mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
94820e60b2
@ -1,5 +1,6 @@
|
||||
如何设置在Quagga BGP路由器中设置IPv6的BGP对等体和过滤
|
||||
如何设置在 Quagga BGP 路由器中设置 IPv6 的 BGP 对等体和过滤
|
||||
================================================================================
|
||||
|
||||
在之前的教程中,我们演示了如何使用Quagga建立一个[完备的BGP路由器][1]和配置[前缀过滤][2]。在本教程中,我们会向你演示如何创建IPv6 BGP对等体并通过BGP通告IPv6前缀。同时我们也将演示如何使用前缀列表和路由映射特性来过滤通告的或者获取到的IPv6前缀。
|
||||
|
||||
### 拓扑 ###
|
||||
@ -47,7 +48,7 @@ Quagga内部提供一个叫作vtysh的shell,其界面与那些主流路由厂
|
||||
|
||||
# vtysh
|
||||
|
||||
提示将改为:
|
||||
提示符将改为:
|
||||
|
||||
router-a#
|
||||
|
||||
@ -65,7 +66,7 @@ Quagga内部提供一个叫作vtysh的shell,其界面与那些主流路由厂
|
||||
|
||||
router-a# configure terminal
|
||||
|
||||
提示将变更成:
|
||||
提示符将变更成:
|
||||
|
||||
router-a(config)#
|
||||
|
||||
@ -246,13 +247,13 @@ Quagga内部提供一个叫作vtysh的shell,其界面与那些主流路由厂
|
||||
via: http://xmodulo.com/ipv6-bgp-peering-filtering-quagga-bgp-router.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
[1]:https://linux.cn/article-4232-1.html
|
||||
[2]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
[3]:http://ask.xmodulo.com/open-port-firewall-centos-rhel.html
|
||||
[4]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
@ -1,8 +1,9 @@
|
||||
如何在 Docker 中通过 Kitematic 交互式执行任务
|
||||
如何在 Windows 上通过 Kitematic 使用 Docker
|
||||
================================================================================
|
||||
在本篇文章中,我们会学习如何在 Windows 操作系统上安装 Kitematic 以及部署一个 Hello World Nginx Web 服务器。Kitematic 是一个自由开源软件,它有现代化的界面设计使得允许我们在 Docker 中交互式执行任务。Kitematic 设计非常漂亮、界面也很不错。我们可以简单快速地开箱搭建我们的容器而不需要输入命令,我们可以在图形用户界面中通过简单的点击从而在容器上部署我们的应用。Kitematic 集成了 Docker Hub,允许我们搜索、拉取任何需要的镜像,并在上面部署应用。它同时也能很好地切换到命令行用户接口模式。目前,它包括了自动映射端口、可视化更改环境变量、配置卷、精简日志以及其它功能。
|
||||
|
||||
下面是在 Windows 上安装 Kitematic 并部署 Hello World Nginx Web 服务器的 3 个简单步骤。
|
||||
在本篇文章中,我们会学习如何在 Windows 操作系统上安装 Kitematic 以及部署一个测试性的 Nginx Web 服务器。Kitematic 是一个具有现代化的界面设计的自由开源软件,它可以让我们在 Docker 中交互式执行任务。Kitematic 设计的非常漂亮、界面美观。使用它,我们可以简单快速地开箱搭建我们的容器而不需要输入命令,可以在图形用户界面中通过简单的点击从而在容器上部署我们的应用。Kitematic 集成了 Docker Hub,允许我们搜索、拉取任何需要的镜像,并在上面部署应用。它同时也能很好地切换到命令行用户接口模式。目前,它包括了自动映射端口、可视化更改环境变量、配置卷、流式日志以及其它功能。
|
||||
|
||||
下面是在 Windows 上安装 Kitematic 并部署测试性 Nginx Web 服务器的 3 个简单步骤。
|
||||
|
||||
### 1. 下载 Kitematic ###
|
||||
|
||||
@ -16,15 +17,15 @@
|
||||
|
||||
### 2. 安装 Kitematic ###
|
||||
|
||||
下载好可执行安装程序之后,我们现在打算在我们的 Windows 操作系统上安装 Kitematic。安装程序现在会开始下载并安装运行 Kitematic 需要的依赖,包括 Virtual Box 和 Docker。如果已经在系统上安装了 Virtual Box,它会把它升级到最新版本。安装程序会在几分钟内完成,但取决于你网络和系统的速度。如果你还没有安装 Virtual Box,它会问你是否安装 Virtual Box 网络驱动。建议安装它,因为它有助于 Virtual Box 的网络。
|
||||
下载好可执行安装程序之后,我们现在就可以在我们的 Windows 操作系统上安装 Kitematic了。安装程序现在会开始下载并安装运行 Kitematic 需要的依赖软件,包括 Virtual Box 和 Docker。如果已经在系统上安装了 Virtual Box,它会把它升级到最新版本。安装程序会在几分钟内完成,但取决于你网络和系统的速度。如果你还没有安装 Virtual Box,它会问你是否安装 Virtual Box 网络驱动。建议安装它,因为它用于 Virtual Box 的网络功能。
|
||||
|
||||

|
||||
|
||||
需要的依赖 Docker 和 Virtual Box 安装完成并运行后,会让我们登录到 Docker Hub。如果我们还没有账户或者还不想登录,可以点击 **SKIP FOR NOW** 继续后面的步骤。
|
||||
所需的依赖 Docker 和 Virtual Box 安装完成并运行后,会让我们登录到 Docker Hub。如果我们还没有账户或者还不想登录,可以点击 **SKIP FOR NOW** 继续后面的步骤。
|
||||
|
||||

|
||||
|
||||
如果你还没有账户,你可以在应用程序上点击注册链接并在 Docker Hub 上创建账户。
|
||||
如果你还没有账户,你可以在应用程序上点击注册(Sign Up)链接并在 Docker Hub 上创建账户。
|
||||
|
||||
完成之后,就会出现 Kitematic 应用程序的第一个界面。正如下面看到的这样。我们可以搜索可用的 docker 镜像。
|
||||
|
||||
@ -50,7 +51,11 @@
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们终于成功在 Windows 操作系统上安装了 Kitematic 并部署了一个 Hello World Ngnix 服务器。总是推荐下载安装 Kitematic 最新的发行版,因为会增加很多新的高级功能。由于 Docker 运行在 64 位平台,当前 Kitematic 也是为 64 位操作系统构建。它只能在 Windows 7 以及更高版本上运行。在这篇教程中,我们部署了一个 Nginx Web 服务器,类似地我们可以在 Kitematic 中简单的点击就能通过镜像部署任何 docker 容器。Kitematic 已经有可用的 Mac OS X 和 Windows 版本,Linux 版本也在开发中很快就会发布。如果你有任何疑问、建议或者反馈,请在下面的评论框中写下来以便我们更改地改进或更新我们的内容。非常感谢!Enjoy :-)
|
||||
我们终于成功在 Windows 操作系统上安装了 Kitematic 并部署了一个 Hello World Ngnix 服务器。推荐下载安装 Kitematic 最新的发行版,因为会增加很多新的高级功能。由于 Docker 运行在 64 位平台,当前 Kitematic 也是为 64 位操作系统构建。它只能在 Windows 7 以及更高版本上运行。
|
||||
|
||||
在这篇教程中,我们部署了一个 Nginx Web 服务器,类似地我们可以在 Kitematic 中简单的点击就能通过镜像部署任何 docker 容器。Kitematic 已经有可用的 Mac OS X 和 Windows 版本,Linux 版本也在开发中很快就会发布。
|
||||
|
||||
如果你有任何疑问、建议或者反馈,请在下面的评论框中写下来以便我们更改地改进或更新我们的内容。非常感谢!Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -58,7 +63,7 @@ via: http://linoxide.com/linux-how-to/interactively-docker-kitematic/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,129 @@
|
||||
如何使用 Weave 以及 Docker 搭建 Nginx 反向代理/负载均衡服务器
|
||||
================================================================================
|
||||
|
||||
Hi, 今天我们将会学习如何使用 Weave 和 Docker 搭建 Nginx 的反向代理/负载均衡服务器。Weave 可以创建一个虚拟网络将 Docker 容器彼此连接在一起,支持跨主机部署及自动发现。它可以让我们更加专注于应用的开发,而不是基础架构。Weave 提供了一个如此棒的环境,仿佛它的所有容器都属于同个网络,不需要端口/映射/连接等的配置。容器中的应用提供的服务在 weave 网络中可以轻易地被外部世界访问,不论你的容器运行在哪里。在这个教程里我们将会使用 weave 快速并且简单地将 nginx web 服务器部署为一个负载均衡器,反向代理一个运行在 Amazon Web Services 里面多个节点上的 docker 容器中的简单 php 应用。这里我们将会介绍 WeaveDNS,它提供一个不需要改变代码就可以让容器利用主机名找到的简单方式,并且能够让其他容器通过主机名连接彼此。
|
||||
|
||||
在这篇教程里,我们将使用 nginx 来将负载均衡分配到一个运行 Apache 的容器集合。最简单轻松的方法就是使用 Weave 来把运行在 ubuntu 上的 docker 容器中的 nginx 配置成负载均衡服务器。
|
||||
|
||||
### 1. 搭建 AWS 实例 ###
|
||||
|
||||
首先,我们需要搭建 Amzaon Web Service 实例,这样才能在 ubuntu 下用 weave 跑 docker 容器。我们将会使用[AWS 命令行][1] 来搭建和配置两个 AWS EC2 实例。在这里,我们使用最小的可用实例,t1.micro。我们需要一个有效的**Amazon Web Services 账户**使用 AWS 命令行界面来搭建和配置。我们先在 AWS 命令行界面下使用下面的命令将 github 上的 weave 仓库克隆下来。
|
||||
|
||||
$ git clone http://github.com/fintanr/weave-gs
|
||||
$ cd weave-gs/aws-nginx-ubuntu-simple
|
||||
|
||||
在克隆完仓库之后,我们执行下面的脚本,这个脚本将会部署两个 t1.micro 实例,每个实例中都是 ubuntu 作为操作系统并用 weave 跑着 docker 容器。
|
||||
|
||||
$ sudo ./demo-aws-setup.sh
|
||||
|
||||
在这里,我们将会在以后用到这些实例的 IP 地址。这些地址储存在一个 weavedemo.env 文件中,这个文件创建于执行 demo-aws-setup.sh 脚本期间。为了获取这些 IP 地址,我们需要执行下面的命令,命令输出类似下面的信息。
|
||||
|
||||
$ cat weavedemo.env
|
||||
|
||||
export WEAVE_AWS_DEMO_HOST1=52.26.175.175
|
||||
export WEAVE_AWS_DEMO_HOST2=52.26.83.141
|
||||
export WEAVE_AWS_DEMO_HOSTCOUNT=2
|
||||
export WEAVE_AWS_DEMO_HOSTS=(52.26.175.175 52.26.83.141)
|
||||
|
||||
请注意这些不是固定的 IP 地址,AWS 会为我们的实例动态地分配 IP 地址。
|
||||
|
||||
我们在 bash 下执行下面的命令使环境变量生效。
|
||||
|
||||
. ./weavedemo.env
|
||||
|
||||
### 2. 启动 Weave 和 WeaveDNS ###
|
||||
|
||||
在安装完实例之后,我们将会在每台主机上启动 weave 以及 weavedns。Weave 以及 weavedns 使得我们能够轻易地将容器部署到一个全新的基础架构以及配置中, 不需要改变代码,也不需要去理解像 Ambassador 容器以及 Link 机制之类的概念。下面是在第一台主机上启动 weave 以及 weavedns 的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch
|
||||
$ sudo weave launch-dns 10.2.1.1/24
|
||||
|
||||
下一步,我也准备在第二台主机上启动 weave 以及 weavedns。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave launch $WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch-dns 10.2.1.2/24
|
||||
|
||||
### 3. 启动应用容器 ###
|
||||
|
||||
现在,我们准备跨两台主机启动六个容器,这两台主机都用 Apache2 Web 服务实例跑着简单的 php 网站。为了在第一个 Apache2 Web 服务器实例跑三个容器, 我们将会使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.1/24 -h ws1.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.2/24 -h ws2.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.3/24 -h ws3.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
在那之后,我们将会在第二个实例上启动另外三个容器,请使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave run --with-dns 10.3.1.4/24 -h ws4.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.5/24 -h ws5.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.6/24 -h ws6.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
注意: 在这里,--with-dns 选项告诉容器使用 weavedns 来解析主机名,-h x.weave.local 则使得 weavedns 能够解析该主机。
|
||||
|
||||
### 4. 启动 Nginx 容器 ###
|
||||
|
||||
在应用容器如预期的运行后,我们将会启动 nginx 容器,它将会在六个应用容器服务之间轮询并提供反向代理或者负载均衡。 为了启动 nginx 容器,请使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.7/24 -ti -h nginx.weave.local -d -p 80:80 fintanr/weave-gs-nginx-simple
|
||||
|
||||
因此,我们的 nginx 容器在 $WEAVE_AWS_DEMO_HOST1 上公开地暴露成为一个 http 服务器。
|
||||
|
||||
### 5. 测试负载均衡服务器 ###
|
||||
|
||||
为了测试我们的负载均衡服务器是否可以工作,我们执行一段可以发送 http 请求给 nginx 容器的脚本。我们将会发送6个请求,这样我们就能看到 nginx 在一次的轮询中服务于每台 web 服务器之间。
|
||||
|
||||
$ ./access-aws-hosts.sh
|
||||
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws1.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws2.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws3.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws4.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws5.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws6.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
|
||||
### 结束语 ###
|
||||
|
||||
我们最终成功地将 nginx 配置成一个反向代理/负载均衡服务器,通过使用 weave 以及运行在 AWS(Amazon Web Service)EC2 里面的 ubuntu 服务器中的 docker。从上面的步骤输出可以清楚的看到我们已经成功地配置了 nginx。我们可以看到请求在一次轮询中被发送到6个应用容器,这些容器在 Apache2 Web 服务器中跑着 PHP 应用。在这里,我们部署了一个容器化的 PHP 应用,使用 nginx 横跨多台在 AWS EC2 上的主机而不需要改变代码,利用 weavedns 使得每个容器连接在一起,只需要主机名就够了,眼前的这些便捷, 都要归功于 weave 以及 weavedns。
|
||||
|
||||
如果你有任何的问题、建议、反馈,请在评论中注明,这样我们才能够做得更好,谢谢:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/nginx-load-balancer-weave-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://console.aws.amazon.com/
|
||||
@ -0,0 +1,114 @@
|
||||
安装 Strongswan :Linux 上一个基于 IPsec 的 VPN 工具
|
||||
================================================================================
|
||||
|
||||
IPsec是一个提供网络层安全的标准。它包含认证头(AH)和安全负载封装(ESP)组件。AH提供包的完整性,ESP组件提供包的保密性。IPsec确保了在网络层的安全特性。
|
||||
|
||||
- 保密性
|
||||
- 数据包完整性
|
||||
- 来源不可抵赖性
|
||||
- 重放攻击防护
|
||||
|
||||
[Strongswan][1]是一个IPsec协议的开源代码实现,Strongswan的意思是强安全广域网(StrongS/WAN)。它支持IPsec的VPN中的两个版本的密钥自动交换(网络密钥交换(IKE)V1和V2)。
|
||||
|
||||
Strongswan基本上提供了在VPN的两个节点/网关之间自动交换密钥的共享,然后它使用了Linux内核的IPsec(AH和ESP)实现。密钥共享使用了之后用于ESP数据加密的IKE 机制。在IKE阶段,strongswan使用OpenSSL的加密算法(AES,SHA等等)和其他加密类库。无论如何,IPsec中的ESP组件使用的安全算法是由Linux内核实现的。Strongswan的主要特性如下:
|
||||
|
||||
- x.509证书或基于预共享密钥认证
|
||||
- 支持IKEv1和IKEv2密钥交换协议
|
||||
- 可选的,对于插件和库的内置完整性和加密测试
|
||||
- 支持椭圆曲线DH群和ECDSA证书
|
||||
- 在智能卡上存储RSA私钥和证书
|
||||
|
||||
它能被使用在客户端/服务器(road warrior模式)和网关到网关的情景。
|
||||
|
||||
### 如何安装 ###
|
||||
|
||||
几乎所有的Linux发行版都支持Strongswan的二进制包。在这个教程,我们会从二进制包安装strongswan,也会从源代码编译带有合适的特性的strongswan。
|
||||
|
||||
### 使用二进制包 ###
|
||||
|
||||
可以使用以下命令安装Strongswan到Ubuntu 14.04 LTS
|
||||
|
||||
$ sudo aptitude install strongswan
|
||||
|
||||

|
||||
|
||||
strongswan的全局配置(strongswan.conf)文件和ipsec配置(ipsec.conf/ipsec.secrets)文件都在/etc/目录下。
|
||||
|
||||
### strongswan源码编译安装的依赖包 ###
|
||||
|
||||
- GMP(strongswan使用的高精度数学库)
|
||||
- OpenSSL(加密算法来自这个库)
|
||||
- PKCS(1,7,8,11,12)(证书编码和智能卡集成)
|
||||
|
||||
#### 步骤 ####
|
||||
|
||||
**1)** 在终端使用下面命令到/usr/src/目录
|
||||
|
||||
$ cd /usr/src
|
||||
|
||||
**2)** 用下面命令从strongswan网站下载源代码
|
||||
|
||||
$ sudo wget http://download.strongswan.org/strongswan-5.2.1.tar.gz
|
||||
|
||||
(strongswan-5.2.1.tar.gz 是当前最新版。)
|
||||
|
||||

|
||||
|
||||
**3)** 用下面命令提取下载的软件,然后进入目录。
|
||||
|
||||
$ sudo tar –xvzf strongswan-5.2.1.tar.gz; cd strongswan-5.2.1
|
||||
|
||||
**4)** 使用configure命令配置strongswan每个想要的选项。
|
||||
|
||||
$ ./configure --prefix=/usr/local -–enable-pkcs11 -–enable-openssl
|
||||
|
||||

|
||||
|
||||
如果GMP库没有安装,配置脚本将会发生下面的错误。
|
||||
|
||||

|
||||
|
||||
因此,首先,使用下面命令安装GMP库然后执行配置脚本。
|
||||
|
||||

|
||||
|
||||
不过,如果GMP已经安装还报上述错误的话,在Ubuntu上使用如下命令,给在路径 /usr/lib,/lib/,/usr/lib/x86_64-linux-gnu/ 下的libgmp.so库创建软连接。
|
||||
|
||||
$ sudo ln -s /usr/lib/x86_64-linux-gnu/libgmp.so.10.1.3 /usr/lib/x86_64-linux-gnu/libgmp.so
|
||||
|
||||

|
||||
|
||||
创建libgmp.so软连接后,再执行./configure脚本也许就找到gmp库了。然而,如果gmp头文件发生其他错误,像下面这样。
|
||||
|
||||

|
||||
|
||||
为解决上面的错误,使用下面命令安装libgmp-dev包
|
||||
|
||||
$ sudo aptitude install libgmp-dev
|
||||
|
||||

|
||||
|
||||
安装gmp的开发库后,在运行一遍配置脚本,如果没有发生错误,则将看见下面的这些输出。
|
||||
|
||||

|
||||
|
||||
使用下面的命令编译安装strongswan。
|
||||
|
||||
$ sudo make ; sudo make install
|
||||
|
||||
安装strongswan后,全局配置(strongswan.conf)和ipsec策略/密码配置文件(ipsec.conf/ipsec.secretes)被放在**/usr/local/etc**目录。
|
||||
|
||||
根据我们的安全需要Strongswan可以用作隧道或者传输模式。它提供众所周知的site-2-site模式和road warrior模式的VPN。它很容易使用在Cisco,Juniper设备上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/security/install-strongswan/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:https://www.strongswan.org/
|
||||
@ -1,48 +1,49 @@
|
||||
在 Debian 中安装 OpenQRM 云计算平台
|
||||
================================================================================
|
||||
|
||||
### 简介 ###
|
||||
|
||||
**openQRM**是一个基于 Web 的开源云计算和数据中心管理平台,可灵活地与企业数据中心的现存组件集成。
|
||||
|
||||
它支持下列虚拟技术:
|
||||
|
||||
- KVM,
|
||||
- XEN,
|
||||
- Citrix XenServer,
|
||||
- VMWare ESX,
|
||||
- LXC,
|
||||
- OpenVZ.
|
||||
- KVM
|
||||
- XEN
|
||||
- Citrix XenServer
|
||||
- VMWare ESX
|
||||
- LXC
|
||||
- OpenVZ
|
||||
|
||||
openQRM 中的杂交云连接器通过 **Amazon AWS**, **Eucalyptus** 或 **OpenStack** 来支持一系列的私有或公有云提供商,以此来按需扩展你的基础设施。它也自动地进行资源调配、 虚拟化、 存储和配置管理,且关注高可用性。集成计费系统的自助服务云门户可使终端用户按需请求新的服务器和应用堆栈。
|
||||
openQRM 中的混合云连接器支持 **Amazon AWS**, **Eucalyptus** 或 **OpenStack** 等一系列的私有或公有云提供商,以此来按需扩展你的基础设施。它也可以自动地进行资源调配、 虚拟化、 存储和配置管理,且保证高可用性。集成的计费系统的自服务云门户可使终端用户按需请求新的服务器和应用堆栈。
|
||||
|
||||
openQRM 有两种不同风格的版本可获取:
|
||||
|
||||
- 企业版
|
||||
- 社区版
|
||||
|
||||
你可以在[这里][1] 查看这两个版本间的区别。
|
||||
你可以在[这里][1]查看这两个版本间的区别。
|
||||
|
||||
### 特点 ###
|
||||
|
||||
- 私有/杂交的云计算平台;
|
||||
- 可管理物理或虚拟的服务器系统;
|
||||
- 可与所有主流的开源或商业的存储技术集成;
|
||||
- 跨平台: Linux, Windows, OpenSolaris, and BSD;
|
||||
- 支持 KVM, XEN, Citrix XenServer, VMWare ESX(i), lxc, OpenVZ 和 VirtualBox;
|
||||
- 支持使用额外的 Amazon AWS, Eucalyptus, Ubuntu UEC 等云资源来进行杂交云设置;
|
||||
- 支持 P2V, P2P, V2P, V2V 迁移和高可用性;
|
||||
- 集成最好的开源管理工具 – 如 puppet, nagios/Icinga 或 collectd;
|
||||
- 有超过 50 个插件来支持扩展功能并与你的基础设施集成;
|
||||
- 针对终端用户的自助门户;
|
||||
- 集成计费系统.
|
||||
- 私有/混合的云计算平台
|
||||
- 可管理物理或虚拟的服务器系统
|
||||
- 集成了所有主流的开源或商业的存储技术
|
||||
- 跨平台: Linux, Windows, OpenSolaris 和 BSD
|
||||
- 支持 KVM, XEN, Citrix XenServer, VMWare ESX(i), lxc, OpenVZ 和 VirtualBox
|
||||
- 支持使用额外的 Amazon AWS, Eucalyptus, Ubuntu UEC 等云资源来进行混合云设置
|
||||
- 支持 P2V, P2P, V2P, V2V 迁移和高可用性
|
||||
- 集成最好的开源管理工具 – 如 puppet, nagios/Icinga 或 collectd
|
||||
- 有超过 50 个插件来支持扩展功能并与你的基础设施集成
|
||||
- 针对终端用户的自服务门户
|
||||
- 集成了计费系统
|
||||
|
||||
### 安装 ###
|
||||
|
||||
在这里我们将在 in Debian 7.5 上安装 openQRM。你的服务器必须至少满足以下要求:
|
||||
在这里我们将在 Debian 7.5 上安装 openQRM。你的服务器必须至少满足以下要求:
|
||||
|
||||
- 1 GB RAM;
|
||||
- 100 GB Hdd(硬盘驱动器);
|
||||
- 可选: Bios 支持虚拟化(Intel CPUs 的 VT 或 AMD CPUs AMD-V).
|
||||
- 1 GB RAM
|
||||
- 100 GB Hdd(硬盘驱动器)
|
||||
- 可选: Bios 支持虚拟化(Intel CPUs 的 VT 或 AMD CPUs AMD-V)
|
||||
|
||||
首先,安装 `make` 软件包来编译 openQRM 源码包:
|
||||
|
||||
@ -52,7 +53,7 @@ openQRM 有两种不同风格的版本可获取:
|
||||
|
||||
然后,逐次运行下面的命令来安装 openQRM。
|
||||
|
||||
从[这里][2] 下载最新的可用版本:
|
||||
从[这里][2]下载最新的可用版本:
|
||||
|
||||
wget http://sourceforge.net/projects/openqrm/files/openQRM-Community-5.1/openqrm-community-5.1.tgz
|
||||
|
||||
@ -66,35 +67,35 @@ openQRM 有两种不同风格的版本可获取:
|
||||
|
||||
sudo make start
|
||||
|
||||
安装期间,你将被询问去更新文件 `php.ini`
|
||||
安装期间,会要求你更新文件 `php.ini`
|
||||
|
||||

|
||||

|
||||
|
||||
输入 mysql root 用户密码。
|
||||
|
||||

|
||||

|
||||
|
||||
再次输入密码:
|
||||
|
||||

|
||||

|
||||
|
||||
选择邮件服务器配置类型。
|
||||
选择邮件服务器配置类型:
|
||||
|
||||

|
||||

|
||||
|
||||
假如你不确定该如何选择,可选择 `Local only`。在我们的这个示例中,我选择了 **Local only** 选项。
|
||||
|
||||

|
||||

|
||||
|
||||
输入你的系统邮件名称,并最后输入 Nagios 管理员密码。
|
||||
|
||||

|
||||

|
||||
|
||||
根据你的网络连接状态,上面的命令可能将花费很长的时间来下载所有运行 openQRM 所需的软件包,请耐心等待。
|
||||
|
||||
最后你将得到 openQRM 配置 URL 地址以及相关的用户名和密码。
|
||||
|
||||

|
||||

|
||||
|
||||
### 配置 ###
|
||||
|
||||
@ -104,23 +105,23 @@ openQRM 有两种不同风格的版本可获取:
|
||||
|
||||
默认的用户名和密码是: **openqrm/openqrm** 。
|
||||
|
||||

|
||||

|
||||
|
||||
选择一个网卡来给 openQRM 管理网络使用。
|
||||
|
||||

|
||||

|
||||
|
||||
选择一个数据库类型,在我们的示例中,我选择了 mysql。
|
||||
|
||||

|
||||

|
||||
|
||||
现在,配置数据库连接并初始化 openQRM, 在这里,我使用 **openQRM** 作为数据库名称, **root** 作为用户的身份,并将 debian 作为数据库的密码。 请小心,你应该输入先前在安装 openQRM 时创建的 mysql root 用户密码。
|
||||
|
||||

|
||||

|
||||
|
||||
祝贺你!! openQRM 已经安装并配置好了。
|
||||
祝贺你! openQRM 已经安装并配置好了。
|
||||
|
||||

|
||||

|
||||
|
||||
### 更新 openQRM ###
|
||||
|
||||
@ -129,16 +130,17 @@ openQRM 有两种不同风格的版本可获取:
|
||||
cd openqrm/src/
|
||||
make update
|
||||
|
||||
到现在为止,我们做的只是在我们的 Ubuntu 服务器中安装和配置 openQRM, 至于 创建、运行虚拟,管理存储,额外的系统集成和运行你自己的私有云等内容,我建议你阅读 [openQRM 管理员指南][3]。
|
||||
到现在为止,我们做的只是在我们的 Debian 服务器中安装和配置 openQRM, 至于 创建、运行虚拟,管理存储,额外的系统集成和运行你自己的私有云等内容,我建议你阅读 [openQRM 管理员指南][3]。
|
||||
|
||||
就是这些了,欢呼吧!周末快乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-openqrm-cloud-computing-platform-debian/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
Ubuntu上使用LVM轻松调整分区并制作快照
|
||||
Ubuntu 上使用 LVM 轻松调整分区并制作快照
|
||||
================================================================================
|
||||

|
||||
|
||||
Ubuntu的安装器提供了一个轻松“使用LVM”的复选框。说明中说,它启用了逻辑卷管理,因此你可以制作快照,并更容易地调整硬盘分区大小——这里将为大家讲述如何完成这些操作。
|
||||
Ubuntu的安装器提供了一个轻松“使用LVM”的复选框。它的描述中说,启用逻辑卷管理可以让你制作快照,并更容易地调整硬盘分区大小——这里将为大家讲述如何完成这些操作。
|
||||
|
||||
LVM是一种技术,某种程度上和[RAID阵列][1]或[Windows上的存储空间][2]类似。虽然该技术在服务器上更为有用,但是它也可以在桌面端PC上使用。
|
||||
LVM是一种技术,某种程度上和[RAID阵列][1]或[Windows上的“存储空间”][2]类似。虽然该技术在服务器上更为有用,但是它也可以在桌面端PC上使用。
|
||||
|
||||
### 你应该在新安装Ubuntu时使用LVM吗? ###
|
||||
|
||||
第一个问题是,你是否想要在安装Ubuntu时使用LVM?如果是,那么Ubuntu让这一切变得很简单,只需要轻点鼠标就可以完成,但是该选项默认是不启用的。正如安装器所说的,它允许你调整分区、创建快照、合并多个磁盘到一个逻辑卷等等——所有这一切都可以在系统运行时完成。不同于传统分区,你不需要关掉你的系统,从Live CD或USB驱动,然后[调整这些不使用的分区][3]。
|
||||
第一个问题是,你是否想要在安装Ubuntu时使用LVM?如果是,那么Ubuntu让这一切变得很简单,只需要轻点鼠标就可以完成,但是该选项默认是不启用的。正如安装器所说的,它允许你调整分区、创建快照、将多个磁盘合并到一个逻辑卷等等——所有这一切都可以在系统运行时完成。不同于传统分区,你不需要关掉你的系统,从Live CD或USB驱动,然后[当这些分区不使用时才能调整][3]。
|
||||
|
||||
完全坦率地说,普通Ubuntu桌面用户可能不会意识到他们是否正在使用LVM。但是,如果你想要在今后做一些更高深的事情,那么LVM就会有所帮助了。LVM可能更复杂,可能会在你今后恢复数据时会导致问题——尤其是在你经验不足时。这里不会有显著的性能损失——LVM是彻底地在Linux内核中实现的。
|
||||
|
||||
@ -18,7 +18,7 @@ LVM是一种技术,某种程度上和[RAID阵列][1]或[Windows上的存储空
|
||||
|
||||
前面,我们已经[说明了何谓LVM][4]。概括来讲,它在你的物理磁盘和呈现在你系统中的分区之间提供了一个抽象层。例如,你的计算机可能装有两个硬盘驱动器,它们的大小都是 1 TB。你必须得在这些磁盘上至少分两个区,每个区大小 1 TB。
|
||||
|
||||
LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传统分区,LVM将在你对这些磁盘初始化后,将它们当作独立的“物理卷”来对待。然后,你就可以基于这些物理卷创建“逻辑卷”。例如,你可以将这两个 1 TB 的磁盘组合成一个 2 TB 的分区,你的系统将只看到一个 2 TB 的卷,而LVM将会在后台处理这一切。一组物理卷以及一组逻辑卷被称之为“卷组”,一个标准的系统只会有一个卷组。
|
||||
LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传统分区,LVM将在你对这些磁盘初始化后,将它们当作独立的“物理卷”来对待。然后,你就可以基于这些物理卷创建“逻辑卷”。例如,你可以将这两个 1 TB 的磁盘组合成一个 2 TB 的分区,你的系统将只看到一个 2 TB 的卷,而LVM将会在后台处理这一切。一组物理卷以及一组逻辑卷被称之为“卷组”,一个典型的系统只会有一个卷组。
|
||||
|
||||
该抽象层使得调整分区、将多个磁盘组合成单个卷、甚至为一个运行着的分区的文件系统创建“快照”变得十分简单,而完成所有这一切都无需先卸载分区。
|
||||
|
||||
@ -28,11 +28,11 @@ LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传
|
||||
|
||||
通常,[LVM通过Linux终端命令来管理][5]。这在Ubuntu上也行得通,但是有个更简单的图形化方法可供大家采用。如果你是一个Linux用户,对GParted或者与其类似的分区管理器熟悉,算了,别瞎掰了——GParted根本不支持LVM磁盘。
|
||||
|
||||
然而,你可以使用Ubuntu附带的磁盘工具。该工具也被称之为GNOME磁盘工具,或者叫Palimpsest。点击停靠盘上的图标来开启它吧,搜索磁盘然后敲击回车。不像GParted,该磁盘工具将会在“其它设备”下显示LVM分区,因此你可以根据需要格式化这些分区,也可以调整其它选项。该工具在Live CD或USB 驱动下也可以使用。
|
||||
然而,你可以使用Ubuntu附带的磁盘工具。该工具也被称之为GNOME磁盘工具,或者叫Palimpsest。点击dash中的图标来开启它吧,搜索“磁盘”然后敲击回车。不像GParted,该磁盘工具将会在“其它设备”下显示LVM分区,因此你可以根据需要格式化这些分区,也可以调整其它选项。该工具在Live CD或USB 驱动下也可以使用。
|
||||
|
||||

|
||||
|
||||
不幸的是,该磁盘工具不支持LVM的大多数强大的特性,没有管理卷组、扩展分区,或者创建快照等选项。对于这些操作,你可以通过终端来实现,但是你没有那个必要。相反,你可以打开Ubuntu软件中心,搜索关键字LVM,然后安装逻辑卷管理工具,你可以在终端窗口中运行**sudo apt-get install system-config-lvm**命令来安装它。安装完之后,你就可以从停靠盘上打开逻辑卷管理工具了。
|
||||
不幸的是,该磁盘工具不支持LVM的大多数强大的特性,没有管理卷组、扩展分区,或者创建快照等选项。对于这些操作,你可以通过终端来实现,但是没有那个必要。相反,你可以打开Ubuntu软件中心,搜索关键字LVM,然后安装逻辑卷管理工具,你可以在终端窗口中运行**sudo apt-get install system-config-lvm**命令来安装它。安装完之后,你就可以从dash上打开逻辑卷管理工具了。
|
||||
|
||||
这个图形化配置工具是由红帽公司开发的,虽然有点陈旧了,但却是唯一的图形化方式,你可以通过它来完成上述操作,将那些终端命令抛诸脑后了。
|
||||
|
||||
@ -40,11 +40,11 @@ LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传
|
||||
|
||||

|
||||
|
||||
卷组视图会列出你所有物理卷和逻辑卷的总览。这里,我们有两个横跨两个独立硬盘驱动器的物理分区,我们有一个交换分区和一个根分区,就像Ubuntu默认设置的分区图表。由于我们从另一个驱动器添加了第二个物理分区,现在那里有大量未使用空间。
|
||||
卷组视图会列出你所有的物理卷和逻辑卷的总览。这里,我们有两个横跨两个独立硬盘驱动器的物理分区,我们有一个交换分区和一个根分区,这是Ubuntu默认设置的分区图表。由于我们从另一个驱动器添加了第二个物理分区,现在那里有大量未使用空间。
|
||||
|
||||

|
||||
|
||||
要扩展逻辑分区到物理空间,你可以在逻辑视图下选择它,点击编辑属性,然后修改大小来扩大分区。你也可以在这里缩减分区。
|
||||
要扩展逻辑分区到物理空间,你可以在逻辑视图下选择它,点击编辑属性,然后修改大小来扩大分区。你也可以在这里缩小分区。
|
||||
|
||||

|
||||
|
||||
@ -55,7 +55,7 @@ system-config-lvm的其它选项允许你设置快照和镜像。对于传统桌
|
||||
via: http://www.howtogeek.com/211937/how-to-use-lvm-on-ubuntu-for-easy-partition-resizing-and-snapshots/
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,89 @@
|
||||
如何在树莓派 2 运行 ubuntu Snappy Core
|
||||
================================================================================
|
||||
物联网(Internet of Things, IoT) 时代即将来临。很快,过不了几年,我们就会问自己当初是怎么在没有物联网的情况下生存的,就像我们现在怀疑过去没有手机的年代。Canonical 就是一个物联网快速发展却还是开放市场下的竞争者。这家公司宣称自己把赌注压到了IoT 上,就像他们已经在“云”上做过的一样。在今年一月底,Canonical 启动了一个基于Ubuntu Core 的小型操作系统,名字叫做 [Ubuntu Snappy Core][1] 。
|
||||
|
||||
Snappy 代表了两种意思,它是一种用来替代 deb 的新的打包格式;也是一个用来更新系统的前端,从CoreOS、红帽子和其他系统借鉴了**原子更新**这个想法。自从树莓派 2 投入市场,Canonical 很快就发布了用于树莓派的Snappy Core 版本。而第一代树莓派因为是基于ARMv6 ,Ubuntu 的ARM 镜像是基于ARMv7 ,所以不能运行ubuntu 。不过这种状况现在改变了,Canonical 通过发布 Snappy Core 的RPI2 镜像,抓住机会证明了Snappy 就是一个用于云计算,特别是用于物联网的系统。
|
||||
|
||||
Snappy 同样可以运行在其它像Amazon EC2, Microsofts Azure, Google的 Compute Engine 这样的云端上,也可以虚拟化在 KVM、Virtuabox 和vagrant 上。Canonical Ubuntu 已经拥抱了微软、谷歌、Docker、OpenStack 这些重量级选手,同时也与一些小项目达成合作关系。除了一些创业公司,比如 Ninja Sphere、Erle Robotics,还有一些开发板生产商,比如 Odroid、Banana Pro, Udoo, PCDuino 和 Parallella 、全志,Snappy 也提供了支持。Snappy Core 同时也希望尽快运行到路由器上来帮助改进路由器生产商目前很少更新固件的策略。
|
||||
|
||||
接下来,让我们看看怎么样在树莓派 2 上运行 Ubuntu Snappy Core。
|
||||
|
||||
用于树莓派2 的Snappy 镜像可以从 [Raspberry Pi 网站][2] 上下载。解压缩出来的镜像必须[写到一个至少8GB 大小的SD 卡][3]。尽管原始系统很小,但是原子升级和回滚功能会占用不小的空间。使用 Snappy 启动树莓派 2 后你就可以使用默认用户名和密码(都是ubuntu)登录系统。
|
||||
|
||||
|
||||
|
||||
sudo 已经配置好了可以直接用,安全起见,你应该使用以下命令来修改你的用户名
|
||||
|
||||
$ sudo usermod -l <new name> <old name>
|
||||
|
||||
或者也可以使用`adduser` 为你添加一个新用户。
|
||||
|
||||
因为RPI缺少硬件时钟,而 Snappy Core 镜像并不知道这一点,所以系统会有一个小 bug:处理某些命令时会报很多错。不过这个很容易解决:
|
||||
|
||||
使用这个命令来确认这个bug 是否影响:
|
||||
|
||||
$ date
|
||||
|
||||
如果输出类似 "Thu Jan 1 01:56:44 UTC 1970", 你可以这样做来改正:
|
||||
|
||||
$ sudo date --set="Sun Apr 04 17:43:26 UTC 2015"
|
||||
|
||||
改成你的实际时间。
|
||||
|
||||

|
||||
|
||||
现在你可能打算检查一下,看看有没有可用的更新。注意通常使用的命令是不行的:
|
||||
|
||||
$ sudo apt-get update && sudo apt-get distupgrade
|
||||
|
||||
这时系统不会让你通过,因为 Snappy 使用它自己精简过的、基于dpkg 的包管理系统。这么做的原因是 Snappy 会运行很多嵌入式程序,而同时你也会试图所有事情尽可能的简化。
|
||||
|
||||
让我们来看看最关键的部分,理解一下程序是如何与 Snappy 工作的。运行 Snappy 的SD 卡上除了 boot 分区外还有3个分区。其中的两个构成了一个重复的文件系统。这两个平行文件系统被固定挂载为只读模式,并且任何时刻只有一个是激活的。第三个分区是一个部分可写的文件系统,用来让用户存储数据。通过更新系统,标记为'system-a' 的分区会保持一个完整的文件系统,被称作核心,而另一个平行的文件系统仍然会是空的。
|
||||
|
||||

|
||||
|
||||
如果我们运行以下命令:
|
||||
|
||||
$ sudo snappy update
|
||||
|
||||
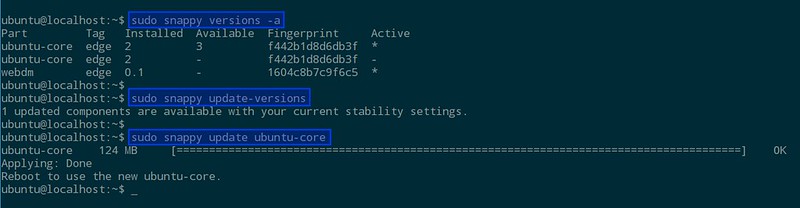
系统将会在'system-b' 上作为一个整体进行更新,这有点像是更新一个镜像文件。接下来你将会被告知要重启系统来激活新核心。
|
||||
|
||||
重启之后,运行下面的命令可以检查你的系统是否已经更新到最新版本,以及当前被激活的是哪个核心
|
||||
|
||||
$ sudo snappy versions -a
|
||||
|
||||
经过更新-重启两步操作,你应该可以看到被激活的核心已经被改变了。
|
||||
|
||||
因为到目前为止我们还没有安装任何软件,所以可以用下面的命令更新:
|
||||
|
||||
$ sudo snappy update ubuntu-core
|
||||
|
||||
如果你打算仅仅更新特定的OS 版本这就够了。如果出了问题,你可以使用下面的命令回滚:
|
||||
|
||||
$ sudo snappy rollback ubuntu-core
|
||||
|
||||
这将会把系统状态回滚到更新之前。
|
||||
|
||||
|
||||
|
||||
再来说说那些让 Snappy 变得有用的软件。这里不会讲的太多关于如何构建软件、向 Snappy 应用商店添加软件的基础知识,但是你可以通过 Freenode 上的IRC 频道 #snappy 了解更多信息,那个上面有很多人参与。你可以通过浏览器访问http://\<ip-address>:4200 来浏览应用商店,然后从商店安装软件,再在浏览器里访问 http://webdm.local 来启动程序。如何构建用于 Snappy 的软件并不难,而且也有了现成的[参考文档][4] 。你也可以很容易的把 DEB 安装包使用Snappy 格式移植到Snappy 上。
|
||||
|
||||
|
||||
|
||||
尽管 Ubuntu Snappy Core 吸引了我们去研究新型的 Snappy 安装包格式和 Canonical 式的原子更新操作,但是因为有限的可用应用,它现在在生产环境里还不是很有用。但是既然搭建一个 Snappy 环境如此简单,这看起来是一个学点新东西的好机会。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/ubuntu-snappy-core-raspberry-pi-2.html
|
||||
|
||||
作者:[Ferdinand Thommes][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/ferdinand
|
||||
[1]:http://www.ubuntu.com/things
|
||||
[2]:http://www.raspberrypi.org/downloads/
|
||||
[3]:http://xmodulo.com/write-raspberry-pi-image-sd-card.html
|
||||
[4]:https://developer.ubuntu.com/en/snappy/
|
||||
@ -1,10 +1,11 @@
|
||||
如何配置MongoDB副本集(Replica Set)
|
||||
如何配置 MongoDB 副本集
|
||||
================================================================================
|
||||
MongoDB已经成为市面上最知名的NoSQL数据库。MongoDB是面向文档的,它的无模式设计使得它在各种各样的WEB应用当中广受欢迎。最让我喜欢的特性之一是它的副本集,副本集将同一数据的多份拷贝放在一组mongod节点上,从而实现数据的冗余以及高可用性。
|
||||
|
||||
这篇教程将向你介绍如何配置一个MongoDB副本集。
|
||||
MongoDB 已经成为市面上最知名的 NoSQL 数据库。MongoDB 是面向文档的,它的无模式设计使得它在各种各样的WEB 应用当中广受欢迎。最让我喜欢的特性之一是它的副本集(Replica Set),副本集将同一数据的多份拷贝放在一组 mongod 节点上,从而实现数据的冗余以及高可用性。
|
||||
|
||||
副本集的最常见配置涉及到一个主节点以及多个副节点。这之后启动的复制行为会从这个主节点到其他副节点。副本集不止可以针对意外的硬件故障和停机事件对数据库提供保护,同时也因为提供了更多的结点从而提高了数据库客户端数据读取的吞吐量。
|
||||
这篇教程将向你介绍如何配置一个 MongoDB 副本集。
|
||||
|
||||
副本集的最常见配置需要一个主节点以及多个副节点。这之后启动的复制行为会从这个主节点到其他副节点。副本集不止可以针对意外的硬件故障和停机事件对数据库提供保护,同时也因为提供了更多的节点从而提高了数据库客户端数据读取的吞吐量。
|
||||
|
||||
### 配置环境 ###
|
||||
|
||||
@ -12,25 +13,25 @@ MongoDB已经成为市面上最知名的NoSQL数据库。MongoDB是面向文档
|
||||
|
||||

|
||||
|
||||
为了达到这个目的,我们使用了3个运行在VirtualBox上的虚拟机。我会在这些虚拟机上安装Ubuntu 14.04,并且安装MongoDB官方包。
|
||||
为了达到这个目的,我们使用了3个运行在 VirtualBox 上的虚拟机。我会在这些虚拟机上安装 Ubuntu 14.04,并且安装 MongoDB 官方包。
|
||||
|
||||
我会在一个虚拟机实例上配置好需要的环境,然后将它克隆到其他的虚拟机实例上。因此,选择一个名为master的虚拟机,执行以下安装过程。
|
||||
我会在一个虚拟机实例上配置好所需的环境,然后将它克隆到其他的虚拟机实例上。因此,选择一个名为 master 的虚拟机,执行以下安装过程。
|
||||
|
||||
首先,我们需要在apt中增加一个MongoDB密钥:
|
||||
首先,我们需要给 apt 增加一个 MongoDB 密钥:
|
||||
|
||||
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
|
||||
|
||||
然后,将官方的MongoDB仓库添加到source.list中:
|
||||
然后,将官方的 MongoDB 仓库添加到 source.list 中:
|
||||
|
||||
$ sudo su
|
||||
# echo "deb http://repo.mongodb.org/apt/ubuntu "$(lsb_release -sc)"/mongodb-org/3.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list
|
||||
|
||||
接下来更新apt仓库并且安装MongoDB。
|
||||
接下来更新 apt 仓库并且安装 MongoDB。
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install -y mongodb-org
|
||||
|
||||
现在对/etc/mongodb.conf做一些更改
|
||||
现在对 /etc/mongodb.conf 做一些更改
|
||||
|
||||
auth = true
|
||||
dbpath=/var/lib/mongodb
|
||||
@ -39,17 +40,17 @@ MongoDB已经成为市面上最知名的NoSQL数据库。MongoDB是面向文档
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
replSet=myReplica
|
||||
|
||||
第一行的作用是确认我们的数据库需要验证才可以使用的。keyfile用来配置用于MongoDB结点间复制行为的密钥文件。replSet用来为副本集设置一个名称。
|
||||
第一行的作用是表明我们的数据库需要验证才可以使用。keyfile 配置用于 MongoDB 节点间复制行为的密钥文件。replSet 为副本集设置一个名称。
|
||||
|
||||
接下来我们创建一个用于所有实例的密钥文件。
|
||||
|
||||
$ echo -n "MyRandomStringForReplicaSet" | md5sum > keyFile
|
||||
|
||||
这将会创建一个含有MD5字符串的密钥文件,但是由于其中包含了一些噪音,我们需要对他们清理后才能正式在MongoDB中使用。
|
||||
这将会创建一个含有 MD5 字符串的密钥文件,但是由于其中包含了一些噪音,我们需要对他们清理后才能正式在 MongoDB 中使用。
|
||||
|
||||
$ echo -n "MyReplicaSetKey" | md5sum|grep -o "[0-9a-z]\+" > keyFile
|
||||
|
||||
grep命令的作用的是把将空格等我们不想要的内容过滤掉之后的MD5字符串打印出来。
|
||||
grep 命令的作用的是把将空格等我们不想要的内容过滤掉之后的 MD5 字符串打印出来。
|
||||
|
||||
现在我们对密钥文件进行一些操作,让它真正可用。
|
||||
|
||||
@ -57,7 +58,7 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
$ sudo chown mongodb:nogroup keyFile
|
||||
$ sudo chmod 400 keyFile
|
||||
|
||||
接下来,关闭此虚拟机。将其Ubuntu系统克隆到其他虚拟机上。
|
||||
接下来,关闭此虚拟机。将其 Ubuntu 系统克隆到其他虚拟机上。
|
||||
|
||||

|
||||
|
||||
@ -67,55 +68,55 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
|
||||
请注意,三个虚拟机示例需要在同一个网络中以便相互通讯。因此,我们需要它们弄到“互联网"上去。
|
||||
|
||||
这里推荐给每个虚拟机设置一个静态IP地址,而不是使用DHCP。这样它们就不至于在DHCP分配IP地址给他们的时候失去连接。
|
||||
这里推荐给每个虚拟机设置一个静态 IP 地址,而不是使用 DHCP。这样它们就不至于在 DHCP 分配IP地址给他们的时候失去连接。
|
||||
|
||||
像下面这样编辑每个虚拟机的/etc/networks/interfaces文件。
|
||||
像下面这样编辑每个虚拟机的 /etc/networks/interfaces 文件。
|
||||
|
||||
在主结点上:
|
||||
在主节点上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.2
|
||||
netmask 255.255.255.0
|
||||
|
||||
在副结点1上:
|
||||
在副节点1上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.3
|
||||
netmask 255.255.255.0
|
||||
|
||||
在副结点2上:
|
||||
在副节点2上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.4
|
||||
netmask 255.255.255.0
|
||||
|
||||
由于我们没有DNS服务,所以需要设置设置一下/etc/hosts这个文件,手工将主机名称放到次文件中。
|
||||
由于我们没有 DNS 服务,所以需要设置设置一下 /etc/hosts 这个文件,手工将主机名称放到此文件中。
|
||||
|
||||
在主结点上:
|
||||
在主节点上:
|
||||
|
||||
127.0.0.1 localhost primary
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
在副结点1上:
|
||||
在副节点1上:
|
||||
|
||||
127.0.0.1 localhost secondary1
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
在副结点2上:
|
||||
在副节点2上:
|
||||
|
||||
127.0.0.1 localhost secondary2
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
使用ping命令检查各个结点之间的连接。
|
||||
使用 ping 命令检查各个节点之间的连接。
|
||||
|
||||
$ ping primary
|
||||
$ ping secondary1
|
||||
@ -123,9 +124,9 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
|
||||
### 配置副本集 ###
|
||||
|
||||
验证各个结点可以正常连通后,我们就可以新建一个管理员用户,用于之后的副本集操作。
|
||||
验证各个节点可以正常连通后,我们就可以新建一个管理员用户,用于之后的副本集操作。
|
||||
|
||||
在主节点上,打开/etc/mongodb.conf文件,将auth和replSet两项注释掉。
|
||||
在主节点上,打开 /etc/mongodb.conf 文件,将 auth 和 replSet 两项注释掉。
|
||||
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
@ -133,21 +134,30 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
#auth = true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
#replSet=myReplica
|
||||
|
||||
在一个新安装的 MongoDB 上配置任何用户或副本集之前,你需要注释掉 auth 行。默认情况下,MongoDB 并没有创建任何用户。而如果在你创建用户前启用了 auth,你就不能够做任何事情。你可以在创建一个用户后再次启用 auth。
|
||||
|
||||
重启mongod进程。
|
||||
修改 /etc/mongodb.conf 之后,重启 mongod 进程。
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
连接MongoDB后,新建管理员用户。
|
||||
现在连接到 MongoDB master:
|
||||
|
||||
$ mongo <master-ip-address>:27017
|
||||
|
||||
连接 MongoDB 后,新建管理员用户。
|
||||
|
||||
> use admin
|
||||
> db.createUser({
|
||||
user:"admin",
|
||||
pwd:"
|
||||
})
|
||||
|
||||
重启 MongoDB:
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
连接到MongoDB,用以下命令将secondary1和secondary2节点添加到我们的副本集中。
|
||||
再次连接到 MongoDB,用以下命令将 副节点1 和副节点2节点添加到我们的副本集中。
|
||||
|
||||
> use admin
|
||||
> db.auth("admin","myreallyhardpassword")
|
||||
@ -156,7 +166,7 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
> rs.add("secondary2:27017")
|
||||
|
||||
|
||||
现在副本集到手了,可以开始我们的项目了。参照 [official driver documentation][1] 来了解如何连接到副本集。如果你想要用Shell来请求数据,那么你需要连接到主节点上来插入或者请求数据,副节点不行。如果你执意要尝试用附件点操作,那么以下错误信息就蹦出来招呼你了。
|
||||
现在副本集到手了,可以开始我们的项目了。参照 [官方驱动文档][1] 来了解如何连接到副本集。如果你想要用 Shell 来请求数据,那么你需要连接到主节点上来插入或者请求数据,副节点不行。如果你执意要尝试用副本集操作,那么以下错误信息就蹦出来招呼你了。
|
||||
|
||||
myReplica:SECONDARY>
|
||||
myReplica:SECONDARY> show databases
|
||||
@ -166,6 +176,12 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
at shellHelper.show (src/mongo/shell/utils.js:630:33)
|
||||
at shellHelper (src/mongo/shell/utils.js:524:36)
|
||||
at (shellhelp2):1:1 at src/mongo/shell/mongo.js:47
|
||||
|
||||
如果你要从 shell 连接到整个副本集,你可以安装如下命令。在副本集中的失败切换是自动的。
|
||||
|
||||
$ mongo primary,secondary1,secondary2:27017/?replicaSet=myReplica
|
||||
|
||||
如果你使用其它驱动语言(例如,JavaScript、Ruby 等等),格式也许不同。
|
||||
|
||||
希望这篇教程能对你有所帮助。你可以使用Vagrant来自动完成你的本地环境配置,并且加速你的代码。
|
||||
|
||||
@ -175,7 +191,7 @@ via: http://xmodulo.com/setup-replica-set-mongodb.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
在 VirtualBox 中使用 Docker Machine 管理主机
|
||||
================================================================================
|
||||
大家好,今天我们学习在 VirtualBox 中使用 Docker Machine 来创建和管理 Docker 主机。Docker Machine 是一个可以帮助我们在电脑上、在云端、在数据中心内创建 Docker 主机的应用。它为根据用户的配置和需求创建服务器并在其上安装 Docker和客户端提供了一个轻松的解决方案。这个 API 可以用于在本地主机、或数据中心的虚拟机、或云端的实例提供 Docker 服务。Docker Machine 支持 Windows、OSX 和 Linux,并且是以一个独立的二进制文件包形式安装的。仍然使用(与现有 Docker 工具)相同的接口,我们就可以充分利用已经提供 Docker 基础框架的生态系统。只要一个命令,用户就能快速部署 Docker 容器。
|
||||
|
||||
本文列出一些简单的步骤用 Docker Machine 来部署 docker 容器。
|
||||
|
||||
### 1. 安装 Docker Machine ###
|
||||
|
||||
Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [github][1] 下载最新版本的 Docker Machine,本文使用 curl 作为下载工具,Docker Machine 版本为 0.2.0。
|
||||
|
||||
**64 位操作系统**
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
**32 位操作系统**
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
下载完成后,找到 **/usr/local/bin** 目录下的 **docker-machine** 文件,让其可以执行:
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
确认是否成功安装了 docker-machine,可以运行下面的命令,它会打印 Docker Machine 的版本信息:
|
||||
|
||||
# docker-machine -v
|
||||
|
||||

|
||||
|
||||
运行下面的命令,安装 Docker 客户端,以便于在我们自己的电脑止运行 Docker 命令:
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. 创建 VirtualBox 虚拟机 ###
|
||||
|
||||
在 Linux 系统上安装完 Docker Machine 后,接下来我们可以安装 VirtualBox 虚拟机,运行下面的就可以了。`--driver virtualbox` 选项表示我们要在 VirtualBox 的虚拟机里面部署 docker,最后的参数“linux” 是虚拟机的名称。这个命令会下载 [boot2docker][2] iso,它是个基于 Tiny Core Linux 的轻量级发行版,自带 Docker 程序,然后 `docker-machine` 命令会创建一个 VirtualBox 虚拟机(LCTT译注:当然,我们也可以选择其他的虚拟机软件)来运行这个 boot2docker 系统。
|
||||
|
||||
# docker-machine create --driver virtualbox linux
|
||||
|
||||

|
||||
|
||||
测试下有没有成功运行 VirtualBox 和 Docker,运行命令:
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
如果执行成功,我们可以看到在 ACTIVE 那列下面会出现一个星号“*”。
|
||||
|
||||
### 3. 设置环境变量 ###
|
||||
|
||||
现在我们需要让 docker 与 docker-machine 通信,运行 `docker-machine env <虚拟机名称>` 来实现这个目的。
|
||||
|
||||
# eval "$(docker-machine env linux)"
|
||||
# docker ps
|
||||
|
||||
这个命令会设置 TLS 认证的环境变量,每次重启机器或者重新打开一个会话都需要执行一下这个命令,我们可以看到它的输出内容:
|
||||
|
||||
# docker-machine env linux
|
||||
|
||||
export DOCKER_TLS_VERIFY=1
|
||||
export DOCKER_CERT_PATH=/Users/<your username>/.docker/machine/machines/dev
|
||||
export DOCKER_HOST=tcp://192.168.99.100:2376
|
||||
|
||||
### 4. 运行 Docker 容器 ###
|
||||
|
||||
完成配置后我们就可以在 VirtualBox 上运行 docker 容器了。测试一下,我们可以运行虚拟机 `docker run busybox` ,并在里面里执行 `echo hello world` 命令,我们可以看到容器的输出信息。
|
||||
|
||||
# docker run busybox echo hello world
|
||||
|
||||

|
||||
|
||||
### 5. 拿到 Docker 主机的 IP ###
|
||||
|
||||
我们可以执行下面的命令获取运行 Docker 的主机的 IP 地址。我们可以看到在 Docker 主机的 IP 地址上的任何暴露出来的端口。
|
||||
|
||||
# docker-machine ip
|
||||
|
||||

|
||||
|
||||
### 6. 管理主机 ###
|
||||
|
||||
现在我们可以随心所欲地使用上述的 docker-machine 命令来不断创建主机了。
|
||||
|
||||
当你使用完 docker 时,可以运行 **docker-machine stop** 来停止所有主机,如果想开启所有主机,运行 **docker-machine start**。
|
||||
|
||||
# docker-machine stop
|
||||
# docker-machine start
|
||||
|
||||
你也可以只停止或开启一台主机:
|
||||
|
||||
$ docker-machine stop linux
|
||||
$ docker-machine start linux
|
||||
|
||||
### 总结 ###
|
||||
|
||||
最后,我们使用 Docker Machine 成功在 VirtualBox 上创建并管理一台 Docker 主机。Docker Machine 确实能让用户快速地在不同的平台上部署 Docker 主机,就像我们这里部署在 VirtualBox 上一样。这个 virtualbox 驱动可以在本地机器上使用,也可以在数据中心的虚拟机上使用。Docker Machine 驱动除了支持本地的 VirtualBox 之外,还支持远端的 Digital Ocean、AWS、Azure、VMware 以及其它基础设施。
|
||||
|
||||
如果你有任何疑问,或者建议,请在评论栏中写出来,我们会不断改进我们的内容。谢谢,祝愉快。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/host-virtualbox-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://github.com/docker/machine/releases
|
||||
[2]:https://github.com/boot2docker/boot2docker
|
||||
@ -1,24 +1,24 @@
|
||||
Trickr:一个开源的Linux桌面RSS新闻速递
|
||||
Tickr:一个开源的 Linux 桌面 RSS 新闻速递应用
|
||||
================================================================================
|
||||

|
||||
|
||||
**最新的!最新的!阅读关于它的一切!**
|
||||
|
||||
好了,所以我们今天要强调的应用程序不是相当于旧报纸的二进制版本—而是它会以一个伟大的方式,将最新的新闻推送到你的桌面上。
|
||||
好了,我们今天要推荐的应用程序可不是旧式报纸的二进制版本——它会以一种漂亮的方式将最新的新闻推送到你的桌面上。
|
||||
|
||||
Tick是一个基于GTK的Linux桌面新闻速递,能够在水平带滚动显示最新头条新闻,以及你最爱的RSS资讯文章标题,当然你可以放置在你桌面的任何地方。
|
||||
Tickr 是一个基于 GTK 的 Linux 桌面新闻速递应用,能够以横条方式滚动显示最新头条新闻以及你最爱的RSS资讯文章标题,当然你可以放置在你桌面的任何地方。
|
||||
|
||||
请叫我Joey Calamezzo;我把我的放在底部,有电视新闻台的风格。
|
||||
请叫我 Joey Calamezzo;我把它放在底部,就像电视新闻台的滚动字幕一样。 (LCTT 译注: Joan Callamezzo 是 Pawnee Today 的主持人,一位 Pawnee 的本地新闻/脱口秀主持人。而本文作者是 Joey。)
|
||||
|
||||
“到你了,子标题”
|
||||
“到你了,副标题”。
|
||||
|
||||
### RSS -还记得吗? ###
|
||||
|
||||
“谢谢段落结尾。”
|
||||
“谢谢,这段结束了。”
|
||||
|
||||
在一个推送通知,社交媒体,以及点击诱饵的时代,哄骗我们阅读最新的令人惊奇的,人人都爱读的清单,RSS看起来有一点过时了。
|
||||
在一个充斥着推送通知、社交媒体、标题党,以及哄骗人们点击的清单体的时代,RSS看起来有一点过时了。
|
||||
|
||||
对我来说?恩,RSS是名副其实的真正简单的聚合。这是将消息通知给我的最简单,最易于管理的方式。我可以在我愿意的时候,管理和阅读一些东西;没必要匆忙的去看,以防这条微博消失在信息流中,或者推送通知消失。
|
||||
对我来说呢?恩,RSS是名副其实的真正简单的聚合(RSS : Really Simple Syndication)。这是将消息通知给我的最简单、最易于管理的方式。我可以在我愿意的时候,管理和阅读一些东西;没必要匆忙的去看,以防这条微博消失在信息流中,或者推送通知消失。
|
||||
|
||||
tickr的美在于它的实用性。你可以不断地有新闻滚动在屏幕的底部,然后不时地瞥一眼。
|
||||
|
||||
@ -32,31 +32,30 @@ tickr的美在于它的实用性。你可以不断地有新闻滚动在屏幕的
|
||||
|
||||
尽管虽然tickr可以从Ubuntu软件中心安装,然而它已经很久没有更新了。当你打开笨拙的不直观的控制面板的时候,没有什么能够比这更让人感觉被遗弃的了。
|
||||
|
||||
打开它:
|
||||
要打开它:
|
||||
|
||||
1. 右键单击tickr条
|
||||
1. 转至编辑>首选项
|
||||
1. 调整各种设置
|
||||
|
||||
选项和设置行的后面,有些似乎是容易理解的。但是知己知彼你能够几乎掌控一切,包括:
|
||||
选项和设置行的后面,有些似乎是容易理解的。但是详细了解这些你才能够掌握一切,包括:
|
||||
|
||||
- 设置滚动速度
|
||||
- 选择鼠标经过时的行为
|
||||
- 资讯更新频率
|
||||
- 字体,包括字体大小和颜色
|
||||
- 分隔符(“delineator”)
|
||||
- 消息分隔符(“delineator”)
|
||||
- tickr在屏幕上的位置
|
||||
- tickr条的颜色和不透明度
|
||||
- 选择每种资讯显示多少文章
|
||||
|
||||
有个值得一提的“怪癖”是,当你点击“应用”按钮,只会更新tickr的屏幕预览。当您退出“首选项”窗口时,请单击“确定”。
|
||||
|
||||
想要滚动条在你的显示屏上水平显示,也需要公平一点的调整,特别是统一显示。
|
||||
想要得到完美的显示效果, 你需要一点点调整,特别是在 Unity 上。
|
||||
|
||||
按下“全宽按钮”,能够让应用程序自动检测你的屏幕宽度。默认情况下,当放置在顶部或底部时,会留下25像素的间距(应用程序被创建在过去的GNOME2.x桌面)。只需添加额外的25像素到输入框,来弥补这个问题。
|
||||
按下“全宽按钮”,能够让应用程序自动检测你的屏幕宽度。默认情况下,当放置在顶部或底部时,会留下25像素的间距(应用程序以前是在GNOME2.x桌面上创建的)。只需添加额外的25像素到输入框,来弥补这个问题。
|
||||
|
||||
其他可供选择的选项包括:选择文章在哪个浏览器打开;tickr是否以一个常规的窗口出现;
|
||||
是否显示一个时钟;以及应用程序多久检查一次文章资讯。
|
||||
其他可供选择的选项包括:选择文章在哪个浏览器打开;tickr是否以一个常规的窗口出现;是否显示一个时钟;以及应用程序多久检查一次文章资讯。
|
||||
|
||||
#### 添加资讯 ####
|
||||
|
||||
@ -76,9 +75,9 @@ tickr自带的有超过30种不同的资讯列表,从技术博客到主流新
|
||||
|
||||
### 在Ubuntu 14.04 LTS或更高版本上安装Tickr ###
|
||||
|
||||
在Ubuntu 14.04 LTS或更高版本上安装Tickr
|
||||
这就是 Tickr,它不会改变世界,但是它能让你知道世界上发生了什么。
|
||||
|
||||
在Ubuntu 14.04 LTS或更高版本中安装,转到Ubuntu软件中心,但要点击下面的按钮。
|
||||
在Ubuntu 14.04 LTS或更高版本中安装,点击下面的按钮转到Ubuntu软件中心。
|
||||
|
||||
- [点击此处进入Ubuntu软件中心安装tickr][1]
|
||||
|
||||
@ -88,7 +87,7 @@ via: http://www.omgubuntu.co.uk/2015/06/tickr-open-source-desktop-rss-news-ticke
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -7,7 +7,7 @@
|
||||
|
||||
这是一个基本扯平的方面。每一个桌面环境都有一些非常好的应用,也有一些不怎么样的。再次强调,Gnome 把那些 KDE 完全错失的小细节给做对了。我不是想说 KDE 中有哪些应用不好。他们都能工作,但仅此而已。也就是说:它们合格了,但确实还没有达到甚至接近100分。
|
||||
|
||||
Gnome 是一个样子,KDE 是另外一种。Dragon 播放器运行得很好,清晰的标出了播放文件、URL或和光盘的按钮,正如你在 Gnome Videos 中能做到的一样……但是在便利的文件名和用户的友好度方面,Gnome 多走了一小步。它默认显示了在你的电脑上检测到的所有影像文件,不需要你做任何事情。KDE 有 [Baloo][](正如之前的 [Nepomuk][2],LCTT 译注:这是 KDE 中一种文件索引服务框架)为什么不使用它们?它们能列出可读取的影像文件……但却没被使用。
|
||||
Gnome 在左,KDE 在右。Dragon 播放器运行得很好,清晰的标出了播放文件、URL或和光盘的按钮,正如你在 Gnome Videos 中能做到的一样……但是在便利的文件名和用户的友好度方面,Gnome 多走了一小步。它默认显示了在你的电脑上检测到的所有影像文件,不需要你做任何事情。KDE 有 [Baloo][](正如之前的 [Nepomuk][2],LCTT 译注:这是 KDE 中一种文件索引服务框架)为什么不使用它们?它们能列出可读取的影像文件……但却没被使用。
|
||||
|
||||
下一步……音乐播放器
|
||||
|
||||
@ -0,0 +1,52 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第四节 GNOME设置)
|
||||
================================================================================
|
||||
|
||||
### 设置 ###
|
||||
|
||||
在这我要挑一挑几个特定 KDE 控制模块的毛病,大部分原因是因为相比它们的对手GNOME来说,糟糕得太可笑,实话说,真是悲哀。
|
||||
|
||||
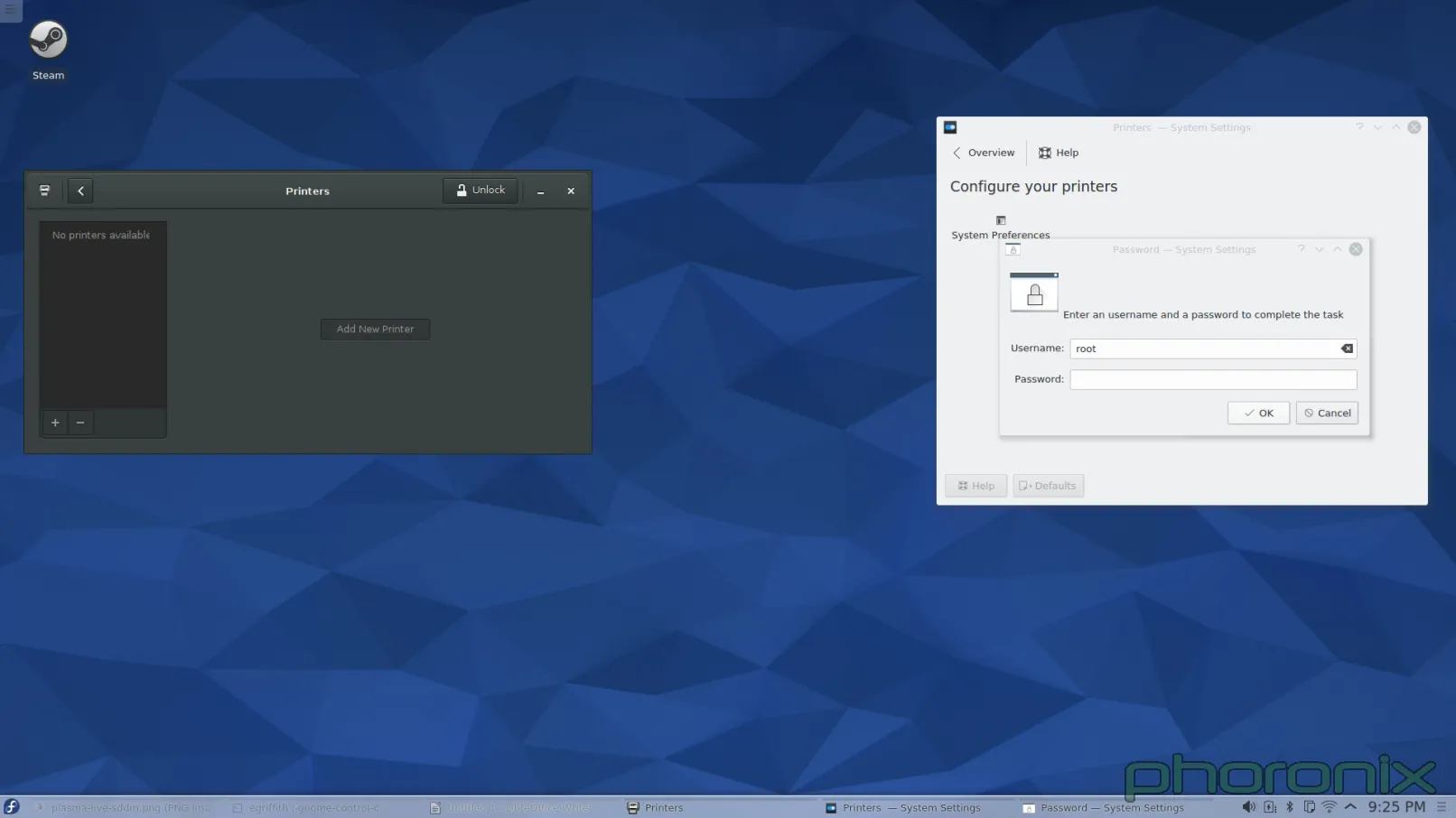
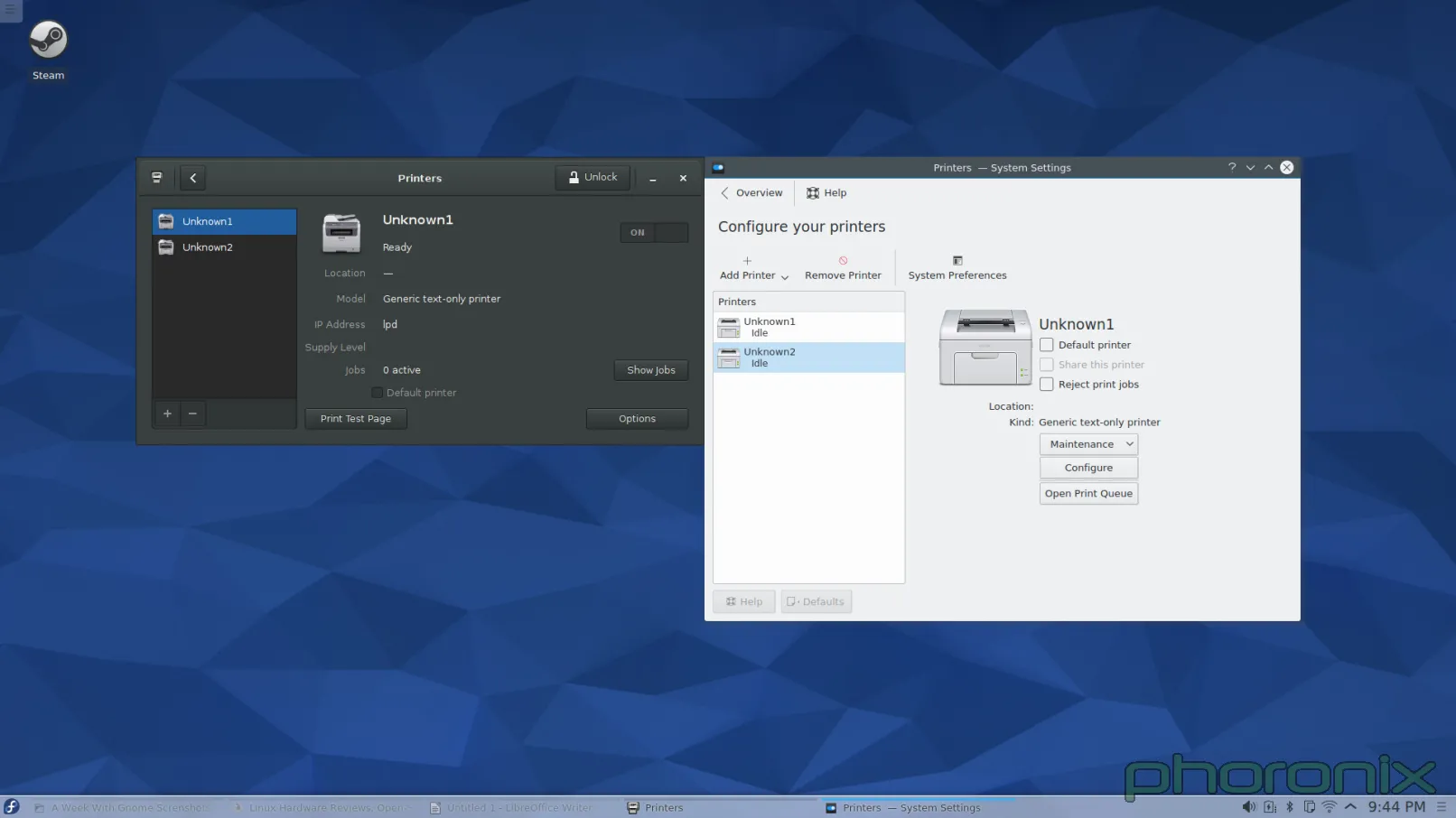
第一个接招的?打印机。
|
||||
|
||||
|
||||
|
||||
GNOME 在左,KDE 在右。你知道左边跟右边的打印程序有什么区别吗?当我在 GNOME 控制中心打开“打印机”时,程序窗口弹出来了,然后这样就可以使用了。而当我在 KDE 系统设置打开“打印机”时,我得到了一条密码提示。甚至我都没能看一眼打印机呢,我就必须先交出 ROOT 密码。
|
||||
|
||||
让我再重复一遍。在今天这个有了 PolicyKit 和 Logind 的日子里,对一个应该是 sudo 的操作,我依然被询问要求 ROOT 的密码。我安装系统的时候甚至都没设置 root 密码。所以我必须跑到 Konsole 去,接着运行 'sudo passwd root' 命令,这样我才能给 root 设一个密码,然后我才能回到系统设置中的打印程序,再交出 root 密码,然后仅仅是看一看哪些打印机可用。完成了这些工作后,当我点击“添加打印机”时,我再次得到请求 ROOT 密码的提示,当我解决了它后再选择一个打印机和驱动时,我再次得到请求 ROOT 密码的提示。仅仅是为了添加一个打印机到系统我就收到三次密码请求!
|
||||
|
||||
而在 GNOME 下添加打印机,在点击打印机程序中的“解锁”之前,我没有得到任何请求 SUDO 密码的提示。整个过程我只被请求过一次,仅此而已。KDE,求你了……采用 GNOME 的“解锁”模式吧。不到一定需要的时候不要发出提示。还有,不管是哪个库,只要它允许 KDE 应用程序绕过 PolicyKit/Logind(如果有的话)并直接请求 ROOT 权限……那就把它封进箱里吧。如果这是个多用户系统,那我要么必须交出 ROOT 密码,要么我必须时时刻刻待命,以免有一个用户需要升级、更改或添加一个新的打印机。而这两种情况都是完全无法接受的。
|
||||
|
||||
有还一件事……
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
这个问题问大家:怎么样看起来更简洁?我在写这篇文章时意识到:当有任何附加的打印机准备好时,Gnome 打印机程序会把过程做得非常简洁,它们在左边上放了一个竖直栏来列出这些打印机。而我在 KDE 中添加第二台打印机时,它突然增加出一个左边栏来。而在添加之前,我脑海中已经有了一个恐怖的画面,它会像图片文件夹显示预览图一样直接在界面里插入另外一个图标。我很高兴也很惊讶的看到我是错的。但是事实是它直接“长出”另外一个从未存在的竖直栏,彻底改变了它的界面布局,而这样也称不上“好”。终究还是一种令人困惑,奇怪而又不直观的设计。
|
||||
|
||||
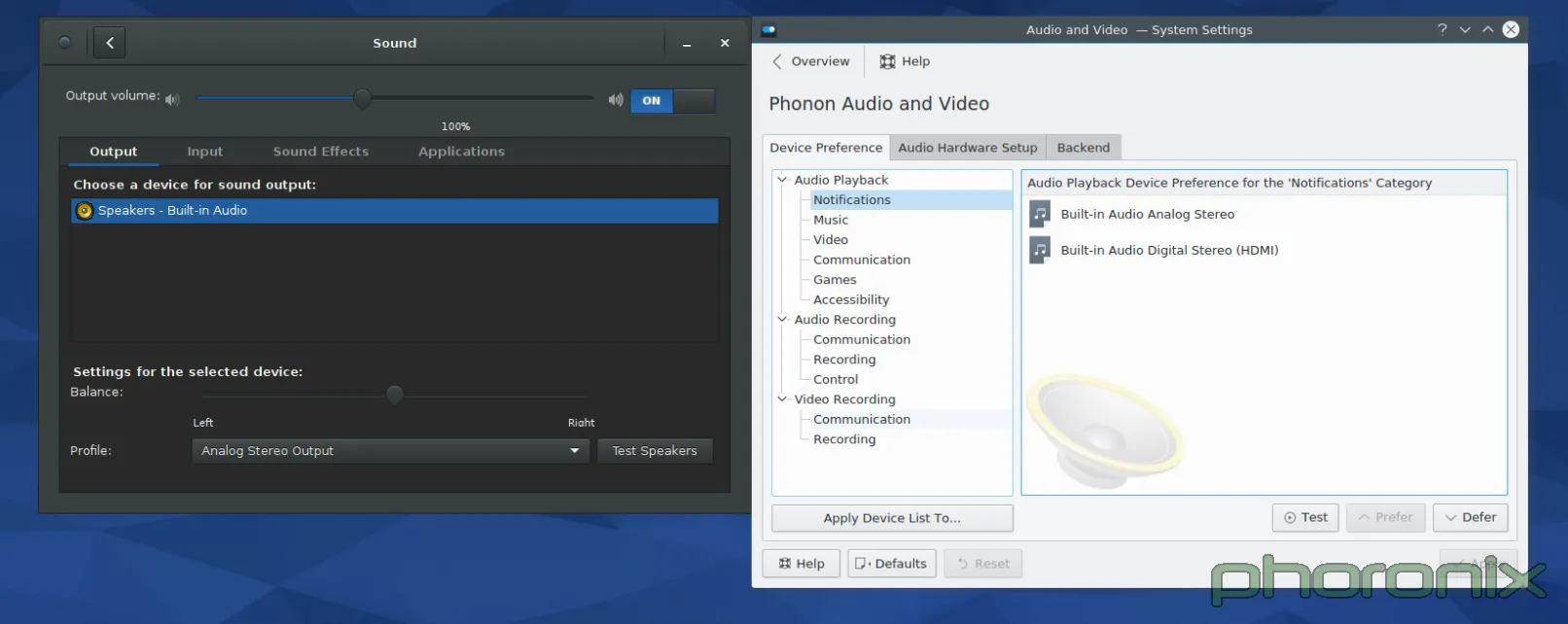
打印机说得够多了……下一个接受我公开石刑的 KDE 系统设置是?多媒体,即 Phonon。
|
||||
|
||||
|
||||
|
||||
一如既往,GNOME 在左边,KDE 在右边。让我们先看看 GNOME 的系统设置先……眼睛移动是从左到右,从上到下,对吧?来吧,就这样做。首先:音量控制滑条。滑条中的蓝色条与空条百分百清晰地消除了哪边是“音量增加”的困惑。在音量控制条后马上就是一个 On/Off 开关,用来开关静音功能。Gnome 的再次得分在于静音后能记住当前设置的音量,而在点击音量增加按钮取消静音后能回到原来设置的音量中来。Kmixer,你个健忘的垃圾,我真的希望我能多讨论你一下。
|
||||
|
||||
继续!输入输出和应用程序的标签选项?每一个应用程序的音量随时可控?Gnome,每过一秒,我爱你越深。音量均衡选项、声音配置、和清晰地标上标志的“测试麦克风”选项。
|
||||
|
||||
我不清楚它能否以一种更干净更简洁的设计实现。是的,它只是一个 Gnome 化的 Pavucontrol,但我想这就是重要的地方。Pavucontrol 在这方面几乎完全做对了,Gnome 控制中心中的“声音”应用程序的改善使它向完美更进了一步。
|
||||
|
||||
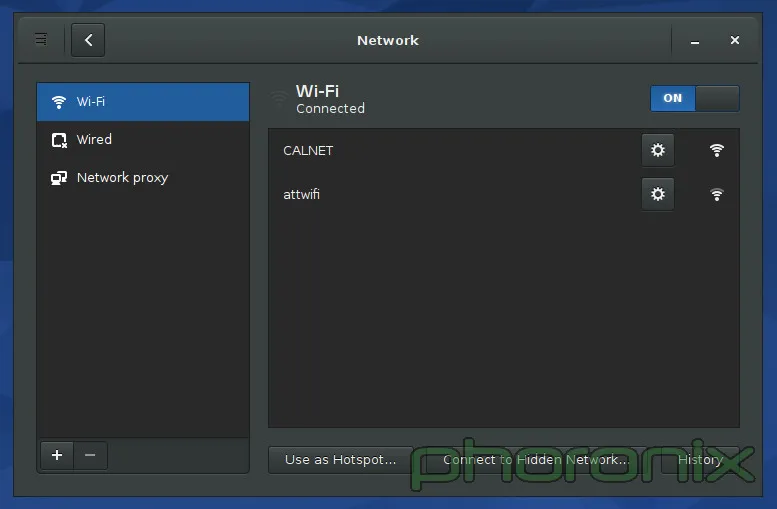
Phonon,该你上了。但开始前我想说:我 TM 看到的是什么?!我知道我看到的是音频设备的优先级列表,但是它呈现的方式有点太坑。还有,那些用户可能关心的那些东西哪去了?拥有一个优先级列表当然很好,它也应该存在,但问题是优先级列表属于那种用户乱搞一两次之后就不会再碰的东西。它还不够重要,或者说不够常用到可以直接放在正中间位置的程度。音量控制滑块呢?对每个应用程序的音量控制功能呢?那些用户使用最频繁的东西呢?好吧,它们在 Kmix 中,一个分离的程序,拥有它自己的配置选项……而不是在系统设置下……这样真的让“系统设置”这个词变得有点用词不当。
|
||||
|
||||
|
||||
|
||||
上面展示的 Gnome 的网络设置。KDE 的没有展示,原因就是我接下来要吐槽的内容了。如果你进入 KDE 的系统设置里,然后点击“网络”区域中三个选项中的任何一个,你会得到一大堆的选项:蓝牙设置、Samba 分享的默认用户名和密码(说真的,“连通性(Connectivity)”下面只有两个选项:SMB 的用户名和密码。TMD 怎么就配得上“连通性”这么大的词?),浏览器身份验证控制(只有 Konqueror 能用……一个已经倒闭的项目),代理设置,等等……我的 wifi 设置哪去了?它们没在这。哪去了?好吧,它们在网络应用程序的设置里面……而不是在网络设置里……
|
||||
|
||||
KDE,你这是要杀了我啊,你有“系统设置”当凶器,拿着它动手吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=4
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,40 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第三节 总结)
|
||||
================================================================================
|
||||
|
||||
### 用户体验和最后想法 ###
|
||||
|
||||
当 Gnome 2.x 和 KDE 4.x 要正面交锋时……我在它们之间左右逢源。我对它们爱恨交织,但总的来说它们使用起来还算是一种乐趣。然后 Gnome 3.x 来了,带着一场 Gnome Shell 的戏剧。那时我就放弃了 Gnome,我尽我所能的避开它。当时它对用户是不友好的,而且不直观,它打破了原有的设计典范,只为平板的统治世界做准备……而根据平板下跌的销量来看,这样的未来不可能实现。
|
||||
|
||||
在 Gnome 3 后续发布了八个版本后,奇迹发生了。Gnome 变得对对用户友好了,变得直观了。它完美吗?当然不。我还是很讨厌它想推动的那种设计范例,我讨厌它总想给我强加一种工作流(work flow),但是在付出时间和耐心后,这两都能被接受。只要你能够回头去看看 Gnome Shell 那外星人一样的界面,然后开始跟 Gnome 的其它部分(特别是控制中心)互动,你就能发现 Gnome 绝对做对了:细节,对细节的关注!
|
||||
|
||||
人们能适应新的界面设计范例,能适应新的工作流—— iPhone 和 iPad 都证明了这一点——但真正让他们操心的一直是“纸割”——那些不完美的细节。
|
||||
|
||||
它带出了 KDE 和 Gnome 之间最重要的一个区别。Gnome 感觉像一个产品,像一种非凡的体验。你用它的时候,觉得它是完整的,你要的东西都触手可及。它让人感觉就像是一个拥有 Windows 或者 OS X 那样桌面体验的 Linux 桌面版:你要的都在里面,而且它是被同一个目标一致的团队中的同一个人写出来的。天,即使是一个应用程序发出的 sudo 请求都感觉是 Gnome 下的一个特意设计的部分,就像在 Windows 下的一样。而在 KDE 下感觉就是随便一个应用程序都能创建的那种各种外观的弹窗。它不像是以系统本身这样的正式身份停下来说“嘿,有个东西要请求管理员权限!你要给它吗?”。
|
||||
|
||||
KDE 让人体验不到有凝聚力的体验。KDE 像是在没有方向地打转,感觉没有完整的体验。它就像是一堆东西往不同的的方向移动,只不过恰好它们都有一个共同享有的工具包而已。如果开发者对此很开心,那么好吧,他们开心就好,但是如果他们想提供最好体验的话,那么就需要多关注那些小地方了。用户体验跟直观应当做为每一个应用程序的设计中心,应当有一个视野,知道 KDE 要提供什么——并且——知道它看起来应该是什么样的。
|
||||
|
||||
是不是有什么原因阻止我在 KDE 下使用 Gnome 磁盘管理? Rhythmbox 呢? Evolution 呢? 没有,没有,没有。但是这样说又错过了关键。Gnome 和 KDE 都称它们自己为“桌面环境”。那么它们就应该是完整的环境,这意味着他们的各个部件应该汇集并紧密结合在一起,意味着你应该使用它们环境下的工具,因为它们说“您在一个完整的桌面中需要的任何东西,我们都支持。”说真的?只有 Gnome 看起来能符合完整的要求。KDE 在“汇集在一起”这一方面感觉就像个半成品,更不用说提供“完整体验”中你所需要的东西。Gnome 磁盘管理没有相应的对手—— kpartionmanage 要求 ROOT 权限。KDE 不运行“首次用户注册”的过程(原文:No 'First Time User' run through。可能是指系统安装过程中KDE没有创建新用户的过程,译注) ,现在也不过是在 Kubuntu 下引入了一个用户管理器。老天,Gnome 甚至提供了地图、笔记、日历和时钟应用。这些应用都是百分百要紧的吗?不,当然不了。但是正是这些应用帮助 Gnome 推动“Gnome 是一种完整丰富的体验”的想法。
|
||||
|
||||
我吐槽的 KDE 问题并非不可能解决,决对不是这样的!但是它需要人去关心它。它需要开发者为他们的作品感到自豪,而不仅仅是为它们实现的功能而感到自豪——组织的价值可大了去了。别夺走用户设置选项的能力—— GNOME 3.x 就是因为缺乏配置选项的能力而为我所诟病,但别把“好吧,你想怎么设置就怎么设置”作为借口而不提供任何理智的默认设置。默认设置是用户将看到的东西,它们是用户从打开软件的第一刻开始进行评判的关键。给用户留个好印象吧。
|
||||
|
||||
我知道 KDE 开发者们知道设计很重要,这也是为什么VDG(Visual Design Group 视觉设计组)存在的原因,但是感觉好像他们没有让 VDG 充分发挥,所以 KDE 里存在组织上的缺陷。不是 KDE 没办法完整,不是它没办法汇集整合在一起然后解决衰败问题,只是开发者们没做到。他们瞄准了靶心……但是偏了。
|
||||
|
||||
还有,在任何人说这句话之前……千万别说“欢迎给我们提交补丁啊"。因为当我开心的为某个人提交补丁时,只要开发者坚持以他们喜欢的却不直观的方式干事,更多这样的烦人事就会不断发生。这不关 Muon 有没有中心对齐。也不关 Amarok 的界面太丑。也不关每次我敲下快捷键后,弹出的音量和亮度调节窗口占用了我一大块的屏幕“地皮”(说真的,有人会把这些东西缩小)。
|
||||
|
||||
这跟心态的冷漠有关,跟开发者们在为他们的应用设计 UI 时根本就不多加思考有关。KDE 团队做的东西都工作得很好。Amarok 能播放音乐。Dragon 能播放视频。Kwin 或 Qt 和 kdelibs 似乎比 Mutter/gtk 更有力更效率(仅根据我的电池电量消耗计算。非科学性测试)。这些都很好,很重要……但是它们呈现的方式也很重要。甚至可以说,呈现方式是最重要的,因为它是用户看到的并与之交互的东西。
|
||||
|
||||
KDE 应用开发者们……让 VDG 参与进来吧。让 VDG 审查并核准每一个“核心”应用,让一个 VDG 的 UI/UX 专家来设计应用的使用模式和使用流程,以此保证其直观性。真见鬼,不管你们在开发的是啥应用,仅仅把它的模型发到 VDG 论坛寻求反馈甚至都可能都能得到一些非常好的指点跟反馈。你有这么好的资源在这,现在赶紧用吧。
|
||||
|
||||
我不想说得好像我一点都不懂感恩。我爱 KDE,我爱那些志愿者们为了给 Linux 用户一个可视化的桌面而付出的工作与努力,也爱可供选择的 Gnome。正是因为我关心我才写这篇文章。因为我想看到更好的 KDE,我想看到它走得比以前更加遥远。而这样做需要每个人继续努力,并且需要人们不再躲避批评。它需要人们对系统互动及系统崩溃的地方都保持诚实。如果我们不能直言批评,如果我们不说“这真垃圾!”,那么情况永远不会变好。
|
||||
|
||||
这周后我会继续使用 Gnome 吗?可能不。应该不。Gnome 还在试着强迫我接受其工作流,而我不想追随,也不想遵循,因为我在使用它的时候感觉变得不够高效,因为它并不遵循我的思维模式。可是对于我的朋友们,当他们问我“我该用哪种桌面环境?”我可能会推荐 Gnome,特别是那些不大懂技术,只要求“能工作”就行的朋友。根据目前 KDE 的形势来看,这可能是我能说出的最狠毒的评估了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=5
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,146 @@
|
||||
如何使用 Datadog 监控 NGINX(第三篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
如果你已经阅读了前面的[如何监控 NGINX][1],你应该知道从你网络环境的几个指标中可以获取多少信息。而且你也看到了从 NGINX 特定的基础中收集指标是多么容易的。但要实现全面,持续的监控 NGINX,你需要一个强大的监控系统来存储并将指标可视化,当异常发生时能提醒你。在这篇文章中,我们将向你展示如何使用 Datadog 安装 NGINX 监控,以便你可以在定制的仪表盘中查看这些指标:
|
||||
|
||||

|
||||
|
||||
Datadog 允许你以单个主机、服务、流程和度量来构建图形和警告,或者使用它们的几乎任何组合构建。例如,你可以监控你的所有主机,或者某个特定可用区域的所有NGINX主机,或者您可以监视具有特定标签的所有主机的一个关键指标。本文将告诉您如何:
|
||||
|
||||
- 在 Datadog 仪表盘上监控 NGINX 指标,就像监控其他系统一样
|
||||
- 当一个关键指标急剧变化时设置自动警报来通知你
|
||||
|
||||
### 配置 NGINX ###
|
||||
|
||||
为了收集 NGINX 指标,首先需要确保 NGINX 已启用 status 模块和一个 报告 status 指标的 URL。一步步的[配置开源 NGINX][2] 和 [NGINX Plus][3] 请参见之前的相关文章。
|
||||
|
||||
### 整合 Datadog 和 NGINX ###
|
||||
|
||||
#### 安装 Datadog 代理 ####
|
||||
|
||||
Datadog 代理是[一个开源软件][4],它能收集和报告你主机的指标,这样就可以使用 Datadog 查看和监控他们。安装这个代理通常[仅需要一个命令][5]
|
||||
|
||||
只要你的代理启动并运行着,你会看到你主机的指标报告[在你 Datadog 账号下][6]。
|
||||
|
||||

|
||||
|
||||
#### 配置 Agent ####
|
||||
|
||||
接下来,你需要为代理创建一个简单的 NGINX 配置文件。在你系统中代理的配置目录应该[在这儿][7]找到。
|
||||
|
||||
在目录里面的 conf.d/nginx.yaml.example 中,你会发现[一个简单的配置文件][8],你可以编辑并提供 status URL 和可选的标签为每个NGINX 实例:
|
||||
|
||||
init_config:
|
||||
|
||||
instances:
|
||||
|
||||
- nginx_status_url: http://localhost/nginx_status/
|
||||
tags:
|
||||
- instance:foo
|
||||
|
||||
当你提供了 status URL 和任意 tag,将配置文件保存为 conf.d/nginx.yaml。
|
||||
|
||||
#### 重启代理 ####
|
||||
|
||||
你必须重新启动代理程序来加载新的配置文件。重新启动命令[在这里][9],根据平台的不同而不同。
|
||||
|
||||
#### 检查配置文件 ####
|
||||
|
||||
要检查 Datadog 和 NGINX 是否正确整合,运行 Datadog 的 info 命令。每个平台使用的命令[看这儿][10]。
|
||||
|
||||
如果配置是正确的,你会看到这样的输出:
|
||||
|
||||
Checks
|
||||
======
|
||||
|
||||
[...]
|
||||
|
||||
nginx
|
||||
-----
|
||||
- instance #0 [OK]
|
||||
- Collected 8 metrics & 0 events
|
||||
|
||||
#### 安装整合 ####
|
||||
|
||||
最后,在你的 Datadog 帐户打开“Nginx 整合”。这非常简单,你只要在 [NGINX 整合设置][11]中点击“Install Integration”按钮。
|
||||
|
||||

|
||||
|
||||
### 指标! ###
|
||||
|
||||
一旦代理开始报告 NGINX 指标,你会看到[一个 NGINX 仪表盘][12]出现在在你 Datadog 可用仪表盘的列表中。
|
||||
|
||||
基本的 NGINX 仪表盘显示有用的图表,囊括了几个[我们的 NGINX 监控介绍][13]中的关键指标。 (一些指标,特别是请求处理时间要求进行日志分析,Datadog 不支持。)
|
||||
|
||||
你可以通过增加 NGINX 之外的重要指标的图表来轻松创建一个全面的仪表盘,以监控你的整个网站设施。例如,你可能想监视你 NGINX 的主机级的指标,如系统负载。要构建一个自定义的仪表盘,只需点击靠近仪表盘的右上角的选项并选择“Clone Dash”来克隆一个默认的 NGINX 仪表盘。
|
||||
|
||||

|
||||
|
||||
你也可以使用 Datadog 的[主机地图][14]在更高层面监控你的 NGINX 实例,举个例子,用颜色标示你所有的 NGINX 主机的 CPU 使用率来辨别潜在热点。
|
||||
|
||||

|
||||
|
||||
### NGINX 指标警告 ###
|
||||
|
||||
一旦 Datadog 捕获并可视化你的指标,你可能会希望建立一些监控自动地密切关注你的指标,并当有问题提醒你。下面将介绍一个典型的例子:一个提醒你 NGINX 吞吐量突然下降时的指标监控器。
|
||||
|
||||
#### 监控 NGINX 吞吐量 ####
|
||||
|
||||
Datadog 指标警报可以是“基于吞吐量的”(当指标超过设定值会警报)或“基于变化幅度的”(当指标的变化超过一定范围会警报)。在这个例子里,我们会采取后一种方式,当每秒传入的请求急剧下降时会提醒我们。下降往往意味着有问题。
|
||||
|
||||
1. **创建一个新的指标监控**。从 Datadog 的“Monitors”下拉列表中选择“New Monitor”。选择“Metric”作为监视器类型。
|
||||
|
||||

|
||||
|
||||
2. **定义你的指标监视器**。我们想知道 NGINX 每秒总的请求量下降的数量,所以我们在基础设施中定义我们感兴趣的 nginx.net.request_per_s 之和。
|
||||
|
||||

|
||||
|
||||
3. **设置指标警报条件**。我们想要在变化时警报,而不是一个固定的值,所以我们选择“Change Alert”。我们设置监控为无论何时请求量下降了30%以上时警报。在这里,我们使用一个一分钟的数据窗口来表示 “now” 指标的值,对横跨该间隔内的平均变化和之前 10 分钟的指标值作比较。
|
||||
|
||||

|
||||
|
||||
4. **自定义通知**。如果 NGINX 的请求量下降,我们想要通知我们的团队。在这个例子中,我们将给 ops 团队的聊天室发送通知,并给值班工程师发送短信。在“Say what’s happening”中,我们会为监控器命名,并添加一个伴随该通知的短消息,建议首先开始调查的内容。我们会 @ ops 团队使用的 Slack,并 @pagerduty [将警告发给短信][15]。
|
||||
|
||||

|
||||
|
||||
5. **保存集成监控**。点击页面底部的“Save”按钮。你现在在监控一个关键的 NGINX [工作指标][16],而当它快速下跌时会给值班工程师发短信。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们谈到了通过整合 NGINX 与 Datadog 来可视化你的关键指标,并当你的网络基础架构有问题时会通知你的团队。
|
||||
|
||||
如果你一直使用你自己的 Datadog 账号,你现在应该可以极大的提升你的 web 环境的可视化,也有能力对你的环境、你所使用的模式、和对你的组织最有价值的指标创建自动监控。
|
||||
|
||||
如果你还没有 Datadog 帐户,你可以注册[免费试用][17],并开始监视你的基础架构,应用程序和现在的服务。
|
||||
|
||||
------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://linux.cn/article-5970-1.html
|
||||
[2]:https://linux.cn/article-5985-1.html#open-source
|
||||
[3]:https://linux.cn/article-5985-1.html#plus
|
||||
[4]:https://github.com/DataDog/dd-agent
|
||||
[5]:https://app.datadoghq.com/account/settings#agent
|
||||
[6]:https://app.datadoghq.com/infrastructure
|
||||
[7]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[8]:https://github.com/DataDog/dd-agent/blob/master/conf.d/nginx.yaml.example
|
||||
[9]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[10]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[11]:https://app.datadoghq.com/account/settings#integrations/nginx
|
||||
[12]:https://app.datadoghq.com/dash/integration/nginx
|
||||
[13]:https://linux.cn/article-5970-1.html
|
||||
[14]:https://www.datadoghq.com/blog/introducing-host-maps-know-thy-infrastructure/
|
||||
[15]:https://www.datadoghq.com/blog/pagerduty/
|
||||
[16]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/#metrics
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/#sign-up
|
||||
[18]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx_with_datadog.md
|
||||
[19]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -2,7 +2,7 @@ Ubuntu 14.04中修复“update information is outdated”错误
|
||||
================================================================================
|
||||

|
||||
|
||||
看到Ubuntu 14.04的顶部面板上那个显示下面这个错误的红色三角形了吗?
|
||||
看到过Ubuntu 14.04的顶部面板上那个显示下面这个错误的红色三角形了吗?
|
||||
|
||||
> 更新信息过时。该错误可能是由网络问题,或者某个仓库不再可用而造成的。请通过从指示器菜单中选择‘显示更新’来手动更新,然后查看是否存在有失败的仓库。
|
||||
>
|
||||
@ -25,7 +25,7 @@ Ubuntu 14.04中修复“update information is outdated”错误
|
||||
|
||||
### 修复‘update information is outdated’错误 ###
|
||||
|
||||
这里讨论的‘解决方案’可能对Ubuntu的这些版本有用:Ubuntu 14.04,12.04或14.04。你所要做的仅仅是打开终端(Ctrl+Alt+T),然后使用下面的命令:
|
||||
这里讨论的‘解决方案’可能对Ubuntu的这些版本有用:Ubuntu 14.04,12.04。你所要做的仅仅是打开终端(Ctrl+Alt+T),然后使用下面的命令:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
@ -47,7 +47,7 @@ via: http://itsfoss.com/fix-update-information-outdated-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -56,4 +56,4 @@ via: http://itsfoss.com/fix-update-information-outdated-ubuntu/
|
||||
[2]:http://itsfoss.com/notification-terminal-command-completion-ubuntu/
|
||||
[3]:http://itsfoss.com/solve-gpg-error-signatures-verified-ubuntu/
|
||||
[4]:http://itsfoss.com/install-spotify-ubuntu-1504/
|
||||
[5]:http://itsfoss.com/fix-update-errors-ubuntu-1404/
|
||||
[5]:https://linux.cn/article-5603-1.html
|
||||
@ -1,10 +1,11 @@
|
||||
在 Linux 中使用日志来排错
|
||||
================================================================================
|
||||
人们创建日志的主要原因是排错。通常你会诊断为什么问题发生在你的 Linux 系统或应用程序中。错误信息或一些列事件可以给你提供造成根本原因的线索,说明问题是如何发生的,并指出如何解决它。这里有几个使用日志来解决的样例。
|
||||
|
||||
人们创建日志的主要原因是排错。通常你会诊断为什么问题发生在你的 Linux 系统或应用程序中。错误信息或一系列的事件可以给你提供找出根本原因的线索,说明问题是如何发生的,并指出如何解决它。这里有几个使用日志来解决的样例。
|
||||
|
||||
### 登录失败原因 ###
|
||||
|
||||
如果你想检查你的系统是否安全,你可以在验证日志中检查登录失败的和登录成功但可疑的用户。当有人通过不正当或无效的凭据来登录时会出现认证失败,经常使用 SSH 进行远程登录或 su 到本地其他用户来进行访问权。这些是由[插入式验证模块][1]来记录,或 PAM 进行短期记录。在你的日志中会看到像 Failed 这样的字符串密码和未知的用户。成功认证记录包括像 Accepted 这样的字符串密码并打开会话。
|
||||
如果你想检查你的系统是否安全,你可以在验证日志中检查登录失败的和登录成功但可疑的用户。当有人通过不正当或无效的凭据来登录时会出现认证失败,这通常发生在使用 SSH 进行远程登录或 su 到本地其他用户来进行访问权时。这些是由[插入式验证模块(PAM)][1]来记录的。在你的日志中会看到像 Failed password 和 user unknown 这样的字符串。而成功认证记录则会包括像 Accepted password 和 session opened 这样的字符串。
|
||||
|
||||
失败的例子:
|
||||
|
||||
@ -30,22 +31,21 @@
|
||||
|
||||
由于没有标准格式,所以你需要为每个应用程序的日志使用不同的命令。日志管理系统,可以自动分析日志,将它们有效的归类,帮助你提取关键字,如用户名。
|
||||
|
||||
日志管理系统可以使用自动解析功能从 Linux 日志中提取用户名。这使你可以看到用户的信息,并能单个的筛选。在这个例子中,我们可以看到,root 用户登录了 2700 次,因为我们筛选的日志显示尝试登录的只有 root 用户。
|
||||
日志管理系统可以使用自动解析功能从 Linux 日志中提取用户名。这使你可以看到用户的信息,并能通过点击过滤。在下面这个例子中,我们可以看到,root 用户登录了 2700 次之多,因为我们筛选的日志仅显示 root 用户的尝试登录记录。
|
||||
|
||||

|
||||
|
||||
日志管理系统也让你以时间为做坐标轴的图标来查看使你更容易发现异常。如果有人在几分钟内登录失败一次或两次,它可能是一个真正的用户而忘记了密码。但是,如果有几百个失败的登录并且使用的都是不同的用户名,它更可能是在试图攻击系统。在这里,你可以看到在3月12日,有人试图登录 Nagios 几百次。这显然不是一个合法的系统用户。
|
||||
日志管理系统也可以让你以时间为做坐标轴的图表来查看,使你更容易发现异常。如果有人在几分钟内登录失败一次或两次,它可能是一个真正的用户而忘记了密码。但是,如果有几百个失败的登录并且使用的都是不同的用户名,它更可能是在试图攻击系统。在这里,你可以看到在3月12日,有人试图登录 Nagios 几百次。这显然不是一个合法的系统用户。
|
||||
|
||||

|
||||
|
||||
### 重启的原因 ###
|
||||
|
||||
|
||||
有时候,一台服务器由于系统崩溃或重启而宕机。你怎么知道它何时发生,是谁做的?
|
||||
|
||||
#### 关机命令 ####
|
||||
|
||||
如果有人手动运行 shutdown 命令,你可以看到它的身份在验证日志文件中。在这里,你可以看到,有人从 IP 50.0.134.125 上作为 ubuntu 的用户远程登录了,然后关闭了系统。
|
||||
如果有人手动运行 shutdown 命令,你可以在验证日志文件中看到它。在这里,你可以看到,有人从 IP 50.0.134.125 上作为 ubuntu 的用户远程登录了,然后关闭了系统。
|
||||
|
||||
Mar 19 18:36:41 ip-172-31-11-231 sshd[23437]: Accepted publickey for ubuntu from 50.0.134.125 port 52538 ssh
|
||||
Mar 19 18:36:41 ip-172-31-11-231 23437]:sshd[ pam_unix(sshd:session): session opened for user ubuntu by (uid=0)
|
||||
@ -53,7 +53,7 @@
|
||||
|
||||
#### 内核初始化 ####
|
||||
|
||||
如果你想看看服务器重新启动的所有原因(包括崩溃),你可以从内核初始化日志中寻找。你需要搜索内核设施和初始化 cpu 的信息。
|
||||
如果你想看看服务器重新启动的所有原因(包括崩溃),你可以从内核初始化日志中寻找。你需要搜索内核类(kernel)和 cpu 初始化(Initializing)的信息。
|
||||
|
||||
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpuset
|
||||
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpu
|
||||
@ -61,9 +61,9 @@
|
||||
|
||||
### 检测内存问题 ###
|
||||
|
||||
有很多原因可能导致服务器崩溃,但一个普遍的原因是内存用尽。
|
||||
有很多原因可能导致服务器崩溃,但一个常见的原因是内存用尽。
|
||||
|
||||
当你系统的内存不足时,进程会被杀死,通常会杀死使用最多资源的进程。当系统正在使用的内存发生错误并且有新的或现有的进程试图使用更多的内存。在你的日志文件查找像 Out of Memory 这样的字符串,内核也会发出杀死进程的警告。这些信息表明系统故意杀死进程或应用程序,而不是允许进程崩溃。
|
||||
当你系统的内存不足时,进程会被杀死,通常会杀死使用最多资源的进程。当系统使用了所有内存,而新的或现有的进程试图使用更多的内存时就会出现错误。在你的日志文件查找像 Out of Memory 这样的字符串或类似 kill 这样的内核警告信息。这些信息表明系统故意杀死进程或应用程序,而不是允许进程崩溃。
|
||||
|
||||
例如:
|
||||
|
||||
@ -75,20 +75,20 @@
|
||||
$ grep “Out of memory” /var/log/syslog
|
||||
[33238.178288] Out of memory: Kill process 6230 (firefox) score 53 or sacrifice child
|
||||
|
||||
请记住,grep 也要使用内存,所以导致内存不足的错误可能只是运行的 grep。这是另一个分析日志的独特方法!
|
||||
请记住,grep 也要使用内存,所以只是运行 grep 也可能导致内存不足的错误。这是另一个你应该中央化存储日志的原因!
|
||||
|
||||
### 定时任务错误日志 ###
|
||||
|
||||
cron 守护程序是一个调度器只在指定的日期和时间运行进程。如果进程运行失败或无法完成,那么 cron 的错误出现在你的日志文件中。你可以找到这些文件在 /var/log/cron,/var/log/messages,和 /var/log/syslog 中,具体取决于你的发行版。cron 任务失败原因有很多。通常情况下,问题出在进程中而不是 cron 守护进程本身。
|
||||
cron 守护程序是一个调度器,可以在指定的日期和时间运行进程。如果进程运行失败或无法完成,那么 cron 的错误出现在你的日志文件中。具体取决于你的发行版,你可以在 /var/log/cron,/var/log/messages,和 /var/log/syslog 几个位置找到这个日志。cron 任务失败原因有很多。通常情况下,问题出在进程中而不是 cron 守护进程本身。
|
||||
|
||||
默认情况下,cron 作业会通过电子邮件发送信息。这里是一个日志中记录的发送电子邮件的内容。不幸的是,你不能看到邮件的内容在这里。
|
||||
默认情况下,cron 任务的输出会通过 postfix 发送电子邮件。这是一个显示了该邮件已经发送的日志。不幸的是,你不能在这里看到邮件的内容。
|
||||
|
||||
Mar 13 16:35:01 PSQ110 postfix/pickup[15158]: C3EDC5800B4: uid=1001 from=<hoover>
|
||||
Mar 13 16:35:01 PSQ110 postfix/cleanup[15727]: C3EDC5800B4: message-id=<20150310110501.C3EDC5800B4@PSQ110>
|
||||
Mar 13 16:35:01 PSQ110 postfix/qmgr[15159]: C3EDC5800B4: from=<hoover@loggly.com>, size=607, nrcpt=1 (queue active)
|
||||
Mar 13 16:35:05 PSQ110 postfix/smtp[15729]: C3EDC5800B4: to=<hoover@loggly.com>, relay=gmail-smtp-in.l.google.com[74.125.130.26]:25, delay=4.1, delays=0.26/0/2.2/1.7, dsn=2.0.0, status=sent (250 2.0.0 OK 1425985505 f16si501651pdj.5 - gsmtp)
|
||||
|
||||
你应该想想 cron 在日志中的标准输出以帮助你定位问题。这里展示你可以使用 logger 命令重定向 cron 标准输出到 syslog。用你的脚本来代替 echo 命令,helloCron 可以设置为任何你想要的应用程序的名字。
|
||||
你可以考虑将 cron 的标准输出记录到日志中,以帮助你定位问题。这是一个你怎样使用 logger 命令重定向 cron 标准输出到 syslog的例子。用你的脚本来代替 echo 命令,helloCron 可以设置为任何你想要的应用程序的名字。
|
||||
|
||||
*/5 * * * * echo ‘Hello World’ 2>&1 | /usr/bin/logger -t helloCron
|
||||
|
||||
@ -97,7 +97,9 @@ cron 守护程序是一个调度器只在指定的日期和时间运行进程。
|
||||
Apr 28 22:20:01 ip-172-31-11-231 CRON[15296]: (ubuntu) CMD (echo 'Hello World!' 2>&1 | /usr/bin/logger -t helloCron)
|
||||
Apr 28 22:20:01 ip-172-31-11-231 helloCron: Hello World!
|
||||
|
||||
每个 cron 作业将根据作业的具体类型以及如何输出数据来记录不同的日志。希望在日志中有问题根源的线索,也可以根据需要添加额外的日志记录。
|
||||
每个 cron 任务将根据任务的具体类型以及如何输出数据来记录不同的日志。
|
||||
|
||||
希望在日志中有问题根源的线索,也可以根据需要添加额外的日志记录。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -107,7 +109,7 @@ via: http://www.loggly.com/ultimate-guide/logging/troubleshooting-with-linux-log
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,138 @@
|
||||
如何在 Ubuntu 15.04 系统中安装 Logwatch
|
||||
================================================================================
|
||||
|
||||
大家好,今天我们会讲述在 Ubuntu 15.04 操作系统上如何安装 Logwatch 软件,它也可以在各种 Linux 系统和类 Unix 系统上安装。Logwatch 是一款可定制的日志分析和日志监控报告生成系统,它可以根据一段时间的日志文件生成您所希望关注的详细报告。它具有易安装、易配置、可审查等特性,同时对其提供的数据的安全性上也有一些保障措施。Logwatch 会扫描重要的操作系统组件像 SSH、网站服务等的日志文件,然后生成用户所关心的有价值的条目汇总报告。
|
||||
|
||||
### 预安装设置 ###
|
||||
|
||||
我们会使用 Ubuntu 15.04 版本的操作系统来部署 Logwatch,所以安装 Logwatch 之前,要确保系统上邮件服务设置是正常可用的。因为它会每天把生成的报告通过日报的形式发送邮件给管理员。您的系统的源库也应该设置可用,以便可以从通用源库来安装 Logwatch。
|
||||
|
||||
然后打开您 ubuntu 系统的终端,用 root 账号登陆,在进入 Logwatch 的安装操作前,先更新您的系统软件包。
|
||||
|
||||
root@ubuntu-15:~# apt-get update
|
||||
|
||||
### 安装 Logwatch ###
|
||||
|
||||
只要你的系统已经更新和已经满足前面说的先决条件,那么就可以在您的机器上输入如下命令来安装 Logwatch。
|
||||
|
||||
root@ubuntu-15:~# apt-get install logwatch
|
||||
|
||||
在安装过程中,一旦您按提示按下“Y”键同意对系统修改的话,Logwatch 将会开始安装一些额外的必须软件包。
|
||||
|
||||
在安装过程中会根据您机器上的邮件服务器设置情况弹出提示对 Postfix 设置的配置界面。在这篇教程中我们使用最容易的 “仅本地(Local only)” 选项。根据您的基础设施情况也可以选择其它的可选项,然后点击“确定”继续。
|
||||
|
||||

|
||||
|
||||
随后您得选择邮件服务器名,这邮件服务器名也会被其它程序使用,所以它应该是一个完全合格域名/全称域名(FQDN)。
|
||||
|
||||

|
||||
|
||||
一旦按下在 postfix 配置提示底端的 “OK”,安装进程就会用 Postfix 的默认配置来安装,并且完成 Logwatch 的整个安装。
|
||||
|
||||

|
||||
|
||||
您可以在终端下发出如下命令来检查 Logwatch 状态,正常情况下它应该是激活状态。
|
||||
|
||||
root@ubuntu-15:~# service postfix status
|
||||
|
||||

|
||||
|
||||
要确认 Logwatch 在默认配置下的安装信息,可以如下示简单的发出“logwatch” 命令。
|
||||
|
||||
root@ubuntu-15:~# logwatch
|
||||
|
||||
上面执行命令的输出就是终端下编制出的报表展现格式。
|
||||
|
||||

|
||||
|
||||
### 配置 Logwatch ###
|
||||
|
||||
在成功安装好 Logwatch 后,我们需要在它的配置文件中做一些修改,配置文件位于如下所示的路径。那么,就让我们用文本编辑器打开它,然后按需要做些变动。
|
||||
|
||||
root@ubuntu-15:~# vim /usr/share/logwatch/default.conf/logwatch.conf
|
||||
|
||||
**输出/格式化选项**
|
||||
|
||||
默认情况下 Logwatch 会以无编码的文本打印到标准输出方式。要改为以邮件为默认方式,需设置“Output = mail”,要改为保存成文件方式,需设置“Output = file”。所以您可以根据您的要求设置其默认配置。
|
||||
|
||||
Output = stdout
|
||||
|
||||
如果使用的是因特网电子邮件配置,要用 Html 格式为默认出格式,需要修改成如下行所示的样子。
|
||||
|
||||
Format = text
|
||||
|
||||
现在增加默认的邮件报告接收人地址,可以是本地账号也可以是完整的邮件地址,需要的都可以在这行上写上
|
||||
|
||||
MailTo = root
|
||||
#MailTo = user@test.com
|
||||
|
||||
默认的邮件发送人可以是本地账号,也可以是您需要使用的其它名字。
|
||||
|
||||
# complete email address.
|
||||
MailFrom = Logwatch
|
||||
|
||||
对这个配置文件保存修改,至于其它的参数就让它保持默认,无需改动。
|
||||
|
||||
**调度任务配置**
|
||||
|
||||
现在编辑在 “daily crons” 目录下的 “00logwatch” 文件来配置从 logwatch 生成的报告需要发送的邮件地址。
|
||||
|
||||
root@ubuntu-15:~# vim /etc/cron.daily/00logwatch
|
||||
|
||||
在这儿您需要作用“--mailto user@test.com”来替换掉“--output mail”,然后保存文件。
|
||||
|
||||

|
||||
|
||||
### 生成报告 ###
|
||||
|
||||
现在我们在终端中执行“logwatch”命令来生成测试报告,生成的结果在终端中会以文本格式显示出来。
|
||||
|
||||
root@ubuntu-15:~#logwatch
|
||||
|
||||
生成的报告开始部分显示的是执行的时间和日期。它包含不同的部分,每个部分以开始标识开始而以结束标识结束,中间显示的是该部分的完整信息。
|
||||
|
||||
这儿显示的是开始的样子,它以显示系统上所有安装的软件包的部分开始,如下所示:
|
||||
|
||||

|
||||
|
||||
接下来的部分显示的日志信息是关于当前系统登录会话、rsyslogs 和当前及最近的 SSH 会话信息。
|
||||
|
||||

|
||||
|
||||
Logwatch 报告最后显示的是安全方面的 sudo 日志及根目录磁盘使用情况,如下示:
|
||||
|
||||

|
||||
|
||||
您也可以打开如下的文件来查看生成的 logwatch 报告电子邮件。
|
||||
|
||||
root@ubuntu-15:~# vim /var/mail/root
|
||||
|
||||
您会看到发送给你配置的用户的所有已生成的邮件及其邮件递交状态。
|
||||
|
||||
### 更多详情 ###
|
||||
|
||||
Logwatch 是一款很不错的工具,可以学习的很多很多,所以如果您对它的日志监控功能很感兴趣的话,也以通过如下所示的简短命令来获得更多帮助。
|
||||
|
||||
root@ubuntu-15:~# man logwatch
|
||||
|
||||
上面的命令包含所有关于 logwatch 的用户手册,所以仔细阅读,要退出手册的话可以简单的输入“q”。
|
||||
|
||||
关于 logwatch 命令的使用,您可以使用如下所示的帮助命令来获得更多的详细信息。
|
||||
|
||||
root@ubuntu-15:~# logwatch --help
|
||||
|
||||
### 结论 ###
|
||||
|
||||
教程结束,您也学会了如何在 Ubuntu 15.04 上对 Logwatch 的安装、配置等全部设置指导。现在您就可以自定义监控您的系统日志,不管是监控所有服务的运行情况还是对特定的服务在指定的时间发送报告都可以。所以,开始使用这工具吧,无论何时有问题或想知道更多关于 logwatch 的使用的都可以给我们留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-use-logwatch-ubuntu-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,70 @@
|
||||
如何在 Linux 终端中知道你的公有 IP
|
||||
================================================================================
|
||||

|
||||
|
||||
公有地址由 InterNIC 分配并由基于类的网络 ID 或基于 CIDR 的地址块构成(被称为 CIDR 块),并保证了在全球互联网中的唯一性。当公有地址被分配时,其路由将会被记录到互联网中的路由器中,这样访问公有地址的流量就能顺利到达。访问目标公有地址的流量可经由互联网抵达。比如,当一个 CIDR 块被以网络 ID 和子网掩码的形式分配给一个组织时,对应的 [网络 ID,子网掩码] 也会同时作为路由储存在互联网中的路由器中。目标是 CIDR 块中的地址的 IP 封包会被导向对应的位置。
|
||||
|
||||
在本文中我将会介绍在几种在 Linux 终端中查看你的公有 IP 地址的方法。这对普通用户来说并无意义,但 Linux 服务器(无GUI或者作为只能使用基本工具的用户登录时)会很有用。无论如何,从 Linux 终端中获取公有 IP 在各种方面都很意义,说不定某一天就能用得着。
|
||||
|
||||
以下是我们主要使用的两个命令,curl 和 wget。你可以换着用。
|
||||
|
||||
### Curl 纯文本格式输出: ###
|
||||
|
||||
curl icanhazip.com
|
||||
curl ifconfig.me
|
||||
curl curlmyip.com
|
||||
curl ip.appspot.com
|
||||
curl ipinfo.io/ip
|
||||
curl ipecho.net/plain
|
||||
curl www.trackip.net/i
|
||||
|
||||
### curl JSON格式输出: ###
|
||||
|
||||
curl ipinfo.io/json
|
||||
curl ifconfig.me/all.json
|
||||
curl www.trackip.net/ip?json (有点丑陋)
|
||||
|
||||
### curl XML格式输出: ###
|
||||
|
||||
curl ifconfig.me/all.xml
|
||||
|
||||
### curl 得到所有IP细节 (挖掘机)###
|
||||
|
||||
curl ifconfig.me/all
|
||||
|
||||
### 使用 DYDNS (当你使用 DYDNS 服务时有用)###
|
||||
|
||||
curl -s 'http://checkip.dyndns.org' | sed 's/.*Current IP Address: \([0-9\.]*\).*/\1/g'
|
||||
curl -s http://checkip.dyndns.org/ | grep -o "[[:digit:].]\+"
|
||||
|
||||
### 使用 Wget 代替 Curl ###
|
||||
|
||||
wget http://ipecho.net/plain -O - -q ; echo
|
||||
wget http://observebox.com/ip -O - -q ; echo
|
||||
|
||||
### 使用 host 和 dig 命令 ###
|
||||
|
||||
如果有的话,你也可以直接使用 host 和 dig 命令。
|
||||
|
||||
host -t a dartsclink.com | sed 's/.*has address //'
|
||||
dig +short myip.opendns.com @resolver1.opendns.com
|
||||
|
||||
### bash 脚本示例: ###
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
PUBLIC_IP=`wget http://ipecho.net/plain -O - -q ; echo`
|
||||
echo $PUBLIC_IP
|
||||
|
||||
简单易用。
|
||||
|
||||
我实际上是在写一个用于记录每日我的路由器中所有 IP 变化并保存到一个文件的脚本。我在搜索过程中找到了这些很好用的命令。希望某天它能帮到其他人。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/14/how-to-get-public-ip-from-linux-terminal/
|
||||
|
||||
译者:[KevinSJ](https://github.com/KevinSJ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,16 +1,17 @@
|
||||
shellinabox–基于Web的Ajax的终端模拟器安装及使用详解
|
||||
shellinabox:一款使用 AJAX 的基于 Web 的终端模拟器
|
||||
================================================================================
|
||||
|
||||
### shellinabox简介 ###
|
||||
|
||||
unixmen的读者朋友们,你们好!
|
||||
通常情况下,我们在访问任何远程服务器时,会使用常见的通信工具如OpenSSH和Putty等。但是,有可能我们在防火墙后面不能使用这些工具访问远程系统,或者防火墙只允许HTTPS流量才能通过。不用担心!即使你在这样的防火墙后面,我们依然有办法来访问你的远程系统。而且,你不需要安装任何类似于OpenSSH或Putty的通讯工具。你只需要有一个支持JavaScript和CSS的现代浏览器,并且你不用安装任何插件或第三方应用软件。
|
||||
|
||||
通常情况下,我们访问任何远程服务器时,使用常见的通信工具如OpenSSH和Putty等。但是如果我们在防火墙外,或者防火墙只允许HTTPS流量才能通过,那么我们就不能再使用这些工具来访问远程系统了。不用担心!即使你在防火墙后面,我们依然有办法来访问你的远程系统。而且,你不需要安装任何类似于OpenSSH或Putty的通讯工具。你只需要有一个支持JavaScript和CSS的现代浏览器。并且你不用安装任何插件或第三方应用软件。
|
||||
这个 **Shell In A Box**,发音是**shellinabox**,是由**Markus Gutschke**开发的一款自由开源的基于Web的Ajax的终端模拟器。它使用AJAX技术,通过Web浏览器提供了类似原生的 Shell 的外观和感受。
|
||||
|
||||
Meet **Shell In A Box**,发音是**shellinabox**,是由**Markus Gutschke**开发的一款免费的,开源的,基于Web的Ajax的终端模拟器。它使用AJAX技术,通过Web浏览器提供的外观和感觉像一个原生壳。该**shellinaboxd**的守护进程实现了一个Web服务器,能够侦听指定的端口。Web服务器发布一个或多个服务,这些服务将在VT100模拟器实现为一个AJAX的Web应用程序显示。默认情况下,端口为4200。你可以更改默认端口到任意选择的任意端口号。在你的远程服务器安装shellinabox以后,如果你想从本地系统接入,打开Web浏览器并导航到:**http://IP-Address:4200/**。输入你的用户名和密码,然后就可以开始使用你远程系统的外壳。看起来很有趣,不是吗?确实!
|
||||
这个**shellinaboxd**守护进程实现了一个Web服务器,能够侦听指定的端口。其Web服务器可以发布一个或多个服务,这些服务显示在用 AJAX Web 应用实现的VT100模拟器中。默认情况下,端口为4200。你可以更改默认端口到任意选择的任意端口号。在你的远程服务器安装shellinabox以后,如果你想从本地系统接入,打开Web浏览器并导航到:**http://IP-Address:4200/**。输入你的用户名和密码,然后就可以开始使用你远程系统的Shell。看起来很有趣,不是吗?确实 有趣!
|
||||
|
||||
**免责声明**:
|
||||
|
||||
shellinabox不是SSH客户端或任何安全软件。它仅仅是一个应用程序,能够通过Web浏览器模拟一个远程系统的壳。同时,它和SSH没有任何关系。这不是防弹的安全的方式来远程控制您的系统。这只是迄今为止最简单的方法之一。无论什么原因,你都不应该在任何公共网络上运行它。
|
||||
shellinabox不是SSH客户端或任何安全软件。它仅仅是一个应用程序,能够通过Web浏览器模拟一个远程系统的Shell。同时,它和SSH没有任何关系。这不是可靠的安全地远程控制您的系统的方式。这只是迄今为止最简单的方法之一。无论如何,你都不应该在任何公共网络上运行它。
|
||||
|
||||
### 安装shellinabox ###
|
||||
|
||||
@ -48,7 +49,7 @@ shellinabox在默认库是可用的。所以,你可以使用命令来安装它
|
||||
|
||||
# vi /etc/sysconfig/shellinaboxd
|
||||
|
||||
更改你的端口到任意数量。因为我在本地网络上测试它,所以我使用默认值。
|
||||
更改你的端口到任意数字。因为我在本地网络上测试它,所以我使用默认值。
|
||||
|
||||
# Shell in a box daemon configuration
|
||||
# For details see shellinaboxd man page
|
||||
@ -98,7 +99,7 @@ shellinabox在默认库是可用的。所以,你可以使用命令来安装它
|
||||
|
||||
### 使用 ###
|
||||
|
||||
现在,去你的客户端系统,打开Web浏览器并导航到:**https://ip-address-of-remote-servers:4200**。
|
||||
现在,在你的客户端系统,打开Web浏览器并导航到:**https://ip-address-of-remote-servers:4200**。
|
||||
|
||||
**注意**:如果你改变了端口,请填写修改后的端口。
|
||||
|
||||
@ -110,13 +111,13 @@ shellinabox在默认库是可用的。所以,你可以使用命令来安装它
|
||||
|
||||

|
||||
|
||||
右键点击你浏览器的空白位置。你可以得到一些有很有用的额外的菜单选项。
|
||||
右键点击你浏览器的空白位置。你可以得到一些有很有用的额外菜单选项。
|
||||
|
||||

|
||||
|
||||
从现在开始,你可以通过本地系统的Web浏览器在你的远程服务器随意操作。
|
||||
|
||||
当你完成时,记得点击**退出**。
|
||||
当你完成工作时,记得输入`exit`退出。
|
||||
|
||||
当再次连接到远程系统时,单击**连接**按钮,然后输入远程服务器的用户名和密码。
|
||||
|
||||
@ -134,7 +135,7 @@ shellinabox在默认库是可用的。所以,你可以使用命令来安装它
|
||||
|
||||
### 结论 ###
|
||||
|
||||
正如我之前提到的,如果你在服务器运行在防火墙后面,那么基于web的SSH工具是非常有用的。有许多基于web的SSH工具,但shellinabox是非常简单并且有用的工具,能从的网络上的任何地方,模拟一个远程系统的壳。因为它是基于浏览器的,所以你可以从任何设备访问您的远程服务器,只要你有一个支持JavaScript和CSS的浏览器。
|
||||
正如我之前提到的,如果你在服务器运行在防火墙后面,那么基于web的SSH工具是非常有用的。有许多基于web的SSH工具,但shellinabox是非常简单而有用的工具,可以从的网络上的任何地方,模拟一个远程系统的Shell。因为它是基于浏览器的,所以你可以从任何设备访问您的远程服务器,只要你有一个支持JavaScript和CSS的浏览器。
|
||||
|
||||
就这些啦。祝你今天有个好心情!
|
||||
|
||||
@ -148,7 +149,7 @@ via: http://www.unixmen.com/shellinabox-a-web-based-ajax-terminal-emulator/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,115 @@
|
||||
Ubuntu 下五个最好的 BT 客户端
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
在寻找 **Ubuntu 中最好的 BT 客户端**吗?事实上,Linux 桌面平台中有许多 BT 客户端,但是它们中的哪些才是**最好的 Ubuntu 客户端**呢?
|
||||
|
||||
我将会列出 Linux 上最好的五个 BT 客户端,它们都拥有着体积轻盈,功能强大的特点,而且还有令人印象深刻的用户界面。自然,易于安装和使用也是特性之一。
|
||||
|
||||
### Ubuntu 下最好的 BT 客户端 ###
|
||||
|
||||
考虑到 Ubuntu 默认安装了 Transmission,所以我将会从这个列表中排除了 Transmission。但是这并不意味着 Transmission 没有资格出现在这个列表中,事实上,Transmission 是一个非常好的BT客户端,这也正是它被包括 Ubuntu 在内的多个发行版默认安装的原因。
|
||||
|
||||
### Deluge ###
|
||||
|
||||

|
||||
|
||||
[Deluge][1] 被 Lifehacker 评选为 Linux 下最好的 BT 客户端,这说明了 Deluge 是多么的有用。而且,并不仅仅只有 Lifehacker 是 Deluge 的粉丝,纵观多个论坛,你都会发现不少 Deluge 的忠实拥趸。
|
||||
|
||||
快速,时尚而直观的界面使得 Deluge 成为 Linux 用户的挚爱。
|
||||
|
||||
Deluge 可在 Ubuntu 的仓库中获取,你能够在 Ubuntu 软件中心中安装它,或者使用下面的命令:
|
||||
|
||||
sudo apt-get install deluge
|
||||
|
||||
### qBittorrent ###
|
||||
|
||||

|
||||
|
||||
正如它的名字所暗示的,[qBittorrent][2] 是著名的 [Bittorrent][3] 应用的 Qt 版本。如果曾经使用过它,你将会看到和 Windows 下的 Bittorrent 相似的界面。同样轻巧并且有着 BT 客户端的所有标准功能, qBittorrent 也可以在 Ubuntu 的默认仓库中找到。
|
||||
|
||||
它可以通过 Ubuntu 软件仓库安装,或者使用下面的命令:
|
||||
|
||||
sudo apt-get install qbittorrent
|
||||
|
||||
|
||||
### Tixati ###
|
||||
|
||||

|
||||
|
||||
[Tixati][4] 是另一个不错的 Ubuntu 下的 BT 客户端。它有着一个默认的黑暗主题,尽管很多人喜欢,但是我例外。它拥有着一切你能在 BT 客户端中找到的功能。
|
||||
|
||||
除此之外,它还有着数据分析的额外功能。你可以在美观的图表中分析流量以及其它数据。
|
||||
|
||||
- [下载 Tixati][5]
|
||||
|
||||
|
||||
|
||||
### Vuze ###
|
||||
|
||||

|
||||
|
||||
[Vuze][6] 是许多 Linux 以及 Windows 用户最喜欢的 BT 客户端。除了标准的功能,你可以直接在应用程序中搜索种子,也可以订阅系列片源,这样就无需再去寻找新的片源了,因为你可以在侧边栏中的订阅看到它们。
|
||||
|
||||
它还配备了一个视频播放器,可以播放带有字幕的高清视频等等。但是我不认为你会用它来代替那些更好的视频播放器,比如 VLC。
|
||||
|
||||
Vuze 可以通过 Ubuntu 软件中心安装或者使用下列命令:
|
||||
|
||||
sudo apt-get install vuze
|
||||
|
||||
|
||||
|
||||
### Frostwire ###
|
||||
|
||||

|
||||
|
||||
[Frostwire][7] 是一个你应该试一下的应用。它不仅仅是一个简单的 BT 客户端,它还可以应用于安卓,你可以用它通过 Wifi 来共享文件。
|
||||
|
||||
你可以在应用中搜索种子并且播放他们。除了下载文件,它还可以浏览本地的影音文件,并且将它们有条理的呈现在播放器中。这同样适用于安卓版本。
|
||||
|
||||
还有一个特点是:Frostwire 提供了独立音乐人的[合法音乐下载][13]。你可以下载并且欣赏它们,免费而且合法。
|
||||
|
||||
- [下载 Frostwire][8]
|
||||
|
||||
|
||||
|
||||
### 荣誉奖 ###
|
||||
|
||||
在 Windows 中,uTorrent(发音:mu torrent)是我最喜欢的 BT 应用。尽管 uTorrent 可以在 Linux 下运行,但是我还是特意忽略了它。因为在 Linux 下使用 uTorrent 不仅困难,而且无法获得完整的应用体验(运行在浏览器中)。
|
||||
|
||||
可以[在这里][9]阅读 Ubuntu下uTorrent 的安装教程。
|
||||
|
||||
#### 快速提示: ####
|
||||
|
||||
大多数情况下,BT 应用不会默认自动启动。如果想改变这一行为,请阅读[如何管理 Ubuntu 下的自启动程序][10]来学习。
|
||||
|
||||
### 你最喜欢的是什么? ###
|
||||
|
||||
这些是我对于 Ubuntu 下最好的 BT 客户端的意见。你最喜欢的是什么呢?请发表评论。也可以查看与本主题相关的[Ubuntu 最好的下载管理器][11]。如果使用 Popcorn Time,试试 [Popcorn Time 技巧][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-torrent-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Xuanwo](https://github.com/Xuanwo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://deluge-torrent.org/
|
||||
[2]:http://www.qbittorrent.org/
|
||||
[3]:http://www.bittorrent.com/
|
||||
[4]:http://www.tixati.com/
|
||||
[5]:http://www.tixati.com/download/
|
||||
[6]:http://www.vuze.com/
|
||||
[7]:http://www.frostwire.com/
|
||||
[8]:http://www.frostwire.com/downloads
|
||||
[9]:http://sysads.co.uk/2014/05/install-utorrent-3-3-ubuntu-14-04-13-10/
|
||||
[10]:http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
[11]:http://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[12]:http://itsfoss.com/popcorn-time-tips/
|
||||
[13]:http://www.frostclick.com/wp/
|
||||
|
||||
@ -0,0 +1,100 @@
|
||||
Linux中通过命令行监控股票报价
|
||||
================================================================================
|
||||
|
||||
如果你是那些股票投资者或者交易者中的一员,那么监控证券市场将是你的日常工作之一。最有可能的是你会使用一个在线交易平台,这个平台有着一些漂亮的实时图表和全部种类的高级股票分析和交易工具。虽然这种复杂的市场研究工具是任何严肃的证券投资者了解市场的必备工具,但是监控最新的股票报价来构建有利可图的投资组合仍然有很长一段路要走。
|
||||
|
||||
如果你是一位长久坐在终端前的全职系统管理员,而证券交易又成了你日常生活中的业余兴趣,那么一个简单地显示实时股票报价的命令行工具会是给你的恩赐。
|
||||
|
||||
在本教程中,让我来介绍一个灵巧而简洁的命令行工具,它可以让你在Linux上从命令行监控股票报价。
|
||||
|
||||
这个工具叫做[Mop][1]。它是用GO编写的一个轻量级命令行工具,可以极其方便地跟踪来自美国市场的最新股票报价。你可以很轻松地自定义要监控的证券列表,它会在一个基于ncurses的便于阅读的界面显示最新的股票报价。
|
||||
|
||||
**注意**:Mop是通过雅虎金融API获取最新的股票报价的。你必须意识到,他们的的股票报价已知会有15分钟的延时。所以,如果你正在寻找0延时的“实时”股票报价,那么Mop就不是你的菜了。这种“现场”股票报价订阅通常可以通过向一些不开放的私有接口付费获取。了解这些之后,让我们来看看怎样在Linux环境下使用Mop吧。
|
||||
|
||||
### 安装 Mop 到 Linux ###
|
||||
|
||||
由于Mop是用Go实现的,你首先需要安装Go语言。如果你还没有安装Go,请参照[此指南][2]将Go安装到你的Linux平台中。请确保按指南中所讲的设置GOPATH环境变量。
|
||||
|
||||
安装完Go后,继续像下面这样安装Mop。
|
||||
|
||||
**Debian,Ubuntu 或 Linux Mint**
|
||||
|
||||
$ sudo apt-get install git
|
||||
$ go get github.com/michaeldv/mop
|
||||
$ cd $GOPATH/src/github.com/michaeldv/mop
|
||||
$ make install
|
||||
|
||||
**Fedora,CentOS,RHEL**
|
||||
|
||||
$ sudo yum install git
|
||||
$ go get github.com/michaeldv/mop
|
||||
$ cd $GOPATH/src/github.com/michaeldv/mop
|
||||
$ make install
|
||||
|
||||
上述命令将安装Mop到$GOPATH/bin。
|
||||
|
||||
现在,编辑你的.bashrc,将$GOPATH/bin写到你的PATH变量中。
|
||||
|
||||
export PATH="$PATH:$GOPATH/bin"
|
||||
|
||||
----------
|
||||
|
||||
$ source ~/.bashrc
|
||||
|
||||
### 使用Mop来通过命令行监控股票报价 ###
|
||||
|
||||
要启动Mop,只需运行名为cmd的命令(LCTT 译注:这名字实在是……)。
|
||||
|
||||
$ cmd
|
||||
|
||||
首次启动,你将看到一些Mop预配置的证券行情自动收录器。
|
||||
|
||||

|
||||
|
||||
报价显示了像最新价格、交易百分比、每日低/高、52周低/高、股息以及年收益率等信息。Mop从[CNN][3]获取市场总览信息,从[雅虎金融][4]获得个股报价,股票报价信息它自己会在终端内周期性更新。
|
||||
|
||||
### 自定义Mop中的股票报价 ###
|
||||
|
||||
让我们来试试自定义证券列表吧。对此,Mop提供了易于记忆的快捷键:‘+’用于添加一只新股,而‘-’则用于移除一只股票。
|
||||
|
||||
要添加新股,请按‘+’,然后输入股票代码来添加(如MSFT)。你可以通过输入一个由逗号分隔的交易代码列表来一次添加多个股票(如”MSFT, AMZN, TSLA”)。
|
||||
|
||||

|
||||
|
||||
从列表中移除股票可以类似地按‘-’来完成。
|
||||
|
||||
### 对Mop中的股票报价排序 ###
|
||||
|
||||
你可以基于任何栏目对股票报价列表进行排序。要排序,请按‘o’,然后使用左/右键来选择排序的基准栏目。当选定了一个特定栏目后,你可以按回车来对列表进行升序排序,或者降序排序。
|
||||
|
||||
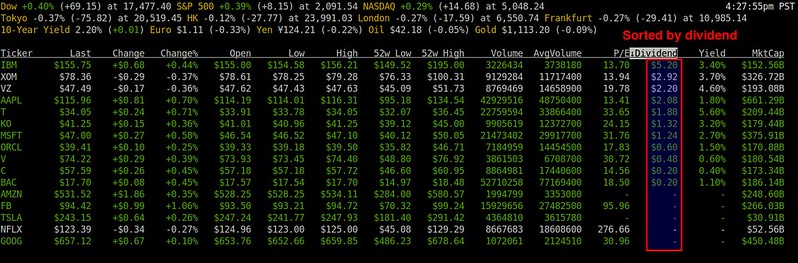
|
||||
|
||||
通过按‘g’,你可以根据股票当日的涨或跌来分组。涨的情况以绿色表示,跌的情况以白色表示。
|
||||
|
||||

|
||||
|
||||
如果你想要访问帮助页,只需要按‘?’。
|
||||
|
||||

|
||||
|
||||
### 尾声 ###
|
||||
|
||||
正如你所见,Mop是一个轻量级的,然而极其方便的证券监控工具。当然,你可以很轻松地从其它别的什么地方,从在线站点,你的智能手机等等访问到股票报价信息。然而,如果你在整天使用终端环境,Mop可以很容易地适应你的工作环境,希望没有让你过多地从你的工作流程中分心。只要让它在你其中一个终端中运行并保持市场日期持续更新,那就够了。
|
||||
|
||||
交易快乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/monitor-stock-quotes-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://github.com/michaeldv/mop
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:http://money.cnn.com/data/markets/
|
||||
[4]:http://finance.yahoo.com/
|
||||
@ -0,0 +1,52 @@
|
||||
Linux无极限:IBM发布LinuxONE大型机
|
||||
================================================================================
|
||||

|
||||
|
||||
LinuxONE Emperor MainframeGood的Ubuntu服务器团队今天发布了一条消息关于[IBM发布了LinuxONE][1],一种只支持Linux的大型机,也可以运行Ubuntu。
|
||||
|
||||
IBM发布的最大的LinuxONE系统称作‘Emperor’,它可以扩展到8000台虚拟机或者上万台容器- 对任何一台Linux系统都可能的记录。
|
||||
|
||||
LinuxONE被IBM称作‘游戏改变者’,它‘释放了Linux的商业潜力’。
|
||||
|
||||
IBM和Canonical正在一起协作为LinuxONE和其他IBM z系统创建Ubuntu发行版。Ubuntu将会在IBM z加入RedHat和SUSE作为首屈一指的Linux发行版。
|
||||
|
||||
随着IBM ‘Emperor’发布的还有LinuxONE Rockhopper,一个为中等规模商业或者组织小一点的大型机。
|
||||
|
||||
IBM是大型机中的领导者,并且占有大型机市场中90%的份额。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/2ABfNrWs-ns?feature=oembed"></iframe>
|
||||
|
||||
### 大型机用于什么? ###
|
||||
|
||||
你阅读这篇文章所使用的电脑在一个‘大铁块’一样的大型机前会显得很矮小。它们是巨大的,笨重的机柜里面充满了高端的组件、自己设计的技术和眼花缭乱的大量存储(就是数据存储,没有空间放钢笔和尺子)。
|
||||
|
||||
大型机被大型机构和商业用来处理和存储大量数据,通过统计来处理数据和处理大规模的事务处理。
|
||||
|
||||
### ‘世界最快的处理器’ ###
|
||||
|
||||
IBM已经与Canonical Ltd组成了团队来在LinuxONE和其他IBM z系统中使用Ubuntu。
|
||||
|
||||
LinuxONE Emperor使用IBM z13处理器。发布于一月的芯片声称是时间上最快的微处理器。它可以在几毫秒内响应事务。
|
||||
|
||||
但是也可以很好地处理高容量的移动事务,z13中的LinuxONE系统也是一个理想的云系统。
|
||||
|
||||
每个核心可以处理超过50个虚拟服务器,总共可以超过8000台虚拟服务器么,这使它以更便宜,更环保、更高效的方式扩展到云。
|
||||
|
||||
**在阅读这篇文章时你不必是一个CIO或者大型机巡查员。LinuxONE提供的可能性足够清晰。**
|
||||
|
||||
来源: [Reuters (h/t @popey)][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ibm-linuxone-mainframe-ubuntu-partnership
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www-03.ibm.com/systems/z/announcement.html
|
||||
[2]:http://www.reuters.com/article/2015/08/17/us-ibm-linuxone-idUSKCN0QM09P20150817
|
||||
@ -0,0 +1,53 @@
|
||||
Ubuntu Linux 来到 IBM 大型机
|
||||
================================================================================
|
||||
最终来到了。在 [LinuxCon][1] 上,IBM 和 [Canonical][2] 宣布 [Ubuntu Linux][3] 不久就会运行在 IBM 大型机 [LinuxONE][1] 上,这是一种只支持 Linux 的大型机,现在也可以运行 Ubuntu 了。
|
||||
|
||||
这个 IBM 发布的最大的 LinuxONE 系统称作‘Emperor’,它可以扩展到 8000 台虚拟机或者上万台容器,这可能是单独一台 Linux 系统的记录。
|
||||
|
||||
LinuxONE 被 IBM 称作‘游戏改变者’,它‘释放了 Linux 的商业潜力’。
|
||||
|
||||

|
||||
|
||||
*很快你就可以在你的 IBM 大型机上安装 Ubuntu Linux orange 啦*
|
||||
|
||||
根据 IBM z 系统的总经理 Ross Mauri 以及 Canonical 和 Ubuntu 的创立者 Mark Shuttleworth 所言,这是因为客户需要。十多年来,IBM 大型机只支持 [红帽企业版 Linux (RHEL)][4] 和 [SUSE Linux 企业版 (SLES)][5] Linux 发行版。
|
||||
|
||||
随着 Ubuntu 越来越成熟,更多的企业把它作为企业级 Linux,也有更多的人希望它能运行在 IBM 大型机上。尤其是银行希望如此。不久,金融 CIO 们就可以满足他们的需求啦。
|
||||
|
||||
在一次采访中 Shuttleworth 说 Ubuntu Linux 在 2016 年 4 月下一次长期支持版 Ubuntu 16.04 中就可以用到大型机上。而在 2014 年底 Canonical 和 IBM 将 [Ubuntu 带到 IBM 的 POWER][6] 架构中就迈出了第一步。
|
||||
|
||||
在那之前,Canonical 和 IBM 差点签署了协议 [在 2011 年实现 Ubuntu 支持 IBM 大型机][7],但最终也没有实现。这次,真的发生了。
|
||||
|
||||
Canonical 的 CEO Jane Silber 解释说 “[把 Ubuntu 平台支持扩大][8]到 [IBM z 系统][9] 是因为认识到需要 z 系统运行其业务的客户数量以及混合云市场的成熟。”
|
||||
|
||||
**Silber 还说:**
|
||||
|
||||
> 由于 z 系统的支持,包括 [LinuxONE][10],Canonical 和 IBM 的关系进一步加深,构建了对 POWER 架构的支持和 OpenPOWER 生态系统。正如 Power 系统的客户受益于 Ubuntu 的可扩展能力,我们的敏捷开发过程也使得类似 POWER8 CAPI (Coherent Accelerator Processor Interface,一致性加速器接口)得到了市场支持,z 系统的客户也可以期望技术进步能快速部署,并从 [Juju][11] 和我们的其它云工具中获益,使得能快速向端用户提供新服务。另外,我们和 IBM 的合作包括实现扩展部署很多 IBM 和 Juju 的软件解决方案。大型机客户对于能通过 Juju 将丰富‘迷人的’ IBM 解决方案、其它软件供应商的产品、开源解决方案部署到大型机上感到高兴。
|
||||
|
||||
Shuttleworth 期望 z 系统上的 Ubuntu 能取得巨大成功。它发展很快,由于对 OpenStack 的支持,希望有卓越云性能的人会感到非常高兴。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/ubuntu-linux-is-coming-to-the-mainframe/
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ibm-linuxone-mainframe-ubuntu-partnership
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a],[Joey-Elijah Sneddon][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh),[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
[2]:http://www.canonical.com/
|
||||
[3]:http://www.ubuntu.comj/
|
||||
[4]:http://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[5]:https://www.suse.com/products/server/
|
||||
[6]:http://www.zdnet.com/article/ibm-doubles-down-on-linux/
|
||||
[7]:http://www.zdnet.com/article/mainframe-ubuntu-linux/
|
||||
[8]:https://insights.ubuntu.com/2015/08/17/ibm-and-canonical-plan-ubuntu-support-on-ibm-z-systems-mainframe/
|
||||
[9]:http://www-03.ibm.com/systems/uk/z/
|
||||
[10]:http://www.zdnet.com/article/linuxone-ibms-new-linux-mainframes/
|
||||
[11]:https://jujucharms.com/
|
||||
@ -0,0 +1,129 @@
|
||||
如何在 Linux 中安装 Visual Studio Code
|
||||
================================================================================
|
||||
大家好,今天我们一起来学习如何在 Linux 发行版中安装 Visual Studio Code。Visual Studio Code 是基于 Electron 优化代码后的编辑器,后者是基于 Chromium 的一款软件,用于为桌面系统发布 io.js 应用。Visual Studio Code 是微软开发的支持包括 Linux 在内的全平台代码编辑器和文本编辑器。它是免费软件但不开源,在专有软件许可条款下发布。它是可以用于我们日常使用的超级强大和快速的代码编辑器。Visual Studio Code 有很多很酷的功能,例如导航、智能感知支持、语法高亮、括号匹配、自动补全、代码片段、支持自定义键盘绑定、并且支持多种语言,例如 Python、C++、Jade、PHP、XML、Batch、F#、DockerFile、Coffee Script、Java、HandleBars、 R、 Objective-C、 PowerShell、 Luna、 Visual Basic、 .Net、 Asp.Net、 C#、 JSON、 Node.js、 Javascript、 HTML、 CSS、 Less、 Sass 和 Markdown。Visual Studio Code 集成了包管理器、库、构建,以及其它通用任务,以加速日常的工作流。Visual Studio Code 中最受欢迎的是它的调试功能,它包括流式支持 Node.js 的预览调试。
|
||||
|
||||
注意:请注意 Visual Studio Code 只支持 64 位的 Linux 发行版。
|
||||
|
||||
下面是在所有 Linux 发行版中安装 Visual Studio Code 的几个简单步骤。
|
||||
|
||||
### 1. 下载 Visual Studio Code 软件包 ###
|
||||
|
||||
首先,我们要从微软服务器中下载 64 位 Linux 操作系统的 Visual Studio Code 安装包,链接是 [http://go.microsoft.com/fwlink/?LinkID=534108][1]。这里我们使用 wget 下载并保存到 tmp/VSCODE 目录。
|
||||
|
||||
# mkdir /tmp/vscode; cd /tmp/vscode/
|
||||
# wget https://az764295.vo.msecnd.net/public/0.3.0/VSCode-linux-x64.zip
|
||||
|
||||
--2015-06-24 06:02:54-- https://az764295.vo.msecnd.net/public/0.3.0/VSCode-linux-x64.zip
|
||||
Resolving az764295.vo.msecnd.net (az764295.vo.msecnd.net)... 93.184.215.200, 2606:2800:11f:179a:1972:2405:35b:459
|
||||
Connecting to az764295.vo.msecnd.net (az764295.vo.msecnd.net)|93.184.215.200|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 64992671 (62M) [application/octet-stream]
|
||||
Saving to: ‘VSCode-linux-x64.zip’
|
||||
100%[================================================>] 64,992,671 14.9MB/s in 4.1s
|
||||
2015-06-24 06:02:58 (15.0 MB/s) - ‘VSCode-linux-x64.zip’ saved [64992671/64992671]
|
||||
|
||||
### 2. 提取软件包 ###
|
||||
|
||||
现在,下载好 Visual Studio Code 的 zip 压缩包之后,我们打算使用 unzip 命令解压它。我们要在终端或者控制台中运行以下命令。
|
||||
|
||||
# unzip /tmp/vscode/VSCode-linux-x64.zip -d /opt/
|
||||
|
||||
注意:如果我们还没有安装 unzip,我们首先需要通过软件包管理器安装它。如果你运行的是 Ubuntu,使用 apt-get,如果运行的是 Fedora、CentOS、可以用 dnf 或 yum 安装它。
|
||||
|
||||
### 3. 运行 Visual Studio Code ###
|
||||
|
||||
展开软件包之后,我们可以直接运行一个名为 Code 的文件启动 Visual Studio Code。
|
||||
|
||||
# sudo chmod +x /opt/VSCode-linux-x64/Code
|
||||
# sudo /opt/VSCode-linux-x64/Code
|
||||
|
||||
如果我们想通过终端在任何地方启动 Code,我们就需要创建 /opt/vscode/Code 的一个链接 /usr/local/bin/code。
|
||||
|
||||
# ln -s /opt/VSCode-linux-x64/Code /usr/local/bin/code
|
||||
|
||||
现在,我们就可以在终端中运行以下命令启动 Visual Studio Code 了。
|
||||
|
||||
# code .
|
||||
|
||||
### 4. 创建桌面启动 ###
|
||||
|
||||
下一步,成功展开 Visual Studio Code 软件包之后,我们打算创建桌面启动程序,使得根据不同桌面环境能够从启动器、菜单、桌面启动它。首先我们要复制一个图标文件到 /usr/share/icons/ 目录。
|
||||
|
||||
# cp /opt/VSCode-linux-x64/resources/app/vso.png /usr/share/icons/
|
||||
|
||||
然后,我们创建一个桌面启动程序,文件扩展名为 .desktop。这里我们使用喜欢的文本编辑器在 /tmp/VSCODE/ 目录中创建名为 visualstudiocode.desktop 的文件。
|
||||
|
||||
# vi /tmp/vscode/visualstudiocode.desktop
|
||||
|
||||
然后,粘贴下面的行到那个文件中。
|
||||
|
||||
[Desktop Entry]
|
||||
Name=Visual Studio Code
|
||||
Comment=Multi-platform code editor for Linux
|
||||
Exec=/opt/VSCode-linux-x64/Code
|
||||
Icon=/usr/share/icons/vso.png
|
||||
Type=Application
|
||||
StartupNotify=true
|
||||
Categories=TextEditor;Development;Utility;
|
||||
MimeType=text/plain;
|
||||
|
||||
创建完桌面文件之后,我们会复制这个桌面文件到 /usr/share/applications/ 目录,这样启动器和菜单中就可以单击启动 Visual Studio Code 了。
|
||||
|
||||
# cp /tmp/vscode/visualstudiocode.desktop /usr/share/applications/
|
||||
|
||||
完成之后,我们可以在启动器或者菜单中启动它。
|
||||
|
||||

|
||||
|
||||
### 在 Ubuntu 中 Visual Studio Code ###
|
||||
|
||||
要在 Ubuntu 14.04/14.10/15.04 Linux 发行版中安装 Visual Studio Code,我们可以使用 Ubuntu Make 0.7。这是在 ubuntu 中安装 code 最简单的方法,因为我们只需要执行几个命令。首先,我们要在我们的 ubuntu linux 发行版中安装 Ubuntu Make 0.7。要安装它,首先要为它添加 PPA。可以通过运行下面命令完成。
|
||||
|
||||
# add-apt-repository ppa:ubuntu-desktop/ubuntu-make
|
||||
|
||||
This ppa proposes package backport of Ubuntu make for supported releases.
|
||||
More info: https://launchpad.net/~ubuntu-desktop/+archive/ubuntu/ubuntu-make
|
||||
Press [ENTER] to continue or ctrl-c to cancel adding it
|
||||
gpg: keyring `/tmp/tmpv0vf24us/secring.gpg' created
|
||||
gpg: keyring `/tmp/tmpv0vf24us/pubring.gpg' created
|
||||
gpg: requesting key A1231595 from hkp server keyserver.ubuntu.com
|
||||
gpg: /tmp/tmpv0vf24us/trustdb.gpg: trustdb created
|
||||
gpg: key A1231595: public key "Launchpad PPA for Ubuntu Desktop" imported
|
||||
gpg: no ultimately trusted keys found
|
||||
gpg: Total number processed: 1
|
||||
gpg: imported: 1 (RSA: 1)
|
||||
OK
|
||||
|
||||
然后,更新本地库索引并安装 ubuntu-make。
|
||||
|
||||
# apt-get update
|
||||
# apt-get install ubuntu-make
|
||||
|
||||
在我们的 ubuntu 操作系统上安装完 Ubuntu Make 之后,我们可以在一个终端中运行以下命令来安装 Code。
|
||||
|
||||
# umake web visual-studio-code
|
||||
|
||||

|
||||
|
||||
运行完上面的命令之后,会要求我们输入想要的安装路径。然后,会请求我们允许在 ubuntu 系统中安装 Visual Studio Code。我们输入“a”(接受)。输入完后,它会在 ubuntu 机器上下载和安装 Code。最后,我们可以在启动器或者菜单中启动它。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们已经成功地在 Linux 发行版上安装了 Visual Studio Code。在所有 linux 发行版上安装 Visual Studio Code 都和上面介绍的相似,我们也可以使用 umake 在 Ubuntu 发行版中安装。Umake 是一个安装开发工具,IDEs 和语言的流行工具。我们可以用 Umake 轻松地安装 Android Studios、Eclipse 和很多其它流行 IDE。Visual Studio Code 是基于 Github 上一个叫 [Electron][2] 的项目,它是 [Atom.io][3] 编辑器的一部分。它有很多 Atom.io 编辑器没有的改进功能。当前 Visual Studio Code 只支持 64 位 linux 操作系统平台。
|
||||
|
||||
如果你有任何疑问、建议或者反馈,请在下面的评论框中留言以便我们改进和更新我们的内容。非常感谢!Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-visual-studio-code-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://go.microsoft.com/fwlink/?LinkID=534108
|
||||
[2]:https://github.com/atom/electron
|
||||
[3]:https://github.com/atom/atom
|
||||
@ -0,0 +1,49 @@
|
||||
Linux有问必答:如何检查MariaDB服务端版本
|
||||
================================================================================
|
||||
> **提问**: 我使用的是一台运行MariaDB的VPS。我该如何检查MariaDB服务端的版本?
|
||||
|
||||
有时候你需要知道你的数据库版本,比如当你升级你数据库或对已知缺陷打补丁时。这里有几种方法找出MariaDB版本的方法。
|
||||
|
||||
### 方法一 ###
|
||||
|
||||
第一种找出版本的方法是登录MariaDB服务器,登录之后,你会看到一些MariaDB的版本信息。
|
||||
|
||||

|
||||
|
||||
另一种方法是在登录MariaDB后出现的命令行中输入‘status’命令。输出会显示服务器的版本还有协议版本。
|
||||
|
||||
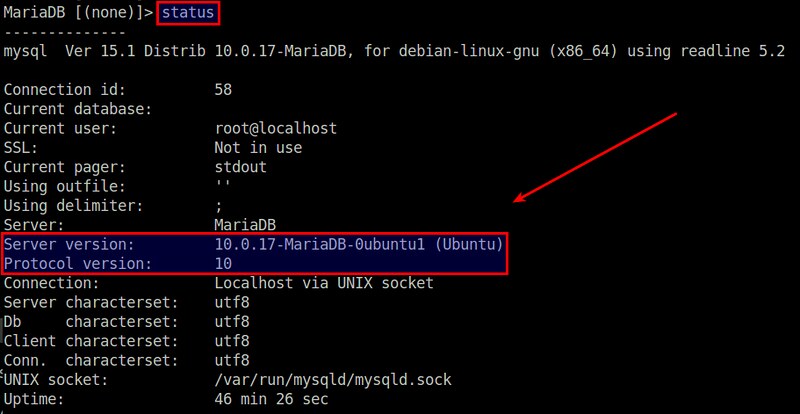
|
||||
|
||||
### 方法二 ###
|
||||
|
||||
如果你不能访问MariaDB服务器,那么你就不能用第一种方法。这种情况下你可以根据MariaDB的安装包的版本来推测。这种方法只有在MariaDB通过包管理器安装的才有用。
|
||||
|
||||
你可以用下面的方法检查MariaDB的安装包。
|
||||
|
||||
#### Debian、Ubuntu或者Linux Mint: ####
|
||||
|
||||
$ dpkg -l | grep mariadb
|
||||
|
||||
下面的输出说明MariaDB的版本是10.0.17。
|
||||
|
||||

|
||||
|
||||
#### Fedora、CentOS或者 RHEL: ####
|
||||
|
||||
$ rpm -qa | grep mariadb
|
||||
|
||||
下面的输出说明安装的版本是5.5.41。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-mariadb-server-version.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,74 @@
|
||||
如何在 Docker 容器中运行 Kali Linux 2.0
|
||||
================================================================================
|
||||
### 介绍 ###
|
||||
|
||||
Kali Linux 是一个对于安全测试人员和白帽的一个知名操作系统。它带有大量安全相关的程序,这让它很容易用于渗透测试。最近,[Kali Linux 2.0][1] 发布了,它被认为是这个操作系统最重要的一次发布。另一方面,Docker 技术由于它的可扩展性和易用性让它变得很流行。Dokcer 让你非常容易地将你的程序带给你的用户。好消息是你可以通过 Docker 运行Kali Linux 了,让我们看看该怎么做 :)
|
||||
|
||||
### 在 Docker 中运行 Kali Linux 2.0 ###
|
||||
|
||||
**相关提示**
|
||||
|
||||
> 如果你还没有在系统中安装docker,你可以运行下面的命令:
|
||||
|
||||
> **对于 Ubuntu/Linux Mint/Debian:**
|
||||
|
||||
> sudo apt-get install docker
|
||||
|
||||
> **对于 Fedora/RHEL/CentOS:**
|
||||
|
||||
> sudo yum install docker
|
||||
|
||||
> **对于 Fedora 22:**
|
||||
|
||||
> dnf install docker
|
||||
|
||||
> 你可以运行下面的命令来启动docker:
|
||||
|
||||
> sudo docker start
|
||||
|
||||
首先运行下面的命令确保 Docker 服务运行正常:
|
||||
|
||||
sudo docker status
|
||||
|
||||
Kali Linux 的开发团队已将 Kali Linux 的 docker 镜像上传了,只需要输入下面的命令来下载镜像。
|
||||
|
||||
docker pull kalilinux/kali-linux-docker
|
||||
|
||||

|
||||
|
||||
下载完成后,运行下面的命令来找出你下载的 docker 镜像的 ID。
|
||||
|
||||
docker images
|
||||
|
||||

|
||||
|
||||
现在运行下面的命令来从镜像文件启动 kali linux docker 容器(这里需用正确的镜像ID替换)。
|
||||
|
||||
docker run -i -t 198cd6df71ab3 /bin/bash
|
||||
|
||||
它会立刻启动容器并且让你登录到该操作系统,你现在可以在 Kaili Linux 中工作了。
|
||||
|
||||

|
||||
|
||||
你可以在容器外面通过下面的命令来验证容器已经启动/运行中了:
|
||||
|
||||
docker ps
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
Docker 是一种最聪明的用来部署和分发包的方式。Kali Linux docker 镜像非常容易上手,也不会消耗很大的硬盘空间,这样也可以很容易地在任何安装了 docker 的操作系统上测试这个很棒的发行版了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/run-kali-linux-2-0-in-docker-container/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxpitstop.com/author/aun/
|
||||
[1]:https://linux.cn/article-6005-1.html
|
||||
@ -0,0 +1,160 @@
|
||||
Alien 魔法:RPM 和 DEB 互转
|
||||
================================================================================
|
||||
|
||||
正如我确信,你们一定知道Linux下的多种软件安装方式:使用发行版所提供的包管理系统([aptitude,yum,或者zypper][1],还可以举很多例子),从源码编译(尽管现在很少用了,但在Linux发展早期却是唯一可用的方法),或者使用各自的低级工具dpkg用于.deb,以及rpm用于.rpm,预编译包,如此这般。
|
||||
|
||||

|
||||
|
||||
*使用Alien将RPM转换成DEB以及将DEB转换成RPM*
|
||||
|
||||
在本文中,我们将为你介绍alien,一个用于在各种不同的Linux包格式相互转换的工具,其最常见的用法是将.rpm转换成.deb(或者反过来)。
|
||||
|
||||
如果你需要某个特定类型的包,而你只能找到其它格式的包的时候,该工具迟早能派得上用场——即使是其作者不再维护,并且在其网站声明:alien将可能永远维持在实验状态。
|
||||
|
||||
例如,有一次,我正查找一个用于喷墨打印机的.deb驱动,但是却没有找到——生产厂家只提供.rpm包,这时候alien拯救了我。我安装了alien,将包进行转换,不久之后我就可以使用我的打印机了,没有任何问题。
|
||||
|
||||
即便如此,我们也必须澄清一下,这个工具不应当用来转换重要的系统文件和库,因为它们在不同的发行版中有不同的配置。只有在前面说的那种情况下所建议的安装方法根本不适合时,alien才能作为最后手段使用。
|
||||
|
||||
最后一项要点是,我们必须注意,虽然我们在本文中使用CentOS和Debian,除了前两个发行版及其各自的家族体系外,据我们所知,alien可以工作在Slackware中,甚至Solaris中。
|
||||
|
||||
### 步骤1:安装Alien及其依赖包 ###
|
||||
|
||||
要安装alien到CentOS/RHEL 7中,你需要启用EPEL和Nux Dextop(是的,是Dextop——不是Desktop)仓库,顺序如下:
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
启用Nux Dextop仓库的包的当前最新版本是0.5(2015年8月10日发布),在安装之前你可以查看[http://li.nux.ro/download/nux/dextop/el7/x86_64/][2]上是否有更新的版本。
|
||||
|
||||
# rpm --import http://li.nux.ro/download/nux/RPM-GPG-KEY-nux.ro
|
||||
# rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-5.el7.nux.noarch.rpm
|
||||
|
||||
然后再做,
|
||||
|
||||
# yum update && yum install alien
|
||||
|
||||
在Fedora中,你只需要运行上面的命令即可。
|
||||
|
||||
在Debian及其衍生版中,只需要:
|
||||
|
||||
# aptitude install alien
|
||||
|
||||
### 步骤2:将.deb转换成.rpm包 ###
|
||||
|
||||
对于本次测试,我们选择了date工具,它提供了一系列日期和时间工具用于处理大量金融数据。我们将下载.deb包到我们的CentOS 7机器中,将它转换成.rpm并安装:
|
||||
|
||||
|
||||
|
||||
检查CentOS版本
|
||||
|
||||
# cat /etc/centos-release
|
||||
# wget http://ftp.us.debian.org/debian/pool/main/d/dateutils/dateutils_0.3.1-1.1_amd64.deb
|
||||
# alien --to-rpm --scripts dateutils_0.3.1-1.1_amd64.deb
|
||||
|
||||

|
||||
|
||||
*在Linux中将.deb转换成.rpm*
|
||||
|
||||
**重要**:(请注意alien是怎样来增加目标包的次版本号的。如果你想要无视该行为,请添加-keep-version标识)。
|
||||
|
||||
如果我们尝试马上安装该包,我们将碰到些许问题:
|
||||
|
||||
# rpm -Uvh dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||

|
||||
|
||||
*安装RPM包*
|
||||
|
||||
要解决该问题,我们需要启用epel-testing仓库,然后安装rpmbuild工具来编辑该包的配置以重建包:
|
||||
|
||||
# yum --enablerepo=epel-testing install rpmrebuild
|
||||
|
||||
然后运行,
|
||||
|
||||
# rpmrebuild -pe dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||
它会打开你的默认文本编辑器。请转到`%files`章节并删除涉及到错误信息中提到的目录的行,然后保存文件并退出:
|
||||
|
||||
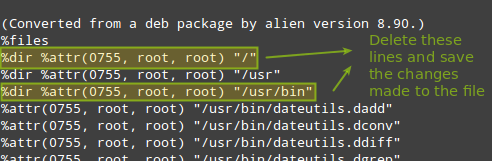
|
||||
|
||||
*转换.deb到Alien版*
|
||||
|
||||
但你退出该文件后,将提示你继续去重构。如果你选择“Y”,该文件会重构到指定的目录(与当前工作目录不同):
|
||||
|
||||
# rpmrebuild –pe dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||

|
||||
|
||||
*构建RPM包*
|
||||
|
||||
现在你可以像以往一样继续来安装包并验证:
|
||||
|
||||
# rpm -Uvh /root/rpmbuild/RPMS/x86_64/dateutils-0.3.1-2.1.x86_64.rpm
|
||||
# rpm -qa | grep dateutils
|
||||
|
||||

|
||||
|
||||
*安装构建RPM包*
|
||||
|
||||
最后,你可以列出date工具包含的各个工具,也可以查看各自的手册页:
|
||||
|
||||
# ls -l /usr/bin | grep dateutils
|
||||
|
||||
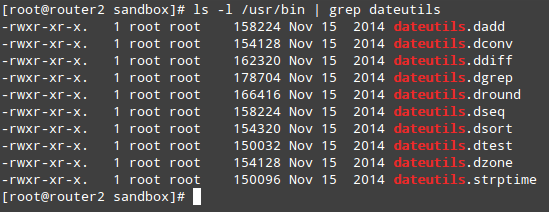
|
||||
|
||||
*验证安装的RPM包*
|
||||
|
||||
### 步骤3:将.rpm转换成.deb包 ###
|
||||
|
||||
在本节中,我们将演示如何将.rpm转换成.deb。在一台32位的Debian Wheezy机器中,让我们从CentOS 6操作系统仓库中下载用于zsh shell的.rpm包。注意,该shell在Debian及其衍生版的默认安装中是不可用的。
|
||||
|
||||
# cat /etc/shells
|
||||
# lsb_release -a | tail -n 4
|
||||
|
||||
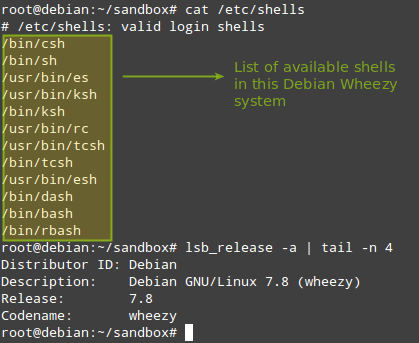
|
||||
|
||||
*检查Shell和Debian操作系统版本*
|
||||
|
||||
# wget http://mirror.centos.org/centos/6/os/i386/Packages/zsh-4.3.11-4.el6.centos.i686.rpm
|
||||
# alien --to-deb --scripts zsh-4.3.11-4.el6.centos.i686.rpm
|
||||
|
||||
你可以安全地无视关于签名丢失的信息:
|
||||
|
||||

|
||||
|
||||
*将.rpm转换成.deb包*
|
||||
|
||||
过了一会儿后,.deb包应该已经生成,并可以安装了:
|
||||
|
||||
# dpkg -i zsh_4.3.11-5_i386.deb
|
||||
|
||||

|
||||
|
||||
*安装RPM转换来的Deb包*
|
||||
|
||||
安装完后,你看看可以zsh是否添加到了合法shell列表中:
|
||||
|
||||
# cat /etc/shells
|
||||
|
||||
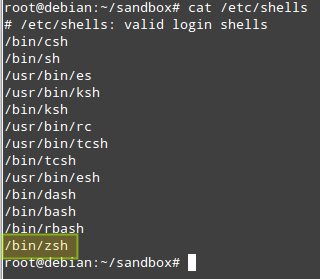
|
||||
|
||||
*确认安装的Zsh包*
|
||||
|
||||
### 小结 ###
|
||||
|
||||
在本文中,我们已经解释了如何将.rpm转换成.deb及其反向转换,这可以作为这类程序不能从仓库中或者作为可分发源代码获得的最后安装手段。你一定想要将本文添加到书签中,因为我们都需要alien。
|
||||
|
||||
请自由分享你关于本文的想法,写到下面的表单中吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/convert-from-rpm-to-deb-and-deb-to-rpm-package-using-alien/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/linux-package-management/
|
||||
[2]:http://li.nux.ro/download/nux/dextop/el7/x86_64/
|
||||
@ -0,0 +1,169 @@
|
||||
Bash 下如何逐行读取一个文件
|
||||
================================================================================
|
||||
|
||||
在 Linux 或类 UNIX 系统下如何使用 KSH 或 BASH shell 逐行读取一个文件?
|
||||
|
||||
在 Linux、OSX、 *BSD 或者类 Unix 系统下你可以使用 while..do..done 的 bash 循环来逐行读取一个文件。
|
||||
|
||||
###在 Bash Unix 或者 Linux shell 中逐行读取一个文件的语法
|
||||
|
||||
对于 bash、ksh、 zsh 和其他的 shells 语法如下
|
||||
|
||||
while read -r line; do COMMAND; done < input.file
|
||||
|
||||
通过 -r 选项传递给 read 命令以防止阻止解释其中的反斜杠转义符。
|
||||
|
||||
在 read 命令之前添加 `IFS=` 选项,来防止首尾的空白字符被去掉。
|
||||
|
||||
while IFS= read -r line; do COMMAND_on $line; done < input.file
|
||||
|
||||
这是更适合人类阅读的语法:
|
||||
|
||||
#!/bin/bash
|
||||
input="/path/to/txt/file"
|
||||
while IFS= read -r var
|
||||
do
|
||||
echo "$var"
|
||||
done < "$input"
|
||||
|
||||
**示例**
|
||||
|
||||
下面是一些例子:
|
||||
|
||||
#!/bin/ksh
|
||||
file="/home/vivek/data.txt"
|
||||
while IFS= read line
|
||||
do
|
||||
# display $line or do somthing with $line
|
||||
echo "$line"
|
||||
done <"$file"
|
||||
|
||||
在 bash shell 中相同的例子:
|
||||
|
||||
#!/bin/bash
|
||||
file="/home/vivek/data.txt"
|
||||
while IFS= read -r line
|
||||
do
|
||||
# display $line or do somthing with $line
|
||||
printf '%s\n' "$line"
|
||||
done <"$file"
|
||||
|
||||
你还可以看看这个更好的:
|
||||
|
||||
#!/bin/bash
|
||||
file="/etc/passwd"
|
||||
while IFS=: read -r f1 f2 f3 f4 f5 f6 f7
|
||||
do
|
||||
# display fields using f1, f2,..,f7
|
||||
printf 'Username: %s, Shell: %s, Home Dir: %s\n' "$f1" "$f7" "$f6"
|
||||
done <"$file"
|
||||
|
||||
示例输出:
|
||||
|
||||
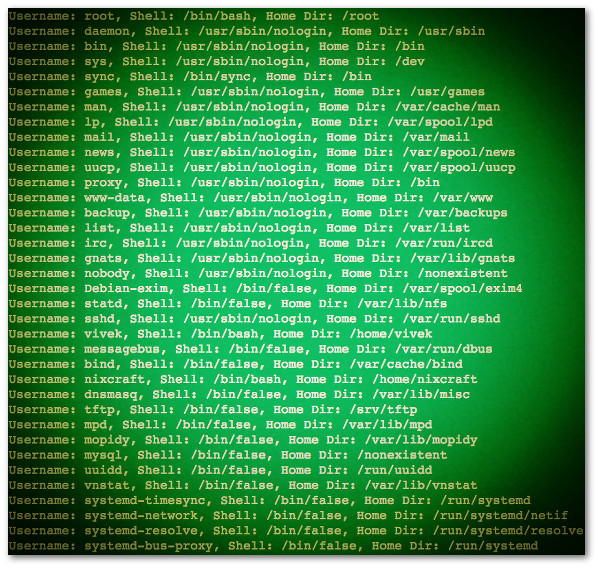
|
||||
|
||||
*图01:Bash 脚本:读取文件并逐行输出文件*
|
||||
|
||||
###Bash 脚本:逐行读取文本文件并创建为 pdf 文件
|
||||
|
||||
我的输入文件如下(faq.txt):
|
||||
|
||||
4|http://www.cyberciti.biz/faq/mysql-user-creation/|Mysql User Creation: Setting Up a New MySQL User Account
|
||||
4096|http://www.cyberciti.biz/faq/ksh-korn-shell/|What is UNIX / Linux Korn Shell?
|
||||
4101|http://www.cyberciti.biz/faq/what-is-posix-shell/|What Is POSIX Shell?
|
||||
17267|http://www.cyberciti.biz/faq/linux-check-battery-status/|Linux: Check Battery Status Command
|
||||
17245|http://www.cyberciti.biz/faq/restarting-ntp-service-on-linux/|Linux Restart NTPD Service Command
|
||||
17183|http://www.cyberciti.biz/faq/ubuntu-linux-determine-your-ip-address/|Ubuntu Linux: Determine Your IP Address
|
||||
17172|http://www.cyberciti.biz/faq/determine-ip-address-of-linux-server/|HowTo: Determine an IP Address My Linux Server
|
||||
16510|http://www.cyberciti.biz/faq/unix-linux-restart-php-service-command/|Linux / Unix: Restart PHP Service Command
|
||||
8292|http://www.cyberciti.biz/faq/mounting-harddisks-in-freebsd-with-mount-command/|FreeBSD: Mount Hard Drive / Disk Command
|
||||
8190|http://www.cyberciti.biz/faq/rebooting-solaris-unix-server/|Reboot a Solaris UNIX System
|
||||
|
||||
我的 bash 脚本:
|
||||
|
||||
#!/bin/bash
|
||||
# Usage: Create pdf files from input (wrapper script)
|
||||
# Author: Vivek Gite <Www.cyberciti.biz> under GPL v2.x+
|
||||
#---------------------------------------------------------
|
||||
|
||||
#Input file
|
||||
_db="/tmp/wordpress/faq.txt"
|
||||
|
||||
#Output location
|
||||
o="/var/www/prviate/pdf/faq"
|
||||
|
||||
_writer="~/bin/py/pdfwriter.py"
|
||||
|
||||
# If file exists
|
||||
if [[ -f "$_db" ]]
|
||||
then
|
||||
# read it
|
||||
while IFS='|' read -r pdfid pdfurl pdftitle
|
||||
do
|
||||
local pdf="$o/$pdfid.pdf"
|
||||
echo "Creating $pdf file ..."
|
||||
#Genrate pdf file
|
||||
$_writer --quiet --footer-spacing 2 \
|
||||
--footer-left "nixCraft is GIT UL++++ W+++ C++++ M+ e+++ d-" \
|
||||
--footer-right "Page [page] of [toPage]" --footer-line \
|
||||
--footer-font-size 7 --print-media-type "$pdfurl" "$pdf"
|
||||
done <"$_db"
|
||||
fi
|
||||
|
||||
###技巧:从 bash 变量中读取
|
||||
|
||||
让我们看看如何在 Debian 或者 Ubuntu Linux 下列出所有安装过的 php 包,请输入:
|
||||
|
||||
# 我将输出内容赋值到一个变量名为 $list中 #
|
||||
|
||||
list=$(dpkg --list php\* | awk '/ii/{print $2}')
|
||||
printf '%s\n' "$list"
|
||||
|
||||
示例输出:
|
||||
|
||||
php-pear
|
||||
php5-cli
|
||||
php5-common
|
||||
php5-fpm
|
||||
php5-gd
|
||||
php5-json
|
||||
php5-memcache
|
||||
php5-mysql
|
||||
php5-readline
|
||||
php5-suhosin-extension
|
||||
|
||||
你现在可以从 $list 中看到它们,并安装这些包:
|
||||
|
||||
#!/bin/bash
|
||||
# BASH can iterate over $list variable using a "here string" #
|
||||
while IFS= read -r pkg
|
||||
do
|
||||
printf 'Installing php package %s...\n' "$pkg"
|
||||
/usr/bin/apt-get -qq install $pkg
|
||||
done <<< "$list"
|
||||
printf '*** Do not forget to run php5enmod and restart the server (httpd or php5-fpm) ***\n'
|
||||
|
||||
示例输出:
|
||||
|
||||
Installing php package php-pear...
|
||||
Installing php package php5-cli...
|
||||
Installing php package php5-common...
|
||||
Installing php package php5-fpm...
|
||||
Installing php package php5-gd...
|
||||
Installing php package php5-json...
|
||||
Installing php package php5-memcache...
|
||||
Installing php package php5-mysql...
|
||||
Installing php package php5-readline...
|
||||
Installing php package php5-suhosin-extension...
|
||||
|
||||
*** Do not forget to run php5enmod and restart the server (httpd or php5-fpm) ***
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/unix-howto-read-line-by-line-from-file/
|
||||
|
||||
作者: VIVEK GIT
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,24 +1,25 @@
|
||||
使用dd命令在Linux和Unix环境下进行硬盘I/O性能检测
|
||||
使用 dd 命令进行硬盘 I/O 性能检测
|
||||
================================================================================
|
||||
如何使用dd命令测试硬盘的性能?如何在linux操作系统下检测硬盘的读写能力?
|
||||
|
||||
如何使用dd命令测试我的硬盘性能?如何在linux操作系统下检测硬盘的读写速度?
|
||||
|
||||
你可以使用以下命令在一个Linux或类Unix操作系统上进行简单的I/O性能测试。
|
||||
|
||||
- **dd命令** :它被用来在Linux和类Unix系统下对硬盘设备进行写性能的检测。
|
||||
- **hparm命令**:它被用来获取或设置硬盘参数,包括测试读性能以及缓存性能等。
|
||||
- **dd命令** :它被用来在Linux和类Unix系统下对硬盘设备进行写性能的检测。
|
||||
- **hparm命令**:它用来在基于 Linux 的系统上获取或设置硬盘参数,包括测试读性能以及缓存性能等。
|
||||
|
||||
在这篇指南中,你将会学到如何使用dd命令来测试硬盘性能。
|
||||
|
||||
### 使用dd命令来监控硬盘的读写性能:###
|
||||
|
||||
- 打开shell终端(这里貌似不能翻译为终端提示符)。
|
||||
- 通过ssh登录到远程服务器。
|
||||
- 打开shell终端。
|
||||
- 或者通过ssh登录到远程服务器。
|
||||
- 使用dd命令来测量服务器的吞吐率(写速度) `dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync`
|
||||
- 使用dd命令测量服务器延迟 `dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync`
|
||||
|
||||
####理解dd命令的选项###
|
||||
|
||||
在这个例子当中,我将使用搭载Ubuntu Linux 14.04 LTS系统的RAID-10(配有SAS SSD的Adaptec 5405Z)服务器阵列来运行。基本语法为:
|
||||
在这个例子当中,我将使用搭载Ubuntu Linux 14.04 LTS系统的RAID-10(配有SAS SSD的Adaptec 5405Z)服务器阵列来运行。基本语法为:
|
||||
|
||||
dd if=/dev/input.file of=/path/to/output.file bs=block-size count=number-of-blocks oflag=dsync
|
||||
## GNU dd语法 ##
|
||||
@ -29,18 +30,19 @@
|
||||
输出样例:
|
||||
|
||||

|
||||
Fig.01: 使用dd命令获取的服务器吞吐率
|
||||
|
||||
*图01: 使用dd命令获取的服务器吞吐率*
|
||||
|
||||
请各位注意在这个实验中,我们写入一个G的数据,可以发现,服务器的吞吐率是135 MB/s,这其中
|
||||
|
||||
- `if=/dev/zero (if=/dev/input.file)` :用来设置dd命令读取的输入文件名。
|
||||
- `of=/tmp/test1.img (of=/path/to/output.file)` :dd命令将input.file写入的输出文件的名字。
|
||||
- `bs=1G (bs=block-size)` :设置dd命令读取的块的大小。例子中为1个G。
|
||||
- `count=1 (count=number-of-blocks)`: dd命令读取的块的个数。
|
||||
- `oflag=dsync (oflag=dsync)` :使用同步I/O。不要省略这个选项。这个选项能够帮助你去除caching的影响,以便呈现给你精准的结果。
|
||||
- `if=/dev/zero` (if=/dev/input.file) :用来设置dd命令读取的输入文件名。
|
||||
- `of=/tmp/test1.img` (of=/path/to/output.file):dd命令将input.file写入的输出文件的名字。
|
||||
- `bs=1G` (bs=block-size) :设置dd命令读取的块的大小。例子中为1个G。
|
||||
- `count=1` (count=number-of-blocks):dd命令读取的块的个数。
|
||||
- `oflag=dsync` (oflag=dsync) :使用同步I/O。不要省略这个选项。这个选项能够帮助你去除caching的影响,以便呈现给你精准的结果。
|
||||
- `conv=fdatasyn`: 这个选项和`oflag=dsync`含义一样。
|
||||
|
||||
在这个例子中,一共写了1000次,每次写入512字节来获得RAID10服务器的延迟时间:
|
||||
在下面这个例子中,一共写了1000次,每次写入512字节来获得RAID10服务器的延迟时间:
|
||||
|
||||
dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync
|
||||
|
||||
@ -50,11 +52,11 @@ Fig.01: 使用dd命令获取的服务器吞吐率
|
||||
1000+0 records out
|
||||
512000 bytes (512 kB) copied, 0.60362 s, 848 kB/s
|
||||
|
||||
请注意服务器的吞吐率以及延迟时间也取决于服务器/应用的加载。所以我推荐你在一个刚刚重启过并且处于峰值时间的服务器上来运行测试,以便得到更加准确的度量。现在你可以在你的所有设备上互相比较这些测试结果了。
|
||||
请注意服务器的吞吐率以及延迟时间也取决于服务器/应用的负载。所以我推荐你在一个刚刚重启过并且处于峰值时间的服务器上来运行测试,以便得到更加准确的度量。现在你可以在你的所有设备上互相比较这些测试结果了。
|
||||
|
||||
####为什么服务器的吞吐率和延迟时间都这么差?###
|
||||
###为什么服务器的吞吐率和延迟时间都这么差?###
|
||||
|
||||
低的数值并不意味着你在使用差劲的硬件。可能是HARDWARE RAID10的控制器缓存导致的。
|
||||
低的数值并不意味着你在使用差劲的硬件。可能是硬件 RAID10的控制器缓存导致的。
|
||||
|
||||
使用hdparm命令来查看硬盘缓存的读速度。
|
||||
|
||||
@ -79,11 +81,12 @@ Fig.01: 使用dd命令获取的服务器吞吐率
|
||||
输出样例:
|
||||
|
||||
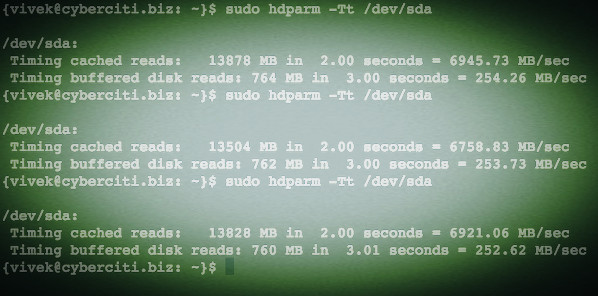
|
||||
Fig.02: 检测硬盘读入以及缓存性能的Linux hdparm命令
|
||||
|
||||
请再一次注意由于文件文件操作的缓存属性,你将总是会看到很高的读速度。
|
||||
*图02: 检测硬盘读入以及缓存性能的Linux hdparm命令*
|
||||
|
||||
**使用dd命令来测试读入速度**
|
||||
请再次注意,由于文件文件操作的缓存属性,你将总是会看到很高的读速度。
|
||||
|
||||
###使用dd命令来测试读取速度###
|
||||
|
||||
为了获得精确的读测试数据,首先在测试前运行下列命令,来将缓存设置为无效:
|
||||
|
||||
@ -91,11 +94,11 @@ Fig.02: 检测硬盘读入以及缓存性能的Linux hdparm命令
|
||||
echo 3 | sudo tee /proc/sys/vm/drop_caches
|
||||
time time dd if=/path/to/bigfile of=/dev/null bs=8k
|
||||
|
||||
**笔记本上的示例**
|
||||
####笔记本上的示例####
|
||||
|
||||
运行下列命令:
|
||||
|
||||
### Cache存在的Debian系统笔记本吞吐率###
|
||||
### 带有Cache的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
###使cache失效###
|
||||
@ -104,10 +107,11 @@ Fig.02: 检测硬盘读入以及缓存性能的Linux hdparm命令
|
||||
###没有Cache的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
**苹果OS X Unix(Macbook pro)的例子**
|
||||
####苹果OS X Unix(Macbook pro)的例子####
|
||||
|
||||
GNU dd has many more options but OS X/BSD and Unix-like dd command need to run as follows to test real disk I/O and not memory add sync option as follows:
|
||||
GNU dd命令有其他许多选项但是在 OS X/BSD 以及类Unix中, dd命令需要像下面那样执行来检测去除掉内存地址同步的硬盘真实I/O性能:
|
||||
|
||||
GNU dd命令有其他许多选项,但是在 OS X/BSD 以及类Unix中, dd命令需要像下面那样执行来检测去除掉内存地址同步的硬盘真实I/O性能:
|
||||
|
||||
## 运行这个命令2-3次来获得更好地结果 ###
|
||||
time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync"
|
||||
@ -124,26 +128,29 @@ GNU dd命令有其他许多选项但是在 OS X/BSD 以及类Unix中, dd命令
|
||||
|
||||
本人Macbook Pro的写速度是635346520字节(635.347MB/s)。
|
||||
|
||||
**不喜欢用命令行?^_^**
|
||||
###不喜欢用命令行?\^_^###
|
||||
|
||||
你可以在Linux或基于Unix的系统上使用disk utility(gnome-disk-utility)这款工具来得到同样的信息。下面的那个图就是在我的Fedora Linux v22 VM上截取的。
|
||||
|
||||
**图形化方法**
|
||||
####图形化方法####
|
||||
|
||||
点击“Activites”或者“Super”按键来在桌面和Activites视图间切换。输入“Disks”
|
||||
|
||||
|
||||
Fig.03: 打开Gnome硬盘工具
|
||||
|
||||
*图03: 打开Gnome硬盘工具*
|
||||
|
||||
在左边的面板上选择你的硬盘,点击configure按钮,然后点击“Benchmark partition”:
|
||||
|
||||
|
||||
Fig.04: 评测硬盘/分区
|
||||
|
||||
最后,点击“Start Benchmark...”按钮(你可能被要求输入管理员用户名和密码):
|
||||
*图04: 评测硬盘/分区*
|
||||
|
||||
最后,点击“Start Benchmark...”按钮(你可能需要输入管理员用户名和密码):
|
||||
|
||||
|
||||
Fig.05: 最终的评测结果
|
||||
|
||||
*图05: 最终的评测结果*
|
||||
|
||||
如果你要问,我推荐使用哪种命令和方法?
|
||||
|
||||
@ -158,7 +165,7 @@ via: http://www.cyberciti.biz/faq/howto-linux-unix-test-disk-performance-with-dd
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,156 @@
|
||||
在 Linux 下使用 RAID(一):介绍 RAID 的级别和概念
|
||||
================================================================================
|
||||
|
||||
RAID 的意思是廉价磁盘冗余阵列(Redundant Array of Inexpensive Disks),但现在它被称为独立磁盘冗余阵列(Redundant Array of Independent Drives)。早先一个容量很小的磁盘都是非常昂贵的,但是现在我们可以很便宜的买到一个更大的磁盘。Raid 是一系列放在一起,成为一个逻辑卷的磁盘集合。
|
||||
|
||||

|
||||
|
||||
*在 Linux 中理解 RAID 设置*
|
||||
|
||||
RAID 包含一组或者一个集合甚至一个阵列。使用一组磁盘结合驱动器组成 RAID 阵列或 RAID 集。将至少两个磁盘连接到一个 RAID 控制器,而成为一个逻辑卷,也可以将多个驱动器放在一个组中。一组磁盘只能使用一个 RAID 级别。使用 RAID 可以提高服务器的性能。不同 RAID 的级别,性能会有所不同。它通过容错和高可用性来保存我们的数据。
|
||||
|
||||
这个系列被命名为“在 Linux 下使用 RAID”,分为9个部分,包括以下主题:
|
||||
|
||||
- 第1部分:介绍 RAID 的级别和概念
|
||||
- 第2部分:在Linux中如何设置 RAID0(条带化)
|
||||
- 第3部分:在Linux中如何设置 RAID1(镜像化)
|
||||
- 第4部分:在Linux中如何设置 RAID5(条带化与分布式奇偶校验)
|
||||
- 第5部分:在Linux中如何设置 RAID6(条带双分布式奇偶校验)
|
||||
- 第6部分:在Linux中设置 RAID 10 或1 + 0(嵌套)
|
||||
- 第7部分:增加现有的 RAID 阵列并删除损坏的磁盘
|
||||
- 第8部分:在 RAID 中恢复(重建)损坏的驱动器
|
||||
- 第9部分:在 Linux 中管理 RAID
|
||||
|
||||
这是9篇系列教程的第1部分,在这里我们将介绍 RAID 的概念和 RAID 级别,这是在 Linux 中构建 RAID 需要理解的。
|
||||
|
||||
### 软件 RAID 和硬件 RAID ###
|
||||
|
||||
软件 RAID 的性能较低,因为其使用主机的资源。 需要加载 RAID 软件以从软件 RAID 卷中读取数据。在加载 RAID 软件前,操作系统需要引导起来才能加载 RAID 软件。在软件 RAID 中无需物理硬件。零成本投资。
|
||||
|
||||
硬件 RAID 的性能较高。他们采用 PCI Express 卡物理地提供有专用的 RAID 控制器。它不会使用主机资源。他们有 NVRAM 用于缓存的读取和写入。缓存用于 RAID 重建时,即使出现电源故障,它会使用后备的电池电源保持缓存。对于大规模使用是非常昂贵的投资。
|
||||
|
||||
硬件 RAID 卡如下所示:
|
||||
|
||||

|
||||
|
||||
*硬件 RAID*
|
||||
|
||||
#### 重要的 RAID 概念 ####
|
||||
|
||||
- **校验**方式用在 RAID 重建中从校验所保存的信息中重新生成丢失的内容。 RAID 5,RAID 6 基于校验。
|
||||
- **条带化**是将切片数据随机存储到多个磁盘。它不会在单个磁盘中保存完整的数据。如果我们使用2个磁盘,则每个磁盘存储我们的一半数据。
|
||||
- **镜像**被用于 RAID 1 和 RAID 10。镜像会自动备份数据。在 RAID 1 中,它会保存相同的内容到其他盘上。
|
||||
- **热备份**只是我们的服务器上的一个备用驱动器,它可以自动更换发生故障的驱动器。在我们的阵列中,如果任何一个驱动器损坏,热备份驱动器会自动用于重建 RAID。
|
||||
- **块**是 RAID 控制器每次读写数据时的最小单位,最小 4KB。通过定义块大小,我们可以增加 I/O 性能。
|
||||
|
||||
RAID有不同的级别。在这里,我们仅列出在真实环境下的使用最多的 RAID 级别。
|
||||
|
||||
- RAID0 = 条带化
|
||||
- RAID1 = 镜像
|
||||
- RAID5 = 单磁盘分布式奇偶校验
|
||||
- RAID6 = 双磁盘分布式奇偶校验
|
||||
- RAID10 = 镜像 + 条带。(嵌套RAID)
|
||||
|
||||
RAID 在大多数 Linux 发行版上使用名为 mdadm 的软件包进行管理。让我们先对每个 RAID 级别认识一下。
|
||||
|
||||
#### RAID 0 / 条带化 ####
|
||||
|
||||
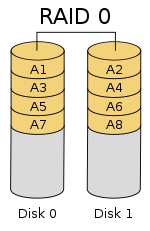
|
||||
|
||||
条带化有很好的性能。在 RAID 0(条带化)中数据将使用切片的方式被写入到磁盘。一半的内容放在一个磁盘上,另一半内容将被写入到另一个磁盘。
|
||||
|
||||
假设我们有2个磁盘驱动器,例如,如果我们将数据“TECMINT”写到逻辑卷中,“T”将被保存在第一盘中,“E”将保存在第二盘,'C'将被保存在第一盘,“M”将保存在第二盘,它会一直继续此循环过程。(LCTT 译注:实际上不可能按字节切片,是按数据块切片的。)
|
||||
|
||||
在这种情况下,如果驱动器中的任何一个发生故障,我们就会丢失数据,因为一个盘中只有一半的数据,不能用于重建 RAID。不过,当比较写入速度和性能时,RAID 0 是非常好的。创建 RAID 0(条带化)至少需要2个磁盘。如果你的数据是非常宝贵的,那么不要使用此 RAID 级别。
|
||||
|
||||
- 高性能。
|
||||
- RAID 0 中容量零损失。
|
||||
- 零容错。
|
||||
- 写和读有很高的性能。
|
||||
|
||||
#### RAID 1 / 镜像化 ####
|
||||
|
||||

|
||||
|
||||
镜像也有不错的性能。镜像可以对我们的数据做一份相同的副本。假设我们有两个2TB的硬盘驱动器,我们总共有4TB,但在镜像中,但是放在 RAID 控制器后面的驱动器形成了一个逻辑驱动器,我们只能看到这个逻辑驱动器有2TB。
|
||||
|
||||
当我们保存数据时,它将同时写入这两个2TB驱动器中。创建 RAID 1(镜像化)最少需要两个驱动器。如果发生磁盘故障,我们可以通过更换一个新的磁盘恢复 RAID 。如果在 RAID 1 中任何一个磁盘发生故障,我们可以从另一个磁盘中获取相同的数据,因为另外的磁盘中也有相同的数据。所以是零数据丢失。
|
||||
|
||||
- 良好的性能。
|
||||
- 总容量丢失一半可用空间。
|
||||
- 完全容错。
|
||||
- 重建会更快。
|
||||
- 写性能变慢。
|
||||
- 读性能变好。
|
||||
- 能用于操作系统和小规模的数据库。
|
||||
|
||||
#### RAID 5 / 分布式奇偶校验 ####
|
||||
|
||||
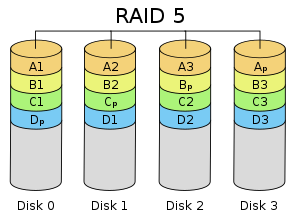
|
||||
|
||||
RAID 5 多用于企业级。 RAID 5 的以分布式奇偶校验的方式工作。奇偶校验信息将被用于重建数据。它从剩下的正常驱动器上的信息来重建。在驱动器发生故障时,这可以保护我们的数据。
|
||||
|
||||
假设我们有4个驱动器,如果一个驱动器发生故障而后我们更换发生故障的驱动器后,我们可以从奇偶校验中重建数据到更换的驱动器上。奇偶校验信息存储在所有的4个驱动器上,如果我们有4个 1TB 的驱动器。奇偶校验信息将被存储在每个驱动器的256G中,而其它768GB是用户自己使用的。单个驱动器故障后,RAID 5 依旧正常工作,如果驱动器损坏个数超过1个会导致数据的丢失。
|
||||
|
||||
- 性能卓越
|
||||
- 读速度将非常好。
|
||||
- 写速度处于平均水准,如果我们不使用硬件 RAID 控制器,写速度缓慢。
|
||||
- 从所有驱动器的奇偶校验信息中重建。
|
||||
- 完全容错。
|
||||
- 1个磁盘空间将用于奇偶校验。
|
||||
- 可以被用在文件服务器,Web服务器,非常重要的备份中。
|
||||
|
||||
#### RAID 6 双分布式奇偶校验磁盘 ####
|
||||
|
||||

|
||||
|
||||
RAID 6 和 RAID 5 相似但它有两个分布式奇偶校验。大多用在大数量的阵列中。我们最少需要4个驱动器,即使有2个驱动器发生故障,我们依然可以更换新的驱动器后重建数据。
|
||||
|
||||
它比 RAID 5 慢,因为它将数据同时写到4个驱动器上。当我们使用硬件 RAID 控制器时速度就处于平均水准。如果我们有6个的1TB驱动器,4个驱动器将用于数据保存,2个驱动器将用于校验。
|
||||
|
||||
- 性能不佳。
|
||||
- 读的性能很好。
|
||||
- 如果我们不使用硬件 RAID 控制器写的性能会很差。
|
||||
- 从两个奇偶校验驱动器上重建。
|
||||
- 完全容错。
|
||||
- 2个磁盘空间将用于奇偶校验。
|
||||
- 可用于大型阵列。
|
||||
- 用于备份和视频流中,用于大规模。
|
||||
|
||||
#### RAID 10 / 镜像+条带 ####
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
RAID 10 可以被称为1 + 0或0 +1。它将做镜像+条带两个工作。在 RAID 10 中首先做镜像然后做条带。在 RAID 01 上首先做条带,然后做镜像。RAID 10 比 01 好。
|
||||
|
||||
假设,我们有4个驱动器。当我逻辑卷上写数据时,它会使用镜像和条带的方式将数据保存到4个驱动器上。
|
||||
|
||||
如果我在 RAID 10 上写入数据“TECMINT”,数据将使用如下方式保存。首先将“T”同时写入两个磁盘,“E”也将同时写入另外两个磁盘,所有数据都写入两块磁盘。这样可以将每个数据复制到另外的磁盘。
|
||||
|
||||
同时它将使用 RAID 0 方式写入数据,遵循将“T”写入第一组盘,“E”写入第二组盘。再次将“C”写入第一组盘,“M”到第二组盘。
|
||||
|
||||
- 良好的读写性能。
|
||||
- 总容量丢失一半的可用空间。
|
||||
- 容错。
|
||||
- 从副本数据中快速重建。
|
||||
- 由于其高性能和高可用性,常被用于数据库的存储中。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经了解了什么是 RAID 和在实际环境大多采用哪个级别的 RAID。希望你已经学会了上面所写的。对于 RAID 的构建必须了解有关 RAID 的基本知识。以上内容可以基本满足你对 RAID 的了解。
|
||||
|
||||
在接下来的文章中,我将介绍如何设置和使用各种级别创建 RAID,增加 RAID 组(阵列)和驱动器故障排除等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
@ -0,0 +1,219 @@
|
||||
在 Linux 下使用 RAID(一):使用 mdadm 工具创建软件 RAID 0 (条带化)
|
||||
================================================================================
|
||||
|
||||
RAID 即廉价磁盘冗余阵列,其高可用性和可靠性适用于大规模环境中,相比正常使用,数据更需要被保护。RAID 是一些磁盘的集合,是包含一个阵列的逻辑卷。驱动器可以组合起来成为一个阵列或称为(组的)集合。
|
||||
|
||||
创建 RAID 最少应使用2个连接到 RAID 控制器的磁盘组成,来构成逻辑卷,可以根据定义的 RAID 级别将更多的驱动器添加到一个阵列中。不使用物理硬件创建的 RAID 被称为软件 RAID。软件 RAID 也叫做穷人 RAID。
|
||||
|
||||
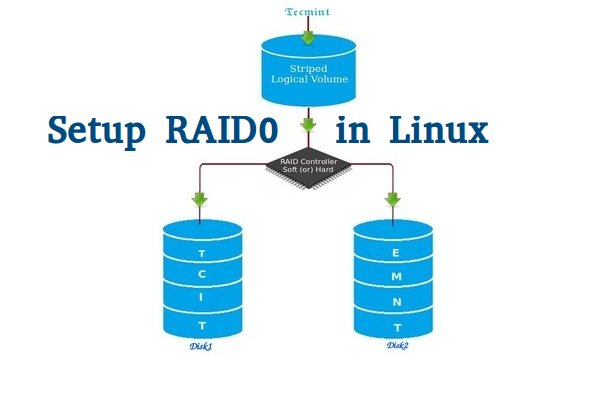
|
||||
|
||||
*在 Linux 中创建 RAID0*
|
||||
|
||||
使用 RAID 的主要目的是为了在发生单点故障时保存数据,如果我们使用单个磁盘来存储数据,如果它损坏了,那么就没有机会取回我们的数据了,为了防止数据丢失我们需要一个容错的方法。所以,我们可以使用多个磁盘组成 RAID 阵列。
|
||||
|
||||
#### 在 RAID 0 中条带是什么 ####
|
||||
|
||||
条带是通过将数据在同时分割到多个磁盘上。假设我们有两个磁盘,如果我们将数据保存到该逻辑卷上,它会将数据保存在两个磁盘上。使用 RAID 0 是为了获得更好的性能,但是如果驱动器中一个出现故障,我们将不能得到完整的数据。因此,使用 RAID 0 不是一种好的做法。唯一的解决办法就是安装有 RAID 0 逻辑卷的操作系统来提高重要文件的安全性。
|
||||
|
||||
- RAID 0 性能较高。
|
||||
- 在 RAID 0 上,空间零浪费。
|
||||
- 零容错(如果硬盘中的任何一个发生故障,无法取回数据)。
|
||||
- 写和读性能都很好。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
创建 RAID 0 允许的最小磁盘数目是2个,但你可以添加更多的磁盘,不过数目应该是2,4,6,8等的偶数。如果你有一个物理 RAID 卡并且有足够的端口,你可以添加更多磁盘。
|
||||
|
||||
在这里,我们没有使用硬件 RAID,此设置只需要软件 RAID。如果我们有一个物理硬件 RAID 卡,我们可以从它的功能界面访问它。有些主板默认内建 RAID 功能,还可以使用 Ctrl + I 键访问它的界面。
|
||||
|
||||
如果你是刚开始设置 RAID,请阅读我们前面的文章,我们已经介绍了一些关于 RAID 基本的概念。
|
||||
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
|
||||
**我的服务器设置**
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.225
|
||||
两块盘 : 20 GB each
|
||||
|
||||
这是9篇系列教程的第2部分,在这部分,我们将看看如何能够在 Linux 上创建和使用 RAID 0(条带化),以名为 sdb 和 sdc 两个 20GB 的硬盘为例。
|
||||
|
||||
### 第1步:更新系统和安装管理 RAID 的 mdadm 软件 ###
|
||||
|
||||
1、 在 Linux 上设置 RAID 0 前,我们先更新一下系统,然后安装`mdadm` 包。mdadm 是一个小程序,这将使我们能够在Linux下配置和管理 RAID 设备。
|
||||
|
||||
# yum clean all && yum update
|
||||
# yum install mdadm -y
|
||||
|
||||
|
||||
|
||||
*安装 mdadm 工具*
|
||||
|
||||
### 第2步:确认连接了两个 20GB 的硬盘 ###
|
||||
|
||||
2、 在创建 RAID 0 前,请务必确认两个硬盘能被检测到,使用下面的命令确认。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||
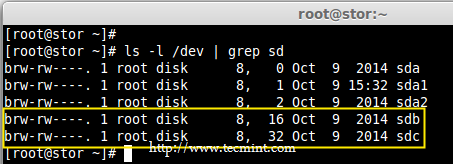
|
||||
|
||||
*检查硬盘*
|
||||
|
||||
3、 一旦检测到新的硬盘驱动器,同时检查是否连接的驱动器已经被现有的 RAID 使用,使用下面的`mdadm` 命令来查看。
|
||||
|
||||
# mdadm --examine /dev/sd[b-c]
|
||||
|
||||
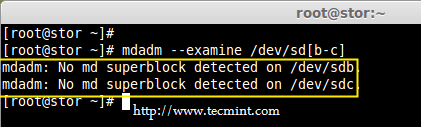
|
||||
|
||||
*检查 RAID 设备*
|
||||
|
||||
从上面的输出我们可以看到,没有任何 RAID 使用 sdb 和 sdc 这两个驱动器。
|
||||
|
||||
### 第3步:创建 RAID 分区 ###
|
||||
|
||||
4、 现在用 sdb 和 sdc 创建 RAID 的分区,使用 fdisk 命令来创建。在这里,我将展示如何创建 sdb 驱动器上的分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
请按照以下说明创建分区。
|
||||
|
||||
- 按`n` 创建新的分区。
|
||||
- 然后按`P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按`P` 来显示创建好的分区。
|
||||
|
||||

|
||||
|
||||
*创建分区*
|
||||
|
||||
请按照以下说明将分区创建为 Linux 的 RAID 类型。
|
||||
|
||||
- 按`L`,列出所有可用的类型。
|
||||
- 按`t` 去修改分区。
|
||||
- 键入`fd` 设置为 Linux 的 RAID 类型,然后按回车确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*在 Linux 上创建 RAID 分区*
|
||||
|
||||
**注**: 请使用上述步骤同样在 sdc 驱动器上创建分区。
|
||||
|
||||
5、 创建分区后,验证这两个驱动器是否正确定义 RAID,使用下面的命令。
|
||||
|
||||
# mdadm --examine /dev/sd[b-c]
|
||||
# mdadm --examine /dev/sd[b-c]1
|
||||
|
||||
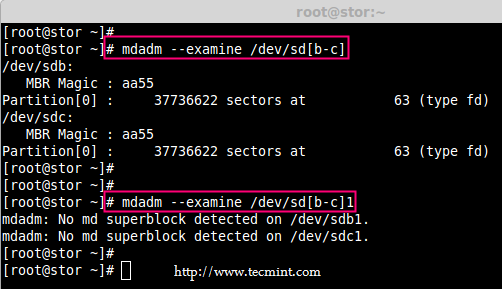
|
||||
|
||||
*验证 RAID 分区*
|
||||
|
||||
### 第4步:创建 RAID md 设备 ###
|
||||
|
||||
6、 现在使用以下命令创建 md 设备(即 /dev/md0),并选择 RAID 合适的级别。
|
||||
|
||||
# mdadm -C /dev/md0 -l raid0 -n 2 /dev/sd[b-c]1
|
||||
# mdadm --create /dev/md0 --level=stripe --raid-devices=2 /dev/sd[b-c]1
|
||||
|
||||
- -C – 创建
|
||||
- -l – 级别
|
||||
- -n – RAID 设备数
|
||||
|
||||
7、 一旦 md 设备已经建立,使用如下命令可以查看 RAID 级别,设备和阵列的使用状态。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||
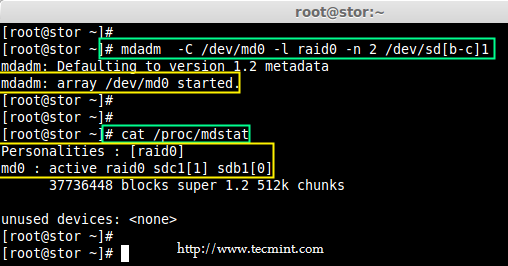
|
||||
|
||||
*查看 RAID 级别*
|
||||
|
||||
# mdadm -E /dev/sd[b-c]1
|
||||
|
||||

|
||||
|
||||
*查看 RAID 设备*
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*查看 RAID 阵列*
|
||||
|
||||
### 第5步:给 RAID 设备创建文件系统 ###
|
||||
|
||||
8、 将 RAID 设备 /dev/md0 创建为 ext4 文件系统,并挂载到 /mnt/raid0 下。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
*创建 ext4 文件系统*
|
||||
|
||||
9、 在 RAID 设备上创建好 ext4 文件系统后,现在创建一个挂载点(即 /mnt/raid0),并将设备 /dev/md0 挂载在它下。
|
||||
|
||||
# mkdir /mnt/raid0
|
||||
# mount /dev/md0 /mnt/raid0/
|
||||
|
||||
10、下一步,使用 df 命令验证设备 /dev/md0 是否被挂载在 /mnt/raid0 下。
|
||||
|
||||
# df -h
|
||||
|
||||
11、 接下来,在挂载点 /mnt/raid0 下创建一个名为`tecmint.txt` 的文件,为创建的文件添加一些内容,并查看文件和目录的内容。
|
||||
|
||||
# touch /mnt/raid0/tecmint.txt
|
||||
# echo "Hi everyone how you doing ?" > /mnt/raid0/tecmint.txt
|
||||
# cat /mnt/raid0/tecmint.txt
|
||||
# ls -l /mnt/raid0/
|
||||
|
||||

|
||||
|
||||
*验证挂载的设备*
|
||||
|
||||
12、 当你验证挂载点后,就可以将它添加到 /etc/fstab 文件中。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
添加以下条目,根据你的安装位置和使用文件系统的不同,自行做修改。
|
||||
|
||||
/dev/md0 /mnt/raid0 ext4 deaults 0 0
|
||||
|
||||

|
||||
|
||||
*添加设备到 fstab 文件中*
|
||||
|
||||
13、 使用 mount 命令的 `-a` 来检查 fstab 的条目是否有误。
|
||||
|
||||
# mount -av
|
||||
|
||||
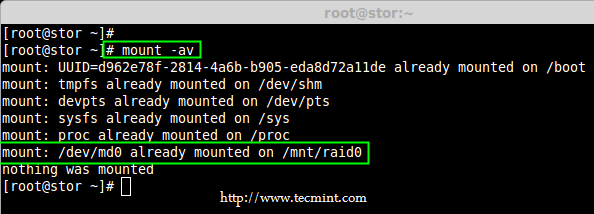
|
||||
|
||||
*检查 fstab 文件是否有误*
|
||||
|
||||
### 第6步:保存 RAID 配置 ###
|
||||
|
||||
14、 最后,保存 RAID 配置到一个文件中,以供将来使用。我们再次使用带有`-s` (scan) 和`-v` (verbose) 选项的 `mdadm` 命令,如图所示。
|
||||
|
||||
# mdadm -E -s -v >> /etc/mdadm.conf
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
# cat /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
*保存 RAID 配置*
|
||||
|
||||
就这样,我们在这里看到,如何通过使用两个硬盘配置具有条带化的 RAID 0 。在接下来的文章中,我们将看到如何设置 RAID 1。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid0-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
@ -1,83 +1,82 @@
|
||||
在 Linux 中使用"两个磁盘"创建 RAID 1(镜像) - 第3部分
|
||||
在 Linux 下使用 RAID(三):用两块磁盘创建 RAID 1(镜像)
|
||||
================================================================================
|
||||
RAID 镜像意味着相同数据的完整克隆(或镜像)写入到两个磁盘中。创建 RAID1 至少需要两个磁盘,它的读取性能或者可靠性比数据存储容量更好。
|
||||
|
||||
**RAID 镜像**意味着相同数据的完整克隆(或镜像),分别写入到两个磁盘中。创建 RAID 1 至少需要两个磁盘,而且仅用于读取性能或者可靠性要比数据存储容量更重要的场合。
|
||||
|
||||
|
||||
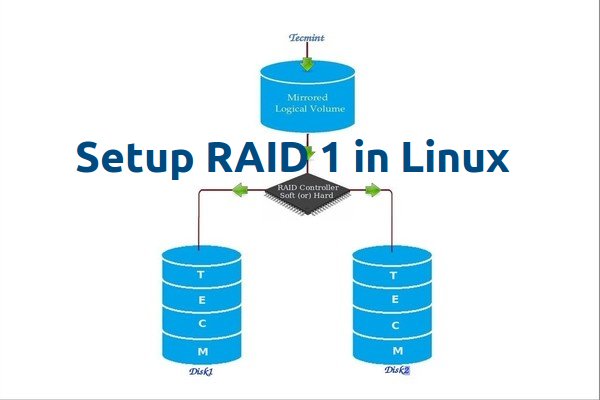
|
||||
|
||||
在 Linux 中设置 RAID1
|
||||
*在 Linux 中设置 RAID 1*
|
||||
|
||||
创建镜像是为了防止因硬盘故障导致数据丢失。镜像中的每个磁盘包含数据的完整副本。当一个磁盘发生故障时,相同的数据可以从其它正常磁盘中读取。而后,可以从正在运行的计算机中直接更换发生故障的磁盘,无需任何中断。
|
||||
|
||||
### RAID 1 的特点 ###
|
||||
|
||||
-镜像具有良好的性能。
|
||||
- 镜像具有良好的性能。
|
||||
|
||||
-磁盘利用率为50%。也就是说,如果我们有两个磁盘每个500GB,总共是1TB,但在镜像中它只会显示500GB。
|
||||
- 磁盘利用率为50%。也就是说,如果我们有两个磁盘每个500GB,总共是1TB,但在镜像中它只会显示500GB。
|
||||
|
||||
-在镜像如果一个磁盘发生故障不会有数据丢失,因为两个磁盘中的内容相同。
|
||||
- 在镜像如果一个磁盘发生故障不会有数据丢失,因为两个磁盘中的内容相同。
|
||||
|
||||
-读取数据会比写入性能更好。
|
||||
- 读取性能会比写入性能更好。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
创建 RAID 1 至少要有两个磁盘,你也可以添加更多的磁盘,磁盘数需为2,4,6,8等偶数。要添加更多的磁盘,你的系统必须有 RAID 物理适配器(硬件卡)。
|
||||
|
||||
创建 RAID 1 至少要有两个磁盘,你也可以添加更多的磁盘,磁盘数需为2,4,6,8的两倍。为了能够添加更多的磁盘,你的系统必须有 RAID 物理适配器(硬件卡)。
|
||||
这里,我们使用软件 RAID 不是硬件 RAID,如果你的系统有一个内置的物理硬件 RAID 卡,你可以从它的功能界面或使用 Ctrl + I 键来访问它。
|
||||
|
||||
这里,我们使用软件 RAID 不是硬件 RAID,如果你的系统有一个内置的物理硬件 RAID 卡,你可以从它的 UI 组件或使用 Ctrl + I 键来访问它。
|
||||
|
||||
需要阅读: [Basic Concepts of RAID in Linux][1]
|
||||
需要阅读: [介绍 RAID 的级别和概念][1]
|
||||
|
||||
#### 在我的服务器安装 ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.226
|
||||
Hostname : rd1.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdb
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.226
|
||||
主机名 : rd1.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdb
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
|
||||
本文将指导你使用 mdadm (创建和管理 RAID 的)一步一步的建立一个软件 RAID 1 或镜像在 Linux 平台上。但同样的做法也适用于其它 Linux 发行版如 RedHat,CentOS,Fedora 等等。
|
||||
本文将指导你在 Linux 平台上使用 mdadm (用于创建和管理 RAID )一步步的建立一个软件 RAID 1 (镜像)。同样的做法也适用于如 RedHat,CentOS,Fedora 等 Linux 发行版。
|
||||
|
||||
### 第1步:安装所需要的并且检查磁盘 ###
|
||||
### 第1步:安装所需软件并且检查磁盘 ###
|
||||
|
||||
1.正如我前面所说,在 Linux 中我们需要使用 mdadm 软件来创建和管理 RAID。所以,让我们用 yum 或 apt-get 的软件包管理工具在 Linux 上安装 mdadm 软件包。
|
||||
1、 正如我前面所说,在 Linux 中我们需要使用 mdadm 软件来创建和管理 RAID。所以,让我们用 yum 或 apt-get 的软件包管理工具在 Linux 上安装 mdadm 软件包。
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
2. 一旦安装好‘mdadm‘包,我们需要使用下面的命令来检查磁盘是否已经配置好。
|
||||
2、 一旦安装好`mdadm`包,我们需要使用下面的命令来检查磁盘是否已经配置好。
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
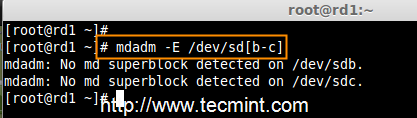
|
||||
|
||||
检查 RAID 的磁盘
|
||||
|
||||
*检查 RAID 的磁盘*
|
||||
|
||||
正如你从上面图片看到的,没有检测到任何超级块,这意味着还没有创建RAID。
|
||||
|
||||
### 第2步:为 RAID 创建分区 ###
|
||||
|
||||
3. 正如我提到的,我们最少使用两个分区 /dev/sdb 和 /dev/sdc 来创建 RAID1。我们首先使用‘fdisk‘命令来创建这两个分区并更改其类型为 raid。
|
||||
3、 正如我提到的,我们使用最少的两个分区 /dev/sdb 和 /dev/sdc 来创建 RAID 1。我们首先使用`fdisk`命令来创建这两个分区并更改其类型为 raid。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
按照下面的说明
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 按两次回车键默认将整个容量分配给它。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 按 ‘L’,列出所有可用的类型。
|
||||
- 按 ‘t’ 修改分区类型。
|
||||
- 键入 ‘fd’ 设置为Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 修改分区类型。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
创建磁盘分区
|
||||
*创建磁盘分区*
|
||||
|
||||
在创建“/dev/sdb”分区后,接下来按照同样的方法创建分区 /dev/sdc 。
|
||||
|
||||
@ -85,59 +84,59 @@ RAID 镜像意味着相同数据的完整克隆(或镜像)写入到两个磁
|
||||
|
||||

|
||||
|
||||
创建第二个分区
|
||||
*创建第二个分区*
|
||||
|
||||
4. 一旦这两个分区创建成功后,使用相同的命令来检查 sdb & sdc 分区并确认 RAID 分区的类型如上图所示。
|
||||
4、 一旦这两个分区创建成功后,使用相同的命令来检查 sdb 和 sdc 分区并确认 RAID 分区的类型如上图所示。
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
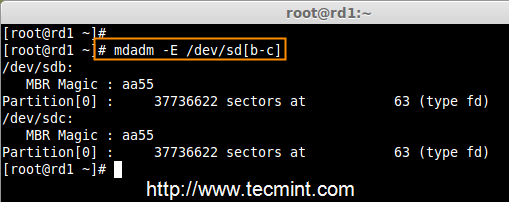
|
||||
|
||||
验证分区变化
|
||||
*验证分区变化*
|
||||
|
||||
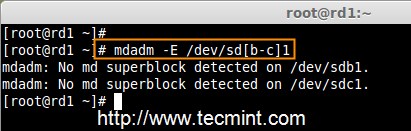
|
||||
|
||||
检查 RAID 类型
|
||||
*检查 RAID 类型*
|
||||
|
||||
**注意**: 正如你在上图所看到的,在 sdb1 和 sdc1 中没有任何对 RAID 的定义,这就是我们没有检测到超级块的原因。
|
||||
|
||||
### 步骤3:创建 RAID1 设备 ###
|
||||
### 第3步:创建 RAID 1 设备 ###
|
||||
|
||||
5.接下来使用以下命令来创建一个名为 /dev/md0 的“RAID1”设备并验证它
|
||||
5、 接下来使用以下命令来创建一个名为 /dev/md0 的“RAID 1”设备并验证它
|
||||
|
||||
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[b-c]1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
创建RAID设备
|
||||
*创建RAID设备*
|
||||
|
||||
6. 接下来使用如下命令来检查 RAID 设备类型和 RAID 阵列
|
||||
6、 接下来使用如下命令来检查 RAID 设备类型和 RAID 阵列
|
||||
|
||||
# mdadm -E /dev/sd[b-c]1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
检查 RAID 设备类型
|
||||
*检查 RAID 设备类型*
|
||||
|
||||

|
||||
|
||||
检查 RAID 设备阵列
|
||||
*检查 RAID 设备阵列*
|
||||
|
||||
从上图中,人们很容易理解,RAID1 已经使用的 /dev/sdb1 和 /dev/sdc1 分区被创建,你也可以看到状态为 resyncing。
|
||||
从上图中,人们很容易理解,RAID 1 已经创建好了,使用了 /dev/sdb1 和 /dev/sdc1 分区,你也可以看到状态为 resyncing(重新同步中)。
|
||||
|
||||
### 第4步:在 RAID 设备上创建文件系统 ###
|
||||
|
||||
7. 使用 ext4 为 md0 创建文件系统并挂载到 /mnt/raid1 .
|
||||
7、 给 md0 上创建 ext4 文件系统
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
创建 RAID 设备文件系统
|
||||
*创建 RAID 设备文件系统*
|
||||
|
||||
8. 接下来,挂载新创建的文件系统到“/mnt/raid1”,并创建一些文件,验证在挂载点的数据
|
||||
8、 接下来,挂载新创建的文件系统到“/mnt/raid1”,并创建一些文件,验证在挂载点的数据
|
||||
|
||||
# mkdir /mnt/raid1
|
||||
# mount /dev/md0 /mnt/raid1/
|
||||
@ -146,51 +145,52 @@ RAID 镜像意味着相同数据的完整克隆(或镜像)写入到两个磁
|
||||
|
||||

|
||||
|
||||
挂载 RAID 设备
|
||||
*挂载 RAID 设备*
|
||||
|
||||
9.为了在系统重新启动自动挂载 RAID1,需要在 fstab 文件中添加条目。打开“/etc/fstab”文件并添加以下行。
|
||||
9、为了在系统重新启动自动挂载 RAID 1,需要在 fstab 文件中添加条目。打开`/etc/fstab`文件并添加以下行:
|
||||
|
||||
/dev/md0 /mnt/raid1 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
自动挂载 Raid 设备
|
||||
*自动挂载 Raid 设备*
|
||||
|
||||
10、 运行`mount -av`,检查 fstab 中的条目是否有错误
|
||||
|
||||
10. 运行“mount -a”,检查 fstab 中的条目是否有错误
|
||||
# mount -av
|
||||
|
||||
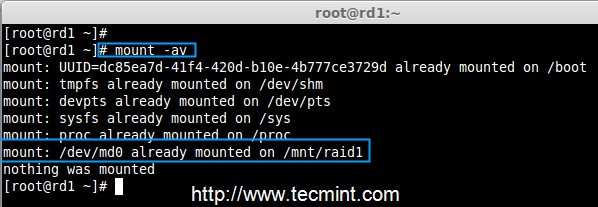
|
||||
|
||||
检查 fstab 中的错误
|
||||
*检查 fstab 中的错误*
|
||||
|
||||
11. 接下来,使用下面的命令保存 raid 的配置到文件“mdadm.conf”中。
|
||||
11、 接下来,使用下面的命令保存 RAID 的配置到文件“mdadm.conf”中。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
保存 Raid 的配置
|
||||
*保存 Raid 的配置*
|
||||
|
||||
上述配置文件在系统重启时会读取并加载 RAID 设备。
|
||||
|
||||
### 第5步:在磁盘故障后检查数据 ###
|
||||
|
||||
12.我们的主要目的是,即使在任何磁盘故障或死机时必须保证数据是可用的。让我们来看看,当任何一个磁盘不可用时会发生什么。
|
||||
12、我们的主要目的是,即使在任何磁盘故障或死机时必须保证数据是可用的。让我们来看看,当任何一个磁盘不可用时会发生什么。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
验证 Raid 设备
|
||||
*验证 RAID 设备*
|
||||
|
||||
在上面的图片中,我们可以看到在 RAID 中有2个设备是可用的并且 Active Devices 是2.现在让我们看看,当一个磁盘拔出(移除 sdc 磁盘)或损坏后会发生什么。
|
||||
在上面的图片中,我们可以看到在 RAID 中有2个设备是可用的,并且 Active Devices 是2。现在让我们看看,当一个磁盘拔出(移除 sdc 磁盘)或损坏后会发生什么。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
测试 RAID 设备
|
||||
*测试 RAID 设备*
|
||||
|
||||
现在,在上面的图片中你可以看到,一个磁盘不见了。我从虚拟机上删除了一个磁盘。此时让我们来检查我们宝贵的数据。
|
||||
|
||||
@ -199,9 +199,9 @@ RAID 镜像意味着相同数据的完整克隆(或镜像)写入到两个磁
|
||||
|
||||
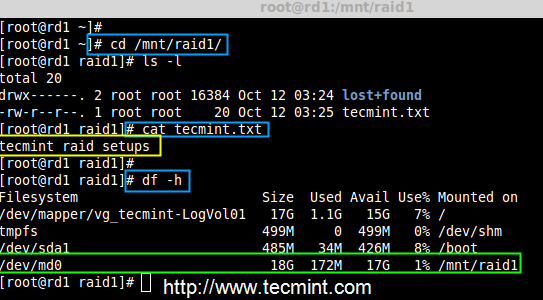
|
||||
|
||||
验证 RAID 数据
|
||||
*验证 RAID 数据*
|
||||
|
||||
你有没有看到我们的数据仍然可用。由此,我们可以知道 RAID 1(镜像)的优势。在接下来的文章中,我们将看到如何设置一个 RAID 5 条带化分布式奇偶校验。希望这可以帮助你了解 RAID 1(镜像)是如何工作的。
|
||||
你可以看到我们的数据仍然可用。由此,我们可以了解 RAID 1(镜像)的优势。在接下来的文章中,我们将看到如何设置一个 RAID 5 条带化分布式奇偶校验。希望这可以帮助你了解 RAID 1(镜像)是如何工作的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -209,9 +209,9 @@ via: http://www.tecmint.com/create-raid1-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
@ -1,89 +1,90 @@
|
||||
|
||||
在 Linux 中创建 RAID 5(条带化与分布式奇偶校验) - 第4部分
|
||||
在 Linux 下使用 RAID(四):创建 RAID 5(条带化与分布式奇偶校验)
|
||||
================================================================================
|
||||
在 RAID 5 中,条带化数据跨多个驱磁盘使用分布式奇偶校验。分布式奇偶校验的条带化意味着它将奇偶校验信息和条带中的数据分布在多个磁盘上,它将有很好的数据冗余。
|
||||
|
||||
在 RAID 5 中,数据条带化后存储在分布式奇偶校验的多个磁盘上。分布式奇偶校验的条带化意味着它将奇偶校验信息和条带化数据分布在多个磁盘上,这样会有很好的数据冗余。
|
||||
|
||||

|
||||
|
||||
在 Linux 中配置 RAID 5
|
||||
*在 Linux 中配置 RAID 5*
|
||||
|
||||
对于此 RAID 级别它至少应该有三个或更多个磁盘。RAID 5 通常被用于大规模生产环境中花费更多的成本来提供更好的数据冗余性能。
|
||||
对于此 RAID 级别它至少应该有三个或更多个磁盘。RAID 5 通常被用于大规模生产环境中,以花费更多的成本来提供更好的数据冗余性能。
|
||||
|
||||
#### 什么是奇偶校验? ####
|
||||
|
||||
奇偶校验是在数据存储中检测错误最简单的一个方法。奇偶校验信息存储在每个磁盘中,比如说,我们有4个磁盘,其中一个磁盘空间被分割去存储所有磁盘的奇偶校验信息。如果任何一个磁盘出现故障,我们可以通过更换故障磁盘后,从奇偶校验信息重建得到原来的数据。
|
||||
奇偶校验是在数据存储中检测错误最简单的常见方式。奇偶校验信息存储在每个磁盘中,比如说,我们有4个磁盘,其中相当于一个磁盘大小的空间被分割去存储所有磁盘的奇偶校验信息。如果任何一个磁盘出现故障,我们可以通过更换故障磁盘后,从奇偶校验信息重建得到原来的数据。
|
||||
|
||||
#### RAID 5 的优点和缺点 ####
|
||||
|
||||
- 提供更好的性能
|
||||
- 提供更好的性能。
|
||||
- 支持冗余和容错。
|
||||
- 支持热备份。
|
||||
- 将失去一个磁盘的容量存储奇偶校验信息。
|
||||
- 将用掉一个磁盘的容量存储奇偶校验信息。
|
||||
- 单个磁盘发生故障后不会丢失数据。我们可以更换故障硬盘后从奇偶校验信息中重建数据。
|
||||
- 事务处理读操作会更快。
|
||||
- 由于奇偶校验占用资源,写操作将是缓慢的。
|
||||
- 适合于面向事务处理的环境,读操作会更快。
|
||||
- 由于奇偶校验占用资源,写操作会慢一些。
|
||||
- 重建需要很长的时间。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
创建 RAID 5 最少需要3个磁盘,你也可以添加更多的磁盘,前提是你要有多端口的专用硬件 RAID 控制器。在这里,我们使用“mdadm”包来创建软件 RAID。
|
||||
|
||||
mdadm 是一个允许我们在 Linux 下配置和管理 RAID 设备的包。默认情况下 RAID 没有可用的配置文件,我们在创建和配置 RAID 后必须将配置文件保存在一个单独的文件中,例如:mdadm.conf。
|
||||
mdadm 是一个允许我们在 Linux 下配置和管理 RAID 设备的包。默认情况下没有 RAID 的配置文件,我们在创建和配置 RAID 后必须将配置文件保存在一个单独的文件 mdadm.conf 中。
|
||||
|
||||
在进一步学习之前,我建议你通过下面的文章去了解 Linux 中 RAID 的基础知识。
|
||||
|
||||
- [Basic Concepts of RAID in Linux – Part 1][1]
|
||||
- [Creating RAID 0 (Stripe) in Linux – Part 2][2]
|
||||
- [Setting up RAID 1 (Mirroring) in Linux – Part 3][3]
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
- [用两块磁盘创建 RAID 1(镜像)][3]
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.227
|
||||
Hostname : rd5.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdb
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
Disk 3 [20GB] : /dev/sdd
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.227
|
||||
主机名 : rd5.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdb
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
|
||||
这篇文章是 RAID 系列9教程的第4部分,在这里我们要建立一个软件 RAID 5(分布式奇偶校验)使用三个20GB(名为/dev/sdb, /dev/sdc 和 /dev/sdd)的磁盘在 Linux 系统或服务器中上。
|
||||
这是9篇系列教程的第4部分,在这里我们要在 Linux 系统或服务器上使用三个20GB(名为/dev/sdb, /dev/sdc 和 /dev/sdd)的磁盘建立带有分布式奇偶校验的软件 RAID 5。
|
||||
|
||||
### 第1步:安装 mdadm 并检验磁盘 ###
|
||||
|
||||
1.正如我们前面所说,我们使用 CentOS 6.5 Final 版本来创建 RAID 设置,但同样的做法也适用于其他 Linux 发行版。
|
||||
1、 正如我们前面所说,我们使用 CentOS 6.5 Final 版本来创建 RAID 设置,但同样的做法也适用于其他 Linux 发行版。
|
||||
|
||||
# lsb_release -a
|
||||
# ifconfig | grep inet
|
||||
|
||||

|
||||
|
||||
CentOS 6.5 摘要
|
||||
*CentOS 6.5 摘要*
|
||||
|
||||
2. 如果你按照我们的 RAID 系列去配置的,我们假设你已经安装了“mdadm”包,如果没有,根据你的 Linux 发行版使用下面的命令安装。
|
||||
2、 如果你按照我们的 RAID 系列去配置的,我们假设你已经安装了“mdadm”包,如果没有,根据你的 Linux 发行版使用下面的命令安装。
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
3. “mdadm”包安装后,先使用‘fdisk‘命令列出我们在系统上增加的三个20GB的硬盘。
|
||||
3、 “mdadm”包安装后,先使用`fdisk`命令列出我们在系统上增加的三个20GB的硬盘。
|
||||
|
||||
# fdisk -l | grep sd
|
||||
|
||||
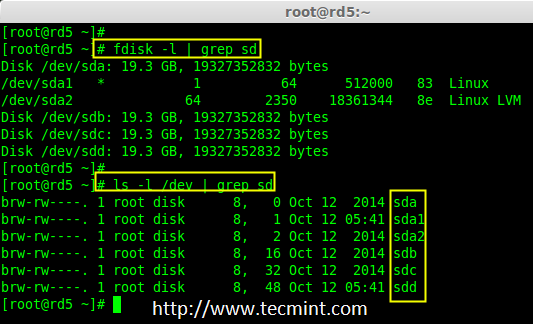
|
||||
|
||||
安装 mdadm 工具
|
||||
*安装 mdadm 工具*
|
||||
|
||||
4. 现在该检查这三个磁盘是否存在 RAID 块,使用下面的命令来检查。
|
||||
4、 现在该检查这三个磁盘是否存在 RAID 块,使用下面的命令来检查。
|
||||
|
||||
# mdadm -E /dev/sd[b-d]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd # 或
|
||||
|
||||
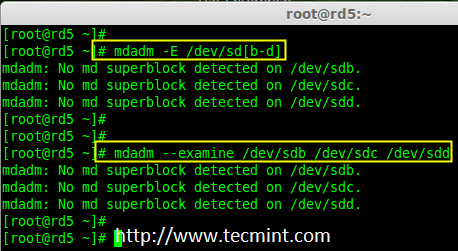
|
||||
|
||||
检查 Raid 磁盘
|
||||
*检查 Raid 磁盘*
|
||||
|
||||
**注意**: 上面的图片说明,没有检测到任何超级块。所以,这三个磁盘中没有定义 RAID。让我们现在开始创建一个吧!
|
||||
|
||||
### 第2步:为磁盘创建 RAID 分区 ###
|
||||
|
||||
5. 首先,在创建 RAID 前我们要为磁盘分区(/dev/sdb, /dev/sdc 和 /dev/sdd),在进行下一步之前,先使用‘fdisk’命令进行分区。
|
||||
5、 首先,在创建 RAID 前磁盘(/dev/sdb, /dev/sdc 和 /dev/sdd)必须有分区,因此,在进行下一步之前,先使用`fdisk`命令进行分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
@ -93,20 +94,20 @@ CentOS 6.5 摘要
|
||||
|
||||
请按照下面的说明在 /dev/sdb 硬盘上创建分区。
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。选择主分区是因为还没有定义过分区。
|
||||
- 接下来选择分区号为1。默认就是1.
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。选择主分区是因为还没有定义过分区。
|
||||
- 接下来选择分区号为1。默认就是1。
|
||||
- 这里是选择柱面大小,我们没必要选择指定的大小,因为我们需要为 RAID 使用整个分区,所以只需按两次 Enter 键默认将整个容量分配给它。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 改变分区类型,按 ‘L’可以列出所有可用的类型。
|
||||
- 按 ‘t’ 修改分区类型。
|
||||
- 这里使用‘fd’设置为 RAID 的类型。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 改变分区类型,按 `L`可以列出所有可用的类型。
|
||||
- 按 `t` 修改分区类型。
|
||||
- 这里使用`fd`设置为 RAID 的类型。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
创建 sdb 分区
|
||||
*创建 sdb 分区*
|
||||
|
||||
**注意**: 我们仍要按照上面的步骤来创建 sdc 和 sdd 的分区。
|
||||
|
||||
@ -118,7 +119,7 @@ CentOS 6.5 摘要
|
||||
|
||||

|
||||
|
||||
创建 sdc 分区
|
||||
*创建 sdc 分区*
|
||||
|
||||
#### 创建 /dev/sdd 分区 ####
|
||||
|
||||
@ -126,93 +127,87 @@ CentOS 6.5 摘要
|
||||
|
||||

|
||||
|
||||
创建 sdd 分区
|
||||
*创建 sdd 分区*
|
||||
|
||||
6. 创建分区后,检查三个磁盘 sdb, sdc, sdd 的变化。
|
||||
6、 创建分区后,检查三个磁盘 sdb, sdc, sdd 的变化。
|
||||
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd
|
||||
|
||||
or
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
# mdadm -E /dev/sd[b-c] # 或
|
||||
|
||||
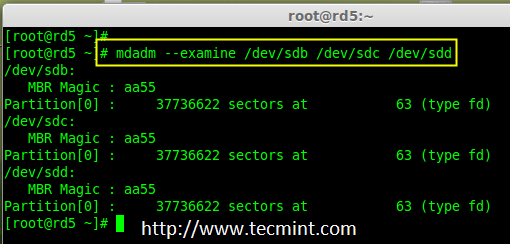
|
||||
|
||||
检查磁盘变化
|
||||
*检查磁盘变化*
|
||||
|
||||
**注意**: 在上面的图片中,磁盘的类型是 fd。
|
||||
|
||||
7.现在在新创建的分区检查 RAID 块。如果没有检测到超级块,我们就能够继续下一步,创建一个新的 RAID 5 的设置在这些磁盘中。
|
||||
7、 现在在新创建的分区检查 RAID 块。如果没有检测到超级块,我们就能够继续下一步,在这些磁盘中创建一个新的 RAID 5 配置。
|
||||
|
||||
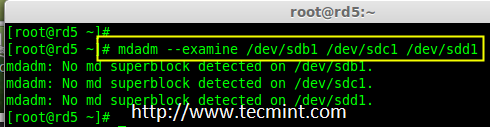
|
||||
|
||||
在分区中检查 Raid
|
||||
*在分区中检查 RAID *
|
||||
|
||||
### 第3步:创建 md 设备 md0 ###
|
||||
|
||||
8. 现在创建一个 RAID 设备“md0”(即 /dev/md0)使用所有新创建的分区(sdb1, sdc1 and sdd1) ,使用以下命令。
|
||||
8、 现在使用所有新创建的分区(sdb1, sdc1 和 sdd1)创建一个 RAID 设备“md0”(即 /dev/md0),使用以下命令。
|
||||
|
||||
# mdadm --create /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1
|
||||
|
||||
or
|
||||
|
||||
# mdadm -C /dev/md0 -l=5 -n=3 /dev/sd[b-d]1
|
||||
# mdadm -C /dev/md0 -l=5 -n=3 /dev/sd[b-d]1 # 或
|
||||
|
||||
9. 创建 RAID 设备后,检查并确认 RAID,包括设备和从 mdstat 中输出的 RAID 级别。
|
||||
9、 创建 RAID 设备后,检查并确认 RAID,从 mdstat 中输出中可以看到包括的设备的 RAID 级别。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
验证 Raid 设备
|
||||
*验证 Raid 设备*
|
||||
|
||||
如果你想监视当前的创建过程,你可以使用‘watch‘命令,使用 watch ‘cat /proc/mdstat‘,它会在屏幕上显示且每隔1秒刷新一次。
|
||||
如果你想监视当前的创建过程,你可以使用`watch`命令,将 `cat /proc/mdstat` 传递给它,它会在屏幕上显示且每隔1秒刷新一次。
|
||||
|
||||
# watch -n1 cat /proc/mdstat
|
||||
|
||||
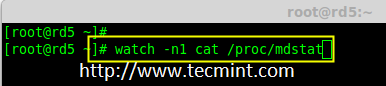
|
||||
|
||||
监控 Raid 5 过程
|
||||
*监控 RAID 5 构建过程*
|
||||
|
||||

|
||||
|
||||
Raid 5 过程概要
|
||||
*Raid 5 过程概要*
|
||||
|
||||
10. 创建 RAID 后,使用以下命令验证 RAID 设备
|
||||
10、 创建 RAID 后,使用以下命令验证 RAID 设备
|
||||
|
||||
# mdadm -E /dev/sd[b-d]1
|
||||
|
||||

|
||||
|
||||
验证 Raid 级别
|
||||
*验证 Raid 级别*
|
||||
|
||||
**注意**: 因为它显示三个磁盘的信息,上述命令的输出会有点长。
|
||||
|
||||
11. 接下来,验证 RAID 阵列的假设,这包含正在运行 RAID 的设备,并开始重新同步。
|
||||
11、 接下来,验证 RAID 阵列,假定包含 RAID 的设备正在运行并已经开始了重新同步。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
验证 Raid 阵列
|
||||
*验证 RAID 阵列*
|
||||
|
||||
### 第4步:为 md0 创建文件系统###
|
||||
|
||||
12. 在挂载前为“md0”设备创建 ext4 文件系统。
|
||||
12、 在挂载前为“md0”设备创建 ext4 文件系统。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
创建 md0 文件系统
|
||||
*创建 md0 文件系统*
|
||||
|
||||
13.现在,在‘/mnt‘下创建目录 raid5,然后挂载文件系统到 /mnt/raid5/ 下并检查下挂载点的文件,你会看到 lost+found 目录。
|
||||
13、 现在,在`/mnt`下创建目录 raid5,然后挂载文件系统到 /mnt/raid5/ 下,并检查挂载点下的文件,你会看到 lost+found 目录。
|
||||
|
||||
# mkdir /mnt/raid5
|
||||
# mount /dev/md0 /mnt/raid5/
|
||||
# ls -l /mnt/raid5/
|
||||
|
||||
14. 在挂载点 /mnt/raid5 下创建几个文件,并在其中一个文件中添加一些内容然后去验证。
|
||||
14、 在挂载点 /mnt/raid5 下创建几个文件,并在其中一个文件中添加一些内容然后去验证。
|
||||
|
||||
# touch /mnt/raid5/raid5_tecmint_{1..5}
|
||||
# ls -l /mnt/raid5/
|
||||
@ -222,9 +217,9 @@ Raid 5 过程概要
|
||||
|
||||

|
||||
|
||||
挂载 Raid 设备
|
||||
*挂载 RAID 设备*
|
||||
|
||||
15. 我们需要在 fstab 中添加条目,否则系统重启后将不会显示我们的挂载点。然后编辑 fstab 文件添加条目,在文件尾追加以下行,如下图所示。挂载点会根据你环境的不同而不同。
|
||||
15、 我们需要在 fstab 中添加条目,否则系统重启后将不会显示我们的挂载点。编辑 fstab 文件添加条目,在文件尾追加以下行。挂载点会根据你环境的不同而不同。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
@ -232,19 +227,19 @@ Raid 5 过程概要
|
||||
|
||||

|
||||
|
||||
自动挂载 Raid 5
|
||||
*自动挂载 RAID 5*
|
||||
|
||||
16. 接下来,运行‘mount -av‘命令检查 fstab 条目中是否有错误。
|
||||
16、 接下来,运行`mount -av`命令检查 fstab 条目中是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
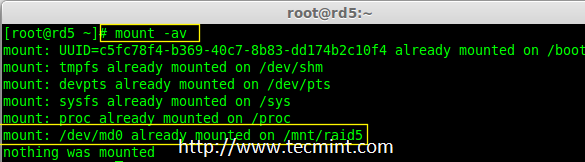
|
||||
|
||||
检查 Fstab 错误
|
||||
*检查 Fstab 错误*
|
||||
|
||||
### 第5步:保存 Raid 5 的配置 ###
|
||||
|
||||
17. 在前面章节已经说过,默认情况下 RAID 没有配置文件。我们必须手动保存。如果此步不跟 RAID 设备将不会存在 md0,它将会跟一些其他数子。
|
||||
17、 在前面章节已经说过,默认情况下 RAID 没有配置文件。我们必须手动保存。如果此步中没有跟随不属于 md0 的 RAID 设备,它会是一些其他随机数字。
|
||||
|
||||
所以,我们必须要在系统重新启动之前保存配置。如果配置保存它在系统重新启动时会被加载到内核中然后 RAID 也将被加载。
|
||||
|
||||
@ -252,17 +247,17 @@ Raid 5 过程概要
|
||||
|
||||

|
||||
|
||||
保存 Raid 5 配置
|
||||
*保存 RAID 5 配置*
|
||||
|
||||
注意:保存配置将保持 RAID 级别的稳定性在 md0 设备中。
|
||||
注意:保存配置将保持 md0 设备的 RAID 级别稳定不变。
|
||||
|
||||
### 第6步:添加备用磁盘 ###
|
||||
|
||||
18.备用磁盘有什么用?它是非常有用的,如果我们有一个备用磁盘,当我们阵列中的任何一个磁盘发生故障后,这个备用磁盘会主动添加并重建进程,并从其他磁盘上同步数据,所以我们可以在这里看到冗余。
|
||||
18、 备用磁盘有什么用?它是非常有用的,如果我们有一个备用磁盘,当我们阵列中的任何一个磁盘发生故障后,这个备用磁盘会进入激活重建过程,并从其他磁盘上同步数据,这样就有了冗余。
|
||||
|
||||
更多关于添加备用磁盘和检查 RAID 5 容错的指令,请阅读下面文章中的第6步和第7步。
|
||||
|
||||
- [Add Spare Drive to Raid 5 Setup][4]
|
||||
- [在 RAID 5 中添加备用磁盘][4]
|
||||
|
||||
### 结论 ###
|
||||
|
||||
@ -274,12 +269,12 @@ via: http://www.tecmint.com/create-raid-5-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid0-in-linux/
|
||||
[3]:http://www.tecmint.com/create-raid1-in-linux/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
[3]:https://linux.cn/article-6093-1.html
|
||||
[4]:http://www.tecmint.com/create-raid-6-in-linux/
|
||||
@ -0,0 +1,320 @@
|
||||
在 Linux 下使用 RAID(五):安装 RAID 6(条带化双分布式奇偶校验)
|
||||
================================================================================
|
||||
|
||||
RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即使两个磁盘发生故障后依然有容错能力。在两个磁盘同时发生故障时,系统的关键任务仍然能运行。它与 RAID 5 相似,但性能更健壮,因为它多用了一个磁盘来进行奇偶校验。
|
||||
|
||||
在之前的文章中,我们已经在 RAID 5 看了分布式奇偶校验,但在本文中,我们将看到的是 RAID 6 双分布式奇偶校验。不要期望比其他 RAID 有更好的性能,除非你也安装了一个专用的 RAID 控制器。在 RAID 6 中,即使我们失去了2个磁盘,我们仍可以通过更换磁盘,从校验中构建数据,然后取回数据。
|
||||
|
||||
|
||||
|
||||
*在 Linux 中安装 RAID 6*
|
||||
|
||||
要建立一个 RAID 6,一组最少需要4个磁盘。RAID 6 甚至在有些组中会有更多磁盘,这样将多个硬盘捆在一起,当读取数据时,它会同时从所有磁盘读取,所以读取速度会更快,当写数据时,因为它要将数据写在条带化的多个磁盘上,所以性能会较差。
|
||||
|
||||
现在,很多人都在讨论为什么我们需要使用 RAID 6,它的性能和其他 RAID 相比并不太好。提出这个问题首先需要知道的是,如果需要高容错性就选择 RAID 6。在每一个用于数据库的高可用性要求较高的环境中,他们需要 RAID 6 因为数据库是最重要,无论花费多少都需要保护其安全,它在视频流环境中也是非常有用的。
|
||||
|
||||
#### RAID 6 的的优点和缺点 ####
|
||||
|
||||
- 性能不错。
|
||||
- RAID 6 比较昂贵,因为它要求两个独立的磁盘用于奇偶校验功能。
|
||||
- 将失去两个磁盘的容量来保存奇偶校验信息(双奇偶校验)。
|
||||
- 即使两个磁盘损坏,数据也不会丢失。我们可以在更换损坏的磁盘后从校验中重建数据。
|
||||
- 读性能比 RAID 5 更好,因为它从多个磁盘读取,但对于没有专用的 RAID 控制器的设备写性能将非常差。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
要创建一个 RAID 6 最少需要4个磁盘。你也可以添加更多的磁盘,但你必须有专用的 RAID 控制器。使用软件 RAID 我们在 RAID 6 中不会得到更好的性能,所以我们需要一个物理 RAID 控制器。
|
||||
|
||||
如果你新接触 RAID 设置,我们建议先看完以下 RAID 文章。
|
||||
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
- [用两块磁盘创建 RAID 1(镜像)][3]
|
||||
- [创建 RAID 5(条带化与分布式奇偶校验)](4)
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.228
|
||||
主机名 : rd6.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdb
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
磁盘 4 [20GB] : /dev/sde
|
||||
|
||||
这是9篇系列教程的第5部分,在这里我们将看到如何在 Linux 系统或者服务器上使用四个 20GB 的磁盘(名为 /dev/sdb、 /dev/sdc、 /dev/sdd 和 /dev/sde)创建和设置软件 RAID 6 (条带化双分布式奇偶校验)。
|
||||
|
||||
### 第1步:安装 mdadm 工具,并检查磁盘 ###
|
||||
|
||||
1、 如果你按照我们最进的两篇 RAID 文章(第2篇和第3篇),我们已经展示了如何安装`mdadm`工具。如果你直接看的这篇文章,我们先来解释下在 Linux 系统中如何使用`mdadm`工具来创建和管理 RAID,首先根据你的 Linux 发行版使用以下命令来安装。
|
||||
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
2、 安装该工具后,然后来验证所需的四个磁盘,我们将会使用下面的`fdisk`命令来检查用于创建 RAID 的磁盘。
|
||||
|
||||
# fdisk -l | grep sd
|
||||
|
||||
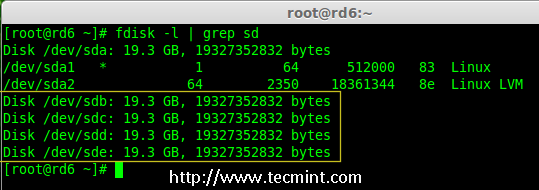
|
||||
|
||||
*在 Linux 中检查磁盘*
|
||||
|
||||
3、 在创建 RAID 磁盘前,先检查下我们的磁盘是否创建过 RAID 分区。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
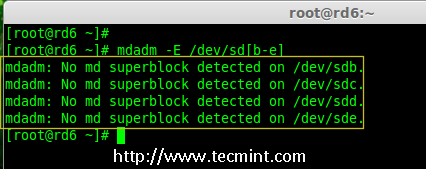
|
||||
|
||||
*在磁盘上检查 RAID 分区*
|
||||
|
||||
**注意**: 在上面的图片中,没有检测到任何 super-block 或者说在四个磁盘上没有 RAID 存在。现在我们开始创建 RAID 6。
|
||||
|
||||
### 第2步:为 RAID 6 创建磁盘分区 ###
|
||||
|
||||
4、 现在在 `/dev/sdb`, `/dev/sdc`, `/dev/sdd` 和 `/dev/sde`上为 RAID 创建分区,使用下面的 fdisk 命令。在这里,我们将展示如何在 sdb 磁盘创建分区,同样的步骤也适用于其他分区。
|
||||
|
||||
**创建 /dev/sdb 分区**
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
请按照说明进行操作,如下图所示创建分区。
|
||||
|
||||
- 按 `n`创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按回车确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*创建 /dev/sdb 分区*
|
||||
|
||||
**创建 /dev/sdc 分区**
|
||||
|
||||
# fdisk /dev/sdc
|
||||
|
||||

|
||||
|
||||
*创建 /dev/sdc 分区*
|
||||
|
||||
**创建 /dev/sdd 分区**
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||

|
||||
|
||||
*创建 /dev/sdd 分区*
|
||||
|
||||
**创建 /dev/sde 分区**
|
||||
|
||||
# fdisk /dev/sde
|
||||
|
||||

|
||||
|
||||
*创建 /dev/sde 分区*
|
||||
|
||||
5、 创建好分区后,检查磁盘的 super-blocks 是个好的习惯。如果 super-blocks 不存在我们可以按前面的创建一个新的 RAID。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
# mdadm --examine /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 # 或
|
||||
|
||||
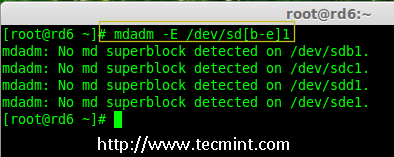
|
||||
|
||||
*在新分区中检查 RAID *
|
||||
|
||||
### 步骤3:创建 md 设备(RAID) ###
|
||||
|
||||
6、 现在可以使用以下命令创建 RAID 设备`md0` (即 /dev/md0),并在所有新创建的分区中应用 RAID 级别,然后确认 RAID 设置。
|
||||
|
||||
# mdadm --create /dev/md0 --level=6 --raid-devices=4 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 Raid 6 设备*
|
||||
|
||||
7、 你还可以使用 watch 命令来查看当前创建 RAID 的进程,如下图所示。
|
||||
|
||||
# watch -n1 cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*检查 RAID 6 创建过程*
|
||||
|
||||
8、 使用以下命令验证 RAID 设备。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
|
||||
**注意**::上述命令将显示四个磁盘的信息,这是相当长的,所以没有截取其完整的输出。
|
||||
|
||||
9、 接下来,验证 RAID 阵列,以确认重新同步过程已经开始。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*检查 Raid 6 阵列*
|
||||
|
||||
### 第4步:在 RAID 设备上创建文件系统 ###
|
||||
|
||||
10、 使用 ext4 为`/dev/md0`创建一个文件系统,并将它挂载在 /mnt/raid6 。这里我们使用的是 ext4,但你可以根据你的选择使用任意类型的文件系统。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
*在 RAID 6 上创建文件系统*
|
||||
|
||||
11、 将创建的文件系统挂载到 /mnt/raid6,并验证挂载点下的文件,我们可以看到 lost+found 目录。
|
||||
|
||||
# mkdir /mnt/raid6
|
||||
# mount /dev/md0 /mnt/raid6/
|
||||
# ls -l /mnt/raid6/
|
||||
|
||||
12、 在挂载点下创建一些文件,在任意文件中添加一些文字并验证其内容。
|
||||
|
||||
# touch /mnt/raid6/raid6_test.txt
|
||||
# ls -l /mnt/raid6/
|
||||
# echo "tecmint raid setups" > /mnt/raid6/raid6_test.txt
|
||||
# cat /mnt/raid6/raid6_test.txt
|
||||
|
||||
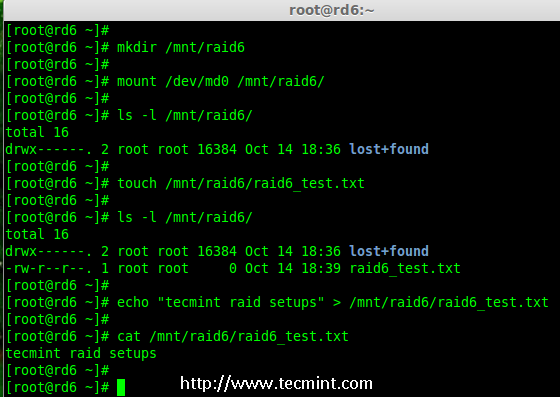
|
||||
|
||||
*验证 RAID 内容*
|
||||
|
||||
13、 在 /etc/fstab 中添加以下条目使系统启动时自动挂载设备,操作系统环境不同挂载点可能会有所不同。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
/dev/md0 /mnt/raid6 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
*自动挂载 RAID 6 设备*
|
||||
|
||||
14、 接下来,执行`mount -a`命令来验证 fstab 中的条目是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
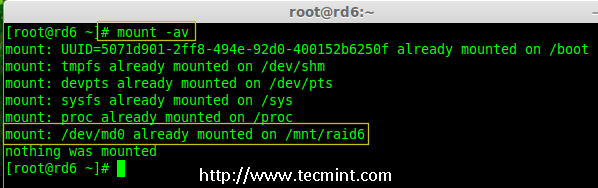
|
||||
|
||||
*验证 RAID 是否自动挂载*
|
||||
|
||||
### 第5步:保存 RAID 6 的配置 ###
|
||||
|
||||
15、 请注意,默认情况下 RAID 没有配置文件。我们需要使用以下命令手动保存它,然后检查设备`/dev/md0`的状态。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
# cat /etc/mdadm.conf
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*保存 RAID 6 配置*
|
||||
|
||||

|
||||
|
||||
*检查 RAID 6 状态*
|
||||
|
||||
### 第6步:添加备用磁盘 ###
|
||||
|
||||
16、 现在,已经使用了4个磁盘,并且其中两个作为奇偶校验信息来使用。在某些情况下,如果任意一个磁盘出现故障,我们仍可以得到数据,因为在 RAID 6 使用双奇偶校验。
|
||||
|
||||
如果第二个磁盘也出现故障,在第三块磁盘损坏前我们可以添加一个新的。可以在创建 RAID 集时加入一个备用磁盘,但我在创建 RAID 集合前没有定义备用的磁盘。不过,我们可以在磁盘损坏后或者创建 RAID 集合时添加一块备用磁盘。现在,我们已经创建好了 RAID,下面让我演示如何添加备用磁盘。
|
||||
|
||||
为了达到演示的目的,我已经热插入了一个新的 HDD 磁盘(即 /dev/sdf),让我们来验证接入的磁盘。
|
||||
|
||||
# ls -l /dev/ | grep sd
|
||||
|
||||
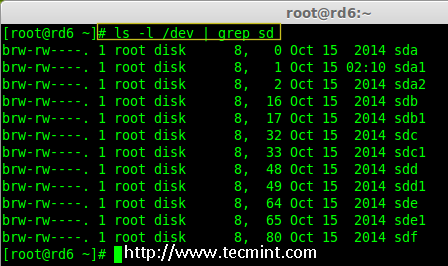
|
||||
|
||||
*检查新磁盘*
|
||||
|
||||
17、 现在再次确认新连接的磁盘没有配置过 RAID ,使用 mdadm 来检查。
|
||||
|
||||
# mdadm --examine /dev/sdf
|
||||
|
||||
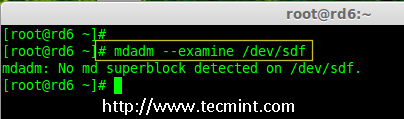
|
||||
|
||||
*在新磁盘中检查 RAID*
|
||||
|
||||
**注意**: 像往常一样,我们早前已经为四个磁盘创建了分区,同样,我们使用 fdisk 命令为新插入的磁盘创建新分区。
|
||||
|
||||
# fdisk /dev/sdf
|
||||
|
||||

|
||||
|
||||
*为 /dev/sdf 创建分区*
|
||||
|
||||
18、 在 /dev/sdf 创建新的分区后,在新分区上确认没有 RAID,然后将备用磁盘添加到 RAID 设备 /dev/md0 中,并验证添加的设备。
|
||||
|
||||
# mdadm --examine /dev/sdf
|
||||
# mdadm --examine /dev/sdf1
|
||||
# mdadm --add /dev/md0 /dev/sdf1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||
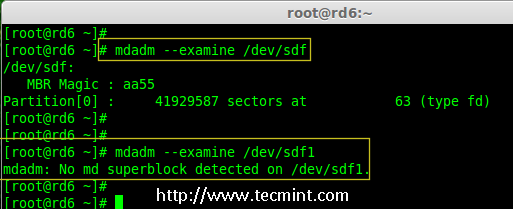
|
||||
|
||||
*在 sdf 分区上验证 Raid*
|
||||
|
||||
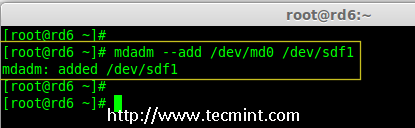
|
||||
|
||||
*添加 sdf 分区到 RAID *
|
||||
|
||||

|
||||
|
||||
*验证 sdf 分区信息*
|
||||
|
||||
### 第7步:检查 RAID 6 容错 ###
|
||||
|
||||
19、 现在,让我们检查备用驱动器是否能自动工作,当我们阵列中的任何一个磁盘出现故障时。为了测试,我将一个磁盘手工标记为故障设备。
|
||||
|
||||
在这里,我们标记 /dev/sdd1 为故障磁盘。
|
||||
|
||||
# mdadm --manage --fail /dev/md0 /dev/sdd1
|
||||
|
||||
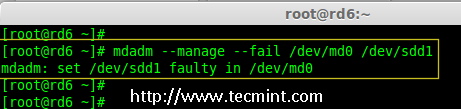
|
||||
|
||||
*检查 RAID 6 容错*
|
||||
|
||||
20、 让我们查看 RAID 的详细信息,并检查备用磁盘是否开始同步。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*检查 RAID 自动同步*
|
||||
|
||||
**哇塞!** 这里,我们看到备用磁盘激活了,并开始重建进程。在底部,我们可以看到有故障的磁盘 /dev/sdd1 标记为 faulty。可以使用下面的命令查看进程重建。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*RAID 6 自动同步*
|
||||
|
||||
### 结论: ###
|
||||
|
||||
在这里,我们看到了如何使用四个磁盘设置 RAID 6。这种 RAID 级别是具有高冗余的昂贵设置之一。在接下来的文章中,我们将看到如何建立一个嵌套的 RAID 10 甚至更多。请继续关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid-6-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
[3]:https://linux.cn/article-6093-1.html
|
||||
[4]:https://linux.cn/article-6102-1.html
|
||||
@ -0,0 +1,275 @@
|
||||
在 Linux 下使用 RAID(六):设置 RAID 10 或 1 + 0(嵌套)
|
||||
================================================================================
|
||||
|
||||
RAID 10 是组合 RAID 1 和 RAID 0 形成的。要设置 RAID 10,我们至少需要4个磁盘。在之前的文章中,我们已经看到了如何使用最少两个磁盘设置 RAID 1 和 RAID 0。
|
||||
|
||||
在这里,我们将使用最少4个磁盘组合 RAID 1 和 RAID 0 来设置 RAID 10。假设我们已经在用 RAID 10 创建的逻辑卷保存了一些数据。比如我们要保存数据 “TECMINT”,它将使用以下方法将其保存在4个磁盘中。
|
||||
|
||||
|
||||
|
||||
*在 Linux 中创建 Raid 10(LCTT 译注:此图有误,请参照文字说明和本系列第一篇文章)*
|
||||
|
||||
RAID 10 是先做镜像,再做条带。因此,在 RAID 1 中,相同的数据将被写入到两个磁盘中,“T”将同时被写入到第一和第二个磁盘中。接着的数据被条带化到另外两个磁盘,“E”将被同时写入到第三和第四个磁盘中。它将继续循环此过程,“C”将同时被写入到第一和第二个磁盘,以此类推。
|
||||
|
||||
(LCTT 译注:原文中此处描述混淆有误,已经根据实际情况进行修改。)
|
||||
|
||||
现在你已经了解 RAID 10 怎样组合 RAID 1 和 RAID 0 来工作的了。如果我们有4个20 GB 的磁盘,总共为 80 GB,但我们将只能得到40 GB 的容量,另一半的容量在构建 RAID 10 中丢失。
|
||||
|
||||
#### RAID 10 的优点和缺点 ####
|
||||
|
||||
- 提供更好的性能。
|
||||
- 在 RAID 10 中我们将失去一半的磁盘容量。
|
||||
- 读与写的性能都很好,因为它会同时进行写入和读取。
|
||||
- 它能解决数据库的高 I/O 磁盘写操作。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
在 RAID 10 中,我们至少需要4个磁盘,前2个磁盘为 RAID 1,其他2个磁盘为 RAID 0,就像我之前说的,RAID 10 仅仅是组合了 RAID 0和1。如果我们需要扩展 RAID 组,最少需要添加4个磁盘。
|
||||
|
||||
**我的服务器设置**
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.229
|
||||
主机名 : rd10.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdd
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
磁盘 4 [20GB] : /dev/sde
|
||||
|
||||
有两种方法来设置 RAID 10,在这里两种方法我都会演示,但我更喜欢第一种方法,使用它来设置 RAID 10 更简单。
|
||||
|
||||
### 方法1:设置 RAID 10 ###
|
||||
|
||||
1、 首先,使用以下命令确认所添加的4块磁盘没有被使用。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||
2、 四个磁盘被检测后,然后来检查磁盘是否存在 RAID 分区。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
|
||||
|
||||
*验证添加的4块磁盘*
|
||||
|
||||
**注意**: 在上面的输出中,如果没有检测到 super-block 意味着在4块磁盘中没有定义过 RAID。
|
||||
|
||||
#### 第1步:为 RAID 分区 ####
|
||||
|
||||
3、 现在,使用`fdisk`,命令为4个磁盘(/dev/sdb, /dev/sdc, /dev/sdd 和 /dev/sde)创建新分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
# fdisk /dev/sde
|
||||
|
||||
#####为 /dev/sdb 创建分区#####
|
||||
|
||||
我来告诉你如何使用 fdisk 为磁盘(/dev/sdb)进行分区,此步也适用于其他磁盘。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
请使用以下步骤为 /dev/sdb 创建一个新的分区。
|
||||
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*为磁盘 sdb 分区*
|
||||
|
||||
**注意**: 请使用上面相同的指令对其他磁盘(sdc, sdd sdd sde)进行分区。
|
||||
|
||||
4、 创建好4个分区后,需要使用下面的命令来检查磁盘是否存在 raid。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
# mdadm --examine /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 # 或
|
||||
|
||||
|
||||
|
||||
*检查磁盘*
|
||||
|
||||
**注意**: 以上输出显示,新创建的四个分区中没有检测到 super-block,这意味着我们可以继续在这些磁盘上创建 RAID 10。
|
||||
|
||||
#### 第2步: 创建 RAID 设备 `md` ####
|
||||
|
||||
5、 现在该创建一个`md`(即 /dev/md0)设备了,使用“mdadm” raid 管理工具。在创建设备之前,必须确保系统已经安装了`mdadm`工具,如果没有请使用下面的命令来安装。
|
||||
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
`mdadm`工具安装完成后,可以使用下面的命令创建一个`md` raid 设备。
|
||||
|
||||
# mdadm --create /dev/md0 --level=10 --raid-devices=4 /dev/sd[b-e]1
|
||||
|
||||
6、 接下来使用`cat`命令验证新创建的 raid 设备。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 md RAID 设备*
|
||||
|
||||
7、 接下来,使用下面的命令来检查4个磁盘。下面命令的输出会很长,因为它会显示4个磁盘的所有信息。
|
||||
|
||||
# mdadm --examine /dev/sd[b-e]1
|
||||
|
||||
8、 接下来,使用以下命令来查看 RAID 阵列的详细信息。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*查看 RAID 阵列详细信息*
|
||||
|
||||
**注意**: 你在上面看到的结果,该 RAID 的状态是 active 和re-syncing。
|
||||
|
||||
#### 第3步:创建文件系统 ####
|
||||
|
||||
9、 使用 ext4 作为`md0′的文件系统,并将它挂载到`/mnt/raid10`下。在这里,我用的是 ext4,你可以使用你想要的文件系统类型。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
*创建 md 文件系统*
|
||||
|
||||
10、 在创建文件系统后,挂载文件系统到`/mnt/raid10`下,并使用`ls -l`命令列出挂载点下的内容。
|
||||
|
||||
# mkdir /mnt/raid10
|
||||
# mount /dev/md0 /mnt/raid10/
|
||||
# ls -l /mnt/raid10/
|
||||
|
||||
接下来,在挂载点下创建一些文件,并在文件中添加些内容,然后检查内容。
|
||||
|
||||
# touch /mnt/raid10/raid10_files.txt
|
||||
# ls -l /mnt/raid10/
|
||||
# echo "raid 10 setup with 4 disks" > /mnt/raid10/raid10_files.txt
|
||||
# cat /mnt/raid10/raid10_files.txt
|
||||
|
||||

|
||||
|
||||
*挂载 md 设备*
|
||||
|
||||
11、 要想自动挂载,打开`/etc/fstab`文件并添加下面的条目,挂载点根据你环境的不同来添加。使用 wq! 保存并退出。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
/dev/md0 /mnt/raid10 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
*挂载 md 设备*
|
||||
|
||||
12、 接下来,在重新启动系统前使用`mount -a`来确认`/etc/fstab`文件是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
|
||||
|
||||
*检查 Fstab 中的错误*
|
||||
|
||||
#### 第四步:保存 RAID 配置 ####
|
||||
|
||||
13、 默认情况下 RAID 没有配置文件,所以我们需要在上述步骤完成后手动保存它。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
*保存 RAID10 的配置*
|
||||
|
||||
就这样,我们使用方法1创建完了 RAID 10,这种方法是比较容易的。现在,让我们使用方法2来设置 RAID 10。
|
||||
|
||||
### 方法2:创建 RAID 10 ###
|
||||
|
||||
1、 在方法2中,我们必须定义2组 RAID 1,然后我们需要使用这些创建好的 RAID 1 的集合来定义一个 RAID 0。在这里,我们将要做的是先创建2个镜像(RAID1),然后创建 RAID0 (条带化)。
|
||||
|
||||
首先,列出所有的可用于创建 RAID 10 的磁盘。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||
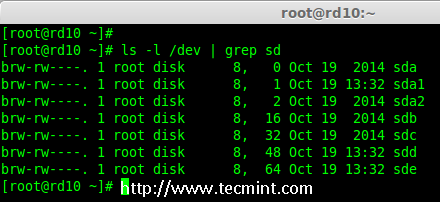
|
||||
|
||||
*列出了 4 个设备*
|
||||
|
||||
2、 将4个磁盘使用`fdisk`命令进行分区。对于如何分区,您可以按照上面的第1步。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
# fdisk /dev/sde
|
||||
|
||||
3、 在完成4个磁盘的分区后,现在检查磁盘是否存在 RAID块。
|
||||
|
||||
# mdadm --examine /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sd[b-e]1
|
||||
|
||||
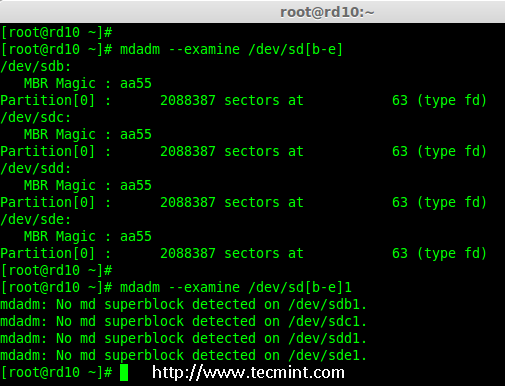
|
||||
|
||||
*检查 4 个磁盘*
|
||||
|
||||
#### 第1步:创建 RAID 1 ####
|
||||
|
||||
4、 首先,使用4块磁盘创建2组 RAID 1,一组为`sdb1′和 `sdc1′,另一组是`sdd1′ 和 `sde1′。
|
||||
|
||||
# mdadm --create /dev/md1 --metadata=1.2 --level=1 --raid-devices=2 /dev/sd[b-c]1
|
||||
# mdadm --create /dev/md2 --metadata=1.2 --level=1 --raid-devices=2 /dev/sd[d-e]1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 RAID 1*
|
||||
|
||||

|
||||
|
||||
*查看 RAID 1 的详细信息*
|
||||
|
||||
#### 第2步:创建 RAID 0 ####
|
||||
|
||||
5、 接下来,使用 md1 和 md2 来创建 RAID 0。
|
||||
|
||||
# mdadm --create /dev/md0 --level=0 --raid-devices=2 /dev/md1 /dev/md2
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 RAID 0*
|
||||
|
||||
#### 第3步:保存 RAID 配置 ####
|
||||
|
||||
6、 我们需要将配置文件保存在`/etc/mdadm.conf`文件中,使其每次重新启动后都能加载所有的 RAID 设备。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||
在此之后,我们需要按照方法1中的第3步来创建文件系统。
|
||||
|
||||
就是这样!我们采用的方法2创建完了 RAID 1+0。我们将会失去一半的磁盘空间,但相比其他 RAID ,它的性能将是非常好的。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这里,我们采用两种方法创建 RAID 10。RAID 10 具有良好的性能和冗余性。希望这篇文章可以帮助你了解 RAID 10 嵌套 RAID。在后面的文章中我们会看到如何扩展现有的 RAID 阵列以及更多精彩的内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid-10-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
@ -0,0 +1,182 @@
|
||||
在 Linux 下使用 RAID(七):在 Raid 中扩展现有的 RAID 阵列和删除故障的磁盘
|
||||
================================================================================
|
||||
|
||||
每个新手都会对阵列(array)这个词所代表的意思产生疑惑。阵列只是磁盘的一个集合。换句话说,我们可以称阵列为一个集合(set)或一组(group)。就像一组鸡蛋中包含6个一样。同样 RAID 阵列中包含着多个磁盘,可能是2,4,6,8,12,16等,希望你现在知道了什么是阵列。
|
||||
|
||||
在这里,我们将看到如何扩展现有的阵列或 RAID 组。例如,如果我们在阵列中使用2个磁盘形成一个 raid 1 集合,在某些情况,如果该组中需要更多的空间,就可以使用 mdadm -grow 命令来扩展阵列大小,只需要将一个磁盘加入到现有的阵列中即可。在说完扩展(添加磁盘到现有的阵列中)后,我们将看看如何从阵列中删除故障的磁盘。
|
||||
|
||||
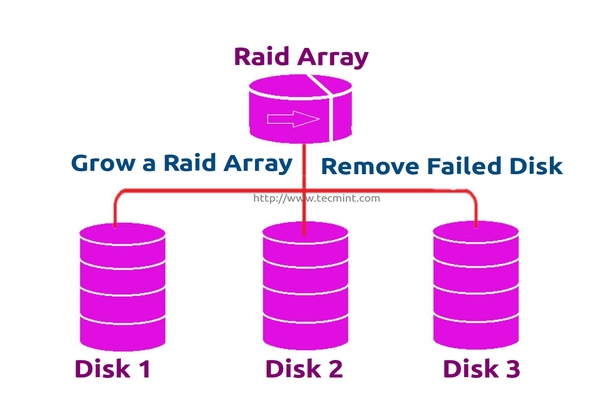
|
||||
|
||||
*扩展 RAID 阵列和删除故障的磁盘*
|
||||
|
||||
假设磁盘中的一个有问题了需要删除该磁盘,但我们需要在删除磁盘前添加一个备用磁盘来扩展该镜像,因为我们需要保存我们的数据。当磁盘发生故障时我们需要从阵列中删除它,这是这个主题中我们将要学习到的。
|
||||
|
||||
#### 扩展 RAID 的特性 ####
|
||||
|
||||
- 我们可以增加(扩展)任意 RAID 集合的大小。
|
||||
- 我们可以在使用新磁盘扩展 RAID 阵列后删除故障的磁盘。
|
||||
- 我们可以扩展 RAID 阵列而无需停机。
|
||||
|
||||
####要求 ####
|
||||
|
||||
- 为了扩展一个RAID阵列,我们需要一个已有的 RAID 组(阵列)。
|
||||
- 我们需要额外的磁盘来扩展阵列。
|
||||
- 在这里,我们使用一块磁盘来扩展现有的阵列。
|
||||
|
||||
在我们了解扩展和恢复阵列前,我们必须了解有关 RAID 级别和设置的基本知识。点击下面的链接了解这些。
|
||||
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP地址 : 192.168.0.230
|
||||
主机名 : grow.tecmintlocal.com
|
||||
2 块现有磁盘 : 1 GB
|
||||
1 块额外磁盘 : 1 GB
|
||||
|
||||
在这里,我们已有一个 RAID ,有2块磁盘,每个大小为1GB,我们现在再增加一个磁盘到我们现有的 RAID 阵列中,其大小为1GB。
|
||||
|
||||
### 扩展现有的 RAID 阵列 ###
|
||||
|
||||
1、 在扩展阵列前,首先使用下面的命令列出现有的 RAID 阵列。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*检查现有的 RAID 阵列*
|
||||
|
||||
**注意**: 以上输出显示,已经有了两个磁盘在 RAID 阵列中,级别为 RAID 1。现在我们增加一个磁盘到现有的阵列里。
|
||||
|
||||
2、 现在让我们添加新的磁盘“sdd”,并使用`fdisk`命令来创建分区。
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||
请使用以下步骤为 /dev/sdd 创建一个新的分区。
|
||||
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按回车确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*为 sdd 创建新的分区*
|
||||
|
||||
3、 一旦新的 sdd 分区创建完成后,你可以使用下面的命令验证它。
|
||||
|
||||
# ls -l /dev/ | grep sd
|
||||
|
||||
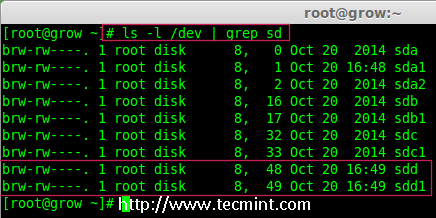
|
||||
|
||||
*确认 sdd 分区*
|
||||
|
||||
4、 接下来,在添加到阵列前先检查磁盘是否有 RAID 分区。
|
||||
|
||||
# mdadm --examine /dev/sdd1
|
||||
|
||||
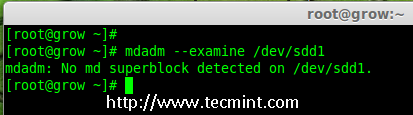
|
||||
|
||||
*在 sdd 分区中检查 RAID*
|
||||
|
||||
**注意**:以上输出显示,该盘有没有发现 super-blocks,意味着我们可以将新的磁盘添加到现有阵列。
|
||||
|
||||
5、 要添加新的分区 /dev/sdd1 到现有的阵列 md0,请使用以下命令。
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||
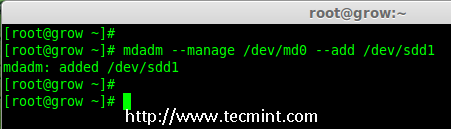
|
||||
|
||||
*添加磁盘到 RAID 阵列*
|
||||
|
||||
6、 一旦新的磁盘被添加后,在我们的阵列中检查新添加的磁盘。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*确认将新磁盘添加到 RAID 中*
|
||||
|
||||
**注意**: 在上面的输出,你可以看到磁盘已经被添加作为备用的。在这里,我们的阵列中已经有了2个磁盘,但我们期待阵列中有3个磁盘,因此我们需要扩展阵列。
|
||||
|
||||
7、 要扩展阵列,我们需要使用下面的命令。
|
||||
|
||||
# mdadm --grow --raid-devices=3 /dev/md0
|
||||
|
||||
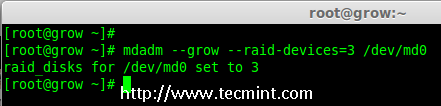
|
||||
|
||||
*扩展 Raid 阵列*
|
||||
|
||||
现在我们可以看到第三块磁盘(sdd1)已被添加到阵列中,在第三块磁盘被添加后,它将从另外两块磁盘上同步数据。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*确认 Raid 阵列*
|
||||
|
||||
**注意**: 对于大容量磁盘会需要几个小时来同步数据。在这里,我们使用的是1GB的虚拟磁盘,所以它非常快在几秒钟内便会完成。
|
||||
|
||||
### 从阵列中删除磁盘 ###
|
||||
|
||||
8、 在数据被从其他两个磁盘同步到新磁盘`sdd1`后,现在三个磁盘中的数据已经相同了(镜像)。
|
||||
|
||||
正如我前面所说的,假定一个磁盘出问题了需要被删除。所以,现在假设磁盘`sdc1`出问题了,需要从现有阵列中删除。
|
||||
|
||||
在删除磁盘前我们要将其标记为失效,然后我们才可以将其删除。
|
||||
|
||||
# mdadm --fail /dev/md0 /dev/sdc1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*在 RAID 阵列中模拟磁盘故障*
|
||||
|
||||
从上面的输出中,我们清楚地看到,磁盘在下面被标记为 faulty。即使它是 faulty 的,我们仍然可以看到 raid 设备有3个,1个损坏了,状态是 degraded。
|
||||
|
||||
现在我们要从阵列中删除 faulty 的磁盘,raid 设备将像之前一样继续有2个设备。
|
||||
|
||||
# mdadm --remove /dev/md0 /dev/sdc1
|
||||
|
||||
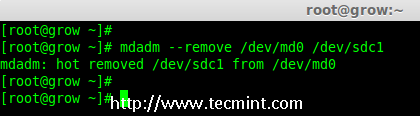
|
||||
|
||||
*在 Raid 阵列中删除磁盘*
|
||||
|
||||
9、 一旦故障的磁盘被删除,然后我们只能使用2个磁盘来扩展 raid 阵列了。
|
||||
|
||||
# mdadm --grow --raid-devices=2 /dev/md0
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*在 RAID 阵列扩展磁盘*
|
||||
|
||||
从上面的输出中可以看到,我们的阵列中仅有2台设备。如果你需要再次扩展阵列,按照如上所述的同样步骤进行。如果你需要添加一个磁盘作为备用,将其标记为 spare,因此,如果磁盘出现故障时,它会自动顶上去并重建数据。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经看到了如何扩展现有的 RAID 集合,以及如何在重新同步已有磁盘的数据后从一个阵列中删除故障磁盘。所有这些步骤都可以不用停机来完成。在数据同步期间,系统用户,文件和应用程序不会受到任何影响。
|
||||
|
||||
在接下来的文章我将告诉你如何管理 RAID,敬请关注更新,不要忘了写评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/grow-raid-array-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
109
published/201508/kde-plasma-5.4.md
Normal file
109
published/201508/kde-plasma-5.4.md
Normal file
@ -0,0 +1,109 @@
|
||||
KDE Plasma 5.4.0 发布,八月特色版
|
||||
=============================
|
||||
|
||||

|
||||
|
||||
2015 年 8 月 25 ,星期二,KDE 发布了 Plasma 5 的一个特色新版本。
|
||||
|
||||
此版本为我们带来了许多非常棒的感受,如优化了对高分辨率的支持,KRunner 自动补全和一些新的 Breeze 漂亮图标。这还为不久以后的技术预览版的 Wayland 桌面奠定了基础。我们还带来了几个新组件,如声音音量部件,显示器校准工具和测试版的用户管理工具。
|
||||
|
||||
###新的音频音量程序
|
||||
|
||||

|
||||
|
||||
新的音频音量程序直接工作于 PulseAudio (Linux 上一个非常流行的音频服务) 之上 ,并且在一个漂亮的简约的界面提供一个完整的音量控制和输出设定。
|
||||
|
||||
###替代的应用控制面板起动器
|
||||
|
||||

|
||||
|
||||
Plasma 5.4 在 kdeplasma-addons 软件包中提供了一个全新的全屏的应用控制面板,它具有应用菜单的所有功能,还支持缩放和全空间键盘导航。新的起动器可以像你目前所用的“最近使用的”或“收藏的文档和联系人”一样简单和快速地查找应用。
|
||||
|
||||
###丰富的艺术图标
|
||||
|
||||

|
||||
|
||||
Plasma 5.4 提供了超过 1400 个的新图标,其中不仅包含 KDE 程序的,而且还为 Inkscape, Firefox 和 Libreoffice 提供 Breeze 主题的艺术图标,可以体验到更加一致和本地化的感觉。
|
||||
|
||||
###KRunner 历史记录
|
||||
|
||||

|
||||
|
||||
KRunner 现在可以记住之前的搜索历史并根据历史记录进行自动补全。
|
||||
|
||||
###Network 程序中实用的图形展示
|
||||
|
||||

|
||||
|
||||
Network 程序现在可以以图形形式显示网络流量了,同时也支持两个新的 VPN 插件:通过 SSH 连接或通过 SSTP 连接。
|
||||
|
||||
###Wayland 技术预览
|
||||
|
||||
随着 Plasma 5.4 ,Wayland 桌面发布了第一个技术预览版。在使用自由图形驱动(free graphics drivers)的系统上可以使用 KWin(Plasma 的 Wayland 合成器和 X11 窗口管理器)通过[内核模式设定][1]来运行 Plasma。现在已经支持的功能需求来自于[手机 Plasma 项目][2],更多的面向桌面的功能还未被完全实现。现在还不能作为替换那些基于 Xorg 的桌面,但可以轻松地对它测试和贡献,以及观看令人激动视频。有关如何在 Wayland 中使用 Plasma 的介绍请到:[KWin 维基页][3]。Wlayland 将随着我们构建的稳定版本而逐步得到改进。
|
||||
|
||||
###其他的改变和添加
|
||||
|
||||
- 优化对高 DPI 支持
|
||||
- 更少的内存占用
|
||||
- 桌面搜索使用了更快的新后端
|
||||
- 便笺增加拖拉支持和键盘导航
|
||||
- 回收站重新支持拖拉
|
||||
- 系统托盘获得更快的可配置性
|
||||
- 文档重新修订和更新
|
||||
- 优化了窄小面板上的数字时钟的布局
|
||||
- 数字时钟支持 ISO 日期
|
||||
- 切换数字时钟 12/24 格式更简单
|
||||
- 日历显示第几周
|
||||
- 任何项目都可以收藏进应用菜单(Kicker),支持收藏文档和 Telepathy 联系人
|
||||
- Telepathy 联系人收藏可以展示联系人的照片和实时状态
|
||||
- 优化程序与容器间的焦点和激活处理
|
||||
- 文件夹视图中各种小修复:更好的默认尺寸,鼠标交互问题以及文本标签换行
|
||||
- 任务管理器更好的呈现起动器默认的应用图标
|
||||
- 可再次通过将程序拖入任务管理器来添加启动器
|
||||
- 可配置中间键点击在任务管理器中的行为:无动作,关闭窗口,启动一个相同的程序的新实例
|
||||
- 任务管理器现在以列排序优先,无论用户是否更倾向于行优先;许多用户更喜欢这样排序是因为它会使更少的任务按钮像窗口一样移来移去
|
||||
- 优化任务管理器的图标和缩放边
|
||||
- 任务管理器中各种小修复:垂直下拉,触摸事件处理现在支持所有系统,组扩展箭头的视觉问题
|
||||
- 提供可用的目的框架技术预览版,可以使用 QuickShare Plasmoid,它可以让许多 web 服务分享文件更容易
|
||||
- 增加了显示器配置工具
|
||||
- 增加的 kwallet-pam 可以在登录时打开 wallet
|
||||
- 用户管理器现在会同步联系人到 KConfig 的设置中,用户账户模块被丢弃了
|
||||
- 应用程序菜单(Kicker)的性能得到改善
|
||||
- 应用程序菜单(Kicker)各种小修复:隐藏/显示程序更加可靠,顶部面板的对齐修复,文件夹视图中 “添加到桌面”更加可靠,在基于 KActivities 的最新模块中有更好的表现
|
||||
- 支持自定义菜单布局 (kmenuedit)和应用程序菜单(Kicker)支持菜单项目分隔
|
||||
- 当在面板中时,改进了文件夹视图,参见 [blog][4]
|
||||
- 将文件夹拖放到桌面容器现在会再次创建一个文件夹视图
|
||||
|
||||
[完整的 Plasma 5.4 变更日志在此](https://www.kde.org/announcements/plasma-5.3.2-5.4.0-changelog.php)
|
||||
|
||||
###Live 镜像
|
||||
|
||||
尝鲜的最简单的方式就是从 U 盘中启动,可以在 KDE 社区 Wiki 中找到 各种 [带有 Plasma 5 的 Live 镜像][5]。
|
||||
|
||||
###下载软件包
|
||||
|
||||
各发行版已经构建了软件包,或者正在构建,wiki 中的列出了各发行版的软件包名:[软件包下载维基页][6]。
|
||||
|
||||
###源码下载
|
||||
|
||||
可以直接从源码中安装 Plasma 5。KDE 社区 Wiki 已经介绍了[怎样编译][7]。
|
||||
|
||||
注意,Plasma 5 与 Plasma 4 不兼容,必须先卸载旧版本,或者安装到不同的前缀处。
|
||||
|
||||
|
||||
- [源代码信息页][8]
|
||||
|
||||
---
|
||||
|
||||
via: https://www.kde.org/announcements/plasma-5.4.0.php
|
||||
|
||||
译者:[Locez](http://locez.com) 校对:[wxy](http://github.com/wxy)
|
||||
|
||||
[1]:https://en.wikipedia.org/wiki/Direct_Rendering_Manager
|
||||
[2]:https://dot.kde.org/2015/07/25/plasma-mobile-free-mobile-platform
|
||||
[3]:https://community.kde.org/KWin/Wayland#Start_a_Plasma_session_on_Wayland
|
||||
[4]:https://blogs.kde.org/2015/06/04/folder-view-panel-popups-are-list-views-again
|
||||
[5]:https://community.kde.org/Plasma/LiveImages
|
||||
[6]:https://community.kde.org/Plasma/Packages
|
||||
[7]:http://community.kde.org/Frameworks/Building
|
||||
[8]:https://www.kde.org/info/plasma-5.4.0.php
|
||||
418
published/20150803 Managing Linux Logs.md
Normal file
418
published/20150803 Managing Linux Logs.md
Normal file
@ -0,0 +1,418 @@
|
||||
Linux 日志管理指南
|
||||
================================================================================
|
||||
|
||||
管理日志的一个最好做法是将你的日志集中或整合到一个地方,特别是在你有许多服务器或多层级架构时。我们将告诉你为什么这是一个好主意,然后给出如何更容易的做这件事的一些小技巧。
|
||||
|
||||
### 集中管理日志的好处 ###
|
||||
|
||||
如果你有很多服务器,查看某个日志文件可能会很麻烦。现代的网站和服务经常包括许多服务器层级、分布式的负载均衡器,等等。找到正确的日志将花费很长时间,甚至要花更长时间在登录服务器的相关问题上。没什么比发现你找的信息没有被保存下来更沮丧的了,或者本该保留的日志文件正好在重启后丢失了。
|
||||
|
||||
集中你的日志使它们查找更快速,可以帮助你更快速的解决产品问题。你不用猜测那个服务器存在问题,因为所有的日志在同一个地方。此外,你可以使用更强大的工具去分析它们,包括日志管理解决方案。一些解决方案能[转换纯文本日志][1]为一些字段,更容易查找和分析。
|
||||
|
||||
集中你的日志也可以使它们更易于管理:
|
||||
|
||||
- 它们更安全,当它们备份归档到一个单独区域时会有意无意地丢失。如果你的服务器宕机或者无响应,你可以使用集中的日志去调试问题。
|
||||
- 你不用担心ssh或者低效的grep命令在陷入困境的系统上需要更多的资源。
|
||||
- 你不用担心磁盘占满,这个能让你的服务器死机。
|
||||
- 你能保持你的产品服务器的安全性,只是为了查看日志无需给你所有团队登录权限。给你的团队从日志集中区域访问日志权限更安全。
|
||||
|
||||
随着集中日志管理,你仍需处理由于网络联通性不好或者耗尽大量网络带宽从而导致不能传输日志到中心区域的风险。在下面的章节我们将要讨论如何聪明的解决这些问题。
|
||||
|
||||
### 流行的日志归集工具 ###
|
||||
|
||||
在 Linux 上最常见的日志归集是通过使用 syslog 守护进程或者日志代理。syslog 守护进程支持本地日志的采集,然后通过syslog 协议传输日志到中心服务器。你可以使用很多流行的守护进程来归集你的日志文件:
|
||||
|
||||
- [rsyslog][2] 是一个轻量后台程序,在大多数 Linux 分支上已经安装。
|
||||
- [syslog-ng][3] 是第二流行的 Linux 系统日志后台程序。
|
||||
- [logstash][4] 是一个重量级的代理,它可以做更多高级加工和分析。
|
||||
- [fluentd][5] 是另一个具有高级处理能力的代理。
|
||||
|
||||
Rsyslog 是集中日志数据最流行的后台程序,因为它在大多数 Linux 分支上是被默认安装的。你不用下载或安装它,并且它是轻量的,所以不需要占用你太多的系统资源。
|
||||
|
||||
如果你需要更多先进的过滤或者自定义分析功能,如果你不在乎额外的系统负载,Logstash 是另一个最流行的选择。
|
||||
|
||||
### 配置 rsyslog.conf ###
|
||||
|
||||
既然 rsyslog 是最广泛使用的系统日志程序,我们将展示如何配置它为日志中心。它的全局配置文件位于 /etc/rsyslog.conf。它加载模块,设置全局指令,和包含位于目录 /etc/rsyslog.d 中的应用的特有的配置。目录中包含的 /etc/rsyslog.d/50-default.conf 指示 rsyslog 将系统日志写到文件。在 [rsyslog 文档][6]中你可以阅读更多相关配置。
|
||||
|
||||
rsyslog 配置语言是是[RainerScript][7]。你可以给日志指定输入,就像将它们输出到另外一个位置一样。rsyslog 已经配置标准输入默认是 syslog ,所以你通常只需增加一个输出到你的日志服务器。这里有一个 rsyslog 输出到一个外部服务器的配置例子。在本例中,**BEBOP** 是一个服务器的主机名,所以你应该替换为你的自己的服务器名。
|
||||
|
||||
action(type="omfwd" protocol="tcp" target="BEBOP" port="514")
|
||||
|
||||
你可以发送你的日志到一个有足够的存储容量的日志服务器来存储,提供查询,备份和分析。如果你存储日志到文件系统,那么你应该建立[日志轮转][8]来防止你的磁盘爆满。
|
||||
|
||||
作为一种选择,你可以发送这些日志到一个日志管理方案。如果你的解决方案是安装在本地你可以发送到系统文档中指定的本地主机和端口。如果你使用基于云提供商,你将发送它们到你的提供商特定的主机名和端口。
|
||||
|
||||
### 日志目录 ###
|
||||
|
||||
你可以归集一个目录或者匹配一个通配符模式的所有文件。nxlog 和 syslog-ng 程序支持目录和通配符(*)。
|
||||
|
||||
常见的 rsyslog 不能直接监控目录。作为一种解决办法,你可以设置一个定时任务去监控这个目录的新文件,然后配置 rsyslog 来发送这些文件到目的地,比如你的日志管理系统。举个例子,日志管理提供商 Loggly 有一个开源版本的[目录监控脚本][9]。
|
||||
|
||||
### 哪个协议: UDP、TCP 或 RELP? ###
|
||||
|
||||
当你使用网络传输数据时,有三个主流协议可以选择。UDP 在你自己的局域网是最常用的,TCP 用在互联网。如果你不能失去(任何)日志,就要使用更高级的 RELP 协议。
|
||||
|
||||
[UDP][10] 发送一个数据包,那只是一个单一的信息包。它是一个只外传的协议,所以它不会发送给你回执(ACK)。它只尝试发送包。当网络拥堵时,UDP 通常会巧妙的降级或者丢弃日志。它通常使用在类似局域网的可靠网络。
|
||||
|
||||
[TCP][11] 通过多个包和返回确认发送流式信息。TCP 会多次尝试发送数据包,但是受限于 [TCP 缓存][12]的大小。这是在互联网上发送送日志最常用的协议。
|
||||
|
||||
[RELP][13] 是这三个协议中最可靠的,但是它是为 rsyslog 创建的,而且很少有行业采用。它在应用层接收数据,如果有错误就会重发。请确认你的日志接受位置也支持这个协议。
|
||||
|
||||
### 用磁盘辅助队列可靠的传送 ###
|
||||
|
||||
如果 rsyslog 在存储日志时遭遇错误,例如一个不可用网络连接,它能将日志排队直到连接还原。队列日志默认被存储在内存里。无论如何,内存是有限的并且如果问题仍然存在,日志会超出内存容量。
|
||||
|
||||
**警告:如果你只存储日志到内存,你可能会失去数据。**
|
||||
|
||||
rsyslog 能在内存被占满时将日志队列放到磁盘。[磁盘辅助队列][14]使日志的传输更可靠。这里有一个例子如何配置rsyslog 的磁盘辅助队列:
|
||||
|
||||
$WorkDirectory /var/spool/rsyslog # 暂存文件(spool)放置位置
|
||||
$ActionQueueFileName fwdRule1 # 暂存文件的唯一名字前缀
|
||||
$ActionQueueMaxDiskSpace 1g # 1gb 空间限制(尽可能大)
|
||||
$ActionQueueSaveOnShutdown on # 关机时保存日志到磁盘
|
||||
$ActionQueueType LinkedList # 异步运行
|
||||
$ActionResumeRetryCount -1 # 如果主机宕机,不断重试
|
||||
|
||||
### 使用 TLS 加密日志 ###
|
||||
|
||||
如果你担心你的数据的安全性和隐私性,你应该考虑加密你的日志。如果你使用纯文本在互联网传输日志,嗅探器和中间人可以读到你的日志。如果日志包含私人信息、敏感的身份数据或者政府管制数据,你应该加密你的日志。rsyslog 程序能使用 TLS 协议加密你的日志保证你的数据更安全。
|
||||
|
||||
建立 TLS 加密,你应该做如下任务:
|
||||
|
||||
1. 生成一个[证书授权(CA)][15]。在 /contrib/gnutls 有一些证书例子,可以用来测试,但是你需要为产品环境创建自己的证书。如果你正在使用一个日志管理服务,它会给你一个证书。
|
||||
1. 为你的服务器生成一个[数字证书][16]使它能启用 SSL 操作,或者使用你自己的日志管理服务提供商的一个数字证书。
|
||||
1. 配置你的 rsyslog 程序来发送 TLS 加密数据到你的日志管理系统。
|
||||
|
||||
这有一个 rsyslog 配置 TLS 加密的例子。替换 CERT 和 DOMAIN_NAME 为你自己的服务器配置。
|
||||
|
||||
$DefaultNetstreamDriverCAFile /etc/rsyslog.d/keys/ca.d/CERT.crt
|
||||
$ActionSendStreamDriver gtls
|
||||
$ActionSendStreamDriverMode 1
|
||||
$ActionSendStreamDriverAuthMode x509/name
|
||||
$ActionSendStreamDriverPermittedPeer *.DOMAIN_NAME.com
|
||||
|
||||
### 应用日志的最佳管理方法 ###
|
||||
|
||||
除 Linux 默认创建的日志之外,归集重要的应用日志也是一个好主意。几乎所有基于 Linux 的服务器应用都把它们的状态信息写入到独立、专门的日志文件中。这包括数据库产品,像 PostgreSQL 或者 MySQL,网站服务器,像 Nginx 或者 Apache,防火墙,打印和文件共享服务,目录和 DNS 服务等等。
|
||||
|
||||
管理员安装一个应用后要做的第一件事是配置它。Linux 应用程序典型的有一个放在 /etc 目录里 .conf 文件。它也可能在其它地方,但是那是大家找配置文件首先会看的地方。
|
||||
|
||||
根据应用程序有多复杂多庞大,可配置参数的数量可能会很少或者上百行。如前所述,大多数应用程序可能会在某种日志文件写它们的状态:配置文件是定义日志设置和其它东西的地方。
|
||||
|
||||
如果你不确定它在哪,你可以使用locate命令去找到它:
|
||||
|
||||
[root@localhost ~]# locate postgresql.conf
|
||||
/usr/pgsql-9.4/share/postgresql.conf.sample
|
||||
/var/lib/pgsql/9.4/data/postgresql.conf
|
||||
|
||||
#### 设置一个日志文件的标准位置 ####
|
||||
|
||||
Linux 系统一般保存它们的日志文件在 /var/log 目录下。一般是这样,但是需要检查一下应用是否保存它们在 /var/log 下的特定目录。如果是,很好,如果不是,你也许想在 /var/log 下创建一个专用目录?为什么?因为其它程序也在 /var/log 下保存它们的日志文件,如果你的应用保存超过一个日志文件 - 也许每天一个或者每次重启一个 - 在这么大的目录也许有点难于搜索找到你想要的文件。
|
||||
|
||||
如果在你网络里你有运行多于一个的应用实例,这个方法依然便利。想想这样的情景,你也许有一打 web 服务器在你的网络运行。当排查任何一个机器的问题时,你就很容易知道确切的位置。
|
||||
|
||||
#### 使用一个标准的文件名 ####
|
||||
|
||||
给你的应用最新的日志使用一个标准的文件名。这使一些事变得容易,因为你可以监控和追踪一个单独的文件。很多应用程序在它们的日志文件上追加一种时间戳。它让 rsyslog 更难于找到最新的文件和设置文件监控。一个更好的方法是使用日志轮转给老的日志文件增加时间。这样更易去归档和历史查询。
|
||||
|
||||
#### 追加日志文件 ####
|
||||
|
||||
日志文件会在每个应用程序重启后被覆盖吗?如果这样,我们建议关掉它。每次重启 app 后应该去追加日志文件。这样,你就可以追溯重启前最后的日志。
|
||||
|
||||
#### 日志文件追加 vs. 轮转 ####
|
||||
|
||||
要是应用程序每次重启后写一个新日志文件,如何保存当前日志?追加到一个单独的、巨大的文件?Linux 系统并不以频繁重启或者崩溃而出名:应用程序可以运行很长时间甚至不间歇,但是也会使日志文件非常大。如果你查询分析上周发生连接错误的原因,你可能无疑的要在成千上万行里搜索。
|
||||
|
||||
我们建议你配置应用每天半晚轮转(rotate)它的日志文件。
|
||||
|
||||
为什么?首先它将变得可管理。找一个带有特定日期的文件名比遍历一个文件中指定日期的条目更容易。文件也小的多:你不用考虑当你打开一个日志文件时 vi 僵住。第二,如果你正发送日志到另一个位置 - 也许每晚备份任务拷贝到归集日志服务器 - 这样不会消耗你的网络带宽。最后第三点,这样帮助你做日志保留。如果你想剔除旧的日志记录,这样删除超过指定日期的文件比用一个应用解析一个大文件更容易。
|
||||
|
||||
#### 日志文件的保留 ####
|
||||
|
||||
你保留你的日志文件多长时间?这绝对可以归结为业务需求。你可能被要求保持一个星期的日志信息,或者管理要求保持一年的数据。无论如何,日志需要在一个时刻或其它情况下从服务器删除。
|
||||
|
||||
在我们看来,除非必要,只在线保持最近一个月的日志文件,并拷贝它们到第二个地方如日志服务器。任何比这更旧的日志可以被转到一个单独的介质上。例如,如果你在 AWS 上,你的旧日志可以被拷贝到 Glacier。
|
||||
|
||||
#### 给日志单独的磁盘分区 ####
|
||||
|
||||
更好的,Linux 通常建议挂载到 /var 目录到一个单独的文件系统。这是因为这个目录的高 I/O。我们推荐挂载 /var/log 目录到一个单独的磁盘系统下。这样可以节省与主要的应用数据的 I/O 竞争。另外,如果一些日志文件变的太多,或者一个文件变的太大,不会占满整个磁盘。
|
||||
|
||||
#### 日志条目 ####
|
||||
|
||||
每个日志条目中应该捕获什么信息?
|
||||
|
||||
这依赖于你想用日志来做什么。你只想用它来排除故障,或者你想捕获所有发生的事?这是一个捕获每个用户在运行什么或查看什么的规则条件吗?
|
||||
|
||||
如果你正用日志做错误排查的目的,那么只保存错误,报警或者致命信息。没有理由去捕获调试信息,例如,应用也许默认记录了调试信息或者另一个管理员也许为了故障排查而打开了调试信息,但是你应该关闭它,因为它肯定会很快的填满空间。在最低限度上,捕获日期、时间、客户端应用名、来源 ip 或者客户端主机名、执行的动作和信息本身。
|
||||
|
||||
#### 一个 PostgreSQL 的实例 ####
|
||||
|
||||
作为一个例子,让我们看看 vanilla PostgreSQL 9.4 安装的主配置文件。它叫做 postgresql.conf,与其它Linux 系统中的配置文件不同,它不保存在 /etc 目录下。下列的代码段,我们可以在我们的 Centos 7 服务器的 /var/lib/pgsql 目录下找到它:
|
||||
|
||||
root@localhost ~]# vi /var/lib/pgsql/9.4/data/postgresql.conf
|
||||
...
|
||||
#------------------------------------------------------------------------------
|
||||
# ERROR REPORTING AND LOGGING
|
||||
#------------------------------------------------------------------------------
|
||||
# - Where to Log -
|
||||
log_destination = 'stderr'
|
||||
# Valid values are combinations of
|
||||
# stderr, csvlog, syslog, and eventlog,
|
||||
# depending on platform. csvlog
|
||||
# requires logging_collector to be on.
|
||||
# This is used when logging to stderr:
|
||||
logging_collector = on
|
||||
# Enable capturing of stderr and csvlog
|
||||
# into log files. Required to be on for
|
||||
# csvlogs.
|
||||
# (change requires restart)
|
||||
# These are only used if logging_collector is on:
|
||||
log_directory = 'pg_log'
|
||||
# directory where log files are written,
|
||||
# can be absolute or relative to PGDATA
|
||||
log_filename = 'postgresql-%a.log' # log file name pattern,
|
||||
# can include strftime() escapes
|
||||
# log_file_mode = 0600 .
|
||||
# creation mode for log files,
|
||||
# begin with 0 to use octal notation
|
||||
log_truncate_on_rotation = on # If on, an existing log file with the
|
||||
# same name as the new log file will be
|
||||
# truncated rather than appended to.
|
||||
# But such truncation only occurs on
|
||||
# time-driven rotation, not on restarts
|
||||
# or size-driven rotation. Default is
|
||||
# off, meaning append to existing files
|
||||
# in all cases.
|
||||
log_rotation_age = 1d
|
||||
# Automatic rotation of logfiles will happen after that time. 0 disables.
|
||||
log_rotation_size = 0 # Automatic rotation of logfiles will happen after that much log output. 0 disables.
|
||||
# These are relevant when logging to syslog:
|
||||
#syslog_facility = 'LOCAL0'
|
||||
#syslog_ident = 'postgres'
|
||||
# This is only relevant when logging to eventlog (win32):
|
||||
#event_source = 'PostgreSQL'
|
||||
# - When to Log -
|
||||
#client_min_messages = notice # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# log
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
#log_min_messages = warning # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic
|
||||
#log_min_error_statement = error # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic (effectively off)
|
||||
#log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements
|
||||
# and their durations, > 0 logs only
|
||||
# statements running at least this number
|
||||
# of milliseconds
|
||||
# - What to Log
|
||||
#debug_print_parse = off
|
||||
#debug_print_rewritten = off
|
||||
#debug_print_plan = off
|
||||
#debug_pretty_print = on
|
||||
#log_checkpoints = off
|
||||
#log_connections = off
|
||||
#log_disconnections = off
|
||||
#log_duration = off
|
||||
#log_error_verbosity = default
|
||||
# terse, default, or verbose messages
|
||||
#log_hostname = off
|
||||
log_line_prefix = '< %m >' # special values:
|
||||
# %a = application name
|
||||
# %u = user name
|
||||
# %d = database name
|
||||
# %r = remote host and port
|
||||
# %h = remote host
|
||||
# %p = process ID
|
||||
# %t = timestamp without milliseconds
|
||||
# %m = timestamp with milliseconds
|
||||
# %i = command tag
|
||||
# %e = SQL state
|
||||
# %c = session ID
|
||||
# %l = session line number
|
||||
# %s = session start timestamp
|
||||
# %v = virtual transaction ID
|
||||
# %x = transaction ID (0 if none)
|
||||
# %q = stop here in non-session
|
||||
# processes
|
||||
# %% = '%'
|
||||
# e.g. '<%u%%%d> '
|
||||
#log_lock_waits = off # log lock waits >= deadlock_timeout
|
||||
#log_statement = 'none' # none, ddl, mod, all
|
||||
#log_temp_files = -1 # log temporary files equal or larger
|
||||
# than the specified size in kilobytes;5# -1 disables, 0 logs all temp files5
|
||||
log_timezone = 'Australia/ACT'
|
||||
|
||||
虽然大多数参数被加上了注释,它们使用了默认值。我们可以看见日志文件目录是 pg_log(log_directory 参数,在 /var/lib/pgsql/9.4/data/ 下的子目录),文件名应该以 postgresql 开头(log_filename参数),文件每天轮转一次(log_rotation_age 参数)然后每行日志记录以时间戳开头(log_line_prefix参数)。特别值得说明的是 log_line_prefix 参数:全部的信息你都可以包含在这。
|
||||
|
||||
看 /var/lib/pgsql/9.4/data/pg_log 目录下展现给我们这些文件:
|
||||
|
||||
[root@localhost ~]# ls -l /var/lib/pgsql/9.4/data/pg_log
|
||||
total 20
|
||||
-rw-------. 1 postgres postgres 1212 May 1 20:11 postgresql-Fri.log
|
||||
-rw-------. 1 postgres postgres 243 Feb 9 21:49 postgresql-Mon.log
|
||||
-rw-------. 1 postgres postgres 1138 Feb 7 11:08 postgresql-Sat.log
|
||||
-rw-------. 1 postgres postgres 1203 Feb 26 21:32 postgresql-Thu.log
|
||||
-rw-------. 1 postgres postgres 326 Feb 10 01:20 postgresql-Tue.log
|
||||
|
||||
所以日志文件名只有星期命名的标签。我们可以改变它。如何做?在 postgresql.conf 配置 log_filename 参数。
|
||||
|
||||
查看一个日志内容,它的条目仅以日期时间开头:
|
||||
|
||||
[root@localhost ~]# cat /var/lib/pgsql/9.4/data/pg_log/postgresql-Fri.log
|
||||
...
|
||||
< 2015-02-27 01:21:27.020 EST >LOG: received fast shutdown request
|
||||
< 2015-02-27 01:21:27.025 EST >LOG: aborting any active transactions
|
||||
< 2015-02-27 01:21:27.026 EST >LOG: autovacuum launcher shutting down
|
||||
< 2015-02-27 01:21:27.036 EST >LOG: shutting down
|
||||
< 2015-02-27 01:21:27.211 EST >LOG: database system is shut down
|
||||
|
||||
### 归集应用的日志 ###
|
||||
|
||||
#### 使用 imfile 监控日志 ####
|
||||
|
||||
习惯上,应用通常记录它们数据在文件里。文件容易在一个机器上寻找,但是多台服务器上就不是很恰当了。你可以设置日志文件监控,然后当新的日志被添加到文件尾部后就发送事件到一个集中服务器。在 /etc/rsyslog.d/ 里创建一个新的配置文件然后增加一个配置文件,然后输入如下:
|
||||
|
||||
$ModLoad imfile
|
||||
$InputFilePollInterval 10
|
||||
$PrivDropToGroup adm
|
||||
|
||||
-----
|
||||
# Input for FILE1
|
||||
$InputFileName /FILE1
|
||||
$InputFileTag APPNAME1
|
||||
$InputFileStateFile stat-APPNAME1 #this must be unique for each file being polled
|
||||
$InputFileSeverity info
|
||||
$InputFilePersistStateInterval 20000
|
||||
$InputRunFileMonitor
|
||||
|
||||
替换 FILE1 和 APPNAME1 为你自己的文件名和应用名称。rsyslog 将发送它到你配置的输出目标中。
|
||||
|
||||
#### 本地套接字日志与 imuxsock ####
|
||||
|
||||
套接字类似 UNIX 文件句柄,所不同的是套接字内容是由 syslog 守护进程读取到内存中,然后发送到目的地。不需要写入文件。作为一个例子,logger 命令发送它的日志到这个 UNIX 套接字。
|
||||
|
||||
如果你的服务器 I/O 有限或者你不需要本地文件日志,这个方法可以使系统资源有效利用。这个方法缺点是套接字有队列大小的限制。如果你的 syslog 守护进程宕掉或者不能保持运行,然后你可能会丢失日志数据。
|
||||
|
||||
rsyslog 程序将默认从 /dev/log 套接字中读取,但是你需要使用如下命令来让 [imuxsock 输入模块][17] 启用它:
|
||||
|
||||
$ModLoad imuxsock
|
||||
|
||||
#### UDP 日志与 imupd ####
|
||||
|
||||
一些应用程序使用 UDP 格式输出日志数据,这是在网络上或者本地传输日志文件的标准 syslog 协议。你的 syslog 守护进程接受这些日志,然后处理它们或者用不同的格式传输它们。备选的,你可以发送日志到你的日志服务器或者到一个日志管理方案中。
|
||||
|
||||
使用如下命令配置 rsyslog 通过 UDP 来接收标准端口 514 的 syslog 数据:
|
||||
|
||||
$ModLoad imudp
|
||||
|
||||
----------
|
||||
|
||||
$UDPServerRun 514
|
||||
|
||||
### 用 logrotate 管理日志 ###
|
||||
|
||||
日志轮转是当日志到达指定的时期时自动归档日志文件的方法。如果不介入,日志文件一直增长,会用尽磁盘空间。最后它们将破坏你的机器。
|
||||
|
||||
logrotate 工具能随着日志的日期截取你的日志,腾出空间。你的新日志文件保持该文件名。你的旧日志文件被重命名加上后缀数字。每次 logrotate 工具运行,就会创建一个新文件,然后现存的文件被逐一重命名。你来决定何时旧文件被删除或归档的阈值。
|
||||
|
||||
当 logrotate 拷贝一个文件,新的文件会有一个新的 inode,这会妨碍 rsyslog 监控新文件。你可以通过增加copytruncate 参数到你的 logrotate 定时任务来缓解这个问题。这个参数会拷贝现有的日志文件内容到新文件然后从现有文件截短这些内容。因为日志文件还是同一个,所以 inode 不会改变;但它的内容是一个新文件。
|
||||
|
||||
logrotate 工具使用的主配置文件是 /etc/logrotate.conf,应用特有设置在 /etc/logrotate.d/ 目录下。DigitalOcean 有一个详细的 [logrotate 教程][18]
|
||||
|
||||
### 管理很多服务器的配置 ###
|
||||
|
||||
当你只有很少的服务器,你可以登录上去手动配置。一旦你有几打或者更多服务器,你可以利用工具的优势使这变得更容易和更可扩展。基本上,所有的事情就是拷贝你的 rsyslog 配置到每个服务器,然后重启 rsyslog 使更改生效。
|
||||
|
||||
#### pssh ####
|
||||
|
||||
这个工具可以让你在很多服务器上并行的运行一个 ssh 命令。使用 pssh 部署仅用于少量服务器。如果你其中一个服务器失败,然后你必须 ssh 到失败的服务器,然后手动部署。如果你有很多服务器失败,那么手动部署它们会话费很长时间。
|
||||
|
||||
#### Puppet/Chef ####
|
||||
|
||||
Puppet 和 Chef 是两个不同的工具,它们能在你的网络按你规定的标准自动的配置所有服务器。它们的报表工具可以使你了解错误情况,然后定期重新同步。Puppet 和 Chef 都有一些狂热的支持者。如果你不确定那个更适合你的部署配置管理,你可以拜读一下 [InfoWorld 上这两个工具的对比][19]
|
||||
|
||||
一些厂商也提供一些配置 rsyslog 的模块或者方法。这有一个 Loggly 上 Puppet 模块的例子。它提供给 rsyslog 一个类,你可以添加一个标识令牌:
|
||||
|
||||
node 'my_server_node.example.net' {
|
||||
# Send syslog events to Loggly
|
||||
class { 'loggly::rsyslog':
|
||||
customer_token => 'de7b5ccd-04de-4dc4-fbc9-501393600000',
|
||||
}
|
||||
}
|
||||
|
||||
#### Docker ####
|
||||
|
||||
Docker 使用容器去运行应用,不依赖于底层服务。所有东西都运行在内部的容器,你可以把它想象为一个功能单元。ZDNet 有一篇关于在你的数据中心[使用 Docker][20] 的深入文章。
|
||||
|
||||
这里有很多方式从 Docker 容器记录日志,包括链接到一个日志容器,记录到一个共享卷,或者直接在容器里添加一个 sysllog 代理。其中最流行的日志容器叫做 [logspout][21]。
|
||||
|
||||
#### 供应商的脚本或代理 ####
|
||||
|
||||
大多数日志管理方案提供一些脚本或者代理,可以从一个或更多服务器相对容易地发送数据。重量级代理会耗尽额外的系统资源。一些供应商像 Loggly 提供配置脚本,来使用现存的 syslog 守护进程更轻松。这有一个 Loggly 上的例子[脚本][22],它能运行在任意数量的服务器上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/managing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a1]
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.esrreycnpnbl
|
||||
[2]:http://www.rsyslog.com/
|
||||
[3]:http://www.balabit.com/network-security/syslog-ng/opensource-logging-system
|
||||
[4]:http://logstash.net/
|
||||
[5]:http://www.fluentd.org/
|
||||
[6]:http://www.rsyslog.com/doc/rsyslog_conf.html
|
||||
[7]:http://www.rsyslog.com/doc/master/rainerscript/index.html
|
||||
[8]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.eck7acdxin87
|
||||
[9]:https://www.loggly.com/docs/file-monitoring/
|
||||
[10]:http://www.networksorcery.com/enp/protocol/udp.htm
|
||||
[11]:http://www.networksorcery.com/enp/protocol/tcp.htm
|
||||
[12]:http://blog.gerhards.net/2008/04/on-unreliability-of-plain-tcp-syslog.html
|
||||
[13]:http://www.rsyslog.com/doc/relp.html
|
||||
[14]:http://www.rsyslog.com/doc/queues.html
|
||||
[15]:http://www.rsyslog.com/doc/tls_cert_ca.html
|
||||
[16]:http://www.rsyslog.com/doc/tls_cert_machine.html
|
||||
[17]:http://www.rsyslog.com/doc/v8-stable/configuration/modules/imuxsock.html
|
||||
[18]:https://www.digitalocean.com/community/tutorials/how-to-manage-log-files-with-logrotate-on-ubuntu-12-10
|
||||
[19]:http://www.infoworld.com/article/2614204/data-center/puppet-or-chef--the-configuration-management-dilemma.html
|
||||
[20]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[21]:https://github.com/progrium/logspout
|
||||
[22]:https://www.loggly.com/docs/sending-logs-unixlinux-system-setup/
|
||||
@ -1,10 +1,10 @@
|
||||
Linux有问必答——如何启用Open vSwitch的日志功能以便调试和排障
|
||||
Linux有问必答:如何启用Open vSwitch的日志功能以便调试和排障
|
||||
================================================================================
|
||||
> **问题** 我试着为我的Open vSwitch部署排障,鉴于此,我想要检查它的由内建日志机制生成的调试信息。我怎样才能启用Open vSwitch的日志功能,并且修改它的日志等级(如,修改成INFO/DEBUG级别)以便于检查更多详细的调试信息呢?
|
||||
|
||||
Open vSwitch(OVS)是Linux平台上用于虚拟切换的最流行的开源部署。由于当今的数据中心日益依赖于软件定义的网络(SDN)架构,OVS被作为数据中心的SDN部署中实际上的标准网络元素而快速采用。
|
||||
Open vSwitch(OVS)是Linux平台上最流行的开源的虚拟交换机。由于当今的数据中心日益依赖于软件定义网络(SDN)架构,OVS被作为数据中心的SDN部署中的事实标准上的网络元素而得到飞速应用。
|
||||
|
||||
Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允许你在各种切换组件中启用并自定义日志,由VLOG生成的日志信息可以被发送到一个控制台,syslog以及一个独立日志文件组合,以供检查。你可以通过一个名为`ovs-appctl`的命令行工具在运行时动态配置OVS日志。
|
||||
Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允许你在各种网络交换组件中启用并自定义日志,由VLOG生成的日志信息可以被发送到一个控制台、syslog以及一个便于查看的单独日志文件。你可以通过一个名为`ovs-appctl`的命令行工具在运行时动态配置OVS日志。
|
||||
|
||||
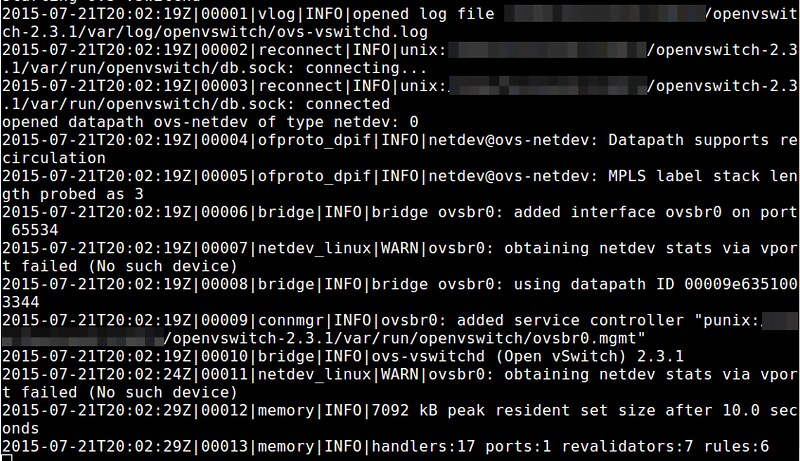
|
||||
|
||||
@ -14,7 +14,7 @@ Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允
|
||||
|
||||
$ sudo ovs-appctl vlog/set module[:facility[:level]]
|
||||
|
||||
- **Module**:OVS中的任何合法组件的名称(如netdev,ofproto,dpif,vswitchd,以及其它大量组件)
|
||||
- **Module**:OVS中的任何合法组件的名称(如netdev,ofproto,dpif,vswitchd等等)
|
||||
- **Facility**:日志信息的目的地(必须是:console,syslog,或者file)
|
||||
- **Level**:日志的详细程度(必须是:emer,err,warn,info,或者dbg)
|
||||
|
||||
@ -36,13 +36,13 @@ Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允
|
||||
|
||||
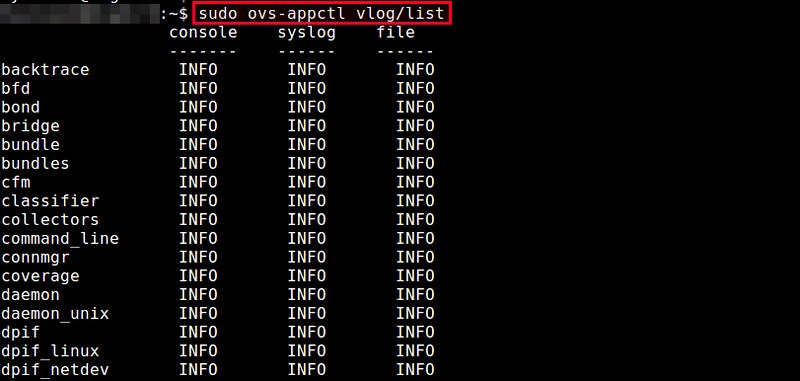
|
||||
|
||||
输出结果显示了用于三个工具(console,syslog,file)的各个模块的调试级别。默认情况下,所有模块的日志等级都被设置为INFO。
|
||||
输出结果显示了用于三个场合(facility:console,syslog,file)的各个模块的调试级别。默认情况下,所有模块的日志等级都被设置为INFO。
|
||||
|
||||
指定任何一个OVS模块,你可以选择性地修改任何特定工具的调试级别。例如,如果你想要在控制台屏幕中查看dpif更为详细的调试信息,可以运行以下命令。
|
||||
指定任何一个OVS模块,你可以选择性地修改任何特定场合的调试级别。例如,如果你想要在控制台屏幕中查看dpif更为详细的调试信息,可以运行以下命令。
|
||||
|
||||
$ sudo ovs-appctl vlog/set dpif:console:dbg
|
||||
|
||||
你将看到dpif模块的console工具已经将其日志等级修改为DBG,而其它两个工具syslog和file的日志级别仍然没有改变。
|
||||
你将看到dpif模块的console工具已经将其日志等级修改为DBG,而其它两个场合syslog和file的日志级别仍然没有改变。
|
||||
|
||||
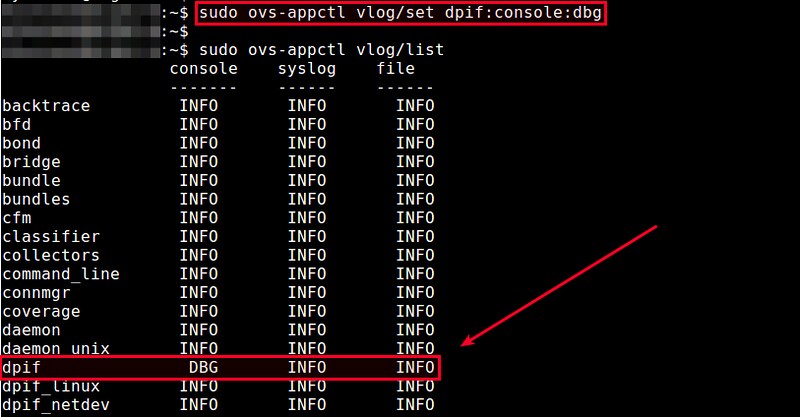
|
||||
|
||||
@ -52,7 +52,7 @@ Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允
|
||||
|
||||
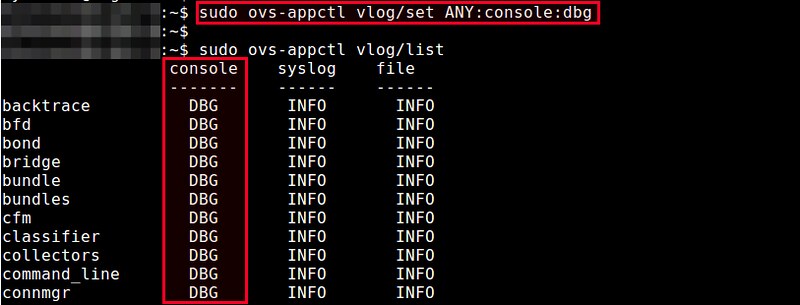
|
||||
|
||||
同时,如果你想要一次性修改所有三个工具的日志级别,你可以指定“ANY”作为工具名。例如,下面的命令将修改每个模块的所有工具的日志级别为DBG。
|
||||
同时,如果你想要一次性修改所有三个场合的日志级别,你可以指定“ANY”作为场合名。例如,下面的命令将修改每个模块的所有场合的日志级别为DBG。
|
||||
|
||||
$ sudo ovs-appctl vlog/set ANY:ANY:dbg
|
||||
|
||||
@ -62,7 +62,7 @@ via: http://ask.xmodulo.com/enable-logging-open-vswitch.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
在Ubuntu 15.04中如何安装和使用Snort
|
||||
在 Ubuntu 15.04 中如何安装和使用 Snort
|
||||
================================================================================
|
||||
对于IT安全而言入侵检测是一件非常重要的事。入侵检测系统用于检测网络中非法与恶意的请求。Snort是一款知名的开源入侵检测系统。Web界面(Snorby)可以用于更好地分析警告。Snort使用iptables/pf防火墙来作为入侵检测系统。本篇中,我们会安装并配置一个开源的IDS系统snort。
|
||||
|
||||
对于网络安全而言入侵检测是一件非常重要的事。入侵检测系统(IDS)用于检测网络中非法与恶意的请求。Snort是一款知名的开源的入侵检测系统。其 Web界面(Snorby)可以用于更好地分析警告。Snort使用iptables/pf防火墙来作为入侵检测系统。本篇中,我们会安装并配置一个开源的入侵检测系统snort。
|
||||
|
||||
### Snort 安装 ###
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
snort所使用的数据采集库(DAQ)用于抽象地调用采集库。这个在snort上就有。下载过程如下截图所示。
|
||||
snort所使用的数据采集库(DAQ)用于一个调用包捕获库的抽象层。这个在snort上就有。下载过程如下截图所示。
|
||||
|
||||

|
||||
|
||||
@ -48,7 +49,7 @@ make和make install 命令的结果如下所示。
|
||||
|
||||

|
||||
|
||||
创建安装目录并在脚本中设置prefix参数。同样也建议启用包性能监控(PPM)标志。
|
||||
创建安装目录并在脚本中设置prefix参数。同样也建议启用包性能监控(PPM)的sourcefire标志。
|
||||
|
||||
#mkdir /usr/local/snort
|
||||
|
||||
@ -56,7 +57,7 @@ make和make install 命令的结果如下所示。
|
||||
|
||||

|
||||
|
||||
配置脚本由于缺少libpcre-dev、libdumbnet-dev 和zlib开发库而报错。
|
||||
配置脚本会由于缺少libpcre-dev、libdumbnet-dev 和zlib开发库而报错。
|
||||
|
||||
配置脚本由于缺少libpcre库报错。
|
||||
|
||||
@ -96,7 +97,7 @@ make和make install 命令的结果如下所示。
|
||||
|
||||

|
||||
|
||||
最终snort在/usr/local/snort/bin中运行。现在它对eth0的所有流量都处在promisc模式(包转储模式)。
|
||||
最后,从/usr/local/snort/bin中运行snort。现在它对eth0的所有流量都处在promisc模式(包转储模式)。
|
||||
|
||||

|
||||
|
||||
@ -106,14 +107,17 @@ make和make install 命令的结果如下所示。
|
||||
|
||||
#### Snort的规则和配置 ####
|
||||
|
||||
从源码安装的snort需要规则和安装配置,因此我们会从/etc/snort下面复制规则和配置。我们已经创建了单独的bash脚本来用于规则和配置。它会设置下面这些snort设置。
|
||||
从源码安装的snort还需要设置规则和配置,因此我们需要复制规则和配置到/etc/snort下面。我们已经创建了单独的bash脚本来用于设置规则和配置。它会设置下面这些snort设置。
|
||||
|
||||
- 在linux中创建snort用户用于snort IDS服务。
|
||||
- 在linux中创建用于snort IDS服务的snort用户。
|
||||
- 在/etc下面创建snort的配置文件和文件夹。
|
||||
- 权限设置并从etc中复制snortsnort源代码
|
||||
- 权限设置并从源代码的etc目录中复制数据。
|
||||
- 从snort文件中移除规则中的#(注释符号)。
|
||||
|
||||
#!/bin/bash##PATH of source code of snort
|
||||
-
|
||||
|
||||
#!/bin/bash#
|
||||
# snort源代码的路径
|
||||
snort_src="/home/test/Downloads/snort-2.9.7.3"
|
||||
echo "adding group and user for snort..."
|
||||
groupadd snort &> /dev/null
|
||||
@ -141,15 +145,15 @@ make和make install 命令的结果如下所示。
|
||||
sed -i 's/include \$RULE\_PATH/#include \$RULE\_PATH/' /etc/snort/snort.conf
|
||||
echo "---DONE---"
|
||||
|
||||
改变脚本中的snort源目录并运行。下面是成功的输出。
|
||||
改变脚本中的snort源目录路径并运行。下面是成功的输出。
|
||||
|
||||

|
||||
|
||||
上面的脚本从snort源中复制下面的文件/文件夹到/etc/snort配置文件中
|
||||
上面的脚本从snort源中复制下面的文件和文件夹到/etc/snort配置文件中
|
||||
|
||||

|
||||
|
||||
、snort的配置非常复杂,然而为了IDS能正常工作需要进行下面必要的修改。
|
||||
snort的配置非常复杂,要让IDS能正常工作需要进行下面必要的修改。
|
||||
|
||||
ipvar HOME_NET 192.168.1.0/24 # LAN side
|
||||
|
||||
@ -173,7 +177,7 @@ make和make install 命令的结果如下所示。
|
||||
|
||||

|
||||
|
||||
下载[下载社区][1]规则并解压到/etc/snort/rules。启用snort.conf中的社区及紧急威胁规则。
|
||||
现在[下载社区规则][1]并解压到/etc/snort/rules。启用snort.conf中的社区及紧急威胁规则。
|
||||
|
||||

|
||||
|
||||
@ -187,7 +191,7 @@ make和make install 命令的结果如下所示。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
本篇中,我们致力于开源IDPS系统snort在Ubuntu上的安装和配置。默认它用于监控时间,然而它可以被配置成用于网络保护的内联模式。snort规则可以在离线模式中可以使用pcap文件测试和分析
|
||||
本篇中,我们关注了开源IDPS系统snort在Ubuntu上的安装和配置。通常它用于监控事件,然而它可以被配置成用于网络保护的在线模式。snort规则可以在离线模式中可以使用pcap捕获文件进行测试和分析
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -195,7 +199,7 @@ via: http://linoxide.com/security/install-snort-usage-ubuntu-15-04/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,16 @@
|
||||
fdupes——Linux中查找并删除重复文件的命令行工具
|
||||
fdupes:Linux中查找并删除重复文件的命令行工具
|
||||
================================================================================
|
||||
对于大多数计算机用户而言,查找并替换重复的文件是一个常见的需求。查找并移除重复文件真是一项领人不胜其烦的工作,它耗时又耗力。如果你的机器上跑着GNU/Linux,那么查找重复文件会变得十分简单,这多亏了`**fdupes**`工具。
|
||||
对于大多数计算机用户而言,查找并替换重复的文件是一个常见的需求。查找并移除重复文件真是一项令人不胜其烦的工作,它耗时又耗力。但如果你的机器上跑着GNU/Linux,那么查找重复文件会变得十分简单,这多亏了`fdupes`工具。
|
||||
|
||||

|
||||
|
||||
Fdupes——在Linux中查找并删除重复文件
|
||||
*fdupes——在Linux中查找并删除重复文件*
|
||||
|
||||
### fdupes是啥东东? ###
|
||||
|
||||
**Fdupes**是Linux下的一个工具,它由**Adrian Lopez**用C编程语言编写并基于MIT许可证发行,该应用程序可以在指定的目录及子目录中查找重复的文件。Fdupes通过对比文件的MD5签名,以及逐字节比较文件来识别重复内容,可以为Fdupes指定大量的选项以实现对文件的列出、删除、替换到文件副本的硬链接等操作。
|
||||
**fdupes**是Linux下的一个工具,它由**Adrian Lopez**用C编程语言编写并基于MIT许可证发行,该应用程序可以在指定的目录及子目录中查找重复的文件。fdupes通过对比文件的MD5签名,以及逐字节比较文件来识别重复内容,fdupes有各种选项,可以实现对文件的列出、删除、替换为文件副本的硬链接等操作。
|
||||
|
||||
对比以下列顺序开始:
|
||||
文件对比以下列顺序开始:
|
||||
|
||||
**大小对比 > 部分 MD5 签名对比 > 完整 MD5 签名对比 > 逐字节对比**
|
||||
|
||||
@ -27,8 +27,9 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
|
||||
**注意**:自Fedora 22之后,默认的包管理器yum被dnf取代了。
|
||||
|
||||
### fdupes命令咋个搞? ###
|
||||
1.作为演示的目的,让我们来在某个目录(比如 tecmint)下创建一些重复文件,命令如下:
|
||||
### fdupes命令如何使用 ###
|
||||
|
||||
1、 作为演示的目的,让我们来在某个目录(比如 tecmint)下创建一些重复文件,命令如下:
|
||||
|
||||
$ mkdir /home/"$USER"/Desktop/tecmint && cd /home/"$USER"/Desktop/tecmint && for i in {1..15}; do echo "I Love Tecmint. Tecmint is a very nice community of Linux Users." > tecmint${i}.txt ; done
|
||||
|
||||
@ -57,7 +58,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
|
||||
"I Love Tecmint. Tecmint is a very nice community of Linux Users."
|
||||
|
||||
2.现在在**tecmint**文件夹内搜索重复的文件。
|
||||
2、 现在在**tecmint**文件夹内搜索重复的文件。
|
||||
|
||||
$ fdupes /home/$USER/Desktop/tecmint
|
||||
|
||||
@ -77,7 +78,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
3.使用**-r**选项在每个目录包括其子目录中递归搜索重复文件。
|
||||
3、 使用**-r**选项在每个目录包括其子目录中递归搜索重复文件。
|
||||
|
||||
它会递归搜索所有文件和文件夹,花一点时间来扫描重复文件,时间的长短取决于文件和文件夹的数量。在此其间,终端中会显示全部过程,像下面这样。
|
||||
|
||||
@ -85,7 +86,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
|
||||
Progress [37780/54747] 69%
|
||||
|
||||
4.使用**-S**选项来查看某个文件夹内找到的重复文件的大小。
|
||||
4、 使用**-S**选项来查看某个文件夹内找到的重复文件的大小。
|
||||
|
||||
$ fdupes -S /home/$USER/Desktop/tecmint
|
||||
|
||||
@ -106,7 +107,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
5.你可以同时使用**-S**和**-r**选项来查看所有涉及到的目录和子目录中的重复文件的大小,如下:
|
||||
5、 你可以同时使用**-S**和**-r**选项来查看所有涉及到的目录和子目录中的重复文件的大小,如下:
|
||||
|
||||
$ fdupes -Sr /home/avi/Desktop/
|
||||
|
||||
@ -131,11 +132,11 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/resume_files/r-csc.html
|
||||
/home/tecmint/Desktop/resume_files/fc.html
|
||||
|
||||
6.不同于在一个或所有文件夹内递归搜索,你可以选择按要求有选择性地在两个或三个文件夹内进行搜索。不必再提醒你了吧,如有需要,你可以使用**-S**和/或**-r**选项。
|
||||
6、 不同于在一个或所有文件夹内递归搜索,你可以选择按要求有选择性地在两个或三个文件夹内进行搜索。不必再提醒你了吧,如有需要,你可以使用**-S**和/或**-r**选项。
|
||||
|
||||
$ fdupes /home/avi/Desktop/ /home/avi/Templates/
|
||||
|
||||
7.要删除重复文件,同时保留一个副本,你可以使用`**-d**`选项。使用该选项,你必须额外小心,否则最终结果可能会是文件/数据的丢失。郑重提醒,此操作不可恢复。
|
||||
7、 要删除重复文件,同时保留一个副本,你可以使用`-d`选项。使用该选项,你必须额外小心,否则最终结果可能会是文件/数据的丢失。郑重提醒,此操作不可恢复。
|
||||
|
||||
$ fdupes -d /home/$USER/Desktop/tecmint
|
||||
|
||||
@ -177,13 +178,13 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
8.从安全角度出发,你可能想要打印`**fdupes**`的输出结果到文件中,然后检查文本文件来决定要删除什么文件。这可以降低意外删除文件的风险。你可以这么做:
|
||||
8、 从安全角度出发,你可能想要打印`fdupes`的输出结果到文件中,然后检查文本文件来决定要删除什么文件。这可以降低意外删除文件的风险。你可以这么做:
|
||||
|
||||
$ fdupes -Sr /home > /home/fdupes.txt
|
||||
|
||||
**注意**:你可以替换`**/home**`为你想要的文件夹。同时,如果你想要递归搜索并打印大小,可以使用`**-r**`和`**-S**`选项。
|
||||
**注意**:你应该替换`/home`为你想要的文件夹。同时,如果你想要递归搜索并打印大小,可以使用`-r`和`-S`选项。
|
||||
|
||||
9.你可以使用`**-f**`选项来忽略每个匹配集中的首个文件。
|
||||
9、 你可以使用`-f`选项来忽略每个匹配集中的首个文件。
|
||||
|
||||
首先列出该目录中的文件。
|
||||
|
||||
@ -205,13 +206,13 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/tecmint9 (another copy).txt
|
||||
/home/tecmint/Desktop/tecmint9 (4th copy).txt
|
||||
|
||||
10.检查已安装的fdupes版本。
|
||||
10、 检查已安装的fdupes版本。
|
||||
|
||||
$ fdupes --version
|
||||
|
||||
fdupes 1.51
|
||||
|
||||
11.如果你需要关于fdupes的帮助,可以使用`**-h**`开关。
|
||||
11、 如果你需要关于fdupes的帮助,可以使用`-h`开关。
|
||||
|
||||
$ fdupes -h
|
||||
|
||||
@ -245,7 +246,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
-v --version display fdupes version
|
||||
-h --help display this help message
|
||||
|
||||
到此为止了。让我知道你到现在为止你是怎么在Linux中查找并删除重复文件的?同时,也让我知道你关于这个工具的看法。在下面的评论部分中提供你有价值的反馈吧,别忘了为我们点赞并分享,帮助我们扩散哦。
|
||||
到此为止了。让我知道你以前怎么在Linux中查找并删除重复文件的吧?同时,也让我知道你关于这个工具的看法。在下面的评论部分中提供你有价值的反馈吧,别忘了为我们点赞并分享,帮助我们扩散哦。
|
||||
|
||||
我正在使用另外一个移除重复文件的工具,它叫**fslint**。很快就会把使用心得分享给大家哦,你们一定会喜欢看的。
|
||||
|
||||
@ -254,10 +255,10 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
via: http://www.tecmint.com/fdupes-find-and-delete-duplicate-files-in-linux/
|
||||
|
||||
作者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[1]:https://linux.cn/article-2324-1.html
|
||||
[2]:https://linux.cn/article-5109-1.html
|
||||
@ -0,0 +1,145 @@
|
||||
Linux 小技巧:Chrome 小游戏,让文字说话,计划作业,重复执行命令
|
||||
================================================================================
|
||||
|
||||
重要的事情说两遍,我完成了一个[Linux提示与彩蛋][1]系列,让你的Linux获得更多创造和娱乐。
|
||||
|
||||

|
||||
|
||||
*Linux提示与彩蛋系列*
|
||||
|
||||
本文,我将会讲解Google-chrome内建小游戏,在终端中如何让文字说话,使用‘at’命令设置作业和使用watch命令重复执行命令。
|
||||
|
||||
### 1. Google Chrome 浏览器小游戏彩蛋 ###
|
||||
|
||||
网线脱掉或者其他什么原因连不上网时,Google Chrome就会出现一个小游戏。声明,我并不是游戏玩家,因此我的电脑上并没有安装任何第三方的恶意游戏。安全是第一位。
|
||||
|
||||
所以当Internet发生出错,会出现一个这样的界面:
|
||||
|
||||

|
||||
|
||||
*不能连接到互联网*
|
||||
|
||||
按下空格键来激活Google-chrome彩蛋游戏。游戏没有时间限制。并且还不需要浪费时间安装使用。
|
||||
|
||||
不需要第三方软件的支持。同样支持Windows和Mac平台,但是我的平台是Linux,我也只谈论Linux。当然在Linux,这个游戏运行很好。游戏简单,但也很花费时间。
|
||||
|
||||
使用空格/向上方向键来跳跃。请看下列截图:
|
||||
|
||||

|
||||
|
||||
*Google Chrome中玩游戏*
|
||||
|
||||
### 2. Linux 终端中朗读文字 ###
|
||||
|
||||
对于那些不能文字朗读的设备,有个小工具可以实现文字说话的转换器。用各种语言写一些东西,espeak就可以朗读给你。
|
||||
|
||||
系统应该默认安装了Espeak,如果你的系统没有安装,你可以使用下列命令来安装:
|
||||
|
||||
# apt-get install espeak (Debian)
|
||||
# yum install espeak (CentOS)
|
||||
# dnf install espeak (Fedora 22 及其以后)
|
||||
|
||||
你可以让espeak接受标准输入的交互输入并及时转换成语音朗读出来。如下:
|
||||
|
||||
$ espeak [按回车键]
|
||||
|
||||
更详细的输出你可以这样做:
|
||||
|
||||
$ espeak --stdout | aplay [按回车键][再次回车]
|
||||
|
||||
espeak设置灵活,也可以朗读文本文件。你可以这样设置:
|
||||
|
||||
$ espeak --stdout /path/to/text/file/file_name.txt | aplay [Hit Enter]
|
||||
|
||||
espeak可以设置朗读速度。默认速度是160词每分钟。使用-s参数来设置。
|
||||
|
||||
设置每分钟30词的语速:
|
||||
|
||||
$ espeak -s 30 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
设置每分钟200词的语速:
|
||||
|
||||
$ espeak -s 200 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
说其他语言,比如北印度语(作者母语),这样设置:
|
||||
|
||||
$ espeak -v hindi --stdout 'टेकमिंट विश्व की एक बेहतरीन लाइंक्स आधारित वेबसाइट है|' | aplay
|
||||
|
||||
你可以使用各种语言,让espeak如上面说的以你选择的语言朗读。使用下列命令来获得语言列表:
|
||||
|
||||
$ espeak --voices
|
||||
|
||||
### 3. 快速调度任务 ###
|
||||
|
||||
我们已经非常熟悉使用[cron][2]守护进程执行一个计划命令。
|
||||
|
||||
Cron是一个Linux系统管理的高级命令,用于计划定时任务如备份或者指定时间或间隔的任何事情。
|
||||
|
||||
但是,你是否知道at命令可以让你在指定时间调度一个任务或者命令?at命令可以指定时间执行指定内容。
|
||||
|
||||
例如,你打算在早上11点2分执行uptime命令,你只需要这样做:
|
||||
|
||||
$ at 11:02
|
||||
uptime >> /home/$USER/uptime.txt
|
||||
Ctrl+D
|
||||
|
||||

|
||||
|
||||
*Linux中计划任务*
|
||||
|
||||
检查at命令是否成功设置,使用:
|
||||
|
||||
$ at -l
|
||||
|
||||

|
||||
|
||||
*浏览计划任务*
|
||||
|
||||
at支持计划多个命令,例如:
|
||||
|
||||
$ at 12:30
|
||||
Command – 1
|
||||
Command – 2
|
||||
…
|
||||
command – 50
|
||||
…
|
||||
Ctrl + D
|
||||
|
||||
### 4. 特定时间重复执行命令 ###
|
||||
|
||||
有时,我们可以需要在指定时间间隔执行特定命令。例如,每3秒,想打印一次时间。
|
||||
|
||||
查看现在时间,使用下列命令。
|
||||
|
||||
$ date +"%H:%M:%S
|
||||
|
||||

|
||||
|
||||
*Linux中查看日期和时间*
|
||||
|
||||
为了每三秒查看一下这个命令的输出,我需要运行下列命令:
|
||||
|
||||
$ watch -n 3 'date +"%H:%M:%S"'
|
||||
|
||||

|
||||
|
||||
*Linux中watch命令*
|
||||
|
||||
watch命令的‘-n’开关设定时间间隔。在上述命令中,我们定义了时间间隔为3秒。你可以按你的需求定义。同样watch
|
||||
也支持其他命令或者脚本。
|
||||
|
||||
至此。希望你喜欢这个系列的文章,让你的linux更有创造性,获得更多快乐。所有的建议欢迎评论。欢迎你也看看其他文章,谢谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/text-to-speech-in-terminal-schedule-a-job-and-watch-commands-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
440
published/20150813 Linux file system hierarchy v2.0.md
Normal file
440
published/20150813 Linux file system hierarchy v2.0.md
Normal file
@ -0,0 +1,440 @@
|
||||
Linux 文件系统结构介绍
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
Linux中的文件是什么?它的文件系统又是什么?那些配置文件又在哪里?我下载好的程序保存在哪里了?在 Linux 中文件系统是标准结构的吗?好了,上图简明地阐释了Linux的文件系统的层次关系。当你苦于寻找配置文件或者二进制文件的时候,这便显得十分有用了。我在下方添加了一些解释以及例子,不过“篇幅较长,可以有空再看”。
|
||||
|
||||
另外一种情况便是当你在系统中获取配置以及二进制文件时,出现了不一致性问题,如果你是在一个大型组织中,或者只是一个终端用户,这也有可能会破坏你的系统(比如,二进制文件运行在旧的库文件上了)。若然你在[你的Linux系统上做安全审计][1]的话,你将会发现它很容易遭到各种攻击。所以,保持一个清洁的操作系统(无论是Windows还是Linux)都显得十分重要。
|
||||
|
||||
### Linux的文件是什么? ###
|
||||
|
||||
对于UNIX系统来说(同样适用于Linux),以下便是对文件简单的描述:
|
||||
|
||||
> 在UNIX系统中,一切皆为文件;若非文件,则为进程
|
||||
|
||||
这种定义是比较正确的,因为有些特殊的文件不仅仅是普通文件(比如命名管道和套接字),不过为了让事情变的简单,“一切皆为文件”也是一个可以让人接受的说法。Linux系统也像UNIX系统一样,将文件和目录视如同物,因为目录只是一个包含了其他文件名的文件而已。程序、服务、文本、图片等等,都是文件。对于系统来说,输入和输出设备,基本上所有的设备,都被当做是文件。
|
||||
|
||||
题图版本历史:
|
||||
|
||||
- Version 2.0 – 17-06-2015
|
||||
- – Improved: 添加标题以及版本历史
|
||||
- – Improved: 添加/srv,/meida和/proc
|
||||
- – Improved: 更新了反映当前的Linux文件系统的描述
|
||||
- – Fixed: 多处的打印错误
|
||||
- – Fixed: 外观和颜色
|
||||
- Version 1.0 – 14-02-2015
|
||||
- – Created: 基本的图表
|
||||
- – Note: 摒弃更低的版本
|
||||
|
||||
### 下载链接 ###
|
||||
|
||||
以下是大图的下载地址。如果你需要其他格式,请跟原作者联系,他会尝试制作并且上传到某个地方以供下载
|
||||
|
||||
- [大图 (PNG 格式) – 2480×1755 px – 184KB][2]
|
||||
- [最大图 (PDF 格式) – 9919x7019 px – 1686KB][3]
|
||||
|
||||
**注意**: PDF格式文件是打印的最好选择,因为它画质很高。
|
||||
|
||||
### Linux 文件系统描述 ###
|
||||
|
||||
为了有序地管理那些文件,人们习惯把这些文件当做是硬盘上的有序的树状结构,正如我们熟悉的'MS-DOS'(磁盘操作系统)就是一个例子。大的分枝包括更多的分枝,分枝的末梢是树的叶子或者普通的文件。现在我们将会以这树形图为例,但晚点我们会发现为什么这不是一个完全准确的一幅图。
|
||||
|
||||
<table cellspacing="2" border="4" style="border-collapse: collapse; width: 731px; height: 2617px;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th scope="col">目录</th>
|
||||
<th scope="col">描述</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/</code>
|
||||
</td>
|
||||
<td><i>主层次</i> 的根,也是整个文件系统层次结构的根目录</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/bin</code>
|
||||
</td>
|
||||
<td>存放在单用户模式可用的必要命令二进制文件,所有用户都可用,如 cat、ls、cp等等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/boot</code>
|
||||
</td>
|
||||
<td>存放引导加载程序文件,例如kernels、initrd等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/dev</code>
|
||||
</td>
|
||||
<td>存放必要的设备文件,例如<code>/dev/null</code> </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/etc</code>
|
||||
</td>
|
||||
<td>存放主机特定的系统级配置文件。其实这里有个关于它名字本身意义上的的争议。在贝尔实验室的UNIX实施文档的早期版本中,/etc表示是“其他(etcetera)目录”,因为从历史上看,这个目录是存放各种不属于其他目录的文件(然而,文件系统目录标准 FSH 限定 /etc 用于存放静态配置文件,这里不该存有二进制文件)。早期文档出版后,这个目录名又重新定义成不同的形式。近期的解释中包含着诸如“可编辑文本配置”或者“额外的工具箱”这样的重定义</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/opt</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存储着新增包的配置文件 <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/sgml</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存放配置文件,比如 catalogs,用于那些处理SGML(译者注:标准通用标记语言)的软件的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/X11</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>X Window 系统11版本的的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/xml</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>配置文件,比如catalogs,用于那些处理XML(译者注:可扩展标记语言)的软件的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/home</code>
|
||||
</td>
|
||||
<td>用户的主目录,包括保存的文件,个人配置,等等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/lib</code>
|
||||
</td>
|
||||
<td><code>/bin/</code> 和 <code>/sbin/</code>中的二进制文件的必需的库文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/lib<架构位数></code>
|
||||
</td>
|
||||
<td>备用格式的必要的库文件。 这样的目录是可选的,但如果他们存在的话肯定是有需要用到它们的程序</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/media</code>
|
||||
</td>
|
||||
<td>可移动的多媒体(如CD-ROMs)的挂载点。(出现于 FHS-2.3)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/mnt</code>
|
||||
</td>
|
||||
<td>临时挂载的文件系统</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/opt</code>
|
||||
</td>
|
||||
<td>可选的应用程序软件包</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/proc</code>
|
||||
</td>
|
||||
<td>以文件形式提供进程以及内核信息的虚拟文件系统,在Linux中,对应进程文件系统(procfs )的挂载点</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/root</code>
|
||||
</td>
|
||||
<td>根用户的主目录</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/sbin</code>
|
||||
</td>
|
||||
<td>必要的系统级二进制文件,比如, init, ip, mount</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/srv</code>
|
||||
</td>
|
||||
<td>系统提供的站点特定数据</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/tmp</code>
|
||||
</td>
|
||||
<td>临时文件 (另见 <code>/var/tmp</code>). 通常在系统重启后删除</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/usr</code>
|
||||
</td>
|
||||
<td><i>二级层级</i>存储用户的只读数据; 包含(多)用户主要的公共文件以及应用程序</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/bin</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>非必要的命令二进制文件 (在单用户模式中不需要用到的);用于所有用户</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/include</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>标准的包含文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/lib</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>库文件,用于<code>/usr/bin/</code> 和 <code>/usr/sbin/</code>中的二进制文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/lib<架构位数></code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>备用格式库(可选的)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/local</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td><i>三级层次</i> 用于本地数据,具体到该主机上的。通常会有下一个子目录, <i>比如</i>, <code>bin/</code>, <code>lib/</code>, <code>share/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/local/sbin</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>非必要系统的二进制文件,比如用于不同网络服务的守护进程</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/share</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>架构无关的 (共享) 数据.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/src</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>源代码,比如内核源文件以及与它相关的头文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/X11R6</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>X Window系统,版本号:11,发行版本:6</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/var</code>
|
||||
</td>
|
||||
<td>各式各样的(Variable)文件,一些随着系统常规操作而持续改变的文件就放在这里,比如日志文件,脱机文件,还有临时的电子邮件文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/cache</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>应用程序缓存数据. 这些数据是由耗时的I/O(输入/输出)的或者是运算本地生成的结果。这些应用程序是可以重新生成或者恢复数据的。当没有数据丢失的时候,可以删除缓存文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/lib</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>状态信息。这些信息随着程序的运行而不停地改变,比如,数据库,软件包系统的元数据等等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/lock</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>锁文件。这些文件用于跟踪正在使用的资源</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/log</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>日志文件。包含各种日志。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/mail</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>内含用户邮箱的相关文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/opt</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>来自附加包的各种数据都会存储在 <code>/var/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/run</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存放当前系统上次启动以来的相关信息,例如当前登入的用户以及当前运行的<a href="http://en.wikipedia.org/wiki/Daemon_%28computing%29">daemons(守护进程)</a>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/spool</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>该spool主要用于存放将要被处理的任务,比如打印队列以及邮件外发队列</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
|
||||
|
||||
<code>/var/mail</code>
|
||||
|
||||
|
||||
|
||||
|
||||
</td>
|
||||
<td>过时的位置,用于放置用户邮箱文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/tmp</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存放重启后保留的临时文件</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Linux的文件类型 ###
|
||||
|
||||
大多数文件仅仅是普通文件,他们被称为`regular`文件;他们包含普通数据,比如,文本、可执行文件、或者程序、程序的输入或输出等等
|
||||
|
||||
虽然你可以认为“在Linux中,一切你看到的皆为文件”这个观点相当保险,但这里仍有着一些例外。
|
||||
|
||||
- `目录`:由其他文件组成的文件
|
||||
- `特殊文件`:用于输入和输出的途径。大多数特殊文件都储存在`/dev`中,我们将会在后面讨论这个问题。
|
||||
- `链接文件`:让文件或者目录出现在系统文件树结构上多个地方的机制。我们将详细地讨论这个链接文件。
|
||||
- `(域)套接字`:特殊的文件类型,和TCP/IP协议中的套接字有点像,提供进程间网络通讯,并受文件系统的访问控制机制保护。
|
||||
- `命名管道` : 或多或少有点像sockets(套接字),提供一个进程间的通信机制,而不用网络套接字协议。
|
||||
|
||||
### 现实中的文件系统 ###
|
||||
|
||||
对于大多数用户和常规系统管理任务而言,“文件和目录是一个有序的类树结构”是可以接受的。然而,对于电脑而言,它是不会理解什么是树,或者什么是树结构。
|
||||
|
||||
每个分区都有它自己的文件系统。想象一下,如果把那些文件系统想成一个整体,我们可以构思一个关于整个系统的树结构,不过这并没有这么简单。在文件系统中,一个文件代表着一个`inode`(索引节点),这是一种包含着构建文件的实际数据信息的序列号:这些数据表示文件是属于谁的,还有它在硬盘中的位置。
|
||||
|
||||
每个分区都有一套属于他们自己的inode,在一个系统的不同分区中,可以存在有相同inode的文件。
|
||||
|
||||
每个inode都表示着一种在硬盘上的数据结构,保存着文件的属性,包括文件数据的物理地址。当硬盘被格式化并用来存储数据时(通常发生在初始系统安装过程,或者是在一个已经存在的系统中添加额外的硬盘),每个分区都会创建固定数量的inode。这个值表示这个分区能够同时存储各类文件的最大数量。我们通常用一个inode去映射2-8k的数据块。当一个新的文件生成后,它就会获得一个空闲的inode。在这个inode里面存储着以下信息:
|
||||
|
||||
- 文件属主和组属主
|
||||
- 文件类型(常规文件,目录文件......)
|
||||
- 文件权限
|
||||
- 创建、最近一次读文件和修改文件的时间
|
||||
- inode里该信息被修改的时间
|
||||
- 文件的链接数(详见下一章)
|
||||
- 文件大小
|
||||
- 文件数据的实际地址
|
||||
|
||||
唯一不在inode的信息是文件名和目录。它们存储在特殊的目录文件。通过比较文件名和inode的数目,系统能够构造出一个便于用户理解的树结构。用户可以通过ls -i查看inode的数目。在硬盘上,inodes有他们独立的空间。
|
||||
|
||||
------------------------
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/18/linux-file-system-hierarchy-v2-0/
|
||||
|
||||
译者:[tnuoccalanosrep](https://github.com/tnuoccalanosrep)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.blackmoreops.com/2015/02/15/in-light-of-recent-linux-exploits-linux-security-audit-is-a-must/
|
||||
[2]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-file-system-hierarchy-v2.0-2480px-blackMORE-Ops.png
|
||||
[3]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-File-System-Hierarchy-blackMORE-Ops.pdf
|
||||
@ -0,0 +1,34 @@
|
||||
看这些孩子在 Ubuntu 的 Linux 终端下玩耍
|
||||
================================================================================
|
||||
我发现了一个孩子们在他们的计算机教室里玩得很开心的视频。我不知道他们在哪里,但我猜测是在印度尼西亚或者马来西亚。视频请自行搭梯子: http://www.youtube.com/z8taQPomp0Y
|
||||
|
||||
### 在Linux终端下面跑火车 ###
|
||||
|
||||
这里没有魔术。只是一个叫做“sl”的命令行工具。我想它是在把ls打错的情况下为了好玩而开发的。如果你曾经在Linux的命令行下工作,你会知道ls是一个最常使用的一个命令,也许也是一个最经常打错的命令。
|
||||
|
||||
如果你想从这个终端下的火车获得一些乐趣,你可以使用下面的命令安装它。
|
||||
|
||||
sudo apt-get install sl
|
||||
|
||||
要运行终端火车,只需要在终端中输入**sl**。它有以下几个选项:
|
||||
|
||||
- -a : 意外模式。你会看见哭救的群众
|
||||
- -l : 显示一个更小的火车但有更多的车厢
|
||||
- -F : 一个飞行的火车
|
||||
- -e : 允许通过Ctrl+C。使用其他模式你不能使用Ctrl+C中断火车。但是,它不能长时间运行。
|
||||
|
||||
正常情况下,你应该会听到汽笛声但是在大多数Linux系统下都不管用,Ubuntu是其中一个。这就是一个意外的终端火车。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/ubuntu-terminal-train/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
@ -0,0 +1,295 @@
|
||||
如何为你的平台部署一个公开的系统状态页
|
||||
================================================================================
|
||||
|
||||
如果你是一个系统管理员,负责关键的 IT 基础设置或公司的服务,你将明白有效的沟通在日常任务中的重要性。假设你的线上存储服务器故障了。你希望团队所有人达成共识你好尽快的解决问题。当你忙来忙去时,你不会想一半的人问你为什么他们不能访问他们的文档。当一个维护计划快到时间了你想在计划前提醒相关人员,这样避免了不必要的开销。
|
||||
|
||||
这一切的要求或多或少改进了你、你的团队、和你服务的用户之间沟通渠道。一个实现它的方法是维护一个集中的系统状态页面,报告和记录故障停机详情、进度更新和维护计划等。这样,在故障期间你避免了不必要的打扰,也可以提醒一些相关方,以及加入一些可选的状态更新。
|
||||
|
||||
有一个不错的**开源, 自承载系统状态页解决方案**叫做 [Cachet][1]。在这个教程,我将要描述如何用 Cachet 部署一个自承载系统状态页面。
|
||||
|
||||
### Cachet 特性 ###
|
||||
|
||||
在详细的配置 Cachet 之前,让我简单的介绍一下它的主要特性。
|
||||
|
||||
- **全 JSON API**:Cachet API 可以让你使用任意的外部程序或脚本(例如,uptime 脚本)连接到 Cachet 来自动报告突发事件或更新状态。
|
||||
- **认证**:Cachet 支持基础认证和 JSON API 的 API 令牌,所以只有认证用户可以更新状态页面。
|
||||
- **衡量系统**:这通常用来展现随着时间推移的自定义数据(例如,服务器负载或者响应时间)。
|
||||
- **通知**:可选地,你可以给任一注册了状态页面的人发送突发事件的提示邮件。
|
||||
- **多语言**:状态页被翻译为11种不同的语言。
|
||||
- **双因子认证**:这允许你使用 Google 的双因子认证来提升 Cachet 管理账户的安全性。
|
||||
- **跨数据库支持**:你可以选择 MySQL,SQLite,Redis,APC 和 PostgreSQL 作为后端存储。
|
||||
|
||||
剩下的教程,我会说明如何在 Linux 上安装配置 Cachet。
|
||||
|
||||
### 第一步:下载和安装 Cachet ###
|
||||
|
||||
Cachet 需要一个 web 服务器和一个后端数据库来运转。在这个教程中,我将使用 LAMP 架构。以下是一些特定发行版上安装 Cachet 和 LAMP 架构的指令。
|
||||
|
||||
#### Debian,Ubuntu 或者 Linux Mint ####
|
||||
|
||||
$ sudo apt-get install curl git apache2 mysql-server mysql-client php5 php5-mysql
|
||||
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
|
||||
$ cd /var/www/cachet
|
||||
$ sudo git checkout v1.1.1
|
||||
$ sudo chown -R www-data:www-data .
|
||||
|
||||
在基于 Debian 的系统上设置 LAMP 架构的更多细节,参考这个[教程][2]。
|
||||
|
||||
#### Fedora, CentOS 或 RHEL ####
|
||||
|
||||
在基于 Red Hat 系统上,你首先需要[设置 REMI 软件库][3](以满足 PHP 的版本需求)。然后执行下面命令。
|
||||
|
||||
$ sudo yum install curl git httpd mariadb-server
|
||||
$ sudo yum --enablerepo=remi-php56 install php php-mysql php-mbstring
|
||||
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
|
||||
$ cd /var/www/cachet
|
||||
$ sudo git checkout v1.1.1
|
||||
$ sudo chown -R apache:apache .
|
||||
$ sudo firewall-cmd --permanent --zone=public --add-service=http
|
||||
$ sudo firewall-cmd --reload
|
||||
$ sudo systemctl enable httpd.service; sudo systemctl start httpd.service
|
||||
$ sudo systemctl enable mariadb.service; sudo systemctl start mariadb.service
|
||||
|
||||
在基于 Red Hat 系统上设置 LAMP 的更多细节,参考这个[教程][4]。
|
||||
|
||||
### 配置 Cachet 的后端数据库###
|
||||
|
||||
下一步是配置后端数据库。
|
||||
|
||||
登录到 MySQL/MariaDB 服务,然后创建一个空的数据库称为‘cachet’。
|
||||
|
||||
$ sudo mysql -uroot -p
|
||||
|
||||
----------
|
||||
|
||||
mysql> create database cachet;
|
||||
mysql> quit
|
||||
|
||||
现在用一个示例配置文件创建一个 Cachet 配置文件。
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo mv .env.example .env
|
||||
|
||||
在 .env 文件里,填写你自己设置的数据库信息(例如,DB\_\*)。其他的字段先不改变。
|
||||
|
||||
APP_ENV=production
|
||||
APP_DEBUG=false
|
||||
APP_URL=http://localhost
|
||||
APP_KEY=SomeRandomString
|
||||
|
||||
DB_DRIVER=mysql
|
||||
DB_HOST=localhost
|
||||
DB_DATABASE=cachet
|
||||
DB_USERNAME=root
|
||||
DB_PASSWORD=<root-password>
|
||||
|
||||
CACHE_DRIVER=apc
|
||||
SESSION_DRIVER=apc
|
||||
QUEUE_DRIVER=database
|
||||
|
||||
MAIL_DRIVER=smtp
|
||||
MAIL_HOST=mailtrap.io
|
||||
MAIL_PORT=2525
|
||||
MAIL_USERNAME=null
|
||||
MAIL_PASSWORD=null
|
||||
MAIL_ADDRESS=null
|
||||
MAIL_NAME=null
|
||||
|
||||
REDIS_HOST=null
|
||||
REDIS_DATABASE=null
|
||||
REDIS_PORT=null
|
||||
|
||||
### 第三步:安装 PHP 依赖和执行数据库迁移 ###
|
||||
|
||||
下面,我们将要安装必要的PHP依赖包。我们会使用 composer 来安装。如果你的系统还没有安装 composer,先安装它:
|
||||
|
||||
$ curl -sS https://getcomposer.org/installer | sudo php -- --install-dir=/usr/local/bin --filename=composer
|
||||
|
||||
现在开始用 composer 安装 PHP 依赖包。
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo composer install --no-dev -o
|
||||
|
||||
下面执行一次性的数据库迁移。这一步会在我们之前创建的数据库里面创建那些所需的表。
|
||||
|
||||
$ sudo php artisan migrate
|
||||
|
||||
假设在 /var/www/cachet/.env 的数据库配置无误,数据库迁移应该像下面显示一样成功完成。
|
||||
|
||||
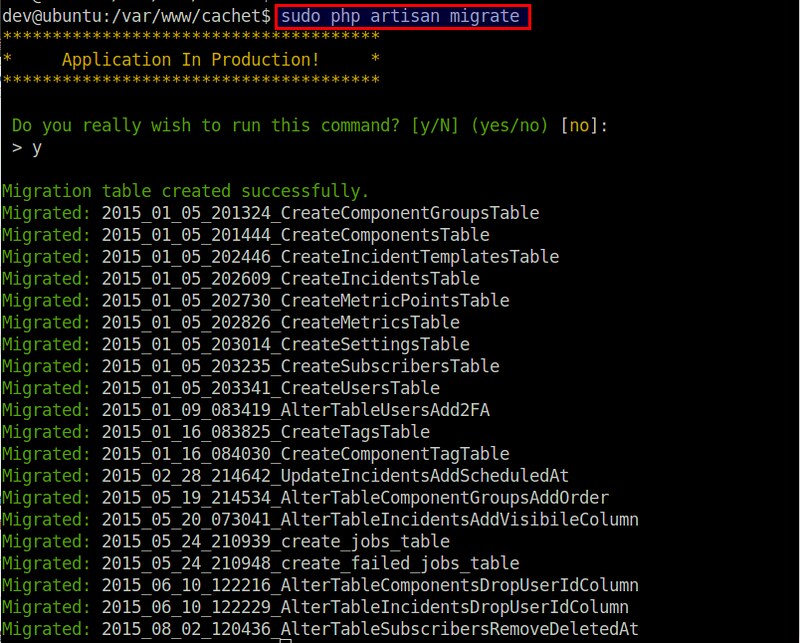
|
||||
|
||||
下面,创建一个密钥,它将用来加密进入 Cachet 的数据。
|
||||
|
||||
$ sudo php artisan key:generate
|
||||
$ sudo php artisan config:cache
|
||||
|
||||
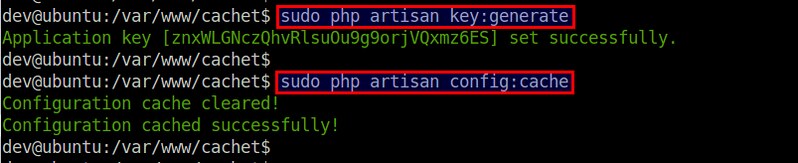
|
||||
|
||||
生成的应用密钥将自动添加到你的 .env 文件 APP\_KEY 变量中。你不需要自己编辑 .env。
|
||||
|
||||
### 第四步:配置 Apache HTTP 服务 ###
|
||||
|
||||
现在到了配置运行 Cachet 的 web 服务的时候了。我们使用 Apache HTTP 服务器,为 Cachet 创建一个新的[虚拟主机][5],如下:
|
||||
|
||||
#### Debian,Ubuntu 或 Linux Mint ####
|
||||
|
||||
$ sudo vi /etc/apache2/sites-available/cachet.conf
|
||||
|
||||
----------
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName cachethost
|
||||
ServerAlias cachethost
|
||||
DocumentRoot "/var/www/cachet/public"
|
||||
<Directory "/var/www/cachet/public">
|
||||
Require all granted
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
启用新虚拟主机和 mod_rewrite:
|
||||
|
||||
$ sudo a2ensite cachet.conf
|
||||
$ sudo a2enmod rewrite
|
||||
$ sudo service apache2 restart
|
||||
|
||||
#### Fedora, CentOS 或 RHEL ####
|
||||
|
||||
在基于 Red Hat 系统上,创建一个虚拟主机文件,如下:
|
||||
|
||||
$ sudo vi /etc/httpd/conf.d/cachet.conf
|
||||
|
||||
----------
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName cachethost
|
||||
ServerAlias cachethost
|
||||
DocumentRoot "/var/www/cachet/public"
|
||||
<Directory "/var/www/cachet/public">
|
||||
Require all granted
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
现在重载 Apache 配置:
|
||||
|
||||
$ sudo systemctl reload httpd.service
|
||||
|
||||
### 第五步:配置 /etc/hosts 来测试 Cachet ###
|
||||
|
||||
这时候,初始的 Cachet 状态页面应该启动运行了,现在测试一下。
|
||||
|
||||
由于 Cachet 被配置为Apache HTTP 服务的虚拟主机,我们需要调整你的客户机的 /etc/hosts 来访问他。你将从这个客户端电脑访问 Cachet 页面。(LCTT 译注:如果你给了这个页面一个正式的主机地址,则不需要这一步。)
|
||||
|
||||
打开 /etc/hosts,加入如下行:
|
||||
|
||||
$ sudo vi /etc/hosts
|
||||
|
||||
----------
|
||||
|
||||
<cachet 服务器的 IP 地址> cachethost
|
||||
|
||||
上面名为“cachethost”必须匹配 Cachet 的 Apache 虚拟主机文件的 ServerName。
|
||||
|
||||
### 测试 Cachet 状态页面 ###
|
||||
|
||||
现在你准备好访问 Cachet 状态页面。在你浏览器地址栏输入 http://cachethost。你将被转到如下的 Cachet 状态页的初始化设置页面。
|
||||
|
||||
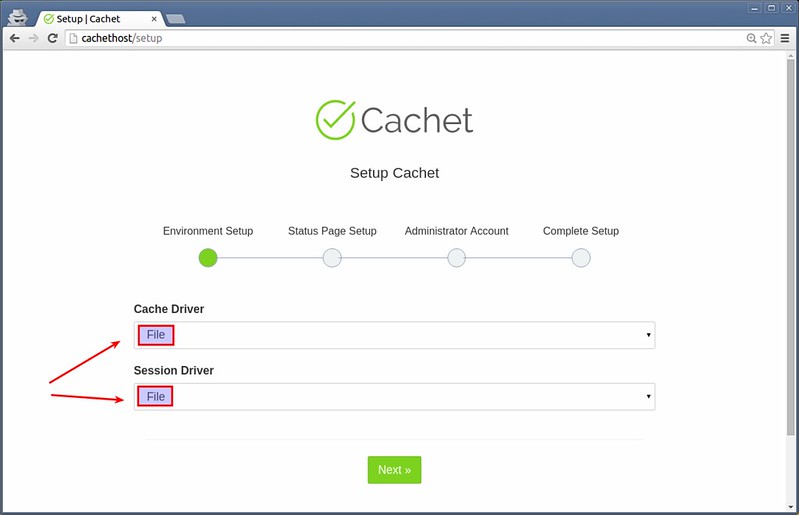
|
||||
|
||||
选择 cache/session 驱动。这里 cache 和 session 驱动两个都选“File”。
|
||||
|
||||
下一步,输入关于状态页面的基本信息(例如,站点名称、域名、时区和语言),以及管理员认证账户。
|
||||
|
||||
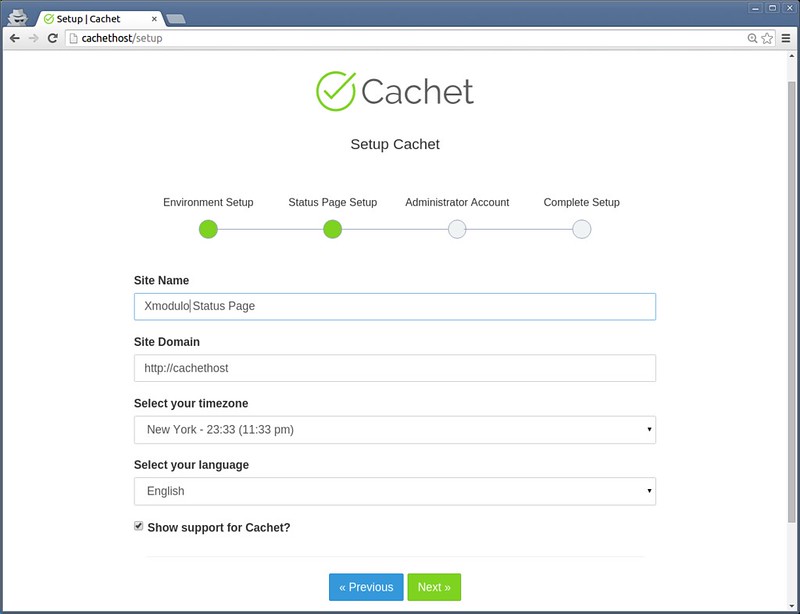
|
||||
|
||||
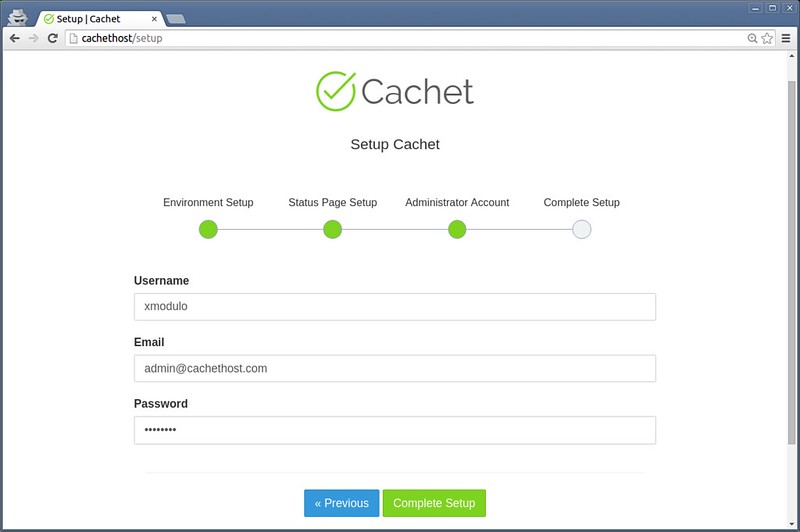
|
||||
|
||||
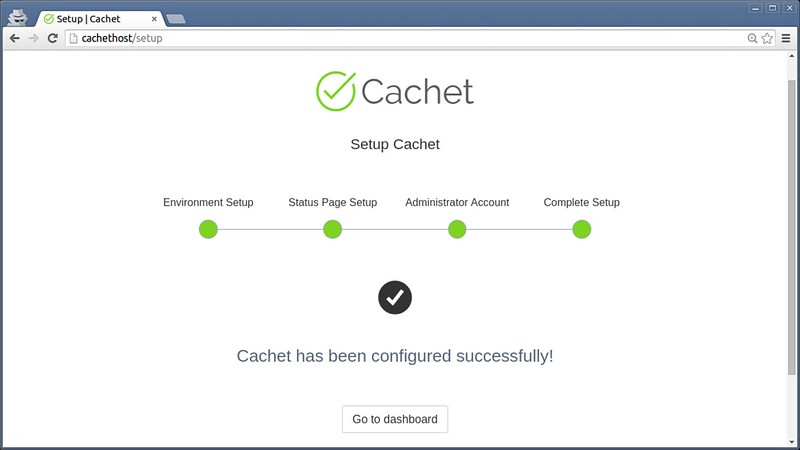
|
||||
|
||||
你的状态页初始化就要完成了。
|
||||
|
||||
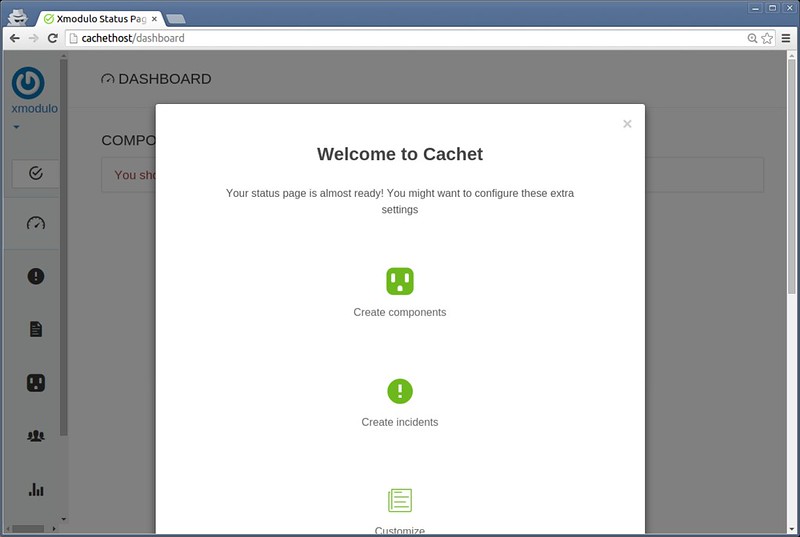
|
||||
|
||||
继续创建组件(你的系统单元)、事件或者任意你要做的维护计划。
|
||||
|
||||
例如,增加一个组件:
|
||||
|
||||
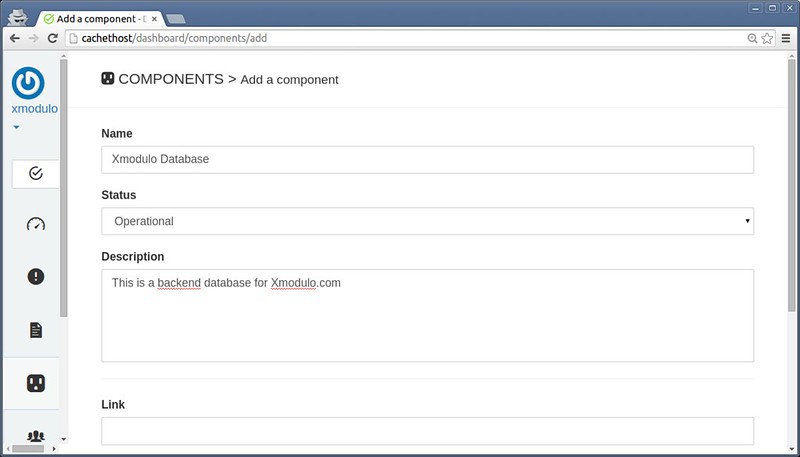
|
||||
|
||||
增加一个维护计划:
|
||||
|
||||
公共 Cachet 状态页就像这样:
|
||||
|
||||
|
||||
|
||||
集成了 SMTP,你可以在状态更新时发送邮件给订阅者。并且你可以使用 CSS 和 markdown 格式来完全自定义布局和状态页面。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
Cachet 是一个相当易于使用,自托管的状态页面软件。Cachet 一个高级特性是支持全 JSON API。使用它的 RESTful API,Cachet 可以轻松连接单独的监控后端(例如,[Nagios][6]),然后回馈给 Cachet 事件报告并自动更新状态。比起手工管理一个状态页它更快和有效率。
|
||||
|
||||
最后一句,我喜欢提及一个事。用 Cachet 设置一个漂亮的状态页面是很简单的,但要将这个软件用好并不像安装它那么容易。你需要完全保障所有 IT 团队习惯准确及时的更新状态页,从而建立公共信息的准确性。同时,你需要教用户去查看状态页面。最后,如果没有很好的填充数据,部署状态页面就没有意义,并且/或者没有一个人查看它。记住这个,尤其是当你考虑在你的工作环境中部署 Cachet 时。
|
||||
|
||||
### 故障排查 ###
|
||||
|
||||
补充,万一你安装 Cachet 时遇到问题,这有一些有用的故障排查的技巧。
|
||||
|
||||
1. Cachet 页面没有加载任何东西,并且你看到如下报错。
|
||||
|
||||
production.ERROR: exception 'RuntimeException' with message 'No supported encrypter found. The cipher and / or key length are invalid.' in /var/www/cachet/bootstrap/cache/compiled.php:6695
|
||||
|
||||
**解决方案**:确保你创建了一个应用密钥,以及明确配置缓存如下所述。
|
||||
|
||||
$ cd /path/to/cachet
|
||||
$ sudo php artisan key:generate
|
||||
$ sudo php artisan config:cache
|
||||
|
||||
2. 调用 composer 命令时有如下报错。
|
||||
|
||||
- danielstjules/stringy 1.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
- laravel/framework v5.1.8 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
- league/commonmark 0.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
|
||||
**解决方案**:确保在你的系统上安装了必要的 PHP 扩展 mbstring ,并且兼容你的 PHP 版本。在基于 Red Hat 的系统上,由于我们从 REMI-56 库安装PHP,所以要从同一个库安装扩展。
|
||||
|
||||
$ sudo yum --enablerepo=remi-php56 install php-mbstring
|
||||
|
||||
3. 你访问 Cachet 状态页面时得到一个白屏。HTTP 日志显示如下错误。
|
||||
|
||||
PHP Fatal error: Uncaught exception 'UnexpectedValueException' with message 'The stream or file "/var/www/cachet/storage/logs/laravel-2015-08-21.log" could not be opened: failed to open stream: Permission denied' in /var/www/cachet/bootstrap/cache/compiled.php:12851
|
||||
|
||||
**解决方案**:尝试如下命令。
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo php artisan cache:clear
|
||||
$ sudo chmod -R 777 storage
|
||||
$ sudo composer dump-autoload
|
||||
|
||||
如果上面的方法不起作用,试试禁止SELinux:
|
||||
|
||||
$ sudo setenforce 0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-system-status-page.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://cachethq.io/
|
||||
[2]:http://xmodulo.com/install-lamp-stack-ubuntu-server.html
|
||||
[3]:https://linux.cn/article-4192-1.html
|
||||
[4]:https://linux.cn/article-5789-1.html
|
||||
[5]:http://xmodulo.com/configure-virtual-hosts-apache-http-server.html
|
||||
[6]:http://xmodulo.com/monitor-common-services-nagios.html
|
||||
@ -0,0 +1,86 @@
|
||||
在 Ubuntu 中如何安装或升级 Linux 内核到4.2
|
||||
================================================================================
|
||||

|
||||
|
||||
Linux 内核 4.2已经发布了。Linus Torvalds 在 [lkml.org][1] 上写到:
|
||||
|
||||
> 通过这周这么小的变动,看来在最后一周 发布 4.2 版本应该不会有问题,当然还有几个修正,但是看起来也并不需要延迟一周。
|
||||
> 所以这就到了,而且 4.3 的合并窗口现已打开。我已经有了几个等待处理的合并请求,明天我开始处理它们,然后在适当的时候放出来。
|
||||
> 从 rc8 以来的简短日志很小,已经附加。这个补丁也很小...
|
||||
|
||||
### 新内核 4.2 有哪些改进?: ###
|
||||
|
||||
- 重写英特尔的x86汇编代码
|
||||
- 支持新的 ARM 板和 SoC
|
||||
- 对 F2FS 的 per-file 加密
|
||||
- AMDGPU 的内核 DRM 驱动程序
|
||||
- 对 Radeon DRM 驱动的 VCE1 视频编码支持
|
||||
- 初步支持英特尔的 Broxton Atom SoC
|
||||
- 支持 ARCv2 和 HS38 CPU 内核
|
||||
- 增加了队列自旋锁的支持
|
||||
- 许多其他的改进和驱动更新。
|
||||
|
||||
### 在 Ubuntu 中如何下载4.2内核 : ###
|
||||
|
||||
此内核版本的二进制包可供下载链接如下:
|
||||
|
||||
- [下载 4.2 内核(.DEB)][1]
|
||||
|
||||
首先检查你的操作系统类型,32位(i386)的或64位(amd64)的,然后使用下面的方式依次下载并安装软件包:
|
||||
|
||||
1. linux-headers-4.2.0-xxx_all.deb
|
||||
1. linux-headers-4.2.0-xxx-generic_xxx_i386/amd64.deb
|
||||
1. linux-image-4.2.0-xxx-generic_xxx_i386/amd64.deb
|
||||
|
||||
安装内核后,在终端((Ctrl+Alt+T))运行`sudo update-grub`命令来更新 grub boot-loader。
|
||||
|
||||
如果你需要一个低延迟系统(例如用于录制音频),请下载并安装下面的包:
|
||||
|
||||
1. linux-headers-4.2.0_xxx_all.deb
|
||||
1. linux-headers-4.2.0-xxx-lowlatency_xxx_i386/amd64.deb
|
||||
1. linux-image-4.2.0-xxx-lowlatency_xxx_i386/amd64.deb
|
||||
|
||||
对于没有图形用户界面的 Ubuntu 服务器,你可以运行下面的命令通过 wget 来逐一抓下载,并通过 dpkg 来安装:
|
||||
|
||||
对于64位的系统请运行:
|
||||
|
||||
cd /tmp/
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200_4.2.0-040200.201508301530_all.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200-generic_4.2.0-040200.201508301530_amd64.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-image-4.2.0-040200-generic_4.2.0-040200.201508301530_amd64.deb
|
||||
|
||||
sudo dpkg -i linux-headers-4.2.0-*.deb linux-image-4.2.0-*.deb
|
||||
|
||||
对于32位的系统,请运行:
|
||||
|
||||
cd /tmp/
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200_4.2.0-040200.201508301530_all.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200-generic_4.2.0-040200.201508301530_i386.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-image-4.2.0-040200-generic_4.2.0-040200.201508301530_i386.deb
|
||||
|
||||
sudo dpkg -i linux-headers-4.2.0-*.deb linux-image-4.2.0-*.deb
|
||||
|
||||
最后,重新启动计算机才能生效。
|
||||
|
||||
要恢复或删除旧的内核,请参阅[通过脚本安装内核][3]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/08/upgrade-kernel-4-2-ubuntu/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:https://lkml.org/lkml/2015/8/30/96
|
||||
[2]:http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/
|
||||
[3]:http://ubuntuhandbook.org/index.php/2015/08/install-latest-kernel-script/
|
||||
@ -0,0 +1,53 @@
|
||||
如何在 Linux 上自动调整屏幕亮度保护眼睛
|
||||
================================================================================
|
||||
|
||||
当你开始在计算机前花费大量时间的时候,问题自然开始显现。这健康吗?怎样才能舒缓我眼睛的压力呢?为什么光线灼烧着我?尽管解答这些问题的研究仍然在不断进行着,许多程序员已经采用了一些应用来改变他们的日常习惯,让他们的眼睛更健康点。在这些应用中,我发现了两个特别有趣的东西:Calise和Redshift。
|
||||
|
||||
### Calise ###
|
||||
|
||||
处于时断时续的开发中,[Calise][1]的意思是“相机光感应器(Camera Light Sensor)”。换句话说,它是一个根据摄像头接收到的光强度计算屏幕最佳的背光级别的开源程序。更进一步地说,Calise可以基于你的地理坐标来考虑你所在地区的天气。我喜欢它是因为它兼容各个桌面,甚至非X系列。
|
||||
|
||||

|
||||
|
||||
它同时附带了命令行界面和图形界面,支持多用户配置,而且甚至可以导出数据为CSV。安装完后,你必须在见证奇迹前对它进行快速校正。
|
||||
|
||||

|
||||
|
||||
不怎么令人喜欢的是,如果你和我一样有被偷窥妄想症,在你的摄像头前面贴了一条胶带,那就会比较不幸了,这会大大影响Calise的精确度。除此之外,Calise还是个很棒的应用,值得我们关注和支持。正如我先前提到的,它在过去几年中经历了一段修修补补的艰难阶段,所以我真的希望这个项目继续开展下去。
|
||||
|
||||

|
||||
|
||||
### Redshift ###
|
||||
|
||||
如果你想过要减少由屏幕导致的眼睛的压力,那么你很可能听过f.lux,它是一个免费的专有软件,用于根据一天中的时间来修改显示器的亮度和配色。然而,如果真的偏好于开源软件,那么一个可选方案就是:[Redshift][2]。灵感来自f.lux,Redshift也可以改变配色和亮度来加强你夜间坐在屏幕前的体验。启动时,你可以使用经度和纬度来配置地理坐标,然后就可以让它在托盘中运行了。Redshift将根据太阳的位置平滑地调整你的配色或者屏幕。在夜里,你可以看到屏幕的色温调向偏暖色,这会让你的眼睛少遭些罪。
|
||||
|
||||

|
||||
|
||||
和Calise一样,它提供了一个命令行界面,同时也提供了一个图形客户端。要快速启动Redshift,只需使用命令:
|
||||
|
||||
$ redshift -l [LAT]:[LON]
|
||||
|
||||
替换[LAT]:[LON]为你的维度和经度。
|
||||
|
||||
然而,它也可以通过gpsd模块来输入你的坐标。对于Arch Linux用户,我推荐你读一读这个[维基页面][3]。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
总而言之,Linux用户没有理由不去保护自己的眼睛,Calise和Redshift两个都很棒。我真希望它们的开发能够继续下去,让它们获得应有的支持。当然,还有比这两个更多的程序可以满足保护眼睛和保持健康的目的,但是我感觉Calise和Redshift会是一个不错的开端。
|
||||
|
||||
如果你有一个经常用来舒缓眼睛的压力的喜欢的程序,请在下面的评论中留言吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/automatically-dim-your-screen-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://calise.sourceforge.net/
|
||||
[2]:http://jonls.dk/redshift/
|
||||
[3]:https://wiki.archlinux.org/index.php/Redshift#Automatic_location_based_on_GPS
|
||||
@ -0,0 +1,182 @@
|
||||
在 Ubuntu 上配置高性能的 HHVM 环境
|
||||
================================================================================
|
||||
|
||||
HHVM全称为 HipHop Virtual Machine,它是一个开源虚拟机,用来运行由 Hack(一种编程语言)和 PHP 开发应用。HHVM 在保证了 PHP 程序员最关注的高灵活性的要求下,通过使用最新的编译方式来取得了非凡的性能。到目前为止,相对于 PHP + [APC (Alternative PHP Cache)][1] ,HHVM 为 FaceBook 在 HTTP 请求的吞吐量上提高了9倍的性能,在内存的占用上,减少了5倍左右的内存占用。
|
||||
|
||||
同时,HHVM 也可以与基于 FastCGI 的 Web 服务器(如 Nginx 或者 Apache )协同工作。
|
||||
|
||||

|
||||
|
||||
*安装 HHVM,Nginx和 Apache 还有 MariaDB*
|
||||
|
||||
在本教程中,我们一起来配置 Nginx/Apache web 服务器、 数据库服务器 MariaDB 和 HHVM 。我们将使用 Ubuntu 15.04 (64 位),因为 HHVM 只能运行在64位系统上。同时,该教程也适用于 Debian 和 Linux Mint。
|
||||
|
||||
### 第一步: 安装 Nginx 或者 Apache 服务器 ###
|
||||
|
||||
1、首先,先进行一次系统的升级并更新软件仓库列表,命令如下
|
||||
|
||||
# apt-get update && apt-get upgrade
|
||||
|
||||

|
||||
|
||||
*系统升级*
|
||||
|
||||
2、 正如我之前说的,HHVM 能和 Nginx 和 Apache 进行集成。所以,究竟使用哪个服务器,这是你的自由,不过,我们会教你如何安装这两个服务器。
|
||||
|
||||
#### 安装 Nginx ####
|
||||
|
||||
我们通过下面的命令安装 Nginx/Apache 服务器
|
||||
|
||||
# apt-get install nginx
|
||||
|
||||

|
||||
|
||||
*安装 Nginx 服务器*
|
||||
|
||||
#### 安装 Apache ####
|
||||
|
||||
# apt-get install apache2
|
||||
|
||||

|
||||
|
||||
*安装 Apache 服务器*
|
||||
|
||||
完成这一步,你能通过以下的链接看到 Nginx 或者 Apache 的默认页面
|
||||
|
||||
http://localhost
|
||||
或
|
||||
http://IP-Address
|
||||
|
||||
|
||||

|
||||
|
||||
*Nginx 默认页面*
|
||||
|
||||

|
||||
|
||||
*Apache 默认页面*
|
||||
|
||||
### 第二步: 安装和配置 MariaDB ###
|
||||
|
||||
3、 这一步,我们将通过如下命令安装 MariaDB,它是一个比 MySQL 性能更好的数据库
|
||||
|
||||
# apt-get install mariadb-client mariadb-server
|
||||
|
||||

|
||||
|
||||
*安装 MariaDB*
|
||||
|
||||
4、 在 MariaDB 成功安装之后,你可以启动它,并且设置 root 密码来保护数据库:
|
||||
|
||||
|
||||
# systemctl start mysql
|
||||
# mysql_secure_installation
|
||||
|
||||
回答以下问题,只需要按下`y`或者 `n`并且回车。请确保你仔细的阅读过说明。
|
||||
|
||||
Enter current password for root (enter for none) = press enter
|
||||
Set root password? [Y/n] = y
|
||||
Remove anonymous users[y/n] = y
|
||||
Disallow root login remotely[y/n] = y
|
||||
Remove test database and access to it [y/n] = y
|
||||
Reload privileges tables now[y/n] = y
|
||||
|
||||
5、 在设置了密码之后,你就可以登录 MariaDB 了。
|
||||
|
||||
|
||||
# mysql -u root -p
|
||||
|
||||
|
||||
### 第三步: 安装 HHVM ###
|
||||
|
||||
6、 在此阶段,我们将安装 HHVM。我们需要添加 HHVM 的仓库到你的`sources.list`文件中,然后更新软件列表。
|
||||
|
||||
# wget -O - http://dl.hhvm.com/conf/hhvm.gpg.key | apt-key add -
|
||||
# echo deb http://dl.hhvm.com/ubuntu DISTRIBUTION_VERSION main | sudo tee /etc/apt/sources.list.d/hhvm.list
|
||||
# apt-get update
|
||||
|
||||
**重要**:不要忘记用你的 Ubuntu 发行版代号替换上述的 DISTRIBUTION_VERSION (比如:lucid, precise, trusty) 或者是 Debian 的 jessie 或者 wheezy。在 Linux Mint 中也是一样的,不过只支持 petra。
|
||||
|
||||
添加了 HHVM 仓库之后,你就可以轻松安装了。
|
||||
|
||||
# apt-get install -y hhvm
|
||||
|
||||
安装之后,就可以启动它,但是它并没有做到开机启动。可以用如下命令做到开机启动。
|
||||
|
||||
# update-rc.d hhvm defaults
|
||||
|
||||
### 第四步: 配置 Nginx/Apache 连接 HHVM ###
|
||||
|
||||
7、 现在,nginx/apache 和 HHVM 都已经安装完成了,并且都独立运行起来了,所以我们需要对它们进行设置,来让它们互相关联。这个关键的步骤,就是需要告知 nginx/apache 将所有的 php 文件,都交给 HHVM 进行处理。
|
||||
|
||||
如果你用了 Nginx,请按照如下步骤:
|
||||
|
||||
nginx 的配置文件在 /etc/nginx/sites-available/default, 并且这些配置文件会在 /usr/share/nginx/html 中寻找文件执行,不过,它不知道如何处理 PHP。
|
||||
|
||||
为了确保 Nginx 可以连接 HHVM,我们需要执行所带的如下脚本。它可以帮助我们正确的配置 Nginx,将 hhvm.conf 放到 上面提到的配置文件 nginx.conf 的头部。
|
||||
|
||||
这个脚本可以确保 Nginx 可以对 .hh 和 .php 的做正确的处理,并且将它们通过 fastcgi 发送给 HHVM。
|
||||
|
||||
# /usr/share/hhvm/install_fastcgi.sh
|
||||
|
||||

|
||||
|
||||
*配置 Nginx、HHVM*
|
||||
|
||||
**重要**: 如果你使用的是 Apache,这里不需要进行配置。
|
||||
|
||||
8、 接下来,你需要使用 hhvm 来提供 php 的运行环境。
|
||||
|
||||
# /usr/bin/update-alternatives --install /usr/bin/php php /usr/bin/hhvm 60
|
||||
|
||||
以上步骤完成之后,你现在可以启动并且测试它了。
|
||||
|
||||
# systemctl start hhvm
|
||||
|
||||
### 第五步: 测试 HHVM 和 Nginx/Apache ###
|
||||
|
||||
9、 为了确认 hhvm 是否工作,你需要在 nginx/apache 的文档根目录下建立 hello.php。
|
||||
|
||||
# nano /usr/share/nginx/html/hello.php [对于 Nginx]
|
||||
或
|
||||
# nano /var/www/html/hello.php [对于 Nginx 和 Apache]
|
||||
|
||||
在文件中添加如下代码:
|
||||
|
||||
<?php
|
||||
if (defined('HHVM_VERSION')) {
|
||||
echo 'HHVM is working';
|
||||
phpinfo();
|
||||
} else {
|
||||
echo 'HHVM is not working';
|
||||
}
|
||||
?>
|
||||
|
||||
然后访问如下链接,确认自己能否看到 "hello world"
|
||||
|
||||
http://localhost/info.php
|
||||
或
|
||||
http://IP-Address/info.php
|
||||
|
||||

|
||||
|
||||
*HHVM 页面*
|
||||
|
||||
如果 “HHVM” 的页面出现了,那就说明你成功了。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
以上的步骤都是非常简单的,希望你能觉得这是一篇有用的教程,如果你在以上的步骤中遇到了问题,给我们留一个评论,我们将全力解决。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-hhvm-and-nginx-apache-with-mariadb-on-debian-ubuntu/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:http://www.tecmint.com/install-apc-alternative-php-cache-in-rhel-centos-fedora/
|
||||
@ -0,0 +1,313 @@
|
||||
RHCSA 系列(一): 回顾基础命令及系统文档
|
||||
================================================================================
|
||||
|
||||
RHCSA (红帽认证系统工程师) 是由 RedHat 公司举行的认证考试,这家公司给商业公司提供开源操作系统和软件,除此之外,还为这些企业和机构提供支持、训练以及咨询服务等。
|
||||
|
||||

|
||||
|
||||
*RHCSA 考试准备指南*
|
||||
|
||||
RHCSA 考试(考试编号 EX200)通过后可以获取由 RedHat 公司颁发的证书. RHCSA 考试是 RHCT(红帽认证技师)的升级版,而且 RHCSA 必须在新的 Red Hat Enterprise Linux(红帽企业版)下完成。RHCT 和 RHCSA 的主要变化就是 RHCT 基于 RHEL5,而 RHCSA 基于 RHEL6 或者7,这两个认证的等级也有所不同。
|
||||
|
||||
红帽认证管理员最起码可以在红帽企业版的环境下执行如下系统管理任务:
|
||||
|
||||
- 理解并会使用命令管理文件、目录、命令行以及系统/软件包的文档
|
||||
- 在不同的启动等级操作运行中的系统,识别和控制进程,启动或停止虚拟机
|
||||
- 使用分区和逻辑卷管理本地存储
|
||||
- 创建并且配置本地文件系统和网络文件系统,设置他们的属性(权限、加密、访问控制表)
|
||||
- 部署、配置、并且控制系统,包括安装、升级和卸载软件
|
||||
- 管理系统用户和组,以及使用集中制的 LDAP 目录进行用户验证
|
||||
- 确保系统安全,包括基础的防火墙规则和 SELinux 配置
|
||||
|
||||
关于你所在国家的考试注册和费用请参考 [RHCSA 认证页面][1]。
|
||||
|
||||
在这个有15章的 RHCSA(红帽认证管理员)备考系列中,我们将覆盖以下的关于红帽企业 Linux 第七版的最新的信息:
|
||||
|
||||
- Part 1: 回顾基础命令及系统文档
|
||||
- Part 2: 在 RHEL7 中如何进行文件和目录管理
|
||||
- Part 3: 在 RHEL7 中如何管理用户和组
|
||||
- Part 4: 使用 nano 和 vim 管理命令,使用 grep 和正则表达式分析文本
|
||||
- Part 5: RHEL7 的进程管理:启动,关机,以及这之间的各种事情
|
||||
- Part 6: 使用 'Parted' 和 'SSM' 来管理和加密系统存储
|
||||
- Part 7: 使用 ACL(访问控制表)并挂载 Samba/NFS 文件分享
|
||||
- Part 8: 加固 SSH,设置主机名并开启网络服务
|
||||
- Part 9: 安装、配置和加固一个 Web 和 FTP 服务器
|
||||
- Part 10: Yum 包管理方式,使用 Cron 进行自动任务管理以及监控系统日志
|
||||
- Part 11: 使用 FirewallD 和 Iptables 设置防火墙,控制网络流量
|
||||
- Part 12: 使用 Kickstart 自动安装 RHEL 7
|
||||
- Part 13: RHEL7:什么是 SeLinux?他的原理是什么?
|
||||
- Part 14: 在 RHEL7 中使用基于 LDAP 的权限控制
|
||||
- Part 15: 虚拟化基础和用KVM管理虚拟机
|
||||
|
||||
在第一章,我们讲解如何在终端或者 Shell 窗口输入和运行正确的命令,并且讲解如何找到、查阅,以及使用系统文档。
|
||||
|
||||

|
||||
|
||||
*RHCSA:回顾必会的 Linux 命令 - 第一部分*
|
||||
|
||||
#### 前提: ####
|
||||
|
||||
至少你要熟悉如下命令
|
||||
|
||||
- [cd 命令][2] (改变目录)
|
||||
- [ls 命令][3] (列举文件)
|
||||
- [cp 命令][4] (复制文件)
|
||||
- [mv 命令][5] (移动或重命名文件)
|
||||
- [touch 命令][6] (创建一个新的文件或更新已存在文件的时间表)
|
||||
- rm 命令 (删除文件)
|
||||
- mkdir 命令 (创建目录)
|
||||
|
||||
在这篇文章中你将会找到更多的关于如何更好的使用他们的正确用法和特殊用法.
|
||||
|
||||
虽然没有严格的要求,但是作为讨论常用的 Linux 命令和在 Linux 中搜索信息方法,你应该安装 RHEL7 来尝试使用文章中提到的命令。这将会使你学习起来更省力。
|
||||
|
||||
- [红帽企业版 Linux(RHEL)7 安装指南][7]
|
||||
|
||||
### 使用 Shell 进行交互 ###
|
||||
|
||||
如果我们使用文本模式登录 Linux,我们就会直接进入到我们的默认 shell 中。另一方面,如果我们使用图形化界面登录,我们必须通过启动一个终端来开启 shell。无论那种方式,我们都会看到用户提示符,并且我们可以在这里输入并且执行命令(当按下回车时,命令就会被执行)。
|
||||
|
||||
命令是由两个部分组成的:
|
||||
|
||||
- 命令本身
|
||||
- 参数
|
||||
|
||||
某些参数,称为选项(通常使用一个连字符开头),会改变命令的行为方式,而另外一些则指定了命令所操作的对象。
|
||||
|
||||
type 命令可以帮助我们识别某一个特定的命令是由 shell 内置的还是由一个单独的包提供的。这样的区别在于我们能够在哪里找到更多关于该命令的更多信息。对 shell 内置的命令,我们需要看 shell 的手册页;如果是其他的,我们需要看软件包自己的手册页。
|
||||
|
||||
|
||||
|
||||
*检查Shell的内置命令*
|
||||
|
||||
在上面的例子中, `cd` 和 `type` 是 shell 内置的命令,`top` 和 `less` 是由 shell 之外的其他的二进制文件提供的(在这种情况下,type将返回命令的位置)。
|
||||
|
||||
其他的内置命令:
|
||||
|
||||
- [echo 命令][8]: 展示字符串
|
||||
- [pwd 命令][9]: 输出当前的工作目录
|
||||
|
||||

|
||||
|
||||
*其它内置命令*
|
||||
|
||||
**exec 命令**
|
||||
|
||||
它用来运行我们指定的外部程序。请注意在多数情况下,只需要输入我们想要运行的程序的名字就行,不过` exec` 命令有一个特殊的特性:不是在 shell 之外创建新的进程运行,而是这个新的进程会替代原来的 shell,可以通过下列命令来验证。
|
||||
|
||||
# ps -ef | grep [shell 进程的PID]
|
||||
|
||||
当新的进程终止时,Shell 也随之终止。运行 `exec top` ,然后按下 `q` 键来退出 top,你会注意到 shell 会话也同时终止,如下面的屏幕录像展示的那样:
|
||||
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://dn-linuxcn.qbox.me/static/video/Linux%20exec%20Command%20Demonstration.mp4"></iframe>
|
||||
|
||||
**export 命令**
|
||||
|
||||
给之后执行的命令的输出环境变量。
|
||||
|
||||
**history 命令**
|
||||
|
||||
展示数行之前的历史命令。命令编号前面前缀上感叹号可以再次执行这个命令。如果我们需要编辑历史列表中的命令,我们可以按下 `Ctrl + r` 并输入与命令相关的第一个字符。我们可以看到的命令会自动补全,可以根据我们目前的需要来编辑它:
|
||||
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://dn-linuxcn.qbox.me/static/video/Linux%20history%20Command%20Demonstration.mp4"></iframe>
|
||||
|
||||
命令列表会保存在一个叫 `.bash_history` 的文件里。`history` 命令是一个非常有用的用于减少输入次数的工具,特别是进行命令行编辑的时候。默认情况下,bash 保留最后输入的500个命令,不过可以通过修改 HISTSIZE 环境变量来增加:
|
||||
|
||||

|
||||
|
||||
*Linux history 命令*
|
||||
|
||||
但上述变化,在我们的下一次启动不会保留。为了保持 HISTSIZE 变量的变化,我们需要通过手工修改文件编辑:
|
||||
|
||||
# 要设置 history 长度,请看 bash(1)文档中的 HISTSIZE 和 HISTFILESIZE
|
||||
HISTSIZE=1000
|
||||
|
||||
**重要**: 我们的更改不会立刻生效,除非我们重启了 shell 。
|
||||
|
||||
**alias 命令**
|
||||
|
||||
没有参数或使用 `-p` 选项时将会以“名称=值”的标准形式输出别名列表。当提供了参数时,就会按照给定的名字和值定义一个别名。
|
||||
|
||||
使用 `alias` ,我们可以创建我们自己的命令,或使用所需的参数修改现有的命令。举个例子,假设我们将 `ls` 定义别名为 `ls –color=auto` ,这样就可以使用不同颜色输出文件、目录、链接等等。
|
||||
|
||||
|
||||
# alias ls='ls --color=auto'
|
||||
|
||||
|
||||
|
||||
*Linux 别名命令*
|
||||
|
||||
**注意**: 你可以给你的“新命令”起任何的名字,并且使用单引号包括很多命令,但是你要用分号区分开它们。如下:
|
||||
|
||||
# alias myNewCommand='cd /usr/bin; ls; cd; clear'
|
||||
|
||||
**exit 命令**
|
||||
|
||||
`exit` 和 `logout` 命令都可以退出 shell 。`exit` 命令可以退出所有的 shell,`logout` 命令只注销登录的 shell(即你用文本模式登录时自动启动的那个)。
|
||||
|
||||
**man 和 info 命令**
|
||||
如果你对某个程序有疑问,可以参考它的手册页,可以使用 `man` 命令调出它。此外,还有一些关于重要文件(inittab、fstab、hosts 等等)、库函数、shell、设备及其他功能的手册页。
|
||||
|
||||
举例:
|
||||
|
||||
- man uname (输出系统信息,如内核名称、处理器、操作系统类型、架构等)
|
||||
- man inittab (初始化守护进程的设置)
|
||||
|
||||
另外一个重要的信息的来源是由 `info` 命令提供的,`info` 命令常常被用来读取 info 文件。这些文件往往比手册页 提供了更多信息。可以通过 `info keyword` 调用某个命令的信息:
|
||||
|
||||
# info ls
|
||||
# info cut
|
||||
|
||||
另外,在 `/usr/share/doc` 文件夹包含了大量的子目录,里面可以找到大量的文档。它们是文本文件或其他可读格式。
|
||||
|
||||
你要习惯于使用这三种方法去查找命令的信息。重点关注每个命令文档中介绍的详细的语法。
|
||||
|
||||
**使用 expand 命令把制表符转换为空格**
|
||||
|
||||
有时候文本文档包含了制表符,但是程序无法很好的处理。或者我们只是简单的希望将制表符转换成空格。这就是用到 `expand` 地方(由GNU核心组件包提供) 。
|
||||
|
||||
举个例子,我们有个文件 NumberList.txt,让我们使用 `expand` 处理它,将制表符转换为一个空格,并且显示在标准输出上。
|
||||
|
||||
# expand --tabs=1 NumbersList.txt
|
||||
|
||||

|
||||
|
||||
*Linux expand 命令*
|
||||
|
||||
unexpand命令可以实现相反的功能(将空格转为制表符)
|
||||
|
||||
**使用 head 输出文件首行及使用 tail 输出文件尾行**
|
||||
|
||||
通常情况下,`head` 命令后跟着文件名时,将会输出该文件的前十行,我们可以通过 `-n` 参数来自定义具体的行数。
|
||||
|
||||
# head -n3 /etc/passwd
|
||||
# tail -n3 /etc/passwd
|
||||
|
||||

|
||||
|
||||
*Linux 的 head 和 tail 命令*
|
||||
|
||||
`tail` 最有意思的一个特性就是能够显示增长的输入文件(`tail -f my.log`,my.log 是我们需要监视的文件。)这在我们监控一个持续增加的日志文件时非常有用。
|
||||
|
||||
- [使用 head 和 tail 命令有效地管理文件][10]
|
||||
|
||||
**使用 paste 按行合并文本文件**
|
||||
|
||||
`paste` 命令一行一行的合并文件,默认会以制表符来区分每个文件的行,或者你可以自定义的其它分隔符。(下面的例子就是输出中的字段使用等号分隔)。
|
||||
|
||||
# paste -d= file1 file2
|
||||
|
||||
|
||||
|
||||
*Linux 中的 merge 命令*
|
||||
|
||||
**使用 split 命令将文件分块**
|
||||
|
||||
`split` 命令常常用于把一个文件切割成两个或多个由我们自定义的前缀命名的文件。可以根据大小、区块、行数等进行切割,生成的文件会有一个数字或字母的后缀。在下面的例子中,我们将切割 bash.pdf ,每个文件 50KB (-b 50KB),使用数字后缀 (-d):
|
||||
|
||||
# split -b 50KB -d bash.pdf bash_
|
||||
|
||||

|
||||
|
||||
*在 Linux 下切割文件*
|
||||
|
||||
你可以使用如下命令来合并这些文件,生成原来的文件:
|
||||
|
||||
# cat bash_00 bash_01 bash_02 bash_03 bash_04 bash_05 > bash.pdf
|
||||
|
||||
**使用 tr 命令替换字符**
|
||||
|
||||
`tr` 命令多用于一对一的替换(改变)字符,或者使用字符范围。和之前一样,下面的实例我们将使用之前的同样文件file2,我们将做:
|
||||
|
||||
- 小写字母 o 变成大写
|
||||
- 所有的小写字母都变成大写字母
|
||||
|
||||
-
|
||||
# cat file2 | tr o O
|
||||
# cat file2 | tr [a-z] [A-Z]
|
||||
|
||||
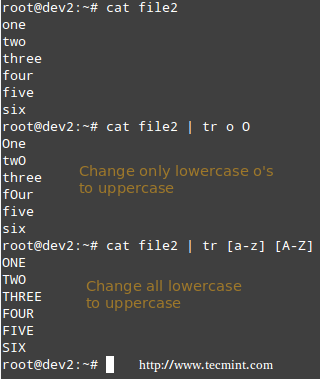
|
||||
|
||||
*在 Linux 中替换字符*
|
||||
|
||||
**使用 uniq 和 sort 检查或删除重复的文字**
|
||||
|
||||
`uniq` 命令可以帮我们查出或删除文件中的重复的行,默认会输出到标准输出,我们应当注意,`uniq`只能查出相邻的相同行,所以,`uniq` 往往和 `sort` 一起使用(`sort` 一般用于对文本文件的内容进行排序)
|
||||
|
||||
默认情况下,`sort` 以第一个字段(使用空格分隔)为关键字段。想要指定不同关键字段,我们需要使用 -k 参数,请注意如何使用 `sort` 和 `uniq` 输出我们想要的字段,具体可以看下面的例子:
|
||||
|
||||
# cat file3
|
||||
# sort file3 | uniq
|
||||
# sort -k2 file3 | uniq
|
||||
# sort -k3 file3 | uniq
|
||||
|
||||

|
||||
|
||||
*删除文件中重复的行*
|
||||
|
||||
**从文件中提取文本的命令**
|
||||
|
||||
`cut` 命令基于字节(-b)、字符(-c)、或者字段(-f)的数量,从输入文件(标准输入或文件)中提取到的部分将会以标准输出上。
|
||||
|
||||
当我们使用字段 `cut` 时,默认的分隔符是一个制表符,不过你可以通过 -d 参数来自定义分隔符。
|
||||
|
||||
# cut -d: -f1,3 /etc/passwd # 这个例子提取了第一和第三字段的文本
|
||||
# cut -d: -f2-4 /etc/passwd # 这个例子提取了第二到第四字段的文本
|
||||
|
||||

|
||||
|
||||
*从文件中提取文本*
|
||||
|
||||
注意,简洁起见,上方的两个输出的结果是截断的。
|
||||
|
||||
**使用 fmt 命令重新格式化文件**
|
||||
|
||||
`fmt` 被用于去“清理”有大量内容或行的文件,或者有多级缩进的文件。新的段落格式每行不会超过75个字符宽,你能通过 -w (width 宽度)参数改变这个设定,它可以设置行宽为一个特定的数值。
|
||||
|
||||
举个例子,让我们看看当我们用 `fmt` 显示定宽为100个字符的时候的文件 /etc/passwd 时会发生什么。再次,输出截断了。
|
||||
|
||||
# fmt -w100 /etc/passwd
|
||||
|
||||

|
||||
|
||||
*Linux 文件重新格式化*
|
||||
|
||||
**使用 pr 命令格式化打印内容**
|
||||
|
||||
`pr` 分页并且在按列或多列的方式显示一个或多个文件。 换句话说,使用 `pr` 格式化一个文件使它打印出来时看起来更好。举个例子,下面这个命令:
|
||||
|
||||
# ls -a /etc | pr -n --columns=3 -h "Files in /etc"
|
||||
|
||||
以一个友好的排版方式(3列)输出/etc下的文件,自定义了页眉(通过 -h 选项实现)、行号(-n)。
|
||||
|
||||

|
||||
|
||||
*Linux的文件格式化*
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中,我们已经讨论了如何在 Shell 或终端以正确的语法输入和执行命令,并解释如何找到,查阅和使用系统文档。正如你看到的一样简单,这就是你成为 RHCSA 的第一大步。
|
||||
|
||||
如果你希望添加一些其他的你经常使用的能够有效帮你完成你的日常工作的基础命令,并愿意分享它们,请在下方留言。也欢迎提出问题。我们期待您的回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://www.redhat.com/en/services/certification/rhcsa
|
||||
[2]:http://linux.cn/article-2479-1.html
|
||||
[3]:https://linux.cn/article-5109-1.html
|
||||
[4]:http://linux.cn/article-2687-1.html
|
||||
[5]:http://www.tecmint.com/rename-multiple-files-in-linux/
|
||||
[6]:http://linux.cn/article-2740-1.html
|
||||
[7]:http://www.tecmint.com/redhat-enterprise-linux-7-installation/
|
||||
[8]:https://linux.cn/article-3948-1.html
|
||||
[9]:https://linux.cn/article-3422-1.html
|
||||
[10]:http://www.tecmint.com/view-contents-of-file-in-linux/
|
||||
@ -1,68 +1,63 @@
|
||||
RHCSA 系列: 如何执行文件并进行文件管理 – Part 2
|
||||
RHCSA 系列(二): 如何进行文件和目录管理
|
||||
================================================================================
|
||||
|
||||
在本篇(RHCSA 第二篇:文件和目录管理)中,我们江回顾一些系统管理员日常任务需要的技能
|
||||
在本篇中,我们将回顾一些系统管理员日常任务需要的技能。
|
||||
|
||||

|
||||
|
||||
*RHCSA: 运行文件以及进行文件夹管理 - 第二部分*
|
||||
|
||||
RHCSA : 运行文件以及进行文件夹管理 - 第二章
|
||||
### 创建,删除,复制和移动文件及目录 ###
|
||||
### 创建、删除、复制和移动文件及目录 ###
|
||||
|
||||
文件和目录管理是每一个系统管理员都应该掌握的必要的技能.它包括了从头开始的创建、删除文本文件(每个程序的核心配置)以及目录(你用来组织文件和其他目录),以及识别存在的文件的类型
|
||||
文件和目录管理是每一个系统管理员都应该掌握的必备技能。它包括了从头开始的创建、删除文本文件(每个程序的核心配置)以及目录(你用来组织文件和其它目录),以及识别已有文件的类型。
|
||||
|
||||
[touch 命令][1] 不仅仅能用来创建空文件,还能用来更新已存在的文件的权限和时间表
|
||||
[`touch` 命令][1] 不仅仅能用来创建空文件,还能用来更新已有文件的访问时间和修改时间。
|
||||
|
||||

|
||||
|
||||
touch 命令示例
|
||||
*touch 命令示例*
|
||||
|
||||
你可以使用 `file [filename]`来判断一个文件的类型 (在你用文本编辑器编辑之前,判断类型将会更方便编辑).
|
||||
你可以使用 `file [filename]`来判断一个文件的类型 (在你用文本编辑器编辑之前,判断类型将会更方便编辑)。
|
||||
|
||||
|
||||
|
||||
file 命令示例
|
||||
*file 命令示例*
|
||||
|
||||
使用`rm [filename]` 可以删除文件
|
||||
使用`rm [filename]` 可以删除文件。
|
||||
|
||||

|
||||
|
||||
rm 命令示例
|
||||
|
||||
对于目录,你可以使用`mkdir [directory]`在已经存在的路径中创建目录,或者使用 `mkdir -p [/full/path/to/directory].`带全路径创建文件夹
|
||||
*rm 命令示例*
|
||||
|
||||
对于目录,你可以使用`mkdir [directory]`在已经存在的路径中创建目录,或者使用 `mkdir -p [/full/path/to/directory]`带全路径创建文件夹。
|
||||
|
||||

|
||||
|
||||
mkdir 命令示例
|
||||
*mkdir 命令示例*
|
||||
|
||||
当你想要去删除目录时,在你使用`rmdir [directory]` 前,你需要先确保目录是空的,或者使用更加强力的命令(小心使用它)`rm -rf [directory]`.后者会强制删除`[directory]`以及他的内容.所以使用这个命令存在一定的风险
|
||||
当你想要去删除目录时,在你使用`rmdir [directory]` 前,你需要先确保目录是空的,或者使用更加强力的命令(小心使用它!)`rm -rf [directory]`。后者会强制删除`[directory]`以及它的内容,所以使用这个命令存在一定的风险。
|
||||
|
||||
### 输入输出重定向以及管道 ###
|
||||
|
||||
命令行环境提供了两个非常有用的功能:允许命令重定向的输入和输出到文件和发送到另一个文件,分别称为重定向和管道
|
||||
命令行环境提供了两个非常有用的功能:允许重定向命令的输入和输出为另一个文件,以及发送命令的输出到另一个命令,这分别称为重定向和管道。
|
||||
|
||||
To understand those two important concepts, we must first understand the three most important types of I/O (Input and Output) streams (or sequences) of characters, which are in fact special files, in the *nix sense of the word.
|
||||
为了理解这两个重要概念,我们首先需要理解通常情况下三个重要的输入输出流的形式
|
||||
为了理解这两个重要概念,我们首先需要理解三个最重要的字符输入输出流类型,以 *nix 的话来说,它们实际上是特殊的文件。
|
||||
|
||||
- 标准输入 (aka stdin) 是指默认使用键盘链接. 换句话说,键盘是输入命令到命令行的标准输入设备。
|
||||
- 标准输出 (aka stdout) 是指默认展示再屏幕上, 显示器接受输出命令,并且展示在屏幕上。
|
||||
- 标准错误 (aka stderr), 是指命令的状态默认输出, 同时也会展示在屏幕上
|
||||
- 标准输入 (即 stdin),默认连接到键盘。 换句话说,键盘是输入命令到命令行的标准输入设备。
|
||||
- 标准输出 (即 stdout),默认连接到屏幕。 找个设备“接受”命令的输出,并展示到屏幕上。
|
||||
- 标准错误 (即 stderr),默认是命令的状态消息出现的地方,它也是屏幕。
|
||||
|
||||
In the following example, the output of `ls /var` is sent to stdout (the screen), as well as the result of ls /tecmint. But in the latter case, it is stderr that is shown.
|
||||
在下面的例子中,`ls /var`的结果被发送到stdout(屏幕展示),就像ls /tecmint 的结果。但在后一种情况下,它是标准错误输出。
|
||||
在下面的例子中,`ls /var`的结果被发送到stdout(屏幕展示),ls /tecmint 的结果也一样。但在后一种情况下,它显示在标准错误输出上。
|
||||
|
||||

|
||||
输入和输出命令实例
|
||||
|
||||
为了更容易识别这些特殊文件,每个文件都被分配有一个文件描述符(用于控制他们的抽象标识)。主要要理解的是,这些文件就像其他人一样,可以被重定向。这就意味着你可以从一个文件或脚本中捕获输出,并将它传送到另一个文件、命令或脚本中。你就可以在在磁盘上存储命令的输出结果,用于稍后的分析
|
||||
*输入和输出命令实例*
|
||||
|
||||
To redirect stdin (fd 0), stdout (fd 1), or stderr (fd 2), the following operators are available.
|
||||
为了更容易识别这些特殊文件,每个文件都被分配有一个文件描述符,这是用于访问它们的抽象标识。主要要理解的是,这些文件就像其它的一样,可以被重定向。这就意味着你可以从一个文件或脚本中捕获输出,并将它传送到另一个文件、命令或脚本中。这样你就可以在磁盘上存储命令的输出结果,用于稍后的分析。
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="226"></colgroup>
|
||||
<colgroup width="743"></colgroup>
|
||||
要重定向 stdin (fd 0)、 stdout (fd 1) 或 stderr (fd 2),可以使用如下操作符。
|
||||
|
||||
<table cellpadding="4" border="1">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">转向操作</span></b></td>
|
||||
@ -70,102 +65,98 @@ To redirect stdin (fd 0), stdout (fd 1), or stderr (fd 2), the following operato
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">标准输出到一个文件。如果目标文件存在,内容就会被重写</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">重定向标准输出到一个文件。如果目标文件存在,内容就会被重写。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">>></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加标准输出到文件尾部</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加标准输出到文件尾部。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">2></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">标准错误输出到一个文件。如果目标文件存在,内容就会被重写</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">重定向标准错误输出到一个文件。如果目标文件存在,内容就会被重写。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">2>></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加标准错误输出到文件尾部.</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加标准错误输出到文件尾部。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">&></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">标准错误和标准输出都到一个文件。如果目标文件存在,内容就会被重写</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">重定向标准错误和标准输出到一个文件。如果目标文件存在,内容就会被重写。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;"><</span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">使用特定的文件做标准输出</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">使用特定的文件做标准输入。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;"><></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">使用特定的文件做标准输出和标准错误</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">使用特定的文件做标准输入和标准输出。</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|
||||
相比与重定向,管道是通过在命令后添加一个竖杠`(|)`再添加另一个命令 .
|
||||
与重定向相比,管道是通过在命令后和另外一个命令前之间添加一个竖杠`(|)`。
|
||||
|
||||
记得:
|
||||
|
||||
- 重定向是用来定向命令的输出到一个文件,或定向一个文件作为输入到一个命令。
|
||||
- 管道是用来将命令的输出转发到另一个命令作为输入。
|
||||
- *重定向*是用来定向命令的输出到一个文件,或把一个文件发送作为到一个命令的输入。
|
||||
- *管道*是用来将命令的输出转发到另一个命令作为其输入。
|
||||
|
||||
#### 重定向和管道的使用实例 ####
|
||||
|
||||
** 例1:将一个命令的输出到文件 **
|
||||
**例1:将一个命令的输出到文件**
|
||||
|
||||
有些时候,你需要遍历一个文件列表。要做到这样,你可以先将该列表保存到文件中,然后再按行读取该文件。虽然你可以遍历直接ls的输出,不过这个例子是用来说明重定向。
|
||||
有些时候,你需要遍历一个文件列表。要做到这样,你可以先将该列表保存到文件中,然后再按行读取该文件。虽然你可以直接遍历ls的输出,不过这个例子是用来说明重定向。
|
||||
|
||||
# ls -1 /var/mail > mail.txt
|
||||
|
||||
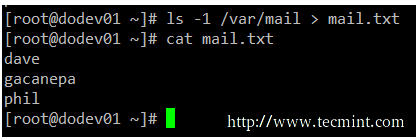
|
||||
|
||||
将一个命令的输出到文件
|
||||
*将一个命令的输出重定向到文件*
|
||||
|
||||
** 例2:重定向stdout和stderr到/dev/null **
|
||||
**例2:重定向stdout和stderr到/dev/null**
|
||||
|
||||
如果不想让标准输出和标准错误展示在屏幕上,我们可以把文件描述符重定向到 `/dev/null` 请注意在执行这个命令时该如何更改输出
|
||||
如果不想让标准输出和标准错误展示在屏幕上,我们可以把这两个文件描述符重定向到 `/dev/null`。请注意对于同样的命令,重定向是如何改变了输出。
|
||||
|
||||
# ls /var /tecmint
|
||||
# ls /var/ /tecmint &> /dev/null
|
||||
|
||||

|
||||
|
||||
重定向stdout和stderr到/dev/null
|
||||
*重定向stdout和stderr到/dev/null*
|
||||
|
||||
#### 例3:使用一个文件作为命令的输入 ####
|
||||
**例3:使用一个文件作为命令的输入**
|
||||
|
||||
当官方的[cat 命令][2]的语法如下时
|
||||
[cat 命令][2]的经典用法如下
|
||||
|
||||
# cat [file(s)]
|
||||
|
||||
您还可以使用正确的重定向操作符传送一个文件作为输入。
|
||||
您还可以使用正确的重定向操作符发送一个文件作为输入。
|
||||
|
||||
# cat < mail.txt
|
||||
|
||||
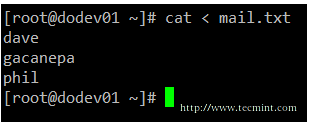
|
||||
|
||||
cat 命令实例
|
||||
*cat 命令实例*
|
||||
|
||||
#### 例4:发送一个命令的输出作为另一个命令的输入 ####
|
||||
**例4:发送一个命令的输出作为另一个命令的输入**
|
||||
|
||||
如果你有一个较大的目录或进程列表,并且想快速定位,你或许需要将列表通过管道传送给grep
|
||||
如果你有一个较大的目录或进程列表,并且想快速定位,你或许需要将列表通过管道传送给grep。
|
||||
|
||||
接下来我们使用管道在下面的命令中,第一个是查找所需的关键词,第二个是除去产生的 `grep command`.这个例子列举了所有与apache用户有关的进程
|
||||
接下来我们会在下面的命令中使用管道,第一个管道是查找所需的关键词,第二个管道是除去产生的 `grep command`。这个例子列举了所有与apache用户有关的进程:
|
||||
|
||||
# ps -ef | grep apache | grep -v grep
|
||||
|
||||

|
||||
|
||||
发送一个命令的输出作为另一个命令的输入
|
||||
*发送一个命令的输出作为另一个命令的输入*
|
||||
|
||||
### 归档,压缩,解包,解压文件 ###
|
||||
|
||||
如果你需要传输,备份,或者通过邮件发送一组文件,你可以使用一个存档(或文件夹)如 [tar][3]工具,通常使用gzip,bzip2,或XZ压缩工具.
|
||||
如果你需要传输、备份、或者通过邮件发送一组文件,你可以使用一个存档(或打包)工具,如 [tar][3],通常与gzip,bzip2,或 xz 等压缩工具配合使用。
|
||||
|
||||
您选择的压缩工具每一个都有自己的定义的压缩速度和速率的。这三种压缩工具,gzip是最古老和提供最小压缩的工具,bzip2提供经过改进的压缩,以及XZ提供最信和最好的压缩。通常情况下,这些文件都是被压缩的如.gz .bz2或.xz
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="165"></colgroup>
|
||||
<colgroup width="137"></colgroup>
|
||||
<colgroup width="366"></colgroup>
|
||||
您选择的压缩工具每一个都有自己不同的压缩速度和压缩率。这三种压缩工具,gzip是最古老和可以较小压缩的工具,bzip2提供经过改进的压缩,以及xz是最新的而且压缩最大。通常情况下,使用这些压缩工具压缩的文件的扩展名依次是.gz、.bz2或.xz。
|
||||
|
||||
<table cellpadding="4" border="1">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">命令</span></b></td>
|
||||
@ -180,12 +171,12 @@ cat 命令实例
|
||||
<tr>
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –concatenate</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">A</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">向归档中添加tar文件</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加tar归档到另外一个归档中</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –append</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">r</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">向归档中添加非tar文件</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加非tar归档到另外一个归档中</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –update</span></td>
|
||||
@ -195,26 +186,22 @@ cat 命令实例
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –diff or –compare</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">d</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">将归档和硬盘的文件夹进行对比</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">将归档中的文件和硬盘的文件进行对比</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="20" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –list</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">t</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">列举一个tar的压缩包</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">列举一个tar压缩包的内容</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –extract or –get</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">x</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">从归档中解压文件</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">从归档中提取文件</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="258"></colgroup>
|
||||
<colgroup width="152"></colgroup>
|
||||
<colgroup width="803"></colgroup>
|
||||
<table cellpadding="4" border="1">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000001;"><b><span style="font-size: medium;">操作参数</span></b></td>
|
||||
@ -234,34 +221,34 @@ cat 命令实例
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –verbose</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> v</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">列举所有文件用于读取或提取,这里包含列表,并显示文件的大小、所有权和时间戳</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">列举所有读取或提取的文件,如果和 --list 参数一起使用,也会显示文件的大小、所有权和时间戳</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>exclude file</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> —</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">排除存档文件。在这种情况下,文件可以是一个实际的文件或目录。</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">从存档中排除文件。在这种情况下,文件可以是一个实际的文件或匹配模式。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>gzip or <span style="font-family: Courier New;">—</span>gunzip</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> z</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">使用gzip压缩文件</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">使用gzip压缩归档</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –bzip2</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> j</span></td>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;">使用bzip2压缩文件</td>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;">使用bzip2压缩归档</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –xz</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> J</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">使用xz压缩文件</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">使用xz压缩归档</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### 例5:创建一个文件,然后使用三种压缩工具压缩####
|
||||
**例5:创建一个tar文件,然后使用三种压缩工具压缩**
|
||||
|
||||
在决定使用一个或另一个工具之前,您可能想比较每个工具的压缩效率。请注意压缩小文件或几个文件,结果可能不会有太大的差异,但可能会给你看出他们的差异
|
||||
在决定使用这个还是那个工具之前,您可能想比较每个工具的压缩效率。请注意压缩小文件或几个文件,结果可能不会有太大的差异,但可能会给你看出它们的差异。
|
||||
|
||||
# tar cf ApacheLogs-$(date +%Y%m%d).tar /var/log/httpd/* # Create an ordinary tarball
|
||||
# tar czf ApacheLogs-$(date +%Y%m%d).tar.gz /var/log/httpd/* # Create a tarball and compress with gzip
|
||||
@ -270,42 +257,42 @@ cat 命令实例
|
||||
|
||||

|
||||
|
||||
tar 命令实例
|
||||
*tar 命令实例*
|
||||
|
||||
#### 例6:归档时同时保存原始权限和所有权 ####
|
||||
**例6:归档时同时保存原始权限和所有权**
|
||||
|
||||
如果你创建的是用户的主目录的备份,你需要要存储的个人文件与原始权限和所有权,而不是通过改变他们的用户帐户或守护进程来执行备份。下面的命令可以在归档时保留文件属性
|
||||
如果你正在从用户的主目录创建备份,你需要要存储的个人文件与原始权限和所有权,而不是通过改变它们的用户帐户或守护进程来执行备份。下面的命令可以在归档时保留文件属性。
|
||||
|
||||
# tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* --same-permissions --same-owner
|
||||
|
||||
### 创建软连接和硬链接 ###
|
||||
|
||||
在Linux中,有2种类型的链接文件:硬链接和软(也称为符号)链接。因为硬链接文件代表另一个名称是由同一点确定,然后链接到实际的数据;符号链接指向的文件名,而不是实际的数据
|
||||
在Linux中,有2种类型的链接文件:硬链接和软(也称为符号)链接。因为硬链接文件只是现存文件的另一个名字,使用相同的 inode 号,它指向实际的数据;而符号链接只是指向的文件名。
|
||||
|
||||
此外,硬链接不占用磁盘上的空间,而符号链接做占用少量的空间来存储的链接本身的文本。硬链接的缺点就是要求他们必须在同一个innode内。而符号链接没有这个限制,符号链接因为只保存了文件名和目录名,所以可以跨文件系统.
|
||||
此外,硬链接不占用磁盘上的空间,而符号链接则占用少量的空间来存储的链接本身的文本。硬链接的缺点就是要求它们必须在同一个文件系统内,因为 inode 在一个文件系统内是唯一的。而符号链接没有这个限制,它们通过文件名而不是 inode 指向其它文件或目录,所以可以跨文件系统。
|
||||
|
||||
创建链接的基本语法看起来是相似的:
|
||||
|
||||
# ln TARGET LINK_NAME #从Link_NAME到Target的硬链接
|
||||
# ln -s TARGET LINK_NAME #从Link_NAME到Target的软链接
|
||||
|
||||
#### 例7:创建硬链接和软链接 ####
|
||||
**例7:创建硬链接和软链接**
|
||||
|
||||
没有更好的方式来形象的说明一个文件和一个指向它的符号链接的关系,而不是创建这些链接。在下面的截图中你会看到文件的硬链接指向它共享相同的节点都是由466个字节的磁盘使用情况确定。
|
||||
没有更好的方式来形象的说明一个文件和一个指向它的硬链接或符号链接的关系,而不是创建这些链接。在下面的截图中你会看到文件和指向它的硬链接共享相同的inode,都是使用了相同的466个字节的磁盘。
|
||||
|
||||
另一方面,在别的磁盘创建一个硬链接将占用5个字节,并不是说你将耗尽存储容量,而是这个例子足以说明一个硬链接和软链接之间的区别。
|
||||
另一方面,在别的磁盘创建一个硬链接将占用5个字节,这并不是说你将耗尽存储容量,而是这个例子足以说明一个硬链接和软链接之间的区别。
|
||||
|
||||

|
||||
|
||||
软连接和硬链接之间的不同
|
||||
*软连接和硬链接之间的不同*
|
||||
|
||||
符号链接的典型用法是在Linux系统的版本文件参考。假设有需要一个访问文件foo X.Y 想图书馆一样经常被访问,你想更新一个就可以而不是更新所有的foo X.Y,这时使用软连接更为明智和安全。有文件被看成foo X.Y的链接符号,从而找到foo X.Y
|
||||
在Linux系统上符号链接的典型用法是指向一个带版本的文件。假设有几个程序需要访问文件fooX.Y,但麻烦是版本经常变化(像图书馆一样)。每次版本更新时我们都需要更新指向 fooX.Y 的单一引用,而更安全、更快捷的方式是,我们可以让程序寻找名为 foo 的符号链接,它实际上指向 fooX.Y。
|
||||
|
||||
这样的话,当你的X和Y发生变化后,你只需更新一个文件,而不是更新每个文件。
|
||||
这样的话,当你的X和Y发生变化后,你只需更新符号链接 foo 到新的目标文件,而不用跟踪每个对目标文件的使用并更新。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中,我们回顾了一些基本的文件和目录管理技能,这是每个系统管理员的工具集的一部分。请确保阅读了本系列的其他部分,以及复习并将这些主题与本教程所涵盖的内容相结合。
|
||||
在这篇文章中,我们回顾了一些基本的文件和目录管理技能,这是每个系统管理员的工具集的一部分。请确保阅读了本系列的其它部分,并将这些主题与本教程所涵盖的内容相结合。
|
||||
|
||||
如果你有任何问题或意见,请随时告诉我们。我们总是很高兴从读者那获取反馈.
|
||||
|
||||
@ -315,11 +302,11 @@ via: http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[1]:https://linux.cn/article-2740-1.html
|
||||
[2]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[3]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
20
sign.md
20
sign.md
@ -1,8 +1,22 @@
|
||||
|
||||
---
|
||||
|
||||
via:
|
||||
via:来源链接
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
作者:[作者名][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,
|
||||
[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:作者链接
|
||||
[1]:文内链接
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
@ -1,117 +0,0 @@
|
||||
Top 5 Torrent Clients For Ubuntu Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Looking for the **best torrent client in Ubuntu**? Indeed there are a number of torrent clients available for desktop Linux. But which ones are the **best Ubuntu torrent clients** among them?
|
||||
|
||||
I am going to list top 5 torrent clients for Linux, which are lightweight, feature rich and have impressive GUI. Ease of installation and using is also a factor.
|
||||
|
||||
### Best torrent programs for Ubuntu ###
|
||||
|
||||
Since Ubuntu comes by default with Transmission, I am going to exclude it from the list. This doesn’t mean that Transmission doesn’t deserve to be on the list. Transmission is a good to have torrent client for Ubuntu and this is the reason why it is the default Torrent application in several Linux distributions, including Ubuntu.
|
||||
|
||||
----------
|
||||
|
||||
### Deluge ###
|
||||
|
||||

|
||||
|
||||
[Deluge][1] has been chosen as the best torrent client for Linux by Lifehacker and that speaks itself of the usefulness of Deluge. And it’s not just Lifehacker who is fan of Deluge, check out any forum and you’ll find a number of people admitting that Deluge is their favorite.
|
||||
|
||||
Fast, sleek and intuitive interface makes Deluge a hot favorite among Linux users.
|
||||
|
||||
Deluge is available in Ubuntu repositories and you can install it in Ubuntu Software Center or by using the command below:
|
||||
|
||||
sudo apt-get install deluge
|
||||
|
||||
----------
|
||||
|
||||
### qBittorrent ###
|
||||
|
||||

|
||||
|
||||
As the name suggests, [qBittorrent][2] is the Qt version of famous [Bittorrent][3] application. You’ll see an interface similar to Bittorrent client in Windows, if you ever used it. Sort of lightweight and have all the standard features of a torrent program, qBittorrent is also available in default Ubuntu repository.
|
||||
|
||||
It could be installed from Ubuntu Software Center or using the command below:
|
||||
|
||||
sudo apt-get install qbittorrent
|
||||
|
||||
----------
|
||||
|
||||
### Tixati ###
|
||||
|
||||

|
||||
|
||||
[Tixati][4] is another nice to have torrent client for Ubuntu. It has a default dark theme which might be preferred by many but not me. It has all the standard features that you can seek in a torrent client.
|
||||
|
||||
In addition to that, there are additional feature of data analysis. You can measure and analyze bandwidth and other statistics in nice charts.
|
||||
|
||||
- [Download Tixati][5]
|
||||
|
||||
----------
|
||||
|
||||
### Vuze ###
|
||||
|
||||

|
||||
|
||||
[Vuze][6] is favorite torrent application of a number of Linux as well as Windows users. Apart from the standard features, you can search for torrents directly in the application. You can also subscribe to episodic content so that you won’t have to search for new contents as you can see it in your subscription in sidebar.
|
||||
|
||||
It also comes with a video player that can play HD videos with subtitles and all. But I don’t think you would like to use it over the better video players such as VLC.
|
||||
|
||||
Vuze can be installed from Ubuntu Software Center or using the command below:
|
||||
|
||||
sudo apt-get install vuze
|
||||
|
||||
----------
|
||||
|
||||
### Frostwire ###
|
||||
|
||||

|
||||
|
||||
[Frostwire][7] is the torrent application you might want to try. It is more than just a simple torrent client. Also available for Android, you can use it to share files over WiFi.
|
||||
|
||||
You can search for torrents from within the application and play them inside the application. In addition to the downloaded files, it can browse your local media and have them organized inside the player. The same is applicable for the Android version.
|
||||
|
||||
An additional feature is that Frostwire also provides access to legal music by indi artists. You can download them and listen to it, for free, for legal.
|
||||
|
||||
- [Download Frostwire][8]
|
||||
|
||||
----------
|
||||
|
||||
### Honorable mention ###
|
||||
|
||||
On Windows, uTorrent (pronounced mu torrent) is my favorite torrent application. While uTorrent may be available for Linux, I deliberately skipped it from the list because installing and using uTorrent in Linux is neither easy nor does it provide a complete application experience (runs with in web browser).
|
||||
|
||||
You can read about uTorrent installation in Ubuntu [here][9].
|
||||
|
||||
#### Quick tip: ####
|
||||
|
||||
Most of the time, torrent applications do not start by default. You might want to change this behavior. Read this post to learn [how to manage startup applications in Ubuntu][10].
|
||||
|
||||
### What’s your favorite? ###
|
||||
|
||||
That was my opinion on the best Torrent clients in Ubuntu. What is your favorite one? Do leave a comment. You can also check the [best download managers for Ubuntu][11] in related posts. And if you use Popcorn Time, check these [Popcorn Time Tips][12].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-torrent-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://deluge-torrent.org/
|
||||
[2]:http://www.qbittorrent.org/
|
||||
[3]:http://www.bittorrent.com/
|
||||
[4]:http://www.tixati.com/
|
||||
[5]:http://www.tixati.com/download/
|
||||
[6]:http://www.vuze.com/
|
||||
[7]:http://www.frostwire.com/
|
||||
[8]:http://www.frostwire.com/downloads
|
||||
[9]:http://sysads.co.uk/2014/05/install-utorrent-3-3-ubuntu-14-04-13-10/
|
||||
[10]:http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
[11]:http://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[12]:http://itsfoss.com/popcorn-time-tips/
|
||||
@ -0,0 +1,229 @@
|
||||
cygmris is translating...
|
||||
Great Open Source Collaborative Editing Tools
|
||||
================================================================================
|
||||
In a nutshell, collaborative writing is writing done by more than one person. There are benefits and risks of collaborative working. Some of the benefits include a more integrated / co-ordinated approach, better use of existing resources, and a stronger, united voice. For me, the greatest advantage is one of the most transparent. That's when I need to take colleagues' views. Sending files back and forth between colleagues is inefficient, causes unnecessary delays and leaves people (i.e. me) unhappy with the whole notion of collaboration. With good collaborative software, I can share notes, data and files, and use comments to share thoughts in real-time or asynchronously. Working together on documents, images, video, presentations, and tasks is made less of a chore.
|
||||
|
||||
There are many ways to collaborate online, and it has never been easier. This article highlights my favourite open source tools to collaborate on documents in real time.
|
||||
|
||||
Google Docs is an excellent productivity application with most of the features I need. It serves as a collaborative tool for editing documents in real time. Documents can be shared, opened, and edited by multiple users simultaneously and users can see character-by-character changes as other collaborators make edits. While Google Docs is free for individuals, it is not open source.
|
||||
|
||||
Here is my take on the finest open source collaborative editors which help you focus on writing without interruption, yet work mutually with others.
|
||||
|
||||
----------
|
||||
|
||||
### Hackpad ###
|
||||
|
||||

|
||||
|
||||
Hackpad is an open source web-based realtime wiki, based on the open source EtherPad collaborative document editor.
|
||||
|
||||
Hackpad allows users to share your docs realtime and it uses color coding to show which authors have contributed to which content. It also allows in line photos, checklists and can also be used for coding as it offers syntax highlighting.
|
||||
|
||||
While Dropbox acquired Hackpad in April 2014, it is only this month that the software has been released under an open source license. It has been worth the wait.
|
||||
|
||||
Features include:
|
||||
|
||||
- Very rich set of functions, similar to those offered by wikis
|
||||
- Take collaborative notes, share data and files, and use comments to share your thoughts in real-time or asynchronously
|
||||
- Granular privacy permissions enable you to invite a single friend, a dozen teammates, or thousands of Twitter followers
|
||||
- Intelligent execution
|
||||
- Directly embed videos from popular video sharing sites
|
||||
- Tables
|
||||
- Syntax highlighting for most common programming languages including C, C#, CSS, CoffeeScript, Java, and HTML
|
||||
|
||||
- Website: [hackpad.com][1]
|
||||
- Source code: [github.com/dropbox/hackpad][2]
|
||||
- Developer: [Contributors][3]
|
||||
- License: Apache License, Version 2.0
|
||||
- Version Number: -
|
||||
|
||||
----------
|
||||
|
||||
### Etherpad ###
|
||||
|
||||

|
||||
|
||||
Etherpad is an open source web-based collaborative real-time editor, allowing authors to simultaneously edit a text document leave comments, and interact with others using an integrated chat.
|
||||
|
||||
Etherpad is implemented in JavaScript, on top of the AppJet platform, with the real-time functionality achieved using Comet streaming.
|
||||
|
||||
Features include:
|
||||
|
||||
- Well designed spartan interface
|
||||
- Simple text formatting features
|
||||
- "Time slider" - explore the history of a pad
|
||||
- Download documents in plain text, PDF, Microsoft Word, Open Document, and HTML
|
||||
- Auto-saves the document at regular, short intervals
|
||||
- Highly customizable
|
||||
- Client side plugins extend the editor functionality
|
||||
- Hundreds of plugins extend Etherpad including support for email notifications, pad management, authentication
|
||||
- Accessibility enabled
|
||||
- Interact with Pad contents in real time from within Node and from your CLI
|
||||
|
||||
- Website: [etherpad.org][4]
|
||||
- Source code: [github.com/ether/etherpad-lite][5]
|
||||
- Developer: David Greenspan, Aaron Iba, J.D. Zamfiresc, Daniel Clemens, David Cole
|
||||
- License: Apache License Version 2.0
|
||||
- Version Number: 1.5.7
|
||||
|
||||
----------
|
||||
|
||||
### Firepad ###
|
||||
|
||||

|
||||
|
||||
Firepad is an open source, collaborative text editor. It is designed to be embedded inside larger web applications with collaborative code editing added in only a few days.
|
||||
|
||||
Firepad is a full-featured text editor, with capabilities like conflict resolution, cursor synchronization, user attribution, and user presence detection. It uses Firebase as a backend, and doesn't need any server-side code. It can be added to any web app. Firepad can use either the CodeMirror editor or the Ace editor to render documents, and its operational transform code borrows from ot.js.
|
||||
|
||||
If you want to extend your web application capabilities by adding the simple document and code editor, Firepad is perfect.
|
||||
|
||||
Firepad is used by several editors, including the Atlassian Stash Realtime Editor, Nitrous.IO, LiveMinutes, and Koding.
|
||||
|
||||
Features include:
|
||||
|
||||
- True collaborative editing
|
||||
- Intelligent OT-based merging and conflict resolution
|
||||
- Support for both rich text and code editing
|
||||
- Cursor position synchronization
|
||||
- Undo / redo
|
||||
- Text highlighting
|
||||
- User attribution
|
||||
- Presence detection
|
||||
- Version checkpointing
|
||||
- Images
|
||||
- Extend Firepad through its API
|
||||
- Supports all modern browsers: Chrome, Safari, Opera 11+, IE8+, Firefox 3.6+
|
||||
|
||||
- Website: [www.firepad.io][6]
|
||||
- Source code: [github.com/firebase/firepad][7]
|
||||
- Developer: Michael Lehenbauer and the team at Firebase
|
||||
- License: MIT
|
||||
- Version Number: 1.1.1
|
||||
|
||||
----------
|
||||
|
||||
### OwnCloud Documents ###
|
||||
|
||||

|
||||
|
||||
ownCloud Documents is an ownCloud app to work with office documents alone and/or collaboratively. It allows up to 5 individuals to collaborate editing .odt and .doc files in a web browser.
|
||||
|
||||
ownCloud is a self-hosted file sync and share server. It provides access to your data through a web interface, sync clients or WebDAV while providing a platform to view, sync and share across devices easily.
|
||||
|
||||
Features include:
|
||||
|
||||
- Cooperative edit, with multiple users editing files simultaneously
|
||||
- Document creation within ownCloud
|
||||
- Document upload
|
||||
- Share and edit files in the browser, and then share them inside ownCloud or through a public link
|
||||
- ownCloud features like versioning, local syncing, encryption, undelete
|
||||
- Seamless support for Microsoft Word documents by way of transparent conversion of file formats
|
||||
|
||||
- Website: [owncloud.org][8]
|
||||
- Source code: [github.com/owncloud/documents][9]
|
||||
- Developer: OwnCloud Inc.
|
||||
- License: AGPLv3
|
||||
- Version Number: 8.1.1
|
||||
|
||||
----------
|
||||
|
||||
### Gobby ###
|
||||
|
||||

|
||||
|
||||
Gobby is a collaborative editor supporting multiple documents in one session and a multi-user chat. All users could work on the file simultaneously without the need to lock it. The parts the various users write are highlighted in different colours and it supports syntax highlighting of various programming and markup languages.
|
||||
|
||||
Gobby allows multiple users to edit the same document together over the internet in real-time. It integrates well with the GNOME environment. It features a client-server architecture which supports multiple documents in one session, document synchronisation on request, password protection and an IRC-like chat for communication out of band. Users can choose a colour to highlight the text they have written in a document.
|
||||
|
||||
A dedicated server called infinoted is also provided.
|
||||
|
||||
Features include:
|
||||
|
||||
- Full-fledged text editing capabilities including syntax highlighting using GtkSourceView
|
||||
- Real-time, lock-free collaborative text editing through encrypted connections (including PFS)
|
||||
- Integrated group chat
|
||||
- Local group undo: Undo does not affect changes of remote users
|
||||
- Shows cursors and selections of remote users
|
||||
- Highlights text written by different users with different colors
|
||||
- Syntax highlighting for most programming languages, auto indentation, configurable tab width
|
||||
- Zeroconf support
|
||||
- Encrypted data transfer including perfect forward secrecy (PFS)
|
||||
- Sessions can be password-protected
|
||||
- Sophisticated access control with Access Control Lists (ACLs)
|
||||
- Highly configurable dedicated server
|
||||
- Automatic saving of documents
|
||||
- Advanced search and replace options
|
||||
- Internationalisation
|
||||
- Full Unicode support
|
||||
|
||||
- Website: [gobby.github.io][10]
|
||||
- Source code: [github.com/gobby][11]
|
||||
- Developer: Armin Burgmeier, Philipp Kern and contributors
|
||||
- License: GNU GPLv2+ and ISC
|
||||
- Version Number: 0.5.0
|
||||
|
||||
----------
|
||||
|
||||
### OnlyOffice ###
|
||||
|
||||

|
||||
|
||||
ONLYOFFICE (formerly known as Teamlab Office) is a multifunctional cloud online office suite integrated with CRM system, document and project management toolset, Gantt chart and email aggregator.
|
||||
|
||||
It allows you to organize business tasks and milestones, store and share your corporate or personal documents, use social networking tools such as blogs and forums, as well as communicate with your team members via corporate IM.
|
||||
|
||||
Manage documents, projects, team and customer relations in one place. OnlyOffice combines text, spreadsheet and presentation editors that include features similar to Microsoft desktop editors (Word, Excel and PowerPoint), but then allow to co-edit, comment and chat in real time.
|
||||
|
||||
OnlyOffice is written in ASP.NET, based on HTML5 Canvas element, and translated to 21 languages.
|
||||
|
||||
Features include:
|
||||
|
||||
- As powerful as a desktop editor when working with large documents, paging and zooming
|
||||
- Document sharing in view / edit modes
|
||||
- Document embedding
|
||||
- Spreadsheet and presentation editors
|
||||
- Co-editing
|
||||
- Commenting
|
||||
- Integrated chat
|
||||
- Mobile applications
|
||||
- Gantt charts
|
||||
- Time management
|
||||
- Access right management
|
||||
- Invoicing system
|
||||
- Calendar
|
||||
- Integration with file storage systems: Google Drive, Box, OneDrive, Dropbox, OwnCloud
|
||||
- Integration with CRM, email aggregator and project management module
|
||||
- Mail server
|
||||
- Mail aggregator
|
||||
- Edit documents, spreadsheets and presentations of the most popular formats: DOC, DOCX, ODT, RTF, TXT, XLS, XLSX, ODS, CSV, PPTX, PPT, ODP
|
||||
|
||||
- Website: [www.onlyoffice.com][12]
|
||||
- Source code: [github.com/ONLYOFFICE/DocumentServer][13]
|
||||
- Developer: Ascensio System SIA
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 7.7
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150823085112605/CollaborativeEditing.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://hackpad.com/
|
||||
[2]:https://github.com/dropbox/hackpad
|
||||
[3]:https://github.com/dropbox/hackpad/blob/master/CONTRIBUTORS
|
||||
[4]:http://etherpad.org/
|
||||
[5]:https://github.com/ether/etherpad-lite
|
||||
[6]:http://www.firepad.io/
|
||||
[7]:https://github.com/firebase/firepad
|
||||
[8]:https://owncloud.org/
|
||||
[9]:http://github.com/owncloud/documents/
|
||||
[10]:https://gobby.github.io/
|
||||
[11]:https://github.com/gobby
|
||||
[12]:https://www.onlyoffice.com/free-edition.aspx
|
||||
[13]:https://github.com/ONLYOFFICE/DocumentServer
|
||||
66
sources/share/20150826 Five Super Cool Open Source Games.md
Normal file
66
sources/share/20150826 Five Super Cool Open Source Games.md
Normal file
@ -0,0 +1,66 @@
|
||||
Translating by H-mudcup
|
||||
Five Super Cool Open Source Games
|
||||
================================================================================
|
||||
In 2014 and 2015, Linux became home to a list of popular commercial titles such as the popular Borderlands, Witcher, Dead Island, and Counter Strike series of games. While this is exciting news, what of the gamer on a budget? Commercial titles are good, but even better are free-to-play alternatives made by developers who know what players like.
|
||||
|
||||
Some time ago, I came across a three year old YouTube video with the ever optimistic title [5 Open Source Games that Don’t Suck][1]. Although the video praises some open source games, I’d prefer to approach the subject with a bit more enthusiasm, at least as far as the title goes. So, here’s my list of five super cool open source games.
|
||||
|
||||
### Tux Racer ###
|
||||
|
||||
|
||||
|
||||
Tux Racer
|
||||
|
||||
[Tux Racer][2] is the first game on this list because I’ve had plenty of experience with it. On a [recent trip to Mexico][3] that my brother and I took with [Kids on Computers][4], Tux Racer was one of the games that kids and teachers alike enjoyed. In this game, players use the Linux mascot, the penguin Tux, to race on downhill ski slopes in time trials in which players challenge their own personal bests. Currently there’s no multiplayer version available, but that could be subject to change. Available for Linux, OS X, Windows, and Android.
|
||||
|
||||
### Warsow ###
|
||||
|
||||

|
||||
|
||||
Warsow
|
||||
|
||||
The [Warsow][5] website explains: “Set in a futuristic cartoonish world, Warsow is a completely free fast-paced first-person shooter (FPS) for Windows, Linux and Mac OS X. Warsow is the Art of Respect and Sportsmanship Over the Web.” I was reluctant to include games from the FPS genre on this list, because many have played games in this genre, but I was amused by Warsow. It prioritizes lots of movement and the game is fast paced with a set of eight weapons to start with. The cartoonish style makes playing feel less serious and more casual, something for friends and family to play together. However, it boasts competitive play, and when I experienced the game I found there were, indeed, some expert players around. Available for Linux, Windows and OS X.
|
||||
|
||||
### M.A.R.S – A ridiculous shooter ###
|
||||
|
||||

|
||||
|
||||
M.A.R.S. – A ridiculous shooter
|
||||
|
||||
[M.A.R.S – A ridiculous shooter][6] is appealing because of it’s vibrant coloring and style. There is support for two players on the same keyboard, but an online multiplayer version is currently in the works — meaning plans to play with friends have to wait for now. Regardless, it’s an entertaining space shooter with a few different ships and weapons to play as. There are different shaped ships, ranging from shotguns, lasers, scattered shots and more (one of the random ships shot bubbles at my opponents, which was funny amid the chaotic gameplay). There are a few modes of play, such as the standard death match against opponents to score a certain limit or score high, along with other modes called Spaceball, Grave-itation Pit and Cannon Keep. Available for Linux, Windows and OS X.
|
||||
|
||||
### Valyria Tear ###
|
||||
|
||||
|
||||
|
||||
Valyria Tear
|
||||
|
||||
[Valyria Tear][7] resembles many fan favorite role-playing games (RPGs) spanning the years. The story is set in the usual era of fantasy games, full of knights, kingdoms and wizardry, and follows the main character Bronann. The design team did great work in designing the world and gives players everything expected from the genre: hidden chests, random monster encounters, non-player character (NPC) interaction, and something no RPG would be complete without: grinding for experience on lower level slime monsters until you’re ready for the big bosses. When I gave it a try, time didn’t permit me to play too far into the campaign, but for those interested there is a ‘[Let’s Play][8]‘ series by YouTube user Yohann Ferriera. Available for Linux, Windows and OS X.
|
||||
|
||||
### SuperTuxKart ###
|
||||
|
||||

|
||||
|
||||
SuperTuxKart
|
||||
|
||||
Last but not least is [SuperTuxKart][9], a clone of Mario Kart that is every bit as fun as the original. It started development around 2000-2004 as Tux Kart, but there were errors in its production which led to a cease in development for a few years. Since development picked up again in 2006, it’s been improving, with version 0.9 debuting four months ago. In the game, our old friend Tux starts in the role of Mario and a few other open source mascots. One recognizable face among them is Suzanne, the monkey mascot for Blender. The graphics are solid and gameplay is fluent. While online play is in the planning stages, split screen multiplayer action is available, with up to four players supported on a single computer. Available for Linux, Windows, OS X, AmigaOS 4, AROS and MorphOS.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fossforce.com/2015/08/five-super-cool-open-source-games/
|
||||
|
||||
作者:Hunter Banks
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.youtube.com/watch?v=BEKVl-XtOP8
|
||||
[2]:http://tuxracer.sourceforge.net/download.html
|
||||
[3]:http://fossforce.com/2015/07/banks-family-values-texas-linux-fest/
|
||||
[4]:http://www.kidsoncomputers.org/an-amazing-week-in-oaxaca
|
||||
[5]:https://www.warsow.net/download
|
||||
[6]:http://mars-game.sourceforge.net/
|
||||
[7]:http://valyriatear.blogspot.com/
|
||||
[8]:https://www.youtube.com/channel/UCQ5KrSk9EqcT_JixWY2RyMA
|
||||
[9]:http://supertuxkart.sourceforge.net/
|
||||
@ -0,0 +1,110 @@
|
||||
Mosh Shell – A SSH Based Client for Connecting Remote Unix/Linux Systems
|
||||
================================================================================
|
||||
Mosh, which stands for Mobile Shell is a command-line application which is used for connecting to the server from a client computer, over the Internet. It can be used as SSH and contains more feature than Secure Shell. It is an application similar to SSH, but with additional features. The application is written originally by Keith Winstein for Unix like operating system and released under GNU GPL v3.
|
||||
|
||||

|
||||
|
||||
Mosh Shell SSH Client
|
||||
|
||||
#### Features of Mosh ####
|
||||
|
||||
- It is a remote terminal application that supports roaming.
|
||||
- Available for all major UNIX-like OS viz., Linux, FreeBSD, Solaris, Mac OS X and Android.
|
||||
- Intermittent Connectivity supported.
|
||||
- Provides intelligent local echo.
|
||||
- Line editing of user keystrokes supported.
|
||||
- Responsive design and Robust Nature over wifi, cellular and long-distance links.
|
||||
- Remain Connected even when IP changes. It usages UDP in place of TCP (used by SSH). TCP time out when connect is reset or new IP assigned but UDP keeps the connection open.
|
||||
- The Connection remains intact when you resume the session after a long time.
|
||||
- No network lag. Shows users typed key and deletions immediately without network lag.
|
||||
- Same old method to login as it was in SSH.
|
||||
- Mechanism to handle packet loss.
|
||||
|
||||
### Installation of Mosh Shell in Linux ###
|
||||
|
||||
On Debian, Ubuntu and Mint alike systems, you can easily install the Mosh package with the help of [apt-get package manager][1] as shown.
|
||||
|
||||
# apt-get update
|
||||
# apt-get install mosh
|
||||
|
||||
On RHEL/CentOS/Fedora based distributions, you need to turn on third party repository called [EPEL][2], in order to install mosh from this repository using [yum package manager][3] as shown.
|
||||
|
||||
# yum update
|
||||
# yum install mosh
|
||||
|
||||
On Fedora 22+ version, you need to use [dnf package manager][4] to install mosh as shown.
|
||||
|
||||
# dnf install mosh
|
||||
|
||||
### How do I use Mosh Shell? ###
|
||||
|
||||
1. Let’s try to login into remote Linux server using mosh shell.
|
||||
|
||||
$ mosh root@192.168.0.150
|
||||
|
||||

|
||||
|
||||
Mosh Shell Remote Connection
|
||||
|
||||
**Note**: Did you see I got an error in connecting since the port was not open in my remote CentOS 7 box. A quick but not recommended solution I performed was:
|
||||
|
||||
# systemctl stop firewalld [on Remote Server]
|
||||
|
||||
The preferred way is to open a port and update firewall rules. And then connect to mosh on a predefined port. For in-depth details on firewalld you may like to visit this post.
|
||||
|
||||
- [How to Configure Firewalld][5]
|
||||
|
||||
2. Let’s assume that the default SSH port 22 was changed to port 70, in this case you can define custom port with the help of ‘-p‘ switch with mosh.
|
||||
|
||||
$ mosh -p 70 root@192.168.0.150
|
||||
|
||||
3. Check the version of installed Mosh.
|
||||
|
||||
$ mosh --version
|
||||
|
||||

|
||||
|
||||
Check Mosh Version
|
||||
|
||||
4. You can close mosh session type ‘exit‘ on the prompt.
|
||||
|
||||
$ exit
|
||||
|
||||
5. Mosh supports a lot of options, which you may see as:
|
||||
|
||||
$ mosh --help
|
||||
|
||||

|
||||
|
||||
Mosh Shell Options
|
||||
|
||||
#### Cons of Mosh Shell ####
|
||||
|
||||
- Mosh requires additional prerequisite for example, allow direct connection via UDP, which was not required by SSH.
|
||||
- Dynamic port allocation in the range of 60000-61000. The first open fort is allocated. It requires one port per connection.
|
||||
- Default port allocation is a serious security concern, especially in production.
|
||||
- IPv6 connections supported, but roaming on IPv6 not supported.
|
||||
- Scrollback not supported.
|
||||
- No X11 forwarding supported.
|
||||
- No support for ssh-agent forwarding.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Mosh is a nice small utility which is available for download in the repository of most of the Linux Distributions. Though it has a few discrepancies specially security concern and additional requirement it’s features like remaining connected even while roaming is its plus point. My recommendation is Every Linux-er who deals with SSH should try this application and mind it, Mosh is worth a try.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-mosh-shell-ssh-client-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[3]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[4]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[5]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
@ -0,0 +1,194 @@
|
||||
5 best open source board games to play online
|
||||
================================================================================
|
||||
I have always had a fascination with board games, in part because they are a device of social interaction, they challenge the mind and, most importantly, they are great fun to play. In my misspent youth, myself and a group of friends gathered together to escape the horrors of the classroom, and indulge in a little escapism. The time provided an outlet for tension and rivalry. Board games help teach diplomacy, how to make and break alliances, bring families and friends together, and learn valuable lessons.
|
||||
|
||||
I had a panache for abstract strategy games such as chess and draughts, as well as word games. I can still never resist a game of Escape from Colditz, a strategy card and dice-based board game, or Risk; two timeless multi-player strategy board games. But Catan remains my favourite board game.
|
||||
|
||||
Board games have seen a resurgence in recent years, and Linux has a good range of board games to choose from. There is a credible implementation of Catan called Pioneers. But for my favourite implementations of classic board games to play online, check out the recommendations below.
|
||||
|
||||
----------
|
||||
|
||||
### TripleA ###
|
||||
|
||||

|
||||
|
||||
TripleA is an open source online turn based strategy game. It allows people to implement and play various strategy board games (ie. Axis & Allies). The TripleA engine has full networking support for online play, support for sounds, XML support for game files, and has its own imaging subsystem that allows for customized user editable maps to be used. TripleA is versatile, scalable and robust.
|
||||
|
||||
TripleA started out as a World War II simulation, but now includes different conflicts, as well as variations and mods of popular games and maps. TripleA comes with multiple games and over 100 more games can be downloaded from the user community.
|
||||
|
||||
Features include:
|
||||
|
||||
- Good interface and attractive graphics
|
||||
- Optional scenarios
|
||||
- Multiplayer games
|
||||
- TripleA comes with the following supported games that uses its game engine (just to name a few):
|
||||
- Axis & Allies : Classic edition (2nd, 3rd with options enabled)
|
||||
- Axis & Allies : Revised Edition
|
||||
- Pact of Steel A&A Variant
|
||||
- Big World 1942 A&A Variant
|
||||
- Four if by Sea
|
||||
- Battle Ship Row
|
||||
- Capture The Flag
|
||||
- Minimap
|
||||
- Hot-seat
|
||||
- Play By EMail mode allows persons to play a game via EMail without having to be connected to each other online
|
||||
- More time to think out moves
|
||||
- Only need to come online to send your turn to the next player
|
||||
- Dice rolls are done by a dedicated dice server that is independent of TripleA
|
||||
- All dice rolls are PGP Verified and email to every player
|
||||
- Every move and every dice roll is logged and saved in TripleA's History Window
|
||||
- An online game can be later continued under PBEM mode
|
||||
- Hard for others to cheat
|
||||
- Hosted online lobby
|
||||
- Utilities for editing maps
|
||||
- Website: [triplea.sourceforge.net][1]
|
||||
- Developer: Sean Bridges (original developer), Mark Christopher Duncan
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 1.8.0.7
|
||||
|
||||
----------
|
||||
|
||||
### Domination ###
|
||||
|
||||

|
||||
|
||||
Domination is an open source game that shares common themes with the hugely popular Risk board game. It has many game options and includes many maps.
|
||||
|
||||
In the classic “World Domination” game of military strategy, you are battling to conquer the world. To win, you must launch daring attacks, defend yourself to all fronts, and sweep across vast continents with boldness and cunning. But remember, the dangers, as well as the rewards, are high. Just when the world is within your grasp, your opponent might strike and take it all away!
|
||||
|
||||
Features include:
|
||||
|
||||
- Simple to learn
|
||||
- Domination - you must occupy all countries on the map, and thereby eliminate all opponents. These can be long, drawn out games
|
||||
- Capital - each player has a country they have selected as a Capital. To win the game, you must occupy all Capitals
|
||||
- Mission - each player draws a random mission. The first to complete their mission wins. Missions may include the elimination of a certain colour, occupation of a particular continent, or a mix of both
|
||||
- Map editor
|
||||
- Simple map format
|
||||
- Multiplayer network play
|
||||
- Single player
|
||||
- Hotseat
|
||||
- 5 user interfaces
|
||||
- Game types:
|
||||
- Play online
|
||||
- Website: [domination.sourceforge.net][2]
|
||||
- Developer: Yura Mamyrin, Christian Weiske, Mike Chaten, and many others
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 1.1.1.5
|
||||
|
||||
----------
|
||||
|
||||
### PyChess ###
|
||||
|
||||

|
||||
|
||||
PyChess is a Gnome inspired chess client written in Python.
|
||||
|
||||
The goal of PyChess, is to provide a fully featured, nice looking, easy to use chess client for the gnome-desktop.
|
||||
|
||||
The client should be usable both to those totally new to chess, those who want to play an occasional game, and those who wants to use the computer to further enhance their play.
|
||||
|
||||
Features include:
|
||||
|
||||
- Attractive interface
|
||||
- Chess Engine Communication Protocol (CECP) and Univeral Chess Interface (UCI) Engine support
|
||||
- Free online play on the Free Internet Chess Server (FICS)
|
||||
- Read and writes PGN, EPD and FEN chess file formats
|
||||
- Built-in Python based engine
|
||||
- Undo and pause functions
|
||||
- Board and piece animation
|
||||
- Drag and drop
|
||||
- Tabbed interface
|
||||
- Hints and spyarrows
|
||||
- Opening book sidepanel using sqlite
|
||||
- Score plot sidepanel
|
||||
- "Enter game" in pgn dialog
|
||||
- Optional sounds
|
||||
- Legal move highlighting
|
||||
- Internationalised or figure pieces in notation
|
||||
- Website: [www.pychess.org][3]
|
||||
- Developer: Thomas Dybdahl Ahle
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 0.12 Anderssen rc4
|
||||
|
||||
----------
|
||||
|
||||
### Scrabble ###
|
||||
|
||||

|
||||
|
||||
Scrabble3D is a highly customizable Scrabble game that not only supports Classic Scrabble and Superscrabble but also 3D games and own boards. You can play local against the computer or connect to a game server to find other players.
|
||||
|
||||
Scrabble is a board game with the goal to place letters crossword like. Up to four players take part and get a limited amount of letters (usually 7 or 8). Consecutively, each player tries to compose his letters to one or more word combining with the placed words on the game array. The value of the move depends on the letters (rare letter get more points) and bonus fields which multiply the value of a letter or the whole word. The player with most points win.
|
||||
|
||||
This idea is extended with Scrabble3D to the third dimension. Of course, a classic game with 15x15 fields or Superscrabble with 21x21 fields can be played and you may configure any field setting by yourself. The game can be played by the provided freeware program against Computer, other local players or via internet. Last but not least it's possible to connect to a game server to find other players and to obtain a rating. Most options are configurable, including the number and valuation of letters, the used dictionary, the language of dialogs and certainly colors, fonts etc.
|
||||
|
||||
Features include:
|
||||
|
||||
- Configurable board, letterset and design
|
||||
- Board in OpenGL graphics with user-definable wavefront model
|
||||
- Game against computer with support of multithreading
|
||||
- Post-hoc game analysis with calculation of best move by computer
|
||||
- Match with other players connected on a game server
|
||||
- NSA rating and highscore at game server
|
||||
- Time limit of games
|
||||
- Localization; use of non-standard digraphs like CH, RR, LL and right to left reading
|
||||
- Multilanguage help / wiki
|
||||
- Network games are buffered and asynchronous games are possible
|
||||
- Running games can be kibitzed
|
||||
- International rules including italian "Cambio Secco"
|
||||
- Challenge mode, What-if-variant, CLABBERS, etc
|
||||
- Website: [sourceforge.net/projects/scrabble][4]
|
||||
- Developer: Heiko Tietze
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 3.1.3
|
||||
|
||||
----------
|
||||
|
||||
### Backgammon ###
|
||||
|
||||

|
||||
|
||||
GNU Backgammon (gnubg) is a strong backgammon program (world-class with a bearoff database installed) usable either as an engine by other programs or as a standalone backgammon game. It is able to play and analyze both money games and tournament matches, evaluate and roll out positions, and more.
|
||||
|
||||
In addition to supporting simple play, it also has extensive analysis features, a tutor mode, adjustable difficulty, and support for exporting annotated games.
|
||||
|
||||
It currently plays at about the level of a championship flight tournament player and is gradually improving.
|
||||
|
||||
gnubg can be played on numerous on-line backgammon servers, such as the First Internet Backgammon Server (FIBS).
|
||||
|
||||
Features include:
|
||||
|
||||
- A command line interface (with full command editing features if GNU readline is available) that lets you play matches and sessions against GNU Backgammon with a rough ASCII representation of the board on text terminals
|
||||
- Support for a GTK+ interface with a graphical board window. Both 2D and 3D graphics are available
|
||||
- Tournament match and money session cube handling and cubeful play
|
||||
- Support for both 1-sided and 2-sided bearoff databases: 1-sided bearoff database for 15 checkers on the first 6 points and optional 2-sided database kept in memory. Optional larger 1-sided and 2-sided databases stored on disk
|
||||
- Automated rollouts of positions, with lookahead and race variance reduction where appropriate. Rollouts may be extended
|
||||
- Functions to generate legal moves and evaluate positions at varying search depths
|
||||
- Neural net functions for giving cubeless evaluations of all other contact and race positions
|
||||
- Automatic and manual annotation (analysis and commentary) of games and matches
|
||||
- Record keeping of statistics of players in games and matches (both native inside GNU Backgammon and externally using relational databases and Python)
|
||||
- Loading and saving analyzed games and matches as .sgf files (Smart Game Format)
|
||||
- Exporting positions, games and matches to: (.eps) Encapsulated Postscript, (.gam) Jellyfish Game, (.html) HTML, (.mat) Jellyfish Match, (.pdf) PDF, (.png) Portable Network Graphics, (.pos) Jellyfish Position, (.ps) PostScript, (.sgf) Gnu Backgammon File, (.tex) LaTeX, (.txt) Plain Text, (.txt) Snowie Text
|
||||
- Import of matches and positions from a number of file formats: (.bkg) Hans Berliner's BKG Format, (.gam) GammonEmpire Game, (.gam) PartyGammon Game, (.mat) Jellyfish Match, (.pos) Jellyfish Position, (.sgf) Gnu Backgammon File, (.sgg) GamesGrid Save Game, (.tmg) TrueMoneyGames, (.txt) Snowie Text
|
||||
- Python Scripting
|
||||
- Native language support; 10 languages complete or in progress
|
||||
- Website: [www.gnubg.org][5]
|
||||
- Developer: Joseph Heled, Oystein Johansen, Jonathan Kinsey, David Montgomery, Jim Segrave, Joern Thyssen, Gary Wong and contributors
|
||||
- License: GPL v2
|
||||
- Version Number: 1.05.000
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150830011533893/BoardGames.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://triplea.sourceforge.net/
|
||||
[2]:http://domination.sourceforge.net/
|
||||
[3]:http://www.pychess.org/
|
||||
[4]:http://sourceforge.net/projects/scrabble/
|
||||
[5]:http://www.gnubg.org/
|
||||
@ -1,127 +0,0 @@
|
||||
Translating by H-mudcup
|
||||
|
||||
Defending the Free Linux World
|
||||
================================================================================
|
||||

|
||||
|
||||
**Co-opetition is a part of open source. The Open Invention Network model allows companies to decide where they will compete and where they will collaborate, explained OIN CEO Keith Bergelt. As open source evolved, "we had to create channels for collaboration. Otherwise, we would have hundreds of entities spending billions of dollars on the same technology."**
|
||||
|
||||
The [Open Invention Network][1], or OIN, is waging a global campaign to keep Linux out of harm's way in patent litigation. Its efforts have resulted in more than 1,000 companies joining forces to become the largest defense patent management organization in history.
|
||||
|
||||
The Open Invention Network was created in 2005 as a white hat organization to protect Linux from license assaults. It has considerable financial backing from original board members that include Google, IBM, NEC, Novell, Philips, [Red Hat][2] and Sony. Organizations worldwide have joined the OIN community by signing the free OIN license.
|
||||
|
||||
Organizers founded the Open Invention Network as a bold endeavor to leverage intellectual property to protect Linux. Its business model was difficult to comprehend. It asked its members to take a royalty-free license and forever forgo the chance to sue other members over their Linux-oriented intellectual property.
|
||||
|
||||
However, the surge in Linux adoptions since then -- think server and cloud platforms -- has made protecting Linux intellectual property a critically necessary strategy.
|
||||
|
||||
Over the past year or so, there has been a shift in the Linux landscape. OIN is doing a lot less talking to people about what the organization is and a lot less explaining why Linux needs protection. There is now a global awareness of the centrality of Linux, according to Keith Bergelt, CEO of OIN.
|
||||
|
||||
"We have seen a culture shift to recognizing how OIN benefits collaboration," he told LinuxInsider.
|
||||
|
||||
### How It Works ###
|
||||
|
||||
The Open Invention Network uses patents to create a collaborative environment. This approach helps ensure the continuation of innovation that has benefited software vendors, customers, emerging markets and investors.
|
||||
|
||||
Patents owned by Open Invention Network are available royalty-free to any company, institution or individual. All that is required to qualify is the signer's agreement not to assert its patents against the Linux system.
|
||||
|
||||
OIN ensures the openness of the Linux source code. This allows programmers, equipment vendors, independent software vendors and institutions to invest in and use Linux without excessive worry about intellectual property issues. This makes it more economical for companies to repackage, embed and use Linux.
|
||||
|
||||
"With the diffusion of copyright licenses, the need for OIN licenses becomes more acute. People are now looking for a simpler or more utilitarian solution," said Bergelt.
|
||||
|
||||
OIN legal defenses are free of charge to members. Members commit to not initiating patent litigation against the software in OIN's list. They also agree to offer their own patents in defense of that software. Ultimately, these commitments result in access to hundreds of thousands of patents cross-licensed by the network, Bergelt explained.
|
||||
|
||||
### Closing the Legal Loopholes ###
|
||||
|
||||
"What OIN is doing is very essential. It offers another layer of IP protection, said Greg R. Vetter, associate professor of law at the [University of Houston Law Center][3].
|
||||
|
||||
Version 2 of the GPL license is thought by some to provide an implied patent license, but lawyers always feel better with an explicit license, he told LinuxInsider.
|
||||
|
||||
What OIN provides is something that bridges that gap. It also provides explicit coverage of the Linux kernel. An explicit patent license is not necessarily part of the GPLv2, but it was added in GPLv3, according to Vetter.
|
||||
|
||||
Take the case of a code writer who produces 10,000 lines of code under GPLv3, for example. Over time, other code writers contribute many more lines of code, which adds to the IP. The software patent license provisions in GPLv3 would protect the use of the entire code base under all of the participating contributors' patents, Vetter said.
|
||||
|
||||
### Not Quite the Same ###
|
||||
|
||||
Patents and licenses are overlapping legal constructs. Figuring out how the two entities work with open source software can be like traversing a minefield.
|
||||
|
||||
"Licenses are legal constructs granting additional rights based on, typically, patent and copyright laws. Licenses are thought to give a permission to do something that might otherwise be infringement of someone else's IP rights," Vetter said.
|
||||
|
||||
Many free and open source licenses (such as the Mozilla Public License, the GNU GPLv3, and the Apache Software License) incorporate some form of reciprocal patent rights clearance. Older licenses like BSD and MIT do not mention patents, Vetter pointed out.
|
||||
|
||||
A software license gives someone else certain rights to use the code the programmer created. Copyright to establish ownership is automatic, as soon as someone writes or draws something original. However, copyright covers only that particular expression and derivative works. It does not cover code functionality or ideas for use.
|
||||
|
||||
Patents cover functionality. Patent rights also can be licensed. A copyright may not protect how someone independently developed implementation of another's code, but a patent fills this niche, Vetter explained.
|
||||
|
||||
### Looking for Safe Passage ###
|
||||
|
||||
The mixing of license and patent legalities can appear threatening to open source developers. For some, even the GPL qualifies as threatening, according to William Hurley, cofounder of [Chaotic Moon Studios][4] and [IEEE][5] Computer Society member.
|
||||
|
||||
"Way back in the day, open source was a different world. Driven by mutual respect and a view of code as art, not property, things were far more open than they are today. I believe that many efforts set upon with the best of intentions almost always end up bearing unintended consequences," Hurley told LinuxInsider.
|
||||
|
||||
Surpassing the 1,000-member mark might carry a mixed message about the significance of intellectual property right protection, he suggested. It might just continue to muddy the already murky waters of today's open source ecosystem.
|
||||
|
||||
"At the end of the day, this shows some of the common misconceptions around intellectual property. Having thousands of developers does not decrease risk -- it increases it. The more developers licensing the patents, the more valuable they appear to be," Hurley said. "The more valuable they appear to be, the more likely someone with similar patents or other intellectual property will try to take advantage and extract value for their own financial gain."
|
||||
|
||||
### Sharing While Competing ###
|
||||
|
||||
Co-opetition is a part of open source. The OIN model allows companies to decide where they will compete and where they will collaborate, explained Bergelt.
|
||||
|
||||
"Many of the changes in the evolution of open source in terms of process have moved us into a different direction. We had to create channels for collaboration. Otherwise, we would have hundreds of entities spending billions of dollars on the same technology," he said.
|
||||
|
||||
A glaring example of this is the early evolution of the cellphone industry. Multiple standards were put forward by multiple companies. There was no sharing and no collaboration, noted Bergelt.
|
||||
|
||||
"That damaged our ability to access technology by seven to 10 years in the U.S. Our experience with devices was far behind what everybody else in the world had. We were complacent with GSM (Global System for Mobile Communications) while we were waiting for CDMA (Code Division Multiple Access)," he said.
|
||||
|
||||
### Changing Landscape ###
|
||||
|
||||
OIN experienced a growth surge of 400 new licensees in the last year. That is indicative of a new trend involving open source.
|
||||
|
||||
"The marketplace reached a critical mass where finally people within organizations recognized the need to explicitly collaborate and to compete. The result is doing both at the same time. This can be messy and taxing," Bergelt said.
|
||||
|
||||
However, it is a sustainable transformation driven by a cultural shift in how people think about collaboration and competition. It is also a shift in how people are embracing open source -- and Linux in particular -- as the lead project in the open source community, he explained.
|
||||
|
||||
One indication is that most significant new projects are not being developed under the GPLv3 license.
|
||||
|
||||
### Two Better Than One ###
|
||||
|
||||
"The GPL is incredibly important, but the reality is there are a number of licensing models being used. The relative addressability of patent issues is generally far lower in Eclipse and Apache and Berkeley licenses that it is in GPLv3," said Bergelt.
|
||||
|
||||
GPLv3 is a natural complement for addressing patent issues -- but the GPL is not sufficient on its own to address the issues of potential conflicts around the use of patents. So OIN is designed as a complement to copyright licenses, he added.
|
||||
|
||||
However, the overlap of patent and license may not do much good. In the end, patents are for offensive purposes -- not defensive -- in almost every case, Bergelt suggested.
|
||||
|
||||
"If you are not prepared to take legal action against others, then a patent may not be the best form of legal protection for your intellectual properties," he said. "We now live in a world where the misconceptions around software, both open and proprietary, combined with an ill-conceived and outdated patent system, leave us floundering as an industry and stifling innovation on a daily basis," he said.
|
||||
|
||||
### Court of Last Resort ###
|
||||
|
||||
It would be nice to think the presence of OIN has dampened a flood of litigation, Bergelt said, or at the very least, that OIN's presence is neutralizing specific threats.
|
||||
|
||||
"We are getting people to lay down their arms, so to say. At the same time, we are creating a new cultural norm. Once you buy into patent nonaggression in this model, the correlative effect is to encourage collaboration," he observed.
|
||||
|
||||
If you are committed to collaboration, you tend not to rush to litigation as a first response. Instead, you think in terms of how can we enable you to use what we have and make some money out of it while we use what you have, Bergelt explained.
|
||||
|
||||
"OIN is a multilateral solution. It encourages signers to create bilateral agreements," he said. "That makes litigation the last course of action. That is where it should be."
|
||||
|
||||
### Bottom Line ###
|
||||
|
||||
OIN is working to prevent Linux patent challenges, Bergelt is convinced. There has not been litigation in this space involving Linux.
|
||||
|
||||
The only thing that comes close are the mobile wars with Microsoft, which focus on elements high in the stack. Those legal challenges may be designed to raise the cost of ownership involving the use of Linux products, Bergelt noted.
|
||||
|
||||
Still, "these are not Linux-related law suits," he said. "They do not focus on what is core to Linux. They focus on what is in the Linux system."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Defending-the-Free-Linux-World-81512.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openinventionnetwork.com/
|
||||
[2]:http://www.redhat.com/
|
||||
[3]:http://www.law.uh.edu/
|
||||
[4]:http://www.chaoticmoon.com/
|
||||
[5]:http://www.ieee.org/
|
||||
@ -1,4 +1,3 @@
|
||||
zpl1025
|
||||
Interviews: Linus Torvalds Answers Your Question
|
||||
================================================================================
|
||||
Last Thursday you had a chance to [ask Linus Torvalds][1] about programming, hardware, and all things Linux. You can read his answers to those questions below. If you'd like to see what he had to say the last time we sat down with him, [you can do so here][2].
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
martin
|
||||
translating...
|
||||
|
||||
Interview: Larry Wall
|
||||
================================================================================
|
||||
|
||||
@ -0,0 +1,344 @@
|
||||
A Linux User Using ‘Windows 10′ After More than 8 Years – See Comparison
|
||||
================================================================================
|
||||
Windows 10 is the newest member of windows NT family of which general availability was made on July 29, 2015. It is the successor of Windows 8.1. Windows 10 is supported on Intel Architecture 32 bit, AMD64 and ARMv7 processors.
|
||||
|
||||

|
||||
|
||||
Windows 10 and Linux Comparison
|
||||
|
||||
As a Linux-user for more than 8 continuous years, I thought to test Windows 10, as it is making a lots of news these days. This article is a breakthrough of my observation. I will be seeing everything from the perspective of a Linux user so you may find it a bit biased towards Linux but with absolutely no false information.
|
||||
|
||||
1. I searched Google with the text “download windows 10” and clicked the first link.
|
||||
|
||||

|
||||
|
||||
Search Windows 10
|
||||
|
||||
You may directly go to link : [https://www.microsoft.com/en-us/software-download/windows10ISO][1]
|
||||
|
||||
2. I was supposed to select a edition from ‘windows 10‘, ‘windows 10 KN‘, ‘windows 10 N‘ and ‘windows 10 single language‘.
|
||||
|
||||

|
||||
|
||||
Select Windows 10 Edition
|
||||
|
||||
For those who want to know details of different editions of Windows 10, here is the brief details of editions.
|
||||
|
||||
- Windows 10 – Contains everything offered by Microsoft for this OS.
|
||||
- Windows 10N – This edition comes without Media-player.
|
||||
- Windows 10KN – This edition comes without media playing capabilities.
|
||||
- Windows 10 Single Language – Only one Language Pre-installed.
|
||||
|
||||
3. I selected the first option ‘Windows 10‘ and clicked ‘Confirm‘. Then I was supposed to select a product language. I choose ‘English‘.
|
||||
|
||||
I was provided with Two Download Links. One for 32-bit and other for 64-bit. I clicked 64-bit, as per my architecture.
|
||||
|
||||

|
||||
|
||||
Download Windows 10
|
||||
|
||||
With my download speed (15Mbps), it took me 3 long hours to download it. Unfortunately there were no torrent file to download the OS, which could otherwise have made the overall process smooth. The OS iso image size is 3.8 GB.
|
||||
|
||||
I could not find an image of smaller size but again the truth is there don’t exist net-installer image like things for Windows. Also there is no way to calculate hash value after the iso image has been downloaded.
|
||||
|
||||
Wonder why so ignorance from windows on such issues. To verify if the iso is downloaded correctly I need to write the image to a disk or to a USB flash drive and then boot my system and keep my finger crossed till the setup is finished.
|
||||
|
||||
Lets start. I made my USB flash drive bootable with the windows 10 iso using dd command, as:
|
||||
|
||||
# dd if=/home/avi/Downloads/Win10_English_x64.iso of=/dev/sdb1 bs=512M; sync
|
||||
|
||||
It took a few minutes to complete the process. I then rebooted the system and choose to boot from USB flash Drive in my UEFI (BIOS) settings.
|
||||
|
||||
#### System Requirements ####
|
||||
|
||||
If you are upgrading
|
||||
|
||||
- Upgrade supported only from Windows 7 SP1 or Windows 8.1
|
||||
|
||||
If you are fresh Installing
|
||||
|
||||
- Processor: 1GHz or faster
|
||||
- RAM : 1GB and Above(32-bit), 2GB and Above(64-bit)
|
||||
- HDD: 16GB and Above(32-bit), 20GB and Above(64-bit)
|
||||
- Graphic card: DirectX 9 or later + WDDM 1.0 Driver
|
||||
|
||||
### Installation of Windows 10 ###
|
||||
|
||||
1. Windows 10 boots. Yet again they changed the logo. Also no information on whats going on.
|
||||
|
||||
|
||||
|
||||
Windows 10 Logo
|
||||
|
||||
2. Selected Language to install, Time & currency format and keyboard & Input methods before clicking Next.
|
||||
|
||||

|
||||
|
||||
Select Language and Time
|
||||
|
||||
3. And then ‘Install Now‘ Menu.
|
||||
|
||||
|
||||
|
||||
Install Windows 10
|
||||
|
||||
4. The next screen is asking for Product key. I clicked ‘skip’.
|
||||
|
||||
|
||||
|
||||
Windows 10 Product Key
|
||||
|
||||
5. Choose from a listed OS. I chose ‘windows 10 pro‘.
|
||||
|
||||

|
||||
|
||||
Select Install Operating System
|
||||
|
||||
6. oh yes the license agreement. Put a check mark against ‘I accept the license terms‘ and click next.
|
||||
|
||||

|
||||
|
||||
Accept License
|
||||
|
||||
7. Next was to upgrade (to windows 10 from previous versions of windows) and Install Windows. Don’t know why custom: Windows Install only is suggested as advanced by windows. Anyway I chose to Install windows only.
|
||||
|
||||

|
||||
|
||||
Select Installation Type
|
||||
|
||||
8. Selected the file-system and clicked ‘next’.
|
||||
|
||||

|
||||
|
||||
Select Install Drive
|
||||
|
||||
9. The installer started to copy files, getting files ready for installation, installing features, installing updates and finishing up. It would be better if the installer would have shown verbose output on the action is it taking.
|
||||
|
||||

|
||||
|
||||
Installing Windows
|
||||
|
||||
10. And then windows restarted. They said reboot was needed to continue.
|
||||
|
||||

|
||||
|
||||
Windows Installation Process
|
||||
|
||||
11. And then all I got was the below screen which reads “Getting Ready”. It took 5+ minutes at this point. No idea what was going on. No output.
|
||||
|
||||

|
||||
|
||||
Windows Getting Ready
|
||||
|
||||
12. yet again, it was time to “Enter Product Key”. I clicked “Do this later” and then used expressed settings.
|
||||
|
||||

|
||||
|
||||
Enter Product Key
|
||||
|
||||

|
||||
|
||||
Select Express Settings
|
||||
|
||||
14. And then three more output screens, where I as a Linuxer expected that the Installer will tell me what it is doing but all in vain.
|
||||
|
||||

|
||||
|
||||
Loading Windows
|
||||
|
||||

|
||||
|
||||
Getting Updates
|
||||
|
||||

|
||||
|
||||
Still Loading Windows
|
||||
|
||||
15. And then the installer wanted to know who owns this machine “My organization” or I myself. Chose “I own it” and then next.
|
||||
|
||||

|
||||
|
||||
Select Organization
|
||||
|
||||
16. Installer prompted me to join “Azure Ad” or “Join a domain”, before I can click ‘continue’. I chooses the later option.
|
||||
|
||||

|
||||
|
||||
Connect Windows
|
||||
|
||||
17. The Installer wants me to create an account. So I entered user_name and clicked ‘Next‘, I was expecting an error message that I must enter a password.
|
||||
|
||||

|
||||
|
||||
Create Account
|
||||
|
||||
18. To my surprise Windows didn’t even showed warning/notification that I must create password. Such a negligence. Anyway I got my desktop.
|
||||
|
||||

|
||||
|
||||
Windows 10 Desktop
|
||||
|
||||
#### Experience of a Linux-user (Myself) till now ####
|
||||
|
||||
- No Net-installer Image
|
||||
- Image size too heavy
|
||||
- No way to check the integrity of iso downloaded (no hash check)
|
||||
- The booting and installation remains same as it was in XP, Windows 7 and 8 perhaps.
|
||||
- As usual no output on what windows Installer is doing – What file copying or what package installing.
|
||||
- Installation was straight forward and easy as compared to the installation of a Linux distribution.
|
||||
|
||||
### Windows 10 Testing ###
|
||||
|
||||
19. The default Desktop is clean. It has a recycle bin Icon on the default desktop. Search web directly from the desktop itself. Additionally icons for Task viewing, Internet browsing, folder browsing and Microsoft store is there. As usual notification bar is present on the bottom right to sum up desktop.
|
||||
|
||||

|
||||
|
||||
Deskop Shortcut Icons
|
||||
|
||||
20. Internet Explorer replaced with Microsoft Edge. Windows 10 has replace the legacy web browser Internet Explorer also known as IE with Edge aka project spartan.
|
||||
|
||||

|
||||
|
||||
Microsoft Edge Browser
|
||||
|
||||
It is fast at least as compared to IE (as it seems it testing). Familiar user Interface. The home screen contains news feed updates. There is also a search bar title that reads ‘Where to next?‘. The browser loads time is considerably low which result in improving overall speed and performance. The memory usages of Edge seems normal.
|
||||
|
||||

|
||||
|
||||
Windows Performance
|
||||
|
||||
Edge has got cortana – Intelligent Personal Assistant, Support for chrome-extension, web Note – Take notes while Browsing, Share – Right from the tab without opening any other TAB.
|
||||
|
||||
#### Experience of a Linux-user (Myself) on this point ####
|
||||
|
||||
21. Microsoft has really improved web browsing. Lets see how stable and fine it remains. It don’t lag as of now.
|
||||
|
||||
22. Though RAM usages by Edge was fine for me, a lots of users are complaining that Edge is notorious for Excessive RAM Usages.
|
||||
|
||||
23. Difficult to say at this point if Edge is ready to compete with Chrome and/or Firefox at this point of time. Lets see what future unfolds.
|
||||
|
||||
#### A few more Virtual Tour ####
|
||||
|
||||
24. Start Menu redesigned – Seems clear and effective. Metro icons make it live. Populated with most commonly applications viz., Calendar, Mail, Edge, Photos, Contact, Temperature, Companion suite, OneNote, Store, Xbox, Music, Movies & TV, Money, News, Store, etc.
|
||||
|
||||

|
||||
|
||||
Windows Look and Feel
|
||||
|
||||
In Linux on Gnome Desktop Environment, I use to search required applications simply by pressing windows key and then type the name of the application.
|
||||
|
||||

|
||||
|
||||
Search Within Desktop
|
||||
|
||||
25. File Explorer – seems clear Designing. Edges are sharp. In the left pane there is link to quick access folders.
|
||||
|
||||

|
||||
|
||||
Windows File Explorer
|
||||
|
||||
Equally clear and effective file explorer on Gnome Desktop Environment on Linux. Removed UN-necessary graphics and images from icons is a plus point.
|
||||
|
||||

|
||||
|
||||
File Browser on Gnome
|
||||
|
||||
26. Settings – Though the settings are a bit refined on Windows 10, you may compare it with the settings on a Linux Box.
|
||||
|
||||
**Settings on Windows**
|
||||
|
||||

|
||||
|
||||
Windows 10 Settings
|
||||
|
||||
**Setting on Linux Gnome**
|
||||
|
||||

|
||||
|
||||
Gnome Settings
|
||||
|
||||
27. List of Applications – List of Application on Linux is better than what they use to provide (based upon my memory, when I was a regular windows user) but still it stands low as compared to how Gnome3 list application.
|
||||
|
||||
**Application Listed by Windows**
|
||||
|
||||

|
||||
|
||||
Application List on Windows 10
|
||||
|
||||
**Application Listed by Gnome3 on Linux**
|
||||
|
||||

|
||||
|
||||
Gnome Application List on Linux
|
||||
|
||||
28. Virtual Desktop – Virtual Desktop feature of Windows 10 is one of those topic which are very much talked about these days.
|
||||
|
||||
Here is the virtual Desktop in Windows 10.
|
||||
|
||||

|
||||
|
||||
Windows Virtual Desktop
|
||||
|
||||
and the virtual Desktop on Linux we are using for more than 2 decades.
|
||||
|
||||

|
||||
|
||||
Virtual Desktop on Linux
|
||||
|
||||
#### A few other features of Windows 10 ####
|
||||
|
||||
29. Windows 10 comes with wi-fi sense. It shares your password with others. Anyone who is in the range of your wi-fi and connected to you over Skype, Outlook, Hotmail or Facebook can be granted access to your wifi network. And mind it this feature has been added as a feature by microsoft to save time and hassle-free connection.
|
||||
|
||||
In a reply to question raised by Tecmint, Microsoft said – The user has to agree to enable wifi sense, everytime on a new network. oh! What a pathetic taste as far as security is concerned. I am not convinced.
|
||||
|
||||
30. Up-gradation from Windows 7 and Windows 8.1 is free though the retail cost of Home and pro editions are approximately $119 and $199 respectively.
|
||||
|
||||
31. Microsoft released first cumulative update for windows 10, which is said to put system into endless crash loop for a few people. Windows perhaps don’t understand such problem or don’t want to work on that part don’t know why.
|
||||
|
||||
32. Microsoft’s inbuilt utility to block/hide unwanted updates don’t work in my case. This means If a update is there, there is no way to block/hide it. Sorry windows users!
|
||||
|
||||
#### A few features native to Linux that windows 10 have ####
|
||||
|
||||
Windows 10 has a lots of features that were taken directly from Linux. If Linux were not released under GNU License perhaps Microsoft would never had the below features.
|
||||
|
||||
33. Command-line package management – Yup! You heard it right. Windows 10 has a built-in package management. It works only in Windows Power Shell. OneGet is the official package manager for windows. Windows package manager in action.
|
||||
|
||||

|
||||
|
||||
Windows 10 Package Manager
|
||||
|
||||
- Border-less windows
|
||||
- Flat Icons
|
||||
- Virtual Desktop
|
||||
- One search for Online+offline search
|
||||
- Convergence of mobile and desktop OS
|
||||
|
||||
### Overall Conclusion ###
|
||||
|
||||
- Improved responsiveness
|
||||
- Well implemented Animation
|
||||
- low on resource
|
||||
- Improved battery life
|
||||
- Microsoft Edge web-browser is rock solid
|
||||
- Supported on Raspberry pi 2.
|
||||
- It is good because windows 8/8.1 was not upto mark and really bad.
|
||||
- It is a the same old wine in new bottle. Almost the same things with brushed up icons.
|
||||
|
||||
What my testing suggest is Windows 10 has improved on a few things like look and feel (as windows always did), +1 for Project spartan, Virtual Desktop, Command-line package management, one search for online and offline search. It is overall an improved product but those who thinks that Windows 10 will prove to be the last nail in the coffin of Linux are mistaken.
|
||||
|
||||
Linux is years ahead of Windows. Their approach is different. In near future windows won’t stand anywhere around Linux and there is nothing for which a Linux user need to go to Windows 10.
|
||||
|
||||
That’s all for now. Hope you liked the post. I will be here again with another interesting post you people will love to read. Provide us with your valuable feedback in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/a-linux-user-using-windows-10-after-more-than-8-years-see-comparison/
|
||||
|
||||
作者:[vishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://www.microsoft.com/en-us/software-download/windows10ISO
|
||||
@ -0,0 +1,46 @@
|
||||
LinuxCon's surprise keynote speaker Linus Torvalds muses about open-source software
|
||||
================================================================================
|
||||
> In a broad-ranging question and answer session, Linus Torvalds, Linux's founder, shared his thoughts on the current state of open source and Linux.
|
||||
|
||||
**SEATTLE** -- [LinuxCon][1] attendees got an early Christmas present when the Wednesday morning "surprise" keynote speaker turned out to be Linux's founder, Linus Torvalds.
|
||||
|
||||

|
||||
|
||||
Jim Zemlin and Linus Torvalds shooting the breeze at LinuxCon in Seattle. -- sjvn
|
||||
|
||||
Jim Zemlin, the Linux Foundation's executive director, opened the question and answer session by quoting from a recent article about Linus, "[Torvalds may be the most influential individual economic force][2] of the past 20 years. ... Torvalds has, in effect, been as instrumental in retooling the production lines of the modern economy as Henry Ford was 100 years earlier."
|
||||
|
||||
Torvalds replied, "I don't think I'm all that powerful, but I'm glad to get all the credit for open source." For someone who's arguably been more influential on technology than Bill Gates, Steve Jobs, or Larry Ellison, Torvalds remains amusingly modest. That's probably one reason [Torvalds, who doesn't suffer fools gladly][3], remains the unchallenged leader of Linux.
|
||||
|
||||
It also helps that he doesn't take himself seriously, except when it comes to code quality. Zemlin reminded him that he was also described in the same article as being "5-feet, ho-hum tall with a paunch, ... his body type and gait resemble that of Tux, the penguin mascot of Linux." Torvald's reply was to grin and say "What is this? A roast?" He added that 5'8" was a perfectly good height.
|
||||
|
||||
More seriously, Zemlin asked Torvalds what he thought about the current excitement over containers. Indeed, at times LinuxCon has felt like DockerCon. Torvalds replied, "I'm glad that the kernel is far removed from containers and other buzzwords. We only care about just the kernel. I'm so focused on the kernel I really don't care. I don't get involved in the politics above the kernel and I'm really happy that I don't know."
|
||||
|
||||
Moving on, Zemlin asked Torvalds what he thought about the demand from the Internet of Things (IoT) for an even smaller Linux kernel. "Everyone has always wished for a smaller kernel," Torvalds said. "But, with all the modules it's still tens of MegaBytes in size. It's shocking that it used to fit into a MB. We'd like it to be mean lean, mean IT machine again."
|
||||
|
||||
But, "Torvalds continued, "It's hard to get rid of unnecessary fat. Things tend to grow. Realistically I don't think we can get down to the sizes we were 20 years ago."
|
||||
|
||||
As for security, the next topic, Torvalds said, "I'm at odds with the security community. They tend to see technology as black and white. If it's not security they don't care at all about it." The truth is "security is bugs. Most of the security issues we've had in the kernel hasn't been that big. Most of them have been really stupid and then some clever person takes advantage of it."
|
||||
|
||||
The bottom line is, "We'll never get rid of bugs so security will never be perfect. We do try to be really careful about code. With user space we have to be very strict." But, "Bugs happen and all you can do is mitigate them. Open source is doing fairly well, but anyone who thinks we'll ever be completely secure is foolish."
|
||||
|
||||
Zemlin concluded by asking Torvalds where he saw Linux ten years from now. Torvalds replied that he doesn't look at it this way. "I'm plodding, pedestrian, I look ahead six months, I don't plan 10 years ahead. I think that's insane."
|
||||
|
||||
Sure, "companies plan ten years, and their plans use open source. Their whole process is very forward thinking. But I'm not worried about 10 years ahead. I look to the next release and the release beyond that."
|
||||
|
||||
For Torvalds, who works at home where "the FedEx guy is no longer surprised to find me in my bathrobe at 2 in the afternoon," looking ahead a few months works just fine. And so do all the businesses -- both technology-based Amazon, Google, Facebook and more mainstream, WalMart, the New York Stock Exchange, and McDonalds -- that live on Linux every day.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/linus-torvalds-muses-about-open-source-software/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
[2]:http://www.bloomberg.com/news/articles/2015-06-16/the-creator-of-linux-on-the-future-without-him
|
||||
[3]:http://www.zdnet.com/article/linus-torvalds-finds-gnome-3-4-to-be-a-total-user-experience-design-failure/
|
||||
@ -0,0 +1,53 @@
|
||||
Which Open Source Linux Distributions Would Presidential Hopefuls Run?
|
||||
================================================================================
|
||||

|
||||
|
||||
Republican presidential candidate Donald Trump
|
||||
|
||||
If people running for president used Linux or another open source operating system, which distribution would it be? That's a key question that the rest of the press—distracted by issues of questionable relevance such as "policy platforms" and whether it's appropriate to add an exclamation point to one's Christian name—has been ignoring. But the ignorance ends here: Read on for this sometime-journalist's take on presidential elections and Linux distributions.
|
||||
|
||||
If this sounds like a familiar topic to those of you who have been reading my drivel for years (is anyone, other than my dear editor, unfortunate enough to have actually done that?), it's because I wrote a [similar post][1] during the last presidential election cycle. Some kind readers took that article more seriously than I intended, so I'll take a moment to point out that I don't actually believe that open source software and political campaigns have anything meaningful to do with one another. I am just trying to amuse myself at the start of a new week.
|
||||
|
||||
But you can make of this what you will. You're the reader, after all.
|
||||
|
||||
### Linux Distributions of Choice: Republicans ###
|
||||
|
||||
Today, I'll cover just the Republicans. And I won't even discuss all of them, since the candidates hoping for the Republican party's nomination are too numerous to cover fully here in one post. But for starters:
|
||||
|
||||
If **Jeb (Jeb!?) Bush** ran Linux, it would be [Debian][2]. It's a relatively boring distribution designed for serious, grown-up hackers—the kind who see it as their mission to be the adults in the pack and clean up the messes that less-experienced open source fans create. Of course, this also makes Debian relatively unexciting, and its user base remains perennially small as a result.
|
||||
|
||||
**Scott Walker**, for his part, would be a [Damn Small Linux][3] (DSL) user. Requiring merely 50MB of disk space and 16MB of RAM to run, DSL can breathe new life into 20-year-old 486 computers—which is exactly what a cost-cutting guru like Walker would want. Of course, the user experience you get from DSL is damn primitive; the platform barely runs a browser. But at least you won't be wasting money on new computer hardware when the stuff you bought in 1993 can still serve you perfectly well.
|
||||
|
||||
How about **Chris Christie**? He'd obviously be clinging to [Relax-and-Recover Linux][4], which bills itself as a "setup-and-forget Linux bare metal disaster recovery solution." "Setup-and-forget" has basically been Christie's political strategy ever since that unfortunate incident on the George Washington Bridge stymied his political momentum. Disaster recovery may or may not bring back everything for Christie in the end, but at least he might succeed in recovering a confidential email or two that accidentally disappeared when his computer crashed.
|
||||
|
||||
As for **Carly Fiorina**, she'd no doubt be using software developed for "[The Machine][5]" operating system from [Hewlett-Packard][6] (HPQ), the company she led from 1999 to 2005. The Machine actually may run several different operating systems, which may or may not be based on Linux—details remain unclear—and its development began well after Fiorina's tenure at HP came to a conclusion. Still, her roots as a successful executive in the IT world form an important part of her profile today, meaning that her ties to HP have hardly been severed fully.
|
||||
|
||||
Last but not least—and you knew this was coming—there's **Donald Trump**. He'd most likely pay a team of elite hackers millions of dollars to custom-build an operating system just for him—even though he could obtain a perfectly good, ready-made operating system for free—to show off how much money he has to waste. He'd then brag about it being the best operating system ever made, though it would of course not be compliant with POSIX or anything else, because that would mean catering to the establishment. The platform would also be totally undocumented, since, if Trump explained how his operating system actually worked, he'd risk giving away all his secrets to the Islamic State—obviously.
|
||||
|
||||
Alternatively, if Trump had to go with a Linux platform already out there, [Ubuntu][7] seems like the most obvious choice. Like Trump, the Ubuntu developers have taken a we-do-what-we-want approach to building open source software by implementing their own, sometimes proprietary applications and interfaces. Free-software purists hate Ubuntu for that, but plenty of ordinary people like it a lot. Of course, whether playing purely by your own rules—in the realms of either software or politics—is sustainable in the long run remains to be seen.
|
||||
|
||||
### Stay Tuned ###
|
||||
|
||||
If you're wondering why I haven't yet mentioned the Democratic candidates, worry not. I am not leaving them out of today's writing because I like them any more or less than the Republicans. (Personally, I think the peculiar American practice of having only two viable political parties—which virtually no other functioning democracy does—is ridiculous, and I am suspicious of all of these candidates as a result.)
|
||||
|
||||
On the contrary, there's plenty to say about the Linux distributions the Democrats might use, too. And I will, in a future post. Stay tuned.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/081715/which-open-source-linux-distributions-would-presidential-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://thevarguy.com/open-source-application-software-companies/aligning-linux-distributions-presidential-hopefuls
|
||||
[2]:http://debian.org/
|
||||
[3]:http://www.damnsmalllinux.org/
|
||||
[4]:http://relax-and-recover.org/
|
||||
[5]:http://thevarguy.com/open-source-application-software-companies/061614/hps-machine-open-source-os-truly-revolutionary
|
||||
[6]:http://hp.com/
|
||||
[7]:http://ubuntu.com/
|
||||
148
sources/talk/20150820 Why did you start using Linux.md
Normal file
148
sources/talk/20150820 Why did you start using Linux.md
Normal file
@ -0,0 +1,148 @@
|
||||
KevinSJ translating
|
||||
Why did you start using Linux?
|
||||
================================================================================
|
||||
> In today's open source roundup: What got you started with Linux? Plus: IBM's Linux only Mainframe. And why you should skip Windows 10 and go with Linux
|
||||
|
||||
### Why did you start using Linux? ###
|
||||
|
||||
Linux has become quite popular over the years, with many users defecting to it from OS X or Windows. But have you ever wondered what got people started with Linux? A redditor asked that question and got some very interesting answers.
|
||||
|
||||
SilverKnight asked his question on the Linux subreddit:
|
||||
|
||||
> I know this has been asked before, but I wanted to hear more from the younger generation why it is that they started using linux and what keeps them here.
|
||||
>
|
||||
> I dont want to discourage others from giving their linux origin stories, because those are usually pretty good, but I was mostly curious about our younger population since there isn't much out there from them yet.
|
||||
>
|
||||
> I myself am 27 and am a linux dabbler. I have installed quite a few different distros over the years but I haven't made the plunge to full time linux. I guess I am looking for some more reasons/inspiration to jump on the bandwagon.
|
||||
>
|
||||
> [More at Reddit][1]
|
||||
|
||||
Fellow redditors in the Linux subreddit responded with their thoughts:
|
||||
|
||||
> **DoublePlusGood**: "I started using Backtrack Linux (now Kali) at 12 because I wanted to be a "1337 haxor". I've stayed with Linux (Archlinux currently) because it lets me have the endless freedom to make my computer do what I want."
|
||||
>
|
||||
> **Zack**: "I'm a Linux user since, I think, the age of 12 or 13, I'm 15 now.
|
||||
>
|
||||
> It started when I got tired with Windows XP at 11 and the waiting, dammit am I impatient sometimes, but waiting for a basic task such as shutting down just made me tired of Windows all together.
|
||||
>
|
||||
> A few months previously I had started participating in discussions in a channel on the freenode IRC network which was about a game, and as freenode usually goes, it was open source and most of the users used Linux.
|
||||
>
|
||||
> I kept on hearing about this Linux but wasn't that interested in it at the time. However, because the channel (and most of freenode) involved quite a bit of programming I started learning Python.
|
||||
>
|
||||
> A year passed and I was attempting to install GNU/Linux (specifically Ubuntu) on my new (technically old, but I had just got it for my birthday) PC, unfortunately it continually froze, for reasons unknown (probably a bad hard drive, or a lot of dust or something else...).
|
||||
>
|
||||
> Back then I was the type to give up on things, so I just continually nagged my dad to try and install Ubuntu, he couldn't do it for the same reasons.
|
||||
>
|
||||
> After wanting Linux for a while I became determined to get Linux and ditch windows for good. So instead of Ubuntu I tried Linux Mint, being a derivative of Ubuntu(?) I didn't have high hopes, but it worked!
|
||||
>
|
||||
> I continued using it for another 6 months.
|
||||
>
|
||||
> During that time a friend on IRC gave me a virtual machine (which ran Ubuntu) on their server, I kept it for a year a bit until my dad got me my own server.
|
||||
>
|
||||
> After the 6 months I got a new PC (which I still use!) I wanted to try something different.
|
||||
>
|
||||
> I decided to install openSUSE.
|
||||
>
|
||||
> I liked it a lot, and on the same Christmas I obtained a Raspberry Pi, and stuck with Debian on it for a while due to the lack of support other distros had for it."
|
||||
>
|
||||
> **Cqz**: "Was about 9 when the Windows 98 machine handed down to me stopped working for reasons unknown. We had no Windows install disk, but Dad had one of those magazines that comes with demo programs and stuff on CDs. This one happened to have install media for Mandrake Linux, and so suddenly I was a Linux user. Had no idea what I was doing but had a lot of fun doing it, and although in following years I often dual booted with various Windows versions, the FLOSS world always felt like home. Currently only have one Windows installation, which is a virtual machine for games."
|
||||
>
|
||||
> **Tosmarcel**: "I was 15 and was really curious about this new concept called 'programming' and then I stumbled upon this Harvard course, CS50. They told users to install a Linux vm to use the command line. But then I asked myself: "Why doesn't windows have this command line?!". I googled 'linux' and Ubuntu was the top result -Ended up installing Ubuntu and deleted the windows partition accidentally... It was really hard to adapt because I knew nothing about linux. Now I'm 16 and running arch linux, never looked back and I love it!"
|
||||
>
|
||||
> **Micioonthet**: "First heard about Linux in the 5th grade when I went over to a friend's house and his laptop was running MEPIS (an old fork of Debian) instead of Windows XP.
|
||||
>
|
||||
> Turns out his dad was a socialist (in America) and their family didn't trust Microsoft. This was completely foreign to me, and I was confused as to why he would bother using an operating system that didn't support the majority of software that I knew.
|
||||
>
|
||||
> Fast forward to when I was 13 and without a laptop. Another friend of mine was complaining about how slow his laptop was, so I offered to buy it off of him so I could fix it up and use it for myself. I paid $20 and got a virus filled, unusable HP Pavilion with Windows Vista. Instead of trying to clean up the disgusting Windows install, I remembered that Linux was a thing and that it was free. I burned an Ubuntu 12.04 disc and installed it right away, and was absolutely astonished by the performance.
|
||||
>
|
||||
> Minecraft (one of the few early Linux games because it ran on Java), which could barely run at 5 FPS on Vista, ran at an entirely playable 25 FPS on a clean install of Ubuntu.
|
||||
>
|
||||
> I actually still have that old laptop and use it occasionally, because why not? Linux doesn't care how old your hardware is.
|
||||
>
|
||||
> I since converted my dad to Linux and we buy old computers at lawn sales and thrift stores for pennies and throw Linux Mint or some other lightweight distros on them."
|
||||
>
|
||||
> **Webtm**: "My dad had every computer in the house with some distribution on it, I think a couple with OpenSUSE and Debian, and his personal computer had Slackware on it. So I remember being little and playing around with Debian and not really getting into it much. So I had a Windows laptop for a few years and my dad asked me if I wanted to try out Debian. It was a fun experience and ever since then I've been using Debian and trying out distributions. I currently moved away from Linux and have been using FreeBSD for around 5 months now, and I am absolutely happy with it.
|
||||
>
|
||||
> The control over your system is fantastic. There are a lot of cool open source projects. I guess a lot of the fun was figuring out how to do the things I want by myself and tweaking those things in ways to make them do something else. Stability and performance is also a HUGE plus. Not to mention the level of privacy when switching."
|
||||
>
|
||||
> **Wyronaut**: "I'm currently 18, but I first started using Linux when I was 13. Back then my first distro was Ubuntu. The reason why I wanted to check out Linux, was because I was hosting little Minecraft game servers for myself and a couple of friends, back then Minecraft was pretty new-ish. I read that the defacto operating system for hosting servers was Linux.
|
||||
>
|
||||
> I was a big newbie when it came to command line work, so Linux scared me a little, because I had to take care of a lot of things myself. But thanks to google and a few wiki pages I managed to get up a couple of simple servers running on a few older PC's I had lying around. Great use for all that older hardware no one in the house ever uses.
|
||||
>
|
||||
> After running a few game servers I started running a few web servers as well. Experimenting with HTML, CSS and PHP. I worked with those for a year or two. Afterwards, took a look at Java. I made the terrible mistake of watching TheNewBoston video's.
|
||||
>
|
||||
> So after like a week I gave up on Java and went to pick up a book on Python instead. That book was Learn Python The Hard Way by Zed A. Shaw. After I finished that at the fast pace of two weeks, I picked up the book C++ Primer, because at the time I wanted to become a game developer. Went trough about half of the book (~500 pages) and burned out on learning. At that point I was spending a sickening amount of time behind my computer.
|
||||
>
|
||||
> After taking a bit of a break, I decided to pick up JavaScript. Read like 2 books, made like 4 different platformers and called it a day.
|
||||
>
|
||||
> Now we're arriving at the present. I had to go through the horrendous process of finding a school and deciding what job I wanted to strive for when I graduated. I ruled out anything in the gaming sector as I didn't want anything to do with graphics programming anymore, I also got completely sick of drawing and modelling. And I found this bachelor that had something to do with netsec and I instantly fell in love. I picked up a couple books on C to shred this vacation period and brushed up on some maths and I'm now waiting for the new school year to commence.
|
||||
>
|
||||
> Right now, I am having loads of fun with Arch Linux, made couple of different arrangements on different PC's and it's going great!
|
||||
>
|
||||
> In a sense Linux is what also got me into programming and ultimately into what I'm going to study in college starting this september. I probably have my future life to thank for it."
|
||||
>
|
||||
> **Linuxllc**: "You also can learn from old farts like me.
|
||||
>
|
||||
> The crutch, The crutch, The crutch. Getting rid of the crutch will inspired you and have good reason to stick with Linux.
|
||||
>
|
||||
> I got rid of my crutch(Windows XP) back in 2003. Took me only 5 days to get all my computer task back and running at a 100% workflow. Including all my peripheral devices. Minus any Windows games. I just play native Linux games."
|
||||
>
|
||||
> **Highclass**: "Hey I'm 28 not sure if this is the age group you are looking for.
|
||||
>
|
||||
> To be honest, I was always interested in computers and the thought of a free operating system was intriguing even though at the time I didn't fully grasp the free software philosophy, to me it was free as in no cost. I also did not find the CLI too intimidating as from an early age I had exposure to DOS.
|
||||
>
|
||||
> I believe my first distro was Mandrake, I was 11 or 12, I messed up the family computer on several occasions.... I ended up sticking with it always trying to push myself to the next level. Now I work in the industry with Linux everyday.
|
||||
>
|
||||
> /shrug"
|
||||
>
|
||||
> Matto: "My computer couldn't run fast enough for XP (got it at a garage sale), so I started looking for alternatives. Ubuntu came up in Google. I was maybe 15 or 16 at the time. Now I'm 23 and have a job working on a product that uses Linux internally."
|
||||
>
|
||||
> [More at Reddit][2]
|
||||
|
||||
### IBM's Linux only Mainframe ###
|
||||
|
||||
IBM has a long history with Linux, and now the company has created a Mainframe that features Ubuntu Linux. The new machine is named LinuxOne.
|
||||
|
||||
Ron Miller reports for TechCrunch:
|
||||
|
||||
> The new mainframes come in two flavors, named for penguins (Linux — penguins — get it?). The first is called Emperor and runs on the IBM z13, which we wrote about in January. The other is a smaller mainframe called the Rockhopper designed for a more “entry level” mainframe buyer.
|
||||
>
|
||||
> You may have thought that mainframes went the way of the dinosaur, but they are still alive and well and running in large institutions throughout the world. IBM as part of its broader strategy to promote the cloud, analytics and security is hoping to expand the potential market for mainframes by running Ubuntu Linux and supporting a range of popular open source enterprise software such as Apache Spark, Node.js, MongoDB, MariaDB, PostgreSQL and Chef.
|
||||
>
|
||||
> The metered mainframe will still sit inside the customer’s on-premises data center, but billing will be based on how much the customer uses the system, much like a cloud model, Mauri explained.
|
||||
>
|
||||
> ...IBM is looking for ways to increase those sales. Partnering with Canonical and encouraging use of open source tools on a mainframe gives the company a new way to attract customers to a small, but lucrative market.
|
||||
>
|
||||
> [More at TechCrunch][3]
|
||||
|
||||
### Why you should skip Windows 10 and opt for Linux ###
|
||||
|
||||
Since Windows 10 has been released there has been quite a bit of media coverage about its potential to spy on users. ZDNet has listed some reasons why you should skip Windows 10 and opt for Linux instead on your computer.
|
||||
|
||||
SJVN reports for ZDNet:
|
||||
|
||||
> You can try to turn Windows 10's data-sharing ways off, but, bad news: Windows 10 will keep sharing some of your data with Microsoft anyway. There is an alternative: Desktop Linux.
|
||||
>
|
||||
> You can do a lot to keep Windows 10 from blabbing, but you can't always stop it from talking. Cortana, Windows 10's voice activated assistant, for example, will share some data with Microsoft, even when it's disabled. That data includes a persistent computer ID to identify your PC to Microsoft.
|
||||
>
|
||||
> So, if that gives you a privacy panic attack, you can either stick with your old operating system, which is likely Windows 7, or move to Linux. Eventually, when Windows 7 is no longer supported, if you want privacy you'll have no other viable choice but Linux.
|
||||
>
|
||||
> There are other, more obscure desktop operating systems that are also desktop-based and private. These include the BSD Unix family such as FreeBSD, PCBSD, and NetBSD and eComStation, OS/2 for the 21st century. Your best choice, though, is a desktop-based Linux with a low learning curve.
|
||||
>
|
||||
> [More at ZDNet][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2972587/linux/why-did-you-start-using-linux.html
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Jim-Lynch/
|
||||
[1]:https://www.reddit.com/r/linux/comments/3hb2sr/question_for_younger_users_why_did_you_start/
|
||||
[2]:https://www.reddit.com/r/linux/comments/3hb2sr/question_for_younger_users_why_did_you_start/
|
||||
[3]:http://techcrunch.com/2015/08/16/ibm-teams-with-canonical-on-linux-mainframe/
|
||||
[4]:http://www.zdnet.com/article/sick-of-windows-spying-on-you-go-linux/
|
||||
@ -0,0 +1,28 @@
|
||||
Linux 4.3 Kernel To Add The MOST Driver Subsystem
|
||||
================================================================================
|
||||
While the [Linux 4.2][1] kernel hasn't been officially released yet, Greg Kroah-Hartman sent in early his pull requests for the various subsystems he maintains for the Linux 4.3 merge window.
|
||||
|
||||
The pull requests sent in by Greg KH on Thursday include the Linux 4.3 merge window updates for the driver core, TTY/serial, USB driver, char/misc, and the staging area. These pull requests don't offer any really shocking changes but mostly routine work on improvements / additions / bug-fixes. The staging area once again is heavy with various fixes and clean-ups but there's also a new driver subsystem.
|
||||
|
||||
Greg mentioned of the [4.3 staging changes][2], "Lots of things all over the place, almost all of them trivial fixups and changes. The usual IIO updates and new drivers and we have added the MOST driver subsystem which is getting cleaned up in the tree. The ozwpan driver is finally being deleted as it is obviously abandoned and no one cares about it."
|
||||
|
||||
The MOST driver subsystem is short for the Media Oriented Systems Transport. The documentation to be added in the Linux 4.3 kernel explains, "The Media Oriented Systems Transport (MOST) driver gives Linux applications access a MOST network: The Automotive Information Backbone and the de-facto standard for high-bandwidth automotive multimedia networking. MOST defines the protocol, hardware and software layers necessary to allow for the efficient and low-cost transport of control, real-time and packet data using a single medium (physical layer). Media currently in use are fiber optics, unshielded twisted pair cables (UTP) and coax cables. MOST also supports various speed grades up to 150 Mbps." As explained, MOST is mostly about Linux in automotive applications.
|
||||
|
||||
While Greg KH sent in his various subsystem updates for Linux 4.3, he didn't yet propose the [KDBUS][5] kernel code be pulled. He's previously expressed plans for [KDBUS in Linux 4.3][3] so we'll wait until the 4.3 merge window officially gets going to see what happens. Stay tuned to Phoronix for more Linux 4.3 kernel coverage next week when the merge window will begin, [assuming Linus releases 4.2][4] this weekend.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=news_item&px=Linux-4.3-Staging-Pull
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://www.phoronix.com/scan.php?page=search&q=Linux+4.2
|
||||
[2]:http://lkml.iu.edu/hypermail/linux/kernel/1508.2/02604.html
|
||||
[3]:http://www.phoronix.com/scan.php?page=news_item&px=KDBUS-Not-In-Linux-4.2
|
||||
[4]:http://www.phoronix.com/scan.php?page=news_item&px=Linux-4.2-rc7-Released
|
||||
[5]:http://www.phoronix.com/scan.php?page=search&q=KDBUS
|
||||
@ -0,0 +1,126 @@
|
||||
How learning data structures and algorithms make you a better developer
|
||||
================================================================================
|
||||
|
||||
> "I'm a huge proponent of designing your code around the data, rather than the other way around, and I think it's one of the reasons git has been fairly successful […] I will, in fact, claim that the difference between a bad programmer and a good one is whether he considers his code or his data structures more important."
|
||||
-- Linus Torvalds
|
||||
|
||||
---
|
||||
|
||||
> "Smart data structures and dumb code works a lot better than the other way around."
|
||||
-- Eric S. Raymond, The Cathedral and The Bazaar
|
||||
|
||||
Learning about data structures and algorithms makes you a stonking good programmer.
|
||||
|
||||
**Data structures and algorithms are patterns for solving problems.** The more of them you have in your utility belt, the greater variety of problems you'll be able to solve. You'll also be able to come up with more elegant solutions to new problems than you would otherwise be able to.
|
||||
|
||||
You'll understand, ***in depth***, how your computer gets things done. This informs any technical decisions you make, regardless of whether or not you're using a given algorithm directly. Everything from memory allocation in the depths of your operating system, to the inner workings of your RDBMS to how your networking stack manages to send data from one corner of Earth to another. All computers rely on fundamental data structures and algorithms, so understanding them better makes you understand the computer better.
|
||||
|
||||
Cultivate a broad and deep knowledge of algorithms and you'll have stock solutions to large classes of problems. Problem spaces that you had difficulty modelling before often slot neatly into well-worn data structures that elegantly handle the known use-cases. Dive deep into the implementation of even the most basic data structures and you'll start seeing applications for them in your day-to-day programming tasks.
|
||||
|
||||
You'll also be able to come up with novel solutions to the somewhat fruitier problems you're faced with. Data structures and algorithms have the habit of proving themselves useful in situations that they weren't originally intended for, and the only way you'll discover these on your own is by having a deep and intuitive knowledge of at least the basics.
|
||||
|
||||
But enough with the theory, have a look at some examples
|
||||
|
||||
###Figuring out the fastest way to get somewhere###
|
||||
Let's say we're creating software to figure out the shortest distance from one international airport to another. Assume we're constrained to following routes:
|
||||
|
||||

|
||||
|
||||
graph of destinations and the distances between them, how can we find the shortest distance say, from Helsinki to London? **Dijkstra's algorithm** is the algorithm that will definitely get us the right answer in the shortest time.
|
||||
|
||||
In all likelihood, if you ever came across this problem and knew that Dijkstra's algorithm was the solution, you'd probably never have to implement it from scratch. Just ***knowing*** about it would point you to a library implementation that solves the problem for you.
|
||||
|
||||
If you did dive deep into the implementation, you'd be working through one of the most important graph algorithms we know of. You'd know that in practice it's a little resource intensive so an extension called A* is often used in it's place. It gets used everywhere from robot guidance to routing TCP packets to GPS pathfinding.
|
||||
|
||||
###Figuring out the order to do things in###
|
||||
Let's say you're trying to model courses on a new Massive Open Online Courses platform (like Udemy or Khan Academy). Some of the courses depend on each other. For example, a user has to have taken Calculus before she's eligible for the course on Newtonian Mechanics. Courses can have multiple dependencies. Here's are some examples of what that might look like written out in YAML:
|
||||
|
||||
# Mapping from course name to requirements
|
||||
#
|
||||
# If you're a physcist or a mathematicisn and you're reading this, sincere
|
||||
# apologies for the completely made-up dependency tree :)
|
||||
courses:
|
||||
arithmetic: []
|
||||
algebra: [arithmetic]
|
||||
trigonometry: [algebra]
|
||||
calculus: [algebra, trigonometry]
|
||||
geometry: [algebra]
|
||||
mechanics: [calculus, trigonometry]
|
||||
atomic_physics: [mechanics, calculus]
|
||||
electromagnetism: [calculus, atomic_physics]
|
||||
radioactivity: [algebra, atomic_physics]
|
||||
astrophysics: [radioactivity, calculus]
|
||||
quantumn_mechanics: [atomic_physics, radioactivity, calculus]
|
||||
|
||||
Given those dependencies, as a user, I want to be able to pick any course and have the system give me an ordered list of courses that I would have to take to be eligible. So if I picked `calculus`, I'd want the system to return the list:
|
||||
|
||||
arithmetic -> algebra -> trigonometry -> calculus
|
||||
|
||||
Two important constraints on this that may not be self-evident:
|
||||
|
||||
- At every stage in the course list, the dependencies of the next course must be met.
|
||||
- We don't want any duplicate courses in the list.
|
||||
|
||||
This is an example of resolving dependencies and the algorithm we're looking for to solve this problem is called topological sort (tsort). Tsort works on a dependency graph like we've outlined in the YAML above. Here's what that would look like in a graph (where each arrow means `requires`):
|
||||
|
||||

|
||||
|
||||
topological sort does is take a graph like the one above and find an ordering in which all the dependencies are met at each stage. So if we took a sub-graph that only contained `radioactivity` and it's dependencies, then ran tsort on it, we might get the following ordering:
|
||||
|
||||
arithmetic
|
||||
algebra
|
||||
trigonometry
|
||||
calculus
|
||||
mechanics
|
||||
atomic_physics
|
||||
radioactivity
|
||||
|
||||
This meets the requirements set out by the use case we described above. A user just has to pick `radioactivity` and they'll get an ordered list of all the courses they have to work through before they're allowed to.
|
||||
|
||||
We don't even need to go into the details of how topological sort works before we put it to good use. In all likelihood, your programming language of choice probably has an implementation of it in the standard library. In the worst case scenario, your Unix probably has the `tsort` utility installed by default, run man `tsort` and have a play with it.
|
||||
|
||||
###Other places tsort get's used###
|
||||
|
||||
- **Tools like** `make` allow you to declare task dependencies. Topological sort is used under the hood to figure out what order the tasks should be executed in.
|
||||
- **Any programming language that has a `require` directive**, indicating that the current file requires the code in a different file to be run first. Here topological sort can be used to figure out what order the files should be loaded in so that each is only loaded once and all dependencies are met.
|
||||
- **Project management tools with Gantt charts**. A Gantt chart is a graph that outlines all the dependencies of a given task and gives you an estimate of when it will be complete based on those dependencies. I'm not a fan of Gantt charts, but it's highly likely that tsort will be used to draw them.
|
||||
|
||||
###Squeezing data with Huffman coding###
|
||||
[Huffman coding](http://en.wikipedia.org/wiki/Huffman_coding) is an algorithm used for lossless data compression. It works by analyzing the data you want to compress and creating a binary code for each character. More frequently occurring characters get smaller codes, so `e` might be encoded as `111` while `x` might be `10010`. The codes are created so that they can be concatenated without a delimeter and still be decoded accurately.
|
||||
|
||||
Huffman coding is used along with LZ77 in the DEFLATE algorithm which is used by gzip to compress things. gzip is used all over the place, in particular for compressing files (typically anything with a `.gz` extension) and for http requests/responses in transit.
|
||||
|
||||
Knowing how to implement and use Huffman coding has a number of benefits:
|
||||
|
||||
- You'll know why a larger compression context results in better compression overall (e.g. the more you compress, the better the compression ratio). This is one of the proposed benefits of SPDY: that you get better compression on multiple HTTP requests/responses.
|
||||
- You'll know that if you're compressing your javascript/css in transit anyway, it's completely pointless to run a minifier on them. Sames goes for PNG files, which use DEFLATE internally for compression already.
|
||||
- If you ever find yourself trying to forcibly decipher encrypted information , you may realize that since repeating data compresses better, the compression ratio of a given bit of ciphertext will help you determine it's [block cipher mode of operation](http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation).
|
||||
|
||||
###Picking what to learn next is hard###
|
||||
Being a programmer involves learning constantly. To operate as a web developer you need to know markup languages, high level languages like ruby/python, regular expressions, SQL and JavaScript. You need to know the fine details of HTTP, how to drive a unix terminal and the subtle art of object oriented programming. It's difficult to navigate that landscape effectively and choose what to learn next.
|
||||
|
||||
I'm not a fast learner so I have to choose what to spend time on very carefully. As much as possible, I want to learn skills and techniques that are evergreen, that is, won't be rendered obsolete in a few years time. That means I'm hesitant to learn the javascript framework of the week or untested programming languages and environments.
|
||||
|
||||
As long as our dominant model of computation stays the same, data structures and algorithms that we use today will be used in some form or another in the future. You can safely spend time on gaining a deep and thorough knowledge of them and know that they will pay dividends for your entire career as a programmer.
|
||||
|
||||
###Sign up to the Happy Bear Software List###
|
||||
Find this article useful? For a regular dose of freshly squeezed technical content delivered straight to your inbox, **click on the big green button below to sign up to the Happy Bear Software mailing list.**
|
||||
|
||||
We'll only be in touch a few times per month and you can unsubscribe at any time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.happybearsoftware.com/how-learning-data-structures-and-algorithms-makes-you-a-better-developer
|
||||
|
||||
作者:[Happy Bear][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.happybearsoftware.com/
|
||||
[1]:http://en.wikipedia.org/wiki/Huffman_coding
|
||||
[2]:http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation
|
||||
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user