diff --git a/published/20171101 -dev-urandom- entropy explained.md b/published/20171101 -dev-urandom- entropy explained.md
new file mode 100644
index 0000000000..8d2efc2904
--- /dev/null
+++ b/published/20171101 -dev-urandom- entropy explained.md
@@ -0,0 +1,104 @@
+/dev/[u]random:对熵的解释
+======
+
+### 熵
+
+当谈到 `/dev/random` 和 `/dev/urandom` 的主题时,你总是会听到这个词:“熵”。每个人对此似乎都有自己的比喻。那为我呢?我喜欢将熵视为“随机果汁”。它是果汁,随机数需要它变得更随机。
+
+如果你曾经生成过 SSL 证书或 GPG 密钥,那么可能已经看到过像下面这样的内容:
+
+```
+We need to generate a lot of random bytes. It is a good idea to perform
+some other action (type on the keyboard, move the mouse, utilize the
+disks) during the prime generation; this gives the random number
+generator a better chance to gain enough entropy.
+++++++++++..+++++.+++++++++++++++.++++++++++...+++++++++++++++...++++++
++++++++++++++++++++++++++++++.+++++..+++++.+++++.+++++++++++++++++++++++++>.
+++++++++++>+++++...........................................................+++++
+Not enough random bytes available. Please do some other work to give
+the OS a chance to collect more entropy! (Need 290 more bytes)
+```
+
+通过在键盘上打字并移动鼠标,你可以帮助生成熵或随机果汁。
+
+你可能会问自己……为什么我需要熵?以及为什么它对于随机数真的变得随机如此重要?那么,假设我们的熵的来源仅限于键盘、鼠标和磁盘 IO 的数据。但是我们的系统是一个服务器,所以我知道没有鼠标和键盘输入。这意味着唯一的因素是你的 IO。如果它是一个单独的、几乎不使用的磁盘,你将拥有较低的熵。这意味着你的系统随机的能力很弱。换句话说,我可以玩概率游戏,并大幅减少破解 ssh 密钥或者解密你认为是加密会话的时间。
+
+好的,但这是很难实现的对吧?不,实际上并非如此。看看这个 [Debian OpenSSH 漏洞][1]。这个特定的问题是由于某人删除了一些负责添加熵的代码引起的。有传言说,他们因为它导致 valgrind 发出警告而删除了它。然而,在这样做的时候,随机数现在少了很多随机性。事实上,熵少了很多,因此暴力破解变成了一个可行的攻击向量。
+
+希望到现在为止,我们理解了熵对安全性的重要性。无论你是否意识到你正在使用它。
+
+### /dev/random 和 /dev/urandom
+
+`/dev/urandom` 是一个伪随机数生成器,缺乏熵它也**不会**停止。
+
+`/dev/random` 是一个真随机数生成器,它会在缺乏熵的时候停止。
+
+大多数情况下,如果我们正在处理实际的事情,并且它不包含你的核心信息,那么 `/dev/urandom` 是正确的选择。否则,如果就使用 `/dev/random`,那么当系统的熵耗尽时,你的程序就会变得有趣。无论它直接失败,或只是挂起——直到它获得足够的熵,这取决于你编写的程序。
+
+### 检查熵
+
+那么,你有多少熵?
+
+```
+[root@testbox test]# cat /proc/sys/kernel/random/poolsize
+4096
+[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
+2975
+```
+
+`/proc/sys/kernel/random/poolsize`,说明熵池的大小(以位为单位)。例如:在停止抽水之前我们应该储存多少随机果汁。`/proc/sys/kernel/random/entropy_avail` 是当前池中随机果汁的数量(以位为单位)。
+
+### 我们如何影响这个数字?
+
+这个数字可以像我们使用它一样耗尽。我可以想出的最简单的例子是将 `/dev/random` 定向到 `/dev/null` 中:
+
+```
+[root@testbox test]# cat /dev/random > /dev/null &
+[1] 19058
+[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
+0
+[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
+1
+```
+
+影响这个最简单的方法是运行 [Haveged][2]。Haveged 是一个守护进程,它使用处理器的“抖动”将熵添加到系统熵池中。安装和基本设置非常简单。
+
+```
+[root@b08s02ur ~]# systemctl enable haveged
+Created symlink from /etc/systemd/system/multi-user.target.wants/haveged.service to /usr/lib/systemd/system/haveged.service.
+[root@b08s02ur ~]# systemctl start haveged
+```
+
+在流量相对中等的机器上:
+
+```
+[root@testbox ~]# pv /dev/random > /dev/null
+ 40 B 0:00:15 [ 0 B/s] [ <=> ]
+ 52 B 0:00:23 [ 0 B/s] [ <=> ]
+ 58 B 0:00:25 [5.92 B/s] [ <=> ]
+ 64 B 0:00:30 [6.03 B/s] [ <=> ]
+^C
+[root@testbox ~]# systemctl start haveged
+[root@testbox ~]# pv /dev/random > /dev/null
+7.12MiB 0:00:05 [1.43MiB/s] [ <=> ]
+15.7MiB 0:00:11 [1.44MiB/s] [ <=> ]
+27.2MiB 0:00:19 [1.46MiB/s] [ <=> ]
+ 43MiB 0:00:30 [1.47MiB/s] [ <=> ]
+^C
+```
+
+使用 `pv` 我们可以看到我们通过管道传递了多少数据。正如你所看到的,在运行 `haveged` 之前,我们是 2.1 位/秒(B/s)。而在开始运行 `haveged` 之后,加入处理器的抖动到我们的熵池中,我们得到大约 1.5MiB/秒。
+
+--------------------------------------------------------------------------------
+
+via: http://jhurani.com/linux/2017/11/01/entropy-explained.html
+
+作者:[James J][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://jblevins.org/log/ssh-vulnkey
+[1]:http://jhurani.com/linux/2017/11/01/%22https://jblevins.org/log/ssh-vulnkey%22
+[2]:http://www.issihosts.com/haveged/
diff --git a/translated/tech/20171121 How To Kill The Largest Process In An Unresponsive Linux System.md b/published/20171121 How To Kill The Largest Process In An Unresponsive Linux System.md
similarity index 62%
rename from translated/tech/20171121 How To Kill The Largest Process In An Unresponsive Linux System.md
rename to published/20171121 How To Kill The Largest Process In An Unresponsive Linux System.md
index 042cd39684..c97a36da8e 100644
--- a/translated/tech/20171121 How To Kill The Largest Process In An Unresponsive Linux System.md
+++ b/published/20171121 How To Kill The Largest Process In An Unresponsive Linux System.md
@@ -1,51 +1,56 @@
-如何在无响应的 Linux 系统中杀掉最大的进程
+如何在无响应的 Linux 系统中杀掉内存消耗最大的进程
======
+

-作为一名博客作者,我收藏了很多博客、网站和论坛用来标记 Linux 和 Unix 相关的内容。有时候,我在浏览器中开启了非常多的标签页,导致操作系统会无响应好几分钟。我不能移动我的鼠标去杀掉一个进程或关闭任何开启的标签页。在这种情况下,我别无选择,只能强制重启系统。当然我也用了 **OneTab** (译者注:OneTab 是一个 Chrome 的 Extension, 可以将标签页转化成一个列表保存。)和 **Greate Suspender** (译者注:Great Suspender 是一个 Chrome 的 Extension, 可以自动冻结标签页)这样浏览器拓展,但它们在这里也起不到太大的作用。 我经常耗尽我的内存。而这就是 **Early OOM** 起作用的时候了。在情况严重,它会杀掉一个未响应系统中的最大的进程。Early OOM 每秒会检测可用内存和空余交换区 10 次,一旦两者都低于 10%,它就会把最大的进程杀死。
+作为一名博客作者,我收藏了很多博客、网站和论坛用来寻找 Linux 和 Unix 相关的内容。有时候,我在浏览器中开启了非常多的标签页,导致操作系统会无响应好几分钟。我不能移动我的鼠标,也不能杀掉一个进程或关闭任何开启的标签页。在这种情况下,我别无选择,只能强制重启系统。当然我也用了 **OneTab** (LCTT 译注:OneTab 是一个 Chrome 的 Extension,可以将标签页转化成一个列表保存。)和 **Greate Suspender** (LCTT 译注:Great Suspender 是一个 Chrome 的 Extension, 可以自动冻结标签页)这样浏览器拓展,但它们在这里也起不到太大的作用。 我经常耗尽我的内存。而这就是 **Early OOM** 起作用的时候了。在情况严重时,它会杀掉一个未响应系统中的内存消耗最大的进程。Early OOM 每秒会检测可用内存和空余交换区 10 次,一旦两者都低于 10%,它就会把最大的进程杀死。
### 为什么用 Early OOM?为什么不用系统内置的 OOM killer?
-在继续讨论下去之前,我想先简短的介绍下 OOM killer,也就是 **O** ut **O** f **M** emory killer。OOM killer 是一个由内核在可用内存非常低的时候使用的进程。它的主要任务是不断的杀死进程,直到释放出足够的内存,是内核正在运行的进程的其余部分能顺利运行。OOM killer 会找到系统中最不重要并且能释放出最多内存的进程,然后杀掉他们。在 **/proc** 目录下的 **pid** 目录中,我们可以看到每个进程的 oom_score。
+在继续讨论下去之前,我想先简短的介绍下 OOM killer,也就是 **O**ut **O**f **M**emory killer。OOM killer 是一个由内核在可用内存非常低的时候使用的进程。它的主要任务是不断的杀死进程,直到释放出足够的内存,使内核正在运行的其它进程能顺利运行。OOM killer 会找到系统中最不重要并且能释放出最多内存的进程,然后杀掉他们。在 `/proc` 目录下的 `pid` 目录中,我们可以看到每个进程的 `oom_score`。
示例:
+
```
$ cat /proc/10299/oom_score
1
```
-一个进程的 oom_score 的值越高,这个进程越有可能在系统内存耗尽的时候被 OOM killer 杀死。
+一个进程的 `oom_score` 的值越高,这个进程越有可能在系统内存耗尽的时候被 OOM killer 杀死。
-Early OOM 的开发者表示,相对于内置的 OOM killer,Early OOM 有一个很大的优点。就像我之前说的那样,OOM killer 会杀掉 oom_score 最高的进程,而这也导致 Chrome 浏览器总是会成为第一个被杀死的进程。为了避免这种情况发生,Early OOM 使用 **/proc/*/status** 而不是 **echo f > /proc/sysrq-trigger**(译者注:这条命令会调用 OOM killer 杀死进程)。开发者还表示,手动触发 OOM killer 在最新版本的 Linux 内核中很可能不会起作用。
+Early OOM 的开发者表示,相对于内置的 OOM killer,Early OOM 有一个很大的优点。就像我之前说的那样,OOM killer 会杀掉 `oom_score` 最高的进程,而这也导致 Chrome 浏览器总是会成为第一个被杀死的进程。为了避免这种情况发生,Early OOM 使用 `/proc/*/status` 而不是 `echo f > /proc/sysrq-trigger`(LCTT 译注:这条命令会调用 OOM killer 杀死进程)。开发者还表示,手动触发 OOM killer 在最新版本的 Linux 内核中很可能不会起作用。
### 安装 Early OOM
-Early OOM 在AUR(Arch User Repository)中可以被找到,所以你可以在 Arch 和它的衍生版本中使用任何 AUR 工具安装它。
+Early OOM 在 AUR(Arch User Repository)中可以找到,所以你可以在 Arch 和它的衍生版本中使用任何 AUR 工具安装它。
+
+使用 [Pacaur][1]:
-使用 [**Pacaur**][1]:
```
pacaur -S earlyoom
```
-使用 [**Packer**][2]:
+使用 [Packer][2]:
+
```
packer -S earlyoom
```
-使用 [**Yaourt**][3]:
+使用 [Yaourt][3]:
+
```
yaourt -S earlyoom
```
-启用并启动 Early OOM daemon:
+启用并启动 Early OOM 守护进程:
+
```
sudo systemctl enable earlyoom
-```
-```
sudo systemctl start earlyoom
```
-在其它的 Linux 发行版中,可以按如下方法编译安装它
+在其它的 Linux 发行版中,可以按如下方法编译安装它:
+
```
git clone https://github.com/rfjakob/earlyoom.git
cd earlyoom
@@ -53,19 +58,22 @@ make
sudo make install
```
-### Early OOM - Kill The Largest Process In An Unresponsive Linux System杀掉无响应 Linux 系统中的最大的进程
+### Early OOM - 杀掉无响应 Linux 系统中的最大的进程
运行如下命令启动 Early OOM:
+
```
earlyoom
```
如果是通过编译源代码安装的, 运行如下命令启动 Early OOM:
+
```
./earlyoom
```
示例输出:
+
```
earlyoom 0.12
mem total: 3863 MiB, min: 386 MiB (10 %)
@@ -82,21 +90,24 @@ mem avail: 1784 MiB (46 %), swap free: 2047 MiB (99 %)
[...]
```
-就像你在上面的输出中可以看到的,Early OOM 将会显示你有多少内存和交换区,以及有多少可用的内存和交换区。记住它会一直保持运行,直到你按下 CTRL+C。
+就像你在上面的输出中可以看到的,Early OOM 将会显示你有多少内存和交换区,以及有多少可用的内存和交换区。记住它会一直保持运行,直到你按下 `CTRL+C`。
如果可用的内存和交换区大小都低于 10%,Early OOM 将会自动杀死最大的进程,直到系统有足够的内存可以流畅的运行。你也可以根据你的需求配置最小百分比值。
设置最小的可用内存百分比,运行:
+
```
earlyoom -m
```
-设置最小可用交换区百分比, 运行:
+设置最小可用交换区百分比, 运行:
+
```
earlyoom -s
```
在帮助部分,可以看到更多详细信息:
+
```
$ earlyoom -h
earlyoom 0.12
@@ -120,15 +131,13 @@ Usage: earlyoom [OPTION]...
谢谢!
-
-
--------------------------------------------------------------------------------
via: https://www.ostechnix.com/kill-largest-process-unresponsive-linux-system/
作者:[Aditya Goturu][a]
译者:[cizezsy](https://github.com/cizezsy)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180326 How To Archive Files And Directories In Linux.md b/published/20180326 How To Archive Files And Directories In Linux.md
similarity index 56%
rename from translated/tech/20180326 How To Archive Files And Directories In Linux.md
rename to published/20180326 How To Archive Files And Directories In Linux.md
index 0c1c211b31..0dbe3efa72 100644
--- a/translated/tech/20180326 How To Archive Files And Directories In Linux.md
+++ b/published/20180326 How To Archive Files And Directories In Linux.md
@@ -1,88 +1,100 @@
在 Linux 中如何归档文件和目录
=====
+

+
在我们之前的教程中,我们讨论了如何[使用 gzip 和 bzip2 压缩和解压缩文件][1]。在本教程中,我们将学习如何在 Linux 归档文件。归档和压缩有什么不同吗?你们中的一些人可能经常认为这些术语有相同的含义。但是,这两者完全不同。归档是将多个文件和目录(相同或不同大小)组合成一个文件的过程。另一方面,压缩是减小文件或目录大小的过程。归档通常用作系统备份的一部分,或者将数据从一个系统移至另一个系统时。希望你了解归档和压缩之间的区别。现在,让我们进入主题。
### 归档文件和目录
归档文件和目录最常见的程序是:
+
1. tar
2. zip
这是一个很大的话题,所以,我将分两部分发表这篇文章。在第一部分中,我们将看到如何使用 tar 命令来归档文件和目录。
-##### 使用 tar 命令归档文件和目录
+### 使用 tar 命令归档文件和目录
-**Tar** 是一个 Unix 命令,代表 **T**ape **A**rchive(这里我将其翻译为 磁带归档,希望校正者修正以下)。它用于将多个文件(相同或不同大小)组合或存储到一个文件中。在 tar 实用程序中有 4 种主要的操作模式。
+**Tar** 是一个 Unix 命令,代表 **T**ape **A**rchive(磁带归档)。它用于将多个文件(相同或不同大小)组合或存储到一个文件中。在 tar 实用程序中有 4 种主要的操作模式。
- 1. **c** – 从文件或目录中建立归档
- 2. **x** – 提取归档
- 3. **r** – 将文件追加到归档
- 4. **t** – 列出归档的内容
+ 1. `c` – 从文件或目录中建立归档
+ 2. `x` – 提取归档
+ 3. `r` – 将文件追加到归档
+ 4. `t` – 列出归档的内容
有关完整的模式列表,参阅 man 手册页。
-**创建一个新的归档**
+#### 创建一个新的归档
+
+为了本指南,我将使用名为 `ostechnix` 的文件夹,其中包含三种不同类型的文件。
-为了本指南,我将使用名为 **ostechnix** 的文件夹,其中包含三种不同类型的文件。
```
$ ls ostechnix/
file.odt image.png song.mp3
```
-现在,让我们为 ostechnix 目录创建一个新的 tar 归档。
+现在,让我们为 `ostechnix` 目录创建一个新的 tar 归档。
+
```
$ tar cf ostechnix.tar ostechnix/
```
-这里,**c**标志指的是创建新的归档,**f** 是指定归档文件。
+这里,`c` 标志指的是创建新的归档,`f` 是指定归档文件。
同样,对当前工作目录中的一组文件创建归档文件,使用以下命令:
+
```
$ tar cf archive.tar file1 file2 file 3
```
-**提取归档**
+#### 提取归档
要在当前目录中提取归档文件,只需执行以下操作:
+
```
$ tar xf ostechnix.tar
```
-我们还可以使用 **C** 标志(大写字母 C)将归档提取到不同的目录中。例如,以下命令在 **Downloads** 目录中提取给定的归档文件。
+我们还可以使用 `C` 标志(大写字母 C)将归档提取到不同的目录中。例如,以下命令将归档文件提取到 `Downloads` 目录中。
+
```
$ tar xf ostechnix.tar -C Downloads/
```
-或者,转到 Downloads 文件夹并像下面一样提取其中的归档。
+或者,转到 `Downloads` 文件夹并像下面一样提取其中的归档。
+
```
$ cd Downloads/
-
$ tar xf ../ostechnix.tar
```
有时,你可能想要提取特定类型的文件。例如,以下命令提取 “.png” 类型的文件。
+
```
$ tar xf ostechnix.tar --wildcards "*.png"
```
-**创建 gzip 和 bzip 格式的压缩归档**
+#### 创建 gzip 和 bzip 格式的压缩归档
-默认情况下,tar 创建归档文件以 **.tar** 结尾。另外,tar 命令可以与压缩实用程序 **gzip** 和 **bzip** 结合使用。文件结尾以 **.tar** 为扩展名使用普通 tar 归档文件,文件以 **tar.gz** 或 **.tgz** 结尾使用 **gzip** 归档并压缩文件,tar 文件以 **tar.bz2** 或 **.tbz** 结尾使用 **bzip** 归档并压缩。
+默认情况下,tar 创建归档文件以 `.tar` 结尾。另外,`tar` 命令可以与压缩实用程序 `gzip` 和 `bzip` 结合使用。文件结尾以 `.tar` 为扩展名使用普通 tar 来归档文件,文件以 `tar.gz` 或 `.tgz` 结尾使用 `gzip` 归档并压缩文件,文件以 `tar.bz2` 或 `.tbz` 结尾使用 `bzip` 归档并压缩。
+
+首先,让我们来创建一个 gzip 归档:
-首先,让我们来**创建一个 gzip 归档**:
```
$ tar czf ostechnix.tar.gz ostechnix/
```
-或者
+或者:
+
```
$ tar czf ostechnix.tgz ostechnix/
```
-这里,我们使用 **z** 标志来使用 gzip 压缩方法压缩归档文件。
+这里,我们使用 `z` 标志来使用 gzip 压缩方法压缩归档文件。
+
+你可以使用 `v` 标志在创建归档时查看进度。
-你可以使用 **v** 标志在创建归档时查看进度。
```
$ tar czvf ostechnix.tar.gz ostechnix/
ostechnix/
@@ -91,80 +103,92 @@ ostechnix/image.png
ostechnix/song.mp3
```
-这里,**v** 指显示进度。
+这里,`v` 指显示进度。
从一个文件列表创建 gzip 归档文件:
+
```
$ tar czf archive.tgz file1 file2 file3
```
要提取当前目录中的 gzip 归档文件,使用:
+
```
$ tar xzf ostechnix.tgz
```
-要提取其他文件夹中的归档,使用 -C 标志:
+要提取到其他文件夹,使用 `-C` 标志:
+
```
$ tar xzf ostechnix.tgz -C Downloads/
```
-现在,让我们创建 **bzip 归档**。为此,请使用下面的 **j** 标志。
+现在,让我们创建 **bzip 归档**。为此,请使用下面的 `j` 标志。
创建一个目录的归档:
```
$ tar cjf ostechnix.tar.bz2 ostechnix/
```
+
或
+
```
$ tar cjf ostechnix.tbz ostechnix/
```
从一个列表文件中创建归档:
+
```
$ tar cjf archive.tar.bz2 file1 file2 file3
```
或
+
```
$ tar cjf archive.tbz file1 file2 file3
```
-为了显示进度,使用 **v** 标志。
+为了显示进度,使用 `v` 标志。
现在,在当前目录下,让我们提取一个 bzip 归档。这样做:
+
```
$ tar xjf ostechnix.tar.bz2
```
或者,提取归档文件到其他目录:
+
```
$ tar xjf ostechnix.tar.bz2 -C Downloads
```
-**一次创建多个目录和/或文件的归档**
+#### 一次创建多个目录和/或文件的归档
+
+这是 `tar` 命令的另一个最酷的功能。要一次创建多个目录或文件的 gzip 归档文件,使用以下文件:
-这是 tar 命令的另一个最酷的功能。要一次创建多个目录或文件的 gzip 归档文件,使用以下文件:
```
$ tar czvf ostechnix.tgz Downloads/ Documents/ ostechnix/file.odt
```
-上述命令创建 **Downloads**, **Documents** 目录和 **ostechnix** 目录下的 **file.odt** 文件的归档,并将归档保存在当前工作目录中。
+上述命令创建 `Downloads`、 `Documents` 目录和 `ostechnix` 目录下的 `file.odt` 文件的归档,并将归档保存在当前工作目录中。
-**在创建归档时跳过目录和/或文件**
+#### 在创建归档时跳过目录和/或文件
-这在备份数据时非常有用。你可以在备份中排除不重要的文件或目录,这是 **–exclude** 选项所能帮助的。例如你想要创建 /home 目录的归档,但不希望包括 Downloads, Documents, Pictures, Music 这些目录。
+这在备份数据时非常有用。你可以在备份中排除不重要的文件或目录,这是 `–exclude` 选项所能帮助的。例如你想要创建 `/home` 目录的归档,但不希望包括 `Downloads`、 `Documents`、 `Pictures`、 `Music` 这些目录。
这是我们的做法:
+
```
$ tar czvf ostechnix.tgz /home/sk --exclude=/home/sk/Downloads --exclude=/home/sk/Documents --exclude=/home/sk/Pictures --exclude=/home/sk/Music
```
-上述命令将对我的 $HOME 目录创建一个 gzip 归档,其中不包括 Downloads, Documents, Pictures 和 Music 目录。要创建 bzip 归档,将 **z** 替换为 **j**,并在上例中使用扩展名 .bz2。
+上述命令将对我的 `$HOME` 目录创建一个 gzip 归档,其中不包括 `Downloads`、`Documents`、`Pictures` 和 `Music` 目录。要创建 bzip 归档,将 `z` 替换为 `j`,并在上例中使用扩展名 `.bz2`。
-**列出归档文件但不提取它们**
+#### 列出归档文件但不提取它们
+
+要列出归档文件的内容,我们使用 `t` 标志。
-要列出归档文件的内容,我们使用 **t** 标志。
```
$ tar tf ostechnix.tar
ostechnix/
@@ -173,7 +197,8 @@ ostechnix/image.png
ostechnix/song.mp3
```
-要查看详细输出,使用 **v** 标志。
+要查看详细输出,使用 `v` 标志。
+
```
$ tar tvf ostechnix.tar
drwxr-xr-x sk/users 0 2018-03-26 19:52 ostechnix/
@@ -182,16 +207,18 @@ drwxr-xr-x sk/users 0 2018-03-26 19:52 ostechnix/
-rw-r--r-- sk/users 112383 2018-02-22 14:35 ostechnix/song.mp3
```
-**追加文件到归档**
+#### 追加文件到归档
+
+文件或目录可以使用 `r` 标志添加/更新到现有的归档。看看下面的命令:
-文件或目录可以使用 **r** 标志添加/更新到现有的归档。看看下面的命令:
```
$ tar rf ostechnix.tar ostechnix/ sk/ example.txt
```
-上面的命令会将名为 **sk** 的目录和名为 **exmple.txt** 添加到 ostechnix.tar 归档文件中。
+上面的命令会将名为 `sk` 的目录和名为 `exmple.txt` 添加到 `ostechnix.tar` 归档文件中。
你可以使用以下命令验证文件是否已添加:
+
```
$ tar tvf ostechnix.tar
drwxr-xr-x sk/users 0 2018-03-26 19:52 ostechnix/
@@ -203,22 +230,24 @@ drwxr-xr-x sk/users 0 2018-03-26 19:52 sk/
-rw-r--r-- sk/users 0 2018-03-26 19:56 example.txt
```
-##### **TL;DR**
+### TL;DR
-**创建 tar 归档:**
- * **普通 tar 归档:** tar -cf archive.tar file1 file2 file3
- * **Gzip tar 归档:** tar -czf archive.tgz file1 file2 file3
- * **Bzip tar 归档:** tar -cjf archive.tbz file1 file2 file3
+创建 tar 归档:
-**提取 tar 归档:**
- * **普通 tar 归档:** tar -xf archive.tar
- * **Gzip tar 归档:** tar -xzf archive.tgz
- * **Bzip tar 归档:** tar -xjf archive.tbz
+ * **普通 tar 归档:** `tar -cf archive.tar file1 file2 file3`
+ * **Gzip tar 归档:** `tar -czf archive.tgz file1 file2 file3`
+ * **Bzip tar 归档:** `tar -cjf archive.tbz file1 file2 file3`
+
+提取 tar 归档:
+
+ * **普通 tar 归档:** `tar -xf archive.tar`
+ * **Gzip tar 归档:** `tar -xzf archive.tgz`
+ * **Bzip tar 归档:** `tar -xjf archive.tbz`
+
+我们只介绍了 `tar` 命令的基本用法,这些对于开始使用 `tar` 命令足够了。但是,如果你想了解更多详细信息,参阅 man 手册页。
-我们只介绍了 tar 命令的基本用法,这些对于开始使用 tar 命令足够了。但是,如果你想了解更多详细信息,参阅 man 手册页。
```
$ man tar
-
```
好吧,这就是全部了。在下一部分中,我们将看到如何使用 Zip 实用程序来归档文件和目录。
@@ -230,9 +259,9 @@ $ man tar
via: https://www.ostechnix.com/how-to-archive-files-and-directories-in-linux-part-1/
作者:[SK][a]
-译者:[MjSeven](https://github.com/MjSeven)
-校对:[校对者ID](https://github.com/校对者ID)
选题:[lujun9972](https://github.com/lujun9972)
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180502 Writing Systemd Services for Fun and Profit.md b/published/20180502 Writing Systemd Services for Fun and Profit.md
similarity index 71%
rename from translated/tech/20180502 Writing Systemd Services for Fun and Profit.md
rename to published/20180502 Writing Systemd Services for Fun and Profit.md
index cec8c0ac74..896f65e1b7 100644
--- a/translated/tech/20180502 Writing Systemd Services for Fun and Profit.md
+++ b/published/20180502 Writing Systemd Services for Fun and Profit.md
@@ -3,26 +3,27 @@

-让我们假设你希望搭建一个游戏服务器,运行 [Minetest][1] 这款非常酷、开源的、以采集 & 合成为主题的沙盒游戏。你希望将游戏运行在位于客厅的服务器中,以便搭建完成后可供你的学校或朋友使用。考虑到内核邮件列表管理就是通过这种方式完成的,那么对你来说也是足够的。
+让我们假设你希望搭建一个游戏服务器,运行 [Minetest][1] 这款非常酷、开源的,以采集 & 合成为主题的沙盒游戏。你希望将游戏运行在位于客厅的服务器中,以便搭建完成后可供你的学校或朋友使用。你知道内核邮件列表的管理就不过就是如此,那么对你来说也是足够的。
但你很快发现每次开机之后需要启动服务器,每次关机之前需要安全地关闭服务器,十分繁琐和麻烦。
最初,你可能用守护进程的方式运行服务器:
-```
-minetest --server &
```
+minetest --server &
+```
+
记住进程 PID 以便后续使用。
接着,你还需要通过邮件或短信的方式将服务器已经启动的信息告知你的朋友。然后你就可以开始游戏了。
-转眼之间,已经凌晨三点,今天的战斗即将告一段落。但在你关闭主机、睡个好觉之前,还需要做一些操作。首先,你需要通知其它玩家服务器即将关闭,找到记录我们之前提到的 PID 的纸条,然后友好地关闭 Minetest 服务器。
+转眼之间,已经凌晨三点,今天的战斗即将告一段落。但在你关闭主机、睡个好觉之前,还需要做一些操作。首先,你需要通知其它玩家服务器即将关闭,找到记录我们之前提到的 PID 的纸条,然后友好地关闭 Minetest 服务进程。
+
```
kill -2
-
```
-因为直接关闭主机电源很可能导致文件损坏。下一步也是最后一步,关闭主机电源。
+这是因为直接关闭主机电源很可能导致文件损坏。下一步也是最后一步,关闭主机电源。
一定有方法能让事情变得更简单。
@@ -30,13 +31,15 @@ kill -2
让我们从构建一个普通用户可以(手动)运行的 systemd 服务开始,然后再逐步增加内容。
-不需要管理员权限即可运行的服务位于 _~/.config/systemd/user/_,故首先需要创建这个目录:
+不需要管理员权限即可运行的服务位于 `~/.config/systemd/user/`,故首先需要创建这个目录:
+
```
cd
mkdir -p ~/.config/systemd/user/
-
```
-有很多类型的 systemd _units_ (曾经叫做 systemd 脚本),包括 _timers_ 和 _paths_ 等,但我们这里关注的是 service 类型。在 _~/.config/systemd/user/_ 目录中创建 _minetest.service_ 文件,使用文本编辑器打开并输入如下内容:
+
+有很多类型的 systemd 单元 (曾经叫做 systemd 脚本),包括“计时器”和“路径”等,但我们这里关注的是“服务”类型。在 `~/.config/systemd/user/` 目录中创建 `minetest.service` 文件,使用文本编辑器打开并输入如下内容:
+
```
# minetest.service
@@ -47,39 +50,38 @@ Documentation= https://wiki.minetest.net/Main_Page
[Service]
Type= simple
ExecStart= /usr/games/minetest --server
-
```
-可以看到 units 中包含不同的段,其中 `[Unit]` 段主要为用户提供信息,给出 unit 的描述及如何获得更多相关文档。
+可以看到该单元中包含不同的段,其中 `[Unit]` 段主要为用户提供信息,给出该单元的描述及如何获得更多相关文档。
-脚本核心位于 `[Service]` 段,首先使用 `Type` 指令确定服务类型。服务[有多种类型][2],下面给出两个示例。如果你运行的进程设置环境变量、调用另外一个进程(主进程)、退出运行,那么你应该使用的服务类型为 `forking`。如果你希望在你的 unit 对应进程结束运行前阻断其他 units 运行,那么你应该使用的服务类型为 `oneshot`。
+脚本核心位于 `[Service]` 段,首先使用 `Type` 指令确定服务类型。服务[有多种类型][2],下面给出两个示例。如果你运行的进程设置环境变量、调用另外一个进程(主进程)、退出运行,那么你应该使用的服务类型为 `forking`。如果你希望在你的单元对应进程结束运行前阻断其他单元运行,那么你应该使用的服务类型为 `oneshot`。
但 Minetest 服务器的情形与上面两种都不同,你希望启动服务器并使其在后台持续运行;这种情况下应该使用 `simple` 类型。
下面来看 `ExecStart` 指令,它给出 systemd 需要运行的程序。在本例中,你希望在后台运行 `minetest` 服务器。如上所示,你可以在可执行程序后面添加参数,但不能将一系列 Bash 命令通过管道连接起来。下面给出的例子无法工作:
+
```
ExecStart: lsmod | grep nvidia > videodrive.txt
-
```
如果你需要将 Bash 命令通过管道连接起来,可以将其封装到一个脚本中,然后运行该脚本。
-还需要注意一点,systemd 要求你给出程序的完整路径。故如果你想使用 `simeple` 类型运行类似 _ls_ 的命令,你需要使用 `ExecStart= /bin/ls`。
+还需要注意一点,systemd 要求你给出程序的完整路径。故如果你想使用 `simple` 类型运行类似 `ls` 的命令,你需要使用 `ExecStart= /bin/ls`。
另外还有 `ExecStop` 指令用于定制服务终止的方式。我们会在第二部分讨论这个指令,但你要了解,如果你没有指定 `ExecStop`,systemd 会帮你尽可能友好地终止进程。
-_systemd.directives_ 的帮助页中包含完整指令列表,另外你可以在[网站][3]上找到同样的列表,点击即可查看每个指令的具体信息。
+`systemd.directives` 的帮助页中包含完整指令列表,另外你可以在该[网站][3]上找到同样的列表,点击即可查看每个指令的具体信息。
+
+虽然只有 6 行,但你的 `minetest.service` 已经是一个有完整功能的 systemd 单元。执行如下命令启动服务:
-虽然只有 6 行,但你的 _minetest.service_ 已经是一个有完整功能的 systemd unit。执行如下命令启动服务:
```
systemd --user start minetest
-
```
-执行如下命令终止服务
+执行如下命令终止服务:
+
```
systemd --user stop minetest
-
```
选项 `--user` 告知 systemd 在你的本地目录中检索服务并用你的用户权限执行服务。
@@ -95,7 +97,7 @@ via: https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-serv
作者:[Paul Brown][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[pinewall](https://github.com/pinewall)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180507 4 Firefox extensions to install now.md b/published/20180507 4 Firefox extensions to install now.md
new file mode 100644
index 0000000000..fc015def61
--- /dev/null
+++ b/published/20180507 4 Firefox extensions to install now.md
@@ -0,0 +1,81 @@
+4 个现在就该去装的 Firefox 扩展
+=====
+
+> 合适的扩展能极大地增强你的浏览器功能,但是仔细的选择也是很重要的。
+
+
+
+正如我在关于 Firefox 扩展的[原创文章][1]中提到的,web 浏览器已成为许多用户计算机体验的关键组件。现代浏览器已经发展成为功能强大且可扩展的平台,扩展可以添加或修改其功能。Firefox 的扩展是使用 WebExtensions API(一种跨浏览器开发系统)构建的。
+
+在第一篇文章中,我问读者:“你应该安装哪些扩展?” 重申一下,这一决定主要取决于你如何使用浏览器,你对隐私的看法,你对扩展程序开发人员的信任程度以及其他个人偏好。自文章发表以来,我推荐的一个扩展(Xmarks)已经停止维护。另外,该文章收到了大量的反馈,在这篇更新中,这些反馈已经被考虑到。
+
+我想再次指出,浏览器扩展通常需要能够阅读和(或)更改你访问的网页上的所有内容。你应该仔细考虑这一点。如果扩展程序修改了你访问的所有网页的访问权限,那么它可能成为键盘记录程序、拦截信用卡信息、在线跟踪、插入广告以及执行各种其他恶意活动。这并不意味着每个扩展程序都会暗中执行这些操作,但在安装任何扩展程序之前,你应该仔细考虑安装源,涉及的权限,风险配置文件以及其他因素。请记住,你可以使用配置文件来管理扩展如何影响你的攻击面 —— 例如,使用没有扩展的专用配置文件来执行网上银行等任务。
+
+考虑到这一点,这里有你可能想要考虑的四个开源 Firefox 扩展。
+
+### uBlock Origin
+
+![ublock origin ad blocker screenshot][2]
+
+我的第一个建议保持不变。[uBlock Origin][3] 是一款快速、低内存消耗、广泛的拦截器,它不仅可以拦截广告,而且还可以执行你自己的内容过滤。 uBlock Origin 的默认行为是使用多个预定义的过滤器列表来拦截广告、跟踪器和恶意软件站点。它允许你任意添加列表和规则,甚至可以锁定到默认拒绝模式。尽管它很强大,但它已被证明是高效和高性能的。它将继续定期更新,并且是该功能的最佳选择之一。
+
+### Privacy Badger
+
+![privacy badger ad blocker][4]
+
+我的第二个建议也保持不变。如果说有什么区别的话,那就是自从我上一篇文章发表以来,隐私问题更被关注了,这使得这个扩展成为一个简单的建议。顾名思义,[Privacy Badger][5] 是一个专注于隐私的扩展,可以拦截广告和其他第三方跟踪器。这是电子前哨基金会基金会(EFF)的一个项目,他们说:
+
+> Privacy Badger 的诞生是我们希望能够推荐一个单独的扩展,它可以自动分析和拦截任何违反用户同意原则的追踪器或广告;在用户没有任何设置、有关知识或配置的情况下,它可以很好地运行;它是由一个明确为其用户而不是为广告商工作的组织所产生的;它使用了算法的方法来决定什么被跟踪,什么没有被跟踪。”
+
+为什么 Privacy Badger 会出现在这个列表上,它的功能与上一个扩展看起来很类似?因为一些原因:首先,它从根本上工作原理与 uBlock Origin 不同。其次,深度防御的实践是一项合理的策略。说到深度防御,EFF 还维护着 [HTTPS Everywhere][6] 扩展,它自动确保 https 用于许多主流网站。当你安装 Privacy Badger 时,你也可以考虑使用 HTTPS Everywhere。
+
+如果你开始认为这篇文章只是对上一篇文章的重新讨论,那么以下是我的建议分歧。
+
+### Bitwarden
+
+![Bitwarden][7]
+
+在上一篇文章中推荐 LastPass 时,我提到这可能是一个有争议的选择。这无疑属实。无论你是否应该使用密码管理器 —— 如果你使用,那么是否应该选择带有浏览器插件的密码管理器 —— 这是一个备受争议的话题,答案很大程度上取决于你的个人风险状况。我认为大多数普通的计算机用户应该使用一个,因为它比最常见的选择要好得多:在任何地方都使用相同的弱密码!我仍然相信这一点。
+
+[Bitwarden][8] 自从我上次点评以后确实更成熟了。像 LastPass 一样,它对用户友好,支持双因素身份验证,并且相当安全。与 LastPass 不同的是,它是[开源的][9]。它可以使用或不使用浏览器插件,并支持从其他解决方案(包括 LastPass)导入。它的核心功能完全免费,它还有一个 10 美元/年的高级版本。
+
+### Vimium-FF
+
+![Vimium][10]
+
+[Vimium][11] 是另一个开源的扩展,它为 Firefox 键盘快捷键提供了类似 Vim 一样的导航和控制,其称之为“黑客的浏览器”。对于 `Ctrl+x`、 `Meta+x` 和 `Alt+x`,分别对应 ``、`` 和 ``,默认值可以轻松定制。一旦你安装了 Vimium,你可以随时键入 `?` 来查看键盘绑定列表。请注意,如果你更喜欢 Emacs,那么也有一些针对这些键绑定的扩展。无论哪种方式,我认为键盘快捷键是未充分利用的生产力推动力。
+
+### 额外福利: Grammarly
+
+不是每个人都有幸在 Opensource.com 上撰写专栏 —— 尽管你应该认真考虑为这个网站撰写文章;如果你有问题,有兴趣,或者想要一个导师,伸出手,让我们聊聊吧。但是,即使没有专栏撰写,正确的语法在各种各样的情况下都是有益的。试一下 [Grammarly][12]。不幸的是,这个扩展不是开源的,但它确实可以确保你输入的所有东西都是清晰的
+、有效的并且没有错误。它通过扫描你文本中的常见的和复杂的语法错误来实现这一点,涵盖了从主谓一致到文章使用,到修饰词的放置这些所有内容。它的基本功能是免费的,它有一个高级版本,每月收取额外的费用。我在这篇文章中使用了它,它发现了许多我的校对没有发现的错误。
+
+再次说明,Grammarly 是这个列表中包含的唯一不是开源的扩展,因此如果你知道类似的高质量开源替代品,请在评论中告诉我们。
+
+这些扩展是我发现有用并推荐给其他人的扩展。请在评论中告诉我你对更新建议的看法。
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/firefox-extensions
+
+作者:[Jeremy Garcia][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jeremy-garcia
+[1]:https://opensource.com/article/18/1/top-5-firefox-extensions
+[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/ublock.png?itok=_QFEbDmq (ublock origin ad blocker screenshot)
+[3]:https://addons.mozilla.org/en-US/firefox/addon/ublock-origin/
+[4]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/privacy_badger_1.0.1.png?itok=qZXQeKtc (privacy badger ad blocker screenshot)
+[5]:https://www.eff.org/privacybadger
+[6]:https://www.eff.org/https-everywhere
+[7]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/bitwarden.png?itok=gZPrCYoi (Bitwarden)
+[8]:https://bitwarden.com/
+[9]:https://github.com/bitwarden
+[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/vimium.png?itok=QRESXjWG (Vimium)
+[11]:https://addons.mozilla.org/en-US/firefox/addon/vimium-ff/
+[12]:https://www.grammarly.com/
diff --git a/translated/tech/20180508 Orbital Apps - A New Generation Of Linux applications.md b/published/20180508 Orbital Apps - A New Generation Of Linux applications.md
similarity index 52%
rename from translated/tech/20180508 Orbital Apps - A New Generation Of Linux applications.md
rename to published/20180508 Orbital Apps - A New Generation Of Linux applications.md
index 79ba51da43..68c3a087bd 100644
--- a/translated/tech/20180508 Orbital Apps - A New Generation Of Linux applications.md
+++ b/published/20180508 Orbital Apps - A New Generation Of Linux applications.md
@@ -1,12 +1,11 @@
-Orbital Apps - 新一代 Linux 程序
+Orbital Apps:新一代 Linux 程序
======

-今天,我们要了解 **Orbital Apps** 或 **ORB**(**O**pen **R**unnable **B**undle)**apps**(开放可运行程序包),一个免费、跨平台的开源程序集合。所有 ORB 程序都是可移动的。你可以将它们安装在你的 Linux 系统或 USB 驱动器上,以便你可以在任何系统上使用相同的程序。它们不需要 root 权限,并且没有依赖关系。所有必需的依赖关系都包含在程序中。只需将 ORB 程序复制到 USB 驱动器并将其插入到任何 Linux 系统中就立即开始使用它们。所有设置和配置以及程序的数据都将存储在 USB 驱动器上。由于不需要在本地驱动器上安装程序,我们可以在联机或脱机的计算机上运行应用程序。这意味着我们不需要 Internet 来下载任何依赖。
+今天,我们要了解 **Orbital Apps** 或 **ORB**(**O**pen **R**unnable **B**undle)**apps**(开放可运行程序包),一个自由的、跨平台的开源程序集合。所有 ORB 程序都是可移动的。你可以将它们安装在你的 Linux 系统或 USB 驱动器上,以便你可以在任何系统上使用相同的程序。它们不需要 root 权限,并且没有依赖关系。所有必需的依赖关系都包含在程序中。只需将 ORB 程序复制到 USB 驱动器并将其插入到任何 Linux 系统中就立即开始使用它们。所有设置和配置以及程序的数据都将存储在 USB 驱动器上。由于不需要在本地驱动器上安装程序,我们可以在联机或脱机的计算机上运行应用程序。这意味着我们不需要 Internet 来下载任何依赖。
-ORB apps are compressed up to 60% smaller, so we can store and use them even from the small sized USB drives. All ORB apps are signed with PGP/RSA and distributed via TLS 1.2. All Applications are packaged without any modifications, they are not even re-compiled. Here is the list of currently available portable ORB applications.
-ORB 程序压缩了 60%,因此我们甚至可以从小型USB驱动器存储和使用它们。所有ORB应用程序都使用PGP / RSA进行签名,并通过TLS 1.2进行分发。所有应用程序打包时都不做任何修改,甚至不会重新编译。以下是当前可用的便携式ORB应用程序列表。
+ORB 程序压缩了 60%,因此我们甚至可以从小型 USB 驱动器存储和使用它们。所有 ORB 应用程序都使用 PGP / RSA 进行签名,并通过 TLS 1.2 进行分发。所有应用程序打包时都不做任何修改,甚至不会重新编译。以下是当前可用的便携式 ORB 应用程序列表。
* abiword
* audacious
@@ -28,34 +27,32 @@ ORB 程序压缩了 60%,因此我们甚至可以从小型USB驱动器存储
* tomahawk
* uget
* vlc
- * 未来还有更多。
+ * 未来还有更多
-
-Orb is open source, so If you’re a developer, feel free to collaborate and add more applications.
Orb 是开源的,所以如果你是开发人员,欢迎协作并添加更多程序。
### 下载并使用可移动 ORB 程序
正如我已经提到的,我们不需要安装可移动 ORB 程序。但是,ORB 团队强烈建议你使用 **ORB 启动器** 来获得更好的体验。 ORB 启动器是一个小的安装程序(小于 5MB),它可帮助你启动 ORB 程序,并获得更好,更流畅的体验。
-让我们先安装 ORB 启动器。为此,[**下载 ORB 启动器**][1]。你可以手动下载 ORB 启动器的 ISO 并将其挂载到文件管理器上。或者在终端中运行以下任一命令来安装它:
+让我们先安装 ORB 启动器。为此,[下载 ORB 启动器][1]。你可以手动下载 ORB 启动器的 ISO 并将其挂载到文件管理器上。或者在终端中运行以下任一命令来安装它:
+
```
$ wget -O - https://www.orbital-apps.com/orb.sh | bash
-
```
如果你没有 wget,请运行:
+
```
$ curl https://www.orbital-apps.com/orb.sh | bash
-
```
询问时输入 root 用户和密码。
就是这样。Orbit 启动器已安装并可以使用。
-现在,进入 [**ORB 可移动程序下载页面**][2],并下载你选择的程序。在本教程中,我会下载 Firefox。
+现在,进入 [ORB 可移动程序下载页面][2],并下载你选择的程序。在本教程中,我会下载 Firefox。
下载完后,进入下载位置并双击 ORB 程序来启动它。点击 Yes 确认。
@@ -67,7 +64,7 @@ Firefox ORB 程序能用了!
同样,你可以立即下载并运行任何程序。
-如果你不想使用 ORB 启动器,请将下载的 .orb 安装程序设置为可执行文件,然后双击它进行安装。不过,建议使用 ORB 启动器,它可让你在使用 ORB 程序时更轻松、更顺畅。
+如果你不想使用 ORB 启动器,请将下载的 `.orb` 安装程序设置为可执行文件,然后双击它进行安装。不过,建议使用 ORB 启动器,它可让你在使用 ORB 程序时更轻松、更顺畅。
就我测试的 ORB 程序而言,它们打开即可使用。希望这篇文章有帮助。今天就是这些。祝你有美好的一天!
@@ -81,7 +78,7 @@ via: https://www.ostechnix.com/orbitalapps-new-generation-ubuntu-linux-applicati
作者:[SK][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/sources/talk/20180419 Is DevOps compatible with part-time community teams b/sources/talk/20180418 Is DevOps compatible with part-time community teams.md
similarity index 53%
rename from sources/talk/20180419 Is DevOps compatible with part-time community teams
rename to sources/talk/20180418 Is DevOps compatible with part-time community teams.md
index d52948020a..e78b96959f 100644
--- a/sources/talk/20180419 Is DevOps compatible with part-time community teams
+++ b/sources/talk/20180418 Is DevOps compatible with part-time community teams.md
@@ -1,40 +1,22 @@
-# Is DevOps compatible with part-time community teams?
-
-### DevOps can greatly benefit projects of all sizes. Here's how to build a DevOps adoption plan for smaller projects.
-
-
-
-Image by :
-
-[WOCinTech Chat][1]. Modified by Opensource.com. [CC BY-SA 4.0][2]
-
-### Get the newsletter
-
-Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
+Is DevOps compatible with part-time community teams?
+======
+
DevOps seems to be the talk of the IT world of late—and for good reason. DevOps has streamlined the process and production of IT development and operations. However, there is also an upfront cost to embracing a DevOps ideology, in terms of time, effort, knowledge, and financial investment. Larger companies may have the bandwidth, budget, and time to make the necessary changes, but is it feasible for part-time, resource-strapped communities?
-Part-time communities are teams of like-minded people who take on projects outside of their normal work schedules. The members of these communities are driven by passion and a shared purpose. For instance, one such community is the [ALM | DevOps Rangers][3]. With 100 rangers engaged across the globe, a DevOps solution may seem daunting; nonetheless, they took on the challenge and embraced the ideology. Through their example, we've learned that DevOps is not only feasible but desirable in smaller teams. To read about their transformation, check out [How DevOps eliminates development bottlenecks][4].
+Part-time communities are teams of like-minded people who take on projects outside of their normal work schedules. The members of these communities are driven by passion and a shared purpose. For instance, one such community is the [ALM | DevOps Rangers][1]. With 100 rangers engaged across the globe, a DevOps solution may seem daunting; nonetheless, they took on the challenge and embraced the ideology. Through their example, we've learned that DevOps is not only feasible but desirable in smaller teams. To read about their transformation, check out [How DevOps eliminates development bottlenecks][2].
> “DevOps is the union of people, process, and products to enable continuous delivery of value to our end customers.” - Donovan Brown
### The cost of DevOps
-As stated above, there is an _upfront_ "cost" to DevOps. The cost manifests itself in many forms, such as the time and collaboration between development, operations, and other stakeholders, planning a smooth-flowing process that delivers continuous value, finding the best DevOps products, and training the team in new technologies, to name a few. This aligns directly with Donovan's definition of DevOps, in fact—a **process** for delivering **continuous value** and the **people** who make that happen.
-
-More DevOps resources
-
-* [What is DevOps?][5]
-* [Free eBook: DevOps with OpenShift][6]
-* [10 bad DevOps habits to break][7]
-* [10 must-read DevOps resources][8]
-* [The latest on DevOps][9]
+As stated above, there is an upfront "cost" to DevOps. The cost manifests itself in many forms, such as the time and collaboration between development, operations, and other stakeholders, planning a smooth-flowing process that delivers continuous value, finding the best DevOps products, and training the team in new technologies, to name a few. This aligns directly with Donovan's definition of DevOps, in fact—a **process** for delivering **continuous value** and the **people** who make that happen.
Streamlined DevOps takes a lot of planning and training just to create the process, and that doesn't even consider the testing phase. We also can't forget the existing in-flight projects that need to be converted into the new system. While the cost increases the more pervasive the transformation—for instance, if an organization aims to unify its entire development organization under a single process, then that would cost more versus transforming a single pilot or subset of the entire portfolio—these upfront costs must be addressed regardless of their scale. There are a lot of resources and products already out there that can be implemented for a smoother transition—but again, we face the time and effort that will be necessary just to research which ones might work best.
In the case of the ALM | DevOps Rangers, they had to halt all projects for a couple of sprints to set up the initial process. Many organizations would not be able to do that. Even part-time groups might have very good reasons to keep things moving, which only adds to the complexity. In such scenarios, additional cutover planning (and therefore additional cost) is needed, and the overall state of the community is one of flux and change, which adds risk, which—you guessed it—requires more cost to mitigate.
-There is also an _ongoing_ "cost" that teams will face with a DevOps mindset: Simple maintenance of the system, training and transitioning new team members, and keeping up with new, improved technologies are all a part of the process.
+There is also an ongoing "cost" that teams will face with a DevOps mindset: Simple maintenance of the system, training and transitioning new team members, and keeping up with new, improved technologies are all a part of the process.
### DevOps for a part-time community
@@ -46,7 +28,7 @@ The answer to that is dependent on a few variables, such as the ability of the t
Luckily, we aren't without examples to demonstrate just how DevOps can benefit a smaller group. Let's take a quick look at the ALM Rangers again. The results from their transformation help us understand how DevOps changed their community:
-
+
As illustrated, there are some huge benefits for part-time community teams. Planning goes from long, arduous design sessions to a quick prototyping and storyboarding process. Builds become automated, reliable, and resilient. Testing and bug detection are proactive instead of reactive, which turns into a happier clientele. Multiple full-time program managers are replaced with self-managing teams with a single part-time manager to oversee projects. Teams become smaller and more efficient, which equates to higher production rates and higher-quality project delivery. With results like these, it's hard to argue against DevOps.
@@ -56,62 +38,36 @@ Still, the upfront and ongoing costs aren't right for every community. The numbe
Another important question to ask: How can a low-bandwidth group make such a massive transition? The good news is that a DevOps transformation doesn’t need to happen all at once. Taken in smaller, more manageable steps, organizations of any size can embrace DevOps.
-1. Determine why DevOps may be the solution you need. Are your projects bottlenecking? Are they running over budget and over time? Of course, these concerns are common for any community, big or small. Answering these questions leads us to step two:
-2. Develop the right framework to improve the engineering process. DevOps is all about automation, collaboration, and streamlining. Rather than trying to fit everyone into the same process box, the framework should support the work habits, preferences, and delivery needs of the community. Some broad standards should be established (for example, that all teams use a particular version control system). Beyond that, however, let the teams decide their own best process.
-3. Use the current products that are already available if they meet your needs. Why reinvent the wheel?
-4. Finally, implement and test the actual DevOps solution. This is, of course, where the actual value of DevOps is realized. There will likely be a few issues and some heartburn, but it will all be worth it in the end because, once established, the products of the community’s work will be nimbler and faster for the users.
+ 1. Determine why DevOps may be the solution you need. Are your projects bottlenecking? Are they running over budget and over time? Of course, these concerns are common for any community, big or small. Answering these questions leads us to step two:
+ 2. Develop the right framework to improve the engineering process. DevOps is all about automation, collaboration, and streamlining. Rather than trying to fit everyone into the same process box, the framework should support the work habits, preferences, and delivery needs of the community. Some broad standards should be established (for example, that all teams use a particular version control system). Beyond that, however, let the teams decide their own best process.
+ 3. Use the current products that are already available if they meet your needs. Why reinvent the wheel?
+ 4. Finally, implement and test the actual DevOps solution. This is, of course, where the actual value of DevOps is realized. There will likely be a few issues and some heartburn, but it will all be worth it in the end because, once established, the products of the community’s work will be nimbler and faster for the users.
+
+
### Reuse DevOps solutions
-One benefit to creating effective CI/CD pipelines is the reusability of those pipelines. Although there is no one-size fits all solution, anyone can adopt a process. There are several pre-made templates available for you to examine, such as build templates on VSTS, ARM templates to deploy Azure resources, and "cookbook"-style textbooks from technical publishers. Once it identifies a process that works well, a community can also create its own template by defining and establishing standards and making that template easily discoverable by the entire community. For more information on DevOps journeys and tools, check out [this site][10].
+One benefit to creating effective CI/CD pipelines is the reusability of those pipelines. Although there is no one-size fits all solution, anyone can adopt a process. There are several pre-made templates available for you to examine, such as build templates on VSTS, ARM templates to deploy Azure resources, and "cookbook"-style textbooks from technical publishers. Once it identifies a process that works well, a community can also create its own template by defining and establishing standards and making that template easily discoverable by the entire community. For more information on DevOps journeys and tools, check out [this site][3].
### Summary
Overall, the success or failure of DevOps relies on the culture of a community. It doesn't matter if the community is a large, resource-rich enterprise or a small, resource-sparse, part-time group. DevOps will still bring solid benefits. The difference is in the approach for adoption and the scale of that adoption. There are both upfront and ongoing costs, but the value greatly outweighs those costs. Communities can use any of the powerful tools available today for their pipelines, and they can also leverage reusability, such as templates, to reduce upfront implementation costs. DevOps is most certainly feasible—and even critical—for the success of part-time community teams.
----
+**[See our related story,[How DevOps eliminates development bottlenecks][4].]**
-**\[See our related story, [How DevOps eliminates development bottlenecks][11].\]**
+--------------------------------------------------------------------------------
+via: https://opensource.com/article/18/4/devops-compatible-part-time-community-teams
-### About the author
+作者:[Edward Fry][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
-[][13]
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-Edward Fry \- Edward a business technophile who revels in blending people, process, and technology to solve real problems with grace and efficiency. As a member of the ALM Rangers, he loves to share his passion for the process of software development and ways to get computers to do the drudge work so that people can dream the big dreams. He also enjoys the art of great software design and architecture and also just likes being immersed in code. When he isn't helping people with technology, he enjoys... [more about Edward Fry][14]
-
-[More about me][15]
-
-* [Learn how you can contribute][16]
-
----
-
-via: [https://opensource.com/article/18/4/devops-compatible-part-time-community-teams][17]
-
-作者: [Edward Fry][18] 选题者: [@lujun9972][19] 译者: [译者ID][20] 校对: [校对者ID][21]
-
-本文由 [LCTT][22] 原创编译,[Linux中国][23] 荣誉推出
-
-[1]: https://www.flickr.com/photos/wocintechchat/25392377053/
-[2]: https://creativecommons.org/licenses/by/4.0/
-[3]: https://github.com/ALM-Rangers
-[4]: https://opensource.com/article/17/11/devops-rangers-transformation
-[5]: https://opensource.com/resources/devops?src=devops_resource_menu1
-[6]: https://www.openshift.com/promotions/devops-with-openshift.html?intcmp=7016000000127cYAAQ&src=devops_resource_menu2
-[7]: https://enterprisersproject.com/article/2018/1/10-bad-devops-habits-break?intcmp=7016000000127cYAAQ&src=devops_resource_menu3
-[8]: https://opensource.com/article/17/12/10-must-read-devops-books?src=devops_resource_menu4
-[9]: https://opensource.com/tags/devops?src=devops_resource_menu5
-[10]: https://www.visualstudio.com/devops/
-[11]: https://opensource.com/article/17/11/devops-rangers-transformation
-[12]: https://opensource.com/tags/devops
-[13]: https://opensource.com/users/edwardf
-[14]: https://opensource.com/users/edwardf
-[15]: https://opensource.com/users/edwardf
-[16]: https://opensource.com/participate
-[17]: https://opensource.com/article/18/4/devops-compatible-part-time-community-teams
-[18]: https://opensource.com/users/edwardf
-[19]: https://github.com/lujun9972
-[20]: https://github.com/译者ID
-[21]: https://github.com/校对者ID
-[22]: https://github.com/LCTT/TranslateProject
-[23]: https://linux.cn/
\ No newline at end of file
+[a]:https://opensource.com/users/edwardf
+[1]:https://github.com/ALM-Rangers
+[2]:https://opensource.com/article/17/11/devops-rangers-transformation
+[3]:https://www.visualstudio.com/devops/
+[4]:https://opensource.com/article/17/11/devops-rangers-transformation
diff --git a/sources/talk/20180425 How will the GDPR impact open source communities b/sources/talk/20180425 How will the GDPR impact open source communities
deleted file mode 100644
index 720df5bdb4..0000000000
--- a/sources/talk/20180425 How will the GDPR impact open source communities
+++ /dev/null
@@ -1,111 +0,0 @@
-# How will the GDPR impact open source communities?
-
-
-
-Image by :
-
-opensource.com
-
-
-
-On May 25, 2018 the [General Data Protection Regulation][1] will go into effect. This new regulation by the European Union will impact how organizations need to protect personal data on a global scale. This could include open source projects, including communities.
-
-### GDPR details
-
-The General Data Protection Regulation (GDPR) was approved by the EU Parliament on April 14, 2016, and will be enforced beginning May 25, 2018. The GDPR replaces the Data Protection Directive 95/46/EC that was designed "to harmonize data privacy laws across Europe, to protect and empower all EU citizens data privacy and to reshape the way organizations across the region approach data privacy."
-
-The aim of the GDPR is to protect the personal data of individuals in the EU in an increasingly data-driven world.
-
-### To whom does it apply
-
-One of the biggest changes that comes with the GDPR is an increased territorial scope. The GDPR applies to all organizations processing the personal data of data subjects residing in the European Union, irrelevant to its location.
-
-While most of the online articles covering the GDPR mention companies selling goods or services, we can also look at this territorial scope with open source projects in mind. There are a few variations, such as a software company (profit) running a community, and a non-profit organization, i.e. an open source software project and its community. Once these communities are run on a global scale, it is most likely that EU-based persons are taking part in this community.
-
-When such a global community has an online presence, using platforms such as a website, forum, issue tracker etcetera, it is very likely that they are processing personal data of these EU persons, such as their names, e-mail addresses and possibly even more. These activities will trigger a need to comply with the GDPR.
-
-### GDPR changes and its impact
-
-The GDPR brings [many changes][2], strengthening data protection and privacy of EU persons, compared to the previous Directive. Some of these changes have a direct impact on a community as described earlier. Let's look at some of these changes.
-
-#### Consent
-
-Let's assume that the community in question uses a forum for its members, and also has one or more forms on their website for registration purposes. With the GDPR you will no longer be able to use one lengthy and illegible privacy policy and terms of conditions. For each of those specific purposes, registering on the forum, and on one of those forms, you will need to obtain explicit consent. This consent must be “freely given, specific, informed, and unambiguous.”
-
-In case of such a form, you could have a checkbox, which should not be pre-checked, with clear text indicating for which purposes the personal data is used, preferably linking to an ‘addendum’ of your existing privacy policy and terms of use.
-
-#### Right to access
-
-EU persons get expanded rights by the GDPR. One of them is the right to ask an organization if, where and which personal data is processed. Upon request, they should also be provided with a copy of this data, free of charge, and in an electronic format if this data subject (e.g. EU citizen) asks for it.
-
-#### Right to be forgotten
-
-Another right EU citizens get through the GDPR is the "right to be forgotten," also known as data erasure. This means that subject to certain limitation, the organization will have to erase his/her data, and possibly even stop any further processing, including by the organization’s third parties.
-
-The above three changes imply that your platform(s) software will need to comply with certain aspects of the GDPR as well. It will need to have specific features such as obtaining and storing consent, extracting data and providing a copy in electronic format to a data subject, and finally the means to erase specific data about a data subject.
-
-#### Breach notification
-
-Under the GDPR, a data breach occurs whenever personal data is taken or stolen without the authorization of the data subject. Once discovered, you should notify your affected community members within 72 hours unless the personal data breach is unlikely to result in a risk to the rights and freedoms of natural persons. This breach notification is mandatory under the GDPR.
-
-#### Register
-
-As an organization, you will become responsible for keeping a register which will include detailed descriptions of all procedures, purposes etc for which you process personal data. This register will act as proof of the organization's compliance with the GDPR’s requirement to maintain a record of personal data processing activities, and will be used for audit purposes.
-
-#### Fines
-
-Organizations that do not comply with the GDPR risk fines up to 4% of annual global turnover or €20 million (whichever is greater). According to the GDPR, "this is the maximum fine that can be imposed for the most serious infringements e.g.not having sufficient customer consent to process data or violating the core of Privacy by Design concepts."
-
-### Final words
-
-My article should not be used as legal advice or a definite guide to GDPR compliance. I have covered some of the parts of the regulation that could be of impact to an open source community, raising awareness about the GDPR and its impact. Obviously, the regulation contains much more which you will need to know about and possibly comply with.
-
-As you can probably conclude yourself, you will have to take steps when you are running a global community, to comply with the GDPR. If you already apply robust security standards in your community, such as ISO 27001, NIST or PCI DSS, you should have a head start.
-
-You can find more information about the GDPR at the following sites/resources:
-
-* [GDPR Portal][3] (by the EU)
-
-* [Official Regulation (EU) 2016/679][4] (GDPR, including translations)
-
-* [What is GDPR? 8 things leaders should know][5] (The Enterprisers Project)
-
-* [How to avoid a GDPR compliance audit: Best practices][6] (The Enterprisers Project)
-
-
-### About the author
-
-[][7]
-
-Robin Muilwijk \- Robin Muilwijk is Advisor Internet and e-Government. He also serves as a community moderator for Opensource.com, an online publication by Red Hat, and as ambassador for The Open Organization. Robin is also Chair of the eZ Community Board, and Community Manager at [eZ Systems][8]. Robin writes and is active on social media to promote and advocate for open source in our businesses and lives.Follow him on Twitter... [more about Robin Muilwijk][9]
-
-[More about me][10]
-
-* [Learn how you can contribute][11]
-
----
-
-via: [https://opensource.com/article/18/4/gdpr-impact][12]
-
-作者: [Robin Muilwijk][13] 选题者: [@lujun9972][14] 译者: [译者ID][15] 校对: [校对者ID][16]
-
-本文由 [LCTT][17] 原创编译,[Linux中国][18] 荣誉推出
-
-[1]: https://www.eugdpr.org/eugdpr.org.html
-[2]: https://www.eugdpr.org/key-changes.html
-[3]: https://www.eugdpr.org/eugdpr.org.html
-[4]: http://eur-lex.europa.eu/legal-content/EN/TXT/?qid=1520531479111&uri=CELEX:32016R0679
-[5]: https://enterprisersproject.com/article/2018/4/what-gdpr-8-things-leaders-should-know
-[6]: https://enterprisersproject.com/article/2017/9/avoiding-gdpr-compliance-audit-best-practices
-[7]: https://opensource.com/users/robinmuilwijk
-[8]: http://ez.no
-[9]: https://opensource.com/users/robinmuilwijk
-[10]: https://opensource.com/users/robinmuilwijk
-[11]: https://opensource.com/participate
-[12]: https://opensource.com/article/18/4/gdpr-impact
-[13]: https://opensource.com/users/robinmuilwijk
-[14]: https://github.com/lujun9972
-[15]: https://github.com/译者ID
-[16]: https://github.com/校对者ID
-[17]: https://github.com/LCTT/TranslateProject
-[18]: https://linux.cn/
\ No newline at end of file
diff --git a/sources/talk/20180426 Get started with Pidgin- An open source replacement for Skype for Business.md b/sources/talk/20180426 Get started with Pidgin- An open source replacement for Skype for Business.md
deleted file mode 100644
index 2e2eb1ffac..0000000000
--- a/sources/talk/20180426 Get started with Pidgin- An open source replacement for Skype for Business.md
+++ /dev/null
@@ -1,65 +0,0 @@
-translating----geekpi
-
-Get started with Pidgin: An open source replacement for Skype for Business
-======
-
-
-Technology is at an interesting crossroads, where Linux rules the server landscape but Microsoft rules the enterprise desktop. Office 365, Skype for Business, Microsoft Teams, OneDrive, Outlook... the list goes on of Microsoft software and services that dominate the enterprise workspace.
-
-What if you could replace that proprietary software with free and open source applications and make them work with an Office 365 backend you have no choice but to use? Buckle up, because that is exactly what we are going to do with Pidgin, an open source replacement for Skype.
-
-### Installing Pidgin and SIPE
-
-Microsoft's Office Communicator became Microsoft Lync which became what we know today as Skype for Business. There are [pay software options][1] for Linux that provide feature parity with Skype for Business, but [Pidgin][2] is a fully free and open source option licensed under the GNU GPL.
-
-Pidgin can be found in just about every Linux distro's repository, so getting your hands on it should not be a problem. The only Skype feature that won't work with Pidgin is screen sharing, and file sharing can be a bit hit or miss—but there are ways to work around it.
-
-You also need a [SIPE][3] plugin, as it's part of the secret sauce to make Pidgin work as a Skype for Business replacement. Please note that the `sipe` library has different names in different distros. For example, the library's name on System76's Pop_OS! is `pidgin-sipe` while in the Solus 3 repo it is simply `sipe`.
-
-With the prerequisites out of the way, you can begin configuring Pidgin.
-
-### Configuring Pidgin
-
-When firing up Pidgin for the first time, click on **Add** to add a new account. In the Basic tab (shown in the screenshot below), select** Office Communicator** in the **Protocol** drop-down, then type your **business email address** in the **Username** field.
-
-
-
-Next, click on the Advanced tab. In the **Server[:Port]** field enter **sipdir.online.lync.com:443** and in **User Agent** enter **UCCAPI/16.0.6965.5308 OC/16.0.6965.2117**.
-
-Your Advanced tab should now look like this:
-
-
-
-You shouldn't need to make any changes to the Proxy tab or the Voice and Video tab. Just to be certain, make sure **Proxy type** is set to **Use Global Proxy Settings** and in the Voice and Video tab, the **Use silence suppression** checkbox is **unchecked**.
-
-
-
-
-
-After you've completed those configurations, click **Add,** and you'll be prompted for your email account's password.
-
-### Adding contacts
-
-To add contacts to your buddy list, click on **Manage Accounts** in the **Buddy Window**. Hover over your account and select **Contact Search** to look up your colleagues. If you run into any problems when searching by first and last name, try searching with your colleague's full email address, and you should always get the right person.
-
-You are now up and running with a Skype for Business replacement that gives you about 98% of the functionality you need to banish the proprietary option from your desktop.
-
-Ray Shimko will be speaking about [Linux in a Microsoft World][4] at [LinuxFest NW][5] April 28-29. See program highlights or register to attend.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/pidgin-open-source-replacement-skype-business
-
-作者:[Ray Shimko][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/shickmo
-[1]:https://tel.red/linux.php
-[2]:https://pidgin.im/
-[3]:http://sipe.sourceforge.net/
-[4]:https://www.linuxfestnorthwest.org/conferences/lfnw18/program/proposals/32
-[5]:https://www.linuxfestnorthwest.org/conferences/lfnw18
diff --git a/sources/talk/20180518 Mastering CI-CD at OpenDev.md b/sources/talk/20180518 Mastering CI-CD at OpenDev.md
new file mode 100644
index 0000000000..cb8b9fdfc8
--- /dev/null
+++ b/sources/talk/20180518 Mastering CI-CD at OpenDev.md
@@ -0,0 +1,53 @@
+Mastering CI/CD at OpenDev
+======
+
+
+After launching in 2017, the [OpenDev Conference][1] is now an annual event. At the inaugural event last September, the conference focus was on edge computing. This year's event, taking place May 22-23, will be focused on Continuous Integration/Continuous Deployment (CI/CD) and will be co-located with the OpenStack Summit in Vancouver.
+
+
+
+I was invited to participate in the program committee for OpenDev CI/CD based on my background on the CI/CD system for the OpenStack project and my recent move into the container space. Today I frequently talk about CI/CD pipelines using various open source technologies, including [Jenkins][3] [GitLab][2],[Spinnaker][4] , and [Artifactory][5]
+
+This event is exciting for me because we're bringing two open source infrastructure ideas together into one event. First, we'll be discussing CI/CD tooling that can be used by any organization. To this end, in the [keynotes][6] we'll hear practical talks about open source CI/CD tooling, including a talk about Spinnaker from Boris Renski and one from Jim Blair on [Zuul][7]. The keynotes also will include higher-level talks about the preference for open technologies, especially across communities and inside open source projects themselves. From Fatih Degirmenci and Daniel Farrell we'll hear about sharing continuous delivery practices across communities, and Benjamin Mako Hill will join us to talk about why free software needs free tools.
+
+Given the relative newness of CI/CD, the rest of the event is a mix of talks, workshops, and collaborative discussions. When selecting from talks and workshops submitted, and coming up with collaborative discussion topics, we wanted to make sure there was a diverse schedule so anyone on the open CI/CD spectrum would find something interesting.
+
+The talks will be standard conference style, selected to cover key topics like crafting CI/CD pipelines, improving security when practicing DevOps, and more specific solutions like container-based [Aptomi][8] on Kubernetes and doing CI/CD in ETSI NFV environments. Many of these sessions will serve as an introduction to these topics, ideal for those who are new to the CI/CD space or any of these specific technologies.
+
+The hands-on workshops are longer and will have specific outcomes in mind for attendees. These include "[Anomaly Detection in Continuous Integration Jobs][9]," "[How to Install Zuul and Configure Your First Jobs][10]," and "[Spinnaker 101: Releasing Software with Velocity and Confidence][11]." (Note that space is limited in these workshops, so an RSVP system has been set up. You'll find an RSVP button on the session links provided here.)
+
+Perhaps what I'm most excited about are the collaborative discussions, and these take up over half of the conference schedule. The topics were chosen by the program committee based on what we've been seeing in our communities. These are "fishbowl"-style sessions, where several people get in a room together to discuss a specific topic around CI/CD.
+
+The idea for this style of session was taken from developer summits that the Ubuntu community pioneered and the OpenStack community continued. Topics for these collaborative discussions include separate sessions for CI and CD fundamentals, improvements that can be made to encourage cross-community collaboration, driving CI/CD culture in organizations, and why open source CI/CD tooling is so important. Shared documents are used to take notes during these sessions to make sure that as much knowledge shared during the session is retained as possible. It's also common for action items to come from these discussions, so community members can push forward initiatives related to the topic being covered.
+
+The event concludes with a [Joint Conclusion Session][12], which will be summarizing the key points from the collaborative discussions and identifying work areas that attendees wish to work on in future.
+
+Registration for this event is included in [OpenStack Summit registration][13], or tickets for this event only can be purchased for $199 onsite at the Vancouver Convention Center. Learn more about tickets and the full agenda on the [OpenDev website][1].
+
+I hope you'll join us in Vancouver for an exciting two days of learning, collaborating and making progress together on CI/CD.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/opendev
+
+作者:[Elizabeth K.Joseph][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/pleia2
+[1]:http://2018.opendevconf.com/
+[2]:https://about.gitlab.com/
+[3]:https://jenkins.io/
+[4]:https://www.spinnaker.io/
+[5]:https://jfrog.com/artifactory/
+[6]:http://2018.opendevconf.com/schedule/
+[7]:https://zuul-ci.org/
+[8]:http://aptomi.io/
+[9]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21692/anomaly-detection-in-continuous-integration-jobs
+[10]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21693/how-to-install-zuul-and-configure-your-first-jobs
+[11]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21699/spinnaker-101-releasing-software-with-velocity-and-confidence
+[12]:https://www.openstack.org/summit/vancouver-2018/summit-schedule/events/21831/opendev-cicd-joint-collab-conclusion
+[13]:https://www.eventbrite.com/e/openstack-summit-may-2018-vancouver-tickets-40845826968?aff=VancouverSummit2018
diff --git a/sources/talk/20180528 What is a Linux server and why does your business need one.md b/sources/talk/20180528 What is a Linux server and why does your business need one.md
new file mode 100644
index 0000000000..424d2ae13a
--- /dev/null
+++ b/sources/talk/20180528 What is a Linux server and why does your business need one.md
@@ -0,0 +1,63 @@
+What is a Linux server and why does your business need one?
+======
+
+
+IT organizations strive to deliver business value by increasing productivity and delivering services faster while remaining flexible enough to incorporate innovations like cloud, containers, and configuration automation. Modern workloads, whether they run on bare metal, virtual machines, containers, or private or public clouds, are expected to be portable and scalable. Supporting all this requires a modern, secure platform.
+
+The most direct route to innovation is not always a straight line. With the growing adoption of private and public clouds, multiple architectures, and virtualization, today’s data center is like a globe, with varying infrastructure choices bringing it dimension and depth. And just as a pilot depends on air traffic controllers to provide continuous updates, your digital transformation journey should be guided by a trusted operating system like Linux to provide continuously updated technology and the most efficient and secure access to innovations like cloud, containers, and configuration automation.
+
+Linux is a family of free, open source software operating systems built around the Linux kernel. Originally developed for personal computers based on the Intel x86 architecture, Linux has since been ported to more platforms than any other operating system. Thanks to the dominance of the Linux kernel-based Android OS on smartphones, Linux has the largest installed base of all general-purpose operating systems. Linux is also the leading operating system on servers and "big iron" systems such as mainframe computers, and it is the only OS used on [TOP500][1] supercomputers.
+
+
+To tap this functionality, many enterprise companies have adopted servers with a high-powered variant of the Linux open source operating system. These are designed to handle the most demanding business application requirements, such as network and system administration, database management, and web services. Linux servers are often chosen over other server operating systems for their stability, security, and flexibility. Leading Linux server operating systems include [Debian][2], [Ubuntu Server][3], [CentOS][4] [Slackware][5] , and [Gentoo][6]
+
+
+What features and benefits on an enterprise-grade Linux server should you consider for an enterprise workload? First, built-in security controls and scale-out manageability through interfaces that are familiar to both Linux and Windows administrators will enable you to focus on business growth instead of reacting to security vulnerabilities and costly management configuration mistakes. The Linux server you choose should provide security technologies and certifications and maintain enhancements to combat intrusions, protect your data, and meet regulatory compliance for an open source project or a specific OS vendor. It should:
+
+ * **Deliver resources with security** using integrated control features such as centralized identity management and [Security-Enhanced Linux][7] (SELinux), mandatory access controls (MAC) on a foundation that is [Common Criteria-][8] and [FIPS 140-2-certified][9], as well as the first Linux container framework support to be Common Criteria-certified.
+ * **Automate regulatory compliance and security configuration remediation** across your system and within containers with image scanning like [OpenSCAP][10] that checks, remediates against vulnerabilities and configuration security baselines, including against [National Checklist Program][11] content for [PCI-DSS][12], [DISA STIG][13], and more. Additionally, it should centralize and scale out configuration remediation across your entire hybrid environment.
+ * **Receive continuous vulnerability security updates** from the upstream community itself or a specific OS vendor, which remedies and delivers all critical issues by next business day, if possible, to minimize business impact.
+
+
+
+As the foundation of your hybrid data center, the Linux server should provide platform manageability and flexible integration with legacy management and automation infrastructure. This will save IT staff time and reduce unplanned downtime compared to a non-paid Linux infrastructure. It should:
+
+ * **Speed image building, deployment, and patch management** across the data center with built-in capabilities and enrich system life-cycle management, provisioning, and enhanced patching, and more.
+ * **Manage individual systems from an easy-to-use web interface** that includes storage, networking, containers, services, and more.
+ * **Automate consistency and compliance** across heterogeneous multiple environments and reduce scripting rework with system roles using native configuration management tools like [Ansible][14], [Chef][15], [Salt][16], [Puppet][17], and more.
+ * **Simplify platform updates** with in-place upgrades that eliminate the hassle of machine migrations and application rebuilds.
+ * **Resolve technical issues** before they impact business operations by using predictive analytics tools to automate identification and remediation of anomalies and their root causes.
+
+
+
+Linux servers are powering innovation around the globe. As the platform for enterprise workloads, a Linux server should provide a stable, secure, and performance-driven foundation for the applications that run the business of today and tomorrow.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/what-linux-server
+
+作者:[Daniel Oh][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/daniel-oh
+[1]:https://en.wikipedia.org/wiki/TOP500
+[2]:https://www.debian.org/
+[3]:https://www.ubuntu.com/download/server
+[4]:https://www.centos.org/
+[5]:http://www.slackware.com/
+[6]:https://www.gentoo.org/
+[7]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
+[8]:https://en.wikipedia.org/wiki/Common_Criteria
+[9]:https://en.wikipedia.org/wiki/FIPS_140-2
+[10]:https://www.open-scap.org/
+[11]:https://www.nist.gov/programs-projects/national-checklist-program
+[12]:https://www.pcisecuritystandards.org/pci_security/
+[13]:https://iase.disa.mil/stigs/Pages/index.aspx
+[14]:https://www.ansible.com/
+[15]:https://www.chef.io/chef/
+[16]:https://saltstack.com/salt-open-source/
+[17]:https://puppet.com/
diff --git a/sources/tech/20171101 -dev-urandom- entropy explained.md b/sources/tech/20171101 -dev-urandom- entropy explained.md
deleted file mode 100644
index e510eab29e..0000000000
--- a/sources/tech/20171101 -dev-urandom- entropy explained.md
+++ /dev/null
@@ -1,110 +0,0 @@
-translating---geekpi
-
-/dev/[u]random: entropy explained
-======
-### Entropy
-
-When the topic of /dev/random and /dev/urandom come up, you always hear this word: “Entropy”. Everyone seems to have their own analogy for it. So why not me? I like to think of Entropy as “Random juice”. It is juice, required for random to be more random.
-
-If you have ever generated an SSL certificate, or a GPG key, you may have seen something like:
-```
-We need to generate a lot of random bytes. It is a good idea to perform
-some other action (type on the keyboard, move the mouse, utilize the
-disks) during the prime generation; this gives the random number
-generator a better chance to gain enough entropy.
-++++++++++..+++++.+++++++++++++++.++++++++++...+++++++++++++++...++++++
-+++++++++++++++++++++++++++++.+++++..+++++.+++++.+++++++++++++++++++++++++>.
-++++++++++>+++++...........................................................+++++
-Not enough random bytes available. Please do some other work to give
-the OS a chance to collect more entropy! (Need 290 more bytes)
-
-```
-
-
-By typing on the keyboard, and moving the mouse, you help generate Entropy, or Random Juice.
-
-You might be asking yourself… Why do I need Entropy? and why it is so important for random to be actually random? Well, lets say our Entropy was limited to keyboard, mouse, and disk IO. But our system is a server, so I know there is no mouse and keyboard input. This means the only factor is your IO. If it is a single disk, that was barely used, you will have low Entropy. This means your systems ability to be random is weak. In other words, I could play the probability game, and significantly decrease the amount of time it would take to crack things like your ssh keys, or decrypt what you thought was an encrypted session.
-
-Okay, but that is pretty unrealistic right? No, actually it isn’t. Take a look at this [Debian OpenSSH Vulnerability][1]. This particular issue was caused by someone removing some of the code responsible for adding Entropy. Rumor has it they removed it because it was causing valgrind to throw warnings. However, in doing that, random is now MUCH less random. In fact, so much less that Brute forcing the private ssh keys generated is now a fesible attack vector.
-
-Hopefully by now we understand how important Entropy is to security. Whether you realize you are using it or not.
-
-### /dev/random & /dev/urandom
-
-
-/dev/urandom is a Psuedo Random Number Generator, and it **does not** block if you run out of Entropy.
-/dev/random is a True Random Number Generator, and it **does** block if you run out of Entropy.
-
-Most often, if we are dealing with something pragmatic, and it doesn’t contain the keys to your nukes, /dev/urandom is the right choice. Otherwise if you go with /dev/random, then when the system runs out of Entropy your application is just going to behave funny. Whether it outright fails, or just hangs until it has enough depends on how you wrote your application.
-
-### Checking the Entropy
-
-So, how much Entropy do you have?
-```
-[root@testbox test]# cat /proc/sys/kernel/random/poolsize
-4096
-[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
-2975
-[root@testbox test]#
-
-```
-
-/proc/sys/kernel/random/poolsize, to state the obvious is the size(in bits) of the Entropy Pool. eg: How much random-juice we should save before we stop pumping more. /proc/sys/kernel/random/entropy_avail, is the amount(in bits) of random-juice in the pool currently.
-
-### How can we influence this number?
-
-The number is drained as we use it. The most crude example I can come up with is catting /dev/random into /dev/null:
-```
-[root@testbox test]# cat /dev/random > /dev/null &
-[1] 19058
-[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
-0
-[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
-1
-[root@testbox test]#
-
-```
-
-The easiest way to influence this is to run [Haveged][2]. Haveged is a daemon that uses the processor “flutter” to add Entropy to the systems Entropy Pool. Installation and basic setup is pretty straight forward
-```
-[root@b08s02ur ~]# systemctl enable haveged
-Created symlink from /etc/systemd/system/multi-user.target.wants/haveged.service to /usr/lib/systemd/system/haveged.service.
-[root@b08s02ur ~]# systemctl start haveged
-[root@b08s02ur ~]#
-
-```
-
-On a machine with relatively moderate traffic:
-```
-[root@testbox ~]# pv /dev/random > /dev/null
- 40 B 0:00:15 [ 0 B/s] [ <=> ]
- 52 B 0:00:23 [ 0 B/s] [ <=> ]
- 58 B 0:00:25 [5.92 B/s] [ <=> ]
- 64 B 0:00:30 [6.03 B/s] [ <=> ]
-^C
-[root@testbox ~]# systemctl start haveged
-[root@testbox ~]# pv /dev/random > /dev/null
-7.12MiB 0:00:05 [1.43MiB/s] [ <=> ]
-15.7MiB 0:00:11 [1.44MiB/s] [ <=> ]
-27.2MiB 0:00:19 [1.46MiB/s] [ <=> ]
- 43MiB 0:00:30 [1.47MiB/s] [ <=> ]
-^C
-[root@testbox ~]#
-
-```
-
-Using pv we are able to see how much data we are passing via pipe. As you can see, before haveged, we were getting 2.1 bits per second(B/s). Whereas after starting haveged, and adding processor flutter to our Entropy pool we get ~1.5MiB/sec.
-
---------------------------------------------------------------------------------
-
-via: http://jhurani.com/linux/2017/11/01/entropy-explained.html
-
-作者:[James J][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://jblevins.org/log/ssh-vulnkey
-[1]:http://jhurani.com/linux/2017/11/01/%22https://jblevins.org/log/ssh-vulnkey%22
-[2]:http://www.issihosts.com/haveged/
diff --git a/sources/tech/20180301 Best Websites For Programmers.md b/sources/tech/20180301 Best Websites For Programmers.md
index 5d26bd8865..a8da658f33 100644
--- a/sources/tech/20180301 Best Websites For Programmers.md
+++ b/sources/tech/20180301 Best Websites For Programmers.md
@@ -1,3 +1,5 @@
+translating----geekpi
+
Best Websites For Programmers
======
![][1]
diff --git a/sources/tech/20180305 Getting started with Python for data science.md b/sources/tech/20180305 Getting started with Python for data science.md
index 920befc58b..cc44fb71e6 100644
--- a/sources/tech/20180305 Getting started with Python for data science.md
+++ b/sources/tech/20180305 Getting started with Python for data science.md
@@ -1,3 +1,4 @@
+Translating by zhouzhuowei
Getting started with Python for data science
======
diff --git a/sources/tech/20190404 Bring some JavaScript to your Java enterprise with Vert.x.md b/sources/tech/20180404 Bring some JavaScript to your Java enterprise with Vert.x.md
similarity index 100%
rename from sources/tech/20190404 Bring some JavaScript to your Java enterprise with Vert.x.md
rename to sources/tech/20180404 Bring some JavaScript to your Java enterprise with Vert.x.md
diff --git a/sources/tech/20180425 Configuring local storage in Linux with Stratis.md b/sources/tech/20180425 Configuring local storage in Linux with Stratis.md
index f76b7f6fca..47746edd77 100644
--- a/sources/tech/20180425 Configuring local storage in Linux with Stratis.md
+++ b/sources/tech/20180425 Configuring local storage in Linux with Stratis.md
@@ -1,3 +1,5 @@
+pinewall translating
+
Configuring local storage in Linux with Stratis
======
diff --git a/sources/tech/20180426 What Stratis learned from ZFS, Btrfs, and Linux Volume Manager - Opensource.com.md b/sources/tech/20180426 What Stratis learned from ZFS, Btrfs, and Linux Volume Manager - Opensource.com.md
index bf658cab42..069c9d9369 100644
--- a/sources/tech/20180426 What Stratis learned from ZFS, Btrfs, and Linux Volume Manager - Opensource.com.md
+++ b/sources/tech/20180426 What Stratis learned from ZFS, Btrfs, and Linux Volume Manager - Opensource.com.md
@@ -1,3 +1,5 @@
+pinewall translating
+
What Stratis learned from ZFS, Btrfs, and Linux Volume Manager | Opensource.com
======

diff --git a/sources/tech/20180523 A Set Of Useful Utilities For Debian And Ubuntu Users.md b/sources/tech/20180523 A Set Of Useful Utilities For Debian And Ubuntu Users.md
new file mode 100644
index 0000000000..e14f5ac850
--- /dev/null
+++ b/sources/tech/20180523 A Set Of Useful Utilities For Debian And Ubuntu Users.md
@@ -0,0 +1,287 @@
+A Set Of Useful Utilities For Debian And Ubuntu Users
+======
+
+
+
+Are you using a Debian-based system? Great! I am here today with a good news for you. Say hello to **“Debian-goodies”** , a collection of useful utilities for Debian-based systems, like Ubuntu, Linux Mint. These set of utilities provides some additional useful commands which are not available by default in the Debian-based systems. Using these tools, the users can find which programs are consuming more disk space, which services need to be restarted after updating the system, search for a file matching a pattern in a package, list the installed packages based on the search string and a lot more. In this brief guide, we will be discussing some useful Debian goodies.
+
+### Debian-goodies – Useful Utilities For Debian And Ubuntu Users
+
+The debian-goodies package is available in the official repositories of Debian and its derivative Ubuntu and other Ubuntu variants such as Linux Mint. To install debian-goodies package, simply run:
+```
+$ sudo apt-get install debian-goodies
+
+```
+
+Debian-goodies has just been installed. Let us go ahead and see some useful utilities.
+
+#### **1. Checkrestart**
+
+Let me start from one of my favorite, the **“checkrestart”** utility. When installing security updates, some running applications might still use the old libraries. In order to apply the security updates completely, you need to find and restart all of them. This is where Checkrestart comes in handy. This utility will find which processes are still using the old versions of libs. You can then restart the services.
+
+To check which daemons need to be restarted after library upgrades, run:
+```
+$ sudo checkrestart
+[sudo] password for sk:
+Found 0 processes using old versions of upgraded files
+
+```
+
+Since I didn’t perform any security updates lately, it shows nothing.
+
+Please note that Checkrestart utility does work well. However, there is a new similar tool named “needrestart” available latest Debian systems. The needrestart is inspired by the checkrestart utility and it does exactly the same job. Needrestart is actively maintained and supports newer technologies such as containers (LXC, Docker).
+
+Here are the features of Needrestart:
+
+ * supports (but does not require) systemd
+ * binary blacklisting (i.e. display managers)
+ * tries to detect pending kernel upgrades
+ * tries to detect required restarts of interpreter based daemons (supports Perl, Python, Ruby)
+ * fully integrated into apt/dpkg using hooks
+
+
+
+It is available in the default repositories too. so, you can install it using command:
+```
+$ sudo apt-get install needrestart
+
+```
+
+Now you can check the list of daemons need to be restarted after updating your system using command:
+```
+$ sudo needrestart
+Scanning processes...
+Scanning linux images...
+
+Running kernel seems to be up-to-date.
+
+Failed to check for processor microcode upgrades.
+
+No services need to be restarted.
+
+No containers need to be restarted.
+
+No user sessions are running outdated binaries.
+
+```
+
+The good thing is Needrestart works on other Linux distributions too. For example, you can install on Arch Linux and its variants from AUR using any AUR helper programs like below.
+```
+$ yaourt -S needrestart
+
+```
+
+On fedora:
+```
+$ sudo dnf install needrestart
+
+```
+
+#### 2. Check-enhancements
+
+The check-enhancements utility is used to find packages which enhance the installed packages. This utility will list all packages that enhances other packages but are not strictly necessary to run it. You can find enhancements for a single package or all installed installed packages using “-ip” or “–installed-packages” flag.
+
+For example, I am going to list the enhancements for gimp package.
+```
+$ check-enhancements gimp
+gimp => gimp-data: Installed: (none) Candidate: 2.8.22-1
+gimp => gimp-gmic: Installed: (none) Candidate: 1.7.9+zart-4build3
+gimp => gimp-gutenprint: Installed: (none) Candidate: 5.2.13-2
+gimp => gimp-help-ca: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-de: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-el: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-en: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-es: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-fr: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-it: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-ja: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-ko: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-nl: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-nn: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-pt: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-ru: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-sl: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-sv: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-plugin-registry: Installed: (none) Candidate: 7.20140602ubuntu3
+gimp => xcftools: Installed: (none) Candidate: 1.0.7-6
+
+```
+
+To list the enhancements for all installed packages, run:
+```
+$ check-enhancements -ip
+autoconf => autoconf-archive: Installed: (none) Candidate: 20170928-2
+btrfs-progs => snapper: Installed: (none) Candidate: 0.5.4-3
+ca-certificates => ca-cacert: Installed: (none) Candidate: 2011.0523-2
+cryptsetup => mandos-client: Installed: (none) Candidate: 1.7.19-1
+dpkg => debsig-verify: Installed: (none) Candidate: 0.18
+[...]
+
+```
+
+#### 3. dgrep
+
+As the name implies, dgrep is used to search all files in specified packages based on the given regex. For instance, I am going to search for files that contains the regex “text” in Vim package.
+```
+$ sudo dgrep "text" vim
+Binary file /usr/bin/vim.tiny matches
+/usr/share/doc/vim-tiny/copyright: that they must include this license text. You can also distribute
+/usr/share/doc/vim-tiny/copyright: include this license text. You are also allowed to include executables
+/usr/share/doc/vim-tiny/copyright: 1) This license text must be included unmodified.
+/usr/share/doc/vim-tiny/copyright: text under a) applies to those changes.
+/usr/share/doc/vim-tiny/copyright: context diff. You can choose what license to use for new code you
+/usr/share/doc/vim-tiny/copyright: context diff will do. The e-mail address to be used is
+/usr/share/doc/vim-tiny/copyright: On Debian systems, the complete text of the GPL version 2 license can be
+[...]
+
+```
+
+The dgrep supports most of grep’s options. Refer the following guide to learn grep commands.
+
+#### 4 dglob
+
+The dglob utility generates a list of package names which match a pattern. For example, find the list of packages that matches the string “vim”.
+```
+$ sudo dglob vim
+vim-tiny:amd64
+vim:amd64
+vim-common:all
+vim-runtime:all
+
+```
+
+By default, dglob will display only the installed packages. If you want to list all packages (installed and not installed), use **-a** flag.
+```
+$ sudo dglob vim -a
+
+```
+
+#### 5. debget
+
+The **debget** utility will download a .deb for a package in APT’s database. Please note that it will only download the given package, not the dependencies.
+```
+$ debget nano
+Get:1 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 nano amd64 2.9.3-2 [231 kB]
+Fetched 231 kB in 2s (113 kB/s)
+
+```
+
+#### 6. dpigs
+
+This is another useful utility in this collection. The **dpigs** utility will find and show you which installed packages occupy the most disk space.
+```
+$ dpigs
+260644 linux-firmware
+167195 linux-modules-extra-4.15.0-20-generic
+75186 linux-headers-4.15.0-20
+64217 linux-modules-4.15.0-20-generic
+55620 snapd
+31376 git
+31070 libicu60
+28420 vim-runtime
+25971 gcc-7
+24349 g++-7
+
+```
+
+As you can see, the linux-firmware packages occupies the most disk space. By default, it will display the **top 10** packages that occupies the most disk space. If you want to display more packages, for example 20, run the following command:
+```
+$ dpigs -n 20
+
+```
+
+#### 7. debman
+
+The **debman** utility allows you to easily view man pages from a binary **.deb** without extracting it. You don’t even need to install the .deb package. The following command displays the man page of nano package.
+```
+$ debman -f nano_2.9.3-2_amd64.deb nano
+
+```
+
+If you don’t have a local copy of the .deb package, use **-p** flag to download and view package’s man page.
+```
+$ debman -p nano nano
+
+```
+
+**Suggested read:**
+
+#### 8. debmany
+
+An installed Debian package has not only a man page, but also includes other files such as acknowledgement, copy right, and read me etc. The **debmany** utility allows you to view and read those files.
+```
+$ debmany vim
+
+```
+
+![][1]
+
+Choose the file you want to view using arrow keys and hit ENTER to view the selected file. Press **q** to go back to the main menu.
+
+If the specified package is not installed, debmany will download it from the APT database and display the man pages. The **dialog** package should be installed to read the man pages.
+
+#### 9. popbugs
+
+If you’re a developer, the **popbugs** utility will be quite useful. It will display a customized release-critical bug list based on packages you use (using popularity-contest data). For those who don’t know, the popularity-contest package sets up a cron job that will periodically anonymously submit to the Debian developers statistics about the most used Debian packages on this system. This information helps Debian make decisions such as which packages should go on the first CD. It also lets Debian improve future versions of the distribution so that the most popular packages are the ones which are installed automatically for new users.
+
+To generate a list of critical bugs and display the result in your default web browser, run:
+```
+$ popbugs
+
+```
+
+Also, you can save the result in a file as shown below.
+```
+$ popbugs --output=bugs.txt
+
+```
+
+#### 10. which-pkg-broke
+
+This command will display all the dependencies of the given package and when each dependency was installed. By using this information, you can easily find which package might have broken another at what time after upgrading the system or a package.
+```
+$ which-pkg-broke vim
+Package has no install time info
+debconf Wed Apr 25 08:08:40 2018
+gcc-8-base:amd64 Wed Apr 25 08:08:41 2018
+libacl1:amd64 Wed Apr 25 08:08:41 2018
+libattr1:amd64 Wed Apr 25 08:08:41 2018
+dpkg Wed Apr 25 08:08:41 2018
+libbz2-1.0:amd64 Wed Apr 25 08:08:41 2018
+libc6:amd64 Wed Apr 25 08:08:42 2018
+libgcc1:amd64 Wed Apr 25 08:08:42 2018
+liblzma5:amd64 Wed Apr 25 08:08:42 2018
+libdb5.3:amd64 Wed Apr 25 08:08:42 2018
+[...]
+
+```
+
+#### 11. dhomepage
+
+The dhomepage utility will display the official website of the given package in your default web browser. For example, the following command will open Vim editor’s home page.
+```
+$ dhomepage vim
+
+```
+
+And, that’s all for now. Debian-goodies is a must-have tool in your arsenal. Even though, we don’t use all those utilities often, they are worth to learn and I am sure they will be really helpful at times.
+
+I hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/debian-goodies-a-set-of-useful-utilities-for-debian-and-ubuntu-users/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:http://www.ostechnix.com/wp-content/uploads/2018/05/debmany.png
diff --git a/sources/tech/20180523 How to dual-boot Linux and Windows.md b/sources/tech/20180523 How to dual-boot Linux and Windows.md
new file mode 100644
index 0000000000..5d80e7925d
--- /dev/null
+++ b/sources/tech/20180523 How to dual-boot Linux and Windows.md
@@ -0,0 +1,223 @@
+How to dual-boot Linux and Windows
+======
+
+
+
+Even though Linux is a great operating system with widespread hardware and software support, the reality is that sometimes you have to use Windows, perhaps due to key apps that won't run under Linux. Thankfully, dual-booting Windows and Linux is very straightforward—and I'll show you how to set it up, with Windows 10 and Ubuntu 18.04, in this article.
+
+Before you get started, make sure you've backed up your computer. Although the dual-boot setup process is not very involved, accidents can still happen. So take the time to back up your important files in case chaos theory comes into play. In addition to backing up your files, consider taking an image backup of the disk as well, though that's not required and can be a more advanced process.
+
+### Prerequisites
+
+To get started, you will need the following five items:
+
+#### 1\. Two USB flash drives (or DVD-Rs)
+
+I recommend installing Windows and Ubuntu via flash drives since they're faster than DVDs. It probably goes without saying, but creating bootable media erases everything on the flash drive. Therefore, make sure the flash drives are empty or contain data you don't care about losing.
+
+If your machine doesn't support booting from USB, you can create DVD media instead. Unfortunately, because no two computers seem to have the same DVD-burning software, I can't walk you through that process. However, if your DVD-burning application has an option to burn from an ISO image, that's the option you need.
+
+#### 2\. A Windows 10 license
+
+If Windows 10 came with your PC, the license will be built into the computer, so you don't need to worry about entering it during installation. If you bought the retail edition, you should have a product key, which you will need to enter during the installation process.
+
+#### 3\. Windows 10 Media Creation Tool
+
+Download and launch the Windows 10 [Media Creation Tool][1]. Once you launch the tool, it will walk you through the steps required to create the Windows media on a USB or DVD-R. Note: Even if you already have Windows 10 installed, it's a good idea to create bootable media anyway, just in case something goes wrong and you need to reinstall it.
+
+#### 4\. Ubuntu 18.04 installation media
+
+Download the [Ubuntu 18.04][2] ISO image.
+
+#### 5\. Etcher software (for making a bootable Ubuntu USB drive)
+
+For creating bootable media for any Linux distribution, I recommend [Etcher][3]. Etcher works on all three major operating systems (Linux, MacOS, and Windows) and is careful not to let you overwrite your current operating system partition.
+
+Once you have downloaded and launched Etcher, click Select image, and point it to the Ubuntu ISO you downloaded in step 4. Next, click Select drive to choose your flash drive, and click Flash! to start the process of turning a flash drive into an Ubuntu installer. (If you're using a DVD-R, use your computer's DVD-burning software instead.)
+
+### Install Windows and Ubuntu
+
+You should be ready to begin. At this point, you should have accomplished the following:
+
+ * Backed up your important files
+ * Created Windows installation media
+ * Created Ubuntu installation media
+
+
+
+There are two ways of going about the installation. First, if you already have Windows 10 installed, you can have the Ubuntu installer resize the partition, and the installation will proceed in the empty space. Or, if you haven't installed Windows 10, install it on a smaller partition you can set up during the installation process. (I'll describe how to do that below.) The second way is preferred and less error-prone. There's a good chance you won't have any issues either way, but installing Windows manually and giving it a smaller partition, then installing Ubuntu, is the easiest way to go.
+
+If you already have Windows 10 on your computer, skip the following Windows installation instructions and proceed to Installing Ubuntu.
+
+#### Installing Windows
+
+Insert the Windows installation media you created into your computer and boot from it. How you do this depends on your computer, but most have a key you can press to initiate the boot menu. On a Dell PC for example, that key is F12. If the flash drive doesn't show up as an option, you may need to restart the computer. Sometimes it will show up only if you've inserted the media before turning on the computer. If you see a message like, "press any key to boot from the installation media," press a key. You should see the following screen. Select your language and keyboard style and click Next.
+
+![Windows setup][5]
+
+Click on Install now to start the Windows installer.
+
+On the next screen, it will ask for your product key. If you don't have one because Windows 10 came with your PC, select "I don't have a product key." It should automatically activate after the installation once it catches up with updates. If you do have a product key, type that in and click Next.
+
+
+![Enter product key][7]
+
+
+Select which version of Windows you want to install. If you have a retail copy, the label will tell you what version you have. Otherwise, it is typically located with the documentation that came with your computer. In most cases, it's going to be either Windows 10 Home or Windows 10 Pro. Most PCs that come with the Home edition have a label that simply reads "Windows 10," while Pro is clearly marked.
+
+
+![Select Windows version][10]
+
+
+Accept the license agreement by checking the box, then click Next.
+
+
+![Accept license terms][12]
+
+
+After accepting the agreement, you have two installation options available. Choose the second option, Custom: Install Windows only (advanced).
+
+
+![Select type of Windows installation][14]
+
+
+The next screen should show your current hard disk configuration.
+
+
+![Hard drive configuration][16]
+
+
+Your results will probably look different than mine. I have never used this hard disk before, so it's completely unallocated. You will probably see one or more partitions for your current operating system. Highlight each partition and remove it.
+
+At this point, your screen will show your entire disk as unallocated. To continue, create a new partition.
+
+
+![Create a new partition][18]
+
+
+Here you can see that I divided the drive in half (or close enough) by creating a partition of 81,920MB (which is close to half of 160GB). Give Windows at least 40GB, preferably 64GB or more. Leave the rest of the drive unallocated, as that's where you'll install Ubuntu later.
+
+Your results will look similar to this:
+
+
+![Leaving a partition with unallocated space][20]
+
+
+Confirm the partitioning looks good to you and click Next. Windows will begin installing.
+
+
+![Installing Windows][22]
+
+
+If your computer successfully boots into Windows, you're all set to move on to the next step.
+
+![Windows desktop][24]
+
+
+#### Installing Ubuntu
+
+Whether it was already there or you worked through the steps above, at this point you should have Windows installed. Now use the Ubuntu installation media you created earlier to boot into Ubuntu. Go ahead and insert the media and boot your computer from it. Again, the exact sequence of keys to access the boot menu varies from one computer to another, so check your documentation if you're not sure. If all goes well, you see the following screen once the media finishes loading:
+
+
+![Ubuntu installation welcome screen][26]
+
+
+Here, you can select between Try Ubuntu or Install Ubuntu. Don't install just yet; instead, click Try Ubuntu. After it finishes loading, you should see the Ubuntu desktop.
+
+
+![Ubuntu desktop][28]
+
+By clicking Try Ubuntu, you have opted to try out Ubuntu before you install it. Here, in Live mode, you can play around with Ubuntu and make sure everything works before you commit to the installation. Ubuntu works with most PC hardware, but it's always better to test it out beforehand. Make sure you can access the internet and get audio and video playback. Going to YouTube and playing a video is a good way of doing all of that at once. If you need to connect to a wireless network, click on the networking icon at the top-right of the screen. There, you can find a list of wireless networks and connect to yours.
+
+Once you're ready to go, double-click on the Install Ubuntu 18.04 LTS icon on the desktop to launch the installer.
+
+Choose the language you want to use for the installation process, then click Continue.
+
+
+![Select language in Ubuntu][30]
+
+
+Next, choose the keyboard layout. Once you've made your selection, click Continue.
+
+
+![Select keyboard in Ubuntu][32]
+
+You have a few options on the screen below. One, you can choose a Normal or a Minimal installation. For most people, the Normal installation is ideal. Advanced users may want to do a Minimal install instead, which has fewer software applications installed by default. In addition, you can choose to download updates and whether or not to include third-party software and drivers. I recommend checking both of those boxes. When done, click Continue.
+
+
+![Choose Ubuntu installation options][34]
+
+The next screen asks whether you want to erase the disk or set up a dual-boot. Since you're dual-booting, choose Install Ubuntu alongside Windows 10. Click Install Now.
+
+
+![install Ubuntu alongside Windows][36]
+
+
+The following screen may appear. If you installed Windows from scratch and left unallocated space on the disk, Ubuntu will automatically set itself up in the empty space, so you won't see this screen. If you already had Windows 10 installed and it's taking up the entire drive, this screen will appear and give you an option to select a disk at the top. If you have just one disk, you can choose how much space to steal from Windows and apply to Ubuntu. You can drag the vertical line in the middle left and right with your mouse to take space away from one and gives it to the other. Adjust this exactly the way you want it, then click Install Now.
+
+
+![Allocate drive space][38]
+
+
+You should see a confirmation screen indicating what Ubuntu plans on doing. If everything looks right, click Continue.
+
+Ubuntu is now installing in the background. You still have some configuration to do, though. While Ubuntu tries its best to figure out your location, you can click on the map to narrow it down to ensure your time zone and other things are set correctly.
+
+Next, fill in the user account information: your name, computer name, username, and password. Click Continue when you're done.
+
+There you have it! The installation is complete. Go ahead and reboot the PC.
+
+If all went according to plan, you should see a screen similar to this when your computer restarts. Choose Ubuntu or Windows 10; the other options are for troubleshooting, so I won't go into them.
+
+Try booting into both Ubuntu and Windows to test them out and make sure everything works as expected. If it does, you now have both Windows and Ubuntu installed on your computer.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/dual-boot-linux
+
+作者:[Jay LaCroix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jlacroix
+[1]:https://www.microsoft.com/en-us/software-download/windows10
+[2]:https://www.ubuntu.com/download/desktop
+[3]:http://www.etcher.io
+[4]:/file/397066
+[5]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_01.png (Windows setup)
+[6]:/file/397076
+[7]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_03.png (Enter product key)
+[8]:data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw== (Click and drag to move)
+[9]:/file/397081
+[10]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_04.png (Select Windows version)
+[11]:/file/397086
+[12]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_05.png (Accept license terms)
+[13]:/file/397091
+[14]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_06.png (Select type of Windows installation)
+[15]:/file/397096
+[16]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_07.png (Hard drive configuration)
+[17]:/file/397101
+[18]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_08.png (Create a new partition)
+[19]:/file/397106
+[20]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_09.png (Leaving a partition with unallocated space)
+[21]:/file/397111
+[22]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_10.png (Installing Windows)
+[23]:/file/397116
+[24]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_11.png (Windows desktop)
+[25]:/file/397121
+[26]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_12.png (Ubuntu installation welcome screen)
+[27]:/file/397126
+[28]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_13.png (Ubuntu desktop)
+[29]:/file/397131
+[30]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_15.png (Select language in Ubuntu)
+[31]:/file/397136
+[32]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_16.png (Select keyboard in Ubuntu)
+[33]:/file/397141
+[34]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_17.png (Choose Ubuntu installation options)
+[35]:/file/397146
+[36]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_18.png (Install Ubuntu alongside Windows)
+[37]:/file/397151
+[38]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_18b.png (Allocate drive space)
diff --git a/sources/tech/20180523 Set up zsh on your Fedora system.md b/sources/tech/20180523 Set up zsh on your Fedora system.md
new file mode 100644
index 0000000000..786a9346cf
--- /dev/null
+++ b/sources/tech/20180523 Set up zsh on your Fedora system.md
@@ -0,0 +1,71 @@
+Set up zsh on your Fedora system
+======
+
+
+
+For some people, the terminal can be scary. But a terminal is more than just a black screen to type in. It usually runs a shell, so called because it wraps around the kernel. The shell is a text-based interface that lets you run commands on the system. It’s also sometimes called a command line interpreter or CLI. Fedora, like most Linux distributions, comes with bash as the default shell. However, it isn’t the only shell available; several other shells can be installed. This article focuses on the Z Shell, or zsh.
+
+Bash is a rewrite of the old Bourne shell (sh) that shipped in UNIX. Zsh is intended to be friendlier than bash, through better interaction. Some of its useful features are:
+
+ * Programmable command line completion
+ * Shared command history between running shell sessions
+ * Spelling correction
+ * Loadable modules
+ * Interactive selection of files and folders
+
+
+
+Zsh is available in the Fedora repositories. To install, run this command:
+```
+$ sudo dnf install zsh
+
+```
+
+### Using zsh
+
+To start using it, just type zsh and the new shell prompts you with a first run wizard. This wizard helps you configure initial features, like history behavior and auto-completion. Or you can opt to keep the [rc file][1] empty:
+
+![zsh First Run Wizzard][2]
+
+If you type 1 the configuration wizard starts. The other options launch the shell immediately.
+
+Note that the user prompt is **%** and not **$** as with bash. A significant feature here is the auto-completion that allows you to move among files and directories with the Tab key, much like a menu:
+
+![zsh cd Feature][3]
+
+Another interesting feature is spelling correction, which helps when writing filenames with mixed cases:
+
+![zsh Auto Completion][4]
+
+## Making zsh your default shell
+
+Zsh offers a lot of plugins, like zsh-syntax-highlighting, and the famous “Oh my zsh” ([check out its page here][5]). You might want to make it the default, so it runs whenever you start a session or open a terminal. To do this, use the chsh (“change shell”) command:
+```
+$ chsh -s $(which zsh)
+
+```
+
+This command tells your system that you want to set (-s) your default shell to the correct location of the shell (which zsh).
+
+Photo by [Kate Ter Haar][6] from [Flickr][7] (CC BY-SA).
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/set-zsh-fedora-system/
+
+作者:[Eduard Lucena][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org/author/x3mboy/
+[1]:https://en.wikipedia.org/wiki/Configuration_file
+[2]:https://fedoramagazine.org/wp-content/uploads/2017/12/zshFirstRun.gif
+[3]:https://fedoramagazine.org/wp-content/uploads/2017/12/zshChangingFeature-1.gif
+[4]:https://fedoramagazine.org/wp-content/uploads/2017/12/zshAutoCompletion.gif
+[5]:http://ohmyz.sh/
+[6]:https://www.flickr.com/photos/katerha/
+[7]:https://www.flickr.com/photos/katerha/34714051013/
diff --git a/sources/tech/20180524 4 Markdown-powered slide generators.md b/sources/tech/20180524 4 Markdown-powered slide generators.md
new file mode 100644
index 0000000000..2835aac916
--- /dev/null
+++ b/sources/tech/20180524 4 Markdown-powered slide generators.md
@@ -0,0 +1,119 @@
+4 Markdown-powered slide generators
+======
+
+
+
+Imagine you've been tapped to give a presentation. As you're preparing your talk, you think, "I should whip up a few slides."
+
+Maybe you prefer the simplicity of [plain text][1], or maybe you think software like LibreOffice Writer is overkill for what you need to do. Or perhaps you just want to embrace your inner geek.
+
+It's easy to turn files formatted with [Markdown][2] into attractive presentation slides. Here are four tools that can do help you do the job.
+
+### Landslide
+
+One of the more flexible applications on this list, [Landslide][3] is a command-line application that takes files formatted with Markdown, [reStructuredText][4], or [Textile][5] and converts them into an HTML file based on [Google’s HTML5 slides template][6].
+
+All you need to do is write up your slides with Markdown, crack open a terminal window, and run the command `landslide` followed by the name of the file. Landslide will spit out presentation.html, which you can open in any web browser. Simple, isn’t it?
+
+Don't let that simplicity fool you. Landslide offers more than a few useful features, such as the ability to add notes and create configuration files for your slides. Why would you want to do that? According to Landslide's developer, it helps with aggregating and reusing source directories across presentations.
+
+
+![landslide.png][8]
+
+Viewing presenter notes in a Landslide presentation
+
+### Marp
+
+[Marp][9] is a work in progress, but it shows promise. Short for "Markdown Presentation Writer," Marp is an [Electron][10] app in which you craft slides using a simple two-pane editor: Write in Markdown in the left pane and you get a preview in the right pane.
+
+Marp supports [GitHub Flavored Markdown][11]. If you need a quick tutorial on using GitHub Flavored Markdown to write slides, check out the [sample presentation][12]. It's a bit more flexible than baseline Markdown.
+
+While Marp comes with only two very basic themes, you can add background images to your slides, resize them, and include math. On the down side, it currently lets you export your slides only as PDF files. To be honest, I wonder why HTML export wasn’t a feature from day one.
+
+
+![marp.png][14]
+
+Editing some simple slides in Marp
+
+### Pandoc
+
+You probably know [pandoc][15] as a magic wand for converting between various markup languages. What you might not know is that pandoc can take a file formatted with Markdown and create attractive HTML slides that work with the [Slidy][16], [Slideous][17], [DZSlides][18], [S5][19], and [Reveal.js][20] presentation frameworks. If you prefer [LaTeX][21], you can also output PDF slides using the [Beamer package][22].
+
+You'll need to [use specific formatting][23] for your slides, but you can add some [variables][24] to control how they behave. You can also change the look and feel of your slides, add pauses between slides, and include speaker notes.
+
+Of course, you must have the supporting files for your preferred presentation framework installed on your computer. Pandoc spits out only the raw slide file.
+
+
+![pandoc.png][26]
+
+Viewing slides created with Pandoc and DZSlides
+
+### Hacker Slides
+
+[Hacker Slides][27] is an application for [Sandstorm][28] and [Sandstorm Oasis][29] that mates Markdown and the [Reveal.js][20] slide framework. The slides are simple, but they can be visually striking.
+
+Craft your slide deck in a two-pane editor in your browser—type in Markdown on the left and see it rendered on the right. When you're ready to present, you can do it from within Sandstorm or get a link that you can share with others to present remotely.
+
+What’s that—you say that you don’t use Sandstorm or Sandstorm Oasis? No worries.There's a [version of Hacker Slides][30] that you can run on your desktop or server.
+
+
+![hacker-slides.png][32]
+
+Editing slides in Hacker Slides
+
+### Two honorable mentions
+
+If you use [Jupyter Notebooks][33] (see community moderator Don Watkins' [article][34]) to publish data or instructional texts, then [Jupyter2slides][35] is for you. It works with Reveal.js to convert a notebook into a nice set of HTML slides.
+
+If you prefer your applications hosted, test-drive [GitPitch][36]. It works with GitHub, GitLab, and Bitbucket. Just push the source files for your slides to a repository on one of those services, point GitPitch to that repository, and your slides are ready to view at the GitPitch site.
+
+Do you have a favorite Markdown-powered slide generator? Share it by leaving a comment.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/markdown-slide-generators
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/scottnesbitt
+[1]:https://plaintextproject.online/
+[2]:https://en.wikipedia.org/wiki/Markdown
+[3]:https://github.com/adamzap/landslide
+[4]:https://en.wikipedia.org/wiki/ReStructuredText
+[5]:https://en.wikipedia.org/wiki/Textile_(markup_language)
+[6]:https://github.com/skaegi/html5slides
+[7]:/file/397441
+[8]:https://opensource.com/sites/default/files/uploads/landslide.png (landslide.png)
+[9]:https://yhatt.github.io/marp/
+[10]:https://en.wikipedia.org/wiki/Electron_(software_framework)
+[11]:https://guides.github.com/features/mastering-markdown/
+[12]:https://raw.githubusercontent.com/yhatt/marp/master/example.md
+[13]:/file/397446
+[14]:https://opensource.com/sites/default/files/uploads/marp.png (marp.png)
+[15]:https://pandoc.org/
+[16]:https://www.w3.org/Talks/Tools/Slidy2/Overview.html#(1)
+[17]:http://goessner.net/articles/slideous/
+[18]:http://paulrouget.com/dzslides/
+[19]:https://meyerweb.com/eric/tools/s5/
+[20]:https://revealjs.com/#/
+[21]:https://www.latex-project.org/
+[22]:https://en.wikipedia.org/wiki/Beamer_(LaTeX)
+[23]:https://pandoc.org/MANUAL.html#producing-slide-shows-with-pandoc
+[24]:https://pandoc.org/MANUAL.html#variables-for-slides
+[25]:/file/397451
+[26]:https://opensource.com/sites/default/files/uploads/pandoc.png (pandoc.png)
+[27]:https://github.com/jacksingleton/hacker-slides
+[28]:https://sandstorm.io/
+[29]:https://oasis.sandstorm.io/
+[30]:https://github.com/msoedov/hacker-slides
+[31]:/file/397456
+[32]:https://opensource.com/sites/default/files/uploads/hacker-slides.png (hacker-slides.png)
+[33]:http://jupyter.org/
+[34]:https://opensource.com/article/18/3/getting-started-jupyter-notebooks
+[35]:https://github.com/datitran/jupyter2slides
+[36]:https://gitpitch.com/
diff --git a/sources/tech/20180524 TrueOS- A Simple BSD Distribution for the Desktop Users.md b/sources/tech/20180524 TrueOS- A Simple BSD Distribution for the Desktop Users.md
new file mode 100644
index 0000000000..1676e25f58
--- /dev/null
+++ b/sources/tech/20180524 TrueOS- A Simple BSD Distribution for the Desktop Users.md
@@ -0,0 +1,147 @@
+TrueOS: A Simple BSD Distribution for the Desktop Users
+======
+**Brief: If you want to try something other than Linux, have a look at TrueOS. It is a BSD distribution specifically aimed at desktop users.**
+
+When you think of It’s FOSS you probably think mainly of Linux. It’s true that we cover mostly Linux-related news and tutorials. But today we are going to do something different.We are going to look at TrueOS BSD distribution.
+
+Linux and BSD, both fall into Unix-like operating system domain. The main difference lies at the core i.e. the kernel as both Linux and BSD have their own kernel implementation.
+
+### TrueOS BSD Review
+
+![TrueOS BSD ][1]
+
+[TrueOS (formerly PC-BSD)][2] is a desktop operating system based on [FreeBSD][3]. The goal of the project is to create a version of BSD that can be easily installed and is ready to use out of the box.
+
+TrueOS contains all of the FreeBSD goodness and includes some improvements of its own. It’s features include:
+
+ * Graphical installer
+ * OpenZFS file system
+ * Automatically configured hardware
+ * Full clang functionality
+ * Upgrades use boot environments so live system is not harmed
+ * Laptop support
+ * Easy system administration
+ * Built-in firewall
+ * Built in support for the [Tor Project][4]
+
+
+
+There are [two version][5] of TrueOS for desktop use. TrueOS Stable is a long-term-release that is updated every 6 months. The most recent version is 18.03. TrueOS Unstable is more of a rolling release. It is based on the latest development version of FreeBSD. TrueOS also support ARM processors with [TrueOS Pico][6].
+
+#### Lumina
+
+![True OS BSD][7]
+
+While TrueOS supports many of the desktop environments that you are used to, it comes with [Lumina][8] installed by default. Started in 2014, Lumina is a lightweight desktop created by the TrueOS team from scratch. Since it is primarily designed for TrueOS and other BSDs, Lumina does not make use of “any of the Linux-based desktop frameworks (ConsoleKit, PolicyKit, D-Bus, systemd, etc..)”. However, it has been [ported][9] for several Linux distros. It currently uses Fluxbox, but they are writing a new window manage for [tighter integration][10].
+
+Lumina does come with its own file manager, media player, archiver and other utilities. The most current version is [1.4.0][11].
+
+#### System Requirements
+
+TrueOS’ [handbook][12] lists the following system requirements
+
+##### Minimum Requirements
+
+ * 64-bit processor
+ * 1 GB RAM
+ * 10 – 15 GB of free hard drive space on a primary partition for a command-line server installation.
+ * Network card
+
+
+
+##### Recommended Requirements
+
+ * 64-bit processor
+ * 4 GB of RAM
+ * 20 – 30 GB of free hard drive space on a primary partition for a graphical desktop installation.
+ * Network card
+ * Sound card
+ * 3D-accelerated video card
+
+
+
+#### Included Applications
+
+The number of applications that come pre-installed in TrueOS is small. Here they are:
+
+ * AppCafe
+ * QupZilla
+ * Photonic
+ * TrueOS PDF Viewer
+ * Trojita email client
+ * Insight File Manager
+ * Lumina Archiver
+ * Lumina Media Player
+ * Lumina Screenshot
+ * Lumina Text Editor
+ * QTerminal
+ * Calculator
+
+
+
+### Installation
+
+I was able to successfully install TrueOS on my Dell Latitude D630. This laptop has an Intel Centrino Duo Core processor running at 2.00 GHz, NVIDIA Quadro NVS 135M graphics chip, and 4 GB of RAM.
+
+The installation process was pretty painless. It was similar to most modern OS installers, you work your way through a series of screens which ask you for information. Interestingly, you don’t have the option to boot into a live environment. You have to install TrueOS, even if you only want to test it.
+
+I would like to note that some BSDs are fairly easy to install. I’ve installed FreeBSD and it took a little over an hour to go from text installer to a GUI. I have not managed to install vanilla Arch yet, but I’m sure it would take longer.
+
+### ![][13]
+
+### Experience
+
+I’ve been wanting to install TrueOS for a while (going back to the PC-BSD days). My only experience with BSD before this had been a web server running FreeBSD. Based on the name, I was expecting a polished desktop experience. After all, it ships with its own desktop environment. My experience was not as good as I had hoped.
+
+Whenever I start using a new operating system, I check to see if the applications that I regularly use are available. TrueOS does come with its own package manager (AppCafe), which made things easy. I was able to quickly install LibreOffice, VLC, FireFox, and Calibre. However, I was unable to install my favorite Markdown editor, ghostwriter. Interestingly, when I searched Markdown in the AppCafe there were quite a few packages listed, but none of them were Markdown editors. I was also unable to install Dropbox, which I use to backup up my writing.
+
+Besides the AppCafe package manager, you can also install applications using the TrueOS ports collection. To figure out how to do this, I turned to the [TrueOS handbook][14]. Unfortunately, the section on [ports][15] was very light on details. This is what I learned from my research on the web. The first step is to download the ports information from GitHub with this command: `git clone http://github.com/trueos/freebsd-ports.git /usr/ports`. From there you need to navigate to the directory of the port you want to install and type `make install`to start the process.
+
+While this process is similar to Arch’s AUR, it limits you to install one package at a time. Also, it takes quite a while to download the entire ports collection. (I have a fast connection and it took over 30 minutes.) When I was searching for information about how to use ports, I did see a command that allows you to only download the ports that you want to install, but that was not included in the TrueOS handbook.
+
+Like macOS and Windows, TrueOS has login and shutdown jingles. While it was cool at first, it got annoying pretty quickly. Especially, when I didn’t expect it.
+
+I applaud the TrueOS team for creating their own desktop environment (especially since the whole TrueOS team consists of less than a dozen people.). They have come a long way from their first release, but it still feels unfinished. One thing that I kept noticing was that the icons in the system tray were not a uniform size. The battery and sound icon were large, but the wifi icon was half the size. Also, when I went to click on the “start” button, I had to make sure to click on the icon, not near it, or the menu would not launch. Most other “start” menus don’t have this problem. They seem to have a large click area, so you don’t miss.
+
+For some reason, I could not get the system clock set. I entered the information for my timezone and location, but TrueOS set the time ahead by five hours.
+
+![][16]
+
+### Final Thoughts
+
+Overall, I like the idea of TrueOS, a user-friendly BSD. It offered an experience that was familiar, but different than any Linux distro. Unfortunately, the lack of applications was disappointing. Also, I wish the TrueOS handbook was more fleshed out in some areas.
+
+I would recommend that you install TrueOS if you want to get the full the BSD experience, complete with its own desktop environment. There is nothing even remotely related to Linux here.
+
+Have you ever TrueOS? What is your favorite version of BSD? Please let us know in the comments below.
+
+If you found this article interesting, please take a minute to share it on social media.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/trueos-bsd-review/
+
+作者:[John Paul][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/trueos-bsd-featured-800x450.jpg
+[2]:https://www.trueos.org
+[3]:https://en.wikipedia.org/wiki/FreeBSD
+[4]:https://www.trueos.org/handbook/using.html#tor-mode
+[5]:https://www.trueos.org/downloads/
+[6]:https://www.trueos.org/trueos-pico/
+[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/02/TrueOSScreenshot2-800x500.png
+[8]:https://lumina-desktop.org
+[9]:https://lumina-desktop.org/get-lumina/
+[10]:https://lumina-desktop.org/faq/
+[11]:https://lumina-desktop.org/version-1-4-0-released/
+[12]:https://www.trueos.org/handbook/introducing.html#hardware-requirements-and-supported-hardware
+[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/02/TrueOSScreenshot5.png
+[14]:https://www.trueos.org/handbook/trueos.html
+[15]:https://www.trueos.org/handbook/using.html#freebsd-ports
+[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/02/TrueOSScreenshot4.png
diff --git a/sources/tech/20180525 15 books for kids who (you want to) love Linux and open source.md b/sources/tech/20180525 15 books for kids who (you want to) love Linux and open source.md
new file mode 100644
index 0000000000..2f6872fa20
--- /dev/null
+++ b/sources/tech/20180525 15 books for kids who (you want to) love Linux and open source.md
@@ -0,0 +1,116 @@
+pinewall translating
+
+15 books for kids who (you want to) love Linux and open source
+======
+
+
+In my job I've heard professionals in tech, from C-level executives to everyone in between, say they want their own kids to learn more about [Linux][1] and [open source][2]. Some of them seem to have an easy time with their kids following closely in their footsteps. And some have a tough time getting their kids to see what makes Linux and open source so cool. Maybe their time will come, maybe it won't. There's a lot of interesting, valuable stuff out there in this big world.
+
+Either way, if you have a kid or know a kid that may be interested in learning more about making something with code or hardware, from games to robots, this list is for you.
+
+### 15 books for kids with a focus on Linux and open source
+
+[Adventures in Raspberry Pi][3] by Carrie Anne Philbin
+
+The tiny, credit-card sized Raspberry Pi has become a huge hit among kids—and adults—interested in programming. It does everything your desktop can do, but with a few basic programming skills you can make it do so much more. With simple instructions, fun projects, and solid skills, Adventures in Raspberry Pi is the ultimate kids' programming guide! (Recommendation by [Joshua Allen Holm][4] | Review is an excerpt from the book's abstract)
+
+[Automate the Boring Stuff with Python][5] by Al Sweigart
+
+This is a classic introduction to programming that's written clearly enough for a motivated 11-year-old to understand and enjoy. Readers will quickly find themselves working on practical and useful tasks while picking up good coding practices almost by accident. The best part: If you like, you can read the whole book online. (Recommendation and review by [DB Clinton][6])
+
+[Coding Games in Scratch][7] by Jon Woodcock
+
+Written for children ages 8-12 with little to no coding experience, this straightforward visual guide uses fun graphics and easy-to-follow instructions to show young learners how to build their own computer projects using Scratch, a popular free programming language. (Recommendation by [Joshua Allen Holm][4] | Review is an excerpt from the book's abstract)
+
+[Doing Math with Python][8] by Amit Saha
+
+Whether you're a student or a teacher who's curious about how you can use Python for mathematics, this book is for you. Beginning with simple mathematical operations in the Python shell to the visualization of data using Python libraries like matplotlib, this books logically takes the reader step by easily followed step from the basics to more complex operations. This book will invite your curiosity about the power of Python with mathematics. (Recommendation and review by [Don Watkins][9])
+
+[Girls Who Code: Learn to Code and Change the World][10] by Reshma Saujani
+
+From the leader of the movement championed by Sheryl Sandberg, Malala Yousafzai, and John Legend, this book is part how-to, part girl-empowerment, and all fun. Bursting with dynamic artwork, down-to-earth explanations of coding principles, and real-life stories of girls and women working at places like Pixar and NASA, this graphically animated book shows what a huge role computer science plays in our lives and how much fun it can be. (Recommendation by [Joshua Allen Holm][4] | Review is an excerpt from the book's abstract)
+
+[Invent Your Own Computer Games with Python][11] by Al Sweigart
+
+This book will teach you how to make computer games using the popular Python programming language—even if you’ve never programmed before! Begin by building classic games like Hangman, Guess the Number, and Tic-Tac-Toe, and then work your way up to more advanced games, like a text-based treasure hunting game and an animated collision-dodging game with sound effects. (Recommendation by [Joshua Allen Holm][4] | Review is an excerpt from the book's abstract)
+
+[Lauren Ipsum: A Story About Computer Science and Other Improbable Things][12] by Carlos Bueno
+
+Written in the spirit of Alice in Wonderland, Lauren Ipsum takes its heroine through a slightly magical world whose natural laws are the laws of logic and computer science and whose puzzles can be solved only through learning and applying the principles of computer code. Computers are never mentioned, but they're at the center of it all. (Recommendation and review by [DB Clinton][6])
+
+[Learn Java the Easy Way: A Hands-On Introduction to Programming][13] by Bryson Payne
+
+Java is the world's most popular programming language, but it’s known for having a steep learning curve. This book takes the chore out of learning Java with hands-on projects that will get you building real, functioning apps right away. (Recommendation by [Joshua Allen Holm][4] | Review is an excerpt from the book's abstract)
+
+[Lifelong Kindergarten][14] by Mitchell Resnick
+
+Kindergarten is becoming more like the rest of school. In this book, learning expert Mitchel Resnick argues for exactly the opposite: The rest of school (even the rest of life) should be more like kindergarten. To thrive in today's fast-changing world, people of all ages must learn to think and act creatively―and the best way to do that is by focusing more on imagining, creating, playing, sharing, and reflecting, just as children do in traditional kindergartens. Drawing on experiences from more than 30 years at MIT's Media Lab, Resnick discusses new technologies and strategies for engaging young people in creative learning experiences. (Recommendation by [Don Watkins][9] | Review from Amazon)
+
+[Python for Kids][15] by Jason Briggs
+
+Jason Briggs has taken the art of teaching Python programming to a new level in this book that can easily be an introductory text for teachers and students as well as parents and kids. Complex concepts are presented with step-by-step directions that will have even neophyte programmers experiencing the success that invites you to learn more. This book is an extremely readable, playful, yet powerful introduction to Python programming. You will learn fundamental data structures like tuples, lists, and maps. The reader is shown how to create functions, reuse code, and use control structures like loops and conditional statements. Kids will learn how to create games and animations, and they will experience the power of Tkinter to create advanced graphics. (Recommendation and review by [Don Watkins][9])
+
+[Scratch Programming Playground][16] by Al Sweigart
+
+Scratch programming is often seen as a playful way to introduce young people to programming. In this book, Al Sweigart demonstrates that Scratch is in fact a much more powerful programming language than most people realize. Masterfully written and presented in his own unique style, Al will have kids exploring the power of Scratch to create complex graphics and animation in no time. (Recommendation and review by [Don Watkins][9])
+
+[Secret Coders][17] by Mike Holmes
+
+From graphic novel superstar (and high school computer programming teacher) Gene Luen Yang comes a wildly entertaining new series that combines logic puzzles and basic programming instruction with a page-turning mystery plot. Stately Academy is the setting, a school that is crawling with mysteries to be solved! (Recommendation by [Joshua Allen Holm][4] | Review is an excerpt from the book's abstract)
+
+[So, You Want to Be a Coder?: The Ultimate Guide to a Career in Programming, Video Game Creation, Robotics, and More!][18] by Jane Bedell
+
+Love coding? Make your passion your profession with this comprehensive guide that reveals a whole host of careers working with code. (Recommendation by [Joshua Allen Holm][4] | Review is an excerpt from the book's abstract)
+
+[Teach Your Kids to Code][19] by Bryson Payne
+
+Are you looking for a playful way to introduce children to programming with Python? Bryson Payne has written a masterful book that uses the metaphor of turtle graphics in Python. This book will have you creating simple programs that are the basis for advanced Python programming. This book is a must-read for anyone who wants to teach young people to program. (Recommendation and review by [Don Watkins][9])
+
+[The Children's Illustrated Guide to Kubernetes][20] by Matt Butcher, illustrated by Bailey Beougher
+
+Introducing Phippy, an intrepid little PHP app, and her journey to Kubernetes. (Recommendation by [Chris Short][21] | Review from [Matt Butcher's blog post][20].)
+
+### Bonus books for babies
+
+[CSS for Babies][22], [Javascript for Babies][23], and [HTML for Babies][24] by Sterling Children's
+
+These concept books familiarize young ones with the kind of shapes and colors that make up web-based programming languages. This beautiful book is a colorful introduction to coding and the web, and it's the perfect gift for any technologically minded family. (Recommendation by [Chris Short][21] | Review from Amazon)
+
+Have other books for babies or kids to share? Let us know in the comments.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/books-kids-linux-open-source
+
+作者:[Jen Wike Huger][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/remyd
+[1]:https://opensource.com/resources/linux
+[2]:https://opensource.com/article/18/3/what-open-source-programming
+[3]:https://www.amazon.com/Adventures-Raspberry-Carrie-Anne-Philbin/dp/1119046025
+[4]:https://opensource.com/users/holmja
+[5]:https://automatetheboringstuff.com/
+[6]:https://opensource.com/users/dbclinton
+[7]:https://www.goodreads.com/book/show/25733628-coding-games-in-scratch
+[8]:https://nostarch.com/doingmathwithpython
+[9]:https://opensource.com/users/don-watkins
+[10]:https://www.amazon.com/Girls-Who-Code-Learn-Change/dp/042528753X
+[11]:http://inventwithpython.com/invent4thed/
+[12]:https://www.amazon.com/gp/product/1593275749/ref=as_li_tl?ie=UTF8&tag=projemun-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=1593275749&linkId=e05e1f12176c4959cc1aa1a050908c4a
+[13]:https://nostarch.com/learnjava
+[14]:http://lifelongkindergarten.net/
+[15]:https://nostarch.com/pythonforkids
+[16]:https://nostarch.com/scratchplayground
+[17]:http://www.secret-coders.com/
+[18]:https://www.amazon.com/So-You-Want-Coder-Programming/dp/1582705798?tag=ad-backfill-amzn-no-or-one-good-20
+[19]:https://opensource.com/education/15/9/review-bryson-payne-teach-your-kids-code
+[20]:https://deis.com/blog/2016/kubernetes-illustrated-guide/
+[21]:https://opensource.com/users/chrisshort
+[22]:https://www.amazon.com/CSS-Babies-Code-Sterling-Childrens/dp/1454921560/
+[23]:https://www.amazon.com/Javascript-Babies-Code-Sterling-Childrens/dp/1454921579/
+[24]:https://www.amazon.com/HTML-Babies-Code-Sterling-Childrens/dp/1454921552
diff --git a/sources/tech/20180525 A Bittorrent Filesystem Based On FUSE.md b/sources/tech/20180525 A Bittorrent Filesystem Based On FUSE.md
new file mode 100644
index 0000000000..08f9498437
--- /dev/null
+++ b/sources/tech/20180525 A Bittorrent Filesystem Based On FUSE.md
@@ -0,0 +1,102 @@
+A Bittorrent Filesystem Based On FUSE
+======
+
+
+The torrents have been around for a long time to share and download data from the Internet. There are plethora of GUI and CLI torrent clients available on the market. Sometimes, you just can not sit and wait for your download to complete. You might want to watch the content immediately. This is where **BTFS** , the bittorent filesystem, comes in handy. Using BTFS, you can mount the torrent file or magnet link as a directory and then use it as any read-only directory in your file tree. The contents of the files will be downloaded on-demand as they are read by applications. Since BTFS runs on top of FUSE, it does not require intervention into the Linux Kernel.
+
+## BTFS – A Bittorrent Filesystem Based On FUSE
+
+### Installing BTFS
+
+BTFS is available in the default repositories of most Linux distributions.
+
+On Arch Linux and its variants, run the following command to install BTFS.
+```
+$ sudo pacman -S btfs
+
+```
+
+On Debian, Ubuntu, Linux Mint:
+```
+$ sudo apt-get install btfs
+
+```
+
+On Gentoo:
+```
+# emerge -av btfs
+
+```
+
+BTFS can also be installed using [**Linuxbrew**][1] package manager.
+```
+$ brew install btfs
+
+```
+
+### Usage
+
+BTFS usage is fairly simple. All you have to find the .torrent file or magnet link and mount it in a directory. The contents of the torrent file or magnet link will be mounted inside the directory of your choice. When a program tries to access the file for reading, the actual data will be downloaded on demand. Furthermore, tools like **ls** , **cat** and **cp** works as expected for manipulating the torrents. Applications like **vlc** and **mplayer** can also work without changes. The thing is the players don’t even know that the actual content is not physically present in the local disk and the content is collected in parts from peers on demand.
+
+Create a directory to mount the torrent/magnet link:
+```
+$ mkdir mnt
+
+```
+
+Mount the torrent/magnet link:
+```
+$ btfs video.torrent mnt
+
+```
+
+[![][2]][3]
+
+Cd to the directory:
+```
+$ cd mnt
+
+```
+
+And, start watching!
+```
+$ vlc
+
+```
+
+Give BTFS a few moments to find and get the website tracker. Once the real data is loaded, BTFS won’t require the tracker any more.
+
+![][4]
+
+To unmount the BTFS filesystem, simply run the following command:
+```
+$ fusermount -u mnt
+
+```
+
+Now, the contents in the mounted directory will be gone. To access the contents again, you need to mount the torrent as described above.
+
+The BTFS application will turn your VLC or Mplayer into Popcorn Time. Mount your favorite TV show or movie torrent file or magnet link and start watching without having to download the entire contents of the torrent or wait for your download to complete. The contents of the torrent or magnet link will be downloaded on demand when accessed by the applications.
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/btfs-a-bittorrent-filesystem-based-on-fuse/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
+[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[3]:http://www.ostechnix.com/wp-content/uploads/2018/05/btfs.png
+[4]:http://www.ostechnix.com/wp-content/uploads/2018/05/btfs-1.png
diff --git a/sources/tech/20180525 Getting started with the Python debugger.md b/sources/tech/20180525 Getting started with the Python debugger.md
new file mode 100644
index 0000000000..560440fd02
--- /dev/null
+++ b/sources/tech/20180525 Getting started with the Python debugger.md
@@ -0,0 +1,287 @@
+Getting started with the Python debugger
+======
+
+
+
+The Python ecosystem is rich with many tools and libraries that improve developers’ lives. For example, the Magazine has previously covered how to [enhance your Python with a interactive shell][1]. This article focuses on another tool that saves you time and improves your Python skills: the Python debugger.
+
+### Python Debugger
+
+The Python standard library provides a debugger called pdb. This debugger provides most features needed for debugging such as breakpoints, single line stepping, inspection of stack frames, and so on.
+
+A basic knowledge of pdb is useful since it’s part of the standard library. You can use it in environments where you can’t install another enhanced debugger.
+
+#### Running pdb
+
+The easiest way to run pdb is from the command line, passing the program to debug as an argument. Considering the following script:
+```
+# pdb_test.py
+#!/usr/bin/python3
+
+from time import sleep
+
+def countdown(number):
+ for i in range(number, 0, -1):
+ print(i)
+ sleep(1)
+
+
+if __name__ == "__main__":
+ seconds = 10
+ countdown(seconds)
+
+```
+
+You can run pdb from the command line like this:
+```
+$ python3 -m pdb pdb_test.py
+> /tmp/pdb_test.py(1)()
+-> from time import sleep
+(Pdb)
+
+```
+
+Another way to use pdb is to set a breakpoint in the program. To do this, import the pdb module and use the set_trace function:
+```
+1 # pdb_test.py
+2 #!/usr/bin/python3
+3
+4 from time import sleep
+5
+6
+7 def countdown(number):
+8 for i in range(number, 0, -1):
+9 import pdb; pdb.set_trace()
+10 print(i)
+11 sleep(1)
+12
+13
+14 if __name__ == "__main__":
+15 seconds = 10
+16 countdown(seconds)
+
+$ python3 pdb_test.py
+> /tmp/pdb_test.py(6)countdown()
+-> print(i)
+(Pdb)
+
+```
+
+The script stops at the breakpoint, and pdb displays the next line in the script. You can also execute the debugger after a failure. This is known as postmortem debugging.
+
+#### Navigate the execution stack
+
+A common use case in debugging is to navigate the execution stack. Once the Python debugger is running, the following commands are useful :
+
++ w(here) : Shows which line is currently executed and where the execution stack is.
+
+
+```
+$ python3 test_pdb.py
+> /tmp/test_pdb.py(10)countdown()
+-> print(i)
+(Pdb) w
+/tmp/test_pdb.py(16)()
+-> countdown(seconds)
+> /tmp/test_pdb.py(10)countdown()
+-> print(i)
+(Pdb)
+
+```
+
++ l(ist) : Shows more context (code) around the current the location.
+
+
+```
+$ python3 test_pdb.py
+> /tmp/test_pdb.py(10)countdown()
+-> print(i)
+(Pdb) l
+5
+6
+7 def countdown(number):
+8 for i in range(number, 0, -1):
+9 import pdb; pdb.set_trace()
+10 -> print(i)
+11 sleep(1)
+12
+13
+14 if __name__ == "__main__":
+15 seconds = 10
+(Pdb)
+
+```
+
++ u(p)/d(own) : Navigate the call stack up or down.
+
+
+```
+$ py3 test_pdb.py
+> /tmp/test_pdb.py(10)countdown()
+-> print(i)
+(Pdb) up
+> /tmp/test_pdb.py(16)()
+-> countdown(seconds)
+(Pdb) down
+> /tmp/test_pdb.py(10)countdown()
+-> print(i)
+(Pdb)
+
+```
+
+#### Stepping through a program
+
+pdb provides the following commands to execute and step through code:
+
++ n(ext): Continue execution until the next line in the current function is reached, or it returns
++ s(tep): Execute the current line and stop at the first possible occasion (either in a function that is called or in the current function)
++ c(ontinue): Continue execution, only stopping at a breakpoint.
+
+
+```
+$ py3 test_pdb.py
+> /tmp/test_pdb.py(10)countdown()
+-> print(i)
+(Pdb) n
+10
+> /tmp/test_pdb.py(11)countdown()
+-> sleep(1)
+(Pdb) n
+> /tmp/test_pdb.py(8)countdown()
+-> for i in range(number, 0, -1):
+(Pdb) n
+> /tmp/test_pdb.py(9)countdown()
+-> import pdb; pdb.set_trace()
+(Pdb) s
+--Call--
+> /usr/lib64/python3.6/pdb.py(1584)set_trace()
+-> def set_trace():
+(Pdb) c
+> /tmp/test_pdb.py(10)countdown()
+-> print(i)
+(Pdb) c
+9
+> /tmp/test_pdb.py(9)countdown()
+-> import pdb; pdb.set_trace()
+(Pdb)
+
+```
+
+The example shows the difference between next and step. Indeed, when using step the debugger stepped into the pdb module source code, whereas next would have just executed the set_trace function.
+
+#### Examine variables content
+
+Where pdb is really useful is examining the content of variables stored in the execution stack. For example, the a(rgs) command prints the variables of the current function, as shown below:
+```
+py3 test_pdb.py
+> /tmp/test_pdb.py(10)countdown()
+-> print(i)
+(Pdb) where
+/tmp/test_pdb.py(16)()
+-> countdown(seconds)
+> /tmp/test_pdb.py(10)countdown()
+-> print(i)
+(Pdb) args
+number = 10
+(Pdb)
+
+```
+
+pdb prints the value of the variable number, in this case 10.
+
+Another command that can be used to print variables value is p(rint).
+```
+$ py3 test_pdb.py
+> /tmp/test_pdb.py(10)countdown()
+-> print(i)
+(Pdb) list
+5
+6
+7 def countdown(number):
+8 for i in range(number, 0, -1):
+9 import pdb; pdb.set_trace()
+10 -> print(i)
+11 sleep(1)
+12
+13
+14 if __name__ == "__main__":
+15 seconds = 10
+(Pdb) print(seconds)
+10
+(Pdb) p i
+10
+(Pdb) p number - i
+0
+(Pdb)
+
+```
+
+As shown in the example’s last command, print can evaluate an expression before displaying the result.
+
+The [Python documentation][2] contains the reference and examples for each of the pdb commands. This is a useful read for someone starting with the Python debugger.
+
+### Enhanced debugger
+
+Some enhanced debuggers provide a better user experience. Most add useful extra features to pdb, such as syntax highlighting, better tracebacks, and introspection. Popular choices of enhanced debuggers include [IPython’s ipdb][3] and [pdb++][4].
+
+These examples show you how to install these two debuggers in a virtual environment. These examples use a new virtual environment, but in the case of debugging an application, the application’s virtual environment should be used.
+
+#### Install IPython’s ipdb
+
+To install the IPython ipdb, use pip in the virtual environment:
+```
+$ python3 -m venv .test_pdb
+$ source .test_pdb/bin/activate
+(test_pdb)$ pip install ipdb
+
+```
+
+To call ipdb inside a script, you must use the following command. Note that the module is called ipdb instead of pdb:
+```
+import ipdb; ipdb.set_trace()
+
+```
+
+IPython’s ipdb is also available in Fedora packages, so you can install it using Fedora’s package manager dnf:
+```
+$ sudo dnf install python3-ipdb
+
+```
+
+#### Install pdb++
+
+You can install pdb++ similarly:
+```
+$ python3 -m venv .test_pdb
+$ source .test_pdb/bin/activate
+(test_pdb)$ pip install pdbp
+
+```
+
+pdb++ overrides the pdb module, and therefore you can use the same syntax to add a breakpoint inside a program:
+```
+import pdb; pdb.set_trace()
+
+```
+
+### Conclusion
+
+Learning how to use the Python debugger saves you time when investigating problems with an application. It can also be useful to understand how a complex part of an application or some libraries work, and thereby improve your Python developer skills.
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/getting-started-python-debugger/
+
+作者:[Clément Verna][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org
+[1]:https://fedoramagazine.org/enhance-python-interactive-shell
+[2]:https://docs.python.org/3/library/pdb.html
+[3]:https://github.com/gotcha/ipdb
+[4]:https://github.com/antocuni/pdb
diff --git a/sources/tech/20180525 How insecure is your router.md b/sources/tech/20180525 How insecure is your router.md
new file mode 100644
index 0000000000..922b97df56
--- /dev/null
+++ b/sources/tech/20180525 How insecure is your router.md
@@ -0,0 +1,80 @@
+How insecure is your router?
+======
+
+
+I've always had a problem with the t-shirt that reads, "There's no place like 127.0.0.1." I know you're supposed to read it as "home," but to me, it says, "There's no place like localhost," which just doesn't have the same ring to it. And in this post, I want to talk about something broader: the entry point to your home network, which for most people will be a cable or broadband router.1 The UK and U.S. governments just published advice that "Russia"2 is attacking routers. This attack will be aimed mostly, I suspect, at organisations (see my previous post "[What's a state actor, and should I care?][1]"), rather than homes, but it's a useful wake-up call for all of us.
+
+### What do routers do?
+
+Routers are important. They provide the link between one network (in this case, our home network) and another one (in this case, the internet, via our ISP's network). In fact, for most of us, the box we think of as "the router"3 is doing a lot more than that. The "routing" bit is what is sounds like; it helps computers on your network find routes to send data to computers outside the network—and vice-versa, for when you're getting data back.
+
+High among a router's other functions, many also perform as a modem. Most of us4 connect to the internet via a phone line—whether cable or standard landline—though there is a growing trend for mobile internet to the home. When you're connecting via a phone line, the signals we use for the internet must be converted to something else and then (at the other end) back again. For those of us old enough to remember the old "dial-up" days, that's what the screechy box next to your computer used to do.
+
+But routers often do more things, sometimes many more things, including traffic logging, acting as a WiFi access point, providing a VPN for external access to your internal network, child access, firewalling, and all the rest.
+
+Home routers are complex things these days; although state actors may not be trying to get into them, other people may.
+
+Does this matter, you ask? Well, if other people can get into your system, they have easy access to attacking your laptops, phones, network drives, and the rest. They can access and delete unprotected personal data. They can plausibly pretend to be you. They can use your network to host illegal data or launch attacks on others. Basically, all the bad things.
+
+Luckily, routers tend to come set up by your ISP, with the implication being that you can leave them, and they'll be nice and safe.
+
+### So we're safe, then?
+
+Unluckily, we're really not.
+
+The first problem is that ISPs are working on a budget, and it's in their best interests to provide cheap kit that just does the job. The quality of ISP-provided routers tends to be pretty terrible. It's also high on the list of things to try to attack by malicious actors: If they know that a particular router model is installed in several million homes, there's a great incentive to find an attack, because an attack on that model will be very valuable to them.
+
+Other problems that arise include:
+
+ * Slowness to fix known bugs or vulnerabilities. Updating firmware can be costly to your ISP, so fixes may be slow to arrive (if they do at all).
+ * Easily derived or default admin passwords, which means attackers don't even need to find a real vulnerability—they can just log in.
+
+
+
+### Measures to take
+
+Here's a quick list of steps you can take to try to improve the security of your first hop to the internet. I've tried to order them in terms of ease—simplest first. Before you do any of these, however, save the configuration data so you can bring it back if you need it.
+
+ 1. **Passwords:** Always, always, always change the admin password for your router. It's probably going to be one you rarely use, so you'll want to record it somewhere. This is one of the few times where you might want to consider taping it to the router itself, as long as the router is in a secure place where only authorised people (you and your family5) have access.
+ 2. **Internal admin access only:** Unless you have very good reasons and you know what you're doing, don't allow machines to administer the router unless they're on your home network. There should be a setting on your router for this.
+ 3. **WiFi passwords:** Once you've done item 2, also ensure that WiFi passwords on your network—whether set on your router or elsewhere—are strong. It's easy to set a "friendly" password to make it easy for visitors to connect to your network, but if a malicious person who happens to be nearby guesses it, the first thing that person will do is to look for routers on the network. As they're on the internal network, they'll have access to it (hence why item 1 is important).
+ 4. **Turn on only the functions that you understand and need:** As I noted above, modern routers have all sorts of cool options. Disregard them. Unless you really need them, and you actually understand what they do and the dangers of turning them on, then leave them off. Otherwise, you're just increasing your attack surface.
+ 5. **Buy your own router:** Replace your ISP-supplied router with a better one. Go to your local computer store and ask for suggestions. You can pay an awful lot, but you can also get something fairly cheap that does the job and is more robust, performant, and easy to secure than the one you have at the moment. You may also want to buy a separate modem. Generally, setting up your modem or router is simple, and you can copy the settings from the ISP-supplied one and it will "just work."
+ 6. **Firmware updates:** I'd love to move this further up the list, but it's not always easy. From time to time, firmware updates appear for your router. Most routers will check automatically and may prompt you to update when you next log in. The problem is that failure to update correctly can cause catastrophic results6 or lose configuration data that you'll need to re-enter. But you really do need to consider keeping a lookout for firmware updates that fix severe security issues and implement them.
+ 7. **Go open source:** There are some great open source router projects out there that allow you to take an existing router and replace all of its firmware/software with open source alternatives. You can find many of them on [Wikipedia][2], and a search for ["router" on Opensource.com][3] will open your eyes to a set of fascinating opportunities. This isn't a step for the faint-hearted, as you'll definitely void the warranty on your router, but if you want to have real control, open source is always the way to go.
+
+
+
+### Other issues
+
+I'd love to pretend that once you've improved the security of your router, all's well and good on your home network, but it's not. What about IoT devices in your home (Alexa, Nest, Ring doorbells, smart lightbulbs, etc.?) What about VPNs to other networks? Malicious hosts via WiFi, malicious apps on your children's phones…?
+
+No, you won't be safe. But, as we've discussed before, although there is no such thing as "secure," it doesn't mean we shouldn't raise the bar and make it harder for the Bad Folks.™
+
+ 1. I'm simplifying—but read on, we'll get there.
+ 2. "Russian state-sponsored cyber actors"
+ 3. Or, in my parents' case, "the internet box," I suspect.
+ 4. This is one of these cases where I don't want comments telling me how you have a direct, 1TB/s connection to your local backbone, thank you very much.
+ 5. Maybe not the entire family.
+ 6. Your router is now a brick, and you have no access to the internet.
+
+
+
+This article originally appeared on [Alice, Eve, and Bob – a security blog][4] and is republished with permission.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/how-insecure-your-router
+
+作者:[Mike Bursell][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/mikecamel
+[1]:https://aliceevebob.com/2018/03/13/whats-a-state-actor-and-should-i-care/
+[2]:https://en.wikipedia.org/wiki/List_of_router_firmware_projects
+[3]:https://opensource.com/sitewide-search?search_api_views_fulltext=router
+[4]:https://aliceevebob.com/2018/04/17/defending-our-homes/
diff --git a/sources/tech/20180525 How to Set Different Wallpaper for Each Monitor in Linux.md b/sources/tech/20180525 How to Set Different Wallpaper for Each Monitor in Linux.md
new file mode 100644
index 0000000000..386149400c
--- /dev/null
+++ b/sources/tech/20180525 How to Set Different Wallpaper for Each Monitor in Linux.md
@@ -0,0 +1,89 @@
+How to Set Different Wallpaper for Each Monitor in Linux
+======
+**Brief: If you want to display different wallpapers on multiple monitors on Ubuntu 18.04 or any other Linux distribution with GNOME, MATE or Budgie desktop environment, this nifty tool will help you achieve this.**
+
+Multi-monitor setup often leads to multiple issues on Linux but I am not going to discuss those issues in this article. I have rather a positive article on multiple monitor support on Linux.
+
+If you are using multiple monitor, perhaps you would like to setup a different wallpaper for each monitor. I am not sure about other Linux distributions and desktop environments, but Ubuntu with [GNOME desktop][1] doesn’t provide this functionality on its own.
+
+Fret not! In this quick tutorial, I’ll show you how to set a different wallpaper for each monitor on Linux distributions with GNOME desktop environment.
+
+### Setting up different wallpaper for each monitor on Ubuntu 18.04 and other Linux distributions
+
+![Different wallaper on each monitor in Ubuntu][2]
+
+I am going to use a nifty tool called [HydraPaper][3] for setting different backgrounds on different monitors. HydraPaper is a [GTK][4] based application to set different backgrounds for each monitor in [GNOME desktop environment][5].
+
+It also supports on [MATE][6] and [Budgie][7] desktop environments. Which means Ubuntu MATE and [Ubuntu Budgie][8] users can also benefit from this application.
+
+#### Install HydraPaper on Linux using FlatPak
+
+HydraPaper can be installed easily using [FlatPak][9]. Ubuntu 18.04 already provides support for FlatPaks so all you need to do is to download the application file and double click on it to open it with the GNOME Software Center.
+
+You can refer to this article to learn [how to enable FlatPak support][10] on your distribution. Once you have the FlatPak support enabled, just download it from [FlatHub][11] and install it.
+
+[Download HydraPaper][12]
+
+#### Using HydraPaper for setting different background on different monitors
+
+Once installed, just look for HydraPaper in application menu and start the application. You’ll see images from your Pictures folder here because by default the application takes images from the Pictures folder of the user.
+
+You can add your own folder(s) where you keep your wallpapers. Do note that it doesn’t find images recursively. If you have nested folders, it will only show images from the top folder.
+
+![Setting up different wallpaper for each monitor on Linux][13]
+
+Using HydraPaper is absolutely simple. Just select the wallpapers for each monitor and click on the apply button at the top. You can easily identify external monitor(s) termed with HDMI.
+
+![Setting up different wallpaper for each monitor on Linux][14]
+
+You can also add selected wallpapers to ‘Favorites’ for quick access. Doing this will move the ‘favorite wallpapers’ from Wallpapers tab to Favorites tab.
+
+![Setting up different wallpaper for each monitor on Linux][15]
+
+You don’t need to start HydraPaper at each boot. Once you set different wallpaper for different monitor, the settings are saved and you’ll see your chosen wallpapers even after restart. This would be expected behavior of course but I thought I would mention the obvious.
+
+One big downside of HydraPaper is in the way it is designed to work. You see, HydraPaper combines your selected wallpapers into one single image and stretches it across the screens giving an impression of having different background on each display. And this becomes an issue when you remove the external display.
+
+For example, when I tried using my laptop without the external display, it showed me an background image like this.
+
+![Dual Monitor wallpaper HydraPaper][16]
+
+Quite obviously, this is not what I would expect.
+
+#### Did you like it?
+
+HydraPaper makes setting up different backgrounds on different monitors a painless task. It supports more than two monitors and monitors with different orientation. Simple interface with only the required features makes it an ideal application for those who always use dual monitors.
+
+How do you set different wallpaper for different monitor on Linux? Do you think HydraPaper is an application worth installing?
+
+Do share your views and if you find this article, please share it on various social media channels such as Twitter and [Reddit][17].
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/wallpaper-multi-monitor/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[1]:https://www.gnome.org/
+[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/multi-monitor-wallpaper-setup-800x450.jpeg
+[3]:https://github.com/GabMus/HydraPaper
+[4]:https://www.gtk.org/
+[5]:https://itsfoss.com/gnome-tricks-ubuntu/
+[6]:https://mate-desktop.org/
+[7]:https://budgie-desktop.org/home/
+[8]:https://itsfoss.com/ubuntu-budgie-18-review/
+[9]:https://flatpak.org
+[10]:https://flatpak.org/setup/
+[11]:https://flathub.org
+[12]:https://flathub.org/apps/details/org.gabmus.hydrapaper
+[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-2-800x631.jpeg
+[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-1.jpeg
+[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-3.jpeg
+[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/hydra-paper-dual-monitor-800x450.jpeg
+[17]:https://www.reddit.com/r/LinuxUsersGroup/
diff --git a/sources/tech/20180525 How to clean up your data in the command line.md b/sources/tech/20180525 How to clean up your data in the command line.md
new file mode 100644
index 0000000000..7280338530
--- /dev/null
+++ b/sources/tech/20180525 How to clean up your data in the command line.md
@@ -0,0 +1,114 @@
+How to clean up your data in the command line
+======
+
+
+I work part-time as a data auditor. Think of me as a proofreader who works with tables of data rather than pages of prose. The tables are exported from relational databases and are usually fairly modest in size: 100,000 to 1,000,000 records and 50 to 200 fields.
+
+I haven't seen an error-free data table, ever. The messiness isn't limited, as you might think, to duplicate records, spelling and formatting errors, and data items placed in the wrong field. I also find:
+
+ * broken records spread over several lines because data items had embedded line breaks
+ * data items in one field disagreeing with data items in another field, in the same record
+ * records with truncated data items, often because very long strings were shoehorned into fields with 50- or 100-character limits
+ * character encoding failures producing the gibberish known as [mojibake][1]
+ * invisible [control characters][2], some of which can cause data processing errors
+ * [replacement characters][3] and mysterious question marks inserted by the last program that failed to understand the data's character encoding
+
+
+
+Cleaning up these problems isn't hard, but there are non-technical obstacles to finding them. The first is everyone's natural reluctance to deal with data errors. Before I see a table, the data owners or managers may well have gone through all five stages of Data Grief:
+
+ 1. There are no errors in our data.
+ 2. Well, maybe there are a few errors, but they're not that important.
+ 3. OK, there are a lot of errors; we'll get our in-house people to deal with them.
+ 4. We've started fixing a few of the errors, but it's time-consuming; we'll do it when we migrate to the new database software.
+ 5. We didn't have time to clean the data when moving to the new database; we could use some help.
+
+
+
+The second progress-blocking attitude is the belief that data cleaning requires dedicated applications—either expensive proprietary programs or the excellent open source program [OpenRefine][4]. To deal with problems that dedicated applications can't solve, data managers might ask a programmer for help—someone good with [Python][5] or [R][6].
+
+But data auditing and cleaning generally don't require dedicated applications. Plain-text data tables have been around for many decades, and so have text-processing tools. Open up a Bash shell and you have a toolbox loaded with powerful text processors like `grep`, `cut`, `paste`, `sort`, `uniq`, `tr`, and `awk`. They're fast, reliable, and easy to use.
+
+I do all my data auditing on the command line, and I've put many of my data-auditing tricks on a ["cookbook" website][7]. Operations I do regularly get stored as functions and shell scripts (see the example below).
+
+Yes, a command-line approach requires that the data to be audited have been exported from the database. And yes, the audit results need to be edited later within the database, or (database permitting) the cleaned data items need to be imported as replacements for the messy ones.
+
+But the advantages are remarkable. `awk` will process a few million records in seconds on a consumer-grade desktop or laptop. Uncomplicated regular expressions will find all the data errors you can imagine. And all of this will happen safely outside the database structure: Command-line auditing cannot affect the database, because it works with data liberated from its database prison.
+
+Readers who trained on Unix will be smiling smugly at this point. They remember manipulating data on the command line many years ago in just these ways. What's happened since then is that processing power and RAM have increased spectacularly, and the standard command-line tools have been made substantially more efficient. Data auditing has never been faster or easier. And now that Microsoft Windows 10 can run Bash and GNU/Linux programs, Windows users can appreciate the Unix and Linux motto for dealing with messy data: Keep calm and open a terminal.
+
+
+![Tshirt, Keep Calm and Open A Terminal][9]
+
+Photo by Robert Mesibov, CC BY
+
+### An example
+
+Suppose I want to find the longest data item in a particular field of a big table. That's not really a data auditing task, but it will show how shell tools work. For demonstration purposes, I'll use the tab-separated table `full0`, which has 1,122,023 records (plus a header line) and 49 fields, and I'll look in field number 36. (I get field numbers with a function explained [on my cookbook site][10].)
+
+The command begins by using `tail` to remove the header line from `full0`. The result is piped to `cut`, which extracts the decapitated field 36. Next in the pipeline is `awk`. Here the variable `big` is initialized to a value of 0; then `awk` tests the length of the data item in the first record. If the length is bigger than 0, `awk` resets `big` to the new length and stores the line number (NR) in the variable `line` and the whole data item in the variable `text`. `awk` then processes each of the remaining 1,122,022 records in turn, resetting the three variables when it finds a longer data item. Finally, it prints out a neatly separated list of line numbers, length of data item, and full text of the longest data item. (In the following code, the commands have been broken up for clarity onto several lines.)
+```
+tail -n +2 full0 \
+
+> | cut -f36 \
+
+> | awk 'BEGIN {big=0} length($0)>big \
+
+> {big=length($0);line=NR;text=$0} \
+
+> END {print "\nline: "line"\nlength: "big"\ntext: "text}'
+
+```
+
+How long does this take? About 4 seconds on my desktop (core i5, 8GB RAM):
+
+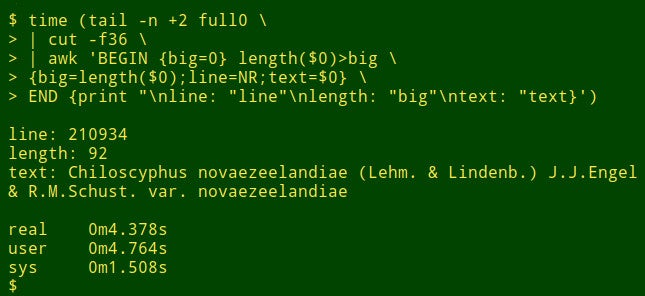
+
+Now for the neat part: I can pop that long command into a shell function, `longest`, which takes as its arguments the filename `($1)` and the field number `($2)`:
+
+
+I can then re-run the command as a function, finding longest data items in other fields and in other files without needing to remember how the command is written:
+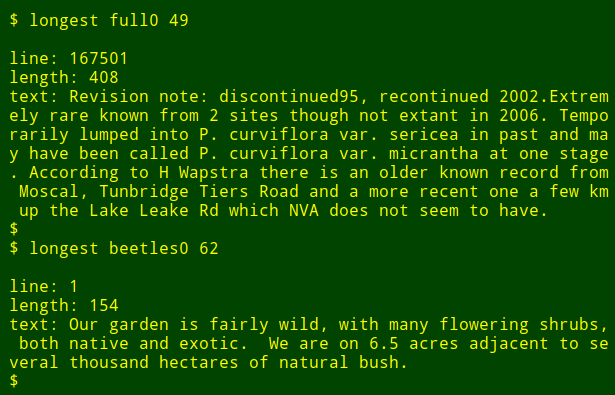
+
+As a final tweak, I can add to the output the name of the numbered field I'm searching. To do this, I use `head` to extract the header line of the table, pipe that line to `tr` to convert tabs to new lines, and pipe the resulting list to `tail` and `head` to print the `$2th` field name on the list, where `$2` is the field number argument. The field name is stored in the shell variable `field` and passed to `awk` for printing as the internal `awk` variable `fld`.
+```
+longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
+
+tail -n +2 "$1" \
+
+| cut -f"$2" | \
+
+awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
+
+{big=length($0);line=NR;text=$0}
+
+END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }
+
+```
+
+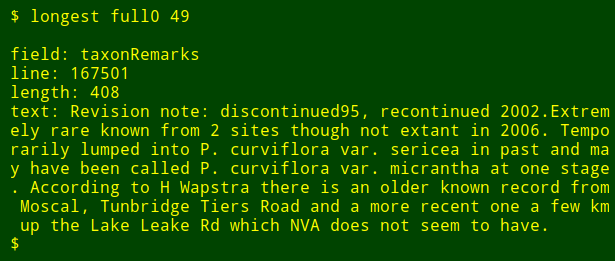
+
+Note that if I'm looking for the longest data item in a number of different fields, all I have to do is press the Up Arrow key to get the last `longest` command, then backspace the field number and enter a new one.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/command-line-data-auditing
+
+作者:[Bob Mesibov][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/bobmesibov
+[1]:https://en.wikipedia.org/wiki/Mojibake
+[2]:https://en.wikipedia.org/wiki/Control_character
+[3]:https://en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_character
+[4]:http://openrefine.org/
+[5]:https://www.python.org/
+[6]:https://www.r-project.org/about.html
+[7]:https://www.polydesmida.info/cookbook/index.html
+[8]:/file/399116
+[9]:https://opensource.com/sites/default/files/uploads/terminal_tshirt.jpg (Tshirt, Keep Calm and Open A Terminal)
+[10]:https://www.polydesmida.info/cookbook/functions.html#fields
diff --git a/sources/tech/20180528 What is behavior-driven Python.md b/sources/tech/20180528 What is behavior-driven Python.md
new file mode 100644
index 0000000000..5931b0b5f7
--- /dev/null
+++ b/sources/tech/20180528 What is behavior-driven Python.md
@@ -0,0 +1,307 @@
+What is behavior-driven Python?
+======
+
+Have you heard about [behavior-driven development][1] (BDD) and wondered what all the buzz is about? Maybe you've caught team members talking in "gherkin" and felt left out of the conversation. Or perhaps you're a Pythonista looking for a better way to test your code. Whatever the circumstance, learning about BDD can help you and your team achieve better collaboration and test automation, and Python's `behave` framework is a great place to start.
+
+### What is BDD?
+
+ * Submitting forms on a website
+ * Searching for desired results
+ * Saving a document
+ * Making REST API calls
+ * Running command-line interface commands
+
+
+
+In software, a behavior is how a feature operates within a well-defined scenario of inputs, actions, and outcomes. Products can exhibit countless behaviors, such as:
+
+Defining a product's features based on its behaviors makes it easier to describe them, develop them, and test them. This is the heart of BDD: making behaviors the focal point of software development. Behaviors are defined early in development using a [specification by example][2] language. One of the most common behavior spec languages is [Gherkin][3], the Given-When-Then scenario format from the [Cucumber][4] project. Behavior specs are basically plain-language descriptions of how a behavior works, with a little bit of formal structure for consistency and focus. Test frameworks can easily automate these behavior specs by "gluing" step texts to code implementations.
+
+Below is an example of a behavior spec written in Gherkin:
+```
+Scenario: Basic DuckDuckGo Search
+
+ Given the DuckDuckGo home page is displayed
+
+ When the user searches for "panda"
+
+ Then results are shown for "panda"
+
+```
+
+At a quick glance, the behavior is intuitive to understand. Except for a few keywords, the language is freeform. The scenario is concise yet meaningful. A real-world example illustrates the behavior. Steps declaratively indicate what should happen—without getting bogged down in the details of how.
+
+The [main benefits of BDD][5] are good collaboration and automation. Everyone can contribute to behavior development, not just programmers. Expected behaviors are defined and understood from the beginning of the process. Tests can be automated together with the features they cover. Each test covers a singular, unique behavior in order to avoid duplication. And, finally, existing steps can be reused by new behavior specs, creating a snowball effect.
+
+### Python's behave framework
+
+`behave` is one of the most popular BDD frameworks in Python. It is very similar to other Gherkin-based Cucumber frameworks despite not holding the official Cucumber designation. `behave` has two primary layers:
+
+ 1. Behavior specs written in Gherkin `.feature` files
+ 2. Step definitions and hooks written in Python modules that implement Gherkin steps
+
+
+
+As shown in the example above, Gherkin scenarios use a three-part format:
+
+ 1. Given some initial state
+ 2. When an action is taken
+ 3. Then verify the outcome
+
+
+
+Each step is "glued" by decorator to a Python function when `behave` runs tests.
+
+### Installation
+
+As a prerequisite, make sure you have Python and `pip` installed on your machine. I strongly recommend using Python 3. (I also recommend using [`pipenv`][6], but the following example commands use the more basic `pip`.)
+
+Only one package is required for `behave`:
+```
+pip install behave
+
+```
+
+Other packages may also be useful, such as:
+```
+pip install requests # for REST API calls
+
+pip install selenium # for Web browser interactions
+
+```
+
+The [behavior-driven-Python][7] project on GitHub contains the examples used in this article.
+
+### Gherkin features
+
+The Gherkin syntax that `behave` uses is practically compliant with the official Cucumber Gherkin standard. A `.feature` file has Feature sections, which in turn have Scenario sections with Given-When-Then steps. Below is an example:
+```
+Feature: Cucumber Basket
+
+ As a gardener,
+
+ I want to carry many cucumbers in a basket,
+
+ So that I don’t drop them all.
+
+
+
+ @cucumber-basket
+
+ Scenario: Add and remove cucumbers
+
+ Given the basket is empty
+
+ When "4" cucumbers are added to the basket
+
+ And "6" more cucumbers are added to the basket
+
+ But "3" cucumbers are removed from the basket
+
+ Then the basket contains "7" cucumbers
+
+```
+
+There are a few important things to note here:
+
+ * Both the Feature and Scenario sections have [short, descriptive titles][8].
+ * The lines immediately following the Feature title are comments ignored by `behave`. It is a good practice to put the user story there.
+ * Scenarios and Features can have tags (notice the `@cucumber-basket` mark) for hooks and filtering (explained below).
+ * Steps follow a [strict Given-When-Then order][9].
+ * Additional steps can be added for any type using `And` and `But`.
+ * Steps can be parametrized with inputs—notice the values in double quotes.
+
+
+
+Scenarios can also be written as templates with multiple input combinations by using a Scenario Outline:
+```
+Feature: Cucumber Basket
+
+
+
+ @cucumber-basket
+
+ Scenario Outline: Add cucumbers
+
+ Given the basket has “” cucumbers
+
+ When "" cucumbers are added to the basket
+
+ Then the basket contains "" cucumbers
+
+
+
+ Examples: Cucumber Counts
+
+ | initial | more | total |
+
+ | 0 | 1 | 1 |
+
+ | 1 | 2 | 3 |
+
+ | 5 | 4 | 9 |
+
+```
+
+Scenario Outlines always have an Examples table, in which the first row gives column titles and each subsequent row gives an input combo. The row values are substituted wherever a column title appears in a step surrounded by angle brackets. In the example above, the scenario will be run three times because there are three rows of input combos. Scenario Outlines are a great way to avoid duplicate scenarios.
+
+There are other elements of the Gherkin language, but these are the main mechanics. To learn more, read the Automation Panda articles [Gherkin by Example][10] and [Writing Good Gherkin][11].
+
+### Python mechanics
+
+Every Gherkin step must be "glued" to a step definition, a Python function that provides the implementation. Each function has a step type decorator with the matching string. It also receives a shared context and any step parameters. Feature files must be placed in a directory named `features/`, while step definition modules must be placed in a directory named `features/steps/`. Any feature file can use step definitions from any module—they do not need to have the same names. Below is an example Python module with step definitions for the cucumber basket features.
+```
+from behave import *
+
+from cucumbers.basket import CucumberBasket
+
+
+
+@given('the basket has "{initial:d}" cucumbers')
+
+def step_impl(context, initial):
+
+ context.basket = CucumberBasket(initial_count=initial)
+
+
+
+@when('"{some:d}" cucumbers are added to the basket')
+
+def step_impl(context, some):
+
+ context.basket.add(some)
+
+
+
+@then('the basket contains "{total:d}" cucumbers')
+
+def step_impl(context, total):
+
+ assert context.basket.count == total
+
+```
+
+Three [step matchers][12] are available: `parse`, `cfparse`, and `re`. The default and simplest marcher is `parse`, which is shown in the example above. Notice how parametrized values are parsed and passed into the functions as input arguments. A common best practice is to put double quotes around parameters in steps.
+
+Each step definition function also receives a [context][13] variable that holds data specific to the current scenario being run, such as `feature`, `scenario`, and `tags` fields. Custom fields may be added, too, to share data between steps. Always use context to share data—never use global variables!
+
+`behave` also supports [hooks][14] to handle automation concerns outside of Gherkin steps. A hook is a function that will be run before or after a step, scenario, feature, or whole test suite. Hooks are reminiscent of [aspect-oriented programming][15]. They should be placed in a special `environment.py` file under the `features/` directory. Hook functions can check the current scenario's tags, as well, so logic can be selectively applied. The example below shows how to use hooks to set up and tear down a Selenium WebDriver instance for any scenario tagged as `@web`.
+```
+from selenium import webdriver
+
+
+
+def before_scenario(context, scenario):
+
+ if 'web' in context.tags:
+
+ context.browser = webdriver.Firefox()
+
+ context.browser.implicitly_wait(10)
+
+
+
+def after_scenario(context, scenario):
+
+ if 'web' in context.tags:
+
+ context.browser.quit()
+
+```
+
+Note: Setup and cleanup can also be done with [fixtures][16] in `behave`.
+
+To offer an idea of what a `behave` project should look like, here's the example project's directory structure:
+
+
+
+Any Python packages and custom modules can be used with `behave`. Use good design patterns to build a scalable test automation solution. Step definition code should be concise.
+
+### Running tests
+
+To run tests from the command line, change to the project's root directory and run the `behave` command. Use the `–help` option to see all available options.
+
+Below are a few common use cases:
+```
+# run all tests
+
+behave
+
+
+
+# run the scenarios in a feature file
+
+behave features/web.feature
+
+
+
+# run all tests that have the @duckduckgo tag
+
+behave --tags @duckduckgo
+
+
+
+# run all tests that do not have the @unit tag
+
+behave --tags ~@unit
+
+
+
+# run all tests that have @basket and either @add or @remove
+
+behave --tags @basket --tags @add,@remove
+
+```
+
+For convenience, options may be saved in [config][17] files.
+
+### Other options
+
+`behave` is not the only BDD test framework in Python. Other good frameworks include:
+
+ * `pytest-bdd` , a plugin for `pytest``behave`, it uses Gherkin feature files and step definition modules, but it also leverages all the features and plugins of `pytest`. For example, it can run Gherkin scenarios in parallel using `pytest-xdist`. BDD and non-BDD tests can also be executed together with the same filters. `pytest-bdd` also offers a more flexible directory layout.
+
+ * `radish` is a "Gherkin-plus" framework—it adds Scenario Loops and Preconditions to the standard Gherkin language, which makes it more friendly to programmers. It also offers rich command line options like `behave`.
+
+ * `lettuce` is an older BDD framework very similar to `behave`, with minor differences in framework mechanics. However, GitHub shows little recent activity in the project (as of May 2018).
+
+
+
+Any of these frameworks would be good choices.
+
+Also, remember that Python test frameworks can be used for any black box testing, even for non-Python products! BDD frameworks are great for web and service testing because their tests are declarative, and Python is a [great language for test automation][18].
+
+This article is based on the author's [PyCon Cleveland 2018][19] talk, [Behavior-Driven Python][20].
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/behavior-driven-python
+
+作者:[Andrew Knight][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/andylpk247
+[1]:https://automationpanda.com/bdd/
+[2]:https://en.wikipedia.org/wiki/Specification_by_example
+[3]:https://automationpanda.com/2017/01/26/bdd-101-the-gherkin-language/
+[4]:https://cucumber.io/
+[5]:https://automationpanda.com/2017/02/13/12-awesome-benefits-of-bdd/
+[6]:https://docs.pipenv.org/
+[7]:https://github.com/AndyLPK247/behavior-driven-python
+[8]:https://automationpanda.com/2018/01/31/good-gherkin-scenario-titles/
+[9]:https://automationpanda.com/2018/02/03/are-gherkin-scenarios-with-multiple-when-then-pairs-okay/
+[10]:https://automationpanda.com/2017/01/27/bdd-101-gherkin-by-example/
+[11]:https://automationpanda.com/2017/01/30/bdd-101-writing-good-gherkin/
+[12]:http://behave.readthedocs.io/en/latest/api.html#step-parameters
+[13]:http://behave.readthedocs.io/en/latest/api.html#detecting-that-user-code-overwrites-behave-context-attributes
+[14]:http://behave.readthedocs.io/en/latest/api.html#environment-file-functions
+[15]:https://en.wikipedia.org/wiki/Aspect-oriented_programming
+[16]:http://behave.readthedocs.io/en/latest/api.html#fixtures
+[17]:http://behave.readthedocs.io/en/latest/behave.html#configuration-files
+[18]:https://automationpanda.com/2017/01/21/the-best-programming-language-for-test-automation/
+[19]:https://us.pycon.org/2018/
+[20]:https://us.pycon.org/2018/schedule/presentation/87/
diff --git a/sources/tech/20180529 5 trending open source machine learning JavaScript frameworks.md b/sources/tech/20180529 5 trending open source machine learning JavaScript frameworks.md
new file mode 100644
index 0000000000..087fba35c7
--- /dev/null
+++ b/sources/tech/20180529 5 trending open source machine learning JavaScript frameworks.md
@@ -0,0 +1,65 @@
+5 trending open source machine learning JavaScript frameworks
+======
+
+
+The tremendous growth of the machine learning field has been driven by the availability of open source tools that allow developers to build applications easily. (For example, [AndreyBu][1], who is from Germany and has more than five years of experience in machine learning, has been utilizing various open source frameworks to build captivating machine learning projects.)
+
+Although the Python programming language powers most of the machine learning frameworks, JavaScript hasn’t been left behind. JavaScript developers have been using various frameworks for training and deploying machine learning models in the browser.
+
+Here are the five trending open source machine learning frameworks in JavaScript.
+
+### 1\. TensorFlow.js
+
+[TensorFlow.js][2] is an open source library that allows you to run machine learning programs completely in the browser. It is the successor of Deeplearn.js, which is no longer supported. TensorFlow.js improves on the functionalities of Deeplearn.js and empowers you to make the most of the browser for a deeper machine learning experience.
+
+With the library, you can use versatile and intuitive APIs to define, train, and deploy models from scratch right in the browser. Furthermore, it automatically offers support for WebGL and Node.js.
+
+If you have pre-existing trained models you want to import to the browser, TensorFlow.js will allow you do that. You can also retrain existing models without leaving the browser.
+
+The [machine learning tools][3] library is a compilation of resourceful open source tools for supporting widespread machine learning functionalities in the browser. The tools provide support for several machine learning algorithms, including unsupervised learning, supervised learning, data processing, artificial neural networks (ANN), math, and regression.
+
+If you are coming from a Python background and looking for something similar to Scikit-learn for JavaScript in-browser machine learning, this suite of tools could have you covered.
+
+### 3\. Keras.js
+
+[Keras.js][4] is another trending open source framework that allows you to run machine learning models in the browser. It offers GPU mode support using WebGL. If you have models in Node.js, you’ll run them only in CPU mode. Keras.js also offers support for models trained using any backend framework, such as the Microsoft Cognitive Toolkit (CNTK).
+
+Some of the Keras models that can be deployed on the client-side browser include Inception v3 (trained on ImageNet), 50-layer Residual Network (trained on ImageNet), and Convolutional variational auto-encoder (trained on MNIST).
+
+### 4\. Brain.js
+
+Machine learning concepts are very math-heavy, which may discourage people from starting. The technicalities and jargons in this field may make beginners freak out. This is where [Brain.js][5] becomes important. It is an open source, JavaScript-powered framework that simplifies the process of defining, training, and running neural networks.
+
+If you are a JavaScript developer who is completely new to machine learning, Brain.js could reduce your learning curve. It can be used with Node.js or in the client-side browser for training machine learning models. Some of the networks that Brain.js supports include feed-forward networks, Ellman networks, and Gated Recurrent Units networks.
+
+### 5\. STDLib
+
+[STDLib][6] is an open source library for powering JavaScript and Node.js applications. If you are looking for a library that emphasizes in-browser support for scientific and numerical web-based machine learning applications, STDLib could suit your needs.
+
+The library comes with comprehensive and advanced mathematical and statistical functions to assist you in building high-performing machine learning models. You can also use its expansive utilities for building applications and other libraries. Furthermore, if you want a framework for data visualization and exploratory data analysis, you’ll find STDLib worthwhile.
+
+### Conclusion
+
+If you are a JavaScript developer who intends to delve into the exciting world of [machine learning][7] or a machine learning expert who intends to start using JavaScript, the above open source frameworks will intrigue you.
+
+Do you know of another open source library that offers in-browser machine learning capabilities? Please let us know in the comment section below.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/machine-learning-javascript-frameworks
+
+作者:[Dr.Michael J.Garbade][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/drmjg
+[1]:https://www.liveedu.tv/andreybu/REaxr-machine-learning-model-python-sklearn-kera/
+[2]:https://js.tensorflow.org/
+[3]:https://github.com/mljs/ml
+[4]:https://transcranial.github.io/keras-js/#/
+[5]:https://github.com/BrainJS/brain.js
+[6]:https://stdlib.io/
+[7]:https://www.liveedu.tv/guides/artificial-intelligence/machine-learning/
diff --git a/sources/tech/20180529 Copying and renaming files on Linux.md b/sources/tech/20180529 Copying and renaming files on Linux.md
new file mode 100644
index 0000000000..2ede0ac1f4
--- /dev/null
+++ b/sources/tech/20180529 Copying and renaming files on Linux.md
@@ -0,0 +1,119 @@
+Copying and renaming files on Linux
+======
+
+Linux users have for many decades been using simple cp and mv commands to copy and rename files. These commands are some of the first that most of us learned and are used every day by possibly millions of people. But there are other techniques, handy variations, and another command for renaming files that offers some unique options.
+
+First, let’s think about why might you want to copy a file. You might need the same file in another location or you might want a copy because you’re going to edit the file and want to be sure you have a handy backup just in case you need to revert to the original file. The obvious way to do that is to use a command like “cp myfile myfile-orig”.
+
+If you want to copy a large number of files, however, that strategy might get old real fast. Better alternatives are to:
+
+ * Use tar to create an archive of all of the files you want to back up before you start editing them.
+ * Use a for loop to make the backup copies easier.
+
+
+
+The tar option is very straightforward. For all files in the current directory, you’d use a command like:
+```
+$ tar cf myfiles.tar *
+
+```
+
+For a group of files that you can identify with a pattern, you’d use a command like this:
+```
+$ tar cf myfiles.tar *.txt
+
+```
+
+In each case, you end up with a myfiles.tar file that contains all the files in the directory or all files with the .txt extension.
+
+An easy loop would allow you to make backup copies with modified names:
+```
+$ for file in *
+> do
+> cp $file $file-orig
+> done
+
+```
+
+When you’re backing up a single file and that file just happens to have a long name, you can rely on using the tab command to use filename completion (hit the tab key after entering enough letters to uniquely identify the file) and use syntax like this to append “-orig” to the copy.
+```
+$ cp file-with-a-very-long-name{,-orig}
+
+```
+
+You then have a file-with-a-very-long-name and a file-with-a-very-long-name file-with-a-very-long-name-orig.
+
+### Renaming files on Linux
+
+The traditional way to rename a file is to use the mv command. This command will move a file to a different directory, change its name and leave it in place, or do both.
+```
+$ mv myfile /tmp
+$ mv myfile notmyfile
+$ mv myfile /tmp/notmyfile
+
+```
+
+But we now also have the rename command to do some serious renaming for us. The trick to using the rename command is to get used to its syntax, but if you know some perl, you might not find it tricky at all.
+
+Here’s a very useful example. Say you wanted to rename the files in a directory to replace all of the uppercase letters with lowercase ones. In general, you don’t find a lot of file with capital letters on Unix or Linux systems, but you could. Here’s an easy way to rename them without having to use the mv command for each one of them. The /A-Z/a-z/ specification tells the rename command to change any letters in the range A-Z to the corresponding letters in a-z.
+```
+$ ls
+Agenda Group.JPG MyFile
+$ rename 'y/A-Z/a-z/' *
+$ ls
+agenda group.jpg myfile
+
+```
+
+You can also use rename to remove file extensions. Maybe you’re tired of seeing text files with .txt extensions. Simply remove them — and in one command.
+```
+$ ls
+agenda.txt notes.txt weekly.txt
+$ rename 's/.txt//' *
+$ ls
+agenda notes weekly
+
+```
+
+Now let’s imagine you have a change of heart and want to put those extensions back. No problem. Just change the command. The trick is understanding that the “s” before the first slash means “substitute”. What’s in between the first two slashes is what we want to change, and what’s in between the second and third slashes is what we want to change it to. So, $ represents the end of the filename, and we’re changing it to “.txt”.
+```
+$ ls
+agenda notes weekly
+$ rename 's/$/.txt/' *
+$ ls
+agenda.txt notes.txt weekly.txt
+
+```
+
+You can change other parts of filenames, as well. Keep the **s/old/new/** rule in mind.
+```
+$ ls
+draft-minutes-2018-03 draft-minutes-2018-04 draft-minutes-2018-05
+$ rename 's/draft/approved/' *minutes*
+$ ls
+approved-minutes-2018-03 approved-minutes-2018-04 approved-minutes-2018-05
+
+```
+
+Note in the examples above that when we use an **s** as in " **s** /old/new/", we are substituting one part of the name with another. When we use **y** , we are transliterating (substituting characters from one range to another).
+
+### Wrap-up
+
+There are a lot of options for copying and renaming files. I hope some of them will make your time on the command line more enjoyable.
+
+Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3276349/linux/copying-and-renaming-files-on-linux.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[1]:https://www.facebook.com/NetworkWorld/
+[2]:https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20180529 Manage your workstation with Ansible- Configure desktop settings.md b/sources/tech/20180529 Manage your workstation with Ansible- Configure desktop settings.md
new file mode 100644
index 0000000000..d04ee6d742
--- /dev/null
+++ b/sources/tech/20180529 Manage your workstation with Ansible- Configure desktop settings.md
@@ -0,0 +1,196 @@
+Manage your workstation with Ansible: Configure desktop settings
+======
+
+
+
+In the [first article][1] of this series on using Ansible to configure a workstation, we set up a repository and configured a few basic things. In the [second part][2], we automated Ansible to apply settings automatically when changes are made to our repository. In this third (and final) article, we'll use Ansible to configure GNOME desktop settings.
+
+This configuration will work only on newer distributions (such as Ubuntu 18.04, which I'll use in my examples). Older versions of Ubuntu will not work, as they ship with a version of `python-psutils` that is too old for Ansible's `dconf` module to work properly. If you're using a newer version of your Linux distribution, you should have no issues.
+
+Before you begin, make sure you've worked through parts one and two of this series, as part three builds upon that groundwork. If you haven't already, download the GitHub repository you've been using in those first two articles. We'll add a few more features to it.
+
+### Set a wallpaper and lock screen
+
+First, we'll create a taskbook to hold our GNOME settings. In the root of the repository, you should have a file named `local.yml`. Add the following line to it:
+```
+- include: tasks/gnome.yml
+
+```
+
+The entire file should now look like this:
+```
+- hosts: localhost
+
+ become: true
+
+ pre_tasks:
+
+ - name: update repositories
+
+ apt: update_cache=yes
+
+ changed_when: False
+
+
+
+ tasks:
+
+ - include: tasks/users.yml
+
+ - include: tasks/cron.yml
+
+ - include: tasks/packages.yml
+
+ - include: tasks/gnome.yml
+
+```
+
+Basically, this added a reference to a file named `gnome.yml` that will be stored in the `tasks` directory inside the repository. We haven't created this file yet, so let's do that now. Create `gnome.yml` file in the `tasks` directory, and place the following content inside:
+```
+- name: Install python-psutil package
+
+ apt: name=python-psutil
+
+
+
+- name: Copy wallpaper file
+
+ copy: src=files/wallpaper.jpg dest=/home/jay/.wallpaper.jpg owner=jay group=jay mode=600
+
+
+
+- name: Set GNOME Wallpaper
+
+ become_user: jay
+
+ dconf: key="/org/gnome/desktop/background/picture-uri" value="'file:///home/jay/.wallpaper.jpg'"
+
+```
+
+Note that this code refers to my username (`jay`) several times, so make sure to replace every occurrence of `jay` with the username you use on your machine. Also, if you're not using Ubuntu 18.04 (as I am), you'll have to change the `apt` line to match the package manager for your chosen distribution and to confirm the name of the `python-psutil` package for your distribution, as it may be different.
+
+`wallpaper.jpg` inside the `files` directory. This file must exist or the Ansible configuration will fail. Inside the `tasks` directory, create a subdirectory named `files`. Find a wallpaper image you like, name it `wallpaper.jpg`, and place it inside the `files` directory. If the file is a PNG image instead of a JPG, change the file extension in both the code and in the repository. If you're not feeling creative, I have an example wallpaper file in the
+
+In the example tasks, I referred to a file namedinside thedirectory. This file must exist or the Ansible configuration will fail. Inside thedirectory, create a subdirectory named. Find a wallpaper image you like, name it, and place it inside thedirectory. If the file is a PNG image instead of a JPG, change the file extension in both the code and in the repository. If you're not feeling creative, I have an example wallpaper file in the [GitHub repository][3] for this article series that you can use.
+
+Once you've made all these changes, commit everything to your GitHub repository, and push those changes. To recap, you should've completed the following:
+
+ * Modified the `local.yml` file to refer to the `tasks/gnome.yml` playbook
+ * Created the `tasks/gnome.yml` playbook with the content mentioned above
+ * Created a `files` directory inside the `tasks` directory, with an image file named `wallpaper.jpg` (or whatever you chose to call it).
+
+
+
+Once you've completed those steps and pushed your changes back to the repository, the configuration should be automatically applied during its next scheduled run. (You may recall that we automated this in the previous article.) If you're in a hurry, you can apply the configuration immediately with the following command:
+```
+sudo ansible-pull -U https://github.com//ansible.git
+
+```
+
+If everything ran correctly, you should see your new wallpaper.
+
+Let's take a moment to go through what the new GNOME taskbook does. First, we added a play to install the `python-psutil` package. If we don't add this, we can't use the `dconf` module, since it requires this package to be installed before we can modify GNOME settings. Next, we used the `copy` module to copy the wallpaper file to our `home` directory, and we named the resulting file starting with a period to hide it. If you'd prefer not to have this file in the root of your `home` directory, you can always instruct this section to copy it somewhere else—it will still work as long as you refer to it at the correct place. In the next play, we used the `dconf` module to change GNOME settings. In this case, we adjusted the `/org/gnome/desktop/background/picture-uri` key and set it equal to `file:///home/jay/.wallpaper.jpg`. Note the quotes in this section of the playbook—you must always use two single-quotes in `dconf` values, and you must also include double-quotes if the value is a string.
+
+Now, let's take our configuration a step further and apply a background to the lock screen. Here's the GNOME taskbook again, but with two additional plays added:
+```
+- name: Install python-psutil package
+
+ apt: name=python-psutil
+
+
+
+- name: Copy wallpaper file
+
+ copy: src=files/wallpaper.jpg dest=/home/jay/.wallpaper.jpg owner=jay group=jay mode=600
+
+
+
+- name: Set GNOME wallpaper
+
+ dconf: key="/org/gnome/desktop/background/picture-uri" value="'file:///home/jay/.wallpaper.jpg'"
+
+
+
+- name: Copy lockscreenfile
+
+ copy: src=files/lockscreen.jpg dest=/home/jay/.lockscreen.jpg owner=jay group=jay mode=600
+
+
+
+- name: Set lock screen background
+
+ become_user: jay
+
+ dconf: key="/org/gnome/desktop/screensaver/picture-uri" value="'file:///home/jay/.lockscreen.jpg'"
+
+```
+
+As you can see, we're pretty much doing the same thing as we did with the wallpaper. We added two additional tasks, one to copy the lock screen image and place it in our `home` directory, and another to apply the setting to GNOME so it will be used. Again, be sure to change your username from `jay` and also name your desired lock screen picture `lockscreen.jpg` and copy it to the `files` directory. Once you've committed these changes to your repository, the new lock screen should be applied during the next scheduled Ansible run.
+
+### Apply a new desktop theme
+
+Setting the wallpaper and lock screen background is cool and all, but let's go even further and apply a desktop theme. First, let's add an instruction to our taskbook to install the package for the `arc` theme. Add the following code to the beginning of the GNOME taskbook:
+```
+- name: Install arc theme
+
+ apt: name=arc-theme
+
+```
+
+Then, at the bottom, add the following play:
+```
+- name: Set GTK theme
+
+ become_user: jay
+
+ dconf: key="/org/gnome/desktop/interface/gtk-theme" value="'Arc'"
+
+```
+
+Did you see GNOME's GTK theme change right before your eyes? We added a play to install the `arc-theme` package via the `apt` module and another play to apply this theme to GNOME.
+
+### Make other customizations
+
+Now that you've changed some GNOME settings, feel free to add additional customizations on your own. Any setting you can tweak in GNOME can be automated this way; setting the wallpapers and the theme were just a few examples. You may be wondering how to find the settings that you want to change. Here's a trick that works for me.
+
+First, take a snapshot of ALL your current `dconf` settings by running the following command on the machine you're managing:
+```
+dconf dump / > before.txt
+
+```
+
+This command exports all your current changes to a file named `before.txt`. Next, manually change the setting you want to automate, and capture the `dconf` settings again:
+```
+dconf dump / > after.txt
+
+```
+
+Now, you can use the `diff` command to see what's different between the two files:
+```
+diff before.txt after.txt
+
+```
+
+This should give you a list of keys that changed. While it's true that changing settings manually defeats the purpose of automation, what you're essentially doing is capturing the keys that change when you update your preferred settings, which then allows you to create Ansible plays to modify those settings so you'll never need to touch those settings again. If you ever need to restore your machine, your Ansible repository will take care of each and every one of your customizations. If you have multiple machines, or even a fleet of workstations, you only have to manually make the change once, and all other workstations will have the new settings applied and be completely in sync.
+
+### Wrapping up
+
+If you've followed along with this series, you should know how to set up Ansible to automate your workstation. These examples offer a useful baseline, and you can use the syntax and examples to make additional customizations. As you go along, you can continue to add new modifications, which will make your Ansible configuration grow over time.
+
+I've used Ansible in this way to automate everything, including my user account and password; configuration files for Vim, tmux, etc.; desktop packages; SSH settings; SSH keys; and basically everything I could ever want to customize. Using this series as a starting point will pave the way for you to completely automate your workstations.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/manage-your-workstation-ansible-part-3
+
+作者:[Jay LaCroix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jlacroix
+[1]:https://opensource.com/article/18/3/manage-workstation-ansible
+[2]:https://opensource.com/article/18/3/manage-your-workstation-configuration-ansible-part-2
+[3]:https://github.com/jlacroix82/ansible_article.git
diff --git a/sources/tech/20180529 The Source Code Line Counter And Analyzer.md b/sources/tech/20180529 The Source Code Line Counter And Analyzer.md
new file mode 100644
index 0000000000..c1a6497cdd
--- /dev/null
+++ b/sources/tech/20180529 The Source Code Line Counter And Analyzer.md
@@ -0,0 +1,122 @@
+The Source Code Line Counter And Analyzer
+======
+
+
+
+**Ohcount** is simple command line utility that analyzes the source code and prints the total number lines of a source code file. It is not just source code line counter, but also detects the popular open source licenses, such as GPL, within a large directory of source code. Additionally, Ohcount can also detect code that targets a particular programming API such as KDE or Win32. As of writing this guide, Ohcount currently supports over 70 popular programming languages. It is written in **C** programming language and is originally developed by **Ohloh** for generating the reports at [www.openhub.net][1].
+
+In this brief tutorial, we are going to how to install and use Ohcount to analyze source code files in Debian, Ubuntu and its variants like Linux Mint.
+
+### Ohcount – The source code line counter
+
+**Installation**
+
+Ohcount is available in the default repositories in Debian and Ubuntu and its derivatives, so you can install it using APT package manager as shown below.
+```
+$ sudo apt-get install ohcount
+
+```
+
+**Usage**
+
+Ohcount usage is extremely simple.
+
+All you have to do is go to the directory where you have the source code that you want to analyze and ohcount program.
+
+Say for example, I am going to analyze the source of code of [**coursera-dl**][2] program.
+```
+$ cd coursera-dl-master/
+
+$ ohcount
+
+```
+
+Here is the line count summary of Coursera-dl program:
+
+![][4]
+
+As you can see, the source code of Coursera-dl program contains 141 files in total. The first column specifies the name of programming languages that the source code consists of. The second column displays the number of files in each programming languages. The third column displays the total number of lines in each programming language. The fourth and fifth lines displays how many lines of comments and its percentage in the code. The sixth column displays the number of blank lines. And the final and seventh column displays total line of codes in each language and the gross total of coursera-dl program.
+
+Alternatively, mention the complete path directly like below.
+```
+$ ohcount coursera-dl-master/
+
+```
+
+The path can be any number of individual files or directories. Directories will be probed recursively. If no path is given, the current directory will be used.
+
+If you don’t want to mention the whole directory path each time, just CD into it and use ohcount utility to analyze the codes in that directory.
+
+To count lines of code per file, use **-i** flag.
+```
+$ ohcount -i
+
+```
+
+**Sample output:**
+
+![][5]
+
+Ohcount utility can also show the annotated source code when you use **-a** flag.
+```
+$ ohcount -a
+
+```
+
+![][6]
+
+As you can see, the contents of all source code files found in this directory is displayed. Each line is prefixed with a tab-delimited language name and semantic categorization (code, comment, or blank).
+
+Some times, you just want to know the license used in the source code. To do so, use **-l** flag.
+```
+$ ohcount -l
+lgpl3, coursera_dl.py
+gpl coursera_dl.py
+
+```
+
+Another available option is **-re** , which is used to print raw entity information to the screen (mainly for debugging).
+```
+$ ohcount -re
+
+```
+
+To find all source code files within the given paths recursively, use **-d** flag.
+```
+$ ohcount -d
+
+```
+
+The above command will display all source code files in the current working directory and the each file name will be prefixed with a tab-delimited language name.
+
+To know more details and supported options, run:
+```
+$ ohcount --help
+
+```
+
+Ohcount is quite useful for developers who wants to analysis the code written by themselves or other developers, and check how many lines that code contains, which languages have been used to write those codes, and the license details of the code etc.
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/ohcount-the-source-code-line-counter-and-analyzer/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:http://www.openhub.net
+[2]:https://www.ostechnix.com/coursera-dl-a-script-to-download-coursera-videos/
+[4]:http://www.ostechnix.com/wp-content/uploads/2018/05/ohcount-2.png
+[5]:http://www.ostechnix.com/wp-content/uploads/2018/05/ohcount-1-5.png
+[6]:http://www.ostechnix.com/wp-content/uploads/2018/05/ohcount-2-2.png
diff --git a/sources/tech/20180530 3 Python command-line tools.md b/sources/tech/20180530 3 Python command-line tools.md
new file mode 100644
index 0000000000..6aad040b71
--- /dev/null
+++ b/sources/tech/20180530 3 Python command-line tools.md
@@ -0,0 +1,270 @@
+3 Python command-line tools
+======
+
+
+
+This article was co-written with [Lacey Williams Henschel][1].
+
+Sometimes the right tool for the job is a command-line application. A command-line application is a program that you interact with and run from something like your shell or Terminal. [Git][2] and [Curl][3] are examples of command-line applications that you might already be familiar with.
+
+Command-line apps are useful when you have a bit of code you want to run several times in a row or on a regular basis. Django developers run commands like `./manage.py runserver` to start their web servers; Docker developers run `docker-compose up` to spin up their containers. The reasons you might want to write a command-line app are as varied as the reasons you might want to write code in the first place.
+
+For this month's Python column, we have three libraries to recommend to Pythonistas looking to write their own command-line tools.
+
+### Click
+
+[Click][4] is our favorite Python package for command-line applications. It:
+
+ * Has great documentation filled with examples
+
+ * Includes instructions on packaging your app as a Python application so it's easier to run
+
+ * Automatically generates useful help text
+
+ * Lets you stack optional and required arguments and even [several commands][5]
+
+ * Has a Django version ([][6]
+
+`django-click`
+
+) for writing management commands
+
+
+
+
+Click uses its `@click.command()` to declare a function as a command and specify required or optional arguments.
+```
+# hello.py
+
+import click
+
+
+
+@click.command()
+
+@click.option('--name', default='', help='Your name')
+
+def say_hello(name):
+
+ click.echo("Hello {}!".format(name))
+
+
+
+if __name__ == '__main__':
+
+ hello()
+
+```
+
+The `@click.option()` decorator declares an [optional argument][7], and the `@click.argument()` decorator declares a [required argument][8]. You can combine optional and required arguments by stacking the decorators. The `echo()` method prints results to the console.
+```
+$ python hello.py --name='Lacey'
+
+Hello Lacey!
+
+```
+
+### Docopt
+
+[Docopt][9] is a command-line application parser, sort of like Markdown for your command-line apps. If you like writing the documentation for your apps as you go, Docopt has by far the best-formatted help text of the options in this article. It isn't our favorite command-line app library because its documentation throws you into the deep end right away, which makes it a little more difficult to get started. Still, it's a lightweight library that is very popular, especially if exceptionally nice documentation is important to you.
+
+`help` and `version` flags.
+
+Docopt is very particular about how you format the required docstring at the top of your file. The top element in your docstring after the name of your tool must be "Usage," and it should list the ways you expect your command to be called (e.g., by itself, with arguments, etc.). Usage should includeandflags.
+
+The second element in your docstring should be "Options," and it should provide more information about the options and arguments you identified in "Usage." The content of your docstring becomes the content of your help text.
+```
+"""HELLO CLI
+
+
+
+Usage:
+
+ hello.py
+
+ hello.py
+
+ hello.py -h|--help
+
+ hello.py -v|--version
+
+
+
+Options:
+
+ Optional name argument.
+
+ -h --help Show this screen.
+
+ -v --version Show version.
+
+"""
+
+
+
+from docopt import docopt
+
+
+
+def say_hello(name):
+
+ return("Hello {}!".format(name))
+
+
+
+
+
+if __name__ == '__main__':
+
+ arguments = docopt(__doc__, version='DEMO 1.0')
+
+ if arguments['']:
+
+ print(say_hello(arguments['']))
+
+ else:
+
+ print(arguments)
+
+```
+
+At its most basic level, Docopt is designed to return your arguments to the console as key-value pairs. If I call the above command without specifying a name, I get a dictionary back:
+```
+$ python hello.py
+
+{'--help': False,
+
+ '--version': False,
+
+ '': None}
+
+```
+
+This shows me I did not input the `help` or `version` flags, and the `name` argument is `None`.
+
+But if I call it with a name, the `say_hello` function will execute.
+```
+$ python hello.py Jeff
+
+Hello Jeff!
+
+```
+
+Docopt allows both required and optional arguments and has different syntax conventions for each. Required arguments should be represented in `ALLCAPS` or in ``, and options should be represented with double or single dashes, like `--name`. Read more about Docopt's [patterns][10] in the docs.
+
+### Fire
+
+[Fire][11] is a Google library for writing command-line apps. We especially like it when your command needs to take more complicated arguments or deal with Python objects, as it tries to handle parsing your argument types intelligently.
+
+Fire's [docs][12] include a ton of examples, but I wish the docs were a bit better organized. Fire can handle [multiple commands in one file][13], commands as methods on [objects][14], and [grouping][15] commands.
+
+Its weakness is the documentation it makes available to the console. Docstrings on your commands don't appear in the help text, and the help text doesn't necessarily identify arguments.
+```
+import fire
+
+
+
+
+
+def say_hello(name=''):
+
+ return 'Hello {}!'.format(name)
+
+
+
+
+
+if __name__ == '__main__':
+
+ fire.Fire()
+
+```
+
+Arguments are made required or optional depending on whether you specify a default value for them in your function or method definition. To call this command, you must specify the filename and the function name, more like Click's syntax:
+```
+$ python hello.py say_hello Rikki
+
+Hello Rikki!
+
+```
+
+You can also pass arguments as flags, like `--name=Rikki`.
+
+### Bonus: Packaging!
+
+Click includes instructions (and highly recommends you follow them) for [packaging][16] your commands using `setuptools`.
+
+To package our first example, add this content to your `setup.py` file:
+```
+from setuptools import setup
+
+
+
+setup(
+
+ name='hello',
+
+ version='0.1',
+
+ py_modules=['hello'],
+
+ install_requires=[
+
+ 'Click',
+
+ ],
+
+ entry_points='''
+
+ [console_scripts]
+
+ hello=hello:say_hello
+
+ ''',
+
+)
+
+```
+
+Everywhere you see `hello`, substitute the name of your module but omit the `.py` extension. Where you see `say_hello`, substitute the name of your function.
+
+Then, run `pip install --editable` to make your command available to the command line.
+
+You can now call your command like this:
+```
+$ hello --name='Jeff'
+
+Hello Jeff!
+
+```
+
+By packaging your command, you omit the extra step in the console of having to type `python hello.py --name='Jeff'` and save yourself several keystrokes. These instructions will probably also work for the other libraries we mentioned.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/3-python-command-line-tools
+
+作者:[Jeff Triplett][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/laceynwilliams
+[1]:https://opensource.com/users/laceynwilliams
+[2]:https://git-scm.com/
+[3]:https://curl.haxx.se/
+[4]:http://click.pocoo.org/5/
+[5]:http://click.pocoo.org/5/commands/
+[6]:https://github.com/GaretJax/django-click
+[7]:http://click.pocoo.org/5/options/
+[8]:http://click.pocoo.org/5/arguments/
+[9]:http://docopt.org/
+[10]:https://github.com/docopt/docopt#usage-pattern-format
+[11]:https://github.com/google/python-fire
+[12]:https://github.com/google/python-fire/blob/master/docs/guide.md
+[13]:https://github.com/google/python-fire/blob/master/docs/guide.md#exposing-multiple-commands
+[14]:https://github.com/google/python-fire/blob/master/docs/guide.md#version-3-firefireobject
+[15]:https://github.com/google/python-fire/blob/master/docs/guide.md#grouping-commands
+[16]:http://click.pocoo.org/5/setuptools/
diff --git a/sources/tech/20180530 Introduction to the Pony programming language.md b/sources/tech/20180530 Introduction to the Pony programming language.md
new file mode 100644
index 0000000000..2f32ea6631
--- /dev/null
+++ b/sources/tech/20180530 Introduction to the Pony programming language.md
@@ -0,0 +1,94 @@
+Introduction to the Pony programming language
+======
+
+
+
+At [Wallaroo Labs][1], where I'm the VP of engineering, we're are building a [high-performance, distributed stream processor][2] written in the [Pony][3] programming language. Most people haven't heard of Pony, but it has been an excellent choice for Wallaroo, and it might be an excellent choice for your next project, too.
+
+> "A programming language is just another tool. It's not about syntax. It's not about expressiveness. It's not about paradigms or models. It's about managing hard problems." —Sylvan Clebsch, creator of Pony
+
+I'm a contributor to the Pony project, but here I'll touch on why Pony is a good choice for applications like Wallaroo and share ways I've used Pony. If you are interested in a more in-depth look at why we use Pony to write Wallaroo, we have a [blog post][4] about that.
+
+### What is Pony?
+
+You can think of Pony as something like "Rust meets Erlang." Pony sports buzzworthy features. It is:
+
+ * Type-safe
+ * Memory-safe
+ * Exception-safe
+ * Data-race-free
+ * Deadlock-free
+
+
+
+Additionally, it's compiled to efficient native code, and it's developed in the open and available under a two-clause BSD license.
+
+That's a lot of features, but here I'll focus on the few that were key to my company adopting Pony.
+
+### Why Pony?
+
+Writing fast, safe, efficient, highly concurrent programs is not easy with most of our existing tools. "Fast, efficient, and highly concurrent" is an achievable goal, but throw in "safe," and things get a lot harder. With Wallaroo, we wanted to accomplish all four, and Pony has made it easy to achieve.
+
+#### Highly concurrent
+
+Pony makes concurrency easy. Part of the way it does that is by providing an opinionated concurrency story. In Pony, all concurrency happens via the [actor model][5].
+
+The actor model is most famous via the implementations in Erlang and Akka. The actor model has been around since the 1970s, and details vary widely from implementation to implementation. What doesn't vary is that all computation is executed by actors that communicate via asynchronous messaging.
+
+Think of the actor model this way: objects in object-oriented programming are state + synchronous methods and actors are state + asynchronous methods.
+
+When an actor receives a message, it executes a corresponding method. That method might operate on a state that is accessible by only that actor. The actor model allows us to use a mutable state in a concurrency-safe manner. Every actor is single-threaded. Two methods within an actor are never run concurrently. This means that, within a given actor, data updates cannot cause data races or other problems commonly associated with threads and mutable states.
+
+#### Fast and efficient
+
+Pony actors are scheduled with an efficient work-stealing scheduler. There's a single Pony scheduler per available CPU. The thread-per-core concurrency model is part of Pony's attempt to work in concert with the CPU to operate as efficiently as possible. The Pony runtime attempts to be as CPU-cache friendly as possible. The less your code thrashes the cache, the better it will run. Pony aims to help your code play nice with CPU caches.
+
+The Pony runtime also features per-actor heaps so that, during garbage collection, there's no "stop the world" garbage collection step. This means your program is always doing at least some work. As a result, Pony programs end up with very consistent performance and predictable latencies.
+
+#### Safe
+
+The Pony type system introduces a novel concept: reference capabilities, which make data safety part of the type system. The type of every variable in Pony includes information about how the data can be shared between actors. The Pony compiler uses the information to verify, at compile time, that your code is data-race- and deadlock-free.
+
+If this sounds a bit like Rust, it's because it is. Pony's reference capabilities and Rust's borrow checker both provide data safety; they just approach it in different ways and have different tradeoffs.
+
+### Is Pony right for you?
+
+Deciding whether to use a new programming language for a non-hobby project is hard. You must weigh the appropriateness of the tool against its immaturity compared to other solutions. So, what about Pony and you?
+
+Pony might be the right solution if you have a hard concurrency problem to solve. Concurrent applications are Pony's raison d'être. If you can accomplish what you want in a single-threaded Python script, you probably don't need Pony. If you have a hard concurrency problem, you should consider Pony and its powerful data-race-free, concurrency-aware type system.
+
+You'll get a compiler that will prevent you from introducing many concurrency-related bugs and a runtime that will give you excellent performance characteristics.
+
+### Getting started with Pony
+
+If you're ready to get started with Pony, your first visit should be the [Learn section][6] of the Pony website. There you will find directions for installing the Pony compiler and resources for learning the language.
+
+If you like to contribute to the language you are using, we have some [beginner-friendly issues][7] waiting for you on GitHub.
+
+Also, I can't wait to start talking with you on [our IRC channel][8] and the [Pony mailing list][9].
+
+To learn more about Pony, attend Sean Allen's talk, [Pony: How I learned to stop worrying and embrace an unproven technology][10], at the [20th OSCON][11], July 16-19, 2018, in Portland, Ore.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/pony
+
+作者:[Sean T Allen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/seantallen
+[1]:http://www.wallaroolabs.com/
+[2]:https://github.com/wallaroolabs/wallaroo
+[3]:https://www.ponylang.org/
+[4]:https://blog.wallaroolabs.com/2017/10/why-we-used-pony-to-write-wallaroo/
+[5]:https://en.wikipedia.org/wiki/Actor_model
+[6]:https://www.ponylang.org/learn/
+[7]:https://github.com/ponylang/ponyc/issues?q=is%3Aissue+is%3Aopen+label%3A%22complexity%3A+beginner+friendly%22
+[8]:https://webchat.freenode.net/?channels=%23ponylang
+[9]:https://pony.groups.io/g/user
+[10]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/speaker/213590
+[11]:https://conferences.oreilly.com/oscon/oscon-or
diff --git a/translated/talk/20180425 How will the GDPR impact open source communities.md b/translated/talk/20180425 How will the GDPR impact open source communities.md
new file mode 100644
index 0000000000..8ae6702dc2
--- /dev/null
+++ b/translated/talk/20180425 How will the GDPR impact open source communities.md
@@ -0,0 +1,104 @@
+# GDPR 将如何影响开源社区?
+
+
+
+图片来源:opensource.com
+
+2018 年 5 月 25 日,[通用数据保护条例][1] 开始生效。欧盟出台的该条例将在全球范围内对企业如何保护个人数据产生重大影响。影响也会波及到开源项目以及开源社区。
+
+### GDPR 概述
+
+GDPR 于 2016 年 4 月 14 日在欧盟议会通过,从 2018 年 5 月 25 日起开始生效。GDPR 用于替代 95/46/EC 号数据保护指令,该指令被设计用于“协调欧洲各国数据隐私法,保护和授权全体欧盟公民的数据隐私,改变欧洲范围内企业处理数据隐私的方式”。
+
+GDPR 目标是在当前日益数据驱动的世界中保护欧盟公民的个人数据。
+
+### 它对谁生效
+
+GDPR 带来的最大改变之一是影响范围的扩大。不管企业本身是否位于欧盟,只要涉及欧盟公民个人数据的处理,GDPR 就会对其生效。
+
+大部分提及 GDPR 的网上文章关注销售商品或服务的公司,但关注影响范围时,我们也不要忘记开源项目。有几种不同的类型,包括运营开源社区的(营利性)软件公司和非营利性组织(例如,开源软件项目及其社区)。对于面向全球的社区,几乎总是会有欧盟居民加入其中。
+
+如果一个面向全球的社区有对应的在线平台,包括网站、论坛和问题跟踪系统等,那么很可能会涉及欧盟居民的个人数据处理,包括姓名、邮箱地址甚至更多。这些处理行为都需要遵循 GDPR。
+
+### GDPR 带来的改变及其影响
+
+相比被替代的指令,GDPR 带来了[很多改变][2],强化了对欧盟居民数据和隐私的保护。正如前文所说,一些改变给社区带来了直接的影响。我们来看看若干改变。
+
+#### 授权
+
+我们假设社区为成员提供论坛,网站中包含若干个用于注册的表单。要遵循 GDPR,你不能再使用冗长、无法辨识的隐私策略和条件条款。无论是每种特殊用途,在论坛注册或使用网站表单注册,你都需要获取明确的授权。授权必须是无条件的、具体的、通知性的以及无歧义的。
+
+以表单为例,你需要提供一个复选框,处于未选中状态并给出个人数据用途的明确说明,一般是当前使用的隐私策略和条件条款附录的超链接。
+
+#### 访问权
+
+GDPR 赋予欧盟公民更多的权利。其中一项权利是向企业查询个人数据包括哪些,保存在哪里;如果数据相关人(例如欧盟公民)提出获取相应数据副本的需求,企业还应免费提供数字形式的数据。
+
+#### 遗忘权
+
+欧盟居民还从 GDPR 获得了“遗忘权”,即数据擦除。该权利是指,在一定限制条件下,企业必须删除个人数据,甚至可能停止其自身或第三方机构后续处理申请人的数据。
+
+上述三种改变要求你的平台软件也要遵循 GDPR 的某些方面。需要提供特定的功能,例如获取并保存授权,提取数据并向数据相关人提供数字形式的副本,以及删除数据相关人对应的数据等。
+
+#### 泄露通知
+
+在 GDPR 看来,不经数据相关人授权情况下使用或偷取个人数据都被视为数据泄露。一旦发现,你应该在 72 小时内通知社区成员,除非这些个人数据不太可能给自然人的权利与自由带来风险。GDPR 强制要求执行泄露通知。
+
+#### 披露记录
+
+企业负责提供一份记录,用于详细披露个人数据处理的过程和目的等。该记录用于证明企业遵从 GDPR 要求,维护了一份个人数据处理行为的记录;同时该记录也用于审计。
+
+#### 罚款
+
+不遵循 GDPR 的企业最高可面临全球年收入总额 4% 或 2000 万欧元 (取两者较大值)的罚款。根据 GDPR,“最高处罚针对严重的侵权行为,包括未经用户充分授权的情况下处理数据,以及违反设计理念中核心隐私部分”。
+
+### 补充说明
+
+本文不应用于法律建议或 GDPR 合规的指导书。我提到了可能对开源社区有影响的条约部分,希望引起大家对 GDPR 及其影响的关注。当然,条约包含了更多你需要了解和可能需要遵循的条款。
+
+你自己也可能认识到,当运营一个面向全球的社区时,需要行动起来使其遵循 GDPR。如果在社区中,你已经遵循包括 ISO 27001,NIST 和 PCI DSS 在内的健壮安全标准,你已经先人一步。
+
+可以从如下网站/资源中获取更多关于 GDPR 的信息:
+
+* [GDPR 官网][3] (欧盟提供)
+* [官方条约 (欧盟) 2016/679][4] (GDPR,包含翻译)
+* [GDPR 是什么? 领导人需要知道的 8 件事][5] (企业人项目)
+* [如何规避 GDPR 合规审计:最佳实践][6] (企业人项目)
+
+
+### 关于作者
+
+[][7]
+
+Robin Muilwijk \- Robin Muilwijk 是一名互联网和电子政务顾问,在 Red Hat 旗下在线发布平台 Opensource.com 担任社区版主,在 Open Organization 担任大使。此外,Robin 还是 eZ 社区董事会成员,[eZ 系统][8] 社区的管理员。Robin 活跃在社交媒体中,促进和支持商业和生活领域的开源项目。可以在 Twitter 上关注 [Robin Muilwijk][9] 以获取更多关于他的信息。
+
+[更多关于我的信息][10]
+
+* [学习如何做出贡献][11]
+
+---
+
+via: [https://opensource.com/article/18/4/gdpr-impact][12]
+
+作者: [Robin Muilwijk][13] 选题者: [@lujun9972][14] 译者: [pinewall][15] 校对: [校对者ID][16]
+
+本文由 [LCTT][17] 原创编译,[Linux中国][18] 荣誉推出
+
+[1]: https://www.eugdpr.org/eugdpr.org.html
+[2]: https://www.eugdpr.org/key-changes.html
+[3]: https://www.eugdpr.org/eugdpr.org.html
+[4]: http://eur-lex.europa.eu/legal-content/EN/TXT/?qid=1520531479111&uri=CELEX:32016R0679
+[5]: https://enterprisersproject.com/article/2018/4/what-gdpr-8-things-leaders-should-know
+[6]: https://enterprisersproject.com/article/2017/9/avoiding-gdpr-compliance-audit-best-practices
+[7]: https://opensource.com/users/robinmuilwijk
+[8]: http://ez.no
+[9]: https://opensource.com/users/robinmuilwijk
+[10]: https://opensource.com/users/robinmuilwijk
+[11]: https://opensource.com/participate
+[12]: https://opensource.com/article/18/4/gdpr-impact
+[13]: https://opensource.com/users/robinmuilwijk
+[14]: https://github.com/lujun9972
+[15]: https://github.com/pinewall
+[16]: https://github.com/校对者ID
+[17]: https://github.com/LCTT/TranslateProject
+[18]: https://linux.cn/
diff --git a/translated/talk/20180426 Get started with Pidgin- An open source replacement for Skype for Business.md b/translated/talk/20180426 Get started with Pidgin- An open source replacement for Skype for Business.md
new file mode 100644
index 0000000000..333424a3e6
--- /dev/null
+++ b/translated/talk/20180426 Get started with Pidgin- An open source replacement for Skype for Business.md
@@ -0,0 +1,63 @@
+开始使用 Pidgin:Skype for Business 的开源替代品
+======
+
+
+技术正处在一个有趣的十字路口,Linux 统治服务器领域,但微软统治企业桌面。 Office 365、Skype for Business、Microsoft Teams、OneDrive、Outlook ......等等,这些是支配企业工作空间的微软软件和服务。
+
+如果你可以使用免费和开源程序替换该专有软件,并使其与你别无选择,但只能使用的 Office 365 的后端一起工作?是的,因为这正是我们要用 Pidgin 做的,它是 Skype 的开源替代品。
+
+### 安装 Pidgin 和 SIPE
+
+微软的 Office Communicator 变成了 Microsoft Lync,它成为我们今天所知的 Skype for Business。现在有针对 Linux 的[付费软件][1]提供了与 Skype for Business 相同的功能,但 [Pidgin][2] 是 GNU GPL 授权的完全免费且开源的选择。
+
+Pidgin 可以在几乎每个 Linux 发行版的仓库中找到,因此,使用它不应该是一个问题。唯一不能在 Pidgin 中使用的 Skype 功能是屏幕共享,并且文件共享可能会失败,但有办法解决这个问题。
+
+你还需要一个 [SIPE][3] 插件,因为它是使 Pidgin 成为 Skype for Business 替代品的秘密武器的一部分。请注意,`sipe` 库在不同的发行版中有不同的名称。例如,库在 System76 的 Pop_OS! 中是 `pidgin-sipe`,而在 Solus 3 仓库中是 `sipe`。
+
+有了先决条件,你可以开始配置 Pidgin。
+
+### 配置 Pidgin
+
+首次启动 Pidgin 时,点击 **Add** 添加一个新帐户。在基本选项卡(如下截图所示)中,选择 **Protocol** 下拉菜单中的 **Office Communicator**,然后在 **Username** 字段中输入你的**公司电子邮件地址**。
+
+
+
+接下来,点击高级选项卡。在 **Server[:Port]** 字段中输入 **sipdir.online.lync.com:443**,在 **User Agent** 中输入 **UCCAPI/16.0.6965.5308 OC/16.0.6965.2117**。
+
+你的高级选项卡现在应该如下所示:
+
+
+
+你不需要对“代理”选项卡或“语音和视频”选项卡进行任何更改。只要确定,请确保 **Proxy type** 设置为 **Use Global Proxy Settings**,并且在语音和视频选项卡中,**Use silence suppression** 复选框为**取消选中**。
+
+
+
+
+
+完成这些配置后,点击 **Add**,系统会提示你输入电子邮件帐户的密码。
+
+### 添加联系人
+
+要将联系人添加到好友列表,请点击**好友窗口**中的 **Manage Accounts**。将鼠标悬停在你的帐户上,然后选择 **Contact Search** 查找你的同事。如果您在使用姓氏和名字进行搜索时遇到任何问题,请尝试使用你同事的完整电子邮件地址进行搜索,你就会找到正确的人。
+
+你现在已经开始使用 Skype for Business 替代产品,该产品可为你提供 98% 的功能,从你的桌面上消除专有软件。
+
+Ray Shimko 将在 4 月 28 日至 29 日的 [LinuxFest NW][5] 上谈论[ Linux 在微软世界][4]。查看计划亮点或注册参加。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/4/pidgin-open-source-replacement-skype-business
+
+作者:[Ray Shimko][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/shickmo
+[1]:https://tel.red/linux.php
+[2]:https://pidgin.im/
+[3]:http://sipe.sourceforge.net/
+[4]:https://www.linuxfestnorthwest.org/conferences/lfnw18/program/proposals/32
+[5]:https://www.linuxfestnorthwest.org/conferences/lfnw18
diff --git a/translated/tech/20180507 4 Firefox extensions to install now.md b/translated/tech/20180507 4 Firefox extensions to install now.md
deleted file mode 100644
index db97507357..0000000000
--- a/translated/tech/20180507 4 Firefox extensions to install now.md
+++ /dev/null
@@ -1,77 +0,0 @@
-4 个 Firefox 扩展
-=====
-
-
-正如我在关于 Firefox 扩展的[原创文章][1]中提到的,web 浏览器已成为许多用户计算(机)验的关键组件。现代浏览器已经发展成为功能强大且可扩展的平台,扩展可以添加或修改其功能。Firefox 的扩展是使用 WebExtensions API(一种跨浏览器开发系统)构建的。
-
-在第一篇文章中,我问读者:“你应该安装哪些扩展?” 重申一下,这一决定主要取决于你如何使用浏览器,你对隐私的看法,你对扩展程序开发人员的信任程度以及其他个人偏好。自文章发表以来,我推荐的一个扩展(Xmarks)已经停止。另外,该文章收到了大量的反馈,在这篇更新中,这些反馈已经被考虑到。
-
-我想再次指出,浏览器扩展通常需要能够阅读和(或)更改你访问的网页上的所有内容。你应该仔细考虑这一点。如果扩展程序修改了你访问的所有网页的访问权限,那么它可能充当键盘记录程序,拦截信用卡信息,在线跟踪,插入广告以及执行各种其他恶意活动。这并不意味着每个扩展程序都会暗中执行这些操作,但在安装任何扩展程序之前,你应该仔细考虑安装源,涉及的权限,风险配置文件以及其他因素。请记住,你可以使用配置文件来管理扩展如何影响你的攻击面 - 例如,使用没有扩展的专用配置文件来 执行网上银行等任务。
-
-考虑到这一点,这里有你可能想要考虑的四个开源 Firefox 扩展。
-
-### uBlock Origin
-
-![ublock origin ad blocker screenshot][2]
-
-我的第一个建议保持不变。[uBlock Origin][3] 是一款快速,低内存,广泛的拦截器,它不仅可以拦截广告,而且还可以执行你自己的内容过滤。 uBlock Origin 的默认行为是使用多个预定义的过滤器列表来拦截广告,跟踪器和恶意软件站点。它允许你任意添加列表和规则,甚至可以锁定到默认拒绝模式。尽管它很强大,但它已被证明是高效和高性能的。它将继续定期更新,并且是该功能的最佳选择之一。
-
-### Privacy Badger
-
-![privacy badger ad blocker][4]
-
-我的第二个建议也保持不变。如果说有什么区别的话,那就是自从我上一篇文章发表以来,隐私问题就一直被带到最前沿,这使得这个扩展成为一个简单的建议。顾名思义,[Privacy Badger][5] 是一个专注于隐私的扩展,可以拦截广告和其他第三方跟踪器。这是 Electronic Freedom (to 校正者:这里 Firefox 添加此扩展后,弹出页面译为电子前哨基金会)基金会的一个项目,他们说:
-
-> Privacy Badger 诞生于我们希望能够推荐一个单独的扩展,它可以自动分析和拦截任何违反用户同意原则的追踪器或广告;在用户没有任何设置、有关知识或配置的情况下,它可以很好地运行;它是由一个明确为其用户而不是为广告商工作的组织所产生的;它使用了算法的方法来决定什么是什么,什么是不跟踪的。”
-
-为什么 Privacy Badger 会出现在这个列表上,它的功能与上一个扩展看起来很类似?因为一些原因。首先,它从根本上工作原理与 uBlock Origin 不同。其次,深度防御的实践是一项合理的策略。说到深度防御,EFF 还维护着 [HTTPS Everywhere][6] 扩展,它自动确保 https 用于许多主流网站。当你安装 Privacy Badger 时,你也可以考虑使用 HTTPS Everywhere。
-
-如果你开始认为这篇文章只是对上一篇文章的重新讨论,那么以下是我的建议分歧。
-
-### Bitwarden
-
-![Bitwarden][7]
-
-在上一篇文章中推荐 LastPass 时,我提到这可能是一个有争议的选择。这无疑属实。无论你是否应该使用密码管理器 - 如果你使用,那么是否应该选择带有浏览器插件的密码管理器 - 这是一个备受争议的话题,答案很大程度上取决于你的个人风险状况。我认为大多数普通的计算机用户应该使用一个,因为它比最常见的选择要好得多:在任何地方都使用相同的弱密码。我仍然相信这一点。
-
-[Bitwarden][8] 自从我上次审视以后确实成熟了。像 LastPass 一样,它对用户友好,支持双因素身份验证,并且相当安全。与 LastPass 不同的是,它是[开源的][9]。它可以使用或不使用浏览器插件,并支持从其他解决方案(包括 LastPass)导入。它的核心功能完全免费,它还有一个 10 美元/年的高级版本。
-
-### Vimium-FF
-
-![Vimium][10]
-
-[Vimium][11] 是另一个开源的扩展,它为 Firefox 键盘快捷键提供了类似 Vim 一样的导航和控制,其称之为“黑客的浏览器”。对于 Ctrl+x, Meta+x 和 Alt+x,分别对应 **< c-x>**, **< m-x>** 和 **< a-x>**,默认值可以轻松定制。一旦你安装了 Vimium,你可以随时键入 **?** 来查看键盘绑定列表。请注意,如果你更喜欢 Emacs,那么也有一些针对这些键绑定的扩展。无论哪种方式,我认为键盘快捷键是未充分利用的生产力推动力。
-
-### 额外福利: Grammarly
-
-不是每个人都有幸在 Opensource.com 上撰写专栏 - 尽管你应该认真考虑为网站撰写文章;如果你有问题,有兴趣,或者想要一个导师,伸出手,让我们聊天吧。但是,即使没有专栏撰写,正确的语法在各种各样的情况下都是有益的。试一下 [Grammarly][12]。不幸的是,这个扩展不是开源的,但它确实可以确保你输入的所有东西都是清晰的,有效的并且没有错误。它通过扫描你文本中的常见的和复杂的语法错误来实现这一点,涵盖了从主谓一致到文章使用到修饰词的放置这些所有内容。它的基本功能是免费的,它有一个高级版本,每月收取额外的费用。我在这篇文章中使用了它,它发现了许多我的校对没有发现的错误。
-
-再次说明,Grammarly 是这个列表中包含的唯一不是开源的扩展,因此如果你知道类似的高质量开源替代品,请在评论中告诉我们。
-
-这些扩展是我发现有用并推荐给其他人的扩展。请在评论中告诉我你对更新建议的看法。
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/5/firefox-extensions
-
-作者:[Jeremy Garcia][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[MjSeven](https://github.com/MjSeven)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jeremy-garcia
-[1]:https://opensource.com/article/18/1/top-5-firefox-extensions
-[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/ublock.png?itok=_QFEbDmq (ublock origin ad blocker screenshot)
-[3]:https://addons.mozilla.org/en-US/firefox/addon/ublock-origin/
-[4]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/privacy_badger_1.0.1.png?itok=qZXQeKtc (privacy badger ad blocker screenshot)
-[5]:https://www.eff.org/privacybadger
-[6]:https://www.eff.org/https-everywhere
-[7]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/bitwarden.png?itok=gZPrCYoi (Bitwarden)
-[8]:https://bitwarden.com/
-[9]:https://github.com/bitwarden
-[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/vimium.png?itok=QRESXjWG (Vimium)
-[11]:https://addons.mozilla.org/en-US/firefox/addon/vimium-ff/
-[12]:https://www.grammarly.com/