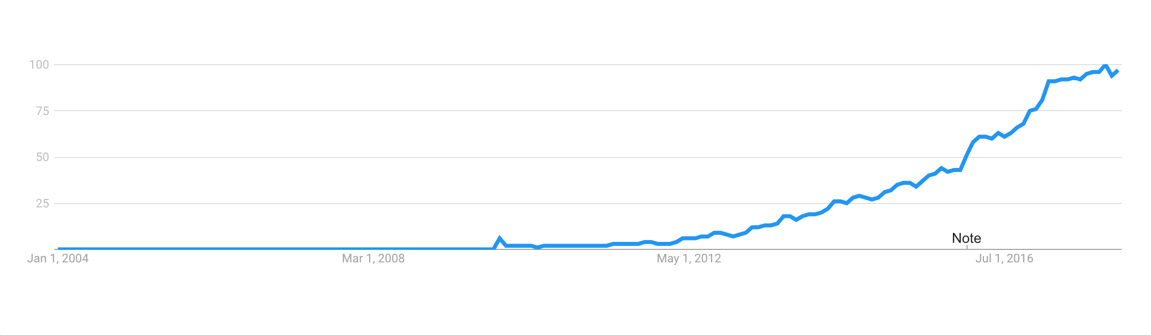
|
||||
|
||||
根据 Google 趋势,Golang 语言非常流行。
|
||||
*根据 Google 趋势,Go 语言非常流行。*
|
||||
|
||||
这篇文章不会讨论一些你经常看到的 Golang 的主要特性。
|
||||
这篇文章不会讨论一些你经常看到的 Go 语言的主要特性。
|
||||
|
||||
相反,我想向您介绍一些相当小众但仍然很重要的功能。在您决定尝试Go后,您才会知道这些功能。
|
||||
相反,我想向您介绍一些相当小众但仍然很重要的功能。只有在您决定尝试 Go 语言后,您才会知道这些功能。
|
||||
|
||||
这些都是表面上没有体现出来的惊人特性,但它们可以为您节省数周或数月的工作量。而且这些特性还可以使软件开发更加愉快。
|
||||
|
||||
阅读本文不需要任何语言经验,所以不比担心 Golang 对你来说是新的事物。如果你想了解更多,可以看看我在底部列出的一些额外的链接,。
|
||||
阅读本文不需要任何语言经验,所以不必担心你还不了解 Go 语言。如果你想了解更多,可以看看我在底部列出的一些额外的链接。
|
||||
|
||||
我们将讨论以下主题:
|
||||
|
||||
* GoDoc
|
||||
|
||||
* 静态代码分析
|
||||
|
||||
* 内置的测试和分析框架
|
||||
|
||||
* 竞争条件检测
|
||||
|
||||
* 学习曲线
|
||||
|
||||
* 反射(Reflection)
|
||||
|
||||
* Opinionatedness(专制独裁的 Go)
|
||||
|
||||
* 反射
|
||||
* Opinionatedness
|
||||
* 文化
|
||||
|
||||
请注意,这个列表不遵循任何特定顺序来讨论。
|
||||
|
||||
### GoDoc
|
||||
|
||||
Golang 非常重视代码中的文档,简洁也是如此。
|
||||
Go 语言非常重视代码中的文档,所以也很简洁。
|
||||
|
||||
[GoDoc][4] 是一个静态代码分析工具,可以直接从代码中创建漂亮的文档页面。GoDoc 的一个显着特点是它不使用任何其他的语言,如 JavaDoc,PHPDoc 或 JSDoc 来注释代码中的结构,只需要用英语。
|
||||
[GoDoc][4] 是一个静态代码分析工具,可以直接从代码中创建漂亮的文档页面。GoDoc 的一个显著特点是它不使用任何其他的语言,如 JavaDoc、PHPDoc 或 JSDoc 来注释代码中的结构,只需要用英语。
|
||||
|
||||
它使用从代码中获取的尽可能多的信息来概述、构造和格式化文档。它有多而全的功能,比如:交叉引用,代码示例以及一个指向版本控制系统仓库的链接。
|
||||
它使用从代码中获取的尽可能多的信息来概述、构造和格式化文档。它有多而全的功能,比如:交叉引用、代码示例,并直接链接到你的版本控制系统仓库。
|
||||
|
||||
而你需要做的只有添加一些好的,像 `// MyFunc transforms Foo into Bar` 这样子的注释,而这些注释也会反映在的文档中。你甚至可以添加一些通过网络接口或者在本地可以实际运行的 [代码示例][5]。
|
||||
而你需要做的只有添加一些像 `// MyFunc transforms Foo into Bar` 这样子的老牌注释,而这些注释也会反映在的文档中。你甚至可以添加一些通过网络界面或者在本地可以实际运行的 [代码示例][5]。
|
||||
|
||||
GoDoc 是 Go 的唯一文档引擎,供整个社区使用。这意味着用 Go 编写的每个库或应用程序都具有相同的文档格式。从长远来看,它可以帮你在浏览这些文档时节省大量时间。
|
||||
GoDoc 是 Go 的唯一文档引擎,整个社区都在使用。这意味着用 Go 编写的每个库或应用程序都具有相同的文档格式。从长远来看,它可以帮你在浏览这些文档时节省大量时间。
|
||||
|
||||
例如,这是我最近一个小项目的 GoDoc 页面:[pullkee — GoDoc][6]。
|
||||
|
||||
### 静态代码分析
|
||||
|
||||
Go 严重依赖于静态代码分析。例子包括 godoc 文档,gofmt 代码格式化,golint 代码风格统一,等等。
|
||||
Go 严重依赖于静态代码分析。例如用于文档的 [godoc][7],用于代码格式化的 [gofmt][8],用于代码风格的 [golint][9],等等。
|
||||
|
||||
其中有很多甚至全部包含在类似 [gometalinter][10] 的项目中,这些将它们全部组合成一个实用程序。
|
||||
它们是如此之多,甚至有一个总揽了它们的项目 [gometalinter][10] ,将它们组合成了单一的实用程序。
|
||||
|
||||
这些工具通常作为独立的命令行应用程序实现,并可轻松与任何编码环境集成。
|
||||
|
||||
@ -67,21 +60,21 @@ Go 严重依赖于静态代码分析。例子包括 godoc 文档,gofmt 代码
|
||||
|
||||
创建自己的分析器非常简单,因为 Go 有专门的内置包来解析和加工 Go 源码。
|
||||
|
||||
你可以从这个链接中了解到更多相关内容: [GothamGo Kickoff Meetup: Go Static Analysis Tools by Alan Donovan][11].
|
||||
你可以从这个链接中了解到更多相关内容: [GothamGo Kickoff Meetup: Alan Donovan 的 Go 静态分析工具][11]。
|
||||
|
||||
### 内置的测试和分析框架
|
||||
|
||||
您是否曾尝试为一个从头开始的 Javascript 项目选择测试框架?如果是这样,你可能会明白经历这种分析瘫痪的斗争。您可能也意识到您没有使用其中 80% 的框架。
|
||||
您是否曾尝试为一个从头开始的 JavaScript 项目选择测试框架?如果是这样,你或许会理解经历这种<ruby>过度分析<rt>analysis paralysis</rt></ruby>的痛苦。您可能也意识到您没有使用其中 80% 的框架。
|
||||
|
||||
一旦您需要进行一些可靠的分析,问题就会重复出现。
|
||||
|
||||
Go 附带内置测试工具,旨在简化和提高效率。它为您提供了最简单的 API,并做出最小的假设。您可以将它用于不同类型的测试,分析,甚至可以提供可执行代码示例。
|
||||
Go 附带内置测试工具,旨在简化和提高效率。它为您提供了最简单的 API,并做出最小的假设。您可以将它用于不同类型的测试、分析,甚至可以提供可执行代码示例。
|
||||
|
||||
它可以开箱即用地生成持续集成友好的输出,而且它的用法很简单,只需运行 `go test`。当然,它还支持高级功能,如并行运行测试,跳过标记代码,以及其他更多功能。
|
||||
它可以开箱即用地生成便于持续集成的输出,而且它的用法很简单,只需运行 `go test`。当然,它还支持高级功能,如并行运行测试,跳过标记代码,以及其他更多功能。
|
||||
|
||||
### 竞争条件检测
|
||||
|
||||
您可能已经了解了 Goroutines,它们在 Go 中用于实现并发代码执行。如果你未曾了解过,[这里][12]有一个非常简短的解释。
|
||||
您可能已经听说了 Goroutine,它们在 Go 中用于实现并发代码执行。如果你未曾了解过,[这里][12]有一个非常简短的解释。
|
||||
|
||||
无论具体技术如何,复杂应用中的并发编程都不容易,部分原因在于竞争条件的可能性。
|
||||
|
||||
@ -93,13 +86,13 @@ Go 附带内置测试工具,旨在简化和提高效率。它为您提供了
|
||||
|
||||
### 学习曲线
|
||||
|
||||
您可以在一个晚上学习所有 Go 的语言功能。我是认真的。当然,还有标准库,以及不同,更具体领域的最佳实践。但是两个小时就足以让你自信地编写一个简单的 HTTP 服务器或命令行应用程序。
|
||||
您可以在一个晚上学习**所有**的 Go 语言功能。我是认真的。当然,还有标准库,以及不同的,更具体领域的最佳实践。但是两个小时就足以让你自信地编写一个简单的 HTTP 服务器或命令行应用程序。
|
||||
|
||||
Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进行了介绍:[The Go Programming Language Blog][15]。
|
||||
Go 语言拥有[出色的文档][14],大部分高级主题已经在他们的博客上进行了介绍:[Go 编程语言博客][15]。
|
||||
|
||||
比起 Java(以及 Java 家族的语言),Javascript,Ruby,Python 甚至 PHP,你可以更轻松地把 Go 语言带到你的团队中。由于环境易于设置,您的团队在完成第一个生产代码之前需要进行的投资要小得多。
|
||||
比起 Java(以及 Java 家族的语言)、Javascript、Ruby、Python 甚至 PHP,你可以更轻松地把 Go 语言带到你的团队中。由于环境易于设置,您的团队在完成第一个生产代码之前需要进行的投资要小得多。
|
||||
|
||||
### 反射(Reflection)
|
||||
### 反射
|
||||
|
||||
代码反射本质上是一种隐藏在编译器下并访问有关语言结构的各种元信息的能力,例如变量或函数。
|
||||
|
||||
@ -107,19 +100,19 @@ Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进
|
||||
|
||||
此外,Go [没有实现一个名为泛型的概念][16],这使得以抽象方式处理多种类型更具挑战性。然而,由于泛型带来的复杂程度,许多人认为不实现泛型对语言实际上是有益的。我完全同意。
|
||||
|
||||
根据 Go 的理念(这是一个单独的主题),您应该努力不要过度设计您的解决方案。这也适用于动态类型编程。尽可能坚持使用静态类型,并在确切知道要处理的类型时使用接口(interfaces)。接口在 Go 中非常强大且无处不在。
|
||||
根据 Go 的理念(这是一个单独的主题),您应该努力不要过度设计您的解决方案。这也适用于动态类型编程。尽可能坚持使用静态类型,并在确切知道要处理的类型时使用<ruby>接口<rt>interface</rt></ruby>。接口在 Go 中非常强大且无处不在。
|
||||
|
||||
但是,仍然存在一些情况,你无法知道你处理的数据类型。一个很好的例子是 JSON。您可以在应用程序中来回转换所有类型的数据。字符串,缓冲区,各种数字,嵌套结构等。
|
||||
但是,仍然存在一些情况,你无法知道你处理的数据类型。一个很好的例子是 JSON。您可以在应用程序中来回转换所有类型的数据。字符串、缓冲区、各种数字、嵌套结构等。
|
||||
|
||||
为了解决这个问题,您需要一个工具来检查运行时的数据并根据其类型和结构采取不同行为。反射(Reflect)可以帮到你。Go 拥有一流的反射包,使您的代码能够像 Javascript 这样的语言一样动态。
|
||||
为了解决这个问题,您需要一个工具来检查运行时的数据并根据其类型和结构采取不同行为。<ruby>反射<rt>Reflect</rt></ruby>可以帮到你。Go 拥有一流的反射包,使您的代码能够像 Javascript 这样的语言一样动态。
|
||||
|
||||
一个重要的警告是知道你使用它所带来的代价 - 并且只有知道在没有更简单的方法时才使用它。
|
||||
一个重要的警告是知道你使用它所带来的代价 —— 并且只有知道在没有更简单的方法时才使用它。
|
||||
|
||||
你可以在这里阅读更多相关信息: [反射的法则 — Go 博客][18].
|
||||
|
||||
您还可以在此处阅读 JSON 包源码中的一些实际代码: [src/encoding/json/encode.go — Source Code][19]
|
||||
|
||||
### Opinionatedness
|
||||
### Opinionatedness(专制独裁的 Go)
|
||||
|
||||
顺便问一下,有这样一个单词吗?
|
||||
|
||||
@ -127,9 +120,9 @@ Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进
|
||||
|
||||
这有时候基本上让我卡住了。我需要花时间思考这些事情而不是编写代码并满足用户。
|
||||
|
||||
首先,我应该注意到我完全可以得到这些惯例的来源,它总是来源于你或者你的团队。无论如何,即使是一群经验丰富的 Javascript 开发人员也可以轻松地发现自己拥有完全不同的工具和范例的大部分经验,以实现相同的结果。
|
||||
首先,我应该注意到我完全知道这些惯例的来源,它总是来源于你或者你的团队。无论如何,即使是一群经验丰富的 Javascript 开发人员也很容易发现他们在实现相同的结果时,而大部分的经验却是在完全不同的工具和范例上。
|
||||
|
||||
这导致整个团队中分析的瘫痪,并且使得个体之间更难以相互协作。
|
||||
这导致整个团队中出现过度分析,并且使得个体之间更难以相互协作。
|
||||
|
||||
嗯,Go 是不同的。即使您对如何构建和维护代码有很多强烈的意见,例如:如何命名,要遵循哪些结构模式,如何更好地实现并发。但你只有一个每个人都遵循的风格指南。你只有一个内置在基本工具链中的测试框架。
|
||||
|
||||
@ -141,11 +134,11 @@ Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进
|
||||
|
||||
人们说,每当你学习一门新的口语时,你也会沉浸在说这种语言的人的某些文化中。因此,您学习的语言越多,您可能会有更多的变化。
|
||||
|
||||
编程语言也是如此。无论您将来如何应用新的编程语言,它总能给的带来新的编程视角或某些特别的技术。
|
||||
编程语言也是如此。无论您将来如何应用新的编程语言,它总能给你带来新的编程视角或某些特别的技术。
|
||||
|
||||
无论是函数式编程,模式匹配(pattern matching)还是原型继承(prototypal inheritance)。一旦你学会了它们,你就可以随身携带这些编程思想,这扩展了你作为软件开发人员所拥有的问题解决工具集。它们也改变了你阅读高质量代码的方式。
|
||||
无论是函数式编程,<ruby>模式匹配<rt>pattern matching</rt></ruby>还是<ruby>原型继承<rt>prototypal inheritance</rt></ruby>。一旦你学会了它们,你就可以随身携带这些编程思想,这扩展了你作为软件开发人员所拥有的问题解决工具集。它们也改变了你阅读高质量代码的方式。
|
||||
|
||||
而 Go 在方面有一项了不起的财富。Go 文化的主要支柱是保持简单,脚踏实地的代码,而不会产生许多冗余的抽象概念,并将可维护性放在首位。大部分时间花费在代码的编写工作上,而不是在修补工具和环境或者选择不同的实现方式上,这也是 Go文化的一部分。
|
||||
而 Go 在这方面有一项了不起的财富。Go 文化的主要支柱是保持简单,脚踏实地的代码,而不会产生许多冗余的抽象概念,并将可维护性放在首位。大部分时间花费在代码的编写工作上,而不是在修补工具和环境或者选择不同的实现方式上,这也是 Go 文化的一部分。
|
||||
|
||||
Go 文化也可以总结为:“应当只用一种方法去做一件事”。
|
||||
|
||||
@ -161,12 +154,11 @@ Go 文化也可以总结为:“应当只用一种方法去做一件事”。
|
||||
|
||||
这不是 Go 的所有惊人的优点的完整列表,只是一些被人低估的特性。
|
||||
|
||||
请尝试一下从 [Go 之旅(A Tour of Go)][20]来开始学习 Go,这将是一个令人惊叹的开始。
|
||||
请尝试一下从 [Go 之旅][20] 来开始学习 Go,这将是一个令人惊叹的开始。
|
||||
|
||||
如果您想了解有关 Go 的优点的更多信息,可以查看以下链接:
|
||||
|
||||
* [你为什么要学习 Go? - Keval Patel][2]
|
||||
|
||||
* [告别Node.js - TJ Holowaychuk][3]
|
||||
|
||||
并在评论中分享您的阅读感悟!
|
||||
@ -175,30 +167,16 @@ Go 文化也可以总结为:“应当只用一种方法去做一件事”。
|
||||
|
||||
不断为您的工作寻找最好的工具!
|
||||
|
||||
* * *
|
||||
|
||||
If you like this article, please consider following me for more, and clicking on those funny green little hands right below this text for sharing. 👏👏👏
|
||||
|
||||
Check out my [Github][21] and follow me on [Twitter][22]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Software Engineer and Traveler. Coding for fun. Javascript enthusiast. Tinkering with Golang. A lot into SOA and Docker. Architect at Velvica.
|
||||
|
||||
------------
|
||||
|
||||
|
||||
-------------------------------------------------------
|
||||
via: https://medium.freecodecamp.org/here-are-some-amazing-advantages-of-go-that-you-dont-hear-much-about-1af99de3b23a
|
||||
|
||||
作者:[Kirill Rogovoy][a]
|
||||
译者:[译者ID](https://github.com/imquanquan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[a]:https://twitter.com/krogovoy
|
||||
[1]:https://github.com/ashleymcnamara/gophers
|
||||
[2]:https://medium.com/@kevalpatel2106/why-should-you-learn-go-f607681fad65
|
||||
[3]:https://medium.com/@tjholowaychuk/farewell-node-js-4ba9e7f3e52b
|
||||
89
published/20180308 What is open source programming.md
Normal file
89
published/20180308 What is open source programming.md
Normal file
@ -0,0 +1,89 @@
|
||||
何谓开源编程?
|
||||
======
|
||||
|
||||
> 开源就是丢一些代码到 GitHub 上。了解一下它是什么,以及不是什么?
|
||||
|
||||

|
||||
|
||||
最简单的来说,开源编程就是编写一些大家可以随意取用、修改的代码。但你肯定听过关于 Go 语言的那个老笑话,说 Go 语言“简单到看一眼就可以明白规则,但需要一辈子去学会运用它”。其实写开源代码也是这样的。往 GitHub、Bitbucket、SourceForge 等网站或者是你自己的博客或网站上丢几行代码不是难事,但想要卓有成效,还需要个人的努力付出和高瞻远瞩。
|
||||
|
||||

|
||||
|
||||
### 我们对开源编程的误解
|
||||
|
||||
首先我要说清楚一点:把你的代码放在 GitHub 的公开仓库中并不意味着把你的代码开源了。在几乎全世界,根本不用创作者做什么,只要作品形成,版权就随之而生了。在创作者进行授权之前,只有作者可以行使版权相关的权力。未经创作者授权的代码,不论有多少人在使用,都是一颗定时炸弹,只有愚蠢的人才会去用它。
|
||||
|
||||
有些创作者很善良,认为“很明显我的代码是免费提供给大家使用的。”,他也并不想起诉那些用了他的代码的人,但这并不意味着这些代码可以放心使用。不论在你眼中创作者们多么善良,他们都 *有权力* 起诉任何使用、修改代码,或未经明确授权就将代码嵌入的人。
|
||||
|
||||
很明显,你不应该在没有指定开源许可证的情况下将你的源代码发布到网上然后期望别人使用它并为其做出贡献。我建议你也尽量避免使用这种代码,甚至疑似未授权的也不要使用。如果你开发了一个函数和例程,它和之前一个疑似未授权代码很像,源代码作者就可以对你就侵权提起诉讼。
|
||||
|
||||
举个例子,Jill Schmill 写了 AwesomeLib 然后未明确授权就把它放到了 GitHub 上,就算 Jill Schmill 不起诉任何人,只要她把 AwesomeLib 的完整版权都卖给 EvilCorp,EvilCorp 就会起诉之前违规使用这段代码的人。这种行为就好像是埋下了计算机安全隐患,总有一天会为人所用。
|
||||
|
||||
没有许可证的代码的危险的,切记。
|
||||
|
||||
### 选择恰当的开源许可证
|
||||
|
||||
假设你正要写一个新程序,而且打算让人们以开源的方式使用它,你需要做的就是选择最贴合你需求的[许可证][1]。和宣传中说的一样,你可以从 GitHub 所支持的 [choosealicense.com][2] 开始。这个网站设计得像个简单的问卷,特别方便快捷,点几下就能找到合适的许可证。
|
||||
|
||||
警示:在选择许可证时不要过于自负,如果你选的是 [Apache 许可证][3]或者 [GPLv3][4] 这种广为使用的许可证,人们很容易理解他们和你都有什么权利,你也不需要请律师来排查其中的漏洞。你选择的许可证使用的人越少,带来的麻烦就越多。
|
||||
|
||||
最重要的一点是: *千万不要试图自己制造许可证!* 自己制造许可证会给大家带来更多的困惑和困扰,不要这样做。如果在现有的许可证中确实找不到你需要的条款,你可以在现有的许可证中附加上你的要求,并且重点标注出来,提醒使用者们注意。
|
||||
|
||||
我知道有些人会站出来说:“我才懒得管什么许可证,我已经把代码发到<ruby>公开领域<rt>public domain</rt></ruby>了。”但问题是,公开领域的法律效力并不是受全世界认可的。在不同的国家,公开领域的效力和表现形式不同。在有些国家的政府管控下,你甚至不可以把自己的源代码发到公开领域。万幸,[Unlicense][5] 可以弥补这些漏洞,它语言简洁,使用几个词清楚地描述了“就把它放到公开领域”,但其效力为全世界认可。
|
||||
|
||||
### 怎样引入许可证
|
||||
|
||||
确定使用哪个许可证之后,你需要清晰而无疑义地指定它。如果你是在 GitHub、GitLab 或 BitBucket 这几个网站发布,你需要构建很多个文件夹,在根文件夹中,你应把许可证创建为一个以 `LICENSE.txt` 命名的明文文件。
|
||||
|
||||
创建 `LICENSE.txt` 这个文件之后还有其它事要做。你需要在每个重要文件的头部添加注释块来申明许可证。如果你使用的是一个现有的许可证,这一步对你来说十分简便。一个 `# 项目名 (c)2018 作者名,GPLv3 许可证,详情见 https://www.gnu.org/licenses/gpl-3.0.en.html` 这样的注释块比隐约指代的许可证的效力要强得多。
|
||||
|
||||
如果你是要发布在自己的网站上,步骤也差不多。先创建 `LICENSE.txt` 文件,放入许可证,再表明许可证出处。
|
||||
|
||||
### 开源代码的不同之处
|
||||
|
||||
开源代码和专有代码的一个主要区别是开源代码写出来就是为了给别人看的。我是个 40 多岁的系统管理员,已经写过许许多多的代码。最开始我写代码是为了工作,为了解决公司的问题,所以其中大部分代码都是专有代码。这种代码的目的很简单,只要能在特定场合通过特定方式发挥作用就行。
|
||||
|
||||
开源代码则大不相同。在写开源代码时,你知道它可能会被用于各种各样的环境中。也许你的用例的环境条件很局限,但你仍旧希望它能在各种环境下发挥理想的效果。不同的人使用这些代码时会出现各种用例,你会看到各类冲突,还有你没有考虑过的思路。虽然代码不一定要满足所有人,但至少应该得体地处理他们遇到的问题,就算解决不了,也可以转换回常见的逻辑,不会给使用者添麻烦。(例如“第 583 行出现零除错误”就不能作为错误地提供命令行参数的响应结果)
|
||||
|
||||
你的源代码也可能逼疯你,尤其是在你一遍又一遍地修改错误的函数或是子过程后,终于出现了你希望的结果,这时你不会叹口气就继续下一个任务,你会把过程清理干净,因为你不会愿意别人看出你一遍遍尝试的痕迹。比如你会把 `$variable`、`$lol` 全都换成有意义的 `$iterationcounter` 和 `$modelname`。这意味着你要认真专业地进行注释(尽管对于你所处的背景知识热度来说它并不难懂),因为你期望有更多的人可以使用你的代码。
|
||||
|
||||
这个过程难免有些痛苦沮丧,毕竟这不是你常做的事,会有些不习惯。但它会使你成为一位更好的程序员,也会让你的代码升华。即使你的项目只有你一位贡献者,清理代码也会节约你后期的很多工作,相信我一年后你再看你的 app 代码时,你会庆幸自己写下的是 `$modelname`,还有清晰的注释,而不是什么不知名的数列,甚至连 `$lol` 也不是。
|
||||
|
||||
### 你并不是为你一人而写
|
||||
|
||||
开源的真正核心并不是那些代码,而是社区。更大的社区的项目维持时间更长,也更容易为人们所接受。因此不仅要加入社区,还要多多为社区发展贡献思路,让自己的项目能够为社区所用。
|
||||
|
||||
蝙蝠侠为了完成目标暗中独自花了很大功夫,你用不着这样,你可以登录 Twitter、Reddit,或者给你项目的相关人士发邮件,发布你正在筹备新项目的消息,仔细聊聊项目的设计初衷和你的计划,让大家一起帮忙,向大家征集数据输入,类似的使用案例,把这些信息整合起来,用在你的代码里。你不用接受所有的建议和请求,但你要对它有个大概把握,这样在你之后完善时可以躲过一些陷阱。
|
||||
|
||||
发布了首次通告这个过程还不算完整。如果你希望大家能够接受你的作品并且使用它,你就要以此为初衷来设计。公众说不定可以帮到你,你不必对公开这件事如临大敌。所以不要闭门造车,既然你是为大家而写,那就开设一个真实、公开的项目,想象你在社区的帮助和监督下,认真地一步步完成它。
|
||||
|
||||
### 建立项目的方式
|
||||
|
||||
你可以在 GitHub、GitLab 或 BitBucket 上免费注册账号来管理你的项目。注册之后,创建知识库,建立 `README` 文件,分配一个许可证,一步步写入代码。这样可以帮你建立好习惯,让你之后和现实中的团队一起工作时,也能目的清晰地朝着目标稳妥地开展工作。这样你做得越久,就越有兴趣 —— 通常会有用户先对你的项目产生兴趣。
|
||||
|
||||
用户会开始提一些问题,这会让你开心也会让你不爽,你应该亲切礼貌地对待他们,就算他们很多人对项目有很多误解甚至根本不知道你的项目做的是什么,你也应该礼貌专业地对待。一方面,你可以引导他们,让他们了解你在干什么。另一方面,他们也会慢慢地将你带入更大的社区。
|
||||
|
||||
如果你的项目很受用户青睐,总会有高级开发者出现,并表示出兴趣。这也许是好事,也可能激怒你。最开始你可能只会做简单的问题修复,但总有一天你会收到拉取请求,有可能是硬编码或特殊用例(可能会让项目变得难以维护),它可能改变你项目的作用域,甚至改变你项目的初衷。你需要学会分辨哪个有贡献,根据这个决定合并哪个,婉拒哪个。
|
||||
|
||||
### 我们为什么要开源?
|
||||
|
||||
开源听起来任务繁重,它也确实是这样。但它对你也有很多好处。它可以在无形之中磨练你,让你写出纯净持久的代码,也教会你与人沟通,团队协作。对于一个志向远大的专业开发者来说,它是最好的简历素材。你的未来雇主很有可能点开你的仓库,了解你的能力范围;而社区项目的开发者也有可能给你带来工作。
|
||||
|
||||
最后,为开源工作,意味着个人的提升,因为你在做的事不是为了你一个人,这比养活自己重要得多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/what-open-source-programming
|
||||
|
||||
作者:[Jim Salter][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[wxy](https://github.com/wxy)、[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-salter
|
||||
[1]: https://opensource.com/tags/licensing
|
||||
[2]: https://choosealicense.com/
|
||||
[3]: https://choosealicense.com/licenses/apache-2.0/
|
||||
[4]: https://choosealicense.com/licenses/gpl-3.0/
|
||||
[5]: https://choosealicense.com/licenses/unlicense/
|
||||
@ -0,0 +1,155 @@
|
||||
用 Hugo 30 分钟搭建静态博客
|
||||
======
|
||||
> 了解 Hugo 如何使构建网站变得有趣。
|
||||
|
||||

|
||||
|
||||
你是不是强烈地想搭建博客来将自己对软件框架等的探索学习成果分享呢?你是不是面对缺乏指导文档而一团糟的项目就有一种想去改变它的冲动呢?或者换个角度,你是不是十分期待能创建一个属于自己的个人博客网站呢?
|
||||
|
||||
很多人在想搭建博客之前都有一些严重的迟疑顾虑:感觉自己缺乏内容管理系统(CMS)的相关知识,更缺乏时间去学习这些知识。现在,如果我说不用花费大把的时间去学习 CMS 系统、学习如何创建一个静态网站、更不用操心如何去强化网站以防止它受到黑客攻击的问题,你就可以在 30 分钟之内创建一个博客?你信不信?利用 Hugo 工具,就可以实现这一切。
|
||||
|
||||
|
||||
|
||||
Hugo 是一个基于 Go 语言开发的静态站点生成工具。也许你会问,为什么选择它?
|
||||
|
||||
* 无需数据库、无需需要各种权限的插件、无需跑在服务器上的底层平台,更没有额外的安全问题。
|
||||
* 都是静态站点,因此拥有轻量级、快速响应的服务性能。此外,所有的网页都是在部署的时候生成,所以服务器负载很小。
|
||||
* 极易操作的版本控制。一些 CMS 平台使用它们自己的版本控制软件(VCS)或者在网页上集成 Git 工具。而 Hugo,所有的源文件都可以用你所选的 VCS 软件来管理。
|
||||
|
||||
### 0-5 分钟:下载 Hugo,生成一个网站
|
||||
|
||||
直白的说,Hugo 使得写一个网站又一次变得有趣起来。让我们来个 30 分钟计时,搭建一个网站。
|
||||
|
||||
为了简化 Hugo 安装流程,这里直接使用 Hugo 可执行安装文件。
|
||||
|
||||
1. 下载和你操作系统匹配的 Hugo [版本][2];
|
||||
2. 压缩包解压到指定路径,例如 windows 系统的 `C:\hugo_dir` 或者 Linux 系统的 `~/hugo_dir` 目录;下文中的变量 `${HUGO_HOME}` 所指的路径就是这个安装目录;
|
||||
3. 打开命令行终端,进入安装目录:`cd ${HUGO_HOME}`;
|
||||
4. 确认 Hugo 已经启动:
|
||||
* Unix 系统:`${HUGO_HOME}/[hugo version]`;
|
||||
* Windows 系统:`${HUGO_HOME}\[hugo.exe version]`,例如:cmd 命令行中输入:`c:\hugo_dir\hugo version`。
|
||||
|
||||
为了书写上的简化,下文中的 `hugo` 就是指 hugo 可执行文件所在的路径(包括可执行文件),例如命令 `hugo version` 就是指命令 `c:\hugo_dir\hugo version` 。(LCTT 译注:可以把 hugo 可执行文件所在的路径添加到系统环境变量下,这样就可以直接在终端中输入 `hugo version`)
|
||||
|
||||
如果命令 `hugo version` 报错,你可能下载了错误的版本。当然,有很多种方法安装 Hugo,更多详细信息请查阅 [官方文档][3]。最稳妥的方法就是把 Hugo 可执行文件放在某个路径下,然后执行的时候带上路径名
|
||||
5. 创建一个新的站点来作为你的博客,输入命令:`hugo new site awesome-blog`;
|
||||
6. 进入新创建的路径下: `cd awesome-blog`;
|
||||
|
||||
恭喜你!你已经创建了自己的新博客。
|
||||
|
||||
### 5-10 分钟:为博客设置主题
|
||||
|
||||
Hugo 中你可以自己构建博客的主题或者使用网上已经有的一些主题。这里选择 [Kiera][4] 主题,因为它简洁漂亮。按以下步骤来安装该主题:
|
||||
|
||||
1. 进入主题所在目录:`cd themes`;
|
||||
2. 克隆主题:`git clone https://github.com/avianto/hugo-kiera kiera`。如果你没有安装 Git 工具:
|
||||
* 从 [Github][5] 上下载 hugo 的 .zip 格式的文件;
|
||||
* 解压该 .zip 文件到你的博客主题 `theme` 路径;
|
||||
* 重命名 `hugo-kiera-master` 为 `kiera`;
|
||||
3. 返回博客主路径:`cd awesome-blog`;
|
||||
4. 激活主题;通常来说,主题(包括 Kiera)都自带文件夹 `exampleSite`,里面存放了内容配置的示例文件。激活 Kiera 主题需要拷贝它提供的 `config.toml` 到你的博客下:
|
||||
* Unix 系统:`cp themes/kiera/exampleSite/config.toml .`;
|
||||
* Windows 系统:`copy themes\kiera\exampleSite\config.toml .`;
|
||||
* 选择 `Yes` 来覆盖原有的 `config.toml`;
|
||||
|
||||
5. ( 可选操作 )你可以选择可视化的方式启动服务器来验证主题是否生效:`hugo server -D` 然后在浏览器中输入 `http://localhost:1313`。可用通过在终端中输入 `Crtl+C` 来停止服务器运行。现在你的博客还是空的,但这也给你留了写作的空间。它看起来如下所示:
|
||||
|
||||
|
||||
|
||||
你已经成功的给博客设置了主题!你可以在官方 [Hugo 主题][4] 网站上找到上百种漂亮的主题供你使用。
|
||||
|
||||
### 10-20 分钟:给博客添加内容
|
||||
|
||||
对于碗来说,它是空的时候用处最大,可以用来盛放东西;但对于博客来说不是这样,空博客几乎毫无用处。在这一步,你将会给博客添加内容。Hugo 和 Kiera 主题都为这个工作提供了方便性。按以下步骤来进行你的第一次提交:
|
||||
|
||||
1. archetypes 将会是你的内容模板。
|
||||
2. 添加主题中的 archtypes 至你的博客:
|
||||
* Unix 系统: `cp themes/kiera/archetypes/* archetypes/`
|
||||
* Windows 系统:`copy themes\kiera\archetypes\* archetypes\`
|
||||
* 选择 `Yes` 来覆盖原来的 `default.md` 内容架构类型
|
||||
|
||||
3. 创建博客 posts 目录:
|
||||
* Unix 系统: `mkdir content/posts`
|
||||
* Windows 系统: `mkdir content\posts`
|
||||
|
||||
4. 利用 Hugo 生成你的 post:
|
||||
* Unix 系统:`hugo nes posts/first-post.md`;
|
||||
* Windows 系统:`hugo new posts\first-post.md`;
|
||||
|
||||
5. 在文本编辑器中打开这个新建的 post 文件:
|
||||
* Unix 系统:`gedit content/posts/first-post.md`;
|
||||
* Windows 系统:`notepadd content\posts\first-post.md`;
|
||||
|
||||
此刻,你可以疯狂起来了。注意到你的提交文件中包括两个部分。第一部分是以 `+++` 符号分隔开的。它包括了提交文档的主要数据,例如名称、时间等。在 Hugo 中,这叫做前缀。在前缀之后,才是正文。下面编辑第一个提交文件内容:
|
||||
|
||||
```
|
||||
+++
|
||||
title = "First Post"
|
||||
date = 2018-03-03T13:23:10+01:00
|
||||
draft = false
|
||||
tags = ["Getting started"]
|
||||
categories = []
|
||||
+++
|
||||
|
||||
Hello Hugo world! No more excuses for having no blog or documentation now!
|
||||
```
|
||||
|
||||
现在你要做的就是启动你的服务器:`hugo server -D`;然后打开浏览器,输入 `http://localhost:1313/`。
|
||||
|
||||

|
||||
|
||||
### 20-30 分钟:调整网站
|
||||
|
||||
前面的工作很完美,但还有一些问题需要解决。例如,简单地命名你的站点:
|
||||
|
||||
1. 终端中按下 `Ctrl+C` 以停止服务器。
|
||||
2. 打开 `config.toml`,编辑博客的名称,版权,你的姓名,社交网站等等。
|
||||
|
||||
当你再次启动服务器后,你会发现博客私人订制味道更浓了。不过,还少一个重要的基础内容:主菜单。快速的解决这个问题。返回 `config.toml` 文件,在末尾插入如下一段:
|
||||
|
||||
```
|
||||
[[menu.main]]
|
||||
name = "Home" #Name in the navigation bar
|
||||
weight = 10 #The larger the weight, the more on the right this item will be
|
||||
url = "/" #URL address
|
||||
[[menu.main]]
|
||||
name = "Posts"
|
||||
weight = 20
|
||||
url = "/posts/"
|
||||
```
|
||||
|
||||
上面这段代码添加了 `Home` 和 `Posts` 到主菜单中。你还需要一个 `About` 页面。这次是创建一个 `.md` 文件,而不是编辑 `config.toml` 文件:
|
||||
|
||||
1. 创建 `about.md` 文件:`hugo new about.md` 。注意它是 `about.md`,不是 `posts/about.md`。该页面不是博客提交内容,所以你不想它显示到博客内容提交当中吧。
|
||||
2. 用文本编辑器打开该文件,输入如下一段:
|
||||
|
||||
```
|
||||
+++
|
||||
title = "About"
|
||||
date = 2018-03-03T13:50:49+01:00
|
||||
menu = "main" #Display this page on the nav menu
|
||||
weight = "30" #Right-most nav item
|
||||
meta = "false" #Do not display tags or categories
|
||||
+++
|
||||
|
||||
> Waves are the practice of the water. Shunryu Suzuki
|
||||
```
|
||||
|
||||
当你启动你的服务器并输入:`http://localhost:1313/`,你将会看到你的博客。(访问我 Gihub 主页上的 [例子][6] )如果你想让文章的菜单栏和 Github 相似,给 `themes/kiera/static/css/styles.css` 打上这个 [补丁][7]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/start-blog-30-minutes-hugo
|
||||
|
||||
作者:[Marek Czernek][a]
译者:[jrg](https://github.com/jrglinux)
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mczernek
|
||||
[1]:https://gohugo.io/
|
||||
[2]:https://github.com/gohugoio/hugo/releases
|
||||
[3]:https://gohugo.io/getting-started/installing/
|
||||
[4]:https://themes.gohugo.io/
|
||||
[5]:https://github.com/avianto/hugo-kiera
|
||||
[6]:https://m-czernek.github.io/awesome-blog/
|
||||
[7]:https://github.com/avianto/hugo-kiera/pull/18/files
|
||||
53
published/20180518 Mastering CI-CD at OpenDev.md
Normal file
53
published/20180518 Mastering CI-CD at OpenDev.md
Normal file
@ -0,0 +1,53 @@
|
||||
在 OpenDev 大会上学习 CI/CD
|
||||
======
|
||||
> 未来的开发工作需要非常精通 CI/CD 流程。
|
||||
|
||||
|
||||
|
||||
在 2017 年启动后,OpenDev 大会现在已是一个年度活动。在去年 9 月的首届活动上,会议的重点是边缘计算。今年的活动,于 5 月 22 - 23 日举行,会议的重点是持续集成和持续发布 (CI/CD),并与 OpenStack 峰会一起在温哥华举行。
|
||||
|
||||
基于我在 OpenStack 项目的 CI/CD 系统的技术背景和我近期进入容器下的 CI/CD 方面的经验,我被邀请加入 OpenDev CI/CD 计划委员会。今天我经常借助很多开源技术,例如 [Jenkins][3]、[GitLab][2]、[Spinnaker][4] 和 [Artifactory][5] 来讨论 CI/CD 流程。
|
||||
|
||||
这次活动对我来说是很激动人心的,因为我们将在这个活动中融合两个开源基础设施理念。首先,我们将讨论可以被任何组织使用的 CI/CD 工具。为此目的,在 [讲演][6] 中,我们将听到关于开源 CI/CD 工具的使用讲演,一场来自 Boris Renski 的关于 Spinnaker 的讲演,和一场来自 Jim Blair 的关于 [Zuul][7] 的讲演。同时,讲演会涉及关于开源技术的偏好的高级别话题,特别是那种跨社区的和本身就是开源项目的。从Fatih Degirmenci 和 Daniel Farrel 那里,我们将听到关于在不同社区分享持续发布实践经历,接着 Benjamin Mako Hill 会为我们带来一场关于为什么自由软件需要自由工具的分享。
|
||||
|
||||
在分享 CI/CD 相对新颖的特性后,接下来的活动是对话、研讨会和协作讨论的混合组合。当从人们所提交的讲座和研讨会中进行选择,并提出协作讨论主题时,我们希望确保有一个多样灵活的日程表,这样任何参与者都能在 CI/CD 活动进程中发现有趣的东西。
|
||||
|
||||
这些讲座会是标准的会议风格,选择涵盖关键主题,如制定 CI/CD 流程,在实践 DevOps 时提升安全性,以及更具体的解决方案,如基于容器关于 Kubernetes 的 [Aptomi][8] 和在 ETSI NFV 环境下 CI/CD。这些会话的大部分将会是作为给新接触 CI/CD 或这些特定技术的参与者关于这些话题和理念的简介。
|
||||
|
||||
交互式的研讨会会持续相对比较长的时间,参与者将会在思想上得到特定的体验。这些研讨会包括 “[在持续集成任务中的异常检测][9]”、“[如何安装 Zuul 和配置第一个任务][10]”,和“[Spinnake 101:快速可靠的软件发布][11]”。(注意这些研讨会空间是有限的,所以设立了一个 RSVP 系统。你们将会在会议的链接里找到一个 RSVP 的按钮。)
|
||||
|
||||
可能最让我最兴奋的是协作讨论,这些协作讨论占据了一半以上的活动安排。协作讨论的主题由计划委员会选取。计划委员会根据我们在社区里所看到来选取对应的主题。这是“鱼缸”风格式的会议,通常是几个人聚在一个房间里围绕着 CI/CD 讨论某一个主题。
|
||||
|
||||
这次会议风格的理念是来自于开发者峰会,最初是由 Ubuntu 社区提出,接着 OpenStack 社区也在活动上采纳。这些协作讨论的主题包含不同的会议,这些会议是关于 CI/CD 基础,可以鼓励跨社区协作的提升举措,在组织里推行 CI/CD 文化,和为什么开源 CI/CD 工具如此重要。采用共享文档来做会议笔记,以确保尽可能的在会议的过程中分享知识。在讨论过程中,提出行动项目也是很常见的,因此社区成员可以推动和所涉及的主题相关的倡议。
|
||||
|
||||
活动将以联合总结会议结束。联合总结会议将总结来自协同讨论的关键点和为即将在这个领域工作的参与者指出可选的职业范围。
|
||||
|
||||
可以在 [OpenStack 峰会注册页][13] 上注册参加活动。或者可以在温哥华唯一指定售票的会议中心购买活动的入场券,价格是 $199。更多关于票和全部的活动安排见官网 [OpenDev 网站][1]。
|
||||
|
||||
我希望你们能够加入我们,并在温哥华渡过令人激动的两天,并且在这两天的活动中学习,协作和在 CI/CD 取得进展。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/opendev
|
||||
|
||||
作者:[Elizabeth K.Joseph][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jamelouis](https://github.com/jamelouis)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pleia2
|
||||
[1]:http://2018.opendevconf.com/
|
||||
[2]:https://about.gitlab.com/
|
||||
[3]:https://jenkins.io/
|
||||
[4]:https://www.spinnaker.io/
|
||||
[5]:https://jfrog.com/artifactory/
|
||||
[6]:http://2018.opendevconf.com/schedule/
|
||||
[7]:https://zuul-ci.org/
|
||||
[8]:http://aptomi.io/
|
||||
[9]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21692/anomaly-detection-in-continuous-integration-jobs
|
||||
[10]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21693/how-to-install-zuul-and-configure-your-first-jobs
|
||||
[11]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21699/spinnaker-101-releasing-software-with-velocity-and-confidence
|
||||
[12]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21831/opendev-cicd-joint-collab-conclusion
|
||||
[13]:https://www.eventbrite.com/e/openstack-summit-may-2018-vancouver-tickets-40845826968?aff=VancouverSummit2018
|
||||
@ -1,152 +1,153 @@
|
||||
Git 使用简介
|
||||
======
|
||||
> 我将向你介绍让 Git 的启动、运行,并和 GitHub 一起使用的基础知识。
|
||||
|
||||

|
||||
|
||||
如果你是一个开发者,那你应该熟悉许多开发工具。你已经花了多年时间来学习一种或者多种编程语言并完善你的技巧。你可以熟练运用图形工具或者命令行工具开发。在你看来,没有任何事可以阻挡你。你的代码, 好像你的思想和你的手指一样,将会创建一个优雅的,完美评价的应用程序,并会风靡世界。
|
||||
如果你是一个开发者,那你应该熟悉许多开发工具。你已经花了多年时间来学习一种或者多种编程语言并打磨你的技巧。你可以熟练运用图形工具或者命令行工具开发。在你看来,没有任何事可以阻挡你。你的代码, 好像你的思想和你的手指一样,将会创建一个优雅的,完美评价的应用程序,并会风靡世界。
|
||||
|
||||
然而,如果你和其他人共同开发一个项目会发生什么呢?或者,你开发的应用程序变地越来越大,下一步你将如何去做?如果你想成功地和其他开发者合作,你定会想用一个分布式版本控制系统。使用这样一个系统,合作开发一个项目变得非常高效和可靠。这样的一个系统便是 [Git][1]。还有一个叫 [GitHub][2] 的方便的存储仓库,来存储你的项目代码,这样你的团队可以检查和修改代码。
|
||||
然而,如果你和其他人共同开发一个项目会发生什么呢?或者,你开发的应用程序变地越来越大,下一步你将如何去做?如果你想成功地和其他开发者合作,你定会想用一个分布式版本控制系统。使用这样一个系统,合作开发一个项目变得非常高效和可靠。这样的一个系统便是 [Git][1]。还有一个叫 [GitHub][2] 的方便的存储仓库,用来存储你的项目代码,这样你的团队可以检查和修改代码。
|
||||
|
||||
我将向你介绍让 Git 的启动、运行,并和 GitHub 一起使用的基础知识,可以让你的应用程序的开发可以提升到一个新的水平。我将在 Ubuntu 18.04 上进行演示,因此如果您选择的发行版本不同,您只需要修改 Git 安装命令以适合你的发行版的软件包管理器。
|
||||
|
||||
我将向你介绍让 Git 的启动、运行,并和 GitHub 一起使用的基础知识,可以让你的应用程序的开发可以提升到一个新的水平。 我将在 Ubuntu 18.04 上进行演示,因此如果您选择的发行版本不同,您只需要修改 Git 安装命令以适合你的发行版的软件包管理器。
|
||||
### Git 和 GitHub
|
||||
|
||||
第一件事就是创建一个免费的 GitHub 账号,打开 [GitHub 注册页面][3],然后填上需要的信息。完成这个之后,你就注备好开始安装 Git 了(这两件事谁先谁后都可以)。
|
||||
|
||||
安装 Git 非常简单,打开一个命令行终端,并输入命令:
|
||||
|
||||
```
|
||||
sudo apt install git-all
|
||||
|
||||
```
|
||||
|
||||
这将会安装大量依赖包,但是你将了解使用 Git 和 GitHub 所需的一切。
|
||||
|
||||
注意:我使用 Git 来下载程序的安装源码。有许多时候,内置的软件管理器不提供某个软件,除了去第三方库中下载源码,我经常去这个软件项目的 Git 主页,像这样克隆:
|
||||
附注:我使用 Git 来下载程序的安装源码。有许多时候,内置的软件管理器不提供某个软件,除了去第三方库中下载源码,我经常去这个软件项目的 Git 主页,像这样克隆:
|
||||
|
||||
```
|
||||
git clone ADDRESS
|
||||
|
||||
```
|
||||
ADDRESS就是那个软件项目的 Git 主页。这样我就可以确保自己安装那个软件的最新发行版了。
|
||||
|
||||
创建一个本地仓库并添加一个文件。
|
||||
下一步就是在你的电脑里创建一个本地仓库(本文称之为newproject,位于~/目录下),打开一个命令行终端,并输入下面的命令:
|
||||
“ADDRESS” 就是那个软件项目的 Git 主页。这样我就可以确保自己安装那个软件的最新发行版了。
|
||||
|
||||
### 创建一个本地仓库并添加一个文件
|
||||
|
||||
下一步就是在你的电脑里创建一个本地仓库(本文称之为 newproject,位于 `~/` 目录下),打开一个命令行终端,并输入下面的命令:
|
||||
|
||||
```
|
||||
cd ~/
|
||||
|
||||
mkdir newproject
|
||||
|
||||
cd newproject
|
||||
|
||||
```
|
||||
|
||||
现在你需要初始化这个仓库。在 ~/newproject 目录下,输入命令 git init,当命令运行完,你就可以看到一个刚刚创建的空的 Git 仓库了(图1)。
|
||||
现在你需要初始化这个仓库。在 `~/newproject` 目录下,输入命令 `git init`,当命令运行完,你就可以看到一个刚刚创建的空的 Git 仓库了(图1)。
|
||||
|
||||
![new repository][5]
|
||||
|
||||
图 1:初始化完成的新仓库
|
||||
*图 1: 初始化完成的新仓库*
|
||||
|
||||
[使用许可][6]
|
||||
|
||||
下一步就是往项目里添加文件。我们在项目根目录(~/newproject)输入下面的命令:
|
||||
下一步就是往项目里添加文件。我们在项目根目录(`~/newproject`)输入下面的命令:
|
||||
|
||||
```
|
||||
touch readme.txt
|
||||
|
||||
```
|
||||
|
||||
现在项目里多了个空文件。输入 git status 来验证 Git 已经检测到多了个新文件(图2)。
|
||||
现在项目里多了个空文件。输入 `git status` 来验证 Git 已经检测到多了个新文件(图2)。
|
||||
|
||||
![readme][8]
|
||||
|
||||
图 2: Git 检测到新文件readme.txt
|
||||
|
||||
[使用许可][6]
|
||||
*图 2: Git 检测到新文件readme.txt*
|
||||
|
||||
即使 Git 检测到新的文件,但它并没有被真正的加入这个项目仓库。为此,你要输入下面的命令:
|
||||
|
||||
```
|
||||
git add readme.txt
|
||||
|
||||
```
|
||||
|
||||
一旦完成这个命令,再输入 git status 命令,可以看到,readme.txt 已经是这个项目里的新文件了(图3)。
|
||||
一旦完成这个命令,再输入 `git status` 命令,可以看到,`readme.txt` 已经是这个项目里的新文件了(图3)。
|
||||
|
||||
![file added][10]
|
||||
|
||||
图 3: 我们的文件已经被添加进临时环境
|
||||
*图 3: 我们的文件已经被添加进临时环境*
|
||||
|
||||
[使用许可][6]
|
||||
### 第一次提交
|
||||
当新文件添加进临时环境之后,我们现在就准备好第一次提交了。什么是提交呢?它是很简单的,一次提交就是记录你更改的项目的文件。创建一次提交也是非常简单的。但是,为提交创建一个描述信息非常重要。通过这样做,你将添加有关提交包含的内容的注释,比如你对文件做出的修改。然而,在这样做之前,我们需要确认我们的 Git 账户,输入以下命令:
|
||||
|
||||
当新文件添加进临时环境之后,我们现在就准备好创建第一个<ruby>提交<rt>commit</rt></ruby>了。什么是提交呢?简单的说,一个提交就是你更改的项目的文件的记录。创建一个提交也是非常简单的。但是,为提交包含一个描述信息非常重要。通过这样做,你可以添加有关该提交包含的内容的注释,比如你对文件做出的何种修改。然而,在这样做之前,我们需要告知 Git 我们的账户,输入以下命令:
|
||||
|
||||
```
|
||||
git config --global user.email EMAIL
|
||||
|
||||
git config --global user.name “FULL NAME”
|
||||
|
||||
```
|
||||
EMAIL 即你的 email 地址,FULL NAME 则是你的姓名。现在你可以通过以下命令创建一个提交:
|
||||
|
||||
“EMAIL” 即你的 email 地址,“FULL NAME” 则是你的姓名。
|
||||
|
||||
现在你可以通过以下命令创建一个提交:
|
||||
|
||||
```
|
||||
git commit -m “Descriptive Message”
|
||||
|
||||
```
|
||||
Descriptive Message 即为你的提交的描述性信息。比如,当你第一次提交是提交一个 readme.txt 文件,你可以这样提交:
|
||||
|
||||
“Descriptive Message” 即为你的提交的描述性信息。比如,当你第一个提交是提交一个 `readme.txt` 文件,你可以这样提交:
|
||||
|
||||
```
|
||||
git commit -m “First draft of readme.txt file”
|
||||
|
||||
```
|
||||
|
||||
你可以看到输出显示一个文件已经修改,并且,为 readnme.txt 创建了一个新模式(图4)
|
||||
你可以看到输出表明一个文件已经修改,并且,为 `readme.txt` 创建了一个新的文件模式(图4)
|
||||
|
||||
![success][12]
|
||||
|
||||
图4:提交成功
|
||||
*图4:提交成功*
|
||||
|
||||
|
||||
### 创建分支并推送至 GitHub
|
||||
|
||||
分支是很重要的,它允许你在项目状态间中移动。假如,你想给你的应用创建一个新的特性。为了这样做,你创建了个新分支。一旦你完成你的新特性,你可以把这个新分支合并到你的主分支中去,使用以下命令创建一个新分支:
|
||||
|
||||
[使用许可][6]
|
||||
### 创建分支并推送至GitHub
|
||||
分支是很重要的,它允许你从项目状态间中移动。假如,你想给你的应用创建一个新的特性。为了这样做,你创建了个新分支。一旦你完成你的新特性,你可以把这个新分支合并到你的主分支中去,使用以下命令创建一个新分支:
|
||||
```
|
||||
git checkout -b BRANCH
|
||||
|
||||
```
|
||||
BRANCH 即为你新分支的名字,一旦执行完命令,输入 git branch 命令来查看是否创建了新分支(图5)
|
||||
|
||||
“BRANCH” 即为你新分支的名字,一旦执行完命令,输入 `git branch` 命令来查看是否创建了新分支(图5)
|
||||
|
||||
![featureX][14]
|
||||
|
||||
图5:名为 featureX 的新分支
|
||||
*图5:名为 featureX 的新分支*
|
||||
|
||||
[使用许可][6]
|
||||
|
||||
接下来,我们需要在GitHub上创建一个仓库。 登录GitHub帐户,请单击帐户主页上的“新建仓库”按钮。 填写必要的信息,然后单击Create repository(图6)。
|
||||
接下来,我们需要在 GitHub 上创建一个仓库。 登录 GitHub 帐户,请单击帐户主页上的“New Repository”按钮。 填写必要的信息,然后单击 “Create repository”(图6)。
|
||||
|
||||
![new repository][16]
|
||||
|
||||
图6:在 GitHub 上新建一个仓库
|
||||
*图6:在 GitHub 上新建一个仓库*
|
||||
|
||||
[使用许可][6]
|
||||
在创建完一个仓库之后,你可以看到一个用于推送本地仓库的地址。若要推送,返回命令行窗口(`~/newproject` 目录中),输入以下命令:
|
||||
|
||||
在创建完一个仓库之后,你可以看到一个用于推送本地仓库的地址。若要推送,返回命令行窗口( ~/newproject 目录中),输入以下命令:
|
||||
```
|
||||
git remote add origin URL
|
||||
|
||||
git push -u origin master
|
||||
|
||||
```
|
||||
URL 即为我们 GitHub 上新建的仓库地址。
|
||||
|
||||
“URL” 即为我们 GitHub 上新建的仓库地址。
|
||||
|
||||
系统会提示您,输入 GitHub 的用户名和密码,一旦授权成功,你的项目将会被推送到 GitHub 仓库中。
|
||||
|
||||
### 拉取项目
|
||||
|
||||
如果你的同事改变了你们 GitHub 上项目的代码,并且已经合并那些更改,你可以拉取那些项目文件到你的本地机器,这样,你系统中的文件就可以和远程用户的文件保持匹配。你可以输入以下命令来做这件事( ~/newproject 在目录中),
|
||||
如果你的同事改变了你们 GitHub 上项目的代码,并且已经合并那些更改,你可以拉取那些项目文件到你的本地机器,这样,你系统中的文件就可以和远程用户的文件保持匹配。你可以输入以下命令来做这件事(`~/newproject` 在目录中),
|
||||
|
||||
```
|
||||
git pull origin master
|
||||
|
||||
```
|
||||
|
||||
以上的命令可以拉取任何新文件或修改过的文件到你的本地仓库。
|
||||
|
||||
### 基础
|
||||
|
||||
这就是从命令行使用 Git 来处理存储在 GitHub 上的项目的基础知识。 还有很多东西需要学习,所以我强烈建议你使用 man git,man git-push 和 man git-pull 命令来更深入地了解 git 命令可以做什么。
|
||||
这就是从命令行使用 Git 来处理存储在 GitHub 上的项目的基础知识。 还有很多东西需要学习,所以我强烈建议你使用 `man git`,`man git-push` 和 `man git-pull` 命令来更深入地了解 `git` 命令可以做什么。
|
||||
|
||||
开发快乐!
|
||||
|
||||
了解更多关于 Linux的 内容,请访问来自 Linux 基金会和 edX 的免费的 ["Introduction to Linux" ][17]课程。
|
||||
了解更多关于 Linux 的 内容,请访问来自 Linux 基金会和 edX 的免费的 ["Introduction to Linux"][17]课程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -155,7 +156,7 @@ via: https://www.linux.com/learn/intro-to-linux/2018/7/introduction-using-git
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[distant1219](https://github.com/distant1219)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,77 @@
|
||||
如何使用 Apache 构建 URL 缩短服务
|
||||
======
|
||||
> 用 Apache HTTP 服务器的 mod_rewrite 功能创建你自己的短链接。
|
||||
|
||||

|
||||
|
||||
很久以前,人们开始在 Twitter 上分享链接。140 个字符的限制意味着 URL 可能消耗一条推文的大部分(或全部),因此人们使用 URL 缩短服务。最终,Twitter 加入了一个内置的 URL 缩短服务([t.co][1])。
|
||||
|
||||
字符数现在不重要了,但还有其他原因要缩短链接。首先,缩短服务可以提供分析功能 —— 你可以看到你分享的链接的受欢迎程度。它还简化了制作易于记忆的 URL。例如,[bit.ly/INtravel][2] 比<https://www.in.gov/ai/appfiles/dhs-countyMap/dhsCountyMap.html>更容易记住。如果你想预先共享一个链接,但还不知道最终地址,这时 URL 缩短服务可以派上用场。。
|
||||
|
||||
与任何技术一样,URL 缩短服务并非都是正面的。通过屏蔽最终地址,缩短的链接可用于指向恶意或冒犯性内容。但是,如果你仔细上网,URL 缩短服务是一个有用的工具。
|
||||
|
||||
我们之前在网站上[发布过缩短服务的文章][3],但也许你想要运行一些由简单的文本文件支持的缩短服务。在本文中,我们将展示如何使用 Apache HTTP 服务器的 mod_rewrite 功能来设置自己的 URL 缩短服务。如果你不熟悉 Apache HTTP 服务器,请查看 David Both 关于[安装和配置][4]它的文章。
|
||||
|
||||
### 创建一个 VirtualHost
|
||||
|
||||
在本教程中,我假设你购买了一个很酷的域名,你将它专门用于 URL 缩短服务。例如,我的网站是 [funnelfiasco.com][5],所以我买了 [funnelfias.co][6] 用于我的 URL 缩短服务(好吧,它不是很短,但它可以满足我的虚荣心)。如果你不将缩短服务作为单独的域运行,请跳到下一部分。
|
||||
|
||||
第一步是设置将用于 URL 缩短服务的 VirtualHost。有关 VirtualHost 的更多信息,请参阅 [David Both 的文章][7]。这步只需要几行:
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
ServerName funnelfias.co
|
||||
</VirtualHost>
|
||||
```
|
||||
|
||||
### 创建重写规则
|
||||
|
||||
此服务使用 HTTPD 的重写引擎来重写 URL。如果你在上面的部分中创建了 VirtualHost,则下面的配置跳到你的 VirtualHost 部分。否则跳到服务器的 VirtualHost 或主 HTTPD 配置。
|
||||
|
||||
```
|
||||
RewriteEngine on
|
||||
RewriteMap shortlinks txt:/data/web/shortlink/links.txt
|
||||
RewriteRule ^/(.+)$ ${shortlinks:$1} [R=temp,L]
|
||||
```
|
||||
|
||||
第一行只是启用重写引擎。第二行在文本文件构建短链接的映射。上面的路径只是一个例子。你需要使用系统上使用有效路径(确保它可由运行 HTTPD 的用户帐户读取)。最后一行重写 URL。在此例中,它接受任何字符并在重写映射中查找它们。你可能希望重写时使用特定的字符串。例如,如果你希望所有缩短的链接都是 “slX”(其中 X 是数字),则将上面的 `(.+)` 替换为 `(sl\d+)`。
|
||||
|
||||
我在这里使用了临时重定向(HTTP 302)。这能让我稍后更新目标 URL。如果希望短链接始终指向同一目标,则可以使用永久重定向(HTTP 301)。用 `permanent` 替换第三行的 `temp`。
|
||||
|
||||
### 构建你的映射
|
||||
|
||||
编辑配置文件 `RewriteMap` 行中的指定文件。格式是空格分隔的键值存储。在每一行上放一个链接:
|
||||
|
||||
```
|
||||
osdc https://opensource.com/users/bcotton
|
||||
twitter https://twitter.com/funnelfiasco
|
||||
swody1 https://www.spc.noaa.gov/products/outlook/day1otlk.html
|
||||
```
|
||||
|
||||
### 重启 HTTPD
|
||||
|
||||
最后一步是重启 HTTPD 进程。这是通过 `systemctl restart httpd` 或类似命令完成的(命令和守护进程名称可能因发行版而不同)。你的链接缩短服务现已启动并运行。当你准备编辑映射时,无需重新启动 Web 服务器。你所要做的就是保存文件,Web 服务器将获取到差异。
|
||||
|
||||
### 未来的工作
|
||||
|
||||
此示例为你提供了基本的 URL 缩短服务。如果你想将开发自己的管理接口作为学习项目,它可以作为一个很好的起点。或者你可以使用它分享容易记住的链接到那些容易忘记的 URL。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/apache-url-shortener
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:http://t.co
|
||||
[2]:http://bit.ly/INtravel
|
||||
[3]:https://opensource.com/article/17/3/url-link-shortener
|
||||
[4]:https://opensource.com/article/18/2/how-configure-apache-web-server
|
||||
[5]:http://funnelfiasco.com
|
||||
[6]:http://funnelfias.co
|
||||
[7]:https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
|
||||
@ -1,47 +1,48 @@
|
||||
PKI 和 密码学中的私钥的角色
|
||||
公钥基础设施和密码学中的私钥的角色
|
||||
======
|
||||
> 了解如何验证某人所声称的身份。
|
||||
|
||||

|
||||
|
||||
在[上一篇文章][1]中,我们概述了密码学并讨论了密码学的核心概念:<ruby>保密性<rt>confidentiality</rt></ruby> (让数据保密),<ruby>完整性<rt>integrity</rt></ruby> (防止数据被篡改)和<ruby>身份认证<rt>authentication</rt></ruby> (确认数据源的<ruby>身份<rt>identity</rt></ruby>)。由于要在存在各种身份混乱的现实世界中完成身份认证,人们逐渐建立起一个复杂的<ruby>技术生态体系<rt>technological ecosystem</rt></ruby>,用于证明某人就是其声称的那个人。在本文中,我们将大致介绍这些体系是如何工作的。
|
||||
在[上一篇文章][1]中,我们概述了密码学并讨论了密码学的核心概念:<ruby>保密性<rt>confidentiality</rt></ruby> (让数据保密)、<ruby>完整性<rt>integrity</rt></ruby> (防止数据被篡改)和<ruby>身份认证<rt>authentication</rt></ruby> (确认数据源的<ruby>身份<rt>identity</rt></ruby>)。由于要在存在各种身份混乱的现实世界中完成身份认证,人们逐渐建立起一个复杂的<ruby>技术生态体系<rt>technological ecosystem</rt></ruby>,用于证明某人就是其声称的那个人。在本文中,我们将大致介绍这些体系是如何工作的。
|
||||
|
||||
### 公钥密码学及数字签名快速回顾
|
||||
### 快速回顾公钥密码学及数字签名
|
||||
|
||||
互联网世界中的身份认证依赖于公钥密码学,其中密钥分为两部分:拥有者需要保密的私钥和可以对外公开的公钥。经过公钥加密过的数据,只能用对应的私钥解密。举个例子,对于希望与[记者][2]建立联系的举报人来说,这个特性非常有用。但就本文介绍的内容而言,私钥更重要的用途是与一个消息一起创建一个<ruby>数字签名<rt>digital signature</rt></ruby>,用于提供完整性和身份认证。
|
||||
|
||||
在实际应用中,我们签名的并不是真实消息,而是经过<ruby>密码学哈希函数<rt>cryptographic hash function</rt></ruby>处理过的消息<ruby>摘要<rt>digest</rt></ruby>。要发送一个包含源代码的压缩文件,发送者会对该压缩文件的 256 比特长度的 [SHA-256][3] 摘要而不是文件本身进行签名,然后用明文发送该压缩包(和签名)。接收者会独立计算收到文件的 SHA-256 摘要,然后结合该摘要、收到的签名及发送者的公钥,使用签名验证算法进行验证。验证过程取决于加密算法,加密算法不同,验证过程也相应不同;而且,由于不断发现微妙的触发条件,签名验证[漏洞][4]依然[层出不穷][5]。如果签名验证通过,说明文件在传输过程中没有被篡改而且来自于发送者,这是因为只有发送者拥有创建签名所需的私钥。
|
||||
在实际应用中,我们签名的并不是真实消息,而是经过<ruby>密码学哈希函数<rt>cryptographic hash function</rt></ruby>处理过的消息<ruby>摘要<rt>digest</rt></ruby>。要发送一个包含源代码的压缩文件,发送者会对该压缩文件的 256 比特长度的 [SHA-256][3] 摘要进行签名,而不是文件本身进行签名,然后用明文发送该压缩包(和签名)。接收者会独立计算收到文件的 SHA-256 摘要,然后结合该摘要、收到的签名及发送者的公钥,使用签名验证算法进行验证。验证过程取决于加密算法,加密算法不同,验证过程也相应不同;而且,很微妙的是签名验证[漏洞][4]依然[层出不穷][5]。如果签名验证通过,说明文件在传输过程中没有被篡改而且来自于发送者,这是因为只有发送者拥有创建签名所需的私钥。
|
||||
|
||||
### 方案中缺失的环节
|
||||
|
||||
上述方案中缺失了一个重要的环节:我们从哪里获得发送者的公钥?发送者可以将公钥与消息一起发送,但除了发送者的自我宣称,我们无法核验其身份。假设你是一名银行柜员,一名顾客走过来向你说,“你好,我是 Jane Doe,我要取一笔钱”。当你要求其证明身份时,她指着衬衫上贴着的姓名标签说道,“看,Jane Doe!”。如果我是这个柜员,我会礼貌的拒绝她的请求。
|
||||
|
||||
如果你认识发送者,你们可以私下见面并彼此交换公钥。如果你并不认识发送者,你们可以私下见面,检查对方的证件,确认真实性后接受对方的公钥。为提高流程效率,你可以举办聚会并邀请一堆人,检查他们的证件,然后接受他们的公钥。此外,如果你认识并信任 Jane Doe (尽管她在银行的表现比较反常),Jane 可以参加聚会,收集大家的公钥然后交给你。事实上,Jane 可以使用她自己的私钥对这些公钥(及对应的身份信息)进行签名,进而你可以从一个[线上密钥库][7]获取公钥(及对应的身份信息)并信任已被 Jane 签名的那部分。如果一个人的公钥被很多你信任的人(即使你并不认识他们)签名,你也可能选择信任这个人。按照这种方式,你可以建立一个[<ruby>信任网络<rt>Web of Trust</rt></ruby>][8]。
|
||||
如果你认识发送者,你们可以私下见面并彼此交换公钥。如果你并不认识发送者,你们可以私下见面,检查对方的证件,确认真实性后接受对方的公钥。为提高流程效率,你可以举办[聚会][6]并邀请一堆人,检查他们的证件,然后接受他们的公钥。此外,如果你认识并信任 Jane Doe(尽管她在银行的表现比较反常),Jane 可以参加聚会,收集大家的公钥然后交给你。事实上,Jane 可以使用她自己的私钥对这些公钥(及对应的身份信息)进行签名,进而你可以从一个[线上密钥库][7]获取公钥(及对应的身份信息)并信任已被 Jane 签名的那部分。如果一个人的公钥被很多你信任的人(即使你并不认识他们)签名,你也可能选择信任这个人。按照这种方式,你可以建立一个<ruby>[信任网络][8]<rt>Web of Trust</rt></ruby>。
|
||||
|
||||
但事情也变得更加复杂:我们需要建立一种标准的编码机制,可以将公钥和其对应的身份信息编码成一个<ruby>数字捆绑<rt>digital bundle</rt></ruby>,以便我们进一步进行签名。更准确的说,这类数字捆绑被称为<ruby>证书<rt>cerificates</rt></ruby>。我们还需要可以创建、使用和管理这些证书的工具链。满足诸如此类的各种需求的方案构成了<ruby>公钥基础设施<rt>public key infrastructure, PKI</rt></ruby>。
|
||||
但事情也变得更加复杂:我们需要建立一种标准的编码机制,可以将公钥和其对应的身份信息编码成一个<ruby>数字捆绑<rt>digital bundle</rt></ruby>,以便我们进一步进行签名。更准确的说,这类数字捆绑被称为<ruby>证书<rt>cerificate</rt></ruby>。我们还需要可以创建、使用和管理这些证书的工具链。满足诸如此类的各种需求的方案构成了<ruby>公钥基础设施<rt>public key infrastructure</rt></ruby>(PKI)。
|
||||
|
||||
### 比信任网络更进一步
|
||||
|
||||
你可以用人际关系网类比信任网络。如果人们之间广泛互信,可以很容易找到(两个人之间的)一条<ruby>短信任链<rt>short path of trust</rt></ruby>:不妨以社交圈为例。基于 [GPG][9] 加密的邮件依赖于信任网络,([理论上][10])只适用于与少量朋友、家庭或同事进行联系的情形。
|
||||
你可以用人际关系网类比信任网络。如果人们之间广泛互信,可以很容易找到(两个人之间的)一条<ruby>短信任链<rt>short path of trust</rt></ruby>:就像一个社交圈。基于 [GPG][9] 加密的邮件依赖于信任网络,([理论上][10])只适用于与少量朋友、家庭或同事进行联系的情形。
|
||||
|
||||
(LCTT 译注:作者提到的“短信任链”应该是暗示“六度空间理论”,即任意两个陌生人之间所间隔的人一般不会超过 6 个。对 GPG 的唱衰,一方面是因为密钥管理的复杂性没有改善,另一方面 Yahoo 和 Google 都提出了更便利的端到端加密方案。)
|
||||
|
||||
在实际应用中,信任网络有一些[<ruby>"硬伤"<rt>significant problems</rt></ruby>][11],主要是在可扩展性方面。当网络规模逐渐增大或者人们之间的连接逐渐降低时,信任网络就会慢慢失效。如果信任链逐渐变长,信任链中某人有意或无意误签证书的几率也会逐渐增大。如果信任链不存在,你不得不自己创建一条信任链;具体而言,你与其它组织建立联系,验证它们的密钥符合你的要求。考虑下面的场景,你和你的朋友要访问一个从未使用过的在线商店。你首先需要核验网站所用的公钥属于其对应的公司而不是伪造者,进而建立安全通信信道,最后完成下订单操作。核验公钥的方法包括去实体店、打电话等,都比较麻烦。这样会导致在线购物变得不那么便利(或者说不那么安全,毕竟很多人会图省事,不去核验密钥)。
|
||||
在实际应用中,信任网络有一些“<ruby>[硬伤][11]<rt>significant problems</rt></ruby>”,主要是在可扩展性方面。当网络规模逐渐增大或者人们之间的连接较少时,信任网络就会慢慢失效。如果信任链逐渐变长,信任链中某人有意或无意误签证书的几率也会逐渐增大。如果信任链不存在,你不得不自己创建一条信任链,与其它组织建立联系,验证它们的密钥以符合你的要求。考虑下面的场景,你和你的朋友要访问一个从未使用过的在线商店。你首先需要核验网站所用的公钥属于其对应的公司而不是伪造者,进而建立安全通信信道,最后完成下订单操作。核验公钥的方法包括去实体店、打电话等,都比较麻烦。这样会导致在线购物变得不那么便利(或者说不那么安全,毕竟很多人会图省事,不去核验密钥)。
|
||||
|
||||
如果世界上有那么几个格外值得信任的人,他们专门负责核验和签发网站证书,情况会怎样呢?你可以只信任他们,那么浏览互联网也会变得更加容易。整体来看,这就是当今互联网的工作方式。那些“格外值得信任的人”就是被称为<ruby>证书颁发机构<rt>cerificate authorities, CAs</rt></ruby>的公司。当网站希望获得公钥签名时,只需向 CA 提交<ruby>证书签名请求<rt>certificate signing request</rt></ruby>。
|
||||
如果世界上有那么几个格外值得信任的人,他们专门负责核验和签发网站证书,情况会怎样呢?你可以只信任他们,那么浏览互联网也会变得更加容易。整体来看,这就是当今互联网的工作方式。那些“格外值得信任的人”就是被称为<ruby>证书颁发机构<rt>cerificate authoritie</rt></ruby>(CA)的公司。当网站希望获得公钥签名时,只需向 CA 提交<ruby>证书签名请求<rt>certificate signing request</rt></ruby>(CSR)。
|
||||
|
||||
CSR 类似于包括公钥和身份信息(在本例中,即服务器的主机名)的<ruby>存根<rt>stub</rt></ruby>证书,但CA 并不会直接对 CSR 本身进行签名。CA 在签名之前会进行一些验证。对于一些证书类型(LCTT 译注:<ruby>DV<rt>Domain Validated</rt></ruby> 类型),CA 只验证申请者的确是 CSR 中列出主机名对应域名的控制者(例如通过邮件验证,让申请者完成指定的域名解析)。[对于另一些证书类型][12] (LCTT 译注:链接中提到<ruby>EV<rt>Extended Validated</rt></ruby> 类型,其实还有 <ruby>OV<rt>Organization Validated</rt></ruby> 类型),CA 还会检查相关法律文书,例如公司营业执照等。一旦验证完成,CA(一般在申请者付费后)会从 CSR 中取出数据(即公钥和身份信息),使用 CA 自己的私钥进行签名,创建一个(签名)证书并发送给申请者。申请者将该证书部署在网站服务器上,当用户使用 HTTPS (或其它基于 [TLS][13] 加密的协议)与服务器通信时,该证书被分发给用户。
|
||||
CSR 类似于包括公钥和身份信息(在本例中,即服务器的主机名)的<ruby>存根<rt>stub</rt></ruby>证书,但 CA 并不会直接对 CSR 本身进行签名。CA 在签名之前会进行一些验证。对于一些证书类型(LCTT 译注:<ruby>域名证实<rt>Domain Validated</rt></ruby>(DV) 类型),CA 只验证申请者的确是 CSR 中列出主机名对应域名的控制者(例如通过邮件验证,让申请者完成指定的域名解析)。[对于另一些证书类型][12] (LCTT 译注:链接中提到<ruby>扩展证实<rt>Extended Validated</rt></ruby>(EV)类型,其实还有 <ruby>OV<rt>Organization Validated</rt></ruby> 类型),CA 还会检查相关法律文书,例如公司营业执照等。一旦验证完成,CA(一般在申请者付费后)会从 CSR 中取出数据(即公钥和身份信息),使用 CA 自己的私钥进行签名,创建一个(签名)证书并发送给申请者。申请者将该证书部署在网站服务器上,当用户使用 HTTPS (或其它基于 [TLS][13] 加密的协议)与服务器通信时,该证书被分发给用户。
|
||||
|
||||
当用户访问该网站时,浏览器获取该证书,接着检查证书中的主机名是否与当前正在连接的网站一致(下文会详细说明),核验 CA 签名有效性。如果其中一步验证不通过,浏览器会给出安全警告并切断与网站的连接。反之,如果验证通过,浏览器会使用证书中的公钥核验服务器发送的签名信息,确认该服务器持有该证书的私钥。有几种算法用于协商后续通信用到的<ruby>共享密钥<rt>shared secret key</rt></ruby>,其中一种也用到了服务器发送的签名信息。<ruby>密钥交换<rt>Key exchange</rt></ruby>算法不在本文的讨论范围,可以参考这个[视频][14],其中仔细说明了一种密钥交换算法。
|
||||
当用户访问该网站时,浏览器获取该证书,接着检查证书中的主机名是否与当前正在连接的网站一致(下文会详细说明),核验 CA 签名有效性。如果其中一步验证不通过,浏览器会给出安全警告并切断与网站的连接。反之,如果验证通过,浏览器会使用证书中的公钥来核验该服务器发送的签名信息,确认该服务器持有该证书的私钥。有几种算法用于协商后续通信用到的<ruby>共享密钥<rt>shared secret key</rt></ruby>,其中一种也用到了服务器发送的签名信息。<ruby>密钥交换<rt>key exchange</rt></ruby>算法不在本文的讨论范围,可以参考这个[视频][14],其中仔细说明了一种密钥交换算法。
|
||||
|
||||
### 建立信任
|
||||
|
||||
你可能会问,“如果 CA 使用其私钥对证书进行签名,也就意味着我们需要使用 CA 的公钥验证证书。那么 CA 的公钥从何而来,谁对其进行签名呢?” 答案是 CA 对自己签名!可以使用证书公钥对应的私钥,对证书本身进行签名!这类签名证书被称为是<ruby>自签名的<rt>self-signed</rt></ruby>;在 PKI 体系下,这意味着对你说“相信我”。(为了表达方便,人们通常说用证书进行了签名,虽然真正用于签名的私钥并不在证书中。)
|
||||
|
||||
通过遵守[浏览器][15]和[操作系统][16]供应商建立的规则,CA 表明自己足够可靠并寻求加入到浏览器或操作系统预装的一组自签名证书中。这些证书被称为“<ruby>信任锚<rt>trust anchors</rt></ruby>”或 <ruby>CA 根证书<rt>root CA certificates</rt></ruby>,被存储在根证书区,我们<ruby>约定<rt>implicitly</rt></ruby>信任该区域内的证书。
|
||||
通过遵守[浏览器][15]和[操作系统][16]供应商建立的规则,CA 表明自己足够可靠并寻求加入到浏览器或操作系统预装的一组自签名证书中。这些证书被称为“<ruby>信任锚<rt>trust anchor</rt></ruby>”或 <ruby>CA 根证书<rt>root CA certificate</rt></ruby>,被存储在根证书区,我们<ruby>约定<rt>implicitly</rt></ruby>信任该区域内的证书。
|
||||
|
||||
CA 也可以签发一种特殊的证书,该证书自身可以作为 CA。在这种情况下,它们可以生成一个证书链。要核验证书链,需要从“信任锚”(也就是 CA 根证书)开始,使用当前证书的公钥核验下一层证书的签名(或其它一些信息)。按照这个方式依次核验下一层证书,直到证书链底部。如果整个核验过程没有问题,信任链也建立完成。当向 CA 付费为网站签发证书时,实际购买的是将证书放置在证书链下的权利。CA 将卖出的证书标记为“不可签发子证书”,这样它们可以在适当的长度终止信任链(防止其继续向下扩展)。
|
||||
|
||||
为何要使用长度超过 2 的信任链呢?毕竟网站的证书可以直接被 CA 根证书签名。在实际应用中,很多因素促使 CA 创建<ruby>中间 CA 证书<rt>intermediate CA certificate</rt></ruby>,最主要是为了方便。由于价值连城,CA 根证书对应的私钥通常被存放在特定的设备中,一种需要多人解锁的<ruby>硬件安全模块<rt>hardware security module, HSM</rt></ruby>,该模块完全离线并被保管在配备监控和报警设备的[地下室][18]中。
|
||||
为何要使用长度超过 2 的信任链呢?毕竟网站的证书可以直接被 CA 根证书签名。在实际应用中,很多因素促使 CA 创建<ruby>中间 CA 证书<rt>intermediate CA certificate</rt></ruby>,最主要是为了方便。由于价值连城,CA 根证书对应的私钥通常被存放在特定的设备中,一种需要多人解锁的<ruby>硬件安全模块<rt>hardware security module</rt></ruby>(HSM),该模块完全离线并被保管在配备监控和报警设备的[地下室][18]中。
|
||||
|
||||
<ruby>CA/浏览器论坛<rt>CAB Forum, CA/Browser Forum</rt></ruby>负责管理 CA,[要求][19]任何与 CA 根证书(LCTT 译注:就像前文提到的那样,这里是指对应的私钥)相关的操作必须由人工完成。设想一下,如果每个证书请求都需要员工将请求内容拷贝到保密介质中、进入地下室、与同事一起解锁 HSM、(使用 CA 根证书对应的私钥)签名证书,最后将签名证书从保密介质中拷贝出来;那么每天为大量网站签发证书是相当繁重乏味的工作。因此,CA 创建内部使用的中间 CA,用于证书签发自动化。
|
||||
|
||||
@ -72,12 +73,12 @@ via: https://opensource.com/article/18/7/private-keys
|
||||
作者:[Alex Wood][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/awood
|
||||
[1]:https://opensource.com/article/18/5/cryptography-pki
|
||||
[1]:https://linux.cn/article-9792-1.html
|
||||
[2]:https://theintercept.com/2014/10/28/smuggling-snowden-secrets/
|
||||
[3]:https://en.wikipedia.org/wiki/SHA-2
|
||||
[4]:https://www.ietf.org/mail-archive/web/openpgp/current/msg00999.html
|
||||
@ -1,80 +1,84 @@
|
||||
这 7 个 Python 库让你写出更易维护的代码
|
||||
让 Python 代码更易维护的七种武器
|
||||
======
|
||||
|
||||
> 检查你的代码的质量,通过这些外部库使其更易维护。
|
||||
|
||||

|
||||
|
||||
> 可读性很重要。
|
||||
> — [Python 之禅(The Zen of Python)][1], Tim Peters
|
||||
> — <ruby>[Python 之禅][1]<rt>The Zen of Python</rt></ruby>,Tim Peters
|
||||
|
||||
尽管很多项目一开始的时候就有可读性和编码标准的要求,但随着项目进入“维护模式”,这些要求都会变得虎头蛇尾。然而,在代码库中保持一致的代码风格和测试标准能够显著减轻维护的压力,也能确保新的开发者能够快速了解项目的情况,同时能更好地保持应用程序的运行良好。
|
||||
随着软件项目进入“维护模式”,对可读性和编码标准的要求很容易落空(甚至从一开始就没有建立过那些标准)。然而,在代码库中保持一致的代码风格和测试标准能够显著减轻维护的压力,也能确保新的开发者能够快速了解项目的情况,同时能更好地全程保持应用程序的质量。
|
||||
|
||||
使用外部库来检查代码的质量不失为保护项目未来可维护性的一个好方法。以下会推荐一些我们最喜爱的[检查代码][2](包括检查 PEP 8 和其它代码风格错误)的库,用它们来强制保持代码风格一致,并确保在项目成熟时有一个可接受的测试覆盖率。
|
||||
|
||||
### 检查你的代码风格
|
||||
|
||||
使用外部库来检查代码运行情况不失为保护项目未来可维护性的一个好方法。以下会推荐一些我们最喜爱的[检查代码][2](包括检查 PEP 8 和其它代码风格错误)的库,用它们来强制保持代码风格一致,并确保在项目成熟时有一个可接受的测试覆盖率。
|
||||
[PEP 8][3] 是 Python 代码风格规范,它规定了类似行长度、缩进、多行表达式、变量命名约定等内容。尽管你的团队自身可能也会有稍微不同于 PEP 8 的代码风格规范,但任何代码风格规范的目标都是在代码库中强制实施一致的标准,使代码的可读性更强、更易于维护。下面三个库就可以用来帮助你美化代码。
|
||||
|
||||
[PEP 8][3]是Python代码风格规范,规定了行长度,缩进,多行表达式、变量命名约定等内容。尽管你的团队自身可能也会有不同于 PEP 8 的代码风格规范,但任何代码风格规范的目标都是在代码库中强制实施一致的标准,使代码的可读性更强、更易于维护。下面三个库就可以用来帮助你美化代码。
|
||||
#### 1、 Pylint
|
||||
|
||||
#### 1\. Pylint
|
||||
[Pylint][4] 是一个检查违反 PEP 8 规范和常见错误的库。它在一些流行的[编辑器和 IDE][5] 中都有集成,也可以单独从命令行运行。
|
||||
|
||||
[Pylint][4] 是一个检查违反 PEP 8 规范和常见错误的库。它在一些流行的编辑器和 IDE 中都有集成,也可以单独从命令行运行。
|
||||
|
||||
执行 `pip install pylint`安装 Pylint 。然后运行 `pylint [options] path/to/dir` 或者 `pylint [options] path/to/module.py` 就可以在命令行中使用 Pylint,它会向控制台输出代码中违反规范和出现错误的地方。
|
||||
执行 `pip install pylint` 安装 Pylint 。然后运行 `pylint [options] path/to/dir` 或者 `pylint [options] path/to/module.py` 就可以在命令行中使用 Pylint,它会向控制台输出代码中违反规范和出现错误的地方。
|
||||
|
||||
你还可以使用 `pylintrc` [配置文件][6]来自定义 Pylint 对哪些代码错误进行检查。
|
||||
|
||||
#### 2\. Flake8
|
||||
#### 2、 Flake8
|
||||
|
||||
对 [Flake8][7] 的描述是“将 PEP 8、Pyflakes(类似 Pylint)、McCabe(代码复杂性检查器)、第三方插件整合到一起,以检查 Python 代码风格和质量的一个 Python 工具”。
|
||||
[Flake8][7] 是“将 PEP 8、Pyflakes(类似 Pylint)、McCabe(代码复杂性检查器)和第三方插件整合到一起,以检查 Python 代码风格和质量的一个 Python 工具”。
|
||||
|
||||
执行 `pip install flake8` 安装 flake8 ,然后执行 `flake8 [options] path/to/dir` 或者 `flake8 [options] path/to/module.py` 可以查看报出的错误和警告。
|
||||
|
||||
和 Pylint 类似,Flake8 允许通过[配置文件][8]来自定义检查的内容。它有非常清晰的文档,包括一些有用的[提交钩子][9],可以将自动检查代码纳入到开发工作流程之中。
|
||||
|
||||
Flake8 也允许集成到一些流行的编辑器和 IDE 当中,但在文档中并没有详细说明。要将 Flake8 集成到喜欢的编辑器或 IDE 中,可以搜索插件(例如 [Sublime Text 的 Flake8 插件][10])。
|
||||
Flake8 也可以集成到一些流行的编辑器和 IDE 当中,但在文档中并没有详细说明。要将 Flake8 集成到喜欢的编辑器或 IDE 中,可以搜索插件(例如 [Sublime Text 的 Flake8 插件][10])。
|
||||
|
||||
#### 3\. Isort
|
||||
#### 3、 Isort
|
||||
|
||||
[Isort][11] 这个库能将你在项目中导入的库按字母顺序,并将其[正确划分为不同部分][12](例如标准库、第三方库,自建的库等)。这样提高了代码的可读性,并且可以在导入的库较多的时候轻松找到各个库。
|
||||
[Isort][11] 这个库能将你在项目中导入的库按字母顺序排序,并将其[正确划分为不同部分][12](例如标准库、第三方库、自建的库等)。这样提高了代码的可读性,并且可以在导入的库较多的时候轻松找到各个库。
|
||||
|
||||
执行 `pip install isort` 安装 isort,然后执行 `isort path/to/module.py` 就可以运行了。文档中还提供了更多的配置项,例如通过配置 `.isort.cfg` 文件来决定 isort 如何处理一个库的多行导入。
|
||||
执行 `pip install isort` 安装 isort,然后执行 `isort path/to/module.py` 就可以运行了。[文档][13]中还提供了更多的配置项,例如通过[配置][14] `.isort.cfg` 文件来决定 isort 如何处理一个库的多行导入。
|
||||
|
||||
和 Flake8、Pylint 一样,isort 也提供了将其与流行的[编辑器和 IDE][15] 集成的插件。
|
||||
|
||||
### 共享代码风格
|
||||
### 分享你的代码风格
|
||||
|
||||
每次文件发生变动之后都用命令行手动检查代码是一件痛苦的事,你可能也不太喜欢通过运行 IDE 中某个插件来实现这个功能。同样地,你的同事可能会用不同的代码检查方式,也许他们的编辑器中也没有安装插件,甚至自己可能也不会严格检查代码和按照警告来更正代码。总之,你共享的代码库将会逐渐地变得混乱且难以阅读。
|
||||
每次文件发生变动之后都用命令行手动检查代码是一件痛苦的事,你可能也不太喜欢通过运行 IDE 中某个插件来实现这个功能。同样地,你的同事可能会用不同的代码检查方式,也许他们的编辑器中也没有那种插件,甚至你自己可能也不会严格检查代码和按照警告来更正代码。总之,你分享出来的代码库将会逐渐地变得混乱且难以阅读。
|
||||
|
||||
一个很好的解决方案是使用一个库,自动将代码按照 PEP 8 规范进行格式化。我们推荐的三个库都有不同的自定义级别来控制如何格式化代码。其中有一些设置较为特殊,例如 Pylint 和 Flake8 ,你需要先行测试,看看是否有你无法忍受蛋有不能修改的默认配置。
|
||||
一个很好的解决方案是使用一个库,自动将代码按照 PEP 8 规范进行格式化。我们推荐的三个库都有不同的自定义级别来控制如何格式化代码。其中有一些设置较为特殊,例如 Pylint 和 Flake8 ,你需要先行测试,看看是否有你无法忍受但又不能修改的默认配置。
|
||||
|
||||
#### 4\. Autopep8
|
||||
#### 4、 Autopep8
|
||||
|
||||
[Autopep8][16] 可以自动格式化指定的模块中的代码,包括重新缩进行,修复缩进,删除多余的空格,并重构常见的比较错误(例如布尔值和 `None` 值)。你可以查看文档中完整的[更正列表][17]。
|
||||
[Autopep8][16] 可以自动格式化指定的模块中的代码,包括重新缩进行、修复缩进、删除多余的空格,并重构常见的比较错误(例如布尔值和 `None` 值)。你可以查看文档中完整的[更正列表][17]。
|
||||
|
||||
运行 `pip install --upgrade autopep8` 安装 autopep8。然后执行 `autopep8 --in-place --aggressive --aggressive <filename>` 就可以重新格式化你的代码。`aggressive` 标记的数量表示 auotopep8 在代码风格控制上有多少控制权。在这里可以详细了解 [aggressive][18] 选项。
|
||||
运行 `pip install --upgrade autopep8` 安装 Autopep8。然后执行 `autopep8 --in-place --aggressive --aggressive <filename>` 就可以重新格式化你的代码。`aggressive` 选项的数量表示 Auotopep8 在代码风格控制上有多少控制权。在这里可以详细了解 [aggressive][18] 选项。
|
||||
|
||||
#### 5\. Yapf
|
||||
#### 5、 Yapf
|
||||
|
||||
[Yapf][19] 是另一种有自己的[配置项][20]列表的重新格式化代码的工具。它与 autopep8 的不同之处在于它不仅会指出代码中违反 PEP 8 规范的地方,还会对没有违反 PEP 8 但代码风格不一致的地方重新格式化,旨在令代码的可读性更强。
|
||||
[Yapf][19] 是另一种有自己的[配置项][20]列表的重新格式化代码的工具。它与 Autopep8 的不同之处在于它不仅会指出代码中违反 PEP 8 规范的地方,还会对没有违反 PEP 8 但代码风格不一致的地方重新格式化,旨在令代码的可读性更强。
|
||||
|
||||
执行`pip install yapf` 安装 Yapf,然后执行 `yapf [options] path/to/dir` 或 `yapf [options] path/to/module.py` 可以对代码重新格式化。
|
||||
执行 `pip install yapf` 安装 Yapf,然后执行 `yapf [options] path/to/dir` 或 `yapf [options] path/to/module.py` 可以对代码重新格式化。[定制选项][20]的完整列表在这里。
|
||||
|
||||
#### 6\. Black
|
||||
#### 6、 Black
|
||||
|
||||
[Black][21] 在代码检查工具当中算是比较新的一个。它与 autopep8 和 Yapf 类似,但限制较多,没有太多的自定义选项。这样的好处是你不需要去决定使用怎么样的代码风格,让 black 来给你做决定就好。你可以在这里查阅 black 的[自定义选项][22]以及[如何在配置文件中对其进行设置][23]。
|
||||
[Black][21] 在代码检查工具当中算是比较新的一个。它与 Autopep8 和 Yapf 类似,但限制较多,没有太多的自定义选项。这样的好处是你不需要去决定使用怎么样的代码风格,让 Black 来给你做决定就好。你可以在这里查阅 Black [有限的自定义选项][22]以及[如何在配置文件中对其进行设置][23]。
|
||||
|
||||
Black 依赖于 Python 3.6+,但它可以格式化用 Python 2 编写的代码。执行 `pip install black` 安装 black,然后执行 `black path/to/dir` 或 `black path/to/module.py` 就可以使用 black 优化你的代码。
|
||||
Black 依赖于 Python 3.6+,但它可以格式化用 Python 2 编写的代码。执行 `pip install black` 安装 Black,然后执行 `black path/to/dir` 或 `black path/to/module.py` 就可以使用 Black 优化你的代码。
|
||||
|
||||
### 检查你的测试覆盖率
|
||||
|
||||
如果你正在进行测试工作,你需要确保提交到代码库的新代码都已经测试通过,并且不会降低测试覆盖率。虽然测试覆盖率不是衡量测试有效性和充分性的唯一指标,但它是确保项目遵循基本测试标准的一种方法。对于计算测试覆盖率,我们推荐使用 Coverage 这个库。
|
||||
如果你正在进行编写测试,你需要确保提交到代码库的新代码都已经测试通过,并且不会降低测试覆盖率。虽然测试覆盖率不是衡量测试有效性和充分性的唯一指标,但它是确保项目遵循基本测试标准的一种方法。对于计算测试覆盖率,我们推荐使用 Coverage 这个库。
|
||||
|
||||
#### 7\. Coverage
|
||||
#### 7、 Coverage
|
||||
|
||||
[Coverage][24] 有数种显示测试覆盖率的方式,包括将结果输出到控制台或 HTML 页面,并指出哪些具体哪些地方没有被覆盖到。你可以通过配置文件自定义 Coverage 检查的内容,让你更方便使用。
|
||||
[Coverage][24] 有数种显示测试覆盖率的方式,包括将结果输出到控制台或 HTML 页面,并指出哪些具体哪些地方没有被覆盖到。你可以通过[配置文件][25]自定义 Coverage 检查的内容,让你更方便使用。
|
||||
|
||||
执行 `pip install coverage` 安装 Converage 。然后执行 `coverage [path/to/module.py] [args]` 可以运行程序并查看输出结果。如果要查看哪些代码行没有被覆盖,执行 `coverage report -m` 即可。
|
||||
|
||||
持续集成(Continuous integration, CI)是在合并和部署代码之前自动检查代码风格错误和测试覆盖率最小值的过程。很多免费或付费的工具都可以用于执行这项工作,具体的过程不在本文中赘述,但 CI 过程是令代码更易读和更易维护的重要步骤,关于这一部分可以参考 [Travis CI][26] 和 [Jenkins][27]。
|
||||
### 持续集成工具
|
||||
|
||||
<ruby>持续集成<rt>Continuous integration</rt></ruby>(CI)是在合并和部署代码之前自动检查代码风格错误和测试覆盖率最小值的过程。很多免费或付费的工具都可以用于执行这项工作,具体的过程不在本文中赘述,但 CI 过程是令代码更易读和更易维护的重要步骤,关于这一部分可以参考 [Travis CI][26] 和 [Jenkins][27]。
|
||||
|
||||
以上这些只是用于检查 Python 代码的各种工具中的其中几个。如果你有其它喜爱的工具,欢迎在评论中分享。
|
||||
|
||||
@ -85,7 +89,7 @@ via: https://opensource.com/article/18/7/7-python-libraries-more-maintainable-co
|
||||
作者:[Jeff Triplett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
162
published/20180804 Installing Andriod on VirtualBox.md
Normal file
162
published/20180804 Installing Andriod on VirtualBox.md
Normal file
@ -0,0 +1,162 @@
|
||||
在 VirtualBox 中安装 Android 系统
|
||||
======
|
||||
|
||||
如果你正在开发 Android 应用,也许会遇到小麻烦。诚然,ios 移动开发有 macOS 系统平台为其提供友好便利性, Android 开发仅有支持少部分 Android 系统(其中还包括可穿戴设备系统)的 Android Studio 工具。
|
||||
|
||||
毋庸置疑,所有的二进制工具、SDK 工具、开发框架工具以及调试器都会产生大量日志和其他各种文件,使得你的文件系统很混乱。一个有效的解决方法就是在 VirtualBox 中安装 Android 系统,这样还解决了 Android 开发中最为棘手问题之一 —— 设备模拟器。你可以在该虚拟机里测试应用程序,也可以使用 Android 的内部功能。因此,让我们迫不及待的开始吧!
|
||||
|
||||
### 准备工作
|
||||
|
||||
首先,你需要在你的系统上安装 VirtualBox,可从[这里][1]下载 Windows 版本、macOS 版本或者各种 Linux 版本的 VitualBox。然后,你需要一个能在 x86 平台运行的 Android 镜像,因为 VirtualBox 为虚拟机提供运行 x86 或者 x86\_64(即 AMD64)平台的功能。
|
||||
|
||||
虽然大部分 Android 设备都在 ARM 上运行,但我们依然可以从 [Android on x86 项目][2] 中获得帮助。这些优秀的开发者已经将 Android 移植到 x86 平台上运行(包括实体机和虚拟机),我们可以下载最新版本的 Android 7.1。你也可以用之前更为稳定的版本,本文写作时最新稳定版是 Android 6.0。
|
||||
|
||||
### 创建 VM 虚拟机
|
||||
|
||||
打开 VirtualBox,单击左上角的 “新建” 按钮,在弹出的窗口中选择 “类型:Linux” ,然后根据下载的 ISO 镜像来确定版本,x86 对应 “32-bit”,x86_64 对应 “64-bit”,此处选择 “Linux 2.6 / 3.x / 4.x (64-bit)”。
|
||||
|
||||
RAM 大小设置为 2 GB 到你系统能提供的最大内存之间。如果你想模拟真实的使用环境你可以设置 6 GB RAM 和 32 GB ROM。
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
创建完成后,你还需要做一些设置,添加更多的处理器核心,提高开机显示内存。在 VM 上打开设置选项,“设置 -> 系统 -> 处理器”,如果硬件条件允许,可以多分配一些处理器。
|
||||
|
||||
![][5]
|
||||
|
||||
在 “设置 -> 显示 -> 显存大小” 中,你可以分配一大块内存并开启 3D 加速功能。
|
||||
|
||||
![][6]
|
||||
|
||||
现在我们可以启动 VM 虚拟机了。
|
||||
|
||||
### 安装 Android
|
||||
|
||||
首次启动 VM 虚拟机,VirtualBox 会提示你需要提供启动媒介,选择之前下载好的Android 镜像。
|
||||
|
||||
![][7]
|
||||
|
||||
下一步,如果想长时间使用 Android,选择 “Installation” 选项,你也可以选择 Live 模式体验 Android 环境。
|
||||
|
||||
![][8]
|
||||
|
||||
按回车键。
|
||||
|
||||
#### 分区
|
||||
|
||||
分区是通过文本界面操作,并没有友好的 GUI 界面,所以每个操作都需要小心对待。例如,在第一屏中还没有创建分区并且只检测到原始(虚拟)硬盘时显示如下。
|
||||
|
||||
![][9]
|
||||
|
||||
红色字母 `C` 和 `D` 表明 `C` 开头选项可以创建或者修改分区,`D` 开头选项可以检测设备。你可以选择 `D` 开头选项,然后它就会检测硬盘,也可不进行这步操作,因为在启动的时候它会自动检测。
|
||||
|
||||
我们选择 `C` 开头选项,在虚拟盘中创建分区。官方不推荐使用 GPT 格式,所以我们选择 “No” 并按回车键。
|
||||
|
||||
![][10]
|
||||
|
||||
现在你被引导到 fdisk 工具页面。
|
||||
|
||||
![][11]
|
||||
|
||||
为了简洁起见,我们就只创建一个较大的分区,使用方向键来选择 “New” ,然后选择 “Primary”,按回车键以确认。
|
||||
|
||||
![][12]
|
||||
|
||||
分区大小系统已经为你计算好了,按回车键确认。
|
||||
|
||||
![][13]
|
||||
|
||||
这个分区就是 Android 系统所在的分区,所以需要它是可启动的。选择 “Bootable”,然后按回车键(上方表格中 “Flags” 标志下面会出现 “boot” 标志),进一步,选择 “Write” 选项,保存刚才的操作记录并写入分区表。
|
||||
|
||||
![][14]
|
||||
|
||||
现在你可以选择退出分区工具,然后继续安装过程。
|
||||
|
||||
![][15]
|
||||
|
||||
#### 文件系统格式化为 EXT4 并安装 Android
|
||||
|
||||
在“Choose Partition”分区页面上会出现一个刚刚我们创建的分区,选择它并点击“OK”进入。
|
||||
|
||||
![][16]
|
||||
|
||||
在下一个菜单中选择 Ext4 作为实际的文件系统,在下一页中选择 “Yes” 然后格式化开始。会提示是否安装 GRUB 引导工具以及是否允许在目录 `/system` 进行读写,都选择 “Yes” 。现在,安装进程开始。
|
||||
|
||||
安装完成后,当系统提示可以重启的时候你可以安全地重启系统。在重启之前,你可以先关机,然后在 VitualBox 的 “设置 -> 存储” 中检查 Android iso 镜像是否还连接在虚拟机上,如果在,将它移除。
|
||||
|
||||
![][17]
|
||||
|
||||
移除安装媒介并保存修改,再去启动 VM 虚拟机。
|
||||
|
||||
#### 运行 Android
|
||||
|
||||
在 GRUB 引导界面,有调试模式和普通模式的选项。我们选择默认选项,如下图所示。
|
||||
|
||||
![][18]
|
||||
|
||||
如果一切正常,你将会看到如下界面:
|
||||
|
||||
![][19]
|
||||
|
||||
如今的 Android 系统使用触摸交互而不是鼠标。不过 Android-x86 平台提供了鼠标操作支持,但开始时可能需要方向键来辅助操作。
|
||||
|
||||
![][20]
|
||||
|
||||
移动到”let’s go“按钮并按下回车键。选择 “Set up as new” 选项,回车确认。
|
||||
|
||||
![][21]
|
||||
|
||||
在提示用谷歌账户登陆之前,系统检查更新并检测设备信息。你可以跳过这一步,直接去设置日期和时间、用户名等。
|
||||
|
||||
还有一些其他的选项,和让你设置一个新的 Android 设备类似。选择 “I Agree” 选项同意有关更新、服务等的相应的选项,当然谷歌的服务条款是不得不同意的。
|
||||
|
||||
![][22]
|
||||
|
||||
在这之后,因为它是个虚拟机,所以可能需要添加额外的 email 账户来设置 “On-body detection”,大部分的选项对我们来说都没有多大作用,因此可以选择 ”All Set“。
|
||||
|
||||
接下来,它会提示你选择主屏应用,这个根据个人需求选择。现在我们进入了一个虚拟的 Android 系统。
|
||||
|
||||
![][23]
|
||||
|
||||
如果你需要在 VM 做一些交互测试,有个可触摸屏幕会提供很大的方便,因为那样才更接近真实使用环境。
|
||||
|
||||
希望这篇教程会给你带来帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxhint.com/install_android_virtualbox/
|
||||
|
||||
作者:[Ranvir Singh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrglinux](https://github.com/jrglinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxhint.com/author/sranvir155/
|
||||
[1]:https://www.virtualbox.org/wiki/Downloads
|
||||
[2]:http://www.android-x86.org/
|
||||
[3]:https://linuxhint.com/wp-content/uploads/2018/08/a.png
|
||||
[4]:https://linuxhint.com/wp-content/uploads/2018/08/a1.png
|
||||
[5]:https://linuxhint.com/wp-content/uploads/2018/08/a2.png
|
||||
[6]:https://linuxhint.com/wp-content/uploads/2018/08/a3.png
|
||||
[7]:https://linuxhint.com/wp-content/uploads/2018/08/a4.png
|
||||
[8]:https://linuxhint.com/wp-content/uploads/2018/08/a5.png
|
||||
[9]:https://linuxhint.com/wp-content/uploads/2018/08/a6.png
|
||||
[10]:https://linuxhint.com/wp-content/uploads/2018/08/a7.png
|
||||
[11]:https://linuxhint.com/wp-content/uploads/2018/08/a8.png
|
||||
[12]:https://linuxhint.com/wp-content/uploads/2018/08/a9.png
|
||||
[13]:https://linuxhint.com/wp-content/uploads/2018/08/a10.png
|
||||
[14]:https://linuxhint.com/wp-content/uploads/2018/08/a11.png
|
||||
[15]:https://linuxhint.com/wp-content/uploads/2018/08/a12.png
|
||||
[16]:https://linuxhint.com/wp-content/uploads/2018/08/a13.png
|
||||
[17]:https://linuxhint.com/wp-content/uploads/2018/08/a14.png
|
||||
[18]:https://linuxhint.com/wp-content/uploads/2018/08/a16.png
|
||||
[19]:https://linuxhint.com/wp-content/uploads/2018/08/a17.png
|
||||
[20]:https://linuxhint.com/wp-content/uploads/2018/08/a18.png
|
||||
[21]:https://linuxhint.com/wp-content/uploads/2018/08/a19.png
|
||||
[22]:https://linuxhint.com/wp-content/uploads/2018/08/a20.png
|
||||
[23]:https://linuxhint.com/wp-content/uploads/2018/08/a21.png
|
||||
|
||||
|
||||
@ -16,12 +16,8 @@ Linux DNS 查询剖析(第四部分)
|
||||
|
||||
在第四部分中,我将介绍容器如何完成 DNS 查询。你想的没错,也不是那么简单。
|
||||
|
||||
* * *
|
||||
|
||||
### 1) Docker 和 DNS
|
||||
|
||||
============================================================
|
||||
|
||||
在 [Linux DNS 查询剖析(第三部分)][3] 中,我们介绍了 `dnsmasq`,其工作方式如下:将 DNS 查询指向到 localhost 地址 `127.0.0.1`,同时启动一个进程监听 `53` 端口并处理查询请求。
|
||||
|
||||
在按上述方式配置 DNS 的主机上,如果运行了一个 Docker 容器,容器内的 `/etc/resolv.conf` 文件会是怎样的呢?
|
||||
@ -72,29 +68,29 @@ google.com. 112 IN A 172.217.23.14
|
||||
|
||||
在这个问题上,Docker 的解决方案是忽略所有可能的复杂情况,即无论主机中使用什么 DNS 服务器,容器内都使用 Google 的 DNS 服务器 `8.8.8.8` 和 `8.8.4.4` 完成 DNS 查询。
|
||||
|
||||
_我的经历:在 2013 年,我遇到了使用 Docker 以来的第一个问题,与 Docker 的这种 DNS 解决方案密切相关。我们公司的网络屏蔽了 `8.8.8.8` 和 `8.8.4.4`,导致容器无法解析域名。_
|
||||
_我的经历:在 2013 年,我遇到了使用 Docker 以来的第一个问题,与 Docker 的这种 DNS 解决方案密切相关。我们公司的网络屏蔽了 `8.8.8.8` 和 `8.8.4.4`,导致容器无法解析域名。_
|
||||
|
||||
这就是 Docker 容器的情况,但对于包括 Kubernetes 在内的容器 _<ruby>编排引擎<rt>orchestrators</rt></ruby>_,情况又有些不同。
|
||||
这就是 Docker 容器的情况,但对于包括 Kubernetes 在内的容器 <ruby>编排引擎<rt>orchestrators</rt></ruby>,情况又有些不同。
|
||||
|
||||
### 2) Kubernetes 和 DNS
|
||||
|
||||
在 Kubernetes 中,最小部署单元是 `pod`;`pod` 是一组相互协作的容器,共享 IP 地址(和其它资源)。
|
||||
在 Kubernetes 中,最小部署单元是 pod;它是一组相互协作的容器,共享 IP 地址(和其它资源)。
|
||||
|
||||
Kubernetes 面临的一个额外的挑战是,将 Kubernetes 服务请求(例如,`myservice.kubernetes.io`)通过对应的<ruby>解析器<rt>resolver</rt></ruby>,转发到具体服务地址对应的<ruby>内网地址<rt>private network</rt></ruby>。这里提到的服务地址被称为归属于“<ruby>集群域<rt>cluster domain</rt></ruby>”。集群域可由管理员配置,根据配置可以是 `cluster.local` 或 `myorg.badger` 等。
|
||||
|
||||
在 Kubernetes 中,你可以为 `pod` 指定如下四种 `pod` 内 DNS 查询的方式。
|
||||
在 Kubernetes 中,你可以为 pod 指定如下四种 pod 内 DNS 查询的方式。
|
||||
|
||||
* Default
|
||||
**Default**
|
||||
|
||||
在这种(名称容易让人误解)的方式中,`pod` 与其所在的主机采用相同的 DNS 查询路径,与前面介绍的主机 DNS 查询一致。我们说这种方式的名称容易让人误解,因为该方式并不是默认选项!`ClusterFirst` 才是默认选项。
|
||||
在这种(名称容易让人误解)的方式中,pod 与其所在的主机采用相同的 DNS 查询路径,与前面介绍的主机 DNS 查询一致。我们说这种方式的名称容易让人误解,因为该方式并不是默认选项!`ClusterFirst` 才是默认选项。
|
||||
|
||||
如果你希望覆盖 `/etc/resolv.conf` 中的条目,你可以添加到 `kubelet` 的配置中。
|
||||
|
||||
* ClusterFirst
|
||||
**ClusterFirst**
|
||||
|
||||
在 `ClusterFirst` 方式中,遇到 DNS 查询请求会做有选择的转发。根据配置的不同,有以下两种方式:
|
||||
|
||||
第一种方式配置相对古老但更简明,即采用一个规则:如果请求的域名不是集群域的子域,那么将其转发到 `pod` 所在的主机。
|
||||
第一种方式配置相对古老但更简明,即采用一个规则:如果请求的域名不是集群域的子域,那么将其转发到 pod 所在的主机。
|
||||
|
||||
第二种方式相对新一些,你可以在内部 DNS 中配置选择性转发。
|
||||
|
||||
@ -115,27 +111,27 @@ data:
|
||||
|
||||
在 `stubDomains` 条目中,可以为特定域名指定特定的 DNS 服务器;而 `upstreamNameservers` 条目则给出,待查询域名不是集群域子域情况下用到的 DNS 服务器。
|
||||
|
||||
这是通过在一个 `pod` 中运行我们熟知的 `dnsmasq` 实现的。
|
||||
这是通过在一个 pod 中运行我们熟知的 `dnsmasq` 实现的。
|
||||
|
||||

|
||||
|
||||
剩下两种选项都比较小众:
|
||||
|
||||
* ClusterFirstWithHostNet
|
||||
**ClusterFirstWithHostNet**
|
||||
|
||||
适用于 `pod` 使用主机网络的情况,例如绕开 Docker 网络配置,直接使用与 `pod` 对应主机相同的网络。
|
||||
适用于 pod 使用主机网络的情况,例如绕开 Docker 网络配置,直接使用与 pod 对应主机相同的网络。
|
||||
|
||||
* None
|
||||
**None**
|
||||
|
||||
`None` 意味着不改变 DNS,但强制要求你在 `pod` <ruby>规范文件<rt>specification</rt></ruby>的 `dnsConfig` 条目中指定 DNS 配置。
|
||||
|
||||
### CoreDNS 即将到来
|
||||
|
||||
除了上面提到的那些,一旦 `CoreDNS` 取代Kubernetes 中的 `kube-dns`,情况还会发生变化。`CoreDNS` 相比 `kube-dns` 具有可配置性更高、效率更高等优势。
|
||||
除了上面提到的那些,一旦 `CoreDNS` 取代 Kubernetes 中的 `kube-dns`,情况还会发生变化。`CoreDNS` 相比 `kube-dns` 具有可配置性更高、效率更高等优势。
|
||||
|
||||
如果想了解更多,参考[这里][5]。
|
||||
|
||||
如果你对 OpenShift 的网络感兴趣,我曾写过一篇[文章][6]可供你参考。但文章中 OpenShift 的版本是 `3.6`,可能有些过时。
|
||||
如果你对 OpenShift 的网络感兴趣,我曾写过一篇[文章][6]可供你参考。但文章中 OpenShift 的版本是 3.6,可能有些过时。
|
||||
|
||||
### 第四部分总结
|
||||
|
||||
@ -152,14 +148,14 @@ via: https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
|
||||
|
||||
作者:[zwischenzugs][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
[2]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
[3]:https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
[1]:https://linux.cn/article-9943-1.html
|
||||
[2]:https://linux.cn/article-9949-1.html
|
||||
[3]:https://linux.cn/article-9972-1.html
|
||||
[4]:https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/#impacts-on-pods
|
||||
[5]:https://coredns.io/
|
||||
[6]:https://zwischenzugs.com/2017/10/21/openshift-3-6-dns-in-pictures/
|
||||
@ -3,46 +3,45 @@
|
||||
|
||||

|
||||
|
||||
有效管理待办事项可以为你的工作效率创造奇迹。有些人更喜欢在文本中保存待办事项,甚至只使用记事本和笔。对于需要更多待办事项功能的用户,他们通常会使用应用程序。在本文中,我们将重点介绍 4 个图形程序和一个基于终端的工具来管理待办事项。
|
||||
有效管理待办事项(to-do)可以为你的工作效率创造奇迹。有些人更喜欢在文本中保存待办事项,甚至只使用记事本和笔。对于需要更多待办事项功能的用户,他们通常会使用应用程序。在本文中,我们将重点介绍 4 个图形程序和一个基于终端的工具来管理待办事项。
|
||||
|
||||
### GNOME To Do
|
||||
|
||||
GNOME To Do][1] 是专为 GNOME 桌面(Fedora Workstation 的默认桌面)设计的个人任务管理器。将 GNOME To Do 与其他程序进行比较时,它有一系列简洁的功能。
|
||||
[GNOME To Do][1] 是专为 GNOME 桌面(Fedora Workstation 的默认桌面)设计的个人任务管理器。GNOME To Do 与其他程序进行比较,它有一系列简洁的功能。
|
||||
|
||||
GNOME To Do 提供列表形式的任务组织,并能为该列表指定颜色。此外,可以为各个任务分配截止日期和优先级,以及每项任务的注释。此外,GNOME To Do 还支持扩展,能添加更多功能,包括支持 [todo.txt][2] 以及与 [todoist][3] 等在线服务同步。
|
||||
GNOME To Do 提供列表形式的任务组织方式,并能为该列表指定颜色。此外,可以为各个任务分配截止日期和优先级,以及每项任务的注释。此外,GNOME To Do 还支持扩展,能添加更多功能,包括支持 [todo.txt][2] 以及与 [todoist][3] 等在线服务同步。
|
||||
|
||||
![][4]
|
||||
|
||||
使用软件中心或者在终端中使用下面的命令安装 GNOME To Do:
|
||||
|
||||
```
|
||||
sudo dnf install gnome-todo
|
||||
|
||||
```
|
||||
|
||||
### Getting things GNOME!
|
||||
|
||||
、在 GNOME To Do 存在之前,在 GNOME 上追踪任务的首选程序是 [Getting things GNOME!][5] 这个稍来的 GNOME 程序有多个窗口层,能然你同时显示多个任务的细节。GTG 没有任务列表,它能在任务中添加子任务,甚至在子任务中添加子任务。GTG 同样能添加截止日期和开始日期。通过插件同步其他程序和服务也是可能的。
|
||||
在 GNOME To Do 出现之前,在 GNOME 上追踪任务的首选程序是 [Getting things GNOME!][5] 这个老式的 GNOME 程序采用多窗口布局,能让你同时显示多个任务的细节。GTG 没有任务列表,它能在任务中添加子任务,甚至在子任务中添加子任务。GTG 同样能添加截止日期和开始日期。也可以通过插件同步其他程序和服务。
|
||||
|
||||
![][6]
|
||||
|
||||
在软件中心或者在终端中使用下面的命令安装 Getting Things GNOME:
|
||||
|
||||
```
|
||||
sudo dnf install gtg
|
||||
|
||||
```
|
||||
|
||||
### Go For It!
|
||||
|
||||
[Go For It!][7] 是一个超级简单的任务管理程序。它能简单地创建一个任务列表,并在完成后标记它们。它没有组任务,也不能创建子任务。默认 Go For It! 将任务存储在 todo.txt 中,这能更方便地同步到在线服务或者其他程序中。额外地,Go For It! 包含了一个简单定时器来追踪你在当前任务花费了多少时间。
|
||||
[Go For It!][7] 是一个超级简单的任务管理程序。它能简单地创建一个任务列表,并在完成后标记它们。它不能将任务分组,也不能创建子任务。Go For It! 默认将任务存储为 todo.txt 格式,这能更方便地同步到在线服务或者其他程序中。额外地,Go For It! 包含了一个简单定时器来追踪你在当前任务花费了多少时间。
|
||||
|
||||
![][8]
|
||||
|
||||
Go For It 能在 Flathub 应用仓库中找到。要安装它,只需[启用 Flathub 作为软件源][9],接着在软件中心中安装。
|
||||
|
||||
Go For It! 能在 Flathub 应用仓库中找到。要安装它,只需[启用 Flathub 作为软件源][9],接着在软件中心中安装。
|
||||
|
||||
### Agenda
|
||||
|
||||
如果你在寻找一款非常简单的待办应用,[Agenda][10] 非常合适。创建任务,标记完成,接着从列表中删除它们。Agenda 会在你删除它们之前显示所有任务(完成或者进行中)。
|
||||
如果你在寻找一款非常简单的待办应用,非 [Agenda][10] 莫属。创建任务,标记完成,接着从列表中删除它们。Agenda 会在你删除它们之前一直显示所有任务(完成的或者进行中)。
|
||||
|
||||
![][11]
|
||||
|
||||
@ -57,12 +56,11 @@ Agenda 能从 Flathub 应用仓库下载。要安装它,只需[启用 Flathub
|
||||
![][14]
|
||||
|
||||
在终端中使用这个命令安装 Taskwarrior:
|
||||
|
||||
```
|
||||
sudo dnf install task
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-tools-to-manage-your-to-do-list-on-fedora/
|
||||
@ -70,7 +68,7 @@ via: https://fedoramagazine.org/5-tools-to-manage-your-to-do-list-on-fedora/
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,78 @@
|
||||
|
||||
Steam 让我们在 Linux 上玩 Windows 的游戏更加容易
|
||||
======
|
||||
|
||||
![Steam Wallpaper][1]
|
||||
|
||||
总所周知,[Linux 游戏][2]库中的游戏只有 Windows 游戏库中的一部分,实际上,许多人甚至都不会考虑将操作系统[转换为 Linux][3],原因很简单,因为他们喜欢的游戏,大多数都不能在这个平台上运行。
|
||||
|
||||
在撰写本文时,Steam 上已有超过 5000 种游戏可以在 Linux 上运行,而 Steam 上的游戏总数已经接近 27000 种了。现在 5000 种游戏可能看起来很多,但还没有达到 27000 种,确实没有。
|
||||
|
||||
虽然几乎所有的新的<ruby>独立游戏<rt>indie game</rt></ruby>都是在 Linux 中推出的,但我们仍然无法在这上面玩很多的 [3A 大作][4]。对我而言,虽然这其中有很多游戏我都很希望能有机会玩,但这从来都不是一个非黑即白的问题。因为我主要是玩独立游戏和[复古游戏][5],所以几乎所有我喜欢的游戏都可以在 Linux 系统上运行。
|
||||
|
||||
### 认识 Proton,Steam 的一个 WINE 复刻
|
||||
|
||||
现在,这个问题已经成为过去式了,因为本周 Valve [宣布][6]要对 Steam Play 进行一次更新,此次更新会将一个名为 Proton 的 Wine 复刻版本添加到 Linux 客户端中。是的,这个工具是开源的,Valve 已经在 [GitHub][7] 上开源了源代码,但该功能仍然处于测试阶段,所以你必须使用测试版的 Steam 客户端才能使用这项功能。
|
||||
|
||||
#### 使用 proton ,可以在 Linux 系统上通过 Steam 运行更多 Windows 游戏
|
||||
|
||||
这对我们这些 Linux 用户来说,实际上意味着什么?简单来说,这意味着我们可以在 Linux 电脑上运行全部 27000 种游戏,而无需配置像 [PlayOnLinux][8] 或 [Lutris][9] 这样的东西。我要告诉你的是,配置这些东西有时候会非常让人头疼。
|
||||
|
||||
对此更为复杂的答案是,某种原因听起来非常美好。虽然在理论上,你可以用这种方式在 Linux 上玩所有的 Windows 平台上的游戏。但只有一少部分游戏在推出时会正式支持 Linux。这少部分游戏包括 《DOOM》、《最终幻想 VI》、《铁拳 7》、《星球大战:前线 2》,和其他几个。
|
||||
|
||||
#### 你可以在 Linux 上玩所有的 Windows 游戏(理论上)
|
||||
|
||||
虽然目前该列表只有大约 30 个游戏,你可以点击“为所有游戏启用 Steam Play”复选框来强制使用 Steam 的 Proton 来安装和运行任意游戏。但你最好不要有太高的期待,它们的稳定性和性能表现不一定有你希望的那么好,所以请把期望值压低一点。
|
||||
|
||||
![Steam Play][10]
|
||||
|
||||
据[这份报告][13],已经有超过一千个游戏可以在 Linux 上玩了。按[此指南][14]来了解如何启用 Steam Play 测试版本。
|
||||
|
||||
#### 体验 Proton,没有我想的那么烂
|
||||
|
||||
例如,我安装了一些难度适中的游戏,使用 Proton 来进行安装。其中一个是《上古卷轴 4:湮没》,在我玩这个游戏的两个小时里,它只崩溃了一次,而且几乎是紧跟在游戏教程的自动保存点之后。
|
||||
|
||||
我有一块英伟达 Gtx 1050 Ti 的显卡。所以我可以使用 1080P 的高配置来玩这个游戏。而且我没有遇到除了这次崩溃之外的任何问题。我唯一真正感到不爽的只有它的帧数没有原本的高。在 90% 的时间里,游戏的帧数都在 60 帧以上,但我知道它的帧数应该能更高。
|
||||
|
||||
我安装和运行的其他所有游戏都运行得很完美,虽然我还没有较长时间地玩过它们中的任何一个。我安装的游戏中包括《森林》、《丧尸围城 4》和《刺客信条 2》。(你觉得我这是喜欢恐怖游戏吗?)
|
||||
|
||||
#### 为什么 Steam(仍然)要下注在 Linux 上?
|
||||
|
||||
现在,一切都很好,这件事为什么会发生呢?为什么 Valve 要花费时间,金钱和资源来做这样的事?我倾向于认为,他们这样做是因为他们懂得 Linux 社区的价值,但是如果要我老实地说,我不相信我们和它有任何的关系。
|
||||
|
||||
如果我一定要在这上面花钱,我想说 Valve 开发了 Proton,因为他们还没有放弃 [Steam Machine][11]。因为 [Steam OS][12] 是基于 Linux 的发行版,在这类东西上面投资可以获取最大的利润,Steam OS 上可用的游戏越多,就会有更多的人愿意购买 Steam Machine。
|
||||
|
||||
可能我是错的,但是我敢打赌啊,我们会在不远的未来看到新一批的 Steam Machine。可能我们会在一年内看到它们,也有可能我们再等五年都见不到,谁知道呢!
|
||||
|
||||
无论哪种方式,我所知道的是,我终于能兴奋地从我的 Steam 游戏库里玩游戏了。这个游戏库是多年来我通过各种慈善包、促销码和不定时地买的游戏慢慢积累的,只不过是想试试让它在 Lutris 中运行。
|
||||
|
||||
#### 为 Linux 上越来越多的游戏而激动?
|
||||
|
||||
你怎么看?你对此感到激动吗?或者说你会害怕只有很少的开发者会开发 Linux 平台上的游戏,因为现在几乎没有需求?Valve 喜欢 Linux 社区,还是说他们喜欢钱?请在下面的评论区告诉我们您的想法,然后重新搜索来查看更多类似这样的开源软件方面的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play-proton/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/steam-wallpaper.jpeg
|
||||
[2]:https://itsfoss.com/linux-gaming-guide/
|
||||
[3]:https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[4]:https://itsfoss.com/triplea-game-review/
|
||||
[5]:https://itsfoss.com/play-retro-games-linux/
|
||||
[6]:https://steamcommunity.com/games/221410
|
||||
[7]:https://github.com/ValveSoftware/Proton/
|
||||
[8]:https://www.playonlinux.com/en/
|
||||
[9]:https://lutris.net/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/SteamProton.jpg
|
||||
[11]:https://store.steampowered.com/sale/steam_machines
|
||||
[12]:https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
[13]:https://spcr.netlify.com/
|
||||
[14]:https://itsfoss.com/steam-play/
|
||||
@ -1,26 +1,27 @@
|
||||
如何在 Linux 上使用 tcpdump 命令捕获和分析数据包
|
||||
======
|
||||
tcpdump 是一个有名的命令行**数据包分析**工具。我们可以使用 tcpdump 命令捕获实时 TCP/IP 数据包,这些数据包也可以保存到文件中。之后这些捕获的数据包可以通过 tcpdump 命令进行分析。tcpdump 命令在网络级故障排除时变得非常方便。
|
||||
|
||||
`tcpdump` 是一个有名的命令行**数据包分析**工具。我们可以使用 `tcpdump` 命令捕获实时 TCP/IP 数据包,这些数据包也可以保存到文件中。之后这些捕获的数据包可以通过 `tcpdump` 命令进行分析。`tcpdump` 命令在网络层面进行故障排除时变得非常方便。
|
||||
|
||||

|
||||
|
||||
tcpdump 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux,可以使用 apt 命令安装它
|
||||
`tcpdump` 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux,可以使用 `apt` 命令安装它。
|
||||
|
||||
```
|
||||
# apt install tcpdump -y
|
||||
```
|
||||
|
||||
在基于 RPM 的 Linux 操作系统上,可以使用下面的 yum 命令安装 tcpdump
|
||||
在基于 RPM 的 Linux 操作系统上,可以使用下面的 `yum` 命令安装 `tcpdump`。
|
||||
|
||||
```
|
||||
# yum install tcpdump -y
|
||||
```
|
||||
|
||||
当我们在没用任何选项的情况下运行 tcpdump 命令时,它将捕获所有接口的数据包。因此,要停止或取消 tcpdump 命令,请输入 '**ctrl+c**'。在本教程中,我们将使用不同的实例来讨论如何捕获和分析数据包,
|
||||
当我们在没用任何选项的情况下运行 `tcpdump` 命令时,它将捕获所有接口的数据包。因此,要停止或取消 `tcpdump` 命令,请键入 `ctrl+c`。在本教程中,我们将使用不同的实例来讨论如何捕获和分析数据包。
|
||||
|
||||
### 示例: 1) 从特定接口捕获数据包
|
||||
### 示例:1)从特定接口捕获数据包
|
||||
|
||||
当我们在没用任何选项的情况下运行 tcpdump 命令时,它将捕获所有接口上的数据包,因此,要从特定接口捕获数据包,请使用选项 '**-i**',后跟接口名称。
|
||||
当我们在没用任何选项的情况下运行 `tcpdump` 命令时,它将捕获所有接口上的数据包,因此,要从特定接口捕获数据包,请使用选项 `-i`,后跟接口名称。
|
||||
|
||||
语法:
|
||||
|
||||
@ -28,7 +29,7 @@ tcpdump 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux
|
||||
# tcpdump -i {接口名}
|
||||
```
|
||||
|
||||
假设我想从接口“enp0s3”捕获数据包
|
||||
假设我想从接口 `enp0s3` 捕获数据包。
|
||||
|
||||
输出将如下所示,
|
||||
|
||||
@ -49,21 +50,21 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
|
||||
```
|
||||
|
||||
### 示例: 2) 从特定接口捕获特定数量数据包
|
||||
### 示例:2)从特定接口捕获特定数量数据包
|
||||
|
||||
假设我们想从特定接口(如“enp0s3”)捕获12个数据包,这可以使用选项 '**-c {数量} -I {接口名称}**' 轻松实现
|
||||
假设我们想从特定接口(如 `enp0s3`)捕获 12 个数据包,这可以使用选项 `-c {数量} -I {接口名称}` 轻松实现。
|
||||
|
||||
```
|
||||
root@compute-0-1 ~]# tcpdump -c 12 -i enp0s3
|
||||
```
|
||||
|
||||
上面的命令将生成如下所示的输出
|
||||
上面的命令将生成如下所示的输出,
|
||||
|
||||
[![N-Number-Packsets-tcpdump-interface][1]][2]
|
||||
|
||||
### 示例: 3) 显示 tcpdump 的所有可用接口
|
||||
### 示例:3)显示 tcpdump 的所有可用接口
|
||||
|
||||
使用 '**-D**' 选项显示 tcpdump 命令的所有可用接口,
|
||||
使用 `-D` 选项显示 `tcpdump` 命令的所有可用接口,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -D
|
||||
@ -86,11 +87,11 @@ root@compute-0-1 ~]# tcpdump -c 12 -i enp0s3
|
||||
[[email protected] ~]#
|
||||
```
|
||||
|
||||
我正在我的一个openstack计算节点上运行tcpdump命令,这就是为什么在输出中你会看到数字接口、标签接口、网桥和vxlan接口
|
||||
我正在我的一个 openstack 计算节点上运行 `tcpdump` 命令,这就是为什么在输出中你会看到数字接口、标签接口、网桥和 vxlan 接口
|
||||
|
||||
### 示例: 4) 捕获带有可读时间戳(-tttt 选项)的数据包
|
||||
### 示例:4)捕获带有可读时间戳的数据包(`-tttt` 选项)
|
||||
|
||||
默认情况下,在tcpdump命令输出中,没有显示可读性好的时间戳,如果您想将可读性好的时间戳与每个捕获的数据包相关联,那么使用 '**-tttt**'选项,示例如下所示,
|
||||
默认情况下,在 `tcpdump` 命令输出中,不显示可读性好的时间戳,如果您想将可读性好的时间戳与每个捕获的数据包相关联,那么使用 `-tttt` 选项,示例如下所示,
|
||||
|
||||
```
|
||||
[[email protected] ~]# tcpdump -c 8 -tttt -i enp0s3
|
||||
@ -108,12 +109,11 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
134 packets received by filter
|
||||
69 packets dropped by kernel
|
||||
[[email protected] ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例: 5) 捕获数据包并将其保存到文件( -w 选项)
|
||||
### 示例:5)捕获数据包并将其保存到文件(`-w` 选项)
|
||||
|
||||
使用 tcpdump 命令中的 '**-w**' 选项将捕获的 TCP/IP 数据包保存到一个文件中,以便我们可以在将来分析这些数据包以供进一步分析。
|
||||
使用 `tcpdump` 命令中的 `-w` 选项将捕获的 TCP/IP 数据包保存到一个文件中,以便我们可以在将来分析这些数据包以供进一步分析。
|
||||
|
||||
语法:
|
||||
|
||||
@ -121,9 +121,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
# tcpdump -w 文件名.pcap -i {接口名}
|
||||
```
|
||||
|
||||
注意:文件扩展名必须为 **.pcap**
|
||||
注意:文件扩展名必须为 `.pcap`。
|
||||
|
||||
假设我要把 '**enp0s3**' 接口捕获到的包保存到文件名为 **enp0s3-26082018.pcap**
|
||||
假设我要把 `enp0s3` 接口捕获到的包保存到文件名为 `enp0s3-26082018.pcap`。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018.pcap -i enp0s3
|
||||
@ -140,24 +140,23 @@ tcpdump: listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 b
|
||||
[root@compute-0-1 ~]# ls
|
||||
anaconda-ks.cfg enp0s3-26082018.pcap
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
捕获并保存大小**大于 N 字节**的数据包
|
||||
捕获并保存大小**大于 N 字节**的数据包。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-2.pcap greater 1024
|
||||
```
|
||||
|
||||
捕获并保存大小**小于 N 字节**的数据包
|
||||
捕获并保存大小**小于 N 字节**的数据包。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-3.pcap less 1024
|
||||
```
|
||||
|
||||
### 示例: 6) 从保存的文件中读取数据包( -r 选项)
|
||||
### 示例:6)从保存的文件中读取数据包(`-r` 选项)
|
||||
|
||||
在上面的例子中,我们已经将捕获的数据包保存到文件中,我们可以使用选项 '**-r**' 从文件中读取这些数据包,例子如下所示,
|
||||
在上面的例子中,我们已经将捕获的数据包保存到文件中,我们可以使用选项 `-r` 从文件中读取这些数据包,例子如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -r enp0s3-26082018.pcap
|
||||
@ -183,12 +182,11 @@ p,TS val 81359114 ecr 81350901], length 508
|
||||
2018-08-25 22:03:17.647502 IP controller0.example.com.amqp > compute-0-1.example.com.57788: Flags [.], ack 1956, win 1432, options [nop,nop,TS val 813
|
||||
52753 ecr 81359114], length 0
|
||||
.........................................................................................................................
|
||||
|
||||
```
|
||||
|
||||
### 示例: 7) 仅捕获特定接口上的 IP 地址数据包( -n 选项)
|
||||
### 示例:7)仅捕获特定接口上的 IP 地址数据包(`-n` 选项)
|
||||
|
||||
使用 tcpdump 命令中的 -n 选项,我们能只捕获特定接口上的 IP 地址数据包,示例如下所示,
|
||||
使用 `tcpdump` 命令中的 `-n` 选项,我们能只捕获特定接口上的 IP 地址数据包,示例如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3
|
||||
@ -211,19 +209,18 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:22:28.539595 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 1572, win 9086, options [nop,nop,TS val 20666614 ecr 82510006], length 0
|
||||
22:22:28.539760 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 1572:1912, ack 1, win 291, options [nop,nop,TS val 82510007 ecr 20666614], length 340
|
||||
.........................................................................
|
||||
|
||||
```
|
||||
|
||||
您还可以使用 tcpdump 命令中的 -c 和 -N 选项捕获 N 个 IP 地址包,
|
||||
您还可以使用 `tcpdump` 命令中的 `-c` 和 `-N` 选项捕获 N 个 IP 地址包,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 25 -n -i enp0s3
|
||||
```
|
||||
|
||||
|
||||
### 示例: 8) 仅捕获特定接口上的TCP数据包
|
||||
### 示例:8)仅捕获特定接口上的 TCP 数据包
|
||||
|
||||
在 tcpdump 命令中,我们能使用 '**tcp**' 选项来只捕获TCP数据包,
|
||||
在 `tcpdump` 命令中,我们能使用 `tcp` 选项来只捕获 TCP 数据包,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -i enp0s3 tcp
|
||||
@ -241,9 +238,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
...................................................................................................................................................
|
||||
```
|
||||
|
||||
### 示例: 9) 从特定接口上的特定端口捕获数据包
|
||||
### 示例:9)从特定接口上的特定端口捕获数据包
|
||||
|
||||
使用 tcpdump 命令,我们可以从特定接口 enp0s3 上的特定端口(例如 22 )捕获数据包
|
||||
使用 `tcpdump` 命令,我们可以从特定接口 `enp0s3` 上的特定端口(例如 22)捕获数据包。
|
||||
|
||||
语法:
|
||||
|
||||
@ -262,13 +259,12 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:54:55.038564 IP 169.144.0.1.39406 > compute-0-1.example.com.ssh: Flags [.], ack 940, win 9177, options [nop,nop,TS val 21153238 ecr 84456505], length 0
|
||||
22:54:55.038708 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 940:1304, ack 1, win 291, options [nop,nop,TS val 84456506 ecr 21153238], length 364
|
||||
............................................................................................................................
|
||||
[root@compute-0-1 ~]#
|
||||
```
|
||||
|
||||
|
||||
### 示例: 10) 在特定接口上捕获来自特定来源 IP 的数据包
|
||||
### 示例:10)在特定接口上捕获来自特定来源 IP 的数据包
|
||||
|
||||
在tcpdump命令中,使用 '**src**' 关键字后跟 '**IP 地址**',我们可以捕获来自特定来源 IP 的数据包,
|
||||
在 `tcpdump` 命令中,使用 `src` 关键字后跟 IP 地址,我们可以捕获来自特定来源 IP 的数据包,
|
||||
|
||||
语法:
|
||||
|
||||
@ -296,17 +292,16 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
10 packets captured
|
||||
12 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例: 11) 在特定接口上捕获来自特定目的IP的数据包
|
||||
### 示例:11)在特定接口上捕获来自特定目的 IP 的数据包
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -n -i {接口名} dst {IP 地址}
|
||||
```
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3 dst 169.144.0.1
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
@ -318,42 +313,39 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
23:10:43.522157 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 800:996, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
23:10:43.522346 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 996:1192, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
.........................................................................................
|
||||
|
||||
```
|
||||
|
||||
### 示例: 12) 捕获两台主机之间的 TCP 数据包通信
|
||||
### 示例:12)捕获两台主机之间的 TCP 数据包通信
|
||||
|
||||
假设我想捕获两台主机 169.144.0.1 和 169.144.0.20 之间的 TCP 数据包,示例如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w two-host-tcp-comm.pcap -i enp0s3 tcp and \(host 169.144.0.1 or host 169.144.0.20\)
|
||||
|
||||
```
|
||||
|
||||
使用 tcpdump 命令只捕获两台主机之间的 SSH 数据包流,
|
||||
使用 `tcpdump` 命令只捕获两台主机之间的 SSH 数据包流,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w ssh-comm-two-hosts.pcap -i enp0s3 src 169.144.0.1 and port 22 and dst 169.144.0.20 and port 22
|
||||
|
||||
```
|
||||
|
||||
示例: 13) 捕获两台主机之间的 UDP 网络数据包(来回)
|
||||
### 示例:13)捕获两台主机之间(来回)的 UDP 网络数据包
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -w -s -i udp and \(host and host \)
|
||||
```
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w two-host-comm.pcap -s 1000 -i enp0s3 udp and \(host 169.144.0.10 and host 169.144.0.20\)
|
||||
|
||||
```
|
||||
|
||||
### 示例: 14) 捕获十六进制和ASCII格式的数据包
|
||||
### 示例:14)捕获十六进制和 ASCII 格式的数据包
|
||||
|
||||
使用 tcpdump 命令,我们可以以 ASCII 和十六进制格式捕获 TCP/IP 数据包,
|
||||
使用 `tcpdump` 命令,我们可以以 ASCII 和十六进制格式捕获 TCP/IP 数据包,
|
||||
|
||||
要使用** -A **选项捕获ASCII格式的数据包,示例如下所示:
|
||||
要使用 `-A` 选项捕获 ASCII 格式的数据包,示例如下所示:
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -A -i enp0s3
|
||||
@ -376,7 +368,7 @@ root@compute-0-1 @..........
|
||||
..................................................................................................................................................
|
||||
```
|
||||
|
||||
要同时以十六进制和 ASCII 格式捕获数据包,请使用** -XX **选项
|
||||
要同时以十六进制和 ASCII 格式捕获数据包,请使用 `-XX` 选项。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -XX -i enp0s3
|
||||
@ -406,10 +398,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
0x0030: 3693 7c0e 0000 0101 080a 015a a734 0568 6.|........Z.4.h
|
||||
0x0040: 39af
|
||||
.......................................................................
|
||||
|
||||
```
|
||||
|
||||
这就是本文的全部内容,我希望您能了解如何使用 tcpdump 命令捕获和分析 TCP/IP 数据包。请分享你的反馈和评论。
|
||||
这就是本文的全部内容,我希望您能了解如何使用 `tcpdump` 命令捕获和分析 TCP/IP 数据包。请分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -418,7 +409,7 @@ via: https://www.linuxtechi.com/capture-analyze-packets-tcpdump-command-linux/
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,89 @@
|
||||
如何使用 Steam Play 在 Linux 上玩仅限 Windows 的游戏
|
||||
======
|
||||
|
||||
> Steam 的新实验功能允许你在 Linux 上玩仅限 Windows 的游戏。以下是如何在 Steam 中使用此功能。
|
||||
|
||||
你已经听说过这个消息。游戏发行平台 [Steam 正在复刻一个 WINE 分支来允许你玩仅限于 Windows 上的游戏][1]。对于 Linux 用户来说,这绝对是一个好消息,因为我们总抱怨 Linux 的游戏数量不足。
|
||||
|
||||
这个新功能仍处于测试阶段,但你现在可以在 Linux 上试用它并在 Linux 上玩仅限 Windows 的游戏。让我们看看如何做到这一点。
|
||||
|
||||
### 使用 Steam Play 在 Linux 中玩仅限 Windows 的游戏
|
||||
|
||||
![Play Windows-only games on Linux][2]
|
||||
|
||||
你需要先安装 Steam。Steam 适用于所有主要 Linux 发行版。我已经详细介绍了[在 Ubuntu 上安装 Steam][3],如果你还没有安装 Steam,你可以参考那篇文章。
|
||||
|
||||
安装了 Steam 并且你已登录到 Steam 帐户,就可以了解如何在 Steam Linux 客户端中启用 Windows 游戏。
|
||||
|
||||
#### 步骤 1:进入帐户设置
|
||||
|
||||
运行 Steam 客户端。在左上角,单击 “Steam”,然后单击 “Settings”。
|
||||
|
||||
![Enable steam play beta on Linux][4]
|
||||
|
||||
#### 步骤 2:选择加入测试计划
|
||||
|
||||
在“Settings”中,从左侧窗口中选择“Account”,然后单击 “Beta participation” 下的 “CHANGE” 按钮。
|
||||
|
||||
![Enable beta feature in Steam Linux][5]
|
||||
|
||||
你应该在此处选择 “Steam Beta Update”。
|
||||
|
||||
![Enable beta feature in Steam Linux][6]
|
||||
|
||||
在此处保存设置后,Steam 将重新启动并下载新的测试版更新。
|
||||
|
||||
#### 步骤 3:启用 Steam Play 测试版
|
||||
|
||||
下载好 Steam 新的测试版更新后,它将重新启动。到这里就差不多了。
|
||||
|
||||
再次进入“Settings”。你现在可以在左侧窗口看到新的 “Steam Play” 选项。单击它并选中复选框:
|
||||
|
||||
* Enable Steam Play for supported titles (你可以玩列入白名单的 Windows 游戏)
|
||||
* Enable Steam Play for all titles (你可以尝试玩所有仅限 Windows 的游戏)
|
||||
|
||||
![Play Windows games on Linux using Steam Play][7]
|
||||
|
||||
我不记得 Steam 是否会再次重启,但我想这无所谓。你现在应该可以在 Linux 上看到安装仅限 Windows 的游戏的选项了。
|
||||
|
||||
比如,我的 Steam 库中有《Age of Empires》,正常情况下这个在 Linux 中没有。但我在 Steam Play 测试版启用所有 Windows 游戏后,现在我可以选择在 Linux 上安装《Age of Empires》了。
|
||||
|
||||
![Install Windows-only games on Linux using Steam][8]
|
||||
|
||||
*现在可以在 Linux 上安装仅限 Windows 的游戏*
|
||||
|
||||
### 有关 Steam Play 测试版功能的信息
|
||||
|
||||
在 Linux 上使用 Steam Play 测试版玩仅限 Windows 的游戏有一些事情你需要知道并且牢记。
|
||||
|
||||
* 目前,[只有 27 个 Steam Play 中的 Windows 游戏被列入白名单][9]。这些白名单游戏可以在 Linux 上无缝运行。
|
||||
* 你可以使用 Steam Play 测试版尝试任何 Windows 游戏,但它可能不是总能运行。有些游戏有时会崩溃,而某些游戏可能根本无法运行。
|
||||
* 在测试版中,你无法 Steam 商店中看到适用于 Linux 的 Windows 限定游戏。你必须自己尝试游戏或参考[这个社区维护的列表][10]以查看该 Windows 游戏的兼容性状态。你也可以通过填写[此表][11]来为列表做出贡献。
|
||||
* 如果你在 Windows 中通过 Steam 下载了游戏,你可以[在 Linux 和 Windows 之间共享 Steam 游戏文件][12]来节省下载的数据。
|
||||
|
||||
我希望本教程能帮助你在 Linux 上运行仅限 Windows 的游戏。你期待在 Linux 上玩哪些游戏?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://linux.cn/article-10054-1.html
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-windows-games-on-linux-featured.jpeg
|
||||
[3]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta.jpeg
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-2.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-3.jpeg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-4.jpeg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/install-windows-games-linux.jpeg
|
||||
[9]:https://steamcommunity.com/games/221410
|
||||
[10]:https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/htmlview?sle=true#
|
||||
[11]:https://docs.google.com/forms/d/e/1FAIpQLSeefaYQduMST_lg0IsYxZko8tHLKe2vtVZLFaPNycyhY4bidQ/viewform
|
||||
[12]:https://linux.cn/article-8027-1.html
|
||||
@ -1,31 +1,33 @@
|
||||
使用 PySimpleGUI 轻松为程序和脚本增加 GUI
|
||||
======
|
||||
|
||||
> 五分钟创建定制 GUI。
|
||||
|
||||

|
||||
|
||||
对于 `.exe` 类型的程序文件,我们可以通过双击鼠标左键打开;但对于 `.py` 类型的 Python 程序,几乎不会有人尝试同样的操作。对于一个(非程序员类型的)典型用户,他们双击打开 `.exe` 文件时预期弹出一个可以交互的窗体。基于 `Tkinter`,可以通过<ruby>标准 Python 安装<rt>standard Python installations</rt></ruby>的方式提供 GUI,但很多程序都不太可能这样做。
|
||||
对于 `.exe` 类型的程序文件,我们可以通过双击鼠标左键打开;但对于 `.py` 类型的 Python 程序,几乎不会有人尝试同样的操作。对于一个(非程序员类型的)典型用户,他们双击打开 `.exe` 文件时预期弹出一个可以交互的窗体。基于 Tkinter,可以通过<ruby>标准 Python 安装<rt>standard Python installations</rt></ruby>的方式提供 GUI,但很多程序都不太可能这样做。
|
||||
|
||||
如果打开 Python 程序并进入 GUI 界面变得如此容易,以至于真正的初学者也可以掌握,会怎样呢?会有人感兴趣并使用吗?这个问题不好回答,因为直到今天创建自定义 GUI 布局仍不是件容易的事情。
|
||||
|
||||
在为程序或脚本增加 GUI 这件事上,似乎存在能力的“错配”。(缺乏这方面能力的)真正的初学者被迫只能使用命令行方式,而很多(具备这方面能力的)高级程序员却不愿意花时间创建一个 `Tkinter` GUI。
|
||||
在为程序或脚本增加 GUI 这件事上,似乎存在能力的“错配”。(缺乏这方面能力的)真正的初学者被迫只能使用命令行方式,而很多(具备这方面能力的)高级程序员却不愿意花时间创建一个 Tkinter GUI。
|
||||
|
||||
### GUI 框架
|
||||
|
||||
Python 的 GUI 框架并不少,其中 `Tkinter`,`wxPython`,`Qt` 和 `Kivy` 是几种比较主流的框架。此外,还有不少在上述框架基础上封装的简化框架,例如 `EasyGUI`,`PyGUI` 和 `Pyforms` 等。
|
||||
Python 的 GUI 框架并不少,其中 Tkinter,wxPython,Qt 和 Kivy 是几种比较主流的框架。此外,还有不少在上述框架基础上封装的简化框架,例如 EasyGUI,PyGUI 和 Pyforms 等。
|
||||
|
||||
但问题在于,对于初学者(这里是指编程经验不超过 6 个月的用户)而言,即使是最简单的主流框架,他们也无从下手;他们也可以选择封装过的(简化)框架,但仍难以甚至无法创建自定义 GUI <ruby>布局<rt>layout</rt></ruby>。即便学会了某种(简化)框架,也需要编写连篇累牍的代码。
|
||||
|
||||
[`PySimpleGUI`][1] 尝试解决上述 GUI 难题,它提供了一种简单明了、易于理解、方便自定义的 GUI 接口。如果使用 `PySimpleGUI`,很多复杂的 GUI 也仅需不到 20 行代码。
|
||||
[PySimpleGUI][1] 尝试解决上述 GUI 难题,它提供了一种简单明了、易于理解、方便自定义的 GUI 接口。如果使用 PySimpleGUI,很多复杂的 GUI 也仅需不到 20 行代码。
|
||||
|
||||
### 秘诀
|
||||
|
||||
`PySimpleGUI` 极为适合初学者的秘诀在于,它已经包含了绝大多数原本需要用户编写的代码。`PySimpleGUI` 处理按钮<ruby>回调<rt>callback</rt></ruby>,无需用户编写代码。对于初学者,在几周内掌握函数的概念已经不容易了,要求其理解回调函数似乎有些强人所难。
|
||||
PySimpleGUI 极为适合初学者的秘诀在于,它已经包含了绝大多数原本需要用户编写的代码。PySimpleGUI 会处理按钮<ruby>回调<rt>callback</rt></ruby>,无需用户编写代码。对于初学者,在几周内掌握函数的概念已经不容易了,要求其理解回调函数似乎有些强人所难。
|
||||
|
||||
在大部分 GUI 框架中,布局 GUI <ruby>小部件<rt>widgets</rt></ruby>通常需要写一些代码,每个小部件至少 1-2 行。`PySimpleGUI` 使用了“auto-packer”技术,可以自动创建布局。因而,布局 GUI 窗口不再需要 `pack` 或 `grid` 系统。
|
||||
在大部分 GUI 框架中,布局 GUI <ruby>小部件<rt>widgets</rt></ruby>通常需要写一些代码,每个小部件至少 1-2 行。PySimpleGUI 使用了 “auto-packer” 技术,可以自动创建布局。因而,布局 GUI 窗口不再需要 pack 或 grid 系统。
|
||||
|
||||
(LCTT 译注:这里提到的 `pack` 和 `grid` 都是 `Tkinter` 的布局管理器,另外一种叫做 `place`)
|
||||
(LCTT 译注:这里提到的 pack 和 grid 都是 Tkinter 的布局管理器,另外一种叫做 place 。)
|
||||
|
||||
最后,`PySimpleGUI` 框架编写中有效利用 Python 语言特性,降低用户代码量并简化GUI 数据返回的方式。在<ruby>窗体<rt>form</rt></ruby>布局中创建小部件时,小部件会被部署到对应的布局中,无需额外的代码。
|
||||
最后,PySimpleGUI 框架编写中有效地利用了 Python 语言特性,降低用户代码量并简化 GUI 数据返回的方式。在<ruby>窗体<rt>form</rt></ruby>布局中创建小部件时,小部件会被部署到对应的布局中,无需额外的代码。
|
||||
|
||||
### GUI 是什么?
|
||||
|
||||
@ -37,13 +39,13 @@ button, values = GUI_Display(gui_layout)
|
||||
|
||||
绝大多数 GUI 支持的用户行为包括鼠标点击(例如,“确认”,“取消”,“保存”,“是”和“否”等)和内容输入。GUI 本质上可以归结为一行代码。
|
||||
|
||||
这也正是 `PySimpleGUI` (简单 GUI 模式)的工作原理。当执行命令显示 GUI 后,除非点击鼠标关闭窗体,否则不会执行任何代码。
|
||||
这也正是 PySimpleGUI (的简单 GUI 模式)的工作原理。当执行命令显示 GUI 后,除非点击鼠标关闭窗体,否则不会执行任何代码。
|
||||
|
||||
当然还有更复杂的 GUI,其中鼠标点击后窗口并不关闭;例如,机器人的远程控制界面,聊天窗口等。这类复杂的窗体也可以用 `PySimpleGUI` 创建。
|
||||
当然还有更复杂的 GUI,其中鼠标点击后窗口并不关闭;例如,机器人的远程控制界面,聊天窗口等。这类复杂的窗体也可以用 PySimpleGUI 创建。
|
||||
|
||||
### 快速创建 GUI
|
||||
|
||||
`PySimpleGUI` 什么时候有用呢?显然,是你需要 GUI 的时候。仅需不超过 5 分钟,就可以让你创建并尝试 GUI。最便捷的 GUI 创建方式就是从 [PySimpleGUI 经典实例][2]中拷贝一份代码。具体操作流程如下:
|
||||
PySimpleGUI 什么时候有用呢?显然,是你需要 GUI 的时候。仅需不超过 5 分钟,就可以让你创建并尝试 GUI。最便捷的 GUI 创建方式就是从 [PySimpleGUI 经典实例][2]中拷贝一份代码。具体操作流程如下:
|
||||
|
||||
* 找到一个与你需求最接近的 GUI
|
||||
* 从经典实例中拷贝代码
|
||||
@ -93,13 +95,14 @@ button, (name,) = form.LayoutAndRead(layout)
|
||||
|
||||
### 5 分钟内创建一个自定义 GUI
|
||||
|
||||
在简单布局的基础上,通过修改经典实例中的代码,5 分钟内即可使用 `PySimpleGUI` 创建自定义布局。
|
||||
在简单布局的基础上,通过修改经典实例中的代码,5 分钟内即可使用 PySimpleGUI 创建自定义布局。
|
||||
|
||||
在 `PySimpleGUI` 中,<ruby>小部件<rt>widgets</rt></ruby>被称为<ruby>元素<rt>elements</rt></ruby>。元素的名称与编码中使用的名称保持一致。
|
||||
在 PySimpleGUI 中,<ruby>小部件<rt>widgets</rt></ruby>被称为<ruby>元素<rt>elements</rt></ruby>。元素的名称与编码中使用的名称保持一致。
|
||||
|
||||
(LCTT 译注:`Tkinter` 中使用小部件这个词)
|
||||
(LCTT 译注:Tkinter 中使用小部件这个词)
|
||||
|
||||
#### 核心元素
|
||||
|
||||
```
|
||||
Text
|
||||
InputText
|
||||
@ -121,7 +124,7 @@ Column
|
||||
|
||||
#### 元素简写
|
||||
|
||||
`PySimpleGUI` 还包含两种元素简写方式。一种是元素类型名称简写,例如 `T` 用作 `Text` 的简写;另一种是元素参数被配置了默认值,你可以无需指定所有参数,例如 `Submit` 按钮默认的文本就是“Submit”。
|
||||
PySimpleGUI 还包含两种元素简写方式。一种是元素类型名称简写,例如 `T` 用作 `Text` 的简写;另一种是元素参数被配置了默认值,你可以无需指定所有参数,例如 `Submit` 按钮默认的文本就是 “Submit”。
|
||||
|
||||
```
|
||||
T = Text
|
||||
@ -164,9 +167,9 @@ RealtimeButton
|
||||
|
||||
(LCTT 译注:其实就是返回 `Button` 类实例的函数)
|
||||
|
||||
上面就是 `PySimpleGUI` 支持的全部元素。如果不在上述列表之中,就不会在你的窗口布局中生效。
|
||||
上面就是 PySimpleGUI 支持的全部元素。如果不在上述列表之中,就不会在你的窗口布局中生效。
|
||||
|
||||
(LCTT 译注:上述都是 `PySimpleGUI` 的类名、类别名或返回实例的函数,自然只能使用列表内的。)
|
||||
(LCTT 译注:上述都是 PySimpleGUI 的类名、类别名或返回实例的函数,自然只能使用列表内的。)
|
||||
|
||||
#### GUI 设计模式
|
||||
|
||||
@ -182,7 +185,7 @@ form = sg.FlexForm('Simple data entry form')
|
||||
button, values = form.LayoutAndRead(layout)
|
||||
```
|
||||
|
||||
(LCTT 译注:这段代码无法运行,只是为了说明每个程序都会用到的设计模式)
|
||||
(LCTT 译注:这段代码无法运行,只是为了说明每个程序都会用到的设计模式。)
|
||||
|
||||
对于绝大多数 GUI,编码流程如下:
|
||||
|
||||
@ -190,7 +193,7 @@ button, values = form.LayoutAndRead(layout)
|
||||
* 以“列表的列表”的形式定义 GUI
|
||||
* 展示 GUI 并获取元素的值
|
||||
|
||||
上述流程与 `PySimpleGUI` 设计模式部分的代码一一对应。
|
||||
上述流程与 PySimpleGUI 设计模式部分的代码一一对应。
|
||||
|
||||
#### GUI 布局
|
||||
|
||||
@ -201,7 +204,6 @@ button, values = form.LayoutAndRead(layout)
|
||||
```
|
||||
layout = [ [Text('Row 1')],
|
||||
[Text('Row 2'), Checkbox('Checkbox 1', OK()), Checkbox('Checkbox 2'), OK()] ]
|
||||
|
||||
```
|
||||
|
||||
上述布局对应的效果如下:
|
||||
@ -220,24 +222,24 @@ button, values = form.LayoutAndRead(layout)
|
||||
|
||||
窗体返回的结果由两部分组成:一部分是被点击按钮的名称,另一部分是一个列表,包含所有用户输入窗体的值。
|
||||
|
||||
在这个例子中,窗体显示后用户直接点击 `OK` 按钮,返回的结果如下:
|
||||
在这个例子中,窗体显示后用户直接点击 “OK” 按钮,返回的结果如下:
|
||||
|
||||
```
|
||||
button == 'OK'
|
||||
values == [False, False]
|
||||
```
|
||||
|
||||
`Checkbox` 类型元素返回 `True` 或 `False` 类型的值。由于默认处于未选中状态,两个元素的值都是 `False`。
|
||||
Checkbox 类型元素返回 `True` 或 `False` 类型的值。由于默认处于未选中状态,两个元素的值都是 `False`。
|
||||
|
||||
### 显示元素的值
|
||||
|
||||
一旦从 GUI 获取返回值,检查返回变量中的值是个不错的想法。与其使用 `print` 语句进行打印,我们不妨坚持使用 GUI 并在一个窗口中输出这些值。
|
||||
|
||||
(LCTT 译注:考虑使用的是 Python 3 版本,`print` 应该是函数而不是语句)
|
||||
(LCTT 译注:考虑使用的是 Python 3 版本,`print` 应该是函数而不是语句。)
|
||||
|
||||
在 `PySimpleGUI` 中,有多种消息框可供选取。传递给消息框(函数)的数据会被显示在消息框中;函数可以接受任意数目的参数,你可以轻松的将所有要查看的变量展示出来。
|
||||
在 PySimpleGUI 中,有多种消息框可供选取。传递给消息框(函数)的数据会被显示在消息框中;函数可以接受任意数目的参数,你可以轻松的将所有要查看的变量展示出来。
|
||||
|
||||
在 `PySimpleGUI` 中,最常用的消息框是 `MsgBox`。要展示上面例子中的数据,只需编写一行代码:
|
||||
在 PySimpleGUI 中,最常用的消息框是 `MsgBox`。要展示上面例子中的数据,只需编写一行代码:
|
||||
|
||||
```
|
||||
MsgBox('The GUI returned:', button, values)
|
||||
@ -245,7 +247,7 @@ MsgBox('The GUI returned:', button, values)
|
||||
|
||||
### 整合
|
||||
|
||||
好了,你已经了解了基础知识,让我们创建一个包含尽可能多 `PySimpleGUI` 元素的窗体吧!此外,为了更好的感观效果,我们将采用绿色/棕褐色的配色方案。
|
||||
好了,你已经了解了基础知识,让我们创建一个包含尽可能多 PySimpleGUI 元素的窗体吧!此外,为了更好的感观效果,我们将采用绿色/棕褐色的配色方案。
|
||||
|
||||
```
|
||||
import PySimpleGUI as sg
|
||||
@ -284,7 +286,7 @@ button, values = form.LayoutAndRead(layout)
|
||||
sg.MsgBox(button, values)
|
||||
```
|
||||
|
||||
看上面要写不少代码,但如果你试着直接使用 `Tkinter` 框架实现同样的 GUI,你很快就会发现 `PySimpleGUI` 版本的代码是多么的简洁。
|
||||
看上面要写不少代码,但如果你试着直接使用 Tkinter 框架实现同样的 GUI,你很快就会发现 PySimpleGUI 版本的代码是多么的简洁。
|
||||
|
||||
|
||||
|
||||
@ -317,7 +319,7 @@ else:
|
||||
|
||||
#### 安装方式
|
||||
|
||||
支持 `Tkinter` 的系统就支持 `PySimpleGUI`,甚至包括<ruby>树莓派<rt>Raspberry Pi</rt></ruby>,但你需要使用 Python 3。
|
||||
支持 Tkinter 的系统就支持 PySimpleGUI,甚至包括<ruby>树莓派<rt>Raspberry Pi</rt></ruby>,但你需要使用 Python 3。
|
||||
|
||||
```
|
||||
pip install PySimpleGUI
|
||||
@ -336,7 +338,7 @@ via: https://opensource.com/article/18/8/pysimplegui
|
||||
作者:[Mike Barnett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
6 个打造你自己的 VPN 的开源工具
|
||||
======
|
||||
|
||||
> 想尝试建立您自己的 VPN,但是不确定从哪里开始吗?
|
||||
|
||||

|
||||
|
||||
如果您想尝试建立您自己的 VPN,但是不确定从哪里开始,那么您来对地方了。我将比较 6 个在您自己的服务器上搭建和使用 VPN 的最好的自由和开源工具。不管您是想为您的企业建立站点到站点的 VPN,还是只是想创建一个远程代理访问以解除访问限制并对 ISP 隐藏你的互联网流量,都可以通过 VPN 来达成。
|
||||
|
||||
根据您的需求和条件,并参考您自己的技术特长、环境以及您想要通过 VPN 实现的目标。需要考虑以下因素:
|
||||
|
||||
* VPN 协议
|
||||
* 客户端的数量和设备类型
|
||||
* 服务端的兼容性
|
||||
* 需要的技术专业能力
|
||||
|
||||
### Algo
|
||||
|
||||
[Algo][1] 是从下往上设计的,可以为需要互联网安全代理的商务旅客创建 VPN 专用网。它“只包括您所需要的最小化的软件”,这意味着为了简单而牺牲了可扩展性。Algo 是基于 StrongSwan 的,但是删除了所有您不需要的东西,这有另外一个好处,那就是去除了新手可能不会注意到的安全漏洞。
|
||||
|
||||
作为额外的奖励,它甚至可以屏蔽广告!
|
||||
|
||||
Algo 只支持 IKEv2 协议和 Wireguard。因为对 IKEv2 的支持现在已经内置在大多数设备中,所以它不需要像 OpenVPN 这样的客户端应用程序。Algo 可以使用 Ansible 在 Ubuntu (首选选项)、Windows、RedHat、CentOS 和 FreeBSD 上部署。 使用 Ansible 可以自动化安装,它会根据您对一组简短的问题的回答来配置服务。卸载和重新部署也非常容易。
|
||||
|
||||
Algo 可能是在本文中安装和部署最简单和最快的 VPN。它非常简洁,考虑周全。如果您不需要其他工具提供的高级功能,只需要一个安全代理,这是一个很好的选择。请注意,Algo 明确表示,它不是为了解除地理封锁或逃避审查,主要是为了加密。
|
||||
|
||||
### Streisand
|
||||
|
||||
[Streisand][2] 可以使用一个命令安装在任何 Ubuntu 16.04 服务器上;这个过程大约需要 10 分钟。它支持 L2TP、OpenConnect、OpenSSH、OpenVPN、Shadowsocks、Stunnel、Tor bridge 和 WireGuard。根据您选择的协议,您可能需要安装客户端应用程序。
|
||||
|
||||
在很多方面,Streisand 与 Algo 相似,但是它提供了更多的协议和定制。这需要更多的工作来管理和维护,但也更加灵活。注意 Streisand 不支持 IKEv2。因为它的多功能性,我认为 Streisand 在某国和土耳其这样的地方绕过审查制度更有效,但是 Algo 的安装更容易和更快。
|
||||
|
||||
使用 Ansible 可以自动化安装,所以不需要太多的专业技术知识。通过向用户发送自定义生成的连接指令,包括服务器 SSL 证书的嵌入副本,可以轻松添加更多用户。
|
||||
|
||||
卸载 Streisand 是一个快速无痛的过程,您也可以随时重新部署。
|
||||
|
||||
### OpenVPN
|
||||
|
||||
[OpenVPN][3] 要求客户端和服务器应用程序使用其同名的协议建立 VPN 连接。OpenVPN 可以根据您的需求进行调整和定制,但它也需要更多专业技术知识。它支持远程访问和站点到站点配置;如果您计划使用 VPN 作为互联网代理,前者是您所需要的。因为在大多数设备上使用 OpenVPN 需要客户端应用程序,所以最终用户必须保持更新。
|
||||
|
||||
服务器端您可以选择部署在云端或你自己的 Linux 服务器上。兼容的发行版包括 CentOS 、Ubuntu 、Debian 和 openSUSE。Windows 、MacOS 、iOS 和 Android 都有客户端应用程序,其他设备也有非官方应用程序。企业可以选择设置一个 OpenVPN 接入服务器,但是对于想要使用社区版的个人来说,这可能有点过分。
|
||||
|
||||
OpenVPN 使用静态密钥加密来配置相对容易,但并不十分安全。相反,我建议使用 [easy-rsa][4] 来设置它,这是一个密钥管理包,可以用来设置公钥基础设施(PKI)。这允许您一次连接多个设备,并因此得到<ruby>完美前向保密<rt>perfect forward secrecy</rt></ruby>和其他好处的保护。OpenVPN 使用 SSL/TLS 进行加密,而且您可以在配置中指定 DNS 服务器。
|
||||
|
||||
OpenVPN 可以穿透防火墙和 NAT 防火墙,这意味着您可以使用它绕过可能会阻止连接的网关和防火墙。它同时支持 TCP 和 UDP 传输。
|
||||
|
||||
### StrongSwan
|
||||
|
||||
您可能会遇到一些名称中有 “Swan” 的各种 VPN 工具。FreeS/WAN 、OpenSwan、LibreSwan 和 [strongSwan][5] 都是同一个项目的分叉,后者是我个人最喜欢的。在服务器端,strongSwan 可以运行在 Linux 2.6、3.x 和 4x 内核、Android、FreeBSD、macOS、iOS 和 Windows 上。
|
||||
|
||||
StrongSwan 使用 IKEv2 协议和 IPSec 。与 OpenVPN 相比,IKEv2 连接速度更快,同时提供了很好的速度和安全性。如果您更喜欢不需要在客户端安装额外应用程序的协议,这将非常有用,因为现在生产的大多数新设备都支持 IKEv2,包括 Windows、MacOS、iOS 和 Android。
|
||||
|
||||
StrongSwan 并不特别容易使用,尽管文档不错,但它使用的词汇与大多数其他工具不同,这可能会让人比较困惑。它的模块化设计让它对企业来说很棒,但这也意味着它不是很精简。这当然不像 Algo 或 Streisand 那么简单。
|
||||
|
||||
访问控制可以基于使用 X.509 属性证书的组成员身份,这是 strongSwan 独有的功能。它支持用于集成到其他环境(如 Windows Active Directory)中的 EAP 身份验证方法。strongSwan 可以穿透NAT 网络防火墙。
|
||||
|
||||
### SoftEther
|
||||
|
||||
[SoftEther][6] 是由日本筑波大学的一名研究生发起的一个项目。SoftEther VPN 服务器和 VPN 网桥可以运行在 Windows、Linux、OSX、FreeBSD 和 Solaris 上,而客户端应用程序可以运行在 Windows、Linux 和 MacOS 上。VPN 网桥主要用于需要设置站点到站点 VPN 的企业,因此单个用户只需要服务器和客户端程序来设置远程访问。
|
||||
|
||||
SoftEther 支持 OpenVPN、L2TP、SSTP 和 EtherIP 协议,由于采用“基于 HTTPS 的以太网”伪装,它自己的 SoftEther 协议声称能够免疫深度数据包检测。SoftEther 还做了一些调整,以减少延迟并增加吞吐量。此外,SoftEther 还包括一个克隆功能,允许您轻松地从 OpenVPN 过渡到 SoftEther。
|
||||
|
||||
SoftEther 可以穿透 NAT 防火墙并绕过防火墙。在只允许 ICMP 和 DNS 数据包的受限网络上,您可以利用 SoftEther 的基于 ICMP 或 DNS 的 VPN 方式来穿透防火墙。SoftEther 可与 IPv4 和 IPv6 一起工作。
|
||||
|
||||
SoftEther 比 OpenVPN 和 strongSwan 更容易设置,但比 Streisand 和 Algo 要复杂。
|
||||
|
||||
### WireGuard
|
||||
|
||||
[WireGuard][7] 是这个名单上最新的工具;它太新了,甚至还没有完成。也就是说,它为部署 VPN 提供了一种快速简便的方法。它旨在通过使 IPSec 更简单、更精简来改进它,就像 SSH 一样。
|
||||
|
||||
与 OpenVPN 一样,WireGuard 既是一种协议,也是一种用于部署使用所述协议的 VPN 的软件工具。一个关键特性是“加密密钥路由”,它将公钥与隧道内允许的 IP 地址列表相关联。
|
||||
|
||||
WireGuard 可用于 Ubuntu、Debian、Fedora、CentOS、MacOS、Windows 和安卓系统。WireGuard 可在 IPv4 和 IPv6 上工作。
|
||||
|
||||
WireGuard 比大多数其他 VPN 协议轻得多,它只在需要发送数据时才发送数据包。
|
||||
|
||||
开发人员说,WireGuard 还不应该被信任,因为它还没有被完全审计过,但是欢迎你给它一个机会。这可能是下一个热门!
|
||||
|
||||
### 自制 VPN vs. 商业 VPN
|
||||
|
||||
制作您自己的 VPN 为您的互联网连接增加了一层隐私和安全,但是如果您是唯一一个使用它的人,那么装备精良的第三方,比如政府机构,将很容易追踪到你的活动。
|
||||
|
||||
此外,如果您计划使用您的 VPN 来解锁地理锁定的内容,自制的 VPN 可能不是最好的选择。因为您只能从一个 IP 地址连接,所以你的 VPN 服务器很容易被阻止。
|
||||
|
||||
好的商业 VPN 不存在这些问题。有了像 [ExpressVPN][8] 这样的提供商,您可以与数十甚至数百个其他用户共享服务器的 IP 地址,这使得跟踪一个用户的活动几乎变得不可能。您也可以从成百上千的服务器中选择,所以如果其中一台被列入黑名单,你可以切换到另一台。
|
||||
|
||||
然而,商业 VPN 的权衡是,您必须相信提供商不会窥探您的互联网流量。一定要选择一个有明确的无日志政策的信誉良好的供应商。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/open-source-tools-vpn
|
||||
|
||||
作者:[Paul Bischoff][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/paulbischoff
|
||||
[1]: https://blog.trailofbits.com/2016/12/12/meet-algo-the-vpn-that-works/
|
||||
[2]: https://github.com/StreisandEffect/streisand
|
||||
[3]: https://openvpn.net/
|
||||
[4]: https://github.com/OpenVPN/easy-rsa
|
||||
[5]: https://www.strongswan.org/
|
||||
[6]: https://www.softether.org/
|
||||
[7]: https://www.wireguard.com/
|
||||
[8]: https://www.comparitech.com/vpn/reviews/expressvpn/
|
||||
@ -0,0 +1,69 @@
|
||||
如何在 Ubuntu 和其他 Linux 发行版中创建照片幻灯片
|
||||
======
|
||||
|
||||
创建照片幻灯片只需点击几下。以下是如何在 Ubuntu 18.04 和其他 Linux 发行版中制作照片幻灯片。
|
||||
|
||||
![How to create slideshow of photos in Ubuntu Linux][1]
|
||||
|
||||
想象一下,你的朋友和亲戚正在拜访你,并请你展示最近的活动/旅行照片。
|
||||
|
||||
你将照片保存在计算机上,并整齐地放在单独的文件夹中。你邀请计算机附近的所有人。你进入该文件夹,单击其中一张图片,然后按箭头键逐个显示照片。
|
||||
|
||||
但那太累了!如果这些图片每隔几秒自动更改一次,那将会好很多。
|
||||
|
||||
这称之为幻灯片,我将向你展示如何在 Ubuntu 中创建照片幻灯片。这能让你在文件夹中循环播放图片并以全屏模式显示它们。
|
||||
|
||||
### 在 Ubuntu 18.04 和其他 Linux 发行版中创建照片幻灯片
|
||||
|
||||
虽然有几种图像浏览器可以做到,但我将向你展示大多数发行版中应该提供的两种最常用的工具。
|
||||
|
||||
#### 方法 1:使用 GNOME 默认图像浏览器浏览照片幻灯片
|
||||
|
||||
如果你在 Ubuntu 18.04 或任何其他发行版中使用 GNOME,那么你很幸运。Gnome 的默认图像浏览器,Eye of GNOME,能够在当前文件夹中显示图片的幻灯片。
|
||||
|
||||
只需单击其中一张图片,你将在程序的右上角菜单中看到设置选项。它看起来像堆叠在一起的三条横栏。
|
||||
|
||||
你会在这里看到几个选项。勾选幻灯片选项,它将全屏显示图像。
|
||||
|
||||
![How to create slideshow of photos in Ubuntu Linux][2]
|
||||
|
||||
默认情况下,图像以 5 秒的间隔变化。你可以进入 “Preferences -> Slideshow” 来更改幻灯片放映间隔。
|
||||
|
||||
![change slideshow interval in Ubuntu][3]
|
||||
|
||||
#### 方法 2:使用 Shotwell Photo Manager 进行照片幻灯片放映
|
||||
|
||||
[Shotwell][4] 是一款流行的 [Linux 照片管理程序][5]。适用于所有主要的 Linux 发行版。
|
||||
|
||||
如果尚未安装,请在你的发行版软件中心中搜索 Shotwell 并安装。
|
||||
|
||||
Shotwell 的运行略有不同。如果你在 Shotwell Viewer 中直接打开照片,则不会看到首选项或者幻灯片的选项。
|
||||
|
||||
对于幻灯片放映和其他选项,你必须打开 Shotwell 并导入包含这些图片的文件夹。导入文件夹后,从左侧窗格中选择该文件夹,然后单击菜单中的 “View”。你应该在此处看到幻灯片选项。只需单击它即可创建所选文件夹中所有图像的幻灯片。
|
||||
|
||||
![How to create slideshow of photos in Ubuntu Linux][6]
|
||||
|
||||
你还可以更改幻灯片设置。当图像以全屏显示时,将显示此选项。只需将鼠标悬停在底部,你就会看到一个设置选项。
|
||||
|
||||
#### 创建照片幻灯片很容易
|
||||
|
||||
如你所见,在 Linux 中创建照片幻灯片非常简单。我希望你觉得这个简单的提示有用。如果你有任何问题或建议,请在下面的评论栏告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/photo-slideshow-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/Create-photos-Slideshow-Linux.png
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/create-slideshow-photos-ubuntu-gnome.jpeg
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/change-slideshow-interval-gnome-image.jpeg
|
||||
[4]: https://wiki.gnome.org/Apps/Shotwell
|
||||
[5]: https://itsfoss.com/linux-photo-management-software/
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/create-slideshow-photos-shotwell.jpeg
|
||||
@ -1,37 +1,36 @@
|
||||
|
||||
|
||||
增强 Vim 编辑器,提高编辑效率
|
||||
======
|
||||
> 这 20 多个有用的命令可以增强你使用 Vi 的体验。
|
||||
|
||||

|
||||
|
||||
编者注:标题和文章最初提到的 `vi` 编辑器,现已更新为编辑器的正确名称:`Vim`。
|
||||
*编者注:标题和文章最初称呼的 `vi` 编辑器,现已更新为编辑器的正确名称:`Vim`。*
|
||||
|
||||
`Vim` 作为一款功能强大、选项丰富的编辑器,为许多用户所热爱。本文介绍了一些在 `Vim` 中默认未启用但实际非常有用的选项。虽然可以在每个 `Vim` 会话中单独启用,但为了创建一个开箱即用的高效编辑环境,还是建议在 `Vim` 的配置文件中配置这些命令。
|
||||
|
||||
## 开始前的准备
|
||||
### 开始前的准备
|
||||
|
||||
这里所说的选项或配置均位于用户主目录中的 `Vim` 启动配置文件 `.vimrc`。 按照下面的说明在 `.vimrc` 中设置选项:
|
||||
|
||||
(注意:`vimrc` 文件也用于 `Linux` 中的全局配置,如 `/etc/vimrc` 或 `/etc/vim/vimrc`。本文所说的 `.vimrc` 均是指位于用户主目录中的 `.vimrc` 文件。)
|
||||
|
||||
`Linux` 系统中:
|
||||
Linux 系统中:
|
||||
|
||||
* 用 `Vim` 打开 `.vimrc` 文件: `vim ~/.vimrc`
|
||||
* 复制本文最后的 `选项列表` 粘贴到 `.vimrc` 文件
|
||||
* 保存并关闭 (`:wq`)
|
||||
|
||||
译者注:此处不建议使用 `Vim` 编辑 `.vimrc` 文件,因为很可能无法粘贴成功,可以选择 `gedit` 编辑器编辑 `.vimrc` 文件。
|
||||
(LCTT 译注:此处不建议使用 `Vim` 编辑 `.vimrc` 文件,因为很可能无法粘贴成功,可以选择 `gedit` 编辑器编辑 `.vimrc` 文件。)
|
||||
|
||||
`Windows` 系统中:
|
||||
Windows 系统中:
|
||||
|
||||
* 首先,[安装 gvim][1]
|
||||
* 打开 `gvim`
|
||||
* 单击 `编辑` -> `启动设置`,打开 `.vimrc` 文件
|
||||
* 复制本文最后的 `选项列表` 粘贴到 `.vimrc` 文件
|
||||
* 单击 `文件` -> `保存`
|
||||
* 单击 “编辑” -> “启动设置”,打开 `_vimrc` 文件
|
||||
* 复制本文最后的 “选项列表” 粘贴到 `_vimrc` 文件
|
||||
* 单击 “文件” -> “保存”
|
||||
|
||||
译者注:此处应注意不要使用 `Windows` 自带的记事本编辑该 `.vimrc` 文件。
|
||||
(LCTT 译注:此处应注意不要使用 `Windows` 自带的记事本编辑该 `_vimrc` 文件,否则可能会因为行结束符不同而导致问题。)
|
||||
|
||||
下面,我们将深入研究提高 `Vim` 编辑效率的选项。主要分为以下几类:
|
||||
|
||||
@ -42,7 +41,7 @@
|
||||
5. 拼写
|
||||
6. 其他选项
|
||||
|
||||
## 1. 缩进 & 制表符
|
||||
### 1. 缩进 & 制表符
|
||||
|
||||
使 `Vim` 在创建新行的时候使用与上一行同样的缩进:
|
||||
|
||||
@ -58,7 +57,7 @@ set smartindent
|
||||
|
||||
注意:`Vim` 具有语言感知功能,且其默认设置可以基于文件中的编程语言来改变配置以提高效率。有许多默认的配置选项,包括 `axs cindent`,`cinoptions`,`indentexpr` 等,没有在这里说明。 `syn` 是一个非常有用的命令,用于设置文件的语法以更改显示模式。
|
||||
|
||||
译者注:这里的 `syn` 是指 `syntax`,可用于设置文件所用的编程语言,开启对应的语法高亮,以及执行自动事件 (`autocmd`)。
|
||||
(LCTT 译注:这里的 `syn` 是指 `syntax`,可用于设置文件所用的编程语言,开启对应的语法高亮,以及执行自动事件 (`autocmd`)。)
|
||||
|
||||
设置文件里的制表符 `(TAB)` 的宽度(以空格的数量表示):
|
||||
|
||||
@ -80,7 +79,7 @@ set expandtab
|
||||
|
||||
注意:这可能会导致依赖于制表符的 `Python` 等编程语言出现问题。这时,你可以根据文件类型设置该选项(请参考 `autocmd`)。
|
||||
|
||||
## 2. 显示 & 格式化
|
||||
### 2. 显示 & 格式化
|
||||
|
||||
要在每行的前面显示行号:
|
||||
|
||||
@ -102,9 +101,9 @@ set textwidth=80
|
||||
set wrapmargin=2
|
||||
```
|
||||
|
||||
译者注:如果 `textwidth` 选项不等于零,本选项无效。
|
||||
(LCTT 译注:如果 `textwidth` 选项不等于零,本选项无效。)
|
||||
|
||||
插入括号时,短暂地跳转到匹配的括号:
|
||||
当光标遍历文件时经过括号时,高亮标识匹配的括号:
|
||||
|
||||
```vim
|
||||
set showmatch
|
||||
@ -112,7 +111,7 @@ set showmatch
|
||||
|
||||
|
||||
|
||||
## 3. 搜索
|
||||
### 3. 搜索
|
||||
|
||||
高亮搜索内容的所有匹配位置:
|
||||
|
||||
@ -144,20 +143,22 @@ set smartcase
|
||||
|
||||
例如,如果文件内容是:
|
||||
|
||||
> test\
|
||||
> Test
|
||||
```
|
||||
test
|
||||
Test
|
||||
```
|
||||
|
||||
当打开 `ignorecase` 和 `smartcase` 选项时,搜索 `test` 时的突出显示:
|
||||
|
||||
> <font color=yellow>test</font>\
|
||||
> <font color=yellow>test</font>
|
||||
> <font color=yellow>Test</font>
|
||||
|
||||
搜索 `Test` 时的突出显示:
|
||||
|
||||
> test\
|
||||
> test
|
||||
> <font color=yellow>Test</font>
|
||||
|
||||
## 4. 浏览 & 滚动
|
||||
### 4. 浏览 & 滚动
|
||||
|
||||
为获得更好的视觉体验,你可能希望将光标放在窗口中间而不是第一行,以下选项使光标距窗口上下保留 5 行。
|
||||
|
||||
@ -165,7 +166,7 @@ set smartcase
|
||||
set scrolloff=5
|
||||
```
|
||||
|
||||
一个例子:
|
||||
一个例子:
|
||||
|
||||
第一张图中 `scrolloff=0`,第二张图中 `scrolloff=5`。
|
||||
|
||||
@ -181,7 +182,7 @@ set laststatus=2
|
||||
|
||||
|
||||
|
||||
## 5. 拼写
|
||||
### 5. 拼写
|
||||
|
||||
`Vim` 有一个内置的拼写检查器,对于文本编辑和编码非常有用。`Vim` 可以识别文件类型并仅对代码中的注释进行拼写检查。使用下面的选项打开英语拼写检查:
|
||||
|
||||
@ -189,9 +190,9 @@ set laststatus=2
|
||||
set spell spelllang=en_us
|
||||
```
|
||||
|
||||
译者注:中文、日文或其它东亚语字符通常会在打开拼写检查时被标为拼写错误,因为拼写检查不支持这些语种,可以在 `spelllang` 选项中加入 `cjk` 来忽略这些错误标注。
|
||||
(LCTT 译注:中文、日文或其它东亚语字符通常会在打开拼写检查时被标为拼写错误,因为拼写检查不支持这些语种,可以在 `spelllang` 选项中加入 `cjk` 来忽略这些错误标注。)
|
||||
|
||||
## 6. 其他选项
|
||||
### 6. 其他选项
|
||||
|
||||
禁止创建备份文件:启用此选项后,`Vim` 将在覆盖文件前创建一个备份,文件成功写入后保留该备份。如果不想保留该备份文件,可以按下面的方式关闭:
|
||||
|
||||
@ -229,9 +230,7 @@ set errorbells
|
||||
set visualbell
|
||||
```
|
||||
|
||||
## 惊喜
|
||||
|
||||
vi provides long-format as well as short-format commands. Either format can be used to set or unset the configuration.
|
||||
### 惊喜
|
||||
|
||||
`Vim` 提供长格式和短格式命令,两种格式都可用于设置或取消选项配置。
|
||||
|
||||
@ -247,8 +246,6 @@ set autoindent
|
||||
set ai
|
||||
```
|
||||
|
||||
To see the current configuration setting of a command without changing its current value, use `?` at the end:
|
||||
|
||||
要在不更改选项当前值的情况下查看其当前设置,可以在 `Vim` 的命令行上使用在末尾加上 `?` 的命令:
|
||||
|
||||
```vim
|
||||
@ -273,71 +270,43 @@ set noautoindent
|
||||
|
||||
|
||||
|
||||
注意:此处列出的命令仅对 `Linux` 上的 `Vim 7.4` 版本和 `Windows` 上的 `Vim 8.0` 版本进行了测试。
|
||||
注意:此处列出的命令仅对 Linux 上的 Vim 7.4 版本和 Windows 上的 Vim 8.0 版本进行了测试。
|
||||
|
||||
这些有用的命令肯定会增强您的 `Vim` 使用体验。你会推荐哪些其他有用的命令?
|
||||
|
||||
## 选项列表
|
||||
### 选项列表
|
||||
|
||||
复制该选项列表粘贴到 `.vimrc` 文件中:
|
||||
|
||||
```vim
|
||||
" Indentation & Tabs
|
||||
|
||||
set autoindent
|
||||
|
||||
set smartindent
|
||||
|
||||
set tabstop=4
|
||||
|
||||
set shiftwidth=4
|
||||
|
||||
set expandtab
|
||||
|
||||
set smarttab
|
||||
|
||||
" Display & format
|
||||
|
||||
set number
|
||||
|
||||
set textwidth=80
|
||||
|
||||
set wrapmargin=2
|
||||
|
||||
set showmatch
|
||||
|
||||
" Search
|
||||
|
||||
set hlsearch
|
||||
|
||||
set incsearch
|
||||
|
||||
set ignorecase
|
||||
|
||||
set smartcase
|
||||
|
||||
" Browse & Scroll
|
||||
|
||||
set scrolloff=5
|
||||
|
||||
set laststatus=2
|
||||
|
||||
" Spell
|
||||
|
||||
set spell spelllang=en_us
|
||||
|
||||
" Miscellaneous
|
||||
|
||||
set nobackup
|
||||
|
||||
set noswapfile
|
||||
|
||||
set autochdir
|
||||
|
||||
set undofile
|
||||
|
||||
set visualbell
|
||||
|
||||
set errorbells
|
||||
```
|
||||
|
||||
@ -348,7 +317,7 @@ via: https://opensource.com/article/18/9/vi-editor-productivity-powerhouse
|
||||
作者:[Girish Managoli][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[idea2act](https://github.com/idea2act)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[apemost](https://github.com/apemost), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,17 +1,15 @@
|
||||
heguangzhi Translating
|
||||
|
||||
8个Linux命令用于有效的进程管理
|
||||
8 个用于有效地管理进程的 Linux 命令
|
||||
======
|
||||
|
||||
> 通过这些关键的命令来全程管理你的应用。
|
||||
|
||||

|
||||
|
||||
一般来说,应用程序的生命周期有三种主要状态:启动、运行和停止。如果我们想成为称职的管理员,每个状态都可以而且应该得到认真的管理。这八个命令可用于管理进程的整个生命周期。
|
||||
|
||||
一般来说,应用程序进程的生命周期有三种主要状态:启动、运行和停止。如果我们想成为称职的管理员,每个状态都可以而且应该得到认真的管理。这八个命令可用于管理进程的整个生命周期。
|
||||
|
||||
### 启动进程
|
||||
|
||||
|
||||
启动进程的最简单方法是在命令行中键入其名称,然后按 Enter 键。如果要启动 Nginx web 服务器,请键入 **nginx** 。也许您只是想看看其版本。
|
||||
启动进程的最简单方法是在命令行中键入其名称,然后按回车键。如果要启动 Nginx web 服务器,请键入 `nginx` 。也许您只是想看看其版本。
|
||||
|
||||
```
|
||||
alan@workstation:~$ nginx
|
||||
@ -20,10 +18,9 @@ alan@workstation:~$ nginx -v
|
||||
nginx version: nginx/1.14.0
|
||||
```
|
||||
|
||||
### 查看您的可执行路径
|
||||
|
||||
### 查看您的可执行路径
|
||||
|
||||
以上启动进程的演示是假设可执行文件位于您的可执行路径中。理解这条路径是是否启动和管理进程的关键。管理员通常会为他们想要的目的定制这条路径。您可以使用 **echo $PATH** 查看您的可执行路径。
|
||||
以上启动进程的演示是假设可执行文件位于您的可执行路径中。理解这个路径是可靠地启动和管理进程的关键。管理员通常会为他们想要的目的定制这条路径。您可以使用 `echo $PATH` 查看您的可执行路径。
|
||||
|
||||
```
|
||||
alan@workstation:~$ echo $PATH
|
||||
@ -32,35 +29,29 @@ alan@workstation:~$ echo $PATH
|
||||
|
||||
#### WHICH
|
||||
|
||||
|
||||
使用 which 命令查看可执行文件的完整路径。
|
||||
使用 `which` 命令查看可执行文件的完整路径。
|
||||
|
||||
```
|
||||
alan@workstation:~$ which nginx
|
||||
alan@workstation:~$ which nginx
|
||||
/opt/nginx/bin/nginx
|
||||
```
|
||||
|
||||
|
||||
我将使用流行的 web 服务器软件 Nginx 作为我的例子。假设安装了 Nginx。如果执行 **which nginx** 的命令什么也不返回,那么 Nginx 就找不到了,因为它只搜索您指定的可执行路径。有三种方法可以补救一个进程不能简单地通过名字启动的情况。首先是键入完整路径。虽然,我不情愿输入全部路径,您会吗?
|
||||
|
||||
我将使用流行的 web 服务器软件 Nginx 作为我的例子。假设安装了 Nginx。如果执行 `which nginx` 的命令什么也不返回,那么是找不到 Nginx 了,因为它只搜索您指定的可执行路径。有三种方法可以补救一个进程不能简单地通过名字启动的情况。首先是键入完整路径 —— 虽然,我不情愿输入全部路径,您会吗?
|
||||
|
||||
```
|
||||
alan@workstation:~$ /home/alan/web/prod/nginx/sbin/nginx -v
|
||||
nginx version: nginx/1.14.0
|
||||
```
|
||||
|
||||
第二个解决方案是将应用程序安装在可执行文件路径中的目录中。然而,这有时可能是办不到的,特别是如果您没有 root 权限。
|
||||
|
||||
第二个解决方案是将应用程序安装在可执行文件路径中的目录中。然而,这可能是不可能的,特别是如果您没有 root 权限。
|
||||
|
||||
|
||||
第三个解决方案是更新您的可执行路径环境变量,包括要使用的特定应用程序的安装目录。这个解决方案是 shell-dependent。例如,Bash 用户需要在他们的 .bashrc 文件中编辑 PATH= line。
|
||||
第三个解决方案是更新您的可执行路径环境变量,包括要使用的特定应用程序的安装目录。这个解决方案是与 shell 相关的。例如,Bash 用户需要在他们的 `.bashrc` 文件中编辑 `PATH=` 行。
|
||||
|
||||
```
|
||||
PATH="$HOME/web/prod/nginx/sbin:$PATH"
|
||||
```
|
||||
|
||||
|
||||
现在,重复您的 echo 和 which命令或者尝试检查版本。容易多了!
|
||||
现在,重复您的 `echo` 和 `which` 命令或者尝试检查版本。容易多了!
|
||||
|
||||
```
|
||||
alan@workstation:~$ echo $PATH
|
||||
@ -77,22 +68,21 @@ nginx version: nginx/1.14.0
|
||||
|
||||
#### NOHUP
|
||||
|
||||
注销或关闭终端时,进程可能不会继续运行。这种特殊情况可以通过在要使用 `nohup` 命令放在要运行的命令前面让进程持续运行。此外,附加一个`&` 符号将会把进程发送到后台,并允许您继续使用终端。例如,假设您想运行 `myprogram.sh` 。
|
||||
|
||||
注销或关闭终端时,进程可能不会继续运行。这种特殊情况可以通过在要使用 nohup 命令放在要运行的命令前面让进程持续运行。此外,附加一个&符号将会把进程发送到后台,并允许您继续使用终端。例如,假设您想运行 myprogram.sh 。
|
||||
```
|
||||
nohup myprogram.sh &
|
||||
```
|
||||
|
||||
nohup 会返回运行进程的PID。接下来我会更多地谈论PID。
|
||||
`nohup` 会返回运行进程的 PID。接下来我会更多地谈论 PID。
|
||||
|
||||
### 管理正在运行的进程
|
||||
|
||||
|
||||
每个进程都有一个唯一的进程标识号 (PID) 。这个数字是我们用来管理每个进程的。我们还可以使用进程名称,我将在下面演示。有几个命令可以检查正在运行的进程的状态。让我们快速看看这些命令。
|
||||
|
||||
#### PS
|
||||
|
||||
最常见的是 ps 命令。ps 的默认输出是当前终端中运行的进程的简单列表。如下所示,第一列包含PID。
|
||||
最常见的是 `ps` 命令。`ps` 的默认输出是当前终端中运行的进程的简单列表。如下所示,第一列包含 PID。
|
||||
|
||||
```
|
||||
alan@workstation:~$ ps
|
||||
@ -101,8 +91,8 @@ PID TTY TIME CMD
|
||||
24148 pts/0 00:00:00 ps
|
||||
```
|
||||
|
||||
我想看看我之前启动的 Nginx 进程。为此,我告诉 `ps` 给我展示每一个正在运行的进程(`-e`)和完整的列表(`-f`)。
|
||||
|
||||
我想看看我之前开始的 Nginx 进程。为此,我告诉 ps 给我展示每一个正在运行的进程( **-e** ) 和完整的列表 ( **-f** )。
|
||||
```
|
||||
alan@workstation:~$ ps -ef
|
||||
UID PID PPID C STIME TTY TIME CMD
|
||||
@ -128,20 +118,19 @@ alan 20536 20526 0 10:39 pts/0 00:00:00 pager
|
||||
alan 20564 20496 0 10:40 pts/1 00:00:00 bash
|
||||
```
|
||||
|
||||
您可以在上面 `ps` 命令的输出中看到 Nginx 进程。这个命令显示了将近 300 行,但是我在这个例子中缩短了它。可以想象,试图处理 300 行过程信息有点混乱。我们可以将这个输出输送到 `grep`,过滤一下仅显示 nginx。
|
||||
|
||||
您可以在上面 ps 命令的输出中看到 Nginx 进程。这个命令显示了将近300行,但是我在这个例子中缩短了它。可以想象,试图处理300行过程信息有点混乱。我们可以将这个输出输送到 grep, 过滤一下仅显示 nginx。
|
||||
```
|
||||
alan@workstation:~$ ps -ef |grep nginx
|
||||
alan 20520 1454 0 10:39 ? 00:00:00 nginx: master process nginx
|
||||
alan 20521 20520 0 10:39 ? 00:00:00 nginx: worker process
|
||||
```
|
||||
|
||||
|
||||
确实更好了。我们可以很快看到,Nginx 有20520和2052的PIDs。
|
||||
确实更好了。我们可以很快看到,Nginx 有 20520 和 20521 的 PID。
|
||||
|
||||
#### PGREP
|
||||
|
||||
pgrep 命令更加简化单独调用 grep 遇到的问题。
|
||||
`pgrep` 命令更加简化单独调用 `grep` 遇到的问题。
|
||||
|
||||
```
|
||||
alan@workstation:~$ pgrep nginx
|
||||
@ -149,7 +138,7 @@ alan@workstation:~$ pgrep nginx
|
||||
20521
|
||||
```
|
||||
|
||||
假设您在一个托管环境中,多个用户正在运行几个不同的 Nginx 实例。您可以使用 **-u** 选项将其他人排除在输出之外。
|
||||
假设您在一个托管环境中,多个用户正在运行几个不同的 Nginx 实例。您可以使用 `-u` 选项将其他人排除在输出之外。
|
||||
|
||||
```
|
||||
alan@workstation:~$ pgrep -u alan nginx
|
||||
@ -160,7 +149,8 @@ alan@workstation:~$ pgrep -u alan nginx
|
||||
#### PIDOF
|
||||
|
||||
|
||||
另一个好用的是pidof。此命令将检查特定二进制文件的 PID,即使另一个同名进程正在运行。为了建立一个例子,我将我的 Nginx 复制到第二个目录,并以相应的前缀集开始。在现实生活中,这个实例可能位于不同的位置,例如由不同用户拥有的目录。如果我运行两个 Nginx 实例,则pidof 输出显示它们的所有进程。
|
||||
另一个好用的是 `pidof`。此命令将检查特定二进制文件的 PID,即使另一个同名进程正在运行。为了建立一个例子,我将我的 Nginx 复制到第二个目录,并以相应的路径前缀启动。在现实生活中,这个实例可能位于不同的位置,例如由不同用户拥有的目录。如果我运行两个 Nginx 实例,则`pidof` 输出显示它们的所有进程。
|
||||
|
||||
```
|
||||
alan@workstation:~$ ps -ef |grep nginx
|
||||
alan 20881 1454 0 11:18 ? 00:00:00 nginx: master process ./nginx -p /home/alan/web/prod/nginxsec
|
||||
@ -169,7 +159,7 @@ alan 20895 1454 0 11:19 ? 00:00:00 nginx: master process ng
|
||||
alan 20896 20895 0 11:19 ? 00:00:00 nginx: worker process
|
||||
```
|
||||
|
||||
使用 grep 或 pgrep 将显示 PID 数字,但我们可能无法辨别哪个实例是哪个。
|
||||
使用 `grep` 或 `pgrep` 将显示 PID 数字,但我们可能无法辨别哪个实例是哪个。
|
||||
|
||||
```
|
||||
alan@workstation:~$ pgrep nginx
|
||||
@ -179,7 +169,7 @@ alan@workstation:~$ pgrep nginx
|
||||
20896
|
||||
```
|
||||
|
||||
pidof 命令可用于确定每个特定 Nginx 实例的PID。
|
||||
`pidof` 命令可用于确定每个特定 Nginx 实例的 PID。
|
||||
|
||||
```
|
||||
alan@workstation:~$ pidof /home/alan/web/prod/nginxsec/sbin/nginx
|
||||
@ -191,7 +181,8 @@ alan@workstation:~$ pidof /home/alan/web/prod/nginx/sbin/nginx
|
||||
|
||||
#### TOP
|
||||
|
||||
top 命令已经有很长时间了,对于查看运行进程的细节和快速识别内存消耗等问题是非常有用的。其默认视图如下所示。
|
||||
`top` 命令已经有很久的历史了,对于查看运行进程的细节和快速识别内存消耗等问题是非常有用的。其默认视图如下所示。
|
||||
|
||||
```
|
||||
top - 11:56:28 up 1 day, 13:37, 1 user, load average: 0.09, 0.04, 0.03
|
||||
Tasks: 292 total, 3 running, 225 sleeping, 0 stopped, 0 zombie
|
||||
@ -210,7 +201,8 @@ KiB Swap: 0 total, 0 free, 0 used. 14176540 ava
|
||||
7 root 20 0 0 0 0 S 0.0 0.0 0:00.08 ksoftirqd/0
|
||||
```
|
||||
|
||||
可以通过键入字母 **s** 和您喜欢的更新秒数来更改更新间隔。为了更容易监控我们的示例 Nginx 进程,我们可以使用 **-p** 选项调用top并通过PID。这个输出要干净得多。
|
||||
可以通过键入字母 `s` 和您喜欢的更新秒数来更改更新间隔。为了更容易监控我们的示例 Nginx 进程,我们可以使用 `-p` 选项并传递 PID 来调用 `top`。这个输出要干净得多。
|
||||
|
||||
```
|
||||
alan@workstation:~$ top -p20881 -p20882 -p20895 -p20896
|
||||
|
||||
@ -226,16 +218,13 @@ KiB Swap: 0 total, 0 free, 0 used. 14177928 ava
|
||||
20896 alan 20 0 12460 1628 912 S 0.0 0.0 0:00.00 nginx
|
||||
```
|
||||
|
||||
在管理进程,特别是终止进程时,正确确定PID是非常重要。此外,如果以这种方式使用top,每当这些进程中的一个停止或一个新进程开始时,top都需要被告知有新的更新。
|
||||
在管理进程,特别是终止进程时,正确确定 PID 是非常重要。此外,如果以这种方式使用 `top`,每当这些进程中的一个停止或一个新进程开始时,`top` 都需要被告知有新的进程。
|
||||
|
||||
### 终止进程
|
||||
|
||||
#### KILL
|
||||
|
||||
Interestingly, there is no stop command. In Linux, there is the kill command. Kill is used to send a signal to a process. The most commonly used signal is "terminate" (SIGTERM) or "kill" (SIGKILL). However, there are many more. Below are some examples. The full list can be shown with **kill -L**.
|
||||
|
||||
|
||||
有趣的是,没有 stop 命令。在 Linux中,有 kill 命令。kill 用于向进程发送信号。最常用的信号是“终止”( SIGTERM )或“杀死”( SIGKILL )。然而,还有更多。下面是一些例子。完整的列表可以用 **kill -L** 显示。
|
||||
有趣的是,没有 `stop` 命令。在 Linux 中,有 `kill` 命令。`kill` 用于向进程发送信号。最常用的信号是“终止”(`SIGTERM`)或“杀死”(`SIGKILL`)。然而,还有更多。下面是一些例子。完整的列表可以用 `kill -L` 显示。
|
||||
|
||||
```
|
||||
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
|
||||
@ -244,10 +233,7 @@ Interestingly, there is no stop command. In Linux, there is the kill command. Ki
|
||||
|
||||
```
|
||||
|
||||
Notice signal number nine is SIGKILL. Usually, we issue a command such as **kill -9 20896**. The default signal is 15, which is SIGTERM. Keep in mind that many applications have their own method for stopping. Nginx uses a **-s** option for passing a signal such as "stop" or "reload." Generally, I prefer to use an application's specific method to stop an operation. However, I'll demonstrate the kill command to stop Nginx process 20896 and then confirm it is stopped with pgrep. The PID 20896 no longer appears.
|
||||
|
||||
注意第九号信号是 SIGKILL。通常,我们会发布一个命令,比如 **kill -9 20896** 。默认信号是15,这是SIGTERM。请记住,许多应用程序都有自己的停止方法。Nginx 使用 **-s** 选项传递信号,如“停止”或“重新加载”。“通常,我更喜欢使用应用程序的特定方法来停止操作。然而,我将演示 kill 命令来停止 Nginx process 20896,然后用 pgrep 确认它已经停止。PID 20896 就不再出现。
|
||||
|
||||
注意第 9 号信号是 `SIGKILL`,通常,我们会发出比如 `kill -9 20896` 这样的命令。默认信号是 15,这是 `SIGTERM`。请记住,许多应用程序都有自己的停止方法。Nginx 使用 `-s` 选项传递信号,如 `stop` 或 `reload`。通常,我更喜欢使用应用程序的特定方法来停止操作。然而,我将演示用 `kill` 命令来停止 Nginx 进程 20896,然后用 `pgrep` 确认它已经停止。PID 20896 就不再出现。
|
||||
|
||||
```
|
||||
alan@workstation:~$ kill -9 20896
|
||||
@ -261,19 +247,14 @@ alan@workstation:~$ pgrep nginx
|
||||
|
||||
#### PKILL
|
||||
|
||||
The command pkill is similar to pgrep in that it can search by name. This means you have to be very careful when using pkill. In my example with Nginx, I might not choose to use it if I only want to kill one Nginx instance. I can pass the Nginx option **-s** **stop** to a specific instance to kill it, or I need to use grep to filter on the full ps output.
|
||||
|
||||
命令 pkill 类似于 pgrep,因为它可以按名称搜索。这意味着在使用 pkill 时必须非常小心。在我的 Nginx 示例中,如果我只想杀死一个 Nginx 实例,我可能不会选择使用它。我可以将 Nginx 选项 **-s** **stop** 传递给特定的实例来消除它,或者我需要使用grep来过滤整个 ps 输出。
|
||||
命令 `pkill` 类似于 `pgrep`,因为它可以按名称搜索。这意味着在使用 `pkill` 时必须非常小心。在我的 Nginx 示例中,如果我只想杀死一个 Nginx 实例,我可能不会选择使用它。我可以将 Nginx 选项 `-s stop` 传递给特定的实例来消除它,或者我需要使用 `grep` 来过滤整个 `ps` 输出。
|
||||
|
||||
```
|
||||
/home/alan/web/prod/nginx/sbin/nginx -s stop
|
||||
|
||||
/home/alan/web/prod/nginxsec/sbin/nginx -s stop
|
||||
```
|
||||
|
||||
If I want to use pkill, I can include the **-f** option to ask pkill to filter across the full command line argument. This of course also applies to pgrep. So, first I can check with **pgrep -a** before issuing the **pkill -f**.
|
||||
|
||||
如果我想使用 pkill,我可以包括 **-f** 选项,让 pkill 过滤整个命令行参数。这当然也适用于 pgrep。所以,在执行 **pkill -f** 之前,首先我可以用 **pgrep -a** 确认一下。
|
||||
如果我想使用 `pkill`,我可以包括 `-f` 选项,让 `pkill` 过滤整个命令行参数。这当然也适用于 `pgrep`。所以,在执行 `pkill -f` 之前,首先我可以用 `pgrep -a` 确认一下。
|
||||
|
||||
```
|
||||
alan@workstation:~$ pgrep -a nginx
|
||||
@ -283,10 +264,7 @@ alan@workstation:~$ pgrep -a nginx
|
||||
20896 nginx: worker process
|
||||
```
|
||||
|
||||
I can also narrow down my result with **pgrep -f**. The same argument used with pkill stops the process.
|
||||
|
||||
我也可以用 **pgrep -f** 缩小我的结果。pkill 使用的相同参数会停止该进程。
|
||||
|
||||
我也可以用 `pgrep -f` 缩小我的结果。`pkill` 使用相同参数会停止该进程。
|
||||
|
||||
```
|
||||
alan@workstation:~$ pgrep -f nginxsec
|
||||
@ -295,15 +273,9 @@ alan@workstation:~$ pgrep -f nginxsec
|
||||
alan@workstation:~$ pkill -f nginxsec
|
||||
```
|
||||
|
||||
The key thing to remember with pgrep (and especially pkill) is that you must always be sure that your search result is accurate so you aren't unintentionally affecting the wrong processes.
|
||||
`pgrep`(尤其是 `pkill`)要记住的关键点是,您必须始终确保搜索结果准确性,这样您就不会无意中影响到错误的进程。
|
||||
|
||||
pgrep (尤其是pkill )要记住的关键点是,您必须始终确保搜索结果准确性,这样您就不会无意中影响到错误的进程。
|
||||
|
||||
Most of these commands have many command line options, so I always recommend reading the [man page][1] on each one. While most of these exist across platforms such as Linux, Solaris, and BSD, there are a few differences. Always test and be ready to correct as needed when working at the command line or writing scripts.
|
||||
|
||||
|
||||
|
||||
大多数这些命令都有许多命令行选项,所以我总是建议阅读每一个命令的 [man page][1]。虽然大多数这些都存在于 Linux、Solaris 和 BSD 等平台上,但也有一些不同之处。在命令行工作或编写脚本时,始终测试并随时准备根据需要进行更正。
|
||||
大多数这些命令都有许多命令行选项,所以我总是建议阅读每一个命令的 [man 手册页][1]。虽然大多数这些命令都存在于 Linux、Solaris 和 BSD 等平台上,但也有一些不同之处。在命令行工作或编写脚本时,始终测试并随时准备根据需要进行更正。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -311,8 +283,8 @@ via: https://opensource.com/article/18/9/linux-commands-process-management
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
308
published/20180905 5 tips to improve productivity with zsh.md
Normal file
308
published/20180905 5 tips to improve productivity with zsh.md
Normal file
@ -0,0 +1,308 @@
|
||||
用 zsh 提高生产力的 5 个技巧
|
||||
======
|
||||
> zsh 提供了数之不尽的功能和特性,这里有五个可以让你在命令行暴增效率的方法。
|
||||
|
||||

|
||||
|
||||
Z shell([zsh][1])是 Linux 和类 Unix 系统中的一个[命令解析器][2]。 它跟 sh (Bourne shell) 家族的其它解析器(如 bash 和 ksh)有着相似的特点,但它还提供了大量的高级特性以及强大的命令行编辑功能,如增强版 Tab 补全。
|
||||
|
||||
在这里不可能涉及到 zsh 的所有功能,[描述][3]它的特性需要好几百页。在本文中,我会列出 5 个技巧,让你通过在命令行使用 zsh 来提高你的生产力。
|
||||
|
||||
### 1、主题和插件
|
||||
|
||||
多年来,开源社区已经为 zsh 开发了数不清的主题和插件。主题是一个预定义提示符的配置,而插件则是一组常用的别名命令和函数,可以让你更方便的使用一种特定的命令或者编程语言。
|
||||
|
||||
如果你现在想开始用 zsh 的主题和插件,那么使用一种 zsh 的配置框架是你最快的入门方式。在众多的配置框架中,最受欢迎的则是 [Oh My Zsh][4]。在默认配置中,它就已经为 zsh 启用了一些合理的配置,同时它也自带上百个主题和插件。
|
||||
|
||||
主题会在你的命令行提示符之前添加一些有用的信息,比如你 Git 仓库的状态,或者是当前使用的 Python 虚拟环境,所以它会让你的工作更高效。只需要看到这些信息,你就不用再敲命令去重新获取它们,而且这些提示也相当酷炫。下图就是我选用的主题 [Powerlevel9k][5]:
|
||||
|
||||
![zsh Powerlevel9K theme][7]
|
||||
|
||||
*zsh 主题 Powerlevel9k*
|
||||
|
||||
除了主题,Oh my Zsh 还自带了大量常用的 zsh 插件。比如,通过启用 Git 插件,你可以用一组简便的命令别名操作 Git, 比如
|
||||
|
||||
```
|
||||
$ alias | grep -i git | sort -R | head -10
|
||||
g=git
|
||||
ga='git add'
|
||||
gapa='git add --patch'
|
||||
gap='git apply'
|
||||
gdt='git diff-tree --no-commit-id --name-only -r'
|
||||
gau='git add --update'
|
||||
gstp='git stash pop'
|
||||
gbda='git branch --no-color --merged | command grep -vE "^(\*|\s*(master|develop|dev)\s*$)" | command xargs -n 1 git branch -d'
|
||||
gcs='git commit -S'
|
||||
glg='git log --stat'
|
||||
```
|
||||
|
||||
zsh 还有许多插件可以用于许多编程语言、打包系统和一些平时在命令行中常用的工具。以下是我 Ferdora 工作站中用到的插件表:
|
||||
|
||||
```
|
||||
git golang fedora docker oc sudo vi-mode virtualenvwrapper
|
||||
```
|
||||
|
||||
### 2、智能的命令别名
|
||||
|
||||
命令别名在 zsh 中十分有用。为你常用的命令定义别名可以节省你的打字时间。Oh My Zsh 默认配置了一些常用的命令别名,包括目录导航命令别名,为常用的命令添加额外的选项,比如:
|
||||
|
||||
```
|
||||
ls='ls --color=tty'
|
||||
grep='grep --color=auto --exclude-dir={.bzr,CVS,.git,.hg,.svn}'
|
||||
```
|
||||
|
||||
除了命令别名以外, zsh 还自带两种额外常用的别名类型:后缀别名和全局别名。
|
||||
|
||||
后缀别名可以让你基于文件后缀,在命令行中利用指定程序打开这个文件。比如,要用 vim 打开 YAML 文件,可以定义以下命令行别名:
|
||||
|
||||
```
|
||||
alias -s {yml,yaml}=vim
|
||||
```
|
||||
|
||||
现在,如果你在命令行中输入任何后缀名为 `yml` 或 `yaml` 文件, zsh 都会用 vim 打开这个文件。
|
||||
|
||||
```
|
||||
$ playbook.yml
|
||||
# Opens file playbook.yml using vim
|
||||
```
|
||||
|
||||
全局别名可以让你创建一个可在命令行的任何地方展开的别名,而不仅仅是在命令开始的时候。这个在你想替换常用文件名或者管道命令的时候就显得非常有用了。比如:
|
||||
|
||||
```
|
||||
alias -g G='| grep -i'
|
||||
```
|
||||
|
||||
要使用这个别名,只要你在想用管道命令的时候输入 `G` 就好了:
|
||||
|
||||
```
|
||||
$ ls -l G do
|
||||
drwxr-xr-x. 5 rgerardi rgerardi 4096 Aug 7 14:08 Documents
|
||||
drwxr-xr-x. 6 rgerardi rgerardi 4096 Aug 24 14:51 Downloads
|
||||
```
|
||||
|
||||
接着,我们就来看看 zsh 是如何导航文件系统的。
|
||||
|
||||
### 3、便捷的目录导航
|
||||
|
||||
当你使用命令行的时候,在不同的目录之间切换访问是最常见的工作了。 zsh 提供了一些十分有用的目录导航功能来简化这个操作。这些功能已经集成到 Oh My Zsh 中了, 而你可以用以下命令来启用它
|
||||
|
||||
```
|
||||
setopt autocd autopushd \ pushdignoredups
|
||||
```
|
||||
|
||||
使用了上面的配置后,你就不用输入 `cd` 来切换目录了,只需要输入目录名称,zsh 就会自动切换到这个目录中:
|
||||
|
||||
```
|
||||
$ pwd
|
||||
/home/rgerardi
|
||||
$ /tmp
|
||||
$ pwd
|
||||
/tmp
|
||||
```
|
||||
|
||||
如果想要回退,只要输入 `-`:
|
||||
|
||||
zsh 会记录你访问过的目录,这样下次你就可以快速切换到这些目录中。如果想要看这个目录列表,只要输入 `dirs -v`:
|
||||
|
||||
```
|
||||
$ dirs -v
|
||||
0 ~
|
||||
1 /var/log
|
||||
2 /var/opt
|
||||
3 /usr/bin
|
||||
4 /usr/local
|
||||
5 /usr/lib
|
||||
6 /tmp
|
||||
7 ~/Projects/Opensource.com/zsh-5tips
|
||||
8 ~/Projects
|
||||
9 ~/Projects/ansible
|
||||
10 ~/Documents
|
||||
```
|
||||
|
||||
如果想要切换到这个列表中的其中一个目录,只需输入 `~#` (`#` 代表目录在列表中的序号)就可以了。比如
|
||||
|
||||
```
|
||||
$ pwd
|
||||
/home/rgerardi
|
||||
$ ~4
|
||||
$ pwd
|
||||
/usr/local
|
||||
```
|
||||
|
||||
你甚至可以用别名组合这些命令,这样切换起来就变得更简单:
|
||||
|
||||
```
|
||||
d='dirs -v | head -10'
|
||||
1='cd -'
|
||||
2='cd -2'
|
||||
3='cd -3'
|
||||
4='cd -4'
|
||||
5='cd -5'
|
||||
6='cd -6'
|
||||
7='cd -7'
|
||||
8='cd -8'
|
||||
9='cd -9'
|
||||
```
|
||||
|
||||
现在你可以通过输入 `d` 来查看这个目录列表的前10个,然后用目录的序号来进行切换:
|
||||
|
||||
```
|
||||
$ d
|
||||
0 /usr/local
|
||||
1 ~
|
||||
2 /var/log
|
||||
3 /var/opt
|
||||
4 /usr/bin
|
||||
5 /usr/lib
|
||||
6 /tmp
|
||||
7 ~/Projects/Opensource.com/zsh-5tips
|
||||
8 ~/Projects
|
||||
9 ~/Projects/ansible
|
||||
$ pwd
|
||||
/usr/local
|
||||
$ 6
|
||||
/tmp
|
||||
$ pwd
|
||||
/tmp
|
||||
```
|
||||
|
||||
最后,你可以在 zsh 中利用 Tab 来自动补全目录名称。你可以先输入目录的首字母,然后按 `TAB` 键来补全它们:
|
||||
|
||||
```
|
||||
$ pwd
|
||||
/home/rgerardi
|
||||
$ p/o/z (TAB)
|
||||
$ Projects/Opensource.com/zsh-5tips/
|
||||
```
|
||||
|
||||
以上仅仅是 zsh 强大的 Tab 补全系统中的一个功能。接来下我们来探索它更多的功能。
|
||||
|
||||
### 4、先进的 Tab 补全
|
||||
|
||||
zsh 强大的补全系统是它的卖点之一。为了简便起见,我称它为 Tab 补全,然而在系统底层,它起到了几个作用。这里通常包括展开以及命令补全,我会在这里用讨论它们。如果想了解更多,详见 [用户手册][8]。
|
||||
|
||||
在 Oh My Zsh 中,命令补全是默认启用的。要启用它,你只要在 `.zshrc` 文件中添加以下命令:
|
||||
|
||||
```
|
||||
autoload -U compinit
|
||||
compinit
|
||||
```
|
||||
|
||||
zsh 的补全系统非常智能。它会尝试唯一提示可用在当前上下文环境中的项目 —— 比如,你输入了 `cd` 和 `TAB`,zsh 只会为你提示目录名,因为它知道其它的项目放在 `cd` 后面没用。
|
||||
|
||||
反之,如果你使用与用户相关的命令便会提示用户名,而 `ssh` 或者 `ping` 这类则会提示主机名。
|
||||
|
||||
zsh 拥有一个巨大而又完整的库,因此它能识别许多不同的命令。比如,如果你使用 `tar` 命令, 你可以按 `TAB` 键,它会为你展示一个可以用于解压的文件列表:
|
||||
|
||||
```
|
||||
$ tar -xzvf test1.tar.gz test1/file1 (TAB)
|
||||
file1 file2
|
||||
```
|
||||
|
||||
如果使用 `git` 的话,这里有个更高级的示例。在这个示例中,当你按 `TAB` 键, zsh 会自动补全当前库可以操作的文件:
|
||||
|
||||
```
|
||||
$ ls
|
||||
original plan.txt zsh-5tips.md zsh_theme_small.png
|
||||
$ git status
|
||||
On branch master
|
||||
Your branch is up to date with 'origin/master'.
|
||||
|
||||
Changes not staged for commit:
|
||||
(use "git add <file>..." to update what will be committed)
|
||||
(use "git checkout -- <file>..." to discard changes in working directory)
|
||||
|
||||
modified: zsh-5tips.md
|
||||
|
||||
no changes added to commit (use "git add" and/or "git commit -a")
|
||||
$ git add (TAB)
|
||||
$ git add zsh-5tips.md
|
||||
```
|
||||
|
||||
zsh 还能识别命令行选项,同时它只会提示与选中子命令相关的命令列表:
|
||||
|
||||
```
|
||||
$ git commit - (TAB)
|
||||
--all -a -- stage all modified and deleted paths
|
||||
--allow-empty -- allow recording an empty commit
|
||||
--allow-empty-message -- allow recording a commit with an empty message
|
||||
--amend -- amend the tip of the current branch
|
||||
--author -- override the author name used in the commit
|
||||
--branch -- show branch information
|
||||
--cleanup -- specify how the commit message should be cleaned up
|
||||
--date -- override the author date used in the commit
|
||||
--dry-run -- only show the list of paths that are to be committed or not, and any untracked
|
||||
--edit -e -- edit the commit message before committing
|
||||
--file -F -- read commit message from given file
|
||||
--gpg-sign -S -- GPG-sign the commit
|
||||
--include -i -- update the given files and commit the whole index
|
||||
--interactive -- interactively update paths in the index file
|
||||
--message -m -- use the given message as the commit message
|
||||
... TRUNCATED ...
|
||||
```
|
||||
|
||||
在按 `TAB` 键之后,你可以使用方向键来选择你想用的命令。现在你就不用记住所有的 `git` 命令项了。
|
||||
|
||||
zsh 还有很多有用的功能。当你用它的时候,你就知道哪些对你才是最有用的。
|
||||
|
||||
### 5、命令行编辑与历史记录
|
||||
|
||||
zsh 的命令行编辑功能也十分有用。默认条件下,它是模拟 emacs 编辑器的。如果你是跟我一样更喜欢用 vi/vim,你可以用以下命令启用 vi 的键绑定。
|
||||
|
||||
```
|
||||
$ bindkey -v
|
||||
```
|
||||
|
||||
如果你使用 Oh My Zsh,`vi-mode` 插件可以启用额外的绑定,同时会在你的命令提示符上增加 vi 的模式提示 —— 这个非常有用。
|
||||
|
||||
当启用 vi 的绑定后,你可以在命令行中使用 vi 命令进行编辑。比如,输入 `ESC+/` 来查找命令行记录。在查找的时候,输入 `n` 来找下一个匹配行,输入 `N` 来找上一个。输入 `ESC` 后,常用的 vi 命令都可以使用,如输入 `0` 跳转到行首,输入 `$` 跳转到行尾,输入 `i` 来插入文本,输入 `a` 来追加文本等等,即使是跟随的命令也同样有效,比如输入 `cw` 来修改单词。
|
||||
|
||||
除了命令行编辑,如果你想修改或重新执行之前使用过的命令,zsh 还提供几个常用的命令行历史功能。比如,你打错了一个命令,输入 `fc`,你可以在你偏好的编辑器中修复最后一条命令。使用哪个编辑是参照 `$EDITOR` 变量的,而默认是使用 vi。
|
||||
|
||||
另外一个有用的命令是 `r`, 它会重新执行上一条命令;而 `r <WORD>` 则会执行上一条包含 `WORD` 的命令。
|
||||
|
||||
最后,输入两个感叹号(`!!`),可以在命令行中回溯最后一条命令。这个十分有用,比如,当你忘记使用 `sudo` 去执行需要权限的命令时:
|
||||
|
||||
```
|
||||
$ less /var/log/dnf.log
|
||||
/var/log/dnf.log: Permission denied
|
||||
$ sudo !!
|
||||
$ sudo less /var/log/dnf.log
|
||||
```
|
||||
|
||||
这个功能让查找并且重新执行之前命令的操作更加方便。
|
||||
|
||||
### 下一步呢?
|
||||
|
||||
这里仅仅介绍了几个可以让你提高生产率的 zsh 特性;其实还有更多功能有待你的发掘;想知道更多的信息,你可以访问以下的资源:
|
||||
|
||||
- [An Introduction to the Z Shell][9]
|
||||
- [A User's Guide to ZSH][10]
|
||||
- [Archlinux Wiki][11]
|
||||
- [zsh-lovers][12]
|
||||
|
||||
你有使用 zsh 提高生产力的技巧可以分享吗?我很乐意在下方评论中看到它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/tips-productivity-zsh
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[tnuoccalanosrep](https://github.com/tnuoccalanosrep)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rgerardi
|
||||
[1]: http://www.zsh.org/
|
||||
[2]: https://en.wikipedia.org/wiki/Shell_(computing)
|
||||
[3]: http://zsh.sourceforge.net/Doc/Release/zsh_toc.html
|
||||
[4]: https://ohmyz.sh/
|
||||
[5]: https://github.com/bhilburn/powerlevel9k
|
||||
[7]: https://opensource.com/sites/default/files/uploads/zsh_theme_small.png (zsh Powerlevel9K theme)
|
||||
[8]: http://zsh.sourceforge.net/Guide/zshguide06.html#l144
|
||||
[9]: http://zsh.sourceforge.net/Intro/intro_toc.html
|
||||
[10]: http://zsh.sourceforge.net/Guide/
|
||||
[11]: https://wiki.archlinux.org/index.php/zsh
|
||||
[12]: https://grml.org/zsh/
|
||||
@ -3,49 +3,49 @@
|
||||
|
||||

|
||||
|
||||
多播 DNS 或 mDNS 允许系统通过在广播查询局域网中的其他资源。Fedora 用户经常在没有复杂名称服务的路由器上拥有多个 Linux 系统。在这种情况下,mDNS 允许你按名称与多个系统通信 - 多数情况下不用路由器。你也不必在所有本地系统上同步类似 /etc/hosts 之类的文件。本文介绍如何设置它。
|
||||
mDNS(<ruby>多播 DNS<rt>Multicast DNS</rt></ruby>)允许系统在局域网中广播查询其他资源的名称。Fedora 用户经常在没有复杂名称服务的路由器上接有多个 Linux 系统。在这种情况下,mDNS 允许你按名称与多个系统通信 —— 多数情况下不用路由器。你也不必在所有本地系统上同步类似 `/etc/hosts` 之类的文件。本文介绍如何设置它。
|
||||
|
||||
mDNS 是一个零配置网络服务,它已经诞生了很长一段时间。Fedora 将 Avahi (包含 mDNS 的零配置系统)作为工作站的一部分。 (mDNS 也是 Bonjour 的一部分,可在 Mac OS 上找到。)
|
||||
mDNS 是一个零配置网络服务,它已经诞生了很长一段时间。Fedora Workstation 带有零配置系统 Avahi(它包含 mDNS)。 (mDNS 也是 Bonjour 的一部分,可在 Mac OS 上找到。)
|
||||
|
||||
本文假设你有两个系统运行受支持的 Fedora 版本(27 或 28)。它们的主机名是 castor 和 pollux。
|
||||
|
||||
### 安装包
|
||||
|
||||
确保系统上安装了 nss-mdns 和 avahi 软件包。你可能是不同的版本,这也没问题:
|
||||
|
||||
```
|
||||
$ rpm -q nss-mdns avahi
|
||||
nss-mdns-0.14.1-1.fc28.x86_64
|
||||
avahi-0.7-13.fc28.x86_64
|
||||
|
||||
```
|
||||
|
||||
Fedora Workstation 默认提供这两个包。如果不存在,请安装它们:
|
||||
|
||||
```
|
||||
$ sudo dnf install nss-mdns avahi
|
||||
|
||||
```
|
||||
|
||||
确保 avahi-daemon.service 单元已启用并正在运行。同样,这是 Fedora Workstation 的默认设置。
|
||||
确保 `avahi-daemon.service` 单元已启用并正在运行。同样,这是 Fedora Workstation 的默认设置。
|
||||
|
||||
```
|
||||
$ sudo systemctl enable --now avahi-daemon.service
|
||||
|
||||
```
|
||||
|
||||
虽然是可选的,但你可能还需要安装 avahi-tools 软件包。该软件包包括许多方便的程序,用于检查系统上的零配置服务的工作情况。使用这个 sudo 命令:
|
||||
虽然是可选的,但你可能还需要安装 avahi-tools 软件包。该软件包包括许多方便的程序,用于检查系统上的零配置服务的工作情况。使用这个 `sudo` 命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install avahi-tools
|
||||
|
||||
```
|
||||
|
||||
/etc/nsswitch.conf 控制系统使用哪个服务用于解析,以及它们的顺序。你应该在那个文件中看到这样的一行:
|
||||
`/etc/nsswitch.conf` 控制系统使用哪个服务用于解析,以及它们的顺序。你应该在那个文件中看到这样的一行:
|
||||
|
||||
```
|
||||
hosts: files mdns4_minimal [NOTFOUND=return] dns myhostname
|
||||
|
||||
```
|
||||
|
||||
注意命令 mdns4_minimal [NOTFOUND=return]。它们告诉你的系统使用多播 DNS 解析程序将主机名解析为 IP 地址。即使该服务有效,如果名称无法解析,也会尝试其余服务。
|
||||
注意命令 `mdns4_minimal [NOTFOUND=return]`。它们告诉你的系统使用多播 DNS 解析程序将主机名解析为 IP 地址。即使该服务有效,如果名称无法解析,也会尝试其余服务。
|
||||
|
||||
如果你没有看到与此类似的配置,则可以对其进行编辑(以 root 用户身份)。但是,nss-mdns 包会为你处理此问题。如果你对自己编辑它感到不舒服,请删除并重新安装该软件包以修复该文件。
|
||||
如果你没有看到与此类似的配置,则可以(以 root 用户身份)对其进行编辑。但是,nss-mdns 包会为你处理此问题。如果你对自己编辑它感到不舒服,请删除并重新安装该软件包以修复该文件。
|
||||
|
||||
在**两个系统**中执行同样的步骤 。
|
||||
|
||||
@ -53,42 +53,36 @@ hosts: files mdns4_minimal [NOTFOUND=return] dns myhostname
|
||||
|
||||
现在你已完成常见的配置工作,请使用以下方法之一设置每个主机的名称:
|
||||
|
||||
1. 如果你正在使用 Fedora Workstation,[你可以使用这个步骤][1]。
|
||||
|
||||
2. 如果没有,请使用 hostnamectl 来做。在第一台机器上这么做:
|
||||
```
|
||||
$ hostnamectl set-hostname castor
|
||||
|
||||
```
|
||||
|
||||
3. 你还可以编辑 /etc/avahi/avahi-daemon.conf,删除主机名设置行上的注释,并在那里设置名称。但是,默认情况下,Avahi 使用系统提供的主机名,因此你**不应该**需要此方法。
|
||||
1. 如果你正在使用 Fedora Workstation,[你可以使用这个步骤][1]。
|
||||
2. 如果没有,请使用 `hostnamectl` 来做。在第一台机器上这么做:`$ hostnamectl set-hostname castor`。
|
||||
3. 你还可以编辑 `/etc/avahi/avahi-daemon.conf`,删除主机名设置行上的注释,并在那里设置名称。但是,默认情况下,Avahi 使用系统提供的主机名,因此你**不应该**需要此方法。
|
||||
|
||||
接下来,重启 Avahi 守护进程,以便它接收更改:
|
||||
|
||||
```
|
||||
$ sudo systemctl restart avahi-daemon.service
|
||||
|
||||
```
|
||||
|
||||
然后正确设置另一台机器:
|
||||
|
||||
```
|
||||
$ hostnamectl set-hostname pollux
|
||||
$ sudo systemctl restart avahi-daemon.service
|
||||
|
||||
```
|
||||
|
||||
只要你的路由器没有禁止 mDNS 流量,你现在应该能够登录到 castor 并 ping 通另一台机器。你应该使用默认的 .local 域名,以便解析正常工作:
|
||||
|
||||
```
|
||||
$ ping pollux.local
|
||||
PING pollux.local (192.168.0.1) 56(84) bytes of data.
|
||||
64 bytes from 192.168.0.1 (192.168.0.1): icmp_seq=1 ttl=64 time=3.17 ms
|
||||
64 bytes from 192.168.0.1 (192.168.0.1): icmp_seq=2 ttl=64 time=1.24 ms
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
如果你在 pollux ping castor.local,同样的技巧也适用 。现在在网络中访问你的系统更方便了!
|
||||
如果你在 pollux `ping castor.local`,同样的技巧也适用。现在在网络中访问你的系统更方便了!
|
||||
|
||||
此外,如果你的路由器宣传这个服务,请不要感到惊讶。现代 WiFi 和有线路由器通常提供这些服务,以使消费者的生活更轻松。
|
||||
此外,如果你的路由器也支持这个服务,请不要感到惊讶。现代 WiFi 和有线路由器通常提供这些服务,以使消费者的生活更轻松。
|
||||
|
||||
此过程适用于大多数系统。但是,如果遇到麻烦,请使用 avahi-browse 和 avahi-tools 软件包中的其他工具来查看可用的服务。
|
||||
|
||||
@ -97,10 +91,7 @@ PING pollux.local (192.168.0.1) 56(84) bytes of data.
|
||||
|
||||
via: https://fedoramagazine.org/find-systems-easily-lan-mdns/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Paul W. Frields][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,245 @@
|
||||
最好的 3 个开源 JavaScript 图表库
|
||||
======
|
||||
> 图表及其它可视化方式让传递数据的信息变得更简单。
|
||||
|
||||

|
||||
|
||||
对于数据可视化和制作精美网站来说,图表和图形很重要。视觉上的展示让分析大块数据及传递信息变得更简单。JavaScript 图表库能让数据以极好的、易于理解的和交互的方式进行可视化,还能够优化你的网站设计。
|
||||
|
||||
本文会带你学习最好的 3 个开源 JavaScript 图表库。
|
||||
|
||||
### 1、 Chart.js
|
||||
|
||||
[Chart.js][1] 是一个开源的 JavaScript 库,你可以在自己的应用中用它创建生动美丽和交互式的图表。使用它需要遵循 MIT 协议。
|
||||
|
||||
使用 Chart.js,你可以创建各种各样令人印象深刻的图表和图形,包括条形图、折线图、范围图、线性标度和散点图。它可以响应各种设备,使用 HTML5 Canvas 元素进行绘制。
|
||||
|
||||
示例代码如下,它使用该库绘制了一个条形图。本例中我们使用 Chart.js 的内容分发网络(CDN)来包含这个库。注意这里使用的数据仅用于展示。
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/Chart.js/2.5.0/Chart.min.js"></script>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<canvas id="bar-chart" width=300" height="150"></canvas>
|
||||
|
||||
<script>
|
||||
|
||||
new Chart(document.getElementById("bar-chart"), {
|
||||
type: 'bar',
|
||||
data: {
|
||||
labels: ["North America", "Latin America", "Europe", "Asia", "Africa"],
|
||||
datasets: [
|
||||
{
|
||||
label: "Number of developers (millions)",
|
||||
backgroundColor: ["red", "blue","yellow","green","pink"],
|
||||
data: [7,4,6,9,3]
|
||||
}
|
||||
]
|
||||
},
|
||||
options: {
|
||||
legend: { display: false },
|
||||
title: {
|
||||
display: true,
|
||||
text: 'Number of Developers in Every Continent'
|
||||
},
|
||||
|
||||
scales: {
|
||||
yAxes: [{
|
||||
ticks: {
|
||||
beginAtZero:true
|
||||
}
|
||||
}]
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
});
|
||||
</script>
|
||||
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
如你所见,通过设置 `type` 和 `bar` 来构造条形图。你可以把条形体的方向改成其他类型 —— 比如把 `type` 设置成 `horizontalBar`。
|
||||
|
||||
在 `backgroundColor` 数组参数中提供颜色类型,就可以设置条形图的颜色。
|
||||
|
||||
颜色被分配给关联数组中相同索引的标签和数据。例如,第二个标签 “Latin American”,颜色会是 “蓝色(blue)”(第二个颜色),数值是 4(data 中的第二个数字)。
|
||||
|
||||
代码的执行结果如下。
|
||||
|
||||
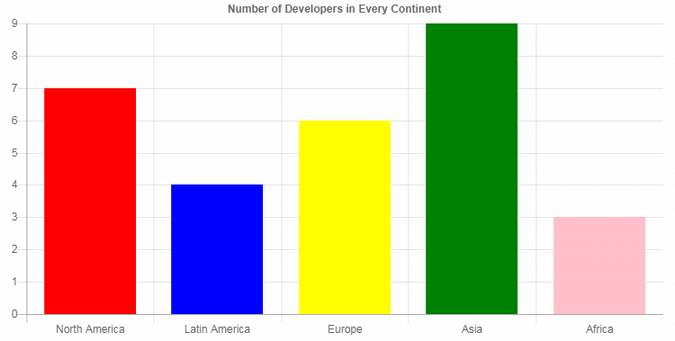
|
||||
|
||||
### 2、 Chartist.js
|
||||
|
||||
[Chartist.js][2] 是一个简单的 JavaScript 动画库,你能够自制美丽的响应式图表,或者进行其他创作。使用它需要遵循 WTFPL 或者 MIT 协议。
|
||||
|
||||
这个库是由一些对现有图表工具不满的开发者进行开发的,它可以为设计师或程序员提供美妙的功能。
|
||||
|
||||
在项目中包含 Chartist.js 库后,你可以使用它们来创建各式各样的图表,包括动画,条形图和折线图。它使用 SVG 来动态渲染图表。
|
||||
|
||||
这里是使用该库绘制一个饼图的例子。
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
|
||||
<link href="https//cdn.jsdelivr.net/chartist.js/latest/chartist.min.css" rel="stylesheet" type="text/css" />
|
||||
|
||||
<style>
|
||||
.ct-series-a .ct-slice-pie {
|
||||
fill: hsl(100, 20%, 50%); /* filling pie slices */
|
||||
stroke: white; /*giving pie slices outline */
|
||||
stroke-width: 5px; /* outline width */
|
||||
}
|
||||
|
||||
.ct-series-b .ct-slice-pie {
|
||||
fill: hsl(10, 40%, 60%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
|
||||
.ct-series-c .ct-slice-pie {
|
||||
fill: hsl(120, 30%, 80%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
|
||||
.ct-series-d .ct-slice-pie {
|
||||
fill: hsl(90, 70%, 30%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
.ct-series-e .ct-slice-pie {
|
||||
fill: hsl(60, 140%, 20%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
|
||||
</style>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<div class="ct-chart ct-golden-section"></div>
|
||||
|
||||
<script src="https://cdn.jsdelivr.net/chartist.js/latest/chartist.min.js"></script>
|
||||
|
||||
<script>
|
||||
|
||||
var data = {
|
||||
series: [45, 35, 20]
|
||||
};
|
||||
|
||||
var sum = function(a, b) { return a + b };
|
||||
|
||||
new Chartist.Pie('.ct-chart', data, {
|
||||
labelInterpolationFnc: function(value) {
|
||||
return Math.round(value / data.series.reduce(sum) * 100) + '%';
|
||||
}
|
||||
});
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
使用 Chartist JavaScript 库,你可以使用各种预先构建好的 CSS 样式,而不是在项目中指定各种与样式相关的部分。你可以使用这些样式来设置已创建的图表的外观。
|
||||
|
||||
比如,预创建的 CSS 类 `.ct-chart` 是用来构建饼状图的容器。还有 `.ct-golden-section` 类可用于获取纵横比,它基于响应式设计进行缩放,帮你解决了计算固定尺寸的麻烦。Chartist 还提供了其它类别的比例容器,你可以在自己的项目中使用它们。
|
||||
|
||||
为了给各个扇形设置样式,可以使用默认的 `.ct-serials-a` 类。字母 `a` 是根据系列的数量变化的(a、b、c,等等),因此它与每个要设置样式的扇形相对应。
|
||||
|
||||
`Chartist.Pie` 方法用来创建一个饼状图。要创建另一种类型的图表,比如折线图,请使用 `Chartist.Line`。
|
||||
|
||||
代码的执行结果如下。
|
||||
|
||||
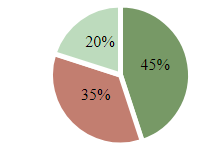
|
||||
|
||||
### 3、 D3.js
|
||||
|
||||
[D3.js][3] 是另一个好用的开源 JavaScript 图表库。使用它需要遵循 BSD 许可证。D3 的主要用途是,根据提供的数据,处理和添加文档的交互功能,。
|
||||
|
||||
借助这个 3D 动画库,你可以通过 HTML5、SVG 和 CSS 来可视化你的数据,并且让你的网站变得更精美。更重要的是,使用 D3,你可以把数据绑定到文档对象模型(DOM)上,然后使用基于数据的函数改变文档。
|
||||
|
||||
示例代码如下,它使用该库绘制了一个简单的条形图。
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
|
||||
<style>
|
||||
.chart div {
|
||||
font: 15px sans-serif;
|
||||
background-color: lightblue;
|
||||
text-align: right;
|
||||
padding:5px;
|
||||
margin:5px;
|
||||
color: white;
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
</style>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<div class="chart"></div>
|
||||
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/d3/5.5.0/d3.min.js"></script>
|
||||
|
||||
<script>
|
||||
|
||||
var data = [342,222,169,259,173];
|
||||
|
||||
d3.select(".chart")
|
||||
.selectAll("div")
|
||||
.data(data)
|
||||
.enter()
|
||||
.append("div")
|
||||
.style("width", function(d){ return d + "px"; })
|
||||
.text(function(d) { return d; });
|
||||
|
||||
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
使用 D3 库的主要概念是应用 CSS 样式选择器来定位 DOM 节点,然后对其执行操作,就像其它的 DOM 框架,比如 JQuery。
|
||||
|
||||
将数据绑定到文档上后,.`enter()` 函数会被调用,为即将到来的数据构建新的节点。所有在 .`enter()` 之后调用的方法会为数据中的每一个项目调用一次。
|
||||
|
||||
代码的执行结果如下。
|
||||
|
||||
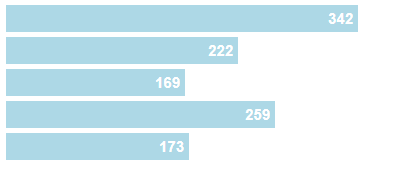
|
||||
|
||||
### 总结
|
||||
|
||||
[JavaScript][4] 图表库提供了强大的工具,你可以将自己的网络资源进行数据可视化。通过这三个开源库,你可以把自己的网站变得更好看,更容易使用。
|
||||
|
||||
你知道其它强大的用于创造 JavaScript 动画效果的前端库吗?请在下方的评论区留言分享。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-javascript-chart-libraries
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[BriFuture](https://github.com/brifuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/drmjg
|
||||
[1]: https://www.chartjs.org/
|
||||
[2]: https://gionkunz.github.io/chartist-js/
|
||||
[3]: https://d3js.org/
|
||||
[4]: https://www.liveedu.tv/guides/programming/javascript/
|
||||
@ -1,33 +1,33 @@
|
||||
Flash Player 的两种开源替代方案
|
||||
======
|
||||
> Adobe 将于 2020 年终止对 Flash 媒体播放器的支持,但仍有很多人们希望访问的 Flash 视频。这里有两个开源的替代品或许可以帮到你。
|
||||
|
||||

|
||||
|
||||
2017 年 7 月,Adobe 为 Flash Media Player 敲响了[丧钟][1],宣布将在 2020 年终止对曾经无处不在的在线视频播放器的支持。但事实上,在一系列损害了其声誉的零日攻击后,Flash 的份额在过去的 8 年一直在下跌。苹果公司在 2010 年宣布它不会支持这项技术后,其未来趋于黯淡,并且在谷歌停止在 Chrome 浏览器中默认启用 Flash(支持 HTML5)后,它的消亡在 2016 年加速。
|
||||
2017 年 7 月,Adobe 为 Flash Media Player 敲响了[丧钟][1],宣布将在 2020 年终止对曾经无处不在的在线视频播放器的支持。但事实上,在一系列损害了其声誉的零日攻击后,Flash 的份额在过去的 8 年一直在下跌。苹果公司在 2010 年宣布它不会支持这项技术后,其未来趋于黯淡,并且在谷歌停止在 Chrome 浏览器中默认启用 Flash(支持 HTML5)后,它的消亡在 2016 年进一步加速。
|
||||
|
||||
即便如此,Adobe 仍然每月发布该软件的更新,截至 2018 年 8 月,它在网站的使用率从 2011 年的 28.5% 下降到[仅 4.4%] [2]。还有更多证据表明 Flash 的下滑:谷歌工程总监 [Parisa Tabriz 说][3]通过浏览器访问 Flash 内容的 Chrome 用户数量从 2014 年的 80% 下降到 2018 年的 8%。
|
||||
|
||||
尽管如今很少有视频创作者以 Flash 格式发布,但仍有很多人们希望在未来几年内访问的 Flash 视频。鉴于官方支持的日期已经屈指可数,开源软件创建者有很好的机会介入 Adobe Flash Media Player 的替代品。这其中两个应用是 Lightspark 和 GNU Gnash。它们都不是完美的替代品,但来自贡献者的帮助可以使它们成为可行的替代品。
|
||||
尽管如今很少有视频创作者以 Flash 格式发布,但仍有很多人们希望在未来几年内访问的 Flash 视频。鉴于官方支持的日期已经屈指可数,开源软件创建者有很好的机会涉足 Adobe Flash 媒体播放器的替代品。这其中两个应用是 Lightspark 和 GNU Gnash。它们都不是完美的替代品,但来自贡献者的帮助可以使它们成为可行的替代品。
|
||||
|
||||
### Lightspark
|
||||
|
||||
[Lightspark][4] 是 Linux 上的 Flash Player 替代品。虽然它仍处于 alpha 状态,但自从 Adobe 在 2017 宣布废弃 Adobe 以来,开发速度已经加快。据其网站称,Lightspark 实现了 60% 的 Flash API,可在许多流行网站包括 BBC 新闻、Google Play 音乐和亚马逊音乐上[使用][5]。
|
||||
|
||||
Lightspark 是用 C++/C 编写的,并在 [LGPLv3][6] 下许可。该项目列出了 41 个贡献者,并正在积极征求错误报告和其他贡献。有关更多信息,请查看其[ GitHub 仓库][5]。
|
||||
Lightspark 是用 C++/C 编写的,并在 [LGPLv3][6] 下许可。该项目列出了 41 个贡献者,并正在积极征求错误报告和其他贡献。有关更多信息,请查看其 [GitHub 仓库][5]。
|
||||
|
||||
### GNU Gnash
|
||||
|
||||
[GNU Gnash][7] 是一个用于 GNU/Linux 操作系统,包括 Ubuntu、Fedora 和 Debian 的 Flash Player。它作为独立软件和插件可用于 Firefox 和 Konqueror 浏览器中。
|
||||
|
||||
Gnash 的主要缺点是它不支持最新版本的 Flash 文件 - 它支持大多数 Flash SWF v7 功能,一些 v8 和 v9 功能,不支持 v10 文件。它处于测试阶段,由于它在[ GNU GPLv3 或更高版本][8]下许可,因此你可以帮助实现它的现代化。访问其[项目页面][9]获取更多信息。
|
||||
Gnash 的主要缺点是它不支持最新版本的 Flash 文件 —— 它支持大多数 Flash SWF v7 功能,一些 v8 和 v9 功能,不支持 v10 文件。它处于测试阶段,由于它在 [GNU GPLv3 或更高版本][8]下许可,因此你可以帮助实现它的现代化。访问其[项目页面][9]获取更多信息。
|
||||
|
||||
### 想要创建Flash吗?
|
||||
### 想要创建 Flash 吗?
|
||||
|
||||
* 仅因为大多数人都不会发布 Flash 视频,但这并不意味着永远不需要创建 SWF 文件。如果你发现自己需要,这两个开源工具可能会有所帮助:
|
||||
|
||||
* [Motion-Twin ActionScript 2 编译器][10](MTASC):一个命令行编译器,它可以在没有 Adobe Animate(Adobe 当前的视频创建软件)的情况下生成 SWF 文件。
|
||||
* [Ming][11]:用 C 编写的可以生成 SWF 文件的库。它还包含一些可用于处理 Flash 的[程序][12]。
|
||||
仅因为大多数人都不会发布 Flash 视频,但这并不意味着永远不需要创建 SWF 文件。如果你发现自己需要,这两个开源工具可能会有所帮助:
|
||||
|
||||
* [Motion-Twin ActionScript 2 编译器][10](MTASC):一个命令行编译器,它可以在没有 Adobe Animate(Adobe 当前的视频创建软件)的情况下生成 SWF 文件。
|
||||
* [Ming][11]:用 C 编写的可以生成 SWF 文件的库。它还包含一些可用于处理 Flash 的[程序][12]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -37,7 +37,7 @@ via: https://opensource.com/alternatives/flash-media-player
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,124 @@
|
||||
Autotrash:一个自动清除旧垃圾的命令行工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Autotrash** 是一个命令行程序,它用于自动清除旧的已删除文件。它将清除超过指定天数的在回收站中的文件。你不需要清空回收站或执行 `SHIFT+DELETE` 以永久清除文件/文件夹。Autortrash 将处理回收站中的内容,并在特定时间段后自动删除它们。简而言之,Autotrash 永远不会让你的垃圾变得太大。
|
||||
|
||||
### 安装 Autotrash
|
||||
|
||||
Autotrash 默认存在于基于 Debian 系统的仓库中。要在 Debian、Ubuntu、Linux Mint 上安装 `autotrash`,请运行:
|
||||
|
||||
```
|
||||
$ sudo apt-get install autotrash
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install autotrash
|
||||
```
|
||||
|
||||
对于 Arch linux 及其变体,你可以使用任何 AUR 助手程序, 如 [**Yay**][1] 安装它。
|
||||
|
||||
```
|
||||
$ yay -S autotrash-git
|
||||
```
|
||||
|
||||
### 自动清除旧的垃圾文件
|
||||
|
||||
每当你运行 `autotrash` 时,它会扫描你的 `~/.local/share/Trash/info` 目录并读取 `.trashinfo` 以找出它们的删除日期。如果文件已在回收站中超过指定的日期,那么就会删除它们。
|
||||
|
||||
让我举几个例子。
|
||||
|
||||
要删除回收站中超过 30 天的文件,请运行:
|
||||
|
||||
```
|
||||
$ autotrash -d 30
|
||||
```
|
||||
|
||||
如上例所示,如果回收站中的文件超过 30 天,Autotrash 会自动将其从回收站中删除。你无需手动删除它们。只需将没用的文件放到回收站即可忘记。Autotrash 将处理已删除的文件。
|
||||
|
||||
以上命令仅处理当前登录用户的垃圾目录。如果要使 autotrash 处理所有用户的垃圾目录(不仅仅是在你的家目录中),请使用 `-t` 选项,如下所示。
|
||||
|
||||
```
|
||||
$ autotrash -td 30
|
||||
```
|
||||
|
||||
Autotrash 还允许你根据回收站可用容量或磁盘可用空间来删除已删除的文件。
|
||||
|
||||
例如,看下下面的例子:
|
||||
|
||||
```
|
||||
$ autotrash --max-free 1024 -d 30
|
||||
```
|
||||
|
||||
根据上面的命令,如果回收站的剩余的空间少于 **1GB**,那么 autotrash 将从回收站中清除超过 **30 天**的已删除文件。如果你的回收站空间不足,这可能很有用。
|
||||
|
||||
我们还可以从回收站中按最早的时间清除文件直到回收站至少有 1GB 的空间。
|
||||
|
||||
```
|
||||
$ autotrash --min-free 1024
|
||||
```
|
||||
|
||||
在这种情况下,对旧的已删除文件没有限制。
|
||||
|
||||
你可以将这两个选项(`--min-free` 和 `--max-free`)组合在一个命令中,如下所示。
|
||||
|
||||
```
|
||||
$ autotrash --max-free 2048 --min-free 1024 -d 30
|
||||
```
|
||||
|
||||
根据上面的命令,如果可用空间小于 **2GB**,`autotrash` 将读取回收站,接着关注容量。此时,删除超过 30 天的文件,如果少于 **1GB** 的可用空间,则删除更新的文件。
|
||||
|
||||
如你所见,所有命令都应由用户手动运行。你可能想知道,我该如何自动执行此任务?这很容易!只需将 `autotrash` 添加为 crontab 任务即可。现在,命令将在计划的时间自动运行,并根据定义的选项清除回收站中的文件。
|
||||
|
||||
要在 crontab 中添加这些命令,请运行:
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
```
|
||||
|
||||
添加任务,例如:
|
||||
|
||||
```
|
||||
@daily /usr/bin/autotrash -d 30
|
||||
```
|
||||
|
||||
现在,autotrash 将每天清除回收站中超过 30 天的文件。
|
||||
|
||||
有关计划任务的更多详细信息,请参阅以下链接。
|
||||
|
||||
+ [Cron 任务的初学者指南]][2]
|
||||
+ [如何在 Linux 中轻松安全地管理 Cron 作业]][3]
|
||||
|
||||
请注意,如果你无意中删除了任何重要文件,它们将在规定的日期后永久消失,所以请小心。
|
||||
|
||||
请参阅手册页以了解有关 Autotrash 的更多信息。
|
||||
|
||||
```
|
||||
$ man autotrash
|
||||
```
|
||||
|
||||
清空回收站或按 `SHIFT+DELETE` 永久删除 Linux 系统中没用的东西没什么大不了的。它只需要几秒钟。但是,如果你需要额外的程序来处理垃圾文件,Autotrash 可能会有所帮助。试一下,看看它是如何工作的。
|
||||
|
||||
就是这些了。希望这个有用。还有更多的好东西。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/autotrash-a-cli-tool-to-automatically-purge-old-trashed-files/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[2]: https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
|
||||
[3]: https://www.ostechnix.com/how-to-easily-and-safely-manage-cron-jobs-in-linux/
|
||||
@ -0,0 +1,74 @@
|
||||
开源与烹饪有什么相似之处?
|
||||
======
|
||||
|
||||

|
||||
|
||||
有什么好的方法,既可以宣传开源的精神又不用写代码呢?这里有个点子:“<ruby>开源食堂<rt>open source cooking</rt></ruby>”。在过去的 8 年间,这就是我们在慕尼黑做的事情。
|
||||
|
||||
开源食堂已经是我们常规的开源宣传活动了,因为我们发现开源与烹饪有很多共同点。
|
||||
|
||||
### 协作烹饪
|
||||
|
||||
[慕尼黑开源聚会][1]自 2009 年 7 月在 [Café Netzwerk][2] 创办以来,已经组织了若干次活动,活动一般在星期五的晚上组织。该聚会为开源项目工作者或者开源爱好者们提供了相互认识的方式。我们的信条是:“<ruby>每四周的星期五属于自由软件<rt>Every fourth Friday for free software</rt></ruby>”。当然在一些周末,我们还会举办一些研讨会。那之后,我们很快加入了很多其他的活动,包括白香肠早餐、桑拿与烹饪活动。
|
||||
|
||||
事实上,第一次开源烹饪聚会举办的有些混乱,但是我们经过这 8 年来以及 15 次的活动,已经可以为 25-30 个与会者提供丰盛的美食了。
|
||||
|
||||
回头看看这些夜晚,我们愈发发现共同烹饪与开源社区协作之间,有很多相似之处。
|
||||
|
||||
### 烹饪步骤中的自由开源精神
|
||||
|
||||
这里是几个烹饪与开源精神相同的地方:
|
||||
|
||||
* 我们乐于合作且朝着一个共同的目标前进
|
||||
* 我们成了一个社区
|
||||
* 由于我们有相同的兴趣与爱好,我们可以更多的了解我们自身与他人,并且可以一同协作
|
||||
* 我们也会犯错,但我们会从错误中学习,并为了共同的利益去分享关于错误的经验,从而让彼此避免再犯相同的错误
|
||||
* 每个人都会贡献自己擅长的事情,因为每个人都有自己的一技之长
|
||||
* 我们会动员其他人去做出贡献并加入到我们之中
|
||||
* 虽说协作是关键,但难免会有点混乱
|
||||
* 每个人都会从中收益
|
||||
|
||||
### 烹饪中的开源气息
|
||||
|
||||
同很多成功的开源聚会一样,开源烹饪也需要一些协作和组织结构。在每次活动之前,我们会组织所有的成员对菜单进行投票,而不单单是直接给每个人分一角披萨,我们希望真正的作出一道美味,迄今为止我们做过日本、墨西哥、匈牙利、印度等地区风味的美食,限于篇幅就不一一列举了。
|
||||
|
||||
就像在生活中,共同烹饪同样需要各个成员之间相互的尊重和理解,所以我们也会试着为素食主义者、食物过敏者、或者对某些事物有偏好的人提供针对性的事物。正式开始烹饪之前,在家预先进行些小规模的测试会非常有帮助(和乐趣!)
|
||||
|
||||
可扩展性也很重要,在杂货店采购必要的食材很容易就消耗掉 3 个小时。所以我们使用一些表格工具(自然是 LibreOffice Calc)来做一些所需要的食材以及相应的成本。
|
||||
|
||||
我们会同志愿者一起,对于每次晚餐我们都有一个“包维护者”,从而及时的制作出菜单并在问题产生的时候寻找一些独到的解决方法。
|
||||
|
||||
虽然不是所有人都是大厨,但是只要给与一些帮助,并比较合理的分配任务和责任,就很容易让每个人都参与其中。某种程度上来说,处理 18kg 的西红柿和 100 个鸡蛋都不会让你觉得是件难事,相信我!唯一的限制是一个烤炉只有四个灶,所以可能是时候对基础设施加大投入了。
|
||||
|
||||
发布有时间要求,当然要求也不那么严格,我们通常会在 21:30 和 01:30 之间的相当“灵活”时间内供应主菜,即便如此,这个时间也是硬性的发布规定。
|
||||
|
||||
最后,像很多开源项目一样,烹饪文档同样有提升的空间。类似洗碟子这样的扫尾工作同样也有可优化的地方。
|
||||
|
||||
### 未来的一些新功能点
|
||||
|
||||
我们预计的一些想法包括:
|
||||
|
||||
* 在其他的国家开展活动
|
||||
* 购买和烹饪一个价值 700 欧元的大南瓜,并且
|
||||
* 找家可以为我们采购提供折扣的商店
|
||||
|
||||
最后一点,也是开源软件的动机:永远记住,还有一些人们生活在阴影中,他们为没有同等的权限去访问资源而苦恼着。我们如何通过开源的精神去帮助他们呢?
|
||||
|
||||
一想到这点,我便期待这下一次的开源烹饪聚会。如果读了上面的东西让你觉得不够完美,并且想自己运作这样的活动,我们非常乐意你能够借鉴我们的想法,甚至抄袭一个。我们也乐意你能够参与到我们其中,甚至做一些演讲和问答。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-cooking
|
||||
|
||||
作者:[Florian Effenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[sd886393](https://github.com/sd886393)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/floeff
|
||||
[1]: https://www.opensourcetreffen.de/
|
||||
[2]: http://www.cafe-netzwerk.de/
|
||||
[3]: https://blog.effenberger.org/2018/05/28/what-do-open-source-and-cooking-have-in-common/
|
||||
[4]: https://en.wikipedia.org/wiki/Free_and_open-source_software
|
||||
@ -3,23 +3,23 @@
|
||||
|
||||
![ZFS filesystem][9]
|
||||
|
||||
今天,我们来谈论一下 ZFS,一个高级文件系统。我们将讨论 ZFS 从何而来,它是什么,以及为什么它在科技界和企业界如此受欢迎。
|
||||
今天,我们来谈论一下 ZFS,一个先进的文件系统。我们将讨论 ZFS 从何而来,它是什么,以及为什么它在科技界和企业界如此受欢迎。
|
||||
|
||||
虽然我是一个美国人,但我更喜欢读成 ZedFS 而不是 ZeeFS,因为前者听起来更酷一些。你可以根据你的个人喜好来发音。
|
||||
|
||||
注意:在这篇文章中,你将会看到很多次 ZFS。当我在谈论特性和安装的时候,我所指的是 OpenZFS 。自从 Oracle 公司放弃 OpenSolaris 项目之后,ZFS(由 Oracle 公司开发)和 OpenZFS 已经走向了不同的发展道路。
|
||||
> 注意:在这篇文章中,你将会看到 ZFS 被提到很多次。当我在谈论特性和安装的时候,我所指的是 OpenZFS 。自从<ruby>甲骨文<rt>Oracle</rt></ruby>公司放弃 OpenSolaris 项目之后,ZFS(由甲骨文公司开发)和 OpenZFS 已经走向了不同的发展道路。(后面详述)
|
||||
|
||||
### ZFS 的历史
|
||||
|
||||
Z 文件系统(ZFS)是在 2001 年由 [Matthew Ahrens 和 Jeff Bonwick][1] 开发的。ZFS 是作为 Sun 公司的[<ruby>微系统<rt>MicroSystem</rt></ruby>][2] [OpenSolaris][3] 的下一代文件系统而设计的。在 2008 年,ZFS 被移植到了 FreeBSD 。同一年,一个新的项目也开始了:[ZFS to Linux][4] 。然而,由于 ZFS 是[通用开发和发布许可证(CDDL)][5]许可的,它和 [GNU 通用公共许可证][6] 不兼容,因此不能将它迁移到 Linux 内核中。为了解决这个问题,绝大多数 Linux 发行版提供了一些方法来安装 ZFS 。
|
||||
<ruby>Z 文件系统<rt>Z File System</rt></ruby>(ZFS)是由 [Matthew Ahrens 和 Jeff Bonwick][1] 在 2001 年开发的。ZFS 是作为[<ruby>太阳微系统<rt>Sun MicroSystem</rt></ruby>][2] 公司的 [OpenSolaris][3] 的下一代文件系统而设计的。在 2008 年,ZFS 被移植到了 FreeBSD 。同一年,一个移植 [ZFS 到 Linux][4] 的项目也启动了。然而,由于 ZFS 是<ruby>[通用开发和发布许可证][5]<rt>Common Development and Distribution License</rt></ruby>(CDDL)许可的,它和 [GNU 通用公共许可证][6] 不兼容,因此不能将它迁移到 Linux 内核中。为了解决这个问题,绝大多数 Linux 发行版提供了一些方法来安装 ZFS 。
|
||||
|
||||
在 Oracle 公司收购 Sun 公司之后不久,微系统 OpenSolaris 就闭源了,这使得 ZFS 的最新开发也闭源了。许多 ZFS 开发者对这件事情非常不开心。[三分之二的 ZFS 核心开发者][1],包括 Ahrens 和 Bonwick,因为这个决定而离开了 Oracle 公司。他们加入其他公司,并于 2013 年 9 月创立了 [OpenZFS][7] 这一项目。该项目引领着 ZFS 的开源开发。
|
||||
在甲骨文公司收购太阳微系统公司之后不久,OpenSolaris 就闭源了,这使得 ZFS 的之后的开发也变成闭源的了。许多 ZFS 开发者对这件事情非常不满。[三分之二的 ZFS 核心开发者][1],包括 Ahrens 和 Bonwick,因为这个决定而离开了甲骨文公司。他们加入了其它公司,并于 2013 年 9 月创立了 [OpenZFS][7] 这一项目。该项目引领着 ZFS 的开源开发。
|
||||
|
||||
让我们回到上面提到的许可证问题上。既然 OpenZFS 项目已经和 Oracle 公司分离开了,有人可能好奇他们为什么不使用和 GPL 兼容的许可证,这样就可以把它加入到 Linux 内核中了。根据 [OpenZFS 官网][8] 的介绍,更改许可证需要联系所有为当前 OpenZFS 实现贡献过代码的人(包括初始公共 ZFS 代码以及 OpenSolaris 代码),并得到他们的许可才行。这几乎是不可能的(因为一些贡献者可能已经去世了或者很难找到),因此他们决定保留原来的许可证。
|
||||
让我们回到上面提到的许可证问题上。既然 OpenZFS 项目已经和 Oracle 公司分离开了,有人可能好奇他们为什么不使用和 GPL 兼容的许可证,这样就可以把它加入到 Linux 内核中了。根据 [OpenZFS 官网][8] 的介绍,更改许可证需要联系所有为当前 OpenZFS 实现贡献过代码的人(包括初始的公共 ZFS 代码以及 OpenSolaris 代码),并得到他们的许可才行。这几乎是不可能的(因为一些贡献者可能已经去世了或者很难找到),因此他们决定保留原来的许可证。
|
||||
|
||||
### ZFS 是什么,它有什么特性?
|
||||
|
||||
正如前面所说过的,ZFS 是一个高级文件系统。因此,它有一些有趣的[特性][10]。比如:
|
||||
正如前面所说过的,ZFS 是一个先进的文件系统。因此,它有一些有趣的[特性][10]。比如:
|
||||
|
||||
* 存储池
|
||||
* 写时拷贝
|
||||
@ -27,28 +27,27 @@ Z 文件系统(ZFS)是在 2001 年由 [Matthew Ahrens 和 Jeff Bonwick][1]
|
||||
* 数据完整性验证和自动修复
|
||||
* RAID-Z
|
||||
* 最大单个文件大小为 16 EB(1 EB = 1024 PB)
|
||||
* 最大 256 万亿的四次方 ZB(1 ZB = 1024 EB)的存储
|
||||
|
||||
|
||||
* 最大 256 千万亿(256*10^15 )的 ZB(1 ZB = 1024 EB)的存储
|
||||
|
||||
让我们来深入了解一下其中一些特性。
|
||||
|
||||
#### 存储池
|
||||
|
||||
与大多数文件系统不同,ZFS 结合了文件系统和卷管理器的特性。这意味着,它与其他文件系统不同,ZFS 可以创建跨域一系列硬盘或池的文件系统。不仅如此,你还可以通过添加硬盘来增大池的存储容量。ZFS 可以进行[分区和格式化][11]。
|
||||
与大多数文件系统不同,ZFS 结合了文件系统和卷管理器的特性。这意味着,它与其他文件系统不同,ZFS 可以创建跨越一系列硬盘或池的文件系统。不仅如此,你还可以通过添加硬盘来增大池的存储容量。ZFS 可以进行[分区和格式化][11]。
|
||||
|
||||
![Pooled storage in ZFS][12]
|
||||
|
||||
*ZFS 存储池*
|
||||
|
||||
#### 写时拷贝
|
||||
|
||||
[<ruby>写时拷贝<rt>Copy-on-write</rt></ruby>][13]是另一个有趣并且很酷的特性。在大多数文件系统上,当数据被重写时,它将永久丢失。而在 ZFS 中,新数据会写到不同的块。写完成之后,更新文件系统元数据信息,使之指向新的数据块(LCTT 译注:更新之后,原数据块成为磁盘上的垃圾,需要有对应的垃圾回收机制)。这确保了如果在写新数据的时候系统崩溃(或者发生其它事,比如突然断电),那么原数据将会保存下来。这也意味着,在系统发生崩溃之后,不需要运行 [fsck][14] 来检查和修复文件系统。
|
||||
<ruby>[写时拷贝][13]<rt>Copy-on-write</rt></ruby>是另一个有趣并且很酷的特性。在大多数文件系统上,当数据被重写时,它将永久丢失。而在 ZFS 中,新数据会写到不同的块。写完成之后,更新文件系统元数据信息,使之指向新的数据块(LCTT 译注:更新之后,原数据块成为磁盘上的垃圾,需要有对应的垃圾回收机制)。这确保了如果在写新数据的时候系统崩溃(或者发生其它事,比如突然断电),那么原数据将会保存下来。这也意味着,在系统发生崩溃之后,不需要运行 [fsck][14] 来检查和修复文件系统。
|
||||
|
||||
#### 快照
|
||||
|
||||
写时拷贝使得 ZFS 有了另一个特性:<ruby>快照<rt>snapshots</rt></ruby>。ZFS 使用快照来跟踪文件系统中的更改。[快照][13]包含文件系统的原始版本(文件系统的一个只读版本),实时文件系统则包含了自从快照创建之后的任何更改。没有使用额外的空间。因为新数据将会写到实时文件系统新分配的块上。如果一个文件被删除了,那么它在快照中的索引也会被删除。所以,快照主要是用来跟踪文件的更改,而不是文件的增加和创建。
|
||||
|
||||
快照可以挂载成只读的,以用来恢复一个文件的过去版本。实时系统也可以回滚到之前的快照。回滚之后,自从快照创建之后的所有更改将会丢失。
|
||||
快照可以挂载成只读的,以用来恢复一个文件的过去版本。实时文件系统也可以回滚到之前的快照。回滚之后,自从快照创建之后的所有更改将会丢失。
|
||||
|
||||
#### 数据完整性验证和自动修复
|
||||
|
||||
@ -56,11 +55,11 @@ Z 文件系统(ZFS)是在 2001 年由 [Matthew Ahrens 和 Jeff Bonwick][1]
|
||||
|
||||
#### RAID-Z
|
||||
|
||||
ZFS 不需要任何额外软件或硬件就可以处理 RAID(磁盘阵列)。毫无奇怪,因为 ZFS 有自己的 RAID 实现:RAID-Z 。RAID-Z 是 RAID-5 的一个变种,不过它克服了 RAID-5 的写漏洞:意外重启之后,数据和校验信息会变得不同步(LCTT 译注:RAID-5 的 stripe 在正写数据时,如果这时候电源中断,那么奇偶校验数据将跟该部分数据不同步,因此前边的写无效;RAID-Z 用了 “variable-width RAID stripes” 技术,因此所有的写都是 full-stripe writes)。为了使用基本级别的 [RAID-Z][15](RAID-Z1),你需要至少三块磁盘,其中两块用来存储数据,另外一块用来存储[奇偶校验信息][16]。而RAID-Z2 需要至少两块磁盘存储数据以及两块磁盘存储校验信息。RAID-Z3 需要至少两块磁盘存储数据以及三块磁盘存储校验信息。另外,只能向 RAID-Z 池中加入偶数倍的磁盘,而不能是奇数倍的。
|
||||
ZFS 不需要任何额外软件或硬件就可以处理 RAID(磁盘阵列)。毫不奇怪,因为 ZFS 有自己的 RAID 实现:RAID-Z 。RAID-Z 是 RAID-5 的一个变种,不过它克服了 RAID-5 的写漏洞:意外重启之后,数据和校验信息会变得不同步(LCTT 译注:RAID-5 的条带在正写入数据时,如果这时候电源中断,那么奇偶校验数据将跟该部分数据不同步,因此前边的写无效;RAID-Z 用了 “可变宽的 RAID 条带” 技术,因此所有的写都是全条带写入)。为了使用[基本级别的 RAID-Z][15](RAID-Z1),你需要至少三块磁盘,其中两块用来存储数据,另外一块用来存储[奇偶校验信息][16]。而 RAID-Z2 需要至少两块磁盘存储数据以及两块磁盘存储校验信息。RAID-Z3 需要至少两块磁盘存储数据以及三块磁盘存储校验信息。另外,只能向 RAID-Z 池中加入偶数倍的磁盘,而不能是奇数倍的。
|
||||
|
||||
#### 巨大的存储潜力
|
||||
|
||||
创建 ZFS 的时候,它就被设计成了[最后一个文件系统][17] 。那时候,大多数文件系统都是 64 位的,ZFS 的创建者决定直接跳到 128 位,等到将来再来证明这是对的。这意味着 ZFS 的容量大小是 32 位或 64 位文件系统的 160 亿亿倍。事实上,Jeff Bonwick(其中一个创建者)说:“完全填满一个 128 位的存储池所需要的[能量][18],从字面上讲,比煮沸海洋需要的还多。”
|
||||
创建 ZFS 的时候,它是作为[最后一个文件系统][17]而设计的 。那时候,大多数文件系统都是 64 位的,ZFS 的创建者决定直接跳到 128 位,等到将来再来证明这是对的。这意味着 ZFS 的容量大小是 32 位或 64 位文件系统的 1600 亿亿倍。事实上,Jeff Bonwick(其中一个创建者)说:“完全填满一个 128 位的存储池所需要的[能量][18],从字面上讲,比煮沸海洋需要的还多。”
|
||||
|
||||
### 如何安装 ZFS?
|
||||
|
||||
@ -85,7 +84,7 @@ via: https://itsfoss.com/what-is-zfs/
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,173 @@
|
||||
每位 Ubuntu 18.04 用户都应该知道的快捷键
|
||||
======
|
||||
|
||||
了解快捷键能够提升您的生产力。这里有一些实用的 Ubuntu 快捷键助您像专业人士一样使用 Ubuntu。
|
||||
|
||||
您可以用键盘和鼠标组合来使用操作系统。
|
||||
|
||||
> 注意:本文中提到的键盘快捷键适用于 Ubuntu 18.04 GNOME 版。 通常,它们中的大多数(或者全部)也适用于其他的 Ubuntu 版本,但我不能够保证。
|
||||
|
||||
![Ubuntu keyboard shortcuts][1]
|
||||
|
||||
### 实用的 Ubuntu 快捷键
|
||||
|
||||
让我们来看一看 Ubuntu GNOME 必备的快捷键吧!通用的快捷键如 `Ctrl+C`(复制)、`Ctrl+V`(粘贴)或者 `Ctrl+S`(保存)不再赘述。
|
||||
|
||||
注意:Linux 中的 Super 键即键盘上带有 Windows 图标的键,本文中我使用了大写字母,但这不代表你需要按下 `shift` 键,比如,`T` 代表键盘上的 ‘t’ 键,而不代表 `Shift+t`。
|
||||
|
||||
#### 1、 Super 键:打开活动搜索界面
|
||||
|
||||
使用 `Super` 键可以打开活动菜单。如果你只能在 Ubuntu 上使用一个快捷键,那只能是 `Super` 键。
|
||||
|
||||
想要打开一个应用程序?按下 `Super` 键然后搜索应用程序。如果搜索的应用程序未安装,它会推荐来自应用中心的应用程序。
|
||||
|
||||
想要看看有哪些正在运行的程序?按下 `Super` 键,屏幕上就会显示所有正在运行的 GUI 应用程序。
|
||||
|
||||
想要使用工作区吗?只需按下 `Super` 键,您就可以在屏幕右侧看到工作区选项。
|
||||
|
||||
#### 2、 Ctrl+Alt+T:打开 Ubuntu 终端窗口
|
||||
|
||||
![Ubuntu Terminal Shortcut][2]
|
||||
|
||||
*使用 Ctrl+alt+T 来打开终端窗口*
|
||||
|
||||
想要打开一个新的终端,您只需使用快捷键 `Ctrl+Alt+T`。这是我在 Ubuntu 中最喜欢的键盘快捷键。 甚至在我的许多 FOSS 教程中,当需要打开终端窗口是,我都会提到这个快捷键。
|
||||
|
||||
#### 3、 Super+L 或 Ctrl+Alt+L:锁屏
|
||||
|
||||
当您离开电脑时锁定屏幕,是最基本的安全习惯之一。您可以使用 `Super+L` 快捷键,而不是繁琐地点击屏幕右上角然后选择锁定屏幕选项。
|
||||
|
||||
有些系统也会使用 `Ctrl+Alt+L` 键锁定屏幕。
|
||||
|
||||
#### 4、 Super+D or Ctrl+Alt+D:显示桌面
|
||||
|
||||
按下 `Super+D` 可以最小化所有正在运行的应用程序窗口并显示桌面。
|
||||
|
||||
再次按 `Super+D` 将重新打开所有正在运行的应用程序窗口,像之前一样。
|
||||
|
||||
您也可以使用 `Ctrl+Alt+D` 来实现此目的。
|
||||
|
||||
#### 5、 Super+A:显示应用程序菜单
|
||||
|
||||
您可以通过单击屏幕左下角的 9 个点打开 Ubuntu 18.04 GNOME 中的应用程序菜单。 但是一个更快捷的方法是使用 `Super+A` 快捷键。
|
||||
|
||||
它将显示应用程序菜单,您可以在其中查看或搜索系统上已安装的应用程序。
|
||||
|
||||
您可以使用 `Esc` 键退出应用程序菜单界面。
|
||||
|
||||
#### 6、 Super+Tab 或 Alt+Tab:在运行中的应用程序间切换
|
||||
|
||||
如果您运行的应用程序不止一个,则可以使用 `Super+Tab` 或 `Alt+Tab` 快捷键在应用程序之间切换。
|
||||
|
||||
按住 `Super` 键同时按下 `Tab` 键,即可显示应用程序切换器。 按住 `Super` 的同时,继续按下 `Tab` 键在应用程序之间进行选择。 当光标在所需的应用程序上时,松开 `Super` 和 `Tab` 键。
|
||||
|
||||
默认情况下,应用程序切换器从左向右移动。 如果要从右向左移动,可使用 `Super+Shift+Tab` 快捷键。
|
||||
|
||||
在这里您也可以用 `Alt` 键代替 `Super` 键。
|
||||
|
||||
> 提示:如果有多个应用程序实例,您可以使用 Super+` 快捷键在这些实例之间切换。
|
||||
|
||||
#### 7、 Super+箭头:移动窗口位置
|
||||
|
||||
<https://player.vimeo.com/video/289091549>
|
||||
|
||||
这个快捷键也适用于 Windows 系统。 使用应用程序时,按下 `Super+左箭头`,应用程序将贴合屏幕的左边缘,占用屏幕的左半边。
|
||||
|
||||
同样,按下 `Super+右箭头`会使应用程序贴合右边缘。
|
||||
|
||||
按下 `Super+上箭头`将最大化应用程序窗口,`Super+下箭头`将使应用程序恢复到其正常的大小。
|
||||
|
||||
#### 8、 Super+M:切换到通知栏
|
||||
|
||||
GNOME 中有一个通知栏,您可以在其中查看系统和应用程序活动的通知,这里也有一个日历。
|
||||
|
||||
![Notification Tray Ubuntu 18.04 GNOME][3]
|
||||
|
||||
*通知栏*
|
||||
|
||||
使用 `Super+M` 快捷键,您可以打开此通知栏。 如果再次按这些键,将关闭打开的通知托盘。
|
||||
|
||||
使用 `Super+V` 也可实现相同的功能。
|
||||
|
||||
#### 9、 Super+空格:切换输入法(用于多语言设置)
|
||||
|
||||
如果您使用多种语言,可能您的系统上安装了多个输入法。 例如,我需要在 Ubuntu 上同时使用[印地语] [4]和英语,所以我安装了印地语(梵文)输入法以及默认的英语输入法。
|
||||
|
||||
如果您也使用多语言设置,则可以使用 `Super+空格` 快捷键快速更改输入法。
|
||||
|
||||
#### 10、 Alt+F2:运行控制台
|
||||
|
||||
这适用于高级用户。 如果要运行快速命令,而不是打开终端并在其中运行命令,则可以使用 `Alt+F2` 运行控制台。
|
||||
|
||||
![Alt+F2 to run commands in Ubuntu][5]
|
||||
|
||||
*控制台*
|
||||
|
||||
当您使用只能在终端运行的应用程序时,这尤其有用。
|
||||
|
||||
#### 11、 Ctrl+Q:关闭应用程序窗口
|
||||
|
||||
如果您有正在运行的应用程序,可以使用 `Ctrl+Q` 快捷键关闭应用程序窗口。您也可以使用 `Ctrl+W` 来实现此目的。
|
||||
|
||||
`Alt+F4` 是关闭应用程序窗口更“通用”的快捷方式。
|
||||
|
||||
它不适用于一些应用程序,如 Ubuntu 中的默认终端。
|
||||
|
||||
#### 12、 Ctrl+Alt+箭头:切换工作区
|
||||
|
||||
![Workspace switching][6]
|
||||
|
||||
*切换工作区*
|
||||
|
||||
如果您是使用工作区的重度用户,可以使用 `Ctrl+Alt+上箭头`和 `Ctrl+Alt+下箭头`在工作区之间切换。
|
||||
|
||||
#### 13、 Ctrl+Alt+Del:注销
|
||||
|
||||
不!在 Linux 中使用著名的快捷键 `Ctrl+Alt+Del` 并不会像在 Windows 中一样打开任务管理器(除非您使用自定义快捷键)。
|
||||
|
||||
![Log Out Ubuntu][7]
|
||||
|
||||
*注销*
|
||||
|
||||
在普通的 GNOME 桌面环境中,您可以使用 `Ctrl+Alt+Del` 键打开关机菜单,但 Ubuntu 并不总是遵循此规范,因此当您在 Ubuntu 中使用 `Ctrl+Alt+Del` 键时,它会打开注销菜单。
|
||||
|
||||
### 在 Ubuntu 中使用自定义键盘快捷键
|
||||
|
||||
您不是只能使用默认的键盘快捷键,您可以根据需要创建自己的自定义键盘快捷键。
|
||||
|
||||
转到“设置->设备->键盘”,您将在这里看到系统的所有键盘快捷键。向下滚动到底部,您将看到“自定义快捷方式”选项。
|
||||
|
||||
![Add custom keyboard shortcut in Ubuntu][8]
|
||||
|
||||
您需要提供易于识别的快捷键名称、使用快捷键时运行的命令,以及您自定义的按键组合。
|
||||
|
||||
### Ubuntu 中你最喜欢的键盘快捷键是什么?
|
||||
|
||||
快捷键无穷无尽。如果需要,你可以看一看所有可能的 [GNOME 快捷键][9],看其中有没有你需要用到的快捷键。
|
||||
|
||||
您可以学习使用您经常使用应用程序的快捷键,这是很有必要的。例如,我使用 Kazam 进行[屏幕录制][10],键盘快捷键帮助我方便地暂停和开始录像。
|
||||
|
||||
您最喜欢、最离不开的 Ubuntu 快捷键是什么?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-shortcuts/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[XiatianSummer](https://github.com/XiatianSummer)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ubuntu-keyboard-shortcuts.jpeg
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ubuntu-terminal-shortcut.jpg
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/notification-tray-ubuntu-gnome.jpeg
|
||||
[4]: https://itsfoss.com/type-indian-languages-ubuntu/
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/console-alt-f2-ubuntu-gnome.jpeg
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/workspace-switcher-ubuntu.png
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/log-out-ubuntu.jpeg
|
||||
[8]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/custom-keyboard-shortcut.jpg
|
||||
[9]: https://wiki.gnome.org/Design/OS/KeyboardShortcuts
|
||||
[10]: https://itsfoss.com/best-linux-screen-recorders/
|
||||
110
published/20180910 3 open source log aggregation tools.md
Normal file
110
published/20180910 3 open source log aggregation tools.md
Normal file
@ -0,0 +1,110 @@
|
||||
3 个开源日志聚合工具
|
||||
======
|
||||
|
||||
> 日志聚合系统可以帮助我们进行故障排除和其它任务。以下是三个主要工具介绍。
|
||||
|
||||

|
||||
|
||||
<ruby>指标聚合<rt>metrics aggregation</rt></ruby>与<ruby>日志聚合<rt>log aggregation</rt></ruby>有何不同?日志不能包括指标吗?日志聚合系统不能做与指标聚合系统相同的事情吗?
|
||||
|
||||
这些是我经常听到的问题。我还看到供应商推销他们的日志聚合系统作为所有可观察问题的解决方案。日志聚合是一个有价值的工具,但它通常对时间序列数据的支持不够好。
|
||||
|
||||
时间序列的指标聚合系统中几个有价值的功能是专门为时间序列数据定制的<ruby>固定间隔<rt>regular interval</rt></ruby>和存储系统。固定间隔允许用户不断地收集实时的数据结果。如果要求日志聚合系统以固定间隔收集指标数据,它也可以。但是,它的存储系统没有针对指标聚合系统中典型的查询类型进行优化。使用日志聚合工具中的存储系统处理这些查询将花费更多的资源和时间。
|
||||
|
||||
所以,我们知道日志聚合系统可能不适合时间序列数据,但是它有什么好处呢?日志聚合系统是收集事件数据的好地方。这些无规律的活动是非常重要的。最好的例子为 web 服务的访问日志,这些很重要,因为我们想知道什么正在访问我们的系统,什么时候访问的。另一个例子是应用程序错误记录 —— 因为它不是正常的操作记录,所以在故障排除过程中可能很有价值的。
|
||||
|
||||
日志记录的一些规则:
|
||||
|
||||
* **须**包含时间戳
|
||||
* **须**格式化为 JSON
|
||||
* **不**记录无关紧要的事件
|
||||
* **须**记录所有应用程序的错误
|
||||
* **可**记录警告错误
|
||||
* **可**开关的日志记录
|
||||
* **须**以可读的形式记录信息
|
||||
* **不**在生产环境中记录信息
|
||||
* **不**记录任何无法阅读或反馈的内容
|
||||
|
||||
### 云的成本
|
||||
|
||||
当研究日志聚合工具时,云服务可能看起来是一个有吸引力的选择。然而,这可能会带来巨大的成本。当跨数百或数千台主机和应用程序聚合时,日志数据是大量的。在基于云的系统中,数据的接收、存储和检索是昂贵的。
|
||||
|
||||
以一个真实的系统来参考,大约 500 个节点和几百个应用程序的集合每天产生 200GB 的日志数据。这个系统可能还有改进的空间,但是在许多 SaaS 产品中,即使将它减少一半,每月也要花费将近 10000 美元。而这通常仅保留 30 天,如果你想查看一年一年的趋势数据,就不可能了。
|
||||
|
||||
并不是要不使用这些基于云的系统,尤其是对于较小的组织它们可能非常有价值的。这里的目的是指出可能会有很大的成本,当这些成本很高时,就可能令人非常的沮丧。本文的其余部分将集中讨论自托管的开源和商业解决方案。
|
||||
|
||||
### 工具选择
|
||||
|
||||
#### ELK
|
||||
|
||||
[ELK][1],即 Elasticsearch、Logstash 和 Kibana 简称,是最流行的开源日志聚合工具。它被 Netflix、Facebook、微软、LinkedIn 和思科使用。这三个组件都是由 [Elastic][2] 开发和维护的。[Elasticsearch][3] 本质上是一个 NoSQL 数据库,以 Lucene 搜索引擎实现的。[Logstash][4] 是一个日志管道系统,可以接收数据,转换数据,并将其加载到像 Elasticsearch 这样的应用中。[Kibana][5] 是 Elasticsearch 之上的可视化层。
|
||||
|
||||
几年前,引入了 Beats 。Beats 是数据采集器。它们简化了将数据运送到 Logstash 的过程。用户不需要了解每种日志的正确语法,而是可以安装一个 Beats 来正确导出 NGINX 日志或 Envoy 代理日志,以便在 Elasticsearch 中有效地使用它们。
|
||||
|
||||
安装生产环境级 ELK 套件时,可能会包括其他几个部分,如 [Kafka][6]、[Redis][7] 和 [NGINX][8]。此外,用 Fluentd 替换 Logstash 也很常见,我们将在后面讨论。这个系统操作起来很复杂,这在早期导致了很多问题和抱怨。目前,这些问题基本上已经被修复,不过它仍然是一个复杂的系统,如果你使用少部分的功能,建议不要使用它了。
|
||||
|
||||
也就是说,有其它可用的服务,所以你不必苦恼于此。可以使用 [Logz.io][9],但是如果你有很多数据,它的标价有点高。当然,你可能规模比较小,没有很多数据。如果你买不起 Logz.io,你可以看看 [AWS Elasticsearch Service][10] (ES) 。ES 是 Amazon Web Services (AWS) 提供的一项服务,它很容易就可以让 Elasticsearch 马上工作起来。它还拥有使用 Lambda 和 S3 将所有AWS 日志记录到 ES 的工具。这是一个更便宜的选择,但是需要一些管理操作,并有一些功能限制。
|
||||
|
||||
ELK 套件的母公司 Elastic [提供][11] 一款更强大的产品,它使用<ruby>开源核心<rt>open core</rt></ruby>模式,为分析工具和报告提供了额外的选项。它也可以在谷歌云平台或 AWS 上托管。由于这种工具和托管平台的组合提供了比大多数 SaaS 选项更加便宜,这也许是最好的选择,并且很有用。该系统可以有效地取代或提供 [安全信息和事件管理][12](SIEM)系统的功能。
|
||||
|
||||
ELK 套件通过 Kibana 提供了很好的可视化工具,但是它缺少警报功能。Elastic 在付费的 X-Pack 插件中提供了警报功能,但是在开源系统没有内置任何功能。Yelp 已经开发了一种解决这个问题的方法,[ElastAlert][13],不过还有其他方式。这个额外的软件相当健壮,但是它增加了已经复杂的系统的复杂性。
|
||||
|
||||
#### Graylog
|
||||
|
||||
[Graylog][14] 最近越来越受欢迎,但它是在 2010 年由 Lennart Koopmann 创建并开发的。两年后,一家公司以同样的名字诞生了。尽管它的使用者越来越多,但仍然远远落后于 ELK 套件。这也意味着它具有较少的社区开发特征,但是它可以使用与 ELK 套件相同的 Beats 。由于 Graylog Collector Sidecar 使用 [Go][15] 编写,所以 Graylog 在 Go 社区赢得了赞誉。
|
||||
|
||||
Graylog 使用 Elasticsearch、[MongoDB][16] 和底层的 Graylog Server 。这使得它像 ELK 套件一样复杂,也许还要复杂一些。然而,Graylog 附带了内置于开源版本中的报警功能,以及其他一些值得注意的功能,如流、消息重写和地理定位。
|
||||
|
||||
流功能可以允许数据在被处理时被实时路由到特定的 Stream。使用此功能,用户可以在单个 Stream 中看到所有数据库错误,在另外的 Stream 中看到 web 服务器错误。当添加新项目或超过阈值时,甚至可以基于这些 Stream 提供警报。延迟可能是日志聚合系统中最大的问题之一,Stream 消除了 Graylog 中的这一问题。一旦日志进入,它就可以通过 Stream 路由到其他系统,而无需完全处理好。
|
||||
|
||||
消息重写功能使用开源规则引擎 [Drools][17] 。允许根据用户定义的规则文件评估所有传入的消息,从而可以删除消息(称为黑名单)、添加或删除字段或修改消息。
|
||||
|
||||
Graylog 最酷的功能或许是它的地理定位功能,它支持在地图上绘制 IP 地址。这是一个相当常见的功能,在 Kibana 也可以这样使用,但是它增加了很多价值 —— 特别是如果你想将它用作 SIEM 系统。地理定位功能在系统的开源版本中提供。
|
||||
|
||||
如果你需要的话,Graylog 公司会提供对开源版本的收费支持。它还为其企业版提供了一个开源核心模式,提供存档、审计日志记录和其他支持。其它提供支持或托管服务的不太多,如果你不需要 Graylog 公司的,你可以托管。
|
||||
|
||||
#### Fluentd
|
||||
|
||||
[Fluentd][18] 是 [Treasure Data][19] 开发的,[CNCF][20] 已经将它作为一个孵化项目。它是用 C 和 Ruby 编写的,并被 [AWS][21] 和 [Google Cloud][22] 所推荐。Fluentd 已经成为许多系统中 logstach 的常用替代品。它可以作为一个本地聚合器,收集所有节点日志并将其发送到中央存储系统。它不是日志聚合系统。
|
||||
|
||||
它使用一个强大的插件系统,提供不同数据源和数据输出的快速和简单的集成功能。因为有超过 500 个插件可用,所以你的大多数用例都应该包括在内。如果没有,这听起来是一个为开源社区做出贡献的机会。
|
||||
|
||||
Fluentd 由于占用内存少(只有几十兆字节)和高吞吐量特性,是 Kubernetes 环境中的常见选择。在像 [Kubernetes][23] 这样的环境中,每个 pod 都有一个 Fluentd 附属件 ,内存消耗会随着每个新 pod 的创建而线性增加。在这种情况下,使用 Fluentd 将大大降低你的系统利用率。这对于 Java 开发的工具来说是一个常见的问题,这些工具旨在为每个节点运行一个工具,而内存开销并不是主要问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-log-aggregation-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://www.elastic.co/webinars/introduction-elk-stack
|
||||
[2]: https://www.elastic.co/
|
||||
[3]: https://www.elastic.co/products/elasticsearch
|
||||
[4]: https://www.elastic.co/products/logstash
|
||||
[5]: https://www.elastic.co/products/kibana
|
||||
[6]: http://kafka.apache.org/
|
||||
[7]: https://redis.io/
|
||||
[8]: https://www.nginx.com/
|
||||
[9]: https://logz.io/
|
||||
[10]: https://aws.amazon.com/elasticsearch-service/
|
||||
[11]: https://www.elastic.co/cloud
|
||||
[12]: https://en.wikipedia.org/wiki/Security_information_and_event_management
|
||||
[13]: https://github.com/Yelp/elastalert
|
||||
[14]: https://www.graylog.org/
|
||||
[15]: https://opensource.com/tags/go
|
||||
[16]: https://www.mongodb.com/
|
||||
[17]: https://www.drools.org/
|
||||
[18]: https://www.fluentd.org/
|
||||
[19]: https://www.treasuredata.com/
|
||||
[20]: https://www.cncf.io/
|
||||
[21]: https://aws.amazon.com/blogs/aws/all-your-data-fluentd/
|
||||
[22]: https://cloud.google.com/logging/docs/agent/
|
||||
[23]: https://opensource.com/resources/what-is-kubernetes
|
||||
|
||||
@ -5,13 +5,13 @@
|
||||
|
||||
今时今日,无论在家里的沙发上,还是在外面的咖啡厅,只要打开笔记本电脑,连上 Wi-Fi,就能通过网络与外界保持联系。但现在的 Wi-Fi 热点们大都能够通过[每张网卡对应的唯一 MAC 地址][1]来追踪你的设备。下面就来看一下如何避免被追踪。
|
||||
|
||||
现在很多人已经开始注重个人隐私这个问题。个人隐私问题并不仅仅指防止他人能够访问到你电脑上的私有内容(这又是另一个问题了),而更多的是指可追踪性,也就是是否能够被轻易地统计和追踪到。大家都应该[对此更加重视][2]。同时,这方面的底线是,服务提供者在得到了用户的授权后才能对用户进行追踪,例如机场的计时 Wi-Fi 只有在用户授权后才能够使用。
|
||||
现在很多人已经开始注重个人隐私这个问题。个人隐私问题并不仅仅指防止他人能够访问到你电脑上的私有内容(这又是另一个问题了),而更多的是指<ruby>可追踪性<rt>legibility</rt></ruby>,也就是是否能够被轻易地统计和追踪到。大家都应该[对此更加重视][2]。同时,这方面的底线是,服务提供者在得到了用户的授权后才能对用户进行追踪,例如机场的计时 Wi-Fi 只有在用户授权后才能够使用。
|
||||
|
||||
因为固定的 MAC 地址能被轻易地追踪到,所以应该定时进行更换,随机的 MAC 地址是一个好的选择。由于 MAC 地址一般只在局域网内使用,因此随机的 MAC 地址也不太容易产生[冲突][3]。
|
||||
因为固定的 MAC 地址能被轻易地追踪到,所以应该定时进行更换,随机的 MAC 地址是一个好的选择。由于 MAC 地址一般只在局域网内使用,因此随机的 MAC 地址也不大会产生[冲突][3]。
|
||||
|
||||
### 配置 NetworkManager
|
||||
|
||||
要将随机的 MAC 地址默认应用与所有的 Wi-Fi 连接,需要创建 /etc/NetworkManager/conf.d/00-macrandomize.conf 这个文件:
|
||||
要将随机的 MAC 地址默认地用于所有的 Wi-Fi 连接,需要创建 `/etc/NetworkManager/conf.d/00-macrandomize.conf` 这个文件:
|
||||
|
||||
```
|
||||
[device]
|
||||
@ -21,51 +21,47 @@ wifi.scan-rand-mac-address=yes
|
||||
wifi.cloned-mac-address=stable
|
||||
ethernet.cloned-mac-address=stable
|
||||
connection.stable-id=${CONNECTION}/${BOOT}
|
||||
|
||||
```
|
||||
|
||||
然后重启 NetworkManager :
|
||||
|
||||
```
|
||||
systemctl restart NetworkManager
|
||||
|
||||
```
|
||||
|
||||
以上配置文件中,将 cloned-mac-address 的值设置为 stable 就可以在每次 NetworkManager 激活连接的时候都生成相同的 MAC 地址,但连接时使用不同的 MAC 地址。如果要在每次激活连接时获得随机的 MAC 地址,需要将 cloned-mac-address 的值设置为 random。
|
||||
以上配置文件中,将 `cloned-mac-address` 的值设置为 `stable` 就可以在每次 NetworkManager 激活连接的时候都生成相同的 MAC 地址,但连接时使用不同的 MAC 地址。如果要在每次激活连接时也获得随机的 MAC 地址,需要将 `cloned-mac-address` 的值设置为 `random`。
|
||||
|
||||
设置为 stable 可以从 DHCP 获取相同的 IP 地址,也可以让 Wi-Fi 的强制主页根据 MAC 地址记住你的登录状态。如果设置为 random ,在每次连接的时候都需要重新认证(或者点击“我同意”),在使用机场 Wi-Fi 的时候会需要到这种 random 模式。可以在 NetworkManager 的[博客文章][4]中参阅到有关使用 nmcli 从终端配置特定连接的详细说明。
|
||||
设置为 `stable` 可以从 DHCP 获取相同的 IP 地址,也可以让 Wi-Fi 的<ruby>[强制主页](https://en.wikipedia.org/wiki/Captive_portal)<rt>captive portal</rt></ruby>根据 MAC 地址记住你的登录状态。如果设置为 `random` ,在每次连接的时候都需要重新认证(或者点击“我同意”),在使用机场 Wi-Fi 的时候会需要到这种 `random` 模式。可以在这篇 NetworkManager 的[博客文章][4]中参阅到有关使用 `nmcli` 从终端配置特定连接的详细说明。
|
||||
|
||||
使用 ip link 命令可以查看当前的 MAC 地址,MAC 地址将会显示在 ether 一词的后面。
|
||||
使用 `ip link` 命令可以查看当前的 MAC 地址,MAC 地址将会显示在 `ether` 一词的后面。
|
||||
|
||||
```
|
||||
$ ip link
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
2: enp2s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000
|
||||
link/ether 52:54:00:5f:d5:4e brd ff:ff:ff:ff:ff:ff
|
||||
link/ether 52:54:00:5f:d5:4e brd ff:ff:ff:ff:ff:ff
|
||||
3: wlp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DORMANT group default qlen 1000
|
||||
link/ether 52:54:00:03:23:59 brd ff:ff:ff:ff:ff:ff
|
||||
|
||||
link/ether 52:54:00:03:23:59 brd ff:ff:ff:ff:ff:ff
|
||||
```
|
||||
|
||||
### 什么时候不能随机化 MAC 地址
|
||||
|
||||
当然,在某些情况下确实需要能被追踪到。例如在家用网络中,可能需要将路由器配置为对电脑分配一致的 IP 地址以进行端口转发;再例如公司的雇主可能需要根据 MAC 地址来提供 Wi-Fi 服务,这时候就需要进行追踪。要更改特定的 Wi-Fi 连接,请使用 nmcli 查看 NetworkManager 连接并显示当前设置:
|
||||
当然,在某些情况下确实需要能被追踪到。例如在家用网络中,可能需要将路由器配置为对电脑分配一致的 IP 地址以进行端口转发;再例如公司的雇主可能需要根据 MAC 地址来提供 Wi-Fi 服务,这时候就需要进行追踪。要更改特定的 Wi-Fi 连接,请使用 `nmcli` 查看 NetworkManager 连接并显示当前设置:
|
||||
|
||||
```
|
||||
$ nmcli c | grep wifi
|
||||
Amtrak_WiFi 5f4b9f75-9e41-47f8-8bac-25dae779cd87 wifi --
|
||||
Amtrak_WiFi 5f4b9f75-9e41-47f8-8bac-25dae779cd87 wifi --
|
||||
StaplesHotspot de57940c-32c2-468b-8f96-0a3b9a9b0a5e wifi --
|
||||
MyHome e8c79829-1848-4563-8e44-466e14a3223d wifi wlp1s0
|
||||
MyHome e8c79829-1848-4563-8e44-466e14a3223d wifi wlp1s0
|
||||
...
|
||||
$ nmcli c show 5f4b9f75-9e41-47f8-8bac-25dae779cd87 | grep cloned
|
||||
802-11-wireless.cloned-mac-address: --
|
||||
802-11-wireless.cloned-mac-address: --
|
||||
$ nmcli c show e8c79829-1848-4563-8e44-466e14a3223d | grep cloned
|
||||
802-11-wireless.cloned-mac-address: stable
|
||||
|
||||
802-11-wireless.cloned-mac-address: stable
|
||||
```
|
||||
|
||||
以下这个例子使用 Amtrak 的完全随机 MAC 地址(使用默认配置)和 MyHome 的永久 MAC 地址(使用 stable 配置)。永久 MAC 地址是在硬件生产的时候分配到网络接口上的,网络管理员能够根据永久 MAC 地址来查看[设备的制造商 ID][5]。
|
||||
这个例子在 Amtrak 使用完全随机 MAC 地址(使用默认配置)和 MyHome 的永久 MAC 地址(使用 `stable` 配置)。永久 MAC 地址是在硬件生产的时候分配到网络接口上的,网络管理员能够根据永久 MAC 地址来查看[设备的制造商 ID][5]。
|
||||
|
||||
更改配置并重新连接活动的接口:
|
||||
|
||||
@ -76,7 +72,6 @@ $ nmcli c down e8c79829-1848-4563-8e44-466e14a3223d
|
||||
$ nmcli c up e8c79829-1848-4563-8e44-466e14a3223d
|
||||
$ ip link
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
你还可以安装 NetworkManager-tui ,就可以通过可视化界面菜单来编辑连接。
|
||||
@ -92,7 +87,7 @@ via: https://fedoramagazine.org/randomize-mac-address-nm/
|
||||
作者:[sheogorath][a],[Stuart D Gathman][b]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,115 @@
|
||||
如何为 Linux 虚拟控制台配置鼠标支持
|
||||
======
|
||||
|
||||

|
||||
|
||||
我使用 Oracle VirtualBox 来测试各种类 Unix 操作系统。我的大多数虚拟机都是<ruby>无头<rt>headless</rt></ruby>服务器,它们没有图形桌面环境。很长一段时间,我一直想知道如何在无头 Linux 服务器的基于文本的终端中使用鼠标。感谢 **GPM**,今天我了解到我们可以在虚拟控制台中使用鼠标进行复制和粘贴操作。 **GPM**,是<ruby>通用鼠标<rt>General Purpose Mouse</rt></ruby>的首字母缩写,它是一个守护程序,可以帮助你配置 Linux 虚拟控制台的鼠标支持。请不要将 GPM 与 **GDM**(<ruby>GNOME 显示管理器<rt>GNOME Display manager</rt></ruby>)混淆。两者有完全不同的用途。
|
||||
|
||||
GPM 在以下场景中特别有用:
|
||||
|
||||
* 新的 Linux 服务器安装或默认情况下不能或不使用 X Windows 的系统,如 Arch Linux 和 Gentoo。
|
||||
* 在虚拟终端/控制台中使用复制/粘贴操作。
|
||||
* 在基于文本的编辑器和浏览器中使用复制/粘贴(例如,emacs、lynx)。
|
||||
* 在文本文件管理器中使用复制/粘贴(例如 Ranger、Midnight commander)。
|
||||
|
||||
在这个简短的教程中,我们将看到如何在类 Unix 操作系统中在基于文本的终端中使用鼠标。
|
||||
|
||||
### 安装 GPM
|
||||
|
||||
要在纯文本 Linux 系统中启用鼠标支持,请安装 GPM 包。它在大多数 Linux 发行版的默认仓库中都有。
|
||||
|
||||
在 Arch Linux 及其变体如 Antergos、Manjaro Linux 上,运行以下命令来安装 GPM:
|
||||
|
||||
```
|
||||
$ sudo pacman -S gpm
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 中:
|
||||
|
||||
```
|
||||
$ sudo apt install gpm
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install gpm
|
||||
```
|
||||
|
||||
在 openSUSE 上:
|
||||
|
||||
```
|
||||
$ sudo zypper install gpm
|
||||
```
|
||||
|
||||
安装后,使用以下命令启用并启动 GPM 服务:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable gpm
|
||||
$ sudo systemctl start gpm
|
||||
```
|
||||
|
||||
在基于 Debian 的系统中,gpm 服务将在你安装后自动启动,因此你无需如上所示手动启动服务。
|
||||
|
||||
### 为 Linux 虚拟控制台配置鼠标支持
|
||||
|
||||
无需特殊配置。GPM 将在你安装并启动 gpm 服务后立即开始工作。
|
||||
|
||||
在安装 GPM 之前,看下我的 Ubuntu 18.04 LTS 服务器的屏幕截图:
|
||||
|
||||

|
||||
|
||||
正如你在上面的截图中看到的,我的 Ubuntu 18.04 LTS 无头服务器中没有可见的鼠标指针。只有一个闪烁的光标,它不能让我选择文本,使用鼠标复制/粘贴文本。在仅限 CLI 的 Linux 服务器中,鼠标根本没用。
|
||||
|
||||
在安装 GPM 后查看 Ubuntu 18.04 LTS 服务器的以下截图:
|
||||
|
||||

|
||||
|
||||
看见了吗?我现在可以选择文字了。
|
||||
|
||||
要选择,复制和粘贴文本,请执行以下操作:
|
||||
|
||||
* 要选择文本,请按下鼠标左键并拖动鼠标。
|
||||
* 选择文本后,放开鼠标左键,并按下中键在同一个或另一个控制台中粘贴文本。
|
||||
* 右键用于扩展选择,就像在 `xterm` 中。
|
||||
* 如果你使用的是双键鼠标,请使用右键粘贴文本。
|
||||
|
||||
就这么简单!
|
||||
|
||||
就像我已经说过的那样,GPM 工作得很好,并且不需要额外的配置。以下是 GPM 配置文件 `/etc/gpm.conf`(或在某些发行版中是 `/etc/conf.d/gpm`)的示例内容:
|
||||
|
||||
```
|
||||
# protected from evaluation (i.e. by quoting them).
|
||||
#
|
||||
# This file is used by /etc/init.d/gpm and can be modified by
|
||||
# "dpkg-reconfigure gpm" or by hand at your option.
|
||||
#
|
||||
device=/dev/input/mice
|
||||
responsiveness=
|
||||
repeat_type=none
|
||||
type=exps2
|
||||
append=''
|
||||
sample_rate=
|
||||
```
|
||||
|
||||
在我的例子中,我使用 USB 鼠标。如果你使用的是其他鼠标,则可能需要更改 `device=/dev/input/mice` 和 `type=exps2` 参数的值。
|
||||
|
||||
有关更多详细信息,请参阅手册页。
|
||||
|
||||
```
|
||||
$ man gpm
|
||||
```
|
||||
|
||||
就是这些了。希望这个有用。还有更多的好东西。敬请期待!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-configure-mouse-support-for-linux-virtual-consoles/
|
||||
|
||||
作者:[SK][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,169 @@
|
||||
让你提高效率的 Linux 技巧
|
||||
======
|
||||
|
||||
> 想要在 Linux 命令行工作中提高效率,你需要使用一些技巧。
|
||||
|
||||

|
||||
|
||||
巧妙的 Linux 命令行技巧能让你节省时间、避免出错,还能让你记住和复用各种复杂的命令,专注在需要做的事情本身,而不是你要怎么做。以下介绍一些好用的命令行技巧。
|
||||
|
||||
### 命令编辑
|
||||
|
||||
如果要对一个已输入的命令进行修改,可以使用 `^a`(`ctrl + a`)或 `^e`(`ctrl + e`)将光标快速移动到命令的开头或命令的末尾。
|
||||
|
||||
还可以使用 `^` 字符实现对上一个命令的文本替换并重新执行命令,例如 `^before^after^` 相当于把上一个命令中的 `before` 替换为 `after` 然后重新执行一次。
|
||||
|
||||
```
|
||||
$ eho hello world <== 错误的命令
|
||||
|
||||
Command 'eho' not found, did you mean:
|
||||
|
||||
command 'echo' from deb coreutils
|
||||
command 'who' from deb coreutils
|
||||
|
||||
Try: sudo apt install <deb name>
|
||||
|
||||
$ ^e^ec^ <== 替换
|
||||
echo hello world
|
||||
hello world
|
||||
|
||||
```
|
||||
|
||||
### 使用远程机器的名称登录到机器上
|
||||
|
||||
如果使用命令行登录其它机器上,可以考虑添加别名。在别名中,可以填入需要登录的用户名(与本地系统上的用户名可能相同,也可能不同)以及远程机器的登录信息。例如使用 `server_name ='ssh -v -l username IP-address'` 这样的别名命令:
|
||||
|
||||
```
|
||||
$ alias butterfly=”ssh -v -l jdoe 192.168.0.11”
|
||||
```
|
||||
|
||||
也可以通过在 `/etc/hosts` 文件中添加记录或者在 DNS 服务器中加入解析记录来把 IP 地址替换成易记的机器名称。
|
||||
|
||||
执行 `alias` 命令可以列出机器上已有的别名。
|
||||
|
||||
```
|
||||
$ alias
|
||||
alias butterfly='ssh -v -l jdoe 192.168.0.11'
|
||||
alias c='clear'
|
||||
alias egrep='egrep --color=auto'
|
||||
alias fgrep='fgrep --color=auto'
|
||||
alias grep='grep --color=auto'
|
||||
alias l='ls -CF'
|
||||
alias la='ls -A'
|
||||
alias list_repos='grep ^[^#] /etc/apt/sources.list /etc/apt/sources.list.d/*'
|
||||
alias ll='ls -alF'
|
||||
alias ls='ls --color=auto'
|
||||
alias show_dimensions='xdpyinfo | grep '\''dimensions:'\'''
|
||||
```
|
||||
|
||||
只要将新的别名添加到 `~/.bashrc` 或类似的文件中,就可以让别名在每次登录后都能立即生效。
|
||||
|
||||
### 冻结、解冻终端界面
|
||||
|
||||
`^s`(`ctrl + s`)将通过执行流量控制命令 XOFF 来停止终端输出内容,这会对 PuTTY 会话和桌面终端窗口产生影响。如果误输入了这个命令,可以使用 `^q`(`ctrl + q`)让终端重新响应。所以只需要记住 `^q` 这个组合键就可以了,毕竟这种情况并不多见。
|
||||
|
||||
### 复用命令
|
||||
|
||||
Linux 提供了很多让用户复用命令的方法,其核心是通过历史缓冲区收集执行过的命令。复用命令的最简单方法是输入 `!` 然后接最近使用过的命令的开头字母;当然也可以按键盘上的向上箭头,直到看到要复用的命令,然后按回车键。还可以先使用 `history` 显示命令历史,然后输入 `!` 后面再接命令历史记录中需要复用的命令旁边的数字。
|
||||
|
||||
```
|
||||
!! <== 复用上一条命令
|
||||
!ec <== 复用上一条以 “ec” 开头的命令
|
||||
!76 <== 复用命令历史中的 76 号命令
|
||||
```
|
||||
|
||||
### 查看日志文件并动态显示更新内容
|
||||
|
||||
使用形如 `tail -f /var/log/syslog` 的命令可以查看指定的日志文件,并动态显示文件中增加的内容,需要监控向日志文件中追加内容的的事件时相当有用。这个命令会输出文件内容的末尾部分,并逐渐显示新增的内容。
|
||||
|
||||
```
|
||||
$ tail -f /var/log/auth.log
|
||||
Sep 17 09:41:01 fly CRON[8071]: pam_unix(cron:session): session closed for user smmsp
|
||||
Sep 17 09:45:01 fly CRON[8115]: pam_unix(cron:session): session opened for user root
|
||||
Sep 17 09:45:01 fly CRON[8115]: pam_unix(cron:session): session closed for user root
|
||||
Sep 17 09:47:00 fly sshd[8124]: Accepted password for shs from 192.168.0.22 port 47792
|
||||
Sep 17 09:47:00 fly sshd[8124]: pam_unix(sshd:session): session opened for user shs by
|
||||
Sep 17 09:47:00 fly systemd-logind[776]: New session 215 of user shs.
|
||||
Sep 17 09:55:01 fly CRON[8208]: pam_unix(cron:session): session opened for user root
|
||||
Sep 17 09:55:01 fly CRON[8208]: pam_unix(cron:session): session closed for user root
|
||||
<== 等待显示追加的内容
|
||||
```
|
||||
|
||||
### 寻求帮助
|
||||
|
||||
对于大多数 Linux 命令,都可以通过在输入命令后加上选项 `--help` 来获得这个命令的作用、用法以及它的一些相关信息。除了 `man` 命令之外, `--help` 选项可以让你在不使用所有扩展选项的情况下获取到所需要的内容。
|
||||
|
||||
```
|
||||
$ mkdir --help
|
||||
Usage: mkdir [OPTION]... DIRECTORY...
|
||||
Create the DIRECTORY(ies), if they do not already exist.
|
||||
|
||||
Mandatory arguments to long options are mandatory for short options too.
|
||||
-m, --mode=MODE set file mode (as in chmod), not a=rwx - umask
|
||||
-p, --parents no error if existing, make parent directories as needed
|
||||
-v, --verbose print a message for each created directory
|
||||
-Z set SELinux security context of each created directory
|
||||
to the default type
|
||||
--context[=CTX] like -Z, or if CTX is specified then set the SELinux
|
||||
or SMACK security context to CTX
|
||||
--help display this help and exit
|
||||
--version output version information and exit
|
||||
|
||||
GNU coreutils online help: <http://www.gnu.org/software/coreutils/>
|
||||
Full documentation at: <http://www.gnu.org/software/coreutils/mkdir>
|
||||
or available locally via: info '(coreutils) mkdir invocation'
|
||||
```
|
||||
|
||||
### 谨慎删除文件
|
||||
|
||||
如果要谨慎使用 `rm` 命令,可以为它设置一个别名,在删除文件之前需要进行确认才能删除。有些系统管理员会默认使用这个别名,对于这种情况,你可能需要看看下一个技巧。
|
||||
|
||||
```
|
||||
$ rm -i <== 请求确认
|
||||
```
|
||||
|
||||
### 关闭别名
|
||||
|
||||
你可以使用 `unalias` 命令以交互方式禁用别名。它不会更改别名的配置,而仅仅是暂时禁用,直到下次登录或重新设置了这一个别名才会重新生效。
|
||||
|
||||
```
|
||||
$ unalias rm
|
||||
```
|
||||
|
||||
如果已经将 `rm -i` 默认设置为 `rm` 的别名,但你希望在删除文件之前不必进行确认,则可以将 `unalias` 命令放在一个启动文件(例如 `~/.bashrc`)中。
|
||||
|
||||
### 使用 sudo
|
||||
|
||||
如果你经常在只有 root 用户才能执行的命令前忘记使用 `sudo`,这里有两个方法可以解决。一是利用命令历史记录,可以使用 `sudo !!`(使用 `!!` 来运行最近的命令,并在前面添加 `sudo`)来重复执行,二是设置一些附加了所需 `sudo` 的命令别名。
|
||||
|
||||
```
|
||||
$ alias update=’sudo apt update’
|
||||
```
|
||||
|
||||
### 更复杂的技巧
|
||||
|
||||
有时命令行技巧并不仅仅是一个别名。毕竟,别名能帮你做的只有替换命令以及增加一些命令参数,节省了输入的时间。但如果需要比别名更复杂功能,可以通过编写脚本、向 `.bashrc` 或其他启动文件添加函数来实现。例如,下面这个函数会在创建一个目录后进入到这个目录下。在设置完毕后,执行 `source .bashrc`,就可以使用 `md temp` 这样的命令来创建目录立即进入这个目录下。
|
||||
|
||||
```
|
||||
md () { mkdir -p "$@" && cd "$1"; }
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
使用 Linux 命令行是在 Linux 系统上工作最有效也最有趣的方法,但配合命令行技巧和巧妙的别名可以让你获得更好的体验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3305811/linux/linux-tricks-that-even-you-can-love.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]: https://www.facebook.com/NetworkWorld/
|
||||
[2]: https://www.linkedin.com/company/network-world
|
||||
|
||||
@ -0,0 +1,46 @@
|
||||
如何在 Ubuntu 16.04 强制 APT 包管理器使用 IPv4
|
||||
======
|
||||
|
||||

|
||||
|
||||
**APT**, 是 **A** dvanced **P** ackage **T** ool 的缩写,是基于 Debian 的系统的默认包管理器。我们可以使用 APT 安装、更新、升级和删除应用程序。最近,我一直遇到一个奇怪的错误。每当我尝试更新我的 Ubuntu 16.04 时,我都会收到此错误 - **“0% [Connecting to in.archive.ubuntu.com (2001:67c:1560:8001::14)]”** ,同时更新流程会卡住很长时间。我的网络连接没问题,我可以 ping 通所有网站,包括 Ubuntu 官方网站。在搜索了一番谷歌后,我意识到 Ubuntu 镜像站点有时无法通过 IPv6 访问。在我强制将 APT 包管理器在更新系统时使用 IPv4 代替 IPv6 访问 Ubuntu 镜像站点后,此问题得以解决。如果你遇到过此错误,可以按照以下说明解决。
|
||||
|
||||
### 强制 APT 包管理器在 Ubuntu 16.04 中使用 IPv4
|
||||
|
||||
要在更新和升级 Ubuntu 16.04 LTS 系统时强制 APT 使用 IPv4 代替 IPv6,只需使用以下命令:
|
||||
|
||||
```
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true update
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true upgrade
|
||||
```
|
||||
|
||||
瞧!这次更新很快就完成了。
|
||||
|
||||
你还可以使用以下命令在 `/etc/apt/apt.conf.d/99force-ipv4` 中添加以下行,以便将来对所有 `apt-get` 事务保持持久性:
|
||||
|
||||
```
|
||||
$ echo 'Acquire::ForceIPv4 "true";' | sudo tee /etc/apt/apt.conf.d/99force-ipv4
|
||||
```
|
||||
|
||||
**免责声明:**
|
||||
|
||||
我不知道最近是否有人遇到这个问题,但我今天在我的 Ubuntu 16.04 LTS 虚拟机中遇到了至少四、五次这样的错误,我按照上面的说法解决了这个问题。我不确定这是推荐的解决方案。请浏览 Ubuntu 论坛来确保此方法合法。由于我只是一个 VM,我只将它用于测试和学习目的,我不介意这种方法的真实性。请自行承担使用风险。
|
||||
|
||||
希望这有帮助。还有更多的好东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-force-apt-package-manager-to-use-ipv4-in-ubuntu-16-04/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,60 @@
|
||||
使用 top 命令了解 Fedora 的内存使用情况
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你使用过 `top` 命令来查看 Fedora 系统中的内存使用情况,你可能会惊讶,看起来消耗的数量比系统可用的内存更多。下面会详细介绍内存使用情况以及如何理解这些数据。
|
||||
|
||||
### 内存实际使用情况
|
||||
|
||||
操作系统对内存的使用方式并不是太通俗易懂。事实上,其背后有很多不为人知的巧妙技术在发挥着作用。通过这些方式,可以在无需用户干预的情况下,让操作系统更有效地使用内存。
|
||||
|
||||
大多数应用程序都不是系统自带的,但每个应用程序都依赖于安装在系统中的库中的一些函数集。在 Fedora 中,RPM 包管理系统能够确保在安装应用程序时也会安装所依赖的库。
|
||||
|
||||
当应用程序运行时,操作系统并不需要将它要用到的所有信息都加载到物理内存中。而是会为存放代码的存储空间构建一个映射,称为虚拟内存。操作系统只把需要的部分加载到内存中,当某一个部分不再需要后,这一部分内存就会被释放掉。
|
||||
|
||||
这意味着应用程序可以映射大量的虚拟内存,而使用较少的系统物理内存。特殊情况下,映射的虚拟内存甚至可以比系统实际可用的物理内存更多!而且在操作系统中这种情况也并不少见。
|
||||
|
||||
另外,不同的应用程序可能会对同一个库都有依赖。Fedora 中的 Linux 内核通常会在各个应用程序之间共享内存,而不需要为不同应用分别加载同一个库的多个副本。类似地,对于同一个应用程序的不同实例也是采用这种方式共享内存。
|
||||
|
||||
如果不首先了解这些细节,`top` 命令显示的数据可能会让人摸不着头脑。下面就举例说明如何正确查看内存使用量。
|
||||
|
||||
### 使用 `top` 命令查看内存使用量
|
||||
|
||||
如果你还没有使用过 `top` 命令,可以打开终端直接执行查看。使用 `Shift + M` 可以按照内存使用量来进行排序。下图是在 Fedora Workstation 中执行的结果,在你的机器上显示的结果可能会略有不同:
|
||||
|
||||
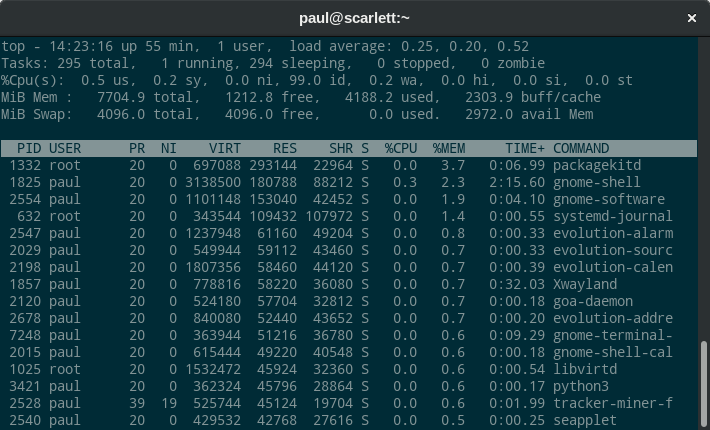
|
||||
|
||||
主要通过以下三列来查看内存使用情况:`VIRT`、`RES` 和 `SHR`。目前以 KB 为单位显示相关数值。
|
||||
|
||||
`VIRT` 列代表该进程映射的<ruby>虚拟<rt>virtual</rt></ruby>内存。如上所述,虚拟内存不是实际消耗的物理内存。例如, GNOME Shell 进程 `gnome-shell` 实际上没有消耗超过 3.1 GB 的物理内存,但它对很多更低或更高级的库都有依赖,系统必须对每个库都进行映射,以确保在有需要时可以加载这些库。
|
||||
|
||||
`RES` 列代表应用程序消耗了多少实际(<ruby>驻留<rt>resident</rt></ruby>)内存。对于 GNOME Shell 大约是 180788 KB。例子中的系统拥有大约 7704 MB 的物理内存,因此内存使用率显示为 2.3%。
|
||||
|
||||
但根据 `SHR` 列显示,其中至少有 88212 KB 是<ruby>共享<rt>shared</rt></ruby>内存,这部分内存可能是其它应用程序也在使用的库函数。这意味着 GNOME Shell 本身大约有 92 MB 内存不与其他进程共享。需要注意的是,上述例子中的其它程序也共享了很多内存。在某些应用程序中,共享内存在内存使用量中会占很大的比例。
|
||||
|
||||
值得一提的是,有时进程之间通过内存通信,这些内存也是共享的,但 `top` 这样的工具却不一定能检测到,所以以上的说明也不一定准确。
|
||||
|
||||
### 关于交换分区
|
||||
|
||||
系统还可以通过交换分区来存储数据(例如硬盘),但读写的速度相对较慢。当物理内存渐渐用满,操作系统就会查找内存中暂时不会使用的部分,将其写出到交换区域等待需要的时候使用。
|
||||
|
||||
因此,如果交换内存的使用量一直偏高,表明系统的物理内存已经供不应求了。有时候一个不正常的应用也有可能导致出现这种情况,但如果这种现象经常出现,就需要考虑提升物理内存或者限制某些程序的运行了。
|
||||
|
||||
感谢 [Stig Nygaard][1] 在 [Flickr][2] 上提供的图片(CC BY 2.0)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/understand-fedora-memory-usage-top/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[1]: https://www.flickr.com/photos/stignygaard/
|
||||
[2]: https://www.flickr.com/photos/stignygaard/3138001676/
|
||||
|
||||
@ -1,30 +1,34 @@
|
||||
在Linux上使用 i3 作为窗口管理器的入门教程
|
||||
i3 窗口管理器入门
|
||||
======
|
||||
|
||||
> 本篇文章会介绍如何在 Fedora 系统中,安装、配置、使用 i3 瓦片式桌面管理器。
|
||||
|
||||

|
||||
|
||||
在我的文章[5 reasons the i3 window manager makes Linux better][1],我分享了选择 [i3 window manager][2] 作为一种Linux桌面替代方案的最主要五个理由。
|
||||
在本篇文章中,我将向大家展示,如何在 Fedora 28 上安装与配置 i3。
|
||||
在我的文章 [i3 桌面让 Linux 更好的 5 个理由][1],我分享了选择 [i3 桌面管理器][2] 作为一种 Linux 桌面替代方案的最主要五个理由。
|
||||
|
||||
### 1\. 安装
|
||||
在本篇文章中,我将向大家展示,如何在 Fedora 28 上安装与简单配置 i3。
|
||||
|
||||
### 1、 安装
|
||||
|
||||
首先进入 Fedora 系统中,打开一个终端。使用 `dnf` 来安装需要的软件包,如下:
|
||||
|
||||
```
|
||||
[ricardo@f28i3 ~]$ sudo dnf install -y i3 i3-ipc i3status i3lock dmenu terminator --exclude=rxvt-unicode
|
||||
Last metadata expiration check: 1:36:15 ago on Wed 08 Aug 2018 12:04:31 PM EDT.
|
||||
Dependencies resolved.
|
||||
================================================================================================
|
||||
Package Arch Version Repository Size
|
||||
Package Arch Version Repository Size
|
||||
================================================================================================
|
||||
Installing:
|
||||
dmenu x86_64 4.8-1.fc28 fedora 33 k
|
||||
i3 x86_64 4.15-1.fc28 fedora 323 k
|
||||
i3-ipc noarch 0.1.4-12.fc28 fedora 14 k
|
||||
i3lock x86_64 2.9.1-2.fc28 fedora 33 k
|
||||
i3status x86_64 2.12-1.fc28 updates 62 k
|
||||
terminator noarch 1.91-4.fc28 fedora 570 k
|
||||
dmenu x86_64 4.8-1.fc28 fedora 33 k
|
||||
i3 x86_64 4.15-1.fc28 fedora 323 k
|
||||
i3-ipc noarch 0.1.4-12.fc28 fedora 14 k
|
||||
i3lock x86_64 2.9.1-2.fc28 fedora 33 k
|
||||
i3status x86_64 2.12-1.fc28 updates 62 k
|
||||
terminator noarch 1.91-4.fc28 fedora 570 k
|
||||
Installing dependencies:
|
||||
dzen2 x86_64 0.8.5-21.20100104svn.fc28 fedora 60 k
|
||||
dzen2 x86_64 0.8.5-21.20100104svn.fc28 fedora 60 k
|
||||
|
||||
... Skipping dependencies/install messages
|
||||
|
||||
@ -36,55 +40,56 @@ Complete!
|
||||
|
||||
据用户目前的系统状态,在命令执行过程中可能会安装很多依赖。等待所有的依赖安装完成,之后重启你的电脑。
|
||||
|
||||
### 2. 登录与初始化
|
||||
### 2、 首次登录与初始化
|
||||
|
||||
在你的机器重启之后,你便可以第一次体验 i3 了。在 GNOME Display Manager (GDM),选择你的用户名,之后先别着急输密码,点击下方的密码输入框下方的小齿轮,之后选择 i3 ,像下方这样:
|
||||
在你的机器重启之后,你便可以第一次体验 i3 了。在 GNOME 显示管理器(GDM)屏幕,选择你的用户名,之后先别着急输密码,点击下方的密码输入框下方的小齿轮,之后选择 i3 而不是 GNOME,像下方这样:
|
||||
|
||||
|
||||
|
||||
输入你的密码,并点击 `Sign In`。在你第一次登入之后,会先看到 i3 的配置界面:
|
||||
输入你的密码,并点击 “Sign In”。在你第一次登入之后,会先看到 i3 的配置界面:
|
||||
|
||||
|
||||
|
||||
点击 `ENTER` 就会在 `$HOME/.config/i3` 生成一个配置文件,之后你可以通过这个配置文件来定制化 i3's 的一些行为。
|
||||
点击回车键就会在 `$HOME/.config/i3` 生成一个配置文件,之后你可以通过这个配置文件来定制化 i3 的一些行为。
|
||||
|
||||
在下一屏,你需要选择你的 `Mod` 键。这一步很关键,因为 `Mod` 键通常都会作为 i3's 命令快捷键的发起键。按 `ENTER` 会选择 `Win` 键作为默认的 `Mod` 键。如果你的键盘没有 `Win` 键,用 `Alt` 键做替代,用方向键键选择后按 `ENTER` 确认。
|
||||
在下一屏,你需要选择你的 `Mod` 键。这一步很关键,因为 `Mod` 键通常都会作为 i3 命令快捷键的发起键。按回车会选择 `Win` 键作为默认的 `Mod` 键。如果你的键盘没有 `Win` 键,用 `Alt` 键做替代,用方向键键选择后按回车键确认。
|
||||
|
||||
|
||||
|
||||
现在你就登录到了 i3 的系统中。由于 i3 是一个最小化的窗口管理器,你会看到一个黑屏窗口,以及屏幕底端显式的状态栏:
|
||||
现在你就登录到了 i3 的系统中。由于 i3 是一个极简的窗口管理器,你会看到一个黑屏窗口,以及屏幕底端显示的状态栏:
|
||||
|
||||

|
||||
|
||||
接下来,让我们看看 i3 的如何实际使用。
|
||||
|
||||
### 3\. 基本的快捷键
|
||||
### 3、 基本的快捷键
|
||||
|
||||
现在你已经登录到了 i3 的会话中,你需要几个基本的快捷键来应对基本的操作。
|
||||
现在你已经登录到了 i3 会话中,你需要几个基本的快捷键来应对基本的操作。
|
||||
|
||||
大多数的 i3 快捷键都会用到之前配置的 `Mod` 键。在下面的例子中,当我提到 `Mod` 键,请根据情况使用你定义的做替换。通常使用 `Win` 键或者 `Alt` 键。
|
||||
|
||||
首先,打开一个终端,使用 `Mod+ENTER`。重复打开几个终端,观察 i3 是如何自动将它们在桌面中排列。默认情况下, i3 会在水平的方向分割屏幕;使用 `Mod + v` 来垂直分割,再按 `Mod + h` 会恢复水平分割模式。
|
||||
首先,要打开一个终端,可以使用 `Mod+ENTER`。重复打开几个终端,观察 i3 是如何自动将它们在桌面中排列。默认情况下, i3 会在水平的方向分割屏幕;使用 `Mod + v` 来垂直分割,再按 `Mod + h` 会恢复水平分割模式。
|
||||
|
||||
|
||||
|
||||
当需要启动其他的应用,按 `Mod + d` 来打开 `dmenu`,一个简单的文字应用菜单。默认情况下,`dmenu` 会呈现出所有在你 `$PATH` 中设置的应用。使用方向键来选择你想启动的应用,同时你可以键入应用的名称,来缩小选择的范围,之后按 `ENTER` 来启动选择的应用。
|
||||
当需要启动其他的应用,按 `Mod + d` 来打开 `dmenu`,一个简单的文字应用菜单。默认情况下,`dmenu` 会呈现出所有在你 `$PATH` 中设置的应用。使用方向键来选择你想启动的应用,同时你可以键入应用的名称,来缩小选择的范围,之后按回车键来启动选择的应用。
|
||||
|
||||

|
||||
|
||||
如果你的应用没有提供退出的方法,你可以使用 i3 来关闭对应的窗口,通过按 `Mod + Shift +q`。注意,你可能会丢失未保存的工作内容。
|
||||
|
||||
最后,当你想关闭会话并退出 i3,按 `Mod + Shift +e`。之后会在窗口的上方提示你是否退出。点击 `Yes, exit i3` 退出,或选择 `X` 来取消。
|
||||
最后,当你想关闭会话并退出 i3,按 `Mod + Shift +e`。之后会在窗口的上方提示你是否退出。点击 “Yes, exit i3” 退出,或选择 “X” 来取消。
|
||||
|
||||

|
||||
|
||||
这些就是 i3 中最基本的快捷键,如果想了解更多,请查阅官方文档 [documentation][3]。
|
||||
这些就是 i3 中最基本的快捷键,如果想了解更多,请查阅官方[文档][3]。
|
||||
|
||||
### 4\. 替换GDM
|
||||
### 4、 替换 GDM
|
||||
|
||||
使用 i3 window manager 会降低你操作系统的内存占用;然而,Fedora 依然会使用 GDM 作为登录的窗口。GDM 会载入几个与 GNOME 相关的库从而占用内存。
|
||||
使用 i3 窗口管理器会降低你操作系统的内存占用;然而,Fedora 依然会使用 GDM 作为登录屏。GDM 会载入几个与 GNOME 相关的库从而占用内存。
|
||||
|
||||
如果你想进一步的降低你的内存占用,你可以使用一些更轻量级的显示管理器来替换 GDM,比如 lightdm :
|
||||
|
||||
如果你想进一步的降低你的内存占用,你可以使用一些更轻量级的窗口管理器来替换 GDM,比如 `lightdm`:
|
||||
```
|
||||
[ricardo@f28i3 ~]$ sudo dnf install -y lightdm
|
||||
[ricardo@f28i3 ~]$ sudo systemctl disable gdm
|
||||
@ -107,7 +112,7 @@ via: https://opensource.com/article/18/8/getting-started-i3-window-manager
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[sd886393](https://github.com/sd886393)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,143 +0,0 @@
|
||||
How to get into DevOps
|
||||
======
|
||||

|
||||
|
||||
I've observed a sharp uptick of developers and systems administrators interested in "getting into DevOps" within the past year or so. This pattern makes sense: In an age in which a single developer can spin up a globally distributed infrastructure for an application with a few dollars and a few API calls, the gap between development and systems administration is closer than ever. Although I've seen plenty of blog posts and articles about cool DevOps tools and thoughts to think about, I've seen fewer content on pointers and suggestions for people looking to get into this work.
|
||||
|
||||
My goal with this article is to draw what that path looks like. My thoughts are based upon several interviews, chats, late-night discussions on [reddit.com/r/devops][1], and random conversations, likely over beer and delicious food. I'm also interested in hearing feedback from those who have made the jump; if you have, please reach out through [my blog][2], [Twitter][3], or in the comments below. I'd love to hear your thoughts and stories.
|
||||
|
||||
### Olde world IT
|
||||
|
||||
Understanding history is key to understanding the future, and DevOps is no exception. To understand the pervasiveness and popularity of the DevOps movement, understanding what IT was like in the late '90s and most of the '00s is helpful. This was my experience.
|
||||
|
||||
I started my career in late 2006 as a Windows systems administrator in a large, multi-national financial services firm. In those days, adding new compute involved calling Dell (or, in our case, CDW) and placing a multi-hundred-thousand-dollar order of servers, networking equipment, cables, and software, all destined for your on- and offsite datacenters. Although VMware was still convincing companies that using virtual machines was, indeed, a cost-effective way of hosting its "performance-sensitive" application, many companies, including mine, pledged allegiance to running applications on their physical hardware.
|
||||
|
||||
Our technology department had an entire group dedicated to datacenter engineering and operations, and its job was to negotiate our leasing rates down to some slightly less absurd monthly rate and ensure that our systems were being cooled properly (an exponentially difficult problem if you have enough equipment). If the group was lucky/wealthy enough, the offshore datacenter crew knew enough about all of our server models to not accidentally pull the wrong thing during after-hours trading. Amazon Web Services and Rackspace were slowly beginning to pick up steam, but were far from critical mass.
|
||||
|
||||
In those days, we also had teams dedicated to ensuring that the operating systems and software running on top of that hardware worked when they were supposed to. The engineers were responsible for designing reliable architectures for patching, monitoring, and alerting these systems as well as defining what the "gold image" looked like. Most of this work was done with a lot of manual experimentation, and the extent of most tests was writing a runbook describing what you did, and ensuring that what you did actually did what you expected it to do after following said runbook. This was important in a large organization like ours, since most of the level 1 and 2 support was offshore, and the extent of their training ended with those runbooks.
|
||||
|
||||
(This is the world that your author lived in for the first three years of his career. My dream back then was to be the one who made the gold standard!)
|
||||
|
||||
Software releases were another beast altogether. Admittedly, I didn't gain a lot of experience working on this side of the fence. However, from stories that I've gathered (and recent experience), much of the daily grind for software development during this time went something like this:
|
||||
|
||||
* Developers wrote code as specified by the technical and functional requirements laid out by business analysts from meetings they weren't invited to.
|
||||
* Optionally, developers wrote unit tests for their code to ensure that it didn't do anything obviously crazy, like try to divide over zero without throwing an exception.
|
||||
* When done, developers would mark their code as "Ready for QA." A quality assurance person would pick up the code and run it in their own environment, which might or might not be like production or even the environment the developer used to test their own code against.
|
||||
* Failures would get sent back to the developers within "a few days or weeks" depending on other business activities and where priorities fell.
|
||||
|
||||
|
||||
|
||||
Although sysadmins and developers didn't often see eye to eye, the one thing they shared a common hatred for was "change management." This was a composition of highly regulated (and in the case of my employer at the time), highly necessary rules and procedures governing when and how technical changes happened in a company. Most companies followed [ITIL][4] practices, which, in a nutshell, asked a lot of questions around why, when, where, and how things happened and provided a process for establishing an audit trail of the decisions that led up to those answers.
|
||||
|
||||
As you could probably gather from my short history lesson, many, many things were done manually in IT. This led to a lot of mistakes. Lots of mistakes led up to lots of lost revenue. Change management's job was to minimize those lost revenues; this usually came in the form of releases only every two weeks and changes to servers, regardless of their impact or size, queued up to occur between Friday at 4 p.m. and Monday at 5:59 a.m. (Ironically, this batching of work led to even more mistakes, usually more serious ones.)
|
||||
|
||||
### DevOps isn't a Tiger Team
|
||||
|
||||
You might be thinking "What is Carlos going on about, and when is he going to talk about Ansible playbooks?" I love Ansible tons, but hang on; this is important.
|
||||
|
||||
Have you ever been assigned to a project where you had to interact with the "DevOps" team? Or did you have to rely on a "configuration management" or "CI/CD" team to ensure your pipeline was set up properly? Have you had to attend meetings about your release and what it pertains to--weeks after the work was marked "code complete"?
|
||||
|
||||
If so, then you're reliving history. All of that comes from all of the above.
|
||||
|
||||
[Silos form][5] out of an instinctual draw to working with people like ourselves. Naturally, it's no surprise that this human trait also manifests in the workplace. I even saw this play out at a 250-person startup where I used to work. When I started, developers all worked in common pods and collaborated heavily with each other. As the codebase grew in complexity, developers who worked on common features naturally aligned with each other to try and tackle the complexity within their own feature. Soon afterwards, feature teams were officially formed.
|
||||
|
||||
Sysadmins and developers at many of the companies I worked at not only formed natural silos like this, but also fiercely competed with each other. Developers were mad at sysadmins when their environments were broken. Developers were mad at sysadmins when their environments were too locked down. Sysadmins were mad that developers were breaking their environments in arbitrary ways all of the time. Sysadmins were mad at developers for asking for way more computing power than they needed. Neither side understood each other, and worse yet, neither side wanted to.
|
||||
|
||||
Most developers were uninterested in the basics of operating systems, kernels, or, in some cases, computer hardware. As well, most sysadmins, even Linux sysadmins, took a 10-foot pole approach to learning how to code. They tried a bit of C in college, hated it and never wanted to touch an IDE again. Consequently, developers threw their environment problems over the wall to sysadmins, sysadmins prioritized them with the hundreds of other things that were thrown over the wall to them, and everyone busy-waited angrily while hating each other. The purpose of DevOps was to put an end to this.
|
||||
|
||||
DevOps isn't a team. CI/CD isn't a group in Jira. DevOps is a way of thinking. According to the movement, in an ideal world, developers, sysadmins, and business stakeholders would be working as one team. While they might not know everything about each other's worlds, not only do they all know enough to understand each other and their backlogs, but they can, for the most part, speak the same language.
|
||||
|
||||
This is the basis behind having all infrastructure and business logic be in code and subject to the same deployment pipelines as the software that sits on top of it. Everybody is winning because everyone understands each other. This is also the basis behind the rise of other tools like chatbots and easily accessible monitoring and graphing.
|
||||
|
||||
[Adam Jacob said][6] it best: "DevOps is the word we will use to describe the operational side of the transition to enterprises being software led."
|
||||
|
||||
### What do I need to know to get into DevOps?
|
||||
|
||||
I'm commonly asked this question, and the answer, like most open-ended questions like this, is: It depends.
|
||||
|
||||
At the moment, the "DevOps engineer" varies from company to company. Smaller companies that have plenty of software developers but fewer folks that understand infrastructure will likely look for people with more experience administrating systems. Other, usually larger and/or older companies that have a solid sysadmin organization will likely optimize for something closer to a [Google site reliability engineer][7], i.e. "a software engineer to design an operations function." This isn't written in stone, however, as, like any technology job, the decision largely depends on the hiring manager sponsoring it.
|
||||
|
||||
That said, we typically look for engineers who are interested in learning more about:
|
||||
|
||||
* How to administrate and architect secure and scalable cloud platforms (usually on AWS, but Azure, Google Cloud Platform, and PaaS providers like DigitalOcean and Heroku are popular too);
|
||||
* How to build and optimize deployment pipelines and deployment strategies on popular [CI/CD][8] tools like Jenkins, Go continuous delivery, and cloud-based ones like Travis CI or CircleCI;
|
||||
* How to monitor, log, and alert on changes in your system with timeseries-based tools like Kibana, Grafana, Splunk, Loggly, or Logstash; and
|
||||
* How to maintain infrastructure as code with configuration management tools like Chef, Puppet, or Ansible, as well as deploy said infrastructure with tools like Terraform or CloudFormation.
|
||||
|
||||
|
||||
|
||||
Containers are becoming increasingly popular as well. Despite the [beef against the status quo][9] surrounding Docker at scale, containers are quickly becoming a great way of achieving an extremely high density of services and applications running on fewer systems while increasing their reliability. (Orchestration tools like Kubernetes or Mesos can spin up new containers in seconds if the host they're being served by fails.) Given this, having knowledge of Docker or rkt and an orchestration platform will go a long way.
|
||||
|
||||
If you're a systems administrator that's looking to get into DevOps, you will also need to know how to write code. Python and Ruby are popular languages for this purpose, as they are portable (i.e., can be used on any operating system), fast, and easy to read and learn. They also form the underpinnings of the industry's most popular configuration management tools (Python for Ansible, Ruby for Chef and Puppet) and cloud API clients (Python and Ruby are commonly used for AWS, Azure, and Google Cloud Platform clients).
|
||||
|
||||
If you're a developer looking to make this change, I highly recommend learning more about Unix, Windows, and networking fundamentals. Even though the cloud abstracts away many of the complications of administrating a system, debugging slow application performance is aided greatly by knowing how these things work. I've included a few books on this topic in the next section.
|
||||
|
||||
If this sounds overwhelming, you aren't alone. Fortunately, there are plenty of small projects to dip your feet into. One such toy project is Gary Stafford's Voter Service, a simple Java-based voting platform. We ask our candidates to take the service from GitHub to production infrastructure through a pipeline. One can combine that with Rob Mile's awesome DevOps Tutorial repository to learn about ways of doing this.
|
||||
|
||||
Another great way of becoming familiar with these tools is taking popular services and setting up an infrastructure for them using nothing but AWS and configuration management. Set it up manually first to get a good idea of what to do, then replicate what you just did using nothing but CloudFormation (or Terraform) and Ansible. Surprisingly, this is a large part of the work that we infrastructure devs do for our clients on a daily basis. Our clients find this work to be highly valuable!
|
||||
|
||||
### Books to read
|
||||
|
||||
If you're looking for other resources on DevOps, here are some theory and technical books that are worth a read.
|
||||
|
||||
#### Theory books
|
||||
|
||||
* [The Phoenix Project][10] by Gene Kim. This is a great book that covers much of the history I explained earlier (with much more color) and describes the journey to a lean company running on agile and DevOps.
|
||||
* [Driving Technical Change][11] by Terrance Ryan. Awesome little book on common personalities within most technology organizations and how to deal with them. This helped me out more than I expected.
|
||||
* [Peopleware][12] by Tom DeMarco and Tim Lister. A classic on managing engineering organizations. A bit dated, but still relevant.
|
||||
* [Time Management for System Administrators][13] by Tom Limoncelli. While this is heavily geared towards sysadmins, it provides great insight into the life of a systems administrator at most large organizations. If you want to learn more about the war between sysadmins and developers, this book might explain more.
|
||||
* [The Lean Startup][14] by Eric Ries. Describes how Eric's 3D avatar company, IMVU, discovered how to work lean, fail fast, and find profit faster.
|
||||
* [Lean Enterprise][15] by Jez Humble and friends. This book is an adaption of The Lean Startup for the enterprise. Both are great reads and do a good job of explaining the business motivation behind DevOps.
|
||||
* [Infrastructure As Code][16] by Kief Morris. Awesome primer on, well, infrastructure as code! It does a great job of describing why it's essential for any business to adopt this for their infrastructure.
|
||||
* [Site Reliability Engineering][17] by Betsy Beyer, Chris Jones, Jennifer Petoff, and Niall Richard Murphy. A book explaining how Google does SRE, or also known as "DevOps before DevOps was a thing." Provides interesting opinions on how to handle uptime, latency, and keeping engineers happy.
|
||||
|
||||
|
||||
|
||||
#### Technical books
|
||||
|
||||
If you're looking for books that'll take you straight to code, you've come to the right section.
|
||||
|
||||
* [TCP/IP Illustrated][18] by the late W. Richard Stevens. This is the classic (and, arguably, complete) tome on the fundamental networking protocols, with special emphasis on TCP/IP. If you've heard of Layers 1, 2, 3, and 4 and are interested in learning more, you'll need this book.
|
||||
* [UNIX and Linux System Administration Handbook][19] by Evi Nemeth, Trent Hein, and Ben Whaley. A great primer into how Linux and Unix work and how to navigate around them.
|
||||
* [Learn Windows Powershell In A Month of Lunches][20] by Don Jones and Jeffrey Hicks. If you're doing anything automated with Windows, you will need to learn how to use Powershell. This is the book that will help you do that. Don Jones is a well-known MVP in this space.
|
||||
* Practically anything by [James Turnbull][21]. He puts out great technical primers on popular DevOps-related tools.
|
||||
|
||||
|
||||
|
||||
From companies deploying everything to bare metal (there are plenty that still do, for good reasons) to trailblazers doing everything serverless, DevOps is likely here to stay for a while. The work is interesting, the results are impactful, and, most important, it helps bridge the gap between technology and business. It's a wonderful thing to see.
|
||||
|
||||
Originally published at [Neurons Firing on a Keyboard][22], CC-BY-SA.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/getting-devops
|
||||
|
||||
作者:[Carlos Nunez][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/carlosonunez
|
||||
[1]:https://www.reddit.com/r/devops/
|
||||
[2]:https://carlosonunez.wordpress.com/
|
||||
[3]:https://twitter.com/easiestnameever
|
||||
[4]:https://en.wikipedia.org/wiki/ITIL
|
||||
[5]:https://www.psychologytoday.com/blog/time-out/201401/getting-out-your-silo
|
||||
[6]:https://twitter.com/adamhjk/status/572832185461428224
|
||||
[7]:https://landing.google.com/sre/interview/ben-treynor.html
|
||||
[8]:https://en.wikipedia.org/wiki/CI/CD
|
||||
[9]:https://thehftguy.com/2016/11/01/docker-in-production-an-history-of-failure/
|
||||
[10]:https://itrevolution.com/book/the-phoenix-project/
|
||||
[11]:https://pragprog.com/book/trevan/driving-technical-change
|
||||
[12]:https://en.wikipedia.org/wiki/Peopleware:_Productive_Projects_and_Teams
|
||||
[13]:http://shop.oreilly.com/product/9780596007836.do
|
||||
[14]:http://theleanstartup.com/
|
||||
[15]:https://info.thoughtworks.com/lean-enterprise-book.html
|
||||
[16]:http://infrastructure-as-code.com/book/
|
||||
[17]:https://landing.google.com/sre/book.html
|
||||
[18]:https://en.wikipedia.org/wiki/TCP/IP_Illustrated
|
||||
[19]:http://www.admin.com/
|
||||
[20]:https://www.manning.com/books/learn-windows-powershell-in-a-month-of-lunches-third-edition
|
||||
[21]:https://jamesturnbull.net/
|
||||
[22]:https://carlosonunez.wordpress.com/2017/03/02/getting-into-devops/
|
||||
@ -1,4 +1,3 @@
|
||||
translating by leowang
|
||||
Moving to Linux from dated Windows machines
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
translating by ynmlml
|
||||
|
||||
Write Dumb Code
|
||||
======
|
||||
The best way you can contribute to an open source project is to remove lines of code from it. We should endeavor to write code that a novice programmer can easily understand without explanation or that a maintainer can understand without significant time investment.
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
How writing can change your career for the better, even if you don't identify as a writer
|
||||
How writing can change your career for the better, even if you don't identify as a writer Translating by FelixYFZ
|
||||
======
|
||||
Have you read Marie Kondo's book [The Life-Changing Magic of Tidying Up][1]? Or did you, like me, buy it and read a little bit and then add it to the pile of clutter next to your bed?
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Translating by FelixYFZ 20 questions DevOps job candidates should be prepared to answer
|
||||
20 questions DevOps job candidates should be prepared to answer Translating by FelixYFZ
|
||||
======
|
||||
|
||||

|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
(translating by runningwater)
|
||||
Microservices Explained
|
||||
======
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
translating by aiwhj
|
||||
3 tips for organizing your open source project's workflow on GitHub
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
Why moving all your workloads to the cloud is a bad idea
|
||||
======
|
||||
|
||||
|
||||
@ -1,79 +0,0 @@
|
||||
What do open source and cooking have in common?
|
||||
======
|
||||
|
||||

|
||||
|
||||
What’s a fun way to promote the principles of free software without actually coding? Here’s an idea: open source cooking. For the past eight years, this is what we’ve been doing in Munich.
|
||||
|
||||
The idea of _open source cooking_ grew out of our regular open source meetups because we realized that cooking and free software have a lot in common.
|
||||
|
||||
### Cooking together
|
||||
|
||||
The [Munich Open Source Meetings][1] is a series of recurring Friday night events that was born in [Café Netzwerk][2] in July 2009. The meetings help provide a way for open source project members and enthusiasts to get to know each other. Our motto is: “Every fourth Friday for free software.” In addition to adding some weekend workshops, we soon introduced other side events, including white sausage breakfast, sauna, and cooking.
|
||||
|
||||
The first official _Open Source Cooking_ meetup was admittedly rather chaotic, but we’ve improved our routine over the past eight years and 15 events, and we’ve mastered the art of cooking delicious food for 25-30 people.
|
||||
|
||||
Looking back at all those evenings, similarities between cooking together and working together in open source communities have become more clear.
|
||||
|
||||
### FLOSS principles at play
|
||||
|
||||
Here are a few ways cooking together is like working together on open source projects:
|
||||
|
||||
* We enjoy collaborating and working toward a result we share.
|
||||
* We’ve become a community.
|
||||
* As we share a common interest and enthusiasm, we learn more about ourselves, each other, and what we’re working on together.
|
||||
* Mistakes happen. We learn from them and share our knowledge to our mutual benefit, so hopefully we avoid repeating the same mistakes.
|
||||
* Everyone contributes what they’re best at, as everyone has something they’re better at than someone else.
|
||||
* We motivate others to contribute and join us.
|
||||
* Coordination is key, but a bit chaotic.
|
||||
* Everyone benefits from the results!
|
||||
|
||||
|
||||
|
||||
### Smells like open source
|
||||
|
||||
Like any successful open source-related meetup, open source cooking requires some coordination and structure. Ahead of the event, we run a _call for recipes_ in which all participants can vote. Rather than throwing a pizza into a microwave, we want to create something delicious and tasty, and so far we’ve had Japanese, Mexican, Hungarian, and Indian food, just to name a few.
|
||||
|
||||
Like in real life, cooking together requires having respect and mutual understanding for each other, so we always try to have dishes for vegans, vegetarians, and people with allergies and food preferences. A little beta test at home can be helpful (and fun!) when preparing for the big release.
|
||||
|
||||
Scalability matters, and shopping for our “build requirements” at the grocery store easily can eat up three hours. We use a spreadsheet (LibreOffice Calc, naturally) for calculating ingredient requirements and costs.
|
||||
|
||||
For every dinner course we have a “package maintainer” working with volunteers to make the menu in time and to find unconventional solutions to problems that arise.
|
||||
|
||||
Not everyone is a cook by profession, but with a little bit of help and a good distribution of tasks and responsibilities, it’s rather easy to parallelize things — at some point, 18kg of tomatoes and 100 eggs really don’t worry you anymore, believe me! The only real scalability limit is the stove with its four hotplates, so maybe it’s time to invest in an infrastructure budget.
|
||||
|
||||
Time-based releasing, on the other hand, isn’t working as reliably as it should, as we usually serve the main dish at a rather “flexible” time between 21:30 und 01:30, but that’s not a release blocker, either.
|
||||
|
||||
And, as with in many open source projects, cooking documentation has room for improvement. Cleanup tasks such as washing the dishes, surely can be optimized further, too.
|
||||
|
||||
### Future flavor releases
|
||||
|
||||
Some of our future ideas include:
|
||||
|
||||
* cooking in a foreign country,
|
||||
* finally buying and cooking that large 700 € pumpkin, and
|
||||
* find a grocery store that donates a percentage of our purchases to a good cause.
|
||||
|
||||
|
||||
|
||||
The last item is also an important aspect about the free software movement: Always remember there are people who are not living on the sunny side, who do not have the same access to resources, and who are otherwise struggling. How can the open nature of what we’re doing help them?
|
||||
|
||||
With all that in mind, I am looking forward to the next Open Source Cooking meetup. If reading about them makes you hungry and you’d like to run own event, we’d love to see you adapt our idea or even fork it. And we’d love to have you join us in a meetup, and perhaps even do some mentoring and QA.
|
||||
|
||||
Article originally appeared on [blog.effenberger.org][3]. Reprinted with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-cooking
|
||||
|
||||
作者:[Florian Effenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/floeff
|
||||
[1]: https://www.opensourcetreffen.de/
|
||||
[2]: http://www.cafe-netzwerk.de/
|
||||
[3]: https://blog.effenberger.org/2018/05/28/what-do-open-source-and-cooking-have-in-common/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Ryze-Borgia
|
||||
|
||||
Linux vs Mac: 7 Reasons Why Linux is a Better Choice than Mac
|
||||
======
|
||||
Recently, we highlighted a few points about [why Linux is better than Windows][1]. Unquestionably, Linux is a superior platform. But, like other operating systems it has its drawbacks as well. For a very particular set of tasks (such as Gaming), Windows OS might prove to be better. And, likewise, for another set of tasks (such as video editing), a Mac-powered system might come in handy. It all trickles down to your preference and what you would like to do with your system. So, in this article, we will highlight a number of reasons why Linux is better than Mac.
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
heguangzhi translating
|
||||
|
||||
|
||||
Linus, His Apology, And Why We Should Support Him
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, Linus Torvalds, the creator of Linux, which powers everything from smartwatches to electrical grids posted [a pretty remarkable note on the kernel mailing list][1].
|
||||
|
||||
As a little bit of backstory, Linus has sometimes come under fire for the ways in which he has expressed feedback, provided criticism, and reacted to various scenarios on the kernel mailing list. This criticism has been fair in many cases: he has been overly aggressive at times, and while the kernel maintainers are a tight-knit group, the optics, particularly for those new to kernel development has often been pretty bad.
|
||||
|
||||
Like many conflict scenarios, this feedback has been communicated back to him in both constructive and non-constructive ways. Historically he has been seemingly reluctant to really internalize this feedback, I suspect partially because (a) the Linux kernel is a very successful project, and (b) some of the critics have at times gone nuclear at him (which often doesn’t work as a strategy towards defensive people). Well, things changed today.
|
||||
|
||||
In his post today he shared some self-reflection on this feedback:
|
||||
|
||||
> This week people in our community confronted me about my lifetime of not understanding emotions. My flippant attacks in emails have been both unprofessional and uncalled for. Especially at times when I made it personal. In my quest for a better patch, this made sense to me. I know now this was not OK and I am truly sorry.
|
||||
|
||||
He went on to not just share an admission that this has been a problem, but to also share a very personal acceptance that he struggles to understand and engage with people’s emotions:
|
||||
|
||||
> The above is basically a long-winded way to get to the somewhat painful personal admission that hey, I need to change some of my behavior, and I want to apologize to the people that my personal behavior hurt and possibly drove away from kernel development entirely. I am going to take time off and get some assistance on how to understand people’s emotions and respond appropriately.
|
||||
|
||||
His post is sure to light up the open source, Linux, and tech world for the next few weeks. For some it will be celebrated as a step in the right direction. For some it will be too little too late, and their animus will remain. For some they will be cautiously supportive, but defer judgement until they have seen his future behavior demonstrate substantive changes.
|
||||
|
||||
### My Take
|
||||
|
||||
I wouldn’t say I know Linus very closely; we have a casual relationship. I see him at conferences from time to time, and we often bump into each other and catch up. I interviewed him for my book and for the Global Learning XPRIZE. From my experience he is a funny, genuine, friendly guy. Interestingly, and not unusually at all for open source, his online persona is rather different to his in-person persona. I am not going to deny that when I would see these dust-ups on LKML, it didn’t reflect the Linus I know. I chalked it down to a mixture of his struggles with social skills, dogmatic pragmatism, and ego.
|
||||
|
||||
His post today is a pretty remarkable change of posture for him, and I encourage that we as a community support him in making these changes.
|
||||
|
||||
**Accepting these personal challenges is tough, particularly for someone in his position**. Linux is a global phenomenon. It has resulted in billions of dollars of technology creation, powering thousands of companies, and changing the norms around of how software is consumed and created. It is easy to forget that Linux was started by a quiet Finnish kid in his university dorm room. It is important to remember that **just because Linux has scaled elegantly, it doesn’t mean that Linus has been able to**. He isn’t a codebase, he is a human being, and bugs are harder to spot and fix in humans. You can’t just deploy a fix immediately. It takes time to identify the problem and foster and grow a change. The starting point for this is to support people in that desire for change, not re-litigate the ills of the past: that will get us nowhere quickly.
|
||||
|
||||
[![Young Linus Torvalds][2]][3]
|
||||
|
||||
I am also mindful of ego. None of us like to admit we have an ago, but we all do. You don’t get to build one of the most fundamental technologies in the last thirty years and not have an ego. He built it…they came…and a revolution was energized because of what he created. While Linus’s ego is more subtle, and thankfully doesn’t extend to faddish self-promotion, overly expensive suits, and forays into Hollywood (quite the opposite), his ego has naturally resulted in abrupt opinions on how his project should run, sometimes plugging fingers in his ears to particularly challenging viewpoints from others. **His post today is a clear example of him putting Linux as a project ahead of his own personal ego**.
|
||||
|
||||
This is important for a few reasons. Firstly, being in such a public position and accepting your personal flaws isn’t a problem many people face, and isn’t a situation many people handle well. I work with a lot of CEOs, and they often say it is the loneliest job on the planet. I have heard American presidents say the same in interviews. This is because they are the top of the tree with all the responsibility and expectations on their shoulders. Put yourself in Linus’s position: his little project has blown up into a global phenomenon, and he didn’t necessarily have the social tools to be able to handle this change. Ego forces these internal struggles under the surface and to push them down and avoid them. So, to accept them as publicly and openly as he did today is a very firm step in the right direction. Now, the true test will be results, but we need to all provide the breathing space for him to accomplish them.
|
||||
|
||||
So, I would encourage everyone to give Linus a shot. This doesn’t mean the frustrations of the past are erased, and he has acknowledged and apologized for these mistakes as a first step. He has accepted he struggles with understanding other’s emotions, and a desire to help improve this for the betterment of the project and himself. **He is a human, and the best tonic for humans to resolve their own internal struggles is the support and encouragement of other humans**. This is not unique to Linus, but to anyone who faces similar struggles.
|
||||
|
||||
All the best, Linus.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.jonobacon.com/2018/09/16/linus-his-apology-and-why-we-should-support-him/
|
||||
|
||||
作者:[Jono Bacon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.jonobacon.com/author/admin/
|
||||
[1]: https://lkml.org/lkml/2018/9/16/167
|
||||
[2]: https://i1.wp.com/www.jonobacon.com/wp-content/uploads/2018/09/linus.jpg?resize=499%2C342&ssl=1
|
||||
[3]: https://i1.wp.com/www.jonobacon.com/wp-content/uploads/2018/09/linus.jpg?ssl=1
|
||||
103
sources/talk/20180917 How gaming turned me into a coder.md
Normal file
103
sources/talk/20180917 How gaming turned me into a coder.md
Normal file
@ -0,0 +1,103 @@
|
||||
How gaming turned me into a coder
|
||||
======
|
||||
|
||||
Text-based adventure gaming leads to a satisfying career in tech.
|
||||
|
||||

|
||||
|
||||
I think the first word I learned to type fast—and I mean really fast—was "fireball."
|
||||
|
||||
Like most of us, I started my typing career with a "hunt-and-peck" technique, using my index fingers and keeping my eyes focused on the keyboard to find letters as I needed them. It's not a technique that allows you to read and write at the same time; you might call it half-duplex. It was okay for typing **cd** and **dir** , but it wasn't nearly fast enough to get ahead in the game. Especially if that game was a MUD.
|
||||
|
||||
### Gaming with multi-user dungeons
|
||||
|
||||
MUD is short for multi-user dungeon. Or multi-user domain, depending on who (and when) you ask. MUDs are text-based adventure games, like [Colossal Cave Adventure][1] and Zork, which you may have heard about in Season 2 [Episode 1][2] of [Command Line Heroes][3]. But MUDs have an extra twist: you aren't the only person playing them. They allow you to group with others to tackle particularly nasty beasts, trade goods, and make new friends. They were the great granddaddies of modern massively multiplayer online role-playing games (MMORPGs) like Everquest and World of Warcraft. And, for an aspiring command-line hero, they offered an experience those modern games still don't.
|
||||
|
||||
My "home MUD" was NyxMud, which you could access by telnetting to port 2000 of nyx.cs.du.edu. It was the first command line I ever mastered. In a lot of ways, it allowed me to be a hero—or at least play the part of one.
|
||||
|
||||
One special quality of NyxMud was that every time you connected to play, you started with an empty inventory. The gold you collected was still there from your last session, but none of your hard-won weapons, armor, or magical items were. So, at the end of every session, you had to make it back to a store to sell everything… and you would get a fraction of what you paid. If you were killed, the first player who encountered your lifeless body could take everything you had.
|
||||
|
||||
![dying and losing everything in a MUD.][5]
|
||||
|
||||
This shows what it looks like when you die and lose everything in a MUD
|
||||
|
||||
This made the game extremely sticky. Selling everything and quitting was a horrible thing to do, fiscally speaking. It meant that your session had to be profitable. If you didn't earn enough gold through looting and quests between the time you bought and sold your gear, you wouldn't be able to equip yourself as well the next time you played. If you died, it was even worse: You might find yourself killing balls of slime with a newbie sword as you scraped together enough gold for better gear.
|
||||
|
||||
I never wanted to "pay the store tax" by selling my gear, which meant a lot of late nights and sleeping through morning biology classes. Every modern game designer wants you to say, "I can't have dinner now, Dad, I have to keep playing or I'm in big trouble." NyxMud had me so hooked that I was saying that several decades ago.
|
||||
|
||||
So when it came time to "cast fireball" or die an imminent and ruinous death, I was forced to learn how to type properly. It also forced me to take a social approach to the game—having friends around to fight off scavengers allowed me to reclaim my gear when I died.
|
||||
|
||||
Command-line heroes all have some things in common: They work with others and they type wicked fast. NyxMud trained me to do both.
|
||||
|
||||
### From gamer to creator
|
||||
|
||||
NyxMud was not the largest MUD by any measure. But it was still an expansive world filled with hundreds of areas and dozens of epic adventures, each one tailored to a different level of a player's advancement. Over time, it became apparent that not all these areas were created by the same person. The term "user-generated content" was yet to be invented, but the concept was dead simple even to my young mind: This entire world was created by a group of people, other players.
|
||||
|
||||
Once you completed each of the challenging quests and achieved level 20, you became a wizard. This was a singularity of sorts, beyond which existed a reality known only to a few. During lunch breaks at school, my circle of friends would muse about the powers of a wizard; you see, we knew wizards could create rooms, beasts, items, and quests. We knew they could kill players at will. We really didn't know much else about their powers. The whole thing was shrouded in mystery.
|
||||
|
||||
In our group of high school friends, Eddie was the first to become a wizard. His flaunting and taunting threw us into overdrive, and Jared was quick to follow. I was last, but only by a day or two. Now that 25 years have passed, let's just call it a three-way tie. We discovered it was pretty much what we thought. We could create rooms, beasts, items, and quests. We could kill players. Oh, and we could become invisible. In NyxMud, that was just about it.
|
||||
|
||||
![a wizard’s private workroom][7]
|
||||
|
||||
This shows a wizard’s private workroom.
|
||||
|
||||
Wizards used the Wand of Creation, an item invented by Quasi (rhymed with "crazy"), the grand wizard. He alone had access to the code for the engine, due to a strict policy set by the administrator of the Nyx system where it ran. So, he created a complicated, magical object that would allow users to generate new game elements. This wand, when invoked, ran the wizard through a menu-based workflow for creating rooms and objects, establishing quest objectives, and designing terrible monsters.
|
||||
|
||||
Having that magical wand was enough. I immediately set to work creating new lands and grand adventures across a series of islands, each with a different, exotic climate and theme. I found immense pleasure in hovering, invisible, as the savage beasts from my imagination would slay intrepid adventurers over and over again. But it was even better to see players persevere after a hard battle, knowing I had tweaked and tuned my quests to be just within the realm of possibility.
|
||||
|
||||
Being accepted into this elite group of creators was one of the more rewarding and satisfying moments of my young life. Each new wizard would have to pass my test, spending countless hours and sleepless nights, just as I did, to complete the quests of the wizards before me. I had proven my value through dedication and contribution. It was just a game, but it was also a community—the first one I encountered, and the one that showed me how powerful a properly run [meritocracy][8] could be.
|
||||
|
||||
### From creator to coder
|
||||
|
||||
NyxMud was based on the LPMud codebase, which was created by Lars Pensjö. LPMud was not the first MUD software developed, but it contained one very important innovation: It allowed players to code the game from within the game. It accomplished this by separating the mudlib, which contained all the content and user-facing functionality, from the driver, which acted as a real-time interpreter for the mudlib and provided access to basic network and storage resources. This architecture meant the mudlib could be edited on-the-fly by virtually untrusted people (e.g., players like me) who could augment the game experience without being able to do anything particularly harmful to the server it was running on. The driver provided an "air gap."
|
||||
|
||||
This air gap was not enough for NyxMud; it was allowed to exist only if a single person could be trusted to write all the code. In most LPMud systems, players who became wizards could use **ls** , **cd** , and **ed** to traverse the mudlib and modify files, all from the same command line they had used countless times for casting fireballs and drinking potions. Quasi went to great lengths to modify the Nyx mudlib so wizards couldn't traipse around the system with a full set of sharp tools. The Wand of Creation was born.
|
||||
|
||||
As a wizard who hadn't played any other MUDs, I didn't miss what I never had. Besides, I didn't have a way to access any systems at the time—telnet was disabled on Nyx, which was my only connection to the internet. But I did have access to Usenet, which provided me with [The Totally Unofficial List of Internet Muds][9]. It was clear there was more of the MUD universe for me to discover. I read all the documentation about mudlibs I could get my hands on and got some exposure to [LPC][10], the niche programming language used to create new content.
|
||||
|
||||
I convinced my dad to make an investment in my future by paying for a shell account at Netcom (remember that?). With that account, I could connect to any MUD I wanted, and, based on several strong recommendations, I chose Viking MUD. It still [exists today][11]. It was a real MUD, the bleeding edge, and it showcased the true potential of a universe built with code instead of the limited menu system of a magical wand. But, to be honest, I never got very far as a player. I really wanted to learn how to code, and I didn't want to slay slimeballs with a noobsword for hours to get there.
|
||||
|
||||
There was a very small window of time—between February and August 1992, according to Lauren P. Burka's [Mud Timeline][12]—where the perfect place existed for my exploration. The Mud Institute (TMI for short) was a very special MUD designed to teach people how to program in LPC, illuminating the darkest corners of the mudlib. It offered immediate omnipotence to all who applied and built a community for the development of a new generation of LPMuds.
|
||||
|
||||
![a snippet of code from the wizard's workroom][14]
|
||||
|
||||
This is a snippet of code from the wizard's workroom.
|
||||
|
||||
This was my first exposure to C programming, as LPC was essentially a flavor of C that shared the same types, control structures, and syntax. It was C with training wheels, designed for rapid creation of content but allowing coders to develop intricate game scenarios (if they had the chops). I had always seen the curly brace on my keyboard, and now I knew what it was used for. The only thing I can remember creating was a special vending machine, somewhat inspired by the Wand of Creation, that would create the monster of your choice on-the-spot.
|
||||
|
||||
TMI was not a long-lasting phenomenon; in fact, it was gone almost before I had a chance to discover it. It quickly abandoned its educational charter, although its efforts were ultimately productive with the release of [MudOS][15]—which still lives through its modern-day descendant, [FluffOS][16]. But what a treasure trove of knowledge about a highly specific subject! Immediately after logging in, I was presented with a complete set of developer tools, a library of instructional materials, and a ton of interesting sample code to learn from.
|
||||
|
||||
I never talked to anyone or asked for any help, and I never had to. The community had published just enough resources for me to get started by myself. I was able to learn the basics of structured programming without a textbook or teacher, all within the context of a fantastical computer game. As a result, I have had a long and (mostly) fulfilling career in technology.
|
||||
|
||||
The line from Field of Dreams, "if you build it, they will come," is almost certainly untrue for communities.** **The folks at The Mud Institute built the makings of a great community, but I can't say they were successful. They didn't become a widely known wizarding school—in fact, it's really hard to find any information about TMI at all. If you build it, they may not come; if they do, you may still fail. But it still accomplished something wonderful that its creators never thought to predict: It got me excited about programming.
|
||||
|
||||
For more on the gamer-to-coder phenomenon and its effect on open source community culture, check out [Episode 1 of Season 2 of Command Line Heroes][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/gamer-coder
|
||||
|
||||
作者:[Ross Turk][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rossturk
|
||||
[1]: https://opensource.com/article/17/6/revisit-colossal-cave-adventure-open-adventure
|
||||
[2]: https://www.redhat.com/en/command-line-heroes/season-2/press-start
|
||||
[3]: https://www.redhat.com/en/command-line-heroes
|
||||
[4]: /file/409311
|
||||
[5]: https://opensource.com/sites/default/files/uploads/sourcecode_wizard_workroom.png (dying and losing everything in a MUD)
|
||||
[6]: /file/409306
|
||||
[7]: https://opensource.com/sites/default/files/uploads/wizard_workroom.png (a wizard’s private workroom)
|
||||
[8]: https://opensource.com/open-organization/16/8/how-make-meritocracy-work
|
||||
[9]: http://textfiles.com/internet/mudlist.txt
|
||||
[10]: https://en.wikipedia.org/wiki/LPC_(programming_language)
|
||||
[11]: https://www.vikingmud.org
|
||||
[12]: http://www.linnaean.org/~lpb/muddex/mudline.html
|
||||
[13]: /file/409301
|
||||
[14]: https://opensource.com/sites/default/files/uploads/firstroom_newplayer.png (a snippet of code from the wizard's workroom)
|
||||
[15]: https://en.wikipedia.org/wiki/MudOS
|
||||
[16]: https://github.com/fluffos/fluffos
|
||||
76
sources/talk/20180919 5 ways DevSecOps changes security.md
Normal file
76
sources/talk/20180919 5 ways DevSecOps changes security.md
Normal file
@ -0,0 +1,76 @@
|
||||
5 ways DevSecOps changes security
|
||||
======
|
||||
|
||||

|
||||
|
||||
There’s been an ongoing kerfuffle over whether we need to expand [DevOps][1] to explicitly bring in security. After all, the thinking goes, [DevOps][2] has always been something of a shorthand for a broad set of new practices, using new tools (often open source) and built on more collaborative cultures. Why not [DevBizOps][3] for better aligning with business needs? Or DevChatOps to emphasize better and faster communications?
|
||||
|
||||
However, [as John Willis wrote earlier this year][4] on his coming around to the [DevSecOps][5] terminology, “Hopefully, someday we will have a world where we no longer have to use the word DevSecOps and security will be an inherent part of all service delivery discussions. Until that day, and at this point, my general conclusion is that it’s just three new characters. More importantly, the name really differentiates the problem statement in a world where we as an industry are not doing a great job on information security.”
|
||||
|
||||
So why aren’t we doing a great job on [information security][6], and what does it mean to do a great job in a DevSecOps context?
|
||||
|
||||
We’ve arguably never done a great job of information security in spite of (or maybe because of) the vast industry of complex point products addressing narrow problems. But we also arguably did a good enough job during the era when defending against threats focused on securing the perimeter, network connections were limited, and most users were employees using company-provided devices.
|
||||
|
||||
Those circumstances haven’t accurately described most organizations’ reality for a number of years now. But the current era, which brings in not only DevSecOps but new application architectural patterns, development practices, and an increasing number of threats, defines a stark new normal that requires a faster pace of change. It’s not so much that DevSecOps in isolation changes security, but that infosec circa 2018 requires new approaches.
|
||||
|
||||
Consider these five areas.
|
||||
|
||||
### Automation
|
||||
|
||||
Lots of automation is a hallmark of DevOps generally. It’s partly about speed. If you’re going to move fast (and not break things), you need to have repeatable processes that execute without a lot of human intervention. Indeed, automation is one of the best entry points for DevOps, even in organizations that are still mostly working on monolithic legacy apps. Automating routine processes associated with configurations or testing with easy-to-use tools such as [Ansible][7] is a common quick hit for starting down the path to DevOps.
|
||||
|
||||
DevSecOps is no different. Security today is a continuous process rather than a discrete checkpoint in the application lifecycle, or even a weekly or monthly check. When vulnerabilities are found and fixes issued by a vendor, it’s important they be applied quickly given that exploits taking advantage of those vulnerabilities will be out soon.
|
||||
|
||||
### "Shift left"
|
||||
|
||||
Traditional security is often viewed as a gatekeeper at the end of the development process. Check all the boxes and your app goes into production. Otherwise, try again. Security teams have a reputation for saying no a lot.
|
||||
|
||||
Therefore, the thinking goes, why not move security earlier (left in a typical left-to-right drawing of a development pipeline)? Security may still say no, but the consequences of rework in early-stage development are a lot less than they are when the app is complete and ready to ship.
|
||||
|
||||
I don’t like the “shift left” term, though. It implies that security is still a one-time event that’s just been moved earlier. Security needs to be a largely automated process everywhere in the application lifecycle, from the supply chain to the development and test process all the way through deployment.
|
||||
|
||||
### Manage dependencies
|
||||
|
||||
One of the big changes we see with modern app development is that you often don’t write most of the code. Using open source libraries and frameworks is one obvious case in point. But you may also just use external services from public cloud providers or other sources. In many cases, this external code and services will dwarf what you write yourself.
|
||||
|
||||
As a result, DevSecOps needs to include a serious focus on your [software supply chain][8]. Are you getting your software from trusted sources? Is it up to date? Is it integrated into the security processes that you use for your own code? What policies do you have in place for which code and APIs you can use? Is commercial support available for the components that you are using for your own production code?
|
||||
|
||||
No set of answers are going to be appropriate in all cases. They may be different for a proof-of-concept versus an at-scale production workload. But, as has been the case in manufacturing for a long time (and DevSecOps has many analogs in how manufacturing has evolved), the integrity of the supply chain is critical.
|
||||
|
||||
### Visibility
|
||||
|
||||
I’ve talked a lot about the need for automation throughout all the stages of the application lifecycle. That makes the assumption that we can see what’s going on in each of those stages.
|
||||
|
||||
Effective DevSecOps requires effective instrumentation so that automation knows what to do. This instrumentation falls into a number of categories. There are long-term and high-level metrics that help tell us if the overall DevSecOps process is working well. There are critical alerts that require immediate human intervention (the security scanning system is down!). There are alerts, such as for a failed scan, that require remediation. And there are logs of the many parameters we capture for later analysis (what’s changing over time? What caused that failure?).
|
||||
|
||||
### Services vs. monoliths
|
||||
|
||||
While DevSecOps practices can be applied across many types of application architectures, they’re most effective with small and loosely coupled components that can be updated and reused without potentially forcing changes elsewhere in the app. In their purest form, these components can be [microservices][9] or functions, but the general principles apply wherever you have loosely coupled services communicating over a network.
|
||||
|
||||
This pattern does introduce some new security challenges. The interactions between components can be complex and the total attack surface can be larger because there are now more entry points to the application across the network.
|
||||
|
||||
On the other hand, this type of architecture also means that automated security and monitoring also has more granular visibility into the application components because they’re no longer buried deep within a monolithic application.
|
||||
|
||||
Don’t get too wrapped up in the DevSecOps term, but take it as a reminder that security is evolving because the way that we write and deploy applications is evolving.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/devsecops-changes-security
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ghaff
|
||||
[1]: https://opensource.com/resources/devops
|
||||
[2]: https://opensource.com/tags/devops
|
||||
[3]: https://opensource.com/article/18/5/steps-apply-devops-culture-beyond-it
|
||||
[4]: https://www.devsecopsdays.com/articles/its-just-a-name
|
||||
[5]: https://opensource.com/article/18/4/devsecops
|
||||
[6]: https://opensource.com/article/18/6/where-cycle-security-devops
|
||||
[7]: https://opensource.com/tags/ansible
|
||||
[8]: https://opensource.com/article/17/1/be-open-source-supply-chain
|
||||
[9]: https://opensource.com/tags/microservices
|
||||
@ -0,0 +1,46 @@
|
||||
How Writing Can Expand Your Skills and Grow Your Career
|
||||
======
|
||||
|
||||

|
||||
|
||||
At the recent [Open Source Summit in Vancouver][1], I participated in a panel discussion called [How Writing can Change Your Career for the Better (Even if You don't Identify as a Writer][2]. The panel was moderated by Rikki Endsley, Community Manager and Editor for Opensource.com, and it included VM (Vicky) Brasseur, Open Source Strategy Consultant; Alex Williams, Founder, Editor in Chief, The New Stack; and Dawn Foster, Consultant, The Scale Factory.
|
||||
|
||||
The talk was [inspired by this article][3], in which Rikki examined some ways that writing can "spark joy" and improve your career in unexpected ways. Full disclosure: I have known Rikki for a long time. We worked at the same company for many years, raised our children together, and remain close friends.
|
||||
|
||||
### Write and learn
|
||||
|
||||
As Rikki noted in the talk description, “even if you don't consider yourself to be ‘a writer,’ you should consider writing about your open source contributions, project, or community.” Writing can be a great way to share knowledge and engage others in your work, but it has personal benefits as well. It can help you meet new people, learn new skills, and improve your communication style.
|
||||
|
||||
I find that writing often clarifies for me what I don’t know about a particular topic. The process highlights gaps in my understanding and motivates me to fill in those gaps through further research, reading, and asking questions.
|
||||
|
||||
“Writing about what you don't know can be much harder and more time consuming, but also much more fulfilling and help your career. I've found that writing about what I don't know helps me learn, because I have to research it and understand it well enough to explain it,” Rikki said.
|
||||
|
||||
Writing about what you’ve just learned can be valuable to other learners as well. In her blog, [Julia Evans][4] often writes about learning new technical skills. She has a friendly, approachable style along with the ability to break down topics into bite-sized pieces. In her posts, Evans takes readers through her learning process, identifying what was and was not helpful to her along the way, essentially removing obstacles for her readers and clearing a path for those new to the topic.
|
||||
|
||||
### Communicate more clearly
|
||||
|
||||
Writing can help you practice thinking and speaking more precisely, especially if you’re writing (or speaking) for an international audience. [In this article,][5] for example, Isabel Drost-Fromm provides tips for removing ambiguity for non-native English speakers. Writing can also help you organize your thoughts before a presentation, whether you’re speaking at a conference or to your team.
|
||||
|
||||
“The process of writing the articles helps me organize my talks and slides, and it was a great way to provide ‘notes’ for conference attendees, while sharing the topic with a larger international audience that wasn't at the event in person,” Rikki stated.
|
||||
|
||||
If you’re interested in writing, I encourage you to do it. I highly recommend the articles mentioned here as a way to get started thinking about the story you have to tell. Unfortunately, our discussion at Open Source Summit was not recorded, but I hope we can do another talk in the future and share more ideas.
|
||||
|
||||
Check out the schedule of talks for Open Source Summit Europe and sign up to receive updates:
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/9/how-writing-can-help-you-learn-new-skills-and-grow-your-career
|
||||
|
||||
作者:[Amber Ankerholz][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/aankerholz
|
||||
[1]: https://events.linuxfoundation.org/events/open-source-summit-north-america-2018/
|
||||
[2]: https://ossna18.sched.com/event/FAOF/panel-discussion-how-writing-can-change-your-career-for-the-better-even-if-you-dont-identify-as-a-writer-moderated-by-rikki-endsley-opensourcecom-red-hat?iframe=no#
|
||||
[3]: https://opensource.com/article/18/2/career-changing-magic-writing
|
||||
[4]: https://jvns.ca/
|
||||
[5]: https://www.linux.com/blog/event/open-source-summit-eu/2017/12/technical-writing-international-audience
|
||||
@ -0,0 +1,167 @@
|
||||
Linux Has a Code of Conduct and Not Everyone is Happy With it
|
||||
======
|
||||
**Linux kernel has a new code of conduct (CoC). Linus Torvalds took a break from Linux kernel development just 30 minutes after signing this code of conduct. And since **the writer of this code of conduct has had a controversial past,** it has now become a point of heated discussion. With all the politics involved, not many people are happy with this new CoC.**
|
||||
|
||||
If you do not know already, [Linux creator Linus Torvalds has apologized for his past behavior and has taken a temporary break from Linux kernel development to improve his behavior][1].
|
||||
|
||||
### The new code of conduct for Linux kernel development
|
||||
|
||||
Linux kernel developers have a code of conduct. It’s not like they didn’t have a code before, but the previous [code of conflict][2] is now replaced by this new code of conduct to “help make the kernel community a welcoming environment to participate in.”
|
||||
|
||||
> “In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation.”
|
||||
|
||||
You can read the entire code of conduct on this commit page.
|
||||
|
||||
[Linux Code of Conduct][33]
|
||||
|
||||
|
||||
### Was Linus Torvalds forced to apologize and take a break?
|
||||
|
||||
![Linus Torvalds Apologizes][3]
|
||||
|
||||
The code of conduct was signed off by Linus Torvalds and Greg Kroah-Hartman (kind of second-in-command after Torvalds). Dan Williams of Intel and Chris Mason from Facebook were some of the other signees.
|
||||
|
||||
If I have read through the timeline correctly, half an hour after signing this code of conduct, Torvalds sent a [mail apologizing for his past behavior][4]. He also announced taking a temporary break to improve upon his behavior.
|
||||
|
||||
But at this point some people started reading between the lines, with a special attention to this line from his mail:
|
||||
|
||||
> **This week people in our community confronted me about my lifetime of not understanding emotions**. My flippant attacks in emails have been both unprofessional and uncalled for. Especially at times when I made it personal. In my quest for a better patch, this made sense to me. I know now this was not OK and I am truly sorry.
|
||||
|
||||
This particular line could be read as if he was coerced into apologizing and taking a break because of the new code of conduct. Though it could also be a precautionary measure to prevent Torvalds from violating the newly created code of conduct.
|
||||
|
||||
### The controversy around Contributor Convent creator Coraline Ada Ehmke
|
||||
|
||||
The Linux code of conduct is based on the [Contributor Covenant, version 1.4][5]. Contributor Convent has been adopted by hundreds of open source projects. Eclipse, Angular, Ruby, Kubernetes are some of the [many adopters of Contributor Convent][6].
|
||||
|
||||
Contributor Covenant has been created by [Coraline Ada Ehmke][7], a software developer, an open-source advocate, and an [LGBT][8] activist. She has been instrumental in promoting diversity in the open source world.
|
||||
|
||||
Coraline has also been vocal about her stance against [meritocracy][9]. The Latin word meritocracy originally refers to a “system under which advancement within the system turns on “merits”, like intelligence, credentials, and education.” But activists like [Coraline believe][10] that meritocracy is a negative system where the worth of an individual is measured not by their humanity, but solely by their intellectual output.
|
||||
|
||||
[![croraline meritocracy][11]][12]
|
||||
Image credit: Twitter user @nickmon1112
|
||||
|
||||
Remember that [Linus Torvalds has repeatedly said that he cares about the code, not the person who writes it][13]. Clearly, this goes against Coraline’s view on meritocracy.
|
||||
|
||||
Coraline has had a troubled incident in the past with a contributor of [Opal project][14]. There was a [discussion taking place on Twitter][15] where Elia, a core contributor to Opal project from Italy, said “(trans people) not accepting reality is the problem here”.
|
||||
|
||||
Coraline was neither in the discussion nor was she a contributor to the Opal project. But as an LGBT activist, she took it to herself and [demanded that Elia be removed from the Opal Project][16] for his ‘views against trans people’. A lengthy and heated discussion took place on Opal’s GitHub repository. Coraline and her supporters, who never contributed to Opal, tried to coerce the moderators into removing Elia, a core contributor of the project.
|
||||
|
||||
While Elia wasn’t removed from the project, Opal project maintainers agreed to put up a code of conduct in place. And this code of conduct was nothing else but Coraline’s famed Contributor Covenant that she had pitched to the maintainers herself.
|
||||
|
||||
But the story didn’t end here. The Contributor Covenant was then modified and a [new clause added in order to get to Elia][17]. The new clause widened the scope of conduct in public spaces. This malicious change was [spotted by the maintainers][18] and they edited the clause. Opal eventually got rid of the Contributor Covenant and put in place its own guideline.
|
||||
|
||||
This is a classic example of how a few offended people, who never contributed a single line of code to the project, tried to oust its core contributor.
|
||||
|
||||
### People’s reaction on Linux Code of Conduct and Torvalds’ apology
|
||||
|
||||
As soon as Linux code of conduct and Torvalds’ apology went public, Social Media and forums were rife with rumors and [speculations][19]. While many people appreciated this new development, there were some who saw a conspiracy by [SJW infiltrating Linux][20].
|
||||
|
||||
A sarcastic tweet by Caroline only fueled the fire.
|
||||
|
||||
> I can’t wait for the mass exodus from Linux now that it’s been infiltrated by SJWs. Hahahah [pic.twitter.com/eFeY6r4ENv][21]
|
||||
>
|
||||
> — Coraline Ada Ehmke (@CoralineAda) [September 16, 2018][22]
|
||||
|
||||
In the wake of the Linux CoC controversy, Coraline openly said that the Contributor Convent code of conduct is a political document. This did not go down well with the people who want the political stuff out of the open source projects.
|
||||
|
||||
> Some people are saying that the Contributor Covenant is a political document, and they’re right.
|
||||
>
|
||||
> — Coraline Ada Ehmke (@CoralineAda) [September 16, 2018][23]
|
||||
|
||||
Nick Monroe, a freelance journalist, dig up the past of Coraline in order to validate his claim that there is more to Linux CoC than meets the eye. You can go by the entire thread if you want.
|
||||
|
||||
> Alright. You've seen this a million times before. It's a code of conduct blah blah blah
|
||||
>
|
||||
> that has social justice baked right into it. blah blah blah.<https://t.co/KuQqeriYeJ>
|
||||
>
|
||||
> But something is different about this. [pic.twitter.com/8NUL2K1gu2][24]
|
||||
>
|
||||
> — Nick Monroe (@nickmon1112) [September 17, 2018][25]
|
||||
|
||||
Nick wasn’t the only one to disapprove of the new Linux CoC. The [SJW][26] involvement led to more skepticism.
|
||||
|
||||
> I guess the big news in Linux today is that the Linux kernel is now governed by a Code of Conduct and a “post meritocracy” world view.
|
||||
>
|
||||
> In principle these CoCs look great. In practice they are abused tools to hunt people SJWs don’t like. And they don’t like a lot of people.
|
||||
>
|
||||
> — Mark Kern (@Grummz) [September 17, 2018][27]
|
||||
|
||||
While there were many who appreciated Torvalds’ apology, there were a few who blamed Torvalds’ attitude:
|
||||
|
||||
> Am I the only one who thinks Linus Torvalds attitude for decades was a prime contributors to how many of the condescending, rudes, jerks in Linux and open source "communities" behaved? I've never once felt welcomed into the Linux community as a new user.
|
||||
>
|
||||
> — Jonathan Frappier (@jfrappier) [September 17, 2018][28]
|
||||
|
||||
And some were simply not amused with his apology:
|
||||
|
||||
> Oh look, an abusive OSS maintainer finally admitted, after *decades* of abusive and toxic behavior, that his behavior *might* be an issue.
|
||||
>
|
||||
> And a bunch of people I follow are tripping all over themselves to give him cookies for that. 🙄🙄🙄
|
||||
>
|
||||
> — Kelly Ellis (@justkelly_ok) [September 17, 2018][29]
|
||||
|
||||
The entire Torvalds apology episode has raised a genuine concern ;)
|
||||
|
||||
> Do we have to put "I don't/do forgive Linus Torvalds" in our bio now?
|
||||
>
|
||||
> — Verónica. (@maria_fibonacci) [September 17, 2018][30]
|
||||
|
||||
Jokes apart, the genuine concern was raised by Sharp, who had [quit Linux Kernel development][31] in 2015 due to the ‘toxic community’.
|
||||
|
||||
> The real test here is whether the community that built Linus up and protected his right to be verbally abusive will change. Linus not only needs to change himself, but the Linux kernel community needs to change as well. <https://t.co/EG5KO43416>
|
||||
>
|
||||
> — Sage Sharp (@_sagesharp_) [September 17, 2018][32]
|
||||
|
||||
### What do you think of Linux Code of Conduct?
|
||||
|
||||
If you ask my opinion, I do think that a Code of Conduct is the need of the time. It guides people in behaving in a respectable way and helps create a positive environment for all kind of people irrespective of their race, ethnicity, religion, nationality and political views (both left and right).
|
||||
|
||||
What are your views on the entire episode? Do you think the CoC will help Linux kernel development? Or will it deteriorate with the involvement of anti-meritocracy SJWs?
|
||||
|
||||
We don’t have a code of conduct at It’s FOSS but let’s keep the discussion civil :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-code-of-conduct/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://itsfoss.com/torvalds-takes-a-break-from-linux/
|
||||
[2]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/CodeOfConflict?id=ddbd2b7ad99a418c60397901a0f3c997d030c65e
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linus-torvalds-apologizes.jpeg
|
||||
[4]: https://lkml.org/lkml/2018/9/16/167
|
||||
[5]: https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
|
||||
[6]: https://www.contributor-covenant.org/adopters
|
||||
[7]: https://en.wikipedia.org/wiki/Coraline_Ada_Ehmke
|
||||
[8]: https://en.wikipedia.org/wiki/LGBT
|
||||
[9]: https://en.wikipedia.org/wiki/Meritocracy
|
||||
[10]: https://modelviewculture.com/pieces/the-dehumanizing-myth-of-the-meritocracy
|
||||
[11]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/croraline-meritocracy.jpg
|
||||
[12]: https://pbs.twimg.com/media/DnTTfi7XoAAdk08.jpg
|
||||
[13]: https://arstechnica.com/information-technology/2015/01/linus-torvalds-on-why-he-isnt-nice-i-dont-care-about-you/
|
||||
[14]: https://opalrb.com/
|
||||
[15]: https://twitter.com/krainboltgreene/status/611569515315507200
|
||||
[16]: https://github.com/opal/opal/issues/941
|
||||
[17]: https://github.com/opal/opal/pull/948/commits/817321e27eccfffb3841f663815c17eecb8ef061#diff-a1ee87dafebc22cbd96979f1b2b7e837R11
|
||||
[18]: https://github.com/opal/opal/pull/948#issuecomment-113486020
|
||||
[19]: https://www.reddit.com/r/linux/comments/9go8cp/linus_torvalds_daughter_has_signed_the/
|
||||
[20]: https://snew.github.io/r/linux/comments/9ghrrj/linuxs_new_coc_is_a_piece_of_shit/
|
||||
[21]: https://t.co/eFeY6r4ENv
|
||||
[22]: https://twitter.com/CoralineAda/status/1041441155874009093?ref_src=twsrc%5Etfw
|
||||
[23]: https://twitter.com/CoralineAda/status/1041465346656530432?ref_src=twsrc%5Etfw
|
||||
[24]: https://t.co/8NUL2K1gu2
|
||||
[25]: https://twitter.com/nickmon1112/status/1041668315947708416?ref_src=twsrc%5Etfw
|
||||
[26]: https://www.urbandictionary.com/define.php?term=SJW
|
||||
[27]: https://twitter.com/Grummz/status/1041524170331287552?ref_src=twsrc%5Etfw
|
||||
[28]: https://twitter.com/jfrappier/status/1041486055038492674?ref_src=twsrc%5Etfw
|
||||
[29]: https://twitter.com/justkelly_ok/status/1041522269002985473?ref_src=twsrc%5Etfw
|
||||
[30]: https://twitter.com/maria_fibonacci/status/1041538148121997313?ref_src=twsrc%5Etfw
|
||||
[31]: https://www.networkworld.com/article/2988850/opensource-subnet/linux-kernel-dev-sarah-sharp-quits-citing-brutal-communications-style.html
|
||||
[32]: https://twitter.com/_sagesharp_/status/1041480963287539712?ref_src=twsrc%5Etfw
|
||||
[33]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=8a104f8b5867c682d994ffa7a74093c54469c11f
|
||||
@ -0,0 +1,51 @@
|
||||
Building a Secure Ecosystem for Node.js
|
||||
======
|
||||
|
||||

|
||||
|
||||
At[Node+JS Interactive][1], attendees collaborate face to face, network, and learn how to improve their skills with JS in serverless, IoT, and more. [Stephanie Evans][2], Content Manager for Back-end Web Development at LinkedIn Learning, will be speaking at the upcoming conference about building a secure ecosystem for Node.js. Here she answers a few questions about teaching and learning basic security practices.
|
||||
|
||||
**Linux.com: Your background is in tech education, can you provide more details on how you would define this and how you got into this area of expertise?**
|
||||
|
||||
**Stephanie Evans:** It sounds cliché, but I’ve always been passionate about education and helping others. After college, I started out as an instructor of a thoroughly analog skill: reading. I worked my way up to hiring and training reading teachers and discovered my passion for helping people share their knowledge and refine their teaching craft. Later, I went to work for McGraw Hill Education, publishing self-study certification books on popular IT certs like CompTIA’s Network+ and Security+, ISAAP’s CISSP, etc. My job was to figure out who the biggest audiences in IT were; what they needed to know to succeed professionally; hire the right book author; and help develop the manuscript with them.
|
||||
|
||||
I moved into online learning/e-learning 4 years ago and shifted to video training courses geared towards developers. I enjoy working with people who spend their time building and solving complex problems. I now manage the video training library for back-end web developers at LinkedIn Learning/Lynda.com and figure out what developers need to know; hire instructors to create that content; and work together to figure out how best to teach it to them. And, then update those courses when they inevitably become out of date.
|
||||
|
||||
**Linux.com: What initially drove you to use your skill set in education to help with security practices?**
|
||||
|
||||
**Evans:** I attend a lot of conferences, watch a lot of talks, and chat to a lot of developers as part of my job. I distinctly remember attending a security best practices talk at a very large, enterprise-tech focused conference and was surprised by the rudimentary content being covered. Poor guy, I’d thought…he’s going to get panned by this audience. But then I looked around and most everyone was engaged. They were learning something new and compelling. And it hit me: I had been in a security echo chamber of my own making. Just like the mainstream developer isn’t working with the cutting-edge technology people are raving about on Twitter, they aren’t necessarily as fluent in basic security practices as I’d assumed. A mix of unawareness, intense time pressure, and perhaps some misplaced trust can lead to a “security later” mentality. But with the global cost of cybercrime up to 6 00 billion a year from 500 billion in 2014 as well as the [exploding amount of data on the web][3]. We can’t afford to be working around security or assuming everyone knows the basics.
|
||||
|
||||
**Linux.com: What do you think are some common misconceptions about security with Node.js and in general with developers?**
|
||||
|
||||
**Evans:** I think one of the biggest misconceptions is that security awareness and practices should come “later” in a developer’s career (and later in the development cycle). Yes, your first priority is to learn that Java and JavaScript are not the same thing—that’s obviously most important. And you do have to understand how to create a form before you can understand how to prevent cross-site -scripting attacks. But helping developers understand—at all stages of their career and learning journey—what the potential vulnerabilities are and how they can be exploited needs to be a much higher priority and come earlier than we may intuitively think.
|
||||
|
||||
I joke with my instructors that we have to sneak in the ‘eat your vegetables’ content to our courses. Security is an exciting, complex and challenging topic, but it can feel like you’re having to eat your vegetables as a developer when you dig into it. Often ‘security’ is a separate department (that can be perceived as ‘slowing things down’ or getting in the way of deploying code) and it can further distance developers from their role in securing their applications.
|
||||
|
||||
I also think that those who truly understand security can feel that it’s overwhelmingly complex to teach—but we have to start somewhere. I attended an introductory npm talk last year that talked about how to work with dependencies and packages…but never once mentioned the possibility of malicious code making it into your application through these packages. I’m all about teaching just enough at the right time and not throwing the kitchen sink of knowledge at new developers. We should stop thinking of security—or even just security awareness—as an intermediate or advanced skill and start bringing it up early and often.
|
||||
|
||||
**Linux.com: How can we infuse tech education into our security practices? Where does this begin?**
|
||||
|
||||
**Evans:** It definitely goes both ways. Clear documentation and practical resources right alongside security recommendations go a long way towards ensuring understanding and adoption. You have to make things as easy as possible if you want people to actually do it. And you have to make those best practices accessible enough to understand.
|
||||
|
||||
The [2018 Node User Survey Report][4] from the Node.js Foundation showed that while learning resources around Node.js and JavaScript development improved, the availability and quality of learning resources for Node.js Security received the lowest scores across the board.
|
||||
|
||||
After documentation and Stack Overflow, many developers rely on online videos and tutorials—we need to push security education to the forefront, rather than expecting developers to seek it out. OWASP, the nodegoat project, and the Node.js Security Working Group are doing great work here to move the needle. I think tech education can do even more to bring security in earlier in the learning journey and create awareness about common exploits and important resources.
|
||||
|
||||
Learn more at [Node+JS Interactive][1], coming up October 10-12, 2018 in Vancouver, Canada.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/node-js/2018/9/building-secure-ecosystem-nodejs
|
||||
|
||||
作者:[The Linux Foundation][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[1]: https://events.linuxfoundation.org/events/node-js-interactive-2018/?utm_source=Linux.com&utm_medium=article&utm_campaign=jsint18
|
||||
[2]: https://jsi2018.sched.com/speaker/stevans1?iframe=no
|
||||
[3]: https://www.forbes.com/sites/bernardmarr/2018/05/21/how-much-data-do-we-create-every-day-the-mind-blowing-stats-everyone-should-read/#101d261a60ba
|
||||
[4]: https://nodejs.org/en/user-survey-report/
|
||||
@ -0,0 +1,126 @@
|
||||
WinWorld – A Large Collection Of Defunct OSs, Software And Games
|
||||
======
|
||||
|
||||

|
||||
|
||||
The other day, I was testing **Dosbox** which is used to [**run MS-DOS games and programs in Linux**][1]. While searching for some classic programs like Turbo C++, I stumbled upon a website named **WinWorld**. I went through a few links in this site and quite surprised. WinWorld has a plenty of good-old and classic OSs, software, applications, development tools, games and a lot of other miscellaneous utilities which are abandoned by the developers a long time ago. It is an online museum run by community members, volunteers and is dedicated to the preservation and sharing of vintage, abandoned, and pre-release software.
|
||||
|
||||
WinWorld was started back in 2003 and its founder claims that the idea to start this site inspired by Yahoo briefcases. The primary purpose of this site is to preserve and share old software. Over the years, many people volunteered to improve this site in numerous ways and the collection of old software in WinWorld has grown exponentially. The entire WinWorld library is free, open and available to everyone.
|
||||
|
||||
### WinWorld Hosts A Huge Collection Of Defunct OSs, Software, System Applications And Games
|
||||
|
||||
Like I already said, WinWorld hosts a huge collection of abandonware which are no-longer in development.
|
||||
|
||||
**Linux and Unix:**
|
||||
|
||||
Here, I have given the complete list of UNIX and LINUX OSs with brief summary of the each OS and the release year of first version.
|
||||
|
||||
* **A/UX** – An early port of Unix to Apple’s 68k based Macintosh platform, released in 1988.
|
||||
* **AIX** – A Unix port originally developed by IBM, released in 1986.
|
||||
* **AT &T System V Unix** – One of the first commercial versions of the Unix OS, released in 1983.
|
||||
* **Banyan VINES** – A network operating system originally designed for Unix, released in 1984.
|
||||
* **Corel Linux** – A commercial Linux distro, released in 1999.
|
||||
* **DEC OSF-1** – A version of UNIX developed by Digital Equipment Corporation (DEC), released in 1991.
|
||||
* **Digital UNIX** – A renamed version of **OSF-1** , released by DEC in 1995.**
|
||||
**
|
||||
* **FreeBSD** **1.0** – The first release of FreeBSD, released in 1993. It is based on 4.3BSD.
|
||||
* **Gentus Linux** – A distribution that failed to comply with GPL. Developed by ABIT and released in 2000.
|
||||
* **HP-UX** – A UNIX variant, released in 1992.
|
||||
* **IRIX** – An a operating system developed by Silicon Graphics Inc (SGI ) and it is released in 1988.
|
||||
* **Lindows** – Similar to Corel Linux. It is developed for commercial purpose and released in 2002.
|
||||
* **Linux Kernel** – A copy of the Linux Sourcecode, version 0.01. Released in the early 90’s.
|
||||
* **Mandrake Linux** – A Linux distribution based on Red Hat Linux. It was later renamed to Mandriva. Released in 1999.
|
||||
* **NEWS-OS** – A variant of BSD, developed by Sony and released in 1989.
|
||||
* **NeXTStep** – A Unix based OS from NeXT computers headed by **Steve Jobs**. It is released in 1987.
|
||||
* **PC/IX** – A UNIX variant created for IBM PCs. Released in 1984.
|
||||
* **Red Hat Linux 5.0** – A commercial Linux distribution by Red Hat.
|
||||
* **Sun Solaris** – A Unix based OS by Sun Microsystems. Released in 1992.
|
||||
* **SunOS** – A Unix-based OS derived from BSD by Sun Microsystems, released in 1982.
|
||||
* **Tru64 UNIX** – A formerly known OSF/1 by DEC.
|
||||
* **Ubuntu 4.10** – The well-known OS based on Debian.This was a beta pre-release, prior to the very first official Ubuntu release.
|
||||
* **Ultrix** – A UNIX clone developed by DEC.
|
||||
* **UnixWare** – A UNIX variant from Novell.
|
||||
* **Xandros Linux** – A proprietary variant of Linux. It is based on Corel Linux. The first version is released in 2003.
|
||||
* **Xenix** – A UNIX variant originally published by Microsoft released in 1984.
|
||||
|
||||
|
||||
|
||||
Not just Linux/Unix, you can find other operating systems including DOS, Windows, Apple/Mac, OS 2, Novell netware and other OSs and shells.
|
||||
|
||||
**DOS & CP/M:**
|
||||
|
||||
* 86-DOS
|
||||
* Concurrent CPM-86 & Concurrent DOS
|
||||
* CP/M 86 & CP/M-80
|
||||
* DOS Plus
|
||||
* DR-DOS
|
||||
* GEM
|
||||
* MP/M
|
||||
* MS-DOS
|
||||
* Multitasking MS-DOS 4.00
|
||||
* Multiuser DOS
|
||||
* PC-DOS
|
||||
* PC-MOS
|
||||
* PTS-DOS
|
||||
* Real/32
|
||||
* Tandy Deskmate
|
||||
* Wendin DOS
|
||||
|
||||
|
||||
|
||||
**Windows:**
|
||||
|
||||
* BackOffice Server
|
||||
* Windows 1.0/2.x/3.0/3.1/95/98/2000/ME/NT 3.X/NT 4.0
|
||||
* Windows Whistler
|
||||
* WinFrame
|
||||
|
||||
|
||||
|
||||
**Apple/Mac:**
|
||||
|
||||
* Mac OS 7/8/9
|
||||
* Mac OS X
|
||||
* System Software (0-6)
|
||||
|
||||
|
||||
|
||||
**OS/2:**
|
||||
|
||||
* Citrix Multiuser
|
||||
* OS/2 1.x
|
||||
* OS/2 2.0
|
||||
* OS/2 3.x
|
||||
* OS/2 Warp 4
|
||||
|
||||
|
||||
|
||||
Also, WinWorld hosts a huge collection of old software, system applications, development tools and games. Go and check them out as well.
|
||||
|
||||
To be honest, I don’t even know the existence of most of the stuffs listed in this site. Some of the tools listed here were released years before I was born.
|
||||
|
||||
Just in case, If you ever in need of or wanted to test a classic stuff (be it a game, software, OS), look nowhere, just head over to WinWorld library and download them that you want to explore. Good luck!
|
||||
|
||||
**Disclaimer:**
|
||||
|
||||
OSTechNix is not affiliated with WinWorld site in any way. We, at OSTechNix, don’t know the authenticity and integrity of the stuffs hosted in this site. Also, downloading software from third-party sites is not safe or may be illegal in your region. Neither the author nor OSTechNix is responsible for any kind of damage. Use this service at your own risk.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/winworld-a-large-collection-of-defunct-oss-software-and-games/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/
|
||||
@ -0,0 +1,74 @@
|
||||
CPU Power Manager – Control And Manage CPU Frequency In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you are a laptop user, you probably know that power management on Linux isn’t really as good as on other OSes. While there are tools like **TLP** , [**Laptop Mode Tools** and **powertop**][1] to help reduce power consumption, overall battery life on Linux isn’t as good as Windows or Mac OS. Another way to reduce power consumption is to limit the frequency of your CPU. While this is something that has always been doable, it generally requires complicated terminal commands, making it inconvenient. But fortunately, there’s a gnome extension that helps you easily set and manage your CPU’s frequency – **CPU Power Manager**. CPU Power Manager uses the **intel_pstate** frequency scaling driver (supported by almost every Intel CPU) to control and manage CPU frequency in your GNOME desktop.
|
||||
|
||||
Another reason to use this extension is to reduce heating in your system. There are many systems out there which can get uncomfortably hot in normal usage. Limiting your CPU’s frequency could reduce heating. It will also decrease the wear and tear on your CPU and other components.
|
||||
|
||||
### Installing CPU Power Manager
|
||||
|
||||
First, go to the [**extension’s page**][2], and install the extension.
|
||||
|
||||
Once the extension has installed, you’ll get a CPU icon at the right side of the Gnome top bar. Click the icon, and you get an option to install the extension:
|
||||
|
||||

|
||||
|
||||
If you click **“Attempt Installation”** , you’ll get a password prompt. The extension needs root privileges to add policykit rule for controlling CPU frequency. This is what the prompt looks like:
|
||||
|
||||

|
||||
|
||||
Type in your password and Click **“Authenticate”** , and that finishes installation. The last action adds a policykit file – **mko.cpupower.setcpufreq.policy** at **/usr/share/polkit-1/actions**.
|
||||
|
||||
After installation is complete, if you click the CPU icon at the top right, you’ll get something like this:
|
||||
|
||||

|
||||
|
||||
### Features
|
||||
|
||||
* **See the current CPU frequency:** Obviously, you can use this window to see the frequency that your CPU is running at.
|
||||
* **Set maximum and minimum frequency:** With this extension, you can set maximum and minimum frequency limits in terms of percentage of max frequency. Once these limits are set, the CPU will operate only in this range of frequencies.
|
||||
* **Turn Turbo Boost On and Off:** This is my favorite feature. Most Intel CPU’s have “Turbo Boost” feature, whereby the one of the cores of the CPU is boosted past the normal maximum frequency for extra performance. While this can make your system more performant, it also increases power consumption a lot. So if you aren’t doing anything intensive, it’s nice to be able to turn off Turbo Boost and save power. In fact, in my case, I have Turbo Boost turned off most of the time.
|
||||
* **Make Profiles:** You can make profiles with max and min frequency that you can turn on/off easily instead of fiddling with max and frequencies.
|
||||
|
||||
|
||||
|
||||
### Preferences
|
||||
|
||||
You can also customize the extension via the preferences window:
|
||||
|
||||

|
||||
|
||||
As you can see, you can set whether CPU frequency is to be displayed, and whether to display it in **Mhz** or **Ghz**.
|
||||
|
||||
You can also edit and create/delete profiles:
|
||||
|
||||

|
||||
|
||||
You can set maximum and minimum frequencies, and turbo boost for each profile.
|
||||
|
||||
### Conclusion
|
||||
|
||||
As I said in the beginning, power management on Linux is not the best, and many people are always looking to eek out a few minutes more out of their Linux laptop. If you are one of those, check out this extension. This is a unconventional method to save power, but it does work. I certainly love this extension, and have been using it for a few months now.
|
||||
|
||||
What do you think about this extension? Put your thoughts in the comments below!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/cpu-power-manager-control-and-manage-cpu-frequency-in-linux/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://www.ostechnix.com/improve-laptop-battery-performance-linux/
|
||||
[2]: https://extensions.gnome.org/extension/945/cpu-power-manager/
|
||||
@ -1,234 +0,0 @@
|
||||
Translating by qhwdw
|
||||
|
||||
# Caffeinated 6.828:Lab 2: Memory Management
|
||||
|
||||
### Introduction
|
||||
|
||||
In this lab, you will write the memory management code for your operating system. Memory management has two components.
|
||||
|
||||
The first component is a physical memory allocator for the kernel, so that the kernel can allocate memory and later free it. Your allocator will operate in units of 4096 bytes, called pages. Your task will be to maintain data structures that record which physical pages are free and which are allocated, and how many processes are sharing each allocated page. You will also write the routines to allocate and free pages of memory.
|
||||
|
||||
The second component of memory management is virtual memory, which maps the virtual addresses used by kernel and user software to addresses in physical memory. The x86 hardware’s memory management unit (MMU) performs the mapping when instructions use memory, consulting a set of page tables. You will modify JOS to set up the MMU’s page tables according to a specification we provide.
|
||||
|
||||
### Getting started
|
||||
|
||||
In this and future labs you will progressively build up your kernel. We will also provide you with some additional source. To fetch that source, use Git to commit changes you’ve made since handing in lab 1 (if any), fetch the latest version of the course repository, and then create a local branch called lab2 based on our lab2 branch, origin/lab2:
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab2 origin/lab2
|
||||
Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
|
||||
Switched to a new branch "lab2"
|
||||
athena%
|
||||
```
|
||||
|
||||
You will now need to merge the changes you made in your lab1 branch into the lab2 branch, as follows:
|
||||
|
||||
```
|
||||
athena% git merge lab1
|
||||
Merge made by recursive.
|
||||
kern/kdebug.c | 11 +++++++++--
|
||||
kern/monitor.c | 19 +++++++++++++++++++
|
||||
lib/printfmt.c | 7 +++----
|
||||
3 files changed, 31 insertions(+), 6 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
Lab 2 contains the following new source files, which you should browse through:
|
||||
|
||||
- inc/memlayout.h
|
||||
- kern/pmap.c
|
||||
- kern/pmap.h
|
||||
- kern/kclock.h
|
||||
- kern/kclock.c
|
||||
|
||||
memlayout.h describes the layout of the virtual address space that you must implement by modifying pmap.c. memlayout.h and pmap.h define the PageInfo structure that you’ll use to keep track of which pages of physical memory are free. kclock.c and kclock.h manipulate the PC’s battery-backed clock and CMOS RAM hardware, in which the BIOS records the amount of physical memory the PC contains, among other things. The code in pmap.c needs to read this device hardware in order to figure out how much physical memory there is, but that part of the code is done for you: you do not need to know the details of how the CMOS hardware works.
|
||||
|
||||
Pay particular attention to memlayout.h and pmap.h, since this lab requires you to use and understand many of the definitions they contain. You may want to review inc/mmu.h, too, as it also contains a number of definitions that will be useful for this lab.
|
||||
|
||||
Before beginning the lab, don’t forget to add exokernel to get the 6.828 version of QEMU.
|
||||
|
||||
### Hand-In Procedure
|
||||
|
||||
When you are ready to hand in your lab code and write-up, add your answers-lab2.txt to the Git repository, commit your changes, and then run make handin.
|
||||
|
||||
```
|
||||
athena% git add answers-lab2.txt
|
||||
athena% git commit -am "my answer to lab2"
|
||||
[lab2 a823de9] my answer to lab2 4 files changed, 87 insertions(+), 10 deletions(-)
|
||||
athena% make handin
|
||||
```
|
||||
|
||||
### Part 1: Physical Page Management
|
||||
|
||||
The operating system must keep track of which parts of physical RAM are free and which are currently in use. JOS manages the PC’s physical memory with page granularity so that it can use the MMU to map and protect each piece of allocated memory.
|
||||
|
||||
You’ll now write the physical page allocator. It keeps track of which pages are free with a linked list of struct PageInfo objects, each corresponding to a physical page. You need to write the physical page allocator before you can write the rest of the virtual memory implementation, because your page table management code will need to allocate physical memory in which to store page tables.
|
||||
|
||||
> Exercise 1
|
||||
>
|
||||
> In the file kern/pmap.c, you must implement code for the following functions (probably in the order given).
|
||||
>
|
||||
> boot_alloc()
|
||||
>
|
||||
> mem_init() (only up to the call to check_page_free_list())
|
||||
>
|
||||
> page_init()
|
||||
>
|
||||
> page_alloc()
|
||||
>
|
||||
> page_free()
|
||||
>
|
||||
> check_page_free_list() and check_page_alloc() test your physical page allocator. You should boot JOS and see whether check_page_alloc() reports success. Fix your code so that it passes. You may find it helpful to add your own assert()s to verify that your assumptions are correct.
|
||||
|
||||
This lab, and all the 6.828 labs, will require you to do a bit of detective work to figure out exactly what you need to do. This assignment does not describe all the details of the code you’ll have to add to JOS. Look for comments in the parts of the JOS source that you have to modify; those comments often contain specifications and hints. You will also need to look at related parts of JOS, at the Intel manuals, and perhaps at your 6.004 or 6.033 notes.
|
||||
|
||||
### Part 2: Virtual Memory
|
||||
|
||||
Before doing anything else, familiarize yourself with the x86’s protected-mode memory management architecture: namely segmentationand page translation.
|
||||
|
||||
> Exercise 2
|
||||
>
|
||||
> Look at chapters 5 and 6 of the Intel 80386 Reference Manual, if you haven’t done so already. Read the sections about page translation and page-based protection closely (5.2 and 6.4). We recommend that you also skim the sections about segmentation; while JOS uses paging for virtual memory and protection, segment translation and segment-based protection cannot be disabled on the x86, so you will need a basic understanding of it.
|
||||
|
||||
### Virtual, Linear, and Physical Addresses
|
||||
|
||||
In x86 terminology, a virtual address consists of a segment selector and an offset within the segment. A linear address is what you get after segment translation but before page translation. A physical address is what you finally get after both segment and page translation and what ultimately goes out on the hardware bus to your RAM.
|
||||
|
||||

|
||||
|
||||
Recall that in part 3 of lab 1, we installed a simple page table so that the kernel could run at its link address of 0xf0100000, even though it is actually loaded in physical memory just above the ROM BIOS at 0x00100000. This page table mapped only 4MB of memory. In the virtual memory layout you are going to set up for JOS in this lab, we’ll expand this to map the first 256MB of physical memory starting at virtual address 0xf0000000 and to map a number of other regions of virtual memory.
|
||||
|
||||
> Exercise 3
|
||||
>
|
||||
> While GDB can only access QEMU’s memory by virtual address, it’s often useful to be able to inspect physical memory while setting up virtual memory. Review the QEMU monitor commands from the lab tools guide, especially the xp command, which lets you inspect physical memory. To access the QEMU monitor, press Ctrl-a c in the terminal (the same binding returns to the serial console).
|
||||
>
|
||||
> Use the xp command in the QEMU monitor and the x command in GDB to inspect memory at corresponding physical and virtual addresses and make sure you see the same data.
|
||||
>
|
||||
> Our patched version of QEMU provides an info pg command that may also prove useful: it shows a compact but detailed representation of the current page tables, including all mapped memory ranges, permissions, and flags. Stock QEMU also provides an info mem command that shows an overview of which ranges of virtual memory are mapped and with what permissions.
|
||||
|
||||
From code executing on the CPU, once we’re in protected mode (which we entered first thing in boot/boot.S), there’s no way to directly use a linear or physical address. All memory references are interpreted as virtual addresses and translated by the MMU, which means all pointers in C are virtual addresses.
|
||||
|
||||
The JOS kernel often needs to manipulate addresses as opaque values or as integers, without dereferencing them, for example in the physical memory allocator. Sometimes these are virtual addresses, and sometimes they are physical addresses. To help document the code, the JOS source distinguishes the two cases: the type uintptr_t represents opaque virtual addresses, and physaddr_trepresents physical addresses. Both these types are really just synonyms for 32-bit integers (uint32_t), so the compiler won’t stop you from assigning one type to another! Since they are integer types (not pointers), the compiler will complain if you try to dereference them.
|
||||
|
||||
The JOS kernel can dereference a uintptr_t by first casting it to a pointer type. In contrast, the kernel can’t sensibly dereference a physical address, since the MMU translates all memory references. If you cast a physaddr_t to a pointer and dereference it, you may be able to load and store to the resulting address (the hardware will interpret it as a virtual address), but you probably won’t get the memory location you intended.
|
||||
|
||||
To summarize:
|
||||
|
||||
| C type | Address type |
|
||||
| ------------ | ------------ |
|
||||
| `T*` | Virtual |
|
||||
| `uintptr_t` | Virtual |
|
||||
| `physaddr_t` | Physical |
|
||||
|
||||
>Question
|
||||
>
|
||||
>Assuming that the following JOS kernel code is correct, what type should variable x have, >uintptr_t or physaddr_t?
|
||||
>
|
||||
>
|
||||
>
|
||||
|
||||
The JOS kernel sometimes needs to read or modify memory for which it knows only the physical address. For example, adding a mapping to a page table may require allocating physical memory to store a page directory and then initializing that memory. However, the kernel, like any other software, cannot bypass virtual memory translation and thus cannot directly load and store to physical addresses. One reason JOS remaps of all of physical memory starting from physical address 0 at virtual address 0xf0000000 is to help the kernel read and write memory for which it knows just the physical address. In order to translate a physical address into a virtual address that the kernel can actually read and write, the kernel must add 0xf0000000 to the physical address to find its corresponding virtual address in the remapped region. You should use KADDR(pa) to do that addition.
|
||||
|
||||
The JOS kernel also sometimes needs to be able to find a physical address given the virtual address of the memory in which a kernel data structure is stored. Kernel global variables and memory allocated by boot_alloc() are in the region where the kernel was loaded, starting at 0xf0000000, the very region where we mapped all of physical memory. Thus, to turn a virtual address in this region into a physical address, the kernel can simply subtract 0xf0000000. You should use PADDR(va) to do that subtraction.
|
||||
|
||||
### Reference counting
|
||||
|
||||
In future labs you will often have the same physical page mapped at multiple virtual addresses simultaneously (or in the address spaces of multiple environments). You will keep a count of the number of references to each physical page in the pp_ref field of thestruct PageInfo corresponding to the physical page. When this count goes to zero for a physical page, that page can be freed because it is no longer used. In general, this count should equal to the number of times the physical page appears below UTOP in all page tables (the mappings above UTOP are mostly set up at boot time by the kernel and should never be freed, so there’s no need to reference count them). We’ll also use it to keep track of the number of pointers we keep to the page directory pages and, in turn, of the number of references the page directories have to page table pages.
|
||||
|
||||
Be careful when using page_alloc. The page it returns will always have a reference count of 0, so pp_ref should be incremented as soon as you’ve done something with the returned page (like inserting it into a page table). Sometimes this is handled by other functions (for example, page_insert) and sometimes the function calling page_alloc must do it directly.
|
||||
|
||||
### Page Table Management
|
||||
|
||||
Now you’ll write a set of routines to manage page tables: to insert and remove linear-to-physical mappings, and to create page table pages when needed.
|
||||
|
||||
> Exercise 4
|
||||
>
|
||||
> In the file kern/pmap.c, you must implement code for the following functions.
|
||||
>
|
||||
> pgdir_walk()
|
||||
>
|
||||
> boot_map_region()
|
||||
>
|
||||
> page_lookup()
|
||||
>
|
||||
> page_remove()
|
||||
>
|
||||
> page_insert()
|
||||
>
|
||||
> check_page(), called from mem_init(), tests your page table management routines. You should make sure it reports success before proceeding.
|
||||
|
||||
### Part 3: Kernel Address Space
|
||||
|
||||
JOS divides the processor’s 32-bit linear address space into two parts. User environments (processes), which we will begin loading and running in lab 3, will have control over the layout and contents of the lower part, while the kernel always maintains complete control over the upper part. The dividing line is defined somewhat arbitrarily by the symbol ULIM in inc/memlayout.h, reserving approximately 256MB of virtual address space for the kernel. This explains why we needed to give the kernel such a high link address in lab 1: otherwise there would not be enough room in the kernel’s virtual address space to map in a user environment below it at the same time.
|
||||
|
||||
You’ll find it helpful to refer to the JOS memory layout diagram in inc/memlayout.h both for this part and for later labs.
|
||||
|
||||
### Permissions and Fault Isolation
|
||||
|
||||
Since kernel and user memory are both present in each environment’s address space, we will have to use permission bits in our x86 page tables to allow user code access only to the user part of the address space. Otherwise bugs in user code might overwrite kernel data, causing a crash or more subtle malfunction; user code might also be able to steal other environments’ private data.
|
||||
|
||||
The user environment will have no permission to any of the memory above ULIM, while the kernel will be able to read and write this memory. For the address range [UTOP,ULIM), both the kernel and the user environment have the same permission: they can read but not write this address range. This range of address is used to expose certain kernel data structures read-only to the user environment. Lastly, the address space below UTOP is for the user environment to use; the user environment will set permissions for accessing this memory.
|
||||
|
||||
### Initializing the Kernel Address Space
|
||||
|
||||
Now you’ll set up the address space above UTOP: the kernel part of the address space. inc/memlayout.h shows the layout you should use. You’ll use the functions you just wrote to set up the appropriate linear to physical mappings.
|
||||
|
||||
> Exercise 5
|
||||
>
|
||||
> Fill in the missing code in mem_init() after the call to check_page().
|
||||
|
||||
Your code should now pass the check_kern_pgdir() and check_page_installed_pgdir() checks.
|
||||
|
||||
> Question
|
||||
>
|
||||
> 1、What entries (rows) in the page directory have been filled in at this point? What addresses do they map and where do they point? In other words, fill out this table as much as possible:
|
||||
>
|
||||
> EntryBase Virtual AddressPoints to (logically):
|
||||
>
|
||||
> 1023 ? Page table for top 4MB of phys memory
|
||||
>
|
||||
> 1022 ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> 2 0x00800000 ?
|
||||
>
|
||||
> 1 0x00400000 ?
|
||||
>
|
||||
> 0 0x00000000 [see next question]
|
||||
>
|
||||
> 2、(From 20 Lecture3) We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel’s memory? What specific mechanisms protect the kernel memory?
|
||||
>
|
||||
> 3、What is the maximum amount of physical memory that this operating system can support? Why?
|
||||
>
|
||||
> 4、How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
|
||||
>
|
||||
> 5、Revisit the page table setup in kern/entry.S and kern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
|
||||
|
||||
### Address Space Layout Alternatives
|
||||
|
||||
The address space layout we use in JOS is not the only one possible. An operating system might map the kernel at low linear addresses while leaving the upper part of the linear address space for user processes. x86 kernels generally do not take this approach, however, because one of the x86’s backward-compatibility modes, known as virtual 8086 mode, is “hard-wired” in the processor to use the bottom part of the linear address space, and thus cannot be used at all if the kernel is mapped there.
|
||||
|
||||
It is even possible, though much more difficult, to design the kernel so as not to have to reserve any fixed portion of the processor’s linear or virtual address space for itself, but instead effectively to allow allow user-level processes unrestricted use of the entire 4GB of virtual address space - while still fully protecting the kernel from these processes and protecting different processes from each other!
|
||||
|
||||
Generalize the kernel’s memory allocation system to support pages of a variety of power-of-two allocation unit sizes from 4KB up to some reasonable maximum of your choice. Be sure you have some way to divide larger allocation units into smaller ones on demand, and to coalesce multiple small allocation units back into larger units when possible. Think about the issues that might arise in such a system.
|
||||
|
||||
This completes the lab. Make sure you pass all of the make grade tests and don’t forget to write up your answers to the questions inanswers-lab2.txt. Commit your changes (including adding answers-lab2.txt) and type make handin in the lab directory to hand in your lab.
|
||||
|
||||
------
|
||||
|
||||
via: <https://sipb.mit.edu/iap/6.828/lab/lab2/>
|
||||
|
||||
作者:[Mit][<https://sipb.mit.edu/iap/6.828/lab/lab2/>]
|
||||
译者:[译者ID](https://github.com/%E8%AF%91%E8%80%85ID)
|
||||
校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,145 +0,0 @@
|
||||
fuzheng1998 translating
|
||||
======
|
||||
Cloud Commander – A Web File Manager With Console And Editor
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Cloud commander** is a web-based file manager application that allows you to view, access, and manage the files and folders of your system from any computer, mobile, and tablet Pc via a web browser. It has two simple and classic panels, and automatically converts it’s size as per your device’s display size. It also has two built-in editors namely **Dword** and **Edward** with support of Syntax-highlighting and one **Console** with support of your system’s command line. So you can edit your files on the go. Cloud Commander server is a cross-platform application that runs on Linux, Windows and Mac OS X operating systems, and the client will run on any web browser. It is written using **JavaScript/Node.Js** , and is licensed under **MIT**.
|
||||
|
||||
In this brief tutorial, let us see how to install Cloud Commander in Ubuntu 18.04 LTS server.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
As I mentioned earlier, Cloud Commander is written using Node.Js. So, in order to install Cloud Commander we need to install Node.Js first. To do so, refer the following guide.
|
||||
|
||||
### Install Cloud Commander
|
||||
|
||||
After installing Node.Js, run the following command to install Cloud Commander:
|
||||
```
|
||||
$ npm i cloudcmd -g
|
||||
|
||||
```
|
||||
|
||||
Congratulations! Cloud Commander has been installed. Let us go ahead and see the basic usage of Cloud Commander.
|
||||
|
||||
### Getting started with Cloud Commander
|
||||
|
||||
Run the following command to start Cloud Commander:
|
||||
```
|
||||
$ cloudcmd
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
url: http://localhost:8000
|
||||
|
||||
```
|
||||
|
||||
Now, open your web browser and navigate to the URL: **<http://localhost:8000** or> **<http://IP-address:8000>**.
|
||||
|
||||
From now on, you can create, delete, view, manage files or folders right in the web browser from the local system or remote system, or mobile, tablet etc.
|
||||
|
||||
![][2]
|
||||
|
||||
As you can see in the above screenshot, Cloud Commander has two panels, ten hotkeys (F1 to F10), and Console.
|
||||
|
||||
Each hotkey does a unique job.
|
||||
|
||||
* F1 – Help
|
||||
* F2 – Rename file/folder
|
||||
* F3 – View files and folders
|
||||
* F4 – Edit files
|
||||
* F5 – Copy files/folders
|
||||
* F6 – Move files/folders
|
||||
* F7 – Create new directory
|
||||
* F8 – Delete file/folder
|
||||
* F9 – Open Menu
|
||||
* F10 – Open config
|
||||
|
||||
|
||||
|
||||
#### Cloud Commander console
|
||||
|
||||
Click on the Console icon. This will open your default system’s shell.
|
||||
|
||||
![][3]
|
||||
|
||||
From this console you can do all sort of administration tasks such as installing packages, removing packages, update your system etc. You can even shutdown or reboot system. Therefore, Cloud Commander is not just a file manager, but also has the functionality of a remote administration tool.
|
||||
|
||||
#### Creating files/folders
|
||||
|
||||
To create a new file or folder Right click on any empty place and go to **New - >File or Directory**.
|
||||
|
||||
![][4]
|
||||
|
||||
#### View files
|
||||
|
||||
You can view pictures, watch audio and video files.
|
||||
|
||||
![][5]
|
||||
|
||||
#### Upload files
|
||||
|
||||
The other cool feature is we can easily upload a file to Cloud Commander system from any system or device.
|
||||
|
||||
To upload a file, right click on any empty space in the Cloud Commander panel, and click on the **Upload** option.
|
||||
|
||||
![][6]
|
||||
|
||||
Select the files you want to upload.
|
||||
|
||||
Also, you can upload files from the Cloud services like Google drive, Dropbox, Amazon cloud drive, Facebook, Twitter, Gmail, GtiHub, Picasa, Instagram and many.
|
||||
|
||||
To upload files from Cloud, right click on any empty space in the panel and select **Upload from Cloud**.
|
||||
|
||||
![][7]
|
||||
|
||||
Select any web service of your choice, for example Google drive. Click **Connect to Google drive** button.
|
||||
|
||||
![][8]
|
||||
|
||||
In the next step, authenticate your google drive with Cloud Commander. Finally, select the files from your Google drive and click **Upload**.
|
||||
|
||||
![][9]
|
||||
|
||||
#### Update Cloud Commander
|
||||
|
||||
To update Cloud Commander to the latest available version, run the following command:
|
||||
```
|
||||
$ npm update cloudcmd -g
|
||||
|
||||
```
|
||||
|
||||
#### Conclusion
|
||||
|
||||
As far as I tested Cloud Commander, It worked like charm. I didn’t face a single issue during the testing in my Ubuntu server. Also, Cloud Commander is not just a web-based file manager, but also acts as a remote administration tool that performs most Linux administration tasks. You can create a files/folders, rename, delete, edit, and view them. Also, You can install, update, upgrade, and remove any package as the way you do in the local system from the Terminal. And, of course, you can even shutdown or restart the system from the Cloud Commander console itself. What do you need more? Give it a try, you will find it useful.
|
||||
|
||||
That’s all for now. I will be here soon with another interesting article. Until then, stay tuned with OSTechNix.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/cloud-commander-a-web-file-manager-with-console-and-editor/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-Google-Chrome_006-4.jpg
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-Google-Chrome_007-2.jpg
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-commander-file-folder-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_008-1.jpg
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2016/05/cloud-commander-upload-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2016/05/upload-from-cloud-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_009-2.jpg
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_010-1.jpg
|
||||
@ -1,4 +1,4 @@
|
||||
Writing a Time Series Database from Scratch
|
||||
[haoqixu翻译中]Writing a Time Series Database from Scratch
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
### fuzheng1998 translating
|
||||
10 Games You Can Play on Linux with Wine
|
||||
======
|
||||

|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by bayar199468
|
||||
7 Best eBook Readers for Linux
|
||||
======
|
||||
**Brief:** In this article, we are covering some of the best ebook readers for Linux. These apps give a better reading experience and some will even help in managing your ebooks.
|
||||
|
||||
@ -1,44 +0,0 @@
|
||||
Review: Algorithms to Live By
|
||||
======
|
||||

|
||||
|
||||
Another read for the work book club. This was my favorite to date, apart from the books I recommended myself.
|
||||
|
||||
One of the foundations of computer science as a field of study is research into algorithms: how do we solve problems efficiently using computer programs? This is a largely mathematical field, but it's often less about ideal or theoretical solutions and more about making the most efficient use of limited resources and arriving at an adequate, if not perfect, answer. Many of these problems are either day-to-day human problems or are closely related to them; after all, the purpose of computer science is to solve practical problems with computers. The question asked by Algorithms to Live By is "can we reverse this?": can we learn lessons from computer science's approach to problems that would help us make day-to-day decisions?
|
||||
|
||||
There's a lot of interesting material in the eleven chapters of this book, but there's also an amusing theme: humans are already very good at this. Many chapters start with an examination of algorithms and mathematical analysis of problems, dive into a discussion of how we can use those results to make better decisions, then talk about studies of the decisions humans actually make... and discover that humans are already applying ad hoc versions of the best algorithms we've come up with, given the constraints of typical life situations. It tends to undermine the stated goal of the book. Thankfully, it in no way undermines interesting discussion of general classes of problems, how computer science has tackled them, and what we've learned about the mathematical and technical shapes of those problems. There's a bit less self-help utility here than I think the authors had intended, but lots of food for thought.
|
||||
|
||||
(That said, it's worth considering whether this congruence is less because humans are already good at this and more because our algorithms are designed from human intuition. Maybe our best algorithms just reflect human thinking. In some cases we've checked our solutions against mathematical ideals, but in other cases they're still just our best guesses to date.)
|
||||
|
||||
This is the sort of a book where a chapter listing is an important part of the review. The areas of algorithms discussed here are optimal stopping, explore/exploit decisions (when to go with the best thing you've found and when to look for something better), sorting, caching, scheduling, Bayes's rule (and prediction in general), overfitting when building models, relaxation (solving an easier problem than your actual problem), randomized algorithms, a collection of networking algorithms, and finally game theory. Each of these has useful insights and thought-provoking discussion of how these sometimes-theoretical concepts map surprisingly well onto daily problems. The book concludes with a discussion of "computational kindness": an encouragement to reduce the required computation and complexity penalty for both yourself and the people you interact with.
|
||||
|
||||
If you have a computer science background (as I do), many of these will be familiar concepts, and you might be dubious that a popularization would tell you much that's new. Give this book a shot, though; the analogies are less stretched than you might fear, and the authors are both careful and smart about how they apply these principles. This book passes with flying colors a key sanity check: the chapters on topics that I know well or have thought about a lot make few or no obvious errors and say useful and important things. For example, the scheduling chapter, which unsurprisingly is about time management, surpasses more than half of the time management literature by jumping straight to the heart of most time management problems: if you're going to do everything on a list, it rarely matters the order in which you do it, so the hardest scheduling problems are about deciding what not to do rather than deciding order.
|
||||
|
||||
The point in the book where the authors won my heart completely was in the chapter on Bayes's rule. Much of the chapter is about Bayesian priors, and how one's knowledge of past events is a vital part of analysis of future probabilities. The authors then discuss the (in)famous marshmallow experiment, in which children are given one marshmallow and told that if they refrain from eating it until the researcher returns, they'll get two marshmallows. Refraining from eating the marshmallow (delayed gratification, in the psychological literature) was found to be associated with better life outcomes years down the road. This experiment has been used and abused for years for all sorts of propaganda about how trading immediate pleasure for future gains leads to a successful life, and how failure in life is because of inability to delay gratification. More evil analyses have (of course) tied that capability to ethnicity, with predictably racist results.
|
||||
|
||||
I have [kind of a thing][1] about the marshmallow experiment. It's a topic that reliably sends me off into angry rants.
|
||||
|
||||
Algorithms to Live By is the only book I have ever read to mention the marshmallow experiment and then apply the analysis that I find far more convincing. This is not a test of innate capability in the children; it's a test of their Bayesian priors. When does it make perfect sense to eat the marshmallow immediately instead of waiting for a reward? When their past experience tells them that adults are unreliable, can't be trusted, disappear for unpredictable lengths of time, and lie. And, even better, the authors supported this analysis with both a follow-up study I hadn't heard of before and with the observation that some children would wait for some time and then "give in." This makes perfect sense if they were subconsciously using a Bayesian model with poor priors.
|
||||
|
||||
This is a great book. It may try a bit too hard in places (applicability of the math of optimal stopping to everyday life is more contingent and strained than I think the authors want to admit), and some of this will be familiar if you've studied algorithms. But the writing is clear, succinct, and very well-edited. No part of the book outlives its welcome; the discussion moves right along. If you find yourself going "I know all this already," you'll still probably encounter a new concept or neat explanation in a few more pages. And sometimes the authors make connections that never would have occurred to me but feel right in retrospect, such as relating exponential backoff in networking protocols to choosing punishments in the criminal justice system. Or the realization that our modern communication world is not constantly connected, it's constantly buffered, and many of us are suffering from the characteristic signs of buffer bloat.
|
||||
|
||||
I don't think you have to be a CS major, or know much about math, to read this book. There is a lot of mathematical details in the end notes if you want to dive in, but the main text is almost always readable and clear, at least so far as I could tell (as someone who was a CS major and has taken a lot of math, so a grain of salt may be indicated). And it still has a lot to offer even if you've studied algorithms for years.
|
||||
|
||||
The more I read of this book, the more I liked it. Definitely recommended if you like reading this sort of analysis of life.
|
||||
|
||||
Rating: 9 out of 10
|
||||
|
||||
Reviewed: 2017-10-22
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.eyrie.org/~eagle/reviews/books/1-62779-037-3.html
|
||||
|
||||
作者:[Brian Christian;Tom Griffiths][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.eyrie.org
|
||||
[1]:https://www.eyrie.org1-59184-679-X.html
|
||||
@ -1,4 +1,4 @@
|
||||
# mandeler translating A CEO's Guide to Emacs
|
||||
A CEO's Guide to Emacs
|
||||
============================================================
|
||||
|
||||
Years—no, decades—ago, I lived in Emacs. I wrote code and documents, managed email and calendar, and shelled all in the editor/OS. I was quite happy. Years went by and I moved to newer, shinier things. As a result, I forgot how to do tasks as basic as efficiently navigating files without a mouse. About three months ago, noticing just how much of my time was spent switching between applications and computers, I decided to give Emacs another try. It was a good decision for several reasons that will be covered in this post. Covered too are `.emacs` and Dropbox tips so that you can set up a good, movable environment.
|
||||
|
||||
@ -1,143 +0,0 @@
|
||||
Translating by DavidChen
|
||||
|
||||
How do groups work on Linux?
|
||||
============================================================
|
||||
|
||||
Hello! Last week, I thought I knew how users and groups worked on Linux. Here is what I thought:
|
||||
|
||||
1. Every process belongs to a user (like `julia`)
|
||||
|
||||
2. When a process tries to read a file owned by a group, Linux a) checks if the user `julia` can access the file, and b) checks which groups `julia` belongs to, and whether any of those groups owns & can access that file
|
||||
|
||||
3. If either of those is true (or if the ‘any’ bits are set right) then the process can access the file
|
||||
|
||||
So, for example, if a process is owned by the `julia` user and `julia` is in the `awesome` group, then the process would be allowed to read this file.
|
||||
|
||||
```
|
||||
r--r--r-- 1 root awesome 6872 Sep 24 11:09 file.txt
|
||||
|
||||
```
|
||||
|
||||
I had not thought carefully about this, but if pressed I would have said that it probably checks the `/etc/group` file at runtime to see what groups you’re in.
|
||||
|
||||
### that is not how groups work
|
||||
|
||||
I found out at work last week that, no, what I describe above is not how groups work. In particular Linux does **not** check which groups a process’s user belongs to every time that process tries to access a file.
|
||||
|
||||
Here is how groups actually work! I learned this by reading Chapter 9 (“Process Credentials”) of [The Linux Programming Interface][1] which is an incredible book. As soon as I realized that I did not understand how users and groups worked, I opened up the table of contents with absolute confidence that it would tell me what’s up, and I was right.
|
||||
|
||||
### how users and groups checks are done
|
||||
|
||||
They key new insight for me was pretty simple! The chapter starts out by saying that user and group IDs are **attributes of the process**:
|
||||
|
||||
* real user ID and group ID;
|
||||
|
||||
* effective user ID and group ID;
|
||||
|
||||
* saved set-user-ID and saved set-group-ID;
|
||||
|
||||
* file-system user ID and group ID (Linux-specific); and
|
||||
|
||||
* supplementary group IDs.
|
||||
|
||||
This means that the way Linux **actually** does group checks to see a process can read a file is:
|
||||
|
||||
* look at the process’s group IDs & supplementary group IDs (from the attributes on the process, **not** by looking them up in `/etc/group`)
|
||||
|
||||
* look at the group on the file
|
||||
|
||||
* see if they match
|
||||
|
||||
Generally when doing access control checks it uses the **effective** user/group ID, not the real user/group ID. Technically when accessing a file it actually uses the **file-system** ids but those are usually the same as the effective uid/gid.
|
||||
|
||||
### Adding a user to a group doesn’t put existing processes in that group
|
||||
|
||||
Here’s another fun example that follows from this: if I create a new `panda` group and add myself (bork) to it, then run `groups` to check my group memberships – I’m not in the panda group!
|
||||
|
||||
```
|
||||
bork@kiwi~> sudo addgroup panda
|
||||
Adding group `panda' (GID 1001) ...
|
||||
Done.
|
||||
bork@kiwi~> sudo adduser bork panda
|
||||
Adding user `bork' to group `panda' ...
|
||||
Adding user bork to group panda
|
||||
Done.
|
||||
bork@kiwi~> groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd
|
||||
|
||||
```
|
||||
|
||||
no `panda` in that list! To double check, let’s try making a file owned by the `panda`group and see if I can access it:
|
||||
|
||||
```
|
||||
$ touch panda-file.txt
|
||||
$ sudo chown root:panda panda-file.txt
|
||||
$ sudo chmod 660 panda-file.txt
|
||||
$ cat panda-file.txt
|
||||
cat: panda-file.txt: Permission denied
|
||||
|
||||
```
|
||||
|
||||
Sure enough, I can’t access `panda-file.txt`. No big surprise there. My shell didn’t have the `panda` group as a supplementary GID before, and running `adduser bork panda` didn’t do anything to change that.
|
||||
|
||||
### how do you get your groups in the first place?
|
||||
|
||||
So this raises kind of a confusing question, right – if processes have groups baked into them, how do you get assigned your groups in the first place? Obviously you can’t assign yourself more groups (that would defeat the purpose of access control).
|
||||
|
||||
It’s relatively clear how processes I **execute** from my shell (bash/fish) get their groups – my shell runs as me, and it has a bunch of group IDs on it. Processes I execute from my shell are forked from the shell so they get the same groups as the shell had.
|
||||
|
||||
So there needs to be some “first” process that has your groups set on it, and all the other processes you set inherit their groups from that. That process is called your **login shell** and it’s run by the `login` program (`/bin/login`) on my laptop. `login` runs as root and calls a C function called `initgroups` to set up your groups (by reading `/etc/group`). It’s allowed to set up your groups because it runs as root.
|
||||
|
||||
### let’s try logging in again!
|
||||
|
||||
So! Let’s say I am running in a shell, and I want to refresh my groups! From what we’ve learned about how groups are initialized, I should be able to run `login` to refresh my groups and start a new login shell!
|
||||
|
||||
Let’s try it:
|
||||
|
||||
```
|
||||
$ sudo login bork
|
||||
$ groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd panda
|
||||
$ cat panda-file.txt # it works! I can access the file owned by `panda` now!
|
||||
|
||||
```
|
||||
|
||||
Sure enough, it works! Now the new shell that `login` spawned is part of the `panda` group! Awesome! This won’t affect any other shells I already have running. If I really want the new `panda` group everywhere, I need to restart my login session completely, which means quitting my window manager and logging in again.
|
||||
|
||||
### newgrp
|
||||
|
||||
Somebody on Twitter told me that if you want to start a new shell with a new group that you’ve been added to, you can use `newgrp`. Like this:
|
||||
|
||||
```
|
||||
sudo addgroup panda
|
||||
sudo adduser bork panda
|
||||
newgrp panda # starts a new shell, and you don't have to be root to run it!
|
||||
|
||||
```
|
||||
|
||||
You can accomplish the same(ish) thing with `sg panda bash` which will start a `bash` shell that runs with the `panda` group.
|
||||
|
||||
### setuid sets the effective user ID
|
||||
|
||||
I’ve also always been a little vague about what it means for a process to run as “setuid root”. It turns out that setuid sets the effective user ID! So if I (`julia`) run a setuid root process (like `passwd`), then the **real** user ID will be set to `julia`, and the **effective** user ID will be set to `root`.
|
||||
|
||||
`passwd` needs to run as root, but it can look at its real user ID to see that `julia`started the process, and prevent `julia` from editing any passwords except for `julia`’s password.
|
||||
|
||||
### that’s all!
|
||||
|
||||
There are a bunch more details about all the edge cases and exactly how everything works in The Linux Programming Interface so I will not get into all the details here. That book is amazing. Everything I talked about in this post is from Chapter 9, which is a 17-page chapter inside a 1300-page book.
|
||||
|
||||
The thing I love most about that book is that reading 17 pages about how users and groups work is really approachable, self-contained, super useful, and I don’t have to tackle all 1300 pages of it at once to learn helpful things :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/20/groups/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://man7.org/tlpi/
|
||||
@ -1,182 +0,0 @@
|
||||
How to Install and Use Wireshark on Debian 9 / Ubuntu 16.04 / 17.10
|
||||
============================================================
|
||||
|
||||
by [Pradeep Kumar][1] · Published November 29, 2017 · Updated November 29, 2017
|
||||
|
||||
[][2]
|
||||
|
||||
Wireshark is free and open source, cross platform, GUI based Network packet analyzer that is available for Linux, Windows, MacOS, Solaris etc. It captures network packets in real time & presents them in human readable format. Wireshark allows us to monitor the network packets up to microscopic level. Wireshark also has a command line utility called ‘tshark‘ that performs the same functions as Wireshark but through terminal & not through GUI.
|
||||
|
||||
Wireshark can be used for network troubleshooting, analyzing, software & communication protocol development & also for education purposed. Wireshark uses a library called ‘pcap‘ for capturing the network packets.
|
||||
|
||||
Wireshark comes with a lot of features & some those features are;
|
||||
|
||||
* Support for a hundreds of protocols for inspection,
|
||||
|
||||
* Ability to capture packets in real time & save them for later offline analysis,
|
||||
|
||||
* A number of filters to analyzing data,
|
||||
|
||||
* Data captured can be compressed & uncompressed on the fly,
|
||||
|
||||
* Various file formats for data analysis supported, output can also be saved to XML, CSV, plain text formats,
|
||||
|
||||
* data can be captured from a number of interfaces like ethernet, wifi, bluetooth, USB, Frame relay , token rings etc.
|
||||
|
||||
In this article, we will discuss how to install Wireshark on Ubuntu/Debain machines & will also learn to use Wireshark for capturing network packets.
|
||||
|
||||
#### Installation of Wireshark on Ubuntu 16.04 / 17.10
|
||||
|
||||
Wireshark is available with default Ubuntu repositories & can be simply installed using the following command. But there might be chances that you will not get the latest version of wireshark.
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo apt-get update
|
||||
linuxtechi@nixworld:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
So to install latest version of wireshark we have to enable or configure official wireshark repository.
|
||||
|
||||
Use the beneath commands one after the another to configure repository and to install latest version of Wireshark utility
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo add-apt-repository ppa:wireshark-dev/stable
|
||||
linuxtechi@nixworld:~$ sudo apt-get update
|
||||
linuxtechi@nixworld:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
Once the Wireshark is installed execute the below command so that non-root users can capture live packets of interfaces,
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo setcap 'CAP_NET_RAW+eip CAP_NET_ADMIN+eip' /usr/bin/dumpcap
|
||||
```
|
||||
|
||||
#### Installation of Wireshark on Debian 9
|
||||
|
||||
Wireshark package and its dependencies are already present in the default debian 9 repositories, so to install latest and stable version of Wireshark on Debian 9, use the following command:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo apt-get update
|
||||
linuxtechi@nixhome:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
During the installation, it will prompt us to configure dumpcap for non-superusers,
|
||||
|
||||
Select ‘yes’ and then hit enter.
|
||||
|
||||
[][3]
|
||||
|
||||
Once the Installation is completed, execute the below command so that non-root users can also capture the live packets of the interfaces.
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo chmod +x /usr/bin/dumpcap
|
||||
```
|
||||
|
||||
We can also use the latest source package to install the wireshark on Ubuntu/Debain & many other Linux distributions.
|
||||
|
||||
#### Installing Wireshark using source code on Debian / Ubuntu Systems
|
||||
|
||||
Firstly download the latest source package (which is 2.4.2 at the time for writing this article), use the following command,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ wget https://1.as.dl.wireshark.org/src/wireshark-2.4.2.tar.xz
|
||||
```
|
||||
|
||||
Next extract the package & enter into the extracted directory,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ tar -xf wireshark-2.4.2.tar.xz -C /tmp
|
||||
linuxtechi@nixhome:~$ cd /tmp/wireshark-2.4.2
|
||||
```
|
||||
|
||||
Now we will compile the code with the following commands,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ ./configure --enable-setcap-install
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ make
|
||||
```
|
||||
|
||||
Lastly install the compiled packages to install Wireshark on the system,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ sudo make install
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ sudo ldconfig
|
||||
```
|
||||
|
||||
Upon installation a separate group for Wireshark will also be created, we will now add our user to the group so that it can work with wireshark otherwise you might get ‘permission denied‘ error when starting wireshark.
|
||||
|
||||
To add the user to the wireshark group, execute the following command,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo usermod -a -G wireshark linuxtechi
|
||||
```
|
||||
|
||||
Now we can start wireshark either from GUI Menu or from terminal with this command,
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ wireshark
|
||||
```
|
||||
|
||||
#### Access Wireshark on Debian 9 System
|
||||
|
||||
[][4]
|
||||
|
||||
Click on Wireshark icon
|
||||
|
||||
[][5]
|
||||
|
||||
#### Access Wireshark on Ubuntu 16.04 / 17.10
|
||||
|
||||
[][6]
|
||||
|
||||
Click on Wireshark icon
|
||||
|
||||
[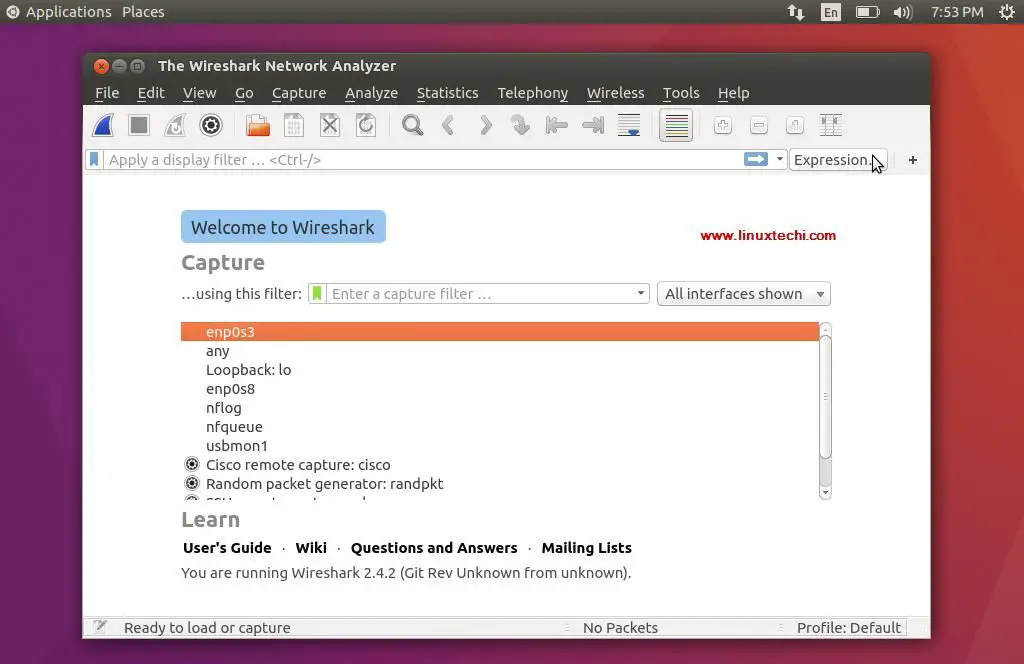][7]
|
||||
|
||||
#### Capturing and Analyzing packets
|
||||
|
||||
Once the wireshark has been started, we should be presented with the wireshark window, example is shown above for Ubuntu and Debian system.
|
||||
|
||||
[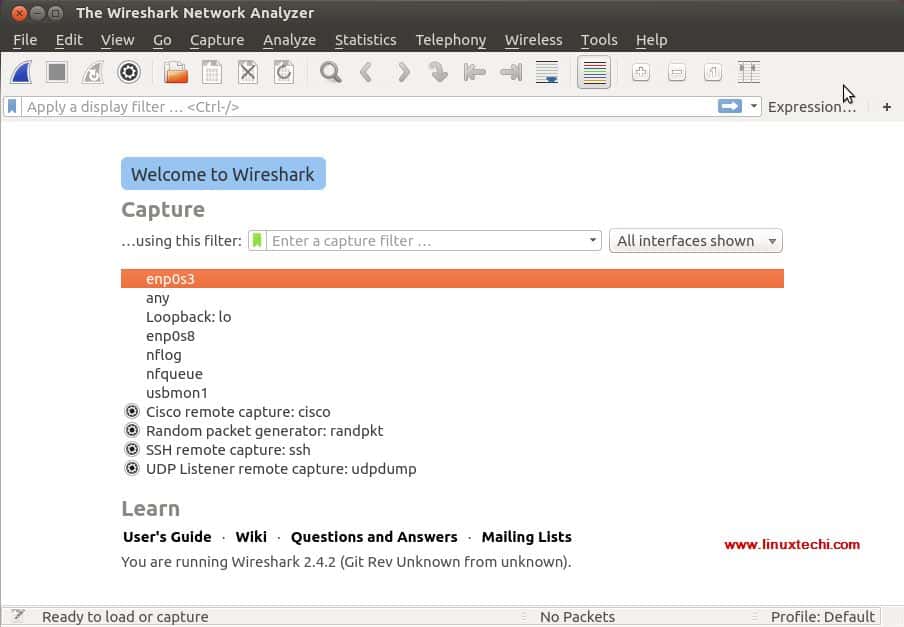][8]
|
||||
|
||||
All these are the interfaces from where we can capture the network packets. Based on the interfaces you have on your system, this screen might be different for you.
|
||||
|
||||
We are selecting ‘enp0s3’ for capturing the network traffic for that inteface. After selecting the inteface, network packets for all the devices on our network start to populate (refer to screenshot below)
|
||||
|
||||
[][9]
|
||||
|
||||
First time we see this screen we might get overwhelmed by the data that is presented in this screen & might have thought how to sort out this data but worry not, one the best features of Wireshark is its filters.
|
||||
|
||||
We can sort/filter out the data based on IP address, Port number, can also used source & destination filters, packet size etc & can also combine 2 or more filters together to create more comprehensive searches. We can either write our filters in ‘Apply a Display Filter‘ tab , or we can also select one of already created rules. To select pre-built filter, click on ‘flag‘ icon , next to ‘Apply a Display Filter‘ tab,
|
||||
|
||||
[][10]
|
||||
|
||||
We can also filter data based on the color coding, By default, light purple is TCP traffic, light blue is UDP traffic, and black identifies packets with errors , to see what these codes mean, click View -> Coloring Rules, also we can change these codes.
|
||||
|
||||
[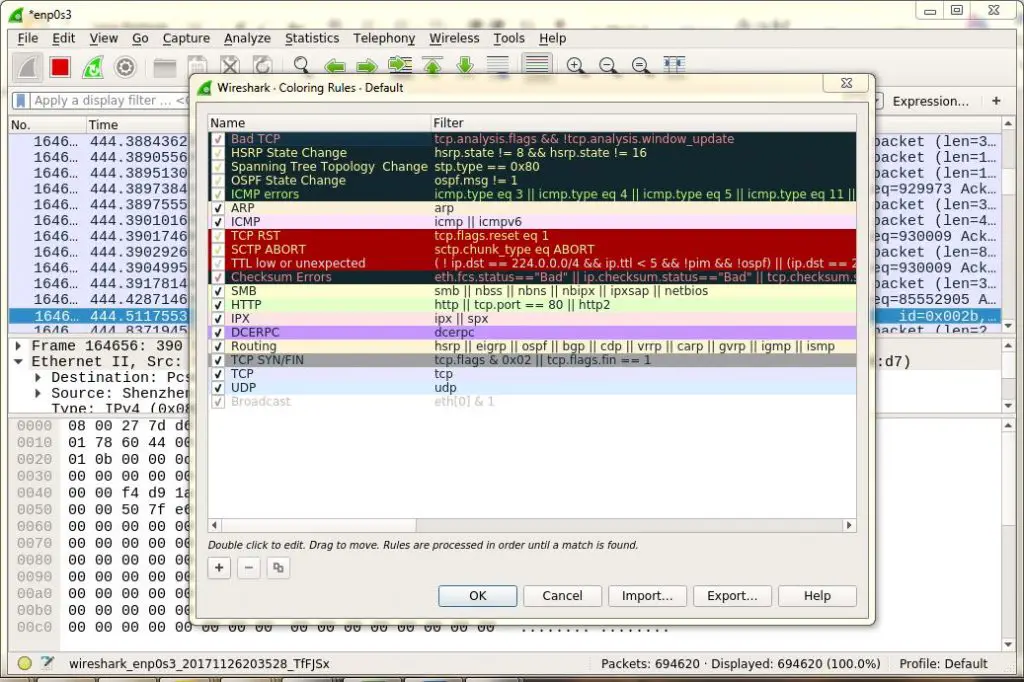][11]
|
||||
|
||||
After we have the results that we need, we can then click on any of the captured packets to get more details about that packet, this will show all the data about that network packet.
|
||||
|
||||
Wireshark is an extremely powerful tool takes some time to getting used to & make a command over it, this tutorial will help you get started. Please feel free to drop in your queries or suggestions in the comment box below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/author/pradeep/
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2017/11/wireshark-Debian-9-Ubuntu-16.04-17.10.jpg
|
||||
[3]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Configure-Wireshark-Debian9.jpg
|
||||
[4]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Access-wireshark-debian9.jpg
|
||||
[5]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Wireshark-window-debian9.jpg
|
||||
[6]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Access-wireshark-Ubuntu.jpg
|
||||
[7]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Wireshark-window-Ubuntu.jpg
|
||||
[8]:https://www.linuxtechi.com/wp-content/uploads/2017/11/wireshark-Linux-system.jpg
|
||||
[9]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Capturing-Packet-from-enp0s3-Ubuntu-Wireshark.jpg
|
||||
[10]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Filter-in-wireshark-Ubuntu.jpg
|
||||
[11]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Packet-Colouring-Wireshark.jpg
|
||||
@ -1,206 +0,0 @@
|
||||
Conditional Rendering in React using Ternaries and Logical AND
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Photo by [Brendan Church][1] on [Unsplash][2]
|
||||
|
||||
There are several ways that your React component can decide what to render. You can use the traditional `if` statement or the `switch` statement. In this article, we’ll explore a few alternatives. But be warned that some come with their own gotchas, if you’re not careful.
|
||||
|
||||
### Ternary vs if/else
|
||||
|
||||
Let’s say we have a component that is passed a `name` prop. If the string is non-empty, we display a greeting. Otherwise we tell the user they need to sign in.
|
||||
|
||||
Here’s a Stateless Function Component (SFC) that does just that.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => {
|
||||
if (name) {
|
||||
return (
|
||||
<div className="hello">
|
||||
Hello {name}
|
||||
</div>
|
||||
);
|
||||
}
|
||||
return (
|
||||
<div className="hello">
|
||||
Please sign in
|
||||
</div>
|
||||
);
|
||||
};
|
||||
```
|
||||
|
||||
Pretty straightforward. But we can do better. Here’s the same component written using a conditional ternary operator.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => (
|
||||
<div className="hello">
|
||||
{name ? `Hello ${name}` : 'Please sign in'}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
Notice how concise this code is compared to the example above.
|
||||
|
||||
A few things to note. Because we are using the single statement form of the arrow function, the `return` statement is implied. Also, using a ternary allowed us to DRY up the duplicate `<div className="hello">` markup. 🎉
|
||||
|
||||
### Ternary vs Logical AND
|
||||
|
||||
As you can see, ternaries are wonderful for `if/else` conditions. But what about simple `if` conditions?
|
||||
|
||||
Let’s look at another example. If `isPro` (a boolean) is `true`, we are to display a trophy emoji. We are also to render the number of stars (if not zero). We could go about it like this.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro ? '🏆' : null}
|
||||
</div>
|
||||
{stars ? (
|
||||
<div>
|
||||
Stars:{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
) : null}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
But notice the “else” conditions return `null`. This is becasue a ternary expects an else condition.
|
||||
|
||||
For simple `if` conditions, we could use something a little more fitting: the logical AND operator. Here’s the same code written using a logical AND.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro && '🏆'}
|
||||
</div>
|
||||
{stars && (
|
||||
<div>
|
||||
Stars:{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
Not too different, but notice how we eliminated the `: null` (i.e. else condition) at the end of each ternary. Everything should render just like it did before.
|
||||
|
||||
|
||||
Hey! What gives with John? There is a `0` when nothing should be rendered. That’s the gotcha that I was referring to above. Here’s why.
|
||||
|
||||
[According to MDN][3], a Logical AND (i.e. `&&`):
|
||||
|
||||
> `expr1 && expr2`
|
||||
|
||||
> Returns `expr1` if it can be converted to `false`; otherwise, returns `expr2`. Thus, when used with Boolean values, `&&` returns `true` if both operands are true; otherwise, returns `false`.
|
||||
|
||||
OK, before you start pulling your hair out, let me break it down for you.
|
||||
|
||||
In our case, `expr1` is the variable `stars`, which has a value of `0`. Because zero is falsey, `0` is returned and rendered. See, that wasn’t too bad.
|
||||
|
||||
I would write this simply.
|
||||
|
||||
> If `expr1` is falsey, returns `expr1`, else returns `expr2`.
|
||||
|
||||
So, when using a logical AND with non-boolean values, we must make the falsey value return something that React won’t render. Say, like a value of `false`.
|
||||
|
||||
There are a few ways that we can accomplish this. Let’s try this instead.
|
||||
|
||||
```
|
||||
{!!stars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
```
|
||||
|
||||
Notice the double bang operator (i.e. `!!`) in front of `stars`. (Well, actually there is no “double bang operator”. We’re just using the bang operator twice.)
|
||||
|
||||
The first bang operator will coerce the value of `stars` into a boolean and then perform a NOT operation. If `stars` is `0`, then `!stars` will produce `true`.
|
||||
|
||||
Then we perform a second NOT operation, so if `stars` is 0, `!!stars` would produce `false`. Exactly what we want.
|
||||
|
||||
If you’re not a fan of `!!`, you can also force a boolean like this (which I find a little wordy).
|
||||
|
||||
```
|
||||
{Boolean(stars) && (
|
||||
```
|
||||
|
||||
Or simply give a comparator that results in a boolean value (which some might say is even more semantic).
|
||||
|
||||
```
|
||||
{stars > 0 && (
|
||||
```
|
||||
|
||||
#### A word on strings
|
||||
|
||||
Empty string values suffer the same issue as numbers. But because a rendered empty string is invisible, it’s not a problem that you will likely have to deal with, or will even notice. However, if you are a perfectionist and don’t want an empty string on your DOM, you should take similar precautions as we did for numbers above.
|
||||
|
||||
### Another solution
|
||||
|
||||
A possible solution, and one that scales to other variables in the future, would be to create a separate `shouldRenderStars` variable. Then you are dealing with boolean values in your logical AND.
|
||||
|
||||
```
|
||||
const shouldRenderStars = stars > 0;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
Then, if in the future, the business rule is that you also need to be logged in, own a dog, and drink light beer, you could change how `shouldRenderStars` is computed, and what is returned would remain unchanged. You could also place this logic elsewhere where it’s testable and keep the rendering explicit.
|
||||
|
||||
```
|
||||
const shouldRenderStars =
|
||||
stars > 0 && loggedIn && pet === 'dog' && beerPref === 'light`;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
I’m of the opinion that you should make best use of the language. And for JavaScript, this means using conditional ternary operators for `if/else`conditions and logical AND operators for simple `if` conditions.
|
||||
|
||||
While we could just retreat back to our safe comfy place where we use the ternary operator everywhere, you now possess the knowledge and power to go forth AND prosper.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Managing Editor at the American Express Engineering Blog http://aexp.io and Director of Engineering @AmericanExpress. MyViews !== ThoseOfMyEmployer.
|
||||
|
||||
----------------
|
||||
|
||||
via: https://medium.freecodecamp.org/conditional-rendering-in-react-using-ternaries-and-logical-and-7807f53b6935
|
||||
|
||||
作者:[Donavon West][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@donavon
|
||||
[1]:https://unsplash.com/photos/pKeF6Tt3c08?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[2]:https://unsplash.com/search/photos/road-sign?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Logical_Operators
|
||||
@ -1,5 +1,3 @@
|
||||
hankchow translating
|
||||
|
||||
Build a bikesharing app with Redis and Python
|
||||
======
|
||||
|
||||
|
||||
@ -1,191 +0,0 @@
|
||||
Start a blog in 30 minutes with Hugo, a static site generator written in Go
|
||||
======
|
||||
|
||||

|
||||
Do you want to start a blog to share your latest adventures with various software frameworks? Do you love a project that is poorly documented and want to fix that? Or do you just want to create a personal website?
|
||||
|
||||
Many people who want to start a blog have a significant caveat: lack of knowledge about a content management system (CMS) or time to learn. Well, what if I said you don't need to spend days learning a new CMS, setting up a basic website, styling it, and hardening it against attackers? What if I said you could create a blog in 30 minutes, start to finish, with [Hugo][1]?
|
||||
|
||||

|
||||
|
||||
Hugo is a static site generator written in Go. Why use Hugo, you ask?
|
||||
|
||||
* Because there is no database, no plugins requiring any permissions, and no underlying platform running on your server, there's no added security concern.
|
||||
* The blog is a set of static websites, which means lightning-fast serve time. Additionally, all pages are rendered at deploy time, so your server's load is minimal.
|
||||
* Version control is easy. Some CMS platforms use their own version control system (VCS) or integrate Git into their interface. With Hugo, all your source files can live natively on the VCS of your choice.
|
||||
|
||||
|
||||
|
||||
### Minutes 0-5: Download Hugo and generate a site
|
||||
|
||||
To put it bluntly, Hugo is here to make writing a website fun again. Let's time the 30 minutes, shall we?
|
||||
|
||||
To simplify the installation of Hugo, download the binary file. To do so:
|
||||
|
||||
1. Download the appropriate [archive][2] for your operating system.
|
||||
|
||||
2. Unzip the archive into a directory of your choice, for example `C:\hugo_dir` or `~/hugo_dir`; this path will be referred to as `${HUGO_HOME}`.
|
||||
|
||||
3. Open the command line and change into your directory: `cd ${HUGO_HOME}`.
|
||||
|
||||
4. Verify that Hugo is working:
|
||||
|
||||
* On Unix: `${HUGO_HOME}/[hugo version]`
|
||||
* On Windows: `${HUGO_HOME}\[hugo.exe version]`
|
||||
For example, `c:\hugo_dir\hugo version`.
|
||||
|
||||
For simplicity, I'll refer to the path to the Hugo binary (including the binary) as `hugo`. For example, `hugo version` would translate to `C:\hugo_dir\hugo version` on your computer.
|
||||
|
||||
If you get an error message, you may have downloaded the wrong version. Also note there are many possible ways to install Hugo. See the [official documentation][3] for more information. Ideally, you put the Hugo binary on PATH. For this quick start, it's fine to use the full path of the Hugo binary.
|
||||
|
||||
|
||||
|
||||
5. Create a new site that will become your blog: `hugo new site awesome-blog`.
|
||||
6. Change into the newly created directory: `cd awesome-blog`.
|
||||
|
||||
|
||||
|
||||
Congratulations! You have just created your new blog.
|
||||
|
||||
### Minutes 5-10: Theme your blog
|
||||
|
||||
With Hugo, you can either theme your blog yourself or use one of the beautiful, ready-made [themes][4]. I chose [Kiera][5] because it is deliciously simple. To install the theme:
|
||||
|
||||
1. Change into the themes directory: `cd themes`.
|
||||
2. Clone your theme: `git clone https://github.com/avianto/hugo-kiera kiera`. If you do not have Git installed:
|
||||
* Download the .zip file from [GitHub][5].
|
||||
* Unzip it to your site's `themes` directory.
|
||||
* Rename the directory from `hugo-kiera-master` to `kiera`.
|
||||
3. Change the directory to the awesome-blog level: `cd awesome-blog`.
|
||||
4. Activate the theme. Themes (including Kiera) often come with a directory called `exampleSite`, which contains example content and an example settings file. To activate Kiera, copy the provided `config.toml` file to your blog:
|
||||
* On Unix: `cp themes/kiera/exampleSite/config.toml .`
|
||||
* On Windows: `copy themes\kiera\exampleSite\config.toml .`
|
||||
* Confirm `Yes` to override the old `config.toml`
|
||||
5. (Optional) You can start your server to visually verify the theme is activated: `hugo server -D` and access `http://localhost:1313` in your web browser. Once you've reviewed your blog, you can turn off the server by pressing `Ctrl+C` in the command line. Your blog is empty, but we're getting someplace. It should look something like this:
|
||||
|
||||

|
||||
|
||||
You have just themed your blog! You can find hundreds of beautiful themes on the official [Hugo themes][4] site.
|
||||
|
||||
### Minutes 10-20: Add content to your blog
|
||||
|
||||
Whereas a bowl is most useful when it is empty, this is not the case for a blog. In this step, you'll add content to your blog. Hugo and the Kiera theme simplify this process. To add your first post:
|
||||
|
||||
1. Article archetypes are templates for your content.
|
||||
2. Add theme archetypes to your blog site:
|
||||
* On Unix: `cp themes/kiera/archetypes/* archetypes/`
|
||||
* On Windows: `copy themes\kiera\archetypes\* archetypes\`
|
||||
* Confirm `Yes` to override the `default.md` archetype
|
||||
3. Create a new directory for your blog posts:
|
||||
* On Unix: `mkdir content/posts`
|
||||
* On Windows: `mkdir content\posts`
|
||||
4. Use Hugo to generate your post:
|
||||
* On Unix: `hugo new posts/first-post.md`
|
||||
* On Windows: `hugo new posts\first-post.md`
|
||||
5. Open the new post in a text editor of your choice:
|
||||
* On Unix: `gedit content/posts/first-post.md`
|
||||
* On Windows: `notepad content\posts\first-post.md`
|
||||
|
||||
|
||||
|
||||
At this point, you can go wild. Notice that your post consists of two sections. The first one is separated by `+++`. It contains metadata about your post, such as its title. In Hugo, this is called front matter. After the front matter, the article begins. Create the first post:
|
||||
```
|
||||
+++
|
||||
|
||||
title = "First Post"
|
||||
|
||||
date = 2018-03-03T13:23:10+01:00
|
||||
|
||||
draft = false
|
||||
|
||||
tags = ["Getting started"]
|
||||
|
||||
categories = []
|
||||
|
||||
+++
|
||||
|
||||
|
||||
|
||||
Hello Hugo world! No more excuses for having no blog or documentation now!
|
||||
|
||||
```
|
||||
|
||||
All you need to do now is start the server: `hugo server -D`. Open your browser and enter: `http://localhost:1313/`.
|
||||

|
||||
|
||||
### Minutes 20-30: Tweak your site
|
||||
|
||||
What we've done is great, but there are still a few niggles to iron out. For example, naming your site is simple:
|
||||
|
||||
1. Stop your server by pressing `Ctrl+C` on the command line.
|
||||
2. Open `config.toml` and edit settings such as the blog's title, copyright, name, your social network links, etc.
|
||||
|
||||
|
||||
|
||||
When you start your server again, you'll see your blog has a bit more personalization. One more basic thing is missing: menus. That's a quick fix as well. Back in `config.toml`, insert the following at the bottom:
|
||||
```
|
||||
[[menu.main]]
|
||||
|
||||
name = "Home" #Name in the navigation bar
|
||||
|
||||
weight = 10 #The larger the weight, the more on the right this item will be
|
||||
|
||||
url = "/" #URL address
|
||||
|
||||
[[menu.main]]
|
||||
|
||||
name = "Posts"
|
||||
|
||||
weight = 20
|
||||
|
||||
url = "/posts/"
|
||||
|
||||
```
|
||||
|
||||
This adds menus for Home and Posts. You still need an About page. Instead of referencing it from the `config.toml` file, reference it from a markdown file:
|
||||
|
||||
1. Create an About file: `hugo new about.md`. Notice that it's `about.md`, not `posts/about.md`. The About page is not a blog post, so you don't want it displayed in the Posts section.
|
||||
2. Open the file in a text editor and enter the following:
|
||||
|
||||
|
||||
```
|
||||
+++
|
||||
|
||||
title = "About"
|
||||
|
||||
date = 2018-03-03T13:50:49+01:00
|
||||
|
||||
menu = "main" #Display this page on the nav menu
|
||||
|
||||
weight = "30" #Right-most nav item
|
||||
|
||||
meta = "false" #Do not display tags or categories
|
||||
|
||||
+++
|
||||
|
||||
|
||||
|
||||
> Waves are the practice of the water. Shunryu Suzuki
|
||||
|
||||
```
|
||||
|
||||
When you start your Hugo server and open `http://localhost:1313/`, you should see your new blog ready to be used. (Check out [my example][6] on my GitHub page.) If you'd like to change the active style of menu items to make the padding slightly nicer (like the GitHub live version), apply [this patch][7] to your `themes/kiera/static/css/styles.css` file.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/start-blog-30-minutes-hugo
|
||||
|
||||
作者:[Marek Czernek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mczernek
|
||||
[1]:https://gohugo.io/
|
||||
[2]:https://github.com/gohugoio/hugo/releases
|
||||
[3]:https://gohugo.io/getting-started/installing/
|
||||
[4]:https://themes.gohugo.io/
|
||||
[5]:https://github.com/avianto/hugo-kiera
|
||||
[6]:https://m-czernek.github.io/awesome-blog/
|
||||
[7]:https://github.com/avianto/hugo-kiera/pull/18/files
|
||||
@ -1,182 +0,0 @@
|
||||
Manipulating Directories in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you are new to this series (and to Linux), [take a look at our first installment][1]. In that article, we worked our way through the tree-like structure of the Linux filesystem, or more precisely, the File Hierarchy Standard. I recommend reading through it to make sure you understand what you can and cannot safely touch. Because this time around, I’ll show how to get all touchy-feely with your directories.
|
||||
|
||||
### Making Directories
|
||||
|
||||
Let's get creative before getting destructive, though. To begin, open a terminal window and use `mkdir` to create a new directory like this:
|
||||
```
|
||||
mkdir <directoryname>
|
||||
|
||||
```
|
||||
|
||||
If you just put the directory name, the directory will appear hanging off the directory you are currently in. If you just opened a terminal, that will be your home directory. In a case like this, we say the directory will be created _relative_ to your current position:
|
||||
```
|
||||
$ pwd #This tells you where you are now -- see our first tutorial
|
||||
/home/<username>
|
||||
$ mkdir newdirectory #Creates /home/<username>/newdirectory
|
||||
|
||||
```
|
||||
|
||||
(Note that you do not have to type the text following the `#`. Text following the pound symbol `#` is considered a comment and is used to explain what is going on. It is ignored by the shell).
|
||||
|
||||
You can create a directory within an existing directory hanging off your current location by specifying it in the command line:
|
||||
```
|
||||
mkdir Documents/Letters
|
||||
|
||||
```
|
||||
|
||||
Will create the _Letters_ directory within the _Documents_ directory.
|
||||
|
||||
You can also create a directory above where you are by using `..` in the path. Say you move into the _Documents/Letters/_ directory you just created and you want to create a _Documents/Memos/_ directory. You can do:
|
||||
```
|
||||
cd Documents/Letters # Move into your recently created Letters/ directory
|
||||
mkdir ../Memos
|
||||
|
||||
```
|
||||
|
||||
Again, all of the above is done relative to you current position. This is called using a _relative path_.
|
||||
|
||||
You can also use an _absolute path_ to directories: This means telling `mkdir` where to put your directory in relation to the root (`/`) directory:
|
||||
```
|
||||
mkdir /home/<username>/Documents/Letters
|
||||
|
||||
```
|
||||
|
||||
Change `<username>` to your user name in the command above and it will be equivalent to executing `mkdir Documents/Letters` from your home directory, except that it will work from wherever you are located in the directory tree.
|
||||
|
||||
As a side note, regardless of whether you use a relative or an absolute path, if the command is successful, `mkdir` will create the directory silently, without any apparent feedback whatsoever. Only if there is some sort of trouble will `mkdir` print some feedback after you hit _[Enter]_.
|
||||
|
||||
As with most other command-line tools, `mkdir` comes with several interesting options. The `-p` option is particularly useful, as it lets you create directories within directories within directories, even if none exist. To create, for example, a directory for letters to your Mom within _Documents/_ , you could do:
|
||||
```
|
||||
mkdir -p Documents/Letters/Family/Mom
|
||||
|
||||
```
|
||||
|
||||
And `mkdir` will create the whole branch of directories above _Mom/_ and also the directory _Mom/_ for you, regardless of whether any of the parent directories existed before you issued the command.
|
||||
|
||||
You can also create several folders all at once by putting them one after another, separated by spaces:
|
||||
```
|
||||
mkdir Letters Memos Reports
|
||||
|
||||
```
|
||||
|
||||
will create the directories _Letters/_ , _Memos/_ and _Reports_ under the current directory.
|
||||
|
||||
### In space nobody can hear you scream
|
||||
|
||||
... Which brings us to the tricky question of spaces in directory names. Can you use spaces in directory names? Yes, you can. Is it advised you use spaces? No, absolutely not. Spaces make everything more complicated and, potentially, dangerous.
|
||||
|
||||
Say you want to create a directory called _letters mom/_. If you didn't know any better, you could type:
|
||||
```
|
||||
mkdir letters mom
|
||||
|
||||
```
|
||||
|
||||
But this is WRONG! WRONG! WRONG! As we saw above, this will create two directories, _letters/_ and _mom/_ , but not _letters mom/_.
|
||||
|
||||
Agreed that this is a minor annoyance: all you have to do is delete the two directories and start over. No big deal.
|
||||
|
||||
But, wait! Deleting directories is where things get dangerous. Imagine you did create _letters mom/_ using a graphical tool, like, say [Dolphin][2] or [Nautilus][3]. If you suddenly decide to delete _letters mom/_ from a terminal, and you have another directory just called _letters/_ under the same directory, and said directory is full of important documents, and you tried this:
|
||||
```
|
||||
rmdir letters mom
|
||||
|
||||
```
|
||||
|
||||
You would risk removing _letters/_. I say "risk" because fortunately `rmdir`, the instruction used to remove directories, has a built in safeguard and will warn you if you try to delete a non-empty directory.
|
||||
|
||||
However, this:
|
||||
```
|
||||
rm -Rf letters mom
|
||||
|
||||
```
|
||||
|
||||
(and this is a pretty standard way of getting rid of directories and their contents) will completely obliterate _letters/_ and will never even tell you what just happened.
|
||||
|
||||
The `rm` command is used to delete files and directories. When you use it with the options `-R` (delete _recursively_ ) and `-f` ( _force_ deletion), it will burrow down into a directory and its subdirectories, deleting all the files they contain, then deleting the subdirectories themselves, then it will delete all the files in the top directory and then the directory itself.
|
||||
|
||||
`rm -Rf` is an instruction you must handle with extreme care.
|
||||
|
||||
My advice is, instead of spaces, use underscores (`_`), but if you still insist on spaces, there are two ways of getting them to work. You can use single or double quotes (`'` or `"`) like so:
|
||||
```
|
||||
mkdir 'letters mom'
|
||||
mkdir "letters dad"
|
||||
|
||||
```
|
||||
|
||||
Or, you can _escape_ the spaces. Some characters have a special meaning for the shell. Spaces, as you have seen, are used to separate options and arguments on the command line. "Separating options and arguments" falls under the category of "special meaning". When you want the shell to ignore the special meaning of a character, you need to _escape_ it and to escape a character, you put a backslash (`\`) in front of it:
|
||||
```
|
||||
mkdir letters\ mom
|
||||
mkdir letter\ dad
|
||||
|
||||
```
|
||||
|
||||
There are other special characters that would need escaping, like the apostrophe or single quote (`'`), double quotes (`"`), and the ampersand (`&`):
|
||||
```
|
||||
mkdir mom\ \&\ dad\'s\ letters
|
||||
|
||||
```
|
||||
|
||||
I know what you're thinking: If the backslash has a special meaning (to wit, telling the shell it has to escape the next character), that makes it a special character, too. Then, how would you escape the escape character which is `\`?
|
||||
|
||||
Turns out, the exact way you escape any other special character:
|
||||
```
|
||||
mkdir special\\characters
|
||||
|
||||
```
|
||||
|
||||
will produce a directory called _special\characters_.
|
||||
|
||||
Confusing? Of course. That's why you should avoid using special characters, including spaces, in directory names.
|
||||
|
||||
For the record, here is a list of special characters you can refer to just in case.
|
||||
|
||||
### Things to Remember
|
||||
|
||||
* Use `mkdir <directory name>` to create a new directory.
|
||||
* Use `rmdir <directory name>` to delete a directory (only works if it is empty).
|
||||
* Use `rm -Rf <directory name>` to annihilate a directory -- use with extreme caution.
|
||||
* Use a relative path to create directories relative to your current directory: `mkdir newdir.`.
|
||||
* Use an absolute path to create directories relative to the root directory (`/`): `mkdir /home/<username>/newdir`
|
||||
* Use `..` to create a directory in the directory above the current directory: `mkdir ../newdir`
|
||||
* You can create several directories all in one go by separating them with spaces on the command line: `mkdir onedir twodir threedir`
|
||||
* You can mix and mash relative and absolute paths when creating several directories simultaneously: `mkdir onedir twodir /home/<username>/threedir`
|
||||
* Using spaces and special characters in directory names guarantees plenty of headaches and heartburn. Don't do it.
|
||||
|
||||
|
||||
|
||||
For more information, you can look up the manuals of `mkdir`, `rmdir` and `rm`:
|
||||
```
|
||||
man mkdir
|
||||
man rmdir
|
||||
man rm
|
||||
|
||||
```
|
||||
|
||||
To exit the man pages, press _[q]_.
|
||||
|
||||
### Next Time
|
||||
|
||||
In the next installment, you'll learn about creating, modifying, and erasing files, as well as everything you need to know about permissions and privileges. See you then!
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][4]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/5/manipulating-directories-linux
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/4/linux-filesystem-explained
|
||||
[2]:https://userbase.kde.org/Dolphin
|
||||
[3]:https://projects-old.gnome.org/nautilus/screenshots.html
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,5 +1,3 @@
|
||||
translating by Auk7F7
|
||||
|
||||
How to Manage Fonts in Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,83 +0,0 @@
|
||||
Free Resources for Securing Your Open Source Code
|
||||
======
|
||||
|
||||

|
||||
|
||||
While the widespread adoption of open source continues at a healthy rate, the recent [2018 Open Source Security and Risk Analysis Report][1] from Black Duck and Synopsys reveals some common concerns and highlights the need for sound security practices. The report examines findings from the anonymized data of over 1,100 commercial codebases with represented Industries from automotive, Big Data, enterprise software, financial services, healthcare, IoT, manufacturing, and more.
|
||||
|
||||
The report highlights a massive uptick in open source adoption, with 96 percent of the applications scanned containing open source components. However, the report also includes warnings about existing vulnerabilities. Among the [findings][2]:
|
||||
|
||||
* “What is worrisome is that 78 percent of the codebases examined contained at least one open source vulnerability, with an average 64 vulnerabilities per codebase.”
|
||||
|
||||
* “Over 54 percent of the vulnerabilities found in audited codebases are considered high-risk vulnerabilities.”
|
||||
|
||||
* Seventeen percent of the codebases contained a highly publicized vulnerability such as Heartbleed, Logjam, Freak, Drown, or Poodle.
|
||||
|
||||
|
||||
|
||||
|
||||
"The report clearly demonstrates that with the growth in open source use, organizations need to ensure they have the tools to detect vulnerabilities in open source components and manage whatever license compliance their use of open source may require," said Tim Mackey, technical evangelist at Black Duck by Synopsys.
|
||||
|
||||
Indeed, with ever more impactful security threats emerging,the need for fluency with security tools and practices has never been more pronounced. Most organizations are aware that network administrators and sysadmins need to have strong security skills, and, in many cases security certifications. [In this article,][3] we explored some of the tools, certifications and practices that many of them wisely embrace.
|
||||
|
||||
The Linux Foundation has also made available many informational and educational resources on security. Likewise, the Linux community offers many free resources for specific platforms and tools. For example, The Linux Foundation has published a [Linux workstation security checklist][4] that covers a lot of good ground. Online publications ranging from the [Fedora security guide][5] to the[Securing Debian Manual][6] can also help users protect against vulnerabilities within specific platforms.
|
||||
|
||||
The widespread use of cloud platforms such as OpenStack is also stepping up the need for cloud-centric security smarts. According to The Linux Foundation’s[Guide to the Open Cloud][7]: “Security is still a top concern among companies considering moving workloads to the public cloud, according to Gartner, despite a strong track record of security and increased transparency from cloud providers. Rather, security is still an issue largely due to companies’ inexperience and improper use of cloud services.”
|
||||
|
||||
For both organizations and individuals, the smallest holes in implementation of routers, firewalls, VPNs, and virtual machines can leave room for big security problems. Here is a collection of free tools that can plug these kinds of holes:
|
||||
|
||||
* [Wireshark][8], a packet analyzer
|
||||
|
||||
* [KeePass Password Safe][9], a free open source password manager
|
||||
|
||||
* [Malwarebytes][10], a free anti-malware and antivirus tool
|
||||
|
||||
* [NMAP][11], a powerful security scanner
|
||||
|
||||
* [NIKTO][12], an open source web server scanner
|
||||
|
||||
* [Ansible][13], a tool for automating secure IT provisioning
|
||||
|
||||
* [Metasploit][14], a tool for understanding attack vectors and doing penetration testing
|
||||
|
||||
|
||||
|
||||
|
||||
Instructional videos abound for these tools. You’ll find a whole[tutorial series][15] for Metasploit, and [video tutorials][16] for Wireshark. Quite a few free ebooks provide good guidance on security as well. For example, one of the common ways for security threats to invade open source platforms occurs in M&A scenarios, where technology platforms are merged—often without proper open source audits. In an ebook titled [Open Source Audits in Merger and Acquisition Transactions][17], from Ibrahim Haddad and The Linux Foundation, you’ll find an overview of the open source audit process and important considerations for code compliance, preparation, and documentation.
|
||||
|
||||
Meanwhile, we’ve[previously covered][18] a free ebook from the editors at[The New Stack][19] called Networking, Security & Storage with Docker & Containers. It covers the latest approaches to secure container networking, as well as native efforts by Docker to create efficient and secure networking practices. The ebook is loaded with best practices for locking down security at scale.
|
||||
|
||||
All of these tools and resources, and many more, can go a long way toward preventing security problems, and an ounce of prevention is, as they say, worth a pound of cure. With security breaches continuing, now is an excellent time to look into the many security and compliance resources for open source tools and platforms available. Learn more about security, compliance, and open source project health [here][20].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/5/free-resources-securing-your-open-source-code
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.blackducksoftware.com/open-source-security-risk-analysis-2018
|
||||
[2]:https://www.prnewswire.com/news-releases/synopsys-report-finds-majority-of-software-plagued-by-known-vulnerabilities-and-license-conflicts-as-open-source-adoption-soars-300648367.html
|
||||
[3]:https://www.linux.com/blog/sysadmin-ebook/2017/8/future-proof-your-sysadmin-career-locking-down-security
|
||||
[4]:http://go.linuxfoundation.org/ebook_workstation_security
|
||||
[5]:https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html
|
||||
[6]:https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html
|
||||
[7]:https://www.linux.com/publications/2016-guide-open-cloud
|
||||
[8]:https://www.wireshark.org/
|
||||
[9]:http://keepass.info/
|
||||
[10]:https://www.malwarebytes.com/
|
||||
[11]:http://searchsecurity.techtarget.co.uk/tip/Nmap-tutorial-Nmap-scan-examples-for-vulnerability-discovery
|
||||
[12]:https://cirt.net/Nikto2
|
||||
[13]:https://www.ansible.com/
|
||||
[14]:https://www.metasploit.com/
|
||||
[15]:http://www.computerweekly.com/tutorial/The-Metasploit-Framework-Tutorial-PDF-compendium-Your-ready-reckoner
|
||||
[16]:https://www.youtube.com/watch?v=TkCSr30UojM
|
||||
[17]:https://www.linuxfoundation.org/resources/open-source-audits-merger-acquisition-transactions/
|
||||
[18]:https://www.linux.com/news/networking-security-storage-docker-containers-free-ebook-covers-essentials
|
||||
[19]:http://thenewstack.io/ebookseries/
|
||||
[20]:https://www.linuxfoundation.org/projects/security-compliance/
|
||||
@ -1,308 +0,0 @@
|
||||
translating by Flowsnow
|
||||
What is behavior-driven Python?
|
||||
======
|
||||

|
||||
Have you heard about [behavior-driven development][1] (BDD) and wondered what all the buzz is about? Maybe you've caught team members talking in "gherkin" and felt left out of the conversation. Or perhaps you're a Pythonista looking for a better way to test your code. Whatever the circumstance, learning about BDD can help you and your team achieve better collaboration and test automation, and Python's `behave` framework is a great place to start.
|
||||
|
||||
### What is BDD?
|
||||
|
||||
* Submitting forms on a website
|
||||
* Searching for desired results
|
||||
* Saving a document
|
||||
* Making REST API calls
|
||||
* Running command-line interface commands
|
||||
|
||||
|
||||
|
||||
In software, a behavior is how a feature operates within a well-defined scenario of inputs, actions, and outcomes. Products can exhibit countless behaviors, such as:
|
||||
|
||||
Defining a product's features based on its behaviors makes it easier to describe them, develop them, and test them. This is the heart of BDD: making behaviors the focal point of software development. Behaviors are defined early in development using a [specification by example][2] language. One of the most common behavior spec languages is [Gherkin][3], the Given-When-Then scenario format from the [Cucumber][4] project. Behavior specs are basically plain-language descriptions of how a behavior works, with a little bit of formal structure for consistency and focus. Test frameworks can easily automate these behavior specs by "gluing" step texts to code implementations.
|
||||
|
||||
Below is an example of a behavior spec written in Gherkin:
|
||||
```
|
||||
Scenario: Basic DuckDuckGo Search
|
||||
|
||||
Given the DuckDuckGo home page is displayed
|
||||
|
||||
When the user searches for "panda"
|
||||
|
||||
Then results are shown for "panda"
|
||||
|
||||
```
|
||||
|
||||
At a quick glance, the behavior is intuitive to understand. Except for a few keywords, the language is freeform. The scenario is concise yet meaningful. A real-world example illustrates the behavior. Steps declaratively indicate what should happen—without getting bogged down in the details of how.
|
||||
|
||||
The [main benefits of BDD][5] are good collaboration and automation. Everyone can contribute to behavior development, not just programmers. Expected behaviors are defined and understood from the beginning of the process. Tests can be automated together with the features they cover. Each test covers a singular, unique behavior in order to avoid duplication. And, finally, existing steps can be reused by new behavior specs, creating a snowball effect.
|
||||
|
||||
### Python's behave framework
|
||||
|
||||
`behave` is one of the most popular BDD frameworks in Python. It is very similar to other Gherkin-based Cucumber frameworks despite not holding the official Cucumber designation. `behave` has two primary layers:
|
||||
|
||||
1. Behavior specs written in Gherkin `.feature` files
|
||||
2. Step definitions and hooks written in Python modules that implement Gherkin steps
|
||||
|
||||
|
||||
|
||||
As shown in the example above, Gherkin scenarios use a three-part format:
|
||||
|
||||
1. Given some initial state
|
||||
2. When an action is taken
|
||||
3. Then verify the outcome
|
||||
|
||||
|
||||
|
||||
Each step is "glued" by decorator to a Python function when `behave` runs tests.
|
||||
|
||||
### Installation
|
||||
|
||||
As a prerequisite, make sure you have Python and `pip` installed on your machine. I strongly recommend using Python 3. (I also recommend using [`pipenv`][6], but the following example commands use the more basic `pip`.)
|
||||
|
||||
Only one package is required for `behave`:
|
||||
```
|
||||
pip install behave
|
||||
|
||||
```
|
||||
|
||||
Other packages may also be useful, such as:
|
||||
```
|
||||
pip install requests # for REST API calls
|
||||
|
||||
pip install selenium # for Web browser interactions
|
||||
|
||||
```
|
||||
|
||||
The [behavior-driven-Python][7] project on GitHub contains the examples used in this article.
|
||||
|
||||
### Gherkin features
|
||||
|
||||
The Gherkin syntax that `behave` uses is practically compliant with the official Cucumber Gherkin standard. A `.feature` file has Feature sections, which in turn have Scenario sections with Given-When-Then steps. Below is an example:
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
|
||||
As a gardener,
|
||||
|
||||
I want to carry many cucumbers in a basket,
|
||||
|
||||
So that I don’t drop them all.
|
||||
|
||||
|
||||
|
||||
@cucumber-basket
|
||||
|
||||
Scenario: Add and remove cucumbers
|
||||
|
||||
Given the basket is empty
|
||||
|
||||
When "4" cucumbers are added to the basket
|
||||
|
||||
And "6" more cucumbers are added to the basket
|
||||
|
||||
But "3" cucumbers are removed from the basket
|
||||
|
||||
Then the basket contains "7" cucumbers
|
||||
|
||||
```
|
||||
|
||||
There are a few important things to note here:
|
||||
|
||||
* Both the Feature and Scenario sections have [short, descriptive titles][8].
|
||||
* The lines immediately following the Feature title are comments ignored by `behave`. It is a good practice to put the user story there.
|
||||
* Scenarios and Features can have tags (notice the `@cucumber-basket` mark) for hooks and filtering (explained below).
|
||||
* Steps follow a [strict Given-When-Then order][9].
|
||||
* Additional steps can be added for any type using `And` and `But`.
|
||||
* Steps can be parametrized with inputs—notice the values in double quotes.
|
||||
|
||||
|
||||
|
||||
Scenarios can also be written as templates with multiple input combinations by using a Scenario Outline:
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
|
||||
|
||||
|
||||
@cucumber-basket
|
||||
|
||||
Scenario Outline: Add cucumbers
|
||||
|
||||
Given the basket has “<initial>” cucumbers
|
||||
|
||||
When "<more>" cucumbers are added to the basket
|
||||
|
||||
Then the basket contains "<total>" cucumbers
|
||||
|
||||
|
||||
|
||||
Examples: Cucumber Counts
|
||||
|
||||
| initial | more | total |
|
||||
|
||||
| 0 | 1 | 1 |
|
||||
|
||||
| 1 | 2 | 3 |
|
||||
|
||||
| 5 | 4 | 9 |
|
||||
|
||||
```
|
||||
|
||||
Scenario Outlines always have an Examples table, in which the first row gives column titles and each subsequent row gives an input combo. The row values are substituted wherever a column title appears in a step surrounded by angle brackets. In the example above, the scenario will be run three times because there are three rows of input combos. Scenario Outlines are a great way to avoid duplicate scenarios.
|
||||
|
||||
There are other elements of the Gherkin language, but these are the main mechanics. To learn more, read the Automation Panda articles [Gherkin by Example][10] and [Writing Good Gherkin][11].
|
||||
|
||||
### Python mechanics
|
||||
|
||||
Every Gherkin step must be "glued" to a step definition, a Python function that provides the implementation. Each function has a step type decorator with the matching string. It also receives a shared context and any step parameters. Feature files must be placed in a directory named `features/`, while step definition modules must be placed in a directory named `features/steps/`. Any feature file can use step definitions from any module—they do not need to have the same names. Below is an example Python module with step definitions for the cucumber basket features.
|
||||
```
|
||||
from behave import *
|
||||
|
||||
from cucumbers.basket import CucumberBasket
|
||||
|
||||
|
||||
|
||||
@given('the basket has "{initial:d}" cucumbers')
|
||||
|
||||
def step_impl(context, initial):
|
||||
|
||||
context.basket = CucumberBasket(initial_count=initial)
|
||||
|
||||
|
||||
|
||||
@when('"{some:d}" cucumbers are added to the basket')
|
||||
|
||||
def step_impl(context, some):
|
||||
|
||||
context.basket.add(some)
|
||||
|
||||
|
||||
|
||||
@then('the basket contains "{total:d}" cucumbers')
|
||||
|
||||
def step_impl(context, total):
|
||||
|
||||
assert context.basket.count == total
|
||||
|
||||
```
|
||||
|
||||
Three [step matchers][12] are available: `parse`, `cfparse`, and `re`. The default and simplest marcher is `parse`, which is shown in the example above. Notice how parametrized values are parsed and passed into the functions as input arguments. A common best practice is to put double quotes around parameters in steps.
|
||||
|
||||
Each step definition function also receives a [context][13] variable that holds data specific to the current scenario being run, such as `feature`, `scenario`, and `tags` fields. Custom fields may be added, too, to share data between steps. Always use context to share data—never use global variables!
|
||||
|
||||
`behave` also supports [hooks][14] to handle automation concerns outside of Gherkin steps. A hook is a function that will be run before or after a step, scenario, feature, or whole test suite. Hooks are reminiscent of [aspect-oriented programming][15]. They should be placed in a special `environment.py` file under the `features/` directory. Hook functions can check the current scenario's tags, as well, so logic can be selectively applied. The example below shows how to use hooks to set up and tear down a Selenium WebDriver instance for any scenario tagged as `@web`.
|
||||
```
|
||||
from selenium import webdriver
|
||||
|
||||
|
||||
|
||||
def before_scenario(context, scenario):
|
||||
|
||||
if 'web' in context.tags:
|
||||
|
||||
context.browser = webdriver.Firefox()
|
||||
|
||||
context.browser.implicitly_wait(10)
|
||||
|
||||
|
||||
|
||||
def after_scenario(context, scenario):
|
||||
|
||||
if 'web' in context.tags:
|
||||
|
||||
context.browser.quit()
|
||||
|
||||
```
|
||||
|
||||
Note: Setup and cleanup can also be done with [fixtures][16] in `behave`.
|
||||
|
||||
To offer an idea of what a `behave` project should look like, here's the example project's directory structure:
|
||||
|
||||
|
||||
|
||||
Any Python packages and custom modules can be used with `behave`. Use good design patterns to build a scalable test automation solution. Step definition code should be concise.
|
||||
|
||||
### Running tests
|
||||
|
||||
To run tests from the command line, change to the project's root directory and run the `behave` command. Use the `–help` option to see all available options.
|
||||
|
||||
Below are a few common use cases:
|
||||
```
|
||||
# run all tests
|
||||
|
||||
behave
|
||||
|
||||
|
||||
|
||||
# run the scenarios in a feature file
|
||||
|
||||
behave features/web.feature
|
||||
|
||||
|
||||
|
||||
# run all tests that have the @duckduckgo tag
|
||||
|
||||
behave --tags @duckduckgo
|
||||
|
||||
|
||||
|
||||
# run all tests that do not have the @unit tag
|
||||
|
||||
behave --tags ~@unit
|
||||
|
||||
|
||||
|
||||
# run all tests that have @basket and either @add or @remove
|
||||
|
||||
behave --tags @basket --tags @add,@remove
|
||||
|
||||
```
|
||||
|
||||
For convenience, options may be saved in [config][17] files.
|
||||
|
||||
### Other options
|
||||
|
||||
`behave` is not the only BDD test framework in Python. Other good frameworks include:
|
||||
|
||||
* `pytest-bdd` , a plugin for `pytest``behave`, it uses Gherkin feature files and step definition modules, but it also leverages all the features and plugins of `pytest`. For example, it can run Gherkin scenarios in parallel using `pytest-xdist`. BDD and non-BDD tests can also be executed together with the same filters. `pytest-bdd` also offers a more flexible directory layout.
|
||||
|
||||
* `radish` is a "Gherkin-plus" framework—it adds Scenario Loops and Preconditions to the standard Gherkin language, which makes it more friendly to programmers. It also offers rich command line options like `behave`.
|
||||
|
||||
* `lettuce` is an older BDD framework very similar to `behave`, with minor differences in framework mechanics. However, GitHub shows little recent activity in the project (as of May 2018).
|
||||
|
||||
|
||||
|
||||
Any of these frameworks would be good choices.
|
||||
|
||||
Also, remember that Python test frameworks can be used for any black box testing, even for non-Python products! BDD frameworks are great for web and service testing because their tests are declarative, and Python is a [great language for test automation][18].
|
||||
|
||||
This article is based on the author's [PyCon Cleveland 2018][19] talk, [Behavior-Driven Python][20].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/behavior-driven-python
|
||||
|
||||
作者:[Andrew Knight][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/andylpk247
|
||||
[1]:https://automationpanda.com/bdd/
|
||||
[2]:https://en.wikipedia.org/wiki/Specification_by_example
|
||||
[3]:https://automationpanda.com/2017/01/26/bdd-101-the-gherkin-language/
|
||||
[4]:https://cucumber.io/
|
||||
[5]:https://automationpanda.com/2017/02/13/12-awesome-benefits-of-bdd/
|
||||
[6]:https://docs.pipenv.org/
|
||||
[7]:https://github.com/AndyLPK247/behavior-driven-python
|
||||
[8]:https://automationpanda.com/2018/01/31/good-gherkin-scenario-titles/
|
||||
[9]:https://automationpanda.com/2018/02/03/are-gherkin-scenarios-with-multiple-when-then-pairs-okay/
|
||||
[10]:https://automationpanda.com/2017/01/27/bdd-101-gherkin-by-example/
|
||||
[11]:https://automationpanda.com/2017/01/30/bdd-101-writing-good-gherkin/
|
||||
[12]:http://behave.readthedocs.io/en/latest/api.html#step-parameters
|
||||
[13]:http://behave.readthedocs.io/en/latest/api.html#detecting-that-user-code-overwrites-behave-context-attributes
|
||||
[14]:http://behave.readthedocs.io/en/latest/api.html#environment-file-functions
|
||||
[15]:https://en.wikipedia.org/wiki/Aspect-oriented_programming
|
||||
[16]:http://behave.readthedocs.io/en/latest/api.html#fixtures
|
||||
[17]:http://behave.readthedocs.io/en/latest/behave.html#configuration-files
|
||||
[18]:https://automationpanda.com/2017/01/21/the-best-programming-language-for-test-automation/
|
||||
[19]:https://us.pycon.org/2018/
|
||||
[20]:https://us.pycon.org/2018/schedule/presentation/87/
|
||||
@ -1,5 +1,3 @@
|
||||
heart4lor translating
|
||||
|
||||
How to Build an Amazon Echo with Raspberry Pi
|
||||
======
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
How to create shortcuts in vi
|
||||
【sd886393认领翻译中】How to create shortcuts in vi
|
||||
======
|
||||
|
||||

|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
translating by amwps290
|
||||
Complete Sed Command Guide [Explained with Practical Examples]
|
||||
======
|
||||
In a previous article, I showed the [basic usage of Sed][1], the stream editor, on a practical use case. Today, be prepared to gain more insight about Sed as we will take an in-depth tour of the sed execution model. This will be also an opportunity to make an exhaustive review of all Sed commands and to dive into their details and subtleties. So, if you are ready, launch a terminal, [download the test files][2] and sit comfortably before your keyboard: we will start our exploration right now!
|
||||
|
||||
@ -1,154 +0,0 @@
|
||||
What's all the C Plus Fuss? Bjarne Stroustrup warns of dangerous future plans for his C++
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Interview** Earlier this year, Bjarne Stroustrup, creator of C++, managing director in the technology division of Morgan Stanley, and a visiting professor of computer science at Columbia University in the US, wrote [a letter][1] inviting those overseeing the evolution of the programming language to “Remember the Vasa!”
|
||||
|
||||
Easy for a Dane to understand no doubt, but perhaps more of a stretch for those with a few gaps in their knowledge of 17th century Scandinavian history. The Vasa was a Swedish warship, commissioned by King Gustavus Adolphus. It was the most powerful warship in the Baltic Sea from its maiden voyage on the August 10, 1628, until a few minutes later when it sank.
|
||||
|
||||
The formidable Vasa suffered from a design flaw: it was top-heavy, so much so that it was [undone by a gust of wind][2]. By invoking the memory of the capsized ship, Stroustrup served up a cautionary tale about the risks facing C++ as more and more features get added to the language.
|
||||
|
||||
Quite a few such features have been suggested. Stroustrup cited 43 proposals in his letter. He contends those participating in the evolution of the ISO standard language, a group known as [WG21][3], are working to advance the language but not together.
|
||||
|
||||
In his letter, he wrote:
|
||||
|
||||
>Individually, many proposals make sense. Together they are insanity to the point of endangering the future of C++.
|
||||
|
||||
He makes clear that he doesn’t interpret the fate of the Vasa to mean that incremental improvements spell doom. Rather, he takes it as a lesson to build a solid foundation, to learn from experience and to test thoroughly.
|
||||
|
||||
With the recent conclusion of the C++ Standardization Committee Meeting in Rapperswil, Switzerland, earlier this month, Stroustrup addressed a few questions put to him by _The Register_ about what's next for the language. (The most recent version is C++17, which arrived last year; the next version C++20 is under development and expected in 2020.)
|
||||
|
||||
**_Register:_ In your note, Remember the Vasa!, you wrote:**
|
||||
|
||||
>The foundation begun in C++11 is not yet complete, and C++17 did little to make our foundation more solid, regular, and complete. Instead, it added significant surface complexity and increased the number of features people need to learn. C++ could crumble under the weight of these – mostly not quite fully-baked – proposals. We should not spend most our time creating increasingly complicated facilities for experts, such as ourselves.
|
||||
|
||||
**Is C++ too challenging for newcomers, and if so, what features do you believe would make the language more accessible?**
|
||||
|
||||
_**Stroustrup:**_ Some parts of C++ are too challenging for newcomers.
|
||||
|
||||
On the other hand, there are parts of C++ that makes it far more accessible to newcomers than C or 1990s C++. The difficulty is to get the larger community to focus on those parts and help beginners and casual C++ users to avoid the parts that are there to support implementers of advanced libraries.
|
||||
|
||||
I recommend the [C++ Core Guidelines][4] as an aide for that.
|
||||
|
||||
Also, my “A Tour of C++” can help people get on the right track with modern C++ without getting lost in 1990s complexities or ensnarled by modern facilities meant for expert use. The second edition of “A Tour of C++” covering C++17 and parts of C++20 is on its way to the stores.
|
||||
|
||||
I and others have taught C++ to 1st year university students with no previous programming experience in 3 months. It can be done as long as you don’t try to dig into every obscure corner of the language and focus on modern C++.
|
||||
|
||||
“Making simple things simple” is a long-term goal of mine. Consider the C++11 range-for loop:
|
||||
```
|
||||
for (int& x : v) ++x; // increment each element of the container v
|
||||
|
||||
```
|
||||
|
||||
where v can be just about any container. In C and C-style C++, that might look like this:
|
||||
```
|
||||
for (int i=0; i<MAX; i++) ++v[i]; // increment each element of the array v
|
||||
|
||||
```
|
||||
|
||||
Some people complained that adding the range-for loop made C++ more complicated, and they were obviously correct because it added a feature, but it made the _use_ of C++ simpler. It also eliminated some common errors with the use of the traditional for loop.
|
||||
|
||||
Another example is the C++11 standard thread library. It is far simpler to use and less error-prone than using the POSIX or Windows thread C APIs directly.
|
||||
|
||||
**_Register:_ How would you characterize the current state of the language?**
|
||||
|
||||
_**Stroustrup:**_ C++11 was a major improvement of C++ and C++14 completed that work. C++17 added quite a few features without offering much support for novel techniques. C++20 looks like it might become a major improvement. The state of compilers and standard-library implementations are excellent and very close to the latest standards. C++17 is already usable. The tool support is improving steadily. There are lots of third-party libraries and many new tools. Unfortunately, those can be hard to find.
|
||||
|
||||
The worries I expressed in the Vasa paper relate to the standards process that combines over-enthusiasm for novel facilities with perfectionism that delays significant improvements. “The best is the enemy of the good.” There were 160 participants at the June Rapperswil meeting. It is hard to keep a consistent focus in a group that large and diverse. There is also a tendency for experts to design more for themselves than for the community at large.
|
||||
|
||||
**Register: Is there a desired state for the language or rather do you strive simply for a desired adaptability to what programmers require at any given time?
|
||||
|
||||
**Stroustrup:** Both. I’d like to see C++ supporting a guaranteed completely type-safe and resource-safe style of programming. This should not be done by restricting applicability or adding cost, but by improved expressiveness and performance. I think it can be done and that the approach of giving programmers better (and easier to use) language facilities can get us there.
|
||||
|
||||
That end-goal will not be met soon or just through language design alone. We need a combination of improved language features, better libraries, static analysis, and rules for effective programming. The C++ Core Guidelines is part of my broad, long-term approach to improve the quality of C++ code.
|
||||
|
||||
**Register: Is there an identifiable threat to C++? If so, what form does that take? (e.g. slow evolution, the attraction of emerging low-level languages, etc...your note seems to suggest it may be too many proposals.)**
|
||||
|
||||
**Stroustrup:** Certainly; we have had 400 papers this year already. They are not all new proposals, of course. Many relate the necessary and unglamorous work on precisely specifying the language and its standard library, but the volume is getting unmanageable. You can find all the committee papers on the WG21 website.
|
||||
|
||||
I wrote the “Remember the Vasa!” as a call to action. I am scared of the pressure to add language features to address immediate needs and fashions, rather than to strengthen the language foundations (e.g. improving the static type system). Adding anything new, however minor carries a cost, such as implementation, teaching, tools upgrades. Major features are those that change the way we think about programming. Those are the ones we must concentrate on.
|
||||
|
||||
The committee has established a “Direction Group” of experienced people with strong track records in many areas of the language, the standard library, implementation, and real-word use. I’m a member and we wrote up something on direction, design philosophy, and suggested areas of emphasis.
|
||||
|
||||
For C++20, we recommend to focus on:
|
||||
|
||||
Concepts
|
||||
Modules (offering proper modularity and dramatic compile-time improvements)
|
||||
Ranges (incl. some of the infinite sequence extensions)
|
||||
Networking Concepts in the standard library
|
||||
|
||||
After the Rappwerwil meeting, the odds are reasonable, though getting modules and networking is obviously a stretch. I’m an optimist and the committee members are working very hard.
|
||||
|
||||
I don’t worry about other languages or new languages. I like programming languages. If a new language offers something useful that other languages don’t, it has a role and we can all learn from it. And then, of course, each language has its own problems. Many of C++’s problems relate to its very wide range of application areas, its very large and diverse user population, and overenthusiasm. Most language communities would love to have such problems.
|
||||
|
||||
**Register: Are there any architectural decisions about the language you've reconsidered?**
|
||||
|
||||
**Stroustrup:** I always consider older decisions and designs when I work on something new. For example, see my History of Programming papers 1, 2.
|
||||
|
||||
There are no major decisions I regret, though there is hardly any feature I wouldn’t do somewhat differently if I had to do it again.
|
||||
|
||||
As ever, the ability to deal directly with hardware plus zero-overhead abstraction is the guiding idea. The use of constructors and destructors to handle resources is key (RAII) and the STL is a good example of what can be done in a C++ library.
|
||||
|
||||
**Register: Does the three-year release cadence, adopted in 2011 it seems, still work? I ask because Java has been dealing with a desire for faster iteration.**
|
||||
|
||||
**Stroustrup:** I think C++20 will be delivered on time (like C++14 and C++17 were) and that the major compilers will conform to it almost instantly. I also hope that C++20 will be a major improvement over C++17.
|
||||
|
||||
I don’t worry too much about how other languages manage their releases. C++ is controlled by a committee working under ISO rules, rather by a corporation or a “beneficent dictator for life.” This will not change. For ISO standards, C++’s three-year cycle is a dramatic innovation. The standard is 5- or 10-year cycles.
|
||||
|
||||
**Register: In your note you wrote:**
|
||||
|
||||
We need a reasonably coherent language that can be used by 'ordinary programmers' whose main concern is to ship great applications on time.
|
||||
|
||||
Are changes to the language sufficient to address this or might this also involve more accessible tooling and educational support?
|
||||
|
||||
**Stroustrup:** I try hard to communicate my ideas of what C++ is and how it might be used and I encourage others to do the same.
|
||||
|
||||
In particular, I encourage presenters and authors to make useful ideas accessible to the great mass of C++ programmers, rather than demonstrating how clever they are by presenting complicated examples and techniques. My 2017 CppCon keynote was “Learning and Teaching C++” and it also pointed to the need for better tools.
|
||||
|
||||
I mentioned build support and package managers. Those have traditionally been areas of weakness for C++. The standards committee now has a tools Study Group and will probably soon have an Education Study group.
|
||||
|
||||
The C++ community has traditionally been completely disorganized, but over the last five years many more meetings and blogs have sprung up to satisfy the community’s appetite for news and support. CppCon, isocpp.org, and Meeting++ are examples.
|
||||
|
||||
Design in a committee is very hard. However committees are a fact of life in all large projects. I am concerned, but being concerned and facing up to the problems is necessary for success.
|
||||
|
||||
**Register: How would you characterize the C++ community process? Are there aspects of the communication and decision making procedure that you'd like to see change?**
|
||||
|
||||
**Stroustrup:** C++ doesn’t have a corporately controlled “community process”; it has an ISO standards process. We can’t significantly change the ISO rules. Ideally, we’d have a small full-time “secretariat” making the final decisions and setting directions, but that’s not going to happen. Instead, we have hundreds of people discussion on-line, about 160 people voting on technical issues, about 70 organizations and 11 nations formally voting on the resulting proposals. That’s messy, but sometimes we make it work.
|
||||
|
||||
**Register: Finally, what upcoming C++ features do you feel will be most beneficial for C++ users?**
|
||||
|
||||
**Stroustrup:**
|
||||
|
||||
+ Concepts to significantly simplify generic programming
|
||||
+ _Parallel algorithms – there is no easier way to use the power of the concurrency features of modern hardware
|
||||
+ Coroutines, if the committee can decide on those for C++20.
|
||||
+ Modules to improve the way organize our source code and dramatically improve compile times. I hope we can get such modules, but it is not yet certain that we can do that for C++20.
|
||||
+ A standard networking library, but it is not yet certain that we can do that for C++20.
|
||||
|
||||
In addition:
|
||||
|
||||
+ Contracts (run-time checked pre-conditions, post-conditions, and assertions) could become significant for many.
|
||||
+ The date and time-zone support library will be significant for many (in industry).
|
||||
|
||||
**Register: Is there anything else you'd like to add?**
|
||||
|
||||
**Stroustrup:** If the C++ standards committee can focus on major issues to solve major problems, C++20 will be great. Until then, we have C++17 that is still far better than many people’s outdated impressions of C++. ®
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.theregister.co.uk/2018/06/18/bjarne_stroustrup_c_plus_plus/
|
||||
|
||||
作者:[Thomas Claburn][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theregister.co.uk/Author/3190
|
||||
[1]:http://open-std.org/JTC1/SC22/WG21/docs/papers/2018/p0977r0.pdf
|
||||
[2]:https://www.vasamuseet.se/en/vasa-history/disaster
|
||||
[3]:http://open-std.org/JTC1/SC22/WG21/
|
||||
[4]:https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md
|
||||
[5]:https://go.theregister.co.uk/tl/1755/shttps://continuouslifecycle.london/
|
||||
@ -1,226 +0,0 @@
|
||||
LuMing translating
|
||||
How To Configure SSH Key-based Authentication In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
### What is SSH Key-based authentication?
|
||||
|
||||
As we all know, **Secure Shell** , shortly **SSH** , is the cryptographic network protocol that allows you to securely communicate/access a remote system over unsecured network, for example Internet. Whenever you send a data over an unsecured network using SSH, the data will be automatically encrypted in the source system, and decrypted in the destination side. SSH provides four authentication methods namely **password-based authentication** , **key-based authentication** , **Host-based authentication** , and **Keyboard authentication**. The most commonly used authentication methods are password-based and key-based authentication.
|
||||
|
||||
In password-based authentication, all you need is the password of the remote system’s user. If you know the password of remote user, you can access the respective system using **“ssh[[email protected]][1]”**. On the other hand, in key-based authentication, you need to generate SSH key pairs and upload the SSH public key to the remote system in order to communicate it via SSH. Each SSH key pair consists of a private key and public key. The private key should be kept within the client system, and the public key should uploaded to the remote systems. You shouldn’t disclose the private key to anyone. Hope you got the basic idea about SSH and its authentication methods.
|
||||
|
||||
In this tutorial, we will be discussing how to configure SSH key-based authentication in Linux.
|
||||
|
||||
### Configure SSH Key-based Authentication In Linux
|
||||
|
||||
For the purpose of this guide, I will be using Arch Linux system as local system and Ubuntu 18.04 LTS as remote system.
|
||||
|
||||
Local system details:
|
||||
|
||||
* **OS** : Arch Linux Desktop
|
||||
* **IP address** : 192.168.225.37 /24
|
||||
|
||||
|
||||
|
||||
Remote system details:
|
||||
|
||||
* **OS** : Ubuntu 18.04 LTS Server
|
||||
* **IP address** : 192.168.225.22/24
|
||||
|
||||
|
||||
|
||||
### Local system configuration
|
||||
|
||||
Like I said already, in SSH key-based authentication method, the public key should be uploaded to the remote system that you want to access via SSH. The public keys will usually be stored in a file called **~/.ssh/authorized_keys** in the remote SSH systems.
|
||||
|
||||
**Important note:** Do not generate key pairs as **root** , as only root would be able to use those keys. Create key pairs as normal user.
|
||||
|
||||
Now, let us create the SSH key pair in the local system. To do so, run the following command in your client system.
|
||||
```
|
||||
$ ssh-keygen
|
||||
|
||||
```
|
||||
|
||||
The above command will create 2048 bit RSA key pair. Enter the passphrase twice. More importantly, Remember your passphrase. You’ll need it later.
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/home/sk/.ssh/id_rsa):
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in /home/sk/.ssh/id_rsa.
|
||||
Your public key has been saved in /home/sk/.ssh/id_rsa.pub.
|
||||
The key fingerprint is:
|
||||
SHA256:wYOgvdkBgMFydTMCUI3qZaUxvjs+p2287Tn4uaZ5KyE [email protected]
|
||||
The key's randomart image is:
|
||||
+---[RSA 2048]----+
|
||||
|+=+*= + |
|
||||
|o.o=.* = |
|
||||
|.oo * o + |
|
||||
|. = + . o |
|
||||
|. o + . S |
|
||||
| . E . |
|
||||
| + o |
|
||||
| +.*o+o |
|
||||
| .o*=OO+ |
|
||||
+----[SHA256]-----+
|
||||
|
||||
```
|
||||
|
||||
In case you have already created the key pair, you will see the following message. Just type “y” to create overwrite the existing key .
|
||||
```
|
||||
/home/username/.ssh/id_rsa already exists.
|
||||
Overwrite (y/n)?
|
||||
|
||||
```
|
||||
|
||||
Please note that **passphrase is optional**. If you give one, you’ll be asked to enter the password every time when you try to SSH a remote system unless you are using any SSH agent to store the password. If you don’t want passphrase(not safe though), simply press ENTER key twice when you’ll be asked to enter the passphrase. However, we recommend you to use passphrase. Using a password-less ssh key is generally not a good idea from a security point of view. They should be limited to very specific cases such as services having to access a remote system without the user intervention (e.g. remote backups with rsync, …).
|
||||
|
||||
If you already have a ssh key without a passphrase in private file **~/.ssh/id_rsa** and wanted to update key with passphrase, use the following command:
|
||||
```
|
||||
$ ssh-keygen -p -f ~/.ssh/id_rsa
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
Enter new passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved with the new passphrase.
|
||||
|
||||
```
|
||||
|
||||
Now, we have created the key pair in the local system. Now, copy the SSH public key to your remote SSH server using command:
|
||||
|
||||
Here, I will be copying the local (Arch Linux) system’s public key to the remote system (Ubuntu 18.04 LTS in my case). Technically speaking, the above command will copy the contents of local system’s **~/.ssh/id_rsa.pub key** into remote system’s **~/.ssh/authorized_keys** file. Clear? Good.
|
||||
|
||||
Type **yes** to continue connecting to your remote SSH server. And, then Enter the root user’s password of the remote system.
|
||||
```
|
||||
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
|
||||
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
|
||||
[email protected]2.168.225.22's password:
|
||||
|
||||
Number of key(s) added: 1
|
||||
|
||||
Now try logging into the machine, with: "ssh '[email protected]'"
|
||||
and check to make sure that only the key(s) you wanted were added.
|
||||
|
||||
```
|
||||
|
||||
If you have already copied the key, but want to update the key with new passphrase, use **-f** option to overwrite the existing key like below.
|
||||
|
||||
We have now successfully added the local system’s SSH public key to the remote system. Now, let us disable the password-based authentication completely in the remote system. Because, we have configured key-based authentication, so we don’t need password-base authentication anymore.
|
||||
|
||||
### Disable SSH Password-based authentication in remote system
|
||||
|
||||
You need to perform the following commands as root or sudo user.
|
||||
|
||||
To disable password-based authentication, go to your remote system’s console and edit **/etc/ssh/sshd_config** configuration file using any editor:
|
||||
```
|
||||
$ sudo vi /etc/ssh/sshd_config
|
||||
|
||||
```
|
||||
|
||||
Find the following line. Uncomment it and set it’s value as **no**.
|
||||
```
|
||||
PasswordAuthentication no
|
||||
|
||||
```
|
||||
|
||||
Restart ssh service to take effect the changes.
|
||||
```
|
||||
$ sudo systemctl restart sshd
|
||||
|
||||
```
|
||||
|
||||
### Access Remote system from local system
|
||||
|
||||
Go to your local system and SSH into your remote server using command:
|
||||
|
||||
Enter the passphrase.
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Enter passphrase for key '/home/sk/.ssh/id_rsa':
|
||||
Last login: Mon Jul 9 09:59:51 2018 from 192.168.225.37
|
||||
[email protected]:~$
|
||||
|
||||
```
|
||||
|
||||
Now, you’ll be able to SSH into your remote system. As you noticed, we have logged-in to the remote system’s account using passphrase which we created earlier using **ssh-keygen** command, not using the actual account’s password.
|
||||
|
||||
If you try to ssh from another client system, you will get this error message. Say for example, I am tried to SSH into my Ubuntu system from my CentOS using command:
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
The authenticity of host '192.168.225.22 (192.168.225.22)' can't be established.
|
||||
ECDSA key fingerprint is 67:fc:69:b7:d4:4d:fd:6e:38:44:a8:2f:08:ed:f4:21.
|
||||
Are you sure you want to continue connecting (yes/no)? yes
|
||||
Warning: Permanently added '192.168.225.22' (ECDSA) to the list of known hosts.
|
||||
Permission denied (publickey).
|
||||
|
||||
```
|
||||
|
||||
As you see in the above output, I can’t SSH into my remote Ubuntu 18.04 systems from any other systems, except the CentOS system.
|
||||
|
||||
### Adding more Client system’s keys to SSH server
|
||||
|
||||
This is very important. Like I said already, you can’t access the remote system via SSH, except the one you configured (In our case, it’s Ubuntu). I want to give permissions to more clients to access the remote SSH server. What should I do? Simple. You need to generate the SSH key pair in all your client systems and copy the ssh public key manually to the remote server that you want to access via SSH.
|
||||
|
||||
To create SSH key pair on your client system’s, run:
|
||||
```
|
||||
$ ssh-keygen
|
||||
|
||||
```
|
||||
|
||||
Enter the passphrase twice. Now, the ssh key pair is generated. You need to copy the public ssh key (not private key) to your remote server manually.
|
||||
|
||||
Display the pub key using command:
|
||||
```
|
||||
$ cat ~/.ssh/id_rsa.pub
|
||||
|
||||
```
|
||||
|
||||
You should an output something like below.
|
||||
|
||||
Copy the entire contents (via USB drive or any medium) and go to your remote server’s console. Create a directory called **ssh** in the home directory as shown below. You need to execute the following commands as root user.
|
||||
```
|
||||
$ mkdir -p ~/.ssh
|
||||
|
||||
```
|
||||
|
||||
Now, append the your client system’s pub key which you generated in the previous step in a file called
|
||||
```
|
||||
echo {Your_public_key_contents_here} >> ~/.ssh/authorized_keys
|
||||
|
||||
```
|
||||
|
||||
Restart ssh service on the remote system. Now, you’ll be able to SSH to your server from the new client.
|
||||
|
||||
If manually adding ssh pubkey seems difficult, enable password-based authentication temporarily in the remote system and copy the key using “ssh-copy-id” command from your local system and finally disable the password-based authentication.
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
And, that’s all for now. SSH Key-based authentication provides an extra layer protection from brute-force attacks. As you can see, configuring key-based authentication is not that difficult either. It is one of the recommended method to keep your Linux servers safe and secure.
|
||||
|
||||
I will be here soon with another useful article. Until then, stay tuned with OSTechNix.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/configure-ssh-key-based-authentication-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/cdn-cgi/l/email-protection
|
||||
@ -1,5 +1,3 @@
|
||||
bestony is translating
|
||||
|
||||
Becoming a senior developer: 9 experiences you'll encounter
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,84 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to build a URL shortener with Apache
|
||||
======
|
||||
|
||||

|
||||
|
||||
Long ago, folks started sharing links on Twitter. The 140-character limit meant that URLs might consume most (or all) of a tweet, so people turned to URL shorteners. Eventually, Twitter added a built-in URL shortener ([t.co][1]).
|
||||
|
||||
Character count isn't as important now, but there are still other reasons to shorten links. For one, the shortening service may provide analytics—you can see how popular the links are that you share. It also simplifies making easy-to-remember URLs. For example, [bit.ly/INtravel][2] is much easier to remember than <https://www.in.gov/ai/appfiles/dhs-countyMap/dhsCountyMap.html>. And URL shorteners can come in handy if you want to pre-share a link but don't know the final destination yet.
|
||||
|
||||
Like any technology, URL shorteners aren't all positive. By masking the ultimate destination, shortened links can be used to direct people to malicious or offensive content. But if you surf carefully, URL shorteners are a useful tool.
|
||||
|
||||
We [covered shorteners previously][3] on this site, but maybe you want to run something simple that's powered by a text file. In this article, we'll show how to use the Apache HTTP server's mod_rewrite feature to set up your own URL shortener. If you're not familiar with the Apache HTTP server, check out David Both's article on [installing and configuring][4] it.
|
||||
|
||||
### Create a VirtualHost
|
||||
|
||||
In this tutorial, I'm assuming you bought a cool domain that you'll use exclusively for the URL shortener. For example, my website is [funnelfiasco.com][5] , so I bought [funnelfias.co][6] to use for my URL shortener (okay, it's not exactly short, but it feeds my vanity). If you won't run the shortener as a separate domain, skip to the next section.
|
||||
|
||||
The first step is to set up the VirtualHost that will be used for the URL shortener. For more information on VirtualHosts, see [David Both's article][7]. This setup requires just a few basic lines:
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
|
||||
ServerName funnelfias.co
|
||||
|
||||
</VirtualHost>
|
||||
|
||||
```
|
||||
|
||||
### Create the rewrites
|
||||
|
||||
This service uses HTTPD's rewrite engine to rewrite the URLs. If you created a VirtualHost in the section above, the configuration below goes into your VirtualHost section. Otherwise, it goes in the VirtualHost or main HTTPD configuration for your server.
|
||||
```
|
||||
RewriteEngine on
|
||||
|
||||
RewriteMap shortlinks txt:/data/web/shortlink/links.txt
|
||||
|
||||
RewriteRule ^/(.+)$ ${shortlinks:$1} [R=temp,L]
|
||||
|
||||
```
|
||||
|
||||
The first line simply enables the rewrite engine. The second line builds a map of the short links from a text file. The path above is only an example; you will need to use a valid path on your system (make sure it's readable by the user account that runs HTTPD). The last line rewrites the URL. In this example, it takes any characters and looks them up in the rewrite map. You may want to have your rewrites use a particular string at the beginning. For example, if you wanted all your shortened links to be of the form "slX" (where X is a number), you would replace `(.+)` above with `(sl\d+)`.
|
||||
|
||||
I used a temporary (HTTP 302) redirect here. This allows me to update the destination URL later. If you want the short link to always point to the same target, you can use a permanent (HTTP 301) redirect instead. Replace `temp` on line three with `permanent`.
|
||||
|
||||
### Build your map
|
||||
|
||||
Edit the file you specified on the `RewriteMap` line of the configuration. The format is a space-separated key-value store. Put one link on each line:
|
||||
```
|
||||
osdc https://opensource.com/users/bcotton
|
||||
|
||||
twitter https://twitter.com/funnelfiasco
|
||||
|
||||
swody1 https://www.spc.noaa.gov/products/outlook/day1otlk.html
|
||||
|
||||
```
|
||||
|
||||
### Restart HTTPD
|
||||
|
||||
The last step is to restart the HTTPD process. This is done with `systemctl restart httpd` or similar (the command and daemon name may differ by distribution). Your link shortener is now up and running. When you're ready to edit your map, you don't need to restart the web server. All you have to do is save the file, and the web server will pick up the differences.
|
||||
|
||||
### Future work
|
||||
|
||||
This example gives you a basic URL shortener. It can serve as a good starting point if you want to develop your own management interface as a learning project. Or you can just use it to share memorable links to forgettable URLs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/apache-url-shortener
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:http://t.co
|
||||
[2]:http://bit.ly/INtravel
|
||||
[3]:https://opensource.com/article/17/3/url-link-shortener
|
||||
[4]:https://opensource.com/article/18/2/how-configure-apache-web-server
|
||||
[5]:http://funnelfiasco.com
|
||||
[6]:http://funnelfias.co
|
||||
[7]:https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
|
||||
@ -1,4 +1,3 @@
|
||||
Translating by leemeans
|
||||
Setting Up a Timer with systemd in Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
translating by wyxplus
|
||||
Building a network attached storage device with a Raspberry Pi
|
||||
======
|
||||
|
||||
|
||||
@ -1,81 +0,0 @@
|
||||
5 of the Best Linux Educational Software and Games for Kids
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux is a very powerful operating system, and that explains why it powers most of the servers on the Internet. Though it may not be the best OS in terms of user friendliness, its diversity is commendable. Everyone has their own need for Linux. Be it for coding, educational purposes or the internet of things (IoT), you’ll always find a suitable Linux distro for every use. To that end, many have dubbed Linux as the OS for future computing.
|
||||
|
||||
Because the future belongs to the kids of today, introducing them to Linux is the best way to prepare them for what the future holds. This OS may not have a reputation for popular games such as FIFA or PES; however, it offers the best educational software and games for kids. These are five of the best Linux educational software to keep your kids ahead of the game.
|
||||
|
||||
**Related** : [The Beginner’s Guide to Using a Linux Distro][1]
|
||||
|
||||
### 1. GCompris
|
||||
|
||||
If you’re looking for the best educational software for kids, [GCompris][2] should be your starting point. This software is specifically designed for kids education and is ideal for kids between two and ten years old. As the pinnacle of all Linux educational software suites for children, GCompris offers about 100 activities for kids. It packs everything you want for your kids from reading practice to science, geography, drawing, algebra, quizzes, and more.
|
||||
|
||||
![Linux educational software and games][3]
|
||||
|
||||
GCompris even has activities for helping your kids learn computer peripherals. If your kids are young and you want them to learn alphabets, colors, and shapes, GCompris has programmes for those, too. What’s more, it also comes with helpful games for kids such as chess, tic-tac-toe, memory, and hangman. GCompris is not a Linux-only app. It’s also available for Windows and Android.
|
||||
|
||||
### 2. TuxMath
|
||||
|
||||
Most students consider math a tough subject. You can change that perception by acquainting your kids with mathematical skills through Linux software applications such as [TuxMath][4]. TuxMath is a top-rated educational Math tutorial game for kids. In this game your role is to help Tux the penguin of Linux protect his planet from a rain of mathematical problems.
|
||||
|
||||
![linux-educational-software-tuxmath-1][5]
|
||||
|
||||
By finding the answer, you help Tux save the planet by destroying the asteroids with your laser before they make an impact. The difficulty of the math problems increases with each level you pass. This game is ideal for kids, as it can help them rack their brains for solutions. Besides making them good at math, it also helps them improve their mental agility.
|
||||
|
||||
### 3. Sugar on a Stick
|
||||
|
||||
[Sugar on a Stick][6] is a dedicated learning program for kids – a brand new pedagogy that has gained a lot of traction. This program provides your kids with a fully-fledged learning platform where they can gain skills in creating, exploring, discovering and also reflecting on ideas. Just like GCompris, Sugar on a Stick comes with a host of learning resources for kids, including games and puzzles.
|
||||
|
||||
![linux-educational-software-sugar-on-a-stick][7]
|
||||
|
||||
The best thing about Sugar on a Stick is that you can set it up on a USB Drive. All you need is an X86-based PC, then plug in the USB, and boot the distro from it. Sugar on a Stick is a project by Sugar Labs – a non-profit organization that is run by volunteers.
|
||||
|
||||
### 4. KDE Edu Suite
|
||||
|
||||
[KDE Edu Suite][8] is a package of software for different user purposes. With a host of applications from different fields, the KDE community has proven that it isn’t just serious about empowering adults; it also cares about bringing the young generation to speed with everything surrounding them. It comes packed with various applications for kids ranging from science to math, geography, and more.
|
||||
|
||||
![linux-educational-software-kde-1][9]
|
||||
|
||||
The KDE Suite can be used for adult needs based on necessities, as a school teaching software, or as a kid’s leaning app. It offers a huge software package and is free to download. The KDE Edu suite can be installed on most GNU/Linux Distros.
|
||||
|
||||
### 5. Tux Paint
|
||||
|
||||
![linux-educational-software-tux-paint-2][10]
|
||||
|
||||
[Tux Paint][11] is another great Linux educational software for kids. This award-winning drawing program is used in schools around the world to help children nurture the art of drawing. It comes with a clean, easy-to-use interface and fun sound effects that help children use the program. There is also an encouraging cartoon mascot that guides kids as they use the program. Tux Paint comes with a variety of drawing tools that help kids unleash their creativity.
|
||||
|
||||
### Summing Up
|
||||
|
||||
Due to the popularity of these educational software for kids, many institutions have embraced these programs as teaching aids in schools and kindergartens. A typical example is [Edubuntu][12], an Ubuntu-derived distro that is widely used by teachers and parents for educating kids.
|
||||
|
||||
Tux Paint is another great example that has grown in popularity over the years and is being used in schools to teach children how to draw. This list is by no means exhaustive. There are hundreds of other Linux educational software and games that can be very useful for your kids.
|
||||
|
||||
If you know of any other great Linux educational software and games for kids, share with us in the comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/5-best-linux-software-packages-for-kids/
|
||||
|
||||
作者:[Kenneth Kimari][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/kennkimari/
|
||||
[1]:https://www.maketecheasier.com/beginner-guide-to-using-linux-distro/ (The Beginner’s Guide to Using a Linux Distro)
|
||||
[2]:http://www.gcompris.net/downloads-en.html
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-gcompris.jpg (Linux educational software and games)
|
||||
[4]:https://tuxmath.en.uptodown.com/ubuntu
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tuxmath-1.jpg (linux-educational-software-tuxmath-1)
|
||||
[6]:http://wiki.sugarlabs.org/go/Sugar_on_a_Stick/Downloads
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-sugar-on-a-stick.png (linux-educational-software-sugar-on-a-stick)
|
||||
[8]:https://edu.kde.org/
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-kde-1.jpg (linux-educational-software-kde-1)
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tux-paint-2.jpg (linux-educational-software-tux-paint-2)
|
||||
[11]:http://www.tuxpaint.org/
|
||||
[12]:http://edubuntu.org/
|
||||
@ -1,221 +0,0 @@
|
||||
Automating backups on a Raspberry Pi NAS
|
||||
======
|
||||

|
||||
|
||||
In the [first part][1] of this three-part series using a Raspberry Pi for network-attached storage (NAS), we covered the fundamentals of the NAS setup, attached two 1TB hard drives (one for data and one for backups), and mounted the data drive on a remote device via the network filesystem (NFS). In part two, we will look at automating backups. Automated backups allow you to continually secure your data and recover from a hardware defect or accidental file removal.
|
||||
|
||||
|
||||
|
||||
### Backup strategy
|
||||
|
||||
Let's get started by coming up with with a backup strategy for our small NAS. I recommend creating daily backups of your data and scheduling them for a time they won't interfere with other NAS activities, including when you need to access or store your files. For example, you could trigger the backup activities each day at 2am.
|
||||
|
||||
You also need to decide how long you'll keep each backup, since you would quickly run out of storage if you kept each daily backup indefinitely. Keeping your daily backups for one week allows you to travel back into your recent history if you realize something went wrong over the previous seven days. But what if you need something from further in the past? Keeping each Monday backup for a month and one monthly backup for a longer period of time should be sufficient. Let's keep the monthly backups for a year and one backup every year for long-distance time travels, e.g., for the last five years.
|
||||
|
||||
This results in a bunch of backups on your backup drive over a five-year period:
|
||||
|
||||
* 7 daily backups
|
||||
* 4 (approx.) weekly backups
|
||||
* 12 monthly backups
|
||||
* 5 annual backups
|
||||
|
||||
|
||||
|
||||
You may recall that your backup drive and your data drive are of equal size (1TB each). How will more than 10 backups of 1TB from your data drive fit onto a 1TB backup disk? If you create full backups, they won't. Instead, you will create incremental backups, reusing the data from the last backup if it didn't change and creating replicas of new or changed files. That way, the backup doesn't double every night, but only grows a little bit depending on the changes that happen to your data over a day.
|
||||
|
||||
Here is my situation: My NAS has been running since August 2016, and 20 backups are on the backup drive. Currently, I store 406GB of files on the data drive. The backups take up 726GB on my backup drive. Of course, this depends heavily on your data's change frequency, but as you can see, the incremental backups don't consume as much space as 20 full backups would. Nevertheless, over time the 1TB disk will probably become insufficient for your backups. Once your data grows close to the 1TB limit (or whatever your backup drive capacity), you should choose a bigger backup drive and move your data there.
|
||||
|
||||
### Creating backups with rsync
|
||||
|
||||
To create a full backup, you can use the rsync command line tool. Here is an example command to create the initial full backup.
|
||||
```
|
||||
pi@raspberrypi:~ $ rsync -a /nas/data/ /nas/backup/2018-08-01
|
||||
|
||||
```
|
||||
|
||||
This command creates a full replica of all data stored on the data drive, mounted on `/nas/data`, on the backup drive. There, it will create the folder `2018-08-01` and create the backup inside it. The `-a` flag starts rsync in archive-mode, which means it preserves all kinds of metadata, like modification dates, permissions, and owners, and copies soft links as soft links.
|
||||
|
||||
Now that you have created your full, initial backup as of August 1, on August 2, you will create your first daily incremental backup.
|
||||
```
|
||||
pi@raspberrypi:~ $ rsync -a --link-dest /nas/backup/2018-08-01/ /nas/data/ /nas/backup/2018-08-02
|
||||
|
||||
```
|
||||
|
||||
This command tells rsync to again create a backup of `/nas/data`. The target directory this time is `/nas/backup/2018-08-02`. The script also specified the `--link-dest` option and passed the location of the last backup as an argument. With this option specified, rsync looks at the folder `/nas/backup/2018-08-01` and checks what data files changed compared to that folder's content. Unchanged files will not be copied, rather they will be hard-linked to their counterparts in yesterday's backup folder.
|
||||
|
||||
When using a hard-linked file from a backup, you won't notice any difference between the initial copy and the link. They behave exactly the same, and if you delete either the link or the initial file, the other will still exist. You can imagine them as two equal entry points to the same file. Here is an example:
|
||||
|
||||
|
||||
|
||||
The left box reflects the state shortly after the second backup. The box in the middle is yesterday's replica. The `file2.txt` didn't exist yesterday, but the image `file1.jpg` did and was copied to the backup drive. The box on the right reflects today's incremental backup. The incremental backup command created `file2.txt`, which didn't exist yesterday. Since `file1.jpg` didn't change since yesterday, today a hard link is created so it doesn't take much additional space on the disk.
|
||||
|
||||
### Automate your backups
|
||||
|
||||
You probably don't want to execute your daily backup command by hand at 2am each day. Instead, you can automate your backup by using a script like the following, which you may want to start with a cron job.
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
|
||||
TODAY=$(date +%Y-%m-%d)
|
||||
|
||||
DATADIR=/nas/data/
|
||||
|
||||
BACKUPDIR=/nas/backup/
|
||||
|
||||
SCRIPTDIR=/nas/data/backup_scripts
|
||||
|
||||
LASTDAYPATH=${BACKUPDIR}/$(ls ${BACKUPDIR} | tail -n 1)
|
||||
|
||||
TODAYPATH=${BACKUPDIR}/${TODAY}
|
||||
|
||||
if [[ ! -e ${TODAYPATH} ]]; then
|
||||
|
||||
mkdir -p ${TODAYPATH}
|
||||
|
||||
fi
|
||||
|
||||
|
||||
|
||||
rsync -a --link-dest ${LASTDAYPATH} ${DATADIR} ${TODAYPATH} $@
|
||||
|
||||
|
||||
|
||||
${SCRIPTDIR}/deleteOldBackups.sh
|
||||
|
||||
```
|
||||
|
||||
The first block calculates the last backup's folder name to use for links and the name of today's backup folder. The second block has the rsync command (as described above). The last block executes a `deleteOldBackups.sh` script. It will clean up the old, unnecessary backups based on the backup strategy outlined above. You could also execute the cleanup script independently from the backup script if you want it to run less frequently.
|
||||
|
||||
The following script is an example implementation of the backup strategy in this how-to article.
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
BACKUPDIR=/nas/backup/
|
||||
|
||||
|
||||
|
||||
function listYearlyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5
|
||||
|
||||
do ls ${BACKUPDIR} | egrep "$(date +%Y -d "${i} year ago")-[0-9]{2}-[0-9]{2}" | sort -u | head -n 1
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listMonthlyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5 6 7 8 9 10 11 12
|
||||
|
||||
do ls ${BACKUPDIR} | egrep "$(date +%Y-%m -d "${i} month ago")-[0-9]{2}" | sort -u | head -n 1
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listWeeklyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4
|
||||
|
||||
do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "last monday -${i} weeks")"
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listDailyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5 6
|
||||
|
||||
do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "-${i} day")"
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function getAllBackups() {
|
||||
|
||||
listYearlyBackups
|
||||
|
||||
listMonthlyBackups
|
||||
|
||||
listWeeklyBackups
|
||||
|
||||
listDailyBackups
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listUniqueBackups() {
|
||||
|
||||
getAllBackups | sort -u
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listBackupsToDelete() {
|
||||
|
||||
ls ${BACKUPDIR} | grep -v -e "$(echo -n $(listUniqueBackups) |sed "s/ /\\\|/g")"
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
cd ${BACKUPDIR}
|
||||
|
||||
listBackupsToDelete | while read file_to_delete; do
|
||||
|
||||
rm -rf ${file_to_delete}
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
This script will first list all the backups to keep (according to our backup strategy), then it will delete all the backup folders that are not necessary anymore.
|
||||
|
||||
To execute the scripts every night to create daily backups, schedule the backup script by running `crontab -e` as the root user. (You need to be in root to make sure it has permission to read all the files on the data drive, no matter who created them.) Add a line like the following, which starts the script every night at 2am.
|
||||
```
|
||||
0 2 * * * /nas/data/backup_scripts/daily.sh
|
||||
|
||||
```
|
||||
|
||||
For more information, read about [scheduling tasks with cron][2].
|
||||
|
||||
* Unmount your backup drive or mount it as read-only when no backups are running
|
||||
* Attach the backup drive to a remote server and sync the files over the internet
|
||||
|
||||
|
||||
|
||||
There are additional things you can do to fortify your backups against accidental removal or damage, including the following:
|
||||
|
||||
This example backup strategy enables you to back up your valuable data to make sure it won't get lost. You can also easily adjust this technique for your personal needs and preferences.
|
||||
|
||||
In part three of this series, we will talk about [Nextcloud][3], a convenient way to store and access data on your NAS system that also provides offline access as it synchronizes your data to the client devices.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/automate-backups-raspberry-pi
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ntlx
|
||||
[1]:https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
[2]:https://opensource.com/article/17/11/how-use-cron-linux
|
||||
[3]:https://nextcloud.com/
|
||||
@ -1,5 +1,3 @@
|
||||
translated by stephenxs
|
||||
|
||||
Top Linux developers' recommended programming books
|
||||
======
|
||||
Without question, Linux was created by brilliant programmers who employed good computer science knowledge. Let the Linux programmers whose names you know share the books that got them started and the technology references they recommend for today's developers. How many of them have you read?
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension)
|
||||
======
|
||||
A Unity feature that I miss (it only actually worked for a short while though) is automatically getting player controls in the Ubuntu Sound Indicator when visiting a website like YouTube in a web browser, so you could pause or stop the video directly from the top bar, as well as see the video / song information and a preview.
|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
An introduction to the Django Python web app framework
|
||||
======
|
||||
|
||||
|
||||
@ -1,108 +0,0 @@
|
||||
5 cool music player apps
|
||||
======
|
||||
|
||||

|
||||
Do you like music? Then Fedora may have just what you’re looking for. This article introduces different music player apps that run on Fedora. You’re covered whether you have an extensive music library, a small one, or none at all. Here are four graphical application and one terminal-based music player that will have you jamming.
|
||||
|
||||
### Quod Libet
|
||||
|
||||
Quod Libet is a complete manager for your large audio library. If you have an extensive audio library that you would like not just listen to, but also manage, Quod Libet might a be a good choice for you.
|
||||
|
||||
![][1]
|
||||
|
||||
Quod Libet can import music from multiple locations on your disk, and allows you to edit tags of the audio files — so everything is under your control. As a bonus, there are various plugins available for anything from a simple equalizer to a [last.fm][2] sync. You can also search and play music directly from [Soundcloud][3].
|
||||
|
||||
Quod Libet works great on HiDPI screens, and is available as an RPM in Fedora or on [Flathub][4] in case you run [Silverblue][5]. Install it using Gnome Software or the command line:
|
||||
```
|
||||
$ sudo dnf install quodlibet
|
||||
|
||||
```
|
||||
|
||||
### Audacious
|
||||
|
||||
If you like a simple music player that could even look like the legendary Winamp, Audacious might be a good choice for you.
|
||||
|
||||
![][6]
|
||||
|
||||
Audacious probably won’t manage all your music at once, but it works great if you like to organize your music as files. You can also export and import playlists without reorganizing the music files themselves.
|
||||
|
||||
As a bonus, you can make it look likeWinamp. To make it look the same as on the screenshot above, go to Settings / Appearance, select Winamp Classic Interface at the top, and choose the Refugee skin right below. And Bob’s your uncle!
|
||||
|
||||
Audacious is available as an RPM in Fedora, and can be installed using the Gnome Software app or the following command on the terminal:
|
||||
```
|
||||
$ sudo dnf install audacious
|
||||
|
||||
```
|
||||
|
||||
### Lollypop
|
||||
|
||||
Lollypop is a music player that provides great integration with GNOME. If you enjoy how GNOME looks, and would like a music player that’s nicely integrated, Lollypop could be for you.
|
||||
|
||||
![][7]
|
||||
|
||||
Apart from nice visual integration with the GNOME Shell, it woks nicely on HiDPI screens, and supports a dark theme.
|
||||
|
||||
As a bonus, Lollypop has an integrated cover art downloader, and a so-called Party Mode (the note button at the top-right corner) that selects and plays music automatically for you. It also integrates with online services such as [last.fm][2] or [libre.fm][8].
|
||||
|
||||
Available as both an RPM in Fedora or a [Flathub][4] for your [Silverblue][5] workstation, install it using the Gnome Software app or using the terminal:
|
||||
```
|
||||
$ sudo dnf install lollypop
|
||||
|
||||
```
|
||||
|
||||
### Gradio
|
||||
|
||||
What if you don’t own any music, but still like to listen to it? Or you just simply love radio? Then Gradio is here for you.
|
||||
|
||||
![][9]
|
||||
|
||||
Gradio is a simple radio player that allows you to search and play internet radio stations. You can find them by country, language, or simply using search. As a bonus, it’s visually integrated into GNOME Shell, works great with HiDPI screens, and has an option for a dark theme.
|
||||
|
||||
Gradio is available on [Flathub][4] which works with both Fedora Workstation and [Silverblue][5]. Install it using the Gnome Software app.
|
||||
|
||||
### sox
|
||||
|
||||
Do you like using the terminal instead, and listening to some music while you work? You don’t have to leave the terminal thanks to sox.
|
||||
|
||||
![][10]
|
||||
|
||||
sox is a very simple, terminal-based music player. All you need to do is to run a command such as:
|
||||
```
|
||||
$ play file.mp3
|
||||
|
||||
```
|
||||
|
||||
…and sox will play it for you. Apart from individual audio files, sox also supports playlists in the m3u format.
|
||||
|
||||
As a bonus, because sox is a terminal-based application, you can run it over ssh. Do you have a home server with speakers attached to it? Or do you want to play music from a different computer? Try using it together with [tmux][11], so you can keep listening even when the session closes.
|
||||
|
||||
sox is available in Fedora as an RPM. Install it by running:
|
||||
```
|
||||
$ sudo dnf install sox
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-cool-music-player-apps/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/asamalik/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/08/qodlibet-300x217.png
|
||||
[2]:https://last.fm
|
||||
[3]:https://soundcloud.com/
|
||||
[4]:https://flathub.org/home
|
||||
[5]:https://teamsilverblue.org/
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/audacious-300x136.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/08/lollypop-300x172.png
|
||||
[8]:https://libre.fm
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/08/gradio.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/08/sox-300x179.png
|
||||
[11]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
@ -1,74 +0,0 @@
|
||||
translated by hopefully2333
|
||||
|
||||
Steam Makes it Easier to Play Windows Games on Linux
|
||||
======
|
||||
![Steam Wallpaper][1]
|
||||
|
||||
It’s no secret that the [Linux gaming][2] library offers only a fraction of what the Windows library offers. In fact, many people wouldn’t even consider [switching to Linux][3] simply because most of the games they want to play aren’t available on the platform.
|
||||
|
||||
At the time of writing this article, Linux has just over 5,000 games available on Steam compared to the library’s almost 27,000 total games. Now, 5,000 games may be a lot, but it isn’t 27,000 games, that’s for sure.
|
||||
|
||||
And though almost every new indie game seems to launch with a Linux release, we are still left without a way to play many [Triple-A][4] titles. For me, though there are many titles I would love the opportunity to play, this has never been a make-or-break problem since almost all of my favorite titles are available on Linux since I primarily play indie and [retro games][5] anyway.
|
||||
|
||||
### Meet Proton: a WINE Fork by Steam
|
||||
|
||||
Now, that problem is a thing of the past since this week Valve [announced][6] a new update to Steam Play that adds a forked version of Wine to the Linux and Mac Steam clients called Proton. Yes, the tool is open-source, and Valve has made the source code available on [Github][7]. The feature is still in beta though, so you must opt into the beta Steam client in order to take advantage of this functionality.
|
||||
|
||||
#### With proton, more Windows games are available for Linux on Steam
|
||||
|
||||
What does that actually mean for us Linux users? In short, it means that both Linux and Mac computers can now play all 27,000 of those games without needing to configure something like [PlayOnLinux][8] or [Lutris][9] to do so! Which, let me tell you, can be quite the headache at times.
|
||||
|
||||
The more complicated answer to this is that it sounds too good to be true for a reason. Though, in theory, you can play literally every Windows game on Linux this way, there is only a short list of games that are officially supported at launch, including DOOM, Final Fantasy VI, Tekken 7, Star Wars: Battlefront 2, and several more.
|
||||
|
||||
#### You can play all Windows games on Linux (in theory)
|
||||
|
||||
Though the list only has about 30 games thus far, you can force enable Steam to install and play any game through Proton by marking the “Enable Steam Play for all titles” checkbox. But don’t get your hopes too high. They do not guarantee the stability and performance you may be hoping for, so keep your expectations reasonable.
|
||||
|
||||
![Steam Play][10]
|
||||
|
||||
#### Experiencing Proton: Not as bad as I expected
|
||||
|
||||
For example, I installed a few moderately taxing games to put Proton through its paces. One of which was The Elder Scrolls IV: Oblivion, and in the two hours I played the game, it only crashed once, and it was almost immediately after an autosave point during the tutorial.
|
||||
|
||||
I have an Nvidia Gtx 1050 Ti, so I was able to play the game at 1080p with high settings, and I didn’t see a single problem outside of that one crash. The only negative feedback I really have is that the framerate was not nearly as high as it would have been if it was a native game. I got above 60 frames 90% of the time, but I admit it could have been better.
|
||||
|
||||
Every other game that I have installed and launched has also worked flawlessly, granted I haven’t played any of them for an extended amount of time yet. Some games I installed include The Forest, Dead Rising 4, H1Z1, and Assassin’s Creed II (can you tell I like horror games?).
|
||||
|
||||
#### Why is Steam (still) betting on Linux?
|
||||
|
||||
Now, this is all fine and dandy, but why did this happen? Why would Valve spend the time, money, and resources needed to implement something like this? I like to think they did so because they value the Linux community, but if I am honest, I don’t believe we had anything to do with it.
|
||||
|
||||
If I had to put money on it, I would say Valve has developed Proton because they haven’t given up on [Steam machines][11] yet. And since [Steam OS][12] is running on Linux, it is in their best interest financially to invest in something like this. The more games available on Steam OS, the more people might be willing to buy a Steam Machine.
|
||||
|
||||
Maybe I am wrong, but I bet this means we will see a new wave of Steam machines coming in the not-so-distant future. Maybe we will see them in one year, or perhaps we won’t see them for another five, who knows!
|
||||
|
||||
Either way, all I know is that I am beyond excited to finally play the games from my Steam library that I have slowly accumulated over the years from all of the Humble Bundles, promo codes, and random times I bought a game on sale just in case I wanted to try to get it running in Lutris.
|
||||
|
||||
#### Excited for more gaming on Linux?
|
||||
|
||||
What do you think? Are you excited about this, or are you afraid fewer developers will create native Linux games because there is almost no need to now? Does Valve love the Linux community, or do they love money? Let us know what you think in the comment section below, and check back in for more FOSS content like this.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play-proton/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/steam-wallpaper.jpeg
|
||||
[2]:https://itsfoss.com/linux-gaming-guide/
|
||||
[3]:https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[4]:https://itsfoss.com/triplea-game-review/
|
||||
[5]:https://itsfoss.com/play-retro-games-linux/
|
||||
[6]:https://steamcommunity.com/games/221410
|
||||
[7]:https://github.com/ValveSoftware/Proton/
|
||||
[8]:https://www.playonlinux.com/en/
|
||||
[9]:https://lutris.net/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/SteamProton.jpg
|
||||
[11]:https://store.steampowered.com/sale/steam_machines
|
||||
[12]:https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
@ -1,116 +0,0 @@
|
||||
[Solved] “sub process usr bin dpkg returned an error code 1″ Error in Ubuntu
|
||||
======
|
||||
If you are encountering “sub process usr bin dpkg returned an error code 1” while installing software on Ubuntu Linux, here is how you can fix it.
|
||||
|
||||
One of the common issue in Ubuntu and other Debian based distribution is the broken packages. You try to update the system or install a new package and you encounter an error like ‘Sub-process /usr/bin/dpkg returned an error code’.
|
||||
|
||||
That’s what happened to me the other day. I was trying to install a radio application in Ubuntu when it threw me this error:
|
||||
```
|
||||
Unpacking python-gst-1.0 (1.6.2-1build1) ...
|
||||
Selecting previously unselected package radiotray.
|
||||
Preparing to unpack .../radiotray_0.7.3-5ubuntu1_all.deb ...
|
||||
Unpacking radiotray (0.7.3-5ubuntu1) ...
|
||||
Processing triggers for man-db (2.7.5-1) ...
|
||||
Processing triggers for desktop-file-utils (0.22-1ubuntu5.2) ...
|
||||
Processing triggers for bamfdaemon (0.5.3~bzr0+16.04.20180209-0ubuntu1) ...
|
||||
Rebuilding /usr/share/applications/bamf-2.index...
|
||||
Processing triggers for gnome-menus (3.13.3-6ubuntu3.1) ...
|
||||
Processing triggers for mime-support (3.59ubuntu1) ...
|
||||
Setting up polar-bookshelf (1.0.0-beta56) ...
|
||||
ln: failed to create symbolic link '/usr/local/bin/polar-bookshelf': No such file or directory
|
||||
dpkg: error processing package polar-bookshelf (--configure):
|
||||
subprocess installed post-installation script returned error exit status 1
|
||||
Setting up python-appindicator (12.10.1+16.04.20170215-0ubuntu1) ...
|
||||
Setting up python-gst-1.0 (1.6.2-1build1) ...
|
||||
Setting up radiotray (0.7.3-5ubuntu1) ...
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
The last three lines are of the utmost importance here.
|
||||
```
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
It tells me that the package polar-bookshelf is causing and issue. This might be crucial to how you fix this error here.
|
||||
|
||||
### Fixing Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
![Fix update errors in Ubuntu Linux][1]
|
||||
|
||||
Let’s try to fix this broken error package. I’ll show several methods that you can try one by one. The initial ones are easy to use and simply no-brainers.
|
||||
|
||||
You should try to run sudo apt update and then try to install a new package or upgrade after trying each of the methods discussed here.
|
||||
|
||||
#### Method 1: Reconfigure Package Database
|
||||
|
||||
The first method you can try is to reconfigure the package database. Probably the database got corrupted while installing a package. Reconfiguring often fixes the problem.
|
||||
```
|
||||
sudo dpkg --configure -a
|
||||
|
||||
```
|
||||
|
||||
#### Method 2: Use force install
|
||||
|
||||
If a package installation was interrupted previously, you may try to do a force install.
|
||||
```
|
||||
sudo apt-get install -f
|
||||
|
||||
```
|
||||
|
||||
#### Method 3: Try removing the troublesome package
|
||||
|
||||
If it’s not an issue for you, you may try to remove the package manually. Please don’t do it for Linux Kernels (packages starting with linux-).
|
||||
```
|
||||
sudo apt remove
|
||||
|
||||
```
|
||||
|
||||
#### Method 4: Remove post info files of the troublesome package
|
||||
|
||||
This should be your last resort. You can try removing the files associated to the package in question from /var/lib/dpkg/info.
|
||||
|
||||
**You need to know a little about basic Linux commands to figure out what’s happening and how can you use the same with your problem.**
|
||||
|
||||
In my case, I had an issue with polar-bookshelf. So I looked for the files associated with it:
|
||||
```
|
||||
ls -l /var/lib/dpkg/info | grep -i polar-bookshelf
|
||||
-rw-r--r-- 1 root root 2324811 Aug 14 19:29 polar-bookshelf.list
|
||||
-rw-r--r-- 1 root root 2822824 Aug 10 04:28 polar-bookshelf.md5sums
|
||||
-rwxr-xr-x 1 root root 113 Aug 10 04:28 polar-bookshelf.postinst
|
||||
-rwxr-xr-x 1 root root 84 Aug 10 04:28 polar-bookshelf.postrm
|
||||
|
||||
```
|
||||
|
||||
Now all I needed to do was to remove these files:
|
||||
```
|
||||
sudo mv /var/lib/dpkg/info/polar-bookshelf.* /tmp
|
||||
|
||||
```
|
||||
|
||||
Use the sudo apt update and then you should be able to install software as usual.
|
||||
|
||||
#### Which method worked for you (if it worked)?
|
||||
|
||||
I hope this quick article helps you in fixing the ‘E: Sub-process /usr/bin/dpkg returned an error code (1)’ error.
|
||||
|
||||
If it did work for you, which method was it? Did you manage to fix this error with some other method? If yes, please share that to help others with this issue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dpkg-returned-an-error-code-1/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/fix-common-update-errors-ubuntu.jpeg
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by jlztan
|
||||
|
||||
Top 10 Raspberry Pi blogs to follow
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by z52527
|
||||
|
||||
|
||||
A Cat Clone With Syntax Highlighting And Git Integration
|
||||
======
|
||||
20180828 A Cat Clone With Syntax Highlighting And Git Integration.md
|
||||
|
||||
@ -1,91 +0,0 @@
|
||||
How to Play Windows-only Games on Linux with Steam Play
|
||||
======
|
||||
The new experimental feature of Steam allows you to play Windows-only games on Linux. Here’s how to use this feature in Steam right now.
|
||||
|
||||
You have heard the news. Game distribution platform [Steam is implementing a fork of WINE to allow you to play games that are available on Windows only][1]. This is definitely a great news for us Linux users for we have complained about the lack of the number of games for Linux.
|
||||
|
||||
This new feature is still in beta but you can try it out and play Windows-only games on Linux right now. Let’s see how to do that.
|
||||
|
||||
### Play Windows-only games in Linux with Steam Play
|
||||
|
||||
![Play Windows-only games on Linux][2]
|
||||
|
||||
You need to install Steam first. Steam is available for all major Linux distributions. I have written in detail about [installing Steam on Ubuntu][3] and you may refer to that article if you don’t have Steam installed yet.
|
||||
|
||||
Once you have Steam installed and you have logged into your Steam account, it’s time to see how to enable Windows games in Steam Linux client.
|
||||
|
||||
#### Step 1: Go to Account Settings
|
||||
|
||||
Run Steam client. On the top left, click on Steam and then on Settings.
|
||||
|
||||
![Enable steam play beta on Linux][4]
|
||||
|
||||
#### Step 2: Opt in to the beta program
|
||||
|
||||
In the Settings, select Account from left side pane and then click on the CHANGE button under Beta participation.
|
||||
|
||||
![Enable beta feature in Steam Linux][5]
|
||||
|
||||
You should select Steam Beta Update here.
|
||||
|
||||
![Enable beta feature in Steam Linux][6]
|
||||
|
||||
Once you save the settings here, Steam will restart and download the new beta updates.
|
||||
|
||||
#### Step 3: Enable Steam Play beta
|
||||
|
||||
Once Steam has downloaded the new beta updates, it will be restarted. Now you are almost set.
|
||||
|
||||
Go to Settings once again. You’ll see a new option Steam Play in the left side pane now. Click on it and check the boxes:
|
||||
|
||||
* Enable Steam Play for supported titles (You can play the whitelisted Windows-only games)
|
||||
* Enable Steam Play for all titles (You can try to play all Windows-only games)
|
||||
|
||||
|
||||
|
||||
![Play Windows games on Linux using Steam Play][7]
|
||||
|
||||
I don’t remember if Steam restarts at this point again or not but I guess that’s trivial. You should now see the option to install Windows-only games on Linux.
|
||||
|
||||
For example, I have Age of Empires in my Steam library which is not available on Linux normally. But after I enabled Steam Play beta for all Windows titles, it now gives me the option for installing Age of Empires on Linux.
|
||||
|
||||
![Install Windows-only games on Linux using Steam][8]
|
||||
Windows-only games can now be installed on Linux
|
||||
|
||||
### Things to know about Steam Play beta feature
|
||||
|
||||
There are a few things you should know and keep in mind about using Windows-only games on Linux with Steam Play beta.
|
||||
|
||||
* At present, [only 27 Windows-games are whitelisted][9] for Steam Play. These whitelisted games work seamlessly on Linux.
|
||||
* You can try any Windows game with Steam Play beta but it might not work all the time. Some games will crash sometimes while some game might not run at all.
|
||||
* While in beta, you won’t see the Windows-only games available for Linux in the Steam store. You’ll have to either try the game on your own or refer to [this community maintained list][10] to see the compatibility status of the said Windows game. You can also contribute to the list by filling [this form][11].
|
||||
* If you have games downloaded on Windows via Steam, you can save some download data by [sharing Steam game files between Linux and Windows][12].
|
||||
|
||||
|
||||
|
||||
I hope this tutorial helped you in running Windows-only games on Linux. Which game(s) are you looking forward to play on Linux?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/steam-play-proton/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-windows-games-on-linux-featured.jpeg
|
||||
[3]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta.jpeg
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-2.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-3.jpeg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-4.jpeg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/install-windows-games-linux.jpeg
|
||||
[9]:https://steamcommunity.com/games/221410
|
||||
[10]:https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/htmlview?sle=true#
|
||||
[11]:https://docs.google.com/forms/d/e/1FAIpQLSeefaYQduMST_lg0IsYxZko8tHLKe2vtVZLFaPNycyhY4bidQ/viewform
|
||||
[12]:https://itsfoss.com/share-steam-files-linux-windows/
|
||||
@ -1,70 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Create a Slideshow of Photos in Ubuntu 18.04 and other Linux Distributions
|
||||
======
|
||||
Creating a slideshow of photos is a matter of a few clicks. Here’s how to make a slideshow of pictures in Ubuntu 18.04 and other Linux distributions.
|
||||
|
||||
![How to create slideshow of photos in Ubuntu Linux][1]
|
||||
|
||||
Imagine yourself in a situation where your friends and family are visiting you and request you to show the pictures of a recent event/trip.
|
||||
|
||||
You have the photos saved on your computers, neatly in a separate folder. You invite everyone near the computer. You go to the folder, click on one of the pictures and start showing them the photos one by one by pressing the arrow keys.
|
||||
|
||||
But that’s tiring! It will be a lot better if those images get changed automatically every few seconds.
|
||||
|
||||
That’s called a slideshow and I am going to show you how to create a slideshow of photos in Ubuntu. This will allow you to loop pictures from a folder and display them in fullscreen mode.
|
||||
|
||||
### Creating photo slideshow in Ubuntu 18.04 and other Linux distributions
|
||||
|
||||
While you could use several image viewers for this purpose, I am going to show you two of the most popular tools that should be available in most distributions.
|
||||
|
||||
#### Method 1: Photo slideshow with GNOME’s default image viewer
|
||||
|
||||
If you are using GNOME in Ubuntu 18.04 or any other distribution, you are in luck. The default image viewer of Gnome, Eye of GNOME, is well capable of displaying the slideshow of pictures in the current folder.
|
||||
|
||||
Just click on one of the pictures and you’ll see the settings option on the top right side of the application menu. It looks like three bars stacked over the top of one another.
|
||||
|
||||
You’ll see several options here. Check the Slideshow box and it will go fullscreen displaying the images.
|
||||
|
||||
![How to create slideshow of photos in Ubuntu Linux][2]
|
||||
|
||||
By default, the images change at an interval of 5 seconds. You can change the slideshow interval by going to the Preferences->Slideshow.
|
||||
|
||||
![change slideshow interval in Ubuntu][3]Changing slideshow interval
|
||||
|
||||
#### Method 2: Photo slideshow with Shotwell Photo Manager
|
||||
|
||||
[Shotwell][4] is a popular [photo management application for Linux][5]. and available for all major Linux distributions.
|
||||
|
||||
If it is not installed already, search for Shotwell in your distribution’s software center and install it.
|
||||
|
||||
Shotwell works slightly different. If you directly open a photo in Shotwell Viewer, you won’t see preferences or options for a slideshow.
|
||||
|
||||
For slideshow and other options, you have to open Shotwell and import the folders containing those pictures. Once you have imported the folder in here, select that folder from left side-pane and then click on View in the menu. You should see the option of Slideshow here. Just click on it to create the slideshow of all the images in the selected folder.
|
||||
|
||||
![How to create slideshow of photos in Ubuntu Linux][6]
|
||||
|
||||
You can also change the slideshow settings. This option is presented when the images are displayed in the full view. Just hover the mouse to the lower bottom and you’ll see a settings option appearing.
|
||||
|
||||
#### It’s easy to create photo slideshow
|
||||
|
||||
As you can see, it’s really simple to create slideshow of photos in Linux. I hope you find this simple tip useful. If you have questions or suggestions, please let me know in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/photo-slideshow-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/Create-photos-Slideshow-Linux.png
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/create-slideshow-photos-ubuntu-gnome.jpeg
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/change-slideshow-interval-gnome-image.jpeg
|
||||
[4]: https://wiki.gnome.org/Apps/Shotwell
|
||||
[5]: https://itsfoss.com/linux-photo-management-software/
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/create-slideshow-photos-shotwell.jpeg
|
||||
@ -1,224 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
5 Ways to Take Screenshot in Linux [GUI and Terminal]
|
||||
======
|
||||
Here are several ways you can take screenshots and edit the screenshots by adding text, arrows etc. Instructions and mentioned screenshot tools are valid for Ubuntu and other major Linux distributions.
|
||||
|
||||
![How to take screenshots in Ubuntu Linux][1]
|
||||
|
||||
When I switched from Windows to Ubuntu as my primary OS, the first thing I was worried about was the availability of screenshot tools. Well, it is easy to utilize the default keyboard shortcuts in order to take screenshots but with a standalone tool, I get to annotate/edit the image while taking the screenshot.
|
||||
|
||||
In this article, we will introduce you to the default methods/tools (without a 3rd party screenshot tool) to take a screenshot while also covering the list of best screenshot tools available for Linux.
|
||||
|
||||
### Method 1: The default way to take screenshot in Linux
|
||||
|
||||
Do you want to capture the image of your entire screen? A specific region? A specific window?
|
||||
|
||||
If you just want a simple screenshot without any annotations/fancy editing capabilities, the default keyboard shortcuts will do the trick. These are not specific to Ubuntu. Almost all Linux distributions and desktop environments support these keyboard shortcuts.
|
||||
|
||||
Let’s take a look at the list of keyboard shortcuts you can utilize:
|
||||
|
||||
**PrtSc** – Save a screenshot of the entire screen to the “Pictures” directory.
|
||||
**Shift + PrtSc** – Save a screenshot of a specific region to Pictures.
|
||||
**Alt + PrtSc** – Save a screenshot of the current window to Pictures.
|
||||
**Ctrl + PrtSc** – Copy the screenshot of the entire screen to the clipboard.
|
||||
**Shift + Ctrl + PrtSc** – Copy the screenshot of a specific region to the clipboard.
|
||||
**Ctrl + Alt + PrtSc** – Copy the screenshot of the current window to the clipboard.
|
||||
|
||||
As you can see, taking screenshots in Linux is absolutely simple with the default screenshot tool. However, if you want to immediately annotate (or other editing features) without importing the screenshot to another application, you can use a dedicated screenshot tool.
|
||||
|
||||
#### **Method 2: Take and edit screenshots in Linux with Flameshot**
|
||||
|
||||
![flameshot][2]
|
||||
|
||||
Feature Overview
|
||||
|
||||
* Annotate (highlight, point, add text, box in)
|
||||
* Blur part of an image
|
||||
* Crop part of an image
|
||||
* Upload to Imgur
|
||||
* Open screenshot with another app
|
||||
|
||||
|
||||
|
||||
Flameshot is a quite impressive screenshot tool which arrived on [GitHub][3] last year.
|
||||
|
||||
If you have been searching for a screenshot tool that helps you annotate, blur, mark, and upload to imgur while being actively maintained unlike some outdated screenshot tools, Flameshot should be the one to have installed.
|
||||
|
||||
Fret not, we will guide you how to install it and configure it as per your preferences.
|
||||
|
||||
To install it on Ubuntu, you just need to search for it on Ubuntu Software center and get it installed. In case you want to use the terminal, here’s the command for it:
|
||||
```
|
||||
sudo apt install flameshot
|
||||
|
||||
```
|
||||
|
||||
If you face any trouble installing, you can follow their [official installation instructions][4]. After installation, you need to configure it. Well, you can always search for it and launch it, but if you want to trigger the Flameshot screenshot tool by using **PrtSc** key, you need to assign a custom keyboard shortcut.
|
||||
|
||||
Here’s how you can do that:
|
||||
|
||||
* Head to the system settings and navigate your way to the Keyboard settings.
|
||||
* You will find all the keyboard shortcuts listed there, ignore them and scroll down to the bottom. Now, you will find a **+** button.
|
||||
* Click the “+” button to add a custom shortcut. You need to enter the following in the fields you get:
|
||||
**Name:** Anything You Want
|
||||
**Command:** /usr/bin/flameshot gui
|
||||
* Finally, set the shortcut to **PrtSc** – which will warn you that the default screenshot functionality will be disabled – so proceed doing it.
|
||||
|
||||
|
||||
|
||||
For reference, your custom keyboard shortcut field should look like this after configuration:
|
||||
|
||||
![][5]
|
||||
Map keyboard shortcut with Flameshot
|
||||
|
||||
### **Method 3: Take and edit screenshots in Linux with Shutter**
|
||||
|
||||
![][6]
|
||||
|
||||
Feature Overview:
|
||||
|
||||
* Annotate (highlight, point, add text, box in)
|
||||
* Blur part of an image
|
||||
* Crop part of an image
|
||||
* Upload to image hosting sites
|
||||
|
||||
|
||||
|
||||
[Shutter][7] is a popular screenshot tool available for all major Linux distributions. Though it seems to be no more being actively developed, it is still an excellent choice for handling screenshots.
|
||||
|
||||
You might encounter certain bugs/errors. The most common problem with Shutter on any latest Linux distro releases is that the ability to edit the screenshots is disabled by default along with the missing applet indicator. But, fret not, we have a solution to that. You just need to follow our guide to[fix the disabled edit option in Shutter and bring back the applet indicator][8].
|
||||
|
||||
After you’re done fixing the problem, you can utilize it to edit the screenshots in a jiffy.
|
||||
|
||||
To install shutter, you can browse the software center and get it from there. Alternatively, you can use the following command in the terminal to install Shutter in Ubuntu-based distributions:
|
||||
```
|
||||
sudo apt install shutter
|
||||
|
||||
```
|
||||
|
||||
As we saw with Flameshot, you can either choose to use the app launcher to search for Shutter and manually launch the application, or you can follow the same set of instructions (with a different command) to set a custom shortcut to trigger Shutter when you press the **PrtSc** key.
|
||||
|
||||
If you are going to assign a custom keyboard shortcut, you just need to use the following in the command field:
|
||||
```
|
||||
shutter -f
|
||||
|
||||
```
|
||||
|
||||
### Method 4: Use GIMP for taking screenshots in Linux
|
||||
|
||||
![][9]
|
||||
|
||||
Feature Overview:
|
||||
|
||||
* Advanced Image Editing Capabilities (Scaling, Adding filters, color correction, Add layers, Crop, and so on.)
|
||||
* Take a screenshot of the selected area
|
||||
|
||||
|
||||
|
||||
If you happen to use GIMP a lot and you probably want some advance edits on your screenshots, GIMP would be a good choice for that.
|
||||
|
||||
You should already have it installed, if not, you can always head to your software center to install it. If you have trouble installing, you can always refer to their [official website for installation instructions][10].
|
||||
|
||||
To take a screenshot with GIMP, you need to first launch it, and then navigate your way through **File- >Create->Screenshot**.
|
||||
|
||||
After you click on the screenshot option, you will be greeted with a couple of tweaks to control the screenshot. That’s just it. Click “ **Snap** ” to take the screenshot and the image will automatically appear within GIMP, ready for you to edit.
|
||||
|
||||
### Method 5: Taking screenshot in Linux using command line tools
|
||||
|
||||
This section is strictly for terminal lovers. If you like using the terminal, you can utilize the **GNOME screenshot** tool or **ImageMagick** or **Deepin Scrot** – which comes baked in on most of the popular Linux distributions.
|
||||
|
||||
To take a screenshot instantly, enter the following command:
|
||||
|
||||
#### GNOME Screenshot (for GNOME desktop users)
|
||||
```
|
||||
gnome-screenshot
|
||||
|
||||
```
|
||||
|
||||
To take a screenshot with a delay, enter the following command (here, **5** – is the number of seconds you want to delay)
|
||||
|
||||
GNOME screenshot is one of the default tools that exists in all distributions with GNOME desktop.
|
||||
```
|
||||
gnome-screenshot -d -5
|
||||
|
||||
```
|
||||
|
||||
#### ImageMagick
|
||||
|
||||
[ImageMagick][11] should be already pre-installed on your system if you are using Ubuntu, Mint, or any other popular Linux distribution. In case, it isn’t there, you can always install it by following the [official installation instructions (from source)][12]. In either case, you can enter the following in the terminal:
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
|
||||
```
|
||||
|
||||
After you have it installed, you can type in the following commands to take a screenshot:
|
||||
|
||||
To take the screenshot of your entire screen:
|
||||
```
|
||||
import -window root image.png
|
||||
|
||||
```
|
||||
|
||||
Here, “image.png” is your desired name for the screenshot.
|
||||
|
||||
To take the screenshot of a specific area:
|
||||
```
|
||||
import image.png
|
||||
|
||||
```
|
||||
|
||||
#### Deepin Scrot
|
||||
|
||||
Deepin Scrot is a slightly advanced terminal-based screenshot tool. Similar to the others, you should already have it installed. If not, get it installed through the terminal by typing:
|
||||
```
|
||||
sudo apt-get install scrot
|
||||
|
||||
```
|
||||
|
||||
After having it installed, follow the instructions below to take a screenshot:
|
||||
|
||||
To take a screenshot of the entire screen:
|
||||
```
|
||||
scrot myimage.png
|
||||
|
||||
```
|
||||
|
||||
To take a screenshot of the selected aread:
|
||||
```
|
||||
scrot -s myimage.png
|
||||
|
||||
```
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
So, these are the best screenshot tools available for Linux. Yes, there are a few more tools available (like [Spectacle][13] for KDE-based distros), but if you end up comparing them, the above-mentioned tools will outshine them.
|
||||
|
||||
In case you find a better screenshot tool than the ones mentioned in our article, feel free to let us know about it in the comments below.
|
||||
|
||||
Also, do tell us about your favorite screenshot tool!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/take-screenshot-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/Taking-Screenshots-in-Linux.png
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/flameshot-pic.png
|
||||
[3]: https://github.com/lupoDharkael/flameshot
|
||||
[4]: https://github.com/lupoDharkael/flameshot#installation
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/flameshot-config-default.png
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/shutter-screenshot.jpg
|
||||
[7]: http://shutter-project.org/
|
||||
[8]: https://itsfoss.com/shutter-edit-button-disabled/
|
||||
[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gimp-screenshot.jpg
|
||||
[10]: https://www.gimp.org/downloads/
|
||||
[11]: https://www.imagemagick.org/script/index.php
|
||||
[12]: https://www.imagemagick.org/script/install-source.php
|
||||
[13]: https://www.kde.org/applications/graphics/spectacle/
|
||||
@ -1,292 +0,0 @@
|
||||
5 tips to improve productivity with zsh
|
||||
======
|
||||
|
||||
### **[翻译中] by tnuoccalanosrep**
|
||||
|
||||

|
||||
|
||||
The Z shell known as [zsh][1] is a [shell][2] for Linux/Unix-like operating systems. It has similarities to other shells in the `sh` (Bourne shell) family, such as as `bash` and `ksh`, but it provides many advanced features and powerful command line editing options, such as enhanced Tab completion.
|
||||
|
||||
It would be impossible to cover all the options of zsh here; there are literally hundreds of pages [documenting][3] its many features. In this article, I'll present five tips to make you more productive using the command line with zsh.
|
||||
|
||||
### 1\. Themes and plugins
|
||||
|
||||
Through the years, the open source community has developed countless themes and plugins for zsh. A theme is a predefined prompt configuration, while a plugin is a set of useful aliases and functions that make it easier to use a specific command or programming language.
|
||||
|
||||
The quickest way to get started using themes and plugins is to use a zsh configuration framework. There are many available, but the most popular is [Oh My Zsh][4]. By default, it enables some sensible zsh configuration options and it comes loaded with hundreds of themes and plugins.
|
||||
|
||||
A theme makes you more productive as it adds useful information to your prompt, such as the status of your Git repository or Python virtualenv in use. Having this information at a glance saves you from typing the equivalent commands to obtain it, and it's a cool look. Here's an example of [Powerlevel9k][5], my theme of choice:
|
||||
|
||||
![zsh Powerlevel9K theme][7]
|
||||
|
||||
The Powerlevel9k theme for zsh
|
||||
|
||||
In addition to themes, Oh My Zsh bundles tons of useful plugins for zsh. For example, enabling the Git plugin gives you access to a number of useful aliases, such as:
|
||||
```
|
||||
$ alias | grep -i git | sort -R | head -10
|
||||
g=git
|
||||
ga='git add'
|
||||
gapa='git add --patch'
|
||||
gap='git apply'
|
||||
gdt='git diff-tree --no-commit-id --name-only -r'
|
||||
gau='git add --update'
|
||||
gstp='git stash pop'
|
||||
gbda='git branch --no-color --merged | command grep -vE "^(\*|\s*(master|develop|dev)\s*$)" | command xargs -n 1 git branch -d'
|
||||
gcs='git commit -S'
|
||||
glg='git log --stat'
|
||||
```
|
||||
|
||||
There are plugins available for many programming languages, packaging systems, and other tools you commonly use on the command line. Here's a list of plugins I use in my Fedora workstation:
|
||||
```
|
||||
git golang fedora docker oc sudo vi-mode virtualenvwrapper
|
||||
```
|
||||
|
||||
### 2\. Clever aliases
|
||||
|
||||
Aliases are very useful in zsh. Defining aliases for your most-used commands saves you a lot of typing. Oh My Zsh configures several useful aliases by default, including aliases to navigate directories and replacements for common commands with additional options such as:
|
||||
```
|
||||
ls='ls --color=tty'
|
||||
grep='grep --color=auto --exclude-dir={.bzr,CVS,.git,.hg,.svn}'
|
||||
```
|
||||
|
||||
In addition to command aliases, zsh enables two additional useful alias types: the suffix alias and the global alias.
|
||||
|
||||
A suffix alias allows you to open the file you type in the command line using the specified program based on the file extension. For example, to open YAML files using vim, define the following alias:
|
||||
```
|
||||
alias -s {yml,yaml}=vim
|
||||
```
|
||||
|
||||
Now if you type any file name ending with `yml` or `yaml` in the command line, zsh opens that file using vim:
|
||||
```
|
||||
$ playbook.yml
|
||||
# Opens file playbook.yml using vim
|
||||
```
|
||||
|
||||
A global alias enables you to create an alias that is expanded anywhere in the command line, not just at the beginning. This is very useful to replace common filenames or piped commands. For example:
|
||||
```
|
||||
alias -g G='| grep -i'
|
||||
```
|
||||
|
||||
To use this alias, type `G` anywhere you would type the piped command:
|
||||
```
|
||||
$ ls -l G do
|
||||
drwxr-xr-x. 5 rgerardi rgerardi 4096 Aug 7 14:08 Documents
|
||||
drwxr-xr-x. 6 rgerardi rgerardi 4096 Aug 24 14:51 Downloads
|
||||
```
|
||||
|
||||
Next, let's see how zsh helps to navigate the filesystem.
|
||||
|
||||
### 3\. Easy directory navigation
|
||||
|
||||
When you're using the command line, navigating across different directories is one of the most common tasks. Zsh makes this easier by providing some useful directory navigation features. These features are enabled with Oh My Zsh, but you can enable them by using this command:
|
||||
```
|
||||
setopt autocd autopushd \ pushdignoredups
|
||||
```
|
||||
|
||||
With these options set, you don't need to type `cd` to change directories. Just type the directory name, and zsh switches to it:
|
||||
```
|
||||
$ pwd
|
||||
/home/rgerardi
|
||||
$ /tmp
|
||||
$ pwd
|
||||
/tmp
|
||||
```
|
||||
|
||||
To move back, type `-`:
|
||||
|
||||
Zsh keeps the history of directories you visited so you can quickly switch to any of them. To see the list, type `dirs -v`:
|
||||
```
|
||||
$ dirs -v
|
||||
0 ~
|
||||
1 /var/log
|
||||
2 /var/opt
|
||||
3 /usr/bin
|
||||
4 /usr/local
|
||||
5 /usr/lib
|
||||
6 /tmp
|
||||
7 ~/Projects/Opensource.com/zsh-5tips
|
||||
8 ~/Projects
|
||||
9 ~/Projects/ansible
|
||||
10 ~/Documents
|
||||
```
|
||||
|
||||
Switch to any directory in this list by typing `~#` where # is the number of the directory in the list. For example:
|
||||
```
|
||||
$ pwd
|
||||
/home/rgerardi
|
||||
$ ~4
|
||||
$ pwd
|
||||
/usr/local
|
||||
```
|
||||
|
||||
Combine these with aliases to make it even easier to navigate:
|
||||
```
|
||||
d='dirs -v | head -10'
|
||||
1='cd -'
|
||||
2='cd -2'
|
||||
3='cd -3'
|
||||
4='cd -4'
|
||||
5='cd -5'
|
||||
6='cd -6'
|
||||
7='cd -7'
|
||||
8='cd -8'
|
||||
9='cd -9'
|
||||
```
|
||||
|
||||
Now you can type `d` to see the first ten items in the list and the number to switch to it:
|
||||
```
|
||||
$ d
|
||||
0 /usr/local
|
||||
1 ~
|
||||
2 /var/log
|
||||
3 /var/opt
|
||||
4 /usr/bin
|
||||
5 /usr/lib
|
||||
6 /tmp
|
||||
7 ~/Projects/Opensource.com/zsh-5tips
|
||||
8 ~/Projects
|
||||
9 ~/Projects/ansible
|
||||
$ pwd
|
||||
/usr/local
|
||||
$ 6
|
||||
/tmp
|
||||
$ pwd
|
||||
/tmp
|
||||
```
|
||||
|
||||
Finally, zsh automatically expands directory names with Tab completion. Type the first letters of the directory names and `TAB` to use it:
|
||||
```
|
||||
$ pwd
|
||||
/home/rgerardi
|
||||
$ p/o/z (TAB)
|
||||
$ Projects/Opensource.com/zsh-5tips/
|
||||
```
|
||||
|
||||
This is just one of the features enabled by zsh's powerful Tab completion system. Let's look at some more.
|
||||
|
||||
### 4\. Advanced Tab completion
|
||||
|
||||
Zsh's powerful completion system is one of its hallmarks. For simplification, I call it Tab completion, but under the hood, more than one thing is happening. There's usually expansion and command completion. I'll discuss them together here. For details, check this [User's Guide][8].
|
||||
|
||||
Command completion is enabled by default with Oh My Zsh. To enable it, add the following lines to your `.zshrc` file:
|
||||
```
|
||||
autoload -U compinit
|
||||
compinit
|
||||
```
|
||||
|
||||
Zsh's completion system is smart. It tries to suggest only items that can be used in certain contexts—for example, if you type `cd` and `TAB`, zsh suggests only directory names as it knows `cd` does not work with anything else.
|
||||
|
||||
Conversely, it suggests usernames when running user-related commands or hostnames when using `ssh` or `ping`, for example.
|
||||
|
||||
It has a vast completion library and understands many different commands. For example, if you're using the `tar` command, you can press Tab to see a list of files available in the package as candidates for extraction:
|
||||
```
|
||||
$ tar -xzvf test1.tar.gz test1/file1 (TAB)
|
||||
file1 file2
|
||||
```
|
||||
|
||||
Here's a more advanced example, using `git`. In this example, when typing `TAB`, zsh automatically completes the name of the only file in the repository that can be staged:
|
||||
```
|
||||
$ ls
|
||||
original plan.txt zsh-5tips.md zsh_theme_small.png
|
||||
$ git status
|
||||
On branch master
|
||||
Your branch is up to date with 'origin/master'.
|
||||
|
||||
Changes not staged for commit:
|
||||
(use "git add <file>..." to update what will be committed)
|
||||
(use "git checkout -- <file>..." to discard changes in working directory)
|
||||
|
||||
modified: zsh-5tips.md
|
||||
|
||||
no changes added to commit (use "git add" and/or "git commit -a")
|
||||
$ git add (TAB)
|
||||
$ git add zsh-5tips.md
|
||||
```
|
||||
|
||||
It also understands command line options and suggests only the ones that are relevant to the subcommand selected:
|
||||
```
|
||||
$ git commit - (TAB)
|
||||
--all -a -- stage all modified and deleted paths
|
||||
--allow-empty -- allow recording an empty commit
|
||||
--allow-empty-message -- allow recording a commit with an empty message
|
||||
--amend -- amend the tip of the current branch
|
||||
--author -- override the author name used in the commit
|
||||
--branch -- show branch information
|
||||
--cleanup -- specify how the commit message should be cleaned up
|
||||
--date -- override the author date used in the commit
|
||||
--dry-run -- only show the list of paths that are to be committed or not, and any untracked
|
||||
--edit -e -- edit the commit message before committing
|
||||
--file -F -- read commit message from given file
|
||||
--gpg-sign -S -- GPG-sign the commit
|
||||
--include -i -- update the given files and commit the whole index
|
||||
--interactive -- interactively update paths in the index file
|
||||
--message -m -- use the given message as the commit message
|
||||
... TRUNCATED ...
|
||||
```
|
||||
|
||||
After typing `TAB`, you can use the arrow keys to navigate the options list and select the one you need. Now you don't need to memorize all those Git options.
|
||||
|
||||
There are many options available. The best way to find what is most helpful to you is by using it.
|
||||
|
||||
### 5\. Command line editing and history
|
||||
|
||||
Zsh's command line editing capabilities are also useful. By default, it emulates emacs. If, like me, you prefer vi/vim, enable vi bindings with the following command:
|
||||
```
|
||||
$ bindkey -v
|
||||
```
|
||||
|
||||
If you're using Oh My Zsh, the `vi-mode` plugin enables additional bindings and a mode indicator on your prompt—very useful.
|
||||
|
||||
After enabling vi bindings, you can edit the command line using vi commands. For example, press `ESC+/` to search the command line history. While searching, pressing `n` brings the next matching line, and `N` the previous one. Most common vi commands work after pressing `ESC` such as `0` to jump to the start of the line, `$` to jump to the end, `i` to insert, `a` to append, etc. Even commands followed by motion work, such as `cw` to change a word.
|
||||
|
||||
In addition to command line editing, zsh provides several useful command line history features if you want to fix or re-execute previous used commands. For example, if you made a mistake, typing `fc` brings the last command in your favorite editor to fix it. It respects the `$EDITOR` variable and by default uses vi.
|
||||
|
||||
Another useful command is `r`, which re-executes the last command; and `r <WORD>`, which executes the last command that contains the string `WORD`.
|
||||
|
||||
Finally, typing double bangs (`!!`) brings back the last command anywhere in the line. This is useful, for instance, if you forgot to type `sudo` to execute commands that require elevated privileges:
|
||||
```
|
||||
$ less /var/log/dnf.log
|
||||
/var/log/dnf.log: Permission denied
|
||||
$ sudo !!
|
||||
$ sudo less /var/log/dnf.log
|
||||
```
|
||||
|
||||
These features make it easier to find and re-use previously typed commands.
|
||||
|
||||
### Where to go from here?
|
||||
|
||||
These are just a few of the zsh features that can make you more productive; there are many more. For additional information, consult the following resources:
|
||||
|
||||
[An Introduction to the Z Shell][9]
|
||||
|
||||
[A User's Guide to ZSH][10]
|
||||
|
||||
[Archlinux Wiki][11]
|
||||
|
||||
[zsh-lovers][12]
|
||||
|
||||
Do you have any zsh productivity tips to share? I would love to hear about them in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/tips-productivity-zsh
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rgerardi
|
||||
[1]: http://www.zsh.org/
|
||||
[2]: https://en.wikipedia.org/wiki/Shell_(computing)
|
||||
[3]: http://zsh.sourceforge.net/Doc/Release/zsh_toc.html
|
||||
[4]: https://ohmyz.sh/
|
||||
[5]: https://github.com/bhilburn/powerlevel9k
|
||||
[7]: https://opensource.com/sites/default/files/uploads/zsh_theme_small.png (zsh Powerlevel9K theme)
|
||||
[8]: http://zsh.sourceforge.net/Guide/zshguide06.html#l144
|
||||
[9]: http://zsh.sourceforge.net/Intro/intro_toc.html
|
||||
[10]: http://zsh.sourceforge.net/Guide/
|
||||
[11]: https://wiki.archlinux.org/index.php/zsh
|
||||
[12]: https://grml.org/zsh/
|
||||
@ -1,246 +0,0 @@
|
||||
3 top open source JavaScript chart libraries
|
||||
======
|
||||
|
||||

|
||||
|
||||
Charts and graphs are important for visualizing data and making websites appealing. Visual presentations make it easier to analyze big chunks of data and convey information. JavaScript chart libraries enable you to visualize data in a stunning, easy to comprehend, and interactive manner and improve your website's design.
|
||||
|
||||
In this article, learn about three top open source JavaScript chart libraries.
|
||||
|
||||
### 1\. Chart.js
|
||||
|
||||
[Chart.js][1] is an open source JavaScript library that allows you to create animated, beautiful, and interactive charts on your application. It's available under the MIT License.
|
||||
|
||||
With Chart.js, you can create various impressive charts and graphs, including bar charts, line charts, area charts, linear scale, and scatter charts. It is completely responsive across various devices and utilizes the HTML5 Canvas element for rendering.
|
||||
|
||||
Here is example code that draws a bar chart using the library. We'll include it in this example using the Chart.js content delivery network (CDN). Note that the data used is for illustration purposes only.
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/Chart.js/2.5.0/Chart.min.js"></script>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<canvas id="bar-chart" width=300" height="150"></canvas>
|
||||
|
||||
|
||||
<script>
|
||||
|
||||
new Chart(document.getElementById("bar-chart"), {
|
||||
type: 'bar',
|
||||
data: {
|
||||
labels: ["North America", "Latin America", "Europe", "Asia", "Africa"],
|
||||
datasets: [
|
||||
{
|
||||
label: "Number of developers (millions)",
|
||||
backgroundColor: ["red", "blue","yellow","green","pink"],
|
||||
data: [7,4,6,9,3]
|
||||
}
|
||||
]
|
||||
},
|
||||
options: {
|
||||
legend: { display: false },
|
||||
title: {
|
||||
display: true,
|
||||
text: 'Number of Developers in Every Continent'
|
||||
},
|
||||
|
||||
scales: {
|
||||
yAxes: [{
|
||||
ticks: {
|
||||
beginAtZero:true
|
||||
}
|
||||
}]
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
});
|
||||
|
||||
</script>
|
||||
|
||||
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
As you can see from this code, bar charts are constructed by setting **type** to **bar**. You can change the direction of the bar to other types—such as setting **type** to **horizontalBar**.
|
||||
|
||||
The bars' colors are set by providing the type of color in the **backgroundColor** array parameter.
|
||||
|
||||
The colors are allocated to the label and data that share the same index in their corresponding array. For example, "Latin America," the second label, will be set to "blue" (the second color) and 4 (the second number in the data).
|
||||
|
||||
Here is the output of this code.
|
||||
|
||||

|
||||
|
||||
### 2\. Chartist.js
|
||||
|
||||
[Chartist.js][2] is a simple JavaScript animation library that allows you to create customizable and beautiful responsive charts and other designs. The open source library is available under the WTFPL or MIT License.
|
||||
|
||||
The library was developed by a group of developers who were dissatisfied with existing charting tools, so it offers wonderful functionalities to designers and developers.
|
||||
|
||||
After including the Chartist.js library and its CSS files in your project, you can use them to create various types of charts, including animations, bar charts, and line charts. It utilizes SVG to render the charts dynamically.
|
||||
|
||||
Here is an example of code that draws a pie chart using the library.
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
|
||||
<link href="https//cdn.jsdelivr.net/chartist.js/latest/chartist.min.css" rel="stylesheet" type="text/css" />
|
||||
|
||||
<style>
|
||||
.ct-series-a .ct-slice-pie {
|
||||
fill: hsl(100, 20%, 50%); /* filling pie slices */
|
||||
stroke: white; /*giving pie slices outline */
|
||||
stroke-width: 5px; /* outline width */
|
||||
}
|
||||
|
||||
.ct-series-b .ct-slice-pie {
|
||||
fill: hsl(10, 40%, 60%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
|
||||
.ct-series-c .ct-slice-pie {
|
||||
fill: hsl(120, 30%, 80%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
|
||||
.ct-series-d .ct-slice-pie {
|
||||
fill: hsl(90, 70%, 30%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
.ct-series-e .ct-slice-pie {
|
||||
fill: hsl(60, 140%, 20%);
|
||||
stroke: white;
|
||||
stroke-width: 5px;
|
||||
}
|
||||
|
||||
</style>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<div class="ct-chart ct-golden-section"></div>
|
||||
|
||||
<script src="https://cdn.jsdelivr.net/chartist.js/latest/chartist.min.js"></script>
|
||||
|
||||
<script>
|
||||
|
||||
var data = {
|
||||
series: [45, 35, 20]
|
||||
};
|
||||
|
||||
var sum = function(a, b) { return a + b };
|
||||
|
||||
new Chartist.Pie('.ct-chart', data, {
|
||||
labelInterpolationFnc: function(value) {
|
||||
return Math.round(value / data.series.reduce(sum) * 100) + '%';
|
||||
}
|
||||
});
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
Instead of specifying various style-related components of your project, the Chartist JavaScript library allows you to use various pre-built CSS styles. You can use them to control the appearance of the created charts.
|
||||
|
||||
|
||||
For example, the pre-created CSS classis used to build the container for the pie chart. And, theclass is used to get the aspect ratios, which scale with responsive designs and saves you the hassle of calculating fixed dimensions. Chartist also provides other classes of container ratios you can utilize in your project.
|
||||
|
||||
For styling the various pie slices, you can use the default . **ct-series-a** class. The letter **a** is iterated with every series count (a, b, c, etc.) such that it corresponds with the slice to be styled.
|
||||
|
||||
The **Chartist.Pie** method is used for creating a pie chart. To create another type of chart, such as a line chart, use **Chartist.Line.**
|
||||
|
||||
Here is the output of the code.
|
||||
|
||||
|
||||
|
||||
### 3\. D3.js
|
||||
|
||||
[D3.js][3] is another great open source JavaScript chart library. It's available under the BSD license. D3 is mainly used for manipulating and adding interactivity to documents based on the provided data.
|
||||
|
||||
You can use this amazing 3D animation library to visualize your data using HTML5, SVG, and CSS and make your website appealing. Essentially, D3 enables you to bind data to the Document Object Model (DOM) and then use data-based functions to make changes to the document.
|
||||
|
||||
Here is example code that draws a simple bar chart using the library.
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
|
||||
<style>
|
||||
.chart div {
|
||||
font: 15px sans-serif;
|
||||
background-color: lightblue;
|
||||
text-align: right;
|
||||
padding:5px;
|
||||
margin:5px;
|
||||
color: white;
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
</style>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<div class="chart"></div>
|
||||
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/d3/5.5.0/d3.min.js"></script>
|
||||
|
||||
<script>
|
||||
|
||||
var data = [342,222,169,259,173];
|
||||
|
||||
d3.select(".chart")
|
||||
.selectAll("div")
|
||||
.data(data)
|
||||
.enter()
|
||||
.append("div")
|
||||
.style("width", function(d){ return d + "px"; })
|
||||
.text(function(d) { return d; });
|
||||
|
||||
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
The main concept in using the D3 library is to first apply CSS-style selections to point to the DOM nodes and then apply operators to manipulate them—just like in other DOM frameworks like jQuery.
|
||||
|
||||
After the data is bound to a document, the . **enter()** function is invoked to build new nodes for incoming data. All the methods invoked after the . **enter()** function will be called for every item in the data.
|
||||
|
||||
Here is the output of the code.
|
||||
|
||||
|
||||
|
||||
### Wrapping up
|
||||
|
||||
[JavaScript][4] charting libraries provide you with powerful tools for implementing data visualization on your web properties. With these three open source libraries, you can enhance the beauty and interactivity of your websites.
|
||||
|
||||
Do you know of another powerful frontend library for creating JavaScript animation effects? Please let us know in the comment section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-javascript-chart-libraries
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/drmjg
|
||||
[1]: https://www.chartjs.org/
|
||||
[2]: https://gionkunz.github.io/chartist-js/
|
||||
[3]: https://d3js.org/
|
||||
[4]: https://www.liveedu.tv/guides/programming/javascript/
|
||||
@ -1,142 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Autotrash – A CLI Tool To Automatically Purge Old Trashed Files
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Autotrash** is a command line utility to automatically purge old trashed files. It will purge files that have been in the trash for more then a given number of days. You don’t need to empty the trash folder or do SHIFT+DELETE to permanently purge the files/folders. Autortrash will handle the contents of your Trash folder and delete them automatically after a particular period of time. In a nutshell, Autotrash will never allow your trash to grow too big.
|
||||
|
||||
### Installing Autotrash
|
||||
|
||||
Autotrash is available in the default repositories of Debian-based systems. To install autotrash on Debian, Ubuntu, Linux Mint, run:
|
||||
|
||||
```
|
||||
$ sudo apt-get install autotrash
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install autotrash
|
||||
|
||||
```
|
||||
|
||||
For Arch linux and its variants, you can install it using any AUR helper programs such as [**Yay**][1].
|
||||
|
||||
```
|
||||
$ yay -S autotrash-git
|
||||
|
||||
```
|
||||
|
||||
### Automatically Purge Old Trashed Files
|
||||
|
||||
Whenever you run autotrash, It will scan your **`~/.local/share/Trash/info`** directory and read the **`.trashinfo`** files to find their deletion date. If the files have been in trash folder for more than the defined date, they will be deleted.
|
||||
|
||||
Let me show you some examples.
|
||||
|
||||
To purge files which are in the trash folder for more than 30 days, run:
|
||||
|
||||
```
|
||||
$ autotrash -d 30
|
||||
|
||||
```
|
||||
|
||||
As per above example, if the files in your Trash folder are more than 30-days old, Autotrash will automatically delete them from your Trash. You don’t need to manually delete them. Just send the unnecessary junk to your trash folder and forget about them. Autotrash will take care of the trashed files.
|
||||
|
||||
The above command will only process currently logged-in user’s trash directory. If you want to make autotrash to process trash directories of all users (not just in your home directory), use **-t** option like below.
|
||||
|
||||
```
|
||||
$ autotrash -td 30
|
||||
|
||||
```
|
||||
|
||||
Autotrash also allows you to delete trashed files based on the space left or available on the trash filesystem.
|
||||
|
||||
For example, have a look at the following example.
|
||||
|
||||
```
|
||||
$ autotrash --max-free 1024 -d 30
|
||||
|
||||
```
|
||||
|
||||
As per the above command, autotrash will only purge trashed files that are older than **30 days** from the trash if there is less than **1GB of space left** on the trash filesystem. This can be useful if your trash filesystem is running out of the space.
|
||||
|
||||
We can also purge files from trash, oldest first, till there is at least 1GB of space on the trash filesystem.
|
||||
|
||||
```
|
||||
$ autotrash --min-free 1024
|
||||
|
||||
```
|
||||
|
||||
In this case, there is no restriction on how old trashed files are.
|
||||
|
||||
You can combine both options ( **`--min-free`** and **`--max-free`** ) in a single command like below.
|
||||
|
||||
```
|
||||
$ autotrash --max-free 2048 --min-free 1024 -d 30
|
||||
|
||||
```
|
||||
|
||||
As per the above command, autotrash will start reading the trash if there is less than **2GB** of free space, then start keeping an eye on. At that point, remove files older than 30 days and if there is less than **1GB** of free space after that remove even newer files.
|
||||
|
||||
As you can see, all command should be manually run by the user. You might wonder, how can I automate this task?? That’s easy! Just add autotrash as crontab entry. Now, the commands will automatically run at a scheduled time and purge the files in your trash depending on the defined options.
|
||||
|
||||
To add these commands in crontab file, run:
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
|
||||
```
|
||||
|
||||
Add the entries, for example:
|
||||
|
||||
```
|
||||
@daily /usr/bin/autotrash -d 30
|
||||
|
||||
```
|
||||
|
||||
Now autotrash will purge files which are in the trash folder for more than 30 days, everyday.
|
||||
|
||||
For more details about scheduling tasks, refer the following links.
|
||||
|
||||
|
||||
+ [A Beginners Guide To Cron Jobs][2]
|
||||
+ [How To Easily And Safely Manage Cron Jobs In Linux][3]
|
||||
|
||||
|
||||
Please be mindful that if you have deleted any important files inadvertently, they will be permanently gone after the defined days, so just be careful.
|
||||
|
||||
Refer man pages to know more about Autotrash.
|
||||
|
||||
```
|
||||
$ man autotrash
|
||||
|
||||
```
|
||||
|
||||
Emptying Trash folder or pressing SHIFT+DELETE to permanently get rid of unnecessary stuffs from the Linux system is no big deal. It will just take a couple seconds. However, if you wanted an extra utility to take care of your junk files, Autotrash might be helpful. Give it a try and see how it works.
|
||||
|
||||
And, that’s all for now. Hope this helps. More good stuffs to come.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/autotrash-a-cli-tool-to-automatically-purge-old-trashed-files/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[2]: https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
|
||||
[3]: https://www.ostechnix.com/how-to-easily-and-safely-manage-cron-jobs-in-linux/
|
||||
@ -1,3 +1,4 @@
|
||||
LuuMing translating
|
||||
How to Use the Netplan Network Configuration Tool on Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,168 +0,0 @@
|
||||
XiatianSummer translating
|
||||
|
||||
13 Keyboard Shortcut Every Ubuntu 18.04 User Should Know
|
||||
======
|
||||
Knowing keyboard shortcuts increase your productivity. Here are some useful Ubuntu shortcut keys that will help you use Ubuntu like a pro.
|
||||
|
||||
You can use an operating system with the combination of keyboard and mouse
|
||||
|
||||
Note: The keyboard shortcuts mentioned in the list is intended for Ubuntu 18.04 GNOME edition. Usually, most of them (if not all) should work on other Ubuntu versions as well, but I cannot vouch for it.
|
||||
|
||||
![Ubuntu keyboard shortcuts][1]
|
||||
|
||||
### Useful Ubuntu keyboard shortcuts
|
||||
|
||||
Let’s have a look at some of the must know keyboard shortcut for Ubuntu GNOME. I have not included universal keyboard shortcuts like Ctrl+C (copy), Ctrl+V (paste) or Ctrl+S (save).
|
||||
|
||||
Note: Super key in Linux refers to the key with Windows logo. I have used capital letters in the shortcuts but it doesn’t mean you have to press the shift key. For example, T means ‘t’ key only, not Shift+t.
|
||||
|
||||
#### 1\. Super key: Opens Activities search
|
||||
|
||||
Super Key Opens the activities menuIf you have to use just one keyboard shortcut on Ubuntu, this has to be the one.
|
||||
|
||||
You want to open an application? Press the super key and search for the application. If the application is not installed, it will even suggest applications from software center.
|
||||
|
||||
You want to see the running applications? Press super key and it will show you all the running GUI applications.
|
||||
|
||||
You want to use workspaces? Simply press the super key and you can see the workspaces option on the right-hand side.
|
||||
|
||||
#### 2\. Ctrl+Alt+T: Ubuntu terminal shortcut
|
||||
|
||||
![Ubuntu Terminal Shortcut][2]Use Ctrl+alt+T to open terminal
|
||||
|
||||
You want to open a new terminal. The combination of three keys Ctrl+Alt+T is what you need. This is my favorite keyboard shortcut in Ubuntu. I even mention it in various tutorials on It’s FOSS when it involves opening a terminal.
|
||||
|
||||
#### 3\. Super+L or Ctrl+Alt+L: Locks the screen
|
||||
|
||||
Locking screen when you are not at your desk is one of the most basic security tips. Instead of going to the top right corner and then choosing the lock screen option, you can simply use the Super+L key combination.
|
||||
|
||||
Some systems also use Ctrl+Alt+L keys for locking the screen.
|
||||
|
||||
#### 4\. Super+D or Ctrl+Alt+D: Show desktop
|
||||
|
||||
Pressing Super+D minimizes all running application windows and shows the desktop.
|
||||
|
||||
Pressing Super+D again will open all the running applications windows as it was previously.
|
||||
|
||||
You may also use Ctrl+Alt+D for this purpose.
|
||||
|
||||
#### 5\. Super+A: Shows the application menu
|
||||
|
||||
You can open the application menu in Ubuntu 18.04 GNOME by clicking on the 9 dots on the left bottom of the screen. However, a quicker way would be to use Super+A key combination.
|
||||
|
||||
It will show the application menu where you can see the installed applications on your systems and can also search for them.
|
||||
|
||||
You can use Esc key to move out of the application menu screen.
|
||||
|
||||
#### 6\. Super+Tab or Alt+Tab: Switch between running applications
|
||||
|
||||
If you have more than one applications running, you can switch between the applications using the Super+Tab or Alt+Tab key combinations.
|
||||
|
||||
Keep holding the super key and press tab and you’ll the application switcher appearing. While holding the super key, keep on tapping the tab key to select between applications. When you are at the desired application, release both super and tab keys.
|
||||
|
||||
By default, the application switcher moves from left to right. If you want to move from right to left, use the Super+Shift+Tab key combination.
|
||||
|
||||
You can also use Alt key instead of Super here.
|
||||
|
||||
Tip: If there are multiple instances of an application, you can switch between those instances by using Super+` key combination.
|
||||
|
||||
#### 7\. Super+Arrow keys: Snap windows
|
||||
|
||||
<https://player.vimeo.com/video/289091549>
|
||||
|
||||
This is available in Windows as well. While using an application, press Super and left arrow key and the application will go to the left edge of the screen, taking half of the screen.
|
||||
|
||||
Similarly, pressing Super and right arrow keys will move the application to the right edge.
|
||||
|
||||
Super and up arrow keys will maximize the application window and super and down arrow will bring the application back to its usual self.
|
||||
|
||||
#### 8\. Super+M: Toggle notification tray
|
||||
|
||||
GNOME has a notification tray where you can see notifications for various system and application activities. You also have the calendar here.
|
||||
|
||||
![Notification Tray Ubuntu 18.04 GNOME][3]
|
||||
Notification Tray
|
||||
|
||||
With Super+M key combination, you can open this notification area. If you press these keys again, an opened notification tray will be closed.
|
||||
|
||||
You can also use Super+V for toggling the notification tray.
|
||||
|
||||
#### 9\. Super+Space: Change input keyboard (for multilingual setup)
|
||||
|
||||
If you are multilingual, perhaps you have more than one keyboards installed on your system. For example, I use [Hindi on Ubuntu][4] along with English and I have Hindi (Devanagari) keyboard installed along with the default English one.
|
||||
|
||||
If you also use a multilingual setup, you can quickly change the input keyboard with the Super+Space shortcut.
|
||||
|
||||
#### 10\. Alt+F2: Run console
|
||||
|
||||
This is for power users. If you want to run a quick command, instead of opening a terminal and running the command there, you can use Alt+F2 to run the console.
|
||||
|
||||
![Alt+F2 to run commands in Ubuntu][5]
|
||||
Console
|
||||
|
||||
This is particularly helpful when you have to use applications that can only be run from the terminal.
|
||||
|
||||
#### 11\. Ctrl+Q: Close an application window
|
||||
|
||||
If you have an application running, you can close the application window using the Ctrl+Q key combination. You can also use Ctrl+W for this purpose.
|
||||
|
||||
Alt+F4 is more ‘universal’ shortcut for closing an application window.
|
||||
|
||||
It not work on a few applications such as the default terminal in Ubuntu.
|
||||
|
||||
#### 12\. Ctrl+Alt+arrow: Move between workspaces
|
||||
|
||||
![Workspace switching][6]
|
||||
Workspace switching
|
||||
|
||||
If you are one of the power users who use workspaces, you can use the Ctrl+Alt+Up arrow and Ctrl+Alt+Down arrow keys to switch between the workspaces.
|
||||
|
||||
#### 13\. Ctrl+Alt+Del: Log out
|
||||
|
||||
No! Like Windows, the famous combination of Ctrl+Alt+Del won’t bring task manager in Linux (unless you use custom keyboard shortcuts for it).
|
||||
|
||||
![Log Out Ubuntu][7]
|
||||
Log Out
|
||||
|
||||
In the normal GNOME desktop environment, you can bring the power off menu using the Ctrl+Alt+Del keys but Ubuntu doesn’t always follow the norms and hence it opens the logout dialogue box when you use Ctrl+Alt+Del in Ubuntu.
|
||||
|
||||
### Use custom keyboard shortcuts in Ubuntu
|
||||
|
||||
You are not limited to the default keyboard shortcuts. You can create your own custom keyboard shortcuts as you like.
|
||||
|
||||
Go to Settings->Devices->Keyboard. You’ll see all the keyboard shortcuts here for your system. Scroll down to the bottom and you’ll see the Custom Shortcuts option.
|
||||
|
||||
![Add custom keyboard shortcut in Ubuntu][8]
|
||||
|
||||
You have to provide an easy-to-recognize name of the shortcut, the command that will be run when the key combinations are used and of course the keys you are going to use for the shortcut.
|
||||
|
||||
### What are your favorite keyboard shortcuts in Ubuntu?
|
||||
|
||||
There is no end to shortcuts. If you want, you can have a look at all the possible [GNOME shortcuts][9] here and see if there are some more shortcuts you would like to use.
|
||||
|
||||
You can, and you should also learn keyboard shortcuts for the applications you use most of the time. For example, I use Kazam for [screen recording][10], and the keyboard shortcuts help me a lot in pausing and resuming the recording.
|
||||
|
||||
What are your favorite Ubuntu shortcuts that you cannot live without?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-shortcuts/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ubuntu-keyboard-shortcuts.jpeg
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/ubuntu-terminal-shortcut.jpg
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/notification-tray-ubuntu-gnome.jpeg
|
||||
[4]: https://itsfoss.com/type-indian-languages-ubuntu/
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/console-alt-f2-ubuntu-gnome.jpeg
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/workspace-switcher-ubuntu.png
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/log-out-ubuntu.jpeg
|
||||
[8]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/custom-keyboard-shortcut.jpg
|
||||
[9]: https://wiki.gnome.org/Design/OS/KeyboardShortcuts
|
||||
[10]: https://itsfoss.com/best-linux-screen-recorders/
|
||||
@ -1,112 +0,0 @@
|
||||
heguangzhi Translating
|
||||
|
||||
3 open source log aggregation tools
|
||||
======
|
||||
Log aggregation systems can help with troubleshooting and other tasks. Here are three top options.
|
||||
|
||||

|
||||
|
||||
How is metrics aggregation different from log aggregation? Can’t logs include metrics? Can’t log aggregation systems do the same things as metrics aggregation systems?
|
||||
|
||||
These are questions I hear often. I’ve also seen vendors pitching their log aggregation system as the solution to all observability problems. Log aggregation is a valuable tool, but it isn’t normally a good tool for time-series data.
|
||||
|
||||
A couple of valuable features in a time-series metrics aggregation system are the regular interval and the storage system customized specifically for time-series data. The regular interval allows a user to derive real mathematical results consistently. If a log aggregation system is collecting metrics in a regular interval, it can potentially work the same way. However, the storage system isn’t optimized for the types of queries that are typical in a metrics aggregation system. These queries will take more resources and time to process using storage systems found in log aggregation tools.
|
||||
|
||||
So, we know a log aggregation system is likely not suitable for time-series data, but what is it good for? A log aggregation system is a great place for collecting event data. These are irregular activities that are significant. An example might be access logs for a web service. These are significant because we want to know what is accessing our systems and when. Another example would be an application error condition—because it is not a normal operating condition, it might be valuable during troubleshooting.
|
||||
|
||||
A handful of rules for logging:
|
||||
|
||||
* DO include a timestamp
|
||||
* DO format in JSON
|
||||
* DON’T log insignificant events
|
||||
* DO log all application errors
|
||||
* MAYBE log warnings
|
||||
* DO turn on logging
|
||||
* DO write messages in a human-readable form
|
||||
* DON’T log informational data in production
|
||||
* DON’T log anything a human can’t read or react to
|
||||
|
||||
|
||||
|
||||
### Cloud costs
|
||||
|
||||
When investigating log aggregation tools, the cloud might seem like an attractive option. However, it can come with significant costs. Logs represent a lot of data when aggregated across hundreds or thousands of hosts and applications. The ingestion, storage, and retrieval of that data are expensive in cloud-based systems.
|
||||
|
||||
As a point of reference from a real system, a collection of around 500 nodes with a few hundred apps results in 200GB of log data per day. There’s probably room for improvement in that system, but even reducing it by half will cost nearly $10,000 per month in many SaaS offerings. This often includes retention of only 30 days, which isn’t very long if you want to look at trending data year-over-year.
|
||||
|
||||
This isn’t to discourage the use of these systems, as they can be very valuable—especially for smaller organizations. The purpose is to point out that there could be significant costs, and it can be discouraging when they are realized. The rest of this article will focus on open source and commercial solutions that are self-hosted.
|
||||
|
||||
### Tool options
|
||||
|
||||
#### ELK
|
||||
|
||||
[ELK][1], short for Elasticsearch, Logstash, and Kibana, is the most popular open source log aggregation tool on the market. It’s used by Netflix, Facebook, Microsoft, LinkedIn, and Cisco. The three components are all developed and maintained by [Elastic][2]. [Elasticsearch][3] is essentially a NoSQL, Lucene search engine implementation. [Logstash][4] is a log pipeline system that can ingest data, transform it, and load it into a store like Elasticsearch. [Kibana][5] is a visualization layer on top of Elasticsearch.
|
||||
|
||||
A few years ago, Beats were introduced. Beats are data collectors. They simplify the process of shipping data to Logstash. Instead of needing to understand the proper syntax of each type of log, a user can install a Beat that will export NGINX logs or Envoy proxy logs properly so they can be used effectively within Elasticsearch.
|
||||
|
||||
When installing a production-level ELK stack, a few other pieces might be included, like [Kafka][6], [Redis][7], and [NGINX][8]. Also, it is common to replace Logstash with Fluentd, which we’ll discuss later. This system can be complex to operate, which in its early days led to a lot of problems and complaints. These have largely been fixed, but it’s still a complex system, so you might not want to try it if you’re a smaller operation.
|
||||
|
||||
That said, there are services available so you don’t have to worry about that. [Logz.io][9] will run it for you, but its list pricing is a little steep if you have a lot of data. Of course, you’re probably smaller and may not have a lot of data. If you can’t afford Logz.io, you could look at something like [AWS Elasticsearch Service][10] (ES). ES is a service Amazon Web Services (AWS) offers that makes it very easy to get Elasticsearch working quickly. It also has tooling to get all AWS logs into ES using Lambda and S3. This is a much cheaper option, but there is some management required and there are a few limitations.
|
||||
|
||||
Elastic, the parent company of the stack, [offers][11] a more robust product that uses the open core model, which provides additional options around analytics tools, and reporting. It can also be hosted on Google Cloud Platform or AWS. This might be the best option, as this combination of tools and hosting platforms offers a cheaper solution than most SaaS options and still provides a lot of value. This system could effectively replace or give you the capability of a [security information and event management][12] (SIEM) system.
|
||||
|
||||
The ELK stack also offers great visualization tools through Kibana, but it lacks an alerting function. Elastic provides alerting functionality within the paid X-Pack add-on, but there is nothing built in for the open source system. Yelp has created a solution to this problem, called [ElastAlert][13], and there are probably others. This additional piece of software is fairly robust, but it increases the complexity of an already complex system.
|
||||
|
||||
#### Graylog
|
||||
|
||||
[Graylog][14] has recently risen in popularity, but it got its start when Lennart Koopmann created it back in 2010. A company was born with the same name two years later. Despite its increasing use, it still lags far behind the ELK stack. This also means it has fewer community-developed features, but it can use the same Beats that the ELK stack uses. Graylog has gained praise in the Go community with the introduction of the Graylog Collector Sidecar written in [Go][15].
|
||||
|
||||
Graylog uses Elasticsearch, [MongoDB][16], and the Graylog Server under the hood. This makes it as complex to run as the ELK stack and maybe a little more. However, Graylog comes with alerting built into the open source version, as well as several other notable features like streaming, message rewriting, and geolocation.
|
||||
|
||||
The streaming feature allows for data to be routed to specific Streams in real time while they are being processed. With this feature, a user can see all database errors in a single Stream and web server errors in a different Stream. Alerts can even be based on these Streams as new items are added or when a threshold is exceeded. Latency is probably one of the biggest issues with log aggregation systems, and Streams eliminate that issue in Graylog. As soon as the log comes in, it can be routed to other systems through a Stream without being processed fully.
|
||||
|
||||
The message rewriting feature uses the open source rules engine [Drools][17]. This allows all incoming messages to be evaluated against a user-defined rules file enabling a message to be dropped (called Blacklisting), a field to be added or removed, or the message to be modified.
|
||||
|
||||
The coolest feature might be Graylog’s geolocation capability, which supports plotting IP addresses on a map. This is a fairly common feature and is available in Kibana as well, but it adds a lot of value—especially if you want to use this as your SIEM system. The geolocation functionality is provided in the open source version of the system.
|
||||
|
||||
Graylog, the company, charges for support on the open source version if you want it. It also offers an open core model for its Enterprise version that offers archiving, audit logging, and additional support. There aren’t many other options for support or hosting, so you’ll likely be on your own if you don’t use Graylog (the company).
|
||||
|
||||
#### Fluentd
|
||||
|
||||
[Fluentd][18] was developed at [Treasure Data][19], and the [CNCF][20] has adopted it as an Incubating project. It was written in C and Ruby and is recommended by [AWS][21] and [Google Cloud][22]. Fluentd has become a common replacement for Logstash in many installations. It acts as a local aggregator to collect all node logs and send them off to central storage systems. It is not a log aggregation system.
|
||||
|
||||
It uses a robust plugin system to provide quick and easy integrations with different data sources and data outputs. Since there are over 500 plugins available, most of your use cases should be covered. If they aren’t, this sounds like an opportunity to contribute back to the open source community.
|
||||
|
||||
Fluentd is a common choice in Kubernetes environments due to its low memory requirements (just tens of megabytes) and its high throughput. In an environment like [Kubernetes][23], where each pod has a Fluentd sidecar, memory consumption will increase linearly with each new pod created. Using Fluentd will drastically reduce your system utilization. This is becoming a common problem with tools developed in Java that are intended to run one per node where the memory overhead hasn’t been a major issue.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-log-aggregation-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://www.elastic.co/webinars/introduction-elk-stack
|
||||
[2]: https://www.elastic.co/
|
||||
[3]: https://www.elastic.co/products/elasticsearch
|
||||
[4]: https://www.elastic.co/products/logstash
|
||||
[5]: https://www.elastic.co/products/kibana
|
||||
[6]: http://kafka.apache.org/
|
||||
[7]: https://redis.io/
|
||||
[8]: https://www.nginx.com/
|
||||
[9]: https://logz.io/
|
||||
[10]: https://aws.amazon.com/elasticsearch-service/
|
||||
[11]: https://www.elastic.co/cloud
|
||||
[12]: https://en.wikipedia.org/wiki/Security_information_and_event_management
|
||||
[13]: https://github.com/Yelp/elastalert
|
||||
[14]: https://www.graylog.org/
|
||||
[15]: https://opensource.com/tags/go
|
||||
[16]: https://www.mongodb.com/
|
||||
[17]: https://www.drools.org/
|
||||
[18]: https://www.fluentd.org/
|
||||
[19]: https://www.treasuredata.com/
|
||||
[20]: https://www.cncf.io/
|
||||
[21]: https://aws.amazon.com/blogs/aws/all-your-data-fluentd/
|
||||
[22]: https://cloud.google.com/logging/docs/agent/
|
||||
[23]: https://opensource.com/resources/what-is-kubernetes
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user