mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
945e51173a
File diff suppressed because one or more lines are too long
@ -0,0 +1,56 @@
|
||||
如何像 NASA 顶级程序员一样编程 —— 10 条重要原则
|
||||
===
|
||||
|
||||
[][1]
|
||||
|
||||
> 引言: 你知道 NASA 顶级程序员如何编写关键任务代码么?为了确保代码更清楚、更安全、且更容易理解,NASA 的喷气推进实验室制定了 10 条编码规则。
|
||||
|
||||
NASA 的开发者是编程界最有挑战性的工作之一。他们编写代码并将开发安全的关键任务应用程序作为其主要关注点。
|
||||
|
||||
在这种情形下,遵守一些严格的编码规则是重要的。这些规则覆盖软件开发的多个方面,例如软件应该如何编码、应该使用哪些语言特性等。
|
||||
|
||||
尽管很难就一个好的编码标准达成共识,NASA 的喷气推进实验室(JPL)遵守一个[编码规则][2],其名为“十的次方:开发安全的关键代码的规则”。
|
||||
|
||||
由于 JPL 长期使用 C 语言,这个规则主要是针对于 C 程序语言编写。但是这些规则也可以很容地应用到其它的程序语言。
|
||||
|
||||
该规则由 JPL 的首席科学家 Gerard J. Holzmann 制定,这些严格的编码规则主要是聚焦于安全。
|
||||
|
||||
NASA 的 10 条编写关键任务代码的规则:
|
||||
|
||||
1. 限制所有代码为极为简单的控制流结构 — 不用 `goto` 语句、`setjmp` 或 `longjmp` 结构,不用间接或直接的递归调用。
|
||||
2. 所有循环必须有一个固定的上限值。必须可以被某个检测工具静态证实,该循环不能达到预置的迭代上限值。如果该上限值不能被静态证实,那么可以认为违背该原则。
|
||||
3. 在初始化后不要使用动态内存分配。
|
||||
4. 如果一个语句一行、一个声明一行的标准格式来参考,那么函数的长度不应该比超过一张纸。通常这意味着每个函数的代码行不能超过 60。
|
||||
5. 代码中断言的密度平均低至每个函数 2 个断言。断言被用于检测那些在实际执行中不可能发生的情况。断言必须没有副作用,并应该定义为布尔测试。当一个断言失败时,应该执行一个明确的恢复动作,例如,把错误情况返回给执行该断言失败的函数调用者。对于静态工具来说,任何能被静态工具证实其永远不会失败或永远不能触发的断言违反了该规则(例如,通过增加无用的 `assert(true)` 语句是不可能满足这个规则的)。
|
||||
6. 必须在最小的范围内声明数据对象。
|
||||
7. 非 void 函数的返回值在每次函数调用时都必须检查,且在每个函数内其参数的有效性必须进行检查。
|
||||
8. 预处理器的使用仅限制于包含头文件和简单的宏定义。符号拼接、可变参数列表(省略号)和递归宏调用都是不允许的。所有的宏必须能够扩展为完整的语法单元。条件编译指令的使用通常是晦涩的,但也不总是能够避免。这意味着即使在一个大的软件开发中超过一两个条件编译指令也要有充足的理由,这超出了避免多次包含头文件的标准做法。每次在代码中这样做的时候必须有基于工具的检查器进行标记,并有充足的理由。
|
||||
9. 应该限制指针的使用。特别是不应该有超过一级的解除指针引用。解除指针引用操作不可以隐含在宏定义或类型声明中。还有,不允许使用函数指针。
|
||||
10. 从开发的第一天起,必须在编译器开启最高级别警告选项的条件下对代码进行编译。在此设置之下,代码必须零警告编译通过。代码必须利用源代码静态分析工具每天至少检查一次或更多次,且零警告通过。
|
||||
|
||||
关于这些规则,NASA 是这么评价的:
|
||||
|
||||
> 这些规则就像汽车中的安全带一样,刚开始你可能感到有一点不适,但是一段时间后就会养成习惯,你会无法想象不使用它们的日子。
|
||||
|
||||
此文是否对你有帮助?不要忘了在下面的评论区写下你的反馈。
|
||||
|
||||
---
|
||||
作者简介:
|
||||
|
||||
Adarsh Verma 是 Fossbytes 的共同创始人,他是一个令人尊敬的企业家,他一直对开源、技术突破和完全保持密切关注。可以通过邮件联系他 — [adarsh.verma@fossbytes.com](mailto:adarsh.verma@fossbytes.com)
|
||||
|
||||
------------------
|
||||
|
||||
via: https://fossbytes.com/nasa-coding-programming-rules-critical/
|
||||
|
||||
作者:[Adarsh Verma][a]
|
||||
译者:[penghuster](https://github.com/penghuster)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fossbytes.com/author/adarsh/
|
||||
[1]:http://fossbytes.com/wp-content/uploads/2016/06/rules-of-coding-nasa.jpg
|
||||
[2]:http://pixelscommander.com/wp-content/uploads/2014/12/P10.pdf
|
||||
[3]:https://fossbytes.com/wp-content/uploads/2016/12/learn-to-code-banner-ad-content-1.png
|
||||
[4]:http://pixelscommander.com/wp-content/uploads/2014/12/P10.pdf
|
||||
35
published/2017 Cloud Integrated Advanced Orchestrator.md
Normal file
35
published/2017 Cloud Integrated Advanced Orchestrator.md
Normal file
@ -0,0 +1,35 @@
|
||||
Ciao:云集成高级编排器
|
||||
============================================================
|
||||
|
||||
<ruby>云集成高级编排器<rt>Cloud Integrated Advanced Orchestrator</rt></ruby> (Ciao) 是一个新的负载调度程序,用来解决当前云操作系统项目的局限性。Ciao 提供了一个轻量级,完全基于 TLS 的最小配置。它是
|
||||
工作量无关的、易于更新、具有优化速度的调度程序,目前已针对 OpenStack 进行了优化。
|
||||
|
||||
其设计决策和创新方法在对安全性、可扩展性、可用性和可部署性的要求下进行:
|
||||
|
||||
- **可扩展性:** 初始设计目标是伸缩超过 5,000 个节点。因此,调度器架构用新的形式实现:
|
||||
- 在 ciao 中,决策制定是去中心化的。它基于拉取模型,允许计算节点从调度代理请求作业。调度程序总能知道启动器的容量,而不要求进行数据更新,并且将调度决策时间保持在最小。启动器异步向调度程序发送容量。
|
||||
- 持久化状态跟踪与调度程序决策制定相分离,它让调度程序保持轻量级。这种分离增加了可靠性、可扩展性和性能。结果是调度程序让出了权限并且这不是瓶颈。
|
||||
- **可用性:** 虚拟机、容器和裸机集成到一个调度器中。所有的负载都被视为平等公民。为了更易于使用,网络通过一个组件间最小化的异步协议进行简化,只需要最少的配置。Ciao 还包括一个新的、简单的 UI。所有的这些功能都集成到一起来简化安装、配置、维护和操作。
|
||||
- **轻松部署:** 升级应该是预期操作,而不是例外情况。这种新的去中心化状态的体系结构能够无缝升级。为了确保基础设施(例如 OpenStack)始终是最新的,它实现了持续集成/持续交付(CI/CD)模型。Ciao 的设计使得它可以立即杀死任何 Ciao 组件,更换它,并重新启动它,对可用性影响最小。
|
||||
- **安全性是必需的:** 与调度程序的连接总是加密的:默认情况下 SSL 是打开的,而不是关闭的。加密是从端到端:所有外部连接都需要 HTTPS,组件之间的内部通信是基于 TLS 的。网络支持的一体化保障了租户分离。
|
||||
|
||||
初步结果证明是显著的:在 65 秒内启动一万个 Docker 容器和五千个虚拟机。进一步优化还在进行。
|
||||
|
||||
- 文档:[https://clearlinux.org/documentation/ciao/ciao.html][3]
|
||||
- Github 链接: [https://github.com/01org/ciao(link is external)][1]
|
||||
- 邮件列表链接: [https://lists.clearlinux.org/mailman/listinfo/ciao-devel][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://clearlinux.org/ciao
|
||||
|
||||
作者:[ciao][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://clearlinux.org/ciao
|
||||
[1]:https://github.com/01org/ciao
|
||||
[2]:https://lists.clearlinux.org/mailman/listinfo/ciao-devel
|
||||
[3]:https://clearlinux.org/documentation/ciao/ciao.html
|
||||
124
published/20170903 Genymotion vs Android Emulator.md
Normal file
124
published/20170903 Genymotion vs Android Emulator.md
Normal file
@ -0,0 +1,124 @@
|
||||
Genymotion vs Android 模拟器
|
||||
============================================================
|
||||
|
||||
> Android 模拟器是否改善到足以取代 Genymotion
|
||||
|
||||
一直以来有关于选择 android 模拟器或者 Genymotion 的争论,我看到很多讨论最后以赞成 Genymotion 而告终。我根据我周围最常见的情况收集了一些数据,基于此,我将连同 Genymotion 全面评估 android 模拟器。
|
||||
|
||||
结论剧透:配置正确时,Android 模拟器比 Genymotion 快。
|
||||
|
||||
使用带 Google API 的 x86(32位)镜像、3GB RAM、四核CPU。
|
||||
|
||||
> - 哈,很高兴我们知道了最终结果
|
||||
> - 现在,让我们深入
|
||||
|
||||
免责声明:我已经测试了我看到的一般情况,即运行测试。所有的基准测试都是在 2015 年中期的 MacBook Pro 上完成的。无论何时我提及 Genymotion 指的都是 Genymotion Desktop。他们还有其他产品,如 Genymotion on Cloud&Genymotion on Demand,但这里没有考虑。我不是说 Genymotion 是不合适的,但运行测试比某些 Android 模拟器慢。
|
||||
|
||||
关于这个问题的一点背景,然后我们将转到具体内容上去。
|
||||
|
||||
_过去:我有一些基准测试,继续下去。_
|
||||
|
||||
很久以前,Android 模拟器是唯一的选择。但是它们太慢了,这是架构改变的原因。对于在 x86 机器上运行的 ARM 模拟器,你能期待什么?每个指令都必须从 ARM 转换为 x86 架构,这使得它的速度非常慢。
|
||||
|
||||
随之而来的是 Android 的 x86 镜像,随着它们摆脱了 ARM 到 x86 平台转化,速度更快了。现在,你可以在 x86 机器上运行 x86 Android 模拟器。
|
||||
|
||||
> - _问题解决了!!!_
|
||||
> - 没有!
|
||||
|
||||
Android 模拟器仍然比人们想要的慢。随后出现了 Genymotion,这是一个在 virtual box 中运行的 Android 虚拟机。与在 qemu 上运行的普通老式 android 模拟器相比,它相当稳定和快速。
|
||||
|
||||
我们来看看今天的情况。
|
||||
|
||||
我在持续集成的基础设施上和我的开发机器上使用 Genymotion。我手头的任务是摆脱持续集成基础设施和开发机器上使用 Genymotion。
|
||||
|
||||
> - 你问为什么?
|
||||
> - 授权费钱。
|
||||
|
||||
在快速看了一下以后,这似乎是一个愚蠢的举动,因为 Android 模拟器的速度很慢而且有 bug,它们看起来适得其反,但是当你深入的时候,你会发现 Android 模拟器是优越的。
|
||||
|
||||
我们的情况是对它们进行集成测试(主要是 espresso)。我们的应用程序中只有 1100 多个测试,Genymotion 需要大约 23 分钟才能运行所有测试。
|
||||
|
||||
在 Genymotion 中我们面临的另一些问题是:
|
||||
|
||||
* 有限的命令行工具([GMTool][1])。
|
||||
* 由于内存问题,它们需要定期重新启动。这是一个手动任务,想象在配有许多机器的持续集成基础设施上进行这些会怎样。
|
||||
|
||||
**进入 Android 模拟器**
|
||||
|
||||
首先是尝试在它给你这么多的选择中设置一个,这会让你会觉得你在赛百味餐厅一样。最大的问题是 x86 或 x86_64 以及是否有 Google API。
|
||||
|
||||
我用这些组合做了一些研究和基准测试,这是我们所想到的。
|
||||
|
||||
鼓声……
|
||||
|
||||
> - 比赛的获胜者是带 Google API 的 x86
|
||||
> - 但是如何胜利的?为什么?
|
||||
|
||||
嗯,我会告诉你每一个问题。
|
||||
|
||||
x86_64 比 x86 慢
|
||||
|
||||
> - 你问慢多少。
|
||||
> - 28.2% 多!!!
|
||||
|
||||
使用 Google API 的模拟器更加稳定,没有它们容易崩溃。
|
||||
|
||||
这使我们得出结论:最好的是带 Google API 的x86。
|
||||
|
||||
在我们抛弃 Genymotion 开始使用模拟器之前。有下面几点重要的细节。
|
||||
|
||||
* 我使用的是带 Google API 的 Nexus 5 镜像。
|
||||
* 我注意到,给模拟器较少的内存会造成了很多 Google API 崩溃。所以为模拟器设定了 3GB 的 RAM。
|
||||
* 模拟器有四核。
|
||||
* HAXM 安装在主机上。
|
||||
|
||||
**基准测试的时候到了**
|
||||
|
||||
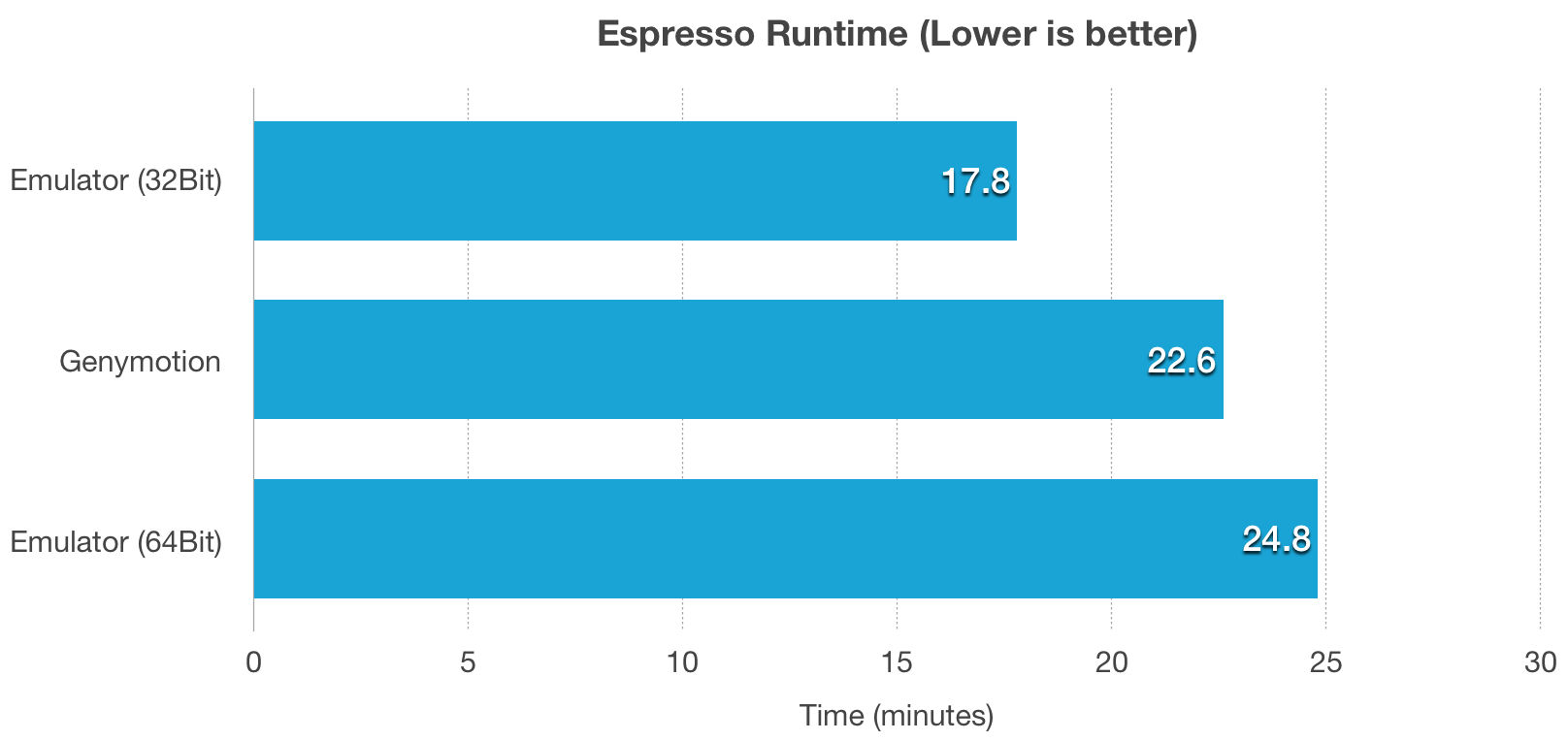
|
||||
|
||||
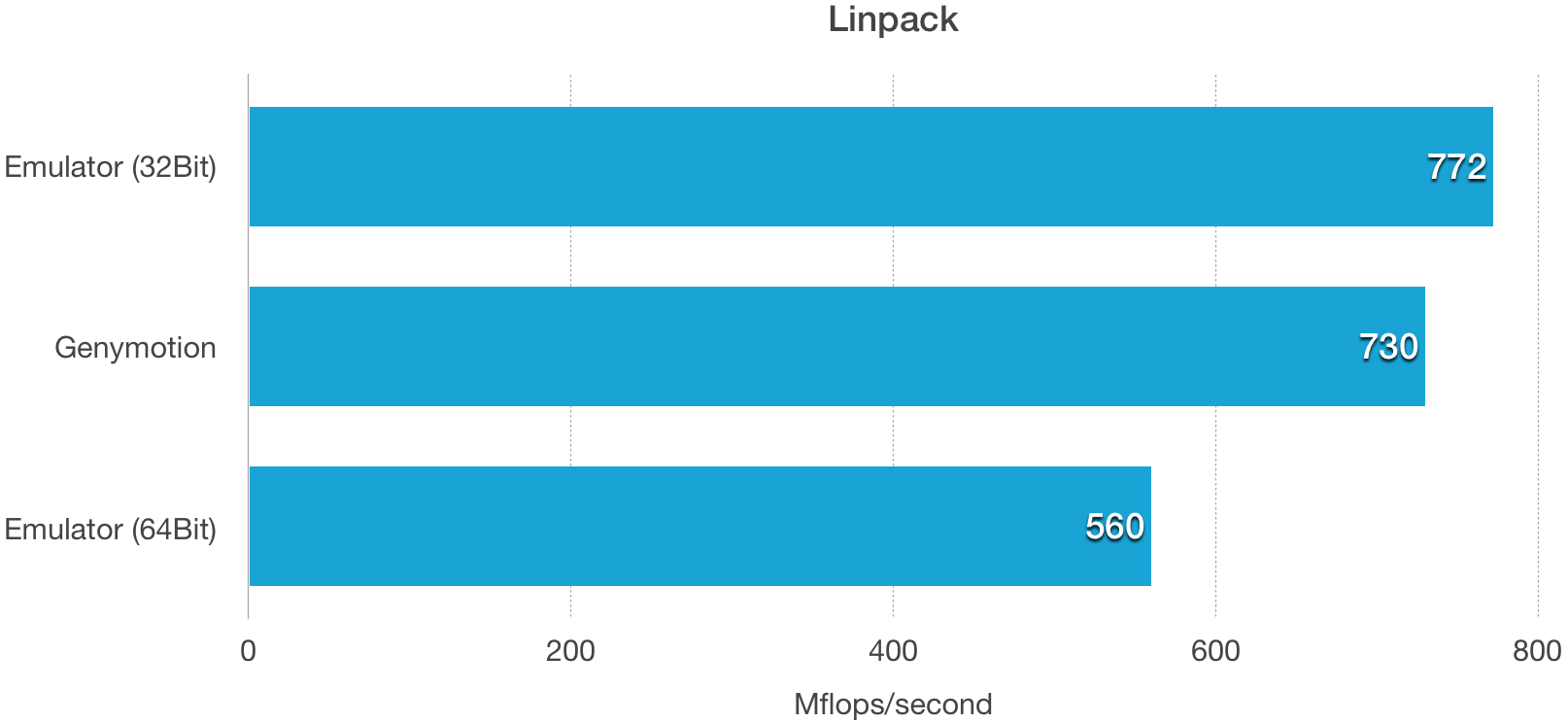
|
||||
|
||||
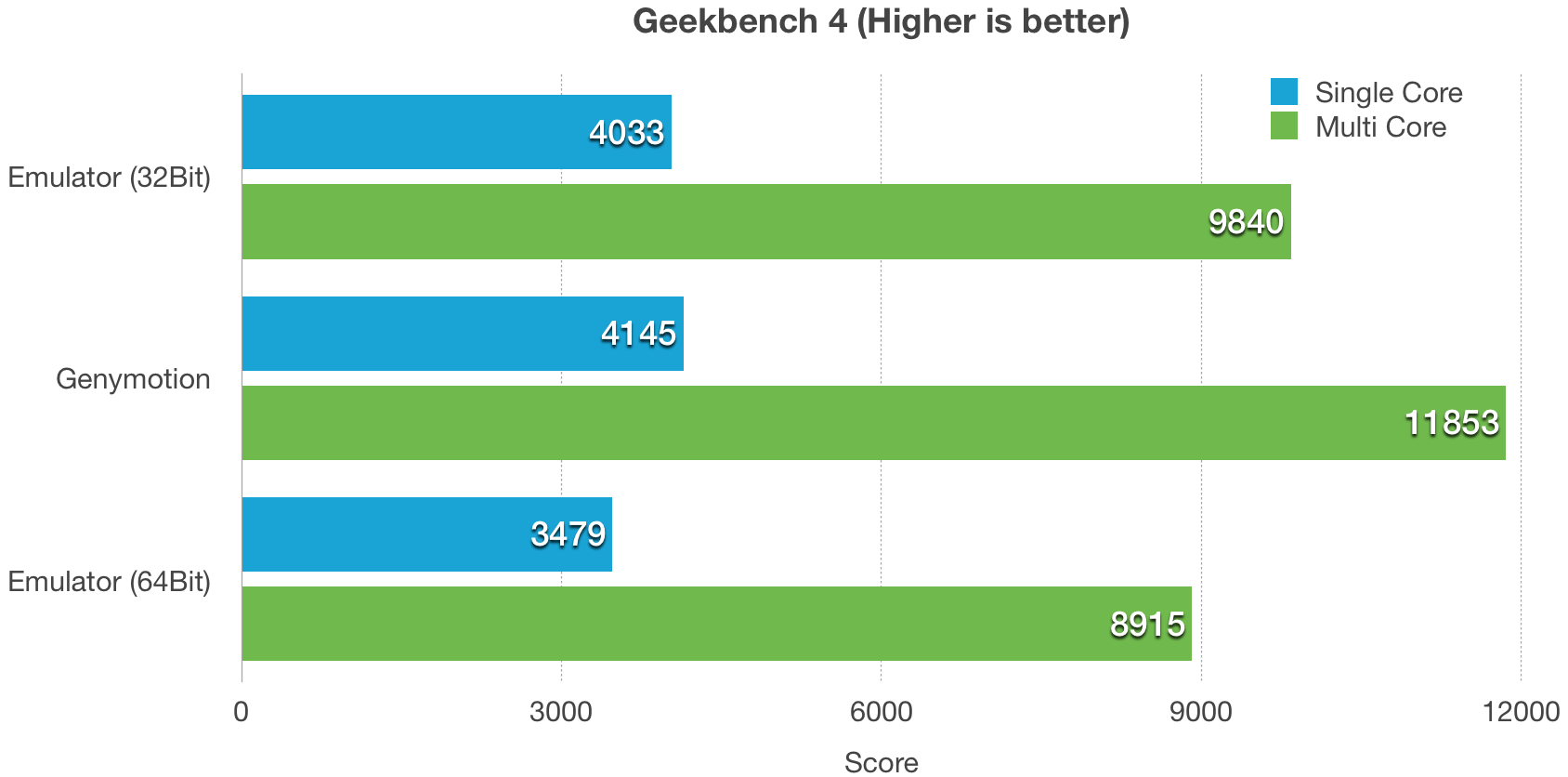
|
||||
|
||||
从基准测试上你可以看到除了 Geekbench4,Android 模拟器都击败了 Genymotion,我感觉更像是virtual box 击败了 qemu。
|
||||
|
||||
> 欢呼模拟器之王
|
||||
|
||||
我们现在有更快的测试执行时间、更好的命令行工具。最新的 [Android 模拟器][2]创下的新的记录。更快的启动时间之类。
|
||||
|
||||
Goolgle 一直努力让
|
||||
|
||||
> Android 模拟器变得更好
|
||||
|
||||
如果你没有在使用 Android 模拟器。我建议你重新试下,可以节省一些钱。
|
||||
|
||||
我尝试的另一个但是没有成功的方案是在 AWS 上运行 [Android-x86][3] 镜像。我能够在 vSphere ESXi Hypervisor 中运行它,但不能在 AWS 或任何其他云平台上运行它。如果有人知道原因,请在下面评论。
|
||||
|
||||
PS:[VMWare 现在可以在 AWS 上使用][4],在 AWS 上使用 [Android-x86][5] 毕竟是有可能的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
嗨,我的名字是 Sumit Gupta。我是来自印度古尔冈的软件/应用/网页开发人员。我做这个是因为我喜欢技术,并且一直迷恋它。我已经工作了 3 年以上,但我还是有很多要学习。他们不是说如果你有知识,让别人点亮他们的蜡烛。
|
||||
|
||||
当在编译时,我阅读很多文章,或者听音乐。
|
||||
|
||||
如果你想联系,下面是我的社交信息和 [email][6]。
|
||||
|
||||
----
|
||||
via: https://www.plightofbyte.com/android/2017/09/03/genymotion-vs-android-emulator/
|
||||
|
||||
作者:[Sumit Gupta][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.plightofbyte.com/about-me
|
||||
[1]:https://docs.genymotion.com/Content/04_Tools/GMTool/GMTool.htm
|
||||
[2]:https://developer.android.com/studio/releases/emulator.html
|
||||
[3]:http://www.android-x86.org/
|
||||
[4]:https://aws.amazon.com/vmware/
|
||||
[5]:http://www.android-x86.org/
|
||||
[6]:thesumitgupta@outlook.com
|
||||
@ -0,0 +1,58 @@
|
||||
OpenMessaging:构建一个分布式消息分发开放标准
|
||||
============================================================
|
||||
|
||||
|
||||
通过在云计算、大数据和标准 API 上的企业及社区的协作,我很高兴 OpenMessaging 项目进入 Linux 基金会。OpenMessaging 社区的目标是为分布式消息分发创建全球采用的、供应商中立的和开放标准,可以部署在云端、内部和混合云情景中。
|
||||
|
||||
阿里巴巴、雅虎、滴滴和 Streamlio 是该项目的创始贡献者。Linux 基金会已与这个初始项目社区合作来建立一个治理模式和结构,以实现运作在消息 API 标准上的生态系统的长期受益。
|
||||
|
||||
由于越来越多的公司和开发者迈向<ruby>云原生应用<rt>cloud native application</rt></ruby>,消息式应用和流式应用的扩展面临的挑战也在不断发展。这包括平台之间的互操作性问题,<ruby>[线路级协议](https://en.wikipedia.org/wiki/Wire_protocol)<rt>wire-level protocol</rt></ruby>之间缺乏兼容性以及系统间缺乏标准的基准测试。
|
||||
|
||||
特别是当数据跨不同的消息平台和流平台进行传输时会出现兼容性问题,这意味着额外的工作和维护成本。现有解决方案缺乏负载平衡、容错、管理、安全性和流功能的标准化指南。目前的系统不能满足现代面向云的消息应用和流应用的需求。这可能导致开发人员额外的工作,并且难以或不可能满足物联网、边缘计算、智能城市等方面的尖端业务需求。
|
||||
|
||||
OpenMessaging 的贡献者正在寻求通过以下方式改进分布式消息分发:
|
||||
|
||||
* 为分布式消息分发创建一个面向全球、面向云、供应商中立的行业标准
|
||||
* 促进用于测试应用程序的标准基准发展
|
||||
* 支持平台独立
|
||||
* 以可伸缩性、灵活性、隔离和安全性为目标的云数据的流和消息分发要求
|
||||
* 培育不断发展的开发贡献者社区
|
||||
|
||||
你可以在这了解有关新项目的更多信息以及如何参与: [http://openmessaging.cloud][1]。
|
||||
|
||||
这些是支持 OpenMessaging 的一些组织:
|
||||
|
||||
“我们多年来一直专注于消息分发和流领域,在此期间,我们探索了 Corba 通知、JMS 和其它标准,来试图解决我们最严格的业务需求。阿里巴巴在评估了可用的替代品后,选择创建一个新的面向云的消息分发标准 OpenMessaging,这是一个供应商中立,且语言无关的标准,并为金融、电子商务、物联网和大数据等领域提供了行业指南。此外,它目地在于跨异构系统和平台间开发消息分发和流应用。我们希望它可以是开放、简单、可扩展和可互操作的。另外,我们要根据这个标准建立一个生态系统,如基准测试、计算和各种连接器。我们希望有新的贡献,并希望大家能够共同努力,推动 OpenMessaging 标准的发展。”
|
||||
|
||||
——阿里巴巴高级架构师 Von Gosling,Apache RocketMQ 的联合创始人,以及 OpenMessaging 的原始发起人
|
||||
|
||||
“随着应用程序消息的复杂性和规模的不断扩大,缺乏标准的接口为开发人员和组织带来了复杂性和灵活性的障碍。Streamlio 很高兴与其他领导者合作推出 OpenMessaging 标准倡议来给客户一个轻松使用高性能、低延迟的消息传递解决方案,如 Apache Pulsar,它提供了企业所需的耐用性、一致性和可用性。“
|
||||
|
||||
—— Streamlio 的软件工程师、Apache Pulsar 的联合创始人以及 Apache BookKeeper PMC 的成员 Matteo Merli
|
||||
|
||||
“Oath(Verizon 旗下领先的媒体和技术品牌,包括雅虎和 AOL)支持开放,协作的举措,并且很乐意加入 OpenMessaging 项目。”
|
||||
|
||||
—— Joe Francis,核心平台总监
|
||||
|
||||
“在滴滴中,我们定义了一组私有的生产者 API 和消费者 API 来隐藏开源的 MQ(如 Apache Kafka、Apache RocketMQ 等)之间的差异,并提供额外的自定义功能。我们计划将这些发布到开源社区。到目前为止,我们已经积累了很多关于 MQ 和 API 统一的经验,并愿意在 OpenMessaging 中与其它 API 一起构建 API 的共同标准。我们真诚地认为,统一和广泛接受的 API 标准可以使 MQ 技术和依赖于它的应用程序受益。”
|
||||
|
||||
—— 滴滴的架构师 Neil Qi_
|
||||
|
||||
“有许多不同的开源消息分发解决方案,包括 Apache ActiveMQ、Apache RocketMQ、Apache Pulsar 和 Apache Kafka。缺乏行业级的可扩展消息分发标准使得评估合适的解决方案变得困难。我们很高兴能够与多个开源项目共同努力,共同确定可扩展的开放消息规范。 Apache BookKeeper 已成功在雅虎(通过 Apache Pulsar)和 Twitter(通过 Apache DistributedLog)的生产环境中部署,它作为其企业级消息系统的持久化、高性能、低延迟存储基础。我们很高兴加入 OpenMessaging 帮助其它项目解决诸如低延迟持久化、一致性和可用性等在消息分发方案中的常见问题。”
|
||||
|
||||
—— Streamlio 的联合创始人、Apache BookKeeper 的 PMC 主席、Apache DistributedLog 的联合创造者,Sijie Guo
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/building-open-standard-distributed-messaging-introducing-openmessaging/
|
||||
|
||||
作者:[Mike Dolan][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/mdolan/
|
||||
[1]:http://openmessaging.cloud/
|
||||
[2]:https://www.linuxfoundation.org/author/mdolan/
|
||||
[3]:https://www.linuxfoundation.org/category/blog/
|
||||
@ -1,34 +1,33 @@
|
||||
什么是 Grafeas?更好地审核容器
|
||||
Grafeas:旨在更好地审计容器
|
||||
============================================================
|
||||
|
||||
### Google 的 Grafeas 为容器的元数据提供了一个从镜像和构建细节到安全漏洞的通用 API。
|
||||
> Google 的 Grafeas 为容器的元数据提供了一个从镜像、构建细节到安全漏洞的通用 API。
|
||||
|
||||

|
||||
Thinkstock
|
||||
|
||||
我们运行的软件从来没有比今天更难保证安全。它分散在本地部署和云服务之间,并由不知数量的开源组件构建,而且以快速的时间表交付,因此保证安全和质量变成了一个挑战。
|
||||
我们运行的软件从来没有比今天更难获得。它分散在本地部署和云服务之间,由不知到有多少的开源组件构建而成,以快速的时间表交付,因此保证安全和质量变成了一个挑战。
|
||||
|
||||
最终的结果是软件难以审核,考虑,安全化和管理。困难的不只是知道 VM 或容器是用什么构建的, 而是由谁来添加、删除或更改的。[Grafeas][5] 最初由 Google 设计,旨在使这些问题更容易解决。
|
||||
最终的结果是软件难以审计、推断、安全化和管理。困难的不只是知道 VM 或容器是用什么构建的, 而是由谁来添加、删除或更改的。[Grafeas][5] 最初由 Google 设计,旨在使这些问题更容易解决。
|
||||
|
||||
### 什么是 Grafeas?
|
||||
|
||||
Grafeas 是一个定义软件组件的元数据 API 的开源项目。这旨在提供一个统一的元数据模式,允许 VM、容器、JAR 文件和其他软件工件描述自己的运行环境以及管理它们的用户。目标是允许像给定环境中使用的软件一样的审核,以及对该软件所做的更改的审核,以一致和可靠的方式进行。
|
||||
Grafeas 是一个定义软件组件的元数据 API 的开源项目。旨在提供一个统一的元数据模式,允许 VM、容器、JAR 文件和其他软件<ruby>工件<rt>artifact</rt></ruby>描述自己的运行环境以及管理它们的用户。目标是允许像在给定环境中使用的软件一样的审计,以及对该软件所做的更改的审计,并以一致和可靠的方式进行。
|
||||
|
||||
Grafeas提供两种格式的元数据 API,备注和事件:
|
||||
Grafeas提供两种格式的元数据 API —— 备注和事件:
|
||||
|
||||
* 备注是有关软件组件的某些方面的细节。可以是已知软件漏洞的描述,有关如何构建软件的详细信息(构建器版本,校验和等),部署历史等。
|
||||
* <ruby>备注<rt>note</rt></ruby>是有关软件工件的某些方面的细节。可以是已知软件漏洞的描述,有关如何构建软件的详细信息(构建器版本、校验和等),部署历史等。
|
||||
* <ruby>事件<rt>occurrence</rt></ruby>是备注的实例,包含了它们创建的地方和方式的细节。例如,已知软件漏洞的详细信息可能会有描述哪个漏洞扫描程序检测到它的情况、何时被检测到的事件信息,以及该漏洞是否被解决。
|
||||
|
||||
* 事件是备注的实例,包含了它们创建的地方和方式的细节。例如,已知软件漏洞的详细信息可能会有描述哪个漏洞扫描程序检测到它的情况、何时被检测到的事件信息,以及该漏洞是否被解决。
|
||||
备注和事件都存储在仓库中。每个备注和事件都使用标识符进行跟踪,该标识符区分它并使其唯一。
|
||||
|
||||
备注和事件都存储在仓库中。每个笔记和事件都使用标识符进行跟踪,该标识符区分它并使其唯一。
|
||||
|
||||
Grafeas 规范包括备注类型的几个基本模式。例如,软件包漏洞模式描述了如何存储 CVE 或漏洞描述的备注信息。现在没有正式的接受新模式类型的流程,但是[这已经在计划][6]创建这样一个流程。
|
||||
Grafeas 规范包括备注类型的几个基本模式。例如,软件包漏洞模式描述了如何存储 CVE 或漏洞描述的备注信息。现在没有接受新模式类型的正式流程,但是[这已经在计划][6]创建这样一个流程。
|
||||
|
||||
### Grafeas 客户端和第三方支持
|
||||
|
||||
现在,Grafeas 主要作为规范和参考形式存在,它有在[ GitHub 上提供][7]。 [Go][8]、[Python][9] 和 [Java][10] 的客户端都可以使用[由 Swagger 生成][11],所以其他语言的客户端也应该不难写出来。
|
||||
现在,Grafeas 主要作为规范和参考形式存在,它在 [GitHub 上提供][7]。 [Go][8]、[Python][9] 和 [Java][10] 的客户端都可以[用 Swagger 生成][11],所以其他语言的客户端也应该不难写出来。
|
||||
|
||||
Google 计划让 Grafeas 广泛使用的关键方案是通过 Kubernetes。 Kubernetes 的一个策略引擎,称为 Kritis,可以根据 Grafeas 元数据对容器采取措施。
|
||||
Google 计划让 Grafeas 广泛使用的主要方式是通过 Kubernetes。 Kubernetes 的一个名为 Kritis 的策略引擎,可以根据 Grafeas 元数据对容器采取措施。
|
||||
|
||||
除 Google 之外的几家公司已经宣布计划将 Grafeas 的支持添加到现有产品中。例如,CoreOS 正在考察 Grafeas 如何与 Tectonic 集成,[Red Hat][12] 和 [IBM][13] 都计划在其容器产品和服务中添加 Grafeas 集成。
|
||||
|
||||
@ -36,9 +35,9 @@ Google 计划让 Grafeas 广泛使用的关键方案是通过 Kubernetes。 Kube
|
||||
|
||||
via: https://www.infoworld.com/article/3230462/security/what-is-grafeas-better-auditing-for-containers.html
|
||||
|
||||
作者:[Serdar Yegulalp ][a]
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,71 +0,0 @@
|
||||
translating by penghuster
|
||||
|
||||
How To Code Like The Top Programmers At NASA — 10 Critical Rules
|
||||
============================================================
|
||||
|
||||
_**[][1] Short Bytes:** Do you know how top programmers write mission-critical code at NASA? To make such code clearer, safer, and easier to understand, NASA’s Jet Propulsion Laboratory has laid 10 rules for developing software._
|
||||
|
||||
The developers at NASA have one of the most challenging jobs in the programming world. They write code and develop mission-critical applications with safety as their primary concerns.
|
||||
|
||||
In such situations, it’s important to follow some serious coding guidelines. These rules cover different aspects of software development like how a software should be written, which language features should be used etc.
|
||||
|
||||
Even though it’s difficult to establish a consensus over a good coding standard, NASA’s Jet Propulsion Laboratory (JPL) follows a set of [guidelines of code][2] named “The Power of Ten–Rules for Developing Safety Critical Code”.
|
||||
|
||||
This guide focuses mainly on code written in C programming languages due to JPL’s long association with the language. But, these guidelines could be easily applied on other programming languages as well.
|
||||
|
||||
Laid by JPL lead scientist Gerard J. Holzmann, these strict coding rules focus on security.
|
||||
|
||||
[][3]
|
||||
|
||||
NASA’s 10 rules for writing mission-critical code:
|
||||
|
||||
1. _Restrict all code to very simple control flow constructs – do not use goto statements, setjmp or longjmp _ constructs _, and direct or indirect recursion._
|
||||
|
||||
2. _All loops must have a fixed_ _upper-bound. It must be trivially possible for a checking tool to prove statically that a preset upper-bound on the number of iterations of a loop cannot be exceeded. If the loop-bound cannot be proven statically, the rule is considered violated._
|
||||
|
||||
3. _Do not use dynamic memory allocation after initialization._
|
||||
|
||||
4. _No function should be longer than what can be printed on a single sheet of paper in a standard reference format with one line per statement and one line per declaration. Typically, this means no more than about 60 lines of code per function._
|
||||
|
||||
5. _The assertion density of the code should average to a minimum of two assertions per function. Assertions are used to check for anomalous conditions that should never happen in real-life executions. Assertions must always be side-effect free and should be defined as Boolean tests. When an assertion fails, an explicit recovery action must be taken, e.g., by returning an error condition to the caller of the function that executes the failing assertion. Any assertion for which a static checking tool can prove that it can never fail or never hold violates this rule (I.e., it is not possible to satisfy the rule by adding unhelpful “assert(true)” statements)._
|
||||
|
||||
6. _Data objects must be declared at the smallest possible level of scope._
|
||||
|
||||
7. _The return value of non-void functions must be checked by each calling function, and the validity of parameters must be checked inside each function._
|
||||
|
||||
8. _The use of the preprocessor must be limited to the inclusion of header files and simple macro definitions. Token pasting, variable argument lists (ellipses), and recursive macro calls are not allowed. All macros must expand into complete syntactic units. The use of conditional compilation directives is often also dubious, but cannot always be avoided. This means that there should rarely be justification for more than one or two conditional compilation directives even in large software development efforts, beyond the standard boilerplate that avoids multiple inclusion of the same header file. Each such use should be flagged by a tool-based checker and justified in the code._
|
||||
|
||||
9. _The use of pointers should be restricted. Specifically, no more than one level of dereferencing is allowed. Pointer dereference operations may not be hidden in macro definitions or inside typedef declarations. Function pointers are not permitted._
|
||||
|
||||
10. _All code must be compiled, from the first day of development, with all compiler warnings enabled at the compiler’s most pedantic setting. All code must compile with these setting without any warnings. All code must be checked daily with at least one, but preferably more than one, state-of-the-art static source code analyzer and should pass the analyses with zero warnings._
|
||||
|
||||
About these rules, here’s what NASA has to say:
|
||||
|
||||
The rules act like the seatbelt in your car: initially they are perhaps a little uncomfortable, but after a while their use becomes second-nature and not using them becomes unimaginable.
|
||||
|
||||
[Source][4]
|
||||
|
||||
Did you find this article helpful? Don’t forget to drop your feedback in the comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Adarsh Verma
|
||||
Fossbytes co-founder and an aspiring entrepreneur who keeps a close eye on open source, tech giants, and security. Get in touch with him by sending an email — adarsh.verma@fossbytes.com
|
||||
|
||||
------------------
|
||||
|
||||
via: https://fossbytes.com/nasa-coding-programming-rules-critical/
|
||||
|
||||
作者:[Adarsh Verma ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fossbytes.com/author/adarsh/
|
||||
[1]:http://fossbytes.com/wp-content/uploads/2016/06/rules-of-coding-nasa.jpg
|
||||
[2]:http://pixelscommander.com/wp-content/uploads/2014/12/P10.pdf
|
||||
[3]:https://fossbytes.com/wp-content/uploads/2016/12/learn-to-code-banner-ad-content-1.png
|
||||
[4]:http://pixelscommander.com/wp-content/uploads/2014/12/P10.pdf
|
||||
@ -1,3 +1,5 @@
|
||||
translating by penghuster
|
||||
|
||||
Designing a Microservices Architecture for Failure
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Chao-zhi
|
||||
|
||||
8 best languages to blog about
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by firmianay
|
||||
|
||||
Examining network connections on Linux systems
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,149 @@
|
||||
Getting Started Analyzing Twitter Data in Apache Kafka through KSQL
|
||||
============================================================
|
||||
|
||||
[KSQL][8] is the open source streaming SQL engine for Apache Kafka. It lets you do sophisticated stream processing on Kafka topics, easily, using a simple and interactive SQL interface. In this short article we’ll see how easy it is to get up and running with a sandbox for exploring it, using everyone’s favourite demo streaming data source: Twitter. We’ll go from ingesting the raw stream of tweets, through to filtering it with predicates in KSQL, to building aggregates such as counting the number of tweets per user per hour.
|
||||
|
||||

|
||||
|
||||
First up, [go grab a copy of Confluent Platform][9]. I’m using the RPM but you can use [tar, zip, etc][10] if you want to. Start the Confluent stack up:
|
||||
|
||||
`$ confluent start`
|
||||
|
||||
(Here’s a [quick tutorial on the confluent CLI][11] if you’re interested!)
|
||||
|
||||
We’ll use Kafka Connect to pull the data from Twitter. The Twitter Connector can be found [on GitHub here][12]. To install it, simply do the following:
|
||||
|
||||
`# Clone the git repo
|
||||
cd /home/rmoff
|
||||
git clone https://github.com/jcustenborder/kafka-connect-twitter.git`
|
||||
|
||||
`# Compile the code
|
||||
cd kafka-connect-twitter
|
||||
mvn clean package`
|
||||
|
||||
To get Kafka Connect [to pick up the connector][13] that we’ve built, you’ll have to modify the configuration file. Since we’re using the Confluent CLI, the configuration file is actually `etc/schema-registry/connect-avro-distributed.properties`, so go modify that and add to it:
|
||||
|
||||
`plugin.path=/home/rmoff/kafka-connect-twitter/target/kafka-connect-twitter-0.2-SNAPSHOT.tar.gz`
|
||||
|
||||
Restart Kafka Connect:
|
||||
`confluent stop connect
|
||||
confluent start connect`
|
||||
|
||||
Once you’ve installed the plugin, you can easily configure it. You can use the Kafka Connect REST API directly, or create your configuration file, which is what I’ll do here. You’ll need to head over to [Twitter to grab your API keys first][14].
|
||||
|
||||
Assuming you’ve written this to `/home/rmoff/twitter-source.json`, you can now run:
|
||||
|
||||
`$ confluent load twitter_source -d /home/rmoff/twitter-source.json`
|
||||
|
||||
And then tweets from everyone’s favourite internet meme star start [rick]-rolling in…
|
||||
|
||||
Now let’s fire up KSQL! First off, download and build it:
|
||||
|
||||
`cd /home/rmoff `
|
||||
`git clone https://github.com/confluentinc/ksql.git `
|
||||
`cd /home/rmoff/ksql `
|
||||
`mvn clean compile install -DskipTests`
|
||||
|
||||
Once it’s built, let’s run it!
|
||||
|
||||
`./bin/ksql-cli local --bootstrap-server localhost:9092`
|
||||
|
||||
Using KSQL, we can take our data that’s held in Kafka topics and query it. First, we need to tell KSQL what the schema of the data in the topic is. A twitter message is actually a pretty huge JSON object, but for brevity let’s just pick a couple of columns to start with:
|
||||
|
||||
`ksql> CREATE STREAM twitter_raw (CreatedAt BIGINT, Id BIGINT, Text VARCHAR) WITH (KAFKA_TOPIC='twitter_json_01', VALUE_FORMAT='JSON');`
|
||||
`Message `
|
||||
`----------------`
|
||||
`Stream created`
|
||||
|
||||
With the schema defined, we can query the stream. To get KSQL to show data from the start of the topic (rather than the current point in time, which is the default), run:
|
||||
|
||||
`ksql> SET 'auto.offset.reset' = 'earliest'; `
|
||||
`Successfully changed local property 'auto.offset.reset' from 'null' to 'earliest'`
|
||||
|
||||
And now let’s see the data. We’ll select just one row using the LIMIT clause:
|
||||
|
||||
Now let’s redefine the stream with all the contents of the tweet payload now defined and available to us:
|
||||
|
||||
Now we can manipulate and examine our data more closely, using normal SQL queries:
|
||||
|
||||
Note that there’s no LIMIT clause, so you’ll see on screen the results of the _continuous query_ . Unlike a query on a relational table that returns a definite number of results, a continuous query is running on unbounded streaming data, so it always has the potential to return more records. Hit Ctrl-C to cancel and return to the KSQL prompt. In the above query we’re doing a few things:
|
||||
|
||||
* TIMESTAMPTOSTRING to convert the timestamp from epoch to a human-readable format
|
||||
|
||||
* EXTRACTJSONFIELD to show one of the nested user fields from the source, which looks like:
|
||||
|
||||
* Applying predicates to what’s shown, using pattern matching against the hashtag, forced to lower case with LCASE.
|
||||
|
||||
For a list of supported functions, see [the KSQL documentation][15].
|
||||
|
||||
We can create a derived stream from this data:
|
||||
|
||||
and query the derived stream:
|
||||
|
||||
Before we finish, let’s see how to do some aggregation.
|
||||
|
||||
You’ll probably get a screenful of results; this is because KSQL is actually emitting the aggregation values for the given hourly window each time it updates. Since we’ve set KSQL to read all messages on the topic (`SET 'auto.offset.reset' = 'earliest';`) it’s reading all of these messages at once and calculating the aggregation updates as it goes. There’s actually a subtlety in what’s going on here that’s worth digging into. Our inbound stream of tweets is just that—a stream. But now that we are creating aggregates, we have actually created a table. A table is a snapshot of a given key’s values at a given point in time. KSQL aggregates data based on the event time of the message, and handles late arriving data by simply restating that relevant window if it updates. Confused? We hope not, but let’s see if we can illustrate this with an example. We’ll declare our aggregate as an actual table:
|
||||
|
||||
Looking at the columns in the table, there are two implicit ones in addition to those we asked for:
|
||||
|
||||
`ksql> DESCRIBE user_tweet_count;
|
||||
|
||||
Field | Type
|
||||
-----------------------------------
|
||||
ROWTIME | BIGINT
|
||||
ROWKEY | VARCHAR(STRING)
|
||||
USER_SCREENNAME | VARCHAR(STRING)
|
||||
TWEET_COUNT | BIGINT
|
||||
ksql>`
|
||||
|
||||
Let’s see what’s in these:
|
||||
|
||||
The `ROWTIME` is the window start time, the `ROWKEY` is a composite of the `GROUP BY`(`USER_SCREENNAME`) plus the window. So we can tidy this up a bit by creating an additional derived table:
|
||||
|
||||
Now it’s easy to query and see the data that we’re interested in:
|
||||
|
||||
### Conclusion
|
||||
|
||||
So there we have it! We’re taking data from Kafka, and easily exploring it using KSQL. Not only can we explore and transform the data, we can use KSQL to easily build stream processing from streams and tables.
|
||||
|
||||

|
||||
|
||||
If you’re interested in what KSQL can do, check out:
|
||||
|
||||
* The [KSQL announcement blog post][1]
|
||||
|
||||
* [Our recent KSQL webinar][2] and [Kafka Summit keynote][3]
|
||||
|
||||
* The [clickstream demo][4] that’s available as part of [KSQL’s GitHub repo][5]
|
||||
|
||||
* A [presentation that I did recently][6] showing how KSQL can underpin a streaming ETL based platform.
|
||||
|
||||
Remember that KSQL is currently in developer preview. Feel free to raise any issues on the KSQL github repo, or come along to the #ksql channel on our [community Slack group][16].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.confluent.io/blog/using-ksql-to-analyse-query-and-transform-data-in-kafka
|
||||
|
||||
作者:[Robin Moffatt ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.confluent.io/blog/author/robin/
|
||||
[1]:https://www.confluent.io/blog/ksql-open-source-streaming-sql-for-apache-kafka/
|
||||
[2]:https://www.confluent.io/online-talk/ksql-streaming-sql-for-apache-kafka/
|
||||
[3]:https://www.confluent.io/kafka-summit-sf17/Databases-and-Stream-Processing-1
|
||||
[4]:https://www.youtube.com/watch?v=A45uRzJiv7I
|
||||
[5]:https://github.com/confluentinc/ksql
|
||||
[6]:https://speakerdeck.com/rmoff/look-ma-no-code-building-streaming-data-pipelines-with-apache-kafka
|
||||
[7]:https://www.confluent.io/blog/author/robin/
|
||||
[8]:https://github.com/confluentinc/ksql/
|
||||
[9]:https://www.confluent.io/download/
|
||||
[10]:https://docs.confluent.io/current/installation.html?
|
||||
[11]:https://www.youtube.com/watch?v=ZKqBptBHZTg
|
||||
[12]:https://github.com/jcustenborder/kafka-connect-twitter
|
||||
[13]:https://docs.confluent.io/current/connect/userguide.html#connect-installing-plugins
|
||||
[14]:https://apps.twitter.com/
|
||||
[15]:https://github.com/confluentinc/ksql/blob/0.1.x/docs/syntax-reference.md
|
||||
[16]:https://slackpass.io/confluentcommunity
|
||||
@ -0,0 +1,277 @@
|
||||
How to set up a Postgres database on a Raspberry Pi
|
||||
============================================================
|
||||
|
||||
### Install and configure the popular open source database system PostgreSQL and use it in your next Raspberry Pi project.
|
||||
|
||||

|
||||
Image credits : Raspberry Pi Foundation. [CC BY-SA 4.0][12].
|
||||
|
||||
Databases are a great way to add data persistence to your project or application. You can write data in one session and it'll be there the next time you want to look. A well-designed database can be efficient at looking up data in large datasets, and you won't have to worry about how it looks, just what you want it to find. It's fairly simple to set up a database for basic [CRUD][13] (create, record, update, delete) applications, which is a common pattern, and it is useful in many projects.
|
||||
|
||||
Why [PostgreSQL][14], commonly known as Postgres? It's considered to be the best open source database in terms of features and performance. It'll feel familiar if you've used MySQL, but when you need more advanced usage, you'll find the optimization in Postgres is far superior. It's easy to install, easy to use, easy to secure, and runs well on the Raspberry Pi 3.
|
||||
|
||||
This tutorial explains how to install Postgres on a Raspberry Pi; create a table; write simple queries; use the pgAdmin GUI on a Raspberry Pi, a PC, or a Mac; and interact with the database from Python.
|
||||
|
||||
Once you've learned the basics, you can take your application a lot further with complex queries joining multiple tables, at which point you need to think about optimization, best design practices, using primary and foreign keys, and more.
|
||||
|
||||
### Installation
|
||||
|
||||
To get started, you'll need to install Postgres and some other packages. Open a terminal window and run the following command while connected to the internet:
|
||||
|
||||
```
|
||||
sudo apt install postgresql libpq-dev postgresql-client
|
||||
postgresql-client-common -y
|
||||
```
|
||||
|
||||
### [postgres-install.png][1]
|
||||
|
||||

|
||||
|
||||
When that's complete, switch to the Postgres user to configure the database:
|
||||
|
||||
```
|
||||
sudo su postgres
|
||||
```
|
||||
|
||||
Now you can create a database user. If you create a user with the same name as one of your Unix user accounts, that user will automatically be granted access to the database. So, for the sake of simplicity in this tutorial, I'll assume you're using the default pi user. Run the **createuser** command to continue:
|
||||
|
||||
```
|
||||
createuser pi -P --interactive
|
||||
```
|
||||
|
||||
When prompted, enter a password (and remember what it is), select **n** for superuser, and **y** for the next two questions.
|
||||
|
||||
### [postgres-createuser.png][2]
|
||||
|
||||

|
||||
|
||||
Now connect to Postgres using the shell and create a test database:
|
||||
|
||||
```
|
||||
$ psql
|
||||
> create database test;
|
||||
```
|
||||
|
||||
Exit from the psql shell and again from the Postgres user by pressing Ctrl+D twice, and you'll be logged in as the pi user again. Since you created a Postgres user called pi, you can access the Postgres shell from here with no credentials:
|
||||
|
||||
```
|
||||
$ psql test
|
||||
```
|
||||
|
||||
You're now connected to the "test" database. The database is currently empty and contains no tables. You can create a simple table from the psql shell:
|
||||
|
||||
```
|
||||
test=> create table people (name text, company text);
|
||||
```
|
||||
|
||||
Now you can insert data into the table:
|
||||
|
||||
```
|
||||
test=> insert into people values ('Ben Nuttall', 'Raspberry Pi Foundation');
|
||||
|
||||
test=> insert into people values ('Rikki Endsley', 'Red Hat');
|
||||
```
|
||||
|
||||
And try a select query:
|
||||
|
||||
```
|
||||
test=> select * from people;
|
||||
|
||||
name | company
|
||||
---------------+-------------------------
|
||||
Ben Nuttall | Raspberry Pi Foundation
|
||||
Rikki Endsley | Red Hat
|
||||
(2 rows)
|
||||
```
|
||||
|
||||
### [postgres-query.png][3]
|
||||
|
||||

|
||||
|
||||
```
|
||||
test=> select name from people where company = 'Red Hat';
|
||||
|
||||
name | company
|
||||
---------------+---------
|
||||
Rikki Endsley | Red Hat
|
||||
(1 row)
|
||||
```
|
||||
|
||||
### pgAdmin
|
||||
|
||||
You might find it useful to use a graphical tool to access the database. PgAdmin is a full-featured PostgreSQL GUI that allows you to create and manage databases and users, create and modify tables, write and execute queries, and browse results in a more familiar view, similar to a spreadsheet. The psql command-line tool is fine for simple queries, and you'll find many power users stick with it for speed (and because they don't need the assistance the GUI gives), but midlevel users may find pgAdmin a more approachable way to learn and do more with a database.
|
||||
|
||||
Another useful thing about pgAdmin is that you can either use it directly on the Pi or on another computer that's remotely connected to the database on the Pi.
|
||||
|
||||
If you want to access it on the Raspberry Pi itself, you can just install it with **apt**:
|
||||
|
||||
```
|
||||
sudo apt install pgadmin3
|
||||
```
|
||||
|
||||
It's exactly the same if you're on a Debian-based system like Ubuntu; if you're on another distribution, try the equivalent command for your system. Alternatively, or if you're on Windows or macOS, try downloading pgAdmin from [pgAdmin.org][15]. Note that the version available in **apt** is pgAdmin3 and a newer version, pgAdmin4, is available from the website.
|
||||
|
||||
To connect to your database with pgAdmin on the same Raspberry Pi, simply open pgAdmin3 from the main menu, click the **new connection** icon, and complete the registration fields. In this case, all you'll need is a name (you choose the connection name, e.g. test), change the username to "pi," and leave the rest of the fields blank (or as they were). Click OK and you'll find a new connection in the side panel on the left.
|
||||
|
||||
### [pgadmin-connect.png][4]
|
||||
|
||||

|
||||
|
||||
To connect to your Pi's database with pgAdmin from another computer, you'll first need to edit the PostgreSQL configuration to allow remote connections:
|
||||
|
||||
1\. Edit the PostgreSQL config file **/etc/postgresql/9.6/main/postgresql.conf** to uncomment the **listen_addresses** line and change its value from **localhost** to *****. Save and exit.
|
||||
|
||||
2\. Edit the **pg_hba** config file **/etc/postgresql/9.6/main/postgresql.conf** to change **127.0.0.1/32** to **0.0.0.0/0** for IPv4 and **::1/128** to **::/0** for IPv6\. Save and exit.
|
||||
|
||||
3\. Restart the PostgreSQL service: **sudo service postgresql restart**.
|
||||
|
||||
Note the version number may be different if you're using an older Raspbian image or another distribution.
|
||||
|
||||
### [postgres-config.png][5]
|
||||
|
||||

|
||||
|
||||
Once that's done, open pgAdmin on your other computer and create a new connection. This time, in addition to giving the connection a name, enter the Pi's IP address as the host (this can be found by hovering over the WiFi icon in the taskbar or by typing **hostname -I** in a terminal).
|
||||
|
||||
### [pgadmin-remote.png][6]
|
||||
|
||||

|
||||
|
||||
Whether you connected locally or remotely, click to open **Server Groups > Servers > test > Schemas > public > Tables**, right-click the **people** table and select **View Data > View top 100 Rows**. You'll now see the data you entered earlier.
|
||||
|
||||
### [pgadmin-view.png][7]
|
||||
|
||||

|
||||
|
||||
You can now create and modify databases and tables, manage users, and write your own custom queries using the GUI. You might find this visual method more manageable than using the command line.
|
||||
|
||||
### Python
|
||||
|
||||
To connect to your database from a Python script, you'll need the [Psycopg2][16]Python package. You can install it with [pip][17]:
|
||||
|
||||
```
|
||||
sudo pip3 install psycopg2
|
||||
```
|
||||
|
||||
Now open a Python editor and write some code to connect to your database:
|
||||
|
||||
```
|
||||
import psycopg2
|
||||
|
||||
conn = psycopg2.connect('dbname=test')
|
||||
cur = conn.cursor()
|
||||
|
||||
cur.execute('select * from people')
|
||||
|
||||
results = cur.fetchall()
|
||||
|
||||
for result in results:
|
||||
print(result)
|
||||
```
|
||||
|
||||
Run this code to see the results of the query. Note that if you're connecting remotely, you'll need to supply more credentials in the connection string, for example, adding the host IP, username, and database password:
|
||||
|
||||
```
|
||||
conn = psycopg2.connect('host=192.168.86.31 user=pi
|
||||
password=raspberry dbname=test')
|
||||
```
|
||||
|
||||
You could even create a function to look up this query specifically:
|
||||
|
||||
```
|
||||
def get_all_people():
|
||||
query = """
|
||||
SELECT
|
||||
*
|
||||
FROM
|
||||
people
|
||||
"""
|
||||
cur.execute(query)
|
||||
return cur.fetchall()
|
||||
```
|
||||
|
||||
And one including a lookup:
|
||||
|
||||
```
|
||||
def get_people_by_company(company):
|
||||
query = """
|
||||
SELECT
|
||||
*
|
||||
FROM
|
||||
people
|
||||
WHERE
|
||||
company = %s
|
||||
"""
|
||||
values = (company, )
|
||||
cur.execute(query, values)
|
||||
return cur.fetchall()
|
||||
```
|
||||
|
||||
Or even a function for adding records:
|
||||
|
||||
```
|
||||
def add_person(name, company):
|
||||
query = """
|
||||
INSERT INTO
|
||||
people
|
||||
VALUES
|
||||
(%s, %s)
|
||||
"""
|
||||
values = (name, company)
|
||||
cur.execute(query, values)
|
||||
```
|
||||
|
||||
Note this uses a safe method of injecting strings into queries. You don't want to get caught out by [little bobby tables][18]!
|
||||
|
||||
### [python-postgres.png][8]
|
||||
|
||||

|
||||
|
||||
Now you know the basics. If you want to take Postgres further, check out this article on [Full Stack Python][19].
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ben Nuttall - Ben Nuttall is the Raspberry Pi Community Manager. In addition to his work for the Raspberry Pi Foundation, he's into free software, maths, kayaking, GitHub, Adventure Time, and Futurama. Follow Ben on Twitter [@ben_nuttall][10].
|
||||
|
||||
-------------
|
||||
|
||||
via: https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi
|
||||
|
||||
作者:[Ben Nuttall ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://opensource.com/file/374246
|
||||
[2]:https://opensource.com/file/374241
|
||||
[3]:https://opensource.com/file/374251
|
||||
[4]:https://opensource.com/file/374221
|
||||
[5]:https://opensource.com/file/374236
|
||||
[6]:https://opensource.com/file/374226
|
||||
[7]:https://opensource.com/file/374231
|
||||
[8]:https://opensource.com/file/374256
|
||||
[9]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021&rate=t-XUFUPa6mURgML4cfL1mjxsmFBG-VQTG4R39QvFVQA
|
||||
[10]:http://www.twitter.com/ben_nuttall
|
||||
[11]:https://opensource.com/user/26767/feed
|
||||
[12]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[13]:https://en.wikipedia.org/wiki/Create,_read,_update_and_delete
|
||||
[14]:https://www.postgresql.org/
|
||||
[15]:https://www.pgadmin.org/download/
|
||||
[16]:http://initd.org/psycopg/
|
||||
[17]:https://pypi.python.org/pypi/pip
|
||||
[18]:https://xkcd.com/327/
|
||||
[19]:https://www.fullstackpython.com/postgresql.html
|
||||
[20]:https://opensource.com/users/bennuttall
|
||||
[21]:https://opensource.com/users/bennuttall
|
||||
[22]:https://opensource.com/users/bennuttall
|
||||
[23]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021#comments
|
||||
[24]:https://opensource.com/tags/raspberry-pi
|
||||
[25]:https://opensource.com/tags/raspberry-pi-column
|
||||
[26]:https://opensource.com/tags/how-tos-and-tutorials
|
||||
[27]:https://opensource.com/tags/programming
|
||||
95
sources/tech/20171013 Best of PostgreSQL 10 for the DBA.md
Normal file
95
sources/tech/20171013 Best of PostgreSQL 10 for the DBA.md
Normal file
@ -0,0 +1,95 @@
|
||||
Best of PostgreSQL 10 for the DBA
|
||||
============================================================
|
||||
|
||||
|
||||
Last week a new PostgreSQL major version with the number 10 was released! Announcement, release notes and the „What’s new“ overview can be found from [here][3], [here][4]and [here][5] – it’s highly recommended reading, so check them out. As usual there have been already quite some blog postings covering all the new stuff, but I guess everyone has their own angle on what is important so as with version 9.6 I’m again throwing in my impressions on the most interesting/relevant features here.
|
||||
|
||||
As always, users who upgrade or initialize a fresh cluster, will enjoy huge performance wins (e.g. better parallelization with parallel index scans, merge joins and uncorrelated sub-queries, faster aggregations, smarter joins and aggregates on remote servers) out of the box without doing anything, but here I would like to look more at the things that you won’t get out of the box but you actually need to take some steps to start benefiting from them. List of below highlighted features is compiled from a DBA’s viewpoint here, soon a post on changes from a developer’s point of view will also follow.
|
||||
|
||||
### Upgrading considerations
|
||||
|
||||
First some hints on upgrading from an existing setup – this time there are some small things that could cause problems when migrating from 9.6 or even older versions, so before the real deal one should definitely test the upgrade on a separate replica and go through the full list of possible troublemakers from the release notes. Most likely pitfalls to watch out for:
|
||||
|
||||
* All functions containing „xlog“ have been renamed to use „wal“ instead of „xlog“
|
||||
|
||||
The latter naming could be confused with normal server logs so a „just in case“ change. If using any 3rd party backup/replication/HA tools check that they are all at latest versions.
|
||||
|
||||
* pg_log folder for server logs (error messages/warnings etc) has been renamed to just „log“
|
||||
|
||||
Make sure to verify that your log parsing/grepping scripts (if having any) work.
|
||||
|
||||
* By default queries will make use of up to 2 background processes
|
||||
|
||||
If using the default 10 postgresql.conf settings on a machine with low number of CPUs you may see resource usage spikes as parallel processing is enabled by default now – which is a good thing though as it should mean faster queries. Set max_parallel_workers_per_gather to 0 if old behaviour is needed.
|
||||
|
||||
* Replication connections from localhost are enabled now by default
|
||||
|
||||
To ease testing etc, localhost and local Unix socket replication connections are now enabled in „trust“ mode (without password) in pg_hba.conf! So if other non-DBA user also have access to real production machines, make sure you change the config.
|
||||
|
||||
### My favourites from a DBA’s point of view
|
||||
|
||||
* Logical replication
|
||||
|
||||
The long awaited feature enables easy setup and minimal performance penalties for application scenarios where you only want to replicate a single table or a subset of tables or all tables, meaning also zero downtime upgrades for following major versions! Historically (Postgres 9.4+ required) this could be achieved only by usage of a 3rd party extension or slowish trigger based solutions. The top feature of version 10 for me.
|
||||
|
||||
* Declarative partitioning
|
||||
|
||||
Old way of managing partitions via inheritance and creating triggers to re-route inserts to correct tables was bothersome to say the least, not to mention the performance impact. Currently supported are „range“ and „list“ partitioning schemes. If someone is missing „hash“ partitioning available in some DB engines, one could use „list“ partitioning with expressions to achieve the same.
|
||||
|
||||
* Usable Hash indexes
|
||||
|
||||
Hash indexes are now WAL-logged thus crash safe and received some performance improvements so that for simple searches they’re actually faster than standard B-tree indexes for bigger amounts of data. Bigger index size though too.
|
||||
|
||||
* Cross-column optimizer statistics
|
||||
|
||||
Such stats needs to be created manually on a set if columns of a table, to point out that the values are actually somehow dependent on each other. This will enable to counter slow query problems where the planner thinks there will be very little data returned (multiplication of probabilities yields very small numbers usually) and will choose for example a „nested loop“ join that does not perform well on bigger amounts of data.
|
||||
|
||||
* Parallel snapshots on replicas
|
||||
|
||||
Now one can use the pg_dump tool to speed up backups on standby servers enormously by using multiple processes (the –jobs flag).
|
||||
|
||||
* Better tuning of parallel processing worker behaviour
|
||||
|
||||
See max_parallel_workers and min_parallel_table_scan_size / min_parallel_index_scan_size parameters. The default values (8MB, 512KB) for the latter two I would recommend to increase a bit though.
|
||||
|
||||
* New built-in monitoring roles for easier tooling
|
||||
|
||||
New roles pg_monitor, pg_read_all_settings, pg_read_all_stats, and pg_stat_scan_tables make life a lot easier for all kinds of monitoring tasks – previously one had to use superuser accounts or some SECURITY DEFINER wrapper functions.
|
||||
|
||||
* Temporary (per session) replication slots for safer replica building
|
||||
|
||||
* A new Contrib extension for checking validity of B-tree indexes
|
||||
|
||||
Does couple of smart checks to discover structural inconsistencies and stuff not covered by page level checksums. Hope to check it out more deeply in nearer future.
|
||||
|
||||
* Psql query tool supports now basic branching (if/elif/else)
|
||||
|
||||
This would for example enable having a single maintenance/monitoring script with version specific branching (different column names for pg_stat* views etc) instead of many version specific scripts.
|
||||
|
||||
```
|
||||
SELECT :VERSION_NAME = '10.0' AS is_v10 \gset
|
||||
\if :is_v10
|
||||
SELECT 'yippee' AS msg;
|
||||
\else
|
||||
SELECT 'time to upgrade!' AS msg;
|
||||
\endif
|
||||
```
|
||||
|
||||
That’s it for this time! Lot of other stuff didn’t got listed of course, so for full time DBAs I’d definitely suggest to look at the notes more thoroughly. And a big thanks to those 300+ people who contributed their effort to this particularly exciting release!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cybertec.at/best-of-postgresql-10-for-the-dba/
|
||||
|
||||
作者:[ Kaarel Moppel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cybertec.at/author/kaarel-moppel/
|
||||
[1]:http://www.cybertec.at/author/kaarel-moppel/
|
||||
[2]:http://www.cybertec.at/best-of-postgresql-10-for-the-dba/
|
||||
[3]:https://www.postgresql.org/about/news/1786/
|
||||
[4]:https://www.postgresql.org/docs/current/static/release-10.html
|
||||
[5]:https://wiki.postgresql.org/wiki/New_in_postgres_10
|
||||
@ -0,0 +1,87 @@
|
||||
Proxy Models in Container Environments
|
||||
============================================================
|
||||
|
||||
### Most of us are familiar with how proxies work, but is it any different in a container-based environment? See what's changed.
|
||||
|
||||
Inline, side-arm, reverse, and forward. These used to be the terms we used to describe the architectural placement of proxies in the network.
|
||||
|
||||
Today, containers use some of the same terminology, but they are introducing new ones. That’s an opportunity for me to extemporaneously expound* on my favorite of all topics: the proxy.
|
||||
|
||||
One of the primary drivers of cloud (once we all got past the pipedream of cost containment) has been scalability. Scale has challenged agility (and sometimes won) in various surveys over the past five years as the number one benefit organizations seek by deploying apps in cloud computing environments.
|
||||
|
||||
That’s in part because in a digital economy (in which we now operate), apps have become the digital equivalent of brick-and-mortar “open/closed” signs and the manifestation of digital customer assistance. Slow, unresponsive apps have the same effect as turning out the lights or understaffing the store.
|
||||
|
||||
Apps need to be available and responsive to meet demand. Scale is the technical response to achieving that business goal. Cloud not only provides the ability to scale, but offers the ability to scale _automatically_ . To do that requires a load balancer. Because that’s how we scale apps – with proxies that load balance traffic/requests.
|
||||
|
||||
Containers are no different with respect to expectations around scale. Containers must scale – and scale automatically – and that means the use of load balancers (proxies).
|
||||
|
||||
If you’re using native capabilities, you’re doing primitive load balancing based on TCP/UDP. Generally speaking, container-based proxy implementations aren’t fluent in HTTP or other application layer protocols and don’t offer capabilities beyond plain old load balancing ([POLB][1]). That’s often good enough, as container scale operates on a cloned, horizontal premise – to scale an app, add another copy and distribute requests across it. Layer 7 (HTTP) routing capabilities are found at the ingress (in [ingress controllers][2] and API gateways) and are used as much (or more) for app routing as they are to scale applications.
|
||||
|
||||
In some cases, however, this is not enough. If you want (or need) more application-centric scale or the ability to insert additional services, you’ll graduate to more robust offerings that can provide programmability or application-centric scalability or both.
|
||||
|
||||
To do that means [plugging-in proxies][3]. The container orchestration environment you’re working in largely determines the deployment model of the proxy in terms of whether it’s a reverse proxy or a forward proxy. Just to keep things interesting, there’s also a third model – sidecar – that is the foundation of scalability supported by emerging service mesh implementations.
|
||||
|
||||
### Reverse Proxy
|
||||
|
||||
[][4]
|
||||
|
||||
A reverse proxy is closest to a traditional model in which a virtual server accepts all incoming requests and distributes them across a pool (farm, cluster) of resources.
|
||||
|
||||
There is one proxy per ‘application’. Any client that wants to connect to the application is instead connected to the proxy, which then chooses and forwards the request to an appropriate instance. If the green app wants to communicate with the blue app, it sends a request to the blue proxy, which determines which of the two instances of the blue app should respond to the request.
|
||||
|
||||
In this model, the proxy is only concerned with the app it is managing. The blue proxy doesn’t care about the instances associated with the orange proxy, and vice-versa.
|
||||
|
||||
### Forward Proxy
|
||||
|
||||
[][5]
|
||||
|
||||
This mode more closely models that of a traditional outbound firewall.
|
||||
|
||||
In this model, each container **node** has an associated proxy. If a client wants to connect to a particular application or service, it is instead connected to the proxy local to the container node where the client is running. The proxy then chooses an appropriate instance of that application and forwards the client's request.
|
||||
|
||||
Both the orange and the blue app connect to the same proxy associated with its node. The proxy then determines which instance of the requested app instance should respond.
|
||||
|
||||
In this model, every proxy must know about every application to ensure it can forward requests to the appropriate instance.
|
||||
|
||||
### Sidecar Proxy
|
||||
|
||||
[][6]
|
||||
|
||||
This mode is also referred to as a service mesh router. In this model, each **container **has its own proxy.
|
||||
|
||||
If a client wants to connect to an application, it instead connects to the sidecar proxy, which chooses an appropriate instance of that application and forwards the client's request. This behavior is the same as a _forward proxy _ model.
|
||||
|
||||
The difference between a sidecar and forward proxy is that sidecar proxies do not need to modify the container orchestration environment. For example, in order to plug-in a forward proxy to k8s, you need both the proxy _and _ a replacement for kube-proxy. Sidecar proxies do not require this modification because it is the app that automatically connects to its “sidecar” proxy instead of being routed through the proxy.
|
||||
|
||||
### Summary
|
||||
|
||||
Each model has its advantages and disadvantages. All three share a reliance on environmental data (telemetry and changes in configuration) as well as the need to integrate into the ecosystem. Some models are pre-determined by the environment you choose, so careful consideration as to future needs – service insertion, security, networking complexity – need to be evaluated before settling on a model.
|
||||
|
||||
We’re still in early days with respect to containers and their growth in the enterprise. As they continue to stretch into production environments it’s important to understand the needs of the applications delivered by containerized environments and how their proxy models differ in implementation.
|
||||
|
||||
*It was extemporaneous when I wrote it down. Now, not so much.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dzone.com/articles/proxy-models-in-container-environments
|
||||
|
||||
作者:[Lori MacVittie ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dzone.com/users/307701/lmacvittie.html
|
||||
[1]:https://f5.com/about-us/blog/articles/go-beyond-polb-plain-old-load-balancing
|
||||
[2]:https://f5.com/about-us/blog/articles/ingress-controllers-new-name-familiar-function-27388
|
||||
[3]:http://clouddocs.f5.com/products/asp/v1.0/
|
||||
[4]:https://devcentral.f5.com/Portals/0/Users/038/38/38/unavailable_is_closed.png?ver=2017-09-12-082118-160
|
||||
[5]:https://devcentral.f5.com/Portals/0/Users/038/38/38/per-node_forward_proxy.jpg?ver=2017-09-14-072419-667
|
||||
[6]:https://devcentral.f5.com/Portals/0/Users/038/38/38/per-pod_sidecar_proxy.jpg?ver=2017-09-14-072424-073
|
||||
[7]:https://dzone.com/users/307701/lmacvittie.html
|
||||
[8]:https://dzone.com/users/307701/lmacvittie.html
|
||||
[9]:https://dzone.com/articles/proxy-models-in-container-environments#
|
||||
[10]:https://dzone.com/cloud-computing-tutorials-tools-news
|
||||
[11]:https://dzone.com/articles/proxy-models-in-container-environments#
|
||||
[12]:https://dzone.com/go?i=243221&u=https%3A%2F%2Fget.platform9.com%2Fjzlp-kubernetes-deployment-models-the-ultimate-guide%2F
|
||||
@ -0,0 +1,128 @@
|
||||
How to implement cloud-native computing with Kubernetes
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Kubernetes and containers can speed up the development process while minimizing programmer and system administration costs, say representatives of the Open Container Initiative and the Cloud Native Computing Foundation. To take advantage of Kubernetes and its related tools to run a cloud-native architecture, start with unappreciated Kubernetes features like namespaces.
|
||||
|
||||
[Kubernetes][2] is far more than a cloud-container manager. As Steve Pousty, [Red Hat's][3] lead developer advocate for [OpenShift][4], explained in a presentation at [the Linux Foundation's][5] [Open Source Summit][6], Kubernetes serves as a "common operating plane for cloud-native computing using containers."
|
||||
|
||||
What does Pousty mean by that? Let's review the basics.
|
||||
|
||||
“Cloud-native computing uses an open source software stack to deploy applications as microservices, package each part into its own container, and dynamically orchestrate those containers to optimize resource utilization,” explains Chris Aniszczyk, executive director of the [Open Container Initiative][7] (OCI) and the [Cloud Native Computing Foundation][8] (CNCF). [Kubernetes takes care of that last element][9] of cloud-native computing. The result is part of a larger transition in IT, moving from servers to virtual machines to buildpacks—and now to [containers][10].
|
||||
|
||||
This data center evolution has netted significant cost savings, in part because it requires fewer dedicated staff, conference presenters say. For example, by using Kubernetes, Google needs only one site reliability engineer per 10,000 machines, according to Aniszczyk.
|
||||
|
||||
Practically speaking, however, system administrators can take advantage of new Kubernetes-related tools and exploit under-appreciated features.
|
||||
|
||||
### Building a native cloud platform
|
||||
|
||||
Pousty explained, "For Red Hat, Kubernetes is the cloud Linux kernel. It's this infrastructure that everybody's going to build on."
|
||||
|
||||
For an example, let's say you have an application within a container image. How do you know it's safe? Red Hat and other companies use [OpenSCAP][11], which is based on the [Security Content Automation Protocol][12] (SCAP), a specification for expressing and manipulating security data in standardized ways. The OpenSCAP project provides open source hardening guides and configuration baselines. You select an appropriate security policy, then use OpenSCAP-approved security tools to make certain the programs within your Kubernetes-controlled containers comply with those customized security standards.
|
||||
|
||||
Unsure how to get started with containers? Yes, we have a guide for that.
|
||||
|
||||
[Get Containers for Dummies][1]
|
||||
|
||||
Red Hat automated this process further using [Atomic Scan][13]; it works with any OpenSCAP provider to scan container images for known security vulnerabilities and policy configuration problems. Atomic Scan mounts read-only file systems. These are passed to the scanning container, along with a writeable directory for the scanner's output.
|
||||
|
||||
This approach has several advantages, Pousty pointed out, primarily, "You can scan a container image without having to actually run it." So, if there is bad code or a flawed security policy within the container, it can't do anything to your system.
|
||||
|
||||
Atomic Scan works much faster than running OpenSCAP manually. Since containers tend to be spun up and destroyed in minutes or hours, Atomic Scan enables Kubernetes users to keep containers secure in container time rather than the much-slower sysadmin time.
|
||||
|
||||
### Tool time
|
||||
|
||||
Another tool that help sysadmins and DevOps make the most of Kubernetes is [CRI-O][14]. This is an OCI-based implementation of the [Kubernetes Container Runtime Interface][15]. CRI-O is a daemon that Kubernetes can use for running container images stored on Docker registries, explains Dan Walsh, a Red Hat consulting engineer and [SELinux][16] project lead. It enables you to launch container images directly from Kubernetes instead of spending time and CPU cycles on launching the [Docker Engine][17]. And it’s image format agnostic.
|
||||
|
||||
In Kubernetes, [kubelets][18] manage pods, or containers’ clusters. With CRI-O, Kubernetes and its kubelets can manage the entire container lifecycle. The tool also isn't wedded to Docker images; you can also use the new [OCI Image Format][19] and [CoreOS's rkt][20] container images.
|
||||
|
||||
Together, these tools are becoming a Kubernetes stack: the orchestrator, the [Container Runtime Interface][21] (CRI), and CRI-O. Lead Kubernetes engineer Kelsey Hightower says, "We don’t really need much from any container runtime—whether it’s Docker or [rkt][22]. Just give us an API to the kernel." The result, promise these techies, is the power to spin containers faster than ever.
|
||||
|
||||
Kubernetes is also speeding up building container images. Until recently, there were [three ways to build containers][23]. The first way is to build container images in place via a Docker or CoreOS. The second approach is to inject custom code into a prebuilt image. Finally, Asset Generation Pipelines use containers to compile assets that are then included during a subsequent image build using Docker's [Multi-Stage Builds][24].
|
||||
|
||||
Now, there's a Kubernetes-native method: Red Hat's [Buildah][25], [a scriptable shell tool][26] for efficiently and quickly building OCI-compliant images and containers. Buildah simplifies creating, building, and updating images while decreasing the learning curve of the container environment, Pousty said. You can use it with Kubernetes to create and spin up containers automatically based on an application's calls. Buildah also saves system resources, because it does not require a container runtime daemon.
|
||||
|
||||
So, rather than actually booting a container and doing all sorts of steps in the container itself, Pousty said, “you mount the file system, do normal operations on your machine as if it were your normal file system, and then commit at the end."
|
||||
|
||||
What this means is that you can pull down an image from a registry, create its matching container, and customize it. Then you can use Buildah within Kubernetes to create new running images as you need them. The end result, he said, is even more speed for running Kubernetes-managed containerized applications, requiring fewer resources.
|
||||
|
||||
### Kubernetes features you didn’t know you had
|
||||
|
||||
You don’t necessarily need to look for outside tools. Kubernetes has several underappreciated features.
|
||||
|
||||
One of them, according to Allan Naim, a Google Cloud global product lead, is [Kubernetes namespaces][27]. In his Open Source Summit speech on Kubernetes best practices, Naim said, "Few people use namespaces—and that's a mistake."
|
||||
|
||||
“Namespaces are the way to partition a single Kubernetes cluster into multiple virtual clusters," said Naim. For example, "you can think of namespaces as family names." So, if "Smith" identifies a family, one member, say, Steve Smith, is just “Steve,” but outside the confines of the family, he's "Steve Smith" or perhaps "Steve Smith from Chicago.”
|
||||
|
||||
More technically, "namespaces are a logical partitioning capability that enable one Kubernetes cluster to be used by multiple users, teams of users, or a single user with multiple applications without confusion,” Naim explained. “Each user, team of users, or application may exist within its namespace, isolated from every other user of the cluster and operating as if it were the sole user of the cluster.”
|
||||
|
||||
Practically speaking, you can use namespaces to mold an enterprise's multiple business/technology entities onto Kubernetes. For example, cloud architects can define the corporate namespace strategy by mapping product, location, team, and cost-center namespaces.
|
||||
|
||||
Another approach Naim suggested is to use namespaces to partition software development pipelines into discrete namespaces. These could be such familiar units as testing, quality assurance, staging, and production. Or namespaces can be used to manage separate customers. For instance, you could create a separate namespace for each customer, customer project, or customer business unit. That makes it easier to distinguish between projects and avoid reusing the same names for resources.
|
||||
|
||||
However, Kubernetes doesn't currently provide a mechanism to enforce access controls across namespaces. Therefore, Naim recommended you don't externally expose programs using this approach. Also keep in mind that namespaces aren't a management cure-all. For example, you can't nest namespaces within one other. In addition, there's no mechanism to enforce security across namespaces.
|
||||
|
||||
Still, used with care, namespaces can be quite useful.
|
||||
|
||||
### Human-centered tips
|
||||
|
||||
Moving from deep technology to project management, Pousty suggested that, in the move to a cloud-native and microservice architecture, you put an operations person on your microservice team. “If you're going to do microservices, your team will end up doing Ops-y work. And, it's kind of foolish not to bring in someone who already knows operations,” he said. “You need the right core competencies on that team. I don't want developers to reinvent the operations wheel."
|
||||
|
||||
Instead, reinvent your work process into one that enables you to make the most from containers and clouds. For that, Kubernetes is great.
|
||||
|
||||
### Cloud-native computing with Kubernetes: Lessons for leaders
|
||||
|
||||
* The cloud-native ecosystem is expanding rapidly. Look for tools that can extend the ways you use containers.
|
||||
|
||||
* Explore less well-known Kubernetes features such as namespaces. They can improve your organization and automation.
|
||||
|
||||
* Make sure development teams deploying to containers have an Ops person involved. Otherwise strife will ensue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Steven J. Vaughan-Nichols, CEO, Vaughan-Nichols & Associates
|
||||
|
||||
Steven J. Vaughan-Nichols, aka sjvn, has been writing about technology and the business of technology since CP/M-80 was the cutting edge, PC operating system; 300bps was a fast Internet connection; WordStar was the state of the art word processor; and we liked it. His work has been published in everything from highly technical publications (IEEE Computer, ACM NetWorker, Byte) to business publications (eWEEK, InformationWeek, ZDNet) to popular technology (Computer Shopper, PC Magazine, PC World) to the mainstream press (Washington Post, San Francisco Chronicle, BusinessWeek).
|
||||
|
||||
---------------------
|
||||
|
||||
|
||||
via: https://insights.hpe.com/articles/how-to-implement-cloud-native-computing-with-kubernetes-1710.html
|
||||
|
||||
作者:[ Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.hpe.com/contributors/steven-j-vaughan-nichols.html
|
||||
[1]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_insights~510287587~Containers_Dummies~sjvn_Kubernetes
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://www.redhat.com/en
|
||||
[4]:https://www.openshift.com/
|
||||
[5]:https://www.linuxfoundation.org/
|
||||
[6]:http://events.linuxfoundation.org/events/open-source-summit-north-america
|
||||
[7]:https://www.opencontainers.org/
|
||||
[8]:https://www.cncf.io/
|
||||
[9]:https://insights.hpe.com/articles/the-basics-explaining-kubernetes-mesosphere-and-docker-swarm-1702.html
|
||||
[10]:https://insights.hpe.com/articles/when-to-use-containers-and-when-not-to-1705.html
|
||||
[11]:https://www.open-scap.org/
|
||||
[12]:https://scap.nist.gov/
|
||||
[13]:https://developers.redhat.com/blog/2016/05/02/introducing-atomic-scan-container-vulnerability-detection/
|
||||
[14]:http://cri-o.io/
|
||||
[15]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[16]:https://wiki.centos.org/HowTos/SELinux
|
||||
[17]:https://docs.docker.com/engine/
|
||||
[18]:https://kubernetes.io/docs/admin/kubelet/
|
||||
[19]:http://www.zdnet.com/article/containers-consolidation-open-container-initiative-1-0-released/
|
||||
[20]:https://coreos.com/rkt/docs/latest/
|
||||
[21]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[22]:https://coreos.com/rkt/
|
||||
[23]:http://chris.collins.is/2017/02/24/three-docker-build-strategies/
|
||||
[24]:https://docs.docker.com/engine/userguide/eng-image/multistage-build/#use-multi-stage-builds
|
||||
[25]:https://github.com/projectatomic/buildah
|
||||
[26]:https://www.projectatomic.io/blog/2017/06/introducing-buildah/
|
||||
[27]:https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
|
||||
260
sources/tech/20171015 Monitoring Slow SQL Queries via Slack.md
Normal file
260
sources/tech/20171015 Monitoring Slow SQL Queries via Slack.md
Normal file
@ -0,0 +1,260 @@
|
||||
# Monitoring Slow SQL Queries via Slack
|
||||
|
||||
### A simple Go recipe for getting notified about slow SQL queries, unexpected errors and other important logs.
|
||||
|
||||
My Slack bot notifying me about a SQL query taking long time to execute. I should fix that soon.
|
||||
|
||||
We can't manage what we don't measure. Every backend application needs our eyes on the database performance. If a specific query gets slower as the data grows, you have to optimize it before it's too late.
|
||||
|
||||
As Slack has became a central to work, it's changing how we monitor our systems, too. Although there are quite nice monitoring tools existing, it's nice to have a Slack bot telling us if there is anything going wrong in the system; an SQL query taking too long to finish for example, or fatal errors in a specific Go package.
|
||||
|
||||
In this blog post, I'll tell how we can achieve this setup by using [a simple logging system][8], and [an existing database library][9] that already supports this feature.
|
||||
|
||||
Using Logger
|
||||
============================================================
|
||||
|
||||
[logger][10] is a tiny library designed for both Go libraries and applications. It has three important features useful for this case;
|
||||
|
||||
* It provides a simple timer for measuring performance.
|
||||
|
||||
* Supports complex output filters, so you can choose logs from specific packages. For example, you can tell logger to output only from database package, and only the timer logs which took more than 500ms.
|
||||
|
||||
* It has a Slack hook, so you can filter and stream logs into Slack.
|
||||
|
||||
Let's look at this example program to see how we use timers, later we'll get to filters, as well:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"github.com/azer/logger"
|
||||
"time"
|
||||
)
|
||||
|
||||
var (
|
||||
users = logger.New("users")
|
||||
database = logger.New("database")
|
||||
)
|
||||
|
||||
func main () {
|
||||
users.Info("Hi!")
|
||||
|
||||
timer := database.Timer()
|
||||
time.Sleep(time.Millisecond * 250) // sleep 250ms
|
||||
timer.End("Connected to database")
|
||||
|
||||
users.Error("Failed to create a new user.", logger.Attrs{
|
||||
"e-mail": "foo@bar.com",
|
||||
})
|
||||
|
||||
database.Info("Just a random log.")
|
||||
|
||||
fmt.Println("Bye.")
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Running this program will give no output:
|
||||
|
||||
```
|
||||
$ go run example-01.go
|
||||
Bye
|
||||
|
||||
```
|
||||
|
||||
Logger is [silent by default][11], so it can be used by libraries internally. We simply pass an environment variable to see the logs:
|
||||
|
||||
For example;
|
||||
|
||||
```
|
||||
$ LOG=database@timer go run example-01.go
|
||||
01:08:54.997 database(250.095587ms): Connected to database.
|
||||
Bye
|
||||
|
||||
```
|
||||
|
||||
The above example we used `database@timer` filter to see timer logs from `database` package. You can try different filters such as;
|
||||
|
||||
* `LOG=*`: enables all logs
|
||||
|
||||
* `LOG=users@error,database`: enables errors from `users`, all logs from `database`.
|
||||
|
||||
* `LOG=*@timer,database@info`: enables timer and error logs from all packages, any logs from `database`.
|
||||
|
||||
* `LOG=*,users@mute`: Enables all logs except from `users`.
|
||||
|
||||
### Sending Logs to Slack
|
||||
|
||||
Logging in console is useful in development environment, but we need a human-friendly interface for production. Thanks to the [slack-hook][12], we can easily integrate the above example with Slack:
|
||||
|
||||
```
|
||||
import (
|
||||
"github.com/azer/logger"
|
||||
"github.com/azer/logger-slack-hook"
|
||||
)
|
||||
|
||||
func init () {
|
||||
logger.Hook(&slackhook.Writer{
|
||||
WebHookURL: "https://hooks.slack.com/services/...",
|
||||
Channel: "slow-queries",
|
||||
Username: "Query Person",
|
||||
Filter: func (log *logger.Log) bool {
|
||||
return log.Package == "database" && log.Level == "TIMER" && log.Elapsed >= 200
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Let's explain what we've done in the above example:
|
||||
|
||||
* Line #5: Set the incoming webhook url. You can get this URL [here][1].
|
||||
|
||||
* Line #6: Choose the channel to stream the logs into.
|
||||
|
||||
* Line #7: The username that will appear as sender.
|
||||
|
||||
* Line #11: Filter for streaming only timer logs which took longer than 200ms.
|
||||
|
||||
Hope this gave you the general idea. Have a look at [logger][13]'s documentation if you got more questions.
|
||||
|
||||
# A Real-World Example: CRUD
|
||||
|
||||
One of the hidden features of [crud][14] -an ORM-ish database library for Go- is an internal logging system using [logger][15]. This allows us to monitor SQL queries being executed easily.
|
||||
|
||||
### Querying
|
||||
|
||||
Let's say you have a simple SQL query which returns username by given e-mail:
|
||||
|
||||
```
|
||||
func GetUserNameByEmail (email string) (string, error) {
|
||||
var name string
|
||||
if err := DB.Read(&name, "SELECT name FROM user WHERE email=?", email); err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
return name, nil
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Ok, this is too short, feels like something missing here. Let's add the full context:
|
||||
|
||||
```
|
||||
import (
|
||||
"github.com/azer/crud"
|
||||
_ "github.com/go-sql-driver/mysql"
|
||||
"os"
|
||||
)
|
||||
|
||||
var db *crud.DB
|
||||
|
||||
func main () {
|
||||
var err error
|
||||
|
||||
DB, err = crud.Connect("mysql", os.Getenv("DATABASE_URL"))
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
username, err := GetUserNameByEmail("foo@bar.com")
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
fmt.Println("Your username is: ", username)
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
So we have a [crud][16] instance that connects to the MySQL database passed through env variable `DATABASE_URL`. If we run this program, we'll see one-line output:
|
||||
|
||||
```
|
||||
$ DATABASE_URL=root:123456@/testdb go run example.go
|
||||
Your username is: azer
|
||||
|
||||
```
|
||||
|
||||
As I mentioned previously, logs are [silent by default][17]. Let's see internal logs of crud:
|
||||
|
||||
```
|
||||
$ LOG=crud go run example.go
|
||||
22:56:29.691 crud(0): SQL Query Executed: SELECT username FROM user WHERE email='foo@bar.com'
|
||||
Your username is: azer
|
||||
|
||||
```
|
||||
|
||||
This is simple and useful enough for seeing how our queries perform in our development environment.
|
||||
|
||||
### CRUD and Slack Integration
|
||||
|
||||
Logger is designed for configuring dependencies' internal logging systems from the application level. This means, you can stream crud's logs into Slack by configuring logger in your application level:
|
||||
|
||||
```
|
||||
import (
|
||||
"github.com/azer/logger"
|
||||
"github.com/azer/logger-slack-hook"
|
||||
)
|
||||
|
||||
func init () {
|
||||
logger.Hook(&slackhook.Writer{
|
||||
WebHookURL: "https://hooks.slack.com/services/...",
|
||||
Channel: "slow-queries",
|
||||
Username: "Query Person",
|
||||
Filter: func (log *logger.Log) bool {
|
||||
return log.Package == "mysql" && log.Level == "TIMER" && log.Elapsed >= 250
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
In the above code:
|
||||
|
||||
* We imported [logger][2] and [logger-slack-hook][3] libraries.
|
||||
|
||||
* We configured the logger library to stream some logs into Slack. This configuration covers all usages of [logger][4] in the codebase, including third-party dependencies.
|
||||
|
||||
* We used a filter to stream only timer logs taking longer than 250 in the MySQL package.
|
||||
|
||||
This usage can be extended beyond just slow query reports. I personally use it for tracking critical errors in specific packages, also statistical logs like a new user signs up or make payments.
|
||||
|
||||
### Packages I mentioned in this post:
|
||||
|
||||
* [crud][5]
|
||||
|
||||
* [logger][6]
|
||||
|
||||
* [logger-slack-hook][7]
|
||||
|
||||
[Let me know][18] if you have any questions or comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/
|
||||
|
||||
作者:[Azer Koçulu ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://azer.bike/
|
||||
[1]:https://my.slack.com/services/new/incoming-webhook/
|
||||
[2]:https://github.com/azer/logger
|
||||
[3]:https://github.com/azer/logger-slack-hook
|
||||
[4]:https://github.com/azer/logger
|
||||
[5]:https://github.com/azer/crud
|
||||
[6]:https://github.com/azer/logger
|
||||
[7]:https://github.com/azer/logger
|
||||
[8]:http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/?utm_source=dbweekly&utm_medium=email#logger
|
||||
[9]:http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/?utm_source=dbweekly&utm_medium=email#crud
|
||||
[10]:https://github.com/azer/logger
|
||||
[11]:http://www.linfo.org/rule_of_silence.html
|
||||
[12]:https://github.com/azer/logger-slack-hook
|
||||
[13]:https://github.com/azer/logger
|
||||
[14]:https://github.com/azer/crud
|
||||
[15]:https://github.com/azer/logger
|
||||
[16]:https://github.com/azer/crud
|
||||
[17]:http://www.linfo.org/rule_of_silence.html
|
||||
[18]:https://twitter.com/afrikaradyo
|
||||
@ -0,0 +1,144 @@
|
||||
translating---geekpi
|
||||
|
||||
Why Use Docker with R? A DevOps Perspective
|
||||
============================================================
|
||||
|
||||
[][11]
|
||||
|
||||
There have been several blog posts going around about why one would use Docker with R.
|
||||
In this post I’ll try to add a DevOps point of view and explain how containerizing
|
||||
R is used in the context of the OpenCPU system for building and deploying R servers.
|
||||
|
||||
> Has anyone in the [#rstats][2] world written really well about the *why* of their use of Docker, as opposed to the the *how*?
|
||||
>
|
||||
> — Jenny Bryan (@JennyBryan) [September 29, 2017][3]
|
||||
|
||||
### 1: Easy Development
|
||||
|
||||
The flagship of the OpenCPU system is the [OpenCPU server][12]:
|
||||
a mature and powerful Linux stack for embedding R in systems and applications.
|
||||
Because OpenCPU is completely open source we can build and ship on DockerHub. A ready-to-go linux server with both OpenCPU and RStudio
|
||||
can be started using the following (use port 8004 or 80):
|
||||
|
||||
```
|
||||
docker run -t -p 8004:8004 opencpu/rstudio
|
||||
|
||||
```
|
||||
|
||||
Now simply open [http://localhost:8004/ocpu/][13] and
|
||||
[http://localhost:8004/rstudio/][14] in your browser!
|
||||
Login via rstudio with user: `opencpu` (passwd: `opencpu`) to build or install apps.
|
||||
See the [readme][15] for more info.
|
||||
|
||||
Docker makes it easy to get started with OpenCPU. The container gives you the full
|
||||
flexibility of a Linux box, without the need to install anything on your system.
|
||||
You can install packages or apps via rstudio server, or use `docker exec` to a
|
||||
root shell on the running server:
|
||||
|
||||
```
|
||||
# Lookup the container ID
|
||||
docker ps
|
||||
|
||||
# Drop a shell
|
||||
docker exec -i -t eec1cdae3228 /bin/bash
|
||||
|
||||
```
|
||||
|
||||
From the shell you can install additional software in the server, customize the apache2 httpd
|
||||
config (auth, proxies, etc), tweak R options, optimize performance by preloading data or
|
||||
packages, etc.
|
||||
|
||||
### 2: Shipping and Deployment via DockerHub
|
||||
|
||||
The most powerful use if Docker is shipping and deploying applications via DockerHub. To create a fully standalone
|
||||
application container, simply use a standard [opencpu image][16]
|
||||
and add your app.
|
||||
|
||||
For the purpose of this blog post I have wrapped up some of the [example apps][17] as docker containers by adding a very simple `Dockerfile` to each repository. For example the [nabel][18] app has a [Dockerfile][19] that contains the following:
|
||||
|
||||
```
|
||||
FROM opencpu/base
|
||||
|
||||
RUN R -e 'devtools::install_github("rwebapps/nabel")'
|
||||
|
||||
```
|
||||
|
||||
It takes the standard [opencpu/base][20]
|
||||
image and then installs the nabel app from the Github [repository][21].
|
||||
The result is a completeley isolated, standalone application. The application can be
|
||||
started by anyone using e.g:
|
||||
|
||||
```
|
||||
docker run -d 8004:8004 rwebapps/nabel
|
||||
|
||||
```
|
||||
|
||||
The `-d` daemonizes on port 8004.
|
||||
Obviously you can tweak the `Dockerfile` to install whatever extra software or settings you need
|
||||
for your application.
|
||||
|
||||
Containerized deployment shows the true power of docker: it allows for shipping fully
|
||||
self contained appliations that work out of the box, without installing any software or
|
||||
relying on paid hosting services. If you do prefer professional hosting, there are
|
||||
many companies that will gladly host docker applications for you on scalable infrastructure.
|
||||
|
||||
### 3 Cross Platform Building
|
||||
|
||||
There is a third way Docker is used for OpenCPU. At each release we build
|
||||
the `opencpu-server` installation package for half a dozen operating systems, which
|
||||
get published on [https://archive.opencpu.org][22].
|
||||
This process has been fully automated using DockerHub. The following images automatically
|
||||
build the enitre stack from source:
|
||||
|
||||
* [opencpu/ubuntu-16.04][4]
|
||||
|
||||
* [opencpu/debian-9][5]
|
||||
|
||||
* [opencpu/fedora-25][6]
|
||||
|
||||
* [opencpu/fedora-26][7]
|
||||
|
||||
* [opencpu/centos-6][8]
|
||||
|
||||
* [opencpu/centos-7][9]
|
||||
|
||||
DockerHub automatically rebuilds this images when a new release is published on Github.
|
||||
All that is left to do is run a [script][23]
|
||||
which pull down the images and copies the `opencpu-server`binaries to the [archive server][24].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.r-bloggers.com/why-use-docker-with-r-a-devops-perspective/
|
||||
|
||||
作者:[Jeroen Ooms][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.r-bloggers.com/author/jeroen-ooms/
|
||||
[1]:https://www.opencpu.org/posts/opencpu-with-docker/
|
||||
[2]:https://twitter.com/hashtag/rstats?src=hash&ref_src=twsrc%5Etfw
|
||||
[3]:https://twitter.com/JennyBryan/status/913785731998289920?ref_src=twsrc%5Etfw
|
||||
[4]:https://hub.docker.com/r/opencpu/ubuntu-16.04/
|
||||
[5]:https://hub.docker.com/r/opencpu/debian-9/
|
||||
[6]:https://hub.docker.com/r/opencpu/fedora-25/
|
||||
[7]:https://hub.docker.com/r/opencpu/fedora-26/
|
||||
[8]:https://hub.docker.com/r/opencpu/centos-6/
|
||||
[9]:https://hub.docker.com/r/opencpu/centos-7/
|
||||
[10]:https://www.r-bloggers.com/
|
||||
[11]:https://www.opencpu.org/posts/opencpu-with-docker
|
||||
[12]:https://www.opencpu.org/download.html
|
||||
[13]:http://localhost:8004/ocpu/
|
||||
[14]:http://localhost:8004/rstudio/
|
||||
[15]:https://hub.docker.com/r/opencpu/rstudio/
|
||||
[16]:https://hub.docker.com/u/opencpu/
|
||||
[17]:https://www.opencpu.org/apps.html
|
||||
[18]:https://rwebapps.ocpu.io/nabel/www/
|
||||
[19]:https://github.com/rwebapps/nabel/blob/master/Dockerfile
|
||||
[20]:https://hub.docker.com/r/opencpu/base/
|
||||
[21]:https://github.com/rwebapps
|
||||
[22]:https://archive.opencpu.org/
|
||||
[23]:https://github.com/opencpu/archive/blob/gh-pages/update.sh
|
||||
[24]:https://archive.opencpu.org/
|
||||
[25]:https://www.r-bloggers.com/author/jeroen-ooms/
|
||||
123
sources/tech/20171017 A tour of Postgres Index Types.md
Normal file
123
sources/tech/20171017 A tour of Postgres Index Types.md
Normal file
@ -0,0 +1,123 @@
|
||||
# A tour of Postgres Index Types
|
||||
|
||||
At Citus we spend a lot of time working with customers on data modeling, optimizing queries, and adding [indexes][3] to make things snappy. My goal is to be as available for our customers as we need to be, in order to make you successful. Part of that is keeping your Citus cluster well tuned and [performant][4] which [we take care][5]of for you. Another part is helping you with everything you need to know about Postgres and Citus. After all a healthy and performant database means a fast performing app and who wouldn’t want that. Today we’re going to condense some of the information we’ve shared directly with customers about Postgres indexes.
|
||||
|
||||
Postgres has a number of index types, and with each new release seems to come with another new index type. Each of these indexes can be useful, but which one to use depends on 1\. the data type and then sometimes 2\. the underlying data within the table, and 3\. the types of lookups performed. In what follows we’ll look at a quick survey of the index types available to you in Postgres and when you should leverage each. Before we dig in, here’s a quick glimpse of the indexes we’ll walk you through:
|
||||
|
||||
* B-Tree
|
||||
|
||||
* Generalized Inverted Index (GIN)
|
||||
|
||||
* Generalized Inverted Seach Tree (GiST)
|
||||
|
||||
* Space partitioned GiST (SP-GiST)
|
||||
|
||||
* Block Range Indexes (BRIN)
|
||||
|
||||
* Hash
|
||||
|
||||
Now onto the indexing
|
||||
|
||||
### In Postgres, a B-Tree index is what you most commonly want
|
||||
|
||||
If you have a degree in Computer Science, then a B-tree index was likely the first one you learned about. A [B-tree index][6] creates a tree that will keep itself balanced and even. When it goes to look something up based on that index it will traverse down the tree to find the key the tree is split on and then return you the data you’re looking for. Using an index is much faster than a sequential scan because it may only have to read a few [pages][7] as opposed to sequentially scanning thousands of them (when you’re returning only a few records).
|
||||
|
||||
If you run a standard `CREATE INDEX` it creates a B-tree for you. B-tree indexes are valuable on the most common data types such as text, numbers, and timestamps. If you’re just getting started indexing your database and aren’t leveraging too many advanced Postgres features within your database, using standard B-Tree indexes is likely the path you want to take.
|
||||
|
||||
### GIN indexes, for columns with multiple values
|
||||
|
||||
Generalized Inverted Indexes, commonly referred to as [GIN][8], are most useful when you have data types that contain multiple values in a single column.
|
||||
|
||||
From the Postgres docs: _“GIN is designed for handling cases where the items to be indexed are composite values, and the queries to be handled by the index need to search for element values that appear within the composite items. For example, the items could be documents, and the queries could be searches for documents containing specific words.”_
|
||||
|
||||
The most common data types that fall into this bucket are:
|
||||
|
||||
* [hStore][1]
|
||||
|
||||
* Arrays
|
||||
|
||||
* Range types
|
||||
|
||||
* [JSONB][2]
|
||||
|
||||
One of the beautiful things about GIN indexes is that they are aware of the data within composite values. But because a GIN index has specific knowledge about the data structure support for each individual type needs to be added, as a result not all datatypes are supported.
|
||||
|
||||
### GiST indexes, for rows that overlap values
|
||||
|
||||
GiST indexes are most useful when you have data that can in some way overlap with the value of that same column but from another row. The best thing about GiST indexes: if you have say a geometry data type and you want to see if two polygons contained some point. In one case a specific point may be contained within box, while another point only exists within one polygon. The most common datatypes where you want to leverage GiST indexes are:
|
||||
|
||||
* Geometry types
|
||||
|
||||
* Text when dealing with full-text search
|
||||
|
||||
GiST indexes have some more fixed constraints around size, whereas GIN indexes can become quite large. As a result, GiST indexes are lossy. From the docs: _“A GiST index is lossy, meaning that the index might produce false matches, and it is necessary to check the actual table row to eliminate such false matches. (PostgreSQL does this automatically when needed.)”_ This doesn’t mean you’ll get wrong results, it just means Postgres has to do a little extra work to filter those false positives before giving your data back to you.
|
||||
|
||||
_Special note: GIN and GiST indexes can often be beneficial on the same column types. One can often boast better performance but larger disk footprint in the case of GIN and vice versa for GiST. When it comes to GIN vs. GiST there isn’t a perfect one size fits all, but the broad rules above apply_
|
||||
|
||||
### SP-GiST indexes, for larger data
|
||||
|
||||
Space partitioned GiST indexes leverage space partitioning trees that came out of some research from [Purdue][9]. SP-GiST indexes are most useful when your data has a natural clustering element to it, and is also not an equally balanced tree. A great example of this is phone numbers (at least US ones). They follow a format of:
|
||||
|
||||
* 3 digits for area code
|
||||
|
||||
* 3 digits for prefix (historically related to a phone carrier’s switch)
|
||||
|
||||
* 4 digits for line number
|
||||
|
||||
This means that you have some natural clustering around the first set of 3 digits, around the second set of 3 digits, then numbers may fan out in a more even distribution. But, with phone numbers some area codes have a much higher saturation than others. The result may be that the tree is very unbalanced. Because of that natural clustering up front and the unequal distribution of data–data like phone numbers could make a good case for SP-GiST.
|
||||
|
||||
### BRIN indexes, for larger data
|
||||
|
||||
Block range indexes can focus on some similar use cases to SP-GiST in that they’re best when there is some natural ordering to the data, and the data tends to be very large. Have a billion record table especially if it’s time series data? BRIN may be able to help. If you’re querying against a large set of data that is naturally grouped together such as data for several zip codes (which then roll up to some city) BRIN helps to ensure that similar zip codes are located near each other on disk.
|
||||
|
||||
When you have very large datasets that are ordered such as dates or zip codes BRIN indexes allow you to skip or exclude a lot of the unnecessary data very quickly. BRIN additionally are maintained as smaller indexes relative to the overall datasize making them a big win for when you have a large dataset.
|
||||
|
||||
### Hash indexes, finally crash safe
|
||||
|
||||
Hash indexes have been around for years within Postgres, but until Postgres 10 came with a giant warning that they were not WAL-logged. This meant if your server crashed and you failed over to a stand-by or recovered from archives using something like [wal-g][10] then you’d lose that index until you recreated it. With Postgres 10 they’re now WAL-logged so you can start to consider using them again, but the real question is should you?
|
||||
|
||||
Hash indexes at times can provide faster lookups than B-Tree indexes, and can boast faster creation times as well. The big issue with them is they’re limited to only equality operators so you need to be looking for exact matches. This makes hash indexes far less flexible than the more commonly used B-Tree indexes and something you won’t want to consider as a drop-in replacement but rather a special case.
|
||||
|
||||
### Which do you use?
|
||||
|
||||
We just covered a lot and if you’re a bit overwhelmed you’re not alone. If all you knew before was `CREATE INDEX` you’ve been using B-Tree indexes all along, and the good news is you’re still performing as well or better than most databases that aren’t Postgres :) As you start to use more Postgres features consider this a cheatsheet for when to use other Postgres types:
|
||||
|
||||
* B-Tree - For most datatypes and queries
|
||||
|
||||
* GIN - For JSONB/hstore/arrays
|
||||
|
||||
* GiST - For full text search and geospatial datatypes
|
||||
|
||||
* SP-GiST - For larger datasets with natural but uneven clustering
|
||||
|
||||
* BRIN - For really large datasets that line up sequentially
|
||||
|
||||
* Hash - For equality operations, and generally B-Tree still what you want here
|
||||
|
||||
If you have any questions or feedback about the post feel free to join us in our [slack channel][11].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
|
||||
作者:[Craig Kerstiens ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
[1]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||
[2]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||
[3]:https://www.citusdata.com/blog/2017/10/11/index-all-the-things-in-postgres/
|
||||
[4]:https://www.citusdata.com/blog/2017/09/29/what-performance-can-you-expect-from-postgres/
|
||||
[5]:https://www.citusdata.com/product/cloud
|
||||
[6]:https://en.wikipedia.org/wiki/B-tree
|
||||
[7]:https://www.8kdata.com/blog/postgresql-page-layout/
|
||||
[8]:https://www.postgresql.org/docs/10/static/gin.html
|
||||
[9]:https://www.cs.purdue.edu/spgist/papers/W87R36P214137510.pdf
|
||||
[10]:https://www.citusdata.com/blog/2017/08/18/introducing-wal-g-faster-restores-for-postgres/
|
||||
[11]:https://slack.citusdata.com/
|
||||
[12]:https://twitter.com/share?url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/&text=A%20tour%20of%20Postgres%20Index%20Types&via=citusdata
|
||||
[13]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
97
sources/tech/20171017 Image Processing on Linux.md
Normal file
97
sources/tech/20171017 Image Processing on Linux.md
Normal file
@ -0,0 +1,97 @@
|
||||
Image Processing on Linux
|
||||
============================================================
|
||||
|
||||
|
||||
I've covered several scientific packages in this space that generate nice graphical representations of your data and work, but I've not gone in the other direction much. So in this article, I cover a popular image processing package called ImageJ. Specifically, I am looking at [Fiji][4], an instance of ImageJ bundled with a set of plugins that are useful for scientific image processing.
|
||||
|
||||
The name Fiji is a recursive acronym, much like GNU. It stands for "Fiji Is Just ImageJ". ImageJ is a useful tool for analyzing images in scientific research—for example, you may use it for classifying tree types in a landscape from aerial photography. ImageJ can do that type categorization. It's built with a plugin architecture, and a very extensive collection of plugins is available to increase the available functionality.
|
||||
|
||||
The first step is to install ImageJ (or Fiji). Most distributions will have a package available for ImageJ. If you wish, you can install it that way and then install the individual plugins you need for your research. The other option is to install Fiji and get the most commonly used plugins at the same time. Unfortunately, most Linux distributions will not have a package available within their package repositories for Fiji. Luckily, however, an easy installation file is available from the main website. It's a simple zip file, containing a directory with all of the files required to run Fiji. When you first start it, you get only a small toolbar with a list of menu items (Figure 1).
|
||||
|
||||

|
||||
|
||||
Figure 1\. You get a very minimal interface when you first start Fiji.
|
||||
|
||||
If you don't already have some images to use as you are learning to work with ImageJ, the Fiji installation includes several sample images. Click the File→Open Samples menu item for a dropdown list of sample images (Figure 2). These samples cover many of the potential tasks you might be interested in working on.
|
||||
|
||||

|
||||
|
||||
Figure 2\. Several sample images are available that you can use as you learn how to work with ImageJ.
|
||||
|
||||
If you installed Fiji, rather than ImageJ alone, a large set of plugins already will be installed. The first one of note is the autoupdater plugin. This plugin checks the internet for updates to ImageJ, as well as the installed plugins, each time ImageJ is started.
|
||||
|
||||
All of the installed plugins are available under the Plugins menu item. Once you have installed a number of plugins, this list can become a bit unwieldy, so you may want to be judicious in your plugin selection. If you want to trigger the updates manually, click the Help→Update Fiji menu item to force the check and get a list of available updates (Figure 3).
|
||||
|
||||

|
||||
|
||||
Figure 3\. You can force a manual check of what updates are available.
|
||||
|
||||
Now, what kind of work can you do with Fiji/ImageJ? One example is doing counts of objects within an image. You can load a sample by clicking File→Open Samples→Embryos.
|
||||
|
||||

|
||||
|
||||
Figure 4\. With ImageJ, you can count objects within an image.
|
||||
|
||||
The first step is to set a scale to the image so you can tell ImageJ how to identify objects. First, select the line button on the toolbar and draw a line over the length of the scale legend on the image. You then can select Analyze→Set Scale, and it will set the number of pixels that the scale legend occupies (Figure 5). You can set the known distance to be 100 and the units to be "um".
|
||||
|
||||

|
||||
|
||||
Figure 5\. For many image analysis tasks, you need to set a scale to the image.
|
||||
|
||||
The next step is to simplify the information within the image. Click Image→Type→8-bit to reduce the information to an 8-bit gray-scale image. To isolate the individual objects, click Process→Binary→Make Binary to threshold the image automatically (Figure 6).
|
||||
|
||||

|
||||
|
||||
Figure 6\. There are tools to do automatic tasks like thresholding.
|
||||
|
||||
Before you can count the objects within the image, you need to remove artifacts like the scale legend. You can do that by using the rectangular selection tool to select it and then click Edit→Clear. Now you can analyze the image and see what objects are there.
|
||||
|
||||
Making sure that there are no areas selected in the image, click Analyze→Analyze Particles to pop up a window where you can select the minimum size, what results to display and what to show in the final image (Figure 7).
|
||||
|
||||

|
||||
|
||||
Figure 7\. You can generate a reduced image with identified particles.
|
||||
|
||||
Figure 8 shows an overall look at what was discovered in the summary results window. There is also a detailed results window for each individual particle.
|
||||
|
||||

|
||||
|
||||
Figure 8\. One of the output results includes a summary list of the particles identified.
|
||||
|
||||
Once you have an analysis worked out for a given image type, you often need to apply the exact same analysis to a series of images. This series may number into the thousands, so it's typically not something you will want to repeat manually for each image. In such cases, you can collect the required steps together into a macro so that they can be reapplied multiple times. Clicking Plugins→Macros→Record pops up a new window where all of your subsequent commands will be recorded. Once all of the steps are finished, you can save them as a macro file and rerun them on other images by clicking Plugins→Macros→Run.
|
||||
|
||||
If you have a very specific set of steps for your workflow, you simply can open the macro file and edit it by hand, as it is a simple text file. There is actually a complete macro language available to you to control the process that is being applied to your images more fully.
|
||||
|
||||
If you have a really large set of images that needs to be processed, however, this still might be too tedious for your workflow. In that case, go to Process→Batch→Macro to pop up a new window where you can set up your batch processing workflow (Figure 9).
|
||||
|
||||

|
||||
|
||||
Figure 9\. You can run a macro on a batch of input image files with a single command.
|
||||
|
||||
From this window, you can select which macro file to apply, the source directory where the input images are located and the output directory where you want the output images to be written. You also can set the output file format and filter the list of images being used as input based on what the filename contains. Once everything is done, start the batch run by clicking the Process button at the bottom of the window.
|
||||
|
||||
If this is a workflow that will be repeated over time, you can save the batch process to a text file by clicking the Save button at the bottom of the window. You then can reload the same workflow by clicking the Open button, also at the bottom of the window. All of this functionality allows you to automate the most tedious parts of your research so you can focus on the actual science.
|
||||
|
||||
Considering that there are more than 500 plugins and more than 300 macros available from the main ImageJ website alone, it is an understatement that I've been able to touch on only the most basic of topics in this short article. Luckily, many domain-specific tutorials are available, along with the very good documentation for the core of ImageJ from the main project website. If you think this tool could be of use to your research, there is a wealth of information to guide you in your particular area of study.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Joey Bernard has a background in both physics and computer science. This serves him well in his day job as a computational research consultant at the University of New Brunswick. He also teaches computational physics and parallel programming.
|
||||
|
||||
--------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/image-processing-linux
|
||||
|
||||
作者:[Joey Bernard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxjournal.com/users/joey-bernard
|
||||
[1]:https://www.linuxjournal.com/tag/science
|
||||
[2]:https://www.linuxjournal.com/tag/statistics
|
||||
[3]:https://www.linuxjournal.com/users/joey-bernard
|
||||
[4]:https://imagej.net/Fiji
|
||||
74
sources/tech/20171017 PingCAP Launches TiDB 1.0.md
Normal file
74
sources/tech/20171017 PingCAP Launches TiDB 1.0.md
Normal file
@ -0,0 +1,74 @@
|
||||
PingCAP Launches TiDB 1.0
|
||||
============================================================
|
||||
|
||||
### PingCAP Launches TiDB 1.0, A Scalable Hybrid Database Solution
|
||||
|
||||
October 16, 2017 - PingCAP Inc., a cutting-edge distributed database technology company, officially announces the release of [TiDB][4] 1.0\. TiDB is an open source distributed Hybrid Transactional/Analytical Processing (HTAP) database that empowers businesses to meet both workloads with a single database.
|
||||
|
||||
In the current database landscape, infrastructure engineers often have to use one database for online transactional processing (OLTP) and another for online analytical processing (OLAP). TiDB aims to break down this separation by building a HTAP database that enables real-time business analysis based on live transactional data. With TiDB, engineers can now spend less time managing multiple database solutions, and more time delivering business value for their companies. One of TiDB’s many users, a financial securities firm, is leveraging this technology to power its application for wealth management and user personas. With TiDB, this firm can easily process web-scale volumes of billing records and conduct mission-critical time sensitive data analysis like never before.
|
||||
|
||||
_“Two and a half years ago, Edward, Dylan and I started this journey to build a new database for an old problem that has long plagued the infrastructure software industry. Today, we are proud to announce that this database, TiDB, is production ready,”_ said Max Liu, co-founder and CEO of PingCAP. _“Abraham Lincoln once said, ‘the best way to predict the future is to create it.’ The future we predicted 771 days ago we now have created, because of the hard work and dedication of not just every member of our team, but also every contributor, user, and partner in our open source community. Today, we celebrate and pay gratitude to the power of the open source spirit. Tomorrow, we will continue to create the future we believe in.”_
|
||||
|
||||
TiDB has already been deployed in production in more than 30 companies in the APAC region, including fast-growing Internet companies like [Mobike][5], [Gaea][6], and [YOUZU][7]. The use cases span multiple industries from online marketplace and gaming, to fintech, media, and travel.
|
||||
|
||||
### TiDB features
|
||||
|
||||
**Horizontal Scalability**
|
||||
|
||||
TiDB grows as your business grows. You can increase the capacity for storage and computation simply by adding more machines.
|
||||
|
||||
**Compatible with MySQL Protocol**
|
||||
|
||||
Use TiDB as MySQL. You can replace MySQL with TiDB to power your application without changing a single line of code in most cases and with nearly no migration cost.
|
||||
|
||||
**Automatic Failover and High Availability**
|
||||
|
||||
Your data and applications are always-on. TiDB automatically handles malfunctions and protects your applications from machine failures or even downtime of an entire data-center.
|
||||
|
||||
**Consistent Distributed Transactions**
|
||||
|
||||
TiDB is analogous to a single-machine RDBMS. You can start a transaction that crosses multiple machines without worrying about consistency. TiDB makes your application code simple and robust.
|
||||
|
||||
**Online DDL**
|
||||
|
||||
Evolve TiDB schemas as your requirement changes. You can add new columns and indexes without stopping or affecting your ongoing operations.
|
||||
|
||||
[Try TiDB Now!][8]
|
||||
|
||||
### Use cases
|
||||
|
||||
[How TiDB tackles fast data growth and complex queries for yuanfudao.com][9]
|
||||
|
||||
[Migration from MySQL to TiDB to handle tens of millions of rows of data per day][10]
|
||||
|
||||
### For more information:
|
||||
|
||||
TiDB internal:
|
||||
|
||||
* [Data Storage][1]
|
||||
|
||||
* [Computing][2]
|
||||
|
||||
* [Scheduling][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pingcap.github.io/blog/2017/10/17/announcement/
|
||||
|
||||
作者:[PingCAP ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://pingcap.github.io/blog/
|
||||
[1]:https://pingcap.github.io/blog/2017/07/11/tidbinternal1/
|
||||
[2]:https://pingcap.github.io/blog/2017/07/11/tidbinternal2/
|
||||
[3]:https://pingcap.github.io/blog/2017/07/20/tidbinternal3/
|
||||
[4]:https://github.com/pingcap/tidb
|
||||
[5]:https://en.wikipedia.org/wiki/Mobike
|
||||
[6]:http://www.gaea.com/en/
|
||||
[7]:http://www.yoozoo.com/aboutEn
|
||||
[8]:https://pingcap.com/doc-QUICKSTART
|
||||
[9]:https://pingcap.github.io/blog/2017/08/08/tidbforyuanfudao/
|
||||
[10]:https://pingcap.github.io/blog/2017/05/22/Comparison-between-MySQL-and-TiDB-with-tens-of-millions-of-data-per-day/
|
||||
@ -0,0 +1,82 @@
|
||||
How containers and microservices change security
|
||||
============================================================
|
||||
|
||||
### Cloud-native applications and infrastructure require a radically different approach to security. Keep these best practices in mind
|
||||
|
||||

|
||||
>thinkstock
|
||||
|
||||
|
||||
|
||||
Today organizations large and small are exploring the adoption of cloud-native software technologies. “Cloud-native” refers to an approach that packages software within standardized units called containers, arranges those units into microservices that interface with each other to form applications, and ensures that running applications are fully automated for greater speed, agility, and scalability.
|
||||
|
||||
Because this approach fundamentally changes how software is built, deployed, and run, it also fundamentally changes how software needs to be protected. Cloud-native applications and infrastructure create several new challenges for security professionals, who will need to establish new security programs that support their organization’s use of cloud-native technologies.
|
||||
|
||||
Let’s take a look at those challenges, and then we’ll discuss a number of best practices security teams should adopt to address them. First the challenges:
|
||||
|
||||
* **Traditional security infrastructure lacks container visibility. **Most existing host-based and network security tools do not have the ability to monitor or capture container activity. These tools were built to secure single operating systems or the traffic between host machines rather than the applications running above, resulting in a loss of visibility into container events, system interactions, and inter-container traffic.
|
||||
|
||||
* **Attack surfaces can change rapidly.** Cloud-native applications are made up of many smaller components called microservices that are highly distributed, each of which must be individually audited and secured. Because these applications are designed to be provisioned and scaled by orchestration systems, their attack surfaces change constantly—and far faster than traditional monolithic applications.
|
||||
|
||||
* **Distributed data flows require continuous monitoring.**Containers and microservices are designed to be lightweight and to interconnect programmatically with each other or external cloud services. This generates large volumes of fast-moving data across the environment to be continuously monitored for indicators of attack and compromise as well as unauthorized data access or exfiltration.
|
||||
|
||||
* **Detection, prevention, and response must be automated. **The speed and volume of events generated by containers overwhelms current security operations workflows. The ephemeral life spans of containers also make it difficult to capture, analyze, and determine the root cause of incidents. Effective threat protection means automating data collection, filtering, correlation, and analysis to be able to react fast enough to new incidents.
|
||||
|
||||
Faced with these new challenges, security professionals will need to establish new security programs that support their organization’s use of cloud-native technologies. Naturally, your security program should address the entire lifecycle of cloud-native applications, which can be split into two distinct phases: the build and deploy phase, and the runtime phase. Each of these phases has a different set of security considerations that must be addressed to form a comprehensive security program.
|
||||
|
||||
|
||||
### Securing container builds and deployment
|
||||
|
||||
Security for the build and deploy phase focuses on applying controls to developer workflows and continuous integration and deployment pipelines to mitigate the risk of security issues that may arise after containers have been launched. These controls can incorporate the following guidelines and best practices:
|
||||
|
||||
* **Keep images as small as possible. **A container image is a lightweight executable that packages application code and its dependencies. Restricting each image to only what is essential for software to run minimizes the attack surface for every container launched from the image. Starting with minimal operating system base images such as Alpine Linux can reduce image sizes and make images easier to manage.
|
||||
|
||||
* **Scan images for known issues. **As images get built, they should be checked for known vulnerabilities and exposures. Each file system layer that makes up an image can be scanned and the results compared to a Common Vulnerabilities and Exposures (CVE) database that is regularly updated. Development and security teams can then address discovered vulnerabilities before the images are used to launch containers.
|
||||
|
||||
* **Digitally sign images. **Once images have been built, their integrity should be verified prior to deployment. Some image formats utilize unique identifiers called digests that can be used to detect when image contents have changed. Signing images with private keys provides cryptographic assurances that each image used to launch containers was created by a trusted party.
|
||||
|
||||
* **Harden and restrict access to the host OS. **Since containers running on a host share the same OS, it is important to ensure that they start with an appropriately restricted set of capabilities. This can be achieved using kernel security features and modules such as Seccomp, AppArmor, and SELinux.
|
||||
|
||||
* **Specify application-level segmentation policies. **Network traffic between microservices can be segmented to limit how they connect to each other. However, this needs to be configured based on application-level attributes such as labels and selectors, abstracting away the complexity of dealing with traditional network details such as IP addresses. The challenge with segmentation is having to define policies upfront that restrict communications without impacting the ability of containers to communicate within and across environments as part of their normal activity.
|
||||
|
||||
* **Protect secrets to be used by containers. **Microservices interfacing with each other frequently exchange sensitive data such as passwords, tokens, and keys, referred to as secrets. These secrets can be accidentally exposed if they are stored in images or environment variables. As a result, several orchestration platforms such as Docker and Kubernetes have integrated secrets management, ensuring that secrets are only distributed to the containers that use them, when they need them.
|
||||
|
||||
Several leading container platforms and tools from companies such as Docker, Red Hat, and CoreOS provide some or all of these capabilities. Getting started with one of these options is the easiest way to ensure robust security during the build and deploy phase.
|
||||
|
||||
However, build and deployment phase controls are still insufficient to ensuring a comprehensive security program. Preempting all security incidents before containers start running is not possible for the following reasons. First, vulnerabilities will never be fully eliminated and new ones are exploited all the time. Second, declarative container metadata and network segmentation policies cannot fully anticipate all legitimate application activity in a highly distributed environment. And third, runtime controls are complex to use and often misconfigured, leaving applications susceptible to threats.
|
||||
|
||||
### Securing containers at runtime
|
||||
|
||||
Runtime phase security encompasses all the functions—visibility, detection, response, and prevention—required to discover and stop attacks and policy violations that occur once containers are running. Security teams need to triage, investigate, and identify the root causes of security incidents in order to fully remediate them. Here are the key aspects of successful runtime phase security:
|
||||
|
||||
|
||||
* **Instrument the entire environment for continuous visibility. **Being able to detect attacks and policy violations starts with being able to capture all activity from running containers in real time to provide an actionable “source of truth.” Various instrumentation frameworks exist to capture different types of container-relevant data. Selecting one that can handle the volume and speed of containers is critical.
|
||||
|
||||
* **Correlate distributed threat indicators. **Containers are designed to be distributed across compute infrastructure based on resource availability. Given that an application may be comprised of hundreds or thousands of containers, indicators of compromise may be spread out across large numbers of hosts, making it harder to pinpoint those that are related as part of an active threat. Large-scale, fast correlation is needed to determine which indicators form the basis for particular attacks.
|
||||
|
||||
* **Analyze container and microservices behavior. **Microservices and containers enable applications to be broken down into minimal components that perform specific functions and are designed to be immutable. This makes it easier to understand normal patterns of expected behavior than in traditional application environments. Deviations from these behavioral baselines may reflect malicious activity and can be used to detect threats with greater accuracy.
|
||||
|
||||
* **Augment threat detection with machine learning.** The volume and speed of data generated in container environments overwhelms conventional detection techniques. Automation and machine learning can enable far more effective behavioral modeling, pattern recognition, and classification to detect threats with increased fidelity and fewer false positives. Beware solutions that use machine learning simply to generate static whitelists used to alert on anomalies, which can result in substantial alert noise and fatigue.
|
||||
|
||||
* **Intercept and block unauthorized container engine commands. **Commands issued to the container engine, e.g., Docker, are used to create, launch, and kill containers as well as run commands inside of running containers. These commands can reflect attempts to compromise containers, meaning it is essential to disallow any unauthorized ones.
|
||||
|
||||
* **Automate actions for response and forensics. **The ephemeral life spans of containers mean that they often leave very little information available for incident response and forensics. Further, cloud-native architectures typically treat infrastructure as immutable, automatically replacing impacted systems with new ones, meaning containers may be gone by the time of investigation. Automation can ensure information is captured, analyzed, and escalated quickly enough to mitigate the impact of attacks and violations.
|
||||
|
||||
Cloud-native software built on container technologies and microservices architectures is rapidly modernizing applications and infrastructure. This paradigm shift forces security professionals to rethink the programs required to effectively protect their organizations. A comprehensive security program for cloud-native software addresses the entire application lifecycle as containers are built, deployed, and run. By implementing a program using the guidelines above, organizations can build a secure foundation for container infrastructures and the applications and services that run on them.
|
||||
|
||||
_Wei Lien Dang is VP of product at StackRox, a security company that provides adaptive threat protection for containers. Previously, he was head of product at CoreOS and held senior product management roles for security and cloud infrastructure at Amazon Web Services, Splunk, and Bracket Computing._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3233139/cloud-computing/how-cloud-native-applications-change-security.html
|
||||
|
||||
作者:[ Wei Lien Dang][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.infoworld.com/blog/new-tech-forum/
|
||||
[1]:https://www.stackrox.com/
|
||||
[2]:https://www.infoworld.com/article/3204171/what-is-docker-linux-containers-explained.html#tk.ifw-infsb
|
||||
[3]:https://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker.html#tk.ifw-infsb
|
||||
42
sources/tech/20171018 IoT Cybersecurity what is plan b.md
Normal file
42
sources/tech/20171018 IoT Cybersecurity what is plan b.md
Normal file
@ -0,0 +1,42 @@
|
||||
# IoT Cybersecurity: What's Plan B?
|
||||
|
||||
In August, four US Senators introduced a bill designed to improve Internet of Things (IoT) security. The IoT Cybersecurity Improvement Act of 2017 is a modest piece of legislation. It doesn't regulate the IoT market. It doesn't single out any industries for particular attention, or force any companies to do anything. It doesn't even modify the liability laws for embedded software. Companies can continue to sell IoT devices with whatever lousy security they want.
|
||||
|
||||
What the bill does do is leverage the government's buying power to nudge the market: any IoT product that the government buys must meet minimum security standards. It requires vendors to ensure that devices can not only be patched, but are patched in an authenticated and timely manner; don't have unchangeable default passwords; and are free from known vulnerabilities. It's about as low a security bar as you can set, and that it will considerably improve security speaks volumes about the current state of IoT security. (Full disclosure: I helped draft some of the bill's security requirements.)
|
||||
|
||||
The bill would also modify the Computer Fraud and Abuse and the Digital Millennium Copyright Acts to allow security researchers to study the security of IoT devices purchased by the government. It's a far narrower exemption than our industry needs. But it's a good first step, which is probably the best thing you can say about this legislation.
|
||||
|
||||
However, it's unlikely this first step will even be taken. I am writing this column in August, and have no doubt that the bill will have gone nowhere by the time you read it in October or later. If hearings are held, they won't matter. The bill won't have been voted on by any committee, and it won't be on any legislative calendar. The odds of this bill becoming law are zero. And that's not just because of current politics -- I'd be equally pessimistic under the Obama administration.
|
||||
|
||||
But the situation is critical. The Internet is dangerous -- and the IoT gives it not just eyes and ears, but also hands and feet. Security vulnerabilities, exploits, and attacks that once affected only bits and bytes now affect flesh and blood.
|
||||
|
||||
Markets, as we've repeatedly learned over the past century, are terrible mechanisms for improving the safety of products and services. It was true for automobile, food, restaurant, airplane, fire, and financial-instrument safety. The reasons are complicated, but basically, sellers don't compete on safety features because buyers can't efficiently differentiate products based on safety considerations. The race-to-the-bottom mechanism that markets use to minimize prices also minimizes quality. Without government intervention, the IoT remains dangerously insecure.
|
||||
|
||||
The US government has no appetite for intervention, so we won't see serious safety and security regulations, a new federal agency, or better liability laws. We might have a better chance in the EU. Depending on how the General Data Protection Regulation on data privacy pans out, the EU might pass a similar security law in 5 years. No other country has a large enough market share to make a difference.
|
||||
|
||||
Sometimes we can opt out of the IoT, but that option is becoming increasingly rare. Last year, I tried and failed to purchase a new car without an Internet connection. In a few years, it's going to be nearly impossible to not be multiply connected to the IoT. And our biggest IoT security risks will stem not from devices we have a market relationship with, but from everyone else's cars, cameras, routers, drones, and so on.
|
||||
|
||||
We can try to shop our ideals and demand more security, but companies don't compete on IoT safety -- and we security experts aren't a large enough market force to make a difference.
|
||||
|
||||
We need a Plan B, although I'm not sure what that is. Comment if you have any ideas.
|
||||
|
||||
This essay previously appeared in the September/October issue of _IEEE Security & Privacy_ .
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I've been writing about security issues on my blog since 2004, and in my monthly newsletter since 1998. I write books, articles, and academic papers. Currently, I'm the Chief Technology Officer of IBM Resilient, a fellow at Harvard's Berkman Center, and a board member of EFF.
|
||||
|
||||
------------------
|
||||
|
||||
|
||||
via: https://www.schneier.com/blog/archives/2017/10/iot_cybersecuri.html
|
||||
|
||||
作者:[Bruce Schneier][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.schneier.com/blog/about/
|
||||
@ -0,0 +1,104 @@
|
||||
Tips to Secure Your Network in the Wake of KRACK
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
The recent KRACK vulnerability targets the link between your device and the Wi-Fi access point, which is probably a router either in your home, your office, or your favorite cafe. These tips can help improve the security of your connection.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
The [KRACK attacks vulnerability][4] is now more than 48 hours old and has been discussed in detail on a number of [technology-related sites][5], so I won’t repeat the technical details of the attack here. To summarize:
|
||||
|
||||
* A flaw in the WPA2 wireless handshake protocol allows attackers to sniff or manipulate the traffic between your device and the wi-fi access point.
|
||||
|
||||
* It is particularly bad for Linux and Android devices, due either to ambiguous wording in the WPA2 standard or to misunderstanding during its implementation. Effectively, until the underlying OS is patched, the vulnerability allows attackers to force all wireless traffic to happen without any encryption at all.
|
||||
|
||||
* This vulnerability can be patched on the client, so the sky hasn’t fallen and the WPA2 wireless encryption standard is not obsoleted in the same sense that the WEP standard is (do NOT “fix” this problem by switching to WEP).
|
||||
|
||||
* Most popular Linux distributions are already shipping updates that fix this vulnerability on the client, so apply your updates dutifully.
|
||||
|
||||
* Android will be shipping fixes for this vulnerability Very Soon. If your device is receiving Android security patches, you will receive a fix before long. If your device is no longer receiving such updates, then this particular vulnerability is merely another reason why you should stop using old, unsupported Android devices.
|
||||
|
||||
That said, from my perspective, Wi-Fi is merely another link in the chain of untrusted infrastructure and we should altogether avoid treating it as a trusted communication channel.
|
||||
|
||||
### Wi-Fi as untrusted infrastructure
|
||||
|
||||
If you’re reading this article from your laptop or your mobile device, then your chain of communication probably looks something like this:
|
||||
|
||||

|
||||
|
||||
The KRACK attack targets the link between your device and the Wi-Fi access point, which is probably a router either in your home, your office, your neighborhood library, or your favorite cafe.
|
||||
|
||||

|
||||
|
||||
In reality, this diagram should look something like this:
|
||||
|
||||

|
||||
|
||||
Wi-Fi is merely the first link in a long chain of communication happening over channels that we should not trust. If I were to guess, the Wi-Fi router you’re using has probably not received a security update since the day it got put together. Worse, it probably came with default or easily guessable administrative credentials that were never changed. Unless you set up and configured that router yourself and you can remember the last time you updated its firmware, you should assume that it is now controlled by someone else and cannot be trusted.
|
||||
|
||||
Past the Wi-Fi router, we enter the zone of generally distrusting the infrastructure at large -- depending on your general paranoia levels. Here we have upstream ISPs and providers, many of whom have been caught monitoring, altering, analyzing, and selling our personal traffic in an attempt to make additional money off our browsing habits. Often their own security patching schedules leave a lot to be desired and end up exposing our traffic to malicious eyes.
|
||||
|
||||
On the Internet at large, we have to worry about powerful state-level actors with ability to manipulate [core networking protocols][6] in order to carry out mass surveillance programs or perform state-level traffic filtering.
|
||||
|
||||
### HTTPS Protocol
|
||||
|
||||
Thankfully, we have a solution to the problem of secure communication over untrusted medium, and we use it every day -- the HTTPS protocol encrypts our Internet traffic point-to-point and ensures that we can trust that the sites we communicate with are who they say they are.
|
||||
|
||||
The Linux Foundation initiatives like [Let’s Encrypt][7] make it easy for site owners worldwide to offer end-to-end encryption that helps ensure that any compromised equipment between our personal devices and the websites we are trying to access does not matter.
|
||||
|
||||

|
||||
|
||||
Well... almost does not matter.
|
||||
|
||||
### DNS remains a problem
|
||||
|
||||
Even if we dutifully use HTTPS to create a trusted communication channel, there is still a chance that an attacker with access to our Wi-Fi router or someone who can alter our Wi-Fi traffic -- as is the case with KRACK -- can trick us into communicating with the wrong website. They can do so by taking advantage of the fact that we still greatly rely on DNS -- an unencrypted, easily spoofed [protocol from the 1980s][8].
|
||||
|
||||

|
||||
|
||||
DNS is a system that translates human-friendly domain names like “linux.com” into IP addresses that computers can use to communicate with each other. To translate a domain name into an IP address, the computer would query the resolver software -- usually running on the Wi-Fi router or on the system itself. The resolver would then query a distributed network of “root” nameservers to figure out which system on the Internet has what is called “authoritative” information about what IP address corresponds to the “linux.com” domain name.
|
||||
|
||||
The trouble is, all this communication happens over unauthenticated, [easily spoofable][9], cleartext protocols, and responses can be easily altered by attackers to make the query return incorrect data. If someone manages to spoof a DNS query and return the wrong IP address, they can manipulate where our system ends up sending the HTTP request.
|
||||
|
||||
Fortunately, HTTPS has a lot of built-in protection to make sure that it is not easy for someone to pretend to be another site. The TLS certificate on the malicious server must match the DNS name you are requesting -- and be issued by a reputable [Certificate Authority][10] recognized by your browser. If that is not the case, the browser will show a big warning that the host you are trying to communicate with is not who they say they are. If you see such warning, please be extremely cautious before choosing to override it, as you could be giving away your secrets to people who will use them against you.
|
||||
|
||||
If the attackers have full control of the router, they can prevent your connection from using HTTPS in the first place, by intercepting the response from the server that instructs your browser to set up a secure connection (this is called “[the SSL strip attack][11]”). To help protect you from this attack, sites may add a [special response header][12] telling your browser to always use HTTPS when communicating with them in the future, but this only works after your first visit. For some very popular sites, browsers now include a [hardcoded list of domains][13] that should always be accessed over HTTPS even on the first visit.
|
||||
|
||||
The solution to DNS spoofing exists and is called [DNSSEC][14], but it has seen very slow adoption due to important hurdles -- real and perceived. Until DNSSEC is used universally, we must assume that DNS information we receive cannot be fully trusted.
|
||||
|
||||
### Use VPN to solve the last-mile security problem
|
||||
|
||||
So, if you cannot trust Wi-Fi -- and/or the wireless router in the basement that is probably older than most of your pets -- what can be done to ensure the integrity of the “last-mile” communication, the one that happens between your device and the Internet at large?
|
||||
|
||||
One acceptable solution is to use a reputable VPN provider that will establish a secure communication link between your system and their infrastructure. The hope here is that they pay closer attention to security than your router vendor and your immediate Internet provider, so they are in a better position to assure that your traffic is protected from being sniffed or spoofed by malicious parties. Using VPN on all your workstations and mobile devices ensures that vulnerabilities like KRACK attacks or insecure routers do not affect the integrity of your communication with the outside world.
|
||||
|
||||

|
||||
|
||||
The important caveat here is that when choosing a VPN provider you must be reasonably assured of their trustworthiness; otherwise, you’re simply trading one set of malicious actors for another. Stay far away from anything offering “free VPN,” as they are probably making money by spying on you and selling your traffic to marketing firms. [This site][2] is a good resource that would allow you to compare various VPN providers to see how they stack against each other.
|
||||
|
||||
Not all of your devices need to have VPN installed on them, but the ones that you use daily to access sites with your private personal information -- and especially anything with access to your money and your identity (government, banking sites, social networking, etc.) must be secured. VPN is not a panacea against all network-level vulnerabilities, but it will definitely help protect you when you’re stuck using unsecured Wi-Fi at the airport, or the next time a KRACK-like vulnerability is discovered.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2017/10/tips-secure-your-network-wake-krack
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.vpnmentor.com/bestvpns/overall/
|
||||
[3]:https://www.linux.com/files/images/krack-securityjpg
|
||||
[4]:https://www.krackattacks.com/
|
||||
[5]:https://blog.cryptographyengineering.com/2017/10/16/falling-through-the-kracks/
|
||||
[6]:https://en.wikipedia.org/wiki/BGP_hijacking
|
||||
[7]:https://letsencrypt.org/
|
||||
[8]:https://en.wikipedia.org/wiki/Domain_Name_System#History
|
||||
[9]:https://en.wikipedia.org/wiki/DNS_spoofing
|
||||
[10]:https://en.wikipedia.org/wiki/Certificate_authority
|
||||
[11]:https://en.wikipedia.org/wiki/Moxie_Marlinspike#Notable_research
|
||||
[12]:https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security
|
||||
[13]:https://hstspreload.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions
|
||||
@ -0,0 +1,188 @@
|
||||
3 Simple, Excellent Linux Network Monitors
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Learn more about your network connections with the iftop, Nethogs, and vnstat tools.[Used with permission][3]
|
||||
|
||||
You can learn an amazing amount of information about your network connections with these three glorious Linux networking commands. iftop tracks network connections by process number, Nethogs quickly reveals what is hogging your bandwidth, and vnstat runs as a nice lightweight daemon to record your usage over time.
|
||||
|
||||
### iftop
|
||||
|
||||
The excellent [iftop][7] listens to the network interface that you specify, and displays connections in a top-style interface.
|
||||
|
||||
This is a great little tool for quickly identifying hogs, measuring speed, and also to maintain a running total of your network traffic. It is rather surprising to see how much bandwidth we use, especially for us old people who remember the days of telephone land lines, modems, screaming kilobits of speed, and real live bauds. We abandoned bauds a long time ago in favor of bit rates. Baud measures signal changes, which sometimes were the same as bit rates, but mostly not.
|
||||
|
||||
If you have just one network interface, run iftop with no options. iftop requires root permissions:
|
||||
|
||||
```
|
||||
$ sudo iftop
|
||||
```
|
||||
|
||||
When you have more than one, specify the interface you want to monitor:
|
||||
|
||||
```
|
||||
$ sudo iftop -i wlan0
|
||||
```
|
||||
|
||||
Just like top, you can change the display options while it is running.
|
||||
|
||||
* **h** toggles the help screen.
|
||||
|
||||
* **n** toggles name resolution.
|
||||
|
||||
* **s** toggles source host display, and **d** toggles the destination hosts.
|
||||
|
||||
* **s** toggles port numbers.
|
||||
|
||||
* **N** toggles port resolution; to see all port numbers toggle resolution off.
|
||||
|
||||
* **t** toggles the text interface. The default display requires ncurses. I think the text display is more readable and better-organized (Figure 1).
|
||||
|
||||
* **p** pauses the display.
|
||||
|
||||
* **q** quits the program.
|
||||
|
||||
### [fig-1.png][4]
|
||||
|
||||

|
||||
Figure 1: The text display is readable and organized.[Used with permission][1]
|
||||
|
||||
When you toggle the display options, iftop continues to measure all traffic. You can also select a single host to monitor. You need the host's IP address and netmask. I was curious how much of a load Pandora put on my sad little meager bandwidth cap, so first I used dig to find their IP address:
|
||||
|
||||
```
|
||||
$ dig A pandora.com
|
||||
[...]
|
||||
;; ANSWER SECTION:
|
||||
pandora.com. 267 IN A 208.85.40.20
|
||||
pandora.com. 267 IN A 208.85.40.50
|
||||
```
|
||||
|
||||
What's the netmask? [ipcalc][8] tells us:
|
||||
|
||||
```
|
||||
$ ipcalc -b 208.85.40.20
|
||||
Address: 208.85.40.20
|
||||
Netmask: 255.255.255.0 = 24
|
||||
Wildcard: 0.0.0.255
|
||||
=>
|
||||
Network: 208.85.40.0/24
|
||||
```
|
||||
|
||||
Now feed the address and netmask to iftop:
|
||||
|
||||
```
|
||||
$ sudo iftop -F 208.85.40.20/24 -i wlan0
|
||||
```
|
||||
|
||||
Is that not seriously groovy? I was surprised to learn that Pandora is easy on my precious bits, using around 500Kb per hour. And, like most streaming services, Pandora's traffic comes in spurts and relies on caching to smooth out the lumps and bumps.
|
||||
|
||||
You can do the same with IPv6 addresses, using the **-G** option. Consult the fine man page to learn the rest of iftop's features, including customizing your default options with a personal configuration file, and applying custom filters (see [PCAP-FILTER][9] for a filter reference).
|
||||
|
||||
### Nethogs
|
||||
|
||||
When you want to quickly learn who is sucking up your bandwidth, Nethogs is fast and easy. Run it as root and specify the interface to listen on. It displays the hoggy application and the process number, so that you may kill it if you so desire:
|
||||
|
||||
```
|
||||
$ sudo nethogs wlan0
|
||||
|
||||
NetHogs version 0.8.1
|
||||
|
||||
PID USER PROGRAM DEV SENT RECEIVED
|
||||
7690 carla /usr/lib/firefox wlan0 12.494 556.580 KB/sec
|
||||
5648 carla .../chromium-browser wlan0 0.052 0.038 KB/sec
|
||||
TOTAL 12.546 556.618 KB/sec
|
||||
```
|
||||
|
||||
Nethogs has few options: cycling between kb/s, kb, b, and mb, sorting by received or sent packets, and adjusting the delay between refreshes. See `man nethogs`, or run `nethogs -h`.
|
||||
|
||||
### vnstat
|
||||
|
||||
[vnstat][10] is the easiest network data collector to use. It is lightweight and does not need root permissions. It runs as a daemon and records your network statistics over time. The `vnstat` command displays the accumulated data:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan0
|
||||
Database updated: Tue Oct 17 08:36:38 2017
|
||||
|
||||
wlan0 since 10/17/2017
|
||||
|
||||
rx: 45.27 MiB tx: 3.77 MiB total: 49.04 MiB
|
||||
|
||||
monthly
|
||||
rx | tx | total | avg. rate
|
||||
------------------------+-------------+-------------+---------------
|
||||
Oct '17 45.27 MiB | 3.77 MiB | 49.04 MiB | 0.28 kbit/s
|
||||
------------------------+-------------+-------------+---------------
|
||||
estimated 85 MiB | 5 MiB | 90 MiB |
|
||||
|
||||
daily
|
||||
rx | tx | total | avg. rate
|
||||
------------------------+-------------+-------------+---------------
|
||||
today 45.27 MiB | 3.77 MiB | 49.04 MiB | 12.96 kbit/s
|
||||
------------------------+-------------+-------------+---------------
|
||||
estimated 125 MiB | 8 MiB | 133 MiB |
|
||||
```
|
||||
|
||||
By default it displays all network interfaces. Use the `-i` option to select a single interface. Merge the data of multiple interfaces this way:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan0+eth0+eth1
|
||||
```
|
||||
|
||||
You can filter the display in several ways:
|
||||
|
||||
* **-h** displays statistics by hours.
|
||||
|
||||
* **-d** displays statistics by days.
|
||||
|
||||
* **-w** and **-m** displays statistics by weeks and months.
|
||||
|
||||
* Watch live updates with the **-l** option.
|
||||
|
||||
This command deletes the database for wlan1 and stops watching it:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan1 --delete
|
||||
```
|
||||
|
||||
This command creates an alias for a network interface. This example uses one of the weird interface names from Ubuntu 16.04:
|
||||
|
||||
```
|
||||
$ vnstat -u -i enp0s25 --nick eth0
|
||||
```
|
||||
|
||||
By default vnstat monitors eth0\. You can change this in `/etc/vnstat.conf`, or create your own personal configuration file in your home directory. See `man vnstat` for a complete reference.
|
||||
|
||||
You can also install vnstati to create simple, colored graphs (Figure 2):
|
||||
|
||||
```
|
||||
$ vnstati -s -i wlx7cdd90a0a1c2 -o vnstat.png
|
||||
```
|
||||
|
||||
|
||||

|
||||
Figure 2: You can create simple colored graphs with vnstati.[Used with permission][2]
|
||||
|
||||
See `man vnstati` for complete options.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/3-simple-excellent-linux-network-monitors
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/files/images/fig-1png-8
|
||||
[5]:https://www.linux.com/files/images/fig-2png-5
|
||||
[6]:https://www.linux.com/files/images/bannerpng-3
|
||||
[7]:http://www.ex-parrot.com/pdw/iftop/
|
||||
[8]:https://www.linux.com/learn/intro-to-linux/2017/8/how-calculate-network-addresses-ipcalc
|
||||
[9]:http://www.tcpdump.org/manpages/pcap-filter.7.html
|
||||
[10]:http://humdi.net/vnstat/
|
||||
@ -0,0 +1,338 @@
|
||||
How to manage Docker containers in Kubernetes with Java
|
||||
==========================
|
||||
|
||||
|
||||
>Orchestrate production-ready systems at enterprise scale.
|
||||
|
||||
Learn basic Kubernetes concepts and mechanisms for automating the deployment, maintenance, and scaling of your Java applications with “Kubernetes for Java Developers.” [Download your free copy][3].
|
||||
|
||||
|
||||
In [_Containerizing Continuous Delivery in Java_][23] we explored the fundamentals of packaging and deploying Java applications within Docker containers. This was only the first step in creating production-ready, container-based systems. Running containers at any real-world scale requires a container orchestration and scheduling platform, and although many exist (i.e., Docker Swarm, Apache Mesos, and AWS ECS), the most popular is [Kubernetes][24]. Kubernetes is used in production at many organizations, and is now hosted by the [Cloud Native Computing Foundation (CNCF)][25]. In this article, we will take the previous simple Java-based, e-commerce shop that we packaged within Docker containers and run this on Kubernetes.
|
||||
|
||||
### The “Docker Java Shopfront” application
|
||||
|
||||
The architecture of the “Docker Java Shopfront” application that we will package into containers and deploy onto Kubernetes can be seen below:
|
||||
|
||||
|
||||
|
||||
|
||||
Before we start creating the required Kubernetes deployment configuration files let’s first learn about core concepts within this container orchestration platform.
|
||||
|
||||
### Kubernetes 101
|
||||
|
||||
Kubernetes is an open source orchestrator for deploying containerized applications that was originally developed by Google. Google has been running containerized applications for many years, and this led to the creation of the [Borg container orchestrator][26] that is used internally within Google, and was the source of inspiration for Kubernetes. If you are not familiar with this technology then a number of core concepts may appear alien at first glance, but they actually hide great power. The first is that Kubernetes embraces the principles of immutable infrastructure. Once a container is deployed the contents (i.e., the application) are not updated by logging into the container and making changes. Instead a new version is deployed. Second, everything in Kubernetes is declaratively configured. The developer or operator specifies the desired state of the system through deployment descriptors and configuration files, and Kubernetes is responsible for making this happen - you don’t need to provide imperative, step-by-step instructions.
|
||||
|
||||
These principles of immutable infrastructure and declarative configuration have a number of benefits: it is easier to prevent configuration drift, or “snowflake” application instances; declarative deployment configuration can be stored within version control, alongside the code; and Kubernetes can be largely self-healing, as if the system experiences failure like an underlying compute node failure, the system can rebuild and rebalance the applications according to the state specified in the declarative configuration.
|
||||
|
||||
Kubernetes provides several abstractions and APIs that make it easier to build these distributed applications, such as those based on the microservice architectural style:
|
||||
|
||||
* [Pods][5] - This is the lowest unit of deployment within Kubernetes, and is essentially a groups of containers. A pod allows a microservice application container to be grouped with other “sidecar” containers that may provide system services like logging, monitoring or communication management. Containers within a pod share a filesystem and network namespace. Note that a single container can be deployed, but it is always deployed within a pod
|
||||
|
||||
* [Services][6] - Kubernetes Services provide load balancing, naming, and discovery to isolate one microservice from another. Services are backed by [Replication Controllers][7], which in turn are responsible for details associated with maintaining the desired number of instances of a pod to be running within the system. Services, Replication Controllers and Pods are connected together in Kubernetes through the use of “[labels][8]”, both for naming and selecting.
|
||||
|
||||
Let’s now create a service for one of our Java-based microservice applications.
|
||||
|
||||
|
||||
### Building Java applications and container images
|
||||
|
||||
Before we first create a container and the associated Kubernetes deployment configuration, we must first ensure that we have installed the following prerequisites:
|
||||
|
||||
* Docker for [Mac][11] / [Windows][12] / [Linux][13] - This allows us to build, run and test Docker containers outside of Kubernetes on our local development machine.
|
||||
|
||||
* [Minikube][14] - This is a tool that makes it easy to run a single-node Kubernetes test cluster on our local development machine via a virtual machine.
|
||||
|
||||
* A [GitHub][15] account, and [Git][16] installed locally - The code examples are stored on GitHub, and by using Git locally you can fork the repository and commit changes to your own personal copy of the application.
|
||||
|
||||
* [Docker Hub][17] account - If you would like to follow along with this tutorial, you will need a Docker Hub account in order to push and store your copies of the container images that we will build below.
|
||||
|
||||
* [Java 8][18] (or 9) SDK and [Maven][19] - We will be building code with the Maven build and dependency tool that uses Java 8 features.
|
||||
|
||||
Clone the project repository from GitHub (optionally you can fork this repository and clone your personal copy), and locate the “shopfront” microservice application: [https://github.com/danielbryantuk/oreilly-docker-java-shopping/][27]
|
||||
|
||||
```
|
||||
$ git clone git@github.com:danielbryantuk/oreilly-docker-java-shopping.git
|
||||
$ cd oreilly-docker-java-shopping/shopfront
|
||||
|
||||
```
|
||||
|
||||
Feel free to load the shopfront code into your editor of choice, such as IntelliJ IDE or Eclipse, and have a look around. Let’s build the application using Maven. The resulting runnable JAR file that contains the application will be located in the ./target directory.
|
||||
|
||||
```
|
||||
$ mvn clean install
|
||||
…
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
[INFO] BUILD SUCCESS
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
[INFO] Total time: 17.210 s
|
||||
[INFO] Finished at: 2017-09-30T11:28:37+01:00
|
||||
[INFO] Final Memory: 41M/328M
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
|
||||
Now we will build the Docker container image. The operating system choice, configuration and build steps for a Docker image are typically specified via a Dockerfile. Let’s look at our example Dockerfile that is located in the shopfront directory:
|
||||
|
||||
```
|
||||
FROM openjdk:8-jre
|
||||
ADD target/shopfront-0.0.1-SNAPSHOT.jar app.jar
|
||||
EXPOSE 8010
|
||||
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
|
||||
|
||||
```
|
||||
|
||||
The first line specifies that our container image should be created “from” the openjdk:8-jre base image. The [openjdk:8-jre][28] image is maintained by the OpenJDK team, and contains everything we need to run a Java 8 application within a Docker container (such as an operating system with the OpenJDK 8 JRE installed and configured). The second line takes the runnable JAR we built above and “adds” this to the image. The third line specifies that port 8010, which our application will listen on, must be “exposed” as externally accessible, and the fourth line specifies the “entrypoint” or command to run when the container is initialized. Let’s build our container:
|
||||
|
||||
|
||||
```
|
||||
$ docker build -t danielbryantuk/djshopfront:1.0 .
|
||||
Successfully built 87b8c5aa5260
|
||||
Successfully tagged danielbryantuk/djshopfront:1.0
|
||||
|
||||
```
|
||||
|
||||
Now let’s push this to Docker Hub. If you haven’t logged into the Docker Hub via your command line, you must do this now, and enter your username and password:
|
||||
|
||||
```
|
||||
$ docker login
|
||||
Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.
|
||||
Username:
|
||||
Password:
|
||||
Login Succeeded
|
||||
$
|
||||
$ docker push danielbryantuk/djshopfront:1.0
|
||||
The push refers to a repository [docker.io/danielbryantuk/djshopfront]
|
||||
9b19f75e8748: Pushed
|
||||
...
|
||||
cf4ecb492384: Pushed
|
||||
1.0: digest: sha256:8a6b459b0210409e67bee29d25bb512344045bd84a262ede80777edfcff3d9a0 size: 2210
|
||||
|
||||
```
|
||||
|
||||
### Deploying onto Kubernetes
|
||||
|
||||
Now let’s run this container within Kubernetes. First, change the “kubernetes” directory in the root of the project:
|
||||
|
||||
```
|
||||
$ cd ../kubernetes
|
||||
|
||||
```
|
||||
|
||||
Open the shopfront-service.yaml Kubernetes deployment file and have a look at the contents:
|
||||
|
||||
```
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: shopfront
|
||||
labels:
|
||||
app: shopfront
|
||||
spec:
|
||||
type: NodePort
|
||||
selector:
|
||||
app: shopfront
|
||||
ports:
|
||||
- protocol: TCP
|
||||
port: 8010
|
||||
name: http
|
||||
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ReplicationController
|
||||
metadata:
|
||||
name: shopfront
|
||||
spec:
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: shopfront
|
||||
spec:
|
||||
containers:
|
||||
- name: shopfront
|
||||
image: danielbryantuk/djshopfront:latest
|
||||
ports:
|
||||
- containerPort: 8010
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
path: /health
|
||||
port: 8010
|
||||
initialDelaySeconds: 30
|
||||
timeoutSeconds: 1
|
||||
|
||||
```
|
||||
|
||||
The first section of the yaml file creates a Service named “shopfront” that will route TCP traffic targeting this service on port 8010 to pods with the label “app: shopfront”. The second section of the configuration file creates a `ReplicationController` that specifies Kubernetes should run one replica (instance) of our shopfront container, which we have declared as part of the “spec” (specification) labelled as “app: shopfront”. We have also specified that the 8010 application traffic port we exposed in our Docker container is open, and declared a “livenessProbe” or healthcheck that Kubernetes can use to determine if our containerized application is running correctly and ready to accept traffic. Let’s start `minikube` and deploy this service (note that you may need to change the specified `minikube` CPU and Memory requirements depending on the resources available on your development machine):
|
||||
|
||||
```
|
||||
$ minikube start --cpus 2 --memory 4096
|
||||
Starting local Kubernetes v1.7.5 cluster...
|
||||
Starting VM...
|
||||
Getting VM IP address...
|
||||
Moving files into cluster...
|
||||
Setting up certs...
|
||||
Connecting to cluster...
|
||||
Setting up kubeconfig...
|
||||
Starting cluster components...
|
||||
Kubectl is now configured to use the cluster.
|
||||
$ kubectl apply -f shopfront-service.yaml
|
||||
service "shopfront" created
|
||||
replicationcontroller "shopfront" created
|
||||
|
||||
```
|
||||
|
||||
You can view all Services within Kubernetes by using the “kubectl get svc” command. You can also view all associated pods by using the “kubectl get pods” command (note that the first time you issue the get pods command, the container may not have finished creating, and is marked as not yet ready):
|
||||
|
||||
```
|
||||
$ kubectl get svc
|
||||
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kubernetes 10.0.0.1 <none> 443/TCP 18h
|
||||
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 12s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
shopfront-0w1js 0/1 ContainerCreating 0 18s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
shopfront-0w1js 1/1 Running 0 2m
|
||||
|
||||
```
|
||||
|
||||
We have now successfully deployed our first Service into Kubernetes!
|
||||
|
||||
### Time for a smoke test
|
||||
|
||||
Let’s use curl to see if we can get data from the shopfront application’s healthcheck endpoint:
|
||||
|
||||
```
|
||||
$ curl $(minikube service shopfront --url)/health
|
||||
{"status":"UP"}
|
||||
|
||||
```
|
||||
|
||||
You can see from the results of the curl against the application/health endpoint that the application is up and running, but we need to deploy the remaining microservice application containers before the application will function as we expect it to.
|
||||
|
||||
### Building the remaining applications
|
||||
|
||||
Now that we have one container up and running let’s build the remaining two supporting microservice applications and containers:
|
||||
|
||||
```
|
||||
$ cd ..
|
||||
$ cd productcatalogue/
|
||||
$ mvn clean install
|
||||
…
|
||||
$ docker build -t danielbryantuk/djproductcatalogue:1.0 .
|
||||
...
|
||||
$ docker push danielbryantuk/djproductcatalogue:1.0
|
||||
...
|
||||
$ cd ..
|
||||
$ cd stockmanager/
|
||||
$ mvn clean install
|
||||
...
|
||||
$ docker build -t danielbryantuk/djstockmanager:1.0 .
|
||||
...
|
||||
$ docker push danielbryantuk/djstockmanager:1.0
|
||||
…
|
||||
|
||||
```
|
||||
|
||||
At this point we have built all of our microservices and the associated Docker images, and also pushed the images to Docker Hub. Let’s now deploy the `productcatalogue` and `stockmanager` services to Kubernetes.
|
||||
|
||||
### Deploying the entire Java application in Kubernetes
|
||||
|
||||
In a similar fashion to the process we used above to deploy the shopfront service, we can now deploy the remaining two microservices within our application to Kubernetes:
|
||||
|
||||
```
|
||||
$ cd ..
|
||||
$ cd kubernetes/
|
||||
$ kubectl apply -f productcatalogue-service.yaml
|
||||
service "productcatalogue" created
|
||||
replicationcontroller "productcatalogue" created
|
||||
$ kubectl apply -f stockmanager-service.yaml
|
||||
service "stockmanager" created
|
||||
replicationcontroller "stockmanager" created
|
||||
$ kubectl get svc
|
||||
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kubernetes 10.0.0.1 <none> 443/TCP 19h
|
||||
productcatalogue 10.0.0.37 <nodes> 8020:31803/TCP 42s
|
||||
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 13m
|
||||
stockmanager 10.0.0.149 <nodes> 8030:30723/TCP 16s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
productcatalogue-79qn4 1/1 Running 0 55s
|
||||
shopfront-0w1js 1/1 Running 0 13m
|
||||
stockmanager-lmgj9 1/1 Running 0 29s
|
||||
|
||||
```
|
||||
|
||||
Depending on how quickly you issue the “kubectl get pods” command, you may see that all of the pods are not yet running. Before moving on to the next section of this article wait until the command shows that all of the pods are running (maybe this is a good time to brew a cup of tea!)
|
||||
|
||||
### Viewing the complete application
|
||||
|
||||
With all services deployed and all associated pods running, we now should be able to access our completed application via the shopfront service GUI. We can open the service in our default browser by issuing the following command in `minikube`:
|
||||
|
||||
```
|
||||
$ minikube service shopfront
|
||||
|
||||
```
|
||||
|
||||
If everything is working correctly, you should see the following page in your browser:
|
||||
|
||||

|
||||
|
||||
### Conclusion
|
||||
|
||||
In this article, we have taken our application that consisted of three Java Spring Boot and Dropwizard microservices, and deployed it onto Kubernetes. There are many more things we need to think about in the future, such as debugging services (perhaps through the use of tools like [Telepresence][29] and [Sysdig][30]), testing and deploying via a continuous delivery pipeline like [Jenkins][31] or [Spinnaker][32], and observing our running system.
|
||||
|
||||
* * *
|
||||
|
||||
_This article was created in collaboration with NGINX. [See our statement of editorial independence][22]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel Bryant works as an Independent Technical Consultant, and is the CTO at SpectoLabs. He currently specialises in enabling continuous delivery within organisations through the identification of value streams, creation of build pipelines, and implementation of effective testing strategies. Daniel’s technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms, and microservice implementations. He also contributes to several open source projects, writes for InfoQ, O’Reilly, and Voxxed, and regularly presents at internatio...
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java
|
||||
|
||||
作者:[ Daniel Bryant ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/d3f4d647-482d-4dce-a0e5-a09773b77150
|
||||
[1]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[2]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[3]:https://www.nginx.com/resources/library/kubernetes-for-java-developers/
|
||||
[4]:https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021
|
||||
[5]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[6]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[7]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||
[8]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[9]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[10]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[11]:https://docs.docker.com/docker-for-mac/install/
|
||||
[12]:https://docs.docker.com/docker-for-windows/install/
|
||||
[13]:https://docs.docker.com/engine/installation/linux/ubuntu/
|
||||
[14]:https://kubernetes.io/docs/tasks/tools/install-minikube/
|
||||
[15]:https://github.com/
|
||||
[16]:https://git-scm.com/
|
||||
[17]:https://hub.docker.com/
|
||||
[18]:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
|
||||
[19]:https://maven.apache.org/
|
||||
[20]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[21]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[22]:http://www.oreilly.com/about/editorial_independence.html
|
||||
[23]:https://www.nginx.com/resources/library/containerizing-continuous-delivery-java/
|
||||
[24]:https://kubernetes.io/
|
||||
[25]:https://www.cncf.io/
|
||||
[26]:https://research.google.com/pubs/pub44843.html
|
||||
[27]:https://github.com/danielbryantuk/oreilly-docker-java-shopping/
|
||||
[28]:https://hub.docker.com/_/openjdk/
|
||||
[29]:https://telepresence.io/
|
||||
[30]:https://www.sysdig.org/
|
||||
[31]:https://wiki.jenkins.io/display/JENKINS/Kubernetes+Plugin
|
||||
[32]:https://www.spinnaker.io/
|
||||
@ -1,42 +0,0 @@
|
||||
云集成高级编排器
|
||||
============================================================
|
||||
|
||||
云集成高级编排器 (ciao) 是一个新的负载调度程序,用来解决当前云操作系统项目的局限性。Ciao 提供了一个轻量级,完全基于 TLS 的最小配置。它是
|
||||
工作量无关,易于更新,具有优化速度的调度程序,目前已针对 OpenStack 进行了优化。
|
||||
|
||||
通过安全性、可扩展性、可用性和可部署性的要求,了解设计决策和创新方法:
|
||||
|
||||
**可扩展性:** 初始设计目标是伸缩超过 5,000 个节点。因此,调度器架构用新的形式实现:
|
||||
|
||||
在 ciao 中,决策是去中心化的。它基于 pull 模型,允许计算节点从调度代理请求作业。调度程序总能知道启动器的容量,而不要求更新,并且将调度决策时间保持在最小。启动器异步向调度程序发送容量。
|
||||
|
||||
持久化状态跟踪与调度程序决策分离,它让调度程序保持轻量级。这种分离增加了可靠性、可扩展性和性能。结果是调度程序让出了权限并且这不是瓶颈。
|
||||
|
||||
**可用性:** 虚拟机、容器和裸机集成到一个调度器中。所有的负载都被视为平等公民。为了更易于使用,网络通过一个组件间最小化、异步协议简化,只需要最少的配置。Ciao 还包括一个新的、简单的UI。集成所有这些功能来简化安装、配置、维护和操作。
|
||||
|
||||
**轻松部署:** 升级应该是期望,而不是例外。这种新的去中心化状态的体系结构能够无缝升级。为了确保基础设施(例如 OpenStack)始终是最新的,它实现了持续集成/持续交付(CI/CD)模型。Ciao 的设计使得它可以立即杀死任何 Ciao 组件,更换它,并重新启动它,对可用性影响最小。
|
||||
|
||||
**安全性是必需的:** 与调度程序的连接总是加密的:默认情况下 SSL 是打开的,而不是关闭的。加密是从端到端:所有外部连接都需要 HTTPS,组件之间的内部通信是基于 TLS 的。网络支持的一体化保障租户分离。
|
||||
|
||||
初步结果证明是显著的:在 65 秒内启动一万个 Docker 容器和五千个虚拟机。进一步优化还在进行。
|
||||
|
||||
文档:[https://clearlinux.org/documentation/ciao/ciao.html][3]
|
||||
|
||||
Github 链接: [https://github.com/01org/ciao(link is external)][1]
|
||||
|
||||
邮件列表链接: [https://lists.clearlinux.org/mailman/listinfo/ciao-devel][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://clearlinux.org/ciao
|
||||
|
||||
作者:[ciao][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://clearlinux.org/ciao
|
||||
[1]:https://github.com/01org/ciao
|
||||
[2]:https://lists.clearlinux.org/mailman/listinfo/ciao-devel
|
||||
[3]:https://clearlinux.org/documentation/ciao/ciao.html
|
||||
@ -1,140 +0,0 @@
|
||||
Genymotion vs Android 模拟器
|
||||
============================================================
|
||||
|
||||
### Android 模拟器是否有足够的改善来取代 Genymotion
|
||||
|
||||
|
||||
一直以来一直有关于选择 android 模拟器或者 Genymotion 的争论,我看到很多讨论最后赞成 Genymotion。
|
||||
我根据我周围最常见的情况收集了一些数据, 基于此, 我将连同 Genymotion 评估所有的 android 模拟器。
|
||||
|
||||
最后结论:配置正确时,Android 模拟器比 Genymotion 快。
|
||||
使用带 Google API 的 x86(32位)镜像、3GB RAM、四核CPU。
|
||||
|
||||
> 哈,很高兴我们跳过了
|
||||
> 现在,让我们深入
|
||||
|
||||
免责声明:我已经测试了我的看到的一般情况,即运行测试。所有的基准测试都是在 2015 年中期的 MacBook Pro 上完成的。
|
||||
无论何时我说 Genymotion 指的都是 Genymotion Desktop。他们还有其他产品,如 Genymotion on Cloud&Genymotion on Demand,这里没有考虑。
|
||||
我不是说 Genymotion 是不合适的,但运行测试比某些 Android 模拟器慢。
|
||||
|
||||
关于这个问题的一点背景,然后我们将跳到好的东西上。
|
||||
|
||||
_过去:我有一些基准测试,继续下去。_
|
||||
|
||||
很久以前,Android 模拟器是唯一的选择。但是它们太慢了,这是架构改变的原因。
|
||||
在 x86 机器上运行的 ARM 模拟器可以期待什么?每个指令都必须从 ARM 转换为 x86 架构,这使得它的速度非常慢。
|
||||
|
||||
随之而来的是 Android 的 x86 镜像,随着它们摆脱了 ARM 到 x86 平台转化,速度更快了。
|
||||
现在,你可以在 x86 机器上运行 x86 Android 模拟器。
|
||||
|
||||
> _问题解决了!!!_
|
||||
>
|
||||
> 没有!
|
||||
|
||||
Android 模拟器仍然比人们想要的慢。
|
||||
随后出现了 Genymotion,这是一个在虚拟机中运行的 Android 虚拟机。但是,与在 qemu 上运行的普通老式 android 模拟器相比,它相当稳定和快速。
|
||||
|
||||
我们来看看今天的情况。
|
||||
|
||||
我的团队在 CI 基础架构和开发机器上使用 Genymotion。手头的任务是摆脱 CI 基础设施和开发机器中使用的所有 Genymotion。
|
||||
|
||||
> 你问为什么?
|
||||
> 授权费钱。
|
||||
|
||||
在快速看了一下以后,这似乎是一个愚蠢的举动,因为 Android 模拟器的速度很慢而且有 bug,但它们看起来适得其反,但是当你深入的时候,你会发现 Android 模拟器是优越的。
|
||||
|
||||
我们的情况是对它们进行集成测试(主要是 espresso)。
|
||||
我们的应用程序中只有 1100 多个测试,Genymotion 需要大约 23 分钟才能运行所有测试。
|
||||
|
||||
在 Genymotion 中我们面临的另一些问题是:
|
||||
|
||||
* 有限的命令行工具([GMTool][1])。
|
||||
|
||||
* 由于内存问题,它们需要定期重新启动。这是一个手动任务,想象在配有许多机器的 CI 基础设施上进行这些会怎样。
|
||||
|
||||
进入 Android 模拟器
|
||||
|
||||
第一次尝试设置其中的一个,它给你这么多的选择,你会觉得你在 Subway 餐厅。
|
||||
最大的问题是 x86 或 x86_64 以及是否有 Google API。
|
||||
|
||||
我用这些组合做了一些研究和基准测试,这是我们想出来的。
|
||||
|
||||
鼓声。。。
|
||||
|
||||
> 比赛的获胜者是带 Google API 的 x86
|
||||
> 但是如何?为什么?
|
||||
|
||||
嗯,我会告诉你每一个的问题。
|
||||
|
||||
x86_64 比 x86 慢
|
||||
|
||||
> 你问慢多少.
|
||||
>
|
||||
> 28.2% 多!!!
|
||||
|
||||
使用 Google API 的模拟器更加稳定,没有它们容易崩溃。
|
||||
|
||||
这使我们得出结论:最好的是带 Google API 的x86。
|
||||
|
||||
在我们抛弃 Genymotion 开始使用模拟器之前。有下面几点重要的细节。
|
||||
|
||||
* 我使用的是带 Google API 的 Nexus 5 镜像。
|
||||
|
||||
* 我注意到,给模拟器较少的 RAM 会造成了很多 Google API 崩溃。所以为模拟器设定了 3GB 的 RAM
|
||||
|
||||
* 模拟器有四核
|
||||
|
||||
* HAXM 安装在主机上。
|
||||
|
||||
基准测试的时候到了
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
从基准测试上你可以看到除了 Geekbench4,Android 模拟器都击败了 Genymotion,Geekbench4 我感觉更像是虚拟机击败 qemu。
|
||||
|
||||
> 欢呼模拟器之王
|
||||
|
||||
We are now having a faster test execution time, better command line tools. Also with the latest [Android Emulator][2], things have gone a notch up. Faster boot time and what not.
|
||||
我们现在有更快的测试执行时间、更好的命令行工具。最新的 [Android Emulator][2] 创下的新的记录。更快的启动时间之类。
|
||||
|
||||
Goolgle 一直努力让
|
||||
|
||||
> Android Emulator 变得更好
|
||||
|
||||
如果你没有在使用 android 模拟器。我建议你重新试下来节省一些钱。
|
||||
|
||||
我尝试的另一个但是没有成功的方案是在 AWS 上运行 [Android-x86][3] 镜像。
|
||||
我能够在 vSphere ESXi Hypervisor 中运行它,但不能在 AWS 或任何其他云平台上运行它。如果有人知道原因,请在下面评论。
|
||||
|
||||
PS:[VMWare 现在可以在 AWS 上使用][4],在 AWS 上使用 [Android-x86][5] 毕竟是有可能的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
嗨,我的名字是 Sumit Gupta。我是来自印度古尔冈的软件/应用/网页开发人员。
|
||||
我做这个是因为我喜欢技术,并且一直迷恋它。我已经工作了 3 年以上,但我还是有很多要学习。他们不是说如果你有只是,让别人点亮他们的蜡烛。
|
||||
|
||||
当在编译时,我阅读很多文章,或者听音乐。
|
||||
|
||||
如果你想联系,下面是我的社交信息和 [email][6]。
|
||||
|
||||
via: https://www.plightofbyte.com/android/2017/09/03/genymotion-vs-android-emulator/
|
||||
|
||||
作者:[Sumit Gupta ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.plightofbyte.com/about-me
|
||||
[1]:https://docs.genymotion.com/Content/04_Tools/GMTool/GMTool.htm
|
||||
[2]:https://developer.android.com/studio/releases/emulator.html
|
||||
[3]:http://www.android-x86.org/
|
||||
[4]:https://aws.amazon.com/vmware/
|
||||
[5]:http://www.android-x86.org/
|
||||
[6]:thesumitgupta@outlook.com
|
||||
@ -1,52 +0,0 @@
|
||||
构建一个分布式消息分发开放标准:介绍 OpenMessaging
|
||||
============================================================
|
||||
|
||||
|
||||
通过在云计算、大数据和标准 API 上的企业和社区的协作,我很高兴 OpenMessaging 项目进入 Linux 基金会。OpenMessaging 社区的目标是为分布式消息分发创建全球采用的、供应商中立的和开放的标准,可以部署在云、内部和混合情景中。
|
||||
|
||||
阿里巴巴、雅虎、滴滴和 Streamlio 是创始项目的贡献者。Linux 基金会已与初始项目社区合作来建立一个治理模式和结构,以实现在消息 API 标准上工作的生态系统的长期利益。。
|
||||
|
||||
由于越来越多的公司和开发者迈向原生云应用,消息和流应用的扩展的挑战也在不断发展。这些包括平台之间的互操作性问题,线路协议之间缺乏兼容性以及系统间缺乏标准的基准测试。
|
||||
|
||||
特别是当数据跨不同的消息和流媒体平台进行传输时会出现兼容性问题,这意味着额外的工作和维护成本。现有解决方案缺乏负载平衡、容错、管理、安全性和流功能的标准化指南。目前的系统不能满足现代面向云的消息和流应用的需求。这可能导致开发人员额外的工作,并且难以或不可能满足物联网、边缘计算、智能城市等方面的尖端业务需求。
|
||||
|
||||
OpenMessaging 的贡献者正在寻求通过以下方式改进分布式消息分发:
|
||||
|
||||
* 为分布式消息分发创建一个面向全球、面向云、供应商中立的行业标准
|
||||
|
||||
* 促进测试应用程序的标准基准
|
||||
|
||||
* 平台独立
|
||||
|
||||
* 以可伸缩性、灵活性、隔离和安全性为目标的云数据流和消息分发要求
|
||||
|
||||
* 培育不断发展的开发社区
|
||||
|
||||
你可以在这了解有关新项目的更多信息以及如何参与: [http://openmessaging.cloud][1]
|
||||
|
||||
这些是支持 OpenMessaging 的一些组织:
|
||||
|
||||
“我们多年来一直专注于消息分发和流媒体领域,在此期间,我们探索了 Corba 通知、JMS 和其他标准,来试图解决我们最严格的业务需求。阿里巴巴在评估可用的替代品后,选择创建一个新的面向云的消息分发标准 OpenMessaging,这是一个供应商中立且语言无关的,并为金融、电子商务、物联网和大数据等领域提供行业指南。此外,它目标在跨异构系统和平台间开发消息分发和流应用。我们希望它可以是开放、简单、可扩展和可互操作的。另外,我们要根据这个标准建立一个生态系统,如基准测试、计算和各种连接器。我们希望有新的贡献,并希望大家能够共同努力,推动 OpenMessaging 标准的发展。” _阿里巴巴高级架构师 Von Gosling,Apache RocketMQ 的联合创始人,以及 OpenMessaging 的原始发起人_
|
||||
|
||||
“随着应用程序的复杂性和规模的不断扩大,缺乏标准的接口为开发人员和组织带来了复杂性和灵活性的障碍。Streamlio 很高兴与其他领导者合作推出 OpenMessaging 标准倡议来给客户轻松使用高性能、低延迟的消息传递解决方案,如 Apache Pulsar,它提供了企业所需的耐用性、一致性和可用性。“_- Streamlio 的软件工程师、Apache Pulsar 的联合创始人以及 Apache BookKeeper PMC 的成员 Matteo Merli_
|
||||
|
||||
“Oath,Verizon 旗下领先的媒体和技术品牌,包括雅虎和 AOL- 支持开放,协作的举措,并且很乐意加入 OpenMessaging 项目。”_-_ _Joe Francis,Core Platforms_
|
||||
|
||||
“在滴滴中,我们定义了一组私有的生产者 API 和消费者 API 来隐藏开源 MQ(如Apache Kafka、Apache RocketMQ 等)之间的差异,并提供额外的自定义功能。我们计划将这些发布到开源社区。到目前为止,我们已经积累了很多关于 MQ 和 API 统一的经验,并愿意在 OpenMessaging 中与其他 API 一起构建 API 的共同标准。我们真诚地认为,统一和广泛接受的 API 标准可以使 MQ 技术和依赖于它的应用程序受益。“ _滴滴的架构师 Neil Qi_
|
||||
|
||||
“有许多不同的开源消息分发解决方案,包括 Apache ActiveMQ、Apache RocketMQ、Apache Pulsar 和 Apache Kafka。缺乏行业上的可扩展消息分发标准使得评估合适的解决方案变得困难。我们很高兴能够支持来自多个开源项目的共同努力,共同确定可扩展的开放消息规范。 Apache BookKeeper 已成功在雅虎(通过 Apache Pulsar)和 Twitter(通过 Apache DistributedLog)的生产环境中部署,它作为其企业级消息系统的持久化、高性能、低延迟存储基础。我们很高兴加入 OpenMessaging 帮助其他项目解决诸如低延迟持久化、一致性和可用性等在消息分发方案中的常见问题。” _- Streamlio 的联合创始人、Apache BookKeeper 的 PMC 主席、Apache DistributedLog 的联合创造者,Sijie Guo_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/building-open-standard-distributed-messaging-introducing-openmessaging/
|
||||
|
||||
作者:[Mike Dolan][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/mdolan/
|
||||
[1]:http://openmessaging.cloud/
|
||||
[2]:https://www.linuxfoundation.org/author/mdolan/
|
||||
[3]:https://www.linuxfoundation.org/category/blog/
|
||||
Loading…
Reference in New Issue
Block a user