mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
commit
9611bac7d1
@ -0,0 +1,164 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11282-1.html)
|
||||
[#]: subject: (How to Install VirtualBox on Ubuntu [Beginner’s Tutorial])
|
||||
[#]: via: (https://itsfoss.com/install-virtualbox-ubuntu)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何在 Ubuntu 上安装 VirtualBox
|
||||
======
|
||||
|
||||
> 本新手教程解释了在 Ubuntu 和其他基于 Debian 的 Linux 发行版上安装 VirtualBox 的各种方法。
|
||||
|
||||

|
||||
|
||||
Oracle 公司的自由开源产品 [VirtualBox][1] 是一款出色的虚拟化工具,专门用于桌面操作系统。与另一款虚拟化工具 [Linux 上的 VMWare Workstation][2] 相比起来,我更喜欢它。
|
||||
|
||||
你可以使用 VirtualBox 等虚拟化软件在虚拟机中安装和使用其他操作系统。
|
||||
|
||||
例如,你可以[在 Windows 上的 VirtualBox 中安装 Linux][3]。同样地,你也可以[用 VirtualBox 在 Linux 中安装 Windows][4]。
|
||||
|
||||
你也可以用 VirtualBox 在你当前的 Linux 系统中安装别的 Linux 发行版。事实上,这就是我用它的原因。如果我听说了一个不错的 Linux 发行版,我会在虚拟机上测试它,而不是安装在真实的系统上。当你想要在安装之前尝试一下别的发行版时,用虚拟机会很方便。
|
||||
|
||||
![Linux installed inside Linux using VirtualBox][5]
|
||||
|
||||
*安装在 Ubuntu 18.04 内的 Ubuntu 18.10*
|
||||
|
||||
在本新手教程中,我将向你展示在 Ubuntu 和其他基于 Debian 的 Linux 发行版上安装 VirtualBox 的各种方法。
|
||||
|
||||
### 在 Ubuntu 和基于 Debian 的 Linux 发行版上安装 VirtualBox
|
||||
|
||||
这里提出的安装方法也适用于其他基于 Debian 和 Ubuntu 的 Linux 发行版,如 Linux Mint、elementar OS 等。
|
||||
|
||||
#### 方法 1:从 Ubuntu 仓库安装 VirtualBox
|
||||
|
||||
**优点**:安装简便
|
||||
|
||||
**缺点**:较旧版本
|
||||
|
||||
在 Ubuntu 上下载 VirtualBox 最简单的方法可能是从软件中心查找并下载。
|
||||
|
||||
![VirtualBox in Ubuntu Software Center][6]
|
||||
|
||||
*VirtualBox 在 Ubuntu 软件中心提供*
|
||||
|
||||
你也可以使用这条命令从命令行安装:
|
||||
|
||||
```
|
||||
sudo apt install virtualbox
|
||||
```
|
||||
|
||||
然而,如果[在安装前检查软件包版本][7],你会看到 Ubuntu 仓库提供的 VirtualBox 版本已经很老了。
|
||||
|
||||
举个例子,在写下本教程时 VirtualBox 的最新版本是 6.0,但是在软件中心提供的是 5.2。这意味着你无法获得[最新版 VirtualBox ][8]中引入的新功能。
|
||||
|
||||
#### 方法 2:使用 Oracle 网站上的 Deb 文件安装 VirtualBox
|
||||
|
||||
**优点**:安装简便,最新版本
|
||||
|
||||
**缺点**:不能更新
|
||||
|
||||
如果你想要在 Ubuntu 上使用 VirtualBox 的最新版本,最简单的方法就是[使用 Deb 文件][9]。
|
||||
|
||||
Oracle 为 VirtiualBox 版本提供了开箱即用的二进制文件。如果查看其下载页面,你将看到为 Ubuntu 和其他发行版下载 deb 安装程序的选项。
|
||||
|
||||
![VirtualBox Linux Download][10]
|
||||
|
||||
你只需要下载 deb 文件并双击它即可安装。就是这么简单。
|
||||
|
||||
- [下载 virtualbox for Ubuntu](https://www.virtualbox.org/wiki/Linux_Downloads)
|
||||
|
||||
然而,这种方法的问题在于你不能自动更新到最新的 VirtualBox 版本。唯一的办法是移除现有版本,下载最新版本并再次安装。不太方便,是吧?
|
||||
|
||||
#### 方法 3:用 Oracle 的仓库安装 VirtualBox
|
||||
|
||||
**优点**:自动更新
|
||||
|
||||
**缺点**:安装略微复杂
|
||||
|
||||
现在介绍的是命令行安装方法,它看起来可能比较复杂,但与前两种方法相比,它更具有优势。你将获得 VirtualBox 的最新版本,并且未来它还将自动更新到更新的版本。我想那就是你想要的。
|
||||
|
||||
要通过命令行安装 VirtualBox,请在你的仓库列表中添加 Oracle VirtualBox 的仓库。添加 GPG 密钥以便你的系统信任此仓库。现在,当你安装 VirtualBox 时,它会从 Oracle 仓库而不是 Ubuntu 仓库安装。如果发布了新版本,本地 VirtualBox 将跟随一起更新。让我们看看怎么做到这一点:
|
||||
|
||||
首先,添加仓库的密钥。你可以通过这一条命令下载和添加密钥:
|
||||
|
||||
```
|
||||
wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
|
||||
```
|
||||
|
||||
> Mint 用户请注意:
|
||||
|
||||
> 下一步只适用于 Ubuntu。如果你使用的是 Linux Mint 或其他基于 Ubuntu 的发行版,请将命令行中的 `$(lsb_release -cs)` 替换成你当前版本所基于的 Ubuntu 版本。例如,Linux Mint 19 系列用户应该使用 bionic,Mint 18 系列用户应该使用 xenial,像这样:
|
||||
|
||||
> ```
|
||||
> sudo add-apt-repository “deb [arch=amd64] <http://download.virtualbox.org/virtualbox/debian> **bionic** contrib“`
|
||||
> ```
|
||||
|
||||
现在用以下命令来将 Oracle VirtualBox 仓库添加到仓库列表中:
|
||||
|
||||
```
|
||||
sudo add-apt-repository "deb [arch=amd64] http://download.virtualbox.org/virtualbox/debian $(lsb_release -cs) contrib"
|
||||
```
|
||||
|
||||
如果你有读过我的文章[检查 Ubuntu 版本][11],你大概知道 `lsb_release -cs` 将打印你的 Ubuntu 系统的代号。
|
||||
|
||||
**注**:如果你看到 “[add-apt-repository command not found][12]” 错误,你需要下载 `software-properties-common` 包。
|
||||
|
||||
现在你已经添加了正确的仓库,请通过此仓库刷新可用包列表并安装 VirtualBox:
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt install virtualbox-6.0
|
||||
```
|
||||
|
||||
**提示**:一个好方法是输入 `sudo apt install virtualbox-` 并点击 `tab` 键以查看可用于安装的各种 VirtualBox 版本,然后通过补全命令来选择其中一个版本。
|
||||
|
||||
![Install VirtualBox via terminal][13]
|
||||
|
||||
### 如何从 Ubuntu 中删除 VirtualBox
|
||||
|
||||
现在你已经学会了如何安装 VirtualBox,我还想和你提一下删除它的步骤。
|
||||
|
||||
如果你是从软件中心安装的,那么删除它最简单的方法是从软件中心下手。你只需要在[已安装的应用程序列表][14]中找到它,然后单击“删除”按钮。
|
||||
|
||||
另一种方式是使用命令行:
|
||||
|
||||
```
|
||||
sudo apt remove virtualbox virtualbox-*
|
||||
```
|
||||
|
||||
请注意,这不会删除你用 VirtualBox 安装的操作系统关联的虚拟机和文件。这并不是一件坏事,因为你可能希望以后或在其他系统中使用它们是安全的。
|
||||
|
||||
### 最后…
|
||||
|
||||
我希望你能在以上方法中选择一种安装 VirtualBox。我还将在另一篇文章中写到如何有效地使用 VirtualBox。目前,如果你有点子、建议或任何问题,请随时在下面发表评论。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-virtualbox-ubuntu
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[beamrolling](https://github.com/beamrolling)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.virtualbox.org
|
||||
[2]: https://itsfoss.com/install-vmware-player-ubuntu-1310/
|
||||
[3]: https://itsfoss.com/install-linux-in-virtualbox/
|
||||
[4]: https://itsfoss.com/install-windows-10-virtualbox-linux/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/linux-inside-linux-virtualbox.png?resize=800%2C450&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/virtualbox-ubuntu-software-center.jpg?ssl=1
|
||||
[7]: https://itsfoss.com/know-program-version-before-install-ubuntu/
|
||||
[8]: https://itsfoss.com/oracle-virtualbox-release/
|
||||
[9]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/virtualbox-download.jpg?resize=800%2C433&ssl=1
|
||||
[11]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[12]: https://itsfoss.com/add-apt-repository-command-not-found/
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/install-virtualbox-ubuntu-terminal.png?resize=800%2C165&ssl=1
|
||||
[14]: https://itsfoss.com/list-installed-packages-ubuntu/
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zionfuo)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11275-1.html)
|
||||
[#]: subject: (Blockchain 2.0 – An Introduction To Hyperledger Project (HLP) [Part 8])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/)
|
||||
[#]: author: (editor https://www.ostechnix.com/author/editor/)
|
||||
|
||||
区块链 2.0:Hyperledger 项目简介(八)
|
||||
======
|
||||
|
||||
![Introduction To Hyperledger Project][1]
|
||||
|
||||
一旦一个新技术平台在积极发展和商业利益方面达到了一定程度的受欢迎程度,全球的主要公司和小型的初创企业都急于抓住这块蛋糕。在当时 Linux 就是这样的一个平台。一旦实现了其应用程序的普及,个人、公司和机构就开始对其表现出兴趣,到 2000 年,Linux 基金会就成立了。
|
||||
|
||||
Linux 基金会旨在通过赞助他们的开发团队来将 Linux 作为一个平台来标准化和发展。Linux 基金会是一个由软件和 IT 巨头([如微软、甲骨文、三星、思科、 IBM 、英特尔等][7])支持的非营利组织。这不包括为改进该平台而提供服务的数百名个人开发者。多年来,Linux 基金会已经在旗下开展了许多项目。**Hyperledger** 项目是迄今为止发展最快的项目。
|
||||
|
||||
在将技术推进至可用且有用的方面上,这种联合主导的开发具有很多优势。为大型项目提供开发标准、库和所有后端协议既昂贵又耗费资源,而且不会从中产生丝毫收入。因此,对于公司来说,通过支持这些组织来汇集他们的资源来开发常见的那些 “烦人” 部分是有很意义的,以及随后完成这些标准部分的工作以简单地即插即用和定制他们的产品。除了这种模型的经济性之外,这种合作努力还产生了标准,使其容易使用和集成到优秀的产品和服务中。
|
||||
|
||||
上述联盟模式,在曾经或当下的创新包括 WiFi(Wi-Fi 联盟)、移动电话等标准。
|
||||
|
||||
### Hyperledger 项目(HLP)简介
|
||||
|
||||
Hyperledger 项目(HLP)于 2015 年 12 月由 Linux 基金会启动,目前是其孵化的增长最快的项目之一。它是一个<ruby>伞式组织<rt>umbrella organization</rt></ruby>,用于合作开发和推进基于[区块链][2]的分布式账本技术 (DLT) 的工具和标准。支持该项目的主要行业参与者包括 IBM、英特尔 和 SAP Ariba [等][3]。HLP 旨在为个人和公司创建框架,以便根据需要创建共享和封闭的区块链,以满足他们自己的需求。其设计原则是开发一个专注于隐私和未来可审计性的全球可部署、可扩展、强大的区块链平台。[^2] 同样要注意的是大多数提出的区块链及其框架。
|
||||
|
||||
### 开发目标和构造:即插即用
|
||||
|
||||
虽然面向企业的平台有以太坊联盟之类的产品,但根据定义,HLP 是面向企业的,并得到行业巨头的支持,他们在 HLP 旗下的许多模块中做出贡献并进一步发展。HLP 还孵化开发的周边项目,并这些创意项目推向公众。HLP 的成员贡献了他们自己的力量,例如 IBM 为如何协作开发贡献了他们的 Fabric 平台。该代码库由 IBM 在其项目组内部研发,并开源出来供所有成员使用。
|
||||
|
||||
这些过程使得 HLP 中的模块具有高度灵活的插件框架,这将支持企业环境中的快速开发和部署。此外,默认情况下,其他对比的平台是开放的<ruby>免许可链<rt>permission-less blockchain</rt></ruby>或是<ruby>公有链<rt>public blockchain</rt></ruby>,甚至可以将它们应用到特定应用当中。HLP 模块本身支持该功能。
|
||||
|
||||
有关公有链和私有链的差异和用例更多地涵盖在[这篇][4]比较文章当中。
|
||||
|
||||
根据该项目执行董事 Brian Behlendorf 的说法,Hyperledger 项目的使命有四个。
|
||||
|
||||
分别是:
|
||||
|
||||
1. 创建企业级 DLT 框架和标准,任何人都可以移植以满足其特定的行业或个人需求。
|
||||
2. 创建一个强大的开源社区来帮助生态系统发展。
|
||||
3. 促进所述的生态系统的行业成员(如成员公司)的参与。
|
||||
4. 为 HLP 社区提供中立且无偏见的基础设施,以收集和分享相关的更新和发展。
|
||||
|
||||
可以在这里访问[原始文档][5]。
|
||||
|
||||
### HLP 的架构
|
||||
|
||||
HLP 由 12 个项目组成,这些项目被归类为独立的模块,每个项目通常都是结构化的,可以独立开发其模块的。在孵化之前,首先对它们的能力和活力进行研究。该组织的任何成员都可以提出附加建议。在项目孵化后,就会进行积极开发,然后才会推出。这些模块之间的互操作性具有很高的优先级,因此这些组之间的定期通信由社区维护。目前,这些项目中有 4 个被归类为活跃项目。被标为活跃意味着它们已经准备好使用,但还没有准备好发布主要版本。这 4 个模块可以说是推动区块链革命的最重要或相当基本的模块。稍后,我们将详细介绍各个模块及其功能。然而,Hyperledger Fabric 平台的简要描述,可以说是其中最受欢迎的。
|
||||
|
||||
### Hyperledger Fabric
|
||||
|
||||
Hyperledger Fabric 是一个完全开源的、基于区块链的许可 (非公开) DLT 平台,设计时考虑了企业的使用。该平台提供了适合企业环境的功能和结构。它是高度模块化的,允许开发人员在不同的共识协议、链上代码协议([智能合约][6])或身份管理系统等中进行选择。这是一个基于区块链的许可平台,它利用身份管理系统,这意味着参与者将知道彼此在企业环境中的身份。Fabric 允许以各种主流编程语言 (包括 Java、Javascript、Go 等) 开发智能合约(“<ruby>链码<rt>chaincode</rt></ruby>”,是 Hyperledger 团队使用的术语)。这使得机构和企业可以利用他们在该领域的现有人才,而无需雇佣或重新培训开发人员来开发他们自己的智能合约。与标准订单验证系统相比,Fabric 还使用<ruby>执行顺序验证<rt>execute-order-validate</rt></ruby>系统来处理智能合约,以提供更好的可靠性,这些系统由提供智能合约功能的其他平台使用。与标准订单验证系统相比,Fabric还使用执行顺序验证系统来处理智能合约,以提供更好的可靠性,这些系统由提供智能合约功能的其他平台使用。Fabric 的其他功能还有可插拔性能、身份管理系统、数据库管理系统、共识平台等,这些功能使它在竞争中保持领先地位。
|
||||
|
||||
### 结论
|
||||
|
||||
诸如 Hyperledger Fabric 平台这样的项目能够在主流用例中更快地采用区块链技术。Hyperledger 社区结构本身支持开放治理原则,并且由于所有项目都是作为开源平台引导的,因此这提高了团队在履行承诺时表现出来的安全性和责任感。
|
||||
|
||||
由于此类项目的主要应用涉及与企业合作及进一步开发平台和标准,因此 Hyperledger 项目目前在其他类似项目前面处于有利地位。
|
||||
|
||||
[^2]: E. Androulaki et al., “Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains,” 2018.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
|
||||
|
||||
作者:[ostechnix][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zionfuo](https://github.com/zionfuo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/Introduction-To-Hyperledger-Project-720x340.png
|
||||
[2]: https://linux.cn/article-10650-1.html
|
||||
[3]: https://www.hyperledger.org/members
|
||||
[4]: https://linux.cn/article-11080-1.html
|
||||
[5]: http://www.hitachi.com/rev/archive/2017/r2017_01/expert/index.html
|
||||
[6]: https://linux.cn/article-10956-1.html
|
||||
[7]: https://www.theinquirer.net/inquirer/news/2182438/samsung-takes-seat-intel-ibm-linux-foundation
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11285-1.html)
|
||||
[#]: subject: (How to transition into a career as a DevOps engineer)
|
||||
[#]: via: (https://opensource.com/article/19/7/how-transition-career-devops-engineer)
|
||||
[#]: author: (Conor Delanbanque https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque)
|
||||
|
||||
如何转职为 DevOps 工程师
|
||||
======
|
||||
|
||||
> 无论你是刚毕业的大学生,还是想在职业中寻求进步的经验丰富的 IT 专家,这些提示都可以帮你成为 DevOps 工程师。
|
||||
|
||||

|
||||
|
||||
DevOps 工程是一个备受称赞的热门职业。不管你是刚毕业正在找第一份工作,还是在利用之前的行业经验的同时寻求学习新技能的机会,本指南都能帮你通过正确的步骤成为 [DevOps 工程师][2]。
|
||||
|
||||
### 让自己沉浸其中
|
||||
|
||||
首先学习 [DevOps][3] 的基本原理、实践以及方法。在使用工具之前,先了解 DevOps 背后的“为什么”。DevOps 工程师的主要目标是在整个软件开发生命周期(SDLC)中提高速度并保持或提高质量,以提供最大的业务价值。阅读文章、观看 YouTube 视频、参加当地小组聚会或者会议 —— 成为热情的 DevOps 社区中的一员,在那里你将从先行者的错误和成功中学习。
|
||||
|
||||
### 考虑你的背景
|
||||
|
||||
如果你有从事技术工作的经历,例如软件开发人员、系统工程师、系统管理员、网络运营工程师或者数据库管理员,那么你已经拥有了广泛的见解和有用的经验,它们可以帮助你在未来成为 DevOps 工程师。如果你在完成计算机科学或任何其他 STEM(LCTT 译注:STEM 是<ruby>科学<rt>Science</rt></ruby>、<ruby>技术<rt>Technology</rt></ruby>、<ruby>工程<rt>Engineering</rt></ruby>和<ruby>数学<rt>Math</rt></ruby>四个学科的首字母缩略字)领域的学业后刚开始职业生涯,那么你将拥有在这个过渡期间需要的一些基本踏脚石。
|
||||
|
||||
DevOps 工程师的角色涵盖了广泛的职责。以下是企业最有可能使用他们的三种方向:
|
||||
|
||||
* **偏向于开发(Dev)的 DevOps 工程师**,在构建应用中扮演软件开发的角色。他们日常工作的一部分是利用持续集成 / 持续交付(CI/CD)、共享仓库、云和容器,但他们不一定负责构建或实施工具。他们了解基础架构,并且在成熟的环境中,能将自己的代码推向生产环境。
|
||||
* **偏向于运维技术(Ops)的 DevOps 工程师**,可以与系统工程师或系统管理员相比较。他们了解软件的开发,但并不会把一天的重心放在构建应用上。相反,他们更有可能支持软件开发团队实现手动流程的自动化,并提高人员和技术系统的效率。这可能意味着分解遗留代码,并用不太繁琐的自动化脚本来运行相同的命令,或者可能意味着安装、配置或维护基础结构和工具。他们确保为任何有需要的团队安装可使用的工具。他们也会通过教团队如何利用 CI / CD 和其他 DevOps 实践来帮助他们。
|
||||
* **网站可靠性工程师(SRE)**,就像解决运维和基础设施的软件工程师。SRE 专注于创建可扩展、高可用且可靠的软件系统。
|
||||
|
||||
在理想的世界中,DevOps 工程师将了解以上所有领域;这在成熟的科技公司中很常见。然而,顶级银行和许多财富 500 强企业的 DevOps 职位通常会偏向开发(Dev)或运营(Ops)。
|
||||
|
||||
### 要学习的技术
|
||||
|
||||
DevOps 工程师需要了解各种技术才能有效完成工作。无论你的背景如何,请从作为 DevOps 工程师需要使用和理解的基本技术开始。
|
||||
|
||||
#### 操作系统
|
||||
|
||||
操作系统是一切运行的地方,拥有相关的基础知识十分重要。[Linux][4] 是你最有可能每天使用的操作系统,尽管有的组织会使用 Windows 操作系统。要开始使用,你可以在家中安装 Linux,在那里你可以随心所欲地中断,并在此过程中学习。
|
||||
|
||||
#### 脚本
|
||||
|
||||
接下来,选择一门语言来学习脚本编程。有很多语言可供选择,包括 Python、Go、Java、Bash、PowerShell、Ruby 和 C / C++。我建议[从 Python 开始][5],因为它相对容易学习和解释,是最受欢迎的语言之一。Python 通常是遵循面向对象编程(OOP)的准则编写的,可用于 Web 开发、软件开发以及创建桌面 GUI 和业务应用程序。
|
||||
|
||||
#### 云
|
||||
|
||||
学习了 [Linux][4] 和 [Python][5] 之后,我认为下一个该学习的是云计算。基础设施不再只是“运维小哥”的事情了,因此你需要接触云平台,例如 AWS 云服务、Azure 或者谷歌云平台。我会从 AWS 开始,因为它有大量免费学习工具,可以帮助你降低作为开发人员、运维人员,甚至面向业务的部门的任何障碍。事实上,你可能会被它提供的东西所淹没。考虑从 EC2、S3 和 VPC 开始,然后看看你从其中想学到什么。
|
||||
|
||||
#### 编程语言
|
||||
|
||||
如果你对 DevOps 的软件开发充满热情,请继续提高你的编程技能。DevOps 中的一些优秀和常用的编程语言和你用于脚本编程的相同:Python、Go、Java、Bash、PowerShell、Ruby 和 C / C++。你还应该熟悉 Jenkins 和 Git / Github,你将会在 CI / CD 过程中经常使用到它们。
|
||||
|
||||
#### 容器
|
||||
|
||||
最后,使用 Docker 和编排平台(如 Kubernetes)等工具开始学习[容器化][6]。网上有大量的免费学习资源,大多数城市都有本地的线下小组,你可以在友好的环境中向有经验的人学习(还有披萨和啤酒哦!)。
|
||||
|
||||
#### 其他的呢?
|
||||
|
||||
如果你缺乏开发经验,你依然可以通过对自动化的热情,提高效率,与他人协作以及改进自己的工作来[参与 DevOps][3]。我仍然建议学习上述工具,但重点不要放在编程 / 脚本语言上。了解基础架构即服务、平台即服务、云平台和 Linux 会非常有用。你可能会设置工具并学习如何构建具有弹性和容错能力的系统,并在编写代码时利用它们。
|
||||
|
||||
### 找一份 DevOps 的工作
|
||||
|
||||
求职过程会有所不同,具体取决于你是否一直从事技术工作,是否正在进入 DevOps 领域,或者是刚开始职业生涯的毕业生。
|
||||
|
||||
#### 如果你已经从事技术工作
|
||||
|
||||
如果你正在从一个技术领域转入 DevOps 角色,首先尝试在你当前的公司寻找机会。你能通过和其他的团队一起工作来重新掌握技能吗?尝试跟随其他团队成员,寻求建议,并在不离开当前工作的情况下获得新技能。如果做不到这一点,你可能需要换另一家公司。如果你能从上面列出的一些实践、工具和技术中学习,你将能在面试时展示相关知识从而占据有利位置。关键是要诚实,不要担心失败。大多数招聘主管都明白你并不知道所有的答案;如果你能展示你一直在学习的东西,并解释你愿意学习更多,你应该有机会获得 DevOps 的工作。
|
||||
|
||||
#### 如果你刚开始职业生涯
|
||||
|
||||
申请雇用初级 DevOps 工程师的公司的空缺机会。不幸的是,许多公司表示他们希望寻找更富有经验的人,并建议你在获得经验后再申请该职位。这是“我们需要经验丰富的人”的典型,令人沮丧的场景,并且似乎没人愿意给你第一次机会。
|
||||
|
||||
然而,并不是所有求职经历都那么令人沮丧;一些公司专注于培训和提升刚从大学毕业的学生。例如,我工作的 [MThree][7] 会聘请应届毕业生并且对其进行 8 周的培训。当完成培训后,参与者们可以充分了解到整个 SDLC,并充分了解它在财富 500 强公司环境中的运用方式。毕业生被聘为 MThree 的客户公司的初级 DevOps 工程师 —— MThree 在前 18 - 24 个月内支付全职工资和福利,之后他们将作为直接雇员加入客户。这是弥合从大学到技术职业的间隙的好方法。
|
||||
|
||||
### 总结
|
||||
|
||||
转职成 DevOps 工程师的方法有很多种。这是一条非常有益的职业路线,可能会让你保持繁忙和挑战 — 并增加你的收入潜力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/how-transition-career-devops-engineer
|
||||
|
||||
作者:[Conor Delanbanque][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[beamrolling](https://github.com/beamrolling)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/hiring_talent_resume_job_career.png?itok=Ci_ulYAH (technical resume for hiring new talent)
|
||||
[2]: https://opensource.com/article/19/7/devops-vs-sysadmin
|
||||
[3]: https://opensource.com/resources/devops
|
||||
[4]: https://opensource.com/resources/linux
|
||||
[5]: https://opensource.com/resources/python
|
||||
[6]: https://opensource.com/article/18/8/sysadmins-guide-containers
|
||||
[7]: https://www.mthreealumni.com/
|
||||
228
published/20190812 How Hexdump works.md
Normal file
228
published/20190812 How Hexdump works.md
Normal file
@ -0,0 +1,228 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (0x996)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11288-1.html)
|
||||
[#]: subject: (How Hexdump works)
|
||||
[#]: via: (https://opensource.com/article/19/8/dig-binary-files-hexdump)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Hexdump 如何工作
|
||||
======
|
||||
|
||||
> Hexdump 能帮助你查看二进制文件的内容。让我们来学习 Hexdump 如何工作。
|
||||
|
||||

|
||||
|
||||
Hexdump 是个用十六进制、十进制、八进制数或 ASCII 码显示二进制文件内容的工具。它是个用于检查的工具,也可用于[数据恢复][2]、逆向工程和编程。
|
||||
|
||||
### 学习基本用法
|
||||
|
||||
Hexdump 让你毫不费力地得到输出结果,依你所查看文件的尺寸,输出结果可能会非常多。本文中我们会创建一个 1x1 像素的 PNG 文件。你可以用图像处理应用如 [GIMP][3] 或 [Mtpaint][4] 来创建该文件,或者也可以在终端内用 [ImageMagick][5] 创建。
|
||||
|
||||
用 ImagiMagick 生成 1x1 像素 PNG 文件的命令如下:
|
||||
|
||||
```
|
||||
$ convert -size 1x1 canvas:black pixel.png
|
||||
```
|
||||
|
||||
你可以用 `file` 命令确认此文件是 PNG 格式:
|
||||
|
||||
```
|
||||
$ file pixel.png
|
||||
pixel.png: PNG image data, 1 x 1, 1-bit grayscale, non-interlaced
|
||||
```
|
||||
|
||||
你可能好奇 `file` 命令是如何判断文件是什么类型。巧的是,那正是 `hexdump` 将要揭示的原理。眼下你可以用你常用的图像查看软件来看看你的单一像素图片(它看上去就像这样:`.`),或者你可以用 `hexdump` 查看文件内部:
|
||||
|
||||
```
|
||||
$ hexdump pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a 0000 0d00 4849 5244
|
||||
0000010 0000 0100 0000 0100 0001 0000 3700 f96e
|
||||
0000020 0024 0000 6704 4d41 0041 b100 0b8f 61fc
|
||||
0000030 0005 0000 6320 5248 004d 7a00 0026 8000
|
||||
0000040 0084 fa00 0000 8000 00e8 7500 0030 ea00
|
||||
0000050 0060 3a00 0098 1700 9c70 51ba 003c 0000
|
||||
0000060 6202 474b 0044 dd01 138a 00a4 0000 7407
|
||||
0000070 4d49 0745 07e3 081a 3539 a487 46b0 0000
|
||||
0000080 0a00 4449 5441 d708 6063 0000 0200 0100
|
||||
0000090 21e2 33bc 0000 2500 4574 7458 6164 6574
|
||||
00000a0 633a 6572 7461 0065 3032 3931 302d 2d37
|
||||
00000b0 3532 3254 3a30 3735 353a 2b33 3231 303a
|
||||
00000c0 ac30 5dcd 00c1 0000 7425 5845 6474 7461
|
||||
00000d0 3a65 6f6d 6964 7966 3200 3130 2d39 3730
|
||||
00000e0 322d 5435 3032 353a 3a37 3335 312b 3a32
|
||||
00000f0 3030 90dd 7de5 0000 0000 4549 444e 42ae
|
||||
0000100 8260
|
||||
0000102
|
||||
```
|
||||
|
||||
透过一个你以前可能从未用过的视角,你所见的是该示例 PNG 文件的内容。它和你在图像查看软件中看到的是完全一样的数据,只是用一种你或许不熟悉的方式编码。
|
||||
|
||||
### 提取熟悉的字符串
|
||||
|
||||
尽管默认的数据输出结果看上去毫无意义,那并不意味着其中没有有价值的信息。你可以用 `--canonical` 选项将输出结果,或至少是其中可翻译的部分,翻译成更加熟悉的字符集:
|
||||
|
||||
```
|
||||
$ hexdump --canonical foo.png
|
||||
00000000 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 |.PNG........IHDR|
|
||||
00000010 00 00 00 01 00 00 00 01 01 00 00 00 00 37 6e f9 |.............7n.|
|
||||
00000020 24 00 00 00 04 67 41 4d 41 00 00 b1 8f 0b fc 61 |$....gAMA......a|
|
||||
00000030 05 00 00 00 20 63 48 52 4d 00 00 7a 26 00 00 80 |.... cHRM..z&...|
|
||||
00000040 84 00 00 fa 00 00 00 80 e8 00 00 75 30 00 00 ea |...........u0...|
|
||||
00000050 60 00 00 3a 98 00 00 17 70 9c ba 51 3c 00 00 00 |`..:....p..Q<...|
|
||||
00000060 02 62 4b 47 44 00 01 dd 8a 13 a4 00 00 00 07 74 |.bKGD..........t|
|
||||
00000070 49 4d 45 07 e3 07 1a 08 39 35 87 a4 b0 46 00 00 |IME.....95...F..|
|
||||
00000080 00 0a 49 44 41 54 08 d7 63 60 00 00 00 02 00 01 |..IDAT..c`......|
|
||||
00000090 e2 21 bc 33 00 00 00 25 74 45 58 74 64 61 74 65 |.!.3...%tEXtdate|
|
||||
000000a0 3a 63 72 65 61 74 65 00 32 30 31 39 2d 30 37 2d |:create.2019-07-|
|
||||
000000b0 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a 30 |25T20:57:53+12:0|
|
||||
000000c0 30 ac cd 5d c1 00 00 00 25 74 45 58 74 64 61 74 |0..]....%tEXtdat|
|
||||
000000d0 65 3a 6d 6f 64 69 66 79 00 32 30 31 39 2d 30 37 |e:modify.2019-07|
|
||||
000000e0 2d 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a |-25T20:57:53+12:|
|
||||
000000f0 30 30 dd 90 e5 7d 00 00 00 00 49 45 4e 44 ae 42 |00...}....IEND.B|
|
||||
00000100 60 82 |`.|
|
||||
00000102
|
||||
```
|
||||
|
||||
在右侧的列中,你看到的是和左侧一样的数据,但是以 ASCII 码展现的。如果你仔细看,你可以从中挑选出一些有用的信息,如文件格式(PNG)以及文件创建、修改日期和时间(向文件底部寻找一下)。
|
||||
|
||||
`file` 命令通过头 8 个字节获取文件类型。程序员会参考 [libpng 规范][6] 来知晓需要查看什么。具体而言,那就是你能在该图像文件的头 8 个字节中看到的字符串 `PNG`。这个事实显而易见,因为它揭示了 `file` 命令是如何知道要报告的文件类型。
|
||||
|
||||
你也可以控制 `hexdump` 显示多少字节,这在处理大于一个像素的文件时很实用:
|
||||
|
||||
```
|
||||
$ hexdump --length 8 pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a
|
||||
0000008
|
||||
```
|
||||
|
||||
`hexdump` 不只限于查看 PNG 或图像文件。你也可以用 `hexdump` 查看你日常使用的二进制文件,如 [ls][7]、[rsync][8],或你想检查的任何二进制文件。
|
||||
|
||||
### 用 hexdump 实现 cat 命令
|
||||
|
||||
阅读 PNG 规范的时候你可能会注意到头 8 个字节中的数据与 `hexdump` 提供的结果看上去不一样。实际上,那是一样的数据,但以一种不同的转换方式展现出来。所以 `hexdump` 的输出是正确的,但取决于你在寻找的信息,其输出结果对你而言不总是直接了当的。出于这个原因,`hexdump` 有一些选项可供用于定义格式和转化其转储的原始数据。
|
||||
|
||||
转换选项可以很复杂,所以用无关紧要的东西练习会比较实用。下面这个简易的介绍,通过重新实现 [cat][9] 命令来演示如何格式化 `hexdump` 的输出。首先,对一个文本文件运行 `hexdump` 来查看其原始数据。通常你可以在硬盘上某处找到 <ruby>[GNU 通用许可证][10]<rt>GNU General Public License</rt></ruby>(GPL)的一份拷贝,也可以用你手头的任何文本文件。你的输出结果可能不同,但下面是如何在你的系统中找到一份 GPL(或至少其部分)的拷贝:
|
||||
|
||||
```
|
||||
$ find /usr/share/doc/ -type f -name "COPYING" | tail -1
|
||||
/usr/share/doc/libblkid-devel/COPYING
|
||||
```
|
||||
|
||||
对其运行 `hexdump`:
|
||||
|
||||
```
|
||||
$ hexdump /usr/share/doc/libblkid-devel/COPYING
|
||||
0000000 6854 7369 6c20 6269 6172 7972 6920 2073
|
||||
0000010 7266 6565 7320 666f 7774 7261 3b65 7920
|
||||
0000020 756f 6320 6e61 7220 6465 7369 7274 6269
|
||||
0000030 7475 2065 7469 6120 646e 6f2f 0a72 6f6d
|
||||
0000040 6964 7966 6920 2074 6e75 6564 2072 6874
|
||||
0000050 2065 6574 6d72 2073 666f 7420 6568 4720
|
||||
0000060 554e 4c20 7365 6573 2072 6547 656e 6172
|
||||
0000070 206c 7550 6c62 6369 4c0a 6369 6e65 6573
|
||||
0000080 6120 2073 7570 6c62 7369 6568 2064 7962
|
||||
[...]
|
||||
```
|
||||
|
||||
如果该文件输出结果很长,用 `--length`(或短选项 `-n`)来控制输出长度使其易于管理。
|
||||
|
||||
原始数据对你而言可能没什么意义,但你已经知道如何将其转换为 ASCII 码:
|
||||
|
||||
```
|
||||
hexdump --canonical /usr/share/doc/libblkid-devel/COPYING
|
||||
00000000 54 68 69 73 20 6c 69 62 72 61 72 79 20 69 73 20 |This library is |
|
||||
00000010 66 72 65 65 20 73 6f 66 74 77 61 72 65 3b 20 79 |free software; y|
|
||||
00000020 6f 75 20 63 61 6e 20 72 65 64 69 73 74 72 69 62 |ou can redistrib|
|
||||
00000030 75 74 65 20 69 74 20 61 6e 64 2f 6f 72 0a 6d 6f |ute it and/or.mo|
|
||||
00000040 64 69 66 79 20 69 74 20 75 6e 64 65 72 20 74 68 |dify it under th|
|
||||
00000050 65 20 74 65 72 6d 73 20 6f 66 20 74 68 65 20 47 |e terms of the G|
|
||||
00000060 4e 55 20 4c 65 73 73 65 72 20 47 65 6e 65 72 61 |NU Lesser Genera|
|
||||
00000070 6c 20 50 75 62 6c 69 63 0a 4c 69 63 65 6e 73 65 |l Public.License|
|
||||
[...]
|
||||
```
|
||||
|
||||
这个输出结果有帮助但太累赘且难于阅读。要将 `hexdump` 的输出结果转换为其选项不支持的其他格式,可组合使用 `--format`(或 `-e`)和专门的格式代码。用来自定义格式的代码和 `printf` 命令使用的类似,所以如果你熟悉 `printf` 语句,你可能会觉得 `hexdump` 自定义格式不难学会。
|
||||
|
||||
在 `hexdump` 中,字符串 `%_p` 告诉 `hexdump` 用你系统的默认字符集输出字符。`--format` 选项的所有格式符号必须以*单引号*包括起来:
|
||||
|
||||
```
|
||||
$ hexdump -e'"%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is fre*
|
||||
software; you can redistribute it and/or.modify it under the terms of the GNU Les*
|
||||
er General Public.License as published by the Fre*
|
||||
Software Foundation; either.version 2.1 of the License, or (at your option) any later.version..*
|
||||
The complete text of the license is available in the..*
|
||||
/Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
这次的输出好些了,但依然不方便阅读。传统上 UNIX 文本文件假定 80 个字符的输出宽度(因为很久以前显示器一行只能显示 80 个字符)。
|
||||
|
||||
尽管这个输出结果未被自定义格式限制输出宽度,你可以用附加选项强制 `hexdump` 一次处理 80 字节。具体而言,通过 80 除以 1 这种形式,你可以告诉 `hexdump` 将 80 字节作为一个单元对待:
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is free software; you can redistribute it and/or.modify it under the terms of the GNU Lesser General Public.License as published by the Free Software Foundation; either.version 2.1 of the License, or (at your option) any later.version...The complete text of the license is available in the.../Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
现在该文件被分割成 80 字节的块处理,但没有任何换行。你可以用 `\n` 字符自行添加换行,在 UNIX 中它代表换行:
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p""\n"'
|
||||
This library is free software; you can redistribute it and/or.modify it under th
|
||||
e terms of the GNU Lesser General Public.License as published by the Free Softwa
|
||||
re Foundation; either.version 2.1 of the License, or (at your option) any later.
|
||||
version...The complete text of the license is available in the.../Documentation/
|
||||
licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
现在你已经(大致上)用 `hexdump` 自定义格式实现了 `cat` 命令。
|
||||
|
||||
### 控制输出结果
|
||||
|
||||
实际上自定义格式是让 `hexdump` 变得有用的方法。现在你已经(至少是原则上)熟悉 `hexdump` 自定义格式,你可以让 `hexdump -n 8` 的输出结果跟 `libpng` 官方规范中描述的 PNG 文件头相匹配了。
|
||||
|
||||
首先,你知道你希望 `hexdump` 以 8 字节的块来处理 PNG 文件。此外,你可能通过识别这些整数从而知道 PNG 格式规范是以十进制数表述的,根据 `hexdump` 文档,十进制用 `%d` 来表示:
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d""\n"' pixel.png
|
||||
13780787113102610
|
||||
```
|
||||
|
||||
你可以在每个整数后面加个空格使输出结果变得完美:
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d ""\n"' pixel.png
|
||||
137 80 78 71 13 10 26 10
|
||||
```
|
||||
|
||||
现在输出结果跟 PNG 规范完美匹配了。
|
||||
|
||||
### 好玩又有用
|
||||
|
||||
Hexdump 是个迷人的工具,不仅让你更多地领会计算机如何处理和转换信息,而且让你了解文件格式和编译的二进制文件如何工作。日常工作时你可以随机地试着对不同文件运行 `hexdump`。你永远不知道你会发现什么样的信息,或是什么时候具有这种洞察力会很实用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/dig-binary-files-hexdump
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[0x996](https://github.com/0x996)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
|
||||
[2]: https://www.redhat.com/sysadmin/find-lost-files-scalpel
|
||||
[3]: http://gimp.org
|
||||
[4]: https://opensource.com/article/17/2/mtpaint-pixel-art-animated-gifs
|
||||
[5]: https://opensource.com/article/17/8/imagemagick
|
||||
[6]: http://www.libpng.org/pub/png/spec/1.2/PNG-Structure.html
|
||||
[7]: https://opensource.com/article/19/7/master-ls-command
|
||||
[8]: https://opensource.com/article/19/5/advanced-rsync
|
||||
[9]: https://opensource.com/article/19/2/getting-started-cat-command
|
||||
[10]: https://en.wikipedia.org/wiki/GNU_General_Public_License
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11283-1.html)
|
||||
[#]: subject: (How To Fix “Kernel driver not installed (rc=-1908)” VirtualBox Error In Ubuntu)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-fix-kernel-driver-not-installed-rc-1908-virtualbox-error-in-ubuntu/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
@ -26,7 +26,7 @@ where: suplibOsInit what: 3 VERR_VM_DRIVER_NOT_INSTALLED (-1908) - The support d
|
||||
|
||||
![][2]
|
||||
|
||||
Ubuntu 中的 “Kernel driver not installed (rc=-1908)” 错误
|
||||
*Ubuntu 中的 “Kernel driver not installed (rc=-1908)” 错误*
|
||||
|
||||
我点击了 OK 关闭消息框,然后在后台看到了另一条消息。
|
||||
|
||||
@ -45,7 +45,7 @@ IMachine {85cd948e-a71f-4289-281e-0ca7ad48cd89}
|
||||
|
||||
![][3]
|
||||
|
||||
启动期间虚拟机意外终止,退出代码为 1(0x1)
|
||||
*启动期间虚拟机意外终止,退出代码为 1(0x1)*
|
||||
|
||||
我不知道该先做什么。我运行以下命令来检查是否有用。
|
||||
|
||||
@ -61,7 +61,7 @@ modprobe: FATAL: Module vboxdrv not found in directory /lib/modules/5.0.0-23-gen
|
||||
|
||||
仔细阅读这两个错误消息后,我意识到我应该更新 Virtualbox 程序。
|
||||
|
||||
如果你在 Ubuntu 及其衍生版(如 Linux Mint)中遇到此错误,你只需使用以下命令重新安装或更新 **“virtualbox-dkms”** 包:
|
||||
如果你在 Ubuntu 及其衍生版(如 Linux Mint)中遇到此错误,你只需使用以下命令重新安装或更新 `virtualbox-dkms` 包:
|
||||
|
||||
```
|
||||
$ sudo apt install virtualbox-dkms
|
||||
@ -82,7 +82,7 @@ via: https://www.ostechnix.com/how-to-fix-kernel-driver-not-installed-rc-1908-vi
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hello-wn)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11276-1.html)
|
||||
[#]: subject: (How to Delete Lines from a File Using the sed Command)
|
||||
[#]: via: (https://www.2daygeek.com/linux-remove-delete-lines-in-file-sed-command/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
@ -10,23 +10,21 @@
|
||||
如何使用 sed 命令删除文件中的行
|
||||
======
|
||||
|
||||
Sed 代表<ruby>流编辑器<rt>Stream Editor</rt></ruby>,常用于 Linux 中基本的文本处理。
|
||||

|
||||
|
||||
sed 命令是 Linux 中的重要命令之一,在文件处理方面有着重要作用。可用于删除或移动与给定模式匹配的特定行,还可以删除文件中的特定行。
|
||||
Sed 代表<ruby>流编辑器<rt>Stream Editor</rt></ruby>,常用于 Linux 中基本的文本处理。`sed` 命令是 Linux 中的重要命令之一,在文件处理方面有着重要作用。可用于删除或移动与给定模式匹配的特定行。
|
||||
|
||||
它还能够从文件中删除表达式,文件可以通过指定分隔符(例如逗号、制表符或空格)进行标识。
|
||||
它还可以删除文件中的特定行,它能够从文件中删除表达式,文件可以通过指定分隔符(例如逗号、制表符或空格)进行标识。
|
||||
|
||||
本文列出了 15 个使用范例,它们可以帮助你掌握 `sed` 命令。
|
||||
|
||||
如果你能理解并且记住这些命令,在你需要使用 `sed` 时,这些命令就能派上用场,帮你节约很多时间。
|
||||
|
||||
本文列出了 15 个使用范例,它们可以帮助你掌握 sed 命令。
|
||||
注意:为了方便演示,我在执行 `sed` 命令时,不使用 `-i` 选项(因为这个选项会直接修改文件内容),被移除了行的文件内容将打印到 Linux 终端。
|
||||
|
||||
如果你能理解并且记住这些命令,在你需要使用 sed 时,这些命令就能派上用场,帮你节约很多时间。
|
||||
但是,如果你想在实际环境中从源文件中删除行,请在 `sed` 命令中使用 `-i` 选项。
|
||||
|
||||
**`注意:`**` ` 为了方便演示,我在执行 sed 命令时,不使用 `-i` 选项,因为这个选项会直接修改文件内容。
|
||||
|
||||
但是,如果你想在实际环境中从源文件中删除行,请在 sed 命令中使用 `-i` 选项。
|
||||
|
||||
演示之前,我创建了 sed-demo.txt 文件,并添加了以下内容和相应行号以便更好地理解。
|
||||
演示之前,我创建了 `sed-demo.txt` 文件,并添加了以下内容和相应行号以便更好地理解。
|
||||
|
||||
```
|
||||
# cat sed-demo.txt
|
||||
@ -47,15 +45,15 @@ sed 命令是 Linux 中的重要命令之一,在文件处理方面有着重要
|
||||
|
||||
使用以下语法删除文件首行。
|
||||
|
||||
**`N`**` ` 表示文件中的第 N 行,`d`选项在 sed 命令中用于删除一行。
|
||||
`N` 表示文件中的第 N 行,`d` 选项在 `sed` 命令中用于删除一行。
|
||||
|
||||
**语法:**
|
||||
语法:
|
||||
|
||||
```
|
||||
sed 'Nd' file
|
||||
```
|
||||
|
||||
使用以下 sed 命令删除 sed-demo.txt 中的第一行。
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的第一行。
|
||||
|
||||
```
|
||||
# sed '1d' sed-demo.txt
|
||||
@ -75,9 +73,9 @@ sed 'Nd' file
|
||||
|
||||
使用以下语法删除文件最后一行。
|
||||
|
||||
**`$`**` ` 符号表示文件的最后一行。
|
||||
`$` 符号表示文件的最后一行。
|
||||
|
||||
使用以下 sed 命令删除 sed-demo.txt 中的最后一行。
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的最后一行。
|
||||
|
||||
```
|
||||
# sed '$d' sed-demo.txt
|
||||
@ -95,7 +93,7 @@ sed 'Nd' file
|
||||
|
||||
### 3) 如何删除指定行?
|
||||
|
||||
使用以下 sed 命令删除 sed-demo.txt 中的第 3 行。
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的第 3 行。
|
||||
|
||||
```
|
||||
# sed '3d' sed-demo.txt
|
||||
@ -113,7 +111,7 @@ sed 'Nd' file
|
||||
|
||||
### 4) 如何删除指定范围内的行?
|
||||
|
||||
使用以下 sed 命令删除 sed-demo.txt 中的第 5 到 7 行。
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的第 5 到 7 行。
|
||||
|
||||
```
|
||||
# sed '5,7d' sed-demo.txt
|
||||
@ -129,9 +127,9 @@ sed 'Nd' file
|
||||
|
||||
### 5) 如何删除多行内容?
|
||||
|
||||
sed 命令能够删除给定行的集合。
|
||||
`sed` 命令能够删除给定行的集合。
|
||||
|
||||
本例中,下面的 sed 命令删除了第 1 行、第 5 行、第 9 行和最后一行。
|
||||
本例中,下面的 `sed` 命令删除了第 1 行、第 5 行、第 9 行和最后一行。
|
||||
|
||||
```
|
||||
# sed '1d;5d;9d;$d' sed-demo.txt
|
||||
@ -146,7 +144,7 @@ sed 命令能够删除给定行的集合。
|
||||
|
||||
### 5a) 如何删除指定范围以外的行?
|
||||
|
||||
使用以下 sed 命令删除 sed-demo.txt 中第 3 到 6 行范围以外的所有行。
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中第 3 到 6 行范围以外的所有行。
|
||||
|
||||
```
|
||||
# sed '3,6!d' sed-demo.txt
|
||||
@ -159,7 +157,7 @@ sed 命令能够删除给定行的集合。
|
||||
|
||||
### 6) 如何删除空行?
|
||||
|
||||
使用以下 sed 命令删除 sed-demo.txt 中的空行。
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的空行。
|
||||
|
||||
```
|
||||
# sed '/^$/d' sed-demo.txt
|
||||
@ -176,9 +174,9 @@ sed 命令能够删除给定行的集合。
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 7) 如何删除包含某个<ruby>表达式<rt>Pattern</rt></ruby>的行?
|
||||
### 7) 如何删除包含某个模式的行?
|
||||
|
||||
使用以下 sed 命令删除 sed-demo.txt 中匹配到 **`System`**` ` 表达式的行。
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中匹配到 `System` 模式的行。
|
||||
|
||||
```
|
||||
# sed '/System/d' sed-demo.txt
|
||||
@ -195,7 +193,7 @@ sed 命令能够删除给定行的集合。
|
||||
|
||||
### 8) 如何删除包含字符串集合中某个字符串的行?
|
||||
|
||||
使用以下 sed 命令删除 sed-demo.txt 中匹配到 **`System`**` ` 或 **`Linux`**` ` 表达式的行。
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中匹配到 `System` 或 `Linux` 表达式的行。
|
||||
|
||||
```
|
||||
# sed '/System\|Linux/d' sed-demo.txt
|
||||
@ -211,7 +209,7 @@ sed 命令能够删除给定行的集合。
|
||||
|
||||
### 9) 如何删除以指定字符开头的行?
|
||||
|
||||
为了测试,我创建了 sed-demo-1.txt 文件,并添加了以下内容。
|
||||
为了测试,我创建了 `sed-demo-1.txt` 文件,并添加了以下内容。
|
||||
|
||||
```
|
||||
# cat sed-demo-1.txt
|
||||
@ -228,7 +226,7 @@ Arch Linux - 1
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
使用以下 sed 命令删除以 **`R`**` ` 字符开头的所有行。
|
||||
使用以下 `sed` 命令删除以 `R` 字符开头的所有行。
|
||||
|
||||
```
|
||||
# sed '/^R/d' sed-demo-1.txt
|
||||
@ -243,7 +241,7 @@ Arch Linux - 1
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
使用以下 sed 命令删除 **`R`**` ` 或者 **`F`**` ` 字符开头的所有行。
|
||||
使用以下 `sed` 命令删除 `R` 或者 `F` 字符开头的所有行。
|
||||
|
||||
```
|
||||
# sed '/^[RF]/d' sed-demo-1.txt
|
||||
@ -259,7 +257,7 @@ Arch Linux - 1
|
||||
|
||||
### 10) 如何删除以指定字符结尾的行?
|
||||
|
||||
使用以下 sed 命令删除 **`m`**` ` 字符结尾的所有行。
|
||||
使用以下 `sed` 命令删除 `m` 字符结尾的所有行。
|
||||
|
||||
```
|
||||
# sed '/m$/d' sed-demo.txt
|
||||
@ -274,7 +272,7 @@ Arch Linux - 1
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
使用以下 sed 命令删除 **`x`**` ` 或者 **`m`**` ` 字符结尾的所有行。
|
||||
使用以下 `sed` 命令删除 `x` 或者 `m` 字符结尾的所有行。
|
||||
|
||||
```
|
||||
# sed '/[xm]$/d' sed-demo.txt
|
||||
@ -290,7 +288,7 @@ Arch Linux - 1
|
||||
|
||||
### 11) 如何删除所有大写字母开头的行?
|
||||
|
||||
使用以下 sed 命令删除所有大写字母开头的行。
|
||||
使用以下 `sed` 命令删除所有大写字母开头的行。
|
||||
|
||||
```
|
||||
# sed '/^[A-Z]/d' sed-demo-1.txt
|
||||
@ -301,9 +299,9 @@ ubuntu
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
### 12) 如何删除指定范围内匹配到<ruby>表达式<rt>Pattern</rt></ruby>的行?
|
||||
### 12) 如何删除指定范围内匹配模式的行?
|
||||
|
||||
使用以下 sed 命令删除第 1 到 6 行中包含 **`Linux`**` ` 表达式的行。
|
||||
使用以下 `sed` 命令删除第 1 到 6 行中包含 `Linux` 表达式的行。
|
||||
|
||||
```
|
||||
# sed '1,6{/Linux/d;}' sed-demo.txt
|
||||
@ -318,9 +316,9 @@ ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 13) 如何删除匹配到<ruby>表达式<rt>Pattern</rt></ruby>的行及其下一行?
|
||||
### 13) 如何删除匹配模式的行及其下一行?
|
||||
|
||||
使用以下 sed 命令删除包含 `System` 表达式的行以及它的下一行。
|
||||
使用以下 `sed` 命令删除包含 `System` 表达式的行以及它的下一行。
|
||||
|
||||
```
|
||||
# sed '/System/{N;d;}' sed-demo.txt
|
||||
@ -337,7 +335,7 @@ ubuntu
|
||||
|
||||
### 14) 如何删除包含数字的行?
|
||||
|
||||
使用以下 sed 命令删除所有包含数字的行。
|
||||
使用以下 `sed` 命令删除所有包含数字的行。
|
||||
|
||||
```
|
||||
# sed '/[0-9]/d' sed-demo-1.txt
|
||||
@ -351,7 +349,7 @@ debian
|
||||
ubuntu
|
||||
```
|
||||
|
||||
使用以下 sed 命令删除所有以数字开头的行。
|
||||
使用以下 `sed` 命令删除所有以数字开头的行。
|
||||
|
||||
```
|
||||
# sed '/^[0-9]/d' sed-demo-1.txt
|
||||
@ -366,7 +364,7 @@ ubuntu
|
||||
Arch Linux - 1
|
||||
```
|
||||
|
||||
使用以下 sed 命令删除所有以数字结尾的行。
|
||||
使用以下 `sed` 命令删除所有以数字结尾的行。
|
||||
|
||||
```
|
||||
# sed '/[0-9]$/d' sed-demo-1.txt
|
||||
@ -383,13 +381,14 @@ ubuntu
|
||||
|
||||
### 15) 如何删除包含字母的行?
|
||||
|
||||
使用以下 sed 命令删除所有包含字母的行。
|
||||
使用以下 `sed` 命令删除所有包含字母的行。
|
||||
|
||||
```
|
||||
# sed '/[A-Za-z]/d' sed-demo-1.txt
|
||||
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-remove-delete-lines-in-file-sed-command/
|
||||
@ -397,7 +396,7 @@ via: https://www.2daygeek.com/linux-remove-delete-lines-in-file-sed-command/
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hello-wn](https://github.com/hello-wn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
116
published/20190823 Managing credentials with KeePassXC.md
Normal file
116
published/20190823 Managing credentials with KeePassXC.md
Normal file
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11278-1.html)
|
||||
[#]: subject: (Managing credentials with KeePassXC)
|
||||
[#]: via: (https://fedoramagazine.org/managing-credentials-with-keepassxc/)
|
||||
[#]: author: (Marco Sarti https://fedoramagazine.org/author/msarti/)
|
||||
|
||||
使用 KeePassXC 管理凭据
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
[上一篇文章][2]我们讨论了使用服务器端技术的密码管理工具。这些工具非常有趣而且适合云安装。在本文中,我们将讨论 KeePassXC,这是一个简单的多平台开源软件,它使用本地文件作为数据库。
|
||||
|
||||
这种密码管理软件的主要优点是简单。无需服务器端技术专业知识,因此可供任何类型的用户使用。
|
||||
|
||||
### 介绍 KeePassXC
|
||||
|
||||
KeePassXC 是一个开源的跨平台密码管理器:它是作为 KeePassX 的一个分支开始开发的,这是个不错的产品,但开发不是非常活跃。它使用 256 位密钥的 AES 算法将密钥保存在加密数据库中,这使得在云端设备(如 pCloud 或 Dropbox)中保存数据库相当安全。
|
||||
|
||||
除了密码,KeePassXC 还允许你在加密皮夹中保存各种信息和附件。它还有一个有效的密码生成器,可以帮助用户正确地管理他的凭据。
|
||||
|
||||
### 安装
|
||||
|
||||
这个程序在标准的 Fedora 仓库和 Flathub 仓库中都有。不幸的是,在沙箱中运行的程序无法使用浏览器集成,所以我建议通过 dnf 安装程序:
|
||||
|
||||
```
|
||||
sudo dnf install keepassxc
|
||||
```
|
||||
|
||||
### 创建你的皮夹
|
||||
|
||||
要创建新数据库,有两个重要步骤:
|
||||
|
||||
* 选择加密设置:默认设置相当安全,增加转换轮次也会增加解密时间。
|
||||
* 选择主密钥和额外保护:主密钥必须易于记忆(如果丢失它,你的皮夹就会丢失!)而足够强大,一个至少有 4 个随机单词的密码可能是一个不错的选择。作为额外保护,你可以选择密钥文件(请记住:你必须始终都有它,否则无法打开皮夹)和/或 YubiKey 硬件密钥。
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
数据库文件将保存到文件系统。如果你想与其他计算机/设备共享,可以将它保存在 U 盘或 pCloud 或 Dropbox 等云存储中。当然,如果你选择云存储,建议使用特别强大的主密码,如果有额外保护则更好。
|
||||
|
||||
### 创建你的第一个条目
|
||||
|
||||
创建数据库后,你可以开始创建第一个条目。对于 Web 登录,请在“条目”选项卡中输入用户名、密码和 URL。你可以根据个人策略指定凭据的到期日期,也可以通过按右侧的按钮下载网站的 favicon 并将其关联为条目的图标,这是一个很好的功能。
|
||||
|
||||
![][5]
|
||||
|
||||
![][6]
|
||||
|
||||
KeePassXC 还提供了一个很好的密码/口令生成器,你可以选择长度和复杂度,并检查对暴力攻击的抵抗程度:
|
||||
|
||||
![][7]
|
||||
|
||||
### 浏览器集成
|
||||
|
||||
KeePassXC 有一个适用于所有主流浏览器的扩展。该扩展允许你填写所有已指定 URL 条目的登录信息。
|
||||
|
||||
必须在 KeePassXC(工具菜单 -> 设置)上启用浏览器集成,指定你要使用的浏览器:
|
||||
|
||||
![][8]
|
||||
|
||||
安装扩展后,必须与数据库建立连接。要执行此操作,请按扩展按钮,然后按“连接”按钮:如果数据库已打开并解锁,那么扩展程序将创建关联密钥并将其保存在数据库中,该密钥对于浏览器是唯一的,因此我建议对它适当命名:
|
||||
|
||||
![][9]
|
||||
|
||||
当你打开 URL 字段中的登录页并且数据库是解锁的,那么这个扩展程序将为你提供与该页面关联的所有凭据:
|
||||
|
||||
![][10]
|
||||
|
||||
通过这种方式,你可以通过 KeePassXC 获取互联网凭据,而无需将其保存在浏览器中。
|
||||
|
||||
### SSH 代理集成
|
||||
|
||||
KeePassXC 的另一个有趣功能是与 SSH 集成。如果你使用 ssh 代理,KeePassXC 能够与之交互并添加你上传的 ssh 密钥到条目中。
|
||||
|
||||
首先,在常规设置(工具菜单 -> 设置)中,你必须启用 ssh 代理并重启程序:
|
||||
|
||||
![][11]
|
||||
|
||||
此时,你需要以附件方式上传你的 ssh 密钥对到条目中。然后在 “SSH 代理” 选项卡中选择附件下拉列表中的私钥,此时会自动填充公钥。不要忘记选择上面的两个复选框,以便在数据库打开/解锁时将密钥添加到代理,并在数据库关闭/锁定时删除:
|
||||
|
||||
![][12]
|
||||
|
||||
现在打开和解锁数据库,你可以使用皮夹中保存的密钥登录 ssh。
|
||||
|
||||
唯一的限制是可以添加到代理的最大密钥数:ssh 服务器默认不接受超过 5 次登录尝试,出于安全原因,建议不要增加此值。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/managing-credentials-with-keepassxc/
|
||||
|
||||
作者:[Marco Sarti][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/msarti/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/keepassxc-816x345.png
|
||||
[2]: https://linux.cn/article-11181-1.html
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-07-33-27.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-07-48-21.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-30-07.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-43-11.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-49-22.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-48-09.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-05-57.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-13-29.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-47-21.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-46-35.png
|
||||
@ -0,0 +1,194 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11286-1.html)
|
||||
[#]: subject: (How to Install Ansible (Automation Tool) on Debian 10 (Buster))
|
||||
[#]: via: (https://www.linuxtechi.com/install-ansible-automation-tool-debian10/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
如何在 Debian 10 上安装 Ansible
|
||||
======
|
||||
|
||||
在如今的 IT 领域,自动化一个是热门话题,每个组织都开始采用自动化工具,像 Puppet、Ansible、Chef、CFEngine、Foreman 和 Katello。在这些工具中,Ansible 是几乎所有 IT 组织中管理 UNIX 和 Linux 系统的首选。在本文中,我们将演示如何在 Debian 10 Sever 上安装和使用 Ansible。
|
||||
|
||||
![Ansible-Install-Debian10][2]
|
||||
|
||||
我的实验室环境:
|
||||
|
||||
* Debian 10 – Ansible 服务器/ 控制节点 – 192.168.1.14
|
||||
* CentOS 7 – Ansible 主机 (Web 服务器)– 192.168.1.15
|
||||
* CentOS 7 – Ansible 主机(DB 服务器)– 192.169.1.17
|
||||
|
||||
我们还将演示如何使用 Ansible 服务器管理 Linux 服务器
|
||||
|
||||
### 在 Debian 10 Server 上安装 Ansible
|
||||
|
||||
我假设你的 Debian 10 中有一个拥有 root 或 sudo 权限的用户。在我这里,我有一个名为 `pkumar` 的本地用户,它拥有 sudo 权限。
|
||||
|
||||
Ansible 2.7 包存在于 Debian 10 的默认仓库中,在命令行中运行以下命令安装 Ansible,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo apt update
|
||||
root@linuxtechi:~$ sudo apt install ansible -y
|
||||
```
|
||||
|
||||
运行以下命令验证 Ansible 版本,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible --version
|
||||
```
|
||||
|
||||

|
||||
|
||||
要安装最新版本的 Ansible 2.8,首先我们必须设置 Ansible 仓库。
|
||||
|
||||
一个接一个地执行以下命令,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ echo "deb http://ppa.launchpad.net/ansible/ansible/ubuntu bionic main" | sudo tee -a /etc/apt/sources.list
|
||||
root@linuxtechi:~$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 93C4A3FD7BB9C367
|
||||
root@linuxtechi:~$ sudo apt update
|
||||
root@linuxtechi:~$ sudo apt install ansible -y
|
||||
root@linuxtechi:~$ sudo ansible --version
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 使用 Ansible 管理 Linux 服务器
|
||||
|
||||
请参考以下步骤,使用 Ansible 控制器节点管理 Linux 类的服务器,
|
||||
|
||||
#### 步骤 1:在 Ansible 服务器及其主机之间交换 SSH 密钥
|
||||
|
||||
在 Ansible 服务器生成 ssh 密钥并在 Ansible 主机之间共享密钥。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo -i
|
||||
root@linuxtechi:~# ssh-keygen
|
||||
root@linuxtechi:~# ssh-copy-id root@linuxtechi
|
||||
root@linuxtechi:~# ssh-copy-id root@linuxtechi
|
||||
```
|
||||
|
||||
#### 步骤 2:创建 Ansible 主机清单
|
||||
|
||||
安装 Ansible 后会自动创建 `/etc/ansible/hosts`,在此文件中我们可以编辑 Ansible 主机或其客户端。我们还可以在家目录中创建自己的 Ansible 主机清单,
|
||||
|
||||
运行以下命令在我们的家目录中创建 Ansible 主机清单。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ vi $HOME/hosts
|
||||
[Web]
|
||||
192.168.1.15
|
||||
|
||||
[DB]
|
||||
192.168.1.17
|
||||
```
|
||||
|
||||
保存并退出文件。
|
||||
|
||||
注意:在上面的主机文件中,我们也可以使用主机名或 FQDN,但为此我们必须确保 Ansible 主机可以通过主机名或者 FQDN 访问。
|
||||
|
||||
#### 步骤 3:测试和使用默认的 Ansible 模块
|
||||
|
||||
Ansible 附带了许多可在 `ansible` 命令中使用的默认模块,示例如下所示。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# ansible -i <host_file> -m <module> <host>
|
||||
```
|
||||
|
||||
这里:
|
||||
|
||||
* `-i ~/hosts`:包含 Ansible 主机列表
|
||||
* `-m`:在之后指定 Ansible 模块,如 ping 和 shell
|
||||
* `<host>`:我们要运行 Ansible 模块的 Ansible 主机
|
||||
|
||||
使用 Ansible ping 模块验证 ping 连接,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping all
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping Web
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping DB
|
||||
```
|
||||
|
||||
命令输出如下所示:
|
||||
|
||||
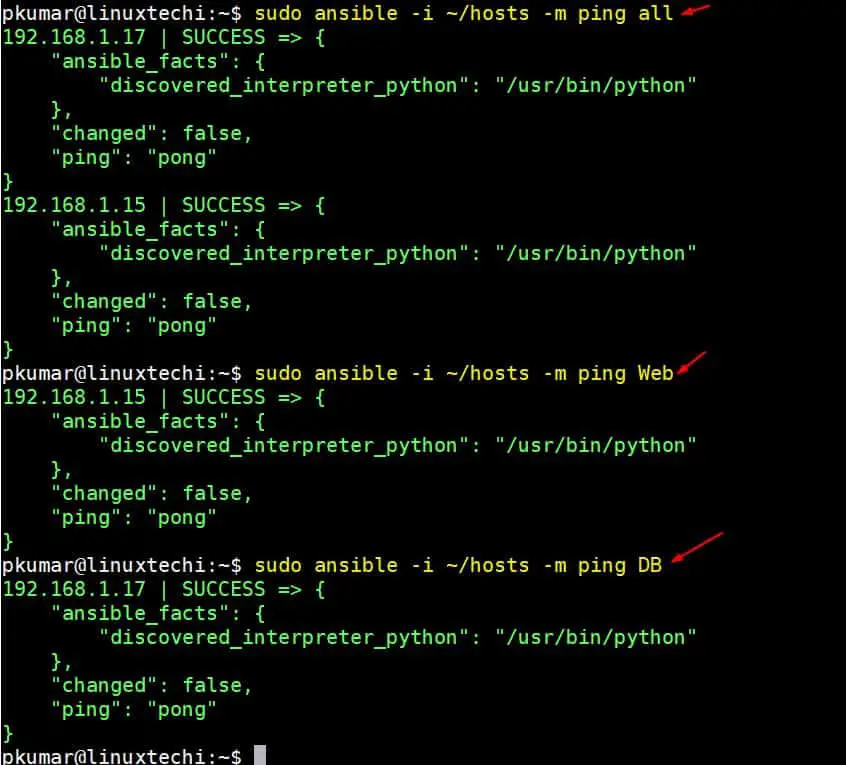
|
||||
|
||||
使用 shell 模块在 Ansible 主机上运行 shell 命令
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
ansible -i <hosts_file> -m shell -a <shell_commands> <host>
|
||||
```
|
||||
|
||||
例子:
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m shell -a "uptime" all
|
||||
192.168.1.17 | CHANGED | rc=0 >>
|
||||
01:48:34 up 1:07, 3 users, load average: 0.00, 0.01, 0.05
|
||||
|
||||
192.168.1.15 | CHANGED | rc=0 >>
|
||||
01:48:39 up 1:07, 3 users, load average: 0.00, 0.01, 0.04
|
||||
|
||||
root@linuxtechi:~$
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m shell -a "uptime ; df -Th / ; uname -r" Web
|
||||
192.168.1.15 | CHANGED | rc=0 >>
|
||||
01:52:03 up 1:11, 3 users, load average: 0.12, 0.07, 0.06
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/mapper/centos-root xfs 13G 1017M 12G 8% /
|
||||
3.10.0-327.el7.x86_64
|
||||
|
||||
root@linuxtechi:~$
|
||||
```
|
||||
|
||||
上面的命令输出表明我们已成功设置 Ansible 控制器节点。
|
||||
|
||||
让我们创建一个安装 nginx 的示例剧本,下面的剧本将在所有服务器上安装 nginx,这些服务器是 Web 主机组的一部分,但在这里,我的主机组下只有一台 centos 7 机器。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ vi nginx.yaml
|
||||
---
|
||||
- hosts: Web
|
||||
tasks:
|
||||
- name: Install latest version of nginx on CentOS 7 Server
|
||||
yum: name=nginx state=latest
|
||||
- name: start nginx
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
```
|
||||
|
||||
现在使用以下命令执行剧本。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible-playbook -i ~/hosts nginx.yaml
|
||||
```
|
||||
|
||||
上面命令的输出类似下面这样,
|
||||
|
||||
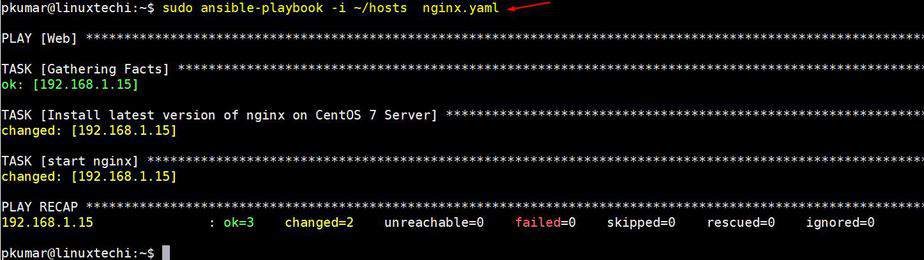
|
||||
|
||||
这表明 Ansible 剧本成功执行了。
|
||||
|
||||
本文就是这些了,请分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/install-ansible-automation-tool-debian10/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/08/Ansible-Install-Debian10.jpg
|
||||
102
published/20190827 A dozen ways to learn Python.md
Normal file
102
published/20190827 A dozen ways to learn Python.md
Normal file
@ -0,0 +1,102 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11280-1.html)
|
||||
[#]: subject: (A dozen ways to learn Python)
|
||||
[#]: via: (https://opensource.com/article/19/8/dozen-ways-learn-python)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
学习 Python 的 12 个方式
|
||||
======
|
||||
|
||||
> 这些资源将帮助你入门并熟练掌握 Python。
|
||||
|
||||

|
||||
|
||||
Python 是世界上[最受欢迎的][2]编程语言之一,它受到了全世界各地的开发者和创客的欢迎。大多数 Linux 和 MacOS 计算机都预装了某个版本的 Python,现在甚至一些 Windows 计算机供应商也开始安装 Python 了。
|
||||
|
||||
也许你尚未学会它,想学习但又不知道在哪里入门。这里的 12 个资源将帮助你入门并熟练掌握 Python。
|
||||
|
||||
### 课程、书籍、文章和文档
|
||||
|
||||
1、[Python 软件基金会][3]提供了出色的信息和文档,可帮助你迈上编码之旅。请务必查看 [Python 入门指南][4]。它将帮助你得到最新版本的 Python,并提供有关编辑器和开发环境的有用提示。该组织还有可以来进一步指导你的[优秀文档][5]。
|
||||
|
||||
2、我的 Python 旅程始于[海龟模块][6]。我首先在 Bryson Payne 的《[教你的孩子编码][7]》中找到了关于 Python 和海龟的内容。这本书是一个很好的资源,购买这本书可以让你看到几十个示例程序,这将激发你的编程好奇心。Payne 博士还在 [Udemy][8] 上以相同的名称开设了一门便宜的课程。
|
||||
|
||||
3、Payne 博士的书激起了我的好奇心,我渴望了解更多。这时我发现了 Al Sweigart 的《[用 Python 自动化无聊的东西][9]》。你可以购买这本书,也可以使用它的在线版本,它与印刷版完全相同且可根据知识共享许可免费获得和分享。Al 的这本书让我学习到了 Python 的基础知识、函数、列表、字典和如何操作字符串等等。这是一本很棒的书,我已经购买了许多本捐赠给了当地图书馆。Al 还提供 [Udemy][10] 课程;使用他的网站上的优惠券代码,只需 10 美元即可参加。
|
||||
|
||||
4、Eric Matthes 撰写了《[Python 速成][11]》,这是由 No Starch Press 出版的 Python 的逐步介绍(如同上面的两本书)。Matthes 还有一个很棒的[伴侣网站][12],其中包括了如何在你的计算机上设置 Python 以及一个用以简化学习曲线的[速查表][13]。
|
||||
|
||||
5、[Python for Everybody][14] 是另一个很棒的 Python 学习资源。该网站可以免费访问 [Charles Severance][15] 的 Coursera 和 edX 认证课程的资料。该网站分为入门、课程和素材等部分,其中 17 个课程按从安装到数据可视化的主题进行分类组织。Severance([@drchuck on Twitter][16]),是密歇根大学信息学院的临床教授。
|
||||
|
||||
6、[Seth Kenlon][17],我们 Opensource.com 的 Python 大师,撰写了大量关于 Python 的文章。Seth 有很多很棒的文章,包括“[用 JSON 保存和加载 Python 数据][18]”,“[用 Python 学习面向对象编程][19]”,“[在 Python 游戏中用 Pygame 放置平台][20]”,等等。
|
||||
|
||||
### 在设备上使用 Python
|
||||
|
||||
7、最近我对 [Circuit Playground Express][21] 非常感兴趣,这是一个运行 [CircuitPython][22] 的设备,CircuitPython 是为微控制器设计的 Python 编程语言的子集。我发现 Circuit Playground Express 和 CircuitPython 是向学生介绍 Python(以及一般编程)的好方法。它的制造商 Adafruit 有一个很好的[系列教程][23],可以让你快速掌握 CircuitPython。
|
||||
|
||||
8、[BBC:Microbit][24] 是另一种入门 Python 的好方法。你可以学习如何使用 [MicroPython][25] 对其进行编程,这是另一种用于编程微控制器的 Python 实现。
|
||||
|
||||
9、学习 Python 的文章如果没有提到[树莓派][26]单板计算机那是不完整的。一旦你有了[舒适][27]而强大的树莓派,你就可以在 Opensource.com 上找到[成吨的][28]使用它的灵感,包括“[7 个值得探索的树莓派项目][29]”,“[在树莓派上复活 Amiga][30]”,和“[如何使用树莓派作为 VPN 服务器][31]”。
|
||||
|
||||
10、许多学校为学生提供了 iOS 设备以支持他们的教育。在尝试帮助这些学校的老师和学生学习用 Python 编写代码时,我发现了 [Trinket.io][32]。Trinket 允许你在浏览器中编写和执行 Python 3 代码。 Trinket 的 [Python 入门][33]教程将向你展示如何在 iOS 设备上使用 Python。
|
||||
|
||||
### 播客
|
||||
|
||||
11、我喜欢在开车的时候听播客,我在 Kelly Paredes 和 Sean Tibor 的 [Teaching Python][34] 播客上找到了大量的信息。他们的内容很适合教育领域。
|
||||
|
||||
12、如果你正在寻找一些更通用的东西,我推荐 Michael Kennedy 的 [Talk Python to Me][35] 播客。它提供了有关 Python 及相关技术的最佳信息。
|
||||
|
||||
你学习 Python 最喜欢的资源是什么?请在评论中分享。
|
||||
|
||||
计算机编程可能是一个有趣的爱好,正如我以前在 Apple II 计算机上编程时所学到的……
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/dozen-ways-learn-python
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming_code_screen_display.jpg?itok=2HMTzqz0 (Code on a screen)
|
||||
[2]: https://insights.stackoverflow.com/survey/2019#most-popular-technologies
|
||||
[3]: https://www.python.org/
|
||||
[4]: https://www.python.org/about/gettingstarted/
|
||||
[5]: https://docs.python.org/3/
|
||||
[6]: https://opensource.com/life/15/8/python-turtle-graphics
|
||||
[7]: https://opensource.com/education/15/9/review-bryson-payne-teach-your-kids-code
|
||||
[8]: https://www.udemy.com/teach-your-kids-to-code/
|
||||
[9]: https://automatetheboringstuff.com/
|
||||
[10]: https://www.udemy.com/automate/?couponCode=PAY_10_DOLLARS
|
||||
[11]: https://nostarch.com/pythoncrashcourse2e
|
||||
[12]: https://ehmatthes.github.io/pcc/
|
||||
[13]: https://ehmatthes.github.io/pcc/cheatsheets/README.html
|
||||
[14]: https://www.py4e.com/
|
||||
[15]: http://www.dr-chuck.com/dr-chuck/resume/bio.htm
|
||||
[16]: https://twitter.com/drchuck/
|
||||
[17]: https://opensource.com/users/seth
|
||||
[18]: https://linux.cn/article-11133-1.html
|
||||
[19]: https://opensource.com/article/19/7/get-modular-python-classes
|
||||
[20]: https://linux.cn/article-10902-1.html
|
||||
[21]: https://opensource.com/article/19/7/circuit-playground-express
|
||||
[22]: https://circuitpython.org/
|
||||
[23]: https://learn.adafruit.com/welcome-to-circuitpython
|
||||
[24]: https://opensource.com/article/19/8/getting-started-bbc-microbit
|
||||
[25]: https://micropython.org/
|
||||
[26]: https://www.raspberrypi.org/
|
||||
[27]: https://projects.raspberrypi.org/en/pathways/getting-started-with-raspberry-pi
|
||||
[28]: https://opensource.com/sitewide-search?search_api_views_fulltext=Raspberry%20Pi
|
||||
[29]: https://opensource.com/article/19/3/raspberry-pi-projects
|
||||
[30]: https://opensource.com/article/19/3/amiga-raspberry-pi
|
||||
[31]: https://opensource.com/article/19/6/raspberry-pi-vpn-server
|
||||
[32]: https://trinket.io/
|
||||
[33]: https://docs.trinket.io/getting-started-with-python#/welcome/where-we-ll-go
|
||||
[34]: https://www.teachingpython.fm/
|
||||
[35]: https://talkpython.fm/
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Mellanox introduces SmartNICs to eliminate network load on CPUs)
|
||||
[#]: via: (https://www.networkworld.com/article/3433924/mellanox-introduces-smartnics-to-eliminate-network-load-on-cpus.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Mellanox introduces SmartNICs to eliminate network load on CPUs
|
||||
======
|
||||
Mellanox unveiled two processors designed to offload network workloads from the CPU -- ConnectX-6 Dx and BlueField-2 – freeing the CPU to do its processing job.
|
||||
![Natali Mis / Getty Images][1]
|
||||
|
||||
If you were wondering what prompted Nvidia to [shell out nearly $7 billion for Mellanox Technologies][2], here’s your answer: The networking hardware provider has introduced a pair of processors for offloading network workloads from the CPU.
|
||||
|
||||
ConnectX-6 Dx and BlueField-2 are cloud SmartNICs and I/O Processing Unit (IPU) solutions, respectively, designed to take the work of network processing off the CPU, freeing it to do its processing job.
|
||||
|
||||
**[ Learn more about SDN: Find out [where SDN is going][3] and learn the [difference between SDN and NFV][4]. | Get regularly scheduled insights: [Sign up for Network World newsletters][5]. ]**
|
||||
|
||||
The company promises up to 200Gbit/sec throughput with ConnectX and BlueField. It said the market for 25Gbit and faster Ethernet was 31% of the total market last year and will grow to 61% next year. With the internet of things (IoT) and artificial intelligence (AI), a lot of data needs to be moved around and Ethernet needs to get a lot faster.
|
||||
|
||||
“The whole vision of [software-defined networking] and NVMe-over-Fabric was a nice vision, but as soon as people tried it in the data center, performance ground to a halt because CPUs couldn’t handle all that data,” said Kevin Deierling, vice president of marketing for Mellanox. “As you do more complex networking, the CPUs are being asked to do all that work on top of running the apps and the hypervisor. It puts a big burden on CPUs if you don’t unload that workload.”
|
||||
|
||||
CPUs are getting larger, with AMD introducing a 64-core Epyc processor and Intel introducing a 56-core Xeon. But keeping those giant CPUs fed is a real challenge. You can’t use a 100Gbit link because the CPU has to look at all that traffic and it gets overwhelmed, argues Deierling.
|
||||
|
||||
“Suddenly 100-200Gbits becomes possible because a CPU doesn’t have to look at every packet and decide which core needs it,” he said.
|
||||
|
||||
The amount of CPU load depends on workload. A telco can have a situation where it’s as much as 70% packet processing. At a minimum workload, 30% of it would be packet processing.
|
||||
|
||||
“Our goal is to bring that to 0% packet processing so the CPU can do what it does best, which is process apps,” he said. Bluefield-2 can process up to 215 million packets per second, Deierling added.
|
||||
|
||||
### ConnectX-6 Dx and BlueField-2 also provide security features
|
||||
|
||||
The two are also focused on offering secure, high-speed interconnects inside the firewall. With standard network security, you have a firewall but minimal security inside the network. So once a hacker breaches your firewall, he often has free reign inside the network.
|
||||
|
||||
With ConnectX-6 Dx and BlueField-2, the latter of which contains a ConnectX-6 Dx processor on the NIC, your internal network communications are also protected, so even if someone breaches your firewall, they can’t get at your data.
|
||||
|
||||
ConnectX-6 Dx SmartNICs provide up to two ports of 25, 50 or 100Gb/s, or a single port of 200Gb/s, Ethernet connectivity powered by 50Gb/s PAM4 SerDes technology and PCIe 4.0 host connectivity. The ConnectX-6 Dx innovative hardware offload engines include IPsec and TLS inline data-in-motion crypto, advanced network virtualization, RDMA over Converged Ethernet (RoCE), and NVMe over Fabrics (NVMe-oF) storage accelerations.
|
||||
|
||||
The BlueField-2 IPU integrates a ConnectX-6 Dx, plus an ARM processor for a single System-on-Chip (SoC), supporting both Ethernet and InfiniBand connectivity up to 200Gb/sec. BlueField-2-based SmartNICs act as a co-processor that puts a computer in front of the computer to transform bare-metal and virtualized environments using advanced software-defined networking, NVMe SNAP storage disaggregation, and enhanced security capabilities.
|
||||
|
||||
Both ConnectX6 Dx and BlueField-2 are due in the fourth quarter.
|
||||
|
||||
### Partnering with Nvidia
|
||||
|
||||
Mellanox is in the process of being acquired by Nvidia, but the two suitors are hardly waiting for government approval. At VMworld, Mellanox announced that its Remote Direct Memory Access (RDMA) networking solutions for VMware vSphere will enable virtualized machine learning with better GPU utilization and efficiency.
|
||||
|
||||
Benchmarks found Nvidia’s virtualized GPUs see a two-fold increase in efficiency by using VMware’s paravirtualized RDMA (PVRDMA) technology than when using traditional networking protocols. And that was when connecting Nvidia T4 GPUs with Mellanox’s ConnectX-5 100 GbE SmartNICs, the older generation that is supplanted by today’s announcement.
|
||||
|
||||
The PVRDMA Ethernet solution enables VM-to-VM communication over RDMA, which boosts data communication performance in virtualized environments while achieving significantly higher efficiency compared with legacy TCP/IP transports. This translates into optimized server and GPU utilization, reduced machine learning training time, and improved scalability.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3433924/mellanox-introduces-smartnics-to-eliminate-network-load-on-cpus.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/08/cso_identity_access_management_abstract_network_connections_circuits_reflected_in_eye_by_natali_mis_gettyimages-654791312_2400x1600-100808178-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3356444/nvidia-grabs-mellanox-out-from-under-intels-nose.html
|
||||
[3]: https://www.networkworld.com/article/3209131/lan-wan/what-sdn-is-and-where-its-going.html
|
||||
[4]: https://www.networkworld.com/article/3206709/lan-wan/what-s-the-difference-between-sdn-and-nfv.html
|
||||
[5]: https://www.networkworld.com/newsletters/signup.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,65 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Endless Grants $500,000 Fund To GNOME Foundation’s Coding Education Challenge)
|
||||
[#]: via: (https://itsfoss.com/endless-gnome-coding-education-challenge/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Endless Grants $500,000 Fund To GNOME Foundation’s Coding Education Challenge
|
||||
======
|
||||
|
||||
The [GNOME foundation][1] recently announced the “**Coding Education Challenge**“, which is a three-stage competition to offer educators and students the opportunity to share their innovative ideas (projects) to teach coding with free and open-source software.
|
||||
|
||||
For the funding (that covers the reward), [Endless][2] has issued a $500,000 (half a million) grant to support the competition and attract more educators/students from across the world. Yes, that is a whole lot of money to be awarded to the team (or individual) that wins the competition.
|
||||
|
||||
In case you didn’t know about **Endless**, here’s a background for you – _they work on increasing digital access to children and help them to make the most out of it while also educating them about it_. Among other projects, they have [Endless OS Linux distribution][3]. They also have [inexpensive mini PCs running Linux][4] to help their educational projects.
|
||||
|
||||
In the [press release][5], **Neil McGovern**, Executive Director, GNOME Foundation mentioned:
|
||||
|
||||
> “We’re very grateful that Endless has come forward to provide more opportunities for individuals to learn about free and open-source ”
|
||||
|
||||
He also added:
|
||||
|
||||
> “We’re excited to see what can be achieved when we empower the creativity and imagination of our global community. We hope to make powerful partnerships between students and educators to explore the possibilities of our rich and diverse software ecosystem. Reaching the next generation of developers is crucial to ensuring that free software continues for many years in the future.”
|
||||
|
||||
**Matt Dalio**, founder of Endless, also shared his thoughts about this competition:
|
||||
|
||||
> “We fully believe in GNOME’s mission of making technology available and providing the tools of digital agency to all. What’s so unique about the GNOME Project is that it delivers a fully-working personal computer system, which is a powerful real-world vehicle to teach kids to code. There are so many potential ways for this competition to build flourishing ecosystems that empower the next generation to create, learn and build.”
|
||||
|
||||
In addition to the announcement of competition and the grant, we do not have more details. However, anyone can submit a proposal for the competition (an individual or a team). Also, it has been decided that there will be 20 winners for the first round and will be rewarded **$6500** each for their ideas.
|
||||
|
||||
[][6]
|
||||
|
||||
Suggested read StationX Announces New Laptop Customized for Manjaro Linux
|
||||
|
||||
For the second stage of the competition, the winners will be asked to provide a working prototype from which 5 winners will be filtered to get **$25,000** each as the prize money.
|
||||
|
||||
In the final stage will involve making an end-product where only two winners will be selected. The runners up shall get **$25,000** and the winner walks away with **$100,000**.
|
||||
|
||||
_**Wrapping Up**_
|
||||
|
||||
I’d love to watch out for more details on ‘Coding Education Challenge’ by GNOME Foundation. We shall update this article for more details on the competition.
|
||||
|
||||
While the grant makes it look like a great initiative by GNOME Foundation, what do you think about it? Feel free to share your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/endless-gnome-coding-education-challenge/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.gnome.org/
|
||||
[2]: https://endlessnetwork.com/
|
||||
[3]: https://endlessos.com/home/
|
||||
[4]: https://endlessos.com/computers/
|
||||
[5]: https://www.gnome.org/news/2019/08/gnome-foundation-launches-coding-education-challenge/
|
||||
[6]: https://itsfoss.com/stationx-manjaro-linux/
|
||||
@ -1,122 +0,0 @@
|
||||
The Rise and Demise of RSS
|
||||
======
|
||||
There are two stories here. The first is a story about a vision of the web’s future that never quite came to fruition. The second is a story about how a collaborative effort to improve a popular standard devolved into one of the most contentious forks in the history of open-source software development.
|
||||
|
||||
In the late 1990s, in the go-go years between Netscape’s IPO and the Dot-com crash, everyone could see that the web was going to be an even bigger deal than it already was, even if they didn’t know exactly how it was going to get there. One theory was that the web was about to be revolutionized by syndication. The web, originally built to enable a simple transaction between two parties—a client fetching a document from a single host server—would be broken open by new standards that could be used to repackage and redistribute entire websites through a variety of channels. Kevin Werbach, writing for Release 1.0, a newsletter influential among investors in the 1990s, predicted that syndication “would evolve into the core model for the Internet economy, allowing businesses and individuals to retain control over their online personae while enjoying the benefits of massive scale and scope.” He invited his readers to imagine a future in which fencing aficionados, rather than going directly to an “online sporting goods site” or “fencing equipment retailer,” could buy a new épée directly through e-commerce widgets embedded into their favorite website about fencing. Just like in the television world, where big networks syndicate their shows to smaller local stations, syndication on the web would allow businesses and publications to reach consumers through a multitude of intermediary sites. This would mean, as a corollary, that consumers would gain significant control over where and how they interacted with any given business or publication on the web.
|
||||
|
||||
RSS was one of the standards that promised to deliver this syndicated future. To Werbach, RSS was “the leading example of a lightweight syndication protocol.” Another contemporaneous article called RSS the first protocol to realize the potential of XML. It was going to be a way for both users and content aggregators to create their own customized channels out of everything the web had to offer. And yet, two decades later, RSS [appears to be a dying technology][1], now used chiefly by podcasters and programmers with tech blogs. Moreover, among that latter group, RSS is perhaps used as much for its political symbolism as its actual utility. Though of course some people really do have RSS readers, stubbornly adding an RSS feed to your blog, even in 2018, is a reactionary statement. That little tangerine bubble has become a wistful symbol of defiance against a centralized web increasingly controlled by a handful of corporations, a web that hardly resembles the syndicated web of Werbach’s imagining.
|
||||
|
||||
The future once looked so bright for RSS. What happened? Was its downfall inevitable, or was it precipitated by the bitter infighting that thwarted the development of a single RSS standard?
|
||||
|
||||
### Muddied Water
|
||||
|
||||
RSS was invented twice. This meant it never had an obvious owner, a state of affairs that spawned endless debate and acrimony. But it also suggests that RSS was an important idea whose time had come.
|
||||
|
||||
In 1998, Netscape was struggling to envision a future for itself. Its flagship product, the Netscape Navigator web browser—once preferred by 80% of web users—was quickly losing ground to Internet Explorer. So Netscape decided to compete in a new arena. In May, a team was brought together to start work on what was known internally as “Project 60.” Two months later, Netscape announced “My Netscape,” a web portal that would fight it out with other portals like Yahoo, MSN, and Excite.
|
||||
|
||||
The following year, in March, Netscape announced an addition to the My Netscape portal called the “My Netscape Network.” My Netscape users could now customize their My Netscape page so that it contained “channels” featuring the most recent headlines from sites around the web. As long as your favorite website published a special file in a format dictated by Netscape, you could add that website to your My Netscape page, typically by clicking an “Add Channel” button that participating websites were supposed to add to their interfaces. A little box containing a list of linked headlines would then appear.
|
||||
|
||||
![A My Netscape Network Channel][2]
|
||||
|
||||
The special file that participating websites had to publish was an RSS file. In the My Netscape Network announcement, Netscape explained that RSS stood for “RDF Site Summary.” This was somewhat of a misnomer. RDF, or the Resource Description Framework, is basically a grammar for describing certain properties of arbitrary resources. (See [my article about the Semantic Web][3] if that sounds really exciting to you.) In 1999, a draft specification for RDF was being considered by the W3C. Though RSS was supposed to be based on RDF, the example RSS document Netscape actually released didn’t use any RDF tags at all, even if it declared the RDF XML namespace. In a document that accompanied the Netscape RSS specification, Dan Libby, one of the specification’s authors, explained that “in this release of MNN, Netscape has intentionally limited the complexity of the RSS format.” The specification was given the 0.90 version number, the idea being that subsequent versions would bring RSS more in line with the W3C’s XML specification and the evolving draft of the RDF specification.
|
||||
|
||||
RSS had been cooked up by Libby and another Netscape employee, Ramanathan Guha. Guha previously worked for Apple, where he came up with something called the Meta Content Framework. MCF was a format for representing metadata about anything from web pages to local files. Guha demonstrated its power by developing an application called [HotSauce][4] that visualized relationships between files as a network of nodes suspended in 3D space. After leaving Apple for Netscape, Guha worked with a Netscape consultant named Tim Bray to produce an XML-based version of MCF, which in turn became the foundation for the W3C’s RDF draft. It’s no surprise, then, that Guha and Libby were keen to incorporate RDF into RSS. But Libby later wrote that the original vision for an RDF-based RSS was pared back because of time constraints and the perception that RDF was “‘too complex’ for the ‘average user.’”
|
||||
|
||||
While Netscape was trying to win eyeballs in what became known as the “portal wars,” elsewhere on the web a new phenomenon known as “weblogging” was being pioneered. One of these pioneers was Dave Winer, CEO of a company called UserLand Software, which developed early content management systems that made blogging accessible to people without deep technical fluency. Winer ran his own blog, [Scripting News][5], which today is one of the oldest blogs on the internet. More than a year before Netscape announced My Netscape Network, on December 15th, 1997, Winer published a post announcing that the blog would now be available in XML as well as HTML.
|
||||
|
||||
Dave Winer’s XML format became known as the Scripting News format. It was supposedly similar to Microsoft’s Channel Definition Format (a “push technology” standard submitted to the W3C in March, 1997), but I haven’t been able to find a file in the original format to verify that claim. Like Netscape’s RSS, it structured the content of Winer’s blog so that it could be understood by other software applications. When Netscape released RSS 0.90, Winer and UserLand Software began to support both formats. But Winer believed that Netscape’s format was “woefully inadequate” and “missing the key thing web writers and readers need.” It could only represent a list of links, whereas the Scripting News format could represent a series of paragraphs, each containing one or more links.
|
||||
|
||||
In June, 1999, two months after Netscape’s My Netscape Network announcement, Winer introduced a new version of the Scripting News format, called ScriptingNews 2.0b1. Winer claimed that he decided to move ahead with his own format only after trying but failing to get anyone at Netscape to care about RSS 0.90’s deficiencies. The new version of the Scripting News format added several items to the `<header>` element that brought the Scripting News format to parity with RSS. But the two formats continued to differ in that the Scripting News format, which Winer nicknamed the “fat” syndication format, could include entire paragraphs and not just links.
|
||||
|
||||
Netscape got around to releasing RSS 0.91 the very next month. The updated specification was a major about-face. RSS no longer stood for “RDF Site Summary”; it now stood for “Rich Site Summary.” All the RDF—and there was almost none anyway—was stripped out. Many of the Scripting News tags were incorporated. In the text of the new specification, Libby explained:
|
||||
|
||||
> RDF references removed. RSS was originally conceived as a metadata format providing a summary of a website. Two things have become clear: the first is that providers want more of a syndication format than a metadata format. The structure of an RDF file is very precise and must conform to the RDF data model in order to be valid. This is not easily human-understandable and can make it difficult to create useful RDF files. The second is that few tools are available for RDF generation, validation and processing. For these reasons, we have decided to go with a standard XML approach.
|
||||
|
||||
Winer was enormously pleased with RSS 0.91, calling it “even better than I thought it would be.” UserLand Software adopted it as a replacement for the existing ScriptingNews 2.0b1 format. For a while, it seemed that RSS finally had a single authoritative specification.
|
||||
|
||||
### The Great Fork
|
||||
|
||||
A year later, the RSS 0.91 specification had become woefully inadequate. There were all sorts of things people were trying to do with RSS that the specification did not address. There were other parts of the specification that seemed unnecessarily constraining—each RSS channel could only contain a maximum of 15 items, for example.
|
||||
|
||||
By that point, RSS had been adopted by several more organizations. Other than Netscape, which seemed to have lost interest after RSS 0.91, the big players were Dave Winer’s UserLand Software; O’Reilly Net, which ran an RSS aggregator called Meerkat; and Moreover.com, which also ran an RSS aggregator focused on news. Via mailing list, representatives from these organizations and others regularly discussed how to improve on RSS 0.91. But there were deep disagreements about what those improvements should look like.
|
||||
|
||||
The mailing list in which most of the discussion occurred was called the Syndication mailing list. [An archive of the Syndication mailing list][6] is still available. It is an amazing historical resource. It provides a moment-by-moment account of how those deep disagreements eventually led to a political rupture of the RSS community.
|
||||
|
||||
On one side of the coming rupture was Winer. Winer was impatient to evolve RSS, but he wanted to change it only in relatively conservative ways. In June, 2000, he published his own RSS 0.91 specification on the UserLand website, meant to be a starting point for further development of RSS. It made no significant changes to the 0.91 specification published by Netscape. Winer claimed in a blog post that accompanied his specification that it was only a “cleanup” documenting how RSS was actually being used in the wild, which was needed because the Netscape specification was no longer being maintained. In the same post, he argued that RSS had succeeded so far because it was simple, and that by adding namespaces or RDF back to the format—some had suggested this be done in the Syndication mailing list—it “would become vastly more complex, and IMHO, at the content provider level, would buy us almost nothing for the added complexity.” In a message to the Syndication mailing list sent around the same time, Winer suggested that these issues were important enough that they might lead him to create a fork:
|
||||
|
||||
> I’m still pondering how to move RSS forward. I definitely want ICE-like stuff in RSS2, publish and subscribe is at the top of my list, but I am going to fight tooth and nail for simplicity. I love optional elements. I don’t want to go down the namespaces and schema road, or try to make it a dialect of RDF. I understand other people want to do this, and therefore I guess we’re going to get a fork. I have my own opinion about where the other fork will lead, but I’ll keep those to myself for the moment at least.
|
||||
|
||||
Arrayed against Winer were several other people, including Rael Dornfest of O’Reilly, Ian Davis (responsible for a search startup called Calaba), and a precocious, 14-year-old Aaron Swartz, who all thought that RSS needed namespaces in order to accommodate the many different things everyone wanted to do with it. On another mailing list hosted by O’Reilly, Davis proposed a namespace-based module system, writing that such a system would “make RSS as extensible as we like rather than packing in new features that over-complicate the spec.” The “namespace camp” believed that RSS would soon be used for much more than the syndication of blog posts, so namespaces, rather than being a complication, were the only way to keep RSS from becoming unmanageable as it supported more and more use cases.
|
||||
|
||||
At the root of this disagreement about namespaces was a deeper disagreement about what RSS was even for. Winer had invented his Scripting News format to syndicate the posts he wrote for his blog. Guha and Libby at Netscape had designed RSS and called it “RDF Site Summary” because in their minds it was a way of recreating a site in miniature within Netscape’s online portal. Davis, writing to the Syndication mailing list, explained his view that RSS was “originally conceived as a way of building mini sitemaps,” and that now he and others wanted to expand RSS “to encompass more types of information than simple news headlines and to cater for the new uses of RSS that have emerged over the last 12 months.” Winer wrote a prickly reply, stating that his Scripting News format was in fact the original RSS and that it had been meant for a different purpose. Given that the people most involved in the development of RSS disagreed about why RSS had even been created, a fork seems to have been inevitable.
|
||||
|
||||
The fork happened after Dornfest announced a proposed RSS 1.0 specification and formed the RSS-DEV Working Group—which would include Davis, Swartz, and several others but not Winer—to get it ready for publication. In the proposed specification, RSS once again stood for “RDF Site Summary,” because RDF had had been added back in to represent metadata properties of certain RSS elements. The specification acknowledged Winer by name, giving him credit for popularizing RSS through his “evangelism.” But it also argued that just adding more elements to RSS without providing for extensibility with a module system—that is, what Winer was suggesting—”sacrifices scalability.” The specification went on to define a module system for RSS based on XML namespaces.
|
||||
|
||||
Winer was furious that the RSS-DEV Working Group had arrogated the “RSS 1.0” name for themselves. In another mailing list about decentralization, he described what the RSS-DEV Working Group had done as theft. Other members of the Syndication mailing list also felt that the RSS-DEV Working Group should not have used the name “RSS” without unanimous agreement from the community on how to move RSS forward. But the Working Group stuck with the name. Dan Brickley, another member of the RSS-DEV Working Group, defended this decision by arguing that “RSS 1.0 as proposed is solidly grounded in the original RSS vision, which itself had a long heritage going back to MCF (an RDF precursor) and related specs (CDF etc).” He essentially felt that the RSS 1.0 effort had a better claim to the RSS name than Winer did, since RDF had originally been a part of RSS. The RSS-DEV Working Group published a final version of their specification in December. That same month, Winer published his own improvement to RSS 0.91, which he called RSS 0.92, on UserLand’s website. RSS 0.92 made several small optional improvements to RSS, among which was the addition of the `<enclosure>` tag soon used by podcasters everywhere. RSS had officially forked.
|
||||
|
||||
It’s not clear to me why a better effort was not made to involve Winer in the RSS-DEV Working Group. He was a prominent contributor to the Syndication mailing list and obviously responsible for much of RSS’ popularity, as the members of the Working Group themselves acknowledged. But Tim O’Reilly, founder and CEO of O’Reilly, explained in a UserLand discussion group that Winer more or less refused to participate:
|
||||
|
||||
> A group of people involved in RSS got together to start thinking about its future evolution. Dave was part of the group. When the consensus of the group turned in a direction he didn’t like, Dave stopped participating, and characterized it as a plot by O’Reilly to take over RSS from him, despite the fact that Rael Dornfest of O’Reilly was only one of about a dozen authors of the proposed RSS 1.0 spec, and that many of those who were part of its development had at least as long a history with RSS as Dave had.
|
||||
|
||||
To this, Winer said:
|
||||
|
||||
> I met with Dale [Dougherty] two weeks before the announcement, and he didn’t say anything about it being called RSS 1.0. I spoke on the phone with Rael the Friday before it was announced, again he didn’t say that they were calling it RSS 1.0. The first I found out about it was when it was publicly announced.
|
||||
>
|
||||
> Let me ask you a straight question. If it turns out that the plan to call the new spec “RSS 1.0” was done in private, without any heads-up or consultation, or for a chance for the Syndication list members to agree or disagree, not just me, what are you going to do?
|
||||
>
|
||||
> UserLand did a lot of work to create and popularize and support RSS. We walked away from that, and let your guys have the name. That’s the top level. If I want to do any further work in Web syndication, I have to use a different name. Why and how did that happen Tim?
|
||||
|
||||
I have not been able to find a discussion in the Syndication mailing list about using the RSS 1.0 name prior to the announcement of the RSS 1.0 proposal.
|
||||
|
||||
RSS would fork again in 2003, when several developers frustrated with the bickering in the RSS community sought to create an entirely new format. These developers created Atom, a format that did away with RDF but embraced XML namespaces. Atom would eventually be specified by [a proposed IETF standard][7]. After the introduction of Atom, there were three competing versions of RSS: Winer’s RSS 0.92 (updated to RSS 2.0 in 2002 and renamed “Really Simple Syndication”), the RSS-DEV Working Group’s RSS 1.0, and Atom.
|
||||
|
||||
### Decline
|
||||
|
||||
The proliferation of competing RSS specifications may have hampered RSS in other ways that I’ll discuss shortly. But it did not stop RSS from becoming enormously popular during the 2000s. By 2004, the New York Times had started offering its headlines in RSS and had written an article explaining to the layperson what RSS was and how to use it. Google Reader, an RSS aggregator ultimately used by millions, was launched in 2005. By 2013, RSS seemed popular enough that the New York Times, in its obituary for Aaron Swartz, called the technology “ubiquitous.” For a while, before a third of the planet had signed up for Facebook, RSS was simply how many people stayed abreast of news on the internet.
|
||||
|
||||
The New York Times published Swartz’ obituary in January, 2013. By that point, though, RSS had actually turned a corner and was well on its way to becoming an obscure technology. Google Reader was shutdown in July, 2013, ostensibly because user numbers had been falling “over the years.” This prompted several articles from various outlets declaring that RSS was dead. But people had been declaring that RSS was dead for years, even before Google Reader’s shuttering. Steve Gillmor, writing for TechCrunch in May, 2009, advised that “it’s time to get completely off RSS and switch to Twitter” because “RSS just doesn’t cut it anymore.” He pointed out that Twitter was basically a better RSS feed, since it could show you what people thought about an article in addition to the article itself. It allowed you to follow people and not just channels. Gillmor told his readers that it was time to let RSS recede into the background. He ended his article with a verse from Bob Dylan’s “Forever Young.”
|
||||
|
||||
Today, RSS is not dead. But neither is it anywhere near as popular as it once was. Lots of people have offered explanations for why RSS lost its broad appeal. Perhaps the most persuasive explanation is exactly the one offered by Gillmor in 2009. Social networks, just like RSS, provide a feed featuring all the latest news on the internet. Social networks took over from RSS because they were simply better feeds. They also provide more benefits to the companies that own them. Some people have accused Google, for example, of shutting down Google Reader in order to encourage people to use Google+. Google might have been able to monetize Google+ in a way that it could never have monetized Google Reader. Marco Arment, the creator of Instapaper, wrote on his blog in 2013:
|
||||
|
||||
> Google Reader is just the latest casualty of the war that Facebook started, seemingly accidentally: the battle to own everything. While Google did technically “own” Reader and could make some use of the huge amount of news and attention data flowing through it, it conflicted with their far more important Google+ strategy: they need everyone reading and sharing everything through Google+ so they can compete with Facebook for ad-targeting data, ad dollars, growth, and relevance.
|
||||
|
||||
So both users and technology companies realized that they got more out of using social networks than they did out of RSS.
|
||||
|
||||
Another theory is that RSS was always too geeky for regular people. Even the New York Times, which seems to have been eager to adopt RSS and promote it to its audience, complained in 2006 that RSS is a “not particularly user friendly” acronym coined by “computer geeks.” Before the RSS icon was designed in 2004, websites like the New York Times linked to their RSS feeds using little orange boxes labeled “XML,” which can only have been intimidating. The label was perfectly accurate though, because back then clicking the link would take a hapless user to a page full of XML. [This great tweet][8] captures the essence of this explanation for RSS’ demise. Regular people never felt comfortable using RSS; it hadn’t really been designed as a consumer-facing technology and involved too many hurdles; people jumped ship as soon as something better came along.
|
||||
|
||||
RSS might have been able to overcome some of these limitations if it had been further developed. Maybe RSS could have been extended somehow so that friends subscribed to the same channel could syndicate their thoughts about an article to each other. But whereas a company like Facebook was able to “move fast and break things,” the RSS developer community was stuck trying to achieve consensus. The Great RSS Fork only demonstrates how difficult it was to do that. So if we are asking ourselves why RSS is no longer popular, a good first-order explanation is that social networks supplanted it. If we ask ourselves why social networks were able to supplant it, then the answer may be that the people trying to make RSS succeed faced a problem much harder than, say, building Facebook. As Dornfest wrote to the Syndication mailing list at one point, “currently it’s the politics far more than the serialization that’s far from simple.”
|
||||
|
||||
So today we are left with centralized silos of information. In a way, we do have the syndicated internet that Kevin Werbach foresaw in 1999. After all, The Onion is a publication that relies on syndication through Facebook and Twitter the same way that Seinfeld relied on syndication to rake in millions after the end of its original run. But syndication on the web only happens through one of a very small number of channels, meaning that none of us “retain control over our online personae” the way that Werbach thought we would. One reason this happened is garden-variety corporate rapaciousness—RSS, an open format, didn’t give technology companies the control over data and eyeballs that they needed to sell ads, so they did not support it. But the more mundane reason is that centralized silos are just easier to design than common standards. Consensus is difficult to achieve and it takes time, but without consensus spurned developers will go off and create competing standards. The lesson here may be that if we want to see a better, more open web, we have to get better at not screwing each other over.
|
||||
|
||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][9] on Twitter or subscribe to the [RSS feed][10] to make sure you know when a new post is out.
|
||||
|
||||
Previously on TwoBitHistory…
|
||||
|
||||
> New post: This week we're traveling back in time in our DeLorean to see what it was like learning to program on early home computers.<https://t.co/qDrwqgIuuy>
|
||||
>
|
||||
> — TwoBitHistory (@TwoBitHistory) [September 2, 2018][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/09/16/the-rise-and-demise-of-rss.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://trends.google.com/trends/explore?date=all&geo=US&q=rss
|
||||
[2]: https://twobithistory.org/images/mnn-channel.gif
|
||||
[3]: https://twobithistory.org/2018/05/27/semantic-web.html
|
||||
[4]: http://web.archive.org/web/19970703020212/http://mcf.research.apple.com:80/hs/screen_shot.html
|
||||
[5]: http://scripting.com/
|
||||
[6]: https://groups.yahoo.com/neo/groups/syndication/info
|
||||
[7]: https://tools.ietf.org/html/rfc4287
|
||||
[8]: https://twitter.com/mgsiegler/status/311992206716203008
|
||||
[9]: https://twitter.com/TwoBitHistory
|
||||
[10]: https://twobithistory.org/feed.xml
|
||||
[11]: https://twitter.com/TwoBitHistory/status/1036295112375115778?ref_src=twsrc%5Etfw
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,80 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Is your enterprise software committing security malpractice?)
|
||||
[#]: via: (https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Is your enterprise software committing security malpractice?
|
||||
======
|
||||
ExtraHop discovered enterprise security and analytic software are "phoning home" and quietly uploading information to servers outside of customers' networks.
|
||||
![Getty Images][1]
|
||||
|
||||
Back when this blog was dedicated to all things Microsoft I routinely railed against the spying aspects of Windows 10. Well, apparently that’s nothing compared to what enterprise security, analytics, and hardware management tools are doing.
|
||||
|
||||
An analytics firm called ExtraHop examined the networks of its customers and found that their security and analytic software was quietly uploading information to servers outside of the customer's network. The company issued a [report and warning][2] last week.
|
||||
|
||||
ExtraHop deliberately chose not to name names in its four examples of enterprise security tools that were sending out data without warning the customer or user. A spokesperson for the company told me via email, “ExtraHop wants the focus of the report to be the trend, which we have observed on multiple occasions and find alarming. Focusing on a specific group would detract from the broader point that this important issue requires more attention from enterprises.”
|
||||
|
||||
**[ For more on IoT security, read [tips to securing IoT on your network][3] and [10 best practices to minimize IoT security vulnerabilities][4]. | Get regularly scheduled insights by [signing up for Network World newsletters][5]. ]**
|
||||
|
||||
### Products committing security malpractice and secretly transmitting data offsite
|
||||
|
||||
[ExtraHop's report][6] found a pretty broad range of products secretly phoning home, including endpoint security software, device management software for a hospital, surveillance cameras, and security analytics software used by a financial institution. It also noted the applications may run afoul of Europe’s [General Data Privacy Regulation (GDPR)][7].
|
||||
|
||||
In every case, ExtraHop provided evidence that the software was transmitting data offsite. In one case, a company noticed that approximately every 30 minutes, a network-connected device was sending UDP traffic out to a known bad IP address. The device in question was a Chinese-made security camera that was phoning home to a known malicious IP address with ties to China.
|
||||
|
||||
And the camera was likely set up independently by an employee at their office for personal security purposes, showing the downside to shadow IT.
|
||||
|
||||
In the cases of the hospital's device management tool and the financial firm's analytics tool, those were violations of data security laws and could expose the company to legal risks even though it was happening without their knowledge.
|
||||
|
||||
**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][8] ]**
|
||||
|
||||
The hospital’s medical device management product was supposed to use the hospital’s Wi-Fi network to only ensure patient data privacy and HIPAA compliance. ExtraHop noticed traffic from the workstation that was managing initial device rollout was opening encrypted SSL:443 connections to vendor-owned cloud storage, a major HIPAA violation.
|
||||
|
||||
ExtraHop notes that while there may not be any malicious activity in these examples, it is still in violation of the law, and administrators need to keep an eye on their networks to monitor traffic for unusual activity.
|
||||
|
||||
"To be clear, we don’t know why these vendors are phoning home data. The companies are all respected security and IT vendors, and in all likelihood, their phoning home of data was either for a legitimate purpose given their architecture design or the result of a misconfiguration," the report says.
|
||||
|
||||
### How to mitigate phoning-home security risks
|
||||
|
||||
To address this security malpractice problem, ExtraHop suggests companies do these five things:
|
||||
|
||||
* Monitor for vendor activity: Watch for unexpected vendor activity on your network, whether they are an active vendor, a former vendor or even a vendor post-evaluation.
|
||||
* Monitor egress traffic: Be aware of egress traffic, especially from sensitive assets such as domain controllers. When egress traffic is detected, always match it to approved applications and services.
|
||||
* Track deployment: While under evaluation, track deployments of software agents.
|
||||
* Understand regulatory considerations: Be informed about the regulatory and compliance considerations of data crossing political and geographic boundaries.
|
||||
* Understand contract agreements: Track whether data is used in compliance with vendor contract agreements.
|
||||
|
||||
|
||||
|
||||
**[ Now read this: [Network World's corporate guide to addressing IoT security][9] ]**
|
||||
|
||||
Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/03/cybersecurity_eye-with-binary_face-recognition_abstract-eye-100751589-large.jpg
|
||||
[2]: https://www.extrahop.com/company/press-releases/2019/extrahop-issues-warning-about-phoning-home/
|
||||
[3]: https://www.networkworld.com/article/3254185/internet-of-things/tips-for-securing-iot-on-your-network.html#nww-fsb
|
||||
[4]: https://www.networkworld.com/article/3269184/10-best-practices-to-minimize-iot-security-vulnerabilities#nww-fsb
|
||||
[5]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
|
||||
[6]: https://www.extrahop.com/resources/whitepapers/eh-security-advisory-calling-home-success/
|
||||
[7]: https://www.csoonline.com/article/3202771/general-data-protection-regulation-gdpr-requirements-deadlines-and-facts.html
|
||||
[8]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[9]: https://www.networkworld.com/article/3269165/internet-of-things/a-corporate-guide-to-addressing-iot-security-concerns.html
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (VMware plan elevates Kubernetes to star enterprise status)
|
||||
[#]: via: (https://www.networkworld.com/article/3434063/vmware-plan-elevates-kubernetes-to-star-enterprise-status.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
VMware plan elevates Kubernetes to star enterprise status
|
||||
======
|
||||
VMware rolls out Tanzu platform to help customer build, run and manage Kubernetes containers
|
||||
![Daniel Masaoka][1]
|
||||
|
||||
San Francisco – VMware has announced an initiative that will help make it easier for current vSphere customers to build and manage Kubernetes containers as the platform evolves.
|
||||
|
||||
The company, at its VMworld customer event, announced VMware Tanzu which is made up of myriad new and existing VMware technologies to create a portfolio of products and services aimed at enterprises looking to more quickly build software in Kubernetes containers.
|
||||
|
||||
[Learn how to make hybrid cloud work][2]
|
||||
|
||||
VMware believes that Kubernetes has emerged as the infrastructure layer to accommodate a diversity of applications. VMware says that from 2018 to 2023 – with new tools/platforms, more developers, agile methods, and lots of code reuse – 500 million new logical apps will be created serving the needs of many application types and spanning all types of environments.
|
||||
|
||||
“We view Tanzu as a comprehensive environment for customers to bridge between the development and operational world. It’ll be super-powerful, enterprise grade Kubernetes platform. Kubernetes is the main tool for this transition and we now have a lot of work to do to make it work,” said Pat Gelsinger, CEO of VMware at the VMworld event.
|
||||
|
||||
Gelsinger noted that VMware’s investments in Kubernetes technologies, including its buy of Heptio, Bitnami and [now Pivital, ][3]make the company a top-three open-source contributor to Kubernetes.
|
||||
|
||||
Key to the grand Tanzu plan is technology VMware calls Project Pacific which will add Kubernetes to vSphere – the company’s flagship virtualization software. By embedding Kubernetes into the control plane of vSphere, it will enable the convergence of containers and VMs onto a single platform. Project Pacific will also add a container runtime into the hypervisor, VMware stated.
|
||||
|
||||
The new native pots for VMware's bare-metal hypervisor ESXi will combine the best properties of Kubernetes pods and VMs to help deliver a secure and high-performance runtime for mission-critical workloads. Additionally, Project Pacific will deliver a native virtual network spanning VMs and containers, VMware stated.
|
||||
|
||||
IT operators will use vSphere tools to deliver Kubernetes clusters to developers, who can then use Kubernetes APIs to access VMware’s [software defined data-center][4] (SDDC) infrastructure. With Project Pacific, both developers and IT operators will gain a consistent view via Kubernetes constructs within vSphere.
|
||||
|
||||
“Project Pacific will embed Kubernetes into the control plane of vSphere, for unified access to compute, storage and networking resources, and also converge VMs and containers using the new Native Pods that are high performing, secure and easy to consume," wrote Kit Colbert vice president and CTO of VMware’s Cloud Platform business unit in a [blog about Project Pacific][5]. “Concretely this will mean that IT Ops can see and manage Kubernetes objects (e.g. pods) from the vSphere Client. It will also mean all the various vSphere scripts, third-party tools, and more will work against Kubernetes.”
|
||||
|
||||
Tanzu will also feature a single management package – VMware Tanzu Mission Control – which will function as a single point of control where customers can manage Kubernetes clusters regardless of where they are running, the company stated.
|
||||
|
||||
Tanzu also utilizes technology VMware bought from Bitnami which offers a catalog of pre-built, scanned, tested and maintained Kubernetes application content. The Bitnami application catalog supports and has been certified for all major Kubernetes platforms, including VMware PKS.
|
||||
|
||||
Tanzu also integrates VMware’s own container technology it currently develops with Pivotal, Pivotal Container Service (PKS), which it just last week said it intends to acquire. PKS delivers Kubernetes-based container services for multi-cloud enterprises and service providers.
|
||||
|
||||
With Project Pacific, IT will have unified visibility into vCenter Server for Kubernetes clusters, containers and existing VMs, as well as apply enterprise-grade vSphere capabilities (like high availability, Distributed Resource Scheduler, and vMotion) at the app level, Colbert wrote.
|
||||
|
||||
VMware didn’t say when Tanzu will become part of vSphere but as features get baked into the platform and tested customers could expect it “soon,” VMware executives said.
|
||||
|
||||
“Kubernetes can help organizations achieve consistency and drive developer velocity across a variety of infrastructures, but enterprises also require effective control, policy and security capabilities. Building on its acquisitions, organic innovation and open-source contributions, VMware has staked out its place as a leader in this rapidly evolving cloud-native industry.” said 451 Research Principal Analyst Jay Lyman in a statement.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3434063/vmware-plan-elevates-kubernetes-to-star-enterprise-status.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2017/08/nwin_016_vmwareceo_edge-100733116-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3119362/hybrid-cloud/how-to-make-hybrid-cloud-work.html#tk.nww-fsb
|
||||
[3]: https://www.networkworld.com/article/3433916/vmware-spends-48b-to-grab-pivotal-carbon-black-to-secure-develop-integrated-cloud-world.html?nsdr=true
|
||||
[4]: https://www.networkworld.com/article/3340259/vmware-s-transformation-takes-hold.html
|
||||
[5]: https://blogs.vmware.com/vsphere/2019/08/introducing-project-pacific.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,155 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (6 crucial tips for leading a cross-functional team)
|
||||
[#]: via: (https://opensource.com/open-organization/19/8/tips-cross-functional-teams)
|
||||
[#]: author: (Michael Doyle https://opensource.com/users/mdoyle)
|
||||
|
||||
6 crucial tips for leading a cross-functional team
|
||||
======
|
||||
Leading work that cuts across teams and departments isn't easy, but
|
||||
taking an open approach will help you succeed. Here's a checklist for
|
||||
getting started.
|
||||
![a big flag flying in a sea of other flags, teamwork][1]
|
||||
|
||||
So you've taken on the challenge of leading your first cross-functional project, one that requires voluntary effort from people across organizational functions to achieve its objective. Congratulations!
|
||||
|
||||
But amidst your excitement over the opportunity to prove yourself, you're also feeling anxious about how you're _actually going to do it_?
|
||||
|
||||
Here are six tips for leveraging [open organization principles][2] to help you shine like the leader you truly want to be. These tips are drawn from my experience having led cross-functional projects, and from my conversations with other-cross functional project leaders.
|
||||
|
||||
### 1\. Start at the top
|
||||
|
||||
Executive sponsors who care will make your work feel like you're not swimming against the tide. Ideally, you'll want a sponsor who understands your project's importance to the organization—someone who can regularly motivate the team by demonstrating how this project delivers on the organization's goals, and who will, in the process, celebrate and promote the successful work the team achieves.
|
||||
|
||||
If your executive sponsor doesn't look like this, then your first responsibility as a leader is to guide them to clarity. Using the open organization value of inclusivity, give your sponsor clear feedback that will help them identify the project's priority. For you to be successful, your executive sponsor needs to clearly understand why they're sponsoring this project and be willing to support it all the way to its completion. That means being prepared to commit some time after the project kick-off to receive updates, remind the team about why this project is important, and to celebrate success. Your duty is to help them understand this.
|
||||
|
||||
Having this conversation with your executive sponsor might seem confrontational, but you're actually stepping up to your role as leader by caring about the success of the project and all the people who will be involved. On a few projects in which I was involved, this step helped the executive sponsor see that they didn't really _need_ this project. Think of all the resources saved because the executive sponsor made that decision earlier rather than later.
|
||||
|
||||
### 2\. Why ask why
|
||||
|
||||
Now that you've secured a committed executive sponsor, it's now time to translate their vision into the team's shared vision.
|
||||
|
||||
This might sound like a trivial step, but it's an important one for achieving team buy-in; it turns the executive sponsor's reasons for the team's existence into the team's _own_ reasons for existing. The open organization value of community is key here, because as the project leader you are helping build the necessary framework that provides the team with an opportunity to contribute to, understand, and agree on the problem scope presented by the project sponsor.
|
||||
|
||||
Notice I said "problem" and not "solution." Guide the team to agree on the _problem_ first, and define and agree on the _solution_ to solve it second. As you do this, make sure that each team member can voice concerns. Listen and note those concerns rather than giving reasons to dismiss them. You're going to need each team member's _real_ commitment to the project—not just a head nod. Listening to team members is the founding conduit through which this happens.
|
||||
|
||||
In an ideal open organization, people come together naturally and for the right reasons. Unfortunately your project exists in a real organization, and sometimes you need more than a verbal agreement to get such buy-in to stick.
|
||||
|
||||
In an ideal open organization, people come together naturally and for the right reasons. Unfortunately your project exists in a _real_ organization, and sometimes you need more than a verbal agreement to get such buy-in to stick. This is once again an opportunity to step up as a leader. Talk to each team member's manager and work together to connect the work they will do on the project to their performance and development plan. You'll want to make sure the team member and their manager are touching base on the project in their one-on-ones and factoring in behavior and outcomes into any financial compensation mechanism your company has (bonuses, salary review, etc.).
|
||||
|
||||
With this key step in place, you'll have the buy-in you need when the going gets tough as team members struggle to prioritize project work with their day-to-day responsibilities.
|
||||
|
||||
### 3\. Lights, camera, action
|
||||
|
||||
Movies work because everyone knows their role and the roles of others. They know what they are supposed to do and when. Your team needs this too, and you can shine as a leader by helping them create it.
|
||||
|
||||
Work with your team to draft some kind of "team agreement," guidelines team members have developed to structure _how_ they must work together to create a positive, productive process.
|
||||
|
||||
Work will flow smoothly if every team member understands what they're expected to deliver. As a leader, you're facilitating the open organization value of collaboration by giving each member an opportunity to define their role. You need to have an idea of the roles required to deliver the project, and you need to consult with the team to make sure each member is a good fit for the role.
|
||||
|
||||
At this point, you'll also start to define common vocabulary the team must understand to ensure they can work together smoothly. Don't take anything for granted here; use any opportunity to establish that common vocabulary by asking team members what they mean when they use potentially vague, ambiguous, or domain-specific vocabulary. For example, a team member might say, "We need to have a robust review process after each milestone." That's a great opportunity to ask, "What does a robust review process look like to you?"
|
||||
|
||||
### 4\. Mirror, mirror on the wall
|
||||
|
||||
Now that you've identified—and documented—the team's roles and common vocabulary, it's time to make sure you define yours.
|
||||
|
||||
Movies work because everyone knows their role and the roles of others. They know what they are supposed to do and when. Your team needs this too, and you can shine as a leader by helping them create it.
|
||||
|
||||
In my experience a project _leader's_ role is different to a project _member's_ role. The leader's job is to work _on_ the project, not in it. Getting bogged down in the tactical and becoming the project's "hero" might scream of individual accomplishment, but it's not going to prove your leadership ability to the organization in the way you're hoping it would when you took on this project in the first place. Let the team know that you're not responsible for managing or owning all actions. Leverage the open organization value of adaptability and use your advantage of seeing a broader view of the work to help the project team see for themselves where the gaps are. Help them make the connections from the tactical work to the strategic. Hold up a mirror so they can see when they're breaking their own rules, as documented in the "team agreement." The project team should expect their leader to keep them on track, focused, organized, and informed.
|
||||
|
||||
Having peer support will help you here. Your peers may know the landscape of people better than you do. They can also double-check your communications before you've rolled them out publicly. Seek out a trusted peer to be your sounding board, and find one or two equally trusted sources who can help you navigate the cross-functional landscape.
|
||||
|
||||
### 5\. Publish or perish
|
||||
|
||||
Communicate well and you'll be that successful leader you're hoping to be. Communicate poorly (or not at all) and you'll be fighting more fires than Steve McQueen's Michael O'Halloran in "The Towering Inferno."
|
||||
|
||||
Communication is not a burden; it's a useful tool for building organizational alliances, and it asks of you only a small amount of time. In return, it delivers immense value.
|
||||
|
||||
As a team, identify a meeting cadence and stick to it. Cut meetings short if there's no remaining value to add to a discussion, but keep the cadence. Cadence is your lead measure. Without a regular cadence the group will slowly disintegrate. Team members need to agree to join the meeting and show up. Let up for a moment here and make it acceptable not to attend, and guess what? That's now the team norm. Don't be that leader.
|
||||
|
||||
Publish your meeting minutes in a location that others can find them. This is essentially the "social proof" that the team is doing its work. Nobody praises a team that acts like a black box. Don't become that team. Transparency all the way.
|
||||
|
||||
And the most overlooked part of this? Measure it. Never assume anything has been read or understood just because it went live on the corporate intranet or swooshed away from your outbox. Find a way to ensure you know whether people have _read_ and _understood_ your materials. You can keep this really simple: just ask them. "What's one pressing question you have from our latest project update?"
|
||||
|
||||
### 6\. (Never) to infinity and beyond
|
||||
|
||||
Communication is not a burden; it's a useful tool for building organizational alliances, and it asks of you only a small amount of time. In return, it delivers immense value.
|
||||
|
||||
Lastly, the project needs to be _time bound_. Team members need some _light_ at the end of the project's tunnel. If the project is multi-year, or multi-phase, then this could mean giving an opportunity for old members to leave and new members to join. Nobody wins in a protracted war.
|
||||
|
||||
Be a great leader and conduct a retrospective when the project is finished so you can add _your_ experience to all of this—and pass it on to someone else leading their first cross-functional project.
|
||||
|
||||
Here's a handy checklist of the key points to set your cross-functional team up for success.
|
||||
|
||||
**Checklist for Leading a Cross-Functional Team**
|
||||
|
||||
Step 1
|
||||
|
||||
✓
|
||||
|
||||
My sponsor is clear on the project's priority and understands what the project team expects from them for the duration of the project.
|
||||
|
||||
Step 2
|
||||
|
||||
✓
|
||||
|
||||
The project team agrees on the problem and understands why this team exists.
|
||||
|
||||
✓
|
||||
|
||||
Each team member's manager understands how this work fits into the team member’s performance and development and will support them in their one-on-ones.
|
||||
|
||||
Step 3
|
||||
|
||||
✓
|
||||
|
||||
Each team member has helped to define and document their role.
|
||||
|
||||
✓
|
||||
|
||||
As a team we have clarified and documented the meaning of common project vocabulary.
|
||||
|
||||
Step 4
|
||||
|
||||
✓
|
||||
|
||||
The team understands my role as project leader.
|
||||
|
||||
✓
|
||||
|
||||
I have identified and engaged peers who will support me personally during this project.
|
||||
|
||||
Step 5
|
||||
|
||||
✓
|
||||
|
||||
The team has set the meeting cadence and committed to attending. And they documented it in the "team agreement."
|
||||
|
||||
✓
|
||||
|
||||
I have identified how I will follow up on team communications to ensure stakeholders are engaged.
|
||||
|
||||
Step 6
|
||||
|
||||
✓
|
||||
|
||||
Team members know how long they are engaged with this project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/8/tips-cross-functional-teams
|
||||
|
||||
作者:[Michael Doyle][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mdoyle
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/leader_flag_people_team_group.png?itok=NvrjQxM6 (a big flag flying in a sea of other flags, teamwork)
|
||||
[2]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
@ -0,0 +1,83 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (VMware boosts load balancing, security intelligence, analytics)
|
||||
[#]: via: (https://www.networkworld.com/article/3434576/vmware-boosts-load-balancing-security-intelligence-analytics.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
VMware boosts load balancing, security intelligence, analytics
|
||||
======
|
||||
At VMworld, VMware says its NSX networking software looks to help customers boost performance, management of virtualized cloud resources.
|
||||
![Thinkstock][1]
|
||||
|
||||
SAN FRANCISCO – VMware has added new features to its core networking software that will let customers more securely control cloud application traffic running on virtual machines, containers or bare metal.
|
||||
|
||||
At its VMworld event, the company announced a new version of the company’s NSX networking software with support for the cloud-based advanced load balancer technology it recently acquired from Avi Networks.
|
||||
|
||||
**[ Also see [How to plan a software-defined data-center network][2] and [Efficient container use requires data-center software networking][3].]**
|
||||
|
||||
The load balancer is included in VMware vRealize Network Insight 5.0 and tied to NSX Intelligence software that lets customers optimize network performance and availability in virtual and physical networks. The load balancer includes a web application firewall and analytics features to help customers securely control and manage traffic.
|
||||
|
||||
[VMware bought Avi in June][4] with the plan to punch up its data-center network-virtualization capabilities by adding Avi’s load balancing, analytics and application-delivery technology to NSX. Avi’s integration with VMware NSX delivers an application-services fabric that synchronizes with the NSX controller to provide automated, elastic load balancing including real-time analytics for applications deployed in a software-defined network environment. The Avi technology also monitors, scales and reconfigures application services in real time in response to changing performance requirements.
|
||||
|
||||
“The load balancer uses a modern interface and architecture to deliver and optimize application delivery in a dynamic fashion," said Rohit Mehra, vice president, Network Infrastructure for IDC. "Leveraging inbuilt advanced analytics and monitoring to deliver scale that is much needed for cloud applications and micro-services, the advanced load balancer will essentially be a nice add-on option to VMware’s NSX networking portfolio. While many customers may benefit from its integration into NSX, VMware will likely keep it as an optional add-on, given the vast majority of its networking clients currently use other ADC platforms.”
|
||||
|
||||
NSX-T Data Center software is targeted at organizations looking to support multivendor cloud-native applications, [bare-metal][5] workloads, [hypervisor][6] environments and the growing hybrid and multi-cloud worlds. The software offers a range of services layer 2 to Layer 7 for workloads running on all types of infrastructure – virtual machines, containers, physical servers and both private and public clouds. NSX-T is the underpinning technology for VMware’s overarching Virtual Cloud Network portfolio that offers a communications-software layer to connect everything from the data center to cloud and edge.
|
||||
|
||||
“NSX now provides a complete set of networking services offered in software. Customers don’t need dedicated hardware systems to do switching, routing or traffic load balancing as NSX treats VM, container and app traffic all the same from the cloud to data center and network edge,” said Tom Gillis, VMware senior vice president and general manager, networking and security business unit.
|
||||
|
||||
Now customers can distribute workloads uniformly across network improving capacity, efficiency and reliability, he said.
|
||||
|
||||
Speaking at the event, a VMware customer said VMware NSX-T Data Center is helping the company secure workloads at a granular level with micro-segmentation, and to fundamentally re-think network design. "We are looking to develop apps as quickly as possible and use NSX to do automation and move faster,” said [Andrew Hrycaj][7], principal network engineer at IHS Markit – a business information provider headquartered in London.
|
||||
|
||||
NSX also helps IT manage a common security policy across different platforms, from containers, to the public cloud with AWS and Azure, to on-prem, simplifying operations and helping with regulatory compliance, while fostering a pervasive security strategy, Hrycaj said.
|
||||
|
||||
At VMworld the company announced version 2.5 of NSX which includes a distributed \analytics engine called NSX Intelligence that VMware says will help eliminate blind spots to reduce security risk and accelerate security-incident remediation through visualization and deep insight into every flow across the entire data center.
|
||||
|
||||
“Traditional approaches involve sending extensive packet data and telemetry to multiple disparate centralized engines for analysis, which increase cost, operational complexity, and limit the depth of analytics,” wrote VMware’s Umesh Mahajan, a senior vice president and general manager networking and security in a [blog about version 2.5][8].
|
||||
|
||||
“In contrast, NSX Intelligence, built natively within the NSX platform, distributes the analytics within the hypervisor on each host, sending back relevant metadata… [and providing] detailed application--topology visualization, automated security-policy recommendations, continuous monitoring of every flow, and an audit trail of security policies, all built into the NSX management console.”
|
||||
|
||||
IDC’s Mehra said: “The NSX Intelligence functionality is indeed very interesting, in that it delivers on the emerging need for deeper visibility and analytics capabilities in cloud IT environments. This can then be used either for network and app optimization goals, or in many cases, will facilitate NSX security and policy enforcement via micro-segmentation and other tools. This functionality, built into NSX, runs parallel to vRealize Network Insight, so it will be interesting to see how they mirror, or rather, complement each other,” he said.
|
||||
|
||||
NSX-T 2.5, also introduces a new deployment and operational approach VMware calls Native Cloud Enforced mode.
|
||||
|
||||
“This mode provides a consistent policy model across the hybrid cloud network and reduces overhead by eliminating the need to install NSX tools in workload VMs in the public cloud,” Mahajan wrote. “The NSX security policies are translated into the cloud provider’s native security constructs via APIs, enabling common and centralized policy enforcement across clouds.”
|
||||
|
||||
Networking software vendor Apstra got into the NSX act by announcing it had more deeply integrated the Apstra Operating System (AOS) with NSX.
|
||||
|
||||
AOS includes a tighter design and operational interoperability between the underlying physical network and software-defined overlay networks with a solution that liberates customers from being locked into any specific network hardware vendor, said Mansour Karam, CEO and founder of Apstra.
|
||||
|
||||
AOS 3.1 adds automation to provide consistent network and security policy for workloads across the physical and virtual/NSX infrastructure, Apstra said. AOS supports VMware vSphere and allows for automatic remediation of network anomalies. AOS’ intent-based analytics perform regular network checks to safeguard configurations between the Apstra managed environment and the vSphere servers are in sync.
|
||||
|
||||
Like other AOS releases, version 3.1 is hardware agnostic and integrated with other networking vendors including Cisco, Arista, Dell and Juniper as well as other vendors such as Microsoft and Cumulus.
|
||||
|
||||
Big Switch also announced that it has extended its Enterprise Virtual Private Cloud (E-VPC) integration to the VMware Cloud Foundation (VCF) and NSX-T. The company's Big Cloud Fabric (BCF) underlay now fully integrates with VMware’s software-defined data center (SDDC) portfolio, including NSX-T, vSphere, VxRail and vSAN, providing unmatched automation, visibility and troubleshooting capabilities.
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3434576/vmware-boosts-load-balancing-security-intelligence-analytics.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2017/09/networking-100735059-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3284352/data-center/how-to-plan-a-software-defined-data-center-network.html
|
||||
[3]: https://www.networkworld.com/article/3297379/data-center/efficient-container-use-requires-data-center-software-networking.html
|
||||
[4]: https://www.networkworld.com/article/3402981/vmware-eyes-avi-networks-for-data-center-software.html
|
||||
[5]: https://www.networkworld.com/article/3261113/why-a-bare-metal-cloud-provider-might-be-just-what-you-need.html?nsdr=true
|
||||
[6]: https://www.networkworld.com/article/3243262/what-is-a-hypervisor.html?nsdr=true
|
||||
[7]: https://www.networkworld.com/article/3223189/how-network-automation-can-speed-deployments-and-improve-security.html
|
||||
[8]: https://blogs.vmware.com/networkvirtualization/2019/08/nsx-t-2-5.html/
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
104
sources/talk/20190827 Why Spinnaker matters to CI-CD.md
Normal file
104
sources/talk/20190827 Why Spinnaker matters to CI-CD.md
Normal file
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why Spinnaker matters to CI/CD)
|
||||
[#]: via: (https://opensource.com/article/19/8/why-spinnaker-matters-cicd)
|
||||
[#]: author: (Swapnil Bhartiya https://opensource.com/users/arnieswap)
|
||||
|
||||
Why Spinnaker matters to CI/CD
|
||||
======
|
||||
Spinnaker provides unique building blocks to create tailor-made, and
|
||||
highly-collaborative continuous delivery pipelines. Join them at
|
||||
Spinnaker Summit.
|
||||
![CICD with gears][1]
|
||||
|
||||
It takes many tools to deliver an artifact into production. Tools for building and testing, tools for creating a deployable artifact like a container image, tools for authentication and authorization, tools for maintaining infrastructure, and more. Seamlessly integrating these tools into a workflow can be transformative for an engineering culture, but doing it yourself can be a tall order.
|
||||
|
||||
As organizations mature, both the number of tools and the number of people managing them tend to grow, often leading to confusing complexity and fragmentation. A bespoke continuous delivery (CD) process may work at a smaller scale, but it becomes increasingly challenging to maintain and understand. It can take a long time for new engineers to discover and sort through all the tools needed to deploy even the simplest of changes.
|
||||
|
||||
[Spinnaker][2] was created to address this issue. It is a generalizable and extensible tool that provides users with the building blocks to create tailor-made continuous delivery pipelines. There is no need to spend time and take on increased risk inventing your own approach when you can instead use a solution that is already trusted and developed by major companies like Netflix and Google for handling the delivery of thousands of applications.
|
||||
|
||||
### Spinnaker's origin
|
||||
|
||||
Netflix used to have a fragmented continuous delivery story. Each organization's delivery system was built specifically for that org, so others were often unable to benefit from that work. Teams considered themselves unique and wove together Jenkins jobs with [Asgard][3]. All of this duplicated effort was not only wasteful but also made it difficult to keep teams savvy and up-to-date with the latest delivery best practices.
|
||||
|
||||
In 2014, teams agreed that a general-purpose continuous integration (CI) tool like Jenkins did not provide a suitable foundation to build a continuous delivery platform with the safety and flexibility they needed. To that end, a new tool was born. Netflix's delivery engineering team collaborated with Google to build Spinnaker, a multi-cloud continuous delivery and infrastructure management tool that would be centrally managed and flexible enough to let teams customize their own delivery, but standardized enough to bring best practices and safety to everyone. Spinnaker codifies our decades of experience writing and delivering software into something everyone can use without going through the same growing pains.
|
||||
|
||||
Since the widespread adoption of Spinnaker in the open source community, the maintainers have continuously added new features and integrations to make Spinnaker even more useful and sticky across companies like Netflix, Google, Airbnb, Pinterest, and Snap.
|
||||
|
||||
### Spinnaker in practice
|
||||
|
||||
With Spinnaker, you can [build flexible pipelines made up of stages][4] to deliver your software the way you need. You can have a Deploy stage, which orchestrates the creation and cleanup of new infrastructure using a blue/green strategy for zero downtime. If you want more direct control on your release process, you can add a Manual Judgment stage that waits for external confirmation. These stages can be woven together into pipelines capable of representing complex and customized delivery workflows.
|
||||
|
||||
[![Spinnaker pipeline][5]][6]
|
||||
|
||||
The flexibility of pipelines, combined with a comprehensive set of built-in stages, enabled Spinnaker to catch on across teams. One clear example of this is our [Canary][7] stage, which evaluates a set of metrics to determine if a deploy is healthy or unhealthy. Before Spinnaker, many teams could not use canaries in their deploy pipelines because it was too cumbersome to integrate with their old canary system. This "batteries-included" Canary stage was the carrot that brought a lot of teams to Spinnaker.
|
||||
|
||||
If you need custom behavior, stages also offer an extension point to encapsulate logic specific to your organization or team. These extensions can be open or closed source. For example, you could add custom functionality that updates the status of a Jira ticket, refreshes a cache, or snapshots a database.
|
||||
|
||||
### Spinnaker customization
|
||||
|
||||
As a generalized tool, Spinnaker can do lots of things out of the box; however, it really shines when you customize it. When you add integrations to other tools in your organization or share best practices, it becomes easier to help teams deploy and operate software safely and reliably.
|
||||
|
||||
![Spinnaker concepts hierarchy][8]
|
||||
|
||||
We've added a diverse variety of custom integrations for Spinnaker to make it sticky. The following may spark ideas for how you could customize Spinnaker to fit your organization.
|
||||
|
||||
#### Improve developer efficiency
|
||||
|
||||
One simple UI customization we've done is to have an icon next to each instance that allows you to copy the SSH command to that instance. We did that by overriding the Instance Details panel in the UI with a Netflix-specific component that takes some information from the config file (the base SSH command), inserts the instance ID into that command, and makes it available as a little clipboard button next to the instance ID.
|
||||
|
||||
#### Improve security
|
||||
|
||||
We've worked closely with our security team for the last five years to work best practices into Spinnaker. One example of that is how we create identity and access management (IAM) roles automatically for each application and use those roles to restrict who can do what in AWS, allowing each team the permissions they need to get their job done.
|
||||
|
||||
We make this happen using two parts: (1) we add a custom class into [Clouddriver][9] (the microservice that does cloud operations) that talks to (2) a Lambda function maintained by our security team.
|
||||
|
||||
For each cloud mutating operation, we check with AWS to see if an IAM role exists with that app name; if it doesn't, we check with the security service to see if we should create one. If a role needs to be created, we call that security service with the info it needs to make sure the IAM role is created successfully.
|
||||
|
||||
Because of this setup, we can easily control the IAM profile that every instance is launched while leaving the meat of the IAM functionality to the security team. This provides them the flexibility to change their implementation, add functionality, or do additional auditing without having to make changes to Spinnaker.
|
||||
|
||||
We often use the pattern of a Spinnaker hook and a resulting partner team service call. It helps to separate Spinnaker's concern, which is to serve as a delivery platform, from the concerns managed by partner teams, such as security. This separation also supports partner teams' ability to innovate independently, resulting in a better, more secure delivery experience for our users.
|
||||
|
||||
#### Improve traceability and auditing
|
||||
|
||||
A final example of a custom integration is sending a [Spinnaker event stream][10] to another service. Spinnaker does a lot of mutating operations, and often you might need to record those events for auditing or compliance purposes. We send all events to our Big Data store so other teams within the company can make use of the data.
|
||||
|
||||
We also manage a [PCI][11]-compliant environment. Previously, we had a co-located Spinnaker instance that ran in this isolated environment to maintain compliance. This year, we enabled the [Fiat][12] authorization microservice in Spinnaker, hardened it, and converged on maintaining all properties with a single Spinnaker.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Continuous delivery is hard to do correctly. Spinnaker is a hardened and well-maintained tool (with approximately 460 merged pull requests in the last month) that has many existing integrations to popular services while also supporting custom integrations for increased flexibility. Large companies like Netflix, Google, Amazon, Nike, Cisco, and Salesforce are actively contributing to Spinnaker. Adopting Spinnaker allows you to centralize your continuous delivery and gain access to best practices. Instead of reinventing the wheel, why not join the Spinnaker community?
|
||||
|
||||
* * *
|
||||
|
||||
_If this topic interests you, come talk to users, maintainers, and other people in the delivery space at the [Spinnaker Summit][13] November 15–17 in San Diego._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/why-spinnaker-matters-cicd
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/arnieswap
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc (CICD with gears)
|
||||
[2]: https://www.spinnaker.io/
|
||||
[3]: https://github.com/Netflix/asgard
|
||||
[4]: https://www.spinnaker.io/concepts/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/spinnaker_edit-pipeline.png (Spinnaker pipeline)
|
||||
[6]: https://www.spinnaker.io/concepts/pipelines/
|
||||
[7]: https://www.spinnaker.io/guides/user/canary/
|
||||
[8]: https://opensource.com/sites/default/files/images/spinnaker-pipeline-tasks-opensourcedotcom.png (Spinnaker concepts hierarchy)
|
||||
[9]: https://github.com/spinnaker/clouddriver
|
||||
[10]: https://www.spinnaker.io/setup/features/notifications/#add-a-listening-webhook-to-spinnaker
|
||||
[11]: https://en.wikipedia.org/wiki/Payment_Card_Industry_Data_Security_Standard
|
||||
[12]: https://github.com/spinnaker/fiat/
|
||||
[13]: http://spinnakersummit.com/
|
||||
@ -0,0 +1,92 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Someone Forked GIMP into Glimpse Because Gimp is an Offensive Word)
|
||||
[#]: via: (https://itsfoss.com/gimp-fork-glimpse/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
Someone Forked GIMP into Glimpse Because Gimp is an Offensive Word
|
||||
======
|
||||
|
||||
In the world of open source applications, forking is common when members of the community want to take an application in a different direction than the rest. The latest newsworthy fork is named [Glimpse][1] and is intended to fix certain issues that users have with the [GNU Image Manipulation Program][2], commonly known as GIMP.
|
||||
|
||||
### Why create a fork of GIMP?
|
||||
|
||||
![][3]
|
||||
|
||||
When you visit the [homepage][1] of the Glimpse app, it says that the goal of the project is to “experiment with other design directions and fix longstanding bugs.” That doesn’t sound too much out of the ordinary. However, if you start reading the project’s blog posts, a different image appears.
|
||||
|
||||
According to the project’s [first blog post][4], they created this fork because they did not like the GIMP name. According to the post, “A number of us disagree that the name of the software is suitable for all users, and after 13 years of the project refusing to budge on this have decided to fork!”
|
||||
|
||||
If you are wondering why these people find the work GIMP disagreeable they answer that question on the [About page][5]:
|
||||
|
||||
> “If English is not your first language, then you may not have realised that the word “gimp” is problematic. In some countries it is considered a slur against disabled people and a playground insult directed at unpopular children. It can also be linked to certain “after dark” activities performed by consenting adults.”
|
||||
|
||||
They also point out that they are not making this move out of political correctness or being oversensitive. “In addition to the pain it can cause to marginalized communities many of us have our own free software advocacy stories about the GNU Image Manipulation Program not being taken seriously as an option by bosses or colleagues in professional settings.”
|
||||
|
||||
As if to answer many questions, they also said, “It is unfortunate that we have to fork the whole project to change the name, but we feel that discussions about the issue are at an impasse and that this is the most positive way forward.”
|
||||
|
||||
[][6]
|
||||
|
||||
Suggested read After 6 Years, GIMP 2.10 is Here With Ravishing New Looks and Tons of New Features
|
||||
|
||||
It looks like the Glimpse name is not written in stone. There is [an issue][7] on their GitHub page about possibly picking another name. Maybe they should just drop GNU. I don’t think the word IMP has a bad connotation.
|
||||
|
||||
### A diverging path
|
||||
|
||||
![GIMP 2.10][8]
|
||||
|
||||
[GIMP][6] has been around for over twenty years, so any kind of fork is a big task. Currently, [they are planning][9] to start by releasing Glimpse 0.1 in September 2019. This will be a soft fork, meaning that changes will be mainly cosmetic as they migrate to a new identity.
|
||||
|
||||
Glimpse 1.0 will be a hard fork where they will be actively changing the codebase and adding to it. They want 1.0 to be a port to GTK3 and have its own documentation. They estimate that this will not take place until GIMP 3 is released in 2020.
|
||||
|
||||
Beyond the 1.0, the Glimpse team has plans to forge their own identity. They plan to work on a “front-end UI rewrite”. They are currently discussing [which language][10] they should use for the rewrite. There seems to be a lot of push for D and Rust. They also [hope to][4] “add new functionality that addresses common user complaints” as time goes on.
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
I have used GIMP a little bit in the past but was never too bothered by the name. To be honest, I didn’t know what it meant for quite a while. Interestingly, when I searched Wikipedia for GIMP, I came across an entry for the [GIMP Project][11], which is a modern dance project in New York that includes disabled people. I guess gimp isn’t considered a derogatory term by everyone.
|
||||
|
||||
To me, it seems like a lot of work to go through to change a name. It also seems like the idea of rewriting the UI was tacked to make the project look more worthwhile. I wonder if they will tweak it to bring a more classic UI like [using Ctrl+S to save in GIMP][12]/Glimpse. Let’s wait and watch.
|
||||
|
||||
[][13]
|
||||
|
||||
Suggested read Finally! WPS Office Has A New Release for Linux
|
||||
|
||||
If you are interested in the project, you can follow them on [Twitter][14], check out their [GitHub account][15], or take a look at their [Patreon page][16].
|
||||
|
||||
Are you offended by the GIMP name? Do you think it is worthwhile to fork an application, just so you can rename it? Let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][17].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/gimp-fork-glimpse/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://getglimpse.app/
|
||||
[2]: https://www.gimp.org/
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/gimp-fork-glimpse.png?resize=800%2C450&ssl=1
|
||||
[4]: https://getglimpse.app/posts/so-it-begins/
|
||||
[5]: https://getglimpse.app/about/
|
||||
[6]: https://itsfoss.com/gimp-2-10-release/
|
||||
[7]: https://github.com/glimpse-editor/Glimpse/issues/92
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/08/gimp-screenshot.jpg?resize=800%2C508&ssl=1
|
||||
[9]: https://getglimpse.app/posts/six-week-checkpoint/
|
||||
[10]: https://github.com/glimpse-editor/Glimpse/issues/70
|
||||
[11]: https://en.wikipedia.org/wiki/The_Gimp_Project
|
||||
[12]: https://itsfoss.com/how-to-solve-gimp-2-8-does-not-save-in-jpeg-or-png-format/
|
||||
[13]: https://itsfoss.com/wps-office-2016-linux/
|
||||
[14]: https://twitter.com/glimpse_editor
|
||||
[15]: https://github.com/glimpse-editor/Glimpse
|
||||
[16]: https://www.patreon.com/glimpse
|
||||
[17]: https://reddit.com/r/linuxusersgroup
|
||||
88
sources/talk/20190828 VMware touts hyperscale SD-WAN.md
Normal file
88
sources/talk/20190828 VMware touts hyperscale SD-WAN.md
Normal file
@ -0,0 +1,88 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (VMware touts hyperscale SD-WAN)
|
||||
[#]: via: (https://www.networkworld.com/article/3434619/vmware-touts-hyperscale-sd-wan.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
VMware touts hyperscale SD-WAN
|
||||
======
|
||||
VMware is teaming up with Dell/EMC to offer a hardware/software package rolled up into a managed SD-WAN service.
|
||||
BlueBay2014 / Getty Images
|
||||
|
||||
SAN FRANCISCO – VMware teamed with Dell/EMC this week to deliver an SD-WAN service that promises to greatly simplify setting up and supporting wide-area-network connectivity.
|
||||
|
||||
The Dell EMC SD-WAN Solution is a package of VMware software with Dell hardware and software that will be managed by Dell and sold as a package by both companies and their partners.
|
||||
|
||||
The package, introduced at the [VMworld event][1] here, includes VMware SD-WAN by VeloCloud software available as a subscription coupled with appliances available in multiple configurations capable of handling 10Mbps to 10Gbps of traffic, depending on customer need, said [Sanjay Uppal,][2] vice president and general manager of VMware’s VeloCloud Business Unit.
|
||||
|
||||
**More about SD-WAN**
|
||||
|
||||
* [How to buy SD-WAN technology: Key questions to consider when selecting a supplier][3]
|
||||
* [How to pick an off-site data-backup method][4]
|
||||
* [SD-Branch: What it is and why you’ll need it][5]
|
||||
* [What are the options for security SD-WAN?][6]
|
||||
|
||||
|
||||
|
||||
“The package is a much simpler way for customers to quickly set up a modern SD-WAN, especially for those customers who don’t have a lot of IT personnel to handle setting up and configuring an SD-WAN,” Uppal said. “Branch office networking can be complex and expensive, and this package uses subscription pricing, and supports cloud-like capabilities and economics.”
|
||||
|
||||
Dell EMC and VMware also announced SmartFabric Director, software that can be part of the service offering. Director enables data-center operators to build, operate and monitor an open network-underlay fabric based on Dell EMC PowerSwitch switches.
|
||||
|
||||
Accoding to Dell, organizations that have embraced overlay software-defined networks need to make sure their physical, underlay networks are tuned to work with the SDN. "A lack of visibility between the two layers can lead to provisioning and configuration errors, hampering network performance,” Dell stated.
|
||||
|
||||
The Director also supports flexible streaming telemetry to gather key operational data and statistics from the fabric switches it oversees, so customers can use it in security and other day-to-day operations, Dell said.
|
||||
|
||||
Analysts said the key to the VMware/Dell package isn’t so much the technology but the fact that it can be sold by so many of Dell and VMware’s partners.
|
||||
|
||||
"Dell will lead on the sales motion with an SD-WAN-as-a-Service offering leveraging its [customer premises equipment] platforms and global service and support capabilities, leveraging SD-WAN technology from VMware/VeloCloud,” said Rohit Mehra, vice president, Network Infrastructure for IDC.
|
||||
|
||||
VMware also used its VMworld event to say its VeloCloud SD-WAN platform and aggregate data gathered from customer networks will let the company offer more powerful network-health and control mechanisms in the future.
|
||||
|
||||
“The SD-WAN VMware/VeloCloud has actually achieved a milestone we think is significant across multiple dimensions, one is architecture. We have proven that we can get to tens of thousands of edges with a single network. In the aggregate, we are crossing 150,000 gateways, over 120 points-of-presence,” Uppal said.
|
||||
|
||||
VMware/Velocloud supports gateways across major cloud providers including Amazon Web Services, Microsoft Azure, Google Cloud Platform, and IBM Cloud as well as multiple carrier underlay networks.
|
||||
|
||||
“From all of those endpoints we can see how the underlay network is performing, what applications are running on it and security threat information. Right now we can use that information to help IT intervene and fix problems manually,” Uppal said. Long-term, the goal is to use the data to train algorithms that VMware is developing to promote self-healing networks that could, for example, detect outages and automatically reroute traffic around them.
|
||||
|
||||
The amount of data VMware gathers from cloud, branch-office and SD-WAN endpoints amounts to a treasure trove. “That is all part of the hyperscale idea," Uppal said.
|
||||
|
||||
There are a number of trends driving the increased use of SD-WAN technologies, Uppal said, a major one being the increased use of containers and cloud-based applications that need access from the edge. “The scope of clients needing SD-WAN service access to the data center or cloud resources is growing and changing rapidly,” he said.
|
||||
|
||||
In the most recent IDC [SD-WAN Infrastructure Forecast][7] report, Mehra wrote about a number of other factors driving SD-WAN evolution. For example:
|
||||
|
||||
* Traditional enterprise WANs are increasingly not meeting the needs of today's modern digital businesses, especially as it relates to supporting SaaS apps and multi- and hybrid-cloud usage.
|
||||
* Enterprises are interested in easier management of multiple connection types across their WAN to improve application performance and end-user experience.
|
||||
|
||||
|
||||
|
||||
“Combined with the rapid embrace of SD-WAN by leading communications service providers globally, these trends continue to drive deployments of SD-WAN, providing enterprises with dynamic management of hybrid WAN connections and the ability to guarantee high levels of quality of service on a per-application basis,” Mehra wrote in the report.
|
||||
|
||||
The report also said that the SD-WAN infrastructure market continues to be highly competitive with sales increasing 64.9% in 2018 to $1.37 billion. IDC stated Cisco holds the largest share of the SD-WAN infrastructure market, with VMware coming in second followed by Silver Peak, Nokia-Nuage, and Riverbed.
|
||||
|
||||
Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3434619/vmware-touts-hyperscale-sd-wan.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3434576/vmware-boosts-load-balancing-security-intelligence-analytics.html
|
||||
[2]: https://www.networkworld.com/article/3387641/beyond-sd-wan-vmwares-vision-for-the-network-edge.html
|
||||
[3]: https://www.networkworld.com/article/3323407/sd-wan/how-to-buy-sd-wan-technology-key-questions-to-consider-when-selecting-a-supplier.html
|
||||
[4]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
|
||||
[5]: https://www.networkworld.com/article/3250664/lan-wan/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[6]: https://www.networkworld.com/article/3285728/sd-wan/what-are-the-options-for-securing-sd-wan.html?nsdr=true
|
||||
[7]: https://www.idc.com/getdoc.jsp?containerId=prUS45380319
|
||||
[8]: https://www.facebook.com/NetworkWorld/
|
||||
[9]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Data center-specific AI completes tasks twice as fast)
|
||||
[#]: via: (https://www.networkworld.com/article/3434597/data-center-specific-ai-completes-tasks-twice-as-fast.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Data center-specific AI completes tasks twice as fast
|
||||
======
|
||||
Researchers at MIT have developed an artificial intelligence-powered system based on reinforcement learning that could revolutionize data center operations.
|
||||
Matejmo / Getty Images
|
||||
|
||||
Data centers running artificial intelligence (AI) will be significantly more efficient than those operating with hand-edited algorithm schedules, say experts at MIT. The researchers there say they have developed an automated scheduler that speeds cluster jobs by up to 20 or 30 percent, and even faster (2x) in peak periods.
|
||||
|
||||
The school’s AI job scheduler works on a type of AI called “reinforcement learning” (RL). That’s a trial-and-error-based machine-learning method that modifies scheduling decisions depending on actual workloads in a specific cluster. AI, when done right, could supersede the current state-of-the-art method, which is algorithms. They often must be fine-tuned by humans, introducing inefficiency.
|
||||
|
||||
“The system could enable data centers to handle the same workload at higher speeds, using fewer resources,” [the school says in a news article related to the tech][1]. The MIT researchers say the data center-adapted form of RL could revolutionize operations.
|
||||
|
||||
**Also read: [AI boosts data center availability and efficiency][2]**
|
||||
|
||||
“If you have a way of doing trial and error using machines, they can try different ways of scheduling jobs and automatically figure out which strategy is better than others,” says Hongzi Mao, a student in the university’s Department of Electrical Engineering and Computer Science, in the article. “Any slight improvement in utilization, even 1%, can save millions of dollars and a lot of energy.”
|
||||
|
||||
### What's wrong with today's data center algorithms
|
||||
|
||||
The problem with the current algorithms for running tasks on thousands of servers at the same time is that they’re not very efficient. Theoretically, they should be, but because workloads (combinations of tasks) are varied, humans get involved in tweaking the performance—a resource, say, might need to be shared between jobs, or some jobs might need to be performed faster than others—but humans can’t handle the range or scope of the edits; the job is just too big.
|
||||
|
||||
Unfathomable permutations for humans in the manually edited scheduling can include the fact that a lower node (smaller computational task) can’t start work until an upper node (larger, more power-requiring computational task) has completed its work. It gets highly complicated allocating the computational resources, the scientists explain.
|
||||
|
||||
Decima, MIT’s system, can process dynamic graphs (representations) of nodes and edges (edges connect nodes, linking tasks), the school says. That hasn’t been possible before with RL because RL hasn’t been able to understand the graphs well enough at scale.
|
||||
|
||||
“Traditional RL systems are not accustomed to processing such dynamic graphs,” MIT says.
|
||||
|
||||
MIT’s graph-oriented AI is different than other forms of AI that are more commonly used with images. Robots, for example, learn the difference between objects in different scenarios by processing images and getting reward signals when they get it right.
|
||||
|
||||
Similar, though, to presenting images to robots, workloads in the Decima system are mimicked until the system, through the receipt of AI reward signals, improves its decisions. A special kind of baselining (comparison to history) then helps Decima figure out which actions are good and which ones are bad, even when the workload sequences only supply poor reward signals due to the complication of the job structures slowing everything down. That baselining is a key differentiator in the MIT system.
|
||||
|
||||
“Decima can find opportunities for [scheduling] optimization that are simply too onerous to realize via manual design/tuning processes,” says Aditya Akella, a professor at University of Wisconsin at Madison, in the MIT article. The team there has developed a number of high-performance schedulers. “Decima can go a step further,” Akella says.
|
||||
|
||||
Join the Network World communities on [Facebook][3] and [LinkedIn][4] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3434597/data-center-specific-ai-completes-tasks-twice-as-fast.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://news.mit.edu/2019/decima-data-processing-0821
|
||||
[2]: https://www.networkworld.com/article/3274654/ai-boosts-data-center-availability-efficiency.html
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Rating IoT devices to gauge their impact on your network)
|
||||
[#]: via: (https://www.networkworld.com/article/3435136/rating-iot-devices-to-gauge-their-impact-on-your-network.html)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
Rating IoT devices to gauge their impact on your network
|
||||
======
|
||||
With the wide range of internet of things devices being connected to business networks, there’s no cookie-cutter solution to building networks to support them, but assessing their needs can help.
|
||||
Natalya Burova / Getty Images
|
||||
|
||||
One difficulty designing [IoT][1] implementations is the large number of moving parts. Most IoT setups are built out of components from many different manufacturers – one company’s sensors here, another’s there, someone else handling the networking and someone else again making the backend.
|
||||
|
||||
To help you get a ballpark sense of what any given implementation will demand from your network, we’ve come up with a basic taxonomy for rating IoT endpoints. It’s got three main axes: delay tolerance, data throughput and processing power. Here is an explainer for each. (Terminology note: We’ll use “IoT setup” or “IoT implementation” to refer to the entirety of the IoT infrastructure being used by a given organization.)
|
||||
|
||||
**Learn about edge networking**
|
||||
|
||||
* [How edge networking and IoT will reshape data centers][2]
|
||||
* [Edge computing best practices][3]
|
||||
* [How edge computing can help secure the IoT][4]
|
||||
|
||||
|
||||
|
||||
### Delay tolerance
|
||||
|
||||
Many IoT implementation don’t require the millisecond-scale delay tolerance that traditional enterprise networks can provide, so that opens up a lot of network-connectivity options and means that going for a lower-priced choice could prove very successful.
|
||||
|
||||
For example, a connected parking meter doesn’t need to report its status to the city more than once a minute or so (if that), so a delay-inducing wireless option like [LoRaWAN][5] might be perfectly acceptable. Some systems of that type even use standard cellular SMS services to send updates back to central hubs.
|
||||
|
||||
For less delay-tolerant applications, like a production line or oil and gas extraction, industrial Ethernet or particularly low-latency wireless links should be used. Older-generation orchestration systems usually have the actual handling of instructions and coordination between machines well in hand, but adding real-time analytics data to the mix can increase network demands.
|
||||
|
||||
### Data throughput
|
||||
|
||||
Again, networking pros used to dealing with nothing less than megabits per second should adjust their expectations here, as there are plenty of IoT devices that require as little as a few kilobits per second or even less.
|
||||
|
||||
Devices with low-bandwidth requirements include smart-building devices such as connected door locks and light switches that mostly say “open” or “closed” or “on” or “off.”
|
||||
|
||||
Fewer demands on a given data link opens up the possibility of using less-capable wireless technology. Low-power WAN and Sigfox might not have the bandwidth to handle large amounts of traffic, but they are well suited for connections that don’t need to move large amounts of data in the first place, and they can cover significant areas. The range of Sigfox is 3 to 50 km depending on the terrain, and for Bluetooth, it’s 100 meters to 1,000 meters, depending on the class of Bluetooth being used.
|
||||
|
||||
Conversely, an IoT setup such as multiple security cameras connected to a central hub to a backend for image analysis will require many times more bandwidth. In such a case the networking piece of the puzzle will have to be more capable and, consequently, more expensive. Widely distributed devices could demand a dedicated [LTE][6] connection, for example, or perhaps even a microcell of their own for coverage.
|
||||
|
||||
Network World / IDG
|
||||
|
||||
### Processing power
|
||||
|
||||
The degree to which an IoT device is capable of doing its own processing is a somewhat indirect measurement of its impact on your network, to be sure, but it’s still relevant in terms of comparing it to other devices that perform a similar function. A device that’s constantly streaming raw data onto the network, without performing any meaningful analysis or shaping of its own, can be a bigger traffic burden than one that’s doing at least some of the work.
|
||||
|
||||
That’s not always the case, of course. Many less-capable devices won’t generate a lot of data with which to clog up whatever network connection they have, while some more-capable ones (let’s say industrial robots with a lot of inbuilt power to processing data they collect) might still generate plenty of traffic.
|
||||
|
||||
But the onboard computing power of a device is still relevant when comparing it to others that perform similar jobs, particularly in sectors like manufacturing and energy extraction where a lot of analysis has to be performed somewhere, whether it’s on the device, at the edge or at the back end.
|
||||
|
||||
It’s even more relevant in the context of an edge setup, where some or all of the data analysis is done on an [edge-gateway device][7] located close to the endpoints. These gateways can be a good choice when fairly complicated analysis has to be performed as close to real-time as possible. But edge gateways don’t have the same resources available as a full-on [data center][8] or cloud so the amount of work that can be done on the endpoint itself remains a crucial concern. Synthesizing raw information into analysis can mean less traffic that has to go on the network.
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3435136/rating-iot-devices-to-gauge-their-impact-on-your-network.html
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
|
||||
[2]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[3]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
|
||||
[4]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
|
||||
[5]: https://www.networkworld.com/article/3235124/internet-of-things-definitions-a-handy-guide-to-essential-iot-terms.html
|
||||
[6]: https://www.networkworld.com/article/3432938/when-private-lte-is-better-than-wi-fi.html
|
||||
[7]: https://www.networkworld.com/article/3327197/edge-gateways-flexible-rugged-iot-enablers.html
|
||||
[8]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (SparkFun continues to innovate thanks to open source hardware)
|
||||
[#]: via: (https://opensource.com/article/19/8/sparkfun-creator-nathan-seidle)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
SparkFun continues to innovate thanks to open source hardware
|
||||
======
|
||||
SparkFun founder Nathan Seidle says companies built around patents
|
||||
become "intellectually unfit" to innovate. Artemis, his new
|
||||
microprocessor for low-power devices, is just one example of the
|
||||
company's nimbleness.
|
||||
![SparkFun Redboard with Artemis][1]
|
||||
|
||||
When [SparkFun Electronics][2] founder and CEO Nathan Seidle was an engineering student at the University of Colorado, he was taught, "Real engineers come up with an idea and patent that idea." However, his experience with SparkFun, which he founded from his college apartment in 2003, is quite the opposite.
|
||||
|
||||
All 600 "SparkFun original" components are for sale on the site in addition to 1000+ resell products. All of the company's schematics and code are licensed under [CC BY-SA][3], with some firmware [CC0][4], and its design files are available on [public GitHub repos][5]. In addition, some of the company's designs are Open Source Hardware Association ([OSHWA][6]) certified.
|
||||
|
||||
Contrary to his college professor's lesson, Nathan sees patents as an anachronism that provide no guarantees to the companies and individuals who hold them. As he explained in a 2013 [TEDx Boulder talk][7], "If your idea can be sold, it will be," even if you have a patent.
|
||||
|
||||
"When a company relies too much on their intellectual property, they become intellectually unfit—they suffer from IP obesity," he says. "There have been numerous companies in history that have had long periods of prosperity only to be quickly left behind when technology shifted. Cloners are going to clone regardless of your business plan."
|
||||
|
||||
### Openness leads to innovation
|
||||
|
||||
Nathan says building a business on open hardware enables companies like SparkFun to innovate faster than those that are more concerned with defending their patents than developing new ideas.
|
||||
|
||||
Nathan says, "At the end of the day, by not relying on IP and patents, we've gotten stronger, more nimble, and built a more enduring business because of open source hardware." Nathan and SparkFun's 100 employees would rather spend their time innovating than litigating, he says.
|
||||
|
||||
His latest innovation is [Artemis][8], a new type of microprocessor module and the most complex thing he has ever designed.
|
||||
|
||||
![SparkFun and Artemis][9]
|
||||
|
||||
He hopes Artemis will enable users to design consumer-grade products and run anything from an Arduino sketch down to a bare-metal model for voice recognition.
|
||||
|
||||
"The Apollo 3 [integrated circuit] that powers Artemis is exceptionally powerful but also mind-bogglingly low power," he says. "At 0.5mA at 48MHz, it really changes the way you think about microcontrollers and low-power devices. Combine that low power with the push by Google to deploy TensorFlow light onto Artemis, and you've got the potential for battery-powered devices that can run machine learning algorithms for weeks on a single coin cell. It's all a bit mind-bending. We created a custom Arduino port from scratch in order to allow users to program Artemis with Arduino but not be limited to any toolchain."
|
||||
|
||||
### Building a sustainable business on open hardware
|
||||
|
||||
Because all of SparkFun's designs and hardware are open source, anyone can take the source files and copy, modify, sell, or do anything they like with them. SparkFun appreciates that people can take its innovations and use them in even more innovative ways, he says.
|
||||
|
||||
"Where many companies bury or open-wash themselves with the 'open source' banner, we like to brag we're two clicks away from the source files: a link on the product page will take you to the repo where you can immediately clone the repo and begin benefiting from our designs," Nathan says.
|
||||
|
||||
You may be wondering how a company can survive when everything is open and available. Nathan believes that open source is more than sustainable. He says it is a necessity given the rapid pace of change. A culture of sharing and openness can mitigate a lot of problems that more closed companies suffer. He says, "We need to avoid the mistakes that others have made, and the only way to do that is to talk openly and share in our mistakes."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/sparkfun-creator-nathan-seidle
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/sparkfun_redboard_artemis.jpg?itok=XGRU-VUF (SparkFun Redboard with Artemis)
|
||||
[2]: https://www.sparkfun.com/
|
||||
[3]: https://creativecommons.org/licenses/by-sa/2.0/
|
||||
[4]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[5]: https://github.com/sparkfun
|
||||
[6]: https://www.oshwa.org/
|
||||
[7]: https://www.youtube.com/watch?v=xGhj_lLNtd0
|
||||
[8]: https://www.sparkfun.com/artemis
|
||||
[9]: https://opensource.com/sites/default/files/uploads/sparkfun_artemis_module_-_low_power_machine_learning_ble_cortex-m4f.jpg (SparkFun and Artemis)
|
||||
@ -0,0 +1,107 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (11 surprising ways you use Linux every day)
|
||||
[#]: via: (https://opensource.com/article/19/8/everyday-tech-runs-linux)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkinshttps://opensource.com/users/rgb-eshttps://opensource.com/users/sethhttps://opensource.com/users/ansilvahttps://opensource.com/users/scottnesbitt)
|
||||
|
||||
11 surprising ways you use Linux every day
|
||||
======
|
||||
What technology runs on Linux? You might be astonished to know just how
|
||||
often you use Linux in your daily life.
|
||||
![Truck steering wheel and dash][1]
|
||||
|
||||
Linux runs almost everything these days, but many people are not aware of that. Some might be aware of Linux and might have heard that this operating system runs supercomputers. According to [Top500][2], Linux now powers the five-hundred fastest computers in the world. Go to their site and [search for "Linux"][3] to see the results for yourself.
|
||||
|
||||
### NASA runs on Linux
|
||||
|
||||
You might not be aware that Linux powers NASA. NASA’s [Pleiades][4] supercomputer runs Linux. The International Space Station [switched from Windows to Linux][5] six years ago due to the operating system's reliability. NASA even recently deployed three "Astrobee" robots—which [run Linux][6]—to the International Space Station.
|
||||
|
||||
### eReaders run on Linux
|
||||
|
||||
I read a great deal, and my go-to device is the Amazon Kindle Paperwhite, which runs Linux (though most people are completely unaware of that fact). If you use any of Amazon’s services—from [Amazon Elastic Compute Cloud (Amazon EC2)][7] to Fire TV—you are running on Linux. When you ask Alexa what time it is, or for the score of your favorite sports team, you are also using Linux, since Alexa is powered by [Fire OS][8] (an Android-based operating system). In fact, [Android][9] was developed by Google as Linux for mobile handsets, and [powers 76%][10] of today’s mobile phones.
|
||||
|
||||
### TV runs on Linux
|
||||
|
||||
If you have a [TiVo][11], you are also running Linux. If you are a Roku user, then you too are using Linux. [Roku OS][12] is a custom version of Linux specifically for Roku devices. You may opt to use Chromecast—which runs on Linux—for video streaming. Linux doesn’t just power set-top boxes and streaming devices, though. It likely runs your smart TV, too. LG uses webOS, which is based on the Linux kernel. Panasonic uses Firefox OS, which is also based on the Linux kernel. Samsung, Phillips, and many more use Linux-based operating systems to power their devices.
|
||||
|
||||
### Smartwatches and laptops run on Linux
|
||||
|
||||
If you own a smartwatch, it’s likely running Linux. School systems throughout the world have been implementing [one-to-one systems][13] where each child is provided their own laptop. A rapidly increasing number of those institutions outfit their students with a Chromebook. These lightweight laptops use [Chrome OS][14], which is based on Linux.
|
||||
|
||||
### Cars run on Linux
|
||||
|
||||
The car you drive might well be running Linux. [Automotive-Grade Linux][15] has enlisted manufacturers like Toyota, Mazda, Mercedes-Benz, and Volkswagen in a project that will see Linux as the standard code base for automobiles. It is also likely that your [in-vehicle infotainment][16] system runs Linux. The [GENIVI Alliance][17] develops "standard approaches for integrating operating systems and middleware present in the centralized and connected vehicle cockpit," according to its website.
|
||||
|
||||
### Gaming runs on Linux
|
||||
|
||||
If you are a gamer, then you might be using [SteamOS][18], which is a Linux-based operating system. Also, if you use any of Google’s myriad of services, then you are running on Linux.
|
||||
|
||||
### Social media runs on Linux
|
||||
|
||||
As you're scrolling and commenting, you may realize what a lot of work these platforms are doing. Perhaps then it's not so surprising that Instagram, Facebook, YouTube, and Twitter all run on Linux.
|
||||
|
||||
Additionally, the new wave of social media, de-centralized, federated nodes of connected communities like [Mastodon][19], [GNU Social][20], [Nextcloud][21] (microblogging platforms similar to Twitter), [Pixelfed][22] (distributed photo sharing), and [Peertube][23] (distributed video sharing) are, at least by default, run on Linux. Being open source, they can each run on any platform, which is a powerful precedence in itself.
|
||||
|
||||
### Businesses and governments run on Linux
|
||||
|
||||
The New York Stock Exchange runs on Linux, as does the Pentagon. The Federal Aviation Administration handles over sixteen million flights a year, and they operate on Linux. The Library of Congress, House of Representatives, Senate, and White House all use Linux.
|
||||
|
||||
### Retail runs on Linux
|
||||
|
||||
That entertainment system in the seat back on your latest flight is likely running on Linux. It’s possible that the point of sale at your favorite store is running Linux. [Tizen OS][24], which is based on Linux, powers an array of smart home and other smart devices. Many public libraries now host their integrated library systems on [Evergreen][25] and [Koha][26]. Both of those systems run on Linux.
|
||||
|
||||
### Apple runs on Linux
|
||||
|
||||
If you are an iOS user who uses [iCloud][27], then you, too, are using a system that runs on Linux. Apple Computer’s company website runs on Linux. If you would like to know what other websites are run on Linux, be sure to use [Netcraft][28] and check the results of "What’s that site running?"
|
||||
|
||||
### Routers run on Linux
|
||||
|
||||
It is possible that the router that connects you to the internet in your home is running Linux. If your current router is _not_ running Linux and you would like to change that, here is an [excellent how-to][29].
|
||||
|
||||
_As you can see, in many ways, Linux powers today’s world. What else might people not realize runs on Linux? Let us know in the comments._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/everyday-tech-runs-linux
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkinshttps://opensource.com/users/rgb-eshttps://opensource.com/users/sethhttps://opensource.com/users/ansilvahttps://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/truck_steering_wheel_drive_car_kubernetes.jpg?itok=0TOzve80 (Truck steering wheel and dash)
|
||||
[2]: https://www.top500.org/
|
||||
[3]: https://www.top500.org/statistics/sublist/
|
||||
[4]: https://www.nas.nasa.gov/hecc/resources/pleiades.html
|
||||
[5]: https://www.extremetech.com/extreme/155392-international-space-station-switches-from-windows-to-linux-for-improved-reliability
|
||||
[6]: https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20180003515.pdf
|
||||
[7]: https://aws.amazon.com/amazon-linux-ami/
|
||||
[8]: https://en.wikipedia.org/wiki/Fire_OS
|
||||
[9]: https://en.wikipedia.org/wiki/Android_(operating_system)
|
||||
[10]: https://gs.statcounter.com/os-market-share/mobile/worldwide/
|
||||
[11]: https://tivo.pactsafe.io/legal.html#open-source-software
|
||||
[12]: https://en.wikipedia.org/wiki/Roku
|
||||
[13]: https://en.wikipedia.org/wiki/One-to-one_computing
|
||||
[14]: https://en.wikipedia.org/wiki/Chrome_OS
|
||||
[15]: https://opensource.com/life/16/8/agl-provides-common-open-code-base
|
||||
[16]: https://opensource.com/business/16/5/interview-alison-chaiken-steven-crumb
|
||||
[17]: https://www.genivi.org/faq
|
||||
[18]: https://store.steampowered.com/steamos/
|
||||
[19]: https://opensource.com/article/17/4/guide-to-mastodon
|
||||
[20]: https://www.gnu.org/software/social/
|
||||
[21]: https://apps.nextcloud.com/apps/social
|
||||
[22]: https://pixelfed.org/
|
||||
[23]: https://joinpeertube.org/en/
|
||||
[24]: https://wiki.tizen.org/Devices
|
||||
[25]: https://evergreen-ils.org/
|
||||
[26]: https://koha-community.org/
|
||||
[27]: https://toolbar.netcraft.com/site_report?url=https://www.icloud.com/
|
||||
[28]: https://www.netcraft.com/
|
||||
[29]: https://opensource.com/life/16/6/why-i-built-my-own-linux-router
|
||||
94
sources/talk/20190830 7 rules for remote-work sanity.md
Normal file
94
sources/talk/20190830 7 rules for remote-work sanity.md
Normal file
@ -0,0 +1,94 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (7 rules for remote-work sanity)
|
||||
[#]: via: (https://opensource.com/article/19/8/rules-remote-work-sanity)
|
||||
[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
|
||||
|
||||
7 rules for remote-work sanity
|
||||
======
|
||||
These rules don't describe my complete practice, but they are an
|
||||
important summary of what I try to do and what keeps me (relatively)
|
||||
sane.
|
||||
![Coding on a computer][1]
|
||||
|
||||
I work remotely and have done so on and off for a good percentage of the past 10 to 15 years. I'm lucky that I'm in a role where this suits my responsibilities, and in a company that is set up for it. Not all roles—those with many customer onsite meetings or those with a major service component—are suited to remote working, of course. But it's clear that an increasing number of organisations are considering having at least some of their workers doing so remotely.
|
||||
|
||||
I've carefully avoided using the phrase either "working from home" or "working at home" above. I've seen discussions that the latter gives a better "vibe" for some reason, but it's not accurate for many remote workers. In fact, it doesn't describe my role perfectly, either. My role is remote, in that I have no company-provided "base"—with a chair, desk, meeting rooms, phone, internet access, etc.—but I don't spend all of my time at home. I spend maybe one-and-a-half weeks a month, on average, travelling—to attend or speak at conferences, to have face-to-face ("F2F") meetings, etc. During these times, I'm generally expected to be contactable and to keep at least vaguely up-to-date on email—although the exact nature of the activities in which I'm engaged, and the urgency of the contacts and email, may increase or reduce my engagement.
|
||||
|
||||
### Open source
|
||||
|
||||
One of the reasons I can work remotely is that I work for a company that works with open source software. I'm currently involved in a very exciting project called [Enarx][2] (which I [announced][3] in May). We have contributors in Europe and the US and interest from further abroad. Our stand-ups are all virtual, and we default to turning on video. At least two of our regulars participate from a treadmill, I will typically stand at my desk. We use GitHub for all our code (it's all open source, of course), and there's basically no reason for us to meet in person very often. We try to celebrate together—agreeing to get cake, wherever we are, to mark special occasions, for instance—and have laptop stickers to brand ourselves and help team unity. We have a shared chat and IRC channel and spend a lot of time communicating via different channels. We're still quite a small team, but it works for now.
|
||||
|
||||
If you're looking for more tips about how to manage, coordinate, and work in remote teams, particularly around open source projects, you'll find lots of [information][4] online.
|
||||
|
||||
### The environment
|
||||
|
||||
When I'm not travelling around the place, I'm based at home. There, I have a commute—depending on weather conditions—of around 30-45 seconds, which is generally pretty bearable. My office is separate from the rest of the house (set in the garden) and outfitted with an office chair, desk, laptop dock, monitor, webcam, phone, keyboard, and printer; these are the obvious work-related items in the room.
|
||||
|
||||
Equally important, however, are the other accoutrements that make for a good working environment. These will vary from person to person, but I also have:
|
||||
|
||||
* A Sonos attached to an amplifier and good speakers
|
||||
* A sofa, often occupied by my dog and sometimes one of the cats
|
||||
* A bookshelf where the books that aren't littering the floor reside
|
||||
* Tea-making facilities (I'm British; this is important)
|
||||
* A fridge filled with milk (for the tea), beer, and wine (don't worry: I don't drink these during work hours, and it's more that the fridge is good for "overflow" from our main kitchen one)
|
||||
* Wide-opening windows and blinds for the summer (we have no air-conditioning; I'm British, remember?)
|
||||
* Underfloor heating _and_ a wood-burning stove for the winter (the former to keep the room above freezing until I get the latter warmed up)
|
||||
* A "[NUC][5]" computer and monitor for activities that aren't specifically work-related
|
||||
* A few spiders
|
||||
|
||||
|
||||
|
||||
What you have will depend on your work style, but these "non-work" items are important (bar the spiders, possibly) to my comfort and work practice. For instance, I often like to listen to music to help me concentrate; I often sit on the sofa with the dog and cats to read long documents; and without the fridge and tea-making facilities, I might as well be American.[1][6]
|
||||
|
||||
### My rules
|
||||
|
||||
How does it work, then? Well, first of all, most of us like human contact from time to time. Some remote workers rent space in a shared work environment and work there most of the time; they prefer an office environment or don't have a dedicated space for working at home. Others will mainly work in coffee shops or on their boat,[2][7] or they may spend half of the year in the office and the other half working from a second home. Whatever you do, finding something that works for you is important. Here's what I tend to do, and why:
|
||||
|
||||
1. **I try to have fairly rigid work hours.** Officially (and as advertised on our intranet for the information of colleagues), I work 10am-6pm UK time. This gives me a good overlap with the US (where many of my colleagues are based) and time in the morning to go for a run or a cycle and/or to walk the dog (see below). I don't always manage these times, but when I flex outward in one direction, I attempt to pull some time back the other way, as otherwise I know I'll just work ridiculous hours.
|
||||
2. **I ensure that I get up and have a cup of tea.** In an office environment, I would typically be interrupted from time to time by conversations, invitations to get tea, physical meetings in meeting rooms, lunch trips, etc. This doesn't happen at home, so it's important to keep moving, or you'll be stuck at your desk frequently for three to four hours at a time. This isn't good for your health or often for your productivity (and I enjoy drinking tea).
|
||||
3. **I have an app that tells me when I've been inactive.** This is new for me, but I like it. If I've basically not moved for an hour, my watch (could be a phone or laptop) tells me to do some exercise. It even suggests something, but I'll often ignore that and get up for some tea, for instance.[3][8]
|
||||
4. **I use my standing desk's up/down capability.** I try to vary my position through the day from standing to sitting and back again. It's good for posture and keeps me more alert.
|
||||
5. **I walk the dog.** If I need to get out of my office and do some deep thinking (or just escape a particularly painful email thread!), I'll take the dog for a walk. Even if I'm not thinking about work for the entire time, I know it'll make me more productive, and if it's a longish walk, I'll make sure I compensate by spending extra time working (which is always easy).
|
||||
6. **I have family rules.** The family knows that when I'm in my office, I'm at work. They can message me on my phone (which I may ignore) or may come to the window to see if I'm available, but if I'm not, I'm not. Emergencies (lack of milk for tea, for example) can be negotiated on a case-by-case basis.
|
||||
7. **I go for tea (and usually cake) at a cafe.** Sometimes, I need to get into a different environment and have a chat with actual people. For me, popping into the car for 10 minutes and going to a cafe is the way to do this. I've found one that makes good cakes (and tea).
|
||||
|
||||
|
||||
|
||||
These rules don't describe my complete practice, but they are an important summary of what I try to do and what keeps me (relatively) sane. Your rules will be different, but I think it's really important to _have_ rules and to make it clear to yourself, your colleagues, your friends, and your family what they are. Remote working is not always easy and requires discipline—but that discipline, more often than not, is in giving yourself some slack, rather than making yourself sit down for eight hours a day.
|
||||
|
||||
* * *
|
||||
|
||||
1\. I realise that many people, including many of my readers, are American. That's fine: you be you. I actively _like_ tea, however (and know how to make it properly, which seems to be an issue when I visit the US).
|
||||
2\. I know a couple of these: lucky, lucky people!
|
||||
3\. Can you spot a pattern?
|
||||
|
||||
* * *
|
||||
|
||||
_This article was originally published on [Alice, Eve, and Bob][9] and is reprinted with the author's permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/rules-remote-work-sanity
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mikecamel
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
|
||||
[2]: https://enarx.io/
|
||||
[3]: https://opensource.com/article/19/5/enarx-security
|
||||
[4]: https://opensource.com/sitewide-search?search_api_views_fulltext=remote%20work
|
||||
[5]: https://en.wikipedia.org/wiki/Next_Unit_of_Computing
|
||||
[6]: tmp.S5SfsQZWG4#1
|
||||
[7]: tmp.S5SfsQZWG4#2
|
||||
[8]: tmp.S5SfsQZWG4#3
|
||||
[9]: https://aliceevebob.com/2019/08/13/my-7-rules-for-remote-work-sanity/
|
||||
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bluetooth finds a role in the industrial internet of things)
|
||||
[#]: via: (https://www.networkworld.com/article/3434526/bluetooth-finds-a-role-in-the-industrial-internet-of-things.html)
|
||||
[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
|
||||
|
||||
Bluetooth finds a role in the industrial internet of things
|
||||
======
|
||||
Market awareness and penetration, plus new technological advancements, are making Bluetooth—yes, Bluetooth—a key networking technology for the IIoT.
|
||||
Michael Brown / IDG
|
||||
|
||||
Like most people, I think of Bluetooth as a useful but consumer-oriented technology that lets me make easy wireless connections from my smartphone to various headsets, portable speakers, automobile, and other devices. And, of course, billions of people rely on Bluetooth for exactly those capabilities. But according to [Chuck Sabin][1], senior director of market development for the [Bluetooth SIG][2], the technology is growing into a key role in the industrial internet of things (IIoT).
|
||||
|
||||
Sabin says, Bluetooth “technology is actually well-suited for both consumer and enterprise markets.” He cites Bluetooth’s easy-to-implement low-power connections. More importantly, though, Bluetooth is ubiquitous, enjoying 90% global awareness and global, multi-vendor interoperability.
|
||||
|
||||
Bluetooth offers low deployment costs and massive economies of scale because it’s already built into virtually every new smartphone, tablet, and personal computer, not to mention a wide variety of wearables, smart speakers, and other devices, notes Sabin. That means IIoT deployments leveraging Bluetooth may be able to avoid having to build a completely proprietary solution to start using wireless systems in smart-building and smart-industry environments.
|
||||
|
||||
**[ Learn more [Download a PDF bundle of five essential articles about IoT in the enterprise][3] ]**
|
||||
|
||||
### 3 things driving Bluetooth adoption in IIoT?
|
||||
|
||||
In addition to Bluetooth’s deep market penetration, Sabin cites three notable technical advancements that are driving Bluetooth adoption in industrial and enterprise IoT applications:
|
||||
|
||||
1. **“The introduction of [Bluetooth 5][4] in 2016 was all about flexibility,”** Sabin explains. Bluetooth 5’s longer range and higher speeds provide the crucial flexibility necessary to support more reliable connections in a wide variety of large, noisy environments, like those of industrial or commercial spaces. For example, Sabin says, “a warehouse is a much different environment than the basement of a nuclear power plant. One is open and requires long-range connections, and the other is a more complex environment with a lot of interference, requiring a reliable connection or device network that can deliver information despite the noise.”
|
||||
|
||||
2. **[Bluetooth mesh][5], released In July of 2017, extends the [Bluetooth Core Specification][6] to enable “industrial-grade” many-to-many communication,** Sabin says, where tens, hundreds, and even thousands of devices can reliably and securely communicate with one another. “Bluetooth mesh networks are ideally suited for control, monitoring, and automation systems,” Sabin claims, and can also reduce latency and improve security.
|
||||
|
||||
3. **More recently, the Bluetooth SIG announced a new [direction-finding feature][7]** **for Bluetooth,** bringing even greater precision to location-services systems used in industrial and enterprise settings. [Bluetooth low energy][8] introduced the ability to roughly determine the location of a Bluetooth device by comparing signal strength between the device being located and the tracking device, at what Sabin calls a “fairly broad—“the device is in this room”—level of accuracy. This led to inexpensive, mass-market indoor location and asset tracking solutions.
|
||||
|
||||
The new direction-finding feature makes this much more precise: “Not only is the device in a specific room, but it’s in the back, left corner,” he says. And the Bluetooth SIG is working to add distance to this feature, so users will know whether “the device is in this specific room, in the back, left the corner, and 30 feet from me right now.” This level of precision will enable new applications, including monitoring for safety and security, Sabin says: for example, helping keep workers out of a toxic environment.
|
||||
|
||||
|
||||
|
||||
|
||||
### IioT Bluetooth use cases
|
||||
|
||||
Put all those developments together, and you enable device networks, Sabin says, where interconnected networks of devices are used to control lighting systems, sensor networks, and asset management solutions.
|
||||
|
||||
The Bluetooth SIG divides smart buildings and smart industry into three primary categories:
|
||||
|
||||
1. **Building automation:** The centralized automation of a factory’s essential systems—including lighting, heating, ventilation, and air conditioning (HVAC) and security—which can help conserve energy, lower operating costs, and improve the life cycle of a building’s core systems.
|
||||
2. **Condition monitoring:** Bluetooth sensor networks deployed across a factory floor or throughout an office building enable real-time monitoring of system performance to make maintenance, updating, and overall management more efficient.
|
||||
3. **Location services:** This can take on many forms, from wayfinding to asset tracking/management to indoor positioning and location and logistics solutions.
|
||||
|
||||
|
||||
|
||||
Use cases in manufacturing include helping manufacturers better monitor location, availability, and condition of equipment and output across the supply chain, Sabin says. Using enterprise wearables is helping manufacturers improve material management and process flow. Bluetooth location services are employing beacons to boost safety and security in chemical and manufacturing plants by creating geo-fences for restricted access and tracking numbers of employees in critical areas.
|
||||
|
||||
**[ [Take this mobile device management course from PluralSight and learn how to secure devices in your company without degrading the user experience.][9] ]**
|
||||
|
||||
Bluetooth Mesh was actually designed with connected lighting in mind, Sabin says, enabling everything from connected lighting in building automation to what he called [Lighting-as-a Platform (LaaP)][10] for deploying these services.
|
||||
|
||||
### Fast growth for Bluetooth in the IIoT
|
||||
|
||||
Based on these trends and advancements, the Bluetooth SIG’s recent [Bluetooth Market Update][11] predicts a 7x growth in annual shipments of Bluetooth smart-building location services devices by 2023, with 374 million Bluetooth smart-building devices shipping that year. The update also sees a 5x growth in annual shipments of Bluetooth smart-industry devices by 2023. These shipments are growing at of 47% a year, Sabin says, and will account for 70% of market shipments in 2023. The report also forecasts a 3.5x increase in shipments of Bluetooth enterprise wearables for smart industry use cases by 2023, with a 28% annual growth rate over the next five years.
|
||||
|
||||
That’s only if everything goes as planned, of course. Sabin warns that industrial and enterprise organizations often adopt new technology relatively slowly, looking for clear ROIs that may not always be fully fleshed out for new technologies. And, yes, no doubt some decision makers still think of Bluetooth as a short-range, point-to-point, consumer-grade technology not ready for enterprise and industrial environments.
|
||||
|
||||
**More about IoT:**
|
||||
|
||||
* [What is the IoT? How the internet of things works][12]
|
||||
* [What is edge computing and how it’s changing the network][13]
|
||||
* [Most powerful Internet of Things companies][14]
|
||||
* [10 Hot IoT startups to watch][15]
|
||||
* [The 6 ways to make money in IoT][16]
|
||||
* [What is digital twin technology? [and why it matters]][17]
|
||||
* [Blockchain, service-centric networking key to IoT success][18]
|
||||
* [Getting grounded in IoT networking and security][3]
|
||||
* [Building IoT-ready networks must become a priority][19]
|
||||
* [What is the Industrial IoT? [And why the stakes are so high]][20]
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][21] and [LinkedIn][22] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3434526/bluetooth-finds-a-role-in-the-industrial-internet-of-things.html
|
||||
|
||||
作者:[Fredric Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Fredric-Paul/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linkedin.com/in/chucksabin/
|
||||
[2]: https://www.bluetooth.com/about-us/
|
||||
[3]: https://www.networkworld.com/article/3269736/internet-of-things/getting-grounded-in-iot-networking-and-security.html
|
||||
[4]: https://www.bluetooth.com/bluetooth-resources/bluetooth-5-go-faster-go-further/
|
||||
[5]: https://www.bluetooth.com/media/mesh-kit/
|
||||
[6]: https://www.bluetooth.com/specifications/bluetooth-core-specification/
|
||||
[7]: https://www.bluetooth.com/media/location-services/
|
||||
[8]: https://en.wikipedia.org/wiki/Bluetooth_Low_Energy
|
||||
[9]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
|
||||
[10]: https://www.bluetooth.com/blog/lighting-as-a-platform-part-1/
|
||||
[11]: https://www.bluetooth.com/bluetooth-resources/2019-bluetooth-market-update/?utm_campaign=bmu&utm_source=internal&utm_medium=pr&utm_content=2019bmu-pr-outreach-ink
|
||||
[12]: https://www.networkworld.com/article/3207535/internet-of-things/what-is-the-iot-how-the-internet-of-things-works.html
|
||||
[13]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
|
||||
[14]: https://www.networkworld.com/article/2287045/internet-of-things/wireless-153629-10-most-powerful-internet-of-things-companies.html
|
||||
[15]: https://www.networkworld.com/article/3270961/internet-of-things/10-hot-iot-startups-to-watch.html
|
||||
[16]: https://www.networkworld.com/article/3279346/internet-of-things/the-6-ways-to-make-money-in-iot.html
|
||||
[17]: https://www.networkworld.com/article/3280225/internet-of-things/what-is-digital-twin-technology-and-why-it-matters.html
|
||||
[18]: https://www.networkworld.com/article/3276313/internet-of-things/blockchain-service-centric-networking-key-to-iot-success.html
|
||||
[19]: https://www.networkworld.com/article/3276304/internet-of-things/building-iot-ready-networks-must-become-a-priority.html
|
||||
[20]: https://www.networkworld.com/article/3243928/internet-of-things/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html
|
||||
[21]: https://www.facebook.com/NetworkWorld/
|
||||
[22]: https://www.linkedin.com/company/network-world
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by robsean
|
||||
Top 5 CAD Software Available for Linux in 2018
|
||||
======
|
||||
[Computer Aided Design (CAD)][1] is an essential part of many streams of engineering. CAD is professionally used is architecture, auto parts design, space shuttle research, aeronautics, bridge construction, interior design, and even clothing and jewelry.
|
||||
|
||||
@ -1,156 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Install VirtualBox on Ubuntu [Beginner’s Tutorial])
|
||||
[#]: via: (https://itsfoss.com/install-virtualbox-ubuntu)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to Install VirtualBox on Ubuntu [Beginner’s Tutorial]
|
||||
======
|
||||
|
||||
**This beginner’s tutorial explains various ways to install VirtualBox on Ubuntu and other Debian-based Linux distributions.**
|
||||
|
||||
Oracle’s free and open source offering [VirtualBox][1] is an excellent virtualization tool, specially for desktop operating systems. I prefer using it over [VMWare Workstation in Linux][2], another virtualization tool.
|
||||
|
||||
You can use virtualization software like VirtualBox for installing and using another operating system within a virtual machine.
|
||||
|
||||
For example, you can [install Linux on VirtualBox inside Windows][3]. Similarly, you can also [install Windows inside Linux using VirtualBox][4].
|
||||
|
||||
You can also use VirtualBox for installing another Linux distribution in your current Linux system. Actually, this is what I use it for. If I hear about a nice Linux distribution, instead of installing it on a real system, I test it on a virtual machine. It’s more convenient when you just want to try out a distribution before making a decision about installing it on your actual machine.
|
||||
|
||||
![Linux installed inside Linux using VirtualBox][5]Ubuntu 18.10 installed inside Ubuntu 18.04
|
||||
|
||||
In this beginner’s tutorial, I’ll show you various ways of installing Oracle VirtualBox on Ubuntu and other Debian-based distributions.
|
||||
|
||||
### Installing VirtualBox on Ubuntu and Debian based Linux distributions
|
||||
|
||||
The installation methods mentioned here should also work for other Debian and Ubuntu-based Linux distributions such as Linux Mint, elementary OS etc.
|
||||
|
||||
#### Method 1: Install VirtualBox from Ubuntu Repository
|
||||
|
||||
**Pros** : Easy installation
|
||||
|
||||
**Cons** : Installs older version
|
||||
|
||||
The easiest way to install VirtualBox on Ubuntu would be to search for it in the Software Center and install it from there.
|
||||
|
||||
![VirtualBox in Ubuntu Software Center][6]VirtualBox is available in Ubuntu Software Center
|
||||
|
||||
You can also install it from the command line using the command:
|
||||
|
||||
```
|
||||
sudo apt install virtualbox
|
||||
```
|
||||
|
||||
However, if you [check the package version before installing it][7], you’ll see that the VirtualBox provided by Ubuntu’s repository is quite old.
|
||||
|
||||
For example, the current VirtualBox version at the time of writing this tutorial is 6.0 but the one in Software Center is 5.2. This means you won’t get the newer features introduced in the [latest version of VirtualBox][8].
|
||||
|
||||
#### Method 2: Install VirtualBox using Deb file from Oracle’s website
|
||||
|
||||
**Pros** : Easily install the latest version
|
||||
|
||||
**Cons** : Can’t upgrade to newer version
|
||||
|
||||
If you want to use the latest version of VirtualBox on Ubuntu, the easiest way would be to [use the deb file][9].
|
||||
|
||||
Oracle provides read to use binary files for VirtualBox releases. If you look at its download page, you’ll see the option to download the deb installer files for Ubuntu and other distributions.
|
||||
|
||||
![VirtualBox Linux Download][10]
|
||||
|
||||
You just have to download this deb file and double click on it to install it. It’s as simple as that.
|
||||
|
||||
However, the problem with this method is that you won’t get automatically updated to the newer VirtualBox releases. The only way is to remove the existing version, download the newer version and install it again. That’s not very convenient, is it?
|
||||
|
||||
#### Method 3: Install VirualBox using Oracle’s repository
|
||||
|
||||
**Pros** : Automatically updates with system updates
|
||||
|
||||
**Cons** : Slightly complicated installation
|
||||
|
||||
Now this is the command line method and it may seem complicated to you but it has advantages over the previous two methods. You’ll get the latest version of VirtualBox and it will be automatically updated to the future releases. That’s what you would want, I presume.
|
||||
|
||||
To install VirtualBox using command line, you add the Oracle VirtualBox’s repository in your list of repositories. You add its GPG key so that your system trusts this repository. Now when you install VirtualBox, it will be installed from Oracle’s repository instead of Ubuntu’s repository. If there is a new version released, VirtualBox install will be updated along with the system updates. Let’s see how to do that.
|
||||
|
||||
First, add the key for the repository. You can download and add the key using this single command.
|
||||
|
||||
```
|
||||
wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
|
||||
```
|
||||
|
||||
```
|
||||
Important for Mint users
|
||||
|
||||
The next step will work for Ubuntu only. If you are using Linux Mint or some other distribution based on Ubuntu, replace $(lsb_release -cs) in the command with the Ubuntu version your current version is based on. For example, Linux Mint 19 series users should use bionic and Mint 18 series users should use xenial. Something like this
|
||||
|
||||
sudo add-apt-repository “deb [arch=amd64] <http://download.virtualbox.org/virtualbox/debian> **bionic** contrib“
|
||||
```
|
||||
|
||||
Now add the Oracle VirtualBox repository in the list of repositories using this command:
|
||||
|
||||
```
|
||||
sudo add-apt-repository "deb [arch=amd64] http://download.virtualbox.org/virtualbox/debian $(lsb_release -cs) contrib"
|
||||
```
|
||||
|
||||
If you have read my article on [checking Ubuntu version][11], you probably know that ‘lsb_release -cs’ will print the codename of your Ubuntu system.
|
||||
|
||||
**Note** : If you see [add-apt-repository command not found][12] error, you’ll have to install software-properties-common package.
|
||||
|
||||
Now that you have the correct repository added, refresh the list of available packages through these repositories and install VirtualBox.
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt install virtualbox-6.0
|
||||
```
|
||||
|
||||
**Tip** : A good idea would be to type sudo apt install **virtualbox–** and hit tab to see the various VirtualBox versions available for installation and then select one of them by typing it completely.
|
||||
|
||||
![Install VirtualBox via terminal][13]
|
||||
|
||||
### How to remove VirtualBox from Ubuntu
|
||||
|
||||
Now that you have learned to install VirtualBox, I would also mention the steps to remove it.
|
||||
|
||||
If you installed it from the Software Center, the easiest way to remove the application is from the Software Center itself. You just have to find it in the [list of installed applications][14] and click the Remove button.
|
||||
|
||||
Another ways is to use the command line.
|
||||
|
||||
```
|
||||
sudo apt remove virtualbox virtualbox-*
|
||||
```
|
||||
|
||||
Note that this will not remove the virtual machines and the files associated with the operating systems you installed using VirtualBox. That’s not entirely a bad thing because you may want to keep them safe to use it later or in some other system.
|
||||
|
||||
**In the end…**
|
||||
|
||||
I hope you were able to pick one of the methods to install VirtualBox. I’ll also write about using it effectively in another article. For the moment, if you have and tips or suggestions or any questions, feel free to leave a comment below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-virtualbox-ubuntu
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.virtualbox.org
|
||||
[2]: https://itsfoss.com/install-vmware-player-ubuntu-1310/
|
||||
[3]: https://itsfoss.com/install-linux-in-virtualbox/
|
||||
[4]: https://itsfoss.com/install-windows-10-virtualbox-linux/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/linux-inside-linux-virtualbox.png?resize=800%2C450&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/virtualbox-ubuntu-software-center.jpg?ssl=1
|
||||
[7]: https://itsfoss.com/know-program-version-before-install-ubuntu/
|
||||
[8]: https://itsfoss.com/oracle-virtualbox-release/
|
||||
[9]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/virtualbox-download.jpg?resize=800%2C433&ssl=1
|
||||
[11]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[12]: https://itsfoss.com/add-apt-repository-command-not-found/
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/install-virtualbox-ubuntu-terminal.png?resize=800%2C165&ssl=1
|
||||
[14]: https://itsfoss.com/list-installed-packages-ubuntu/
|
||||
@ -1,245 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina)?)
|
||||
[#]: via: (https://www.2daygeek.com/upgrade-linux-mint-19-1-tessa-to-linux-mint-19-2-tina/)
|
||||
[#]: author: (2daygeek http://www.2daygeek.com/author/2daygeek/)
|
||||
|
||||
How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina)?
|
||||
======
|
||||
|
||||
Linux Mint 19.2 “Tina” was released on Aug 02nd 2019, it is a long term support release, which is based on Ubuntu 18.04 LTS (Bionic Beaver).
|
||||
|
||||
It will be supported until 2023. It comes with updated software and brings refinements and many new features to make your desktop even more comfortable to use.
|
||||
|
||||
Linux Mint 19.2 features with Cinnamon 4.2, Linux kernel 4.15, and Ubuntu 18.04 package base.
|
||||
|
||||
**`Note:`**` ` Don’t forget to take backup of your important data. If something goes wrong you can restore the data from the backup after fresh installation.
|
||||
|
||||
Backup can be done either rsnapshot or timeshift.
|
||||
|
||||
Linux Mint 19.2 “Tina” Release notes can be found in the following link.
|
||||
|
||||
* **[Linux Mint 19.2 (Tina) Release Notes][1]**
|
||||
|
||||
|
||||
|
||||
There are three ways that we can upgrade to Linux Mint 19.2 “Tina”.
|
||||
|
||||
* Upgrade Linux Mint 19.2 (Tina) Using Native Method
|
||||
* Upgrade Linux Mint 19.2 (Tina) Using Mintupgrade Utility
|
||||
* Upgrade Linux Mint 19.2 (Tina) Using GUI
|
||||
|
||||
|
||||
|
||||
### How to Perform The Upgrade from Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina)?
|
||||
|
||||
Upgrading the Linux Mint system is an easy and painless task. It can be done three ways.
|
||||
|
||||
### Method-1: Upgrade Linux Mint 19.2 (Tina) Using Native Method
|
||||
|
||||
This is one of the native and standard method to perform the upgrade for Linux Mint system.
|
||||
|
||||
To do so, follow the below procedures.
|
||||
|
||||
Make sure that your current Linux Mint system is up-to-date.
|
||||
|
||||
Update your existing software to latest available version using the following commands.
|
||||
|
||||
### Step-1:
|
||||
|
||||
Refresh the repositories index by running the following command.
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
Run the following command to install the available updates on system.
|
||||
|
||||
```
|
||||
$ sudo apt upgrade
|
||||
```
|
||||
|
||||
Run the following command to perform the available minor upgrade with in version.
|
||||
|
||||
```
|
||||
$ sudo apt full-upgrade
|
||||
```
|
||||
|
||||
By default, it will remove obsolete packages by running the above command. However, i advise you to run the below commands.
|
||||
|
||||
```
|
||||
$ sudo apt autoremove
|
||||
|
||||
$ sudo apt clean
|
||||
```
|
||||
|
||||
You may need to reboot the system, if a new kernel is installed. If so, run the following command.
|
||||
|
||||
```
|
||||
$ sudo shutdown -r now
|
||||
```
|
||||
|
||||
Finally check the currently installed version.
|
||||
|
||||
```
|
||||
$ lsb_release -a
|
||||
|
||||
No LSB modules are available.
|
||||
Distributor ID: Linux Mint
|
||||
Description: Linux Mint 19.1 (Tessa)
|
||||
Release: 19.1
|
||||
Codename: Tessa
|
||||
```
|
||||
|
||||
### Step-2: Update/Modify the /etc/apt/sources.list file
|
||||
|
||||
After reboot, modify the sources.list file and point from Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina).
|
||||
|
||||
First backup the below config files using the cp command.
|
||||
|
||||
```
|
||||
$ sudo cp /etc/apt/sources.list /root
|
||||
$ sudo cp -r /etc/apt/sources.list.d/ /root
|
||||
```
|
||||
|
||||
Modify the “sources.list” file and point to Linux Mint 19.1 (Tina).
|
||||
|
||||
```
|
||||
$ sudo sed -i 's/tessa/tina/g' /etc/apt/sources.list
|
||||
$ sudo sed -i 's/tessa/tina/g' /etc/apt/sources.list.d/*
|
||||
```
|
||||
|
||||
Refresh the repositories index by running the following command.
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
Run the following command to install the available updates on system. During the upgrade you may need to confirm for service restart and config file replace so, just follow on-screen instructions.
|
||||
|
||||
The upgrade may take some time depending on the number of updates and your Internet speed.
|
||||
|
||||
```
|
||||
$ sudo apt upgrade
|
||||
```
|
||||
|
||||
Run the following command to perform a complete upgrade of the system.
|
||||
|
||||
```
|
||||
$ sudo apt full-upgrade
|
||||
```
|
||||
|
||||
By default, the above command will remove obsolete packages. However, i advise you to run the below commands once again.
|
||||
|
||||
```
|
||||
$ sudo apt autoremove
|
||||
|
||||
$ sudo apt clean
|
||||
```
|
||||
|
||||
Finally reboot the system to boot with Linux Mint 19.2 (Tina).
|
||||
|
||||
```
|
||||
$ sudo shutdown -r now
|
||||
```
|
||||
|
||||
The upgraded Linux Mint version can be verified by running the following command.
|
||||
|
||||
```
|
||||
$ lsb_release -a
|
||||
|
||||
No LSB modules are available.
|
||||
Distributor ID: Linux Mint
|
||||
Description: Linux Mint 19.2 (Tina)
|
||||
Release: 19.2
|
||||
Codename: Tina
|
||||
```
|
||||
|
||||
### Method-2: Upgrade Linux Mint 19.2 (Tina) Using Mintupgrade Utility
|
||||
|
||||
This is Mint official utility that allow us to perform the smooth upgrade for Linux Mint system.
|
||||
|
||||
Use the below command to install mintupgrade package.
|
||||
|
||||
```
|
||||
$ sudo apt install mintupgrade
|
||||
```
|
||||
|
||||
Make sure you have installed the latest version of mintupgrade package.
|
||||
|
||||
```
|
||||
$ apt version mintupgrade
|
||||
```
|
||||
|
||||
Run the below command as a normal user to simulate an upgrade and follow on-screen instructions.
|
||||
|
||||
```
|
||||
$ mintupgrade check
|
||||
```
|
||||
|
||||
Use the below command to download the packages necessary to upgrade to Linux Mint 19.2 (Tina) and follow on screen instructions.
|
||||
|
||||
```
|
||||
$ mintupgrade download
|
||||
```
|
||||
|
||||
Run the following command to apply the upgrades and follow on-screen instructions.
|
||||
|
||||
```
|
||||
$ mintupgrade upgrade
|
||||
```
|
||||
|
||||
Once upgrade done successfully, Reboot the system and check the upgraded version.
|
||||
|
||||
```
|
||||
$ lsb_release -a
|
||||
|
||||
No LSB modules are available.
|
||||
Distributor ID: Linux Mint
|
||||
Description: Linux Mint 19.2 (Tina)
|
||||
Release: 19.2
|
||||
Codename: Tina
|
||||
```
|
||||
|
||||
### Method-3: Upgrade Linux Mint 19.2 (Tina) Using GUI
|
||||
|
||||
Alternatively, we can perform the upgrade through GUI.
|
||||
|
||||
### Step-1:
|
||||
|
||||
Create a system snapshot through Timeshift. If anything goes wrong, you can easily restore your operating system to its previous state.
|
||||
|
||||
### Step-2:
|
||||
|
||||
Open the Update Manager, click on the Refresh button to check for any new version of mintupdate and mint-upgrade-info. If there are updates for these packages, apply them.
|
||||
|
||||
Launch the System Upgrade by clicking on “Edit->Upgrade to Linux Mint 19.2 Tina”.
|
||||
[![][2]![][2]][3]
|
||||
|
||||
Follow the instructions on the screen. If asked whether to keep or replace configuration files, choose to replace them.
|
||||
[![][2]![][2]][4]
|
||||
|
||||
### Step-3:
|
||||
|
||||
Once the upgrade is finished, reboot your computer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/upgrade-linux-mint-19-1-tessa-to-linux-mint-19-2-tina/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.2daygeek.com/author/2daygeek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linuxtechnews.com/linux-mint-19-2-tina-released-check-what-is-new-feature/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2019/08/linux-mint-19-2-tina-mintupgrade.png
|
||||
[4]: https://www.2daygeek.com/wp-content/uploads/2019/08/linux-mint-19-2-tina-mintupgrade-1.png
|
||||
@ -1,240 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (0x996)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How Hexdump works)
|
||||
[#]: via: (https://opensource.com/article/19/8/dig-binary-files-hexdump)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/shishz)
|
||||
|
||||
How Hexdump works
|
||||
======
|
||||
Hexdump helps you investigate the contents of binary files. Learn how
|
||||
hexdump works.
|
||||
![Magnifying glass on code][1]
|
||||
|
||||
Hexdump is a utility that displays the contents of binary files in hexadecimal, decimal, octal, or ASCII. It’s a utility for inspection and can be used for [data recovery][2], reverse engineering, and programming.
|
||||
|
||||
### Learning the basics
|
||||
|
||||
Hexdump provides output with very little effort on your part and depending on the size of the file you’re looking at, there can be a lot of output. For the purpose of this article, create a 1x1 PNG file. You can do this with a graphics application such as [GIMP][3] or [Mtpaint][4], or you can create it in a terminal with [ImageMagick][5].
|
||||
|
||||
Here’s a command to generate a 1x1 pixel PNG with ImageMagick:
|
||||
|
||||
|
||||
```
|
||||
$ convert -size 1x1 canvas:black pixel.png
|
||||
```
|
||||
|
||||
You can confirm that this file is a PNG with the **file** command:
|
||||
|
||||
|
||||
```
|
||||
$ file pixel.png
|
||||
pixel.png: PNG image data, 1 x 1, 1-bit grayscale, non-interlaced
|
||||
```
|
||||
|
||||
You may wonder how the **file** command is able to determine what kind of file it is. Coincidentally, that’s what **hexdump** will reveal. For now, you can view your one-pixel graphic in the image viewer of your choice (it looks like this: **.** ), or you can view what’s inside the file with **hexdump**:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a 0000 0d00 4849 5244
|
||||
0000010 0000 0100 0000 0100 0001 0000 3700 f96e
|
||||
0000020 0024 0000 6704 4d41 0041 b100 0b8f 61fc
|
||||
0000030 0005 0000 6320 5248 004d 7a00 0026 8000
|
||||
0000040 0084 fa00 0000 8000 00e8 7500 0030 ea00
|
||||
0000050 0060 3a00 0098 1700 9c70 51ba 003c 0000
|
||||
0000060 6202 474b 0044 dd01 138a 00a4 0000 7407
|
||||
0000070 4d49 0745 07e3 081a 3539 a487 46b0 0000
|
||||
0000080 0a00 4449 5441 d708 6063 0000 0200 0100
|
||||
0000090 21e2 33bc 0000 2500 4574 7458 6164 6574
|
||||
00000a0 633a 6572 7461 0065 3032 3931 302d 2d37
|
||||
00000b0 3532 3254 3a30 3735 353a 2b33 3231 303a
|
||||
00000c0 ac30 5dcd 00c1 0000 7425 5845 6474 7461
|
||||
00000d0 3a65 6f6d 6964 7966 3200 3130 2d39 3730
|
||||
00000e0 322d 5435 3032 353a 3a37 3335 312b 3a32
|
||||
00000f0 3030 90dd 7de5 0000 0000 4549 444e 42ae
|
||||
0000100 8260
|
||||
0000102
|
||||
```
|
||||
|
||||
What you’re seeing is the contents of the sample PNG file through a lens you may have never used before. It’s the exact same data you see in an image viewer, encoded in a way that’s probably unfamiliar to you.
|
||||
|
||||
### Extracting familiar strings
|
||||
|
||||
Just because the default data dump seems meaningless, that doesn’t mean it’s devoid of valuable information. You can translate this output or at least the parts that actually translate, to a more familiar character set with the **\--canonical** option:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump --canonical foo.png
|
||||
00000000 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 |.PNG........IHDR|
|
||||
00000010 00 00 00 01 00 00 00 01 01 00 00 00 00 37 6e f9 |.............7n.|
|
||||
00000020 24 00 00 00 04 67 41 4d 41 00 00 b1 8f 0b fc 61 |$....gAMA......a|
|
||||
00000030 05 00 00 00 20 63 48 52 4d 00 00 7a 26 00 00 80 |.... cHRM..z&...|
|
||||
00000040 84 00 00 fa 00 00 00 80 e8 00 00 75 30 00 00 ea |...........u0...|
|
||||
00000050 60 00 00 3a 98 00 00 17 70 9c ba 51 3c 00 00 00 |`..:....p..Q<...|
|
||||
00000060 02 62 4b 47 44 00 01 dd 8a 13 a4 00 00 00 07 74 |.bKGD..........t|
|
||||
00000070 49 4d 45 07 e3 07 1a 08 39 35 87 a4 b0 46 00 00 |IME.....95...F..|
|
||||
00000080 00 0a 49 44 41 54 08 d7 63 60 00 00 00 02 00 01 |..IDAT..c`......|
|
||||
00000090 e2 21 bc 33 00 00 00 25 74 45 58 74 64 61 74 65 |.!.3...%tEXtdate|
|
||||
000000a0 3a 63 72 65 61 74 65 00 32 30 31 39 2d 30 37 2d |:create.2019-07-|
|
||||
000000b0 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a 30 |25T20:57:53+12:0|
|
||||
000000c0 30 ac cd 5d c1 00 00 00 25 74 45 58 74 64 61 74 |0..]....%tEXtdat|
|
||||
000000d0 65 3a 6d 6f 64 69 66 79 00 32 30 31 39 2d 30 37 |e:modify.2019-07|
|
||||
000000e0 2d 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a |-25T20:57:53+12:|
|
||||
000000f0 30 30 dd 90 e5 7d 00 00 00 00 49 45 4e 44 ae 42 |00...}....IEND.B|
|
||||
00000100 60 82 |`.|
|
||||
00000102
|
||||
```
|
||||
|
||||
In the right column, you see the same data that’s on the left but presented as ASCII. If you look carefully, you can pick out some useful information, such as the file’s format (PNG) and—toward the bottom—the date and time the file was created and last modified. The dots represent symbols that aren’t present in the ASCII character set, which is to be expected because binary formats aren’t restricted to mundane letters and numbers.
|
||||
|
||||
The **file** command knows from the first 8 bytes what this file is. The [libpng specification][6] alerts programmers what to look for. You can see that within the first 8 bytes of this image file, specifically, is the string **PNG**. That fact is significant because it reveals how the **file** command knows what kind of file to report.
|
||||
|
||||
You can also control how many bytes **hexdump** displays, which is useful with files larger than one pixel:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump --length 8 pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a
|
||||
0000008
|
||||
```
|
||||
|
||||
You don’t have to limit **hexdump** to PNG or graphic files. You can run **hexdump** against binaries you run on a daily basis as well, such as [ls][7], [rsync][8], or any binary format you want to inspect.
|
||||
|
||||
### Implementing cat with hexdump
|
||||
|
||||
If you read the PNG spec, you may notice that the data in the first 8 bytes looks different than what **hexdump** provides. Actually, it’s the same data, but it’s presented using a different conversion. So, the output of **hexdump** is true, but not always directly useful to you, depending on what you’re looking for. For that reason, **hexdump** has options to format and convert the raw data it dumps.
|
||||
|
||||
The conversion options can get complex, so it’s useful to practice with something trivial first. Here’s a gentle introduction to formatting **hexdump** output by reimplementing the [**cat**][9] command. First, run **hexdump** on a text file to see its raw data. You can usually find a copy of the [GNU General Public License (GPL)][10] license somewhere on your hard drive, or you can use any text file you have handy. Your output may differ, but here’s how to find a copy of the GPL on your system (or at least part of it):
|
||||
|
||||
|
||||
```
|
||||
$ find /usr/share/doc/ -type f -name "COPYING" | tail -1
|
||||
/usr/share/doc/libblkid-devel/COPYING
|
||||
```
|
||||
|
||||
Run **hexdump** against it:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump /usr/share/doc/libblkid-devel/COPYING
|
||||
0000000 6854 7369 6c20 6269 6172 7972 6920 2073
|
||||
0000010 7266 6565 7320 666f 7774 7261 3b65 7920
|
||||
0000020 756f 6320 6e61 7220 6465 7369 7274 6269
|
||||
0000030 7475 2065 7469 6120 646e 6f2f 0a72 6f6d
|
||||
0000040 6964 7966 6920 2074 6e75 6564 2072 6874
|
||||
0000050 2065 6574 6d72 2073 666f 7420 6568 4720
|
||||
0000060 554e 4c20 7365 6573 2072 6547 656e 6172
|
||||
0000070 206c 7550 6c62 6369 4c0a 6369 6e65 6573
|
||||
0000080 6120 2073 7570 6c62 7369 6568 2064 7962
|
||||
[...]
|
||||
```
|
||||
|
||||
If the file’s output is very long, use the **\--length** (or **-n** for short) to make it manageable for yourself.
|
||||
|
||||
The raw data probably means nothing to you, but you already know how to convert it to ASCII:
|
||||
|
||||
|
||||
```
|
||||
hexdump --canonical /usr/share/doc/libblkid-devel/COPYING
|
||||
00000000 54 68 69 73 20 6c 69 62 72 61 72 79 20 69 73 20 |This library is |
|
||||
00000010 66 72 65 65 20 73 6f 66 74 77 61 72 65 3b 20 79 |free software; y|
|
||||
00000020 6f 75 20 63 61 6e 20 72 65 64 69 73 74 72 69 62 |ou can redistrib|
|
||||
00000030 75 74 65 20 69 74 20 61 6e 64 2f 6f 72 0a 6d 6f |ute it and/or.mo|
|
||||
00000040 64 69 66 79 20 69 74 20 75 6e 64 65 72 20 74 68 |dify it under th|
|
||||
00000050 65 20 74 65 72 6d 73 20 6f 66 20 74 68 65 20 47 |e terms of the G|
|
||||
00000060 4e 55 20 4c 65 73 73 65 72 20 47 65 6e 65 72 61 |NU Lesser Genera|
|
||||
00000070 6c 20 50 75 62 6c 69 63 0a 4c 69 63 65 6e 73 65 |l Public.License|
|
||||
[...]
|
||||
```
|
||||
|
||||
That output is helpful but unwieldy and difficult to read. To format **hexdump**’s output beyond what’s offered by its own options, use **\--format** (or **-e**) along with specialized formatting codes. The shorthand used for formatting is similar to what the **printf** command uses, so if you are familiar with **printf** statements, you may find **hexdump** formatting easier to learn.
|
||||
|
||||
In **hexdump**, the character sequence **%_p** tells **hexdump** to print a character in your system’s default character set. All formatting notation for the **\--format** option must be enclosed in _single quotes_:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -e'"%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is fre*
|
||||
software; you can redistribute it and/or.modify it under the terms of the GNU Les*
|
||||
er General Public.License as published by the Fre*
|
||||
Software Foundation; either.version 2.1 of the License, or (at your option) any later.version..*
|
||||
The complete text of the license is available in the..*
|
||||
/Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
This output is better, but still inconvenient to read. Traditionally, UNIX text files assume an 80-character output width (because long ago, monitors tended to fit only 80 characters across).
|
||||
|
||||
While this output isn’t bound by formatting, you can force **hexdump** to process 80 bytes at a time with additional options. Specifically, by dividing 80 by one, you can tell **hexdump** to treat 80 bytes as one unit:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is free software; you can redistribute it and/or.modify it under the terms of the GNU Lesser General Public.License as published by the Free Software Foundation; either.version 2.1 of the License, or (at your option) any later.version...The complete text of the license is available in the.../Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
Now the file is processed in 80-byte chunks, but it’s lost any sense of new lines. You can add your own with the **\n** character, which in UNIX represents a new line:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p""\n"'
|
||||
This library is free software; you can redistribute it and/or.modify it under th
|
||||
e terms of the GNU Lesser General Public.License as published by the Free Softwa
|
||||
re Foundation; either.version 2.1 of the License, or (at your option) any later.
|
||||
version...The complete text of the license is available in the.../Documentation/
|
||||
licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
You have now (approximately) implemented the **cat** command with **hexdump** formatting.
|
||||
|
||||
### Controlling the output
|
||||
|
||||
Formatting is, realistically, how you make **hexdump** useful. Now that you’re familiar, in principle at least, with **hexdump** formatting, you can make the output of **hexdump -n 8** match the output of the PNG header as described by the official **libpng** spec.
|
||||
|
||||
First, you know that you want **hexdump** to process the PNG file in 8-byte chunks. Furthermore, you may know by integer recognition that the PNG spec is documented in decimal, which is represented by **%d** according to the **hexdump** documentation:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d""\n"' pixel.png
|
||||
13780787113102610
|
||||
```
|
||||
|
||||
You can make the output perfect by adding a blank space after each integer:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d ""\n"' pixel.png
|
||||
137 80 78 71 13 10 26 10
|
||||
```
|
||||
|
||||
The output is now a perfect match to the PNG specification.
|
||||
|
||||
### Hexdumping for fun and profit
|
||||
|
||||
Hexdump is a fascinating tool that not only teaches you more about how computers process and convert information, but also about how file formats and compiled binaries function. You should try running **hexdump** on files at random throughout the day as you work. You never know what kinds of information you may find, nor when having that insight may be useful.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/dig-binary-files-hexdump
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sethhttps://opensource.com/users/shishz
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
|
||||
[2]: https://www.redhat.com/sysadmin/find-lost-files-scalpel
|
||||
[3]: http://gimp.org
|
||||
[4]: https://opensource.com/article/17/2/mtpaint-pixel-art-animated-gifs
|
||||
[5]: https://opensource.com/article/17/8/imagemagick
|
||||
[6]: http://www.libpng.org/pub/png/spec/1.2/PNG-Structure.html
|
||||
[7]: https://opensource.com/article/19/7/master-ls-command
|
||||
[8]: https://opensource.com/article/19/5/advanced-rsync
|
||||
[9]: https://opensource.com/article/19/2/getting-started-cat-command
|
||||
[10]: https://en.wikipedia.org/wiki/GNU_General_Public_License
|
||||
@ -1,117 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Check Your IP Address in Ubuntu [Beginner’s Tip])
|
||||
[#]: via: (https://itsfoss.com/check-ip-address-ubuntu/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
How To Check Your IP Address in Ubuntu [Beginner’s Tip]
|
||||
======
|
||||
|
||||
Wonder what’s your IP address? Here are several ways to check IP address in Ubuntu and other Linux distributions.
|
||||
|
||||
![][1]
|
||||
|
||||
### What is an IP Address?
|
||||
|
||||
An **Internet Protocol address** (commonly referred to as **IP address**) is a numerical label assigned to each device connected to a computer network (using the Internet Protocol). An IP address serves both the purpose of identification and localisation of a machine.
|
||||
|
||||
The **IP address** is _unique_ within the network, allowing the communication between all connected devices.
|
||||
|
||||
You should also know that there are two **types of IP addresses**: **public** and **private**. The **public IP address** is the address used to communicate over the Internet, the same way your physical address is used for postal mail. However, in the context of a local network (such as a home where are router is used), each device is assigned a **private IP address** unique within this sub-network. This is used inside this local network, without directly exposing the public IP (which is used by the router to communicate with the Internet).
|
||||
|
||||
Another distinction can be made between **IPv4** and **IPv6** protocol. **IPv4** is the classic IP format,consisting of a basic 4 part structure, with four bytes separated by dots (e.g. 127.0.0.1). However, with the growing number of devices, IPv4 will soon be unable to offer enough addresses. This is why **IPv6** was invented, a format using **128-bit addresses** (compared to the **32-bit addresses** used by **IPv4**).
|
||||
|
||||
## Checking your IP Address in Ubuntu [Terminal Method]
|
||||
|
||||
The fastest and the simplest way to check your IP address is by using the ip command. You can use this command in the following fashion:
|
||||
|
||||
```
|
||||
ip addr show
|
||||
```
|
||||
|
||||
It will show you both IPv4 and IPv6 addresses:
|
||||
|
||||
![Display IP Address in Ubuntu Linux][2]
|
||||
|
||||
Actually, you can further shorten this command to just `ip a`. It will give you the exact same result.
|
||||
|
||||
```
|
||||
ip a
|
||||
```
|
||||
|
||||
If you prefer to get minimal details, you can also use **hostname**:
|
||||
|
||||
```
|
||||
hostname -I
|
||||
```
|
||||
|
||||
There are some other [ways to check IP address in Linux][3] but these two commands are more than enough to serve the purpose.
|
||||
|
||||
[][4]
|
||||
|
||||
Suggested read How to Disable IPv6 on Ubuntu Linux
|
||||
|
||||
What about ifconfig?
|
||||
|
||||
Long-time users might be tempted to use ifconfig (part of net-tools), but that program is deprecated. Some newer Linux distributions don’t include this package anymore and if you try running it, you’ll see ifconfig command not found error.
|
||||
|
||||
## Checking IP address in Ubuntu [GUI Method]
|
||||
|
||||
If you are not comfortable with the command line, you can also check IP address graphically.
|
||||
|
||||
Open up the Ubuntu Applications Menu (**Show Applications** in the bottom-left corner of the screen) and search for **Settings** and click on the icon:
|
||||
|
||||
![Applications Menu Settings][5]
|
||||
|
||||
This should open up the **Settings Menu**. Go to **Network**:
|
||||
|
||||
![Network Settings Ubuntu][6]
|
||||
|
||||
Pressing on the **gear icon** next to your connection should open up a window with more settings and information about your link to the network, including your IP address:
|
||||
|
||||
![IP Address GUI Ubuntu][7]
|
||||
|
||||
## Bonus Tip: Checking your Public IP Address (for desktop computers)
|
||||
|
||||
First of all, to check your **public IP address** (used for communicating with servers etc.) you can [use curl command][8]. Open up a terminal and enter the following command:
|
||||
|
||||
```
|
||||
curl ifconfig.me
|
||||
```
|
||||
|
||||
This should simply return your IP address with no additional bulk information. I would recommend being careful when sharing this address, since it is the equivalent to giving out your personal address.
|
||||
|
||||
**Note:** _If **curl** isn’t installed on your system, simply use **sudo apt install curl -y** to solve the problem, then try again._
|
||||
|
||||
Another simple way you can see your public IP address is by searching for **ip address** on Google.
|
||||
|
||||
**Summary**
|
||||
|
||||
In this article I went through the different ways you can find your IP address in Uuntu Linux, as well as giving you a basic overview of what IP addresses are used for and why they are so important for us.
|
||||
|
||||
I hope you enjoyed this quick guide. Let us know if you found this explanation helpful in the comments section!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/check-ip-address-ubuntu/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/checking-ip-address-ubuntu.png?resize=800%2C450&ssl=1
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/ip_addr_show.png?fit=800%2C493&ssl=1
|
||||
[3]: https://linuxhandbook.com/find-ip-address/
|
||||
[4]: https://itsfoss.com/disable-ipv6-ubuntu-linux/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/applications_menu_settings.jpg?fit=800%2C309&ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/network_settings_ubuntu.jpg?fit=800%2C591&ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/ip_address_gui_ubuntu.png?fit=800%2C510&ssl=1
|
||||
[8]: https://linuxhandbook.com/curl-command-examples/
|
||||
@ -1,122 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Managing credentials with KeePassXC)
|
||||
[#]: via: (https://fedoramagazine.org/managing-credentials-with-keepassxc/)
|
||||
[#]: author: (Marco Sarti https://fedoramagazine.org/author/msarti/)
|
||||
|
||||
Managing credentials with KeePassXC
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
A [previous article][2] discussed password management tools that use server-side technology. These tools are very interesting and suitable for a cloud installation.
|
||||
In this article we will talk about KeePassXC, a simple multi-platform open source software that uses a local file as a database.
|
||||
The main advantage of this type of password management is simplicity. No server-side technology expertise is required and can therefore be used by any type of user.
|
||||
|
||||
### Introducing KeePassXC
|
||||
|
||||
KeePassXC is an open source cross platform password manager: its development started as a fork of KeePassX, a good product but with a not very active development. It saves the secrets in an encrypted database with AES algorithm using 256 bit key, this makes it reasonably safe to save the database in a cloud drive storage such as pCloud or Dropbox.
|
||||
|
||||
In addition to the passwords, KeePassXC allows you to save various information and attachments in the encrypted wallet. It also has a valid password generator that helps the user to correctly manage his credentials.
|
||||
|
||||
### Installation
|
||||
|
||||
The program is available both in the standard Fedora repository and in the Flathub repository. Unfortunately the integration with the browser does not work with the application running in the sandbox, so I suggest to install the program via dnf:
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
sudo dnf install keepassxc
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
### Creating your wallet
|
||||
|
||||
To create a new database there are two important steps:
|
||||
|
||||
* Choose the encryption settings: the default settings are reasonably safe, increasing the transform rounds also increases the decryption time.
|
||||
* Choose the master key and additional protections: the master key must be easy to remember (if you lose it your wallet is lost!) but strong enough, a passphrase with at least 4 random words can be a good choice. As additional protection you can choose a key file (remember: you must always have it available otherwise you cannot open the wallet) and / or a YubiKey hardware key.
|
||||
|
||||
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
The database file will be saved to the file system. If you want to share with other computers / devices you can save it on a USB key or in a cloud storage like pCloud or Dropbox. Of course, if you choose a cloud storage, a particularly strong master password is recommended, better if accompanied by additional protection.
|
||||
|
||||
### Creating your first entry
|
||||
|
||||
Once the database has been created, you can start creating your first entry. For a web login specify a username, password and url in the Entry tab. Optionally you can specify an expiration date for the credentials based on your personal policy: also by pressing the button on the right the favicon of the site is downloaded and associated as an icon of the entry, this is a nice feature.
|
||||
|
||||
![][5]
|
||||
|
||||
![][6]
|
||||
|
||||
KeePassXC also offers a good password / passphrase generator, you can choose length and complexity and check the degree of resistance to a brute force attack:
|
||||
|
||||
![][7]
|
||||
|
||||
### Browser integration
|
||||
|
||||
KeePassXC has an extension available for all major browsers. The extension allows you to fill in the login information for all the entries whose URL is specified.
|
||||
|
||||
Browser integration must be enabled on KeePassXC (Tools menu -> Settings) specifying which browsers you intend to use:
|
||||
|
||||
![][8]
|
||||
|
||||
Once the extension is installed, it is necessary to create a connection with the database. To do this, press the extension button and then the Connect button: if the database is open and unlocked the extension will create an association key and save it in the database, the key is unique to the browser so I suggest naming it appropriately :
|
||||
|
||||
![][9]
|
||||
|
||||
When you reach the login page specified in the Url field and the database is unlocked, the extension will offer you all the credentials you have associated with that page:
|
||||
|
||||
![][10]
|
||||
|
||||
In this way, browsing with KeePassXC running you will have your internet credentials available without necessarily saving them in the browser.
|
||||
|
||||
### SSH agent integration
|
||||
|
||||
Another interesting feature of KeePassXC is the integration with SSH. If you have ssh-agent running KeePassXC is able to interact and add the ssh keys that you have uploaded as attachments to your entries.
|
||||
|
||||
First of all in the general settings (Tools menu -> Settings) you have to enable the ssh agent and restart the program:
|
||||
|
||||
![][11]
|
||||
|
||||
At this point it is required to upload your ssh key pair as an attachment to your entry. Then in the “SSH agent” tab select the private key in the attachment drop-down list, the public key will be populated automatically. Don’t forget to select the two checkboxes above to allow the key to be added to the agent when the database is opened / unlocked and removed when the database is closed / locked:
|
||||
|
||||
![][12]
|
||||
|
||||
Now with the database open and unlocked you can log in ssh using the keys saved in your wallet.
|
||||
|
||||
The only limitation is in the maximum number of keys that can be added to the agent: ssh servers do not accept by default more than 5 login attempts, for security reasons it is not recommended to increase this value.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/managing-credentials-with-keepassxc/
|
||||
|
||||
作者:[Marco Sarti][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/msarti/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/keepassxc-816x345.png
|
||||
[2]: https://fedoramagazine.org/manage-your-passwords-with-bitwarden-and-podman/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-07-33-27.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-07-48-21.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-30-07.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-43-11.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-49-22.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-48-09.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-05-57.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-13-29.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-47-21.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-46-35.png
|
||||
@ -1,196 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Install Ansible (Automation Tool) on Debian 10 (Buster))
|
||||
[#]: via: (https://www.linuxtechi.com/install-ansible-automation-tool-debian10/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
How to Install Ansible (Automation Tool) on Debian 10 (Buster)
|
||||
======
|
||||
|
||||
Now a days in IT field, automation is the hot topic and every organization is start adopting the automation tools like **Puppet**, **Ansible**, **Chef**, **CFEngine**, **Foreman** and **Katello**. Out of these tools Ansible is the first choice of almost all the IT organization to manage UNIX and Linux like systems. In this article we will demonstrate on how to install and use ansible tool on Debian 10 Sever.
|
||||
|
||||
[![Ansible-Install-Debian10][1]][2]
|
||||
|
||||
My Lab details:
|
||||
|
||||
* Debian 10 – Ansible Server/ controller Node – 192.168.1.14
|
||||
* CentOS 7 – Ansible Host (Web Server) – 192.168.1.15
|
||||
* CentOS 7 – Ansible Host (DB Server) – 192.169.1.17
|
||||
|
||||
|
||||
|
||||
We will also demonstrate how Linux Servers can be managed using Ansible Server
|
||||
|
||||
### Ansible Installation on Debian 10 Server
|
||||
|
||||
I am assuming in your Debian 10 system you have a user which has either root privileges or sudo rights. In my setup I have a local user named “pkumar” with sudo rights.
|
||||
|
||||
Ansible 2.7 packages are available in default Debian 10 repositories, run the following commands from command line to install Ansible,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo apt update
|
||||
root@linuxtechi:~$ sudo apt install ansible -y
|
||||
```
|
||||
|
||||
Run the below command to verify the ansible version,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible --version
|
||||
```
|
||||
|
||||
![ansible-version][1]
|
||||
|
||||
To Install latest version of Ansible 2.8, first we must set Ansible repositories.
|
||||
|
||||
Execute the following commands one after the another,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ echo "deb http://ppa.launchpad.net/ansible/ansible/ubuntu bionic main" | sudo tee -a /etc/apt/sources.list
|
||||
root@linuxtechi:~$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 93C4A3FD7BB9C367
|
||||
root@linuxtechi:~$ sudo apt update
|
||||
root@linuxtechi:~$ sudo apt install ansible -y
|
||||
root@linuxtechi:~$ sudo ansible --version
|
||||
```
|
||||
|
||||
![latest-ansible-version][1]
|
||||
|
||||
### Managing Linux Servers using Ansible
|
||||
|
||||
Refer the following steps to manage Linux like servers using Ansible controller node,
|
||||
|
||||
### Step:1) Exchange the SSH keys between Ansible Server and its hosts
|
||||
|
||||
Generate the ssh keys from ansible server and shared the keys among the ansible hosts
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo -i
|
||||
root@linuxtechi:~# ssh-keygen
|
||||
root@linuxtechi:~# ssh-copy-id root@linuxtechi
|
||||
root@linuxtechi:~# ssh-copy-id root@linuxtechi
|
||||
```
|
||||
|
||||
### Step:2) Create Ansible Hosts inventory file
|
||||
|
||||
When ansible is installed then /etc/hosts file is created created automatically, in this file we can mentioned the ansible hosts or its clients. We can also create our own ansible host inventory file in our home directory,
|
||||
|
||||
Read More on : [**How to Manage Ansible Static and Dynamic Host Inventory**][3]
|
||||
|
||||
Run the below command to create ansible hosts inventory in our home directory
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ vi $HOME/hosts
|
||||
[Web]
|
||||
192.168.1.15
|
||||
|
||||
[DB]
|
||||
192.168.1.17
|
||||
```
|
||||
|
||||
Save and exit the file
|
||||
|
||||
**Note:** In above hosts file we can also use host name or FQDN as well but for that we have to make sure that ansible hosts are reachable and accessible by hostname or fqdn.
|
||||
|
||||
### Step:3) Test and Use default ansible modules
|
||||
|
||||
Ansible comes with lot of default modules which can used in ansible command, examples are shown below,
|
||||
|
||||
Syntax:
|
||||
|
||||
# ansible -i <host_file> -m <module> <host>
|
||||
|
||||
Where:
|
||||
|
||||
* **-i ~/hosts**: contains list of ansible hosts
|
||||
* **-m:** after -m specify the ansible module like ping & shell
|
||||
* **<host>:** Ansible hosts where we want to run the ansible modules
|
||||
|
||||
|
||||
|
||||
Verify ping connectivity using ansible ping module
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping all
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping Web
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping DB
|
||||
```
|
||||
|
||||
Output of above commands would be something like below:
|
||||
|
||||
![Ansible-ping-module-examples][1]
|
||||
|
||||
Running shell commands on ansible hosts using shell module
|
||||
|
||||
**Syntax:** # ansible -i <hosts_file> -m shell -a <shell_commands> <host>
|
||||
|
||||
Example:
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m shell -a "uptime" all
|
||||
192.168.1.17 | CHANGED | rc=0 >>
|
||||
01:48:34 up 1:07, 3 users, load average: 0.00, 0.01, 0.05
|
||||
|
||||
192.168.1.15 | CHANGED | rc=0 >>
|
||||
01:48:39 up 1:07, 3 users, load average: 0.00, 0.01, 0.04
|
||||
|
||||
root@linuxtechi:~$
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m shell -a "uptime ; df -Th / ; uname -r" Web
|
||||
192.168.1.15 | CHANGED | rc=0 >>
|
||||
01:52:03 up 1:11, 3 users, load average: 0.12, 0.07, 0.06
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/mapper/centos-root xfs 13G 1017M 12G 8% /
|
||||
3.10.0-327.el7.x86_64
|
||||
|
||||
root@linuxtechi:~$
|
||||
```
|
||||
|
||||
Above commands output confirms that we have successfully setup ansible controller node
|
||||
|
||||
Let’s create a sample NGINX installation playbook, below playbook will install nginx on all server which are part of Web host group, but in my case I have one centos 7 machine under this host group.
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ vi nginx.yaml
|
||||
---
|
||||
- hosts: Web
|
||||
tasks:
|
||||
- name: Install latest version of nginx on CentOS 7 Server
|
||||
yum: name=nginx state=latest
|
||||
- name: start nginx
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
```
|
||||
|
||||
Now execute the playbook using following command,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible-playbook -i ~/hosts nginx.yaml
|
||||
```
|
||||
|
||||
output of above command would be something like below,
|
||||
|
||||
![nginx-installation-playbook-debian10][1]
|
||||
|
||||
This confirms that Ansible playbook has been executed successfully, that’s all from article, please do share your feedback and comments.
|
||||
|
||||
Read Also: [**How to Download and Use Ansible Galaxy Roles in Ansible Playbook**][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/install-ansible-automation-tool-debian10/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/08/Ansible-Install-Debian10.jpg
|
||||
[3]: https://www.linuxtechi.com/manage-ansible-static-and-dynamic-host-inventory/
|
||||
[4]: https://www.linuxtechi.com/use-ansible-galaxy-roles-ansible-playbook/
|
||||
134
sources/tech/20190826 How to rename a group of files on Linux.md
Normal file
134
sources/tech/20190826 How to rename a group of files on Linux.md
Normal file
@ -0,0 +1,134 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to rename a group of files on Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3433865/how-to-rename-a-group-of-files-on-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
How to rename a group of files on Linux
|
||||
======
|
||||
To rename a group of files with a single command, use the rename command. It requires the use of regular expressions and can tell you what changes will be made before making them.
|
||||
![Manchester City Library \(CC BY-SA 2.0\)][1]
|
||||
|
||||
For decades, Linux users have been renaming files with the **mv** command. It’s easy, and the command does just what you expect. Yet sometimes you need to rename a large group of files. When that is the case, the **rename** command can make the task a lot easier. It just requires a little finesse with regular expressions.
|
||||
|
||||
**[ Two-Minute Linux Tips: [Learn how to master a host of Linux commands in these 2-minute video tutorials][2] ]**
|
||||
|
||||
Unlike the **mv** command, **rename** isn’t going to allow you to simply specify the old and new names. Instead, it uses a regular expression like those you'd use with Perl. In the example below, the "s" specifies that we're substituting the second string (old) for the first, thus changing **this.new** to **this.old**.
|
||||
|
||||
```
|
||||
$ rename 's/new/old/' this.new
|
||||
$ ls this*
|
||||
this.old
|
||||
```
|
||||
|
||||
A change as simple as that would be easier using **mv this.new this.old**, but change the literal string “this” to the wild card “*” and you would rename all of your *.new files to *.old files with a single command:
|
||||
|
||||
```
|
||||
$ ls *.new
|
||||
report.new schedule.new stats.new this.new
|
||||
$ rename 's/new/old/' *.new
|
||||
$ ls *.old
|
||||
report.old schedule.old stats.old this.old
|
||||
```
|
||||
|
||||
As you might expect, the **rename** command isn’t restricted to changing file extensions. If you needed to change files named “report.*” to “review.*”, you could manage that with a command like this:
|
||||
|
||||
```
|
||||
$ rename 's/report/review/' *
|
||||
```
|
||||
|
||||
The strings supplied in the regular expressions can make changes to any portion of a file name — whether file names or extensions.
|
||||
|
||||
```
|
||||
$ rename 's/123/124/' *
|
||||
$ ls *124*
|
||||
status.124 report124.txt
|
||||
```
|
||||
|
||||
If you add the **-v** option to a **rename** command, the command will provide some feedback so that you can see the changes you made, maybe including any you didn’t intend — making it easier to notice and revert changes as needed.
|
||||
|
||||
```
|
||||
$ rename -v 's/123/124/' *
|
||||
status.123 renamed as status.124
|
||||
report123.txt renamed as report124.txt
|
||||
```
|
||||
|
||||
On the other hand, using the **-n** (or **\--nono**) option makes the **rename** command tell you the changes that it would make without actually making them. This can save you from making changes you may not be intending to make and then having to revert those changes.
|
||||
|
||||
```
|
||||
$ rename -n 's/old/save/' *
|
||||
rename(logger.man-old, logger.man-save)
|
||||
rename(lyrics.txt-old, lyrics.txt-save)
|
||||
rename(olderfile-, saveerfile-)
|
||||
rename(oldfile, savefile)
|
||||
rename(review.old, review.save)
|
||||
rename(schedule.old, schedule.save)
|
||||
rename(stats.old, stats.save)
|
||||
rename(this.old, this.save)
|
||||
```
|
||||
|
||||
If you're then happy with those changes, you can then run the command without the **-n** option to make the file name changes.
|
||||
|
||||
Notice, however, that the “.” within the regular expressions will not be treated as a period, but as a wild card that will match any character. Some of the changes in the examples above and below are likely not what was intended by the person typing the command.
|
||||
|
||||
```
|
||||
$ rename -n 's/.old/.save/' *
|
||||
rename(logger.man-old, logger.man.save)
|
||||
rename(lyrics.txt-old, lyrics.txt.save)
|
||||
rename(review.old, review.save)
|
||||
rename(schedule.old, schedule.save)
|
||||
rename(stats.old, stats.save)
|
||||
rename(this.old, this.save)
|
||||
```
|
||||
|
||||
To ensure that a period is taken literally, put a backslash in front of it. This will keep it from being interpreted as a wild card and matching any character. Notice that only the “.old” files are selected when this change is made.
|
||||
|
||||
```
|
||||
$ rename -n 's/\.old/.save/' *
|
||||
rename(review.old, review.save)
|
||||
rename(schedule.old, schedule.save)
|
||||
rename(stats.old, stats.save)
|
||||
rename(this.old, this.save)
|
||||
```
|
||||
|
||||
A command like the one below would change all uppercase letters in file names to lowercase except that the -n option is being used to make sure we review the changes that would be made before we run the command to make the changes. Notice the use of the “y” in the regular expression; it’s required for making the case changes.
|
||||
|
||||
```
|
||||
$ rename -n 'y/A-Z/a-z/' W*
|
||||
rename(WARNING_SIGN.pdf, warning_sign.pdf)
|
||||
rename(Will_Gardner_buttons.pdf, will_gardner_buttons.pdf)
|
||||
rename(Wingding_Invites.pdf, wingding_invites.pdf)
|
||||
rename(WOW-buttons.pdf, wow-buttons.pdf)
|
||||
```
|
||||
|
||||
In the example above, we're changing all uppercase letters to lowercase, but only in file names that begin with an uppercase W.
|
||||
|
||||
### Wrap-up
|
||||
|
||||
The **rename** command is very helpful when you need to rename a lot of files. Just be careful not to make more changes than you intended. Keep in mind that the **-n** (or spelled out as **\--nono**) option can help you avoid time-consuming mistakes.
|
||||
|
||||
**[Now read this: [Linux hardening: A 15-step checklist for a secure Linux server][3] ]**
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3433865/how-to-rename-a-group-of-files-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/08/card-catalog-machester_city_library-100809242-large.jpg
|
||||
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[3]: http://www.networkworld.com/article/3143050/linux/linux-hardening-a-15-step-checklist-for-a-secure-linux-server.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
313
sources/tech/20190828 Introduction to the Linux chmod command.md
Normal file
313
sources/tech/20190828 Introduction to the Linux chmod command.md
Normal file
@ -0,0 +1,313 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Introduction to the Linux chmod command)
|
||||
[#]: via: (https://opensource.com/article/19/8/linux-chmod-command)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdosshttps://opensource.com/users/mralexjuarezhttps://opensource.com/users/brsonhttps://opensource.com/users/seth)
|
||||
|
||||
Introduction to the Linux chmod command
|
||||
======
|
||||
Chmod, which sets read, write, and execute permissions, is one of the
|
||||
most important Linux security commands.
|
||||
![5 pengiuns floating on iceburg][1]
|
||||
|
||||
Every object on your Linux system has a permission mode that describes what actions a user can perform on it. There are three types of permissions: read (**r**), write (**w**), and execute (**x**).
|
||||
|
||||
To **read** a file is to view its contents. For example, a text file must have **read** permission for someone to read the text within. If the user wants to add a sentence to that file, it needs **write** permission. The **execute** permission enables someone to run a file, such as a shell script or a binary program file.
|
||||
|
||||
### Basic permissions
|
||||
|
||||
The **ls -l** command displays the permissions assigned to a file. For example:
|
||||
|
||||
|
||||
```
|
||||
ls -l
|
||||
-rw-rw-r-- 1 bruce bruce 0 Jul 30 16:25 schedule1.txt
|
||||
```
|
||||
|
||||
Some permissions (**rw**) appear more than once because they are referring to different entities: _user_, _group_, and _other_. _User_ is synonymous with the owner, and _group_ refers to the user's primary group, both of which are **bruce**. _Other_ refers to all other users.
|
||||
|
||||
The first position denotes the object's type: **-** for a file, **d** for a directory, and **l** for a symbolic link. The next nine positions are grouped in threes and describe the permission mode. The positions are ordered **r**,**w**,**x**, and the groups are ordered **user**, **group**, **other**.
|
||||
|
||||
\--- --- --- | rwx rwx rwx
|
||||
---|---
|
||||
uuu ggg ooo | u=user, g=group, o=other
|
||||
|
||||
#### Files
|
||||
|
||||
A file with read, write, and execute bits set for all entities would appear:
|
||||
|
||||
|
||||
```
|
||||
`rwxrwxrwx`
|
||||
```
|
||||
|
||||
Of course, we don't usually configure files this permissively in the real world; this is just an illustration of how each position is used.
|
||||
|
||||
In the following example, a file is configured for its owner (**pablo**) to have read and write permissions, for members of the group to only have read permission, and for everyone else to have no permissions.
|
||||
|
||||
|
||||
```
|
||||
`-rw-r----- 1 pablo pablo 0 Jul 30 16:25 textfile`
|
||||
```
|
||||
|
||||
The **chmod** command modifies the permission mode of objects in the system. It is one of the most used and important commands in the set of Linux security commands.
|
||||
|
||||
A plus (**+**) symbol adds a permission, and a minus (**-**) symbol removes a permission. You can read **chmod u+r** as "user plus read," as it gives the user _read_ permission. The command **chmod u-r** means "user minus read," as it takes the _read_ permission away from the user.
|
||||
|
||||
#### Directories
|
||||
|
||||
The same three permissions also apply to a directory. A directory must have the _read_ permission for a user to view its contents. It will need _write_ permission for a user to add to the directory (e.g., to create a new file). For a user to change to a directory (**cd**), it must have _execute_ permission.
|
||||
|
||||
|
||||
```
|
||||
`drw-rw-r-- 2 pablo pablo 4096 Jul 30 15:56 JBOSS`
|
||||
```
|
||||
|
||||
Pablo may be the owner of the JBOSS directory, but since he doesn't have execute permission, he can not **cd** into it. He can use the command **chmod u+x** to add the permission, and then he can **cd** into it.
|
||||
|
||||
|
||||
```
|
||||
$ cd JBOSS
|
||||
bash: cd: JBOSS: Permission denied
|
||||
$ chmod u+x JBOSS
|
||||
$ ls -l
|
||||
drwxrw-r-- 2 pablo pablo 4096 Jul 30 15:56 JBOSS
|
||||
$ cd JBOSS
|
||||
$ pwd
|
||||
/opt/JBOSS
|
||||
```
|
||||
|
||||
#### Combined arguments
|
||||
|
||||
You can combine arguments using a comma. In this example, you only need one command to set permissions so the group cannot write to a file nor can the rest of the world read it:
|
||||
|
||||
|
||||
```
|
||||
$ chmod o-r,g-w readme.txt
|
||||
$ ls -l
|
||||
-rw-r----- 1 pablo share 0 Jul 31 13:34 readme.txt
|
||||
```
|
||||
|
||||
You can read this as "others minus read and group minus write."
|
||||
|
||||
Suppose Denise has written a Bash script called **home_backup.sh** and wants to give it _execute_ permission. She also wants to prevent anyone else from reading, writing, or executing it. One way to do this is with the plus and minus symbols:
|
||||
|
||||
|
||||
```
|
||||
`$ chmod go-rw,u+x home_backup.sh`
|
||||
```
|
||||
|
||||
Another way is by using the equals (**=**) symbol. This will set the permissions absolutely without regard for previous settings. Note that there is a space after the second equals; this indicates a value of **none**:
|
||||
|
||||
|
||||
```
|
||||
`$ chmod u=rwx,go= home_backup.sh`
|
||||
```
|
||||
|
||||
You can read this as "permissions for user equal read, write, and execute and permissions for group and other equal none."
|
||||
|
||||
### Numeric mode
|
||||
|
||||
Chmod also supports a numeric mode, which uses values assigned to each position:
|
||||
|
||||
owner
|
||||
|
||||
group
|
||||
|
||||
other
|
||||
|
||||
r
|
||||
|
||||
w
|
||||
|
||||
x
|
||||
|
||||
r
|
||||
|
||||
w
|
||||
|
||||
x
|
||||
|
||||
r
|
||||
|
||||
w
|
||||
|
||||
x
|
||||
|
||||
400
|
||||
|
||||
200
|
||||
|
||||
100
|
||||
|
||||
40
|
||||
|
||||
20
|
||||
|
||||
10
|
||||
|
||||
4
|
||||
|
||||
2
|
||||
|
||||
1
|
||||
|
||||
The total value of a set of permissions can be calculated and passed to the chmod command as a single argument. Take the example with Denise and her backup script. If she uses numeric mode to set the permissions on her script, she must first calculate the value total:
|
||||
|
||||
|
||||
```
|
||||
`-rwx------ 1 denise denise 0 Jul 31 13:53 home_backup.sh`
|
||||
```
|
||||
|
||||
Denise adds the numbers that correspond to each permission she wants to apply:
|
||||
|
||||
**400 + 200 + 100 = 700**
|
||||
|
||||
Her command will be **chmod 700 home_backup.sh**. Suppose Denise wanted to reset the original permissions on the file:
|
||||
|
||||
|
||||
```
|
||||
`-rw-rw-r-- 1 denise denise 0 Jul 31 13:53 home_backup.sh`
|
||||
```
|
||||
|
||||
The value of these permissions calculates to 664:
|
||||
|
||||
**400 + 200 + 40 + 20 + 4 = 664**
|
||||
|
||||
Denise can use the command **chmod 664 home_backup.sh** to restore the original permissions.
|
||||
|
||||
### Special modes
|
||||
|
||||
Three other modes can be set on an object:
|
||||
|
||||
name | symbolic | numeric
|
||||
---|---|---
|
||||
setuid | s | 4000
|
||||
setgid | s | 2000
|
||||
sticky | t | 1000
|
||||
|
||||
The **SetUID** bit enforces user ownership on an executable file. When it is set, the file will execute with the file owner's user ID, not the person running it.
|
||||
|
||||
|
||||
```
|
||||
`$ chmod u+s`
|
||||
```
|
||||
|
||||
The **SetGID** bit enforces group ownership on files and directories. When it is set, any file or directory created in a directory will get the directory's group ownership, not the user's. When it is set on a file, the file will always be executed as its owning group rather than as the user:
|
||||
|
||||
|
||||
```
|
||||
`$ chmod g+s`
|
||||
```
|
||||
|
||||
The **sticky** bit, also referred to as the "restricted deletion flag," can be set on a directory to prevent anyone except the directory's owner from deleting a file in that directory:
|
||||
|
||||
|
||||
```
|
||||
`$ chmod o+t`
|
||||
```
|
||||
|
||||
The sticky bit can be set in numerical mode by adding its value to those of the other permissions. If you have an object with a value of 755 and you want to set the sticky bit, add 1000:
|
||||
|
||||
**1000 + 400 + 200 + 100 + 40 + 10 + 4 + 1 = 1755**
|
||||
|
||||
This command would be **chmod 1755**. Several symbolic methods are equivalent; one example is **chmod u=rwx,go=rx,o+t**.
|
||||
|
||||
### Extras
|
||||
|
||||
The letter **a** is a shortcut to assign permissions to all users. The command **chmod a+rwx** is equivalent to **chmod ugo+rwx**.
|
||||
|
||||
#### Recursive
|
||||
|
||||
Like many other Linux commands, chmod has a recursive argument, **-R**, which allows you to operate on a directory and its contents recursively. By recursive, It is meant that the command will attempt to operate on all objects below the specified directory rather than just the directory itself. This example starts in an empty directory and adds the **-v** (verbose) argument, so chmod will report what it is doing:
|
||||
|
||||
|
||||
```
|
||||
$ ls -l . conf
|
||||
.:
|
||||
drwxrwxr-x 2 alan alan 4096 Aug 5 15:33 conf
|
||||
|
||||
conf:
|
||||
-rw-rw-r-- 1 alan alan 0 Aug 5 15:33 conf.xml
|
||||
$ chmod -vR 700 conf
|
||||
mode of 'conf' changed from 0775 (rwxrwxr-x) to 0700 (rwx------)
|
||||
mode of 'conf/conf.xml' changed from 0664 (rw-rw-r--) to 0700 (rwx------)
|
||||
```
|
||||
|
||||
#### Reference
|
||||
|
||||
A reference file command (**\--reference=RFILE**) can be used to duplicate the mode of another file (**RFILE**), known as a reference file. This is handy when you are changing modes on files to match a certain configuration or when you don't know the exact mode—or don't want to take time to calculate it:
|
||||
|
||||
|
||||
```
|
||||
$ ls -l
|
||||
-rw-r--r-x 1 alan alan 0 Aug 5 17:10 notes.txt
|
||||
-rw-rw-r-- 1 alan alan 0 Aug 5 17:10 readme.txt
|
||||
$ chmod --reference=readme.txt notes.txt
|
||||
$ ls -l
|
||||
-rw-rw-r-- 1 alan alan 0 Aug 5 17:10 notes.txt
|
||||
-rw-rw-r-- 1 alan alan 0 Aug 5 17:10 readme.txt
|
||||
```
|
||||
|
||||
#### Report changes
|
||||
|
||||
The chmod command also has a **-c** (**\--changes**) argument, which tells chmod to report only when a change is made (versus **-v**, or **-verbose**, which tells chmod to report all its output). Chmod will still report other things, such as if an operation is not allowed.
|
||||
|
||||
The argument **-f** (**\--silent**, **\--quiet**) suppresses most error messages. Using this argument with **-c** will show only real changes.
|
||||
|
||||
#### Preserve root
|
||||
|
||||
The root (**/**) of the Linux filesystem should be treated with great respect. If someone makes a command mistake at this level, the consequences can be terrible and leave a system completely useless, particularly when you are running a recursive command that will make any kind of change—or worse: deletions. Fortunately, the chmod command's **\--preserve-root** argument will protect and preserve the root. If the argument is used with a recursive chmod command on the root, nothing will happen, and you will see this message:
|
||||
|
||||
|
||||
```
|
||||
[alan@localhost ~]# chmod -cfR --preserve-root a+w /
|
||||
chmod: it is dangerous to operate recursively on '/'
|
||||
chmod: use --no-preserve-root to override this failsafe
|
||||
```
|
||||
|
||||
The option has no effect when it is not used with recursive. However, if the root user runs the command, the permissions of the **/** will change, but not those of other files or directories.
|
||||
|
||||
|
||||
```
|
||||
[alan@localhost ~]$ chmod -c --preserve-root a+w /
|
||||
chmod: changing permissions of '/': Operation not permitted
|
||||
[root@localhost /]# chmod -c --preserve-root a+w /
|
||||
mode of '/' changed from 0555 (r-xr-xr-x) to 0777 (rwxrwxrwx)
|
||||
```
|
||||
|
||||
Surprisingly, this is not the default argument; **\--no-preserve-root** is. If you run a command without the "preserve" option, it will default to "no preserve" mode and possibly change permissions on files that shouldn't be changed.
|
||||
|
||||
|
||||
```
|
||||
[alan@localhost ~]$ chmod -cfR a+x /
|
||||
mode of '/proc/1525/task/1525/comm' changed from 0644 (rw-r--r--) to 0755 (rwxr-xr-x)
|
||||
mode of '/proc/1541/task/1541/comm' changed from 0644 (rw-r--r--) to 0755 (rwxr-xr-x)
|
||||
mode of '/proc/1541/task/1580/comm' changed from 0644 (rw-r--r--) to 0755 (rwxr-xr-x)
|
||||
mode of '/proc/1541/task/1592/comm' changed from 0644 (rw-r--r--) to 0755 (rwxr-xr-x)
|
||||
mode of '/proc/1557/task/1557/comm' changed from 0644 (rw-r--r--) to 0755 (rwxr-xr-x)
|
||||
mode of '/proc/1558/task/1558/comm' changed from 0644 (rw-r--r--) to 0755 (rwxr-xr-x)
|
||||
mode of '/proc/1561/task/1561/comm' changed from 0644 (rw-r--r--) to 0755 (rwxr-xr-x)
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
All objects on a Linux system have a set of permissions. It is important to check and maintain them occasionally to prevent unwanted access.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/linux-chmod-command
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdosshttps://opensource.com/users/mralexjuarezhttps://opensource.com/users/brsonhttps://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux31x_cc.png?itok=Pvim4U-B (5 pengiuns floating on iceburg)
|
||||
@ -0,0 +1,174 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Managing Ansible environments on MacOS with Conda)
|
||||
[#]: via: (https://opensource.com/article/19/8/using-conda-ansible-administration-macos)
|
||||
[#]: author: (James Farrell https://opensource.com/users/jamesf)
|
||||
|
||||
Managing Ansible environments on MacOS with Conda
|
||||
======
|
||||
Conda corrals everything you need for Ansible into a virtual environment
|
||||
and keeps it separate from your other projects.
|
||||
![CICD with gears][1]
|
||||
|
||||
If you are a Python developer using MacOS and involved with Ansible administration, you may want to use the Conda package manager to keep your Ansible work separate from your core OS and other local projects.
|
||||
|
||||
Ansible is based on Python. Conda is not required to make Ansible work on MacOS, but it does make managing Python versions and package dependencies easier. This allows you to use an upgraded Python version on MacOS and keep Python package dependencies separate between your system, Ansible, and other programming projects.
|
||||
|
||||
There are other ways to install Ansible on MacOS. You could use [Homebrew][2], but if you are into Python development (or Ansible development), you might find managing Ansible in a Python virtual environment reduces some confusion. I find this to be simpler; rather than trying to load a Python version and dependencies into the system or in **/usr/local**, Conda helps me corral everything I need for Ansible into a virtual environment and keep it all completely separate from other projects.
|
||||
|
||||
This article focuses on using Conda to manage Ansible as a Python project to keep it clean and separated from other projects. Read on to learn how to install Conda, create a new virtual environment, install Ansible, and test it.
|
||||
|
||||
### Prelude
|
||||
|
||||
Recently, I wanted to learn [Ansible][3], so I needed to figure out the best way to install it.
|
||||
|
||||
I am generally wary of installing things into my daily use workstation. I especially dislike applying manual updates to the vendor's default OS installation (a preference I developed from years of Unix system administration). I really wanted to use Python 3.7, but MacOS packages the older 2.7, and I was not going to install any global Python packages that might interfere with the core MacOS system.
|
||||
|
||||
So, I started my Ansible work using a local Ubuntu 18.04 virtual machine. This provided a real level of safe isolation, but I soon found that managing it was tedious. I set out to see how to get a flexible but isolated Ansible system on native MacOS.
|
||||
|
||||
Since Ansible is based on Python, Conda seemed to be the ideal solution.
|
||||
|
||||
### Installing Conda
|
||||
|
||||
Conda is an open source utility that provides convenient package- and environment-management features. It can help you manage multiple versions of Python, install package dependencies, perform upgrades, and maintain project isolation. If you are manually managing Python virtual environments, Conda will help streamline and manage your work. Surf on over to the [Conda documentation][4] for all the details.
|
||||
|
||||
I chose the [Miniconda][5] Python 3.7 installation for my workstation because I wanted the latest Python version. Regardless of which version you select, you can always install new virtual environments with other versions of Python.
|
||||
|
||||
To install Conda, download the PKG format file, do the usual double-click, and select the "Install for me only" option. The install took about 158MB of space on my system.
|
||||
|
||||
After the installation, bring up a terminal to see what you have. You should see:
|
||||
|
||||
* A new **miniconda3** directory in your **home**
|
||||
* The shell prompt modified to prepend the word "(base)"
|
||||
* **.bash_profile** updated with Conda-specific settings
|
||||
|
||||
|
||||
|
||||
Now that the base is installed, you have your first Python virtual environment. Running the usual Python version check should prove this, and your PATH will point to the new location:
|
||||
|
||||
|
||||
```
|
||||
(base) $ which python
|
||||
/Users/jfarrell/miniconda3/bin/python
|
||||
(base) $ python --version
|
||||
Python 3.7.1
|
||||
```
|
||||
|
||||
Now that Conda is installed, the next step is to set up a virtual environment, then get Ansible installed and running.
|
||||
|
||||
### Creating a virtual environment for Ansible
|
||||
|
||||
I want to keep Ansible separate from my other Python projects, so I created a new virtual environment and switched over to it:
|
||||
|
||||
|
||||
```
|
||||
(base) $ conda create --name ansible-env --clone base
|
||||
(base) $ conda activate ansible-env
|
||||
(ansible-env) $ conda env list
|
||||
```
|
||||
|
||||
The first command clones the Conda base into a new virtual environment called **ansible-env**. The clone brings in the Python 3.7 version and a bunch of default Python modules that you can add to, remove, or upgrade as needed.
|
||||
|
||||
The second command changes the shell context to this new **ansible-env** environment. It sets the proper paths for Python and the modules it contains. Notice that your shell prompt changes after the **conda activate ansible-env** command.
|
||||
|
||||
The third command is not required; it lists what Python modules are installed with their version and other data.
|
||||
|
||||
You can always switch out of a virtual environment and into another with Conda's **activate** command. This will bring you back to the base: **conda activate base**.
|
||||
|
||||
### Installing Ansible
|
||||
|
||||
There are various ways to install Ansible, but using Conda keeps the Ansible version and all desired dependencies packaged in one place. Conda provides the flexibility both to keep everything separated and to add in other new environments as needed (as I'll demonstrate later).
|
||||
|
||||
To install a relatively recent version of Ansible, use:
|
||||
|
||||
|
||||
```
|
||||
(base) $ conda activate ansible-env
|
||||
(ansible-env) $ conda install -c conda-forge ansible
|
||||
```
|
||||
|
||||
Since Ansible is not part of Conda's default channels, the **-c** is used to search and install from an alternate channel. Ansible is now installed into the **ansible-env** virtual environment and is ready to use.
|
||||
|
||||
### Using Ansible
|
||||
|
||||
Now that you have installed a Conda virtual environment, you're ready to use it. First, make sure the node you want to control has your workstation's SSH key installed to the right user account.
|
||||
|
||||
Bring up a new shell and run some basic Ansible commands:
|
||||
|
||||
|
||||
```
|
||||
(base) $ conda activate ansible-env
|
||||
(ansible-env) $ ansible --version
|
||||
ansible 2.8.1
|
||||
config file = None
|
||||
configured module search path = ['/Users/jfarrell/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
|
||||
ansible python module location = /Users/jfarrell/miniconda3/envs/ansibleTest/lib/python3.7/site-packages/ansible
|
||||
executable location = /Users/jfarrell/miniconda3/envs/ansibleTest/bin/ansible
|
||||
python version = 3.7.1 (default, Dec 14 2018, 13:28:58) [Clang 4.0.1 (tags/RELEASE_401/final)]
|
||||
(ansible-env) $ ansible all -m ping -u ansible
|
||||
192.168.99.200 | SUCCESS => {
|
||||
"ansible_facts": {
|
||||
"discovered_interpreter_python": "/usr/bin/python"
|
||||
},
|
||||
"changed": false,
|
||||
"ping": "pong"
|
||||
}
|
||||
```
|
||||
|
||||
Now that Ansible is working, you can pull your playbooks out of source control and start using them from your MacOS workstation.
|
||||
|
||||
### Cloning the new Ansible for Ansible development
|
||||
|
||||
This part is purely optional; it's only needed if you want additional virtual environments to modify Ansible or to safely experiment with questionable Python modules. You can clone your main Ansible environment into a development copy with:
|
||||
|
||||
|
||||
```
|
||||
(ansible-env) $ conda create --name ansible-dev --clone ansible-env
|
||||
(ansible-env) $ conda activte ansible-dev
|
||||
(ansible-dev) $
|
||||
```
|
||||
|
||||
### Gotchas to look out for
|
||||
|
||||
Occasionally you may get into trouble with Conda. You can usually delete a bad environment with:
|
||||
|
||||
|
||||
```
|
||||
$ conda activate base
|
||||
$ conda remove --name ansible-dev --all
|
||||
```
|
||||
|
||||
If you get errors that you cannot resolve, you can usually delete the environment directly by finding it in **~/miniconda3/envs** and removing the entire directory. If the base becomes corrupt, you can remove the entire **~/miniconda3** directory and reinstall it from the PKG file. Just be sure to preserve any desired environments you have in **~/miniconda3/envs**, or use the Conda tools to dump the environment configuration and recreate it later.
|
||||
|
||||
The **sshpass** program is not included on MacOS. It is needed only if your Ansible work requires you to supply Ansible with an SSH login password. You can find the current [sshpass source][6] on SourceForge.
|
||||
|
||||
Finally, the base Conda Python module list may lack some Python modules you need for your work. If you need to install one, the **conda install <package>** command is preferred, but **pip** can be used where needed, and Conda will recognize the install modules.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Ansible is a powerful automation utility that's worth all the effort to learn. Conda is a simple and effective Python virtual environment management tool.
|
||||
|
||||
Keeping software installs separated on your MacOS environment is a prudent approach to maintain stability and sanity with your daily work environment. Conda can be especially helpful to upgrade your Python version, separate Ansible from your other projects, and safely hack on Ansible.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/using-conda-ansible-administration-macos
|
||||
|
||||
作者:[James Farrell][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jamesf
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc (CICD with gears)
|
||||
[2]: https://brew.sh/
|
||||
[3]: https://docs.ansible.com/?extIdCarryOver=true&sc_cid=701f2000001OH6uAAG
|
||||
[4]: https://conda.io/projects/conda/en/latest/index.html
|
||||
[5]: https://docs.conda.io/en/latest/miniconda.html
|
||||
[6]: https://sourceforge.net/projects/sshpass/
|
||||
121
sources/tech/20190828 Using GNS3 with Fedora.md
Normal file
121
sources/tech/20190828 Using GNS3 with Fedora.md
Normal file
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using GNS3 with Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/using-gns3-with-fedora/)
|
||||
[#]: author: (Shaun Assam https://fedoramagazine.org/author/sassam/)
|
||||
|
||||
Using GNS3 with Fedora
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
GNS3 is [an amazing tool][2] that allows IT professionals to, quite simply, create a virtual lab. The software can virtualize or emulate a variety of systems called appliances. These appliances range from Cisco routers and switches to nodes such as Windows Server, CentOS, and Fedora. GNS3 also has the capability to utilize [containers][3]. If you’re designing and testing proof-of-concept ideas, recreating environments for troubleshooting, or want to delve into the world of network engineering, GNS3 might be for you.
|
||||
|
||||
As seen on their website, GNS3 is well acquainted in the enterprise world. Companies using it span from tech businesses like Intel, to scientific organizations like NASA. Even renown banks and telecom companies are included in the list. This adds great credibility to the power and reliability this open-source tool provides.
|
||||
|
||||
### Installation
|
||||
|
||||
For Fedora users, GNS3 can be easily installed from the official repository. From the command-line type:
|
||||
|
||||
```
|
||||
sudo dnf install gns3-server gns3-gui
|
||||
```
|
||||
|
||||
The reason for the separate packages is because GNS3 can be configured as a dedicated server. This is useful for teams to collaborate while working on a project, or problem. The dedicated servers can be installed on bare-metal or as a virtual machine.
|
||||
|
||||
GNS3 requires a computer with virtualization capabilities. This allows the software to utilize the computer’s hardware to increase the performance when running the appliances. To use Spice/VNC as a console install the _virt-viewer_ package.
|
||||
|
||||
When the installation is complete, an icon will be placed among the applications for GNS3.
|
||||
|
||||
![][4]
|
||||
|
||||
### Initial setup
|
||||
|
||||
Opening GNS3 for the first time will open the Setup Wizard. The options on the first screen allow users to either setup an isolated VM environment, run the topologies from the local computer, or to use a remote server. The examples in this article are performed on the local machine.
|
||||
|
||||
The next screen configures the application to connect to the local machine running GNS3 server. Here we see the path to the application installed locally on the server, host binding address, and port. These settings can be tweaked to match your setup. However, for a quick setup it’s best to accept the defaults.
|
||||
|
||||
Once the settings are verified, a confirmation will appear stating the connection to the local server was successful. The last screen in the wizard will provide a summary. Click the **Finish** button to complete the setup.
|
||||
|
||||
![][5]
|
||||
|
||||
### Finding appliances in the GNS3 Marketplace
|
||||
|
||||
Before venturing into the GUI, this would be a good time to visit the [GNS3 Marketplace][6]. The marketplace contains appliances, pre-configured labs, and software for use with GNS3. The options in the Marketplace are vast and beyond the scope of this article. However, let’s download an appliance to see how it works.
|
||||
|
||||
First, select the appliance you want (the examples in this article will use OpenWRT). Select the template for that appliance to download. Appliance templates are JSON files with the extension _gns3a_.
|
||||
|
||||
You can also install OS nodes without a template, or create your own. [OSBoxes.org][7] has a variety of pre-built VMWare images (VMDK) that are compatible with GNS3. For this article we’ll use the Fedora 64-bit VMWare image. You can also find images for many other distributions such as CentOS, Ubuntu, and Kali Linux.
|
||||
|
||||
To use Cisco appliances a service agreement or subscription to VIRL is needed to download the IOS images from Cisco. For links and guides to legally download Cisco IOS, check out David Bombal’s site at <https://davidbombal.com/gns3-download-cisco-ios-images-virl-images-best-get/>.
|
||||
|
||||
You may also need to install Dynamips which is not included in the official repos. However, a simple web search will point to the RPM package.
|
||||
|
||||
![][8]
|
||||
|
||||
### Importing appliances to GNS3
|
||||
|
||||
Now that we have some appliances let’s build a small and simple topology using the templates and images we just downloaded.
|
||||
|
||||
After the initial setup the **New appliance template** window will open. From here we can import template files like the _gns3a_ file downloaded from the Marketplace. Other options for adding appliances without a template include IOS devices, VMs, and Docker containers.
|
||||
|
||||
To add the OpenWRT router, click **Import an appliance template file**. This will open the **Add appliance** wizard. Review the information on the first screen which shows the category, vendor, architecture, and KVM status for that appliance, and click **Next**. Now select the **Server type** to run the appliance and click **Next**. This is where we can specify whether we want to run it on a remote server, in a GNS3 VM, or on the local machine. After verifying the server requirements click **Next** to continue the installation.
|
||||
|
||||
At this point it’s time to install the image file for the OpenWRT appliance. Select the version and click the **Download** button. This will go to the site containing the image file and download it. This article will use OpenWRT 18.06.4 downloaded from the project’s website. If the version of the image is not in the list, click the button to **Create a new version**, and enter the version number (in this case 18.06.4). Select the filename and click **Import** to import the image. GNS3 will then ask if you would like to copy the image and decompress it (if necessary). Accept it and complete the install.
|
||||
|
||||
![][9]
|
||||
|
||||
### Adding appliances without a template
|
||||
|
||||
To add the Fedora VM downloaded from OSBoxes, click on one of the icons on the left and select **New appliance template** near the bottom. Select **Add a Qemu virtual machine** and click **Next**. Enter a name for the appliance (in this case Fedora 30) then click **Next**. Verify the QEMU binary path and input the amount of RAM to use for the VM, then select the **Console type**. On the next screen select **New image** and browse for the VMDK file. Depending on the file-size it may take a few moments. To copy/import the image select **Yes** and once it’s completed click **Finish**.
|
||||
|
||||
![][10]
|
||||
|
||||
### Adding and connecting nodes in GNS3
|
||||
|
||||
Now that we have some appliances, let’s build a simple topology with OpenWRT and Fedora in GNS3. The icons on the left represent Routers, Switches, End devices, and Security devices. The second-last shows all appliances, and the bottom option is to _Add a link_ which connects the nodes to each other.
|
||||
|
||||
Click on the **Routers** icon and drag the OpenWRT router onto the empty workspace to the right. Click on the **End devices** icon and do the same for the computer node. Depending on how large the file is, it may take a few moments for the PC node to appear in the workspace. To connect the nodes, click **Add a link** then click on a node, select the interface (i.e. Ethernet0), then do the same with the other node (as seen in the demo below).
|
||||
|
||||
You can customize the consoles by going to the menu bar and selecting **Edit > Preferences > General**. Select the tab for **Console applications** and click the **Edit** button. From here you can choose your favourite terminal in the drop-down menu and even customize it in the text-box below.
|
||||
|
||||
Once everything is in place, start the nodes by clicking the green (play) button at the top. The lights in the Topology Summary section will turn green indicating the nodes are on. To open the consoles for the nodes, click the **Console to all devices** button to the left (it looks like a terminal icon). The Remote Viewer window for Fedora and a terminal window for OpenWRT will open.
|
||||
|
||||
Once complete you can turn off the nodes individually by right-clicking on the node and selecting **Stop**, or to stop all nodes click the red **Stop** button in the top bar.
|
||||
|
||||
![][11]
|
||||
|
||||
### Conclusion
|
||||
|
||||
GNS3 is a powerful piece of software with features that are beyond the scope of this article. The software is similar to Cisco’s Packet Tracer. However, Packet Tracer is a simulator with limitations to the program’s coding. GNS3 on the other hand virtualizes/emulates the nodes using the hardware’s actual OS. This provides full functionality and a closer experience to the actual hardware.
|
||||
|
||||
The [GNS3 documentation][12] site offers an enormous amount of resources that delve further into the workings of the application. They also offer training courses for those interested in digging deep into the workings of the software.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/using-gns3-with-fedora/
|
||||
|
||||
作者:[Shaun Assam][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/sassam/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/gns3.png-816x345.jpg
|
||||
[2]: https://gns3.com
|
||||
[3]: https://fedoramagazine.org/running-containers-with-podman/
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/08/gns3-app-icon-1024x768.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/08/gns3-initial-setup.gif
|
||||
[6]: https://www.gns3.com/marketplace
|
||||
[7]: https://www.osboxes.org
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2019/08/gns3-marketplace.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/08/gns3-adding-appliance-template.gif
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2019/08/gns3-adding-vm-image-without-template.gif
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2019/08/gns3-demo.gif
|
||||
[12]: https://docs.gns3.com
|
||||
240
sources/tech/20190828 What are environment variables in Bash.md
Normal file
240
sources/tech/20190828 What are environment variables in Bash.md
Normal file
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What are environment variables in Bash?)
|
||||
[#]: via: (https://opensource.com/article/19/8/what-are-environment-variables)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
What are environment variables in Bash?
|
||||
======
|
||||
Learn about environment variables in Bash in our miniseries: Variables
|
||||
in shells.
|
||||
![x sign ][1]
|
||||
|
||||
Environment variables contain information about your login session, stored for the system shell to use when executing commands. They exist whether you’re using Linux, Mac, or Windows. Many of these variables are set by default during installation or user creation.
|
||||
|
||||
While environment variables apply to all modern systems, this article specifically addresses environment variables in the Bash shell on Linux, BSD, Mac, and Cygwin.
|
||||
|
||||
### Understanding environment variables
|
||||
|
||||
Environment variables are no different, technically, than variables. They can be set, recalled, and cleared with exactly the same syntax used for variables. If you’re not used to using variables in Bash, read my [variables in Bash][2] article before continuing.
|
||||
|
||||
You don’t often use environment variables directly. They’re referenced by individual applications and daemons as needed. For instance, your home directory is set as an environment variable when you log in. For example, on Linux you can see your **HOME** environment variable's contents like this:
|
||||
|
||||
|
||||
```
|
||||
$ echo $HOME
|
||||
HOME=/home/seth
|
||||
```
|
||||
|
||||
On a Mac:
|
||||
|
||||
|
||||
```
|
||||
$ echo $HOME
|
||||
HOME=/Users/bogus
|
||||
```
|
||||
|
||||
On Windows:
|
||||
|
||||
|
||||
```
|
||||
`C:\Users\bogus`
|
||||
```
|
||||
|
||||
You can view all environment variables set on your system with the **env** command. ****The list is long, so pipe the output through **more** to make it easier to read:
|
||||
|
||||
|
||||
```
|
||||
$ env | more
|
||||
TERM=xterm-256color
|
||||
LESSOPEN=||/usr/bin/lesspipe.sh %s
|
||||
USER=seth
|
||||
SUDO_EDITOR=emacs
|
||||
WWW_HOME=<http://mirror.lagoon.nc/pub/slackware/slackware64-current/ChangeLog.txt>
|
||||
VISUAL=emacs
|
||||
DISPLAY=:0
|
||||
PS1=$
|
||||
XDG_DATA_DIRS=/home/seth/.local/share/flatpak/exports/share/:/var/lib/flatpak/exports/share/:/usr/local/share/:/usr/share/
|
||||
PATH=/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/snap/bin:/home/seth/bin:/home/seth/.local/bin:/snap/bin
|
||||
GDMSESSION=gnome
|
||||
MAIL=/var/spool/mail/seth
|
||||
[...]
|
||||
```
|
||||
|
||||
Environment variables can be useful when you want to override default settings, or when you need to manage new settings that your system has no reason to create on its own. For instance, when you type a command, the only reason your computer knows how to _find_ the application corresponding to that command is that the **PATH** environment variable tells it where to look. This variable lists valid directories for your operating system to search for commands, whether that command is [**ls**][3] or [cp][4], or a graphical application like Firefox or [Lutris][5], or anything else.
|
||||
|
||||
Different environment variables get used by different systems. Your **PATH** variable is vital to your terminal emulator, for instance, but a lot less significant to, say, Java (which has its own paths, which point to important Java libraries). However, the **USER** variable is used by several systems as a way to identify who is requesting a service. For example, if you’re on a multiuser system and need to check your local mailbox, your mail command knows which mail spool to retrieve based on the **MAIL** and **USER** variables.
|
||||
|
||||
### Setting an environment variable
|
||||
|
||||
Usually, the installer program, whether it’s **dnf** on Fedora, **apt** on Ubuntu, **brew** on Mac, or a custom installer, updates your environment variables for a new application. Sometimes, though, when you’re installing something outside of your distribution’s intended toolset, you may have to manage an environment variable yourself. Or you might choose to add an environment variable to suit your preferences. If you decide you want to keep some applications in a **bin** folder located in your home directory, then you must add that directory to your **PATH** so your operating system knows to look there for applications to run when you issue a command.
|
||||
|
||||
#### Temporary environment variables
|
||||
|
||||
You can add a location to your path the way you create throw-away variables. It works, but only as long as the shell you used to modify your system path remains open. For instance, open a Bash shell and modify your system path:
|
||||
|
||||
|
||||
```
|
||||
$ export PATH=$PATH:/home/seth/bin
|
||||
```
|
||||
|
||||
Confirm the result:
|
||||
|
||||
|
||||
```
|
||||
$ echo $PATH
|
||||
PATH=/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/snap/bin:/home/seth/bin:/home/seth/.local/bin:/snap/bin:/home/seth/bin
|
||||
```
|
||||
|
||||
Close the session:
|
||||
|
||||
|
||||
```
|
||||
$ exit
|
||||
```
|
||||
|
||||
Open a new one and take a look at the **PATH** variable:
|
||||
|
||||
|
||||
```
|
||||
$ echo $PATH
|
||||
PATH=/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/snap/bin:/home/seth/bin:/home/seth/.local/bin:/snap/bin
|
||||
```
|
||||
|
||||
This variable has reverted to its default state because **PATH** isn’t getting set with each new shell. For that, you must configure your variables to load any time a shell is launched.
|
||||
|
||||
#### Permanent environment variables
|
||||
|
||||
You can set your own persistent environment variables in your shell configuration file, the most common of which is **~/.bashrc**. If you’re a system administrator managing several users, you can also set environment variables in a script placed in the **/etc/profile.d** directory.
|
||||
|
||||
The syntax for setting a variable by configuration file is the same as setting a variable in your shell:
|
||||
|
||||
|
||||
```
|
||||
export PATH=$PATH:/snap/bin:/home/seth/bin
|
||||
```
|
||||
|
||||
Close the current shell, or else force it to load the updated config:
|
||||
|
||||
|
||||
```
|
||||
$ . ~/.bashrc
|
||||
```
|
||||
|
||||
Finally, take another look at your system path:
|
||||
|
||||
|
||||
```
|
||||
$ echo $PATH
|
||||
PATH=/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/snap/bin:/home/seth/bin:/home/seth/.local/bin:/snap/bin:/home/seth/bin
|
||||
```
|
||||
|
||||
It is now set correctly to include your additional custom directory.
|
||||
|
||||
### Discovering other environment variables
|
||||
|
||||
You can create and manipulate environment variables at will, and some applications do just that. This fact means that many of your environment variables aren’t used by most of your applications, and if you add your own arbitrary variables then some could be used by nothing at all. So the question is: How do you find out which environment variables are meaningful?
|
||||
|
||||
The answer lies in an application’s documentation. For instance, to find out what options are available to you for your general Bash environment, you can read the Bash documentation. While the Bash man page mentions many important variables, the GNU info page for Bash features two exhaustive lists of useful Bourne Shell and Bash environment variables, and how each is used.
|
||||
|
||||
For example, in the info page list:
|
||||
|
||||
|
||||
```
|
||||
'HISTCONTROL'
|
||||
A colon-separated list of values controlling how commands are saved
|
||||
on the history list. If the list of values includes 'ignorespace',
|
||||
lines which begin with a space character are not saved in the
|
||||
history list. A value of 'ignoredups' causes lines which match the
|
||||
previous history entry to not be saved. A value of 'ignoreboth' is
|
||||
shorthand for 'ignorespace' and 'ignoredups'.
|
||||
[...]
|
||||
```
|
||||
|
||||
This output tells you that the **HISTCONTROL** environment variable controls how your Bash history is presented, and what values you can use to customize that experience. In this example, the **ignoredups** value tells the output of the **history** command to ignore duplicate lines.
|
||||
|
||||
You can test this one easily. First, issue the same command twice in a row:
|
||||
|
||||
|
||||
```
|
||||
$ echo "hello world"
|
||||
hello world
|
||||
$ echo "hello world"
|
||||
hello world
|
||||
```
|
||||
|
||||
View your history, or at least the most recent entries:
|
||||
|
||||
|
||||
```
|
||||
$ history | tail -5
|
||||
996 man bash
|
||||
997 info bash
|
||||
998 echo "hello world"
|
||||
999 echo "hello world"
|
||||
1000 history
|
||||
```
|
||||
|
||||
You can see that duplicate entries are indeed listed now.
|
||||
|
||||
Set a new environment variable in your **.bashrc** file based on what you read in the info page:
|
||||
|
||||
|
||||
```
|
||||
export HISTCONTROL=$HISTCONTROL:ignorespace:ignoredups
|
||||
```
|
||||
|
||||
Save and then load your new configuration:
|
||||
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
Issue two commands twice in a row:
|
||||
|
||||
|
||||
```
|
||||
$ echo "hello once"
|
||||
hello once
|
||||
$ echo "hello once"
|
||||
hello once
|
||||
```
|
||||
|
||||
View the most recent entries in your history:
|
||||
|
||||
|
||||
```
|
||||
$ history | tail -5
|
||||
1000 history
|
||||
1001 emacs ~/.bashrc
|
||||
1002 source ~/.bashrc
|
||||
1003 echo "hello once"
|
||||
1004 history
|
||||
```
|
||||
|
||||
Duplicate entries are now collapsed into one entry because of your new environment variable, just as the info page specified.
|
||||
|
||||
Finding relevant environment variables is usually a matter of reading the documentation for the application you want to affect. Most environment variables are specific to what one application needs to run smoothly. For general entries, your shell’s documentation is the logical place to look. If you write scripts or applications that require new environment variables, be sure to define those variables in your own documentation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/what-are-environment-variables
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/x_stop_terminate_program_kill.jpg?itok=9rM8i9x8 (x sign )
|
||||
[2]: https://opensource.com/article/19/8/using-variables-bash
|
||||
[3]: https://opensource.com/article/19/7/master-ls-command
|
||||
[4]: https://opensource.com/article/19/8/copying-files-linux
|
||||
[5]: https://opensource.com/article/18/10/lutris-open-gaming-platform
|
||||
@ -0,0 +1,341 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with HTTPie for API testing)
|
||||
[#]: via: (https://opensource.com/article/19/8/getting-started-httpie)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshezhttps://opensource.com/users/mkalindepauleduhttps://opensource.com/users/jamesf)
|
||||
|
||||
Getting started with HTTPie for API testing
|
||||
======
|
||||
Debug API clients with HTTPie, an easy-to-use command-line tool written
|
||||
in Python.
|
||||
![Raspberry pie with slice missing][1]
|
||||
|
||||
[HTTPie][2] is a delightfully easy to use and easy to upgrade HTTP client. Pronounced "aitch-tee-tee-pie" and run as **http**, it is a command-line tool written in Python to access the web.
|
||||
|
||||
Since this how-to is about an HTTP client, you need an HTTP server to try it out; in this case, [httpbin.org][3], a simple, open source HTTP request-and-response service. The httpbin.org site is a powerful way to test to test web API clients and carefully manage and show details in requests and responses, but for now we will focus on the power of HTTPie.
|
||||
|
||||
### An alternative to Wget and cURL
|
||||
|
||||
You might have heard of the venerable [Wget][4] or the slightly newer [cURL][5] tools that allow you to access the web from the command line. They were written to access websites, whereas HTTPie is for accessing _web APIs_.
|
||||
|
||||
Website requests are designed to be between a computer and an end user who is reading and responding to what they see. This doesn't depend much on structured responses. However, API requests make _structured_ calls between two computers. The human is not part of the picture, and the parameters of a command-line tool like HTTPie handle this effectively.
|
||||
|
||||
### Install HTTPie
|
||||
|
||||
There are several ways to install HTTPie. You can probably get it as a package for your package manager, whether you use **brew**, **apt**, **yum**, or **dnf**. However, if you have configured [virtualenvwrapper][6], you can own your own installation:
|
||||
|
||||
|
||||
```
|
||||
$ mkvirtualenv httpie
|
||||
...
|
||||
(httpie) $ pip install httpie
|
||||
...
|
||||
(httpie) $ deactivate
|
||||
$ alias http=~/.virtualenvs/httpie/bin/http
|
||||
$ http -b GET <https://httpbin.org/get>
|
||||
{
|
||||
"args": {},
|
||||
"headers": {
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate",
|
||||
"Host": "httpbin.org",
|
||||
"User-Agent": "HTTPie/1.0.2"
|
||||
},
|
||||
"origin": "104.220.242.210, 104.220.242.210",
|
||||
"url": "<https://httpbin.org/get>"
|
||||
}
|
||||
```
|
||||
|
||||
By aliasing **http** directly to the command inside the virtual environment, you can run it even when the virtual environment is not active. You can put the **alias** command in **.bash_profile** or **.bashrc** so you can upgrade HTTPie with the command:
|
||||
|
||||
|
||||
```
|
||||
`$ ~/.virtualenvs/httpie/bin/pip install -U pip`
|
||||
```
|
||||
|
||||
### Query a website with HTTPie
|
||||
|
||||
HTTPie can simplify querying and testing an API. One option for running it, **-b** (also known as **\--body**), was used above. Without it, HTTPie will print the entire response, including the headers, by default:
|
||||
|
||||
|
||||
```
|
||||
$ http GET <https://httpbin.org/get>
|
||||
HTTP/1.1 200 OK
|
||||
Access-Control-Allow-Credentials: true
|
||||
Access-Control-Allow-Origin: *
|
||||
Connection: keep-alive
|
||||
Content-Encoding: gzip
|
||||
Content-Length: 177
|
||||
Content-Type: application/json
|
||||
Date: Fri, 09 Aug 2019 20:19:47 GMT
|
||||
Referrer-Policy: no-referrer-when-downgrade
|
||||
Server: nginx
|
||||
X-Content-Type-Options: nosniff
|
||||
X-Frame-Options: DENY
|
||||
X-XSS-Protection: 1; mode=block
|
||||
|
||||
{
|
||||
"args": {},
|
||||
"headers": {
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate",
|
||||
"Host": "httpbin.org",
|
||||
"User-Agent": "HTTPie/1.0.2"
|
||||
},
|
||||
"origin": "104.220.242.210, 104.220.242.210",
|
||||
"url": "<https://httpbin.org/get>"
|
||||
}
|
||||
```
|
||||
|
||||
This is crucial when debugging an API service because a lot of information is sent in the headers. For example, it is often important to see which cookies are being sent. Httpbin.org provides options to set cookies (for testing purposes) through the URL path. The following sets a cookie titled **opensource** to the value **awesome**:
|
||||
|
||||
|
||||
```
|
||||
$ http GET <https://httpbin.org/cookies/set/opensource/awesome>
|
||||
HTTP/1.1 302 FOUND
|
||||
Access-Control-Allow-Credentials: true
|
||||
Access-Control-Allow-Origin: *
|
||||
Connection: keep-alive
|
||||
Content-Length: 223
|
||||
Content-Type: text/html; charset=utf-8
|
||||
Date: Fri, 09 Aug 2019 20:22:39 GMT
|
||||
Location: /cookies
|
||||
Referrer-Policy: no-referrer-when-downgrade
|
||||
Server: nginx
|
||||
Set-Cookie: opensource=awesome; Path=/
|
||||
X-Content-Type-Options: nosniff
|
||||
X-Frame-Options: DENY
|
||||
X-XSS-Protection: 1; mode=block
|
||||
|
||||
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
|
||||
<title>Redirecting...</title>
|
||||
<h1>Redirecting...</h1>
|
||||
<p>You should be redirected automatically to target URL:
|
||||
<a href="/cookies">/cookies</a>. If not click the link.
|
||||
```
|
||||
|
||||
Notice the **Set-Cookie: opensource=awesome; Path=/** header. This shows the cookie you expected to be set is set correctly and with a **/** path. Also notice that, even though you got a **302** redirect, **http** did not follow it. If you want to follow redirects, you need to ask for it explicitly with the **\--follow** flag:
|
||||
|
||||
|
||||
```
|
||||
$ http --follow GET <https://httpbin.org/cookies/set/opensource/awesome>
|
||||
HTTP/1.1 200 OK
|
||||
Access-Control-Allow-Credentials: true
|
||||
Access-Control-Allow-Origin: *
|
||||
Connection: keep-alive
|
||||
Content-Encoding: gzip
|
||||
Content-Length: 66
|
||||
Content-Type: application/json
|
||||
Date: Sat, 10 Aug 2019 01:33:34 GMT
|
||||
Referrer-Policy: no-referrer-when-downgrade
|
||||
Server: nginx
|
||||
X-Content-Type-Options: nosniff
|
||||
X-Frame-Options: DENY
|
||||
X-XSS-Protection: 1; mode=block
|
||||
|
||||
{
|
||||
"cookies": {
|
||||
"opensource": "awesome"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
But now you cannot see the original **Set-Cookie** header. In order to see intermediate replies, you need to use **\--all**:
|
||||
|
||||
|
||||
```
|
||||
$ http --headers --all --follow \
|
||||
GET <https://httpbin.org/cookies/set/opensource/awesome>
|
||||
HTTP/1.1 302 FOUND
|
||||
Access-Control-Allow-Credentials: true
|
||||
Access-Control-Allow-Origin: *
|
||||
Content-Type: text/html; charset=utf-8
|
||||
Date: Sat, 10 Aug 2019 01:38:40 GMT
|
||||
Location: /cookies
|
||||
Referrer-Policy: no-referrer-when-downgrade
|
||||
Server: nginx
|
||||
Set-Cookie: opensource=awesome; Path=/
|
||||
X-Content-Type-Options: nosniff
|
||||
X-Frame-Options: DENY
|
||||
X-XSS-Protection: 1; mode=block
|
||||
Content-Length: 223
|
||||
Connection: keep-alive
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Access-Control-Allow-Credentials: true
|
||||
Access-Control-Allow-Origin: *
|
||||
Content-Encoding: gzip
|
||||
Content-Type: application/json
|
||||
Date: Sat, 10 Aug 2019 01:38:41 GMT
|
||||
Referrer-Policy: no-referrer-when-downgrade
|
||||
Server: nginx
|
||||
X-Content-Type-Options: nosniff
|
||||
X-Frame-Options: DENY
|
||||
X-XSS-Protection: 1; mode=block
|
||||
Content-Length: 66
|
||||
Connection: keep-alive
|
||||
```
|
||||
|
||||
Printing the body is uninteresting because you are mostly interested in the cookies. If you want to see the headers from the intermediate request but the body from the final request, you can do that with:
|
||||
|
||||
|
||||
```
|
||||
$ http --print hb --history-print h --all --follow \
|
||||
GET <https://httpbin.org/cookies/set/opensource/awesome>
|
||||
HTTP/1.1 302 FOUND
|
||||
Access-Control-Allow-Credentials: true
|
||||
Access-Control-Allow-Origin: *
|
||||
Content-Type: text/html; charset=utf-8
|
||||
Date: Sat, 10 Aug 2019 01:40:56 GMT
|
||||
Location: /cookies
|
||||
Referrer-Policy: no-referrer-when-downgrade
|
||||
Server: nginx
|
||||
Set-Cookie: opensource=awesome; Path=/
|
||||
X-Content-Type-Options: nosniff
|
||||
X-Frame-Options: DENY
|
||||
X-XSS-Protection: 1; mode=block
|
||||
Content-Length: 223
|
||||
Connection: keep-alive
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Access-Control-Allow-Credentials: true
|
||||
Access-Control-Allow-Origin: *
|
||||
Content-Encoding: gzip
|
||||
Content-Type: application/json
|
||||
Date: Sat, 10 Aug 2019 01:40:56 GMT
|
||||
Referrer-Policy: no-referrer-when-downgrade
|
||||
Server: nginx
|
||||
X-Content-Type-Options: nosniff
|
||||
X-Frame-Options: DENY
|
||||
X-XSS-Protection: 1; mode=block
|
||||
Content-Length: 66
|
||||
Connection: keep-alive
|
||||
|
||||
{
|
||||
"cookies": {
|
||||
"opensource": "awesome"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You can control exactly what is being printed with **\--print** and override what is printed for intermediate requests with **\--history-print**.
|
||||
|
||||
### Download binary files with HTTPie
|
||||
|
||||
Sometimes the body is non-textual and needs to be sent to a file that can be opened by a different application:
|
||||
|
||||
|
||||
```
|
||||
$ http GET <https://httpbin.org/image/jpeg>
|
||||
HTTP/1.1 200 OK
|
||||
Access-Control-Allow-Credentials: true
|
||||
Access-Control-Allow-Origin: *
|
||||
Connection: keep-alive
|
||||
Content-Length: 35588
|
||||
Content-Type: image/jpeg
|
||||
Date: Fri, 09 Aug 2019 20:25:49 GMT
|
||||
Referrer-Policy: no-referrer-when-downgrade
|
||||
Server: nginx
|
||||
X-Content-Type-Options: nosniff
|
||||
X-Frame-Options: DENY
|
||||
X-XSS-Protection: 1; mode=block
|
||||
|
||||
+-----------------------------------------+
|
||||
| NOTE: binary data not shown in terminal |
|
||||
+-----------------------------------------+
|
||||
```
|
||||
|
||||
To get the right image, you need to save it to a file:
|
||||
|
||||
|
||||
```
|
||||
$ http --download GET <https://httpbin.org/image/jpeg>
|
||||
HTTP/1.1 200 OK
|
||||
Access-Control-Allow-Credentials: true
|
||||
Access-Control-Allow-Origin: *
|
||||
Connection: keep-alive
|
||||
Content-Length: 35588
|
||||
Content-Type: image/jpeg
|
||||
Date: Fri, 09 Aug 2019 20:28:13 GMT
|
||||
Referrer-Policy: no-referrer-when-downgrade
|
||||
Server: nginx
|
||||
X-Content-Type-Options: nosniff
|
||||
X-Frame-Options: DENY
|
||||
X-XSS-Protection: 1; mode=block
|
||||
|
||||
Downloading 34.75 kB to "jpeg.jpe"
|
||||
Done. 34.75 kB in 0.00068s (50.05 MB/s)
|
||||
```
|
||||
|
||||
Try it! The picture is adorable.
|
||||
|
||||
### Sending custom requests with HTTPie
|
||||
|
||||
You can also send specific headers. This is useful for custom web APIs that require a non-standard header:
|
||||
|
||||
|
||||
```
|
||||
$ http GET <https://httpbin.org/headers> X-Open-Source-Com:Awesome
|
||||
{
|
||||
"headers": {
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate",
|
||||
"Host": "httpbin.org",
|
||||
"User-Agent": "HTTPie/1.0.2",
|
||||
"X-Open-Source-Com": "Awesome"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Finally, if you want to send JSON fields (although it is possible to specify exact content), for many less-nested inputs, you can use a shortcut:
|
||||
|
||||
|
||||
```
|
||||
$ http --body PUT <https://httpbin.org/anything> open-source=awesome author=moshez
|
||||
{
|
||||
"args": {},
|
||||
"data": "{\"open-source\": \"awesome\", \"author\": \"moshez\"}",
|
||||
"files": {},
|
||||
"form": {},
|
||||
"headers": {
|
||||
"Accept": "application/json, */*",
|
||||
"Accept-Encoding": "gzip, deflate",
|
||||
"Content-Length": "46",
|
||||
"Content-Type": "application/json",
|
||||
"Host": "httpbin.org",
|
||||
"User-Agent": "HTTPie/1.0.2"
|
||||
},
|
||||
"json": {
|
||||
"author": "moshez",
|
||||
"open-source": "awesome"
|
||||
},
|
||||
"method": "PUT",
|
||||
"origin": "73.162.254.113, 73.162.254.113",
|
||||
"url": "<https://httpbin.org/anything>"
|
||||
}
|
||||
```
|
||||
|
||||
The next time you are debugging a web API, whether your own or someone else's, put down your cURL and reach for HTTPie, the command-line client for web APIs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/getting-started-httpie
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshezhttps://opensource.com/users/mkalindepauleduhttps://opensource.com/users/jamesf
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/pie-raspberry-bake-make-food.png?itok=QRV_R8Fa (Raspberry pie with slice missing)
|
||||
[2]: https://httpie.org/
|
||||
[3]: https://github.com/postmanlabs/httpbin
|
||||
[4]: https://en.wikipedia.org/wiki/Wget
|
||||
[5]: https://en.wikipedia.org/wiki/CURL
|
||||
[6]: https://opensource.com/article/19/6/virtual-environments-python-macos
|
||||
@ -0,0 +1,146 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Three Ways to Exclude Specific/Certain Packages from Yum Update)
|
||||
[#]: via: (https://www.2daygeek.com/redhat-centos-yum-update-exclude-specific-packages/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Three Ways to Exclude Specific/Certain Packages from Yum Update
|
||||
======
|
||||
|
||||
As part of system update, you may need to exclude few of the packages due to application dependency in Red Hat based system.
|
||||
|
||||
If yes, how to exclude, how many ways that can be done.
|
||||
|
||||
Yes, it can be done in three ways, we will teach you all three methods in this article.
|
||||
|
||||
A package manager is a collection of tools that allow users to easily manage packages in Linux system.
|
||||
|
||||
It allows users to install, update/upgrade, remove, query, re-install, and search packages in Linux system.
|
||||
|
||||
For Red Hat and it’s clone, we uses **[yum Package Manager][1]** and **[rpm Package Manager][2]** for package management.
|
||||
|
||||
### What’s yum?
|
||||
|
||||
yum stands for Yellowdog Updater, Modified. Yum is an automatic updater and package installer/remover for rpm systems.
|
||||
|
||||
It automatically resolve dependencies when installing a package.
|
||||
|
||||
### What’s rpm?
|
||||
|
||||
rpm stands for Red Hat Package Manager is a powerful package management tool for Red Hat system.
|
||||
|
||||
The name RPM refers to `.rpm` file format that containing compiled software’s and necessary libraries for the package.
|
||||
|
||||
You may interested to read the following articles, which is related to this topic. If so, navigate to appropriate links.
|
||||
|
||||
* **[How To Check Available Security Updates On Red Hat (RHEL) And CentOS System][3]**
|
||||
* **[Four Ways To Install Security Updates On Red Hat (RHEL) And CentOS Systems][4]**
|
||||
* **[Two Methods To Check Or List Installed Security Updates on Redhat (RHEL) And CentOS System][5]**
|
||||
|
||||
|
||||
|
||||
### Method-1: Exclude Packages with yum Command Manually or Temporarily
|
||||
|
||||
We can use `--exclude or -x` switch with yum command to exclude specific packages from getting updated through yum command.
|
||||
|
||||
I can say, this is a temporary method or On-Demand method. If you want to exclude specific package only once then we can go with this method.
|
||||
|
||||
The below command will update all packages except kernel.
|
||||
|
||||
To exclude single package.
|
||||
|
||||
```
|
||||
# yum update --exclude=kernel
|
||||
|
||||
or
|
||||
|
||||
# yum update -x 'kernel'
|
||||
```
|
||||
|
||||
To exclude multiple packages. The below command will update all packages except kernel and php.
|
||||
|
||||
```
|
||||
# yum update --exclude=kernel* --exclude=php*
|
||||
|
||||
or
|
||||
|
||||
# yum update --exclude httpd,php
|
||||
```
|
||||
|
||||
### Method-2: Exclude Packages with yum Command Permanently
|
||||
|
||||
This is permanent method and you can use this, if you are frequently performing the patch update.
|
||||
|
||||
To do so, add the required packages in /etc/yum.conf to disable packages updates permanently.
|
||||
|
||||
Once you add an entry, you don’t need to specify these package each time you run yum update command. Also, this prevent packages from any accidental update.
|
||||
|
||||
```
|
||||
# vi /etc/yum.conf
|
||||
|
||||
[main]
|
||||
cachedir=/var/cache/yum/$basearch/$releasever
|
||||
keepcache=0
|
||||
debuglevel=2
|
||||
logfile=/var/log/yum.log
|
||||
exactarch=1
|
||||
obsoletes=1
|
||||
gpgcheck=1
|
||||
plugins=1
|
||||
installonly_limit=3
|
||||
exclude=kernel* php*
|
||||
```
|
||||
|
||||
### Method-3: Exclude Packages Using Yum versionlock plugin
|
||||
|
||||
This is also permanent method similar to above. Yum versionlock plugin allow users to lock specified packages from being updated through yum command.
|
||||
|
||||
To do so, run the following command. The below command will exclude the freetype package from yum update.
|
||||
|
||||
Alternatively, you can add the package entry directly in “/etc/yum/pluginconf.d/versionlock.list” file.
|
||||
|
||||
```
|
||||
# yum versionlock add freetype
|
||||
|
||||
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
|
||||
Adding versionlock on: 0:freetype-2.8-12.el7
|
||||
versionlock added: 1
|
||||
```
|
||||
|
||||
Run the following command to check the list of packages locked by versionlock plugin.
|
||||
|
||||
```
|
||||
# yum versionlock list
|
||||
|
||||
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
|
||||
0:freetype-2.8-12.el7.*
|
||||
versionlock list done
|
||||
```
|
||||
|
||||
Run the following command to discards the list.
|
||||
|
||||
```
|
||||
# yum versionlock clear
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/redhat-centos-yum-update-exclude-specific-packages/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[2]: https://www.2daygeek.com/rpm-command-examples/
|
||||
[3]: https://www.2daygeek.com/check-list-view-find-available-security-updates-on-redhat-rhel-centos-system/
|
||||
[4]: https://www.2daygeek.com/install-security-updates-on-redhat-rhel-centos-system/
|
||||
[5]: https://www.2daygeek.com/check-installed-security-updates-on-redhat-rhel-and-centos-system/
|
||||
138
sources/tech/20190829 Variables in PowerShell.md
Normal file
138
sources/tech/20190829 Variables in PowerShell.md
Normal file
@ -0,0 +1,138 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Variables in PowerShell)
|
||||
[#]: via: (https://opensource.com/article/19/8/variables-powershell)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Variables in PowerShell
|
||||
======
|
||||
In our miniseries Variables in Shells, learn how to handle local
|
||||
variables in PowerShell.
|
||||
![Shells in a competition][1]
|
||||
|
||||
In computer science (and casual computing), a variable is a location in memory that holds arbitrary information for later use. In other words, it’s a temporary storage container for you to put data into and get data out of. In the Bash shell, that data can be a word (a _string_, in computer lingo) or a number (an _integer_).
|
||||
|
||||
You may have never (knowingly) used a variable before on your computer, but you probably have used a variable in another area of your life. When you say things like "give me that" or "look at this," you’re using grammatical variables (you think of them as _pronouns_). The meaning of "this" and "that" depends on whatever you’re picturing in your mind, or whatever you’re pointing to as an indicator for your audience to know what you’re referring to. When you do math, you use variables to stand in for unknown values, even though you probably don’t call them variables.
|
||||
|
||||
This article addresses variables in [PowerShell][2], which runs on Windows, Linux, or Mac. Users of the open source [Bash][3] shell should refer to my article about variables in the Bash shell instead (although you can run PowerShell on Linux, and it is open source, so you can still follow along with this article).
|
||||
|
||||
**Note:** The examples in this article are from a PowerShell session running on the open source operating system Linux, so if you’re on Windows or Mac the file paths will differ. However, Windows converts **/** to **\** automatically, and all examples work across all platforms, provided that you substitute obvious differences (for instance, it is statistically unlikely that your username is **seth**).
|
||||
|
||||
### What are variables for?
|
||||
|
||||
Whether you need variables in PowerShell depends on what you do in a terminal. For some users, variables are an essential means of managing data, while for others they’re minor and temporary conveniences, or for some, they may as well not exist.
|
||||
|
||||
Ultimately, variables are a tool. You can use them when you find a use for them, or leave them alone in the comfort of knowing they’re managed by your OS. Knowledge is power, though, and understanding how variables work in Bash can lead you to all kinds of unexpected creative problem-solving.
|
||||
|
||||
### Set a variable
|
||||
|
||||
You don’t need special permissions to create a variable. They’re free to create, free to use, and generally harmless. In PowerShell, you create a variable by defining a variable name and then setting its value with the **Set-Variable** command. The example below creates a new variable called **FOO** and sets its value to the string **$HOME/Documents**:
|
||||
|
||||
|
||||
```
|
||||
`PS> Set-Variable -Name FOO -Value "$HOME/Documents"`
|
||||
```
|
||||
|
||||
Success is eerily silent, so you may not feel confident that your variable got set. You can see the results for yourself with the **Get-Variable** (**gv** for short) command. To ensure that the variable is read exactly as you defined it, you can also wrap it in quotes. Doing so preserves any special characters that might appear in the variable; in this example, that doesn’t apply, but it’s still a good habit to form:
|
||||
|
||||
|
||||
```
|
||||
PS> Get-Variable "FOO" -valueOnly
|
||||
/home/seth/Documents
|
||||
```
|
||||
|
||||
Notice that the contents of **FOO** aren’t exactly what you set. The literal string you set for the variable was **$HOME/Documents**, but now it’s showing up as **/home/seth/Documents**. This happened because you can nest variables. The **$HOME** variable points to the current user’s home directory, whether it’s in **C:\Users** on Windows, **/home** on Linux, or **/Users** on Mac. Since **$HOME** was embedded in **FOO**, that variable gets _expanded_ when recalled. Using default variables in this way helps you write portable scripts that operate across platforms.
|
||||
|
||||
Variables usually are meant to convey information from one system to another. In this simple example, your variable is not very useful, but it can still communicate information. For instance, because the content of the **FOO** variable is a [file path][4], you can use **FOO** as a shortcut to the directory its value references.
|
||||
|
||||
To reference the variable **FOO**’s _contents_ and not the variable itself, prepend the variable with a dollar sign (**$**):
|
||||
|
||||
|
||||
```
|
||||
PS> pwd
|
||||
/home/seth
|
||||
PS> cd "$FOO"
|
||||
PS> pwd
|
||||
/home/seth/Documents
|
||||
```
|
||||
|
||||
### Clear a variable
|
||||
|
||||
You can remove a variable with the **Remove-Variable** command:
|
||||
|
||||
|
||||
```
|
||||
PS> Remove-Variable -Name "FOO"
|
||||
PS> gv "FOO"
|
||||
gv : Cannot find a variable with the name 'FOO'.
|
||||
[...]
|
||||
```
|
||||
|
||||
In practice, removing a variable is not usually necessary. Variables are relatively "cheap," so you can create them and forget them when you don’t need them anymore. However, there may be times you want to ensure a variable is empty to avoid conveying unwanted information to another process that might read that variable.
|
||||
|
||||
### Create a new variable with collision protection
|
||||
|
||||
Sometimes, you may have reason to believe a variable was already set by you or some other process. If you would rather not override it, you can either use **New-Variable**, which is designed to fail if a variable with the same name already exists, or you can use a conditional statement to check for a variable first:
|
||||
|
||||
|
||||
```
|
||||
PS> New-Variable -Name FOO -Value "example"
|
||||
New-Variable : A variable with name 'FOO' already exists.
|
||||
```
|
||||
|
||||
**Note:** In these examples, assume that **FOO** is set to **/home/seth/Documents**.
|
||||
|
||||
Alternately, you can construct a simple **if** statement to check for an existing variable:
|
||||
|
||||
|
||||
```
|
||||
PS> if ( $FOO )
|
||||
>> { gv FOO } else
|
||||
>> { Set-Variable -Name "FOO" -Value "quux" }
|
||||
```
|
||||
|
||||
### Add to a variable
|
||||
|
||||
Instead of overwriting a variable, you can add to an existing one. In PowerShell, variables have diverse types, including string, integer, and array. When choosing to create a variable with, essentially, more than one value, you must decide whether you need a [character-delimited string][5] or an [array][6]. You may not care one way or the other, but the application receiving the variable’s data may expect one or the other, so make your choice based on your target.
|
||||
|
||||
To append data to a string variable, use the **=+** syntax:
|
||||
|
||||
|
||||
```
|
||||
PS> gv FOO
|
||||
foo
|
||||
PS> $FOO =+ "$FOO,bar"
|
||||
PS> gv FOO
|
||||
foo,bar
|
||||
PS> $FOO.getType().Name
|
||||
String
|
||||
```
|
||||
|
||||
Arrays are special types of variables in PowerShell and require an ArrayList object. That’s out of scope for this article, as it requires delving deeper into PowerShell’s .NET internals.
|
||||
|
||||
### Go global with environment variables
|
||||
|
||||
So far the variables created in this article have been _local_, meaning that they apply only to the PowerShell session you create them in. To create variables that are accessible to other processes, you can create environment variables, which will be covered in a future article.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/variables-powershell
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/shelloff.png?itok=L8pjHXjW (Shells in a competition)
|
||||
[2]: https://en.wikipedia.org/wiki/PowerShell
|
||||
[3]: https://www.gnu.org/software/bash/
|
||||
[4]: https://opensource.com/article/19/8/understanding-file-paths-linux
|
||||
[5]: https://en.wikipedia.org/wiki/Delimiter
|
||||
[6]: https://en.wikipedia.org/wiki/Array_data_structure
|
||||
202
sources/tech/20190829 What is an Object in Java.md
Normal file
202
sources/tech/20190829 What is an Object in Java.md
Normal file
@ -0,0 +1,202 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What is an Object in Java?)
|
||||
[#]: via: (https://opensource.com/article/19/8/what-object-java)
|
||||
[#]: author: (Chris Hermansen https://opensource.com/users/clhermansenhttps://opensource.com/users/mdowdenhttps://opensource.com/users/sethhttps://opensource.com/users/drmjghttps://opensource.com/users/jamesfhttps://opensource.com/users/clhermansen)
|
||||
|
||||
What is an Object in Java?
|
||||
======
|
||||
Java's approach to object-oriented programming is the basis for almost
|
||||
everything in the language. Here's what you need to know.
|
||||
![Coffee beans and a cup of coffee][1]
|
||||
|
||||
Java is an object-oriented programming language, which views the world as a collection of objects that have both _properties_ and _behavior_. Java's version of object-orientedness is pretty straightforward, and it's the basis for almost everything in the language. Because it's so essential to Java, I'll explain a bit about what's under the covers to help anyone new to the language.
|
||||
|
||||
### Inheritance
|
||||
|
||||
In general, all [Cartesian geometric objects][2], like circles, squares, triangles, lines, and points, have basic properties, like location and extension. Objects with zero extension, like points, usually don't have anything more than that. Objects like lines have more—e.g., the start and endpoint of a line segment or two points along a line (if it's a "true line"). Objects like squares or triangles have still more—the corner points, for example—whereas circles may have a center and radius.
|
||||
|
||||
We can see there is a simple hierarchy at work here: The general geometric object can be _extended_ into specific geometric objects, like points, lines, squares, etc. Each specific geometric object _inherits_ the basic geometric properties of location and extension and adds its own properties.
|
||||
|
||||
This is an example of _single inheritance_. Java's original object-oriented model allowed only single inheritance, where objects cannot belong to more than one inheritance hierarchy. This design decision comes out of the kinds of ambiguities programmers found themselves facing in [complex multiple-inheritance scenarios][3], typically in cases where "interesting design decisions" led to several possible implementations of the function **foo()** as defined (and re-defined) in the hierarchy.
|
||||
|
||||
Since Java 8, there has been a limited multiple inheritance structure in place that requires specific actions on behalf of the programmer to ensure there are no ambiguities.
|
||||
|
||||
### Strong and static typing
|
||||
|
||||
Java is _strongly_ and _statically_ typed. What does this mean?
|
||||
|
||||
A _statically_ typed language is one where the type of a variable is known at compile time. In this situation, it is not possible to assign a value of type B to a variable whose declared type is A, unless there is a conversion mechanism to turn a value of type B into a value of type A. An example of this type of conversion is turning an integer value, like 1, 2, or 42, into a floating-point value, like 1.0, 2.0, or 42.0.
|
||||
|
||||
A _strongly_ typed language is one where very few (or perhaps no) type conversions are applied automatically. For example, whereas a strongly typed language might permit automatic conversion of _integer_ to _real_, it will never permit automatic conversion of _real_ to _integer_ since that conversion requires either rounding or truncation in the general case.
|
||||
|
||||
### Primitive types, classes, and objects
|
||||
|
||||
Java provides a number of primitive types: _byte_ (an eight-bit signed integer); _short_ (a 16-bit signed integer); _int_ (a 32-bit signed integer); _long_ (a 64-bit signed integer); _float_ (a single precision 32-bit IEEE floating-point number); _double_ (a double precision 64-bit IEEE floating-point number); _boolean_ (true or false); and _char_ (a 16-bit Unicode character).
|
||||
|
||||
Beyond those primitive types, Java allows the programmer to create new types using _class declarations_. Class declarations are used to define object templates, including their properties and behavior. Once a class is declared, _instances_ of that class can generally be created using the **new** keyword. These instances correspond directly to the "objects" we have been discussing. Java comes with a library of useful class definitions, including some simple basic classes such as _String_, which is used to hold a sequence of characters like "Hello, world."
|
||||
|
||||
Let's define a simple message class that contains the name of the sender as well as the message text:
|
||||
|
||||
|
||||
```
|
||||
class Message {
|
||||
[String][4] sender;
|
||||
[String][4] text;
|
||||
public Message([String][4] sender, [String][4] text) {
|
||||
this.sender = sender;
|
||||
this.text = text;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
There are several important things to note in this class declaration:
|
||||
|
||||
1. The class is (by convention) always declared with a leading capital letter.
|
||||
2. The **Message** class contains two properties (or fields):
|
||||
– a String field called **sender**
|
||||
– a String field called **text**
|
||||
Properties or fields are (by convention) always declared with a leading lower-case letter.
|
||||
3. There is some kind of thing that starts with **public Message**.
|
||||
– It is a _method_ (methods define the behavior of an object).
|
||||
– It is used to _construct_ instances of the class **Message**.
|
||||
– Constructor methods always take the same name as the class and are understood to return an instance of the class once it's constructed.
|
||||
– Other methods are (by convention) always declared with a leading lower-case letter.
|
||||
– This constructor is "public," meaning any caller can access it.
|
||||
4. As part of the construction process, some lines start with **this**.
|
||||
– **this** refers to the present instance of the class.
|
||||
– Thus **this.sender** refers to the sender property of the object.
|
||||
– Whereas plain **sender** refers to the parameter of the **Message** constructor method.
|
||||
– Therefore, these two lines are copying the values provided in the call to the constructor into the fields of the object itself.
|
||||
|
||||
|
||||
|
||||
So we have the **Method** class definition. How do we use it? The following code excerpt shows one possible way:
|
||||
|
||||
|
||||
```
|
||||
`Message message = new Message("system", "I/O error");`
|
||||
```
|
||||
|
||||
Here we see:
|
||||
|
||||
1. The declaration of the variable **message** of type **Message**
|
||||
2. The creation of a new instance of the **Message** class with **sender** set to "system" and **text** set to "I/O error"
|
||||
3. The assignment of that new instance of **Message** to the variable **message**
|
||||
4. If later in the code, the variable **message** is assigned a different value (another instance of **Message**) and no other variable was created that referred to this instance of **Message**, then this instance is no longer used by anything and can be garbage-collected.
|
||||
|
||||
|
||||
|
||||
The key thing happening here is that we are creating an object of type **Message** and keeping a reference to that object in the variable **message**.
|
||||
|
||||
We can now use that message; for instance, we can print the values in the **sender** and **text** properties, like this:
|
||||
|
||||
|
||||
```
|
||||
[System][5].out.println("message sender = " + message.sender);
|
||||
[System][5].out.println("message text = " + message.text);
|
||||
```
|
||||
|
||||
This is a very simple and unsophisticated class definition. We can modify this class definition in a number of ways:
|
||||
|
||||
1. We can make the implementation details of properties invisible to callers by using the keyword **private** in front of the declarations, allowing us to change the implementation without affecting callers.
|
||||
2. If we choose to conceal properties in the class, we would then typically define procedures for _getting_ and _setting_ those properties; by convention in Java these would be defined as:
|
||||
– **public String getSender()**
|
||||
– **public String getText()**
|
||||
– **public void setSender(String sender)**
|
||||
– **public void setText(String text)**
|
||||
3. In some cases, we may wish to have "read-only" properties; in those cases, we would not define setters for such properties.
|
||||
4. We can make the constructor of the class invisible to callers by using the **private** keyword instead of **public**. We might wish to do this when we have another class whose responsibility is creating and managing a pool of messages (possibly executing in another process or even on another system).
|
||||
|
||||
|
||||
|
||||
Now, suppose we want a kind of message that records when it was generated. We could declare it this like:
|
||||
|
||||
|
||||
```
|
||||
class TimedMessage extends Message {
|
||||
long creationTime;
|
||||
public TimedMessage([String][4] sender, [String][4] text) {
|
||||
super(sender, text);
|
||||
this.creationTime = [System][5].currentTimeMillis();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Here we see some new things:
|
||||
|
||||
1. **TimedMessage** is _extending_ the **Message** class—that is, **TimedMessage** is inheriting properties and behavior from **Message**.
|
||||
2. The constructor calls the constructor in its parent, or _superclass_, with the values of **sender** and **text** passed in, as **super(sender, text)**, in order to make sure its inherited properties are properly initialized.
|
||||
3. **TimedMessage** adds a new property, **creationTime**, and the constructor sets it to be the current system time in milliseconds.
|
||||
4. Time in milliseconds in Java is kept as a long (64-bit) value (0 is 1 January, 1970 00:00:00 UTC).
|
||||
5. As a bit of an aside, the name **creationTime** suggests it should be a read-only property, which also suggests that the other properties be read-only; that is, **TimedMessage** instances should probably not be reused nor have their properties altered.
|
||||
|
||||
|
||||
|
||||
### The Object class
|
||||
|
||||
"The Object class" sounds like a kind of contradiction in terms, doesn't it? But notice that the first class we defined, **Message**, did not _appear_ to extend anything—but it _actually_ did. All classes that don't specifically extend another class have the class **Object** as their immediate and only parent; therefore, all classes have the **Object** class as their ultimate superclass.
|
||||
|
||||
You can [learn more about the **Object** class][6] in Java's docs. Let's (briefly) review some interesting details:
|
||||
|
||||
1. **Object** has the constructor **Object()**, that is, with no parameters.
|
||||
2. **Object** provides some useful methods to all of its subclasses, including:
|
||||
– **clone()**, which creates and returns a copy of the instance at hand
|
||||
– **equals(Object anotherObject)**, which determines whether **anotherObject** is equal to the instance of **Object** at hand
|
||||
– **finalize()**, which is used to garbage-collect the instance at hand when it is no longer used (see above)
|
||||
– **getClass()**, which returns the class used to declare the instance at hand
|
||||
— The value returned by this is an instance of the [**Class** class][7], which permits learning about the declaring class at runtime—a process referred to _introspection_.
|
||||
3. **hashCode()** is an integer value that gives a nearly unique value for the instance at hand.
|
||||
– If the hash codes of two distinct instances are equal, then they may be equal; a detailed comparison of the properties (and perhaps methods) is necessary to determine complete equality;
|
||||
– If the hash codes are not equal, then the instances are also not equal.
|
||||
– Therefore, hash codes can speed up equality tests.
|
||||
– A hash code can also be used to create a [**HashMap**][8] (a map is an associative array or dictionary that uses the hash code to speed up lookups) and a [**HashSet**][9] (a set is a collection of objects; the programmer can test whether an instance is in a set or not; hash codes are used to speed up the test).
|
||||
4. **notify()**, **notifyAll()**, **wait()**, **wait(long timeout)**, and **wait(long timeout, int nanos)** communicate between collaborating instances executing on separate threads.
|
||||
5. **toString()** produces a printable version of the instance.
|
||||
|
||||
|
||||
|
||||
### Concluding thoughts
|
||||
|
||||
We've touched on some important aspects of object-oriented programming, Java-style. There are six important, related topics that will be covered in future articles:
|
||||
|
||||
* Namespaces and packages
|
||||
* Overriding methods in subclasses—for instance, the String class has its own specific **hashCode()** method that recognizes its meaning as an array of characters; this is accomplished by overriding the **hashCode()** method inherited from Object
|
||||
* Interfaces, which permit describing behavior that must be provided by a class that implements the interface; instances of classes that implement a given interface can be referred to by that interface when the only thing of interest is that specific behavior
|
||||
* Arrays of primitives or classes and collections of classes (such as lists, maps, and sets)
|
||||
* Overloading of methods—where several methods with the same name and similar behavior have different parameters
|
||||
* Using libraries that don't come with the Java distribution
|
||||
|
||||
|
||||
|
||||
Is there anything you would like to read next? Let us know in the comments and stay tuned!
|
||||
|
||||
Michael Dowden takes a look at four Java web frameworks built for scalability.
|
||||
|
||||
Optimizing your Java code requires an understanding of how the different elements in Java interact...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/what-object-java
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansenhttps://opensource.com/users/mdowdenhttps://opensource.com/users/sethhttps://opensource.com/users/drmjghttps://opensource.com/users/jamesfhttps://opensource.com/users/clhermansen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/java-coffee-mug.jpg?itok=Bj6rQo8r (Coffee beans and a cup of coffee)
|
||||
[2]: https://en.wikipedia.org/wiki/Analytic_geometry
|
||||
[3]: https://en.wikipedia.org/wiki/Multiple_inheritance
|
||||
[4]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||
[5]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
|
||||
[6]: https://docs.oracle.com/javase/8/docs/api/java/lang/Object.html
|
||||
[7]: https://docs.oracle.com/javase/8/docs/api/java/lang/Class.html
|
||||
[8]: https://docs.oracle.com/javase/8/docs/api/java/util/HashMap.html
|
||||
[9]: https://docs.oracle.com/javase/8/docs/api/java/util/HashSet.html
|
||||
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Change your Linux terminal color theme)
|
||||
[#]: via: (https://opensource.com/article/19/8/add-color-linux-terminal)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Change your Linux terminal color theme
|
||||
======
|
||||
Your terminal has plenty of options that allow you to theme what you
|
||||
see.
|
||||
![Terminal command prompt on orange background][1]
|
||||
|
||||
If you spend most of your day staring into a terminal, it's only natural that you want it to look pleasing. Beauty is in the eye of the beholder, and terminals have come a long way since the days of CRT serial consoles. So, the chances are good that your software terminal window has plenty of options to theme what you see—however you define beauty.
|
||||
|
||||
### Settings
|
||||
|
||||
Most popular software terminal applications, including GNOME, KDE, and Xfce, ship with the option to change their color theme. Adjusting your theme is as easy as adjusting application preferences. Fedora, RHEL, and Ubuntu ship with GNOME by default, so this article uses that terminal as its example, but the process is similar for Konsole, Xfce terminal, and many others.
|
||||
|
||||
First, navigate to the application's Preferences or Settings panel. In GNOME terminal, you reach it through the Application menu along the top of the screen or in the right corner of the window.
|
||||
|
||||
In Preferences, click the plus symbol (+) next to Profiles to create a new theme profile. In your new profile, click the Colors tab.
|
||||
|
||||
![GNOME Terminal preferences][2]
|
||||
|
||||
In the Colors tab, deselect the Use Colors From System Theme option so that the rest of the window will become active. As a starting point, you can select a built-in color scheme. These include light themes, with bright backgrounds and dark foreground text, as well as dark themes, with dark backgrounds and light foreground text.
|
||||
|
||||
The Default Color swatches define both the foreground and background colors when no other setting (such as settings from the dircolors command) overrides them. The Palette sets the colors defined by the dircolors command. These colors are used by your terminal, in the form of the LS_COLORS environment variable, to add color to the output of the [ls][3] command. If none of them appeal to you, change them on this screen.
|
||||
|
||||
When you're happy with your theme, close the Preferences window.
|
||||
|
||||
To change your terminal to your new profile, click on the Application menu, and select Profile. Choose your new profile and enjoy your custom theme.
|
||||
|
||||
![GNOME Terminal profile selection][4]
|
||||
|
||||
### Command options
|
||||
|
||||
If your terminal doesn't have a fancy settings window, it may still provide options for colors in your launch command. The xterm and rxvt terminals (the old one and the Unicode-enabled variant, sometimes called urxvt or rxvt-unicode) provide such options, so you can still theme your terminal emulator—even without desktop environments and big GUI frameworks.
|
||||
|
||||
The two obvious options are the foreground and background colors, defined by **-fg** and **-bg**, respectively. The argument for each option is the color _name_ rather than its ANSI number. For example:
|
||||
|
||||
|
||||
```
|
||||
`$ urxvt -bg black -fg green`
|
||||
```
|
||||
|
||||
These settings set the default foreground and background. Should any other rule govern the color of a specific file or device type, those colors are used. See the [dircolors][5] command for information on how to set those.
|
||||
|
||||
You can also set the color of the text cursor (not the mouse cursor) with **-cr**:
|
||||
|
||||
|
||||
```
|
||||
`$ urxvt -bg black -fg green -cr teal`
|
||||
```
|
||||
|
||||
![Setting color in urxvt][6]
|
||||
|
||||
Your terminal emulator may have more options, like a border color (**-bd** in rxvt), cursor blink (**-bc** and **+bc** in urxvt), and even background transparency. Refer to your terminal's man page to find out what cool features are available.
|
||||
|
||||
To launch your terminal with your choice of colors, you can add the options either to the command or the menu you use to launch the terminal (such as your Fluxbox menu file, a **.desktop** file in **$HOME/.local/share/applications**, or similar). Alternatively, you can use the [xrdb][7] tool to manage X-related resources (but that's out of scope for this article).
|
||||
|
||||
### Home is where the customization is
|
||||
|
||||
Customizing your Linux machine doesn't mean you have to learn how to program. You can and should make small but meaningful changes to make your digital home feel that much more comfortable. And there's no better place to start than the terminal!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/add-color-linux-terminal
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/terminal_command_linux_desktop_code.jpg?itok=p5sQ6ODE (Terminal command prompt on orange background)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/gnome-terminal-preferences.jpg (GNOME Terminal preferences)
|
||||
[3]: https://opensource.com/article/19/7/master-ls-command
|
||||
[4]: https://opensource.com/sites/default/files/uploads/gnome-terminal-profile-select.jpg (GNOME Terminal profile selection)
|
||||
[5]: http://man7.org/linux/man-pages/man1/dircolors.1.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/urxvt-color.jpg (Setting color in urxvt)
|
||||
[7]: https://www.x.org/releases/X11R7.7/doc/man/man1/xrdb.1.xhtml
|
||||
@ -0,0 +1,110 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Command line quick tips: Using pipes to connect tools)
|
||||
[#]: via: (https://fedoramagazine.org/command-line-quick-tips-using-pipes-to-connect-tools/)
|
||||
[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
Command line quick tips: Using pipes to connect tools
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
One of the most powerful concepts of Linux is carried on from its predecessor, UNIX. Your Fedora system has a bunch of useful, single-purpose utilities available for all sorts of simple operations. Like building blocks, you can attach them in creative and complex ways. _Pipes_ are key to this concept.
|
||||
|
||||
Before you hear about pipes, though, it’s helpful to know the basic concept of input and output. Many utilities in your Fedora system can operate against files. But they can often take input not stored on a disk. You can think of input flowing freely into a process such as a utility as its _standard input_ (also sometimes called _stdin_).
|
||||
|
||||
Similarly, a tool or process can display information to the screen by default. This is often because its default output is connected to the terminal. You can think of the free-flowing output of a process as its _standard output_ (or _stdout_ — go figure!).
|
||||
|
||||
### Examples of standard input and output
|
||||
|
||||
Often when you run a tool, it outputs to the terminal. Take for instance this simple sequence command using the _seq_ tool:
|
||||
|
||||
```
|
||||
$ seq 1 6
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
```
|
||||
|
||||
The output, which is simply to count integers up from 1 to 6, one number per line, comes to the screen. But you could also send it to a file using the **>** character. The shell interpreter uses this character to mean “redirect _standard output_ to a file whose name follows.” So as you can guess, this command puts the output into a file called _six.txt:_
|
||||
|
||||
```
|
||||
$ seq 1 6 > six.txt
|
||||
```
|
||||
|
||||
Notice nothing comes to the screen. You’ve sent the ouptut into a file instead. If you run the command _cat six.txt_ you can verify that.
|
||||
|
||||
You probably remember the simple use of the _grep_ command [from a previous article][2]. You could ask _grep_ to search for a pattern in a file by simply declaring the file name. But that’s simply a convenience feature in _grep_. Technically it’s built to take _standard input_, and search that.
|
||||
|
||||
The shell uses the **<** character similarly to mean “redirect _standard input_ from a file whose name follows.” So you could just as well search for the number **4** in the file _six.txt_ this way:
|
||||
|
||||
```
|
||||
$ grep 4 < six.txt
|
||||
4
|
||||
```
|
||||
|
||||
Of course the output here is, by default, the content of any line with a match. So _grep_ finds the digit **4** in the file and outputs that line to _standard output_.
|
||||
|
||||
### Introducing pipes
|
||||
|
||||
Now imagine: what if you took the standard output of one tool, and instead of sending it to the terminal, you sent it into another tool’s standard input? This is the essence of the pipe.
|
||||
|
||||
Your shell uses the vertical bar character **|** to represent a pipe between two commands. You can find it on most keyboard above the backslash **\** character. It’s used like this:
|
||||
|
||||
```
|
||||
$ command1 | command2
|
||||
```
|
||||
|
||||
For most simple utilities, you wouldn’t use an output filename option on _command1_, nor an input file option on _command2_. (You might use other options, though.) Instead of using files, you’re sending the output of _command1_ directly into _command2_. You can use as many pipes in a row as needed, creating complex pipelines of several commands in a row.
|
||||
|
||||
This (relatively useless) example combines the commands above:
|
||||
|
||||
```
|
||||
$ seq 1 6 | grep 4
|
||||
4
|
||||
```
|
||||
|
||||
What happened here? The _seq_ command outputs the integers 1 through 6, one line at a time. The _grep_ command processes that output line by line, searching for a match on the digit **4**, and outputs any matching line.
|
||||
|
||||
Here’s a slightly more useful example. Let’s say you want to find out if TCP port 22, the _ssh_ port, is open on your system. You could find this out using the _ss_ command* by looking through its copious output. Or you could figure out its filter language and use that. Or you could use pipes. For example, pipe it through _grep_ looking for the _ssh_ port label:
|
||||
|
||||
```
|
||||
$ ss -tl | grep ssh
|
||||
LISTEN 0 128 0.0.0.0:ssh 0.0.0.0:*
|
||||
LISTEN 0 128 [::]:ssh [::]:*
|
||||
```
|
||||
|
||||
_* Those readers familiar with the venerable_ netstat _command may note it is mostly obsolete, as stated in its [man page][3]._
|
||||
|
||||
That’s a lot easier than reading through many lines of output. And of course, you can combine redirectors and pipes, for instance:
|
||||
|
||||
```
|
||||
$ ss -tl | grep ssh > ssh-listening.txt
|
||||
```
|
||||
|
||||
This is barely scratching the surface of pipes. Let your imagination run wild. Have fun piping!
|
||||
|
||||
* * *
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/command-line-quick-tips-using-pipes-to-connect-tools/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2018/10/commandlinequicktips-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/command-line-quick-tips-searching-with-grep/
|
||||
[3]: https://linux.die.net/man/8/netstat
|
||||
@ -0,0 +1,261 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Create and Use Swap File on Linux)
|
||||
[#]: via: (https://itsfoss.com/create-swap-file-linux/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to Create and Use Swap File on Linux
|
||||
======
|
||||
|
||||
This tutorial discusses the concept of swap file in Linux, why it is used and its advantages over the traditional swap partition. You’ll learn how to create swap file or resize it.
|
||||
|
||||
### What is a swap file in Linux?
|
||||
|
||||
A swap file allows Linux to simulate the disk space as RAM. When your system starts running out of RAM, it uses the swap space to and swaps some content of the RAM on to the disk space. This frees up the RAM to serve more important processes. When the RAM is free again, it swaps back the data from the disk. I recommend [reading this article to learn more about swap on Linux][1].
|
||||
|
||||
Traditionally, swap space is used as a separate partition on the disk. When you install Linux, you create a separate partition just for swap. But this trend has changed in the recent years.
|
||||
|
||||
With swap file, you don’t need a separate partition anymore. You create a file under root and tell your system to use it as the swap space.
|
||||
|
||||
With dedicated swap partition, resizing the swap space is a nightmare and an impossible task in many cases. But with swap files, you can resize them as you like.
|
||||
|
||||
Recent versions of Ubuntu and some other Linux distributions have started [using the swap file by default][2]. Even if you don’t create a swap partition, Ubuntu creates a swap file of around 1 GB on its own.
|
||||
|
||||
Let’s see some more on swap files.
|
||||
|
||||
![][3]
|
||||
|
||||
### Check swap space in Linux
|
||||
|
||||
Before you go and start adding swap space, it would be a good idea to check whether you have swap space already available in your system.
|
||||
|
||||
You can check it with the [free command in Linux][4]. In my case, my [Dell XPS][5] has 14GB of swap.
|
||||
|
||||
```
|
||||
free -h
|
||||
total used free shared buff/cache available
|
||||
Mem: 7.5G 4.1G 267M 971M 3.1G 2.2G
|
||||
Swap: 14G 0B 14G
|
||||
```
|
||||
|
||||
The free command gives you the size of the swap space but it doesn’t tell you if it’s a real swap partition or a swap file. The swapon command is better in this regard.
|
||||
|
||||
```
|
||||
swapon --show
|
||||
NAME TYPE SIZE USED PRIO
|
||||
/dev/nvme0n1p4 partition 14.9G 0B -2
|
||||
```
|
||||
|
||||
As you can see, I have 14.9 GB of swap space and it’s on a separate partition. If it was a swap file, the type would have been file instead of partition.
|
||||
|
||||
```
|
||||
swapon --show
|
||||
NAME TYPE SIZE USED PRIO
|
||||
/swapfile file 2G 0B -2
|
||||
```
|
||||
|
||||
If you don’ have a swap space on your system, it should show something like this:
|
||||
|
||||
```
|
||||
free -h
|
||||
total used free shared buff/cache available
|
||||
Mem: 7.5G 4.1G 267M 971M 3.1G 2.2G
|
||||
Swap: 0B 0B 0B
|
||||
```
|
||||
|
||||
The swapon command won’t show any output.
|
||||
|
||||
### Create swap file on Linux
|
||||
|
||||
If your system doesn’t have swap space or if you think the swap space is not adequate enough, you can create swap file on Linux. You can create multiple swap files as well.
|
||||
|
||||
[][6]
|
||||
|
||||
Suggested read Fix Missing System Settings In Ubuntu 14.04 [Quick Tip]
|
||||
|
||||
Let’s see how to create swap file on Linux. I am using Ubuntu 18.04 in this tutorial but it should work on other Linux distributions as well.
|
||||
|
||||
#### Step 1: Make a new swap file
|
||||
|
||||
First thing first, create a file with the size of swap space you want. Let’s say that I want to add 1 GB of swap space to my system. Use the fallocate command to create a file of size 1 GB.
|
||||
|
||||
```
|
||||
sudo fallocate -l 1G /swapfile
|
||||
```
|
||||
|
||||
It is recommended to allow only root to read and write to the swap file. You’ll even see warning like “insecure permissions 0644, 0600 suggested” when you try to use this file for swap area.
|
||||
|
||||
```
|
||||
sudo chmod 600 /swapfile
|
||||
```
|
||||
|
||||
Do note that the name of the swap file could be anything. If you need multiple swap spaces, you can give it any appropriate name like swap_file_1, swap_file_2 etc. It’s just a file with a predefined size.
|
||||
|
||||
#### Step 2: Mark the new file as swap space
|
||||
|
||||
Your need to tell the Linux system that this file will be used as swap space. You can do that with [mkswap][7] tool.
|
||||
|
||||
```
|
||||
sudo mkswap /swapfile
|
||||
```
|
||||
|
||||
You should see an output like this:
|
||||
|
||||
```
|
||||
Setting up swapspace version 1, size = 1024 MiB (1073737728 bytes)
|
||||
no label, UUID=7e1faacb-ea93-4c49-a53d-fb40f3ce016a
|
||||
```
|
||||
|
||||
#### Step 3: Enable the swap file
|
||||
|
||||
Now your system knows that the file swapfile can be used as swap space. But it is not done yet. You need to enable the swap file so that your system can start using this file as swap.
|
||||
|
||||
```
|
||||
sudo swapon /swapfile
|
||||
```
|
||||
|
||||
Now if you check the swap space, you should see that your Linux system recognizes and uses it as the swap area:
|
||||
|
||||
```
|
||||
swapon --show
|
||||
NAME TYPE SIZE USED PRIO
|
||||
/swapfile file 1024M 0B -2
|
||||
```
|
||||
|
||||
#### Step 4: Make the changes permanent
|
||||
|
||||
Whatever you have done so far is temporary. Reboot your system and all the changes will disappear.
|
||||
|
||||
You can make the changes permanent by adding the newly created swap file to /etc/fstab file.
|
||||
|
||||
It’s always a good idea to make a backup before you make any changes to the /etc/fstab file.
|
||||
|
||||
```
|
||||
sudo cp /etc/fstab /etc/fstab.back
|
||||
```
|
||||
|
||||
Now you can add the following line to the end of /etc/fstab file:
|
||||
|
||||
```
|
||||
/swapfile none swap sw 0 0
|
||||
```
|
||||
|
||||
You can do it manually using a [command line text editor][8] or you just use the following command:
|
||||
|
||||
```
|
||||
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
|
||||
```
|
||||
|
||||
Now you have everything in place. Your swap file will be used even after you reboot your Linux system.
|
||||
|
||||
### Adjust swappiness
|
||||
|
||||
The swappiness parameters determines how often the swap space should be used. The swappiness value ranges from 0 to 100. Higher value means the swap space will be used more frequently.
|
||||
|
||||
The default swappiness in Ubuntu desktop is 60 while in server it is 1. You can check the swappiness with the following command:
|
||||
|
||||
```
|
||||
cat /proc/sys/vm/swappiness
|
||||
```
|
||||
|
||||
Why servers should use a low swappiness? Because swap is slower than RAM and for a better performance, the RAM should be utilized as much as possible. On servers, the performance factor is crucial and hence the swappinness is as low as possible.
|
||||
|
||||
[][9]
|
||||
|
||||
Suggested read How to Replace One Linux Distribution With Another From Dual Boot [Keeping Home Partition]
|
||||
|
||||
You can change the swappiness on the fly using the following systemd command:
|
||||
|
||||
```
|
||||
sudo sysctl vm.swappiness=25
|
||||
```
|
||||
|
||||
This change it only temporary though. If you want to make it permanent, you can edit the /etc/sysctl.conf file and add the swappiness value in the end of the file:
|
||||
|
||||
```
|
||||
vm.swappiness=25
|
||||
```
|
||||
|
||||
### Resizing swap space on Linux
|
||||
|
||||
There are a couple of ways you can resize the swap space on Linux. But before you see that, you should learn a few things around it.
|
||||
|
||||
When you ask your system to stop using a swap file for swap area, it transfers all the data (pages to be precise) back to RAM. So you should have enough free RAM before you swap off.
|
||||
|
||||
This is why a good practice is to create and enable another temporary swap file. This way, when you swap off the original swap area, your system will use the temporary swap file. Now you can resize the original swap space. You can manually remove the temporary swap file or leave it as it is and it will be automatically deleted on the next boot.
|
||||
|
||||
If you have enough free RAM or if you created a temporary swap space, swapoff your original file.
|
||||
|
||||
```
|
||||
sudo swapoff /swapfile
|
||||
```
|
||||
|
||||
Now you can use fallocate command to change the size of the file. Let’s say, you change it to 2 GB in size:
|
||||
|
||||
```
|
||||
sudo fallocate -l 2G /swapfile
|
||||
```
|
||||
|
||||
Now mark the file as swap space again:
|
||||
|
||||
```
|
||||
sudo mkswap /swapfile
|
||||
```
|
||||
|
||||
And turn the swap on again:
|
||||
|
||||
```
|
||||
sudo swapon /swapfile
|
||||
```
|
||||
|
||||
You may also choose to have multiple swap files at the same time.
|
||||
|
||||
### Removing swap file in Linux
|
||||
|
||||
You may have your reasons for not using swap file on Linux. If you want to remove it, the process is similar to what you just saw in resizing the swap.
|
||||
|
||||
First, make sure that you have enough free RAM. Now swap off the file:
|
||||
|
||||
```
|
||||
sudo swapoff /swapfile
|
||||
```
|
||||
|
||||
The next step is to remove the respective entry from the /etc/fstab file.
|
||||
|
||||
And in the end, you can remove the file to free up the space:
|
||||
|
||||
```
|
||||
sudo rm /swapfile
|
||||
```
|
||||
|
||||
**Do you swap?**
|
||||
|
||||
I think you now have a good understanding of swap file concept in Linux. You can now easily create swap file or resize them as per your need.
|
||||
|
||||
If you have anything to add on this topic or if you have any doubts, please leave a comment below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/create-swap-file-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/swap-size/
|
||||
[2]: https://help.ubuntu.com/community/SwapFaq
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/swap-file-linux.png?resize=800%2C450&ssl=1
|
||||
[4]: https://linuxhandbook.com/free-command/
|
||||
[5]: https://itsfoss.com/dell-xps-13-ubuntu-review/
|
||||
[6]: https://itsfoss.com/fix-missing-system-settings-ubuntu-1404-quick-tip/
|
||||
[7]: http://man7.org/linux/man-pages/man8/mkswap.8.html
|
||||
[8]: https://itsfoss.com/command-line-text-editors-linux/
|
||||
[9]: https://itsfoss.com/replace-linux-from-dual-boot/
|
||||
191
sources/tech/20190830 How to Install Linux on Intel NUC.md
Normal file
191
sources/tech/20190830 How to Install Linux on Intel NUC.md
Normal file
@ -0,0 +1,191 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Install Linux on Intel NUC)
|
||||
[#]: via: (https://itsfoss.com/install-linux-on-intel-nuc/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to Install Linux on Intel NUC
|
||||
======
|
||||
|
||||
The previous week, I got myself an [Intel NUC][1]. Though it is a tiny device, it is equivalent to a full-fledged desktop CPU. Most of the [Linux-based mini PCs][2] are actually built on top of the Intel NUC devices.
|
||||
|
||||
I got the ‘barebone’ NUC with 8th generation Core i3 processor. Barebone means that the device has no RAM, no hard disk and obviously, no operating system. I added an [8GB RAM from Crucial][3] (around $33) and a [240 GB Western Digital SSD][4] (around $45).
|
||||
|
||||
Altogether, I had a desktop PC ready in under $400. I already have a screen and keyboard-mouse pair so I am not counting them in the expense.
|
||||
|
||||
![A brand new Intel NUC NUC8i3BEH at my desk with Raspberry Pi 4 lurking behind][5]
|
||||
|
||||
The main reason why I got Intel NUC is that I want to test and review various Linux distributions on real hardware. I have a [Raspberry Pi 4][6] which works as an entry-level desktop but it’s an [ARM][7] device and thus there are only a handful of Linux distributions available for Raspberry Pi.
|
||||
|
||||
_The Amazon links in the article are affiliate links. Please read our [affiliate policy][8]._
|
||||
|
||||
### Installing Linux on Intel NUC
|
||||
|
||||
I started with Ubuntu 18.04 LTS version because that’s what I had available at the moment. You can follow this tutorial for other distributions as well. The steps should remain the same at least till the partition step which is the most important one in the entire procedure.
|
||||
|
||||
#### Step 1: Create a live Linux USB
|
||||
|
||||
Download Ubuntu 18.04 from its website. Use another computer to [create a live Ubuntu USB][9]. You can use a tool like [Rufus][10] or [Etcher][11]. On Ubuntu, you can use the default Startup Disk Creator tool.
|
||||
|
||||
#### Step 2: Make sure the boot order is correct
|
||||
|
||||
Insert your USB and power on the NUC. As soon as you see the Intel NUC written on the screen, press F2 to go to BIOS settings.
|
||||
|
||||
![BIOS Settings in Intel NUC][12]
|
||||
|
||||
In here, just make sure that boot order is set to boot from USB first. If not, change the boot order.
|
||||
|
||||
If you had to make any changes, press F10 to save and exit. Else, use Esc to exit the BIOS.
|
||||
|
||||
#### Step 3: Making the correct partition to install Linux
|
||||
|
||||
Now when it boots again, you’ll see the familiar Grub screen that allows you to try Ubuntu live or install it. Choose to install it.
|
||||
|
||||
[][13]
|
||||
|
||||
Suggested read 3 Ways to Check Linux Kernel Version in Command Line
|
||||
|
||||
First few installation steps are simple. You choose the keyboard layout, and the network connection (if any) and other simple steps.
|
||||
|
||||
![Choose the keyboard layout while installing Ubuntu Linux][14]
|
||||
|
||||
You may go with the normal installation that has a handful of useful applications installed by default.
|
||||
|
||||
![][15]
|
||||
|
||||
The interesting screen comes next. You have two options:
|
||||
|
||||
* **Erase disk and install Ubuntu**: Simplest option that will install Ubuntu on the entire disk. If you want to use only one operating system on the Intel NUC, choose this option and Ubuntu will take care of the rest.
|
||||
* **Something Else**: This is the advanced option if you want to take control of things. In my case, I want to install multiple Linux distribution on the same SSD. So I am opting for this advanced option.
|
||||
|
||||
|
||||
|
||||
![][16]
|
||||
|
||||
_**If you opt for “Erase disk and install Ubuntu”, click continue and go to the step 4.**_
|
||||
|
||||
If you are going with the advanced option, follow the rest of the step 3.
|
||||
|
||||
Select the SSD disk and click on New Partition Table.
|
||||
|
||||
![][17]
|
||||
|
||||
It will show you a warning. Just hit Continue.
|
||||
|
||||
![][18]
|
||||
|
||||
Now you’ll see a free space of the size of your SSD disk. My idea is to create an EFI System Partition for the EFI boot loader, a root partition and a home partition. I am not creating a [swap partition][19]. Ubuntu creates a swap file on its own and if the need be, I can extend the swap by creating additional swap files.
|
||||
|
||||
I’ll leave almost 200 GB of free space on the disk so that I could install other Linux distributions here. You can utilize all of it for your home partitions. Keeping separate root and home partitions help you when you want to save reinstall the system
|
||||
|
||||
Select the free space and click on the plus sign to add a partition.
|
||||
|
||||
![][20]
|
||||
|
||||
Usually 100 MB is sufficient for the EFI but some distributions may need more space so I am going with 500 MB of EFI partition.
|
||||
|
||||
![][21]
|
||||
|
||||
Next, I am using 20 GB of root space. If you are going to use only one distributions, you can increase it to 40 GB easily.
|
||||
|
||||
Root is where the system files are kept. Your program cache and installed applications keep some files under the root directory. I recommend [reading about the Linux filesystem hierarchy][22] to get more knowledge on this topic.
|
||||
|
||||
[][23]
|
||||
|
||||
Suggested read Share Folders On Local Network Between Ubuntu And Windows
|
||||
|
||||
Provide the size, choose Ext4 file system and use / as the mount point.
|
||||
|
||||
![][24]
|
||||
|
||||
The next is to create a home partition. Again, if you want to use only one Linux distribution, go for the remaining free space. Else, choose a suitable disk space for the Home partition.
|
||||
|
||||
Home is where your personal documents, pictures, music, download and other files are stored.
|
||||
|
||||
![][25]
|
||||
|
||||
Now that you have created EFI, root and home partitions, you are ready to install Ubuntu Linux. Hit the Install Now button.
|
||||
|
||||
![][26]
|
||||
|
||||
It will give you a warning about the new changes being written to the disk. Hit continue.
|
||||
|
||||
![][27]
|
||||
|
||||
#### Step 4: Installing Ubuntu Linux
|
||||
|
||||
Things are pretty straightforward from here onward. Choose your time zone right now or change it later.
|
||||
|
||||
![][28]
|
||||
|
||||
On the next screen, choose a username, hostname and the password.
|
||||
|
||||
![][29]
|
||||
|
||||
It’s a wait an watch game for next 7-8 minutes.
|
||||
|
||||
![][30]
|
||||
|
||||
Once the installation is over, you’ll be prompted for a restart.
|
||||
|
||||
![][31]
|
||||
|
||||
When you restart, you should remove the live USB otherwise you’ll boot into the installation media again.
|
||||
|
||||
That’s all you need to do to install Linux on an Intel NUC device. Quite frankly, you can use the same procedure on any other system.
|
||||
|
||||
**Intel NUC and Linux: how do you use it?**
|
||||
|
||||
I am loving the Intel NUC. It doesn’t take space on the desk and yet it is powerful enough to replace the regular bulky desktop CPU. You can easily upgrade it to 32GB of RAM. You can install two SSD on it. Altogether, it provides some scope of configuration and upgrade.
|
||||
|
||||
If you are looking to buy a desktop computer, I highly recommend [Intel NUC][1] mini PC. If you are not comfortable installing the OS on your own, you can [buy one of the Linux-based mini PCs][2].
|
||||
|
||||
Do you own an Intel NUC? How’s your experience with it? Do you have any tips to share it with us? Do leave a comment below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-linux-on-intel-nuc/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.amazon.com/Intel-NUC-Mainstream-Kit-NUC8i3BEH/dp/B07GX4X4PW?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07GX4X4PW (Intel NUC)
|
||||
[2]: https://itsfoss.com/linux-based-mini-pc/
|
||||
[3]: https://www.amazon.com/Crucial-Single-PC4-19200-SODIMM-260-Pin/dp/B01BIWKP58?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01BIWKP58 (8GB RAM from Crucial)
|
||||
[4]: https://www.amazon.com/Western-Digital-240GB-Internal-WDS240G1G0B/dp/B01M9B2VB7?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01M9B2VB7 (240 GB Western Digital SSD)
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/intel-nuc.jpg?resize=800%2C600&ssl=1
|
||||
[6]: https://itsfoss.com/raspberry-pi-4/
|
||||
[7]: https://en.wikipedia.org/wiki/ARM_architecture
|
||||
[8]: https://itsfoss.com/affiliate-policy/
|
||||
[9]: https://itsfoss.com/create-live-usb-of-ubuntu-in-windows/
|
||||
[10]: https://rufus.ie/
|
||||
[11]: https://www.balena.io/etcher/
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/boot-screen-nuc.jpg?ssl=1
|
||||
[13]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
|
||||
[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-1_tutorial.jpg?ssl=1
|
||||
[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-2_tutorial.jpg?ssl=1
|
||||
[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-3_tutorial.jpg?ssl=1
|
||||
[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-4_tutorial.jpg?ssl=1
|
||||
[18]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-5_tutorial.jpg?ssl=1
|
||||
[19]: https://itsfoss.com/swap-size/
|
||||
[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-6_tutorial.jpg?ssl=1
|
||||
[21]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-7_tutorial.jpg?ssl=1
|
||||
[22]: https://linuxhandbook.com/linux-directory-structure/
|
||||
[23]: https://itsfoss.com/share-folders-local-network-ubuntu-windows/
|
||||
[24]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-8_tutorial.jpg?ssl=1
|
||||
[25]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-9_tutorial.jpg?ssl=1
|
||||
[26]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-10_tutorial.jpg?ssl=1
|
||||
[27]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-11_tutorial.jpg?ssl=1
|
||||
[28]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-12_tutorial.jpg?ssl=1
|
||||
[29]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-13_tutorial.jpg?ssl=1
|
||||
[30]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-14_tutorial.jpg?ssl=1
|
||||
[31]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-15_tutorial.jpg?ssl=1
|
||||
@ -1,101 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to transition into a career as a DevOps engineer)
|
||||
[#]: via: (https://opensource.com/article/19/7/how-transition-career-devops-engineer)
|
||||
[#]: author: (Conor Delanbanque https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque)
|
||||
|
||||
如何转职为 DevOps 工程师
|
||||
======
|
||||
无论你是刚毕业的大学生,还是想在职业中寻求进步的经验丰富的 IT 专家,这些提示都可以帮你成为 DevOps 工程师。
|
||||
|
||||
![technical resume for hiring new talent][1]
|
||||
|
||||
DevOps 工程是一个备受称赞的热门职业。不管你是刚毕业正在找第一份工作,还是在利用之前的行业经验的同时寻求学习新技能的机会,本指南都能帮你通过正确的步骤成为[ DevOps 工程师][2].
|
||||
|
||||
### 让自己沉浸其中
|
||||
|
||||
首先学习 [DevOps][3] 的基本原理,实践以及方法。在使用工具之前,先了解 DevOps 背后的“为什么”。DevOps 工程师的主要目标是在整个软件开发生命周期(SDLC)中提高速度并保持或提高质量,以提供最大的业务价值。阅读文章,观看 YouTube 视频,参加当地小组聚会或者会议 — 成为热情的 DevOps 社区中的一员,在那里你将从先行者的错误和成功中学习。
|
||||
|
||||
### 考虑你的背景
|
||||
|
||||
如果你有从事技术工作的经历,例如软件开发人员,系统工程师,系统管理员,网络运营工程师或者数据库管理员,那么你已经拥有了广泛的见解和有用的经验,它们可以帮助你在未来成为 DevOps 工程师。如果你在完成计算机科学或任何其他 STEM(译者注,STEM 是科学 Science,技术 Technology,工程 Engineering 和数学 Math四个学科的首字母缩略字)领域的学业后刚开始职业生涯,那么你将拥有在这个过渡期间需要的一些基本踏脚石。
|
||||
|
||||
DevOps 工程师的角色涵盖了广泛的职责。以下是企业最有可能使用他们的三种方向:
|
||||
|
||||
* **偏向于开发(Dev)的 DevOps 工程师**在构建应用中扮演软件开发的角色。他们日常工作的一部分是利用持续集成 / 持续交付(CI/CD),共享仓库,云和容器,但他们不一定负责构建或实施工具。他们了解基础架构,并且在成熟的环境中,能将自己的代码推向生产环境。
|
||||
* **偏向于运维技术(Ops)的 DevOps 工程师**可以与系统工程师或系统管理员进行比较。他们了解软件的开发,但并不会把一天的重心放在构建应用上。相反,他们更有可能支持软件开发团队将手动流程自动化的过程,并提高人员和技术系统的效率。这可能意味着分解遗留代码并用较少繁琐的自动化脚本来运行相同的命令,或者可能意味着安装,配置或维护基础结构和工具。他们确保为任何有需要的团队安装可使用的工具。他们也会通过教授如何利用 CI / CD 和其他 DevOps 实践来帮助团队。
|
||||
* **网站可靠性工程师(SRE)** 就像解决运维和基础设施的软件工程师。SRE 专注于创建可扩展,高度可用且可靠的软件系统。
|
||||
|
||||
|
||||
|
||||
在理想的世界中,DevOps 工程师将了解以上所有领域;这在成熟的科技公司中很常见。然而,顶级银行和许多财富 500 强企业的 DevOps 职位通常会偏向开发(Dev)或运营(Ops)。
|
||||
|
||||
### 要学习的技术
|
||||
|
||||
DevOps 工程师需要了解各种技术才能有效完成工作。无论你的背景如何,请从作为 DevOps 工程师使用和理解的基础技术入手。
|
||||
|
||||
#### 操作系统
|
||||
|
||||
操作系统是所有东西运行的地方,拥有相关的基础知识十分重要。 [Linux ][4]是你最有可能每天使用的操作系统,尽管有的组织会使用 Windows 操作系统。要开始使用,你可以在家中安装 Linux,在那里你可以随心所欲地打破并学习。
|
||||
|
||||
#### 脚本
|
||||
|
||||
接下来,选择一门语言来学习脚本。有很多语言可供选择,包括 Python,Go,Java,Bash,PowerShell,Ruby,和 C / C++。我建议[从 Python 开始][5],因为它相对容易学习和解释,是最受欢迎的语言之一。Python 通常是为了遵循面向对象编程(OOP)的基础而写的,可用于 Web 开发,软件开发以及创建桌面 GUI 和业务应用程序。
|
||||
|
||||
#### 云
|
||||
|
||||
学习了 [Linux][4] 和 [Python][5] 之后,我认为下一个该学习的是云计算。基础设施不再只是“运维小哥”的事情了,因此你需要接触云平台,例如 AWS 云服务,Azure 或者谷歌云平台。我会从 AWS 开始,因为它有大量免费学习工具,可以帮助你降低作为开发人员,运维,甚至面向业务的组件的任何障碍。事实上,你可能会被它提供的东西所淹没。考虑从 EC2, S3 和 VPC 开始,然后看看你从其中想学到什么。
|
||||
|
||||
#### 编程语言
|
||||
|
||||
如果你带着对软件开发的热情来到 DevOps,请继续提高你的编程技能。DevOps 中的一些优秀和常用语言与脚本相同:Python,Go,Java,Bash,PowerShell,Ruby 和 C / C++。你还应该熟悉 Jenkins 和 Git / Github,你将会在 CI / CD 过程中经常使用到它们。
|
||||
|
||||
#### 容器
|
||||
|
||||
最后,使用 Docker 和编排平台(如 Kubernetes)等工具开始学习[容器化][6]。网上有大量的免费学习资源,大多数城市都有本地的线下小组,你可以在友好的环境中向有经验的人学习(还有披萨和啤酒哦!)。
|
||||
|
||||
#### 其他的呢?
|
||||
|
||||
如果你缺乏开发经验,你依然可以通过对自动化的热情,效率的提高,与他人协作以及改进自己的工作[参与到 DevOps 中][3]来。我仍然建议学习上述工具,但重点不要放在编程 / 脚本语言上。了解基础架构即服务,平台即服务,云平台和 Linux 会非常有用。你可能正在设置工具并学习如何构建有弹性和容错性的系统,并在写代码时利用它们。
|
||||
|
||||
### 找一份 DevOps 的工作
|
||||
|
||||
求职过程会有所不同,具体取决于你是否一直从事技术工作,并且正在进入 DevOps 领域,或者你是刚开始职业生涯的毕业生。
|
||||
|
||||
#### 如果你已经从事技术工作
|
||||
|
||||
如果你正在从一个技术领域转入 DevOps 角色,首先尝试在你当前的公司寻找机会。你可以和其他的团队一起工作吗?尝试影响其他团队成员,寻求建议,并在不离开当前工作的情况下获得新技能。如果做不到这一点,你可能需要换另一家公司。如果你能从上面列出的一些实践,工具和技术中学习,你将能在面试时展示相关知识中占据有利位置。关键是要诚实,不要让自己陷入失败中。大多数招聘主管都了解你不知道所有的答案;如果你能展示你所学到的东西,并解释你愿意学习更多,你应该有机会获得 DevOps 的工作。
|
||||
|
||||
#### 如果你刚开始职业生涯
|
||||
|
||||
申请雇用初级 DevOps 工程师的公司的开放机会。不幸的是,许多公司表示他们希望寻找更富有经验的人,并建议你在获得经验后再申请该职位。这是“我们需要经验丰富的人”的典型,令人沮丧的场景,并且似乎没人愿意给你第一次机会。
|
||||
|
||||
然而,并不是所有求职经历都那么令人沮丧;一些公司专注于培训和提升刚从大学毕业的学生。例如,我工作的 [MThree][7] 聘请来应届毕业生并且对其进行了 8 周的培训。当完成培训后,参与者们可以充分了解到整个 SDLC,并很好地了解它在财富 500 强公司相关环境中的应用。毕业生被聘为 MThree 的客户公司的初级 DevOps 工程师 — MThree 在前 18 - 24 个月内支付全职工资和福利,之后他们将作为直接雇员加入客户。这是弥合从大学到技术职业的间隙的好方法。
|
||||
|
||||
### 总结
|
||||
|
||||
转换成 DevOps 工程师的方法有很多种。这是一条非常有益的职业路线,可能会让你保持繁忙和挑战 — 并增加你的收入潜力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/how-transition-career-devops-engineer
|
||||
|
||||
作者:[Conor Delanbanque][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[beamrolling](https://github.com/beamrolling)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/hiring_talent_resume_job_career.png?itok=Ci_ulYAH (technical resume for hiring new talent)
|
||||
[2]: https://opensource.com/article/19/7/devops-vs-sysadmin
|
||||
[3]: https://opensource.com/resources/devops
|
||||
[4]: https://opensource.com/resources/linux
|
||||
[5]: https://opensource.com/resources/python
|
||||
[6]: https://opensource.com/article/18/8/sysadmins-guide-containers
|
||||
[7]: https://www.mthreealumni.com/
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Is your enterprise software committing security malpractice?)
|
||||
[#]: via: (https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
你的企业软件在安全方面玩忽职守了吗?
|
||||
======
|
||||
ExtraHop 发现企业安全和分析软件正在“打电话回家”,悄悄地将信息上传到客户网络外的服务器上。
|
||||
![Getty Images][1]
|
||||
|
||||
这个博客专注于微软的一切事情,我常常抱怨、反对微软的间谍活动方面。嗯,很明显的,微软的这些跟企业安全、分析和硬件管理工具所做的相比,都不算什么。
|
||||
|
||||
一家叫做 ExtraHop 的分析公司检查了其客户的网络,并发现客户的安全和分析软件悄悄地将信息上传到客户网络外的服务器上。这家公司上周发布了一份报告来进行警示。
|
||||
|
||||
ExtraHop 故意选择不对这四个例子中的企业安全工具进行点名,这些工具在没有警告用户或使用者的情况发送了数据。这家公司的一位发言人通过电子邮件告诉我,“ExtraHop 希望报告的重点能成为趋势,我们已经多次观察到了这种令人担心的情况。这个重要问题需要企业的更多关注,而只是关注一个特殊群体会阻止它成为一种更广泛的观点”
|
||||
|
||||
**[ 有关物联网安全方面的更多信息,请阅读网络上保护物联网的提示和最小化物联网安全漏洞的 10 个最佳实践。| 通过注册 Network World 时事新闻来定期获取见解期刊。][5]. ]**
|
||||
|
||||
### 产品在安全提交传输方面玩忽职守,并且偷偷地传输数据到异地
|
||||
|
||||
ExtraHop 的报告中称发现了一系列的产品在偷偷地传输数据回自己的服务器上,包括终端安全软件,医院设备管理软件,监控摄像头,和金融机构使用的安全分析软件。报告中同样指出,这些应用涉嫌违反了欧洲的通用数据隐私法规(GDPR)。
|
||||
|
||||
在每个案例里,ExtraHop 都提供了这些软件传输数据到异地的证据,在其中一个案例中,一家公司注意到,大约每隔 30 分钟,一台连接了网络的设备就会发送 UDP 数据包给一个已知的恶意 IP 地址。有问题的是一台中国制造的安全摄像头,这个摄像头正在访问一个已知的和中国有联系的恶意 IP 地址。
|
||||
|
||||
出于保护个人安全的目的,摄像头很可能由其办公室的一名员工独立设置,这显示出 IT 阴影一面的缺陷。
|
||||
|
||||
医院设备的管理工具和金融公司的分析工具是属于这种情况,这些工具违反了数据安全法。即使公司不知道这个事,公司也会面临法律风险。
|
||||
|
||||
**[ [
|
||||
通过 PluralSight 的综合在线课程成为信息安全系统专家,现在提供 10 天的免费试用!][8] ]**
|
||||
|
||||
该医院的医疗设备管理产品应该只使用医院的 WiFi 网络,以此来确保患者的数据隐私和 HIPAA 合规。管理初始设备上线的工作站正在打开加密的 ssl:443 来连接到供应商自己的云存储服务器,这是一个主要的 HIPAA 违规。
|
||||
|
||||
ExtraHop 指出,尽管这些例子中可能没有任何的恶意活动。但它仍然违反了法律规定,管理员需要密切关注他们的网络,以此来监视异常活动的流量。
|
||||
|
||||
“要明确的是,我们不知道供应商为什么要把数据传回自己的服务器。这些公司都是受人尊敬的 IT 安全供应商,并且很有可能,这些数据是由他们的程序框架设计好给出的并用于合法目的,或者是错误配置的结果” 报告中说。
|
||||
|
||||
### 如何减轻数据外传的安全风险
|
||||
|
||||
为了解决这种安全方面玩忽职守的问题,ExtraHop 建议公司做下面这五件事:
|
||||
|
||||
* 监视供应商的活动:在你的网络上密切注意供应商的非正常活动,无论他们是活跃供应商,以前的供应商,还是评估后的供应商。
|
||||
* 监控出口流量:了解出口流量,尤其是来自域控制器等敏感资产的出口流量。当检测到出口流量时,始终将其与核准的应用程序和服务进行匹配。
|
||||
* 跟踪部署:在评估过程中,跟踪软件代理的部署。
|
||||
* 理解监管方面的考量因素:了解数据跨越政治、地址边界的监管和合规考量因素。
|
||||
* 理解合同协议:跟踪数据的使用是否符合供应商合同上的协议。
|
||||
|
||||
|
||||
|
||||
**[ 现在开始阅读这篇:Network World 解决物联网安全问题的企业指南][9] ]**
|
||||
|
||||
加入 Facebook 和领英上的 Network World 社区,评论最上方的主题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/03/cybersecurity_eye-with-binary_face-recognition_abstract-eye-100751589-large.jpg
|
||||
[2]: https://www.extrahop.com/company/press-releases/2019/extrahop-issues-warning-about-phoning-home/
|
||||
[3]: https://www.networkworld.com/article/3254185/internet-of-things/tips-for-securing-iot-on-your-network.html#nww-fsb
|
||||
[4]: https://www.networkworld.com/article/3269184/10-best-practices-to-minimize-iot-security-vulnerabilities#nww-fsb
|
||||
[5]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
|
||||
[6]: https://www.extrahop.com/resources/whitepapers/eh-security-advisory-calling-home-success/
|
||||
[7]: https://www.csoonline.com/article/3202771/general-data-protection-regulation-gdpr-requirements-deadlines-and-facts.html
|
||||
[8]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[9]: https://www.networkworld.com/article/3269165/internet-of-things/a-corporate-guide-to-addressing-iot-security-concerns.html
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -1,86 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zionfuo)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Blockchain 2.0 – An Introduction To Hyperledger Project (HLP) [Part 8])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/)
|
||||
[#]: author: (editor https://www.ostechnix.com/author/editor/)
|
||||
|
||||
区块链2.0:Hyperledger项目简介(八)
|
||||
======
|
||||
|
||||
![Introduction To Hyperledger Project][1]
|
||||
|
||||
一旦,一个新技术平台在积极发展和商业利益方面达到了普及的门槛,全球的主要公司和小型的初创企业都急于抓住这块蛋糕。在当时**Linux**就是这样的平台。一旦实现了其应用程序的普及,个人、公司和机构就开始对其表现出兴趣,到2000年,**Linux基金会**成立了。
|
||||
|
||||
Linux 基金会旨在通过赞助他们的开发团队来制定规范和开发Linux作为平台。Linux基金会是一个由软件和IT巨头(如微软、甲骨文、三星、思科、 IBM 、英特尔等[[1][7]]支持的非营利组织。这不包括为改善平台而提供服务的数百名个人开发者。多年来,Linux基金会已经开展了许多项目。**Hyperledger**项目是迄今为止发展最快的项目。
|
||||
|
||||
在将技术推进至可用且有用的方面上,这种联合主导的开发具有很多优势。为大型项目提供开发标准、库和所有后端协议既昂贵又资源密集型,而且不会从中产生丝毫收入。因此, 对于公司来说,通过支持这些组织来汇集他们的资源来开发常见的那些 “烦人” 部分是有很意义的,以及随后完成这些标准部分的工作以简单地即插即用和定制他们的产品。除了模型的经济性之外,这种合作努力还产生了标准,使其容易使用和集成到优秀的产品和服务中。
|
||||
|
||||
上述联盟模式,在曾经或当下使WiFi (The Wi-Fi alliance) 、移动电话等标准在制定方面得到了创新。
|
||||
|
||||
|
||||
### Hyperledger (HLP) 项目简介
|
||||
|
||||
Hyperledger 项目于 2015年12月由 Linux 基金会启动,目前是其孵化的增长最快的项目之一。它是一个伞式组织(umbrella organization),用于合作开发和推进基于[区块链][2]的分布式账本技术 (DLT) 的工具和标准。支持该项目的主要行业参与者包括**IBM**、**英特尔**和**SAP Ariba**[等][3]。HLP 旨在为个人和公司创建框架,以便根据需要创建共享和封闭的区块链,以满足他们自己的需求。设计原则是开发一个专注于隐私和未来可审计性的全球可部署、可扩展、强大的区块链平台。
|
||||
|
||||
### 开发目标和构造: 即插即用
|
||||
|
||||
虽然面向企业的平台有以太坊联盟之类的产品,但根据定义,HLP是面向企业的,并得到行业巨头的支持,他们在HLP旗下的许多模块中做出贡献并进一步发展。还孵化开发的周边项目,并这些创意项目推向公众。Hyperledger 项目的成员贡献了他们自己的力量,例如IBM如何为协作开发贡献他们的Fabric平台。该代码库由IBM在其内部研究和开发,并开源出来供所有成员使用。
|
||||
|
||||
这些过程使得 HLP 中的模块具有高度灵活的插件框架,这将支持企业设置中的快速开发和推出。此外,默认情况下,其他类似的平台是开放的**无需许可链**(permission-less blockchain)或是**公有链**(public blockchain),HLP模块本身就是支持通过调试可以适应特定的功能。
|
||||
|
||||
在这篇关于[公有链和私有链][4]的比较入门文章中,更多地涵盖了公有链和私有链的差异和用例。
|
||||
|
||||
根据项目执行董事**Brian Behlendorf**的说法,Hyperledger项目的使命有四个。
|
||||
|
||||
分别是:
|
||||
|
||||
1. 创建企业级DLT框架和标准,任何人都可以移植以满足其特定的工业或个人需求。
|
||||
2. 创建一个强大的开源社区来帮助生态系统。
|
||||
3. 促进所述生态系统的行业成员(如成员公司)的参与。
|
||||
4. 为HLP社区提供中立且无偏见的基础设施,以收集和分享相关的更新和发展。
|
||||
|
||||
可以在这里访问[原始文档][5]。
|
||||
|
||||
### HLP的架构
|
||||
|
||||
HLP由12个项目组成,这些项目被归类为独立的模块,每个项目通常都是独立构建和工作的,以开发他们的模块。在孵化之前,首先对它们的能力和生存能力进行研究。组织的任何成员都可以提出增加的建议。在项目孵化后,就会出现积极开发,然后才会推出。这些模块之间的互操作性被赋予了很高的优先级,因此这些组之间的定期通信由社区维护。目前,这些项目中有4个被归类为活动项目。活动标签意味着这些标签已经准备好使用,但还没有准备好发布重大版本。这4个模块可以说是推动区块链革命的最重要或最基本的模块。稍后,我们将详细介绍各个模块及其功能。然而,Hyperledger Fabric平台的简要描述,可以说是其中最受欢迎的。
|
||||
|
||||
### Hyperledger Fabric
|
||||
|
||||
**Hyperledger Fabric**[2]是一个完全开源的、基于区块链的许可 (非公开) DLT 平台,设计时考虑了企业的使用。该平台提供了适合企业环境的功能和结构。它是高度模块化的,允许开发人员在不同的一致协议、**链码协议**([智能合约][6]) 或身份管理系统等中进行选择。这是一个基于区块链的许可平台,利用身份管理系统,这意味着参与者将知道彼此在企业环境中需要的身份。Fabric允许以各种主流编程语言 (包括Java、Javascript、Go等) 开发智能合约(“链码”,是Hyperledger团队使用的术语)。这使得机构和企业可以利用他们在该领域的现有人才,而无需雇佣或重新培训开发人员来开发他们自己的智能合约。与标准订单验证系统相比,Fabric还使用执行顺序验证系统来处理智能合约,以提供更好的可靠性,这些系统由提供智能合约功能的其他平台使用。与标准订单验证系统相比,Fabric还使用执行顺序验证系统来处理智能合约,以提供更好的可靠性,这些系统由提供智能合约功能的其他平台使用。可插拔性能、身份管理系统、数据库管理系统、共识平台等是Fabric的其他功能,这些功能使它在竞争中保持领先地位。
|
||||
|
||||
|
||||
### 结论
|
||||
|
||||
诸如Hyperledger Fabric平台这样的项目能够在主流用例中更快地采用区块链技术。Hyperledger社区结构本身支持开放治理原则,并且由于所有项目都是作为开源平台引导的,因此这提高了团队在履行承诺时表现出来的安全性和责任感。
|
||||
|
||||
由于此类项目的主要应用涉及与企业合作及进一步开发平台和标准,因此Hyperledger项目目前在其他类似项目前面处于有利地位。
|
||||
|
||||
**参考资料**
|
||||
|
||||
* **[1][Samsung takes a seat with Intel and IBM at the Linux Foundation | TheINQUIRER][7]**
|
||||
* **[2] E. Androulaki et al., “Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains,” 2018.**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
|
||||
|
||||
作者:[editor][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zionfuo](https://github.com/zionfuo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/Introduction-To-Hyperledger-Project-720x340.png
|
||||
[2]: https://www.ostechnix.com/blockchain-2-0-an-introduction/
|
||||
[3]: https://www.hyperledger.org/members
|
||||
[4]: https://www.ostechnix.com/blockchain-2-0-public-vs-private-blockchain-comparison/
|
||||
[5]: http://www.hitachi.com/rev/archive/2017/r2017_01/expert/index.html
|
||||
[6]: https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/
|
||||
[7]: https://www.theinquirer.net/inquirer/news/2182438/samsung-takes-seat-intel-ibm-linux-foundation
|
||||
@ -0,0 +1,245 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina)?)
|
||||
[#]: via: (https://www.2daygeek.com/upgrade-linux-mint-19-1-tessa-to-linux-mint-19-2-tina/)
|
||||
[#]: author: (2daygeek http://www.2daygeek.com/author/2daygeek/)
|
||||
|
||||
如何升级 Linux Mint 19.1 (Tessa) 为 Linux Mint 19.2 (Tina)?
|
||||
======
|
||||
|
||||
Linux Mint 19.2 “Tina” 在2019年8月2日发布,它是一个基于 Ubuntu 18.04 LTS (Bionic Beaver) 的长期支持版本。
|
||||
|
||||
它将被支持到2023年。它带来更新过的软件和精细的改进和很多新的特色来使你的桌面使用地更舒适。
|
||||
|
||||
Linux Mint 19.2 特色有 Cinnamon 4.2 ,Linux 内核 4.15 ,和 Ubuntu 18.04 软件包基础。
|
||||
|
||||
**`注意:`**` ` 不要忘记备份你的重要数据。如果一些东西出错,在最新的安装后,你可以从备份中恢复数据。
|
||||
|
||||
备份可以通过 rsnapshot 或 timeshift 完成。
|
||||
|
||||
Linux Mint 19.2 “Tina” 发布日志可以在下面的链接中找到。
|
||||
|
||||
* **[Linux Mint 19.2 (Tina) 发布日志][1]**
|
||||
|
||||
|
||||
|
||||
这里有三种方法,能让我们升级为 Linux Mint 19.2 “Tina”。
|
||||
|
||||
* 使用本地方法升级 Linux Mint 19.2 (Tina)
|
||||
* 使用 Mintupgrade 实用程序方法升级 Linux Mint 19.2 (Tina)
|
||||
* 使用 GUI 升级 Linux Mint 19.2 (Tina)
|
||||
|
||||
|
||||
|
||||
### 如何从 Linux Mint 19.1 (Tessa) 升级为 Linux Mint 19.2 (Tina)?
|
||||
|
||||
升级 Linux Mint 系统是一项简单轻松的任务。有三种方法可以完成。
|
||||
|
||||
### 方法-1: 使用本地方法升级 Linux Mint 19.2 (Tina)
|
||||
|
||||
这是执行升级 Linux Mint 系统的本地和标准的方法之一。
|
||||
|
||||
为做到这点,遵循下面的程序步骤。
|
||||
|
||||
确保你当前 Linux Mint 系统是最新的。
|
||||
|
||||
使用下面的命令来更新你现在的软件为最新可用版本。
|
||||
|
||||
### Step-1:
|
||||
|
||||
通过运行下面的命令来刷新存储库索引。
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
运行下面的命令来在系统上安装可用的更新。
|
||||
|
||||
```
|
||||
$ sudo apt upgrade
|
||||
```
|
||||
|
||||
运行下面的命令来在版本中执行可用的次要更新。
|
||||
|
||||
```
|
||||
$ sudo apt full-upgrade
|
||||
```
|
||||
|
||||
默认情况下,它将通过上面的命令来移除过时的软件包。但是,我建议你运行下面的命令。
|
||||
|
||||
```
|
||||
$ sudo apt autoremove
|
||||
|
||||
$ sudo apt clean
|
||||
```
|
||||
|
||||
如果安装一个新的内核,你可能需要重启系统。如果是这样,运行下面的命令。
|
||||
|
||||
```
|
||||
$ sudo shutdown -r now
|
||||
```
|
||||
|
||||
最后检查当前安装的版本。
|
||||
|
||||
```
|
||||
$ lsb_release -a
|
||||
|
||||
No LSB modules are available.
|
||||
Distributor ID: Linux Mint
|
||||
Description: Linux Mint 19.1 (Tessa)
|
||||
Release: 19.1
|
||||
Codename: Tessa
|
||||
```
|
||||
|
||||
### 步骤-2: 更新/修改 /etc/apt/sources.list 文件
|
||||
|
||||
在重启后,修改 sources.list 文件,并从 Linux Mint 19.1 (Tessa) 指向 Linux Mint 19.2 (Tina)。
|
||||
|
||||
首先,使用 cp 命令备份下面的配置文件。
|
||||
|
||||
```
|
||||
$ sudo cp /etc/apt/sources.list /root
|
||||
$ sudo cp -r /etc/apt/sources.list.d/ /root
|
||||
```
|
||||
|
||||
修改 “sources.list” 文件,并指向 Linux Mint 19.2 (Tina)。
|
||||
|
||||
```
|
||||
$ sudo sed -i 's/tessa/tina/g' /etc/apt/sources.list
|
||||
$ sudo sed -i 's/tessa/tina/g' /etc/apt/sources.list.d/*
|
||||
```
|
||||
|
||||
通过运行下面的命令来刷新存储库索引。
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
运行下面的命令来在系统上安装可用的更新。在升级过程中,你可用需要确认服务重启和配置文件替换,因此,只需遵循屏幕上的指令。
|
||||
|
||||
升级可能花费一些时间,具体依赖于更新的数量和你的网络速度。
|
||||
|
||||
```
|
||||
$ sudo apt upgrade
|
||||
```
|
||||
|
||||
运行下面的命令来执行一次完整的系统升级。
|
||||
|
||||
```
|
||||
$ sudo apt full-upgrade
|
||||
```
|
||||
|
||||
默认情况下,上面的命令将移除过时的软件包。但是,我建议你再次运行下面的命令。
|
||||
|
||||
```
|
||||
$ sudo apt autoremove
|
||||
|
||||
$ sudo apt clean
|
||||
```
|
||||
|
||||
最后重启系统来启动 Linux Mint 19.2 (Tina)。
|
||||
|
||||
```
|
||||
$ sudo shutdown -r now
|
||||
```
|
||||
|
||||
升级后的 Linux Mint 版本可以通过运行下面的命令验证。
|
||||
|
||||
```
|
||||
$ lsb_release -a
|
||||
|
||||
No LSB modules are available.
|
||||
Distributor ID: Linux Mint
|
||||
Description: Linux Mint 19.2 (Tina)
|
||||
Release: 19.2
|
||||
Codename: Tina
|
||||
```
|
||||
|
||||
### 方法-2: 使用 Mintupgrade 实用程序升级 Linux Mint 19.2 (Tina)
|
||||
|
||||
这是 Mint 官方实用程序,它允许我们对 Linux Mint 系统执行平滑升级。
|
||||
|
||||
使用下面的命令来安装 mintupgrade 软件包。
|
||||
|
||||
```
|
||||
$ sudo apt install mintupgrade
|
||||
```
|
||||
|
||||
确保你已经安装 mintupgrade 软件包的最新版本。
|
||||
|
||||
```
|
||||
$ apt version mintupgrade
|
||||
```
|
||||
|
||||
以一个普通用户来运行下面的命令以模拟一次升级,遵循屏幕上的指令。
|
||||
|
||||
```
|
||||
$ mintupgrade check
|
||||
```
|
||||
|
||||
使用下面的命令来下载需要的软件包来升级为 Linux Mint 19.2 (Tina) ,遵循屏幕上的指令。
|
||||
|
||||
```
|
||||
$ mintupgrade download
|
||||
```
|
||||
|
||||
运行下面的命令来运用升级,最新屏幕上的指令。
|
||||
|
||||
```
|
||||
$ mintupgrade upgrade
|
||||
```
|
||||
|
||||
在成功升级后,重启系统,并检查升级后的版本。
|
||||
|
||||
```
|
||||
$ lsb_release -a
|
||||
|
||||
No LSB modules are available.
|
||||
Distributor ID: Linux Mint
|
||||
Description: Linux Mint 19.2 (Tina)
|
||||
Release: 19.2
|
||||
Codename: Tina
|
||||
```
|
||||
|
||||
### 方法-3: 使用 GUI 升级 Linux Mint 19.2 (Tina)
|
||||
|
||||
或者,我们可以通过 GUI 执行升级。
|
||||
|
||||
### 步骤-1:
|
||||
|
||||
通过 Timeshift 创建一个系统快照。如果一些东西出错,你可以简单地恢复你的操作系统到它先前状态。
|
||||
|
||||
### 步骤-2:
|
||||
|
||||
打开更新管理器,单击刷新按钮来检查 mintupdate 和 mint-upgrade-info 的任何新版本。如果有这些软件包的更新,应用它们。
|
||||
|
||||
通过单击 “编辑-> 升级到 Linux Mint 19.2 Tina”来启动系统升级。
|
||||
[![][2]![][2]][3]
|
||||
|
||||
遵循屏幕上的指令。如果被询问是否保留或替换配置文件,选择替换它们。
|
||||
[![][2]![][2]][4]
|
||||
|
||||
### 步骤-3:
|
||||
|
||||
在升级完成后,重启你的电脑。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/upgrade-linux-mint-19-1-tessa-to-linux-mint-19-2-tina/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.2daygeek.com/author/2daygeek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linuxtechnews.com/linux-mint-19-2-tina-released-check-what-is-new-feature/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2019/08/linux-mint-19-2-tina-mintupgrade.png
|
||||
[4]: https://www.2daygeek.com/wp-content/uploads/2019/08/linux-mint-19-2-tina-mintupgrade-1.png
|
||||
@ -0,0 +1,112 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Check Your IP Address in Ubuntu [Beginner’s Tip])
|
||||
[#]: via: (https://itsfoss.com/check-ip-address-ubuntu/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
如何在 Ubuntu 中检查你的 IP 地址(初学者教程)
|
||||
======
|
||||
|
||||
不知道你的 IP 地址是什么?以下是在 Ubuntu 和其他 Linux 发行版中检查 IP 地址的几种方法。
|
||||
|
||||
![][1]
|
||||
|
||||
### 什么是 IP 地址?
|
||||
|
||||
**互联网协议地址**(通常称为 **IP 地址**)是分配给连接到计算机网络的每个设备(使用互联网协议)的数字标签。IP 地址用于识别和定位机器。
|
||||
|
||||
**IP 地址**在网络中是_唯一的_,使得所有连接设备能够通信。
|
||||
|
||||
你还应该知道有两种**类型的 IP 地址**:**公有**和**私有**。**公有 IP 地址**是用于互联网通信的地址,这与你用于邮件的物理地址相同。但是,在本地网络(例如使用路由器的家庭)的环境中,会为每个设备分配在该子网内唯一的**私有 IP 地址**。这在本地网络中使用,而不直接暴露公有 IP(路由器用它与互联网通信)。
|
||||
|
||||
另外还有区分 **IPv4** 和 **IPv6** 协议。**IPv4** 是经典的 IP 格式,它由基本的 4 部分结构组成,四个字节用点分隔(例如 127.0.0.1)。但是,随着设备数量的增加,IPv4 很快就无法提供足够的地址。这就是 **IPv6** 被发明的原因,它使用 **128 位地址**的格式(与 **IPv4** 使用的 **32 位地址**相比)。
|
||||
|
||||
## 在 Ubuntu 中检查你的 IP 地址(终端方式)
|
||||
|
||||
检查 IP 地址的最快和最简单的方法是使用 ip 命令。你可以按以下方式使用此命令:
|
||||
|
||||
```
|
||||
ip addr show
|
||||
```
|
||||
|
||||
它将同时显示 IPv4 和 IPv6 地址:
|
||||
|
||||
![Display IP Address in Ubuntu Linux][2]
|
||||
|
||||
实际上,你可以进一步缩短这个命令 `ip a`。它会给你完全相同的结果。
|
||||
|
||||
```
|
||||
ip a
|
||||
```
|
||||
|
||||
如果你希望获得最少的细节,也可以使用 **hostname**:
|
||||
|
||||
```
|
||||
hostname -I
|
||||
```
|
||||
|
||||
还有一些[在 Linux 中检查 IP 地址的方法][3],但是这两个命令足以满足这个目的。
|
||||
|
||||
ifconfig 如何?
|
||||
|
||||
老用户可能会想要使用 ifconfig(net-tools 的一部分),但该程序已被弃用。一些较新的 Linux 发行版不再包含此软件包,如果你尝试运行它,你将看到 ifconfig 命令未找到的错误。
|
||||
|
||||
## 在 Ubuntu 中检查你的 IP 地址(GUI 方式)
|
||||
|
||||
如果你对命令行不熟悉,你还可以使用图形方式检查 IP 地址。
|
||||
|
||||
打开 Ubuntu 应用菜单(在屏幕左下角**显示应用**)并搜索**Settings**,然后单击图标:
|
||||
|
||||
![Applications Menu Settings][5]
|
||||
|
||||
这应该会打开**设置菜单**。进入**网络**:
|
||||
|
||||
![Network Settings Ubuntu][6]
|
||||
|
||||
按下连接旁边的**齿轮图标**会打开一个窗口,其中包含更多设置和有关你网络链接的信息,其中包括你的 IP 地址:
|
||||
|
||||
![IP Address GUI Ubuntu][7]
|
||||
|
||||
## 额外提示:检查你的公共 IP 地址(适用于台式计算机)
|
||||
|
||||
首先,要检查你的**公有 IP 地址**(用于与服务器通信),你可以[使用 curl 命令][8]。打开终端并输入以下命令:
|
||||
|
||||
```
|
||||
curl ifconfig.me
|
||||
```
|
||||
|
||||
这应该只会返回你的 IP 地址而没有其他多余信息。我建议在分享这个地址时要小心,因为这相当于公布你的个人地址。
|
||||
|
||||
**注意:** _如果 **curl** 没有安装,只需使用 **sudo apt install curl -y** 来解决问题,然后再试一次。_
|
||||
|
||||
另一种可以查看公共 IP 地址的简单方法是在 Google 中搜索 **ip address**。
|
||||
|
||||
**总结**
|
||||
|
||||
在本文中,我介绍了在 Uuntu Linux 中找到 IP 地址的不同方法,并向你概述了 IP 地址的用途以及它们对我们如此重要的原因。
|
||||
|
||||
我希望你喜欢这篇文章。如果你觉得文章有用,请在评论栏告诉我们!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/check-ip-address-ubuntu/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/checking-ip-address-ubuntu.png?resize=800%2C450&ssl=1
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/ip_addr_show.png?fit=800%2C493&ssl=1
|
||||
[3]: https://linuxhandbook.com/find-ip-address/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/applications_menu_settings.jpg?fit=800%2C309&ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/network_settings_ubuntu.jpg?fit=800%2C591&ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/ip_address_gui_ubuntu.png?fit=800%2C510&ssl=1
|
||||
[8]: https://linuxhandbook.com/curl-command-examples/
|
||||
Loading…
Reference in New Issue
Block a user