mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
96a87f0810
@ -1,9 +1,10 @@
|
||||
translating by yongshouzhang
|
||||
|
||||
7 tools for analyzing performance in Linux with bcc/BPF
|
||||
|
||||
7个 Linux 下使用 bcc/BPF 的性能分析工具
|
||||
============================================================
|
||||
|
||||
### Look deeply into your Linux code with these Berkeley Packet Filter (BPF) Compiler Collection (bcc) tools.
|
||||
###使用伯克利的包过滤(BPF)编译器集合(BCC)工具深度探查你的 linux 代码。
|
||||
|
||||
[][7] 21 Nov 2017 [Brendan Gregg][8] [Feed][9]
|
||||
|
||||
@ -12,37 +13,38 @@ translating by yongshouzhang
|
||||
[4 comments][11]
|
||||

|
||||
|
||||
Image by :
|
||||
图片来源 :
|
||||
|
||||
opensource.com
|
||||
|
||||
A new technology has arrived in Linux that can provide sysadmins and developers with a large number of new tools and dashboards for performance analysis and troubleshooting. It's called the enhanced Berkeley Packet Filter (eBPF, or just BPF), although these enhancements weren't developed in Berkeley, they operate on much more than just packets, and they do much more than just filtering. I'll discuss one way to use BPF on the Fedora and Red Hat family of Linux distributions, demonstrating on Fedora 26.
|
||||
在 linux 中出现的一种新技术能够为系统管理员和开发者提供大量用于性能分析和故障排除的新工具和仪表盘。 它被称为增强的伯克利数据包过滤器(eBPF,或BPF),虽然这些改进并不由伯克利开发,它们不仅仅是处理数据包,更多的是过滤。我将讨论在 Fedora 和 Red Hat Linux 发行版中使用 BPF 的一种方法,并在 Fedora 26 上演示。
|
||||
|
||||
BPF can run user-defined sandboxed programs in the kernel to add new custom capabilities instantly. It's like adding superpowers to Linux, on demand. Examples of what you can use it for include:
|
||||
BPF 可以在内核中运行用户定义的沙盒程序,以立即添加新的自定义功能。这就像可按需给 Linux 系统添加超能力一般。 你可以使用它的例子包括如下:
|
||||
|
||||
* Advanced performance tracing tools: programmatic low-overhead instrumentation of filesystem operations, TCP events, user-level events, etc.
|
||||
* 高级性能跟踪工具:文件系统操作、TCP事件、用户级事件等的编程低开销检测。
|
||||
|
||||
* Network performance: dropping packets early on to improve DDOS resilience, or redirecting packets in-kernel to improve performance
|
||||
* 网络性能 : 尽早丢弃数据包以提高DDoS的恢复能力,或者在内核中重定向数据包以提高性能。
|
||||
|
||||
* Security monitoring: 24x7 custom monitoring and logging of suspicious kernel and userspace events
|
||||
* 安全监控 : 24x7 小时全天候自定义检测和记录内核空间与用户空间内的可疑事件。
|
||||
|
||||
BPF programs must pass an in-kernel verifier to ensure they are safe to run, making it a safer option, where possible, than writing custom kernel modules. I suspect most people won't write BPF programs themselves, but will use other people's. I've published many on GitHub as open source in the [BPF Compiler Collection (bcc)][12] project. bcc provides different frontends for BPF development, including Python and Lua, and is currently the most active project for BPF tooling.
|
||||
在可能的情况下,BPF 程序必须通过一个内核验证机制来保证它们的安全运行,这比写自定义的内核模块更安全。我在此假设大多数人并不编写自己的 BPF 程序,而是使用别人写好的。在 GitHub 上的 [BPF Compiler Collection (bcc)][12] 项目中,我已发布许多开源代码。bcc 提供不同的 BPF 开发前端支持,包括Python和Lua,并且是目前最活跃的 BPF 模具项目。
|
||||
|
||||
### 7 useful new bcc/BPF tools
|
||||
### 7 个有用的 bcc/BPF 新工具
|
||||
|
||||
为了了解BCC / BPF工具和他们的乐器,我创建了下面的图表并添加到项目中
|
||||
To understand the bcc/BPF tools and what they instrument, I created the following diagram and added it to the bcc project:
|
||||
|
||||
### [bcc_tracing_tools.png][13]
|
||||
### [bcc_跟踪工具.png][13]
|
||||
|
||||
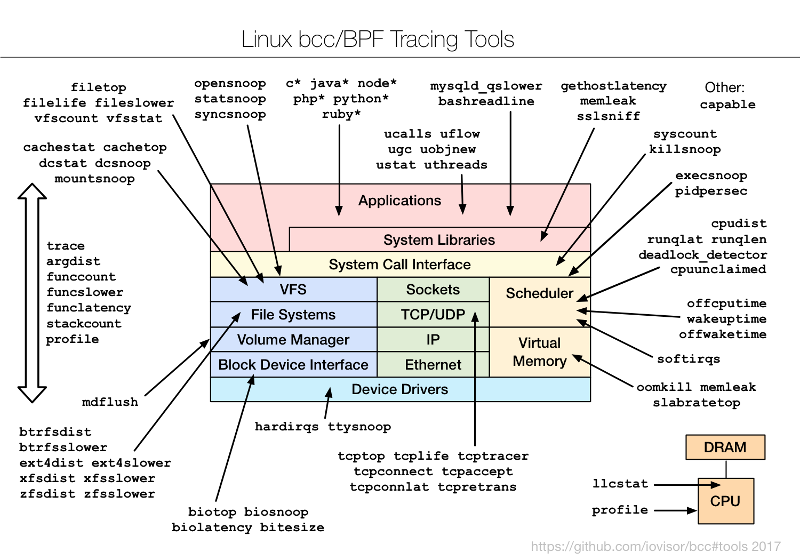
|
||||

|
||||
|
||||
Brendan Gregg, [CC BY-SA 4.0][14]
|
||||
|
||||
These are command-line interface (CLI) tools you can use over SSH (secure shell). Much analysis nowadays, including at my employer, is conducted using GUIs and dashboards. SSH is a last resort. But these CLI tools are still a good way to preview BPF capabilities, even if you ultimately intend to use them only through a GUI when available. I've began adding BPF capabilities to an open source GUI, but that's a topic for another article. Right now I'd like to share the CLI tools, which you can use today.
|
||||
这些是命令行界面工具,你可以通过 SSH (安全外壳)使用它们。目前大多数分析,包括我的老板,是用 GUIs 和仪表盘进行的。SSH是最后的手段。但这些命令行工具仍然是预览BPF能力的好方法,即使你最终打算通过一个可用的 GUI 使用它。我已着手向一个开源 GUI 添加BPF功能,但那是另一篇文章的主题。现在我想分享你今天可以使用的 CLI 工具。
|
||||
|
||||
### 1\. execsnoop
|
||||
|
||||
Where to start? How about watching new processes. These can consume system resources, but be so short-lived they don't show up in top(1) or other tools. They can be instrumented (or, using the industry jargon for this, they can be traced) using [execsnoop][15]. While tracing, I'll log in over SSH in another window:
|
||||
从哪儿开始? 如何查看新的进程。这些可以消耗系统资源,但很短暂,它们不会出现在 top(1)命令或其他工具中。 这些新进程可以使用[execsnoop] [15]进行检测(或使用行业术语,可以追踪)。 在追踪时,我将在另一个窗口中通过 SSH 登录:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/execsnoop
|
||||
@ -65,12 +67,13 @@ grep 12255 12254 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COL
|
||||
grepconf.sh 12256 12239 0 /usr/libexec/grepconf.sh -c
|
||||
grep 12257 12256 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
|
||||
```
|
||||
哇。 那是什么? 什么是grepconf.sh? 什么是 /etc/GREP_COLORS? 而且 grep通过运行自身阅读它自己的配置文件? 这甚至是如何工作的?
|
||||
|
||||
Welcome to the fun of system tracing. You can learn a lot about how the system is really working (or not working, as the case may be) and discover some easy optimizations along the way. execsnoop works by tracing the exec() system call, which is usually used to load different program code in new processes.
|
||||
欢迎来到有趣的系统追踪世界。 你可以学到很多关于系统是如何工作的(或者一些情况下根本不工作),并且发现一些简单的优化。 execsnoop 通过跟踪 exec()系统调用来工作,exec() 通常用于在新进程中加载不同的程序代码。
|
||||
|
||||
### 2\. opensnoop
|
||||
|
||||
Continuing from above, so, grepconf.sh is likely a shell script, right? I'll run file(1) to check, and also use the [opensnoop][16] bcc tool to see what file is opening:
|
||||
从上面继续,所以,grepconf.sh可能是一个shell脚本,对吧? 我将运行file(1)来检查,并使用[opensnoop][16] bcc 工具来查看打开的文件:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
@ -88,16 +91,18 @@ PID COMM FD ERR PATH
|
||||
1 systemd 16 0 /proc/565/cgroup
|
||||
1 systemd 16 0 /proc/536/cgroup
|
||||
```
|
||||
像execsnoop和opensnoop这样的工具每个事件打印一行。上图显示 file(1)命令当前打开(或尝试打开)的文件:返回的文件描述符(“FD”列)对于 /etc/magic.mgc 是-1,而“ERR”列指示它是“文件未找到”。我不知道该文件,也不知道 file(1)正在读取的 /usr/share/misc/magic.mgc 文件。我不应该感到惊讶,但是 file(1)在识别文件类型时没有问题:
|
||||
|
||||
```
|
||||
# file /usr/share/misc/magic.mgc /etc/magic
|
||||
/usr/share/misc/magic.mgc: magic binary file for file(1) cmd (version 14) (little endian)
|
||||
/etc/magic: magic text file for file(1) cmd, ASCII text
|
||||
```
|
||||
opensnoop通过跟踪 open()系统调用来工作。为什么不使用 strace -feopen file 命令呢? 这将在这种情况下起作用。然而,opensnoop 的一些优点在于它能在系统范围内工作,并且跟踪所有进程的 open()系统调用。注意上例的输出中包括了从systemd打开的文件。Opensnoop 也应该有更低的开销:BPF 跟踪已经被优化,并且当前版本的 strace(1)仍然使用较老和较慢的 ptrace(2)接口。
|
||||
|
||||
### 3\. xfsslower
|
||||
|
||||
bcc/BPF can analyze much more than just syscalls. The [xfsslower][17] tool traces common XFS filesystem operations that have a latency of greater than 1 millisecond (the argument):
|
||||
bcc/BPF 不仅仅可以分析系统调用。[xfsslower][17] 工具跟踪具有大于1毫秒(参数)延迟的常见XFS文件系统操作。
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/xfsslower 1
|
||||
@ -114,14 +119,15 @@ TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
|
||||
14:17:46 cksum 4168 R 65536 128 1.01 grub2-fstest
|
||||
[...]
|
||||
```
|
||||
在上图输出中,我捕获了多个延迟超过 1 毫秒 的 cksum(1)读数(字段“T”等于“R”)。这个工作是在 xfsslower 工具运行的时候,通过在 XFS 中动态地设置内核函数实现,当它结束的时候解除检测。其他文件系统也有这个 bcc 工具的版本:ext4slower,btrfsslower,zfsslower 和 nfsslower。
|
||||
|
||||
This is a useful tool and an important example of BPF tracing. Traditional analysis of filesystem performance focuses on block I/O statistics—what you commonly see printed by the iostat(1) tool and plotted by many performance-monitoring GUIs. Those statistics show how the disks are performing, but not really the filesystem. Often you care more about the filesystem's performance than the disks, since it's the filesystem that applications make requests to and wait for. And the performance of filesystems can be quite different from that of disks! Filesystems may serve reads entirely from memory cache and also populate that cache via a read-ahead algorithm and for write-back caching. xfsslower shows filesystem performance—what the applications directly experience. This is often useful for exonerating the entire storage subsystem; if there is really no filesystem latency, then performance issues are likely to be elsewhere.
|
||||
这是个有用的工具,也是 BPF 追踪的重要例子。对文件系统性能的传统分析主要集中在块 I/O 统计信息 - 通常你看到的是由 iostat(1)工具打印并由许多性能监视 GUI 绘制的图表。这些统计数据显示了磁盘如何执行,但不是真正的文件系统。通常比起磁盘你更关心文件系统的性能,因为应用程序是在文件系统中发起请求和等待。并且文件系统的性能可能与磁盘的性能大为不同!文件系统可以完全从内存缓存中读取数据,也可以通过预读算法和回写缓存填充缓存。xfsslower 显示了文件系统的性能 - 应用程序直接体验到什么。这对于免除整个存储子系统通常是有用的; 如果确实没有文件系统延迟,那么性能问题很可能在别处。
|
||||
|
||||
### 4\. biolatency
|
||||
|
||||
Although filesystem performance is important to study for understanding application performance, studying disk performance has merit as well. Poor disk performance will affect the application eventually, when various caching tricks can no longer hide its latency. Disk performance is also a target of study for capacity planning.
|
||||
虽然文件系统性能对于理解应用程序性能非常重要,但研究磁盘性能也是有好处的。当各种缓存技巧不能再隐藏其延迟时,磁盘的低性能终会影响应用程序。 磁盘性能也是容量规划研究的目标。
|
||||
|
||||
The iostat(1) tool shows the average disk I/O latency, but averages can be misleading. It can be useful to study the distribution of I/O latency as a histogram, which can be done using [biolatency][18]:
|
||||
iostat(1)工具显示平均磁盘 I/O 延迟,但平均值可能会引起误解。 以直方图的形式研究 I/O 延迟的分布是有用的,这可以通过使用 [biolatency] 来实现[18]:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/biolatency
|
||||
@ -141,8 +147,9 @@ Tracing block device I/O... Hit Ctrl-C to end.
|
||||
1024 -> 2047 : 117 |******** |
|
||||
2048 -> 4095 : 8 | |
|
||||
```
|
||||
这是另一个有用的工具和例子; 它使用一个名为maps的BPF特性,它可以用来实现高效的内核内摘要统计。从内核级别到用户级别的数据传输仅仅是“计数”列。 用户级程序生成其余的。
|
||||
|
||||
It's worth noting that many of these tools support CLI options and arguments as shown by their USAGE message:
|
||||
值得注意的是,其中许多工具支持CLI选项和参数,如其使用信息所示:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/biolatency -h
|
||||
@ -168,10 +175,11 @@ examples:
|
||||
./biolatency -Q # include OS queued time in I/O time
|
||||
./biolatency -D # show each disk device separately
|
||||
```
|
||||
它们的行为像其他Unix工具是通过设计,以协助采用。
|
||||
|
||||
### 5\. tcplife
|
||||
|
||||
Another useful tool and example, this time showing lifespan and throughput statistics of TCP sessions, is [tcplife][19]:
|
||||
另一个有用的工具是[tcplife][19] ,该例显示TCP会话的生命周期和吞吐量统计
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/tcplife
|
||||
@ -181,10 +189,11 @@ PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS
|
||||
12844 wget 10.0.2.15 34250 54.204.39.132 443 11 1870 5712.26
|
||||
12851 curl 10.0.2.15 34252 54.204.39.132 443 0 74 505.90
|
||||
```
|
||||
在你说:“我不能只是刮 tcpdump(8)输出这个?”之前请注意,运行 tcpdump(8)或任何数据包嗅探器,在高数据包速率系统上花费的开销会很大,即使tcpdump(8)的用户级和内核级机制已经过多年优化(可能更差)。tcplife不会测试每个数据包; 它只会监视TCP会话状态的变化,从而影响会话的持续时间。它还使用已经跟踪吞吐量的内核计数器,以及处理和命令信息(“PID”和“COMM”列),这些对 tcpdump(8)等线上嗅探工具是做不到的。
|
||||
|
||||
### 6\. gethostlatency
|
||||
|
||||
Every previous example involves kernel tracing, so I need at least one user-level tracing example. Here is [gethostlatency][20], which instruments gethostbyname(3) and related library calls for name resolution:
|
||||
之前的每个例子都涉及到内核跟踪,所以我至少需要一个用户级跟踪的例子。 这是[gethostlatency] [20],其中gethostbyname(3)和相关的库调用名称解析:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/gethostlatency
|
||||
@ -198,22 +207,24 @@ TIME PID COMM LATms HOST
|
||||
06:45:07 12952 curl 13.64 opensource.cats
|
||||
06:45:19 13139 curl 13.10 opensource.cats
|
||||
```
|
||||
是的,它始终是DNS,所以有一个工具来监视系统范围内的DNS请求可以很方便(这只有在应用程序使用标准系统库时才有效)看看我如何跟踪多个查找“opensource.com”? 第一个是188.98毫秒,然后是更快,不到10毫秒,毫无疑问,缓存的作用。它还追踪多个查找“opensource.cats”,一个可悲的不存在的主机,但我们仍然可以检查第一个和后续查找的延迟。 (第二次查找后是否有一点负面缓存?)
|
||||
|
||||
### 7\. trace
|
||||
|
||||
Okay, one more example. The [trace][21] tool was contributed by Sasha Goldshtein and provides some basic printf(1) functionality with custom probes. For example:
|
||||
好的,再举一个例子。 [trace] [21]工具由Sasha Goldshtein提供,并提供了一些基本的printf(1)功能和自定义探针。 例如:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/trace 'pam:pam_start "%s: %s", arg1, arg2'
|
||||
PID TID COMM FUNC -
|
||||
13266 13266 sshd pam_start sshd: root
|
||||
```
|
||||
在这里,我正在跟踪 libpam 及其 pam_start(3)函数并将其两个参数都打印为字符串。 Libpam 用于可插入的身份验证模块系统,输出显示 sshd 为“root”用户(我登录)调用了 pam_start()。 USAGE消息中有更多的例子(“trace -h”),而且所有这些工具在bcc版本库中都有手册页和示例文件。 例如trace_example.txt和trace.8。
|
||||
|
||||
### Install bcc via packages
|
||||
### 通过包安装 bcc
|
||||
|
||||
The best way to install bcc is from an iovisor repository, following the instructions from the bcc [INSTALL.md][22]. [IO Visor][23] is the Linux Foundation project that includes bcc. The BPF enhancements these tools use were added in the 4.x series Linux kernels, up to 4.9\. This means that Fedora 25, with its 4.8 kernel, can run most of these tools; and Fedora 26, with its 4.11 kernel, can run them all (at least currently).
|
||||
安装 bcc 最佳的方法是从 iovisor 仓储库中安装,按照 bcc [INSTALL.md][22]。[IO Visor] [23]是包含 bcc 的Linux基金会项目。4.x系列Linux内核中增加了这些工具使用的BPF增强功能,上至4.9 \。这意味着拥有4.8内核的 Fedora 25可以运行大部分这些工具。 Fedora 26及其4.11内核可以运行它们(至少目前)。
|
||||
|
||||
If you are on Fedora 25 (or Fedora 26, and this post was published many months ago—hello from the distant past!), then this package approach should just work. If you are on Fedora 26, then skip to the [Install via Source][24] section, which avoids a [known][25] and [fixed][26] bug. That bug fix hasn't made its way into the Fedora 26 package dependencies at the moment. The system I'm using is:
|
||||
如果你使用的是Fedora 25(或者Fedora 26,而且这个帖子已经在很多个月前发布了 - 你好,来自遥远的过去!),那么这个包的方法应该是正常的。 如果您使用的是Fedora 26,那么请跳至“通过源代码安装”部分,该部分避免了已知的固定错误。 这个错误修复目前还没有进入Fedora 26软件包的依赖关系。 我使用的系统是:
|
||||
|
||||
```
|
||||
# uname -a
|
||||
@ -221,6 +232,7 @@ Linux localhost.localdomain 4.11.8-300.fc26.x86_64 #1 SMP Thu Jun 29 20:09:48 UT
|
||||
# cat /etc/fedora-release
|
||||
Fedora release 26 (Twenty Six)
|
||||
```
|
||||
以下是我所遵循的安装步骤,但请参阅INSTALL.md获取更新的版本:
|
||||
|
||||
```
|
||||
# echo -e '[iovisor]\nbaseurl=https://repo.iovisor.org/yum/nightly/f25/$basearch\nenabled=1\ngpgcheck=0' | sudo tee /etc/yum.repos.d/iovisor.repo
|
||||
@ -230,6 +242,7 @@ Total download size: 37 M
|
||||
Installed size: 143 M
|
||||
Is this ok [y/N]: y
|
||||
```
|
||||
安装完成后,您可以在/ usr / share中看到新的工具:
|
||||
|
||||
```
|
||||
# ls /usr/share/bcc/tools/
|
||||
@ -237,6 +250,7 @@ argdist dcsnoop killsnoop softirqs trace
|
||||
bashreadline dcstat llcstat solisten ttysnoop
|
||||
[...]
|
||||
```
|
||||
试着运行其中一个:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
@ -248,6 +262,7 @@ Traceback (most recent call last):
|
||||
raise Exception("Failed to compile BPF module %s" % src_file)
|
||||
Exception: Failed to compile BPF module
|
||||
```
|
||||
运行失败,提示/lib/modules/4.11.8-300.fc26.x86_64/build丢失。 如果你也这样做,那只是因为系统缺少内核头文件。 如果你看看这个文件指向什么(这是一个符号链接),然后使用“dnf whatprovides”来搜索它,它会告诉你接下来需要安装的包。 对于这个系统,它是:
|
||||
|
||||
```
|
||||
# dnf install kernel-devel-4.11.8-300.fc26.x86_64
|
||||
@ -257,6 +272,7 @@ Installed size: 63 M
|
||||
Is this ok [y/N]: y
|
||||
[...]
|
||||
```
|
||||
现在
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
@ -267,10 +283,11 @@ PID COMM FD ERR PATH
|
||||
11792 ls 3 0 /lib64/libc.so.6
|
||||
[...]
|
||||
```
|
||||
运行起来了。 这是从另一个窗口中的ls命令捕捉活动。 请参阅前面的部分以获取其他有用的命令
|
||||
|
||||
### Install via source
|
||||
### 通过源码安装
|
||||
|
||||
If you need to install from source, you can also find documentation and updated instructions in [INSTALL.md][27]. I did the following on Fedora 26:
|
||||
如果您需要从源代码安装,您还可以在[INSTALL.md] [27]中找到文档和更新说明。 我在Fedora 26上做了如下的事情:
|
||||
|
||||
```
|
||||
sudo dnf install -y bison cmake ethtool flex git iperf libstdc++-static \
|
||||
@ -282,12 +299,16 @@ sudo dnf install -y \
|
||||
sudo pip install pyroute2
|
||||
sudo dnf install -y clang clang-devel llvm llvm-devel llvm-static ncurses-devel
|
||||
```
|
||||
除 netperf 外一切妥当,其中有以下错误:
|
||||
|
||||
```
|
||||
Curl error (28): Timeout was reached for http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm [Connection timed out after 120002 milliseconds]
|
||||
```
|
||||
|
||||
Here are the remaining bcc compilation and install steps:
|
||||
不必理会,netperf是可选的 - 它只是用于测试 - 而 bcc 没有它也会编译成功。
|
||||
|
||||
以下是 bcc 编译和安装余下的步骤:
|
||||
|
||||
|
||||
```
|
||||
git clone https://github.com/iovisor/bcc.git
|
||||
@ -296,6 +317,7 @@ cmake .. -DCMAKE_INSTALL_PREFIX=/usr
|
||||
make
|
||||
sudo make install
|
||||
```
|
||||
在这一点上,命令应该起作用:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
@ -319,29 +341,27 @@ More Linux resources
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
This was a quick tour of the new BPF performance analysis superpowers that you can use on the Fedora and Red Hat family of operating systems. I demonstrated the popular
|
||||
### 写在最后和其他前端
|
||||
|
||||
[bcc][28]
|
||||
这是一个可以在 Fedora 和 Red Hat 系列操作系统上使用的新 BPF 性能分析强大功能的快速浏览。我演示了BPF的流行前端 [bcc][28] ,并包含了其在 Fedora 上的安装说明。bcc 附带了60多个用于性能分析的新工具,这将帮助您充分利用Linux系统。也许你会直接通过SSH使用这些工具,或者一旦它们支持BPF,你也可以通过监视GUI来使用相同的功能。
|
||||
|
||||
frontend to BPF and included install instructions for Fedora. bcc comes with more than 60 new tools for performance analysis, which will help you get the most out of your Linux systems. Perhaps you will use these tools directly over SSH, or perhaps you will use the same functionality via monitoring GUIs once they support BPF.
|
||||
此外,bcc并不是开发中唯一的前端。[ply][29]和[bpftrace][30],旨在为快速编写自定义工具提供更高级的语言。此外,[SystemTap] [31]刚刚发布[版本3.2] [32],包括一个早期的实验性eBPF后端。 如果这一点继续得到发展,它将为运行多年来开发的许多SystemTap脚本和攻击集(库)提供一个生产安全和高效的引擎。 (使用SystemTap和eBPF将成为另一篇文章的主题。)
|
||||
|
||||
Also, bcc is not the only frontend in development. There are [ply][29] and [bpftrace][30], which aim to provide higher-level language for quickly writing custom tools. In addition, [SystemTap][31] just released [version 3.2][32], including an early, experimental eBPF backend. Should this continue to be developed, it will provide a production-safe and efficient engine for running the many SystemTap scripts and tapsets (libraries) that have been developed over the years. (Using SystemTap with eBPF would be good topic for another post.)
|
||||
如果您需要开发自定义工具,那么也可以使用 bcc 来实现,尽管语言比 SystemTap,ply 或 bpftrace 要冗长得多。 我的 bcc 工具可以作为代码示例,另外我还贡献了[教程] [33]来开发 Python 中的 bcc 工具。 我建议先学习bcc多工具,因为在需要编写新工具之前,你可能会从里面获得很多里程。 您可以从他们 bcc 存储库[funccount] [34],[funclatency] [35],[funcslower] [36],[stackcount] [37],[trace] [38] ,[argdist] [39] 的示例文件中研究 bcc。
|
||||
|
||||
If you need to develop custom tools, you can do that with bcc as well, although the language is currently much more verbose than SystemTap, ply, or bpftrace. My bcc tools can serve as code examples, plus I contributed a [tutorial][33] for developing bcc tools in Python. I'd recommend learning the bcc multi-tools first, as you may get a lot of mileage from them before needing to write new tools. You can study the multi-tools from their example files in the bcc repository: [funccount][34], [funclatency][35], [funcslower][36], [stackcount][37], [trace][38], and [argdist][39].
|
||||
感谢[Opensource.com] [40]进行编辑。
|
||||
|
||||
Thanks to [Opensource.com][40] for edits.
|
||||
### 专题
|
||||
|
||||
### Topics
|
||||
|
||||
[Linux][41][SysAdmin][42]
|
||||
[Linux][41][系统管理员][42]
|
||||
|
||||
### About the author
|
||||
|
||||
[][43] Brendan Gregg
|
||||
|
||||
-
|
||||
Brendan Gregg是Netflix的一名高级性能架构师,在那里他进行大规模的计算机性能设计,分析和调优。[关于更多] [44]
|
||||
|
||||
Brendan Gregg is a senior performance architect at Netflix, where he does large scale computer performance design, analysis, and tuning.[More about me][44]
|
||||
|
||||
* [Learn how you can contribute][6]
|
||||
|
||||
Loading…
Reference in New Issue
Block a user