mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
911af33301
@ -1,5 +1,6 @@
|
||||
安装Strongswan - Linux上一个基于IPsec的vpn工具
|
||||
安装 Strongswan :Linux 上一个基于 IPsec 的 VPN 工具
|
||||
================================================================================
|
||||
|
||||
IPsec是一个提供网络层安全的标准。它包含认证头(AH)和安全负载封装(ESP)组件。AH提供包的完整性,ESP组件提供包的保密性。IPsec确保了在网络层的安全特性。
|
||||
|
||||
- 保密性
|
||||
@ -7,27 +8,27 @@ IPsec是一个提供网络层安全的标准。它包含认证头(AH)和安全
|
||||
- 来源不可抵赖性
|
||||
- 重放攻击防护
|
||||
|
||||
[Strongswan][1]是一个IPsec协议实现的开源代码,Strongswan代表强壮开源广域网(StrongS/WAN)。它支持IPsec的VPN两个版本的密钥自动交换(网络密钥交换(IKE)V1和V2)。
|
||||
[Strongswan][1]是一个IPsec协议的开源代码实现,Strongswan的意思是强安全广域网(StrongS/WAN)。它支持IPsec的VPN中的两个版本的密钥自动交换(网络密钥交换(IKE)V1和V2)。
|
||||
|
||||
Strongswan基本上提供了自动交换密钥共享VPN两个节点或网络,然后它使用Linux内核的IPsec(AH和ESP)实现。密钥共享使用了IKE机制的特性使用ESP编码数据。在IKE阶段,strongswan使用OpenSSL加密算法(AES,SHA等等)和其他加密类库。无论如何,ESP组成IPsec使用的安全算法,它是Linux内核实现的。Strongswan的主要特性是下面这些。
|
||||
Strongswan基本上提供了在VPN的两个节点/网关之间自动交换密钥的共享,然后它使用了Linux内核的IPsec(AH和ESP)实现。密钥共享使用了之后用于ESP数据加密的IKE 机制。在IKE阶段,strongswan使用OpenSSL的加密算法(AES,SHA等等)和其他加密类库。无论如何,IPsec中的ESP组件使用的安全算法是由Linux内核实现的。Strongswan的主要特性如下:
|
||||
|
||||
- x.509证书或基于预共享密钥认证
|
||||
- 支持IKEv1和IKEv2密钥交换协议
|
||||
- 可选内置插件和库的完整性和加密测试
|
||||
- 支持椭圆曲线DH群体和ECDSA证书
|
||||
- 可选的,对于插件和库的内置完整性和加密测试
|
||||
- 支持椭圆曲线DH群和ECDSA证书
|
||||
- 在智能卡上存储RSA私钥和证书
|
||||
|
||||
它能被使用在客户端或服务器(road warrior模式)和网关到网关的情景。
|
||||
它能被使用在客户端/服务器(road warrior模式)和网关到网关的情景。
|
||||
|
||||
### 如何安装 ###
|
||||
|
||||
几乎所有的Linux发行版都支持Strongswan的二进制包。在这个教程,我们将从二进制包安装strongswan也编译strongswan合适的特性的源代码。
|
||||
几乎所有的Linux发行版都支持Strongswan的二进制包。在这个教程,我们会从二进制包安装strongswan,也会从源代码编译带有合适的特性的strongswan。
|
||||
|
||||
### 使用二进制包 ###
|
||||
|
||||
可以使用以下命令安装Strongswan到Ubuntu 14.04 LTS
|
||||
|
||||
$sudo aptitude install strongswan
|
||||
$ sudo aptitude install strongswan
|
||||
|
||||

|
||||
|
||||
@ -35,35 +36,35 @@ strongswan的全局配置(strongswan.conf)文件和ipsec配置(ipsec.conf/
|
||||
|
||||
### strongswan源码编译安装的依赖包 ###
|
||||
|
||||
- GMP(strongswan使用的Mathematical/Precision 库)
|
||||
- OpenSSL(加密算法在这个库里)
|
||||
- PKCS(1,7,8,11,12)(证书编码和智能卡与Strongswan集成)
|
||||
- GMP(strongswan使用的高精度数学库)
|
||||
- OpenSSL(加密算法来自这个库)
|
||||
- PKCS(1,7,8,11,12)(证书编码和智能卡集成)
|
||||
|
||||
#### 步骤 ####
|
||||
|
||||
**1)** 在终端使用下面命令到/usr/src/目录
|
||||
|
||||
$cd /usr/src
|
||||
$ cd /usr/src
|
||||
|
||||
**2)** 用下面命令从strongswan网站下载源代码
|
||||
|
||||
$sudo wget http://download.strongswan.org/strongswan-5.2.1.tar.gz
|
||||
$ sudo wget http://download.strongswan.org/strongswan-5.2.1.tar.gz
|
||||
|
||||
(strongswan-5.2.1.tar.gz 是最新版。)
|
||||
(strongswan-5.2.1.tar.gz 是当前最新版。)
|
||||
|
||||

|
||||
|
||||
**3)** 用下面命令提取下载软件,然后进入目录。
|
||||
**3)** 用下面命令提取下载的软件,然后进入目录。
|
||||
|
||||
$sudo tar –xvzf strongswan-5.2.1.tar.gz; cd strongswan-5.2.1
|
||||
$ sudo tar –xvzf strongswan-5.2.1.tar.gz; cd strongswan-5.2.1
|
||||
|
||||
**4)** 使用configure命令配置strongswan每个想要的选项。
|
||||
|
||||
./configure --prefix=/usr/local -–enable-pkcs11 -–enable-openssl
|
||||
$ ./configure --prefix=/usr/local -–enable-pkcs11 -–enable-openssl
|
||||
|
||||

|
||||
|
||||
如果GMP库没有安装,然后配置脚本将会发生下面的错误。
|
||||
如果GMP库没有安装,配置脚本将会发生下面的错误。
|
||||
|
||||

|
||||
|
||||
@ -71,19 +72,19 @@ strongswan的全局配置(strongswan.conf)文件和ipsec配置(ipsec.conf/
|
||||
|
||||

|
||||
|
||||
无论如何,如果GMP已经安装而且还一致报错,然后在Ubuntu上使用下面命令创建libgmp.so库的软连到/usr/lib,/lib/,/usr/lib/x86_64-linux-gnu/路径下。
|
||||
不过,如果GMP已经安装还报上述错误的话,在Ubuntu上使用如下命令,给在路径 /usr/lib,/lib/,/usr/lib/x86_64-linux-gnu/ 下的libgmp.so库创建软连接。
|
||||
|
||||
$ sudo ln -s /usr/lib/x86_64-linux-gnu/libgmp.so.10.1.3 /usr/lib/x86_64-linux-gnu/libgmp.so
|
||||
|
||||

|
||||
|
||||
创建libgmp.so软连后,再执行./configure脚本也许就找到gmp库了。无论如何,gmp头文件也许发生其他错误,像下面这样。
|
||||
创建libgmp.so软连接后,再执行./configure脚本也许就找到gmp库了。然而,如果gmp头文件发生其他错误,像下面这样。
|
||||
|
||||

|
||||
|
||||
为解决上面的错误,使用下面命令安装libgmp-dev包
|
||||
|
||||
$sudo aptitude install libgmp-dev
|
||||
$ sudo aptitude install libgmp-dev
|
||||
|
||||

|
||||
|
||||
@ -105,7 +106,7 @@ via: http://linoxide.com/security/install-strongswan/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,89 @@
|
||||
如何在树莓派 2 运行 ubuntu Snappy Core
|
||||
================================================================================
|
||||
物联网(Internet of Things, IoT) 时代即将来临。很快,过不了几年,我们就会问自己当初是怎么在没有物联网的情况下生存的,就像我们现在怀疑过去没有手机的年代。Canonical 就是一个物联网快速发展却还是开放市场下的竞争者。这家公司宣称自己把赌注压到了IoT 上,就像他们已经在“云”上做过的一样。在今年一月底,Canonical 启动了一个基于Ubuntu Core 的小型操作系统,名字叫做 [Ubuntu Snappy Core][1] 。
|
||||
|
||||
Snappy 代表了两种意思,它是一种用来替代 deb 的新的打包格式;也是一个用来更新系统的前端,从CoreOS、红帽子和其他系统借鉴了**原子更新**这个想法。自从树莓派 2 投入市场,Canonical 很快就发布了用于树莓派的Snappy Core 版本。而第一代树莓派因为是基于ARMv6 ,Ubuntu 的ARM 镜像是基于ARMv7 ,所以不能运行ubuntu 。不过这种状况现在改变了,Canonical 通过发布 Snappy Core 的RPI2 镜像,抓住机会证明了Snappy 就是一个用于云计算,特别是用于物联网的系统。
|
||||
|
||||
Snappy 同样可以运行在其它像Amazon EC2, Microsofts Azure, Google的 Compute Engine 这样的云端上,也可以虚拟化在 KVM、Virtuabox 和vagrant 上。Canonical Ubuntu 已经拥抱了微软、谷歌、Docker、OpenStack 这些重量级选手,同时也与一些小项目达成合作关系。除了一些创业公司,比如 Ninja Sphere、Erle Robotics,还有一些开发板生产商,比如 Odroid、Banana Pro, Udoo, PCDuino 和 Parallella 、全志,Snappy 也提供了支持。Snappy Core 同时也希望尽快运行到路由器上来帮助改进路由器生产商目前很少更新固件的策略。
|
||||
|
||||
接下来,让我们看看怎么样在树莓派 2 上运行 Ubuntu Snappy Core。
|
||||
|
||||
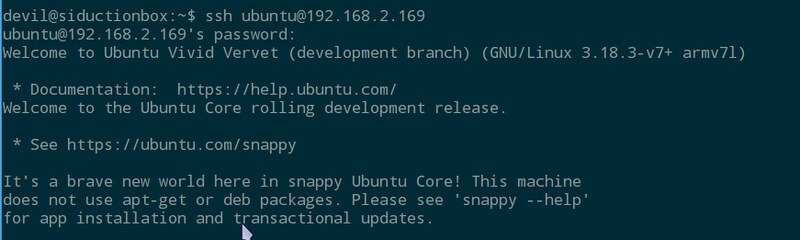
用于树莓派2 的Snappy 镜像可以从 [Raspberry Pi 网站][2] 上下载。解压缩出来的镜像必须[写到一个至少8GB 大小的SD 卡][3]。尽管原始系统很小,但是原子升级和回滚功能会占用不小的空间。使用 Snappy 启动树莓派 2 后你就可以使用默认用户名和密码(都是ubuntu)登录系统。
|
||||
|
||||
|
||||
|
||||
sudo 已经配置好了可以直接用,安全起见,你应该使用以下命令来修改你的用户名
|
||||
|
||||
$ sudo usermod -l <new name> <old name>
|
||||
|
||||
或者也可以使用`adduser` 为你添加一个新用户。
|
||||
|
||||
因为RPI缺少硬件时钟,而 Snappy Core 镜像并不知道这一点,所以系统会有一个小 bug:处理某些命令时会报很多错。不过这个很容易解决:
|
||||
|
||||
使用这个命令来确认这个bug 是否影响:
|
||||
|
||||
$ date
|
||||
|
||||
如果输出类似 "Thu Jan 1 01:56:44 UTC 1970", 你可以这样做来改正:
|
||||
|
||||
$ sudo date --set="Sun Apr 04 17:43:26 UTC 2015"
|
||||
|
||||
改成你的实际时间。
|
||||
|
||||

|
||||
|
||||
现在你可能打算检查一下,看看有没有可用的更新。注意通常使用的命令是不行的:
|
||||
|
||||
$ sudo apt-get update && sudo apt-get distupgrade
|
||||
|
||||
这时系统不会让你通过,因为 Snappy 使用它自己精简过的、基于dpkg 的包管理系统。这么做的原因是 Snappy 会运行很多嵌入式程序,而同时你也会试图所有事情尽可能的简化。
|
||||
|
||||
让我们来看看最关键的部分,理解一下程序是如何与 Snappy 工作的。运行 Snappy 的SD 卡上除了 boot 分区外还有3个分区。其中的两个构成了一个重复的文件系统。这两个平行文件系统被固定挂载为只读模式,并且任何时刻只有一个是激活的。第三个分区是一个部分可写的文件系统,用来让用户存储数据。通过更新系统,标记为'system-a' 的分区会保持一个完整的文件系统,被称作核心,而另一个平行的文件系统仍然会是空的。
|
||||
|
||||

|
||||
|
||||
如果我们运行以下命令:
|
||||
|
||||
$ sudo snappy update
|
||||
|
||||
系统将会在'system-b' 上作为一个整体进行更新,这有点像是更新一个镜像文件。接下来你将会被告知要重启系统来激活新核心。
|
||||
|
||||
重启之后,运行下面的命令可以检查你的系统是否已经更新到最新版本,以及当前被激活的是哪个核心
|
||||
|
||||
$ sudo snappy versions -a
|
||||
|
||||
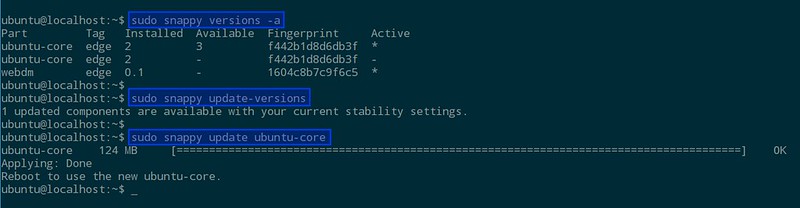
经过更新-重启两步操作,你应该可以看到被激活的核心已经被改变了。
|
||||
|
||||
因为到目前为止我们还没有安装任何软件,所以可以用下面的命令更新:
|
||||
|
||||
$ sudo snappy update ubuntu-core
|
||||
|
||||
如果你打算仅仅更新特定的OS 版本这就够了。如果出了问题,你可以使用下面的命令回滚:
|
||||
|
||||
$ sudo snappy rollback ubuntu-core
|
||||
|
||||
这将会把系统状态回滚到更新之前。
|
||||
|
||||
|
||||
|
||||
再来说说那些让 Snappy 变得有用的软件。这里不会讲的太多关于如何构建软件、向 Snappy 应用商店添加软件的基础知识,但是你可以通过 Freenode 上的IRC 频道 #snappy 了解更多信息,那个上面有很多人参与。你可以通过浏览器访问http://\<ip-address>:4200 来浏览应用商店,然后从商店安装软件,再在浏览器里访问 http://webdm.local 来启动程序。如何构建用于 Snappy 的软件并不难,而且也有了现成的[参考文档][4] 。你也可以很容易的把 DEB 安装包使用Snappy 格式移植到Snappy 上。
|
||||
|
||||
|
||||
|
||||
尽管 Ubuntu Snappy Core 吸引了我们去研究新型的 Snappy 安装包格式和 Canonical 式的原子更新操作,但是因为有限的可用应用,它现在在生产环境里还不是很有用。但是既然搭建一个 Snappy 环境如此简单,这看起来是一个学点新东西的好机会。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/ubuntu-snappy-core-raspberry-pi-2.html
|
||||
|
||||
作者:[Ferdinand Thommes][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/ferdinand
|
||||
[1]:http://www.ubuntu.com/things
|
||||
[2]:http://www.raspberrypi.org/downloads/
|
||||
[3]:http://xmodulo.com/write-raspberry-pi-image-sd-card.html
|
||||
[4]:https://developer.ubuntu.com/en/snappy/
|
||||
@ -1,6 +1,6 @@
|
||||
在 VirtualBox 中使用 Docker Machine 管理主机
|
||||
================================================================================
|
||||
大家好,今天我们学习在 VirtualBox 中使用 Docker Machine 来创建和管理 Docker 主机。Docker Machine 是一个应用,用于在我们的电脑上、在云端、在数据中心创建 Docker 主机,然后用户可以使用 Docker 客户端来配置一些东西。这个 API 为本地主机、或数据中心的虚拟机、或云端的实例提供 Docker 服务。Docker Machine 支持 Windows、OSX 和 Linux,并且是以一个独立的二进制文件包形式安装的。使用(与现有 Docker 工具)相同的接口,我们就可以充分利用已经提供 Docker 基础框架的生态系统。只要一个命令,用户就能快速部署 Docker 容器。
|
||||
大家好,今天我们学习在 VirtualBox 中使用 Docker Machine 来创建和管理 Docker 主机。Docker Machine 是一个可以帮助我们在电脑上、在云端、在数据中心内创建 Docker 主机的应用。它为根据用户的配置和需求创建服务器并在其上安装 Docker和客户端提供了一个轻松的解决方案。这个 API 可以用于在本地主机、或数据中心的虚拟机、或云端的实例提供 Docker 服务。Docker Machine 支持 Windows、OSX 和 Linux,并且是以一个独立的二进制文件包形式安装的。仍然使用(与现有 Docker 工具)相同的接口,我们就可以充分利用已经提供 Docker 基础框架的生态系统。只要一个命令,用户就能快速部署 Docker 容器。
|
||||
|
||||
本文列出一些简单的步骤用 Docker Machine 来部署 docker 容器。
|
||||
|
||||
@ -8,15 +8,15 @@
|
||||
|
||||
Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [github][1] 下载最新版本的 Docker Machine,本文使用 curl 作为下载工具,Docker Machine 版本为 0.2.0。
|
||||
|
||||
** 64 位操作系统 **
|
||||
**64 位操作系统**
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
** 32 位操作系统 **
|
||||
**32 位操作系统**
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
下载完成后,找到 **/usr/local/bin** 目录下的 **docker-machine** 文件,执行一下:
|
||||
下载完成后,找到 **/usr/local/bin** 目录下的 **docker-machine** 文件,让其可以执行:
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
@ -28,12 +28,12 @@ Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [gi
|
||||
|
||||
运行下面的命令,安装 Docker 客户端,以便于在我们自己的电脑止运行 Docker 命令:
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. 创建 VirtualBox 虚拟机 ###
|
||||
|
||||
在 Linux 系统上安装完 Docker Machine 后,接下来我们可以安装 VirtualBox 虚拟机,运行下面的就可以了。--driver virtualbox 选项表示我们要在 VirtualBox 的虚拟机里面部署 docker,最后的参数“linux” 是虚拟机的名称。这个命令会下载 [boot2docker][2] iso,它是个基于 Tiny Core Linux 的轻量级发行版,自带 Docker 程序,然后 docker-machine 命令会创建一个 VirtualBox 虚拟机(LCTT:当然,我们也可以选择其他的虚拟机软件)来运行这个 boot2docker 系统。
|
||||
在 Linux 系统上安装完 Docker Machine 后,接下来我们可以安装 VirtualBox 虚拟机,运行下面的就可以了。`--driver virtualbox` 选项表示我们要在 VirtualBox 的虚拟机里面部署 docker,最后的参数“linux” 是虚拟机的名称。这个命令会下载 [boot2docker][2] iso,它是个基于 Tiny Core Linux 的轻量级发行版,自带 Docker 程序,然后 `docker-machine` 命令会创建一个 VirtualBox 虚拟机(LCTT译注:当然,我们也可以选择其他的虚拟机软件)来运行这个 boot2docker 系统。
|
||||
|
||||
# docker-machine create --driver virtualbox linux
|
||||
|
||||
@ -49,7 +49,7 @@ Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [gi
|
||||
|
||||
### 3. 设置环境变量 ###
|
||||
|
||||
现在我们需要让 docker 与虚拟机通信,运行 docker-machine env <虚拟机名称> 来实现这个目的。
|
||||
现在我们需要让 docker 与 docker-machine 通信,运行 `docker-machine env <虚拟机名称>` 来实现这个目的。
|
||||
|
||||
# eval "$(docker-machine env linux)"
|
||||
# docker ps
|
||||
@ -64,7 +64,7 @@ Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [gi
|
||||
|
||||
### 4. 运行 Docker 容器 ###
|
||||
|
||||
完成配置后我们就可以在 VirtualBox 上运行 docker 容器了。测试一下,在虚拟机里执行 **docker run busybox echo hello world** 命令,我们可以看到容器的输出信息。
|
||||
完成配置后我们就可以在 VirtualBox 上运行 docker 容器了。测试一下,我们可以运行虚拟机 `docker run busybox` ,并在里面里执行 `echo hello world` 命令,我们可以看到容器的输出信息。
|
||||
|
||||
# docker run busybox echo hello world
|
||||
|
||||
@ -72,7 +72,7 @@ Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [gi
|
||||
|
||||
### 5. 拿到 Docker 主机的 IP ###
|
||||
|
||||
我们可以执行下面的命令获取 Docker 主机的 IP 地址。
|
||||
我们可以执行下面的命令获取运行 Docker 的主机的 IP 地址。我们可以看到在 Docker 主机的 IP 地址上的任何暴露出来的端口。
|
||||
|
||||
# docker-machine ip
|
||||
|
||||
@ -94,7 +94,9 @@ Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [gi
|
||||
|
||||
### 总结 ###
|
||||
|
||||
最后,我们使用 Docker Machine 成功在 VirtualBox 上创建并管理一台 Docker 主机。Docker Machine 确实能让用户快速地在不同的平台上部署 Docker 主机,就像我们这里部署在 VirtualBox 上一样。这个 --driver virtulbox 驱动可以在本地机器上使用,也可以在数据中心的虚拟机上使用。Docker Machine 驱动除了支持本地的 VirtualBox 之外,还支持远端的 Digital Ocean、AWS、Azure、VMware 以及其他基础设施。如果你有任何疑问,或者建议,请在评论栏中写出来,我们会不断改进我们的内容。谢谢,祝愉快。
|
||||
最后,我们使用 Docker Machine 成功在 VirtualBox 上创建并管理一台 Docker 主机。Docker Machine 确实能让用户快速地在不同的平台上部署 Docker 主机,就像我们这里部署在 VirtualBox 上一样。这个 virtualbox 驱动可以在本地机器上使用,也可以在数据中心的虚拟机上使用。Docker Machine 驱动除了支持本地的 VirtualBox 之外,还支持远端的 Digital Ocean、AWS、Azure、VMware 以及其它基础设施。
|
||||
|
||||
如果你有任何疑问,或者建议,请在评论栏中写出来,我们会不断改进我们的内容。谢谢,祝愉快。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -102,7 +104,7 @@ via: http://linoxide.com/linux-how-to/host-virtualbox-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,7 +2,7 @@ Ubuntu 14.04中修复“update information is outdated”错误
|
||||
================================================================================
|
||||

|
||||
|
||||
看到Ubuntu 14.04的顶部面板上那个显示下面这个错误的红色三角形了吗?
|
||||
看到过Ubuntu 14.04的顶部面板上那个显示下面这个错误的红色三角形了吗?
|
||||
|
||||
> 更新信息过时。该错误可能是由网络问题,或者某个仓库不再可用而造成的。请通过从指示器菜单中选择‘显示更新’来手动更新,然后查看是否存在有失败的仓库。
|
||||
>
|
||||
@ -25,7 +25,7 @@ Ubuntu 14.04中修复“update information is outdated”错误
|
||||
|
||||
### 修复‘update information is outdated’错误 ###
|
||||
|
||||
这里讨论的‘解决方案’可能对Ubuntu的这些版本有用:Ubuntu 14.04,12.04或14.04。你所要做的仅仅是打开终端(Ctrl+Alt+T),然后使用下面的命令:
|
||||
这里讨论的‘解决方案’可能对Ubuntu的这些版本有用:Ubuntu 14.04,12.04。你所要做的仅仅是打开终端(Ctrl+Alt+T),然后使用下面的命令:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
@ -47,7 +47,7 @@ via: http://itsfoss.com/fix-update-information-outdated-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -56,4 +56,4 @@ via: http://itsfoss.com/fix-update-information-outdated-ubuntu/
|
||||
[2]:http://itsfoss.com/notification-terminal-command-completion-ubuntu/
|
||||
[3]:http://itsfoss.com/solve-gpg-error-signatures-verified-ubuntu/
|
||||
[4]:http://itsfoss.com/install-spotify-ubuntu-1504/
|
||||
[5]:http://itsfoss.com/fix-update-errors-ubuntu-1404/
|
||||
[5]:https://linux.cn/article-5603-1.html
|
||||
@ -1,10 +1,11 @@
|
||||
在 Linux 中使用日志来排错
|
||||
================================================================================
|
||||
人们创建日志的主要原因是排错。通常你会诊断为什么问题发生在你的 Linux 系统或应用程序中。错误信息或一些列事件可以给你提供造成根本原因的线索,说明问题是如何发生的,并指出如何解决它。这里有几个使用日志来解决的样例。
|
||||
|
||||
人们创建日志的主要原因是排错。通常你会诊断为什么问题发生在你的 Linux 系统或应用程序中。错误信息或一系列的事件可以给你提供找出根本原因的线索,说明问题是如何发生的,并指出如何解决它。这里有几个使用日志来解决的样例。
|
||||
|
||||
### 登录失败原因 ###
|
||||
|
||||
如果你想检查你的系统是否安全,你可以在验证日志中检查登录失败的和登录成功但可疑的用户。当有人通过不正当或无效的凭据来登录时会出现认证失败,经常使用 SSH 进行远程登录或 su 到本地其他用户来进行访问权。这些是由[插入式验证模块][1]来记录,或 PAM 进行短期记录。在你的日志中会看到像 Failed 这样的字符串密码和未知的用户。成功认证记录包括像 Accepted 这样的字符串密码并打开会话。
|
||||
如果你想检查你的系统是否安全,你可以在验证日志中检查登录失败的和登录成功但可疑的用户。当有人通过不正当或无效的凭据来登录时会出现认证失败,这通常发生在使用 SSH 进行远程登录或 su 到本地其他用户来进行访问权时。这些是由[插入式验证模块(PAM)][1]来记录的。在你的日志中会看到像 Failed password 和 user unknown 这样的字符串。而成功认证记录则会包括像 Accepted password 和 session opened 这样的字符串。
|
||||
|
||||
失败的例子:
|
||||
|
||||
@ -30,22 +31,21 @@
|
||||
|
||||
由于没有标准格式,所以你需要为每个应用程序的日志使用不同的命令。日志管理系统,可以自动分析日志,将它们有效的归类,帮助你提取关键字,如用户名。
|
||||
|
||||
日志管理系统可以使用自动解析功能从 Linux 日志中提取用户名。这使你可以看到用户的信息,并能单个的筛选。在这个例子中,我们可以看到,root 用户登录了 2700 次,因为我们筛选的日志显示尝试登录的只有 root 用户。
|
||||
日志管理系统可以使用自动解析功能从 Linux 日志中提取用户名。这使你可以看到用户的信息,并能通过点击过滤。在下面这个例子中,我们可以看到,root 用户登录了 2700 次之多,因为我们筛选的日志仅显示 root 用户的尝试登录记录。
|
||||
|
||||

|
||||
|
||||
日志管理系统也让你以时间为做坐标轴的图标来查看使你更容易发现异常。如果有人在几分钟内登录失败一次或两次,它可能是一个真正的用户而忘记了密码。但是,如果有几百个失败的登录并且使用的都是不同的用户名,它更可能是在试图攻击系统。在这里,你可以看到在3月12日,有人试图登录 Nagios 几百次。这显然不是一个合法的系统用户。
|
||||
日志管理系统也可以让你以时间为做坐标轴的图表来查看,使你更容易发现异常。如果有人在几分钟内登录失败一次或两次,它可能是一个真正的用户而忘记了密码。但是,如果有几百个失败的登录并且使用的都是不同的用户名,它更可能是在试图攻击系统。在这里,你可以看到在3月12日,有人试图登录 Nagios 几百次。这显然不是一个合法的系统用户。
|
||||
|
||||

|
||||
|
||||
### 重启的原因 ###
|
||||
|
||||
|
||||
有时候,一台服务器由于系统崩溃或重启而宕机。你怎么知道它何时发生,是谁做的?
|
||||
|
||||
#### 关机命令 ####
|
||||
|
||||
如果有人手动运行 shutdown 命令,你可以看到它的身份在验证日志文件中。在这里,你可以看到,有人从 IP 50.0.134.125 上作为 ubuntu 的用户远程登录了,然后关闭了系统。
|
||||
如果有人手动运行 shutdown 命令,你可以在验证日志文件中看到它。在这里,你可以看到,有人从 IP 50.0.134.125 上作为 ubuntu 的用户远程登录了,然后关闭了系统。
|
||||
|
||||
Mar 19 18:36:41 ip-172-31-11-231 sshd[23437]: Accepted publickey for ubuntu from 50.0.134.125 port 52538 ssh
|
||||
Mar 19 18:36:41 ip-172-31-11-231 23437]:sshd[ pam_unix(sshd:session): session opened for user ubuntu by (uid=0)
|
||||
@ -53,7 +53,7 @@
|
||||
|
||||
#### 内核初始化 ####
|
||||
|
||||
如果你想看看服务器重新启动的所有原因(包括崩溃),你可以从内核初始化日志中寻找。你需要搜索内核设施和初始化 cpu 的信息。
|
||||
如果你想看看服务器重新启动的所有原因(包括崩溃),你可以从内核初始化日志中寻找。你需要搜索内核类(kernel)和 cpu 初始化(Initializing)的信息。
|
||||
|
||||
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpuset
|
||||
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpu
|
||||
@ -61,9 +61,9 @@
|
||||
|
||||
### 检测内存问题 ###
|
||||
|
||||
有很多原因可能导致服务器崩溃,但一个普遍的原因是内存用尽。
|
||||
有很多原因可能导致服务器崩溃,但一个常见的原因是内存用尽。
|
||||
|
||||
当你系统的内存不足时,进程会被杀死,通常会杀死使用最多资源的进程。当系统正在使用的内存发生错误并且有新的或现有的进程试图使用更多的内存。在你的日志文件查找像 Out of Memory 这样的字符串,内核也会发出杀死进程的警告。这些信息表明系统故意杀死进程或应用程序,而不是允许进程崩溃。
|
||||
当你系统的内存不足时,进程会被杀死,通常会杀死使用最多资源的进程。当系统使用了所有内存,而新的或现有的进程试图使用更多的内存时就会出现错误。在你的日志文件查找像 Out of Memory 这样的字符串或类似 kill 这样的内核警告信息。这些信息表明系统故意杀死进程或应用程序,而不是允许进程崩溃。
|
||||
|
||||
例如:
|
||||
|
||||
@ -75,20 +75,20 @@
|
||||
$ grep “Out of memory” /var/log/syslog
|
||||
[33238.178288] Out of memory: Kill process 6230 (firefox) score 53 or sacrifice child
|
||||
|
||||
请记住,grep 也要使用内存,所以导致内存不足的错误可能只是运行的 grep。这是另一个分析日志的独特方法!
|
||||
请记住,grep 也要使用内存,所以只是运行 grep 也可能导致内存不足的错误。这是另一个你应该中央化存储日志的原因!
|
||||
|
||||
### 定时任务错误日志 ###
|
||||
|
||||
cron 守护程序是一个调度器只在指定的日期和时间运行进程。如果进程运行失败或无法完成,那么 cron 的错误出现在你的日志文件中。你可以找到这些文件在 /var/log/cron,/var/log/messages,和 /var/log/syslog 中,具体取决于你的发行版。cron 任务失败原因有很多。通常情况下,问题出在进程中而不是 cron 守护进程本身。
|
||||
cron 守护程序是一个调度器,可以在指定的日期和时间运行进程。如果进程运行失败或无法完成,那么 cron 的错误出现在你的日志文件中。具体取决于你的发行版,你可以在 /var/log/cron,/var/log/messages,和 /var/log/syslog 几个位置找到这个日志。cron 任务失败原因有很多。通常情况下,问题出在进程中而不是 cron 守护进程本身。
|
||||
|
||||
默认情况下,cron 作业会通过电子邮件发送信息。这里是一个日志中记录的发送电子邮件的内容。不幸的是,你不能看到邮件的内容在这里。
|
||||
默认情况下,cron 任务的输出会通过 postfix 发送电子邮件。这是一个显示了该邮件已经发送的日志。不幸的是,你不能在这里看到邮件的内容。
|
||||
|
||||
Mar 13 16:35:01 PSQ110 postfix/pickup[15158]: C3EDC5800B4: uid=1001 from=<hoover>
|
||||
Mar 13 16:35:01 PSQ110 postfix/cleanup[15727]: C3EDC5800B4: message-id=<20150310110501.C3EDC5800B4@PSQ110>
|
||||
Mar 13 16:35:01 PSQ110 postfix/qmgr[15159]: C3EDC5800B4: from=<hoover@loggly.com>, size=607, nrcpt=1 (queue active)
|
||||
Mar 13 16:35:05 PSQ110 postfix/smtp[15729]: C3EDC5800B4: to=<hoover@loggly.com>, relay=gmail-smtp-in.l.google.com[74.125.130.26]:25, delay=4.1, delays=0.26/0/2.2/1.7, dsn=2.0.0, status=sent (250 2.0.0 OK 1425985505 f16si501651pdj.5 - gsmtp)
|
||||
|
||||
你应该想想 cron 在日志中的标准输出以帮助你定位问题。这里展示你可以使用 logger 命令重定向 cron 标准输出到 syslog。用你的脚本来代替 echo 命令,helloCron 可以设置为任何你想要的应用程序的名字。
|
||||
你可以考虑将 cron 的标准输出记录到日志中,以帮助你定位问题。这是一个你怎样使用 logger 命令重定向 cron 标准输出到 syslog的例子。用你的脚本来代替 echo 命令,helloCron 可以设置为任何你想要的应用程序的名字。
|
||||
|
||||
*/5 * * * * echo ‘Hello World’ 2>&1 | /usr/bin/logger -t helloCron
|
||||
|
||||
@ -97,7 +97,9 @@ cron 守护程序是一个调度器只在指定的日期和时间运行进程。
|
||||
Apr 28 22:20:01 ip-172-31-11-231 CRON[15296]: (ubuntu) CMD (echo 'Hello World!' 2>&1 | /usr/bin/logger -t helloCron)
|
||||
Apr 28 22:20:01 ip-172-31-11-231 helloCron: Hello World!
|
||||
|
||||
每个 cron 作业将根据作业的具体类型以及如何输出数据来记录不同的日志。希望在日志中有问题根源的线索,也可以根据需要添加额外的日志记录。
|
||||
每个 cron 任务将根据任务的具体类型以及如何输出数据来记录不同的日志。
|
||||
|
||||
希望在日志中有问题根源的线索,也可以根据需要添加额外的日志记录。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -107,7 +109,7 @@ via: http://www.loggly.com/ultimate-guide/logging/troubleshooting-with-linux-log
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
如何在 Linux 中安装 Visual Studio Code
|
||||
================================================================================
|
||||
大家好,今天我们一起来学习如何在 Linux 发行版中安装 Visual Studio Code。Visual Studio Code 是基于 Electron 优化代码后的编辑器,后者是基于 Chromium 的一款软件,用于为桌面系统发布 io.js 应用。Visual Studio Code 是微软开发的包括 Linux 在内的全平台代码编辑器和文本编辑器。它是免费软件但不开源,在专有软件许可条款下发布。它是我们日常使用的超级强大和快速的代码编辑器。Visual Studio Code 有很多很酷的功能,例如导航、智能感知支持、语法高亮、括号匹配、自动补全、片段、支持自定义键盘绑定、并且支持多种语言,例如 Python、C++、Jade、PHP、XML、Batch、F#、DockerFile、Coffee Script、Java、HandleBars、 R、 Objective-C、 PowerShell、 Luna、 Visual Basic、 .Net、 Asp.Net、 C#、 JSON、 Node.js、 Javascript、 HTML、 CSS、 Less、 Sass 和 Markdown。Visual Studio Code 集成了包管理器和库,并构建通用任务使得加速每日的工作流。Visual Studio Code 中最受欢迎的是它的调试功能,它包括流式支持 Node.js 的预览调试。
|
||||
大家好,今天我们一起来学习如何在 Linux 发行版中安装 Visual Studio Code。Visual Studio Code 是基于 Electron 优化代码后的编辑器,后者是基于 Chromium 的一款软件,用于为桌面系统发布 io.js 应用。Visual Studio Code 是微软开发的支持包括 Linux 在内的全平台代码编辑器和文本编辑器。它是免费软件但不开源,在专有软件许可条款下发布。它是可以用于我们日常使用的超级强大和快速的代码编辑器。Visual Studio Code 有很多很酷的功能,例如导航、智能感知支持、语法高亮、括号匹配、自动补全、代码片段、支持自定义键盘绑定、并且支持多种语言,例如 Python、C++、Jade、PHP、XML、Batch、F#、DockerFile、Coffee Script、Java、HandleBars、 R、 Objective-C、 PowerShell、 Luna、 Visual Basic、 .Net、 Asp.Net、 C#、 JSON、 Node.js、 Javascript、 HTML、 CSS、 Less、 Sass 和 Markdown。Visual Studio Code 集成了包管理器、库、构建,以及其它通用任务,以加速日常的工作流。Visual Studio Code 中最受欢迎的是它的调试功能,它包括流式支持 Node.js 的预览调试。
|
||||
|
||||
注意:请注意 Visual Studio Code 只支持 64 位 Linux 发行版。
|
||||
注意:请注意 Visual Studio Code 只支持 64 位的 Linux 发行版。
|
||||
|
||||
下面是在所有 Linux 发行版中安装 Visual Studio Code 的几个简单步骤。
|
||||
|
||||
@ -32,12 +32,12 @@
|
||||
|
||||
### 3. 运行 Visual Studio Code ###
|
||||
|
||||
提取软件包之后,我们可以直接运行一个名为 Code 的文件启动 Visual Studio Code。
|
||||
展开软件包之后,我们可以直接运行一个名为 Code 的文件启动 Visual Studio Code。
|
||||
|
||||
# sudo chmod +x /opt/VSCode-linux-x64/Code
|
||||
# sudo /opt/VSCode-linux-x64/Code
|
||||
|
||||
如果我们想启动 Code 并通过终端能在任何地方打开,我们就需要创建 /opt/vscode/Code 的一个链接 /usr/local/bin/code。
|
||||
如果我们想通过终端在任何地方启动 Code,我们就需要创建 /opt/vscode/Code 的一个链接 /usr/local/bin/code。
|
||||
|
||||
# ln -s /opt/VSCode-linux-x64/Code /usr/local/bin/code
|
||||
|
||||
@ -47,11 +47,11 @@
|
||||
|
||||
### 4. 创建桌面启动 ###
|
||||
|
||||
下一步,成功抽取 Visual Studio Code 软件包之后,我们打算创建桌面启动程序,使得根据不同桌面环境能够从启动器、菜单、桌面启动它。首先我们要复制一个图标文件到 /usr/share/icons/ 目录。
|
||||
下一步,成功展开 Visual Studio Code 软件包之后,我们打算创建桌面启动程序,使得根据不同桌面环境能够从启动器、菜单、桌面启动它。首先我们要复制一个图标文件到 /usr/share/icons/ 目录。
|
||||
|
||||
# cp /opt/VSCode-linux-x64/resources/app/vso.png /usr/share/icons/
|
||||
|
||||
然后,我们创建一个桌面启动程序,文件扩展名为 .desktop。这里我们在 /tmp/VSCODE/ 目录中使用喜欢的文本编辑器创建名为 visualstudiocode.desktop 的文件。
|
||||
然后,我们创建一个桌面启动程序,文件扩展名为 .desktop。这里我们使用喜欢的文本编辑器在 /tmp/VSCODE/ 目录中创建名为 visualstudiocode.desktop 的文件。
|
||||
|
||||
# vi /tmp/vscode/visualstudiocode.desktop
|
||||
|
||||
@ -99,17 +99,19 @@
|
||||
# apt-get update
|
||||
# apt-get install ubuntu-make
|
||||
|
||||
在我们的 ubuntu 操作系统上安装完 Ubuntu Make 之后,我们打算在一个终端中运行以下命令安装 Code。
|
||||
在我们的 ubuntu 操作系统上安装完 Ubuntu Make 之后,我们可以在一个终端中运行以下命令来安装 Code。
|
||||
|
||||
# umake web visual-studio-code
|
||||
|
||||

|
||||
|
||||
运行完上面的命令之后,会要求我们输入想要的安装路径。然后,会请求我们允许在 ubuntu 系统中安装 Visual Studio Code。我们敲击 “a”。点击完后,它会在 ubuntu 机器上下载和安装 Code。最后,我们可以在启动器或者菜单中启动它。
|
||||
运行完上面的命令之后,会要求我们输入想要的安装路径。然后,会请求我们允许在 ubuntu 系统中安装 Visual Studio Code。我们输入“a”(接受)。输入完后,它会在 ubuntu 机器上下载和安装 Code。最后,我们可以在启动器或者菜单中启动它。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们已经成功地在 Linux 发行版上安装了 Visual Studio Code。在所有 linux 发行版上安装 Visual Studio Code 都和上面介绍的相似,我们同样可以使用 umake 在 linux 发行版中安装。Umake 是一个安装开发工具,IDEs 和语言流行的工具。我们可以用 Umake 轻松地安装 Android Studios、Eclipse 和很多其它流行 IDE。Visual Studio Code 是基于 Github 上一个叫 [Electron][2] 的项目,它是 [Atom.io][3] 编辑器的一部分。它有很多 Atom.io 编辑器没有的改进功能。当前 Visual Studio Code 只支持 64 位 linux 操作系统平台。如果你有任何疑问、建议或者反馈,请在下面的评论框中留言以便我们改进和更新我们的内容。非常感谢!Enjoy :-)
|
||||
我们已经成功地在 Linux 发行版上安装了 Visual Studio Code。在所有 linux 发行版上安装 Visual Studio Code 都和上面介绍的相似,我们也可以使用 umake 在 Ubuntu 发行版中安装。Umake 是一个安装开发工具,IDEs 和语言的流行工具。我们可以用 Umake 轻松地安装 Android Studios、Eclipse 和很多其它流行 IDE。Visual Studio Code 是基于 Github 上一个叫 [Electron][2] 的项目,它是 [Atom.io][3] 编辑器的一部分。它有很多 Atom.io 编辑器没有的改进功能。当前 Visual Studio Code 只支持 64 位 linux 操作系统平台。
|
||||
|
||||
如果你有任何疑问、建议或者反馈,请在下面的评论框中留言以便我们改进和更新我们的内容。非常感谢!Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -117,7 +119,7 @@ via: http://linoxide.com/linux-how-to/install-visual-studio-code-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
20
sign.md
20
sign.md
@ -1,8 +1,22 @@
|
||||
|
||||
---
|
||||
|
||||
via:
|
||||
via:来源链接
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
作者:[作者名][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,
|
||||
[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:作者链接
|
||||
[1]:文内链接
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
@ -1,125 +0,0 @@
|
||||
Defending the Free Linux World
|
||||
================================================================================
|
||||

|
||||
|
||||
**Co-opetition is a part of open source. The Open Invention Network model allows companies to decide where they will compete and where they will collaborate, explained OIN CEO Keith Bergelt. As open source evolved, "we had to create channels for collaboration. Otherwise, we would have hundreds of entities spending billions of dollars on the same technology."**
|
||||
|
||||
The [Open Invention Network][1], or OIN, is waging a global campaign to keep Linux out of harm's way in patent litigation. Its efforts have resulted in more than 1,000 companies joining forces to become the largest defense patent management organization in history.
|
||||
|
||||
The Open Invention Network was created in 2005 as a white hat organization to protect Linux from license assaults. It has considerable financial backing from original board members that include Google, IBM, NEC, Novell, Philips, [Red Hat][2] and Sony. Organizations worldwide have joined the OIN community by signing the free OIN license.
|
||||
|
||||
Organizers founded the Open Invention Network as a bold endeavor to leverage intellectual property to protect Linux. Its business model was difficult to comprehend. It asked its members to take a royalty-free license and forever forgo the chance to sue other members over their Linux-oriented intellectual property.
|
||||
|
||||
However, the surge in Linux adoptions since then -- think server and cloud platforms -- has made protecting Linux intellectual property a critically necessary strategy.
|
||||
|
||||
Over the past year or so, there has been a shift in the Linux landscape. OIN is doing a lot less talking to people about what the organization is and a lot less explaining why Linux needs protection. There is now a global awareness of the centrality of Linux, according to Keith Bergelt, CEO of OIN.
|
||||
|
||||
"We have seen a culture shift to recognizing how OIN benefits collaboration," he told LinuxInsider.
|
||||
|
||||
### How It Works ###
|
||||
|
||||
The Open Invention Network uses patents to create a collaborative environment. This approach helps ensure the continuation of innovation that has benefited software vendors, customers, emerging markets and investors.
|
||||
|
||||
Patents owned by Open Invention Network are available royalty-free to any company, institution or individual. All that is required to qualify is the signer's agreement not to assert its patents against the Linux system.
|
||||
|
||||
OIN ensures the openness of the Linux source code. This allows programmers, equipment vendors, independent software vendors and institutions to invest in and use Linux without excessive worry about intellectual property issues. This makes it more economical for companies to repackage, embed and use Linux.
|
||||
|
||||
"With the diffusion of copyright licenses, the need for OIN licenses becomes more acute. People are now looking for a simpler or more utilitarian solution," said Bergelt.
|
||||
|
||||
OIN legal defenses are free of charge to members. Members commit to not initiating patent litigation against the software in OIN's list. They also agree to offer their own patents in defense of that software. Ultimately, these commitments result in access to hundreds of thousands of patents cross-licensed by the network, Bergelt explained.
|
||||
|
||||
### Closing the Legal Loopholes ###
|
||||
|
||||
"What OIN is doing is very essential. It offers another layer of IP protection, said Greg R. Vetter, associate professor of law at the [University of Houston Law Center][3].
|
||||
|
||||
Version 2 of the GPL license is thought by some to provide an implied patent license, but lawyers always feel better with an explicit license, he told LinuxInsider.
|
||||
|
||||
What OIN provides is something that bridges that gap. It also provides explicit coverage of the Linux kernel. An explicit patent license is not necessarily part of the GPLv2, but it was added in GPLv3, according to Vetter.
|
||||
|
||||
Take the case of a code writer who produces 10,000 lines of code under GPLv3, for example. Over time, other code writers contribute many more lines of code, which adds to the IP. The software patent license provisions in GPLv3 would protect the use of the entire code base under all of the participating contributors' patents, Vetter said.
|
||||
|
||||
### Not Quite the Same ###
|
||||
|
||||
Patents and licenses are overlapping legal constructs. Figuring out how the two entities work with open source software can be like traversing a minefield.
|
||||
|
||||
"Licenses are legal constructs granting additional rights based on, typically, patent and copyright laws. Licenses are thought to give a permission to do something that might otherwise be infringement of someone else's IP rights," Vetter said.
|
||||
|
||||
Many free and open source licenses (such as the Mozilla Public License, the GNU GPLv3, and the Apache Software License) incorporate some form of reciprocal patent rights clearance. Older licenses like BSD and MIT do not mention patents, Vetter pointed out.
|
||||
|
||||
A software license gives someone else certain rights to use the code the programmer created. Copyright to establish ownership is automatic, as soon as someone writes or draws something original. However, copyright covers only that particular expression and derivative works. It does not cover code functionality or ideas for use.
|
||||
|
||||
Patents cover functionality. Patent rights also can be licensed. A copyright may not protect how someone independently developed implementation of another's code, but a patent fills this niche, Vetter explained.
|
||||
|
||||
### Looking for Safe Passage ###
|
||||
|
||||
The mixing of license and patent legalities can appear threatening to open source developers. For some, even the GPL qualifies as threatening, according to William Hurley, cofounder of [Chaotic Moon Studios][4] and [IEEE][5] Computer Society member.
|
||||
|
||||
"Way back in the day, open source was a different world. Driven by mutual respect and a view of code as art, not property, things were far more open than they are today. I believe that many efforts set upon with the best of intentions almost always end up bearing unintended consequences," Hurley told LinuxInsider.
|
||||
|
||||
Surpassing the 1,000-member mark might carry a mixed message about the significance of intellectual property right protection, he suggested. It might just continue to muddy the already murky waters of today's open source ecosystem.
|
||||
|
||||
"At the end of the day, this shows some of the common misconceptions around intellectual property. Having thousands of developers does not decrease risk -- it increases it. The more developers licensing the patents, the more valuable they appear to be," Hurley said. "The more valuable they appear to be, the more likely someone with similar patents or other intellectual property will try to take advantage and extract value for their own financial gain."
|
||||
|
||||
### Sharing While Competing ###
|
||||
|
||||
Co-opetition is a part of open source. The OIN model allows companies to decide where they will compete and where they will collaborate, explained Bergelt.
|
||||
|
||||
"Many of the changes in the evolution of open source in terms of process have moved us into a different direction. We had to create channels for collaboration. Otherwise, we would have hundreds of entities spending billions of dollars on the same technology," he said.
|
||||
|
||||
A glaring example of this is the early evolution of the cellphone industry. Multiple standards were put forward by multiple companies. There was no sharing and no collaboration, noted Bergelt.
|
||||
|
||||
"That damaged our ability to access technology by seven to 10 years in the U.S. Our experience with devices was far behind what everybody else in the world had. We were complacent with GSM (Global System for Mobile Communications) while we were waiting for CDMA (Code Division Multiple Access)," he said.
|
||||
|
||||
### Changing Landscape ###
|
||||
|
||||
OIN experienced a growth surge of 400 new licensees in the last year. That is indicative of a new trend involving open source.
|
||||
|
||||
"The marketplace reached a critical mass where finally people within organizations recognized the need to explicitly collaborate and to compete. The result is doing both at the same time. This can be messy and taxing," Bergelt said.
|
||||
|
||||
However, it is a sustainable transformation driven by a cultural shift in how people think about collaboration and competition. It is also a shift in how people are embracing open source -- and Linux in particular -- as the lead project in the open source community, he explained.
|
||||
|
||||
One indication is that most significant new projects are not being developed under the GPLv3 license.
|
||||
|
||||
### Two Better Than One ###
|
||||
|
||||
"The GPL is incredibly important, but the reality is there are a number of licensing models being used. The relative addressability of patent issues is generally far lower in Eclipse and Apache and Berkeley licenses that it is in GPLv3," said Bergelt.
|
||||
|
||||
GPLv3 is a natural complement for addressing patent issues -- but the GPL is not sufficient on its own to address the issues of potential conflicts around the use of patents. So OIN is designed as a complement to copyright licenses, he added.
|
||||
|
||||
However, the overlap of patent and license may not do much good. In the end, patents are for offensive purposes -- not defensive -- in almost every case, Bergelt suggested.
|
||||
|
||||
"If you are not prepared to take legal action against others, then a patent may not be the best form of legal protection for your intellectual properties," he said. "We now live in a world where the misconceptions around software, both open and proprietary, combined with an ill-conceived and outdated patent system, leave us floundering as an industry and stifling innovation on a daily basis," he said.
|
||||
|
||||
### Court of Last Resort ###
|
||||
|
||||
It would be nice to think the presence of OIN has dampened a flood of litigation, Bergelt said, or at the very least, that OIN's presence is neutralizing specific threats.
|
||||
|
||||
"We are getting people to lay down their arms, so to say. At the same time, we are creating a new cultural norm. Once you buy into patent nonaggression in this model, the correlative effect is to encourage collaboration," he observed.
|
||||
|
||||
If you are committed to collaboration, you tend not to rush to litigation as a first response. Instead, you think in terms of how can we enable you to use what we have and make some money out of it while we use what you have, Bergelt explained.
|
||||
|
||||
"OIN is a multilateral solution. It encourages signers to create bilateral agreements," he said. "That makes litigation the last course of action. That is where it should be."
|
||||
|
||||
### Bottom Line ###
|
||||
|
||||
OIN is working to prevent Linux patent challenges, Bergelt is convinced. There has not been litigation in this space involving Linux.
|
||||
|
||||
The only thing that comes close are the mobile wars with Microsoft, which focus on elements high in the stack. Those legal challenges may be designed to raise the cost of ownership involving the use of Linux products, Bergelt noted.
|
||||
|
||||
Still, "these are not Linux-related law suits," he said. "They do not focus on what is core to Linux. They focus on what is in the Linux system."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Defending-the-Free-Linux-World-81512.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openinventionnetwork.com/
|
||||
[2]:http://www.redhat.com/
|
||||
[3]:http://www.law.uh.edu/
|
||||
[4]:http://www.chaoticmoon.com/
|
||||
[5]:http://www.ieee.org/
|
||||
@ -1,97 +0,0 @@
|
||||
Fix No Bootable Device Found Error After Installing Ubuntu
|
||||
================================================================================
|
||||
Usually, I dual boot Ubuntu and Windows but this time I decided to go for a clean Ubuntu installation i.e. eliminating Windows completely. After the clean install of Ubuntu, I ended up with a screen saying **no bootable device found** instead of the Grub screen. Clearly, the installation messed up with the UEFI boot settings.
|
||||
|
||||

|
||||
|
||||
I am going to show you how I fixed **no bootable device found error after installing Ubuntu in Acer laptops**. It is important that I mention that I am using Acer Aspire R13 because we have to change things in firmware settings and those settings might look different from manufacturer to manufacturer and from device to device.
|
||||
|
||||
So before you go on trying the steps mentioned here, let’s first see what state my computer was in during this error:
|
||||
|
||||
- My Acer Aspire R13 came preinstalled with Windows 8.1 and with UEFI boot manager
|
||||
- Secure boot was not turned off (my laptop has just come from repair and the service guy had put the secure boot on again, I did not know until I ran up in the problem). You can read this post to know [how disable secure boot in Acer laptops][1]
|
||||
- I chose to install Ubuntu by erasing everything i.e. existing Windows 8.1, various partitions etc.
|
||||
- After installing Ubuntu, I saw no bootable device found error while booting from the hard disk. Booting from live USB worked just fine
|
||||
|
||||
In my opinion, not disabling the secure boot was the reason of this error. However, I have no data to backup my claim. It is just a hunch. Interestingly, dual booting Windows and Linux often ends up in common Grub issues like these two:
|
||||
|
||||
- [error: no such partition grub rescue][2]
|
||||
- [Minimal BASH like line editing is supported][3]
|
||||
|
||||
If you are in similar situation, you can try the fix which worked for me.
|
||||
|
||||
### Fix no bootable device found error after installing Ubuntu ###
|
||||
|
||||
Pardon me for poor quality images. My OnePlus camera seems to be not very happy with my laptop screen.
|
||||
|
||||
#### Step 1 ####
|
||||
|
||||
Turn the power off and boot into boot settings. I had to press Fn+F2 (to press F2 key) on Acer Aspire R13 quickly. You have to be very quick with it if you are using SSD hard disk because SSDs are very fast in booting. Depending upon your manufacturer/model, you might need to use Del or F10 or F12 keys.
|
||||
|
||||
#### Step 2 ####
|
||||
|
||||
In the boot settings, make sure that Secure Boot is turned on. It should be under the Boot tab.
|
||||
|
||||
#### Step 3 ####
|
||||
|
||||
Go to Security tab and look for “Select an UEFI file as trusted for executing” and click enter.
|
||||
|
||||

|
||||
|
||||
Just for your information, what we are going to do here is to add the UEFI settings file (it was generated while Ubuntu installation) among the trusted UEFI boots in your device. If you remember, UEFI boot’s main aim is to provide security and since Secure Boot was not disabled (perhaps) the device did not intend to boot from the newly installed OS. Adding it as trusted, kind of whitelisting, will let the device boot from the Ubuntu UEFI file.
|
||||
|
||||
#### Step 4 ####
|
||||
|
||||
You should see your hard disk like HDD0 etc here. If you have more than one hard disk, I hope you remember where did you install Ubuntu. Press Enter here as well.
|
||||
|
||||

|
||||
|
||||
#### Step 5 ####
|
||||
|
||||
You should see <EFI> here. Press enter.
|
||||
|
||||

|
||||
|
||||
#### Step 6 ####
|
||||
|
||||
You’ll see <Ubuntu> in next screen. Don’t get impatient, you are almost there
|
||||
|
||||

|
||||
|
||||
#### Step 7 ####
|
||||
|
||||
You’ll see shimx64.efi, grubx64.efi and MokManager.efi file here. The important one is shimx64.efi here. Select it and click enter.
|
||||
|
||||
|
||||

|
||||
|
||||
In next screen, type Yes and click enter.
|
||||
|
||||

|
||||
|
||||
#### Step 8 ####
|
||||
|
||||
Once we have added it as trused EFI file to be executed, press F10 to save and exit.
|
||||
|
||||

|
||||
|
||||
Reboot your system and this time you should be seeing the familiar Grub screen. Even if you do not see Grub screen, you should at least not be seeing “no bootable device found” screen anymore. You should be able to boot into Ubuntu.
|
||||
|
||||
If your Grub screen was messed up after the fix but you got to login into it, you can reinstall Grub to boot into the familiar purple Grub screen of Ubuntu.
|
||||
|
||||
I hope this tutorial helped you to fix no bootable device found error. Any questions or suggestions or a word of thanks is always welcomed.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/no-bootable-device-found-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/disable-secure-boot-in-acer/
|
||||
[2]:http://itsfoss.com/solve-error-partition-grub-rescue-ubuntu-linux/
|
||||
[3]:http://itsfoss.com/fix-minimal-bash-line-editing-supported-grub-error-linux/
|
||||
@ -1,166 +0,0 @@
|
||||
ictlyh Translating
|
||||
Part 5 - How to Manage System Logs (Configure, Rotate and Import Into Database) in RHEL 7
|
||||
================================================================================
|
||||
In order to keep your RHEL 7 systems secure, you need to know how to monitor all of the activities that take place on such systems by examining log files. Thus, you will be able to detect any unusual or potentially malicious activity and perform system troubleshooting or take another appropriate action.
|
||||
|
||||

|
||||
|
||||
RHCE Exam: Manage System LogsUsing Rsyslogd and Logrotate – Part 5
|
||||
|
||||
In RHEL 7, the [rsyslogd][1] daemon is responsible for system logging and reads its configuration from /etc/rsyslog.conf (this file specifies the default location for all system logs) and from files inside /etc/rsyslog.d, if any.
|
||||
|
||||
### Rsyslogd Configuration ###
|
||||
|
||||
A quick inspection of the [rsyslog.conf][2] will be helpful to start. This file is divided into 3 main sections: Modules (since rsyslog follows a modular design), Global directives (used to set global properties of the rsyslogd daemon), and Rules. As you will probably guess, this last section indicates what gets logged or shown (also known as the selector) and where, and will be our focus throughout this article.
|
||||
|
||||
A typical line in rsyslog.conf is as follows:
|
||||
|
||||

|
||||
|
||||
Rsyslogd Configuration
|
||||
|
||||
In the image above, we can see that a selector consists of one or more pairs Facility:Priority separated by semicolons, where Facility describes the type of message (refer to [section 4.1.1 in RFC 3164][3] to see the complete list of facilities available for rsyslog) and Priority indicates its severity, which can be one of the following self-explanatory words:
|
||||
|
||||
- debug
|
||||
- info
|
||||
- notice
|
||||
- warning
|
||||
- err
|
||||
- crit
|
||||
- alert
|
||||
- emerg
|
||||
|
||||
Though not a priority itself, the keyword none means no priority at all of the given facility.
|
||||
|
||||
**Note**: That a given priority indicates that all messages of such priority and above should be logged. Thus, the line in the example above instructs the rsyslogd daemon to log all messages of priority info or higher (regardless of the facility) except those belonging to mail, authpriv, and cron services (no messages coming from this facilities will be taken into account) to /var/log/messages.
|
||||
|
||||
You can also group multiple facilities using the colon sign to apply the same priority to all of them. Thus, the line:
|
||||
|
||||
*.info;mail.none;authpriv.none;cron.none /var/log/messages
|
||||
|
||||
Could be rewritten as
|
||||
|
||||
*.info;mail,authpriv,cron.none /var/log/messages
|
||||
|
||||
In other words, the facilities mail, authpriv, and cron are grouped and the keyword none is applied to the three of them.
|
||||
|
||||
#### Creating a custom log file ####
|
||||
|
||||
To log all daemon messages to /var/log/tecmint.log, we need to add the following line either in rsyslog.conf or in a separate file (easier to manage) inside /etc/rsyslog.d:
|
||||
|
||||
daemon.* /var/log/tecmint.log
|
||||
|
||||
Let’s restart the daemon (note that the service name does not end with a d):
|
||||
|
||||
# systemctl restart rsyslog
|
||||
|
||||
And check the contents of our custom log before and after restarting two random daemons:
|
||||
|
||||

|
||||
|
||||
Create Custom Log File
|
||||
|
||||
As a self-study exercise, I would recommend you play around with the facilities and priorities and either log additional messages to existing log files or create new ones as in the previous example.
|
||||
|
||||
### Rotating Logs using Logrotate ###
|
||||
|
||||
To prevent log files from growing endlessly, the logrotate utility is used to rotate, compress, remove, and alternatively mail logs, thus easing the administration of systems that generate large numbers of log files.
|
||||
|
||||
Logrotate runs daily as a cron job (/etc/cron.daily/logrotate) and reads its configuration from /etc/logrotate.conf and from files located in /etc/logrotate.d, if any.
|
||||
|
||||
As with the case of rsyslog, even when you can include settings for specific services in the main file, creating separate configuration files for each one will help organize your settings better.
|
||||
|
||||
Let’s take a look at a typical logrotate.conf:
|
||||
|
||||

|
||||
|
||||
Logrotate Configuration
|
||||
|
||||
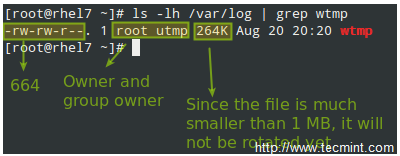
In the example above, logrotate will perform the following actions for /var/loh/wtmp: attempt to rotate only once a month, but only if the file is at least 1 MB in size, then create a brand new log file with permissions set to 0664 and ownership given to user root and group utmp. Next, only keep one archived log, as specified by the rotate directive:
|
||||
|
||||
|
||||
|
||||
Logrotate Logs Monthly
|
||||
|
||||
Let’s now consider another example as found in /etc/logrotate.d/httpd:
|
||||
|
||||

|
||||
|
||||
Rotate Apache Log Files
|
||||
|
||||
You can read more about the settings for logrotate in its man pages ([man logrotate][4] and [man logrotate.conf][5]). Both files are provided along with this article in PDF format for your reading convenience.
|
||||
|
||||
As a system engineer, it will be pretty much up to you to decide for how long logs will be stored and in what format, depending on whether you have /var in a separate partition / logical volume. Otherwise, you really want to consider removing old logs to save storage space. On the other hand, you may be forced to keep several logs for future security auditing according to your company’s or client’s internal policies.
|
||||
|
||||
#### Saving Logs to a Database ####
|
||||
|
||||
Of course examining logs (even with the help of tools such as grep and regular expressions) can become a rather tedious task. For that reason, rsyslog allows us to export them into a database (OTB supported RDBMS include MySQL, MariaDB, PostgreSQL, and Oracle.
|
||||
|
||||
This section of the tutorial assumes that you have already installed the MariaDB server and client in the same RHEL 7 box where the logs are being managed:
|
||||
|
||||
# yum update && yum install mariadb mariadb-server mariadb-client rsyslog-mysql
|
||||
# systemctl enable mariadb && systemctl start mariadb
|
||||
|
||||
Then use the `mysql_secure_installation` utility to set the password for the root user and other security considerations:
|
||||
|
||||

|
||||
|
||||
Secure MySQL Database
|
||||
|
||||
Note: If you don’t want to use the MariaDB root user to insert log messages to the database, you can configure another user account to do so. Explaining how to do that is out of the scope of this tutorial but is explained in detail in [MariaDB knowledge][6] base. In this tutorial we will use the root account for simplicity.
|
||||
|
||||
Next, download the createDB.sql script from [GitHub][7] and import it into your database server:
|
||||
|
||||
# mysql -u root -p < createDB.sql
|
||||
|
||||

|
||||
|
||||
Save Server Logs to Database
|
||||
|
||||
Finally, add the following lines to /etc/rsyslog.conf:
|
||||
|
||||
$ModLoad ommysql
|
||||
$ActionOmmysqlServerPort 3306
|
||||
*.* :ommysql:localhost,Syslog,root,YourPasswordHere
|
||||
|
||||
Restart rsyslog and the database server:
|
||||
|
||||
# systemctl restart rsyslog
|
||||
# systemctl restart mariadb
|
||||
|
||||
#### Querying the Logs using SQL syntax ####
|
||||
|
||||
Now perform some tasks that will modify the logs (like stopping and starting services, for example), then log to your DB server and use standard SQL commands to display and search in the logs:
|
||||
|
||||
USE Syslog;
|
||||
SELECT ReceivedAt, Message FROM SystemEvents;
|
||||
|
||||

|
||||
|
||||
Query Logs in Database
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have explained how to set up system logging, how to rotate logs, and how to redirect the messages to a database for easier search. We hope that these skills will be helpful as you prepare for the [RHCE exam][8] and in your daily responsibilities as well.
|
||||
|
||||
As always, your feedback is more than welcome. Feel free to use the form below to reach us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-linux-system-logs-using-rsyslogd-and-logrotate/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/wp-content/pdf/rsyslogd.pdf
|
||||
[2]:http://www.tecmint.com/wp-content/pdf/rsyslog.conf.pdf
|
||||
[3]:https://tools.ietf.org/html/rfc3164#section-4.1.1
|
||||
[4]:http://www.tecmint.com/wp-content/pdf/logrotate.pdf
|
||||
[5]:http://www.tecmint.com/wp-content/pdf/logrotate.conf.pdf
|
||||
[6]:https://mariadb.com/kb/en/mariadb/create-user/
|
||||
[7]:https://github.com/sematext/rsyslog/blob/master/plugins/ommysql/createDB.sql
|
||||
[8]:http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
127
translated/talk/20141223 Defending the Free Linux World.md
Normal file
127
translated/talk/20141223 Defending the Free Linux World.md
Normal file
@ -0,0 +1,127 @@
|
||||
Translating by H-mudcup
|
||||
|
||||
守卫自由的Linux世界
|
||||
================================================================================
|
||||

|
||||
|
||||
**"合作是开源的一部分。OIN的CEO Keith Bergelt解释说,开放创新网络(Open Invention Network)模式允许众多企业和公司决定它们该在哪较量,在哪合作。随着开源的演变,“我们需要为合作创造渠道。否则我们将会有几百个团体把数十亿美元花费到同样的技术上。”**
|
||||
|
||||
[开放创新网络(Open Invention Network)][1],既OIN,正在全球范围内开展让 Linux 远离专利诉讼的伤害的活动。它的努力得到了一千多个公司的热烈回应,它们的加入让这股力量成为了历史上最大的反专利管理组织。
|
||||
|
||||
开放创新网络以白帽子组织的身份创建于2005年,目的是保护 Linux 免受来自许可证方面的困扰。包括Google、 IBM、 NEC、 Novell、 Philips、 [Red Hat][2] 和 Sony这些成员的董事会给予了它可观的经济支持。世界范围内的多个组织通过签署自由 OIN 协议加入了这个社区。
|
||||
|
||||
创立开放创新网络的组织成员把它当作利用知识产权保护 Linux 的大胆尝试。它的商业模式非常的难以理解。它要求它的成员持无专利证并永远放弃由于 Linux 相关知识产权起诉其他成员的机会。
|
||||
|
||||
然而,从 Linux 收购风波——想想服务器和云平台——那时起,保护 Linux 知识产权的策略就变得越加的迫切。
|
||||
|
||||
在过去的几年里,Linux 的版图曾经历了一场变革。OIN 不必再向人们解释这个组织的定义,也不必再解释为什么 Linux 需要保护。据 OIN 的 CEO Keith Bergelt 说,现在 Linux 的重要性得到了全世界的关注。
|
||||
|
||||
“我们已经见到了一场人们了解到OIN如何让合作受益的文化变革,”他对 LinuxInsider 说。
|
||||
|
||||
### 如何运作 ###
|
||||
|
||||
开放创新网络使用专利权的方式创建了一个协作环境。这种方法有助于确保创新的延续。这已经使很多软件商贩、顾客、新型市场和投资者受益。
|
||||
|
||||
开放创新网络的专利证可以让任何公司、公共机构或个人免版权使用。这些权利的获得建立在签署者同意不会专为了维护专利而攻击 Linux 系统的基础上。
|
||||
|
||||
OIN 确保 Linux 的源代码保持开放的状态。这让编程人员、设备出售人员、独立软件开发者和公共机构在投资和使用 Linux 时不用过多的担心知识产权的问题。这让对 Linux 进行重新装配、嵌入和使用的公司省了不少钱。
|
||||
|
||||
“随着版权许可证越来越广泛的使用,对 OIN 许可证的需求也变得更加的迫切。现在,人们正在寻找更加简单或更功利的解决方法”,Bergelt 说。
|
||||
|
||||
OIN 法律防御援助对成员是免费的。成员必须承诺不对 OIN 名单带上的软件发起专利诉讼。为了保护该软件,他们也同意提供他们自己的专利。最终,这些保证将导致几十万的交叉许可通过网络连接,Bergelt 如此解释道。
|
||||
|
||||
### 填补法律漏洞 ###
|
||||
|
||||
“OIN 正在做的事情是非常必要的。它提供额另一层 IP 保护,”[休斯顿法律中心大学][3]的副教授 Greg R. Vetter 这样说道。
|
||||
|
||||
他回答 LinuxInsider 说,某些人设想的第二版 GPL 许可证会隐含的提供专利许可,但是律师们更喜欢明确的许可。
|
||||
|
||||
OIN 所提供的许可填补了这个空白。它还明确的覆盖了 Linux 核心。据 Vetter 说,明确的专利许可并不是 GPLv2 中的必要部分,但是这个部分曾在 GPLv3 中。
|
||||
|
||||
拿一个在 GPLv3 中写了10000行代码的代码编写者来说。随着时间推移,其他的代码编写者会贡献更多行的代码到 IP 中。GPLv3 中的软件专利许可条款将保护所有基于参与其中的贡献者的专利的全部代码的使用,Vetter 如此说道。
|
||||
|
||||
### 并不完全一样 ###
|
||||
|
||||
专利权和许可证在法律结构上层层叠叠互相覆盖。弄清两者对开源软件的作用就像是穿越雷区。
|
||||
|
||||
Vetter 说“许可证是授予通常是建立在专利和版权法律上的额外权利的法律结构。许可证被认为是给予了人们做一些的可能会侵犯到其他人的 IP 权利的事的许可。”
|
||||
|
||||
Vetter 指出,很多自由开源许可证(例如 Mozilla 公共许可、GNU、GPLv3 以及 Apache 软件许可)融合了某些互惠专利权的形式。Vetter 指出,像 BSD 和 MIT 这样旧的许可证不会提到专利。
|
||||
|
||||
一个软件的许可证让其他人可以在某种程度上使用这个编程人员创造的代码。版权对所属权的建立是自动的,只要某个人写或者画了某个原创的东西。然而,版权只覆盖了个别的表达方式和衍生的作品。他并没有涵盖代码的功能性或可用的想法。
|
||||
|
||||
专利涵盖了功能性。专利权还可以成为许可证。版权可能无法保护某人如何独立的对另一个人的代码的实现的开发,但是专利填补了这个小瑕疵,Vetter 解释道。
|
||||
|
||||
### 寻找安全通道 ###
|
||||
|
||||
许可证和专利混合的法律性质可能会对开源开发者产生威胁。据 [Chaotic Moon Studios][4] 的创办者之一、 [IEEE][5] 计算机协会成员 William Hurley 说,对于某些人来说即使是 GPL 也会成为威胁。
|
||||
|
||||
"在很久以前,开源是个完全不同的世界。被彼此间的尊重和把代码视为艺术而非资产的观点所驱动,那时的程序和代码比现在更加的开放。我相信很多为最好的意图所做的努力几乎最后总是背负着意外的结果,"Hurley 这样告诉 LinuxInsider。
|
||||
|
||||
他暗示说,成员人数超越了1000人可能带来了一个关于知识产权保护重要性的混乱信息。这可能会继续搅混开源生态系统这滩浑水。
|
||||
|
||||
“最终,这些显现出了围绕着知识产权的常见的一些错误概念。拥有几千个开发者并不会减少风险——而是增加。给专利许可的开发者越多,它们看起来就越值钱,”Hurley 说。“它们看起来越值钱,有着类似专利的或者其他知识产权的人就越可能试图利用并从中榨取他们自己的经济利益。”
|
||||
|
||||
### 共享与竞争共存 ###
|
||||
|
||||
竞合策略是开源的一部分。OIN 模型让各个公司能够决定他们将在哪竞争以及在哪合作,Bergelt 解释道。
|
||||
|
||||
“开源演化中的许多改变已经把我们移到了另一个方向上。我们必须为合作创造渠道。否则我们将会有几百个团体把数十亿美元花费到同样的技术上,”他说。
|
||||
|
||||
手机产业的革新就是个很好的例子。各个公司放出了不同的标准。没有共享,没有合作,Bergelt 解释道。
|
||||
|
||||
他说:“这让我们在美国接触技术的能力落后了七到五年。我们接触设备的经验远远落后于世界其他地方的人。在我们等待 CDMA (Code Division Multiple Access 码分多址访问通信技术)时自满于 GSM (Global System for Mobile Communications 全球移动通信系统)。”
|
||||
|
||||
### 改变格局 ###
|
||||
|
||||
OIN 在去年经历了增长了400个新许可的浪潮。这意味着着开源有了新趋势。
|
||||
|
||||
Bergelt 说:“市场到达了一个临界点,组织内的人们终于意识到直白地合作和竞争的需要。结果是两件事同时进行。这可能会变得复杂、费力。”
|
||||
|
||||
然而,这个由人们开始考虑合作和竞争的文化革新所驱动的转换过程是可以忍受的。他解释说,这也是人们在以把开源作为开源社区的最重要的工程的方式拥抱开源——尤其是 Linux——的转变。
|
||||
|
||||
还有一个迹象是,最具意义的新工程都没有在 GPLv3 许可下开发。
|
||||
|
||||
### 二个总比一个好 ###
|
||||
|
||||
“GPL 极为重要,但是事实是有一堆的许可模型正被使用着。在Eclipse、Apache 和 Berkeley 许可中,专利问题的相对可解决性通常远远低于在 GPLv3 中的。”Bergelt 说。
|
||||
|
||||
GPLv3 对于解决专利问题是个自然的补充——但是 GPL 自身不足以独自解决围绕专利使用的潜在冲突。所以 OIN 的设计是以能够补充版权许可为目的的,他补充道。
|
||||
|
||||
然而,层层叠叠的专利和许可也许并没有带来多少好处。到最后,专利在几乎所有的案例中都被用于攻击目的——而不是防御目的,Bergelt 暗示说。
|
||||
|
||||
“如果你不准备对其他人采取法律行动,那么对于你的知识财产来说专利可能并不是最佳的法律保护方式”,他说。“我们现在生活在一个对软件——开放和专有——误会重重的世界里。这些软件还被错误并过时的专利系统所捆绑。我们每天在工业化的被窒息的创新中挣扎”,他说。
|
||||
|
||||
### 法院是最后的手段###
|
||||
|
||||
想到 OIN 的出现抑制了诉讼的泛滥就感到十分欣慰,Bergelt 说,或者至少可以说 OIN 的出现扼制了特定的某些威胁。
|
||||
|
||||
“可以说我们让人们放下它们了的武器。同时我们正在创建一种新的文化规范。一旦你入股这个模型中的非侵略专利,所产生的相关影响就是对合作的鼓励”,他说。
|
||||
|
||||
如果你愿意承诺合作,你的第一反应就会趋向于不急着起诉。相反的,你会想如何让我们允许你使用我们所拥有的东西并让它为你赚钱,而同时我们也能使用你所拥有的东西,Bergelt 解释道。
|
||||
|
||||
“OIN 是个多面的解决方式。他鼓励签署者创造双赢协议”,他说。“这让起诉成为最逼不得已的行为。那才是它的位置。”
|
||||
|
||||
### 底线###
|
||||
|
||||
Bergelt 坚信,OIN 的运作是为了阻止 Linux 受到专利伤害。在 Linux 的世界里没有诉讼的地方。
|
||||
|
||||
唯一临近的是和微软的移动大战,这主要关系到堆栈中高的元素。那些来自法律的挑战可能是为了提高包括使用 Linux 产品的所属权的成本,Bergelt 说。
|
||||
|
||||
尽管如此“这些并不是有关 Linux 诉讼”,他说。“他们的重点并不在于 Linux 的核心。他们关注的是 Linux 系统里都有些什么。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Defending-the-Free-Linux-World-81512.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openinventionnetwork.com/
|
||||
[2]:http://www.redhat.com/
|
||||
[3]:http://www.law.uh.edu/
|
||||
[4]:http://www.chaoticmoon.com/
|
||||
[5]:http://www.ieee.org/
|
||||
@ -1,89 +0,0 @@
|
||||
如何在树莓派2 代运行ubuntu Snappy Core
|
||||
================================================================================
|
||||
物联网(Internet of Things, IoT) 时代即将来临。很快,过不了几年,我们就会问自己当初是怎么在没有物联网的情况下生存的,就像我们现在怀疑过去没有手机的年代。Canonical 就是一个物联网快速发展却还是开放市场下的竞争者。这家公司宣称自己把赌注压到了IoT 上,就像他们已经在“云”上做过的一样。。在今年一月底,Canonical 启动了一个基于Ubuntu Core 的小型操作系统,名字叫做 [Ubuntu Snappy Core][1] 。
|
||||
|
||||
Snappy 是一种用来替代deb 的新的打包格式,是一个用来更新系统的前端,从CoreOS、红帽子和其他系统借鉴了**原子更新**这个想法。树莓派2 代投入市场,Canonical 很快就发布了用于树莓派的Snappy Core 版本。而第一代树莓派因为是基于ARMv6 ,Ubuntu 的ARM 镜像是基于ARMv7 ,所以不能运行ubuntu 。不过这种状况现在改变了,Canonical 通过发布用于RPI2 的镜像,抓住机会证明了Snappy 就是一个用于云计算,特别是用于物联网的系统。
|
||||
|
||||
Snappy 同样可以运行在其它像Amazon EC2, Microsofts Azure, Google的 Compute Engine 这样的云端上,也可以虚拟化在KVM、Virtuabox 和vagrant 上。Canonical Ubuntu 已经拥抱了微软、谷歌、Docker、OpenStack 这些重量级选手,同时也与一些小项目达成合作关系。除了一些创业公司,比如Ninja Sphere、Erle Robotics,还有一些开发板生产商,比如Odroid、Banana Pro, Udoo, PCDuino 和Parallella 、全志,Snappy 也提供了支持。Snappy Core 同时也希望尽快运行到路由器上来帮助改进路由器生产商目前很少更新固件的策略。
|
||||
|
||||
接下来,让我们看看怎么样在树莓派2 上运行Snappy。
|
||||
|
||||
用于树莓派2 的Snappy 镜像可以从 [Raspberry Pi 网站][2] 上下载。解压缩出来的镜像必须[写到一个至少8GB 大小的SD 卡][3]。尽管原始系统很小,但是原子升级和回滚功能会占用不小的空间。使用Snappy 启动树莓派2 后你就可以使用默认用户名和密码(都是ubuntu)登录系统。
|
||||
|
||||

|
||||
|
||||
sudo 已经配置好了可以直接用,安全起见,你应该使用以下命令来修改你的用户名
|
||||
|
||||
$ sudo usermod -l <new name> <old name>
|
||||
|
||||
或者也可以使用`adduser` 为你添加一个新用户。
|
||||
|
||||
因为RPI缺少硬件时钟,而Snappy 并不知道这一点,所以系统会有一个小bug:处理某些命令时会报很多错。不过这个很容易解决:
|
||||
|
||||
使用这个命令来确认这个bug 是否影响:
|
||||
|
||||
$ date
|
||||
|
||||
如果输出是 "Thu Jan 1 01:56:44 UTC 1970", 你可以这样做来改正:
|
||||
|
||||
$ sudo date --set="Sun Apr 04 17:43:26 UTC 2015"
|
||||
|
||||
改成你的实际时间。
|
||||
|
||||

|
||||
|
||||
现在你可能打算检查一下,看看有没有可用的更新。注意通常使用的命令:
|
||||
|
||||
$ sudo apt-get update && sudo apt-get distupgrade
|
||||
|
||||
不过这时系统不会让你通过,因为Snappy 使用它自己精简过的、基于dpkg 的包管理系统。这么做的原因是Snappy 会运行很多嵌入式程序,而同时你也会想着所有事情尽可能的简化。
|
||||
|
||||
让我们来看看最关键的部分,理解一下程序是如何与Snappy 工作的。运行Snappy 的SD 卡上除了boot 分区外还有3个分区。其中的两个构成了一个重复的文件系统。这两个平行文件系统被固定挂载为只读模式,并且任何时刻只有一个是激活的。第三个分区是一个部分可写的文件系统,用来让用户存储数据。通过更新系统,标记为'system-a' 的分区会保持一个完整的文件系统,被称作核心,而另一个平行文件系统仍然会是空的。
|
||||
|
||||

|
||||
|
||||
如果我们运行以下命令:
|
||||
|
||||
$ sudo snappy update
|
||||
|
||||
系统将会在'system-b' 上作为一个整体进行更新,这有点像是更新一个镜像文件。接下来你将会被告知要重启系统来激活新核心。
|
||||
|
||||
重启之后,运行下面的命令可以检查你的系统是否已经更新到最新版本,以及当前被激活的是那个核心
|
||||
|
||||
$ sudo snappy versions -a
|
||||
|
||||
经过更新-重启两步操作,你应该可以看到被激活的核心已经被改变了。
|
||||
|
||||
因为到目前为止我们还没有安装任何软件,下面的命令:
|
||||
|
||||
$ sudo snappy update ubuntu-core
|
||||
|
||||
将会生效,而且如果你打算仅仅更新特定的OS 版本,这也是一个办法。如果出了问题,你可以使用下面的命令回滚:
|
||||
|
||||
$ sudo snappy rollback ubuntu-core
|
||||
|
||||
这将会把系统状态回滚到更新之前。
|
||||
|
||||

|
||||
|
||||
再来说说那些让Snappy 有用的软件。这里不会讲的太多关于如何构建软件、向Snappy 应用商店添加软件的基础知识,但是你可以通过Freenode 上的IRC 频道#snappy 了解更多信息,那个上面有很多人参与。你可以通过浏览器访问http://<ip-address>:4200 来浏览应用商店,然后从商店安装软件,再在浏览器里访问http://webdm.local 来启动程序。如何构建用于Snappy 的软件并不难,而且也有了现成的[参考文档][4] 。你也可以很容易的把DEB 安装包使用Snappy 格式移植到Snappy 上。
|
||||
|
||||

|
||||
|
||||
尽管Ubuntu Snappy Core 吸引我们去研究新型的Snappy 安装包格式和Canonical 式的原子更新操作,但是因为有限的可用应用,它现在在生产环境里还不是很有用。但是既然搭建一个Snappy 环境如此简单,这看起来是一个学点新东西的好机会。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/ubuntu-snappy-core-raspberry-pi-2.html
|
||||
|
||||
作者:[Ferdinand Thommes][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/ferdinand
|
||||
[1]:http://www.ubuntu.com/things
|
||||
[2]:http://www.raspberrypi.org/downloads/
|
||||
[3]:http://xmodulo.com/write-raspberry-pi-image-sd-card.html
|
||||
[4]:https://developer.ubuntu.com/en/snappy/
|
||||
@ -0,0 +1,97 @@
|
||||
修复安装完 Ubuntu 后无可引导设备错误
|
||||
================================================================================
|
||||
通常情况下,我启动 Ubuntu 和 Windows 双系统,但是这次我决定完全消除 Windows 纯净安装 Ubuntu。纯净安装 Ubuntu 完成后,结束时屏幕输出 **no bootable device found** 而不是进入 GRUB 界面。显然,安装搞砸了 UEFI 引导设置。
|
||||
|
||||

|
||||
|
||||
我会告诉你我是如何修复**在宏碁笔记本上安装 Ubuntu 后出现无可引导设备错误**。我声明了我使用的是宏碁灵越 R13,这很重要,因为我们需要更改固件设置,而这些设置可能因制造商和设备有所不同。
|
||||
|
||||
因此在你开始这里介绍的步骤之前,先看一下发生这个错误时我计算机的状态:
|
||||
|
||||
- 我的宏碁灵越 R13 预装了 Windows8.1 和 UEFI 引导管理器
|
||||
- 关闭了 Secure boot(我的笔记本刚维修过,维修人员又启用了它,直到出现了问题我才发现)。你可以阅读这篇博文了解[如何在宏碁笔记本中关闭 secure boot][1]
|
||||
- 我通过选择清除所有东西安装 Ubuntu,例如现有的 Windows 8.1,各种分区等。
|
||||
- 安装完 Ubuntu 之后,从硬盘启动时我看到无可引导设备错误。但能从 USB 设备正常启动
|
||||
|
||||
在我看来,没有禁用 secure boot 可能是这个错误的原因。但是,我没有数据支撑我的观点。这仅仅是预感。有趣的是,双系统启动 Windows 和 Linux 经常会出现这两个 Grub 问题:
|
||||
|
||||
- [error: no such partition grub rescue][2]
|
||||
- [Minimal BASH like line editing is supported][3]
|
||||
|
||||
如果你遇到类似的情况,你可以试试我的修复方法。
|
||||
|
||||
### 修复安装完 Ubuntu 后无可引导设备错误 ###
|
||||
|
||||
请原谅我没有丰富的图片。我的一加相机不能很好地拍摄笔记本屏幕。
|
||||
|
||||
#### 第一步 ####
|
||||
|
||||
关闭电源并进入 boot 设置。我需要在宏碁灵越 R13 上快速地按 Fn+F2。如果你使用固态硬盘的话要按的非常快,因为固态硬盘启动速度很快。取决于你的制造商,你可能要用 Del 或 F10 或者 F12。
|
||||
|
||||
#### 第二步 ####
|
||||
|
||||
在 boot 设置中,确保启用了 Secure Boot。它在 Boot 标签里。
|
||||
|
||||
#### 第三步 ####
|
||||
|
||||
进入到 Security 标签,查找 “Select an UEFI file as trusted for executing” 并敲击回车。
|
||||
|
||||

|
||||
|
||||
特意说明,我们这一步是要在你的设备中添加 UEFI 设置文件(安装 Ubuntu 的时候生成)到可信 UEFI 启动。如果你记得的话,UEFI 启动的主要目的是提供安全性,由于(可能)没有禁用 Secure Boot,设备不会试图从新安装的操作系统中启动。添加它到类似白名单的可信列表,会使设备从 Ubuntu UEFI 文件启动。
|
||||
|
||||
#### 第四步 ####
|
||||
|
||||
在这里你可以看到你的硬盘,例如 HDD0。如果你有多块硬盘,我希望你记住你安装 Ubuntu 的那块。同样敲击回车。
|
||||
|
||||

|
||||
|
||||
#### 第五步 ####
|
||||
|
||||
你应该可以看到 <EFI>,敲击回车。
|
||||
|
||||

|
||||
|
||||
#### 第六步 ####
|
||||
|
||||
在下一个屏幕中你会看到 <Ubuntu>。耐心点,马上就好了。
|
||||
|
||||

|
||||
|
||||
#### 第七步 ####
|
||||
|
||||
你可以看到 shimx64.efi,grubx64.efi 和 MokManager.efi 文件。重要的是 shimx64.efi。选中它并敲击回车。
|
||||
|
||||
|
||||

|
||||
|
||||
在下一个屏幕中,输入 Yes 并敲击回车。
|
||||
|
||||

|
||||
|
||||
#### 第八步 ####
|
||||
|
||||
当我们添加它到可信 EFI 文件并执行时,按 F10 保存并退出。
|
||||
|
||||

|
||||
|
||||
重启你的系统,这时你就可以看到熟悉的 GRUB 界面了。就算你没有看到 Grub 界面,起码也再也不会看到“无可引导设备”。你应该可以进入 Ubuntu 了。
|
||||
|
||||
如果修复后搞乱了你的 Grub 界面,但你确实能登录系统,你可以重装 Grub 并进入到 Ubuntu 熟悉的紫色 Grub 界面。
|
||||
|
||||
我希望这篇指南能帮助你修复无可引导设备错误。欢迎提出任何疑问、建议或者感谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/no-bootable-device-found-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/disable-secure-boot-in-acer/
|
||||
[2]:http://itsfoss.com/solve-error-partition-grub-rescue-ubuntu-linux/
|
||||
[3]:http://itsfoss.com/fix-minimal-bash-line-editing-supported-grub-error-linux/
|
||||
@ -0,0 +1,169 @@
|
||||
第五部分 - 如何在 RHEL 7 中管理系统日志(配置、旋转以及导入到数据库)
|
||||
================================================================================
|
||||
为了确保你的 RHEL 7 系统安全,你需要通过查看日志文件监控系统中发生的所有活动。这样,你就可以检测任何不正常或有潜在破坏的活动并进行系统故障排除或者其它恰当的操作。
|
||||
|
||||

|
||||
|
||||
(译者注:[日志旋转][9]是系统管理中归档每天产生的日志文件的自动化过程)
|
||||
|
||||
RHCE 考试 - 第五部分:使用 Rsyslog 和 Logrotate 管理系统日志
|
||||
|
||||
在 RHEL 7 中,[rsyslogd][1] 守护进程负责系统日志,它从 /etc/rsyslog.conf(该文件指定所有系统日志的默认路径)和 /etc/rsyslog.d 中的所有文件(如果有的话)读取配置信息。
|
||||
|
||||
### Rsyslogd 配置 ###
|
||||
|
||||
快速浏览一下 [rsyslog.conf][2] 会是一个好的开端。该文件分为 3 个主要部分:模块(rsyslong 按照模块化设计),全局指令(用于设置 rsyslogd 守护进程的全局属性),以及规则。正如你可能猜想的,最后一个部分指示获取,显示以及在哪里保存什么的日志(也称为选择子),这也是这篇博文关注的重点。
|
||||
|
||||
rsyslog.conf 中典型的一行如下所示:
|
||||
|
||||

|
||||
|
||||
Rsyslogd 配置
|
||||
|
||||
在上面的图片中,我们可以看到一个选择子包括了一个或多个用分号分隔的设备:优先级(Facility:Priority)对,其中设备描述了消息类型(参考 [RFC 3164 4.1.1 章节][3] 查看 rsyslog 可用的完整设备列表),优先级指示它的严重性,这可能是以下几种之一:
|
||||
|
||||
- debug
|
||||
- info
|
||||
- notice
|
||||
- warning
|
||||
- err
|
||||
- crit
|
||||
- alert
|
||||
- emerg
|
||||
|
||||
尽管自身并不是一个优先级,关键字 none 意味着指定设备没有任何优先级。
|
||||
|
||||
**注意**:给定一个优先级表示该优先级以及之上的消息都应该记录到日志中。因此,上面例子中的行指示 rsyslogd 守护进程记录所有优先级为 info 以及以上(不管是什么设备)的除了属于 mail、authpriv、以及 cron 服务(不考虑来自这些设备的消息)的消息到 /var/log/messages。
|
||||
|
||||
你也可以使用逗号将多个设备分为一组,对同组中的设备使用相同的优先级。例如下面这行:
|
||||
|
||||
*.info;mail.none;authpriv.none;cron.none /var/log/messages
|
||||
|
||||
也可以这样写:
|
||||
|
||||
*.info;mail,authpriv,cron.none /var/log/messages
|
||||
|
||||
换句话说,mail、authpriv 以及 cron 被分为一组,并使用关键字 none。
|
||||
|
||||
#### 创建自定义日志文件 ####
|
||||
|
||||
要把所有的守护进程消息记录到 /var/log/tecmint.log,我们需要在 rsyslog.conf 或者 /etc/rsyslog.d 目录中的单独文件(易于管理)添加下面一行:
|
||||
|
||||
daemon.* /var/log/tecmint.log
|
||||
|
||||
然后重启守护进程(注意服务名称不以 d 结尾):
|
||||
|
||||
# systemctl restart rsyslog
|
||||
|
||||
在随机重启两个守护进程之前和之后查看自定义日志的内容:
|
||||
|
||||

|
||||
|
||||
创建自定义日志文件
|
||||
|
||||
作为一个自学练习,我建议你重点关注设备和优先级,添加额外的消息到已有的日志文件或者像上面那样创建一个新的日志文件。
|
||||
|
||||
### 使用 Logrotate 旋转日志 ###
|
||||
|
||||
为了防止日志文件无限制增长,logrotate 工具用于旋转、压缩、移除或者通过电子邮件发送日志,从而减轻管理会产生大量日志文件系统的困难。
|
||||
|
||||
Logrotate 作为一个 cron 作业(/etc/cron.daily/logrotate)每天运行,并从 /etc/logrotate.conf 和 /etc/logrotate.d 中的文件(如果有的话)读取配置信息。
|
||||
|
||||
对于 rsyslog,即使你可以在主文件中为指定服务包含设置,为每个服务创建单独的配置文件能帮助你更好地组织设置。
|
||||
|
||||
让我们来看一个典型的 logrotate.conf:
|
||||
|
||||

|
||||
|
||||
Logrotate 配置
|
||||
|
||||
在上面的例子中,logrotate 会为 /var/log/wtmp 进行以下操作:尝试每个月旋转一次,但至少文件要大于 1MB,然后用 0664 权限、用户 root、组 utmp 创建一个新的日志文件。下一步只保存一个归档日志,正如旋转指令指定的:
|
||||
|
||||

|
||||
|
||||
每月 Logrotate 日志
|
||||
|
||||
让我们再来看看 /etc/logrotate.d/httpd 中的另一个例子:
|
||||
|
||||

|
||||
|
||||
旋转 Apache 日志文件
|
||||
|
||||
你可以在 logrotate 的 man 手册([man logrotate][4] 和 [man logrotate.conf][5])中阅读更多有关它的设置。为了方便你的阅读,本文还提供了两篇文章的 PDF 格式。
|
||||
|
||||
作为一个系统工程师,很可能由你决定多久按照什么格式保存一次日志,取决于你是否有一个单独的分区/逻辑卷给 /var。否则,你真的要考虑删除旧日志以节省存储空间。另一方面,根据你公司和客户内部的政策,为了以后的安全审核,你可能被迫要保留多个日志。
|
||||
|
||||
#### 保存日志到数据库 ####
|
||||
|
||||
当然检查日志可能是一个很繁琐的工作(即使有类似 grep 工具和正则表达式的帮助)。因为这个原因,rsyslog 允许我们把它们导出到数据库(OTB 支持的关系数据库管理系统包括 MySQL、MariaDB、PostgreSQL 和 Oracle)。
|
||||
|
||||
指南的这部分假设你已经在要管理日志的 RHEL 7 上安装了 MariaDB 服务器和客户端:
|
||||
|
||||
# yum update && yum install mariadb mariadb-server mariadb-client rsyslog-mysql
|
||||
# systemctl enable mariadb && systemctl start mariadb
|
||||
|
||||
然后使用 `mysql_secure_installation` 工具为 root 用户设置密码以及其它安全考量:
|
||||
|
||||
|
||||

|
||||
|
||||
保证 MySQL 数据库安全
|
||||
|
||||
注意:如果你不想用 MariaDB root 用户插入日志消息到数据库,你也可以配置用另一个用户账户。如何实现的介绍已经超出了本文的范围,但在 [MariaDB 知识][6] 中有详细解析。为了简单在这篇指南中我们会使用 root 账户。
|
||||
|
||||
下一步,从 [GitHub][7] 下载 createDB.sql 脚本并导入到你的数据库服务器:
|
||||
|
||||
# mysql -u root -p < createDB.sql
|
||||
|
||||

|
||||
|
||||
保存服务器日志到数据库
|
||||
|
||||
最后,添加下面的行到 /etc/rsyslog.conf:
|
||||
|
||||
$ModLoad ommysql
|
||||
$ActionOmmysqlServerPort 3306
|
||||
*.* :ommysql:localhost,Syslog,root,YourPasswordHere
|
||||
|
||||
重启 rsyslog 和数据库服务器:
|
||||
|
||||
# systemctl restart rsyslog
|
||||
# systemctl restart mariadb
|
||||
|
||||
#### 使用 SQL 语法查询日志 ####
|
||||
|
||||
现在执行一些会改变日志的操作(例如停止和启动服务),然后登陆到你的 DB 服务器并使用标准的 SQL 命令显示和查询日志:
|
||||
|
||||
USE Syslog;
|
||||
SELECT ReceivedAt, Message FROM SystemEvents;
|
||||
|
||||

|
||||
|
||||
在数据库中查询日志
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中我们介绍了如何设置系统日志,如果旋转日志以及为了简化查询如何重定向消息到数据库。我们希望这些技巧能对你准备 [RHCE 考试][8] 和日常工作有所帮助。
|
||||
|
||||
正如往常,非常欢迎你的反馈。用下面的表单和我们联系吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-linux-system-logs-using-rsyslogd-and-logrotate/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/wp-content/pdf/rsyslogd.pdf
|
||||
[2]:http://www.tecmint.com/wp-content/pdf/rsyslog.conf.pdf
|
||||
[3]:https://tools.ietf.org/html/rfc3164#section-4.1.1
|
||||
[4]:http://www.tecmint.com/wp-content/pdf/logrotate.pdf
|
||||
[5]:http://www.tecmint.com/wp-content/pdf/logrotate.conf.pdf
|
||||
[6]:https://mariadb.com/kb/en/mariadb/create-user/
|
||||
[7]:https://github.com/sematext/rsyslog/blob/master/plugins/ommysql/createDB.sql
|
||||
[8]:http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
[9]:https://en.wikipedia.org/wiki/Log_rotation
|
||||
Loading…
Reference in New Issue
Block a user