mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
8ee629c469
75
lctt2018.md
Normal file
75
lctt2018.md
Normal file
@ -0,0 +1,75 @@
|
||||
LCTT 2018:五周年纪念日
|
||||
======
|
||||
|
||||
我是老王,可能大家有不少人知道我,由于历史原因,我有好几个生日(;o),但是这些年来,我又多了一个生日,或者说纪念日——每过两年,我就要严肃认真地写一篇 [LCTT](https://linux.cn/lctt) 生日纪念文章。
|
||||
|
||||
喏,这一篇,就是今年的了,LCTT 如今已经五岁了!
|
||||
|
||||
或许如同小孩子过生日总是比较快乐,而随着年岁渐长,过生日往往有不少负担——比如说,每次写这篇纪念文章时,我就需要回忆、反思这两年的做了些什么,往往颇为汗颜。
|
||||
|
||||
不过不管怎么说,总要总结一下这两年我们做了什么,有什么不足,也发一些展望吧。
|
||||
|
||||
### 江山代有英豪出
|
||||
|
||||
LCTT,如同一般的开源贡献组织,总是有不断的新老传承。我们的翻译组,也有不少成员,由于工作学习的原因,慢慢淡出,但同时,也不断有新的成员加入并接过前辈手中的旗帜(就是没人接我的)。
|
||||
|
||||
> **加入方式**
|
||||
|
||||
> 请首先加入翻译组的 QQ 群,群号是:**198889102**,加群时请说明是“**志愿者**”。加入后记得修改您的群名片为您的 GitHub 的 ID。
|
||||
|
||||
> 加入的成员,请先阅读 [WIKI 如何开始](https://github.com/LCTT/TranslateProject/wiki/01-%E5%A6%82%E4%BD%95%E5%BC%80%E5%A7%8B)。
|
||||
|
||||
比如说,我们这两年来,oska874 承担了主要的选题工作,然后 lujun9972 适时的出现接过了不少选题工作;再比如说,qhwdw 出现后承担了大量繁难文章的翻译,pityonline 则专注于校对,甚至其校对的严谨程度让我都甘拜下风。还有 MjSeven 也同 qhwdw 一样,以极高的翻译频率从一星译者迅速登顶五星译者。当然,还有 Bestony、Locez、VizV 等人为 LCTT 提供了不少技术支持和开发工作。
|
||||
|
||||
### 硕果累累
|
||||
|
||||
我们并没有特别的招新渠道,但是总是时不时会有新的成员慕名而来,到目前为止,我们已经有 [331](https://linux.cn/lctt-list) 位做过贡献的成员,已经翻译发布了 3885 篇译文,合计字节达 33MB 之多!
|
||||
|
||||
这两年,我们不但翻译了很多技术、新闻和评论类文章,也新增了新的翻译类型:[漫画](https://linux.cn/talk/comic/),其中一些漫画得到了很多好评。
|
||||
|
||||
我们发布的文章有一些达到了 100000+ 的访问量,这对于我们这种技术垂直内容可不容易。
|
||||
|
||||
而同时,[Linux 中国](https://linux.cn/)也发布了近万篇文章,而这一篇,应该就是第 [9999](https://linux.cn/article-9999-1.html) 篇文章,我们将在明天,进入新的篇章。
|
||||
|
||||
### 贡献者主页和贡献者证书
|
||||
|
||||
为了彰显诸位贡献者的贡献,我们为每位贡献者创立的自己的专页,并据此建立了[排行榜](https://linux.cn/lctt-list)。
|
||||
|
||||
同时,我们还特意请 Bestony 和“一一”设计开发和”贡献者证书”,大家可以在 [LCTT 贡献平台](https://lctt.linux.cn/)中领取。
|
||||
|
||||
### 规则进化
|
||||
|
||||
LCTT 最初创立时,甚至都没有采用 PR 模式。但是随着贡献者的增多,我们也逐渐在改善我们的流程、方法。
|
||||
|
||||
之前采用了很粗糙的 PR 模式,对 PR 中的文件、提交乃至于信息都没有进行硬性约束。后来在 VizV 的帮助下,建立了对 PR 的合规性检查;又在 pityonline 的督促下,采用了更为严格的 PR 审查机制。
|
||||
|
||||
LCTT 创立几年来,我们的一些流程和规范,已经成为其它一些翻译组的参考范本,我们也希望我们的这些经验,可以进一步帮助到其它的开源社区。
|
||||
|
||||
### 仓库重建和版权问题
|
||||
|
||||
今年还发生一次严重的事故,由于对选题来源把控不严和对版权问题没有引起足够的重视,我们引用的一篇文章违背了原文的版权规定,结果被原文作者投诉到 GitHub。而我并没有及时看到 GitHub 给我发的 DMCA 处理邮件,因此错过了处理窗口期,从而被 GitHub 将整个库予以删除。
|
||||
|
||||
出现这样的重大失误之后,经过大家的帮助,我们历经周折才将仓库基本恢复。这要特别感谢 VizV 的辛苦工作。
|
||||
|
||||
在此之后,我们对译文选文的规则进行了梳理,并全面清查了文章版权。这个教训对我们来说弥足沉重。
|
||||
|
||||
### 通证时代
|
||||
|
||||
在 Linux 中国及 LCTT 发展过程中,我一直小心翼翼注意商业化的问题。严格来说,没有经济支持的开源组织如同无根之木,无源之水,是长久不了的。而商业化的技术社区又难免为了三斗米而折腰。所以往往很多技术社区要么渐渐凋零,要么就变成了商业机构。
|
||||
|
||||
从中国电信辞职后,我专职运营 Linux 中国这个开源社区已经近三年了,其间也有一些商业性收入,但是仅能勉强承担基本的运营费用。
|
||||
|
||||
这种尴尬的局面,使我,以及其它的开源社区同仁们纷纷寻求更好的发展之路。
|
||||
|
||||
去年参加中国开源年会时,在闭门会上,大家的讨论启发了我和诸位同仁,我们认为,开源社区结合通证经济,似乎是一条可行的开源社区发展之路。
|
||||
|
||||
今年 8 月 1 日,我们经过了半年的论证和实验,[发布了社区通证 LCCN](https://linux.cn/article-9886-1.html),并已经初步发放到了各位译者手中。我们还在继续建设通证生态各种工具,如合约、交易商城等。
|
||||
|
||||
我们希望能够通过通证为开源社区转入新的活力,也愿意将在探索道路上遇到的问题和解决的思路、工具链分享给更多的社区。
|
||||
|
||||
### 总结
|
||||
|
||||
从上一次总结以来,这又是七百多天,时光荏苒,而 LCTT 的创立也近两千天了。我希望,我们的翻译组以及更多的贡献者可以在通证经济的推动下,找到自洽、自治的发展道路;也希望能有更多的贡献者涌现出来接过我们的大旗,将开源发扬光大。
|
||||
|
||||
wxy
|
||||
2018/9/9 夜
|
||||
@ -0,0 +1,66 @@
|
||||
Scrot:让你在命令行中进行截屏更加简单
|
||||
======
|
||||
|
||||
> Scrot 是一个简单、灵活,并且提供了许多选项的 Linux 命令行截屏工具。
|
||||
|
||||
[][1]
|
||||
|
||||
|
||||
Linux 桌面上有许多用于截屏的优秀工具,比如 [Ksnapshot][1] 和 [Shutter][2] 。甚至 GNOME 桌面自带的简易截屏工具也能够很好的工作。但是,如果你很少截屏,或者你使用的 Linux 发行版没有内建截屏工具,或者你使用的是一台资源有限的老电脑,那么你该怎么办呢?
|
||||
|
||||
或许你可以转向命令行,使用一个叫做 [Scrot][4] 的实用工具。它能够完成简单的截屏工作,同时它所具有的一些特性也许会让你感到非常惊喜。
|
||||
|
||||
### 走近 Scrot
|
||||
|
||||
许多 Linux 发行版都会预先安装上 Scrot ,可以输入 `which scrot` 命令来查看系统中是否安装有 Scrot 。如果没有,那么可以使用你的 Linux 发行版的包管理器来安装。如果你想从源代码编译安装,那么也可以从 [GitHub][5] 上下载源代码。
|
||||
|
||||
如果要进行截屏,首先打开一个终端窗口,然后输入 `scrot [filename]` ,`[filename]` 是你想要保存的图片文件的名字(比如 `desktop.png`)。如果缺省了该参数,那么 scrot 会自动创建一个名字,比如 `2017-09-24-185009_1687x938_scrot.png` 。(这个名字缺乏了对图片内容的描述,这就是为什么最好在命令中指定一个名字作为参数。)
|
||||
|
||||
如果不带任何参数运行 Scrot,那么它将会对整个桌面进行截屏。如果不想这样,那么你也可以对屏幕中的一个小区域进行截图。
|
||||
|
||||
### 对单一窗口进行截屏
|
||||
|
||||
可以通过输入 `scrot -u [filename]` 命令来对一个窗口进行截屏。
|
||||
|
||||
`-u` 选项告诉 Scrot 对当前窗口进行截屏,这通常是我们正在工作的终端窗口,也许不是你想要的。
|
||||
|
||||
如果要对桌面上的另一个窗口进行截屏,需要输入 `scrot -s [filename]` 。
|
||||
|
||||
`-s` 选项可以让你做下面两件事的其中一件:
|
||||
|
||||
* 选择一个打开着的窗口
|
||||
* 在一个窗口的周围或一片区域画一个矩形进行捕获
|
||||
|
||||
你也可以设置一个时延,这样让你能够有时间来选择你想要捕获的窗口。可以通过 `scrot -u -d [num] [filename]` 来设置时延。
|
||||
|
||||
`-d` 选项告诉 Scrot 在捕获窗口前先等待一段时间,`[num]` 是需要等待的秒数。指定为 `-d 5` (等待 5 秒)应该能够让你有足够的时间来选择窗口。
|
||||
|
||||
### 更多有用的选项
|
||||
|
||||
Scrot 还提供了许多额外的特性(绝大多数我从来没有使用过)。下面是我发现的一些有用的选项:
|
||||
|
||||
* `-b` 捕获窗口的边界
|
||||
* `-t` 捕获窗口并创建一个缩略图。当你需要把截图张贴到网上的时候,这会非常有用
|
||||
* `-c` 当你同时使用了 `-d` 选项的时候,在终端中创建倒计时
|
||||
|
||||
如果你想了解 Scrot 的其他选项,可以在终端中输入 `man scrot` 来查看它的手册,或者[在线阅读][6]。然后开始使用 Scrot 进行截屏。
|
||||
|
||||
虽然 Scrot 很简单,但它的确能够工作得很好。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/taking-screen-captures-linux-command-line-scrot
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/community-penguins-osdc-lead.png?itok=BmqsAF4A
|
||||
[2]:https://www.kde.org/applications/graphics/ksnapshot/
|
||||
[3]:https://launchpad.net/shutter
|
||||
[4]:https://github.com/dreamer/scrot
|
||||
[5]:http://manpages.ubuntu.com/manpages/precise/man1/scrot.1.html
|
||||
[6]:https://github.com/dreamer/scrot
|
||||
@ -1,34 +1,35 @@
|
||||
API Star: Python 3 的 API 框架 – Polyglot.Ninja()
|
||||
API Star:一个 Python 3 的 API 框架
|
||||
======
|
||||
|
||||
为了在 Python 中快速构建 API,我主要依赖于 [Flask][1]。最近我遇到了一个名为 “API Star” 的基于 Python 3 的新 API 框架。由于几个原因,我对它很感兴趣。首先,该框架包含 Python 新特点,如类型提示和 asyncio。接着它再进一步并且为开发人员提供了很棒的开发体验。我们很快就会讲到这些功能,但在我们开始之前,我首先要感谢 Tom Christie,感谢他为 Django REST Framework 和 API Star 所做的所有工作。
|
||||
为了在 Python 中快速构建 API,我主要依赖于 [Flask][1]。最近我遇到了一个名为 “API Star” 的基于 Python 3 的新 API 框架。由于几个原因,我对它很感兴趣。首先,该框架包含 Python 新特点,如类型提示和 asyncio。而且它再进一步为开发人员提供了很棒的开发体验。我们很快就会讲到这些功能,但在我们开始之前,我首先要感谢 Tom Christie,感谢他为 Django REST Framework 和 API Star 所做的所有工作。
|
||||
|
||||
现在说回 API Star -- 我感觉这个框架很有成效。我可以选择基于 asyncio 编写异步代码,或者可以选择传统后端方式就像 WSGI 那样。它配备了一个命令行工具 - `apistar` 来帮助我们更快地完成工作。它支持 Django ORM 和 SQLAlchemy,这是可选的。它有一个出色类型系统,使我们能够定义输入和输出的约束,API Star 可以自动生成 api 模式(包括文档),提供验证和序列化功能等等。虽然 API Star 专注于构建 API,但你也可以非常轻松地在其上构建 Web 应用程序。在我们自己构建一些东西之前,所有这些可能都没有意义的。
|
||||
现在说回 API Star —— 我感觉这个框架很有成效。我可以选择基于 asyncio 编写异步代码,或者可以选择传统后端方式就像 WSGI 那样。它配备了一个命令行工具 —— `apistar` 来帮助我们更快地完成工作。它支持 Django ORM 和 SQLAlchemy,这是可选的。它有一个出色的类型系统,使我们能够定义输入和输出的约束,API Star 可以自动生成 API 的模式(包括文档),提供验证和序列化功能等等。虽然 API Star 专注于构建 API,但你也可以非常轻松地在其上构建 Web 应用程序。在我们自己构建一些东西之前,所有这些可能都没有意义的。
|
||||
|
||||
### 开始
|
||||
|
||||
我们将从安装 API Star 开始。为此实验创建一个虚拟环境是一个好主意。如果你不知道如何创建一个虚拟环境,不要担心,继续往下看。
|
||||
|
||||
```
|
||||
pip install apistar
|
||||
|
||||
```
|
||||
|
||||
(译注:上面的命令是在 Python 3 虚拟环境下使用的)
|
||||
|
||||
如果你没有使用虚拟环境或者 Python 3 的 `pip`,它被称为 `pip3`,那么使用 `pip3 install apistar` 代替。
|
||||
如果你没有使用虚拟环境或者你的 Python 3 的 `pip` 名为 `pip3`,那么使用 `pip3 install apistar` 代替。
|
||||
|
||||
一旦我们安装了这个包,我们就应该可以使用 `apistar` 命令行工具了。我们可以用它创建一个新项目,让我们在当前目录中创建一个新项目。
|
||||
|
||||
```
|
||||
apistar new .
|
||||
|
||||
```
|
||||
|
||||
现在我们应该创建两个文件:`app.py`,它包含主应用程序,然后是 `test.py`,它用于测试。让我们来看看 `app.py` 文件:
|
||||
|
||||
```
|
||||
from apistar import Include, Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
from apistar.handlers import docs_urls, static_urls
|
||||
|
||||
|
||||
def welcome(name=None):
|
||||
if name is None:
|
||||
return {'message': 'Welcome to API Star!'}
|
||||
@ -46,34 +47,34 @@ app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
在我们深入研究代码之前,让我们运行应用程序并查看它是否正常工作。我们在浏览器中输入 `http://127.0.0.1:8080/`,我们将得到以下响应:
|
||||
|
||||
```
|
||||
{"message": "Welcome to API Star!"}
|
||||
|
||||
```
|
||||
|
||||
如果我们输入:`http://127.0.0.1:8080/?name=masnun`
|
||||
|
||||
```
|
||||
{"message": "Welcome to API Star, masnun!"}
|
||||
|
||||
```
|
||||
|
||||
同样的,输入 `http://127.0.0.1:8080/docs/`,我们将看到自动生成的 API 文档。
|
||||
|
||||
现在让我们来看看代码。我们有一个 `welcome` 函数,它接收一个名为 `name` 的参数,其默认值为 `None`。API Star 是一个智能的 api 框架。它将尝试在 url 路径或者查询字符串中找到 `name` 键并将其传递给我们的函数,它还基于其生成 API 文档。这真是太好了,不是吗?
|
||||
现在让我们来看看代码。我们有一个 `welcome` 函数,它接收一个名为 `name` 的参数,其默认值为 `None`。API Star 是一个智能的 API 框架。它将尝试在 url 路径或者查询字符串中找到 `name` 键并将其传递给我们的函数,它还基于其生成 API 文档。这真是太好了,不是吗?
|
||||
|
||||
然后,我们创建一个 `Route` 和 `Include` 实例列表,并将列表传递给 `App` 实例。`Route` 对象用于定义用户自定义路由。顾名思义,`Include` 包含了在给定的路径下的其它 url 路径。
|
||||
然后,我们创建一个 `Route` 和 `Include` 实例的列表,并将列表传递给 `App` 实例。`Route` 对象用于定义用户自定义路由。顾名思义,`Include` 包含了在给定的路径下的其它 url 路径。
|
||||
|
||||
### 路由
|
||||
|
||||
路由很简单。当构造 `App` 实例时,我们需要传递一个列表作为 `routes` 参数,这个列表应该有我们刚才看到的 `Route` 或 `Include` 对象组成。对于 `Route`,我们传递一个 url 路径,http 方法和可调用的请求处理程序(函数或者其他)。对于 `Include` 实例,我们传递一个 url 路径和一个 `Routes` 实例列表。
|
||||
|
||||
##### 路径参数
|
||||
#### 路径参数
|
||||
|
||||
我们可以在花括号内添加一个名称来声明 url 路径参数。例如 `/user/{user_id}` 定义了一个 url,其中 `user_id` 是路径参数,或者说是一个将被注入到处理函数(实际上是可调用的)中的变量。这有一个简单的例子:
|
||||
|
||||
```
|
||||
from apistar import Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
@ -91,22 +92,22 @@ app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
如果我们访问 `http://127.0.0.1:8080/user/23`,我们将得到以下响应:
|
||||
|
||||
```
|
||||
{"message": "Your profile id is: 23"}
|
||||
|
||||
```
|
||||
|
||||
但如果我们尝试访问 `http://127.0.0.1:8080/user/some_string`,它将无法匹配。因为我们定义了 `user_profile` 函数,且为 `user_id` 参数添加了一个类型提示。如果它不是整数,则路径不匹配。但是如果我们继续删除类型提示,只使用 `user_profile(user_id)`,它将匹配此 url。这也展示了 API Star 的智能之处和利用类型和好处。
|
||||
|
||||
#### 包含/分组路由
|
||||
|
||||
有时候将某些 url 组合在一起是有意义的。假设我们有一个处理用户相关功能的 `user` 模块,将所有与用户相关的 url 分组在 `/user` 路径下可能会更好。例如 `/user/new`, `/user/1`, `/user/1/update` 等等。我们可以轻松地在单独的模块或包中创建我们的处理程序和路由,然后将它们包含在我们自己的路由中。
|
||||
有时候将某些 url 组合在一起是有意义的。假设我们有一个处理用户相关功能的 `user` 模块,将所有与用户相关的 url 分组在 `/user` 路径下可能会更好。例如 `/user/new`、`/user/1`、`/user/1/update` 等等。我们可以轻松地在单独的模块或包中创建我们的处理程序和路由,然后将它们包含在我们自己的路由中。
|
||||
|
||||
让我们创建一个名为 `user` 的新模块,文件名为 `user.py`。我们将以下代码放入这个文件:
|
||||
|
||||
```
|
||||
from apistar import Route
|
||||
|
||||
@ -128,10 +129,10 @@ user_routes = [
|
||||
Route("/{user_id}/update", "GET", user_update),
|
||||
Route("/{user_id}/profile", "GET", user_profile),
|
||||
]
|
||||
|
||||
```
|
||||
|
||||
现在我们可以从 app 主文件中导入 `user_routes`,并像这样使用它:
|
||||
|
||||
```
|
||||
from apistar import Include
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
@ -146,7 +147,6 @@ app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
现在 `/user/new` 将委托给 `user_new` 函数。
|
||||
@ -154,21 +154,22 @@ if __name__ == '__main__':
|
||||
### 访问查询字符串/查询参数
|
||||
|
||||
查询参数中传递的任何参数都可以直接注入到处理函数中。比如 url `/call?phone=1234`,处理函数可以定义一个 `phone` 参数,它将从查询字符串/查询参数中接收值。如果 url 查询字符串不包含 `phone` 的值,那么它将得到 `None`。我们还可以为参数设置一个默认值,如下所示:
|
||||
|
||||
```
|
||||
def welcome(name=None):
|
||||
if name is None:
|
||||
return {'message': 'Welcome to API Star!'}
|
||||
return {'message': 'Welcome to API Star, %s!' % name}
|
||||
|
||||
```
|
||||
|
||||
在上面的例子中,我们为 `name` 设置了一个默认值 `None`。
|
||||
|
||||
### 注入对象
|
||||
|
||||
通过给一个请求程序添加类型提示,我们可以将不同的对象注入到视图中。注入请求相关对象有助于处理程序直接从内部访问它们。API Star 内置的 `http` 包中有几个内置对象。我们也可以使用它的类型系统来创建我们自己的自定义对象并将它们注入到我们的函数中。API Star 还根据指定的约束进行数据验证。
|
||||
通过给一个请求程序添加类型提示,我们可以将不同的对象注入到视图中。注入请求相关的对象有助于处理程序直接从内部访问它们。API Star 内置的 `http` 包中有几个内置对象。我们也可以使用它的类型系统来创建我们自己的自定义对象并将它们注入到我们的函数中。API Star 还根据指定的约束进行数据验证。
|
||||
|
||||
让我们定义自己的 `User` 类型,并将其注入到我们的请求处理程序中:
|
||||
|
||||
```
|
||||
from apistar import Include, Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
@ -197,10 +198,10 @@ app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
现在如果我们发送这样的请求:
|
||||
|
||||
```
|
||||
curl -X POST \
|
||||
http://127.0.0.1:8080/ \
|
||||
@ -214,6 +215,7 @@ curl -X POST \
|
||||
### 发送响应
|
||||
|
||||
如果你已经注意到,到目前为止,我们只可以传递一个字典,它将被转换为 JSON 并作为默认返回。但是,我们可以使用 `apistar` 中的 `Response` 类来设置状态码和其它任意响应头。这有一个简单的例子:
|
||||
|
||||
```
|
||||
from apistar import Route, Response
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
@ -236,15 +238,13 @@ app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
它应该返回纯文本响应和一个自定义标响应头。请注意,`content` 应该是字节,而不是字符串。这就是我编码它的原因。
|
||||
|
||||
### 继续
|
||||
|
||||
我刚刚介绍了 API
|
||||
Star 的一些特性,API Star 中还有许多非常酷的东西,我建议通过 [Github Readme][2] 文件来了解这个优秀框架所提供的不同功能的更多信息。我还将尝试在未来几天内介绍关于 API Star 的更多简短的,集中的教程。
|
||||
我刚刚介绍了 API Star 的一些特性,API Star 中还有许多非常酷的东西,我建议通过 [Github Readme][2] 文件来了解这个优秀框架所提供的不同功能的更多信息。我还将尝试在未来几天内介绍关于 API Star 的更多简短的,集中的教程。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -253,7 +253,7 @@ via: http://polyglot.ninja/api-star-python-3-api-framework/
|
||||
|
||||
作者:[MASNUN][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,60 +1,56 @@
|
||||
Etcher.io 入门
|
||||
======
|
||||
> 用这个易用的媒体创建工具来创建一个可引导的 USB 盘或 SD 卡。
|
||||
|
||||

|
||||
|
||||
可启动 USB 盘是尝试新的 Linux 发行版的很好的方式,以便在安装之前查看你是否喜欢它。虽然一些 Linux 发行版(如 [Fedora][1])可以轻松创建可启动媒体,但大多数其他发行版提供 ISO 或镜像文件,并将创建媒体决定留给用户。用户总是可以选择使用 `dd` 在命令行上创建媒体 - 但让我们面对它,即使对于最有经验的用户来说,这仍然很痛苦。还有其他程序,如 Mac 上的 UnetBootIn、Disk Utility 和 Windows 上的 Win32DiskImager,它们都可以创建可启动的 USB。
|
||||
可启动 USB 盘是尝试新的 Linux 发行版的很好的方式,以便在安装之前查看你是否喜欢它。虽然一些 Linux 发行版(如 [Fedora][1])可以轻松创建可启动媒体,但大多数其他发行版提供 ISO 或镜像文件,并将创建媒体决定留给用户。用户总是可以选择使用 `dd` 在命令行上创建媒体——但让我们面对现实,即使对于最有经验的用户来说,这仍然很痛苦。也有一些其它程序,如 Mac 上的 UnetBootIn、Disk Utility 和 Windows 上的 Win32DiskImager,它们都可以创建可启动的 USB。
|
||||
|
||||
### 安装 Etcher
|
||||
|
||||
大约 18 个月前,我遇到了 [Etcher.io][2],这是一个很棒的开源项目,可以在 Linux、Windows 或 MacOS 上轻松,简单地创建媒体。Etcher.io 已成为我为 Linux 创建可启动媒体的“首选”程序。我可以轻松下载 ISO 或 IMG 文件并将其刻录到闪存和 SD 卡。这是一个 [Apache 2.0][3] 许可证下的开源项目,[源代码][4] 可在 GitHub 上获得。
|
||||
大约 18 个月前,我遇到了 [Etcher.io][2],这是一个很棒的开源项目,可以在 Linux、Windows 或 MacOS 上轻松、简单地创建媒体。Etcher.io 已成为我为 Linux 创建可启动媒体的“首选”程序。我可以轻松下载 ISO 或 IMG 文件并将其刻录到闪存和 SD 卡。这是一个 [Apache 2.0][3] 许可证下的开源项目,[源代码][4] 可在 GitHub 上获得。
|
||||
|
||||
进入 [Etcher.io][5] 网站,然后单击适用于你的操作系统-32 位或 64 位 Linux,32 位或 64 位 Windows 或 MacOS 的下载链接。
|
||||
进入 [Etcher.io][5] 网站,然后单击适用于你的操作系统:32 位或 64 位 Linux、32 位或 64 位 Windows 或 MacOS 的下载链接。
|
||||
|
||||
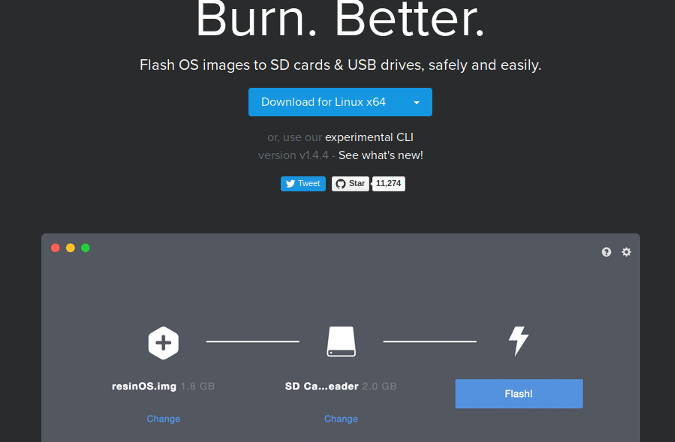
|
||||
|
||||
Etcher 在 GitHub 仓库中提供了很好的指导,用于将 Etcher 添加到你的 Linux 实用程序集合中。
|
||||
Etcher 在 GitHub 仓库中提供了很好的指导,可以将 Etcher 添加到你的 Linux 实用程序集合中。
|
||||
|
||||
如果你使用的是 Debian 或 Ubuntu,请添加 Etcher Debian 仓库:
|
||||
|
||||
```
|
||||
$echo "deb https://dl.bintray.com/resin-io/debian stable etcher" | sudo tee /etc/apt/sources.list.d/etcher.list
|
||||
```
|
||||
$echo "deb https://dl.bintray.com/resin-io/debian stable etcher" | sudo tee
|
||||
|
||||
/etc/apt/sources.list.d/etcher.list
|
||||
|
||||
|
||||
|
||||
信任 Bintray.com GPG 密钥
|
||||
|
||||
```
|
||||
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 379CE192D401AB61
|
||||
|
||||
```
|
||||
|
||||
然后更新你的系统并安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install etcher-electron
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是 Fedora 或 Red Hat Enterprise Linux,请添加 Etcher RPM 仓库:
|
||||
|
||||
```
|
||||
$ sudo wget https://bintray.com/resin-io/redhat/rpm -O /etc/yum.repos.d/bintray-
|
||||
|
||||
resin-io-redhat.repo
|
||||
|
||||
$ sudo wget https://bintray.com/resin-io/redhat/rpm -O /etc/yum.repos.d/bintray-resin-io-redhat.repo
|
||||
```
|
||||
|
||||
使用以下任一方式更新和安装:
|
||||
|
||||
```
|
||||
$ sudo yum install -y etcher-electron
|
||||
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
$ sudo dnf install -y etcher-electron
|
||||
|
||||
```
|
||||
|
||||
### 创建可启动盘
|
||||
@ -65,13 +61,13 @@ $ sudo dnf install -y etcher-electron
|
||||
|
||||

|
||||
|
||||
单击 **Select Image**。在本例中,我想创建一个可启动的 USB 盘,以便在新计算机上安装 Ubermix。在我选择了我的 Ubermix 镜像文件并将我的 USB 盘插入计算机,Etcher.io “看到”了驱动器,我就可以开始在 USB 上安装 Ubermix 了。
|
||||
单击 “Select Image”。在本例中,我想创建一个可启动的 USB 盘,以便在新计算机上安装 Ubermix。在我选择了我的 Ubermix 镜像文件并将我的 USB 盘插入计算机,Etcher.io “看到”了驱动器,我就可以开始在 USB 上安装 Ubermix 了。
|
||||
|
||||
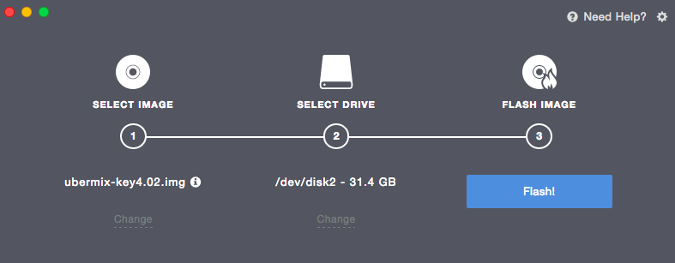
|
||||
|
||||
在我点击 **Flash** 后,安装就开始了。所需时间取决于镜像的大小。在驱动器上安装镜像后,软件会验证安装。最后,一条提示宣布我的媒体创建已经完成。
|
||||
在我点击 “Flash” 后,安装就开始了。所需时间取决于镜像的大小。在驱动器上安装镜像后,软件会验证安装。最后,一条提示宣布我的媒体创建已经完成。
|
||||
|
||||
如果您需要[ Etcher 的帮助][7],请通过其 [Discourse][8] 论坛联系社区。Etcher 非常易于使用,它已经取代了我所有其他的媒体创建工具,因为它们都不像 Etcher 那样轻松地完成工作。
|
||||
如果您需要 [Etcher 的帮助][7],请通过其 [Discourse][8] 论坛联系社区。Etcher 非常易于使用,它已经取代了我所有其他的媒体创建工具,因为它们都不像 Etcher 那样轻松地完成工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -80,7 +76,7 @@ via: https://opensource.com/article/18/7/getting-started-etcherio
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
如何在 Ubuntu 和其他 Linux 发行版中安装 2048 游戏
|
||||
如何在 Linux 中安装 2048 游戏
|
||||
======
|
||||
**流行的移动益智游戏 2048 也可以在 Ubuntu 和 Linux 发行版上玩。啊!你甚至可以在 Linux 终端上玩 2048。如果你的生产率因为这个让人上瘾的游戏下降,请不要怪我。**
|
||||
|
||||
> 流行的移动益智游戏 2048 也可以在 Ubuntu 和 Linux 发行版上玩。啊!你甚至可以在 Linux 终端上玩 2048。如果你的生产率因为这个让人上瘾的游戏下降,请不要怪我。
|
||||
|
||||
早在 2014 年,2048 就是 iOS 和 Android 上最受欢迎的游戏之一。这款令人上瘾的游戏非常受欢迎,它在 Linux 上有[浏览器版][1]、桌面版和终端版。
|
||||
|
||||
<https://giphy.com/embed/wT8XEi5gckwJW>
|
||||

|
||||
|
||||
通过向上和向下,向左和向右移动滑块来玩这个小游戏。这个益智游戏的目的是通过组合匹配的滑块到数字 2048。因此 2+2 变成 4,4+4 变成 16,依此类推。这可能听起来简单而无聊,但相信我是一个令人上瘾的游戏。
|
||||
|
||||
@ -13,9 +14,9 @@
|
||||
在 Ubuntu 和其他 Linux 中有些 2048 游戏。你可以在软件中心中搜索它,你可以在那里找到一些。
|
||||
|
||||
有一个[基于 Qt ][2]的 2048 游戏,你可以在 Ubuntu 和其他基于 Debian 和 Ubuntu 的 Linux 发行版上安装。你可以使用以下命令安装它:
|
||||
|
||||
```
|
||||
sudo apt install 2048-qt
|
||||
|
||||
```
|
||||
|
||||
安装完成后,你可以在菜单中找到该游戏并启动它。你可以使用箭头键移动数字。你的最高分也会保存。
|
||||
@ -28,14 +29,14 @@ sudo apt install 2048-qt
|
||||
|
||||
现在,有几种方法可以在 Linux 终端中玩 2048。我在这里提其中两个。
|
||||
|
||||
#### 1\. term2048 Snap 程序
|
||||
#### 1、term2048 Snap 程序
|
||||
|
||||
有一个名为 [term2048][6] 的[ snap 程序][5]可以安装在任何[支持 Snap 的 Linux 发行版][7]中。
|
||||
有一个名为 [term2048][6] 的 [snap 程序][5]可以安装在任何[支持 Snap 的 Linux 发行版][7]中。
|
||||
|
||||
如果你启用了 Snap,只需使用此命令安装 term2048:
|
||||
|
||||
```
|
||||
sudo snap install term2048
|
||||
|
||||
```
|
||||
|
||||
Ubuntu 用户也可以在软件中心找到这个游戏并从那里安装它。
|
||||
@ -48,17 +49,17 @@ Ubuntu 用户也可以在软件中心找到这个游戏并从那里安装它。
|
||||
|
||||
你可以使用箭头键移动。
|
||||
|
||||
#### 2\. 2048 游戏的 Bash 脚本
|
||||
#### 2、2048 游戏的 Bash 脚本
|
||||
|
||||
这个游戏实际上是一个 shell 脚本,你可以在任何 Linux 终端上运行。从 Github 下载游戏/脚本:
|
||||
|
||||
[下载 Bash2048][10]
|
||||
- [下载 Bash2048][10]
|
||||
|
||||
解压下载的文件。进入解压后的目录,你将看到名为 2048.sh 的 shell 脚本。只需运行 shell 脚本。游戏将立即开始。你可以使用箭头键移动滑块。
|
||||
|
||||
![Linux Terminal game 2048][11]
|
||||
|
||||
#### 你在Linux上玩什么游戏?
|
||||
### 你在Linux上玩什么游戏?
|
||||
|
||||
如果你喜欢在 Linux 终端上玩游戏,你也应该尝试 [Linux 终端中的经典 Snake 游戏][12]。
|
||||
|
||||
@ -71,7 +72,7 @@ via: https://itsfoss.com/2048-game/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,9 +3,9 @@
|
||||
|
||||

|
||||
|
||||
Visual Studio Code,简称 VS Code,是一个开源的文本编辑器,包含用于构建和调试应用程序的工具。安装启用 Python 扩展后,VS Code 可以配置成 Python 开发的理想工作环境。本文将介绍一些有用的 VS Code 扩展,并配置它们以充分提高 Python 开发效率。
|
||||
Visual Studio Code,简称 VS Code,是一个开源的文本编辑器,包含用于构建和调试应用程序的工具。安装启用 Python 扩展后,VS Code 可以配置成理想的 Python 开发工作环境。本文将介绍一些有用的 VS Code 扩展,并配置它们以充分提高 Python 开发效率。
|
||||
|
||||
如果你的计算机上还没有安装 VS Code,可以参考文章 [Using Visual Studio Code on Fedora ](https://fedoramagazine.org/using-visual-studio-code-fedora/) 安装。
|
||||
如果你的计算机上还没有安装 VS Code,可以参考文章 [在 Fedora 上使用 VS Code](https://fedoramagazine.org/using-visual-studio-code-fedora/) 来安装。
|
||||
|
||||
### 在 VS Code 中安装 Python 扩展
|
||||
|
||||
@ -20,11 +20,12 @@ VS Code 通过两个 JSON 文件管理设置:
|
||||
* 一个文件用于 VS Code 的全局设置,作用于所有的项目
|
||||
* 另一个文件用于特殊设置,作用于单独项目
|
||||
|
||||
可以用快捷键 **Ctrl+,** (逗号)打开全局设置,也可以通过 **文件 -> 首选项 -> 设置** 来打开。
|
||||
可以用快捷键 `Ctrl+,` (逗号)打开全局设置,也可以通过 **文件 -> 首选项 -> 设置** 来打开。
|
||||
|
||||
#### 设置 Python 路径
|
||||
|
||||
您可以在全局设置中配置 python.pythonPath 使 VS Code 自动为每个项目选择最适合的 Python 解释器。 。
|
||||
您可以在全局设置中配置 `python.pythonPath` 使 VS Code 自动为每个项目选择最适合的 Python 解释器。
|
||||
|
||||
```
|
||||
// 将设置放在此处以覆盖默认设置和用户设置。
|
||||
// Path to Python, you can use a custom version of Python by modifying this setting to include the full path.
|
||||
@ -33,18 +34,20 @@ VS Code 通过两个 JSON 文件管理设置:
|
||||
}
|
||||
```
|
||||
|
||||
这样,VS Code 将使用虚拟环境目录 .venv 下项目根目录中的 Python 解释器。
|
||||
这样,VS Code 将使用虚拟环境目录 `.venv` 下项目根目录中的 Python 解释器。
|
||||
|
||||
#### 使用环境变量
|
||||
|
||||
默认情况下,VS Code 使用项目根目录下的 .env 文件中定义的环境变量。 这对于设置环境变量很有用,如:
|
||||
默认情况下,VS Code 使用项目根目录下的 `.env` 文件中定义的环境变量。 这对于设置环境变量很有用,如:
|
||||
|
||||
```
|
||||
PYTHONWARNINGS="once"
|
||||
```
|
||||
|
||||
可使程序在运行时显示警告。
|
||||
|
||||
可以通过设置 python.envFile 来加载其他的默认环境变量文件:
|
||||
可以通过设置 `python.envFile` 来加载其他的默认环境变量文件:
|
||||
|
||||
```
|
||||
// Absolute path to a file containing environment variable definitions.
|
||||
"python.envFile": "${workspaceFolder}/.env",
|
||||
@ -52,9 +55,10 @@ PYTHONWARNINGS="once"
|
||||
|
||||
### 代码分析
|
||||
|
||||
Python 扩展还支持不同的代码分析工具(pep8,flake8,pylint)。要启用你喜欢的或者正在进行的项目所使用的分析工具,只需要进行一些简单的配置。
|
||||
Python 扩展还支持不同的代码分析工具(pep8、flake8、pylint)。要启用你喜欢的或者正在进行的项目所使用的分析工具,只需要进行一些简单的配置。
|
||||
|
||||
扩展默认情况下使用 pylint 进行代码分析。你可以这样配置以使用 flake8 进行分析:
|
||||
|
||||
```
|
||||
"python.linting.pylintEnabled": false,
|
||||
"python.linting.flake8Path": "${workspaceRoot}/.venv/bin/flake8",
|
||||
@ -68,7 +72,8 @@ Python 扩展还支持不同的代码分析工具(pep8,flake8,pylint)。
|
||||
|
||||
### 格式化代码
|
||||
|
||||
可以配置 VS Code 使其自动格式化代码。目前支持 autopep8,black 和 yapf。下面的设置将启用 “black” 模式。
|
||||
可以配置 VS Code 使其自动格式化代码。目前支持 autopep8、black 和 yapf。下面的设置将启用 “black” 模式。
|
||||
|
||||
```
|
||||
// Provider for formatting. Possible options include 'autopep8', 'black', and 'yapf'.
|
||||
"python.formatting.provider": "black",
|
||||
@ -77,7 +82,7 @@ Python 扩展还支持不同的代码分析工具(pep8,flake8,pylint)。
|
||||
"editor.formatOnSave": true,
|
||||
```
|
||||
|
||||
如果不需要编辑器在保存时自动格式化代码,可以将 editor.formatOnSave 设置为 false 并手动使用快捷键 **Ctrl + Shift + I** 格式化当前文档中的代码。 注意,项目的虚拟环境中需要安装有 black,此示例方能有效。
|
||||
如果不需要编辑器在保存时自动格式化代码,可以将 `editor.formatOnSave` 设置为 `false` 并手动使用快捷键 `Ctrl + Shift + I` 格式化当前文档中的代码。 注意,项目的虚拟环境中需要安装有 black,此示例方能有效。
|
||||
|
||||
### 运行任务
|
||||
|
||||
@ -89,40 +94,43 @@ VS Code 的一个重要特点是它可以运行任务。需要运行的任务保
|
||||
|
||||
![][4]
|
||||
|
||||
编辑如下所示的 tasks.json 文件,创建新任务来运行 Flask 开发服务:
|
||||
编辑如下所示的 `tasks.json` 文件,创建新任务来运行 Flask 开发服务:
|
||||
|
||||
```
|
||||
{
|
||||
// See https://go.microsoft.com/fwlink/?LinkId=733558
|
||||
// for the documentation about the tasks.json format
|
||||
"version": "2.0.0",
|
||||
"tasks": [
|
||||
// See https://go.microsoft.com/fwlink/?LinkId=733558
|
||||
// for the documentation about the tasks.json format
|
||||
"version": "2.0.0",
|
||||
"tasks": [
|
||||
{
|
||||
|
||||
"label": "Run Debug Server",
|
||||
"type": "shell",
|
||||
"command": "${workspaceRoot}/.venv/bin/flask run -h 0.0.0.0 -p 5000",
|
||||
"group": {
|
||||
"kind": "build",
|
||||
"isDefault": true
|
||||
"label": "Run Debug Server",
|
||||
"type": "shell",
|
||||
"command": "${workspaceRoot}/.venv/bin/flask run -h 0.0.0.0 -p 5000",
|
||||
"group": {
|
||||
"kind": "build",
|
||||
"isDefault": true
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Flask 开发服务使用环境变量来获取应用程序的入口点。 如 **使用环境变量** 一节所说,可以在 .env 文件中声明这些变量:
|
||||
Flask 开发服务使用环境变量来获取应用程序的入口点。 如 **使用环境变量** 一节所说,可以在 `.env` 文件中声明这些变量:
|
||||
|
||||
```
|
||||
FLASK_APP=wsgi.py
|
||||
FLASK_DEBUG=True
|
||||
```
|
||||
|
||||
这样就可以使用快捷键 **Ctrl + Shift + B** 来执行任务了。
|
||||
这样就可以使用快捷键 `Ctrl + Shift + B` 来执行任务了。
|
||||
|
||||
### 单元测试
|
||||
|
||||
VS Code 还支持单元测试框架 pytest,unittest 和 nosetest。启用测试框架后,可以在 VS Code 中单独运行搜索到的单元测试,通过测试套件运行测试或者运行所有的测试。
|
||||
VS Code 还支持单元测试框架 pytest、unittest 和 nosetest。启用测试框架后,可以在 VS Code 中单独运行搜索到的单元测试,通过测试套件运行测试或者运行所有的测试。
|
||||
|
||||
例如,可以这样启用 pytest 测试框架:
|
||||
|
||||
```
|
||||
"python.unitTest.pyTestEnabled": true,
|
||||
"python.unitTest.pyTestPath": "${workspaceRoot}/.venv/bin/pytest",
|
||||
@ -140,7 +148,7 @@ via: https://fedoramagazine.org/vscode-python-howto/
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[idea2act](https://github.com/idea2act)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,114 +1,116 @@
|
||||
10 个在 Linux 上也有的流行 Windows 程序
|
||||
10 个在 Linux 上也有的流行的 Windows 程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
回顾过去,2018 年是 Linux 社区的好年景。许多仅在 Windows 和/或 Mac上 有的程序可在 Linux 平台上使用了,而且不用麻烦。向 [Snap][3] 和 [Flatpak][4] 技术致敬,这些技术已经为 Linux 用户带来了许多“受限制”的程序。
|
||||
|
||||
**另请阅读**:[所有很酷的 Linux 程序和工具][5]
|
||||
**另请阅读**:[很酷的 Linux 程序和工具大全][5]
|
||||
|
||||
今天,我们为你提供了一个有名的 Windows 程序列表,你不需要寻找它们的替代品,因为它们已经在 Linux 上可用。
|
||||
|
||||
### 1\. Skype
|
||||
### 1、Skype
|
||||
|
||||
它可以说是世界上最受欢迎的 VoIP 程序,**Skype** 提供出色的视频和语音通话质量,以及其他功能,如拨打本地和国际电话、固定电话、即时消息、表情符号等功能。
|
||||
|
||||
可以说是世界上最受欢迎的 VoIP 程序,**Skype** 提供出色的视频和语音通话质量,以及其他功能,如拨打本地和国际电话、固定电话、即时消息、表情符号等功能。
|
||||
```
|
||||
$ sudo snap install skype --classic
|
||||
|
||||
```
|
||||
|
||||
### 2\. Spotify
|
||||
### 2、Spotify
|
||||
|
||||
**Spotify** 是最流行的音乐流媒体平台,在很长一段时间里,Linux 用户需要使用脚本和一些手段才能在他们的机器上设置该程序,感谢 snap,安装和使用 Spotify 就像点击一个按钮那样简单。
|
||||
|
||||
**Spotify** 是最流行的音乐流媒体平台,在很长一段时间里,Linux 用户需要使用脚本和黑客技巧在他们的机器上设置程序,感谢 snap,安装和使用 Spotify 就像点击一个按钮那样简单。
|
||||
```
|
||||
$ sudo snap install spotify
|
||||
|
||||
```
|
||||
|
||||
### 3\. Minecraft
|
||||
### 3、Minecraft
|
||||
|
||||
**Minecraft** 被证明是一款年度好游戏。更酷的是,它持续地得到维护。如果你不了解 Minecraft,它是一款冒险游戏,它可以让你在一个无限无边的虚拟世界中使用积木创建任何你想创建的虚拟事物。
|
||||
|
||||
**Minecraft** 被证明是一款年度好游戏。更酷的是,它持续地得到维护。如果你不了解 Mincraft,它是一款冒险游戏,它可以让你在一个无限无边的虚拟世界中使用积木创建任何你想创建的虚拟事物。
|
||||
```
|
||||
$ sudo snap install minecraft
|
||||
|
||||
```
|
||||
|
||||
### 4\. JetBrains Dev Suite
|
||||
### 4、JetBrains Dev Suite
|
||||
|
||||
**JetBrains** 以其高级开发 IDE 套件而闻名,其最受欢迎的程序声称可在 Linux 上使用而不会有任何麻烦。
|
||||
**JetBrains** 以其高级的开发 IDE 套件而闻名,他们这个最受欢迎的程序声称可在 Linux 上使用而不会有任何麻烦。
|
||||
|
||||
#### 安装 IDEA Community – Java IDE
|
||||
|
||||
```
|
||||
$ sudo snap install intellij-idea-community --classic
|
||||
|
||||
```
|
||||
|
||||
#### 安装 PyCharm EDU – Python IDE
|
||||
|
||||
```
|
||||
$ sudo snap install pycharm-educational --classic
|
||||
|
||||
```
|
||||
|
||||
#### 安装 PhpStorm – PHP IDE
|
||||
|
||||
```
|
||||
$ sudo snap install phpstorm --classic
|
||||
|
||||
```
|
||||
|
||||
#### 安装 WebStorm – JavaScript IDE
|
||||
|
||||
```
|
||||
$ sudo snap install webstorm --classic
|
||||
|
||||
```
|
||||
|
||||
#### 安装 RubyMine – Ruby and Rails IDE
|
||||
|
||||
```
|
||||
$ sudo snap install rubymine --classic
|
||||
|
||||
```
|
||||
|
||||
### 5\. PowerShell
|
||||
### 5、PowerShell
|
||||
|
||||
**PowerShell** 是一个用于管理 PC 自动化和配置的平台,它提供了一个带有相关脚本语言的命令行 shell。如果你认为它仅在 Windows 上可用,那么请再想一想。
|
||||
|
||||
```
|
||||
$ sudo snap install powershell --classic
|
||||
|
||||
```
|
||||
|
||||
### 6\. Ghost
|
||||
### 6、Ghost
|
||||
|
||||
**Ghost** 是一款现代桌面程序,可让用户在无干扰的环境中管理多个 Ghost 博客、杂志、在线出版物等。
|
||||
|
||||
```
|
||||
$ sudo snap install ghost-desktop
|
||||
|
||||
```
|
||||
|
||||
### 7\. MySQL Workbench
|
||||
### 7、MySQL Workbench
|
||||
|
||||
**MySQL Workbench** 是一个 GUI 程序,用于设计和管理集成 SQL 功能的数据库。
|
||||
|
||||
[**下载 MySQL Workbench**][6]
|
||||
- [**下载 MySQL Workbench**][6]
|
||||
|
||||
### 8\. PlayOnLinux 中的 Adobe App Suite
|
||||
### 8、PlayOnLinux 中的 Adobe App Suite
|
||||
|
||||
你可能错过了我们在 [PlayOnLinux][7] 上发表的文章,所以这是另一个了解的机会。
|
||||
|
||||
PlayOnLinux 基本上是 **wine** 的改进实现,允许用户更轻松地安装 Adobe 的创意云程序。请注意,试用和订阅限制仍然适用。
|
||||
PlayOnLinux 基本上是 **wine** 的改进版本,允许用户更轻松地安装 Adobe 的创意云程序。请注意,试用和订阅限制仍然适用。
|
||||
|
||||
[**如何使用 PlayOnLinux**][8]
|
||||
- [**如何使用 PlayOnLinux**][8]
|
||||
|
||||
### 9\. Slack
|
||||
### 9、Slack
|
||||
|
||||
这据说是开发人员和项目经理之间最常用的团队沟通软件,**Slack** 提供了每个人似乎无法满足的有各种文档和消息管理功能的工作空间。
|
||||
|
||||
```
|
||||
$ sudo snap install slack --classic
|
||||
|
||||
```
|
||||
|
||||
### 10\. Blender
|
||||
### 10、Blender
|
||||
|
||||
**Blender** 是最受欢迎的 3D 创作程序之一。它是免费的、开源的,并且支持完整 3D 管道。
|
||||
|
||||
```
|
||||
$ sudo snap install blender --classic
|
||||
|
||||
```
|
||||
|
||||
就是这些了!我们知道列表还有很多,但我们只能列出这么多。我们是否省略了你认为应该将其列入清单的任何程序?在下面的评论栏添加你的建议。
|
||||
@ -117,10 +119,10 @@ $ sudo snap install blender --classic
|
||||
|
||||
via: https://www.fossmint.com/install-popular-windows-apps-on-linux/
|
||||
|
||||
作者:[Martins D. Okoi;View All Posts][a]
|
||||
作者:[Martins D. Okoi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,158 @@
|
||||
初学者指南:在 Ubuntu Linux 上安装和使用 Git 和 GitHub
|
||||
======
|
||||
|
||||
Github 是一个存放着世界上最棒的一些软件项目的宝藏,这些软件项目由全世界的开发者无私贡献。这个看似简单,实则非常强大的平台因为大大帮助了那些对开发大规模软件感兴趣的开发者而被开源社区所称道。
|
||||
|
||||
这篇向导是对于安装和使用 GitHub 的的一个快速说明,本文还将涉及诸如创建本地仓库,如何链接这个本地仓库到包含你的项目的远程仓库(这样每个人都能看到你的项目了),以及如何提交改变并最终推送所有的本地内容到 Github。
|
||||
|
||||
请注意这篇向导假设你对 Git 术语有基本的了解,如推送、拉取请求(PR)、提交、仓库等等。并且希望你在 GitHub 上已注册成功并记下了你的 GitHub 用户名,那么我们这就进入正题吧:
|
||||
|
||||
### 1、在 Linux 上安装 Git
|
||||
|
||||
下载并安装 Git:
|
||||
|
||||
```
|
||||
sudo apt-get install git
|
||||
```
|
||||
|
||||
上面的命令适用于 Ubuntu 并且应该在所有最新版的 Ubuntu 上都能工作,它们在 Ubuntu 16.04 和 Ubuntu 18.04 LTS(Bionic Beaver)上都测试过,在将来的版本上应该也能工作。
|
||||
|
||||
### 2、配置 GitHub
|
||||
|
||||
一旦安装完成,接下去就是配置 GitHub 用户的详细配置信息。请使用下面的两条命令,并确保用你自己的 GitHub 用户名替换 `user_name`,用你创建 GitHub 账户的电子邮件替换 `email_id`。
|
||||
|
||||
```
|
||||
git config --global user.name "user_name"
|
||||
git config --global user.email "email_id"
|
||||
```
|
||||
|
||||
下面的图片显示的例子是如何用我的 GitHub 用户名:“akshaypai” 和我的邮件地址 “abc123@gmail.com” 来配置上面的命令。
|
||||
|
||||
[![Git config][3]][4]
|
||||
|
||||
### 3、创建本地仓库
|
||||
|
||||
在你的系统上创建一个目录。它将会被作为本地仓库使用,稍后它会被推送到 GitHub 的远程仓库。请使用如下命令:
|
||||
|
||||
```
|
||||
git init Mytest
|
||||
```
|
||||
|
||||
如果目录被成功创建,你会看到如下信息:
|
||||
|
||||
```
|
||||
Initialized empty Git repository in /home/akshay/Mytest/.git/
|
||||
```
|
||||
|
||||
这行信息可能随你的系统不同而变化。
|
||||
|
||||
这里,`Mytest` 是创建的目录,而 `init` 将其转化为一个 GitHub 仓库。将当前目录改为这个新创建的目录。
|
||||
|
||||
```
|
||||
cd Mytest
|
||||
```
|
||||
|
||||
### 4、新建一个 README 文件来描述仓库
|
||||
|
||||
现在创建一个 `README` 文件并输入一些文本,如 “this is git setup on linux”。README 文件一般用于描述这个仓库用来放置什么内容或这个项目是关于什么的。例如:
|
||||
|
||||
```
|
||||
gedit README
|
||||
```
|
||||
|
||||
你可以使用任何文本编辑器。我喜欢使用 gedit。`README` 文件的内容可以为:
|
||||
|
||||
```
|
||||
This is a git repo
|
||||
```
|
||||
|
||||
### 5、将仓库里的文件加入一个索引
|
||||
|
||||
这是很重要的一步。这里我们会将所有需要推送到 GitHub 的内容都加入一个索引。这些内容可能包括你第一次加入仓库的文本文件或者应用程序,也有可能是对已存在文件的一些编辑(文件的一个更新版本)。
|
||||
|
||||
既然我们已经有了 `README` 文件,那么让我们创建一个别的文件吧,如一个简单的 C 程序,我们叫它 `sample.c`。文件内容是:
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
int main()
|
||||
{
|
||||
printf("hello world");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
现在我们有两个文件了。`README` 和 `sample.c`。
|
||||
|
||||
用下面的命令将它们加入索引:
|
||||
|
||||
```
|
||||
git add README
|
||||
git add smaple.c
|
||||
```
|
||||
|
||||
请注意 `git add` 命令能将任意数量的文件和目录加入到索引。这里,当我说 “索引” 的时候,我是指一个有一定空间的缓冲区,这个缓冲区存储了所有已经被加入到 Git 仓库的文件或目录。
|
||||
|
||||
### 6、将所作的改动加入索引
|
||||
|
||||
所有的文件都加好以后,你就可以提交了。这意味着你已经确定了最终的文件改动(或增加),现在它们已经准备好被上传到我们自己的仓库了。请使用命令:
|
||||
|
||||
```
|
||||
git commit -m "some_message"
|
||||
```
|
||||
|
||||
“some_message” 在上面的命令里可以是一些简单的信息如“我的第一次提交”或者“编辑了readme 文件”,等等。
|
||||
|
||||
### 7、在 GitHub 上创建一个仓库
|
||||
|
||||
在 GitHub 上创建一个仓库。请注意仓库的名字必须和你本地创建的仓库的名字严格一致。在这个例子里是 “Mytest”。请首先登录你的 [GitHub](https://github.com) 账户。点击页面右上角的 “+” 符号,并选择“create nw repository”。如下图所示填入详细信息,点击 “create repository”。
|
||||
|
||||
[![Creating a repository on GitHub][5]][6]
|
||||
|
||||
一旦创建完成,我们就能将本地的仓库推送到 GitHub 你名下的仓库,用下列命令连接 GitHub 上的仓库:
|
||||
|
||||
> 请注意:请确保在运行下列命令前替换了路径中的 “user_name” 和 “Mytest” 为你的 GitHub 用户名和目录名!
|
||||
|
||||
```
|
||||
git remote add origin https://github.com/user\_name/Mytest.git>
|
||||
```
|
||||
|
||||
### 8、将本地仓库里的文件推送到 GitHub 仓库
|
||||
|
||||
最后一步是用下列的命令将本地仓库的内容推送到远程仓库(GitHub):
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
当提示登录名和密码时键入登录名和密码。
|
||||
|
||||
下面的图片显示了步骤 5 到步骤 8 的流程
|
||||
|
||||
[![Pushing files in local repository to GitHub repository][7]][8]
|
||||
|
||||
上述将 Mytest 目录里的所有内容(文件)推送到了 GitHub。对于以后的项目或者创建新的仓库,你可以直接从步骤 3 开始。最后,如果你登录你的 GitHub 账户并点击你的 Mytest 仓库,你会看到这两个文件:`README` 和 `sample.c` 已经被上传并像如下图片显示:
|
||||
|
||||
[![Content uploaded to Github][9]][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-git-and-github-on-ubuntu/
|
||||
|
||||
作者:[Akshay Pai][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/DavidChenLiang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
|
||||
[1]:https://github.com/
|
||||
[2]:https://www.howtoforge.com/cdn-cgi/l/email-protection
|
||||
[3]:https://www.howtoforge.com/images/ubuntu_github_getting_started/config.png
|
||||
[4]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/config.png
|
||||
[5]:https://www.howtoforge.com/images/ubuntu_github_getting_started/details.png
|
||||
[6]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/details.png
|
||||
[7]:https://www.howtoforge.com/images/ubuntu_github_getting_started/steps.png
|
||||
[8]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/steps.png
|
||||
[9]:https://www.howtoforge.com/images/ubuntu_github_getting_started/final.png
|
||||
[10]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/final.png
|
||||
149
published/20180808 5 open source role-playing games for Linux.md
Normal file
149
published/20180808 5 open source role-playing games for Linux.md
Normal file
@ -0,0 +1,149 @@
|
||||
|
||||
五个 Linux 上的开源角色扮演游戏
|
||||
======
|
||||
|
||||
> 换一个新的身份,并用这些开源的角色扮演游戏探索新世界。
|
||||
|
||||

|
||||
|
||||
游戏是 Linux 的传统弱项之一,感谢 Steam、GOG 和其他的游戏开发商将商业游戏移植到了多个操作系统,Linux 的这个弱项在近几年有所改观,但是这些游戏通常都不是开源的。当然,这些游戏可以在开源系统上运行,但是对于开源的纯粹主义者来说这还不够好。
|
||||
|
||||
那么,有没有一款能让只使用自由开源软件的人在不影响他们开源理念的情况下也能享受到可靠游戏体验的精致游戏呢?
|
||||
|
||||
当然有啦!虽然开源游戏不太可能和拥有大量开发预算的 3A 级大作相媲美,但有许多类型的开源游戏也很有趣,而且它们可以直接从大多数主要的 Linux 发行版的仓库中进行安装。即使某个游戏没有被某些仓库打包,你也可以很简单地从这个游戏的官网下载它,并进行安装和运行。
|
||||
|
||||
这篇文章着眼于角色扮演游戏,我已经写过关于[街机游戏][1]、[棋牌游戏][2]、[益智游戏][3],以及[赛车和飞行游戏][4]。在本系列的最后一篇文章中,我打算覆盖战略游戏和模拟游戏这两方面。
|
||||
|
||||
### Endless Sky
|
||||
|
||||
|
||||
|
||||
[Endless Sky][5] 是 Ambrosia Software 的 [Escape Velocity][6] 系列的开源克隆品。玩家乘坐一艘宇宙飞船,在不同的世界之间旅行来运送货物和乘客,并在沿途中承接其他任务,或者玩家也可以变成海盗,并从其他货船中偷取货物。这个游戏让玩家自己决定要如何去体验这个游戏,以太阳系为背景的超大地图是非常具有探索性的。Endless Sky 是那些违背正常游戏类别分类的游戏之一。但这个兼具动作、角色扮演、太空模拟和交易这四种类型的游戏非常值得一试。
|
||||
|
||||
如果要安装 Endless Sky ,请运行下面的命令。
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
dnf install endless-sky
|
||||
```
|
||||
|
||||
在 Debian/Ubuntu 上:
|
||||
|
||||
```
|
||||
apt install endless-sky
|
||||
```
|
||||
|
||||
### FreeDink
|
||||
|
||||
|
||||
|
||||
[FreeDink][7] 是 [Dink Smallwood][8] 的开源版本,Dink Smallwood 是一个由 RTSoft 在 1997 年发售的动作角色扮演游戏。Dink Smallwood 在 1999 年时变为了免费游戏,并在 2003 年时公布了源代码。在 2008 年时,游戏的数据除了少部分的声音文件,都在开源协议下进行了开源。FreeDink 用一些替代的声音文件替换了缺少的那部分文件,来提供了一个完整的游戏。游戏的玩法类似于任天堂的[塞尔达传说][9]系列。玩家控制的角色和 Dink Smallwood 同名,他在从一个任务地点移动到下一个任务地点的时候,探索这个充满隐藏物品和隐藏洞穴的世界地图。由于这个游戏的年龄,FreeDink 不能和现代的商业游戏相抗衡,但它仍然是一个拥有着有趣故事的有趣的游戏。游戏可以通过 [D-Mods][10] 进行扩展,D-Mods 是提供额外任务的附加模块,但是 D-Mods 在复杂性、质量,和年龄适应性上确实有很大的差异。游戏主要适合青少年,但也有部分额外组件适用于成年玩家。
|
||||
|
||||
要安装 FreeDink ,请运行下面的命令。
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
dnf install freedink
|
||||
```
|
||||
|
||||
在 Debian/Ubuntu 上:
|
||||
|
||||
```
|
||||
apt install freedink
|
||||
```
|
||||
|
||||
### ManaPlus
|
||||
|
||||
|
||||
|
||||
从技术上讲,[ManaPlus][11] 本身并不是一个游戏,它是一个访问各种大型多人在线角色扮演游戏的客户端。[The Mana World][12] 和 [Evol Online][13] 是两款可以通过 ManaPlus 访问的开源游戏,但是游戏的服务器不在那里。这个游戏的 2D 精灵图像让人想起超级任天堂游戏,虽然 ManaPlus 支持的游戏没有一款能像商业游戏那样受欢迎的,但它们都有一个有趣的世界,并且在绝大部分时间里都有至少一小部分玩家在线。一个玩家不太可能遇到很多的其他玩家,但通常都能有足够的人一起在这个 [MMORPG][14] 游戏里进行冒险,而不是一个需要连接到服务器的单机游戏。Mana World 和 Evol Online 的开发者联合起来进行未来的开发,但是对于目前而言,Mana World 的历史服务器和 Evol Online 提供了不同的游戏体验。
|
||||
|
||||
要安装 ManaPlus,请运行下面的命令。
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
dnf install manaplus
|
||||
```
|
||||
|
||||
在 Debian/Ubuntu 上:
|
||||
|
||||
```
|
||||
apt install manaplus
|
||||
```
|
||||
|
||||
### Minetest
|
||||
|
||||
|
||||
|
||||
使用 [Minetest][15] 来在一个开放式世界里进行探索和创造,Minetest 是 Minecraft 的克隆品。就像它所基于的 Minecraft 一样,Minetest 提供了一个开放的世界,玩家可以在这个世界里探索和创造他们想要的一切。Minetest 提供了各种各样的方块和工具,对于想要一个比 Minecraft 更加开放的游戏的人来说,Minetest 是一个很好的替代品。除了基本的游戏之外,Minetest 还可以通过[额外的模块][16]进行可扩展,增加更多的选项。
|
||||
|
||||
如果要安装 Minetest ,请运行下面的命令。
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
dnf install minetest
|
||||
```
|
||||
|
||||
在 Debian/Ubuntu 上:
|
||||
|
||||
```
|
||||
apt install minetest
|
||||
```
|
||||
|
||||
### NetHack
|
||||
|
||||
|
||||
|
||||
[NetHack][17] 是一款经典的 [Roguelike][18] 类型的角色扮演游戏,玩家可以从不同的角色种族、分类和阵营中进行选择,来探索这个多层次的地下城。这个游戏的目的就是找回 Yendor 的护身符,玩家从地下层的第一层开始探索,并尝试向下一层移动,每一层都是随机生成的,这样每次都能获得不同的游戏体验。虽然这个游戏只具有 ASCII 图形和基本图形,但是游戏玩法的深度能够弥补画面的不足。玩家如果想要更好一些的画面的话,可能就需要去查看 [NetHack 的 Vulture][19] 了,这个方式可以提供更好的图像、声音和背景音乐。
|
||||
|
||||
如果要安装 NetHack ,请运行下面的命令。
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
dnf install nethack
|
||||
```
|
||||
|
||||
在 Debian/Ubuntu 上:
|
||||
|
||||
```
|
||||
apt install nethack-x11 or apt install nethack-console
|
||||
```
|
||||
|
||||
我有错过了你最喜欢的角色扮演游戏吗?请在下面的评论区分享出来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/role-playing-games-linux
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
[1]:https://opensource.com/article/18/1/arcade-games-linux
|
||||
[2]:https://opensource.com/article/18/3/card-board-games-linux
|
||||
[3]:https://opensource.com/article/18/6/puzzle-games-linux
|
||||
[4]:https://opensource.com/article/18/7/racing-flying-games-linux
|
||||
[5]:https://endless-sky.github.io/
|
||||
[6]:https://en.wikipedia.org/wiki/Escape_Velocity_(video_game)
|
||||
[7]:http://www.gnu.org/software/freedink/
|
||||
[8]:http://www.rtsoft.com/pages/dink.php
|
||||
[9]:https://en.wikipedia.org/wiki/The_Legend_of_Zelda
|
||||
[10]:http://www.dinknetwork.com/files/category_dmod/
|
||||
[11]:http://manaplus.org/
|
||||
[12]:http://www.themanaworld.org/
|
||||
[13]:http://evolonline.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Massively_multiplayer_online_role-playing_game
|
||||
[15]:https://www.minetest.net/
|
||||
[16]:https://wiki.minetest.net/Mods
|
||||
[17]:https://www.nethack.org/
|
||||
[18]:https://en.wikipedia.org/wiki/Roguelike
|
||||
[19]:http://www.darkarts.co.za/vulture-for-nethack
|
||||
@ -1,37 +1,39 @@
|
||||
介绍 Linux 中的管道和命名管道
|
||||
======
|
||||
|
||||
> 要在命令间移动数据?使用管道可使此过程便捷。
|
||||
|
||||

|
||||
|
||||
在 Linux 中,`pipe` 能让你将一个命令的输出发送给另一个命令。管道,如它的名称那样,能重定向一个进程的标准输出、输入、和错误到另一个进程,以便于进一步处理。
|
||||
在 Linux 中,`pipe` 能让你将一个命令的输出发送给另一个命令。管道,如它的名称那样,能重定向一个进程的标准输出、输入和错误到另一个进程,以便于进一步处理。
|
||||
|
||||
`pipe` 或者 `unnamed pipe` 命令的语法是在两个命令之间加上 `|` 字符:
|
||||
“管道”(或称“未命名管道”)命令的语法是在两个命令之间加上 `|` 字符:
|
||||
|
||||
```
|
||||
Command-1 | Command-2 | ...| Command-N
|
||||
```
|
||||
|
||||
`Command-1 | Command-2 | …| Command-N`
|
||||
|
||||
这里,管道不能通过另一个会话访问;它被临时创建用于接收 `Command-1` 的执行并重定向标准输出。它在成功执行之后删除。
|
||||
这里,该管道不能通过另一个会话访问;它被临时创建用于接收 `Command-1` 的执行并重定向标准输出。它在成功执行之后删除。
|
||||
|
||||
|
||||
|
||||
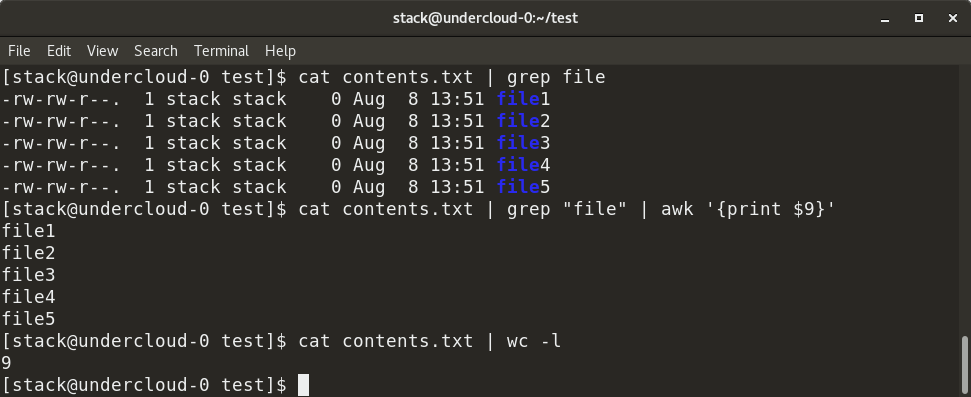
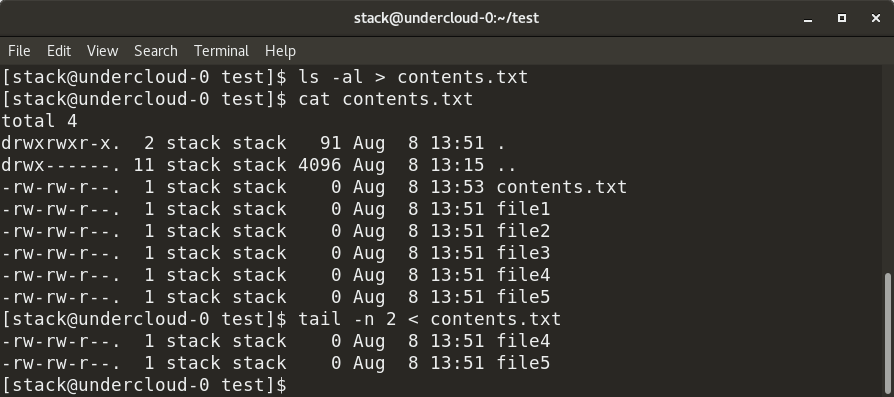
在上面的示例中,contents.txt 包含特定目录中所有文件的列表 - 具体来说,就 是ls -al 命令的输出。我们首先通过管道(如图所示)使用 contents.txt 中的 “file” 关键字 grep 文件名,因此 cat 命令的输出作为 grep 命令的输入提供。接下来,我们添加管道来执行 awk 命令,该命令显示 grep 命令的过滤输出中的第 9 列。我们还可以使用 wc -l 命令计算 contents.txt 中的行数。
|
||||
在上面的示例中,`contents.txt` 包含特定目录中所有文件的列表 —— 具体来说,就是 `ls -al` 命令的输出。我们首先通过管道(如图所示)使用 “file” 关键字从 `contents.txt` 中 `grep` 文件名,因此 `cat` 命令的输出作为 `grep` 命令的输入提供。接下来,我们添加管道来执行 `awk` 命令,该命令显示 `grep` 命令的过滤输出中的第 9 列。我们还可以使用 `wc -l` 命令计算 `contents.txt` 中的行数。
|
||||
|
||||
只要系统启动并运行或直到它被删除,命名管道就可以持续使用。它是一个遵循 [FIFO][1](先进先出)机制的特殊文件。它可以像普通文件一样使用。也就是,你可以写入,从中读取,然后打开或关闭它。要创建命名管道,命令为:
|
||||
|
||||
```
|
||||
mkfifo <pipe-name>
|
||||
|
||||
```
|
||||
|
||||
这将创建一个命名管道文件,它甚至可以在多个 shell 会话中使用。
|
||||
|
||||
创建 FIFO 命名管道的另一种方法是使用此命令:
|
||||
|
||||
```
|
||||
mknod p <pipe-name>
|
||||
|
||||
```
|
||||
|
||||
`>` 符号。要重定向任何命令的标准输入,请使用 `<` 符号。
|
||||
要重定向任何命令的标准输出到其它命令,请使用 `>` 符号。要重定向任何命令的标准输入,请使用 `<` 符号。
|
||||
|
||||
|
||||
|
||||
@ -41,9 +43,9 @@ mknod p <pipe-name>
|
||||
|
||||
|
||||
|
||||
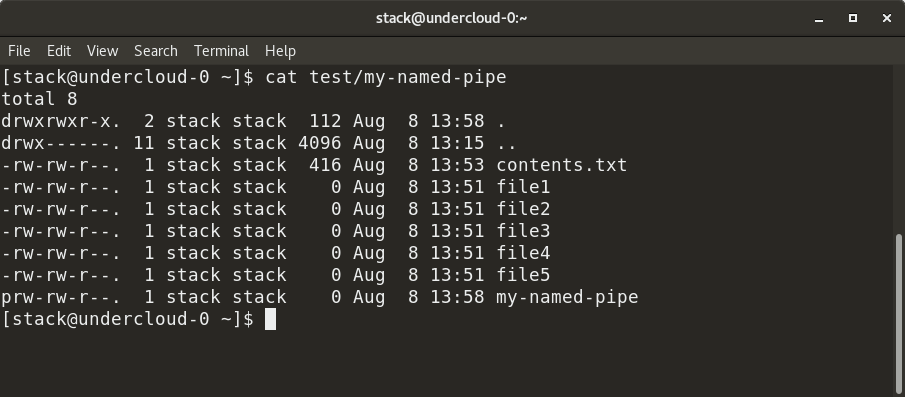
这里,我们创建了一个命名管道 `my-named-pipe`,并将 `ls -al` 命令的输出重定向到命名管道。我们可以打开一个新的 shell 会话并 `cat` 命名管道的内容,如前所述,它显示了 `ls -al`命令的输出。请注意,命名管道的大小为零,并有一副标志 “p”。
|
||||
这里,我们创建了一个命名管道 `my-named-pipe`,并将 `ls -al` 命令的输出重定向到命名管道。我们可以打开一个新的 shell 会话并 `cat` 命名管道的内容,如前所述,它显示了 `ls -al` 命令的输出。请注意,命名管道的大小为零,并有一个标志 “p”。
|
||||
|
||||
因此,下次你在 Linux 终端上使用命令并在命令之间移动数据时,希望管道使过程快速简便。
|
||||
因此,下次你在 Linux 终端上使用命令并在命令之间移动数据时,希望管道使这个过程快速简便。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -52,7 +54,7 @@ via: https://opensource.com/article/18/8/introduction-pipes-linux
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,27 +1,28 @@
|
||||
如何将 WordPress 博客发布到静态 GitLab Pages 上
|
||||
======
|
||||
|
||||
> 通过 GitLab 或 GitHub Pages 来提供一个 WordPress 镜像站点, 从而最小化安全问题。
|
||||
|
||||

|
||||
|
||||
很久以前,我为一个家庭成员建立了一个 WordPress 博客。现在有很多选择,但是当时如果你需要一个带有 WYSIWYG 编辑器的基于网络的 CMS,那么当时很少有不错的选择。运行良好的一个不幸的副作用是博客随着时间的推移产生了很多内容。这意味着我要经常更新 WordPress 以防止不断出现的漏洞。
|
||||
很久以前,我为一个家庭成员建立了一个 WordPress 博客。如今有很多选择,但是当时如果你需要一个带有所见即所得的编辑器的基于 Web 的 CMS,那么就没什么像样的的选择了。而一切运行良好的不幸的副作用是随着时间的推移该博客产生了很多内容。这意味着我要经常更新 WordPress 以防止不断出现的漏洞。
|
||||
|
||||
因此,我决定劝说家人切换到 [Hugo][1] 会相对容易,然后可以在 [GitLab][2] 上托管博客。但是尝试提取所有内容并将其转换为 [Markdown][3] 变成了一个巨大的麻烦。有自动脚本完成了 95% 的工作,但并不完美。手动更新所有帖子不是我想做的事情,所以最终,我放弃了试图移动博客。
|
||||
因此,当我决定劝说家人切换到 [Hugo][1] 会相对容易,然后可以在 [GitLab][2] 上托管博客。但是尝试提取所有内容并将其转换为 [Markdown][3] 变成了一个巨大的麻烦。有自动脚本完成了 95% 的工作,但并不完美。手动更新所有帖子不是我想做的事情,所以最终,我放弃了试图移动博客。
|
||||
|
||||
最近,我又开始考虑这个问题,并意识到有一个我没有考虑过的解决方案:我可以继续维护 WordPress 服务器,但将其设置为发布静态镜像,并使用 [GitLab Pages][4](或 [ GitHub Pages][5] ,如果你喜欢的话)服务。这能让我自动化 [Let's Encrypt][6] 证书续订并消除与托管 WordPress 站点相关的安全问题。然而,这意味着评论将无法使用,但在这种情况下感觉就像是一个小损失,因为博客没有收到很多评论。
|
||||
最近,我又开始考虑这个问题,并意识到有一个我没有考虑过的解决方案:我可以继续维护 WordPress 服务器,但将其设置为发布静态镜像,并使用 [GitLab Pages][4](或 [GitHub Pages][5] ,如果你喜欢的话)提供服务。这能让我自动化 [Let's Encrypt][6] 证书续订并消除与托管 WordPress 站点相关的安全问题。然而,这意味着评论将无法使用,但在这种情况下感觉就像是一个小损失,因为博客没有收到很多评论。
|
||||
|
||||
这是我提出的解决方案,到目前为止似乎运作良好:
|
||||
|
||||
* WordPress 站点中的 URL 没有链接到或来自其他任何地方,以减少它被利用的几率。在此例中,我们将使用 <http://private.localconspiracy.com>(即使此站点实际上是使用 Pelican 构建的)。
|
||||
* 为公共 URL <https://www.localconspiracy.com> [在 GitLab Pages 上设置托管][7]。
|
||||
* 添加 [cron job][8],确定两个 URL 之间的最后构建日期何时不同。如果构建日期不同,则镜像 WordPress 版本。
|
||||
* 托管 WordPress 站点中的 URL 没有链接到或来自其他任何地方,以减少它被利用的几率。在此例中,我们将使用 <http://private.localconspiracy.com>(即使此站点实际上是使用 Pelican 构建的)。
|
||||
* 将公共 URL <https://www.localconspiracy.com> [托管到 GitLab Pages 上][7]。
|
||||
* 添加 [cron 任务][8],确定两个 URL 之间的最后构建日期何时不同。如果构建日期不同,则镜像 WordPress 版本。
|
||||
* 使用 `wget` 镜像后,将所有链接从“私有”更新成“公共”。
|
||||
* 运行 `git push` 来发布新内容。
|
||||
|
||||
|
||||
|
||||
这是我使用的两个脚本:
|
||||
|
||||
`check-diff.sh` (cron 每 15 分钟调用一次)
|
||||
`check-diff.sh` (cron 每 15 分钟调用一次):
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
@ -34,7 +35,8 @@ then
|
||||
fi
|
||||
```
|
||||
|
||||
`mirror.sh:`
|
||||
`mirror.sh`:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
@ -62,7 +64,7 @@ git push origin master
|
||||
|
||||
就是这些了!现在,当博客发生变化时,在 15 分钟内将网站镜像到静态版本并推送到仓库,这将在 GitLab Pages 中反映出来。
|
||||
|
||||
如果你想[在本地运行 WordPress][9],这个概念可以进一步扩展。在这种情况下,你不需要服务器来托管你的 WordPress 博客。你可以在本机运行它。在这种情况下,你的博客不可能被利用。只要你可以在本地运行 `wget`,就可以使用上面的方法在 GitLab Pages 上托管 WordPress 站点。
|
||||
如果你想[在本地运行 WordPress][9],这个概念可以进一步扩展。在这种情况下,你不需要服务器来托管你的 WordPress 博客。你可以在本机运行它。在这种情况下,你的博客不可能被攻击利用。只要你可以在本地运行 `wget`,就可以使用上面的方法在 GitLab Pages 上托管 WordPress 站点。
|
||||
|
||||
_这篇文章最初发表于 [Local Conspiracy] [10]。允许转载。_
|
||||
|
||||
@ -72,8 +74,8 @@ via: https://opensource.com/article/18/8/publish-wordpress-static-gitlab-pages-s
|
||||
|
||||
作者:[Christopher Aedo][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,88 +1,86 @@
|
||||
如何从 Linux 命令行安装软件
|
||||
======
|
||||
> 学习一种不同的包管理器和怎么使用它。
|
||||
|
||||

|
||||
|
||||
如果你在任何时间都使用 Linux,你很快就会发现有很多不同的方法可以做同样的事情。这包括通过命令行在 Linux 上安装应用。我已经是大约 25 年的 Linux 用户,我一次又一次地回到命令行来安装我的应用。
|
||||
如果你在一直在使用 Linux,你很快就会发现做同样的事情有很多不同的方法。这包括通过命令行在 Linux 上安装应用。我已经是大约 25 年的 Linux 用户,我一次又一次地回到命令行来安装我的应用。
|
||||
|
||||
从命令行安装应用程序最常用的方法是使用称为包管理器的软件库(存储软件的地方)。所有 Linux 应用都作为软件包分发,这些软件包只不过是与软件包管理系统相关的文件。每个 Linux 发行版都附带一个包管理系统,但它们并不完全相同。
|
||||
从命令行安装应用程序最常用的方法是使用称为包管理器通过软件库(存储软件的地方)安装。所有 Linux 应用都作为软件包分发,这些软件包只不过是与软件包管理系统相关的文件。每个 Linux 发行版都附带一个包管理系统,但它们并不完全相同。
|
||||
|
||||
### 什么是包管理系统?
|
||||
|
||||
包管理系统由多组工具和文件格式组成,它们一起用于安装、更新和卸载 Linux 应用。两种最常见的包管理系统来自 Red Hat 和 Debian。 Red Hat、CentOS 和 Fedora 都使用 `rpm` 系统(.rpm 文件),而Debian、Ubuntu、Mint 和 Ubuntu 都使用 `dpkg`(.deb 文件)。Gentoo Linux 使用名为 Portage 的系统,Arch Linux 只使用 tarball(.tar 文件)。这些系统之间的主要区别在于它们如何安装和维护应用。
|
||||
包管理系统由一组工具和文件格式组成,它们一起用于安装、更新和卸载 Linux 应用。两种最常见的包管理系统来自 Red Hat 和 Debian。 Red Hat、CentOS 和 Fedora 都使用 `rpm` 系统(.rpm 文件),而 Debian、Ubuntu、Mint 和 Ubuntu 都使用 `dpkg`(.deb 文件)。Gentoo Linux 使用名为 Portage 的系统,Arch Linux 只使用 tarball(.tar 文件)。这些系统之间的主要区别在于它们如何安装和维护应用。
|
||||
|
||||
你可能想知道 `.rpm`、`.deb` 或 `.tar` 文件中的内容。你可能会惊讶地发现,所有这些都只是普通的老式归档文件(如 `.zip`),其中包含应用的代码,如何安装它的说明,依赖项(它可能依赖的其他应用),以及配置文件的位置。读取和执行所有这些指令的软件称为包管理器。
|
||||
|
||||
### Debian、Ubuntu、Mint 等
|
||||
|
||||
Debian、Ubuntu、Mint 和其他基于 Debian 的发行版都使用 `.deb` 文件和 `dpkg` 包管理系统。有两种方法可以通过此系统安装应用。你可以使用 `apt` 程序从仓库进行安装,也可以使用 `dpkg` 程序从 `.deb` 文件安装应用。我们来看看如何做到这两点。
|
||||
Debian、Ubuntu、Mint 和其它基于 Debian 的发行版都使用 `.deb` 文件和 `dpkg` 包管理系统。有两种方法可以通过此系统安装应用。你可以使用 `apt` 程序从仓库进行安装,也可以使用 `dpkg` 程序从 `.deb` 文件安装应用。我们来看看如何做到这两点。
|
||||
|
||||
使用 `apt` 安装应用非常简单:
|
||||
|
||||
```
|
||||
$ sudo apt install app_name
|
||||
|
||||
```
|
||||
|
||||
通过 `apt` 卸载应用也非常简单:
|
||||
|
||||
```
|
||||
$ sudo apt remove app_name
|
||||
|
||||
```
|
||||
|
||||
要升级已安装的应用,首先需要更新应用仓库:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
|
||||
```
|
||||
|
||||
完成后,你可以使用以下命令更新任何程序:
|
||||
|
||||
```
|
||||
$ sudo apt upgrade
|
||||
|
||||
```
|
||||
|
||||
如果你只想更新一个应用,该怎么办?没问题。
|
||||
|
||||
```
|
||||
$ sudo apt update app_name
|
||||
|
||||
```
|
||||
|
||||
最后,假设你要安装的应用不存在于 Debian 仓库中,但有 `.deb` 下载。
|
||||
|
||||
```
|
||||
$ sudo dpkg -i app_name.deb
|
||||
|
||||
```
|
||||
|
||||
### Red Hat、CentOS 和 Fedora
|
||||
|
||||
默认情况下,Red Hat 使用多个包管理系统。这些系统在使用自己的命令时,互相仍然非常相似,而且与 Debian 中使用的也相似。例如,我们可以使用 `yum` 或 `dnf` 管理器来安装应用。
|
||||
|
||||
```
|
||||
$ sudo yum install app_name
|
||||
|
||||
$ sudo dnf install app_name
|
||||
|
||||
```
|
||||
|
||||
`.rpm` 格式的应用也可以使用 `rpm` 命令安装。
|
||||
|
||||
```
|
||||
$ sudo rpm -i app_name.rpm
|
||||
|
||||
```
|
||||
|
||||
删除不需要的应用同样容易。
|
||||
|
||||
```
|
||||
$ sudo yum remove app_name
|
||||
|
||||
$ sudo dnf remove app_name
|
||||
|
||||
```
|
||||
|
||||
更新应用同样容易。
|
||||
|
||||
```
|
||||
$ yum update
|
||||
|
||||
$ sudo dnf upgrade --refresh
|
||||
|
||||
```
|
||||
|
||||
如你所见,从命令行安装、卸载和更新 Linux 应用并不难。事实上,一旦你习惯它,你会发现它比使用基于桌面 GUI 的管理工具更快!
|
||||
@ -96,7 +94,7 @@ via: https://opensource.com/article/18/8/how-install-software-linux-command-line
|
||||
作者:[Patrick H.Mullins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,86 +3,83 @@
|
||||
|
||||

|
||||
|
||||
几个月前,我在[**Ubuntu 18.04 上安装了 LAMP**][1]。今天,我尝试以 root 用户身份登录数据库,但我完全忘记了密码。经过一阵 Google 搜索并浏览一些文章后,我成功重置了密码。对于那些想知道如何做到这一点的人,这个简短的教程解释了如何在类 Unix 操作系统中重置 MySQL 或 MariaDB Root 密码。
|
||||
几个月前,我在[Ubuntu 18.04 上安装了 LAMP][1]。今天,我尝试以 root 用户身份登录数据库,但我完全忘记了密码。经过一阵 Google 搜索并浏览一些文章后,我成功重置了密码。对于那些想知道如何做到这一点的人,这个简短的教程解释了如何在类 Unix 操作系统中重置 MySQL 或 MariaDB Root 密码。
|
||||
|
||||
### 重置 MySQL 或 MariaDB Root 密码
|
||||
|
||||
首先,停止数据库。
|
||||
|
||||
如果你使用 MySQL,请输入以下命令并下按回车键。
|
||||
|
||||
```
|
||||
$ sudo systemctl stop mysql
|
||||
|
||||
```
|
||||
|
||||
对于 MariaDB:
|
||||
|
||||
```
|
||||
$ sudo systemctl stop mariadb
|
||||
|
||||
```
|
||||
|
||||
接下来,使用以下命令在没有权限检查的情况下重新启动数据库:
|
||||
|
||||
```
|
||||
$ sudo mysqld_safe --skip-grant-tables &
|
||||
|
||||
```
|
||||
|
||||
这里, **`--skip-grant-tables`** 选项让你在没有密码和所有权限的情况下进行连接。如果使用此选项启动服务器,它还会启用 `--skip-networking` 选项,这用于防止其他客户端连接到数据库服务器。并且,**( &)**符号用于在后台运行命令,因此你可以在以下步骤中输入其他命令。请注意,上述命令很危险,并且你的数据库会变得不安全。你应该只在短时间内运行此命令以重置密码。
|
||||
这里, `--skip-grant-tables` 选项让你在没有密码和所有权限的情况下进行连接。如果使用此选项启动服务器,它还会启用 `--skip-networking` 选项,这用于防止其他客户端连接到数据库服务器。并且,`&` 符号用于在后台运行命令,因此你可以在以下步骤中输入其他命令。请注意,上述命令很危险,并且你的数据库会变得不安全。你应该只在短时间内运行此命令以重置密码。
|
||||
|
||||
接下来,以 root 用户身份登录 MySQL/MariaDB 服务器:
|
||||
|
||||
```
|
||||
$ mysql
|
||||
|
||||
```
|
||||
|
||||
在 **mysql >** 或 **MariaDB [(none)] >** 提示符下,运行以下命令重置 root 用户密码:
|
||||
|
||||
```
|
||||
UPDATE mysql.user SET Password=PASSWORD('NEW-PASSWORD') WHERE User='root';
|
||||
|
||||
```
|
||||
|
||||
使用你自己的密码替换上述命令中的 **NEW-PASSWORD**。
|
||||
|
||||
然后,输入以下命令退出 mysql 控制台。
|
||||
|
||||
```
|
||||
FLUSH PRIVILEGES;
|
||||
|
||||
exit
|
||||
|
||||
```
|
||||
|
||||
最后,关闭之前使用 `--skip-grant-tables` 选项运行的数据库。为此,运行:
|
||||
|
||||
```
|
||||
$ sudo mysqladmin -u root -p shutdown
|
||||
|
||||
```
|
||||
|
||||
系统将要求你输入在上一步中设置的 mysql/mariadb 用户密码。
|
||||
系统将要求你输入在上一步中设置的 MySQL/MariaDB 用户密码。
|
||||
|
||||
现在,使用以下命令正常启动 MySQL/MariaDB 服务:
|
||||
|
||||
现在,使用以下命令正常启动 mysql/mariadb 服务:
|
||||
```
|
||||
$ sudo systemctl start mysql
|
||||
|
||||
```
|
||||
|
||||
对于 MariaDB:
|
||||
|
||||
```
|
||||
$ sudo systemctl start mariadb
|
||||
|
||||
```
|
||||
|
||||
使用以下命令验证密码是否确实已更改:
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
|
||||
```
|
||||
|
||||
今天就是这些了。还有更多好东西。敬请期待!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-reset-mysql-or-mariadb-root-password/
|
||||
@ -90,7 +87,7 @@ via: https://www.ostechnix.com/how-to-reset-mysql-or-mariadb-root-password/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,147 +0,0 @@
|
||||
ucasFL translating
|
||||
|
||||
Trash-Cli : A Command Line Interface For Trashcan On Linux
|
||||
======
|
||||
Everyone knows about `Trashcan` which is common for all users like Linux, or Windows, or Mac. Whenever you delete a file or folder, it will be moved to trash.
|
||||
|
||||
Note that moving files to the trash does not free up space on the file system until the Trashcan is empty.
|
||||
|
||||
Trash stores deleted files temporarily which help us to restore when it's necessary, if you don't want these files then delete it permanently (empty the trash).
|
||||
|
||||
Make sure, you won't find any files or folders in the trash when you delete using `rm` command. So, think twice before performing rm command. If you did a mistake that's it, it'll go away and you can't restore back. since metadata is not stored on disk nowadays.
|
||||
|
||||
Trash is a feature provided by the desktop manager such as GNOME, KDE, and XFCE, etc, as per [freedesktop.org specification][1]. when you delete a file or folder from file manger then it will go to trash and the trash folder can be found @ `$HOME/.local/share/Trash`.
|
||||
|
||||
Trash folder contains two folder `files` & `info`. Files folder stores actual deleted files and folders & Info folder contains deleted files & folders information such as file path, deleted date & time in separate file.
|
||||
|
||||
You might ask, Why you want CLI utility When having GUI Trashcan, most of the NIX guys (including me) play around CLI instead of GUI even though when they working GUI based system. So, if some one looking for CLI based Trashcan then this is the right choice for them.
|
||||
|
||||
### What's Trash-Cli
|
||||
|
||||
[trash-cli][2] is a command line interface for Trashcan utility compliant with the FreeDesktop.org trash specifications. It stores the name, original path, deletion date, and permissions of each trashed file.
|
||||
|
||||
### How to Install Trash-Cli in Linux
|
||||
|
||||
Trash-Cli is available on most of the Linux distribution official repository, so run the following command to install.
|
||||
|
||||
For **`Debian/Ubuntu`** , use [apt-get command][3] or [apt command][4] to install Trash-Cli.
|
||||
```
|
||||
$ sudo apt install trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** , use [YUM Command][5] to install Trash-Cli.
|
||||
```
|
||||
$ sudo yum install trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** , use [DNF Command][6] to install Trash-Cli.
|
||||
```
|
||||
$ sudo dnf install trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** , use [Pacman Command][7] to install Trash-Cli.
|
||||
```
|
||||
$ sudo pacman -S trash-cli
|
||||
|
||||
```
|
||||
|
||||
For **`openSUSE`** , use [Zypper Command][8] to install Trash-Cli.
|
||||
```
|
||||
$ sudo zypper in trash-cli
|
||||
|
||||
```
|
||||
|
||||
If you distribution doesn't offer Trash-cli, we can easily install from pip. Your system should have pip package manager, in order to install python packages.
|
||||
```
|
||||
$ sudo pip install trash-cli
|
||||
Collecting trash-cli
|
||||
Downloading trash-cli-0.17.1.14.tar.gz
|
||||
Installing collected packages: trash-cli
|
||||
Running setup.py bdist_wheel for trash-cli ... done
|
||||
Successfully installed trash-cli-0.17.1.14
|
||||
|
||||
```
|
||||
|
||||
### How to Use Trash-Cli
|
||||
|
||||
It's not a big deal since it's offering native syntax. It provides following commands.
|
||||
|
||||
* **`trash-put:`** Delete files and folders.
|
||||
* **`trash-list:`** Pint Deleted files and folders.
|
||||
* **`trash-restore:`** Restore a file or folder from trash.
|
||||
* **`trash-rm:`** Remove individual files from the trashcan.
|
||||
* **`trash-empty:`** Empty the trashcan(s).
|
||||
|
||||
|
||||
|
||||
Let's try some examples to experiment this.
|
||||
|
||||
1) Delete files and folders : In our case, we are going to send a file named `2g.txt` and folder named `magi` to Trash by running following command.
|
||||
```
|
||||
$ trash-put 2g.txt magi
|
||||
|
||||
```
|
||||
|
||||
You can see the same in file manager.
|
||||
|
||||
2) Pint Delete files and folders : To view deleted files and folders, run the following command. As i can see detailed infomation about deleted files and folders such as name, date & time, and file path.
|
||||
```
|
||||
$ trash-list
|
||||
2017-10-01 01:40:50 /home/magi/magi/2g.txt
|
||||
2017-10-01 01:40:50 /home/magi/magi/magi
|
||||
|
||||
```
|
||||
|
||||
3) Restore a file or folder from trash : At any point of time you can restore a files and folders by running following command. It will ask you to enter the choice which you want to restore. In our case, we are going to restore `2g.txt` file, so my option is `0`.
|
||||
```
|
||||
$ trash-restore
|
||||
0 2017-10-01 01:40:50 /home/magi/magi/2g.txt
|
||||
1 2017-10-01 01:40:50 /home/magi/magi/magi
|
||||
What file to restore [0..1]: 0
|
||||
|
||||
```
|
||||
|
||||
4) Remove individual files from the trashcan : If you want to remove specific files from trashcan, run the following command. In our case, we are going to remove `magi` folder.
|
||||
```
|
||||
$ trash-rm magi
|
||||
|
||||
```
|
||||
|
||||
5) Empty the trashcan : To remove everything from the trashcan, run the following command.
|
||||
```
|
||||
$ trash-empty
|
||||
|
||||
```
|
||||
|
||||
6) Remove older then X days file : Alternatively you can remove older then X days files so, run the following command to do it. In our case, we are going to remove `10` days old items from trashcan.
|
||||
```
|
||||
$ trash-empty 10
|
||||
|
||||
```
|
||||
|
||||
trash-cli works great but if you want to try alternative, give a try to [gvfs-trash][9] & [autotrash][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/trash-cli-command-line-trashcan-linux-system/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://freedesktop.org/wiki/Specifications/trash-spec/
|
||||
[2]:https://github.com/andreafrancia/trash-cli
|
||||
[3]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[6]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[8]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[9]:http://manpages.ubuntu.com/manpages/trusty/man1/gvfs-trash.1.html
|
||||
[10]:https://github.com/bneijt/autotrash
|
||||
@ -1,72 +0,0 @@
|
||||
ucasFL translating
|
||||
|
||||
# Scrot: Linux command-line screen grabs made simple
|
||||
|
||||
by [Scott Nesbitt][a] · November 30, 2017
|
||||
|
||||
> Scrot is a basic, flexible tool that offers a number of handy options for taking screen captures from the Linux command line.
|
||||
|
||||
[][1]
|
||||
|
||||
|
||||
|
||||
There are great tools on the Linux desktop for taking screen captures, such as [KSnapshot][2] and [Shutter][3]. Even the simple utility that comes with the GNOME desktop does a pretty good job of capturing screens. But what if you rarely need to take screen captures? Or you use a Linux distribution without a built-in capture tool, or an older computer with limited resources?
|
||||
|
||||
Turn to the command line and a little utility called [Scrot][4]. It does a fine job of taking simple screen captures, and it includes a few features that might surprise you.
|
||||
|
||||
### Getting started with Scrot
|
||||
Many Linux distributions come with Scrot already installed—to check, type `which scrot`. If it isn't there, you can install Scrot using your distro's package manager. If you're willing to compile the code, grab it [from GitHub][5].
|
||||
|
||||
To take a screen capture, crack open a terminal window and type `scrot [filename]`, where `[filename]` is the name of file to which you want to save the image (for example, `desktop.png`). If you don't include a name for the file, Scrot will create one for you, such as `2017-09-24-185009_1687x938_scrot.png`. (That filename isn't as descriptive it could be, is it? That's why it's better to add one to the command.)
|
||||
|
||||
Running Scrot with no options takes a screen capture of your entire desktop. If you don't want to do that, Scrot lets you focus on smaller portions of your screen.
|
||||
|
||||
### Taking a screen capture of a single window
|
||||
|
||||
Tell Scrot to take a screen capture of a single window by typing `scrot -u [filename]`.
|
||||
|
||||
The `-u` option tells Scrot to grab the window currently in focus. That's usually the terminal window you're working in, which might not be the one you want.
|
||||
|
||||
To grab another window on your desktop, type `scrot -s [filename]`.
|
||||
|
||||
The `-s` option lets you do one of two things:
|
||||
|
||||
* select an open window, or
|
||||
|
||||
* draw a rectangle around a window or a portion of a window to capture it.
|
||||
|
||||
You can also set a delay, which gives you a little more time to select the window you want to capture. To do that, type `scrot -u -d [num] [filename]`.
|
||||
|
||||
The `-d` option tells Scrot to wait before grabbing the window, and `[num]` is the number of seconds to wait. Specifying `-d 5` (wait five seconds) should give you enough time to choose a window.
|
||||
|
||||
### More useful options
|
||||
|
||||
Scrot offers a number of additional features (most of which I never use). The ones I find most useful include:
|
||||
|
||||
* `-b` also grabs the window's border
|
||||
|
||||
* `-t` grabs a window and creates a thumbnail of it. This can be useful when you're posting screen captures online.
|
||||
|
||||
* `-c` creates a countdown in your terminal when you use the `-d` option.
|
||||
|
||||
To learn about Scrot's other options, check out the its documentation by typing `man scrot` in a terminal window, or [read it online][6]. Then start snapping images of your screen.
|
||||
|
||||
It's basic, but Scrot gets the job done nicely.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/taking-screen-captures-linux-command-line-scrot
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/community-penguins-osdc-lead.png?itok=BmqsAF4A
|
||||
[2]:https://www.kde.org/applications/graphics/ksnapshot/
|
||||
[3]:https://launchpad.net/shutter
|
||||
[4]:https://github.com/dreamer/scrot
|
||||
[5]:http://manpages.ubuntu.com/manpages/precise/man1/scrot.1.html
|
||||
[6]:https://github.com/dreamer/scrot
|
||||
@ -1,133 +0,0 @@
|
||||
Top 7 open source project management tools for agile teams
|
||||
======
|
||||
|
||||
|
||||
|
||||
Opensource.com has surveyed the landscape of popular open source project management tools. We've done this before—but this year we've added a twist. This time, we're looking specifically at tools that support [agile][1] methodology, including related practices such as [Scrum][2], Lean, and Kanban.
|
||||
|
||||
The growth of interest in and use of agile is why we've decided to focus on these types of tools this year. A majority of organizations—71%—say they [are using agile approaches][3] at least sometimes. In addition, agile projects are [28% more successful][4] than projects managed with traditional approaches.
|
||||
|
||||
For this roundup, we looked at the project management tools we covered in [2014][5], [2015][6], and [2016][7] and plucked the ones that support agile, then did research to uncover any additions or changes. Whether your organization is already using agile or is one of the many planning to adopt agile approaches in 2018, one of these seven open source project management tools may be exactly what you're looking for.
|
||||
|
||||
### MyCollab
|
||||
|
||||
|
||||
|
||||
[MyCollab][8] is a suite of three collaboration modules for small and midsize businesses: project management, customer relationship management (CRM), and document creation and editing software. There are two licensing options: a commercial "ultimate" edition, which is faster and can be run on-premises or in the cloud, and the open source "community edition," which is the version we're interested in here.
|
||||
|
||||
The community edition doesn't have a cloud option and is slower, due to not using query cache, but provides essential project management features, including tasks, issues management, activity stream, roadmap view, and a Kanban board for agile teams. While it doesn't have a separate mobile app, it works on mobile devices as well as Windows, MacOS, Linux, and Unix computers.
|
||||
|
||||
The latest version of MyCollab is 5.4.10 and the source code is available on [GitHub][9]. It is licensed under AGPLv3 and requires a Java runtime and MySQL stack to operate. It's available for [download][10] for Windows, Linux, Unix, and MacOS.
|
||||
|
||||
### Odoo
|
||||
|
||||
|
||||
|
||||
[Odoo][11] is more than project management software; it's a full, integrated business application suite that includes accounting, human resources, website & e-commerce, inventory, manufacturing, sales management (CRM), and other tools.
|
||||
|
||||
The free and open source community edition has limited [features][12] compared to the paid enterprise suite. Its project management application includes a Kanban-style task-tracking view for agile teams, which was updated in its latest release, Odoo 11.0, to include a progress bar and animation for tracking project status. The project management tool also includes Gantt charts, tasks, issues, graphs, and more. Odoo has a thriving [community][13] and provides [user guides][14] and other training resources.
|
||||
|
||||
It is licensed under GPLv3 and requires Python and PostgreSQL. It is available for [download][15] for Windows, Linux, and Red Hat Package Manager, as a [Docker][16] image, and as source on [GitHub][17].
|
||||
|
||||
### OpenProject
|
||||
|
||||
|
||||
|
||||
[OpenProject][18] is a powerful open source project management tool that is notable for its ease of use and rich project management and team collaboration features.
|
||||
|
||||
Its modules support project planning, scheduling, roadmap and release planning, time tracking, cost reporting, budgeting, bug tracking, and agile and Scrum. Its agile features, including creating stories, prioritizing sprints, and tracking tasks, are integrated with OpenProject's other modules.
|
||||
|
||||
OpenProject is licensed under GPLv3 and its source code is available on [GitHub][19]. Its latest version, 7.3.2. is available for [download][20] for Linux; you can learn more about installing and configuring it in Birthe Lindenthal's article "[Getting started with OpenProject][21]."
|
||||
|
||||
### OrangeScrum
|
||||
|
||||
|
||||
|
||||
As you would expect from its name, [OrangeScrum][22] supports agile methodologies, specifically with a Scrum task board and Kanban-style workflow view. It's geared for smaller organizations—freelancers, agencies, and small and midsize businesses.
|
||||
|
||||
The open source version offers many of the [features][23] in OrangeScrum's paid editions, including a mobile app, resource utilization, and progress tracking. Other features, including Gantt charts, time logs, invoicing, and client management, are available as paid add-ons, and the paid editions include a cloud option, which the community version does not.
|
||||
|
||||
OrangeScrum is licensed under GPLv3 and is based on the CakePHP framework. It requires Apache, PHP 5.3 or higher, and MySQL 4.1 or higher, and works on Windows, Linux, and MacOS. Its latest release, 1.6.1. is available for [download][24], and its source code can be found on [GitHub][25].
|
||||
|
||||
### ]project-open[
|
||||
|
||||
|
||||
|
||||
[]project-open[][26] is a dual-licensed enterprise project management tool, meaning that its core is open source, and some additional features are available in commercially licensed modules. According to the project's [comparison][27] of the community and enterprise editions, the open source core offers plenty of features for small and midsize organizations.
|
||||
|
||||
]project-open[ supports [agile][28] projects with Scrum and Kanban support, as well as classic Gantt/waterfall projects and hybrid or mixed projects.
|
||||
|
||||
The application is licensed under GPL and the [source code][29] is accessible via CVS. ]project-open[ is available as [installers][26] for both Linux and Windows, but also in cloud images and as a virtual appliance.
|
||||
|
||||
### Taiga
|
||||
|
||||
|
||||
|
||||
[Taiga][30] is an open source project management platform that focuses on Scrum and agile development, with features including a Kanban board, tasks, sprints, issues, a backlog, and epics. Other features include ticket management, multi-project support, wiki pages, and third-party integrations.
|
||||
|
||||
It also offers a free mobile app for iOS, Android, and Windows devices, and provides import tools that make it easy to migrate from other popular project management applications.
|
||||
|
||||
Taiga is free for public projects, with no restrictions on either the number of projects or the number of users. For private projects, there is a wide range of [paid plans][31] available under a "freemium" model, but, notably, the software's features are the same, no matter which type of plan you have.
|
||||
|
||||
Taiga is licensed under GNU Affero GPLv3, and requires a stack that includes Nginx, Python, and PostgreSQL. The latest release, [3.1.0 Perovskia atriplicifolia][32], is available on [GitHub][33].
|
||||
|
||||
### Tuleap
|
||||
|
||||
|
||||
|
||||
[Tuleap][34] is an application lifecycle management (ALM) platform that aims to manage projects for every type of team—small, midsize, large, waterfall, agile, or hybrid—but its support for agile teams is prominent. Notably, it offers support for Scrum, Kanban, sprints, tasks, reports, continuous integration, backlogs, and more.
|
||||
|
||||
Other [features][35] include issue tracking, document tracking, collaboration tools, and integration with Git, SVN, and Jenkins, all of which make it an appealing choice for open source software development projects.
|
||||
|
||||
Tuleap is licensed under GPLv2. More information, including Docker and CentOS downloads, is available on their [Get Started][36] page. You can also get the source code for its latest version, 9.14, on Tuleap's [Git][37].
|
||||
|
||||
The trouble with this type of list is that it's usually out of date as soon as it's published. Are you using an open source project management tool that supports agile that we forgot to include? Or do you have feedback on the ones we mentioned? Please leave a comment below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/agile-project-management-tools
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:http://agilemanifesto.org/principles.html
|
||||
[2]:https://opensource.com/resources/scrum
|
||||
[3]:https://www.pmi.org/-/media/pmi/documents/public/pdf/learning/thought-leadership/pulse/pulse-of-the-profession-2017.pdf
|
||||
[4]:https://www.pwc.com/gx/en/actuarial-insurance-services/assets/agile-project-delivery-confidence.pdf
|
||||
[5]:https://opensource.com/business/14/1/top-project-management-tools-2014
|
||||
[6]:https://opensource.com/business/15/1/top-project-management-tools-2015
|
||||
[7]:https://opensource.com/business/16/3/top-project-management-tools-2016
|
||||
[8]:https://community.mycollab.com/
|
||||
[9]:https://github.com/MyCollab/mycollab
|
||||
[10]:https://www.mycollab.com/ce-registration/
|
||||
[11]:https://www.odoo.com/
|
||||
[12]:https://www.odoo.com/page/editions
|
||||
[13]:https://www.odoo.com/page/community
|
||||
[14]:https://www.odoo.com/documentation/user/11.0/
|
||||
[15]:https://www.odoo.com/page/download
|
||||
[16]:https://hub.docker.com/_/odoo/
|
||||
[17]:https://github.com/odoo/odoo
|
||||
[18]:https://www.openproject.org/
|
||||
[19]:https://github.com/opf/openproject
|
||||
[20]:https://www.openproject.org/download-and-installation/
|
||||
[21]:https://opensource.com/article/17/11/how-install-and-use-openproject
|
||||
[22]:https://www.orangescrum.org/
|
||||
[23]:https://www.orangescrum.org/compare-orangescrum
|
||||
[24]:http://www.orangescrum.org/free-download
|
||||
[25]:https://github.com/Orangescrum/orangescrum/
|
||||
[26]:http://www.project-open.com/en/list-installers
|
||||
[27]:http://www.project-open.com/en/products/editions.html
|
||||
[28]:http://www.project-open.com/en/project-type-agile
|
||||
[29]:http://www.project-open.com/en/developers-cvs-checkout
|
||||
[30]:https://taiga.io/
|
||||
[31]:https://tree.taiga.io/support/subscription-and-plans/payment-process-faqs/#q.-what-s-about-custom-plans-private-projects-with-more-than-25-members-?
|
||||
[32]:https://blog.taiga.io/taiga-perovskia-atriplicifolia-release-310.html
|
||||
[33]:https://github.com/taigaio
|
||||
[34]:https://www.tuleap.org/
|
||||
[35]:https://www.tuleap.org/features/project-management
|
||||
[36]:https://www.tuleap.org/get-started
|
||||
[37]:https://tuleap.net/plugins/git/tuleap/tuleap/stable
|
||||
@ -1,212 +0,0 @@
|
||||
ucasFL translating
|
||||
|
||||
How To Compress And Decompress Files In Linux
|
||||
======
|
||||
|
||||

|
||||
Compressing is quite useful when backing up important files and also sending large files over Internet. Please note that compressing an already compressed file adds extra overhead, hence you will get a slightly bigger file. So, stop compressing a compressed file. There are many programs to compress and decompress files in GNU/Linux. In this tutorial, we’re going to learn about two applications only.
|
||||
|
||||
### Compress and decompress files
|
||||
|
||||
The most common programs used to compress files in Unix-like systems are:
|
||||
|
||||
1. gzip
|
||||
2. bzip2
|
||||
|
||||
|
||||
|
||||
##### 1\. Compress and decompress files using Gzip program
|
||||
|
||||
The gzip is an utility to compress and decompress files using Lempel-Ziv coding (LZ77) algorithm.
|
||||
|
||||
**1.1 Compress files**
|
||||
|
||||
To compress a file named **ostechnix.txt** , replacing it with a gzipped compressed version, run:
|
||||
```
|
||||
$ gzip ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
Gzip will replace the original file **ostechnix.txt** with a gzipped compressed version named **ostechnix.txt.gz**.
|
||||
|
||||
The gzip command can also be used in other ways too. One fine example is we can create a compressed version of a specific command’s output. Look at the following command.
|
||||
```
|
||||
$ ls -l Downloads/ | gzip > ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
The above command creates compressed version of the directory listing of Downloads folder.
|
||||
|
||||
**1.2 Compress files and write the output to different files (Don’t replace the original file)
|
||||
**
|
||||
|
||||
By default, gzip program will compress the given file, replacing it with a gzipped compressed version. You can, however, keep the original file and write the output to standard output. For example, the following command, compresses **ostechnix.txt** and writes the output to **output.txt.gz**.
|
||||
```
|
||||
$ gzip -c ostechnix.txt > output.txt.gz
|
||||
|
||||
```
|
||||
|
||||
Similarly, to decompress a gzipped file specifying the output filename:
|
||||
```
|
||||
$ gzip -c -d output.txt.gz > ostechnix1.txt
|
||||
|
||||
```
|
||||
|
||||
The above command decompresses the **output.txt.gz** file and writes the output to **ostechnix1.txt** file. In both cases, it won’t delete the original file.
|
||||
|
||||
**1.3 Decompress files**
|
||||
|
||||
To decompress the file **ostechnix.txt.gz** , replacing it with the original uncompressed version, we do:
|
||||
```
|
||||
$ gzip -d ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
We can also use gunzip to decompress the files.
|
||||
```
|
||||
$ gunzip ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
**1.4 View contents of compressed files without decompressing them**
|
||||
|
||||
To view the contents of the compressed file using gzip without decompressing it, use **-c** flag as shown below:
|
||||
```
|
||||
$ gunzip -c ostechnix1.txt.gz
|
||||
|
||||
```
|
||||
|
||||
Alternatively, use **zcat** utility like below.
|
||||
```
|
||||
$ zcat ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
You can also pipe the output to “less” command to view the output page by page like below.
|
||||
```
|
||||
$ gunzip -c ostechnix1.txt.gz | less
|
||||
|
||||
$ zcat ostechnix.txt.gz | less
|
||||
|
||||
```
|
||||
|
||||
Alternatively, there is a **zless** program which performs the same function as the pipeline above.
|
||||
```
|
||||
$ zless ostechnix1.txt.gz
|
||||
|
||||
```
|
||||
|
||||
**1.5 Compress file with gzip by specifying compression level**
|
||||
|
||||
Another notable advantage of gzip is it supports compression level. It supports 3 compression levels as given below.
|
||||
|
||||
* **1** – Fastest (Worst)
|
||||
* **9** – Slowest (Best)
|
||||
* **6** – Default level
|
||||
|
||||
|
||||
|
||||
To compress a file named **ostechnix.txt** , replacing it with a gzipped compressed version with **best** compression level, we use:
|
||||
```
|
||||
$ gzip -9 ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
**1.6 Concatenate multiple compressed files**
|
||||
|
||||
It is also possible to concatenate multiple compressed files into one. How? Have a look at the following example.
|
||||
```
|
||||
$ gzip -c ostechnix1.txt > output.txt.gz
|
||||
|
||||
$ gzip -c ostechnix2.txt >> output.txt.gz
|
||||
|
||||
```
|
||||
|
||||
The above two commands will compress ostechnix1.txt and ostechnix2.txt and saves them in one file named **output.txt.gz**.
|
||||
|
||||
You can view the contents of both files (ostechnix1.txt and ostechnix2.txt) without extracting them using any one of the following commands:
|
||||
```
|
||||
$ gunzip -c output.txt.gz
|
||||
|
||||
$ gunzip -c output.txt
|
||||
|
||||
$ zcat output.txt.gz
|
||||
|
||||
$ zcat output.txt
|
||||
|
||||
```
|
||||
|
||||
For more details, refer the man pages.
|
||||
```
|
||||
$ man gzip
|
||||
|
||||
```
|
||||
|
||||
##### 2\. Compress and decompress files using bzip2 program
|
||||
|
||||
The **bzip2** is very similar to gzip program, but uses different compression algorithm named the Burrows-Wheeler block sorting text compression algorithm, and Huffman coding. The files compressed using bzip2 will end with **.bz2** extension.
|
||||
|
||||
Like I said, the usage of bzip2 is almost same as gzip. Just replace **gzip** in the above examples with **bzip2** , **gunzip** with **bunzip2** , **zcat** with **bzcat** and so on.
|
||||
|
||||
To compress a file using bzip2, replacing it with compressed version, run:
|
||||
```
|
||||
$ bzip2 ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
If you don’t want to replace the original file, use **-c** flag and write the output to a new file.
|
||||
```
|
||||
$ bzip2 -c ostechnix.txt > output.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
To decompress a compressed file:
|
||||
```
|
||||
$ bzip2 -d ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
$ bunzip2 ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
To view the contents of a compressed file without decompressing it:
|
||||
```
|
||||
$ bunzip2 -c ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
$ bzcat ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ man bzip2
|
||||
|
||||
```
|
||||
|
||||
##### Summary
|
||||
|
||||
In this tutorial, we learned what is gzip and bzip2 programs and how to use them to compress and decompress files with some examples in GNU/Linux. In this next, guide we are going to learn how to archive files and directories in Linux.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-compress-and-decompress-files-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -1,3 +1,4 @@
|
||||
Zafiry translating...
|
||||
What is a Makefile and how does it work?
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
heguangzhi Translating
|
||||
|
||||
6 open source tools for making your own VPN
|
||||
======
|
||||
|
||||
|
||||
@ -1,43 +1,46 @@
|
||||
|
||||
理解 Linux 文件系统:ext4 以及更多文件系统
|
||||
==========================================
|
||||
理解 Linux 文件系统:ext4 等文件系统
|
||||
=======
|
||||
|
||||
> 了解 ext4 的历史,包括其与 ext3 和之前的其它文件系统之间的区别。
|
||||
|
||||

|
||||
|
||||
目前的大部分 Linux 文件系统都默认采用 ext4 文件系统, 正如以前的 Linux 发行版默认使用 ext3、ext2 以及更久前的 ext。对于不熟悉 Linux 或文件系统的朋友而言,你可能不清楚 ext4 相对于上一版本 ext3 带来了什么变化。你可能还想知道在一连串关于可替代文件系统例如 btrfs、xfs 和 zfs 不断被发布的情况下,ext4 是否仍然能得到进一步的发展 。
|
||||
|
||||
在一篇文章中,我们不可能讲述文件系统的所有方面,但我们尝试让您尽快了解 Linux 默认文件系统的发展历史,包括它的产生以及未来发展。我仔细研究了维基百科里的各种关于 ext 文件系统文章、kernel.org‘s wiki 中关于 ext4 的条目以及结合自己的经验写下这篇文章。
|
||||
目前的大部分 Linux 文件系统都默认采用 ext4 文件系统, 正如以前的 Linux 发行版默认使用 ext3、ext2 以及更久前的 ext。
|
||||
|
||||
对于不熟悉 Linux 或文件系统的朋友而言,你可能不清楚 ext4 相对于上一版本 ext3 带来了什么变化。你可能还想知道在一连串关于替代的文件系统例如 btrfs、xfs 和 zfs 不断被发布的情况下,ext4 是否仍然能得到进一步的发展。
|
||||
|
||||
在一篇文章中,我们不可能讲述文件系统的所有方面,但我们尝试让您尽快了解 Linux 默认文件系统的发展历史,包括它的产生以及未来发展。我仔细研究了维基百科里的各种关于 ext 文件系统文章、kernel.org 的 wiki 中关于 ext4 的条目以及结合自己的经验写下这篇文章。
|
||||
|
||||
### ext 简史
|
||||
|
||||
#### MINIX 文件系统
|
||||
|
||||
在有 ext 之前, 使用的是 MINIX 文件系统。如果你不熟悉 Linux 历史, 那么可以理解为 MINIX 相对于 IBM PC/AT 微型计算机来说是一个非常小的类 Unix 系统。Andrew Tannenbaum 为了教学的目的而开发了它并于 1987 年发布了源代码(印刷版!)。
|
||||
|
||||
在有 ext 之前, 使用的是 MINIX 文件系统。如果你不熟悉 Linux 历史, 那么可以理解为 MINIX 是用于 IBM PC/AT 微型计算机的一个非常小的类 Unix 系统。Andrew Tannenbaum 为了教学的目的而开发了它,并于 1987 年发布了源代码(以印刷版的格式!)。
|
||||
|
||||

|
||||
|
||||
*IBM 1980 中期的 PC/AT,[MBlairMartin](https://commons.wikimedia.org/wiki/File:IBM_PC_AT.jpg),[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/deed.en)*
|
||||
|
||||
虽然你可以读阅 MINIX 的源代码,但实际上它并不是免费的开源软件(FOSS)。出版 Tannebaum 著作的出版商要求你花 69 美元的许可费来获得 MINIX 的操作权,而这笔费用包含在书籍的费用中。尽管如此,在那时来说非常便宜,并且 MINIX 的使用得到迅速发展,很快超过了 Tannebaum 当初使用它来教授操作系统编码的意图。在整个 20 世纪 90 年代,你可以发现 MINIX 的安装在世界各个大学里面非常流行。
|
||||
而此时,年轻的 Lius Torvalds 使用 MINIX 来开发原始 Linux 内核,并于 1991 年首次公布。而后在 1992 年 12 月在 GPL 开源协议下发布。
|
||||
虽然你可以细读 MINIX 的源代码,但实际上它并不是自由开源软件(FOSS)。出版 Tannebaum 著作的出版商要求你花 69 美元的许可费来运行 MINIX,而这笔费用包含在书籍的费用中。尽管如此,在那时来说非常便宜,并且 MINIX 的使用得到迅速发展,很快超过了 Tannebaum 当初使用它来教授操作系统编码的意图。在整个 20 世纪 90 年代,你可以发现 MINIX 的安装在世界各个大学里面非常流行。而此时,年轻的 Lius Torvalds 使用 MINIX 来开发原始 Linux 内核,并于 1991 年首次公布。而后在 1992 年 12 月在 GPL 开源协议下发布。
|
||||
|
||||
但是等等,这是一篇以*文件系统*为主题的文章不是吗?是的,MINIX 有自己的文件系统,早期的 Linux 版本依赖于它。跟 MINIX 一样,Linux 的文件系统也如同玩具那般小 —— MINX 文件系统最多能处理 14 个字符的文件名,并且只能处理 64MB 的存储空间。到了 1991 年,一般的硬盘尺寸已经达到了 40-140MB。很显然,Linux 需要一个更好的文件系统。
|
||||
但是等等,这是一篇以*文件系统*为主题的文章不是吗?是的,MINIX 有自己的文件系统,早期的 Linux 版本依赖于它。跟 MINIX 一样,Linux 的文件系统也如同玩具那般小 —— MINIX 文件系统最多能处理 14 个字符的文件名,并且只能处理 64MB 的存储空间。到了 1991 年,一般的硬盘尺寸已经达到了 40-140MB。很显然,Linux 需要一个更好的文件系统。
|
||||
|
||||
#### ext
|
||||
|
||||
当 Linus 开发出刚起步的 Linux 内核时,Rémy Card 从事第一代的 ext 文件系统的开发工作。 ext 文件系统在 1992 首次实现并发布 —— 仅在 Linux 首次发布后的一年! —— ext 解决了 MINIX 文件系统中最糟糕的问题。
|
||||
|
||||
1992年的 ext 使用在 Linux 内核中的新虚拟文件系统(VFS)抽象层。与之前的 MINIX 文件系统不同的是,ext 可以处理高达 2GB 存储空间并处理 255 个字符的文件名。
|
||||
1992 年的 ext 使用在 Linux 内核中的新虚拟文件系统(VFS)抽象层。与之前的 MINIX 文件系统不同的是,ext 可以处理高达 2GB 存储空间并处理 255 个字符的文件名。
|
||||
|
||||
但 ext 并没有长时间占统治地位,主要是由于它的原始时间戳(每个文件仅有一个时间戳,而不是今天我们所熟悉的有 inode 、最近文件访问时间和最新文件修改时间的时间戳。)仅仅一年后,ext2 就替代了它。
|
||||
但 ext 并没有长时间占统治地位,主要是由于它原始的时间戳(每个文件仅有一个时间戳,而不是今天我们所熟悉的有 inode 、最近文件访问时间和最新文件修改时间的时间戳。)仅仅一年后,ext2 就替代了它。
|
||||
|
||||
#### ext2
|
||||
|
||||
Rémy 很快就意识到 ext 的局限性,所以一年后他设计出 ext2 替代它。当 ext 仍然根植于 "玩具” 操作系统时,ext2 从一开始就被设计为一个商业级文件系统,沿用 BSD 的 Berkeley 文件系统的设计原理。
|
||||
Rémy 很快就意识到 ext 的局限性,所以一年后他设计出 ext2 替代它。当 ext 仍然根植于 “玩具” 操作系统时,ext2 从一开始就被设计为一个商业级文件系统,沿用 BSD 的 Berkeley 文件系统的设计原理。
|
||||
|
||||
Ext2 提供了 GB 级别的最大文件大小和 TB 级别的文件系统大小,使其在 20 世纪 90 年代的地位牢牢巩固在文件系统大联盟中。很快它被广泛地使用,无论是在 Linux 内核中还是最终在 MINIX 中,且利用第三方模块可以使其应用于 MacOs 和 Windows。
|
||||
Ext2 提供了 GB 级别的最大文件大小和 TB 级别的文件系统大小,使其在 20 世纪 90 年代的地位牢牢巩固在文件系统大联盟中。很快它被广泛地使用,无论是在 Linux 内核中还是最终在 MINIX 中,且利用第三方模块可以使其应用于 MacOS 和 Windows。
|
||||
|
||||
但这里仍然有一些问题需要解决:ext2 文件系统与 20 世纪 90 年代的大多数文件系统一样,如果在将数据写入到磁盘的时候,系统发生奔溃或断电,则容易发生灾难性的数据损坏。随着时间的推移,由于碎片(单个文件存储在多个位置,物理上其分散在旋转的磁盘上),它们也遭受了严重的性能损失。
|
||||
但这里仍然有一些问题需要解决:ext2 文件系统与 20 世纪 90 年代的大多数文件系统一样,如果在将数据写入到磁盘的时候,系统发生崩溃或断电,则容易发生灾难性的数据损坏。随着时间的推移,由于碎片(单个文件存储在多个位置,物理上其分散在旋转的磁盘上),它们也遭受了严重的性能损失。
|
||||
|
||||
尽管存在这些问题,但今天 ext2 还是用在某些特殊的情况下 —— 最常见的是,作为便携式 USB 拇指驱动器的文件系统格式。
|
||||
|
||||
@ -45,21 +48,19 @@ Ext2 提供了 GB 级别的最大文件大小和 TB 级别的文件系统大小
|
||||
|
||||
1998 年, 在 ext2 被采用后的 6 年后,Stephen Tweedie 宣布他正在致力于改进 ext2。这成了 ext3,并于 2001 年 11 月在 2.4.15 内核版本中被采用到 Linux 内核主线中。
|
||||
|
||||
|
||||
![Packard Bell 计算机][2]
|
||||
|
||||
20世纪90年代中期的 Packard Bell 计算机, [Spacekid][3], [CC0][4]
|
||||
*20 世纪 90 年代中期的 Packard Bell 计算机,[Spacekid][3],[CC0][4]*
|
||||
|
||||
在大部分情况下,Ext2 在 Linux 发行版中做得很好,但像 FAT、FAT32、HFS 和当时的其他文件系统一样 —— 在断电时容易发生灾难性的破坏。如果在将数据写入文件系统时候发生断电,则可能会将其留在所谓 *不一致* 的状态 —— 事情只完成一半而另一半未完成。这可能导致大量文件丢失或损坏,这些文件与正在保存的文件无关甚至导致整个文件系统无法卸载。
|
||||
在大部分情况下,Ext2 在 Linux 发行版中工作得很好,但像 FAT、FAT32、HFS 和当时的其他文件系统一样 —— 在断电时容易发生灾难性的破坏。如果在将数据写入文件系统时候发生断电,则可能会将其留在所谓*不一致*的状态 —— 事情只完成一半而另一半未完成。这可能导致大量文件丢失或损坏,这些文件与正在保存的文件无关甚至导致整个文件系统无法卸载。
|
||||
|
||||
Ext3 和 20 世纪 90 年代后期的其他文件系统,如微软的 NTFS ,使用*日志*来解决这个问题。 日志是磁盘上的一种特殊分配,其写入存储在事务中;如果事务完成写入磁盘,则日志中的数据将提交给文件系统它本身。如果文件在它提交操作前崩溃,则重新启动的系统识别其为未完成的事务而将其进行回滚,就像从未发生过一样。这意味着正在处理的文件可能依然会丢失,但文件系统本身保持一致,且其他所有数据都是安全的。
|
||||
Ext3 和 20 世纪 90 年代后期的其他文件系统,如微软的 NTFS ,使用*日志*来解决这个问题。日志是磁盘上的一种特殊的分配区域,其写入被存储在事务中;如果该事务完成磁盘写入,则日志中的数据将提交给文件系统自身。如果系统在该操作提交前崩溃,则重新启动的系统识别其为未完成的事务而将其进行回滚,就像从未发生过一样。这意味着正在处理的文件可能依然会丢失,但文件系统*本身*保持一致,且其他所有数据都是安全的。
|
||||
|
||||
在使用 ext3 文件系统的 Linux 内核中实现了三个级别的日志记录方式:**日记(journal)** , **顺序(ordered)** , 和 **回写(writeback)**。
|
||||
|
||||
* **日记(Journal)** 是最低风险模式,在将数据和元数据提交给文件系统之前将其写入日志。这可以保证正在写入的文件与整个文件系统的一致性,但其显著降低了性能。
|
||||
* **顺序(Ordered)** 是大多数 Linux 发行版默认模式;ordered 模式将元数据写入日志且直接将数据提交到文件系统。顾名思义,这里的操作顺序是固定的:首先,元数据提交到日志;其次,数据写入文件系统,然后才将日志中关联的元数据更新到文件系统。这确保了在发生奔溃时,与未完整写入相关联的元数据仍在日志中,且文件系统可以在回滚日志时清理那些不完整的写入事务。在 ordered 模式下,系统崩溃可能导致在崩溃期间文件被主动写入或损坏,但文件系统它本身 —— 以及未被主动写入的文件 —— 确保是安全的。
|
||||
* **回写(Writeback)** 是第三种模式 —— 也是最不安全的日志模式。在 writeback 模式下,像 ordered 模式一样,元数据会被记录,但数据不会。与 ordered 模式不同,元数据和数据都可以以任何有利于获得最佳性能的顺序写入。这可以显著提高性能,但安全性低很多。尽管 wireteback 模式仍然保证文件系统本身的安全性,但在奔溃或之前写入的文件很容易丢失或损坏。
|
||||
在使用 ext3 文件系统的 Linux 内核中实现了三个级别的日志记录方式:<ruby>日记<rt>journal</rt></ruby>、<ruby>顺序<rt>ordered</rt></ruby>和<ruby>回写<rt>writeback</rt></ruby>。
|
||||
|
||||
* **日记** 是最低风险模式,在将数据和元数据提交给文件系统之前将其写入日志。这可以保证正在写入的文件与整个文件系统的一致性,但其显著降低了性能。
|
||||
* **顺序** 是大多数 Linux 发行版默认模式;顺序模式将元数据写入日志而直接将数据提交到文件系统。顾名思义,这里的操作顺序是固定的:首先,元数据提交到日志;其次,数据写入文件系统,然后才将日志中关联的元数据更新到文件系统。这确保了在发生崩溃时,那些与未完整写入相关联的元数据仍在日志中,且文件系统可以在回滚日志时清理那些不完整的写入事务。在顺序模式下,系统崩溃可能导致在崩溃期间文件的错误被主动写入,但文件系统它本身 —— 以及未被主动写入的文件 —— 确保是安全的。
|
||||
* **回写** 是第三种模式 —— 也是最不安全的日志模式。在回写模式下,像顺序模式一样,元数据会被记录到日志,但数据不会。与顺序模式不同,元数据和数据都可以以任何有利于获得最佳性能的顺序写入。这可以显著提高性能,但安全性低很多。尽管回写模式仍然保证文件系统本身的安全性,但在崩溃或崩溃之前写入的文件很容易丢失或损坏。
|
||||
|
||||
跟之前的 ext2 类似,ext3 使用 16 位内部寻址。这意味着对于有着 4K 块大小的 ext3 在最大规格为 16TiB 的文件系统中可以处理的最大文件大小为 2TiB。
|
||||
|
||||
@ -67,182 +68,167 @@ Ext3 和 20 世纪 90 年代后期的其他文件系统,如微软的 NTFS ,
|
||||
|
||||
Theodore Ts'o (是当时 ext3 主要开发人员) 在 2006 年发表的 ext4 ,于两年后在 2.6.28 内核版本中被加入到了 Linux 主线。
|
||||
|
||||
Ts’o 将 ext4 描述为一个显著扩展 ext3 的临时技术,但它仍然依赖于旧技术。他预计 ext4 终将会被真正的下一代文件系统所取代。
|
||||
Ts’o 将 ext4 描述为一个显著扩展 ext3 但仍然依赖于旧技术的临时技术。他预计 ext4 终将会被真正的下一代文件系统所取代。
|
||||
|
||||

|
||||
|
||||
Ext4 在功能上与 Ext3 在功能上非常相似,但大大支持文件系统、提高了对碎片的抵抗力,有更高的性能以及更好的时间戳。
|
||||
*Dell Precision 380 工作站,[Lance Fisher](https://commons.wikimedia.org/wiki/File:Dell_Precision_380_Workstation.jpeg),[CC BY-SA 2.0](https://creativecommons.org/licenses/by-sa/2.0/deed.en)*
|
||||
|
||||
### Ext4 vs ext3
|
||||
Ext4 在功能上与 Ext3 在功能上非常相似,但支持大文件系统、提高了对碎片的抵抗力,有更高的性能以及更好的时间戳。
|
||||
|
||||
Ext3 和 Ext4 有一些非常明确的差别,在这里集中讨论下。
|
||||
### ext4 vs ext3
|
||||
|
||||
ext3 和 ext4 有一些非常明确的差别,在这里集中讨论下。
|
||||
|
||||
#### 向后兼容性
|
||||
|
||||
Ext4 特地设计为尽可能地向后兼容 ext3。这不仅允许 ext3 文件系统升级到 ext4;也允许 ext4 驱动程序在 ext3 模式下自动挂载 ext3 文件系统,因此使它无需单独维护两个代码库。
|
||||
ext4 特地设计为尽可能地向后兼容 ext3。这不仅允许 ext3 文件系统原地升级到 ext4;也允许 ext4 驱动程序以 ext3 模式自动挂载 ext3 文件系统,因此使它无需单独维护两个代码库。
|
||||
|
||||
#### 大文件系统
|
||||
|
||||
Ext3 文进系统使用 32 为寻址,这限制它仅支持 2TiB 文件大小和 16TiB 文件系统系统大小(这是假设在块大小为 4KiB 的情况下,一些 ext3 文件系统使用更小的块大小,因此对其进一步做了限制)。
|
||||
ext3 文件系统使用 32 位寻址,这限制它仅支持 2TiB 文件大小和 16TiB 文件系统系统大小(这是假设在块大小为 4KiB 的情况下,一些 ext3 文件系统使用更小的块大小,因此对其进一步被限制)。
|
||||
|
||||
Ext4 使用 48 位的内部寻址,理论上可以在文件系统上分配高达 16TiB 大小的文件,其中文件系统大小最高可达 1000 000 TiB(1EiB)。在早期 ext4 的实现中 有些用户空间的程序仍然将其限制为最大大小为 16TiB 的文件系统,但截至 2011 年,e2fsprogs 已经直接支持大于 16TiB 大小的 ext4 文件系统。例如,红帽企业 Linux 合同上仅支持最高 50TiB 的 ext4 文件系统,并建议 ext4 卷不超过 100TiB。
|
||||
ext4 使用 48 位的内部寻址,理论上可以在文件系统上分配高达 16TiB 大小的文件,其中文件系统大小最高可达 1000000 TiB(1EiB)。在早期 ext4 的实现中有些用户空间的程序仍然将其限制为最大大小为 16TiB 的文件系统,但截至 2011 年,e2fsprogs 已经直接支持大于 16TiB 大小的 ext4 文件系统。例如,红帽企业 Linux 在其合同上仅支持最高 50TiB 的 ext4 文件系统,并建议 ext4 卷不超过 100TiB。
|
||||
|
||||
#### 分配改进
|
||||
#### 分配方式改进
|
||||
|
||||
Ext4 在将存储块写入磁盘之前对存储块的分配方式进行了大量改进,这可以显著提高读写性能。
|
||||
ext4 在将存储块写入磁盘之前对存储块的分配方式进行了大量改进,这可以显著提高读写性能。
|
||||
|
||||
##### 区段(extent)
|
||||
##### 区段
|
||||
|
||||
extent 是一系列连续的物理块大小 (最多达 128 MiB,假设块大小为 4KiB),可以一次性保留和寻址。使用区段可以减少给定未见所需的 inode 数量,并显著减少碎片并提高写入大文件时的性能。
|
||||
<ruby>区段<rt>extent</rt></ruby>是一系列连续的物理块 (最多达 128 MiB,假设块大小为 4KiB),可以一次性保留和寻址。使用区段可以减少给定文件所需的 inode 数量,并显著减少碎片并提高写入大文件时的性能。
|
||||
|
||||
##### 多块分配
|
||||
|
||||
Ext3 为每一个新分配的块调用一次块分配器。当多个块调用同时打开分配器时,很容易导致严重的碎片。然而,ext4 使用延迟分配,这允许它合并写入并更好地决定如何为尚未提交的写入分配块。
|
||||
ext3 为每一个新分配的块调用一次块分配器。当多个写入同时打开分配器时,很容易导致严重的碎片。然而,ext4 使用延迟分配,这允许它合并写入并更好地决定如何为尚未提交的写入分配块。
|
||||
|
||||
##### 持续的预分配
|
||||
##### 持久的预分配
|
||||
|
||||
在为文件预分配磁盘空间时,大部分文件系统必须在创建时将零写入该文件的块中。Ext4 允许使用 `fallocate()`,它保证了空间的可用性(并试图为它找到连续的空间),而不需要县写入它。
|
||||
这显著提高了写入和将来读取流和数据库应用程序的写入数据的性能。
|
||||
在为文件预分配磁盘空间时,大部分文件系统必须在创建时将零写入该文件的块中。ext4 允许替代使用 `fallocate()`,它保证了空间的可用性(并试图为它找到连续的空间),而不需要先写入它。这显著提高了写入和将来读取流和数据库应用程序的写入数据的性能。
|
||||
|
||||
##### 延迟分配
|
||||
|
||||
这是一个耐人嚼味而有争议性的功能。延迟分配允许 ext4 等待分配将写入数据的实际块,直到它准备好将数据提交到磁盘。(相比之下,即使数据仍然在写入缓存,ext3 也会立即分配块。)
|
||||
这是一个耐人寻味而有争议性的功能。延迟分配允许 ext4 等待分配将写入数据的实际块,直到它准备好将数据提交到磁盘。(相比之下,即使数据仍然在往写入缓存中写入,ext3 也会立即分配块。)
|
||||
|
||||
当缓存中的数据累积时,延迟分配块允许文件系统做出更好的选择。然而不幸的是,当程序员想确保数据完全刷新到磁盘时,它增加了在还没有专门编写调用 ‘fsync()’方法的程序中的数据丢失的可能性。
|
||||
当缓存中的数据累积时,延迟分配块允许文件系统对如何分配块做出更好的选择,降低碎片(写入,以及稍后的读)并显著提升性能。然而不幸的是,它*增加*了还没有专门调用 `fsync()` 方法(当程序员想确保数据完全刷新到磁盘时)的程序的数据丢失的可能性。
|
||||
|
||||
假设一个程序完全重写了一个文件:
|
||||
|
||||
`fd=open("file" ,O_TRUNC); write(fd, data); close(fd);`
|
||||
```
|
||||
fd=open("file" ,O_TRUNC); write(fd, data); close(fd);
|
||||
```
|
||||
|
||||
使用旧的文件系统, `close(fd);` 足以保证 `file` 中的内存刷新到磁盘。即使严格来说,写不是事务性的,但如果文件关闭后发生崩溃,则丢失数据的风险很小。如果写入不成功(由于程序上的错误、磁盘上的错误、断电等),文件的原始版本和较新版本都可能丢失数据或损坏。如果其他进程在写入文件时访问文件,则会看到损坏的版本。
|
||||
如果其他进程打开文件并且不希望其内容发生更改 —— 例如,映射到多个正在运行的程序的共享库。这些进程可能会崩溃。
|
||||
使用旧的文件系统, `close(fd);` 足以保证 `file` 中的内容刷新到磁盘。即使严格来说,写不是事务性的,但如果文件关闭后发生崩溃,则丢失数据的风险很小。
|
||||
|
||||
如果写入不成功(由于程序上的错误、磁盘上的错误、断电等),文件的原始版本和较新版本都可能丢失数据或损坏。如果其他进程在写入文件时访问文件,则会看到损坏的版本。如果其他进程打开文件并且不希望其内容发生更改 —— 例如,映射到多个正在运行的程序的共享库。这些进程可能会崩溃。
|
||||
|
||||
为了避免这些问题,一些程序员完全避免使用 `O_TRUNC`。相反,他们可能会写入一个新文件,关闭它,然后将其重命名为旧文件名:
|
||||
|
||||
`fd=open("newfile"); write(fd, data); close(fd); rename("newfile", "file");`
|
||||
```
|
||||
fd=open("newfile"); write(fd, data); close(fd); rename("newfile", "file");
|
||||
```
|
||||
|
||||
在没有延迟分配的文件系统下,这足以避免上面列出的潜在的损坏和崩溃问题:因为`rename()` 是原子操作,所以它不会被崩溃中断;并且运行的程序将引用旧的。现在 `file` 的未链接版本主要有一个打开的文件文件句柄即可。
|
||||
但是因为 ext4 的延迟分配会导致写入被延迟和重新排序,`rename("newfile","file")` 可以在 `newfile` 的内容实际写入磁盘内容之前执行,这打开了并行进行再次获得 `file` 坏版本的问题。
|
||||
在*没有*延迟分配的文件系统下,这足以避免上面列出的潜在的损坏和崩溃问题:因为`rename()` 是原子操作,所以它不会被崩溃中断;并且运行的程序将继续引用旧的文件。现在 `file` 的未链接版本只要有一个打开的文件文件句柄即可。但是因为 ext4 的延迟分配会导致写入被延迟和重新排序,`rename("newfile","file")` 可以在 `newfile` 的内容实际写入磁盘内容之前执行,这出现了并行进行再次获得 `file` 坏版本的问题。
|
||||
|
||||
|
||||
为了缓解这种情况,Linux 内核(自版本 2.6.30 )尝试检测这些常见代码情况并强制立即分配。这减少但不能防止数据丢失的可能性 —— 并且它对新文件没有任何帮助。如果你是一位开发人员,请注意:
|
||||
|
||||
保证数据立即写入磁盘的方法是正确调用 `fsync()` 。
|
||||
为了缓解这种情况,Linux 内核(自版本 2.6.30 )尝试检测这些常见代码情况并强制立即分配。这会减少但不能防止数据丢失的可能性 —— 并且它对新文件没有任何帮助。如果你是一位开发人员,请注意:保证数据立即写入磁盘的唯一方法是正确调用 `fsync()` 。
|
||||
|
||||
#### 无限制的子目录
|
||||
|
||||
Ext3 仅限于 32000 个子目录;ext4 允许无限数量的子目录。从 2.6.23 内核版本开始,ext4 使用 HTree 索引来减少大量子目录的性能损失。
|
||||
ext3 仅限于 32000 个子目录;ext4 允许无限数量的子目录。从 2.6.23 内核版本开始,ext4 使用 HTree 索引来减少大量子目录的性能损失。
|
||||
|
||||
#### 日志校验
|
||||
|
||||
Ext3 没有对日志进行校验,这给内核直接控制之外的磁盘或控制器设备带来了自己的缓存问题。如果控制器或具有子集对缓存的磁盘确实无序写入,则可能会破坏 ext3 的日记事务顺序,
|
||||
从而可能破坏在崩溃期间(或之前一段时间)写入的文件。
|
||||
ext3 没有对日志进行校验,这给处于内核直接控制之外的磁盘或带有自己的缓存的控制器设备带来了问题。如果控制器或具有自己的缓存的磁盘脱离了写入顺序,则可能会破坏 ext3 的日记事务顺序,从而可能破坏在崩溃期间(或之前一段时间)写入的文件。
|
||||
|
||||
理论上,这个问题可以使用 write barriers —— 在安装文件系统时,你在挂载选项设置 `barrier=1` ,然后将设备 `fsync` 一直向下调用直到 metal。通过实践,可以发现存储设备和控制器经常不遵守 write barriers —— 提高性能(和 benchmarks,跟竞争对手比较),但增加了本应该防止数据损坏的可能性。
|
||||
理论上,这个问题可以使用写入<ruby>障碍<rt>barrier</rt></ruby> —— 在安装文件系统时,你在挂载选项设置 `barrier=1` ,然后设备就会忠实地执行 `fsync` 一直向下到底层硬件。通过实践,可以发现存储设备和控制器经常不遵守写入障碍 —— 提高性能(和跟竞争对手比较的性能基准),但增加了本应该防止数据损坏的可能性。
|
||||
|
||||
对日志进行校验和允许文件系统奔溃后意识到其某些条目在第一次安装时无效或无序。因此,这避免了即使部分存储设备不存在 barriers ,也会回滚部分或无序日志条目和进一步损坏的文件系统的错误。
|
||||
对日志进行校验和允许文件系统崩溃后第一次挂载时意识到其某些条目是无效或无序的。因此,这避免了回滚部分条目或无序日志条目的错误,并进一步损坏的文件系统——即使部分存储设备假做或不遵守写入障碍。
|
||||
|
||||
#### 快速文件系统检查
|
||||
|
||||
在 ext3 下,整个文件系统 —— 包括已删除或空文件 —— 在 `fsck` 被调用时需要检查。相比之下,ext4 标记了未分配块和 inode 表的小部分,从而允许 `fsck` 完全跳过它们。
|
||||
这大大减少了在大多数文件系统上运行 `fsck` 的时间,并从内核 2.6.24 开始实现。
|
||||
在 ext3 下,在 `fsck` 被调用时会检查整个文件系统 —— 包括已删除或空文件。相比之下,ext4 标记了 inode 表未分配的块和扇区,从而允许 `fsck` 完全跳过它们。这大大减少了在大多数文件系统上运行 `fsck` 的时间,它实现于内核 2.6.24。
|
||||
|
||||
#### 改进的时间戳
|
||||
|
||||
Ext3 提供粒度为一秒的时间戳。虽然足以满足大多数用途,但任务关键型应用程序经常需要更严格的时间控制。Ext4 通过提供纳秒级的时间戳,使其可用于那些企业,科学以及任务关键型的应用程序。
|
||||
ext3 提供粒度为一秒的时间戳。虽然足以满足大多数用途,但任务关键型应用程序经常需要更严格的时间控制。ext4 通过提供纳秒级的时间戳,使其可用于那些企业、科学以及任务关键型的应用程序。
|
||||
|
||||
Ext3文件系统也没有提供足够的位来存储 2038 年 1 月 18 日以后的日期。Ext4 在这里增加了两位,将 [the Unix epoch][5] 扩展了 408 年。如果你在公元 2446 年读到这篇文章,
|
||||
你很有可能已经转移到一个更好的文件系统 —— 如果你还在测量 UTC 00:00,1970 年 1 月 1 日以来的时间,这会让我非常非常高兴。
|
||||
ext3 文件系统也没有提供足够的位来存储 2038 年 1 月 18 日以后的日期。ext4 在这里增加了两个位,将 [Unix 纪元][5] 扩展了 408 年。如果你在公元 2446 年读到这篇文章,你很有可能已经转移到一个更好的文件系统 —— 如果你还在测量自 1970 年 1 月 1 日 00:00(UTC)以来的时间,这会让我死后得以安眠。
|
||||
|
||||
#### 在线碎片整理
|
||||
|
||||
ext2 和 ext3 都不直接支持在线碎片整理 —— 即在挂载时会对文件系统进行碎片整理。Ext2 有一个包含的实用程序,**e2defrag**,它的名字暗示 —— 它需要在文件系统未挂载时脱机运行。(显然,这对于根文件系统来说非常有问题。)在 ext3 中的情况甚至更糟糕 —— 虽然 ext3 比 ext2 更不容易受到严重碎片的影响,但 ext3 文件系统运行 **e2defrag** 可能会导致灾难性损坏和数据丢失。
|
||||
ext2 和 ext3 都不直接支持在线碎片整理 —— 即在挂载时会对文件系统进行碎片整理。ext2 有一个包含的实用程序,`e2defrag`,它的名字暗示 —— 它需要在文件系统未挂载时脱机运行。(显然,这对于根文件系统来说非常有问题。)在 ext3 中的情况甚至更糟糕 —— 虽然 ext3 比 ext2 更不容易受到严重碎片的影响,但 ext3 文件系统运行 `e2defrag` 可能会导致灾难性损坏和数据丢失。
|
||||
|
||||
尽管 ext3 最初被认为“不受碎片影响”,但对同一文件(例如 BitTorrent)采用大规模并行写入过程的过程清楚地表明情况并非完全如此。一些用户空间攻击和解决方法,例如 [Shake][6],
|
||||
以这种或那种方式解决了这个问题 —— 但它们比真正的、文件系统感知的、内核级碎片整理过程更慢并且在各方面都不太令人满意。
|
||||
尽管 ext3 最初被认为“不受碎片影响”,但对同一文件(例如 BitTorrent)采用大规模并行写入过程的过程清楚地表明情况并非完全如此。一些用户空间的手段和解决方法,例如 [Shake][6],以这样或那样方式解决了这个问题 —— 但它们比真正的、文件系统感知的、内核级碎片整理过程更慢并且在各方面都不太令人满意。
|
||||
|
||||
Ext4通过 **e4defrag** 解决了这个问题,且是一个在线、内核模式、文件系统感知、块和范围级别的碎片整理实用程序。
|
||||
ext4通过 `e4defrag` 解决了这个问题,且是一个在线、内核模式、文件系统感知、块和区段级别的碎片整理实用程序。
|
||||
|
||||
### 正在进行的ext4开发
|
||||
### 正在进行的 ext4 开发
|
||||
|
||||
Ext4,正如 Monty Python 中瘟疫感染者曾经说过的那样,“我还没死呢!” 虽然它的[主要开发人员][7]认为它只是一个真正的[下一代文件系统][8]的权宜之计,但是在一段时间内,没有任何可能的候选人准备好(由于技术或许可问题)部署为根文件系统。
|
||||
ext4,正如 Monty Python 中瘟疫感染者曾经说过的那样,“我还没死呢!” 虽然它的[主要开发人员][7]认为它只是一个真正的[下一代文件系统][8]的权宜之计,但是在一段时间内,没有任何可能的候选人准备好(由于技术或许可问题)部署为根文件系统。
|
||||
|
||||
在未来的 ext4 版本中仍然有一些关键功能,包括元数据校验和、一流的配额支持和大型分配块。
|
||||
在未来的 ext4 版本中仍然有一些关键功能要开发,包括元数据校验和、一流的配额支持和大分配块。
|
||||
|
||||
#### 元数据校验和
|
||||
|
||||
由于 ext4 具有冗余超级块,因此为文件系统校验其中的元数据提供了一种方法,可以自行确定主超级块是否已损坏并需要使用备用块。可以在没有校验和的情况下,从损坏的超级块恢复 —— 但是用户首先需要意识到它已损坏,然后尝试使用备用方法手动挂载文件系统。由于在某些情况下,使用损坏的主超级块安装文件系统读写可能会造成进一步的损坏,即使是经验丰富的用户也无法避免,这也不是一个完美的解决方案!
|
||||
|
||||
与 btrfs 或 zfs 等下一代文件系统提供的极其强大的每块校验和相比,ext4 的元数据校验和功能非常弱。但它总比没有好。虽然校验和所有的事情都听起来很简单!—— 事实上,将校验和连接到文件系统有一些重大的挑战; 请参阅[设计文档][9]了解详细信息。
|
||||
与 btrfs 或 zfs 等下一代文件系统提供的极其强大的每块校验和相比,ext4 的元数据校验和的功能非常弱。但它总比没有好。虽然校验**所有的事情**都听起来很简单!—— 事实上,将校验和与文件系统连接到一起有一些重大的挑战;请参阅[设计文档][9]了解详细信息。
|
||||
|
||||
#### 一流的配额支持
|
||||
|
||||
等等,配额?!从 ext2 出现的那条开始我们就有了这些!是的,但他们一直都是事后的想法,而且他们总是有点傻逼。这里可能不值得详细介绍,
|
||||
但[设计文档][10]列出了配额将从用户空间移动到内核中的方式,并且能够更加正确和高效地执行。
|
||||
等等,配额?!从 ext2 出现的那天开始我们就有了这些!是的,但它们一直都是事后的添加的东西,而且它们总是犯傻。这里可能不值得详细介绍,但[设计文档][10]列出了配额将从用户空间移动到内核中的方式,并且能够更加正确和高效地执行。
|
||||
|
||||
#### 大分配块
|
||||
随着时间的推移,那些讨厌的存储系统不断变得越来越大。由于一些固态硬盘已经使用 8K 硬件模块,因此 ext4 对 4K 模块的当前限制越来越受到限制。
|
||||
较大的存储块可以显着减少碎片并提高性能,代价是增加“松弛”空间(当您只需要块的一部分来存储文件或文件的最后一块时留下的空间)。
|
||||
|
||||
随着时间的推移,那些讨厌的存储系统不断变得越来越大。由于一些固态硬盘已经使用 8K 硬件块大小,因此 ext4 对 4K 模块的当前限制越来越受到限制。较大的存储块可以显著减少碎片并提高性能,代价是增加“松弛”空间(当您只需要块的一部分来存储文件或文件的最后一块时留下的空间)。
|
||||
|
||||
您可以在[设计文档][11]中查看详细说明。
|
||||
|
||||
### ext4的实际限制
|
||||
### ext4 的实际限制
|
||||
|
||||
Ext4 是一个健壮,稳定的文件系统。它是大多数人应该都在 2018 年用它作为根文件系统,但它无法处理所有需求。让我们简单地谈谈你不应该期待的一些事情 —— 现在或可能在未来。
|
||||
ext4 是一个健壮、稳定的文件系统。如今大多数人都应该在用它作为根文件系统,但它无法处理所有需求。让我们简单地谈谈你不应该期待的一些事情 —— 现在或可能在未来:
|
||||
|
||||
虽然 ext4 可以处理高达 1 EiB 大小相当于 1,000,000 TiB 大小的数据,但你真的、真的不应该尝试这样做。除了仅仅能够记住更多块的地址之外,还存在规模上的问题
|
||||
并且现在 ext4 不会处理(并且可能永远不会)超过 50 —— 100TiB 的数据。
|
||||
虽然 ext4 可以处理高达 1 EiB 大小(相当于 1,000,000 TiB)大小的数据,但你真的、*真的*不应该尝试这样做。除了能够记住更多块的地址之外,还存在规模上的问题。并且现在 ext4 不会处理(并且可能永远不会)超过 50 —— 100TiB 的数据。
|
||||
|
||||
Ext4 也不足以保证数据的完整性。随着日志记录的重大进展又回到了前 3 天,它并未涵盖数据损坏的许多常见原因。如果数据已经在磁盘上被[破坏][12]——由于故障硬件,
|
||||
宇宙射线的影响(是的,真的),或者数据随时间的简单降级 —— ext4无法检测或修复这种损坏。
|
||||
ext4 也不足以保证数据的完整性。随着日志记录的重大进展又回到了 ext3 的那个时候,它并未涵盖数据损坏的许多常见原因。如果数据已经在磁盘上被[破坏][12]——由于故障硬件,宇宙射线的影响(是的,真的),或者只是数据随时间衰减 —— ext4 无法检测或修复这种损坏。
|
||||
|
||||
最后两点是,ext4 只是一个纯文件系统,而不是存储卷管理器。这意味着,即使你有多个磁盘 ——也就是奇偶校验或冗余,理论上你可以从 ext4 中恢复损坏的数据,但无法知道使用它是否对你有利。虽然理论上可以在离散层中分离文件系统和存储卷管理系统而不会丢失自动损坏检测和修复功能,但这不是当前存储系统的设计方式,并且它将给新设计带来重大挑战。
|
||||
基于上面两点,ext4 只是一个纯*文件系统*,而不是存储卷管理器。这意味着,即使你有多个磁盘——也就是奇偶校验或冗余,理论上你可以从 ext4 中恢复损坏的数据,但无法知道使用它是否对你有利。虽然理论上可以在不同的层中分离文件系统和存储卷管理系统而不会丢失自动损坏检测和修复功能,但这不是当前存储系统的设计方式,并且它将给新设计带来重大挑战。
|
||||
|
||||
### 备用文件系统
|
||||
在我们开始之前,提醒一句:要非常小心这是没有内置任何备用的文件系统,并直接支持为您分配的主线内核的一部分!
|
||||
|
||||
即使文件系统是安全的,如果在内核升级期间出现问题,使用它作为根文件系统也是非常可怕的。如果你没有充分的想法通过一个 chroot 去使用介质引导,耐心地操作内核模块和 grub 配置,
|
||||
和 DKMS...不要在一个很重要的系统中去掉对根文件的备份。
|
||||
在我们开始之前,提醒一句:要非常小心,没有任何备用的文件系统作为主线内核的一部分而内置和直接支持!
|
||||
|
||||
可能有充分的理由使用您的发行版不直接支持的文件系统 —— 但如果您这样做,我强烈建议您在系统启动并可用后再安装它。
|
||||
(例如,您可能有一个 ext4 根文件系统,但是将大部分数据存储在 zfs 或 btrfs 池中。)
|
||||
即使一个文件系统是*安全的*,如果在内核升级期间出现问题,使用它作为根文件系统也是非常可怕的。如果你没有充分的理由通过一个 chroot 去使用替代介质引导,耐心地操作内核模块、 grub 配置和 DKMS...不要在一个很重要的系统中去掉预留的根文件。
|
||||
|
||||
可能有充分的理由使用您的发行版不直接支持的文件系统 —— 但如果您这样做,我强烈建议您在系统启动并可用后再安装它。(例如,您可能有一个 ext4 根文件系统,但是将大部分数据存储在 zfs 或 btrfs 池中。)
|
||||
|
||||
#### XFS
|
||||
|
||||
XFS 与 非 ext 文件系统在Linux下的主线一样。它是一个 64 位的日志文件系统,自 2001 年以来内置于 Linux 内核中,为大型文件系统和高度并发性提供了高性能
|
||||
(即,大量的进程都会立即写入文件系统)。
|
||||
XFS 与非 ext 文件系统在 Linux 中的主线中的地位一样。它是一个 64 位的日志文件系统,自 2001 年以来内置于 Linux 内核中,为大型文件系统和高度并发性提供了高性能(即,大量的进程都会立即写入文件系统)。
|
||||
|
||||
从 RHEL 7开始,XFS 成为 Red Hat Enterprise Linux 的默认文件系统。对于家庭或小型企业用户来说,它仍然有一些缺点 —— 最值得注意的是,重新调整现有 XFS 文件系统
|
||||
是一件非常痛苦的事情,不如创建另一个并复制数据更有意义。
|
||||
从 RHEL 7 开始,XFS 成为 Red Hat Enterprise Linux 的默认文件系统。对于家庭或小型企业用户来说,它仍然有一些缺点 —— 最值得注意的是,重新调整现有 XFS 文件系统是一件非常痛苦的事情,不如创建另一个并复制数据更有意义。
|
||||
|
||||
虽然 XFS 是稳定且是高性能的,但它和 ext4 之间没有足够的具体的最终用途差异来推荐它在非默认值的任何地方使用(例如,RHEL7),除非它解决了对 ext4 的特定问题,例如> 50 TiB容量的文件系统。
|
||||
虽然 XFS 是稳定且是高性能的,但它和 ext4 之间没有足够具体的最终用途差异,以值得推荐在非默认(例如,RHEL7)的任何地方使用它,除非它解决了对 ext4 的特定问题,例如 > 50 TiB 容量的文件系统。
|
||||
|
||||
XFS 在任何方面都不是 ZFS,btrfs 甚至 WAFL(专有 SAN 文件系统)的“下一代”文件系统。就像 ext4 一样,它应该被视为一种更好的方式的权宜之计。
|
||||
XFS 在任何方面都不是 ZFS、btrfs 甚至 WAFL(一个专有的 SAN 文件系统)的“下一代”文件系统。就像 ext4 一样,它应该被视为一种更好的方式的权宜之计。
|
||||
|
||||
#### ZFS
|
||||
|
||||
ZFS 由 Sun Microsystems 开发,以 zettabyte 命名 —— 相当于 1 万亿 GB —— 因为它理论上可以解决大型存储系统。
|
||||
|
||||
作为真正的下一代文件系统,ZFS 提供卷管理(能够在单个文件系统中处理多个单独的存储设备),块级加密校验和(允许以极高的准确率检测数据损坏),
|
||||
[自动损坏修复][12](其中冗余或奇偶校验存储可用),[快速异步增量复制][13],内联压缩等,[还有更多][14]。
|
||||
作为真正的下一代文件系统,ZFS 提供卷管理(能够在单个文件系统中处理多个单独的存储设备),块级加密校验和(允许以极高的准确率检测数据损坏),[自动损坏修复][12](其中冗余或奇偶校验存储可用),[快速异步增量复制][13],内联压缩等,[以及更多][14]。
|
||||
|
||||
从 Linux 用户的角度来看,ZFS 的最大问题是许可证问题。ZFS 许可证是 CDDL 许可证,这是一种与 GPL 冲突的半许可许可证。关于在 Linux 内核中使用 ZFS 的意义存在很多争议,
|
||||
其争议范围从“它是 GPL 违规”到“它是 CDDL 违规”到“它完全没问题,它还没有在法庭上进行过测试。 “ 最值得注意的是,自2016 年以来,Canonical 已将 ZFS 代码内联
|
||||
在其默认内核中,而且目前尚无法律挑战。
|
||||
从 Linux 用户的角度来看,ZFS 的最大问题是许可证问题。ZFS 许可证是 CDDL 许可证,这是一种与 GPL 冲突的半许可许可证。关于在 Linux 内核中使用 ZFS 的意义存在很多争议,其争议范围从“它是 GPL 违规”到“它是 CDDL 违规”到“它完全没问题,它还没有在法庭上进行过测试。 ” 最值得注意的是,自 2016 年以来 Canonical 已将 ZFS 代码内联在其默认内核中,而且目前尚无法律挑战。
|
||||
|
||||
此时,即使我作为一个非常狂热于 ZFS 的用户,我也不建议将 ZFS 作为 Linux的 root 文件系统。如果你想在 Linux 上利用 ZFS 的优势,在 ext4 上设置一个小的根文件系统,
|
||||
然后将 ZFS 放在你剩余的存储上,把数据,应用程序以及你喜欢的东西放在它上面 —— 但在 ext4 上保持 root,直到你的发行版明显支持 zfs 根目录。
|
||||
此时,即使我作为一个非常狂热于 ZFS 的用户,我也不建议将 ZFS 作为 Linux 的 root 文件系统。如果你想在 Linux 上利用 ZFS 的优势,用 ext4 设置一个小的根文件系统,然后将 ZFS 用在你剩余的存储上,把数据、应用程序以及你喜欢的东西放在它上面 —— 但把 root 保留在 ext4 上,直到你的发行版明显支持 zfs 根目录。
|
||||
|
||||
#### BTRFS
|
||||
|
||||
Btrfs 是 B-Tree Filesystem 的简称,通常发音为 “butter” —— 由 Chris Mason 于 2007 年在 Oracle 任职期间宣布。BTRFS 旨在跟 ZFS 有大部分相同的目标,
|
||||
提供多种设备管理,每块校验、异步复制、直列压缩等,[还有更多][8]。
|
||||
Btrfs 是 B-Tree Filesystem 的简称,通常发音为 “butter” —— 由 Chris Mason 于 2007 年在 Oracle 任职期间发布。BTRFS 旨在跟 ZFS 有大部分相同的目标,提供多种设备管理、每块校验、异步复制、直列压缩等,[还有更多][8]。
|
||||
|
||||
截至 2018 年,btrfs 相当稳定,可用作标准的单磁盘文件系统,但可能不应该依赖于卷管理器。与许多常见用例中的 ext4,XFS 或 ZFS 相比,它存在严重的性能问题,
|
||||
其下一代功能 —— 复制(replication),多磁盘拓扑和快照管理 —— 可能非常多,其结果可能是从灾难性地性能降低到实际数据的丢失。
|
||||
截至 2018 年,btrfs 相当稳定,可用作标准的单磁盘文件系统,但可能不应该依赖于卷管理器。与许多常见用例中的 ext4、XFS 或 ZFS 相比,它存在严重的性能问题,其下一代功能 —— 复制、多磁盘拓扑和快照管理 —— 可能非常多,其结果可能是从灾难性地性能降低到实际数据的丢失。
|
||||
|
||||
btrfs 的持续状态是有争议的; SUSE Enterprise Linux 在 2015 年采用它作为默认文件系统,而 Red Hat 宣布它将不再支持从 2017 年开始使用 RHEL 7.4 的 btrfs。
|
||||
可能值得注意的是,生产,支持的 btrfs 部署将其用作单磁盘文件系统,而不是作为一个多磁盘卷管理器 —— a la ZFS —— 甚至 Synology 在它的存储设备使用 BTRFS,
|
||||
btrfs 的维持状态是有争议的;SUSE Enterprise Linux 在 2015 年采用它作为默认文件系统,而 Red Hat 于 2017 年宣布它从 RHEL 7.4 开始不再支持 btrfs。可能值得注意的是,该产品支持 btrfs 部署用作单磁盘文件系统,而不是像 ZFS 中的多磁盘卷管理器,甚至 Synology 在它的存储设备使用 BTRFS,
|
||||
但是它在传统 Linux 内核 RAID(mdraid)之上分层来管理磁盘。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -251,7 +237,7 @@ via: https://opensource.com/article/18/4/ext4-filesystem
|
||||
|
||||
作者:[Jim Salter][a]
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,87 +1,84 @@
|
||||
ucasFL translating
|
||||
|
||||
How To Set Up PF Firewall on FreeBSD to Protect a Web Server
|
||||
如何在 FreeBSD 上设置 PF 防火墙来保护 Web 服务器
|
||||
======
|
||||
|
||||
I am a new FreeBSD server user and moved from netfilter on Linux. How do I setup a firewall with PF on FreeBSD server to protect a web server with single public IP address and interface?
|
||||
[![How To Set Up a Firewall with PF on FreeBSD to Protect a Web Server][1]][1]
|
||||
|
||||
我是从 Linux 迁移过来的 FreeBSD 新用户,Linux 中使用的是 netfilter 防火墙框架(LCTT 译注:netfilter 是由 Rusty Russell 提出的 Linux 2.4 内核防火墙框架)。那么在 FreeBSD 上,我该如何设置 PF 防火墙,从而来保护只有一个公共 IP 地址和端口的 web 服务器呢?
|
||||
|
||||
PF is an acronym for packet filter. It was created for OpenBSD but has been ported to FreeBSD and other operating systems. It is a stateful packet filtering engine. This tutorial will show you how to set up a firewall with PF on FreeBSD 10.x and 11.x server to protect your web server.
|
||||
PF 是<ruby>包过滤器<rt>packet filter</rt></ruby>的简称。它是为 OpenBSD开发的,但是已经被移植到了 FreeBSD 以及其它操作系统上。PF 是一个状态包过滤引擎。在这篇教程中,我将向你展示如何在 FreeBSD 10.x 以及 11.x 中设置 PF 防火墙,从而来保护 web 服务器。
|
||||
|
||||
### 第一步:开启 PF 防火墙
|
||||
|
||||
## Step 1 - Turn on PF firewall
|
||||
你需要把下面这几行内容添加到文件 “/etc/rc.conf” 文件中:
|
||||
|
||||
You need to add the following three lines to /etc/rc.conf file:
|
||||
```
|
||||
# echo 'pf_enable="YES"' >> /etc/rc.conf
|
||||
# echo 'pf_rules="/usr/local/etc/pf.conf"' >> /etc/rc.conf
|
||||
# echo 'pflog_enable="YES"' >> /etc/rc.conf
|
||||
# echo 'pflog_logfile="/var/log/pflog"' >> /etc/rc.conf
|
||||
```
|
||||
Where,
|
||||
在这里:
|
||||
|
||||
1. **pf_enable="YES"** - Turn on PF service.
|
||||
2. **pf_rules="/usr/local/etc/pf.conf"** - Read PF rules from this file.
|
||||
3. **pflog_enable="YES"** - Turn on logging support for PF.
|
||||
4. **pflog_logfile="/var/log/pflog"** - File where pflogd should store the logfile i.e. store logs in /var/log/pflog file.
|
||||
1. **pf_enable="YES"** - 开启 PF 服务
|
||||
2. **pf_rules="/usr/local/etc/pf.conf"** - 从文件 “/usr/local/etc/pf.conf” 中读取 PF 规则
|
||||
3. **pflog_enable="YES"** - 为 PF 服务打开日志支持
|
||||
4. **pflog_logfile="/var/log/pflog"** - 存储日志的文件,即日志存于文件 “/var/log/pflog” 中
|
||||
|
||||
### 第二步:在 “/usr/local/etc/pf.conf” 文件中创建防火墙规则
|
||||
|
||||
输入下面这个命令打开文件(超级用户模式下):
|
||||
|
||||
[![How To Set Up a Firewall with PF on FreeBSD to Protect a Web Server][1]][1]
|
||||
|
||||
## Step 2 - Creating firewall rules in /usr/local/etc/pf.conf
|
||||
|
||||
Type the following command:
|
||||
```
|
||||
# vi /usr/local/etc/pf.conf
|
||||
```
|
||||
Append the following PF rulesets :
|
||||
在文件中添加下面这些 PF 规则集:
|
||||
|
||||
```
|
||||
# vim: set ft=pf
|
||||
# /usr/local/etc/pf.conf
|
||||
|
||||
## Set your public interface ##
|
||||
## 设置公共端口 ##
|
||||
ext_if="vtnet0"
|
||||
|
||||
## Set your server public IP address ##
|
||||
## 设置服务器公共 IP 地址 ##
|
||||
ext_if_ip="172.xxx.yyy.zzz"
|
||||
|
||||
## Set and drop these IP ranges on public interface ##
|
||||
## 设置并删除下面这些公共端口上的 IP 范围 ##
|
||||
martians = "{ 127.0.0.0/8, 192.168.0.0/16, 172.16.0.0/12, \
|
||||
10.0.0.0/8, 169.254.0.0/16, 192.0.2.0/24, \
|
||||
0.0.0.0/8, 240.0.0.0/4 }"
|
||||
|
||||
## Set http(80)/https (443) port here ##
|
||||
## 设置 http(80)/https (443) 端口 ##
|
||||
webports = "{http, https}"
|
||||
|
||||
## enable these services ##
|
||||
## 启用下面这些服务 ##
|
||||
int_tcp_services = "{domain, ntp, smtp, www, https, ftp, ssh}"
|
||||
int_udp_services = "{domain, ntp}"
|
||||
|
||||
## Skip loop back interface - Skip all PF processing on interface ##
|
||||
## 跳过回环端口 - 跳过端口上的所有 PF 处理 ##
|
||||
set skip on lo
|
||||
|
||||
## Sets the interface for which PF should gather statistics such as bytes in/out and packets passed/blocked ##
|
||||
## 设置 PF 应该统计的端口信息,如发送/接收字节数,通过/禁止的包的数目 ##
|
||||
set loginterface $ext_if
|
||||
|
||||
## Set default policy ##
|
||||
## 设置默认策略 ##
|
||||
block return in log all
|
||||
block out all
|
||||
|
||||
# Deal with attacks based on incorrect handling of packet fragments
|
||||
# 基于 IP 分片的错误处理来防御攻击
|
||||
scrub in all
|
||||
|
||||
# Drop all Non-Routable Addresses
|
||||
# 删除所有不可达路由地址
|
||||
block drop in quick on $ext_if from $martians to any
|
||||
block drop out quick on $ext_if from any to $martians
|
||||
|
||||
## Blocking spoofed packets
|
||||
## 禁止欺骗包
|
||||
antispoof quick for $ext_if
|
||||
|
||||
# Open SSH port which is listening on port 22 from VPN 139.xx.yy.zz Ip only
|
||||
# I do not allow or accept ssh traffic from ALL for security reasons
|
||||
# 打开 SSH 端口,SSH 服务仅从 VPN IP 139.xx.yy.zz 监听 22 号端口
|
||||
# 出于安全原因,我不允许/接收 SSH 流量
|
||||
pass in quick on $ext_if inet proto tcp from 139.xxx.yyy.zzz to $ext_if_ip port = ssh flags S/SA keep state label "USER_RULE: Allow SSH from 139.xxx.yyy.zzz"
|
||||
## Use the following rule to enable ssh for ALL users from any IP address #
|
||||
## 使用下面这些规则来为所有来自任何 IP 地址的用户开启 SSH 服务 #
|
||||
## pass in inet proto tcp to $ext_if port ssh
|
||||
### [ OR ] ###
|
||||
## pass in inet proto tcp to $ext_if port 22
|
||||
@ -92,44 +89,46 @@ pass inet proto icmp icmp-type echoreq
|
||||
# All access to our Nginx/Apache/Lighttpd Webserver ports
|
||||
pass proto tcp from any to $ext_if port $webports
|
||||
|
||||
# Allow essential outgoing traffic
|
||||
# 允许重要的发送流量
|
||||
pass out quick on $ext_if proto tcp to any port $int_tcp_services
|
||||
pass out quick on $ext_if proto udp to any port $int_udp_services
|
||||
|
||||
# Add custom rules below
|
||||
# 在下面添加自定义规则
|
||||
```
|
||||
|
||||
Save and close the file. PR [welcome here to improve rulesets][2]. To check for syntax error, run:
|
||||
保存并关闭文件。欢迎来参考我的[规则集][2]。如果要检查语法错误,可以运行:
|
||||
|
||||
`# service pf check`
|
||||
OR
|
||||
或
|
||||
`/etc/rc.d/pf check`
|
||||
OR
|
||||
或
|
||||
`# pfctl -n -f /usr/local/etc/pf.conf `
|
||||
|
||||
## Step 3 - Start PF firewall
|
||||
### 第三步:开始运行 PF 防火墙
|
||||
|
||||
The commands are as follows. Be careful you might be disconnected from your server over ssh based session:
|
||||
命令如下。请小心,如果是基于 SSH 的会话,你可能会和服务器断开连接。
|
||||
|
||||
### Start PF
|
||||
*开启 PF 防火墙:*
|
||||
|
||||
`# service pf start`
|
||||
|
||||
### Stop PF
|
||||
*停用 PF 防火墙:*
|
||||
|
||||
`# service pf stop`
|
||||
|
||||
### Check PF for syntax error
|
||||
*检查语法错误:*
|
||||
|
||||
`# service pf check`
|
||||
|
||||
### Restart PF
|
||||
*重启服务:*
|
||||
|
||||
`# service pf restart`
|
||||
|
||||
### See PF status
|
||||
*查看 PF 状态:*
|
||||
|
||||
`# service pf status`
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Status: Enabled for 0 days 00:02:18 Debug: Urgent
|
||||
|
||||
@ -167,24 +166,24 @@ Counters
|
||||
map-failed 0 0.0/s
|
||||
```
|
||||
|
||||
#### 开启/关闭/重启 pflog 服务的命令
|
||||
|
||||
### Command to start/stop/restart pflog service
|
||||
|
||||
Type the following commands:
|
||||
输入下面这些命令
|
||||
```
|
||||
# service pflog start
|
||||
# service pflog stop
|
||||
# service pflog restart
|
||||
```
|
||||
|
||||
## Step 4 - A quick introduction to pfctl command
|
||||
### 第四步:`pfctl` 命令的简单介绍
|
||||
|
||||
You need to use the pfctl command to see PF ruleset and parameter configuration including status information from the packet filter. Let us see all common commands:
|
||||
你需要使用 `pfctl` 命令来查看 PF 规则集和参数配置,包括来自<ruby>包过滤器<rt>packet filter</rt></ruby>的状态信息。让我们来看一下所有常见命令:
|
||||
|
||||
### Show PF rules information
|
||||
#### 显示 PF 规则信息
|
||||
|
||||
`# pfctl -s rules`
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
|
||||
```
|
||||
block return in log all
|
||||
block drop out all
|
||||
@ -203,15 +202,15 @@ pass out quick on vtnet0 proto udp from any to any port = domain keep state
|
||||
pass out quick on vtnet0 proto udp from any to any port = ntp keep state
|
||||
```
|
||||
|
||||
#### Show verbose output for each rule
|
||||
#### 显示每条规则的详细内容
|
||||
|
||||
`# pfctl -v -s rules`
|
||||
|
||||
#### Add rule numbers with verbose output for each rule
|
||||
在每条规则的详细输出中添加规则编号:
|
||||
|
||||
`# pfctl -vvsr show`
|
||||
|
||||
#### Show state
|
||||
#### 显示状态信息
|
||||
|
||||
```
|
||||
# pfctl -s state
|
||||
@ -219,18 +218,19 @@ pass out quick on vtnet0 proto udp from any to any port = ntp keep state
|
||||
# pfctl -s state | grep 'something'
|
||||
```
|
||||
|
||||
### How to disable PF from the CLI
|
||||
#### 如何在命令行中禁止 PF 服务
|
||||
|
||||
`# pfctl -d `
|
||||
|
||||
### How to enable PF from the CLI
|
||||
#### 如何在命令行中启用 PF 服务
|
||||
|
||||
`# pfctl -e `
|
||||
|
||||
### How to flush ALL PF rules/nat/tables from the CLI
|
||||
#### 如何在命令行中刷新 PF 规则/NAT/路由表
|
||||
|
||||
`# pfctl -F all`
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
|
||||
```
|
||||
rules cleared
|
||||
nat cleared
|
||||
@ -241,27 +241,29 @@ pf: statistics cleared
|
||||
pf: interface flags reset
|
||||
```
|
||||
|
||||
#### How to flush only the PF RULES from the CLI
|
||||
#### 如何在命令行中仅刷新 PF 规则
|
||||
|
||||
`# pfctl -F rules `
|
||||
|
||||
#### How to flush only queue's from the CLI
|
||||
#### 如何在命令行中仅刷新队列
|
||||
|
||||
`# pfctl -F queue `
|
||||
|
||||
#### How to flush all stats that are not part of any rule from the CLI
|
||||
#### 如何在命令行中刷新统计信息(它不是任何规则的一部分)
|
||||
|
||||
`# pfctl -F info`
|
||||
|
||||
#### How to clear all counters from the CLI
|
||||
#### 如何在命令行中清除所有计数器
|
||||
|
||||
`# pfctl -z clear `
|
||||
|
||||
## Step 5 - See PF log
|
||||
### 第五步:查看 PF 日志
|
||||
|
||||
PF 日志是二进制格式的。使用下面这一命令来查看:
|
||||
|
||||
PF logs are in binary format. To see them type:
|
||||
`# tcpdump -n -e -ttt -r /var/log/pflog`
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Aug 29 15:41:11.757829 rule 0/(match) block in on vio0: 86.47.225.151.55806 > 45.FOO.BAR.IP.23: S 757158343:757158343(0) win 52206 [tos 0x28]
|
||||
Aug 29 15:41:44.193309 rule 0/(match) block in on vio0: 5.196.83.88.25461 > 45.FOO.BAR.IP.26941: S 2224505792:2224505792(0) ack 4252565505 win 17520 (DF) [tos 0x24]
|
||||
@ -297,30 +299,32 @@ Aug 29 15:55:07.001743 rule 0/(match) block in on vio0: 190.83.174.214.58863 > 4
|
||||
Aug 29 15:55:51.269549 rule 0/(match) block in on vio0: 142.217.201.69.26112 > 45.FOO.BAR.IP.22: S 757158343:757158343(0) win 22840 <mss 1460>
|
||||
Aug 29 15:58:41.346028 rule 0/(match) block in on vio0: 169.1.29.111.29765 > 45.FOO.BAR.IP.23: S 757158343:757158343(0) win 28509
|
||||
Aug 29 15:59:11.575927 rule 0/(match) block in on vio0: 187.160.235.162.32427 > 45.FOO.BAR.IP.5358: S 22445:22445(0) win 14600 [tos 0x28]
|
||||
Aug 29 15:59:37.826598 rule 0/(match) block in on vio0: 94.74.81.97.54656 > 45.FOO.BAR.IP.3128: S 2720157526:2720157526(0) win 1024 [tos 0x28]
|
||||
Aug 29 15:59:37.826598 rule 0/(match) block in on vio0: 94.74.81.97.54656 > 45.FOO.BAR.IP.3128: S 2720157526:2720157526(0) win 1024 [tos 0x28]stateful
|
||||
Aug 29 15:59:37.991171 rule 0/(match) block in on vio0: 94.74.81.97.54656 > 45.FOO.BAR.IP.3128: R 2720157527:2720157527(0) win 1200 [tos 0x28]
|
||||
Aug 29 16:01:36.990050 rule 0/(match) block in on vio0: 182.18.8.28.23299 > 45.FOO.BAR.IP.445: S 1510146048:1510146048(0) win 16384
|
||||
```
|
||||
|
||||
To see live log run:
|
||||
如果要查看实时日志,可以运行:
|
||||
`# tcpdump -n -e -ttt -i pflog0`
|
||||
For more info the [PF FAQ][3], [FreeBSD HANDBOOK][4] and the following man pages:
|
||||
|
||||
如果你想了解更多信息,可以访问 [PF FAQ][3] 和 [FreeBSD HANDBOOK][4] 以及下面这些 man 页面:
|
||||
|
||||
```
|
||||
# man tcpdump
|
||||
# man pfctl
|
||||
# man pf
|
||||
```
|
||||
|
||||
## about the author:
|
||||
### 关于作者
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][5], [Facebook][6], [Google+][7].
|
||||
我是 nixCraft 的创立者,一个经验丰富的系统管理员,同时也是一位 Linux 操作系统/Unix shell 脚本培训师。我在不同的行业与全球客户工作过,包括 IT、教育、国防和空间研究、以及非营利组织。你可以在 [Twitter][5]、[Facebook][6] 或 [Google+][7] 上面关注我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-set-up-a-firewall-with-pf-on-freebsd-to-protect-a-web-server/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -332,4 +336,4 @@ via: https://www.cyberciti.biz/faq/how-to-set-up-a-firewall-with-pf-on-freebsd-t
|
||||
[4]:https://www.freebsd.org/doc/handbook/firewalls.html
|
||||
[5]:https://twitter.com/nixcraft
|
||||
[6]:https://facebook.com/nixcraft
|
||||
[7]:https://plus.google.com/+CybercitiBiz
|
||||
[7]:https://plus.google.com/+CybercitiBiz
|
||||
@ -0,0 +1,150 @@
|
||||
Trash-Cli : Linux 上的命令行回收站工具
|
||||
======
|
||||
|
||||
相信每个人都对<ruby>回收站<rt>trashcan</rt></ruby>很熟悉,因为无论是对 Linux 用户,还是 Windows 用户,或者 Mac 用户来说,它都很常见。当你删除一个文件或目录的时候,该文件或目录会被移动到回收站中。
|
||||
|
||||
需要注意的是,当把文件移动到回收站以后,文件系统空间并没有被释放,除非把回收站清空。
|
||||
|
||||
如果不想永久删除文件的话(清空回收站),可以利用回收站临时存储被删除了的文件,从而在必要的时候能够帮助我们恢复删除了的文件。
|
||||
|
||||
但是,如果在命令行使用 `rm` 命令进行删除操作,那么你是不可能在回收站中找到任何被删除了的文件或目录的。所以,在执行 `rm` 命令前请一定要三思。如果你犯了错误(执行了 `rm` 命令),那么文件就被永久删除了,无法再恢复回来,因为存储在磁盘上的元数据已经不在了。
|
||||
|
||||
根据 [freedesktop.org 规范][1],<ruby>垃圾<rt>trash</rt></ruby>是由桌面管理器比如 GNOME、KDE 和 XFCE 等提供的一个特性。当通过文件管理器删除一个文件或目录的时候,该文件或目录将会成为<ruby>垃圾<rt>trash</rt></ruby>,然后被移动到回收站中,回收站对应的目录是 `$HOME/.local/share/Trash` 。
|
||||
|
||||
回收站目录包含两个子目录:`files` 和 `info` 。`files` 目录存储实际被删除了的文件和目录,`info` 目录包含被删除了的文件和目录的信息,比如文件路径、删除日期和时间,每个文件单独存储。
|
||||
|
||||
你可能会问,既然已经有了<ruby>图形用户界面<rt>GUI</rt></ruby>的回收站,为什么还需要命令行工具呢?因为对于大多数使用 *NIX 系统的家伙(包括我)来说,即使使用的是基于图形用户界面的系统,也更喜欢使用命令行而不是图形用户界面。所以,如果有人在寻找一个命令行回收站工具,那么这儿有一个不错的选择。
|
||||
|
||||
### Trash-Cli 是什么
|
||||
|
||||
[trash-cli][2] 是一个命令行回收站工具,并且符合 FreeDesktop.org 的<ruby>垃圾<rt>trash</rt></ruby>规范。它能够存储每一个垃圾文件的名字、原始路径、删除日期和权限。
|
||||
|
||||
### 如何在 Linux 上安装 Trash-Cli
|
||||
|
||||
绝大多数的 Linux 发行版官方仓库都提供了 Trash-Cli 的安装包,所以你可以运行下面这些命令来安装。
|
||||
|
||||
对于 Debian/Ubuntu 用户,使用 [apt-get][3] 或 [apt][4] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo apt install trash-cli
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 用户,使用 [yum][5] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo yum install trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 Fedora 用户,使用 [dnf][6] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo dnf install trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 Arch Linux 用户,使用 [pacman][7] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo pacman -S trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 openSUSE 用户,使用 [zypper][8] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo zypper in trash-cli
|
||||
|
||||
```
|
||||
|
||||
如果你的发行版中没有提供 Trash-Cli 的安装包,那么你也可以使用 pip 来安装。为了能够安装 python 包,你的系统中应该会有 pip 包管理器。
|
||||
|
||||
```
|
||||
$ sudo pip install trash-cli
|
||||
Collecting trash-cli
|
||||
Downloading trash-cli-0.17.1.14.tar.gz
|
||||
Installing collected packages: trash-cli
|
||||
Running setup.py bdist_wheel for trash-cli ... done
|
||||
Successfully installed trash-cli-0.17.1.14
|
||||
|
||||
```
|
||||
|
||||
### 如何使用 Trash-Cli
|
||||
|
||||
Trash-Cli 的使用不难,因为它提供了一个很简单的语法。Trash-Cli 提供了下面这些命令:
|
||||
|
||||
* `trash-put`: 删除文件和目录(仅放入回收站中)
|
||||
* `trash-list` :列出被删除了的文件和目录
|
||||
* `trash-restore`:从回收站中恢复文件或目录 trash.
|
||||
* `trash-rm`:删除回收站中的文件
|
||||
* `trash-empty`:清空回收站
|
||||
|
||||
下面,让我们通过一些例子来试验一下。
|
||||
|
||||
1)删除文件和目录:在这个例子中,我们通过运行下面这个命令,将 2g.txt 这一文件和 magi 这一文件夹移动到回收站中。
|
||||
|
||||
```
|
||||
$ trash-put 2g.txt magi
|
||||
```
|
||||
|
||||
和你在文件管理器中看到的一样。
|
||||
|
||||
2)列出被删除了的文件和目录:为了查看被删除了的文件和目录,你需要运行下面这个命令。之后,你可以在输出中看到被删除文件和目录的详细信息,比如名字、删除日期和时间,以及文件路径。
|
||||
|
||||
```
|
||||
$ trash-list
|
||||
2017-10-01 01:40:50 /home/magi/magi/2g.txt
|
||||
2017-10-01 01:40:50 /home/magi/magi/magi
|
||||
```
|
||||
|
||||
3)从回收站中恢复文件或目录:任何时候,你都可以通过运行下面这个命令来恢复文件和目录。它将会询问你来选择你想要恢复的文件或目录。在这个例子中,我打算恢复 2g.txt 文件,所以我的选择是 0 。
|
||||
|
||||
```
|
||||
$ trash-restore
|
||||
0 2017-10-01 01:40:50 /home/magi/magi/2g.txt
|
||||
1 2017-10-01 01:40:50 /home/magi/magi/magi
|
||||
What file to restore [0..1]: 0
|
||||
```
|
||||
|
||||
4)从回收站中删除文件:如果你想删除回收站中的特定文件,那么可以运行下面这个命令。在这个例子中,我将删除 magi 目录。
|
||||
|
||||
```
|
||||
$ trash-rm magi
|
||||
```
|
||||
|
||||
5)清空回收站:如果你想删除回收站中的所有文件和目录,可以运行下面这个命令。
|
||||
|
||||
```
|
||||
$ trash-empty
|
||||
```
|
||||
|
||||
6)删除超过 X 天的垃圾文件:或者,你可以通过运行下面这个命令来删除回收站中超过 X 天的文件。在这个例子中,我将删除回收站中超过 10 天的项目。
|
||||
|
||||
```
|
||||
$ trash-empty 10
|
||||
|
||||
```
|
||||
|
||||
Trash-Cli 可以工作的很好,但是如果你想尝试它的一些替代品,那么你也可以试一试 [gvfs-trash][9] 和 [autotrash][10] 。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/trash-cli-command-line-trashcan-linux-system/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://freedesktop.org/wiki/Specifications/trash-spec/
|
||||
[2]:https://github.com/andreafrancia/trash-cli
|
||||
[3]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[6]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[8]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[9]:http://manpages.ubuntu.com/manpages/trusty/man1/gvfs-trash.1.html
|
||||
[10]:https://github.com/bneijt/autotrash
|
||||
@ -0,0 +1,168 @@
|
||||
heguangzhi Translating
|
||||
|
||||
|
||||
|
||||
面向敏捷开发团队的7个开源项目管理工具
|
||||
======
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
Opensource.com 以前对流行的开源项目管理工具的过相应的调研。但是今年我们增加了一个特点。本次,我们特别关注支持[敏捷][1]方法的工具,包括相关的实践,如[Scrum][2]、 Lean, and Kanban。
|
||||
|
||||
|
||||
对敏捷开发的兴趣和使用的增长是我们今年决定专注于这些工具的原因。大多数组织-71%的人说他们至少使用了敏捷方法(3)[are using agile approaches][3]。此外,敏捷项目比传统方法管理的项目要高出28%(4)[28% more successful][4] 。
|
||||
|
||||
|
||||
我们查看了[2014][5]、[2015][6]和[2016][7]中涉及的项目管理工具,并挑选了支持敏捷的工具,然后进行了研究并做了添加或更改。不管您的组织是否已经在使用敏捷开发,或者是2018年采用敏捷方法的作为众多计划之一,这七个开源项目管理工具之一可能正是您所要找寻的。
|
||||
|
||||
### MyCollab
|
||||
|
||||

|
||||
|
||||
|
||||
MyCollab][8]是一套针对中小型企业的三个协作模块:项目管理、客户关系管理(CRM)和文档创建和编辑的软件。有两个许可选项:一个商业的“终极”版本,它更快,可以在内部或云中运行;另一个开源的“社区版本”,这个正是我们感兴趣的版本。
|
||||
|
||||
由于没有使用查询缓存,社区版本没有云选项,并且速度较慢,但是提供了基本的项目管理特性,包括任务、问题管理、活动流、路线图视图和敏捷团队看板。虽然它没有单独的移动应用程序,但它也适用于移动设备,包括 Windows、Mac OS、Linux 和 UNIX 计算机。
|
||||
|
||||
The latest version of MyCollab is 5.4.10 and the source code is available on [GitHub][9]. It is licensed under AGPLv3 and requires a Java runtime and MySQL stack to operate. It's available for [download][10] for Windows, Linux, Unix, and MacOS.
|
||||
|
||||
|
||||
|
||||
|
||||
MyCulb的最新版本是5.4.10,源代码可在 [GitHub][9] 上下载。它是在 AgPLv3 下进行授权的,需要 Java 运行和 MySQL支持。它可运行于 Windows、Linux、UNIX 和 MacOS 。下载地址 [download][10]。
|
||||
|
||||
### Odoo
|
||||
|
||||

|
||||
|
||||
|
||||
[Odoo][11] 不仅仅是项目管理软件;它是一个完整的集成商业应用套件,包括会计、人力资源、网站和电子商务、库存、制造、销售管理(CRM)和其他工具。
|
||||
|
||||
与付费企业套件相比,免费开源社区版具有有限的[特性][12] 。它的项目管理应用程序包括敏捷团队的看板式任务跟踪视图,在最新版本Odoo 11.0中更新了该视图,以包括用于跟踪项目状态的进度条和动画。项目管理工具还包括甘特图、任务、问题、图表等等。Odoo有一个繁荣的[社区][13],并提供 [用户指南][14] 及其他培训资源。
|
||||
|
||||
|
||||
它是在 GPLv3 下授权的,需要 Python 和 PostgreSQL 支持。作为[Docker][16] 镜像 可以运行在 Windows、Linux 和 Red Hat 包管理器中,下载地址[download][15],源代码[GitHub][17]。
|
||||
|
||||
### OpenProject
|
||||
|
||||

|
||||
|
||||
|
||||
[OpenProject][18] 是一个强大的开源项目管理工具,以其易用性和丰富的项目管理和团队协作特性而著称。
|
||||
|
||||
|
||||
它的模块支持项目计划、调度、路线图和发布计划、时间跟踪、成本报告、预算、bug跟踪以及敏捷和Scrum。它的敏捷特性,包括创建Story、确定sprint的优先级以及跟踪任务,都与OpenProject的其他模块集成在一起。
|
||||
|
||||
|
||||
OpenProject 在 GPLv3 下获得许可,其源代码可在[GitHub][19]上。最新版本7.3.2 for Linux [download][20];您可以在 Birthe Lindenthal 的文章 “[Getting start of OpenProject][21]"中了解更多关于安装和配置它的信息。
|
||||
|
||||
### OrangeScrum
|
||||
|
||||

|
||||
|
||||
|
||||
正如从其名称中猜到的,[OrangeScrum][22]支持敏捷方法,特别是使用Scrum任务板和看板式工作流视图。它面向较小的组织自由职业者、中介机构和中小型企业。
|
||||
|
||||
源版本提供了 OrangeScrum 付费版本中的许多[特性][23],包括移动应用程序、资源利用率和进度跟踪。其他特性,包括甘特图、时间日志、发票和客户端管理,可以作为付费附加组件提供,付费版本包括云选项,而社区版本不提供。
|
||||
|
||||
OrangeScrum 是基于 GPLv3 授权的,是基于 CakePHP 框架开发。它需要 Apache、PHP 5.3 或更高版本和 MySQL 4.1 或更高版本支持,并可以在 Windows、Linux 和 Mac OS 上运行。其最新版本1.1.1,下载地址 [download][24],其源码[GitHub] [25]。
|
||||
|
||||
|
||||
### ]project-open[
|
||||
|
||||

|
||||
|
||||
|
||||
[]project-open[][26]是一个双许可的企业项目管理工具,这意味着其核心是开源的,并且在商业许可的模块中可以使用一些附加特性。根据社区和企业版本的项目[比较][27],开源核心为中小型组织提供了许多特性。
|
||||
|
||||
]project-open[ 支持Scrum和看板[敏捷][28]项目,以及经典的甘特/瀑布项目和混合或混合项目。
|
||||
|
||||
|
||||
该应用程序是在 GPL 下授权的,并且[source code][29]是通过 CVS 访问的。 ]project-open[ 在 Linux 和 Windows 的安装可用 [installers][26],但也可以在云镜像和虚拟设备中使用。
|
||||
|
||||
### Taiga
|
||||
|
||||

|
||||
|
||||
|
||||
[Taiga][30] 是一个开源项目管理平台,它专注于Scrum和敏捷开发,其特征包括看板、任务、sprints、问题、backlog 和epics。其他功能包括 ticke 管理、多项目支持、Wiki页面和第三方集成。
|
||||
|
||||
它还为iOS、Android和Windows设备提供免费的移动应用程序,并提供导入工具,使从其他流行的项目管理应用程序迁移变得容易。
|
||||
|
||||
|
||||
Taiga 对于公共项目是免费的,对项目数量或用户数量没有限制。对于私有项目,在“免费增值”模式下,有很多[付费计划][31]可用,但是值得注意的是,无论您有哪种类型,软件的功能特性都是一样的。
|
||||
|
||||
|
||||
Taiga 是在GNU Affero GPLv3 下授权的,并且软件需要 Nginx、Python 和 PostgreSQL 支持。最新版本[3.1.0 PrimovsialpopiculoLII][32],可在[GitHub][33]上下载。
|
||||
|
||||
### Tuleap
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
[Tuleap][34]是一个应用程序生命周期管理(ALM)平台,旨在为每种类型的团队管理项目——小型、中型、大型、瀑布、敏捷或混合型——但是它对敏捷团队的支持是显著的。值得注意的是,它为Scrum、看板、sprints、任务、报告、持续集成、backlogs等提供支持.
|
||||
|
||||
|
||||
其他的[特性][35]包括问题跟踪、文档跟踪、协作工具,以及与 Git、SVN 和 Jenkins 的集成,所有这些都使它成为开放源码软件开发项目的吸引人的选择。
|
||||
|
||||
|
||||
TuleAP 是在 GPLv2 下授权的。更多信息,包括 Docker 和 CentOS 下载,可以在他们的 [Get Started][36] 页面上找到。您还可以在TuleAP的 [Git][37] 上获取其最新版本9.14的源代码。
|
||||
|
||||
|
||||
这种类型的列表的麻烦在于它一发布就过时了。使用开源项目管理工具来支持我们忘记包含的敏捷吗?或者你对我们提到的有反馈吗?请在下面留下评论。
|
||||
|
||||
这种类型的文章的麻烦在于它一发布就过时了。那些您正在使用开源项目管理工具,而被我们遗漏了?或者您对我们提到的有反馈意见吗?请在下面留下留言。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/agile-project-management-tools
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:http://agilemanifesto.org/principles.html
|
||||
[2]:https://opensource.com/resources/scrum
|
||||
[3]:https://www.pmi.org/-/media/pmi/documents/public/pdf/learning/thought-leadership/pulse/pulse-of-the-profession-2017.pdf
|
||||
[4]:https://www.pwc.com/gx/en/actuarial-insurance-services/assets/agile-project-delivery-confidence.pdf
|
||||
[5]:https://opensource.com/business/14/1/top-project-management-tools-2014
|
||||
[6]:https://opensource.com/business/15/1/top-project-management-tools-2015
|
||||
[7]:https://opensource.com/business/16/3/top-project-management-tools-2016
|
||||
[8]:https://community.mycollab.com/
|
||||
[9]:https://github.com/MyCollab/mycollab
|
||||
[10]:https://www.mycollab.com/ce-registration/
|
||||
[11]:https://www.odoo.com/
|
||||
[12]:https://www.odoo.com/page/editions
|
||||
[13]:https://www.odoo.com/page/community
|
||||
[14]:https://www.odoo.com/documentation/user/11.0/
|
||||
[15]:https://www.odoo.com/page/download
|
||||
[16]:https://hub.docker.com/_/odoo/
|
||||
[17]:https://github.com/odoo/odoo
|
||||
[18]:https://www.openproject.org/
|
||||
[19]:https://github.com/opf/openproject
|
||||
[20]:https://www.openproject.org/download-and-installation/
|
||||
[21]:https://opensource.com/article/17/11/how-install-and-use-openproject
|
||||
[22]:https://www.orangescrum.org/
|
||||
[23]:https://www.orangescrum.org/compare-orangescrum
|
||||
[24]:http://www.orangescrum.org/free-download
|
||||
[25]:https://github.com/Orangescrum/orangescrum/
|
||||
[26]:http://www.project-open.com/en/list-installers
|
||||
[27]:http://www.project-open.com/en/products/editions.html
|
||||
[28]:http://www.project-open.com/en/project-type-agile
|
||||
[29]:http://www.project-open.com/en/developers-cvs-checkout
|
||||
[30]:https://taiga.io/
|
||||
[31]:https://tree.taiga.io/support/subscription-and-plans/payment-process-faqs/#q.-what-s-about-custom-plans-private-projects-with-more-than-25-members-?
|
||||
[32]:https://blog.taiga.io/taiga-perovskia-atriplicifolia-release-310.html
|
||||
[33]:https://github.com/taigaio
|
||||
[34]:https://www.tuleap.org/
|
||||
[35]:https://www.tuleap.org/features/project-management
|
||||
[36]:https://www.tuleap.org/get-started
|
||||
[37]:https://tuleap.net/plugins/git/tuleap/tuleap/stable
|
||||
@ -0,0 +1,211 @@
|
||||
如何在 Linux 中压缩和解压缩文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
当在备份重要文件和通过网络发送大文件的时候,对文件进行压缩非常有用。请注意,压缩一个已经压缩过的文件会增加额外开销,因此你将会得到一个更大一些的文件。所以,请不要压缩已经压缩过的文件。在 GNU/Linux 中,有许多程序可以用来压缩和解压缩文件。在这篇教程中,我们仅学习其中两个应用程序。
|
||||
|
||||
### 压缩和解压缩文件
|
||||
|
||||
在类 Unix 系统中,最常见的用来压缩文件的程序是:
|
||||
|
||||
1. gzip
|
||||
2. bzip2
|
||||
|
||||
|
||||
|
||||
##### 1\. 使用 Gzip 程序来压缩和解压缩文件
|
||||
|
||||
Gzip 是一个使用 Lempel-Ziv 编码(LZ77)算法来压缩和解压缩文件的实用工具。
|
||||
|
||||
**1.1 压缩文件**
|
||||
|
||||
如果要压缩一个名为 ostechnix.txt 的文件,使之成为 gzip 格式的压缩文件,那么只需运行如下命令:
|
||||
```
|
||||
$ gzip ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
上面的命令运行结束之后,将会出现一个名为 ostechnix.txt.gz 的 gzip 格式压缩文件,代替原始的 ostechnix.txt 文件。
|
||||
|
||||
gzip 命令还可以有其他用法。一个有趣的例子是,我们可以将一个特定命令的输出通过管道传递,然后作为 gzip 程序的输入来创建一个压缩文件。看下面的命令:
|
||||
```
|
||||
$ ls -l Downloads/ | gzip > ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
上面的命令将会创建一个 gzip 格式的压缩文件,文件的内容为 “Downloads” 目录的目录项。
|
||||
|
||||
**1.2 压缩文件并将输出写到新文件中(不覆盖原始文件)
|
||||
**
|
||||
|
||||
默认情况下,gzip 程序会压缩给定文件,并以压缩文件替代原始文件。但是,你也可以保留原始文件,并将输出写到标准输出。比如,下面这个命令将会压缩 ostechnix.txt 文件,并将输出写入文件 output.txt.gz 。
|
||||
```
|
||||
$ gzip -c ostechnix.txt > output.txt.gz
|
||||
|
||||
```
|
||||
|
||||
类似地,要解压缩一个 gzip 格式的压缩文件并指定输出文件的文件名,只需运行:
|
||||
```
|
||||
$ gzip -c -d output.txt.gz > ostechnix1.txt
|
||||
|
||||
```
|
||||
|
||||
上面的命令将会解压缩 output.txt.gz 文件,并将输出写入到文件 ostechnix1.txt 中。在上面两个例子中,原始文件均不会被删除。
|
||||
|
||||
**1.3 解压缩文件**
|
||||
|
||||
如果要解压缩 ostechnix.txt.gz 文件,并以原始未压缩版本的文件来代替它,那么只需运行:
|
||||
```
|
||||
$ gzip -d ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
我们也可以使用 gunzip 程序来解压缩文件:
|
||||
```
|
||||
$ gunzip ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
**1.4 在不解压缩的情况下查看压缩文件的内容**
|
||||
|
||||
如果你想在不解压缩的情况下,使用 gzip 程序查看压缩文件的内容,那么可以像下面这样使用 -c 选项:
|
||||
```
|
||||
$ gunzip -c ostechnix1.txt.gz
|
||||
|
||||
```
|
||||
|
||||
或者,你也可以像下面这样使用 zcat 程序:
|
||||
```
|
||||
$ zcat ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
你也可以通过管道将输出传递给 less 命令,从而一页一页的来查看输出,就像下面这样:
|
||||
```
|
||||
$ gunzip -c ostechnix1.txt.gz | less
|
||||
|
||||
$ zcat ostechnix.txt.gz | less
|
||||
|
||||
```
|
||||
|
||||
另外,zless 程序也能够实现和上面的管道同样的功能。
|
||||
```
|
||||
$ zless ostechnix1.txt.gz
|
||||
|
||||
```
|
||||
|
||||
**1.5 使用 gzip 压缩文件并指定压缩级别**
|
||||
|
||||
Gzip 的另外一个显著优点是支持压缩级别。它支持下面给出的 3 个压缩级别:
|
||||
|
||||
* **1** – 最快 (最差)
|
||||
* **9** – 最慢 (最好)
|
||||
* **6** – 默认级别
|
||||
|
||||
|
||||
|
||||
要压缩名为 ostechnix.txt 的文件,使之成为“最好”压缩级别的 gzip 压缩文件,可以运行:
|
||||
```
|
||||
$ gzip -9 ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
**1.6 连接多个压缩文件**
|
||||
|
||||
我们也可以把多个需要压缩的文件压缩到同一个文件中。如何实现呢?看下面这个例子。
|
||||
```
|
||||
$ gzip -c ostechnix1.txt > output.txt.gz
|
||||
|
||||
$ gzip -c ostechnix2.txt >> output.txt.gz
|
||||
|
||||
```
|
||||
|
||||
上面的两个命令将会压缩文件 ostechnix1.txt 和 ostechnix2.txt,并将输出保存到一个文件 output.txt.gz 中。
|
||||
|
||||
你可以通过下面其中任何一个命令,在不解压缩的情况下,查看两个文件 ostechnix1.txt 和 ostechnix2.txt 的内容:
|
||||
```
|
||||
$ gunzip -c output.txt.gz
|
||||
|
||||
$ gunzip -c output.txt
|
||||
|
||||
$ zcat output.txt.gz
|
||||
|
||||
$ zcat output.txt
|
||||
|
||||
```
|
||||
|
||||
如果你想了解关于 gzip 的更多细节,请参阅它的 man 手册。
|
||||
```
|
||||
$ man gzip
|
||||
|
||||
```
|
||||
|
||||
##### 2\. 使用 bzip2 程序来压缩和解压缩文件
|
||||
|
||||
bzip2 和 gzip 非常类似,但是 bzip2 使用的是 Burrows-Wheeler 块排序压缩算法,并使用<ruby>哈夫曼<rt>Huffman</rt></ruby>编码。使用 bzip2 压缩的文件以 “.bz2” 扩展结尾。
|
||||
|
||||
正如我上面所说的, bzip2 的用法和 gzip 几乎完全相同。只需在上面的例子中将 gzip 换成 bzip2,将 gunzip 换成 bunzip2,将 zcat 换成 bzcat 即可。
|
||||
|
||||
要使用 bzip2 压缩一个文件,并以压缩后的文件取而代之,只需运行:
|
||||
```
|
||||
$ bzip2 ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
如果你不想替换原始文件,那么可以使用 -c 选项,并把输出写入到新文件中。
|
||||
```
|
||||
$ bzip2 -c ostechnix.txt > output.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
如果要解压缩文件,则运行:
|
||||
```
|
||||
$ bzip2 -d ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
或者,
|
||||
```
|
||||
$ bunzip2 ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
如果要在不解压缩的情况下查看一个压缩文件的内容,则运行:
|
||||
```
|
||||
$ bunzip2 -c ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
或者,
|
||||
```
|
||||
$ bzcat ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
如果你想了解关于 bzip2 的更多细节,请参阅它的 man 手册。
|
||||
```
|
||||
$ man bzip2
|
||||
|
||||
```
|
||||
|
||||
##### 总结
|
||||
|
||||
在这篇教程中,我们学习了 gzip 和 bzip2 程序是什么,并通过 GNU/Linux 下的一些例子学习了如何使用它们来压缩和解压缩文件。接下来,我们将要学习如何在 Linux 中将文件和目录归档。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-compress-and-decompress-files-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -1,147 +0,0 @@
|
||||
在Ubuntu Linux上安装和使用Git和GitHub:初学者指南
|
||||
======
|
||||
|
||||
Github是一个存放着世界上最棒的一些软件项目的宝藏,这些软件项目由全世界的开发者无私贡献。这个看似简单,实则非常强大的平台因为大大帮助了那些对开发大规模软件感兴趣的开发者而被开源社区所称道。
|
||||
|
||||
这篇向导是对于安装和使用GitHub的的一个快速说明,本文还将涉及诸如创建本地仓库,如何链接这个本地仓库到包含你的项目的远程仓库(这样每个人都能看到你的项目了), 以及如何提交改变并最终推送所有的本地内容到Github。
|
||||
|
||||
请注意这篇向导假设你对Git术语有基本的了解,如推送,拉取请求,提交,仓库等等。并且希望你在GitHub上已注册成功并记下了你的GitHub用户名,那么我们这就进入正题吧:
|
||||
|
||||
### 1 在Linux上安装Git
|
||||
|
||||
下载并安装Git:
|
||||
|
||||
```
|
||||
sudo apt-get install git
|
||||
```
|
||||
|
||||
上面的命令适用于Ubuntu并且应该在所有最新版的Ubuntu上都能工作,它们在Ubuntu 16.04和Ubuntu 18.04 LTS (Bionic Beaver)上都测试过,在将来的版本上应该也能工作。
|
||||
|
||||
|
||||
### 2 配置GitHub
|
||||
|
||||
一旦安装完成,接下去就是配置GitHub用户的详细配置信息。请使用下面的两条命令并确保用你自己的GitHub用户名替换"user_name",用你创建GitHub账户的电子邮件替换“email_id”。
|
||||
|
||||
```
|
||||
git config --global user.name "user_name"
|
||||
|
||||
git config --global user.email "email_id"
|
||||
|
||||
```
|
||||
|
||||
下面的图片显示的例子是如何用我的 GitHub “用户名”:“akshaypai”和我的"邮件地址"[[email protected]][2]来配置上面的命令。
|
||||
|
||||
[![Git config][3]][4]
|
||||
|
||||
### 3 创建本地仓库
|
||||
在你的系统上创建一个目录。它将会被作为本地仓库使用,稍后它会被推送到 GitHub 的远程仓库。请使用如下命令:
|
||||
|
||||
```
|
||||
git init Mytest
|
||||
```
|
||||
如果目录被成功创建,你会看到如下信息:
|
||||
|
||||
Initialized empty Git repository in /home/akshay/Mytest/.git/
|
||||
|
||||
这行信息可能随你的系统不同而变化。
|
||||
这里,Mytest 是创建的目录而“init” 将其转化为一个 GitHub 仓库。将当前目录改为这个新创建的目录。
|
||||
|
||||
```
|
||||
cd Mytest
|
||||
```
|
||||
|
||||
### 4 新建一个 REAME 文件来描述仓库
|
||||
现在创建一个 README 文件并输入一些文本,如“this is git setup on linux”。REAME 文件一般用于描述这个仓库用来放置什么内容或这个项目是关于什么的。例如:
|
||||
|
||||
```
|
||||
gedit README
|
||||
```
|
||||
你可以使用任何文本编辑器。我喜欢使用gedit。README文件的内容可以为:
|
||||
|
||||
This is a git repo
|
||||
|
||||
### 5 将仓库里的文件加入一个索引
|
||||
这是很重要的一步。这里我们会将所有需要推送到 GitHub 的内容都加入一个索引。这些内容可能包括你第一次加入仓库的文本文件或者应用程序,也有可能是对已存在文件的一些编辑(文件的一个更新版本)。
|
||||
既然我们已经有了 README 文件,那么让我们创建一个别的文件吧,如一个简单的 C 程序,我们叫它sample.c。文件内容是:
|
||||
|
||||
```
|
||||
|
||||
#include<stdio.h>
|
||||
int main()
|
||||
{
|
||||
printf("hello world");
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
现在我们有两个文件了。
|
||||
README 和 sample.c
|
||||
用下面的命令将他们加入索引:
|
||||
|
||||
```
|
||||
git add README
|
||||
|
||||
git add smaple.c
|
||||
```
|
||||
|
||||
请注意“git add” 命令能将任意数量的文件和目录加入到索引。这里,当我说“ 索引” 的时候,我是指一个有一定空间的缓冲区,这个缓冲区存储了所有已经被加入到 Git 仓库的文件或目录。
|
||||
|
||||
### 6 将所作的改动加入索引
|
||||
所有的文件都加好以后,你就可以提交了。这意味着你已经确定了最终的文件改动( 或增加),现在他们已经准备好被上传到我们自己的仓库了。请使用命令:
|
||||
|
||||
```
|
||||
git commit -m "some_message"
|
||||
```
|
||||
“some_message”在上面的命令里可以是一些简单的信息如“我的第一次提交”或者“ 编辑了readme 文件”,等等。
|
||||
|
||||
### 7 在GitHub上创建一个仓库
|
||||
在 GitHub 上创建一个仓库。请注意仓库的名字必须和你本地创建的仓库的名字严格一致。在这个例子里是'Mytest'。请首先登陆你的 GitHub 账户<https://github.com>。点击页面右上角 的"plus(+)"符号,并选择"create nw repository"。如下图所示填入详细信息,点击“create repository”。
|
||||
|
||||
[![Creating a repository on GitHub][5]][6]
|
||||
一旦创建完成,我们就能将本地的仓库推送到 GitHub 你名下的仓库,用下列命令连接 GitHub 上的仓库:
|
||||
请注意:请确保在运行下列命令前替换了路径中的“user_name” 和“Mytest”为你的 GitHub 用户名和目录名!
|
||||
|
||||
```
|
||||
git remote add origin https://github.com/user\_name/Mytest.git>
|
||||
```
|
||||
|
||||
### 8 将本地仓库里的文件推送的GitHub仓库
|
||||
最后一步是用下列的命令将本地仓库的内容推送到远程仓库(GitHub)
|
||||
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
当提示登陆名和密码时键入登陆名和密码。
|
||||
下面的图片显示了步骤5到步骤8的流程
|
||||
|
||||
[![Pushing files in local repository to GitHub repository][7]][8]
|
||||
|
||||
上述将 Mytest 目录里的所有内容(文件) 推送到了GitHub。对于以后的项目或者创建新的仓库,你可以直接从步骤3开始。最后,如果你登陆你的 GitHub 账户并点击你的Mytest 仓库,你会看到这两个文件:README 和sample.c 已经被上传并像如下 图片显示:
|
||||
|
||||
[![Content uploaded to Github][9]][10]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-git-and-github-on-ubuntu/
|
||||
|
||||
作者:[Akshay Pai][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/DavidChenLiang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
|
||||
[1]:https://github.com/
|
||||
[2]:https://www.howtoforge.com/cdn-cgi/l/email-protection
|
||||
[3]:https://www.howtoforge.com/images/ubuntu_github_getting_started/config.png
|
||||
[4]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/config.png
|
||||
[5]:https://www.howtoforge.com/images/ubuntu_github_getting_started/details.png
|
||||
[6]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/details.png
|
||||
[7]:https://www.howtoforge.com/images/ubuntu_github_getting_started/steps.png
|
||||
[8]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/steps.png
|
||||
[9]:https://www.howtoforge.com/images/ubuntu_github_getting_started/final.png
|
||||
[10]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/final.png
|
||||
@ -1,107 +0,0 @@
|
||||
|
||||
五个 Linux 上的开源角色扮演游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
游戏是 Linux 的传统弱点之一,感谢 Stean、GOG 和其他的游戏开发商将商业游戏移植到了多个操作系统,Linux 的这个弱点在近几年有所改观,但是这些游戏通常都不是开源的。当然,这些游戏可以在开源系统上运行,但是对于开源的纯粹主义者来说这还不够好。
|
||||
|
||||
那么,有没有一款能让只使用免费和开源软件的人在不影响他们开源理念的情况下也能享受到可靠游戏体验的精致游戏呢?
|
||||
|
||||
当然有啦!虽然开源游戏不太可能和拥有大量开发预算的 3A 级大作相媲美,但有许多类型的开源游戏也很有趣,而且他们可以直接从大多数主要的 Linux 发行版的仓库中进行安装。即使某个游戏没有被某些仓库打包,你也可以很简单地从这个游戏的官网下载它,并进行安装和运行。
|
||||
|
||||
这篇文章着眼于角色扮演游戏,我已经写过关于街机游戏,棋牌游戏,益智游戏,以及赛车和飞行游戏。在本系列的最后一篇文章中,我打算覆盖战略游戏和模拟游戏这两方面。
|
||||
|
||||
### Endless Sky
|
||||
|
||||

|
||||
|
||||
Endless Sky 是 Ambrosia Software 的 Escape Velocity 系列的开源克隆。玩家乘坐一艘宇宙飞船,在不同的世界之间旅行来运送货物和乘客,并在沿途中承接其他任务,或者玩家也可以变成海盗,并从其他货船中偷取货物。这个游戏让玩家自己决定要如何去体验这个游戏,以太阳系为背景的超大地图是非常具有探索性的。Endless Sky 是那些违背正常游戏类别分类的游戏之一。但这个兼具动作、角色扮演、太空模拟和交易这四种类型的游戏非常值得一试。
|
||||
|
||||
如果要安装 Endless Sky ,请运行下面的命令:
|
||||
|
||||
在 Fedora 上: `dnf install endless-sky`
|
||||
|
||||
在 Debian/Ubuntu 上: `apt install endless-sky`
|
||||
|
||||
### FreeDink
|
||||
|
||||

|
||||
|
||||
FreeDink 是 Dink Smallwood 的开源版本,Dink Smallwood 是一个由 RTSoft 在1997 年发售的动作角色扮演游戏。Dink Smallwood 在 1999 年时变为了免费游戏,并在 2003 年时公布了源代码。在 2008 年时,游戏的数据除了少部分的声音文件,都在开源协议下进行了开源。FreeDink 用一些替代的声音文件替换了缺少的那部分文件,来提供了一个完整的游戏。游戏的玩法类似于任天堂的塞尔达传说系列。玩家控制的角色和 Dink Smallwood 同名,他在从一个任务地点移动到下一个任务地点的时候,探索这个充满隐藏物品和隐藏洞穴的世界地图。由于这个游戏的年龄,FreeDink 不能和现代的商业游戏相抗衡,但它仍然是一个拥有着有趣故事的有趣的游戏。游戏可以通过 D-Mods 进行扩展,D-Mods 是提供额外任务的附加模块,但是 D-Mods 在复杂性,质量,和年龄适应性上确实有很大的差异。游戏主要适合青少年,但也有部分额外组件适用于成年玩家。
|
||||
|
||||
要安装 FreeDink ,请运行下面的命令:
|
||||
|
||||
在 Fedora 上: `dnf install freedink`
|
||||
|
||||
在 Debian/Ubuntu 上: `apt install freedink`
|
||||
|
||||
### ManaPlus
|
||||
|
||||

|
||||
|
||||
从技术上讲,ManaPlus 本身并不是一个游戏,它是一个访问各种大型多人在线角色扮演游戏的客户端。The Mana World 和 Evol Online 是两款可以通过 ManaPlus 访问的开源游戏,但是游戏的服务器不在那里。这个游戏的 2D 精灵图像让人想起超级任天堂游戏,虽然 ManaPlus 支持的游戏没有一款能像商业游戏那样受欢迎的,但他们都有一个有趣的世界,并且在绝大部分时间里都有至少一小部分玩家在线。一个玩家不太可能遇到很多的其他玩家,但通常都能有足够的人一起在这个 MMORPG 游戏里进行冒险,而不是一个需要连接到服务器的单机游戏。Mana World 和 Evol Online 的开发者联合起来进行未来的开发,但是对于目前而言,Mana World 的历史服务器和 Evol Online 提供了不同的游戏体验。
|
||||
|
||||
要安装 ManaPlus,请运行下面的命令:
|
||||
|
||||
在 Fedora 上: `dnf install manaplus`
|
||||
|
||||
在 Debian/Ubuntu 上: `apt install manaplus`
|
||||
|
||||
### Minetest
|
||||
|
||||

|
||||
|
||||
使用 Minetest 来在一个开放式世界里进行探索和创造,Minetest 是 Minecraft 的克隆,就像它所基于的游戏一样,Minetest 提供了一个开放的世界,玩家可以在这个世界里探索和创造他们想要的一切。Minetest 提供了各种各样的方块和工具,对于想要一个比 Minecraft 更加开放的游戏的人来说,Minetest 是一个很好的替代品。除了基本的游戏之外,Minetest 还可以通过额外的模块进行可扩展,增加更多的选项。
|
||||
|
||||
如果要安装 Minetest ,请运行下面的命令:
|
||||
|
||||
在 Fedora 上: `dnf install minetest`
|
||||
|
||||
在 Debian/Ubuntu 上: `apt install minetest`
|
||||
|
||||
### NetHack
|
||||
|
||||

|
||||
|
||||
NetHack 是一款经典的 Roguelike 类型的角色扮演游戏,玩家可以从不同的角色种族、层次和路线中进行选择,来探索这个多层次的地下层。这个游戏的目的就是找回 Yendor 的护身符,玩家从地下层的第一层开始探索,并尝试向下一层移动,每一层都是随机生成的,这样每次都能获得不同的游戏体验。虽然这个游戏只具有 ASCII 图形和基本图形,但是游戏玩法的深度能够弥补画面的不足。玩家如果想要更好一些的画面的话,可能就需要去查看 NetHack 中的 Vulture 了,这个选项可以提供更好的图像、声音和背景音乐。
|
||||
|
||||
如果要安装 NetHack ,请运行下面的命令:
|
||||
|
||||
在 Fedora 上: `dnf install nethack`
|
||||
|
||||
在 Debian/Ubuntu 上: `apt install nethack-x11 or apt install nethack-console`
|
||||
|
||||
我有错过了你最喜欢的角色扮演游戏吗?请在下面的评论区分享出来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/role-playing-games-linux
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
[1]:https://opensource.com/article/18/1/arcade-games-linux
|
||||
[2]:https://opensource.com/article/18/3/card-board-games-linux
|
||||
[3]:https://opensource.com/article/18/6/puzzle-games-linux
|
||||
[4]:https://opensource.com/article/18/7/racing-flying-games-linux
|
||||
[5]:https://endless-sky.github.io/
|
||||
[6]:https://en.wikipedia.org/wiki/Escape_Velocity_(video_game)
|
||||
[7]:http://www.gnu.org/software/freedink/
|
||||
[8]:http://www.rtsoft.com/pages/dink.php
|
||||
[9]:https://en.wikipedia.org/wiki/The_Legend_of_Zelda
|
||||
[10]:http://www.dinknetwork.com/files/category_dmod/
|
||||
[11]:http://manaplus.org/
|
||||
[12]:http://www.themanaworld.org/
|
||||
[13]:http://evolonline.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Massively_multiplayer_online_role-playing_game
|
||||
[15]:https://www.minetest.net/
|
||||
[16]:https://wiki.minetest.net/Mods
|
||||
[17]:https://www.nethack.org/
|
||||
[18]:https://en.wikipedia.org/wiki/Roguelike
|
||||
[19]:http://www.darkarts.co.za/vulture-for-nethack
|
||||
Loading…
Reference in New Issue
Block a user