diff --git a/published/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md b/published/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md
new file mode 100644
index 0000000000..e2d88ce4ec
--- /dev/null
+++ b/published/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md
@@ -0,0 +1,146 @@
+如何使用 yum-cron 自动更新 RHEL/CentOS Linux
+======
+
+`yum` 命令是 RHEL / CentOS Linux 系统中用来安装和更新软件包的一个工具。我知道如何使用 [yum 命令行][1] 更新系统,但是我想用 cron 任务自动更新软件包。该如何配置才能使得 `yum` 使用 [cron 自动更新][2]系统补丁或更新呢?
+
+首先需要安装 yum-cron 软件包。该软件包提供以 cron 命令运行 `yum` 更新所需的文件。如果你想要每晚通过 cron 自动更新可以安装这个软件包。
+
+### CentOS/RHEL 6.x/7.x 上安装 yum cron
+
+输入以下 [yum 命令][3]:
+
+```
+$ sudo yum install yum-cron
+```
+
+
+
+使用 CentOS/RHEL 7.x 上的 `systemctl` 启动服务:
+
+```
+$ sudo systemctl enable yum-cron.service
+$ sudo systemctl start yum-cron.service
+$ sudo systemctl status yum-cron.service
+```
+
+在 CentOS/RHEL 6.x 系统中,运行:
+
+```
+$ sudo chkconfig yum-cron on
+$ sudo service yum-cron start
+```
+
+
+
+`yum-cron` 是 `yum` 的一个替代方式。使得 cron 调用 `yum` 变得非常方便。该软件提供了元数据更新、更新检查、下载和安装等功能。`yum-cron` 的各种功能可以使用配置文件配置,而不是输入一堆复杂的命令行参数。
+
+### 配置 yum-cron 自动更新 RHEL/CentOS Linux
+
+使用 vi 等编辑器编辑文件 `/etc/yum/yum-cron.conf` 和 `/etc/yum/yum-cron-hourly.conf`:
+
+```
+$ sudo vi /etc/yum/yum-cron.conf
+```
+
+确保更新可用时自动更新:
+
+```
+apply_updates = yes
+```
+
+可以设置通知 email 的发件地址。注意: localhost` 将会被 `system_name` 的值代替。
+
+```
+email_from = root@localhost
+```
+
+列出发送到的 email 地址。
+
+```
+email_to = your-it-support@some-domain-name
+```
+
+发送 email 信息的主机名。
+
+```
+email_host = localhost
+```
+
+[CentOS/RHEL 7.x][4] 上不想更新内核的话,添加以下内容:
+
+```
+exclude=kernel*
+```
+
+RHEL/CentOS 6.x 下[添加以下内容来禁用内核更新][5]:
+
+```
+YUM_PARAMETER=kernel*
+```
+
+[保存并关闭文件][6]。如果想每小时更新系统的话修改文件 `/etc/yum/yum-cron-hourly.conf`,否则文件 `/etc/yum/yum-cron.conf` 将使用以下命令每天运行一次(使用 [cat 命令][7] 查看):
+
+```
+$ cat /etc/cron.daily/0yum-daily.cron
+```
+
+示例输出:
+
+```
+#!/bin/bash
+
+# Only run if this flag is set. The flag is created by the yum-cron init
+# script when the service is started -- this allows one to use chkconfig and
+# the standard "service stop|start" commands to enable or disable yum-cron.
+if [[ ! -f /var/lock/subsys/yum-cron ]]; then
+ exit 0
+fi
+
+# Action!
+exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
+[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
+#!/bin/bash
+
+# Only run if this flag is set. The flag is created by the yum-cron init
+# script when the service is started -- this allows one to use chkconfig and
+# the standard "service stop|start" commands to enable or disable yum-cron.
+if [[ ! -f /var/lock/subsys/yum-cron ]]; then
+ exit 0
+fi
+
+# Action!
+exec /usr/sbin/yum-cron
+```
+
+完成配置。现在你的系统将每天自动更新一次。更多细节请参照 yum-cron 的说明手册。
+
+```
+$ man yum-cron
+```
+
+### 关于作者
+
+作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。获取更多有关系统管理、Linux/Unix 和开源话题请关注[我的 RSS/XML 地址][12]。
+
+--------------------------------------------------------------------------------
+
+via: https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/
+
+作者:[Vivek Gite][a]
+译者:[shipsw](https://github.com/shipsw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.cyberciti.biz/
+[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
+[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
+[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ [4]:https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/
+[5]:https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/
+[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
+[7]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/
+[8]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
+[9]:https://twitter.com/nixcraft
+[10]:https://facebook.com/nixcraft
+[11]:https://plus.google.com/+CybercitiBiz
+[12]:https://www.cyberciti.biz/atom/atom.xml
diff --git a/translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md b/published/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
similarity index 51%
rename from translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
rename to published/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
index d486a777de..cfeade8a8b 100644
--- a/translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
+++ b/published/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
@@ -1,18 +1,20 @@
-使用一个命令重置 Linux 桌面到默认设置
+使用一个命令重置 Linux 桌面为默认设置
======
+

-前段时间,我们分享了一篇关于 [**Resetter**][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
+前段时间,我们分享了一篇关于 [Resetter][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
### 将 Linux 桌面重置为默认设置
-这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 **Arch Linux MATE** 和 **Ubuntu 16.04 Unity** 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
+这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 Arch Linux MATE 和 Ubuntu 16.04 Unity 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
-**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中的固定应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
+**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中固定的应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
-好的是它只会重置桌面设置。它不会影响其他不使用 dconf 的程序。此外,它不会删除你的个人资料。
+好的是它只会重置桌面设置。它不会影响其他不使用 `dconf` 的程序。此外,它不会删除你的个人资料。
现在,让我们开始。要将 Ubuntu Unity 或其他带有 GNOME/MATE 环境的 Linux 桌面重置,运行下面的命令:
+
```
dconf reset -f /
```
@@ -29,12 +31,13 @@ dconf reset -f /
看见了么?现在,我的 Ubuntu 桌面已经回到了出厂设置。
-有关 “dconf” 命令的更多详细信息,请参阅手册页。
+有关 `dconf` 命令的更多详细信息,请参阅手册页。
+
```
man dconf
```
-在重置桌面上我个人更喜欢 “Resetter” 而不是 “dconf” 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 “dconf” 命令在几分钟内将你的 Linux 系统重置为默认设置。
+在重置桌面上我个人更喜欢 “Resetter” 而不是 `dconf` 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 `dconf` 命令在几分钟内将你的 Linux 系统重置为默认设置。
就是这样了。希望这个有帮助。我将很快发布另一篇有用的指导。敬请关注!
@@ -48,12 +51,12 @@ via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-comma
作者:[Edwin Arteaga][a]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]:https://www.ostechnix.com
-[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
+[1]:https://linux.cn/article-9217-1.html
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
-[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
+[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png
+[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png
diff --git a/published/20171102 What is huge pages in Linux.md b/published/20171102 What is huge pages in Linux.md
new file mode 100644
index 0000000000..1f1d0b50a0
--- /dev/null
+++ b/published/20171102 What is huge pages in Linux.md
@@ -0,0 +1,140 @@
+Linux 中的“大内存页”(hugepage)是个什么?
+======
+
+> 学习 Linux 中的大内存页。理解什么是“大内存页”,如何进行配置,如何查看当前状态以及如何禁用它。
+
+![Huge Pages in Linux][1]
+
+本文中我们会详细介绍大内存页,让你能够回答:Linux 中的“大内存页”是什么?在 RHEL6、RHEL7、Ubuntu 等 Linux 中,如何启用/禁用“大内存页”?如何查看“大内存页”的当前值?
+
+首先让我们从“大内存页”的基础知识开始讲起。
+
+### Linux 中的“大内存页”是个什么玩意?
+
+“大内存页”有助于 Linux 系统进行虚拟内存管理。顾名思义,除了标准的 4KB 大小的页面外,它们还能帮助管理内存中的巨大的页面。使用“大内存页”,你最大可以定义 1GB 的页面大小。
+
+在系统启动期间,你能用“大内存页”为应用程序预留一部分内存。这部分内存,即被“大内存页”占用的这些存储器永远不会被交换出内存。它会一直保留其中,除非你修改了配置。这会极大地提高像 Oracle 数据库这样的需要海量内存的应用程序的性能。
+
+### 为什么使用“大内存页”?
+
+在虚拟内存管理中,内核维护一个将虚拟内存地址映射到物理地址的表,对于每个页面操作,内核都需要加载相关的映射。如果你的内存页很小,那么你需要加载的页就会很多,导致内核会加载更多的映射表。而这会降低性能。
+
+使用“大内存页”,意味着所需要的页变少了。从而大大减少由内核加载的映射表的数量。这提高了内核级别的性能最终有利于应用程序的性能。
+
+简而言之,通过启用“大内存页”,系统具只需要处理较少的页面映射表,从而减少访问/维护它们的开销!
+
+### 如何配置“大内存页”?
+
+运行下面命令来查看当前“大内存页”的详细内容。
+
+```
+root@kerneltalks # grep Huge /proc/meminfo
+AnonHugePages: 0 kB
+HugePages_Total: 0
+HugePages_Free: 0
+HugePages_Rsvd: 0
+HugePages_Surp: 0
+Hugepagesize: 2048 kB
+```
+
+从上面输出可以看到,每个页的大小为 2MB(`Hugepagesize`),并且系统中目前有 `0` 个“大内存页”(`HugePages_Total`)。这里“大内存页”的大小可以从 `2MB` 增加到 `1GB`。
+
+运行下面的脚本可以知道系统当前需要多少个巨大页。该脚本取之于 Oracle。
+
+```
+#!/bin/bash
+#
+# hugepages_settings.sh
+#
+# Linux bash script to compute values for the
+# recommended HugePages/HugeTLB configuration
+#
+# Note: This script does calculation for all shared memory
+# segments available when the script is run, no matter it
+# is an Oracle RDBMS shared memory segment or not.
+# Check for the kernel version
+KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
+# Find out the HugePage size
+HPG_SZ=`grep Hugepagesize /proc/meminfo | awk {'print $2'}`
+# Start from 1 pages to be on the safe side and guarantee 1 free HugePage
+NUM_PG=1
+# Cumulative number of pages required to handle the running shared memory segments
+for SEG_BYTES in `ipcs -m | awk {'print $5'} | grep "[0-9][0-9]*"`
+do
+ MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
+ if [ $MIN_PG -gt 0 ]; then
+ NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
+ fi
+done
+# Finish with results
+case $KERN in
+ '2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
+ echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
+ '2.6' | '3.8' | '3.10' | '4.1' ) echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
+ *) echo "Unrecognized kernel version $KERN. Exiting." ;;
+esac
+# End
+```
+
+将它以 `hugepages_settings.sh` 为名保存到 `/tmp` 中,然后运行之:
+
+```
+root@kerneltalks # sh /tmp/hugepages_settings.sh
+Recommended setting: vm.nr_hugepages = 124
+```
+
+你的输出类似如上结果,只是数字会有一些出入。
+
+这意味着,你系统需要 124 个每个 2MB 的“大内存页”!若你设置页面大小为 4MB,则结果就变成了 62。你明白了吧?
+
+### 配置内核中的“大内存页”
+
+本文最后一部分内容是配置上面提到的 [内核参数 ][2] ,然后重新加载。将下面内容添加到 `/etc/sysctl.conf` 中,然后输入 `sysctl -p` 命令重新加载配置。
+
+```
+vm.nr_hugepages=126
+```
+
+注意我们这里多加了两个额外的页,因为我们希望在实际需要的页面数量之外多一些额外的空闲页。
+
+现在,内核已经配置好了,但是要让应用能够使用这些“大内存页”还需要提高内存的使用阀值。新的内存阀值应该为 126 个页 x 每个页 2 MB = 252 MB,也就是 258048 KB。
+
+你需要编辑 `/etc/security/limits.conf` 中的如下配置:
+
+```
+soft memlock 258048
+hard memlock 258048
+```
+
+某些情况下,这些设置是在指定应用的文件中配置的,比如 Oracle DB 就是在 `/etc/security/limits.d/99-grid-oracle-limits.conf` 中配置的。
+
+这就完成了!你可能还需要重启应用来让应用来使用这些新的巨大页。
+
+### 如何禁用“大内存页”?
+
+“大内存页”默认是开启的。使用下面命令来查看“大内存页”的当前状态。
+
+```
+root@kerneltalks# cat /sys/kernel/mm/transparent_hugepage/enabled
+[always] madvise never
+```
+
+输出中的 `[always]` 标志说明系统启用了“大内存页”。
+
+若使用的是基于 RedHat 的系统,则应该要查看的文件路径为 `/sys/kernel/mm/redhat_transparent_hugepage/enabled`。
+
+若想禁用“大内存页”,则在 `/etc/grub.conf` 中的 `kernel` 行后面加上 `transparent_hugepage=never`,然后重启系统。
+
+--------------------------------------------------------------------------------
+
+via: https://kerneltalks.com/services/what-is-huge-pages-in-linux/
+
+作者:[Shrikant Lavhate][a]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://kerneltalks.com
+[1]:https://a1.kerneltalks.com/wp-content/uploads/2017/11/hugepages-in-linux.png
+[2]:https://kerneltalks.com/linux/how-to-tune-kernel-parameters-in-linux/
diff --git a/translated/tech/20171115 How to create better documentation with a kanban board.md b/published/20171115 How to create better documentation with a kanban board.md
similarity index 66%
rename from translated/tech/20171115 How to create better documentation with a kanban board.md
rename to published/20171115 How to create better documentation with a kanban board.md
index 289555963b..fa92553ea2 100644
--- a/translated/tech/20171115 How to create better documentation with a kanban board.md
+++ b/published/20171115 How to create better documentation with a kanban board.md
@@ -1,22 +1,24 @@
-如何使用看板创建更好的文档
+如何使用看板(kanban)创建更好的文档
======
+> 通过卡片分类和看板来给用户提供他们想要的信息。
+

-如果你正在处理文档、网站或其他面向用户的内容,那么了解用户希望找到的内容(包括他们想要的信息以及信息的组织和结构)很有帮助。毕竟,如果人们无法找到他们想要的东西,那么出色的内容就没有用。
+如果你正在处理文档、网站或其他面向用户的内容,那么了解用户希望找到的内容(包括他们想要的信息以及信息的组织和结构)很有帮助。毕竟,如果人们无法找到他们想要的东西,那么再出色的内容也没有用。
-卡片分类是一种简单而有效的方式,可以从用户那里收集有关菜单界面和页面的内容。最简单的实现方式是在你计划在网站或文章分类标注一些索引卡,并要求用户按照查找信息的方式对卡进行分类。变体包括让人们编写自己的菜单标题或内容元素。
+卡片分类是一种简单而有效的方式,可以从用户那里收集有关菜单界面和页面的内容。最简单的实现方式是在计划在网站或文档中的部分分类标注一些索引卡,并要求用户按照查找信息的方式对卡片进行分类。一个变体是让人们编写自己的菜单标题或内容元素。
-我们的目标是了解用户的期望以及他们希望在哪里找到它,而不是自己弄清楚菜单和布局。当与用户处于相同的物理位置时,这是相对简单的,但当莫尝试从多个位置的人员获得反馈时,这会更具挑战性。
+我们的目标是了解用户的期望以及他们希望在哪里找到它,而不是自己弄清楚菜单和布局。当与用户处于相同的物理位置时,这是相对简单的,但当尝试从多个位置的人员获得反馈时,这会更具挑战性。
-我发现[看板][1]对于这些情况是一个很好的工具。它允许人们轻松拖动虚拟卡进行分类和排名,而且与专门卡片分类软件不同,它们是多用途的。
+我发现[看板][1]对于这些情况是一个很好的工具。它允许人们轻松拖动虚拟卡片进行分类和排名,而且与专门卡片分类软件不同,它们是多用途的。
我经常使用 Trello 进行卡片分类,但有几种你可能想尝试的[开源替代品][2]。
### 怎么运行的
-我最成功的 kanban 实验是在写 [Gluster][3] 文档的时候- 一个免费开源的可扩展网络存储文件系统。我需要携带大量随时间增长的文档,并将其分成若干类别以创建引导系统。由于我没有必要的技术知识来分类,我向 Gluster 团队和开发人员社区寻求指导。
+我最成功的看板体验是在写 [Gluster][3] 文档的时候 —— 这是一个自由开源的可扩展的网络存储文件系统。我需要携带大量随着时间而增长的文档,并将其分成若干类别以创建导航系统。由于我没有必要的技术知识来分类,我向 Gluster 团队和开发人员社区寻求指导。
-首先,我创建了一个共享看板。我列出了一些通用名称,这些名称可以为我计划在文档中涵盖的所有主题排序和创建卡片。我标记了一些不同颜色的卡片,以表明某个主题缺失并需要创建,或者它存在并需要删除。然后,我把所有卡片放入“未排序”一列,并要求人们将它们拖到他们认为应该组织卡片的地方,然后给我一个他们认为是理想状态的截图。
+首先,我创建了一个共享看板。我列出了一些通用名称,这些名称可以为我计划在文档中涵盖的所有主题排序和创建卡片。我标记了一些不同颜色的卡片,以表明某个主题缺失并需要创建,或者它存在并需要删除。然后,我把所有卡片放入“未排序”一列,并要求人们将它们拖到他们认为这些卡片应该组织到的地方,然后给我一个他们认为是理想状态的截图。
处理所有截图是最棘手的部分。我希望有一个合并或共识功能可以帮助我汇总每个人的数据,而不必检查一堆截图。幸运的是,在第一个人对卡片进行分类之后,人们或多或少地对该结构达成一致,而只做了很小的修改。当对某个主题的位置有不同意见时,我发起一个快速会议,让人们可以解释他们的想法,并且可以排除分歧。
@@ -24,7 +26,7 @@
在这里,很容易将捕捉到的信息转换为菜单并对其进行优化。如果用户认为项目应该成为子菜单,他们通常会在评论中或在电话聊天时告诉我。对菜单组织的看法因人们的工作任务而异,所以从来没有完全达成一致意见,但用户进行测试意味着你不会对人们使用什么以及在哪里查找有很多盲点。
-将卡片分类与分析功能配对,可以让你更深入地了解人们在寻找什么。有一次,当我对一些我正在写培训文档进行分析时,我惊讶地发现搜索量最大的页面是关于资本的。所以我在顶层菜单层面上显示了该页面,即使我的“逻辑”设置将它放在了子菜单中。
+将卡片分类与分析功能配对,可以让你更深入地了解人们在寻找什么。有一次,当我对一些我正在写的培训文档进行分析时,我惊讶地发现搜索量最大的页面是关于资本的。所以我在顶层菜单层面上显示了该页面,即使我的“逻辑”设置将它放在了子菜单中。
我发现看板卡片分类是一种很好的方式,可以帮助我创建用户想要查看的内容,并将其放在希望被找到的位置。你是否发现了另一种对用户友好的组织内容的方法?或者看板的另一种有趣用途是什么?如果有的话,请在评论中分享你的想法。
@@ -34,7 +36,7 @@ via: https://opensource.com/article/17/11/kanban-boards-card-sorting
作者:[Heidi Waterhouse][a]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md b/published/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md
similarity index 66%
rename from translated/tech/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md
rename to published/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md
index 233daa72b2..fd9e9cdcba 100644
--- a/translated/tech/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md
+++ b/published/20180127 How to install KVM on CentOS 7 - RHEL 7 Headless Server.md
@@ -1,56 +1,79 @@
如何在 CentOS 7 / RHEL 7 终端服务器上安装 KVM
======
-如何在 CnetOS 7 或 RHEL 7( Red Hat 企业版 Linux) 服务器上安装和配置 KVM(基于内核的虚拟机)?如何在 CnetOS 7 上设置 KMV 并使用云镜像/ cloud-init 来安装客户虚拟机?
+如何在 CnetOS 7 或 RHEL 7(Red Hat 企业版 Linux)服务器上安装和配置 KVM(基于内核的虚拟机)?如何在 CentOS 7 上设置 KVM 并使用云镜像 / cloud-init 来安装客户虚拟机?
+
+基于内核的虚拟机(KVM)是 CentOS 或 RHEL 7 的虚拟化软件。KVM 可以将你的服务器变成虚拟机管理器。本文介绍如何在 CentOS 7 或 RHEL 7 中使用 KVM 设置和管理虚拟化环境。还介绍了如何使用命令行在物理服务器上安装和管理虚拟机(VM)。请确保在服务器的 BIOS 中启用了**虚拟化技术(VT)**。你也可以运行以下命令[测试 CPU 是否支持 Intel VT 和 AMD_V 虚拟化技术][1]。
-基于内核的虚拟机(KVM)是 CentOS 或 RHEL 7 的虚拟化软件。KVM 将你的服务器变成虚拟机管理程序。本文介绍如何在 CentOS 7 或 RHEL 7 中使用 KVM 设置和管理虚拟化环境。还介绍了如何使用 CLI 在物理服务器上安装和管理虚拟机(VM)。确保在服务器的 BIOS 中启用了**虚拟化技术(vt)**。你也可以运行以下命令[测试 CPU 是否支持 Intel VT 和 AMD_V 虚拟化技术][1]。
```
$ lscpu | grep Virtualization
Virtualization: VT-x
```
-### 按照 CentOS 7/RHEL 7 终端服务器上的 KVM 安装步骤进行操作
+按照 CentOS 7/RHEL 7 终端服务器上的 KVM 安装步骤进行操作。
-#### 步骤 1: 安装 kvm
+### 步骤 1: 安装 kvm
输入以下 [yum 命令][2]:
-`# yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install`
+
+```
+# yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install
+```
[![How to install KVM on CentOS 7 RHEL 7 Headless Server][3]][3]
启动 libvirtd 服务:
+
```
# systemctl enable libvirtd
# systemctl start libvirtd
```
-#### 步骤 2: 确认 kvm 安装
+### 步骤 2: 确认 kvm 安装
-确保使用 lsmod 命令和 [grep命令][4] 加载 KVM 模块:
-`# lsmod | grep -i kvm`
+使用 `lsmod` 命令和 [grep命令][4] 确认加载了 KVM 模块:
-#### 步骤 3: 配置桥接网络
+```
+# lsmod | grep -i kvm
+```
+
+### 步骤 3: 配置桥接网络
+
+默认情况下,由 libvirtd 配置基于 dhcpd 的网桥。你可以使用以下命令验证:
-默认情况下,由 libvirtd 配置的基于 dhcpd 的网桥。你可以使用以下命令验证:
```
# brctl show
# virsh net-list
```
+
[![KVM default networking][5]][5]
-所有虚拟机(客户机器)只能在同一台服务器上对其他虚拟机进行网络访问。为你创建的私有网络是 192.168.122.0/24。验证:
-`# virsh net-dumpxml default`
+所有虚拟机(客户机)只能对同一台服务器上的其它虚拟机进行网络访问。为你创建的私有网络是 192.168.122.0/24。验证:
+
+```
+# virsh net-dumpxml default
+```
+
+如果你希望你的虚拟机可用于 LAN 上的其他服务器,请在连接到你的 LAN 的服务器上设置一个网桥。更新你的网卡配置文件,如 ifcfg-enp3s0 或 em1:
+
+```
+# vi /etc/sysconfig/network-scripts/ifcfg-enp3s0
+```
-如果你希望你的虚拟机可用于 LAN 上的其他服务器,请在连接到你的 LAN 的服务器上设置一个网桥。更新你的网卡配置文件,如 ifcfg-enp3s0 或 em1:
-`# vi /etc/sysconfig/network-scripts/enp3s0 `
添加一行:
+
```
BRIDGE=br0
```
-[使用 vi 保存并关闭文件][6]。编辑 /etc/sysconfig/network-scripts/ifcfg-br0 :
-`# vi /etc/sysconfig/network-scripts/ifcfg-br0`
-添加以下东西:
+[使用 vi 保存并关闭文件][6]。编辑 `/etc/sysconfig/network-scripts/ifcfg-br0`:
+
+```
+# vi /etc/sysconfig/network-scripts/ifcfg-br0
+```
+
+添加以下内容:
+
```
DEVICE="br0"
# I am getting ip from DHCP server #
@@ -62,29 +85,38 @@ TYPE="Bridge"
DELAY="0"
```
-重新启动网络服务(警告:ssh命令将断开连接,最好重新启动该设备):
-`# systemctl restart NetworkManager`
+重新启动网络服务(警告:ssh 命令将断开连接,最好重新启动该设备):
-用 brctl 命令验证它:
-`# brctl show`
+```
+# systemctl restart NetworkManager
+```
-#### 步骤 4: 创建你的第一个虚拟机
+用 `brctl` 命令验证它:
+
+```
+# brctl show
+```
+
+### 步骤 4: 创建你的第一个虚拟机
+
+我将会创建一个 CentOS 7.x 虚拟机。首先,使用 `wget` 命令获取 CentOS 7.x 最新的 ISO 镜像:
-我将会创建一个 CentOS 7.x 虚拟机。首先,使用 wget 命令获取 CentOS 7.x 最新的 ISO 镜像:
```
# cd /var/lib/libvirt/boot/
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/CentOS-7-x86_64-Minimal-1708.iso
```
验证 ISO 镜像:
+
```
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/sha256sum.txt
# sha256sum -c sha256sum.txt
```
-##### 创建 CentOS 7.x 虚拟机
+#### 创建 CentOS 7.x 虚拟机
在这个例子中,我创建了 2GB RAM,2 个 CPU 核心,1 个网卡和 40 GB 磁盘空间的 CentOS 7.x 虚拟机,输入:
+
```
# virt-install \
--virt-type=kvm \
@@ -98,35 +130,41 @@ DELAY="0"
--disk path=/var/lib/libvirt/images/centos7.qcow2,size=40,bus=virtio,format=qcow2
```
-从另一个终端通过 ssh 和 type 配置 vnc 登录:
+从另一个终端通过 `ssh` 配置 vnc 登录,输入:
+
```
# virsh dumpxml centos7 | grep v nc
```
-请记录下端口值(即 5901)。你需要使用 SSH 客户端来建立隧道和 VNC 客户端才能访问远程 vnc 服务区。在客户端/桌面/ macbook pro 系统中输入以下 SSH 端口转化命令:
-`$ ssh vivek@server1.cyberciti.biz -L 5901:127.0.0.1:5901`
+请记录下端口值(即 5901)。你需要使用 SSH 客户端来建立隧道和 VNC 客户端才能访问远程 vnc 服务器。在客户端/桌面/ macbook pro 系统中输入以下 SSH 端口转发命令:
+
+```
+$ ssh vivek@server1.cyberciti.biz -L 5901:127.0.0.1:5901
+```
一旦你建立了 ssh 隧道,你可以将你的 VNC 客户端指向你自己的 127.0.0.1 (localhost) 地址和端口 5901,如下所示:
+
[![][7]][7]
你应该看到 CentOS Linux 7 客户虚拟机安装屏幕如下:
+
[![][8]][8]
现在只需按照屏幕说明进行操作并安装CentOS 7。一旦安装完成后,请继续并单击重启按钮。 远程服务器关闭了我们的 VNC 客户端的连接。 你可以通过 KVM 客户端重新连接,以配置服务器的其余部分,包括基于 SSH 的会话或防火墙。
-#### 步骤 5: 使用云镜像
+### 使用云镜像
-以上安装方法对于学习目的或单个虚拟机而言是可行的。你需要部署大量的虚拟机吗? 尝试云镜像。你可以根据需要修改预先构建的云图像。例如,使用 [Cloud-init][9] 添加用户,ssh 密钥,设置时区等等,这是处理云实例的早期初始化的事实上的多分发包。让我们看看如何创建带有 1024MB RAM,20GB 磁盘空间和 1 个 vCPU 的 CentOS 7 虚拟机。(译注: vCPU 即电脑中的虚拟处理器)
+以上安装方法对于学习目的或单个虚拟机而言是可行的。你需要部署大量的虚拟机吗? 可以试试云镜像。你可以根据需要修改预先构建的云镜像。例如,使用 [Cloud-init][9] 添加用户、ssh 密钥、设置时区等等,这是处理云实例的早期初始化的事实上的多分发包。让我们看看如何创建带有 1024MB RAM,20GB 磁盘空间和 1 个 vCPU 的 CentOS 7 虚拟机。(LCTT 译注: vCPU 即电脑中的虚拟处理器)
-##### 获取 CentOS 7 云镜像
+#### 获取 CentOS 7 云镜像
```
# cd /var/lib/libvirt/boot
# wget http://cloud.centos.org/centos/7/images/CentOS-7-x86_64-GenericCloud.qcow2
```
-##### 创建所需的目录
+#### 创建所需的目录
```
# D=/var/lib/libvirt/images
@@ -135,31 +173,39 @@ DELAY="0"
mkdir: created directory '/var/lib/libvirt/images/centos7-vm1'
```
-##### 创建元数据文件
+#### 创建元数据文件
```
# cd $D/$VM
# vi meta-data
```
-添加以下东西:
+添加以下内容:
+
```
instance-id: centos7-vm1
local-hostname: centos7-vm1
```
-##### 创建用户数据文件
+#### 创建用户数据文件
+
+我将使用 ssh 密钥登录到虚拟机。所以确保你有 ssh 密钥:
+
+```
+# ssh-keygen -t ed25519 -C "VM Login ssh key"
+```
-我将使用 ssh 密钥登录到虚拟机。所以确保你有 ssh-keys:
-`# ssh-keygen -t ed25519 -C "VM Login ssh key"`
[![ssh-keygen command][10]][11]
-请参阅 "[如何在 Linux/Unix 系统上设置 SSH 密钥][12]" 来获取更多信息。编辑用户数据如下:
+请参阅 “[如何在 Linux/Unix 系统上设置 SSH 密钥][12]” 来获取更多信息。编辑用户数据如下:
+
```
# cd $D/$VM
# vi user-data
```
-添加如下(根据你的设置替换主机名,用户,ssh-authorized-keys):
+
+添加如下(根据你的设置替换 `hostname`、`users`、`ssh-authorized-keys`):
+
```
#cloud-config
@@ -199,14 +245,14 @@ runcmd:
- yum -y remove cloud-init
```
-##### 复制云镜像
+#### 复制云镜像
```
# cd $D/$VM
# cp /var/lib/libvirt/boot/CentOS-7-x86_64-GenericCloud.qcow2 $VM.qcow2
```
-##### 创建 20GB 磁盘映像
+#### 创建 20GB 磁盘映像
```
# cd $D/$VM
@@ -215,25 +261,30 @@ runcmd:
# virt-resize --quiet --expand /dev/sda1 $VM.qcow2 $VM.new.image
```
[![Set VM image disk size][13]][13]
-覆盖它的缩放图片:
+
+用压缩后的镜像覆盖它:
+
```
# cd $D/$VM
# mv $VM.new.image $VM.qcow2
```
-##### 创建一个 cloud-init ISO
+#### 创建一个 cloud-init ISO
+
+```
+# mkisofs -o $VM-cidata.iso -V cidata -J -r user-data meta-data
+```
-`# mkisofs -o $VM-cidata.iso -V cidata -J -r user-data meta-data`
[![Creating a cloud-init ISO][14]][14]
-##### 创建一个 pool
+#### 创建一个池
```
# virsh pool-create-as --name $VM --type dir --target $D/$VM
Pool centos7-vm1 created
```
-##### 安装 CentOS 7 虚拟机
+#### 安装 CentOS 7 虚拟机
```
# cd $D/$VM
@@ -247,23 +298,31 @@ Pool centos7-vm1 created
--graphics spice \
--noautoconsole
```
+
删除不需要的文件:
+
```
# cd $D/$VM
# virsh change-media $VM hda --eject --config
# rm meta-data user-data centos7-vm1-cidata.iso
```
-##### 查找虚拟机的 IP 地址
+#### 查找虚拟机的 IP 地址
-`# virsh net-dhcp-leases default`
+```
+# virsh net-dhcp-leases default
+```
[![CentOS7-VM1- Created][15]][15]
-##### 登录到你的虚拟机
+#### 登录到你的虚拟机
+
+使用 ssh 命令:
+
+```
+# ssh vivek@192.168.122.85
+```
-使用 ssh 命令:
-`# ssh vivek@192.168.122.85`
[![Sample VM session][16]][16]
### 有用的命令
@@ -272,7 +331,9 @@ Pool centos7-vm1 created
#### 列出所有虚拟机
-`# virsh list --all`
+```
+# virsh list --all
+```
#### 获取虚拟机信息
@@ -283,21 +344,33 @@ Pool centos7-vm1 created
#### 停止/关闭虚拟机
-`# virsh shutdown centos7-vm1`
+```
+# virsh shutdown centos7-vm1
+```
#### 开启虚拟机
-`# virsh start centos7-vm1`
+```
+# virsh start centos7-vm1
+```
#### 将虚拟机标记为在引导时自动启动
-`# virsh autostart centos7-vm1`
+```
+# virsh autostart centos7-vm1
+```
#### 重新启动(软安全重启)虚拟机
-`# virsh reboot centos7-vm1`
+```
+# virsh reboot centos7-vm1
+```
+
重置(硬重置/不安全)虚拟机
-`# virsh reset centos7-vm1`
+
+```
+# virsh reset centos7-vm1
+```
#### 删除虚拟机
@@ -309,7 +382,9 @@ Pool centos7-vm1 created
# VM=centos7-vm1
# rm -ri $D/$VM
```
-查看 virsh 命令类型的完整列表
+
+查看 virsh 命令类型的完整列表:
+
```
# virsh help | less
# virsh help | grep reboot
@@ -321,11 +396,11 @@ Pool centos7-vm1 created
--------------------------------------------------------------------------------
-via: [https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/](https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/)
+via: https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/
作者:[Vivek Gite][a]
译者:[MjSeven](https://github.com/MjSeven)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180130 Use of du - df commands (with examples).md b/published/20180130 Use of du - df commands (with examples).md
similarity index 59%
rename from translated/tech/20180130 Use of du - df commands (with examples).md
rename to published/20180130 Use of du - df commands (with examples).md
index 40327aad3a..5f0f6e9c42 100644
--- a/translated/tech/20180130 Use of du - df commands (with examples).md
+++ b/published/20180130 Use of du - df commands (with examples).md
@@ -1,85 +1,85 @@
du 及 df 命令的使用(附带示例)
======
-在本文中,我将讨论 du 和 df 命令。du 和 df 命令都是 Linux 系统的重要工具,来显示 Linux 文件系统的磁盘使用情况。这里我们将通过一些例子来分享这两个命令的用法。
-**(推荐阅读:[使用 scp 和 rsync 命令传输文件][1])**
+在本文中,我将讨论 `du` 和 `df` 命令。`du` 和 `df` 命令都是 Linux 系统的重要工具,来显示 Linux 文件系统的磁盘使用情况。这里我们将通过一些例子来分享这两个命令的用法。
-**(另请阅读:[使用 dd 和 cat 命令为 Linux 系统克隆磁盘][2])**
+- **(推荐阅读:[使用 scp 和 rsync 命令传输文件][1])**
+- **(另请阅读:[使用 dd 和 cat 命令为 Linux 系统克隆磁盘][2])**
### du 命令
-du(disk usage 的简称)是用于查找文件和目录的磁盘使用情况的命令。du 命令在与各种选项一起使用时能以多种格式提供结果。
+`du`(disk usage 的简称)是用于查找文件和目录的磁盘使用情况的命令。`du` 命令在与各种选项一起使用时能以多种格式提供结果。
下面是一些例子:
- **1- 得到一个目录下所有子目录的磁盘使用概况**
+#### 1、 得到一个目录下所有子目录的磁盘使用概况
```
- $ du /home
+$ du /home
```
![du command][4]
-该命令的输出将显示 /home 中的所有文件和目录以及显示块大小。
+该命令的输出将显示 `/home` 中的所有文件和目录以及显示块大小。
-**2- 以人类可读格式也就是 kb、mb 等显示文件/目录大小**
+#### 2、 以人类可读格式也就是 kb、mb 等显示文件/目录大小
```
- $ du -h /home
+$ du -h /home
```
![du command][6]
-**3- 目录的总磁盘大小**
+#### 3、 目录的总磁盘大小
```
- $ du -s /home
+$ du -s /home
```
![du command][8]
-它是 /home 目录的总大小
+它是 `/home` 目录的总大小
### df 命令
-df(disk filesystem 的简称)用于显示 Linux 系统的磁盘利用率。
+df(disk filesystem 的简称)用于显示 Linux 系统的磁盘利用率。(LCTT 译注:`df` 可能应该是 disk free 的简称。)
下面是一些例子。
-**1- 显示设备名称、总块数、总磁盘空间、已用磁盘空间、可用磁盘空间和文件系统上的挂载点。**
+#### 1、 显示设备名称、总块数、总磁盘空间、已用磁盘空间、可用磁盘空间和文件系统上的挂载点。
```
- $ df
+$ df
```
![df command][10]
-**2- 人类可读格式的信息**
+#### 2、 人类可读格式的信息
```
- $ df -h
+$ df -h
```
![df command][12]
上面的命令以人类可读格式显示信息。
-**3- 显示特定分区的信息**
+#### 3、 显示特定分区的信息
```
- $ df -hT /etc
+$ df -hT /etc
```
![df command][14]
--hT 加上目标目录将以可读格式显示 /etc 的信息。
+`-hT` 加上目标目录将以可读格式显示 `/etc` 的信息。
-虽然 du 和 df 命令有更多选项,但是这些例子可以让你初步了解。如果在这里找不到你要找的东西,那么你可以参考有关命令的 man 页面。
+虽然 `du` 和 `df` 命令有更多选项,但是这些例子可以让你初步了解。如果在这里找不到你要找的东西,那么你可以参考有关命令的 man 页面。
另外,[**在这**][15]阅读我的其他帖子,在那里我分享了一些其他重要和经常使用的 Linux 命令。
-如往常一样,你的评论和疑问是受欢迎的,因此在下面留下你的评论和疑问,我会回复你。
+如往常一样,欢迎你留下评论和疑问,因此在下面留下你的评论和疑问,我会回复你。
--------------------------------------------------------------------------------
@@ -87,7 +87,7 @@ via: http://linuxtechlab.com/du-df-commands-examples/
作者:[SHUSAIN][a]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180202 How to Manage PGP and SSH Keys with Seahorse.md b/published/20180202 How to Manage PGP and SSH Keys with Seahorse.md
similarity index 54%
rename from translated/tech/20180202 How to Manage PGP and SSH Keys with Seahorse.md
rename to published/20180202 How to Manage PGP and SSH Keys with Seahorse.md
index 789137066c..7fe2949666 100644
--- a/translated/tech/20180202 How to Manage PGP and SSH Keys with Seahorse.md
+++ b/published/20180202 How to Manage PGP and SSH Keys with Seahorse.md
@@ -1,114 +1,94 @@
如何使用 Seahorse 管理 PGP 和 SSH 密钥
============================================================
-

-学习使用 Seahorse GUI 工具去管理 PGP 和 SSH 密钥。[Creative Commons Zero][6]
-安全无异于内心的平静。毕竟,安全是许多用户迁移到 Linux 的最大理由。但是当你可以采用几种方法和技术去确保你的桌面或者服务器系统的安全时,你为什么还要停止使用差不多已经接受的平台呢?
+> 学习使用 Seahorse GUI 工具去管理 PGP 和 SSH 密钥。
-其中一项技术涉及到密钥 —在 PGP 和 SSH 中,PGP 密钥允许你去加密和解密电子邮件和文件,而 SSH 密钥允许你使用一个额外的安全层去登入服务器。
+安全即内心的平静。毕竟,安全是许多用户迁移到 Linux 的最大理由。但是为什么要止步于仅仅采用该平台,你还可以采用多种方法和技术去确保你的桌面或者服务器系统的安全。
-当然,你可以通过命令行接口(CLI)来管理这些密钥,但是,如果你使用一个华丽的 GUI 桌面环境呢?经验丰富的 Linux 用户可能对于摆脱命令行来工作感到很不适应,但是,并不是所有用户都具备与他们相同的技术和水平因此,使用 GUI!
+其中一项技术涉及到密钥 —— 用在 PGP 和 SSH 中。PGP 密钥允许你去加密和解密电子邮件和文件,而 SSH 密钥允许你使用一个额外的安全层去登入服务器。
+
+当然,你可以通过命令行接口(CLI)来管理这些密钥,但是,如果你使用一个华丽的 GUI 桌面环境呢?经验丰富的 Linux 用户可能对于脱离命令行来工作感到很不适应,但是,并不是所有用户都具备与他们相同的技术和水平,因此,使用 GUI 吧!
在本文中,我将带你探索如何使用 [Seahorse][14] GUI 工具来管理 PGP 和 SSH 密钥。Seahorse 有非常强大的功能,它可以:
* 加密/解密/签名文件和文本。
-
* 管理你的密钥和密钥对。
-
* 同步你的密钥和密钥对到远程密钥服务器。
-
* 签名和发布密钥。
-
* 缓存你的密码。
-
* 备份密钥和密钥对。
-
* 在任何一个 GDK 支持的格式中添加一个图像作为一个 OpenPGP photo ID。
-
* 创建、配置、和缓存 SSH 密钥。
-对于那些不了解 Seahorse 的人来说,它是一个在 GNOME 密钥对中管理加密密钥和密码的 GNOME 应用程序。不用担心,Seahorse 可以安装在许多的桌面上。并且由于 Seahorse 是在标准仓库中创建的,你可以打开你的桌面应用商店(比如,Ubuntu Software 或者 Elementary OS AppCenter)去安装它。因此,你可以在你的发行版的应用商店中点击去安装它。安装完成后,你就可以去使用这个很方便的工具了。
+对于那些不了解 Seahorse 的人来说,它是一个管理 GNOME 钥匙环中的加密密钥和密码的 GNOME 应用程序。不用担心,Seahorse 可以安装在许多的桌面环境上。并且由于 Seahorse 可以在标准的仓库中找到,你可以打开你的桌面应用商店(比如,Ubuntu Software 或者 Elementary OS AppCenter)去安装它。你可以在你的发行版的应用商店中点击去安装它。安装完成后,你就可以去使用这个很方便的工具了。
我们开始去使用它吧。
### PGP 密钥
-我们需要做的第一件事情就是生成一个新的 PGP 密钥。正如前面所述,PGP 密钥可以用于加密电子邮件(使用一些工具,像 [Thunderbird][15] 的 [Enigmail][16] 或者使用 [Evolution][17] 内置的加密功能)。一个 PGP 密钥也可以用于加密文件。任何人使用你的公钥都可以解密你的电子邮件和文件。没有 PGP 密钥是做不到的。
+我们需要做的第一件事情就是生成一个新的 PGP 密钥。正如前面所述,PGP 密钥可以用于加密电子邮件(通过一些工具,像 [Thunderbird][15] 的 [Enigmail][16] 或者使用 [Evolution][17] 内置的加密功能)。PGP 密钥也可以用于加密文件。任何人都可以使用你的公钥加密电子邮件和文件发给你(LCTT 译注:原文此处“加密”误作“解密”)。没有 PGP 密钥是做不到的。
使用 Seahorse 创建一个新的 PGP 密钥对是非常简单的。以下是操作步骤:
1. 打开 Seahorse 应用程序
-
-2. 在主面板的左上角点击 + 按钮
-
-3. 选择 PGP Key(如图 1 )
-
-4. 点击 Continue
-
+2. 在主面板的左上角点击 “+” 按钮
+3. 选择 “PGP 密钥”(如图 1 )
+4. 点击 “继续”
5. 当提示时,输入完整的名字和电子邮件地址
-
-6. 点击 Create
-
+6. 点击 “创建”

-图 1:使用 Seahorse 创建一个 PGP 密钥。[Used with permission][1]
-在创建你的 PGP 密钥期间,你可以点击 Advanced key options 展开选项部分,在那里你可以为密钥添加注释信息、加密类型、密钥长度、以及过期时间(如图 2)。
+*图 1:使用 Seahorse 创建一个 PGP 密钥。*
+在创建你的 PGP 密钥期间,你可以点击 “高级密钥选项” 展开选项部分,在那里你可以为密钥添加注释信息、加密类型、密钥长度、以及过期时间(如图 2)。

-图 2:PGP 密钥高级选项[Used with permission][2]
+
+*图 2:PGP 密钥高级选项*
增加注释部分可以很方便帮你记住密钥的用途(或者其它的信息)。
-要使用你创建的 PGP,可在密钥列表中双击它。在结果窗口中,点击 Names 和 Signatures 选项卡。在这个窗口中,你可以签名你的密钥(表示你信任这个密钥)。点击 Sign 按钮然后(在结果窗口中)标识 how carefully you’ve checked this key 和 how others will see the signature(如图 3)。
+要使用你创建的 PGP,可在密钥列表中双击它。在结果窗口中,点击 “名字” 和 “签名” 选项卡。在这个窗口中,你可以签名你的密钥(表示你信任这个密钥)。点击 “签名” 按钮然后(在结果窗口中)指出 “你是如何仔细的检查这个密钥的?” 和 “其他人将如何看到该签名”(如图 3)。

-图 3:签名一个密钥表示信任级别。[Used with permission][3]
-当你处理其它人的密钥时,密钥签名是非常重要的,因为一个签名的密钥将确保你的系统(和你)做了这项工作并且完全信任这个重要的密钥。
+*图 3:签名一个密钥表示信任级别。*
-谈到导入的密钥,Seahorse 可以允许你很容易地去导入其他人的公钥文件(这个文件以 .asc 为后缀)。你的系统上有其他人的公钥,意味着你可以解密从他们那里发送给你的电子邮件和文件。然而,Seahorse 在很长的一段时间内都存在一个 [已知的 bug][18]。这个问题是,Seahorse 导入使用 GPG 版本 1,但是显示的是 GPG 版本 2。这意味着,在这个存在了很长时间的 bug 被修复之前,导入公钥总是失败的。如果你想导入一个公钥文件到 Seahorse 中,你只能去使用命令行。因此,如果有人发送给你一个文件 olivia.asc,你想去导入到 Seahorse 中使用它,你将只能运行命令 gpg2 --import olivia.asc。那个密钥将出现在 GnuPG 密钥列表中。你可以打开密钥,点击 I trust signatures 按钮,然后在问题 how carefully you’ve checked the key 中,点击 Sign this key 按钮去标示。
+当你处理其它人的密钥时,密钥签名是非常重要的,因为一个签名的密钥将确保你的系统(和你)做了这项签名工作并且完全信任这个重要的密钥。
+
+谈到导入的密钥,Seahorse 可以允许你很容易地去导入其他人的公钥文件(这个文件以 `.asc` 为后缀)。你的系统上有其他人的公钥,意味着你可以加密发送给他们的电子邮件和文件(LCTT 译注:原文将“加密”误作“解密”)。然而,Seahorse 在很长的一段时间内都存在一个 [已知的 bug][18]。这个问题是,Seahorse 导入使用 GPG 版本 1,但是显示的是 GPG 版本 2。这意味着,在这个存在了很长时间的 bug 被修复之前,导入公钥总是失败的。如果你想导入一个公钥文件到 Seahorse 中,你只能去使用命令行。因此,如果有人发送给你一个文件 `olivia.asc`,你想去导入到 Seahorse 中使用它,你将只能运行命令 `gpg2 --import olivia.asc`。那个密钥将出现在 GnuPG 密钥列表中。你可以打开该密钥,点击 “我信任签名” 按钮,然后在问题 “你是如何仔细地检查该密钥的?” 中,点击 “签名这个密钥” 按钮去签名。
### SSH 密钥
现在我们来谈谈我认为 Seahorse 中最重要的一个方面 — SSH 密钥。Seahorse 不仅可以很容易地生成一个 SSH 密钥,而且它也可以很容易地将生成的密钥发送到服务器上,因此,你可以享受到 SSH 密钥验证的好处。下面是如何生成一个新的密钥以及如何导出它到一个远程服务器上。
1. 打开 Seahorse 应用程序
-
-2. 点击 + 按钮
-
-3. 选择 Secure Shell Key
-
-4. 点击 Continue
-
+2. 点击 “+” 按钮
+3. 选择 “Secure Shell Key”
+4. 点击 “Continue”
5. 提供一个密钥描述信息
-
-6. 点击 Set Up 去创建密钥
-
+6. 点击 “Set Up” 去创建密钥
7. 输入密钥的验证密钥
-
8. 点击 OK
-
-9. 输入远程服务器地址和服务器上的登陆名(如图 4)
-
+9. 输入远程服务器地址和服务器上的登录名(如图 4)
10. 输入远程用户的密码
-
11. 点击 OK

-图 4:上传一个 SSH 密钥到远程服务器。[Used with permission][4]
-新密钥将上传到远程服务器上以准备好使用它。如果你的服务器已经设置为使用 SSH 密钥验证,那就一切就绪了。
+*图 4:上传一个 SSH 密钥到远程服务器。*
-需要注意的是,在创建一个 SSH 密钥期间,你可以点击 Advanced key options 去展开它,配置加密类型和密钥长度(如图 5)。
+新密钥将上传到远程服务器上以备使用。如果你的服务器已经设置为使用 SSH 密钥验证,那就一切就绪了。
+需要注意的是,在创建一个 SSH 密钥期间,你可以点击 “高级密钥选项”去展开它,配置加密类型和密钥长度(如图 5)。

-图 5:高级 SSH 密钥选项。[Used with permission][5]
+
+*图 5:高级 SSH 密钥选项。*
### Linux 新手必备
@@ -120,9 +100,9 @@
via: https://www.linux.com/learn/intro-to-linux/2018/2/how-manage-pgp-and-ssh-keys-seahorse
-作者:[JACK WALLEN ][a]
+作者:[JACK WALLEN][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxt](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180204 LKRG- Linux to Get a Loadable Kernel Module for Runtime Integrity Checking.md b/published/20180204 LKRG- Linux to Get a Loadable Kernel Module for Runtime Integrity Checking.md
new file mode 100644
index 0000000000..1ce18d33f9
--- /dev/null
+++ b/published/20180204 LKRG- Linux to Get a Loadable Kernel Module for Runtime Integrity Checking.md
@@ -0,0 +1,61 @@
+LKRG:用于运行时完整性检查的可加载内核模块
+======
+![LKRG logo][1]
+
+开源社区的人们正在致力于一个 Linux 内核的新项目,它可以让内核更安全。命名为 Linux 内核运行时防护(Linux Kernel Runtime Guard,简称:LKRG),它是一个在 Linux 内核执行运行时完整性检查的可加载内核模块(LKM)。
+
+它的用途是检测对 Linux 内核的已知的或未知的安全漏洞利用企图,以及去阻止这种攻击企图。
+
+LKRG 也可以检测正在运行的进程的提权行为,在漏洞利用代码运行之前杀掉这个运行进程。
+
+### 这个项目开发始于 2011 年,首个版本已经发布
+
+因为这个项目开发的较早,LKRG 的当前版本仅仅是通过内核消息去报告违反内核完整性的行为,但是随着这个项目的成熟,将会部署一个完整的漏洞利用缓减系统。
+
+LKRG 的成员 Alexander Peslyak 解释说,这个项目从 2011 年启动,并且 LKRG 已经经历了一个“重新开发"阶段。
+
+LKRG 的首个公开版本是 LKRG v0.0,它现在可以从 [这个页面][2] 下载使用。[这里][3] 是这个项目的维基,为支持这个项目,它也有一个 [Patreon 页面][4]。
+
+虽然 LKRG 仍然是一个开源项目,LKRG 的维护者也计划做一个 LKRG Pro 版本,这个版本将包含一个专用的 LKRG 发行版,它将支持对特定漏洞利用的检测,比如,容器泄漏。开发团队计划从 LKRG Pro 基金中提取部分资金用于保证项目的剩余工作。
+
+### LKRG 是一个内核模块而不是一个补丁。
+
+一个类似的项目是附加内核监视器(AKO),但是 LKRG 与 AKO 是不一样的,因为 LKRG 是一个内核加载模块而不是一个补丁。LKRG 开发团队决定将它设计为一个内核模块是因为,在内核上打补丁对安全性、系统稳定性以及性能都有很直接的影响。
+
+而以内核模块的方式提供,可以在每个系统上更容易部署 LKRG,而不必去修改核心的内核代码,修改核心的内核代码非常复杂并且很容易出错。
+
+LKRG 内核模块在目前主流的 Linux 发行版上都可以使用,比如,RHEL7、OpenVZ 7、Virtuozzo 7、以及 Ubuntu 16.04 到最新的主线版本。
+
+### 它并非是一个完美的解决方案
+
+LKRG 的创建者警告用户,他们并不认为 LKRG 是一个完美的解决方案,它**提供不了**坚不可摧和 100% 的安全。他们说,LKRG 是 “设计为**可旁通**的”,并且仅仅提供了“多元化安全” 的**一个**方面。
+
+> 虽然 LKRG 可以防御许多已有的 Linux 内核漏洞利用,而且也有可能会防御将来许多的(包括未知的)未特意设计去绕过 LKRG 的安全漏洞利用。它是设计为可旁通的(尽管有时候是以更复杂和/或低可利用为代价的)。因此,他们说 LKRG 通过多元化提供安全,就像运行一个不常见的操作系统内核一样,也就不会有真实运行一个不常见的操作系统的可用性弊端。
+
+LKRG 有点像基于 Windows 的防病毒软件,它也是工作于内核级别去检测漏洞利用和恶意软件。但是,LKRG 团队说,他们的产品比防病毒软件以及其它终端安全软件更加安全,因为它的基础代码量比较小,所以在内核级别引入新 bug 和漏洞的可能性就更小。
+
+### 运行当前版本的 LKRG 大约会带来 6.5% 的性能损失
+
+Peslyak 说 LKRG 是非常适用于 Linux 机器的,它在修补内核的安全漏洞后不需要重启动机器。LKRG 允许用户持续运行带有安全措施的机器,直到在一个计划的维护窗口中测试和部署关键的安全补丁为止。
+
+经测试显示,安装 LKRG v0.0 后大约会产生 6.5% 性能影响,但是,Peslyak 说将在后续的开发中持续降低这种影响。
+
+测试也显示,LKRG 检测到了 CVE-2014-9322 (BadIRET)、CVE-2017-5123 (waitid(2) missing access_ok)、以及 CVE-2017-6074 (use-after-free in DCCP protocol) 的漏洞利用企图,但是没有检测到 CVE-2016-5195 (Dirty COW) 的漏洞利用企图。开发团队说,由于前面提到的“可旁通”的设计策略,LKRG 没有检测到 Dirty COW 提权攻击。
+
+> 在 Dirty COW 的测试案例中,由于 bug 机制的原因,使得 LKRG 发生了 “旁通”,并且这也是一种利用方法,它也是将来类似的以用户空间为目标的绕过 LKRG 的一种方法。这样的漏洞利用是否会是普通情况(不太可能!除非 LKRG 或者类似机制的软件流行起来),以及对它的可用性的(负面的)影响是什么?(对于那些直接目标是用户空间的内核漏洞来说,这不太重要,也并不简单)。
+
+--------------------------------------------------------------------------------
+
+via: https://www.bleepingcomputer.com/news/linux/lkrg-linux-to-get-a-loadable-kernel-module-for-runtime-integrity-checking/
+
+作者:[Catalin Cimpanu][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.bleepingcomputer.com/author/catalin-cimpanu/
+[1]:https://www.bleepstatic.com/content/posts/2018/02/04/LKRG-logo.png
+[2]:http://www.openwall.com/lkrg/
+[3]:http://openwall.info/wiki/p_lkrg/Main
+[4]:https://www.patreon.com/p_lkrg
diff --git a/translated/tech/20180205 New Linux User- Try These 8 Great Essential Linux Apps.md b/published/20180205 New Linux User- Try These 8 Great Essential Linux Apps.md
similarity index 74%
rename from translated/tech/20180205 New Linux User- Try These 8 Great Essential Linux Apps.md
rename to published/20180205 New Linux User- Try These 8 Great Essential Linux Apps.md
index 69a0817bd2..9ca22f9550 100644
--- a/translated/tech/20180205 New Linux User- Try These 8 Great Essential Linux Apps.md
+++ b/published/20180205 New Linux User- Try These 8 Great Essential Linux Apps.md
@@ -7,13 +7,13 @@ Linux 新用户?来试试这 8 款重要的软件
下面这些应用程序大多不是 Linux 独有的。如果有过使用 Windows/Mac 的经验,您很可能会熟悉其中一些软件。根据兴趣和需求,下面的程序可能不全符合您的要求,但是在我看来,清单里大多数甚至全部的软件,对于新用户开启 Linux 之旅都是有帮助的。
-**相关链接** : [每一个 Linux 用户都应该使用的 11 个便携软件][1]
+**相关链接** : [每一个 Linux 用户都应该使用的 11 个可移植软件][1]
### 1. Chromium 网页浏览器
![linux-apps-01-chromium][2]
-很难有一个不需要使用网页浏览器的用户。您可以看到陈旧的 Linux 发行版几乎都会附带 Firefox(火狐浏览器)或者其他 [Linux 浏览器][3],关于浏览器,强烈建议您尝试 [Chromium][4]。它是谷歌浏览器的开源版。Chromium 的主要优点是速度和安全性。它同样拥有大量的附加组件。
+几乎不会不需要使用网页浏览器的用户。您可以看到陈旧的 Linux 发行版几乎都会附带 Firefox(火狐浏览器)或者其他 [Linux 浏览器][3],关于浏览器,强烈建议您尝试 [Chromium][4]。它是谷歌浏览器的开源版。Chromium 的主要优点是速度和安全性。它同样拥有大量的附加组件。
### 2. LibreOffice
@@ -21,13 +21,13 @@ Linux 新用户?来试试这 8 款重要的软件
[LibreOffice][6] 是一个开源办公套件,其包括文字处理(Writer)、电子表格(Calc)、演示(Impress)、数据库(Base)、公式编辑器(Math)、矢量图和流程图(Draw)应用程序。它与 Microsoft Office 文档兼容,如果其基本功能不能满足需求,您可以使用 [LibreOffice 拓展][7]。
-LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Linux 的计算机,安装它是有必要的。
+LibreOffice 显然是 Linux 应用中至关重要的一员,如果您使用 Linux 的计算机,安装它是有必要的。
-### 3. GIMP(GNU Image Manipulation Program、GUN 图像处理程序)
+### 3. GIMP(GUN 图像处理程序)
![linux-apps-03-gimp][8]
-[GIMP][9] 是一款非常强大的开源图片处理程序,它类似于 Photoshop。通过 GIMP,您可以编辑或是创建用于 web 或是打印的光栅图(位图)。如果您对专业的图片处理没有概念,Linux 自然提供有更简单的图像编辑器,GIMP 看上去可能会复杂一点。GIMP 并不单纯提供图片裁剪和大小调整,它更覆盖了图层、滤镜、遮罩、路径和其他一些高级功能。
+[GIMP][9] 是一款非常强大的开源图片处理程序,它类似于 Photoshop。通过 GIMP,您可以编辑或是创建用于 Web 或是打印的光栅图(位图)。如果您对专业的图片处理没有概念,Linux 自然提供有更简单的图像编辑器,GIMP 看上去可能会复杂一点。GIMP 并不单纯提供图片裁剪和大小调整,它更覆盖了图层、滤镜、遮罩、路径和其他一些高级功能。
### 4. VLC 媒体播放器
@@ -39,15 +39,15 @@ LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Lin
![linux-apps-05-jitsi][12]
-[Jitsy][13] 完全是关于通讯的。您可以借助它使用 Google talk、Facebook chat、Yahoo、ICQ 和 XMPP。它是用于音视频通话(包括电话会议),桌面流和群组聊天的多用户工具。会话会被加密。Jistsy 同样能帮助您传输文件或记录电话。
+[Jitsy][13] 完全是关于通讯的。您可以借助它使用 Google talk、Facebook chat、Yahoo、ICQ 和 XMPP。它是用于音视频通话(包括电话会议),桌面流和群组聊天的多用户工具。会话会被加密。Jistsy 同样能帮助您传输文件或记录电话。
### 6. Synaptic
![linux-apps-06-synaptic][14]
-[Synaptic][15] 是一款基于 Debian 的系统发行版的另一款应用程序安装程序。并不是所有基于 Debian 的 Linux 都安装有它,如果您使用基于 Debian 的 Linux 操作系统没有预装,也许您可以试一试。Synaptic 是一款用于添加或移除系统应用的 GUI 工具,甚至相对于许多发行版默认安装的 [软件中心包管理器][16] ,经验丰富的 Linux 用户更亲睐于 Sunaptic。
+[Synaptic][15] 是一款基于 Debian 系统发行版的另一款应用程序安装程序。并不是所有基于 Debian 的 Linux 都安装有它,如果您使用基于 Debian 的 Linux 操作系统没有预装,也许您可以试一试。Synaptic 是一款用于添加或移除系统应用的 GUI 工具,甚至相对于许多发行版默认安装的 [软件中心包管理器][16] ,经验丰富的 Linux 用户更亲睐于 Sunaptic。
-**相关链接** : [10 款您没听说过的充当生产力的 Linux 应用程序][17]
+**相关链接** : [10 款您没听说过的 Linux 生产力应用程序][17]
### 7. VirtualBox
@@ -59,9 +59,9 @@ LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Lin
![linux-apps-08-aisleriot][20]
-对于 Linux 的新用户来说,一款纸牌游戏并不是刚需,但是它真的太有趣了。当您进入这款纸牌游戏,您会发现,这是一款极好的纸牌包。[AisleRiot][21] 是 Linux 标志性的应用程序,原因是 - 它涵盖超过八十中纸牌游戏,包括流行的 Klondike、Bakers Dozen、Camelot 等等,这些只是预告片 - 它是会上瘾的,您可能会花很长时间沉迷于此!
+对于 Linux 的新用户来说,一款纸牌游戏并不是刚需,但是它真的太有趣了。当您进入这款纸牌游戏,您会发现,这是一款极好的纸牌游戏包。[AisleRiot][21] 是 Linux 标志性的应用程序,原因是 - 它涵盖超过八十种纸牌游戏,包括流行的 Klondike、Bakers Dozen、Camelot 等等,作为预警 - 它是会上瘾的,您可能会花很长时间沉迷于此!
-根据您所使用的发行版,这些软件会有不同的安装方法。但是大多数都可以通过您使用的发行版中的包管理器安装使用,甚至它们可能会预装在您的发行版上。安装并且尝试它们想必是最好的,如果不和您的胃口,您可以轻松地删除它们。
+根据您所使用的发行版,这些软件会有不同的安装方法。但是大多数都可以通过您使用的发行版中的包管理器安装使用,甚至它们可能会预装在您的发行版上。安装并且尝试它们想必是最好的,如果不合您的胃口,您可以轻松地删除它们。
--------------------------------------------------------------------------------
@@ -69,7 +69,7 @@ via: https://www.maketecheasier.com/essential-linux-apps/
作者:[Ada Ivanova][a]
译者:[CYLeft](https://github.com/CYLeft)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180213 Getting started with the RStudio IDE.md b/published/20180213 Getting started with the RStudio IDE.md
similarity index 58%
rename from translated/tech/20180213 Getting started with the RStudio IDE.md
rename to published/20180213 Getting started with the RStudio IDE.md
index 762165fa13..28e26691d7 100644
--- a/translated/tech/20180213 Getting started with the RStudio IDE.md
+++ b/published/20180213 Getting started with the RStudio IDE.md
@@ -1,49 +1,48 @@
-开始使用 RStudio IDE
+RStudio IDE 入门
======
+> 用于统计技术的 R 项目是分析数据的有力方式,而 RStudio IDE 则可使这一切更加容易。
+

-从我记事起,我就一直在与数字玩耍。作为 20 世纪 70 年代后期的本科生,我开始上统计学的课程,学习如何检查和分析数据以揭示某些意义。
+从我记事起,我就一直喜欢摆弄数字。作为 20 世纪 70 年代后期的大学生,我上过统计学的课程,学习了如何检查和分析数据以揭示其意义。
-那时候,我有一部科学计算器,它让统计计算变得比以前容易很多。在 90 年代早期,作为一名从事 t 检验,相关性以及 [ANOVA][1] 研究的教育心理学研究生,我开始通过精心编写输入 IBM 主机的文本文件来进行计算。这个主机是对我的手持计算器的一个改进,但是一个小的间距错误会使得整个过程无效,而且这个过程仍然有点乏味。
+那时候,我有一部科学计算器,它让统计计算变得比以往更容易。在 90 年代早期,作为一名从事 t 检验、相关性以及 [ANOVA][1] 研究的教育心理学研究生,我开始通过精心编写输入到 IBM 主机的文本文件来进行计算。这个主机远超我的手持计算器,但是一个小的空格错误就会导致整个过程无效,而且这个过程仍然有点乏味。
-撰写论文时,尤其是我的毕业论文,我需要一种方法能够根据我的数据来创建图表并将它们嵌入到文字处理文档中。我着迷于 Microsoft Excel 及其数字运算能力以及可以用计算结果创建出的大量图表。但每一步都有成本。在 20 世纪 90 年代,除了 Excel,还有其他专有软件包,比如 SAS 和 SPSS+,但对于我那已经满满的研究生时间表来说,学习曲线是一项艰巨的任务。
+撰写论文时,尤其是我的毕业论文,我需要一种方法能够根据我的数据来创建图表,并将它们嵌入到文字处理文档中。我着迷于 Microsoft Excel 及其数字运算能力以及可以用计算结果创建出的大量图表。但这条路每一步都有成本。在 20 世纪 90 年代,除了 Excel,还有其他专有软件包,比如 SAS 和 SPSS+,但对于我那已经满满的研究生时间表来说,学习曲线是一项艰巨的任务。
### 快速回到现在
-最近,由于我对数据科学的兴趣浓厚,加上对 Linux 和开源软件的浓厚兴趣,我阅读了大量的数据科学文章,并在 Linux 会议上听了许多数据科学演讲者谈论他们的工作。因此,我开始对编程语言 R(一种开源的统计计算软件)非常感兴趣。
+最近,由于我对数据科学的兴趣浓厚,加上对 Linux 和开源软件感兴趣,我阅读了大量的数据科学文章,并在 Linux 会议上听了许多数据科学演讲者谈论他们的工作。因此,我开始对编程语言 R(一种开源的统计计算软件)非常感兴趣。
-起初,这只是一个火花。当我和我的朋友 Michael J. Gallagher 博士谈论他如何在他的 [博士论文][2] 研究中使用 R 时,这个火花便增大了。最后,我访问了 [R project][3] 的网站,并了解到我可以轻松地安装 [R for Linux][4]。游戏开始!
+起初,这只是一个偶发的一个想法。当我和我的朋友 Michael J. Gallagher 博士谈论他如何在他的 [博士论文][2] 研究中使用 R 时,这个火花便增大了。最后,我访问了 [R 项目][3] 的网站,并了解到我可以轻松地安装 [R for Linux][4]。游戏开始!
### 安装 R
-根据你的操作系统和分布情况,安装 R 会稍有不同。请参阅 [Comprehensive R Archive Network][5] (CRAN) 网站上的安装指南。CRAN 提供了在 [各种 Linux 发行版][6],[Fedora,RHEL,及其衍生版][7],[MacOS][8] 和 [Windows][9] 上的安装指示。
+根据你的操作系统和发行版情况,安装 R 会稍有不同。请参阅 [Comprehensive R Archive Network][5] (CRAN)网站上的安装指南。CRAN 提供了在 [各种 Linux 发行版][6],[Fedora,RHEL,及其衍生版][7],[MacOS][8] 和 [Windows][9] 上的安装指示。
-我在使用 Ubuntu,则按照 CRAN 的指示,将以下行加入到我的 `/etc/apt/sources.list` 文件中:
+我在使用 Ubuntu,按照 CRAN 的指示,将以下行加入到我的 `/etc/apt/sources.list` 文件中:
```
deb https:///bin/linux/ubuntu artful/
-
```
接着我在终端运行下面命令:
```
$ sudo apt-get update
-
$ sudo apt-get install r-base
-
```
-根据 CRAN,“需要从源码编译 R 的用户【如包的维护者,或者任何通过 `install.packages()` 安装包的用户】也应该安装 `r-base-dev` 的包。”
+根据 CRAN 说明,“需要从源码编译 R 的用户[如包的维护者,或者任何通过 `install.packages()` 安装包的用户]也应该安装 `r-base-dev` 的包。”
-### 使用 R 和 Rstudio
+### 使用 R 和 RStudio
-安装好了 R,我就准备了解更多关于使用这个强大的工具的信息。Gallagher 博士推荐了 [DataCamp][10] 上的 “Start learning R”,并且我也找到了适用于 R 新手的免费课程。两门课程都帮助我学习 R 的命令和语法。我还参加了 [Udemy][12] 上的 R 在线编程课程,并从 [No Starch Press][14] 上购买了 [Book of R][13]。
+安装好了 R,我就准备了解更多关于使用这个强大的工具的信息。Gallagher 博士推荐了 [DataCamp][10] 上的 “R 语言入门”,并且我也在 [Code School][11] 找到了适用于 R 新手的免费课程。两门课程都帮助我学习了 R 的命令和语法。我还参加了 [Udemy][12] 上的 R 在线编程课程,并从 [No Starch 出版社][14] 上购买了 [R 之书][13]。
-在阅读更多内容并观看 YouTube 视频后,我意识到我还应该安装 [RStudio][15]。Rstudio 是 R 的开源 IDE,易于在 [Debian, Ubuntu, Fedora, 和 RHEL][16] 上安装。它也可以安装在 MacOS 和 Windows 上。
+在阅读更多内容并观看 YouTube 视频后,我意识到我还应该安装 [RStudio][15]。Rstudio 是 R 语言的开源 IDE,易于在 [Debian、Ubuntu、 Fedora 和 RHEL][16] 上安装。它也可以安装在 MacOS 和 Windows 上。
-根据 Rstudio 网站的说明,可以根据你的偏好对 IDE 进行自定义,具体方法是选择工具菜单,然后从中选择全局选项。
+根据 RStudio 网站的说明,可以根据你的偏好对 IDE 进行自定义,具体方法是选择工具菜单,然后从中选择全局选项。

@@ -51,11 +50,11 @@ R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo

-你可能想要开始学习如何将 R 和一些样本数据结合起来使用,然后将这些知识应用到自己的数据上得到描述性统计。我自己没有丰富的数据来分析,但我搜索了可以使用的数据集 [datasets][18];这样一个数据集(我并没有用这个例子)是由圣路易斯联邦储备银行提供的 [经济研究数据][19]。我对一个题为“美国商业航空公司的乘客里程(1937-1960)”很感兴趣,因此我将它导入 RStudio 以测试 IDE 的功能。Rstudio 可以接受各种格式的数据,包括 CSV,Excel,SPSS 和 SAS。
+你可能想要开始学习如何将 R 和一些样本数据结合起来使用,然后将这些知识应用到自己的数据上得到描述性统计。我自己没有丰富的数据来分析,但我搜索了可以使用的数据集 [datasets][18];有一个这样的数据集(我并没有用这个例子)是由圣路易斯联邦储备银行提供的 [经济研究数据][19]。我对一个题为“美国商业航空公司的乘客里程(1937-1960)”很感兴趣,因此我将它导入 RStudio 以测试 IDE 的功能。RStudio 可以接受各种格式的数据,包括 CSV、Excel、SPSS 和 SAS。
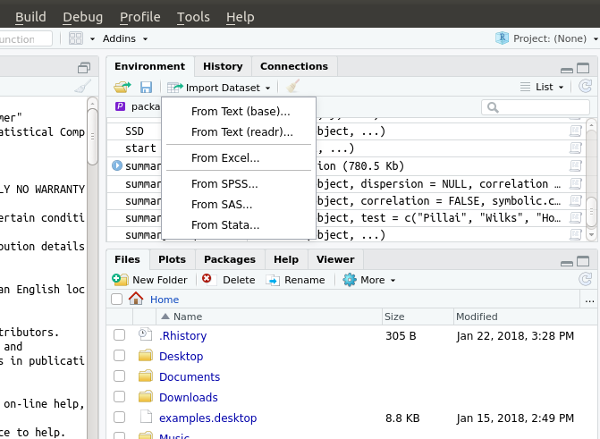
-数据导入后,我使用 `summary(AirPassengers)` 命令获取数据的一些初始描述性统计信息。按回车键后,我得到了 1949-1960 年的每月航空公司旅客的摘要以及其他数据,包括飞机乘客数量的最小值,最大值,第一四分位数,第三四分位数。中位数以及平均数。
+数据导入后,我使用 `summary(AirPassengers)` 命令获取数据的一些初始描述性统计信息。按回车键后,我得到了 1949-1960 年的每月航空公司旅客的摘要以及其他数据,包括飞机乘客数量的最小值、最大值、四分之一位数、四分之三位数、中位数以及平均数。

@@ -63,7 +62,7 @@ R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo

-接下来,我生成了一个数据直方图,通过输入 `hist(AirPassengers);` 得到,这以图形的方式显示此数据集;Rstudio 可以将数据导出为 PNG,PDF,JPEG,TIFF,SVG,EPS 或 BMP。
+接下来,我生成了一个数据直方图,通过输入 `hist(AirPassengers);` 得到,这会以图形的方式显示此数据集;RStudio 可以将数据导出为 PNG、PDF、JPEG、TIFF、SVG、EPS 或 BMP。
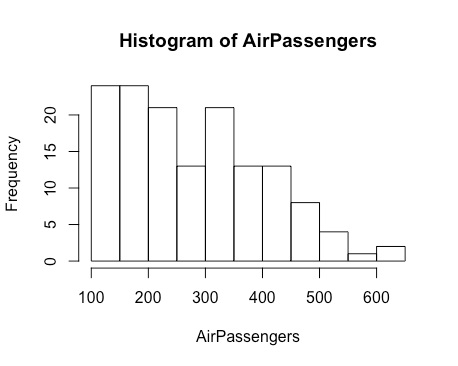
@@ -79,9 +78,9 @@ R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo
在 R 提示符下输入 `help()` 可以很容易找到帮助信息。输入你正在寻找的信息的特定主题可以找到具体的帮助信息,例如 `help(sd)` 可以获得有关标准差的帮助。通过在提示符处输入 `contributors()` 可以获得有关 R 项目贡献者的信息。您可以通过在提示符处输入 `citation()` 来了解如何引用 R。通过在提示符出输入 `license()` 可以很容易地获得 R 的许可证信息。
-R 是在 GNU General Public License(1991 年 6 月的版本 2,或者 2007 年 6 月的版本 3)的条款下发布的。有关 R 许可证的更多信息,请参考 [R Project website][20]。
+R 是在 GNU General Public License(1991 年 6 月的版本 2,或者 2007 年 6 月的版本 3)的条款下发布的。有关 R 许可证的更多信息,请参考 [R 项目官网][20]。
-另外,RStudio 在 GUI 中提供了完美的帮助菜单。该区域包括 RStudio 备忘单(可作为 PDF 下载),[RStudio][21]的在线学习,RStudio 文档,支持和 [许可证信息][22]。
+另外,RStudio 在 GUI 中提供了完美的帮助菜单。该区域包括 RStudio 快捷表(可作为 PDF 下载),[RStudio][21]的在线学习、RStudio 文档、支持和 [许可证信息][22]。
--------------------------------------------------------------------------------
@@ -89,7 +88,7 @@ via: https://opensource.com/article/18/2/getting-started-RStudio-IDE
作者:[Don Watkins][a]
译者:[szcf-weiya](https://github.com/szcf-weiya)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/sources/tech/20140225 How To Safely Generate A Random Number - Quarrelsome.md b/sources/tech/20140225 How To Safely Generate A Random Number - Quarrelsome.md
deleted file mode 100644
index 6ba977eeed..0000000000
--- a/sources/tech/20140225 How To Safely Generate A Random Number - Quarrelsome.md
+++ /dev/null
@@ -1,95 +0,0 @@
-translating by kimii
-How To Safely Generate A Random Number — Quarrelsome
-======
-### Use urandom
-
-Use [urandom][1]. Use [urandom][2]. Use [urandom][3]. Use [urandom][4]. Use [urandom][5]. Use [urandom][6].
-
-### But what about for crypto keys?
-
-Still [urandom][6].
-
-### Why not {SecureRandom, OpenSSL, havaged, &c}?
-
-These are userspace CSPRNGs. You want to use the kernel’s CSPRNG, because:
-
- * The kernel has access to raw device entropy.
-
- * It can promise not to share the same state between applications.
-
- * A good kernel CSPRNG, like FreeBSD’s, can also promise not to feed you random data before it’s seeded.
-
-
-
-
-Study the last ten years of randomness failures and you’ll read a litany of userspace randomness failures. [Debian’s OpenSSH debacle][7]? Userspace random. Android Bitcoin wallets [repeating ECDSA k’s][8]? Userspace random. Gambling sites with predictable shuffles? Userspace random.
-
-Userspace OpenSSL also seeds itself from “from uninitialized memory, magical fairy dust and unicorn horns” generators almost always depend on the kernel’s generator anyways. Even if they don’t, the security of your whole system sure does. **A userspace CSPRNG doesn’t add defense-in-depth; instead, it creates two single points of failure.**
-
-### Doesn’t the man page say to use /dev/random?
-
-You But, more on this later. Stay your pitchforks. should ignore the man page. Don’t use /dev/random. The distinction between /dev/random and /dev/urandom is a Unix design wart. The man page doesn’t want to admit that, so it invents a security concern that doesn’t really exist. Consider the cryptographic advice in random(4) an urban legend and get on with your life.
-
-### But what if I need real random values, not psuedorandom values?
-
-Both urandom and /dev/random provide the same kind of randomness. Contrary to popular belief, /dev/random doesn’t provide “true random” data. For cryptography, you don’t usually want “true random”.
-
-Both urandom and /dev/random are based on a simple idea. Their design is closely related to that of a stream cipher: a small secret is stretched into an indefinite stream of unpredictable values. Here the secrets are “entropy”, and the stream is “output”.
-
-Only on Linux are /dev/random and urandom still meaningfully different. The Linux kernel CSPRNG rekeys itself regularly (by collecting more entropy). But /dev/random also tries to keep track of how much entropy remains in its kernel pool, and will occasionally go on strike if it decides not enough remains. This design is as silly as I’ve made it sound; it’s akin to AES-CTR blocking based on how much “key” is left in the “keystream”.
-
-If you use /dev/random instead of urandom, your program will unpredictably (or, if you’re an attacker, very predictably) hang when Linux gets confused about how its own RNG works. Using /dev/random will make your programs less stable, but it won’t make them any more cryptographically safe.
-
-### There’s a catch here, isn’t there?
-
-No, but there’s a Linux kernel bug you might want to know about, even though it doesn’t change which RNG you should use.
-
-On Linux, if your software runs immediately at boot, and/or the OS has just been installed, your code might be in a race with the RNG. That’s bad, because if you win the race, there could be a window of time where you get predictable outputs from urandom. This is a bug in Linux, and you need to know about it if you’re building platform-level code for a Linux embedded device.
-
-This is indeed a problem with urandom (and not /dev/random) on Linux. It’s also a [bug in the Linux kernel][9]. But it’s also easily fixed in userland: at boot, seed urandom explicitly. Most Linux distributions have done this for a long time. But don’t switch to a different CSPRNG.
-
-### What about on other operating systems?
-
-FreeBSD and OS X do away with the distinction between urandom and /dev/random; the two devices behave identically. Unfortunately, the man page does a poor job of explaining why this is, and perpetuates the myth that Linux urandom is scary.
-
-FreeBSD’s kernel crypto RNG doesn’t block regardless of whether you use /dev/random or urandom. Unless it hasn’t been seeded, in which case both block. This behavior, unlike Linux’s, makes sense. Linux should adopt it. But if you’re an app developer, this makes little difference to you: Linux, FreeBSD, iOS, whatever: use urandom.
-
-### tl;dr
-
-Use urandom.
-
-### Epilog
-
-[ruby-trunk Feature #9569][10]
-
-> Right now, SecureRandom.random_bytes tries to detect an OpenSSL to use before it tries to detect /dev/urandom. I think it should be the other way around. In both cases, you just need random bytes to unpack, so SecureRandom could skip the middleman (and second point of failure) and just talk to /dev/urandom directly if it’s available.
-
-Resolution:
-
-> /dev/urandom is not suitable to be used to generate directly session keys and other application level random data which is generated frequently.
->
-> [the] random(4) [man page] on GNU/Linux [says]…
-
-Thanks to Matthew Green, Nate Lawson, Sean Devlin, Coda Hale, and Alex Balducci for reading drafts of this. Fair warning: Matthew only mostly agrees with me.
-
---------------------------------------------------------------------------------
-
-via: https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/
-
-作者:[Thomas;Erin;Matasano][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://sockpuppet.org/blog
-[1]:http://blog.cr.yp.to/20140205-entropy.html
-[2]:http://cr.yp.to/talks/2011.09.28/slides.pdf
-[3]:http://golang.org/src/pkg/crypto/rand/rand_unix.go
-[4]:http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key
-[5]:http://stackoverflow.com/a/5639631
-[6]:https://twitter.com/bramcohen/status/206146075487240194
-[7]:http://research.swtch.com/openssl
-[8]:http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/
-[9]:https://factorable.net/weakkeys12.extended.pdf
-[10]:https://bugs.ruby-lang.org/issues/9569
diff --git a/sources/tech/20171102 Testing IPv6 Networking in KVM- Part 1.md b/sources/tech/20171102 Testing IPv6 Networking in KVM- Part 1.md
deleted file mode 100644
index 149be0678b..0000000000
--- a/sources/tech/20171102 Testing IPv6 Networking in KVM- Part 1.md
+++ /dev/null
@@ -1,82 +0,0 @@
-Testing IPv6 Networking in KVM: Part 1
-======
-
-
-
-Nothing beats hands-on playing with IPv6 addresses to get the hang of how they work, and setting up a little test lab in KVM is as easy as falling over — and more fun. In this two-part series, we will learn about IPv6 private addressing and configuring test networks in KVM.
-
-### QEMU/KVM/Virtual Machine Manager
-
-Let's start with understanding what KVM is. Here I use KVM as a convenient shorthand for the combination of QEMU, KVM, and the Virtual Machine Manager that is typically bundled together in Linux distributions. The simplified explanation is that QEMU emulates hardware, and KVM is a kernel module that creates the guest state on your CPU and manages access to memory and the CPU. Virtual Machine Manager is a lovely graphical overlay to all of this virtualization and hypervisor goodness.
-
-But you're not stuck with pointy-clicky, no, for there are also fab command-line tools to use — such as virsh and virt-install.
-
-If you're not experienced with KVM, you might want to start with [Creating Virtual Machines in KVM: Part 1][1] and [Creating Virtual Machines in KVM: Part 2 - Networking][2].
-
-### IPv6 Unique Local Addresses
-
-Configuring IPv6 networking in KVM is just like configuring IPv4 networks. The main difference is those weird long addresses. [Last time][3], we talked about the different types of IPv6 addresses. There is one more IPv6 unicast address class, and that is unique local addresses, fc00::/7 (see [RFC 4193][4]). This is analogous to the private address classes in IPv4, 10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16.
-
-This diagram illustrates the structure of the unique local address space. 48 bits define the prefix and global ID, 16 bits are for subnets, and the remaining 64 bits are the interface ID:
-```
-| 7 bits |1| 40 bits | 16 bits | 64 bits |
-+--------|-+------------|-----------|----------------------------+
-| Prefix |L| Global ID | Subnet ID | Interface ID |
-+--------|-+------------|-----------|----------------------------+
-
-```
-
-Here is another way to look at it, which is might be more helpful for understanding how to manipulate these addresses:
-```
-| Prefix | Global ID | Subnet ID | Interface ID |
-+--------|--------------|-------------|----------------------+
-| fd | 00:0000:0000 | 0000 | 0000:0000:0000:0000 |
-+--------|--------------|-------------|----------------------+
-
-```
-
-fc00::/7 is divided into two /8 blocks, fc00::/8 and fd00::/8. fc00::/8 is reserved for future use. So, unique local addresses always start with fd, and the rest is up to you. The L bit, which is the eighth bit, is always set to 1, which makes fd00::/8. Setting it to zero makes fc00::/8. You can see this with subnetcalc:
-```
-$ subnetcalc fd00::/8 -n
-Address = fd00::
- fd00 = 11111101 00000000
-
-$ subnetcalc fc00::/8 -n
-Address = fc00::
- fc00 = 11111100 00000000
-
-```
-
-RFC 4193 requires that addresses be randomly generated. You can invent addresses any way you choose, as long as they start with fd, because the IPv6 cops aren't going to invade your home and give you a hard time. Still, it is a best practice to follow what RFCs say. The addresses must not be assigned sequentially or with well-known numbers. RFC 4193 includes an algorithm for building a pseudo-random address generator, or you can find any number of generators online.
-
-Unique local addresses are not centrally managed like global unicast addresses (assigned to you by your Internet service provider), but even so the probability of address collisions is very low. This is a nice benefit when you need to merge some local networks or want to route between discrete private networks.
-
-You can mix unique local addresses and global unicast addresses on the same subnets. Unique local addresses are routable and require no extra router tweaks. However, you should configure your border routers and firewalls to not allow them to leave your network except between private networks at different locations.
-
-RFC 4193 advises against mingling AAAA and PTR records with your global unicast address records, because there is no guarantee that they will be unique, even though the odds of duplicates are low. Just like we do with IPv4 addresses, keep your private local name services and public name services separate. The tried-and-true combination of Dnsmasq for local name services and BIND for public name services works just as well for IPv6 as it does for IPv4.
-
-### Pseudo-Random Address Generator
-
-One example of an online address generator is [Local IPv6 Address Generator][5]. You can find many cool online tools like this. You can use it to create a new address for you, or use it with your existing global ID and play with creating subnets.
-
-Come back next week to learn how to plug all of this IPv6 goodness into KVM and do live testing.
-
-Learn more about Linux through the free ["Introduction to Linux" ][6]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
-
-作者:[Carla Schroder][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/cschroder
-[1]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-1
-[2]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-2-networking
-[3]:https://www.linux.com/learn/intro-to-linux/2017/10/calculating-ipv6-subnets-linux
-[4]:https://tools.ietf.org/html/rfc4193
-[5]:https://www.ultratools.com/tools/rangeGenerator
-[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20171205 What DevOps teams really need from a CIO.md b/sources/tech/20171205 What DevOps teams really need from a CIO.md
deleted file mode 100644
index d86f549d18..0000000000
--- a/sources/tech/20171205 What DevOps teams really need from a CIO.md
+++ /dev/null
@@ -1,59 +0,0 @@
-What DevOps teams really need from a CIO
-======
-IT leaders can learn from plenty of material exploring [DevOps][1] and the challenging cultural shift required for [making the DevOps transition][2]. But are you in tune with the short and long term challenges that a DevOps team faces - and what they really need from a CIO?
-
-In my conversations with DevOps team members, some of what I heard might surprise you. DevOps pros (whether part of an internal or external team) want to put the following things at the top of your CIO radar screen.
-
-### 1. Communication
-
-First and foremost, DevOps pros need peer-level communication. An experienced DevOps team is extremely knowledgeable on current DevOps trends, successes, and failures in the industry and is interested in sharing this information. DevOps concepts are difficult to convey, so be open to a new working relationship in which there are regular (don't worry, not weekly) conversations about the current state of your IT, how the pieces in the environment communicate, and your overall IT estate.
-
-**[ Want even more wisdom from CIOs on leading DevOps? See our comprehensive resource,[DevOps: The IT Leader's Guide][3]. ]**
-
-Conversely, be prepared to share current business needs and goals with the DevOps team. Business objectives no longer exist in isolation from IT: They are now an integral component of what drives your IT advancements, and your IT determines how effectively you can execute on your business needs and goals.
-
-Focus on participating rather than leading. You are still the ultimate arbiter when it comes to decisions, but understand that these decisions are best made collaboratively in order to empower and motivate your DevOps team.
-
-### 2. Reduction of technical debt
-
-Second, strive to better understand technical debt and how DevOps efforts are going to reduce it. Your DevOps team is working hard on this front. In this case, technical debt refers to the manpower and infrastructure resources that are usurped daily by maintaining and adding new features on top of a monolithic, non-sustainable environment (read Rube Goldberg).
-
-Common CIO questions include:
-
- * Why do we need to do things in a new way?
- * Why are we spending time and money on this?
- * If there's no new functionality, just existing pieces being broken out with automation, then where is the gain?
-
-
-
-The "if it ain't broke don't fix it" thinking is understandable. But if the car is driving fine while everyone on the road accelerates past you, your environment IS broken. Precious resources continue to be sucked into propping up or augmenting an environmental kluge.
-
-Addressing every issue in isolation results in a compromised choice from the start that is worsened with each successive patch - layer upon layer added to a foundation that wasn't built to support it. In actuality, this approach is similar to plugging a continuously failing dike. Sooner or later you run out of fingers and the whole thing buckles under the added pressures, drowning your resources.
-
-The solution: automation. The result of automation is scalability - less effort per person to maintain and grow your IT environment. If adding manpower is the only way to grow your business, then scalability is a pipe dream.
-
-Automation reduces your manpower requirements and provides the flexibility required for continued IT evolution. Simple, right? Yes, but you must be prepared for delayed gratification. An upfront investment of time and effort for architectural and structural changes is required in order to reap the back-end financial benefits of automation with improved productivity and efficiency. Embracing these challenges as an IT leader is crucial in order for your DevOps team to successfully execute.
-
-### 3. Trust
-
-Lastly, trust your DevOps team and make sure they know it. DevOps experts understand that this is a tough request, but they must have your unquestionable support and your willingness to actively participate. It will often be a "learn as you go" experience for you as the DevOps team successively refines your IT environment, while they themselves adapt to ever-changing technology.
-
-Listen, listen, listen to them and trust them. DevOps changes are valuable and well worth the time and money through increased efficiency, productivity, and business responsiveness. Trusting your DevOps team gives them the freedom to make the most effective IT improvements.
-
-The new CIO bottom line: To maximize your DevOps team's potential, leave your leadership comfort zone and embrace a "CIOps" transition. Continuously work on finding common ground with the DevOps team throughout the DevOps transition, to help your organization achieve long-term IT success.
-
-
---------------------------------------------------------------------------------
-
-via: https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio
-
-作者:[John Allessio][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://enterprisersproject.com/user/john-allessio
-[1]:https://enterprisersproject.com/tags/devops
-[2]:https://www.redhat.com/en/insights/devops?intcmp=701f2000000tjyaAAA
-[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
diff --git a/sources/tech/20171213 Will DevOps steal my job-.md b/sources/tech/20171213 Will DevOps steal my job-.md
deleted file mode 100644
index 72694ae69e..0000000000
--- a/sources/tech/20171213 Will DevOps steal my job-.md
+++ /dev/null
@@ -1,58 +0,0 @@
-Will DevOps steal my job?
-======
-
->Are you worried automation will replace people in the workplace? You may be right, but here's why that's not a bad thing.
-
-
->Image by : opensource.com
-
-It's a common fear: Will DevOps be the end of my job? After all, DevOps means developers doing operations, right? DevOps is automation. What if I automate myself out of a job? Do continuous delivery and containers mean operations staff are obsolete? DevOps is all about coding: infrastructure-as-code and testing-as-code and this-or-that-as-code. What if I don't have the skill set to be a part of this?
-
-[DevOps][1] is a looming change, disruptive in the field, with seemingly fanatical followers talking about changing the world with the [Three Ways][2]--the three underpinnings of DevOps--and the tearing down of walls. It can all be overwhelming. So what's it going to be--is DevOps going to steal my job?
-
-### The first fear: I'm not needed
-
-As developers managing the entire lifecycle of an application, it's all too easy to get caught up in the idea of DevOps. Containers are probably a big contributing factor to this line of thought. When containers exploded onto the scene, they were touted as a way for developers to build, test, and deploy their code all-in-one. What role does DevOps leave for the operations team, or testing, or QA?
-
-This stems from a misunderstanding of the principles of DevOps. The first principle of DevOps, or the First Way, is _Systems Thinking_ , or placing emphasis on a holistic approach to managing and understanding the whole lifecycle of an application or service. This does not mean that the developers of the application learn and manage the whole process. Rather, it is the collaboration of talented and skilled individuals to ensure success as a whole. To make developers solely responsible for the process is practically the extreme opposite of this tenant--essentially the enshrining of a single silo with the importance of the entire lifecycle.
-
-There is a place for specialization in DevOps. Just as the classically educated software engineer with knowledge of linear regression and binary search is wasted writing Ansible playbooks and Docker files, the highly skilled sysadmin with the knowledge of how to secure a system and optimize database performance is wasted writing CSS and designing user flows. The most effective group to write, test, and maintain an application is a cross-discipline, functional team of people with diverse skill sets and backgrounds.
-
-### The second fear: My job will be automated
-
-Accurate or not, DevOps can sometimes be seen as a synonym for automation. What work is left for operations staff and testing teams when automated builds, testing, deployment, monitoring, and notifications are a huge part of the application lifecycle? This focus on automation can be partially related to the Second Way: _Amplify Feedback Loops_. This second tenant of DevOps deals with prioritizing quick feedback between teams in the opposite direction an application takes to deployment --from monitoring and maintaining to deployment, testing, development, etc., and the emphasis to make the feedback important and actionable. While the Second Way is not specifically related to automation, many of the automation tools teams use within their deployment pipelines facilitate quick notification and quick action, or course-correction based on feedback in support of this tenant. Traditionally done by humans, it is easy to understand why a focus on automation might lead to anxiety about the future of one's job.
-
-Automation is just a tool, not a replacement for people. Smart people trapped doing the same things over and over, pushing the big red George Jetson button are a wasted, untapped wealth of intelligence and creativity. Automation of the drudgery of daily work means more time to spend solving real problems and coming up with creative solutions. Humans are needed to figure out the "how and why;" computers can handle the "copy and paste."
-
-There will be no end of repetitive, predictable things to automate, and automation frees teams to focus on higher-order tasks in their field. Monitoring teams, no longer spending all their time configuring alerts or managing trending configuration, can start to focus on predicting alarms, correlating statistics, and creating proactive solutions. Systems administrators, freed of scheduled patching or server configuration, can spend time focusing on fleet management, performance, and scaling. Unlike the striking images of factory floors and assembly lines totally devoid of humans, automated tasks in the DevOps world mean humans can focus on creative, rewarding tasks instead of mind-numbing drudgery.
-
-### The third fear: I do not have the skillset for this
-
-"How am I going to keep up with this? I don't know how to automate. Everything is code now--do I have to be a developer and write code for a living to work in DevOps?" The third fear is ultimately a fear of self-confidence. As the culture changes, yes, teams will be asked to change along with it, and some may fear they lack the skills to perform what their jobs will become.
-
-Most folks, however, are probably already closer than they think. What is the Dockerfile, or configuration management like Puppet or Ansible, but environment as code? System administrators already write shell scripts and Python programs to handle repetitive tasks for them. It's hardly a stretch to learn a little more and begin using some of the tools already at their disposal to solve more problems--orchestration, deployment, maintenance-as-code--especially when freed from the drudgery of manual tasks to focus on growth.
-
-The answer to this fear lies in the third tenant of DevOps, the Third Way: _A Culture of Continual Experimentation and Learning_. The ability to try and fail and learn from mistakes without blame is a major factor in creating ever-more creative solutions. The Third Way is empowered by the first two ways --allowing for for quick detection of and repair of problems, and just as the developer is free to try and learn, other teams are as well. Operations teams that have never used configuration management or written programs to automate infrastructure provisioning are free to try and learn. Testing and QA teams are free to implement new testing pipelines and automate approval and release processes. In a culture that embraces learning and growing, everyone has the freedom to acquire the skills they need to succeed at and enjoy their job.
-
-### Conclusion
-
-Any disruptive practice or change in an industry can create fear or uncertainty, and DevOps is no exception. A concern for one's job is a reasonable response to the hundreds of articles and presentations enumerating the countless practices and technologies seemingly dedicated to empowering developers to take responsibility for every aspect of the industry.
-
-In truth, however, DevOps is "[a cross-disciplinary community of practice dedicated to the study of building, evolving, and operating rapidly changing resilient systems at scale][3]." DevOps means the end of silos, but not specialization. It is the delegation of drudgery to automated systems, freeing you to do what people do best: think and imagine. And if you're motivated to learn and grow, there will be no end of opportunities to solve new and challenging problems.
-
-Will DevOps take away your job? Yes, but it will give you a better one.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/17/12/will-devops-steal-my-job
-
-作者:[Chris Collins][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/clcollins
-[1]:https://opensource.com/resources/devops
-[2]:http://itrevolution.com/the-three-ways-principles-underpinning-devops/
-[3]:https://theagileadmin.com/what-is-devops/
diff --git a/sources/tech/20180102 How To Find (Top-10) Largest Files In Linux.md b/sources/tech/20180102 How To Find (Top-10) Largest Files In Linux.md
deleted file mode 100644
index 77c6238c9c..0000000000
--- a/sources/tech/20180102 How To Find (Top-10) Largest Files In Linux.md
+++ /dev/null
@@ -1,191 +0,0 @@
-Translating by jessie-pang
-
-How To Find (Top-10) Largest Files In Linux
-======
-When you are running out of disk space in system, you may prefer to check with df command or du command or ncdu command but all these will tell you only current directory files and doesn't shows the system wide files.
-
-You have to spend huge amount of time to get the largest files in the system using the above commands, that to you have to navigate to each and every directory to achieve this.
-
-It's making you to face trouble and this is not the right way to do it.
-
-If so, what would be the suggested way to get top 10 largest files in Linux?
-
-I have spend a lot of time with google but i didn't found this. Everywhere i could see an article which list the top 10 files in the current directory. So, i want to make this article useful for people whoever looking to get the top 10 largest files in the system.
-
-In this tutorial, we are going to teach you how to find top 10 largest files in Linux system using below four methods.
-
-### Method-1 :
-
-There is no specific command available in Linux to do this, hence we are using more than one command (all together) to get this done.
-```
-# find / -type f -print0 | xargs -0 du -h | sort -rh | head -n 10
-
-1.4G /swapfile
-1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
-564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
-378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
-377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
-100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
-93M /usr/lib/firefox/libxul.so
-84M /var/lib/snapd/snaps/core_3604.snap
-84M /var/lib/snapd/snaps/core_3440.snap
-84M /var/lib/snapd/snaps/core_3247.snap
-
-```
-
-**Details :**
-**`find`** : It 's a command, Search for files in a directory hierarchy.
-**`/`** : Check in the whole system (starting from / directory)
-**`-type`** : File is of type
-
-**`f`** : Regular file
-**`-print0`** : Print the full file name on the standard output, followed by a null character
-**`|`** : Control operator that send the output of one program to another program for further processing.
-
-**`xargs`** : It 's a command, which build and execute command lines from standard input.
-**`-0`** : Input items are terminated by a null character instead of by whitespace
-**`du -h`** : It 's a command to calculate disk usage with human readable format
-
-**`sort`** : It 's a command, Sort lines of text files
-**`-r`** : Reverse the result of comparisons
-**`-h`** : Print the output with human readable format
-
-**`head`** : It 's a command, Output the first part of files
-**`n -10`** : Print the first 10 files.
-
-### Method-2 :
-
-This is an another way to find or check top 10 largest files in Linux system. Here also, we are putting few commands together to achieve this.
-```
-# find / -type f -exec du -Sh {} + | sort -rh | head -n 10
-
-1.4G /swapfile
-1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
-564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
-378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
-377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
-100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
-93M /usr/lib/firefox/libxul.so
-84M /var/lib/snapd/snaps/core_3604.snap
-84M /var/lib/snapd/snaps/core_3440.snap
-84M /var/lib/snapd/snaps/core_3247.snap
-
-```
-
-**Details :**
-**`find`** : It 's a command, Search for files in a directory hierarchy.
-**`/`** : Check in the whole system (starting from / directory)
-**`-type`** : File is of type
-
-**`f`** : Regular file
-**`-exec`** : This variant of the -exec action runs the specified command on the selected files
-**`du`** : It 's a command to estimate file space usage.
-
-**`-S`** : Do not include size of subdirectories
-**`-h`** : Print sizes in human readable format
-**`{}`** : Summarize disk usage of each FILE, recursively for directories.
-
-**`|`** : Control operator that send the output of one program to another program for further processing.
-**`sort`** : It 's a command, Sort lines of text files
-**`-r`** : Reverse the result of comparisons
-
-**`-h`** : Compare human readable numbers
-**`head`** : It 's a command, Output the first part of files
-**`n -10`** : Print the first 10 files.
-
-### Method-3 :
-
-It 's an another method to find or search top 10 largest files in Linux system.
-```
-# find / -type f -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
-
-84M /var/lib/snapd/snaps/core_3247.snap
-84M /var/lib/snapd/snaps/core_3440.snap
-84M /var/lib/snapd/snaps/core_3604.snap
-93M /usr/lib/firefox/libxul.so
-100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
-377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
-378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
-564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
-1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
-1.4G /swapfile
-
-```
-
-**Details :**
-**`find`** : It 's a command, Search for files in a directory hierarchy.
-**`/`** : Check in the whole system (starting from / directory)
-**`-type`** : File is of type
-
-**`f`** : Regular file
-**`-print0`** : Print the full file name on the standard output, followed by a null character
-**`|`** : Control operator that send the output of one program to another program for further processing.
-
-**`xargs`** : It 's a command, which build and execute command lines from standard input.
-**`-0`** : Input items are terminated by a null character instead of by whitespace
-**`du`** : It 's a command to estimate file space usage.
-
-**`sort`** : It 's a command, Sort lines of text files
-**`-n`** : Compare according to string numerical value
-**`tail -10`** : It 's a command, output the last part of files (last 10 files)
-
-**`cut`** : It 's a command, remove sections from each line of files
-**`-f2`** : Select only these fields value.
-**`-I{}`** : Replace occurrences of replace-str in the initial-arguments with names read from standard input.
-
-**`-s`** : Display only a total for each argument
-**`-h`** : Print sizes in human readable format
-**`{}`** : Summarize disk usage of each FILE, recursively for directories.
-
-### Method-4 :
-
-It 's an another method to find or search top 10 largest files in Linux system.
-```
-# find / -type f -ls | sort -k 7 -r -n | head -10 | column -t | awk '{print $7,$11}'
-
-1494845440 /swapfile
-1085984380 /home/magi/ubuntu-17.04-desktop-amd64.iso
-591003648 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
-395770383 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
-394891761 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
-103999072 /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
-97356256 /usr/lib/firefox/libxul.so
-87896064 /var/lib/snapd/snaps/core_3604.snap
-87793664 /var/lib/snapd/snaps/core_3440.snap
-87089152 /var/lib/snapd/snaps/core_3247.snap
-
-```
-
-**Details :**
-**`find`** : It 's a command, Search for files in a directory hierarchy.
-**`/`** : Check in the whole system (starting from / directory)
-**`-type`** : File is of type
-
-**`f`** : Regular file
-**`-ls`** : List current file in ls -dils format on standard output.
-**`|`** : Control operator that send the output of one program to another program for further processing.
-
-**`sort`** : It 's a command, Sort lines of text files
-**`-k`** : start a key at POS1
-**`-r`** : Reverse the result of comparisons
-
-**`-n`** : Compare according to string numerical value
-**`head`** : It 's a command, Output the first part of files
-**`-10`** : Print the first 10 files.
-
-**`column`** : It 's a command, formats its input into multiple columns.
-**`-t`** : Determine the number of columns the input contains and create a table.
-**`awk`** : It 's a command, Pattern scanning and processing language
-**`'{print $7,$11}'`** : Print only mentioned column.
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/
-
-作者:[Magesh Maruthamuthu][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.2daygeek.com/author/magesh/
diff --git a/sources/tech/20180125 Keep Accurate Time on Linux with NTP.md b/sources/tech/20180125 Keep Accurate Time on Linux with NTP.md
deleted file mode 100644
index 817931c2a4..0000000000
--- a/sources/tech/20180125 Keep Accurate Time on Linux with NTP.md
+++ /dev/null
@@ -1,146 +0,0 @@
-Keep Accurate Time on Linux with NTP
-======
-
-
-
-How to keep the correct time and keep your computers synchronized without abusing time servers, using NTP and systemd.
-
-### What Time is It?
-
-Linux is funky when it comes to telling the time. You might think that the `time` tells the time, but it doesn't because it is a timer that measures how long a process runs. To get the time, you run the `date` command, and to view more than one date, you use `cal`. Timestamps on files are also a source of confusion as they are typically displayed in two different ways, depending on your distro defaults. This example is from Ubuntu 16.04 LTS:
-```
-$ ls -l
-drwxrwxr-x 5 carla carla 4096 Mar 27 2017 stuff
-drwxrwxr-x 2 carla carla 4096 Dec 8 11:32 things
--rw-rw-r-- 1 carla carla 626052 Nov 21 12:07 fatpdf.pdf
--rw-rw-r-- 1 carla carla 2781 Apr 18 2017 oddlots.txt
-
-```
-
-Some display the year, some display the time, which makes ordering your files rather a mess. The GNU default is files dated within the last six months display the time instead of the year. I suppose there is a reason for this. If your Linux does this, try `ls -l --time-style=long-iso` to display the timestamps all the same way, sorted alphabetically. See [How to Change the Linux Date and Time: Simple Commands][1] to learn all manner of fascinating ways to manage the time on Linux.
-
-### Check Current Settings
-
-NTP, the network time protocol, is the old-fashioned way of keeping correct time on computers. `ntpd`, the NTP daemon, periodically queries a public time server and adjusts your system time as needed. It's a simple lightweight protocol that is easy to set up for basic use. Systemd has barged into NTP territory with the `systemd-timesyncd.service`, which acts as a client to `ntpd`.
-
-Before messing with NTP, let's take a minute to check that current time settings are correct.
-
-There are (at least) two timekeepers on your system: system time, which is managed by the Linux kernel, and the hardware clock on your motherboard, which is also called the real-time clock (RTC). When you enter your system BIOS, you see the hardware clock time and you can change its settings. When you install a new Linux, and in some graphical time managers, you are asked if you want your RTC set to the UTC (Coordinated Universal Time) zone. It should be set to UTC, because all time zone and daylight savings time calculations are based on UTC. Use the `hwclock` command to check:
-```
-$ sudo hwclock --debug
-hwclock from util-linux 2.27.1
-Using the /dev interface to the clock.
-Hardware clock is on UTC time
-Assuming hardware clock is kept in UTC time.
-Waiting for clock tick...
-...got clock tick
-Time read from Hardware Clock: 2018/01/22 22:14:31
-Hw clock time : 2018/01/22 22:14:31 = 1516659271 seconds since 1969
-Time since last adjustment is 1516659271 seconds
-Calculated Hardware Clock drift is 0.000000 seconds
-Mon 22 Jan 2018 02:14:30 PM PST .202760 seconds
-
-```
-
-"Hardware clock is kept in UTC time" confirms that your RTC is on UTC, even though it translates the time to your local time. If it were set to local time it would report "Hardware clock is kept in local time."
-
-You should have a `/etc/adjtime` file. If you don't, sync your RTC to system time:
-```
-$ sudo hwclock -w
-
-```
-
-This should generate the file, and the contents should look like this example:
-```
-$ cat /etc/adjtime
-0.000000 1516661953 0.000000
-1516661953
-UTC
-
-```
-
-The new-fangled systemd way is to run `timedatectl`, which does not need root permissions:
-```
-$ timedatectl
- Local time: Mon 2018-01-22 14:17:51 PST
- Universal time: Mon 2018-01-22 22:17:51 UTC
- RTC time: Mon 2018-01-22 22:17:51
- Time zone: America/Los_Angeles (PST, -0800)
- Network time on: yes
-NTP synchronized: yes
- RTC in local TZ: no
-
-```
-
-"RTC in local TZ: no" confirms that it is on UTC time. What if it is on local time? There are, as always, multiple ways to change it. The easy way is with a nice graphical configuration tool, like YaST in openSUSE. You can use `timedatectl`:
-```
-$ timedatectl set-local-rtc 0
-```
-
-Or edit `/etc/adjtime`, replacing UTC with LOCAL.
-
-### systemd-timesyncd Client
-
-Now I'm tired, and we've just gotten to the good part. Who knew timekeeping was so complex? We haven't even scratched the surface; read `man 8 hwclock` to get an idea of how time is kept on computers.
-
-Systemd provides the `systemd-timesyncd.service` client, which queries remote time servers and adjusts your system time. Configure your servers in `/etc/systemd/timesyncd.conf`. Most Linux distributions provide a default configuration that points to time servers that they maintain, like Fedora:
-```
-[Time]
-#NTP=
-#FallbackNTP=0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
-
-```
-
-You may enter any other servers you desire, such as your own local NTP server, on the `NTP=` line in a space-delimited list. (Remember to uncomment this line.) Anything you put on the `NTP=` line overrides the fallback.
-
-What if you are not using systemd? Then you need only NTP.
-
-### Setting up NTP Server and Client
-
-It is a good practice to set up your own LAN NTP server, so that you are not pummeling public NTP servers from all of your computers. On most Linuxes NTP comes in the `ntp` package, and most of them provide `/etc/ntp.conf` to configure the service. Consult [NTP Pool Time Servers][2] to find the NTP server pool that is appropriate for your region. Then enter 4-5 servers in your `/etc/ntp.conf` file, with each server on its own line:
-```
-driftfile /var/ntp.drift
-logfile /var/log/ntp.log
-server 0.europe.pool.ntp.org
-server 1.europe.pool.ntp.org
-server 2.europe.pool.ntp.org
-server 3.europe.pool.ntp.org
-
-```
-
-The `driftfile` tells `ntpd` where to store the information it needs to quickly synchronize your system clock with the time servers at startup, and your logs should have their own home instead of getting dumped into the syslog. Use your Linux distribution defaults for these files if it provides them.
-
-Now start the daemon; on most Linuxes this is `sudo systemctl start ntpd`. Let it run for a few minutes, then check its status:
-```
-$ ntpq -p
- remote refid st t when poll reach delay offset jitter
-==============================================================
-+dev.smatwebdesi 192.168.194.89 3 u 25 64 37 92.456 -6.395 18.530
-*chl.la 127.67.113.92 2 u 23 64 37 75.175 8.820 8.230
-+four0.fairy.mat 35.73.197.144 2 u 22 64 37 116.272 -10.033 40.151
--195.21.152.161 195.66.241.2 2 u 27 64 37 107.559 1.822 27.346
-
-```
-
-I have no idea what any of that means, other than your daemon is talking to the remote time servers, and that is what you want. To permanently enable it, run `sudo systemctl enable ntpd`. If your Linux doesn't use systemd then it is your homework to figure out how to run `ntpd`.
-
-Now you can set up `systemd-timesyncd` on your other LAN hosts to use your local NTP server, or install NTP on them and enter your local server in their `/etc/ntp.conf` files.
-
-NTP servers take a beating, and demand continually increases. You can help by running your own public NTP server. Come back next week to learn how.
-
-Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
-
-作者:[CARLA SCHRODER][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/cschroder
-[1]:https://www.linux.com/learn/how-change-linux-date-and-time-simple-commands
-[2]:http://support.ntp.org/bin/view/Servers/NTPPoolServers
-[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180127 Your instant Kubernetes cluster.md b/sources/tech/20180127 Your instant Kubernetes cluster.md
deleted file mode 100644
index b17619762a..0000000000
--- a/sources/tech/20180127 Your instant Kubernetes cluster.md
+++ /dev/null
@@ -1,171 +0,0 @@
-Your instant Kubernetes cluster
-============================================================
-
-
-This is a condensed and updated version of my previous tutorial [Kubernetes in 10 minutes][10]. I've removed just about everything I can so this guide still makes sense. Use it when you want to create a cluster on the cloud or on-premises as fast as possible.
-
-### 1.0 Pick a host
-
-We will be using Ubuntu 16.04 for this guide so that you can copy/paste all the instructions. Here are several environments where I've tested this guide. Just pick where you want to run your hosts.
-
-* [DigitalOcean][1] - developer cloud
-
-* [Civo][2] - UK developer cloud
-
-* [Packet][3] - bare metal cloud
-
-* 2x Dell Intel i7 boxes - at home
-
-> Civo is a relatively new developer cloud and one thing that I really liked was how quickly they can bring up hosts - in about 25 seconds. I'm based in the UK so I also get very low latency.
-
-### 1.1 Provision the machines
-
-You can get away with a single host for testing but I'd recommend at least three so we have a single master and two worker nodes.
-
-Here are some other guidelines:
-
-* Pick dual-core hosts with ideally at least 2GB RAM
-
-* If you can pick a custom username when provisioning the host then do that rather than root. For example Civo offers an option of `ubuntu`, `civo` or `root`.
-
-Now run through the following steps on each machine. It should take you less than 5-10 minutes. If that's too slow for you then you can use my utility script [kept in a Gist][11]:
-
-```
-$ curl -sL https://gist.githubusercontent.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c/raw/23fc4cd13910eac646b13c4f8812bab3eeebab4c/configure.sh | sh
-
-```
-
-### 1.2 Login and install Docker
-
-Install Docker from the Ubuntu apt repository. This will be an older version of Docker but as Kubernetes is tested with old versions of Docker it will work in our favour.
-
-```
-$ sudo apt-get update \
- && sudo apt-get install -qy docker.io
-
-```
-
-### 1.3 Disable the swap file
-
-This is now a mandatory step for Kubernetes. The easiest way to do this is to edit `/etc/fstab` and to comment out the line referring to swap.
-
-To save a reboot then type in `sudo swapoff -a`.
-
-> Disabling swap memory may appear like a strange requirement at first. If you are curious about this step then [read more here][4].
-
-### 1.4 Install Kubernetes packages
-
-```
-$ sudo apt-get update \
- && sudo apt-get install -y apt-transport-https \
- && curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
-
-$ echo "deb http://apt.kubernetes.io/ kubernetes-xenial main" \
- | sudo tee -a /etc/apt/sources.list.d/kubernetes.list \
- && sudo apt-get update
-
-$ sudo apt-get update \
- && sudo apt-get install -y \
- kubelet \
- kubeadm \
- kubernetes-cni
-
-```
-
-### 1.5 Create the cluster
-
-At this point we create the cluster by initiating the master with `kubeadm`. Only do this on the master node.
-
-> Despite any warnings I have been assured by [Weaveworks][5] and Lucas (the maintainer) that `kubeadm` is suitable for production use.
-
-```
-$ sudo kubeadm init
-
-```
-
-If you missed a step or there's a problem then `kubeadm` will let you know at this point.
-
-Take a copy of the Kube config:
-
-```
-mkdir -p $HOME/.kube
-sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
-sudo chown $(id -u):$(id -g) $HOME/.kube/config
-
-```
-
-Make sure you note down the join token command i.e.
-
-```
-$ sudo kubeadm join --token c30633.d178035db2b4bb9a 10.0.0.5:6443 --discovery-token-ca-cert-hash sha256:
-
-```
-
-### 2.0 Install networking
-
-Many networking providers are available for Kubernetes, but none are included by default, so let's use Weave Net from [Weaveworks][12] which is one of the most popular options in the Kubernetes community. It tends to work out of the box without additional configuration.
-
-```
-$ kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
-
-```
-
-If you have private networking enabled on your host then you may need to alter the private subnet that Weavenet uses for allocating IP addresses to Pods (containers). Here's an example of how to do that:
-
-```
-$ curl -SL "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')&env.IPALLOC_RANGE=172.16.6.64/27" \
-| kubectl apply -f -
-
-```
-
-> Weave also have a very cool visualisation tool called Weave Cloud. It's free and will show you the path traffic is taking between your Pods. [See here for an example with the OpenFaaS project][6].
-
-### 2.2 Join the worker nodes to the cluster
-
-Now you can switch to each of your workers and use the `kubeadm join` command from 1.5\. Once you run that log out of the workers.
-
-### 3.0 Profit
-
-That's it - we're done. You have a cluster up and running and can deploy your applications. If you need to setup a dashboard UI then consult the [Kubernetes documentation][13].
-
-```
-$ kubectl get nodes
-NAME STATUS ROLES AGE VERSION
-openfaas1 Ready master 20m v1.9.2
-openfaas2 Ready 19m v1.9.2
-openfaas3 Ready 19m v1.9.2
-
-```
-
-If you want to see my running through creating a cluster step-by-step and showing you how `kubectl` works then checkout my video below and make sure you subscribe
-
-
-You can also get an "instant" Kubernetes cluster on your Mac for development using Minikube or Docker for Mac Edge edition. [Read my review and first impressions here][14].
-
-
---------------------------------------------------------------------------------
-
-via: https://blog.alexellis.io/your-instant-kubernetes-cluster/
-
-作者:[Alex Ellis ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://blog.alexellis.io/author/alex/
-[1]:https://www.digitalocean.com/
-[2]:https://www.civo.com/
-[3]:https://packet.net/
-[4]:https://github.com/kubernetes/kubernetes/issues/53533
-[5]:https://weave.works/
-[6]:https://www.weave.works/blog/openfaas-gke
-[7]:https://blog.alexellis.io/tag/kubernetes/
-[8]:https://blog.alexellis.io/tag/k8s/
-[9]:https://blog.alexellis.io/tag/cloud-native/
-[10]:https://www.youtube.com/watch?v=6xJwQgDnMFE
-[11]:https://gist.github.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c
-[12]:https://weave.works/
-[13]:https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/
-[14]:https://blog.alexellis.io/docker-for-mac-with-kubernetes/
-[15]:https://blog.alexellis.io/your-instant-kubernetes-cluster/#
\ No newline at end of file
diff --git a/sources/tech/20180129 A look inside Facebooks open source program.md b/sources/tech/20180129 A look inside Facebooks open source program.md
index 3610cec043..c76a524026 100644
--- a/sources/tech/20180129 A look inside Facebooks open source program.md
+++ b/sources/tech/20180129 A look inside Facebooks open source program.md
@@ -1,3 +1,5 @@
+translating---geekpi
+
A look inside Facebook's open source program
============================================================
diff --git a/sources/tech/20180130 Install AWFFull web server log analysis application on ubuntu 17.10.md b/sources/tech/20180130 Install AWFFull web server log analysis application on ubuntu 17.10.md
deleted file mode 100644
index a5e81bf708..0000000000
--- a/sources/tech/20180130 Install AWFFull web server log analysis application on ubuntu 17.10.md
+++ /dev/null
@@ -1,97 +0,0 @@
-translating----geekpi
-
-Install AWFFull web server log analysis application on ubuntu 17.10
-======
-
-
-AWFFull is a web server log analysis program based on "The Webalizer".AWFFull produces usage statistics in HTML format for viewing with a browser. The results are presented in both columnar and graphical format, which facilitates interpretation. Yearly, monthly, daily and hourly usage statistics are presented, along with the ability to display usage by site, URL, referrer, user agent (browser), user name,search strings, entry/exit pages, and country (some information may not be available if not present in the log file being processed).
-
-
-
-AWFFull supports CLF (common log format) log files, as well as Combined log formats as defined by NCSA and others, and variations of these which it attempts to handle intelligently. In addition, AWFFull also supports wu-ftpd xferlog formatted log files, allowing analysis of ftp servers, and squid proxy logs. Logs may also be compressed, via gzip.
-
-AWFFull is a web server log analysis program based on "The Webalizer".AWFFull produces usage statistics in HTML format for viewing with a browser. The results are presented in both columnar and graphical format, which facilitates interpretation. Yearly, monthly, daily and hourly usage statistics are presented, along with the ability to display usage by site, URL, referrer, user agent (browser), user name,search strings, entry/exit pages, and country (some information may not be available if not present in the log file being processed).AWFFull supports CLF (common log format) log files, as well as Combined log formats as defined by NCSA and others, and variations of these which it attempts to handle intelligently. In addition, AWFFull also supports wu-ftpd xferlog formatted log files, allowing analysis of ftp servers, and squid proxy logs. Logs may also be compressed, via gzip.
-
-If a compressed log file is detected, it will be automatically uncompressed while it is read. Compressed logs must have the standard gzip extension of .gz.
-
-### Changes from Webalizer
-
-AWFFull is based on the Webalizer code and has a number of large and small changes. These include:
-
-o Beyond the raw statistics: Making use of published formulae to provide additional insights into site usage.
-
-o GeoIP IP Address look-ups for more accurate country detection.
-
-o Resizable graphs.
-
-o Integration with GNU gettext allowing for ease of translations.Currently 32 languages are supported.
-
-o Display more than 12 months of the site history on the front page.
-
-o Additional page count tracking and sort by same.
-
-o Some minor visual tweaks, including Geolizer's use of Kb, Mb etc for Volumes.
-
-o Additional Pie Charts for URL counts, Entry and Exit Pages, and Sites.
-
-o Horizontal lines on graphs that are more sensible and easier to read.
-
-o User Agent and Referral tracking is now calculated via PAGES not HITS.
-
-o GNU style long command line options are now supported (eg --help).
-
-o Can choose what is a page by excluding "what isn't" vs the original "what is" method.
-
-o Requests to the site being analysed are displayed with the matching referring URL.
-
-o A Table of 404 Errors, and the referring URL can be generated.
-
-o An external CSS file can be used with the generated html.
-
-o Manual performance optimisation of the config file is now easier with a post analysis summary output.
-
-o Specified IP's & Addresses can be assigned to a given country.
-
-o Additional Dump options for detailed analysis with other tools.
-
-o Lotus Domino v6 logs are now detected and processed.
-
-**Install awffull on ubuntu 17.10**
-
-> sudo apt-get install awffull
-
-### Configuring AWFFULL
-
-You have to edit awffull config file at /etc/awffull/awffull.conf. If you have multiple virtual websites running in the same machine, you can make several copies of the default config file.
-
-> sudo vi /etc/awffull/awffull.conf
-
-Make sure the following lines are there
-
-> LogFile /var/log/apache2/access.log.1
-> OutputDir /var/www/html/awffull
-
-Save and exit the file
-
-You can run the awffull config using the following command
-
-> awffull -c [your config file name]
-
-This will create all the required files under /var/www/html/awffull directory so you can access your webserver stats using http://serverip/awffull/
-
-You should see similar to the following screen
-
-If you have more site and you can automate the process using shell script and cron job.
-
-
---------------------------------------------------------------------------------
-
-via: http://www.ubuntugeek.com/install-awffull-web-server-log-analysis-application-on-ubuntu-17-10.html
-
-作者:[ruchi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://www.ubuntugeek.com/author/ubuntufix
diff --git a/sources/tech/20180131 Microservices vs. monolith How to choose.md b/sources/tech/20180131 Microservices vs. monolith How to choose.md
index 35056b1ee0..a337f3c85f 100644
--- a/sources/tech/20180131 Microservices vs. monolith How to choose.md
+++ b/sources/tech/20180131 Microservices vs. monolith How to choose.md
@@ -1,3 +1,4 @@
+Translating by qhwdw
Microservices vs. monolith: How to choose
============================================================
@@ -173,4 +174,4 @@ via: https://opensource.com/article/18/1/how-choose-between-monolith-microservic
[19]:https://opensource.com/users/jakelumetta
[20]:https://opensource.com/users/jakelumetta
[21]:https://opensource.com/tags/microservices
-[22]:https://opensource.com/tags/devops
\ No newline at end of file
+[22]:https://opensource.com/tags/devops
diff --git a/sources/tech/20180201 How to Run Your Own Public Time Server on Linux.md b/sources/tech/20180201 How to Run Your Own Public Time Server on Linux.md
deleted file mode 100644
index 752d06bc6a..0000000000
--- a/sources/tech/20180201 How to Run Your Own Public Time Server on Linux.md
+++ /dev/null
@@ -1,101 +0,0 @@
-How to Run Your Own Public Time Server on Linux
-======
-
-
-
-One of the most important public services is timekeeping, but it doesn't get a lot of attention. Most public time servers are run by volunteers to help meet always-increasing demands. Learn how to run your own public time server and contribute to an essential public good. (See [Keep Accurate Time on Linux with NTP][1] to learn how to set up a LAN time server.)
-
-### Famous Time Server Abusers
-
-Like everything in life, even something as beneficial as time servers are subject to abuse fueled by either incompetence or malice.
-
-Vendors of consumer network appliances are notorious for creating big messes. The first one I recall happened in 2003, when Netgear hard-coded the address of the University of Wisconsin-Madison's NTP server into their routers. All of a sudden the server was getting hammered with requests, and as Netgear sold more routers, the worse it got. Adding to the fun, the routers were programmed to send requests every second, which is way too many. Netgear issued a firmware upgrade, but few users ever upgrade their devices, and a number of them are pummeling the University of Wisconsin-Madison's NTP server to this day. Netgear gave them a pile of money, which hopefully will cover their costs until the last defective router dies. Similar ineptitudes were perpetrated by D-Link, Snapchat, TP-Link, and others.
-
-The NTP protocol has become a choice vector for distributed denial-of-service attacks, using both reflection and amplification. It is called reflection when an attacker uses a forged source address to target a victim; the attacker sends requests to multiple servers, which then reply and bombard the forged address. Amplification is a large reply to a small request. For example, on Linux the `ntpq` command is a useful tool to query your NTP servers to verify that they are operating correctly. Some replies, such as lists of peers, are large. Combine reflection with amplification, and an attacker can get a return of 10x or more on the bandwidth they spend on the attack.
-
-How do you protect your nice beneficial public NTP server? Start by using NTP 4.2.7p26 or newer, which hopefully is not an issue with your Linux distribution because that version was released in 2010. That release shipped with the most significant abuse vectors disabled as the default. The [current release is 4.2.8p10][2], released in 2017.
-
-Another step you can take, which you should be doing anyway, is use ingress and egress filtering on your network. Block packets from entering your network that claim to be from your network, and block outgoing packets with forged return addresses. Ingress filtering helps you, and egress filtering helps you and everyone else. Read [BCP38.info][3] for much more information.
-
-### Stratum 0, 1, 2 Time Servers
-
-NTP is more than 30 years old, one of the oldest Internet protocols that is still widely used. Its purpose is keep computers synchronized to Coordinated Universal Time (UTC). The NTP network is both hierarchical, organized into strata, and peer. Stratum 0 contains master timekeeping devices such as atomic clocks. Stratum 1 time servers synchronize with Stratum 0 devices. Stratum 2 time servers synchronize with Stratum 1 time servers, and Stratum 3 with Stratum 2. The NTP protocol supports 16 strata, though in real life there not that many. Servers in each stratum also peer with each other.
-
-In the olden days, we selected individual NTP servers for our client configurations. Those days are long gone, and now the better way is to use the [NTP pool addresses][4], which use round-robin DNS to share the load. Pool addresses are only for clients, such as individual PCs and your local LAN NTP server. When you run your own public server you won't use the pool addresses.
-
-### Public NTP Server Configuration
-
-There are two steps to running a public NTP server: set up your server, and then apply to join the NTP server pool. Running a public NTP server is a noble deed, but make sure you know what you're getting into. Joining the NTP pool is a long-term commitment, because even if you run it for a short time and then quit, you'll be receiving requests for years.
-
-You need a static public IP address, a permanent reliable Internet connection with at least 512Kb/s bandwidth, and know how to configure your firewall correctly. NTP uses UDP port 123. The machine itself doesn't have to be any great thing, and a lot of admins piggyback NTP on other public-facing servers such as Web servers.
-
-Configuring a public NTP server is just like configuring a LAN NTP server, with a few more configurations. Start by reading the [Rules of Engagement][5]. Follow the rules and mind your manners; almost everyone maintaining a time server is a volunteer just like you. Then select 4-7 Stratum 2 upstream time servers from [StratumTwoTimeServers][6]. Select some that are geographically close to your upstream Internet service provider (mine is 300 miles away), read their access policies, and then use `ping` and `mtr` to find the servers with the lowest latency and least number of hops.
-
-This example `/etc/ntp.conf` includes both IPv4 and IPv6 and basic safeguards:
-```
-# stratum 2 server list
-server servername_1 iburst
-server servername_2 iburst
-server servername_3 iburst
-server servername_4 iburst
-server servername_5 iburst
-
-# access restrictions
-restrict -4 default kod noquery nomodify notrap nopeer limited
-restrict -6 default kod noquery nomodify notrap nopeer limited
-
-# Allow ntpq and ntpdc queries only from localhost
-restrict 127.0.0.1
-restrict ::1
-
-```
-
-Start your NTP server, let it run for a few minutes, and then test that it is querying the remote servers:
-```
-$ ntpq -p
- remote refid st t when poll reach delay offset jitter
-=================================================================
-+tock.no-such-ag 200.98.196.212 2 u 36 64 7 98.654 88.439 65.123
-+PBX.cytranet.ne 45.33.84.208 3 u 37 64 7 72.419 113.535 129.313
-*eterna.binary.n 199.102.46.70 2 u 39 64 7 92.933 98.475 56.778
-+time.mclarkdev. 132.236.56.250 3 u 37 64 5 111.059 88.029 74.919
-
-```
-
-Good so far. Now test from another PC, using your NTP server name. The following example shows correct output. If something is not correct you'll see an error message.
-```
-$ ntpdate -q _yourservername_
-server 66.96.99.10, stratum 2, offset 0.017690, delay 0.12794
-server 98.191.213.2, stratum 1, offset 0.014798, delay 0.22887
-server 173.49.198.27, stratum 2, offset 0.020665, delay 0.15012
-server 129.6.15.28, stratum 1, offset -0.018846, delay 0.20966
-26 Jan 11:13:54 ntpdate[17293]: adjust time server 98.191.213.2 offset 0.014798 sec
-
-```
-
-Once your server is running satisfactorily apply at [manage.ntppool.org][7] to join the pool.
-
-See the official handbook, [The Network Time Protocol (NTP) Distribution][8] to learn about all the command and configuration options, and advanced features such as management, querying, and authentication. Visit the following sites to learn pretty much everything you need about running a time server.
-
-Learn more about Linux through the free ["Introduction to Linux" ][9]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/2/how-run-your-own-public-time-server-linux
-
-作者:[CARLA SCHRODER][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/cschroder
-[1]:https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
-[2]:http://www.ntp.org/downloads.html
-[3]:http://www.bcp38.info/index.php/Main_Page
-[4]:http://www.pool.ntp.org/en/use.html
-[5]:http://support.ntp.org/bin/view/Servers/RulesOfEngagement
-[6]:http://support.ntp.org/bin/view/Servers/StratumTwoTimeServers?redirectedfrom=Servers.StratumTwo
-[7]:https://manage.ntppool.org/manage
-[8]:https://www.eecis.udel.edu/~mills/ntp/html/index.html
-[9]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180213 How to clone, modify, add, and delete files in Git.md b/sources/tech/20180213 How to clone, modify, add, and delete files in Git.md
index fa6648cee0..a58a2b6b85 100644
--- a/sources/tech/20180213 How to clone, modify, add, and delete files in Git.md
+++ b/sources/tech/20180213 How to clone, modify, add, and delete files in Git.md
@@ -1,3 +1,5 @@
+Translating by MjSeven
+
How to clone, modify, add, and delete files in Git
======

diff --git a/sources/tech/20180220 How to format academic papers on Linux with groff -me.md b/sources/tech/20180220 How to format academic papers on Linux with groff -me.md
deleted file mode 100644
index a7902856db..0000000000
--- a/sources/tech/20180220 How to format academic papers on Linux with groff -me.md
+++ /dev/null
@@ -1,266 +0,0 @@
-translating by amwps290
-How to format academic papers on Linux with groff -me
-======
-
-
-
-I was an undergraduate student when I discovered Linux in 1993. I was so excited to have the power of a Unix system right in my dorm room, but despite its many capabilities, Linux lacked applications. Word processors like LibreOffice and OpenOffice were years away. If you wanted to use a word processor, you likely booted your system into MS-DOS and used WordPerfect, the shareware GalaxyWrite, or a similar program.
-
-`nroff` and `troff`. They are different interfaces to the same system: `nroff` generates plaintext output, suitable for screens or line printers, and `troff` generates very pretty output, usually for printing on a laser printer.
-
-That was my method, since I needed to write papers for my classes, but I preferred staying in Linux. I knew from our "big Unix" campus computer lab that Unix systems provided a set of text-formatting programs calledand. They are different interfaces to the same system:generates plaintext output, suitable for screens or line printers, andgenerates very pretty output, usually for printing on a laser printer.
-
-On Linux, `nroff` and `troff` are combined as GNU troff, more commonly known as [groff][1]. I was happy to see a version of groff included in my early Linux distribution, so I set out to learn how to use it to write class papers. The first macro set I learned was the `-me` macro package, a straightforward, easy to learn macro set.
-
-The first thing to know about `groff` is that it processes and formats text according to a set of macros. A macro is usually a two-character command, set on a line by itself, with a leading dot. A macro might carry one or more options. When `groff` encounters one of these macros while processing a document, it will automatically format the text appropriately.
-
-Below, I'll share the basics of using `groff -me` to write simple documents like class papers. I won't go deep into the details, like how to create nested lists, keeps and displays, tables, and figures.
-
-### Paragraphs
-
-Let's start with an easy example you see in almost every type of document: paragraphs. Paragraphs can be formatted with the first line either indented or not (i.e., flush against the left margin). Many printed documents, including academic papers, magazines, journals, and books, use a combination of the two types, with the first (leading) paragraph in a document or chapter flush left and all other (regular) paragraphs indented. In `groff -me`, you can use both paragraph types: leading paragraphs (`.lp`) and regular paragraphs (`.pp`).
-```
-.lp
-
-This is the first paragraph.
-
-.pp
-
-This is a standard paragraph.
-
-```
-
-### Text formatting
-
-The macro to format text in bold is `.b` and to format in italics is `.i`. If you put `.b` or `.i` on a line by itself, then all text that comes after it will be in bold or italics. But it's more likely you just want to put one or a few words in bold or italics. To make one word bold or italics, put that word on the same line as `.b` or `.i`, as an option. To format multiple words in **bold** or italics, enclose your text in quotes.
-```
-.pp
-
-You can do basic formatting such as
-
-.i italics
-
-or
-
-.b "bold text."
-
-```
-
-In the above example, the period at the end of **bold text** will also be in bold type. In most cases, that's not what you want. It's more correct to only have the words **bold text** in bold, but not the trailing period. To get the effect you want, you can add a second argument to `.b` or `.i` to indicate any text that should trail the bolded or italicized text, but in normal type. For example, you might do this to ensure that the trailing period doesn't show up in bold type.
-```
-.pp
-
-You can do basic formatting such as
-
-.i italics
-
-or
-
-.b "bold text" .
-
-```
-
-### Lists
-
-With `groff -me`, you can create two types of lists: bullet lists (`.bu`) and numbered lists (`.np`).
-```
-.pp
-
-Bullet lists are easy to make:
-
-.bu
-
-Apple
-
-.bu
-
-Banana
-
-.bu
-
-Pineapple
-
-.pp
-
-Numbered lists are as easy as:
-
-.np
-
-One
-
-.np
-
-Two
-
-.np
-
-Three
-
-.pp
-
-Note that numbered lists will reset at the next pp or lp.
-
-```
-
-### Subheads
-
-If you're writing a long paper, you might want to divide your content into sections. With `groff -me`, you can create numbered headings (`.sh`) and unnumbered headings (`.uh`). In either, enclose the section title in quotes as an argument. For numbered headings, you also need to provide the heading level: `1` will give a first-level heading (e.g., 1.). Similarly, `2` and `3` will give second and third level headings, such as 2.1 or 3.1.1.
-```
-.uh Introduction
-
-.pp
-
-Provide one or two paragraphs to describe the work
-
-and why it is important.
-
-.sh 1 "Method and Tools"
-
-.pp
-
-Provide a few paragraphs to describe how you
-
-did the research, including what equipment you used
-
-```
-
-### Smart quotes and block quotes
-
-It's standard in any academic paper to cite other people's work as evidence. If you're citing a brief quote to highlight a key message, you can just type quotes around your text. But groff won't automatically convert your quotes into the "smart" or "curly" quotes used by modern word processing systems. To create them in `groff -me`, insert an inline macro to create the left quote (`\*(lq`) and right quote mark (`\*(rq`).
-```
-.pp
-
-Christine Peterson coined the phrase \*(lqopen source.\*(rq
-
-```
-
-There's also a shortcut in `groff -me` to create these quotes (`.q`) that I find easier to use.
-```
-.pp
-
-Christine Peterson coined the phrase
-
-.q "open source."
-
-```
-
-If you're citing a longer quote that spans several lines, you'll want to use a block quote. To do this, insert the blockquote macro (`.(q`) at the beginning and end of the quote.
-```
-.pp
-
-Christine Peterson recently wrote about open source:
-
-.(q
-
-On April 7, 1998, Tim O'Reilly held a meeting of key
-
-leaders in the field. Announced in advance as the first
-
-.q "Freeware Summit,"
-
-by April 14 it was referred to as the first
-
-.q "Open Source Summit."
-
-.)q
-
-```
-
-### Footnotes
-
-To insert a footnote, include the footnote macro (`.(f`) before and after the footnote text, and use an inline macro (`\**`) to add the footnote mark. The footnote mark should appear both in the text and in the footnote itself.
-```
-.pp
-
-Christine Peterson recently wrote about open source:\**
-
-.(f
-
-\**Christine Peterson.
-
-.q "How I coined the term open source."
-
-.i "OpenSource.com."
-
-1 Feb 2018.
-
-.)f
-
-.(q
-
-On April 7, 1998, Tim O'Reilly held a meeting of key
-
-leaders in the field. Announced in advance as the first
-
-.q "Freeware Summit,"
-
-by April 14 it was referred to as the first
-
-.q "Open Source Summit."
-
-.)q
-
-```
-
-### Cover page
-
-Most class papers require a cover page containing the paper's title, your name, and the date. Creating a cover page in `groff -me` requires some assembly. I find the easiest way is to use centered blocks of text and add extra lines between the title, name, and date. (I prefer to use two blank lines between each.) At the top of your paper, start with the title page (`.tp`) macro, insert five blank lines (`.sp 5` ), then add the centered text (`.(c`), and extra blank lines (`.sp 2`).
-```
-.tp
-
-.sp 5
-
-.(c
-
-.b "Writing Class Papers with groff -me"
-
-.)c
-
-.sp 2
-
-.(c
-
-Jim Hall
-
-.)c
-
-.sp 2
-
-.(c
-
-February XX, 2018
-
-.)c
-
-.bp
-
-```
-
-The last macro (`.bp`) tells groff to add a page break after the title page.
-
-### Learning more
-
-Those are the essentials of writing professional-looking a paper in `groff -me` with leading and indented paragraphs, bold and italics text, bullet and numbered lists, numbered and unnumbered section headings, block quotes, and footnotes.
-
-I've included a sample groff file to demonstrate all of this formatting. Save the `lorem-ipsum.me` file to your system and run it through groff. The `-Tps` option sets the output type to PostScript so you can send the document to a printer or convert it to a PDF file using the `ps2pdf` program.
-```
-groff -Tps -me lorem-ipsum.me > lorem-ipsum.me.ps
-
-ps2pdf lorem-ipsum.me.ps lorem-ipsum.me.pdf
-
-```
-
-If you'd like to use more advanced functions in `groff -me`, refer to Eric Allman's "Writing Papers with Groff using `−me`," which you should find on your system as `meintro.me` in groff's `doc` directory. It's a great reference document that explains other ways to format papers using the `groff -me` macros.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-me
-
-作者:[Jim Hall][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jim-hall
-[1]:https://www.gnu.org/software/groff/
diff --git a/sources/tech/20180302 10 Quick Tips About sudo command for Linux systems.md b/sources/tech/20180302 10 Quick Tips About sudo command for Linux systems.md
index bcfad89a12..3fe7d3ca49 100644
--- a/sources/tech/20180302 10 Quick Tips About sudo command for Linux systems.md
+++ b/sources/tech/20180302 10 Quick Tips About sudo command for Linux systems.md
@@ -1,3 +1,5 @@
+translating by szcf-weiya
+
10 Quick Tips About sudo command for Linux systems
======
diff --git a/sources/tech/20180307 An Open Source Desktop YouTube Player For Privacy-minded People.md b/sources/tech/20180307 An Open Source Desktop YouTube Player For Privacy-minded People.md
deleted file mode 100644
index 8c0db2716a..0000000000
--- a/sources/tech/20180307 An Open Source Desktop YouTube Player For Privacy-minded People.md
+++ /dev/null
@@ -1,92 +0,0 @@
-translating---geekpi
-
-An Open Source Desktop YouTube Player For Privacy-minded People
-======
-
-
-
-You already know that we need a Google account to subscribe channels and download videos from YouTube. If you don’t want Google track what you’re doing on YouTube, well, there is an open source YouTube player named **“FreeTube”**. It allows you to watch, search and download Youtube videos and subscribe your favorite channels without an account, which prevents Google from having your information. It gives you complete ad-free experience. Another notable advantage is it has a built-in basic HTML5 player to watch videos. Since we’re not using the built-in YouTube player, Google can’t track the “views” and the video analytics either. FreeTube only sends your IP details, but this also can be overcome by using a VPN. It is completely free, open source and available for GNU/Linux, Mac OS X, and Windows.
-
-### Features
-
-* Watch videos without ads.
-* Prevent Google from tracking what you watch using cookies or JavaScript.
-* Subscribe to channels without an account.
-* Store subscriptions, history, and saved videos locally.
-* Import / Backup subscriptions.
-* Mini Player.
-* Light / Dark Theme.
-* Free, Open Source.
-* Cross-platform.
-
-
-
-### Installing FreeTube
-
-Go to the [**releases page**][1] and grab the version depending upon the OS you use. For the purpose of this guide, I will be using **.tar.gz** file.
-```
-$ wget https://github.com/FreeTubeApp/FreeTube/releases/download/v0.1.3-beta/FreeTube-linux-x64.tar.xz
-
-```
-
-Extract the downloaded archive:
-```
-$ tar xf FreeTube-linux-x64.tar.xz
-
-```
-
-Go to the Freetube folder:
-```
-$ cd FreeTube-linux-x64/
-
-```
-
-Launch Freeube using command:
-```
-$ ./FreeTub
-
-```
-
-This is how FreeTube default interface looks like.
-
-![][3]
-
-### Usage
-
-FreeTube currently uses **YouTube API** to search for videos. And then, It uses **Youtube-dl HTTP API** to grab the raw video files and play them in a basic HTML5 video player. Since subscriptions, history, and saved videos are stored locally on your system, your details will not be sent to Google or anyone else.
-
-Enter the video name in the search box and hit ENTER key. FreeTube will list out the results based on your search query.
-
-![][4]
-
-You can click on any video to play it.
-
-![][5]
-
-If you want to change the theme or default API, import/export subscriptions, go to the **Settings** section.
-
-![][6]
-
-Please note that FreeTube is still in **beta** stage, so there will be bugs. If there are any bugs, please report them in the GitHub page given at the end of this guide.
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/freetube-an-open-source-desktop-youtube-player-for-privacy-minded-people/
-
-作者:[SK][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://github.com/FreeTubeApp/FreeTube/releases
-[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-1.png
-[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-3.png
-[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-5-1.png
-[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-2.png
diff --git a/sources/tech/20180308 How to set up a print server on a Raspberry Pi.md b/sources/tech/20180308 How to set up a print server on a Raspberry Pi.md
deleted file mode 100644
index 77589083c2..0000000000
--- a/sources/tech/20180308 How to set up a print server on a Raspberry Pi.md
+++ /dev/null
@@ -1,87 +0,0 @@
-How to set up a print server on a Raspberry Pi
-======
-
-
-
-I like to work on small projects at home, so this year I picked up a [Raspberry Pi 3 Model B][1], a great model for home hobbyists like me. With built-in wireless on the Raspberry Pi 3 Model B, I can connect the Pi to my home network without a cable. This makes it really easy to put the Raspberry Pi to use right where it is needed.
-
-At our house, my wife and I both have laptops, but we have just one printer: a slightly used HP Color LaserJet. Because our printer doesn't have a wireless card and can't connect to wireless networks, we usually leave the LaserJet connected to my laptop, since I do most of the printing. While that arrangement works most of the time, sometimes my wife would like to print something without having to go through me.
-
-### Basic setup
-
-I realized we really needed a solution to connect the printer to the wireless network so both of us could print to it whenever we wanted. I could buy a wireless print server to connect the USB printer to the wireless network, but I decided instead to use my Raspberry Pi to build a print server to make the LaserJet available to anyone in our house.
-
-Setting up the Raspberry Pi is fairly straightforward. I downloaded the [Raspbian][2] image and wrote that to my microSD card. Then, I booted the Raspberry Pi with an HDMI display, a USB keyboard, and a USB mouse. With that, I was ready to go!
-
-The Raspbian system automatically boots into a graphical desktop environment where I performed most of the basic setup: setting the keyboard language, connecting to my wireless network, setting the password for the regular user account (`pi`), and setting the password for the system administrator account (`root`).
-
-I don't plan to use the Raspberry Pi as a desktop system. I only want to use it remotely from my regular Linux computer. So, I also used Raspbian's graphical administration tool to set the Raspberry Pi to boot into console mode, but not to automatically login as the `pi` user.
-
-Once I rebooted the Raspberry Pi, I needed to make a few other system tweaks so I could use the Pi as a "server" on my network. I set the Dynamic Host Configuration Protocol (DHCP) client to use a static IP address; by default, the DHCP client might pick any available network address, which would make it tricky to know how to connect to the Raspberry Pi over the network. My home network uses a private class A network, so my router's IP address is `10.0.0.1` and all my IP addresses are `10.0.0.x`. In my case, IP addresses in the lower range are safe, so I set up a static IP address on the wireless network at `10.0.0.11` by adding these lines to the `/etc/dhcpcd.conf` file:
-```
-interface wlan0
-
-static ip_address=10.0.0.11/24
-
-static routers=10.0.0.1
-
-static domain_name_servers=8.8.8.8 8.8.4.4
-
-```
-
-Before I rebooted again, I made sure that the secure shell daemon (SSHD) was running (you can set what services start at boot-up in Preferences). This allowed me to use a secure shell (SSH) client from my regular Linux system to connect to the Raspberry Pi over the network.
-
-### Print setup
-
-Now that my Raspberry Pi was on the network, I did the rest of the setup remotely, using SSH, from my regular Linux desktop machine. Make sure your printer is connected to the Raspberry Pi before taking the following steps.
-
-Setting up printing is fairly easy. The modern print server is called CUPS, which stands for the Common Unix Printing System. Any recent Unix system should be able to print through a CUPS print server. To set up CUPS on Raspberry Pi, you just need to enter a few commands to install the CUPS software, allow printing by other systems, and restart the print server with the new configuration:
-```
-$ sudo apt-get install cups
-
-$ sudo cupsctl --remote-any
-
-$ sudo /etc/init.d/cups restart
-
-```
-
-Setting up a printer in CUPS is also straightforward and can be done through a web browser. CUPS listens on port 631, so just use your favorite web browser and surf to:
-```
-https://10.0.0.11:631/
-
-```
-
-Your web browser may complain that it doesn't recognize the web server's https certificate; just accept it, and login as the system administrator. You should see the standard CUPS panel:
-
-
-From there, navigate to the Administration tab, and select Add Printer.
-
-
-
-If your printer is already connected via USB, you should be able to easily select the printer's make and model. Don't forget to tick the Share This Printer box so others can use it, too. And now your printer should be set up in CUPS:
-
-
-
-### Client setup
-
-Setting up a network printer from the Linux desktop should be quite simple. My desktop is GNOME, and you can add the network printer right from the GNOME Settings application. Just navigate to Devices and Printers and unlock the panel. Click on the Add button to add the printer.
-
-On my system, GNOME Settings automatically discovered the network printer and added it. If that doesn't happen for you, you may need to add the IP address for your Raspberry Pi to manually add the printer.
-
-
-
-And that's it! We are now able to print to the Color LaserJet over the wireless network from wherever we are in the house. I no longer need to be physically connected to the printer, and everyone in the family can print on their own.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/print-server-raspberry-pi
-
-作者:[Jim Hall][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jim-hall
-[1]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
-[2]:https://www.raspberrypi.org/downloads/
diff --git a/translated/tech/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md b/translated/tech/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md
deleted file mode 100644
index b17db43664..0000000000
--- a/translated/tech/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md
+++ /dev/null
@@ -1,141 +0,0 @@
-translating by shipsw
-
-如何使用 yum-cron 自动更新 RHEL/CentOS Linux
-======
-yum 命令是 RHEL / CentOS Linux 系统中用来安装和更新软件包的一个工具。知道如何使用 [yum 命令行] 更新系统,但是我想用 cron 手工更新软件包。该如何配置才能使得 yum 使用 [cron 自动更新][2]系统补丁或更新呢?
-
-首先需要安装 yum-cron 软件包。该软件包提供以 cron 命令运行 yum 更新所需的文件。安装这个软件可以使得 yum 以 cron 命令每晚更新。
-
-### CentOS/RHEL 6.x/7.x 上安装 yum cron
-
-输入以下 [yum 命令][3]:
-`$ sudo yum install yum-cron`
-
-
-使用 **CentOS/RHEL 7.x** 上的 systemctl 启动服务:
-```
-$ sudo systemctl enable yum-cron.service
-$ sudo systemctl start yum-cron.service
-$ sudo systemctl status yum-cron.service
-```
-在 **CentOS/RHEL 6.x** 系统中,运行:
-```
-$ sudo chkconfig yum-cron on
-$ sudo service yum-cron start
-```
-
-
-yum-cron 是 yum 的一个调用接口。使得 cron 调用 yum 变得非常方便。该软件提供元数据更新,更新检查、下载和安装等功能。yum-cron 的不同功能可以使用高配置文件配置,而不是输入一堆复杂的命令行参数。
-
-### 配置 yum-cron 自动更新 RHEL/CentOS Linux
-
-使用 vi 等编辑器编辑文件 /etc/yum/yum-cron.conf 和 /etc/yum/yum-cron-hourly.conf:
-`$ sudo vi /etc/yum/yum-cron.conf`
-确保更新可用时自动更新
-`apply_updates = yes`
-可以设置通知 email 地址。注意: localhost 将会被系统名称代替。
-`email_from = root@localhost`
-email 通知地址列表。
-`email_to = your-it-support@some-domain-name`
-发送 email 信息的主机名。
-`email_host = localhost`
-[CentOS/RHEL 7.x][4] 上不想更新内核的话,添加以下内容:
-`exclude=kernel*`
-RHEL/CentOS 6.x 下[添加以下内容来禁用内核更新][5]:
-`YUM_PARAMETER=kernel*`
-[保存并关闭文件][6]。如果想每小时更新系统的话修改文件 /etc/yum/yum-cron-hourly.conf,否则文件 /etc/yum/yum-cron.conf 将使用以下命令每天运行一次[cat 命令][7]:
-`$ cat /etc/cron.daily/0yum-daily.cron`
-示例输出:
-```
-#!/bin/bash
-
-# Only run if this flag is set. The flag is created by the yum-cron init
-# script when the service is started -- this allows one to use chkconfig and
-# the standard "service stop|start" commands to enable or disable yum-cron.
-if [[ ! -f /var/lock/subsys/yum-cron ]]; then
- exit 0
-fi
-
-# Action!
-exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
-[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
-#!/bin/bash
-
-# Only run if this flag is set. The flag is created by the yum-cron init
-# script when the service is started -- this allows one to use chkconfig and
-# the standard "service stop|start" commands to enable or disable yum-cron.
-if [[ ! -f /var/lock/subsys/yum-cron ]]; then
- exit 0
-fi
-
-# Action!
-exec /usr/sbin/yum-cron
-```
-
-完成配置。现在你的系统将每天自动更新一次。更多细节请参照 yum-cron 的说明手册。
-`$ man yum-cron`
-
-### 方法二 – 使用 shell 脚本
-
-**警告** : 以下命令已经过时了. 不要在 RHEL/CentOS 6.x/7.x 系统中使用。 我写在这里仅仅是因为历史原因,该命令适合 CentOS/RHEL version 4.x/5.x 上运行。
-
-让我们看看如何在 CentOS/RHEL 上配置 yum 安全更新包的检索和安装。你可以使用 CentOS / RHEL 提供的 yum-updatesd 服务。然而,系统提供的服务开销有点大。你可以使用以下的 shell 脚本配置每天后每周的系统更新。
-
- * **/etc/cron.daily/yumupdate.sh** 每天更新
- * **/etc/cron.weekly/yumupdate.sh** 每周更新
-
-
-
-#### 系统更新的示例脚本
-
-以下脚本功能是使用 [cron][8] 定时安装更新更新:
-```
-#!/bin/bash
-YUM=/usr/bin/yum
-$YUM -y -R 120 -d 0 -e 0 update yum
-$YUM -y -R 10 -e 0 -d 0 update
-```
-
-(Code listing -01: /etc/cron.daily/yumupdate.sh)
-
-其中:
-
- 1. 第一条命令更新 yum 自己。
- 2. **-R 120** : 设置允许一条命令前的等待最长时间
- 3. **-e 0** : 设置错误级别为 0 (范围 0-10)。0 意味着只有关键性错误才会显示。
- 4. -d 0 : 设置 debug 级别为 0 。增加或减少打印日志的量。(范围 0-10)
- 5. **-y** : 默认同意;任何提示问题默认回答为 yes。
-
-
-
-设置脚本的执行权限:
-`# chmod +x /etc/cron.daily/yumupdate.sh`
-
-
-### 关于作者
-
-作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。**获取更多有关系统管理、Linux/Unix 和开源话题请关注[我的 RSS/XML 地址][12]**。
-
---------------------------------------------------------------------------------
-
-via: https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/
-
-作者:[Vivek Gite][a]
-译者:[shipsw](https://github.com/shipsw)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.cyberciti.biz/
-[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
-[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
-[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
-[4]:https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/
-[5]:https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/
-[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
-[7]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ (See Linux/Unix cat command examples for more info)
-[8]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
-[9]:https://twitter.com/nixcraft
-[10]:https://facebook.com/nixcraft
-[11]:https://plus.google.com/+CybercitiBiz
-[12]:https://www.cyberciti.biz/atom/atom.xml
diff --git a/translated/tech/20140225 How To Safely Generate A Random Number - Quarrelsome.md b/translated/tech/20140225 How To Safely Generate A Random Number - Quarrelsome.md
new file mode 100644
index 0000000000..23765b77ba
--- /dev/null
+++ b/translated/tech/20140225 How To Safely Generate A Random Number - Quarrelsome.md
@@ -0,0 +1,94 @@
+如何安全地生成随机数 - 争论
+======
+### 使用 urandom
+
+使用 urandom。使用 urandom。使用 urandom。使用 urandom。使用 urandom。使用 urandom。
+
+### 但对于密码学密钥呢?
+
+仍然使用 urandom[6]。
+
+### 为什么不是 SecureRandom, OpenSSL, havaged 或者 c 语言实现呢?
+
+这些是用户空间的 CSPRNG(伪随机数生成器)。你应该想用内核的 CSPRNG,因为:
+
+ * 内核可以访问原始设备熵。
+
+ * 它保证不在应用程序之间共享相同的状态。
+
+ * 一个好的内核 CSPRNG,像 FreeBSD 中的,也可以保证在提供种子之前不给你随机数据。
+
+
+
+
+研究过去十年中的随机失败案例,你会看到一连串的用户空间随机失败。[Debian 的 OpenSSH 崩溃][7]?用户空间随机。安卓的比特币钱包[重复 ECDSA k's][8]?用户空间随机。可预测洗牌的赌博网站?用户空间随机。
+
+用户空间生成器几乎总是依赖于内核的生成器。即使它们不这样做,整个系统的安全性也会确保如此。**用户空间的 CSPRNG 不会增加防御深度;相反,它会产生两个单点故障。**
+
+### 手册页不是说使用/dev/random嘛?
+
+这个稍后详述,保留你的想法。你应该忽略掉手册页。不要使用 /dev/random。/dev/random 和 /dev/urandom 之间的区别是 Unix 设计缺陷。手册页不想承认这一点,因此它产生了一个并不存在的安全问题。把 random(4) 上的密码学上的建议当作传奇,继续你的生活。
+
+### 但是如果我需要的是真随机值,而非伪随机值呢?
+
+Urandom 和 /dev/random 提供的是同一类型的随机。与流行的观念相反,/dev/random 不提供“真正的随机”。从密码学上来说,你通常不需要“真正的随机”。
+
+Urandom 和 /dev/random 都基于一个简单的想法。它们的设计与流密码的设计密切相关:一个小秘密被延伸到不可预测值的不确定流中。 这里的秘密是“熵”,而流是“输出”。
+
+只在 Linux 上 /dev/random 和 urandom 仍然有意义上的不同。Linux 内核的 CSPRNG 定期进行密钥更新(通过收集更多的熵)。但是 /dev/random 也试图跟踪内核池中剩余的熵,并且如果它没有足够的剩余熵时,偶尔也会罢工。这种设计和我所说的一样蠢;这与基于“密钥流”中剩下多少“密钥”的 AES-CTR 设计类似。
+
+如果你使用 /dev/random 而非 urandom,那么当 Linux 对自己的 RNG(随机数生成器)如何工作感到困惑时,你的程序将不可预测地(或者如果你是攻击者,非常可预测地)挂起。使用 /dev/random 会使你的程序不太稳定,但在密码学角度上它也不会让程序更加安全。
+
+### 这里有个缺陷,不是吗?
+
+不是,但存在一个你可能想要了解的 Linux 内核 bug,即使这并不能改变你应该使用哪一个 RNG。
+
+在 Linux 上,如果你的软件在引导时立即运行,并且/或者刚刚安装了操作系统,那么你的代码可能会与 RNG 发生竞争。这很糟糕,因为如果你赢了比赛,那么你可能会在一段时间内从 urandom 获得可预测的输出。这是 Linux 中的一个 bug,如果你正在为 Linux 嵌入式设备构建平台级代码,那你需要了解它。
+
+在 Linux 上,这确实是 urandom(而不是 /dev/random)的问题。这也是[Linux 内核中的错误][9]。 但它也容易在用户空间中修复:在引导时,明确地为 urandom 提供种子。长期以来,大多数 Linux 发行版都是这么做的。但不要切换到不同的 CSPRNG。
+
+### 在其它操作系统上呢?
+
+FreeBSD 和 OS X 消除了 urandom 和 /dev/random 之间的区别; 这两个设备的行为是相同的。不幸的是,手册页在解释为什么这样做上干的很糟糕,并延续了 Linux 上 urandom 可怕的神话。
+
+无论你使用 /dev/random 还是 urandom,FreeBSD 的内核加密 RNG 都不会阻塞。 除非它没有被提供种子,在这种情况下,这两者都会阻塞。与 Linux 不同,这种行为是有道理的。Linux 应该采用它。但是,如果你是一名应用程序开发人员,这对你几乎没有什么影响:Linux,FreeBSD,iOS,无论什么:使用 urandom 吧。
+
+### 太长了,懒得看
+
+直接使用 urandom 吧。
+
+### 结语
+
+[ruby-trunk Feature #9569][10]
+
+> 现在,在尝试检测 /dev/urandom 之前,SecureRandom.random_bytes 会尝试检测要使用的 OpenSSL。 我认为这应该反过来。在这两种情况下,你只需要将随机字节进行解压,所以 SecureRandom 可以跳过中间人(和第二个故障点),如果可用的话可以直接与 /dev/urandom 进行交互。
+
+总结:
+
+> /dev/urandom 不适合用来直接生成会话密钥和频繁生成其他应用程序级随机数据
+>
+> GNU/Linux 上的 random(4) 手册所述......
+
+感谢 Matthew Green, Nate Lawson, Sean Devlin, Coda Hale, and Alex Balducci 阅读了本文草稿。公正警告:Matthew 只是大多同意我的观点。
+
+--------------------------------------------------------------------------------
+
+via: https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/
+
+作者:[Thomas;Erin;Matasano][a]
+译者:[kimii](https://github.com/kimii)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://sockpuppet.org/blog
+[1]:http://blog.cr.yp.to/20140205-entropy.html
+[2]:http://cr.yp.to/talks/2011.09.28/slides.pdf
+[3]:http://golang.org/src/pkg/crypto/rand/rand_unix.go
+[4]:http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key
+[5]:http://stackoverflow.com/a/5639631
+[6]:https://twitter.com/bramcohen/status/206146075487240194
+[7]:http://research.swtch.com/openssl
+[8]:http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/
+[9]:https://factorable.net/weakkeys12.extended.pdf
+[10]:https://bugs.ruby-lang.org/issues/9569
diff --git a/translated/tech/20171102 Testing IPv6 Networking in KVM- Part 1.md b/translated/tech/20171102 Testing IPv6 Networking in KVM- Part 1.md
new file mode 100644
index 0000000000..45a696511f
--- /dev/null
+++ b/translated/tech/20171102 Testing IPv6 Networking in KVM- Part 1.md
@@ -0,0 +1,82 @@
+在 KVM 中测试 IPv6 网络(第 1 部分)
+======
+
+
+
+要理解 IPv6 地址是如何工作的,没有比亲自动手去实践更好的方法了,在 KVM 中配置一个小的测试实验室非常容易 —— 也很有趣。这个系列的文章共有两个部分,我们将学习关于 IPv6 私有地址的知识,以及如何在 KVM 中配置测试网络。
+
+### QEMU/KVM/虚拟机管理器
+
+我们先来了解什么是 KVM。在这里,我将使用 KVM 来表示 QEMU、KVM、以及虚拟机管理器的一个组合,虚拟机管理器在 Linux 发行版中一般内置了。简单解释就是,QEMU 模拟硬件,而 KVM 是一个内核模块,它在你的 CPU 上创建一个 “访客领地”,并去管理它们对内存和 CPU 的访问。虚拟机管理器是一个涵盖虚拟化和管理程序的图形工具。
+
+但是你不能被图形界面下 “点击” 操作的方式 "缠住" ,因为,它们也有命令行工具可以使用 —— 比如 virsh 和 virt-install。
+
+如果你在使用 KVM 方面没有什么经验,你可以从 [在 KVM 中创建虚拟机:第 1 部分][1] 和 [在 KVM 中创建虚拟机:第 2 部分 - 网络][2] 开始学起。
+
+### IPv6 唯一本地地址
+
+在 KVM 中配置 IPv6 网络与配置 IPv4 网络很类似。它们的主要不同在于这些怪异的长地址。[上一次][3],我们讨论了 IPv6 地址的不同类型。其中有一个 IPv6 单播地址类,fc00::/7(详细情况请查阅 [RFC 4193][4]),它类似于 IPv4 中的私有地址 —— 10.0.0.0/8、172.16.0.0/12、和 192.168.0.0/16。
+
+下图解释了这个唯一本地地址空间的结构。前 48 位定义了前缀和全局 ID,随后的 16 位是子网,剩余的 64 位是接口 ID:
+```
+| 7 bits |1| 40 bits | 16 bits | 64 bits |
++--------|-+------------|-----------|----------------------------+
+| Prefix |L| Global ID | Subnet ID | Interface ID |
++--------|-+------------|-----------|----------------------------+
+
+```
+
+下面是另外一种表示方法,它可能更有助于你理解这些地址是如何管理的:
+```
+| Prefix | Global ID | Subnet ID | Interface ID |
++--------|--------------|-------------|----------------------+
+| fd | 00:0000:0000 | 0000 | 0000:0000:0000:0000 |
++--------|--------------|-------------|----------------------+
+
+```
+
+fc00::/7 共分成两个 /8 地址块,fc00::/8 和 fd00::/8。fc00::/8 是为以后使用保留的。因此,唯一本地地址通常都是以 fd 开头的,而剩余部分是由你使用的。L 位,也就是第八位,它总是设置为 1,这样它可以表示为 fd00::/8。设置为 0 时,它就表示为 fc00::/8。你可以使用 `subnetcalc` 来看到这些东西:
+```
+$ subnetcalc fd00::/8 -n
+Address = fd00::
+ fd00 = 11111101 00000000
+
+$ subnetcalc fc00::/8 -n
+Address = fc00::
+ fc00 = 11111100 00000000
+
+```
+
+RFC 4193 要求地址必须随机产生。你可以用你选择的任何方法来造出个地址,只要它们以 `fd` 打头就可以,因为 IPv6 范围非常大,它不会因为地址耗尽而无法使用。当然,最佳实践还是按 RFCs 的要求来做。地址不能按顺序分配或者使用众所周知的数字。RFC 4193 包含一个构建伪随机地址生成器的算法,或者你可以在线找到任何生成器产生的数字。
+
+唯一本地地址不像全局单播地址(它由你的因特网服务提供商分配)那样进行中心化管理,即使如此,发生地址冲突的可能性也是非常低的。当你需要去合并一些本地网络或者想去在不相关的私有网络之间路由时,这是一个非常好的优势。
+
+在同一个子网中,你可以混用唯一本地地址和全局单播地址。唯一本地地址是可路由的,并且它并不会因此要求对路由器做任何调整。但是,你应该在你的边界路由器和防火墙上配置为不允许它们离开你的网络,除非是在不同位置的两个私有网络之间。
+
+RFC4193 建议,不要混用全局单播地址的 AAAA 和 PTR 记录,因为虽然它们重复的机率非常低,但是并不能保证它们就是独一无二的。就像我们使用的 IPv4 地址一样,要保持你本地的私有名称服务和公共名称服务的独立。将本地名称服务使用的 Dnsmasq 和公共名称服务使用的 BIND 组合起来,是一个在 IPv4 网络上经过实战检验的可靠组合,这个组合也同样适用于 IPv6 网络。
+
+### 伪随机地址生成器
+
+在线地址生成器的一个示例是 [本地 IPv6 地址生成器][5]。你可以在线找到许多这样很酷的工具。你可以使用它来为你创建一个新地址,或者使用它在你的现有全局 ID 下为你创建子网。
+
+下周我们将讲解如何在 KVM 中配置这些 IPv6 的地址,并现场测试它们。
+
+通过来自 Linux 基金会和 edX 的免费在线课程 ["Linux 入门" ][6] 学习更多的 Linux 知识。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
+
+作者:[Carla Schroder][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/cschroder
+[1]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-1
+[2]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-2-networking
+[3]:https://www.linux.com/learn/intro-to-linux/2017/10/calculating-ipv6-subnets-linux
+[4]:https://tools.ietf.org/html/rfc4193
+[5]:https://www.ultratools.com/tools/rangeGenerator
+[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/translated/tech/20171102 What is huge pages in Linux.md b/translated/tech/20171102 What is huge pages in Linux.md
deleted file mode 100644
index ee261956ad..0000000000
--- a/translated/tech/20171102 What is huge pages in Linux.md
+++ /dev/null
@@ -1,137 +0,0 @@
-Linux 中的 huge pages 是个什么玩意?
-======
-学习 Linux 中的 huge pages( 巨大页)。理解什么是 hugepages,如何进行配置,如何查看当前状态以及如何禁用它。
-
-![Huge Pages in Linux][1]
-
-本文,我们会详细介绍 huge page,让你能够回答:Linux 中的 huge page 是什么玩意?在 RHEL6,RHEL7,Ubuntu 等 Linux 中,如何启用/禁用 huge pages?如何查看 huge page 的当前值?
-
-首先让我们从 Huge page 的基础知识开始讲起。
-
-### Linux 中的 Huge page 是个什么玩意?
-
-Huge pages 有助于 Linux 系统进行虚拟内存管理。顾名思义,除了标准的 4KB 大小的页面外,他们还能帮助管理内存中的巨大页面。使用 huge pages,你最大可以定义 1GB 的页面大小。
-
-在系统启动期间,huge pages 会为应用程序预留一部分内存。这部分内存,即被 huge pages 占用的这些存储器永远不会被交换出内存。它会一直保留其中除非你修改了配置。这会极大地提高像 Orcle 数据库这样的需要海量内存的应用程序的性能。
-
-### 为什么使用巨大的页?
-
-在虚拟内存管理中,内核维护一个将虚拟内存地址映射到物理地址的表,对于每个页面操作,内核都需要加载相关的映射标。如果你的内存页很小,那么你需要加载的页就会很多,导致内核加载更多的映射表。而这会降低性能。
-
-使用巨大的页,意味着所需要的页变少了。从而大大减少由内核加载的映射表的数量。这提高了内核级别的性能最终有利于应用程序的性能。
-
-简而言之,通过启用 huge pages,系统具只需要处理较少的页面映射表,从而减少访问/维护它们的开销!
-
-### 如何配置 huge pages?
-
-运行下面命令来查看当前 huge pages 的详细内容。
-
-```
-root@kerneltalks # grep Huge /proc/meminfo
-AnonHugePages: 0 kB
-HugePages_Total: 0
-HugePages_Free: 0
-HugePages_Rsvd: 0
-HugePages_Surp: 0
-Hugepagesize: 2048 kB
-```
-
-从上面输出可以看到,每个页的大小为 2MB(`Hugepagesize`) 并且系统中目前有 0 个页 (`HugePages_Total`)。这里巨大页的大小可以从 2MB 增加到 1GB。
-
-运行下面的脚本可以获取系统当前需要多少个巨大页。该脚本取之于 Oracle。
-
-```
-#!/bin/bash
-#
-# hugepages_settings.sh
-#
-# Linux bash script to compute values for the
-# recommended HugePages/HugeTLB configuration
-#
-# Note: This script does calculation for all shared memory
-# segments available when the script is run, no matter it
-# is an Oracle RDBMS shared memory segment or not.
-# Check for the kernel version
-KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
-# Find out the HugePage size
-HPG_SZ=`grep Hugepagesize /proc/meminfo | awk {'print $2'}`
-# Start from 1 pages to be on the safe side and guarantee 1 free HugePage
-NUM_PG=1
-# Cumulative number of pages required to handle the running shared memory segments
-for SEG_BYTES in `ipcs -m | awk {'print $5'} | grep "[0-9][0-9]*"`
-do
- MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
- if [ $MIN_PG -gt 0 ]; then
- NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
- fi
-done
-# Finish with results
-case $KERN in
- '2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
- echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
- '2.6' | '3.8' | '3.10' | '4.1' ) echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
- *) echo "Unrecognized kernel version $KERN. Exiting." ;;
-esac
-# End
-```
-将它以 `hugepages_settings.sh` 为名保存到 `/tmp` 中,然后运行之:
-```
-root@kerneltalks # sh /tmp/hugepages_settings.sh
-Recommended setting: vm.nr_hugepages = 124
-```
-
-输出如上结果,只是数字会有一些出入。
-
-这意味着,你系统需要 124 个每个 2MB 的巨大页!若你设置页面大小为 4MB,则结果就变成了 62。你明白了吧?
-
-### 配置内核中的 hugepages
-
-本文最后一部分内容是配置上面提到的 [内核参数 ][2] 然后重新加载。将下面内容添加到 `/etc/sysctl.conf` 中,然后输入 `sysctl -p` 命令重新加载配置。
-
-```
-vm .nr_hugepages=126
-```
-
-注意我们这里多加了两个额外的页,因为我们希望在实际需要的页面数量外多一些额外的空闲页。
-
-现在,内核已经配置好了,但是要让应用能够使用这些巨大页还需要提高内存的使用阀值。新的内存阀值应该为 126 个页 x 每个页 2 MB = 252 MB,也就是 258048 KB。
-
-你需要编辑 `/etc/security/limits.conf` 中的如下配置
-
-```
-soft memlock 258048
-hard memlock 258048
-```
-
-某些情况下,这些设置是在指定应用的文件中配置的,比如 Oracle DB 就是在 `/etc/security/limits.d/99-grid-oracle-limits.conf` 中配置的。
-
-这就完成了!你可能还需要重启应用来让应用来使用这些新的巨大页。
-
-### 如何禁用 hugepages?
-
-HugePages 默认是开启的。使用下面命令来查看 hugepages 的当前状态。
-
-```
-root@kerneltalks# cat /sys/kernel/mm/transparent_hugepage/enabled
-[always] madvise never
-```
-
-输出中的 `[always]` 标志说明系统启用了 hugepages。
-
-若使用的是基于 RedHat 的系统,则应该要查看的文件路径为 `/sys/kernel/mm/redhat_transparent_hugepage/enabled`。
-
-若想禁用巨大页,则在 `/etc/grub.conf` 中的 `kernel` 行后面加上 `transparent_hugepage=never`,然后重启系统。
-
---------------------------------------------------------------------------------
-
-via: https://kerneltalks.com/services/what-is-huge-pages-in-linux/
-
-作者:[Shrikant Lavhate][a]
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://kerneltalks.com
-[1]:https://c1.kerneltalks.com/wp-content/uploads/2017/11/hugepages-in-linux.png
-[2]:https://kerneltalks.com/linux/how-to-tune-kernel-parameters-in-linux/
diff --git a/translated/tech/20171205 What DevOps teams really need from a CIO.md b/translated/tech/20171205 What DevOps teams really need from a CIO.md
new file mode 100644
index 0000000000..4780ca8a26
--- /dev/null
+++ b/translated/tech/20171205 What DevOps teams really need from a CIO.md
@@ -0,0 +1,58 @@
+CIO 真正需要 DevOps 团队做什么?
+======
+IT 领导者可以从大量的 [DevOps][1] 材料和 [向 DevOps 转变][2] 所要求的文化挑战中学习。但是,你在一个 DevOps 团队面对长期或短期挑战的调整中 —— 一个 CIO 真正需要他们做的是什么呢?
+
+在我与 DevOps 团队成员的谈话中,我听到的其中一些内容让你感到非常的意外。DevOps 专家(无论是内部团队的还是外部团队的)都希望将下列的事情放在你的 CIO 优先关注的级别。
+
+### 1. 沟通
+
+第一个也是最重要的一个,DevOps 专家需要面对面的沟通。一个经验丰富的 DevOps 团队是非常了解当前 DevOps 的趋势,以及成功、和失败的经验,并且他们非常乐意去分享这些信息。表达 DevOps 的概念是很困难的,因此,要在这种新的工作关系中保持开放,定期(不用担心,不用每周)讨论有关你的 IT 的当前状态,如何评价你的沟通环境,以及你的整体的 IT 产业。
+
+**[想从领导 DevOps 的 CIO 们处学习更多的知识吗?查看我们的综合资源,[DevOps: IT 领导者指南][3]。 ]**
+
+相反,你应该准备好与 DevOps 团队去共享当前的业务需求和目标。业务不再是独立于 IT 的东西:它们现在是驱动 IT 发展的重要因素,并且 IT 决定了你的业务需求和目标运行的效果如何。
+
+注重参与而不是领导。在需要做决策的时候,你仍然是最终的决策者,但是,理解这些决策的最好方式是协作,这样,你的 DevOps 团队将有更多的自主权,并因此受到更多激励。
+
+### 2. 降低技术债务
+
+第二,力争更好地理解技术债务,并在 DevOps 中努力降低它。你的 DevOps 团队面对的工作都非常难。在这种情况下,技术债务是指在一个庞大的、不可持续的环境(查看 Rube Goldberg)之中,通过维护和增加新功能而占用的人力资源和基础设备资源。
+
+常见的 CIO 问题包括:
+
+ * 为什么我们要用一种新方法去做这件事情?
+ * 为什么我们要在它上面花费时间和金钱?
+ * 如果这里没有新功能,只是现有组件实现了自动化,那么我们的收益是什么?
+
+
+
+"如果没有坏,就不要去修理它“ ,这样的事情是可以理解的。但是,如果你正在路上好好的开车,而每个人都加速超过你,这时候,你的环境就被破坏了。持续投入宝贵的资源去支撑或扩张拼凑起来的环境。
+
+选择妥协,并且一个接一个的打补丁,以这种方式去处理每个独立的问题,结果将从一开始就变得很糟糕 —— 在一个不能支撑建筑物的地基上,一层摞一层地往上堆。事实上,这种方法就像不断地在电脑中插入坏磁盘一样。迟早有一天,面对出现的问题,你将会毫无办法。在外面持续增加的压力下,整个事情将变得一团糟,完全吞噬掉你的资源。
+
+这种情况下,解决方案就是:自动化。使用自动化的结果是良好的可伸缩性 —— 每个维护人员在 IT 环境的维护和增长方面花费更少的努力。如果增加人力资源是实现业务增长的唯一办法,那么,可伸缩性就是白日做梦。
+
+自动化降低了你的人力资源需求,并且对持续进行的 IT 提供了更灵活的需求。很简单,对吗?是的,但是你必须为迟到的满意做好心理准备。为了在提高生产力和效率的基础上获得后端经济效益,需要预先投入时间和精力对架构和结构进行变更。为了你的 DevOps 团队能够成功,接受这些挑战,对 IT 领导者来说是非常重要的。
+
+### 3. 信任
+
+最后,相信你的 DevOps 团队并且一定要理解他们。DevOps 专家也知道这个要求很难,但是他们必须有你的强大支持和你参与实践的意愿。因为 DevOps 团队持续改进你的 IT 环境,他们自身也在不断地适应这些变化的技术,而这些变化通常正是 “你要去学习的经验”。
+
+倾听,倾听,倾听他们,并且相信他们。DevOps 的改变是非常有价值的,而且也是值的去投入时间和金钱的。它可以提高效率、生产力、和业务响应能力。信任你的 DevOps 团队,并且给予他们更多的自由,实现更高效率的 IT 改进。
+
+新 CIO 的底线是:将你的 DevOps 团队的潜力最大化,离开你的领导 “舒适区”,拥抱一个 “CIOps" 的转变。通过 DevOps 转变,持续地与你的 DevOps 团队共同成长,以帮助你的组织获得长期的 IT 成功。
+
+--------------------------------------------------------------------------------
+
+via: https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio
+
+作者:[John Allessio][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://enterprisersproject.com/user/john-allessio
+[1]:https://enterprisersproject.com/tags/devops
+[2]:https://www.redhat.com/en/insights/devops?intcmp=701f2000000tjyaAAA
+[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
diff --git a/translated/tech/20171213 Will DevOps steal my job-.md b/translated/tech/20171213 Will DevOps steal my job-.md
new file mode 100644
index 0000000000..065d638bfa
--- /dev/null
+++ b/translated/tech/20171213 Will DevOps steal my job-.md
@@ -0,0 +1,58 @@
+DevOps 将让你失业?
+======
+
+>你是否担心工作中自动化将代替人?可能是对的,但是这并不是件坏事。
+
+
+>Image by : opensource.com
+
+这是一个很正常的担心:DevOps 最终会让你失业?毕竟,DevOps 意味着开发人员做运营,对吗?DevOps 是自动化的。如果我的工作都自动化了,我去做什么?实行持续分发和容器化意味着运营已经过时了吗?对于 DevOps 来说,所有的东西都是代码:基础设施是代码、测试是代码、这个和那个都是代码。如果我没有这些技能怎么办?
+
+[DevOps][1] 是一个即将到来的变化,将颠覆这一领域,狂热的拥挤者们正在谈论,如何使用 [三种方法][2] 去改变世界 —— 即 DevOps 的三大基础 —— 去推翻一个旧的世界。它是势不可档的。那么,问题来了 —— DevOps 将会让我失业吗?
+
+### 第一个担心:再也不需要我了
+
+由于开发者来管理应用程序的整个生命周期,接受 DevOps 的理念很容易。容器化可能是影响这一想法的重要因素。当容器化在各种场景下铺开之后,它们被吹嘘成开发者构建、测试、和部署他们代码的一站式解决方案。DevOps 对于运营、测试、以及 QA 团队来说,有什么作用呢?
+
+这源于对 DevOps 原则的误解。DevOps 的第一原则,或者第一方法是,_系统思考_ ,或者强调整体管理方法和了解应用程序或服务的整个生命周期。这并不意味着应用程序的开发者将学习和管理整个过程。相反,是拥有各个专业和技能的人共同合作,以确保成功。让开发者对这一过程完全负责的作法,几乎是将开发者置于使用者的对立面—— 本质上就是 “将鸡蛋放在了一个篮子里”。
+
+在 DevOps 中有一个为你保留的专门职位。就像将一个受过传统教育的、拥有线性回归和二分查找知识的软件工程师,被用去写一些 Ansible playbooks 和 Docker 文件,这是一种浪费。而对于那些拥有高级技能,知道如何保护一个系统和优化数据库执行的系统管理员,被浪费在写一些 CSS 和设计用户流这样的工作上。写代码、做测试、和维护应用程序的高效团队一般是跨学科、跨职能的、拥有不同专业技术和背景的人组成的混编团队。
+
+### 第二个担心:我的工作将被自动化
+
+或许是,或许不是,DevOps 可能在有时候是自动化的同义词。当自动化构建、测试、部署、监视、以及提醒等事项,已经占据了整个应用程序生命周期管理的时候,还会给我们剩下什么工作呢?这种对自动化的关注可能与第二个方法有关:_放大反馈循环_。DevOps 的第二个方法是在团队和部署的应用程序之间,采用相反的方向优先处理快速反馈 —— 从监视和维护部署、测试、开发、等等,通过强调,使反馈更加重要并且可操作。虽然这第二种方式与自动化并不是特别相关,许多自动化工具团队在它们的部署流水线中使用,以促进快速提醒和快速行动,或者基于对使用者的支持业务中产生的反馈来改进。传统的做法是靠人来完成的,这就可以理解为什么自动化可能会导致未来一些人失业的焦虑了。
+
+自动化只是一个工具,它并不能代替人。聪明的人使用它来做一些重复的工作,不去开发智力和创造性的财富,而是去按红色的 “George Jetson” 按钮是一种极大的浪费。让每天工作中的苦活自动化,意味着有更多的时间去解决真正的问题和即将到来的创新的解决方案。人类需要解决更多的 “怎么做和为什么” 问题,而计算机只能处理 “复制和粘贴”。
+
+并不会仅限于在可重复的、可预见的事情上进行自动化,自动化让团队有更多的时间和精力去专注于本领域中更高级别的任务上。监视团队不再花费他们的时间去配置报警或者管理传统的配置,它们可能专注于预测可能的报警、相关性统计、以及设计可能的预案。系统管理员从计划补丁或服务器配置中解放出来,可以花费更多的时间专注于整体管理、性能、和可伸缩性。与工厂车间和装配线上完全没有人的景像不同,DevOps 中的自动化任务,意味着人更多关注于创造性的、有更高价值的任务,而不是一些重复的、让人麻木的苦差事。
+
+### 第三个担心:我没有这些技能怎么办
+
+"我怎么去继续做这些事情?我不懂如何自动化。现在所有的工作都是代码 —— 我不是开发人员,我不会做 DevOps 中写代码的工作“,第三个担心是一种不自信的担心。由于文化的改变,是的,团队将也会要求随之改变,一些人可能担心,他们缺乏继续做他们工作的技能。
+
+然而,大多数人或许已经比他们所想的更接近。Dockerfile 是什么,或者像 Puppet 或 Ansible 配置管理是什么,但是环境即代码,系统管理员已经写了 shell 脚本和 Python 程序去处理他们重复的任务。学习更多的知识并使用已有的工具处理他们的更多问题 —— 编排、部署、维护即代码 —— 尤其是当从繁重的手动任务中解放出来,专注于成长时。
+
+在 DevOps 的使用者中去回答这第三个担心,第三个方法是:_一种不断实验和学习的文化_。尝试、失败、并从错误中吸取教训而不是责怪它们的能力,是设计出更有创意的解决方案的重要因素。第三个方法是为前两个方法授权—— 允许快速检测和修复问题,并且开发人员可以自由地尝试和学习,其它的团队也是如此。从未使用过配置管理或者写过自动供给基础设施程序的运营团队也要自由尝试并学习。测试和 QA 团队也要自由实现新测试流水线,并且自动批准和发布新流程。在一个拥抱学习和成长的文化中,每个人都可以自由地获取他们需要的技术,去享受工作带来的成功和喜悦。
+
+### 结束语
+
+在一个行业中,任何可能引起混乱的实践或变化都会产生担心和不确定,DevOps 也不例外。对自己工作的担心是对成百上千的文章和演讲的合理回应,其中列举了无数的实践和技术,而这些实践和技术正致力于授权开发者对行业的各个方面承担职责。
+
+然而,事实上,DevOps 是 "[一个跨学科的沟通实践,致力于研究构建、进化、和运营快速变化的弹性系统][3]"。 DevOps 意味着终结 ”筒仓“,但并不专业化。它是受委托去做苦差事的自动化系统,解放你,让你去做人类更擅长做的事:思考和想像。并且,如果你愿意去学习和成长,它将不会终结你解决新的、挑战性的问题的机会。
+
+DevOps 会让你失业吗?会的,但它同时给你提供了更好的工作。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/17/12/will-devops-steal-my-job
+
+作者:[Chris Collins][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/clcollins
+[1]:https://opensource.com/resources/devops
+[2]:http://itrevolution.com/the-three-ways-principles-underpinning-devops/
+[3]:https://theagileadmin.com/what-is-devops/
diff --git a/translated/tech/20180102 How To Find (Top-10) Largest Files In Linux.md b/translated/tech/20180102 How To Find (Top-10) Largest Files In Linux.md
new file mode 100644
index 0000000000..37765828bf
--- /dev/null
+++ b/translated/tech/20180102 How To Find (Top-10) Largest Files In Linux.md
@@ -0,0 +1,241 @@
+如何查找 Linux 中最大的 10 个文件
+======
+
+
+当系统的磁盘空间不足时,您可能更愿意使用 `df`、`du` 或 `ncdu` 命令进行检查,但这些命令只会显示当前目录的文件,并不会显示整个系统范围的文件。
+
+您得花费大量的时间才能用上述命令获取系统中最大的文件,因为要进入到每个目录重复运行上述命令。
+
+这个方法比较麻烦,也并不恰当。
+
+如果是这样,那么该如何在 Linux 中找到最大的 10 个文件呢?
+
+我在谷歌上搜索了很久,却没发现类似的文章,我反而看到了很多关于列出当前目录中最大的 10 个文件的文章。所以,我希望这篇文章对那些有类似需求的人有所帮助。
+
+本教程中,我们将教您如何使用以下四种方法在 Linux 系统中查找最大的前 10 个文件。
+
+### 方法 1:
+
+在 Linux 中没有特定的命令可以直接执行此操作,因此我们需要将多个命令结合使用。
+
+```
+# find / -type f -print0 | xargs -0 du -h | sort -rh | head -n 10
+
+1.4G /swapfile
+1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
+564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
+378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
+377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
+100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
+93M /usr/lib/firefox/libxul.so
+84M /var/lib/snapd/snaps/core_3604.snap
+84M /var/lib/snapd/snaps/core_3440.snap
+84M /var/lib/snapd/snaps/core_3247.snap
+
+```
+
+**详解:**
+
+**`find`**:在目录结构中搜索文件的命令
+
+**`/`**:在整个系统(从根目录开始)中查找
+
+**`-type`**:指定文件类型
+
+**`f`**:普通文件
+
+**`-print0`**:输出完整的文件名,其后跟一个空字符
+
+**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
+
+**`xargs`**:将标准输入转换成命令行参数的命令
+
+**`-0`**:以空字符(null)而不是空白字符(whitespace)(LCTT 译者注:即空格、制表符和换行)来分割记录
+
+**`du -h`**:以可读格式计算磁盘空间使用情况的命令
+
+**`sort`**:对文本文件进行排序的命令
+
+**`-r`**:反转结果
+
+**`-h`**:用可读格式打印输出
+
+**`head`**:输出文件开头部分的命令
+
+**`n -10`**:打印前 10 个文件
+
+### 方法 2:
+
+这是查找 Linux 系统中最大的前 10 个文件的另一种方法。我们依然使用多个命令共同完成这个任务。
+
+```
+# find / -type f -exec du -Sh {} + | sort -rh | head -n 10
+
+1.4G /swapfile
+1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
+564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
+378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
+377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
+100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
+93M /usr/lib/firefox/libxul.so
+84M /var/lib/snapd/snaps/core_3604.snap
+84M /var/lib/snapd/snaps/core_3440.snap
+84M /var/lib/snapd/snaps/core_3247.snap
+
+```
+
+**详解:**
+
+**`find`**:在目录结构中搜索文件的命令
+
+**`/`**:在整个系统(从根目录开始)中查找
+
+**`-type`**:指定文件类型
+
+**`f`**:普通文件
+
+**`-exec`**:在所选文件上运行指定命令
+
+**`du`**:计算文件占用的磁盘空间的命令
+
+**`-S`**:不包含子目录的大小
+
+**`-h`**:以可读格式打印
+
+**`{}`**:递归地查找目录,统计每个文件占用的磁盘空间
+
+**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
+
+**`sort`**:对文本文件进行按行排序的命令
+
+**`-r`**:反转结果
+
+**`-h`**:用可读格式打印输出
+
+**`head`**:输出文件开头部分的命令
+
+**`n -10`**:打印前 10 个文件
+
+### 方法 3:
+
+这里介绍另一种方法,在 Linux 系统中搜索最大的前 10 个文件。
+
+```
+# find / -type f -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
+
+84M /var/lib/snapd/snaps/core_3247.snap
+84M /var/lib/snapd/snaps/core_3440.snap
+84M /var/lib/snapd/snaps/core_3604.snap
+93M /usr/lib/firefox/libxul.so
+100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
+377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
+378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
+564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
+1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
+1.4G /swapfile
+
+```
+
+**详解:**
+
+**`find`**:在目录结构中搜索文件的命令
+
+**`/`**:在整个系统(从根目录开始)中查找
+
+**`-type`**:指定文件类型
+
+**`f`**:普通文件
+
+**`-print0`**:输出完整的文件名,其后跟一个空字符
+
+**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
+
+**`xargs`**:将标准输入转换成命令行参数的命令
+
+**`-0`**:以空字符(null)而不是空白字符(whitespace)来分割记录
+
+**`du`**:计算文件占用的磁盘空间的命令
+
+**`sort`**:对文本文件进行按行排序的命令
+
+**`-n`**:根据数字大小进行比较
+
+**`tail -10`**:输出文件结尾部分的命令(最后 10 个文件)
+
+**`cut`**:从每行删除特定部分的命令
+
+**`-f2`**:只选择特定字段值
+
+**`-I{}`**:将初始参数中出现的每个替换字符串都替换为从标准输入读取的名称
+
+**`-s`**:仅显示每个参数的总和
+
+**`-h`**:用可读格式打印输出
+
+**`{}`**:递归地查找目录,统计每个文件占用的磁盘空间
+
+### 方法 4:
+
+还有一种在 Linux 系统中查找最大的前 10 个文件的方法。
+
+```
+# find / -type f -ls | sort -k 7 -r -n | head -10 | column -t | awk '{print $7,$11}'
+
+1494845440 /swapfile
+1085984380 /home/magi/ubuntu-17.04-desktop-amd64.iso
+591003648 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
+395770383 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
+394891761 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
+103999072 /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
+97356256 /usr/lib/firefox/libxul.so
+87896064 /var/lib/snapd/snaps/core_3604.snap
+87793664 /var/lib/snapd/snaps/core_3440.snap
+87089152 /var/lib/snapd/snaps/core_3247.snap
+
+```
+
+**详解:**
+
+**`find`**:在目录结构中搜索文件的命令
+
+**`/`**:在整个系统(从根目录开始)中查找
+
+**`-type`**:指定文件类型
+
+**`f`**:普通文件
+
+**`-ls`**:在标准输出中以 `ls -dils` 的格式列出当前文件
+
+**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
+
+**`sort`**:对文本文件进行按行排序的命令
+
+**`-k`**:按指定列进行排序
+
+**`-r`**:反转结果
+
+**`-n`**:根据数字大小进行比较
+
+**`head`**:输出文件开头部分的命令
+
+**`-10`**:打印前 10 个文件
+
+**`column`**:将其输入格式化为多列的命令
+
+**`-t`**:确定输入包含的列数并创建一个表
+
+**`awk`**:样式扫描和处理语言
+
+**`'{print $7,$11}'`**:只打印指定的列
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/
+
+作者:[Magesh Maruthamuthu][a]
+译者:[jessie-pang](https://github.com/jessie-pang)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.2daygeek.com/author/magesh/
\ No newline at end of file
diff --git a/translated/tech/20180125 Keep Accurate Time on Linux with NTP.md b/translated/tech/20180125 Keep Accurate Time on Linux with NTP.md
new file mode 100644
index 0000000000..d2eddc0d63
--- /dev/null
+++ b/translated/tech/20180125 Keep Accurate Time on Linux with NTP.md
@@ -0,0 +1,146 @@
+在 Linux 上使用 NTP 保持精确的时间
+======
+
+
+
+如何保持正确的时间,如何使用 NTP 和 systemd 让你的计算机在不滥用时间服务器的前提下保持同步。
+
+### 它的时间是多少?
+
+当让 Linux 来告诉你时间的时候,它是很奇怪的。你可能认为是使用 `time` 命令来告诉你时间,其实并不是,因为 `time` 只是一个测量一个进程运行了多少时间的计时器。为得到时间,你需要运行的是 `date` 命令,你想查看更多的日期,你可以运行 `cal` 命令。文件上的时间戳也是一个容易混淆的地方,因为根据你的发行版默认情况不同,它一般有两种不同的显示方法。下面是来自 Ubuntu 16.04 LTS 的示例:
+```
+$ ls -l
+drwxrwxr-x 5 carla carla 4096 Mar 27 2017 stuff
+drwxrwxr-x 2 carla carla 4096 Dec 8 11:32 things
+-rw-rw-r-- 1 carla carla 626052 Nov 21 12:07 fatpdf.pdf
+-rw-rw-r-- 1 carla carla 2781 Apr 18 2017 oddlots.txt
+
+```
+
+有些显示年,有些显示时间,这样的方式让你的文件更混乱。GNU 默认的情况是,如果你的文件在六个月以内,则显示时间而不是年。我想这样做可能是有原因的。如果你的 Linux 是这样的,尝试用 `ls -l --time-style=long-iso` 命令,让时间戳用同一种方式去显示,按字母顺序排序。查阅 [如何更改 Linux 的日期和时间:简单的命令][1] 去学习 Linux 上管理时间的各种方法。
+
+### 检查当前设置
+
+NTP —— 网络时间协议,它是老式的保持计算机正确时间的方法。`ntpd` 是 NTP 守护程序,它通过周期性地查询公共时间服务器来按需调整你的计算机时间。它是一个简单的、轻量级的协议,使用它的基本功能时设置非常容易。Systemd 通过使用 `systemd-timesyncd.service` 已经越俎代庖 “干了 NTP 的活”,它可以用作 `ntpd` 的客户端。
+
+在我们开始与 NTP “打交道” 之前,先花一些时间来了检查一下当前的时间设置是否正确。
+
+你的系统上(至少)有两个时钟:系统时间 —— 它由 Linux 内核管理,第二个是你的主板上的硬件时钟,它也称为实时时钟(RTC)。当你进入系统的 BIOS 时,你可以看到你的硬件时钟的时间,你也可以去改变它的设置。当你安装一个新的 Linux 时,在一些图形化的时间管理器中,你会被询问是否设置你的 RTC 为 UTC(协调世界时间)时区,因为所有的时区和夏令时都是基于 UTC 的。你可以使用 `hwclock` 命令去检查:
+```
+$ sudo hwclock --debug
+hwclock from util-linux 2.27.1
+Using the /dev interface to the clock.
+Hardware clock is on UTC time
+Assuming hardware clock is kept in UTC time.
+Waiting for clock tick...
+...got clock tick
+Time read from Hardware Clock: 2018/01/22 22:14:31
+Hw clock time : 2018/01/22 22:14:31 = 1516659271 seconds since 1969
+Time since last adjustment is 1516659271 seconds
+Calculated Hardware Clock drift is 0.000000 seconds
+Mon 22 Jan 2018 02:14:30 PM PST .202760 seconds
+
+```
+
+"硬件时钟用 UTC 时间维护" 确认了你的计算机的 RTC 是使用 UTC 时间,虽然你的本地时间是通过 UTC 转换来的。如果设置本地时间,它将报告 “硬件时钟用本地时间维护”。
+
+如果你不同步你的 RTC 到系统时间,你应该有一个 `/etc/adjtime` 文件。
+```
+$ sudo hwclock -w
+
+```
+
+这个命令将生成这个文件,它将包含如下示例中的内容:
+```
+$ cat /etc/adjtime
+0.000000 1516661953 0.000000
+1516661953
+UTC
+
+```
+
+新发明的 systemd 方式是去运行 `timedatectl` 命令,运行它不需要 root 权限:
+```
+$ timedatectl
+ Local time: Mon 2018-01-22 14:17:51 PST
+ Universal time: Mon 2018-01-22 22:17:51 UTC
+ RTC time: Mon 2018-01-22 22:17:51
+ Time zone: America/Los_Angeles (PST, -0800)
+ Network time on: yes
+NTP synchronized: yes
+ RTC in local TZ: no
+
+```
+
+"RTC in local TZ: no" 确认了它没有使用 UTC 时间。如果要改变它的本地时间,怎么办?这里有许多种方法可以做到。最简单的方法是使用一个图形配置工具,比如像 openSUSE 中的 YaST。你可使用 `timedatectl`:
+```
+$ timedatectl set-local-rtc 0
+```
+
+或者编辑 `/etc/adjtime`,将 UTC 替换为 LOCAL。
+
+### systemd-timesyncd 客户端
+
+现在,我已经累了,但是我们刚到非常精彩的部分。谁能想到计时如此复杂?我们甚至还没有了解到它的皮毛;阅读 `man 8 hwclock` 去了解你的计算机如何保持时间的详细内容。
+
+Systemd 提供了 `systemd-timesyncd.service` 客户端,它查询远程时间服务器并调整你的本地系统时间。在 `/etc/systemd/timesyncd.conf` 中配置你的服务器。大多数 Linux 发行版都提供一个默认配置,它指向他们维护的时间服务器上,比如,以下是 Fedora 的:
+```
+[Time]
+#NTP=
+#FallbackNTP=0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
+
+```
+
+你可以输入你希望的其它时间服务器,比如你自己的本地 NTP 服务器,在 `NTP=` 行上输入一个以空格分隔的服务器列表。(别忘了取消这一行的注释)`NTP=` 行上的任何内容都将覆盖掉 fallback 行上的配置项。
+
+如果你不想使用 systemd 呢?那么,你将需要一个 NTP。
+
+### 配置 NTP 服务器和客户端
+
+配置你自己的局域网 NTP 服务器是一个非常好的实践,这样你的网内计算机就不需要不停查询公共 NTP 服务器。在大多数 Linux 的 `ntp` 包中都带了 NTP,它们大多都提供 `/etc/ntp.conf` 文件去配置服务器。查阅 [NTP 时间服务器池][2] 去找到你所在的区域的合适的 NTP 服务器池。然后在你的 `/etc/ntp.conf` 中输入 4- 5 个服务器,每个服务器用单独的一行:
+```
+driftfile /var/ntp.drift
+logfile /var/log/ntp.log
+server 0.europe.pool.ntp.org
+server 1.europe.pool.ntp.org
+server 2.europe.pool.ntp.org
+server 3.europe.pool.ntp.org
+
+```
+
+`driftfile` 告诉 `ntpd` 在这里保存的信息是用于在启动时,使用时间服务器去快速同步你的系统时钟的。而日志将保存在他们自己指定的目录中,而不是转储到 syslog 中。如果你的 Linux 发行版默认提供了这些文件,请使用它们。
+
+现在去启动守护程序;在大多数主流的 Linux 中它的命令是 `sudo systemctl start ntpd`。让它运行几分钟之后,我们再次去检查它的状态:
+```
+$ ntpq -p
+ remote refid st t when poll reach delay offset jitter
+==============================================================
++dev.smatwebdesi 192.168.194.89 3 u 25 64 37 92.456 -6.395 18.530
+*chl.la 127.67.113.92 2 u 23 64 37 75.175 8.820 8.230
++four0.fairy.mat 35.73.197.144 2 u 22 64 37 116.272 -10.033 40.151
+-195.21.152.161 195.66.241.2 2 u 27 64 37 107.559 1.822 27.346
+
+```
+
+我不知道这些内容是什么意思,但重要的是,你的守护程序已经与时间服务器开始对话了,而这正是我们所需要的。你可以去运行 `sudo systemctl enable ntpd` 命令,永久启用它。如果你的 Linux 没有使用 systemd,那么,给你留下的家庭作业就是找出如何去运行 `ntpd`。
+
+现在,你可以在你的局域网中的其它计算机上设置 `systemd-timesyncd`,这样它们就可以使用你的本地 NTP 服务器了,或者,在它们上面安装 NTP,然后在它们的 `/etc/ntp.conf` 上输入你的本地 NTP 服务器。
+
+NTP 服务器持续地接受客户端查询,并且这种需求在不断增加。你可以通过运行你自己的公共 NTP 服务器来提供帮助。下周我们将学习如何运行你自己的公共服务器。
+
+通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门" ][3] 来学习更多 Linux 的知识。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
+
+作者:[CARLA SCHRODER][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/cschroder
+[1]:https://www.linux.com/learn/how-change-linux-date-and-time-simple-commands
+[2]:http://support.ntp.org/bin/view/Servers/NTPPoolServers
+[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/translated/tech/20180127 Your instant Kubernetes cluster.md b/translated/tech/20180127 Your instant Kubernetes cluster.md
new file mode 100644
index 0000000000..ac06ba730f
--- /dev/null
+++ b/translated/tech/20180127 Your instant Kubernetes cluster.md
@@ -0,0 +1,170 @@
+“开箱即用” 的 Kubernetes 集群
+============================================================
+
+
+这是我以前的 [10 分钟内配置 Kubernetes][10] 教程的精简版和更新版。我删除了一些我认为可以去掉的内容,所以,这个指南仍然是可理解的。当你想在云上创建一个集群或者尽可能快地构建基础设施时,你可能会用到它。
+
+### 1.0 挑选一个主机
+
+我们在本指南中将使用 Ubuntu 16.04,这样你就可以直接拷贝/粘贴所有的指令。下面是我用本指南测试过的几种环境。根据你运行的主机,你可以从中挑选一个。
+
+* [DigitalOcean][1] - 开发者云
+
+* [Civo][2] - UK 开发者云
+
+* [Packet][3] - 裸机云
+
+* 2x Dell Intel i7 服务器 —— 它在我家中
+
+> Civo 是一个相对较新的开发者云,我比较喜欢的一点是,它开机时间只有 25 秒,我就在英国,因此,它的延迟很低。
+
+### 1.1 准备机器
+
+你可以使用一个单台主机进行测试,但是,我建议你至少使用三台机器,这样你就有一个主节点和两个工作节点。
+
+下面是一些其他的指导原则:
+
+* 最好选至少有 2 GB 内存的双核主机
+
+* 在准备主机的时候,如果你可以自定义用户名,那么就不要使用 root。例如,Civo 通常让你在 `ubuntu`、`civo` 或者 `root` 中选一个。
+
+现在,在每台机器上都运行以下的步骤。它将需要 5-10 钟时间。如果你觉得太慢了,你可以使用我的脚本 [kept in a Gist][11]:
+
+```
+$ curl -sL https://gist.githubusercontent.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c/raw/23fc4cd13910eac646b13c4f8812bab3eeebab4c/configure.sh | sh
+
+```
+
+### 1.2 登入和安装 Docker
+
+从 Ubuntu 的 apt 仓库中安装 Docker。它的版本可能有点老,但是,Kubernetes 在老版本的 Docker 中是测试过的,工作的很好。
+
+```
+$ sudo apt-get update \
+ && sudo apt-get install -qy docker.io
+
+```
+
+### 1.3 禁用 swap 文件
+
+这是 Kubernetes 的强制步骤。实现它很简单,编辑 `/etc/fstab` 文件,然后注释掉引用 swap 的行即可。
+
+保存它,重启后输入 `sudo swapoff -a`。
+
+> 一开始就禁用 swap 内存,你可能觉得这个要求很奇怪,如果你对这个做法感到好奇,你可以去 [这里阅读它的相关内容][4]。
+
+### 1.4 安装 Kubernetes 包
+
+```
+$ sudo apt-get update \
+ && sudo apt-get install -y apt-transport-https \
+ && curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
+
+$ echo "deb http://apt.kubernetes.io/ kubernetes-xenial main" \
+ | sudo tee -a /etc/apt/sources.list.d/kubernetes.list \
+ && sudo apt-get update
+
+$ sudo apt-get update \
+ && sudo apt-get install -y \
+ kubelet \
+ kubeadm \
+ kubernetes-cni
+
+```
+
+### 1.5 创建集群
+
+这时候,我们使用 `kubeadm` 初始化主节点并创建集群。这一步仅在主节点上操作。
+
+> 虽然有警告,但是 [Weaveworks][5] 和 Lucas(他们是维护者)向我保证,`kubeadm` 是可用于生产系统的。
+
+```
+$ sudo kubeadm init
+
+```
+
+如果你错过一个步骤或者有问题,`kubeadm` 将会及时告诉你。
+
+我们复制一份 Kube 配置:
+
+```
+mkdir -p $HOME/.kube
+sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
+sudo chown $(id -u):$(id -g) $HOME/.kube/config
+
+```
+
+确保你一定要记下如下的加入 token 命令。
+
+```
+$ sudo kubeadm join --token c30633.d178035db2b4bb9a 10.0.0.5:6443 --discovery-token-ca-cert-hash sha256:
+
+```
+
+### 2.0 安装网络
+
+Kubernetes 可用于任何网络供应商的产品或服务,但是,默认情况下什么也没有,因此,我们使用来自 [Weaveworks][12] 的 Weave Net,它是 Kebernetes 社区中非常流行的选择之一。它倾向于不需要额外配置的 “开箱即用”。
+
+```
+$ kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
+
+```
+
+如果在你的主机上启用了私有网络,那么,你可能需要去修改 Weavenet 使用的私有子网络,以便于为 Pods(容器)分配 IP 地址。下面是命令示例:
+
+```
+$ curl -SL "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')&env.IPALLOC_RANGE=172.16.6.64/27" \
+| kubectl apply -f -
+
+```
+
+> Weave 也有很酷的称为 Weave Cloud 的可视化工具。它是免费的,你可以在它上面看到你的 Pods 之间的路径流量。[这里有一个使用 OpenFaaS 项目的示例][6]。
+
+### 2.2 在集群中加入工作节点
+
+现在,你可以切换到你的每一台工作节点,然后使用 1.5 节中的 `kubeadm join` 命令。运行完成后,登出那个工作节点。
+
+### 3.0 收益
+
+到此为止 —— 我们全部配置完成了。你现在有一个正在运行着的集群,你可以在它上面部署应用程序。如果你需要设置仪表板 UI,你可以去参考 [Kubernetes 文档][13]。
+
+```
+$ kubectl get nodes
+NAME STATUS ROLES AGE VERSION
+openfaas1 Ready master 20m v1.9.2
+openfaas2 Ready 19m v1.9.2
+openfaas3 Ready 19m v1.9.2
+
+```
+
+如果你想看到我一步一步创建集群并且展示 `kubectl` 如何工作的视频,你可以看下面我的视频,你可以订阅它。
+
+
+想在你的 Mac 电脑上,使用 Minikube 或者 Docker 的 Mac Edge 版本,安装一个 “开箱即用” 的 Kubernetes 集群,[阅读在这里的我的评估和第一印象][14]。
+
+--------------------------------------------------------------------------------
+
+via: https://blog.alexellis.io/your-instant-kubernetes-cluster/
+
+作者:[Alex Ellis ][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://blog.alexellis.io/author/alex/
+[1]:https://www.digitalocean.com/
+[2]:https://www.civo.com/
+[3]:https://packet.net/
+[4]:https://github.com/kubernetes/kubernetes/issues/53533
+[5]:https://weave.works/
+[6]:https://www.weave.works/blog/openfaas-gke
+[7]:https://blog.alexellis.io/tag/kubernetes/
+[8]:https://blog.alexellis.io/tag/k8s/
+[9]:https://blog.alexellis.io/tag/cloud-native/
+[10]:https://www.youtube.com/watch?v=6xJwQgDnMFE
+[11]:https://gist.github.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c
+[12]:https://weave.works/
+[13]:https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/
+[14]:https://blog.alexellis.io/docker-for-mac-with-kubernetes/
+[15]:https://blog.alexellis.io/your-instant-kubernetes-cluster/#
diff --git a/translated/tech/20180130 Install AWFFull web server log analysis application on ubuntu 17.10.md b/translated/tech/20180130 Install AWFFull web server log analysis application on ubuntu 17.10.md
new file mode 100644
index 0000000000..50f2f00451
--- /dev/null
+++ b/translated/tech/20180130 Install AWFFull web server log analysis application on ubuntu 17.10.md
@@ -0,0 +1,89 @@
+在 Ubuntu 17.10 上安装 AWFFull Web 服务器日志分析应用程序
+======
+
+
+AWFFull 是基于 “Webalizer” 的 Web 服务器日志分析程序。AWFFull 以 HTML 格式生成使用统计信息以便用浏览器查看。结果以柱状和图形两种格式显示,这有利于解释。它提供每年、每月、每日和每小时使用统计数据,并显示网站、URL、referrer、user agent(浏览器)、用户名、搜索字符串、进入/退出页面和国家(如果一些信息不存在于处理后日志中那么就没有)。AWFFull 支持 CLF(通用日志格式)日志文件,以及由 NCSA 和其他人定义的组合日志格式,它还能只能地处理这些格式的变体。另外,AWFFull 还支持 wu-ftpd xferlog 格式的日志文件,它能够分析 ftp 服务器和 squid 代理日志。日志也可以通过 gzip 压缩。
+
+如果检测到压缩日志文件,它将在读取时自动解压缩。压缩日志必须是 .gz 扩展名的标准 gzip 压缩。
+
+### 对于 Webalizer 的修改
+
+AWFFull 基于 Webalizer 的代码,并有许多大的和小的变化。包括:
+
+o 不止原始统计数据:利用已发布的公式,提供额外的网站使用情况。
+
+o GeoIP IP 地址能更准确地检测国家。
+
+o 可缩放的图形
+
+o 与 GNU gettext 集成,能够轻松翻译。目前支持 32 种语言。
+
+o 在首页显示超过 12 个月的网站历史记录。
+
+o 额外的页面计数跟踪和排序。
+
+o 一些小的可视化调整,包括 Geolizer 使用在卷中使用 Kb、Mb。
+
+o 额外的用于 URL 计数、进入和退出页面、站点的饼图
+
+o 图形上的水平线更有意义,更易于阅读。
+
+o User Agent 和 Referral 跟踪现在通过 PAGES 而非 HITS 进行计算。
+
+o 现在支持 GNU 风格的长命令行选项(例如 --help)。
+
+o 可以通过排除“什么不是”以及原始的“什么是”来选择页面。
+
+o 对被分析站点的请求以匹配的引用 URL 显示。
+
+o 404 错误表,并且可以生成引用 URL。
+
+o 外部 CSS 文件可以与生成的 html 一起使用。
+
+o POST 分析总结使得手动优化配置文件性能更简单。
+
+o 指定的 IP 和地址可以分配给指定的国家。
+
+o 便于使用其他工具详细分析的转储选项。
+
+o 支持检测并处理 Lotus Domino v6 日志。
+
+**在 Ubuntu 17.10 上安装 awffull**
+
+> sudo apt-get install awffull
+
+### 配置 AWFFULL
+
+你必须在 /etc/awffull/awffull.conf 中编辑 awffull 配置文件。如果你在同一台计算机上运行多个虚拟站点,则可以制作多个默认配置文件的副本。
+
+> sudo vi /etc/awffull/awffull.conf
+
+确保有下面这几行
+
+> LogFile /var/log/apache2/access.log.1
+> OutputDir /var/www/html/awffull
+
+保存并退出文件
+
+你可以使用以下命令运行 awffull
+
+> awffull -c [your config file name]
+
+这将在 /var/www/html/awffull 目录下创建所有必需的文件,以便你可以使用 http://serverip/awffull/
+
+你应该看到类似于下面的页面
+
+如果你有更多站点,你可以使用 shell 和计划任务自动化这个过程。
+
+
+--------------------------------------------------------------------------------
+
+via: http://www.ubuntugeek.com/install-awffull-web-server-log-analysis-application-on-ubuntu-17-10.html
+
+作者:[ruchi][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.ubuntugeek.com/author/ubuntufix
diff --git a/translated/tech/20180201 How to Run Your Own Public Time Server on Linux.md b/translated/tech/20180201 How to Run Your Own Public Time Server on Linux.md
new file mode 100644
index 0000000000..70eae1596d
--- /dev/null
+++ b/translated/tech/20180201 How to Run Your Own Public Time Server on Linux.md
@@ -0,0 +1,101 @@
+如何在 Linux 上运行你自己的公共时间服务器
+======
+
+
+
+公共服务最重要的一点就是守时,但是很多人并没有意识到这一点。大多数公共时间服务器都是由志愿者管理,以满足不断增长的需求。学习如何运行你自己的时间服务器,为基本的公共利益做贡献。(查看 [在 Linux 上使用 NTP 保持精确时间][1] 去学习如何设置一台局域网时间服务器)
+
+### 著名的时间服务器滥用事件
+
+就像现实生活中任何一件事情一样,即便是像时间服务器这样的公益项目,也会遭受不称职的或者恶意的滥用。
+
+消费类网络设备的供应商因制造了大混乱而臭名昭著。我回想起的第一件事发生在 2003 年,那时,Netgear 在它们的路由器中硬编码了 University of Wisconsin-Madison 的 NTP 时间服务器地址。使得时间服务器的查询请求突然增加,随着 NetGear 卖出越来越多的路由器,这种情况越发严重。更有意思的是,路由器的程序设置是每秒钟发送一次请求,这将使服务器难堪重负。后来 Netgear 发布了升级固件,但是,升级他们的设备的用户很少,并且他们的其中一些用户的设备,到今天为止,还在不停地每秒钟查询一次 University of Wisconsin-Madison 的 NTP 服务器。Netgear 给 University of Wisconsin-Madison 捐献了一些钱,以帮助弥补他们带来的成本增加,直到这些路由器全部淘汰。类似的事件还有 D-Link、Snapchat、TP-Link 等等。
+
+对 NTP 协议进行反射和放大,已经成为发起 DDoS 攻击的一个选择。当攻击者使用一个伪造的源地址向目标受害者发送请求,称为反射;攻击者发送请求到多个服务器,这些服务器将回复请求,这样就使伪造的地址受到轰炸。放大是指一个很小的请求收到大量的回复信息。例如,在 Linux 上,`ntpq` 命令是一个查询你的 NTP 服务器并验证它们的系统时间是否正确的很有用的工具。一些回复,比如,对端列表,是非常大的。组合使用反射和放大,攻击者可以将 10 倍甚至更多带宽的数据量发送到被攻击者。
+
+那么,如何保护提供公益服务的公共 NTP 服务器呢?从使用 NTP 4.2.7p26 或者更新的版本开始,它们可以帮助你的 Linux 发行版不会发生前面所说的这种问题,因为它们都是在 2010 年以后发布的。这个发行版都默认禁用了最常见的滥用攻击。目前,[最新版本是 4.2.8p10][2],它发布于 2017 年。
+
+你可以采用的另一个措施是,在你的网络上启用入站和出站过滤器。阻塞进入你的网络的数据包,以及拦截发送到伪造地址的出站数据包。入站过滤器帮助你,而出站过滤器则帮助你和其他人。阅读 [BCP38.info][3] 了解更多信息。
+
+### 层级为 0、1、2 的时间服务器
+
+NTP 有超过 30 年的历史了,它是至今还在使用的最老的因特网协议之一。它的用途是保持计算机与协调世界时间(UTC)的同步。NTP 网络是分层组织的,并且同层的设备是对等的。层次 0 包含主守时设备,比如,原子钟。层级 1 的时间服务器与层级 0 的设备同步。层级 2 的设备与层级 1 的设备同步,层级 3 的设备与层级 2 的设备同步。NTP 协议支持 16 个层级,现实中并没有使用那么多的层级。同一个层级的服务器是相互对等的。
+
+过去很长一段时间内,我们都为客户端选择配置单一的 NTP 服务器,而现在更好的做法是使用 [NTP 服务器地址池][4],它使用往返的 DNS 信息去共享负载。池地址只是为客户端服务的,比如单一的 PC 和你的本地局域网 NTP 服务器。当你运行一台自己的公共服务器时,你不能使用这些池中的地址。
+
+### 公共 NTP 服务器配置
+
+运行一台公共 NTP 服务器只有两步:设置你的服务器,然后加入到 NTP 服务器池。运行一台公共的 NTP 服务器是一种很高尚的行为,但是你得先知道如何加入到 NTP 服务器池中。加入 NTP 服务器池是一种长期责任,因为即使你加入服务器池后,运行了很短的时间马上退出,然后接下来的很多年你仍然会接收到请求。
+
+你需要一个静态的公共 IP 地址,一个至少 512Kb/s 带宽的、可靠的、持久的因特网连接。NTP 使用的是 UDP 的 123 端口。它对机器本身要求并不高,很多管理员在其它的面向公共的服务器(比如,Web 服务器)上顺带架设了 NTP 服务。
+
+配置一台公共的 NTP 服务器与配置一台用于局域网的 NTP 服务器是一样的,只需要几个配置。我们从阅读 [协议规则][5] 开始。遵守规则并注意你的行为;几乎每个时间服务器的维护者都是像你这样的志愿者。然后,从 [StratumTwoTimeServers][6] 中选择 2 台层级为 4-7 的上游服务器。选择的时候,选取地理位置上靠近(小于 300 英里的)你的因特网服务提供商的上游服务器,阅读他们的访问规则,然后,使用 `ping` 和 `mtr` 去找到延迟和跳数最小的服务器。
+
+以下的 `/etc/ntp.conf` 配置示例文件,包括了 IPv4 和 IPv6,以及基本的安全防护:
+```
+# stratum 2 server list
+server servername_1 iburst
+server servername_2 iburst
+server servername_3 iburst
+server servername_4 iburst
+server servername_5 iburst
+
+# access restrictions
+restrict -4 default kod noquery nomodify notrap nopeer limited
+restrict -6 default kod noquery nomodify notrap nopeer limited
+
+# Allow ntpq and ntpdc queries only from localhost
+restrict 127.0.0.1
+restrict ::1
+
+```
+
+启动你的 NTP 服务器,让它运行几分钟,然后测试它对远程服务器的查询:
+```
+$ ntpq -p
+ remote refid st t when poll reach delay offset jitter
+=================================================================
++tock.no-such-ag 200.98.196.212 2 u 36 64 7 98.654 88.439 65.123
++PBX.cytranet.ne 45.33.84.208 3 u 37 64 7 72.419 113.535 129.313
+*eterna.binary.n 199.102.46.70 2 u 39 64 7 92.933 98.475 56.778
++time.mclarkdev. 132.236.56.250 3 u 37 64 5 111.059 88.029 74.919
+
+```
+
+目前表现很好。现在从另一台 PC 上使用你的 NTP 服务器名字进行测试。以下的示例是一个正确的输出。如果有不正确的地方,你将看到一些错误信息。
+```
+$ ntpdate -q _yourservername_
+server 66.96.99.10, stratum 2, offset 0.017690, delay 0.12794
+server 98.191.213.2, stratum 1, offset 0.014798, delay 0.22887
+server 173.49.198.27, stratum 2, offset 0.020665, delay 0.15012
+server 129.6.15.28, stratum 1, offset -0.018846, delay 0.20966
+26 Jan 11:13:54 ntpdate[17293]: adjust time server 98.191.213.2 offset 0.014798 sec
+
+```
+
+一旦你的服务器运行的很好,你就可以向 [manage.ntppool.org][7] 申请加入池中。
+
+查看官方的手册 [分布式网络时间服务器(NTP)][8] 学习所有的命令、配置选项、以及高级特性,比如,管理、查询、和验证。访问以下的站点学习关于运行一台时间服务器所需要的一切东西。
+
+通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门" ][9] 学习更多 Linux 的知识。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/2/how-run-your-own-public-time-server-linux
+
+作者:[CARLA SCHRODER][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/cschroder
+[1]:https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
+[2]:http://www.ntp.org/downloads.html
+[3]:http://www.bcp38.info/index.php/Main_Page
+[4]:http://www.pool.ntp.org/en/use.html
+[5]:http://support.ntp.org/bin/view/Servers/RulesOfEngagement
+[6]:http://support.ntp.org/bin/view/Servers/StratumTwoTimeServers?redirectedfrom=Servers.StratumTwo
+[7]:https://manage.ntppool.org/manage
+[8]:https://www.eecis.udel.edu/~mills/ntp/html/index.html
+[9]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/translated/tech/20180204 LKRG- Linux to Get a Loadable Kernel Module for Runtime Integrity Checking.md b/translated/tech/20180204 LKRG- Linux to Get a Loadable Kernel Module for Runtime Integrity Checking.md
deleted file mode 100644
index e56b3c06d3..0000000000
--- a/translated/tech/20180204 LKRG- Linux to Get a Loadable Kernel Module for Runtime Integrity Checking.md
+++ /dev/null
@@ -1,65 +0,0 @@
-LKRG:Linux 的适用于运行时完整性检查的可加载内核模块
-======
-![LKRG logo][1]
-
-开源社区的成员正在致力于一个 Linux 内核的新项目,它可以让内核更安全。命名为 Linux 内核运行时防护(Linux Kernel Runtime Guard,简称:LKRG),它是一个在 Linux 内核执行运行时完整性检查时的可加载内核模块。
-
-它的用途是检测对 Linux 内核的已知的或未知的安全漏洞利用企图,以及去阻止这种攻击企图。
-
-LKRG 也可以检测正在运行的进程的提权行为,在漏洞利用代码运行之前杀掉这个运行进程。
-
-### 这个项目从 2011 年开始开发以来,首个版本已经发布。
-
-因为这个项目开发的较早,LKRG 的当前版本仅仅是通过内核消息去报告违反内核完整性的行为,但是随着这个项目的成熟,一个完整的漏洞利用缓减系统将会部署。
-
-LKRG 的成员 Alexander Peslyak 解释说,这个项目从 2011 年启动,并且 LKRG 已经经历了“预开发"阶段。
-
-LKRG 的首个公开版本是 — LKRG v0.0 — 它现在可以从 [这个页面][2] 下载使用。[这里][3] 是这个项目的维基,为支持这个项目,它也有一个 [Patreon 页面][4]。
-
-虽然 LKRG 还是一个开源项目,LKRG 的维护者也计划做一个 LKRG Pro 版本,这个版本将包含一个专用的 LKRG 发行版,它将支持对特定漏洞利用的检测,比如,容器泄漏。开发团队计划从 LKRG Pro 基金中提取部分资金用于保证项目的剩余工作。
-
-### LKRG 是一个内核模块而不是一个补丁。
-
-一个类似的项目是去增加一个内核监视功能(AKO),但是 LKRG 与 AKO 是不一样的,因为 LKRG 是一个内核加载模式而不是一个补丁。LKRG 开发团队决定将它设计为一个内核模块是因为,在内核上打补丁对安全性、系统稳定性以及性能都有很直接的影响。
-
-而作为内核模块的方式,可以在每个系统上更容易部署去 LKRG,而不必去修改核心的内核代码,修改核心的内核代码非常复杂并且很容易出错。
-
-LKRG 内核模块在目前主流的 Linux 发行版上都可以使用,比如,RHEL7、OpenVZ 7、Virtuozzo 7、以及 Ubuntu 16.04 到最新的主线版本。
-
-### 它并非是一个完美的解决方案
-
-LKRG 的创建者警告用户,他们并不认为 LKRG 是一个完美的解决方案,它**提供不了**坚不可摧和 100% 的安全。他们说,LKRG 是 "设计为**可旁通**的",并且仅仅提供了"多元化安全" 的**一个**方面。
-
-```
-虽然 LKRG 可以防御许多对 Linux 内核的已存在的漏洞利用,而且也有可能会防御将来许多的(包括未知的)未特意设计去绕过 LKRG 的安全漏洞利用。它是设计为可旁通的(尽管有时候是以更复杂和/或低可利用为代价的)。因此,他们说 LKRG 通过多元化提供安全,就像运行一个不常见的操作系统内核一样,也就不会有真实运行一个不常见的操作系统的可用性弊端。
-```
-
-LKRG 有点像基于 Windows 的防病毒软件,它也是工作于内核级别去检测漏洞利用和恶意软件。但是,LKRG 团队说,他们的产品比防病毒软件以及其它终端安全软件更加安全,因为它的基础代码量比较小,所以在内核级别引入新 bug 和漏洞的可能性就更小。
-
-### 运行当前版本的 LKRG 大约会带来 6.5% 的性能损失
-
-Peslyak 说 LKRG 是非常适用于 Linux 机器的,它在修补内核的安全漏洞后不需要重启动机器。LKRG 允许用户去持续运行带有安全措施的机器,直到在一个计划的维护窗口中测试和部署关键的安全补丁为止。
-
-经测试显示,安装 LKRG v0.0 后大约会产生 6.5% 性能影响,但是,Peslyak 说将在后续的开发中持续降低这种影响。
-
-测试也显示,LKRG 检测到了 CVE-2014-9322 (BadIRET)、CVE-2017-5123 (waitid(2) missing access_ok)、以及 CVE-2017-6074 (use-after-free in DCCP protocol) 的漏洞利用企图,但是没有检测到 CVE-2016-5195 (Dirty COW) 的漏洞利用企图。开发团队说,由于前面提到的”可旁通“的设计策略,LKRG 没有检测到 Dirty COW 提权攻击。
-
-```
-在 Dirty COW 的测试案例中,由于 bug 机制的原因,使得 LKRG 发生了 "旁通",并且这也是一种利用方法,它也是将来类似的以用户空间为目标的绕过 LKRG 的一种方法。这样的漏洞利用是否会是普通情况(不太可能!除非 LKRG 或者类似机制的软件流行起来),以及对它的可用性的(负面的)影响是什么?(对于那些直接目标是用户空间的内核漏洞来说,这不太重要,也并不简单)。
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.bleepingcomputer.com/news/linux/lkrg-linux-to-get-a-loadable-kernel-module-for-runtime-integrity-checking/
-
-作者:[Catalin Cimpanu][a]
-译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.bleepingcomputer.com/author/catalin-cimpanu/
-[1]:https://www.bleepstatic.com/content/posts/2018/02/04/LKRG-logo.png
-[2]:http://www.openwall.com/lkrg/
-[3]:http://openwall.info/wiki/p_lkrg/Main
-[4]:https://www.patreon.com/p_lkrg
diff --git a/translated/tech/20180220 How to format academic papers on Linux with groff -me.md b/translated/tech/20180220 How to format academic papers on Linux with groff -me.md
new file mode 100644
index 0000000000..55b2e48517
--- /dev/null
+++ b/translated/tech/20180220 How to format academic papers on Linux with groff -me.md
@@ -0,0 +1,277 @@
+# 在 Linux 上使用 groff -me 格式化你的学术论文
+
+
+
+当我在 1993 年发现 Linux 时,我还是一名本科生。我很兴奋在我的宿舍里拥有 Unix 系统的强大功能,但是尽管它有很多功能,Linux 却缺乏应用程序。像 LibreOffice 和 OpenOffice 这样的文字处理程序还需要几年的时间。如果你想使用文字处理器,你可能会将你的系统引导到 MS-DOS 中,并使用 WordPerfect、shareware GalaxyWrite 或类似的程序。
+
+`nroff` 和 `troff ` 。它们是同一系统的不同接口:`nroff` 生成纯文本输出,适用于屏幕或行式打印机,而 `troff` 产生非常优美的输出,通常用于在激光打印机上打印。
+
+这就是我的方法,因为我需要为我的课程写论文,但我更喜欢呆在 Linux 中。我从我们的 “大 Unix ” 校园计算机实验室得知,Unix 系统提供了一组文本格式化的程序。它们是同一系统的不同接口:生成纯文本的输出,适合于屏幕或行打印机,或者生成非常优美的输出,通常用于在激光打印机上打印。
+
+在 Linux 上,`nroff` 和 `troff` 被合并为 GNU troff,通常被称为 [groff][1]。 我很高兴看到早期的 Linux 发行版中包含了某个版本的 groff,因此我着手学习如何使用它来编写课程论文。 我学到的第一个宏集是 `-me` 宏包,一个简单易学的宏集。
+
+关于 `groff` ,首先要了解的是它根据一组宏处理和格式化文本。一个宏通常是一个两个字符的命令,它自己设置在一行上,并带有一个引导点。宏可能包含一个或多个选项。当 groff 在处理文档时遇到这些宏中的一个时,它会自动对文本进行格式化。
+
+下面,我将分享使用 `groff -me` 编写课程论文等简单文档的基础知识。 我不会深入细节进行讨论,比如如何创建嵌套列表,保存和显示,以及使用表格和数字。
+
+### 段落
+
+让我们从一个简单的例子开始,在几乎所有类型的文档中都可以看到:段落。段落可以格式化第一行的缩进或不缩进(即,与左边齐平)。 包括学术论文,杂志,期刊和书籍在内的许多印刷文档都使用了这两种类型的组合,其中文档或章节中的第一个(主要)段落与左侧的所有段落以及所有其他(常规)段落缩进。 在 `groff -me`中,您可以使用两种段落类型:前导段落(`.lp`)和常规段落(`.pp`)。
+
+```
+.lp
+
+This is the first paragraph.
+
+.pp
+
+This is a standard paragraph.
+
+```
+
+### 文本格式
+
+用粗体格式化文本的宏是 `.b`,斜体格式是 `.i` 。 如果您将 `.b` 或 `.i` 放在一行上,则后面的所有文本将以粗体或斜体显示。 但更有可能你只是想用粗体或斜体来表示一个或几个词。 要将一个词加粗或斜体,将该单词放在与 `.b` 或 `.i` 相同的行上作为选项。 要用**粗体**或斜体格式化多个单词,请将文字用引号引起来。
+
+```
+.pp
+
+You can do basic formatting such as
+
+.i italics
+
+or
+
+.b "bold text."
+
+```
+
+在上面的例子中,粗体文本结尾的句点也是粗体。 在大多数情况下,这不是你想要的。 只要文字是粗体字,而不是后面的句点也是粗体字。 要获得您想要的效果,您可以向 `.b` 或 `.i` 添加第二个参数,以指示要以粗体或斜体显示的文本,但是正常类型的文本。 您可以这样做,以确保尾随句点不会以粗体显示。
+
+```
+.pp
+
+You can do basic formatting such as
+
+.i italics
+
+or
+
+.b "bold text" .
+
+```
+
+### 列表
+
+使用 `groff -me`,您可以创建两种类型的列表:无序列表(`.bu`)和有序列表(`.np`)。
+
+```
+.pp
+
+Bullet lists are easy to make:
+
+.bu
+
+Apple
+
+.bu
+
+Banana
+
+.bu
+
+Pineapple
+
+.pp
+
+Numbered lists are as easy as:
+
+.np
+
+One
+
+.np
+
+Two
+
+.np
+
+Three
+
+.pp
+
+Note that numbered lists will reset at the next pp or lp.
+
+```
+
+### 副标题
+
+如果你正在写一篇长论文,你可能想把你的内容分成几部分。使用 `groff -me`,您可以创建编号的标题 (`.sh`) 和未编号的标题 (`.uh`)。在这两种方法中,将节标题作为参数括起来。对于编号的标题,您还需要提供标题级别 `:1` 将给出一个一级标题(例如,1)。同样,`2` 和 `3` 将给出第二和第三级标题,如 2.1 或 3.1.1。
+
+```
+.uh Introduction
+
+.pp
+
+Provide one or two paragraphs to describe the work
+
+and why it is important.
+
+.sh 1 "Method and Tools"
+
+.pp
+
+Provide a few paragraphs to describe how you
+
+did the research, including what equipment you used
+
+```
+
+### 智能引号和块引号
+
+在任何学术论文中,引用他人的工作作为证据都是正常的。如果你引用一个简短的引用来突出一个关键信息,你可以在你的文本周围键入引号。但是 groff 不会自动将你的引用转换成现代文字处理系统所使用的“智能”或“卷曲”引用。要在 `groff -me` 中创建它们,插入一个内联宏来创建左引号(`\*(lq`)和右引号(`\*(rq`)。
+
+```
+.pp
+
+Christine Peterson coined the phrase \*(lqopen source.\*(rq
+
+```
+
+`groff -me` 中还有一个快捷方式来创建这些引号(`.q`),我发现它更易于使用。
+
+```
+.pp
+
+Christine Peterson coined the phrase
+
+.q "open source."
+
+```
+
+如果引用的是跨越几行的较长的引用,则需要使用一个块引用。为此,在引用的开头和结尾插入块引用宏(
+
+`.(q`)。
+
+```
+.pp
+
+Christine Peterson recently wrote about open source:
+
+.(q
+
+On April 7, 1998, Tim O'Reilly held a meeting of key
+
+leaders in the field. Announced in advance as the first
+
+.q "Freeware Summit,"
+
+by April 14 it was referred to as the first
+
+.q "Open Source Summit."
+
+.)q
+
+```
+
+### 脚注
+
+要插入脚注,请在脚注文本前后添加脚注宏(`.(f`),并使用内联宏(`\ **`)添加脚注标记。脚注标记应出现在文本中和脚注中。
+
+```
+.pp
+
+Christine Peterson recently wrote about open source:\**
+
+.(f
+
+\**Christine Peterson.
+
+.q "How I coined the term open source."
+
+.i "OpenSource.com."
+
+1 Feb 2018.
+
+.)f
+
+.(q
+
+On April 7, 1998, Tim O'Reilly held a meeting of key
+
+leaders in the field. Announced in advance as the first
+
+.q "Freeware Summit,"
+
+by April 14 it was referred to as the first
+
+.q "Open Source Summit."
+
+.)q
+
+```
+
+### 封面
+
+大多数课程论文都需要一个包含论文标题,姓名和日期的封面。 在 `groff -me` 中创建封面需要一些组件。 我发现最简单的方法是使用居中的文本块并在标题,名称和日期之间添加额外的行。 (我倾向于在每一行之间使用两个空行)。在文章顶部,从标题页(`.tp`)宏开始,插入五个空白行(`.sp 5`),然后添加居中文本(`.(c`) 和额外的空白行(`.sp 2`)。
+
+```
+.tp
+
+.sp 5
+
+.(c
+
+.b "Writing Class Papers with groff -me"
+
+.)c
+
+.sp 2
+
+.(c
+
+Jim Hall
+
+.)c
+
+.sp 2
+
+.(c
+
+February XX, 2018
+
+.)c
+
+.bp
+
+```
+
+最后一个宏(`.bp`)告诉 groff 在标题页后添加一个分页符。
+
+### 更多内容
+
+这些是用 `groff-me` 写一份专业的论文非常基础的东西,包括前导和缩进段落,粗体和斜体,有序和无需列表,编号和不编号的章节标题,块引用以及脚注。
+
+我已经包含一个示例 groff 文件来演示所有这些格式。 将 `lorem-ipsum.me` 文件保存到您的系统并通过 groff 运行。 `-Tps` 选项将输出类型设置为 `PostScript` ,以便您可以将文档发送到打印机或使用 `ps2pdf` 程序将其转换为 PDF 文件。
+
+```
+groff -Tps -me lorem-ipsum.me > lorem-ipsum.me.ps
+
+ps2pdf lorem-ipsum.me.ps lorem-ipsum.me.pdf
+
+```
+
+如果你想使用 groff-me 的更多高级功能,请参阅 Eric Allman 所著的 “使用 `Groff-me` 来写论文”,你可以在你系统的 groff 的 `doc` 目录下找到一个名叫 `meintro.me` 的文件。这份文档非常完美的说明了如何使用 `groff-me` 宏来格式化你的论文。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-me
+
+作者:[Jim Hall][a]
+译者:[amwps290](https://github.com/amwps290)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jim-hall
+[1]:https://www.gnu.org/software/groff/
diff --git a/translated/tech/20180307 An Open Source Desktop YouTube Player For Privacy-minded People.md b/translated/tech/20180307 An Open Source Desktop YouTube Player For Privacy-minded People.md
new file mode 100644
index 0000000000..20a352349d
--- /dev/null
+++ b/translated/tech/20180307 An Open Source Desktop YouTube Player For Privacy-minded People.md
@@ -0,0 +1,90 @@
+注重隐私的开源桌面 YouTube 播放器
+======
+
+
+
+你已经知道我们需要 Google 帐户才能订阅频道并从 YouTube 下载视频。如果你不希望 Google 追踪你在 YouTube 上的行为,那么有一个名为 **“FreeTube”** 的开源 Youtube 播放器。它能让你无需使用帐户观看、搜索和下载 Youtube 视频并订阅你喜爱的频道,这可以防止 Google 获取你的信息。它为你提供完整的无广告体验。另一个值得注意的优势是它有一个内置的基础的 HTML5 播放器来观看视频。由于我们没有使用内置的 YouTube 播放器,因此 Google 无法跟踪“观看次数”,也无法视频分析。FreeTube 只会发送你的 IP 详细信息,但这也可以通过使用 VPN 来解决。它是完全免费、开源的,可用于 GNU/Linux、Mac OS X 和 Windows。
+
+### 功能
+
+* 观看没有广告的视频。
+* 防止 Google 使用 Cookie 或 JavaScript 跟踪你观看的内容。
+* 无须帐户订阅频道。
+* 本地存储订阅、历史记录和已保存的视频。
+* 导入/备份订阅。
+* 迷你播放器。
+* 轻/黑暗的主题。
+* 免费、开源。
+* 跨平台。
+
+
+
+### 安装 FreeTube
+
+进入[**发布页面**][1]并根据你使用的操作系统获取版本。在本指南中,我将使用 **.tar.gz** 文件。
+```
+$ wget https://github.com/FreeTubeApp/FreeTube/releases/download/v0.1.3-beta/FreeTube-linux-x64.tar.xz
+
+```
+
+解压下载的归档:
+```
+$ tar xf FreeTube-linux-x64.tar.xz
+
+```
+
+进入 Freetube 文件夹:
+```
+$ cd FreeTube-linux-x64/
+
+```
+
+使用命令启动 Freeube:
+```
+$ ./FreeTub
+
+```
+
+这就是 FreeTube 默认界面的样子。
+
+![][3]
+
+### 用法
+
+FreeTube 目前使用 **YouTube API ** 搜索视频。然后,它使用 **Youtube-dl HTTP API** 获取原始视频文件并在基础的 HTML5 视频播放器中播放它们。由于订阅、历史记录和已保存的视频都存储在本地系统中,因此你的详细信息将不会发送给 Google 或其他任何人。
+
+在搜索框中输入视频名称,然后按下回车键。FreeTube 会根据你的搜索查询列出结果。
+
+![][4]
+
+你可以点击任何视频来播放它。
+
+![][5]
+
+如果你想更改主题或默认 API、导入/导出订阅,请进入**设置**部分。
+
+![][6]
+
+请注意,FreeTube 仍处于 **beta** 阶段,所以仍然有 bug。如果有任何 bug,请在本指南最后给出的 GitHub 页面上报告。
+
+干杯!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/freetube-an-open-source-desktop-youtube-player-for-privacy-minded-people/
+
+作者:[SK][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://github.com/FreeTubeApp/FreeTube/releases
+[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-1.png
+[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-3.png
+[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-5-1.png
+[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-2.png
diff --git a/translated/tech/20180308 How to set up a print server on a Raspberry Pi.md b/translated/tech/20180308 How to set up a print server on a Raspberry Pi.md
new file mode 100644
index 0000000000..0b53281d7f
--- /dev/null
+++ b/translated/tech/20180308 How to set up a print server on a Raspberry Pi.md
@@ -0,0 +1,87 @@
+如何将树莓派配置为打印服务器
+======
+
+
+
+我喜欢在家做一些小项目,因此,今年我选择使用一个 [树莓派 3 Model B][1],这是一个像我这样的业余爱好者非常适合的东西。使用树莓派 3 Model B 的无线功能,我可以不使用线缆将树莓派连接到我的家庭网络中。这样可以很容易地将树莓派用到各种它所需要的地方。
+
+在家里,我和我的妻子都使用笔记本电脑,但是我们只有一台打印机:一台使用的并不频繁的 HP 彩色激光打印机。因为我们的打印机并不内置无线网卡,因此,它不能直接连接到无线网络中,一般情况下,使用我的笔记本电脑时,我并不连接打印机,因为,我做的大多数工作并不需要打印。虽然这种安排在大多数时间都没有问题,但是,有时候,我的妻子想在不 “麻烦” 我的情况下,自己去打印一些东西。
+
+### 基本设置
+
+我觉得我们需要一个将打印机连接到无线网络的解决方案,以便于我们都能够随时随地打印。我本想买一个无线打印服务器将我的 USB 打印机连接到家里的无线网络上。后来,我决定使用我的树莓派,将它设置为打印服务器,这样就可以让家里的每个人都可以随时来打印。
+
+设置树莓派是非常简单的事。我下载了 [Raspbian][2] 镜像,并将它写入到我的 microSD 卡中。然后,使用它引导连接了一个 HDMI 显示器、一个 USB 键盘和一个 USB 鼠标的树莓派。之后,我们开始对它进行设置!
+
+这个树莓派系统自动引导到一个图形桌面,然后我做了一些基本设置:设置键盘语言、连接无线网络、设置普通用户帐户(`pi`)的密码、设置管理员用户(`root`)的密码。
+
+我并不打算将树莓派运行在桌面环境下。我一般是通过我的普通的 Linux 计算机远程来使用它。因此,我使用树莓派的图形化管理工具,去设置将树莓派引导到控制台模式,而且不以 `pi` 用户自动登入。
+
+重新启动树莓派之后,我需要做一些其它的系统方面的小调整,以便于我在家用网络中使用树莓派做为 “服务器”。我设置它的 DHCP 客户端为使用静态 IP 地址;默认情况下,DHCP 客户端可能任选一个可用的网络地址,这样我会不知道应该用哪个地址连接到树莓派。我的家用网络使用一个私有的 A 类地址,因此,我的路由器的 IP 地址是 `10.0.0.1`,并且我的全部可用地 IP 地址是 `10.0.0.x`。在我的案例中,低位的 IP 地址是安全的,因此,我通过在 `/etc/dhcpcd.conf` 中添加如下的行,设置它的无线网络使用 `10.0.0.11` 这个静态地址。
+```
+interface wlan0
+
+static ip_address=10.0.0.11/24
+
+static routers=10.0.0.1
+
+static domain_name_servers=8.8.8.8 8.8.4.4
+
+```
+
+在我再次重启之前,我需要去确认安全 shell 守护程序(SSHD)已经正常运行(你可以在 “偏好” 中设置哪些服务在引导时启动它)。这样我就可以使用 SSH 从普通的 Linux 系统上基于网络连接到树莓派中。
+
+### 打印设置
+
+现在,我的树莓派已经在网络上正常工作了,我通过 SSH 从我的 Linux 电脑上远程连接它,接着做剩余的设置。在继续设置之前,确保你的打印机已经连接到树莓派上。
+
+设置打印机很容易。现在的打印服务器都称为 CUPS,它是标准的通用 Unix 打印系统。任何最新的 Unix 系统都可以通过 CUPS 打印服务器来打印。为了在树莓派上设置 CUPS 打印服务器。你需要通过几个命令去安装 CUPS 软件,并使用新的配置来重启打印服务器,这样就可以允许其它系统来打印了。
+```
+$ sudo apt-get install cups
+
+$ sudo cupsctl --remote-any
+
+$ sudo /etc/init.d/cups restart
+
+```
+
+在 CUPS 中设置打印机也是非常简单的,你可以通过一个 Web 界面来完成。CUPS 监听端口是 631,因此你可以在浏览器中收藏这个地址:
+```
+https://10.0.0.11:631/
+
+```
+
+你的 Web 浏览器可能会弹出警告,因为它不认可这个 Web 浏览器的 https 证书;选择 ”接受它“,然后以管理员用户登入系统,你将看到如下的标准的 CUPS 面板:
+
+
+这时候,导航到管理标签,选择 “Add Printer"。
+
+
+
+如果打印机已经通过 USB 连接,你只需要简单地选择这个打印机和型号。不要忘记去勾选共享这个打印机的选择框,因为其它人也要使用它。现在,你的打印机已经在 CUPS 中设置好了。
+
+
+
+### 客户端设置
+
+从 Linux 中设置一台网络打印机非常简单。我的桌面环境是 GNOME,你可以从 GNOME 的设置应用程序中添加网络打印机。只需要导航到设备和打印机,然后解锁这个面板。点击 “Add" 按钮去添加打印机。
+
+在我的系统中,GNOME 设置为 ”自动发现网络打印机并添加它“。如果你的系统不是这样,你需要通过树莓派的 IP 地址,手动去添加打印机。
+
+
+
+设置到此为止!我们现在已经可以通过家中的无线网络来使用这台打印机了。我不再需要物理连接到这台打印机了,家里的任何人都可以使用它了!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/3/print-server-raspberry-pi
+
+作者:[Jim Hall][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jim-hall
+[1]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
+[2]:https://www.raspberrypi.org/downloads/