mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
8f83f9ff9c
231
published/20150717 How to monitor NGINX- Part 1.md
Normal file
231
published/20150717 How to monitor NGINX- Part 1.md
Normal file
@ -0,0 +1,231 @@
|
||||
如何监控 NGINX(第一篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
### NGINX 是什么? ###
|
||||
|
||||
[NGINX][1] (发音为 “engine X”) 是一种流行的 HTTP 和反向代理服务器。作为一个 HTTP 服务器,NGINX 可以使用较少的内存非常高效可靠地提供静态内容。作为[反向代理][2],它可以用作多个后端服务器或类似缓存和负载平衡这样的其它应用的单一访问控制点。NGINX 是一个自由开源的产品,并有一个具备更全的功能的叫做 NGINX Plus 的商业版。
|
||||
|
||||
NGINX 也可以用作邮件代理和通用的 TCP 代理,但本文并不直接讨论 NGINX 的那些用例的监控。
|
||||
|
||||
### NGINX 主要指标 ###
|
||||
|
||||
通过监控 NGINX 可以 捕获到两类问题:NGINX 本身的资源问题,和出现在你的基础网络设施的其它问题。大多数 NGINX 用户会用到以下指标的监控,包括**每秒请求数**,它提供了一个由所有最终用户活动组成的上层视图;**服务器错误率** ,这表明你的服务器已经多长没有处理看似有效的请求;还有**请求处理时间**,这说明你的服务器处理客户端请求的总共时长(并且可以看出性能降低或当前环境的其他问题)。
|
||||
|
||||
更一般地,至少有三个主要的指标类别来监视:
|
||||
|
||||
- 基本活动指标
|
||||
- 错误指标
|
||||
- 性能指标
|
||||
|
||||
下面我们将分析在每个类别中最重要的 NGINX 指标,以及用一个相当普遍但是值得特别提到的案例来说明:使用 NGINX Plus 作反向代理。我们还将介绍如何使用图形工具或可选择的监控工具来监控所有的指标。
|
||||
|
||||
本文引用指标术语[来自我们的“监控 101 系列”][3],,它提供了一个指标收集和警告框架。
|
||||
|
||||
#### 基本活跃指标 ####
|
||||
|
||||
无论你在怎样的情况下使用 NGINX,毫无疑问你要监视服务器接收多少客户端请求和如何处理这些请求。
|
||||
|
||||
NGINX Plus 上像开源 NGINX 一样可以报告基本活跃指标,但它也提供了略有不同的辅助模块。我们首先讨论开源的 NGINX,再来说明 NGINX Plus 提供的其他指标的功能。
|
||||
|
||||
**NGINX**
|
||||
|
||||
下图显示了一个客户端连接的过程,以及开源版本的 NGINX 如何在连接过程中收集指标。
|
||||
|
||||

|
||||
|
||||
Accepts(接受)、Handled(已处理)、Requests(请求)是一直在增加的计数器。Active(活跃)、Waiting(等待)、Reading(读)、Writing(写)随着请求量而增减。
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)|
|
||||
|-----------|-----------------|-------------------------------------------------------------------------------------------------------------------------|
|
||||
| Accepts | NGINX 所接受的客户端连接数 | 资源: 功能 |
|
||||
| Handled | 成功的客户端连接数 | 资源: 功能 |
|
||||
| Active | 当前活跃的客户端连接数| 资源: 功能 |
|
||||
| Dropped(已丢弃,计算得出)| 丢弃的连接数(接受 - 已处理)| 工作:错误*|
|
||||
| Requests | 客户端请求数 | 工作:吞吐量 |
|
||||
|
||||
|
||||
_*严格的来说,丢弃的连接是 [一个资源饱和指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics),但是因为饱和会导致 NGINX 停止服务(而不是延后该请求),所以,“已丢弃”视作 [一个工作指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics) 比较合适。_
|
||||
|
||||
NGINX worker 进程接受 OS 的连接请求时 **Accepts** 计数器增加,而**Handled** 是当实际的请求得到连接时(通过建立一个新的连接或重新使用一个空闲的)。这两个计数器的值通常都是相同的,如果它们有差别则表明连接被**Dropped**,往往这是由于资源限制,比如已经达到 NGINX 的[worker_connections][4]的限制。
|
||||
|
||||
一旦 NGINX 成功处理一个连接时,连接会移动到**Active**状态,在这里对客户端请求进行处理:
|
||||
|
||||
Active状态
|
||||
|
||||
- **Waiting**: 活跃的连接也可以处于 Waiting 子状态,如果有在此刻没有活跃请求的话。新连接可以绕过这个状态并直接变为到 Reading 状态,最常见的是在使用“accept filter(接受过滤器)” 和 “deferred accept(延迟接受)”时,在这种情况下,NGINX 不会接收 worker 进程的通知,直到它具有足够的数据才开始响应。如果连接设置为 keep-alive ,那么它在发送响应后将处于等待状态。
|
||||
|
||||
- **Reading**: 当接收到请求时,连接离开 Waiting 状态,并且该请求本身使 Reading 状态计数增加。在这种状态下 NGINX 会读取客户端请求首部。请求首部是比较小的,因此这通常是一个快速的操作。
|
||||
|
||||
- **Writing**: 请求被读取之后,其使 Writing 状态计数增加,并保持在该状态,直到响应返回给客户端。这意味着,该请求在 Writing 状态时, 一方面 NGINX 等待来自上游系统的结果(系统放在 NGINX “后面”),另外一方面,NGINX 也在同时响应。请求往往会在 Writing 状态花费大量的时间。
|
||||
|
||||
通常,一个连接在同一时间只接受一个请求。在这种情况下,Active 连接的数目 == Waiting 的连接 + Reading 请求 + Writing 。然而,较新的 SPDY 和 HTTP/2 协议允许多个并发请求/响应复用一个连接,所以 Active 可小于 Waiting 的连接、 Reading 请求、Writing 请求的总和。 (在撰写本文时,NGINX 不支持 HTTP/2,但预计到2015年期间将会支持。)
|
||||
|
||||
**NGINX Plus**
|
||||
|
||||
正如上面提到的,所有开源 NGINX 的指标在 NGINX Plus 中是可用的,但另外也提供其他的指标。本节仅说明了 NGINX Plus 可用的指标。
|
||||
|
||||
|
||||

|
||||
|
||||
Accepted (已接受)、Dropped,总数是不断增加的计数器。Active、 Idle(空闲)和处于 Current(当前)处理阶段的各种状态下的连接或请求的当前数量随着请求量而增减。
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)|
|
||||
|-----------|-----------------|-------------------------------------------------------------------------------------------------------------------------|
|
||||
| Accepted | NGINX 所接受的客户端连接数 | 资源: 功能 |
|
||||
| Dropped |丢弃的连接数(接受 - 已处理)| 工作:错误*|
|
||||
| Active | 当前活跃的客户端连接数| 资源: 功能 |
|
||||
| Idle | 没有当前请求的客户端连接| 资源: 功能 |
|
||||
| Total(全部) | 客户端请求数 | 工作:吞吐量 |
|
||||
|
||||
_*严格的来说,丢弃的连接是 [一个资源饱和指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics),但是因为饱和会导致 NGINX 停止服务(而不是延后该请求),所以,“已丢弃”视作 [一个工作指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics) 比较合适。_
|
||||
|
||||
当 NGINX Plus worker 进程接受 OS 的连接请求时 **Accepted** 计数器递增。如果 worker 进程为请求建立连接失败(通过建立一个新的连接或重新使用一个空闲),则该连接被丢弃, **Dropped** 计数增加。通常连接被丢弃是因为资源限制,如 NGINX Plus 的[worker_connections][4]的限制已经达到。
|
||||
|
||||
**Active** 和 **Idle** 和[如上所述][5]的开源 NGINX 的“active” 和 “waiting”状态是相同的,但是有一点关键的不同:在开源 NGINX 上,“waiting”状态包括在“active”中,而在 NGINX Plus 上“idle”的连接被排除在“active” 计数外。**Current** 和开源 NGINX 是一样的也是由“reading + writing” 状态组成。
|
||||
|
||||
**Total** 为客户端请求的累积计数。请注意,单个客户端连接可涉及多个请求,所以这个数字可能会比连接的累计次数明显大。事实上,(total / accepted)是每个连接的平均请求数量。
|
||||
|
||||
**开源 和 Plus 之间指标的不同**
|
||||
|
||||
|NGINX (开源) |NGINX Plus|
|
||||
|-----------------------|----------------|
|
||||
| accepts | accepted |
|
||||
| dropped 通过计算得来| dropped 直接得到 |
|
||||
| reading + writing| current|
|
||||
| waiting| idle|
|
||||
| active (包括 “waiting”状态) | active (排除 “idle” 状态)|
|
||||
| requests| total|
|
||||
|
||||
**提醒指标: 丢弃连接**
|
||||
|
||||
被丢弃的连接数目等于 Accepts 和 Handled 之差(NGINX 中),或是可直接得到标准指标(NGINX Plus 中)。在正常情况下,丢弃连接数应该是零。如果在每个单位时间内丢弃连接的速度开始上升,那么应该看看是否资源饱和了。
|
||||
|
||||

|
||||
|
||||
**提醒指标: 每秒请求数**
|
||||
|
||||
按固定时间间隔采样你的请求数据(开源 NGINX 的**requests**或者 NGINX Plus 中**total**) 会提供给你单位时间内(通常是分钟或秒)所接受的请求数量。监测这个指标可以查看进入的 Web 流量尖峰,无论是合法的还是恶意的,或者突然的下降,这通常都代表着出现了问题。每秒请求数若发生急剧变化可以提醒你的环境出现问题了,即使它不能告诉你确切问题的位置所在。请注意,所有的请求都同样计数,无论 URL 是什么。
|
||||
|
||||

|
||||
|
||||
**收集活跃指标**
|
||||
|
||||
开源的 NGINX 提供了一个简单状态页面来显示基本的服务器指标。该状态信息以标准格式显示,实际上任何图形或监控工具可以被配置去解析这些相关数据,以用于分析、可视化、或提醒。NGINX Plus 提供一个 JSON 接口来供给更多的数据。阅读相关文章“[NGINX 指标收集][6]”来启用指标收集的功能。
|
||||
|
||||
#### 错误指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| 4xx 代码 | 客户端错误计数 | 工作:错误 | NGINX 日志, NGINX Plus|
|
||||
| 5xx 代码| 服务器端错误计数 | 工作:错误 | NGINX 日志, NGINX Plus|
|
||||
|
||||
NGINX 错误指标告诉你服务器是否经常返回错误而不是正常工作。客户端错误返回4XX状态码,服务器端错误返回5XX状态码。
|
||||
|
||||
**提醒指标: 服务器错误率**
|
||||
|
||||
服务器错误率等于在单位时间(通常为一到五分钟)内5xx错误状态代码的总数除以[状态码][7](1XX,2XX,3XX,4XX,5XX)的总数。如果你的错误率随着时间的推移开始攀升,调查可能的原因。如果突然增加,可能需要采取紧急行动,因为客户端可能收到错误信息。
|
||||
|
||||

|
||||
|
||||
关于客户端错误的注意事项:虽然监控4XX是很有用的,但从该指标中你仅可以捕捉有限的信息,因为它只是衡量客户的行为而不捕捉任何特殊的 URL。换句话说,4xx出现的变化可能是一个信号,例如网络扫描器正在寻找你的网站漏洞时。
|
||||
|
||||
**收集错误度量**
|
||||
|
||||
虽然开源 NGINX 不能马上得到用于监测的错误率,但至少有两种方法可以得到:
|
||||
|
||||
- 使用商业支持的 NGINX Plus 提供的扩展状态模块
|
||||
- 配置 NGINX 的日志模块将响应码写入访问日志
|
||||
|
||||
关于这两种方法,请阅读相关文章“[NGINX 指标收集][6]”。
|
||||
|
||||
#### 性能指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| request time (请求处理时间)| 处理每个请求的时间,单位为秒 | 工作:性能 | NGINX 日志|
|
||||
|
||||
**提醒指标: 请求处理时间**
|
||||
|
||||
请求处理时间指标记录了 NGINX 处理每个请求的时间,从读到客户端的第一个请求字节到完成请求。较长的响应时间说明问题在上游。
|
||||
|
||||
**收集处理时间指标**
|
||||
|
||||
NGINX 和 NGINX Plus 用户可以通过添加 $request_time 变量到访问日志格式中来捕捉处理时间数据。关于配置日志监控的更多细节在[NGINX指标收集][6]。
|
||||
|
||||
#### 反向代理指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| 上游服务器的活跃链接 | 当前活跃的客户端连接 | 资源:功能 | NGINX Plus |
|
||||
| 上游服务器的 5xx 错误代码| 服务器错误 | 工作:错误 | NGINX Plus |
|
||||
| 每个上游组的可用服务器 | 服务器传递健康检查 | 资源:可用性| NGINX Plus
|
||||
|
||||
[反向代理][9]是 NGINX 最常见的使用方法之一。商业支持的 NGINX Plus 显示了大量有关后端(或“上游 upstream”)的服务器指标,这些与反向代理设置相关的。本节重点介绍了几个 NGINX Plus 用户可用的关键上游指标。
|
||||
|
||||
NGINX Plus 首先将它的上游指标按组分开,然后是针对单个服务器的。因此,例如,你的反向代理将请求分配到五个上游的 Web 服务器上,你可以一眼看出是否有单个服务器压力过大,也可以看出上游组中服务器的健康状况,以确保良好的响应时间。
|
||||
|
||||
**活跃指标**
|
||||
|
||||
**每上游服务器的活跃连接**的数量可以帮助你确认反向代理是否正确的分配工作到你的整个服务器组上。如果你正在使用 NGINX 作为负载均衡器,任何一台服务器处理的连接数的明显偏差都可能表明服务器正在努力消化请求,或者是你配置使用的负载均衡的方法(例如[round-robin 或 IP hashing][10])不是最适合你流量模式的。
|
||||
|
||||
**错误指标**
|
||||
|
||||
错误指标,上面所说的高于5XX(服务器错误)状态码,是监控指标中有价值的一个,尤其是响应码部分。 NGINX Plus 允许你轻松地提取**每个上游服务器的 5xx 错误代码**的数量,以及响应的总数量,以此来确定某个特定服务器的错误率。
|
||||
|
||||
**可用性指标**
|
||||
|
||||
对于 web 服务器的运行状况,还有另一种角度,NGINX 可以通过**每个组中当前可用服务器的总量**很方便监控你的上游组的健康。在一个大的反向代理上,你可能不会非常关心其中一个服务器的当前状态,就像你只要有可用的服务器组能够处理当前的负载就行了。但监视上游组内的所有工作的服务器总量可为判断 Web 服务器的健康状况提供一个更高层面的视角。
|
||||
|
||||
**收集上游指标**
|
||||
|
||||
NGINX Plus 上游指标显示在内部 NGINX Plus 的监控仪表盘上,并且也可通过一个JSON 接口来服务于各种外部监控平台。在我们的相关文章“[NGINX指标收集][6]”中有个例子。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经谈到了一些有用的指标,你可以使用表格来监控 NGINX 服务器。如果你是刚开始使用 NGINX,监控下面提供的大部分或全部指标,可以让你很好的了解你的网络基础设施的健康和活跃程度:
|
||||
|
||||
- [已丢弃的连接][12]
|
||||
- [每秒请求数][13]
|
||||
- [服务器错误率][14]
|
||||
- [请求处理数据][15]
|
||||
|
||||
最终,你会学到更多,更专业的衡量指标,尤其是关于你自己基础设施和使用情况的。当然,监控哪一项指标将取决于你可用的工具。参见相关的文章来[逐步指导你的指标收集][6],不管你使用 NGINX 还是 NGINX Plus。
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最少的设置来收集和监控所有 Web 服务器的指标。 [在本文中][17]了解如何用 NGINX Datadog来监控,并开始[免费试用 Datadog][18]吧。
|
||||
|
||||
### 诚谢 ###
|
||||
|
||||
在文章发表之前非常感谢 NGINX 团队审阅这篇,并提供重要的反馈和说明。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://nginx.org/en/
|
||||
[2]:http://nginx.com/resources/glossary/reverse-proxy-server/
|
||||
[3]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/
|
||||
[4]:http://nginx.org/en/docs/ngx_core_module.html#worker_connections
|
||||
[5]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#active-state
|
||||
[6]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[7]:http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
|
||||
[8]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[9]:https://en.wikipedia.org/wiki/Reverse_proxy
|
||||
[10]:http://nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[11]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[12]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#dropped-connections
|
||||
[13]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#requests-per-second
|
||||
[14]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#server-error-rate
|
||||
[15]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#request-processing-time
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[18]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#sign-up
|
||||
[19]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx.md
|
||||
[20]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -1,32 +1,32 @@
|
||||
无忧之道:Docker中容器的备份、恢复和迁移
|
||||
================================================================================
|
||||
今天,我们将学习如何快速地对docker容器进行快捷备份、恢复和迁移。[Docker][1]是一个开源平台,用于自动化部署应用,以通过快捷的途径在称之为容器的轻量级软件层下打包、发布和运行这些应用。它使得应用平台独立,因为它扮演了Linux上一个额外的操作系统级虚拟化的自动化抽象层。它通过其组件cgroups和命名空间利用Linux内核的资源分离特性,达到避免虚拟机开销的目的。它使得用于部署和扩展web应用、数据库和后端服务的大规模构建块无需依赖于特定的堆栈或供应者。
|
||||
今天,我们将学习如何快速地对docker容器进行快捷备份、恢复和迁移。[Docker][1]是一个开源平台,用于自动化部署应用,以通过快捷的途径在称之为容器的轻量级软件层下打包、发布和运行这些应用。它使得应用平台独立,因为它扮演了Linux上一个额外的操作系统级虚拟化的自动化抽象层。它通过其组件cgroups和命名空间利用Linux内核的资源分离特性,达到避免虚拟机开销的目的。它使得用于部署和扩展web应用、数据库和后端服务的大规模构建组件无需依赖于特定的堆栈或供应者。
|
||||
|
||||
所谓的容器,就是那些创建自Docker镜像的软件层,它包含了独立的Linux文件系统和开箱即用的应用程序。如果我们有一个在盒子中运行着的Docker容器,并且想要备份这些容器以便今后使用,或者想要迁移这些容器,那么,本教程将帮助你掌握在Linux操作系统中备份、恢复和迁移Docker容器。
|
||||
所谓的容器,就是那些创建自Docker镜像的软件层,它包含了独立的Linux文件系统和开箱即用的应用程序。如果我们有一个在机器中运行着的Docker容器,并且想要备份这些容器以便今后使用,或者想要迁移这些容器,那么,本教程将帮助你掌握在Linux操作系统中备份、恢复和迁移Docker容器的方法。
|
||||
|
||||
我们怎样才能在Linux中备份、恢复和迁移Docker容器呢?这里为您提供了一些便捷的步骤。
|
||||
|
||||
### 1. 备份容器 ###
|
||||
|
||||
首先,为了备份Docker中的容器,我们会想看看我们想要备份的容器列表。要达成该目的,我们需要在我们运行这Docker引擎,并已创建了容器的Linux机器中运行 docker ps 命令。
|
||||
首先,为了备份Docker中的容器,我们会想看看我们想要备份的容器列表。要达成该目的,我们需要在我们运行着Docker引擎,并已创建了容器的Linux机器中运行 docker ps 命令。
|
||||
|
||||
# docker ps
|
||||
|
||||

|
||||
|
||||
在此之后,我们要选择我们想要备份的容器,然后我们会去创建该容器的快照。我们可以使用 docker commit 命令来创建快照。
|
||||
在此之后,我们要选择我们想要备份的容器,然后去创建该容器的快照。我们可以使用 docker commit 命令来创建快照。
|
||||
|
||||
# docker commit -p 30b8f18f20b4 container-backup
|
||||
|
||||

|
||||
|
||||
该命令会生成一个作为Docker镜像的容器快照,我们可以通过运行 docker images 命令来查看Docker镜像,如下。
|
||||
该命令会生成一个作为Docker镜像的容器快照,我们可以通过运行 `docker images` 命令来查看Docker镜像,如下。
|
||||
|
||||
# docker images
|
||||
|
||||

|
||||
|
||||
正如我们所看见的,上面做的快照已经作为Docker镜像保存了。现在,为了备份该快照,我们有两个选择,一个是我们可以登陆进Docker注册中心,并推送该镜像;另一个是我们可以将Docker镜像打包成tarball备份,以供今后使用。
|
||||
正如我们所看见的,上面做的快照已经作为Docker镜像保存了。现在,为了备份该快照,我们有两个选择,一个是我们可以登录进Docker注册中心,并推送该镜像;另一个是我们可以将Docker镜像打包成tar包备份,以供今后使用。
|
||||
|
||||
如果我们想要在[Docker注册中心][2]上传或备份镜像,我们只需要运行 docker login 命令来登录进Docker注册中心,然后推送所需的镜像即可。
|
||||
|
||||
@ -39,23 +39,23 @@
|
||||
|
||||

|
||||
|
||||
如果我们不想备份到docker注册中心,而是想要将此镜像保存在本地机器中,以供日后使用,那么我们可以将其作为tarball备份。要完成该操作,我们需要运行以下 docker save 命令。
|
||||
如果我们不想备份到docker注册中心,而是想要将此镜像保存在本地机器中,以供日后使用,那么我们可以将其作为tar包备份。要完成该操作,我们需要运行以下 `docker save` 命令。
|
||||
|
||||
# docker save -o ~/container-backup.tar container-backup
|
||||
|
||||

|
||||
|
||||
要验证tarball时候已经生成,我们只需要在保存tarball的目录中运行 ls 命令。
|
||||
要验证tar包是否已经生成,我们只需要在保存tar包的目录中运行 ls 命令即可。
|
||||
|
||||
### 2. 恢复容器 ###
|
||||
|
||||
接下来,在我们成功备份了我们的Docker容器后,我们现在来恢复这些被快照成Docker镜像的容器。如果我们已经在注册中心推送了这些Docker镜像,那么我们仅仅需要把那个Docker镜像拖回并直接运行即可。
|
||||
接下来,在我们成功备份了我们的Docker容器后,我们现在来恢复这些制作了Docker镜像快照的容器。如果我们已经在注册中心推送了这些Docker镜像,那么我们仅仅需要把那个Docker镜像拖回并直接运行即可。
|
||||
|
||||
# docker pull arunpyasi/container-backup:test
|
||||
|
||||

|
||||
|
||||
但是,如果我们将这些Docker镜像作为tarball文件备份到了本地,那么我们只要使用 docker load 命令,后面加上tarball的备份路径,就可以加载该Docker镜像了。
|
||||
但是,如果我们将这些Docker镜像作为tar包文件备份到了本地,那么我们只要使用 docker load 命令,后面加上tar包的备份路径,就可以加载该Docker镜像了。
|
||||
|
||||
# docker load -i ~/container-backup.tar
|
||||
|
||||
@ -63,7 +63,7 @@
|
||||
|
||||
# docker images
|
||||
|
||||
在镜像被加载后,我们将从加载的镜像去运行Docker容器。
|
||||
在镜像被加载后,我们将用加载的镜像去运行Docker容器。
|
||||
|
||||
# docker run -d -p 80:80 container-backup
|
||||
|
||||
@ -71,11 +71,11 @@
|
||||
|
||||
### 3. 迁移Docker容器 ###
|
||||
|
||||
迁移容器同时涉及到了上面两个操作,备份和恢复。我们可以将任何一个Docker容器从一台机器迁移到另一台机器。在迁移过程中,首先我们将容器的备份作为快照Docker镜像。然后,该Docker镜像或者是被推送到了Docker注册中心,或者被作为tarball文件保存到了本地。如果我们将镜像推送到了Docker注册中心,我们简单地从任何我们想要的机器上使用 docker run 命令来恢复并运行该容器。但是,如果我们将镜像打包成tarball备份到了本地,我们只需要拷贝或移动该镜像到我们想要的机器上,加载该镜像并运行需要的容器即可。
|
||||
迁移容器同时涉及到了上面两个操作,备份和恢复。我们可以将任何一个Docker容器从一台机器迁移到另一台机器。在迁移过程中,首先我们将把容器备份为Docker镜像快照。然后,该Docker镜像或者是被推送到了Docker注册中心,或者被作为tar包文件保存到了本地。如果我们将镜像推送到了Docker注册中心,我们简单地从任何我们想要的机器上使用 docker run 命令来恢复并运行该容器。但是,如果我们将镜像打包成tar包备份到了本地,我们只需要拷贝或移动该镜像到我们想要的机器上,加载该镜像并运行需要的容器即可。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
最后,我们已经学习了如何快速地备份、恢复和迁移Docker容器,本教程适用于各个成功运行Docker的操作系统平台。真的,Docker是一个相当简单易用,然而功能却十分强大的工具。它的命令相当易记,这些命令都非常短,带有许多简单而强大的标记和参数。上面的方法让我们备份容器时很是安逸,使得我们可以在日后很轻松地恢复它们。这会帮助我们恢复我们的容器和镜像,即便主机系统崩溃,甚至意外地被清除。如果你还有很多问题、建议、反馈,请在下面的评论框中写出来吧,可以帮助我们改进或更新我们的内容。谢谢大家!享受吧 :-)
|
||||
最后,我们已经学习了如何快速地备份、恢复和迁移Docker容器,本教程适用于各个可以成功运行Docker的操作系统平台。真的,Docker是一个相当简单易用,然而功能却十分强大的工具。它的命令相当易记,这些命令都非常短,带有许多简单而强大的标记和参数。上面的方法让我们备份容器时很是安逸,使得我们可以在日后很轻松地恢复它们。这会帮助我们恢复我们的容器和镜像,即便主机系统崩溃,甚至意外地被清除。如果你还有很多问题、建议、反馈,请在下面的评论框中写出来吧,可以帮助我们改进或更新我们的内容。谢谢大家!享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -83,7 +83,7 @@ via: http://linoxide.com/linux-how-to/backup-restore-migrate-containers-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,75 @@
|
||||
选择成为软件开发工程师的5个原因
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
这个星期我将给本地一所高中做一次有关于程序猿是怎样工作的演讲。我是志愿(由 [Transfer][1] 组织的)来到这所学校谈论我的工作的。这个学校本周将有一个技术主题日,并且他们很想听听科技行业是怎样工作的。因为我是从事软件开发的,这也是我将和学生们讲的内容。演讲的其中一部分是我为什么觉得软件开发是一个很酷的职业。主要原因如下:
|
||||
|
||||
### 5个原因 ###
|
||||
|
||||
**1、创造性**
|
||||
|
||||
如果你问别人创造性的工作有哪些,别人通常会说像作家,音乐家或者画家那样的(工作)。但是极少有人知道软件开发也是一项非常具有创造性的工作。它是最符合创造性定义的了,因为你创造了一个以前没有的新功能。这种解决方案可以在整体和细节上以很多形式来展现。我们经常会遇到一些需要做权衡的场景(比如说运行速度与内存消耗的权衡)。当然前提是这种解决方案必须是正确的。这些所有的行为都是需要强大的创造性的。
|
||||
|
||||
**2、协作性**
|
||||
|
||||
另外一个表象是程序猿们独自坐在他们的电脑前,然后撸一天的代码。但是软件开发事实上通常总是一个团队努力的结果。你会经常和你的同事讨论编程问题以及解决方案,并且和产品经理、测试人员、客户讨论需求以及其他问题。
|
||||
经常有人说,结对编程(2个开发人员一起在一个电脑上编程)是一种流行的最佳实践。
|
||||
|
||||
**3、高需性**
|
||||
|
||||
世界上越来越多的人在用软件,正如 [Marc Andreessen](https://en.wikipedia.org/wiki/Marc_Andreessen) 所说 " [软件正在吞噬世界][2] "。虽然程序猿现在的数量非常巨大(在斯德哥尔摩,程序猿现在是 [最普遍的职业][3] ),但是,需求量一直处于供不应求的局面。据软件公司说,他们最大的挑战之一就是 [找到优秀的程序猿][4] 。我也经常接到那些想让我跳槽的招聘人员打来的电话。我知道至少除软件行业之外的其他行业的雇主不会那么拼(的去招聘)。
|
||||
|
||||
**4、高酬性**
|
||||
|
||||
软件开发可以带来不菲的收入。卖一份你已经开发好的软件的额外副本是没有 [边际成本][5] 的。这个事实与对程序猿的高需求意味着收入相当可观。当然还有许多更捞金的职业,但是相比一般人群,我认为软件开发者确实“日进斗金”(知足吧!骚年~~)。
|
||||
|
||||
**5、前瞻性**
|
||||
|
||||
有许多工作岗位消失,往往是由于它们可以被计算机和软件代替。但是所有这些新的程序依然需要开发和维护,因此,程序猿的前景还是相当好的。
|
||||
|
||||
### 但是...###
|
||||
|
||||
**外包又是怎么一回事呢?**
|
||||
|
||||
难道所有外包到其他国家的软件开发的薪水都很低吗?这是一个理想丰满,现实骨感的例子(有点像 [瀑布开发模型][6] )。软件开发基本上跟设计的工作一样,是一个探索发现的工作。它受益于强有力的合作。更进一步说,特别当你的主打产品是软件的时候,你所掌握的开发知识是绝对的优势。知识在整个公司中分享的越容易,那么公司的发展也将越来越好。
|
||||
|
||||
换一种方式去看待这个问题。软件外包已经存在了相当一段时间了。但是对本土程序猿的需求量依旧非常高。因为许多软件公司看到了雇佣本土程序猿的带来的收益要远远超过了相对较高的成本(其实还是赚了)。
|
||||
|
||||
### 如何成为人生大赢家 ###
|
||||
|
||||
虽然我有许多我认为软件开发是一件非常有趣的事情的理由 (详情见: [为什么我热爱编程][7] )。但是这些理由,并不适用于所有人。幸运的是,尝试编程是一件非常容易的事情。在互联网上有数不尽的学习编程的资源。例如,[Coursera][8] 和 [Udacity][9] 都拥有很好的入门课程。如果你从来没有撸过码,可以尝试其中一个免费的课程,找找感觉。
|
||||
|
||||
寻找一个既热爱又能谋生的事情至少有2个好处。首先,由于你天天去做,工作将比你简单的只为谋生要有趣的多。其次,如果你真的非常喜欢,你将更好的擅长它。我非常喜欢下面一副关于伟大工作组成的韦恩图(作者 [@eskimon)][10]) 。因为编码的薪水确实相当不错,我认为如果你真的喜欢它,你将有一个很好的机会,成为人生的大赢家!
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://henrikwarne.com/2014/12/08/5-reasons-why-software-developer-is-a-great-career-choice/
|
||||
|
||||
作者:[Henrik Warne][a]
|
||||
译者:[mousycoder](https://github.com/mousycoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:http://henrikwarne.com/
|
||||
[1]:http://www.transfer.nu/omoss/transferinenglish.jspx?pageId=23
|
||||
[2]:http://www.wsj.com/articles/SB10001424053111903480904576512250915629460
|
||||
[3]:http://www.di.se/artiklar/2014/6/12/jobbet-som-tar-over-landet/
|
||||
[4]:http://computersweden.idg.se/2.2683/1.600324/examinationstakten-racker-inte-for-branschens-behov
|
||||
[5]:https://en.wikipedia.org/wiki/Marginal_cost
|
||||
[6]:https://en.wikipedia.org/wiki/Waterfall_model
|
||||
[7]:http://henrikwarne.com/2012/06/02/why-i-love-coding/
|
||||
[8]:https://www.coursera.org/
|
||||
[9]:https://www.udacity.com/
|
||||
[10]:https://eskimon.wordpress.com/about/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
99
sources/talk/20150806 5 heroes of the Linux world.md
Normal file
99
sources/talk/20150806 5 heroes of the Linux world.md
Normal file
@ -0,0 +1,99 @@
|
||||
5 heroes of the Linux world
|
||||
================================================================================
|
||||
Who are these people, seen and unseen, whose work affects all of us every day?
|
||||
|
||||

|
||||
Image courtesy [Christopher Michel/Flickr][1]
|
||||
|
||||
### High-flying penguins ###
|
||||
|
||||
Linux and open source is driven by passionate people who write best-of-breed software and then release the code to the public so anyone can use it, without any strings attached. (Well, there is one string attached and that’s licence.)
|
||||
|
||||
Who are these people? These heroes of the Linux world, whose work affects all of us every day. Allow me to introduce you.
|
||||
|
||||

|
||||
Image courtesy Swapnil Bhartiya
|
||||
|
||||
### Klaus Knopper ###
|
||||
|
||||
Klaus Knopper, an Austrian developer who lives in Germany, is the founder of Knoppix and Adriana Linux, which he developed for his blind wife.
|
||||
|
||||
Knoppix holds a very special place in heart of those Linux users who started using Linux before Ubuntu came along. What makes Knoppix so special is that it popularized the concept of Live CD. Unlike Windows or Mac OS X, you could run the entire operating system from the CD without installing anything on the system. It allowed new users to test Linux on their systems without formatting the hard drive. The live feature of Linux alone contributed heavily to its popularity.
|
||||
|
||||

|
||||
Image courtesy [Fórum Internacional Software Live/Flickr][2]
|
||||
|
||||
### Lennart Pottering ###
|
||||
|
||||
Lennart Pottering is yet another genius from Germany. He has written so many core components of a Linux (as well as BSD) system that it’s hard to keep track. Most of his work is towards the successors of aging or broken components of the Linux systems.
|
||||
|
||||
Pottering wrote the modern init system systemd, which shook the Linux world and created a [rift in the Debian community][3].
|
||||
|
||||
While Linus Torvalds has no problems with systemd, and praises it, he is not a huge fan of the way systemd developers (including the co-author Kay Sievers,) respond to bug reports and criticism. At one point Linus said on the LKML (Linux Kernel Mailing List) that he would [never work with Sievers][4].
|
||||
|
||||
Lennart is also the author of Pulseaudio, sound server on Linux and Avahi, zero-configuration networking (zeroconf) implementation.
|
||||
|
||||

|
||||
Image courtesy [Meego Com/Flickr][5]
|
||||
|
||||
### Jim Zemlin ###
|
||||
|
||||
Jim Zemlin isn't a developer, but as founder of The Linux Foundation he is certainly one of the most important figures of the Linux world.
|
||||
|
||||
In 2007, The Linux Foundation was formed as a result of merger between two open source bodies: the Free Standards Group and the Open Source Development Labs. Zemlin was the executive director of the Free Standards Group. Post-merger Zemlin became the executive director of The Linux Foundation and has held that position since.
|
||||
|
||||
Under his leadership, The Linux Foundation has become the central figure in the modern IT world and plays a very critical role for the Linux ecosystem. In order to ensure that key developers like Torvalds and Kroah-Hartman can focus on Linux, the foundation sponsors them as fellows.
|
||||
|
||||
Zemlin also made the foundation a bridge between companies so they can collaborate on Linux while at the same time competing in the market. The foundation also organizes many conferences around the world and [offers many courses for Linux developers][6].
|
||||
|
||||
People may think of Zemlin as Linus Torvalds' boss, but he refers to himself as "Linus Torvalds' janitor."
|
||||
|
||||

|
||||
Image courtesy [Coscup/Flickr][7]
|
||||
|
||||
### Greg Kroah-Hartman ###
|
||||
|
||||
Greg Kroah-Hartman is known as second-in-command of the Linux kernel. The ‘gentle giant’ is the maintainer of the stable branch of the kernel and of staging subsystem, USB, driver core, debugfs, kref, kobject, and the [sysfs][8] kernel subsystems along with many other components of a Linux system.
|
||||
|
||||
He is also credited for device drivers for Linux. One of his jobs is to travel around the globe, meet hardware makers and persuade them to make their drivers available for Linux. The next time you plug some random USB device to your system and it works out of the box, thank Kroah-Hartman. (Don't thank the distro. Some distros try to take credit for the work Kroah-Hartman or the Linux kernel did.)
|
||||
|
||||
Kroah-Hartman previously worked for Novell and then joined the Linux Foundation as a fellow, alongside Linus Torvalds.
|
||||
|
||||
Kroah-Hartman is the total opposite of Linus and never rants (at least publicly). One time there was some ripple was when he stated that [Canonical doesn’t contribute much to the Linux kernel][9].
|
||||
|
||||
On a personal level, Kroah-Hartman is extremely helpful to new developers and users and is easily accessible.
|
||||
|
||||

|
||||
Image courtesy Swapnil Bhartiya
|
||||
|
||||
### Linus Torvalds ###
|
||||
|
||||
No collection of Linux heroes would be complete without Linus Torvalds. He is the author of the Linux kernel, the most used open source technology on the planet and beyond. His software powers everything from space stations to supercomputers, military drones to mobile devices and tiny smartwatches. Linus remains the authority on the Linux kernel and makes the final decision on which patches to merge to the kernel.
|
||||
|
||||
Linux isn't Torvalds' only contribution open source. When he got fed-up with the existing software revision control systems, which his kernel heavily relied on, he wrote his own, called Git. Git enjoys the same reputation as Linux; it is the most used version control system in the world.
|
||||
|
||||
Torvalds is also a passionate scuba diver and when he found no decent dive logs for Linux, he wrote his own and called it SubSurface.
|
||||
|
||||
Torvalds is [well known for his rants][10] and once admitted that his ego is as big as a small planet. But he is also known for admitting his mistakes if he realizes he was wrong.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2955001/linux/5-heros-of-the-linux-world.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Swapnil-Bhartiya/
|
||||
[1]:https://flic.kr/p/siJ25M
|
||||
[2]:https://flic.kr/p/uTzj54
|
||||
[3]:http://www.itwire.com/business-it-news/open-source/66153-systemd-fallout-two-debian-technical-panel-members-resign
|
||||
[4]:http://www.linuxveda.com/2014/04/04/linus-torvalds-systemd-kay-sievers/
|
||||
[5]:https://flic.kr/p/9Lnhpu
|
||||
[6]:http://www.itworld.com/article/2951968/linux/linux-foundation-offers-cheaper-courses-and-certifications-for-india.html
|
||||
[7]:https://flic.kr/p/hBv8Pp
|
||||
[8]:https://en.wikipedia.org/wiki/Sysfs
|
||||
[9]:https://www.youtube.com/watch?v=CyHAeGBFS8k
|
||||
[10]:http://www.itworld.com/article/2873200/operating-systems/11-technologies-that-tick-off-linus-torvalds.html
|
||||
@ -0,0 +1,81 @@
|
||||
Torvalds 2.0: Patricia Torvalds on computing, college, feminism, and increasing diversity in tech
|
||||
================================================================================
|
||||

|
||||
Image by : Photo by Becky Svartström. Modified by Opensource.com. [CC BY-SA 4.0][1]
|
||||
|
||||
Patricia Torvalds isn't the Torvalds name that pops up in Linux and open source circles. Yet.
|
||||
|
||||

|
||||
|
||||
At 18, Patricia is a feminist with a growing list of tech achievements, open source industry experience, and her sights set on diving into her freshman year of college at Duke University's Pratt School of Engineering. She works for [Puppet Labs][2] in Portland, Oregon, as an intern, but soon she'll head to Durham, North Carolina, to start the fall semester of college.
|
||||
|
||||
In this exclusive interview, Patricia explains what got her interested in computer science and engineering (spoiler alert: it wasn't her father), what her high school did "right" with teaching tech, the important role feminism plays in her life, and her thoughts on the lack of diversity in technology.
|
||||
|
||||

|
||||
|
||||
### What made you interested in studying computer science and engineering? ###
|
||||
|
||||
My interest in tech really grew throughout high school. I wanted to go into biology for a while, until around my sophomore year. I had a web design internship at the Portland VA after my sophomore year. And I took an engineering class called Exploratory Ventures, which sent an ROV into the Pacific ocean late in my sophomore year, but the turning point was probably when I was named a regional winner and national runner up for the [NCWIT Aspirations in Computing][3] award halfway through my junior year.
|
||||
|
||||
The award made me feel validated in my interest, of course, but I think the most important part of it was getting to join a Facebook group for all the award winners. The girls who have won the award are absolutely incredible and so supportive of each other. I was definitely interested in computer science before I won the award, because of my work in XV and at the VA, but having these girls to talk to solidified my interest and has kept it really strong. Teaching XV—more on that later—my junior and senior year, also, made engineering and computer science really fun for me.
|
||||
|
||||
### What do you plan to study? And do you already know what you want to do after college? ###
|
||||
|
||||
I hope to major in either Mechanical or Electrical and Computer Engineering as well as Computer Science, and minor in Women's Studies. After college, I hope to work for a company that supports or creates technology for social good, or start my own company.
|
||||
|
||||
### My daughter had one high school programming class—Visual Basic. She was the only girl in her class, and she ended up getting harassed and having a miserable experience. What was your experience like? ###
|
||||
|
||||
My high school began offering computer science classes my senior year, and I took Visual Basic as well! The class wasn't bad, but I was definitely one of three or four girls in the class of 20 or so students. Other computing classes seemed to have similar gender breakdowns. However, my high school was extremely small and the teacher was supportive of inclusivity in tech, so there was no harassment that I noticed. Hopefully the classes become more diverse in future years.
|
||||
|
||||
### What did your schools do right technology-wise? And how could they have been better? ###
|
||||
|
||||
My high school gave us consistent access to computers, and teachers occasionally assigned technology-based assignments in unrelated classes—we had to create a website for a social studies class a few times—which I think is great because it exposes everyone to tech. The robotics club was also pretty active and well-funded, but fairly small; I was not a member. One very strong component of the school's technology/engineering program is actually a student-taught engineering class called Exploratory Ventures, which is a hands-on class that tackles a new engineering or computer science problem every year. I taught it for two years with a classmate of mine, and have had students come up to me and tell me they're interested in pursuing engineering or computer science as a result of the class.
|
||||
|
||||
However, my high school was not particularly focused on deliberately including young women in these programs, and it isn't very racially diverse. The computing-based classes and clubs were, by a vast majority, filled with white male students. This could definitely be improved on.
|
||||
|
||||
### Growing up, how did you use technology at home? ###
|
||||
|
||||
Honestly, when I was younger I used my computer time (my dad created a tracker, which logged us off after an hour of Internet use) to play Neopets or similar games. I guess I could have tried to mess with the tracker or played on the computer without Internet use, but I just didn't. I sometimes did little science projects with my dad, and I remember once printing "Hello world" in the terminal with him a thousand times, but mostly I just played online games with my sisters and didn't get my start in computing until high school.
|
||||
|
||||
### You were active in the Feminism Club at your high school. What did you learn from that experience? What feminist issues are most important to you now? ###
|
||||
|
||||
My friend and I co-founded Feminism Club at our high school late in our sophomore year. We did receive lots of resistance to the club at first, and while that never entirely went away, by the time we graduated feminist ideals were absolutely a part of the school's culture. The feminist work we did at my high school was generally on a more immediate scale and focused on issues like the dress code.
|
||||
|
||||
Personally, I'm very focused on intersectional feminism, which is feminism as it applies to other aspects of oppression like racism and classism. The Facebook page [Guerrilla Feminism][4] is a great example of an intersectional feminism and has done so much to educate me. I currently run the Portland branch.
|
||||
|
||||
Feminism is also important to me in terms of diversity in tech, although as an upper-class white woman with strong connections in the tech world, the problems here affect me much less than they do other people. The same goes for my involvement in intersectional feminism. Publications like [Model View Culture][5] are very inspiring to me, and I admire Shanley Kane so much for what she does.
|
||||
|
||||
### What advice would you give parents who want to teach their children how to program? ###
|
||||
|
||||
Honestly, nobody ever pushed me into computer science or engineering. Like I said, for a long time I wanted to be a geneticist. I got a summer internship doing web design for the VA the summer after my sophomore year and totally changed my mind. So I don't know if I can fully answer that question.
|
||||
|
||||
I do think genuine interest is important, though. If my dad had sat me down in front of the computer and told me to configure a webserver when I was 12, I don't think I'd be interested in computer science. Instead, my parents gave me a lot of free reign to do what I wanted, which was mostly coding terrible little HTML sites for my Neopets. Neither of my younger sisters are interested in engineering or computer science, and my parents don't care. I'm really lucky my parents have given me and my sisters the encouragement and resources to explore our interests.
|
||||
|
||||
Still, I grew up saying my future career would be "like my dad's"—even when I didn't know what he did. He has a pretty cool job. Also, one time when I was in middle school, I told him that and he got a little choked up and said I wouldn't think that in high school. So I guess that motivated me a bit.
|
||||
|
||||
### What suggestions do you have for leaders in open source communities to help them attract and maintain a more diverse mix of contributors? ###
|
||||
|
||||
I'm actually not active in particular open source communities. I feel much more comfortable discussing computing with other women; I'm a member of the [NCWIT Aspirations in Computing][6] network and it's been one of the most important aspects of my continued interest in technology, as well as the Facebook group [Ladies Storm Hackathons][7].
|
||||
|
||||
I think this applies well to attracting and maintaining a talented and diverse mix of contributors: Safe spaces are important. I have seen the misogynistic and racist comments made in some open source communities, and subsequent dismissals when people point out the issues. I think that in maintaining a professional community there have to be strong standards on what constitutes harassment or inappropriate conduct. Of course, people can—and will—have a variety of opinions on what they should be able to express in open source communities, or any community. However, if community leaders actually want to attract and maintain diverse talent, they need to create a safe space and hold community members to high standards.
|
||||
|
||||
I also think that some community leaders just don't value diversity. It's really easy to argue that tech is a meritocracy, and the reason there are so few marginalized people in tech is just that they aren't interested, and that the problem comes from earlier on in the pipeline. They argue that if someone is good enough at their job, their gender or race or sexual orientation doesn't matter. That's the easy argument. But I was raised not to make excuses for mistakes. And I think the lack of diversity is a mistake, and that we should be taking responsibility for it and actively trying to make it better.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/life/15/8/patricia-torvalds-interview
|
||||
|
||||
作者:[Rikki Endsley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/rikki-endsley
|
||||
[1]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[2]:https://puppetlabs.com/
|
||||
[3]:https://www.aspirations.org/
|
||||
[4]:https://www.facebook.com/guerrillafeminism
|
||||
[5]:https://modelviewculture.com/
|
||||
[6]:https://www.aspirations.org/
|
||||
[7]:https://www.facebook.com/groups/LadiesStormHackathons/
|
||||
@ -1,52 +0,0 @@
|
||||
Translating by XLCYun.
|
||||
A Week With GNOME As My Linux Desktop: What They Get Right & Wrong - Page 4 - GNOME Settings
|
||||
================================================================================
|
||||
### Settings ###
|
||||
|
||||
There are a few specific KDE Control modules that I am going to pick at, mostly because they are so laughable horrible compared to their gnome counter-part that its honestly pathetic.
|
||||
|
||||
First one up? Printers.
|
||||
|
||||
|
||||
|
||||
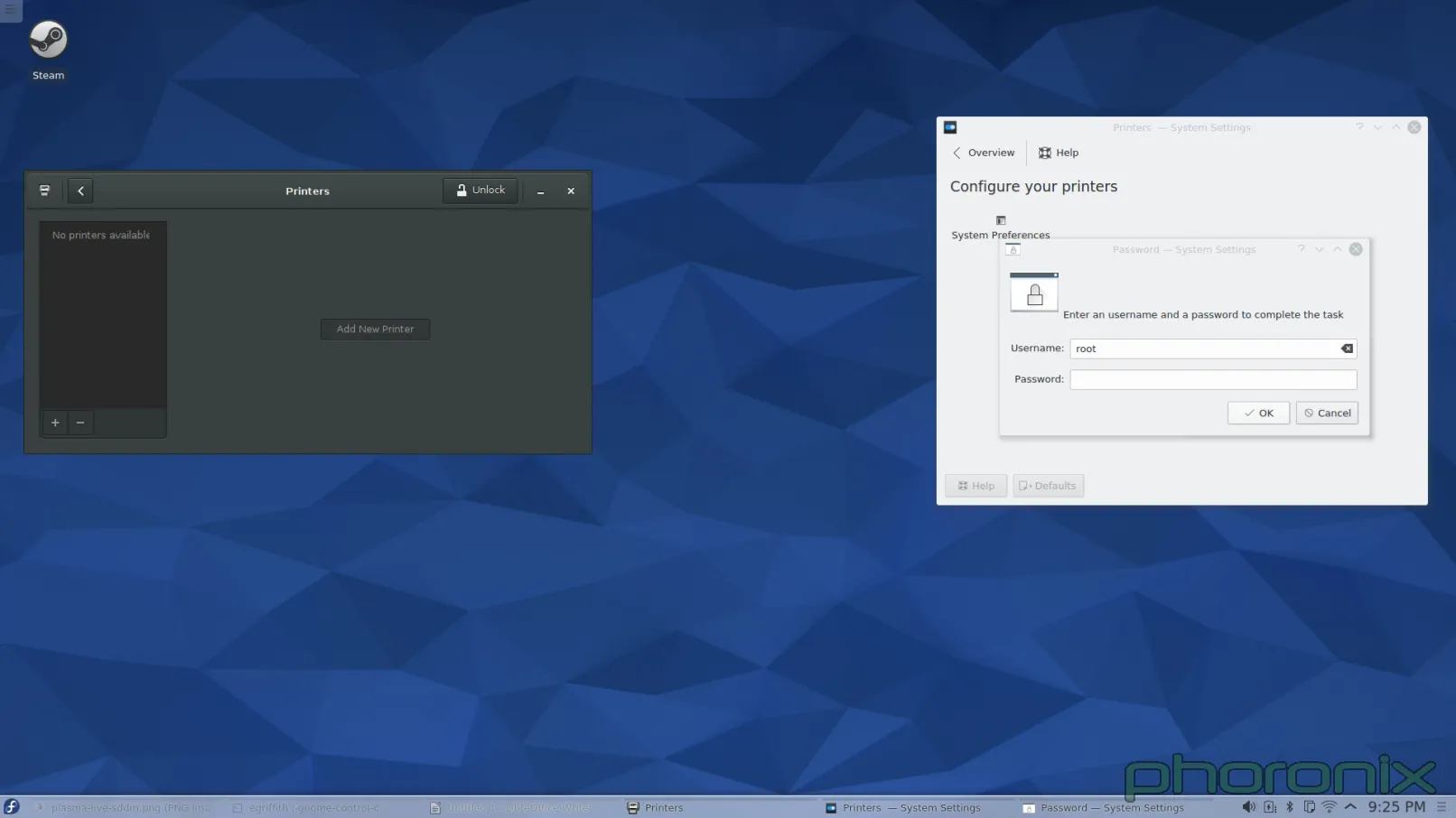
Gnome is on the left, KDE is on the right. You know what the difference is between the printer applet on the left, and the one on the right? When I opened up Gnome Control Center and hit "Printers" the applet popped up and nothing happened. When I opened up KDE System Settings and hit "Printers" I got a password prompt. Before I was even allowed to LOOK at the printers I had to give up ROOT'S password.
|
||||
|
||||
Let me just re-iterate that. In this, the days of PolicyKit and Logind, I am still being asked for Root's password for what should be a sudo operation. I didn't even SETUP root's password when I installed the system. I had to drop down to Konsole and run 'sudo passwd root' so that I could GIVE root a password so that I could go back into System Setting's printer applet and then give up root's password to even LOOK at what printers were available. Once I did that I got prompted for root's password AGAIN when I hit "Add Printer" then I got prompted for root's password AGAIN after I went through and selected a printer and driver. Three times I got asked for ROOT'S password just to add a printer to the system.
|
||||
|
||||
When I added a printer under Gnome I didn't get prompted for my SUDO password until I hit "Unlock" in the printer applet. I got asked once, then I never got asked again. KDE, I am begging you... Adopt Gnome's "Unlock" methodology. Do not prompt for a password until you really need one. Furthermore, whatever library is out there that allows for KDE applications to bypass PolicyKit / Logind (if its available) and prompt directly for root... Bin that code. If this was a multi-user system I either have to give up root's password, or be there every second of every day in order to put it in any time a user might have to update, change, or add a new printer. Both options are completely unacceptable.
|
||||
|
||||
One more thing...
|
||||
|
||||
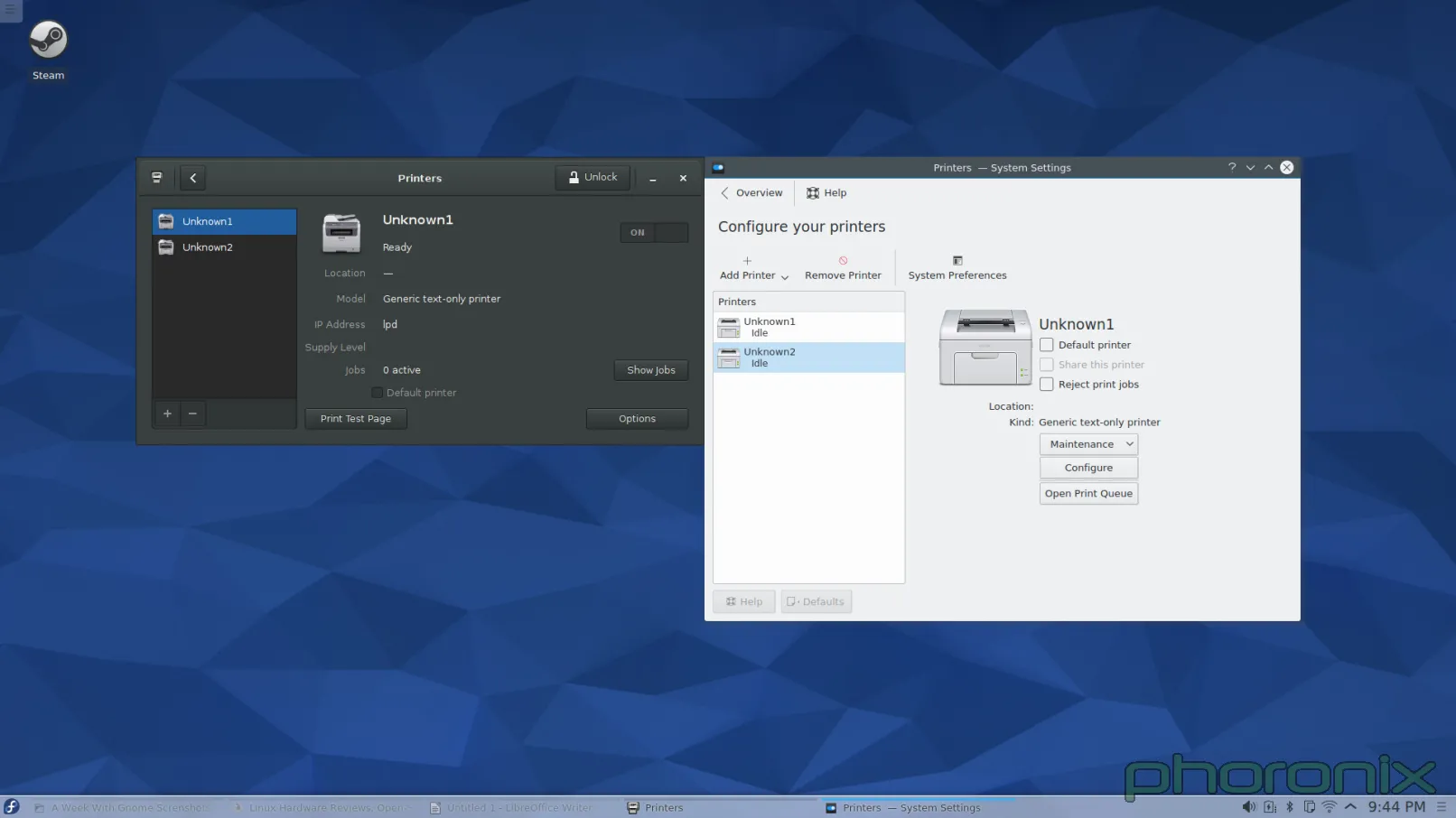
|
||||
|
||||
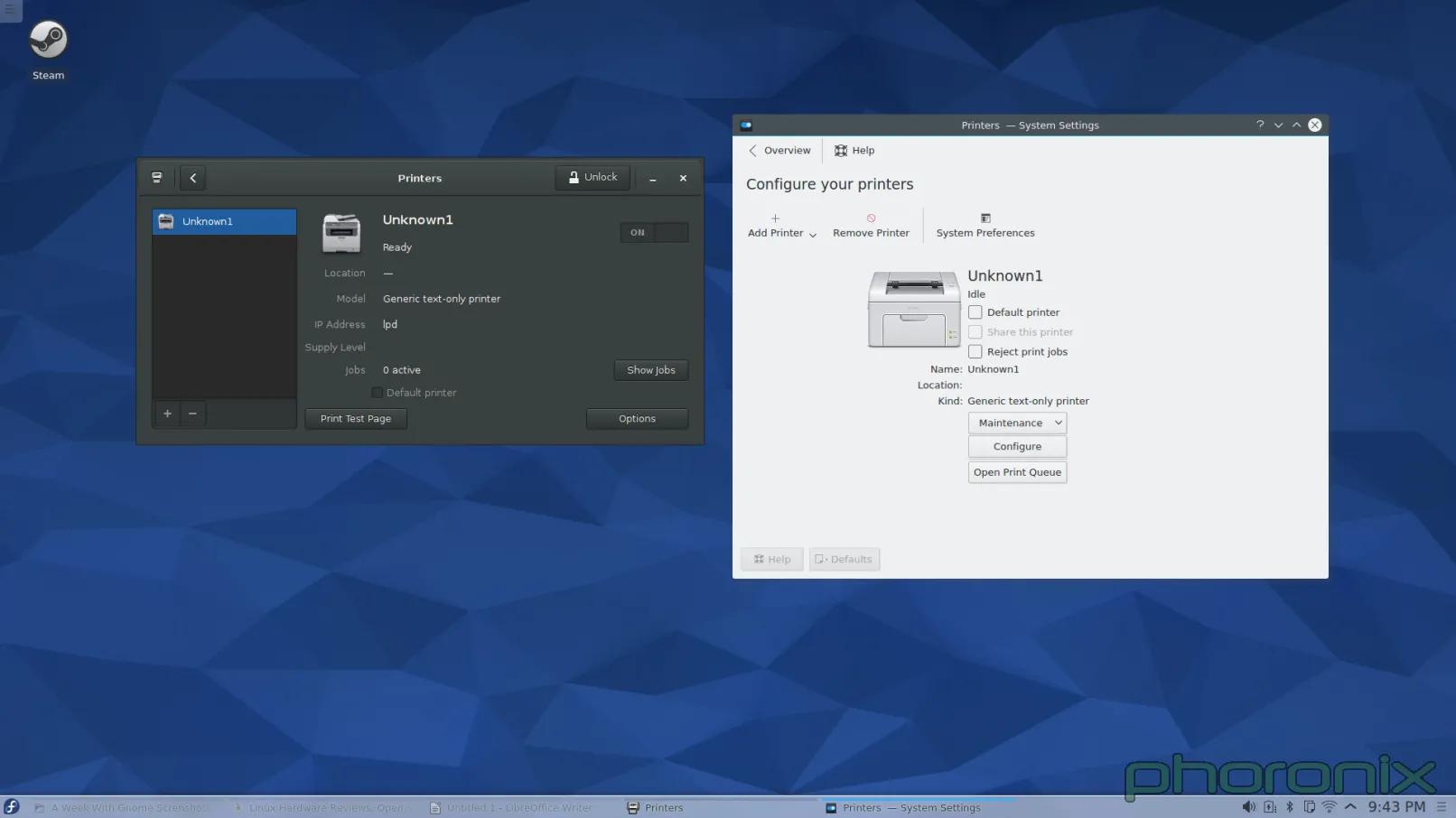
|
||||
|
||||
Question to the forums: What looks cleaner to you? I had this realization when I was writing this article: Gnome's applet makes it very clear where any additional printers are going to go, they set aside a column on the left to list them. Before I added a second printer to KDE, and it suddenly grew a left side column, I had this nightmare-image in my head of the applet just shoving another icon into the screen and them being listed out like preview images in a folder of pictures. I was pleasantly surprised to see that I was wrong but the fact that the applet just 'grew' another column that didn't exist before and drastically altered its presentation is not really 'good' either. It's a design that's confusing, shocking, and non-intuitive.
|
||||
|
||||
Enough about printers though... Next KDE System Setting that is up for my public stoning? Multimedia, Aka Phonon.
|
||||
|
||||
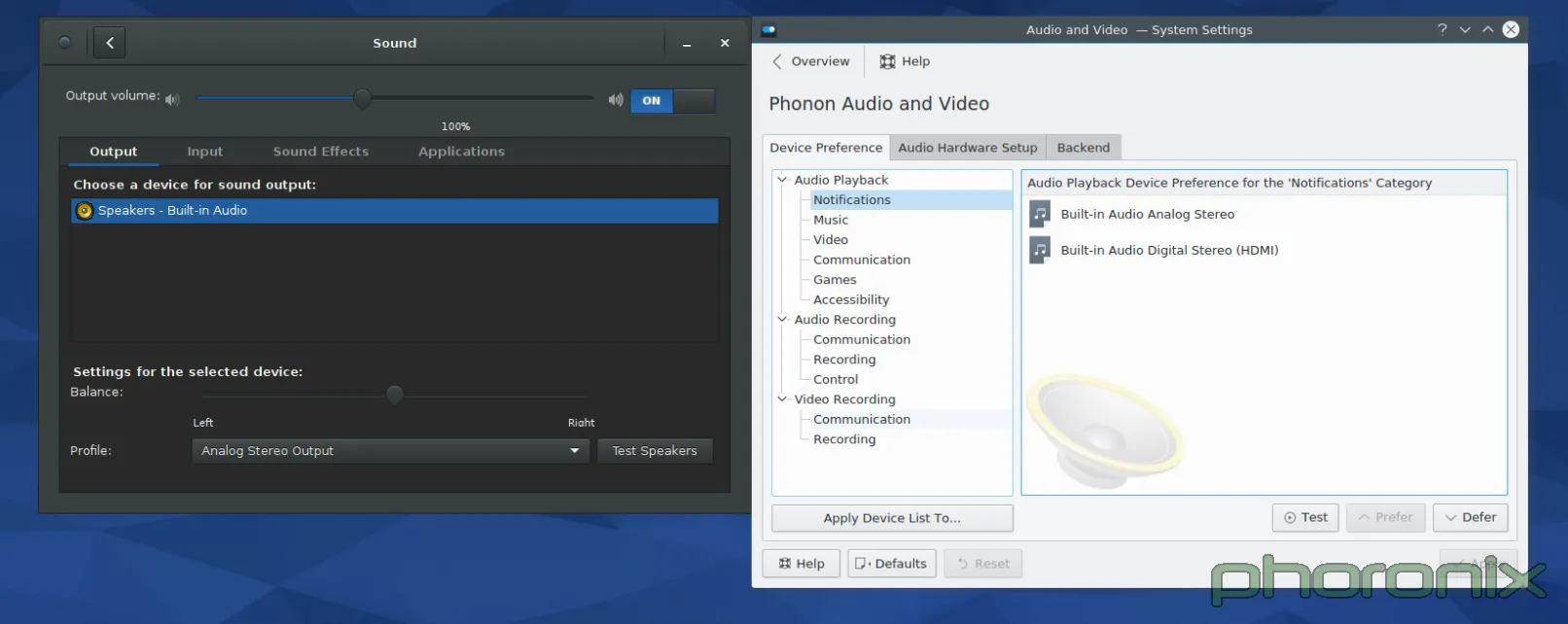
|
||||
|
||||
As always, Gnome's on the left, KDE is on the right. Let's just run through the Gnome setting first... The eyes go left to right, top to bottom, right? So let's do the same. First up: volume control slider. The blue hint against the empty bar with 100% clearly marked removes all confusion about which way is "volume up." Immediately after the slider is an easy On/Off toggle that functions a mute on/off. Points to Gnome for remembering what the volume was set to BEFORE I muted sound, and returning to that same level AFTER I press volume-up to un-mute. Kmixer, you amnesiac piece of crap, I wish I could say as much about you.
|
||||
|
||||
Moving on! Tabbed options for Output, Input and Applications? With per application volume controls within easy reach? Gnome I love you more and more with every passing second. Balance options, sound profiles, and a clearly marked "Test Speakers" option.
|
||||
|
||||
I'm not sure how this could have been implemented in a cleaner, more concise way. Yes, it's just a Gnome-ized Pavucontrol but I think that's the point. Pavucontrol got it mostly right to begin with, the Sound applet in Gnome Control Center just refines it slightly to make it even closer to perfect.
|
||||
|
||||
Phonon, you're up. And let me start by saying: What the fsck am I looking at? -I- get that I am looking at the priority list for the audio devices on the system, but the way it is presented is a bit of a nightmare. Also where are the things the user probably cares about? A priority list is a great thing to have, it SHOULD be available, but it's something the user messes with once or twice and then never touches again. It's not important, or common, enough to warrant being front and center. Where's the volume slider? Where's per application controls? The things that users will be using more frequently? Well.. those are under Kmix, a separate program, with its own settings and configuration... not under the System Settings... which kind of makes System Settings a bit of a misnomer. And in that same vein, Let's hop over to network settings.
|
||||
|
||||
|
||||
|
||||
Presented above is the Gnome Network Settings. KDE's isn't included because of the reason I'm about to hit on. If you go to KDE's System Settings and hit any of the three options under the "Network" Section you get tons of options: Bluetooth settings, default username and password for Samba shares (Seriously, "Connectivity" only has 2 options: Username and password for SMB shares. How the fsck does THAT deserve the all-inclusive title "Connectivity"?), controls for Browser Identification (which only work for Konqueror...a dead project), proxy settings, etc... Where's my wifi settings? They aren't there. Where are they? Well, they are in the network applet's private settings... not under Network Settings...
|
||||
|
||||
KDE, you're killing me. You have "System Settings" USE IT!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=4
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,40 +0,0 @@
|
||||
Translating by XLCYun.
|
||||
A Week With GNOME As My Linux Desktop: What They Get Right & Wrong - Page 5 - Conclusion
|
||||
================================================================================
|
||||
### User Experience and Closing Thoughts ###
|
||||
|
||||
When Gnome 2.x and KDE 4.x were going head to head.. I jumped between the two quite happily. Some things I loved, some things I hated, but over all they were both a pleasure to use. Then Gnome 3.x came around and all of the drama with Gnome Shell. I swore off Gnome and avoided it every chance I could. It wasn't user friendly, it was non-intuitive, it broke an establish paradigm in preparation for tablet's taking over the world... A future that, judging from the dropping sales of tablets, will never come.
|
||||
|
||||
Eight releases of Gnome 3 later and the unimaginable happened. Gnome got user friendly. Gnome got intuitive. Is it perfect? Of course not. I still hate the paradigm it tries to push, I hate how it tries to force a work flow onto me, but both of those things can be gotten used to with time and patience. Once you have managed to look past Gnome Shell's alien appearance and you start interacting with it and the other parts of Gnome (Control Center especially) you see what Gnome has definitely gotten right: the little things. The attention to detail.
|
||||
|
||||
People can adapt to new paradigms, people can adapt to new work flows-- the iPhone and iPad proved that-- but what will always bother them are the paper cuts.
|
||||
|
||||
Which brings up an important distinction between KDE and Gnome. Gnome feels like a product. It feels like a singular experience. When you use it, it feels like it is complete and that everything you need is at your fingertips. It feel's like THE Linux desktop in the same way that Windows or OS X have THE desktop experience: what you need is there and it was all written by the same guys working on the same team towards the same goal. Hell, even an application prompting for sudo access feels like an intentional part of the desktop under Gnome, much the way that it is under Windows. In KDE it's just some random-looking window popup that any application could have created. It doesn't feel like a part of the system stopping and going "Hey! Something has requested administrative rights! Do you want to let it go through?" in an official capacity.
|
||||
|
||||
KDE doesn't feel like cohesive experience. KDE doesn't feel like it has a direction its moving in, it doesn't feel like a full experience. KDE feels like its a bunch of pieces that are moving in a bunch of different directions, that just happen to have a shared toolkit beneath them. If that's what the developers are happy with, then fine, good for them, but if the developers still have the hope of offering the best experience possible then the little stuff needs to matter. The user experience and being intuitive needs to be at the forefront of every single application, there needs to be a vision of what KDE wants to offer -and- how it should look.
|
||||
|
||||
Is there anything stopping me from using Gnome Disks under KDE? Rhythmbox? Evolution? Nope. Nope. Nope. But that misses the point. Gnome and KDE both market themselves as "Desktop Environments." They are supposed to be full -environments-, that means they all the pieces come and fit together, that you use that environment's tools because they are saying "We support everything you need to have a full desktop." Honestly? Only Gnome seems to fit the bill of being complete. KDE feel's half-finished when it comes to "coming together" part, let alone offering everything you need for a "full experience". There's no counterpart to Gnome Disks-- kpartitionmanager prompts for root. No "First Time User" run through, it just now got a user manager in Kubuntu. Hell, Gnome even provides a Maps, Notes, Calendar and Clock application. Do all of these applications matter 100%? No, of course not. But the fact that Gnome has them helps to push the idea that Gnome is a full and complete experience.
|
||||
|
||||
My complaints about KDE are not impossible to fix, not by a long shot. But it requires people to care. It requires developers to take pride in their work beyond just function-- form counts for a whole hell of a lot. Don't take away the user's ability to configure things-- the lack of configuration is one of my biggest gripes with GNOME 3.x, but don't use "Well you can configure it however you want," as an excuse for not providing sane defaults. The defaults are what users are going to see, they are what the users are going to judge from the first moment they open your application. Make it a good impression.
|
||||
|
||||
I know the KDE developers know design matters, that is WHY the Visual Design Group exists, but it feels like they aren't using the VDG to their fullest. And therein lies KDE's hamartia. It's not that KDE can't be complete, it's not that it can't come together and fix the downfalls, it just that they haven't. They aimed for the bulls eye... but they missed.
|
||||
|
||||
And before anyone says it... Don't say "Patches are welcome." Because while I can happily submit patches for the individual annoyances more will just keep coming as developers keep on their marry way of doing things in non-intuitive ways. This isn't about Muon not being center-aligned. This isn't about Amarok having an ugly UI. This isn't about the volume and brightness pop-up notifiers taking up a large chunk of my screen real-estate every time I hit my hotkeys (seriously, someone shrink those things).
|
||||
|
||||
This is about a mentality of apathy, this is about developers apparently not thinking things through when they make the UI for their applications. Everything the KDE Community does works fine. Amarok plays music. Dragon Player plays videos. Kwin / Qt & kdelibs is seemingly more power efficient than Mutter / gtk (according to my battery life times. Non-scientific testing). Those things are all well and good, and important.. but the presentation matters to. Arguably, the presentation matters the most because that is what user's see and interact with.
|
||||
|
||||
To KDE application developers... Get the VDG involved. Make every single 'core' application get its design vetted and approved by the VDG, have a UI/UX expert from the VDG go through the usage patterns and usage flow of your application to make sure its intuitive. Hell, even just posting a mock up to the VDG forums and asking for feedback would probably get you some nice pointers and feedback for whatever application you're working on. You have this great resource there, now actually use them.
|
||||
|
||||
I am not trying to sound ungrateful. I love KDE, I love the work and effort that volunteers put into giving Linux users a viable desktop, and an alternative to Gnome. And it is because I care that I write this article. Because I want to see KDE excel, I want to see it go further and farther than it has before. But doing that requires work on everyone's part, and it requires that people don't hold back criticism. It requires that people are honest about their interaction with the system and where it falls apart. If we can't give direct criticism, if we can't say "This sucks!" then it will never get better.
|
||||
|
||||
Will I still use Gnome after this week? Probably not, no. Gnome still trying to force a work flow on me that I don't want to follow or abide by, I feel less productive when I'm using it because it doesn't follow my paradigm. For my friends though, when they ask me "What desktop environment should I use?" I'm probably going to recommend Gnome, especially if they are less technical users who want things to "just work." And that is probably the most damning assessment I could make in regards to the current state of KDE.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=5
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,409 +0,0 @@
|
||||
translation by strugglingyouth
|
||||
How to monitor NGINX - Part 1
|
||||
================================================================================
|
||||

|
||||
|
||||
### What is NGINX? ###
|
||||
|
||||
[NGINX][1] (pronounced “engine X”) is a popular HTTP server and reverse proxy server. As an HTTP server, NGINX serves static content very efficiently and reliably, using relatively little memory. As a [reverse proxy][2], it can be used as a single, controlled point of access for multiple back-end servers or for additional applications such as caching and load balancing. NGINX is available as a free, open-source product or in a more full-featured, commercially distributed version called NGINX Plus.
|
||||
|
||||
NGINX can also be used as a mail proxy and a generic TCP proxy, but this article does not directly address NGINX monitoring for these use cases.
|
||||
|
||||
### Key NGINX metrics ###
|
||||
|
||||
By monitoring NGINX you can catch two categories of issues: resource issues within NGINX itself, and also problems developing elsewhere in your web infrastructure. Some of the metrics most NGINX users will benefit from monitoring include **requests per second**, which provides a high-level view of combined end-user activity; **server error rate**, which indicates how often your servers are failing to process seemingly valid requests; and **request processing time**, which describes how long your servers are taking to process client requests (and which can point to slowdowns or other problems in your environment).
|
||||
|
||||
More generally, there are at least three key categories of metrics to watch:
|
||||
|
||||
- Basic activity metrics
|
||||
- Error metrics
|
||||
- Performance metrics
|
||||
|
||||
Below we’ll break down a few of the most important NGINX metrics in each category, as well as metrics for a fairly common use case that deserves special mention: using NGINX Plus for reverse proxying. We will also describe how you can monitor all of these metrics with your graphing or monitoring tools of choice.
|
||||
|
||||
This article references metric terminology [introduced in our Monitoring 101 series][3], which provides a framework for metric collection and alerting.
|
||||
|
||||
#### Basic activity metrics ####
|
||||
|
||||
Whatever your NGINX use case, you will no doubt want to monitor how many client requests your servers are receiving and how those requests are being processed.
|
||||
|
||||
NGINX Plus can report basic activity metrics exactly like open-source NGINX, but it also provides a secondary module that reports metrics slightly differently. We discuss open-source NGINX first, then the additional reporting capabilities provided by NGINX Plus.
|
||||
|
||||
**NGINX**
|
||||
|
||||
The diagram below shows the lifecycle of a client connection and how the open-source version of NGINX collects metrics during a connection.
|
||||
|
||||

|
||||
|
||||
Accepts, handled, and requests are ever-increasing counters. Active, waiting, reading, and writing grow and shrink with request volume.
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts</td>
|
||||
<td style="text-align: left;">Count of client connections attempted by NGINX</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">handled</td>
|
||||
<td style="text-align: left;">Count of successful client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped (calculated)</td>
|
||||
<td style="text-align: left;">Count of dropped connections (accepts – handled)</td>
|
||||
<td style="text-align: left;">Work: Errors*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests</td>
|
||||
<td style="text-align: left;">Count of client requests</td>
|
||||
<td style="text-align: left;">Work: Throughput</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td colspan="3" style="text-align: left;">*<em>Strictly speaking, dropped connections is <a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics">a metric of resource saturation</a>, but since saturation causes NGINX to stop servicing some work (rather than queuing it up for later), “dropped” is best thought of as <a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics">a work metric</a>.</em></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
The **accepts** counter is incremented when an NGINX worker picks up a request for a connection from the OS, whereas **handled** is incremented when the worker actually gets a connection for the request (by establishing a new connection or reusing an open one). These two counts are usually the same—any divergence indicates that connections are being **dropped**, often because a resource limit, such as NGINX’s [worker_connections][4] limit, has been reached.
|
||||
|
||||
Once NGINX successfully handles a connection, the connection moves to an **active** state, where it remains as client requests are processed:
|
||||
|
||||
Active state
|
||||
|
||||
- **Waiting**: An active connection may also be in a Waiting substate if there is no active request at the moment. New connections can bypass this state and move directly to Reading, most commonly when using “accept filter” or “deferred accept”, in which case NGINX does not receive notice of work until it has enough data to begin working on the response. Connections will also be in the Waiting state after sending a response if the connection is set to keep-alive.
|
||||
- **Reading**: When a request is received, the connection moves out of the waiting state, and the request itself is counted as Reading. In this state NGINX is reading a client request header. Request headers are lightweight, so this is usually a fast operation.
|
||||
- **Writing**: After the request is read, it is counted as Writing, and remains in that state until a response is returned to the client. That means that the request is Writing while NGINX is waiting for results from upstream systems (systems “behind” NGINX), and while NGINX is operating on the response. Requests will often spend the majority of their time in the Writing state.
|
||||
|
||||
Often a connection will only support one request at a time. In this case, the number of Active connections == Waiting connections + Reading requests + Writing requests. However, the newer SPDY and HTTP/2 protocols allow multiple concurrent requests/responses to be multiplexed over a connection, so Active may be less than the sum of Waiting, Reading, and Writing. (As of this writing, NGINX does not support HTTP/2, but expects to add support during 2015.)
|
||||
|
||||
**NGINX Plus**
|
||||
|
||||
As mentioned above, all of open-source NGINX’s metrics are available within NGINX Plus, but Plus can also report additional metrics. The section covers the metrics that are only available from NGINX Plus.
|
||||
|
||||

|
||||
|
||||
Accepted, dropped, and total are ever-increasing counters. Active, idle, and current track the current number of connections or requests in each of those states, so they grow and shrink with request volume.
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepted</td>
|
||||
<td style="text-align: left;">Count of client connections attempted by NGINX</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped</td>
|
||||
<td style="text-align: left;">Count of dropped connections</td>
|
||||
<td style="text-align: left;">Work: Errors*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">idle</td>
|
||||
<td style="text-align: left;">Client connections with zero current requests</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">total</td>
|
||||
<td style="text-align: left;">Count of client requests</td>
|
||||
<td style="text-align: left;">Work: Throughput</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td colspan="3" style="text-align: left;">*<em>Strictly speaking, dropped connections is a metric of resource saturation, but since saturation causes NGINX to stop servicing some work (rather than queuing it up for later), “dropped” is best thought of as a work metric.</em></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
The **accepted** counter is incremented when an NGINX Plus worker picks up a request for a connection from the OS. If the worker fails to get a connection for the request (by establishing a new connection or reusing an open one), then the connection is dropped and **dropped** is incremented. Ordinarily connections are dropped because a resource limit, such as NGINX Plus’s [worker_connections][4] limit, has been reached.
|
||||
|
||||
**Active** and **idle** are the same as “active” and “waiting” states in open-source NGINX as described [above][5], with one key exception: in open-source NGINX, “waiting” falls under the “active” umbrella, whereas in NGINX Plus “idle” connections are excluded from the “active” count. **Current** is the same as the combined “reading + writing” states in open-source NGINX.
|
||||
|
||||
**Total** is a cumulative count of client requests. Note that a single client connection can involve multiple requests, so this number may be significantly larger than the cumulative number of connections. In fact, (total / accepted) yields the average number of requests per connection.
|
||||
|
||||
**Metric differences between Open-Source and Plus**
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;">NGINX (open-source)</th>
|
||||
<th style="text-align: left;">NGINX Plus</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts</td>
|
||||
<td style="text-align: left;">accepted</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped must be calculated</td>
|
||||
<td style="text-align: left;">dropped is reported directly</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">reading + writing</td>
|
||||
<td style="text-align: left;">current</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">waiting</td>
|
||||
<td style="text-align: left;">idle</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active (includes “waiting” states)</td>
|
||||
<td style="text-align: left;">active (excludes “idle” states)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests</td>
|
||||
<td style="text-align: left;">total</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
**Metric to alert on: Dropped connections**
|
||||
|
||||
The number of connections that have been dropped is equal to the difference between accepts and handled (NGINX) or is exposed directly as a standard metric (NGINX Plus). Under normal circumstances, dropped connections should be zero. If your rate of dropped connections per unit time starts to rise, look for possible resource saturation.
|
||||
|
||||

|
||||
|
||||
**Metric to alert on: Requests per second**
|
||||
|
||||
Sampling your request data (**requests** in open-source, or **total** in Plus) with a fixed time interval provides you with the number of requests you’re receiving per unit of time—often minutes or seconds. Monitoring this metric can alert you to spikes in incoming web traffic, whether legitimate or nefarious, or sudden drops, which are usually indicative of problems. A drastic change in requests per second can alert you to problems brewing somewhere in your environment, even if it cannot tell you exactly where those problems lie. Note that all requests are counted the same, regardless of their URLs.
|
||||
|
||||

|
||||
|
||||
**Collecting activity metrics**
|
||||
|
||||
Open-source NGINX exposes these basic server metrics on a simple status page. Because the status information is displayed in a standardized form, virtually any graphing or monitoring tool can be configured to parse the relevant data for analysis, visualization, or alerting. NGINX Plus provides a JSON feed with much richer data. Read the companion post on [NGINX metrics collection][6] for instructions on enabling metrics collection.
|
||||
|
||||
#### Error metrics ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">4xx codes</td>
|
||||
<td style="text-align: left;">Count of client errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX logs, NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes</td>
|
||||
<td style="text-align: left;">Count of server errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX logs, NGINX Plus</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
NGINX error metrics tell you how often your servers are returning errors instead of producing useful work. Client errors are represented by 4xx status codes, server errors with 5xx status codes.
|
||||
|
||||
**Metric to alert on: Server error rate**
|
||||
|
||||
Your server error rate is equal to the number of 5xx errors divided by the total number of [status codes][7] (1xx, 2xx, 3xx, 4xx, 5xx), per unit of time (often one to five minutes). If your error rate starts to climb over time, investigation may be in order. If it spikes suddenly, urgent action may be required, as clients are likely to report errors to the end user.
|
||||
|
||||

|
||||
|
||||
A note on client errors: while it is tempting to monitor 4xx, there is limited information you can derive from that metric since it measures client behavior without offering any insight into particular URLs. In other words, a change in 4xx could be noise, e.g. web scanners blindly looking for vulnerabilities.
|
||||
|
||||
**Collecting error metrics**
|
||||
|
||||
Although open-source NGINX does not make error rates immediately available for monitoring, there are at least two ways to capture that information:
|
||||
|
||||
- Use the expanded status module available with commercially supported NGINX Plus
|
||||
- Configure NGINX’s log module to write response codes in access logs
|
||||
|
||||
Read the companion post on NGINX metrics collection for detailed instructions on both approaches.
|
||||
|
||||
#### Performance metrics ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">request time</td>
|
||||
<td style="text-align: left;">Time to process each request, in seconds</td>
|
||||
<td style="text-align: left;">Work: Performance</td>
|
||||
<td style="text-align: left;">NGINX logs</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
**Metric to alert on: Request processing time**
|
||||
|
||||
The request time metric logged by NGINX records the processing time for each request, from the reading of the first client bytes to fulfilling the request. Long response times can point to problems upstream.
|
||||
|
||||
**Collecting processing time metrics**
|
||||
|
||||
NGINX and NGINX Plus users can capture data on processing time by adding the $request_time variable to the access log format. More details on configuring logs for monitoring are available in our companion post on [NGINX metrics collection][8].
|
||||
|
||||
#### Reverse proxy metrics ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">Active connections by upstream server</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes by upstream server</td>
|
||||
<td style="text-align: left;">Server errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">Available servers per upstream group</td>
|
||||
<td style="text-align: left;">Servers passing health checks</td>
|
||||
<td style="text-align: left;">Resource: Availability</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
One of the most common ways to use NGINX is as a [reverse proxy][9]. The commercially supported NGINX Plus exposes a large number of metrics about backend (or “upstream”) servers, which are relevant to a reverse proxy setup. This section highlights a few of the key upstream metrics that are available to users of NGINX Plus.
|
||||
|
||||
NGINX Plus segments its upstream metrics first by group, and then by individual server. So if, for example, your reverse proxy is distributing requests to five upstream web servers, you can see at a glance whether any of those individual servers is overburdened, and also whether you have enough healthy servers in the upstream group to ensure good response times.
|
||||
|
||||
**Activity metrics**
|
||||
|
||||
The number of **active connections per upstream server** can help you verify that your reverse proxy is properly distributing work across your server group. If you are using NGINX as a load balancer, significant deviations in the number of connections handled by any one server can indicate that the server is struggling to process requests in a timely manner or that the load-balancing method (e.g., [round-robin or IP hashing][10]) you have configured is not optimal for your traffic patterns
|
||||
|
||||
**Error metrics**
|
||||
|
||||
Recall from the error metric section above that 5xx (server error) codes are a valuable metric to monitor, particularly as a share of total response codes. NGINX Plus allows you to easily extract the number of **5xx codes per upstream server**, as well as the total number of responses, to determine that particular server’s error rate.
|
||||
|
||||
**Availability metrics**
|
||||
|
||||
For another view of the health of your web servers, NGINX also makes it simple to monitor the health of your upstream groups via the total number of **servers currently available within each group**. In a large reverse proxy setup, you may not care very much about the current state of any one server, just as long as your pool of available servers is capable of handling the load. But monitoring the total number of servers that are up within each upstream group can provide a very high-level view of the aggregate health of your web servers.
|
||||
|
||||
**Collecting upstream metrics**
|
||||
|
||||
NGINX Plus upstream metrics are exposed on the internal NGINX Plus monitoring dashboard, and are also available via a JSON interface that can serve up metrics into virtually any external monitoring platform. See examples in our companion post on [collecting NGINX metrics][11].
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this post we’ve touched on some of the most useful metrics you can monitor to keep tabs on your NGINX servers. If you are just getting started with NGINX, monitoring most or all of the metrics in the list below will provide good visibility into the health and activity levels of your web infrastructure:
|
||||
|
||||
- [Dropped connections][12]
|
||||
- [Requests per second][13]
|
||||
- [Server error rate][14]
|
||||
- [Request processing time][15]
|
||||
|
||||
Eventually you will recognize additional, more specialized metrics that are particularly relevant to your own infrastructure and use cases. Of course, what you monitor will depend on the tools you have and the metrics available to you. See the companion post for [step-by-step instructions on metric collection][16], whether you use NGINX or NGINX Plus.
|
||||
|
||||
At Datadog, we have built integrations with both NGINX and NGINX Plus so that you can begin collecting and monitoring metrics from all your web servers with a minimum of setup. Learn how to monitor NGINX with Datadog [in this post][17], and get started right away with [a free trial of Datadog][18].
|
||||
|
||||
### Acknowledgments ###
|
||||
|
||||
Many thanks to the NGINX team for reviewing this article prior to publication and providing important feedback and clarifications.
|
||||
|
||||
----------
|
||||
|
||||
Source Markdown for this post is available [on GitHub][19]. Questions, corrections, additions, etc.? Please [let us know][20].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
|
||||
作者:K Young
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://nginx.org/en/
|
||||
[2]:http://nginx.com/resources/glossary/reverse-proxy-server/
|
||||
[3]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/
|
||||
[4]:http://nginx.org/en/docs/ngx_core_module.html#worker_connections
|
||||
[5]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#active-state
|
||||
[6]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[7]:http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
|
||||
[8]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[9]:https://en.wikipedia.org/wiki/Reverse_proxy
|
||||
[10]:http://nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[11]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[12]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#dropped-connections
|
||||
[13]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#requests-per-second
|
||||
[14]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#server-error-rate
|
||||
[15]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#request-processing-time
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[18]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#sign-up
|
||||
[19]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx.md
|
||||
[20]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -1,3 +1,6 @@
|
||||
|
||||
Translating by dingdongnigetou
|
||||
|
||||
Howto Configure Nginx as Rreverse Proxy / Load Balancer with Weave and Docker
|
||||
================================================================================
|
||||
Hi everyone today we'll learnHowto configure Nginx as Rreverse Proxy / Load balancer with Weave and Docker Weave creates a virtual network that connects Docker containers with each other, deploys across multiple hosts and enables their automatic discovery. It allows us to focus on developing our application, rather than our infrastructure. It provides such an awesome environment that the applications uses the network as if its containers were all plugged into the same network without need to configure ports, mappings, link, etc. The services of the application containers on the network can be easily accessible to the external world with no matter where its running. Here, in this tutorial we'll be using weave to quickly and easily deploy nginx web server as a load balancer for a simple php application running in docker containers on multiple nodes in Amazon Web Services. Here, we will be introduced to WeaveDNS, which provides a simple way for containers to find each other using hostname with no changes in codes and tells other containers to connect to those names.
|
||||
@ -123,4 +126,4 @@ via: http://linoxide.com/linux-how-to/nginx-load-balancer-weave-docker/
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://console.aws.amazon.com/
|
||||
[1]:http://console.aws.amazon.com/
|
||||
|
||||
@ -1,65 +0,0 @@
|
||||
translation by strugglingyouth
|
||||
Handy commands for profiling your Unix file systems
|
||||
================================================================================
|
||||

|
||||
Credit: Sandra H-S
|
||||
|
||||
One of the problems that seems to plague nearly all file systems -- Unix and others -- is the continuous buildup of files. Almost no one takes the time to clean out files that they no longer use and file systems, as a result, become so cluttered with material of little or questionable value that keeping them them running well, adequately backed up, and easy to manage is a constant challenge.
|
||||
|
||||
One way that I have seen to help encourage the owners of all that data detritus to address the problem is to create a summary report or "profile" of a file collection that reports on such things as the number of files; the oldest, newest, and largest of those files; and a count of who owns those files. If someone realizes that a collection of half a million files contains none less than five years old, they might go ahead and remove them -- or, at least, archive and compress them. The basic problem is that huge collections of files are overwhelming and most people are afraid that they might accidentally delete something important. Having a way to characterize a file collection can help demonstrate the nature of the content and encourage those digital packrats to clean out their nests.
|
||||
|
||||
When I prepare a file system summary report on Unix, a handful of Unix commands easily provide some very useful statistics. To count the files in a directory, you can use a find command like this.
|
||||
|
||||
$ find . -type f | wc -l
|
||||
187534
|
||||
|
||||
Finding the oldest and newest files is a bit more complicated, but still quite easy. In the commands below, we're using the find command again to find files, displaying the data with a year-month-day format that makes it possible to sort by file age, and then displaying the top -- thus the oldest -- file in that list.
|
||||
|
||||
In the second command, we do the same, but print the last line -- thus the newest -- file.
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | sort | head -n 1
|
||||
2006-02-03+02:40:33 ./skel/.xemacs/init.el
|
||||
$ find -type f -printf '%T+ %p\n' | sort | tail -n 1
|
||||
2015-07-19+14:20:16 ./.bash_history
|
||||
|
||||
The %T (file date and time) and %p (file name with path) parameters with the printf command allow this to work.
|
||||
|
||||
If we're looking at home directories, we're undoubtedly going to find that history files are the newest files and that isn't likely to be a very interesting bit of information. You can omit those files by "un-grepping" them or you can omit all files that start with dots as shown below.
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | grep -v "\./\." | sort | tail -n 1
|
||||
2015-07-19+13:02:12 ./isPrime
|
||||
|
||||
Finding the largest file involves using the %s (size) parameter and we include the file name (%f) since that's what we want the report to show.
|
||||
|
||||
$ find -type f -printf '%s %f \n' | sort -n | uniq | tail -1
|
||||
20183040 project.org.tar
|
||||
|
||||
To summarize file ownership, use the %u (owner)
|
||||
|
||||
$ find -type f -printf '%u \n' | grep -v "\./\." | sort | uniq -c
|
||||
180034 shs
|
||||
7500 jdoe
|
||||
|
||||
If your file system also records the last access date, it can be very useful to show that files haven't been accessed in, say, more than two years. This would give your reviewers an important insight into the value of those files. The last access parameter (%a) could be used like this:
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | head -n 1
|
||||
Fri Dec 15 03:00:30 2006+ ./statreport
|
||||
|
||||
Of course, if the most recently accessed file is also in the deep dark past, that's likely to get even more of a reaction.
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | tail -n 1
|
||||
Wed Nov 26 03:00:27 2007+ ./my-notes
|
||||
|
||||
Getting a sense of what's in a file system or large directory by creating a summary report showing the file date ranges, the largest files, the file owners, and the oldest and new access times can help to demonstrate how current and how important a file collection is and help its owners decide if it's time to clean up.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2949898/linux/profiling-your-file-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Sandra-Henry_Stocker/
|
||||
@ -1,3 +1,4 @@
|
||||
wyangsun translating
|
||||
Managing Linux Logs
|
||||
================================================================================
|
||||
A key best practice for logging is to centralize or aggregate your logs in one place, especially if you have multiple servers or tiers in your architecture. We’ll tell you why this is a good idea and give tips on how to do it easily.
|
||||
@ -415,4 +416,4 @@ via: http://www.loggly.com/ultimate-guide/logging/managing-linux-logs/
|
||||
[19]:http://www.infoworld.com/article/2614204/data-center/puppet-or-chef--the-configuration-management-dilemma.html
|
||||
[20]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[21]:https://github.com/progrium/logspout
|
||||
[22]:https://www.loggly.com/docs/sending-logs-unixlinux-system-setup/
|
||||
[22]:https://www.loggly.com/docs/sending-logs-unixlinux-system-setup/
|
||||
|
||||
@ -0,0 +1,429 @@
|
||||
Installation Guide for Puppet on Ubuntu 15.04
|
||||
================================================================================
|
||||
Hi everyone, today in this article we'll learn how to install puppet to manage your server infrastructure running ubuntu 15.04. Puppet is an open source software configuration management tool which is developed and maintained by Puppet Labs that allows us to automate the provisioning, configuration and management of a server infrastructure. Whether we're managing just a few servers or thousands of physical and virtual machines to orchestration and reporting, puppet automates tasks that system administrators often do manually which frees up time and mental space so sysadmins can work on improving other aspects of your overall setup. It ensures consistency, reliability and stability of the automated jobs processed. It facilitates closer collaboration between sysadmins and developers, enabling more efficient delivery of cleaner, better-designed code. Puppet is available in two solutions configuration management and data center automation. They are **puppet open source and puppet enterprise**. Puppet open source is a flexible, customizable solution available under the Apache 2.0 license, designed to help system administrators automate the many repetitive tasks they regularly perform. Whereas puppet enterprise edition is a proven commercial solution for diverse enterprise IT environments which lets us get all the benefits of open source puppet, plus puppet apps, commercial-only enhancements, supported modules and integrations, and the assurance of a fully supported platform. Puppet uses SSL certificates to authenticate communication between master and agent nodes.
|
||||
|
||||
In this tutorial, we will cover how to install open source puppet in an agent and master setup running ubuntu 15.04 linux distribution. Here, Puppet master is a server from where all the configurations will be controlled and managed and all our remaining servers will be puppet agent nodes, which is configured according to the configuration of puppet master server. Here are some easy steps to install and configure puppet to manage our server infrastructure running Ubuntu 15.04.
|
||||
|
||||
### 1. Setting up Hosts ###
|
||||
|
||||
In this tutorial, we'll use two machines, one as puppet master server and another as puppet node agent both running ubuntu 15.04 "Vivid Vervet" in both the machines. Here is the infrastructure of the server that we're gonna use for this tutorial.
|
||||
|
||||
puppet master server with IP 44.55.88.6 and hostname : puppetmaster
|
||||
puppet node agent with IP 45.55.86.39 and hostname : puppetnode
|
||||
|
||||
Now we'll add the entry of the machines to /etc/hosts on both machines node agent and master server.
|
||||
|
||||
# nano /etc/hosts
|
||||
|
||||
45.55.88.6 puppetmaster.example.com puppetmaster
|
||||
45.55.86.39 puppetnode.example.com puppetnode
|
||||
|
||||
Please note that the Puppet Master server must be reachable on port 8140. So, we'll need to open port 8140 in it.
|
||||
|
||||
### 2. Updating Time with NTP ###
|
||||
|
||||
As puppet nodes needs to maintain accurate system time to avoid problems when it issues agent certificates. Certificates can appear to be expired if there is time difference, the time of the both the master and the node agent must be synced with each other. To sync the time, we'll update the time with NTP. To do so, here's the command below that we need to run on both master and node agent.
|
||||
|
||||
# ntpdate pool.ntp.org
|
||||
|
||||
17 Jun 00:17:08 ntpdate[882]: adjust time server 66.175.209.17 offset -0.001938 sec
|
||||
|
||||
Now, we'll update our local repository index and install ntp as follows.
|
||||
|
||||
# apt-get update && sudo apt-get -y install ntp ; service ntp restart
|
||||
|
||||
### 3. Puppet Master Package Installation ###
|
||||
|
||||
There are many ways to install open source puppet. In this tutorial, we'll download and install a debian binary package named as **puppetlabs-release** packaged by the Puppet Labs which will add the source of the **puppetmaster-passenger** package. The puppetmaster-passenger includes the puppet master with apache web server. So, we'll now download the Puppet Labs package.
|
||||
|
||||
# cd /tmp/
|
||||
# wget https://apt.puppetlabs.com/puppetlabs-release-trusty.deb
|
||||
|
||||
--2015-06-17 00:19:26-- https://apt.puppetlabs.com/puppetlabs-release-trusty.deb
|
||||
Resolving apt.puppetlabs.com (apt.puppetlabs.com)... 192.155.89.90, 2600:3c03::f03c:91ff:fedb:6b1d
|
||||
Connecting to apt.puppetlabs.com (apt.puppetlabs.com)|192.155.89.90|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 7384 (7.2K) [application/x-debian-package]
|
||||
Saving to: ‘puppetlabs-release-trusty.deb’
|
||||
|
||||
puppetlabs-release-tr 100%[===========================>] 7.21K --.-KB/s in 0.06s
|
||||
|
||||
2015-06-17 00:19:26 (130 KB/s) - ‘puppetlabs-release-trusty.deb’ saved [7384/7384]
|
||||
|
||||
After the download has been completed, we'll wanna install the package.
|
||||
|
||||
# dpkg -i puppetlabs-release-trusty.deb
|
||||
|
||||
Selecting previously unselected package puppetlabs-release.
|
||||
(Reading database ... 85899 files and directories currently installed.)
|
||||
Preparing to unpack puppetlabs-release-trusty.deb ...
|
||||
Unpacking puppetlabs-release (1.0-11) ...
|
||||
Setting up puppetlabs-release (1.0-11) ...
|
||||
|
||||
Then, we'll update the local respository index with the server using apt package manager.
|
||||
|
||||
# apt-get update
|
||||
|
||||
Then, we'll install the puppetmaster-passenger package by running the below command.
|
||||
|
||||
# apt-get install puppetmaster-passenger
|
||||
|
||||
**Note**: While installing we may get an error **Warning: Setting templatedir is deprecated. See http://links.puppetlabs.com/env-settings-deprecations (at /usr/lib/ruby/vendor_ruby/puppet/settings.rb:1139:in `issue_deprecation_warning')** but we no need to worry, we'll just simply ignore this as it says that the templatedir is deprecated so, we'll simply disbale that setting in the configuration. :)
|
||||
|
||||
To check whether puppetmaster has been installed successfully in our Master server not not, we'll gonna try to check its version.
|
||||
|
||||
# puppet --version
|
||||
|
||||
3.8.1
|
||||
|
||||
We have successfully installed puppet master package in our puppet master box. As we are using passenger with apache, the puppet master process is controlled by apache server, that means it runs when apache is running.
|
||||
|
||||
Before continuing, we'll need to stop the Puppet master by stopping the apache2 service.
|
||||
|
||||
# systemctl stop apache2
|
||||
|
||||
### 4. Master version lock with Apt ###
|
||||
|
||||
As We have puppet version as 3.8.1, we need to lock the puppet version update as this will mess up the configurations while updating the puppet. So, we'll use apt's locking feature for that. To do so, we'll need to create a new file **/etc/apt/preferences.d/00-puppet.pref** using our favorite text editor.
|
||||
|
||||
# nano /etc/apt/preferences.d/00-puppet.pref
|
||||
|
||||
Then, we'll gonna add the entries in the newly created file as:
|
||||
|
||||
# /etc/apt/preferences.d/00-puppet.pref
|
||||
Package: puppet puppet-common puppetmaster-passenger
|
||||
Pin: version 3.8*
|
||||
Pin-Priority: 501
|
||||
|
||||
Now, it will not update the puppet while running updates in the system.
|
||||
|
||||
### 5. Configuring Puppet Config ###
|
||||
|
||||
Puppet master acts as a certificate authority and must generate its own certificates which is used to sign agent certificate requests. First of all, we'll need to remove any existing SSL certificates that were created during the installation of package. The default location of puppet's SSL certificates is /var/lib/puppet/ssl. So, we'll remove the entire ssl directory using rm command.
|
||||
|
||||
# rm -rf /var/lib/puppet/ssl
|
||||
|
||||
Then, we'll configure the certificate. While creating the puppet master's certificate, we need to include every DNS name at which agent nodes can contact the master at. So, we'll edit the master's puppet.conf using our favorite text editor.
|
||||
|
||||
# nano /etc/puppet/puppet.conf
|
||||
|
||||
The output seems as shown below.
|
||||
|
||||
[main]
|
||||
logdir=/var/log/puppet
|
||||
vardir=/var/lib/puppet
|
||||
ssldir=/var/lib/puppet/ssl
|
||||
rundir=/var/run/puppet
|
||||
factpath=$vardir/lib/facter
|
||||
templatedir=$confdir/templates
|
||||
|
||||
[master]
|
||||
# These are needed when the puppetmaster is run by passenger
|
||||
# and can safely be removed if webrick is used.
|
||||
ssl_client_header = SSL_CLIENT_S_DN
|
||||
ssl_client_verify_header = SSL_CLIENT_VERIFY
|
||||
|
||||
Here, we'll need to comment the templatedir line to disable the setting as it has been already depreciated. After that, we'll add the following line at the end of the file under [main].
|
||||
|
||||
server = puppetmaster
|
||||
environment = production
|
||||
runinterval = 1h
|
||||
strict_variables = true
|
||||
certname = puppetmaster
|
||||
dns_alt_names = puppetmaster, puppetmaster.example.com
|
||||
|
||||
This configuration file has many options which might be useful in order to setup own configuration. A full description of the file is available at Puppet Labs [Main Config File (puppet.conf)][1].
|
||||
|
||||
After editing the file, we'll wanna save that and exit.
|
||||
|
||||
Now, we'll gonna generate a new CA certificates by running the following command.
|
||||
|
||||
# puppet master --verbose --no-daemonize
|
||||
|
||||
Info: Creating a new SSL key for ca
|
||||
Info: Creating a new SSL certificate request for ca
|
||||
Info: Certificate Request fingerprint (SHA256): F6:2F:69:89:BA:A5:5E:FF:7F:94:15:6B:A7:C4:20:CE:23:C7:E3:C9:63:53:E0:F2:76:D7:2E:E0:BF:BD:A6:78
|
||||
...
|
||||
Notice: puppetmaster has a waiting certificate request
|
||||
Notice: Signed certificate request for puppetmaster
|
||||
Notice: Removing file Puppet::SSL::CertificateRequest puppetmaster at '/var/lib/puppet/ssl/ca/requests/puppetmaster.pem'
|
||||
Notice: Removing file Puppet::SSL::CertificateRequest puppetmaster at '/var/lib/puppet/ssl/certificate_requests/puppetmaster.pem'
|
||||
Notice: Starting Puppet master version 3.8.1
|
||||
^CNotice: Caught INT; storing stop
|
||||
Notice: Processing stop
|
||||
|
||||
Now, the certificate is being generated. Once we see **Notice: Starting Puppet master version 3.8.1**, the certificate setup is complete. Then we'll press CTRL-C to return to the shell.
|
||||
|
||||
If we wanna look at the cert information of the certificate that was just created, we can get the list by running in the following command.
|
||||
|
||||
# puppet cert list -all
|
||||
|
||||
+ "puppetmaster" (SHA256) 33:28:97:86:A1:C3:2F:73:10:D1:FB:42:DA:D5:42:69:71:84:F0:E2:8A:01:B9:58:38:90:E4:7D:B7:25:23:EC (alt names: "DNS:puppetmaster", "DNS:puppetmaster.example.com")
|
||||
|
||||
### 6. Creating a Puppet Manifest ###
|
||||
|
||||
The default location of the main manifest is /etc/puppet/manifests/site.pp. The main manifest file contains the definition of configuration that is used to execute in the puppet node agent. Now, we'll create the manifest file by running the following command.
|
||||
|
||||
# nano /etc/puppet/manifests/site.pp
|
||||
|
||||
Then, we'll add the following lines of configuration in the file that we just opened.
|
||||
|
||||
# execute 'apt-get update'
|
||||
exec { 'apt-update': # exec resource named 'apt-update'
|
||||
command => '/usr/bin/apt-get update' # command this resource will run
|
||||
}
|
||||
|
||||
# install apache2 package
|
||||
package { 'apache2':
|
||||
require => Exec['apt-update'], # require 'apt-update' before installing
|
||||
ensure => installed,
|
||||
}
|
||||
|
||||
# ensure apache2 service is running
|
||||
service { 'apache2':
|
||||
ensure => running,
|
||||
}
|
||||
|
||||
The above lines of configuration are responsible for the deployment of the installation of apache web server across the node agent.
|
||||
|
||||
### 7. Starting Master Service ###
|
||||
|
||||
We are now ready to start the puppet master. We can start it by running the apache2 service.
|
||||
|
||||
# systemctl start apache2
|
||||
|
||||
Here, our puppet master is running, but it isn't managing any agent nodes yet. Now, we'll gonna add the puppet node agents to the master.
|
||||
|
||||
**Note**: If you get an error **Job for apache2.service failed. See "systemctl status apache2.service" and "journalctl -xe" for details.** then it must be that there is some problem with the apache server. So, we can see the log what exactly has happened by running **apachectl start** under root or sudo mode. Here, while performing this tutorial, we got a misconfiguration of the certificates under **/etc/apache2/sites-enabled/puppetmaster.conf** file. We replaced **SSLCertificateFile /var/lib/puppet/ssl/certs/server.pem with SSLCertificateFile /var/lib/puppet/ssl/certs/puppetmaster.pem** and commented **SSLCertificateKeyFile** line. Then we'll need to rerun the above command to run apache server.
|
||||
|
||||
### 8. Puppet Agent Package Installation ###
|
||||
|
||||
Now, as we have our puppet master ready and it needs an agent to manage, we'll need to install puppet agent into the nodes. We'll need to install puppet agent in every nodes in our infrastructure we want puppet master to manage. We'll need to make sure that we have added our node agents in the DNS. Now, we'll gonna install the latest puppet agent in our agent node ie. puppetnode.example.com .
|
||||
|
||||
We'll run the following command to download the Puppet Labs package in our puppet agent nodes.
|
||||
|
||||
# cd /tmp/
|
||||
# wget https://apt.puppetlabs.com/puppetlabs-release-trusty.deb\
|
||||
|
||||
--2015-06-17 00:54:42-- https://apt.puppetlabs.com/puppetlabs-release-trusty.deb
|
||||
Resolving apt.puppetlabs.com (apt.puppetlabs.com)... 192.155.89.90, 2600:3c03::f03c:91ff:fedb:6b1d
|
||||
Connecting to apt.puppetlabs.com (apt.puppetlabs.com)|192.155.89.90|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 7384 (7.2K) [application/x-debian-package]
|
||||
Saving to: ‘puppetlabs-release-trusty.deb’
|
||||
|
||||
puppetlabs-release-tr 100%[===========================>] 7.21K --.-KB/s in 0.04s
|
||||
|
||||
2015-06-17 00:54:42 (162 KB/s) - ‘puppetlabs-release-trusty.deb’ saved [7384/7384]
|
||||
|
||||
Then, as we're running ubuntu 15.04, we'll use debian package manager to install it.
|
||||
|
||||
# dpkg -i puppetlabs-release-trusty.deb
|
||||
|
||||
Now, we'll gonna update the repository index using apt-get.
|
||||
|
||||
# apt-get update
|
||||
|
||||
Finally, we'll gonna install the puppet agent directly from the remote repository.
|
||||
|
||||
# apt-get install puppet
|
||||
|
||||
Puppet agent is always disabled by default, so we'll need to enable it. To do so we'll need to edit /etc/default/puppet file using a text editor.
|
||||
|
||||
# nano /etc/default/puppet
|
||||
|
||||
Then, we'll need to change value of **START** to "yes" as shown below.
|
||||
|
||||
START=yes
|
||||
|
||||
Then, we'll need to save and exit the file.
|
||||
|
||||
### 9. Agent Version Lock with Apt ###
|
||||
|
||||
As We have puppet version as 3.8.1, we need to lock the puppet version update as this will mess up the configurations while updating the puppet. So, we'll use apt's locking feature for that. To do so, we'll need to create a file /etc/apt/preferences.d/00-puppet.pref using our favorite text editor.
|
||||
|
||||
# nano /etc/apt/preferences.d/00-puppet.pref
|
||||
|
||||
Then, we'll gonna add the entries in the newly created file as:
|
||||
|
||||
# /etc/apt/preferences.d/00-puppet.pref
|
||||
Package: puppet puppet-common
|
||||
Pin: version 3.8*
|
||||
Pin-Priority: 501
|
||||
|
||||
Now, it will not update the Puppet while running updates in the system.
|
||||
|
||||
### 10. Configuring Puppet Node Agent ###
|
||||
|
||||
Next, We must make a few configuration changes before running the agent. To do so, we'll need to edit the agent's puppet.conf
|
||||
|
||||
# nano /etc/puppet/puppet.conf
|
||||
|
||||
It will look exactly like the Puppet master's initial configuration file.
|
||||
|
||||
This time also we'll comment the **templatedir** line. Then we'll gonna delete the [master] section, and all of the lines below it.
|
||||
|
||||
Assuming that the puppet master is reachable at "puppet-master", the agent should be able to connect to the master. If not we'll need to use its fully qualified domain name ie. puppetmaster.example.com .
|
||||
|
||||
[agent]
|
||||
server = puppetmaster.example.com
|
||||
certname = puppetnode.example.com
|
||||
|
||||
After adding this, it will look alike this.
|
||||
|
||||
[main]
|
||||
logdir=/var/log/puppet
|
||||
vardir=/var/lib/puppet
|
||||
ssldir=/var/lib/puppet/ssl
|
||||
rundir=/var/run/puppet
|
||||
factpath=$vardir/lib/facter
|
||||
#templatedir=$confdir/templates
|
||||
|
||||
[agent]
|
||||
server = puppetmaster.example.com
|
||||
certname = puppetnode.example.com
|
||||
|
||||
After done with that, we'll gonna save and exit it.
|
||||
|
||||
Next, we'll wanna start our latest puppet agent in our Ubuntu 15.04 nodes. To start our puppet agent, we'll need to run the following command.
|
||||
|
||||
# systemctl start puppet
|
||||
|
||||
If everything went as expected and configured properly, we should not see any output displayed by running the above command. When we run an agent for the first time, it generates an SSL certificate and sends a request to the puppet master then if the master signs the agent's certificate, it will be able to communicate with the agent node.
|
||||
|
||||
**Note**: If you are adding your first node, it is recommended that you attempt to sign the certificate on the puppet master before adding your other agents. Once you have verified that everything works properly, then you can go back and add the remaining agent nodes further.
|
||||
|
||||
### 11. Signing certificate Requests on Master ###
|
||||
|
||||
While puppet agent runs for the first time, it generates an SSL certificate and sends a request for signing to the master server. Before the master will be able to communicate and control the agent node, it must sign that specific agent node's certificate.
|
||||
|
||||
To get the list of the certificate requests, we'll run the following command in the puppet master server.
|
||||
|
||||
# puppet cert list
|
||||
|
||||
"puppetnode.example.com" (SHA256) 31:A1:7E:23:6B:CD:7B:7D:83:98:33:8B:21:01:A6:C4:01:D5:53:3D:A0:0E:77:9A:77:AE:8F:05:4A:9A:50:B2
|
||||
|
||||
As we just setup our first agent node, we will see one request. It will look something like the following, with the agent node's Domain name as the hostname.
|
||||
|
||||
Note that there is no + in front of it which indicates that it has not been signed yet.
|
||||
|
||||
Now, we'll go for signing a certification request. In order to sign a certification request, we should simply run **puppet cert sign** with the **hostname** as shown below.
|
||||
|
||||
# puppet cert sign puppetnode.example.com
|
||||
|
||||
Notice: Signed certificate request for puppetnode.example.com
|
||||
Notice: Removing file Puppet::SSL::CertificateRequest puppetnode.example.com at '/var/lib/puppet/ssl/ca/requests/puppetnode.example.com.pem'
|
||||
|
||||
The Puppet master can now communicate and control the node that the signed certificate belongs to.
|
||||
|
||||
If we want to sign all of the current requests, we can use the -all option as shown below.
|
||||
|
||||
# puppet cert sign --all
|
||||
|
||||
### Removing a Puppet Certificate ###
|
||||
|
||||
If we wanna remove a host from it or wanna rebuild a host then add it back to it. In this case, we will want to revoke the host's certificate from the puppet master. To do this, we will want to use the clean action as follows.
|
||||
|
||||
# puppet cert clean hostname
|
||||
|
||||
Notice: Revoked certificate with serial 5
|
||||
Notice: Removing file Puppet::SSL::Certificate puppetnode.example.com at '/var/lib/puppet/ssl/ca/signed/puppetnode.example.com.pem'
|
||||
Notice: Removing file Puppet::SSL::Certificate puppetnode.example.com at '/var/lib/puppet/ssl/certs/puppetnode.example.com.pem'
|
||||
|
||||
If we want to view all of the requests signed and unsigned, run the following command:
|
||||
|
||||
# puppet cert list --all
|
||||
|
||||
+ "puppetmaster" (SHA256) 33:28:97:86:A1:C3:2F:73:10:D1:FB:42:DA:D5:42:69:71:84:F0:E2:8A:01:B9:58:38:90:E4:7D:B7:25:23:EC (alt names: "DNS:puppetmaster", "DNS:puppetmaster.example.com")
|
||||
|
||||
### 12. Deploying a Puppet Manifest ###
|
||||
|
||||
After we configure and complete the puppet manifest, we'll wanna deploy the manifest to the agent nodes server. To apply and load the main manifest we can simply run the following command in the agent node.
|
||||
|
||||
# puppet agent --test
|
||||
|
||||
Info: Retrieving pluginfacts
|
||||
Info: Retrieving plugin
|
||||
Info: Caching catalog for puppetnode.example.com
|
||||
Info: Applying configuration version '1434563858'
|
||||
Notice: /Stage[main]/Main/Exec[apt-update]/returns: executed successfully
|
||||
Notice: Finished catalog run in 10.53 seconds
|
||||
|
||||
This will show us all the processes how the main manifest will affect a single server immediately.
|
||||
|
||||
If we wanna run a puppet manifest that is not related to the main manifest, we can simply use puppet apply followed by the manifest file path. It only applies the manifest to the node that we run the apply from.
|
||||
|
||||
# puppet apply /etc/puppet/manifest/test.pp
|
||||
|
||||
### 13. Configuring Manifest for a Specific Node ###
|
||||
|
||||
If we wanna deploy a manifest only to a specific node then we'll need to configure the manifest as follows.
|
||||
|
||||
We'll need to edit the manifest on the master server using a text editor.
|
||||
|
||||
# nano /etc/puppet/manifest/site.pp
|
||||
|
||||
Now, we'll gonna add the following lines there.
|
||||
|
||||
node 'puppetnode', 'puppetnode1' {
|
||||
# execute 'apt-get update'
|
||||
exec { 'apt-update': # exec resource named 'apt-update'
|
||||
command => '/usr/bin/apt-get update' # command this resource will run
|
||||
}
|
||||
|
||||
# install apache2 package
|
||||
package { 'apache2':
|
||||
require => Exec['apt-update'], # require 'apt-update' before installing
|
||||
ensure => installed,
|
||||
}
|
||||
|
||||
# ensure apache2 service is running
|
||||
service { 'apache2':
|
||||
ensure => running,
|
||||
}
|
||||
}
|
||||
|
||||
Here, the above configuration will install and deploy the apache web server only to the two specified nodes having shortname puppetnode and puppetnode1. We can add more nodes that we need to get deployed with the manifest specifically.
|
||||
|
||||
### 14. Configuring Manifest with a Module ###
|
||||
|
||||
Modules are useful for grouping tasks together, they are many available in the Puppet community which anyone can contribute further.
|
||||
|
||||
On the puppet master, we'll gonna install the **puppetlabs-apache** module using the puppet module command.
|
||||
|
||||
# puppet module install puppetlabs-apache
|
||||
|
||||
**Warning**: Please do not use this module on an existing apache setup else it will purge your apache configurations that are not managed by puppet.
|
||||
|
||||
Now we'll gonna edit the main manifest ie **site.pp** using a text editor.
|
||||
|
||||
# nano /etc/puppet/manifest/site.pp
|
||||
|
||||
Now add the following lines to install apache under puppetnode.
|
||||
|
||||
node 'puppet-node' {
|
||||
class { 'apache': } # use apache module
|
||||
apache::vhost { 'example.com': # define vhost resource
|
||||
port => '80',
|
||||
docroot => '/var/www/html'
|
||||
}
|
||||
}
|
||||
|
||||
Then we'll wanna save and exit it. Then, we'll wanna rerun the manifest to deploy the configuration to the agents for our infrastructure.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Finally we have successfully installed puppet to manage our Server Infrastructure running Ubuntu 15.04 "Vivid Vervet" linux operating system. We learned how puppet works, configure a manifest configuration, communicate with nodes and deploy the manifest on the agent nodes with secure SSL certification. Controlling, managing and configuring repeated task in several N number of nodes is very easy with puppet open source software configuration management tool. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-puppet-ubuntu-15-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://docs.puppetlabs.com/puppet/latest/reference/config_file_main.html
|
||||
@ -0,0 +1,70 @@
|
||||
Translating by GOlinu!
|
||||
Linux FAQs with Answers--How to enable logging in Open vSwitch for debugging and troubleshooting
|
||||
================================================================================
|
||||
> **Question:** I am trying to troubleshoot my Open vSwitch deployment. For that I would like to inspect its debug messages generated by its built-in logging mechanism. How can I enable logging in Open vSwitch, and change its logging level (e.g., to INFO/DEBUG level) to check more detailed debug information?
|
||||
|
||||
Open vSwitch (OVS) is the most popular open-source implementation of virtual switch on the Linux platform. As the today's data centers increasingly rely on the software-defined network (SDN) architecture, OVS is fastly adopted as the de-facto standard network element in data center's SDN deployments.
|
||||
|
||||
Open vSwitch has a built-in logging mechanism called VLOG. The VLOG facility allows one to enable and customize logging within various components of the switch. The logging information generated by VLOG can be sent to a combination of console, syslog and a separate log file for inspection. You can configure OVS logging dynamically at run-time with a command-line tool called `ovs-appctl`.
|
||||
|
||||
|
||||
|
||||
Here is how to enable logging and customize logging levels in Open vSwitch with `ovs-appctl`.
|
||||
|
||||
The syntax of `ovs-appctl` to customize VLOG is as follows.
|
||||
|
||||
$ sudo ovs-appctl vlog/set module[:facility[:level]]
|
||||
|
||||
- **Module**: name of any valid component in OVS (e.g., netdev, ofproto, dpif, vswitchd, and many others)
|
||||
- **Facility**: destination of logging information (must be: console, syslog or file)
|
||||
- **Level**: verbosity of logging (must be: emer, err, warn, info, or dbg)
|
||||
|
||||
In OVS source code, module name is defined in each source file in the form of:
|
||||
|
||||
VLOG_DEFINE_THIS_MODULE(<module-name>);
|
||||
|
||||
For example, in lib/netdev.c, you will see:
|
||||
|
||||
VLOG_DEFINE_THIS_MODULE(netdev);
|
||||
|
||||
which indicates that lib/netdev.c is part of netdev module. Any logging messages generated in lib/netdev.c will belong to netdev module.
|
||||
|
||||
In OVS source code, there are multiple severity levels used to define several different kinds of logging messages: VLOG_INFO() for informational, VLOG_WARN() for warning, VLOG_ERR() for error, VLOG_DBG() for debugging, VLOG_EMERG for emergency. Logging level and facility determine which logging messages are sent where.
|
||||
|
||||
To see a full list of available modules, facilities, and their respective logging levels, run the following commands. This command must be invoked after you have started OVS.
|
||||
|
||||
$ sudo ovs-appctl vlog/list
|
||||
|
||||
|
||||
|
||||
The output shows the debug levels of each module for three different facilities (console, syslog, file). By default, all modules have their logging level set to INFO.
|
||||
|
||||
Given any one OVS module, you can selectively change the debug level of any particular facility. For example, if you want to see more detailed debug messages of dpif module at the console screen, run the following command.
|
||||
|
||||
$ sudo ovs-appctl vlog/set dpif:console:dbg
|
||||
|
||||
You will see that dpif module's console facility has changed its logging level to DBG. The logging level of two other facilities, syslog and file, remains unchanged.
|
||||
|
||||
|
||||
|
||||
If you want to change the logging level for all modules, you can specify "ANY" as the module name. For example, the following command will change the console logging level of every module to DBG.
|
||||
|
||||
$ sudo ovs-appctl vlog/set ANY:console:dbg
|
||||
|
||||
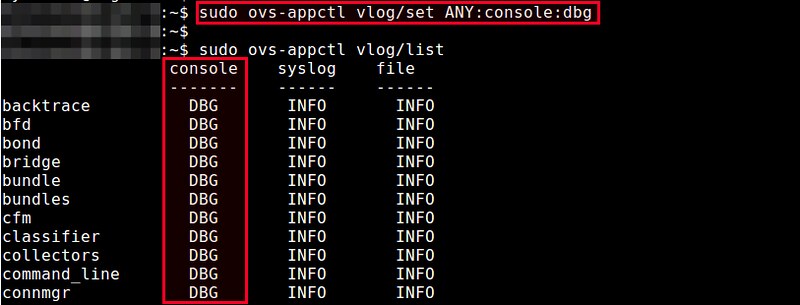
|
||||
|
||||
Also, if you want to change the logging level of all three facilities at once, you can specify "ANY" as the facility name. For example, the following command will change the logging level of all facilities for every module to DBG.
|
||||
|
||||
$ sudo ovs-appctl vlog/set ANY:ANY:dbg
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/enable-logging-open-vswitch.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,74 @@
|
||||
Translating by Ping
|
||||
|
||||
Linux FAQs with Answers--How to install git on Linux
|
||||
================================================================================
|
||||
> **Question:** I am trying to clone a project from a public Git repository, but I am getting "git: command not found" error. How can I install git on [insert your Linux distro]?
|
||||
|
||||
Git is a popular open-source version control system (VCS) originally developed for Linux environment. Contrary to other VCS tools like CVS or SVN, Git's revision control is considered "distributed" in a sense that your local Git working directory can function as a fully-working repository with complete history and version-tracking capabilities. In this model, each collaborator commits to his or her local repository (as opposed to always committing to a central repository), and optionally push to a centralized repository if need be. This brings in scalability and redundancy to the revision control system, which is a must in any kind of large-scale collaboration.
|
||||
|
||||
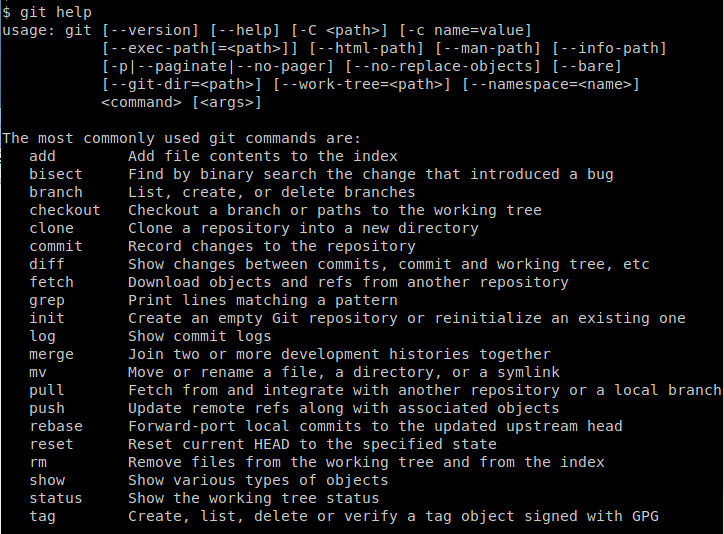
|
||||
|
||||
### Install Git with a Package Manager ###
|
||||
|
||||
Git is shipped with all major Linux distributions. Thus the easiest way to install Git is by using your Linux distro's package manager.
|
||||
|
||||
**Debian, Ubuntu, or Linux Mint**
|
||||
|
||||
$ sudo apt-get install git
|
||||
|
||||
**Fedora, CentOS or RHEL**
|
||||
|
||||
$ sudo yum install git
|
||||
|
||||
**Arch Linux**
|
||||
|
||||
$ sudo pacman -S git
|
||||
|
||||
**OpenSUSE**
|
||||
|
||||
$ sudo zypper install git
|
||||
|
||||
**Gentoo**
|
||||
|
||||
$ emerge --ask --verbose dev-vcs/git
|
||||
|
||||
### Install Git from the Source ###
|
||||
|
||||
If for whatever reason you want to built Git from the source, you can follow the instructions below.
|
||||
|
||||
**Install Dependencies**
|
||||
|
||||
Before building Git, first install dependencies.
|
||||
|
||||
**Debian, Ubuntu or Linux**
|
||||
|
||||
$ sudo apt-get install libcurl4-gnutls-dev libexpat1-dev gettext libz-dev libssl-dev asciidoc xmlto docbook2x
|
||||
|
||||
**Fedora, CentOS or RHEL**
|
||||
|
||||
$ sudo yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel asciidoc xmlto docbook2x
|
||||
|
||||
#### Compile Git from the Source ####
|
||||
|
||||
Download the latest release of Git from [https://github.com/git/git/releases][1]. Then build and install Git under /usr as follows.
|
||||
|
||||
Note that if you want to install it under a different directory (e.g., /opt), replace "--prefix=/usr" in configure command with something else.
|
||||
|
||||
$ cd git-x.x.x
|
||||
$ make configure
|
||||
$ ./configure --prefix=/usr
|
||||
$ make all doc info
|
||||
$ sudo make install install-doc install-html install-info
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-git-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/git/git/releases
|
||||
@ -2,7 +2,7 @@
|
||||
================================================================================
|
||||
*作者声明: 如果你是因为某种神迹而在没看标题的情况下点开了这篇文章,那么我想再重申一些东西...这是一篇评论文章。文中的观点都是我自己的,不代表Phoronix和Michael的观点。它们完全是我自己的想法。
|
||||
|
||||
另外,没错……这可能是一篇引战的文章。我希望社团成员们更沉稳一些,因为我确实想在KDE和Gnome的社团上发起讨论,反馈。因此当我想指出——我所看到的——一个瑕疵时,我会尽量地做到具体而直接。这样,相关的讨论也能做到同样的具体和直接。再次声明:本文另一可选标题为“被[剪纸][1]千刀万剐”(原文剪纸一词为papercuts, 指易修复而烦人的漏洞,译者注)。
|
||||
另外,没错……这可能是一篇引战的文章。我希望社团成员们更沉稳一些,因为我确实想在KDE和Gnome的社团上发起讨论,反馈。因此当我想指出——我所看到的——一个瑕疵时,我会尽量地做到具体而直接。这样,相关的讨论也能做到同样的具体和直接。再次声明:本文另一可选标题为“被[细纸片][1]千刀万剐”(原文含paper cuts一词,指易修复但烦人的缺陷,译者注)。
|
||||
|
||||
现在,重申完毕……文章开始。
|
||||
|
||||
|
||||
@ -0,0 +1,54 @@
|
||||
将GNOME作为我的Linux桌面的一周: 他们做对的与做错的 - 第四节 - GNOME设置
|
||||
================================================================================
|
||||
### Settings设置 ###
|
||||
|
||||
在这我要挑一挑几个特定KDE控制模块的毛病,大部分原因是因为相比它们的对手GNOME来说,糟糕得太可笑,实话说,真是悲哀。
|
||||
|
||||
第一个接招的?打印机。
|
||||
|
||||

|
||||
|
||||
GNOME在左,KDE在右。你知道左边跟右边的打印程序有什么区别吗?当我在GNOME控制中心打开“打印机”时,程序窗口弹出来了,之后没有也没发生。而当我在KDE系统设置打开“打印机”时,我收到了一条密码提示。甚至我都没能看一眼打印机呢,我就必须先交出ROOT密码。
|
||||
|
||||
让我再重复一遍。在今天,PolicyKit和Logind的日子里,对一个应该是sudo的操作,我依然被询问要求ROOT的密码。我安装系统的时候甚至都没设置root密码。所以我必须跑到Konsole去,然后运行'sudo passwd root'命令,这样我才能给root设一个密码,这样我才能回到系统设置中的打印程序,然后交出root密码,然后仅仅是看一看哪些打印机可用。完成了这些工作后,当我点击“添加打印机”时,我再次收到请求ROOT密码的提示,当我解决了它后再选择一个打印机和驱动时,我再次收到请求ROOT密码的提示。仅仅是为了添加一个打印机到系统我就收到三次密码请求。
|
||||
|
||||
而在GNOME下添加打印机,在点击打印机程序中的”解锁“之前,我没有收到任何请求SUDO密码的提示。整个过程我只被请求过一次,仅此而已。KDE,求你了……采用GNOME的”解锁“模式吧。不到一定需要的时候不要发出提示。还有,不管是哪个库,只要它允许KDE应用程序绕过PolicyKit/Logind(如果有的话)并直接请求ROOT权限……那就把它封进箱里吧。如果这是个多用户系统,那我要么必须交出ROOT密码,要么我必须时时刻刻呆着以免有一个用户需要升级、更改或添加一个新的打印机。而这两种情况都是完全无法接受的。
|
||||
|
||||
有还一件事……
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
给论坛的问题:怎么样看起来更简洁?我在写这篇文章时意识到:当有任何的附加打印机准备好时,Gnome打印机程序会把过程做得非常简洁,它们在左边上放了一个竖直栏来列出这些打印机。而我在KDE添加第二台打印机时,它突然增加出一个左边栏来。而在添加之前,我脑海中已经有了一个恐怖的画面它会像图片文件夹显示预览图一样,直接插入另外一个图标到界面里去。我很高兴也很惊讶的看到我是错的。但是事实是它直接”长出”另外一个从末存在的竖直栏,彻底改变了它的界面布局,而这样也称不上“好”。终究还是一种令人困惑,奇怪而又不直观的设计。
|
||||
|
||||
打印机说得够多了……下一个接受我公开石刑的KDE系统设置是?多媒体,即Phonon。
|
||||
|
||||

|
||||
|
||||
一如既往,GNOME在左边,KDE在右边。让我们先看看GNOME的系统设置先……眼睛从左到右,从上到下,对吧?来吧,就这样做。首先:音量控制滑条。滑条中的蓝色条与空白条百分百清晰地消除了哪边是“音量增加”的困惑。在音量控制条后马上就是一个On/Off开关,用来开关静音功能。Gnome的再次得分在于静音后能记住当前设置的音量,而在点击音量增加按钮取消静音后能回到原来设置的音量中来。Kmixer,你个健忘的垃圾,我真的希望我能多讨论你。
|
||||
|
||||
|
||||
继续!输入输出和应用程序的标签选项?每一个应用程序的音量随时可控?Gnome,每过一秒,我爱你越深。均衡的选项设置,声音配置,和清晰地标上标志的“测试麦克风”选项。
|
||||
|
||||
|
||||
|
||||
我不清楚它能否以一种更干净更简洁的设计实现。是的,它只是一个Gnome化的Pavucontrol,但我想这就是重要的地方。Pavucontrol在这方面几乎完全做对了,Gnome控制中心中的“声音”应用程序的改善使它向完美更进了一步。
|
||||
|
||||
Phonon,该你上了。但开始前我想说:我TM看到的是什么?我知道我看到的是音频设备的权限列表,但是它呈现的方式有点太坑。还有,那些用户可能关心的那些东西哪去了?拥有一个权限列表当然很好,它也应该存在,但问题是权限列表属于那种用户乱搞一两次之后就不会再碰的东西。它还不够重要,或者说常用到可以直接放在正中间位置的程度。音量控制滑块呢?对每个应用程序的音量控制功能呢?那些用户使用最频繁的东西呢?好吧,它们在Kmix中,一个分离的程序,拥有它自己的配置选项……而不是在系统设置下……这样真的让“系统设置”这个词变得有点用词不当。
|
||||
|
||||

|
||||
|
||||
上面展示的Gnome的网络设置。KDE的没有展示,原因就是我接下来要吐槽的内容了。如果你进入KDE的系统设置里,然后点击“网络”区域中三个选项中的任何一个,你会得到一大堆的选项:蓝牙设置,Samba分享的默认用户名和密码(说真的,“连通性(Connectivity)”下面只有两个选项:SMB的用户名和密码。TMD怎么就配得上“连通性”这么大的词?),浏览器身份验证控制(只有Konqueror能用……一个已经倒闭的项目),代理设置,等等……我的wifi设置哪去了?它们没在这。哪去了?好吧,它们在网络应用程序的设置里面……而不是在网络设置里……
|
||||
|
||||
KDE,你这是要杀了我啊,你有“系统设置”当凶器,拿着它动手吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=4
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,39 @@
|
||||
将GNOME作为我的Linux桌面的一周:他们做对的与做错的 - 第五节 - 总结
|
||||
================================================================================
|
||||
### 用户体验和最后想法 ###
|
||||
|
||||
当Gnome 2.x和KDE 4.x要正面交锋时……我相当开心的跳到其中。我爱的东西它们有,恨的东西也有,但总的来说它们使用起来还算是一种乐趣。然后Gnome 3.x来了,带着一场Gnome Shell的戏剧。那时我就放弃了Gnome,我尽我所能的避开它。当时它对用户是不友好的,而且不直观,它打破了原有的设计典范,只为平板的统治世界做准备……而根据平板下跌的销量来看,这样的未来不可能实现。
|
||||
|
||||
Gnome 3后续发面了八个版本后,奇迹发生了。Gnome变得对对用户友好了。变得直观了。它完美吗?当然不了。我还是很讨厌它想推动的那种设计范例,我讨厌它总想把工作流(work flow)强加给我,但是在时间和耐心的作用下,这两都能被接受。只要你能够回头去看看Gnome Shell那外星人一样的界面,然后开始跟Gnome的其它部分(特别是控制中心)互动,你就能发现Gnome绝对做对了:细节。对细节的关注!
|
||||
|
||||
人们能适应新的界面设计范例,能适应新的工作流——iPhone和iPad都证明了这一点——但真正一直让他们操心的是“纸片的割伤”(paper cuts,此处指易于修复但烦人的缺陷,译注)。
|
||||
|
||||
它带出了KDE和Gnome之间最重要的一个区别。Gnome感觉像一个产品。像一种非凡的体验。你用它的时候,觉得它是完整的,你要的东西都在你的指尖。它让人感觉就像是一个拥有windows或者OS X那样桌面体验的Linux桌面版:你要的都在里面,而且它是被同一个目标一致的团队中的同一个人写出来的。天,即使是一个应用程序发出的sudo请求都感觉是Gnome下的一个特意设计的部分,就像在Windows下的一样。而在KDE它就像是任何应用程序都能创建的那种随机外观的弹窗。它不像是以系统的一部分这样的正式身份停下来说“嘿,有个东西要请求管理员权限!你要给它吗?”。
|
||||
|
||||
KDE让人体验不到有凝聚力的体验。KDE像是在没有方向地打转,感觉没有完整的体验。它就像是一堆东西往不同的的方向移动,只不过恰好它们都有一个共同享有的工具包。如果开发者对此很开心,那么好吧,他们开心就好,但是如果他们想提供最好体验的话,那么就需要多关注那些小地方了。用户体验跟直观应当做为每一个应用程序的设计中心,应当有一个视野,知道KDE要提供什么——并且——知道它看起来应该是什么样的。
|
||||
|
||||
是不是有什么原因阻止我在KDE下使用Gnome磁盘管理? Rhythmbox? Evolution? 没有。没有。没有。但是这样说又错过了关键。Gnome和KDE都称它们为“桌面环境”。那么它们就应该是完整的环境,这意味着他们的各个部件应该汇集并紧密结合在一起,意味着你使用它们环境下的工具,因为它们说“您在一个完整的桌面中需要的任何东西,我们都支持。”说真的?只有Gnome看起来能符合完整的要求。KDE在“汇集在一起”这一方面感觉就像个半成品,更不用说提供“完整体验”中你所需要的东西。Gnome磁盘管理没有相应的对手——kpartionmanage要求ROOT权限。KDE不运行“首次用户注册”的过程(原文:No 'First Time User' run through.可能是指系统安装过程中KDE没有创建新用户的过程,译注) ,现在也不过是在Kubuntu下引入了一个用户管理器。老天,Gnome甚至提供了地图,笔记,日历和时钟应用。这些应用都是百分百要紧的吗?不,当然不了。但是正是这些应用帮助Gnome推动“Gnome是一种完整丰富的体验”的想法。
|
||||
|
||||
我吐槽的KDE问题并非不可能解决,决对不是这样的!但是它需要人去关心它。它需要开发者为他们的作品感到自豪,而不仅仅是为它们实现的功能而感到自豪——组织的价值可大了去了。别夺走用户设置选项的能力——GNOME 3.x就是因为缺乏配置选项的能力而为我所诟病,但别把“好吧,你想怎么设置就怎么设置,”作为借口而不提供任何理智的默认设置。默认设置是用户将看到的东西,它们是用户从打开软件的第一刻开始进行评判的关键。给用户留个好印象吧。
|
||||
|
||||
我知道KDE开发者们知道设计很重要,这也是为什么Visual Design Group(视觉设计团体)存在的原因,但是感觉好像他们没有让VDG充分发挥。所以KDE里存在组织上的缺陷。不是KDE没办法完整,不是它没办法汇集整合在一起然后解决衰败问题,只是开发者们没做到。他们瞄准了靶心……但是偏了。
|
||||
|
||||
还有,在任何人说这句话之前……千万别说“补丁很受欢迎啊"。因为当我开心的为个人提交补丁时,只要开发者坚持以他们喜欢的却不直观的方式干事,更多这样的烦事就会不断发生。这不关Muon有没有中心对齐。也不关Amarok的界面太丑。也不关每次我敲下快捷键后,弹出的音量和亮度调节窗口占用了我一大块的屏幕“房地产”(说真的,有人会去缩小这些东西)。
|
||||
|
||||
这跟心态的冷漠有关,跟开发者们在为他们的应用设计UI时根本就不多加思考有关。KDE团队做的东西都工作得很好。Amarok能播放音乐。Dragon能播放视频。Kwin或Qt和kdelibs似乎比Mutter/gtk更有力更效率(仅根本我的电池电量消耗计算。非科学性测试)。这些都很好,很重要……但是它们呈现的方式也很重要。甚至可以说,呈现方式是最重要的,因为它是用户看到的和与之交互的东西。
|
||||
|
||||
KDE应用开发者们……让VDG参与进来吧。让VDG审查并核准每一个”核心“应用,让一个VDG的UI/UX专家来设计应用的使用模式和使用流程,以此保证其直观性。真见鬼,不管你们在开发的是啥应用,仅仅把它的模型发到VDG论坛寻求反馈甚至都可能都能得到一些非常好的指点跟反馈。你有这么好的资源在这,现在赶紧用吧。
|
||||
|
||||
我不想说得好像我一点都不懂感恩。我爱KDE,我爱那些志愿者们为了给Linux用户一个可视化的桌面而付出的工作与努力,也爱可供选择的Gnome。正是因为我关心我才写这篇文章。因为我想看到更好的KDE,我想看到它走得比以前更加遥远。而这样做需要每个人继续努力,并且需要人们不再躲避批评。它需要人们对系统互动及系统崩溃的地方都保持诚实。如果我们不能直言批评,如果我们不说”这真垃圾!”,那么情况永远不会变好。
|
||||
|
||||
这周后我会继续使用Gnome吗?可能不,不。Gnome还在试着强迫我接受其工作流,而我不想追随,也不想遵循,因为我在使用它的时候感觉变得不够高效,因为它并不遵循我的思维模式。可是对于我的朋友们,当他们问我“我该用哪种桌面环境?”我可能会推荐Gnome,特别是那些不大懂技术,只要求“能工作”就行的朋友。根据目前KDE的形势来看,这可能是我能说出的最狠毒的评估了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=5
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,66 @@
|
||||
|
||||
很实用的命令来分析你的 Unix 文件系统
|
||||
================================================================================
|
||||

|
||||
Credit: Sandra H-S
|
||||
|
||||
其中一个问题几乎困扰着所有的文件系统 -- 包括 Unix 和其他的 -- 那就是文件的不断积累。几乎没有人愿意花时间清理掉他们不再使用的文件和文件系统,结果,文件变得很混乱,很难找到有用的东西使它们运行良好,能够得到备份,并且易于管理,这将是一种持久的挑战。
|
||||
|
||||
我见过的一种解决问题的方法是鼓励使用者将所有的数据碎屑创建成一个总结报告或"profile"这样一个文件集合来报告所有的文件数量;最老的,最新的,最大的文件;并统计谁拥有这些文件。如果有人看到一个包含五十万个文件的文件夹并且时间不小于五年,他们可能会去删除哪些文件 -- 或者,至少归档和压缩。主要问题是太大的文件夹会使人产生压制性害怕误删一些重要的东西。有一个描述文件夹的方法能帮助显示文件的性质并期待你去清理它。
|
||||
|
||||
|
||||
当我准备做 Unix 文件系统的总结报告时,几个有用的 Unix 命令能提供一些非常有用的统计信息。要计算目录中的文件数,你可以使用这样一个 find 命令。
|
||||
|
||||
$ find . -type f | wc -l
|
||||
187534
|
||||
|
||||
查找最老的和最新的文件是比较复杂,但还是相当方便的。在下面的命令,我们使用 find 命令再次查找文件,以文件时间排序并按年-月-日的格式显示在顶部 -- 因此最老的 -- 的文件在列表中。
|
||||
|
||||
在第二个命令,我们做同样的,但打印的是最后一行 -- 这是最新的 -- 文件
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | sort | head -n 1
|
||||
2006-02-03+02:40:33 ./skel/.xemacs/init.el
|
||||
$ find -type f -printf '%T+ %p\n' | sort | tail -n 1
|
||||
2015-07-19+14:20:16 ./.bash_history
|
||||
|
||||
printf 命令输出 %T(文件日期和时间)和 %P(带路径的文件名)参数。
|
||||
|
||||
如果我们在查找家目录时,无疑会发现,history 文件是最新的,这不像是一个很有趣的信息。你可以通过 "un-grepping" 来忽略这些文件,也可以忽略以.开头的文件,如下图所示的。
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | grep -v "\./\." | sort | tail -n 1
|
||||
2015-07-19+13:02:12 ./isPrime
|
||||
|
||||
寻找最大的文件使用 %s(大小)参数,包括文件名(%f),因为这就是我们想要在报告中显示的。
|
||||
|
||||
$ find -type f -printf '%s %f \n' | sort -n | uniq | tail -1
|
||||
20183040 project.org.tar
|
||||
|
||||
打印文件的所有着者,使用%u(所有者)
|
||||
|
||||
$ find -type f -printf '%u \n' | grep -v "\./\." | sort | uniq -c
|
||||
180034 shs
|
||||
7500 jdoe
|
||||
|
||||
如果文件系统能记录上次的访问日期,也将是非常有用的来看该文件有没有被访问,比方说,两年之内。这将使你能明确分辨这些文件的价值。最后一个访问参数(%a)这样使用:
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | head -n 1
|
||||
Fri Dec 15 03:00:30 2006+ ./statreport
|
||||
|
||||
当然,如果最近访问的文件也是在很久之前的,这将使你有更多的处理时间。
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | tail -n 1
|
||||
Wed Nov 26 03:00:27 2007+ ./my-notes
|
||||
|
||||
一个文件系统要层次分明,为大目录创建一个总结报告,显示该文件的日期范围,最大的文件,文件所有者,最老的和访问时间都可以帮助文件拥有者判断当前有哪些文件夹是重要的哪些该清理了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2949898/linux/profiling-your-file-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Sandra-Henry_Stocker/
|
||||
@ -0,0 +1,49 @@
|
||||
Linux有问必答——如何修复Linux上的“ImportError: No module named wxversion”错误
|
||||
================================================================================
|
||||
|
||||
> **问题** 我试着在[你的Linux发行版]上运行一个Python应用,但是我得到了这个错误"ImportError: No module named wxversion."。我怎样才能解决Python程序中的这个错误呢?
|
||||
|
||||
Looking for python... 2.7.9 - Traceback (most recent call last):
|
||||
File "/home/dev/playonlinux/python/check_python.py", line 1, in
|
||||
import os, wxversion
|
||||
ImportError: No module named wxversion
|
||||
failed tests
|
||||
|
||||
该错误表明,你的Python应用是基于GUI的,依赖于一个名为wxPython的缺失模块。[wxPython][1]是一个用于wxWidgets GUI库的Python扩展模块,普遍被C++程序员用来设计GUI应用。该wxPython扩展允许Python开发者在任何Python应用中方便地设计和整合GUI。
|
||||
To solve this import error, you need to install wxPython on your Linux, as described below.
|
||||
|
||||
### 安装wxPython到Debian,Ubuntu或Linux Mint ###
|
||||
|
||||
$ sudo apt-get install python-wxgtk2.8
|
||||
|
||||
### 安装wxPython到Fedora ###
|
||||
|
||||
$ sudo yum install wxPython
|
||||
|
||||
### 安装wxPython到CentOS/RHEL ###
|
||||
|
||||
wxPython可以在CentOS/RHEL的EPEL仓库中获取到,而基本仓库中则没有。因此,首先要在你的系统中[启用EPEL仓库][2],然后使用yum命令来安装。
|
||||
|
||||
$ sudo yum install wxPython
|
||||
|
||||
### 安装wxPython到Arch Linux ###
|
||||
|
||||
$ sudo pacman -S wxpython
|
||||
|
||||
### 安装wxPython到Gentoo ###
|
||||
|
||||
$ emerge wxPython
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/importerror-no-module-named-wxversion.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://wxpython.org/
|
||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
Loading…
Reference in New Issue
Block a user