mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
8f5fddf671
@ -0,0 +1,172 @@
|
|||||||
|
IT 灾备:系统管理员对抗自然灾害
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 面对倾泻的洪水或地震时业务需要继续运转。在飓风卡特里娜、桑迪和其他灾难中幸存下来的系统管理员向在紧急状况下负责 IT 的人们分享真实世界中的建议。
|
||||||
|
|
||||||
|
说到自然灾害,2017 年可算是多灾多难。(LCTT 译注:本文发表于 2017 年)飓风哈维、厄玛和玛莉亚给休斯顿、波多黎各、弗罗里达和加勒比造成了严重破坏。此外,西部的野火将多处住宅和商业建筑付之一炬。
|
||||||
|
|
||||||
|
再来一篇关于[有备无患][1]的警示文章 —— 当然其中都是好的建议 —— 是很简单的,但这无法帮助网络管理员应对湿漉漉的烂摊子。那些善意的建议中大多数都假定掌权的人乐于投入资金来实施这些建议。
|
||||||
|
|
||||||
|
我们对真实世界更感兴趣。不如让我们来充分利用这些坏消息。
|
||||||
|
|
||||||
|
一个很好的例子:自然灾害的一个后果是老板可能突然愿意给灾备计划投入预算。如同一个纽约地区的系统管理员所言,“[我发现飓风桑迪的最大好处][2]是我们的客户对 IT 投资更有兴趣了,但愿你也能得到更多预算。”
|
||||||
|
|
||||||
|
不过别指望这种意愿持续很久。任何想提议改进基础设施的系统管理员最好趁热打铁。如同另一位飓风桑迪中幸存下来的 IT 专员懊悔地提及那样,“[对 IT 开支最初的兴趣持续到当年为止][3]。到了第二年,任何尚未开工的计划都因为‘预算约束’被搁置了,大约 6 个月之后则完全被遗忘。”
|
||||||
|
|
||||||
|
在管理层忘记恶劣的自然灾害也可能降临到好公司头上之前提醒他们这点会有所帮助。根据<ruby>商业和家庭安全协会<rt>Institute for Business & Home Safety</rt></ruby>的说法,[自然灾害后歇业的公司中 25% 再也没能重新开业][4]。<ruby>联邦紧急事务管理署<rt>FEMA</rt></ruby>认为这过于乐观。根据他们的统计,“灾后 [40% 的小公司再也没能重新开门营业][5]。”
|
||||||
|
|
||||||
|
如果你是个系统管理员,你能帮忙挽救你的公司。这里有一些幸存者的最好的主意,这些主意是基于他们从过去几次自然灾害中得到的经验。
|
||||||
|
|
||||||
|
### 制订一个计划
|
||||||
|
|
||||||
|
当灯光忽明忽暗,狂风象火车机车一样怒号时,就该启动你的业务持续计划和灾备计划了。
|
||||||
|
|
||||||
|
有太多的系统管理员报告当暴风雨来临时这两个计划中一个也没有。这并不令人惊讶。2014 年<ruby>[灾备预备状态委员会][6]<rt>Disaster Recovery Preparedness Council</rt></ruby>发现[世界范围内被调查的公司中有 73% 没有足够的灾备计划][7]。
|
||||||
|
|
||||||
|
“**足够**”是关键词。正如一个系统管理员 2016 年在 Reddit 上写的那样,“[我们的灾备计划就是一场灾难。][8]我们所有的数据都备份在离这里大约 30 英里的一个<ruby>存储区域网络<rt>SAN</rt></ruby>。我们没有将数据重新上线的硬件,甚至好几天过去了都没能让核心服务器启动运行起来。我们是个年营收 40 亿美元的公司,却不愿为适当的设备投入几十万美元,或是在数据中心添置几台服务器。当添置硬件的提案被提出的时候,我们的管理层说,‘嗐,碰到这种事情的机会能有多大呢’。”
|
||||||
|
|
||||||
|
同一个帖子中另一个人说得更简洁:“眼下我的灾备计划只能在黑暗潮湿的角落里哭泣,但愿没人在乎损失的任何东西。”
|
||||||
|
|
||||||
|
如果你在哭泣,但愿你至少不是独自流泪。任何灾备计划,即便是 IT 部门制订的灾备计划,必须确定[你能跟别人通讯][10],如同系统管理员 Jim Thompson 从卡特里娜飓风中得到的教训:“确保你有一个与人们通讯的计划。在一场严重的区域性灾难期间,你将无法给身处灾区的任何人打电话。”
|
||||||
|
|
||||||
|
有一个选择可能会让有技术头脑的人感兴趣:<ruby>[业余电台][11]<rt>ham radio</rt></ruby>。[它在波多黎各发挥了巨大作用][12]。
|
||||||
|
|
||||||
|
### 列一个愿望清单
|
||||||
|
|
||||||
|
第一步是承认问题。“许多公司实际上对灾备计划不感兴趣,或是消极对待”,[Micro Focus][14] 的首席架构师 [Joshua Focus][13] 说。“将灾备看作业务持续性的一个方面是种不同的视角。所有公司都要应对业务持续性,所以灾备应被视为业务持续性的一部分。”
|
||||||
|
|
||||||
|
IT 部门需要将其需求书面化以确保适当的灾备和业务持续性计划。即使是你不知道如何着手,或尤其是这种时候,也是如此。正如一个系统管理员所言,“我喜欢有一个‘想法转储’,让所有计划、点子、改进措施毫无保留地提出来。(这)[对一类情况尤其有帮助,即当你提议变更][15],并付诸实施,接着 6 个月之后你警告过的状况就要来临。”现在你做好了一切准备并且可以开始讨论:“如同我们之前在 4 月讨论过的那样……”
|
||||||
|
|
||||||
|
因此,当你的管理层对业务持续性计划回应道“嗐,碰到这种事的机会能有多大呢?”的时候你能做些什么呢?有个系统管理员称这也完全是管理层的正常行为。在这种糟糕的处境下,老练的系统管理员建议用书面形式把这些事情记录下来。记录应清楚表明你告知管理层需要采取的措施,且[他们拒绝采纳建议][16]。“总的来说就是有足够的书面材料能让他们搓成一根绳子上吊,”该系统管理员补充道。
|
||||||
|
|
||||||
|
如果那也不起作用,恢复一个被洪水淹没的数据中心的相关经验对你[找个新工作][17]是很有帮助的。
|
||||||
|
|
||||||
|
### 保护有形的基础设施
|
||||||
|
|
||||||
|
“[我们的办公室是幢摇摇欲坠的建筑][18],”飓风哈维重创休斯顿之后有个系统管理员提到。“我们盲目地进入那幢建筑,现场的基础设施糟透了。正是我们给那幢建筑里带去了最不想要的一滴水,现在基础设施整个都沉在水下了。”
|
||||||
|
|
||||||
|
尽管如此,如果你想让数据中心继续运转——或在暴风雨过后恢复运转 —— 你需要确保该场所不仅能经受住你所在地区那些意料中的灾难,而且能经受住那些意料之外的灾难。一个旧金山的系统管理员知道为什么重要的是确保公司的服务器安置在可以承受里氏 7 级地震的建筑内。一家圣路易斯的公司知道如何应对龙卷风。但你应当为所有可能发生的事情做好准备:加州的龙卷风、密苏里州的地震,或[僵尸末日][19](给你在 IT 预算里增加一把链锯提供了充分理由)。
|
||||||
|
|
||||||
|
在休斯顿的情况下,[多数数据中心保持运转][20],因为它们是按照抵御暴风雨和洪水的标准建造的。[Data Foundry][21] 的首席技术官 Edward Henigin 说他们公司的数据中心之一,“专门建造的休斯顿 2 号的设计能抵御 5 级飓风的风速。这个场所的公共供电没有中断,我们得以避免切换到后备发电机。”
|
||||||
|
|
||||||
|
那是好消息。坏消息是伴随着超级飓风桑迪于 2012 年登场,如果[你的数据中心没准备好应对洪水][22],你会陷入一个麻烦不断的世界。一个不能正常运转的数据中心 [Datagram][23] 服务的客户包括 Gawker、Gizmodo 和 Buzzfeed 等知名网站。
|
||||||
|
|
||||||
|
当然,有时候你什么也做不了。正如某个波多黎各圣胡安的系统管理员在飓风厄玛扫过后悲伤地写到,“发电机没油了。服务器机房靠电池在运转但是没有(空调)。[永别了,服务器][24]。”由于 <ruby>MPLS<rt>Multiprotocol Lable Switching</rt></ruby> 线路亦中断,该系统管理员没法切换到灾备措施:“多么充实的一天。”
|
||||||
|
|
||||||
|
总而言之,IT 专业人士需要了解他们所处的地区,了解他们面临的风险并将他们的服务器安置在能抵御当地自然灾害的数据中心内。
|
||||||
|
|
||||||
|
### 关于云的争议
|
||||||
|
|
||||||
|
当暴风雨席卷一切时避免 IT 数据中心失效的最佳方法就是确保灾备数据中心在其他地方。选择地点时需要审慎的决策。你的灾备数据中心不应在会被同一场自然灾害影响到的<ruby>地域<rt>region</rt></ruby>;你的资源应安置在多个<ruby>可用区<rt>availability zone</rt></ruby>内。考虑一下主备数据中心位于一场地震中的同一条断层带上,或是主备数据中心易于受互通河道导致的洪灾影响这类情况。
|
||||||
|
|
||||||
|
有些系统管理员[利用云作为冗余设施][25]。例如,总是用微软 Azure 云存储服务保存副本以确保持久性和高可用性。根据你的选择,Azure 复制功能将你的数据要么拷贝到同一个数据中心要么拷贝到另一个数据中心。多数公有云提供类似的自动备份服务以确保数据安全,不论你的数据中心发生什么情况——除非你的云服务供应商全部设施都在暴风雨的行进路径上。
|
||||||
|
|
||||||
|
昂贵么?是的。跟业务中断 1、2 天一样昂贵么?并非如此。
|
||||||
|
|
||||||
|
信不过公有云?可以考虑 <ruby>colo<rt>colocation</rt></ruby> 服务。有了 colo,你依旧拥有你的硬件,运行你自己的应用,但这些硬件可以远离麻烦。例如飓风哈维期间,一家公司“虚拟地”将它的资源从休斯顿搬到了其位于德克萨斯奥斯汀的 colo。但是那些本地数据中心和 colo 场所需要准备好应对灾难;这点是你选择场所时要考虑的一个因素。举个例子,一个寻找 colo 场所的西雅图系统管理员考虑的“全都是抗震和旱灾应对措施(加固的地基以及补给冷却系统的运水卡车)。”
|
||||||
|
|
||||||
|
### 周围一片黑暗时
|
||||||
|
|
||||||
|
正如 Forrester Research 的分析师 Rachel Dines 在一份为[灾备期刊][27]所做的调查中报告的那样,宣布的灾难中[最普遍的原因就是断电][26]。尽管你能应对一般情况下的断电,飓风、火灾和洪水的考验会超越设备的极限。
|
||||||
|
|
||||||
|
某个系统管理员挖苦式的计划是什么呢?“趁 UPS 完蛋之前把你能关的机器关掉,不能关的就让它崩溃咯。然后,[喝个痛快直到供电恢复][28]。”
|
||||||
|
|
||||||
|
在 2016 年德尔塔和西南航空停电事故之后,IT 员工推动的一个更加严肃的计划是由一个有管理的服务供应商为其客户[部署不间断电源][29]:“对于至关重要的部分,在供电中断时我们结合使用<ruby>简单网络管理协议<rt>SNMP</rt></ruby>信令和 <ruby>PowerChute 网络关机<rt>PowerChute Nrework Shutdown</rt></ruby>客户端来关闭设备。至于重新开机,那取决于客户。有些是自动启动,有些则需要人工干预。”
|
||||||
|
|
||||||
|
另一种做法是用来自两个供电所的供电线路支持数据中心。例如,[西雅图威斯汀大厦数据中心][30]有来自不同供电所的多路 13.4 千伏供电线路,以及多个 480 伏三相变电箱。
|
||||||
|
|
||||||
|
预防严重断电的系统不是“通用的”设备。系统管理员应当[为数据中心请求一台定制的柴油发电机][31]。除了按你特定的需求调整,发电机必须能迅速跳至全速运转并承载全部电力负荷而不致影响系统负载性能。”
|
||||||
|
|
||||||
|
这些发电机也必须加以保护。例如,将你的发电机安置在泛洪区的一楼就不是个聪明的主意。位于纽约<ruby>百老街<rt>Broad street</rt></ruby>的数据中心在超级飓风桑迪期间就是类似情形,备用发电机的燃料油桶在地下室 —— 并且被水淹了。尽管一场[“人力接龙”用容量 5 加仑的水桶将柴油输送到 17 段楼梯之上的发电机][32]使 [Peer 1 Hosting][33] 得以继续运营,但这不是一个切实可行的业务持续计划。
|
||||||
|
|
||||||
|
正如多数数据中心专家所知那样,如果你有时间 —— 假设一个飓风离你有一天的距离 —— 确保你的发电机正常工作,加满油,准备好当供电线路被刮断时立即开启,不管怎样你之前应当每月测试你的发电机。你之前是那么做的,是吧?是就好!
|
||||||
|
|
||||||
|
### 测试你对备份的信心
|
||||||
|
|
||||||
|
普通用户几乎从不备份,检查备份是否实际完好的就更少了。系统管理员对此更加了解。
|
||||||
|
|
||||||
|
有些 [IT 部门在寻求将他们的备份迁移到云端][34]。但有些系统管理员仍对此不买账 —— 他们有很好的理由。最近有人报告,“在用了整整 5 天[从亚马逊 Glacier 恢复了(400 GB)数据][35]之后,我欠了亚马逊将近 200 美元的传输费,并且(我还是)处于未完全恢复状态,还差大约 100 GB 文件。”
|
||||||
|
|
||||||
|
结果是有些系统管理员依然喜欢磁带备份。磁带肯定不够时髦,但正如操作系统专家 Andrew S. Tanenbaum 说的那样,“[永远不要低估一辆装满磁带在高速上飞驰的旅行车的带宽][36]。”
|
||||||
|
|
||||||
|
目前每盘磁带可以存储 10 TB 数据;有的进行中的实验可在磁带上存储高达 200 TB 数据。诸如<ruby>[线性磁带文件系统][37]<rt>Linear Tape File System</rt></ruby>之类的技术允许你象访问网络硬盘一样读取磁带数据。
|
||||||
|
|
||||||
|
然而对许多人而言,磁带[绝对是最后选择的手段][38]。没关系,因为备份应该有大量的可选方案。在这种情况下,一个系统管理员说到,“故障时我们会用这些方法(恢复备份):(Windows)服务器层面的 VSS (Volume Shadow Storage)快照,<ruby>存储区域网络<rt>SAN</rt></ruby>层面的卷快照,以及存储区域网络层面的异地归档快照。但是万一有什么事情发生并摧毁了我们的虚拟机,存储区域网络和备份存储区域网络,我们还是可以取回磁带并恢复数据。”
|
||||||
|
|
||||||
|
当麻烦即将到来时,可使用副本工具如 [Veeam][39],它会为你的服务器创建一个虚拟机副本。若出现故障,副本会自动启动。没有麻烦,没有手忙脚乱,正如某个系统管理员在这个流行的系统管理员帖子中所说,“[我爱你 Veeam][40]。”
|
||||||
|
|
||||||
|
### 网络?什么网络?
|
||||||
|
|
||||||
|
当然,如果员工们无法触及他们的服务,没有任何云、colo 和远程数据中心能帮到你。你不需要一场自然灾害来证明冗余互联网连接的正确性。只需要一台挖断线路的挖掘机或断掉的光缆就能让你在工作中渡过糟糕的一天。
|
||||||
|
|
||||||
|
“理想状态下”,某个系统管理员明智地观察到,“你应该有[两路互联网接入线路连接到有独立基础设施的两个 ISP][41]。例如,你不希望两个 ISP 都依赖于同一根光缆。你也不希望采用两家本地 ISP,并发现他们的上行带宽都依赖于同一家骨干网运营商。”
|
||||||
|
|
||||||
|
聪明的系统管理员知道他们公司的互联网接入线路[必须是商业级别的][43],带有<ruby>服务等级协议<rt>service-level agreement(SLA)</rt></ruby>,其中包含“修复时间”条款。或者更好的是采用<ruby>互联网接入专线<rt></rt>dedicated Internet access</ruby>。技术上这与任何其他互联网接入方式没有区别。区别在于互联网接入专线不是一种“尽力而为”的接入方式,而是你会得到明确规定的专供你使用的带宽并附有服务等级协议。这种专线不便宜,但正如一句格言所说的那样,“速度、可靠性、便宜,只能挑两个。”当你的业务跑在这条线路上并且一场暴风雨即将来袭,“可靠性”必须是你挑的两个之一。
|
||||||
|
|
||||||
|
### 晴空重现之时
|
||||||
|
|
||||||
|
你没法准备应对所有自然灾害,但你可以为其中很多做好计划。有一个深思熟虑且经过测试的灾备和业务持续计划,并逐字逐句严格执行,当竞争对手溺毙的时候,你的公司可以幸存下来。
|
||||||
|
|
||||||
|
### 系统管理员对抗自然灾害:给领导者的教训
|
||||||
|
|
||||||
|
* 你的 IT 员工得说多少次:不要仅仅备份,还得测试备份?
|
||||||
|
* 没电就没公司。确保你的服务器有足够的应急电源来满足业务需要,并确保它们能正常工作。
|
||||||
|
* 如果你的公司在一场自然灾害中幸存下来,或者避开了灾害,明智的系统管理员知道这就是向管理层申请被他们推迟的灾备预算的时候了。因为下次你就未必有这么幸运了。
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.hpe.com/us/en/insights/articles/it-disaster-recovery-sysadmins-vs-natural-disasters-1711.html
|
||||||
|
|
||||||
|
作者:[Steven-J-Vaughan-Nichols][a]
|
||||||
|
译者:[0x996](https://github.com/0x996)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.hpe.com/us/en/insights/contributors/steven-j-vaughan-nichols.html
|
||||||
|
[1]:https://www.hpe.com/us/en/insights/articles/what-is-disaster-recovery-really-1704.html
|
||||||
|
[2]:https://www.reddit.com/r/sysadmin/comments/6wricr/dear_houston_tx_sysadmins/
|
||||||
|
[3]:https://www.reddit.com/r/sysadmin/comments/6wricr/dear_houston_tx_sysadmins/dma6gse/
|
||||||
|
[4]:https://disastersafety.org/wp-content/uploads/open-for-business-english.pdf
|
||||||
|
[5]:https://www.fema.gov/protecting-your-businesses
|
||||||
|
[6]:http://drbenchmark.org/about-us/our-council/
|
||||||
|
[7]:https://www.prnewswire.com/news-releases/global-benchmark-study-reveals-73-of-companies-are-unprepared-for-disaster-recovery-248359051.html
|
||||||
|
[8]:https://www.reddit.com/r/sysadmin/comments/3cob1k/what_does_your_disaster_recovery_plan_look_like/csxh8sn/
|
||||||
|
[9]:https://www.hpe.com/us/en/resources/servers/datacenter-trends-challenges.html?jumpid=in_insights~510287587~451research_datacenter~sjvnSysadmin
|
||||||
|
[10]:http://www.theregister.co.uk/2015/07/12/surviving_hurricane_katrina
|
||||||
|
[11]:https://theprepared.com/guides/beginners-guide-amateur-ham-radio-preppers/
|
||||||
|
[12]:http://www.npr.org/2017/09/29/554600989/amateur-radio-operators-stepped-in-to-help-communications-with-puerto-rico
|
||||||
|
[13]:http://www8.hp.com/us/en/software/joshua-brusse.html
|
||||||
|
[14]:https://www.microfocus.com/
|
||||||
|
[15]:https://www.reddit.com/r/sysadmin/comments/6wricr/dear_houston_tx_sysadmins/dma87xv/
|
||||||
|
[16]:https://www.hpe.com/us/en/insights/articles/my-boss-asked-me-to-do-what-how-to-handle-worrying-work-requests-1710.html
|
||||||
|
[17]:https://www.hpe.com/us/en/insights/articles/sysadmin-survival-guide-1707.html
|
||||||
|
[18]:https://www.reddit.com/r/sysadmin/comments/6wk92q/any_houston_admins_executing_their_dr_plans_this/dm8xj0q/
|
||||||
|
[19]:https://community.spiceworks.com/how_to/1243-ensure-your-dr-plan-is-ready-for-a-zombie-apocolypse
|
||||||
|
[20]:http://www.datacenterdynamics.com/content-tracks/security-risk/houston-data-centers-withstand-hurricane-harvey/98867.article
|
||||||
|
[21]:https://www.datafoundry.com/
|
||||||
|
[22]:http://www.datacenterknowledge.com/archives/2012/10/30/major-flooding-nyc-data-centers
|
||||||
|
[23]:https://datagram.com/
|
||||||
|
[24]:https://www.reddit.com/r/sysadmin/comments/6yjb3p/shutting_down_everything_blame_irma/
|
||||||
|
[25]:https://www.hpe.com/us/en/insights/articles/everything-you-need-to-know-about-clouds-and-hybrid-it-1701.html
|
||||||
|
[26]:https://www.drj.com/images/surveys_pdf/forrester/2011Forrester_survey.pdf
|
||||||
|
[27]:https://www.drj.com
|
||||||
|
[28]:https://www.reddit.com/r/sysadmin/comments/4x3mmq/datacenter_power_failure_procedures_what_do_yours/d6c71p1/
|
||||||
|
[29]:https://www.reddit.com/r/sysadmin/comments/4x3mmq/datacenter_power_failure_procedures_what_do_yours/
|
||||||
|
[30]:https://cloudandcolocation.com/datacenters/the-westin-building-seattle-data-center/
|
||||||
|
[31]:https://www.techrepublic.com/article/what-to-look-for-in-a-data-center-backup-generator/
|
||||||
|
[32]:http://www.datacenterknowledge.com/archives/2012/10/31/peer-1-mobilizes-diesel-bucket-brigade-at-75-broad
|
||||||
|
[33]:https://www.cogecopeer1.com/
|
||||||
|
[34]:https://www.reddit.com/r/sysadmin/comments/7a6m7n/aws_glacier_archival/
|
||||||
|
[35]:https://www.reddit.com/r/sysadmin/comments/63mypu/the_dangers_of_cloudberry_and_amazon_glacier_how/
|
||||||
|
[36]:https://en.wikiquote.org/wiki/Andrew_S._Tanenbaum
|
||||||
|
[37]:http://www.snia.org/ltfs
|
||||||
|
[38]:https://www.reddit.com/r/sysadmin/comments/5visaq/backups_how_many_of_you_still_have_tapes/de2d0qm/
|
||||||
|
[39]:https://helpcenter.veeam.com/docs/backup/vsphere/failover.html?ver=95
|
||||||
|
[40]:https://www.reddit.com/r/sysadmin/comments/5rttuo/i_love_you_veeam/
|
||||||
|
[41]:https://www.reddit.com/r/sysadmin/comments/5rmqfx/ars_surviving_a_cloudbased_disaster_recovery_plan/dd90auv/
|
||||||
|
[42]:https://www.hpe.com/us/en/insights/articles/how-do-you-evaluate-cloud-service-agreements-and-slas-very-carefully-1705.html
|
||||||
|
[43]:http://www.e-vergent.com/what-is-dedicated-internet-access/
|
||||||
138
published/20171216 Sysadmin 101- Troubleshooting.md
Normal file
138
published/20171216 Sysadmin 101- Troubleshooting.md
Normal file
@ -0,0 +1,138 @@
|
|||||||
|
系统管理员入门:排除故障
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我通常会严格保持此博客的技术性,将观察、意见等内容保持在最低限度。但是,这篇和接下来的几篇文章将介绍刚进入系统管理/SRE/系统工程师/sysops/devops-ops(无论你想称自己是什么)角色的常见的基础知识。
|
||||||
|
|
||||||
|
请跟我来!
|
||||||
|
|
||||||
|
> “我的网站很慢!”
|
||||||
|
|
||||||
|
我只是随机选择了本文的问题类型,这也可以应用于任何与系统管理员相关的故障排除。我并不是要炫耀那些可以发现最多的信息的最聪明的“金句”。它也不是一个详尽的、一步步指导的、并在最后一个方框中导向“利润”一词的“流程图”。
|
||||||
|
|
||||||
|
我会通过一些例子展示常规的方法。
|
||||||
|
|
||||||
|
示例场景仅用于说明本文目的。它们有时会做一些不适用于所有情况的假设,而且肯定会有很多读者在某些时候说“哦,但我觉得你会发现……”。
|
||||||
|
|
||||||
|
但那可能会让我们错失重点。
|
||||||
|
|
||||||
|
十多年来,我一直在从事于支持工作,或在支持机构工作,有一件事让我一次又一次地感到震惊,这促使我写下了这篇文章。
|
||||||
|
|
||||||
|
**有许多技术人员在遇到问题时的本能反应,就是不管三七二十一去尝试可能的解决方案。**
|
||||||
|
|
||||||
|
*“我的网站很慢,所以”,*
|
||||||
|
|
||||||
|
* 我将尝试增大 `MaxClients`/`MaxRequestWorkers`/`worker_connections`
|
||||||
|
* 我将尝试提升 `innodb_buffer_pool_size`/`effective_cache_size`
|
||||||
|
* 我打算尝试启用 `mod_gzip`(遗憾的是,这是真实的故事)
|
||||||
|
|
||||||
|
*“我曾经看过这个问题,它是因为某种原因造成的 —— 所以我估计还是这个原因,它应该能解决这个问题。”*
|
||||||
|
|
||||||
|
这浪费了很多时间,并会让你在黑暗中盲目乱撞,胡乱鼓捣。
|
||||||
|
|
||||||
|
你的 InnoDB 的缓冲池也许达到 100% 的利用率,但这可能只是因为有人运行了一段时间的一次性大型报告导致的。如果没有排除这种情况,那你就是在浪费时间。
|
||||||
|
|
||||||
|
### 开始之前
|
||||||
|
|
||||||
|
在这里,我应该说明一下,虽然这些建议同样适用于许多角色,但我是从一般的支持系统管理员的角度来撰写的。在一个成熟的内部组织中,或与规模较大的、规范管理的或“企业级”客户合作时,你通常会对一切都进行检测、测量、绘制、整理(甚至不是文字),并发出警报。那么你的方法也往往会有所不同。让我们在这里先忽略这种情况。
|
||||||
|
|
||||||
|
如果你没有这种东西,那就随意了。
|
||||||
|
|
||||||
|
### 澄清问题
|
||||||
|
|
||||||
|
首先确定实际上是什么问题。“慢”可以是多种形式的。是收到第一个字节的时间吗?从糟糕的 Javascript 加载和每页加载要拉取 15 MB 的静态内容,这是一个完全不同类型的问题。是慢,还是比通常慢?这是两个非常不同的解决方案!
|
||||||
|
|
||||||
|
在你着手做某事之前,确保你知道实际报告和遇到的问题。找到问题的根源通常很困难,但即便找不到也必须找到问题本身。
|
||||||
|
|
||||||
|
否则,这相当于系统管理员带着一把刀去参加枪战。
|
||||||
|
|
||||||
|
### 唾手可得
|
||||||
|
|
||||||
|
首次登录可疑服务器时,你可以查找一些常见的嫌疑对象。事实上,你应该这样做!每当我登录到服务器时,我都会发出一些命令来快速检查一些事情:我们是否发生了页交换(`free` / `vmstat`),磁盘是否繁忙(`top` / `iostat` / `iotop`),是否有丢包(`netstat` / `proc` / `net` / `dev`),是否处于连接数过多的状态(`netstat`),有什么东西占用了 CPU(`top`),谁在这个服务器上(`w` / `who`),syslog 和 `dmesg` 中是否有引人注目的消息?
|
||||||
|
|
||||||
|
如果你从 RAID 控制器得到 2000 条抱怨直写式缓存没有生效的消息,那么继续进行是没有意义的。
|
||||||
|
|
||||||
|
这用不了半分钟。如果什么都没有引起你的注意 —— 那么继续。
|
||||||
|
|
||||||
|
### 重现问题
|
||||||
|
|
||||||
|
如果某处确实存在问题,并且找不到唾手可得的信息。
|
||||||
|
|
||||||
|
那么采取所有步骤来尝试重现问题。当你可以重现该问题时,你就可以观察它。**当你能观察到时,你就可以解决。**如果在第一步中尚未显现出或覆盖了问题所在,询问报告问题的人需要采取哪些确切步骤来重现问题。
|
||||||
|
|
||||||
|
对于由太阳耀斑或只能运行在 OS/2 上的客户端引起的问题,重现并不总是可行的。但你的第一个停靠港应该是至少尝试一下!在一开始,你所知道的是“某人认为他们的网站很慢”。对于那些人,他们可能还在用他们的 GPRS 手机,也可能正在安装 Windows 更新。你在这里挖掘得再深也是浪费时间。
|
||||||
|
|
||||||
|
尝试重现!
|
||||||
|
|
||||||
|
### 检查日志
|
||||||
|
|
||||||
|
我对于有必要包括这一点感到很难过。但是我曾经看到有人在运行 `tail /var/log/...` 之后几分钟就不看了。大多数 *NIX 工具都特别喜欢记录日志。任何明显的错误都会在大多数应用程序日志中显得非常突出。检查一下。
|
||||||
|
|
||||||
|
### 缩小范围
|
||||||
|
|
||||||
|
如果没有明显的问题,但你可以重现所报告的问题,那也很棒。所以,你现在知道网站是慢的。现在你已经把范围缩小到:浏览器的渲染/错误、应用程序代码、DNS 基础设施、路由器、防火墙、网卡(所有的)、以太网电缆、负载均衡器、数据库、缓存层、会话存储、Web 服务器软件、应用程序服务器、内存、CPU、RAID 卡、磁盘等等。
|
||||||
|
|
||||||
|
根据设置添加一些其他可能的罪魁祸首。它们也可能是 SAN,也不要忘记硬件 WAF!以及…… 你明白我的意思。
|
||||||
|
|
||||||
|
如果问题是接收到第一个字节的时间,你当然会开始对 Web 服务器去应用上已知的修复程序,就是它响应缓慢,你也觉得几乎就是它,对吧?但是你错了!
|
||||||
|
|
||||||
|
你要回去尝试重现这个问题。只是这一次,你要试图消除尽可能多的潜在问题来源。
|
||||||
|
|
||||||
|
你可以非常轻松地消除绝大多数可能的罪魁祸首:你能从服务器本地重现问题吗?恭喜,你刚刚节省了自己必须尝试修复 BGP 路由的时间。
|
||||||
|
|
||||||
|
如果不能,请尝试使用同一网络上的其他计算机。如果可以的话,至少你可以将防火墙移到你的嫌疑人名单上,(但是要注意一下那个交换机!)
|
||||||
|
|
||||||
|
是所有的连接都很慢吗?虽然服务器是 Web 服务器,但并不意味着你不应该尝试使用其他类型的服务进行重现问题。[netcat][1] 在这些场景中非常有用(但是你的 SSH 连接可能会一直有延迟,这可以作为线索)! 如果这也很慢,你至少知道你很可能遇到了网络问题,可以忽略掉整个 Web 软件及其所有组件的问题。用这个知识(我不收 200 美元)再次从顶部开始,按你的方式由内到外地进行!
|
||||||
|
|
||||||
|
即使你可以在本地复现 —— 仍然有很多“因素”留下。让我们排除一些变量。你能用普通文件重现它吗? 如果 `i_am_a_1kb_file.html` 很慢,你就知道它不是数据库、缓存层或 OS 以外的任何东西和 Web 服务器本身的问题。
|
||||||
|
|
||||||
|
你能用一个需要解释或执行的 `hello_world.(py|php|js|rb..)` 文件重现问题吗?如果可以的话,你已经大大缩小了范围,你可以专注于少数事情。如果 `hello_world` 可以马上工作,你仍然学到了很多东西!你知道了没有任何明显的资源限制、任何满的队列或在任何地方卡住的 IPC 调用,所以这是应用程序正在做的事情或它正在与之通信的事情。
|
||||||
|
|
||||||
|
所有页面都慢吗?或者只是从第三方加载“实时分数数据”的页面慢?
|
||||||
|
|
||||||
|
**这可以归结为:你仍然可以重现这个问题所涉及的最少量的“因素”是什么?**
|
||||||
|
|
||||||
|
我们的示例是一个缓慢的网站,但这同样适用于几乎所有问题。邮件投递?你能在本地投递吗?能发给自己吗?能发给<常见的服务提供者>吗?使用小的、纯文本的消息进行测试。尝试直到遇到 2MB 拥堵时。使用 STARTTLS 和不使用 STARTTLS 呢?按你的方式由内到外地进行!
|
||||||
|
|
||||||
|
这些步骤中的每一步都只需要几秒钟,远远快于实施大多数“可能的”修复方案。
|
||||||
|
|
||||||
|
### 隔离观察
|
||||||
|
|
||||||
|
到目前为止,当你去除特定组件时无法重现问题时,你可能已经偶然发现了问题所在。
|
||||||
|
|
||||||
|
但如果你还没有,或者你仍然不知道**为什么**:一旦你找到了一种方法来重现问题,你和问题之间的“东西”(某个技术术语)最少,那么就该开始隔离和观察了。
|
||||||
|
|
||||||
|
请记住,许多服务可以在前台运行和/或启用调试。对于某些类别的问题,执行此操作通常非常有帮助。
|
||||||
|
|
||||||
|
这也是你的传统武器库发挥作用的地方。`strace`、`lsof`、`netstat`、`GDB`、`iotop`、`valgrind`、语言分析器(cProfile、xdebug、ruby-prof ……)那些类型的工具。
|
||||||
|
|
||||||
|
一旦你走到这一步,你就很少能摆脱剖析器或调试器了。
|
||||||
|
|
||||||
|
[strace][2] 通常是一个非常好的起点。
|
||||||
|
|
||||||
|
你可能会注意到应用程序停留在某个连接到端口 3306 的套接字文件描述符上的特定 `read()` 调用上。你会知道该怎么做。
|
||||||
|
|
||||||
|
转到 MySQL 并再次从顶部开始。显而易见:“等待某某锁”、死锁、`max_connections` ……进而:是所有查询?还是只写请求?只有某些表?还是只有某些存储引擎?等等……
|
||||||
|
|
||||||
|
你可能会注意到调用外部 API 资源的 `connect()` 需要五秒钟才能完成,甚至超时。你会知道该怎么做。
|
||||||
|
|
||||||
|
你可能会注意到,在同一对文件中有 1000 个调用 `fstat()` 和 `open()` 作为循环依赖的一部分。你会知道该怎么做。
|
||||||
|
|
||||||
|
它可能不是那些特别的东西,但我保证,你会发现一些东西。
|
||||||
|
|
||||||
|
如果你只是从这一部分学到一点,那也不错;学习使用 `strace` 吧!**真的**学习它,阅读整个手册页。甚至不要跳过历史部分。`man` 每个你还不知道它做了什么的系统调用。98% 的故障排除会话以 `strace` 而终结。
|
||||||
|
|
||||||
|
---------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://northernmost.org/blog/troubleshooting-101/index.html
|
||||||
|
|
||||||
|
作者:[Erik Ljungstrom][a]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://northernmost.org
|
||||||
|
[1]:http://nc110.sourceforge.net/
|
||||||
|
[2]:https://linux.die.net/man/1/strace
|
||||||
@ -0,0 +1,137 @@
|
|||||||
|
两种 cp 命令的绝佳用法的快捷方式
|
||||||
|
===================
|
||||||
|
|
||||||
|
> 这篇文章是关于如何在使用 cp 命令进行备份以及同步时提高效率。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
去年七月,我写了一篇[关于 cp 命令的两种绝佳用法][7]的文章:备份一个文件,以及同步一个文件夹的备份。
|
||||||
|
|
||||||
|
虽然这些工具确实很好用,但同时,输入这些命令太过于累赘了。为了解决这个问题,我在我的 Bash 启动文件里创建了一些 Bash 快捷方式。现在,我想把这些捷径分享给你们,以便于你们在需要的时候可以拿来用,或者是给那些还不知道怎么使用 Bash 的别名以及函数的用户提供一些思路。
|
||||||
|
|
||||||
|
### 使用 Bash 别名来更新一个文件夹的副本
|
||||||
|
|
||||||
|
如果要使用 `cp` 来更新一个文件夹的副本,通常会使用到的命令是:
|
||||||
|
|
||||||
|
```
|
||||||
|
cp -r -u -v SOURCE-FOLDER DESTINATION-DIRECTORY
|
||||||
|
```
|
||||||
|
|
||||||
|
其中 `-r` 代表“向下递归访问文件夹中的所有文件”,`-u` 代表“更新目标”,`-v` 代表“详细模式”,`SOURCE-FOLDER` 是包含最新文件的文件夹的名称,`DESTINATION-DIRECTORY` 是包含必须同步的`SOURCE-FOLDER` 副本的目录。
|
||||||
|
|
||||||
|
因为我经常使用 `cp` 命令来复制文件夹,我会很自然地想起使用 `-r` 选项。也许再想地更深入一些,我还可以想起用 `-v` 选项,如果再想得再深一层,我会想起用选项 `-u`(不知道这个选项是代表“更新”还是“同步”还是一些什么其它的)。
|
||||||
|
|
||||||
|
或者,还可以使用[Bash 的别名功能][8]来将 `cp` 命令以及其后的选项转换成一个更容易记忆的单词,就像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
alias sync='cp -r -u -v'
|
||||||
|
```
|
||||||
|
|
||||||
|
如果我将其保存在我的主目录中的 `.bash_aliases` 文件中,然后启动一个新的终端会话,我可以使用该别名了,例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
sync Pictures /media/me/4388-E5FE
|
||||||
|
```
|
||||||
|
|
||||||
|
可以将我的主目录中的图片文件夹与我的 USB 驱动器中的相同版本同步。
|
||||||
|
|
||||||
|
不清楚 `sync` 是否已经定义了?你可以在终端里输入 `alias` 这个单词来列出所有正在使用的命令别名。
|
||||||
|
|
||||||
|
喜欢吗?想要现在就立即使用吗?那就现在打开终端,输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
echo "alias sync='cp -r -u -v'" >> ~/.bash_aliases
|
||||||
|
```
|
||||||
|
|
||||||
|
然后启动一个新的终端窗口并在命令提示符下键入 `alias`。你应该看到这样的东西:
|
||||||
|
|
||||||
|
```
|
||||||
|
me@mymachine~$ alias
|
||||||
|
|
||||||
|
alias alert='notify-send --urgency=low -i "$([ $? = 0 ] && echo terminal || echo error)" "$(history|tail -n1|sed -e '\''s/^\s*[0-9]\+\s*//;s/[;&|]\s*alert$//'\'')"'
|
||||||
|
alias egrep='egrep --color=auto'
|
||||||
|
alias fgrep='fgrep --color=auto'
|
||||||
|
alias grep='grep --color=auto'
|
||||||
|
alias gvm='sdk'
|
||||||
|
alias l='ls -CF'
|
||||||
|
alias la='ls -A'
|
||||||
|
alias ll='ls -alF'
|
||||||
|
alias ls='ls --color=auto'
|
||||||
|
alias sync='cp -r -u -v'
|
||||||
|
me@mymachine:~$
|
||||||
|
```
|
||||||
|
|
||||||
|
这里你能看到 `sync` 已经定义了。
|
||||||
|
|
||||||
|
### 使用 Bash 函数来为备份编号
|
||||||
|
|
||||||
|
若要使用 `cp` 来备份一个文件,通常使用的命令是:
|
||||||
|
|
||||||
|
```
|
||||||
|
cp --force --backup=numbered WORKING-FILE BACKED-UP-FILE
|
||||||
|
```
|
||||||
|
|
||||||
|
其中 `--force` 代表“强制制作副本”,`--backup= numbered` 代表“使用数字表示备份的生成”,`WORKING-FILE` 是我们希望保留的当前文件,`BACKED-UP-FILE` 与 `WORKING-FILE` 的名称相同,并附加生成信息。
|
||||||
|
|
||||||
|
我们不仅需要记得所有 `cp` 的选项,我们还需要记得去重复输入 `WORKING-FILE` 的名字。但当[Bash 的函数功能][9]已经可以帮我们做这一切,为什么我们还要不断地重复这个过程呢?就像这样:
|
||||||
|
|
||||||
|
再一次提醒,你可将下列内容保存入你在家目录下的 `.bash_aliases` 文件里:
|
||||||
|
|
||||||
|
```
|
||||||
|
function backup {
|
||||||
|
if [ $# -ne 1 ]; then
|
||||||
|
echo "Usage: $0 filename"
|
||||||
|
elif [ -f $1 ] ; then
|
||||||
|
echo "cp --force --backup=numbered $1 $1"
|
||||||
|
cp --force --backup=numbered $1 $1
|
||||||
|
else
|
||||||
|
echo "$0: $1 is not a file"
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
我将此函数称之为 `backup`,因为我的系统上没有任何其他名为 `backup` 的命令,但你可以选择适合的任何名称。
|
||||||
|
|
||||||
|
第一个 `if` 语句是用于检查是否提供有且只有一个参数,否则,它会用 `echo` 命令来打印出正确的用法。
|
||||||
|
|
||||||
|
`elif` 语句是用于检查提供的参数所指向的是一个文件,如果是的话,它会用第二个 `echo` 命令来打印所需的 `cp` 的命令(所有的选项都是用全称来表示)并且执行它。
|
||||||
|
|
||||||
|
如果所提供的参数不是一个文件,文件中的第三个 `echo` 用于打印错误信息。
|
||||||
|
|
||||||
|
在我的家目录下,如果我执行 `backup` 这个命令,我可以发现目录下多了一个文件名为`checkCounts.sql.~1~` 的文件,如果我再执行一次,便又多了另一个名为 `checkCounts.sql.~2~` 的文件。
|
||||||
|
|
||||||
|
成功了!就像所想的一样,我可以继续编辑 `checkCounts.sql`,但如果我可以经常地用这个命令来为文件制作快照的话,我可以在我遇到问题的时候回退到最近的版本。
|
||||||
|
|
||||||
|
也许在未来的某个时间,使用 `git` 作为版本控制系统会是一个好主意。但像上文所介绍的 `backup` 这个简单而又好用的工具,是你在需要使用快照的功能时却还未准备好使用 `git` 的最好工具。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
在我的上一篇文章里,我保证我会通过使用脚本,shell 里的函数以及别名功能来简化一些机械性的动作来提高生产效率。
|
||||||
|
|
||||||
|
在这篇文章里,我已经展示了如何在使用 `cp` 命令同步或者备份文件时运用 shell 函数以及别名功能来简化操作。如果你想要了解更多,可以读一下这两篇文章:[怎样通过使用命令别名功能来减少敲击键盘的次数][10] 以及由我的同事 Greg 和 Seth 写的 [Shell 编程:shift 方法和自定义函数介绍][11]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/1/two-great-uses-cp-command-update
|
||||||
|
|
||||||
|
作者:[Chris Hermansen][a]
|
||||||
|
译者:[zyk2290](https://github.com/zyk2290)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/clhermansen
|
||||||
|
[1]:https://opensource.com/users/clhermansen
|
||||||
|
[2]:https://opensource.com/users/clhermansen
|
||||||
|
[3]:https://opensource.com/user/37806/feed
|
||||||
|
[4]:https://opensource.com/article/18/1/two-great-uses-cp-command-update?rate=J_7R7wSPbukG9y8jrqZt3EqANfYtVAwZzzpopYiH3C8
|
||||||
|
[5]:https://opensource.com/article/18/1/two-great-uses-cp-command-update#comments
|
||||||
|
[6]:https://www.flickr.com/photos/internetarchivebookimages/14803082483/in/photolist-oy6EG4-pZR3NZ-i6r3NW-e1tJSX-boBtf7-oeYc7U-o6jFKK-9jNtc3-idt2G9-i7NG1m-ouKjXe-owqviF-92xFBg-ow9e4s-gVVXJN-i1K8Pw-4jybMo-i1rsBr-ouo58Y-ouPRzz-8cGJHK-85Evdk-cru4Ly-rcDWiP-gnaC5B-pAFsuf-hRFPcZ-odvBMz-hRCE7b-mZN3Kt-odHU5a-73dpPp-hUaaAi-owvUMK-otbp7Q-ouySkB-hYAgmJ-owo4UZ-giHgqu-giHpNc-idd9uQ-osAhcf-7vxk63-7vwN65-fQejmk-pTcLgA-otZcmj-fj1aSX-hRzHQk-oyeZfR
|
||||||
|
[7]:https://opensource.com/article/17/7/two-great-uses-cp-command
|
||||||
|
[8]:https://opensource.com/article/17/5/introduction-alias-command-line-tool
|
||||||
|
[9]:https://opensource.com/article/17/1/shell-scripting-shift-method-custom-functions
|
||||||
|
[10]:https://opensource.com/article/17/5/introduction-alias-command-line-tool
|
||||||
|
[11]:https://opensource.com/article/17/1/shell-scripting-shift-method-custom-functions
|
||||||
|
[12]:https://opensource.com/tags/linux
|
||||||
|
[13]:https://opensource.com/users/clhermansen
|
||||||
|
[14]:https://opensource.com/users/clhermansen
|
||||||
@ -0,0 +1,201 @@
|
|||||||
|
本地开发如何测试 Webhook
|
||||||
|
===================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
[Webhook][10] 可用于外部系统通知你的系统发生了某个事件或更新。可能最知名的 [Webhook][10] 类型是支付服务提供商(PSP)通知你的系统支付状态有了更新。
|
||||||
|
|
||||||
|
它们通常以监听的预定义 URL 的形式出现,例如 `http://example.com/webhooks/payment-update`。同时,另一个系统向该 URL 发送具有特定有效载荷的 POST 请求(例如支付 ID)。一旦请求进入,你就会获得支付 ID,可以通过 PSP 的 API 用这个支付 ID 向它们询问最新状态,然后更新你的数据库。
|
||||||
|
|
||||||
|
其他例子可以在这个对 Webhook 的出色的解释中找到:[https://sendgrid.com/blog/whats-webhook/][12]。
|
||||||
|
|
||||||
|
只要系统可通过互联网公开访问(这可能是你的生产环境或可公开访问的临时环境),测试这些 webhook 就相当顺利。而当你在笔记本电脑上或虚拟机内部(例如,Vagrant 虚拟机)进行本地开发时,它就变得困难了。在这些情况下,发送 webhook 的一方无法公开访问你的本地 URL。此外,监视发送的请求也很困难,这可能使开发和调试变得困难。
|
||||||
|
|
||||||
|
因此,这个例子将解决:
|
||||||
|
|
||||||
|
* 测试来自本地开发环境的 webhook,该环境无法通过互联网访问。从服务器向 webhook 发送数据的服务无法访问它。
|
||||||
|
* 监控发送的请求和数据,以及应用程序生成的响应。这样可以更轻松地进行调试,从而缩短开发周期。
|
||||||
|
|
||||||
|
前置需求:
|
||||||
|
|
||||||
|
* *可选*:如果你使用虚拟机(VM)进行开发,请确保它正在运行,并确保在 VM 中完成后续步骤。
|
||||||
|
* 对于本教程,我们假设你定义了一个 vhost:`webhook.example.vagrant`。我在本教程中使用了 Vagrant VM,但你可以自由选择 vhost。
|
||||||
|
* 按照这个[安装说明][3]安装 `ngrok`。在 VM 中,我发现它的 Node 版本也很有用:[https://www.npmjs.com/package/ngrok][4],但你可以随意使用其他方法。
|
||||||
|
|
||||||
|
我假设你没有在你的环境中运行 SSL,但如果你使用了,请将在下面的示例中的端口 80 替换为端口 433,`http://` 替换为 `https://`。
|
||||||
|
|
||||||
|
### 使 webhook 可测试
|
||||||
|
|
||||||
|
我们假设以下示例代码。我将使用 PHP,但请将其视作伪代码,因为我留下了一些关键部分(例如 API 密钥、输入验证等)没有编写。
|
||||||
|
|
||||||
|
第一个文件:`payment.php`。此文件创建一个 `$payment` 对象,将其注册到 PSP。然后它获取客户需要访问的 URL,以便支付并将用户重定向到客户那里。
|
||||||
|
|
||||||
|
请注意,此示例中的 `webhook.example.vagrant` 是我们为开发设置定义的本地虚拟主机。它无法从外部世界进入。
|
||||||
|
|
||||||
|
```
|
||||||
|
<?php
|
||||||
|
/*
|
||||||
|
* This file creates a payment and tells the PSP what webhook URL to use for updates
|
||||||
|
* After creating the payment, we get a URL to send the customer to in order to pay at the PSP
|
||||||
|
*/
|
||||||
|
$payment = [
|
||||||
|
'order_id' => 123,
|
||||||
|
'amount' => 25.00,
|
||||||
|
'description' => 'Test payment',
|
||||||
|
'redirect_url' => 'http://webhook.example.vagrant/redirect.php',
|
||||||
|
'webhook_url' => 'http://webhook.example.vagrant/webhook.php',
|
||||||
|
];
|
||||||
|
|
||||||
|
$payment = $paymentProvider->createPayment($payment);
|
||||||
|
header("Location: " . $payment->getPaymentUrl());
|
||||||
|
```
|
||||||
|
|
||||||
|
第二个文件:`webhook.php`。此文件等待 PSP 调用以获得有关更新的通知。
|
||||||
|
|
||||||
|
```
|
||||||
|
<?php
|
||||||
|
/*
|
||||||
|
* This file gets called by the PSP and in the $_POST they submit an 'id'
|
||||||
|
* We can use this ID to get the latest status from the PSP and update our internal systems afterward
|
||||||
|
*/
|
||||||
|
|
||||||
|
$paymentId = $_POST['id'];
|
||||||
|
$paymentInfo = $paymentProvider->getPayment($paymentId);
|
||||||
|
$status = $paymentInfo->getStatus();
|
||||||
|
|
||||||
|
// Perform actions in here to update your system
|
||||||
|
if ($status === 'paid') {
|
||||||
|
..
|
||||||
|
}
|
||||||
|
elseif ($status === 'cancelled') {
|
||||||
|
..
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
我们的 webhook URL 无法通过互联网访问(请记住它:`webhook.example.vagrant`)。因此,PSP 永远不可能调用文件 `webhook.php`,你的系统将永远不会知道付款状态,这最终导致订单永远不会被运送给客户。
|
||||||
|
|
||||||
|
幸运的是,`ngrok` 可以解决这个问题。 [ngrok][13] 将自己描述为:
|
||||||
|
|
||||||
|
> ngrok 通过安全隧道将 NAT 和防火墙后面的本地服务器暴露给公共互联网。
|
||||||
|
|
||||||
|
让我们为我们的项目启动一个基本的隧道。在你的环境中(在你的系统上或在 VM 上)运行以下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
ngrok http -host-header=rewrite webhook.example.vagrant:80
|
||||||
|
```
|
||||||
|
|
||||||
|
> 阅读其文档可以了解更多配置选项:[https://ngrok.com/docs][14]。
|
||||||
|
|
||||||
|
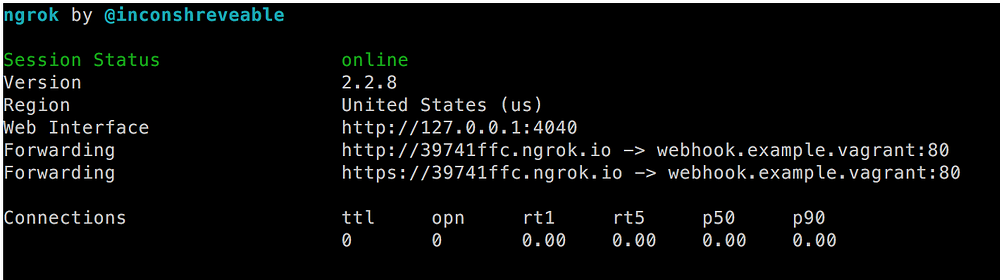
会出现这样的屏幕:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
*ngrok 输出*
|
||||||
|
|
||||||
|
我们刚刚做了什么?基本上,我们指示 `ngrok` 在端口 80 建立了一个到 `http://webhook.example.vagrant` 的隧道。同一个 URL 也可以通过 `http://39741ffc.ngrok.io` 或 `https://39741ffc.ngrok.io` 访问,它们能被任何知道此 URL 的人通过互联网公开访问。
|
||||||
|
|
||||||
|
请注意,你可以同时获得 HTTP 和 HTTPS 两个服务。这个文档提供了如何将此限制为 HTTPS 的示例:[https://ngrok.com/docs#bind-tls][16]。
|
||||||
|
|
||||||
|
那么,我们如何让我们的 webhook 现在工作起来?将 `payment.php` 更新为以下代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
<?php
|
||||||
|
/*
|
||||||
|
* This file creates a payment and tells the PSP what webhook URL to use for updates
|
||||||
|
* After creating the payment, we get a URL to send the customer to in order to pay at the PSP
|
||||||
|
*/
|
||||||
|
$payment = [
|
||||||
|
'order_id' => 123,
|
||||||
|
'amount' => 25.00,
|
||||||
|
'description' => 'Test payment',
|
||||||
|
'redirect_url' => 'http://webhook.example.vagrant/redirect.php',
|
||||||
|
'webhook_url' => 'https://39741ffc.ngrok.io/webhook.php',
|
||||||
|
];
|
||||||
|
|
||||||
|
$payment = $paymentProvider->createPayment($payment);
|
||||||
|
header("Location: " . $payment->getPaymentUrl());
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,我们告诉 PSP 通过 HTTPS 调用此隧道 URL。只要 PSP 通过隧道调用 webhook,`ngrok` 将确保使用未修改的有效负载调用内部 URL。
|
||||||
|
|
||||||
|
### 如何监控对 webhook 的调用?
|
||||||
|
|
||||||
|
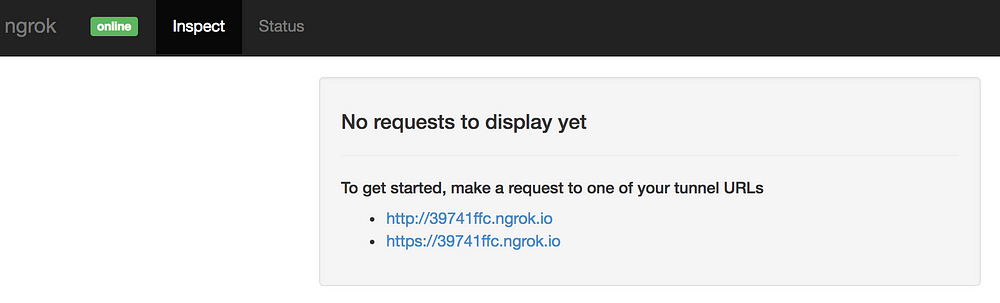
你在上面看到的屏幕截图概述了对隧道主机的调用,这些数据相当有限。幸运的是,`ngrok` 提供了一个非常好的仪表板,允许你检查所有调用:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
我不会深入研究这个问题,因为它是不言自明的,你只要运行它就行了。因此,我将解释如何在 Vagrant 虚拟机上访问它,因为它不是开箱即用的。
|
||||||
|
|
||||||
|
仪表板将允许你查看所有调用、其状态代码、标头和发送的数据。你将看到应用程序生成的响应。
|
||||||
|
|
||||||
|
仪表板的另一个优点是它允许你重放某个调用。假设你的 webhook 代码遇到了致命的错误,开始新的付款并等待 webhook 被调用将会很繁琐。重放上一个调用可以使你的开发过程更快。
|
||||||
|
|
||||||
|
默认情况下,仪表板可在 `http://localhost:4040` 访问。
|
||||||
|
|
||||||
|
### 虚拟机中的仪表盘
|
||||||
|
|
||||||
|
为了在 VM 中完成此工作,你必须执行一些额外的步骤:
|
||||||
|
|
||||||
|
首先,确保可以在端口 4040 上访问 VM。然后,在 VM 内创建一个文件已存放此配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
web_addr: 0.0.0.0:4040
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,杀死仍在运行的 `ngrok` 进程,并使用稍微调整过的命令启动它:
|
||||||
|
|
||||||
|
```
|
||||||
|
ngrok http -config=/path/to/config/ngrok.conf -host-header=rewrite webhook.example.vagrant:80
|
||||||
|
```
|
||||||
|
|
||||||
|
尽管 ID 已经更改,但你将看到类似于上一屏幕截图的屏幕。之前的网址不再有效,但你有了一个新网址。 此外,`Web Interface` URL 已更改:
|
||||||
|
|
||||||
|
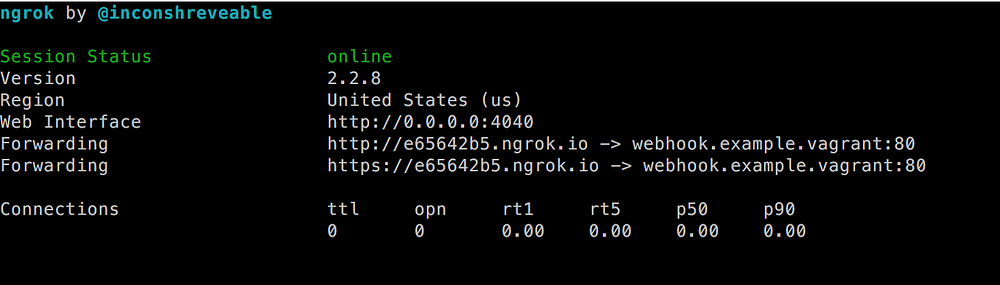
|
||||||
|
|
||||||
|
现在将浏览器指向 `http://webhook.example.vagrant:4040` 以访问仪表板。另外,对 `https://e65642b5.ngrok.io/webhook.php` 做个调用。这可能会导致你的浏览器出错,但仪表板应显示正有一个请求。
|
||||||
|
|
||||||
|
### 最后的备注
|
||||||
|
|
||||||
|
上面的例子是伪代码。原因是每个外部系统都以不同的方式使用 webhook。我试图基于一个虚构的 PSP 实现给出一个例子,因为可能很多开发人员在某个时刻肯定会处理付款。
|
||||||
|
|
||||||
|
请注意,你的 webhook 网址也可能被意图不好的其他人使用。确保验证发送给它的任何输入。
|
||||||
|
|
||||||
|
更好的的,可以向 URL 添加令牌,该令牌对于每个支付是唯一的。只有你的系统和发送 webhook 的系统才能知道此令牌。
|
||||||
|
|
||||||
|
祝你测试和调试你的 webhook 顺利!
|
||||||
|
|
||||||
|
注意:我没有在 Docker 上测试过本教程。但是,这个 Docker 容器看起来是一个很好的起点,并包含了明确的说明:[https://github.com/wernight/docker-ngrok][19] 。
|
||||||
|
|
||||||
|
--------
|
||||||
|
|
||||||
|
via: https://medium.freecodecamp.org/testing-webhooks-while-using-vagrant-for-development-98b5f3bedb1d
|
||||||
|
|
||||||
|
作者:[Stefan Doorn][a]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://medium.freecodecamp.org/@stefandoorn
|
||||||
|
[1]:https://unsplash.com/photos/MYTyXb7fgG0?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||||
|
[2]:https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||||
|
[3]:https://ngrok.com/download
|
||||||
|
[4]:https://www.npmjs.com/package/ngrok
|
||||||
|
[5]:http://webhook.example.vagrnat/
|
||||||
|
[6]:http://39741ffc.ngrok.io/
|
||||||
|
[7]:http://39741ffc.ngrok.io/
|
||||||
|
[8]:http://webhook.example.vagrant:4040/
|
||||||
|
[9]:https://e65642b5.ngrok.io/webhook.php.
|
||||||
|
[10]:https://sendgrid.com/blog/whats-webhook/
|
||||||
|
[11]:http://example.com/webhooks/payment-update%29
|
||||||
|
[12]:https://sendgrid.com/blog/whats-webhook/
|
||||||
|
[13]:https://ngrok.com/
|
||||||
|
[14]:https://ngrok.com/docs
|
||||||
|
[15]:http://39741ffc.ngrok.io%2C/
|
||||||
|
[16]:https://ngrok.com/docs#bind-tls
|
||||||
|
[17]:http://localhost:4040./
|
||||||
|
[18]:https://e65642b5.ngrok.io/webhook.php.
|
||||||
|
[19]:https://github.com/wernight/docker-ngrok
|
||||||
|
[20]:https://github.com/stefandoorn
|
||||||
|
[21]:https://twitter.com/stefan_doorn
|
||||||
|
[22]:https://www.linkedin.com/in/stefandoorn
|
||||||
@ -0,0 +1,106 @@
|
|||||||
|
Logreduce:用 Python 和机器学习去除日志噪音
|
||||||
|
======
|
||||||
|
|
||||||
|
> Logreduce 可以通过从大量日志数据中挑选出异常来节省调试时间。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
持续集成(CI)作业会生成大量数据。当一个作业失败时,弄清楚出了什么问题可能是一个繁琐的过程,它涉及到调查日志以发现根本原因 —— 这通常只能在全部的作业输出的一小部分中找到。为了更容易地将最相关的数据与其余数据分开,可以使用先前成功运行的作业结果来训练 [Logreduce][1] 机器学习模型,以从失败的运行日志中提取异常。
|
||||||
|
|
||||||
|
此方法也可以应用于其他用例,例如,从 [Journald][2] 或其他系统级的常规日志文件中提取异常。
|
||||||
|
|
||||||
|
### 使用机器学习来降低噪音
|
||||||
|
|
||||||
|
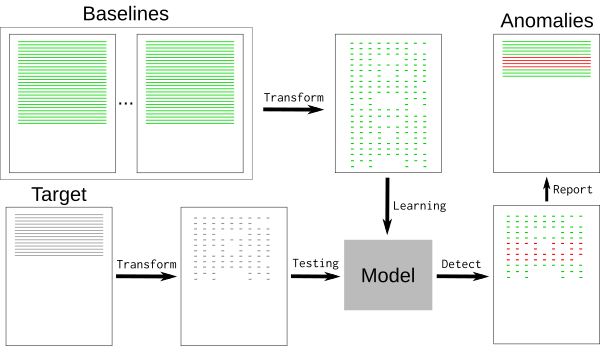
典型的日志文件包含许多标称事件(“基线”)以及与开发人员相关的一些例外事件。基线可能包含随机元素,例如难以检测和删除的时间戳或唯一标识符。要删除基线事件,我们可以使用 [k-最近邻模式识别算法][3](k-NN)。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
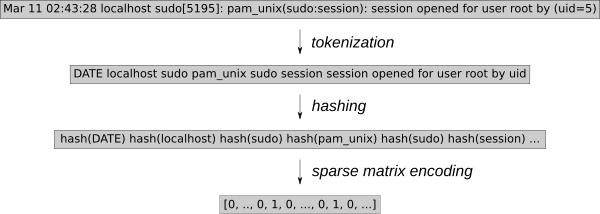
日志事件必须转换为可用于 k-NN 回归的数值。使用通用特征提取工具 [HashingVectorizer][4] 可以将该过程应用于任何类型的日志。它散列每个单词并在稀疏矩阵中对每个事件进行编码。为了进一步减少搜索空间,这个标记化过程删除了已知的随机单词,例如日期或 IP 地址。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
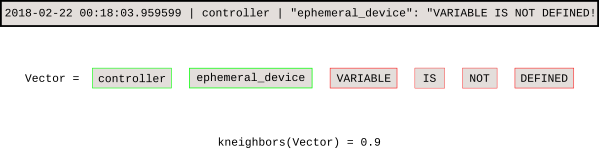
训练模型后,k-NN 搜索可以告诉我们每个新事件与基线的距离。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
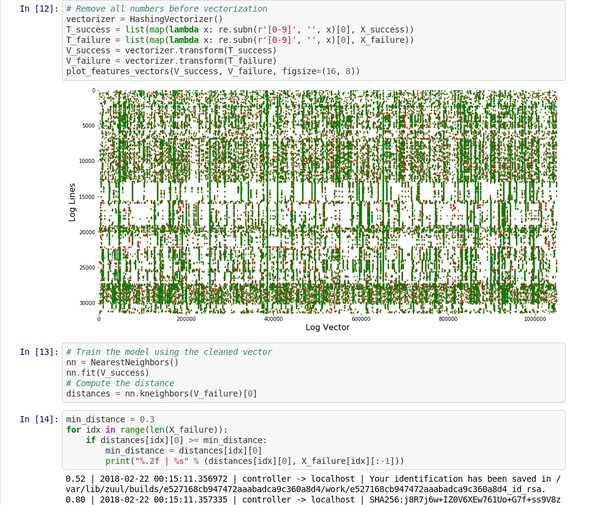
这个 [Jupyter 笔记本][5] 演示了该稀疏矩阵向量的处理和图形。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Logreduce 介绍
|
||||||
|
|
||||||
|
Logreduce Python 软件透明地实现了这个过程。Logreduce 的最初目标是使用构建数据库来协助分析 [Zuul CI][6] 作业的失败问题,现在它已集成到 [Software Factory 开发车间][7]的作业日志处理中。
|
||||||
|
|
||||||
|
最简单的是,Logreduce 会比较文件或目录并删除相似的行。Logreduce 为每个源文件构建模型,并使用以下语法输出距离高于定义阈值的任何目标行:`distance | filename:line-number: line-content`。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ logreduce diff /var/log/audit/audit.log.1 /var/log/audit/audit.log
|
||||||
|
INFO logreduce.Classifier - Training took 21.982s at 0.364MB/s (1.314kl/s) (8.000 MB - 28.884 kilo-lines)
|
||||||
|
0.244 | audit.log:19963: type=USER_AUTH acct="root" exe="/usr/bin/su" hostname=managesf.sftests.com
|
||||||
|
INFO logreduce.Classifier - Testing took 18.297s at 0.306MB/s (1.094kl/s) (5.607 MB - 20.015 kilo-lines)
|
||||||
|
99.99% reduction (from 20015 lines to 1
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
更高级的 Logreduce 用法可以离线训练模型以便重复使用。可以使用基线的许多变体来拟合 k-NN 搜索树。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ logreduce dir-train audit.clf /var/log/audit/audit.log.*
|
||||||
|
INFO logreduce.Classifier - Training took 80.883s at 0.396MB/s (1.397kl/s) (32.001 MB - 112.977 kilo-lines)
|
||||||
|
DEBUG logreduce.Classifier - audit.clf: written
|
||||||
|
$ logreduce dir-run audit.clf /var/log/audit/audit.log
|
||||||
|
```
|
||||||
|
|
||||||
|
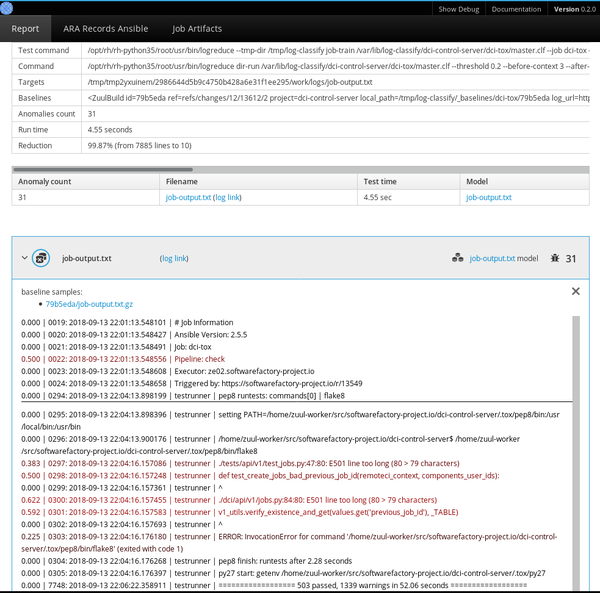
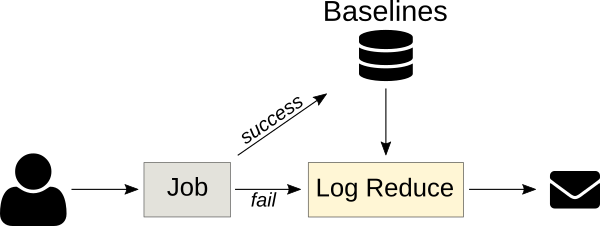
Logreduce 还实现了接口,以发现 Journald 时间范围(天/周/月)和 Zuul CI 作业构建历史的基线。它还可以生成 HTML 报告,该报告在一个简单的界面中将在多个文件中发现的异常进行分组。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 管理基线
|
||||||
|
|
||||||
|
使用 k-NN 回归进行异常检测的关键是拥有一个已知良好基线的数据库,该模型使用数据库来检测偏离太远的日志行。此方法依赖于包含所有标称事件的基线,因为基线中未找到的任何内容都将报告为异常。
|
||||||
|
|
||||||
|
CI 作业是 k-NN 回归的重要目标,因为作业的输出通常是确定性的,之前的运行结果可以自动用作基线。 Logreduce 具有 Zuul 作业角色,可以将其用作失败的作业发布任务的一部分,以便发布简明报告(而不是完整作业的日志)。只要可以提前构建基线,该原则就可以应用于其他情况。例如,标称系统的 [SoS 报告][8] 可用于查找缺陷部署中的问题。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
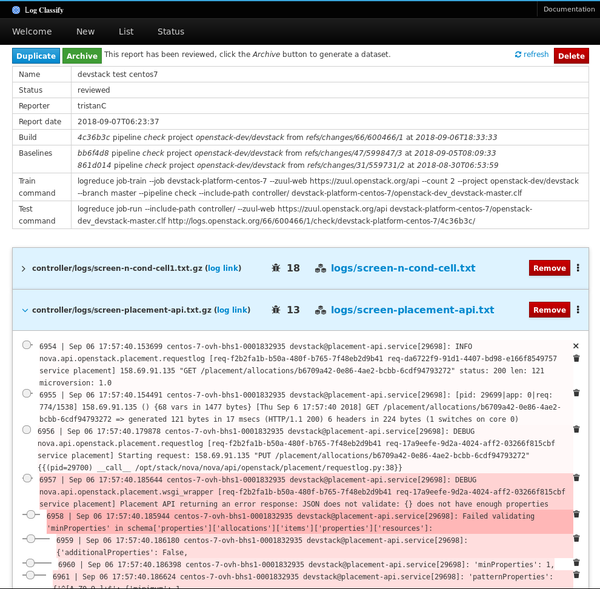
### 异常分类服务
|
||||||
|
|
||||||
|
下一版本的 Logreduce 引入了一种服务器模式,可以将日志处理卸载到外部服务,在外部服务中可以进一步分析该报告。它还支持导入现有报告和请求以分析 Zuul 构建。这些服务以异步方式运行分析,并具有 Web 界面以调整分数并消除误报。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
已审核的报告可以作为独立数据集存档,其中包含目标日志文件和记录在一个普通的 JSON 文件中的异常行的分数。
|
||||||
|
|
||||||
|
### 项目路线图
|
||||||
|
|
||||||
|
Logreduce 已经能有效使用,但是有很多机会来改进该工具。未来的计划包括:
|
||||||
|
|
||||||
|
* 策划在日志文件中发现的许多带注释的异常,并生成一个公共域数据集以进行进一步研究。日志文件中的异常检测是一个具有挑战性的主题,并且有一个用于测试新模型的通用数据集将有助于识别新的解决方案。
|
||||||
|
* 重复使用带注释的异常模型来优化所报告的距离。例如,当用户通过将距离设置为零来将日志行标记为误报时,模型可能会降低未来报告中这些日志行的得分。
|
||||||
|
* 对存档异常取指纹特征以检测新报告何时包含已知的异常。因此,该服务可以通知用户该作业遇到已知问题,而不是报告异常的内容。解决问题后,该服务可以自动重新启动该作业。
|
||||||
|
* 支持更多基准发现接口,用于 SOS 报告、Jenkins 构建、Travis CI 等目标。
|
||||||
|
|
||||||
|
如果你有兴趣参与此项目,请通过 #log-classify Freenode IRC 频道与我们联系。欢迎反馈!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/9/quiet-log-noise-python-and-machine-learning
|
||||||
|
|
||||||
|
作者:[Tristan de Cacqueray][a]
|
||||||
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/tristanc
|
||||||
|
[1]: https://pypi.org/project/logreduce/
|
||||||
|
[2]: http://man7.org/linux/man-pages/man8/systemd-journald.service.8.html
|
||||||
|
[3]: https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
|
||||||
|
[4]: http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.HashingVectorizer.html
|
||||||
|
[5]: https://github.com/TristanCacqueray/anomaly-detection-workshop-opendev/blob/master/datasets/notebook/anomaly-detection-with-scikit-learn.ipynb
|
||||||
|
[6]: https://zuul-ci.org
|
||||||
|
[7]: https://www.softwarefactory-project.io
|
||||||
|
[8]: https://sos.readthedocs.io/en/latest/
|
||||||
|
[9]: https://www.openstack.org/summit/berlin-2018/summit-schedule/speakers/4307
|
||||||
|
[10]: https://www.openstack.org/summit/berlin-2018/
|
||||||
@ -0,0 +1,130 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11200-1.html)
|
||||||
|
[#]: subject: (How to detect automatically generated emails)
|
||||||
|
[#]: via: (https://arp242.net/weblog/autoreply.html)
|
||||||
|
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||||
|
|
||||||
|
如何检测自动生成的电子邮件
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
当你用电子邮件系统发送自动回复时,你需要注意不要向自动生成的电子邮件发送回复。最好的情况下,你将获得无用的投递失败消息。更可能的是,你会得到一个无限的电子邮件循环和一个混乱的世界。
|
||||||
|
|
||||||
|
事实证明,可靠地检测自动生成的电子邮件并不总是那么容易。以下是基于为此编写的检测器并使用它扫描大约 100,000 封电子邮件(大量的个人存档和公司存档)的观察结果。
|
||||||
|
|
||||||
|
### Auto-submitted 信头
|
||||||
|
|
||||||
|
由 [RFC 3834][1] 定义。
|
||||||
|
|
||||||
|
这是表示你的邮件是自动回复的“官方”标准。如果存在 `Auto-Submitted` 信头,并且其值不是 `no`,你应该**不**发送回复。
|
||||||
|
|
||||||
|
### X-Auto-Response-Suppress 信头
|
||||||
|
|
||||||
|
[由微软][2]定义。
|
||||||
|
|
||||||
|
此信头由微软 Exchange、Outlook 和其他一些产品使用。许多新闻订阅等都设定了这个。如果 `X-Auto-Response-Suppress` 包含 `DR`(“抑制投递报告”)、`AutoReply`(“禁止 OOF 通知以外的自动回复消息”)或 `All`,你应该**不**发送回复。
|
||||||
|
|
||||||
|
### List-Id 和 List-Unsubscribe 信头
|
||||||
|
|
||||||
|
由 [RFC 2919][3] 定义。
|
||||||
|
|
||||||
|
你通常不希望给邮件列表或新闻订阅发送自动回复。几乎所有的邮件列表和大多数新闻订阅都至少设置了其中一个信头。如果存在这些信头中的任何一个,你应该**不**发送回复。这个信头的值不重要。
|
||||||
|
|
||||||
|
### Feedback-ID 信头
|
||||||
|
|
||||||
|
[由谷歌][4]定义。
|
||||||
|
|
||||||
|
Gmail 使用此信头识别邮件是否是新闻订阅,并使用它为这些新闻订阅的所有者生成统计信息或报告。如果此信头存在,你应该**不**发送回复。这个信头的值不重要。
|
||||||
|
|
||||||
|
### 非标准方式
|
||||||
|
|
||||||
|
上述方法定义明确(即使有些是非标准的)。不幸的是,有些电子邮件系统不使用它们中的任何一个 :-( 这里有一些额外的措施。
|
||||||
|
|
||||||
|
#### Precedence 信头
|
||||||
|
|
||||||
|
在 [RFC 2076][5] 中没有真正定义,不鼓励使用它(但通常会遇到此信头)。
|
||||||
|
|
||||||
|
请注意,不建议检查是否存在此信头,因为某些邮件使用 `normal` 和其他一些(少见的)值(尽管这不常见)。
|
||||||
|
|
||||||
|
我的建议是如果其值不区分大小写地匹配 `bulk`、`auto_reply` 或 `list`,则**不**发送回复。
|
||||||
|
|
||||||
|
#### 其他不常见的信头
|
||||||
|
|
||||||
|
这是我遇到的另外的一些(不常见的)信头。如果设置了其中一个,我建议**不**发送自动回复。大多数邮件也设置了上述信头之一,但有些没有(这并不常见)。
|
||||||
|
|
||||||
|
* `X-MSFBL`:无法真正找到定义(Microsoft 信头?),但我只有自动生成的邮件带有此信头。
|
||||||
|
* `X-Loop`:在任何地方都没有真正定义过,有点罕见,但有时有。它通常设置为不应该收到电子邮件的地址,但也会遇到 `X-Loop: yes`。
|
||||||
|
* `X-Autoreply`:相当罕见,并且似乎总是具有 `yes` 的值。
|
||||||
|
|
||||||
|
#### Email 地址
|
||||||
|
|
||||||
|
检查 `From` 或 `Reply-To` 信头是否包含 `noreply`、`no-reply` 或 `no_reply`(正则表达式:`^no.?reply@`)。
|
||||||
|
|
||||||
|
#### 只有 HTML 部分
|
||||||
|
|
||||||
|
如果电子邮件只有 HTML 部分,而没有文本部分,则表明这是一个自动生成的邮件或新闻订阅。几乎所有邮件客户端都设置了文本部分。
|
||||||
|
|
||||||
|
#### 投递失败消息
|
||||||
|
|
||||||
|
许多传递失败消息并不能真正表明它们是失败的。一些检查方法:
|
||||||
|
|
||||||
|
* `From` 包含 `mailer-daemon` 或 `Mail Delivery Subsystem`
|
||||||
|
|
||||||
|
#### 特定的邮件库特征
|
||||||
|
|
||||||
|
许多邮件类库留下了某种痕迹,大多数常规邮件客户端使用自己的数据覆盖它。检查这个似乎工作得相当可靠。
|
||||||
|
|
||||||
|
* `X-Mailer: Microsoft CDO for Windows 2000`:由某些微软软件设置;我只能在自动生成的邮件中找到它。是的,在 2015 年它仍然在使用。
|
||||||
|
* `Message-ID` 信头包含 `.JavaMail.`:我发现了一些(5 个 50k 大小的)常规消息,但不是很多;绝大多数(数千封)邮件是新闻订阅、订单确认等。
|
||||||
|
* `^X-Mailer` 以 `PHP` 开头。这应该会同时看到 `X-Mailer: PHP/5.5.0` 和 `X-Mailer: PHPmailer XXX XXX`。与 “JavaMail” 相同。
|
||||||
|
* 出现了 `X-Library`;似乎只有 [Indy][6] 设定了这个。
|
||||||
|
* `X-Mailer` 以 `wdcollect` 开头。由一些 Plesk 邮件设置。
|
||||||
|
* `X-Mailer` 以 `MIME-tools` 开头。
|
||||||
|
|
||||||
|
### 最后的预防措施:限制回复的数量
|
||||||
|
|
||||||
|
即使遵循上述所有建议,你仍可能会遇到一个避开所有这些检测的电子邮件程序。这可能非常危险,因为电子邮件系统只是“如果有电子邮件那么发送”,就有可能导致无限的电子邮件循环。
|
||||||
|
|
||||||
|
出于这个原因,我建议你记录你自动发送的电子邮件,并将此速率限制为在几分钟内最多几封电子邮件。这将打破循环链条。
|
||||||
|
|
||||||
|
我们使用每五分钟一封电子邮件的设置,但没这么严格的设置可能也会运作良好。
|
||||||
|
|
||||||
|
### 你需要为自动回复设置什么信头
|
||||||
|
|
||||||
|
具体细节取决于你发送的邮件类型。这是我们用于自动回复邮件的内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
Auto-Submitted: auto-replied
|
||||||
|
X-Auto-Response-Suppress: All
|
||||||
|
Precedence: auto_reply
|
||||||
|
```
|
||||||
|
|
||||||
|
### 反馈
|
||||||
|
|
||||||
|
你可以发送电子邮件至 [martin@arp242.net][7] 或 [创建 GitHub 议题][8]以提交反馈、问题等。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://arp242.net/weblog/autoreply.html
|
||||||
|
|
||||||
|
作者:[Martin Tournoij][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://arp242.net/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: http://tools.ietf.org/html/rfc3834
|
||||||
|
[2]: https://msdn.microsoft.com/en-us/library/ee219609(v=EXCHG.80).aspx
|
||||||
|
[3]: https://tools.ietf.org/html/rfc2919)
|
||||||
|
[4]: https://support.google.com/mail/answer/6254652?hl=en
|
||||||
|
[5]: http://www.faqs.org/rfcs/rfc2076.html
|
||||||
|
[6]: http://www.indyproject.org/index.en.aspx
|
||||||
|
[7]: mailto:martin@arp242.net
|
||||||
|
[8]: https://github.com/Carpetsmoker/arp242.net/issues/new
|
||||||
235
published/20190304 How to Install MongoDB on Ubuntu.md
Normal file
235
published/20190304 How to Install MongoDB on Ubuntu.md
Normal file
@ -0,0 +1,235 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11175-1.html)
|
||||||
|
[#]: subject: (How to Install MongoDB on Ubuntu)
|
||||||
|
[#]: via: (https://itsfoss.com/install-mongodb-ubuntu)
|
||||||
|
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||||
|
|
||||||
|
如何在 Ubuntu 上安装 MongoDB
|
||||||
|
======
|
||||||
|
|
||||||
|
> 本教程介绍了在 Ubuntu 和基于 Ubuntu 的 Linux 发行版上安装 MongoDB 的两种方法。
|
||||||
|
|
||||||
|
[MongoDB][1] 是一个越来越流行的自由开源的 NoSQL 数据库,它将数据存储在类似 JSON 的灵活文档集中,这与 SQL 数据库中常见的表格形式形成对比。
|
||||||
|
|
||||||
|
你很可能发现在现代 Web 应用中使用 MongoDB。它的文档模型使得使用各种编程语言能非常直观地访问和处理它。
|
||||||
|
|
||||||
|
![mongodb Ubuntu][2]
|
||||||
|
|
||||||
|
在本文中,我将介绍两种在 Ubuntu 上安装 MongoDB 的方法。
|
||||||
|
|
||||||
|
### 在基于 Ubuntu 的发行版上安装 MongoDB
|
||||||
|
|
||||||
|
1. 使用 Ubuntu 仓库安装 MongoDB。简单但不是最新版本的 MongoDB
|
||||||
|
2. 使用其官方仓库安装 MongoDB。稍微复杂,但你能得到最新版本的 MongoDB。
|
||||||
|
|
||||||
|
第一种安装方法更容易,但如果你计划使用官方支持的最新版本,那么我建议使用第二种方法。
|
||||||
|
|
||||||
|
有些人可能更喜欢使用 snap 包。Ubuntu 软件中心提供了 snap,但我不建议使用它们,因为他们现在已经过期了,因此我这里不会提到。
|
||||||
|
|
||||||
|
### 方法 1:从 Ubuntu 仓库安装 MongoDB
|
||||||
|
|
||||||
|
这是在系统中安装 MongoDB 的简便方法,你只需输入一个命令即可。
|
||||||
|
|
||||||
|
#### 安装 MongoDB
|
||||||
|
|
||||||
|
首先,确保你的包是最新的。打开终端并输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt update && sudo apt upgrade -y
|
||||||
|
```
|
||||||
|
|
||||||
|
继续安装 MongoDB:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt install mongodb
|
||||||
|
```
|
||||||
|
|
||||||
|
这就完成了!MongoDB 现在安装到你的计算机上了。
|
||||||
|
|
||||||
|
MongoDB 服务应该在安装时自动启动,但要检查服务状态:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl status mongodb
|
||||||
|
```
|
||||||
|
|
||||||
|
![Check if the MongoDB service is running.][3]
|
||||||
|
|
||||||
|
你可以看到该服务是**活动**的。
|
||||||
|
|
||||||
|
#### 运行 MongoDB
|
||||||
|
|
||||||
|
MongoDB 目前是一个 systemd 服务,因此我们使用 `systemctl` 来检查和修改它的状态,使用以下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl status mongodb
|
||||||
|
sudo systemctl stop mongodb
|
||||||
|
sudo systemctl start mongodb
|
||||||
|
sudo systemctl restart mongodb
|
||||||
|
```
|
||||||
|
|
||||||
|
你也可以修改 MongoDB 是否自动随系统启动(默认:启用):
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl disable mongodb
|
||||||
|
sudo systemctl enable mongodb
|
||||||
|
```
|
||||||
|
|
||||||
|
要开始使用(创建和编辑)数据库,请输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
mongo
|
||||||
|
```
|
||||||
|
|
||||||
|
这将启动 **mongo shell**。有关查询和选项的详细信息,请查看[手册][4]。
|
||||||
|
|
||||||
|
**注意:**根据你计划使用 MongoDB 的方式,你可能需要调整防火墙。不过这超出了本篇的内容,并且取决于你的配置。
|
||||||
|
|
||||||
|
#### 卸载 MongoDB
|
||||||
|
|
||||||
|
如果你从 Ubuntu 仓库安装 MongoDB 并想要卸载它(可能要使用官方支持的方式安装),请输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl stop mongodb
|
||||||
|
sudo apt purge mongodb
|
||||||
|
sudo apt autoremove
|
||||||
|
```
|
||||||
|
|
||||||
|
这应该会完全卸载 MongoDB。确保**备份**你可能想要保留的任何集合或文档,因为它们将被删除!
|
||||||
|
|
||||||
|
### 方法 2:在 Ubuntu 上安装 MongoDB 社区版
|
||||||
|
|
||||||
|
这是推荐的安装 MongoDB 的方法,它使用包管理器。你需要多打几条命令,对于 Linux 新手而言,这可能会感到害怕。
|
||||||
|
|
||||||
|
但没有什么可怕的!我们将一步步说明安装过程。
|
||||||
|
|
||||||
|
#### 安装 MongoDB
|
||||||
|
|
||||||
|
由 MongoDB Inc. 维护的包称为 `mongodb-org`,而不是 `mongodb`(这是 Ubuntu 仓库中包的名称)。在开始之前,请确保系统上未安装 `mongodb`。因为包之间会发生冲突。让我们开始吧!
|
||||||
|
|
||||||
|
首先,我们必须导入公钥:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,你需要在源列表中添加一个新的仓库,以便你可以安装 MongoDB 社区版并获得自动更新:
|
||||||
|
|
||||||
|
```
|
||||||
|
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu $(lsb_release -cs)/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list
|
||||||
|
```
|
||||||
|
|
||||||
|
要安装 `mongodb-org`,我们需要更新我们的包数据库,以便系统知道可用的新包:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt update
|
||||||
|
```
|
||||||
|
|
||||||
|
现在你可以安装**最新稳定版**的 MongoDB:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt install -y mongodb-org
|
||||||
|
```
|
||||||
|
|
||||||
|
或者某个**特定版本**(在 `=` 后面修改版本号)
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt install -y mongodb-org=4.0.6 mongodb-org-server=4.0.6 mongodb-org-shell=4.0.6 mongodb-org-mongos=4.0.6 mongodb-org-tools=4.0.6
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你选择安装特定版本,请确保在所有位置都修改了版本号。如果你修改了 `mongodb-org=4.0.6`,你将安装最新版本。
|
||||||
|
|
||||||
|
默认情况下,使用包管理器(`apt-get`)更新时,MongoDB 将更新为最新的版本。要阻止这种情况发生(并冻结为已安装的版本),请使用:
|
||||||
|
|
||||||
|
```
|
||||||
|
echo "mongodb-org hold" | sudo dpkg --set-selections
|
||||||
|
echo "mongodb-org-server hold" | sudo dpkg --set-selections
|
||||||
|
echo "mongodb-org-shell hold" | sudo dpkg --set-selections
|
||||||
|
echo "mongodb-org-mongos hold" | sudo dpkg --set-selections
|
||||||
|
echo "mongodb-org-tools hold" | sudo dpkg --set-selections
|
||||||
|
```
|
||||||
|
|
||||||
|
你现在已经成功安装了 MongoDB!
|
||||||
|
|
||||||
|
#### 配置 MongoDB
|
||||||
|
|
||||||
|
默认情况下,包管理器将创建 `/var/lib/mongodb` 和 `/var/log/mongodb`,MongoDB 将使用 `mongodb` 用户帐户运行。
|
||||||
|
|
||||||
|
我不会去更改这些默认设置,因为这超出了本指南的范围。有关详细信息,请查看[手册][5]。
|
||||||
|
|
||||||
|
`/etc/mongod.conf` 中的设置在启动/重新启动 **mongodb** 服务实例时生效。
|
||||||
|
|
||||||
|
##### 运行 MongoDB
|
||||||
|
|
||||||
|
要启动 mongodb 的守护进程 `mongod`,请输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo service mongod start
|
||||||
|
```
|
||||||
|
|
||||||
|
现在你应该验证 `mongod` 进程是否已成功启动。此信息(默认情况下)保存在 `/var/log/mongodb/mongod.log` 中。我们来看看文件的内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo cat /var/log/mongodb/mongod.log
|
||||||
|
```
|
||||||
|
|
||||||
|
![Check MongoDB logs to see if the process is running properly.][6]
|
||||||
|
|
||||||
|
只要你在某处看到:`[initandlisten] waiting for connections on port 27017`,就说明进程正常运行。
|
||||||
|
|
||||||
|
**注意**:27017 是 `mongod` 的默认端口。
|
||||||
|
|
||||||
|
要停止/重启 `mongod`,请输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo service mongod stop
|
||||||
|
sudo service mongod restart
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,你可以通过打开 **mongo shell** 来使用 MongoDB:
|
||||||
|
|
||||||
|
```
|
||||||
|
mongo
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 卸载 MongoDB
|
||||||
|
|
||||||
|
运行以下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo service mongod stop
|
||||||
|
sudo apt purge mongodb-org*
|
||||||
|
```
|
||||||
|
|
||||||
|
要删除**数据库**和**日志文件**(确保**备份**你要保留的内容!):
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo rm -r /var/log/mongodb
|
||||||
|
sudo rm -r /var/lib/mongodb
|
||||||
|
```
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
MongoDB 是一个很棒的 NoSQL 数据库,它易于集成到现代项目中。我希望本教程能帮助你在 Ubuntu 上安装它!在下面的评论中告诉我们你计划如何使用 MongoDB。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/install-mongodb-ubuntu
|
||||||
|
|
||||||
|
作者:[Sergiu][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/sergiu/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.mongodb.com/
|
||||||
|
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/mongodb-ubuntu.jpeg?resize=800%2C450&ssl=1
|
||||||
|
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/mongodb_check_status.jpg?fit=800%2C574&ssl=1
|
||||||
|
[4]: https://docs.mongodb.com/manual/tutorial/getting-started/
|
||||||
|
[5]: https://docs.mongodb.com/manual/
|
||||||
|
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/mongodb_org_check_logs.jpg?fit=800%2C467&ssl=1
|
||||||
@ -0,0 +1,228 @@
|
|||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "wxy"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-11198-1.html"
|
||||||
|
[#]: subject: "How To Parse And Pretty Print JSON With Linux Commandline Tools"
|
||||||
|
[#]: via: "https://www.ostechnix.com/how-to-parse-and-pretty-print-json-with-linux-commandline-tools/"
|
||||||
|
[#]: author: "EDITOR https://www.ostechnix.com/author/editor/"
|
||||||
|
|
||||||
|
如何用 Linux 命令行工具解析和格式化输出 JSON
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
JSON 是一种轻量级且与语言无关的数据存储格式,易于与大多数编程语言集成,也易于人类理解 —— 当然,如果格式正确的话。JSON 这个词代表 **J**ava **S**cript **O**bject **N**otation,虽然它以 JavaScript 开头,而且主要用于在服务器和浏览器之间交换数据,但现在正在用于许多领域,包括嵌入式系统。在这里,我们将使用 Linux 上的命令行工具解析并格式化打印 JSON。它对于在 shell 脚本中处理大型 JSON 数据或在 shell 脚本中处理 JSON 数据非常有用。
|
||||||
|
|
||||||
|
### 什么是格式化输出?
|
||||||
|
|
||||||
|
JSON 数据的结构更具人性化。但是在大多数情况下,JSON 数据会存储在一行中,甚至没有行结束字符。
|
||||||
|
|
||||||
|
显然,这对于手动阅读和编辑不太方便。
|
||||||
|
|
||||||
|
这是<ruby>格式化输出<rt>pretty print</rt></ruby>就很有用。这个该名称不言自明:重新格式化 JSON 文本,使人们读起来更清晰。这被称为 **JSON 格式化输出**。
|
||||||
|
|
||||||
|
### 用 Linux 命令行工具解析和格式化输出 JSON
|
||||||
|
|
||||||
|
可以使用命令行文本处理器解析 JSON 数据,例如 `awk`、`sed` 和 `gerp`。实际上 `JSON.awk` 是一个来做这个的 awk 脚本。但是,也有一些专用工具可用于同一目的。
|
||||||
|
|
||||||
|
1. `jq` 或 `jshon`,shell 下的 JSON 解析器,它们都非常有用。
|
||||||
|
2. Shell 脚本,如 `JSON.sh` 或 `jsonv.sh`,用于在 bash、zsh 或 dash shell 中解析JSON。
|
||||||
|
3. `JSON.awk`,JSON 解析器 awk 脚本。
|
||||||
|
4. 像 `json.tool` 这样的 Python 模块。
|
||||||
|
5. `undercore-cli`,基于 Node.js 和 javascript。
|
||||||
|
|
||||||
|
在本教程中,我只关注 `jq`,这是一个 shell 下的非常强大的 JSON 解析器,具有高级过滤和脚本编程功能。
|
||||||
|
|
||||||
|
### JSON 格式化输出
|
||||||
|
|
||||||
|
JSON 数据可能放在一行上使人难以解读,因此为了使其具有一定的可读性,JSON 格式化输出就可用于此目的的。
|
||||||
|
|
||||||
|
**示例:**来自 `jsonip.com` 的数据,使用 `curl` 或 `wget` 工具获得 JSON 格式的外部 IP 地址,如下所示。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ wget -cq http://jsonip.com/ -O -
|
||||||
|
```
|
||||||
|
|
||||||
|
实际数据看起来类似这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
{"ip":"111.222.333.444","about":"/about","Pro!":"http://getjsonip.com"}
|
||||||
|
```
|
||||||
|
|
||||||
|
现在使用 `jq` 格式化输出它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ wget -cq http://jsonip.com/ -O - | jq '.'
|
||||||
|
```
|
||||||
|
|
||||||
|
通过 `jq` 过滤了该结果之后,它应该看起来类似这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"ip": "111.222.333.444",
|
||||||
|
"about": "/about",
|
||||||
|
"Pro!": "http://getjsonip.com"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
同样也可以通过 Python `json.tool` 模块做到。示例如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat anything.json | python -m json.tool
|
||||||
|
```
|
||||||
|
|
||||||
|
这种基于 Python 的解决方案对于大多数用户来说应该没问题,但是如果没有预安装或无法安装 Python 则不行,比如在嵌入式系统上。
|
||||||
|
|
||||||
|
然而,`json.tool` Python 模块具有明显的优势,它是跨平台的。因此,你可以在 Windows、Linux 或 Mac OS 上无缝使用它。
|
||||||
|
|
||||||
|
### 如何用 jq 解析 JSON
|
||||||
|
|
||||||
|
首先,你需要安装 `jq`,它已被大多数 GNU/Linux 发行版选中,并使用各自的软件包安装程序命令进行安装。
|
||||||
|
|
||||||
|
在 Arch Linux 上:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo pacman -S jq
|
||||||
|
```
|
||||||
|
|
||||||
|
在 Debian、Ubuntu、Linux Mint 上:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt-get install jq
|
||||||
|
```
|
||||||
|
|
||||||
|
在 Fedora 上:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install jq
|
||||||
|
```
|
||||||
|
|
||||||
|
在 openSUSE 上:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo zypper install jq
|
||||||
|
```
|
||||||
|
|
||||||
|
对于其它操作系统或平台参见[官方的安装指导][1]。
|
||||||
|
|
||||||
|
#### jq 的基本过滤和标识符功能
|
||||||
|
|
||||||
|
`jq` 可以从 `STDIN` 或文件中读取 JSON 数据。你可以根据情况使用。
|
||||||
|
|
||||||
|
单个符号 `.` 是最基本的过滤器。这些过滤器也称为**对象标识符-索引**。`jq` 使用单个 `.` 过滤器基本上相当将输入的 JSON 文件格式化输出。
|
||||||
|
|
||||||
|
- **单引号**:不必始终使用单引号。但是如果你在一行中组合几个过滤器,那么你必须使用它们。
|
||||||
|
- **双引号**:你必须用两个双引号括起任何特殊字符,如 `@`、`#`、`$`,例如 `jq .foo.”@bar”`。
|
||||||
|
- **原始数据打印**:不管出于任何原因,如果你只需要最终解析的数据(不包含在双引号内),请使用带有 `-r` 标志的 `jq` 命令,如下所示:`jq -r .foo.bar`。
|
||||||
|
|
||||||
|
#### 解析特定数据
|
||||||
|
|
||||||
|
要过滤出 JSON 的特定部分,你需要了解格式化输出的 JSON 文件的数据层次结构。
|
||||||
|
|
||||||
|
来自维基百科的 JSON 数据示例:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"firstName": "John",
|
||||||
|
"lastName": "Smith",
|
||||||
|
"age": 25,
|
||||||
|
"address": {
|
||||||
|
"streetAddress": "21 2nd Street",
|
||||||
|
"city": "New York",
|
||||||
|
"state": "NY",
|
||||||
|
"postalCode": "10021"
|
||||||
|
},
|
||||||
|
"phoneNumber": [
|
||||||
|
{
|
||||||
|
"type": "home",
|
||||||
|
"number": "212 555-1234"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"type": "fax",
|
||||||
|
"number": "646 555-4567"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"gender": {
|
||||||
|
"type": "male"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
我将在本教程中将此 JSON 数据用作示例,将其保存为 `sample.json`。
|
||||||
|
|
||||||
|
假设我想从 `sample.json` 文件中过滤出地址。所以命令应该是这样的:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ jq .address sample.json
|
||||||
|
```
|
||||||
|
|
||||||
|
示例输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"streetAddress": "21 2nd Street",
|
||||||
|
"city": "New York",
|
||||||
|
"state": "NY",
|
||||||
|
"postalCode": "10021"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
再次,我想要邮政编码,然后我要添加另一个**对象标识符-索引**,即另一个过滤器。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat sample.json | jq .address.postalCode
|
||||||
|
```
|
||||||
|
|
||||||
|
另请注意,**过滤器区分大小写**,并且你必须使用完全相同的字符串来获取有意义的输出,否则就是 null。
|
||||||
|
|
||||||
|
#### 从 JSON 数组中解析元素
|
||||||
|
|
||||||
|
JSON 数组的元素包含在方括号内,这无疑是非常通用的。
|
||||||
|
|
||||||
|
要解析数组中的元素,你必须使用 `[]` 标识符以及其他对象标识符索引。
|
||||||
|
|
||||||
|
在此示例 JSON 数据中,电话号码存储在数组中,要从此数组中获取所有内容,你只需使用括号,像这个示例:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ jq .phoneNumber[] sample.json
|
||||||
|
```
|
||||||
|
|
||||||
|
假设你只想要数组的第一个元素,然后使用从 `0` 开始的数组对象编号,对于第一个项目,使用 `[0]`,对于下一个项目,它应该每步增加 1。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ jq .phoneNumber[0] sample.json
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 脚本编程示例
|
||||||
|
|
||||||
|
假设我只想要家庭电话,而不是整个 JSON 数组数据。这就是用 `jq` 命令脚本编写的方便之处。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat sample.json | jq -r '.phoneNumber[] | select(.type == "home") | .number'
|
||||||
|
```
|
||||||
|
|
||||||
|
首先,我将一个过滤器的结果传递给另一个,然后使用 `select` 属性选择特定类型的数据,再次将结果传递给另一个过滤器。
|
||||||
|
|
||||||
|
解释每种类型的 `jq` 过滤器和脚本编程超出了本教程的范围和目的。强烈建议你阅读 `jq` 手册,以便更好地理解下面的内容。
|
||||||
|
|
||||||
|
资源:
|
||||||
|
|
||||||
|
- https://stedolan.github.io/jq/manual/
|
||||||
|
- http://www.compciv.org/recipes/cli/jq-for-parsing-json/
|
||||||
|
- https://lzone.de/cheat-sheet/jq
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.ostechnix.com/how-to-parse-and-pretty-print-json-with-linux-commandline-tools/
|
||||||
|
|
||||||
|
作者:[ostechnix][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.ostechnix.com/author/editor/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://stedolan.github.io/jq/download/
|
||||||
@ -1,74 +1,64 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: ( )
|
[#]: translator: (wxy)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11195-1.html)
|
||||||
[#]: subject: (Check storage performance with dd)
|
[#]: subject: (Check storage performance with dd)
|
||||||
[#]: via: (https://fedoramagazine.org/check-storage-performance-with-dd/)
|
[#]: via: (https://fedoramagazine.org/check-storage-performance-with-dd/)
|
||||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||||
|
|
||||||
Check storage performance with dd
|
使用 dd 检查存储性能
|
||||||
======
|
======
|
||||||
|
|
||||||
![][1]
|
![][1]
|
||||||
|
|
||||||
This article includes some example commands to show you how to get a _rough_ estimate of hard drive and RAID array performance using the _dd_ command. Accurate measurements would have to take into account things like [write amplification][2] and [system call overhead][3], which this guide does not. For a tool that might give more accurate results, you might want to consider using [hdparm][4].
|
本文包含一些示例命令,向你展示如何使用 `dd` 命令*粗略*估计硬盘驱动器和 RAID 阵列的性能。准确的测量必须考虑诸如[写入放大][2]和[系统调用开销][3]之类的事情,本指南不会考虑这些。对于可能提供更准确结果的工具,你可能需要考虑使用 [hdparm][4]。
|
||||||
|
|
||||||
To factor out performance issues related to the file system, these examples show how to test the performance of your drives and arrays at the block level by reading and writing directly to/from their block devices. **WARNING** : The _write_ tests will destroy any data on the block devices against which they are run. **Do not run them against any device that contains data you want to keep!**
|
为了分解与文件系统相关的性能问题,这些示例显示了如何通过直接读取和写入块设备来在块级测试驱动器和阵列的性能。**警告**:*写入*测试将会销毁用来运行测试的块设备上的所有数据。**不要对包含你想要保留的数据的任何设备运行这些测试!**
|
||||||
|
|
||||||
### Four tests
|
### 四个测试
|
||||||
|
|
||||||
Below are four example dd commands that can be used to test the performance of a block device:
|
下面是四个示例 `dd` 命令,可用于测试块设备的性能:
|
||||||
|
|
||||||
1. One process reading from $MY_DISK:
|
1、 从 `$MY_DISK` 读取的一个进程:
|
||||||
|
|
||||||
```
|
```
|
||||||
# dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache
|
# dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache
|
||||||
```
|
```
|
||||||
|
|
||||||
2. One process writing to $MY_DISK:
|
2、写入到 `$MY_DISK` 的一个进程:
|
||||||
|
|
||||||
```
|
```
|
||||||
# dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct
|
# dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct
|
||||||
```
|
```
|
||||||
|
|
||||||
3. Two processes reading concurrently from $MY_DISK:
|
3、从 `$MY_DISK` 并发读取的两个进程:
|
||||||
|
|
||||||
```
|
```
|
||||||
# (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache &); (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache skip=200 &)
|
# (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache &); (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache skip=200 &)
|
||||||
```
|
```
|
||||||
|
|
||||||
4. Two processes writing concurrently to $MY_DISK:
|
4、 并发写入到 `$MY_DISK` 的两个进程:
|
||||||
|
|
||||||
```
|
```
|
||||||
# (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct &); (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct skip=200 &)
|
# (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct &); (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct skip=200 &)
|
||||||
```
|
```
|
||||||
|
|
||||||
|
- 执行读写测试时,相应的 `iflag=nocache` 和 `oflag=direct` 参数非常重要,因为没有它们,`dd` 命令有时会显示从[内存][5]中传输数据的结果速度,而不是从硬盘。
|
||||||
|
- `bs` 和 `count` 参数的值有些随意,我选择的值应足够大,以便在大多数情况下为当前硬件提供合适的平均值。
|
||||||
|
- `null` 和 `zero` 设备在读写测试中分别用于目标和源,因为它们足够快,不会成为性能测试中的限制因素。
|
||||||
|
- 并发读写测试中第二个 `dd` 命令的 `skip=200` 参数是为了确保 `dd` 的两个副本在硬盘驱动器的不同区域上运行。
|
||||||
|
|
||||||
|
### 16 个示例
|
||||||
|
|
||||||
|
下面是演示,显示针对以下四个块设备中之一运行上述四个测试中的各个结果:
|
||||||
|
|
||||||
– The _iflag=nocache_ and _oflag=direct_ parameters are important when performing the read and write tests (respectively) because without them the dd command will sometimes show the resulting speed of transferring the data to/from [RAM][5] rather than the hard drive.
|
1. `MY_DISK=/dev/sda2`(用在示例 1-X 中)
|
||||||
|
2. `MY_DISK=/dev/sdb2`(用在示例 2-X 中)
|
||||||
|
3. `MY_DISK=/dev/md/stripped`(用在示例 3-X 中)
|
||||||
|
4. `MY_DISK=/dev/md/mirrored`(用在示例 4-X 中)
|
||||||
|
|
||||||
– The values for the _bs_ and _count_ parameters are somewhat arbitrary and what I have chosen should be large enough to provide a decent average in most cases for current hardware.
|
首先将计算机置于*救援*模式,以减少后台服务的磁盘 I/O 随机影响测试结果的可能性。**警告**:这将关闭所有非必要的程序和服务。在运行这些命令之前,请务必保存你的工作。你需要知道 `root` 密码才能进入救援模式。`passwd` 命令以 `root` 用户身份运行时,将提示你(重新)设置 `root` 帐户密码。
|
||||||
|
|
||||||
– The _null_ and _zero_ devices are used for the destination and source (respectively) in the read and write tests because they are fast enough that they will not be the limiting factor in the performance tests.
|
|
||||||
|
|
||||||
– The _skip=200_ parameter on the second dd command in the concurrent read and write tests is to ensure that the two copies of dd are operating on different areas of the hard drive.
|
|
||||||
|
|
||||||
### 16 examples
|
|
||||||
|
|
||||||
Below are demonstrations showing the results of running each of the above four tests against each of the following four block devices:
|
|
||||||
|
|
||||||
1. MY_DISK=/dev/sda2 (used in examples 1-X)
|
|
||||||
2. MY_DISK=/dev/sdb2 (used in examples 2-X)
|
|
||||||
3. MY_DISK=/dev/md/stripped (used in examples 3-X)
|
|
||||||
4. MY_DISK=/dev/md/mirrored (used in examples 4-X)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
A video demonstration of the these tests being run on a PC is provided at the end of this guide.
|
|
||||||
|
|
||||||
Begin by putting your computer into _rescue_ mode to reduce the chances that disk I/O from background services might randomly affect your test results. **WARNING** : This will shutdown all non-essential programs and services. Be sure to save your work before running these commands. You will need to know your _root_ password to get into rescue mode. The _passwd_ command, when run as the root user, will prompt you to (re)set your root account password.
|
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo -i
|
$ sudo -i
|
||||||
@ -77,14 +67,14 @@ $ sudo -i
|
|||||||
# systemctl rescue
|
# systemctl rescue
|
||||||
```
|
```
|
||||||
|
|
||||||
You might also want to temporarily disable logging to disk:
|
你可能还想暂时禁止将日志记录到磁盘:
|
||||||
|
|
||||||
```
|
```
|
||||||
# sed -r -i.bak 's/^#?Storage=.*/Storage=none/' /etc/systemd/journald.conf
|
# sed -r -i.bak 's/^#?Storage=.*/Storage=none/' /etc/systemd/journald.conf
|
||||||
# systemctl restart systemd-journald.service
|
# systemctl restart systemd-journald.service
|
||||||
```
|
```
|
||||||
|
|
||||||
If you have a swap device, it can be temporarily disabled and used to perform the following tests:
|
如果你有交换设备,可以暂时禁用它并用于执行后面的测试:
|
||||||
|
|
||||||
```
|
```
|
||||||
# swapoff -a
|
# swapoff -a
|
||||||
@ -93,7 +83,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
# mdadm --zero-superblock $MY_DEVS
|
# mdadm --zero-superblock $MY_DEVS
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 1-1 (reading from sda)
|
#### 示例 1-1 (从 sda 读取)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||||
@ -106,7 +96,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 1.7003 s, 123 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 1.7003 s, 123 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 1-2 (writing to sda)
|
#### 示例 1-2 (写入到 sda)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||||
@ -119,7 +109,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67117 s, 125 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 1.67117 s, 125 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 1-3 (reading concurrently from sda)
|
#### 示例 1-3 (从 sda 并发读取)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||||
@ -135,7 +125,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 3.52614 s, 59.5 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 3.52614 s, 59.5 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 1-4 (writing concurrently to sda)
|
#### 示例 1-4 (并发写入到 sda)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||||
@ -150,7 +140,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 3.60872 s, 58.1 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 3.60872 s, 58.1 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 2-1 (reading from sdb)
|
#### 示例 2-1 (从 sdb 读取)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||||
@ -163,7 +153,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67285 s, 125 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 1.67285 s, 125 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 2-2 (writing to sdb)
|
#### 示例 2-2 (写入到 sdb)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||||
@ -176,7 +166,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67198 s, 125 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 1.67198 s, 125 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 2-3 (reading concurrently from sdb)
|
#### 示例 2-3 (从 sdb 并发读取)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||||
@ -192,7 +182,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 3.57736 s, 58.6 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 3.57736 s, 58.6 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 2-4 (writing concurrently to sdb)
|
#### 示例 2-4 (并发写入到 sdb)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||||
@ -208,7 +198,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 3.81475 s, 55.0 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 3.81475 s, 55.0 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 3-1 (reading from RAID0)
|
#### 示例 3-1 (从 RAID0 读取)
|
||||||
|
|
||||||
```
|
```
|
||||||
# mdadm --create /dev/md/stripped --homehost=any --metadata=1.0 --level=0 --raid-devices=2 $MY_DEVS
|
# mdadm --create /dev/md/stripped --homehost=any --metadata=1.0 --level=0 --raid-devices=2 $MY_DEVS
|
||||||
@ -222,7 +212,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 0.837419 s, 250 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 0.837419 s, 250 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 3-2 (writing to RAID0)
|
#### 示例 3-2 (写入到 RAID0)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=/dev/md/stripped
|
# MY_DISK=/dev/md/stripped
|
||||||
@ -235,7 +225,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 0.823648 s, 255 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 0.823648 s, 255 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 3-3 (reading concurrently from RAID0)
|
#### 示例 3-3 (从 RAID0 并发读取)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=/dev/md/stripped
|
# MY_DISK=/dev/md/stripped
|
||||||
@ -251,7 +241,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 1.80016 s, 116 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 1.80016 s, 116 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 3-4 (writing concurrently to RAID0)
|
#### 示例 3-4 (并发写入到 RAID0)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=/dev/md/stripped
|
# MY_DISK=/dev/md/stripped
|
||||||
@ -267,7 +257,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 1.81323 s, 116 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 1.81323 s, 116 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 4-1 (reading from RAID1)
|
#### 示例 4-1 (从 RAID1 读取)
|
||||||
|
|
||||||
```
|
```
|
||||||
# mdadm --stop /dev/md/stripped
|
# mdadm --stop /dev/md/stripped
|
||||||
@ -282,7 +272,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 1.74963 s, 120 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 1.74963 s, 120 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 4-2 (writing to RAID1)
|
#### 示例 4-2 (写入到 RAID1)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=/dev/md/mirrored
|
# MY_DISK=/dev/md/mirrored
|
||||||
@ -295,7 +285,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 1.74625 s, 120 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 1.74625 s, 120 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 4-3 (reading concurrently from RAID1)
|
#### 示例 4-3 (从 RAID1 并发读取)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=/dev/md/mirrored
|
# MY_DISK=/dev/md/mirrored
|
||||||
@ -311,7 +301,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67685 s, 125 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 1.67685 s, 125 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Example 4-4 (writing concurrently to RAID1)
|
#### 示例 4-4 (并发写入到 RAID1)
|
||||||
|
|
||||||
```
|
```
|
||||||
# MY_DISK=/dev/md/mirrored
|
# MY_DISK=/dev/md/mirrored
|
||||||
@ -327,7 +317,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
209715200 bytes (210 MB, 200 MiB) copied, 4.1067 s, 51.1 MB/s
|
209715200 bytes (210 MB, 200 MiB) copied, 4.1067 s, 51.1 MB/s
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Restore your swap device and journald configuration
|
#### 恢复交换设备和日志配置
|
||||||
|
|
||||||
```
|
```
|
||||||
# mdadm --stop /dev/md/stripped /dev/md/mirrored
|
# mdadm --stop /dev/md/stripped /dev/md/mirrored
|
||||||
@ -339,23 +329,19 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
|||||||
# reboot
|
# reboot
|
||||||
```
|
```
|
||||||
|
|
||||||
### Interpreting the results
|
### 结果解读
|
||||||
|
|
||||||
Examples 1-1, 1-2, 2-1, and 2-2 show that each of my drives read and write at about 125 MB/s.
|
示例 1-1、1-2、2-1 和 2-2 表明我的每个驱动器以大约 125 MB/s 的速度读写。
|
||||||
|
|
||||||
Examples 1-3, 1-4, 2-3, and 2-4 show that when two reads or two writes are done in parallel on the same drive, each process gets at about half the drive’s bandwidth (60 MB/s).
|
示例 1-3、1-4、2-3 和 2-4 表明,当在同一驱动器上并行完成两次读取或写入时,每个进程的驱动器带宽大约为一半(60 MB/s)。
|
||||||
|
|
||||||
The 3-x examples show the performance benefit of putting the two drives together in a RAID0 (data stripping) array. The numbers, in all cases, show that the RAID0 array performs about twice as fast as either drive is able to perform on its own. The trade-off is that you are twice as likely to lose everything because each drive only contains half the data. A three-drive array would perform three times as fast as a single drive (all drives being equal) but it would be thrice as likely to suffer a [catastrophic failure][6].
|
3-X 示例显示了将两个驱动器放在 RAID0(数据条带化)阵列中的性能优势。在所有情况下,这些数字表明 RAID0 阵列的执行速度是任何一个驱动器能够独立提供的速度的两倍。相应的是,丢失所有内容的可能性也是两倍,因为每个驱动器只包含一半的数据。一个三个驱动器阵列的执行速度是单个驱动器的三倍(所有驱动器规格都相同),但遭受[灾难性故障][6]的可能也是三倍。
|
||||||
|
|
||||||
The 4-x examples show that the performance of the RAID1 (data mirroring) array is similar to that of a single disk except for the case where multiple processes are concurrently reading (example 4-3). In the case of multiple processes reading, the performance of the RAID1 array is similar to that of the RAID0 array. This means that you will see a performance benefit with RAID1, but only when processes are reading concurrently. For example, if a process tries to access a large number of files in the background while you are trying to use a web browser or email client in the foreground. The main benefit of RAID1 is that your data is unlikely to be lost [if a drive fails][7].
|
4-X 示例显示 RAID1(数据镜像)阵列的性能类似于单个磁盘的性能,除了多个进程同时读取的情况(示例4-3)。在多个进程读取的情况下,RAID1 阵列的性能类似于 RAID0 阵列的性能。这意味着你将看到 RAID1 的性能优势,但仅限于进程同时读取时。例如,当你在前台使用 Web 浏览器或电子邮件客户端时,进程会尝试访问后台中的大量文件。RAID1 的主要好处是,[如果驱动器出现故障][7],你的数据不太可能丢失。
|
||||||
|
|
||||||
### Video demo
|
### 故障排除
|
||||||
|
|
||||||
Testing storage throughput using dd
|
如果上述测试未按预期执行,则可能是驱动器坏了或出现故障。大多数现代硬盘都内置了自我监控、分析和报告技术([SMART][8])。如果你的驱动器支持它,`smartctl` 命令可用于查询你的硬盘驱动器的内部统计信息:
|
||||||
|
|
||||||
### Troubleshooting
|
|
||||||
|
|
||||||
If the above tests aren’t performing as you expect, you might have a bad or failing drive. Most modern hard drives have built-in Self-Monitoring, Analysis and Reporting Technology ([SMART][8]). If your drive supports it, the _smartctl_ command can be used to query your hard drive for its internal statistics:
|
|
||||||
|
|
||||||
```
|
```
|
||||||
# smartctl --health /dev/sda
|
# smartctl --health /dev/sda
|
||||||
@ -363,21 +349,21 @@ If the above tests aren’t performing as you expect, you might have a bad or fa
|
|||||||
# smartctl -x /dev/sda
|
# smartctl -x /dev/sda
|
||||||
```
|
```
|
||||||
|
|
||||||
Another way that you might be able to tune your PC for better performance is by changing your [I/O scheduler][9]. Linux systems support several I/O schedulers and the current default for Fedora systems is the [multiqueue][10] variant of the [deadline][11] scheduler. The default performs very well overall and scales extremely well for large servers with many processors and large disk arrays. There are, however, a few more specialized schedulers that might perform better under certain conditions.
|
另一种可以调整 PC 以获得更好性能的方法是更改 [I/O 调度程序][9]。Linux 系统支持多个 I/O 调度程序,Fedora 系统的当前默认值是 [deadline][11] 调度程序的 [multiqueue][10] 变体。默认情况下它的整体性能非常好,并且对于具有许多处理器和大型磁盘阵列的大型服务器,其扩展性极为出色。但是,有一些更专业的调度程序在某些条件下可能表现更好。
|
||||||
|
|
||||||
To view which I/O scheduler your drives are using, issue the following command:
|
要查看驱动器正在使用的 I/O 调度程序,请运行以下命令:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ for i in /sys/block/sd?/queue/scheduler; do echo "$i: $(<$i)"; done
|
$ for i in /sys/block/sd?/queue/scheduler; do echo "$i: $(<$i)"; done
|
||||||
```
|
```
|
||||||
|
|
||||||
You can change the scheduler for a drive by writing the name of the desired scheduler to the /sys/block/<device name>/queue/scheduler file:
|
你可以通过将所需调度程序的名称写入 `/sys/block/<device name>/queue/scheduler` 文件来更改驱动器的调度程序:
|
||||||
|
|
||||||
```
|
```
|
||||||
# echo bfq > /sys/block/sda/queue/scheduler
|
# echo bfq > /sys/block/sda/queue/scheduler
|
||||||
```
|
```
|
||||||
|
|
||||||
You can make your changes permanent by creating a [udev rule][12] for your drive. The following example shows how to create a udev rule that will set all [rotational drives][13] to use the [BFQ][14] I/O scheduler:
|
你可以通过为驱动器创建 [udev 规则][12]来永久更改它。以下示例显示了如何创建将所有的[旋转式驱动器][13]设置为使用 [BFQ][14] I/O 调度程序的 udev 规则:
|
||||||
|
|
||||||
```
|
```
|
||||||
# cat << END > /etc/udev/rules.d/60-ioscheduler-rotational.rules
|
# cat << END > /etc/udev/rules.d/60-ioscheduler-rotational.rules
|
||||||
@ -385,7 +371,7 @@ ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="1", ATTR{queue
|
|||||||
END
|
END
|
||||||
```
|
```
|
||||||
|
|
||||||
Here is another example that sets all [solid-state drives][15] to use the [NOOP][16] I/O scheduler:
|
这是另一个设置所有的[固态驱动器][15]使用 [NOOP][16] I/O 调度程序的示例:
|
||||||
|
|
||||||
```
|
```
|
||||||
# cat << END > /etc/udev/rules.d/60-ioscheduler-solid-state.rules
|
# cat << END > /etc/udev/rules.d/60-ioscheduler-solid-state.rules
|
||||||
@ -393,11 +379,7 @@ ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue
|
|||||||
END
|
END
|
||||||
```
|
```
|
||||||
|
|
||||||
Changing your I/O scheduler won’t affect the raw throughput of your devices, but it might make your PC seem more responsive by prioritizing the bandwidth for the foreground tasks over the background tasks or by eliminating unnecessary block reordering.
|
更改 I/O 调度程序不会影响设备的原始吞吐量,但通过优先考虑后台任务的带宽或消除不必要的块重新排序,可能会使你的 PC 看起来响应更快。
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
_Photo by _[ _James Donovan_][17]_ on _[_Unsplash_][18]_._
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -405,8 +387,8 @@ via: https://fedoramagazine.org/check-storage-performance-with-dd/
|
|||||||
|
|
||||||
作者:[Gregory Bartholomew][a]
|
作者:[Gregory Bartholomew][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[wxy](https://github.com/wxy)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,92 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (LazyWolfLin)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11176-1.html)
|
||||||
|
[#]: subject: (Continuous integration testing for the Linux kernel)
|
||||||
|
[#]: via: (https://opensource.com/article/19/6/continuous-kernel-integration-linux)
|
||||||
|
[#]: author: (Major Hayden https://opensource.com/users/mhayden)
|
||||||
|
|
||||||
|
Linux 内核的持续集成测试
|
||||||
|
======
|
||||||
|
|
||||||
|
> CKI 团队是如何防止 bug 被合并到 Linux 内核中。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Linux 内核的每个发布版本包含了来自 1,700 个开发者产生的 14,000 个变更集,很显然,这使得 Linux 内核快速迭代的同时也产生了巨大的复杂性问题。内核上 Bug 有小麻烦也有大问题,有时是系统崩溃,有时是数据丢失。
|
||||||
|
|
||||||
|
随着越来越多的项目对于持续集成(CI)的呼声,[内核持续集成(CKI)][2]小组秉承着一个任务目标:防止 Bug 被合并到内核当中。
|
||||||
|
|
||||||
|
### Linux 测试问题
|
||||||
|
|
||||||
|
许多 Linux 发行版只在需要的时候对 Linux 内核进行测试。而这种测试往往只在版本发布时或者用户发现错误时进行。
|
||||||
|
|
||||||
|
有时候,出现玄学问题时,维护人员需要在包含了数万个补丁的变更中匆忙地寻找哪个补丁导致这个新的玄学 Bug。诊断 Bug 需要专业的硬件设备、一系列的触发器以及内核相关的专业知识。
|
||||||
|
|
||||||
|
#### CI 和 Linux
|
||||||
|
|
||||||
|
许多现代软件代码库都采用某种自动化 CI 测试机制,能够在提交进入代码存储库之前对其进行测试。这种自动化测试使得维护人员可以通过查看 CI 测试报告来发现软件质量问题以及大多数的错误。一些简单的项目,比如某个 Python 库,附带的大量工具使得整个检查过程更简单。
|
||||||
|
|
||||||
|
在任何测试之前都需要配置和编译 Linux。而这么做将耗费大量的时间和计算资源。此外,Linux 内核必需在虚拟机或者裸机上启动才能进行测试。而访问某些硬件架构需要额外的开销或者非常慢的仿真。因此,人们必须确定一组能够触发错误或者验证修复的测试集。
|
||||||
|
|
||||||
|
#### CKI 团队如何运作?
|
||||||
|
|
||||||
|
Red Hat 公司的 CKI 团队当前正追踪来自数个内部内核分支和上游的[稳定内核分支树][3]等内核分支的更改。我们关注每个代码库的两类关键事件:
|
||||||
|
|
||||||
|
1. 当维护人员合并 PR 或者补丁时,代码库变化后的最终结果。
|
||||||
|
2. 当开发人员通过拼凑或者稳定补丁队列发起变更合并时。
|
||||||
|
|
||||||
|
当这些事件发生时,自动化工具开始执行,[GitLab CI 管道][4]开始进行测试。一旦管道开始执行 [linting][5] 脚本、合并每一个补丁,并为多种硬件架构编译内核,真正的测试便开始了。我们会在六分钟内完成四种硬件架构的内核编译工作,并且通常会在两个小时或更短的时间内将反馈提交到稳定邮件列表中。(自 2019 年 1 月起)每月执行超过 100,000 次内核测试,并完成了超过 11,000 个 GitLab 管道。
|
||||||
|
|
||||||
|
每个内核都会在本地硬件架构上启动,其中包含:
|
||||||
|
|
||||||
|
* [aarch64][6]:64 位 [ARM][7],例如 [Cavium(当前是 Marvell)ThunderX][8]。
|
||||||
|
* [ppc64/ppc64le][9]:大端和小端的 [IBM POWER][10] 系统。
|
||||||
|
* [s390x][11]:[IBM Zseries][12] 大型机
|
||||||
|
* [x86_64][13]:[Intel][14] 和 [AMD][15] 工作站、笔记本和服务器。
|
||||||
|
|
||||||
|
这些内核上运行了包括 [Linux 测试项目(LTP)][16]在内的多个测试,其中包括使用常用测试工具的大量测试。我们 CKI 团队开源了超过 44 个测试并将继续开源更多测试。
|
||||||
|
|
||||||
|
### 参与其中
|
||||||
|
|
||||||
|
上游的内核测试工作日渐增多。包括 [Google][17]、Intel、[Linaro][18] 和 [Sony][19] 在内的许多公司为各种内核提供了测试输出。每一项工作都专注于为上游内核以及每个公司的客户群带来价值。
|
||||||
|
|
||||||
|
如果你或者你的公司想要参与这一工作,请参加在 9 月份在葡萄牙里斯本举办的 [Linux Plumbers Conference 2019][20]。在会议结束后的两天加入我们的 Kernel CI hackfest 活动,并推动快速内核测试的发展。
|
||||||
|
|
||||||
|
更多详细信息,[请见][21]我在 Texas Linux Fest 2019 上的演讲。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/6/continuous-kernel-integration-linux
|
||||||
|
|
||||||
|
作者:[Major Hayden][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[LazyWolfLin](https://github.com/LazyWolfLin)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/mhayden
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_kernel_clang_vscode.jpg?itok=fozZ4zrr "Linux kernel source code (C) in Visual Studio Code"
|
||||||
|
[2]: https://cki-project.org/
|
||||||
|
[3]: https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html
|
||||||
|
[4]: https://docs.gitlab.com/ee/ci/pipelines.html
|
||||||
|
[5]: https://en.wikipedia.org/wiki/Lint_(software)
|
||||||
|
[6]: https://en.wikipedia.org/wiki/ARM_architecture
|
||||||
|
[7]: https://www.arm.com/
|
||||||
|
[8]: https://www.marvell.com/server-processors/thunderx-arm-processors/
|
||||||
|
[9]: https://en.wikipedia.org/wiki/Ppc64
|
||||||
|
[10]: https://www.ibm.com/it-infrastructure/power
|
||||||
|
[11]: https://en.wikipedia.org/wiki/Linux_on_z_Systems
|
||||||
|
[12]: https://www.ibm.com/it-infrastructure/z
|
||||||
|
[13]: https://en.wikipedia.org/wiki/X86-64
|
||||||
|
[14]: https://www.intel.com/
|
||||||
|
[15]: https://www.amd.com/
|
||||||
|
[16]: https://github.com/linux-test-project/ltp
|
||||||
|
[17]: https://www.google.com/
|
||||||
|
[18]: https://www.linaro.org/
|
||||||
|
[19]: https://www.sony.com/
|
||||||
|
[20]: https://www.linuxplumbersconf.org/
|
||||||
|
[21]: https://docs.google.com/presentation/d/1T0JaRA0wtDU0aTWTyASwwy_ugtzjUcw_ZDmC5KFzw-A/edit?usp=sharing
|
||||||
@ -0,0 +1,227 @@
|
|||||||
|
10 个 Linux 中最好的 Visio 替代品
|
||||||
|
======
|
||||||
|
|
||||||
|
> 如果你正在 Linux 中寻找一个好的 Visio 查看器,这里有一些可以在 Linux 中使用的微软 Visio 的替代方案。
|
||||||
|
|
||||||
|
[微软 Visio][1] 是创建或生成关键任务图和矢量表示的绝佳工具。虽然它可能是制作平面图或其他类型图表的好工具 —— 但它既不是免费的,也不是开源的
|
||||||
|
|
||||||
|
此外,微软 Visio 不是一个独立的产品。它与微软 Office 捆绑在一起。我们过去已经看过 [MS Office 的开源替代品][2]。今天我们将看看你可以在 Linux 上使用哪些工具代替 Visio。
|
||||||
|
|
||||||
|
### 适用于 Linux 的最佳 微软 Visio 备选方案
|
||||||
|
|
||||||
|
![用于 Linux 的微软 Visio 备选方案][4]
|
||||||
|
|
||||||
|
此处为强制性免责声明。该列表不是排名。排名第三的产品并不比排名第六的好。
|
||||||
|
|
||||||
|
我还提到了两个可以从 Web 界面使用的非开源 Visio 软件。
|
||||||
|
|
||||||
|
| 软件 | 类型 | 许可证类型 |
|
||||||
|
| --- | --- | --- |
|
||||||
|
| [LibreOffice Draw][6] | 桌面软件 | 自由开源 |
|
||||||
|
| [OpenOffice Draw][10] | 桌面软件 | 自由开源 |
|
||||||
|
| [Dia][12] | 桌面软件 | 自由开源 |
|
||||||
|
| [yED Graph Editor][14] | 桌面和基于 Web | 免费增值 |
|
||||||
|
| [Inkscape][16] | 桌面软件 | 自由开源 |
|
||||||
|
| [Pencil][18] | 桌面和基于 Web | 自由开源 |
|
||||||
|
| [Graphviz][20] | 桌面软件 | 自由开源 |
|
||||||
|
| [darw.io][22] | 桌面和基于 Web | 自由开源 |
|
||||||
|
| [Lucidchart][24] | 基于 Web | 免费增值 |
|
||||||
|
| [Calligra Flow][27] | 桌面软件 | 自由开源 |
|
||||||
|
|
||||||
|
|
||||||
|
### 1、LibreOffice Draw
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
LibreOffice Draw 模块是微软 Visio 的最佳开源替代方案之一。在它的帮助下,你可以选择制作一个想法的速写或一个复杂的专业平面布置图来展示。流程图、组织结构图、网络图、小册子、海报等等!所有这些都不需要花一分钱。
|
||||||
|
|
||||||
|
好的是它与 LibreOffice 捆绑在一起,默认情况下安装在大多数 Linux 发行版中。
|
||||||
|
|
||||||
|
#### 主要功能概述:
|
||||||
|
|
||||||
|
* 用于制作宣传册/海报的样式和格式工具
|
||||||
|
* Calc 数据可视化
|
||||||
|
* PDF 文件编辑功能
|
||||||
|
* 通过操作图库中的图片来创建相册
|
||||||
|
* 灵活的绘图工具类似于 微软 Visio (智能连接器,尺寸线等)的工具
|
||||||
|
* 支持 .VSD 文件(打开)
|
||||||
|
|
||||||
|
官网:[LibreOffice Draw][6]
|
||||||
|
|
||||||
|
### 2、Apache OpenOffice Draw
|
||||||
|
|
||||||
|
![][7]
|
||||||
|
|
||||||
|
很多人都知道 OpenOffice(LibreOffice 项目最初就是基于它的),但他们并没有真正意识到 Apache OpenOffice Draw 可以作为微软 Visio 的替代方案。但事实上,它是另一个令人惊奇的开源图表软件工具。与 LibreOffice Draw 不同,它不支持编辑 PDF 文件,但它为任何类型的图表创建提供了绘图工具。
|
||||||
|
|
||||||
|
这只是个警告。仅当你的系统中已经有 OpenOffice 时才使用此工具。这是因为[安装 OpenOffice][8] 是一件痛苦的事情,而且它已经[不再继续开发][9]。
|
||||||
|
|
||||||
|
#### 主要功能概述:
|
||||||
|
|
||||||
|
* 快速创建 3D 形状控制器
|
||||||
|
* 创建作品的 flash 版本(.swf)
|
||||||
|
* 样式和格式工具
|
||||||
|
* 与微软 Visio 类似的灵活绘图工具(智能连接器、尺寸线等)
|
||||||
|
|
||||||
|
官网:[Apache OpenOffice Draw][10]
|
||||||
|
|
||||||
|
### 3、Dia
|
||||||
|
|
||||||
|
![][11]
|
||||||
|
|
||||||
|
Dia 是另一个有趣的开源工具。它可能不像前面提到的那样处于积极开发之中。但是,如果你正在寻找一个自由而开源的替代微软 Visio 的简单而体面的图表,那么 Dia 可能是你的选择。这个工具可能唯一让你失望的地方就是它的用户界面。除此之外,它还允许你为复杂的图使用强大的工具(但它看起来可能不太好 —— 所以我们建议你用于更简单的图)。
|
||||||
|
|
||||||
|
#### 主要功能概述:
|
||||||
|
|
||||||
|
* 它可以通过命令行使用
|
||||||
|
* 样式和格式工具
|
||||||
|
* 用于自定义形状的形状存储库
|
||||||
|
* 与微软 Visio 类似的绘图工具(特殊对象、网格线、图层等)
|
||||||
|
* 跨平台
|
||||||
|
|
||||||
|
官网:[Dia][12]
|
||||||
|
|
||||||
|
### 4、yED Graph Editor
|
||||||
|
|
||||||
|
[视频](https://youtu.be/OmSTwKw7dX4)
|
||||||
|
|
||||||
|
是最受欢迎的免费的微软 Visio 替代方案之一。如果你对它是一个免费软件而不是开源项目有些担心,你仍然可以通过 web 浏览器免费使用 [yED 的实时编辑器][13]。如果你想用一个非常易于使用的界面快速绘制图表,这是最好的建议之一。
|
||||||
|
|
||||||
|
#### 主要功能概述:
|
||||||
|
|
||||||
|
* 拖放功能,方便图表制作
|
||||||
|
* 支持导入外部数据进行链接
|
||||||
|
|
||||||
|
官网:[yED Graph Editor][14]
|
||||||
|
|
||||||
|
### 5、Inkscape
|
||||||
|
|
||||||
|
![][15]
|
||||||
|
|
||||||
|
Inkscape 是一个自由开源的矢量图形编辑器。你将拥有创建流程图或数据流程图的基本功能。它不提供高级的图表绘制工具,而是提供创建更简单图表的基本工具。因此,当你希望通过使用图库中的可用符号,在图库连接器工具的帮助下生成基本图时,Inkscape 可能是你的 Visio 替代品。
|
||||||
|
|
||||||
|
#### 主要功能概述:
|
||||||
|
|
||||||
|
* 连接器工具
|
||||||
|
* 灵活的绘图工具
|
||||||
|
* 广泛的文件格式兼容性
|
||||||
|
|
||||||
|
官网:[Inkscape][16]
|
||||||
|
|
||||||
|
### 6、Pencil 项目
|
||||||
|
|
||||||
|
![][17]
|
||||||
|
|
||||||
|
Pencil 项目是一个令人印象深刻的开源项目,适用于 Windows、Mac 以及 Linux。它具有易于使用的图形界面,使绘图更容易和方便。它有一个很好的内建形状和符号的集合,可以使你的图表看起来很棒。它还内置了 Android 和 iOS UI 模板,可以让你在需要时创建应用程序原型。
|
||||||
|
|
||||||
|
你也可以将其安装为 Firefox 扩展,但该扩展不能使用项目的最新版本。
|
||||||
|
|
||||||
|
#### 主要功能概述:
|
||||||
|
|
||||||
|
* 轻松浏览剪贴画(使用 openclipart.org)
|
||||||
|
* 导出为 ODT 文件/PDF 文件
|
||||||
|
* 图表连接工具
|
||||||
|
* 跨平台
|
||||||
|
|
||||||
|
官网:[Pencil 项目][18]
|
||||||
|
|
||||||
|
### 7、Graphviz
|
||||||
|
|
||||||
|
![][19]
|
||||||
|
|
||||||
|
Graphviz 略有不同。它不是绘图工具,而是专用的图形可视化工具。如果你在网络图中需要多个设计来表示一个节点,那么一定要使用这个工具。当然,你不能用这个工具做平面布置图(至少这不容易)。因此,它最适合于网络图、生物信息学、数据库连接和类似的东西。
|
||||||
|
|
||||||
|
#### 主要功能概述:
|
||||||
|
|
||||||
|
* 支持命令行使用
|
||||||
|
* 支持自定义形状和表格节点布局
|
||||||
|
* 基本样式和格式设置工具
|
||||||
|
|
||||||
|
官网:[Graphviz][20]
|
||||||
|
|
||||||
|
### 8、Draw.io
|
||||||
|
|
||||||
|
[视频](https://youtu.be/Z0D96ZikMkc)
|
||||||
|
|
||||||
|
Draw.io 主要是一个基于 Web 的免费图表工具,它的强大的工具几乎可以制作任何类型的图表。你只需要拖放然后连接它们以创建流程图、ER 图或任何相关的。此外,如果你喜欢该工具,则可以尝试[离线桌面版本][21]。
|
||||||
|
|
||||||
|
#### 主要功能概述:
|
||||||
|
|
||||||
|
* 直接上传到云存储服务
|
||||||
|
* 自定义形状
|
||||||
|
* 样式和格式工具
|
||||||
|
* 跨平台
|
||||||
|
|
||||||
|
官网:[Draw.io][22]
|
||||||
|
|
||||||
|
### 9、Lucidchart
|
||||||
|
|
||||||
|
![][23]
|
||||||
|
|
||||||
|
Lucidchart 是一个基于 Web 的高级图表工具,它提供了一个具有有限功能的免费订阅。你可以使用免费订阅创建几种类型的图表,并将其导出为图像或 PDF。但是,免费版本不支持数据链接和 Visio 导入/导出功能。如果你不需要数据链接功能,Lucidchart 可以说是一个生成漂亮的图表的非常好的工具。
|
||||||
|
|
||||||
|
#### 主要功能概述:
|
||||||
|
|
||||||
|
* 可以集成到 Slack、Jira 核心、Confluence
|
||||||
|
* 能够制作产品模型
|
||||||
|
* 导入 Visio 文件
|
||||||
|
|
||||||
|
官网:[Lucidchart][24]
|
||||||
|
|
||||||
|
### 10、Calligra Flow
|
||||||
|
|
||||||
|
![calligra flow][25]
|
||||||
|
|
||||||
|
Calligra Flow 是 [Calligra 项目][26]的一部分,旨在提供自由开源的软件工具。使用 Calligra flow 你可以轻松地创建网络图、实体关系图、流程图等
|
||||||
|
|
||||||
|
#### 主要功能概述:
|
||||||
|
|
||||||
|
* 各种模具盒
|
||||||
|
* 样式和格式工具
|
||||||
|
|
||||||
|
官网:[Calligra Flow][27]
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
既然你已经了解到了这些最好的自由开源的 Visio 替代方案,你对它们有什么看法?
|
||||||
|
|
||||||
|
对于你任何方面的需求,它们是否优于 微软 Visio?另外,如果我们错过了你最喜欢的基于 Linux 的替代微软 Visio 的绘图工具,请在下面的评论中告诉我们。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/visio-alternatives-linux/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
译者:[ZhiW5217](https://github.com/ZhiW5217)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://itsfoss.com/author/ankush/
|
||||||
|
[1]:https://products.office.com/en/visio/flowchart-software
|
||||||
|
[2]:https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||||
|
[3]:data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=
|
||||||
|
[4]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/visio-alternatives-linux-featured.png
|
||||||
|
[5]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/libreoffice-draw-microsoft-visio-alternatives.jpg
|
||||||
|
[6]:https://www.libreoffice.org/discover/draw/
|
||||||
|
[7]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/apache-open-office-draw.jpg
|
||||||
|
[8]:https://itsfoss.com/install-openoffice-ubuntu-linux/
|
||||||
|
[9]:https://itsfoss.com/openoffice-shutdown/
|
||||||
|
[10]:https://www.openoffice.org/product/draw.html
|
||||||
|
[11]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/dia-screenshot.jpg
|
||||||
|
[12]:http://dia-installer.de/
|
||||||
|
[13]:https://www.yworks.com/products/yed-live
|
||||||
|
[14]:https://www.yworks.com/products/yed
|
||||||
|
[15]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/inkscape-screenshot.jpg
|
||||||
|
[16]:https://inkscape.org/en/
|
||||||
|
[17]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/pencil-project.jpg
|
||||||
|
[18]:http://pencil.evolus.vn/Downloads.html
|
||||||
|
[19]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/graphviz.jpg
|
||||||
|
[20]:http://graphviz.org/
|
||||||
|
[21]:https://about.draw.io/integrations/#integrations_offline
|
||||||
|
[22]:https://about.draw.io/
|
||||||
|
[23]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/lucidchart-visio-alternative.jpg
|
||||||
|
[24]:https://www.lucidchart.com/
|
||||||
|
[25]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/12/calligra-flow.jpg
|
||||||
|
[26]:https://www.calligra.org/
|
||||||
|
[27]:https://www.calligra.org/flow/
|
||||||
@ -0,0 +1,126 @@
|
|||||||
|
MX Linux:一款专注于简洁性的中等体量发行版
|
||||||
|
======
|
||||||
|
|
||||||
|
> 这个发行版可以使任何人在 Linux 上如家一般。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Linux 有着如此多种的发行版。许多发行版为了使自己与众不同而做出了很多改变。另一方面,许多发行版之间的区别又是如此之小,你可能会问为什么有人还愿意不厌其烦的重复别人已经做过的工作呢?也正是基于这一疑惑,让我好奇为什么 [antiX][1] 和 [MEPIS][2]这两个社区要联合推出一个特殊的发行版,考虑到具体情况应该会是一个搭载 Xfce 桌面并基于 antiX 的版本,由 MEPIS 社区承担开发。
|
||||||
|
|
||||||
|
这一开发中的使用 Xfce 桌面的 antiX 系统是否会基于它之前的发行版呢?毕竟,antiX 旨在提供一个“基于 Debian 稳定版的快速、轻量级、易于安装的非 systemd 的 live CD 发行版”。antiX 所搭载的桌面是 [LXDE][3],能够极好的满足关于轻量化系统的相关要求和特性。那究竟是什么原因使得 antiX 决定构建另一个轻量化发行版呢,仅仅是因为这次换成了 Xfce 吗?好吧,Linux 社区中的任何人都知道,增加了不同风格的好的轻量级发行版是值得一试的(特别是可以使得我们的旧硬件摆脱进入垃圾填埋场的宿命)。当然,LXDE 和 Xfce 并不完全属于同一类别。LXDE 应该被认为是一个真正的轻量级桌面,而 Xfce 应该被认为是一个中等体量的桌面。朋友们,这就是为什么 MX Linux 是 antiX 的一个重要迭代的关键。一个基于 Debian 的中等体量的发行版,它包含你完成工作所需的所有工具。
|
||||||
|
|
||||||
|
但是在 MX Linux 中有一些直接从 antiX 借用来的非常有用的东西 —— 那就是安装工具。当我初次设置了 VirtualBox 虚拟机来安装 MX Linux 时,我认为安装的系统将是我已经习惯的典型的、非常简单的 Linux 系统。令我非常惊讶的是,MX Linux 使用的 antiX 安装程序打破了以往的痛点,特别是对于那些对尝试 Linux 持观望态度的人来说。
|
||||||
|
|
||||||
|
因此,甚至在我开始尝试 MX Linux 之前,我就对它有了深刻的印象。让我们来看看是什么让这个发行版的安装如此特别,最后再来看看桌面。
|
||||||
|
|
||||||
|
你可以从[这里][4]下载 MX Linux 17.1。系统的最低要求是:
|
||||||
|
|
||||||
|
* CD/DVD驱动器(以及能够从该驱动器引导的 BIOS)或 live USB(以及能够从 USB 引导的 BIOS)
|
||||||
|
* 英特尔 i486 或 AMD 处理器
|
||||||
|
* 512 MB 内存
|
||||||
|
* 5 GB 硬盘空间
|
||||||
|
* 扬声器,AC97 或 HDA-compatible 声卡
|
||||||
|
* 作为一个 LiveUSB 使用,需要 4 GB 空间
|
||||||
|
|
||||||
|
### 安装
|
||||||
|
|
||||||
|
MX Linux 安装程序使安装 Linux 变得轻而易举。虽然它可能不是外观最现代化的安装工具,但也已经差不多了。安装的要点是从选择磁盘和选择安装类型开始的(图 1)。
|
||||||
|
|
||||||
|
![install][6]
|
||||||
|
|
||||||
|
*图 1:MX Linux 的安装程序截图之一*
|
||||||
|
|
||||||
|
下一个重要的界面(图 2)要求你设置一个计算机名称、域名和(如果需要的话,为微软网络设置)工作组。
|
||||||
|
|
||||||
|
![network][8]
|
||||||
|
|
||||||
|
*图 2:设置网络名称*
|
||||||
|
|
||||||
|
配置工作组的能力是第一个真正值得称赞的。这是我记忆中第一款在安装期间提供此选项的发行版。它还应该提示你,MX Linux 提供了开箱即用的共享目录功能。它做到了,而且深藏功与名。它并不完美,但它可以在不需要安装任何额外包的情况下工作(稍后将详细介绍)。
|
||||||
|
|
||||||
|
最后一个重要的安装界面(需要用户交互)是创建用户帐户和 root 权限的密码(图 3)。
|
||||||
|
|
||||||
|
![user][9]
|
||||||
|
|
||||||
|
*图 3:设置用户帐户详细信息和 root 用户密码*
|
||||||
|
|
||||||
|
最后一个界面设置完成后,安装将完成并要求重新启动。重启后,你将看到登录屏幕。登录并享受 MX Linux 带来的体验。
|
||||||
|
|
||||||
|
### 使用
|
||||||
|
|
||||||
|
Xfce 桌面是一个非常容易上手的界面。默认设置将面板位于屏幕的左边缘(图 4)。
|
||||||
|
|
||||||
|
![desktop][11]
|
||||||
|
|
||||||
|
*图 4:MX Linux 的默认桌面*
|
||||||
|
|
||||||
|
如果你想将面板移动到更传统的位置,右键单击面板上的空白点,然后单击“面板”>“面板首选项”。在显示的窗口中(图 5),单击样式下拉菜单,在桌面栏、垂直栏或水平栏之间进行选择你想要的模式。
|
||||||
|
|
||||||
|
![panel][13]
|
||||||
|
|
||||||
|
*图 5:配置 MX Linux 面板*
|
||||||
|
|
||||||
|
桌面栏和垂直选项的区别在于,在桌面栏模式下,面板垂直对齐,就像在垂直模式下一样,但是插件是水平放置的。这意味着你可以创建更宽的面板(用于宽屏布局)。如果选择水平布局,它将默在顶部,然后你必须取消锁定面板,单击关闭,然后(使用面板左侧边缘的拖动手柄)将其拖动到底部。你可以回到面板设置窗口并重新锁定面板。
|
||||||
|
|
||||||
|
除此之外,使用 Xfce 桌面对于任何级别的用户来说都是无需动脑筋的事情……就是这么简单。你会发现很多涵盖了生产力(LibreOffice、Orage Calendar、PDF-Shuffler)、图像(GIMP)、通信(Firefox、Thunderbird、HexChat)、多媒体(Clementine、guvcview SMTube、VLC媒体播放器)的软件,和一些 MX Linux 专属的工具(称为 MX 工具,涵盖了 live-USB 驱动器制作工具、网络助手、包管理工具、仓库管理工具、live ISO 快照工具等等)。
|
||||||
|
|
||||||
|
### Samba
|
||||||
|
|
||||||
|
让我们讨论一下如何将文件夹共享到你的网络。正如我所提到的,你不需要安装任何额外的包就可以使其正常工作。只需打开文件管理器,右键单击任何位置,并选择网络上的共享文件夹。系统将提示你输入管理密码(已在安装期间设置)。验证成功之后,Samba 服务器配置工具将打开(图 6)。
|
||||||
|
|
||||||
|
![sharing][15]
|
||||||
|
|
||||||
|
*图 6:向网络共享一个目录*
|
||||||
|
|
||||||
|
单击“+”按钮配置你的共享。你将被要求指定一个目录,为共享提供一个名称/描述,然后决定该共享是否可写和可见(图 7)。
|
||||||
|
|
||||||
|
![sharing][17]
|
||||||
|
|
||||||
|
*图 7:在 MX Linux 上配置共享*
|
||||||
|
|
||||||
|
当你单击 Access 选项时,你可以选择是让每个人都访问共享,还是限于特定的用户。问题就出在这里。此时,没有用户可以共享。为什么?因为它们还没有被添加。有两种方法可以把它们添加到共享:从命令行或使用我们已经打开的工具。让我们用一种更为简单的方法。在 Samba 服务器配置工具的主窗口中,单击“首选项” > “Samba 用户”。在弹出的窗口中,单击“添加用户”。
|
||||||
|
|
||||||
|
将出现一个新窗口(图 8),你需要从下拉框中选择用户,输入 Windows 用户名,并为用户键入/重新键入密码。
|
||||||
|
|
||||||
|
![Samba][19]
|
||||||
|
|
||||||
|
*图 8:向 Samba 添加用户*
|
||||||
|
|
||||||
|
一旦你单击“确定”,这用户就会被添加,并且基于你的网络的对用户的共享功能也随之启用。创建 Samba 共享从未变得如此容易。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
MX Linux 使任何从桌面操作系统转到 Linux 都变得非常简单。尽管有些人可能会觉得桌面界面不太现代,但发行版的主要关注点不是美观,而是简洁。为此,MX Linux 以出色的方式取得了成功。Linux 的这个特色发行版可以让任何人在使用 Linux 的过程中感到宾至如归。尝试这一中等体量的发行版,看看它能否作为你的日常系统。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linux.com/learn/intro-to-linux/2018/4/mx-linux-mid-weight-distro-focused-simplicity
|
||||||
|
|
||||||
|
作者:[JACK WALLEN][a]
|
||||||
|
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linux.com/users/jlwallen
|
||||||
|
[1]:https://antixlinux.com/
|
||||||
|
[2]:https://en.wikipedia.org/wiki/MEPIS
|
||||||
|
[3]:https://lxde.org/
|
||||||
|
[4]:https://mxlinux.org/download-links
|
||||||
|
[5]:/files/images/mxlinux1jpg
|
||||||
|
[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mxlinux_1.jpg?itok=i9bNScjH (install)
|
||||||
|
[7]:/licenses/category/used-permission
|
||||||
|
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mxlinux_2.jpg?itok=72nWxkGo
|
||||||
|
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mxlinux_3.jpg?itok=ppf2l_bm (user)
|
||||||
|
[10]:/files/images/mxlinux4jpg
|
||||||
|
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mxlinux_4.jpg?itok=mS1eBy9m (desktop)
|
||||||
|
[12]:/files/images/mxlinux5jpg
|
||||||
|
[13]:https://www.linux.com/sites/lcom/files/styles/floated_images/public/mxlinux_5.jpg?itok=wsN1hviN (panel)
|
||||||
|
[14]:/files/images/mxlinux6jpg
|
||||||
|
[15]:https://www.linux.com/sites/lcom/files/styles/floated_images/public/mxlinux_6.jpg?itok=vw8mIp9T (sharing)
|
||||||
|
[16]:/files/images/mxlinux7jpg
|
||||||
|
[17]:https://www.linux.com/sites/lcom/files/styles/floated_images/public/mxlinux_7.jpg?itok=tRIWdcEk (sharing)
|
||||||
|
[18]:/files/images/mxlinux8jpg
|
||||||
|
[19]:https://www.linux.com/sites/lcom/files/styles/floated_images/public/mxlinux_8.jpg?itok=ZS6lhZN2 (Samba)
|
||||||
|
[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||||
@ -1,73 +1,56 @@
|
|||||||
使用 Ansible 管理工作站:配置桌面设置
|
使用 Ansible 管理你的工作站:配置桌面设置
|
||||||
======
|
======
|
||||||
|
|
||||||
|
> 在本系列第三篇(也是最后一篇)文章中,我们将使用 Ansible 自动化配置 GNOME 桌面设置。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
在本系列关于使用 Ansible 配置工作站的[第一篇文章][1]中,我们设置了一个仓库并配置了一些基本的东西。在[第二篇文章][2]中,我们配置了 Ansible 以使其在对仓库进行更改时自动应用设置。在第三篇(也是最后一篇)文章中,我们将使用 Ansible 配置 GNOME 桌面设置。
|
在本系列关于使用 Ansible 配置工作站的[第一篇文章][1]中,我们设置了一个仓库并配置了一些基本的东西。在[第二篇文章][2]中,我们配置了 Ansible 以使其在对仓库进行更改时自动应用设置。在第三篇(也是最后一篇)文章中,我们将使用 Ansible 配置 GNOME 桌面设置。
|
||||||
|
|
||||||
此配置只适用于较新的发行版(例如我将在示例中使用的 Ubuntu 18.04)。较旧版本的 Ubuntu 将无法运行,因为它们附带了一个老版本的 `python-psutils`,对于 Ansible 的 `dconf` 模块无法正常工作。如果你使用的是较新版本的 Linux 发行版,则应该没有问题。
|
此配置只适用于较新的发行版(例如我将在示例中使用的 Ubuntu 18.04)。较旧版本的 Ubuntu 将无法运行,因为它们附带了一个老版本的 `python-psutils`,对于 Ansible 的 `dconf` 模块无法正常工作。如果你使用的是较新版本的 Linux 发行版,则应该没有问题。
|
||||||
|
|
||||||
在开始之前,确保你已经完成了本系列的第一部分和第二部分,因为第三部分建立在此基础之上的。如果还没有,下载前两篇文章中一直使用的 GitHub 仓库,我们将为其添加更多功能。
|
在开始之前,确保你已经完成了本系列的第一部分和第二部分,因为第三部分建立在此基础之上的。如果还没有,下载前两篇文章中一直使用的 GitHub [仓库][3],我们将为其添加更多功能。
|
||||||
|
|
||||||
### 设置壁纸和锁屏
|
### 设置壁纸和锁屏
|
||||||
|
|
||||||
首先,我们将创建一个任务手册来保存我们的 GNOME 设置。在仓库的根目录中,应该有一个名为 `local.yml` 的文件,添加以下行:
|
首先,我们将创建一个任务手册来保存我们的 GNOME 设置。在仓库的根目录中,应该有一个名为 `local.yml` 的文件,添加以下行:
|
||||||
|
|
||||||
```
|
```
|
||||||
- include: tasks/gnome.yml
|
- include: tasks/gnome.yml
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
整个文件应如下所示:
|
整个文件应如下所示:
|
||||||
|
|
||||||
```
|
```
|
||||||
- hosts: localhost
|
- hosts: localhost
|
||||||
|
become: true
|
||||||
|
pre_tasks:
|
||||||
|
- name: update repositories
|
||||||
|
apt: update_cache=yes
|
||||||
|
changed_when: False
|
||||||
|
|
||||||
become: true
|
tasks:
|
||||||
|
- include: tasks/users.yml
|
||||||
pre_tasks:
|
- include: tasks/cron.yml
|
||||||
|
- include: tasks/packages.yml
|
||||||
- name: update repositories
|
- include: tasks/gnome.yml
|
||||||
|
|
||||||
apt: update_cache=yes
|
|
||||||
|
|
||||||
changed_when: False
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
tasks:
|
|
||||||
|
|
||||||
- include: tasks/users.yml
|
|
||||||
|
|
||||||
- include: tasks/cron.yml
|
|
||||||
|
|
||||||
- include: tasks/packages.yml
|
|
||||||
|
|
||||||
- include: tasks/gnome.yml
|
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
基本上,这添加了对名为 `gnome.yml` 文件的引用,它将存储在仓库内的 `tasks` 目录中。我们还没有创建这个文件,现在就来创建它。在 `tasks` 目录中创建 `gnome.yml` 文件,并将以下内容放入:
|
基本上,这添加了对名为 `gnome.yml` 文件的引用,它将存储在仓库内的 `tasks` 目录中。我们还没有创建这个文件,现在就来创建它。在 `tasks` 目录中创建 `gnome.yml` 文件,并将以下内容放入:
|
||||||
|
|
||||||
```
|
```
|
||||||
- name: Install python-psutil package
|
- name: Install python-psutil package
|
||||||
|
apt: name=python-psutil
|
||||||
apt: name=python-psutil
|
|
||||||
|
|
||||||
|
|
||||||
- name: Copy wallpaper file
|
- name: Copy wallpaper file
|
||||||
|
copy: src=files/wallpaper.jpg dest=/home/jay/.wallpaper.jpg owner=jay group=jay mode=600
|
||||||
copy: src=files/wallpaper.jpg dest=/home/jay/.wallpaper.jpg owner=jay group=jay mode=600
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
- name: Set GNOME Wallpaper
|
- name: Set GNOME Wallpaper
|
||||||
|
become_user: jay
|
||||||
become_user: jay
|
dconf: key="/org/gnome/desktop/background/picture-uri" value="'file:///home/jay/.wallpaper.jpg'"
|
||||||
|
|
||||||
dconf: key="/org/gnome/desktop/background/picture-uri" value="'file:///home/jay/.wallpaper.jpg'"
|
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
注意,此代码多次引用我的用户名(`jay`),因此确保使用你机器上的用户名替换每次出现的 `jay`。另外,如果你没有像我一样使用 Ubuntu 18.04,你将不得不更改 `apt` 一行来匹配你所选择的发行版的包管理器,并确认 `python-psutil` 包的名称,因为它可能有所不同。
|
注意,此代码多次引用我的用户名(`jay`),因此确保使用你机器上的用户名替换每次出现的 `jay`。另外,如果你没有像我一样使用 Ubuntu 18.04,你将必须更改 `apt` 一行来匹配你所选择的发行版的包管理器,并确认 `python-psutil` 包的名称,因为它可能有所不同。
|
||||||
|
|
||||||
|
|
||||||
在示例任务中,我引用了 `file` 目录下的 `wallpaper.jpg` 文件,此文件必须存在,否则 Ansible 配置将失败。在 `tasks` 目录中,创建一个名为 `files` 的子目录。找到你喜欢的壁纸图片,将其命名为 `wallpaper.jpg`,然后把它放在 `files` 目录中。如果文件是 PNG 图像而不是 JPG,在代码和仓库中更改文件扩展名。如果你觉得没有创意,我在 [GitHub 仓库][3] 中有一个示例壁纸文件,你可以使用它。
|
在示例任务中,我引用了 `file` 目录下的 `wallpaper.jpg` 文件,此文件必须存在,否则 Ansible 配置将失败。在 `tasks` 目录中,创建一个名为 `files` 的子目录。找到你喜欢的壁纸图片,将其命名为 `wallpaper.jpg`,然后把它放在 `files` 目录中。如果文件是 PNG 图像而不是 JPG,在代码和仓库中更改文件扩展名。如果你觉得没有创意,我在 [GitHub 仓库][3] 中有一个示例壁纸文件,你可以使用它。
|
||||||
|
|
||||||
@ -77,49 +60,34 @@
|
|||||||
* 使用上面提到的内容创建 `tasks/gnome.yml`
|
* 使用上面提到的内容创建 `tasks/gnome.yml`
|
||||||
* 在 `tasks` 目录中创建一个 `files` 目录,其中有一个名为 `wallpaper.jpg` 的图像文件(或者你选择的任何名称)。
|
* 在 `tasks` 目录中创建一个 `files` 目录,其中有一个名为 `wallpaper.jpg` 的图像文件(或者你选择的任何名称)。
|
||||||
|
|
||||||
|
完成这些步骤并将更改推送到仓库后,配置应该在下次计划运行期间自动应用。(你可能还记得我们在上一篇文章中对此进行了自动化。)如果你想节省时间,可以使用以下命令立即应用配置:
|
||||||
|
|
||||||
完成这些步骤并将更改推送到仓库后,配置应该在下次计划运行期间自动应用。(你可能还记得我们在上一篇文章中对此进行了自动化。)如果你赶时间,可以使用以下命令立即应用配置:
|
|
||||||
```
|
```
|
||||||
sudo ansible-pull -U https://github.com/<github_user>/ansible.git
|
sudo ansible-pull -U https://github.com/<github_user>/ansible.git
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
如果一切正常,你应该可以看到你的新壁纸。
|
如果一切正常,你应该可以看到你的新壁纸。
|
||||||
|
|
||||||
让我们花一点时间来了解新 GNOME 任务手册的功能。首先,我们添加了一个计划来安装 `python-psutil` 包。如果不添加它,我们就不能使用 `dconf` 模块,因为它需要在修改 GNOME 设置之前安装这个包。接下来,我们使用 `copy` 模块将壁纸文件复制到我们的 `home` 目录,并将生成的文件命名为以点开头的隐藏文件。如果你不希望此文件放在 `home` 目录的根目录中,你可以随时指示此部分将其复制到其它位置 - 只要你在正确的位置引用它,它仍然可以工作。在下一个计划中,我们使用 `dconf` 模块来更改 GNOME 设置。在这种情况下,我们调整了 `/org/gnome/desktop/background/picture-uri` 键并将其设置为 `file:///home/jay/.wallpaper.jpg`。注意本节中的引号 - 你必须在 `dconf` 值中使用两个单引号,如果值是一个字符串,还必须包含双引号。
|
让我们花一点时间来了解新的 GNOME 任务手册的功能。首先,我们添加了一个计划来安装 `python-psutil` 包。如果不添加它,我们就不能使用 `dconf` 模块,因为它需要在修改 GNOME 设置之前安装这个包。接下来,我们使用 `copy` 模块将壁纸文件复制到我们的 `home` 目录,并将生成的文件命名为以点开头的隐藏文件。如果你不希望此文件放在 `home` 目录的根目录中,你可以随时指示此部分将其复制到其它位置 —— 只要你在正确的位置引用它,它仍然可以工作。在下一个计划中,我们使用 `dconf` 模块来更改 GNOME 设置。在这种情况下,我们调整了 `/org/gnome/desktop/background/picture-uri` 键并将其设置为 `file:///home/jay/.wallpaper.jpg`。注意本节中的引号 —— 你必须在 `dconf` 值中使用两个单引号,如果值是一个字符串,还必须包含在双引号内。
|
||||||
|
|
||||||
|
现在,让我们进一步进行配置,并将背景应用于锁屏。这是现在的 GNOME 任务手册,但增加了两个额外的计划:
|
||||||
|
|
||||||
现在,让我们进一步进行配置,并将背景应用于锁屏。这是 GNOME 任务手册,但增加了两个额外的计划:
|
|
||||||
```
|
```
|
||||||
- name: Install python-psutil package
|
- name: Install python-psutil package
|
||||||
|
apt: name=python-psutil
|
||||||
apt: name=python-psutil
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
- name: Copy wallpaper file
|
- name: Copy wallpaper file
|
||||||
|
copy: src=files/wallpaper.jpg dest=/home/jay/.wallpaper.jpg owner=jay group=jay mode=600
|
||||||
copy: src=files/wallpaper.jpg dest=/home/jay/.wallpaper.jpg owner=jay group=jay mode=600
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
- name: Set GNOME wallpaper
|
- name: Set GNOME wallpaper
|
||||||
|
dconf: key="/org/gnome/desktop/background/picture-uri" value="'file:///home/jay/.wallpaper.jpg'"
|
||||||
dconf: key="/org/gnome/desktop/background/picture-uri" value="'file:///home/jay/.wallpaper.jpg'"
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
- name: Copy lockscreenfile
|
- name: Copy lockscreenfile
|
||||||
|
copy: src=files/lockscreen.jpg dest=/home/jay/.lockscreen.jpg owner=jay group=jay mode=600
|
||||||
copy: src=files/lockscreen.jpg dest=/home/jay/.lockscreen.jpg owner=jay group=jay mode=600
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
- name: Set lock screen background
|
- name: Set lock screen background
|
||||||
|
become_user: jay
|
||||||
become_user: jay
|
dconf: key="/org/gnome/desktop/screensaver/picture-uri" value="'file:///home/jay/.lockscreen.jpg'"
|
||||||
|
|
||||||
dconf: key="/org/gnome/desktop/screensaver/picture-uri" value="'file:///home/jay/.lockscreen.jpg'"
|
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
正如你所看到的,我们做的事情和设置壁纸时差不多。我们添加了两个额外的任务,一个是复制锁屏图像并将其放在我们的 `home` 目录中,另一个是将设置应用于 GNOME 以便使用它。同样,确保将 `jay` 更改为你的用户名,并命名你想要的锁屏图片 `lockscreen.jpg`,并将其复制到 `files` 目录。将这些更改提交到仓库后,在下一次计划的 Ansible 运行期间就会应用新的锁屏。
|
正如你所看到的,我们做的事情和设置壁纸时差不多。我们添加了两个额外的任务,一个是复制锁屏图像并将其放在我们的 `home` 目录中,另一个是将设置应用于 GNOME 以便使用它。同样,确保将 `jay` 更改为你的用户名,并命名你想要的锁屏图片 `lockscreen.jpg`,并将其复制到 `files` 目录。将这些更改提交到仓库后,在下一次计划的 Ansible 运行期间就会应用新的锁屏。
|
||||||
@ -127,52 +95,49 @@ sudo ansible-pull -U https://github.com/<github_user>/ansible.git
|
|||||||
### 应用新的桌面主题
|
### 应用新的桌面主题
|
||||||
|
|
||||||
设置壁纸和锁屏背景很酷,但是让我们更进一步来应用桌面主题。首先,让我们在我们的任务手册中添加一条指令来安装 `arc` 主题的包。将以下代码添加到 GNOME 任务手册的开头:
|
设置壁纸和锁屏背景很酷,但是让我们更进一步来应用桌面主题。首先,让我们在我们的任务手册中添加一条指令来安装 `arc` 主题的包。将以下代码添加到 GNOME 任务手册的开头:
|
||||||
|
|
||||||
```
|
```
|
||||||
- name: Install arc theme
|
- name: Install arc theme
|
||||||
|
|
||||||
apt: name=arc-theme
|
apt: name=arc-theme
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
然后,在底部,添加以下任务:
|
然后,在底部,添加以下动作:
|
||||||
|
|
||||||
```
|
```
|
||||||
- name: Set GTK theme
|
- name: Set GTK theme
|
||||||
|
|
||||||
become_user: jay
|
become_user: jay
|
||||||
|
|
||||||
dconf: key="/org/gnome/desktop/interface/gtk-theme" value="'Arc'"
|
dconf: key="/org/gnome/desktop/interface/gtk-theme" value="'Arc'"
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
你看到 GNOME 的 GTK 主题在你眼前变化了吗?我们添加了一个任务来通过 `apt` 模块安装 `arc-theme` 包,另一个任务将这个主题应用到 GNOME。
|
你看到 GNOME 的 GTK 主题在你眼前变化了吗?我们添加了一个动作来通过 `apt` 模块安装 `arc-theme` 包,另一个动作将这个主题应用到 GNOME。
|
||||||
|
|
||||||
### 进行其它定制
|
### 进行其它定制
|
||||||
|
|
||||||
既然你已经更改了一些 GNOME 设置,你可以随意添加其它定制。你在 GNOME 中调整的任何设置都可以通过这种方式自动完成,设置壁纸和主题只是几个例子。你可能想知道如何找到要更改的设置,以下一个适合我的技巧。
|
既然你已经更改了一些 GNOME 设置,你可以随意添加其它定制。你在 GNOME 中调整的任何设置都可以通过这种方式自动完成,设置壁纸和主题只是几个例子。你可能想知道如何找到要更改的设置,以下是一个我用的技巧。
|
||||||
|
|
||||||
首先,通过在你管理的计算机上运行以下命令,获取所有当前 `dconf` 设置的快照:
|
首先,通过在你管理的计算机上运行以下命令,获取所有当前 `dconf` 设置的快照:
|
||||||
|
|
||||||
```
|
```
|
||||||
dconf dump / > before.txt
|
dconf dump / > before.txt
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
此命令将所有当前更改导出到名为 `before.txt` 的文件中。接下来,手动更改要自动化的设置,并再次获取 `dconf` 设置:
|
此命令将所有当前更改导出到名为 `before.txt` 的文件中。接下来,手动更改要自动化的设置,并再次获取 `dconf` 设置:
|
||||||
|
|
||||||
```
|
```
|
||||||
dconf dump / > after.txt
|
dconf dump / > after.txt
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
现在,你可以使用 `diff` 命令查看两个文件之间的不同之处:
|
现在,你可以使用 `diff` 命令查看两个文件之间的不同之处:
|
||||||
|
|
||||||
```
|
```
|
||||||
diff before.txt after.txt
|
diff before.txt after.txt
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
这应该会给你一个已更改键的列表。虽然手动更改设置确实违背了自动化的目的,但你实际上正在做的是获取更新首选设置时更改的键,这允许你创建 Ansible 任务以修改这些设置,这样你就再也不需要碰这些设置了。如果你需要还原机器,Ansible 仓库将负责你的每个定制。如果你有多台计算机,甚至是一组工作站,则只需手动进行一次更改,所有其他工作站都将应用新设置并完全同步。
|
这应该会给你一个已更改键值的列表。虽然手动更改设置确实违背了自动化的目的,但你实际上正在做的是获取更新首选设置时更改的键,这允许你创建 Ansible 任务以修改这些设置,这样你就再也不需要碰这些设置了。如果你需要还原机器,Ansible 仓库会处理好你的每个定制。如果你有多台计算机,甚至是一组工作站,则只需手动进行一次更改,所有其他工作站都将应用新设置并完全同步。
|
||||||
|
|
||||||
### 最后
|
### 最后
|
||||||
|
|
||||||
如果你已经阅读完本系列文章,你应该知道如何设置 Ansible 来自动化工作站。这些示例提供了一个有用的基线,你可以使用语法和示例进行其他定制。随着你的前进,你可以继续添加新的修改,这将使你的 Ansible 配置一直增长。
|
如果你已经阅读完本系列文章,你应该知道如何设置 Ansible 来自动化工作站。这些示例提供了一个有用的基础,你可以使用这些语法和示例进行其他定制。随着你的进展,你可以继续添加新的修改,这将使你的 Ansible 配置一直增长。
|
||||||
|
|
||||||
我已经用 Ansible 以这种方式自动化了一切,包括我的用户帐户和密码、Vim、tmux 等配置文件、桌面包、SSH 设置、SSH 密钥,基本上我想要自定义的一切都使用了。以本系列文章作为起点,将为你实现工作站的完全自动化铺平道路。
|
我已经用 Ansible 以这种方式自动化了一切,包括我的用户帐户和密码、Vim、tmux 等配置文件、桌面包、SSH 设置、SSH 密钥,基本上我想要自定义的一切都使用了。以本系列文章作为起点,将为你实现工作站的完全自动化铺平道路。
|
||||||
|
|
||||||
@ -183,11 +148,11 @@ via: https://opensource.com/article/18/5/manage-your-workstation-ansible-part-3
|
|||||||
作者:[Jay LaCroix][a]
|
作者:[Jay LaCroix][a]
|
||||||
选题:[lujun9972](https://github.com/lujun9972 )
|
选题:[lujun9972](https://github.com/lujun9972 )
|
||||||
译者:[MjSeven](https://github.com/MjSeven)
|
译者:[MjSeven](https://github.com/MjSeven)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
[a]:https://opensource.com/users/jlacroix
|
[a]:https://opensource.com/users/jlacroix
|
||||||
[1]:https://opensource.com/article/18/3/manage-workstation-ansible
|
[1]:https://linux.cn/article-10434-1.html
|
||||||
[2]:https://opensource.com/article/18/3/manage-your-workstation-configuration-ansible-part-2
|
[2]:https://linux.cn/article-10449-1.html
|
||||||
[3]:https://github.com/jlacroix82/ansible_article.git
|
[3]:https://github.com/jlacroix82/ansible_article.git
|
||||||
@ -1,8 +1,8 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (geekpi)
|
[#]: translator: (geekpi)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11066-1.html)
|
||||||
[#]: subject: (How To Find The Port Number Of A Service In Linux)
|
[#]: subject: (How To Find The Port Number Of A Service In Linux)
|
||||||
[#]: via: (https://www.ostechnix.com/how-to-find-the-port-number-of-a-service-in-linux/)
|
[#]: via: (https://www.ostechnix.com/how-to-find-the-port-number-of-a-service-in-linux/)
|
||||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||||
@ -16,9 +16,9 @@
|
|||||||
|
|
||||||
### 在 Linux 中查找服务的端口号
|
### 在 Linux 中查找服务的端口号
|
||||||
|
|
||||||
**方法1:使用 [grep][2] 命令**
|
#### 方法1:使用 grep 命令
|
||||||
|
|
||||||
要使用 grep 命令在 Linux 中查找指定服务的默认端口号,只需运行:
|
要使用 `grep` 命令在 Linux 中查找指定服务的默认端口号,只需运行:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ grep <port> /etc/services
|
$ grep <port> /etc/services
|
||||||
@ -84,11 +84,11 @@ tftp 69/tcp
|
|||||||
[...]
|
[...]
|
||||||
```
|
```
|
||||||
|
|
||||||
**方法 2:使用 getent 命令**
|
#### 方法 2:使用 getent 命令
|
||||||
|
|
||||||
如你所见,上面的命令显示指定搜索词 “ssh”、“http” 和 “ftp” 的所有端口名称和数字。这意味着,你将获得与给定搜索词匹配的所有端口名称的相当长的输出。
|
如你所见,上面的命令显示指定搜索词 “ssh”、“http” 和 “ftp” 的所有端口名称和数字。这意味着,你将获得与给定搜索词匹配的所有端口名称的相当长的输出。
|
||||||
|
|
||||||
但是,你可以使用 “getent” 命令精确输出结果,如下所示:
|
但是,你可以使用 `getent` 命令精确输出结果,如下所示:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ getent services ssh
|
$ getent services ssh
|
||||||
@ -114,17 +114,15 @@ http 80/tcp
|
|||||||
$ getent services
|
$ getent services
|
||||||
```
|
```
|
||||||
|
|
||||||
**方法 3:使用 Whatportis 程序**
|
#### 方法 3:使用 Whatportis 程序
|
||||||
|
|
||||||
**Whatportis** 是一个简单的 python 脚本,来用于查找端口名称和端口号。与上述命令不同,此程序以漂亮的表格形式输出。
|
Whatportis 是一个简单的 Python 脚本,来用于查找端口名称和端口号。与上述命令不同,此程序以漂亮的表格形式输出。
|
||||||
|
|
||||||
确保已安装 PIP 包管理器。如果没有,请参考以下链接。
|
确保已安装 pip 包管理器。如果没有,请参考以下链接。
|
||||||
|
|
||||||
* [**如何使用 Pip 管理 Python 包**][6]
|
- [如何使用 pip 管理 Python 包][6]
|
||||||
|
|
||||||
|
安装 pip 后,运行以下命令安装 Whatportis 程序。
|
||||||
|
|
||||||
安装 PIP 后,运行以下命令安装 Whatportis 程序。
|
|
||||||
|
|
||||||
```
|
```
|
||||||
$ pip install whatportis
|
$ pip install whatportis
|
||||||
@ -144,9 +142,9 @@ $ whatportis http
|
|||||||
|
|
||||||
![][7]
|
![][7]
|
||||||
|
|
||||||
在 Linux 中查找服务的端口号
|
*在 Linux 中查找服务的端口号*
|
||||||
|
|
||||||
如果你不知道服务的确切名称,请使用 **–like** 标志来显示相关结果。
|
如果你不知道服务的确切名称,请使用 `–like` 标志来显示相关结果。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ whatportis mysql --like
|
$ whatportis mysql --like
|
||||||
@ -158,7 +156,7 @@ $ whatportis mysql --like
|
|||||||
$ whatportis 993
|
$ whatportis 993
|
||||||
```
|
```
|
||||||
|
|
||||||
你甚至可以以 **JSON** 格式显示结果。
|
你甚至可以以 JSON 格式显示结果。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ whatportis 993 --json
|
$ whatportis 993 --json
|
||||||
@ -168,9 +166,7 @@ $ whatportis 993 --json
|
|||||||
|
|
||||||
有关更多详细信息,请参阅 GitHub 仓库。
|
有关更多详细信息,请参阅 GitHub 仓库。
|
||||||
|
|
||||||
* [**Whatportis GitHub 仓库**][9]
|
* [Whatportis GitHub 仓库][9]
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
就是这些了。你现在知道了如何使用三种简单方法在 Linux 中查找端口名称和端口号。如果你知道任何其他方法/命令,请在下面的评论栏告诉我。我会查看并更相应地更新本指南。
|
就是这些了。你现在知道了如何使用三种简单方法在 Linux 中查找端口名称和端口号。如果你知道任何其他方法/命令,请在下面的评论栏告诉我。我会查看并更相应地更新本指南。
|
||||||
|
|
||||||
@ -181,7 +177,7 @@ via: https://www.ostechnix.com/how-to-find-the-port-number-of-a-service-in-linux
|
|||||||
作者:[sk][a]
|
作者:[sk][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
179
published/201907/20180902 Learning BASIC Like It-s 1983.md
Normal file
179
published/201907/20180902 Learning BASIC Like It-s 1983.md
Normal file
@ -0,0 +1,179 @@
|
|||||||
|
穿越到 1983 年学习 BASIC
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
1983 年时我还没出生,这让我略有一些遗憾。但我特别遗憾的是,是我没有经历过 8 位计算机时代的到来,因为我认为那些初次接触到还相对简单和受限的计算机的人们,拥有超过如今的我们的巨大优势。
|
||||||
|
|
||||||
|
今天,(几乎)每个人知道如何使用计算机,但是即使是在计算机行业当中,也很少有人能明白任何一台计算机内部的所有内容。现在软件分为[如此多的层次][1],做的是如此不同的事情,没有哪个人能知道哪些是必不可少的。而在 1983 年,家用电脑足够傻大粗,努力一些的人就能了解到一台特定的计算机是如何工作的。那样的一个人可能不会像今天的我觉得操作系统那么神秘,因为如今的操作系统已经在硬件上叠加了太多的抽象层。我希望这些抽象层逐一引入以易于理解;而今天,新的程序员们不得不自上而下、按时间回溯地尝试理解它们。
|
||||||
|
|
||||||
|
很多著名的程序员,尤其在计算机游戏行业,孩童时期就在苹果 II 和 Commodore 64 这样的 8 位计算机上开始编写游戏,John Romero、Richard Garriott 和 Chris Roberts 都是这样的例子。这好理解。在 8 位计算机时代,很多游戏只能在计算机杂志和[书籍][2]中以印刷的 BASIC 程序清单方式得到。如果你想玩其中一款游戏,就必须手工键入整个程序。不可避免的,你可能遇到一些问题,所以你就得调试你的程序。等到你让它可以工作起来了,你就已经对程序是如何运行的有了足够的了解,你就可以开始自己修改它了。如果你是一个狂热的游戏玩家,你几乎必然会成为一名优秀的程序员。
|
||||||
|
|
||||||
|
在我的童年时期我也玩电脑游戏。但是我玩的游戏是在 CD-ROM 上的。我有时发现我自己必须得搜索一下如何修复崩溃的安装程序,这可能涉及编辑 Windows 注册表之类的东西。可能是这种小故障的排除让我感觉很棒,所以我才考虑在大学里学习计算机科学。但是在大学中从不教我一些计算机如何工作的或如何控制它们的关键性的东西。
|
||||||
|
|
||||||
|
当然,现在我可以告诉计算机去干什么。尽管如此,我还是不禁感到,我缺少一些根本的见解 —— 只有那些伴随着更简单的计算机编程而成长的人才有的深刻见解。我不禁在想,如果在上世纪 80 年代初就接触到计算机会是什么样子?它们与今天使用计算机的体验相比有何不同?
|
||||||
|
|
||||||
|
这篇文章将与通常的 Two-Bit History 的文章有一点不同,因为我将为这些问题尝试设想一个答案。
|
||||||
|
|
||||||
|
### 1983
|
||||||
|
|
||||||
|
就在上周,你在电视上看到了 [Commodore 64 的广告][3] ,现在 M\*A\*S\*H 播完了(LCTT 译注: 这是一部上世纪 70 年代初的电视剧),星期一晚上你可以找点新的事情做了。这个 Commodore 64 甚至看起来比鲁迪(LCTT 译注:应该是下文中拥有 Apple II 的人)的家人放在他们家地下室的 Apple II 更好。而且,广告中吹嘘说新的计算机会让你的朋友们“挤破”你家的大门。你知道学校里的几个家伙宁愿在你家闲逛,也不愿去鲁迪家里,只要他们能玩 Zork 就行。
|
||||||
|
|
||||||
|
所以,你得说服你的父母去买一台。你的母亲说,这事可以考虑,只要你不去游戏厅玩街机就给你买一台家庭电脑。虽然不太情愿,但是你还是同意了。而你的父亲则想,他可以用 MultiPlan (LCTT 译注:电子表格程序)跟踪家庭的资金状况,MultiPlan 是他曾听说过的一个电子表格程序,这就是为什么这台计算机被放在客厅的原因。然而,一年后,你仍然是唯一使用它的人。最终,他们同意你把它搬到了你的卧室的桌子上,正好位于你的警察海报下方。
|
||||||
|
|
||||||
|
(你的姐姐对这个决定表示抗议,但是,在 1983 年电脑这种东西[并不适合女孩][4]。)
|
||||||
|
|
||||||
|
你的父亲在下班路上从 [ComputerLand][5] 那里把它捎了回来。你俩把盒子放置在电视机的旁边,并打开了它。外包装上说“欢迎来到友好的计算机世界”。而二十分钟以后你就不再信这句话了 —— 你俩仍然在尝试把 Commodore 连接到电视机上,并在想电视机的天线电缆到底是 75 欧姆还是 300 欧姆的同轴电缆。但是,最终你把电视机调到了频道 3,看到了一个颗粒状的、紫色的图像。
|
||||||
|
|
||||||
|
![Commodore 64 启动屏幕][6]
|
||||||
|
|
||||||
|
计算机显示了一个 `READY`。你的爸爸把计算机推向了你,这意思是你是第一个尝试它的人。你小心翼翼地敲击每个字母,键入了 `HELLO`。然而计算机的回应是令人困惑的。
|
||||||
|
|
||||||
|
![Commodore 64 语法错误][7]
|
||||||
|
|
||||||
|
你尝试输入了一些稍有不同的单词,然而回应总是一样的。你父亲说,你最好仔细读一下手册的其它部分。这绝非易事,[随 Commodore 64 一起提供的手册][8] 是一本小一些的书。但是这不会困住你,因为手册的介绍预示着奇迹。
|
||||||
|
|
||||||
|
它声称,Commodore 64 有“微型计算机行业中最先进的图画制作器”,能允许“你设计拥有四种不同颜色的图画,就像你在街机视频游戏里看到的一样”。Commodore 64 也有“内置的音乐和声音效果,可以与很多著名的音乐合成器相媲美”。所有的这些工具都置身于你的手边,手册会引导你完成所有这些:
|
||||||
|
|
||||||
|
> 与所有提供的硬件一样重要的是,这本用户指南将提高你对计算机的理解。它无法在这里告诉你有关计算机的所有信息,但是它会向你推荐各种出版物,以获取有关所提出主题的更多详细信息。Commodore 希望你真正喜欢你的新 COMMODORE 64。要想真正得到乐趣,请记住:编程不是一种一天就能学会的东西。通读这个用户指南你要有耐心。
|
||||||
|
|
||||||
|
那一夜,你在床上通读了整整前三个章节:“安装”、“入门”和“BASIC 编程入门”,在你最终睡着时,手册还打开着放在了胸前。
|
||||||
|
|
||||||
|
### Commodore BASIC
|
||||||
|
|
||||||
|
现在是星期六早上,你渴望尝试你所学到的新东西。手册里教给你的第一件事是如何更改在显示器上的颜色。你按照操作说明,按下 `CTRL-9` 来进入反色输入模式,然后按住空格键来创建了一个长长的空行。你可以使用 `CTRL-1` 到 `CTRL-8` 在不同的颜色之间交换,这让你的电视机屏幕焕发出了新的力量。
|
||||||
|
|
||||||
|
![Commodore 64 颜色带][9]
|
||||||
|
|
||||||
|
尽管这很酷,但你觉得这不能算是编程。要对计算机编程,你昨晚已经学会了如何做,你必须以一种称为 BASIC 的语言与计算机交谈。对你来说,BASIC 看起来就像星球大战中的东西一样科幻,但是,到 1983 年时,其实 BASIC 已经快有二十岁了。它是由两位达特茅斯教授 John Kemeny 和 Tom Kurtz 发明的,他们想让社会科学和人文科学中的本科生也可以使用计算机。它被广泛使用在微型计算机上,在大学的数学课上很受欢迎。在比尔盖茨和保罗艾伦为 Altair 编写了微软 BASIC 解释器后,它就成为了微型计算机上的标准。但是这本手册对此没有任何解释,那么多年你都没学过它。
|
||||||
|
|
||||||
|
手册中建议你尝试的第一个 BASIC 命令是 `PRINT` 命令。你输入了 `PRINT "COMMODORE 64"`,很慢,因为你需要花费一点时间才能在按键 `2` 上面找到引号符号。你单击 `RETURN`,这一次,计算机没有抱怨,完全是按照你告诉它做的,在下一行中显示了 “COMMODORE 64” 。
|
||||||
|
|
||||||
|
现在你尝试对各种不同的东西使用 `PRINT` 命令:两个数字加在一起,两个数字乘在一起,甚至几个十进制数字。你不再输入 `PRINT` ,而是使用 `?` 代替,因为手册中告诉你 `?` 是 `PRINT` 的一个缩写,通常专业程序员都这么使用。你感觉自己已经像是一个专家了,不过你想起你还没有进行到第三章“BASIC 编程入门”。
|
||||||
|
|
||||||
|
你很快就开始了。该章节提示你编写你的第一个真正的 BASIC 程序。你输入 `NEW` 并单击 `RETURN`,它给了你一个干净的<ruby>黑板<rt>slate</rt></ruby>。然后你在其中输入你的程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
10 ?"COMMODORE 64"
|
||||||
|
20 GOTO 10
|
||||||
|
```
|
||||||
|
|
||||||
|
手册里解释说 10 和 20 是行号。它们为计算机排序了语句。它们也允许程序员在某些命令中引用程序的其它行,正像你在这里使用的 `GOTO` 命令一样,它将程序指回到行 10。“这是一个很好的编程习惯”,手册认为,“以 10 的增量来编号行,可以防止你以后需要插入一些语句”。
|
||||||
|
|
||||||
|
你输入 `RUN`,并凝视充满了 “COMMODORE 64” 的屏幕,它一遍又一遍的重复。
|
||||||
|
|
||||||
|
![Commodore 64 显示反复打印 "Commodore 64" 的结果][10]
|
||||||
|
|
||||||
|
你不确定这不会引爆你的计算机,过了一秒钟你才想起来应该单击 `RUN/STOP` 按键来打断循环。
|
||||||
|
|
||||||
|
手册接下来的一些部分向你介绍了变量,它告诉你变量像“在计算机中许多的盒子,它们每个可以容纳一个数字或一个文本字符串”。以一个 `%` 符号结尾的变量是一个整数,与此同时,以一个 `$` 符号结尾的变量是一个字符串。其余的所有变量是一些称为“浮点”变量的东西。手册警告你要小心变量名称,因为计算机仅会识别变量名称的前两个字母,尽管它不限制你想创建的名称有多长。(这并没有特别让你困扰,但是要是在 30 年后来看,这可能会让人们感到太疯狂了)
|
||||||
|
|
||||||
|
你接着学习 `IF... THEN...` 和 `FOR... NEXT...` 结构体。有了这些新的工具,你感觉有能力来解决接下来手册丢给你的重大挑战。“如果你是个有野心的人”,没错,“输入下面的程序,并查看会发生什么。”该程序比你目前为止看到的程序更长、更复杂,但是,你很想知道它做了什么:
|
||||||
|
|
||||||
|
```
|
||||||
|
10 REM BOUNCING BALL
|
||||||
|
20 PRINT "{CLR/HOME}"
|
||||||
|
25 FOR X = 1 TO 10 : PRINT "{CRSR/DOWN}" : NEXT
|
||||||
|
30 FOR BL = 1 TO 40
|
||||||
|
40 PRINT " ●{CRSR LEFT}";:REM (● is a Shift-Q)
|
||||||
|
50 FOR TM = 1 TO 5
|
||||||
|
60 NEXT TM
|
||||||
|
70 NEXT BL
|
||||||
|
75 REM MOVE BALL RIGHT TO LEFT
|
||||||
|
80 FOR BL = 40 TO 1 STEP -1
|
||||||
|
90 PRINT " {CRSR LEFT}{CRSR LEFT}●{CRSR LEFT}";
|
||||||
|
100 FOR TM = 1 TO 5
|
||||||
|
110 NEXT TM
|
||||||
|
120 NEXT BL
|
||||||
|
130 GOTO 20
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的程序充分利用了 Commodore 64 最酷的功能之一。当把不可打印的命令字符作为字符串的一部分传递到 `PRINT` 命令时,它们会执行其操作,而不是被打印到屏幕上。这允许你重新摆放你程序中打印的字符串。(LCTT 译注:上述程序中如 `{CRSR LEFT}` 之类的控制字符执行类似 “在行中向左移动一个位置” 的操作,因此上述程序中利用这些字符操作了一个圆点字符四处移动,如下图。)
|
||||||
|
|
||||||
|
输入上面的程序你花费了很长时间。你犯一些错误,并不得不重新输入一些行。但是,你最终能够按下 `RUN`,并看到了一幅杰作:
|
||||||
|
|
||||||
|
![Commodore 64 反弹球][11]
|
||||||
|
|
||||||
|
你觉得这恐怕是你见过的最酷的事了。不过你几乎转头就忘记了它,因为马上你就学到了 BASIC 的内置函数,像 `RND`(它返回一个随机数字)和 `CHR$`(它返回与一个给定数字代码匹配的字符),这个手册向你展示一个程序,这个程序有名到什么程度呢?直到许多年后,它仍然被当成了一个[短文选集][12]的标题:
|
||||||
|
|
||||||
|
```
|
||||||
|
10 PRINT "{CLR/HOME}"
|
||||||
|
20 PRINT CHR$(205.5 + RND(1));
|
||||||
|
40 GOTO 20
|
||||||
|
```
|
||||||
|
|
||||||
|
当运行时,上面的程序会生成一个随机的迷宫:
|
||||||
|
|
||||||
|
![Commodore 64 迷宫程序][13]
|
||||||
|
|
||||||
|
这绝对是你曾经见过最酷的事。
|
||||||
|
|
||||||
|
### PEEK 和 POKE
|
||||||
|
|
||||||
|
现在你已经看过了 Commodore 64 手册的前四章节,包含那篇 “高级的 BASIC” 的章节,所以你感到十分自豪。在这个星期六早上,你学习到了很多东西。但是这个下午(在赶快吃了点午饭后),你将继续学习一些使这个放在你的客厅中的奇妙机器变得不再神秘的东西。
|
||||||
|
|
||||||
|
手册中的下一个章节标题是“高级颜色和图像命令”。它从回顾你今天早上首先键入的彩色条开始,并向你展示了如何在一个程序中做同样的事。然后它教给了你如何更改屏幕的背景颜色。
|
||||||
|
|
||||||
|
为此,你需要使用 BASIC 的 `PEEK` 和 `POKE` 命令。这些命令分别允许你检查和写入一个存储器地址。Commodore 64 有一个主背景颜色和一个边框背景颜色。每个都通过一个特定的内存地址控制。你可以把你喜欢的任何颜色值写入到这些地址,以使用这些背景颜色和边框颜色。
|
||||||
|
|
||||||
|
手册中解释:
|
||||||
|
|
||||||
|
> 正像变量可以被认为机器中你放置信息的“盒子”一样,你也可以认为在计算机中代表特定内存位置的是一些特殊定义的“盒子”。
|
||||||
|
>
|
||||||
|
> Commodore 64 会查看这些内存位置来了解屏幕的背景和边框应该是什么样的颜色,什么样的字符应该被显示在屏幕上,以及显示在哪里,等等其它任务。
|
||||||
|
|
||||||
|
你编写了一个程序来遍历所有可用的背景和边界的颜色的组合:
|
||||||
|
|
||||||
|
```
|
||||||
|
10 FOR BA = 0 TO 15
|
||||||
|
20 FOR BO = 0 TO 15
|
||||||
|
30 POKE 53280, BA
|
||||||
|
40 POKE 53281, BO
|
||||||
|
50 FOR X = 1 TO 500 : NEXT X
|
||||||
|
60 NEXT BO : NEXT BA
|
||||||
|
```
|
||||||
|
|
||||||
|
虽然 `POKE` 命令以及它的大操作数一开始时看起来很吓人,现在你看到那个数字的实际值其实不是很要紧。显然,你必须得到正确的数字,但是所有的数字代表的是一个“盒子”,Commodore 只是正好存储在地址 53280 处而已。这个盒子有一个特殊的用途:Commodore 使用它来确定屏幕背景应该是什么颜色。
|
||||||
|
|
||||||
|
![Commodore 64 更改背景颜色][14]
|
||||||
|
|
||||||
|
你认为这简直棒极了。只需要写入到内存中一个专用的盒子,你可以控制一台计算机的基础属性。你不确定 Commodore 64 的电路系统如何读取你写入在内存中的值并更改屏幕的颜色的,但是,你不知道这些也没事。至少你知道结果是怎么样的。
|
||||||
|
|
||||||
|
### 特殊容器
|
||||||
|
|
||||||
|
在那个周六,你没有读完整本手册,因为你现在有点精疲力尽了。但是你最终会全部读完它。在这个过程中,你学到更多的 Commodore 64 专用的盒子。有一些盒子你可以写入来控制在屏幕上显示什么——这也是一个盒子,事实上,是控制每一个位置出现的字符。在第六章节 “精灵图形” 中,你学到可以让你定义可以移动和甚至缩放图像的特殊盒子。在第七章节 “创造声音” 中,你学到能写入以便使你的 Commodore 64 歌唱 “Michael Row the Boat Ashore” 的盒子。Commodore 64,事实证明,它和你可能以后学习到的一个称为 API 的关系甚少。控制 Commodore 64 大多涉及写入到电路系统赋予特殊意义的内存地址。
|
||||||
|
|
||||||
|
多年来,你花费在这些特殊盒子的时光一直伴随着你。甚至几十年后,当你在一个拥有大量的图形或声音 API 的机器上编程时,你知道,隐藏于其背后的,这些 API 最终是写入到这些盒子之类的东西里面的。你有时会好奇那些只使用过 API 的年轻程序员,他们肯定是觉得 API 为他们做到的这一切。可能他们认为这些 API 调用了一些其它隐藏的 API。但是,那些隐藏的 API 调用了什么?你不由得同情这些年轻的程序员们,因为他们一定会非常迷惑。
|
||||||
|
|
||||||
|
如果你喜欢这篇文章,也喜欢它每两周发布的一篇新文章的话,那么请在 Twitter 上关注 [@TwoBitHistory][15] 或订阅 [RSS 源][16]来确保你知道新的文章发布出来。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via:https://twobithistory.org/2018/09/02/learning-basic.html
|
||||||
|
|
||||||
|
作者:[Two-Bit History][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[robsean](https://github.com/robsean)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://twobithistory.org
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.youtube.com/watch?v=kZRE7HIO3vk
|
||||||
|
[2]: https://en.wikipedia.org/wiki/BASIC_Computer_Games
|
||||||
|
[3]: https://www.youtube.com/watch?v=ZekAbt2o6Ms
|
||||||
|
[4]: https://www.npr.org/sections/money/2014/10/21/357629765/when-women-stopped-coding
|
||||||
|
[5]: https://www.youtube.com/watch?v=MA_XtT3VAVM
|
||||||
|
[6]: https://twobithistory.org/images/c64_startup.png
|
||||||
|
[7]: https://twobithistory.org/images/c64_error.png
|
||||||
|
[8]: ftp://www.zimmers.net/pub/cbm/c64/manuals/C64_Users_Guide.pdf
|
||||||
|
[9]: https://twobithistory.org/images/c64_colors.png
|
||||||
|
[10]: https://twobithistory.org/images/c64_print_loop.png
|
||||||
|
[11]: https://twobithistory.org/images/c64_ball.gif
|
||||||
|
[12]: http://10print.org/
|
||||||
|
[13]: https://twobithistory.org/images/c64_maze.gif
|
||||||
|
[14]: https://twobithistory.org/images/c64_background.gif
|
||||||
|
[15]: https://twitter.com/TwoBitHistory
|
||||||
|
[16]: https://twobithistory.org/feed.xml
|
||||||
|
[17]: https://twitter.com/TwoBitHistory/status/1030974776821665793?ref_src=twsrc%5Etfw
|
||||||
@ -0,0 +1,173 @@
|
|||||||
|
在树莓派上玩怀旧游戏的 5 种方法
|
||||||
|
======
|
||||||
|
|
||||||
|
> 使用这些用于树莓派的开源平台来重温游戏的黄金时代。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
他们使它们不像过去那样子了,对吧?我是说,电子游戏。
|
||||||
|
|
||||||
|
当然,现在的设备更强大了。<ruby>赛达尔公主<rt>Princess Zelda</rt></ruby>在过去每个边只有 16 个像素,而现在的图像处理能力足够处理她头上的每根头发。今天的处理器打败 1988 年的处理器简直不费吹灰之力。
|
||||||
|
|
||||||
|
但是你知道缺少什么吗?乐趣。
|
||||||
|
|
||||||
|
你有数之不尽的游戏,按下一个按钮就可以完成教程任务。可能有故事情节,当然杀死坏蛋也可以不需要故事情节,你需要的只是跳跃和射击。因此,毫不奇怪,树莓派最持久的流行用途之一就是重温上世纪八九十年代的 8 位和 16 位游戏的黄金时代。但从哪里开始呢?
|
||||||
|
|
||||||
|
在树莓派上有几种方法可以玩怀旧游戏。每一种都有自己的优点和缺点,我将在这里讨论这些。
|
||||||
|
|
||||||
|
### RetroPie
|
||||||
|
|
||||||
|
[RetroPie][1] 可能是树莓派上最受欢迎的复古游戏平台。它是一个可靠的万能选手,是模拟经典桌面和控制台游戏系统的绝佳选择。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 介绍
|
||||||
|
|
||||||
|
RetroPie 构建在 [Raspbian][2] 上运行。如果你愿意,它也可以安装在现有的 Raspbian 镜像上。它使用 [EmulationStation][3] 作为开源仿真器库(包括 [Libretro][4] 仿真器)的图形前端。
|
||||||
|
|
||||||
|
不过,你要玩游戏其实并不需要理解上面的任何一个词。
|
||||||
|
|
||||||
|
#### 它有什么好处
|
||||||
|
|
||||||
|
入门很容易。你需要做的就是将镜像刻录到 SD 卡,配置你的控制器、复制游戏,然后开始杀死坏蛋。
|
||||||
|
|
||||||
|
它的庞大用户群意味着有大量的支持和信息,活跃的在线社区也可以求助问题。
|
||||||
|
|
||||||
|
除了随 RetroPie 镜像一起安装的仿真器之外,还有一个可以从包管理器安装的庞大的仿真器库,并且它一直在增长。RetroPie 还提供了用户友好的菜单系统来管理这些,可以节省你的时间。
|
||||||
|
|
||||||
|
从 RetroPie 菜单中可以轻松添加 Kodi 和配备了 Chromium 浏览器的 Raspbian 桌面。这意味着你的这套复古游戏装备也适于作为家庭影院、[YouTube][5]、[SoundCloud][6] 以及所有其它“休息室电脑”产品。
|
||||||
|
|
||||||
|
RetroPie 还有许多其它自定义选项:你可以更改菜单中的图形,为不同的模拟器设置不同的控制手柄配置,使你的树莓派文件系统的所有内容对你的本地 Windows 网络可见等等。
|
||||||
|
|
||||||
|
RetroPie 建立在 Raspbian 上,这意味着你可以探索这个树莓派最受欢迎的操作系统。你所发现的大多数树莓派项目和教程都是为 Raspbian 编写的,因此可以轻松地自定义和安装新内容。我已经使用我的 RetroPie 装备作为无线桥接器,在上面安装了 MIDI 合成器,自学了一些 Python,更重要的是,所有这些都没有影响它作为游戏机的用途。
|
||||||
|
|
||||||
|
#### 它有什么不太好的
|
||||||
|
|
||||||
|
RetroPie 的安装简单和易用性在某种程度上是一把双刃剑。你可以在 RetroPie 上玩了很长时间,而甚至没有学习过哪怕像 `sudo apt-get` 这样简单的东西,但这也意味着你错过了很多树莓派的体验。
|
||||||
|
|
||||||
|
但不一定必须如此;当你需要时,命令行仍然存在于底层,但是也许用户与 Bash shell 有点隔离,而使它最终并没有看上去那么可怕、另外,RetroPie 的主菜单只能通过控制手柄操作,当你没有接入手柄时,这可能很烦人,因为你一直将该系统用于游戏之外的事情。
|
||||||
|
|
||||||
|
#### 它适用于谁?
|
||||||
|
|
||||||
|
任何想直接玩一些游戏的人,任何想拥有最大、最好的模拟器库的人,以及任何想在不玩游戏的时候开始探索 Linux 的人。
|
||||||
|
|
||||||
|
### Recalbox
|
||||||
|
|
||||||
|
[Recalbox][7] 是一个较新的树莓派开源模拟器套件。它还支持其它基于 ARM 的小型计算机。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 介绍
|
||||||
|
|
||||||
|
与 Retropie 一样, Recalbox 基于 EmulationStation 和 Libretro。它的不同之处在于它不是基于 Raspbian 构建的,而是基于它自己的 Linux 发行版:RecalboxOS。
|
||||||
|
|
||||||
|
#### 它有什么好处
|
||||||
|
|
||||||
|
Recalbox 的设置比 RetroPie 更容易。你甚至不需要做 SD 卡镜像;只需复制一些文件即可。它还为一些游戏控制器提供开箱即用的支持,可以让你更快地开始游戏。它预装了 Kodi。这是一个现成的游戏和媒体平台。
|
||||||
|
|
||||||
|
#### 它有什么不太好的
|
||||||
|
|
||||||
|
Recalbox 比 RetroPie 拥有更少的仿真器、更少的自定义选项和更小的用户社区。
|
||||||
|
|
||||||
|
你的 Recalbox 装备可能一直用于模拟器和 Kodi,安装成什么样就是什么样。如果你想深入了解 Linux,你可能需要为 Raspbian 提供一个新的 SD 卡。
|
||||||
|
|
||||||
|
#### 它适用于谁?
|
||||||
|
|
||||||
|
如果你想要绝对简单的复古游戏体验,并且不想玩一些比较少见的游戏平台模拟器,或者你害怕一些技术性工作(也没有兴趣去做),那么 Recalbox 非常适合你。
|
||||||
|
|
||||||
|
对于大多数读者来说,Recalbox 可能最适合推荐给你那些不太懂技术的朋友或亲戚。它超级简单的设置和几乎没什么选项甚至可以让你免去帮助他们解决问题。
|
||||||
|
|
||||||
|
### 做个你自己的
|
||||||
|
|
||||||
|
好,你可能已经注意到 Retropie 和 Recalbox 都是由许多相同的开源组件构建的。那么为什么不自己把它们组合在一起呢?
|
||||||
|
|
||||||
|
#### 介绍
|
||||||
|
|
||||||
|
无论你想要的是什么,开源软件的本质意味着你可以使用现有的模拟器套件作为起点,或者随意使用它们。
|
||||||
|
|
||||||
|
#### 它有什么好处
|
||||||
|
|
||||||
|
如果你想有自己的自定义界面,我想除了亲自动手别无它法。这也是安装在 RetroPie 中没有的仿真器的方法,例如 [BeebEm][8]) 或 [ArcEm][9]。
|
||||||
|
|
||||||
|
#### 它有什么不太好的
|
||||||
|
|
||||||
|
嗯,工作量有点大。
|
||||||
|
|
||||||
|
#### 它适用于谁?
|
||||||
|
|
||||||
|
喜欢鼓捣的人,有动手能力的人,开发者,经验丰富的业余爱好者等。
|
||||||
|
|
||||||
|
### 原生 RISC OS 游戏体验
|
||||||
|
|
||||||
|
现在有一匹黑马:[RISC OS][10],它是 ARM 设备的原始操作系统。
|
||||||
|
|
||||||
|
#### 介绍
|
||||||
|
|
||||||
|
在 ARM 成为世界上最受欢迎的 CPU 架构之前,它最初是作为 Acorn Archimedes 的处理器而开发的。现在看起来这像是一种被遗忘的野兽,但是那几年,它作为世界上最强大的台式计算机独领风骚了好几年,并且吸引了大量的游戏开发项目。
|
||||||
|
|
||||||
|
树莓派中的 ARM 处理器是 Archimedes 的曾孙辈的 CPU,所以我们仍然可以在其上安装 RISC OS,只要做一点工作,就可以让这些游戏运行起来。这与我们到上面所介绍的仿真器方式不同,我们是在玩为该操作系统和 CPU 架构开发的游戏。
|
||||||
|
|
||||||
|
#### 它有什么好处
|
||||||
|
|
||||||
|
这是 RISC OS 的完美展现,这绝对是操作系统的瑰宝,非常值得一试。
|
||||||
|
|
||||||
|
事实上,你使用的是和以前几乎相同的操作系统来加载和玩你的游戏,这使得你的复古游戏装备像是一个时间机器一样,这无疑为该项目增添了一些魅力和复古价值。
|
||||||
|
|
||||||
|
有一些精彩的游戏只在 Archimedes 上发布过。Archimedes 的巨大硬件优势也意味着它通常拥有许多多平台游戏大作的最佳图形和最流畅的游戏体验。这类游戏的版权持有者非常慷慨,可以合法地免费下载它们。
|
||||||
|
|
||||||
|
#### 它有什么不太好的
|
||||||
|
|
||||||
|
安装了 RISC OS 之后,它仍然需要一些努力才能让游戏运行起来。这是 [入门指南][11]。
|
||||||
|
|
||||||
|
对于休息室来说,这绝对不是一个很好的全能选手。没有什么比 [Kodi][12] 更好的了。它有一个网络浏览器 [NetSurf][13],但它在支持现代 Web 方面还需要一些努力。你不会像使用模拟器套件那样得到大量可以玩的游戏。RISC OS Open 对于爱好者来说可以免费下载和使用,而且很多源代码已经开源,尽管由于这个名字,它不是一个 100% 的开源操作系统。
|
||||||
|
|
||||||
|
#### 它适用于谁?
|
||||||
|
|
||||||
|
这是专为追求新奇的人,绝对怀旧的人,想要探索一个来自上世纪 80 年代的有趣的操作系统的人,怀旧过去的 Acorn 机器的人,以及想要一个完全不同的怀旧游戏项目的人而设计的。
|
||||||
|
|
||||||
|
### 终端游戏
|
||||||
|
|
||||||
|
你是否真的需要安装模拟器或者一个异域风情的操作系统才能重温辉煌的日子?为什么不从命令行安装一些原生 Linux 游戏呢?
|
||||||
|
|
||||||
|
#### 介绍
|
||||||
|
|
||||||
|
有一系列原生的 Linux 游戏经过测试可以在 [树莓派][14] 上运行。
|
||||||
|
|
||||||
|
#### 它有什么好处
|
||||||
|
|
||||||
|
你可以使用命令行从程序包安装其中的大部分,然后开始玩。很容易。如果你已经有了一个跑起来的 Raspbian,那么它可能是你运行游戏的最快途径。
|
||||||
|
|
||||||
|
#### 它有什么不太好的
|
||||||
|
|
||||||
|
严格来说,这并不是真正的复古游戏。Linux 诞生于 1991 年,过了一段时间才成为了一个游戏平台。这些不是经典的 8 位和 16 位时代的游戏体验;后来有一些移植的游戏或受复古影响的游戏。
|
||||||
|
|
||||||
|
#### 它适用于谁?
|
||||||
|
|
||||||
|
如果你只是想找点乐子,这没问题。但如果你想重温过去,那就不完全是这样了。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/9/retro-gaming-raspberry-pi
|
||||||
|
|
||||||
|
作者:[James Mawson][a]
|
||||||
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
|
译者:[canhetingsky](https://github.com/canhetingsky)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/dxmjames
|
||||||
|
[1]: https://retropie.org.uk/
|
||||||
|
[2]: https://www.raspbian.org/
|
||||||
|
[3]: https://emulationstation.org/
|
||||||
|
[4]: https://www.libretro.com/
|
||||||
|
[5]: https://www.youtube.com/
|
||||||
|
[6]: https://soundcloud.com/
|
||||||
|
[7]: https://www.recalbox.com/
|
||||||
|
[8]: http://www.mkw.me.uk/beebem/
|
||||||
|
[9]: http://arcem.sourceforge.net/
|
||||||
|
[10]: https://opensource.com/article/18/7/gentle-intro-risc-os
|
||||||
|
[11]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
|
||||||
|
[12]: https://kodi.tv/
|
||||||
|
[13]: https://www.netsurf-browser.org/
|
||||||
|
[14]: https://www.raspberrypi.org/forums/viewtopic.php?f=78&t=51794
|
||||||
@ -0,0 +1,72 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (WangYueScream)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11116-1.html)
|
||||||
|
[#]: subject: (Introducing kids to computational thinking with Python)
|
||||||
|
[#]: via: (https://opensource.com/article/19/2/break-down-stereotypes-python)
|
||||||
|
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||||
|
|
||||||
|
|
||||||
|
利用 Python 引导孩子的计算机思维
|
||||||
|
========================
|
||||||
|
|
||||||
|
> 编程可以给低收入家庭的学生提供足够的技能、信心和知识,进而让他们摆脱因为家庭收入低带来的经济和社会地位上的劣势。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
尽管暑假期间底特律公共图书馆的[帕克曼分部][1]挤满了无聊的孩子并且占用了所有的电脑,图书馆工作人员并不觉得这会是个问题,反而更多是一个机会。他们成立一个名为 [Parkman Coders][2] 的编程社团,社团以 [Qumisha Goss][3] 为首,她是图书管理员,也负责利用 Python 的魔力引导弱势儿童的计算机思维。
|
||||||
|
|
||||||
|
四年前 [Qumisha Goss][3] 刚发起 Parkman Coders 计划的时候, “Q”(代表她)并不是太懂编程。之后她通过努力成为图书馆里教学和技术方面的专家和树莓派认证讲师。
|
||||||
|
|
||||||
|
社团最开始采用 [Scratch][4] 教学,但很快学生就对这种图形化的块编程感到乏味,他们觉得这就是个“婴儿玩具”。Q 坦言,“我们意识到是时候需要在课程内容这方面做些改变了,如果是为了维持课程内容对初学者的友好性继续选择 Scratch 教学,这无疑会影响孩子们后期继续保持对编程的关注。”因此,她开始教授孩子们 Python。
|
||||||
|
|
||||||
|
Q 是在 [Code.org][5] 平台玩地牢骷髅怪物这个关卡的时候第一次接触到 Python。她最开始是通过 《[Python Programming: An Introduction to Computer Science][6]》 和 《[Python for Kids][7]》 这两本书学习的 Python。她也推荐 《[Automate the Boring Stuff with Python][8]》 和 《[Lauren Ipsum: A Story about Computer Science and Other Improbable Things][9]》 这两本书。
|
||||||
|
|
||||||
|
### 建立一个基于树莓派的创客空间
|
||||||
|
|
||||||
|
Q 决定使用[树莓派][10]电脑来避免学生可能会因为自己的不当操作对图书馆的电脑造成损害,而且这些电脑因为便携性等问题也不方便用来构建组成一个创客空间。[树莓派][10]的购买价格加上它的灵活性和便携性包括生态圈里面的一些适合教学的自由免费软件,让大家更能感受到她的决策的可行性和可靠性。
|
||||||
|
|
||||||
|
虽然图书馆发起 [Parkman Coders][2] 社区计划的本意是通过努力创造一个吸引孩子们的学习空间,进而维持图书馆的平和,但社区发展的很快,很受大家欢迎,以至于这座建立于 1921 的大楼的空间,电脑和插座都不够用了。他们最开始是 20 个孩子共享 10 台[树莓派][10]来进行授课,但后来图书馆陆续收到了来自个人和公司比如 Microsoft、4H,和 Detroit Public Library Foundation 的资金援助从而能够购买更多设备以支撑社区的进一步壮大发展。
|
||||||
|
|
||||||
|
目前,每节课程大概有 40 个孩子参加,而且图书馆也有了足够的[树莓派][10]让参与者人手一台设备甚至还可以送出去一些。鉴于不少 [Parkman Coders][2] 的参与者来自于低收入家庭,图书馆也能提供别人捐赠的 Chromebooks 给他们使用。
|
||||||
|
|
||||||
|
Q 说,“当孩子们的表现可以证明他们能够很好的使用[树莓派][10]或者 [Microbit][11] 而且定期来参加课程,我们也会提供设备允许他们可以带回家练习。但即便这样也还是会遇到很多问题,比如他们在家无法访问网络或者没有显示器、键盘、鼠标等外设。”
|
||||||
|
|
||||||
|
### 利用 Python 学习生存技能,打破束缚
|
||||||
|
|
||||||
|
Q 说,“我认为教授孩子们计算机科学的主要目的是让他们学会批判性思考和解决问题的能力。我希望随着孩子们长大成人,不管他们选择在哪个领域继续发展他们的未来,这些经验教训都会一直伴随他们成长。此外,我也希望这个课程能够激发孩子们对创造的自豪感。能够清楚的意识到‘这是我做的’是一种很强烈、很有用的感受。而且一旦孩子们越早能够有这种成功的体验,我相信未来的路上他们都会满怀热情迎接新的挑战而不是逃避。”
|
||||||
|
|
||||||
|
她继续分享道,“在学习编程的过程中,你不得不对单词的拼写和大小写高度警惕。受限于孩子年龄,有时候阅读认知会是个大问题。为了确保课程受众的包容性,我们会在授课过程中大声拼读,同样我们也会极力鼓励孩子们大声说出他们不知道的或者不能正确拼写的单词,以便我们纠正。”
|
||||||
|
|
||||||
|
Q 也会尝试尽力去给需要帮助的孩子们更多的关注。她解释道,“如果我确认有孩子遇到困难不能跟上我们的授课进度,我们会尝试在课下时间安排老师辅导帮助他,但还是会允许他们继续参加编程。我们想帮助到他们而不是让他们因为挫败而沮丧的不再参与进来。”
|
||||||
|
|
||||||
|
最重要的是,[Parkman Coders][2] 计划所追求的是能够帮助每个孩子认识到每个人都会有独特的技能和能力。参与进来的大部分孩子都是非裔美国人,一半是女孩。Q 直言,“我们所生活在的这个世界,我们成长的过程中,伴随着各种各种的社会偏见,这些都常常会限制我们对自己所能达到的成就的准确认知。”她坚信孩子们需要一个没有偏见的空间,“他们可以尝试很多新事物,不会因为担心犯错责骂而束手束脚,可以放心大胆的去求知探索。”
|
||||||
|
|
||||||
|
Q 和 [Parkman Coders][2] 计划所营造的环境氛围能够帮助到参与者摆脱低家庭收入带来的劣势。如果说社区能够发展壮大到今天的规模真有什么独特秘诀的话,那大概就是,Q 解释道,“确保你有一个令人舒适的空间,充满了理解与宽容,这样大家才会被吸引过来。让来的人不忘初心,做好传道受业解惑的准备;当大家参与进来并感觉到充实愉悦,自然而然会想要留下来。”
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/2/break-down-stereotypes-python
|
||||||
|
|
||||||
|
作者:[Don Watkins][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[WangYueScream](https://github.com/WangYueScream)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/don-watkins
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://detroitpubliclibrary.org/locations/parkman
|
||||||
|
[2]: https://www.dplfound.org/single-post/2016/05/15/Parkman-Branch-Coders
|
||||||
|
[3]: https://www.linkedin.com/in/qumisha-goss-b3bb5470
|
||||||
|
[4]: https://scratch.mit.edu/
|
||||||
|
[5]: http://Code.org
|
||||||
|
[6]: https://www.amazon.com/Python-Programming-Introduction-Computer-Science/dp/1887902996
|
||||||
|
[7]: https://nostarch.com/pythonforkids
|
||||||
|
[8]: https://automatetheboringstuff.com/
|
||||||
|
[9]: https://nostarch.com/laurenipsum
|
||||||
|
[10]: https://www.raspberrypi.org/
|
||||||
|
[11]: https://microbit.org/guide/
|
||||||
@ -0,0 +1,171 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (lujun9972)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11061-1.html)
|
||||||
|
[#]: subject: (Create a Custom System Tray Indicator For Your Tasks on Linux)
|
||||||
|
[#]: via: (https://fosspost.org/tutorials/custom-system-tray-icon-indicator-linux)
|
||||||
|
[#]: author: (M.Hanny Sabbagh https://fosspost.org/author/mhsabbagh)
|
||||||
|
|
||||||
|
在 Linux 上为你的任务创建一个自定义的系统托盘指示器
|
||||||
|
======
|
||||||
|
|
||||||
|
系统托盘图标如今仍是一个很神奇的功能。只需要右击图标,然后选择想要的动作,你就可以大幅简化你的生活并且减少日常行为中的大量无用的点击。
|
||||||
|
|
||||||
|
一说到有用的系统托盘图标,我们很容易就想到 Skype、Dropbox 和 VLC:
|
||||||
|
|
||||||
|
![Create a Custom System Tray Indicator For Your Tasks on Linux][1]
|
||||||
|
|
||||||
|
然而系统托盘图标实际上要更有用得多;你可以根据自己的需求创建自己的系统托盘图标。本指导将会教你通过简单的几个步骤来实现这一目的。
|
||||||
|
|
||||||
|
### 前置条件
|
||||||
|
|
||||||
|
我们将要用 Python 来实现一个自定义的系统托盘指示器。Python 可能已经默安装在所有主流的 Linux 发行版中了,因此你只需要确定一下它已经被安装好了(此处使用版本为 2.7)。另外,我们还需要安装好 `gir1.2-appindicator3` 包。该库能够让我们很容易就能创建系统图标指示器。
|
||||||
|
|
||||||
|
在 Ubuntu/Mint/Debian 上安装:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt-get install gir1.2-appindicator3
|
||||||
|
```
|
||||||
|
|
||||||
|
在 Fedora 上安装:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo dnf install libappindicator-gtk3
|
||||||
|
```
|
||||||
|
|
||||||
|
对于其他发行版,只需要搜索包含 “appindicator” 的包就行了。
|
||||||
|
|
||||||
|
在 GNOME Shell 3.26 开始,系统托盘图标被删除了。你需要安装 [这个扩展][2](或者其他扩展)来为桌面启用该功能。否则你无法看到我们创建的指示器。
|
||||||
|
|
||||||
|
### 基础代码
|
||||||
|
|
||||||
|
下面是该指示器的基础代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/usr/bin/python
|
||||||
|
import os
|
||||||
|
from gi.repository import Gtk as gtk, AppIndicator3 as appindicator
|
||||||
|
def main():
|
||||||
|
indicator = appindicator.Indicator.new("customtray", "semi-starred-symbolic", appindicator.IndicatorCategory.APPLICATION_STATUS)
|
||||||
|
indicator.set_status(appindicator.IndicatorStatus.ACTIVE)
|
||||||
|
indicator.set_menu(menu())
|
||||||
|
gtk.main()
|
||||||
|
def menu():
|
||||||
|
menu = gtk.Menu()
|
||||||
|
|
||||||
|
command_one = gtk.MenuItem('My Notes')
|
||||||
|
command_one.connect('activate', note)
|
||||||
|
menu.append(command_one)
|
||||||
|
exittray = gtk.MenuItem('Exit Tray')
|
||||||
|
exittray.connect('activate', quit)
|
||||||
|
menu.append(exittray)
|
||||||
|
|
||||||
|
menu.show_all()
|
||||||
|
return menu
|
||||||
|
|
||||||
|
def note(_):
|
||||||
|
os.system("gedit $HOME/Documents/notes.txt")
|
||||||
|
def quit(_):
|
||||||
|
gtk.main_quit()
|
||||||
|
if __name__ == "__main__":
|
||||||
|
main()
|
||||||
|
```
|
||||||
|
|
||||||
|
我们待会会解释一下代码是怎么工作的。但是现在,让我们将该文本保存为 `tray.py`,然后使用 Python 运行之:
|
||||||
|
|
||||||
|
```
|
||||||
|
python tray.py
|
||||||
|
```
|
||||||
|
|
||||||
|
我们会看到指示器运行起来了,如下图所示:
|
||||||
|
|
||||||
|
![Create a Custom System Tray Indicator For Your Tasks on Linux 13][3]
|
||||||
|
|
||||||
|
现在,让我们解释一下这个魔法的原理:
|
||||||
|
|
||||||
|
* 前三行代码仅仅用来指明 Python 的路径并且导入需要的库。
|
||||||
|
* `def main()` :此为指示器的主函数。该函数的代码用来初始化并创建指示器。
|
||||||
|
* `indicator = appindicator.Indicator.new("customtray","semi-starred-symbolic",appindicator.IndicatorCategory.APPLICATION_STATUS)` :这里我们指明创建一个名为 `customtray` 的新指示器。这是指示器的唯一名称,这样系统就不会与其他运行中的指示器搞混了。同时我们使用名为 `semi-starred-symbolic` 的图标作为指示器的默认图标。你可以将之改成任何其他值;比如 `firefox` (如果你希望该指示器使用 FireFox 的图标),或任何其他你想用的图标名。最后与 `APPLICATION_STATUS` 相关的部分是指明指示器类别/范围的常规代码。
|
||||||
|
* `indicator.set_status(appindicator.IndicatorStatus.ACTIVE)`:这一行激活指示器。
|
||||||
|
* `indicator.set_menu(menu())`:这里说的是我们想使用 `menu()` 函数(我们会在后面定义) 来为我们的指示器创建菜单项。这很重要,可以让你右击指示器后看到一个可以实施行为的列表。
|
||||||
|
* `gtk.main()`:运行 GTK 主循环。
|
||||||
|
* 在 `menu()` 中我们定义了想要指示器提供的行为或项目。`command_one = gtk.MenuItem('My Notes')` 仅仅使用文本 “My notes” 来初始化第一个菜单项,接下来 `command_one.connect('activate',note)` 将菜单的 `activate` 信号与后面定义的 `note()` 函数相连接;换句话说,我们告诉我们的系统:“当该菜单项被点击,运行 `note()` 函数”。最后,`menu.append(command_one)` 将菜单项添加到列表中。
|
||||||
|
* `exittray` 相关的行是为了创建一个退出的菜单项,以便让你在想要的时候关闭指示器。
|
||||||
|
* `menu.show_all()` 以及 `return menu` 只是返回菜单项给指示器的常规代码。
|
||||||
|
* 在 `note(_)` 下面是点击 “My Notes” 菜单项时需要执行的代码。这里只是 `os.system("gedit $HOME/Documents/notes.txt")` 这一句话;`os.system` 函数允许你在 Python 中运行 shell 命令,因此这里我们写了一行命令来使用 `gedit` 打开家目录下 `Documents` 目录中名为 `notes.txt` 的文件。例如,这个可以称为你今后的日常笔记程序了!
|
||||||
|
|
||||||
|
### 添加你所需要的任务
|
||||||
|
|
||||||
|
你只需要修改代码中的两块地方:
|
||||||
|
|
||||||
|
1. 在 `menu()` 中为你想要的任务定义新的菜单项。
|
||||||
|
2. 创建一个新的函数让给该菜单项被点击时执行特定的行为。
|
||||||
|
|
||||||
|
所以,比如说你想要创建一个新菜单项,在点击后,会使用 VLC 播放硬盘中某个特定的视频/音频文件?要做到这一点,只需要在第 17 行处添加下面三行内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
command_two = gtk.MenuItem('Play video/audio')
|
||||||
|
command_two.connect('activate', play)
|
||||||
|
menu.append(command_two)
|
||||||
|
```
|
||||||
|
|
||||||
|
然后在第 30 行添加下面内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
def play(_):
|
||||||
|
os.system("vlc /home/<username>/Videos/somevideo.mp4")
|
||||||
|
```
|
||||||
|
|
||||||
|
将` `/home/<username>/Videos/somevideo.mp4` 替换成你想要播放的视频/音频文件路径。现在保存该文件然后再次运行该指示器:
|
||||||
|
|
||||||
|
```
|
||||||
|
python tray.py
|
||||||
|
```
|
||||||
|
|
||||||
|
你将会看到:
|
||||||
|
|
||||||
|
![Create a Custom System Tray Indicator For Your Tasks on Linux 15][4]
|
||||||
|
|
||||||
|
而且当你点击新创建的菜单项时,VLC 会开始播放!
|
||||||
|
|
||||||
|
要创建其他项目/任务,只需要重复上面步骤即可。但是要小心,需要用其他命令来替换 `command_two`,比如 `command_three`,这样在变量之间才不会产生冲突。然后定义新函数,就像 `play(_)` 函数那样。
|
||||||
|
|
||||||
|
可能性是无穷的;比如我用这种方法来从网上获取数据(使用 urllib2 库)并显示出来。我也用它来在后台使用 `mpg123` 命令播放 mp3 文件,而且我还定义了另一个菜单项来 `killall mpg123` 以随时停止播放音频。比如 Steam 上的 CS:GO 退出很费时间(窗口并不会自动关闭),因此,作为一个变通的方法,我只是最小化窗口然后点击某个自建的菜单项,它会执行 `killall -9 csgo_linux64` 命令。
|
||||||
|
|
||||||
|
你可以使用这个指示器来做任何事情:升级系统包、运行其他脚本——字面上的任何事情。
|
||||||
|
|
||||||
|
### 自动启动
|
||||||
|
|
||||||
|
我们希望系统托盘指示器能在系统启动后自动启动,而不用每次都手工运行。要做到这一点,只需要在自启动应用程序中添加下面命令即可(但是你需要将 `tray.py` 的路径替换成你自己的路径):
|
||||||
|
|
||||||
|
```
|
||||||
|
nohup python /home/<username>/tray.py &
|
||||||
|
```
|
||||||
|
|
||||||
|
下次重启系统,指示器会在系统启动后自动开始工作了!
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
你现在知道了如何为你想要的任务创建自己的系统托盘指示器了。根据每天需要运行的任务的性质和数量,此方法可以节省大量时间。有些人偏爱从命令行创建别名,但是这需要你每次都打开终端窗口或者需要有一个可用的下拉式终端仿真器,而这里,这个系统托盘指示器一直在工作,随时可用。
|
||||||
|
|
||||||
|
你以前用过这个方法来运行你的任务吗?很想听听你的想法。
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fosspost.org/tutorials/custom-system-tray-icon-indicator-linux
|
||||||
|
|
||||||
|
作者:[M.Hanny Sabbagh][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[lujun9972](https://github.com/lujun9972)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fosspost.org/author/mhsabbagh
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/Screenshot-at-2019-02-28-0808.png?resize=407%2C345&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 12)
|
||||||
|
[2]: https://extensions.gnome.org/extension/1031/topicons/
|
||||||
|
[3]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/03/Screenshot-at-2019-03-02-1041.png?resize=434%2C140&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 14)
|
||||||
|
[4]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/03/Screenshot-at-2019-03-02-1141.png?resize=440%2C149&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 16)
|
||||||
@ -0,0 +1,295 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11147-1.html)
|
||||||
|
[#]: subject: (ClusterShell – A Nifty Tool To Run Commands On Cluster Nodes In Parallel)
|
||||||
|
[#]: via: (https://www.2daygeek.com/clustershell-clush-run-commands-on-cluster-nodes-remote-system-in-parallel-linux/)
|
||||||
|
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||||
|
|
||||||
|
ClusterShell:一个在集群节点上并行运行命令的好工具
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我们过去曾写过两篇如何并行地在多个远程服务器上运行命令的文章:[并行 SSH(PSSH)][1] 和[分布式 Shell(DSH)][2]。今天,我们将讨论相同类型的主题,但它允许我们在集群节点上执行相同的操作。你可能会想,我可以编写一个小的 shell 脚本来实现这个目的,而不是安装这些第三方软件包。
|
||||||
|
|
||||||
|
当然,你是对的,如果要在十几个远程系统中运行一些命令,那么你不需要使用它。但是,你的脚本需要一些时间来完成此任务,因为它是按顺序运行的。想想你要是在一千多台服务器上运行一些命令会是什么样子?在这种情况下,你的脚本用处不大。此外,完成任务需要很长时间。所以,要克服这种问题和情况,我们需要可以在远程计算机上并行运行命令。
|
||||||
|
|
||||||
|
为此,我们需要在一个并行应用程序中使用它。我希望这个解释可以解决你对并行实用程序的疑虑。
|
||||||
|
|
||||||
|
### ClusterShell
|
||||||
|
|
||||||
|
[ClusterShell][3] 是一个事件驱动的开源 Python 库,旨在在服务器场或大型 Linux 集群上并行运行本地或远程命令。(`clush` 即 [ClusterShell][3])。
|
||||||
|
|
||||||
|
它将处理在 HPC 集群上遇到的常见问题,例如在节点组上操作,使用优化过的执行算法运行分布式命令,以及收集结果和合并相同的输出,或检索返回代码。
|
||||||
|
|
||||||
|
ClusterShell 可以利用已安装在系统上的现有远程 shell 设施,如 SSH。
|
||||||
|
|
||||||
|
ClusterShell 的主要目标是通过为开发人员提供轻量级、但可扩展的 Python API 来改进高性能集群的管理。它还提供了 `clush`、`clubak` 和 `cluset`/`nodeset` 等方便的命令行工具,可以让传统的 shell 脚本利用这个库的一些功能。
|
||||||
|
|
||||||
|
ClusterShell 是用 Python 编写的,它需要 Python(v2.6+ 或 v3.4+)才能在你的系统上运行。
|
||||||
|
|
||||||
|
### 如何在 Linux 上安装 ClusterShell?
|
||||||
|
|
||||||
|
ClusterShell 包在大多数发行版的官方包管理器中都可用。因此,使用发行版包管理器工具进行安装。
|
||||||
|
|
||||||
|
对于 Fedora 系统,使用 [DNF 命令][4]来安装 clustershell。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install clustershell
|
||||||
|
```
|
||||||
|
|
||||||
|
如果系统默认是 Python 2,这会安装 Python 2 模块和工具,可以运行以下命令安装 Python 3 开发包。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install python3-clustershell
|
||||||
|
```
|
||||||
|
|
||||||
|
在执行 clustershell 安装之前,请确保你已在系统上启用 [EPEL 存储库][5]。
|
||||||
|
|
||||||
|
对于 RHEL/CentOS 系统,使用 [YUM 命令][6] 来安装 clustershell。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo yum install clustershell
|
||||||
|
```
|
||||||
|
|
||||||
|
如果系统默认是 Python 2,这会安装 Python 2 模块和工具,可以运行以下命令安装 Python 3 开发包。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo yum install python34-clustershell
|
||||||
|
```
|
||||||
|
|
||||||
|
对于 openSUSE Leap 系统,使用 [Zypper 命令][7] 来安装 clustershell。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo zypper install clustershell
|
||||||
|
```
|
||||||
|
|
||||||
|
如果系统默认是 Python 2,这会安装 Python 2 模块和工具,可以运行以下命令安装 Python 3 开发包。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo zypper install python3-clustershell
|
||||||
|
```
|
||||||
|
|
||||||
|
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][8] 或 [APT 命令][9] 来安装 clustershell。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt install clustershell
|
||||||
|
```
|
||||||
|
|
||||||
|
### 如何在 Linux 使用 PIP 安装 ClusterShell?
|
||||||
|
|
||||||
|
可以使用 PIP 安装 ClusterShell,因为它是用 Python 编写的。
|
||||||
|
|
||||||
|
在执行 clustershell 安装之前,请确保你已在系统上启用了 [Python][10] 和 [PIP][11]。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo pip install ClusterShell
|
||||||
|
```
|
||||||
|
|
||||||
|
### 如何在 Linux 上使用 ClusterShell?
|
||||||
|
|
||||||
|
与其他实用程序(如 `pssh` 和 `dsh`)相比,它是直接了当的优秀工具。它有很多选项可以在远程并行执行。
|
||||||
|
|
||||||
|
在开始使用 clustershell 之前,请确保你已启用系统上的[无密码登录][12]。
|
||||||
|
|
||||||
|
以下配置文件定义了系统范围的默认值。你不需要修改这里的任何东西。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat /etc/clustershell/clush.conf
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你想要创建一个服务器组,那也可以。默认情况下有一些示例,请根据你的要求执行相同操作。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat /etc/clustershell/groups.d/local.cfg
|
||||||
|
```
|
||||||
|
|
||||||
|
只需按以下列格式运行 clustershell 命令即可从给定节点获取信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ clush -w 192.168.1.4,192.168.1.9 cat /proc/version
|
||||||
|
192.168.1.9: Linux version 4.15.0-45-generic ([email protected]) (gcc version 7.3.0 (Ubuntu 7.3.0-16ubuntu3)) #48-Ubuntu SMP Tue Jan 29 16:28:13 UTC 2019
|
||||||
|
192.168.1.4: Linux version 3.10.0-957.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC) ) #1 SMP Thu Nov 8 23:39:32 UTC 2018
|
||||||
|
```
|
||||||
|
|
||||||
|
选项:
|
||||||
|
|
||||||
|
* `-w:` 你要运行该命令的节点。
|
||||||
|
|
||||||
|
你可以使用正则表达式而不是使用完整主机名和 IP:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ clush -w 192.168.1.[4,9] uname -r
|
||||||
|
192.168.1.9: 4.15.0-45-generic
|
||||||
|
192.168.1.4: 3.10.0-957.el7.x86_64
|
||||||
|
```
|
||||||
|
|
||||||
|
或者,如果服务器位于同一 IP 系列中,则可以使用以下格式:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ clush -w 192.168.1.[4-9] date
|
||||||
|
192.168.1.6: Mon Mar 4 21:08:29 IST 2019
|
||||||
|
192.168.1.7: Mon Mar 4 21:08:29 IST 2019
|
||||||
|
192.168.1.8: Mon Mar 4 21:08:29 IST 2019
|
||||||
|
192.168.1.5: Mon Mar 4 09:16:30 CST 2019
|
||||||
|
192.168.1.9: Mon Mar 4 21:08:29 IST 2019
|
||||||
|
192.168.1.4: Mon Mar 4 09:16:30 CST 2019
|
||||||
|
```
|
||||||
|
|
||||||
|
clustershell 允许我们以批处理模式运行命令。使用以下格式来实现此目的:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ clush -w 192.168.1.4,192.168.1.9 -b
|
||||||
|
Enter 'quit' to leave this interactive mode
|
||||||
|
Working with nodes: 192.168.1.[4,9]
|
||||||
|
clush> hostnamectl
|
||||||
|
---------------
|
||||||
|
192.168.1.4
|
||||||
|
---------------
|
||||||
|
Static hostname: CentOS7.2daygeek.com
|
||||||
|
Icon name: computer-vm
|
||||||
|
Chassis: vm
|
||||||
|
Machine ID: 002f47b82af248f5be1d67b67e03514c
|
||||||
|
Boot ID: f9b37a073c534dec8b236885e754cb56
|
||||||
|
Virtualization: kvm
|
||||||
|
Operating System: CentOS Linux 7 (Core)
|
||||||
|
CPE OS Name: cpe:/o:centos:centos:7
|
||||||
|
Kernel: Linux 3.10.0-957.el7.x86_64
|
||||||
|
Architecture: x86-64
|
||||||
|
---------------
|
||||||
|
192.168.1.9
|
||||||
|
---------------
|
||||||
|
Static hostname: Ubuntu18
|
||||||
|
Icon name: computer-vm
|
||||||
|
Chassis: vm
|
||||||
|
Machine ID: 27f6c2febda84dc881f28fd145077187
|
||||||
|
Boot ID: f176f2eb45524d4f906d12e2b5716649
|
||||||
|
Virtualization: oracle
|
||||||
|
Operating System: Ubuntu 18.04.2 LTS
|
||||||
|
Kernel: Linux 4.15.0-45-generic
|
||||||
|
Architecture: x86-64
|
||||||
|
clush> free -m
|
||||||
|
---------------
|
||||||
|
192.168.1.4
|
||||||
|
---------------
|
||||||
|
total used free shared buff/cache available
|
||||||
|
Mem: 1838 641 217 19 978 969
|
||||||
|
Swap: 2047 0 2047
|
||||||
|
---------------
|
||||||
|
192.168.1.9
|
||||||
|
---------------
|
||||||
|
total used free shared buff/cache available
|
||||||
|
Mem: 1993 352 1067 1 573 1473
|
||||||
|
Swap: 1425 0 1425
|
||||||
|
clush> w
|
||||||
|
---------------
|
||||||
|
192.168.1.4
|
||||||
|
---------------
|
||||||
|
09:21:14 up 3:21, 3 users, load average: 0.00, 0.01, 0.05
|
||||||
|
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||||
|
daygeek :0 :0 06:02 ?xdm? 1:28 0.30s /usr/libexec/gnome-session-binary --session gnome-classic
|
||||||
|
daygeek pts/0 :0 06:03 3:17m 0.06s 0.06s bash
|
||||||
|
daygeek pts/1 192.168.1.6 06:03 52:26 0.10s 0.10s -bash
|
||||||
|
---------------
|
||||||
|
192.168.1.9
|
||||||
|
---------------
|
||||||
|
21:13:12 up 3:12, 1 user, load average: 0.08, 0.03, 0.00
|
||||||
|
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||||
|
daygeek pts/0 192.168.1.6 20:42 29:41 0.05s 0.05s -bash
|
||||||
|
clush> quit
|
||||||
|
```
|
||||||
|
|
||||||
|
如果要在一组节点上运行该命令,请使用以下格式:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ clush -w @dev uptime
|
||||||
|
or
|
||||||
|
$ clush -g dev uptime
|
||||||
|
or
|
||||||
|
$ clush --group=dev uptime
|
||||||
|
|
||||||
|
192.168.1.9: 21:10:10 up 3:09, 1 user, load average: 0.09, 0.03, 0.01
|
||||||
|
192.168.1.4: 09:18:12 up 3:18, 3 users, load average: 0.01, 0.02, 0.05
|
||||||
|
```
|
||||||
|
|
||||||
|
如果要在多个节点组上运行该命令,请使用以下格式:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ clush -w @dev,@uat uptime
|
||||||
|
or
|
||||||
|
$ clush -g dev,uat uptime
|
||||||
|
or
|
||||||
|
$ clush --group=dev,uat uptime
|
||||||
|
|
||||||
|
192.168.1.7: 07:57:19 up 59 min, 1 user, load average: 0.08, 0.03, 0.00
|
||||||
|
192.168.1.9: 20:27:20 up 1:00, 1 user, load average: 0.00, 0.00, 0.00
|
||||||
|
192.168.1.5: 08:57:21 up 59 min, 1 user, load average: 0.00, 0.01, 0.05
|
||||||
|
```
|
||||||
|
|
||||||
|
clustershell 允许我们将文件复制到远程计算机。将本地文件或目录复制到同一个远程节点:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ clush -w 192.168.1.[4,9] --copy /home/daygeek/passwd-up.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
我们可以通过运行以下命令来验证它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ clush -w 192.168.1.[4,9] ls -lh /home/daygeek/passwd-up.sh
|
||||||
|
192.168.1.4: -rwxr-xr-x. 1 daygeek daygeek 159 Mar 4 09:00 /home/daygeek/passwd-up.sh
|
||||||
|
192.168.1.9: -rwxr-xr-x 1 daygeek daygeek 159 Mar 4 20:52 /home/daygeek/passwd-up.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
将本地文件或目录复制到不同位置的远程节点:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ clush -g uat --copy /home/daygeek/passwd-up.sh --dest /tmp
|
||||||
|
```
|
||||||
|
|
||||||
|
我们可以通过运行以下命令来验证它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ clush --group=uat ls -lh /tmp/passwd-up.sh
|
||||||
|
192.168.1.7: -rwxr-xr-x. 1 daygeek daygeek 159 Mar 6 07:44 /tmp/passwd-up.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
将文件或目录从远程节点复制到本地系统:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ clush -w 192.168.1.7 --rcopy /home/daygeek/Documents/magi.txt --dest /tmp
|
||||||
|
```
|
||||||
|
|
||||||
|
我们可以通过运行以下命令来验证它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls -lh /tmp/magi.txt.192.168.1.7
|
||||||
|
-rw-r--r-- 1 daygeek daygeek 35 Mar 6 20:24 /tmp/magi.txt.192.168.1.7
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.2daygeek.com/clustershell-clush-run-commands-on-cluster-nodes-remote-system-in-parallel-linux/
|
||||||
|
|
||||||
|
作者:[Magesh Maruthamuthu][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.2daygeek.com/author/magesh/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.2daygeek.com/pssh-parallel-ssh-run-execute-commands-on-multiple-linux-servers/
|
||||||
|
[2]: https://www.2daygeek.com/dsh-run-execute-shell-commands-on-multiple-linux-servers-at-once/
|
||||||
|
[3]: https://cea-hpc.github.io/clustershell/
|
||||||
|
[4]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||||
|
[5]: https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
|
||||||
|
[6]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||||
|
[7]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||||
|
[8]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||||
|
[9]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||||
|
[10]: https://www.2daygeek.com/3-methods-to-install-latest-python3-package-on-centos-6-system/
|
||||||
|
[11]: https://www.2daygeek.com/install-pip-manage-python-packages-linux/
|
||||||
|
[12]: https://www.2daygeek.com/linux-passwordless-ssh-login-using-ssh-keygen/
|
||||||
@ -1,15 +1,16 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (chen-ni)
|
[#]: translator: (chen-ni)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11076-1.html)
|
||||||
[#]: subject: (Can schools be agile?)
|
[#]: subject: (Can schools be agile?)
|
||||||
[#]: via: (https://opensource.com/open-organization/19/4/education-culture-agile)
|
[#]: via: (https://opensource.com/open-organization/19/4/education-culture-agile)
|
||||||
[#]: author: (Ben Owens https://opensource.com/users/engineerteacher/users/ke4qqq/users/n8chz/users/don-watkins)
|
[#]: author: (Ben Owens https://opensource.com/users/engineerteacher/users/ke4qqq/users/n8chz/users/don-watkins)
|
||||||
|
|
||||||
学校可以变得敏捷吗?
|
学校可以变得敏捷吗?
|
||||||
======
|
======
|
||||||
我们一定不会希望用商业的方式运作我们的学校 —— 但是更加注重持续改进的教育机构是可以让我们受益的。
|
> 我们一定不会希望用商业的方式运作我们的学校 —— 但是更加注重持续改进的教育机构是可以让我们受益的。
|
||||||
|
|
||||||
![][1]
|
![][1]
|
||||||
|
|
||||||
我们都有过那种感觉一件事情“似曾相识”的经历。在 1980 年代末期我经常会有这种感觉,那时候我刚刚进入工业领域不久。当时正赶上一波组织变革的热潮,美国制造业在尝试各种各样不同的模型,让企业领导、经理人和像我这样的工程师重新思考我们应该如何处理质量、成本、创新以及股东价值这样的问题。我们似乎每一年(有时候更加频繁)都需要通过学习一本书来找到让我们更精简、更扁平、更灵活以及更加能满足顾客需求的“最佳方案”。
|
我们都有过那种感觉一件事情“似曾相识”的经历。在 1980 年代末期我经常会有这种感觉,那时候我刚刚进入工业领域不久。当时正赶上一波组织变革的热潮,美国制造业在尝试各种各样不同的模型,让企业领导、经理人和像我这样的工程师重新思考我们应该如何处理质量、成本、创新以及股东价值这样的问题。我们似乎每一年(有时候更加频繁)都需要通过学习一本书来找到让我们更精简、更扁平、更灵活以及更加能满足顾客需求的“最佳方案”。
|
||||||
@ -24,7 +25,7 @@
|
|||||||
|
|
||||||
这种不断改进的文化氛围遇到的第一个阻碍是,教育界普遍不愿意从其它行业借鉴可以为自己所用的思想 —— 特别是来自商界的思想。第二个阻碍是,主导教育界的仍然是一种自上而下的、等级制度森严的领导模式。人们往往只能在小范围内讨论这种系统性的、持续的改进方案,比如包括校长、助理校长、学校监管人(LCTT 译注:美国地方政府下设的一种官职,每个学校监管人管理一定数量的学校,接受学校校长的汇报)等等在内的学校领导和区域领袖。但是一小群人的参与是远远不足以带来整个组织层面的文化改革的。
|
这种不断改进的文化氛围遇到的第一个阻碍是,教育界普遍不愿意从其它行业借鉴可以为自己所用的思想 —— 特别是来自商界的思想。第二个阻碍是,主导教育界的仍然是一种自上而下的、等级制度森严的领导模式。人们往往只能在小范围内讨论这种系统性的、持续的改进方案,比如包括校长、助理校长、学校监管人(LCTT 译注:美国地方政府下设的一种官职,每个学校监管人管理一定数量的学校,接受学校校长的汇报)等等在内的学校领导和区域领袖。但是一小群人的参与是远远不足以带来整个组织层面的文化改革的。
|
||||||
|
|
||||||
在进一步展开观点之前,我想强调一下,上面所做的概括一定是存在例外情况 的(我自己就见到过很多),不过我觉得任何一个教育界的利益相关者都应该会同意以下两点基本假设:
|
在进一步展开观点之前,我想强调一下,上面所做的概括一定是存在例外情况的(我自己就见到过很多),不过我觉得任何一个教育界的利益相关者都应该会同意以下两点基本假设:
|
||||||
|
|
||||||
1. 为学生提供高质量的、公平的教育和教学系统的工作所涉及到的任何人都应该将持续不断的改进作为思维方式里的重要部分;
|
1. 为学生提供高质量的、公平的教育和教学系统的工作所涉及到的任何人都应该将持续不断的改进作为思维方式里的重要部分;
|
||||||
2. 如果学校领导在做决策的时候可以更多地参考那些离学生最近的工作者的意见,那么学生以及学生所在的社区都将更加受益;
|
2. 如果学校领导在做决策的时候可以更多地参考那些离学生最近的工作者的意见,那么学生以及学生所在的社区都将更加受益;
|
||||||
@ -37,12 +38,11 @@
|
|||||||
|
|
||||||
我并不是要呼吁大家像经营商业一样经营我们的学校。我所主张的是,用一种清晰而客观的态度去看待任何行业的任何思想,只要它们有可能帮助我们更好地迎合学生个体的需求。不过,如果想有效率地实现这个目标,我们需要仔细研究这个 100 多年来都停滞不前的领导结构。
|
我并不是要呼吁大家像经营商业一样经营我们的学校。我所主张的是,用一种清晰而客观的态度去看待任何行业的任何思想,只要它们有可能帮助我们更好地迎合学生个体的需求。不过,如果想有效率地实现这个目标,我们需要仔细研究这个 100 多年来都停滞不前的领导结构。
|
||||||
|
|
||||||
|
|
||||||
### 把不断改进作为努力的目标
|
### 把不断改进作为努力的目标
|
||||||
|
|
||||||
有一种说法认为教育和其它行业之间存在着巨大的差异,我虽然赞同这种说法,但同时也相信“重新思考组织和领导结构”这件事情对于任何一个希望对利益相关者负责(并且可以及时作出响应)的主体来说都是适用的。大多数其它行业都已经在重新审视它们传统的、封闭的、等级森严的结构,并且采用可以鼓励员工基于共有的优秀目标发挥自主性的组织结构 —— 这种组织结构对于不断改进来说十分关键。我们的学校和行政区是时候放开眼界了,而不应该拘泥于只听到来自内部的声音,因为它们的用意虽然是好的,但都没有脱离现有的范式。
|
有一种说法认为教育和其它行业之间存在着巨大的差异,我虽然赞同这种说法,但同时也相信“重新思考组织和领导结构”这件事情对于任何一个希望对利益相关者负责(并且可以及时作出响应)的主体来说都是适用的。大多数其它行业都已经在重新审视它们传统的、封闭的、等级森严的结构,并且采用可以鼓励员工基于共有的优秀目标发挥自主性的组织结构 —— 这种组织结构对于不断改进来说十分关键。我们的学校和行政区是时候放开眼界了,而不应该拘泥于只听到来自内部的声音,因为它们的用意虽然是好的,但都没有脱离现有的范式。
|
||||||
|
|
||||||
对于任何希望开始或者加速这个转变过程的学校,我推荐一本很好的书:Jim Whitehurst 的《开放的组织》(这不应该让你感到意外)。这本书不仅可以帮助我们理解教育者如何创造更加开放、覆盖面更广的领导领导结构 —— 在这样的结构下,互相尊重让人们可以基于实时数据作出更加灵活的决策 —— 并且它所使用的语言风格也和教育者们所习惯使用的奇怪的词汇库非常契合(这种词汇库简直是教育者们第二天性)。任何组织都可以借鉴开放组织的思维提供的实用主义方法让组织成员更加开放:分享想法和资源、拥抱以共同协作为核心的文化、通过快速制作原型来开发创新思维、基于价值(而不是提出者的职级)来评估一个想法,以及创造一种融入到组织 DNA 里的很强的社区观念。通过众包的方式,这样的开放组织不仅可以从组织内部,也能够从组织外部收集想法,创造一种可以让本地化的、以学生为中心的创新蓬勃发展的环境。
|
对于任何希望开始或者加速这个转变过程的学校,我推荐一本很好的书:Jim Whitehurst 的《开放组织》(这不应该让你感到意外)。这本书不仅可以帮助我们理解教育者如何创造更加开放、覆盖面更广的领导领导结构 —— 在这样的结构下,互相尊重让人们可以基于实时数据作出更加灵活的决策 —— 并且它所使用的语言风格也和教育者们所习惯使用的奇怪的词汇库非常契合(这种词汇库简直是教育者们第二天性)。任何组织都可以借鉴开放组织的思维提供的实用主义方法让组织成员更加开放:分享想法和资源、拥抱以共同协作为核心的文化、通过快速制作原型来开发创新思维、基于价值(而不是提出者的职级)来评估一个想法,以及创造一种融入到组织 DNA 里的很强的社区观念。通过众包的方式,这样的开放组织不仅可以从组织内部,也能够从组织外部收集想法,创造一种可以让本地化的、以学生为中心的创新蓬勃发展的环境。
|
||||||
|
|
||||||
最重要的事情是:在快速变化的未来,我们在过去所做的事情不一定仍然适用了 —— 认清楚这一点对于创造一个不断改进的文化氛围是十分关键的。对于教育者来说,这意味着我们不能只是简单地依赖在针对工厂模型发展出来的解决方案和实践方式了。我们必须从其它行业(比如说非营利组织、军事、医疗以及商业 —— 没错,甚至是商业)里借鉴数不清的最佳方案,这样至少应该能让我们 *知道* 如何找到让学生受益最大的办法。从教育界传统的陈词滥调里超脱出来,才有机会拥有更广阔的视角。我们可以更好地顾全大局,用更客观地视角看待我们遇到的问题,同时也知道我们在什么方面已经做得很不错。
|
最重要的事情是:在快速变化的未来,我们在过去所做的事情不一定仍然适用了 —— 认清楚这一点对于创造一个不断改进的文化氛围是十分关键的。对于教育者来说,这意味着我们不能只是简单地依赖在针对工厂模型发展出来的解决方案和实践方式了。我们必须从其它行业(比如说非营利组织、军事、医疗以及商业 —— 没错,甚至是商业)里借鉴数不清的最佳方案,这样至少应该能让我们 *知道* 如何找到让学生受益最大的办法。从教育界传统的陈词滥调里超脱出来,才有机会拥有更广阔的视角。我们可以更好地顾全大局,用更客观地视角看待我们遇到的问题,同时也知道我们在什么方面已经做得很不错。
|
||||||
|
|
||||||
@ -50,7 +50,6 @@
|
|||||||
|
|
||||||
坚持不懈地追求不断改进这件事情,不应该只局限于那种努力在一个全球化的、创新的经济环境中争取竞争力的机构,或者是负责运营学校的少数几个人。当机构里的每一个人都能不断思考怎样才能让今天比昨天做得更好的时候,这就是一个拥有优秀的文化氛围的机构。这种非常有注重协作性和创新的文化氛围,正是我们希望在这些负责改变年轻人命运的机构身上看到的。
|
坚持不懈地追求不断改进这件事情,不应该只局限于那种努力在一个全球化的、创新的经济环境中争取竞争力的机构,或者是负责运营学校的少数几个人。当机构里的每一个人都能不断思考怎样才能让今天比昨天做得更好的时候,这就是一个拥有优秀的文化氛围的机构。这种非常有注重协作性和创新的文化氛围,正是我们希望在这些负责改变年轻人命运的机构身上看到的。
|
||||||
|
|
||||||
|
|
||||||
我非常期待,有朝一日我能在学校里感受到这种精神,然后微笑着对自己说:“这种感觉多么似曾相识啊。”
|
我非常期待,有朝一日我能在学校里感受到这种精神,然后微笑着对自己说:“这种感觉多么似曾相识啊。”
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
@ -60,7 +59,7 @@ via: https://opensource.com/open-organization/19/4/education-culture-agile
|
|||||||
作者:[Ben Owens][a]
|
作者:[Ben Owens][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[chen-ni](https://github.com/chen-ni)
|
译者:[chen-ni](https://github.com/chen-ni)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,30 +1,30 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (LazyWolfLin)
|
[#]: translator: (LazyWolfLin)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11075-1.html)
|
||||||
[#]: subject: (Looking into Linux modules)
|
[#]: subject: (Looking into Linux modules)
|
||||||
[#]: via: (https://www.networkworld.com/article/3391362/looking-into-linux-modules.html#tk.rss_all)
|
[#]: via: (https://www.networkworld.com/article/3391362/looking-into-linux-modules.html)
|
||||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||||
|
|
||||||
Looking into Linux modules
|
深入学习 Linux 内核模块
|
||||||
======
|
======
|
||||||
The lsmod command can tell you which kernel modules are currently loaded on your system, along with some interesting details about their use.
|
|
||||||
|
> lsmod 命令能够告诉你当前系统上加载了哪些内核模块,以及关于使用它们的一些有趣的细节。
|
||||||
|
|
||||||
![Rob Oo \(CC BY 2.0\)][1]
|
![Rob Oo \(CC BY 2.0\)][1]
|
||||||
|
|
||||||
### What are Linux modules?
|
### 什么是 Linux 内核模块?
|
||||||
|
|
||||||
Kernel modules are chunks of code that are loaded and unloaded into the kernel as needed, thus extending the functionality of the kernel without requiring a reboot. In fact, unless users inquire about modules using commands like **lsmod** , they won't likely know that anything has changed.
|
内核模块是可以根据需要加载到内核中或从内核中卸载的代码块,因此无需重启就可以扩展内核的功能。事实上,除非用户使用类似 `lsmod` 这样的命令来查询模块信息,否则用户不太可能知道内核发生的任何变化。
|
||||||
|
|
||||||
One important thing to understand is that there are _lots_ of modules that will be in use on your Linux system at all times and that a lot of details are available if you're tempted to dive into the details.
|
需要知道的重要一点是,在你的 Linux 系统上总会有*很多*可用的模块,并且如果你可以深入其中了解到很多细节。
|
||||||
|
|
||||||
One of the prime ways that lsmod is used is to examine modules when a system isn't working properly. However, most of the time, modules load as needed and users don't need to be aware of how they are working.
|
`lsmod` 的主要用途之一是在系统不能正常工作时检查模块。然而,大多数情况下,模块会根据需要加载的,而且用户不需要知道它们如何运作。
|
||||||
|
|
||||||
**[ Also see:[Must-know Linux Commands][2] ]**
|
### 显示内核模块
|
||||||
|
|
||||||
### Listing modules
|
显示内核模块最简单的方法是使用 `lsmod` 命令。虽然这个命令包含了很多细节,但输出却是非常用户友好。
|
||||||
|
|
||||||
The easiest way to list modules is with the **lsmod** command. While this command provides a lot of detail, this is the most user-friendly output.
|
|
||||||
|
|
||||||
```
|
```
|
||||||
$ lsmod
|
$ lsmod
|
||||||
@ -103,44 +103,40 @@ e1000e 245760 0
|
|||||||
floppy 81920 0
|
floppy 81920 0
|
||||||
```
|
```
|
||||||
|
|
||||||
In the output above:
|
在上面的输出中:
|
||||||
|
|
||||||
* "Module" shows the name of each module
|
* `Module` 显示每个模块的名称
|
||||||
* "Size" shows the module size (not how much memory it is using)
|
* `Size` 显示每个模块的大小(并不是它们占的内存大小)
|
||||||
* "Used by" shows each module's usage count and the referring modules
|
* `Used by` 显示每个模块被使用的次数和使用它们的模块
|
||||||
|
|
||||||
|
显然,这里有*很多*模块。加载的模块数量取决于你的系统和版本以及正在运行的内容。我们可以这样计数:
|
||||||
|
|
||||||
Clearly, that's a _lot_ of modules. The number of modules loaded will depend on your system and distribution and what's running. We can count them like this:
|
|
||||||
|
|
||||||
```
|
```
|
||||||
$ lsmod | wc -l
|
$ lsmod | wc -l
|
||||||
67
|
67
|
||||||
```
|
```
|
||||||
|
|
||||||
To see the number of modules available on the system (not just running), try this command:
|
要查看系统中可用的模块数(不止运行当中的),试试这个命令:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ modprobe -c | wc -l
|
$ modprobe -c | wc -l
|
||||||
41272
|
41272
|
||||||
```
|
```
|
||||||
|
|
||||||
### Other commands for examining modules
|
### 与内核模块相关的其他命令
|
||||||
|
|
||||||
Linux provides several commands for listing, loading and unloading, examining, and checking the status of modules.
|
Linux 提供了几条用于罗列、加载及卸载、测试,以及检查模块状态的命令。
|
||||||
|
|
||||||
* depmod -- generates modules.dep and map files
|
* `depmod` —— 生成 `modules.dep` 和映射文件
|
||||||
* insmod -- a simple program to insert a module into the Linux Kernel
|
* `insmod` —— 一个往 Linux 内核插入模块的程序
|
||||||
* lsmod -- show the status of modules in the Linux Kernel
|
* `lsmod` —— 显示 Linux 内核中模块状态
|
||||||
* modinfo -- show information about a Linux Kernel module
|
* `modinfo` —— 显示 Linux 内核模块信息
|
||||||
* modprobe -- add and remove modules from the Linux Kernel
|
* `modprobe` —— 添加或移除 Linux 内核模块
|
||||||
* rmmod -- a simple program to remove a module from the Linux Kernel
|
* `rmmod` —— 一个从 Linux 内核移除模块的程序
|
||||||
|
|
||||||
|
### 显示内置的内核模块
|
||||||
|
|
||||||
|
正如前文所说,`lsmod` 命令是显示内核模块最方便的命令。然而,也有其他方式可以显示它们。`modules.builtin` 文件中列出了所有构建在内核中的模块,在 `modprobe` 命令尝试添加文件中的模块时会使用它。注意,以下命令中的 `$(uname -r)` 提供了内核版本的名称。
|
||||||
### Listing modules that are built in
|
|
||||||
|
|
||||||
As mentioned above, the **lsmod** command is the most convenient command for listing modules. There are, however, other ways to examine them. The modules.builtin file lists all modules that are built into the kernel and is used by modprobe when trying to load one of these modules. Note that **$(uname -r)** in the commands below provides the name of the kernel release.
|
|
||||||
|
|
||||||
```
|
```
|
||||||
$ more /lib/modules/$(uname -r)/modules.builtin | head -10
|
$ more /lib/modules/$(uname -r)/modules.builtin | head -10
|
||||||
@ -156,7 +152,7 @@ kernel/fs/configfs/configfs.ko
|
|||||||
kernel/fs/crypto/fscrypto.ko
|
kernel/fs/crypto/fscrypto.ko
|
||||||
```
|
```
|
||||||
|
|
||||||
You can get some additional detail on a module by using the **modinfo** command, though nothing that qualifies as an easy explanation of what service the module provides. The omitted details from the output below include a lengthy signature.
|
你可以使用 `modinfo` 获得一个模块的更多细节,虽然没有对模块提供的服务的简单说明。下面输出内容中省略了冗长的签名。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ modinfo floppy | head -16
|
$ modinfo floppy | head -16
|
||||||
@ -178,35 +174,31 @@ sig_key:
|
|||||||
sig_hashalgo: md4
|
sig_hashalgo: md4
|
||||||
```
|
```
|
||||||
|
|
||||||
You can load or unload a module using the **modprobe** command. Using a command like the one below, you can locate the kernel object associated with a particular module:
|
你可以使用 `modprobe` 命令加载或卸载模块。使用下面这条命令,你可以找到特定模块关联的内核对象:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ find /lib/modules/$(uname -r) -name floppy*
|
$ find /lib/modules/$(uname -r) -name floppy*
|
||||||
/lib/modules/5.0.0-13-generic/kernel/drivers/block/floppy.ko
|
/lib/modules/5.0.0-13-generic/kernel/drivers/block/floppy.ko
|
||||||
```
|
```
|
||||||
|
|
||||||
If you needed to load the module, you could use a command like this one:
|
如果你想要加载模块,你可以使用这个命令:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo modprobe floppy
|
$ sudo modprobe floppy
|
||||||
```
|
```
|
||||||
|
|
||||||
### Wrap-up
|
### 总结
|
||||||
|
|
||||||
Clearly the loading and unloading of modules is a big deal. It makes Linux systems considerably more flexible and efficient than if they ran with a one-size-fits-all kernel. It also means you can make significant changes — including adding hardware — without rebooting.
|
很明显,内核模块的加载和卸载非常重要。它使得 Linux 系统比使用通用内核运行时更加灵活和高效。这同样意味着你可以进行重大更改而无需重启,例如添加硬件。
|
||||||
|
|
||||||
**[ Two-Minute Linux Tips:[Learn how to master a host of Linux commands in these 2-minute video tutorials][3] ]**
|
|
||||||
|
|
||||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
via: https://www.networkworld.com/article/3391362/looking-into-linux-modules.html#tk.rss_all
|
via: https://www.networkworld.com/article/3391362/looking-into-linux-modules.html
|
||||||
|
|
||||||
作者:[Sandra Henry-Stocker][a]
|
作者:[Sandra Henry-Stocker][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[LazyWolfLin](https://github.com/LazyWolfLin)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,97 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (zionfuo)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11080-1.html)
|
||||||
|
[#]: subject: (Blockchain 2.0 – Public Vs Private Blockchain Comparison [Part 7])
|
||||||
|
[#]: via: (https://www.ostechnix.com/blockchain-2-0-public-vs-private-blockchain-comparison/)
|
||||||
|
[#]: author: (editor https://www.ostechnix.com/author/editor/)
|
||||||
|
|
||||||
|
区块链 2.0:公有链与私有链(七)
|
||||||
|
======
|
||||||
|
|
||||||
|
![Public vs Private blockchain][1]
|
||||||
|
|
||||||
|
[区块链 2.0][2]系列的前一篇文章探索了[智能合同的现状][3]。这篇文章旨在揭示可以创建的不同类型的区块链。它们每个都用于非常不同的应用程序,并且根据用例的不同,每个应用程序所遵循的协议也不同。现在,让我们将公有链之于私有链对比一下开源软件之于专有技术。
|
||||||
|
|
||||||
|
正如我们所知,基于区块链的分布式分类账本的基本三层结构如下:
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
*图 1 – 区块链分布式账本的基本结构*
|
||||||
|
|
||||||
|
这里提到的类型之间的差异主要归因于底层区块链其所依赖的协议。该协议规定了参与者的规则和参与的方式。
|
||||||
|
|
||||||
|
阅读本文时,请记住以下几点事项:
|
||||||
|
|
||||||
|
- 任何平台的产生都是为了解决需求而生。技术应该采取最好的方向。例如,区块链具有巨大的应用价值,其中一些可能需要丢弃在其他情形中看起来很重要的功能。在这方面,**分布式存储**就是最好的例子。
|
||||||
|
- 区块链本质上是一个数据库系统,通过时间戳和区块的形式组织数据来跟踪信息。此类区块链的创建者可以选择谁有权产出这些区块并进行修改。
|
||||||
|
- 区块链也可以“中心化”,参与的程度可以限定于由“中央权威”认定为符合条件的人。
|
||||||
|
|
||||||
|
大多数区块链要么是公有的,要么是私有的。广义上说,公有链可以被认为是开源软件的等价物,大多数私有链可以被视为源自公有链的专有平台。下图应该会让大多数人明显地看出基本的区别。
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
*图 2 – 公有链/私有链与开源/专有技术的对比*
|
||||||
|
|
||||||
|
虽然这是最受欢迎的理解。但是这并不是说所有的私有链都是从公有链中衍生出来的。
|
||||||
|
|
||||||
|
### 公有链
|
||||||
|
|
||||||
|
公有链可以被视为是一个无需许可的、开放的平台或网络。任何拥有专业知识和计算资源的人都可以参与其中。这将产生以下影响:
|
||||||
|
|
||||||
|
- 任何人都可以加入公有链网络并参与到其中。“参与者” 所需要的只是稳定的网络资源和计算资源。
|
||||||
|
- 参与行为包括了读取、写入、验证和提供交易期间的共识。比特币矿工就是很好的例子。作为网络的参与者,矿工会得到比特币作为回报。
|
||||||
|
- 平台完全去中心,完全冗余。
|
||||||
|
- 由于去中心化,没有一个实体可以完全控制分类账本中记录的数据。所有 (或大多数) 参与者都需要通过验证区块的方式检查数据。
|
||||||
|
- 这意味着,一旦信息被验证和记录,就不能轻易改变。即使能改变,也不可能不留下痕迹。
|
||||||
|
- 在比特币和莱特币等平台上,参与者的身份仍然是匿名的。设计这些平台的目的是保护和保护用户身份。这主要是由上层协议栈提供的功能。
|
||||||
|
- 公有链有比特币、莱特币、以太坊等不同的网络。
|
||||||
|
- 广泛的去中心化意味着,在区块链分布式网络实现的交易,获得共识可能需要一段时间,对于旨在每时每刻都在推动大量交易的大型企业来说,吞吐量可能是一个挑战。
|
||||||
|
- 开放式参与,使比特币等公有链中的大量参与者,往往会增加对计算设备和能源成本的初始投资。
|
||||||
|
- 公有链以设计安全著称。它们的实现依靠以下几点:
|
||||||
|
- 匿名参与者
|
||||||
|
- 多个节点上的分布式和冗余的加密存储
|
||||||
|
- 创建和更改数据需要大量的共识
|
||||||
|
|
||||||
|
### 私有链
|
||||||
|
|
||||||
|
相比之下,私有链是一个*被许可的区块链**。这意味着:
|
||||||
|
|
||||||
|
- 参与网络的许可受到限制,并由监督网络的所有者或机构主持。这意味着,即使个人能够存储数据并进行交易(例如,发送和接收付款),这些交易的验证和存储也只能由选定的参与者来完成。
|
||||||
|
- 参与者一旦获得中心机构的许可,将受到条款的限制。例如,在金融机构运营的私有链网络中,并不是每个客户都可以访问整个区块链的分布式账本,甚至在那些获得许可的客户中吗,也不是每个人都能访问所有的东西。在这种情况下,中心机构将授予访问选择服务的权限。这通常被称为 “**通道**”。
|
||||||
|
- 与公有链相比,这种系统具有更大的吞吐量能力,也展示了更快的交易速度,因为区块只需要由少数几个人验证。
|
||||||
|
|
||||||
|
私有链通常在其协议中没有任何特征。这使得该系统仅与目前使用的大多数基于云的数据库系统一样安全。
|
||||||
|
|
||||||
|
### 智者的观点
|
||||||
|
|
||||||
|
需要注意的一点是,它们被命名为公有或私有(或开源、闭源)的事实与底层代码库无关。在这两种情况下,平台所基于的代码或文字基础可能是公开的,也可能不是公开的。R3 是一家 DLT(<ruby>分布式分类账本<rt>**D**istributed **L**edger **T**echnology</rt></ruby>)公司,领导着由 200 多家跨国机构组成的公有财团。他们的目标是在金融和商业领域进一步发展区块链和相关分布式账本技术。corda 是这一共同努力的产物。R3 将 corda 定义为专门为企业构建的区块链平台。其代码库同样是开源的,鼓励世界各地的开发人员为这个项目做出贡献。然而,考虑到 corda 面临的业务性质和旨在满足的需求,corda 被归类为许可的封闭区块链平台。这意味着企业可以在部署后选择网络的参与者,并通过使用原生可用的智能合约工具选择这些参与者可以访问的信息类型。
|
||||||
|
|
||||||
|
虽然像比特币和以太坊这样的公有链负责该领域的广泛认知和发展,但仍然可以认为,为企业或商业环境中的特定用例设计的私有链将在短期内引领货币投资。这些都是我们大多数人在不久的将来会看到以实际方式运用起来的平台。
|
||||||
|
|
||||||
|
请继续阅读本系列中下一篇有关 Hyperledger 项目的文章。
|
||||||
|
|
||||||
|
- [区块链 2.0:Hyperledger(HLP)项目介绍][6]
|
||||||
|
|
||||||
|
我们正在研究更多有趣的区块链技术话题。敬请期待!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.ostechnix.com/blockchain-2-0-public-vs-private-blockchain-comparison/
|
||||||
|
|
||||||
|
作者:[ostechnix][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zionfuo](https://github.com/zionfuo)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.ostechnix.com/author/editor/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/Public-Vs-Private-Blockchain-720x340.png
|
||||||
|
[2]: https://linux.cn/article-10650-1.html
|
||||||
|
[3]: https://linux.cn/article-11013-1.html
|
||||||
|
[4]: http://www.ostechnix.com/wp-content/uploads/2019/04/blockchain-architecture.png
|
||||||
|
[5]: http://www.ostechnix.com/wp-content/uploads/2019/04/Public-vs-Private-blockchain-comparison.png
|
||||||
|
[6]: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
|
||||||
@ -1,30 +1,32 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (luuming)
|
[#]: translator: (luuming)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11067-1.html)
|
||||||
[#]: subject: (When to be concerned about memory levels on Linux)
|
[#]: subject: (When to be concerned about memory levels on Linux)
|
||||||
[#]: via: (https://www.networkworld.com/article/3394603/when-to-be-concerned-about-memory-levels-on-linux.html)
|
[#]: via: (https://www.networkworld.com/article/3394603/when-to-be-concerned-about-memory-levels-on-linux.html)
|
||||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||||
|
|
||||||
何时需要关注 linux 的内存层面?
|
何时需要关注 Linux 的内存用量?
|
||||||
======
|
======
|
||||||
Linux 上的内存管理很复杂。尽管使用率高但未必存在问题。你也应当关注一些其他的事情。
|
|
||||||
![Qfamily \(CC BY 2.0\)][1]
|
> Linux 上的内存管理很复杂。尽管使用率高但未必存在问题。你也应当关注一些其他的事情。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
在 Linux 上用光内存通常并不意味着存在严重的问题。为什么?因为健康的 Linux 系统会在内存中缓存磁盘活动,基本上占用掉了未被使用的内存,这显然是一件好事情。
|
在 Linux 上用光内存通常并不意味着存在严重的问题。为什么?因为健康的 Linux 系统会在内存中缓存磁盘活动,基本上占用掉了未被使用的内存,这显然是一件好事情。
|
||||||
|
|
||||||
换句话说,它不让内存浪费掉。使用空闲的内存增加磁盘访问速度,并且不占用运行中应用程序的内存。你也能够想到,使用这种内存缓存比起直接访问硬盘驱动(HDD)快上数百倍,也比明显快于直接访问固态硬盘驱动。内存占满或几乎占满通常意味着系统正在尽可能高效地运行当中——并不是运行中遇到了问题。
|
换句话说,它不让内存浪费掉。使用空闲的内存增加磁盘访问速度,并且不占用运行中应用程序的内存。你也能够想到,使用这种内存缓存比起直接访问硬盘驱动器(HDD)快上数百倍,也比明显快于直接访问固态硬盘驱动。内存占满或几乎占满通常意味着系统正在尽可能高效地运行当中 —— 并不是运行中遇到了问题。
|
||||||
|
|
||||||
### 缓存如何工作
|
### 缓存如何工作
|
||||||
|
|
||||||
磁盘缓存简单地意味着系统充分利用未使用的资源(空闲内存)来加速磁盘读取与写入。应用程序不会失去任何东西,并且大多数时间里能够按需求获得更多的内存。此外,磁盘缓存不会导致应用程序使用交换分区。反而,用作磁盘缓存的内存空间当被需要时会立即归还,并且磁盘内容会被更新。
|
磁盘缓存简单地意味着系统充分利用未使用的资源(空闲内存)来加速磁盘读取与写入。应用程序不会失去任何东西,并且大多数时间里能够按需求获得更多的内存。此外,磁盘缓存不会导致应用程序转而使用交换分区。反而,用作磁盘缓存的内存空间当被需要时会立即归还,并且磁盘内容会被更新。
|
||||||
|
|
||||||
### 主要和次要的页故障
|
### 主要和次要的页故障
|
||||||
|
|
||||||
Linux 系统通过分割物理内存为进程分配空间,将分割成的块称为“页”,并且映射这些页到每个进程的虚拟内存上。不再会用到的页也许会从内存中移除,尽管相关的进程还在运行。当进程需要一个没有被映射或没在内存中页时,故障便会产生。所以,“<ruby>故障<rt>fault</rt></ruby>”并不意味着“<ruby>错误<rt>error</rt></ruby>”而是“<ruby>不可用<rt>unavailables</rt></ruby>”,并且故障在内存管理中扮演者一个重要的角色。
|
Linux 系统通过分割物理内存来为进程分配空间,将分割成的块称为“页”,并且映射这些页到每个进程的虚拟内存上。不再会用到的页也许会从内存中移除,尽管相关的进程还在运行。当进程需要一个没有被映射或没在内存中页时,故障便会产生。所以,这个“<ruby>故障<rt>fault</rt></ruby>”并不意味着“<ruby>错误<rt>error</rt></ruby>”而是“<ruby>不可用<rt>unavailables</rt></ruby>”,并且故障在内存管理中扮演者一个重要的角色。
|
||||||
|
|
||||||
次要故障意味着在内存中的页未分配给请求的进程或未在内存管理单元中标记为出现。主要故障意味着页不保留在内存中。
|
次要故障意味着在内存中的页未分配给请求的进程,或未在内存管理单元中标记为出现。主要故障意味着页没有保留在内存中。
|
||||||
|
|
||||||
如果你想切身感受一下次要页故障和主要页故障出现的频率,像这样试一下 `ps` 命令。注意我们要的是与页故障和产生它的命令相关的项。输出中省略了很多行。`MINFL` 显示出次要故障的数目,而 `MAJFL` 表示了主要故障的数目。
|
如果你想切身感受一下次要页故障和主要页故障出现的频率,像这样试一下 `ps` 命令。注意我们要的是与页故障和产生它的命令相关的项。输出中省略了很多行。`MINFL` 显示出次要故障的数目,而 `MAJFL` 表示了主要故障的数目。
|
||||||
|
|
||||||
@ -45,7 +47,7 @@ $ ps -eo min_flt,maj_flt,cmd
|
|||||||
927 0 gdm-session-worker [pam/gdm-password]
|
927 0 gdm-session-worker [pam/gdm-password]
|
||||||
```
|
```
|
||||||
|
|
||||||
汇报单一进程,你可以尝试这样的命令:
|
汇报单一进程,你可以尝试这样的命令(LCTT 译注:参数里面的 `1` 是要查看的进程的 PID):
|
||||||
|
|
||||||
```
|
```
|
||||||
$ ps -o min_flt,maj_flt 1
|
$ ps -o min_flt,maj_flt 1
|
||||||
@ -53,7 +55,7 @@ $ ps -o min_flt,maj_flt 1
|
|||||||
230064 150
|
230064 150
|
||||||
```
|
```
|
||||||
|
|
||||||
你也可以添加其他的项,例如进程所有者的 UID 和 GID。
|
你也可以添加其他的显示字段,例如进程所有者的 UID 和 GID。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ ps -o min_flt,maj_flt,cmd,args,uid,gid 1
|
$ ps -o min_flt,maj_flt,cmd,args,uid,gid 1
|
||||||
@ -63,7 +65,7 @@ $ ps -o min_flt,maj_flt,cmd,args,uid,gid 1
|
|||||||
|
|
||||||
### 多少才算满?
|
### 多少才算满?
|
||||||
|
|
||||||
一种较好的方法来掌握内存究竟使用了多少是用 `free -m` 命令。`-m` 选项指定了数字的单位是 <ruby>MiBs<rt>mebibytes</rt></ruby> 而不是字节。
|
一种较好的方法来掌握内存究竟使用了多少是用 `free -m` 命令。`-m` 选项指定了数字的单位是 <ruby>MiB<rt>mebibyte</rt></ruby> 而不是字节。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ free -m
|
$ free -m
|
||||||
@ -76,7 +78,7 @@ Swap: 3535 0 3535
|
|||||||
|
|
||||||
### 什么时候要担心
|
### 什么时候要担心
|
||||||
|
|
||||||
如果 Linux 系统上的性能表现良好——应用程序响应度高,命令行没有显示出问题——很可能系统状况良好。记住,一些应用也许会出于某种原因而变慢,但它不影响整个系统。
|
如果 Linux 系统上的性能表现良好 —— 应用程序响应度高,命令行没有显示出问题 —— 很可能系统状况良好。记住,一些应用也许会出于某种原因而变慢,但它不影响整个系统。
|
||||||
|
|
||||||
过多的硬故障也许表明确实存在问题,但要将其与观察到的性能相比较。
|
过多的硬故障也许表明确实存在问题,但要将其与观察到的性能相比较。
|
||||||
|
|
||||||
@ -91,11 +93,10 @@ Swap: 3535 0 3535
|
|||||||
|
|
||||||
### Linux 性能很复杂
|
### Linux 性能很复杂
|
||||||
|
|
||||||
把所有的放在一边,Linux 系统上的内存可能会变满,并且性能可能会降低。当系统出现问题时不要仅将单一的内存使用报告作为指标。
|
抛开这些不说,Linux 系统上的内存可能会变满,并且性能可能会降低。当系统出现问题时不要仅将单一的内存使用报告作为指标。
|
||||||
|
|
||||||
Linux 系统的内存管理很复杂,因为它采取的措施需要确保系统资源得到最好的利用。不要受到一开始内存占满的欺骗,使你认为系统存在问题,但实际上并没有。
|
Linux 系统的内存管理很复杂,因为它采取的措施需要确保系统资源得到最好的利用。不要受到一开始内存占满的欺骗,使你认为系统存在问题,但实际上并没有。
|
||||||
|
|
||||||
在 [Facebook][4] 和 [LinkedIn][5] 上加入网络研讨会发表你的评论。
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -104,7 +105,7 @@ via: https://www.networkworld.com/article/3394603/when-to-be-concerned-about-mem
|
|||||||
作者:[Sandra Henry-Stocker][a]
|
作者:[Sandra Henry-Stocker][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[LuuMing](https://github.com/LuuMing)
|
译者:[LuuMing](https://github.com/LuuMing)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,196 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11145-1.html)
|
||||||
|
[#]: subject: (Best Linux Distributions for Beginners)
|
||||||
|
[#]: via: (https://itsfoss.com/best-linux-beginners/)
|
||||||
|
[#]: author: (Aquil Roshan https://itsfoss.com/author/aquil/)
|
||||||
|
|
||||||
|
最适合于初学者的 Linux 发行版
|
||||||
|
======
|
||||||
|
|
||||||
|
> 在本文中,我们将看到**最适合于初学者的 Linux 发行版**。这将有助于 Linux 新用户选择他们的第一个发行版。
|
||||||
|
|
||||||
|
让我们面对现实,[Linux][1] 可能会给新用户带来巨大的复杂性。但是,带来这种复杂性的并不是 Linux 本身。相反,是“新奇”因素导致了这种情况。并不是怀旧,但我记得第一次使用 Linux 时,我甚至不知道会发生什么。我喜欢它,但最初这对我来说像是逆流游泳一样。
|
||||||
|
|
||||||
|
不知道从何处着手可能是一个令人沮丧的原因,特别是对于那些在 PC 上运行 Windows 之外的其它系统没有概念的人来说。
|
||||||
|
|
||||||
|
Linux 不仅仅是一个操作系统,而是一个理念:在这里大家共同成长,也适合于每个人的不同需要。我们已经介绍过:
|
||||||
|
|
||||||
|
* [Windows 用户的最佳 Linux 发行版][2]
|
||||||
|
* [最佳轻量级 Linux 发行版][3]
|
||||||
|
* [黑客攻击的最佳 Linux 发行版][4]
|
||||||
|
* [最佳 Linux 游戏发行版][5]
|
||||||
|
* [隐私和匿名的最佳 Linux 发行版][6]
|
||||||
|
* [看起来像 MacOS 的最佳 Linux 发行版][7]
|
||||||
|
|
||||||
|
除此之外,还有一些能够特别满足新人需求的发行版。这里有一些这样的适合初学者的 Linux 发行版。你也可以在视频中观看并[订阅我们的 YouTube 频道][8]以获取更多与 Linux 相关的视频。
|
||||||
|
|
||||||
|
[视频](https://youtu.be/QC2B2-gCbbI)
|
||||||
|
|
||||||
|
### 最适合于初学者的 Linux 发行版
|
||||||
|
|
||||||
|
请记住,此列表没有特别的顺序。编制此列表的主要标准是易于安装、开箱即用的硬件和软件、易用性和软件包的可用性。
|
||||||
|
|
||||||
|
#### 1、Ubuntu
|
||||||
|
|
||||||
|
如果你在互联网上研究过 Linux,那么你很可能遇到过 Ubuntu。Ubuntu 是领先的 Linux 发行版之一,它也是开始 Linux 之旅的完美之选。
|
||||||
|
|
||||||
|
![][9]
|
||||||
|
|
||||||
|
Ubuntu 被视为人性化的 Linux,这是因为 Ubuntu 在通用可用性上付出了很多努力。Ubuntu 并不要求你在技术方面懂得很多才能使用它。它打破了 “Linux = 命令行麻烦”这一概念。这是 Ubuntu 飙升到今天的主要优势之一。
|
||||||
|
|
||||||
|
Ubuntu 提供了非常方便的安装程序。这个安装程序以简单的英语(或你想要的任何主要语言)描述安装过程。你甚至可以在实际执行安装过程之前尝试使用 Ubuntu。安装程序提供了简单的选项:
|
||||||
|
|
||||||
|
* 删除旧操作系统以安装 Ubuntu。
|
||||||
|
* 与 Windows 或任何其他现有操作系统[一起][10]安装 Ubuntu(每次启动时都会提供要启动的操作系统的选择列表)。
|
||||||
|
* 让高级用户自行配置分区。
|
||||||
|
|
||||||
|
*初学者提示:如果你不确定该怎么做,请选择第二个选项。*
|
||||||
|
|
||||||
|
Ubuntu 的用户界面采用 GNOME。它简单、高效。你可以通过按 Windows 键搜索从应用程序到文件的任何内容。有什么比这更简单的吗?
|
||||||
|
|
||||||
|
没有驱动程序安装问题,因为 Ubuntu 附带硬件检测器,可以检测、下载和安装适用于你的 PC 的最佳驱动程序。此外,安装会附带所有基本软件,如音乐播放器、视频播放器、办公套件和一些消磨时间的游戏。
|
||||||
|
|
||||||
|
Ubuntu 拥有出色的文档和社区支持。[Ubuntu 论坛][11]和 [Ask Ubuntu][12] 几乎在 Ubuntu 的所有方面都提供了可观的高质量支持。你的一些问题很有可能已经得到了回答,这些答案是适合初学者的。
|
||||||
|
|
||||||
|
请在[官方网站][13]查看并下载 [Ubuntu][13]。
|
||||||
|
|
||||||
|
#### 2、Linux Mint Cinnamon
|
||||||
|
|
||||||
|
多年来,Linux Mint 一直是 [Distrowatch][14] 上的**排名第一的** Linux 发行版。我必须说,这是当之无愧的宝座。Linux Mint 是我个人的最爱之一。它优雅、秀气,提供了卓越的计算体验(开箱即用)。
|
||||||
|
|
||||||
|
![][15]
|
||||||
|
|
||||||
|
Linux Mint 带有 Cinnamon 桌面环境。仍处于熟悉 Linux 软件阶段的 Linux 新用户会发现 Cinnamon 非常有用。所有软件都按类别分组,非常易于访问。虽然这不是一个令人兴奋的功能,但对于不了解 Linux 软件名称的新用户来说,这是一个巨大的好处。
|
||||||
|
|
||||||
|
Linux Mint 很快,在旧电脑上也运行良好。Linux Mint 建立在坚如磐石的 Ubuntu 基础之上。它使用与 Ubuntu 相同的软件存储库。而对于 Ubuntu 软件存储库,仅在广泛测试后 Ubuntu 才会将软件推送在其中。这意味着用户不必处理某些新软件容易出现的意外崩溃和故障,对于新的 Linux 用户来说这可能是一个真正不可接受的。
|
||||||
|
|
||||||
|
![][17]
|
||||||
|
|
||||||
|
Windows 7 爱好者如果没有真的升级到微软 Windows 10 的话,那将会发现 Linux Mint 的可爱。 Linux Mint 桌面非常类似于 Windows 7 桌面。类似的工具栏、类似的菜单、类似的托盘图标都绝对会使 Windows 用户感到十分熟悉。
|
||||||
|
|
||||||
|
就个人而言,我更倾向于向 Linux 世界的新人推荐 Linux Mint,因为 Linux Mint 确实给用户留下了足够的印象,会让他们接受它。对我来说,Linux Mint 应该是面向初学者的 Linux 列表中的首位。
|
||||||
|
|
||||||
|
请在这里查看 [Linux Mint][18],看看 Cinnamon 版。
|
||||||
|
|
||||||
|
#### 3、Zorin OS
|
||||||
|
|
||||||
|
大多数计算机用户是 Windows 用户。当 [Windows 用户拿到一个 Linux][2] 时,他必须经历相当多的“去知识过程”。大量的操作已经固定在我们的肌肉记忆当中。例如,每次要启动应用程序时,鼠标都会移动屏幕的左下角(“开始”菜单)。因此,如果我们能够在 Linux 上找到一些可以缓解这些问题的东西,那就成功了一半了。进入 Zorin OS。
|
||||||
|
|
||||||
|
![][19]
|
||||||
|
|
||||||
|
Zorin OS 是一款基于 Ubuntu 的高度打磨的 Linux 发行版,完全是为 Windows 难民制作的。尽管几乎每个 Linux 发行版都可供任何人使用,但是当桌面看起来太陌生时,有些人可能会不情愿使用。Zorin OS 避开了这个障碍,因为它与 Windows 外观明显相似。
|
||||||
|
|
||||||
|
对 Linux 新手来说,软件包管理器是一个新概念。这就是为什么 Zorin OS 带有一个巨大的(我的意思是真的很大)预安装软件列表。你需要的任何东西,很有可能都已经安装在 Zorin OS 上了。好像这还不够,[Wine 和 PlayOnLinux][20] 也预先安装好了,所以你也可以在这里运行你喜爱的 Windows 软件和[游戏][21]。
|
||||||
|
|
||||||
|
![][22]
|
||||||
|
|
||||||
|
Zorin OS 配备了一款名为 “Zorin look changer” 的惊人的主题引擎。它提供了一些重要的自定义选项和预设,可以使你的操作系统看起来像 Windows 7、XP、2000 甚至是 Mac,你会有宾至如归的感觉。
|
||||||
|
|
||||||
|
![][23]
|
||||||
|
|
||||||
|
正是这些功能使 Zorin OS 成为**适合初学者的最佳 Linux 发行版**。查看 [Zorin OS 网站][24]以了解更多信息和下载该操作系统。
|
||||||
|
|
||||||
|
#### 4、Elementary OS
|
||||||
|
|
||||||
|
我们已经看过了给 Windows 用户准备的 Linux 发行版,让我们为 MacOS 用户也提供一些东西。Elementary OS 成名非常迅速,现在总是被列入顶级发行列表之中,这一切都归功于其美学本质。其灵感来自于 MacOS,Elementary OS 是最美丽的 Linux 发行版之一。
|
||||||
|
|
||||||
|
![][25]
|
||||||
|
|
||||||
|
Elementary OS 是又一个基于 Ubuntu 的操作系统,这意味着操作系统本身无疑是稳定的。Elementary OS 带有 Pantheon 桌面环境。你马上就会注意到它与 MacOS 桌面的相似之处。这对于转换到 Linux 的 MacOS 用户来说是一个优势,因为他们会对桌面非常适应,这确实简化了应对此变化的过程。
|
||||||
|
|
||||||
|
![][26]
|
||||||
|
|
||||||
|
它的菜单简单,可根据用户喜好自定义。该操作系统是零侵入性的,因此你可以真正专注于工作。它附带了非常少量的预安装软件。因此,新用户都不会被庞杂的内容吓跑。但是,嘿,它具备开箱即用所需要的一切。如果需要更多软件,Elementary OS 提供了一个整洁的 AppCenter。它易于访问且简单易用,一切都在一个地方,你可以一键获得所需的所有软件和升级。
|
||||||
|
|
||||||
|
经验表明,[Elementary OS][28] 真的是一个很棒的软件。绝对值得[试一试][28]。
|
||||||
|
|
||||||
|
#### 5、Linux Mint Mate
|
||||||
|
|
||||||
|
许多来了解 Linux 的人都希望让旧电脑焕发新生。随着 Windows 10 的普及,几年前许多具有不错配置的计算机已经变得无力应对。在谷歌上快速搜索一下会建议你在这样的电脑上安装 Linux。通过这种方式,你可以让它们在之后一段时间仍旧能保持水准。如果你正在寻找可以运行在旧计算机上的操作系统,Linux Mint Mate 是一个很棒的 Linux 发行版。
|
||||||
|
|
||||||
|
![][29]
|
||||||
|
|
||||||
|
Linux Mint Mate 非常轻便,资源利用效率高,而仍然是一个漂亮的发行版。它可以在计算能力较弱的计算机上平稳运行。桌面环境没有各种花哨的东西。但它在功能上和任何其他桌面环境相比毫不逊色。这个操作系统是非侵入式的,允许你获得高效的计算体验而不会妨碍你。
|
||||||
|
|
||||||
|
同样,Linux Mint Mate 基于 Ubuntu,具有巨大而坚实的 Ubuntu 软件存储库的优势。它预装了最少数量的必需软件。提供了简便的驱动程序安装和设置管理。
|
||||||
|
|
||||||
|
即使你只有 512 MB 的内存和 9 GB 的硬盘空间(当然是越多越好),你也可以运行 Linux Mint Mate。
|
||||||
|
|
||||||
|
Mate 桌面环境非常简单易用,没有什么费解的地方。对于 Linux 初学者来说,这确实是一个巨大的优势,更有理由 [尝试 Linux Mint Mate][30]。
|
||||||
|
|
||||||
|
#### 6、Manjaro Linux
|
||||||
|
|
||||||
|
好吧。任何一个 Linux 的老用户都会说,即使只是在大方向上,引导新手接触 Arch Linux 都是一种罪过。但是听我说。
|
||||||
|
|
||||||
|
Arch 被认为是专家级 Linux,因为它的安装过程非常复杂。Manajro 和 Arch Linux 有着共同的起源,但它们在其他方面存在很大差异。
|
||||||
|
|
||||||
|
![][31]
|
||||||
|
|
||||||
|
Manajro Linux 具有非常适合初学者的安装程序。许多事情都是自动化的,比如使用“硬件检测”进行驱动程序安装。Manjaro 极大地解决了困扰许多其它 Linux 发行版的硬件驱动程序的麻烦。即使你遇到任何问题,Manjaro 也有很棒的社区支持。
|
||||||
|
|
||||||
|
Manjaro 拥有自己的软件存储库,其维护了最新的软件。虽然优先向用户提供最新软件,但它是以保证稳定性不会受到损害为前提的。这是 Arch 和 Manjaro 之间的主要区别之一。Manjaro 延迟软件包的发布以确保它们绝对稳定并且不会导致回退。你还可以访问 Manjaro 上的 Arch User Repository(AUR),因此你可以随时获得所需的一切。
|
||||||
|
|
||||||
|
如果你想了解更多有关 Manjaro 功能的信息,请阅读我的同事 [John 的 Manjaro Linux 经历以及为什么他会被它迷住][32]。
|
||||||
|
|
||||||
|
![][33]
|
||||||
|
|
||||||
|
Manjaro Linux 有 XFCE、KDE、Gnome、Cinnamon 以及更多桌面环境,请查看[官方网站][34]。
|
||||||
|
|
||||||
|
要安装上述 6 个操作系统中的任何一个,你需要创建一个可启动的 U 盘。如果你当前正在使用 Windows [请使用本指南][35]。Mac OS 用户可以[遵循本指南][36]。
|
||||||
|
|
||||||
|
### 你选择哪个最适合初学者的 Linux 发行版?
|
||||||
|
|
||||||
|
Linux 可能会有学习曲线,但这是一件不会让每个人都感到后悔的事情。进一步获得一个 ISO 文件并体验一下 Linux 吧。如果你已经是 Linux 用户,请分享这篇文章,并帮助人们在这个爱的季节爱上 Linux 吧。加油!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/best-linux-beginners/
|
||||||
|
|
||||||
|
作者:[Aquil Roshan][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/aquil/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.linux.com/what-is-linux
|
||||||
|
[2]: https://itsfoss.com/windows-like-linux-distributions/
|
||||||
|
[3]: https://itsfoss.com/lightweight-linux-beginners/
|
||||||
|
[4]: https://itsfoss.com/linux-hacking-penetration-testing/
|
||||||
|
[5]: https://itsfoss.com/linux-gaming-distributions/
|
||||||
|
[6]: https://itsfoss.com/privacy-focused-linux-distributions/
|
||||||
|
[7]: https://itsfoss.com/macos-like-linux-distros/
|
||||||
|
[8]: https://www.youtube.com/c/itsfoss
|
||||||
|
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/06/ubuntu-18-04-desktop.jpeg?resize=800%2C450&ssl=1
|
||||||
|
[10]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||||
|
[11]: https://ubuntuforums.org/
|
||||||
|
[12]: http://askubuntu.com/
|
||||||
|
[13]: https://www.ubuntu.com/
|
||||||
|
[14]: https://distrowatch.com/
|
||||||
|
[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/LM_Home.jpg?ssl=1
|
||||||
|
[16]: https://itsfoss.com/install-visual-studio-code-ubuntu/
|
||||||
|
[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/LM_SS.jpg?ssl=1
|
||||||
|
[18]: https://linuxmint.com/
|
||||||
|
[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/Zorin.jpg?ssl=1
|
||||||
|
[20]: https://itsfoss.com/use-windows-applications-linux/
|
||||||
|
[21]: https://itsfoss.com/linux-gaming-guide/
|
||||||
|
[22]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/Zorin-office.jpg?ssl=1
|
||||||
|
[23]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/OSX.jpg?ssl=1
|
||||||
|
[24]: https://zorinos.com/
|
||||||
|
[25]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/02/Pantheon-Desktop.jpg?resize=800%2C500&ssl=1
|
||||||
|
[26]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/Application-Menu.jpg?ssl=1
|
||||||
|
[27]: https://itsfoss.com/slack-use-linux/
|
||||||
|
[28]: https://elementary.io/
|
||||||
|
[29]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/mate.jpg?ssl=1
|
||||||
|
[30]: http://blog.linuxmint.com/?p=3182
|
||||||
|
[31]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/manajro.jpg?ssl=1
|
||||||
|
[32]: https://itsfoss.com/why-use-manjaro-linux/
|
||||||
|
[33]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/manjaro-kde.jpg?ssl=1
|
||||||
|
[34]: https://manjaro.org/
|
||||||
|
[35]: https://www.ubuntu.com/download/desktop/create-a-usb-stick-on-windows
|
||||||
|
[36]: https://www.ubuntu.com/download/desktop/create-a-usb-stick-on-macos
|
||||||
@ -0,0 +1,129 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11160-1.html)
|
||||||
|
[#]: subject: (Convert Markdown files to word processor docs using pandoc)
|
||||||
|
[#]: via: (https://opensource.com/article/19/5/convert-markdown-to-word-pandoc)
|
||||||
|
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt/users/jason-van-gumster/users/kikofernandez)
|
||||||
|
|
||||||
|
使用 pandoc 将 Markdown 转换为格式化文档
|
||||||
|
======
|
||||||
|
|
||||||
|
> 生活在普通文本世界么?以下是无需使用文字处理器而创建别人要的格式化文档的方法。
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
如果你生活在[普通文本][2]世界里,总会有人要求你提供格式化文档。我就经常遇到这个问题,特别是在 Day JobTM。虽然我已经给与我合作的开发团队之一介绍了用于撰写和审阅发行说明的 [Docs Like Code][3] 工作流程,但是还有少数人对 GitHub 和使用 [Markdown][4] 没有兴趣,他们更喜欢为特定的专有应用格式化的文档。
|
||||||
|
|
||||||
|
好消息是,你不会被卡在将未格式化的文本复制粘贴到文字处理器的问题当中。使用 [pandoc][5],你可以快速地给人们他们想要的东西。让我们看看如何使用 pandoc 将文档从 Markdown 转换为 Linux 中的文字处理器格式。
|
||||||
|
|
||||||
|
请注意,pandoc 也可用于从两种 BSD([NetBSD][7] 和 [FreeBSD][8])到 Chrome OS、MacOS 和 Windows 等的各种操作系统。
|
||||||
|
|
||||||
|
### 基本转换
|
||||||
|
|
||||||
|
首先,在你的计算机上[安装 pandoc][9]。然后,打开控制台终端窗口,并导航到包含要转换的文件的目录。
|
||||||
|
|
||||||
|
输入此命令以创建 ODT 文件(可以使用 [LibreOffice Writer][10] 或 [AbiWord][11] 等字处理器打开):
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -t odt filename.md -o filename.odt
|
||||||
|
```
|
||||||
|
|
||||||
|
记得用实际文件名称替换 `filename`。如果你需要为其他文字处理器(你知道我的意思)创建一个文件,替换命令行的 `odt` 为 `docx`。以下是本文转换为 ODT 文件时的内容:
|
||||||
|
|
||||||
|
![Basic conversion results with pandoc.][12]
|
||||||
|
|
||||||
|
这些转换结果虽然可用,但有点乏味。让我们看看如何为转换后的文档添加更多样式。
|
||||||
|
|
||||||
|
### 带样式转换
|
||||||
|
|
||||||
|
`pandoc` 有一个漂亮的功能,使你可以在将带标记的纯文本文件转换为字处理器格式时指定样式模板。在此文件中,你可以编辑文档中的少量样式,包括控制段落、文章标题和副标题、段落标题、说明、基本的表格和超链接的样式。
|
||||||
|
|
||||||
|
让我们来看看能做什么。
|
||||||
|
|
||||||
|
#### 创建模板
|
||||||
|
|
||||||
|
要设置文档样式,你不能只是使用任何一个模板就行。你需要生成 pandoc 称之为引用模板的文件,这是将文本文件转换为文字处理器文档时使用的模板。要创建此文件,请在终端窗口中键入以下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -o custom-reference.odt --print-default-data-file reference.odt
|
||||||
|
```
|
||||||
|
|
||||||
|
此命令创建一个名为 `custom-reference.odt` 的文件。如果你正在使用其他文字处理程序,请将命令行中的 “odt” 更改为 “docx”。
|
||||||
|
|
||||||
|
在 LibreOffice Writer 中打开模板文件,然后按 `F11` 打开 LibreOffice Writer 的 “样式” 窗格。虽然 [pandoc 手册][13]建议不要对该文件进行其他更改,但我会在必要时更改页面大小并添加页眉和页脚。
|
||||||
|
|
||||||
|
#### 使用模板
|
||||||
|
|
||||||
|
那么,你要如何使用刚刚创建的模板?有两种方法可以做到这一点。
|
||||||
|
|
||||||
|
最简单的方法是将模板放在家目录的 `.pandoc` 文件夹中,如果该文件夹不存在,则必须先创建该文件夹。当转换文档时,`pandoc` 会使用此模板文件。如果你需要多个模板,请参阅下一节了解如何从多个模板中进行选择。
|
||||||
|
|
||||||
|
使用模板的另一种方法是在命令行键入以下转换选项:
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -t odt file-name.md --reference-doc=path-to-your-file/reference.odt -o file-name.odt
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你想知道使用自定义模板转换后的文件是什么样的,这是一个示例:
|
||||||
|
|
||||||
|
![A document converted using a pandoc style template.][14]
|
||||||
|
|
||||||
|
#### 选择模板
|
||||||
|
|
||||||
|
很多人只需要一个 `pandoc` 模板,但是,有些人需要不止一个。
|
||||||
|
|
||||||
|
例如,在我的日常工作中,我使用了几个模板:一个带有 DRAFT 水印,一个带有表示内部使用的水印,另一个用于文档的最终版本。每种类型的文档都需要不同的模板。
|
||||||
|
|
||||||
|
如果你有类似的需求,可以像使用单个模板一样创建文件 `custom-reference.odt`,将生成的文件重命名为例如 `custom-reference-draft.odt` 这样的名字,然后在 LibreOffice Writer 中打开它并修改样式。对你需要的每个模板重复此过程。
|
||||||
|
|
||||||
|
接下来,将文件复制到家目录中。如果你愿意,你甚至可以将它们放在 `.pandoc` 文件夹中。
|
||||||
|
|
||||||
|
要在转换时选择特定模板,你需要在终端中运行此命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -t odt file-name.md --reference-doc=path-to-your-file/custom-template.odt -o file-name.odt
|
||||||
|
```
|
||||||
|
|
||||||
|
改变 `custom-template.odt` 为你的模板文件名。
|
||||||
|
|
||||||
|
### 结语
|
||||||
|
|
||||||
|
为了不用记住我不经常使用的一组选项,我拼凑了一些简单的、非常蹩脚的单行脚本,这些脚本封装了每个模板的选项。例如,我运行脚本 `todraft.sh` 以使用带有 DRAFT 水印的模板创建文字处理器文档。你可能也想要这样做。
|
||||||
|
|
||||||
|
以下是使用包含 DRAFT 水印的模板的脚本示例:
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -t odt $1.md -o $1.odt --reference-doc=~/Documents/pandoc-templates/custom-reference-draft.odt
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 pandoc 是一种不必放弃命令行生活而以人们要求的格式提供文档的好方法。此工具也不仅适用于 Markdown。我在本文中讨论的内容还可以让你在各种标记语言之间创建和转换文档。有关更多详细信息,请参阅前面链接的 [pandoc 官网][5]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/5/convert-markdown-to-word-pandoc
|
||||||
|
|
||||||
|
作者:[Scott Nesbitt][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/scottnesbitt/users/jason-van-gumster/users/kikofernandez
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb
|
||||||
|
[2]: https://plaintextproject.online/
|
||||||
|
[3]: https://www.docslikecode.com/
|
||||||
|
[4]: https://en.wikipedia.org/wiki/Markdown
|
||||||
|
[5]: https://pandoc.org/
|
||||||
|
[6]: /resources/linux
|
||||||
|
[7]: https://www.netbsd.org/
|
||||||
|
[8]: https://www.freebsd.org/
|
||||||
|
[9]: https://pandoc.org/installing.html
|
||||||
|
[10]: https://www.libreoffice.org/discover/writer/
|
||||||
|
[11]: https://www.abisource.com/
|
||||||
|
[12]: https://opensource.com/sites/default/files/uploads/pandoc-wp-basic-conversion_600_0.png (Basic conversion results with pandoc.)
|
||||||
|
[13]: https://pandoc.org/MANUAL.html
|
||||||
|
[14]: https://opensource.com/sites/default/files/uploads/pandoc-wp-conversion-with-tpl_600.png (A document converted using a pandoc style template.)
|
||||||
@ -0,0 +1,202 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (runningwater)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11086-1.html)
|
||||||
|
[#]: subject: (How to set up virtual environments for Python on MacOS)
|
||||||
|
[#]: via: (https://opensource.com/article/19/6/virtual-environments-python-macos)
|
||||||
|
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg/users/moshez/users/mbbroberg/users/moshez)
|
||||||
|
|
||||||
|
MacOS 系统中如何设置 Python 虚拟环境
|
||||||
|
======
|
||||||
|
|
||||||
|
> 使用 pyenv 和 virtualwrapper 来管理你的虚拟环境,可以避免很多困惑。
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
作为 Python 开发者和 MacOS 用户,拿到新机器首先要做的就是设置 Python 开发环境。下面是最佳实践(虽然我们已经写过 [在 MacOS 上管理 Python 的其它方法][2])。
|
||||||
|
|
||||||
|
### 预备
|
||||||
|
|
||||||
|
首先,打开终端,在其冰冷毫无提示的窗口输入 `xcode-select --install` 命令。点击确认后,基本的开发环境就会被配置上。MacOS 上需要此步骤来设置本地开发实用工具库,根据 [OS X Daily][3] 的说法,其包括 ”许多常用的工具、实用程序和编译器,如 make、GCC、clang、perl、svn、git、size、strip、strings、libtool、cpp、what 及许多在 Linux 中系统默认安装的有用命令“。
|
||||||
|
|
||||||
|
接下来,安装 [Homebrew][4], 执行如下的 Ruby 脚本。
|
||||||
|
|
||||||
|
```
|
||||||
|
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你像我一样,对随意就运行的来源于互联网的脚本心存疑虑的话,可以点击上面的脚本去仔细看看其具体功能。
|
||||||
|
|
||||||
|
一旦安装完成后,就恭喜了,你拥有了一个优秀的包管理工具。自然的,你可能接下来会执行 `brew install python` 或其他的命令。不要这样,哈哈!Homebrew 是为我们提供了一个 Python 的管理版本,但让此工具来管理我们的 Python 环境话,很快会失控的。我们需要 [pyenv][5],一款简单的 Python 版本管理工具,它可以安装运行在 [许多操作系统][6] 上。运行如下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ brew install pyenv
|
||||||
|
```
|
||||||
|
|
||||||
|
想要每次打开命令提示框时 `pyenv` 都会运行的话,需要把下面的内容加入你的配置文件中(MacOS 中默认为 `.bash_profile`,位于家目录下):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd ~/
|
||||||
|
$ echo 'eval "$(pyenv init -)"' >> .bash_profile
|
||||||
|
```
|
||||||
|
|
||||||
|
添加此行内容后,每个终端都会启动 `pyenv` 来管理其 `PATH` 环境变量,并插入你想要运行的 Python 版本(而不是在环境变量里面设置的初始版本。更详细的信息,请阅读 “[如何给 Linux 系统设置 PATH 变量][7]”)。打开新的终端以使修改的 `.bash_profile` 文件生效。
|
||||||
|
|
||||||
|
在安装你中意的 Python 版本前,需要先安装一些有用的工具,如下示:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ brew install zlib sqlite
|
||||||
|
```
|
||||||
|
|
||||||
|
`pyenv` 依赖于 [zlib][8] 压缩算法和 [SQLite][9] 数据库,如果未正确配置,往往会[导致构建问题][10]。将这些导出配置命令加入当前的终端窗口执行,确保它们安装完成。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ export LDFLAGS="-L/usr/local/opt/zlib/lib -L/usr/local/opt/sqlite/lib"
|
||||||
|
$ export CPPFLAGS="-I/usr/local/opt/zlib/include -I/usr/local/opt/sqlite/include"
|
||||||
|
```
|
||||||
|
|
||||||
|
现在准备工作已经完成,是时候安装一个适合于现代人的 Python 版本了:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pyenv install 3.7.3
|
||||||
|
```
|
||||||
|
|
||||||
|
去喝杯咖啡吧,挑些豆类,亲自烧烤,然后品尝。说这些的意思是上面的安装过程需要一段时间。
|
||||||
|
|
||||||
|
### 添加虚拟环境
|
||||||
|
|
||||||
|
一旦完成,就可以愉快地使用虚拟环境了。如没有接下来的步骤的话,你只能在你所有的工作项目中共享同一个 Python 开发环境。使用虚拟环境来隔离每个项目的依赖关系的管理方式,比起 Python 自身提供的开箱即用功能来说,更加清晰明确和更具有重用性。基于这些原因,把 `virtualenvwrapper` 安装到 Python 环境中吧:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pyenv global 3.7.3
|
||||||
|
# Be sure to keep the $() syntax in this command so it can evaluate
|
||||||
|
$ $(pyenv which python3) -m pip install virtualenvwrapper
|
||||||
|
```
|
||||||
|
|
||||||
|
再次打开 `.bash_profile` 文件,把下面内容添加进去,使得每次打开新终端时它都有效:
|
||||||
|
|
||||||
|
```
|
||||||
|
# We want to regularly go to our virtual environment directory
|
||||||
|
$ echo 'export WORKON_HOME=~/.virtualenvs' >> .bash_profile
|
||||||
|
# If in a given virtual environment, make a virtual environment directory
|
||||||
|
# If one does not already exist
|
||||||
|
$ echo 'mkdir -p $WORKON_HOME' >> .bash_profile
|
||||||
|
# Activate the new virtual environment by calling this script
|
||||||
|
# Note that $USER will substitute for your current user
|
||||||
|
$ echo '. ~/.pyenv/versions/3.7.3/bin/virtualenvwrapper.sh' >> .bash_profile
|
||||||
|
```
|
||||||
|
|
||||||
|
关掉终端再重新打开(或者运行 `exec /bin/bash -l` 来刷新当前的终端会话),你会看到 `virtualenvwrapper` 正在初始化环境配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ exec /bin/bash -l
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/premkproject
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/postmkproject
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/initialize
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/premkvirtualenv
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/postmkvirtualenv
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/prermvirtualenv
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/postrmvirtualenv
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/predeactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/postdeactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/preactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/postactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/get_env_details
|
||||||
|
```
|
||||||
|
|
||||||
|
从此刻开始,你的所有工作都是在虚拟环境中的,其允许你使用临时环境来安全地开发。使用此工具链,你可以根据工作所需,设置多个项目并在它们之间切换:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ mkvirtualenv test1
|
||||||
|
Using base prefix '/Users/moshe/.pyenv/versions/3.7.3'
|
||||||
|
New python executable in /Users/moshe/.virtualenvs/test1/bin/python3
|
||||||
|
Also creating executable in /Users/moshe/.virtualenvs/test1/bin/python
|
||||||
|
Installing setuptools, pip, wheel...
|
||||||
|
done.
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/test1/bin/predeactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/test1/bin/postdeactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/test1/bin/preactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/test1/bin/postactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/test1/bin/get_env_details
|
||||||
|
(test1)$ mkvirtualenv test2
|
||||||
|
Using base prefix '/Users/moshe/.pyenv/versions/3.7.3'
|
||||||
|
New python executable in /Users/moshe/.virtualenvs/test2/bin/python3
|
||||||
|
Also creating executable in /Users/moshe/.virtualenvs/test2/bin/python
|
||||||
|
Installing setuptools, pip, wheel...
|
||||||
|
done.
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/test2/bin/predeactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/test2/bin/postdeactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/test2/bin/preactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/test2/bin/postactivate
|
||||||
|
virtualenvwrapper.user_scripts creating /Users/moshe/.virtualenvs/test2/bin/get_env_details
|
||||||
|
(test2)$ ls $WORKON_HOME
|
||||||
|
get_env_details postmkvirtualenv premkvirtualenv
|
||||||
|
initialize postrmvirtualenv prermvirtualenv
|
||||||
|
postactivate preactivate test1
|
||||||
|
postdeactivate predeactivate test2
|
||||||
|
postmkproject premkproject
|
||||||
|
(test2)$ workon test1
|
||||||
|
(test1)$
|
||||||
|
```
|
||||||
|
|
||||||
|
此处,使用 `deactivate` 命令可以退出当前环境。
|
||||||
|
|
||||||
|
### 推荐实践
|
||||||
|
|
||||||
|
你可能已经在比如 `~/src` 这样的目录中添加了长期的项目。当要开始了一个新项目时,进入此目录,为此项目增加子文件夹,然后使用强大的 Bash 解释程序自动根据你的目录名来命令虚拟环境。例如,名称为 “pyfun” 的项目:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ mkdir -p ~/src/pyfun && cd ~/src/pyfun
|
||||||
|
$ mkvirtualenv $(basename $(pwd))
|
||||||
|
# we will see the environment initialize
|
||||||
|
(pyfun)$ workon
|
||||||
|
pyfun
|
||||||
|
test1
|
||||||
|
test2
|
||||||
|
(pyfun)$ deactivate
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
当需要处理此项目时,只要进入该目录,输入如下命令重新连接虚拟环境:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd ~/src/pyfun
|
||||||
|
(pyfun)$ workon .
|
||||||
|
```
|
||||||
|
|
||||||
|
初始化虚拟环境意味着对 Python 版本和所加载的模块的时间点的拷贝。由于依赖关系会发生很大的改变,所以偶尔需要刷新项目的虚拟环境。这种情况,你可以通过删除虚拟环境来安全的执行此操作,源代码是不受影响的,如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd ~/src/pyfun
|
||||||
|
$ rmvirtualenv $(basename $(pwd))
|
||||||
|
$ mkvirtualenv $(basename $(pwd))
|
||||||
|
```
|
||||||
|
|
||||||
|
这种使用 `pyenv` 和 `virtualwrapper` 管理虚拟环境的方法可以避免开发环境和运行环境中 Python 版本的不一致出现的苦恼。这是避免混淆的最简单方法 - 尤其是你工作的团队很大的时候。
|
||||||
|
|
||||||
|
如果你是初学者,正准备配置 Python 环境,可以阅读下 [MacOS 中使用 Python 3][2] 文章。 你们有关于 Python 相关的问题吗,不管是初学者的还是中级使用者的?给我们留下评论信息,我们在下篇文章中会考虑讲解。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/6/virtual-environments-python-macos
|
||||||
|
|
||||||
|
作者:[Matthew Broberg][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[runningwater](https://github.com/runningwater)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/mbbroberg/users/moshez/users/mbbroberg/users/moshez
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python_snake_file_box.jpg?itok=UuDVFLX-
|
||||||
|
[2]: https://opensource.com/article/19/5/python-3-default-macos
|
||||||
|
[3]: http://osxdaily.com/2014/02/12/install-command-line-tools-mac-os-x/
|
||||||
|
[4]: https://brew.sh/
|
||||||
|
[5]: https://github.com/pyenv/pyenv
|
||||||
|
[6]: https://github.com/pyenv/pyenv/wiki
|
||||||
|
[7]: https://opensource.com/article/17/6/set-path-linux
|
||||||
|
[8]: https://zlib.net/
|
||||||
|
[9]: https://www.sqlite.org/index.html
|
||||||
|
[10]: https://github.com/pyenv/pyenv/wiki/common-build-problems#build-failed-error-the-python-zlib-extension-was-not-compiled-missing-the-zlib
|
||||||
@ -0,0 +1,97 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (GraveAccent)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11098-1.html)
|
||||||
|
[#]: subject: (5G will augment Wi-Fi, not replace it)
|
||||||
|
[#]: via: (https://www.networkworld.com/article/3399978/5g-will-augment-wi-fi-not-replace-it.html)
|
||||||
|
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||||
|
|
||||||
|
|
||||||
|
5G 会增强 Wi-Fi,而不是取代它
|
||||||
|
======
|
||||||
|
> Aruba 战略和企业发展副总裁 Jeff Lipton 为 5G 炒作增添了一些干货,讨论了它和 Wi-Fi 如何协同工作以及如何最大化两者的价值。
|
||||||
|
|
||||||
|
![Thinkstock][1]
|
||||||
|
|
||||||
|
如今可以说没有技术主题比 [5G][2] 更热。这是最近 [移动世界大会][3] 节目的一个主题,并且已经在其他活动中占据了主导地位,例如 Enterprise Connect 和我参加的几乎所有供应商活动。
|
||||||
|
|
||||||
|
一些供应商将 5G 定位为解决所有网络问题的灵丹妙药,并预测它将消除所有其他形式的网络。像这样的观点显然是极端的,但我相信 5G 会对网络行业产生影响,网络工程师应该意识到这一点。
|
||||||
|
|
||||||
|
为了帮助为 5G 炒作带来一些现实感,我最近采访了一家惠普公司旗下的 Aruba 公司的战略和企业发展副总裁 Jeff Lipton,因为我知道惠普已经深入参与了 5G 和 Wi-Fi 的发展。
|
||||||
|
|
||||||
|
![Jeff Lipton, VP of strategy and corporate development, Aruba][4]
|
||||||
|
|
||||||
|
### Zeus Kerravala: 5G 被吹捧为“明日之星”。你是这样看的吗?
|
||||||
|
|
||||||
|
**Jeff Lipton:** 接下来的重点是连接“事物”并从这些事物中产生可操作的见解和背景。5G 是服务于这一趋势的技术之一。Wi-Fi 6 是另一个,还有边缘计算、蓝牙低功耗(BLE)、人工智能(AI)和机器学习(ML)。这一切都很重要,全都有自己的用武之地。
|
||||||
|
|
||||||
|
### 你是否在企业中看到 5G 的风头盖过 Wi-Fi?
|
||||||
|
|
||||||
|
**Lipton:** 与所有蜂窝接入一样,如果你需要<ruby>宏观区域覆盖<rt>macro area coverage</rt></ruby>和高速切换,使用 5G 是合适的。但对于大多数企业级应用程序而言,它通常不需要这些功能。从性能角度来看,[Wi-Fi 6][5] 和 5G 在大多数指标上大致相等,包括吞吐量、延迟、可靠性和连接密度。它们并不相似的地方在经济方面,Wi-Fi 要好得多。我不认为很多客户愿意用 Wi-Fi 交换 5G,除非他们需要宏观覆盖或高速切换。
|
||||||
|
|
||||||
|
### Wi-Fi 和 5G 可以共存吗? 企业如何一起使用 5G 和 Wi-Fi?
|
||||||
|
|
||||||
|
**Lipton:** Wi-Fi 和 5G 可以共存并且应该是互补的。5G 架构将蜂窝核心和无线接入网络(RAN)分离。因此,Wi-Fi 可以是企业无线电前端,并与 5G 核心紧密连接。由于 Wi-Fi(特别是 Wi-Fi 6)的经济有利,并且性能非常好,我们设想许多服务提供商会使用 Wi-Fi 作为其 5G 系统的无线电前端,充当其分布式天线(DAS)和小型蜂窝系统的替代方案。
|
||||||
|
|
||||||
|
> “Wi-Fi 和 5G 可以并且应该是互补的。” — Jeff Lipton
|
||||||
|
|
||||||
|
### 如果一个企业打算完全转向 5G,那将如何实现以及它的实用性如何?
|
||||||
|
|
||||||
|
**Lipton:** 为了将 5G 用于主要的室内访问方式,客户需要升级其网络和几乎所有设备。5G 在室外提供良好的覆盖,但蜂窝信号不能可靠地穿透建筑物,5G 会使这个问题变得更糟,因为它部分依赖于更高频率的无线电。因此,服务提供商需要一种提供室内覆盖的方法。为了提供这种覆盖,他们会部署 DAS 或小型蜂窝系统 —— 由终端客户支付费用。然后,客户将他们的设备直连到这些蜂窝系统,并为每个设备支付服务合同。
|
||||||
|
|
||||||
|
这种方法存在一些问题。首先,DAS 和小型蜂窝系统比 Wi-Fi 网络贵得多。并且成本不会仅限于网络。每台设备都需要一台 5G 蜂窝调制解调器,批量价格高达数十美元,而终端用户通常需要花费一百多美元。由于目前很少或者没有 MacBook、PC、打印机、AppleTV 有 5G 调制解调器,因此需要对这些设备进行升级。我不相信很多企业会愿意支付这笔额外费用并升级他们的大部分设备以获得尚不明确的好处。
|
||||||
|
|
||||||
|
### 经济性是 5G 与 Wi-Fi 之争的一个要素吗?
|
||||||
|
|
||||||
|
**Lipton:** 经济性始终是一个要素。让我们将对话集中在室内企业级应用程序上,因为这是一些运营商打算用 5G 定位的用例。我们已经提到升级到 5G 将要求企业部署昂贵的 DAS 或小型蜂窝系统用于室内覆盖,几乎将所有设备升级到包含 5G 调制解调器,并为每个设备支付服务合同。理解 5G 蜂窝网络和 DAS 系统在许可频谱上运行也很重要,这类似于一条私人高速公路。服务提供商为此频谱支付了数十亿美元,这笔费用需要货币化并嵌入服务成本中。因此,从部署和生命周期的角度来看,Wi-Fi 在经济上比 5G 有利。
|
||||||
|
|
||||||
|
### 5G 与 Wi-Fi 相比有任何安全隐患吗?
|
||||||
|
|
||||||
|
**Lipton:** 一些人认为蜂窝技术比 Wi-Fi 更安全,但事实并非如此。LTE 相对安全,但也有弱点。例如,普渡大学和爱荷华大学的研究人员表示,LTE 容易受到一系列攻击,包括数据拦截和设备跟踪。5G 通过多种认证方法和更好的密钥管理改进了 LTE 安全性。
|
||||||
|
|
||||||
|
Wi-Fi 的安全性也没有停滞不前而是在继续发展。当然,不遵循最佳实践的 Wi-Fi 实现,例如那些甚至没有基本密码保护的实现,并不是最佳的。但那些配置了适当的访问控制和密码的则是非常安全的。随着新标准 —— 特别是 WPA3 和<ruby>增强开放<rt>Enhanced Open</rt></ruby> —— Wi-Fi 网络安全性进一步提高。
|
||||||
|
|
||||||
|
同样重要的是要记住,企业已根据其特定需求对安全性和合规性解决方案进行了大量投资。对于包括 5G 在内的蜂窝网络,企业将失去部署所选安全性和合规性解决方案的能力,以及对流量流的大多数可见性。虽然 5G 的未来版本将通过称为网络切片的功能提供高级别的自定义,但企业仍将失去他们目前需要的和拥有的安全性和合规性定制级别。
|
||||||
|
|
||||||
|
### 关于 5G 与 Wi-Fi 之间的讨论的补充想法
|
||||||
|
|
||||||
|
**Lipton:** 围绕 Wi-Fi 与 5G 的争论忽略了这一点。它们都有自己的用武之地,而且它们在很多方面都是互补的。由于需要连接和分析越来越多的东西,Wi-Fi 和 5G 市场都将增长。如果客户需要宏观覆盖或高速切换,并且可以为这些功能支付额外成本,那么 5G 是可行的。
|
||||||
|
|
||||||
|
5G 也适用于客户需要物理网络分段的某些工业用例。但对于绝大多数企业客户而言,Wi-Fi 将继续像现在一样证明自己作为可靠、安全且经济高效的无线接入技术的价值。
|
||||||
|
|
||||||
|
**更多关于 802.11ax (Wi-Fi 6):**
|
||||||
|
|
||||||
|
* [为什么 802.11ax 是无线网络的下一件大事][7]
|
||||||
|
* [FAQ:802.11ax Wi-Fi][8]
|
||||||
|
* [Wi-Fi 6 (802.11ax) 正在来到你附近的路由器][9]
|
||||||
|
* [带有 OFDMA 的 Wi-Fi 6 打开了一个全新的无线可能性世界][10]
|
||||||
|
* [802.11ax 预览:支持 Wi-Fi 6 的接入点和路由器随时可用][11]
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.networkworld.com/article/3399978/5g-will-augment-wi-fi-not-replace-it.html
|
||||||
|
|
||||||
|
作者:[Zeus Kerravala][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[GraveAccent](https://github.com/graveaccent)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://images.idgesg.net/images/article/2019/05/wireless_connection_speed_connectivity_bars_cell_tower_5g_by_thinkstock-100796921-large.jpg
|
||||||
|
[2]: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html
|
||||||
|
[3]: https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html
|
||||||
|
[4]: https://images.idgesg.net/images/article/2019/06/headshot_jlipton_aruba-100798360-small.jpg
|
||||||
|
[5]: https://www.networkworld.com/article/3215907/why-80211ax-is-the-next-big-thing-in-wi-fi.html
|
||||||
|
[6]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
|
||||||
|
[7]: https://www.networkworld.com/article/3215907/mobile-wireless/why-80211ax-is-the-next-big-thing-in-wi-fi.html
|
||||||
|
[8]: https://%20https//www.networkworld.com/article/3048196/mobile-wireless/faq-802-11ax-wi-fi.html
|
||||||
|
[9]: https://www.networkworld.com/article/3311921/mobile-wireless/wi-fi-6-is-coming-to-a-router-near-you.html
|
||||||
|
[10]: https://www.networkworld.com/article/3332018/wi-fi/wi-fi-6-with-ofdma-opens-a-world-of-new-wireless-possibilities.html
|
||||||
|
[11]: https://www.networkworld.com/article/3309439/mobile-wireless/80211ax-preview-access-points-and-routers-that-support-the-wi-fi-6-protocol-on-tap.html
|
||||||
|
[12]: https://www.facebook.com/NetworkWorld/
|
||||||
|
[13]: https://www.linkedin.com/company/network-world
|
||||||
@ -1,8 +1,8 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (qfzy1233)
|
[#]: translator: (qfzy1233)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11058-1.html)
|
||||||
[#]: subject: (Zorin OS Becomes Even More Awesome With Zorin 15 Release)
|
[#]: subject: (Zorin OS Becomes Even More Awesome With Zorin 15 Release)
|
||||||
[#]: via: (https://itsfoss.com/zorin-os-15-release/)
|
[#]: via: (https://itsfoss.com/zorin-os-15-release/)
|
||||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||||
@ -10,24 +10,25 @@
|
|||||||
随着 Zorin 15 的发布,Zorin OS 变得更为强大
|
随着 Zorin 15 的发布,Zorin OS 变得更为强大
|
||||||
======
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
长久以来 Zorin OS 一直在 [初学者适用的Linux发行版排行][1] 中占有一席之地。的确,它可能不是最受欢迎的,但是对于从 Windows 阵营转向 Linux 的用户而言,它一定是最好的一个发行版。
|
长久以来 Zorin OS 一直在 [初学者适用的Linux发行版排行][1] 中占有一席之地。的确,它可能不是最受欢迎的,但是对于从 Windows 阵营转向 Linux 的用户而言,它一定是最好的一个发行版。
|
||||||
|
|
||||||
我还记得,在几年前,我的一位朋友一直坚持让我安装[Zorin OS][2]。就我个人而言,当时我并不喜欢它的 UI 风格。但是,现如今 Zorin OS 15 发布了,这也让我有了更多的理由安装并将它作为我日常的操作系统。
|
我还记得,在几年前,我的一位朋友一直坚持让我安装 [Zorin OS][2]。就我个人而言,当时我并不喜欢它的 UI 风格。但是,现如今 Zorin OS 15 发布了,这也让我有了更多的理由安装并将它作为我日常的操作系统。
|
||||||
|
|
||||||
不要担心,在这篇文章里,我会向你介绍你所需要了解的一切。
|
不要担心,在这篇文章里,我会向你介绍你所需要了解的一切。
|
||||||
|
|
||||||
|
|
||||||
### Zorin 15 中的新特性
|
### Zorin 15 中的新特性
|
||||||
|
|
||||||
让我们来看一下最新版本的 Zorin 有哪些主要的改变。Zorin 15 以 Ubuntu 18.04.2 为底层,因此带来了许多性能上的提升。除此之外,也有许多的 UI (用户界面)得到了改进。
|
让我们来看一下最新版本的 Zorin 有哪些主要的改变。Zorin 15 是基于 Ubuntu 18.04.2 的,因此带来了许多性能上的提升。除此之外,也有许多 UI(用户界面)的改进。
|
||||||
|
|
||||||
#### Zorin Connect
|
#### Zorin Connect
|
||||||
|
|
||||||
![Zorin Connect][3]
|
![Zorin Connect][3]
|
||||||
|
|
||||||
Zorin OS 15 最主要的一个亮点就是 - Zorin Connect。如果你使用的是安卓设备,那你一定会喜欢这一功能。类似于[PushBullet][4](LCTT译注:PushBullet-子弹推送,一款跨平台推送工具),[Zorin Connect][5]会提升你的手机和桌面一体化的体验。
|
Zorin OS 15 最主要的一个亮点就是 —— Zorin Connect。如果你使用的是安卓设备,那你一定会喜欢这一功能。类似于 [PushBullet][4](LCTT 译注:PushBullet,子弹推送,一款跨平台推送工具), [Zorin Connect][5] 会提升你的手机和桌面一体化的体验。
|
||||||
|
|
||||||
你可以在桌面上同步智能手机的通知,同时还可以回复它。最要命的是,你甚至可以回复短信并查看这部分对话。
|
你可以在桌面上同步智能手机的通知,同时还可以回复它。甚至,你可以回复短信并查看对话。
|
||||||
|
|
||||||
总的来说,你可以体验到以下功能:
|
总的来说,你可以体验到以下功能:
|
||||||
|
|
||||||
@ -35,29 +36,23 @@ Zorin OS 15 最主要的一个亮点就是 - Zorin Connect。如果你使用的
|
|||||||
* 将你的手机作为电脑的遥控器
|
* 将你的手机作为电脑的遥控器
|
||||||
* 使用手机控制电脑上媒体的播放,并且当有来电接入时自动停止播放
|
* 使用手机控制电脑上媒体的播放,并且当有来电接入时自动停止播放
|
||||||
|
|
||||||
|
正如他们在[官方公告][6]中提到的, 数据的传输仅限于本地网络之间,并且不会有数据被上传到云端服务器。通过以下操作体验 Zorin Connect ,找到:Zorin menu (Zorin 菜单) > System Tools (系统工具) > Zorin Connect。
|
||||||
|
|
||||||
|
#### 新的桌面主题(包含夜间模式!)
|
||||||
正如他们在[官方公告][6]中提到的, 数据的传输仅限于本地网络之间,并且不会有数据被上传到云端服务器。通过以下操作体验 Zorin Connect ,找到 – Zorin menu (Zorin 菜单) > System Tools (系统工具) > Zorin Connect。
|
|
||||||
|
|
||||||
[][5]
|
|
||||||
|
|
||||||
#### 新的桌面主题(包含夜间模式!)
|
|
||||||
|
|
||||||
![Zorin 夜间模式][7]
|
![Zorin 夜间模式][7]
|
||||||
|
|
||||||
一提到 “夜间模式” 我就毫无抵抗力。对我而言,这是Zorin OS 15 自带的最好的功能。
|
一提到 “夜间模式” 我就毫无抵抗力。对我而言,这是Zorin OS 15 自带的最好的功能。
|
||||||
|
|
||||||
[][8]
|
当我启用了界面的深色模式时,我的眼睛感到如此舒适,你不想来试试么?
|
||||||
|
|
||||||
当我在任意界面深色模式时,我的眼睛都舒适,你不想来试试么?
|
它不单单是一个深色的主题,而是 UI 更干净直观,并且带有恰到好处的新动画。你可以从 Zorin 内置的外观应用程序里找到所有的相关设置。
|
||||||
|
|
||||||
它不单单是一个深色的主题,而是 UI 更干净直观,并且带有恰到好处的新动画。你可以从Zorin 内置的外观应用程序里找到所有的相关内建的所有设置。
|
|
||||||
|
|
||||||
#### 自适应背景调整 & 深色浅色模式
|
#### 自适应背景调整 & 深色浅色模式
|
||||||
|
|
||||||
你可以选择让桌面背景根据一天中每小时的环境亮度进行自动调整。此外,如果你想避免蓝光给眼睛带来伤害,你可以使用夜间模式。
|
你可以选择让桌面背景根据一天中每小时的环境亮度进行自动调整。此外,如果你想避免蓝光给眼睛带来伤害,你可以使用夜间模式。
|
||||||
|
|
||||||
#### To do app
|
#### 代办事项应用
|
||||||
|
|
||||||
![Todo][9]
|
![Todo][9]
|
||||||
|
|
||||||
@ -65,25 +60,25 @@ Zorin OS 15 最主要的一个亮点就是 - Zorin Connect。如果你使用的
|
|||||||
|
|
||||||
#### 还有更多么?
|
#### 还有更多么?
|
||||||
|
|
||||||
是的!其他主要的变化包括对 Flatpak 的支持,支持平板笔记本二合一电脑的触摸布局,DND 模式,以及一些重新设计的应用程序(设置,Libre Office),以此来给你更好的用户体验。
|
是的!其他主要的变化包括对 Flatpak 的支持,支持平板笔记本二合一电脑的触摸布局,DND 模式,以及一些重新设计的应用程序(设置、Libre Office),以此来给你更好的用户体验。
|
||||||
|
|
||||||
如果你想要了解所有更新和改动的详细信息,你可以查看[官方公告][6]。如果你已经是Zorin的用户,你应该已经注意到他们他们的网站已经启用了一个全新的外观。
|
如果你想要了解所有更新和改动的详细信息,你可以查看[官方公告][6]。如果你已经是 Zorin 的用户,你应该已经注意到他们的网站也已经启用了一个全新的外观。
|
||||||
|
|
||||||
### 下载 Zorin OS 15
|
### 下载 Zorin OS 15
|
||||||
|
|
||||||
**注释** : _今年的晚些时候将会推出从 Zorin OS 12 直升 15 版本而不需要重新安装的升级包。_
|
**注释** : 今年的晚些时候将会推出从 Zorin OS 12 直升 15 版本而不需要重新安装的升级包。
|
||||||
|
|
||||||
为了防止您不够了解,Zorin OS有三个版本—旗舰版本、核心板和轻量版。
|
提示一下,Zorin OS 有三个版本:旗舰版本、核心板和轻量版。
|
||||||
|
|
||||||
如果你想支持开发者和项目,同时解锁 Zorin OS 全部的功能,你可以花39美元购买旗舰版本。
|
如果你想支持开发者和项目,同时解锁 Zorin OS 全部的功能,你可以花 39 美元购买旗舰版本。
|
||||||
|
|
||||||
如果你只是想要一些基本功能,核心版就可以了(你可以免费下载)。如果是情况下,比如如果你有一台旧电脑,那么你可以使用轻量版。
|
如果你只是想要一些基本功能,核心版就可以了(你可以免费下载)。如果是这种情况,比如你有一台旧电脑,那么你可以使用轻量版。
|
||||||
|
|
||||||
[下载 ZORIN OS 15][10]
|
- [下载 ZORIN OS 15][10]
|
||||||
|
|
||||||
**你觉得 Zorin 15 怎么样?**
|
你觉得 Zorin 15 怎么样?
|
||||||
|
|
||||||
我肯定会尝试一下,将 Zorin OS 作为我的主要操作系统-(手动狗头)。你呢?你觉得最新的版本怎么样?欢迎在下面的评论中告诉我们。
|
我肯定会尝试一下,将 Zorin OS 作为我的主要操作系统 -(手动狗头)。你呢?你觉得最新的版本怎么样?欢迎在下面的评论中告诉我们。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -91,8 +86,8 @@ via: https://itsfoss.com/zorin-os-15-release/
|
|||||||
|
|
||||||
作者:[Ankush Das][a]
|
作者:[Ankush Das][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -100,12 +95,12 @@ via: https://itsfoss.com/zorin-os-15-release/
|
|||||||
[b]: https://github.com/lujun9972
|
[b]: https://github.com/lujun9972
|
||||||
[1]: https://itsfoss.com/best-linux-beginners/
|
[1]: https://itsfoss.com/best-linux-beginners/
|
||||||
[2]: https://zorinos.com/
|
[2]: https://zorinos.com/
|
||||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-connect.jpg?fit=800%2C473&ssl=1
|
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-connect.jpg
|
||||||
[4]: https://www.pushbullet.com/
|
[4]: https://www.pushbullet.com/
|
||||||
[5]: https://play.google.com/store/apps/details?id=com.zorinos.zorin_connect&hl=en_IN
|
[5]: https://play.google.com/store/apps/details?id=com.zorinos.zorin_connect&hl=en_IN
|
||||||
[6]: https://zoringroup.com/blog/2019/06/05/zorin-os-15-is-here-faster-easier-more-connected/
|
[6]: https://zoringroup.com/blog/2019/06/05/zorin-os-15-is-here-faster-easier-more-connected/
|
||||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-dark-mode.jpg?fit=722%2C800&ssl=1
|
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-dark-mode.jpg
|
||||||
[8]: https://itsfoss.com/necunos-linux-smartphone/
|
[8]: https://itsfoss.com/necunos-linux-smartphone/
|
||||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/Todo.jpg?fit=800%2C652&ssl=1
|
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/Todo.jpg
|
||||||
[10]: https://zorinos.com/download/
|
[10]: https://zorinos.com/download/
|
||||||
[11]: https://itsfoss.com/ubuntu-1404-codenamed-trusty-tahr/
|
[11]: https://itsfoss.com/ubuntu-1404-codenamed-trusty-tahr/
|
||||||
@ -0,0 +1,214 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11101-1.html)
|
||||||
|
[#]: subject: (4 tools to help you drive Kubernetes)
|
||||||
|
[#]: via: (https://opensource.com/article/19/6/tools-drive-kubernetes)
|
||||||
|
[#]: author: (Scott McCarty https://opensource.com/users/fatherlinux/users/fatherlinux/users/fatherlinux/users/fatherlinux)
|
||||||
|
|
||||||
|
帮助你驾驭 Kubernetes 的 4 个工具
|
||||||
|
======
|
||||||
|
|
||||||
|
> 学习如何驾驭 Kubernetes 比如何建造它更重要,这些工具可以帮助你更快上路。
|
||||||
|
|
||||||
|
![Tools in a workshop][1]
|
||||||
|
|
||||||
|
在本系列的第三篇文章中,[Kubernetes 基础:首先学习如何使用][2],我强调你应该学会使用 Kubernetes,而不是建造它。我还解释说,在 Kubernetes 中,你必须学习最小的一组原语来建模应用程序。我想强调这一点:你需要学习的这组原语是最简单的原语集,你可以通过它们学习如何实现生产级的应用程序部署(即高可用性 [HA]、多容器、多应用程序)。换句话说,学习 Kubernetes 内置的原语集比学习集群软件、集群文件系统、负载平衡器、让人发疯的 Apache 和 Nginx 的配置、路由器、交换机、防火墙和存储后端更容易 —— 这些是你在传统的 IT 环境(虚拟机或裸机)中建模简单的 HA 应用程序所需要的东西。
|
||||||
|
|
||||||
|
在这第四篇文章中,我将分享一些有助于你学习快速驾驭 Kubernetes 的工具。
|
||||||
|
|
||||||
|
### 1、Katacoda
|
||||||
|
|
||||||
|
无疑,[Katacoda][3] 是试驾 Kubernetes 集群的最简单方法。只需单击一下,五秒钟后就可以将基于 Web 的终端直接连接到正在运行的 Kubernetes 集群中。这对于使用和学习来说非常棒。我甚至将它用于演示和测试新想法。Katacoda 提供了一个完整的临时环境,在你使用完毕后可以回收利用。
|
||||||
|
|
||||||
|
![OpenShift Playground][4]
|
||||||
|
|
||||||
|
*[OpenShift Playground][5]*
|
||||||
|
|
||||||
|
![Kubernetes Playground][6]
|
||||||
|
|
||||||
|
*[Kubernetes Playground][7]*
|
||||||
|
|
||||||
|
Katacoda 提供了一个临时的环境和更深入的实验室环境。例如,我最近三四年主讲的 [Linux Container Internals Lab][3] 是在 Katacoda 中构建的。
|
||||||
|
|
||||||
|
Katacoda 在其主站点上维护了若干 [Kubernetes 和云教程][8]并与 Red Hat 合作以支持了一个 [OpenShift 的专用学习门户][9]。了解一下,它们是极好的学习资源。
|
||||||
|
|
||||||
|
当你第一次学习驾驶翻斗车时,最好先观察一下其他人的驾驶方式。
|
||||||
|
|
||||||
|
### 2、Podman generate kube
|
||||||
|
|
||||||
|
`podman generate kube` 命令是一个很棒的子命令,可以帮助用户自然地从运行简单容器的简单容器引擎转换到运行许多容器的集群用例(正如我在[上篇文章][2]中所描述的那样)。[Podman][10] 通过让你启动一个新的容器,然后导出这个可工作的 Kube YAML,并在 Kubernetes 中启动它来实现这一点。看看这个(你可以在 [Katacoda lab][3] 中运行它,它已经有了 Podman 和 OpenShift)。
|
||||||
|
|
||||||
|
首先,请注意运行容器的语法与 Docker 非常相似:
|
||||||
|
|
||||||
|
```
|
||||||
|
podman run -dtn two-pizza quay.io/fatherlinux/two-pizza
|
||||||
|
```
|
||||||
|
|
||||||
|
不过这个是其它容器引擎所没有的:
|
||||||
|
|
||||||
|
```
|
||||||
|
podman generate kube two-pizza
|
||||||
|
```
|
||||||
|
|
||||||
|
输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
# Generation of Kubernetes YAML is still under development!
|
||||||
|
#
|
||||||
|
# Save the output of this file and use kubectl create -f to import
|
||||||
|
# it into Kubernetes.
|
||||||
|
#
|
||||||
|
# Created with podman-1.3.1
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Pod
|
||||||
|
metadata:
|
||||||
|
creationTimestamp: "2019-06-07T08:08:12Z"
|
||||||
|
labels:
|
||||||
|
app: two-pizza
|
||||||
|
name: two-pizza
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- command:
|
||||||
|
- /bin/sh
|
||||||
|
- -c
|
||||||
|
- bash -c 'while true; do /usr/bin/nc -l -p 3306 < /srv/hello.txt; done'
|
||||||
|
env:
|
||||||
|
- name: PATH
|
||||||
|
value: /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
|
||||||
|
- name: TERM
|
||||||
|
value: xterm
|
||||||
|
- name: HOSTNAME
|
||||||
|
- name: container
|
||||||
|
value: oci
|
||||||
|
image: quay.io/fatherlinux/two-pizza:latest
|
||||||
|
name: two-pizza
|
||||||
|
resources: {}
|
||||||
|
securityContext:
|
||||||
|
allowPrivilegeEscalation: true
|
||||||
|
capabilities: {}
|
||||||
|
privileged: false
|
||||||
|
readOnlyRootFilesystem: false
|
||||||
|
tty: true
|
||||||
|
workingDir: /
|
||||||
|
status: {}
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Service
|
||||||
|
metadata:
|
||||||
|
creationTimestamp: "2019-06-07T08:08:12Z"
|
||||||
|
labels:
|
||||||
|
app: two-pizza
|
||||||
|
name: two-pizza
|
||||||
|
spec:
|
||||||
|
selector:
|
||||||
|
app: two-pizza
|
||||||
|
type: NodePort
|
||||||
|
status:
|
||||||
|
loadBalancer: {}
|
||||||
|
```
|
||||||
|
|
||||||
|
你现在有了一些可以的工作 Kubernetes YAML,你可以用它作为练习的起点来学习、调整等等。`-s` 标志可以为你创造一项服务。[Brent Baude][11] 甚至致力于[添加卷/持久卷断言][12]等新功能。如果想进一步深入,请在 Brent 的博客文章《[Podman 现在可以轻松过渡到 Kubernetes 和 CRI-O][13]》中了解他的工作。
|
||||||
|
|
||||||
|
### 3、oc new-app
|
||||||
|
|
||||||
|
`oc new-app` 命令非常强大。它是特定于 OpenShift 的,所以它在默认的 Kubernetes 中不可用,但是当你开始学习 Kubernetes 时它非常有用。让我们从快速命令开始创建一个相当复杂的应用程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
oc new-project -n example
|
||||||
|
oc new-app -f https://raw.githubusercontent.com/openshift/origin/master/examples/quickstarts/cakephp-mysql.json
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 `oc new-app`,你可以从 OpenShift 开发人员那里偷取模板,并在开发原语来描述你自己的应用程序时拥有一个已知良好的起点。运行上述命令后,你的 Kubernetes 命名空间(在 OpenShift 中)将由若干新的已定义资源填充。
|
||||||
|
|
||||||
|
```
|
||||||
|
oc get all
|
||||||
|
```
|
||||||
|
|
||||||
|
输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
NAME READY STATUS RESTARTS AGE
|
||||||
|
pod/cakephp-mysql-example-1-build 0/1 Completed 0 4m
|
||||||
|
pod/cakephp-mysql-example-1-gz65l 1/1 Running 0 1m
|
||||||
|
pod/mysql-1-nkhqn 1/1 Running 0 4m
|
||||||
|
|
||||||
|
NAME DESIRED CURRENT READY AGE
|
||||||
|
replicationcontroller/cakephp-mysql-example-1 1 1 1 1m
|
||||||
|
replicationcontroller/mysql-1 1 1 1 4m
|
||||||
|
|
||||||
|
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||||
|
service/cakephp-mysql-example ClusterIP 172.30.234.135 <none> 8080/TCP 4m
|
||||||
|
service/mysql ClusterIP 172.30.13.195 <none> 3306/TCP 4m
|
||||||
|
|
||||||
|
NAME REVISION DESIRED CURRENT TRIGGERED BY
|
||||||
|
deploymentconfig.apps.openshift.io/cakephp-mysql-example 1 1 1 config,image(cakephp-mysql-example:latest)
|
||||||
|
deploymentconfig.apps.openshift.io/mysql 1 1 1 config,image(mysql:5.7)
|
||||||
|
|
||||||
|
NAME TYPE FROM LATEST
|
||||||
|
buildconfig.build.openshift.io/cakephp-mysql-example Source Git 1
|
||||||
|
|
||||||
|
NAME TYPE FROM STATUS STARTED DURATION
|
||||||
|
build.build.openshift.io/cakephp-mysql-example-1 Source Git@47a951e Complete 4 minutes ago 2m27s
|
||||||
|
|
||||||
|
NAME DOCKER REPO TAGS UPDATED
|
||||||
|
imagestream.image.openshift.io/cakephp-mysql-example docker-registry.default.svc:5000/example/cakephp-mysql-example latest About aminute ago
|
||||||
|
|
||||||
|
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
|
||||||
|
route.route.openshift.io/cakephp-mysql-example cakephp-mysql-example-example.2886795271-80-rhsummit1.environments.katacoda.com cakephp-mysql-example <all> None
|
||||||
|
```
|
||||||
|
|
||||||
|
这样做的好处是你可以删除 Pod,观察复制控制器如何重新创建它们,缩放 Pod 等等。你可以使用模板并将其更改为其他应用程序(这是我第一次启动时所做的)。
|
||||||
|
|
||||||
|
### 4、Visual Studio Code
|
||||||
|
|
||||||
|
我把我最喜欢的放在最后。我的大部分工作都使用 [vi][14],但我从来没有为 Kubernetes 找到一个好的语法高亮器和代码补完插件(如果有的话,请告诉我)。相反,我发现微软的 [VS Code][15] 有一套杀手级的插件,可以完成 Kubernetes 资源的创建并提供样板。
|
||||||
|
|
||||||
|
![VS Code plugins UI][16]
|
||||||
|
|
||||||
|
首先,安装上图中显示的 Kubernetes 和 YAML 插件。
|
||||||
|
|
||||||
|
![Autocomplete in VS Code][17]
|
||||||
|
|
||||||
|
然后,你可以从头开始创建新的 YAML 文件,并自动补完 Kubernetes 资源。上面的示例显示了一个服务。
|
||||||
|
|
||||||
|
![VS Code autocomplete filling in boilerplate for an object][18]
|
||||||
|
|
||||||
|
当你使用自动补完并选择服务资源时,它会填充该对象的一些模板。当你第一次学习使用 Kubernetes 时,这非常棒。你可以构建 Pod、服务、复制控制器、部署等。当你从头开始构建这些文件甚至修改你使用 `podman generate kube` 创建的文件时,这是一个非常好的功能。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
这四个工具(如果算上两个插件,则为六个)将帮助你学习驾驭 Kubernetes,而不是构造或装备它。在本系列的最后一篇文章中,我将讨论为什么 Kubernetes 如此适合运行这么多不同的工作负载。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/6/tools-drive-kubernetes
|
||||||
|
|
||||||
|
作者:[Scott McCarty][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/fatherlinux/users/fatherlinux/users/fatherlinux/users/fatherlinux
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tools_workshop_blue_mechanic.jpg?itok=4YXkCU-J (Tools in a workshop)
|
||||||
|
[2]: https://linux.cn/article-11036-1.html
|
||||||
|
[3]: https://learn.openshift.com/subsystems/container-internals-lab-2-0-part-1
|
||||||
|
[4]: https://opensource.com/sites/default/files/uploads/openshift-playground.png (OpenShift Playground)
|
||||||
|
[5]: https://learn.openshift.com/playgrounds/openshift311/
|
||||||
|
[6]: https://opensource.com/sites/default/files/uploads/kubernetes-playground.png (Kubernetes Playground)
|
||||||
|
[7]: https://katacoda.com/courses/kubernetes/playground
|
||||||
|
[8]: https://katacoda.com/learn
|
||||||
|
[9]: http://learn.openshift.com/
|
||||||
|
[10]: https://podman.io/
|
||||||
|
[11]: https://developers.redhat.com/blog/author/bbaude/
|
||||||
|
[12]: https://github.com/containers/libpod/issues/2303
|
||||||
|
[13]: https://developers.redhat.com/blog/2019/01/29/podman-kubernetes-yaml/
|
||||||
|
[14]: https://en.wikipedia.org/wiki/Vi
|
||||||
|
[15]: https://code.visualstudio.com/
|
||||||
|
[16]: https://opensource.com/sites/default/files/uploads/vscode_-_kubernetes_red_hat_-_plugins.png (VS Code plugins UI)
|
||||||
|
[17]: https://opensource.com/sites/default/files/uploads/vscode_-_kubernetes_service_-_autocomplete.png (Autocomplete in VS Code)
|
||||||
|
[18]: https://opensource.com/sites/default/files/uploads/vscode_-_kubernetes_service_-_boiler_plate.png (VS Code autocomplete filling in boilerplate for an object)
|
||||||
@ -1,36 +1,37 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (geekpi)
|
[#]: translator: (geekpi)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11063-1.html)
|
||||||
[#]: subject: (Free and Open Source Trello Alternative OpenProject 9 Released)
|
[#]: subject: (Free and Open Source Trello Alternative OpenProject 9 Released)
|
||||||
[#]: via: (https://itsfoss.com/openproject-9-release/)
|
[#]: via: (https://itsfoss.com/openproject-9-release/)
|
||||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||||
|
|
||||||
替代 Trello 的免费开源 OpenProject 9 发布了
|
替代 Trello 的 OpenProject 9 发布了
|
||||||
======
|
======
|
||||||
|
|
||||||
|
|
||||||
[OpenProject][1] 是一个开源项目协作管理软件。它是 [Trello][2] 和 [Jira][3] 等专有方案的替代品。
|
[OpenProject][1] 是一个开源项目协作管理软件。它是 [Trello][2] 和 [Jira][3] 等专有方案的替代品。
|
||||||
|
|
||||||
如果个人使用,你可以免费使用它,并在你自己的服务器上进行设置(并托管它)。这样,你就可以控制数据。
|
如果个人使用,你可以免费使用它,并在你自己的服务器上进行设置(并托管它)。这样,你就可以控制数据。
|
||||||
|
|
||||||
当然,如果你是[云或企业版用户][4],那么你可以使用高级功能和更优先的帮助。
|
当然,如果你是[企业云版的用户][4],那么你可以使用高级功能和更优先的帮助。
|
||||||
|
|
||||||
OpenProject 9 的重点是新的看板试图,包列表视图和工作模板。
|
OpenProject 9 的重点是新的面板视图,包列表视图和工作模板。
|
||||||
|
|
||||||
如果你对此不了解,可以尝试一下。但是,如果你是现有用户 - 在迁移到 OpenProject 9 之前,你应该知道这些新功能。
|
如果你对此不了解,可以尝试一下。但是,如果你是已有用户 —— 在迁移到 OpenProject 9 之前,你应该知道这些新功能。
|
||||||
|
|
||||||
### OpenProject 9 有什么新功能?
|
### OpenProject 9 有什么新功能?
|
||||||
|
|
||||||
以下是最新版 OpenProjec t的一些主要更改。
|
以下是最新版 OpenProject 的一些主要更改。
|
||||||
|
|
||||||
#### Scrum 和敏捷看板
|
#### Scrum 和敏捷面板
|
||||||
|
|
||||||
![][5]
|
![][5]
|
||||||
|
|
||||||
对于云和企业版,有一个新的 [scrum][6] 和[敏捷][7]看板视图。你还可以 [kanban 风格][8]方式展示你的工作,从而更轻松地支持你的敏捷和 scrum 团队。
|
对于企业云版,有了一个新的 [scrum][6] 和[敏捷][7]面板视图。你还可以[看板风格][8]方式展示你的工作,从而更轻松地支持你的敏捷和 scrum 团队。
|
||||||
|
|
||||||
新的看板视图使你可以轻松了解为该任务分配的人员并快速更新状态。你还有不同的看板视图选项,如基本看板、状态看板和版本看板。
|
新的面板视图使你可以轻松了解为该任务分配的人员并快速更新状态。你还有不同的面板视图选项,如基本面板、状态面板和版本面板。
|
||||||
|
|
||||||
#### 工作包模板
|
#### 工作包模板
|
||||||
|
|
||||||
@ -46,9 +47,9 @@ OpenProject 9 的重点是新的看板试图,包列表视图和工作模板。
|
|||||||
|
|
||||||
#### “我的”页面的可自定义工作包视图
|
#### “我的”页面的可自定义工作包视图
|
||||||
|
|
||||||
“我的”页面显示你正在处理的内容(以及进度),它不应该一直很无聊。因此,现在你可以自定义它,甚至可以添加甘特图来可视化你的工作。
|
“我的”页面显示你正在处理的内容(以及进度),它不应该一直那么呆板。因此,现在你可以自定义它,甚至可以添加甘特图来可视化你的工作。
|
||||||
|
|
||||||
**总结**
|
### 总结
|
||||||
|
|
||||||
有关迁移和安装的详细说明,请参阅[官方的公告帖][12],其中包含了必要的细节。
|
有关迁移和安装的详细说明,请参阅[官方的公告帖][12],其中包含了必要的细节。
|
||||||
|
|
||||||
@ -61,7 +62,7 @@ via: https://itsfoss.com/openproject-9-release/
|
|||||||
作者:[Ankush Das][a]
|
作者:[Ankush Das][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,222 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (zgj1024)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11077-1.html)
|
||||||
|
[#]: subject: (How to set ulimit and file descriptors limit on Linux Servers)
|
||||||
|
[#]: via: (https://www.linuxtechi.com/set-ulimit-file-descriptors-limit-linux-servers/)
|
||||||
|
[#]: author: (Shashidhar Soppin https://www.linuxtechi.com/author/shashidhar/)
|
||||||
|
|
||||||
|
如何在 Linux 服务器上设置 ulimit 和文件描述符数限制
|
||||||
|
======
|
||||||
|
**简介**:在生产环境中遇到打开文件数这类的挑战如今已是司空见惯的事情了。因为许多应用程序是基于 Java 和 Apache 的,安装和配置它们可能会导致打开过多的文件(文件描述符)。如果打开的文件描述符超过了默认设置的限制,就可能会面临访问控制问题,受阻于打开文件的挑战。许多生产环境因此而陷入停滞状态。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
幸运的是,在基于 Linux 的服务器上,都有 `ulimit` 命令,通过它可以查看、设置、获取文件打开的状态和配置详情。此命令配备了许多选项,通过这些组合可以设置打开文件的数量。下面逐个命令用示例做了详细说明。
|
||||||
|
|
||||||
|
### 查看任何 Linux 系统中当前打开文件数的限制
|
||||||
|
|
||||||
|
要在 Linux 服务器上得到打开文件数的限制,请执行以下命令,
|
||||||
|
|
||||||
|
```
|
||||||
|
[root@ubuntu ~]# cat /proc/sys/fs/file-max
|
||||||
|
146013
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的数字表明用户可以在每个用户登录会话中打开 ‘146013’ 个文件。
|
||||||
|
|
||||||
|
```
|
||||||
|
[root@centos ~]# cat /proc/sys/fs/file-max
|
||||||
|
149219
|
||||||
|
[root@debian ~]# cat /proc/sys/fs/file-max
|
||||||
|
73906
|
||||||
|
```
|
||||||
|
|
||||||
|
这清楚地表明,各个 Linux 操作系统具有不同的打开文件数限制。这基于各自系统中运行的依赖关系和应用程序。
|
||||||
|
|
||||||
|
### ulimit 命令
|
||||||
|
|
||||||
|
顾名思义,`ulimit`(用户限制)用于显示和设置登录用户的资源限制。当我们使用 `-a` 选项运行 `ulimit` 命令时,它将打印登录用户的所有资源限制。现在让我们在 Ubuntu/Debian 和 CentOS 系统上运行 `ulimit -a`,
|
||||||
|
|
||||||
|
#### Ubuntu / Debian 系统
|
||||||
|
|
||||||
|
```
|
||||||
|
shashi@Ubuntu ~}$ ulimit -a
|
||||||
|
core file size (blocks, -c) 0
|
||||||
|
data seg size (kbytes, -d) unlimited
|
||||||
|
scheduling priority (-e) 0
|
||||||
|
file size (blocks, -f) unlimited
|
||||||
|
pending signals (-i) 5731
|
||||||
|
max locked memory (kbytes, -l) 64
|
||||||
|
max memory size (kbytes, -m) unlimited
|
||||||
|
open files (-n) 1024
|
||||||
|
pipe size (512 bytes, -p) 8
|
||||||
|
POSIX message queues (bytes, -q) 819200
|
||||||
|
real-time priority (-r) 0
|
||||||
|
stack size (kbytes, -s) 8192
|
||||||
|
cpu time (seconds, -t) unlimited
|
||||||
|
max user processes (-u) 5731
|
||||||
|
virtual memory (kbytes, -v) unlimited
|
||||||
|
file locks (-x) unlimited
|
||||||
|
```
|
||||||
|
|
||||||
|
#### CentOS 系统
|
||||||
|
|
||||||
|
```
|
||||||
|
shashi@centos ~}$ ulimit -a
|
||||||
|
core file size (blocks, -c) 0
|
||||||
|
data seg size (kbytes, -d) unlimited
|
||||||
|
scheduling priority (-e) 0
|
||||||
|
file size (blocks, -f) unlimited
|
||||||
|
pending signals (-i) 5901
|
||||||
|
max locked memory (kbytes, -l) 64
|
||||||
|
max memory size (kbytes, -m) unlimited
|
||||||
|
open files (-n) 1024
|
||||||
|
pipe size (512 bytes, -p) 8
|
||||||
|
POSIX message queues (bytes, -q) 819200
|
||||||
|
real-time priority (-r) 0
|
||||||
|
stack size (kbytes, -s) 8192
|
||||||
|
cpu time (seconds, -t) unlimited
|
||||||
|
max user processes (-u) 5901
|
||||||
|
virtual memory (kbytes, -v) unlimited
|
||||||
|
file locks (-x) unlimited
|
||||||
|
```
|
||||||
|
|
||||||
|
正如我们可以在这里看到的,不同的操作系统具有不同的限制设置。所有这些限制都可以使用 `ulimit` 命令进行配置/更改。
|
||||||
|
|
||||||
|
要显示单个资源限制,可以在 `ulimit` 命令中传递特定的参数,下面列出了一些参数:
|
||||||
|
|
||||||
|
* `ulimit -n` –> 显示打开文件数限制
|
||||||
|
* `ulimit -c` –> 显示核心转储文件大小
|
||||||
|
* `umilit -u` –> 显示登录用户的最大用户进程数限制
|
||||||
|
* `ulimit -f` –> 显示用户可以拥有的最大文件大小
|
||||||
|
* `umilit -m` –> 显示登录用户的最大内存大小
|
||||||
|
* `ulimit -v` –> 显示最大内存大小限制
|
||||||
|
|
||||||
|
使用以下命令检查登录用户打开文件数量的硬限制和软限制:
|
||||||
|
|
||||||
|
```
|
||||||
|
shashi@Ubuntu ~}$ ulimit -Hn
|
||||||
|
1048576
|
||||||
|
shashi@Ubuntu ~}$ ulimit -Sn
|
||||||
|
1024
|
||||||
|
```
|
||||||
|
|
||||||
|
### 如何修复达到最大文件数限制的问题?
|
||||||
|
|
||||||
|
让我们假设我们的 Linux 服务器已经达到了打开文件的最大数量限制,并希望在系统范围扩展该限制,例如,我们希望将 100000 设置为打开文件数量的限制。
|
||||||
|
|
||||||
|
```
|
||||||
|
root@ubuntu~]# sysctl -w fs.file-max=100000
|
||||||
|
fs.file-max = 100000
|
||||||
|
```
|
||||||
|
|
||||||
|
上述更改将在下次重启之前有效,因此要使这些更改在重启后仍存在,请编辑文件 `/etc/sysctl.conf` 并添加相同的参数,
|
||||||
|
|
||||||
|
```
|
||||||
|
root@ubuntu~]# vi /etc/sysctl.conf
|
||||||
|
fs.file-max = 100000
|
||||||
|
```
|
||||||
|
|
||||||
|
保存文件并退出。
|
||||||
|
|
||||||
|
运行下面命令,使上述更改立即生效,而无需注销和重新启动。
|
||||||
|
|
||||||
|
```
|
||||||
|
root@ubuntu~]# sysctl -p
|
||||||
|
```
|
||||||
|
|
||||||
|
现在验证新的更改是否生效。
|
||||||
|
|
||||||
|
```
|
||||||
|
root@ubuntu~]# cat /proc/sys/fs/file-max
|
||||||
|
100000
|
||||||
|
```
|
||||||
|
|
||||||
|
使用以下命令找出当前正在使用的文件描述符数量:
|
||||||
|
|
||||||
|
```
|
||||||
|
[root@ansible ~]# more /proc/sys/fs/file-nr
|
||||||
|
1216 0 100000
|
||||||
|
```
|
||||||
|
|
||||||
|
注意:命令 `sysctl -p` 用于在不重新启动和注销的情况下提交更改。
|
||||||
|
|
||||||
|
### 通过 limit.conf 文件设置用户级资源限制
|
||||||
|
|
||||||
|
`/etc/sysctl.conf` 文件用于设置系统范围的资源限制,但如果要为 Oracle、MariaDB 和 Apache 等特定用户设置资源限制,则可以通过 `/etc/security/limits.conf` 文件去实现。
|
||||||
|
|
||||||
|
示例 `limits.conf` 如下所示,
|
||||||
|
|
||||||
|
```
|
||||||
|
root@ubuntu~]# cat /etc/security/limits.conf
|
||||||
|
```
|
||||||
|
|
||||||
|
![Limits-conf-linux-part1][1]
|
||||||
|
|
||||||
|
![Limits-conf-linux-part2][2]
|
||||||
|
|
||||||
|
假设我们要为 linuxtechi 用户设置打开文件数量的硬限制和软限制,而对于 oracle 用户设置打开进程数量的硬限制和软限制,编辑文件 `/etc/security/limits.conf` 并添加以下行:
|
||||||
|
|
||||||
|
```
|
||||||
|
# hard limit for max opened files for linuxtechi user
|
||||||
|
linuxtechi hard nofile 4096
|
||||||
|
# soft limit for max opened files for linuxtechi user
|
||||||
|
linuxtechi soft nofile 1024
|
||||||
|
|
||||||
|
# hard limit for max number of process for oracle user
|
||||||
|
oracle hard nproc 8096
|
||||||
|
# soft limit for max number of process for oracle user
|
||||||
|
oracle soft nproc 4096
|
||||||
|
```
|
||||||
|
|
||||||
|
保存文件并退出。
|
||||||
|
|
||||||
|
**注意:** 如果你想对一个组而不是用户进行资源限制,那么也可以通过 `limits.conf` 文件,输入 `@<组名>` 代替用户名,其余项都是相同的,示例如下,
|
||||||
|
|
||||||
|
```
|
||||||
|
# hard limit for max opened files for sysadmin group
|
||||||
|
@sysadmin hard nofile 4096
|
||||||
|
# soft limit for max opened files for sysadmin group
|
||||||
|
@sysadmin soft nofile 1024
|
||||||
|
```
|
||||||
|
|
||||||
|
验证新的更改是否生效:
|
||||||
|
|
||||||
|
```
|
||||||
|
~]# su - linuxtechi
|
||||||
|
~]$ ulimit -n -H
|
||||||
|
4096
|
||||||
|
~]$ ulimit -n -S
|
||||||
|
1024
|
||||||
|
|
||||||
|
~]# su - oracle
|
||||||
|
~]$ ulimit -H -u
|
||||||
|
8096
|
||||||
|
~]$ ulimit -S -u
|
||||||
|
4096
|
||||||
|
```
|
||||||
|
|
||||||
|
注:其他主要使用的命令是 [lsof][3],可用于找出“当前打开了多少个文件”,这命令对管理员非常有帮助。
|
||||||
|
|
||||||
|
### 结尾
|
||||||
|
|
||||||
|
正如在介绍部分提到的,`ulimit` 命令非常强大,可以帮助用户配置并确保应用程序安装更加流畅而没有任何瓶颈。此命令有助于修复基于 Linux 的服务器中的(打开)大量文件的限制。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linuxtechi.com/set-ulimit-file-descriptors-limit-linux-servers/
|
||||||
|
|
||||||
|
作者:[Shashidhar Soppin][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zgj1024](https://github.com/zgj1024)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.linuxtechi.com/author/shashidhar/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.linuxtechi.com/wp-content/uploads/2019/06/Limits-conf-linux-part1-1024x677.jpg
|
||||||
|
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/06/Limits-conf-linux-part2-1024x443.jpg
|
||||||
|
[3]: https://www.linuxtechi.com/lsof-command-examples-linux-geeks/
|
||||||
@ -1,16 +1,18 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (chen-ni)
|
[#]: translator: (chen-ni)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11064-1.html)
|
||||||
[#]: subject: (IPython is still the heart of Jupyter Notebooks for Python developers)
|
[#]: subject: (IPython is still the heart of Jupyter Notebooks for Python developers)
|
||||||
[#]: via: (https://opensource.com/article/19/6/ipython-still-heart-jupyterlab)
|
[#]: via: (https://opensource.com/article/19/6/ipython-still-heart-jupyterlab)
|
||||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg/users/marcobravo)
|
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg/users/marcobravo)
|
||||||
|
|
||||||
对 Python 开发者而言,IPython 仍然是 Jupyter Notebook 的核心
|
对 Python 开发者而言,IPython 仍然是 Jupyter Notebook 的核心
|
||||||
======
|
======
|
||||||
Jupyter 项目提供的魔法般的开发体验很大程度上得益于它的 IPython 基因。
|
|
||||||
![I love Free Software FSFE celebration][1]
|
> Jupyter 项目提供的魔法般的开发体验很大程度上得益于它的 IPython 基因。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
最近刚刚写过我为什么觉得觉得 Jupyter 项目(特别是 JupyterLab)提供了一种 [魔法般的 Python 开发体验][2]。在研究这些不同项目之间的关联的时候,我回顾了一下 Jupyter 最初从 IPython 分支出来的这段历史。正如 Jupyter 项目的 [大拆分™ 声明][3] 所说:
|
最近刚刚写过我为什么觉得觉得 Jupyter 项目(特别是 JupyterLab)提供了一种 [魔法般的 Python 开发体验][2]。在研究这些不同项目之间的关联的时候,我回顾了一下 Jupyter 最初从 IPython 分支出来的这段历史。正如 Jupyter 项目的 [大拆分™ 声明][3] 所说:
|
||||||
|
|
||||||
@ -34,7 +36,7 @@ Jupyter 项目提供的魔法般的开发体验很大程度上得益于它的 IP
|
|||||||
|
|
||||||
### IPython 如今的作用
|
### IPython 如今的作用
|
||||||
|
|
||||||
IPython 提供了一个强大的、交互性的 Python shell,以及 Jupyter 的内核。安装完成之后,我可以在任何命令行运行 **ipython** 本身,将它当作一个(比默认 Python shell 好太多的)Python shell 来使用:
|
IPython 提供了一个强大的、交互性的 Python shell,以及 Jupyter 的内核。安装完成之后,我可以在任何命令行运行 `ipython` 本身,将它当作一个(比默认 Python shell 好太多的)Python shell 来使用:
|
||||||
|
|
||||||
|
|
||||||
```
|
```
|
||||||
@ -50,15 +52,15 @@ In [4]: print(average)
|
|||||||
6.571428571428571
|
6.571428571428571
|
||||||
```
|
```
|
||||||
|
|
||||||
这就让我们发现了一个更为重要的问题:是IPython 让 JupyterLab 可以在项目中执行代码,并且支持了一系列被称为 *magic*的功能(感谢 Nicholas Reith 在我上一篇文章的评论里提到这点)。
|
这就让我们发现了一个更为重要的问题:是 IPython 让 JupyterLab 可以在项目中执行代码,并且支持了一系列被称为 *Magic* 的功能(感谢 Nicholas Reith 在我上一篇文章的评论里提到这点)。
|
||||||
|
|
||||||
### IPython 让魔法成为现实
|
### IPython 让魔法成为现实
|
||||||
|
|
||||||
JupyterLab 和其它使用 IPython 的前端工具可以让你感觉像是在最喜欢的 IDE 或者是终端模拟器的环境下工作。我非常喜欢 [dotfiles][5] 快捷键功能,magic 也有类似 dotfile 的特征。比如说,可以试一下 **[%bookmark][6]** 这个命令。我把默认开发文件夹 **~/Develop** 关联到了一个可以在任何时候直接跳转的快捷方式上。
|
JupyterLab 和其它使用 IPython 的前端工具可以让你感觉像是在最喜欢的 IDE 或者是终端模拟器的环境下工作。我非常喜欢 [点文件][5] 快捷键功能,Magic 也有类似点文件的特征。比如说,可以试一下 [%bookmark][6] 这个命令。我把默认开发文件夹 `~/Develop` 关联到了一个可以在任何时候直接跳转的快捷方式上。
|
||||||
|
|
||||||
![Screenshot of commands from JupyterLab][7]
|
![Screenshot of commands from JupyterLab][7]
|
||||||
|
|
||||||
**%bookmark**、**%cd**,以及我在前一篇文章里介绍过的 **!** 操作符,都是由 IPython 支持的。正如这篇 [文档][8] 所说:
|
`%bookmark`、`%cd`,以及我在前一篇文章里介绍过的 `!` 操作符,都是由 IPython 支持的。正如这篇 [文档][8] 所说:
|
||||||
|
|
||||||
> Jupyter 用户你们好:Magic 功能是 IPython 内核提供的专属功能。一个内核是否支持 Magic 功能是由该内核的开发者针对该内核所决定的。
|
> Jupyter 用户你们好:Magic 功能是 IPython 内核提供的专属功能。一个内核是否支持 Magic 功能是由该内核的开发者针对该内核所决定的。
|
||||||
|
|
||||||
@ -66,7 +68,7 @@ JupyterLab 和其它使用 IPython 的前端工具可以让你感觉像是在最
|
|||||||
|
|
||||||
作为一个好奇的新手,我之前并不是特别确定 IPython 是否仍然和 Jupyter 生态还有任何联系。现在我对 IPython 的持续开发有了新的认识和,并且意识到它正是 JupyterLab 强大的用户体验的来源。这也是相当有才华的一批贡献者进行最前沿研究的成果,所以如果你在学术论文中使用到了 Jupyter 项目的话别忘了引用他们。为了方便引用,他们还提供了一个 [现成的引文][9]。
|
作为一个好奇的新手,我之前并不是特别确定 IPython 是否仍然和 Jupyter 生态还有任何联系。现在我对 IPython 的持续开发有了新的认识和,并且意识到它正是 JupyterLab 强大的用户体验的来源。这也是相当有才华的一批贡献者进行最前沿研究的成果,所以如果你在学术论文中使用到了 Jupyter 项目的话别忘了引用他们。为了方便引用,他们还提供了一个 [现成的引文][9]。
|
||||||
|
|
||||||
如果你在考虑参与哪个开源项目的贡献的话,一定不要忘了 IPython 哦。记得看看 [最新发布说明][10],在这里可以找到 magic 功能的完整列表。
|
如果你在考虑参与哪个开源项目的贡献的话,一定不要忘了 IPython 哦。记得看看 [最新发布说明][10],在这里可以找到 Magic 功能的完整列表。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -74,8 +76,8 @@ via: https://opensource.com/article/19/6/ipython-still-heart-jupyterlab
|
|||||||
|
|
||||||
作者:[Matthew Broberg][a]
|
作者:[Matthew Broberg][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[chen-ni](https://github.com/chen-ni)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,54 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11141-1.html)
|
||||||
|
[#]: subject: (Use ImageGlass to quickly view JPG images as a slideshow)
|
||||||
|
[#]: via: (https://opensource.com/article/19/6/use-imageglass-view-jpg-images-slideshow-windows-10)
|
||||||
|
[#]: author: (Jeff Macharyas https://opensource.com/users/jeffmacharyas)
|
||||||
|
|
||||||
|
使用 ImageGlass 以幻灯片形式快速查看 JPG 图像
|
||||||
|
======
|
||||||
|
|
||||||
|
> 想要在 Windows 10 中以幻灯片形式逐个查看文件夹中的图像么?开源软件可以做到。
|
||||||
|
|
||||||
|
![Looking back with binoculars][1]
|
||||||
|
|
||||||
|
欢迎阅读今天的系列文章 “我该如何让它实现?”就我而言,我试图在 Windows 10 上以幻灯片形式查看 JPG 图像的文件夹。像往常一样,我转向开源来解决这个问题。
|
||||||
|
|
||||||
|
在 Mac 上,以幻灯片形式查看 JPG 图像文件夹只需选择文件夹中的所有图像(`Command-A`),然后按 `Option-Command-Y` 即可。之后,你可以使用箭头键向前翻动。当然,在 Windows 中,你可以通过选择第一个图像,然后单击窗口中黄色的**管理**栏,然后选择**幻灯片**来执行类似的操作。在那里,你可以控制速度,但只能做到:慢、中、快。
|
||||||
|
|
||||||
|
我希望像在 Windows 中能像 Mac 一样翻下一张图片。自然地,我 Google 搜索了一下并找到了一个方案。我发现了 [ImageGlass][2] 这个开源应用,其许可证是 [GPL 3.0][3],并且它完美地做到了。这是它的样子:
|
||||||
|
|
||||||
|
![Viewing an image in ImageGlass.][4]
|
||||||
|
|
||||||
|
### 关于 ImageGlass
|
||||||
|
|
||||||
|
ImageGlass 是由 Dương Diệu Pháp 开发的,根据他的网站,他是一名越南开发人员,在 Chainstack 负责前端。他与在美国的 [Kevin Routley][5] 协作,后者“为 ImageGlass 开发新功能”。源代码可以在 [GitHub][6] 上找到。
|
||||||
|
|
||||||
|
ImageGlass 支持最常见的图像格式,包括 JPG、GIF、PNG、WEBP、SVG 和 RAW。用户可以轻松自定义扩展名列表。
|
||||||
|
|
||||||
|
我遇到的具体问题是需要找到一张用于目录封面的图像。不幸的是,它在一个包含数十张照片的文件夹中。在 ImageGlass 中以幻灯片浏览照片,在我想要的照片前停止,并将其下载到我的项目文件夹中变得很容易。开源再次帮助了我,该应用只花了很短的时间下载和使用。
|
||||||
|
|
||||||
|
在 2016 年 3 月 10 日,Jason Baker 在他的文章 [9 款 Picasa 的开源替代品][7] 中将 ImageGlass 列为其中之一。如果你有需求,里面还有一些其他有趣的图像相关工具。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/6/use-imageglass-view-jpg-images-slideshow-windows-10
|
||||||
|
|
||||||
|
作者:[Jeff Macharyas][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/jeffmacharyas
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/look-binoculars-sight-see-review.png?itok=NOw2cm39 (Looking back with binoculars)
|
||||||
|
[2]: https://imageglass.org/
|
||||||
|
[3]: https://github.com/d2phap/ImageGlass/blob/master/LICENSE
|
||||||
|
[4]: https://opensource.com/sites/default/files/uploads/imageglass-screenshot.png (Viewing an image in ImageGlass.)
|
||||||
|
[5]: https://github.com/fire-eggs
|
||||||
|
[6]: https://github.com/d2phap/ImageGlass
|
||||||
|
[7]: https://opensource.com/alternatives/picasa
|
||||||
@ -1,16 +1,18 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (chen-ni)
|
[#]: translator: (chen-ni)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11106-1.html)
|
||||||
[#]: subject: (The innovation delusion)
|
[#]: subject: (The innovation delusion)
|
||||||
[#]: via: (https://opensource.com/open-organization/19/6/innovation-delusion)
|
[#]: via: (https://opensource.com/open-organization/19/6/innovation-delusion)
|
||||||
[#]: author: (Jim Whitehurst https://opensource.com/users/jwhitehurst/users/jwhitehurst/users/n8chz/users/dhdeans)
|
[#]: author: (Jim Whitehurst https://opensource.com/users/jwhitehurst/users/jwhitehurst/users/n8chz/users/dhdeans)
|
||||||
|
|
||||||
创新的幻觉
|
创新的幻觉
|
||||||
======
|
======
|
||||||
创新是一种混乱的过程,但是关于创新的故事却很有条理。我们不应该把两者搞混了。
|
|
||||||
![gears and lightbulb to represent innovation][1]
|
> 创新是一种混乱的过程,但是关于创新的故事却很有条理。我们不应该把两者搞混了。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
如果说 [传统的规划方法已经消亡了][2],为什么这么多机构还在孜孜不倦地运用那些针对工业革命所设计的规划方法呢?
|
如果说 [传统的规划方法已经消亡了][2],为什么这么多机构还在孜孜不倦地运用那些针对工业革命所设计的规划方法呢?
|
||||||
|
|
||||||
@ -44,11 +46,11 @@
|
|||||||
|
|
||||||
### 开放(并且混乱的)创新
|
### 开放(并且混乱的)创新
|
||||||
|
|
||||||
机构(特别是领导们)喜欢把成功说成是一件计划之内的事情 - 好像成功人士可以驾驭混乱,并且几乎可以预测未来。但是这些言论都是事后诸葛亮罢了,他们在讲述自己充满偶然性的经历的时候会刻意将无序的事情整理一番,对于毫无确定性的事情也会说“我们就是想要那么做的”。
|
机构(特别是领导们)喜欢把成功说成是一件计划之内的事情 —— 好像成功人士可以驾驭混乱,并且几乎可以预测未来。但是这些言论都是事后诸葛亮罢了,他们在讲述自己充满偶然性的经历的时候会刻意将无序的事情整理一番,对于毫无确定性的事情也会说“我们就是想要那么做的”。
|
||||||
|
|
||||||
但是正如我前面说的,我们不应该相信这些故事是创新过程的真实还原,也不应该在这种错误的假设的基础之上去构建未来的方案或者实验。
|
但是正如我前面说的,我们不应该相信这些故事是创新过程的真实还原,也不应该在这种错误的假设的基础之上去构建未来的方案或者实验。
|
||||||
|
|
||||||
试想有另一家摩托车制造商想要复制本田公司在超级幼兽上的成功,就逐字逐句地照搬波士顿咨询总结的故事。由于本田公司成功的 **故事** 听上去是如此有逻辑,并且是线性的,这家新公司也许会假定他们可以通过类似的程序得到同样的结果:制定目标、谋划行动,然后针对可预期的结果进行执行。但是我们知道本田公司并不是真的靠这种“制定、谋划、执行”的方式赢得他们的市场份额的。他们是通过灵活性和一点运气获得成功的 - 更像是“尝试、学习、修改”。
|
试想有另一家摩托车制造商想要复制本田公司在超级幼兽上的成功,就逐字逐句地照搬波士顿咨询总结的故事。由于本田公司成功的 **故事** 听上去是如此有逻辑,并且是线性的,这家新公司也许会假定他们可以通过类似的程序得到同样的结果:制定目标、谋划行动,然后针对可预期的结果进行执行。但是我们知道本田公司并不是真的靠这种“制定、谋划、执行”的方式赢得他们的市场份额的。他们是通过灵活性和一点运气获得成功的 —— 更像是“尝试、学习、修改”。
|
||||||
|
|
||||||
当我们可以真正理解并且接受“创新过程是混乱的”这个事实的时候,我们就可以换种方式思考如何让我们的机构实现创新了。与其将资源浪费在预先制定的计划上,**强迫** 创新以一种线性时间线的方式发生,我们不如去构建一些开放并且敏捷的机构,可以 **在创新发生的时候做出及时的响应**。
|
当我们可以真正理解并且接受“创新过程是混乱的”这个事实的时候,我们就可以换种方式思考如何让我们的机构实现创新了。与其将资源浪费在预先制定的计划上,**强迫** 创新以一种线性时间线的方式发生,我们不如去构建一些开放并且敏捷的机构,可以 **在创新发生的时候做出及时的响应**。
|
||||||
|
|
||||||
@ -69,7 +71,7 @@ via: https://opensource.com/open-organization/19/6/innovation-delusion
|
|||||||
作者:[Jim Whitehurst][a]
|
作者:[Jim Whitehurst][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[chen-ni](https://github.com/chen-ni)
|
译者:[chen-ni](https://github.com/chen-ni)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,26 +1,27 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (LuuMing)
|
[#]: translator: (LuuMing)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11079-1.html)
|
||||||
[#]: subject: (Tracking down library injections on Linux)
|
[#]: subject: (Tracking down library injections on Linux)
|
||||||
[#]: via: (https://www.networkworld.com/article/3404621/tracking-down-library-injections-on-linux.html)
|
[#]: via: (https://www.networkworld.com/article/3404621/tracking-down-library-injections-on-linux.html)
|
||||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||||
|
|
||||||
追溯 Linux 上的库注入
|
追溯 Linux 上的库注入
|
||||||
======
|
======
|
||||||
<ruby>库注入<rt>Library injections</rt></ruby>在 Linux 上不如 Windows 上常见,但它仍然是一个问题。下来看看它们如何工作的,以及如何鉴别它们。
|
> <ruby>库注入<rt>Library injections</rt></ruby>在 Linux 上不如 Windows 上常见,但它仍然是一个问题。下来看看它们如何工作的,以及如何鉴别它们。
|
||||||
![Sandra Henry-Stocker][1]
|
|
||||||
|
|
||||||
尽管在 Linux 系统上几乎见不到,但库(Linux 上的共享目标文件)注入仍是一个严峻的威胁。在采访了来自 AT&T 公司 Alien 实验室的 Jaime Blasco 后,我更加意识到了其中一些攻击是多么的易实施。
|
|
||||||
|
|
||||||
在这篇文章中,我会介绍一种攻击方法和它的几种检测手段。我也会提供一些展示攻击细节的链接和一些检测工具。首先,引入一个小小的背景。
|
尽管在 Linux 系统上几乎见不到,但库(Linux 上的共享目标文件)注入仍是一个严峻的威胁。在采访了来自 AT&T 公司 Alien 实验室的 Jaime Blasco 后,我更加意识到了其中一些攻击是多么的易实施。
|
||||||
|
|
||||||
|
在这篇文章中,我会介绍一种攻击方法和它的几种检测手段。我也会提供一些展示攻击细节的链接和一些检测工具。首先,引入一个小小的背景信息。
|
||||||
|
|
||||||
### 共享库漏洞
|
### 共享库漏洞
|
||||||
|
|
||||||
DLL 和 .so 文件都是允许代码(有时候是数据)被不同的进程共享的共享库文件。公用的代码可以放进一个文件中使得每个需要它的进程可以重新使用而不是多次被重写。这也促进了对公用代码的管理。
|
DLL 和 .so 文件都是允许代码(有时候是数据)被不同的进程共享的共享库文件。公用的代码可以放进一个文件中使得每个需要它的进程可以重新使用而不是多次被重写。这也促进了对公用代码的管理。
|
||||||
|
|
||||||
Linux 进程经常使用这些共享库。`ldd`(显示共享对象依赖)命令可以为任何程序显示共享库。这里有一些例子:
|
Linux 进程经常使用这些共享库。(显示共享对象依赖的)`ldd` 命令可以对任何程序文件显示其共享库。这里有一些例子:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ ldd /bin/date
|
$ ldd /bin/date
|
||||||
@ -39,7 +40,7 @@ $ ldd /bin/netstat
|
|||||||
|
|
||||||
`linux-vdso.so.1` (在一些系统上也许会有不同的名字)是内核自动映射到每个进程地址空间的文件。它的工作是找到并定位进程所需的其他共享库。
|
`linux-vdso.so.1` (在一些系统上也许会有不同的名字)是内核自动映射到每个进程地址空间的文件。它的工作是找到并定位进程所需的其他共享库。
|
||||||
|
|
||||||
利用这种库加载机制的一种方法是通过使用 `LD_PRELOAD` 环境变量。正如 Jaime Blasco 在他的研究中所解释的那样,“`LD_PRELOAD` 是最简单且最受欢迎的方法来在进程启动时加载共享库。可以使用共享库的路径配置环境变量,以便在加载其他共享对象之前加载该共享库。”
|
对库加载机制加以利用的一种方法是通过使用 `LD_PRELOAD` 环境变量。正如 Jaime Blasco 在他的研究中所解释的那样,“`LD_PRELOAD` 是在进程启动时加载共享库的最简单且最受欢迎的方法。可以将此环境变量配置到共享库的路径,以便在加载其他共享对象之前加载该共享库。”
|
||||||
|
|
||||||
为了展示有多简单,我创建了一个极其简单的共享库并且赋值给我的(之前不存在) `LD_PRELOAD` 环境变量。之后我使用 `ldd` 命令查看它对于常用 Linux 命令的影响。
|
为了展示有多简单,我创建了一个极其简单的共享库并且赋值给我的(之前不存在) `LD_PRELOAD` 环境变量。之后我使用 `ldd` 命令查看它对于常用 Linux 命令的影响。
|
||||||
|
|
||||||
@ -47,7 +48,7 @@ $ ldd /bin/netstat
|
|||||||
$ export LD_PRELOAD=/home/shs/shownum.so
|
$ export LD_PRELOAD=/home/shs/shownum.so
|
||||||
$ ldd /bin/date
|
$ ldd /bin/date
|
||||||
linux-vdso.so.1 (0x00007ffe005ce000)
|
linux-vdso.so.1 (0x00007ffe005ce000)
|
||||||
/home/shs/shownum.so (0x00007f1e6b65f000) <== there it is
|
/home/shs/shownum.so (0x00007f1e6b65f000) <== 它在这里
|
||||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1e6b458000)
|
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1e6b458000)
|
||||||
/lib64/ld-linux-x86-64.so.2 (0x00007f1e6b682000)
|
/lib64/ld-linux-x86-64.so.2 (0x00007f1e6b682000)
|
||||||
```
|
```
|
||||||
@ -58,13 +59,13 @@ $ ldd /bin/date
|
|||||||
|
|
||||||
### osquery 工具可以检测库注入
|
### osquery 工具可以检测库注入
|
||||||
|
|
||||||
`osquery` 工具(可以在 [osquery.io][4]下载)提供了一个非常独特的方式来照看 Linux 系统。它基本上将操作系统表示为高性能关系数据库。然后,也许你会猜到,这就意味着它可以用来查询并且生成 SQL 表,该表提供了诸如以下的详细信息:
|
`osquery` 工具(可以在 [osquery.io][4]下载)提供了一个非常独特的查看 Linux 系统的方式。它基本上将操作系统视作一个高性能的关系数据库。然后,也许你会猜到,这就意味着它可以用来查询并且生成 SQL 表,该表提供了诸如以下的详细信息:
|
||||||
|
|
||||||
* 运行中的进程
|
* 运行中的进程
|
||||||
* 加载的内核模块
|
* 加载的内核模块
|
||||||
* 进行的网络链接
|
* 打开的网络链接
|
||||||
|
|
||||||
一个提供了进程信息的内核表叫做 `process_envs`。它提供了各种进程使用环境变量的详细信息。Jaime Blasco 提供了一个相当复杂的查询,可以使用 `osquery` 标识使用 `LD_PRELOAD` 的进程。
|
一个提供了进程信息的内核表叫做 `process_envs`。它提供了各种进程使用环境变量的详细信息。Jaime Blasco 提供了一个相当复杂的查询,可以使用 `osquery` 识别出使用 `LD_PRELOAD` 的进程。
|
||||||
|
|
||||||
注意,这个查询是从 `process_envs` 表中获取数据。攻击 ID(T1055)参考 [Mitre 对攻击方法的解释][5]。
|
注意,这个查询是从 `process_envs` 表中获取数据。攻击 ID(T1055)参考 [Mitre 对攻击方法的解释][5]。
|
||||||
|
|
||||||
@ -74,16 +75,16 @@ SELECT process_envs.pid as source_process_id, process_envs.key as environment_va
|
|||||||
|
|
||||||
注意 `LD_PRELOAD` 环境变量有时是合法使用的。例如,各种安全监控工具可能会使用到它,因为开发人员需要进行故障排除、调试或性能分析。然而,它的使用仍然很少见,应当加以防范。
|
注意 `LD_PRELOAD` 环境变量有时是合法使用的。例如,各种安全监控工具可能会使用到它,因为开发人员需要进行故障排除、调试或性能分析。然而,它的使用仍然很少见,应当加以防范。
|
||||||
|
|
||||||
同样值得注意的是 osquery 可以交互使用或是作为定期查询的守护进程去运行。了解更多请查阅文章末尾给出的参考。
|
同样值得注意的是 `osquery` 可以交互使用或是作为定期查询的守护进程去运行。了解更多请查阅文章末尾给出的参考。
|
||||||
|
|
||||||
你也能够通过查看用户的环境设置定位到 `LD_PRELOAD` 的使用。如果 `LD_PRELOAD` 使用用户账户配置,你可以使用这样的命令来查看(在认证了个人身法之后):
|
你也能够通过查看用户的环境设置来定位 `LD_PRELOAD` 的使用。如果在用户账户中使用了 `LD_PRELOAD`,你可以使用这样的命令来查看(假定以个人身份登录后):
|
||||||
|
|
||||||
```
|
```
|
||||||
$ env | grep PRELOAD
|
$ env | grep PRELOAD
|
||||||
LD_PRELOAD=/home/username/userlib.so
|
LD_PRELOAD=/home/username/userlib.so
|
||||||
```
|
```
|
||||||
|
|
||||||
如果你之前没有听说过 osquery,别太在意。它正在成为一个更受欢迎的工具。事实上就在上周,Linux 基金会宣布用新的 [osquery 基金会][6]支持 osquery 社区。
|
如果你之前没有听说过 `osquery`,也别太在意。它正在成为一个更受欢迎的工具。事实上就在上周,Linux 基金会宣布打造了新的 [osquery 基金会][6]以支持 osquery 社区。
|
||||||
|
|
||||||
#### 总结
|
#### 总结
|
||||||
|
|
||||||
@ -93,15 +94,13 @@ LD_PRELOAD=/home/username/userlib.so
|
|||||||
|
|
||||||
重要的参考和工具的链接:
|
重要的参考和工具的链接:
|
||||||
|
|
||||||
* [用 osquery 追寻 Linux 库注入][7],AT&T 网络安全
|
* [用 osquery 追寻 Linux 库注入][7],AT&T Cybersecurity
|
||||||
* [Linux:我的内存怎么了?][8],TrustedSec
|
* [Linux:我的内存怎么了?][8],TrustedSec
|
||||||
* [osquery 下载网站][4]
|
* [下载 osquery][4]
|
||||||
* [osquery 关系模式][9]
|
* [osquery 模式][9]
|
||||||
* [osqueryd(osquery 守护进程)][10]
|
* [osqueryd(osquery 守护进程)][10]
|
||||||
* [Mitre 的攻击框架][11]
|
* [Mitre 的攻击框架][11]
|
||||||
* [新的 osquery 基金会宣布][6]
|
* [新的 osquery 基金会成立][6]
|
||||||
|
|
||||||
在 [Facebook][12] 和 [LinkedIn][13] 上加入网络会议参与讨论。
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -110,7 +109,7 @@ via: https://www.networkworld.com/article/3404621/tracking-down-library-injectio
|
|||||||
作者:[Sandra Henry-Stocker][a]
|
作者:[Sandra Henry-Stocker][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[LuuMing](https://github.com/LuuMing)
|
译者:[LuuMing](https://github.com/LuuMing)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
202
published/201907/20190627 How to use Tig to browse Git logs.md
Normal file
202
published/201907/20190627 How to use Tig to browse Git logs.md
Normal file
@ -0,0 +1,202 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11069-1.html)
|
||||||
|
[#]: subject: (How to use Tig to browse Git logs)
|
||||||
|
[#]: via: (https://opensource.com/article/19/6/what-tig)
|
||||||
|
[#]: author: (Olaf Alders https://opensource.com/users/oalders/users/mbbroberg/users/marcobravo)
|
||||||
|
|
||||||
|
如何使用 Tig 浏览 Git 日志
|
||||||
|
======
|
||||||
|
|
||||||
|
> Tig 可不仅仅是 Git 的文本界面。以下是它如何增强你的日常工作流程。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果你使用 Git 作为你的版本控制系统,你可能已经让自己接受了 Git 是一个复杂的野兽的事实。它是一个很棒的工具,但浏览 Git 仓库可能很麻烦。因此像 [Tig][2] 这样的工具出现了。
|
||||||
|
|
||||||
|
来自 [Tig 手册页][3]:
|
||||||
|
|
||||||
|
> Tig 是 `git`(1) 的基于 ncurses 的文本界面。它主要用作 Git 仓库浏览器,但也有助于在块级别暂存提交更改,并作为各种 Git 命令的输出分页器。
|
||||||
|
|
||||||
|
这基本上意味着 Tig 提供了一个可以在终端中运行的基于文本的用户界面。Tig 可以让你轻松浏览你的 Git 日志,但它可以做的远不止让你从最后的提交跳到前一个提交。
|
||||||
|
|
||||||
|
![Tig screenshot][4]
|
||||||
|
|
||||||
|
这篇快速入门的 Tig 中的许多例子都是直接从其出色的手册页中拿出来的。我强烈建议你阅读它以了解更多信息。
|
||||||
|
|
||||||
|
### 安装 Tig
|
||||||
|
|
||||||
|
* Fedora 和 RHEL: `sudo dnf install tig`
|
||||||
|
* Ubuntu 和 Debian: `sudo apt install tig`
|
||||||
|
* MacOS: `:brew install tig`
|
||||||
|
|
||||||
|
有关更多方式,请参阅官方[安装说明][5]。
|
||||||
|
|
||||||
|
### 浏览当前分支中的提交
|
||||||
|
|
||||||
|
如果要浏览分支中的最新提交,请输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
tig
|
||||||
|
```
|
||||||
|
|
||||||
|
就是这样。这个三字符命令将启动一个浏览器,你可以在其中浏览当前分支中的提交。你可以将其视为 `git log` 的封装器。
|
||||||
|
|
||||||
|
要浏览这些输出,可以使用向上和向下箭头键从一个提交移动到另一个提交。按回车键将会垂直分割窗口,右侧包含所选提交的内容。你可以继续在左侧的提交历史记录中上下浏览,你的更改将显示在右侧。使用 `k` 和 `j` 可以逐行上下浏览,`-` 和空格键可以在右侧上下翻页。使用 `q` 退出右侧窗格。
|
||||||
|
|
||||||
|
搜索 `tig` 输出也很简单。使用 `/` (向前)或 `?` (向后)在左右窗格中搜索。
|
||||||
|
|
||||||
|
![Searching Tig][6]
|
||||||
|
|
||||||
|
这些就足以让你浏览你的提交信息了。这里有很多的键绑定,但单击 `h` 将显示“帮助”菜单,你可以在其中发现其导航和命令选项。你还可以使用 `/` 和 `?` 来搜索“帮助”菜单。使用 `q` 退出帮助。
|
||||||
|
|
||||||
|
![Tig Help][7]
|
||||||
|
|
||||||
|
### 浏览单个文件的修改
|
||||||
|
|
||||||
|
由于 Tig 是 `git log` 的封装器,它可以方便地接受可以传递给 `git log` 的相同参数。例如,要浏览单个文件的提交历史记录,请输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
tig README.md
|
||||||
|
```
|
||||||
|
|
||||||
|
将其与被封装的 Git 命令的输出进行比较,以便更清楚地了解 Tig 如何增强输出。
|
||||||
|
|
||||||
|
```
|
||||||
|
git log README.md
|
||||||
|
```
|
||||||
|
|
||||||
|
要在原始 Git 输出中包含补丁,你可以添加 `-p` 选项:
|
||||||
|
|
||||||
|
```
|
||||||
|
git log -p README.md
|
||||||
|
```
|
||||||
|
|
||||||
|
如果要将提交范围缩小到特定日期范围,请尝试以下操作:
|
||||||
|
|
||||||
|
```
|
||||||
|
tig --after="2017-01-01" --before="2018-05-16" -- README.md
|
||||||
|
```
|
||||||
|
|
||||||
|
再一次,你可以将其与原始的 Git 版本进行比较:
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
git log --after="2017-01-01" --before="2018-05-16" -- README.md
|
||||||
|
```
|
||||||
|
|
||||||
|
### 浏览谁更改了文件
|
||||||
|
|
||||||
|
有时你想知道谁对文件进行了更改以及原因。命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
tig blame README.md
|
||||||
|
```
|
||||||
|
|
||||||
|
器本质上是 `git blame` 的封装。正如你所期望的那样,它允许你查看谁是编辑指定行的最后一人,它还允许你查看到引入该行的提交。这有点像 vim 的 `vim-fugitive` 插件提供的 `:Gblame` 命令。
|
||||||
|
|
||||||
|
### 浏览你的暂存区
|
||||||
|
|
||||||
|
如果你像我一样,你可能会在你的暂存区做了许多修改。你很容易忘记它们。你可以通过以下方式查看暂存处中的最新项目:
|
||||||
|
|
||||||
|
```
|
||||||
|
git stash show -p stash@{0}
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以通过以下方式找到第二个最新项目:
|
||||||
|
|
||||||
|
```
|
||||||
|
git stash show -p stash@{1}
|
||||||
|
```
|
||||||
|
|
||||||
|
以此类推。如果你在需要它们时调用这些命令,那么你会有比我更清晰的记忆。
|
||||||
|
|
||||||
|
与上面的 Git 命令一样,Tig 可以通过简单的调用轻松增强你的 Git 输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
tig stash
|
||||||
|
```
|
||||||
|
|
||||||
|
尝试在有暂存的仓库中执行此命令。你将能够浏览*并搜索*你的暂存项,快速浏览你的那些修改。
|
||||||
|
|
||||||
|
### 浏览你的引用
|
||||||
|
|
||||||
|
Git ref 是指你提交的东西的哈希值。这包括文件和分支。使用 `tig refs` 命令可以浏览所有的 ref 并深入查看特定提交。
|
||||||
|
|
||||||
|
```
|
||||||
|
tig refs
|
||||||
|
```
|
||||||
|
|
||||||
|
完成后,使用 `q` 回到前面的菜单。
|
||||||
|
|
||||||
|
### 浏览 git 状态
|
||||||
|
|
||||||
|
如果要查看哪些文件已被暂存,哪些文件未被跟踪,请使用 `tig status`,它是 `git status` 的封装。
|
||||||
|
|
||||||
|
![Tig status][8]
|
||||||
|
|
||||||
|
### 浏览 git grep
|
||||||
|
|
||||||
|
你可以使用 `grep` 命令在文本文件中搜索表达式。命令 `tig grep` 允许你浏览 `git grep` 的输出。例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
tig grep -i foo lib/Bar
|
||||||
|
```
|
||||||
|
|
||||||
|
它会让你浏览 `lib/Bar` 目录中以大小写敏感的方式搜索 `foo` 的输出。
|
||||||
|
|
||||||
|
### 通过标准输入管道输出给 Tig
|
||||||
|
|
||||||
|
如果要将提交 ID 列表传递给 Tig,那么必须使用 `--stdin` 标志,以便 `tig show` 从标准输入读取。否则,`tig show` 会在没有输入的情况下启动(出现空白屏幕)。
|
||||||
|
|
||||||
|
```
|
||||||
|
git rev-list --author=olaf HEAD | tig show --stdin
|
||||||
|
```
|
||||||
|
|
||||||
|
### 添加自定义绑定
|
||||||
|
|
||||||
|
你可以使用 [rc][9] 文件自定义 Tig。以下是如何根据自己的喜好添加一些有用的自定义键绑定的示例。
|
||||||
|
|
||||||
|
在主目录中创建一个名为 `.tigrc` 的文件。在你喜欢的编辑器中打开 `~/.tigrc` 并添加:
|
||||||
|
|
||||||
|
```
|
||||||
|
# 应用选定的暂存内容
|
||||||
|
bind stash a !?git stash apply %(stash)
|
||||||
|
|
||||||
|
# 丢弃选定的暂存内容
|
||||||
|
bind stash x !?git stash drop %(stash)
|
||||||
|
```
|
||||||
|
|
||||||
|
如上所述,运行 `tig stash` 以浏览你的暂存。但是,通过这些绑定,你可以按 `a` 将暂存中的项目应用到仓库,并按 `x` 从暂存中删除项目。请记住,你要在浏览暂存*列表*时,才能执行这些命令。如果你正在浏览暂存*项*,请输入 `q` 退出该视图,然后按 `a` 或 `x` 以获得所需效果。
|
||||||
|
|
||||||
|
有关更多信息,你可以阅读有关 [Tig 键绑定][10]。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
我希望这有助于演示 Tig 如何增强你的日常工作流程。Tig 可以做更强大的事情(比如暂存代码行),但这超出了这篇介绍性文章的范围。这里有足够的让你置身于危险的信息,但还有更多值得探索的地方。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/6/what-tig
|
||||||
|
|
||||||
|
作者:[Olaf Alders][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/oalders/users/mbbroberg/users/marcobravo
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb (A person programming)
|
||||||
|
[2]: https://jonas.github.io/tig/
|
||||||
|
[3]: http://manpages.ubuntu.com/manpages/bionic/man1/tig.1.html
|
||||||
|
[4]: https://opensource.com/sites/default/files/uploads/tig.jpg (Tig screenshot)
|
||||||
|
[5]: https://jonas.github.io/tig/INSTALL.html
|
||||||
|
[6]: https://opensource.com/sites/default/files/uploads/tig-search.png (Searching Tig)
|
||||||
|
[7]: https://opensource.com/sites/default/files/uploads/tig-help.png (Tig Help)
|
||||||
|
[8]: https://opensource.com/sites/default/files/uploads/tig-status.png (Tig status)
|
||||||
|
[9]: https://en.wikipedia.org/wiki/Run_commands
|
||||||
|
[10]: https://github.com/jonas/tig/wiki/Bindings
|
||||||
@ -0,0 +1,52 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11073-1.html)
|
||||||
|
[#]: subject: (Undo releases Live Recorder 5.0 for Linux debugging)
|
||||||
|
[#]: via: (https://www.networkworld.com/article/3405584/undo-releases-live-recorder-5-0-for-linux-debugging.html)
|
||||||
|
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||||
|
|
||||||
|
Undo 发布用于 Linux 调试的 Live Recorder 5.0
|
||||||
|
======
|
||||||
|
> 随着 Undo 发布 Live Recorder 5.0,这使得在多进程系统上的调试变得更加轻松。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
随着 Undo 发布 Live Recorder 5.0,Linux 调试迈出了一大步。该产品于上个月发布,这使得在多进程系统上的调试变得更加轻松。它基于<ruby>飞行记录仪技术<rt>flight recorder technology</rt></ruby>,它更加深入进程之中,以深入了解每个进程的情况。这包括内存、线程、程序流,服务调用等。为了实现这一目标,Live Recorder 5.0 的记录、重放和调试功能都得到了增强,能够:
|
||||||
|
|
||||||
|
* 记录进程更改共享内存变量的确切顺序。甚至可以针对特定变量并在任何进程中跳转到最后修改该变量的一行。
|
||||||
|
* 通过随机化线程执行来暴露潜在缺陷,以帮助揭示竞态、崩溃和其他多线程缺陷。
|
||||||
|
* 记录并重放单个 Kubernetes 和 Docker 容器的执行,以帮助在微服务环境中更快地解决缺陷。
|
||||||
|
|
||||||
|
Undo Live Recorder 使工程团队能够记录和重放任何软件程序的执行,而无论软件多么复杂。并且可以诊断和修复测试或生产中问题的根本原因。
|
||||||
|
|
||||||
|
根据你的许可证,Live Recorder 可以在命令行中使用 `live-record` 命令,但有点类似于 `strace`,但它不会打印系统调用和信号,而是创建一个“Undo 录制”。然后你可以调试录制中捕获的失败(远比分析核心转储高效!)。这些录制也可以与其他工作人员共享,并可以使用可逆调试器进行重放,以进一步调查崩溃原因或其他问题。
|
||||||
|
|
||||||
|
Undo 引擎支持以下 Linux 发行版:
|
||||||
|
|
||||||
|
* Red Hat Enterprise Linux 6.8、6.9、6.10、7.4、7.5、7.6 和 8.0
|
||||||
|
* Fedora 28、29 和 30
|
||||||
|
* SuSE Linux Enterprise Server 12.3、12.4 和 15
|
||||||
|
* Ubuntu 16.04 LTS、18.04 LTS、18.10 和 19.04
|
||||||
|
|
||||||
|
Undo 是一家快速发展的,有风险投资支持的技术初创公司,它的总部位于旧金山和英国剑桥。他们称 Live Recorder 可以 100% 确定导致任何软件故障的因素 —— 即使在最复杂的软件环境中也是如此。
|
||||||
|
|
||||||
|
在 [Facebook][2] 和 [LinkedIn][3] 上加入 Network World 社区,评论你想说的话题。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.networkworld.com/article/3405584/undo-releases-live-recorder-5-0-for-linux-debugging.html
|
||||||
|
|
||||||
|
作者:[Sandra Henry-Stocker][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://images.idgesg.net/images/article/2019/06/flight_data_recorder-100800552-large.jpg
|
||||||
|
[2]: https://www.facebook.com/NetworkWorld/
|
||||||
|
[3]: https://www.linkedin.com/company/network-world
|
||||||
@ -0,0 +1,51 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11092-1.html)
|
||||||
|
[#]: subject: (Donald Trump Now Wants to Ban End-to-End Encryption)
|
||||||
|
[#]: via: (https://news.softpedia.com/news/donald-trump-now-wants-to-ban-end-to-end-encryption-526567.shtml)
|
||||||
|
[#]: author: (Bogdan Popa https://news.softpedia.com/editors/browse/bogdan-popa)
|
||||||
|
|
||||||
|
美国总统特朗普要禁用端到端加密
|
||||||
|
======
|
||||||
|
|
||||||
|
> 美国官方在开会讨论端到端加密。
|
||||||
|
|
||||||
|
在[禁止][1]和[解禁][2]华为之后,美国总统唐纳德特朗普现在将目光盯上了端到端加密,据一份新的报告声称,白宫高级官员本周会面讨论了政府可以在这方面采取的第一项动作。
|
||||||
|
|
||||||
|
[Politico][3] 援引了三位知情人士的话指出,来自几个关键机构的二号官员讨论了针对端到端加密的潜在攻击。
|
||||||
|
|
||||||
|
“这两条路径是,要么就加密问题发表声明或一般立场,并且[说]他们将继续致力于解决方案,或者要求国会立法,”Politico 援引一位消息人士的话说。
|
||||||
|
|
||||||
|
虽然美国政府希望终止美国公司开发的软件中的端到端加密功能,但这一提议却招致了美国各机构代表的不同反应。
|
||||||
|
|
||||||
|
Politico 指出,例如,国土安全部 “内部存在分歧”,因为该机构意识到禁止端到端加密可能产生的安全隐患。
|
||||||
|
|
||||||
|
### 加密争议
|
||||||
|
|
||||||
|
推动制定这项针对端到端加密的规定,被视为美国情报机构和执法部门努力获取属于犯罪分子和恐怖分子的设备和数据的决定性步骤。
|
||||||
|
|
||||||
|
大多数美国公司已经将加密捆绑到他们的产品当中,这包括苹果和谷歌,它阻止了调查人员访问嫌疑人的数据。科技公司将端到端加密定位为一项关键的隐私功能,其中一些人警告说,任何针对它的监管都可能影响到国家安全。
|
||||||
|
|
||||||
|
特别是苹果公司,它是反对加密监管的最大公司之一。该公司[拒绝解锁圣贝纳迪诺恐怖分子使用的 iPhone][4],解释说侵入该设备会损害所有客户的安全。
|
||||||
|
|
||||||
|
FBI 最终使用了第三方开发的软件解锁了该设备。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://news.softpedia.com/news/donald-trump-now-wants-to-ban-end-to-end-encryption-526567.shtml
|
||||||
|
|
||||||
|
作者:[Bogdan Popa][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://news.softpedia.com/editors/browse/bogdan-popa
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://news.softpedia.com/news/google-bans-huawei-from-using-android-google-play-gmail-other-services-526083.shtml
|
||||||
|
[2]: https://news.softpedia.com/news/breaking-donald-trump-says-huawei-can-buy-american-products-again-526564.shtml
|
||||||
|
[3]: https://www.politico.com/story/2019/06/27/trump-officials-weigh-encryption-crackdown-1385306
|
||||||
|
[4]: https://news.softpedia.com/news/judge-orders-apple-to-help-the-fbi-hack-san-bernardino-shooter-s-iphone-500517.shtml
|
||||||
@ -1,8 +1,8 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (chen-ni)
|
[#]: translator: (chen-ni)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11059-1.html)
|
||||||
[#]: subject: (Ubuntu or Fedora: Which One Should You Use and Why)
|
[#]: subject: (Ubuntu or Fedora: Which One Should You Use and Why)
|
||||||
[#]: via: (https://itsfoss.com/ubuntu-vs-fedora/)
|
[#]: via: (https://itsfoss.com/ubuntu-vs-fedora/)
|
||||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||||
@ -10,9 +10,9 @@
|
|||||||
你应该选择 Ubuntu 还是 Fedora?
|
你应该选择 Ubuntu 还是 Fedora?
|
||||||
======
|
======
|
||||||
|
|
||||||
_**摘要:选择 Ubuntu 还是 Fedora?它们的区别是什么?哪一个更好?你应该使用哪一个?看看这篇对比 Ubuntu 和 Fedora 的文章吧。**_
|
> 选择 Ubuntu 还是 Fedora?它们的区别是什么?哪一个更好?你应该使用哪一个?看看这篇对比 Ubuntu 和 Fedora 的文章吧。
|
||||||
|
|
||||||
Ubuntu 和 Fedora 都是最流行的 Linux 发行版之一,在两者之间做出选择实非易事。在这篇文章里,我会对比一下 Ubuntu 和 Fedora 的不同特点,帮助你进行决策。
|
[Ubuntu][1] 和 [Fedora][2] 都是最流行的 Linux 发行版之一,在两者之间做出选择实非易事。在这篇文章里,我会对比一下 Ubuntu 和 Fedora 的不同特点,帮助你进行决策。
|
||||||
|
|
||||||
请注意,这篇文章主要是从桌面版的角度进行对比的。Fedora 或者 Ubuntu 针对容器的特殊版本不会被考虑在内。
|
请注意,这篇文章主要是从桌面版的角度进行对比的。Fedora 或者 Ubuntu 针对容器的特殊版本不会被考虑在内。
|
||||||
|
|
||||||
@ -57,7 +57,7 @@ Ubuntu 和 Fedora 默认都使用 GNOME 桌面环境。
|
|||||||
|
|
||||||
![GNOME Desktop in Fedora][6]
|
![GNOME Desktop in Fedora][6]
|
||||||
|
|
||||||
Fedora 使用的是 stock GNOME 桌面,而 Ubuntu 则在此基础上做了个性化调整,让它看起来就像 Ubuntu 之前使用的 Unity 桌面环境。
|
Fedora 使用的是原装的 GNOME 桌面,而 Ubuntu 则在此基础上做了个性化调整,让它看起来就像 Ubuntu 之前使用的 Unity 桌面环境。
|
||||||
|
|
||||||
![GNOME desktop customized by Ubuntu][7]
|
![GNOME desktop customized by Ubuntu][7]
|
||||||
|
|
||||||
@ -69,15 +69,13 @@ Fedora 通过 [Fedora Spins][8] 的方式提供了一些不同桌面环境的版
|
|||||||
|
|
||||||
#### 软件包管理和可用软件数量
|
#### 软件包管理和可用软件数量
|
||||||
|
|
||||||
Ubuntu 使用 APT 软件包管理器提供软件并进行管理(包括应用程序、库,以及其它所需代码),而 Fedora 使用 DNF 软件包管理器。
|
Ubuntu 使用 APT 软件包管理器提供软件并进行管理(包括应用程序、库,以及其它所需编解码器),而 Fedora 使用 DNF 软件包管理器。
|
||||||
|
|
||||||
[][9]
|
|
||||||
|
|
||||||
[Ubuntu 拥有庞大的软件仓库][10],能够让你轻松安装数以千计的程序,包括 FOSS(LCTT 译注:Free and Open-Source Software 的缩写,自由开源软件)和非 FOSS 的软件。Fedora 则只专注于提供开源软件。虽然这一点在最近的版本里有所转变,但是 Fedora 的软件仓库在规模上仍然比 Ubuntu 的要逊色一些。
|
[Ubuntu 拥有庞大的软件仓库][10],能够让你轻松安装数以千计的程序,包括 FOSS(LCTT 译注:Free and Open-Source Software 的缩写,自由开源软件)和非 FOSS 的软件。Fedora 则只专注于提供开源软件。虽然这一点在最近的版本里有所转变,但是 Fedora 的软件仓库在规模上仍然比 Ubuntu 的要逊色一些。
|
||||||
|
|
||||||
一些第三方软件开发者为 Linux 提供像 .exe 文件一样可以点击安装的软件包。在 Ubuntu 里这些软件包是 .deb 格式的,在 Fedora 里是 .rpm 格式的。
|
一些第三方软件开发者为 Linux 提供像 .exe 文件一样可以点击安装的软件包。在 Ubuntu 里这些软件包是 .deb 格式的,在 Fedora 里是 .rpm 格式的。
|
||||||
|
|
||||||
大多数软件供应商都为 Linux 用户提供 DEM 和 RPM 文件,但是我也经历过供应商只提供 DEB 文件的情况。比如说 SEO 工具 [Screaming Frog][11] 就只提供 DEB 软件包。反过来,一个软件只有 RPM 格式但是没有 DEB 格式这种情况就极其罕见了。
|
大多数软件供应商都为 Linux 用户提供 DEB 和 RPM 文件,但是我也经历过供应商只提供 DEB 文件的情况。比如说 SEO 工具 [Screaming Frog][11] 就只提供 DEB 软件包。反过来,一个软件只有 RPM 格式但是没有 DEB 格式这种情况就极其罕见了。
|
||||||
|
|
||||||
#### 硬件支持
|
#### 硬件支持
|
||||||
|
|
||||||
@ -113,9 +111,9 @@ Fedora 则是红帽公司的一个社区项目。红帽公司是一个专注于
|
|||||||
|
|
||||||
#### 在背后支持的企业
|
#### 在背后支持的企业
|
||||||
|
|
||||||
Ubuntu 和 Fedora 都有来自母公司的支持。Ubuntu 源自 [Canonical][21] 公司,而 Fedora 源自 [红帽公司][22](现在是 [IBM 的一部分][23])。背后企业的支持非常重要,因为可以确保 Linux 发行版良好的维护。
|
Ubuntu 和 Fedora 都有来自母公司的支持。Ubuntu 源自 [Canonical][21] 公司,而 Fedora 源自 [红帽公司][22](现在是 [IBM 的一部分][23])。背后企业的支持非常重要,因为可以确保 Linux 发行版良好的维护。
|
||||||
|
|
||||||
有一些发行版是由一群独立的业余爱好者们共同创建的,但是在工作负荷之下经常会崩溃。你也许见过一些还算比较流行的发行版项目仅仅是因为这个原因而终止了。很多这样的发行版由于开发者没有足够的业余时间可以投入到项目上而不得不终止,比如 [Antergos][24] 和 Korora。
|
有一些发行版是由一群独立的业余爱好者们共同创建的,但是在工作压力之下经常会结束。你也许见过一些还算比较流行的发行版项目仅仅是因为这个原因而终止了。很多这样的发行版由于开发者没有足够的业余时间可以投入到项目上而不得不终止,比如 [Antergos][24] 和 Korora。
|
||||||
|
|
||||||
Ubuntu 和 Fedora 的背后都有基于 Linux 的企业的支持,这让它们比其它独立的发行版更胜一筹。
|
Ubuntu 和 Fedora 的背后都有基于 Linux 的企业的支持,这让它们比其它独立的发行版更胜一筹。
|
||||||
|
|
||||||
@ -131,7 +129,7 @@ Fedora 同样有服务端版本,并且也有人在使用。但是大多数系
|
|||||||
|
|
||||||
学习 Fedora 可以更好地帮助你使用红帽企业级 Linux(RHEL)。RHEL 是一个付费产品,你需要购买订阅才可以使用。如果你希望在服务器上运行一个和 Fedora 或者红帽类似的操作系统,我推荐使用 CentOS。[CentOS][26] 同样是红帽公司附属的一个社区项目,但是专注于服务端。
|
学习 Fedora 可以更好地帮助你使用红帽企业级 Linux(RHEL)。RHEL 是一个付费产品,你需要购买订阅才可以使用。如果你希望在服务器上运行一个和 Fedora 或者红帽类似的操作系统,我推荐使用 CentOS。[CentOS][26] 同样是红帽公司附属的一个社区项目,但是专注于服务端。
|
||||||
|
|
||||||
#### 结论
|
### 结论
|
||||||
|
|
||||||
你可以看到,Ubuntu 和 Fedora 有很多相似之处。不过就可用软件数量、驱动安装和线上支持来说,Ubuntu 的确更有优势。**Ubuntu 也因此成为了一个更好的选择,尤其是对于没有经验的 Linux 新手而言。**
|
你可以看到,Ubuntu 和 Fedora 有很多相似之处。不过就可用软件数量、驱动安装和线上支持来说,Ubuntu 的确更有优势。**Ubuntu 也因此成为了一个更好的选择,尤其是对于没有经验的 Linux 新手而言。**
|
||||||
|
|
||||||
@ -147,8 +145,8 @@ via: https://itsfoss.com/ubuntu-vs-fedora/
|
|||||||
|
|
||||||
作者:[Abhishek Prakash][a]
|
作者:[Abhishek Prakash][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[chen-ni](https://github.com/chen-ni)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,8 +1,8 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (chen-ni)
|
[#]: translator: (chen-ni)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11072-1.html)
|
||||||
[#]: subject: (Jupyter and data science in Fedora)
|
[#]: subject: (Jupyter and data science in Fedora)
|
||||||
[#]: via: (https://fedoramagazine.org/jupyter-and-data-science-in-fedora/)
|
[#]: via: (https://fedoramagazine.org/jupyter-and-data-science-in-fedora/)
|
||||||
[#]: author: (Avi Alkalay https://fedoramagazine.org/author/aviram/)
|
[#]: author: (Avi Alkalay https://fedoramagazine.org/author/aviram/)
|
||||||
@ -27,15 +27,15 @@
|
|||||||
|
|
||||||
请注意,这些问题的答案是在任何数据库里都查询不到的,因为它们尚不存在,需要被计算出来才行。这就是我们数据科学家从事的工作。
|
请注意,这些问题的答案是在任何数据库里都查询不到的,因为它们尚不存在,需要被计算出来才行。这就是我们数据科学家从事的工作。
|
||||||
|
|
||||||
在这篇文章中你会学习如何将 Fedora 系统打造成数据科学家的开发环境和生产系统。其中大多数基本软件都有 RPM 软件包,但是最先进的组件目前只能通过 Python 的 **pip** 工具安装。
|
在这篇文章中你会学习如何将 Fedora 系统打造成数据科学家的开发环境和生产系统。其中大多数基本软件都有 RPM 软件包,但是最先进的组件目前只能通过 Python 的 `pip` 工具安装。
|
||||||
|
|
||||||
### Jupyter IDE
|
### Jupyter IDE
|
||||||
|
|
||||||
大多数现代数据科学家使用 Python 工作。他们工作中很重要的一部分是 <ruby>探索性数据分析<rt>Exploratory Data Analysis<rt></ruby>(EDA)。EDA 是一种手动进行的、交互性的过程,包括提取数据、探索数据特征、寻找相关性、通过绘制图形进行数据可视化并理解数据的分布特征,以及实现简易的预测模型。
|
大多数现代数据科学家使用 Python 工作。他们工作中很重要的一部分是 <ruby>探索性数据分析<rt>Exploratory Data Analysis<rt></ruby>(EDA)。EDA 是一种手动进行的、交互性的过程,包括提取数据、探索数据特征、寻找相关性、通过绘制图形进行数据可视化并理解数据的分布特征,以及实现原型预测模型。
|
||||||
|
|
||||||
Jupyter 是能够完美胜任该工作的一个 web 应用。Jupyter 使用的 Notebook 文件支持丰富的文本,包括渲染精美的数学公式(得益于 [mathjax][2])、代码块和代码输出(包括图形输出)。
|
Jupyter 是能够完美胜任该工作的一个 web 应用。Jupyter 使用的 Notebook 文件支持富文本,包括渲染精美的数学公式(得益于 [mathjax][2])、代码块和代码输出(包括图形输出)。
|
||||||
|
|
||||||
Notebook 文件的后缀是 **.ipynb**,意思是“交互式 Python Notebook”。
|
Notebook 文件的后缀是 `.ipynb`,意思是“交互式 Python Notebook”。
|
||||||
|
|
||||||
#### 搭建并运行 Jupyter
|
#### 搭建并运行 Jupyter
|
||||||
|
|
||||||
@ -44,20 +44,21 @@ Notebook 文件的后缀是 **.ipynb**,意思是“交互式 Python Notebook
|
|||||||
```
|
```
|
||||||
$ sudo dnf install python3-notebook mathjax sscg
|
$ sudo dnf install python3-notebook mathjax sscg
|
||||||
```
|
```
|
||||||
|
|
||||||
你或许需要安装数据科学家常用的一些附加可选模块:
|
你或许需要安装数据科学家常用的一些附加可选模块:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo dnf install python3-seaborn python3-lxml python3-basemap python3-scikit-image python3-scikit-learn python3-sympy python3-dask+dataframe python3-nltk
|
$ sudo dnf install python3-seaborn python3-lxml python3-basemap python3-scikit-image python3-scikit-learn python3-sympy python3-dask+dataframe python3-nltk
|
||||||
```
|
```
|
||||||
|
|
||||||
设置一个用来登陆 Notebook 的 web 界面的密码,从而避免使用冗长的令牌。你可以在终端里任何一个位置运行下面的命令:
|
设置一个用来登录 Notebook 的 web 界面的密码,从而避免使用冗长的令牌。你可以在终端里任何一个位置运行下面的命令:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ mkdir -p $HOME/.jupyter
|
$ mkdir -p $HOME/.jupyter
|
||||||
$ jupyter notebook password
|
$ jupyter notebook password
|
||||||
```
|
```
|
||||||
|
|
||||||
然后输入你的密码,这时会自动创建 ** $HOME/.jupyter/jupyter_notebook_config.json ** 这个文件,包含了你的密码的加密后版本。
|
然后输入你的密码,这时会自动创建 `$HOME/.jupyter/jupyter_notebook_config.json` 这个文件,包含了你的密码的加密后版本。
|
||||||
|
|
||||||
接下来,通过使用 SSLby 为 Jupyter 的 web 服务器生成一个自签名的 HTTPS 证书:
|
接下来,通过使用 SSLby 为 Jupyter 的 web 服务器生成一个自签名的 HTTPS 证书:
|
||||||
|
|
||||||
@ -65,7 +66,7 @@ $ jupyter notebook password
|
|||||||
$ cd $HOME/.jupyter; sscg
|
$ cd $HOME/.jupyter; sscg
|
||||||
```
|
```
|
||||||
|
|
||||||
配置 Jupyter 的最后一步是编辑 **$HOME/.jupyter/jupyter_notebook_config.json** 这个文件。按照下面的模版编辑该文件:
|
配置 Jupyter 的最后一步是编辑 `$HOME/.jupyter/jupyter_notebook_config.json` 这个文件。按照下面的模版编辑该文件:
|
||||||
|
|
||||||
```
|
```
|
||||||
{
|
{
|
||||||
@ -83,9 +84,9 @@ $ cd $HOME/.jupyter; sscg
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
红色的部分应该替换为你的文件夹。蓝色的部分在你创建完密码之后就已经自动生成了。绿色的部分是 **sscg** 生成的和加密相关的文件。
|
`/home/aviram/` 应该替换为你的文件夹。`sha1:abf58...87b` 这个部分在你创建完密码之后就已经自动生成了。`service.pem` 和 `service-key.pem` 是 `sscg` 生成的和加密相关的文件。
|
||||||
|
|
||||||
接下来创建一个用来存放 notebook 文件的文件夹,应该和上面配置里 **notebook_dir** 一致:
|
接下来创建一个用来存放 Notebook 文件的文件夹,应该和上面配置里 `notebook_dir` 一致:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ mkdir $HOME/Notebooks
|
$ mkdir $HOME/Notebooks
|
||||||
@ -97,40 +98,40 @@ $ mkdir $HOME/Notebooks
|
|||||||
$ jupyter notebook
|
$ jupyter notebook
|
||||||
```
|
```
|
||||||
|
|
||||||
或者是将下面这行代码添加到 **$HOME/.bashrc** 文件,创建一个叫做 **jn** 的快捷命令:
|
或者是将下面这行代码添加到 `$HOME/.bashrc` 文件,创建一个叫做 `jn` 的快捷命令:
|
||||||
|
|
||||||
```
|
```
|
||||||
alias jn='jupyter notebook'
|
alias jn='jupyter notebook'
|
||||||
```
|
```
|
||||||
|
|
||||||
运行 **jn** 命令之后,你可以通过网络内部的任何一个浏览器访问 **<https://your-fedora-host.com:8888>** (LCTT 译注:将域名替换为服务器的域名),就可以看到 Jupyter 的用户界面了,需要使用前面设置的密码登录。你可以尝试键入一些 Python 代码和标记文本,看起来会像下面这样:
|
运行 `jn` 命令之后,你可以通过网络内部的任何一个浏览器访问 `<https://your-fedora-host.com:8888>` (LCTT 译注:请将域名替换为服务器的域名),就可以看到 Jupyter 的用户界面了,需要使用前面设置的密码登录。你可以尝试键入一些 Python 代码和标记文本,看起来会像下面这样:
|
||||||
|
|
||||||
![Jupyter with a simple notebook][4]
|
![Jupyter with a simple notebook][4]
|
||||||
|
|
||||||
除了 IPython 环境,安装过程还会生成一个由 **terminado** 提供的基于 web 的 Unix 终端。有人觉得这很实用,也有人觉得这样不是很安全。你可以在配置文件里禁用这个功能。
|
除了 IPython 环境,安装过程还会生成一个由 `terminado` 提供的基于 web 的 Unix 终端。有人觉得这很实用,也有人觉得这样不是很安全。你可以在配置文件里禁用这个功能。
|
||||||
|
|
||||||
### JupyterLab — 下一代 Jupyter
|
### JupyterLab:下一代 Jupyter
|
||||||
|
|
||||||
JupyterLab 是下一代的 Jupyter,拥有更好的用户界面和对工作空间更强的操控性。在写这篇文章的时候 JupyterLab 还没有可用的 RPM 软件包,但是你可以使用 **pip** 轻松完成安装:
|
JupyterLab 是下一代的 Jupyter,拥有更好的用户界面和对工作空间更强的操控性。在写这篇文章的时候 JupyterLab 还没有可用的 RPM 软件包,但是你可以使用 `pip` 轻松完成安装:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ pip3 install jupyterlab --user
|
$ pip3 install jupyterlab --user
|
||||||
$ jupyter serverextension enable --py jupyterlab
|
$ jupyter serverextension enable --py jupyterlab
|
||||||
```
|
```
|
||||||
|
|
||||||
然后运行 **jupiter notebook** 命令或者 **jn** 快捷命令。访问 **<http://your-linux-host.com:8888/**lab**>** LCTT 译注:将域名替换为服务器的域名)就可以使用 JupyterLab 了。
|
然后运行 `jupiter notebook` 命令或者 `jn` 快捷命令。访问 `<http://your-linux-host.com:8888/`lab`>` (LCTT 译注:将域名替换为服务器的域名)就可以使用 JupyterLab 了。
|
||||||
|
|
||||||
### 数据科学家使用的工具
|
### 数据科学家使用的工具
|
||||||
|
|
||||||
在下面这一节里,你将会了解到数据科学家使用的一些工具及其安装方法。除非另作说明,这些工具应该已经有 Fedora 软件包版本,并且已经作为前面组件所需要的软件包而被安装了。
|
在下面这一节里,你将会了解到数据科学家使用的一些工具及其安装方法。除非另作说明,这些工具应该已经有 Fedora 软件包版本,并且已经作为前面组件所需要的软件包而被安装了。
|
||||||
|
|
||||||
#### **Numpy**
|
#### Numpy
|
||||||
|
|
||||||
**Numpy** 是一个针对 C 语言优化过的高级库,用来处理内存里的大型数据集。它支持高级多维矩阵及其运算,并且包含了 log()、exp()、三角函数等数学函数。
|
Numpy 是一个针对 C 语言优化过的高级库,用来处理大型的内存数据集。它支持高级多维矩阵及其运算,并且包含了 `log()`、`exp()`、三角函数等数学函数。
|
||||||
|
|
||||||
#### Pandas
|
#### Pandas
|
||||||
|
|
||||||
在我看来,正是 Pandas 成就了 Python 作为数据科学首选平台的地位。Pandas 构建在 numpy 之上,可以让数据准备和数据呈现工作变得简单很多。你可以把它想象成一个没有用户界面的电子表格程序,但是能够处理的数据集要大得多。Pandas 支持从 SQL 数据库或者 CSV 等格式的文件中提取数据、按列或者按行进行操作、数据筛选,以及通过 matplotlib 实现数据可视化的一部分功能。
|
在我看来,正是 Pandas 成就了 Python 作为数据科学首选平台的地位。Pandas 构建在 Numpy 之上,可以让数据准备和数据呈现工作变得简单很多。你可以把它想象成一个没有用户界面的电子表格程序,但是能够处理的数据集要大得多。Pandas 支持从 SQL 数据库或者 CSV 等格式的文件中提取数据、按列或者按行进行操作、数据筛选,以及通过 Matplotlib 实现数据可视化的一部分功能。
|
||||||
|
|
||||||
#### Matplotlib
|
#### Matplotlib
|
||||||
|
|
||||||
@ -140,23 +141,23 @@ Matplotlib 是一个用来绘制 2D 和 3D 数据图像的库,在图象注解
|
|||||||
|
|
||||||
#### Seaborn
|
#### Seaborn
|
||||||
|
|
||||||
Seaborn 构建在 matplotlib 之上,它的绘图功能经过了优化,更加适合数据的统计学研究,比如说可以自动显示所绘制数据的近似回归线或者正态分布曲线。
|
Seaborn 构建在 Matplotlib 之上,它的绘图功能经过了优化,更加适合数据的统计学研究,比如说可以自动显示所绘制数据的近似回归线或者正态分布曲线。
|
||||||
|
|
||||||
![Linear regression visualised with SeaBorn][6]
|
![Linear regression visualised with SeaBorn][6]
|
||||||
|
|
||||||
#### [StatsModels][7]
|
#### StatsModels
|
||||||
|
|
||||||
StatsModels 为统计学和经济计量学的数据分析问题(例如线形回归和逻辑回归)提供算法支持,同时提供经典的 [时间序列算法][8] 家族:ARIMA。
|
[StatsModels][7] 为统计学和经济计量学的数据分析问题(例如线形回归和逻辑回归)提供算法支持,同时提供经典的 [时间序列算法][8] 家族 ARIMA。
|
||||||
|
|
||||||
![Normalized number of passengers across time \(blue\) and ARIMA-predicted number of passengers \(red\)][9]
|
![Normalized number of passengers across time \(blue\) and ARIMA-predicted number of passengers \(red\)][9]
|
||||||
|
|
||||||
#### Scikit-learn
|
#### Scikit-learn
|
||||||
|
|
||||||
作为机器学习生态系统的核心部件,[scikit][10] 为不同类型的问题提供预测算法,包括 [回归问题][11](算法包括 Elasticnet、Gradient Boosting、随机森林等等)、[分类问题][11] 和聚类问题(算法包括 K-means 和 DBSCAN 等等),并且拥有设计精良的 API。Scikit 还定义了一些专门的 Python 类,用来支持数据操作的高级技巧,比如将数据集拆分为训练集和测试集、降维算法、数据准备管道流程等等。
|
作为机器学习生态系统的核心部件,[Scikit][10] 为不同类型的问题提供预测算法,包括 [回归问题][11](算法包括 Elasticnet、Gradient Boosting、随机森林等等)、[分类问题][11] 和聚类问题(算法包括 K-means 和 DBSCAN 等等),并且拥有设计精良的 API。Scikit 还定义了一些专门的 Python 类,用来支持数据操作的高级技巧,比如将数据集拆分为训练集和测试集、降维算法、数据准备管道流程等等。
|
||||||
|
|
||||||
#### XGBoost
|
#### XGBoost
|
||||||
|
|
||||||
XGBoost 是目前可以使用的最先进的回归器和分类器。它并不是 scikit-learn 的一部分,但是却遵循了 scikit 的 API。[XGBoost][12] 并没有针对 Fedora 的软件包,但可以使用 pip 安装。[使用英伟达显卡可以提升 XGBoost 算法的性能][13],但是这并不能通过 **pip** 软件包来实现。如果你希望使用这个功能,可以针对 CUDA (LCTT 译注:英伟达开发的并行计算平台)自己进行编译。使用下面这个命令安装 XGBoost:
|
XGBoost 是目前可以使用的最先进的回归器和分类器。它并不是 Scikit-learn 的一部分,但是却遵循了 Scikit 的 API。[XGBoost][12] 并没有针对 Fedora 的软件包,但可以使用 `pip` 安装。[使用英伟达显卡可以提升 XGBoost 算法的性能][13],但是这并不能通过 `pip` 软件包来实现。如果你希望使用这个功能,可以针对 CUDA (LCTT 译注:英伟达开发的并行计算平台)自己进行编译。使用下面这个命令安装 XGBoost:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ pip3 install xgboost --user
|
$ pip3 install xgboost --user
|
||||||
@ -164,7 +165,7 @@ $ pip3 install xgboost --user
|
|||||||
|
|
||||||
#### Imbalanced Learn
|
#### Imbalanced Learn
|
||||||
|
|
||||||
[imbalanced-learn][14] 是一个解决数据欠采样和过采样问题的工具。比如在反欺诈问题中,欺诈数据相对于正常数据来说数量非常小,这个时候就需要对欺诈数据进行数据增强,从而让预测器能够更好地适应数据集。使用 **pip** 安装:
|
[Imbalanced-learn][14] 是一个解决数据欠采样和过采样问题的工具。比如在反欺诈问题中,欺诈数据相对于正常数据来说数量非常小,这个时候就需要对欺诈数据进行数据增强,从而让预测器能够更好地适应数据集。使用 `pip` 安装:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ pip3 install imblearn --user
|
$ pip3 install imblearn --user
|
||||||
@ -174,31 +175,30 @@ $ pip3 install imblearn --user
|
|||||||
|
|
||||||
[Natural Language toolkit][15](简称 NLTK)是一个处理人类语言数据的工具,举例来说,它可以被用来开发一个聊天机器人。
|
[Natural Language toolkit][15](简称 NLTK)是一个处理人类语言数据的工具,举例来说,它可以被用来开发一个聊天机器人。
|
||||||
|
|
||||||
|
|
||||||
#### SHAP
|
#### SHAP
|
||||||
|
|
||||||
机器学习算法拥有强大的预测能力,但并不能够很好地解释为什么做出这样或那样的预测。[SHAP][16] 可以通过分析训练后的模型来解决这个问题。
|
机器学习算法拥有强大的预测能力,但并不能够很好地解释为什么做出这样或那样的预测。[SHAP][16] 可以通过分析训练后的模型来解决这个问题。
|
||||||
|
|
||||||
![Where SHAP fits into the data analysis process][17]
|
![Where SHAP fits into the data analysis process][17]
|
||||||
|
|
||||||
使用 **pip** 安装:
|
使用 `pip` 安装:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ pip3 install shap --user
|
$ pip3 install shap --user
|
||||||
```
|
```
|
||||||
|
|
||||||
#### [Keras][18]
|
#### Keras
|
||||||
|
|
||||||
Keras 是一个深度学习和神经网络模型的库,使用 **pip** 安装:
|
[Keras][18] 是一个深度学习和神经网络模型的库,使用 `pip` 安装:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo dnf install python3-h5py
|
$ sudo dnf install python3-h5py
|
||||||
$ pip3 install keras --user
|
$ pip3 install keras --user
|
||||||
```
|
```
|
||||||
|
|
||||||
#### [TensorFlow][19]
|
#### TensorFlow
|
||||||
|
|
||||||
TensorFlow 是一个非常流行的神经网络模型搭建工具,使用 **pip** 安装:
|
[TensorFlow][19] 是一个非常流行的神经网络模型搭建工具,使用 `pip` 安装:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ pip3 install tensorflow --user
|
$ pip3 install tensorflow --user
|
||||||
@ -215,7 +215,7 @@ via: https://fedoramagazine.org/jupyter-and-data-science-in-fedora/
|
|||||||
作者:[Avi Alkalay][a]
|
作者:[Avi Alkalay][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[chen-ni](https://github.com/chen-ni)
|
译者:[chen-ni](https://github.com/chen-ni)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
259
published/201907/20190702 Make Linux stronger with firewalls.md
Normal file
259
published/201907/20190702 Make Linux stronger with firewalls.md
Normal file
@ -0,0 +1,259 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (chen-ni)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11093-1.html)
|
||||||
|
[#]: subject: (Make Linux stronger with firewalls)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/make-linux-stronger-firewalls)
|
||||||
|
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||||
|
|
||||||
|
使用防火墙让你的 Linux 更加强大
|
||||||
|
======
|
||||||
|
> 掌握防火墙的工作原理,以及如何设置防火墙来提高 Linux 的安全性
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
所有人都听说过防火墙(哪怕仅仅是在网络犯罪片里看到过相关的情节设定),很多人也知道他们的计算机里很可能正运行着防火墙,但是很少有人明白在必要的时候如何驾驭防火墙。
|
||||||
|
|
||||||
|
防火墙被用来拦截那些不请自来的网络流量,然而不同网络需要的安全级别也不尽相同。比如说,和在外面一家咖啡馆里使用公共 WiFi 相比,你在家里的时候可以更加信任网络里的其它计算机和设备。你或许希望计算机能够区分可以信任和不可信任的网络,不过最好还是应该学会自己去管理(或者至少是核实)你的安全设置。
|
||||||
|
|
||||||
|
### 防火墙的工作原理
|
||||||
|
|
||||||
|
网络里不同设备之间的通信是通过一种叫做<ruby>端口<rt>port</rt></ruby>的网关实现的。这里的端口指的并不是像 USB 端口 或者 HDMI 端口这样的物理连接。在网络术语中,端口是一个纯粹的虚拟概念,用来表示某种类型的数据到达或离开一台计算机时候所走的路径。其实也可以换个名字来称呼,比如叫“连接”或者“门口”,不过 [早在 1981 年的时候][2] 它们就被称作端口了,这个叫法也沿用至今。其实端口这个东西没有任何特别之处,只是一种用来指代一个可能会发生数据传输的地址的方式。
|
||||||
|
|
||||||
|
1972 年,发布了一份 [端口号列表][3](那时候的端口被称为“<ruby>套接字<rt>socket</rt></ruby>”),并且从此演化为一组众所周知的标准端口号,帮助管理特定类型的网络流量。比如说,你每天访问网站的时候都会使用 80 和 443 端口,因为互联网上的绝大多数人都同意(或者是默认)数据从 web 服务器上传输的时候是通过这两个端口的。如果想要验证这一点,你可以在使用浏览器访问网站的时候在 URL 后面加上一个非标准的端口号码。比如说,访问 `example.com:42` 的请求会被拒绝,因为 example.com 在 42 端口上并不提供网站服务。
|
||||||
|
|
||||||
|
![Navigating to a nonstandard port produces an error][4]
|
||||||
|
|
||||||
|
如果你是通过 80 端口访问同一个网站,就可以(不出所料地)正常访问了。你可以在 URL 后面加上 `:80` 来指定使用 80 端口,不过由于 80 端口是 HTTP 访问的标准端口,所以你的浏览器其实已经默认在使用 80 端口了。
|
||||||
|
|
||||||
|
当一台计算机(比如说 web 服务器)准备在指定端口接收网络流量的时候,保持该端口向网络流量开放是一种可以接受的(也是必要的)行为。但是不需要接收流量的端口如果也处在开放状态就比较危险了,这就是需要用防火墙解决的问题。
|
||||||
|
|
||||||
|
#### 安装 firewalld
|
||||||
|
|
||||||
|
有很多种配置防火墙的方式,这篇文章介绍 [firewalld][5]。在桌面环境下它被集成在<ruby>网络管理器<rt>Network Manager</rt></ruby>里,在终端里则是集成在 `firewall-cmd` 里。很多 Linux 发行版都预装了这些工具。如果你的发行版里没有,你可以把这篇文章当成是管理防火墙的通用性建议,在你所使用的防火墙软件里使用类似的方法,或者你也可以选择安装 `firewalld`。
|
||||||
|
|
||||||
|
比如说在 Ubuntu 上,你必须启用 universe 软件仓库,关闭默认的 `ufw` 防火墙,然后再安装 `firewalld`:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo systemctl disable ufw
|
||||||
|
$ sudo add-apt-repository universe
|
||||||
|
$ sudo apt install firewalld
|
||||||
|
```
|
||||||
|
|
||||||
|
Fedora、CentOS、RHEL、OpenSUSE,以及其它很多发行版默认就包含了 `firewalld`。
|
||||||
|
|
||||||
|
无论你使用哪个发行版,如果希望防火墙发挥作用,就必须保持它在开启状态,并且设置成开机自动加载。你应该尽可能减少在防火墙维护工作上所花费的精力。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo systemctl enable --now firewalld
|
||||||
|
```
|
||||||
|
|
||||||
|
### 使用网络管理器选择区域
|
||||||
|
|
||||||
|
或许你每天都会连接到很多不同的网络。在工作的时候使用的是一个网络,在咖啡馆里是另一个,在家里又是另一个。你的计算机可以判断出哪一个网络的使用频率比较高,但是它并不知道哪一个是你信任的网络。
|
||||||
|
|
||||||
|
一个防火墙的<ruby>区域<rt>zone</rt></ruby>里包含了端口开放和关闭的预设规则。你可以通过使用区域来选择一个对当前网络最适用的策略。
|
||||||
|
|
||||||
|
你可以打开网络管理器里的连接编辑器(可以在应用菜单里找到),或者是使用 `nm-connection-editor &` 命令以获取所有可用区域的列表。
|
||||||
|
|
||||||
|
![Network Manager Connection Editor][6]
|
||||||
|
|
||||||
|
在网络连接列表中,双击你现在所使用的网络。
|
||||||
|
|
||||||
|
在出现的网络配置窗口中,点击“通用”标签页。
|
||||||
|
|
||||||
|
在“通用”面板中,点击“防火墙区域”旁边的下拉菜单以获取所有可用区域的列表。
|
||||||
|
|
||||||
|
![Firewall zones][7]
|
||||||
|
|
||||||
|
也可以使用下面的终端命令以获取同样的列表:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --get-zones
|
||||||
|
```
|
||||||
|
|
||||||
|
每个区域的名称已经可以透露出设计者创建这个区域的意图,不过你也可以使用下面这个终端命令获取任何一个区域的详细信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --zone work --list-all
|
||||||
|
work
|
||||||
|
target: default
|
||||||
|
icmp-block-inversion: no
|
||||||
|
interfaces:
|
||||||
|
sources:
|
||||||
|
services: ssh dhcpv6-client
|
||||||
|
ports:
|
||||||
|
protocols:
|
||||||
|
[...]
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个例子中,`work` 区域的配置是允许接收 SSH 和 DHCPv6-client 的流量,但是拒绝接收其他任何用户没有明确请求的流量。(换句话说,`work` 区域并不会在你浏览网站的时候拦截 HTTP 响应流量,但是 **会** 拦截一个针对你计算机上 80 端口的 HTTP 请求。)
|
||||||
|
|
||||||
|
你可以依次查看每一个区域,弄清楚它们分别都允许什么样的流量。比较常见的有:
|
||||||
|
|
||||||
|
* `work`:这个区域应该在你非常信任的网络上使用。它允许 SSH、DHCPv6 和 mDNS,并且还可以添加更多允许的项目。该区域非常适合作为一个基础配置,然后在此之上根据日常办公的需求自定义一个工作环境。
|
||||||
|
* `public`: 用在你不信任的网络上。这个区域的配置和工作区域是一样的,但是你不应该再继续添加其它任何允许项目。
|
||||||
|
* `drop`: 所有传入连接都会被丢弃,并且不会有任何响应。在不彻底关闭网络的条件下,这已经是最接近隐形模式的配置了,因为只允许传出网络连接(不过随便一个端口扫描器就可以通过传出流量检测到你的计算机,所以这个区域并不是一个隐形装置)。如果你在使用公共 WiFi,这个区域可以说是最安全的选择;如果你觉得当前的网络比较危险,这个区域也一定是最好的选择。
|
||||||
|
* `block`: 所有传入连接都会被拒绝,但是会返回一个消息说明所请求的端口被禁用了。只有你主动发起的网络连接是被允许的。这是一个友好版的 `drop` 区域,因为虽然还是没有任何一个端口允许传入流量,但是说明了会拒绝接收任何不是本机主动发起的连接。
|
||||||
|
* `home`: 在你信任网络里的其它计算机的情况下使用这个区域。该区域只会允许你所选择的传入连接,但是你可以根据需求添加更多的允许项目。
|
||||||
|
* `internal`: 和工作区域类似,该区域适用于内部网络,你应该在基本信任网络里的计算机的情况下使用。你可以根据需求开放更多的端口和服务,同时保持和工作区域不同的一套规则。
|
||||||
|
* `trusted`: 接受所有的网络连接。适合在故障排除的情况下或者是在你绝对信任的网络上使用。
|
||||||
|
|
||||||
|
### 为网络指定一个区域
|
||||||
|
|
||||||
|
你可以为你的任何一个网络连接都指定一个区域,并且对于同一个网络的不同连接方式(比如以太网、WiFi 等等)也可以指定不同的区域。
|
||||||
|
|
||||||
|
选择你想要的区域,点击“保存”按钮提交修改。
|
||||||
|
|
||||||
|
![Setting a new zone][8]
|
||||||
|
|
||||||
|
养成为网络连接指定区域的习惯的最好办法是从你最常用的网络开始。为你的家庭网络指定家庭区域,为工作网络指定工作区域,为你最喜欢的图书馆或者咖啡馆的网络指定公关区域。
|
||||||
|
|
||||||
|
一旦你为所有常用的网络都指定了一个区域,在之后加入新的网络的时候(无论是一个新的咖啡馆还是你朋友家的网络),试图也为它指定一个区域吧。这样可以很好地让你意识到不同的网络的安全性是不一样的,你并不会仅仅因为使用了 Linux 而比任何人更加安全。
|
||||||
|
|
||||||
|
### 默认区域
|
||||||
|
|
||||||
|
每次你加入一个新的网络的时候,`firewalld` 并不会提示你进行选择,而是会指定一个默认区域。你可以在终端里输入下面这个命令来获取你的默认区域:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --get-default
|
||||||
|
public
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个例子里,默认区域是 `public` 区域。你应该保证该区域有非常严格的限制规则,这样在将它指定到未知网络中的时候才比较安全。或者你也可以设置你自己的默认区域。
|
||||||
|
|
||||||
|
比如说,如果你是一个比较多疑的人,或者需要经常接触不可信任的网络的话,你可以设置一个非常严格的默认区域:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --set-default-zone drop
|
||||||
|
success
|
||||||
|
$ sudo firewall-cmd --get-default
|
||||||
|
drop
|
||||||
|
```
|
||||||
|
|
||||||
|
这样一来,任何你新加入的网络都会被指定使用 `drop` 区域,除非你手动将它制定为另一个没有这么严格的区域。
|
||||||
|
|
||||||
|
### 通过开放端口和服务实现自定义区域
|
||||||
|
|
||||||
|
Firewalld 的开发者们并不是想让他们设定的区域能够适应世界上所有不同的网络和所有级别的信任程度。你可以直接使用这些区域,也可以在它们基础上进行个性化配置。
|
||||||
|
|
||||||
|
你可以根据自己所需要进行的网络活动决定开放或关闭哪些端口,这并不需要对防火墙有多深的理解。
|
||||||
|
|
||||||
|
#### 预设服务
|
||||||
|
|
||||||
|
在你的防火墙上添加许可的最简单的方式就是添加预设服务。严格来讲,你的防火墙并不懂什么是“服务”,因为它只知道端口号码和使用协议的类型。不过在标准和传统的基础之上,防火墙可以为你提供一套端口和协议的组合。
|
||||||
|
|
||||||
|
比如说,如果你是一个 web 开发者并且希望你的计算机对本地网络开放(这样你的同事就可以看到你正在搭建的网站了),可以添加 `http` 和 `https` 服务。如果你是一名游戏玩家,并且在为你的游戏公会运行开源的 [murmur][9] 语音聊天服务器,那么你可以添加 `murmur` 服务。还有其它很多可用的服务,你可以使用下面这个命令查看:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --get-services
|
||||||
|
amanda-client amanda-k5-client bacula bacula-client \
|
||||||
|
bgp bitcoin bitcoin-rpc ceph cfengine condor-collector \
|
||||||
|
ctdb dhcp dhcpv6 dhcpv6-client dns elasticsearch \
|
||||||
|
freeipa-ldap freeipa-ldaps ftp [...]
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你找到了一个自己需要的服务,可以将它添加到当前的防火墙配置中,比如说:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --add-service murmur
|
||||||
|
```
|
||||||
|
|
||||||
|
这个命令 **在你的默认区域里** 添加了指定服务所需要的所有端口和协议,不过在重启计算机或者防火墙之后就会失效。如果想让你的修改永久有效,可以使用 `--permanent` 标志:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --add-service murmur --permanent
|
||||||
|
```
|
||||||
|
|
||||||
|
你也可以将这个命令用于一个非默认区域:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --add-service murmur --permanent --zone home
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 端口
|
||||||
|
|
||||||
|
有时候你希望允许的流量并不在 `firewalld` 定义的服务之中。也许你想在一个非标准的端口上运行一个常规服务,或者就是想随意开放一个端口。
|
||||||
|
|
||||||
|
举例来说,也许你正在运行开源的 [虚拟桌游][10] 软件 [MapTool][11]。由于 MapTool 服务器应该使用哪个端口这件事情并没有一个行业标准,所以你可以自行决定使用哪个端口,然后在防火墙上“开一个洞”,让它允许该端口上的流量。
|
||||||
|
|
||||||
|
实现方式和添加服务差不多:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --add-port 51234/tcp
|
||||||
|
```
|
||||||
|
|
||||||
|
这个命令 **在你的默认区域** 里将 51234 端口向 TCP 传入连接开放,不过在重启计算机或者防火墙之后就会失效。如果想让你的修改永久有效,可以使用 `--permanent` 标志:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --add-port 51234/tcp --permanent
|
||||||
|
```
|
||||||
|
|
||||||
|
你也可以将这个命令用于一个非默认区域:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --add-port 51234/tcp --permanent --zone home
|
||||||
|
```
|
||||||
|
|
||||||
|
在路由器的防火墙上设置允许流量和在本机上设置的方式是不同的。你的路由器可能会为它的内嵌防火墙提供一个不同的配置界面(原理上是相同的),不过这就超出本文范围了。
|
||||||
|
|
||||||
|
### 移除端口和服务
|
||||||
|
|
||||||
|
如果你不再需要某项服务或者某个端口了,并且设置的时候没有使用 `--permanent` 标志的话,那么可以通过重启防火墙来清除修改。
|
||||||
|
|
||||||
|
如果你已经将修改设置为永久生效了,可以使用 `--remove-port` 或者 `--remove-service` 标志来清除:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --remove-port 51234/tcp --permanent
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以通过在命令中指定一个区域以将端口或者服务从一个非默认区域中移除。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --remove-service murmur --permanent --zone home
|
||||||
|
```
|
||||||
|
|
||||||
|
### 自定义区域
|
||||||
|
|
||||||
|
你可以随意使用 `firewalld` 默认提供的这些区域,不过也完全可以创建自己的区域。比如如果希望有一个针对游戏的特别区域,你可以创建一个,然后只有在玩儿游戏的时候切换到该区域。
|
||||||
|
|
||||||
|
如果想要创建一个新的空白区域,你可以创建一个名为 `game` 的新区域,然后重新加载防火墙规则,这样你的新区域就启用了:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --new-zone game --permanent
|
||||||
|
success
|
||||||
|
$ sudo firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
一旦创建好并且处于启用状态,你就可以通过添加玩游戏时所需要的服务和端口来实现个性化定制了。
|
||||||
|
|
||||||
|
### 勤勉
|
||||||
|
|
||||||
|
从今天起开始思考你的防火墙策略吧。不用着急,可以试着慢慢搭建一些合理的默认规则。你也许需要花上一段时间才能习惯于思考防火墙的配置问题,以及弄清楚你使用了哪些网络服务,不过无论是处在什么样的环境里,只要稍加探索你就可以让自己的 Linux 工作站变得更为强大。
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/make-linux-stronger-firewalls
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[chen-ni](https://github.com/chen-ni)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_buildtogether.png?itok=9Tvz64K5 (People working together to build )
|
||||||
|
[2]: https://tools.ietf.org/html/rfc793
|
||||||
|
[3]: https://tools.ietf.org/html/rfc433
|
||||||
|
[4]: https://opensource.com/sites/default/files/uploads/web-port-nonstandard.png (Navigating to a nonstandard port produces an error)
|
||||||
|
[5]: https://firewalld.org/
|
||||||
|
[6]: https://opensource.com/sites/default/files/uploads/nm-connection-editor.png (Network Manager Connection Editor)
|
||||||
|
[7]: https://opensource.com/sites/default/files/uploads/nm-zone.png (Firewall zones)
|
||||||
|
[8]: https://opensource.com/sites/default/files/uploads/nm-set.png (Setting a new zone)
|
||||||
|
[9]: https://www.mumble.com/
|
||||||
|
[10]: https://opensource.com/article/18/5/maptool
|
||||||
|
[11]: https://github.com/RPTools
|
||||||
@ -1,48 +1,44 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: ( )
|
[#]: translator: (hopefully2333)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-11132-1.html)
|
||||||
[#]: subject: (How to Manually Install Security Updates on Debian/Ubuntu?)
|
[#]: subject: (How to Manually Install Security Updates on Debian/Ubuntu?)
|
||||||
[#]: via: (https://www.2daygeek.com/manually-install-security-updates-ubuntu-debian/)
|
[#]: via: (https://www.2daygeek.com/manually-install-security-updates-ubuntu-debian/)
|
||||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||||
|
|
||||||
How to Manually Install Security Updates on Debian/Ubuntu?
|
如何在 Debian/Ubuntu 上手动安装安全更新?
|
||||||
======
|
======
|
||||||
|
|
||||||
Installing a package in Linux from command line is a simple task.
|
在 Linux 上通过命令行安装一个包程序是一件简单的事。在一行命令中组合使用多个命令能让你更加简单地完成任务。
|
||||||
|
|
||||||
In a single command or combining of multiple commands could make you to complete your task easily.
|
安全更新也同样如此。
|
||||||
|
|
||||||
The same can be done for security updates as well.
|
在这个教程里面,我们会向你展示如何查看可用的安全更新,以及如何在 Ubuntu、LinuxMint 等等这些基于 Debian 的系统中安装它们。
|
||||||
|
|
||||||
In this tutorial, we will show you how to check available security update and install them on Debian based systems such as Ubuntu, LinuxMint, etc,.
|
有三种方法可以完成这件事,下面会详细地描述这三种方法。
|
||||||
|
|
||||||
It can be done using three methods. All these methods are described in this article in details.
|
作为一个 Linux 管理员,你应该让你的系统保持为最新,这会让你的系统更安全,保护你的系统抵抗意想不到的攻击。
|
||||||
|
|
||||||
As a Linux administrator, you should keep your system up-to-date, that makes your system more secure. It protects your system against unwanted attack.
|
如果你因为一些应用的依赖问题不能解决,导致不能给所有的系统进行全部更新。那至少,你应该打上安全补丁来让你的系统 100% 符合要求。
|
||||||
|
|
||||||
If you are not able to patch entire system with all updates due to some application dependency. At-least, you should install only security patches to make your system 100% compliance.
|
### 方法一:如何检查 Debian/Ubuntu 中是否有任何可用的安全更新?
|
||||||
|
|
||||||
### How to Install unattended-upgrades package in Debian/Ubuntu?
|
在进行补丁安装之前,检查可用安全更新列表始终是一个好习惯。它会为你提供将在你的系统中进行更新的软件包的列表。
|
||||||
|
|
||||||
By default `unattended-upgrades` package should be installed on your system. But in case if it’s not installed use the following command to install it.
|
默认情况下,你的系统上应该是已经安装了 `unattended-upgrades` 包的。但是如果你的系统没有装这个包,那么请使用下面的命令来安装它。
|
||||||
|
|
||||||
Use **[APT-GET Command][1]** or **[APT Command][2]** to install unattended-upgrades package.
|
使用 [APT-GET 命令][1] 或者 [APT 命令][2] 来安装 `unattended-upgrades` 包。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo apt-get install unattended-upgrades
|
$ sudo apt-get install unattended-upgrades
|
||||||
or
|
或
|
||||||
$ sudo apt install unattended-upgrades
|
$ sudo apt install unattended-upgrades
|
||||||
```
|
```
|
||||||
|
|
||||||
### Method-1: How to Check if any Security Updates are available in Debian/Ubuntu?
|
**什么是试运行?** 大多数的 Linux 命令都有一个试运行选项,它会给出实际的输出但不会下载或安装任何东西。
|
||||||
|
|
||||||
It’s always a good practice to check list of available security updates before performing the patch installation. It will give you the list of packages that are going to be updated in your system.
|
为此,你需要在 `unattended-upgrades` 命令中添加 `--dry-run` 选项。
|
||||||
|
|
||||||
**What’s dry run?** Most of the Linux commands have a dry run option, which stimulate the actual output but nothing will be downloaded or installed.
|
|
||||||
|
|
||||||
To do so, you need to add `--dry-run` option with unattended-upgrades command.
|
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo unattended-upgrade --dry-run -d
|
$ sudo unattended-upgrade --dry-run -d
|
||||||
@ -101,21 +97,21 @@ vim-tiny
|
|||||||
xxd
|
xxd
|
||||||
```
|
```
|
||||||
|
|
||||||
If the above command output says **“No packages found that can be upgraded unattended and no pending auto-removals”** in the Terminal, this implies your System is up-to-date.
|
如果在终端里,上面的命令输出说 “No packages found that can be upgraded unattended and no pending auto-removals”,这意味着你的系统已经是最新的了。
|
||||||
|
|
||||||
### How to Install available Security Updates in Debian/Ubuntu?
|
#### 如何在 Debian/Ubuntu 中安装可用的安全更新?
|
||||||
|
|
||||||
If your got any package updates in the above command output. Then run the following command to install them.
|
如果你在上面的命令输出中获得了任意的软件包更新,就运行下面的命令来安装它们。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo unattended-upgrade -d
|
$ sudo unattended-upgrade -d
|
||||||
```
|
```
|
||||||
|
|
||||||
Alternatively this can be done from apt-get command. It’s bit tricky. However, i would suggest users to go with first option.
|
除此之外,你也可以使用 `apt-get` 命令来进行安装。但是这个方法有点棘手,我会建议用户用第一个选项。
|
||||||
|
|
||||||
### Method-2: How to Check if any Security Updates are available in Debian/Ubuntu Using apt-get Command?
|
### 方法二:如何使用 apt-get 命令在 Debian/Ubuntu 中检查是否有可用的安全更新?
|
||||||
|
|
||||||
Run the following command to check list of available security updates in your Debian/Ubuntu system
|
在你的 Debian/Ubuntu 系统中运行下面的命令来查看可用安全更新的列表。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo apt-get -s dist-upgrade | grep "^Inst" | grep -i securi
|
$ sudo apt-get -s dist-upgrade | grep "^Inst" | grep -i securi
|
||||||
@ -160,19 +156,19 @@ Inst gcc [4:7.3.0-3ubuntu2.1] (4:7.4.0-1ubuntu2.3 Ubuntu:18.04/bionic-updates, U
|
|||||||
Inst g++ [4:7.3.0-3ubuntu2.1] (4:7.4.0-1ubuntu2.3 Ubuntu:18.04/bionic-updates, Ubuntu:18.04/bionic-security [amd64])
|
Inst g++ [4:7.3.0-3ubuntu2.1] (4:7.4.0-1ubuntu2.3 Ubuntu:18.04/bionic-updates, Ubuntu:18.04/bionic-security [amd64])
|
||||||
```
|
```
|
||||||
|
|
||||||
### How to Install available Security Updates in Debian/Ubuntu Using apt-get Command?
|
#### 如何使用 apt-get 命令在 Debian/Ubuntu 系统中安装可用的安全更新?
|
||||||
|
|
||||||
If you found any package updates in the above output. Finally run the following command to install them.
|
如果你在上面命令的输出中发现任何的软件包更新。就运行下面的命令来安装它们。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo apt-get -s dist-upgrade | grep "^Inst" | grep -i securi | awk -F " " {'print $2'} | xargs apt-get install
|
$ sudo apt-get -s dist-upgrade | grep "^Inst" | grep -i securi | awk -F " " {'print $2'} | xargs apt-get install
|
||||||
```
|
```
|
||||||
|
|
||||||
Alternatively this can be done from apt command. It’s bit tricky. However, i would suggest users to go with first option.
|
除此之外,也可以使用 `apt` 命令来完成。但是这个方法有点棘手,我会建议用户用第一个方式。
|
||||||
|
|
||||||
### Method-3: How to Check if any Security Updates are available in Debian/Ubuntu Using apt Command?
|
### 方法三:如何使用 apt 命令在 Debian/Ubuntu 系统中检查是否有可用的安全更新?
|
||||||
|
|
||||||
Run the following command to check list of available security updates in your Debian/Ubuntu system
|
在 Debian/Ubuntu 系统中运行下面的命令来查看可用安全更新的列表。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo apt list --upgradable | grep -e "-security"
|
$ sudo apt list --upgradable | grep -e "-security"
|
||||||
@ -217,15 +213,15 @@ vim-tiny/bionic-updates,bionic-security 2:8.0.1453-1ubuntu1.1 amd64 [upgradable
|
|||||||
xxd/bionic-updates,bionic-security 2:8.0.1453-1ubuntu1.1 amd64 [upgradable from: 2:8.0.1453-1ubuntu1]
|
xxd/bionic-updates,bionic-security 2:8.0.1453-1ubuntu1.1 amd64 [upgradable from: 2:8.0.1453-1ubuntu1]
|
||||||
```
|
```
|
||||||
|
|
||||||
### How to Install available Security Updates in Debian/Ubuntu Using apt Command?
|
#### 如何在 Debian/Ubuntu 系统中使用 apt 命令来安装可用的安全更新?
|
||||||
|
|
||||||
If you found any package updates in the above output. Finally run the following command to install them.
|
如果你在上面命令的输出中发现任何的软件包更新。就运行下面的命令来安装它们。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo apt list --upgradable | grep -e "-security" | awk -F "/" '{print $1}' | xargs apt install
|
$ sudo apt list --upgradable | grep -e "-security" | awk -F "/" '{print $1}' | xargs apt install
|
||||||
```
|
```
|
||||||
|
|
||||||
Also, the following file will give you the packages update count.
|
同样,下面的文件也会告诉你更新包的总数。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo cat /var/lib/update-notifier/updates-available
|
$ sudo cat /var/lib/update-notifier/updates-available
|
||||||
@ -240,8 +236,8 @@ via: https://www.2daygeek.com/manually-install-security-updates-ubuntu-debian/
|
|||||||
|
|
||||||
作者:[Magesh Maruthamuthu][a]
|
作者:[Magesh Maruthamuthu][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
191
published/201907/20190703 Parse arguments with Python.md
Normal file
191
published/201907/20190703 Parse arguments with Python.md
Normal file
@ -0,0 +1,191 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11144-1.html)
|
||||||
|
[#]: subject: (Parse arguments with Python)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/parse-arguments-python)
|
||||||
|
[#]: author: (Seth Kenlon https://opensource.com/users/seth/users/notsag)
|
||||||
|
|
||||||
|
使用 Python 解析参数
|
||||||
|
======
|
||||||
|
|
||||||
|
> 使用 argparse 模块像专业人士一样解析参数。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果你在使用 [Python][2] 进行开发,你可能会在终端中使用命令,即使只是为了启动 Python 脚本或使用 [pip][3] 安装 Python 模块。命令可能简单而单一:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls
|
||||||
|
```
|
||||||
|
|
||||||
|
命令也可能需要参数:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls example
|
||||||
|
```
|
||||||
|
|
||||||
|
命令也可以有选项或标志:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls --color example
|
||||||
|
```
|
||||||
|
|
||||||
|
有时选项也有参数:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --list-all --zone home
|
||||||
|
```
|
||||||
|
|
||||||
|
### 参数
|
||||||
|
|
||||||
|
POSIX shell 会自动将你输入的内容作为命令分成数组。例如,这是一个简单的命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls example
|
||||||
|
```
|
||||||
|
|
||||||
|
命令 `ls` 的位置是 `$0`,参数 `example` 位置是 `$1`。
|
||||||
|
|
||||||
|
你**可以**写一个循环迭代每项。确定它是否是命令、选项还是参数。并据此采取行动。幸运的是,已经有一个名为 [argparse][4] 的模块。
|
||||||
|
|
||||||
|
### argparse
|
||||||
|
|
||||||
|
argparse 模块很容易集成到 Python 程序中,并有多种便利功能。例如,如果你的用户更改选项的顺序或使用一个不带参数的选项(称为**布尔**,意味着选项可以打开或关闭设置),然后另一个需要参数(例如 `--color red`),argparse 可以处理多种情况。如果你的用户忘记了所需的选项,那么 argparse 模块可以提供友好的错误消息。
|
||||||
|
|
||||||
|
要在应用中使用 argparse,首先要定义为用户提供的选项。你可以接受几种不同的参数,而语法一致又简单。
|
||||||
|
|
||||||
|
这是一个简单的例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/usr/bin/env python
|
||||||
|
import argparse
|
||||||
|
import sys
|
||||||
|
|
||||||
|
def getOptions(args=sys.argv[1:]):
|
||||||
|
parser = argparse.ArgumentParser(description="Parses command.")
|
||||||
|
parser.add_argument("-i", "--input", help="Your input file.")
|
||||||
|
parser.add_argument("-o", "--output", help="Your destination output file.")
|
||||||
|
parser.add_argument("-n", "--number", type=int, help="A number.")
|
||||||
|
parser.add_argument("-v", "--verbose",dest='verbose',action='store_true', help="Verbose mode.")
|
||||||
|
options = parser.parse_args(args)
|
||||||
|
return options
|
||||||
|
```
|
||||||
|
|
||||||
|
此示例代码创建一个名为 `getOptions` 的函数,并告诉 Python 查看每个可能的参数,前面有一些可识别的字符串(例如 `--input` 或者 `-i`)。 Python 找到的任何选项都将作为 `options` 对象从函数中返回(`options` 是一个任意名称,且没有特殊含义。它只是一个包含函数已解析的所有参数的摘要的数据对象)。
|
||||||
|
|
||||||
|
默认情况下,Python 将用户给出的任何参数视为字符串。如果需要提取整数(数字),则必须指定选项 `type=int`,如示例代码中的 `--number` 选项。
|
||||||
|
|
||||||
|
如果你有一个只是关闭和打开功能的参数,那么你必须使用 `boolean` 类型,就像示例代码中的 `--verbose` 标志一样。这种选项只保存 `True` 或 `False`,用户用来指定是否使用标志。如果使用该选项,那么会激活 `stored_true`。
|
||||||
|
|
||||||
|
当 `getOptions` 函数运行时,你就可以使用 `options` 对象的内容,并让程序根据用户调用命令的方式做出决定。你可以使用测试打印语句查看 `options` 的内容。将其添加到示例文件的底部:
|
||||||
|
|
||||||
|
```
|
||||||
|
print(getOptions())
|
||||||
|
```
|
||||||
|
|
||||||
|
然后带上参数运行代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python3 ./example.py -i foo -n 4
|
||||||
|
Namespace(input='foo', number=4, output=None, verbose=False)
|
||||||
|
```
|
||||||
|
|
||||||
|
### 检索值
|
||||||
|
|
||||||
|
示例代码中的 `options` 对象包含了用户提供的选项后面的值(或派生的布尔值)。例如,在示例代码中,可以通过 `options.number` 来检索 `--number`。
|
||||||
|
|
||||||
|
```
|
||||||
|
options = getOptions(sys.argv[1:])
|
||||||
|
|
||||||
|
if options.verbose:
|
||||||
|
print("Verbose mode on")
|
||||||
|
else:
|
||||||
|
print("Verbose mode off")
|
||||||
|
|
||||||
|
print(options.input)
|
||||||
|
print(options.output)
|
||||||
|
print(options.number)
|
||||||
|
|
||||||
|
# 这里插入你的 Python 代码
|
||||||
|
```
|
||||||
|
|
||||||
|
示例中的布尔选项 `--verbose` 是通过测试 `options.verbose` 是否为 `True`(意味着用户使用了 `--verbose` 标志)或 `False`(用户没有使用 `--verbose` 标志),并采取相应的措施。
|
||||||
|
|
||||||
|
### 帮助和反馈
|
||||||
|
|
||||||
|
argparse 还包含一个内置的 `--help`(简写 `-h`)选项,它提供了有关如何使用命令的提示。这是从你的代码派生的,因此生成此帮助系统不需要额外的工作:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./example.py --help
|
||||||
|
usage: example.py [-h] [-i INPUT] [-o OUTPUT] [-n NUMBER] [-v]
|
||||||
|
|
||||||
|
Parses command.
|
||||||
|
|
||||||
|
optional arguments:
|
||||||
|
-h, --help show this help message and exit
|
||||||
|
-i INPUT, --input INPUT
|
||||||
|
Your input file.
|
||||||
|
-o OUTPUT, --output OUTPUT
|
||||||
|
Your destination output file.
|
||||||
|
-n NUMBER, --number NUMBER
|
||||||
|
A number.
|
||||||
|
-v, --verbose Verbose mode.
|
||||||
|
```
|
||||||
|
|
||||||
|
### 像专业人士一样用 Python 解析
|
||||||
|
|
||||||
|
这是一个简单的示例,来演示如何在 Python 应用中的解析参数以及如何快速有效地记录它的语法。下次编写 Python 脚本时,请使用 argparse 为其提供一些选项。你以后会感到自得,你的命令不会像一个快速的临时脚本,更像是一个“真正的” Unix 命令!
|
||||||
|
|
||||||
|
以下是可用于测试的示例代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/usr/bin/env python3
|
||||||
|
# GNU All-Permissive License
|
||||||
|
# Copying and distribution of this file, with or without modification,
|
||||||
|
# are permitted in any medium without royalty provided the copyright
|
||||||
|
# notice and this notice are preserved. This file is offered as-is,
|
||||||
|
# without any warranty.
|
||||||
|
|
||||||
|
import argparse
|
||||||
|
import sys
|
||||||
|
|
||||||
|
def getOptions(args=sys.argv[1:]):
|
||||||
|
parser = argparse.ArgumentParser(description="Parses command.")
|
||||||
|
parser.add_argument("-i", "--input", help="Your input file.")
|
||||||
|
parser.add_argument("-o", "--output", help="Your destination output file.")
|
||||||
|
parser.add_argument("-n", "--number", type=int, help="A number.")
|
||||||
|
parser.add_argument("-v", "--verbose",dest='verbose',action='store_true', help="Verbose mode.")
|
||||||
|
options = parser.parse_args(args)
|
||||||
|
return options
|
||||||
|
|
||||||
|
options = getOptions(sys.argv[1:])
|
||||||
|
|
||||||
|
if options.verbose:
|
||||||
|
print("Verbose mode on")
|
||||||
|
else:
|
||||||
|
print("Verbose mode off")
|
||||||
|
|
||||||
|
print(options.input)
|
||||||
|
print(options.output)
|
||||||
|
print(options.number)
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/parse-arguments-python
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth/users/notsag
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cobol-card-punch-programming-code.png?itok=6W6PUqUi (COBOL punch card)
|
||||||
|
[2]: https://www.python.org/
|
||||||
|
[3]: https://pip.pypa.io/en/stable/installing/
|
||||||
|
[4]: https://pypi.org/project/argparse/
|
||||||
@ -0,0 +1,109 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11171-1.html)
|
||||||
|
[#]: subject: (Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux)
|
||||||
|
[#]: via: (https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/)
|
||||||
|
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||||
|
|
||||||
|
在 Linux 上用 Bash 脚本监控 messages 日志
|
||||||
|
======
|
||||||
|
|
||||||
|
目前市场上有许多开源监控工具可用于监控 Linux 系统的性能。当系统达到指定的阈值限制时,它将发送电子邮件警报。它可以监视 CPU 利用率、内存利用率、交换利用率、磁盘空间利用率等所有内容。
|
||||||
|
|
||||||
|
如果你只有很少的系统并且想要监视它们,那么编写一个小的 shell 脚本可以使你的任务变得非常简单。
|
||||||
|
|
||||||
|
在本教程中,我们添加了一个 shell 脚本来监视 Linux 系统上的 messages 日志。
|
||||||
|
|
||||||
|
我们过去添加了许多有用的 shell 脚本。如果要查看这些内容,请导航至以下链接。
|
||||||
|
|
||||||
|
- [如何使用 shell 脚本监控系统的日常活动?][1]
|
||||||
|
|
||||||
|
此脚本将检查 `/var/log/messages` 文件中的 “warning“、“error” 和 “critical”,如果发现任何有关的东西,就给指定电子邮件地址发邮件。
|
||||||
|
|
||||||
|
如果服务器有许多匹配的字符串,我们就不能经常运行这个可能填满收件箱的脚本,我们可以在一天内运行一次。
|
||||||
|
|
||||||
|
为了解决这个问题,我让脚本以不同的方式触发电子邮件。
|
||||||
|
|
||||||
|
如果 `/var/log/messages` 文件中昨天的日志中找到任何给定字符串,则脚本将向给定的电子邮件地址发送电子邮件警报。
|
||||||
|
|
||||||
|
**注意:**你需要更改电子邮件地址,而不是我们的电子邮件地址。
|
||||||
|
|
||||||
|
```
|
||||||
|
# vi /opt/scripts/os-log-alert.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/bash
|
||||||
|
#Set the variable which equal to zero
|
||||||
|
prev_count=0
|
||||||
|
|
||||||
|
count=$(grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | egrep -wi 'warning|error|critical' | wc -l)
|
||||||
|
|
||||||
|
if [ "$prev_count" -lt "$count" ] ; then
|
||||||
|
# Send a mail to given email id when errors found in log
|
||||||
|
SUBJECT="WARNING: Errors found in log on "`date --date='yesterday' '+%b %e'`""
|
||||||
|
# This is a temp file, which is created to store the email message.
|
||||||
|
MESSAGE="/tmp/logs.txt"
|
||||||
|
TO="2daygeek@gmail.com"
|
||||||
|
echo "ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin." >> $MESSAGE
|
||||||
|
echo "Hostname: `hostname`" >> $MESSAGE
|
||||||
|
echo -e "\n" >> $MESSAGE
|
||||||
|
echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
|
||||||
|
echo "Error messages in the log file as below" >> $MESSAGE
|
||||||
|
echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
|
||||||
|
grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | awk '{ $3=""; print}' | egrep -wi 'warning|error|critical' >> $MESSAGE
|
||||||
|
mail -s "$SUBJECT" "$TO" < $MESSAGE
|
||||||
|
#rm $MESSAGE
|
||||||
|
fi
|
||||||
|
```
|
||||||
|
|
||||||
|
为 `os-log-alert.sh` 文件设置可执行权限。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ chmod +x /opt/scripts/os-log-alert.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
最后添加一个 cron 任务来自动执行此操作。它将每天 7 点钟运行。
|
||||||
|
|
||||||
|
```
|
||||||
|
# crontab -e
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
0 7 * * * /bin/bash /opt/scripts/os-log-alert.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
**注意:**你将在每天 7 点收到昨天日志的电子邮件提醒。
|
||||||
|
|
||||||
|
**输出:**你将收到类似下面的电子邮件提醒。
|
||||||
|
|
||||||
|
```
|
||||||
|
ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin.
|
||||||
|
|
||||||
|
+-----------------------------------------------------+
|
||||||
|
Error messages in the log file as below
|
||||||
|
+-----------------------------------------------------+
|
||||||
|
Jul 3 02:40:11 ns1 kernel: php-fpm[3175]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||||
|
Jul 3 02:50:14 ns1 kernel: lmtp[8249]: segfault at 20 ip 00007f9cc05295e4 sp 00007ffc57bca1a0 error 4 in libdovecot-storage.so.0.0.0[7f9cc04df000+148000]
|
||||||
|
Jul 3 15:36:09 ns1 kernel: php-fpm[17846]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||||
|
Jul 3 15:45:54 ns1 pure-ftpd: (?@5.188.62.5) [WARNING] Authentication failed for user [daygeek]
|
||||||
|
Jul 3 16:25:36 ns1 pure-ftpd: (?@104.140.148.58) [WARNING] Sorry, cleartext sessions and weak ciphers are not accepted on this server.#012Please reconnect using TLS security mechanisms.
|
||||||
|
Jul 3 16:44:20 ns1 kernel: php-fpm[8979]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/
|
||||||
|
|
||||||
|
作者:[Magesh Maruthamuthu][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.2daygeek.com/author/magesh/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.2daygeek.com/category/shell-script/
|
||||||
@ -0,0 +1,96 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11089-1.html)
|
||||||
|
[#]: subject: (Copy and paste at the Linux command line with xclip)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/xclip)
|
||||||
|
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||||
|
|
||||||
|
使用 xclip 在 Linux 命令行中复制粘贴
|
||||||
|
======
|
||||||
|
> 了解如何在 Linux 中使用 xclip。
|
||||||
|
|
||||||
|
![Green paperclips][1]
|
||||||
|
|
||||||
|
在使用 Linux 桌面工作时,你通常如何复制全部或部分文本?你可能会在文本编辑器中打开文件,选择全部或仅选择要复制的文本,然后将其粘贴到其他位置。
|
||||||
|
|
||||||
|
这样没问题。但是你可以使用 [xclip][2] 在命令行中更有效地完成工作。`xclip` 提供了在终端窗口中运行的命令与 Linux 图形桌面环境中的剪贴板之间的管道。
|
||||||
|
|
||||||
|
### 安装 xclip
|
||||||
|
|
||||||
|
`xclip` 并不是许多 Linux 发行版的标准套件。要查看它是否已安装在你的计算机上,请打开终端窗口并输入 `which xclip`。如果该命令返回像 `/usr/bin/xclip` 这样的输出,那么你可以开始使用了。否则,你需要安装 `xclip`。
|
||||||
|
|
||||||
|
为此,请使用你的发行版的包管理器。如果你喜欢冒险,你可以[从 GitHub 获取源代码][2]并自己编译。
|
||||||
|
|
||||||
|
### 基础使用
|
||||||
|
|
||||||
|
假设你要将文件的内容复制到剪贴板。在 `xclip` 中可以使用两种方法。输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
xclip file_name
|
||||||
|
```
|
||||||
|
|
||||||
|
或者
|
||||||
|
|
||||||
|
```
|
||||||
|
xclip -sel clip file_name
|
||||||
|
```
|
||||||
|
|
||||||
|
两个命令之间有什么区别(除了第二个命令更长)?第一个命令在你使用鼠标中键粘贴的情况下有效。但是,不是每个人都这样做。许多人习惯使用右键单击菜单或按 `Ctrl+V` 粘贴文本。如果你时其中之一(我就是!),使用 `-sel clip` 选项可确保你可以粘贴要粘贴的内容。
|
||||||
|
|
||||||
|
### 将 xclip 与其他应用一起使用
|
||||||
|
|
||||||
|
将文件内容直接复制到剪贴板是个巧妙的技巧。很可能你不会经常这样做。还有其他方法可以使用 `xclip`,其中包括将其与另一个命令行程序结合。
|
||||||
|
|
||||||
|
结合是用管道(`|`)完成的。管道将一个命令行程序的输出重定向到另一个命令行程序。这样我们就会有更多的可能性,我们来看看其中的三个。
|
||||||
|
|
||||||
|
假设你是系统管理员,你需要将日志文件的最后 30 行复制到 bug 报告中。在文本编辑器中打开文件,向下滚动到最后,复制和粘贴有一点工作量。为什么不使用 `xclip` 和 [tail][3] 来快速轻松地完成?运行此命令以复制最后 30 行:
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
tail -n 30 logfile.log | xclip -sel clip
|
||||||
|
```
|
||||||
|
|
||||||
|
我的写作有相当一部分用于内容管理系统 (CMS) 或者在其他网络中发布。但是,我从不使用 CMS 的 WYSIWYG 编辑器来编写 - 我采用 [Markdown][5] 格式离线编写[纯文本][4]。也就是说,许多编辑器都有 HTML 模式。通过使用此命令,我可以使用 [Pandoc][6] 将 Markdown 格式的文件转换为 HTML 并将其一次性复制到剪贴板:
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -t html file.md | xclip -sel clip
|
||||||
|
```
|
||||||
|
|
||||||
|
在其他地方,粘贴完成。
|
||||||
|
|
||||||
|
我的两个网站使用 [GitLab Pages][7] 托管。我使用名为 [Certbot][8] 的工具为这些站点生成 HTTPS 证书,每当我更新它时,我需要将每个站点的证书复制到 GitLab。结合 [cat][9] 命令和 xclip 比使用编辑器更快,更有效。例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
cat /etc/letsencrypt/live/website/fullchain.pem | xclip -sel clip
|
||||||
|
```
|
||||||
|
|
||||||
|
这就是全部可以用 xclip 做的事么?当然不是。我相信你可以找到更多用途来满足你的需求。
|
||||||
|
|
||||||
|
### 最后总结
|
||||||
|
|
||||||
|
不是每个人都会使用 `xclip`。没关系。然而,它是一个在你需要它时非常方便的一个小工具。而且,正如我几次发现的那样,你不知道什么时候需要它。等到时候,你会很高兴能用上 `xclip`。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/xclip
|
||||||
|
|
||||||
|
作者:[Scott Nesbitt][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/scottnesbitt
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/life_paperclips.png?itok=j48op49T (Green paperclips)
|
||||||
|
[2]: https://github.com/astrand/xclip
|
||||||
|
[3]: https://en.wikipedia.org/wiki/Tail_(Unix)
|
||||||
|
[4]: https://plaintextproject.online
|
||||||
|
[5]: https://gumroad.com/l/learnmarkdown
|
||||||
|
[6]: https://pandoc.org
|
||||||
|
[7]: https://docs.gitlab.com/ee/user/project/pages/
|
||||||
|
[8]: https://certbot.eff.org/
|
||||||
|
[9]: https://en.wikipedia.org/wiki/Cat_(Unix)
|
||||||
121
published/201907/20190705 Manage your shell environment.md
Normal file
121
published/201907/20190705 Manage your shell environment.md
Normal file
@ -0,0 +1,121 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11095-1.html)
|
||||||
|
[#]: subject: (Manage your shell environment)
|
||||||
|
[#]: via: (https://fedoramagazine.org/manage-your-shell-environment/)
|
||||||
|
[#]: author: (Eduard Lucena https://fedoramagazine.org/author/x3mboy/)
|
||||||
|
|
||||||
|
管理你的 shell 环境
|
||||||
|
======
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
前段时间,Fedora Magazine 发表了一篇 [介绍 ZSH][2] 的文章,它是 Fedora 默认的 bash shell 的替代品。这一次,我们将着重定制它来更有效地使用它。本文中显示的所有概念也适用于其他 shell,例如 bash。
|
||||||
|
|
||||||
|
### 别名
|
||||||
|
|
||||||
|
别名是命令的快捷方式。为那些需要经常执行,但需要很长时间输入的长命令创建快捷方式很有用。语法是:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ alias yourAlias='complex command with arguments'
|
||||||
|
```
|
||||||
|
|
||||||
|
它们并不总是用来缩短长命令。重要的是,你将它们用于你经常执行的任务。可能的例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ alias dnfUpgrade='dnf -y upgrade'
|
||||||
|
```
|
||||||
|
|
||||||
|
这样,为了进行系统升级,我只需输入 `dnfUpgrade` 而不用输入完整的 `dnf` 命令。
|
||||||
|
|
||||||
|
在终端中设置别名的问题是,一旦终端会话关闭,别名就会丢失。要永久设置它们,请使用资源文件。
|
||||||
|
|
||||||
|
### 资源文件
|
||||||
|
|
||||||
|
资源文件(即 rc 文件)是在会话或进程开始时(每个用户在开启新终端窗口或启动 vim 等新程序时)加载的配置文件。对于 ZSH,资源文件是 `.zshrc`,对于 bash,它是 `.bashrc`。
|
||||||
|
|
||||||
|
要使别名成为永久别名,你可以将它们放入资源文件中。你可以使用你选择的文本编辑器编辑资源文件。这里使用 vim:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vim $HOME/.zshrc
|
||||||
|
```
|
||||||
|
|
||||||
|
或者对于 bash:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vim $HOME/.bashrc
|
||||||
|
```
|
||||||
|
|
||||||
|
请注意,资源文件的位置是相对于家目录指定的。这是 ZSH(或 bash)默认为每个用户查找该文件的位置。
|
||||||
|
|
||||||
|
还有一种是将你的配置放在任何其他文件中,然后读取它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ source /path/to/your/rc/file
|
||||||
|
```
|
||||||
|
|
||||||
|
同样,在会话中直接读取它只会将其应用于会话,因此要使其永久化,请将 `source` 命令添加到资源文件中。将文件放在不同位置的优点是你可以随时读取它。这在共享环境中很有用。
|
||||||
|
|
||||||
|
### 环境变量
|
||||||
|
|
||||||
|
环境变量是分配了特定名称的值,你可以在脚本和命令中调用它们。它们以美元符号(`$`)开始。其中最常见的是指向主目录的 `$HOME`。
|
||||||
|
|
||||||
|
顾名思义,环境变量是你环境的一部分。使用以下语法设置变量:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ http_proxy="http://your.proxy"
|
||||||
|
```
|
||||||
|
|
||||||
|
要使其成为环境变量,请使用以下命令将其导出:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ export $http_proxy
|
||||||
|
```
|
||||||
|
|
||||||
|
要查看当前设置的所有环境变量,请使用 `env` 命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ env
|
||||||
|
```
|
||||||
|
|
||||||
|
该命令输出会话中可用的所有变量。要演示如何在命令中使用它们,请尝试运行以下 `echo` 命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ echo $PWD
|
||||||
|
/home/fedora
|
||||||
|
$ echo $USER
|
||||||
|
fedora
|
||||||
|
```
|
||||||
|
|
||||||
|
这里发生了变量扩展,即存储在变量中的值在命令中使用。
|
||||||
|
|
||||||
|
另一个有用的变量是 `$PATH`,它定义了 shell 查找二进制文件的目录。
|
||||||
|
|
||||||
|
### $PATH 变量
|
||||||
|
|
||||||
|
有许多对于操作系统很重要的目录或文件夹(在图形环境中调用它们的方式)。某些目录设置为保存可直接在 shell 中使用的二进制文件。这些目录在 `$PATH` 变量中定义。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ echo $PATH
|
||||||
|
/usr/lib64/qt-3.3/bin:/usr/share/Modules/bin:/usr/lib64/ccache:/usr/local/bin:/usr/bin:/bin:/usr/local/sbin:/usr/sbin:/usr/libexec/sdcc:/usr/libexec/sdcc:/usr/bin:/bin:/sbin:/usr/sbin:/opt/FortiClient
|
||||||
|
```
|
||||||
|
|
||||||
|
当你希望在 shell 中访问自己的二进制文件(或脚本)时,这会有帮助。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/manage-your-shell-environment/
|
||||||
|
|
||||||
|
作者:[Eduard Lucena][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/x3mboy/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://fedoramagazine.org/wp-content/uploads/2018/05/manage-shell-env-816x345.jpg
|
||||||
|
[2]: https://fedoramagazine.org/set-zsh-fedora-system/
|
||||||
@ -0,0 +1,136 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11115-1.html)
|
||||||
|
[#]: subject: (How To Delete A Repository And GPG Key In Ubuntu)
|
||||||
|
[#]: via: (https://www.ostechnix.com/how-to-delete-a-repository-and-gpg-key-in-ubuntu/)
|
||||||
|
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||||
|
|
||||||
|
如何在 Ubuntu 中删除仓库及其 GPG 密钥
|
||||||
|
======
|
||||||
|
|
||||||
|
![Delete A Repository And GPG Key In Ubuntu][1]
|
||||||
|
|
||||||
|
前几天我们讨论了如何在基于 RPM 和 DEB 的系统中[列出已安装的仓库][2]。今天,我们将学习如何在 Ubuntu 中删除仓库及其 GPG 密钥。对于不知道仓库的人,仓库(简称 repo)是开发人员存储软件包的地方。仓库的软件包经过全面测试,并由 Ubuntu 开发人员专门为每个版本构建。用户可以使用 Apt 包管理器在他们的 Ubuntu 系统上下载和安装这些包。Ubuntu 有四个官方仓库,即 Main、Universe、Restricted 和 Multiverse。
|
||||||
|
|
||||||
|
除了官方仓库外,还有许多由开发人员(或软件包维护人员)维护的非官方仓库。非官方仓库通常有官方仓库中不可用的包。所有包都由包维护者用一对密钥(公钥和私钥)签名。如你所知,公钥是发给用户的,私钥必须保密。每当你在源列表中添加新的仓库时,如果 Apt 包管理器想要信任新添加的仓库,你还应该添加仓库密钥(公钥)。使用仓库密钥,你可以确保从正确的人那里获得包。到这里希望你对软件仓库和仓库密钥有了一个基本的了解。现在让我们继续看看如果在 Ubuntu 系统中不再需要仓库及其密钥,那么该如何删除它。
|
||||||
|
|
||||||
|
### 在 Ubuntu 中删除仓库
|
||||||
|
|
||||||
|
每当使用 `add-apt-repository` 命令添加仓库时,它都将保存在 `/etc/apt/sources.list` 中。
|
||||||
|
|
||||||
|
要从 Ubuntu 及其衍生版中删除软件仓库,只需打开 `/etc/apt/sources.list` 文件并查找仓库名字并将其删除即可。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo nano /etc/apt/sources.list
|
||||||
|
```
|
||||||
|
|
||||||
|
正如你在下面的截图中看到的,我在我的 Ubuntu 系统中添加了 [Oracle Virtualbox][3] 仓库。
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
*virtualbox 仓库*
|
||||||
|
|
||||||
|
要删除此仓库,只需删除该条目即可。保存并关闭文件。
|
||||||
|
|
||||||
|
如果你已添加 PPA 仓库,请查看 `/etc/apt/sources.list.d/` 目录并删除相应的条目。
|
||||||
|
|
||||||
|
或者,你可以使用 `add-apt-repository` 命令删除仓库。例如,我要删除 [Systemback][5] 仓库,如下所示。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo add-apt-repository -r ppa:nemh/systemback
|
||||||
|
```
|
||||||
|
|
||||||
|
最后,使用以下命令更新软件源列表:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt update
|
||||||
|
```
|
||||||
|
|
||||||
|
### 删除仓库密钥
|
||||||
|
|
||||||
|
我们使用 `apt-key` 命令添加仓库密钥。首先,让我们使用命令列出添加的密钥:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt-key list
|
||||||
|
```
|
||||||
|
|
||||||
|
此命令将列出所有添加的仓库密钥。
|
||||||
|
|
||||||
|
```
|
||||||
|
/etc/apt/trusted.gpg
|
||||||
|
--------------------
|
||||||
|
pub rsa1024 2010-10-31 [SC]
|
||||||
|
3820 03C2 C8B7 B4AB 813E 915B 14E4 9429 73C6 2A1B
|
||||||
|
uid [ unknown] Launchpad PPA for Kendek
|
||||||
|
|
||||||
|
|
||||||
|
pub rsa4096 2016-04-22 [SC]
|
||||||
|
B9F8 D658 297A F3EF C18D 5CDF A2F6 83C5 2980 AECF
|
||||||
|
uid [ unknown] Oracle Corporation (VirtualBox archive signing key) <[email protected]>
|
||||||
|
sub rsa4096 2016-04-22 [E]
|
||||||
|
|
||||||
|
|
||||||
|
/etc/apt/trusted.gpg.d/ubuntu-keyring-2012-archive.gpg
|
||||||
|
------------------------------------------------------
|
||||||
|
pub rsa4096 2012-05-11 [SC]
|
||||||
|
790B C727 7767 219C 42C8 6F93 3B4F E6AC C0B2 1F32
|
||||||
|
uid [ unknown] Ubuntu Archive Automatic Signing Key (2012) <[email protected]>
|
||||||
|
|
||||||
|
|
||||||
|
/etc/apt/trusted.gpg.d/ubuntu-keyring-2012-cdimage.gpg
|
||||||
|
------------------------------------------------------
|
||||||
|
pub rsa4096 2012-05-11 [SC]
|
||||||
|
8439 38DF 228D 22F7 B374 2BC0 D94A A3F0 EFE2 1092
|
||||||
|
uid [ unknown] Ubuntu CD Image Automatic Signing Key (2012) <[email protected]>
|
||||||
|
|
||||||
|
|
||||||
|
/etc/apt/trusted.gpg.d/ubuntu-keyring-2018-archive.gpg
|
||||||
|
------------------------------------------------------
|
||||||
|
pub rsa4096 2018-09-17 [SC]
|
||||||
|
F6EC B376 2474 EDA9 D21B 7022 8719 20D1 991B C93C
|
||||||
|
uid [ unknown] Ubuntu Archive Automatic Signing Key (2018) <[email protected]>
|
||||||
|
```
|
||||||
|
|
||||||
|
正如你在上面的输出中所看到的,那串长的(40 个字符)十六进制值是仓库密钥。如果你希望 APT 包管理器停止信任该密钥,只需使用以下命令将其删除:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt-key del "3820 03C2 C8B7 B4AB 813E 915B 14E4 9429 73C6 2A1B"
|
||||||
|
```
|
||||||
|
|
||||||
|
或者,仅指定最后 8 个字符:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt-key del 73C62A1B
|
||||||
|
```
|
||||||
|
|
||||||
|
完成!仓库密钥已被删除。运行以下命令更新仓库列表:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt update
|
||||||
|
```
|
||||||
|
|
||||||
|
资源:
|
||||||
|
|
||||||
|
* [软件仓库 – Ubuntu 社区 Wiki][6]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.ostechnix.com/how-to-delete-a-repository-and-gpg-key-in-ubuntu/
|
||||||
|
|
||||||
|
作者:[sk][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.ostechnix.com/author/sk/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Delete-a-repository-in-ubuntu-720x340.png
|
||||||
|
[2]: https://www.ostechnix.com/find-list-installed-repositories-commandline-linux/
|
||||||
|
[3]: https://www.ostechnix.com/install-oracle-virtualbox-ubuntu-16-04-headless-server/
|
||||||
|
[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/virtualbox-repository.png
|
||||||
|
[5]: https://www.ostechnix.com/systemback-restore-ubuntu-desktop-and-server-to-previous-state/
|
||||||
|
[6]: https://help.ubuntu.com/community/Repositories/Ubuntu
|
||||||
@ -0,0 +1,95 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11163-1.html)
|
||||||
|
[#]: subject: (How to enable DNS-over-HTTPS (DoH) in Firefox)
|
||||||
|
[#]: via: (https://www.zdnet.com/article/how-to-enable-dns-over-https-doh-in-firefox/)
|
||||||
|
[#]: author: (Catalin Cimpanu https://www.zdnet.com/meet-the-team/us/catalin.cimpanu/)
|
||||||
|
|
||||||
|
如何在 Firefox 中启用 DNS-over-HTTPS(DoH)
|
||||||
|
======
|
||||||
|
|
||||||
|
DNS-over-HTTPS(DoH)协议目前是谈论的焦点,Firefox 是唯一支持它的浏览器。但是,Firefox 默认不启用此功能,用户必须经历许多步骤并修改多个设置才能启动并运行 DoH。
|
||||||
|
|
||||||
|
在开始如何在 Firefox 中启用 DoH 支持的分步教程之前,让我们先描述它的原理。
|
||||||
|
|
||||||
|
### DNS-over-HTTPS 的工作原理
|
||||||
|
|
||||||
|
DNS-over-HTTPS 协议通过获取用户在浏览器中输入的域名,并向 DNS 服务器发送查询,以了解托管该站点的 Web 服务器的 IP 地址。
|
||||||
|
|
||||||
|
这也是正常 DNS 的工作原理。但是,DoH 通过 443 端口的加密 HTTPS 连接接受 DNS 查询将其发送到兼容 DoH 的 DNS 服务器(解析器),而不是在 53 端口上发送纯文本。这样,DoH 就会在常规 HTTPS 流量中隐藏 DNS 查询,因此第三方监听者将无法嗅探流量,并了解用户的 DNS 查询,从而推断他们将要访问的网站。
|
||||||
|
|
||||||
|
此外,DNS-over-HTTPS 的第二个特性是该协议工作在应用层。应用可以带上内部硬编码的 DoH 兼容的 DNS 解析器列表,从而向它们发送 DoH 查询。这种操作模式绕过了系统级别的默认 DNS 设置,在大多数情况下,这些设置是由本地 Internet 服务提供商(ISP)设置的。这也意味着支持 DoH 的应用可以有效地绕过本地 ISP 流量过滤器并访问可能被本地电信公司或当地政府阻止的内容 —— 这也是 DoH 目前被誉为用户隐私和安全的福音的原因。
|
||||||
|
|
||||||
|
这是 DoH 在推出后不到两年的时间里获得相当大的普及的原因之一,同时也是一群[英国 ISP 因为 Mozilla 计划支持 DoH 协议而提名它为 2019 年的“互联网恶棍” (Internet Villian)][1]的原因,ISP 认为 DoH 协议会阻碍他们过滤不良流量的努力。(LCTT 译注:后来这一奖项的提名被取消。)
|
||||||
|
|
||||||
|
作为回应,并且由于英国政府阻止访问侵犯版权内容的复杂情况,以及 ISP 自愿阻止访问虐待儿童网站的情况,[Mozilla 已决定不为英国用户默认启用此功能][2]。
|
||||||
|
|
||||||
|
下面的分步指南将向英国和世界各地的 Firefox 用户展示如何立即启用该功能,而不用等到 Mozilla 将来启用它 —— 如果它会这么做的话。在 Firefox 中有两种启用 DoH 支持的方法。
|
||||||
|
|
||||||
|
### 方法 1:通过 Firefox 设置
|
||||||
|
|
||||||
|
**步骤 1:**进入 Firefox 菜单,选择**工具**,然后选择**首选项**。 可选在 URL 栏中输入 `about:preferences`,然后按下回车。这将打开 Firefox 的首选项。
|
||||||
|
|
||||||
|
**步骤 2:**在**常规**中,向下滚动到**网络设置**,然后按**设置**按钮。
|
||||||
|
|
||||||
|
![DoH section in Firefox settings][3]
|
||||||
|
|
||||||
|
**步骤3:**在弹出窗口中,向下滚动并选择“**Enable DNS over HTTPS**”,然后配置你需要的 DoH 解析器。你可以使用内置的 Cloudflare 解析器(该公司与 Mozilla [达成协议][4],记录更少的 Firefox 用户数据),或者你可以在[这个列表][4]中选择一个。
|
||||||
|
|
||||||
|
![DoH section in Firefox settings][6]
|
||||||
|
|
||||||
|
### 方法 2:通过 about:config
|
||||||
|
|
||||||
|
**步骤 1:**在 URL 栏中输入 `about:config`,然后按回车访问 Firefox 的隐藏配置面板。在这里,用户需要启用和修改三个设置。
|
||||||
|
|
||||||
|
**步骤 2:**第一个设置是 `network.trr.mode`。这打开了 DoH 支持。此设置支持四个值:
|
||||||
|
|
||||||
|
* `0` - 标准 Firefox 安装中的默认值(当前为 5,表示禁用 DoH)
|
||||||
|
* `1` - 启用 DoH,但 Firefox 依据哪个请求更快返回选择使用 DoH 或者常规 DNS
|
||||||
|
* `2` - 启用 DoH,常规 DNS 作为备用
|
||||||
|
* `3` - 启用 DoH,并禁用常规 DNS
|
||||||
|
* `5` - 禁用 DoH
|
||||||
|
|
||||||
|
值为 2 工作得最好
|
||||||
|
|
||||||
|
![DoH in Firefox][7]
|
||||||
|
|
||||||
|
**步骤3:**需要修改的第二个设置是 `network.trr.uri`。这是与 DoH 兼容的 DNS 服务器的 URL,Firefox 将向它发送 DoH DNS 查询。默认情况下,Firefox 使用 Cloudflare 的 DoH服务,地址是:<https://mozilla.cloudflare-dns.com/dns-query>。但是,用户可以使用自己的 DoH 服务器 URL。他们可以从[这个列表][8]中选择其中一个可用的。Mozilla 在 Firefox 中使用 Cloudflare 的原因是因为与这家公司[达成了协议][4],之后 Cloudflare 将收集来自 Firefox 用户的 DoH 查询的非常少的数据。
|
||||||
|
|
||||||
|
[DoH in Firefox][9]
|
||||||
|
|
||||||
|
**步骤4:**第三个设置是可选的,你可以跳过此设置。 但是如果设置不起作用,你可以使用此作为步骤 3 的备用。该选项名为 `network.trr.bootstrapAddress`,它是一个输入字段,用户可以输入步骤 3 中兼容 DoH 的 DNS 解析器的 IP 地址。对于 Cloudflare,它是 1.1.1.1。 对于 Google 服务,它是 8.8.8.8。 如果你使用了另一个 DoH 解析器的 URL,如果有必要的话,你需要追踪那台服务器的 IP 地址并输入。
|
||||||
|
|
||||||
|
![DoH in Firefox][10]
|
||||||
|
|
||||||
|
通常,在步骤 3 中输入的 URL 应该足够了。
|
||||||
|
设置应该立即生效,但如果它们不起作用,请重新启动 Firefox。
|
||||||
|
|
||||||
|
文章信息来源:[Mozilla Wiki][11]
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.zdnet.com/article/how-to-enable-dns-over-https-doh-in-firefox/
|
||||||
|
|
||||||
|
作者:[Catalin Cimpanu][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.zdnet.com/meet-the-team/us/catalin.cimpanu/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://linux.cn/article-11068-1.html
|
||||||
|
[2]: https://www.zdnet.com/article/mozilla-no-plans-to-enable-dns-over-https-by-default-in-the-uk/
|
||||||
|
[3]: https://zdnet1.cbsistatic.com/hub/i/2019/07/07/df30c7b0-3a20-4de7-8640-3dea6d249a49/121bd379b6232e1e2a97c35ea8c7764e/doh-settings-1.png
|
||||||
|
[4]: https://developers.cloudflare.com/1.1.1.1/commitment-to-privacy/privacy-policy/firefox/
|
||||||
|
[6]: https://zdnet3.cbsistatic.com/hub/i/2019/07/07/8608af28-2a28-4ff1-952b-9b6d2deb1ea6/b1fc322caaa2c955b1a2fb285daf0e42/doh-settings-2.png
|
||||||
|
[7]: https://zdnet1.cbsistatic.com/hub/i/2019/07/06/0232b3a7-82c6-4a6f-90c1-faf0c090254c/6db9b36509021c460fcc7fe825bb74c5/doh-1.png
|
||||||
|
[8]: https://github.com/curl/curl/wiki/DNS-over-HTTPS#publicly-available-servers
|
||||||
|
[9]: https://zdnet2.cbsistatic.com/hub/i/2019/07/06/4dd1d5c1-6fa7-4f5b-b7cd-b544748edfed/baa7a70ac084861d94a744a57a3147ad/doh-2.png
|
||||||
|
[10]: https://zdnet1.cbsistatic.com/hub/i/2019/07/06/8ec20a28-673c-4a17-8195-16579398e90a/538fe8420f9b24724aeb4a6c8d4f0f0f/doh-3.png
|
||||||
|
[11]: https://wiki.mozilla.org/Trusted_Recursive_Resolver
|
||||||
@ -0,0 +1,100 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (chen-ni)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11068-1.html)
|
||||||
|
[#]: subject: (Say WHAAAT? Mozilla has Been Nominated for the “Internet Villain” Award in the UK)
|
||||||
|
[#]: via: (https://itsfoss.com/mozilla-internet-villain/)
|
||||||
|
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||||
|
|
||||||
|
什么?!Mozilla 被提名英国“互联网恶棍”奖
|
||||||
|
======
|
||||||
|
|
||||||
|
Mozilla Firefox 是目前最流行的浏览器之一。很多用户喜欢它胜过 Chrome 就是因为它鼓励隐私保护,并且可以通过一些选项设置让你的互联网活动尽可能地私密。
|
||||||
|
|
||||||
|
不过最近推出的功能之一 —— 仍然处于测试阶段的 [DoH (DNS-over-HTTPS)][1] 功能却受到了英国互联网服务提供商行业协会的负面评价。
|
||||||
|
|
||||||
|
英国<ruby>互联网服务提供商行业协会<rt>Internet Services Providers Association</rt></ruby>(ISPA)决定将 Mozilla 列入 2019 年“互联网恶棍”奖的最终入围者名单。该奖项将在 ISPA 于 7 月 11 日在伦敦举行的颁奖典礼上进行颁发。
|
||||||
|
|
||||||
|
![][3]
|
||||||
|
|
||||||
|
### 为什么说 “Mozilla” 是 “互联网恶棍”?
|
||||||
|
|
||||||
|
ISPA 在他们的声明中表示,Mozilla 因为支持了 DoH(DNS-over-HTTPS)而被视为“互联网恶棍”。
|
||||||
|
|
||||||
|
> [@mozilla][4] 被提名为 [#ISPA][5] 的 [#互联网恶棍][6] 是因为他们试图推行 DNS-over-HTTPS 以绕开英国的内容过滤系统和家长监护模式,破坏了英国 [#互联网][7] 安全准则。 <https://t.co/d9NaiaJYnk> [pic.twitter.com/WeZhLq2uvi][8]
|
||||||
|
>
|
||||||
|
> — 英国互联网提供商行业协会 (ISPAUK) (@ISPAUK) [2019 年 7 月 4 日][9]
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
和 Mozilla 一同被列入最终入围者名单的还有欧盟《版权法第 13 条》和美国总统特朗普。ISPA 在他们的声明里是这样解释的:
|
||||||
|
|
||||||
|
**Mozilla**:因为试图推行 DNS-over-HTTPS 以绕开英国的内容过滤系统和家长监护模式,破坏了英国互联网安全准则。
|
||||||
|
|
||||||
|
**欧盟《版权法第 13 条》**:因为要求各平台使用“内容识别技术”,威胁到了线上言论自由。
|
||||||
|
|
||||||
|
**美国总统特朗普**:因为在试图保护其国家安全的过程中,为复杂的全球通信供应链带来了巨大的不确定性。
|
||||||
|
|
||||||
|
### 什么是 DNS-over-HTTPS?
|
||||||
|
|
||||||
|
你可以将 DoH 理解为,域名解析服务(DNS)的请求通过 HTTPS 连接加密传输。
|
||||||
|
|
||||||
|
传统意义上的 DNS 请求是不会被加密的,因此你的 DNS 提供商或者是互联网服务提供商(ISP)可以监视或者是控制你的浏览行为。如果没有 DoH,你很容易被 DNS 提供商强制拦截和进行内容过滤,并且你的互联网服务提供商也同样可以做到。
|
||||||
|
|
||||||
|
然而 DoH 颠覆了这一点,可以让你得到一个私密的浏览体验。
|
||||||
|
|
||||||
|
你可以研究一下 [Mozilla 是如何开展和 Cloudflare 的合作的][11],并且可以自己配置一下 DoH(如果需要的话)。
|
||||||
|
|
||||||
|
### DoH 有用吗?
|
||||||
|
|
||||||
|
既有用又没有用。
|
||||||
|
|
||||||
|
当然了,从事情的一方面来看,DoH 可以帮助用户绕过 DNS 或者互联网服务提供商强制的内容过滤系统。如果说 DoH 有助于满足我们避开互联网审查的需求,那么它是一件好事情。
|
||||||
|
|
||||||
|
不过从事情的另一方面来看,如果你是一位家长,而你的孩子在 Mozilla Firefox 上使用了 DoH 的话,你就无法 [设置内容过滤器][12] 了。这取决于 [防火墙配置][13] 的好坏。
|
||||||
|
|
||||||
|
DoH 可能会成为一些人绕过家长监护的手段,这可能不是一件好事。
|
||||||
|
|
||||||
|
如果我这样的说法有问题,你可以在下面的评论区纠正我。
|
||||||
|
|
||||||
|
并且,使用 DoH 就意味着你没办法使用本地 host 文件了(如果你正用它作为广告拦截或者是其它用途的话)。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
你是如何看待 DoH 的呢?它足够好吗?
|
||||||
|
|
||||||
|
你又是如何看待 ISPA 的决定的呢?你觉得他们这样的声明是不是在鼓励互联网审查和政府对网民的监控呢?
|
||||||
|
|
||||||
|
我个人觉得这个提名决定非常可笑。即使 DoH 并不是所有人都需要的那个终极功能,能够有一种保护个人隐私的选择也总不是件坏事。
|
||||||
|
|
||||||
|
在下面的评论区里发表你的看法吧。最后我想引用这么一句话:
|
||||||
|
|
||||||
|
> 在谎言遍地的时代,说真话是一种革命行为。(LCTT 译注:引自乔治奥威尔)
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/mozilla-internet-villain/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[chen-ni](https://github.com/chen-ni)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://en.wikipedia.org/wiki/DNS_over_HTTPS
|
||||||
|
[2]: https://www.ispa.org.uk/ispa-announces-finalists-for-2019-internet-heroes-and-villains-trump-and-mozilla-lead-the-way-as-villain-nominees/
|
||||||
|
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/mozilla-internet-villain.jpg?resize=800%2C450&ssl=1
|
||||||
|
[4]: https://twitter.com/mozilla?ref_src=twsrc%5Etfw
|
||||||
|
[5]: https://twitter.com/hashtag/ISPAs?src=hash&ref_src=twsrc%5Etfw
|
||||||
|
[6]: https://twitter.com/hashtag/InternetVillain?src=hash&ref_src=twsrc%5Etfw
|
||||||
|
[7]: https://twitter.com/hashtag/internet?src=hash&ref_src=twsrc%5Etfw
|
||||||
|
[8]: https://t.co/WeZhLq2uvi
|
||||||
|
[9]: https://twitter.com/ISPAUK/status/1146725374455373824?ref_src=twsrc%5Etfw
|
||||||
|
[10]: https://itsfoss.com/why-firefox/
|
||||||
|
[11]: https://blog.nightly.mozilla.org/2018/06/01/improving-dns-privacy-in-firefox/
|
||||||
|
[12]: https://itsfoss.com/how-to-block-porn-by-content-filtering-on-ubuntu/
|
||||||
|
[13]: https://itsfoss.com/set-up-firewall-gufw/
|
||||||
184
published/201907/20190708 10 ways to get started with Linux.md
Normal file
184
published/201907/20190708 10 ways to get started with Linux.md
Normal file
@ -0,0 +1,184 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11124-1.html)
|
||||||
|
[#]: subject: (10 ways to get started with Linux)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/ways-get-started-linux)
|
||||||
|
[#]: author: (Seth Kenlon https://opensource.com/users/seth/users/don-watkins)
|
||||||
|
|
||||||
|
Linux 入门十法
|
||||||
|
======
|
||||||
|
|
||||||
|
> 想要进入 Linux 之门,试试这十个方法。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
文章《[什么是 Linux 用户?][2]》的作者 Anderson Silva 明确表示,现今人们使用 Linux(在某种程度上)就像使用 Windows 一样,只要你对“使用 Linux”这个事情定义得足够广义。尽管如此,如果你的生活中没有太多的使用 Linux 的机会,现在正是以前所未有的方式尝试 Linux 的好时机。
|
||||||
|
|
||||||
|
以下是 Linux 入门的十种方法。你可以试试其中一个或者全部试试。
|
||||||
|
|
||||||
|
### 1、加入免费 shell 计划
|
||||||
|
|
||||||
|
![Free shell screenshot][3]
|
||||||
|
|
||||||
|
有很多人在用不上的服务器上运行 Linux (请记住,“Linux 服务器”可以是从最新的超级计算机到丢弃的、已经用了 12 年的笔记本电脑中的任何一个)。为了充分利用多余的计算机,许多管理员用这些备用的机器提供了免费的 shell 帐户。
|
||||||
|
|
||||||
|
如果你想要登录到 Linux 终端中学习命令、shell 脚本、Python 以及 Web 开发的基础知识,那么免费的 shell 帐户是一种简单、免费的入门方式。下面是一个可以体验一下的简短列表:
|
||||||
|
|
||||||
|
* [Freeshell.de][4] 是一个自 2002 年以来一直在线服务的公用 Linux 系统。你可以通过 SSH、IPv6 和 OpenSSL 进行访问,以获得 Linux shell 体验,并且可以使用 MySQL 数据库。
|
||||||
|
* [Blinkenshell][5] 提供了一个学习 Unix、使用 IRC、托管简单网站和共享文件的 Linux shell。它自 2006 年以来一直在线服务。
|
||||||
|
* [SDF 公用 Unix 系统][6]成立于 1987 年,提供了免费的 NetBSD 账户。当然,NetBSD 不是 Linux,但它是开源的 Unix,因此它提供了类似的体验。它也有几个自制应用程序,因此它不但有普通的免费 shell,还提供了老派 BBS。
|
||||||
|
|
||||||
|
免费 shell 帐户常会受到滥用,因此你表现出的可信程度和积极参与协作的意愿越多,你的体验就越好。你可以通过专门请求或小额捐赠来证明你的诚意,通常可以访问数据库引擎、编译器和高级编程语言。你还可以要求安装其他软件或库,但需经管理员批准。
|
||||||
|
|
||||||
|
#### 如何使用
|
||||||
|
|
||||||
|
公用 shell 帐户是尝试真正的 Linux 系统的好方法。你无法获得 root 权限这一事实意味着你可以学习本地软件管理,而无需做更多的维护工作。你可以做很多实际操作,以完成真正的工作,尽管它们对于学习关键任务还不够。
|
||||||
|
|
||||||
|
### 2、试试 Windows WSL 2 里面的 Linux
|
||||||
|
|
||||||
|
不管你信不信,微软从 2019 年 6 月开始在 Windows 里面带上了 Linux,这意味着你可以从 Windows 运行 Linux 应用程序,这是 [Windows 里的 Linux 子系统][7]的第二版(WSL 2)。虽然它主要针对开发人员,但 Windows 用户可以发现 WSL 2 是一个来自于他们熟悉的桌面上的 Linux 环境,而没有被任何虚拟化占用额外资源。这是一个以进程方式运行在 Windows 机器上的 Linux。现阶段,它仍然是一个新的动向和正在进行中的工作,因此它可能会发生变化。如果你试图用它承担重任,你可能会遇到一两个错误,但是如果你只是想入门 Linux、学习一些命令,并感受在基于文本的环境如何完成工作,那么 WSL 2 可能正是你所需要的。
|
||||||
|
|
||||||
|
#### 如何使用
|
||||||
|
|
||||||
|
WSL 还没有明确的用途或目的,但它在 Windows 机器上提供了 Linux 环境。你可以获得 root 访问权限,并可以运行 Linux 发行版和应用程序,因此这是一种简单而无缝的学习方式。但是,即使 WSL *是Linux*,它也不能给你典型的 Linux 体验。它是由 Windows 提供的 Linux,而这不太会是你在现实世界中遇到的情况。WSL 是一个开发和教育工具,但如果你可以使用它,那么你应该试试它。
|
||||||
|
|
||||||
|
### 3、把 Linux 放到可启动的 U 盘上
|
||||||
|
|
||||||
|
![Porteus Linux][8]
|
||||||
|
|
||||||
|
便携 Linux 可以安装到 U 盘上随身携带,并用该 U 盘启动你遇到的任何计算机。你可以获得个性化的 Linux 桌面,而无需担心所用于启动的主机上的数据。该计算机上原有的系统不会与你的 Linux 系统相接触,并且你的 Linux 操作系统也不会影响计算机。它非常适合酒店商务中心、图书馆、学校的公共计算机,或者只是给自己一个不时启动 Linux 的借口。
|
||||||
|
|
||||||
|
与许多其他快速获得的 Linux shell 不同,此方法为你提供了一个完整而强大的 Linux 系统,包括桌面环境,可访问你需要的任何软件以及持久的数据存储。
|
||||||
|
|
||||||
|
这个系统永远不会改变。你要保存的任何数据都将写入压缩的文件系统中,然后在引导时将其作为覆盖层应用于该系统。这种灵活性允许你选择是以持久模式启动,将所有数据保存回 U 盘;还是以临时模式启动,以便一旦关闭电源,你所做的一切都会消失。换句话说,你可以将其用作不受信任的计算机上的安全信息亭或你信任的计算机上的便携式操作系统。
|
||||||
|
|
||||||
|
你可以尝试很多 [U 盘发行版][9],有些带有精简的桌面环境,适用于低功耗计算机,而另一些带有完整的桌面环境。我偏爱 [Porteus][10] Linux。在过去的八年里,我每天都把它放在我的钥匙链上,在商务旅行中使用它作为我的主要计算平台,如果在工作场所或家中计算机发生问题,它也会用作工具盘。它是一个可靠而稳定的操作系统,有趣且易于使用。
|
||||||
|
|
||||||
|
在 Mac 或 Windows 上,下载 [Fedora Media Writer][11] 以创建你下载的任何便携式发行版的可启动 U 盘。
|
||||||
|
|
||||||
|
#### 如何使用
|
||||||
|
|
||||||
|
从 U 盘启动一个 “实时 Linux” 可提供完整的 Linux 发行版环境。虽然数据存储与你安装到硬盘驱动器的系统略有不同,但其它的所有内容都与你在 Linux 桌面上所期望的一样。在便携式 Linux 操作系统上你几乎没有什么不能做的,所以在你的钥匙串上挂上一个以解锁你遇到的每台计算机的全部潜力吧。
|
||||||
|
|
||||||
|
### 4、在线游览
|
||||||
|
|
||||||
|
![Linux tour screenshot][12]
|
||||||
|
|
||||||
|
Ubuntu 的某个人想到了在浏览器中托管 Ubuntu GNOME 桌面的好主意。如果想要自己尝试一下,可以打开 Web 浏览器并导航到 [tour.ubuntu.com][13]。你可以选择要演示的活动,也可以跳过单个课程并单击 “<ruby>四处看看<rt>Show Yourself Around</rt></ruby>” 按钮。
|
||||||
|
|
||||||
|
即使你是 Linux 桌面的新用户,你也可能会发现“四处看看”功能比你想象的更还简单。在线游览中,你可以四处看看,查看可用的应用程序,以及查看典型的默认 Linux 桌面。你不能在 Firefox 中调整设置或启动另一个在线游览(这是我尝试过的第一件事),虽然你可以完成安装应用程序的动作,但你无法启动它们。但是,如果你之前从未使用过 Linux 桌面,并且想要看到各种新奇的东西,那这就是一场旋风之旅。
|
||||||
|
|
||||||
|
#### 如何使用
|
||||||
|
|
||||||
|
在线游览真的只是一次旅行。如果你从未见过 Linux 桌面,那么这是一个了解它的情况的机会。这不是一个正式的使用,而是一个吸引过客的展示。
|
||||||
|
|
||||||
|
### 5、在浏览器中用 JavaScript 运行 Linux
|
||||||
|
|
||||||
|
![JSLinux][14]
|
||||||
|
|
||||||
|
就在不久之前,虚拟化的计算成本还很高,还仅限于使用先进的硬件的用户。而现在虚拟化已被优化到可以由 JavaScript 引擎执行的程度,这要归功于 Fabrice Bellard,它是优秀的开源 [QEMU][15] 机器仿真器和虚拟器的创建者。
|
||||||
|
|
||||||
|
Bellard 还启动了 JSLinux 项目,该项目允许你在浏览器中运行 Linux 和其他操作系统,这算是闲暇时间的一个乐趣。它仍然是一个实验性项目,但它是一个技术奇迹。打开 Web 浏览器导航到 [JSLinux][16] 页面,你可以启动基于文本的 Linux shell 或精简的图形 Linux 环境。你可以上传和下载文件到 JSLinux 主机上或(在理论上可以)将文件发送到一个网络备份位置,因为 JSLinux 可以通过 VPN 套接字访问互联网(尽管上限速度取决于 VPN 服务)。
|
||||||
|
|
||||||
|
#### 如何使用
|
||||||
|
|
||||||
|
你不会在 JSLinux 上正经使用多少时间,这个环境可能太不寻常了,无法学习 Linux 正常工作的广泛课程。但是,如果你厌倦了在一台普通的 PC 上运行 Linux 并想在一个真正独特的平台上试用 Linux,那么 JSLinux 就属于这种。
|
||||||
|
|
||||||
|
### 6、阅读关于它的书
|
||||||
|
|
||||||
|
并非每种 Linux 体验都要用到计算机。也许你是那种喜欢在开始新事物之前保持距离先观察和研究的人,或者你可能还不清楚 “Linux” 所包含的内容,或者你喜欢全情投入其中。关于 Linux 如何工作、运行 Linux 的方式以及 Linux 世界中有什么,有很多书可以读。
|
||||||
|
|
||||||
|
你越熟悉开源世界,就越容易理解常用术语,将城市神话与实际经验区分开来。我们不时会发布[图书清单] [17],但我的最爱之一是 Hazel Russman 的《[The Charm of Linux][18]》。这是一个从不同角度巡览 Linux 的过程,是由一位独立作者在发现 Linux 时兴奋之余写作的。
|
||||||
|
|
||||||
|
#### 如何使用
|
||||||
|
|
||||||
|
没有什么能比一本好书更好。这是体验 Linux 的最不传统的方法,但对于喜欢印刷文字的人来说,它既舒适又有效。
|
||||||
|
|
||||||
|
### 7、弄块树莓派
|
||||||
|
|
||||||
|
![Raspberry Pi 4][19]
|
||||||
|
|
||||||
|
如果你正在使用[树莓派][20],那么你就正在运行 Linux。Linux 和低功耗计算很容易上手。关于树莓派的好处,除了价格低于 100 美元之外,它的[网站][21]是专为教育而设计的。你可以了解树莓派所能做的一切,当你了解之后,就知道了 Linux 可以为你做些什么。
|
||||||
|
|
||||||
|
#### 如何使用
|
||||||
|
|
||||||
|
树莓派被设计为低功耗计算机。这意味着你不能像过去那样做那么多的多任务处理,但这是一种避免不堪重负的方便方法。树莓派是学习 Linux 及其附带的所有可能性的好方法,它是发现环保、小型、简化计算能力的有趣方式。并且一定要关注 Opensource.com 上的[提示][22]、[技巧][23]和[有趣的][24][活动] [25],特别是在每年三月份的树莓派之周的期间。
|
||||||
|
|
||||||
|
### 8、赶上容器热潮
|
||||||
|
|
||||||
|
如果你从事于神话般的[云服务][26]的后端工作,那么你已经听说过容器热潮。虽然你可以在 Windows、Azure、Mac 和 Linux 上运行 Docker 和 Kubernetes,但你可能不知道容器本身就是 Linux。云计算应用和基础设施实际上是精简的 Linux 系统,部分虚拟化,部分基于裸机。如果启动容器,则会启动微型的超特定的 Linux 发行版。
|
||||||
|
|
||||||
|
容器与虚拟机或物理服务器[不同][27]。它们不打算用作通用操作系统。但是,如果你在容器中进行开发,你可以停下来四处打量一下,你将了解到 Linux 系统的结构、保存重要文件的位置以及最常见的命令。你甚至可以[在线尝试容器][28],你可以在我的文章中[深入到 Linux 容器的背后][29]了解它们如何工作的。
|
||||||
|
|
||||||
|
#### 如何使用
|
||||||
|
|
||||||
|
根据设计,容器特定于一个单一任务,但它们是 Linux,因此它们非常灵活。你可以如你预期的使用它们,也可以在你的 Linux 实验当中将容器构建到大部分完整系统中。它虽然不提供桌面 Linux 体验,但它是完整的 Linux 体验。
|
||||||
|
|
||||||
|
### 9、以虚拟机方式安装 Linux
|
||||||
|
|
||||||
|
虚拟化是尝试操作系统的简便方法,[VirtualBox][30] 是一种很好的开源虚拟化方法。VirtualBox 可以在 Windows 和 Mac 上运行,因此你可以将 Linux 安装为虚拟机(VM)并使用它,就好像它只是一个应用程序一样。如果你不习惯安装操作系统,VirtualBox 也是一种尝试 Linux 的非常安全的方式,而不会意外地将其安装覆盖在你通常的操作系统上。
|
||||||
|
|
||||||
|
#### 如何使用
|
||||||
|
|
||||||
|
将 Linux 作为虚拟机运行既方便又简单,既可以作为试运行使用,也可以在需要 Linux 环境时进行双启动或重启进入。它功能齐全,因为它使用虚拟硬件,宿主操作系统负责驱动你的外围设备。将 Linux 作为虚拟机运行的唯一缺点主要是心理上的。如果你打算使用 Linux 作为主要操作系统,但最终默认在宿主操作系统上做除了特定于 Linux 的大多数任务,那么虚拟机就会让你失望。否则,虚拟机是现代技术的胜利,在 VirtualBox 中使用 Linux 可以为你提供 Linux 所提供的所有最佳功能。
|
||||||
|
|
||||||
|
### 10、安装一个 Linux
|
||||||
|
|
||||||
|
![Fedora Silverblue][31]
|
||||||
|
|
||||||
|
如果对上述方式有疑问,那么总会有传统的方式。如果你想给予 Linux 应有的关注,你可以下载 Linux,将安装程序刻录到 U 盘(或 DVD,如果你更喜欢光学介质的话),并将其安装在你的计算机上。Linux 是开源的,所以任何想要花时间打包 Linux 的人都可以分发 Linux,并且可以将所有可用的部分分配到通常称为发行版的内容中。无论问哪一个 Linux 用户什么发行版是“最好的”,你必然都会得到一个不同的答案(主要是因为这个术语“最佳”通常是尚未定义的)。大多数人都认可:你应该使用适合你的 Linux 发行版,这意味着你应该测试一些流行的发行版,并坚持使你的计算机按照你期望的行为行事。这是一种务实和功能性的方法。例如,如果发行版无法识别你的网络摄像头而你希望它可以正常工作,则可以使用一个可识别该网络摄像头的发行版。
|
||||||
|
|
||||||
|
如果你之前从未安装过操作系统,你会发现大多数 Linux 发行版都包含一个友好且简单的安装程序。只需下载一个发行版(它们以 ISO 文件提供),然后下载 [Fedora Media Writer][11] 来创建一个可启动的安装 U 盘。
|
||||||
|
|
||||||
|
#### 如何使用
|
||||||
|
|
||||||
|
安装 Linux 并将其用作操作系统是迈向熟悉它的一步。怎么使用它都可以。你可能会发现一些你从未了解过的所需的必备功能,你可能会比你想象的更多地了解计算机,并且可能会改变你的世界观。你使用一个 Linux 桌面,或者是因为它易于下载和安装,或者是因为你想要削弱公司中某些人的霸主地位,或者只是因为它可以帮助你完成工作。
|
||||||
|
|
||||||
|
无论你的原因是什么,只需尝试使用上面这些任何(或所有)这些方式。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/ways-get-started-linux
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth/users/don-watkins
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_Penguin_Image_520x292_12324207_0714_mm_v1a.png?itok=p7cWyQv9 (Penguins gathered together in the Artic)
|
||||||
|
[2]: https://opensource.com/article/19/6/what-linux-user
|
||||||
|
[3]: https://opensource.com/sites/default/files/uploads/freeshell.png (Free shell screenshot)
|
||||||
|
[4]: https://freeshell.de
|
||||||
|
[5]: https://blinkenshell.org/wiki/Start
|
||||||
|
[6]: https://sdf.org/
|
||||||
|
[7]: https://devblogs.microsoft.com/commandline/wsl-2-is-now-available-in-windows-insiders/
|
||||||
|
[8]: https://opensource.com/sites/default/files/uploads/porteus.jpg (Porteus Linux)
|
||||||
|
[9]: https://linux.cn/article-11040-1.html
|
||||||
|
[10]: http://porteus.org
|
||||||
|
[11]: https://getfedora.org/en/workstation/download/
|
||||||
|
[12]: https://opensource.com/sites/default/files/uploads/linux_tour.jpg (Linux tour screenshot)
|
||||||
|
[13]: http://tour.ubuntu.com/en/#
|
||||||
|
[14]: https://opensource.com/sites/default/files/uploads/jslinux.jpg (JSLinux)
|
||||||
|
[15]: https://www.qemu.org
|
||||||
|
[16]: https://bellard.org/jslinux/
|
||||||
|
[17]: https://opensource.com/article/19/1/tech-books-new-skils
|
||||||
|
[18]: http://www.lulu.com/shop/hazel-russman/the-charm-of-linux/paperback/product-21229401.html
|
||||||
|
[19]: https://opensource.com/sites/default/files/uploads/raspberry-pi-4-case.jpg (Raspberry Pi 4)
|
||||||
|
[20]: https://opensource.com/resources/raspberry-pi
|
||||||
|
[21]: https://www.raspberrypi.org/
|
||||||
|
[22]: https://opensource.com/article/19/3/raspberry-pi-projects
|
||||||
|
[23]: https://opensource.com/article/19/3/piflash
|
||||||
|
[24]: https://opensource.com/article/19/3/gamepad-raspberry-pi
|
||||||
|
[25]: https://opensource.com/life/16/3/make-music-raspberry-pi-milkytracker
|
||||||
|
[26]: https://opensource.com/resources/cloud
|
||||||
|
[27]: https://opensource.com/article/19/6/how-ssh-running-container
|
||||||
|
[28]: https://linuxcontainers.org/lxd/try-it/
|
||||||
|
[29]: https://opensource.com/article/18/11/behind-scenes-linux-containers
|
||||||
|
[30]: https://virtualbox.org
|
||||||
|
[31]: https://opensource.com/sites/default/files/uploads/fedora-silverblue.png (Fedora Silverblue)
|
||||||
@ -0,0 +1,126 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (MjSeven)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11123-1.html)
|
||||||
|
[#]: subject: (Command line quick tips: Permissions)
|
||||||
|
[#]: via: (https://fedoramagazine.org/command-line-quick-tips-permissions/)
|
||||||
|
[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
|
||||||
|
|
||||||
|
命令行快速提示:权限
|
||||||
|
======
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
Fedora 与所有基于 Linux 的系统一样,它提供了一组强大的安全特性。其中一个基本特性是文件和文件夹上的*权限*。这些权限保护文件和文件夹免受未经授权的访问。本文将简要介绍这些权限,并向你展示如何使用它们共享对文件夹的访问。
|
||||||
|
|
||||||
|
### 权限基础
|
||||||
|
|
||||||
|
Fedora 本质上是一个多用户操作系统,它也有*组*,用户可以是其成员。但是,想象一下一个没有权限概念的多用户系统,不同的登录用户可以随意阅读彼此的内容。你可以想象到这对隐私或安全性并不是很好。
|
||||||
|
|
||||||
|
Fedora 上的任何文件或文件夹都分配了三组权限。第一组用于拥有文件或文件夹的*用户*,第二组用于拥有它的*组*,第三组用于其他人,即既不是该文件的用户也不是拥有该文件的组中的用户。有时这被称为*全世界*。
|
||||||
|
|
||||||
|
### 权限意味着什么
|
||||||
|
|
||||||
|
每组权限都有三种形式:*读*、*写*和*执行*。其中每个都可以用首字母来代替,即 `r`、`w`、`x`。
|
||||||
|
|
||||||
|
#### 文件权限
|
||||||
|
|
||||||
|
对于*文件*,权限的含义如下所示:
|
||||||
|
|
||||||
|
* 读(`r`):可以读取文件内容
|
||||||
|
* 写(`w`):可以更改文件内容
|
||||||
|
* 执行(`x`):可以执行文件 —— 这主要用于打算直接运行的程序或脚本
|
||||||
|
|
||||||
|
当你对任何文件进行详细信息列表查看时,可以看到这三组权限。尝试查看系统上的 `/etc/services` 文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls -l /etc/services
|
||||||
|
-rw-r--r--. 1 root root 692241 Apr 9 03:47 /etc/services
|
||||||
|
```
|
||||||
|
|
||||||
|
注意列表左侧的权限组。如上所述,这些表明三种用户的权限:拥有该文件的用户,拥有该文件的组以及其他人。用户所有者是 `root`,组所有者是 `root` 组。用户所有者具有对文件的读写权限,`root` 组中的任何人都只能读取该文件。最后,其他任何人也只能读取该文件。(最左边的 `-` 显示这是一个常规文件。)
|
||||||
|
|
||||||
|
顺便说一下,你通常会在许多(但不是所有)系统配置文件上发现这组权限,它们只由系统管理员而不是普通用户更改。通常,普通用户需要读取其内容。
|
||||||
|
|
||||||
|
#### 文件夹(目录)权限
|
||||||
|
|
||||||
|
对于文件夹,权限的含义略有不同:
|
||||||
|
|
||||||
|
* 读(`r`):可以读取文件夹内容(例如 `ls` 命令)
|
||||||
|
* 写(`w`):可以更改文件夹内容(可以在此文件夹中创建或删除文件)
|
||||||
|
* 执行(`x`):可以搜索文件夹,但无法读取其内容。(这听起来可能很奇怪,但解释起来需要更复杂的文件系统细节,这超出了本文的范围,所以现在就这样吧。)
|
||||||
|
|
||||||
|
看一下 `/etc/grub.d` 文件夹的例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls -ld /etc/grub.d
|
||||||
|
drwx------. 2 root root 4096 May 23 16:28 /etc/grub.d
|
||||||
|
```
|
||||||
|
|
||||||
|
注意最左边的 `d`,它显示这是一个目录或文件夹。权限显示用户所有者(`root`)可以读取、更改和 `cd` 到此文件夹中。但是,没有其他人可以这样做 —— 无论他们是否是 `root` 组的成员。注意,你不能 `cd` 进入该文件夹。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd /etc/grub.d
|
||||||
|
bash: cd: /etc/grub.d: Permission denied
|
||||||
|
```
|
||||||
|
|
||||||
|
注意你自己的主目录是如何设置的:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls -ld $HOME
|
||||||
|
drwx------. 221 paul paul 28672 Jul 3 14:03 /home/paul
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,注意除了作为所有者之外,没有人可以访问此文件夹中的任何内容。这是特意的!你不希望其他人能够在共享系统上读取你的私人内容。
|
||||||
|
|
||||||
|
### 创建共享文件夹
|
||||||
|
|
||||||
|
你可以利用此权限功能轻松创建一个文件夹以在组内共享。假设你有一个名为 `finance` 的小组,其中有几个成员需要共享文档。因为这些是用户文档,所以将它们存储在 `/home` 文件夹层次结构中是个好主意。
|
||||||
|
|
||||||
|
首先,[使用 sudo][2] 创建一个共享文件夹,并将其设置为 `finance` 组所有:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo mkdir -p /home/shared/finance
|
||||||
|
$ sudo chgrp finance /home/shared/finance
|
||||||
|
```
|
||||||
|
|
||||||
|
默认情况下,新文件夹具有这些权限。注意任何人都可以读取或搜索它,即使他们无法创建或删除其中的文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
drwxr-xr-x. 2 root root 4096 Jul 6 15:35 finance
|
||||||
|
```
|
||||||
|
|
||||||
|
对于金融数据来说,这似乎不是一个好主意。接下来,使用 `chmod` 命令更改共享文件夹的模式(权限)。注意,使用 `g` 更改所属组的权限,使用 `o` 更改其他用户的权限。同样,`u` 会更改用户所有者的权限:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo chmod g+w,o-rx /home/shared/finance
|
||||||
|
```
|
||||||
|
|
||||||
|
生成的权限看起来更好。现在,`finance` 组中的任何人(或用户所有者 `root`)都可以完全访问该文件夹及其内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
drwxrwx---. 2 root finance 4096 Jul 6 15:35 finance
|
||||||
|
```
|
||||||
|
|
||||||
|
如果其他用户尝试访问共享文件夹,他们将无法执行此操作。太棒了!现在,我们的金融部门可以将文档放在一个共享的地方。
|
||||||
|
|
||||||
|
### 其他说明
|
||||||
|
|
||||||
|
还有其他方法可以操作这些权限。例如,你可能希望将此文件夹中的任何文件设置为 `finance` 组所拥有。这需要本文未涉及的其他设置,但请继续关注我们,以了解关于该主题的更多信息。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/command-line-quick-tips-permissions/
|
||||||
|
|
||||||
|
作者:[Paul W. Frields][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[MjSeven](https://github.com/MjSeven)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/pfrields/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://fedoramagazine.org/wp-content/uploads/2018/10/commandlinequicktips-816x345.jpg
|
||||||
|
[2]: https://fedoramagazine.org/howto-use-sudo/
|
||||||
@ -0,0 +1,214 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (robsean)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11083-1.html)
|
||||||
|
[#]: subject: (Debian 10 (Buster) Installation Steps with Screenshots)
|
||||||
|
[#]: via: (https://www.linuxtechi.com/debian-10-buster-installation-guide/)
|
||||||
|
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||||
|
|
||||||
|
图解 Debian 10(Buster)安装步骤
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Debian 项目发布了它的最新稳定版 Debian 10,其代号是 “Buster”,这个发布版将获得 5 年的支持。Debian 10 可用于 32 位和 64 位系统。这个发布版带来很多新的特色,列出下面一些特色:
|
||||||
|
|
||||||
|
* 引入新的 Debian 10 的主题 “FuturePrototype”
|
||||||
|
* 新版本的电脑桌面环境 GNOME 3.30、Cinnamon 3.8、KDE Plasma 5.14、MATE 1.20、Xfce 4.12
|
||||||
|
* 长期支持版内核 4.19.0-4
|
||||||
|
* 新的 Python 3 (3.7.2)、Perl 5.28、PHP 7.3
|
||||||
|
* iptables 替换为 nftables
|
||||||
|
* 更新 LibreOffice 6.1、GIMP 2.10.8
|
||||||
|
* 更新 OpenJDK 11、MariaDB 10.3 和 Apache 2.4.38
|
||||||
|
* 更新 Chromium 73.0、Firefox 60.7
|
||||||
|
* 改进 UEFI 支持
|
||||||
|
|
||||||
|
在这篇文章中,我们将演示如何在你的笔记本电脑和台式电脑上安装 Debian 10 “Buster” 工作站。
|
||||||
|
|
||||||
|
Debian 10 建议系统要求:
|
||||||
|
|
||||||
|
* 2 GB 内存
|
||||||
|
* 2 GHz 双核处理器
|
||||||
|
* 10 GB 可用硬盘空间
|
||||||
|
* 可启动安装介质(USB / DVD)
|
||||||
|
* 网络连接(可选)
|
||||||
|
|
||||||
|
让我们跳转到 Debian 10 的安装步骤。
|
||||||
|
|
||||||
|
### 步骤:1)下载 Debian 10 ISO 文件
|
||||||
|
|
||||||
|
从它的官方入口网站,下载 Debian 10 ISO 文件,
|
||||||
|
|
||||||
|
- https://www.debian.org/releases/buster/debian-installer/
|
||||||
|
|
||||||
|
ISO 文件下载完成后刻录它到 USB 或 DVD,使其可用来启动。
|
||||||
|
|
||||||
|
### 步骤:2)使用安装可启动介质(USB / DVD)启动你的电脑系统
|
||||||
|
|
||||||
|
重启你将安装 Debian 10 的电脑,转到 BIOS 设置,并设置启动介质为 USB 或 DVD。 用可启动介质启动电脑后,那么我们将看到下面的屏幕。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
选择第一个选项 “Graphical Install”。
|
||||||
|
|
||||||
|
### 步骤:3)选择你的首选语言、位置和键盘布局
|
||||||
|
|
||||||
|
在这个步骤中,你将被要求选择你的首选语言。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
点击 “Continue”。
|
||||||
|
|
||||||
|
选择你的首选位置,电脑系统将依照位置自动设置时区。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
现在选择适合于你安装设备的键盘布局。
|
||||||
|
|
||||||
|
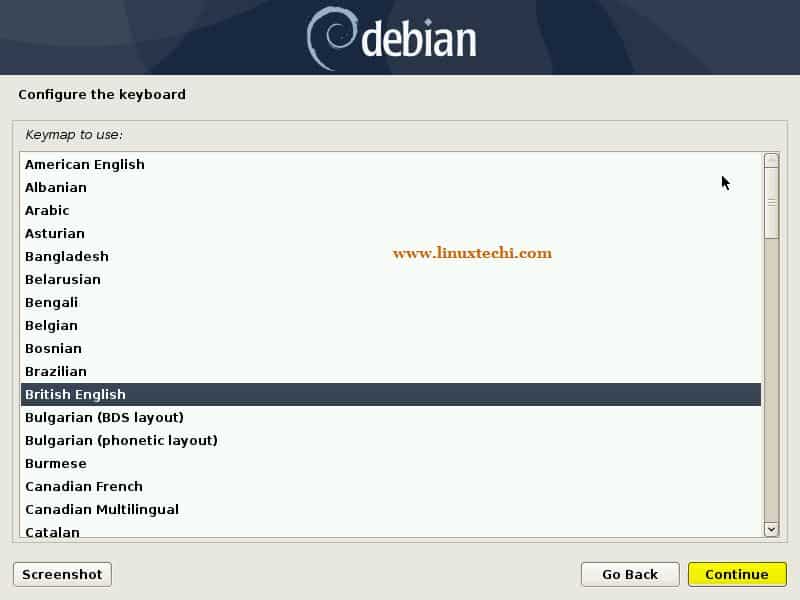
|
||||||
|
|
||||||
|
点击 “Continue” 以继续。
|
||||||
|
|
||||||
|
### 步骤:4)为 Debian 10 系统设置主机名称和域名
|
||||||
|
|
||||||
|
设置适合于你的环境的主机名,然后在 “Continue” 上单击,就我而言, 我指定主机名为 “debian10-buster”。
|
||||||
|
|
||||||
|
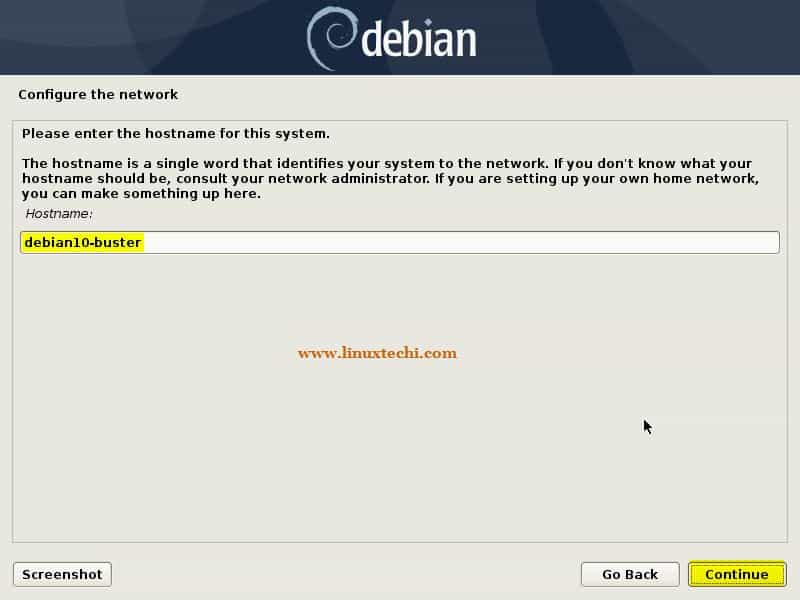
|
||||||
|
|
||||||
|
指定适合于环境的域名,并安装,然后在 “Continue” 上单击。
|
||||||
|
|
||||||
|
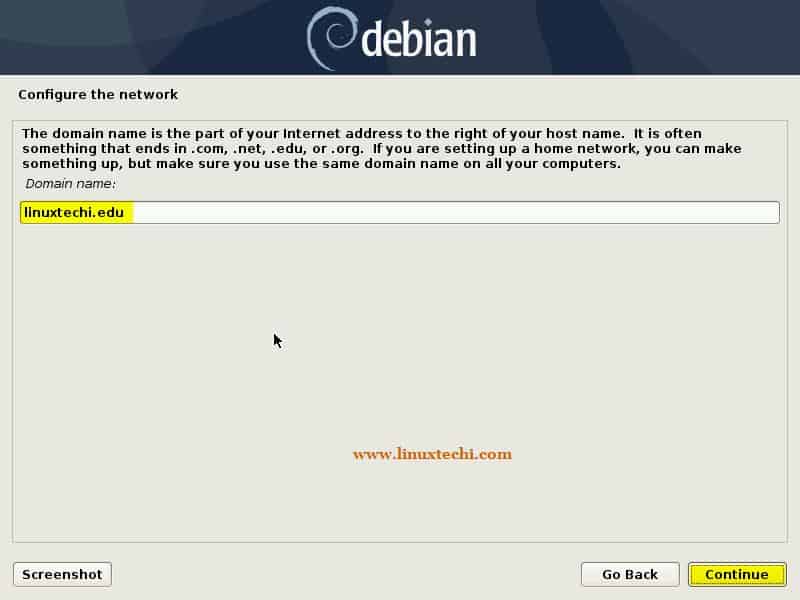
|
||||||
|
|
||||||
|
### 步骤:5)指定 root 用户的密码
|
||||||
|
|
||||||
|
在下面的屏幕中指定 root 密码,然后在 “Continue” 上单击。
|
||||||
|
|
||||||
|
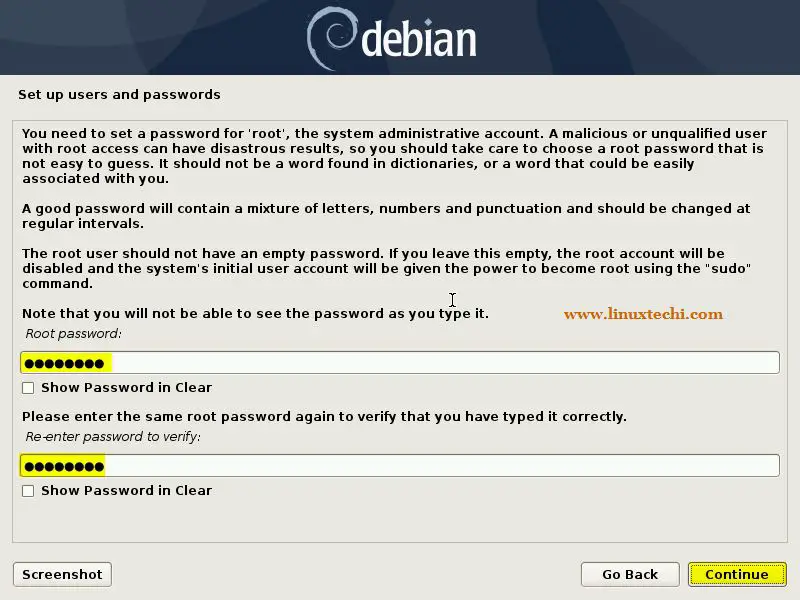
|
||||||
|
|
||||||
|
### 步骤:6)创建本地用户和它的密码
|
||||||
|
|
||||||
|
在这个步骤中,你将被提示指定本地用户具体信息,如完整的姓名、用户名和密码,
|
||||||
|
|
||||||
|
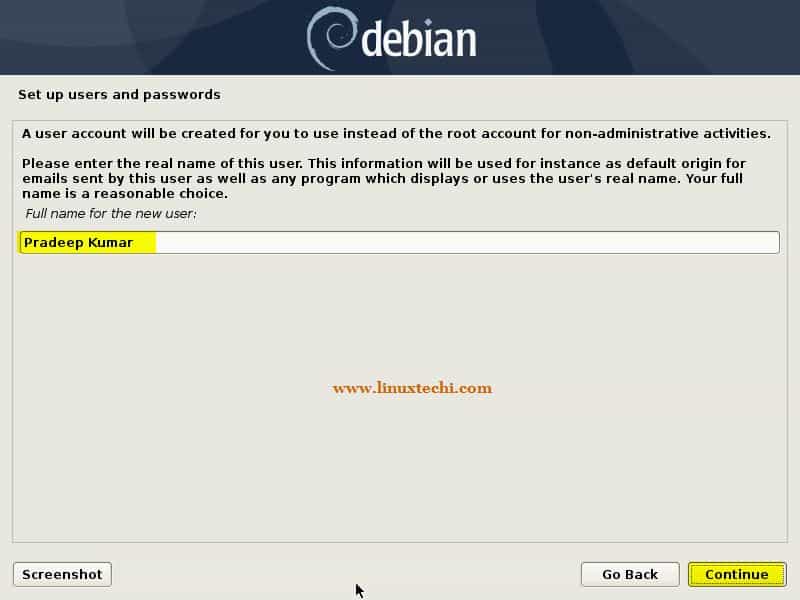
|
||||||
|
|
||||||
|
在 “Continue” 上单击。
|
||||||
|
|
||||||
|
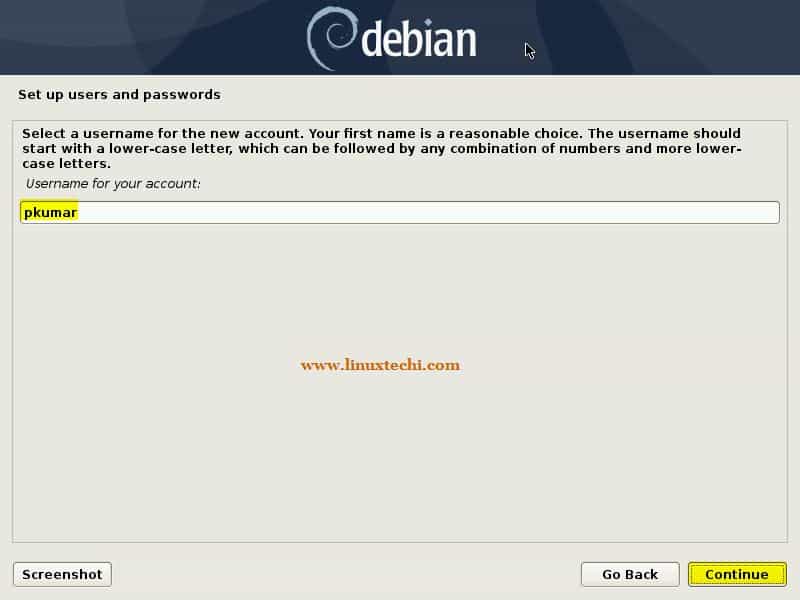
|
||||||
|
|
||||||
|
在 “Continue” 上单击,并在接下来的窗口中指定密码。
|
||||||
|
|
||||||
|
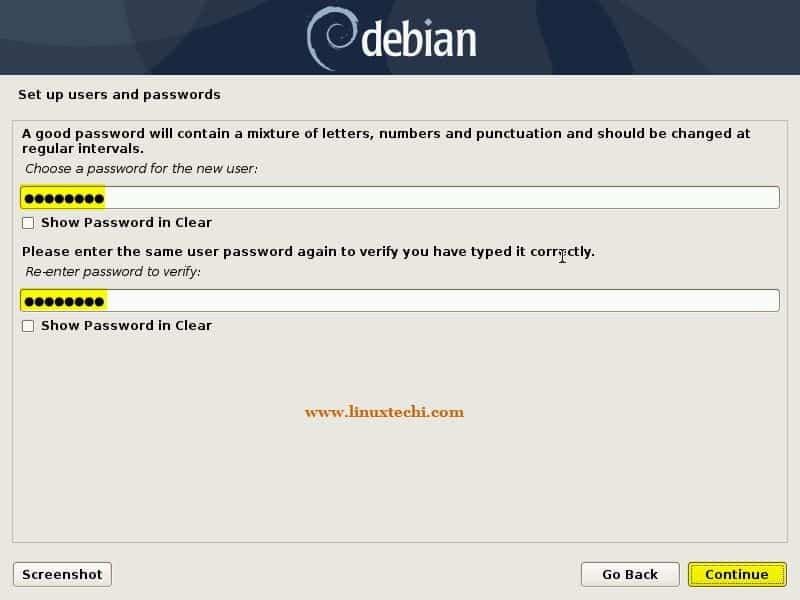
|
||||||
|
|
||||||
|
### 步骤:7)为 Debian 10 选择硬盘分区方案
|
||||||
|
|
||||||
|
在这个步骤中,为 Debian 10 选择硬盘分区方案,就我而言,我有 40 GB 硬盘可用于操作系统安装。分区方案有两种类型:
|
||||||
|
|
||||||
|
* 向导分区(安装器将自动创建需要的分区)
|
||||||
|
* 手动分区(正如名字所示,使用这种方式,我们可以手动创建分区方案)
|
||||||
|
|
||||||
|
在这篇教程中,我们将在我 42 GB 硬盘上使用带有 LVM 的向导分区。
|
||||||
|
|
||||||
|
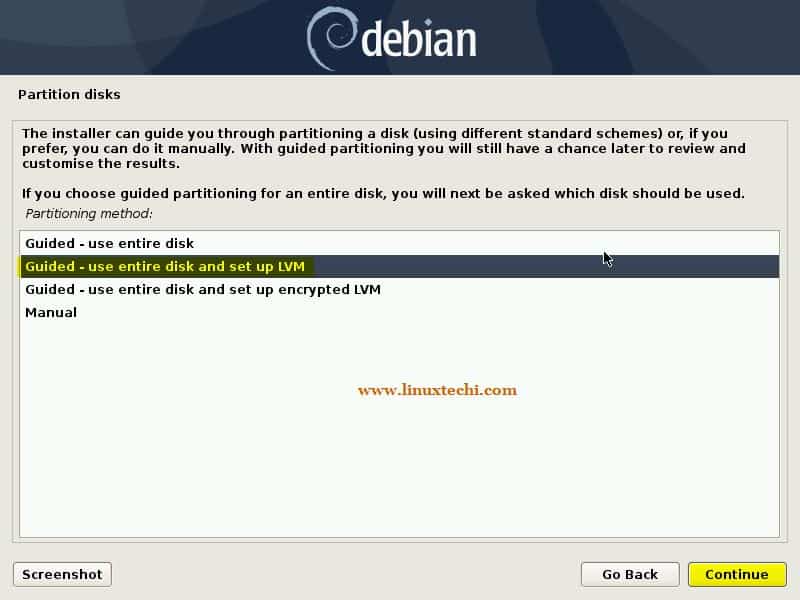
|
||||||
|
|
||||||
|
在 “Continue” 上单击来继续,
|
||||||
|
|
||||||
|
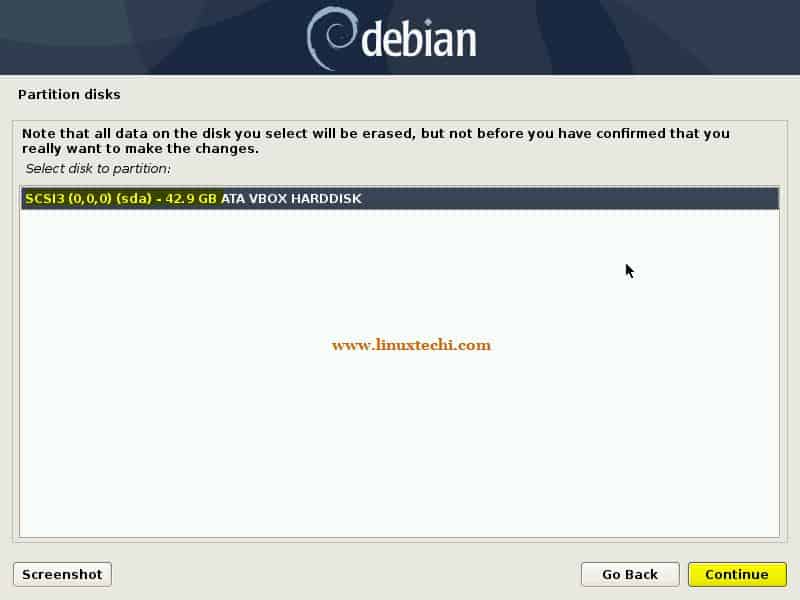
|
||||||
|
|
||||||
|
正如我们所视,我大约有 42 GB 硬盘空间,选择 “Continue”。
|
||||||
|
|
||||||
|
在接下来的屏幕中,你将被要求选择分区,如果是 Linux 新用户,那么选择第一个选项。假使你想要一个独立的 home 分区,那么选择第二种方案,否则选择第三种方案,它们将为 `/home`、`/var` 和 `/tmp` 创建独立的分区。
|
||||||
|
|
||||||
|
就我而言,我将通过选择第三种选项来为 `/home`、`/var` 和 `/tmp` 创建独立的分区。
|
||||||
|
|
||||||
|
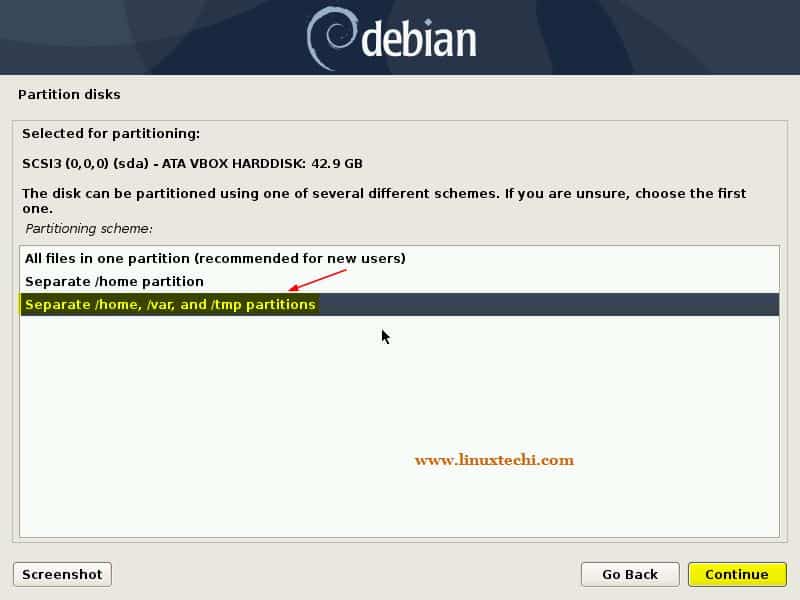
|
||||||
|
|
||||||
|
在接下来的屏幕中,选择 “yes” 来将更改写到磁盘中,配置 LVM ,然后在 “Continue” 上单击。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在接下来的屏幕中,将显示分区表,验证分区大小、文件系统类型和挂载点。
|
||||||
|
|
||||||
|
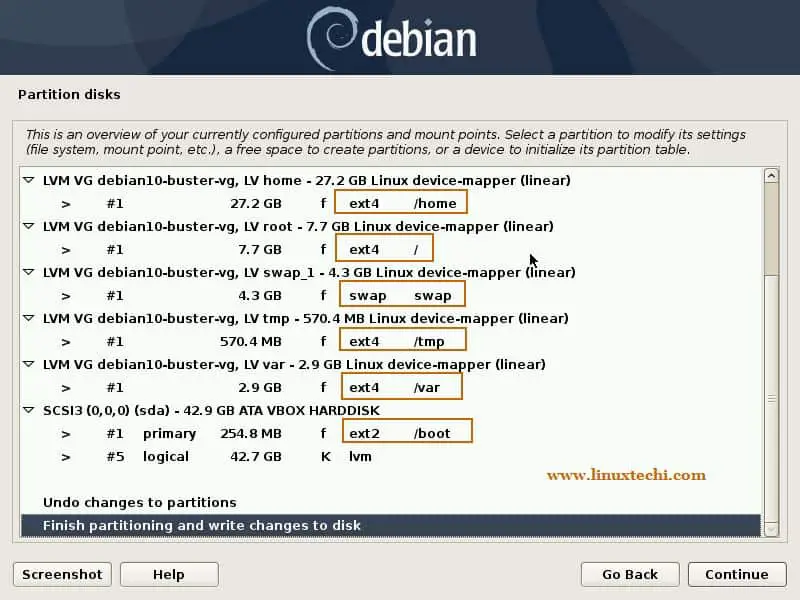
|
||||||
|
|
||||||
|
在 “Continue” 上单击来继续,
|
||||||
|
|
||||||
|
在接下来的屏幕中,选择 “yes” 来写更改到磁盘中,
|
||||||
|
|
||||||
|
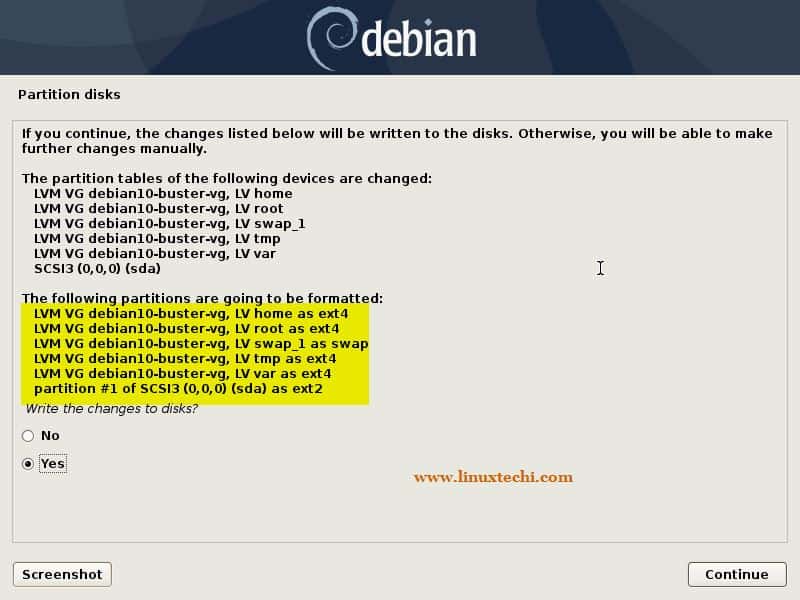
|
||||||
|
|
||||||
|
在 “Continue” 上单击来继续安装,
|
||||||
|
|
||||||
|
### 步骤:7)Debian 10 安装开始
|
||||||
|
|
||||||
|
在这一步骤中,Debian 10 的安装已经开始,并正在进行中,
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在安装期间,安装器将提示你扫描 CD/DVD 以配置软件包管理器,选择 “No” ,然后在 “Continue” 上单击。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在接下来的屏幕中,如果你想配置基于网络的软件包管理器选择 “yes” ,但是为了使这个方式工作,要确保你的系统连接到了网络,否则选择 “No”。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在 “Continue” 上单击来配置基于你本地的软件包管理器,在接下来的几个屏幕中,你将被提示选择本地和 Debian 软件包存储库 URL ,然后你将获得下面的屏幕。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
选择 “No” 来跳过软件包审查步骤,然后在 “Continue” 上单击。
|
||||||
|
|
||||||
|
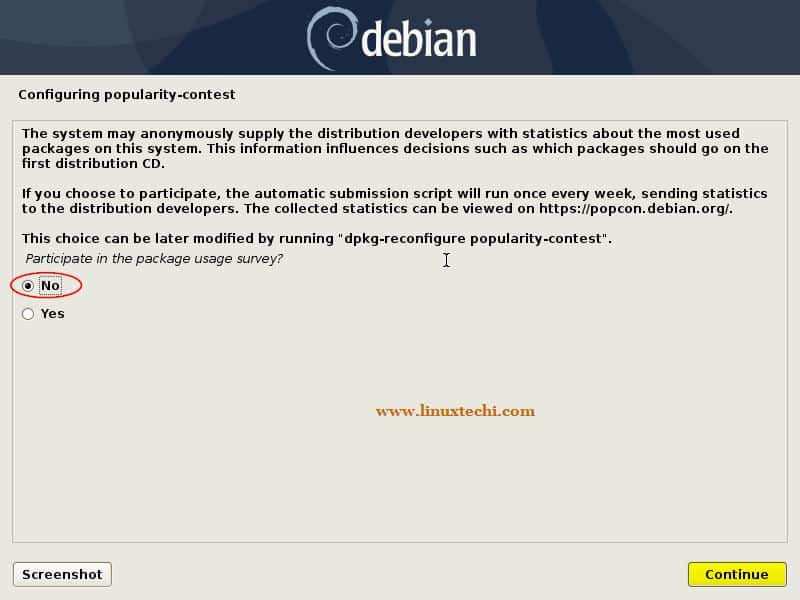
|
||||||
|
|
||||||
|
在接下来的窗口中,你将被提示选择电脑桌面环境和其它软件包,就我而言,我选择 “Gnome Desktop” ,“SSH Server” 和 “Standard System utilities”。
|
||||||
|
|
||||||
|
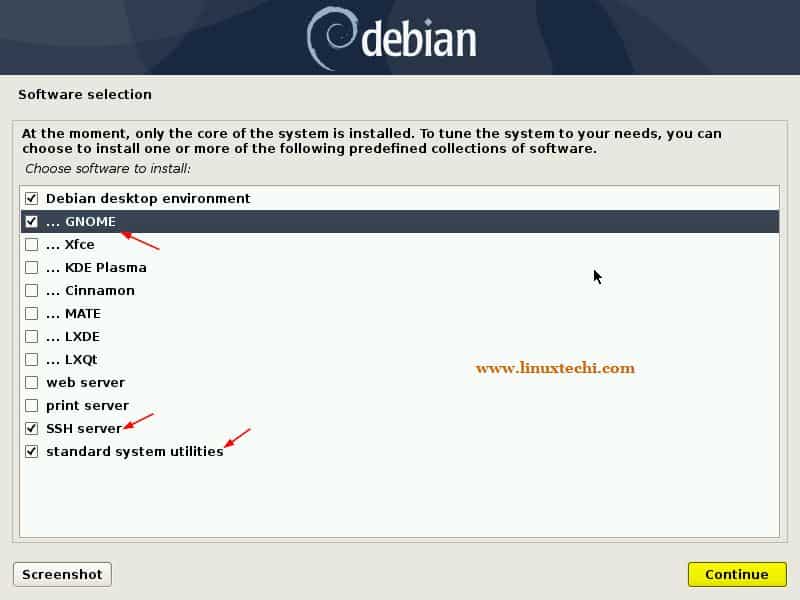
|
||||||
|
|
||||||
|
在 “Continue” 上单击来继续安装,
|
||||||
|
|
||||||
|
选择选项 “yes” 来安装 Grub 引导加载程序。
|
||||||
|
|
||||||
|
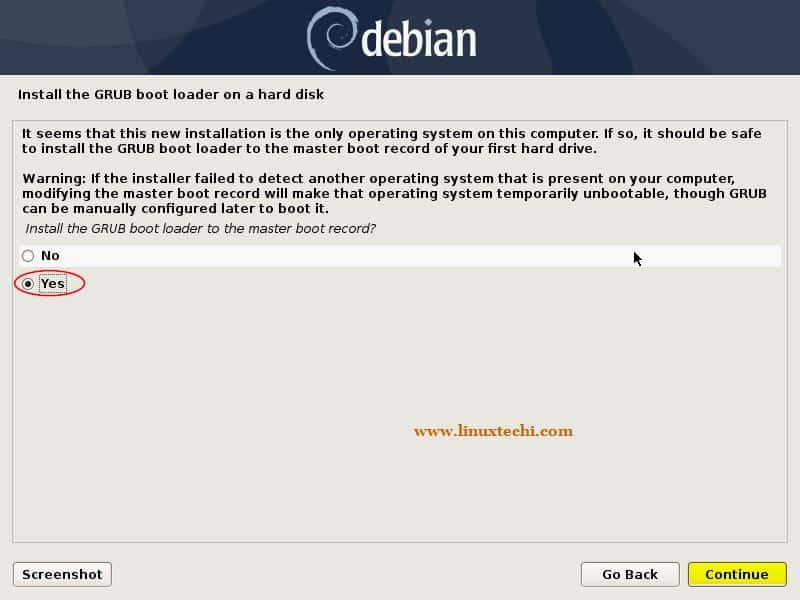
|
||||||
|
|
||||||
|
在 “Continue” 上单击来继续,然后在接下来的窗口中选择将安装引导加载程序的磁盘(`/dev/sda`)。
|
||||||
|
|
||||||
|
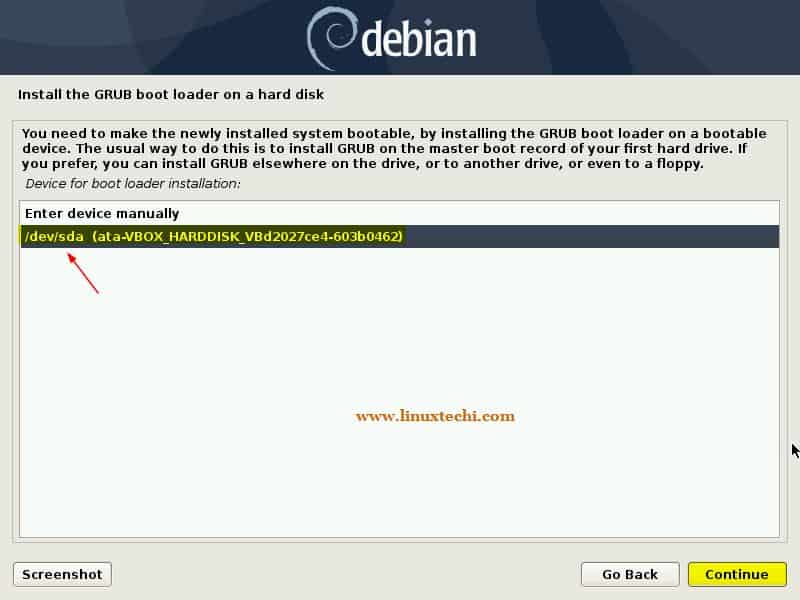
|
||||||
|
|
||||||
|
在 “Continue” 上单击来继续安装,一旦安装完成,安装器将提示我们来重启系统,
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在 “Continue” 上单击来重启你的系统,不要忘记在 BIOS 设置中更改启动介质,以便系统从我们已经安装 Debian 10 操作系统的硬盘启动。
|
||||||
|
|
||||||
|
### 步骤:8)启动你新安装的 Debian 10 系统
|
||||||
|
|
||||||
|
在成功安装后,一旦我们重启系统,我们将获取下面的引导加载程序屏幕。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
选择第一个选项 “Debian GNU/Linux” 并敲击回车键。
|
||||||
|
|
||||||
|
一旦系统启动,使用我在安装期间创建的本地用户和它的密码。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在成功登录后,将看到如下电脑桌面屏幕,
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
这证实 Debian 10 已经成功安装,这就是本文的全部,探索这个令人激动的 Linux 发行版吧,玩得开心 😊
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linuxtechi.com/debian-10-buster-installation-guide/
|
||||||
|
|
||||||
|
作者:[Pradeep Kumar][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[robsean](https://github.com/robsean)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
@ -0,0 +1,75 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11082-1.html)
|
||||||
|
[#]: subject: (Linux Games Get A Performance Boost for AMD GPUs Thanks to Valve’s New Compiler)
|
||||||
|
[#]: via: (https://itsfoss.com/linux-games-performance-boost-amd-gpu/)
|
||||||
|
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||||
|
|
||||||
|
借助 Valve 的新编译器,Linux 游戏在 AMD GPU 中获得了性能提升
|
||||||
|
======
|
||||||
|
|
||||||
|
Steam 寻求公众反馈以便为 AMD GPU 测试 ACO(一个新的 Mesa [着色器][1]编译器)已经有几天了。
|
||||||
|
|
||||||
|
目前,AMD 驱动程序使用 LLVM 作为着色器编译器。而 [Mesa][2] 则是一个开源的 [LLVM][3] 的替代品。因此,在这种情况下,Valve 希望支持 AMD 显卡以提高 Linux 游戏在各种 Linux 发行版上的性能。
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
为了提高游戏性能,编译时间至关重要,使用新的 ACO 编译器,它将时间缩短了近 50%。 Valve 在其 [Steam 社区][5]的帖子中解释了更多关于它的信息:
|
||||||
|
|
||||||
|
> AMD OpenGL 和 Vulkan 驱动程序目前使用的着色器编译器是上游 LLVM 项目的一部分。该项目规模庞大,并且有许多不同的目标,游戏着色器的在线编译只是其中之一。这可能会导致不同的开发权衡,其中改进游戏特定功能比其他情况更难,特定于游戏的功能也经常被 LLVM 的开发人员因其他事情破坏。特别是,着色器编译速度就是这样一个例子:它在大多数其他场景中并不是一个关键因素,只能锦上添花。但是对于游戏来说,编译时间是至关重要的,而缓慢的着色器编译可能导致几乎无法播放的顿挫。
|
||||||
|
|
||||||
|
### Linux 游戏真的有性能提升吗?
|
||||||
|
|
||||||
|
是的,没错。
|
||||||
|
|
||||||
|
这里的主要亮点是编译时间。如果着色器编译时间急剧减少,理论上应该会改善游戏的性能。
|
||||||
|
|
||||||
|
而且,根据[最初的基准报告][6],我们确实看到了一些重大改进。
|
||||||
|
|
||||||
|
![][7]
|
||||||
|
|
||||||
|
当然,游戏中的 FPS 改进并不是很大。但是,它在早期阶段仍然是一个很好的进步。
|
||||||
|
|
||||||
|
如果你对编译时间的改进感到好奇,下面是结果:
|
||||||
|
|
||||||
|
![][8]
|
||||||
|
|
||||||
|
是的,即使大幅的编译时间减少也不会大幅影响游戏中的 FPS。但是,它仍然是一件大事,因为目前,这是一项正在进行中的工作。所以,我们可以有更多期待。
|
||||||
|
|
||||||
|
但是,还能做些什么呢?
|
||||||
|
|
||||||
|
好吧,ACO 还没完成。下面是为什么(在 Valve 中提到):
|
||||||
|
|
||||||
|
> 现在,ACO 只处理像素和计算着色器阶段。当其余的阶段实现时,我们预计编译时间将进一步减少。
|
||||||
|
|
||||||
|
#### 总结
|
||||||
|
|
||||||
|
尽管我没有配备 AMD GPU,但我很有兴趣看到对 Linux 游戏场景的改进。
|
||||||
|
|
||||||
|
此外,随着事情进展,我们将期待更多的基准和报告。
|
||||||
|
|
||||||
|
你怎么看待?请在下面的评论中告诉我们你的想法。如果你有基本报告要分享,请告诉我们。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/linux-games-performance-boost-amd-gpu/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://en.wikipedia.org/wiki/Shader
|
||||||
|
[2]: https://en.wikipedia.org/wiki/Mesa_(computer_graphics)
|
||||||
|
[3]: https://en.wikipedia.org/wiki/LLVM
|
||||||
|
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/Improved-Linux-Gaming.png?resize=800%2C450&ssl=1
|
||||||
|
[5]: https://steamcommunity.com/games/221410/announcements/detail/1602634609636894200
|
||||||
|
[6]: https://gist.github.com/pendingchaos/aba1e4c238cf039d17089f29a8c6aa63
|
||||||
|
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/fps-improvement-amd.png?fit=800%2C412&ssl=1
|
||||||
|
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/compile-time-amd-gpu-linux.png?ssl=1
|
||||||
@ -0,0 +1,57 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11097-1.html)
|
||||||
|
[#]: subject: (From BASIC to Ruby: Life lessons from first programming languages on Command Line Heroes)
|
||||||
|
[#]: via: (https://opensource.com/19/7/command-line-heroes-ruby-basic)
|
||||||
|
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg)
|
||||||
|
|
||||||
|
从 BASIC 到 Ruby:入门编程语言的体悟
|
||||||
|
======
|
||||||
|
|
||||||
|
> 为什么 BASIC 是一种备受喜爱的入门语言?下一代该如何学习编程?
|
||||||
|
|
||||||
|
![Listen to the Command Line Heroes Podcast][1]
|
||||||
|
|
||||||
|
《[Command Line Heroes][2]》 第三季的第二集今天抵达了,它对我的入门编程的怀旧让我回到了过去。
|
||||||
|
|
||||||
|
(LCTT 译注:《Command Line Heroes》 是红帽公司制作的播客,讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。其第一季制作于 2017 年,邀请到了谷歌、NASA 等重量级企业的技术专家担当嘉宾,讲述操作系统战争风云、美国航天局如何开源等等,涉及开源、操作系统、容器、DevOps、云计算等话题。)
|
||||||
|
|
||||||
|
### 语言会影响可访问性
|
||||||
|
|
||||||
|
这一集告诉我,BASIC 是计算机的理解力民主化的一次巨大飞跃。我很难想象,在一个不太遥远的、计算机尚且是稀罕之物的时代,是 BASIC 改变了世界。正如 [Saron Yitbarek][3] 提到的那样,“在早些年编程,你几乎得有个博士学位才行。”BASIC 是一个巨大的飞跃,它专注于可用性(适合初学者的命令)和资源共享(单个计算机的分时操作)。它使得编程不在局限于当时的“计算机玩家”(我喜欢这集中的这句话),并帮助了新一代人参与了进来。进入编程领域的壁垒得以下降。
|
||||||
|
|
||||||
|
### 入门编程语言
|
||||||
|
|
||||||
|
这一集的核心话题是围绕学习入门语言展开的。关于学习什么编程语言以及如何学习,有很多建议。关于这个问题[在这里][4]已经写了很多。我喜欢听到 Saron 以 Ruby 作为她的介绍的故事,以及它以一种几乎意想不到的方式变得有趣。我有一些类似的经历,因为我在一些项目中用到了 Ruby。它的灵活性让我感到开心。当我(对编程)感到紧张时,正是这种快乐让我重新回到它的身边,并且它有一些能够使语言如此充满情感的强大功能。
|
||||||
|
|
||||||
|
我第一次体验编程是用 HTML 和 CSS,但我第一个重型编程语言是 Java。我永远不会忘记在课堂的第一天被告知要记住 `public static void main`,但没有告知我关于它意味着什么的任何信息。我们花了很多时间在面向对象编程的上下文环境中探讨它是什么,但它从未像我在 Ruby 中使用 `.each` 迭代列表,或者像在 Python 中用 `import numpy` 做一些数学魔术那样感到兴奋。然后我听说孩子们正在学习如何使用 Python 编写 [Minecraft][5] 或使用像 [Scratch][6] 这样的可视化编程语言,我因此而悟,BASIC 的遗产正在以新的方式存在。
|
||||||
|
|
||||||
|
我从这一集中获取到的内容:
|
||||||
|
|
||||||
|
* 请记住,没有人出生就是程序员。每个人都没有这样的背景。你并不孤单。
|
||||||
|
* 学习一门语言。任何一种都行。如果你有选择的可能,那么请选择能带给你最大乐趣的那个。
|
||||||
|
* 不要忘记所有语言都可以构建一些东西。请为人类创造有意义的事物。
|
||||||
|
|
||||||
|
《Command Line Heroes》整个第三季将涉及编程语言。[请在此处订阅来学习你想要了解的有关编程语言的起源][2],我很乐意在下面的评论中听到你的想法。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/19/7/command-line-heroes-ruby-basic
|
||||||
|
|
||||||
|
作者:[Matthew Broberg][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/mbbroberg
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/ep1_blog-header-520x292_lgr.png?itok=I8IS1hkt (Listen to the Command Line Heroes Podcast)
|
||||||
|
[2]: https://www.redhat.com/en/command-line-heroes
|
||||||
|
[3]: https://twitter.com/saronyitbarek
|
||||||
|
[4]: https://linux.cn/article-8379-1.html
|
||||||
|
[5]: https://opensource.com/life/15/5/getting-started-minecraft-pi
|
||||||
|
[6]: https://opensource.com/education/11/6/how-teach-next-generation-open-source-scratch
|
||||||
@ -0,0 +1,180 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11104-1.html)
|
||||||
|
[#]: subject: (Pipx – Install And Run Python Applications In Isolated Environments)
|
||||||
|
[#]: via: (https://www.ostechnix.com/pipx-install-and-run-python-applications-in-isolated-environments/)
|
||||||
|
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||||
|
|
||||||
|
Pipx:在隔离环境中安装和运行 Python 应用
|
||||||
|
======
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
我们始终建议在虚拟环境中安装 Python 应用以避免彼此冲突。Pip 包管理器可以帮助我们在隔离的环境中安装 Python 应用,我们使用两个工具,即 `venv` 和 `virtualenv`。还有一个 Python.org 推荐的名为 [Pipenv][2] 的 Python 包管理器也可以用来安装 Python 应用。与 Pip 不同,Pipenv 默认会自动创建虚拟环境。这意味着你不再需要为项目手动创建虚拟环境。今天,我偶然发现了一个名为 “Pipx” 的类似工具,它是一个自由开源程序,允许你在隔离的虚拟环境中安装和运行 Python 应用。
|
||||||
|
|
||||||
|
使用 Pipx,我们可以轻松安装 PyPI 中托管的数千个 Python 应用,而不会有太多麻烦。好的是,你可以使用常规用户权限执行所有操作。你不需要成为 “root” 用户或不需要具有 “sudo” 权限。值得一提的是,Pipx 可以从临时环境运行程序,而无需安装它。当你经常测试同一程序的多个版本时,这将非常方便。随 Pipx 一起安装的软件包可以随时列出、升级或卸载。Pipx 是一个跨平台的程序,因此它可以在 Linux、Mac OS 和 Windows 上运行。
|
||||||
|
|
||||||
|
### 安装 Pipx
|
||||||
|
|
||||||
|
Python 3.6+ 、Pip 和 `venv` 模块是安装 `pipx` 所必需的。确保按照以下指南中的说明安装它们。
|
||||||
|
|
||||||
|
* [如何使用 Pip 管理 Python 包][3]
|
||||||
|
|
||||||
|
此处,需要 `venv` 来创建虚拟环境。
|
||||||
|
|
||||||
|
接下来,运行以下命令安装 Pipx。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python3 -m pip install --user pipx
|
||||||
|
$ python3 -m userpath append ~/.local/bin
|
||||||
|
```
|
||||||
|
|
||||||
|
`pipx` 二进制文件的默认位置是 `~/.local/bin`。你可以使用 `PIPX_BIN_DIR` 环境变量覆盖它。如果要覆盖 `PIPX_BIN_DIR`,只需运行 `userpath append $PIPX_BIN_DIR`,确保它在你的路径中。
|
||||||
|
|
||||||
|
Pipx 的默认虚拟环境位置是 `~/.local/pipx`。这可以用环境变量 `PIPX_HOME` 覆盖。
|
||||||
|
|
||||||
|
让我们继续看看如何使用 Pipx 安装 Python 应用。
|
||||||
|
|
||||||
|
### 使用 Pipx 在隔离环境中安装和运行 Python 应用
|
||||||
|
|
||||||
|
以下是 Pipx 入门的几个例子
|
||||||
|
|
||||||
|
#### 安装 Python 包
|
||||||
|
|
||||||
|
要全局安装 Python 应用,例如 cowsay,请运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pipx install cowsay
|
||||||
|
```
|
||||||
|
|
||||||
|
此命令将自动创建虚拟环境,在其中安装包并包的可执行文件放在 `$PATH` 中。
|
||||||
|
|
||||||
|
示例输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
installed package cowsay 2.0.3, Python 3.6.8
|
||||||
|
These binaries are now globally available
|
||||||
|
- cowsay
|
||||||
|
done! ✨ 🌟 ✨
|
||||||
|
```
|
||||||
|
|
||||||
|
![1][4]
|
||||||
|
|
||||||
|
*使用 Pipx 安装 Python 应用*
|
||||||
|
|
||||||
|
让我们测试新安装的 cowsay 程序:
|
||||||
|
|
||||||
|
![1][5]
|
||||||
|
|
||||||
|
在这里,我从官方网站上摘取了这些例子。你可以安装/测试任何其他的 Python 包。
|
||||||
|
|
||||||
|
#### 列出 Python 包
|
||||||
|
|
||||||
|
要使用 Pipx 列出所有已安装的应用,请运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pipx list
|
||||||
|
```
|
||||||
|
|
||||||
|
示例输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
venvs are in /home/sk/.local/pipx/venvs
|
||||||
|
binaries are exposed on your $PATH at /home/sk/.local/bin
|
||||||
|
package cowsay 2.0.3, Python 3.6.8
|
||||||
|
- cowsay
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你尚未安装任何软件包,你将看到以下输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
nothing has been installed with pipx 😴
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 升级包
|
||||||
|
|
||||||
|
要升级包,只需执行以下操作:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pipx upgrade cowsay
|
||||||
|
```
|
||||||
|
|
||||||
|
要一次性升级所有已安装的软件包,请使用:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pipx upgrade-all
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 从临时虚拟环境运行应用
|
||||||
|
|
||||||
|
有时,你可能希望运行特定的 Python 程序,但并不实际安装它。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pipx run pycowsay moooo
|
||||||
|
```
|
||||||
|
|
||||||
|
![1][6]
|
||||||
|
|
||||||
|
*在临时隔离虚拟环境中运行 Python 应用*
|
||||||
|
|
||||||
|
此命令实际上并不安装指定程序,而是从临时虚拟环境运行它。你可以使用此命令快速测试 Python 应用。
|
||||||
|
|
||||||
|
你甚至可以直接运行 .py 文件。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pipx run https://gist.githubusercontent.com/cs01/fa721a17a326e551ede048c5088f9e0f/raw/6bdfbb6e9c1132b1c38fdd2f195d4a24c540c324/pipx-demo.py
|
||||||
|
pipx is working!
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 卸载软件包
|
||||||
|
|
||||||
|
可以使用以下命令卸载软件包:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pipx uninstall cowsay
|
||||||
|
```
|
||||||
|
|
||||||
|
要删除所有已安装的包:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pipx uninstall-all
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 获得帮助
|
||||||
|
|
||||||
|
要查看帮助部分,请运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pipx --help
|
||||||
|
```
|
||||||
|
|
||||||
|
就是这些了。如果你一直在寻找安全,方便和可靠的程序来安装和运行 Python 应用,Pipx 可能是一个不错的选择。
|
||||||
|
|
||||||
|
资源:
|
||||||
|
|
||||||
|
* [Pipx 的 GitHub 仓库][7]
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.ostechnix.com/pipx-install-and-run-python-applications-in-isolated-environments/
|
||||||
|
|
||||||
|
作者:[sk][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.ostechnix.com/author/sk/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/pipx-720x340.png
|
||||||
|
[2]: https://www.ostechnix.com/pipenv-officially-recommended-python-packaging-tool/
|
||||||
|
[3]: https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||||
|
[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/Install-Python-Applications-Using-Pipx.png
|
||||||
|
[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/Test-Python-application.png
|
||||||
|
[6]: https://www.ostechnix.com/wp-content/uploads/2019/07/Run-Python-Applications-In-Isolated-Environments.png
|
||||||
|
[7]: https://github.com/pipxproject/pipx
|
||||||
@ -0,0 +1,62 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (vizv)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11113-1.html)
|
||||||
|
[#]: subject: (Sysadmin vs SRE: What's the difference?)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/sysadmins-vs-sres)
|
||||||
|
[#]: author: (Vince Power https://opensource.com/users/vincepower/users/craig5/users/dawnparzych/users/penglish)
|
||||||
|
|
||||||
|
系统管理员与网站可靠性工程师(SRE)对比:区别在那儿?
|
||||||
|
======
|
||||||
|
|
||||||
|
> 系统管理员和网站可靠性工程师(SRE,下同)对于任何组织来讲都很重要。本篇将介绍下两者的不同之处。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在 IT 行业,成为多面手或是专家的争议一直存在。99% 的传统系统管理员都被归到了多面手这类。<ruby>[网站可靠性工程师][2]<rt>site reliability engineer</rt></ruby>(SRE)的角色则更加专精,并且在如 Google 般有着一定规模的头部公司中对其的需求不断增加。但总的来说这两者对于跑着应用的基础设施有着同样的目标:为应用的消费者提供良好的体验。然而两者的出发点却截然不同。
|
||||||
|
|
||||||
|
### 系统管理员:中立善良的化身
|
||||||
|
|
||||||
|
系统管理员一般都是从基础的桌面或网络支持成长过来的,并一路习得大多数系统管理员都会掌握的广泛的技能。此时这些系统管理员会对他们所负责的系统和应用了如指掌。他们会知道一号服务器上的应用每隔一个星期二就需要重启一次,或是九号服务器周三会静默的崩溃。他们会对服务器的监视作出微调以忽略无关紧要的信息,尽管那个被标记为<ruby>致命<rt>fatal<rt></ruby>的错误信息每个月第三个周日都会显示。
|
||||||
|
|
||||||
|
总的来讲,系统管理员了解如何照料那些跑着你核心业务的服务器。这些系统管理员已经成长到开始使用自动化工具去处理所有归他们管的服务器上的例行任务。他们虽然喜欢使用模板、<ruby>黄金镜像<rt>golden images</rt></ruby>、以及标准,但同时也有着足够的灵活度去修改一个服务器上的参数以解决错误,并注释为什么那个服务器的配置与众不同。
|
||||||
|
|
||||||
|
尽管系统管理员很伟大,但他们也有着一些怪癖。其中一项就是没有他们神圣的授权你永远也获取不了系统的 root 访问权限,另一项则是任何不是出于他们的主意的变更都要在文档中被记录为应用提供方的要求,并仍然需要再次核对。
|
||||||
|
|
||||||
|
他们所管理的服务器是他们的地盘,没有人可以随意干涉。
|
||||||
|
|
||||||
|
### SRE:灭霸将为之自豪
|
||||||
|
|
||||||
|
与成为系统管理员的道路相反,从开发背景和从系统管理员背景成长为 SRE 的可能性相近。SRE 的职位出现的时长与应用开发环境的生命周期相近。
|
||||||
|
|
||||||
|
随着一个组织的发展而引入的类似于[持续集成][4]和[持续发布][5] (CI/CD) 的 [DevOps][3] 概念,通常会出现技能空缺,以让这些<ruby>不可变<rt>immutable</rt></ruby>的应用部署到多个环境并随着业务需求进行扩展。这将是 SRE 的舞台。的确,一个系统管理员可以学习额外的工具,但大体上成为一个全职的职位更容易跟的上发展。一个专精的专家更有意义。
|
||||||
|
|
||||||
|
SRE 使用如<ruby>[代码即基础设施][6]<rt>infrastructure-as-code</rt></ruby>的概念去制作模板,然后调用它们来部署用以运行应用的环境,并以使用一键完整重现每个应用和它们的环境作为目标。因此会出现这样的情况:测试环境中一号服务器里的一号应用的二进制文件与生产环境中十五号服务器的完全一致,仅环境相关的变量如密码和数据库链接字串有所不同。
|
||||||
|
|
||||||
|
SRE 也会在配置发生改变时完全销毁一个环境并重新构建它。对于任何系统他们都不带一点感情。每个系统只是个被打了标记和安排了生命周期的数字而已,甚至连例行的对服务器打补丁也要重新部署整个<ruby>应用栈<rt>application stack</rt></ruby>
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
对于一些情况,尤其是运维一些大型的基于 DevOps 的环境时,一个 SRE 所能提供的用于处理各种规模的业务的专业技能当然更具优势。但每次他们在运气不好走入死胡同时都会去寻求他的系统管理员友人或是 [来自地狱的混蛋运维(BOFH)][7] ,得到他那身经百战的故障排除技能,和那些用于给组织提供价值的丰富经验的帮助。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/sysadmins-vs-sres
|
||||||
|
|
||||||
|
作者:[Vince Power][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[vizv](https://github.com/vizv)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/vincepower/users/craig5/users/dawnparzych/users/penglish
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux11x_cc.png?itok=XMDOouJR (People work on a computer server with devices)
|
||||||
|
[2]: https://en.wikipedia.org/wiki/Site_Reliability_Engineering
|
||||||
|
[3]: https://opensource.com/resources/devops
|
||||||
|
[4]: https://en.wikipedia.org/wiki/Continuous_integration
|
||||||
|
[5]: https://en.wikipedia.org/wiki/Continuous_delivery
|
||||||
|
[6]: https://en.wikipedia.org/wiki/Infrastructure_as_code
|
||||||
|
[7]: http://www.bofharchive.com/BOFH.html
|
||||||
@ -0,0 +1,178 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (robsean)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11120-1.html)
|
||||||
|
[#]: subject: (32-bit life support: Cross-compiling with GCC)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/cross-compiling-gcc)
|
||||||
|
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||||
|
|
||||||
|
32 位支持:使用 GCC 交叉编译
|
||||||
|
======
|
||||||
|
|
||||||
|
> 使用 GCC 在单一的构建机器上来为不同的 CPU 架构交叉编译二进制文件。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果你是一个开发者,要创建二进制软件包,像一个 RPM、DEB、Flatpak 或 Snap 软件包,你不得不为各种不同的目标平台编译代码。典型的编译目标包括 32 位和 64 位的 x86 和 ARM。你可以在不同的物理或虚拟机器上完成你的构建,但这需要你为何几个系统。作为代替,你可以使用 GNU 编译器集合 ([GCC][2]) 来交叉编译,在单一的构建机器上为几个不同的 CPU 架构产生二进制文件。
|
||||||
|
|
||||||
|
假设你有一个想要交叉编译的简单的掷骰子游戏。在大多数系统上,以 C 语言来编写这个相对简单,出于给添加现实的复杂性的目的,我以 C++ 语言写这个示例,所以程序依赖于一些不在 C 语言中东西 (具体来说就是 `iostream`)。
|
||||||
|
|
||||||
|
```
|
||||||
|
#include <iostream>
|
||||||
|
#include <cstdlib>
|
||||||
|
|
||||||
|
using namespace std;
|
||||||
|
|
||||||
|
void lose (int c);
|
||||||
|
void win (int c);
|
||||||
|
void draw ();
|
||||||
|
|
||||||
|
int main() {
|
||||||
|
int i;
|
||||||
|
do {
|
||||||
|
cout << "Pick a number between 1 and 20: \n";
|
||||||
|
cin >> i;
|
||||||
|
int c = rand ( ) % 21;
|
||||||
|
if (i > 20) lose (c);
|
||||||
|
else if (i < c ) lose (c);
|
||||||
|
else if (i > c ) win (c);
|
||||||
|
else draw ();
|
||||||
|
}
|
||||||
|
while (1==1);
|
||||||
|
}
|
||||||
|
|
||||||
|
void lose (int c )
|
||||||
|
{
|
||||||
|
cout << "You lose! Computer rolled " << c << "\n";
|
||||||
|
}
|
||||||
|
|
||||||
|
void win (int c )
|
||||||
|
{
|
||||||
|
cout << "You win!! Computer rolled " << c << "\n";
|
||||||
|
}
|
||||||
|
|
||||||
|
void draw ( )
|
||||||
|
{
|
||||||
|
cout << "What are the chances. You tied. Try again, I dare you! \n";
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
在你的系统上使用 `g++` 命令编译它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ g++ dice.cpp -o dice
|
||||||
|
```
|
||||||
|
|
||||||
|
然后,运行它来确认其工作:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./dice
|
||||||
|
Pick a number between 1 and 20:
|
||||||
|
[...]
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以使用 `file` 命令来查看你刚刚生产的二进制文件的类型:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ file ./dice
|
||||||
|
dice: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically
|
||||||
|
linked (uses shared libs), for GNU/Linux 5.1.15, not stripped
|
||||||
|
```
|
||||||
|
|
||||||
|
同样重要,使用 `ldd` 命令来查看它链接哪些库:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ldd dice
|
||||||
|
linux-vdso.so.1 => (0x00007ffe0d1dc000)
|
||||||
|
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6
|
||||||
|
(0x00007fce8410e000)
|
||||||
|
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6
|
||||||
|
(0x00007fce83d4f000)
|
||||||
|
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6
|
||||||
|
(0x00007fce83a52000)
|
||||||
|
/lib64/ld-linux-x86-64.so.2 (0x00007fce84449000)
|
||||||
|
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1
|
||||||
|
(0x00007fce8383c000)
|
||||||
|
```
|
||||||
|
|
||||||
|
从这些测试中,你已经确认了两件事:你刚刚运行的二进制文件是 64 位的,并且它链接的是 64 位库。
|
||||||
|
|
||||||
|
这意味着,为实现 32 位交叉编译,你必需告诉 `g++` 来:
|
||||||
|
|
||||||
|
1. 产生一个 32 位二进制文件
|
||||||
|
2. 链接 32 位库,而不是 64 位库
|
||||||
|
|
||||||
|
### 设置你的开发环境
|
||||||
|
|
||||||
|
为编译成 32 位二进制,你需要在你的系统上安装 32 位的库和头文件。如果你运行一个纯 64 位系统,那么,你没有 32 位的库或头文件,并且需要安装一个基础集合。最起码,你需要 C 和 C++ 库(`glibc` 和 `libstdc++`)以及 GCC 库(`libgcc`)的 32 位版本。这些软件包的名称可能在每个发行版中不同。在 Slackware 系统上,一个纯 64 位的带有 32 位兼容的发行版,可以从 [Alien BOB][3] 提供的 `multilib` 软件包中获得。在 Fedora、CentOS 和 RHEL 系统上:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ yum install libstdc++-*.i686
|
||||||
|
$ yum install glibc-*.i686
|
||||||
|
$ yum install libgcc.i686
|
||||||
|
```
|
||||||
|
|
||||||
|
不管你正在使用什么系统,你同样必须安装一些你工程使用的 32 位库。例如,如果你在你的工程中包含 `yaml-cpp`,那么,在编译工程前,你必需安装 `yaml-cpp` 的 32 位版本,或者,在很多系统上,安装 `yaml-cpp` 的开发软件包(例如,在 Fedora 系统上的 `yaml-cpp-devel`)。
|
||||||
|
|
||||||
|
一旦这些处理好了,编译是相当简单的:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ g++ -m32 dice.cpp -o dice32 -L /usr/lib -march=i686
|
||||||
|
```
|
||||||
|
|
||||||
|
`-m32` 标志告诉 GCC 以 32 位模式编译。`-march=i686` 选项进一步定义来使用哪种最优化类型(参考 `info gcc` 了解选项列表)。`-L` 标志设置你希望 GCC 来链接的库的路径。对于 32 位来说通常是 `/usr/lib`,不过,这依赖于你的系统是如何设置的,它可以是 `/usr/lib32`,甚至 `/opt/usr/lib`,或者任何你知道存放你的 32 位库的地方。
|
||||||
|
|
||||||
|
在代码编译后,查看你的构建的证据:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ file ./dice32
|
||||||
|
dice: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV),
|
||||||
|
dynamically linked (uses shared libs) [...]
|
||||||
|
```
|
||||||
|
|
||||||
|
接着,当然, `ldd ./dice32` 也会指向你的 32 位库。
|
||||||
|
|
||||||
|
### 不同的架构
|
||||||
|
|
||||||
|
在 64 位相同的处理器家族上允许 GCC 做出很多关于如何编译代码的假设来编译 32 位软件。如果你需要为完全不同的处理器编译,你必需安装适当的交叉构建实用程序。安装哪种实用程序取决于你正在编译的东西。这个过程比为相同的 CPU 家族编译更复杂一点。
|
||||||
|
|
||||||
|
当你为相同处理器家族交叉编译时,你可以期待找到与 32 位库集的相同的 64 位库集,因为你的 Linux 发行版是同时维护这二者的。当为一个完全不同的架构编译时,你可能不得不穷追你的代码所需要的库。你需要的版本可能不在你的发行版的存储库中,因为你的发行版可能不为你的目标系统提供软件包,或者它不在容易到达的位置提供所有的软件包。如果你正在编译的代码是你写的,那么你可能非常清楚它的依赖关系是什么,并清楚在哪里找到它们。如果代码是你下载的,并需要编译,那么你可能不熟悉它的要求。在这种情况下,研究正确编译代码需要什么(它们通常被列在 `README` 或 `INSTALL` 文件中,当然也出现在源文件代码自身之中),然后收集需要的组件。
|
||||||
|
|
||||||
|
例如,如果你需要为 ARM 编译 C 代码,你必须首先在 Fedora 或 RHEL 上安装 `gcc-arm-linux-gnu`(32 位)或 `gcc-aarch64-linux-gnu`(64 位);或者,在 Ubuntu 上安装 `arm-linux-gnueabi-gcc` 和 `binutils-arm-linux-gnueabi`。这提供你需要用来构建(至少)一个简单的 C 程序的命令和库。此外,你需要你的代码使用的任何库。你可以在惯常的位置(大多数系统上在 `/usr/include`)放置头文件,或者,你可以放置它们在一个你选择的目录,并使用 `-I` 选项将 GCC 指向它。
|
||||||
|
|
||||||
|
当编译时,不使用标准的 `gcc` 或 `g++` 命令。作为代替,使用你安装的 GCC 实用程序。例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ arm-linux-gnu-g++ dice.cpp \
|
||||||
|
-I/home/seth/src/crossbuild/arm/cpp \
|
||||||
|
-o armdice.bin
|
||||||
|
```
|
||||||
|
|
||||||
|
验证你构建的内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ file armdice.bin
|
||||||
|
armdice.bin: ELF 32-bit LSB executable, ARM, EABI5 version 1 (SYSV) [...]
|
||||||
|
```
|
||||||
|
|
||||||
|
### 库和可交付结果
|
||||||
|
|
||||||
|
这是一个如何使用交叉编译的简单的示例。在真实的生活中,你的源文件代码可能产生的不止于一个二进制文件。虽然你可以手动管理,在这里手动管理可能不是好的正当理由。在我接下来的文章中,我将说明 GNU 自动工具,GNU 自动工具做了使你的代码可移植的大部分工作。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/cross-compiling-gcc
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[robsean](https://github.com/robsean)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tools_osyearbook2016_sysadmin_cc.png?itok=Y1AHCKI4 (Wratchet set tools)
|
||||||
|
[2]: https://gcc.gnu.org/
|
||||||
|
[3]: http://www.slackware.com/~alien/multilib/
|
||||||
@ -0,0 +1,111 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11099-1.html)
|
||||||
|
[#]: subject: (How To Find Virtualbox Version From Commandline In Linux)
|
||||||
|
[#]: via: (https://www.ostechnix.com/how-to-find-virtualbox-version-from-commandline-in-linux/)
|
||||||
|
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||||
|
|
||||||
|
在 Linux 中如何从命令行查找 VirtualBox 版本
|
||||||
|
======
|
||||||
|
|
||||||
|
![FInd Virtualbox version from commandline In Linux][1]
|
||||||
|
|
||||||
|
我使用 Oracle VirtualBox 和 [KVM][2] 虚拟化程序[测试不同的 Linux 操作系统][3]。虽然我偶尔使用 KVM,但 Virtualbox 始终是我的首选。不是因为我不喜欢 KVM,而是因为我只是习惯了 VirtualBox。当在我的 Ubuntu 无头服务器上使用 [Virtualbox][4] 时,我需要知道 VirtualBox 的版本。如果它有 GUI,我可以进入 Virtualbox -> About -> Help 轻松找到它。但我的是没有 GUI 的 Ubuntu 服务器。如果你想知道如何在 Linux 中从命令行查找 VirtualBox 版本,可以采用以下几种方法。
|
||||||
|
|
||||||
|
|
||||||
|
### 在 Linux 中从命令行查找 VirtualBox 版本
|
||||||
|
|
||||||
|
要查找已安装的 VirtualBox 的版本,请打开终端并运行以下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vboxmanage --version
|
||||||
|
```
|
||||||
|
|
||||||
|
示例输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
5.2.18_Ubuntur123745
|
||||||
|
```
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
*在 Linux 中从命令行查找 Virtualbox 版本*
|
||||||
|
|
||||||
|
正如你在上面的输出中看到的,安装的 VirtualBox 的版本是 5.2。
|
||||||
|
|
||||||
|
查找 VirtualBox 版本的另一种方法是:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vbox-img --version
|
||||||
|
```
|
||||||
|
|
||||||
|
示例输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
5.2.18_Ubuntur123745
|
||||||
|
```
|
||||||
|
|
||||||
|
或者,你可以使用 `head` 和 `awk` 命令来查找 VirtualBox 版本。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ virtualbox --help | head -n 1 | awk '{print $NF}'
|
||||||
|
```
|
||||||
|
|
||||||
|
示例输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
5.2.18_Ubuntu
|
||||||
|
```
|
||||||
|
|
||||||
|
或者,使用 `echo` 命令结合 `head` 和 `awk` 命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ echo $(virtualbox --help | head -n 1 | awk '{print $NF}')
|
||||||
|
```
|
||||||
|
|
||||||
|
示例输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
5.2.18_Ubuntu
|
||||||
|
```
|
||||||
|
|
||||||
|
以上命令适用于任何 Linux 发行版。如果你使用的是 Ubuntu,你可以使用 `dpkg` 命令查看 VirtualBox 版本。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ dpkg -l | grep virtualbox | awk '{print $3}'
|
||||||
|
```
|
||||||
|
|
||||||
|
示例输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
5.2.30-130521~Ubuntu~bionic
|
||||||
|
5.2.18-dfsg-2~ubuntu18.04.5
|
||||||
|
```
|
||||||
|
|
||||||
|
就是这些了。这些是从 Linux 中的终端查找 Oracle Virtualbox 版本的几种方法。希望这篇文章很有用。
|
||||||
|
|
||||||
|
参考来自:
|
||||||
|
|
||||||
|
* [AskUbuntu][6]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.ostechnix.com/how-to-find-virtualbox-version-from-commandline-in-linux/
|
||||||
|
|
||||||
|
作者:[sk][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.ostechnix.com/author/sk/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Find-Virtualbox-Version-1-720x340.png
|
||||||
|
[2]: https://www.ostechnix.com/setup-headless-virtualization-server-using-kvm-ubuntu/
|
||||||
|
[3]: https://www.ostechnix.com/test-100-linux-and-unix-operating-systems-online-for-free/
|
||||||
|
[4]: https://www.ostechnix.com/install-oracle-virtualbox-ubuntu-16-04-headless-server/
|
||||||
|
[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/Find-Virtualbox-Version.png
|
||||||
|
[6]: https://askubuntu.com/questions/420363/how-do-i-check-virtualbox-version-from-cli
|
||||||
@ -0,0 +1,256 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (0x996)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11118-1.html)
|
||||||
|
[#]: subject: (Test 200+ Linux And Unix Operating Systems Online For Free)
|
||||||
|
[#]: via: (https://www.ostechnix.com/test-100-linux-and-unix-operating-systems-online-for-free/)
|
||||||
|
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||||
|
|
||||||
|
在线试用 200 多种 Linux 和 Unix 操作系统
|
||||||
|
======
|
||||||
|
|
||||||
|
![DistroTest——在线试用200多种Linux和Unix操作系统][1]
|
||||||
|
|
||||||
|
不久前我们介绍过[OSBoxes][2],该网站提供了一系列免费且开箱即用的 Linux 和 Unix 虚拟机。你可以在你的 Linux 系统中下载这些虚拟机并用 VirtualBox 或 VMWare workstation 试用。今天,我偶然发现一个名叫 “DistroTest” 的类似服务。与 OSBoxes 不同之处在于 DistroTest 让你免费试用现场版 Linux 和 Unix 操作系统。你可以在线试用 200 多种 Linux 和 Unix 操作系统而无需在本地安装它们。只要打开该网站,选择你需要的 Linux/Unix 发行版,然后开始试用!
|
||||||
|
|
||||||
|
两个名为 Klemann Andy 和 Forster Tobias 的好心人用 Qemu 在 Debian 上运行了这项网络服务。这里列出的公开发行版在使用上没有任何限制。你可以象使用本地系统一样使用系统的所有功能。你可以安装和卸载软件。你可以测试安装的程序,甚至删除或格式化硬盘,删除系统文件。简而言之,DistroTest让喜欢尝试不同发行版的的人自行决定:
|
||||||
|
|
||||||
|
* 最适合他们的发行版
|
||||||
|
* 想要哪种图形界面
|
||||||
|
* 他们可以选择哪些配置
|
||||||
|
|
||||||
|
本文撰写之时,DistroTest 提供了 227 种操作系统的 711 个版本。我已经使用 Linux 很多年,但我从未听说过这里列出的一些发行版。说实话我甚至不知道 Linux 操作系统有如此之多的版本。
|
||||||
|
|
||||||
|
DistroTest 网站提供的 Linux 发行版的列表如下。(LCTT 译注:其中也包括部分非 Linux 的操作系统如 FreeBSD 和 FreeDOS,或是分区工具如 Gparted)
|
||||||
|
|
||||||
|
* 4mLinux
|
||||||
|
* AbsoluteLinux
|
||||||
|
* AlpineLinux
|
||||||
|
* Antergos
|
||||||
|
* antiX Linux
|
||||||
|
* Aptosid
|
||||||
|
* ArchBang
|
||||||
|
* ArchLabs
|
||||||
|
* ArchLinux
|
||||||
|
* Archman
|
||||||
|
* ArchStrike
|
||||||
|
* ArtixLinux
|
||||||
|
* AryaLinux
|
||||||
|
* AvLinux
|
||||||
|
* BackBoxLinux
|
||||||
|
* BigLinux
|
||||||
|
* Bio-Linux
|
||||||
|
* BlackArch
|
||||||
|
* BlackLab
|
||||||
|
* BlackPantherOS
|
||||||
|
* blag
|
||||||
|
* BlankOn
|
||||||
|
* Bluestar
|
||||||
|
* Bodhi
|
||||||
|
* BunsenLabs
|
||||||
|
* Caine
|
||||||
|
* Calculate Linux Desktop
|
||||||
|
* CentOS 7
|
||||||
|
* Chakra
|
||||||
|
* ChaletOS
|
||||||
|
* ClearOS
|
||||||
|
* Clonezilla
|
||||||
|
* ConnochaetOS
|
||||||
|
* Cucumber
|
||||||
|
* Damn Small Linux
|
||||||
|
* Debian
|
||||||
|
* Devil-Linux
|
||||||
|
* Devuan
|
||||||
|
* DragonFly BSD
|
||||||
|
* Dragora
|
||||||
|
* Dyne:bolic
|
||||||
|
* Edubuntu
|
||||||
|
* elementaryOS
|
||||||
|
* Elive Linux
|
||||||
|
* Emmabuntüs
|
||||||
|
* Emmabuntüs
|
||||||
|
* Endless OS
|
||||||
|
* EnsoOS
|
||||||
|
* Exe GNU/Linux
|
||||||
|
* ExTiX
|
||||||
|
* Fatdog64
|
||||||
|
* Fedora
|
||||||
|
* FerenOS
|
||||||
|
* FreeBSD
|
||||||
|
* FreeDOS
|
||||||
|
* Frugalware
|
||||||
|
* Frugalware
|
||||||
|
* G4L
|
||||||
|
* GeckoLinux
|
||||||
|
* Gentoo
|
||||||
|
* GNewSense
|
||||||
|
* GoboLinux
|
||||||
|
* Gparted
|
||||||
|
* GreenieLinux
|
||||||
|
* GRML
|
||||||
|
* GuixSD
|
||||||
|
* Haiku
|
||||||
|
* Heads
|
||||||
|
* Kali Linux
|
||||||
|
* Kanotix
|
||||||
|
* KaOS
|
||||||
|
* Knoppix
|
||||||
|
* Kodachi
|
||||||
|
* KolibriOS
|
||||||
|
* Korora
|
||||||
|
* Kwort
|
||||||
|
* Linux Lite
|
||||||
|
* Linux Mint
|
||||||
|
* LiveRaizo
|
||||||
|
* LMDE
|
||||||
|
* LXLE OS
|
||||||
|
* Macpup
|
||||||
|
* Mageia
|
||||||
|
* MakuluLinux
|
||||||
|
* Manjaro
|
||||||
|
* MauiLinux
|
||||||
|
* MenuetOS
|
||||||
|
* MiniNo
|
||||||
|
* Modicia
|
||||||
|
* Musix
|
||||||
|
* MX Linux
|
||||||
|
* Nas4Free
|
||||||
|
* Neptune
|
||||||
|
* NetBSD
|
||||||
|
* Netrunner
|
||||||
|
* NixOs
|
||||||
|
* NuTyX
|
||||||
|
* OpenIndiana
|
||||||
|
* OpenMandriva
|
||||||
|
* openSUSE
|
||||||
|
* OracleLinux
|
||||||
|
* OSGeo live
|
||||||
|
* OviOS
|
||||||
|
* Parabola
|
||||||
|
* Pardus
|
||||||
|
* Parrot
|
||||||
|
* Parsix
|
||||||
|
* PCLinuxOS
|
||||||
|
* PeachOSI
|
||||||
|
* Peppermint
|
||||||
|
* Pinguy
|
||||||
|
* PinguyOS
|
||||||
|
* plopLinux
|
||||||
|
* PointLinux
|
||||||
|
* Pop!_OS
|
||||||
|
* PORTEUS
|
||||||
|
* Puppy Linux
|
||||||
|
* PureOS
|
||||||
|
* Q4OS
|
||||||
|
* QubesOS
|
||||||
|
* Quirky
|
||||||
|
* ReactOS
|
||||||
|
* Redcore
|
||||||
|
* Rescatux
|
||||||
|
* RevengeOS
|
||||||
|
* RoboLinux
|
||||||
|
* Rockstor
|
||||||
|
* ROSA
|
||||||
|
* Runtu
|
||||||
|
* Sabayon
|
||||||
|
* SalentOS
|
||||||
|
* Salix
|
||||||
|
* ScientificLinux
|
||||||
|
* Siduction
|
||||||
|
* Slax
|
||||||
|
* SliTaz
|
||||||
|
* Solus
|
||||||
|
* SolydK
|
||||||
|
* SparkyLinux
|
||||||
|
* Springdale
|
||||||
|
* Stresslinux
|
||||||
|
* SubgraphOS
|
||||||
|
* SwagArch (18.03)
|
||||||
|
* Tails
|
||||||
|
* Tanglu
|
||||||
|
* Tiny Core
|
||||||
|
* Trisquel
|
||||||
|
* TrueOS
|
||||||
|
* TurnKey Linux
|
||||||
|
* Ubuntu及其官方衍生版本
|
||||||
|
* Uruk
|
||||||
|
* VectorLinux
|
||||||
|
* VineLinux
|
||||||
|
* VoidLinux
|
||||||
|
* Voyager
|
||||||
|
* VyOS
|
||||||
|
* WattOs
|
||||||
|
* Zentyal
|
||||||
|
* Zenwalk
|
||||||
|
* Zevenet
|
||||||
|
* Zorin OS
|
||||||
|
|
||||||
|
### 如何使用?
|
||||||
|
|
||||||
|
要试用任何操作系统,点击下面的链接: https://distrotest.net/
|
||||||
|
|
||||||
|
在这个网站,你会看到可用的操作系统列表。单击你想了解的发行版名称即可。
|
||||||
|
|
||||||
|
![1][4]
|
||||||
|
|
||||||
|
用 DistroTest 试用 200 多种Linux和Unix操作系统
|
||||||
|
|
||||||
|
本文中我会试用 Arch Linux。
|
||||||
|
|
||||||
|
单击发行版链接后,在跳转到的页面单击 “System start” 按钮即可启动所选操作系统。
|
||||||
|
|
||||||
|
![1][5]
|
||||||
|
|
||||||
|
此现场版操作系统会在新浏览器窗口中启动。你可以通过内建的 noVNC viewer 访问它。请在浏览器中启用/允许 DistroTest 网站的弹出窗口,否则无法看到弹出的 noVNC 窗口。
|
||||||
|
|
||||||
|
按回车启动现场版系统。
|
||||||
|
|
||||||
|
![1][6]
|
||||||
|
|
||||||
|
这就是 Arch Linux 现场版系统:
|
||||||
|
|
||||||
|
![1][7]
|
||||||
|
|
||||||
|
你可以免费使用这个系统 1 小时。你可以试用该现场版操作系统、安装应用、卸载应用、删除或修改系统文件、测试配置或脚本。每次关机后,一切都会恢复成默认配置。
|
||||||
|
|
||||||
|
一旦试用结束,回到 DistroTest 页面并停止你试用的系统。如果你不想启用 DistroTest 页面的弹出窗口,用你本地系统安装的任意 VNC 客户端也可以。VNC 登录信息可在同一页面找到。
|
||||||
|
|
||||||
|
![1][8]
|
||||||
|
|
||||||
|
DistroTest 服务对两类用户比较实用:想在线试用 Linux/Unix 系统,或是没有喜欢的操作系统现场版 ISO 镜像文件的人。我在 4G 网络上测试的结果一切正常。
|
||||||
|
|
||||||
|
### 实际上,我没法在这个虚拟机里安装新软件
|
||||||
|
|
||||||
|
试用期间我注意到的一个问题是这个虚拟机没有联网。除了本地环回接口之外没有其他网络接口。没有联网也没有本地镜像源的情况下我没法下载和安装新软件。我不知道为何网站声称可以安装软件。也许在这点上我遗漏了什么。我在 DistroTest 上能做的只是看看现成的系统,试用现场版而不能安装任何软件。
|
||||||
|
|
||||||
|
推荐阅读:
|
||||||
|
|
||||||
|
* [免费在线学习和练习 Linux命令!][9]
|
||||||
|
* [在浏览器中运行 Linux 和其他操作系统][10]
|
||||||
|
|
||||||
|
暂时就这样了。我不知道 DistroTest 团队如何设法托管了这么多操作系统。我肯定这会花不少时间。这的确是件值得称赞的工作。我非常感激项目成员的无私行为。荣誉归于你们。加油!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.ostechnix.com/test-100-linux-and-unix-operating-systems-online-for-free/
|
||||||
|
|
||||||
|
作者:[sk][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[0x996](https://github.com/0x996)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.ostechnix.com/author/sk/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.ostechnix.com/wp-content/uploads/2018/07/test-Linux-and-Unix-online-686x340.jpg
|
||||||
|
[2]: https://www.ostechnix.com/osboxes-free-unixlinux-virtual-machines-for-vmware-and-virtualbox/
|
||||||
|
[3]: https://distrotest.net/
|
||||||
|
[4]: https://www.ostechnix.com/wp-content/uploads/2018/07/Distrotest-5.png
|
||||||
|
[5]: https://www.ostechnix.com/wp-content/uploads/2018/07/Distrotest-1.png
|
||||||
|
[6]: https://www.ostechnix.com/wp-content/uploads/2018/07/Distrotest-2.png
|
||||||
|
[7]: https://www.ostechnix.com/wp-content/uploads/2018/07/Distrotest-3.png
|
||||||
|
[8]: https://www.ostechnix.com/wp-content/uploads/2018/07/Distrotest-4-1.png
|
||||||
|
[9]: https://www.ostechnix.com/learn-and-practice-linux-commands-online-for-free/
|
||||||
|
[10]: https://www.ostechnix.com/run-linux-operating-systems-browser/
|
||||||
@ -0,0 +1,144 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11125-1.html)
|
||||||
|
[#]: subject: (How to install Elasticsearch on MacOS)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/installing-elasticsearch-macos)
|
||||||
|
[#]: author: (Lauren Maffeo https://opensource.com/users/lmaffeo/users/don-watkins)
|
||||||
|
|
||||||
|
如何在 MacOS 上安装 Elasticsearch
|
||||||
|
======
|
||||||
|
|
||||||
|
> 安装 Elasticsearch 很复杂!以下是如何在 Mac 上安装。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
[Elasticsearch][2] 是一个用 Java 开发的开源全文搜索引擎。用户上传 JSON 格式的数据集。然后,Elasticsearch 在向集群索引中的文档添加可搜索的引用之前先保存原始文档。
|
||||||
|
|
||||||
|
Elasticsearch 创建还不到九年,但它是最受欢迎的企业搜索引擎。Elastic 在 2019 年 6 月 25 日发布了最新的更新版本 7.2.0。
|
||||||
|
|
||||||
|
[Kibana][3] 是 Elasticsearch 的开源数据可视化工具。此工具可帮助用户在 Elasticsearch 集群的内容索引之上创建可视化。
|
||||||
|
|
||||||
|
[Sunbursts][4]、[地理空间数据地图][5]、[关系分析][6]和实时数据面板只是其中几个功能。并且由于 Elasticsearch 的机器学习能力,你可以了解哪些属性可能会影响你的数据(如服务器或 IP 地址)并查找异常模式。
|
||||||
|
|
||||||
|
在上个月的 [DevFest DC][7] 中,Booz Allen Hamilton 的首席数据科学家 [Summer Rankin 博士][8]将 TED Talk 的内容数据集上传到了 Elasticsearch,然后使用 Kibana 快速构建了面板。出于好奇,几天后我去了一个 Elasticsearch 聚会。
|
||||||
|
|
||||||
|
由于本课程针对的是新手,因此我们从第一步开始:在我们的笔记本上安装 Elastic 和 Kibana。如果没有安装这两个包,我们无法将莎士比亚的文本数据集作为测试 JSON 文件创建可视化了。
|
||||||
|
|
||||||
|
接下来,我将分享在 MacOS 上下载、安装和运行 Elasticsearch V7.1.1 的分步说明。这是我在 2019 年 6 月中旬参加 Elasticsearch 聚会时的最新版本。
|
||||||
|
|
||||||
|
### 下载适合 MacOS 的 Elasticsearch
|
||||||
|
|
||||||
|
1、进入 <https://www.elastic.co/downloads/elasticsearch>,你会看到下面的页面:
|
||||||
|
|
||||||
|
![The Elasticsearch download page.][9]
|
||||||
|
|
||||||
|
2、在**下载**区,单击 **MacOS**,将 Elasticsearch TAR 文件(例如,`elasticsearch-7.1.1-darwin-x86_64.tar`)下载到 `Downloads` 文件夹。
|
||||||
|
|
||||||
|
3、双击此文件并解压到自己的文件夹中(例如,`elasticsearch-7.1.1`),这其中包含 TAR 中的所有文件。
|
||||||
|
|
||||||
|
**提示**:如果你希望 Elasticsearch 放在另一个文件夹中,现在可以移动它。
|
||||||
|
|
||||||
|
### 在 MacOS 命令行中运行 Elasticsearch
|
||||||
|
|
||||||
|
如果你愿意,你可以只用命令行运行 Elasticsearch。只需遵循以下流程:
|
||||||
|
|
||||||
|
1、[打开终端窗口][10]。
|
||||||
|
|
||||||
|
2、在终端窗口中,输入你的 Elasticsearch 文件夹。例如(如果你移动了程序,请将 `Downloads` 更改为正确的路径):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd ~Downloads/elasticsearch-1.1.0
|
||||||
|
```
|
||||||
|
|
||||||
|
3、切换到 Elasticsearch 的 `bin` 子文件夹,然后启动该程序。例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd bin
|
||||||
|
$ ./elasticsearch
|
||||||
|
```
|
||||||
|
|
||||||
|
这是我启动 Elasticsearch 1.1.0 时命令行终端显示的一些输出:
|
||||||
|
|
||||||
|
![Terminal output when running Elasticsearch.][11]
|
||||||
|
|
||||||
|
**注意**:默认情况下,Elasticsearch 在前台运行,这可能会导致计算机速度变慢。按 `Ctrl-C` 可以阻止 Elasticsearch 运行。
|
||||||
|
|
||||||
|
### 使用 GUI 运行 Elasticsearch
|
||||||
|
|
||||||
|
如果你更喜欢点击操作,你可以像这样运行 Elasticsearch:
|
||||||
|
|
||||||
|
1、打开一个新的 **Finder** 窗口。
|
||||||
|
|
||||||
|
2、在左侧 Finder 栏中选择 `Downloads`(如果你将 Elasticsearch 移动了另一个文件夹,请进入它)。
|
||||||
|
|
||||||
|
3、打开名为 `elasticsearch-7.1.1` 的文件夹(对于此例)。出现了八个子文件夹。
|
||||||
|
|
||||||
|
![The elasticsearch/bin menu.][12]
|
||||||
|
|
||||||
|
4、打开 `bin` 子文件夹。如上面的截图所示,此子文件夹中有 20 个文件。
|
||||||
|
|
||||||
|
5、单击第一个文件,即 `elasticsearch`。
|
||||||
|
|
||||||
|
请注意,你可能会收到安全警告,如下所示:
|
||||||
|
|
||||||
|
![The security warning dialog box.][13]
|
||||||
|
|
||||||
|
这时候要打开程序需要:
|
||||||
|
|
||||||
|
1. 在警告对话框中单击 **OK**。
|
||||||
|
2. 打开**系统偏好**。
|
||||||
|
3. 单击**安全和隐私**,打开如下窗口:
|
||||||
|
|
||||||
|
![Where you can allow your computer to open the downloaded file.][14]
|
||||||
|
4. 单击**永远打开**,打开如下所示的确认对话框:
|
||||||
|
|
||||||
|
![Security confirmation dialog box.][15]
|
||||||
|
5. 单击**打开**。会打开一个终端窗口并启动 Elasticsearch。
|
||||||
|
|
||||||
|
启动过程可能需要一段时间,所以让它继续运行。最终,它将完成,你最后将看到类似这样的输出:
|
||||||
|
|
||||||
|
![Launching Elasticsearch in MacOS.][16]
|
||||||
|
|
||||||
|
### 了解更多
|
||||||
|
|
||||||
|
安装 Elasticsearch 之后,就可以开始探索了!
|
||||||
|
|
||||||
|
该工具的 [Elasticsearch:开始使用][17]指南会根据你的目标指导你。它的介绍视频介绍了在 [Elasticsearch Service][18] 上启动托管集群,执行基本搜索查询,通过创建、读取、更新和删除(CRUD)REST API 等方式操作数据的步骤。
|
||||||
|
|
||||||
|
本指南还提供文档链接,开发控制台命令,培训订阅以及 Elasticsearch Service 的免费试用版。此试用版允许你在 AWS 和 GCP 上部署 Elastic 和 Kibana 以支持云中的 Elastic 集群。
|
||||||
|
|
||||||
|
在本文的后续内容中,我们将介绍在 MacOS 上安装 Kibana 所需的步骤。此过程将通过不同的数据可视化将你的 Elasticsearch 查询带到一个新的水平。 敬请关注!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/installing-elasticsearch-macos
|
||||||
|
|
||||||
|
作者:[Lauren Maffeo][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/lmaffeo/users/don-watkins
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/search_find_code_issue_bug_programming.png?itok=XPrh7fa0 (magnifying glass on computer screen)
|
||||||
|
[2]: https://www.getapp.com/it-management-software/a/qbox-dot-io-hosted-elasticsearch/
|
||||||
|
[3]: https://www.elastic.co/products/kibana
|
||||||
|
[4]: https://en.wikipedia.org/wiki/Pie_chart#Ring
|
||||||
|
[5]: https://en.wikipedia.org/wiki/Spatial_analysis
|
||||||
|
[6]: https://en.wikipedia.org/wiki/Correlation_and_dependence
|
||||||
|
[7]: https://www.devfestdc.org/
|
||||||
|
[8]: https://www.summerrankin.com/about
|
||||||
|
[9]: https://opensource.com/sites/default/files/uploads/wwa1f3_600px_0.png (The Elasticsearch download page.)
|
||||||
|
[10]: https://support.apple.com/en-ca/guide/terminal/welcome/mac
|
||||||
|
[11]: https://opensource.com/sites/default/files/uploads/io6t1a_600px.png (Terminal output when running Elasticsearch.)
|
||||||
|
[12]: https://opensource.com/sites/default/files/uploads/o43yku_600px.png (The elasticsearch/bin menu.)
|
||||||
|
[13]: https://opensource.com/sites/default/files/uploads/elasticsearch_security_warning_500px.jpg (The security warning dialog box.)
|
||||||
|
[14]: https://opensource.com/sites/default/files/uploads/the_general_tab_of_the_system_preferences_security_and_privacy_window.jpg (Where you can allow your computer to open the downloaded file.)
|
||||||
|
[15]: https://opensource.com/sites/default/files/uploads/confirmation_dialog_box.jpg (Security confirmation dialog box.)
|
||||||
|
[16]: https://opensource.com/sites/default/files/uploads/y5dvtu_600px.png (Launching Elasticsearch in MacOS.)
|
||||||
|
[17]: https://www.elastic.co/webinars/getting-started-elasticsearch?ultron=%5BB%5D-Elastic-US+CA-Exact&blade=adwords-s&Device=c&thor=elasticsearch&gclid=EAIaIQobChMImdbvlqOP4wIVjI-zCh3P_Q9mEAAYASABEgJuAvD_BwE
|
||||||
|
[18]: https://info.elastic.co/elasticsearch-service-gaw-v10-nav.html?ultron=%5BB%5D-Elastic-US+CA-Exact&blade=adwords-s&Device=c&thor=elasticsearch%20service&gclid=EAIaIQobChMI_MXHt-SZ4wIVJBh9Ch3wsQfPEAAYASAAEgJo9fD_BwE
|
||||||
@ -0,0 +1,149 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11142-1.html)
|
||||||
|
[#]: subject: (Type Linux Commands In Capital Letters To Run Them As Sudo User)
|
||||||
|
[#]: via: (https://www.ostechnix.com/type-linux-commands-in-capital-letters-to-run-them-as-sudo-user/)
|
||||||
|
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||||
|
|
||||||
|
用大写字母输入 Linux 命令以将其作为 sudo 用户运行
|
||||||
|
======
|
||||||
|
|
||||||
|
![Type Linux Commands In Capital Letters To Run Them As Sudo User][1]
|
||||||
|
|
||||||
|
我非常喜欢 Linux 社区的原因是他们创建了很多有趣的项目,你很少能在任何其他操作系统中找到它们。不久前,我们看了一个名为 [Hollywood][2] 的有趣项目,它在类 Ubuntu 系统将终端变成了好莱坞技术情景剧的黑客界面。还有一些其他工具,例如 `cowsay`、`fortune`、`sl` 和 `toilet` 等,用来消磨时间自娱自乐!它们可能没有用,但这些程序娱乐性不错并且使用起来很有趣。今天,我偶然发现了另一个名为 `SUDO` 的类似工具。正如名字暗示的那样,你无论何时用大写字母输入 Linux 命令,`SUDO` 程序都会将它们作为 sudo 用户运行!这意味着,你无需在要运行的 Linux 命令前面输入 `sudo`。很酷,不是么?
|
||||||
|
|
||||||
|
### 安装 SUDO
|
||||||
|
|
||||||
|
> 提醒一句:
|
||||||
|
|
||||||
|
> 在安装这个程序(或任何程序)之前,请查看源代码(最后给出的链接),并查看是否包含会损害你的系统的可疑/恶意代码。在 VM 中测试它。如果你喜欢或觉得它很有用,你可以在个人/生产系统中使用它。
|
||||||
|
|
||||||
|
用 Git 克隆 `SUDO` 仓库:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git clone https://github.com/jthistle/SUDO.git
|
||||||
|
```
|
||||||
|
|
||||||
|
此命令将克隆 SUDO GIT 仓库的内容,并将它们保存在当前目录下的 `SUDO` 的目录中。
|
||||||
|
|
||||||
|
```
|
||||||
|
Cloning into 'SUDO'...
|
||||||
|
remote: Enumerating objects: 42, done.
|
||||||
|
remote: Counting objects: 100% (42/42), done.
|
||||||
|
remote: Compressing objects: 100% (29/29), done.
|
||||||
|
remote: Total 42 (delta 17), reused 30 (delta 12), pack-reused 0
|
||||||
|
Unpacking objects: 100% (42/42), done.
|
||||||
|
```
|
||||||
|
|
||||||
|
切换到 `SUDO` 目录:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd SUDO/
|
||||||
|
```
|
||||||
|
|
||||||
|
并使用命令安装它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./install.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
该命令将在 `~/.bashrc` 文件中添加以下行:
|
||||||
|
|
||||||
|
```
|
||||||
|
[...]
|
||||||
|
# SUDO - shout at bash to su commands
|
||||||
|
# Distributed under GNU GPLv2, @jthistle on github
|
||||||
|
|
||||||
|
shopt -s expand_aliases
|
||||||
|
|
||||||
|
IFS_=${IFS}
|
||||||
|
IFS=":" read -ra PATHS <<< "$PATH"
|
||||||
|
|
||||||
|
for i in "${PATHS[@]}"; do
|
||||||
|
for j in $( ls "$i" ); do
|
||||||
|
if [ ${j^^} != $j ] && [ $j != "sudo" ]; then
|
||||||
|
alias ${j^^}="sudo $j"
|
||||||
|
fi
|
||||||
|
done
|
||||||
|
done
|
||||||
|
|
||||||
|
alias SUDO='sudo $(history -p !!)'
|
||||||
|
|
||||||
|
IFS=${IFS_}
|
||||||
|
|
||||||
|
# end SUDO
|
||||||
|
```
|
||||||
|
|
||||||
|
它还会备份你的 `~/.bashrc` 并将其保存为 `~/.bashrc.old`。如果有重大错误,你可以恢复它。
|
||||||
|
|
||||||
|
最后,使用命令更新更改:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ source ~/.bashrc
|
||||||
|
```
|
||||||
|
|
||||||
|
### 现在,用大写字母中输入 Linux 命令,将它们作为 Sudo 用户运行
|
||||||
|
|
||||||
|
通常我们像下面那样执行需要 sudo/root 权限的命令。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo mkdir /ostechnix
|
||||||
|
```
|
||||||
|
|
||||||
|
对么?没错!上面的命令将在根目录(`/`)中创建名为 `ostechnix` 的目录。让我们使用 `Ctrl + c` 取消。
|
||||||
|
|
||||||
|
一旦安装了 `SUDO`,你就可以**在不使用 sudo 的情况下输入任何大写 Linux 命令**并运行它们。因此,你可以像下面那样运行上面的命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ MKDIR /ostechnix
|
||||||
|
$ TOUCH /ostechnix/test.txt
|
||||||
|
$ LS /ostechnix
|
||||||
|
```
|
||||||
|
|
||||||
|
![][3]
|
||||||
|
|
||||||
|
用大写字母输入 Linux 命令以将其作为 sudo 用户运行
|
||||||
|
|
||||||
|
请注意**它无法绕过 sudo 密码**。你仍然需要键入 `sudo` 密码才能执行给定的命令。它只会有助于避免在每个命令前面输入 `sudo`。
|
||||||
|
|
||||||
|
相关阅读:
|
||||||
|
|
||||||
|
* [如何在 Linux 中没有 sudo 密码运行特定命令][4]
|
||||||
|
* [如何恢复用户的 sudo 权限][5]
|
||||||
|
* [如何在 Ubuntu 上为用户授予和删除 sudo 权限][6]
|
||||||
|
* [如何在 Linux 系统中查找所有 sudo 用户][7]
|
||||||
|
* [如何在终端中输入密码时显示星号][8]
|
||||||
|
* [如何更改 Linux 中的 sudo 提示符][9]
|
||||||
|
|
||||||
|
|
||||||
|
当然,输入 `sudo` 只需几秒钟,所以这不是什么大问题。 我必须告诉这是一个用来消磨时间的有趣且无用的项目。 如果你不喜欢它,那就去学习一些有用的东西吧。 如果你喜欢它,试一试,玩得开心!
|
||||||
|
|
||||||
|
资源:
|
||||||
|
|
||||||
|
* [SUDO GitHub 仓库][10]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.ostechnix.com/type-linux-commands-in-capital-letters-to-run-them-as-sudo-user/
|
||||||
|
|
||||||
|
作者:[sk][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.ostechnix.com/author/sk/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/sudo-720x340.png
|
||||||
|
[2]: https://www.ostechnix.com/turn-ubuntu-terminal-hollywood-technical-melodrama-hacker-interface/
|
||||||
|
[3]: https://www.ostechnix.com/wp-content/uploads/2019/07/SUDO-in-action.gif
|
||||||
|
[4]: https://www.ostechnix.com/run-particular-commands-without-sudo-password-linux/
|
||||||
|
[5]: https://www.ostechnix.com/how-to-restore-sudo-privileges-to-a-user/
|
||||||
|
[6]: https://www.ostechnix.com/how-to-grant-and-remove-sudo-privileges-to-users-on-ubuntu/
|
||||||
|
[7]: https://www.ostechnix.com/find-sudo-users-linux-system/
|
||||||
|
[8]: https://www.ostechnix.com/display-asterisks-type-password-terminal/
|
||||||
|
[9]: https://www.ostechnix.com/change-sudo-prompt-linux-unix/
|
||||||
|
[10]: https://github.com/jthistle/SUDO
|
||||||
78
published/201907/20190712 MTTR is dead, long live CIRT.md
Normal file
78
published/201907/20190712 MTTR is dead, long live CIRT.md
Normal file
@ -0,0 +1,78 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11155-1.html)
|
||||||
|
[#]: subject: (MTTR is dead, long live CIRT)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/measure-operational-performance)
|
||||||
|
[#]: author: (Julie Gunderson https://opensource.com/users/juliegund/users/kearnsjd/users/ophir)
|
||||||
|
|
||||||
|
MTTR 已死,CIRT 长存
|
||||||
|
======
|
||||||
|
|
||||||
|
> 通过关注影响业务的事件,CIRT 是衡量运维绩效的更准确方法。
|
||||||
|
|
||||||
|
![Green graph of measurements][1]
|
||||||
|
|
||||||
|
IT 运维圈子的玩法正在发生变化,这意味着过去的规则越来越不合理。机构需要适当环境中的准确的、可理解的、且可操作的指标,以衡量运维绩效并推动关键业务转型。
|
||||||
|
|
||||||
|
越多的客户使用现代工具,他们管理的事件类型的变化越多,将所有这些不同事件粉碎到一个桶中以计算平均解决时间来表示运维绩效的意义就越少,这就是 IT 一直以来在做的事情。
|
||||||
|
|
||||||
|
### 历史与指标
|
||||||
|
|
||||||
|
历史表明,在分析信号以防止错误和误解时,背景信息是关键。例如,在 20 世纪 80 年代,瑞典建立了一个分析水听器信号的系统,以提醒他们在瑞典当地水域出现的俄罗斯潜艇。瑞典人使用了他们认为代表一类俄罗斯潜艇的声学特征 —— 但实际上是鲱鱼在遇到潜在捕食者时释放的[气泡声][2]。这种对指标的误解加剧了各国之间的紧张关系,几乎导致了战争。
|
||||||
|
|
||||||
|
![Funny fish cartoon][3]
|
||||||
|
|
||||||
|
<ruby>平均解决时间<rt>Mean Time To Resolve</rt></ruby>(MTTR)是运维经理用于获得实现目标洞察力的主要运维绩效指标。这是一项基于<ruby>系统可靠性工程<rt>systems reliability engineering</rt></ruby>的古老措施。MTTR 已被许多行业采用,包括制造、设施维护以及最近的 IT 运维,它代表了解决在特定时间段内创建的事件所需的平均时间。
|
||||||
|
|
||||||
|
MTTR 的计算方法是将所有事件(从事件创建时间到解决时间)所需的时间除以事件总数。
|
||||||
|
|
||||||
|
![MTTR formula][4]
|
||||||
|
|
||||||
|
正如它所说的,MTTR 是 **所有** 事件的平均值。MTTR 将高紧急事件和低紧急事件混为一谈。它还会重复计算每个单独的、未分组的事件,并得出有效的解决时间。它包括了在相同上下文中手动解决和自动解决的事件。它将在创建了几天(或几个月)甚至完全被忽略的事件混合在一起。最后,MTTR 包括每个小的瞬态突发事件(在 120 秒内自动关闭的事件),这些突发事件要么是非问题噪音,要么已由机器快速解决。
|
||||||
|
|
||||||
|
![Variability in incident types][5]
|
||||||
|
|
||||||
|
MTTR 将所有事件(无论何种类型)抛入一个桶中,将它们全部混合在一起,并计算整个集合中的“平均”解决时间。这种过于简单化的方法导致运维执行方式的的噪音、错误和误导性指示。
|
||||||
|
|
||||||
|
### 一种衡量绩效的新方法
|
||||||
|
|
||||||
|
<ruby>关键事件响应时间<rt>Critical Incident Response Time</rt></ruby>(CIRT)是评估运维绩效的一种更准确的新方法。PagerDuty 创立了 CIRT 的概念,但该方法可供所有人免费使用。
|
||||||
|
|
||||||
|
CIRT 通过使用以下技术剔除来自信号的噪声,其重点关注最有可能影响业务的事件:
|
||||||
|
|
||||||
|
1. 真正影响(或可能影响)业务的事件很少是低紧急事件,因此要排除所有低紧急事件。
|
||||||
|
2. 真正影响业务的事件很少(如果有的话)可以无需人为干预而通过监控工具自动解决,因此要排除未由人工解决的事件。
|
||||||
|
3. 在 120 秒内解决的短暂、爆发性和瞬态事件几乎不可能是真正影响业务的事件,因此要排除它们。
|
||||||
|
4. 长时间未被注意、提交或忽略(未确认、未解决)的事件很少会对业务造成影响;排除它们。注意:此阈值可以是特定于客户的统计推导数字(例如,高于均值的两个标准差),以避免使用任意数字。
|
||||||
|
5. 由单独警报产生的个别未分组事件并不代表较大的业务影响事件。因此,模拟具有非常保守的阈值(例如,两分钟)的事件分组以计算响应时间。
|
||||||
|
|
||||||
|
应用这些假设对响应时间有什么影响?简而言之,效果非常非常大!
|
||||||
|
|
||||||
|
通过在关键的、影响业务的事件中关注运维绩效,解决时间分布变窄并极大地向左偏移,因为现在它处理类似类型的事件而不是所有事件。
|
||||||
|
|
||||||
|
由于 MTTR 计算的响应时间长得多、人为地偏差,因此它是运维绩效较差的一个指标。另一方面,CIRT 是一项有意的措施,专注于对业务最重要的事件。
|
||||||
|
|
||||||
|
与 CIRT 一起使用的另一个关键措施是确认和解决事故的百分比。这很重要,因为它验证 CIRT(或 MTTA / MTTR)是否值得利用。例如,如果 MTTR 结果很低,比如 10 分钟,那听起来不错,但如果只有 42% 的事件得到解决,那么 MTTR 是可疑的。
|
||||||
|
|
||||||
|
总之,CIRT 和确认、解决事件的百分比形成了一组有价值的指标,可以让你更好地了解运营的执行情况。衡量绩效是提高绩效的第一步,因此这些新措施对于实现机构的可持续、可衡量的改进周期至关重要。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/measure-operational-performance
|
||||||
|
|
||||||
|
作者:[Julie Gunderson][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/juliegund/users/kearnsjd/users/ophir
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_lead-steps-measure.png?itok=DG7rFZPk (Green graph of measurements)
|
||||||
|
[2]: http://blogfishx.blogspot.com/2014/05/herring-fart-to-communicate.html
|
||||||
|
[3]: https://opensource.com/sites/default/files/uploads/fish.png (Funny fish cartoon)
|
||||||
|
[4]: https://opensource.com/sites/default/files/uploads/mttr.png (MTTR formula)
|
||||||
|
[5]: https://opensource.com/sites/default/files/uploads/incidents.png (Variability in incident types)
|
||||||
@ -0,0 +1,251 @@
|
|||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "zianglei"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-11108-1.html"
|
||||||
|
[#]: subject: "Make an RGB cube with Python and Scribus"
|
||||||
|
[#]: via: "https://opensource.com/article/19/7/rgb-cube-python-scribus"
|
||||||
|
[#]: author: "Greg Pittman https://opensource.com/users/greg-p/users/greg-p"
|
||||||
|
|
||||||
|
使用 Python 和 Scribus 创建一个 RGB 立方体
|
||||||
|
======
|
||||||
|
|
||||||
|
> 使用 Scribus 的 Python 脚本编写器功能,开发一个显示 RGB 色谱的 3D 立方体。
|
||||||
|
|
||||||
|
![cubes coming together to create a larger cube][1]
|
||||||
|
|
||||||
|
当我决定这个夏天要玩色彩游戏时,我想到通常色彩都是在色轮上描绘的。这些色彩通常都是使用色素而不是光,并且你失去了任何对颜色亮度或光度变化的感觉。
|
||||||
|
|
||||||
|
作为色轮的替代,我想在立方体表面使用一系列图形来显示 RGB 频谱。色彩的 RGB 值将在具有 X、Y、Z 轴的三维图形上展示。例如,一个平面将会保持 B(蓝色)为 0,其余的坐标轴将显示当我将 R(红色)和 G (绿色)的值从 0 绘制到 255 时发生的情况。
|
||||||
|
|
||||||
|
事实证明,使用 [Scribus][2] 及其 [Python 脚本编写器][3] 功能实现这一点并不困难。我可以创建 RGB 颜色,使矩形显示颜色,并以 2D 格式排列它们。我决定设置颜色值的间隔为 5,并让矩形按 5 个点(pt)进行绘图。因此,对于每个 2D 图形,我将使用大约 250 种颜色,立方体的一个边有 250 个点(pt),也就是 3.5 英寸。
|
||||||
|
|
||||||
|
我使用下面这段 Python 代码完成了绿 - 红图的任务:
|
||||||
|
|
||||||
|
```python
|
||||||
|
x = 300
|
||||||
|
y = 300
|
||||||
|
r = 0
|
||||||
|
g = 0
|
||||||
|
b = 0
|
||||||
|
|
||||||
|
if scribus.newDoc(scribus.PAPER_LETTER, (0,0,0,0),scribus.PORTRAIT, 1, scribus.UNIT_POINTS, scribus.NOFACINGPAGES, scribus.FIRSTPAGERIGHT):
|
||||||
|
while r < 256:
|
||||||
|
while g < 256:
|
||||||
|
newcolor = str(r) + '_' + str(g) + '_' + str(b)
|
||||||
|
if newcolor == '0_0_0':
|
||||||
|
newcolor = 'Black'
|
||||||
|
scribus.defineColorRGB(newcolor,r, g, b)
|
||||||
|
rect = scribus.createRect(x + g, y, 5, 5)
|
||||||
|
scribus.setFillColor(newcolor, rect)
|
||||||
|
scribus.setLineColor(newcolor, rect)
|
||||||
|
g = g + 5
|
||||||
|
g = 0
|
||||||
|
r = r + 5
|
||||||
|
y = y – 5
|
||||||
|
```
|
||||||
|
|
||||||
|
这个脚本在 `300,300` 位置开始绘制图形,这个位置大约是一个美国信件大小的纸张的水平中心,大概是垂直方向从顶部到底的三分之一位置;这是图像的原点,然后它沿着 X 轴(绿色值)水平构建图形,然后返回到 Y 轴,向上移动 5 个点,然后绘制下一条矩形线。
|
||||||
|
|
||||||
|
![Red-Green graph][4]
|
||||||
|
|
||||||
|
这看起来很简单;我只需要调整一下数字就可以把立方体的另一面画出来。但这不仅仅是再画两个图,一个是蓝 - 绿色,另一个是红 - 蓝色的问题。我想创建一个展开的立方体,这样我就可以打印、剪开然后折叠它,创建一个 RGB 的 3D 视图。因此,下一部分(向下的页面)的原点(黑色的角落)需要在左上角,其水平方向是绿色,垂直方向是蓝色。
|
||||||
|
|
||||||
|
“调整数字”最终或多或少变成了试错,从而得到我想要的东西。在创建了第二个图之后,我需要第三个图,它是红 - 蓝色的,原点位于左上角,红色向左递增,蓝色向下递增。
|
||||||
|
|
||||||
|
下面是最终效果图:
|
||||||
|
|
||||||
|
![First half of RGB cube][5]
|
||||||
|
|
||||||
|
当然,这只是这个立方体的前半部分。我需要做一个类似的形状,除了原点应该是白色(而不是黑色)来表示高值。这是我希望自己更聪明的时候之一,因为我不仅需要做出一个类似的整体形状,还需要以镜像的方式与第一个形状交互(我认为)。有时候,尝试和错误是你唯一的朋友。
|
||||||
|
|
||||||
|
结果是这样的;我使用了一个单独的脚本,因为在一个美国信件大小的页面上没有足够的空间同时容纳这两个图案。
|
||||||
|
|
||||||
|
![Second half of RGB cube][6]
|
||||||
|
|
||||||
|
现在,是时候轮到打印机了!在这里,你可以直观了解彩色打印机如何处理 RGB 颜色到 CMYK 颜色的转换以及打印颜色密集空间。
|
||||||
|
|
||||||
|
接下来,朋友们,是剪切粘贴时间!我可以用胶带,但我不想改变表面的外观,所以我在切割的时候在两边留下了一些空间,这样我就可以把它们粘在里面了。根据我的经验,在复印纸上打印会产生一些不需要的皱纹,所以在我的复印纸原型完成后,我把立方体打印在了更厚的纸上,表面是哑光的。
|
||||||
|
|
||||||
|
![RGB cubes][7]
|
||||||
|
|
||||||
|
请记住,这只是 RGB 空间边界的一个视图;更准确地说,你必须做出一个可以在中间切片的实心立方体。例如,这是一个实心 RGB 立方体在蓝色 = 120 的切片。
|
||||||
|
|
||||||
|
![RGB cube slice][8]
|
||||||
|
|
||||||
|
最后,我做这个项目很开心。如果您也想参与其中,这里有两个脚本。
|
||||||
|
|
||||||
|
这是前半部分:
|
||||||
|
|
||||||
|
```python
|
||||||
|
#!/usr/bin/env python
|
||||||
|
# black2rgb.py
|
||||||
|
"""
|
||||||
|
Creates one-half of RGB cube with Black at origin
|
||||||
|
"""
|
||||||
|
|
||||||
|
import scribus
|
||||||
|
|
||||||
|
x = 300
|
||||||
|
y = 300
|
||||||
|
r = 0
|
||||||
|
g = 0
|
||||||
|
b = 0
|
||||||
|
|
||||||
|
if scribus.newDoc(scribus.PAPER_LETTER, (0,0,0,0),scribus.PORTRAIT, 1, scribus.UNIT_POINTS, scribus.NOFACINGPAGES, scribus.FIRSTPAGERIGHT):
|
||||||
|
while r < 256:
|
||||||
|
while g < 256:
|
||||||
|
newcolor = str(r) + '_' + str(g) + '_' + str(b)
|
||||||
|
if newcolor == '0_0_0':
|
||||||
|
newcolor = 'Black'
|
||||||
|
scribus.defineColorRGB(newcolor,r, g, b)
|
||||||
|
rect = scribus.createRect(x + g, y, 5, 5)
|
||||||
|
scribus.setFillColor(newcolor, rect)
|
||||||
|
scribus.setLineColor(newcolor, rect)
|
||||||
|
g = g + 5
|
||||||
|
g = 0
|
||||||
|
r = r + 5
|
||||||
|
y = y - 5
|
||||||
|
|
||||||
|
r = 0
|
||||||
|
g = 0
|
||||||
|
y = 305
|
||||||
|
|
||||||
|
while b < 256:
|
||||||
|
while g < 256:
|
||||||
|
newcolor = str(r) + '_' + str(g) + '_' + str(b)
|
||||||
|
if newcolor == '0_0_0':
|
||||||
|
newcolor = 'Black'
|
||||||
|
scribus.defineColorRGB(newcolor,r, g, b)
|
||||||
|
rect = scribus.createRect(x + g, y, 5, 5)
|
||||||
|
scribus.setFillColor(newcolor, rect)
|
||||||
|
scribus.setLineColor(newcolor, rect)
|
||||||
|
g = g + 5
|
||||||
|
g = 0
|
||||||
|
b = b + 5
|
||||||
|
y = y + 5
|
||||||
|
|
||||||
|
r = 255
|
||||||
|
g = 0
|
||||||
|
y = 305
|
||||||
|
x = 39
|
||||||
|
b = 0
|
||||||
|
|
||||||
|
while b < 256:
|
||||||
|
while r >= 0:
|
||||||
|
newcolor = str(r) + '_' + str(g) + '_' + str(b)
|
||||||
|
if newcolor == '0_0_0':
|
||||||
|
newcolor = 'Black'
|
||||||
|
scribus.defineColorRGB(newcolor,r, g, b)
|
||||||
|
rect = scribus.createRect(x, y, 5, 5)
|
||||||
|
scribus.setFillColor(newcolor, rect)
|
||||||
|
scribus.setLineColor(newcolor, rect)
|
||||||
|
r = r - 5
|
||||||
|
x = x+5
|
||||||
|
b = b + 5
|
||||||
|
x = 39.5
|
||||||
|
r = 255
|
||||||
|
y = y + 5
|
||||||
|
|
||||||
|
scribus.setRedraw(True)
|
||||||
|
scribus.redrawAll()
|
||||||
|
```
|
||||||
|
|
||||||
|
后半部分:
|
||||||
|
|
||||||
|
|
||||||
|
```python
|
||||||
|
#!/usr/bin/env python
|
||||||
|
# white2rgb.py
|
||||||
|
"""
|
||||||
|
Creates one-half of RGB cube with White at origin
|
||||||
|
"""
|
||||||
|
|
||||||
|
import scribus
|
||||||
|
|
||||||
|
x = 300
|
||||||
|
y = 300
|
||||||
|
r = 255
|
||||||
|
g = 255
|
||||||
|
b = 255
|
||||||
|
|
||||||
|
if scribus.newDoc(scribus.PAPER_LETTER, (0,0,0,0),scribus.PORTRAIT, 1, scribus.UNIT_POINTS, scribus.NOFACINGPAGES, scribus.FIRSTPAGERIGHT):
|
||||||
|
while g >= 0:
|
||||||
|
while r >= 0:
|
||||||
|
newcolor = str(r) + '_' + str(g) + '_' + str(b)
|
||||||
|
if newcolor == '255_255_255':
|
||||||
|
newcolor = 'White'
|
||||||
|
scribus.defineColorRGB(newcolor,r, g, b)
|
||||||
|
rect = scribus.createRect(x + 255 - r, y, 5, 5)
|
||||||
|
scribus.setFillColor(newcolor, rect)
|
||||||
|
scribus.setLineColor(newcolor, rect)
|
||||||
|
r = r - 5
|
||||||
|
r = 255
|
||||||
|
g = g - 5
|
||||||
|
y = y - 5
|
||||||
|
|
||||||
|
r = 255
|
||||||
|
g = 255
|
||||||
|
y = 305
|
||||||
|
|
||||||
|
while b >= 0:
|
||||||
|
while r >= 0:
|
||||||
|
newcolor = str(r) + '_' + str(g) + '_' + str(b)
|
||||||
|
if newcolor == '255_255_255':
|
||||||
|
newcolor = 'White'
|
||||||
|
scribus.defineColorRGB(newcolor,r, g, b)
|
||||||
|
rect = scribus.createRect(x + 255 - r, y, 5, 5)
|
||||||
|
scribus.setFillColor(newcolor, rect)
|
||||||
|
scribus.setLineColor(newcolor, rect)
|
||||||
|
r = r - 5
|
||||||
|
r = 255
|
||||||
|
b = b - 5
|
||||||
|
y = y + 5
|
||||||
|
|
||||||
|
r = 255
|
||||||
|
g = 0
|
||||||
|
y = 305
|
||||||
|
x = 39
|
||||||
|
b = 255
|
||||||
|
|
||||||
|
while b >= 0:
|
||||||
|
while g < 256:
|
||||||
|
newcolor = str(r) + '_' + str(g) + '_' + str(b)
|
||||||
|
if newcolor == '255_255_255':
|
||||||
|
newcolor = 'White'
|
||||||
|
scribus.defineColorRGB(newcolor,r, g, b)
|
||||||
|
rect = scribus.createRect(x + g, y, 5, 5)
|
||||||
|
scribus.setFillColor(newcolor, rect)
|
||||||
|
scribus.setLineColor(newcolor, rect)
|
||||||
|
g = g + 5
|
||||||
|
g = 0
|
||||||
|
b = b - 5
|
||||||
|
y = y + 5
|
||||||
|
|
||||||
|
scribus.setRedraw(True)
|
||||||
|
scribus.redrawAll()
|
||||||
|
```
|
||||||
|
|
||||||
|
由于我创建了大量的颜色,所以当看到 Scribus 文件比我用它创建的 PDF 文件大得多的时候,我并不感到惊讶。例如,我的 Scribus SLA 文件是 3.0MB,而从中生成的 PDF 只有 70KB。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/rgb-cube-python-scribus
|
||||||
|
|
||||||
|
作者:[Greg Pittman][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zianglei](https://github.com/zianglei)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/greg-p/users/greg-p
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cube_innovation_process_block_container.png?itok=vkPYmSRQ "cubes coming together to create a larger cube"
|
||||||
|
[2]: https://www.scribus.net/
|
||||||
|
[3]: https://opensource.com/sites/default/files/ebooks/pythonscriptingwithscribus.pdf
|
||||||
|
[4]: https://opensource.com/sites/default/files/uploads/redgreengraph.png "Red-Green graph"
|
||||||
|
[5]: https://opensource.com/sites/default/files/uploads/rgbcubefirsthalf.png "First half of RGB cube"
|
||||||
|
[6]: https://opensource.com/sites/default/files/uploads/rgbcubesecondhalf.png "Second half of RGB cube"
|
||||||
|
[7]: https://opensource.com/sites/default/files/uploads/rgbcubecompositephoto.png "RGB cubes"
|
||||||
|
[8]: https://opensource.com/sites/default/files/uploads/rgbcubeslice.png "RGB cube slice"
|
||||||
@ -0,0 +1,106 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11128-1.html)
|
||||||
|
[#]: subject: (ElectronMail – a Desktop Client for ProtonMail and Tutanota)
|
||||||
|
[#]: via: (https://itsfoss.com/electronmail/)
|
||||||
|
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||||
|
|
||||||
|
ElectronMail:ProtonMail 和 Tutanota 的桌面客户端
|
||||||
|
======
|
||||||
|
|
||||||
|
互联网上的大多数人都拥有来自 Google 等大公司的电子邮件帐户,但这些帐户不尊重你的隐私。值得庆幸的是,目前有 [Tutanota][1] 和 [ProtonMail][2] 等具有隐私意识的替代品。问题是并非所有人都有桌面客户端。今天,我们将研究一个为你解决该问题的项目。我们来看看 ElectronMail 吧。
|
||||||
|
|
||||||
|
> ‘Electron’ 警告!
|
||||||
|
|
||||||
|
> 以下应用是使用 Electron 构建的(也就是名为 ElectronMail 的原因之一)。如果使用 Electron 让你感到不安,请将此视为触发警告。
|
||||||
|
|
||||||
|
### ElectronMail:Tutanota 和 ProtonMail 的桌面客户端
|
||||||
|
|
||||||
|
![Electron Mail About][3]
|
||||||
|
|
||||||
|
[ElectronMail][4] 可以简单地视作 ProtonMail 和 Tutanota 的电子邮件客户端。它使用三大技术构建:[Electron][5]、[TypeScript][6] 和 [Angular][7]。它包括以下功能:
|
||||||
|
|
||||||
|
* 针对每个电子邮件提供商提供多帐户支持
|
||||||
|
* 加密本地存储
|
||||||
|
* 适用于 Linux、Windows、macOS 和 FreeBSD
|
||||||
|
* 原生通知系统
|
||||||
|
* 带有未读消息总数的系统托盘图标
|
||||||
|
* 用主密码保护帐户信息
|
||||||
|
* 可切换的视图布局
|
||||||
|
* 可离线访问电子邮件
|
||||||
|
* 电子邮件在本地加密存储
|
||||||
|
* 批量导出电子邮件为 EML 文件
|
||||||
|
* 全文搜索
|
||||||
|
* 内置/预打包的 Web 客户端
|
||||||
|
* 可以为每个帐户配置代理
|
||||||
|
* 拼写检查
|
||||||
|
* 支持双因素身份验证,以提高安全性
|
||||||
|
|
||||||
|
目前,ElectronMail 仅支持 Tutanota 和 ProtonMail。我觉得他们将来会增加更多。根据 [GitHub 页面][4]:“多电子邮件提供商支持。目前支持 ProtonMail 和 Tutanota。”
|
||||||
|
|
||||||
|
ElectronMail 目前是 MIT 许可证。
|
||||||
|
|
||||||
|
#### 如何安装 ElectronMail
|
||||||
|
|
||||||
|
目前,有几种方法可以在 Linux 上安装 ElectronMail。对于Arch 和基于 Arch 的发行版,你可以从[Arch 用户仓库][8]安装它。ElectrionMail 还有一个 Snap 包。要安装它,只需输入 `sudo snap install electron-mail` 即可。
|
||||||
|
|
||||||
|
对于所有其他 Linux 发行版,你可以[下载][9] `.deb` 或 `.rpm` 文件。
|
||||||
|
|
||||||
|
![Electron Mail Inbox][10]
|
||||||
|
|
||||||
|
你也可以[下载][9]用于 Windows 中的 `.exe` 安装程序或用于 macOS 的 `.dmg` 文件。甚至还有给 FreeBSD 用的文件。
|
||||||
|
|
||||||
|
#### 删除 ElectronMail
|
||||||
|
|
||||||
|
如果你安装了 ElectronMail 并确定它不适合你,那么[开发者][12]建议采用几个步骤。 **在卸载应用之前,请务必遵循以下步骤。**
|
||||||
|
|
||||||
|
如果你使用了“保持登录”功能,请单击菜单上的“注销”。这将删除本地保存的主密码。卸载 ElectronMail 后也可以删除主密码,但这涉及编辑系统密钥链。
|
||||||
|
|
||||||
|
你还需要手动删除设置文件夹。在系统托盘中选择应用图标后,单击“打开设置文件夹”可以找到它。
|
||||||
|
|
||||||
|
![Electron Mail Setting][13]
|
||||||
|
|
||||||
|
### 我对 ElectronMail 的看法
|
||||||
|
|
||||||
|
我通常不使用电子邮件客户端。事实上,我主要依赖于 Web 客户端。所以,这个应用对我没太大用处。
|
||||||
|
|
||||||
|
话虽这么说,但是 ElectronMail 看着不错,而且很容易设置。它有大量开箱即用的功能,并且高级功能并不难使用。
|
||||||
|
|
||||||
|
我遇到的一个问题与搜索有关。根据功能列表,ElectronMail 支持全文搜索。但是,Tutanota 的免费版本仅支持有限的搜索。我想知道 ElectronMail 如何处理这个问题。
|
||||||
|
|
||||||
|
最后,ElectronMail 只是一个基于 Web Email 的一个 Electron 封装。我宁愿在浏览器中打开它们,而不是将单独的系统资源用于运行 Electron。如果你只[使用 Tutanota,他们有自己官方的 Electron 桌面客户端][14]。你可以尝试一下。
|
||||||
|
|
||||||
|
我最大的问题是安全性。这是两个非常安全的电子邮件应用的非官方应用。如果有办法捕获你的登录信息或阅读你的电子邮件怎么办?比我聪明的人必须通过源代码才能确定。这始终是一个安全项目的非官方应用的问题。
|
||||||
|
|
||||||
|
你有没有使用过 ElectronMail?你认为是否值得安装 ElectronMail?你最喜欢的邮件客户端是什么?请在下面的评论中告诉我们。
|
||||||
|
|
||||||
|
如果你发现这篇文章很有趣,请花一点时间在社交媒体、Hacker News 或 [Reddit][15] 上分享它。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/electronmail/
|
||||||
|
|
||||||
|
作者:[John Paul][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/john/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://itsfoss.com/tutanota-review/
|
||||||
|
[2]: https://itsfoss.com/protonmail/
|
||||||
|
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/electron-mail-about.jpg?resize=800%2C500&ssl=1
|
||||||
|
[4]: https://github.com/vladimiry/ElectronMail
|
||||||
|
[5]: https://electronjs.org/
|
||||||
|
[6]: http://www.typescriptlang.org/
|
||||||
|
[7]: https://angular.io/
|
||||||
|
[8]: https://aur.archlinux.org/packages/electronmail-bin
|
||||||
|
[9]: https://github.com/vladimiry/ElectronMail/releases
|
||||||
|
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/electron-mail-inbox.jpg?ssl=1
|
||||||
|
[12]: https://github.com/vladimiry
|
||||||
|
[14]: https://linux.cn/article-10688-1.html
|
||||||
|
[15]: http://reddit.com/r/linuxusersgroup
|
||||||
@ -0,0 +1,79 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11110-1.html)
|
||||||
|
[#]: subject: (Excellent! Ubuntu LTS Users Will Now Get the Latest Nvidia Driver Updates [No PPA Needed Anymore])
|
||||||
|
[#]: via: (https://itsfoss.com/ubuntu-lts-latest-nvidia-drivers/)
|
||||||
|
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||||
|
|
||||||
|
好消息!Ubuntu LTS 用户不需要 PPA 也可以获得最新的 Nvidia 驱动更新
|
||||||
|
======
|
||||||
|
|
||||||
|
> 要在 Ubuntu LTS 上获得的最新 Nvidia 驱动程序,你不必再使用 PPA 了。最新的驱动程序现在将在 Ubuntu LTS 版本的存储库中提供。
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
你可能已经注意到在 Ubuntu 上安装最新和最好的 Nvidia 二进制驱动程序更新的麻烦。
|
||||||
|
|
||||||
|
默认情况下,Ubuntu 提供开源的 [Nvidia Nouveau 驱动程序][2],这有时会导致 Ubuntu 卡在启动屏幕上。
|
||||||
|
|
||||||
|
你也可以轻松地[在 Ubuntu 中安装专有的 Nvidia 驱动程序][3]。问题是默认 [Ubuntu 存储库][4]中的 Nvidia 驱动程序不是最新的。为此,几年前 [Ubuntu 引入了一个专门的 PPA][5]以解决这个问题。
|
||||||
|
|
||||||
|
[使用官方 PPA][6] 仍然是安装闭源图形驱动程序的一个不错的解决方法。但是,它绝对不是最方便的选择。
|
||||||
|
|
||||||
|
但是,现在,Ubuntu 同意将最新的 Nvidia 驱动程序更新作为 SRU([StableReleaseUpdates][7])的一部分提供。所以,你将在使用 Ubuntu LTS 版本时也拥有 Nvidia 驱动程序了。
|
||||||
|
|
||||||
|
好吧,这意味着你不再需要在 Ubuntu LTS 版本上单独下载/安装 Nvidia 图形驱动程序。
|
||||||
|
|
||||||
|
就像你会获得浏览器或核心操作系统更新(或安全更新)的更新包一样,你将获得所需的 Nvidia 二进制驱动程序的更新包。
|
||||||
|
|
||||||
|
### 这个最新的 Nvidia 显卡驱动程序可靠吗?
|
||||||
|
|
||||||
|
SRU 字面上指的是 Ubuntu(或基于 Ubuntu 的发行版)的稳定更新。因此,要获得最新的图形驱动程序,你应该等待它作为稳定更新释出,而不是选择预先发布的更新程序。
|
||||||
|
|
||||||
|
当然,没有人能保证它能在所有时间内都正常工作 —— 但安装起来比预先发布的更安全。
|
||||||
|
|
||||||
|
### 怎样获得最新的 Nvidia 驱动程序?
|
||||||
|
|
||||||
|
![Software Updates Nvidia][8]
|
||||||
|
|
||||||
|
你只需从软件更新选项中的其他驱动程序部分启用“使用 NVIDIA 驱动程序元数据包……”。
|
||||||
|
|
||||||
|
最初,[The Linux Experiment][10] 通过视频分享了这个消息 —— 然后 Ubuntu 的官方 Twitter 作为公告重新推送了它。你可以观看下面的视频以获取更多详细信息:
|
||||||
|
|
||||||
|
- [https://youtu.be/NFdeWTQIpjo](https://youtu.be/NFdeWTQIpjo)
|
||||||
|
|
||||||
|
### 支持哪些 Ubuntu LTS 版本?
|
||||||
|
|
||||||
|
目前,Ubuntu 18.04 LTS 已经可用了,它也将很快在 Ubuntu 16.04 LTS 上可用(随后的 LTS 也将次第跟上)。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
现在你可以安装最新的 Nvidia 二进制驱动程序更新了,你认为这有何帮助?
|
||||||
|
|
||||||
|
如果你已经测试了预先发布的软件包,请在下面的评论中告诉我们你对此的看法。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/ubuntu-lts-latest-nvidia-drivers/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/nvidia-ubuntu-logo.png?resize=800%2C450&ssl=1
|
||||||
|
[2]: https://nouveau.freedesktop.org/wiki/
|
||||||
|
[3]: https://itsfoss.com/install-additional-drivers-ubuntu/
|
||||||
|
[4]: https://itsfoss.com/ubuntu-repositories/
|
||||||
|
[5]: https://itsfoss.com/ubuntu-official-ppa-graphics/
|
||||||
|
[6]: https://itsfoss.com/ppa-guide/
|
||||||
|
[7]: https://wiki.ubuntu.com/StableReleaseUpdates
|
||||||
|
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/software-updates-nvidia.jpg?fit=800%2C542&ssl=1
|
||||||
|
[9]: https://itsfoss.com/ubuntu-17-04-release-features/
|
||||||
|
[10]: https://twitter.com/thelinuxEXP
|
||||||
@ -0,0 +1,72 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (heguangzhi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11130-1.html)
|
||||||
|
[#]: subject: (Become a lifelong learner and succeed at work)
|
||||||
|
[#]: via: (https://opensource.com/open-organization/19/7/informal-learning-adaptability)
|
||||||
|
[#]: author: (Colin Willis https://opensource.com/users/colinwillishttps://opensource.com/users/marcobravo)
|
||||||
|
|
||||||
|
|
||||||
|
成为终身学习者,并在工作中取得成功
|
||||||
|
======
|
||||||
|
|
||||||
|
> 在具有适应性文化的开放组织中,学习应该一直持续 —— 但不会总是出现在正式场合。我们真的明白它是如何工作的吗?
|
||||||
|
|
||||||
|
![Writing in a notebook][1]
|
||||||
|
|
||||||
|
持续学习是指人们为发展自己而进行的持续的、职业驱动的、有意识的学习过程。对于那些自认是持续学习者的人来说,学习从未停止 —— 这些人从日常经历中看到学习机会。与同事进行辩论、反思反馈、在互联网上寻找问题的解决方案、尝试新事物或冒险都是一个人在工作中可以进行的非正式学习活动的例子。
|
||||||
|
|
||||||
|
持续学习是开放组织中任何人的核心能力。毕竟,开放的组织是建立在同行相互思考、争论和行动的基础上的。在开放组织的模棱两可、话语驱动的世界中茁壮成长,每天都需要员工具备这些技能。
|
||||||
|
|
||||||
|
不幸的是,科学文献在传播我们在工作中学习的知识方面、帮助个人欣赏和发展自己的学习能力方面,做得很差。因此,在本文系列中,我将向你介绍非正式学习,并帮助你理解将学习视为一种技能会如何帮助你在任何组织中茁壮成长,尤其是在开放式组织中。
|
||||||
|
|
||||||
|
### 为什么这么正式?
|
||||||
|
|
||||||
|
迄今为止,对组织中学习的科学研究主要集中在正式学习而不是非正式学习的设计、交付和评估上。
|
||||||
|
|
||||||
|
投资于员工知识、技能和能力的发展是一个组织保持其相对于竞争对手优势的重要方式。组织通过创建或购买课程、在线课程、研讨会等来使学习机会正规化。这些课程旨在像个人传授与工作相关的内容,就像学校里的班级一样。对于一个组织来说,提供一门课程是一种简单(如果成本高昂的话)的方法,可以确保其员工的技能或知识保持最新。同样,教室环境是研究人员的天然实验室,使得基于培训的研究和工作不仅可能,而且强大。
|
||||||
|
|
||||||
|
当然,有些东西人们不需要培训来学习;通常,人们通过研究答案、与同事交谈、思考、实验或适应变化来学习。事实上,[最近的评估表明][2] 70% 到 80% 的与工作相关的知识不是在培训中学到的,而是在工作中非正式学到的。这并不是说正规的培训无效;培训可能非常有效,但它是一种精确的干预方式。在工作的大部分方面正式培训一个人是不现实的,尤其是当这些工作变得更加复杂的时候。
|
||||||
|
|
||||||
|
因此,非正式学习,或者任何发生在结构化学习环境之外的学习,对工作场所来说是极其重要的。事实上,[最近的科学证据][3]表明,非正式学习比正式培训更能预测工作表现。
|
||||||
|
|
||||||
|
那么,为什么机构和科学界如此关注培训呢?
|
||||||
|
|
||||||
|
### 循环过程
|
||||||
|
|
||||||
|
除了我前面提到的原因,研究非正式学习可能非常困难。与正式学习不同,非正式学习发生在非结构化环境中,高度依赖于个人,很难或不可能观察到。
|
||||||
|
|
||||||
|
直到最近,大多数关于非正式学习的研究都集中在定义非正式学习的合格特征和确定非正式学习在理论上是如何与工作经验联系在一起的。研究人员描述了一个[动态的周期性过程][4],通过这个过程,个人可以在组织中非正式地学习。
|
||||||
|
|
||||||
|
与正式学习一样,非正式学习发生在非结构化环境中,高度依赖于个人,很难或不可能观察。
|
||||||
|
|
||||||
|
在这个过程中,个人和组织都有创造学习机会的机构。例如,一个人可能对学习某样东西感兴趣,并为此表现出学习行为。组织以向个人提供反馈的形式,可能表明需要学习。这可能是一个糟糕的绩效评估、一个在项目中发表的评论、或者一个不是个人指导的组织环境的更广泛的变化。这些力量在组织环境中(例如,有人尝试了一个新想法,他或她的同事认识到并奖励了这种行为)或者通过在个人的头脑中反思(例如,有人反思了关于他或她的表现的,并决定在学习工作中付出更多的努力)。与培训不同,非正式学习不遵循正式的线性过程。个人可以随时体验过程的任何部分,同时体验过程的多个部分。
|
||||||
|
|
||||||
|
### 开放组织中的非正式学习
|
||||||
|
|
||||||
|
具体而言,在开放组织中,既减少了对等级制度的重视程度,又更加注重对参与式文化的重视程度,这两者都推动了这种非正式的学习。简而言之,开放式组织只是为个人和组织环境提供了更多互动和激发学习的机会。此外,想法和变革需要开放式组织中员工给予更广泛的认同 —— 而认同需要对他人的适应性和洞察力的欣赏。
|
||||||
|
|
||||||
|
也就是说,仅仅增加学习机会并不能保证学习会发生或成功。有人甚至可能会说,开放式组织中常见的模糊性和公开性话语可能会阻止不擅长持续学习的人——同样,随着时间的推移学习的习惯和开放式组织的核心能力——尽可能有效地为组织做出贡献。
|
||||||
|
|
||||||
|
解决这些问题需要一种以一致的方式跟踪非正式学习。最近,科学界呼吁创造衡量非正式学习的方法,这样就可以进行系统的研究来解决非正式学习的前因后果的问题。我自己的研究集中在这一呼吁上,我花了几年时间发展和完善我们对非正式学习行为的理解,以便可以衡量它们。
|
||||||
|
|
||||||
|
在本文系列的第二部分,我将重点介绍我最近在一个开放式组织中进行的一项研究的成果,在该研究中,我测试了我对非正式学习行为的研究,并将它们与更广泛的工作环境和个人工作成果联系起来。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/open-organization/19/7/informal-learning-adaptability
|
||||||
|
|
||||||
|
作者:[Colin Willis][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/colinwillishttps://opensource.com/users/marcobravo
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/notebook-writing-pen.jpg?itok=uA3dCfu_ (Writing in a notebook)
|
||||||
|
[2]: https://www.groupoe.com/images/Accelerating_On-the-Job-Learning_-_White_Paper.pdf
|
||||||
|
[3]: https://www.researchgate.net/publication/316490244_Antecedents_and_Outcomes_of_Informal_Learning_Behaviors_a_Meta-Analysis
|
||||||
|
[4]: https://psycnet.apa.org/record/2008-13469-009
|
||||||
128
published/201907/20190716 Save and load Python data with JSON.md
Normal file
128
published/201907/20190716 Save and load Python data with JSON.md
Normal file
@ -0,0 +1,128 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (HankChow)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11133-1.html)
|
||||||
|
[#]: subject: (Save and load Python data with JSON)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/save-and-load-data-python-json)
|
||||||
|
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||||
|
|
||||||
|
使用 Python 处理 JSON 格式的数据
|
||||||
|
======
|
||||||
|
|
||||||
|
> 如果你不希望从头开始创造一种数据格式来存放数据,JSON 是一个很好的选择。如果你对 Python 有所了解,就更加事半功倍了。下面就来介绍一下如何使用 Python 处理 JSON 数据。
|
||||||
|
|
||||||
|
![Cloud and databsae incons][1]
|
||||||
|
|
||||||
|
[JSON][2] 的全称是 <ruby>JavaScript 对象表示法<rt>JavaScript Object Notation</rt></ruby>。这是一种以键值对的形式存储数据的格式,并且很容易解析,因而成为了一种被广泛使用的数据格式。另外,不要因为 JSON 名称而望文生义,JSON 并不仅仅在 JavaScript 中使用,它也可以在其它语言中使用。下文会介绍它是如何在 Python 中使用的。
|
||||||
|
|
||||||
|
首先我们给出一个 JSON 示例:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"name":"tux",
|
||||||
|
"health":"23",
|
||||||
|
"level":"4"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
上面是一个和编程语言无关的原生 JSON 数据。熟悉 Python 的人会看出来这个 JSON 数据跟 Python 中的<ruby>字典<rt>dictionary</rt></ruby>长得很像。而这两者之间确实非常相似,如果你对 Python 中的列表和字典数据结构有一定的理解,那么 JSON 理解起来也不难。
|
||||||
|
|
||||||
|
### 使用字典存放数据
|
||||||
|
|
||||||
|
如果你的应用需要存储一些结构复杂的数据,不妨考虑使用 JSON 格式。对比你可能曾经用过的自定义格式的文本配置文件,JSON 提供了更加结构化的可递归的存储格式。同时,Python 自带的 `json` 模块已经提供了可以将 JSON 数据导入/导出应用时所需的所有解析库。因此,你不需要针对 JSON 自行编写代码进行解析,而其他开发人员在与你的应用进行数据交互的时候也不需要去解析新的数据格式。正是这个原因,JSON 在数据交换时被广泛地采用了。
|
||||||
|
|
||||||
|
以下是一段在 Python 中使用嵌套字典的代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/usr/bin/env python3
|
||||||
|
|
||||||
|
import json
|
||||||
|
|
||||||
|
# instantiate an empty dict
|
||||||
|
team = {}
|
||||||
|
|
||||||
|
# add a team member
|
||||||
|
team['tux'] = {'health': 23, 'level': 4}
|
||||||
|
team['beastie'] = {'health': 13, 'level': 6}
|
||||||
|
team['konqi'] = {'health': 18, 'level': 7}
|
||||||
|
```
|
||||||
|
|
||||||
|
这段代码声明了一个名为 `team` 的字典,并初始化为一个空字典。
|
||||||
|
|
||||||
|
如果要给这个字典添加内容,首先需要创建一个键,例如上面示例中的 `tux`、`beastie`、`konqi`,然后为这些键一一提供对应的值。上面示例中的值由一个个包含游戏玩家信息的字典充当。
|
||||||
|
|
||||||
|
字典是一种可变的变量。字典中的数据可以随时添加、删除或更新。这样的特性使得字典成为了应用程序存储数据的极好选择。
|
||||||
|
|
||||||
|
### 使用 JSON 格式存储数据
|
||||||
|
|
||||||
|
如果存放在字典中的数据需要持久存储,这些数据就需要写到文件当中。这个时候就需要用到 Python 中的 `json` 模块了:
|
||||||
|
|
||||||
|
```
|
||||||
|
with open('mydata.json', 'w') as f:
|
||||||
|
json.dump(team, f)
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的代码首先创建了一个名为 `mydata.json` 的文件,然后以写模式打开了这个文件,这个被打开的文件以变量 `f` 表示(当然也可以用任何你喜欢的名称,例如 `file`、`output` 等)。而 `json` 模块中的 `dump()` 方法则是用于将一个字典输出到一个文件中。
|
||||||
|
|
||||||
|
从应用中导出数据就是这么简单,同时这些导出的数据是结构化的、可理解的。现在可以查看导出的数据:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat mydata.json
|
||||||
|
{"tux": {"health": 23, "level": 4}, "beastie": {"health": 13, "level": 6}, "konqi": {"health": 18, "level": 7}}
|
||||||
|
```
|
||||||
|
|
||||||
|
### 从 JSON 文件中读取数据
|
||||||
|
|
||||||
|
如果已经将数据以 JSON 格式导出到文件中了,也有可能需要将这些数据读回到应用中去。这个时候,可以使用 Python `json` 模块中的 `load()` 方法:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/usr/bin/env python3
|
||||||
|
|
||||||
|
import json
|
||||||
|
|
||||||
|
f = open('mydata.json')
|
||||||
|
team = json.load(f)
|
||||||
|
|
||||||
|
print(team['tux'])
|
||||||
|
print(team['tux']['health'])
|
||||||
|
print(team['tux']['level'])
|
||||||
|
|
||||||
|
print(team['beastie'])
|
||||||
|
print(team['beastie']['health'])
|
||||||
|
print(team['beastie']['level'])
|
||||||
|
|
||||||
|
# when finished, close the file
|
||||||
|
f.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
这个方法实现了和保存文件大致相反的操作。使用一个变量 `f` 来表示打开了的文件,然后使用 `json` 模块中的 `load()` 方法读取文件中的数据并存放到 `team` 变量中。
|
||||||
|
|
||||||
|
其中的 `print()` 展示了如何查看读取到的数据。在过于复杂的字典中迭代调用字典键的时候有可能会稍微转不过弯来,但只要熟悉整个数据的结构,就可以慢慢摸索出其中的逻辑。
|
||||||
|
|
||||||
|
当然,这里使用 `print()` 的方式太不灵活了。你可以将其改写成使用 `for` 循环的形式:
|
||||||
|
|
||||||
|
```
|
||||||
|
for i in team.values():
|
||||||
|
print(i)
|
||||||
|
```
|
||||||
|
|
||||||
|
### 使用 JSON
|
||||||
|
|
||||||
|
如上所述,在 Python 中可以很轻松地处理 JSON 数据。因此只要你的数据符合 JSON 的模式,就可以选择使用 JSON。JSON 非常灵活易用,下次使用 Python 的时候不妨尝试一下。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/save-and-load-data-python-json
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[HankChow](https://github.com/HankChow)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bus_cloud_database.png?itok=lhhU42fg (Cloud and databsae incons)
|
||||||
|
[2]: https://json.org
|
||||||
@ -0,0 +1,126 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11149-1.html)
|
||||||
|
[#]: subject: (Bond WiFi and Ethernet for easier networking mobility)
|
||||||
|
[#]: via: (https://fedoramagazine.org/bond-wifi-and-ethernet-for-easier-networking-mobility/)
|
||||||
|
[#]: author: (Ben Cotton https://fedoramagazine.org/author/bcotton/)
|
||||||
|
|
||||||
|
绑定 WiFi 和以太网,以使网络间移动更轻松
|
||||||
|
======
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
有时一个网络接口是不够的。网络绑定允许将多条网络连接与单个逻辑接口一起工作。你可能因为需要给单条连接更多的带宽而这么做,或者你可能希望在有线和无线网络之间来回切换而不会丢失网络连接。
|
||||||
|
|
||||||
|
我是后面一种情况。在家工作的好处之一是,当天气晴朗时,在阳光明媚的阳台而不是在室内工作是很愉快的。但每当我这样做时,我都会失去网络连接。IRC、SSH、VPN,一切都断开了,客户端重连至少需要一会。本文介绍了如何在 Fedora 30 笔记本上设置网络绑定,以便从笔记本扩展坞的有线连接无缝切换到 WiFi。
|
||||||
|
|
||||||
|
在 Linux 中,接口绑定由内核模块 `bonding` 处理。默认情况下,Fedora 没有启用此功能,但它包含在 `kernel-core` 软件包中。这意味着启用接口绑定只需一个命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo modprobe bonding
|
||||||
|
```
|
||||||
|
|
||||||
|
请注意,这只会在你重启之前生效。要永久启用接口绑定,请在 `/etc/modules-load.d` 目录中创建一个名为 `bonding.conf` 的文件,该文件仅包含单词 `bonding`。
|
||||||
|
|
||||||
|
现在你已启用绑定,现在可以创建绑定接口了。首先,你必须获取要绑定的接口的名称。要列出可用的接口,请运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nmcli device status
|
||||||
|
```
|
||||||
|
|
||||||
|
你将看到如下输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
DEVICE TYPE STATE CONNECTION
|
||||||
|
enp12s0u1 ethernet connected Wired connection 1
|
||||||
|
tun0 tun connected tun0
|
||||||
|
virbr0 bridge connected virbr0
|
||||||
|
wlp2s0 wifi disconnected --
|
||||||
|
p2p-dev-wlp2s0 wifi-p2p disconnected --
|
||||||
|
enp0s31f6 ethernet unavailable --
|
||||||
|
lo loopback unmanaged --
|
||||||
|
virbr0-nic tun unmanaged --
|
||||||
|
```
|
||||||
|
|
||||||
|
在本例中,有两个(有线)以太网接口可用。 `enp12s0u1` 在笔记本电脑扩展坞上,你可以通过 `STATE` 列知道它已连接。另一个是 `enp0s31f6`,是笔记本电脑中的内置端口。还有一个名为 `wlp2s0` 的 WiFi 连接。 `enp12s0u1` 和 `wlp2s0` 是我们在这里感兴趣的两个接口。(请注意,阅读本文无需了解网络设备的命名方式,但如果你感兴趣,可以查看 [systemd.net-naming-scheme 手册页][2]。)
|
||||||
|
|
||||||
|
第一步是创建绑定接口:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nmcli connection add type bond ifname bond0 con-name bond0
|
||||||
|
```
|
||||||
|
|
||||||
|
在此示例中,绑定接口名为 `bond0`。`con-name bond0` 将连接名称设置为 `bond0`。直接这样做会有一个名为 `bond-bond0` 的连接。你还可以将连接名设置得更加人性化,例如 “Docking station bond” 或 “Ben”。
|
||||||
|
|
||||||
|
下一步是将接口添加到绑定接口:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nmcli connection add type ethernet ifname enp12s0u1 master bond0 con-name bond-ethernet
|
||||||
|
sudo nmcli connection add type wifi ifname wlp2s0 master bond0 ssid Cotton con-name bond-wifi
|
||||||
|
```
|
||||||
|
|
||||||
|
如上所示,连接名称被设置为[更具描述性][3]。请务必使用系统上相应的接口名称替换 `enp12s0u1` 和 `wlp2s0`。对于 WiFi 接口,请使用你自己的网络名称 (SSID)替换我的 “Cotton”。如果你的 WiFi 连接有密码(这当然会有!),你也需要将其添加到配置中。以下假设你使用 [WPA2-PSK][4] 身份验证
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nmcli connection modify bond-wifi wifi-sec.key-mgmt wpa-psk
|
||||||
|
sudo nmcli connection edit bond-wif
|
||||||
|
```
|
||||||
|
|
||||||
|
第二条命令将进入交互式编辑器,你可以在其中输入密码,而无需将其记录在 shell 历史记录中。输入以下内容,将 `password` 替换为你的实际密码。
|
||||||
|
|
||||||
|
```
|
||||||
|
set wifi-sec.psk password
|
||||||
|
save
|
||||||
|
quit
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,你可以启动你的绑定接口以及你创建的辅助接口。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nmcli connection up bond0
|
||||||
|
sudo nmcli connection up bond-ethernet
|
||||||
|
sudo nmcli connection up bond-wifi
|
||||||
|
```
|
||||||
|
|
||||||
|
你现在应该能够在不丢失网络连接的情况下断开有线或无线连接。
|
||||||
|
|
||||||
|
### 警告:使用其他 WiFi 网络时
|
||||||
|
|
||||||
|
在指定的 WiFi 网络间移动时,此配置很有效,但是当远离此网络时,那么绑定中使用的 SSID 就不可用了。从理论上讲,可以为每个使用的 WiFi 连接添加一个接口,但这似乎并不合理。相反,你可以禁用绑定接口:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nmcli connection down bond0
|
||||||
|
```
|
||||||
|
|
||||||
|
回到定义的 WiFi 网络时,只需按上述方式启动绑定接口即可。
|
||||||
|
|
||||||
|
### 微调你的绑定
|
||||||
|
|
||||||
|
默认情况下,绑定接口使用“<ruby>轮询<rt>round-robin</rt></ruby>”模式。这会在接口上平均分配负载。但是,如果你有有线和无线连接,你可能希望更喜欢有线连接。 `active-backup` 模式能实现此功能。你可以在创建接口时指定模式和主接口,或者之后使用此命令(绑定接口应该关闭):
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nmcli connection modify bond0 +bond.options "mode=active-backup,primary=enp12s0u1"
|
||||||
|
```
|
||||||
|
|
||||||
|
[内核文档][5]提供了有关绑定选项的更多信息。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/bond-wifi-and-ethernet-for-easier-networking-mobility/
|
||||||
|
|
||||||
|
作者:[Ben Cotton][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/bcotton/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/networkingmobility-816x345.jpg
|
||||||
|
[2]: https://www.freedesktop.org/software/systemd/man/systemd.net-naming-scheme.html
|
||||||
|
[3]: https://en.wikipedia.org/wiki/Master/slave_(technology)#Terminology_concerns
|
||||||
|
[4]: https://en.wikipedia.org/wiki/Wi-Fi_Protected_Access#Target_users_(authentication_key_distribution)
|
||||||
|
[5]: https://www.kernel.org/doc/Documentation/networking/bonding.txt
|
||||||
113
published/201907/20190717 How to install Kibana on MacOS.md
Normal file
113
published/201907/20190717 How to install Kibana on MacOS.md
Normal file
@ -0,0 +1,113 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11135-1.html)
|
||||||
|
[#]: subject: (How to install Kibana on MacOS)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/installing-kibana-macos)
|
||||||
|
[#]: author: (Lauren Maffeo https://opensource.com/users/lmaffeo)
|
||||||
|
|
||||||
|
如何在 MacOS 上安装 Kibana
|
||||||
|
======
|
||||||
|
|
||||||
|
> Elasticsearch 当安装好了之后,Kibana 插件可以为这个功能强大的搜索工具添加可视化功能。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在我之前的文章中,我向 Mac 用户介绍了[安装 Elasticsearch][2] 的步骤,这是世界上最受欢迎的企业级搜索引擎。(这里有一篇针对 Linux 用户的[单独文章][3]。)其自然语言处理能力使得 Elasticsearch 在数据集中查找细节方面表现出色。一旦你发现了你需要的数据,如果你已经安装了 [Kibana][4],你可以将它提升到一个新的水平。
|
||||||
|
|
||||||
|
Kibana 是 Elasticsearch 的开源的数据可视化插件。当你在 Elasticsearch 中找到了数据,Kibana 就会帮助你将其放入折线图、[时间序列查询][5]、地理空间地图等。该工具非常适合于必须展示其研究成果的数据科学家,尤其是那些使用开源数据的人。
|
||||||
|
|
||||||
|
### 安装 Kibana
|
||||||
|
|
||||||
|
你需要在 Elasticsearch 之外单独安装 Kibana。因为我安装了 Elasticsearch 7.1.1,所以我将安装 Kibana 1.1。版本的匹配非常重要,Kibana 需要针对相同版本的 Elasticsearch 节点运行。 (Kibana 运行在 node.js 上。)
|
||||||
|
|
||||||
|
以下是我为 MacOS 安装 Kibana 7.1.1 时所遵循的步骤:
|
||||||
|
|
||||||
|
1、确保 Elasticsearch 已下载并运行。如果需要,请参阅上一篇文章。
|
||||||
|
|
||||||
|
**注意**:你至少需要先安装 Elasticsearch 1.4.4 或更高版本才能使用 Kibana。这是因为你需要向 Kibana 提供要连接的 Elasticsearch 实例的 URL 以及你要搜索的 Elasticsearch 索引。通常,最好安装两者的最新版本。
|
||||||
|
|
||||||
|
2、单击[此处][6]下载 Kibana。你将看到如下的网页,它会提示你在**下载**部分的右上角下载 Kibana for Mac:
|
||||||
|
|
||||||
|
![Download Kibana here.][7]
|
||||||
|
|
||||||
|
3、在你的 `Downloads` 文件夹中,打开 .tar 文件以展开它。此操作将创建一个具有相同名称的文件夹(例如,`kibana-7.1.1-darwin-x86_64`)。
|
||||||
|
|
||||||
|
4、如果你希望 Kibana 放在另一个文件夹中,请立即移动它。
|
||||||
|
|
||||||
|
仔细检查 Elasticsearch 是否正在运行,如果没有,请在继续之前启动它。(如果你需要说明,请参阅上一篇文章。)
|
||||||
|
|
||||||
|
### 打开 Kibana 插件
|
||||||
|
|
||||||
|
Elasticsearch 运行起来后,你现在可以启动 Kibana 了。该过程类似于启动 Elasticsearch:
|
||||||
|
|
||||||
|
1、从 Mac 的 `Downloads` 文件夹(或 Kibana 移动到的新文件夹)里,打开 Kibana 文件夹(即 `~Downloads/kibana-7.1.1-darwin-x86_64`)。
|
||||||
|
|
||||||
|
2、打开 `bin` 子文件夹。
|
||||||
|
|
||||||
|
![The Kibana bin folder.][8]
|
||||||
|
|
||||||
|
3、运行 `kibana-plugin`。你可能会遇到上一篇文章中出现的相同安全警告:
|
||||||
|
|
||||||
|
![Security warning][9]
|
||||||
|
|
||||||
|
通常,如果收到此警告,请按照那篇文章中的说明清除警告并打开 Kibana。请注意,如果我在终端中没有运行 Elasticsearch 的情况下打开该插件,我会收到相同的安全警告。要解决此问题,如上一篇文章中所述,打开 Elasticsearch 并在终端中运行它。使用 GUI 启动 Elasticsearch 也应该打开终端。
|
||||||
|
|
||||||
|
然后,我右键单击 `kibana-plugin` 并选择“打开”。这个解决方案对我有用,但你可能需要尝试几次。 我的 Elasticsearch 聚会中的几个人在他们的设备上打开 Kibana 时遇到了一些麻烦。
|
||||||
|
|
||||||
|
### 更改 Kibana 的主机和端口号
|
||||||
|
|
||||||
|
Kibana 的默认设置将其配置为在 `localhost:5601` 上运行。你需要更新文件(在这个例子的情况下)`~Downloads/kibana-7.1.1-darwin-x86_64/config/kibana.yml` 以在运行 Kibana 之前更改主机或端口号。
|
||||||
|
|
||||||
|
![The Kibana config directory.][10]
|
||||||
|
|
||||||
|
以下是我的 Elasticsearch 聚会组里配置 Kibana 时终端的样子,因此默认为 `http://localhost:9200`,这是查询 Elasticsearch 实例时使用的 URL:
|
||||||
|
|
||||||
|
![Configuring Kibana's host and port connections.][11]
|
||||||
|
|
||||||
|
### 从命令行运行 Kibana
|
||||||
|
|
||||||
|
打开插件后,可以从命令行或 GUI 运行 Kibana。这是终端连接到 Elasticsearch 后的样子:
|
||||||
|
|
||||||
|
![Kibana running once it's connected to Elasticsearch.][12]
|
||||||
|
|
||||||
|
与 Elasticsearch 一样,Kibana 默认在前台运行。你可以按 `Ctrl-C` 来停止它。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
Elasticsearch 和 Kibana 是占用大量存储空间的大型软件包。有这么多人一次下载这两个软件包,当我的Elasticsearch 会员和我下载它们两个时,我平均要下载几分钟。这可能是由于 WiFi 不佳和/或用户数量太多,但如果发生同样的事情,请记住这种可能性。
|
||||||
|
|
||||||
|
之后,由于我的笔记本电脑存储空间不足,我无法上传我们正在使用的 JSON 文件。我能够按照讲师的可视化进行操作,但无法实时使用 Kibana。因此,在下载 Elasticsearch 和 Kibana 之前,请确保设备上有足够的空间(至少几千兆字节)来上传和使用这些工具搜索文件。
|
||||||
|
|
||||||
|
要了解有关 Kibana 的更多信息,他们的用户指南[简介][13]是理想的。(你可以根据你正在使用的 Kibana 版本配置该指南。)他们的演示还向你展示了如何[在几分钟内构建仪表板][14],然后进行首次部署。
|
||||||
|
|
||||||
|
玩得开心!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/installing-kibana-macos
|
||||||
|
|
||||||
|
作者:[Lauren Maffeo][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/lmaffeo
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/analytics-graphs-charts.png?itok=sersoqbV (Analytics: Charts and Graphs)
|
||||||
|
[2]: https://linux.cn/article-11125-1.html
|
||||||
|
[3]: https://opensource.com/article/19/7/installing-elasticsearch-and-kibana-linux
|
||||||
|
[4]: https://www.elastic.co/products/kibana
|
||||||
|
[5]: https://en.wikipedia.org/wiki/Time_series
|
||||||
|
[6]: https://www.elastic.co/downloads/kibana
|
||||||
|
[7]: https://opensource.com/sites/default/files/uploads/download_kibana.png (Download Kibana here.)
|
||||||
|
[8]: https://opensource.com/sites/default/files/uploads/kibana_bin_folder.png (The Kibana bin folder.)
|
||||||
|
[9]: https://opensource.com/sites/default/files/uploads/security_warning.png (Security warning)
|
||||||
|
[10]: https://opensource.com/sites/default/files/uploads/kibana_config_directory.png (The Kibana config directory.)
|
||||||
|
[11]: https://opensource.com/sites/default/files/uploads/kibana_host_port_config.png (Configuring Kibana's host and port connections.)
|
||||||
|
[12]: https://opensource.com/sites/default/files/uploads/kibana_running.png (Kibana running once it's connected to Elasticsearch.)
|
||||||
|
[13]: https://www.elastic.co/guide/en/kibana/7.2/introduction.html
|
||||||
|
[14]: https://www.elastic.co/webinars/getting-started-kibana?baymax=rtp&elektra=docs&storm=top-video&iesrc=ctr
|
||||||
219
published/201907/20190717 Mastering user groups on Linux.md
Normal file
219
published/201907/20190717 Mastering user groups on Linux.md
Normal file
@ -0,0 +1,219 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (0x996)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11148-1.html)
|
||||||
|
[#]: subject: (Mastering user groups on Linux)
|
||||||
|
[#]: via: (https://www.networkworld.com/article/3409781/mastering-user-groups-on-linux.html)
|
||||||
|
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||||
|
|
||||||
|
掌握 Linux 用户组
|
||||||
|
======
|
||||||
|
|
||||||
|
> 在 Linux 系统中管理用户组并不费力,但相关命令可能比你所知的更为灵活。
|
||||||
|
|
||||||
|
![Scott 97006 \(CC BY 2.0\)][1]
|
||||||
|
|
||||||
|
在 Linux 系统中用户组起着重要作用。用户组提供了一种简单方法供一组用户互相共享文件。用户组也允许系统管理员更加有效地管理用户权限,因为管理员可以将权限分配给用户组而不是逐一分配给单个用户。
|
||||||
|
|
||||||
|
尽管通常只要在系统中添加用户账户就会创建用户组,关于用户组如何工作以及如何运用用户组还有很多需要了解的。
|
||||||
|
|
||||||
|
### 一个用户一个用户组?
|
||||||
|
|
||||||
|
Linux 系统中多数用户账户被设为用户名与用户组名相同。用户 `jdoe` 会被赋予一个名为 `jdoe` 的用户组,且成为该新建用户组的唯一成员。如本例所示,该用户的登录名,用户 id 和用户组 id 在新建账户时会被添加到 `/etc/passwd` 和 `/etc/group` 文件中:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo useradd jdoe
|
||||||
|
$ grep jdoe /etc/passwd
|
||||||
|
jdoe:x:1066:1066:Jane Doe:/home/jdoe:/bin/sh
|
||||||
|
$ grep jdoe /etc/group
|
||||||
|
jdoe:x:1066:
|
||||||
|
```
|
||||||
|
|
||||||
|
这些文件中的配置使系统得以在文本(`jdoe`)和数字(`1066`)这两种用户 id 形式之间互相转换—— `jdoe` 就是 `1006`,且 `1006` 就是 `jdoe`。
|
||||||
|
|
||||||
|
分配给每个用户的 UID(用户 id)和 GID(用户组 id)通常是一样的,并且顺序递增。若上例中 Jane Doe 是最近添加的用户,分配给下一个新用户的用户 id 和用户组 id 很可能都是 1067。
|
||||||
|
|
||||||
|
### GID = UID?
|
||||||
|
|
||||||
|
UID 和 GID 可能不一致。例如,如果你用 `groupadd` 命令添加一个用户组而不指定用户组 id,系统会分配下一个可用的用户组 id(在本例中为 1067)。下一个添加到系统中的用户其 UID 会是 1067 而 GID 则为 1068。
|
||||||
|
|
||||||
|
你可以避免这个问题,方法是添加用户组的时候指定一个较小的用户组 id 而不是接受默认值。在下面的命令中我们添加一个用户组并提供一个 GID,这个 GID 小于用于用户账户的 GID 取值范围。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo groupadd -g 500 devops
|
||||||
|
```
|
||||||
|
|
||||||
|
创建账户时你可以指定一个共享用户组,如果这样对你更合适的话。例如你可能想把新来的开发人员加入同一个 DevOps 用户组而不是一人一个用户组。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo useradd -g staff bennyg
|
||||||
|
$ grep bennyg /etc/passwd
|
||||||
|
bennyg:x:1064:50::/home/bennyg:/bin/sh
|
||||||
|
```
|
||||||
|
|
||||||
|
### 主要用户组和次要用户组
|
||||||
|
|
||||||
|
用户组实际上有两种:<ruby>主要用户组<rt>primary group</rt></ruby>和<ruby>次要用户组<rt>secondary group</rt></ruby>。
|
||||||
|
|
||||||
|
主要用户组是保存在 `/etc/passwd` 文件中的用户组,该用户组在账户创建时配置。当用户创建一个文件时,用户的主要用户组与此文件关联。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ whoami
|
||||||
|
jdoe
|
||||||
|
$ grep jdoe /etc/passwd
|
||||||
|
jdoe:x:1066:1066:John Doe:/home/jdoe:/bin/bash
|
||||||
|
^
|
||||||
|
|
|
||||||
|
+-------- 主要用户组
|
||||||
|
$ touch newfile
|
||||||
|
$ ls -l newfile
|
||||||
|
-rw-rw-r-- 1 jdoe jdoe 0 Jul 16 15:22 newfile
|
||||||
|
^
|
||||||
|
|
|
||||||
|
+-------- 主要用户组
|
||||||
|
```
|
||||||
|
|
||||||
|
用户一旦拥有账户之后被加入的那些用户组是次要用户组。次要用户组成员关系在 `/etc/group` 文件中显示。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ grep devops /etc/group
|
||||||
|
devops:x:500:shs,jadep
|
||||||
|
^
|
||||||
|
|
|
||||||
|
+-------- shs 和 jadep 的次要用户组
|
||||||
|
```
|
||||||
|
|
||||||
|
`/etc/group` 文件给用户组分配组名称(例如 `500` = `devops`)并记录次要用户组成员。
|
||||||
|
|
||||||
|
### 首选的准则
|
||||||
|
|
||||||
|
每个用户是他自己的主要用户组成员,并可以成为任意多个次要用户组成员,这样的一种准则允许用户更加容易地将个人文件和需要与同事分享的文件分开。当用户创建一个文件时,用户所属的不同用户组的成员不一定有访问权限。用户必须用 `chgrp` 命令将文件和次要用户组关联起来。
|
||||||
|
|
||||||
|
### 哪里也不如自己的家目录
|
||||||
|
|
||||||
|
添加新账户时一个重要的细节是 `useradd` 命令并不一定为新用户添加一个<ruby>家目录<rt>/home</rt></ruby>家目录。若你只有某些时候想为用户添加家目录,你可以在 `useradd` 命令中加入 `-m` 选项(可以把它想象成“安家”选项)。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo useradd -m -g devops -c "John Doe" jdoe2
|
||||||
|
```
|
||||||
|
|
||||||
|
此命令中的选项如下:
|
||||||
|
|
||||||
|
* `-m` 创建家目录并在其中生成初始文件
|
||||||
|
* `-g` 指定用户归属的用户组
|
||||||
|
* `-c` 添加账户描述信息(通常是用户的姓名)
|
||||||
|
|
||||||
|
若你希望总是创建家目录,你可以编辑 `/etc/login.defs` 文件来更改默认工作方式。更改或添加 `CREATE_HOME` 变量并将其设置为 `yes`:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ grep CREATE_HOME /etc/login.defs
|
||||||
|
CREATE_HOME yes
|
||||||
|
```
|
||||||
|
|
||||||
|
另一种方法是用自己的账户设置别名从而让 `useradd` 一直带有 `-m` 选项。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ alias useradd=’useradd -m’
|
||||||
|
```
|
||||||
|
|
||||||
|
确保将该别名添加到你的 `~/.bashrc` 文件或类似的启动文件中以使其永久生效。
|
||||||
|
|
||||||
|
### 深入了解 /etc/login.defs
|
||||||
|
|
||||||
|
下面这个命令可列出 `/etc/login.defs` 文件中的全部设置。下面的 `grep` 命令会隐藏所有注释和空行。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat /etc/login.defs | grep -v "^#" | grep -v "^$"
|
||||||
|
MAIL_DIR /var/mail
|
||||||
|
FAILLOG_ENAB yes
|
||||||
|
LOG_UNKFAIL_ENAB no
|
||||||
|
LOG_OK_LOGINS no
|
||||||
|
SYSLOG_SU_ENAB yes
|
||||||
|
SYSLOG_SG_ENAB yes
|
||||||
|
FTMP_FILE /var/log/btmp
|
||||||
|
SU_NAME su
|
||||||
|
HUSHLOGIN_FILE .hushlogin
|
||||||
|
ENV_SUPATH PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
|
||||||
|
ENV_PATH PATH=/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
|
||||||
|
TTYGROUP tty
|
||||||
|
TTYPERM 0600
|
||||||
|
ERASECHAR 0177
|
||||||
|
KILLCHAR 025
|
||||||
|
UMASK 022
|
||||||
|
PASS_MAX_DAYS 99999
|
||||||
|
PASS_MIN_DAYS 0
|
||||||
|
PASS_WARN_AGE 7
|
||||||
|
UID_MIN 1000
|
||||||
|
UID_MAX 60000
|
||||||
|
GID_MIN 1000
|
||||||
|
GID_MAX 60000
|
||||||
|
LOGIN_RETRIES 5
|
||||||
|
LOGIN_TIMEOUT 60
|
||||||
|
CHFN_RESTRICT rwh
|
||||||
|
DEFAULT_HOME yes
|
||||||
|
CREATE_HOME yes <===
|
||||||
|
USERGROUPS_ENAB yes
|
||||||
|
ENCRYPT_METHOD SHA512
|
||||||
|
```
|
||||||
|
|
||||||
|
注意此文件中的各种设置会决定用户 id 的取值范围以及密码使用期限和其他设置(如 umask)。
|
||||||
|
|
||||||
|
### 如何显示用户所属的用户组
|
||||||
|
|
||||||
|
出于各种原因用户可能是多个用户组的成员。用户组成员身份给与用户对用户组拥有的文件和目录的访问权限,有时候这种工作方式是至关重要的。要生成某个用户所属用户组的清单,用 `groups` 命令即可。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ groups jdoe
|
||||||
|
jdoe : jdoe adm admin cdrom sudo dip plugdev lpadmin staff sambashare
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以键入不带任何参数的 `groups` 命令来列出你自己的用户组。
|
||||||
|
|
||||||
|
### 如何添加用户至用户组
|
||||||
|
|
||||||
|
如果你想添加一个已有用户至别的用户组,你可以仿照下面的命令操作:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo usermod -a -G devops jdoe
|
||||||
|
```
|
||||||
|
|
||||||
|
你也可以指定逗号分隔的用户组列表来添加一个用户至多个用户组:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo usermod -a -G devops,mgrs jdoe
|
||||||
|
```
|
||||||
|
|
||||||
|
参数 `-a` 意思是“添加”,`-G` 指定用户组列表。
|
||||||
|
|
||||||
|
你可以编辑 `/etc/group` 文件将用户名从用户组成员名单中删除,从而将用户从用户组中移除。`usermod` 命令或许也有个选项用于从用户组中删除某个成员。
|
||||||
|
|
||||||
|
```
|
||||||
|
fish:x:16:nemo,dory,shark
|
||||||
|
|
|
||||||
|
V
|
||||||
|
fish:x:16:nemo,dory
|
||||||
|
```
|
||||||
|
|
||||||
|
### 提要
|
||||||
|
|
||||||
|
添加和管理用户组并非特别困难,但长远来看配置账户时的一致性可使这项工作更容易些。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.networkworld.com/article/3409781/mastering-user-groups-on-linux.html
|
||||||
|
|
||||||
|
作者:[Sandra Henry-Stocker][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[0x996](https://github.com/0x996)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://images.idgesg.net/images/article/2019/07/carrots-100801917-large.jpg
|
||||||
|
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||||
|
[3]: https://www.networkworld.com/article/3391029/must-know-linux-commands.html
|
||||||
|
[4]: https://www.facebook.com/NetworkWorld/
|
||||||
|
[5]: https://www.linkedin.com/company/network-world
|
||||||
@ -0,0 +1,98 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11121-1.html)
|
||||||
|
[#]: subject: (Epic Games Backs Blender Foundation with $1.2m Epic MegaGrants)
|
||||||
|
[#]: via: (https://itsfoss.com/epic-games-blender-grant/)
|
||||||
|
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||||
|
|
||||||
|
Epic Games 给予 Blender 基金会 120 万美元的拨款支持
|
||||||
|
======
|
||||||
|
|
||||||
|
[Epic MegaGrants][1] 是 [Epic Games][2] 的一个计划,用于支持游戏开发人员、企业专业人士、内容创建者和工具开发人员使用<ruby>虚幻引擎<rt>Unreal Engine</rt></ruby>(UE)做出神奇的作品或增强 3D 图形社区的开源功能。
|
||||||
|
|
||||||
|
作为该计划的一部分,Epic Games 给予 [Blender 基金会][3] 120 万美元拨款以帮助改善他们的发展。如果你还不知道,Blender 是[最好的开源视频编辑][4]之一,特别是以创建专业的 3D 计算机图形而闻名。
|
||||||
|
|
||||||
|
**Tim Sweeney**(Epic Games 的创始人兼首席执行官)这样评论这笔授予:
|
||||||
|
|
||||||
|
> “开放式工具、库和平台对数字内容生态系统的未来至关重要。……Blender 是艺术社区持久的资源,我们的目标是确保其进步,造福所有创作者。”
|
||||||
|
|
||||||
|
即使这是个好消息,也有人对此不满意。在本文中,我们将看一下得到该拨款后的 Blender 基金会的计划,以及人们对此的看法。
|
||||||
|
|
||||||
|
### Blender 基金会的改进计划
|
||||||
|
|
||||||
|
![Image Credit : BlenderNation][5]
|
||||||
|
|
||||||
|
在[新闻稿][6]当中,Blender 基金会提到了如何利用这笔资金以及用于何种目的:
|
||||||
|
|
||||||
|
> “Epic MegaGrant 将在未来三年内逐步交付,并将为 Blender 的<ruby>专业 Blender 发展计划<rt>Professionalizing Blender Development Initiative</rt></ruby>做出贡献。”
|
||||||
|
|
||||||
|
所以,没错,这笔财务帮助将以现金提供 —— 但是,它要在 3 年内完成。也就是说,我们要期待 Blender 基金会及其软件质量得到重大改进还有很长时间。
|
||||||
|
|
||||||
|
这是 **Ton Roosendaal**(Blender 基金会的创始人)需要说明的它将如何被利用:
|
||||||
|
|
||||||
|
> “Epic Games 的支持对 Blender 是一个重要里程碑,”Blender 基金会的创始人兼董事长 Ton Roosendaal 说道。“由于这项拨款,我们将对我们的项目组织进行大量投入,以改善支持、协作和代码质量实践。因此,我们期望更多来自该行业的贡献者加入我们的项目。”
|
||||||
|
|
||||||
|
### 为什么人们对此不是很喜欢?
|
||||||
|
|
||||||
|
让我澄清一下,就我个人而言,我不喜欢用 Epic Game 的市场或客户端玩游戏。
|
||||||
|
|
||||||
|
由于各种原因(功能、隐私等),我更喜欢 [Steam][7] 而不是 Epic Games。
|
||||||
|
|
||||||
|
Epic Games 被称为游戏社区中的坏人,因为它最近几款游戏专属于其平台 —— 尽管很多人警告用户该平台上的隐私问题。
|
||||||
|
|
||||||
|
不仅如此,Epic Games 的首席执行官在过去发过这样的推特:
|
||||||
|
|
||||||
|
> 安装 Linux 相当于人们不喜欢美国的政治趋势时就搬到加拿大。
|
||||||
|
>
|
||||||
|
> 不,我们必须为今天的自由而战,如今我们拥有自由。
|
||||||
|
>
|
||||||
|
> - Tim Sweeney(@TimSweeneyEpic)[2018年2月15日][8]
|
||||||
|
|
||||||
|
嗯,这并不直接暗示他讨厌 Linux 或者没有积极推动 Linux 的游戏开发 —— 但是只是因为很多历史情况,人们并不真正信任 Epic Games 的决策。所以,他们并不欣赏与 Blender 基金会的联系(即使这个财务帮助是积极的)。
|
||||||
|
|
||||||
|
这与财务帮助无关。但是,Epic Games 缺乏良好的声誉(当然是主观的),因此,人们对此的看法是消极的。看看拨款公告后的一些推文:
|
||||||
|
|
||||||
|
> 希望不要走向排它……这可能会破坏你的声誉。
|
||||||
|
>
|
||||||
|
> - Ray(@ Epicshadow1994)[2019年7月15日][9]
|
||||||
|
|
||||||
|
> 我对将来会变成什么样感到怀疑。EPIC 最近一直在采取敌对战术。
|
||||||
|
>
|
||||||
|
> - acrid Heartwood(@acrid_heartwood)[2019年7月15日][10]
|
||||||
|
|
||||||
|
### 总而言之
|
||||||
|
|
||||||
|
你仍然可以[通过 Lutris 在 Linux 上运行 Epic Games][11],但这是很单薄的非官方尝试。Epic Games 没有表示有兴趣正式支持该项目。
|
||||||
|
|
||||||
|
所以,很明显不是每个人都信任 Epic Games。因此,这个消息带来了各种消极反应。
|
||||||
|
|
||||||
|
但是,这笔拨款肯定会帮助 Blender 基金会改善其组织和软件质量。
|
||||||
|
|
||||||
|
你怎么看待这件事?请在下面的评论中告诉我们您的想法。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/epic-games-blender-grant/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.unrealengine.com/en-US/megagrants
|
||||||
|
[2]: https://www.epicgames.com/store/en-US/
|
||||||
|
[3]: https://www.blender.org/
|
||||||
|
[4]: https://itsfoss.com/open-source-video-editors/
|
||||||
|
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/epic-games-blender-megagrant.jpg?resize=800%2C450&ssl=1
|
||||||
|
[6]: https://www.blender.org/press/epic-games-supports-blender-foundation-with-1-2-million-epic-megagrant/
|
||||||
|
[7]: https://itsfoss.com/install-steam-ubuntu-linux/
|
||||||
|
[8]: https://twitter.com/TimSweeneyEpic/status/964284402741149698?ref_src=twsrc%5Etfw
|
||||||
|
[9]: https://twitter.com/Epicshadow1994/status/1150787326626263042?ref_src=twsrc%5Etfw
|
||||||
|
[10]: https://twitter.com/acrid_heartwood/status/1150789691979030528?ref_src=twsrc%5Etfw
|
||||||
|
[11]: https://linux.cn/article-10968-1.html
|
||||||
@ -0,0 +1,145 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11151-1.html)
|
||||||
|
[#]: subject: (How to run virtual machines with virt-manager)
|
||||||
|
[#]: via: (https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/)
|
||||||
|
[#]: author: (Marco Sarti https://fedoramagazine.org/author/msarti/)
|
||||||
|
|
||||||
|
如何使用 virt-manager 运行虚拟机
|
||||||
|
======
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
在早些年,在同一台笔记本中运行多个操作系统只能双启动。当时,这些操作系统很难同时运行或彼此交互。许多年过去了,在普通的 PC 上,可以通过虚拟化在一个系统中运行另一个系统。
|
||||||
|
|
||||||
|
最近的 PC 或笔记本(包括价格适中的笔记本电脑)都有硬件虚拟化,可以运行性能接近物理主机的虚拟机。
|
||||||
|
|
||||||
|
虚拟化因此变得常见,它可以用来测试操作系统、学习新技术、创建自己的家庭云、创建自己的测试环境等等。本文将指导你使用 Fedora 上的 Virt Manager 来设置虚拟机。
|
||||||
|
|
||||||
|
### 介绍 QEMU/KVM 和 Libvirt
|
||||||
|
|
||||||
|
与所有其他 Linux 系统一样,Fedora 附带了虚拟化扩展支持。它由作为内核模块之一的 KVM(基于内核的虚拟机)提供支持。
|
||||||
|
|
||||||
|
QEMU 是一个完整的系统仿真器,它可与 KVM 协同工作,允许你使用硬件和外部设备创建虚拟机。
|
||||||
|
|
||||||
|
最后,[libvirt][2] 能让你管理基础设施的 API 层,即创建和运行虚拟机。
|
||||||
|
|
||||||
|
这三个技术都是开源的,我们将在 Fedora Workstation 上安装它们。
|
||||||
|
|
||||||
|
### 安装
|
||||||
|
|
||||||
|
#### 步骤 1:安装软件包
|
||||||
|
|
||||||
|
安装是一个相当简单的操作。 Fedora 仓库提供了 “virtualization” 软件包组,其中包含了你需要的所有包。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo dnf install @virtualization
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 步骤 2:编辑 libvirtd 配置
|
||||||
|
|
||||||
|
默认情况下,系统管理仅限于 root 用户,如果要启用常规用户,那么必须按以下步骤操作。
|
||||||
|
|
||||||
|
打开 `/etc/libvirt/libvirtd.conf` 进行编辑:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo vi /etc/libvirt/libvirtd.conf
|
||||||
|
```
|
||||||
|
|
||||||
|
将 UNIX 域套接字组所有者设置为 libvirt:
|
||||||
|
|
||||||
|
```
|
||||||
|
unix_sock_group = "libvirt"
|
||||||
|
```
|
||||||
|
|
||||||
|
调整 UNIX 域套接字的读写权限:
|
||||||
|
|
||||||
|
```
|
||||||
|
unix_sock_rw_perms = "0770"
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 步骤 3:启动并启用 libvirtd 服务
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl start libvirtd
|
||||||
|
sudo systemctl enable libvirtd
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 步骤 4:将用户添加到组
|
||||||
|
|
||||||
|
为了管理 libvirt 与普通用户,你必须将用户添加到 `libvirt` 组,否则每次启动 `virt-manager` 时,都会要求你输入 sudo 密码。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo usermod -a -G libvirt $(whoami)
|
||||||
|
```
|
||||||
|
|
||||||
|
这会将当前用户添加到组中。你必须注销并重新登录才能应用更改。
|
||||||
|
|
||||||
|
### 开始使用 virt-manager
|
||||||
|
|
||||||
|
可以通过命令行 (`virsh`) 或通过 `virt-manager` 图形界面管理 libvirt 系统。如果你想做虚拟机自动化配置,那么命令行非常有用,例如使用 [Ansible][3],但在本文中我们将专注于用户友好的图形界面。
|
||||||
|
|
||||||
|
`virt-manager` 界面很简单。主窗口显示连接列表,其中包括本地系统连接。
|
||||||
|
|
||||||
|
连接设置包括虚拟网络和存储定义。你可以定义多个虚拟网络,这些网络可用于在客户端系统之间以及客户端系统和主机之间进行通信。
|
||||||
|
|
||||||
|
### 创建你的第一个虚拟机
|
||||||
|
|
||||||
|
要开始创建新虚拟机,请按下主窗口左上角的按钮:
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
向导的第一步需要选择安装模式。你可以选择本地安装介质、网络引导/安装或导入现有虚拟磁盘:
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
选择本地安装介质,下一步将需要选择 ISO 镜像路径:
|
||||||
|
|
||||||
|
![ ][6]
|
||||||
|
|
||||||
|
随后的两个步骤能让你调整新虚拟机的 CPU、内存和磁盘大小。最后一步将要求你选择网络选项:如果你希望虚拟机通过 NAT 与外部隔离,请选择默认网络。如果你希望从外部访问虚拟机,那么选择桥接。请注意,如果选择桥接,那么虚拟机则无法与主机通信。
|
||||||
|
|
||||||
|
如果要在启动设置之前查看或更改配置,请选中“安装前自定义配置”:
|
||||||
|
|
||||||
|
![][7]
|
||||||
|
|
||||||
|
虚拟机配置窗口能让你查看和修改硬件配置。你可以添加磁盘、网络接口、更改引导选项等。满意后按“开始安装”:
|
||||||
|
|
||||||
|
![][8]
|
||||||
|
|
||||||
|
此时,你将被重定向到控制台来继续安装操作系统。操作完成后,你可以从控制台访问虚拟机:
|
||||||
|
|
||||||
|
![][9]
|
||||||
|
|
||||||
|
刚刚创建的虚拟机将出现在主窗口的列表中,你还能看到 CPU 和内存占用率的图表:
|
||||||
|
|
||||||
|
![][10]
|
||||||
|
|
||||||
|
libvirt 和 `virt-manager` 是功能强大的工具,它们可以以企业级管理为你的虚拟机提供出色的自定义。如果你需要更简单的东西,请注意 Fedora Workstation [预安装的 GNOME Boxes 已经能够满足基础的虚拟化要求][11]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/
|
||||||
|
|
||||||
|
作者:[Marco Sarti][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/msarti/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/virt-manager-816x346.jpg
|
||||||
|
[2]: https://libvirt.org/
|
||||||
|
[3]: https://fedoramagazine.org/get-the-latest-ansible-2-8-in-fedora/
|
||||||
|
[4]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-09-41-45.png
|
||||||
|
[5]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-09-30-53.png
|
||||||
|
[6]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-42-39.png
|
||||||
|
[7]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-43-21.png
|
||||||
|
[8]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-44-58.png
|
||||||
|
[9]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-55-35.png
|
||||||
|
[10]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-11-09-22.png
|
||||||
|
[11]: https://fedoramagazine.org/getting-started-with-virtualization-in-gnome-boxes/
|
||||||
@ -0,0 +1,218 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (MjSeven)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11158-1.html)
|
||||||
|
[#]: subject: (Getting help for Linux shell built-ins)
|
||||||
|
[#]: via: (https://www.networkworld.com/article/3410350/getting-help-for-linux-shell-built-ins.html)
|
||||||
|
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||||
|
|
||||||
|
获取有关 Linux shell 内置命令的帮助
|
||||||
|
======
|
||||||
|
|
||||||
|
> Linux 内置命令属于用户 shell 的一部分,本文将告诉你如何识别它们并获取使用它们的帮助。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Linux 内置命令是内置于 shell 中的命令,很像内置于墙中的书架。与标准 Linux 命令存储在 `/usr/bin` 中的方式不同,你不会找到它们的独立文件,你可能使用过相当多的内置命令,但你不会感觉到它们与 `ls` 和 `pwd` 等命令有何不同。
|
||||||
|
|
||||||
|
内置命令与其他 Linux 命令一样使用,它们可能要比不属于 shell 的类似命令运行得快一些。Bash 内置命令包括 `alias`、`export` 和 `bg` 等。
|
||||||
|
|
||||||
|
正如你担心的那样,因为内置命令是特定于 shell 的,所以它们不会提供手册页。使用 `man` 来查看 `bg`,你会看到这样的东西:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ man bg
|
||||||
|
No manual entry for bg
|
||||||
|
```
|
||||||
|
|
||||||
|
判断内置命令的另一个提示是当你使用 `which` 命令来识别命令的来源时,Bash 不会响应,表示没有与内置命令关联的文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ which bg
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
另一方面,如果你的 shell 是 `/bin/zsh`,你可能会得到一个更有启发性的响应:
|
||||||
|
|
||||||
|
```
|
||||||
|
% which bg
|
||||||
|
bg: shell built-in command
|
||||||
|
```
|
||||||
|
|
||||||
|
bash 提供了额外的帮助信息,但它是通过使用 `help` 命令实现的:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ help bg
|
||||||
|
bg: bg [job_spec ...]
|
||||||
|
Move jobs to the background.
|
||||||
|
|
||||||
|
Place the jobs identified by each JOB_SPEC in the background, as if they
|
||||||
|
had been started with `&'. If JOB_SPEC is not present, the shell's notion
|
||||||
|
of the current job is used.
|
||||||
|
|
||||||
|
Exit Status:
|
||||||
|
Returns success unless job control is not enabled or an error occurs.
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你想要查看 bash 提供的所有内置命令的列表,使用 `compgen -b` 命令。通过管道将命令输出到列中,以获得较好格式的清单。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ compgen -b | column
|
||||||
|
. compgen exit let return typeset
|
||||||
|
: complete export local set ulimit
|
||||||
|
[ compopt false logout shift umask
|
||||||
|
alias continue fc mapfile shopt unalias
|
||||||
|
bg declare fg popd source unset
|
||||||
|
bind dirs getopts printf suspend wait
|
||||||
|
break disown hash pushd test
|
||||||
|
builtin echo help pwd times
|
||||||
|
caller enable history read trap
|
||||||
|
cd eval jobs readarray true
|
||||||
|
command exec kill readonly type
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你使用 `help` 命令,你将看到一个内置命令列表以及简短描述。但是,这个列表被截断了(以 `help` 命令结尾):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ help
|
||||||
|
GNU bash, version 5.0.3(1)-release (x86_64-pc-linux-gnu)
|
||||||
|
These shell commands are defined internally. Type `help' to see this list.
|
||||||
|
Type `help name' to find out more about the function `name'.
|
||||||
|
Use `info bash' to find out more about the shell in general.
|
||||||
|
Use `man -k' or `info' to find out more about commands not in this list.
|
||||||
|
|
||||||
|
A star (*) next to a name means that the command is disabled.
|
||||||
|
|
||||||
|
job_spec [&] history [-c] [-d offset] [n] or histo>
|
||||||
|
(( expression )) if COMMANDS; then COMMANDS; [ elif CO>
|
||||||
|
. filename [arguments] jobs [-lnprs] [jobspec ...] or jobs ->
|
||||||
|
: kill [-s sigspec | -n signum | -sigsp>
|
||||||
|
[ arg... ] let arg [arg ...]
|
||||||
|
[[ expression ]] local [option] name[=value] ...
|
||||||
|
alias [-p] [name[=value] ... ] logout [n]
|
||||||
|
bg [job_spec ...] mapfile [-d delim] [-n count] [-O ori>
|
||||||
|
bind [-lpsvPSVX] [-m keymap] [-f filen> popd [-n] [+N | -N]
|
||||||
|
break [n] printf [-v var] format [arguments]
|
||||||
|
builtin [shell-builtin [arg ...]] pushd [-n] [+N | -N | dir]
|
||||||
|
caller [expr] pwd [-LP]
|
||||||
|
case WORD in [PATTERN [| PATTERN]...) > read [-ers] [-a array] [-d delim] [-i>
|
||||||
|
cd [-L|[-P [-e]] [-@]] [dir] readarray [-d delim] [-n count] [-O o>
|
||||||
|
command [-pVv] command [arg ...] readonly [-aAf] [name[=value] ...] or>
|
||||||
|
compgen [-abcdefgjksuv] [-o option] [-> return [n]
|
||||||
|
complete [-abcdefgjksuv] [-pr] [-DEI] > select NAME [in WORDS ... ;] do COMMA>
|
||||||
|
compopt [-o|+o option] [-DEI] [name ..> set [-abefhkmnptuvxBCHP] [-o option-n>
|
||||||
|
continue [n] shift [n]
|
||||||
|
coproc [NAME] command [redirections] shopt [-pqsu] [-o] [optname ...]
|
||||||
|
declare [-aAfFgilnrtux] [-p] [name[=va> source filename [arguments]
|
||||||
|
dirs [-clpv] [+N] [-N] suspend [-f]
|
||||||
|
disown [-h] [-ar] [jobspec ... | pid . <p>'> test [expr]
|
||||||
|
echo [-neE] [arg ...] time [-p] pipeline
|
||||||
|
enable [-a] [-dnps] [-f filename] [nam> times
|
||||||
|
eval [arg ...] trap [-lp] [[arg] signal_spec ...]
|
||||||
|
exec [-cl] [-a name] [command [argumen> true
|
||||||
|
exit [n] type [-afptP] name [name ...]
|
||||||
|
export [-fn] [name[=value] ...] or exp> typeset [-aAfFgilnrtux] [-p] name[=va>
|
||||||
|
false ulimit [-SHabcdefiklmnpqrstuvxPT] [li>
|
||||||
|
fc [-e ename] [-lnr] [first] [last] or> umask [-p] [-S] [mode]
|
||||||
|
fg [job_spec] unalias [-a] name [name ...]
|
||||||
|
for NAME [in WORDS ... ] ; do COMMANDS> unset [-f] [-v] [-n] [name ...]
|
||||||
|
for (( exp1; exp2; exp3 )); do COMMAND> until COMMANDS; do COMMANDS; done
|
||||||
|
function name { COMMANDS ; } or name (> variables - Names and meanings of som>
|
||||||
|
getopts optstring name [arg] wait [-fn] [id ...]
|
||||||
|
hash [-lr] [-p pathname] [-dt] [name .> while COMMANDS; do COMMANDS; done
|
||||||
|
help [-dms] [pattern ...] { COMMANDS ; }
|
||||||
|
```
|
||||||
|
|
||||||
|
从上面的清单中可以看出,`help` 命令本身就是内置的。
|
||||||
|
|
||||||
|
你可以通过向 `help` 命令提供你感兴趣的内置命令名称来获取关于它们的更多信息,例如 `help dirs`:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ help dirs
|
||||||
|
dirs: dirs [-clpv] [+N] [-N]
|
||||||
|
Display directory stack.
|
||||||
|
|
||||||
|
Display the list of currently remembered directories. Directories
|
||||||
|
find their way onto the list with the `pushd' command; you can get
|
||||||
|
back up through the list with the `popd' command.
|
||||||
|
|
||||||
|
Options:
|
||||||
|
-c clear the directory stack by deleting all of the elements
|
||||||
|
-l do not print tilde-prefixed versions of directories relative
|
||||||
|
to your home directory
|
||||||
|
-p print the directory stack with one entry per line
|
||||||
|
-v print the directory stack with one entry per line prefixed
|
||||||
|
with its position in the stack
|
||||||
|
|
||||||
|
Arguments:
|
||||||
|
+N Displays the Nth entry counting from the left of the list
|
||||||
|
shown by dirs when invoked without options, starting with
|
||||||
|
zero.
|
||||||
|
|
||||||
|
-N Displays the Nth entry counting from the right of the list
|
||||||
|
shown by dirs when invoked without options, starting with
|
||||||
|
zero.
|
||||||
|
|
||||||
|
Exit Status:
|
||||||
|
Returns success unless an invalid option is supplied or an error occurs.
|
||||||
|
```
|
||||||
|
|
||||||
|
内置命令提供了每个 shell 的大部分功能。你使用的任何 shell 都有一些内置命令,但是如何获取这些内置命令的信息可能因 shell 而异。例如,对于 `zsh`,你可以使用 `man zshbuiltins` 命令获得其内置命令的描述。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ man zshbuiltins
|
||||||
|
|
||||||
|
ZSHBUILTINS(1) General Commands Manual ZSHBUILTINS(1)
|
||||||
|
|
||||||
|
NAME
|
||||||
|
zshbuiltins - zsh built-in commands
|
||||||
|
|
||||||
|
SHELL BUILTIN COMMANDS
|
||||||
|
Some shell builtin commands take options as described in individual en‐
|
||||||
|
tries; these are often referred to in the list below as `flags' to avoid
|
||||||
|
confusion with shell options, which may also have an effect on the behav‐
|
||||||
|
iour of builtin commands. In this introductory section, `option' always
|
||||||
|
has the meaning of an option to a command that should be familiar to most
|
||||||
|
command line users.
|
||||||
|
…
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个冗长的手册页中,你将找到一个内置命令列表,其中包含有用的描述,如下摘录中所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
bg [ job ... ]
|
||||||
|
job ... &
|
||||||
|
Put each specified job in the background, or the current job if
|
||||||
|
none is specified.
|
||||||
|
|
||||||
|
bindkey
|
||||||
|
See the section `Zle Builtins' in zshzle(1).
|
||||||
|
|
||||||
|
break [ n ]
|
||||||
|
Exit from an enclosing for, while, until, select or repeat loop.
|
||||||
|
If an arithmetic expression n is specified, then break n levels
|
||||||
|
instead of just one.
|
||||||
|
```
|
||||||
|
|
||||||
|
### 最后
|
||||||
|
|
||||||
|
Linux 内置命令对于每个 shell 都很重要,它的操作类似特定于 shell 的命令一样。如果你经常使用不同的 shell,并注意到你经常使用的某些命令似乎不存在或者不能按预期工作,那么它可能是你使用的其他 shell 之一中的内置命令。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.networkworld.com/article/3410350/getting-help-for-linux-shell-built-ins.html
|
||||||
|
|
||||||
|
作者:[Sandra Henry-Stocker][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[MjSeven](https://github.com/MjSeven)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://images.idgesg.net/images/article/2019/07/linux_penguin-100802549-large.jpg
|
||||||
|
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||||
|
[3]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||||
|
[4]: https://www.facebook.com/NetworkWorld/
|
||||||
|
[5]: https://www.linkedin.com/company/network-world
|
||||||
@ -0,0 +1,112 @@
|
|||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "hello-wn"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-11156-1.html"
|
||||||
|
[#]: subject: "How to Create a User Account Without useradd Command in Linux?"
|
||||||
|
[#]: via: "https://www.2daygeek.com/linux-user-account-creation-in-manual-method/"
|
||||||
|
[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
|
||||||
|
|
||||||
|
在 Linux 中不使用 useradd 命令如何创建用户账号
|
||||||
|
========
|
||||||
|
|
||||||
|
Linux 中有三个命令可以用来创建用户账号。你尝试过在 Linux 中手动创建用户吗?我的意思是不使用上面说的三个命令。
|
||||||
|
|
||||||
|
如果你不知道怎么做,本文可以手把手教你,并向你展示细节部分。
|
||||||
|
|
||||||
|
你可能想,这怎么可能?别担心,正如我们多次提到的那样,在 Linux 上任何事都可以搞定。这只是其中一例。
|
||||||
|
|
||||||
|
是的,我们可以做到的。想了解更多吗?
|
||||||
|
|
||||||
|
- [在 Linux 中创建用户的三种方法][1]
|
||||||
|
- [在 Linux 中批量创建用户的两种方法][2]
|
||||||
|
|
||||||
|
话不多说,让我们开始吧。
|
||||||
|
|
||||||
|
首先,我们要找出最后创建的 UID 和 GID 信息。 掌握了这些信息之后,就可以继续下一步。
|
||||||
|
|
||||||
|
```
|
||||||
|
# cat /etc/passwd | tail -1
|
||||||
|
tuser1:x:1153:1154:Test User:/home/tuser1:/bin/bash
|
||||||
|
```
|
||||||
|
|
||||||
|
根据以上输出,最后创建的用户 UID 是 1153,GID 是 1154。为了试验,我们将在系统中添加 `tuser2` 用户。
|
||||||
|
|
||||||
|
现在,在`/etc/passwd` 文件中添加一条用户信息。 总共七个字段,你需要添加一些必要信息。
|
||||||
|
|
||||||
|
```
|
||||||
|
+-----------------------------------------------------------------------+
|
||||||
|
|username:password:UID:GID:Comments:User Home Directory:User Login Shell|
|
||||||
|
+-----------------------------------------------------------------------+
|
||||||
|
| | | | | | |
|
||||||
|
1 2 3 4 5 6 7
|
||||||
|
```
|
||||||
|
|
||||||
|
1. 用户名:这个字段表示用户名称。字符长度必须在 1 到 32 之间。
|
||||||
|
2. 密码(`x`):表示存储在 `/etc/shadow` 文件中的加密密码。
|
||||||
|
3. 用户 ID:表示用户的 ID(UID),每个用户都有独一无二的 UID。UID 0 保留给 root 用户,UID 1-99 保留给系统用户,UID 100-999 保留给系统账号/组。
|
||||||
|
4. 组 ID:表示用户组的 ID(GID),每个用户组都有独一无二的 GID,存储在 `/etc/group` 文件中。
|
||||||
|
5. 注释/用户 ID 信息:这个字段表示备注,用于描述用户信息。
|
||||||
|
6. 主目录(`/home/$USER`):表示用户的主目录。
|
||||||
|
7. shell(`/bin/bash`):表示用户使用的 shell。
|
||||||
|
|
||||||
|
在文件最后添加用户信息。
|
||||||
|
|
||||||
|
```
|
||||||
|
# vi /etc/passwd
|
||||||
|
|
||||||
|
tuser2:x:1154:1155:Test User2:/home/tuser2:/bin/bash
|
||||||
|
```
|
||||||
|
|
||||||
|
你需要创建相同名字的用户组。同样地,在 `/etc/group` 文件中添加用户组信息。
|
||||||
|
|
||||||
|
```
|
||||||
|
# vi /etc/group
|
||||||
|
|
||||||
|
tuser2:x:1155:
|
||||||
|
```
|
||||||
|
|
||||||
|
做完以上两步之后,给用户设置一个密码。
|
||||||
|
|
||||||
|
```
|
||||||
|
# passwd tuser2
|
||||||
|
|
||||||
|
Changing password for user tuser2.
|
||||||
|
New password:
|
||||||
|
Retype new password:
|
||||||
|
passwd: all authentication tokens updated successfully.
|
||||||
|
```
|
||||||
|
|
||||||
|
最后,试着登录新创建的用户。
|
||||||
|
|
||||||
|
```
|
||||||
|
# ssh [email protected]
|
||||||
|
|
||||||
|
[email protected]'s password:
|
||||||
|
Creating directory '/home/tuser2'.
|
||||||
|
|
||||||
|
$ls -la
|
||||||
|
|
||||||
|
total 16
|
||||||
|
drwx------. 2 tuser2 tuser2 59 Jun 17 09:46 .
|
||||||
|
drwxr-xr-x. 15 root root 4096 Jun 17 09:46 ..
|
||||||
|
-rw-------. 1 tuser2 tuser2 18 Jun 17 09:46 .bash_logout
|
||||||
|
-rw-------. 1 tuser2 tuser2 193 Jun 17 09:46 .bash_profile
|
||||||
|
-rw-------. 1 tuser2 tuser2 231 Jun 17 09:46 .bashrc
|
||||||
|
```
|
||||||
|
|
||||||
|
------
|
||||||
|
|
||||||
|
via: https://www.2daygeek.com/linux-user-account-creation-in-manual-method/
|
||||||
|
|
||||||
|
作者:[Magesh Maruthamuthu][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[hello-wn](https://github.com/hello-wn)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.2daygeek.com/author/magesh/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.2daygeek.com/linux-user-account-creation-useradd-adduser-newusers/
|
||||||
|
[2]: https://www.2daygeek.com/linux-bulk-users-creation-useradd-newusers/
|
||||||
328
published/201907/20190724 Master the Linux -ls- command.md
Normal file
328
published/201907/20190724 Master the Linux -ls- command.md
Normal file
@ -0,0 +1,328 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11159-1.html)
|
||||||
|
[#]: subject: (Master the Linux 'ls' command)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/master-ls-command)
|
||||||
|
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||||
|
|
||||||
|
精通 Linux 的 ls 命令
|
||||||
|
======
|
||||||
|
|
||||||
|
> Linux 的 ls 命令拥有数量惊人的选项,可以提供有关文件的重要信息。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
`ls` 命令可以列出一个 [POSIX][2] 系统上的文件。这是一个简单的命令,但它经常被低估,不是它能做什么(因为它确实只做了一件事),而是你该如何优化对它的使用。
|
||||||
|
|
||||||
|
要知道在最重要的 10 个终端命令中,这个简单的 `ls` 命令可以排进前三,因为 `ls` 不会*只是*列出文件,它还会告诉你有关它们的重要信息。它会告诉你诸如拥有文件或目录的人、每个文件修改的时间、甚至是什么类型的文件。它的附带功能能让你了解你在哪里、附近有些什么,以及你可以用它们做什么。
|
||||||
|
|
||||||
|
如果你对 `ls` 的体验仅限于你的发行版在 `.bashrc` 中的别名,那么你可能错失了它。
|
||||||
|
|
||||||
|
### GNU 还是 BSD?
|
||||||
|
|
||||||
|
在了解 `ls` 的隐藏能力之前,你必须确定你正在运行哪个 `ls` 命令。有两个最流行的版本:包含在 GNU coreutils 包中的 GNU 版本,以及 BSD 版本。如果你正在运行 Linux,那么你很可能已经安装了 GNU 版本的 `ls`(LCTT 译注:几乎可以完全确定)。如果你正在运行 BSD 或 MacOS,那么你有的是 BSD 版本。本文会介绍它们的不同之处。
|
||||||
|
|
||||||
|
你可以使用 `--version` 选项找出你计算机上的版本:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls --version
|
||||||
|
```
|
||||||
|
|
||||||
|
如果它返回有关 GNU coreutils 的信息,那么你拥有的是 GNU 版本。如果它返回一个错误,你可能正在运行的是 BSD 版本(运行 `man ls | head` 以确定)。
|
||||||
|
|
||||||
|
你还应该调查你的发行版可能具有哪些预设选项。终端命令的自定义通常放在 `$HOME/.bashrc` 或 `$HOME/.bash_aliases` 或 `$HOME/.profile` 中,它们是通过将 `ls` 别名化为更复杂的 `ls` 命令来完成的。例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
alias ls='ls --color'
|
||||||
|
```
|
||||||
|
|
||||||
|
发行版提供的预设非常有用,但它们确实很难分辨出哪些是 `ls` 本身的特性,哪些是它的附加选项提供的。你要是想要运行 `ls` 命令本身而不是它的别名,你可以用反斜杠“转义”命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ \ls
|
||||||
|
```
|
||||||
|
|
||||||
|
### 分类
|
||||||
|
|
||||||
|
单独运行 `ls` 会以适合你终端的列数列出文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls ~/example
|
||||||
|
bunko jdk-10.0.2
|
||||||
|
chapterize otf2ttf.ff
|
||||||
|
despacer overtar.sh
|
||||||
|
estimate.sh pandoc-2.7.1
|
||||||
|
fop-2.3 safe_yaml
|
||||||
|
games tt
|
||||||
|
```
|
||||||
|
|
||||||
|
这是有用的信息,但所有这些文件看起来基本相同,没有方便的图标来快速表示出哪个是目录、文本文件或图像等等。
|
||||||
|
|
||||||
|
使用 `-F`(或 GNU 上的长选项 `--classify`)以在每个条目之后显示标识文件类型的指示符:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls ~/example
|
||||||
|
bunko jdk-10.0.2/
|
||||||
|
chapterize* otf2ttf.ff*
|
||||||
|
despacer* overtar.sh*
|
||||||
|
estimate.sh pandoc@
|
||||||
|
fop-2.3/ pandoc-2.7.1/
|
||||||
|
games/ tt*
|
||||||
|
```
|
||||||
|
|
||||||
|
使用此选项,终端中列出的项目使用简写符号来按文件类型分类:
|
||||||
|
|
||||||
|
* 斜杠(`/`)表示目录(或“文件夹”)。
|
||||||
|
* 星号(`*`)表示可执行文件。这包括二进制文件(编译代码)以及脚本(具有[可执行权限][3]的文本文件)。
|
||||||
|
* 符号(`@`)表示符号链接(或“别名”)。
|
||||||
|
* 等号(`=`)表示套接字。
|
||||||
|
* 在 BSD 上,百分号(`%`)表示<ruby>涂改<rt>whiteout</rt></ruby>(某些文件系统上的文件删除方法)。
|
||||||
|
* 在 GNU 上,尖括号(`>`)表示<ruby>门<rt>door</rt></ruby>([Illumos][4] 和 Solaris上的进程间通信)。
|
||||||
|
* 竖线(`|`)表示 [FIFO][5] 管道。
|
||||||
|
|
||||||
|
这个选项的一个更简单的版本是 `-p`,它只区分文件和目录。
|
||||||
|
|
||||||
|
(LCTT 译注:在支持彩色的终端上,使用 `--color` 选项可以以不同的颜色来区分文件类型,但要注意如果将输出导入到管道中,则颜色消失。)
|
||||||
|
|
||||||
|
### 长列表
|
||||||
|
|
||||||
|
从 `ls` 获取“长列表”的做法是如此常见,以至于许多发行版将 `ll` 别名为 `ls -l`。长列表提供了许多重要的文件属性,例如权限、拥有每个文件的用户、文件所属的组、文件大小(以字节为单位)以及文件上次更改的日期:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls -l
|
||||||
|
-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
|
||||||
|
-rwxrwxr-x. 1 seth users 662 Apr 29 22:27 factorial
|
||||||
|
-rwxrwx---. 1 seth users 20697793 Jun 29 2018 fop-2.3-bin.tar.gz
|
||||||
|
-rwxrwxr-x. 1 seth users 6210 May 22 10:22 geteltorito
|
||||||
|
-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
|
||||||
|
[...]
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你不想以字节为单位,请添加 `-h` 标志(或 GNU 中的 `--human`)以将文件大小转换为更加人性化的表示方法:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls --human
|
||||||
|
-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
|
||||||
|
-rwxrwxr-x. 1 seth seth 662 Apr 29 22:27 factorial
|
||||||
|
-rwxrwx---. 1 seth users 20M Jun 29 2018 fop-2.3-bin.tar.gz
|
||||||
|
-rwxrwxr-x. 1 seth seth 6.1K May 22 10:22 geteltorito
|
||||||
|
-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
要看到更少的信息,你可以带有 `-o` 选项只显示所有者的列,或带有 `-g` 选项只显示所属组的列:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls -o
|
||||||
|
-rwxrwx---. 1 seth 455 Mar 2 2017 estimate.sh
|
||||||
|
-rwxrwxr-x. 1 seth 662 Apr 29 22:27 factorial
|
||||||
|
-rwxrwx---. 1 seth 20M Jun 29 2018 fop-2.3-bin.tar.gz
|
||||||
|
-rwxrwxr-x. 1 seth 6.1K May 22 10:22 geteltorito
|
||||||
|
-rwxrwx---. 1 seth 177 Nov 12 2018 html4mutt.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
也可以将两个选项组合使用以显示两者。
|
||||||
|
|
||||||
|
### 时间和日期格式
|
||||||
|
|
||||||
|
`ls` 的长列表格式通常如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
|
||||||
|
-rwxrwxr-x. 1 seth users 662 Apr 29 22:27 factorial
|
||||||
|
-rwxrwx---. 1 seth users 20697793 Jun 29 2018 fop-2.3-bin.tar.gz
|
||||||
|
-rwxrwxr-x. 1 seth users 6210 May 22 10:22 geteltorito
|
||||||
|
-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
月份的名字不便于排序,无论是通过计算还是识别(取决于你的大脑是否倾向于喜欢字符串或整数)。你可以使用 `--time-style` 选项和格式名称更改时间戳的格式。可用格式为:
|
||||||
|
|
||||||
|
* `full-iso`:ISO 完整格式(1970-01-01 21:12:00)
|
||||||
|
* `long-iso`:ISO 长格式(1970-01-01 21:12)
|
||||||
|
* `iso`:iso 格式(01-01 21:12)
|
||||||
|
* `locale`:本地化格式(使用你的区域设置)
|
||||||
|
* `posix-STYLE`:POSIX 风格(用区域设置定义替换 `STYLE`)
|
||||||
|
|
||||||
|
你还可以使用 `date` 命令的正式表示法创建自定义样式。
|
||||||
|
|
||||||
|
### 按时间排序
|
||||||
|
|
||||||
|
通常,`ls` 命令按字母顺序排序。你可以使用 `-t` 选项根据文件的最近更改的时间(最新的文件最先列出)进行排序。
|
||||||
|
|
||||||
|
例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ touch foo bar baz
|
||||||
|
$ ls
|
||||||
|
bar baz foo
|
||||||
|
$ touch foo
|
||||||
|
$ ls -t
|
||||||
|
foo bar baz
|
||||||
|
```
|
||||||
|
|
||||||
|
### 列出方式
|
||||||
|
|
||||||
|
`ls` 的标准输出平衡了可读性和空间效率,但有时你需要按照特定方式排列的文件列表。
|
||||||
|
|
||||||
|
要以逗号分隔文件列表,请使用 `-m`:
|
||||||
|
|
||||||
|
```
|
||||||
|
ls -m ~/example
|
||||||
|
bar, baz, foo
|
||||||
|
```
|
||||||
|
|
||||||
|
要强制每行一个文件,请使用 `-1` 选项(这是数字 1,而不是小写的 L):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls -1 ~/bin/
|
||||||
|
bar
|
||||||
|
baz
|
||||||
|
foo
|
||||||
|
```
|
||||||
|
|
||||||
|
要按文件扩展名而不是文件名对条目进行排序,请使用 `-X`(这是大写 X):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls
|
||||||
|
bar.xfc baz.txt foo.asc
|
||||||
|
$ ls -X
|
||||||
|
foo.asc baz.txt bar.xfc
|
||||||
|
```
|
||||||
|
|
||||||
|
### 隐藏杂项
|
||||||
|
|
||||||
|
在某些 `ls` 列表中有一些你可能不关心的条目。例如,元字符 `.` 和 `..` 分别代表“本目录”和“父目录”。如果你熟悉在终端中如何切换目录,你可能已经知道每个目录都将自己称为 `.`,并将其父目录称为 `..`,因此当你使用 `-a` 选项显示隐藏文件时并不需要它经常提醒你。
|
||||||
|
|
||||||
|
要显示几乎所有隐藏文件(`.` 和 `..` 除外),请使用 `-A` 选项:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls -a
|
||||||
|
.
|
||||||
|
..
|
||||||
|
.android
|
||||||
|
.atom
|
||||||
|
.bash_aliases
|
||||||
|
[...]
|
||||||
|
$ ls -A
|
||||||
|
.android
|
||||||
|
.atom
|
||||||
|
.bash_aliases
|
||||||
|
[...]
|
||||||
|
```
|
||||||
|
|
||||||
|
有许多优秀的 Unix 工具有保存备份文件的传统,它们会在保存文件的名称后附加一些特殊字符作为备份文件。例如,在 Vim 中,备份会以在文件名后附加 `~` 字符的文件名保存。
|
||||||
|
|
||||||
|
这些类型的备份文件已经多次使我免于愚蠢的错误,但是经过多年享受它们提供的安全感后,我觉得不需要用视觉证据来证明它们存在。我相信 Linux 应用程序可以生成备份文件(如果它们声称这样做的话),我很乐意相信它们存在 —— 而不用必须看到它们。
|
||||||
|
|
||||||
|
要隐藏备份文件,请使用 `-B` 或 `--ignore-backups` 隐藏常用备份格式(此选项在 BSD 的 `ls` 中不可用):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls
|
||||||
|
bar.xfc baz.txt foo.asc~ foo.asc
|
||||||
|
$ ls -B
|
||||||
|
bar.xfc baz.txt foo.asc
|
||||||
|
```
|
||||||
|
|
||||||
|
当然,备份文件仍然存在;它只是过滤掉了,你不必看到它。
|
||||||
|
|
||||||
|
除非另有配置,GNU Emacs 在文件名的开头和结尾添加哈希字符(`#`)来保存备份文件(`#file#`)。其他应用程序可能使用不同的样式。使用什么模式并不重要,因为你可以使用 `--hide` 选项创建自己的排除项:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls
|
||||||
|
bar.xfc baz.txt #foo.asc# foo.asc
|
||||||
|
$ ls --hide="#*#"
|
||||||
|
bar.xfc baz.txt foo.asc
|
||||||
|
```
|
||||||
|
|
||||||
|
### 递归地列出目录
|
||||||
|
|
||||||
|
除非你在指定目录上运行 `ls`,否则子目录的内容不会与 `ls` 命令一起列出:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls -F
|
||||||
|
example/ quux* xyz.txt
|
||||||
|
$ ls -R
|
||||||
|
quux xyz.txt
|
||||||
|
|
||||||
|
./example:
|
||||||
|
bar.xfc baz.txt #foo.asc# foo.asc
|
||||||
|
```
|
||||||
|
|
||||||
|
### 使用别名使其永久化
|
||||||
|
|
||||||
|
`ls` 命令可能是 shell 会话期间最常使用的命令。这是你的眼睛和耳朵,为你提供上下文信息和确认命令的结果。虽然有很多选项很有用,但 `ls` 之美的一部分就是简洁:两个字符和回车键,你就知道你到底在哪里以及附近有什么。如果你不得不停下思考(更不用说输入)几个不同的选项,它会变得不那么方便,所以通常情况下,即使最有用的选项也不会用了。
|
||||||
|
|
||||||
|
解决方案是为你的 `ls` 命令添加别名,以便在使用它时,你可以获得最关心的信息。
|
||||||
|
|
||||||
|
要在 Bash shell 中为命令创建别名,请在主目录中创建名为 `.bash_aliases` 的文件(必须在开头包含 `.`)。 在此文件中,列出要创建的别名,然后是要为其创建别名的命令。例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
alias ls='ls -A -F -B --human --color'
|
||||||
|
```
|
||||||
|
|
||||||
|
这一行导致你的 Bash shell 将 `ls` 命令解释为 `ls -A -F -B --human --color`。
|
||||||
|
|
||||||
|
你不必仅限于重新定义现有命令,还可以创建自己的别名:
|
||||||
|
|
||||||
|
```
|
||||||
|
alias ll='ls -l'
|
||||||
|
alias la='ls -A'
|
||||||
|
alias lh='ls -h'
|
||||||
|
```
|
||||||
|
|
||||||
|
要使别名起作用,shell 必须知道 `.bash_aliases` 配置文件存在。在编辑器中打开 `.bashrc` 文件(如果它不存在则创建它),并包含以下代码块:
|
||||||
|
|
||||||
|
```
|
||||||
|
if [ -e $HOME/.bash_aliases ]; then
|
||||||
|
source $HOME/.bash_aliases
|
||||||
|
fi
|
||||||
|
```
|
||||||
|
|
||||||
|
每次加载 `.bashrc`(这是一个新的 Bash shell 启动的时候),Bash 会将 `.bash_aliases` 加载到你的环境中。你可以关闭并重新启动 Bash 会话,或者直接强制它执行此操作:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ source ~/.bashrc
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你忘了你是否有别名命令,`which` 命令可以告诉你:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ which ls
|
||||||
|
alias ls='ls -A -F -B --human --color'
|
||||||
|
/usr/bin/ls
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你将 `ls` 命令别名为带有选项的 `ls` 命令,则可以通过将反斜杠前缀到 `ls` 前来覆盖你的别名。例如,在示例别名中,使用 `-B` 选项隐藏备份文件,这意味着无法使用 `ls` 命令显示备份文件。 可以覆盖该别名以查看备份文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls
|
||||||
|
bar baz foo
|
||||||
|
$ \ls
|
||||||
|
bar baz baz~ foo
|
||||||
|
```
|
||||||
|
|
||||||
|
### 做一件事,把它做好
|
||||||
|
|
||||||
|
`ls` 命令有很多选项,其中许多是特定用途的或高度依赖于你所使用的终端。在 GNU 系统上查看 `info ls`,或在 GNU 或 BSD 系统上查看 `man ls` 以了解更多选项。
|
||||||
|
|
||||||
|
你可能会觉得奇怪的是,一个以每个工具“做一件事,把它做好”的前提而闻名的系统会让其最常见的命令背负 50 个选项。但是 `ls` 只做一件事:它列出文件,而这 50 个选项允许你控制接收列表的方式,`ls` 的这项工作做得非常、*非常*好。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/master-ls-command
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/sethhttps://opensource.com/users/sambocettahttps://opensource.com/users/scottnesbitthttps://opensource.com/users/sethhttps://opensource.com/users/marcobravohttps://opensource.com/users/sethhttps://opensource.com/users/don-watkinshttps://opensource.com/users/sethhttps://opensource.com/users/jamesfhttps://opensource.com/users/seth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
|
||||||
|
[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||||
|
[3]: https://opensource.com/article/19/6/understanding-linux-permissions
|
||||||
|
[4]: https://www.illumos.org/
|
||||||
|
[5]: https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)
|
||||||
@ -0,0 +1,105 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11170-1.html)
|
||||||
|
[#]: subject: (WPS Office on Linux is a Free Alternative to Microsoft Office)
|
||||||
|
[#]: via: (https://itsfoss.com/wps-office-linux/)
|
||||||
|
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||||
|
|
||||||
|
WPS Office:Linux 上的 Microsoft Office 的免费替代品
|
||||||
|
======
|
||||||
|
|
||||||
|
> 如果你在寻找 Linux 上 Microsoft Office 免费替代品,那么 WPS Office 是最佳选择之一。它可以免费使用,并兼容 MS Office 文档格式。
|
||||||
|
|
||||||
|
[WPS Office][1] 是一个跨平台的办公生产力套件。它轻巧,并且与 Microsoft Office、Google Docs/Sheets/Slide 和 Adobe PDF 完全兼容。
|
||||||
|
|
||||||
|
对于许多用户而言,WPS Office 足够直观,并且能够满足他们的需求。由于它在外观和兼容性方面与 Microsoft Office 非常相似,因此广受欢迎。
|
||||||
|
|
||||||
|
![WPS Office 2019 All In One Mode][2]
|
||||||
|
|
||||||
|
WPS office 由中国的金山公司创建。对于 Windows 用户而言,WPS Office 有免费版和高级版。对于 Linux 用户,WPS Office 可通过其[社区项目][3]免费获得。
|
||||||
|
|
||||||
|
> **非 FOSS 警告!**
|
||||||
|
|
||||||
|
> WPS Office 不是一个开源软件。因为它对于 Linux 用户免费使用,我们已经在这介绍过它,有时我们也会介绍即使不是开源的 Linux 软件。
|
||||||
|
|
||||||
|
### Linux 上的 WPS Office
|
||||||
|
|
||||||
|
![WPS Office in Linux | Image Credit: Ubuntu Handbook][4]
|
||||||
|
|
||||||
|
WPS Office 有四个主要组件:
|
||||||
|
|
||||||
|
* WPS 文字
|
||||||
|
* WPS 演示
|
||||||
|
* WPS 表格
|
||||||
|
* WPS PDF
|
||||||
|
|
||||||
|
WPS Office 与 MS Office 完全兼容,支持 .doc、.docx、.dotx、.ppt、.pptx、.xls、.xlsx、.docm、.dotm、.xml、.txt、.html、.rtf (等其他),以及它自己的格式(.wps、.wpt)。它还默认包含 Microsoft 字体(以确保兼容性),它可以导出 PDF 并提供超过 10 种语言的拼写检查功能。
|
||||||
|
|
||||||
|
但是,它在 ODT、ODP 和其他开放文档格式方面表现不佳。
|
||||||
|
|
||||||
|
三个主要的 WPS Office 应用都有与 Microsoft Office 非常相似的界面,都有相同的 Ribbon UI。尽管存在细微差别,但使用习惯仍然相对一致。你可以使用 WPS Office 轻松克隆任何 Microsoft Office/LibreOffice 文档。
|
||||||
|
|
||||||
|
![WPS Office Writer][5]
|
||||||
|
|
||||||
|
你可能唯一不喜欢的是一些默认的样式设置(一些标题下面有很多空间等),但这些可以很容易地调整。
|
||||||
|
|
||||||
|
默认情况下,WPS 以 .docx、.pptx 和 .xlsx 文件类型保存文件。你还可以将文档保存到 **[WPS 云][7]**中并与他人协作。另一个不错的功能是能从[这里][8]下载大量模板。
|
||||||
|
|
||||||
|
### 在 Linux 上安装 WPS Office
|
||||||
|
|
||||||
|
WPS 为 Linux 发行版提供 DEB 和 RPM 安装程序。如果你使用的是 Debian/Ubuntu 或基于 Fedora 的发行版,那么安装 WPS Office 就简单了。
|
||||||
|
|
||||||
|
你可以在下载区那下载 Linux 中的 WPS:
|
||||||
|
|
||||||
|
- [下载 WPS Office for Linux][9]
|
||||||
|
|
||||||
|
向下滚动,你将看到最新版本包的链接:
|
||||||
|
|
||||||
|
![WPS Office Download][10]
|
||||||
|
|
||||||
|
下载适合你发行版的文件。只需双击 DEB 或者 RPM 就能[安装它们][11]。这会打开软件中心,你将看到安装选项:
|
||||||
|
|
||||||
|
![WPS Office Install Package][12]
|
||||||
|
|
||||||
|
几秒钟后,应用应该成功安装到你的系统上了!
|
||||||
|
|
||||||
|
你现在可以在“应用程序”菜单中搜索 **WPS**,查找 WPS Office 套件中所有的应用:
|
||||||
|
|
||||||
|
![WPS Applications Menu][13]
|
||||||
|
|
||||||
|
### 你是否使用 WPS Office 或其他软件?
|
||||||
|
|
||||||
|
还有其他 [Microsoft Office 的开源替代方案][14],但它们与 MS Office 的兼容性很差。
|
||||||
|
|
||||||
|
就个人而言,我更喜欢 LibreOffice,但如果你必须要用到 Microsoft Office,你可以尝试在 Linux 上使用 WPS Office。它看起来和 MS Office 类似,并且与 MS 文档格式具有良好的兼容性。它在 Linux 上是免费的,因此你也不必担心 Office 365 订阅。
|
||||||
|
|
||||||
|
你在系统上使用什么办公套件?你曾经在 Linux 上使用过 WPS Office 吗?你的体验如何?
|
||||||
|
|
||||||
|
----------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/wps-office-linux/
|
||||||
|
|
||||||
|
作者:[Sergiu][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/sergiu/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.wps.com/
|
||||||
|
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps2019-all-in-one-mode.png?resize=800%2C526&ssl=1
|
||||||
|
[3]: http://wps-community.org/
|
||||||
|
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps-2019-Linux.jpg?resize=800%2C450&ssl=1
|
||||||
|
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps-office-writer.png?resize=800%2C454&ssl=1
|
||||||
|
[7]: https://account.wps.com/?cb=https%3A%2F%2Fdrive.wps.com%2F
|
||||||
|
[8]: https://template.wps.com/
|
||||||
|
[9]: http://wps-community.org/downloads
|
||||||
|
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_office_download.jpg?fit=800%2C413&ssl=1
|
||||||
|
[11]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||||
|
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_office_install_package.png?fit=800%2C719&ssl=1
|
||||||
|
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_applications_menu.jpg?fit=800%2C355&ssl=1
|
||||||
|
[14]: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||||
@ -0,0 +1,141 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11152-1.html)
|
||||||
|
[#]: subject: (How to Enable Canonical Kernel Livepatch Service on Ubuntu LTS System?)
|
||||||
|
[#]: via: (https://www.2daygeek.com/enable-canonical-kernel-livepatch-service-on-ubuntu-lts-system/)
|
||||||
|
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||||
|
|
||||||
|
如何在 Ubuntu LTS 系统上启用 Canonical 的内核实时补丁服务
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Canonical 在 Ubuntu 14.04 LTS 系统中引入了<ruby>内核实时补丁服务<rt>Kernel Livepatch Service</rt></ruby>。实时补丁服务允许你安装和应用关键的 Linux 内核安全更新,而无需重新启动系统。这意味着,在应用内核补丁程序后,你无需重新启动系统。而通常情况下,我们需要在安装内核补丁后重启 Linux 服务器才能供系统使用。
|
||||||
|
|
||||||
|
实时修补非常快。大多数内核修复程序只需要几秒钟。Canonical 的实时补丁服务对于不超过 3 个系统的用户无需任何费用。你可以通过命令行在桌面和服务器中启用 Canonical 实时补丁服务。
|
||||||
|
|
||||||
|
这个实时补丁系统旨在解决高级和关键的 Linux 内核安全漏洞。
|
||||||
|
|
||||||
|
有关[支持的系统][1]和其他详细信息,请参阅下表。
|
||||||
|
|
||||||
|
Ubuntu 版本 | 架构 | 内核版本 | 内核变体
|
||||||
|
---|---|---|---
|
||||||
|
Ubuntu 18.04 LTS | 64-bit x86 | 4.15 | 仅 GA 通用和低电压内核
|
||||||
|
Ubuntu 16.04 LTS | 64-bit x86 | 4.4 | 仅 GA 通用和低电压内核
|
||||||
|
Ubuntu 14.04 LTS | 64-bit x86 | 4.4 | 仅 Hardware Enablement 内核
|
||||||
|
|
||||||
|
**注意**:Ubuntu 14.04 中的 Canonical 实时补丁服务 LTS 要求用户在 Trusty 中运行 Ubuntu v4.4 内核。如果你当前没有运行使用该服务,请重新启动到此内核。
|
||||||
|
|
||||||
|
为此,请按照以下步骤操作。
|
||||||
|
|
||||||
|
### 如何获取实时补丁令牌?
|
||||||
|
|
||||||
|
导航到 [Canonical 实时补丁服务页面][2],如果要使用免费服务,请选择“Ubuntu 用户”。它适用于不超过 3 个系统的用户。如果你是 “UA 客户” 或多于 3 个系统,请选择 “Ubuntu customer”。最后,单击 “Get your Livepatch token” 按钮。
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
确保你已经在 “Ubuntu One” 中拥有帐号。否则,可以创建一个新的。
|
||||||
|
|
||||||
|
登录后,你将获得你的帐户密钥。
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
### 在系统中安装 Snap 守护程序
|
||||||
|
|
||||||
|
实时补丁系统通过快照包安装。因此,请确保在 Ubuntu 系统上安装了 snapd 守护程序。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt update
|
||||||
|
$ sudo apt install snapd
|
||||||
|
```
|
||||||
|
|
||||||
|
### 如何系统中安装和配置实时补丁服务?
|
||||||
|
|
||||||
|
通过运行以下命令安装 `canonical-livepatch` 守护程序。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo snap install canonical-livepatch
|
||||||
|
canonical-livepatch 9.4.1 from Canonical* installed
|
||||||
|
```
|
||||||
|
|
||||||
|
运行以下命令以在 Ubuntu 计算机上启用实时内核补丁程序。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo canonical-livepatch enable xxxxc4xxxx67xxxxbxxxxbxxxxfbxx4e
|
||||||
|
|
||||||
|
Successfully enabled device. Using machine-token: xxxxc4xxxx67xxxxbxxxxbxxxxfbxx4e
|
||||||
|
```
|
||||||
|
|
||||||
|
运行以下命令查看实时补丁机器的状态。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo canonical-livepatch status
|
||||||
|
|
||||||
|
client-version: 9.4.1
|
||||||
|
architecture: x86_64
|
||||||
|
cpu-model: Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
|
||||||
|
last-check: 2019-07-24T12:30:04+05:30
|
||||||
|
boot-time: 2019-07-24T12:11:06+05:30
|
||||||
|
uptime: 19m11s
|
||||||
|
status:
|
||||||
|
- kernel: 4.15.0-55.60-generic
|
||||||
|
running: true
|
||||||
|
livepatch:
|
||||||
|
checkState: checked
|
||||||
|
patchState: nothing-to-apply
|
||||||
|
version: ""
|
||||||
|
fixes: ""
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 `--verbose` 开关运行上述相同的命令,以获取有关实时修补机器的更多信息。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo canonical-livepatch status --verbose
|
||||||
|
```
|
||||||
|
|
||||||
|
如果要手动运行补丁程序,请执行以下命令。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo canonical-livepatch refresh
|
||||||
|
|
||||||
|
Before refresh:
|
||||||
|
|
||||||
|
kernel: 4.15.0-55.60-generic
|
||||||
|
fully-patched: true
|
||||||
|
version: ""
|
||||||
|
|
||||||
|
After refresh:
|
||||||
|
|
||||||
|
kernel: 4.15.0-55.60-generic
|
||||||
|
fully-patched: true
|
||||||
|
version: ""
|
||||||
|
```
|
||||||
|
|
||||||
|
`patchState` 会有以下状态之一:
|
||||||
|
|
||||||
|
* `applied`:未发现任何漏洞
|
||||||
|
* `nothing-to-apply`:成功找到并修补了漏洞
|
||||||
|
* `kernel-upgrade-required`:实时补丁服务无法安装补丁来修复漏洞
|
||||||
|
|
||||||
|
请注意,安装内核补丁与在系统上升级/安装新内核不同。如果安装了新内核,则必须重新引导系统以激活新内核。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.2daygeek.com/enable-canonical-kernel-livepatch-service-on-ubuntu-lts-system/
|
||||||
|
|
||||||
|
作者:[Magesh Maruthamuthu][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.2daygeek.com/author/magesh/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://wiki.ubuntu.com/Kernel/Livepatch
|
||||||
|
[2]: https://auth.livepatch.canonical.com/
|
||||||
|
[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||||
|
[4]: https://www.2daygeek.com/wp-content/uploads/2019/07/enable-canonical-livepatch-service-on-ubuntu-lts-system-1.jpg
|
||||||
|
[5]: https://www.2daygeek.com/wp-content/uploads/2019/07/enable-canonical-livepatch-service-on-ubuntu-lts-system-2.jpg
|
||||||
@ -0,0 +1,70 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11167-1.html)
|
||||||
|
[#]: subject: (Is This the End of Floppy Disk in Linux? Linus Torvalds Marks Floppy Disks ‘Orphaned’)
|
||||||
|
[#]: via: (https://itsfoss.com/end-of-floppy-disk-in-linux/)
|
||||||
|
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||||
|
|
||||||
|
Linux 中的软盘走向终结了吗?Torvalds 将软盘的驱动标记为“孤儿”
|
||||||
|
======
|
||||||
|
|
||||||
|
> 在 Linux 内核最近的提交当中,Linus Torvalds 将软盘的驱动程序标记为孤儿。这标志着软盘在 Linux 中步入结束了吗?
|
||||||
|
|
||||||
|
有可能你很多年没见过真正的软盘了。如果你正在寻找带软盘驱动器的计算机,可能需要去博物馆里看看。
|
||||||
|
|
||||||
|
在二十多年前,软盘是用于存储数据和运行操作系统的流行介质。[早期的 Linux 发行版][1]使用软盘进行“分发”。软盘也广泛用于保存和传输数据。
|
||||||
|
|
||||||
|
你有没有想过为什么许多应用程序中的保存图标看起来像软盘?因为它就是软盘啊!软盘常用于保存数据,因此许多应用程序将其用作保存图标,并且这个传统一直延续至今。
|
||||||
|
|
||||||
|
![][2]
|
||||||
|
|
||||||
|
今天我为什么要说起软盘?因为 Linus Torvalds 在一个 Linux 内核代码的提交里标记软盘的驱动程序为“孤儿”。
|
||||||
|
|
||||||
|
### 在 Linux 内核中被标记为“孤儿”的软盘驱动程序
|
||||||
|
|
||||||
|
正如你可以在 [GitHub 镜像上的提交][3]中看到的那样,开发人员 Jiri 不再使用带有软驱的工作计算机了。而如果没有正确的硬件,Jiri 将无法继续开发。这就是 Torvalds 将其标记为孤儿的原因。
|
||||||
|
|
||||||
|
> 越来越难以找到可以实际工作的软盘的物理硬件,虽然 Willy 能够对此进行测试,但我认为从实际的硬件角度来看,这个驱动程序几乎已经死了。目前仍然销售的硬件似乎主要是基于 USB 的,根本不使用这种传统的驱动器。
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
### “孤儿”在 Linux 内核中意味着什么?
|
||||||
|
|
||||||
|
“孤儿”意味着没有开发人员能够或愿意支持这部分代码。如果没有其他人出现继续维护和开发它,孤儿模块可能会被弃用并最终删除。
|
||||||
|
|
||||||
|
### 它没有被立即删除
|
||||||
|
|
||||||
|
Torvalds 指出,各种虚拟环境模拟器仍在使用软盘驱动器。所以软盘的驱动程序不会被立即丢弃。
|
||||||
|
|
||||||
|
> 各种 VM 环境中仍然在仿真旧的软盘控制器,因此该驱动程序不会消失,但让我们看看是否有人有兴趣进一步维护它。
|
||||||
|
|
||||||
|
为什么不永远保持内核中的软盘驱动器支持呢?因为这将构成安全威胁。即使没有真正的计算机使用软盘驱动程序,虚拟机仍然拥有它,这将使虚拟机容易受到攻击。
|
||||||
|
|
||||||
|
### 一个时代的终结?
|
||||||
|
|
||||||
|
这将是一个时代的结束还是会有其他人出现并承担起在 Linux 中继续维护软盘驱动程序的责任?只有时间会给出答案。
|
||||||
|
|
||||||
|
在 Linux 内核中,软盘驱动器成为孤儿我不觉得有什么可惜的。
|
||||||
|
|
||||||
|
在过去的十五年里我没有使用过软盘,我怀疑很多人也是如此。那么你呢?你有没有用过软盘?如果是的话,你最后一次使用它的时间是什么时候?
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/end-of-floppy-disk-in-linux/
|
||||||
|
|
||||||
|
作者:[Abhishek Prakash][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/abhishek/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://itsfoss.com/earliest-linux-distros/
|
||||||
|
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/floppy-disk-icon-of-saving.png?resize=800%2C300&ssl=1
|
||||||
|
[3]: https://github.com/torvalds/linux/commit/47d6a7607443ea43dbc4d0f371bf773540a8f8f4
|
||||||
|
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/End-of-Floppy-in-Linux.png?resize=800%2C450&ssl=1
|
||||||
|
[5]: https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||||
82
published/201907/20191110 What is DevSecOps.md
Normal file
82
published/201907/20191110 What is DevSecOps.md
Normal file
@ -0,0 +1,82 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (PandaWizard)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11102-1.html)
|
||||||
|
[#]: subject: (What is DevSecOps?)
|
||||||
|
[#]: via: (https://opensource.com/article/19/1/what-devsecops)
|
||||||
|
[#]: author: (Brett Hunoldt https://opensource.com/users/bretthunoldtcom)
|
||||||
|
|
||||||
|
什么是 DevSecOps?
|
||||||
|
======
|
||||||
|
|
||||||
|
> DevSecOps 的实践之旅开始于 DevSecOps 增权、赋能和培养。下面就介绍如何开始学习使用 DevSecOps。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> Stephen Streichsbier 说过: DevSecOps 使得组织可以用 DevOps 的速度发布内在安全的软件。
|
||||||
|
|
||||||
|
DevSecOps 是一场关于 DevOps 概念实践或艺术形式的变革。为了更好理解 DevSecOps,你应该首先理解 DevOps 的含义。
|
||||||
|
|
||||||
|
DevOps 起源于通过合并开发和运维实践,消除隔离,统一关注点,提升团队和产品的效率和性能。它是一种注重于构建容易维护和易于平常自动运营的产品和服务的新型协作方式。
|
||||||
|
|
||||||
|
安全在很多团队中都是常见的隔离点。安全的核心关注点是保护团队,而有时这也意味着创建延缓新服务或是新产品发布的障碍或策略,用于保障任何事都能被很好的理解和安全的执行,并且没有给团队带来不必要的风险。
|
||||||
|
|
||||||
|
因为安全隔离点方面的明显特征和它可能带来的摩擦,开发和运维有时会避开安全要求以满足客观情况。在一些公司,这种隔离形成了一种产品安全完全是安全团队责任的期望,并取决于安全团队去寻找产品的安全缺陷或是可能带来的问题。
|
||||||
|
|
||||||
|
DevSecOps 看起来是通过给开发或是运维角色加强或是建立安全意识,或是在产品团队中引入一个安全工程师角色,在产品设计中找到安全问题,从而把安全要求汇聚在 Devops 中。
|
||||||
|
|
||||||
|
这样使得公司能更快发布和更新产品,并且充分相信安全已经嵌入产品中。
|
||||||
|
|
||||||
|
### 坚固的软件哪里适用 DevSecOps?
|
||||||
|
|
||||||
|
建造坚固的软件是 DevOps 文化的一个层面而不是一个特别的实践,它完善和增强了 DevSecOps 实践。想想一款坚固的软件就像是某些经历过残酷战斗过程的事物。
|
||||||
|
|
||||||
|
有必要指出坚固的软件并不是 100% 安全可靠的(虽然它可能最终是在某些方面)。然而,它被设计成可以处理大部分被抛过来的问题。
|
||||||
|
|
||||||
|
践行坚固软件最重要的原则是促进竞争、实践、可控的失败与合作。
|
||||||
|
|
||||||
|
### 你该如何开始学习 DevSecOps ?
|
||||||
|
|
||||||
|
开始实践 DevSecOps 涉及提升安全需求和在开发过程中尽可能早的阶段进行实践。它最终在公司文化上提升了安全的重要性,使得安全成为所有人的责任,而并不只是安全团队的责任。
|
||||||
|
|
||||||
|
你可能在团队中听说过“<ruby>左上升<rt>shift left</rt></ruby>”这个词,如果你把开发周期线扁平化到一条横线上,以包括产品变革的的关键时期:从初始化到设计、建造、测试以及最终的运行,安全的目的就是尽早的参与进来。这使得风险可以在设计中能更好的评估、交流和减轻。“左提升”的含义是指促使安全能在开发周期线上更往左走。
|
||||||
|
|
||||||
|
这个过程始于三个关键要素:
|
||||||
|
|
||||||
|
* <ruby>增权<rt>empowerment</rt></ruby>
|
||||||
|
* <ruby>赋能<rt>enablement</rt></ruby>
|
||||||
|
* <ruby>培养<rt>education</rt></ruby>
|
||||||
|
|
||||||
|
增权,在我看来,是关于释放控制权以及使得团队(在理性分析下)做出独立决定而不用害怕失败或影响。这个过程的唯一告诫信息就是要严格的做出明智的决定(不要比这更低要求)。
|
||||||
|
|
||||||
|
为了实现增权,商务和行政支持(通过内部销售、展示来建立,通过建立矩阵来展示这项投资的回报)是打破历史障碍和割裂的团队的关键。合并安全人员到开发和运维团队中,提升交流和透明度有助于开始 DevSecOps 之旅。
|
||||||
|
|
||||||
|
这个整合和移动使得团队只关注单一的结果:打造一个他们共同负责的产品,让开发和安全人员相互依赖合作。这将引领你们共同走向增权。这是产品研发团队的共同责任,并保证每个可分割的产品都保持其安全性。
|
||||||
|
|
||||||
|
赋能涉及正确的使用掌握在团队手中的工具和资源。这是建立一种通过论坛、维基、信息聚合的知识分享文化。
|
||||||
|
|
||||||
|
打造一种注重自动化、重复任务应该编码来尽可能减少以后的操作并增强安全性的理念。这种场景不仅仅是提供知识,而是让这种知识能够通过多种渠道和媒介(通过某些工具)可获取,以便它可以被团队或是个人以他喜欢的方式去消化和分享。当团队成员正在编码时一种媒介可能工作的很好,而当他们在进行中时另一种可能更好。让工具简单可用,让团队用上它们。
|
||||||
|
|
||||||
|
不同的 DevSecOps 团队有不同的喜好,因此允许他们尽可能的保持独立。这是一个微妙的平衡工作,因为你确实希望实现规模经济和产品间共享的能力。在选择中协作和参与,并更新工具方法有助于减少使用中的障碍。
|
||||||
|
|
||||||
|
最后,也可能是最重要的,DevSecOps 是有关训练和兴趣打造。聚会、社交或是组织中通常的报告会都是让同事们教学和分享他们的知识的很棒的方式。有时,这些会突出其他人可能没有考虑过的共同挑战、顾虑或风险。分享和教学也是一种高效的学习和指导团队的方法。
|
||||||
|
|
||||||
|
在我个人经验中,每个团队的文化都是独一无二的,因此你不能用一种“普适”的方法。走进你的团队并找到他们想要使用的工具方法。尝试不同的论坛和聚会并找出最适用于你们文化的方式。寻找反馈并询问团队如何工作,他们喜欢什么以及对应的原因。适应和学习,保持乐观,不要停止尝试,你们将会有所收获。
|
||||||
|
|
||||||
|
- [下载 DevSecOps 的入门手册][1]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/1/what-devsecops
|
||||||
|
|
||||||
|
作者:[Brett Hunoldt][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[PandaWizard](https://github.com/PandaWizard)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/bretthunoldtcom
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/downloads/devsecops
|
||||||
@ -0,0 +1,98 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11182-1.html)
|
||||||
|
[#]: subject: (Enable ‘Tap to click’ on Ubuntu Login Screen [Quick Tip])
|
||||||
|
[#]: via: (https://itsfoss.com/enable-tap-to-click-on-ubuntu-login-screen/)
|
||||||
|
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||||
|
|
||||||
|
如何在 Ubuntu 登录屏幕上启用轻击
|
||||||
|
======
|
||||||
|
|
||||||
|
> <ruby>轻击<rt>tap to click</rt></ruby>选项在 Ubuntu 18.04 GNOME 桌面的登录屏幕上不起作用。在本教程中,你将学习如何在 Ubuntu 登录屏幕上启用“轻击”。
|
||||||
|
|
||||||
|
安装 Ubuntu 后我做的第一件事就是确保启用了轻击功能。作为笔记本电脑用户,我更喜欢轻击触摸板进行左键单击。这比使用触摸板上的左键单击按钮更方便。
|
||||||
|
|
||||||
|
我登录并使用操作系统时可以轻击。但是,如果你在登录屏幕上,轻击不起作用,这是一个烦恼。
|
||||||
|
|
||||||
|
在 Ubuntu(或使用 GNOME 桌面的其他发行版)的 [GDM 登录屏幕][1]上,你必须单击用户名才能显示密码字段。现在,如果你习惯了轻击,即使你已启用了它并在登录系统后可以使用,它也无法在登录屏幕上运行。
|
||||||
|
|
||||||
|
这是一个轻微的烦恼,但仍然是一个烦恼。好消息是你可以解决这个烦恼。让我告诉你如何在这个快速提示中做到这一点。
|
||||||
|
|
||||||
|
### 在 Ubuntu 登录屏幕上启用轻击
|
||||||
|
|
||||||
|
![][2]
|
||||||
|
|
||||||
|
你必须在这里使用终端和一些命令。我希望你能够适应。
|
||||||
|
|
||||||
|
[在 Ubuntu 中使用 Ctrl + Alt + T 快捷键打开终端][3]。由于 Ubuntu 18.04 仍在使用 X 显示服务器,因此需要启用它才能连接到 [X 服务器][4]。为此,你可以将 `gdm` 添加到访问控制列表中。
|
||||||
|
|
||||||
|
首先切换到 `root` 用户。这是必需的,因为你必须稍后切换为 `gdm` 用户,而不能以非 `root` 用户身份执行此操作。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo -i
|
||||||
|
```
|
||||||
|
|
||||||
|
[在 Ubuntu 中没有为 root 用户设置密码][5]。你可以使用管理员用户帐户访问它。因此,当要求输入密码时,请使用你自己的密码。输入密码时,屏幕上不会显示任何输入内容。
|
||||||
|
|
||||||
|
```
|
||||||
|
xhost +SI:localuser:gdm
|
||||||
|
```
|
||||||
|
|
||||||
|
这是我的输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
xhost +SI:localuser:gdm
|
||||||
|
localuser:gdm being added to access control list
|
||||||
|
```
|
||||||
|
|
||||||
|
现在运行此命令,以便 `gdm` 用户具有正确的轻击设置。
|
||||||
|
|
||||||
|
```
|
||||||
|
gsettings set org.gnome.desktop.peripherals.touchpad tap-to-click true
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你看到这样的警告:`(process:6339): dconf-WARNING **: 19:52:21.217: Unable to open /root/.local/share/flatpak/exports/share/dconf/profile/user: Permission denied`。别担心。忽略它就行。
|
||||||
|
|
||||||
|
[][6]
|
||||||
|
|
||||||
|
这将使你能够轻击登录屏幕。为什么在系统设置中进行更改之前无法使用轻击?这是因为在登录屏幕上,你还没有选择用户名。只有在屏幕上选择用户时才能使用你的帐户。这就是你必须使用用户 `gdm` 并使用它添加正确设置的原因。
|
||||||
|
|
||||||
|
重新启动 Ubuntu,你会看到现在可以使用轻击来选择你的用户帐户。
|
||||||
|
|
||||||
|
#### 还原改变
|
||||||
|
|
||||||
|
如果你因为某些原因不喜欢在 Ubuntu 登录界面轻击,可以还原更改。
|
||||||
|
|
||||||
|
你必须执行上一节中的所有步骤:切换到 `root`,将 `gdm` 与 X 服务器连接,切换到 `gdm` 用户。但是,你需要运行此命令,而不是上一个命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
gsettings set org.gnome.desktop.peripherals.touchpad tap-to-click false
|
||||||
|
```
|
||||||
|
|
||||||
|
就是这样。
|
||||||
|
|
||||||
|
正如我所说,这是一件小事。我的意思是你可以轻松地点击左键而不是轻击。这只是一次单击的问题。但是,当你在几次轻击后被迫使用左键单击时,它会打破操作“连续性”。
|
||||||
|
|
||||||
|
我希望你喜欢这个快速的小调整。如果你知道其他一些很酷的调整,请与我们分享。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/enable-tap-to-click-on-ubuntu-login-screen/
|
||||||
|
|
||||||
|
作者:[Abhishek Prakash][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/abhishek/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://wiki.archlinux.org/index.php/GDM
|
||||||
|
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/tap-to-click-on-ubuntu-login.jpg?ssl=1
|
||||||
|
[3]: https://itsfoss.com/ubuntu-shortcuts/
|
||||||
|
[4]: https://en.wikipedia.org/wiki/X.Org_Server
|
||||||
|
[5]: https://itsfoss.com/change-password-ubuntu/
|
||||||
|
[6]: https://itsfoss.com/change-hostname-ubuntu/
|
||||||
@ -0,0 +1,306 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11173-1.html)
|
||||||
|
[#]: subject: (Install NetData Performance Monitoring Tool On Linux)
|
||||||
|
[#]: via: (https://www.ostechnix.com/netdata-real-time-performance-monitoring-tool-linux/)
|
||||||
|
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||||
|
|
||||||
|
在 Linux 上安装 NetData 性能监控工具
|
||||||
|
======
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
**NetData** 是一个用于系统和应用的分布式实时性能和健康监控工具。它提供了对系统中实时发生的所有事情的全面检测。你可以在高度互动的 Web 仪表板中查看结果。使用 Netdata,你可以清楚地了解现在发生的事情,以及之前系统和应用中发生的事情。你无需成为专家即可在 Linux 系统中部署此工具。NetData 开箱即用,零配置、零依赖。只需安装它然后坐等,之后 NetData 将负责其余部分。
|
||||||
|
|
||||||
|
它有自己的内置 Web 服务器,以图形形式显示结果。NetData 非常快速高效,安装后可立即开始分析系统性能。它是用 C 编程语言编写的,所以它非常轻量。它占用的单核 CPU 使用率不到 3%,内存占用 10-15MB。我们可以轻松地在任何现有网页上嵌入图表,并且它还有一个插件 API,以便你可以监控任何应用。
|
||||||
|
|
||||||
|
以下是 Linux 系统中 NetData 的监控列表。
|
||||||
|
|
||||||
|
* CPU 使用率
|
||||||
|
* RAM 使用率
|
||||||
|
* 交换内存使用率
|
||||||
|
* 内核内存使用率
|
||||||
|
* 硬盘及其使用率
|
||||||
|
* 网络接口
|
||||||
|
* IPtables
|
||||||
|
* Netfilter
|
||||||
|
* DDoS 保护
|
||||||
|
* 进程
|
||||||
|
* 应用
|
||||||
|
* NFS 服务器
|
||||||
|
* Web 服务器 (Apache 和 Nginx)
|
||||||
|
* 数据库服务器 (MySQL),
|
||||||
|
* DHCP 服务器
|
||||||
|
* DNS 服务器
|
||||||
|
* 电子邮件服务
|
||||||
|
* 代理服务器
|
||||||
|
* Tomcat
|
||||||
|
* PHP
|
||||||
|
* SNP 设备
|
||||||
|
* 等等
|
||||||
|
|
||||||
|
NetData 是自由开源工具,它支持 Linux、FreeBSD 和 Mac OS。
|
||||||
|
|
||||||
|
### 在 Linux 上安装 NetData
|
||||||
|
|
||||||
|
Netdata 可以安装在任何安装了 Bash 的 Linux 发行版上。
|
||||||
|
|
||||||
|
最简单的安装 Netdata 的方法是从终端运行以下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ bash <(curl -Ss https://my-netdata.io/kickstart-static64.sh)
|
||||||
|
```
|
||||||
|
|
||||||
|
这将下载并安装启动和运行 Netdata 所需的一切。
|
||||||
|
|
||||||
|
有些用户可能不想在没有研究的情况下将某些东西直接注入到 Bash。如果你不喜欢此方法,可以按照以下步骤在系统上安装它。
|
||||||
|
|
||||||
|
#### 在 Arch Linux 上
|
||||||
|
|
||||||
|
Arch Linux 默认仓库中提供了最新版本。所以,我们可以使用以下 [pacman][2] 命令安装它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo pacman -S netdata
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 在基于 DEB 和基于 RPM 的系统上
|
||||||
|
|
||||||
|
在基于 DEB (Ubuntu / Debian)或基于 RPM(RHEL / CentOS / Fedora) 系统的默认仓库没有 NetData。我们需要从它的 Git 仓库手动安装 NetData。
|
||||||
|
|
||||||
|
首先安装所需的依赖项:
|
||||||
|
|
||||||
|
```
|
||||||
|
# Debian / Ubuntu
|
||||||
|
$ sudo apt-get install zlib1g-dev uuid-dev libuv1-dev liblz4-dev libjudy-dev libssl-dev libmnl-dev gcc make git autoconf autoconf-archive autogen automake pkg-config curl
|
||||||
|
|
||||||
|
# Fedora
|
||||||
|
$ sudo dnf install zlib-devel libuuid-devel libuv-devel lz4-devel Judy-devel openssl-devel libmnl-devel gcc make git autoconf autoconf-archive autogen automake pkgconfig curl findutils
|
||||||
|
|
||||||
|
# CentOS / Red Hat Enterprise Linux
|
||||||
|
$ sudo yum install epel-release
|
||||||
|
$ sudo yum install autoconf automake curl gcc git libmnl-devel libuuid-devel openssl-devel libuv-devel lz4-devel Judy-devel lm_sensors make MySQL-python nc pkgconfig python python-psycopg2 PyYAML zlib-devel
|
||||||
|
|
||||||
|
# openSUSE
|
||||||
|
$ sudo zypper install zlib-devel libuuid-devel libuv-devel liblz4-devel judy-devel openssl-devel libmnl-devel gcc make git autoconf autoconf-archive autogen automake pkgconfig curl findutils
|
||||||
|
```
|
||||||
|
|
||||||
|
安装依赖项后,在基于 DEB 或基于 RPM 的系统上安装 NetData,如下所示。
|
||||||
|
|
||||||
|
Git 克隆 NetData 仓库:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git clone https://github.com/netdata/netdata.git --depth=100
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的命令将在当前工作目录中创建一个名为 `netdata` 的目录。
|
||||||
|
|
||||||
|
切换到 `netdata` 目录:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd netdata/
|
||||||
|
```
|
||||||
|
|
||||||
|
最后,使用命令安装并启动 NetData:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo ./netdata-installer.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
**示例输出:**
|
||||||
|
|
||||||
|
```
|
||||||
|
Welcome to netdata!
|
||||||
|
Nice to see you are giving it a try!
|
||||||
|
|
||||||
|
You are about to build and install netdata to your system.
|
||||||
|
|
||||||
|
It will be installed at these locations:
|
||||||
|
|
||||||
|
- the daemon at /usr/sbin/netdata
|
||||||
|
- config files at /etc/netdata
|
||||||
|
- web files at /usr/share/netdata
|
||||||
|
- plugins at /usr/libexec/netdata
|
||||||
|
- cache files at /var/cache/netdata
|
||||||
|
- db files at /var/lib/netdata
|
||||||
|
- log files at /var/log/netdata
|
||||||
|
- pid file at /var/run
|
||||||
|
|
||||||
|
This installer allows you to change the installation path.
|
||||||
|
Press Control-C and run the same command with --help for help.
|
||||||
|
|
||||||
|
Press ENTER to build and install netdata to your system > ## Press ENTER key
|
||||||
|
```
|
||||||
|
|
||||||
|
安装完成后,你将在最后看到以下输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
-------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
OK. NetData is installed and it is running (listening to *:19999).
|
||||||
|
|
||||||
|
-------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
INFO: Command line options changed. -pidfile, -nd and -ch are deprecated.
|
||||||
|
If you use custom startup scripts, please run netdata -h to see the
|
||||||
|
corresponding options and update your scripts.
|
||||||
|
|
||||||
|
Hit http://localhost:19999/ from your browser.
|
||||||
|
|
||||||
|
To stop netdata, just kill it, with:
|
||||||
|
|
||||||
|
killall netdata
|
||||||
|
|
||||||
|
To start it, just run it:
|
||||||
|
|
||||||
|
/usr/sbin/netdata
|
||||||
|
|
||||||
|
|
||||||
|
Enjoy!
|
||||||
|
|
||||||
|
Uninstall script generated: ./netdata-uninstaller.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
![][3]
|
||||||
|
|
||||||
|
*安装 NetData*
|
||||||
|
|
||||||
|
NetData 已安装并启动。
|
||||||
|
|
||||||
|
要在其他 Linux 发行版上安装 Netdata,请参阅[官方安装说明页面][4]。
|
||||||
|
|
||||||
|
### 在防火墙或者路由器上允许 NetData 的默认端口
|
||||||
|
|
||||||
|
如果你的系统在防火墙或者路由器后面,那么必须允许默认端口 `19999` 以便从任何远程系统访问 NetData 的 web 界面。
|
||||||
|
|
||||||
|
#### 在 Ubuntu/Debian 中
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo ufw allow 19999
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 在 CentOS/RHEL/Fedora 中
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo firewall-cmd --permanent --add-port=19999/tcp
|
||||||
|
|
||||||
|
$ sudo firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
### 启动/停止 NetData
|
||||||
|
|
||||||
|
要在使用 Systemd 的系统上启用和启动 Netdata 服务,请运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo systemctl enable netdata
|
||||||
|
$ sudo systemctl start netdata
|
||||||
|
```
|
||||||
|
|
||||||
|
要停止:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo systemctl stop netdata
|
||||||
|
```
|
||||||
|
|
||||||
|
要在使用 Init 的系统上启用和启动 Netdata 服务,请运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo service netdata start
|
||||||
|
$ sudo chkconfig netdata on
|
||||||
|
```
|
||||||
|
|
||||||
|
要停止:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo service netdata stop
|
||||||
|
```
|
||||||
|
|
||||||
|
### 通过 Web 浏览器访问 NetData
|
||||||
|
|
||||||
|
打开 Web 浏览器,然后打开 `http://127.0.0.1:19999` 或者 `http://localhost:19999/` 或者 `http://ip-address:19999`。你应该看到如下页面。
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
*Netdata 仪表板*
|
||||||
|
|
||||||
|
在仪表板中,你可以找到 Linux 系统的完整统计信息。向下滚动以查看每个部分。
|
||||||
|
|
||||||
|
你可以随时打开 `http://localhost:19999/netdata.conf` 来下载和/或查看 NetData 默认配置文件。
|
||||||
|
|
||||||
|
![][6]
|
||||||
|
|
||||||
|
*Netdata 配置文件*
|
||||||
|
|
||||||
|
### 更新 NetData
|
||||||
|
|
||||||
|
在 Arch Linux 中,只需运行以下命令即可更新 NetData。如果仓库中提供了更新版本,那么就会自动安装该版本。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo pacman -Syyu
|
||||||
|
```
|
||||||
|
|
||||||
|
在基于 DEB 或 RPM 的系统中,只需进入已克隆它的目录(此例中是 `netdata`)。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd netdata
|
||||||
|
```
|
||||||
|
|
||||||
|
拉取最新更新:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git pull
|
||||||
|
```
|
||||||
|
|
||||||
|
然后,使用命令重新构建并更新它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo ./netdata-installer.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
### 卸载 NetData
|
||||||
|
|
||||||
|
进入克隆 NetData 的文件夹。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd netdata
|
||||||
|
```
|
||||||
|
|
||||||
|
然后,使用命令卸载它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo ./netdata-uninstaller.sh --force
|
||||||
|
```
|
||||||
|
|
||||||
|
在 Arch Linux 中,使用以下命令卸载它。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo pacman -Rns netdata
|
||||||
|
```
|
||||||
|
|
||||||
|
### 资源
|
||||||
|
|
||||||
|
* [NetData 网站][7]
|
||||||
|
* [NetData 的 GitHub 页面][8]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.ostechnix.com/netdata-real-time-performance-monitoring-tool-linux/
|
||||||
|
|
||||||
|
作者:[sk][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.ostechnix.com/author/sk/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.ostechnix.com/wp-content/uploads/2016/06/Install-netdata-720x340.png
|
||||||
|
[2]: https://www.ostechnix.com/getting-started-pacman/
|
||||||
|
[3]: https://www.ostechnix.com/wp-content/uploads/2016/06/Deepin-Terminal_002-6.png
|
||||||
|
[4]: https://docs.netdata.cloud/packaging/installer/
|
||||||
|
[5]: https://www.ostechnix.com/wp-content/uploads/2016/06/Netdata-dashboard.png
|
||||||
|
[6]: https://www.ostechnix.com/wp-content/uploads/2016/06/Netdata-config-file.png
|
||||||
|
[7]: http://netdata.firehol.org/
|
||||||
|
[8]: https://github.com/firehol/netdata
|
||||||
77
published/20190711 What is a golden image.md
Normal file
77
published/20190711 What is a golden image.md
Normal file
@ -0,0 +1,77 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11202-1.html)
|
||||||
|
[#]: subject: (What is a golden image?)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/what-golden-image)
|
||||||
|
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||||
|
|
||||||
|
什么是黄金镜像?
|
||||||
|
======
|
||||||
|
|
||||||
|
> 正在开发一个将广泛分发的项目吗?了解一下黄金镜像吧,以便在出现问题时轻松恢复到“完美”状态。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果你正在从事于质量保证、系统管理或媒体制作(没想到吧),你可能听说过<ruby>正式版<rt>gold master</rt></ruby>这一术语的某些变体,如<ruby>黄金镜像<rt>golden image</rt></ruby>或<ruby>母片<rt>master image</rt></ruby>等等。这个术语已经进入了每个参与创建**完美**模具的人的集体意识,然后从该模具中产生许多复制品。母片或黄金镜像就是:一种虚拟模具,你可以从中打造可分发的模型。
|
||||||
|
|
||||||
|
在媒体制作中,这就是所有人努力开发母片的过程。这个最终产品是独一无二的。它看起来和听起来像是可以看和听的最好的电影或专辑(或其他任何东西)。可以制作和压缩该母片的副本并发送给急切的公众。
|
||||||
|
|
||||||
|
在软件中,与该术语相关联的也是类似的意思。一旦软件经过编译和一再测试,完美的构建成果就会被声明为**黄金版本**,不允许对它进一步更改,并且所有可分发的副本都是从此母片生成的(当软件是用 CD 或 DVD 分发时,这实际上就是母盘)。
|
||||||
|
|
||||||
|
在系统管理中,你可能会遇到你的机构所选的操作系统的黄金镜像,其中的重要设置已经就绪,如安装好的虚拟专用网络(VPN)证书、设置好的电子邮件收件服务器的邮件客户端等等。同样,你可能也会在虚拟机(VM)的世界中听到这个术语,其中精心配置了虚拟驱动器的黄金镜像是所有克隆的新虚拟机的源头。
|
||||||
|
|
||||||
|
### GNOME Boxes
|
||||||
|
|
||||||
|
正式版的概念很简单,但往往忽视将其付诸实践。有时,你的团队很高兴能够达成他们的目标,但没有人停下来考虑将这些成就指定为权威版本。在其他时候,没有简单的机制来做到这一点。
|
||||||
|
|
||||||
|
黄金镜像等同于部分历史的保存和提前备份计划。一旦你制作了一个完美的模型,无论你正在努力做什么,你都应该为自己保留这项工作,因为它不仅标志着你的进步,而且如果你继续工作时遇到问题,它就会成为一个后备。
|
||||||
|
|
||||||
|
[GNOME Boxes][2],是随 GNOME 桌面一起提供的虚拟化平台,可以用作简单的演示用途。如果你从未使用过 GNOME Boxes,你可以在 Alan Formy-Duval 的文章 [GNOME Boxes 入门][3]中学习它的基础知识。
|
||||||
|
|
||||||
|
想象一下,你使用 GNOME Boxes 创建虚拟机,然后将操作系统安装到该 VM 中。现在,你想要制作一个黄金镜像。GNOME Boxes 已经率先摄取了你的安装快照,可以作为更多的操作系统安装的黄金镜像。
|
||||||
|
|
||||||
|
打开 GNOME Boxes 并在仪表板视图中,右键单击任何虚拟机,然后选择**属性**。在**属性**窗口中,选择**快照**选项卡。由 GNOME Boxes 自动创建的第一个快照是“Just Installed”。顾名思义,这是你最初安装到虚拟机上的操作系统。
|
||||||
|
|
||||||
|
![The Just Installed snapshot, or initial golden image, in GNOME Boxes.][4]
|
||||||
|
|
||||||
|
如果你的虚拟机变成了你不想要的状态,你可以随时恢复为“Just Installed”镜像。
|
||||||
|
|
||||||
|
当然,如果你已经为自己调整了环境,那么在安装后恢复操作系统将是一个极大的工程。这就是为什么虚拟机的常见工作流程是:首先安装操作系统,然后根据你的要求或偏好修改它,然后拍摄快照,将该快照声明为配置好的黄金镜像。例如,如果你使用虚拟机进行 [Flatpak][5] 打包,那么在初始安装之后,你可以添加软件和 Flatpak 开发工具,构建工作环境,然后拍摄快照。创建快照后,你可以重命名该虚拟机以指示其真实用途。
|
||||||
|
|
||||||
|
要重命名虚拟机,请在仪表板视图中右键单击其缩略图,然后选择**属性**。在**属性**窗口中,输入新名称:
|
||||||
|
|
||||||
|
![Renaming your VM image in GNOME Boxes.][6]
|
||||||
|
|
||||||
|
要克隆你的黄金映像,请右键单击 GNOME Boxes 界面中的虚拟机,然后选择**克隆**。
|
||||||
|
|
||||||
|
![Cloning your golden image in GNOME Boxes.][7]
|
||||||
|
|
||||||
|
你现在可以从黄金映像的最新快照中克隆了。
|
||||||
|
|
||||||
|
### 黄金镜像
|
||||||
|
|
||||||
|
很少有学科无法从黄金镜像中受益。无论你是在 [Git][8] 中标记版本、在 Boxes 中拍摄快照、出版原型黑胶唱片、打印书籍以进行审核、设计用于批量生产的丝网印刷、还是制作文字模具,到处都是各种原型。这只是现代技术让我们人类更聪明而不是更努力的另一种方式,因此为你的项目制作一个黄金镜像,并根据需要随时生成克隆吧。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/what-golden-image
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/origami_star_gold_best_top.jpg?itok=aEc0eutt (Gold star)
|
||||||
|
[2]: https://wiki.gnome.org/Apps/Boxes
|
||||||
|
[3]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||||
|
[4]: https://opensource.com/sites/default/files/uploads/snapshots.jpg (The Just Installed snapshot, or initial golden image.)
|
||||||
|
[5]: https://opensource.com/business/16/8/flatpak
|
||||||
|
[6]: https://opensource.com/sites/default/files/uploads/boxes-rename_0.jpg (Renaming your virtual machine in GNOME Boxes.)
|
||||||
|
[7]: https://opensource.com/sites/default/files/uploads/boxes-clone.jpg (Cloning your golden image in GNOME Boxes.)
|
||||||
|
[8]: https://git-scm.com
|
||||||
349
published/20190715 Understanding software design patterns.md
Normal file
349
published/20190715 Understanding software design patterns.md
Normal file
@ -0,0 +1,349 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (arrowfeng)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11208-1.html)
|
||||||
|
[#]: subject: (Understanding software design patterns)
|
||||||
|
[#]: via: (https://opensource.com/article/19/7/understanding-software-design-patterns)
|
||||||
|
[#]: author: (Bryant Son https://opensource.com/users/brsonhttps://opensource.com/users/erezhttps://opensource.com/users/brson)
|
||||||
|
|
||||||
|
理解软件设计模式
|
||||||
|
======
|
||||||
|
> 设计模式可以帮助消除冗余代码。学习如何利用 Java 使用单例模式、工厂模式和观察者模式。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果你是一名正在致力于计算机科学或者相关学科的程序员或者学生,很快,你将会遇到一条术语 “<ruby>软件设计模式<rt>software design pattern</rt></ruby>”。根据维基百科,“*[软件设计模式][2]是在平常的软件设计工作中所遭遇的问题的一种通用的、可重复使用的解决方案*”。我对该定义的理解是:当在从事于一个编码项目时,你经常会思考,“嗯,这里貌似是冗余代码,我觉得是否能改变这些代码使之更灵活和便于修改?”因此,你会开始考虑怎样分割那些保持不变的内容和需要经常改变的内容。
|
||||||
|
|
||||||
|
> **设计模式**是一种通过分割那些保持不变的部分和经常变化的部分,让你的代码更容易修改的方法。
|
||||||
|
|
||||||
|
不出意外的话,每个从事编程项目的人都可能会有同样的思考。特别是那些工业级别的项目,在那里通常工作着数十甚至数百名开发者;协作过程表明必须有一些标准和规则来使代码更加优雅并适应变化。这就是为什么我们有了 [面向对象编程][3](OOP)和 [软件框架工具][4]。设计模式有点类似于 OOP,但它通过将变化视为自然开发过程的一部分而进一步发展。基本上,设计模式利用了一些 OOP 的思想,比如抽象和接口,但是专注于改变的过程。
|
||||||
|
|
||||||
|
当你开始开发项目时,你经常会听到这样一个术语*重构*,它意味着*通过改变代码使它变得更优雅和可复用*;这就是设计模式耀眼的地方。当你处理现有代码时(无论是由其他人构建还是你自己过去构建的),了解设计模式可以帮助你以不同的方式看待事物,你将发现问题以及改进代码的方法。
|
||||||
|
|
||||||
|
有很多种设计模式,其中单例模式、工厂模式和观察者模式三种最受欢迎,在这篇文章中我将会一一介绍它们。
|
||||||
|
|
||||||
|
### 如何遵循本指南
|
||||||
|
|
||||||
|
无论你是一位有经验的编程工作者还是一名刚刚接触的新手,我想让这篇教程让每个人都很容易理解。设计模式概念并不容易理解,减少开始旅程时的学习曲线始终是首要任务。因此,除了这篇带有图表和代码片段的文章外,我还创建了一个 [GitHub 仓库][5],你可以克隆仓库并在你的电脑上运行这些代码来实现这三种设计模式。你也可以观看我创建的 [YouTube视频][6]。
|
||||||
|
|
||||||
|
#### 必要条件
|
||||||
|
|
||||||
|
如果你只是想了解一般的设计模式思想,则无需克隆示例项目或安装任何工具。但是,如果要运行示例代码,你需要安装以下工具:
|
||||||
|
|
||||||
|
* **Java 开发套件(JDK)**:我强烈建议使用 [OpenJDK][7]。
|
||||||
|
* **Apache Maven**:这个简单的项目使用 [Apache Maven][8] 构建;好的是许多 IDE 自带了Maven。
|
||||||
|
* **交互式开发编辑器(IDE)**:我使用 [社区版 IntelliJ][9],但是你也可以使用 [Eclipse IDE][10] 或者其他你喜欢的 Java IDE。
|
||||||
|
* **Git**:如果你想克隆这个工程,你需要 [Git][11] 客户端。
|
||||||
|
|
||||||
|
安装好 Git 后运行下列命令克隆这个工程:
|
||||||
|
|
||||||
|
```
|
||||||
|
git clone https://github.com/bryantson/OpensourceDotComDemos.git
|
||||||
|
```
|
||||||
|
|
||||||
|
然后在你喜欢的 IDE 中,你可以将 TopDesignPatterns 仓库中的代码作为 Apache Maven 项目导入。
|
||||||
|
|
||||||
|
我使用的是 Java,但你也可以使用支持[抽象原则][12]的任何编程语言来实现设计模式。
|
||||||
|
|
||||||
|
### 单例模式:避免每次创建一个对象
|
||||||
|
|
||||||
|
<ruby>[单例模式][13]<rt>singleton pattern</rt></ruby>是非常流行的设计模式,它的实现相对来说很简单,因为你只需要一个类。然而,许多开发人员争论单例设计模式的是否利大于弊,因为它缺乏明显的好处并且容易被滥用。很少有开发人员直接实现单例;相反,像 Spring Framework 和 Google Guice 等编程框架内置了单例设计模式的特性。
|
||||||
|
|
||||||
|
但是了解单例模式仍然有巨大的用处。单例模式确保一个类仅创建一次且提供了一个对它的全局访问点。
|
||||||
|
|
||||||
|
> **单例模式**:确保仅创建一个实例且避免在同一个项目中创建多个实例。
|
||||||
|
|
||||||
|
下面这幅图展示了典型的类对象创建过程。当客户端请求创建一个对象时,构造函数会创建或者实例化一个对象并调用方法返回这个类给调用者。但是每次请求一个对象都会发生这样的情况:构造函数被调用,一个新的对象被创建并且它返回了一个独一无二的对象。我猜面向对象语言的创建者有每次都创建一个新对象的理由,但是单例过程的支持者说这是冗余的且浪费资源。
|
||||||
|
|
||||||
|
![Normal class instantiation][14]
|
||||||
|
|
||||||
|
下面这幅图使用单例模式创建对象。这里,构造函数仅当对象首次通过调用预先设计好的 `getInstance()` 方法时才会被调用。这通常通过检查该值是否为 `null` 来完成,并且这个对象被作为私有变量保存在单例类的内部。下次 `getInstance()` 被调用时,这个类会返回第一次被创建的对象。而没有新的对象产生;它只是返回旧的那一个。
|
||||||
|
|
||||||
|
![Singleton pattern instantiation][15]
|
||||||
|
|
||||||
|
下面这段代码展示了创建单例模式最简单的方法:
|
||||||
|
|
||||||
|
```
|
||||||
|
package org.opensource.demo.singleton;
|
||||||
|
|
||||||
|
public class OpensourceSingleton {
|
||||||
|
|
||||||
|
private static OpensourceSingleton uniqueInstance;
|
||||||
|
|
||||||
|
private OpensourceSingleton() {
|
||||||
|
}
|
||||||
|
|
||||||
|
public static OpensourceSingleton getInstance() {
|
||||||
|
if (uniqueInstance == null) {
|
||||||
|
uniqueInstance = new OpensourceSingleton();
|
||||||
|
}
|
||||||
|
return uniqueInstance;
|
||||||
|
}
|
||||||
|
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
在调用方,这里展示了如何调用单例类来获取对象:
|
||||||
|
|
||||||
|
```
|
||||||
|
Opensource newObject = Opensource.getInstance();
|
||||||
|
```
|
||||||
|
|
||||||
|
这段代码很好的验证了单例模式的思想:
|
||||||
|
|
||||||
|
1. 当 `getInstance()` 被调用时,它通过检查 `null` 值来检查对象是否已经被创建。
|
||||||
|
2. 如果值为 `null`,它会创建一个新对象并把它保存到私有域,返回这个对象给调用者。否则直接返回之前被创建的对象。
|
||||||
|
|
||||||
|
单例模式实现的主要问题是它忽略了并行进程。当多个进程使用线程同时访问资源时,这个问题就产生了。对于这种情况有对应的解决方案,它被称为*双重检查锁*,用于多线程安全,如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
package org.opensource.demo.singleton;
|
||||||
|
|
||||||
|
public class ImprovedOpensourceSingleton {
|
||||||
|
|
||||||
|
private volatile static ImprovedOpensourceSingleton uniqueInstance;
|
||||||
|
|
||||||
|
private ImprovedOpensourceSingleton() {}
|
||||||
|
|
||||||
|
public static ImprovedOpensourceSingleton getInstance() {
|
||||||
|
if (uniqueInstance == null) {
|
||||||
|
synchronized (ImprovedOpensourceSingleton.class) {
|
||||||
|
if (uniqueInstance == null) {
|
||||||
|
uniqueInstance = new ImprovedOpensourceSingleton();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
return uniqueInstance;
|
||||||
|
}
|
||||||
|
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
再强调一下前面的观点,确保只有在你认为这是一个安全的选择时才直接实现你的单例模式。最好的方法是通过使用一个制作精良的编程框架来利用单例功能。
|
||||||
|
|
||||||
|
### 工厂模式:将对象创建委派给工厂类以隐藏创建逻辑
|
||||||
|
|
||||||
|
<ruby>[工厂模式][16]<rt>factory pattern</rt></ruby>是另一种众所周知的设计模式,但是有一小点复杂。实现工厂模式的方法有很多,而下列的代码示例为最简单的实现方式。为了创建对象,工厂模式定义了一个接口,让它的子类去决定实例化哪一个类。
|
||||||
|
|
||||||
|
> **工厂模式**:将对象创建委派给工厂类,因此它能隐藏创建逻辑。
|
||||||
|
|
||||||
|
下列的图片展示了最简单的工厂模式是如何实现的。
|
||||||
|
|
||||||
|
![Factory pattern][17]
|
||||||
|
|
||||||
|
客户端请求工厂类创建类型为 x 的某个对象,而不是客户端直接调用对象创建。根据其类型,工厂模式决定要创建和返回的对象。
|
||||||
|
|
||||||
|
在下列代码示例中,`OpensourceFactory` 是工厂类实现,它从调用者那里获取*类型*并根据该输入值决定要创建和返回的对象:
|
||||||
|
|
||||||
|
```
|
||||||
|
package org.opensource.demo.factory;
|
||||||
|
|
||||||
|
public class OpensourceFactory {
|
||||||
|
|
||||||
|
public OpensourceJVMServers getServerByVendor([String][18] name) {
|
||||||
|
if(name.equals("Apache")) {
|
||||||
|
return new Tomcat();
|
||||||
|
}
|
||||||
|
else if(name.equals("Eclipse")) {
|
||||||
|
return new Jetty();
|
||||||
|
}
|
||||||
|
else if (name.equals("RedHat")) {
|
||||||
|
return new WildFly();
|
||||||
|
}
|
||||||
|
else {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
`OpenSourceJVMServer` 是一个 100% 的抽象类(即接口类),它指示要实现的是什么,而不是怎样实现:
|
||||||
|
|
||||||
|
```
|
||||||
|
package org.opensource.demo.factory;
|
||||||
|
|
||||||
|
public interface OpensourceJVMServers {
|
||||||
|
public void startServer();
|
||||||
|
public void stopServer();
|
||||||
|
public [String][18] getName();
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
这是一个 `OpensourceJVMServers` 类的实现示例。当 `RedHat` 被作为类型传递给工厂类,`WildFly` 服务器将被创建:
|
||||||
|
|
||||||
|
```
|
||||||
|
package org.opensource.demo.factory;
|
||||||
|
|
||||||
|
public class WildFly implements OpensourceJVMServers {
|
||||||
|
public void startServer() {
|
||||||
|
[System][19].out.println("Starting WildFly Server...");
|
||||||
|
}
|
||||||
|
|
||||||
|
public void stopServer() {
|
||||||
|
[System][19].out.println("Shutting Down WildFly Server...");
|
||||||
|
}
|
||||||
|
|
||||||
|
public [String][18] getName() {
|
||||||
|
return "WildFly";
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### 观察者模式:订阅主题并获取相关更新的通知
|
||||||
|
|
||||||
|
最后是<ruby>[观察者模式][20]<rt>observer pattern</rt></ruby>。像单例模式那样,很少有专业的程序员直接实现观察者模式。但是,许多消息队列和数据服务实现都借用了观察者模式的概念。观察者模式在对象之间定义了一对多的依赖关系,当一个对象的状态发生改变时,所有依赖它的对象都将被自动地通知和更新。
|
||||||
|
|
||||||
|
> **观察者模式**:如果有更新,那么订阅了该话题/主题的客户端将被通知。
|
||||||
|
|
||||||
|
理解观察者模式的最简单方法是想象一个邮件列表,你可以在其中订阅任何主题,无论是开源、技术、名人、烹饪还是您感兴趣的任何其他内容。每个主题维护者一个它的订阅者列表,在观察者模式中它们相当于观察者。当某一个主题更新时,它所有的订阅者(观察者)都将被通知这次改变。并且订阅者总是能取消某一个主题的订阅。
|
||||||
|
|
||||||
|
如下图所示,客户端可以订阅不同的主题并添加观察者以获得最新信息的通知。因为观察者不断的监听着这个主题,这个观察者会通知客户端任何发生的改变。
|
||||||
|
|
||||||
|
![Observer pattern][21]
|
||||||
|
|
||||||
|
让我们来看看观察者模式的代码示例,从主题/话题类开始:
|
||||||
|
|
||||||
|
```
|
||||||
|
package org.opensource.demo.observer;
|
||||||
|
|
||||||
|
public interface Topic {
|
||||||
|
|
||||||
|
public void addObserver([Observer][22] observer);
|
||||||
|
public void deleteObserver([Observer][22] observer);
|
||||||
|
public void notifyObservers();
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
这段代码描述了一个为不同的主题去实现已定义方法的接口。注意一个观察者如何被添加、移除和通知的。
|
||||||
|
|
||||||
|
这是一个主题的实现示例:
|
||||||
|
|
||||||
|
```
|
||||||
|
package org.opensource.demo.observer;
|
||||||
|
|
||||||
|
import java.util.List;
|
||||||
|
import java.util.ArrayList;
|
||||||
|
|
||||||
|
public class Conference implements Topic {
|
||||||
|
private List<Observer> listObservers;
|
||||||
|
private int totalAttendees;
|
||||||
|
private int totalSpeakers;
|
||||||
|
private [String][18] nameEvent;
|
||||||
|
|
||||||
|
public Conference() {
|
||||||
|
listObservers = new ArrayList<Observer>();
|
||||||
|
}
|
||||||
|
|
||||||
|
public void addObserver([Observer][22] observer) {
|
||||||
|
listObservers.add(observer);
|
||||||
|
}
|
||||||
|
|
||||||
|
public void deleteObserver([Observer][22] observer) {
|
||||||
|
int i = listObservers.indexOf(observer);
|
||||||
|
if (i >= 0) {
|
||||||
|
listObservers.remove(i);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
public void notifyObservers() {
|
||||||
|
for (int i=0, nObservers = listObservers.size(); i < nObservers; ++ i) {
|
||||||
|
[Observer][22] observer = listObservers.get(i);
|
||||||
|
observer.update(totalAttendees,totalSpeakers,nameEvent);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
public void setConferenceDetails(int totalAttendees, int totalSpeakers, [String][18] nameEvent) {
|
||||||
|
this.totalAttendees = totalAttendees;
|
||||||
|
this.totalSpeakers = totalSpeakers;
|
||||||
|
this.nameEvent = nameEvent;
|
||||||
|
notifyObservers();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
这段代码定义了一个特定主题的实现。当发生改变时,这个实现调用它自己的方法。注意这将获取观察者的数量,它以列表方式存储,并且可以通知和维护观察者。
|
||||||
|
|
||||||
|
这是一个观察者类:
|
||||||
|
|
||||||
|
```
|
||||||
|
package org.opensource.demo.observer;
|
||||||
|
|
||||||
|
public interface [Observer][22] {
|
||||||
|
public void update(int totalAttendees, int totalSpeakers, [String][18] nameEvent);
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
这个类定义了一个接口,不同的观察者可以实现该接口以执行特定的操作。
|
||||||
|
|
||||||
|
例如,实现了该接口的观察者可以在会议上打印出与会者和发言人的数量:
|
||||||
|
|
||||||
|
```
|
||||||
|
package org.opensource.demo.observer;
|
||||||
|
|
||||||
|
public class MonitorConferenceAttendees implements [Observer][22] {
|
||||||
|
private int totalAttendees;
|
||||||
|
private int totalSpeakers;
|
||||||
|
private [String][18] nameEvent;
|
||||||
|
private Topic topic;
|
||||||
|
|
||||||
|
public MonitorConferenceAttendees(Topic topic) {
|
||||||
|
this.topic = topic;
|
||||||
|
topic.addObserver(this);
|
||||||
|
}
|
||||||
|
|
||||||
|
public void update(int totalAttendees, int totalSpeakers, [String][18] nameEvent) {
|
||||||
|
this.totalAttendees = totalAttendees;
|
||||||
|
this.totalSpeakers = totalSpeakers;
|
||||||
|
this.nameEvent = nameEvent;
|
||||||
|
printConferenceInfo();
|
||||||
|
}
|
||||||
|
|
||||||
|
public void printConferenceInfo() {
|
||||||
|
[System][19].out.println(this.nameEvent + " has " + totalSpeakers + " speakers and " + totalAttendees + " attendees");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### 接下来
|
||||||
|
|
||||||
|
现在你已经阅读了这篇对于设计模式的介绍引导,你还可以去寻求了解其他设计模式,例如外观模式,模版模式和装饰器模式。也有一些并发和分布式系统的设计模式如断路器模式和锚定模式。
|
||||||
|
|
||||||
|
可是,我相信最好的磨砺你的技能的方式首先是通过在你的业余项目或者练习中实现这些设计模式。你甚至可以开始考虑如何在实际项目中应用这些设计模式。接下来,我强烈建议你查看 OOP 的 [SOLID 原则][23]。之后,你就准备好了解其他设计模式。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/understanding-software-design-patterns
|
||||||
|
|
||||||
|
作者:[Bryant Son][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/brsonhttps://opensource.com/users/erezhttps://opensource.com/users/brson
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003601_05_mech_osyearbook2016_cloud_cc.png?itok=XSV7yR9e (clouds in the sky with blue pattern)
|
||||||
|
[2]: https://en.wikipedia.org/wiki/Software_design_pattern
|
||||||
|
[3]: https://en.wikipedia.org/wiki/Object-oriented_programming
|
||||||
|
[4]: https://en.wikipedia.org/wiki/Software_framework
|
||||||
|
[5]: https://github.com/bryantson/OpensourceDotComDemos/tree/master/TopDesignPatterns
|
||||||
|
[6]: https://www.youtube.com/watch?v=VlBXYtLI7kE&feature=youtu.be
|
||||||
|
[7]: https://openjdk.java.net/
|
||||||
|
[8]: https://maven.apache.org/
|
||||||
|
[9]: https://www.jetbrains.com/idea/download/#section=mac
|
||||||
|
[10]: https://www.eclipse.org/ide/
|
||||||
|
[11]: https://git-scm.com/
|
||||||
|
[12]: https://en.wikipedia.org/wiki/Abstraction_principle_(computer_programming)
|
||||||
|
[13]: https://en.wikipedia.org/wiki/Singleton_pattern
|
||||||
|
[14]: https://opensource.com/sites/default/files/uploads/designpatterns1_normalclassinstantiation.jpg (Normal class instantiation)
|
||||||
|
[15]: https://opensource.com/sites/default/files/uploads/designpatterns2_singletonpattern.jpg (Singleton pattern instantiation)
|
||||||
|
[16]: https://en.wikipedia.org/wiki/Factory_method_pattern
|
||||||
|
[17]: https://opensource.com/sites/default/files/uploads/designpatterns3_factorypattern.jpg (Factory pattern)
|
||||||
|
[18]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||||
|
[19]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
|
||||||
|
[20]: https://en.wikipedia.org/wiki/Observer_pattern
|
||||||
|
[21]: https://opensource.com/sites/default/files/uploads/designpatterns4_observerpattern.jpg (Observer pattern)
|
||||||
|
[22]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+observer
|
||||||
|
[23]: https://en.wikipedia.org/wiki/SOLID
|
||||||
@ -0,0 +1,161 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (robsean)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11172-1.html)
|
||||||
|
[#]: subject: (How to Upgrade Debian 9 (Stretch) to Debian 10 (Buster) via Command Line)
|
||||||
|
[#]: via: (https://www.linuxtechi.com/upgrade-debian-9-to-debian-10-command-line/)
|
||||||
|
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||||
|
|
||||||
|
如何通过命令行升级 Debian 9 为 Debian 10
|
||||||
|
======
|
||||||
|
|
||||||
|
我们已经在先前的文章中看到如何安装 [Debian 10(Buster)][1]。今天,我们将学习如何从 Debian 9 升级为 Debian 10,虽然我们已将看到 Debian 10 和它的特色,所以这里我们不会深入介绍。但是可能读者没有机会读到那篇文章,让我们快速了解一下 Debian 10 和它的新功能。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在差不多两年的开发后,Debian 团队最终发布一个稳定版本,Debian 10 的代码名称是 Buster。Buster 是一个 LTS (长期支持支持)版本,因此未来将由 Debian 支持 5 年。
|
||||||
|
|
||||||
|
### Debian 10(Buster)新的特色
|
||||||
|
|
||||||
|
Debian 10(Buster)回报给大多数 Debian 爱好者大量的新特色。一些特色包括:
|
||||||
|
|
||||||
|
* GNOME 桌面 3.30
|
||||||
|
* 默认启用 AppArmor
|
||||||
|
* 支持 Linux 内核 4.19.0-4
|
||||||
|
* 支持 OpenJDk 11.0
|
||||||
|
* 从 Nodejs 4 ~ 8 升级到 Nodejs 10.15.2
|
||||||
|
* Iptables 替换为 NFTables
|
||||||
|
|
||||||
|
等等。
|
||||||
|
|
||||||
|
### 从 Debian 9 到 Debian 10 的逐步升级指南
|
||||||
|
|
||||||
|
在我们开始升级 Debian 10 前,让我们看看升级需要的必备条件:
|
||||||
|
|
||||||
|
#### 步骤 1) Debian 升级必备条件
|
||||||
|
|
||||||
|
* 一个良好的网络连接
|
||||||
|
* root 用户权限
|
||||||
|
* 数据备份
|
||||||
|
|
||||||
|
备份你所有的应用程序代码库、数据文件、用户账号详细信息、配置文件是极其重要的,以便在升级出错时,你可以总是可以还原到先前的版本。
|
||||||
|
|
||||||
|
#### 步骤 2) 升级 Debian 9 现有的软件包
|
||||||
|
|
||||||
|
接下来的步骤是升级你所有现有的软件包,因为一些软件包被标志为保留不能升级,从 Debian 9 升级为 Debian 10 有失败或引发一些问题的可能性。所以,我们不冒任何风险,更好地升级软件包。使用下面的代码来升级软件包:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt update && sudo apt upgrade -y
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 步骤 3) 修改软件包存储库文件 /etc/sources.list
|
||||||
|
|
||||||
|
接下来的步骤是修改软件包存储库文件 `/etc/sources.list`,你需要用文本 `Buster` 替换 `Stretch`。
|
||||||
|
|
||||||
|
但是,在你更改任何东西前,确保如下创建一个 `sources.list` 文件的备份:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
|
||||||
|
```
|
||||||
|
|
||||||
|
现在使用下面的 `sed` 命令来在软件包存储库文件中使用 `buster` 替换 `stretch`,示例如下显示:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo sed -i 's/stretch/buster/g' /etc/apt/sources.list
|
||||||
|
root@linuxtechi:~$ sudo sed -i 's/stretch/buster/g' /etc/apt/sources.list.d/*.list
|
||||||
|
```
|
||||||
|
|
||||||
|
更新后,你需要如下更新软件包存储库索引:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt update
|
||||||
|
```
|
||||||
|
|
||||||
|
在开始升级你现有的 Debian 操作系统前,让我们使用下面的命令验证当前版本,
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ cat /etc/*-release
|
||||||
|
PRETTY_NAME="Debian GNU/Linux 9 (stretch)"
|
||||||
|
NAME="Debian GNU/Linux"
|
||||||
|
VERSION_ID="9"
|
||||||
|
VERSION="9 (stretch)"
|
||||||
|
ID=debian
|
||||||
|
HOME_URL="https://www.debian.org/"
|
||||||
|
SUPPORT_URL="https://www.debian.org/support"
|
||||||
|
BUG_REPORT_URL="https://bugs.debian.org/"
|
||||||
|
root@linuxtechi:~$
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 步骤 4) 从 Debian 9 升级到 Debian 10
|
||||||
|
|
||||||
|
你做完所有的更改后,是时候从 Debian 9 升级到 Debian 10 了。但是在这之前,再次如下确保更新你的软件包:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt update && sudo apt upgrade -y
|
||||||
|
```
|
||||||
|
|
||||||
|
在软件包升级期间,你将被提示启动服务,所以选择你较喜欢的选项。
|
||||||
|
|
||||||
|
一旦你系统的所有软件包升级完成,就升级你的发行版的软件包。使用下面的代码来升级发行版:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt dist-upgrade -y
|
||||||
|
```
|
||||||
|
|
||||||
|
升级过程可能花费一些时间,取决于你的网络速度。记住在升级过程中,你将被询问一些问题,在软件包升级后是否需要重启服务、你是否需要保留现存的配置文件等。如果你不想进行一些自定义更改,简单地键入 “Y” ,来让升级过程继续。
|
||||||
|
|
||||||
|
#### 步骤 5) 验证升级
|
||||||
|
|
||||||
|
一旦升级过程完成,重启你的机器,并使用下面的方法检测版本:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ lsb_release -a
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你获得如下输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
Distributor ID: Debian
|
||||||
|
Description: Debian GNU/Linux 10 (buster)
|
||||||
|
Release: 10
|
||||||
|
Codename: buster
|
||||||
|
root@linuxtechi:~$
|
||||||
|
```
|
||||||
|
|
||||||
|
是的,你已经成功地从 Debian 9 升级到 Debian 10。
|
||||||
|
|
||||||
|
验证升级的备用方法:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ cat /etc/*-release
|
||||||
|
PRETTY_NAME="Debian GNU/Linux 10 (buster)"
|
||||||
|
NAME="Debian GNU/Linux"
|
||||||
|
VERSION_ID="10"
|
||||||
|
VERSION="10 (buster)"
|
||||||
|
VERSION_CODENAME=buster
|
||||||
|
ID=debian
|
||||||
|
HOME_URL="https://www.debian.org/"
|
||||||
|
SUPPORT_URL="https://www.debian.org/support"
|
||||||
|
BUG_REPORT_URL="https://bugs.debian.org/"
|
||||||
|
root@linuxtechi:~$
|
||||||
|
```
|
||||||
|
|
||||||
|
### 结束
|
||||||
|
|
||||||
|
希望上面的逐步指南为你提供了从 Debian 9(Stretch)简单地升级为 Debian 10(Buster)的所有信息。在评论部分,请给予你使用 Debian 10 的反馈、建议、体验。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linuxtechi.com/upgrade-debian-9-to-debian-10-command-line/
|
||||||
|
|
||||||
|
作者:[Pradeep Kumar][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[robsean](https://github.com/robsean)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://linux.cn/article-11083-1.html
|
||||||
@ -0,0 +1,78 @@
|
|||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "hello-wn"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-11183-1.html"
|
||||||
|
[#]: subject: "3 types of metric dashboards for DevOps teams"
|
||||||
|
[#]: via: "https://opensource.com/article/19/7/dashboards-devops-teams"
|
||||||
|
[#]: author: "Daniel Oh https://opensource.com/users/daniel-oh"
|
||||||
|
|
||||||
|
DevOps 团队必备的 3 种指标仪表板
|
||||||
|
=========
|
||||||
|
|
||||||
|
> 仪表板可以帮助 DevOps 团队观测和监控系统,以提高性能。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
指标仪表板帮助 [DevOps][2] 团队监控整个 DevOps 平台,以便实时响应<ruby>议题<rt>issue</rt></ruby>。在处理生产环境宕机或者应用服务中断等情况时,指标仪表板显得尤为重要。
|
||||||
|
|
||||||
|
DevOps 仪表板聚合了多个监测工具的指标,为开发和运维团队生成监控报告。它还允许团队跟踪多项指标,例如服务部署时间、程序 bug、报错信息、工作项、待办事项等等。
|
||||||
|
|
||||||
|
下面三种指标仪表板可以帮助 DevOps 团队监测系统,改善服务性能。
|
||||||
|
|
||||||
|
### 敏捷项目管理仪表板
|
||||||
|
|
||||||
|
这种类型的仪表板为 DevOps 团队的工作项提供可视化视图,优化敏捷项目的工作流。有利于提高团队协作效率,对工作进行可视化并提供灵活的视图 —— 就像我们过去在白板上使用便利贴来共享项目进度、<ruby>议题<rt>issue</rt></ruby>和待办事项一样。
|
||||||
|
|
||||||
|
- [Kanban boards][3] 允许 DevOps 团队创建卡片、标签、任务和栏目,便于持续交付敏捷项目。
|
||||||
|
- [Burndown charts][4] 对指定时间段内未完成的工作或待办事项提供可视化视图,并记录团队当前的效率和轨迹,这些指标通常用于敏捷项目和 DevOps 项目管理。
|
||||||
|
- [Jira boards][5] 帮助 DevOps 团队创建议题、计划迭代并生成团队总结。这些灵活的仪表板还能帮助团队综合考虑并确定个人和团队任务的优先级;实时查看、汇报和跟踪正在进行的工作;并提高团队绩效。
|
||||||
|
- [GitHub project boards][6] 帮助确定团队任务的优先级。它们还支持拉取请求,因此团队成员可以方便地提交 DevOps 项目相关的信息。
|
||||||
|
|
||||||
|
### 应用程序监控仪表板
|
||||||
|
|
||||||
|
开发者负责优化应用和服务的性能,并开发新功能。应用程序监控面板则帮助开发者在<ruby>持续集成/持续开发<rt>CI / CD</rt></ruby>流程下,加快修复 bug、增强程序健壮性、发布安全修丁的进度。另外,这些可视化仪表板有利于查看请求模式、请求耗时、报错和网络拓扑信息。
|
||||||
|
|
||||||
|
- [Jaeger][7] 帮助开发人员跟踪请求数量、请求响应时间等。对于分布式网络系统上的云原生应用程序,它还使用 [Istio 服务网格][8]加强了监控和跟踪。
|
||||||
|
- [OpenCensus][9] 帮助团队查看运行应用程序的主机上的数据,它还提供了一个可插拔的导出系统,用于将数据导出到数据中心。
|
||||||
|
|
||||||
|
### DevOps 平台监控面板
|
||||||
|
|
||||||
|
你可能使用多种技术和工具在云上或本地构建 DevOps 平台,但 Linux 容器管理工具(如 Kubernetes 和 OpenShift )更利于搭建出一个成功的 DevOps 平台。因为 Linux 容器的不可变性和可移植性使得应用程序从开发环境到生产环境的编译、测试和部署变得更快更容易。
|
||||||
|
|
||||||
|
DevOps 平台监控仪表板帮助运营团队从机器/节点故障和服务报错中收集各种按时序排列的数据,用于编排应用程序容器和基于软件的基础架构,如网络(SDN)和存储(SDS)。这些仪表板还能可视化多维数据格式,方便地查询数据模式。
|
||||||
|
|
||||||
|
- [Prometheus dashboards][12] 从平台节点或者运行中的容器化应用中收集指标。帮助 DevOps 团队构建基于指标的监控系统和仪表板,监控微服务的客户端/服务器工作负载,及时识别出异常节点故障。
|
||||||
|
- [Grafana boards][13] 帮助收集事件驱动的各项指标,包括服务响应持续时间、请求量、<ruby>客户端/服务器<rt>client/server</rt></ruby>工作负载、网络流量等,并提供了可视化面板。DevOps 团队可以通过多种方式分享指标面板,也可以生成编码的当前监控数据快照分享给其他团队。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
这些仪表板提供了可视化的工作流程,能够发现团队协作、应用程序交付和平台状态中的各种问题。它们帮助开发团队增强其在快速应用交付、安全运行和自动化 CI/CD 等领域的能力。
|
||||||
|
|
||||||
|
------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/dashboards-devops-teams
|
||||||
|
|
||||||
|
作者:[Daniel Oh][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[hello-wn](https://github.com/hello-wn)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/daniel-ohhttps://opensource.com/users/daniel-ohhttps://opensource.com/users/heronthecli
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png
|
||||||
|
[2]: https://opensource.com/resources/devops
|
||||||
|
[3]: https://opensource.com/article/19/1/productivity-tool-taskboard
|
||||||
|
[4]: https://openpracticelibrary.com/practice/burndown/
|
||||||
|
[5]: https://www.atlassian.com/software/jira
|
||||||
|
[6]: https://opensource.com/life/15/11/short-introduction-github
|
||||||
|
[7]: https://www.jaegertracing.io/
|
||||||
|
[8]: https://opensource.com/article/19/3/getting-started-jaeger
|
||||||
|
[9]: https://opencensus.io/
|
||||||
|
[10]: https://opensource.com/article/18/11/intro-software-defined-networking
|
||||||
|
[11]: https://opensource.com/business/14/10/sage-weil-interview-openstack-ceph
|
||||||
|
[12]: https://opensource.com/article/18/12/introduction-prometheus
|
||||||
|
[13]: https://opensource.com/article/17/8/linux-grafana
|
||||||
|
|
||||||
@ -0,0 +1,126 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11181-1.html)
|
||||||
|
[#]: subject: (Manage your passwords with Bitwarden and Podman)
|
||||||
|
[#]: via: (https://fedoramagazine.org/manage-your-passwords-with-bitwarden-and-podman/)
|
||||||
|
[#]: author: (Eric Gustavsson https://fedoramagazine.org/author/egustavs/)
|
||||||
|
|
||||||
|
使用 Bitwarden 和 Podman 管理你的密码
|
||||||
|
======
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
在过去的一年中,你可能会遇到一些试图向你推销密码管理器的广告。比如 [LastPass][2]、[1Password][3] 或 [Dashlane][4]。密码管理器消除了记住所有网站密码的负担。你不再需要使用重复或容易记住的密码。相反,你只需要记住一个可以解锁所有其他密码的密码。
|
||||||
|
|
||||||
|
通过使用一个强密码而不是许多弱密码,这可以使你更安全。如果你有基于云的密码管理器(例如 LastPass、1Password 或 Dashlane),你还可以跨设备同步密码。不幸的是,这些产品都不是开源的。幸运的是,还有其他开源替代品。
|
||||||
|
|
||||||
|
### 开源密码管理器
|
||||||
|
|
||||||
|
替代方案包括 Bitwarden、[LessPass][5] 或 [KeePass][6]。Bitwarden 是一款[开源密码管理器][7],它会将所有密码加密存储在服务器上,它的工作方式与 LastPass、1Password 或 Dashlane 相同。LessPass 有点不同,因为它专注于成为无状态密码管理器。这意味着它根据主密码、网站和用户名生成密码,而不是保存加密的密码。另一方面,KeePass 是一个基于文件的密码管理器,它的插件和应用具有很大的灵活性。
|
||||||
|
|
||||||
|
这三个应用中的每一个都有其自身的缺点。Bitwarden 将所有东西保存在一个地方,并通过其 API 和网站接口暴露给网络。LessPass 无法保存自定义密码,因为它是无状态的,因此你需要使用它生成的密码。KeePass 是一个基于文件的密码管理器,因此无法在设备之间轻松同步。你可以使用云存储和 [WebDAV][8] 来解决此问题,但是有许多客户端不支持它,如果设备无法正确同步,你可能会遇到文件冲突。
|
||||||
|
|
||||||
|
本文重点介绍 Bitwarden。
|
||||||
|
|
||||||
|
### 运行非官方的 Bitwarden 实现
|
||||||
|
|
||||||
|
有一个名为 [bitwarden_rs][9] 的服务器及其 API 的社区实现。这个实现是完全开源的,因为它可以使用 SQLite 或 MariaDB/MySQL,而不是官方服务器使用的专有 Microsoft SQL Server。
|
||||||
|
|
||||||
|
有一点重要的是要认识到官方和非官方版本之间存在一些差异。例如,[官方服务器已经由第三方审核][10],而非官方服务器还没有。在实现方面,非官方版本缺少[电子邮件确认和采用 Duo 或邮件码的双因素身份验证][11]。
|
||||||
|
|
||||||
|
让我们在 SELinux 中运行服务器。根据 bitwarden_rs 的文档,你可以如下构建一个 Podman 命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ podman run -d \
|
||||||
|
--userns=keep-id \
|
||||||
|
--name bitwarden \
|
||||||
|
-e SIGNUPS_ALLOWED=false \
|
||||||
|
-e ROCKET_PORT=8080 \
|
||||||
|
-v /home/egustavs/Bitwarden/bw-data/:/data/:Z \
|
||||||
|
-p 8080:8080 \
|
||||||
|
bitwardenrs/server:latest
|
||||||
|
```
|
||||||
|
|
||||||
|
这将下载 bitwarden_rs 镜像并在用户命名空间下的用户容器中运行它。它使用 1024 以上的端口,以便非 root 用户可以绑定它。它还使用 `:Z` 更改卷的 SELinux 上下文,以防止在 `/data` 中的读写权限问题。
|
||||||
|
|
||||||
|
如果你在某个域下托管它,建议将此服务器放在 Apache 或 Nginx 的反向代理下。这样,你可以使用 80 和 443 端口指向容器的 8080 端口,而无需以 root 身份运行容器。
|
||||||
|
|
||||||
|
### 在 systemd 下运行
|
||||||
|
|
||||||
|
Bitwarden 现在运行了,你可能希望保持这种状态。接下来,创建一个使容器保持运行的单元文件,如果它没有响应则自动重新启动,并在系统重启后开始运行。创建文件 `/etc/systemd/system/bitwarden.service`:
|
||||||
|
|
||||||
|
```
|
||||||
|
[Unit]
|
||||||
|
Description=Bitwarden Podman container
|
||||||
|
Wants=syslog.service
|
||||||
|
|
||||||
|
[Service]
|
||||||
|
User=egustavs
|
||||||
|
Group=egustavs
|
||||||
|
TimeoutStartSec=0
|
||||||
|
ExecStart=/usr/bin/podman run 'bitwarden'
|
||||||
|
ExecStop=-/usr/bin/podman stop -t 10 'bitwarden'
|
||||||
|
Restart=always
|
||||||
|
RestartSec=30s
|
||||||
|
KillMode=none
|
||||||
|
|
||||||
|
[Install]
|
||||||
|
WantedBy=multi-user.target
|
||||||
|
```
|
||||||
|
|
||||||
|
现在使用 [sudo][12] 启用并启动该服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo systemctl enable bitwarden.service && sudo systemctl start bitwarden.service
|
||||||
|
$ systemctl status bitwarden.service
|
||||||
|
bitwarden.service - Bitwarden Podman container
|
||||||
|
Loaded: loaded (/etc/systemd/system/bitwarden.service; enabled; vendor preset: disabled)
|
||||||
|
Active: active (running) since Tue 2019-07-09 20:23:16 UTC; 1 day 14h ago
|
||||||
|
Main PID: 14861 (podman)
|
||||||
|
Tasks: 44 (limit: 4696)
|
||||||
|
Memory: 463.4M
|
||||||
|
```
|
||||||
|
|
||||||
|
成功了!Bitwarden 现在运行了并将继续运行。
|
||||||
|
|
||||||
|
### 添加 LetsEncrypt
|
||||||
|
|
||||||
|
如果你有域名,强烈建议你使用类似 LetsEncrypt 的加密证书运行你的 Bitwarden 实例。Certbot 是一个为我们创建 LetsEncrypt 证书的机器人,这里有个[在 Fedora 中操作的指南][13]。
|
||||||
|
|
||||||
|
生成证书后,你可以按照 [bitwarden_rs 指南中关于 HTTPS 的部分来][14]。只要记得将 `:Z` 附加到 LetsEncrypt 来处理权限,而不用更改端口。
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
照片由 [CMDR Shane][15] 拍摄,发表在 [Unsplash][16] 上。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/manage-your-passwords-with-bitwarden-and-podman/
|
||||||
|
|
||||||
|
作者:[Eric Gustavsson][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/egustavs/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/bitwarden-816x345.jpg
|
||||||
|
[2]: https://www.lastpass.com
|
||||||
|
[3]: https://1password.com/
|
||||||
|
[4]: https://www.dashlane.com/
|
||||||
|
[5]: https://lesspass.com/
|
||||||
|
[6]: https://keepass.info/
|
||||||
|
[7]: https://bitwarden.com/
|
||||||
|
[8]: https://en.wikipedia.org/wiki/WebDAV
|
||||||
|
[9]: https://github.com/dani-garcia/bitwarden_rs/
|
||||||
|
[10]: https://blog.bitwarden.com/bitwarden-completes-third-party-security-audit-c1cc81b6d33
|
||||||
|
[11]: https://github.com/dani-garcia/bitwarden_rs/wiki#missing-features
|
||||||
|
[12]: https://fedoramagazine.org/howto-use-sudo/
|
||||||
|
[13]: https://certbot.eff.org/instructions
|
||||||
|
[14]: https://github.com/dani-garcia/bitwarden_rs/wiki/Enabling-HTTPS
|
||||||
|
[15]: https://unsplash.com/@cmdrshane?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||||
|
[16]: https://unsplash.com/search/photos/password?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||||
@ -0,0 +1,94 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11185-1.html)
|
||||||
|
[#]: subject: (Command line quick tips: More about permissions)
|
||||||
|
[#]: via: (https://fedoramagazine.org/command-line-quick-tips-more-about-permissions/)
|
||||||
|
[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
|
||||||
|
|
||||||
|
命令行快速提示:权限进阶
|
||||||
|
======
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
前一篇文章[介绍了 Fedora 系统上有关文件权限的一些基础知识][2]。本部分介绍使用权限管理文件访问和共享的其他方法。它建立在前一篇文章中的知识和示例的基础上,所以如果你还没有阅读过那篇文章,请[查看][2]它。
|
||||||
|
|
||||||
|
### 符号与八进制
|
||||||
|
|
||||||
|
在上一篇文章中,你了解到文件有三个不同的权限集。拥有该文件的用户有一个集合,拥有该文件的组的成员有一个集合,然后最终一个集合适用于其他所有人。在长列表(`ls -l`)中这些权限使用符号模式显示在屏幕上。
|
||||||
|
|
||||||
|
每个集合都有 `r`、`w` 和 `x` 条目,表示特定用户(所有者、组成员或其他)是否可以读取、写入或执行该文件。但是还有另一种表达这些权限的方法:八进制模式。
|
||||||
|
|
||||||
|
你已经习惯了[十进制][3]编号系统,它有十个不同的值(`0` 到 `9`)。另一方面,八进制系统有八个不同的值(`0` 到 `7`)。在表示权限时,八进制用作速记来显示 `r`、`w` 和 `x` 字段的值。将每个字段视为具有如下值:
|
||||||
|
|
||||||
|
* `r` = 4
|
||||||
|
* `w` = 2
|
||||||
|
* `x` = 1
|
||||||
|
|
||||||
|
现在,你可以使用单个八进制值表达任何组合。例如,读取和写入权限(但没有执行权限)的值为 `6`。读取和执行权限的值仅为 `5`。文件的 `rwxr-xr-x` 符号权限的八进制值为 `755`。
|
||||||
|
|
||||||
|
与符号值类似,你可以使用八进制值使用 `chmod` 命令设置文件权限。以下两个命令对文件设置相同的权限:
|
||||||
|
|
||||||
|
```
|
||||||
|
chmod u=rw,g=r,o=r myfile1
|
||||||
|
chmod 644 myfile1
|
||||||
|
```
|
||||||
|
|
||||||
|
### 特殊权限位
|
||||||
|
|
||||||
|
文件上还有几个特殊权限位。这些被称为 `setuid`(或 `suid`)、`setgid`(或 `sgid`),以及<ruby>粘滞位<rt>sticky bit</rt></ruby>(或<ruby>阻止删除位<rt>delete inhibit</rt></ruby>)。 将此视为另一组八进制值:
|
||||||
|
|
||||||
|
* `setuid` = 4
|
||||||
|
* `setgid` = 2
|
||||||
|
* `sticky` = 1
|
||||||
|
|
||||||
|
**除非**该文件是可执行的,否则 `setuid` 位是被忽略的。如果是可执行的这种情况,则该文件(可能是应用程序或脚本)的运行就像拥有该文件的用户启动的一样。`setuid` 的一个很好的例子是 `/bin/passwd` 实用程序,它允许用户设置或更改密码。此实用程序必须能够写入到不允许普通用户更改的文件中(LCTT 译注:此处是指 `/etc/passwd` 和 `/etc/shadow`)。因此它需要精心编写,由 `root` 用户拥有,并具有 `setuid` 位,以便它可以更改密码相关文件。
|
||||||
|
|
||||||
|
`setgid` 位对于可执行文件的工作方式类似。该文件将使用拥有它的组的权限运行。但是,`setgid` 对于目录还有一个额外的用途。如果在具有 `setgid` 权限的目录中创建文件,则该文件的组所有者将设置为该目录的组所有者。
|
||||||
|
|
||||||
|
最后,虽然文件粘滞位没有意义会被忽略,但它对目录很有用。在目录上设置的粘滞位将阻止用户删除其他用户拥有的该目录中的文件。
|
||||||
|
|
||||||
|
在八进制模式下使用 `chmod` 设置这些位的方法是添加一个值前缀,例如 `4755`,可以将 `setuid` 添加到可执行文件中。在符号模式下,`u` 和 `g` 也可用于设置或删除 `setuid` 和 `setgid`,例如 `u+s,g+s`。粘滞位使用 `o+t` 设置。(其他的组合,如 `o+s` 或 `u+t`,是没有意义的,会被忽略。)
|
||||||
|
|
||||||
|
### 共享与特殊权限
|
||||||
|
|
||||||
|
回想一下前一篇文章中关于需要共享文件的财务团队的示例。可以想象,特殊权限位有助于更有效地解决问题。原来的解决方案只是创建了一个整个组可以写入的目录:
|
||||||
|
|
||||||
|
```
|
||||||
|
drwxrwx---. 2 root finance 4096 Jul 6 15:35 finance
|
||||||
|
```
|
||||||
|
|
||||||
|
此目录的一个问题是,`finance` 组成员的用户 `dwayne` 和 `jill` 可以删除彼此的文件。这对于共享空间来说不是最佳选择。它在某些情况下可能有用,但在处理财务记录时可能不会!
|
||||||
|
|
||||||
|
另一个问题是此目录中的文件可能无法真正共享,因为它们将由 `dwayne` 和 `jill` 的默认组拥有 - 很可能用户私有组也命名为 `dwayne` 和 `jill`,而不是 `finance`。
|
||||||
|
|
||||||
|
解决此问题的更好方法是在文件夹上设置 `setgid` 和粘滞位。这将做两件事:使文件夹中创建的文件自动归 `finance` 组所有,并防止 `dwayne` 和 `jill` 删除彼此的文件。下面这些命令中的任何一个都可以工作:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo chmod 3770 finance
|
||||||
|
sudo chmod u+rwx,g+rwxs,o+t finance
|
||||||
|
```
|
||||||
|
|
||||||
|
该文件的长列表现在显示了所应用的新特殊权限。粘滞位显示为 `T` 而不是 `t`,因为 `finance` 组之外的用户无法搜索该文件夹。
|
||||||
|
|
||||||
|
```
|
||||||
|
drwxrws--T. 2 root finance 4096 Jul 6 15:35 finance
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/command-line-quick-tips-more-about-permissions/
|
||||||
|
|
||||||
|
作者:[Paul W. Frields][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/pfrields/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://fedoramagazine.org/wp-content/uploads/2018/10/commandlinequicktips-816x345.jpg
|
||||||
|
[2]: https://linux.cn/article-11123-1.html
|
||||||
|
[3]: https://en.wikipedia.org/wiki/Decimal
|
||||||
@ -0,0 +1,288 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (robsean)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-11178-1.html)
|
||||||
|
[#]: subject: (Top 8 Things to do after Installing Debian 10 (Buster))
|
||||||
|
[#]: via: (https://www.linuxtechi.com/things-to-do-after-installing-debian-10/)
|
||||||
|
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||||
|
|
||||||
|
Debian 10(Buster)安装后要做的前 8 件事
|
||||||
|
======
|
||||||
|
|
||||||
|
Debian 10 的代号是 Buster,它是来自 Debian 家族的最新 LTS 发布版本,并包含大量的特色功能。因此,如果你已经在你的电脑上安装了 Debian 10,并在思考接下来该做什么,那么,请继续阅读这篇文章直到结尾,因为我们为你提供在安装 Debian 10 后要做的前 8 件事。对于还没有安装 Debian 10 的人们,请阅读这篇指南 [图解 Debian 10 (Buster) 安装步骤][1]。 让我们继续这篇文章。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 1) 安装和配置 sudo
|
||||||
|
|
||||||
|
在设置完成 Debian 10 后,你需要做的第一件事是安装 sudo 软件包,因为它能够使你获得管理员权限来安装你需要的软件包。为安装和配置 sudo,请使用下面的命令:
|
||||||
|
|
||||||
|
变成 root 用户,然后使用下面的命令安装 sudo 软件包,
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ su -
|
||||||
|
Password:
|
||||||
|
root@linuxtechi:~# apt install sudo -y
|
||||||
|
```
|
||||||
|
|
||||||
|
添加你的本地用户到 sudo 组,使用下面的 [usermod][2] 命令,
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~# usermod -aG sudo pkumar
|
||||||
|
root@linuxtechi:~#
|
||||||
|
```
|
||||||
|
|
||||||
|
现在验证是否本地用户获得 sudo 权限:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ id
|
||||||
|
uid=1000(pkumar) gid=1000(pkumar) groups=1000(pkumar),27(sudo)
|
||||||
|
root@linuxtechi:~$ sudo vi /etc/hosts
|
||||||
|
[sudo] password for pkumar:
|
||||||
|
root@linuxtechi:~$
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2) 校正日期和时间
|
||||||
|
|
||||||
|
在你成功配置 sudo 软件包后,接下来,你需要根据你的位置来校正日期和时间。为了校正日期和时间,
|
||||||
|
|
||||||
|
转到系统 **设置** –> **详细说明** –> **日期和时间** ,然后更改为适合你的位置的时区。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
一旦时区被更改,你可以看到时钟中的时间自动更改。
|
||||||
|
|
||||||
|
### 3) 应用所有更新
|
||||||
|
|
||||||
|
在 Debian 10 安装后,建议安装所有 Debian 10 软件包存储库中可用的更新,执行下面的 `apt` 命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt update
|
||||||
|
root@linuxtechi:~$ sudo apt upgrade -y
|
||||||
|
```
|
||||||
|
|
||||||
|
**注意:** 如果你是 vi 编辑器的忠实粉丝,那么使用下面的 `apt` 命令安装 `vim`:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt install vim -y
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4) 安装 Flash 播放器插件
|
||||||
|
|
||||||
|
默认情况下,Debian 10(Buster)存储库不包含 Flash 插件,因此,用户需要遵循下面的介绍来在他们的系统中查找和安装 flash 播放器。
|
||||||
|
|
||||||
|
为 Flash 播放器配置存储库:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ echo "deb http://ftp.de.debian.org/debian buster main contrib" | sudo tee -a /etc/apt/sources.list
|
||||||
|
deb http://ftp.de.debian.org/debian buster main contrib
|
||||||
|
root@linuxtechi:~
|
||||||
|
```
|
||||||
|
|
||||||
|
现在使用下面的命令更新软件包索引:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt update
|
||||||
|
```
|
||||||
|
|
||||||
|
使用下面的 `apt` 命令安装 Flash 插件:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt install pepperflashplugin-nonfree -y
|
||||||
|
```
|
||||||
|
|
||||||
|
一旦软件包被成功安装,接下来,尝试播放 YouTube 中的视频:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 5) 安装软件,如 VLC、Skype、FileZilla 和截图工具
|
||||||
|
|
||||||
|
如此,现在我们已经启用 Flash 播放器,是时候在我们的 Debian 10 系统中安装所有其它的软件,如 VLC、Skype,Filezilla 和截图工具(flameshot)。
|
||||||
|
|
||||||
|
#### 安装 VLC 多媒体播放器
|
||||||
|
|
||||||
|
为在你的系统中安装 VLC 播放器,使用下面的 `apt` 命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt install vlc -y
|
||||||
|
```
|
||||||
|
|
||||||
|
在成功安装 VLC 播放器后,尝试播放你喜欢的视频。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### 安装 Skype
|
||||||
|
|
||||||
|
首先,下载最新的 Skype 软件包:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ wget https://go.skype.com/skypeforlinux-64.deb
|
||||||
|
```
|
||||||
|
|
||||||
|
接下来,使用 `apt` 命令安装软件包:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt install ./skypeforlinux-64.deb
|
||||||
|
```
|
||||||
|
|
||||||
|
在成功安装 Skype 后,尝试访问它,并输入你的用户名和密码。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 安装 Filezilla
|
||||||
|
|
||||||
|
为在你的系统中安装 Filezilla,使用下面的 `apt` 命令,
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt install filezilla -y
|
||||||
|
```
|
||||||
|
|
||||||
|
一旦 FileZilla 软件包被成功安装,尝试访问它。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### 安装截图工具(flameshot)
|
||||||
|
|
||||||
|
使用下面的命令来安装截图工具:flameshot,
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt install flameshot -y
|
||||||
|
```
|
||||||
|
|
||||||
|
**注意:** Shutter 工具在 Debian 10 中已被移除。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 6) 启用和启动防火墙
|
||||||
|
|
||||||
|
总是建议启动防火墙来使你的网络安全。如果你希望在 Debian 10 中启用防火墙, **UFW**(简单的防火墙)是最好的控制防火墙的工具。UFW 在 Debian 存储库中可用,它非常容易安装,如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt install ufw
|
||||||
|
```
|
||||||
|
|
||||||
|
在你安装 UFW 后,接下来的步骤是设置防火墙。因此,设置防火墙,通过拒绝端口来禁用所有的传入流量,并且只允许需要的端口传出,像 ssh、http 和 https。
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo ufw default deny incoming
|
||||||
|
Default incoming policy changed to 'deny'
|
||||||
|
(be sure to update your rules accordingly)
|
||||||
|
root@linuxtechi:~$ sudo ufw default allow outgoing
|
||||||
|
Default outgoing policy changed to 'allow'
|
||||||
|
(be sure to update your rules accordingly)
|
||||||
|
root@linuxtechi:~$
|
||||||
|
```
|
||||||
|
|
||||||
|
允许 SSH 端口:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo ufw allow ssh
|
||||||
|
Rules updated
|
||||||
|
Rules updated (v6)
|
||||||
|
root@linuxtechi:~$
|
||||||
|
```
|
||||||
|
|
||||||
|
假使你在系统中已经安装 Web 服务器,那么使用下面的 `ufw` 命令来在防火墙中允许它们的端口:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo ufw allow 80
|
||||||
|
Rules updated
|
||||||
|
Rules updated (v6)
|
||||||
|
root@linuxtechi:~$ sudo ufw allow 443
|
||||||
|
Rules updated
|
||||||
|
Rules updated (v6)
|
||||||
|
root@linuxtechi:~$
|
||||||
|
```
|
||||||
|
|
||||||
|
最后,你可以使用下面的命令启用 UFW:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo ufw enable
|
||||||
|
Command may disrupt existing ssh connections. Proceed with operation (y|n)? y
|
||||||
|
Firewall is active and enabled on system startup
|
||||||
|
root@linuxtechi:~$
|
||||||
|
```
|
||||||
|
|
||||||
|
假使你想检查你的防火墙的状态,你可以使用下面的命令检查它:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo ufw status
|
||||||
|
```
|
||||||
|
|
||||||
|
### 7) 安装虚拟化软件(VirtualBox)
|
||||||
|
|
||||||
|
安装 Virtualbox 的第一步是将 Oracle VirtualBox 存储库的公钥导入到你的 Debian 10 系统:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
|
||||||
|
OK
|
||||||
|
root@linuxtechi:~$ wget -q https://www.virtualbox.org/download/oracle_vbox.asc -O- | sudo apt-key add -
|
||||||
|
OK
|
||||||
|
root@linuxtechi:~$
|
||||||
|
```
|
||||||
|
|
||||||
|
如果导入成功,你将看到一个 “OK” 显示信息。
|
||||||
|
|
||||||
|
接下来,你需要添加存储库到仓库列表:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo add-apt-repository "deb http://download.virtualbox.org/virtualbox/debian buster contrib"
|
||||||
|
root@linuxtechi:~$
|
||||||
|
```
|
||||||
|
|
||||||
|
最后,是时候在你的系统中安装 VirtualBox 6.0:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt update
|
||||||
|
root@linuxtechi:~$ sudo apt install virtualbox-6.0 -y
|
||||||
|
```
|
||||||
|
|
||||||
|
一旦 VirtualBox 软件包被成功安装,尝试访问它,并开始创建虚拟机。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 8) 安装最新的 AMD 驱动程序
|
||||||
|
|
||||||
|
最后,你也可以安装需要的附加 AMD 显卡驱动程序(如 ATI 专有驱动)和 Nvidia 图形驱动程序。为安装最新的 AMD 驱动程序,首先,我们需要修改 `/etc/apt/sources.list` 文件,在包含 **main** 和 **contrib** 的行中添加 **non-free** 单词,示例如下显示:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo vi /etc/apt/sources.list
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
...
|
||||||
|
deb http://deb.debian.org/debian/ buster main non-free contrib
|
||||||
|
deb-src http://deb.debian.org/debian/ buster main non-free contrib
|
||||||
|
|
||||||
|
deb http://security.debian.org/debian-security buster/updates main contrib non-free
|
||||||
|
deb-src http://security.debian.org/debian-security buster/updates main contrib non-free
|
||||||
|
|
||||||
|
deb http://ftp.us.debian.org/debian/ buster-updates main contrib non-free
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,使用下面的 `apt` 命令来在 Debian 10 系统中安装最新的 AMD 驱动程序。
|
||||||
|
|
||||||
|
```
|
||||||
|
root@linuxtechi:~$ sudo apt update
|
||||||
|
root@linuxtechi:~$ sudo apt install firmware-linux firmware-linux-nonfree libdrm-amdgpu1 xserver-xorg-video-amdgpu -y
|
||||||
|
```
|
||||||
|
|
||||||
|
这就是这篇文章的全部内容,我希望你了解在安装 Debian 10 后应该做什么。请在下面的评论区,分享你的反馈和评论。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linuxtechi.com/things-to-do-after-installing-debian-10/
|
||||||
|
|
||||||
|
作者:[Pradeep Kumar][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[robsean](https://github.com/robsean)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://linux.cn/article-11083-1.html
|
||||||
|
[2]: https://www.linuxtechi.com/linux-commands-to-manage-local-accounts/
|
||||||
131
published/20190730 How to create a pull request in GitHub.md
Executable file
131
published/20190730 How to create a pull request in GitHub.md
Executable file
@ -0,0 +1,131 @@
|
|||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "furrybear"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-11215-1.html"
|
||||||
|
[#]: subject: "How to create a pull request in GitHub"
|
||||||
|
[#]: via: "https://opensource.com/article/19/7/create-pull-request-github"
|
||||||
|
[#]: author: "Kedar Vijay Kulkarni https://opensource.com/users/kkulkarn"
|
||||||
|
|
||||||
|
如何在 Github 上创建一个拉取请求
|
||||||
|
======
|
||||||
|
|
||||||
|
> 学习如何复刻一个仓库,进行更改,并要求维护人员审查并合并它。
|
||||||
|
|
||||||
|
![a checklist for a team][1]
|
||||||
|
|
||||||
|
你知道如何使用 git 了,你有一个 [GitHub][2] 仓库并且可以向它推送。这一切都很好。但是你如何为他人的 GitHub 项目做出贡献? 这是我在学习 git 和 GitHub 之后想知道的。在本文中,我将解释如何<ruby>复刻<rt>fork</rt></ruby>一个 git 仓库、进行更改并提交一个<ruby>拉取请求<rt>pull request</rt></ruby>。
|
||||||
|
|
||||||
|
当你想要在一个 GitHub 项目上工作时,第一步是复刻一个仓库。
|
||||||
|
|
||||||
|
![Forking a GitHub repo][3]
|
||||||
|
|
||||||
|
你可以使用[我的演示仓库][4]试一试。
|
||||||
|
|
||||||
|
当你在这个页面时,单击右上角的 “Fork”(复刻)按钮。这将在你的 GitHub 用户账户下创建我的演示仓库的一个新副本,其 URL 如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
https://github.com/<你的用户名>/demo
|
||||||
|
```
|
||||||
|
|
||||||
|
这个副本包含了原始仓库中的所有代码、分支和提交。
|
||||||
|
|
||||||
|
接下来,打开你计算机上的终端并运行命令来<ruby>克隆<rt>clone</rt></ruby>仓库:
|
||||||
|
|
||||||
|
```
|
||||||
|
git clone https://github.com/<你的用户名>/demo
|
||||||
|
```
|
||||||
|
|
||||||
|
一旦仓库被克隆后,你需要做两件事:
|
||||||
|
|
||||||
|
1、通过发出命令创建一个新分支 `new_branch` :
|
||||||
|
|
||||||
|
```
|
||||||
|
git checkout -b new_branch
|
||||||
|
```
|
||||||
|
|
||||||
|
2、使用以下命令为上游仓库创建一个新的<ruby>远程<rt>remote</rt></ruby>:
|
||||||
|
|
||||||
|
```
|
||||||
|
git remote add upstream https://github.com/kedark3/demo
|
||||||
|
```
|
||||||
|
|
||||||
|
在这种情况下,“上游仓库”指的是你创建复刻来自的原始仓库。
|
||||||
|
|
||||||
|
现在你可以更改代码了。以下代码创建一个新分支,进行任意更改,并将其推送到 `new_branch` 分支:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git checkout -b new_branch
|
||||||
|
Switched to a new branch ‘new_branch’
|
||||||
|
$ echo “some test file” > test
|
||||||
|
$ cat test
|
||||||
|
Some test file
|
||||||
|
$ git status
|
||||||
|
On branch new_branch
|
||||||
|
No commits yet
|
||||||
|
Untracked files:
|
||||||
|
(use "git add <file>..." to include in what will be committed)
|
||||||
|
test
|
||||||
|
nothing added to commit but untracked files present (use "git add" to track)
|
||||||
|
$ git add test
|
||||||
|
$ git commit -S -m "Adding a test file to new_branch"
|
||||||
|
[new_branch (root-commit) 4265ec8] Adding a test file to new_branch
|
||||||
|
1 file changed, 1 insertion(+)
|
||||||
|
create mode 100644 test
|
||||||
|
$ git push -u origin new_branch
|
||||||
|
Enumerating objects: 3, done.
|
||||||
|
Counting objects: 100% (3/3), done.
|
||||||
|
Writing objects: 100% (3/3), 918 bytes | 918.00 KiB/s, done.
|
||||||
|
Total 3 (delta 0), reused 0 (delta 0)
|
||||||
|
Remote: Create a pull request for ‘new_branch’ on GitHub by visiting:
|
||||||
|
Remote: <http://github.com/example/Demo/pull/new/new\_branch>
|
||||||
|
Remote:
|
||||||
|
* [new branch] new_branch -> new_branch
|
||||||
|
```
|
||||||
|
|
||||||
|
一旦你将更改推送到您的仓库后, “Compare & pull request”(比较和拉取请求)按钮将出现在GitHub。
|
||||||
|
|
||||||
|
![GitHub's Compare & Pull Request button][5]
|
||||||
|
|
||||||
|
单击它,你将进入此屏幕:
|
||||||
|
|
||||||
|
![GitHub's Open pull request button][6]
|
||||||
|
|
||||||
|
单击 “Create pull request”(创建拉取请求)按钮打开一个拉取请求。这将允许仓库的维护者们审查你的贡献。然后,如果你的贡献是没问题的,他们可以合并它,或者他们可能会要求你做一些改变。
|
||||||
|
|
||||||
|
### 精简版
|
||||||
|
|
||||||
|
总之,如果您想为一个项目做出贡献,最简单的方法是:
|
||||||
|
|
||||||
|
1. 找到您想要贡献的项目
|
||||||
|
2. 复刻它
|
||||||
|
3. 将其克隆到你的本地系统
|
||||||
|
4. 建立一个新的分支
|
||||||
|
5. 进行你的更改
|
||||||
|
6. 将其推送回你的仓库
|
||||||
|
7. 单击 “Compare & pull request”(比较和拉取请求)按钮
|
||||||
|
8. 单击 “Create pull request”(创建拉取请求)以打开一个新的拉取请求
|
||||||
|
|
||||||
|
如果审阅者要求更改,请重复步骤 5 和 6,为你的拉取请求添加更多提交。
|
||||||
|
|
||||||
|
快乐编码!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/19/7/create-pull-request-github
|
||||||
|
|
||||||
|
作者:[Kedar Vijay Kulkarni][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[furrybear](https://github.com/furrybear)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/kkulkarnhttps://opensource.com/users/fontanahttps://opensource.com/users/mhanwellhttps://opensource.com/users/mysentimentshttps://opensource.com/users/greg-p
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/checklist_hands_team_collaboration.png?itok=u82QepPk "a checklist for a team"
|
||||||
|
[2]: https://github.com/
|
||||||
|
[3]: https://opensource.com/sites/default/files/uploads/forkrepo.png "Forking a GitHub repo"
|
||||||
|
[4]: https://github.com/kedark3/demo
|
||||||
|
[5]: https://opensource.com/sites/default/files/uploads/compare-and-pull-request-button.png "GitHub's Compare & Pull Request button"
|
||||||
|
[6]: https://opensource.com/sites/default/files/uploads/open-a-pull-request_crop.png "GitHub's Open pull request button"
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user