mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-07 22:11:09 +08:00
Merge pull request #2 from LCTT/master
Update TranslateProject to 07-04
This commit is contained in:
commit
91c91bfe0a
@ -1,14 +1,15 @@
|
||||
在 Ubuntu Linux 中使用 WEBP 图片
|
||||
在 Ubuntu Linux 中使用 WebP 图片
|
||||
=========================================
|
||||
|
||||

|
||||
>简介:这篇指南会向你展示如何在 Linux 下查看 WebP 图片以及将 WebP 图片转换为 JPEG 或 PNG 格式。
|
||||
|
||||
### 什么是 WEBP?
|
||||
> 简介:这篇指南会向你展示如何在 Linux 下查看 WebP 图片以及将 WebP 图片转换为 JPEG 或 PNG 格式。
|
||||
|
||||
Google 为图片推出 [WebP 文件格式][0]已经超过五年了。Google 说,WebP 提供有损和无损压缩,相比 JPEG 压缩,WebP 压缩文件大小能更小约 25%。
|
||||
### 什么是 WebP?
|
||||
|
||||
Google 的目标是让 WebP 成为 web 图片的新标准,但是我没能看到这一切发生。已经五年过去了,除了谷歌的生态系统以外它仍未被接受成为一个标准。但正如我们所知的,Google 对它的技术很有进取心。几个月前 Google 将 Google Plus 的所有图片改为了 WebP 格式。
|
||||
自从 Google 推出 [WebP 图片格式][0],已经过去五年了。Google 说,WebP 提供有损和无损压缩,相比 JPEG 压缩,WebP 压缩文件大小,能更小约 25%。
|
||||
|
||||
Google 的目标是让 WebP 成为 web 图片的新标准,但是并没有成为现实。已经五年过去了,除了谷歌的生态系统以外它仍未被接受成为一个标准。但正如我们所知的,Google 对它的技术很有进取心。几个月前 Google 将 Google Plus 的所有图片改为了 WebP 格式。
|
||||
|
||||
如果你用 Google Chrome 从 Google Plus 上下载那些图片,你会得到 WebP 图片,不论你之前上传的是 PNG 还是 JPEG。这都不是重点。真正的问题在于当你尝试着在 Ubuntu 中使用默认的 GNOME 图片查看器打开它时你会看到如下错误:
|
||||
|
||||
@ -17,7 +18,8 @@ Google 的目标是让 WebP 成为 web 图片的新标准,但是我没能看
|
||||
> **Unrecognized image file format(未识别文件格式)**
|
||||
|
||||

|
||||
>GNOME 图片查看器不支持 WebP 图片
|
||||
|
||||
*GNOME 图片查看器不支持 WebP 图片*
|
||||
|
||||
在这个教程里,我们会看到
|
||||
|
||||
@ -41,7 +43,8 @@ sudo apt-get install gthumb
|
||||
一旦安装完成,你就可以简单地右键点击 WebP 图片,选择 gThumb 来打开它。你现在应该可以看到如下画面:
|
||||
|
||||

|
||||
>gThumb 中显示的 WebP 图片
|
||||
|
||||
*gThumb 中显示的 WebP 图片*
|
||||
|
||||
### 让 gThumb 成为 Ubuntu 中 WebP 图片的默认应用
|
||||
|
||||
@ -50,28 +53,30 @@ sudo apt-get install gthumb
|
||||
#### 步骤 1:右键点击 WebP 文件选择属性。
|
||||
|
||||

|
||||
>从右键菜单中选择属性
|
||||
|
||||
*从右键菜单中选择属性*
|
||||
|
||||
#### 步骤 2:转到打开方式标签,选择 gThumb 并点击设置为默认。
|
||||
|
||||

|
||||
>让 gThumb 成为 Ubuntu 中 WebP 图片的默认应用
|
||||
|
||||
*让 gThumb 成为 Ubuntu 中 WebP 图片的默认应用*
|
||||
|
||||
### 让 gThumb 成为所有图片的默认应用
|
||||
|
||||
gThumb 的功能比图片查看器更多。举个例子,你可以做一些简单的编辑,给图片添加滤镜等。添加滤镜的效率没有 XnRetro(在[ Linux 下添加类似 Instagram 滤镜效果][5]的专用工具)那么高,但它还是有一些基础的滤镜可以用。
|
||||
gThumb 的功能比图片查看器更多。举个例子,你可以做一些简单的图片编辑,给图片添加滤镜等。添加滤镜的效率没有 XnRetro(在[ Linux 下添加类似 Instagram 滤镜效果][5]的专用工具)那么高,但它还是有一些基础的滤镜可以用。
|
||||
|
||||
我非常喜欢 gThumb 并且决定让它成为默认的图片查看器。如果你也想在 Ubuntu 中让 gThumb 成为所有图片的默认默认应用,遵照以下步骤操作:
|
||||
我非常喜欢 gThumb 并且决定让它成为默认的图片查看器。如果你也想在 Ubuntu 中让 gThumb 成为所有图片的默认应用,遵照以下步骤操作:
|
||||
|
||||
#### 步骤1:打开系统设置
|
||||
步骤1:打开系统设置
|
||||
|
||||

|
||||
|
||||
#### 步骤2:转到详情(Details)
|
||||
步骤2:转到详情(Details)
|
||||
|
||||

|
||||
|
||||
#### 步骤3:在这里将 gThumb 设置为图片的默认应用
|
||||
步骤3:在这里将 gThumb 设置为图片的默认应用
|
||||
|
||||

|
||||
|
||||
@ -100,7 +105,7 @@ sudo apt-get install webp
|
||||
|
||||
##### 将 JPEG/PNG 转换为 WebP
|
||||
|
||||
我们将使用 cwebp 命令(它代表压缩为 WebP 吗?)来将 JPEG 或 PNG 文件转换为 WebP。命令格式是这样的:
|
||||
我们将使用 cwebp 命令(它代表转换为 WebP 的意思吗?)来将 JPEG 或 PNG 文件转换为 WebP。命令格式是这样的:
|
||||
|
||||
```
|
||||
cwebp -q [图片质量] [JPEG/PNG_文件名] -o [WebP_文件名]
|
||||
@ -132,7 +137,7 @@ dwebp example.webp -o example.png
|
||||
|
||||
[下载 XnConvert][1]
|
||||
|
||||
XnConvert 是个强大的工具,你可以用它来批量修改图片尺寸。但在这个教程里,我们只能看到如何将单个 WebP 图片转换为 PNG/JPEG。
|
||||
XnConvert 是个强大的工具,你可以用它来批量修改图片尺寸。但在这个教程里,我们只介绍如何将单个 WebP 图片转换为 PNG/JPEG。
|
||||
|
||||
打开 XnConvert 并选择输入文件:
|
||||
|
||||
@ -148,24 +153,24 @@ XnConvert 是个强大的工具,你可以用它来批量修改图片尺寸。
|
||||
|
||||
也许你一点都不喜欢 WebP 图片格式,也不想在 Linux 仅仅为了查看 WebP 图片而安装一个新软件。如果你不得不将 WebP 文件转换以备将来使用,这会是件更痛苦的事情。
|
||||
|
||||
一个解决这个问题更简单,不那么痛苦的途径是安装一个 Chrome 扩展 Save Image as PNG。有了这个插件,你可以右键点击 WebP 图片并直接存储为 PNG 格式。
|
||||
解决这个问题的一个更简单、不那么痛苦的途径是安装一个 Chrome 扩展 Save Image as PNG。有了这个插件,你可以右键点击 WebP 图片并直接存储为 PNG 格式。
|
||||
|
||||

|
||||
>在 Google Chrome 中将 WebP 图片保存为 PNG 格式
|
||||
|
||||
[获取 Save Image as PNG 扩展][2]
|
||||
*在 Google Chrome 中将 WebP 图片保存为 PNG 格式*
|
||||
|
||||
- [获取 Save Image as PNG 扩展][2]
|
||||
|
||||
### 你的选择是?
|
||||
|
||||
我希望这个详细的教程能够帮你在 Linux 上获取 WebP 支持并帮你转换 WebP 图片。你在 Linux 怎么处理 WebP 图片?你使用哪个工具?以上描述的方法中,你最喜欢哪一个?
|
||||
|
||||
我希望这个详细的教程能够帮你在 Linux 上支持 WebP 并帮你转换 WebP 图片。你在 Linux 怎么处理 WebP 图片?你使用哪个工具?以上描述的方法中,你最喜欢哪一个?
|
||||
|
||||
----------------------
|
||||
via: http://itsfoss.com/webp-ubuntu-linux/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
via: http://itsfoss.com/webp-ubuntu-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,279 @@
|
||||
Microservices with Python RabbitMQ and Nameko
|
||||
==============================================
|
||||
|
||||
>"Micro-services is the new black" - Splitting the project in to independently scalable services is the currently the best option to ensure the evolution of the code. In Python there is a Framework called "Nameko" which makes it very easy and powerful.
|
||||
|
||||
### Micro services
|
||||
|
||||
>The term "Microservice Architecture" has sprung up over the last few years to describe a particular way of designing software applications as suites of independently deployable services. - M. Fowler
|
||||
|
||||
I recommend reading the [Fowler's posts][1] to understand the theory behind it.
|
||||
|
||||
#### Ok I so what does it mean?
|
||||
|
||||
In brief a Micro Service Architecture exists when your system is divided in small (single context bound) responsibilities blocks, those blocks doesn't know each other, they only have a common point of communication, generally a message queue, and does know the communication protocol and interfaces.
|
||||
|
||||
#### Give me a real-life example
|
||||
|
||||
>The code is available on github: <http://github.com/rochacbruno/nameko-example> take a look at service and api folders for more info.
|
||||
|
||||
Consider you have an REST API, that API has an endpoint receiving some data and you need to perform some kind of computation with that data, instead of blocking the caller you can do it asynchronously, return an status "OK - Your request will be processed" to the caller and do it in a background task.
|
||||
|
||||
Also you want to send an email notification when the computation is finished without blocking the main computing process, so it is better to delegate the "email sending" to another service.
|
||||
|
||||
#### Scenario
|
||||
|
||||

|
||||
|
||||
### Show me the code!
|
||||
|
||||
Lets create the system to understand it in practice.
|
||||
|
||||
#### Environment
|
||||
|
||||
We need an environment with:
|
||||
|
||||
- A running RabbitMQ
|
||||
- Python VirtualEnv for services
|
||||
- Python VirtualEnv for API
|
||||
|
||||
#### Rabbit
|
||||
|
||||
The easiest way to have a RabbitMQ in development environment is running its official docker container, considering you have Docker installed run:
|
||||
|
||||
```
|
||||
docker run -d --hostname my-rabbit --name some-rabbit -p 15672:15672 -p 5672:5672 rabbitmq:3-management
|
||||
```
|
||||
|
||||
Go to the browser and access <http://localhost:15672> using credentials guest:guest if you can login to RabbitMQ dashboard it means you have it running locally for development.
|
||||
|
||||

|
||||
|
||||
#### The Service environment
|
||||
|
||||
Now lets create the Micro Services to consume our tasks. We'll have a service for computing and another for mail, follow the steps.
|
||||
|
||||
In a shell create the root project directory
|
||||
|
||||
```
|
||||
$ mkdir myproject
|
||||
$ cd myproject
|
||||
```
|
||||
|
||||
Create and activate a virtualenv (you can also use virtualenv-wrapper)
|
||||
|
||||
```
|
||||
$ virtualenv service_env
|
||||
$ source service_env/bin/activate
|
||||
```
|
||||
|
||||
Install nameko framework and yagmail
|
||||
|
||||
```
|
||||
(service_env)$ pip install nameko
|
||||
(service_env)$ pip install yagmail
|
||||
```
|
||||
|
||||
#### The service code
|
||||
|
||||
Now having that virtualenv prepared (consider you can run service in a server and API in another) lets code the nameko RPC Services.
|
||||
|
||||
We are going to put both services in a single python module, but you can also split in separate modules and also run them in separate servers if needed.
|
||||
|
||||
In a file called `service.py`
|
||||
|
||||
```
|
||||
import yagmail
|
||||
from nameko.rpc import rpc, RpcProxy
|
||||
|
||||
|
||||
class Mail(object):
|
||||
name = "mail"
|
||||
|
||||
@rpc
|
||||
def send(self, to, subject, contents):
|
||||
yag = yagmail.SMTP('myname@gmail.com', 'mypassword')
|
||||
# read the above credentials from a safe place.
|
||||
# Tip: take a look at Dynaconf setting module
|
||||
yag.send(to=to.encode('utf-8),
|
||||
subject=subject.encode('utf-8),
|
||||
contents=[contents.encode('utf-8)])
|
||||
|
||||
|
||||
class Compute(object):
|
||||
name = "compute"
|
||||
mail = RpcProxy('mail')
|
||||
|
||||
@rpc
|
||||
def compute(self, operation, value, other, email):
|
||||
operations = {'sum': lambda x, y: int(x) + int(y),
|
||||
'mul': lambda x, y: int(x) * int(y),
|
||||
'div': lambda x, y: int(x) / int(y),
|
||||
'sub': lambda x, y: int(x) - int(y)}
|
||||
try:
|
||||
result = operations[operation](value, other)
|
||||
except Exception as e:
|
||||
self.mail.send.async(email, "An error occurred", str(e))
|
||||
raise
|
||||
else:
|
||||
self.mail.send.async(
|
||||
email,
|
||||
"Your operation is complete!",
|
||||
"The result is: %s" % result
|
||||
)
|
||||
return result
|
||||
```
|
||||
|
||||
Now with the above services definition we need to run it as a Nameko RPC service.
|
||||
|
||||
>NOTE: We are going to run it in a console and leave it running, but in production it is recommended to put the service to run using supervisord or an alternative.
|
||||
|
||||
Run the service and let it running in a shell
|
||||
|
||||
```
|
||||
(service_env)$ nameko run service --broker amqp://guest:guest@localhost
|
||||
starting services: mail, compute
|
||||
Connected to amqp://guest:**@127.0.0.1:5672//
|
||||
Connected to amqp://guest:**@127.0.0.1:5672//
|
||||
```
|
||||
|
||||
#### Testing it
|
||||
|
||||
Go to another shell (with the same virtenv) and test it using nameko shell
|
||||
|
||||
```
|
||||
(service_env)$ nameko shell --broker amqp://guest:guest@localhost
|
||||
Nameko Python 2.7.9 (default, Apr 2 2015, 15:33:21)
|
||||
[GCC 4.9.2] shell on linux2
|
||||
Broker: amqp://guest:guest@localhost
|
||||
>>>
|
||||
```
|
||||
|
||||
You are now in the RPC client testing shell exposing the n.rpc object, play with it
|
||||
|
||||
```
|
||||
>>> n.rpc.mail.send("name@email.com", "testing", "Just testing")
|
||||
```
|
||||
|
||||
The above should sent an email and we can also call compute service to test it, note that it also spawns an async mail sending with result.
|
||||
|
||||
```
|
||||
>>> n.rpc.compute.compute('sum', 30, 10, "name@email.com")
|
||||
40
|
||||
>>> n.rpc.compute.compute('sub', 30, 10, "name@email.com")
|
||||
20
|
||||
>>> n.rpc.compute.compute('mul', 30, 10, "name@email.com")
|
||||
300
|
||||
>>> n.rpc.compute.compute('div', 30, 10, "name@email.com")
|
||||
3
|
||||
```
|
||||
|
||||
### Calling the micro-service through the API
|
||||
|
||||
In a different shell (or even a different server) prepare the API environment
|
||||
|
||||
Create and activate a virtualenv (you can also use virtualenv-wrapper)
|
||||
|
||||
```
|
||||
$ virtualenv api_env
|
||||
$ source api_env/bin/activate
|
||||
```
|
||||
|
||||
Install Nameko, Flask and Flasgger
|
||||
|
||||
```
|
||||
(api_env)$ pip install nameko
|
||||
(api_env)$ pip install flask
|
||||
(api_env)$ pip install flasgger
|
||||
```
|
||||
|
||||
>NOTE: In api you dont need the yagmail because it is service responsability
|
||||
|
||||
Lets say you have the following code in a file `api.py`
|
||||
|
||||
```
|
||||
from flask import Flask, request
|
||||
from flasgger import Swagger
|
||||
from nameko.standalone.rpc import ClusterRpcProxy
|
||||
|
||||
app = Flask(__name__)
|
||||
Swagger(app)
|
||||
CONFIG = {'AMQP_URI': "amqp://guest:guest@localhost"}
|
||||
|
||||
|
||||
@app.route('/compute', methods=['POST'])
|
||||
def compute():
|
||||
"""
|
||||
Micro Service Based Compute and Mail API
|
||||
This API is made with Flask, Flasgger and Nameko
|
||||
---
|
||||
parameters:
|
||||
- name: body
|
||||
in: body
|
||||
required: true
|
||||
schema:
|
||||
id: data
|
||||
properties:
|
||||
operation:
|
||||
type: string
|
||||
enum:
|
||||
- sum
|
||||
- mul
|
||||
- sub
|
||||
- div
|
||||
email:
|
||||
type: string
|
||||
value:
|
||||
type: integer
|
||||
other:
|
||||
type: integer
|
||||
responses:
|
||||
200:
|
||||
description: Please wait the calculation, you'll receive an email with results
|
||||
"""
|
||||
operation = request.json.get('operation')
|
||||
value = request.json.get('value')
|
||||
other = request.json.get('other')
|
||||
email = request.json.get('email')
|
||||
msg = "Please wait the calculation, you'll receive an email with results"
|
||||
subject = "API Notification"
|
||||
with ClusterRpcProxy(CONFIG) as rpc:
|
||||
# asynchronously spawning and email notification
|
||||
rpc.mail.send.async(email, subject, msg)
|
||||
# asynchronously spawning the compute task
|
||||
result = rpc.compute.compute.async(operation, value, other, email)
|
||||
return msg, 200
|
||||
|
||||
app.run(debug=True)
|
||||
```
|
||||
|
||||
Put the above API to run in a different shell or server
|
||||
|
||||
```
|
||||
(api_env) $ python api.py
|
||||
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
and then access the url <http://localhost:5000/apidocs/index.html> you will see the Flasgger UI and you can interact with the api and start producing tasks on queue to the service to consume.
|
||||
|
||||

|
||||
|
||||
>NOTE: You can see the shell where service is running for logging, prints and error messages. You can also access the RabbitMQ dashboard to see if there is some message in process there.
|
||||
|
||||
There is a lot of more advanced things you can do with Nameko framework you can find more information on <https://nameko.readthedocs.org/en/stable/>
|
||||
|
||||
Let's Micro Serve!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://brunorocha.org/python/microservices-with-python-rabbitmq-and-nameko.html
|
||||
|
||||
作者: [Bruno Rocha][a]
|
||||
译者: [译者ID](https://github.com/译者ID)
|
||||
校对: [校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://facebook.com/rochacbruno
|
||||
[1]:http://martinfowler.com/articles/microservices.html
|
||||
@ -0,0 +1,64 @@
|
||||
INSTALL MATE 1.14 IN UBUNTU MATE 16.04 (XENIAL XERUS) VIA PPA
|
||||
=================================================================
|
||||
|
||||
MATE Desktop 1.14 is now available for Ubuntu MATE 16.04 (Xenial Xerus). According to the release [announcement][1], it took about 2 months to release MATE Desktop 1.14 in a PPA because everything has been well tested, so you shouldn't encounter any issues.
|
||||
|
||||

|
||||
|
||||
**The PPA currently provides MATE 1.14.1 (Ubuntu MATE 16.04 ships with MATE 1.12.x by default), which includes changes such as:**
|
||||
|
||||
- client-side decoration apps now render correctly in all themes;
|
||||
- touchpad configuration now supports edge and two-finger scrolling independently;
|
||||
- python extensions in Caja can now be managed separately;
|
||||
- all three window focus modes are selectable;
|
||||
- MATE Panel now has the ability to change icon sizes for menubar and menu items;
|
||||
- volume and Brightness OSD can now be enabled/disabled;
|
||||
- many other improvements and bug fixes.
|
||||
|
||||
MATE 1.14 also includes improved support for GTK+3 across the entire desktop, as well as various other GTK+3 tweaks however, the PPA packages are built with GTK+2 "to ensure compatibility with Ubuntu MATE 16.04 and all the 3rd party MATE applets, plugins and extensions", mentions the Ubuntu MATE blog.
|
||||
|
||||
A complete MATE 1.14 changelog can be found [HERE][2].
|
||||
|
||||
### Upgrade to MATE Desktop 1.14.x in Ubuntu MATE 16.04
|
||||
|
||||
To upgrade to the latest MATE Desktop 1.14.x in Ubuntu MATE 16.04 using the official Xenial MATE PPA, open a terminal and use the following commands:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:ubuntu-mate-dev/xenial-mate
|
||||
sudo apt update
|
||||
sudo apt dist-upgrade
|
||||
```
|
||||
|
||||
**Note**: mate-netspeed applet will be removed when upgrading. That's because the applet is now part of the mate-applets package, so it's still available.
|
||||
|
||||
Once the upgrade finishes, restart your system. That's it!
|
||||
|
||||
### How to revert the changes
|
||||
|
||||
If you're not satisfied with MATE 1.14, you encountered some bugs, etc., and you want to go back to the MATE version available in the official repositories, you can purge the PPA and downgrade the packages.
|
||||
|
||||
To do this, use the following commands:
|
||||
|
||||
```
|
||||
sudo apt install ppa-purge
|
||||
sudo ppa-purge ppa:ubuntu-mate-dev/xenial-mate
|
||||
```
|
||||
|
||||
After all the MATE packages are downgraded, restart the system.
|
||||
|
||||
via [Ubuntu MATE blog][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.webupd8.org/2016/06/install-mate-114-in-ubuntu-mate-1604.html
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.webupd8.org/p/about.html
|
||||
[1]: https://ubuntu-mate.org/blog/mate-desktop-114-for-xenial-xerus/
|
||||
[2]: http://mate-desktop.com/blog/2016-04-08-mate-1-14-released/
|
||||
[3]: https://ubuntu-mate.org/blog/mate-desktop-114-for-xenial-xerus/
|
||||
231
sources/tech/20160620 Detecting cats in images with OpenCV.md
Normal file
231
sources/tech/20160620 Detecting cats in images with OpenCV.md
Normal file
@ -0,0 +1,231 @@
|
||||
Detecting cats in images with OpenCV
|
||||
=======================================
|
||||
|
||||

|
||||
|
||||
Did you know that OpenCV can detect cat faces in images…right out-of-the-box with no extras?
|
||||
|
||||
I didn’t either.
|
||||
|
||||
But after [Kendrick Tan broke the story][1], I had to check it out for myself…and do a little investigative work to see how this cat detector seemed to sneak its way into the OpenCV repository without me noticing (much like a cat sliding into an empty cereal box, just waiting to be discovered).
|
||||
|
||||
In the remainder of this blog post, I’ll demonstrate how to use OpenCV’s cat detector to detect cat faces in images. This same technique can be applied to video streams as well.
|
||||
|
||||
>Looking for the source code to this post? [Jump right to the downloads section][2].
|
||||
|
||||
|
||||
### Detecting cats in images with OpenCV
|
||||
|
||||
If you take a look at the [OpenCV repository][3], specifically within the [haarcascades directory][4] (where OpenCV stores all its pre-trained Haar classifiers to detect various objects, body parts, etc.), you’ll notice two files:
|
||||
|
||||
- haarcascade_frontalcatface.xml
|
||||
- haarcascade_frontalcatface_extended.xml
|
||||
|
||||
Both of these Haar cascades can be used detecting “cat faces” in images. In fact, I used these very same cascades to generate the example image at the top of this blog post.
|
||||
|
||||
Doing a little investigative work, I found that the cascades were trained and contributed to the OpenCV repository by the legendary [Joseph Howse][5] who’s authored a good many tutorials, books, and talks on computer vision.
|
||||
|
||||
In the remainder of this blog post, I’ll show you how to utilize Howse’s Haar cascades to detect cats in images.
|
||||
|
||||
Cat detection code
|
||||
|
||||
Let’s get started detecting cats in images with OpenCV. Open up a new file, name it cat_detector.py , and insert the following code:
|
||||
|
||||
### Detecting cats in images with OpenCVPython
|
||||
|
||||
```
|
||||
# import the necessary packages
|
||||
import argparse
|
||||
import cv2
|
||||
|
||||
# construct the argument parse and parse the arguments
|
||||
ap = argparse.ArgumentParser()
|
||||
ap.add_argument("-i", "--image", required=True,
|
||||
help="path to the input image")
|
||||
ap.add_argument("-c", "--cascade",
|
||||
default="haarcascade_frontalcatface.xml",
|
||||
help="path to cat detector haar cascade")
|
||||
args = vars(ap.parse_args())
|
||||
```
|
||||
|
||||
Lines 2 and 3 import our necessary Python packages while Lines 6-12 parse our command line arguments. We only require a single argument here, the input `--image` that we want to detect cat faces in using OpenCV.
|
||||
|
||||
We can also (optionally) supply a path our Haar cascade via the `--cascade` switch. We’ll default this path to `haarcascade_frontalcatface.xml` and assume you have the `haarcascade_frontalcatface.xml` file in the same directory as your cat_detector.py script.
|
||||
|
||||
Note: I’ve conveniently included the code, cat detector Haar cascade, and example images used in this tutorial in the “Downloads” section of this blog post. If you’re new to working with Python + OpenCV (or Haar cascades), I would suggest downloading the provided .zip file to make it easier to follow along.
|
||||
|
||||
Next, let’s detect the cats in our input image:
|
||||
|
||||
```
|
||||
# load the input image and convert it to grayscale
|
||||
image = cv2.imread(args["image"])
|
||||
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
|
||||
|
||||
# load the cat detector Haar cascade, then detect cat faces
|
||||
# in the input image
|
||||
detector = cv2.CascadeClassifier(args["cascade"])
|
||||
rects = detector.detectMultiScale(gray, scaleFactor=1.3,
|
||||
minNeighbors=10, minSize=(75, 75))
|
||||
```
|
||||
|
||||
On Lines 15 and 16 we load our input image from disk and convert it to grayscale (a normal pre-processing step before passing the image to a Haar cascade classifier, although not strictly required).
|
||||
|
||||
Line 20 loads our Haar cascade from disk (in this case, the cat detector) and instantiates the cv2.CascadeClassifier object.
|
||||
|
||||
Detecting cat faces in images with OpenCV is accomplished on Lines 21 and 22 by calling the detectMultiScale method of the detector object. We pass four parameters to the detectMultiScale method, including:
|
||||
|
||||
1. Our image, gray , that we want to detect cat faces in.
|
||||
2.A scaleFactor of our [image pyramid][6] used when detecting cat faces. A larger scale factor will increase the speed of the detector, but could harm our true-positive detection accuracy. Conversely, a smaller scale will slow down the detection process, but increase true-positive detections. However, this smaller scale can also increase the false-positive detection rate as well. See the “A note on Haar cascades” section of this blog post for more information.
|
||||
3. The minNeighbors parameter controls the minimum number of detected bounding boxes in a given area for the region to be considered a “cat face”. This parameter is very helpful in pruning false-positive detections.
|
||||
4. Finally, the minSize parameter is pretty self-explanatory. This value ensures that each detected bounding box is at least width x height pixels (in this case, 75 x 75).
|
||||
|
||||
The detectMultiScale function returns rects , a list of 4-tuples. These tuples contain the (x, y)-coordinates and width and height of each detected cat face.
|
||||
|
||||
Finally, let’s draw a rectangle surround each cat face in the image:
|
||||
|
||||
```
|
||||
# loop over the cat faces and draw a rectangle surrounding each
|
||||
for (i, (x, y, w, h)) in enumerate(rects):
|
||||
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
|
||||
cv2.putText(image, "Cat #{}".format(i + 1), (x, y - 10),
|
||||
cv2.FONT_HERSHEY_SIMPLEX, 0.55, (0, 0, 255), 2)
|
||||
|
||||
# show the detected cat faces
|
||||
cv2.imshow("Cat Faces", image)
|
||||
cv2.waitKey(0)
|
||||
```
|
||||
|
||||
Given our bounding boxes (i.e., rects ), we loop over each of them individually on Line 25.
|
||||
|
||||
We then draw a rectangle surrounding each cat face on Line 26, while Lines 27 and 28 displays an integer, counting the number of cats in the image.
|
||||
|
||||
Finally, Lines 31 and 32 display the output image to our screen.
|
||||
|
||||
### Cat detection results
|
||||
|
||||
To test our OpenCV cat detector, be sure to download the source code to this tutorial using the “Downloads” section at the bottom of this post.
|
||||
|
||||
Then, after you have unzipped the archive, you should have the following three files/directories:
|
||||
|
||||
1. cat_detector.py : Our Python + OpenCV script used to detect cats in images.
|
||||
2. haarcascade_frontalcatface.xml : The cat detector Haar cascade.
|
||||
3. images : A directory of testing images that we’re going to apply the cat detector cascade to.
|
||||
|
||||
From there, execute the following command:
|
||||
|
||||
Detecting cats in images with OpenCVShell
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_01.jpg
|
||||
```
|
||||
|
||||
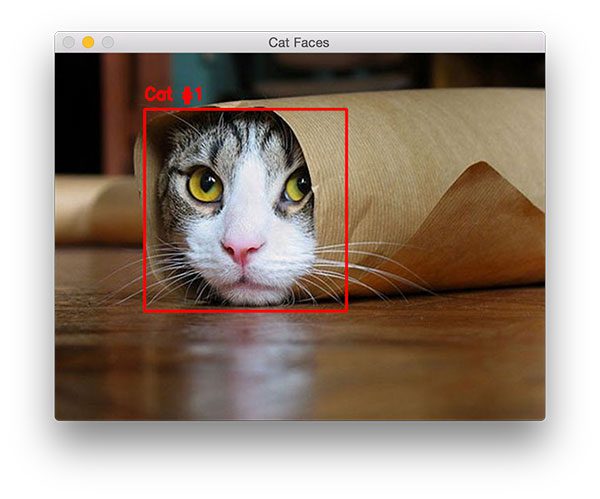
|
||||
>Figure 1: Detecting a cat face in an image, even with parts of the cat occluded
|
||||
|
||||
Notice that we have been able to detect the cat face in the image, even though the rest of its body is obscured.
|
||||
|
||||
Let’s try another image:
|
||||
|
||||
```
|
||||
python cat_detector.py --image images/cat_02.jpg
|
||||
```
|
||||
|
||||

|
||||
>Figure 2: A second example of detecting a cat in an image with OpenCV, this time the cat face is slightly different
|
||||
|
||||
This cat’s face is clearly different from the other one, as it’s in the middle of a “meow”. In either case, the cat detector cascade is able to correctly find the cat face in the image.
|
||||
|
||||
The same is true for this image as well:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_03.jpg
|
||||
```
|
||||
|
||||
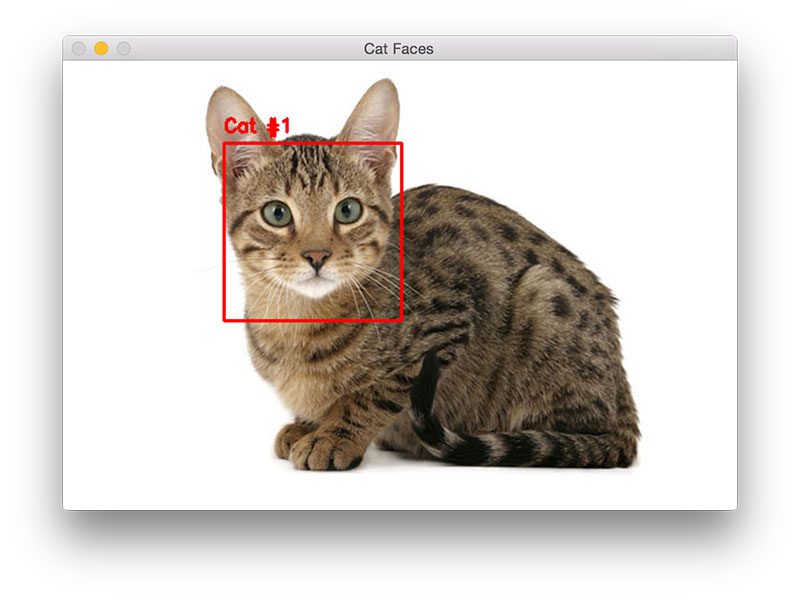
|
||||
>Figure 3: Cat detection with OpenCV and Python
|
||||
|
||||
Our final example demonstrates detecting multiple cats in an image using OpenCV and Python:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_04.jpg
|
||||
```
|
||||
|
||||

|
||||
>Figure 4: Detecting multiple cats in the same image with OpenCV
|
||||
|
||||
Note that the Haar cascade can return bounding boxes in an order that you may not like. In this case, the middle cat is actually labeled as the third cat. You can resolve this “issue” by sorting the bounding boxes according to their (x, y)-coordinates for a consistent ordering.
|
||||
|
||||
#### A quick note on accuracy
|
||||
|
||||
It’s important to note that in the comments section of the .xml files, Joseph Howe details that the cat detector Haar cascades can report cat faces where there are actually human faces.
|
||||
|
||||
In this case, he recommends performing both face detection and cat detection, then discarding any cat bounding boxes that overlap with the face bounding boxes.
|
||||
|
||||
#### A note on Haar cascades
|
||||
|
||||
First published in 2001 by Paul Viola and Michael Jones, [Rapid Object Detection using a Boosted Cascade of Simple Features][7], this original work has become one of the most cited papers in computer vision.
|
||||
|
||||
This algorithm is capable of detecting objects in images, regardless of their location and scale. And perhaps most intriguing, the detector can run in real-time on modern hardware.
|
||||
|
||||
In their paper, Viola and Jones focused on training a face detector; however, the framework can also be used to train detectors for arbitrary “objects”, such as cars, bananas, road signs, etc.
|
||||
|
||||
#### The problem?
|
||||
|
||||
The biggest problem with Haar cascades is getting the detectMultiScale parameters right, specifically scaleFactor and minNeighbors . You can easily run into situations where you need to tune both of these parameters on an image-by-image basis, which is far from ideal when utilizing an object detector.
|
||||
|
||||
The scaleFactor variable controls your [image pyramid][8] used to detect objects at various scales of an image. If your scaleFactor is too large, then you’ll only evaluate a few layers of the image pyramid, potentially leading to you missing objects at scales that fall in between the pyramid layers.
|
||||
|
||||
On the other hand, if you set scaleFactor too low, then you evaluate many pyramid layers. This will help you detect more objects in your image, but it (1) makes the detection process slower and (2) substantially increases the false-positive detection rate, something that Haar cascades are known for.
|
||||
|
||||
To remember this, we often apply [Histogram of Oriented Gradients + Linear SVM detection][9] instead.
|
||||
|
||||
The HOG + Linear SVM framework parameters are normally much easier to tune — and best of all, HOG + Linear SVM enjoys a much smaller false-positive detection rate. The only downside is that it’s harder to get HOG + Linear SVM to run in real-time.
|
||||
|
||||
### Interested in learning more about object detection?
|
||||
|
||||

|
||||
>Figure 5: Learn how to build custom object detectors inside the PyImageSearch Gurus course.
|
||||
|
||||
If you’re interested in learning how to train your own custom object detectors, be sure to take a look at the PyImageSearch Gurus course.
|
||||
|
||||
Inside the course, I have 15 lessons covering 168 pages of tutorials dedicated to teaching you how to build custom object detectors from scratch. You’ll discover how to detect road signs, faces, cars (and nearly any other object) in images by applying the HOG + Linear SVM framework for object detection.
|
||||
|
||||
To learn more about the PyImageSearch Gurus course (and grab 10 FREE sample lessons), just click the button below:
|
||||
|
||||
### Summary
|
||||
|
||||
In this blog post, we learned how to detect cats in images using the default Haar cascades shipped with OpenCV. These Haar cascades were trained and contributed to the OpenCV project by [Joseph Howse][9], and were originally brought to my attention [in this post][10] by Kendrick Tan.
|
||||
|
||||
While Haar cascades are quite useful, we often use HOG + Linear SVM instead, as it’s a bit easier to tune the detector parameters, and more importantly, we can enjoy a much lower false-positive detection rate.
|
||||
|
||||
I detail how to build custom HOG + Linear SVM object detectors to recognize various objects in images, including cars, road signs, and much more [inside the PyImageSearch Gurus course][11].
|
||||
|
||||
Anyway, I hope you enjoyed this blog post!
|
||||
|
||||
Before you go, be sure to signup for the PyImageSearch Newsletter using the form below to be notified when new blog posts are published.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/
|
||||
|
||||
作者:[Adrian Rosebrock][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.pyimagesearch.com/author/adrian/
|
||||
[1]: http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html
|
||||
[2]: http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/#
|
||||
[3]: https://github.com/Itseez/opencv
|
||||
[4]: https://github.com/Itseez/opencv/tree/master/data/haarcascades
|
||||
[5]: http://nummist.com/
|
||||
[6]: http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/
|
||||
[7]: https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf
|
||||
[8]: http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/
|
||||
[9]: http://www.pyimagesearch.com/2014/11/10/histogram-oriented-gradients-object-detection/
|
||||
[10]: http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html
|
||||
[11]: https://www.pyimagesearch.com/pyimagesearch-gurus/
|
||||
|
||||
|
||||
|
||||
122
sources/tech/20160623 Advanced Image Processing with Python.md
Normal file
122
sources/tech/20160623 Advanced Image Processing with Python.md
Normal file
@ -0,0 +1,122 @@
|
||||
Advanced Image Processing with Python
|
||||
======================================
|
||||
|
||||

|
||||
|
||||
Building an image processing search engine is no easy task. There are several concepts, tools, ideas and technologies that go into it. One of the major image-processing concepts is reverse image querying (RIQ) or reverse image search. Google, Cloudera, Sumo Logic and Birst are among the top organizations to use reverse image search. Great for analyzing images and making use of mined data, RIQ provides a very good insight into analytics.
|
||||
|
||||
### Top Companies and Reverse Image Search
|
||||
|
||||
There are many top tech companies that are using RIQ to best effect. For example, Pinterest first brought in visual search in 2014. It subsequently released a white paper in 2015, revealing the architecture. Reverse image search enabled Pinterest to obtain visual features from fashion objects and display similar product recommendations.
|
||||
|
||||
As is generally known, Google images uses reverse image search allowing users to upload an image and then search for connected images. The submitted image is analyzed and a mathematical model made out of it, by advanced algorithm use. The image is then compared with innumerable others in the Google databases before results are matched and similar results obtained.
|
||||
|
||||
**Here is a graph representation from the OpenCV 2.4.9 Features Comparison Report:**
|
||||
|
||||

|
||||
|
||||
### Algorithms & Python Libraries
|
||||
|
||||
Before we get down to the workings of it, let us rush through the main elements that make building an image processing search engine with Python possible:
|
||||
|
||||
### Patented Algorithms
|
||||
|
||||
#### SIFT (Scale-Invariant Feature Transform) Algorithm
|
||||
|
||||
1. A patented technology with nonfree functionality that uses image identifiers in order to identify a similar image, even those clicked from different angles, sizes, depths and scale, that they are included in the search results. Check the detailed video on SIFT here.
|
||||
2. SIFT correctly matches the search criteria with a large database of features from many images.
|
||||
3. Matching same images with different viewpoints and matching invariant features to obtain search results is another SIFT feature. Read more about scale-invariant keypoints here.
|
||||
|
||||
#### SURF (Speeded Up Robust Features) Algorithm
|
||||
|
||||
1. [SURF][1] is also patented with nonfree functionality and a more ‘speeded’ up version of SIFT. Unlike SIFT, SURF approximates Laplacian of Gaussian (unlike SIFT) with Box Filter.
|
||||
|
||||
2. SURF relies on the determinant of Hessian Matrix for both its location and scale.
|
||||
|
||||
3. Rotation invariance is not a requisite in many applications. So not finding this orientation speeds up the process.
|
||||
|
||||
4. SURF includes several features that the speed improved in each step. Three times faster than SIFT, SURF is great with rotation and blurring. It is not as great in illumination and viewpoint change though.
|
||||
|
||||
5. Open CV, a programming function library provides SURF functionalities. SURF.compute() and SURF. Detect() can be used to find descriptors and keypoints. Read more about SURF [here][2].
|
||||
|
||||
### Open Source Algorithms
|
||||
|
||||
#### KAZE Algorithm
|
||||
|
||||
1.KAZE is a open source 2D multiscale and novel feature detection and description algorithm in nonlinear scale spaces. Efficient techniques in Additive Operator Splitting (AOS) and variable conductance diffusion is used to build the nonlinear scale space.
|
||||
|
||||
2. Multiscale image processing basics are simple – Creating an image’s scale space while filtering original image with right function over enhancing time or scale.
|
||||
|
||||
#### AKAZE (Accelerated-KAZE) Algorithm
|
||||
|
||||
1. As the name suggests, this is a faster mode to image search, finding matching keypoints between two images. AKAZE uses a binary descriptor and nonlinear scale space that balances accuracy and speed.
|
||||
|
||||
#### BRISK (Binary Robust Invariant Scalable Keypoints) Algorithm
|
||||
|
||||
1. BRISK is great for description, keypoint detection and matching.
|
||||
|
||||
2. An algorithm that is highly adaptive, scale-space FAST-based detector along with a bit-string descriptor, helps speed up the search significantly.
|
||||
|
||||
3. Scale-space keypoint detection and keypoint description helps optimize the performance with relation to the task at hand.
|
||||
|
||||
#### FREAK (Fast Retina Keypoint)
|
||||
|
||||
1. This is a novel keypoint descriptor inspired by the human eye.A binary strings cascade is efficiently computed by an image intensity comparison. The FREAK algorithm allows faster computing with lower memory load as compared to BRISK, SURF and SIFT.
|
||||
|
||||
#### ORB (Oriented FAST and Rotated BRIEF)
|
||||
|
||||
1.A fast binary descriptor, ORB is resistant to noise and rotation invariant. ORB builds on the FAST keypoint detector and the BRIEF descriptor, elements attributed to its low cost and good performance.
|
||||
|
||||
2. Apart from the fast and precise orientation component, efficiently computing the oriented BRIEF, analyzing variance and co-relation of oriented BRIEF features, is another ORB feature.
|
||||
|
||||
### Python Libraries
|
||||
|
||||
#### Open CV
|
||||
|
||||
1. OpenCV is available for both academic and commercial use. A open source machine learning and computer vision library, OpenCV makes it easy for organizations to utilize and modify code.
|
||||
|
||||
2. Over 2500 optimized algorithms, including state-of-the-art machine learning and computer vision algorithms serve various image search purposes – face detection, object identification, camera movement tracking, finding similar images from image database, following eye movements, scenery recognition, etc.
|
||||
|
||||
3. Top companies like Google, IBM, Yahoo, IBM, Sony, Honda, Microsoft and Intel make wide use of OpenCV.
|
||||
|
||||
4. OpenCV uses Python, Java, C, C++ and MATLAB interfaces while supporting Windows, Linux, Mac OS and Android.
|
||||
|
||||
#### Python Imaging Library (PIL)
|
||||
|
||||
1. The Python Imaging Library (PIL) supports several file formats while providing image processing and graphics solutions.The open source PIL adds image processing capabilities to your Python interpreter.
|
||||
2. The standard procedure for image manipulation include image enhancing, transparency and masking handling, image filtering, per-pixel manipulation, etc.
|
||||
|
||||
For detailed statistics and graphs, view the OpenCV 2.4.9 Features Comparison Report [here][3].
|
||||
|
||||
### Building an Image Search Engine
|
||||
|
||||
An image search engine helps pick similar images from a prepopulated set of image base. The most popular among these is Google’s well known image search engine. For starters, there are various approaches to build a system like this. To mention a few:
|
||||
|
||||
1.Using image extraction, image description extraction, meta data extraction and search result extraction to build an image search engine.
|
||||
2. Define your image descriptor, dataset indexing, define your similarity metric and then search and rank.
|
||||
3. Select image to be searched, select directory for carrying out search, search directory for all pictures, create picture feature index, evaluate same feature for search picture, match pictures in search and obtain matched pictures.
|
||||
|
||||
Our approach basically began with comparing grayscaled versions of the images, gradually moving on to complex feature matching algorithms like SIFT and SURF, and then finally settling down to am open source solution called BRISK. All these algorithms give efficient results with minor changes in performance and latency. An engine built on these algorithms have numerous applications like analyzing graphic data for popularity statistics, identification of objects in graphic contents, and many more.
|
||||
|
||||
**Example**: An image search engine needs to be build by an IT company for a client. So if a brand logo image is submitted in the search, all related brand image searches show up as results. The obtained results can also be used for analytics by the client, allowing them to estimate the brand popularity as per the geographic location. Its still early days though, RIQ or reverse image search has not been exploited to its full extent yet.
|
||||
|
||||
This concludes our article on building an image search engine using Python. Check our blog section out for the latest on technology and programming.
|
||||
|
||||
Statistics Source: OpenCV 2.4.9 Features Comparison Report (computer-vision-talks.com)
|
||||
|
||||
(Guidance and additional inputs by Ananthu Nair.)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cuelogic.com/blog/advanced-image-processing-with-python/
|
||||
|
||||
作者:[Snehith Kumbla][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cuelogic.com/blog/author/snehith-kumbla/
|
||||
[1]: http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_feature2d/py_surf_intro/py_surf_intro.html
|
||||
[2]: http://www.vision.ee.ethz.ch/~surf/eccv06.pdf
|
||||
[3]: https://docs.google.com/spreadsheets/d/1gYJsy2ROtqvIVvOKretfxQG_0OsaiFvb7uFRDu5P8hw/edit#gid=10
|
||||
@ -1,127 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
How to permanently mount a Windows share on Linux
|
||||
==================================================
|
||||
|
||||
>If you get tired of having to remount Windows shares when you reboot your Linux box, read about an easy way to make those shares permanently mount.
|
||||
|
||||

|
||||
>Image: Jack Wallen
|
||||
|
||||
It has never been easier for Linux to interact within a Windows network. And considering how many businesses are adopting Linux, those two platforms have to play well together. Fortunately, with the help of a few tools, you can easily map Windows network drives onto a Linux machine, and even ensure they are still there upon rebooting the Linux machine.
|
||||
|
||||
### Before we get started
|
||||
|
||||
For this to work, you will be using the command line. The process is pretty simple, but you will be editing the /etc/fstab file, so do use caution.
|
||||
Also, I assume you already have Samba working properly so you can manually mount shares from a Windows network to your Linux box, and that you know the IP address of the machine hosting the share.
|
||||
|
||||
Are you ready? Let's go.
|
||||
|
||||
### Create your mount point
|
||||
|
||||
The first thing we're going to do is create a folder that will serve as the mount point for the share. For the sake of simplicity, we'll name this folder share and we'll place it in /media. Open your terminal window and issue the command:
|
||||
|
||||
```
|
||||
sudo mkdir /media/share
|
||||
```
|
||||
|
||||
### A few installations
|
||||
|
||||
Now we have to install the system that allows for cross-platform file sharing; this system is cifs-utils. From the terminal window, issue the command:
|
||||
|
||||
```
|
||||
sudo apt-get install cifs-utils
|
||||
```
|
||||
|
||||
This command will also install all of the dependencies for cifs-utils.
|
||||
|
||||
Once this is installed, open up the file /etc/nsswitch.conf and look for the line:
|
||||
|
||||
```
|
||||
hosts: files mdns4_minimal [NOTFOUND=return] dns
|
||||
```
|
||||
|
||||
Edit that line so it looks like:
|
||||
|
||||
```
|
||||
hosts: files mdns4_minimal [NOTFOUND=return] wins dns
|
||||
```
|
||||
|
||||
Now you must install windbind so that your Linux machine can resolve Windows computer names on a DHCP network. From the terminal, issue this command:
|
||||
|
||||
```
|
||||
sudo apt-get install libnss-windbind windbind
|
||||
```
|
||||
|
||||
Restart networking with the command:
|
||||
|
||||
```
|
||||
sudo service networking restart
|
||||
```
|
||||
|
||||
### Mount the network drive
|
||||
|
||||
Now we're going to map the network drive. This is where we must edit the /etc/fstab file. Before you make that first edit, back up the file with this command:
|
||||
|
||||
```
|
||||
sudo cp /etc/fstab /etc/fstab.old
|
||||
```
|
||||
|
||||
If you need to restore that file, issue the command:
|
||||
|
||||
```
|
||||
sudo mv /etc/fstab.old /etc/fstab
|
||||
```
|
||||
|
||||
Create a credentials file in your home directory called .smbcredentials. In that file, add your username and password, like so (USER is the actual username and password is the actual password):
|
||||
|
||||
```
|
||||
username=USER
|
||||
|
||||
password=PASSWORD
|
||||
```
|
||||
|
||||
You now have to know the Group ID (GID) and User ID (UID) of the user that will be mounting the drive. Issue the command:
|
||||
|
||||
```
|
||||
id USER
|
||||
```
|
||||
|
||||
USER is the actual username, and you should see something like:
|
||||
|
||||
```
|
||||
uid=1000(USER) gid=1000(GROUP)
|
||||
```
|
||||
|
||||
USER is the actual username, and GROUP is the group name. The numbers before (USER) and (GROUP) will be used in the /etc/fstab file.
|
||||
|
||||
It's time to edit the /etc/fstab file. Open that file in your editor and add the following line to the end (replace everything in ALL CAPS and the IP address of the remote machine):
|
||||
|
||||
```
|
||||
//192.168.1.10/SHARE /media/share cifs credentials=/home/USER/.smbcredentials,iocharset=uft8,gid=GID,udi=UID,file_mode=0777,dir_mode=0777 0 0
|
||||
```
|
||||
|
||||
**Note**: The above should be on a single line.
|
||||
|
||||
Save and close that file. Issue the command sudo mount -a and the share will be mounted. Check in /media/share and you should see the files and folders on the network share.
|
||||
|
||||
### Sharing made easy
|
||||
|
||||
Thanks to cifs-utils and Samba, mapping network shares is incredibly easy on a Linux machine. And now, you won't have to manually remount those shares every time your machine boots.
|
||||
|
||||
For more networking tips and tricks, sign up for our Data Center newsletter.
|
||||
[SUBSCRIBE](https://secure.techrepublic.com/user/login/?regSource=newsletter-button&position=newsletter-button&appId=true&redirectUrl=http%3A%2F%2Fwww.techrepublic.com%2Farticle%2Fhow-to-permanently-mount-a-windows-share-on-linux%2F&)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techrepublic.com/article/how-to-permanently-mount-a-windows-share-on-linux/
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.techrepublic.com/search/?a=jack+wallen
|
||||
|
||||
|
||||
@ -0,0 +1,124 @@
|
||||
How to Hide Linux Command Line History by Going Incognito
|
||||
================================================================
|
||||
|
||||

|
||||
|
||||
If you’re a Linux command line user, you’ll agree that there are times when you do not want certain commands you run to be recorded in the command line history. There could be many reasons for this. For example, you’re at a certain position in your company, and you have some privileges that you don’t want others to abuse. Or, there are some critical commands that you don’t want to run accidentally while you’re browsing the history list.
|
||||
|
||||
But is there a way to control what goes into the history list and what doesn’t? Or, in other words, can we turn on a web browser-like incognito mode in the Linux command line? The answer is yes, and there are many ways to achieve this, depending on what exactly you want. In this article we will discuss some of the popular solutions available.
|
||||
|
||||
Note: all the commands presented in this article have been tested on Ubuntu.
|
||||
|
||||
### Different ways available
|
||||
|
||||
The first two ways we’ll describe here have already been covered in [one of our previous articles][1]. If you are already aware of them, you can skip over these. However, if you aren’t aware, you’re advised to go through them carefully.
|
||||
|
||||
#### 1. Insert space before command
|
||||
|
||||
Yes, you read it correctly. Insert a space in the beginning of a command, and it will be ignored by the shell, meaning the command won’t be recorded in history. However, there’s a dependency – the said solution will only work if the HISTCONTROL environment variable is set to “ignorespace” or “ignoreboth,” which is by default in most cases.
|
||||
|
||||
So, a command like the following:
|
||||
|
||||
```
|
||||
[space]echo "this is a top secret"
|
||||
```
|
||||
|
||||
Won’t appear in the history if you’ve already done this command:
|
||||
|
||||
```
|
||||
export HISTCONTROL = ignorespace
|
||||
```
|
||||
|
||||
The below screenshot is an example of this behavior.
|
||||
|
||||

|
||||
|
||||
The fourth “echo” command was not recorded in the history as it was run with a space in the beginning.
|
||||
|
||||
#### 2. Disable the entire history for the current session
|
||||
|
||||
If you want to disable the entire history for a session, you can easily do that by unsetting the HISTSIZE environment variable before you start with your command line work. To unset the variable run the following command:
|
||||
|
||||
```
|
||||
export HISTFILE=0
|
||||
```
|
||||
|
||||
HISTFILE is the number of lines (or commands) that can be stored in the history list for an ongoing bash session. By default, this variable has a set value – for example, 1000 in my case.
|
||||
|
||||
So, the command mentioned above will set the environment variable’s value to zero, and consequently nothing will be stored in the history list until you close the terminal. Keep in mind that you’ll also not be able to see the previously run commands by pressing the up arrow key or running the history command.
|
||||
|
||||
#### 3. Erase the entire history after you’re done
|
||||
|
||||
This can be seen as an alternative to the solution mentioned in the previous section. The only difference is that in this case you run a command AFTER you’re done with all your work. Thh following is the command in question:
|
||||
|
||||
```
|
||||
history -cw
|
||||
```
|
||||
|
||||
As already mentioned, this will have the same effect as the HISTFILE solution mentioned above.
|
||||
|
||||
#### 4. Turn off history only for the work you do
|
||||
|
||||
While the solutions (2 and 3) described above do the trick, they erase the entire history, something which might be undesired in many situations. There might be cases in which you want to retain the history list up until the point you start your command line work. For situations like these you need to run the following command before starting with your work:
|
||||
|
||||
```
|
||||
[space]set +o history
|
||||
```
|
||||
|
||||
Note: [space] represents a blank space.
|
||||
|
||||
The above command will disable the history temporarily, meaning whatever you do after running this command will not be recorded in history, although all the stuff executed prior to the above command will be there as it is in the history list.
|
||||
|
||||
To re-enable the history, run the following command:
|
||||
|
||||
```
|
||||
[Space]set -o history
|
||||
```
|
||||
|
||||
This brings things back to normal again, meaning any command line work done after the above command will show up in the history.
|
||||
|
||||
#### 5. Delete specific commands from history
|
||||
|
||||
Now suppose the history list already contains some commands that you didn’t want to be recorded. What can be done in this case? It’s simple. You can go ahead and remove them. The following is how to accomplish this:
|
||||
|
||||
```
|
||||
[space]history | grep "part of command you want to remove"
|
||||
```
|
||||
|
||||
The above command will output a list of matching commands (that are there in the history list) with a number [num] preceding each of them.
|
||||
|
||||
Once you’ve identified the command you want to remove, just run the following command to remove that particular entry from the history list:
|
||||
|
||||
```
|
||||
history -d [num]
|
||||
```
|
||||
|
||||
The following screenshot is an example of this.
|
||||
|
||||

|
||||
|
||||
The second ‘echo’ command was removed successfully.
|
||||
|
||||
Alternatively, you can just press the up arrow key to take a walk back through the history list, and once the command of your interest appears on the terminal, just press “Ctrl + U” to totally blank the line, effectively removing it from the list.
|
||||
|
||||
### Conclusion
|
||||
|
||||
There are multiple ways in which you can manipulate the Linux command line history to suit your needs. Keep in mind, however, that it’s usually not a good practice to hide or remove a command from history, although it’s also not wrong, per se, but you should be aware of what you’re doing and what effects it might have.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-command-line-history-incognito/?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+maketecheasier
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/himanshu/
|
||||
[1]: https://www.maketecheasier.com/command-line-history-linux/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,52 @@
|
||||
USE TASK MANAGER EQUIVALENT IN LINUX
|
||||
====================================
|
||||
|
||||

|
||||
|
||||
These are some of the most frequently asked questions by Linux beginners, “**is there a task manager for Linux**“, “how do you open task manager in Linux” ?
|
||||
|
||||
People who are coming from Windows know how useful is the task manager. You press the Ctrl+Alt+Del to get to task manager in Windows. This task manager shows you all the running processes and their memory consumption. You can choose to end a process from this task manager application.
|
||||
|
||||
When you have just begun with Linux, you look for a **task manager equivalent in Linux** as well. An expert Linux user prefers the command line way to find processes and memory consumption etc but you don’t have to go that way, at least not when you are just starting with Linux.
|
||||
|
||||
All major Linux distributions have a task manager equivalent. Mostly, **it is called System Monitor** but it actually depends on your Linux distribution and the [desktop environment][1] it uses.
|
||||
|
||||
In this article, we’ll see how to find and use the task manager in Linux with GNOME as the [desktop environment][2].
|
||||
|
||||
### TASK MANAGER EQUIVALENT IN LINUX WITH GNOME DESKTOP
|
||||
|
||||
While using GNOME, press super key (Windows Key) and look for System Monitor:
|
||||
|
||||

|
||||
|
||||
When you start the System Monitor, it shows you all the running processes and the memory consumption by them.
|
||||
|
||||

|
||||
|
||||
You can select a process and click on End process to kill it.
|
||||
|
||||

|
||||
|
||||
You can also see some statistics about your system in the Resources tab such as CPU consumption per core basis, memory usage, network usage etc.
|
||||
|
||||

|
||||
|
||||
This was the graphical way. If you want to go command line way, just run the command ‘top’ in terminal and you can see all the running processes and their memory consumption. You can easily [kill processes in Linux][3] command line.
|
||||
|
||||
This all you need to know about task manager equivalent in Fedora Linux. I hope you find this quick tutorial helpful. If you have questions or suggestions, feel free to ask.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/task-manager-linux/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://wiki.archlinux.org/index.php/desktop_environment
|
||||
[2]: https://itsfoss.com/best-linux-desktop-environments/
|
||||
[3]: https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/
|
||||
@ -0,0 +1,42 @@
|
||||
CANONICAL CONSIDERING TO DROP 32 BIT SUPPORT IN UBUNTU
|
||||
========================================================
|
||||
|
||||

|
||||
|
||||
Yesterday, developer [Dimitri John Ledkov][1] wrote a message on the [Ubuntu Mailing list][2] calling for the end of i386 support by Ubuntu 18.10. Ledkov argues that more software is being developed with 64-bit support. He is also concerned that it will be difficult to provide security support for the aging i386 architecture.
|
||||
|
||||
Ledkov also argues that building i386 images is not free, but takes quite a bit of Canonical’s resources.
|
||||
|
||||
>Building i386 images is not “for free”, it comes at the cost of utilizing our build farm, QA and validation time. Whilst we have scalable build-farms, i386 still requires all packages, autopackage tests, and ISOs to be revalidated across our infrastructure. As well as take up mirror space & bandwidth.
|
||||
|
||||
Ledkov offers a plan where the 16.10, 17.04, and 17.10 versions of Ubuntu will continue to have i386 kernels, netboot installers, and cloud images, but drop i386 ISO for desktop and server. The 18.04 LTS would then drop support for i386 kernels, netboot installers, and cloud images, but still provide the ability for i386 programs to run on 64-bit architecture. Then, 18.10 would end the i386 port and limit legacy 32-bit applications to snaps, containers, and virtual machines.
|
||||
|
||||
Ledkov’s plan had not been accepted yet, but it shows a definite push toward eliminating 32-bit support.
|
||||
|
||||
### GOOD NEWS
|
||||
|
||||
Don’t despair yet. this will not affect the distros used to resurrect your old system. [Martin Wimpress][3], the creator of [Ubuntu MATE][4], revealed during a discussion on Googl+ that these changes will only affect mainline Ubuntu.
|
||||
|
||||
>The i386 archive will continue to exist into 18.04 and flavours can continue to elect to build i386 isos. There is however a security concern, in that some larger applications (Firefox, Chromium, LibreOffice) are already presenting challenges in terms of applying some security patches to older LTS releases. So flavours are being asked to be mindful of the support period they can reasonably be expected to support i386 versions for.
|
||||
|
||||
### THOUGHTS
|
||||
|
||||
I understand why they need to make this move from a security standpoint, but it’s going to make people move away from mainline Ubuntu to either one of the flavors or a different architecture. Thankfully, we have alternative [lightweight Linux distributions][5].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-32-bit-support-drop/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[John Paul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]: https://plus.google.com/+DimitriJohnLedkov
|
||||
[2]: https://lists.ubuntu.com/archives/ubuntu-devel-discuss/2016-June/016661.html
|
||||
[3]: https://twitter.com/m_wimpress
|
||||
[4]: http://ubuntu-mate.org/
|
||||
[5]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
@ -0,0 +1,122 @@
|
||||
如何在 Linux 上永久挂载一个 Windows 共享
|
||||
==================================================
|
||||
|
||||
> 如果你已经厌倦了每次重启 Linux 就得重新挂载 Windows 共享,读读这个让共享永久挂载的简单方法。
|
||||
|
||||

|
||||
>图片: Jack Wallen
|
||||
|
||||
在 Linux 上和一个 Windows 网络进行交互从来就不是件轻松的事情。想想多少企业正在采用 Linux,这两个平台不得不一起好好协作。幸运的是,有了一些工具的帮助,你可以轻松地将 Windows 网络驱动器映射到一台 Linux 机器上,甚至可以确保在重启 Linux 机器之后共享还在。
|
||||
|
||||
### 在我们开始之前
|
||||
|
||||
要实现这个,你需要用到命令行。过程十分简单,但你需要编辑 /etc/fstab 文件,所以小心操作。还有,我假设你已经有正常工作的 Samba 了,可以手动从 Windows 网络挂载共享到你的 Linux 机器,还知道这个共享的主机 IP 地址。
|
||||
|
||||
准备好了吗?那就开始吧。
|
||||
|
||||
### 创建你的挂载点
|
||||
|
||||
我们要做的第一件事是创建一个文件夹,他将作为共享的挂载点。为了简单起见,我们将这个文件夹命名为 share,放在 /media 之下。打开你的终端执行以下命令:
|
||||
|
||||
```
|
||||
sudo mkdir /media/share
|
||||
```
|
||||
|
||||
### 一些安装
|
||||
|
||||
现在我们得安装允许跨平台文件共享的系统;这个系统是 cifs-utils。在终端窗口输入:
|
||||
|
||||
```
|
||||
sudo apt-get install cifs-utils
|
||||
```
|
||||
|
||||
这个命令同时还会安装 cifs-utils 所有的依赖。
|
||||
|
||||
安装完成之后,打开文件 /etc/nsswitch.conf 并找到这一行:
|
||||
|
||||
```
|
||||
hosts: files mdns4_minimal [NOTFOUND=return] dns
|
||||
```
|
||||
|
||||
编辑这一行,让它看起来像这样:
|
||||
|
||||
```
|
||||
hosts: files mdns4_minimal [NOTFOUND=return] wins dns
|
||||
```
|
||||
|
||||
现在你必须安装 windbind 让你的 Linux 机器可以在 DHCP 网络中解析 Windows 机器名。在终端里执行:
|
||||
|
||||
```
|
||||
sudo apt-get install libnss-windbind windbind
|
||||
```
|
||||
|
||||
用这个命令重启网络服务:
|
||||
|
||||
```
|
||||
sudo service networking restart
|
||||
```
|
||||
|
||||
### 挂载网络驱动器
|
||||
|
||||
现在我们要映射网络驱动器。这里我们必须编辑 /etc/fstab 文件。在你做第一次编辑之前,用这个命令备份以下这个文件:
|
||||
|
||||
```
|
||||
sudo cp /etc/fstab /etc/fstab.old
|
||||
```
|
||||
|
||||
如果你需要恢复这个文件,执行以下命令:
|
||||
|
||||
```
|
||||
sudo mv /etc/fstab.old /etc/fstab
|
||||
```
|
||||
|
||||
在你的主目录创建一个认证信息文件 .smbcredentials。在这个文件里添加你的用户名和密码,就像这样(USER 和 PASSWORD 是实际的用户名和密码):
|
||||
|
||||
```
|
||||
username=USER
|
||||
|
||||
password=PASSWORD
|
||||
```
|
||||
|
||||
你需要知道挂载这个驱动器的用户的组 ID(GID)和用户 ID(UID)。执行命令:
|
||||
|
||||
```
|
||||
id USER
|
||||
```
|
||||
|
||||
USER 是实际的用户名,你应该会看到类似这样的信息:
|
||||
|
||||
```
|
||||
uid=1000(USER) gid=1000(GROUP)
|
||||
```
|
||||
|
||||
USER 是实际的用户名,GROUP 是组名。在(USER)和(GROUP)之前的数字将会被用在 /etc/fstab 文件之中。
|
||||
|
||||
是时候编辑 /etc/fstab 文件了。在你的编辑器中打开那个文件并添加下面这行到文件末尾(替换以下全大写字段以及远程机器的 IP 地址):
|
||||
|
||||
```
|
||||
//192.168.1.10/SHARE /media/share cifs credentials=/home/USER/.smbcredentials,iocharset=uft8,gid=GID,udi=UID,file_mode=0777,dir_mode=0777 0 0
|
||||
```
|
||||
|
||||
**注意**:上面这些内容应该在同一行上。
|
||||
|
||||
保存并关闭那个文件。执行 sudo mount -a 命令,共享将被挂载。检查一下 /media/share,你应该能看到那个网络共享上的文件和文件夹了。
|
||||
|
||||
### 共享很简单
|
||||
|
||||
有了 cifs-utils 和 Samba,映射网络共享在一台 Linux 机器上简单得让人难以置信。现在,你再也不用在每次机器启动的时候手动重新挂载那些共享了。
|
||||
|
||||
更多网络提示和技巧,订阅我们的 Data Center 消息吧。
|
||||
[订阅](https://secure.techrepublic.com/user/login/?regSource=newsletter-button&position=newsletter-button&appId=true&redirectUrl=http%3A%2F%2Fwww.techrepublic.com%2Farticle%2Fhow-to-permanently-mount-a-windows-share-on-linux%2F&)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techrepublic.com/article/how-to-permanently-mount-a-windows-share-on-linux/
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.techrepublic.com/search/?a=jack+wallen
|
||||
Loading…
Reference in New Issue
Block a user