diff --git a/published/20180116 Command Line Heroes- Season 1- OS Wars_2.md b/published/20180116 Command Line Heroes- Season 1- OS Wars_2.md
new file mode 100644
index 0000000000..68f6f81913
--- /dev/null
+++ b/published/20180116 Command Line Heroes- Season 1- OS Wars_2.md
@@ -0,0 +1,171 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11296-1.html)
+[#]: subject: (Command Line Heroes: Season 1: OS Wars)
+[#]: via: (https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux)
+[#]: author: (redhat https://www.redhat.com)
+
+《代码英雄》第一季(2):操作系统战争(下)Linux 崛起
+======
+
+> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗故事。
+
+
+
+本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第一季(2):操作系统战争(下)](https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux) 的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/2199861a.mp3)脚本。
+
+> 微软帝国控制着 90% 的用户。操作系统的完全标准化似乎是板上钉钉的事了。但是一个不太可能的英雄出现在开源反叛组织中。戴着眼镜,温文尔雅的林纳斯·托瓦兹免费发布了他的 Linux® 程序。微软打了个趔趄,并且开始重整旗鼓而来,战场从个人电脑转向互联网。
+
+**Saron Yitbarek:** 这玩意开着的吗?让我们进一段史诗般的星球大战的开幕吧,开始了。
+
+配音:第二集:Linux® 的崛起。微软帝国控制着 90% 的桌面用户。操作系统的全面标准化似乎是板上钉钉的事了。然而,互联网的出现将战争的焦点从桌面转向了企业,在该领域,所有商业组织都争相构建自己的服务器。*[00:00:30]*与此同时,一个不太可能的英雄出现在开源反叛组织中。固执、戴着眼镜的 林纳斯·托瓦兹免费发布了他的 Linux 系统。微软打了个趔趄,并且开始重整旗鼓而来。
+
+**Saron Yitbarek:** 哦,我们书呆子就是喜欢那样。上一次我们讲到哪了?苹果和微软互相攻伐,试图在一场争夺桌面用户的战争中占据主导地位。*[00:01:00]* 在第一集的结尾,我们看到微软获得了大部分的市场份额。很快,由于互联网的兴起以及随之而来的开发者大军,整个市场都经历了一场地震。互联网将战场从在家庭和办公室中的个人电脑用户转移到拥有数百台服务器的大型商业客户中。
+
+这意味着巨量资源的迁移。突然间,所有相关企业不仅被迫为服务器空间和网站建设付费,而且还必须集成软件来进行资源跟踪和数据库监控等工作。*[00:01:30]* 你需要很多开发人员来帮助你。至少那时候大家都是这么做的。
+
+在操作系统之战的第二部分,我们将看到优先级的巨大转变,以及像林纳斯·托瓦兹和理查德·斯托尔曼这样的开源反逆者是如何成功地在微软和整个软件行业的核心地带引发恐惧的。
+
+我是 Saron Yitbarek,你现在收听的是代码英雄,一款红帽公司原创的播客节目。*[00:02:00]* 每一集,我们都会给你带来“从码开始”改变技术的人的故事。
+
+好。想象一下你是 1991 年时的微软。你自我感觉良好,对吧?满怀信心。确立了全球主导的地位感觉不错。你已经掌握了与其他企业合作的艺术,但是仍然将大部分开发人员、程序员和系统管理员排除在联盟之外,而他们才是真正的步兵。*[00:02:30]* 这时出现了个叫林纳斯·托瓦兹的芬兰极客。他和他的开源程序员团队正在开始发布 Linux,这个操作系统内核是由他们一起编写出来的。
+
+坦白地说,如果你是微软公司,你并不会太在意 Linux,甚至不太关心开源运动,但是最终,Linux 的规模变得如此之大,以至于微软不可能不注意到。*[00:03:00]* Linux 第一个版本出现在 1991 年,当时大概有 1 万行代码。十年后,变成了 300 万行代码。如果你想知道,今天则是 2000 万行代码。
+
+*[00:03:30]* 让我们停留在 90 年代初一会儿。那时 Linux 还没有成为我们现在所知道的庞然大物。这个奇怪的病毒式的操作系统只是正在这个星球上蔓延,全世界的极客和黑客都爱上了它。那时候我还太年轻,但有点希望我曾经经历过那个时候。在那个时候,发现 Linux 就如同进入了一个秘密社团一样。就像其他人分享地下音乐混音带一样,程序员与朋友们分享 Linux CD 集。
+
+开发者 Tristram Oaten *[00:03:40]* 讲讲你 16 岁时第一次接触 Linux 的故事吧。
+
+**Tristram Oaten:** 我和我的家人去了红海的 Hurghada 潜水度假。那是一个美丽的地方,强烈推荐。第一天,我喝了自来水。也许,我妈妈跟我说过不要这么做。我整个星期都病得很厉害,没有离开旅馆房间。*[00:04:00]* 当时我只带了一台新安装了 Slackware Linux 的笔记本电脑,我听说过这玩意并且正在尝试使用它。所有的东西都在 8 张 cd 里面。这种情况下,我只能整个星期都去了解这个外星一般的系统。我阅读手册,摆弄着终端。我记得当时我甚至不知道一个点(表示当前目录)和两个点(表示前一个目录)之间的区别。
+
+*[00:04:30]* 我一点头绪都没有。犯过很多错误,但慢慢地,在这种强迫的孤独中,我突破了障碍,开始理解并明白命令行到底是怎么回事。假期结束时,我没有看过金字塔、尼罗河等任何埃及遗址,但我解锁了现代世界的一个奇迹。我解锁了 Linux,接下来的事大家都知道了。
+
+**Saron Yitbarek:** 你会从很多人那里听到关于这个故事的不同说法。访问 Linux 命令行是一种革命性的体验。
+
+**David Cantrell:** *[00:05:00]* 它给了我源代码。我当时的感觉是,“太神奇了。”
+
+**Saron Yitbarek:** 我们正在参加一个名为 Flock to Fedora 的 2017 年 Linux 开发者大会。
+
+**David Cantrell:** ……非常有吸引力。我觉得我对这个系统有了更多的控制力,它越来越吸引我。我想,从 1995 年我第一次编译 Linux 内核那时起,我就迷上了它。
+
+**Saron Yitbarek:** 开发者 David Cantrell 与 Joe Brockmire。
+
+**Joe Brockmeier:** *[00:05:30]* 我在 Cheap Software 转的时候发现了一套四张 CD 的 Slackware Linux。它看起来来非常令人兴奋而且很有趣,所以我把它带回家,安装在第二台电脑上,开始摆弄它,有两件事情让我感到很兴奋:一个是,我运行的不是 Windows,另一个是 Linux 的开源特性。
+
+**Saron Yitbarek:** *[00:06:00]* 某种程度上来说,对命令行的使用总是存在的。在开源真正开始流行还要早的几十年前,人们(至少在开发人员中是这样)总是希望能够做到完全控制。让我们回到操作系统大战之前的那个时代,在苹果和微软为他们的 GUI 而战之前。那时也有代码英雄。保罗·琼斯教授(在线图书馆 ibiblio.org 的负责人)在那个古老的时代,就是一名开发人员。
+
+**Paul Jones:** *[00:06:30]* 从本质上讲,互联网在那个时候客户端-服务器架构还是比较少的,而更多的是点对点架构的。确实,我们会说,某种 VAX 到 VAX 的连接(LCTT 译注:DEC 的一种操作系统),某种科学工作站到科学工作站的连接。这并不意味着没有客户端-服务端的架构及应用程序,但这的确意味着,最初的设计是思考如何实现点对点,*[00:07:00]* 它与 IBM 一直在做的东西相对立。IBM 给你的只有哑终端,这种终端只能让你管理用户界面,却无法让你像真正的终端一样为所欲为。
+
+**Saron Yitbarek:** 图形用户界面在普通用户中普及的同时,在工程师和开发人员中总是存在着一股相反的力量。早在 Linux 出现之前的二十世纪七八十年代,这股力量就存在于 Emacs 和 GNU 中。有了斯托尔曼的自由软件基金会后,总有某些人想要使用命令行,但上世纪 90 年代的 Linux 提供了前所未有的东西。
+
+*[00:07:30]* Linux 和其他开源软件的早期爱好者是都是先驱。我正站在他们的肩膀上。我们都是。
+
+你现在收听的是代码英雄,一款由红帽公司原创的播客。这是操作系统大战的第二部分:Linux 崛起。
+
+**Steven Vaughan-Nichols:** 1998 年的时候,情况发生了变化。
+
+**Saron Yitbarek:** *[00:08:00]* Steven Vaughan-Nichols 是 zdnet.com 的特约编辑,他已经写了几十年关于技术商业方面的文章了。他将向我们讲述 Linux 是如何慢慢变得越来越流行,直到自愿贡献者的数量远远超过了在 Windows 上工作的微软开发人员的数量的。不过,Linux 从未真正追上微软桌面客户的数量,这也许就是微软最开始时忽略了 Linux 及其开发者的原因。Linux 真正大放光彩的地方是在服务器机房。当企业开始线上业务时,每个企业都需要一个满足其需求的独特编程解决方案。
+
+*[00:08:30]* WindowsNT 于 1993 年问世,当时它已经在与其他的服务器操作系统展开竞争了,但是许多开发人员都在想,“既然我可以通过 Apache 构建出基于 Linux 的廉价系统,那我为什么要购买 AIX 设备或大型 Windows 设备呢?”关键点在于,Linux 代码已经开始渗透到几乎所有网上的东西中。
+
+**Steven Vaughan-Nichols:** *[00:09:00]* 令微软感到惊讶的是,它开始意识到,Linux 实际上已经开始有一些商业应用,不是在桌面环境,而是在商业服务器上。因此,他们发起了一场运动,我们称之为 FUD - 恐惧、不确定和怀疑。他们说,“哦,Linux 这玩意,真的没有那么好。它不太可靠。你一点都不能相信它”。
+
+**Saron Yitbarek:** 这种软宣传式的攻击持续了一段时间。微软也不是唯一一个对 Linux 感到紧张的公司。这其实是整个行业在对抗这个奇怪新人的挑战。*[00:09:30]* 例如,任何与 UNIX 有利害关系的人都可能将 Linux 视为篡夺者。有一个案例很著名,那就是 SCO 组织(它发行过一种 UNIX 版本)在过去 10 多年里发起一系列的诉讼,试图阻止 Linux 的传播。SCO 最终失败而且破产了。与此同时,微软一直在寻找机会,他们必须要采取动作,只是不清楚具体该怎么做。
+
+**Steven Vaughan-Nichols:** *[00:10:00]* 让微软真正担心的是,第二年,在 2000 年的时候,IBM 宣布,他们将于 2001 年投资 10 亿美元在 Linux 上。现在,IBM 已经不再涉足个人电脑业务。(那时)他们还没有走出去,但他们正朝着这个方向前进,他们将 Linux 视为服务器和大型计算机的未来,在这一点上,剧透警告,IBM 是正确的。*[00:10:30]* Linux 将主宰服务器世界。
+
+**Saron Yitbarek:** 这已经不再仅仅是一群黑客喜欢他们对命令行的绝地武士式的控制了。金钱的投入对 Linux 助力极大。Linux 国际的执行董事 John “Mad Dog” Hall 有一个故事可以解释为什么会这样。我们通过电话与他取得了联系。
+
+**John Hall:** *[00:11:00]* 我有一个名叫 Dirk Holden 的朋友,他是德国德意志银行的系统管理员,他也参与了个人电脑上早期 X Windows 系统图形项目的工作。有一天我去银行拜访他,我说:“Dirk,你银行里有 3000 台服务器,用的都是 Linux。为什么不用 Microsoft NT 呢?”*[00:11:30]* 他看着我说:“是的,我有 3000 台服务器,如果使用微软的 Windows NT 系统,我需要 2999 名系统管理员。”他继续说道:“而使用 Linux,我只需要四个。”这真是完美的答案。
+
+**Saron Yitbarek:** 程序员们着迷的这些东西恰好对大公司也极具吸引力。但由于 FUD 的作用,一些企业对此持谨慎态度。*[00:12:00]* 他们听到开源,就想:“开源。这看起来不太可靠,很混乱,充满了 BUG”。但正如那位银行经理所指出的,金钱有一种有趣的方式,可以说服人们克服困境。甚至那些只需要网站的小公司也加入了 Linux 阵营。与一些昂贵的专有选择相比,使用一个廉价的 Linux 系统在成本上是无法比拟的。如果你是一家雇佣专业人员来构建网站的商店,那么你肯定想让他们使用 Linux。
+
+让我们快进几年。Linux 运行每个人的网站上。Linux 已经征服了服务器世界,然后智能手机也随之诞生。*[00:12:30]* 当然,苹果和他们的 iPhone 占据了相当大的市场份额,而且微软也希望能进入这个市场,但令人惊讶的是,Linux 也在那,已经做好准备了,迫不及待要大展拳脚。
+
+作家兼记者 James Allworth。
+
+**James Allworth:** 肯定还有容纳第二个竞争者的空间,那本可以是微软,但是实际上却是 Android,而 Andrid 基本上是基于 Linux 的。众所周知,Android 被谷歌所收购,现在运行在世界上大部分的智能手机上,谷歌在 Linux 的基础上创建了 Android。*[00:13:00]* Linux 使他们能够以零成本从一个非常复杂的操作系统开始。他们成功地实现了这一目标,最终将微软挡在了下一代设备之外,至少从操作系统的角度来看是这样。
+
+**Saron Yitbarek:** *[00:13:30]* 这可是个大地震,很大程度上,微软有被埋没的风险。John Gossman 是微软 Azure 团队的首席架构师。他还记得当时困扰公司的困惑。
+
+**John Gossman:** 像许多公司一样,微软也非常担心知识产权污染。他们认为,如果允许开发人员使用开源代码,那么他们可能只是将一些代码复制并粘贴到某些产品中,就会让某种病毒式的许可证生效从而引发未知的风险……他们也很困惑,*[00:14:00]* 我认为,这跟公司文化有关,很多公司,包括微软,都对开源开发的意义和商业模式之间的分歧感到困惑。有一种观点认为,开源意味着你所有的软件都是免费的,人们永远不会付钱。
+
+**Saron Yitbarek:** 任何投资于旧的、专有软件模型的人都会觉得这里发生的一切对他们构成了威胁。当你威胁到像微软这样的大公司时,是的,他们一定会做出反应。*[00:14:30]* 他们推动所有这些 FUD —— 恐惧、不确定性和怀疑是有道理的。当时,商业运作的方式基本上就是相互竞争。不过,如果是其他公司的话,他们可能还会一直怀恨在心,抱残守缺,但到了 2013 年的微软,一切都变了。
+
+微软的云计算服务 Azure 上线了,令人震惊的是,它从第一天开始就提供了 Linux 虚拟机。*[00:15:00]* 史蒂夫·鲍尔默,这位把 Linux 称为癌症的首席执行官,已经离开了,代替他的是一位新的有远见的首席执行官萨提亚·纳德拉。
+
+**John Gossman:** 萨提亚有不同的看法。他属于另一个世代。比保罗、比尔和史蒂夫更年轻的世代,他对开源有不同的看法。
+
+**Saron Yitbarek:** 还是来自微软 Azure 团队的 John Gossman。
+
+**John Gossman:** *[00:15:30]* 大约四年前,处于实际需要,我们在 Azure 中添加了 Linux 支持。如果访问任何一家企业客户,你都会发现他们并不会才试着决定是使用 Windows 还是使用 Linux、 使用 .net 还是使用 Java ^TM 。他们在很久以前就做出了决定 —— 大约 15 年前才有这样的一些争论。*[00:16:00]* 现在,我见过的每一家公司都混合了 Linux 和 Java、Windows 和 .net、SQL Server、Oracle 和 MySQL —— 基于专有源代码的产品和开放源代码的产品。
+
+如果你打算运维一个云服务,允许这些公司在云上运行他们的业务,那么你根本不能告诉他们,“你可以使用这个软件,但你不能使用那个软件。”
+
+**Saron Yitbarek:** *[00:16:30]* 这正是萨提亚·纳德拉采纳的哲学思想。2014 年秋季,他站在舞台上,希望传递一个重要信息。“微软爱 Linux”。他接着说,“20% 的 Azure 业务量已经是 Linux 了,微软将始终对 Linux 发行版提供一流的支持。”没有哪怕一丝对开源的宿怨。
+
+为了说明这一点,在他们的背后有一个巨大的标志,上面写着:“Microsoft ❤️ Linux”。哇噢。对我们中的一些人来说,这种转变有点令人震惊,但实际上,无需如此震惊。下面是 Steven Levy,一名科技记者兼作家。
+
+**Steven Levy:** *[00:17:00]* 当你在踢足球的时候,如果草坪变滑了,那么你也许会换一种不同的鞋子。他们当初就是这么做的。*[00:17:30]* 他们不能否认现实,而且他们里面也有聪明人,所以他们必须意识到,这就是这个世界的运行方式,不管他们早些时候说了什么,即使他们对之前的言论感到尴尬,但是让他们之前关于开源多么可怕的言论影响到现在明智的决策那才真的是疯了。
+
+**Saron Yitbarek:** 微软低下了它高傲的头。你可能还记得苹果公司,经过多年的孤立无援,最终转向与微软构建合作伙伴关系。现在轮到微软进行 180 度转变了。*[00:18:00]* 经过多年的与开源方式的战斗后,他们正在重塑自己。要么改变,要么死亡。Steven Vaughan-Nichols。
+
+**Steven Vaughan-Nichols:** 即使是像微软这样规模的公司也无法与数千个开发着包括 Linux 在内的其它大项目的开源开发者竞争。很长时间以来他们都不愿意这么做。前微软首席执行官史蒂夫·鲍尔默对 Linux 深恶痛绝。*[00:18:30]* 由于它的 GPL 许可证,他视 Linux 为一种癌症,但一旦鲍尔默被扫地出门,新的微软领导层说,“这就好像试图命令潮流不要过来,但潮水依然会不断涌进来。我们应该与 Linux 合作,而不是与之对抗。”
+
+**Saron Tiebreak:** 事实上,互联网技术史上最大的胜利之一就是微软最终决定做出这样的转变。*[00:19:00]* 当然,当微软出现在开源圈子时,老一代的铁杆 Linux 支持者是相当怀疑的。他们不确定自己是否能接受这些家伙,但正如 Vaughan-Nichols 所指出的,今天的微软已经不是以前的微软了。
+
+**Steven Vaughan-Nichols:** 2017 年的微软既不是史蒂夫·鲍尔默的微软,也不是比尔·盖茨的微软。这是一家完全不同的公司,有着完全不同的方法,而且,一旦使用了开源,你就无法退回到之前。*[00:19:30]* 开源已经吞噬了整个技术世界。从未听说过 Linux 的人可能对它并不了解,但是每次他们访问 Facebook,他们都在运行 Linux。每次执行谷歌搜索时,你都在运行 Linux。
+
+*[00:20:00]* 每次你用 Android 手机,你都在运行 Linux。它确实无处不在,微软无法阻止它,而且我认为以为微软能以某种方式接管它的想法,太天真了。
+
+**Saron Yitbarek:** 开源支持者可能一直担心微软会像混入羊群中的狼一样,但事实是,开源软件的本质保护了它无法被完全控制。*[00:20:30]* 没有一家公司能够拥有 Linux 并以某种特定的方式控制它。Greg Kroah-Hartman 是 Linux 基金会的一名成员。
+
+**Greg Kroah-Hartman:** 每个公司和个人都以自私的方式为 Linux 做出贡献。他们之所以这样做是因为他们想要解决他们所面临的问题,可能是硬件无法工作,或者是他们想要添加一个新功能来做其他事情,又或者想在他们的产品中使用它。这很棒,因为他们会把代码贡献回去,此后每个人都会从中受益,这样每个人都可以用到这份代码。正是因为这种自私,所有的公司,所有的人都能从中受益。
+
+**Saron Yitbarek:** *[00:21:00]* 微软已经意识到,在即将到来的云战争中,与 Linux 作战就像与空气作战一样。Linux 和开源不是敌人,它们是空气。如今,微软以白金会员的身份加入了 Linux 基金会。他们成为 GitHub 开源项目的头号贡献者。*[00:21:30]* 2017 年 9 月,他们甚至加入了开源促进联盟。现在,微软在开源许可证下发布了很多代码。微软的 John Gossman 描述了他们开源 .net 时所发生的事情。起初,他们并不认为自己能得到什么回报。
+
+**John Gossman:** 我们本没有指望来自社区的贡献,然而,三年后,超过 50% 的对 .net 框架库的贡献来自于微软之外。这包括大量的代码。*[00:22:00]* 三星为 .net 提供了 ARM 支持。Intel 和 ARM 以及其他一些芯片厂商已经为 .net 框架贡献了特定于他们处理器的代码生成,以及数量惊人的修复、性能改进等等 —— 既有单个贡献者也有社区。
+
+**Saron Yitbarek:** 直到几年前,今天的这个微软,这个开放的微软,还是不可想象的。
+
+*[00:22:30]* 我是 Saron Yitbarek,这里是代码英雄。好吧,我们已经看到了为了赢得数百万桌面用户的爱而战的激烈场面。我们已经看到开源软件在专有软件巨头的背后悄然崛起,并攫取了巨大的市场份额。*[00:23:00]* 我们已经看到了一批批的代码英雄将编程领域变成了我你今天看到的这个样子。如今,大企业正在吸收开源软件,通过这一切,每个人都从他人那里受益。
+
+在技术的西部荒野,一贯如此。苹果受到施乐的启发,微软受到苹果的启发,Linux 受到 UNIX 的启发。进化、借鉴、不断成长。如果比喻成大卫和歌利亚(LCTT 译注:西方经典的以弱胜强战争中的两个主角)的话,开源软件不再是大卫,但是,你知道吗?它也不是歌利亚。*[00:23:30]* 开源已经超越了传统。它已经成为其他人战斗的战场。随着开源道路变得不可避免,新的战争,那些在云计算中进行的战争,那些在开源战场上进行的战争正在加剧。
+
+这是 Steven Levy,他是一名作者。
+
+**Steven Levy:** 基本上,到目前为止,包括微软在内,有四到五家公司,正以各种方式努力把自己打造成为全方位的平台,比如人工智能领域。你能看到智能助手之间的战争,你猜怎么着?*[00:24:00]* 苹果有一个智能助手,叫 Siri。微软有一个,叫 Cortana。谷歌有谷歌助手。三星也有一个智能助手。亚马逊也有一个,叫 Alexa。我们看到这些战斗遍布各地。也许,你可以说,最热门的人工智能平台将控制我们生活中所有的东西,而这五家公司就是在为此而争斗。
+
+**Saron Yitbarek:** *[00:24:30]* 如果你正在寻找另一个反叛者,它们就像 Linux 奇袭微软那样,偷偷躲在 Facebook、谷歌或亚马逊身后,你也许要等很久,因为正如作家 James Allworth 所指出的,成为一个真正的反叛者只会变得越来越难。
+
+**James Allworth:** 规模一直以来都是一种优势,但规模优势本质上……怎么说呢,我认为以前它们在本质上是线性的,现在它们在本质上是指数型的了,所以,一旦你开始以某种方法走在前面,另一个新玩家要想赶上来就变得越来越难了。*[00:25:00]* 我认为在互联网时代这大体来说来说是正确的,无论是因为规模,还是数据赋予组织的竞争力的重要性和优势。一旦你走在前面,你就会吸引更多的客户,这就给了你更多的数据,让你能做得更好,这之后,客户还有什么理由选择排名第二的公司呢,难道是因为因为他们落后了这么远么?*[00:25:30]* 我认为在云的时代这个逻辑也不会有什么不同。
+
+**Saron Yitbarek:** 这个故事始于史蒂夫·乔布斯和比尔·盖茨这样的非凡的英雄,但科技的进步已经呈现出一种众包、有机的感觉。我认为据说我们的开源英雄林纳斯·托瓦兹在第一次发明 Linux 内核时甚至没有一个真正的计划。他无疑是一位才华横溢的年轻开发者,但他也像潮汐前的一滴水一样。*[00:26:00]* 变革是不可避免的。据估计,对于一家专有软件公司来说,用他们老式的、专有的方式创建一个 Linux 发行版将花费他们超过 100 亿美元。这说明了开源的力量。
+
+最后,这并不是一个专有模型所能与之竞争的东西。成功的公司必须保持开放。这是最大、最终极的教训。*[00:26:30]* 还有一点要记住:当我们连接在一起的时候,我们在已有基础上成长和建设的能力是无限的。不管这些公司有多大,我们都不必坐等他们给我们更好的东西。想想那些为了纯粹的创造乐趣而学习编码的新开发者,那些自己动手丰衣足食的人。
+
+未来的优秀程序员无管来自何方,只要能够访问代码,他们就能构建下一个大项目。
+
+*[00:27:00]* 以上就是我们关于操作系统战争的两个故事。这场战争塑造了我们的数字生活。争夺主导地位的斗争从桌面转移到了服务器机房,最终进入了云计算领域。过去的敌人难以置信地变成了盟友,众包的未来让一切都变得开放。*[00:27:30]* 听着,我知道,在这段历史之旅中,还有很多英雄我们没有提到,所以给我们写信吧。分享你的故事。[Redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes) 。我恭候佳音。
+
+在本季剩下的时间里,我们将学习今天的英雄们在创造什么,以及他们要经历什么样的战斗才能将他们的创造变为现实。让我们从壮丽的编程一线回来看看更多的传奇故事吧。我们每两周放一集新的博客。几周后,我们将为你带来第三集:敏捷革命。
+
+*[00:28:00]* 代码英雄是一款红帽公司原创的播客。要想免费自动获得新一集的代码英雄,请订阅我们的节目。只要在苹果播客、Spotify、谷歌 Play,或其他应用中搜索“Command Line Heroes”。然后点击“订阅”。这样你就会第一个知道什么时候有新剧集了。
+
+我是 Saron Yitbarek。感谢收听。继续编码。
+
+--------------------------------------------------------------------------------
+
+via: https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux
+
+作者:[redhat][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.redhat.com
+[b]: https://github.com/lujun9972
diff --git a/published/20180704 BASHing data- Truncated data items.md b/published/20180704 BASHing data- Truncated data items.md
new file mode 100644
index 0000000000..dad03bf3da
--- /dev/null
+++ b/published/20180704 BASHing data- Truncated data items.md
@@ -0,0 +1,115 @@
+如何发现截断的数据项
+======
+
+**截断**(形容词):缩写、删节、缩减、剪切、剪裁、裁剪、修剪……
+
+数据项被截断的一种情况是将其输入到数据库字段中,该字段的字符限制比数据项的长度要短。例如,字符串:
+
+```
+Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE of Yermo CA
+```
+
+是 60 个字符长。如果你将其输入到具有 50 个字符限制的“位置”字段,则可以获得:
+
+```
+Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE #末尾带有一个空格
+```
+
+截断也可能导致数据错误,比如你打算输入:
+
+```
+Sally Ann Hunter (aka Sally Cleveland)
+```
+
+但是你忘记了闭合的括号:
+
+```
+Sally Ann Hunter (aka Sally Cleveland
+```
+
+这会让使用数据的用户觉得 Sally 是否有被修剪掉了数据项的其它的别名。
+
+截断的数据项很难检测。在审核数据时,我使用三种不同的方法来查找可能的截断,但我仍然可能会错过一些。
+
+**数据项的长度分布。**第一种方法是捕获我在各个字段中找到的大多数截断的数据。我将字段传递给 `awk` 命令,该命令按字段宽度计算数据项,然后我使用 `sort` 以宽度的逆序打印计数。例如,要检查以 `tab` 分隔的文件 `midges` 中的第 33 个字段:
+
+```
+awk -F"\t" 'NR>1 {a[length($33)]++} \
+ END {for (i in a) print i FS a[i]}' midges | sort -nr
+```
+
+![distro1][1]
+
+最长的条目恰好有 50 个字符,这是可疑的,并且在该宽度处存在数据项的“凸起”,这更加可疑。检查这些 50 个字符的项目会发现截断:
+
+![distro2][2]
+
+我用这种方式检查的其他数据表有 100、200 和 255 个字符的“凸起”。在每种情况下,这种“凸起”都包含明显的截断。
+
+**未匹配的括号。**第二种方法查找类似 `...(Sally Cleveland` 的数据项。一个很好的起点是数据表中所有标点符号的统计。这里我检查文件 `mag2`:
+
+```
+grep -o "[[:punct:]]" file | sort | uniqc
+```
+
+![punct][3]
+
+请注意,`mag2` 中的开括号和闭括号的数量不相等。要查看发生了什么,我使用 `unmatched` 函数,它接受三个参数并检查数据表中的所有字段。第一个参数是文件名,第二个和第三个是开括号和闭括号,用引号括起来。
+
+```
+unmatched()
+{
+ awk -F"\t" -v start="$2" -v end="$3" \
+ '{for (i=1;i<=NF;i++) \
+ if (split($i,a,start) != split($i,b,end)) \
+ print "line "NR", field "i":\n"$i}' "$1"
+}
+```
+
+如果在字段中找到开括号和闭括号之间不匹配,则 `unmatched` 会报告行号和字段号。这依赖于 `awk` 的 `split` 函数,它返回由分隔符分隔的元素数(包括空格)。这个数字总是比分隔符的数量多一个:
+
+![split][4]
+
+这里 `ummatched` 检查 `mag2` 中的圆括号并找到一些可能的截断:
+
+![unmatched][5]
+
+我使用 `unmatched` 来找到不匹配的圆括号 `()`、方括号 `[]`、花括号 `{}` 和尖括号 `<>`,但该函数可用于任何配对的标点字符。
+
+**意外的结尾。**第三种方法查找以尾随空格或非终止标点符号结尾的数据项,如逗号或连字符。这可以在单个字段上用 `cut` 用管道输入到 `grep` 完成,或者用 `awk` 一步完成。在这里,我正在检查以制表符分隔的表 `herp5` 的字段 47,并提取可疑数据项及其行号:
+
+```
+cut -f47 herp5 | grep -n "[ ,;:-]$"
+或
+awk -F"\t" '$47 ~ /[ ,;:-]$/ {print NR": "$47}' herp5
+```
+
+![herps5][6]
+
+用于制表符分隔文件的 awk 命令的全字段版本是:
+
+```
+awk -F"\t" '{for (i=1;i<=NF;i++) if ($i ~ /[ ,;:-]$/) \
+ print "line "NR", field "i":\n"$i}' file
+```
+
+**谨慎的想法。**在我对字段进行的验证测试期间也会出现截断。例如,我可能会在“年”的字段中检查合理的 4 位数条目,并且有个 `198` 可能是 198n?还是 1898 年?带有丢失字符的截断数据项是个谜。 作为数据审计员,我只能报告(可能的)字符损失,并建议数据编制者或管理者恢复(可能)丢失的字符。
+
+--------------------------------------------------------------------------------
+
+via: https://www.polydesmida.info/BASHing/2018-07-04.html
+
+作者:[polydesmida][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.polydesmida.info/
+[1]:https://www.polydesmida.info/BASHing/img1/2018-07-04_1.png
+[2]:https://www.polydesmida.info/BASHing/img1/2018-07-04_2.png
+[3]:https://www.polydesmida.info/BASHing/img1/2018-07-04_3.png
+[4]:https://www.polydesmida.info/BASHing/img1/2018-07-04_4.png
+[5]:https://www.polydesmida.info/BASHing/img1/2018-07-04_5.png
+[6]:https://www.polydesmida.info/BASHing/img1/2018-07-04_6.png
diff --git a/published/20181113 Eldoc Goes Global.md b/published/20181113 Eldoc Goes Global.md
new file mode 100644
index 0000000000..4714f966a1
--- /dev/null
+++ b/published/20181113 Eldoc Goes Global.md
@@ -0,0 +1,48 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11306-1.html)
+[#]: subject: (Eldoc Goes Global)
+[#]: via: (https://emacsredux.com/blog/2018/11/13/eldoc-goes-global/)
+[#]: author: (Bozhidar Batsov https://emacsredux.com)
+
+Emacs:Eldoc 全局化了
+======
+
+
+
+最近我注意到 Emacs 25.1 增加了一个名为 `global-eldoc-mode` 的模式,它是流行的 `eldoc-mode` 的一个全局化的变体。而且与 `eldoc-mode` 不同的是,`global-eldoc-mode` 默认是开启的!
+
+这意味着你可以删除 Emacs 配置中为主模式开启 `eldoc-mode` 的代码了:
+
+```
+;; That code is now redundant
+(add-hook 'emacs-lisp-mode-hook #'eldoc-mode)
+(add-hook 'ielm-mode-hook #'eldoc-mode)
+(add-hook 'cider-mode-hook #'eldoc-mode)
+(add-hook 'cider-repl-mode-hook #'eldoc-mode)
+```
+
+[有人说][1] `global-eldoc-mode` 在某些不支持的模式中会有性能问题。我自己从未遇到过,但若你像禁用它则只需要这样:
+
+```
+(global-eldoc-mode -1)
+```
+
+现在是时候清理我的配置了!删除代码就是这么爽!
+
+--------------------------------------------------------------------------------
+
+via: https://emacsredux.com/blog/2018/11/13/eldoc-goes-global/
+
+作者:[Bozhidar Batsov][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://emacsredux.com
+[b]: https://github.com/lujun9972
+[1]: https://emacs.stackexchange.com/questions/31414/how-to-globally-disable-eldoc
diff --git a/published/20190401 Build and host a website with Git.md b/published/20190401 Build and host a website with Git.md
new file mode 100644
index 0000000000..fd3b19a04f
--- /dev/null
+++ b/published/20190401 Build and host a website with Git.md
@@ -0,0 +1,223 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11303-1.html)
+[#]: subject: (Build and host a website with Git)
+[#]: via: (https://opensource.com/article/19/4/building-hosting-website-git)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+用 Git 建立和托管网站
+======
+
+> 你可以让 Git 帮助你轻松发布你的网站。在我们《鲜为人知的 Git 用法》系列的第一篇文章中学习如何做到。
+
+
+
+[Git][2] 是一个少有的能将如此多的现代计算封装到一个程序之中的应用程序,它可以用作许多其他应用程序的计算引擎。虽然它以跟踪软件开发中的源代码更改而闻名,但它还有许多其他用途,可以让你的生活更轻松、更有条理。在这个 Git 系列中,我们将分享七种鲜为人知的使用 Git 的方法。
+
+创建一个网站曾经是极其简单的,而同时它又是一种黑魔法。回到 Web 1.0 的旧时代(不是每个人都会这样称呼它),你可以打开任何网站,查看其源代码,并对 HTML 及其内联样式和基于表格的布局进行反向工程,在这样的一两个下午之后,你就会感觉自己像一个程序员一样。不过要让你创建的页面放到互联网上,仍然有一些问题,因为这意味着你需要处理服务器、FTP 以及 webroot 目录和文件权限。虽然从那时起,现代网站变得愈加复杂,但如果你让 Git 帮助你,自出版可以同样容易(或更容易!)。
+
+### 用 Hugo 创建一个网站
+
+[Hugo][3] 是一个开源的静态站点生成器。静态网站是过去的 Web 的基础(如果你回溯到很久以前,那就是 Web 的*全部*了)。静态站点有几个优点:它们相对容易编写,因为你不必编写代码;它们相对安全,因为页面上没有执行代码;并且它们可以非常快,因为除了在页面上传输的任何内容之外没有任何处理。
+
+Hugo 并不是唯一一个静态站点生成器。[Grav][4]、[Pico][5]、[Jekyll][6]、[Podwrite][7] 以及许多其他的同类软件都提供了一种创建一个功能最少的、只需要很少维护的网站的简单方法。Hugo 恰好是内置集成了 GitLab 集成的一个静态站点生成器,这意味着你可以使用免费的 GitLab 帐户生成和托管你的网站。
+
+Hugo 也有一些非常大的用户。例如,如果你曾经去过 [Let's Encrypt](https://letsencrypt.org/) 网站,那么你已经用过了一个用 Hugo 构建的网站。
+
+![Let's Encrypt website][8]
+
+#### 安装 Hugo
+
+Hugo 是跨平台的,你可以在 [Hugo 的入门资源][9]中找到适用于 MacOS、Windows、Linux、OpenBSD 和 FreeBSD 的安装说明。
+
+如果你使用的是 Linux 或 BSD,最简单的方法是从软件存储库或 ports 树安装 Hugo。确切的命令取决于你的发行版,但在 Fedora 上,你应该输入:
+
+```
+$ sudo dnf install hugo
+```
+
+通过打开终端并键入以下内容确认你已正确安装:
+
+```
+$ hugo help
+```
+
+这将打印 `hugo` 命令的所有可用选项。如果你没有看到,你可能没有正确安装 Hugo 或需要[将该命令添加到你的路径][10]。
+
+#### 创建你的站点
+
+要构建 Hugo 站点,你必须有个特定的目录结构,通过输入以下命令 Hugo 将为你生成它:
+
+```
+$ hugo new site mysite
+```
+
+你现在有了一个名为 `mysite` 的目录,它包含构建 Hugo 网站所需的默认目录。
+
+Git 是你将网站放到互联网上的接口,因此切换到你新的 `mysite` 文件夹,并将其初始化为 Git 存储库:
+
+```
+$ cd mysite
+$ git init .
+```
+
+Hugo 与 Git 配合的很好,所以你甚至可以使用 Git 为你的网站安装主题。除非你计划开发你正在安装的主题,否则可以使用 `--depth` 选项克隆该主题的源的最新状态:
+
+```
+$ git clone --depth 1 https://github.com/darshanbaral/mero.git themes/mero
+```
+
+现在为你的网站创建一些内容:
+
+```
+$ hugo new posts/hello.md
+```
+
+使用你喜欢的文本编辑器编辑 `content/posts` 目录中的 `hello.md` 文件。Hugo 接受 Markdown 文件,并会在发布时将它们转换为经过主题化的 HTML 文件,因此你的内容必须采用 [Markdown 格式][11]。
+
+如果要在帖子中包含图像,请在 `static` 目录中创建一个名为 `images` 的文件夹。将图像放入此文件夹,并使用以 `/images` 开头的绝对路径在标记中引用它们。例如:
+
+```
+
+```
+
+#### 选择主题
+
+你可以在 [themes.gohugo.io][12] 找到更多主题,但最好在测试时保持一个基本主题。标准的 Hugo 测试主题是 [Ananke][13]。某些主题具有复杂的依赖关系,而另外一些主题如果没有复杂的配置的话,也许不会以你预期的方式呈现页面。本例中使用的 Mero 主题捆绑了一个详细的 `config.toml` 配置文件,但是(为了简单起见)我将在这里只提供基本的配置。在文本编辑器中打开名为 `config.toml` 的文件,并添加三个配置参数:
+
+```
+languageCode = "en-us"
+title = "My website on the web"
+theme = "mero"
+
+[params]
+ author = "Seth Kenlon"
+ description = "My hugo demo"
+```
+
+#### 预览
+
+在你准备发布之前不必(预先)在互联网上放置任何内容。在你开发网站时,你可以通过启动 Hugo 附带的仅限本地访问的 Web 服务器来预览你的站点。
+
+```
+$ hugo server --buildDrafts --disableFastRender
+```
+
+打开 Web 浏览器并导航到 以查看正在进行的工作。
+
+### 用 Git 发布到 GitLab
+
+要在 GitLab 上发布和托管你的站点,请为你的站点内容创建一个存储库。
+
+要在 GitLab 中创建存储库,请单击 GitLab 的 “Projects” 页面中的 “New Project” 按钮。创建一个名为 `yourGitLabUsername.gitlab.io` 的空存储库,用你的 GitLab 用户名或组名替换 `yourGitLabUsername`。你必须使用此命名方式作为该项目的名称。你也可以稍后为其添加自定义域。
+
+不要在 GitLab 上包含许可证或 README 文件(因为你已经在本地启动了一个项目,现在添加这些文件会使将你的数据推向 GitLab 时更加复杂,以后你可以随时添加它们)。
+
+在 GitLab 上创建空存储库后,将其添加为 Hugo 站点的本地副本的远程位置,该站点已经是一个 Git 存储库:
+
+```
+$ git remote add origin git@gitlab.com:skenlon/mysite.git
+```
+
+创建名为 `.gitlab-ci.yml` 的 GitLab 站点配置文件并输入以下选项:
+
+```
+image: monachus/hugo
+
+variables:
+ GIT_SUBMODULE_STRATEGY: recursive
+
+pages:
+ script:
+ - hugo
+ artifacts:
+ paths:
+ - public
+ only:
+ - master
+```
+
+`image` 参数定义了一个为你的站点提供服务的容器化图像。其他参数是告诉 GitLab 服务器在将新代码推送到远程存储库时要执行的操作的说明。有关 GitLab 的 CI/CD(持续集成和交付)选项的更多信息,请参阅 [GitLab 文档的 CI/CD 部分][14]。
+
+#### 设置排除的内容
+
+你的 Git 存储库已配置好,在 GitLab 服务器上构建站点的命令也已设置,你的站点已准备好发布了。对于你的第一个 Git 提交,你必须采取一些额外的预防措施,以便你不会对你不打算进行版本控制的文件进行版本控制。
+
+首先,将构建你的站点时 Hugo 创建的 `/public` 目录添加到 `.gitignore` 文件。你无需在 Git 中管理已完成发布的站点;你需要跟踪的是你的 Hugo 源文件。
+
+```
+$ echo "/public" >> .gitignore
+```
+
+如果不创建 Git 子模块,则无法在 Git 存储库中维护另一个 Git 存储库。为了简单起见,请移除嵌入的存储库的 `.git` 目录,以使主题(存储库)只是一个主题(目录)。
+
+请注意,你**必须**将你的主题文件添加到你的 Git 存储库,以便 GitLab 可以访问该主题。如果不提交主题文件,你的网站将无法成功构建。
+
+```
+$ mv themes/mero/.git ~/.local/share/Trash/files/
+```
+
+你也可以像使用[回收站][15]一样使用 `trash`:
+
+```
+$ trash themes/mero/.git
+```
+
+现在,你可以将本地项目目录的所有内容添加到 Git 并将其推送到 GitLab:
+
+```
+$ git add .
+$ git commit -m 'hugo init'
+$ git push -u origin HEAD
+```
+
+### 用 GitLab 上线
+
+将代码推送到 GitLab 后,请查看你的项目页面。有个图标表示 GitLab 正在处理你的构建。第一次推送代码可能需要几分钟,所以请耐心等待。但是,请不要**一直**等待,因为该图标并不总是可靠地更新。
+
+![GitLab processing your build][16]
+
+当你在等待 GitLab 组装你的站点时,请转到你的项目设置并找到 “Pages” 面板。你的网站准备就绪后,它的 URL 就可以用了。该 URL 是 `yourGitLabUsername.gitlab.io/yourProjectName`。导航到该地址以查看你的劳动成果。
+
+![Previewing Hugo site][17]
+
+如果你的站点无法正确组装,GitLab 提供了可以深入了解 CI/CD 管道的日志。查看错误消息以找出发生了什么问题。
+
+### Git 和 Web
+
+Hugo(或 Jekyll 等类似工具)只是利用 Git 作为 Web 发布工具的一种方式。使用服务器端 Git 挂钩,你可以使用最少的脚本设计你自己的 Git-to-web 工作流。使用 GitLab 的社区版,你可以自行托管你自己的 GitLab 实例;或者你可以使用 [Gitolite][18] 或 [Gitea][19] 等替代方案,并使用本文作为自定义解决方案的灵感来源。祝你玩得开心!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/4/building-hosting-website-git
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web_browser_desktop_devlopment_design_system_computer.jpg?itok=pfqRrJgh (web development and design, desktop and browser)
+[2]: https://git-scm.com/
+[3]: http://gohugo.io
+[4]: http://getgrav.org
+[5]: http://picocms.org/
+[6]: https://jekyllrb.com
+[7]: http://slackermedia.info/podwrite/
+[8]: https://opensource.com/sites/default/files/uploads/letsencrypt-site.jpg (Let's Encrypt website)
+[9]: https://gohugo.io/getting-started/installing
+[10]: https://opensource.com/article/17/6/set-path-linux
+[11]: https://commonmark.org/help/
+[12]: https://themes.gohugo.io/
+[13]: https://themes.gohugo.io/gohugo-theme-ananke/
+[14]: https://docs.gitlab.com/ee/ci/#overview
+[15]: http://slackermedia.info/trashy
+[16]: https://opensource.com/sites/default/files/uploads/hugo-gitlab-cicd.jpg (GitLab processing your build)
+[17]: https://opensource.com/sites/default/files/uploads/hugo-demo-site.jpg (Previewing Hugo site)
+[18]: http://gitolite.com
+[19]: http://gitea.io
diff --git a/published/20190408 A beginner-s guide to building DevOps pipelines with open source tools.md b/published/20190408 A beginner-s guide to building DevOps pipelines with open source tools.md
new file mode 100644
index 0000000000..bbd85a891f
--- /dev/null
+++ b/published/20190408 A beginner-s guide to building DevOps pipelines with open source tools.md
@@ -0,0 +1,345 @@
+[#]: collector: (lujun9972)
+[#]: translator: (LuuMing)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11307-1.html)
+[#]: subject: (A beginner's guide to building DevOps pipelines with open source tools)
+[#]: via: (https://opensource.com/article/19/4/devops-pipeline)
+[#]: author: (Bryant Son https://opensource.com/users/brson/users/milindsingh/users/milindsingh/users/dscripter)
+
+使用开源工具构建 DevOps 流水线的初学者指南
+======
+
+> 如果你是 DevOps 新人,请查看这 5 个步骤来构建你的第一个 DevOps 流水线。
+
+
+
+DevOps 已经成为解决软件开发过程中出现的缓慢、孤立或者其他故障的默认方式。但是当你刚接触 DevOps 并且不确定从哪开始时,就意义不大了。本文探索了什么是 DevOps 流水线并且提供了创建它的 5 个步骤。尽管这个教程并不全面,但可以给你以后上手和扩展打下基础。首先,插入一个小故事。
+
+### 我的 DevOps 之旅
+
+我曾经在花旗集团的云小组工作,开发基础设施即服务网页应用来管理花旗的云基础设施,但我经常对研究如何让开发流水线更加高效以及如何带给团队积极的文化感兴趣。我在 Greg Lavender 推荐的书中找到了答案。Greg Lavender 是花旗的云架构和基础设施工程(即 [Phoenix 项目][2])的 CTO。这本书尽管解释的是 DevOps 原理,但它读起来像一本小说。
+
+书后面的一张表展示了不同公司部署在发布环境上的频率:
+
+公司 | 部署频率
+---|---
+Amazon | 23,000 次/天
+Google | 5,500 次/天
+Netflix | 500 次/天
+Facebook | 1 次/天
+Twitter | 3 次/周
+典型企业 | 1 次/9 个月
+
+Amazon、Google、Netflix 怎么能做到如此之频繁?那是因为这些公司弄清楚了如何去实现一个近乎完美的 DevOps 流水线。
+
+但在花旗实施 DevOps 之前,情况并非如此。那时候,我的团队拥有不同构建阶段的环境,但是在开发服务器上的部署非常手工。所有的开发人员都只能访问一个基于 IBM WebSphere Application 社区版的开发环境服务器。问题是当多个用户同时尝试部署时,服务器就会宕机,因此开发人员在部署时就得互相通知,这一点相当痛苦。此外,还存在代码测试覆盖率低、手动部署过程繁琐以及无法根据定义的任务或用户需求跟踪代码部署的问题。
+
+我意识到必须做些事情,同时也找到了一个有同样感受的同事。我们决定合作去构建一个初始的 DevOps 流水线 —— 他设置了一个虚拟机和一个 Tomcat 服务器,而我则架设了 Jenkins,集成了 Atlassian Jira、BitBucket 和代码覆盖率测试。这个业余项目非常成功:我们近乎全自动化了开发流水线,并在开发服务器上实现了几乎 100% 的正常运行,我们可以追踪并改进代码覆盖率测试,并且 Git 分支能够与部署任务和 jira 任务关联在一起。此外,大多数用来构建 DevOps 所使用的工具都是开源的。
+
+现在我意识到了我们的 DevOps 流水线是多么的原始,因为我们没有利用像 Jenkins 文件或 Ansible 这样的高级设置。然而,这个简单的过程运作良好,这也许是因为 [Pareto][3] 原则(也被称作 80/20 法则)。
+
+### DevOps 和 CI/CD 流水线的简要介绍
+
+如果你问一些人,“什么是 DevOps?”,你或许会得到一些不同的回答。DevOps,就像敏捷,已经发展到涵盖着诸多不同的学科,但大多数人至少会同意这些:DevOps 是一个软件开发实践或一个软件开发生命周期(SDLC),并且它的核心原则是一种文化上的变革 —— 开发人员与非开发人员呼吸着同一片天空的气息,之前手工的事情变得自动化;每个人做着自己擅长的事;同一时间的部署变得更加频繁;吞吐量提升;灵活度增加。
+
+虽然拥有正确的软件工具并非实现 DevOps 环境所需的唯一东西,但一些工具却是必要的。最关键的一个便是持续集成和持续部署(CI/CD)。在流水线环境中,拥有不同的构建阶段(例如:DEV、INT、TST、QA、UAT、STG、PROD),手动的工作能实现自动化,开发人员可以实现高质量的代码,灵活而且大量部署。
+
+这篇文章描述了一个构建 DevOps 流水线的五步方法,就像下图所展示的那样,使用开源的工具实现。
+
+![Complete DevOps pipeline][4]
+
+闲话少说,让我们开始吧。
+
+### 第一步:CI/CD 框架
+
+首先你需要的是一个 CI/CD 工具,Jenkins,是一个基于 Java 的 MIT 许可下的开源 CI/CD 工具,它是推广 DevOps 运动的工具,并已成为了事实标准。
+
+所以,什么是 Jenkins?想象它是一种神奇的万能遥控,能够和许多不同的服务器和工具打交道,并且能够将它们统一安排起来。就本身而言,像 Jenkins 这样的 CI/CD 工具本身是没有用的,但随着接入不同的工具与服务器时会变得非常强大。
+
+Jenkins 仅是众多构建 DevOps 流水线的开源 CI/CD 工具之一。
+
+名称 | 许可证
+---|---
+[Jenkins][5] | Creative Commons 和 MIT
+[Travis CI][6] | MIT
+[CruiseControl][7] | BSD
+[Buildbot][8] | GPL
+[Apache Gump][9] | Apache 2.0
+[Cabie][10] | GNU
+
+下面就是使用 CI/CD 工具时 DevOps 看起来的样子。
+
+![CI/CD tool][11]
+
+你的 CI/CD 工具在本地主机上运行,但目前你还不能够做些别的。让我们紧随 DevOps 之旅的脚步。
+
+### 第二步:源代码控制管理
+
+验证 CI/CD 工具可以执行某些魔术的最佳(也可能是最简单)方法是与源代码控制管理(SCM)工具集成。为什么需要源代码控制?假设你在开发一个应用。无论你什么时候构建应用,无论你使用的是 Java、Python、C++、Go、Ruby、JavaScript 或任意一种语言,你都在编程。你所编写的程序代码称为源代码。在一开始,特别是只有你一个人工作时,将所有的东西放进本地文件夹里或许都是可以的。但是当项目变得庞大并且邀请其他人协作后,你就需要一种方式来避免共享代码修改时的合并冲突。你也需要一种方式来恢复一个之前的版本——备份、复制并粘贴的方式已经过时了。你(和你的团队)想要更好的解决方式。
+
+这就是 SCM 变得不可或缺的原因。SCM 工具通过在仓库中保存代码来帮助进行版本控制与多人协作。
+
+尽管这里有许多 SCM 工具,但 Git 是最标准恰当的。我极力推荐使用 Git,但如果你喜欢这里仍有其他的开源工具。
+
+名称 | 许可证
+---|---
+[Git][12] | GPLv2 & LGPL v2.1
+[Subversion][13] | Apache 2.0
+[Concurrent Versions System][14] (CVS) | GNU
+[Vesta][15] | LGPL
+[Mercurial][16] | GNU GPL v2+
+
+拥有 SCM 之后,DevOps 流水线看起来就像这样。
+
+![Source control management][17]
+
+CI/CD 工具能够自动化进行源代码检入检出以及完成成员之间的协作。还不错吧?但是,如何才能把它变成可工作的应用程序,使得数十亿人来使用并欣赏它呢?
+
+### 第三步:自动化构建工具
+
+真棒!现在你可以检出代码并将修改提交到源代码控制,并且可以邀请你的朋友就源代码控制进行协作。但是到目前为止你还没有构建出应用。要想让它成为一个网页应用,必须将其编译并打包成可部署的包或可执行程序(注意,像 JavaScript 或 PHP 这样的解释型编程语言不需要进行编译)。
+
+于是就引出了自动化构建工具。无论你决定使用哪一款构建工具,它们都有一个共同的目标:将源代码构建成某种想要的格式,并且将清理、编译、测试、部署到某个位置这些任务自动化。构建工具会根据你的编程语言而有不同,但这里有一些通常使用的开源工具值得考虑。
+
+名称 | 许可证 | 编程语言
+---|---|---
+[Maven][18] | Apache 2.0 | Java
+[Ant][19] | Apache 2.0 | Java
+[Gradle][20] | Apache 2.0 | Java
+[Bazel][21] | Apache 2.0 | Java
+[Make][22] | GNU | N/A
+[Grunt][23] | MIT | JavaScript
+[Gulp][24] | MIT | JavaScript
+[Buildr][25] | Apache | Ruby
+[Rake][26] | MIT | Ruby
+[A-A-P][27] | GNU | Python
+[SCons][28] | MIT | Python
+[BitBake][29] | GPLv2 | Python
+[Cake][30] | MIT | C#
+[ASDF][31] | Expat (MIT) | LISP
+[Cabal][32] | BSD | Haskell
+
+太棒了!现在你可以将自动化构建工具的配置文件放进源代码控制管理系统中,并让你的 CI/CD 工具构建它。
+
+![Build automation tool][33]
+
+一切都如此美好,对吧?但是在哪里部署它呢?
+
+### 第四步:网页应用服务器
+
+到目前为止,你有了一个可执行或可部署的打包文件。对任何真正有用的应用程序来说,它必须提供某种服务或者接口,所以你需要一个容器来发布你的应用。
+
+对于网页应用,网页应用服务器就是容器。应用程序服务器提供了环境,让可部署包中的编程逻辑能够被检测到、呈现界面,并通过打开套接字为外部世界提供网页服务。在其他环境下你也需要一个 HTTP 服务器(比如虚拟机)来安装服务应用。现在,我假设你将会自己学习这些东西(尽管我会在下面讨论容器)。
+
+这里有许多开源的网页应用服务器。
+
+名称 | 协议 | 编程语言
+---|---|---
+[Tomcat][34] | Apache 2.0 | Java
+[Jetty][35] | Apache 2.0 | Java
+[WildFly][36] | GNU Lesser Public | Java
+[GlassFish][37] | CDDL & GNU Less Public | Java
+[Django][38] | 3-Clause BSD | Python
+[Tornado][39] | Apache 2.0 | Python
+[Gunicorn][40] | MIT | Python
+[Python Paste][41] | MIT | Python
+[Rails][42] | MIT | Ruby
+[Node.js][43] | MIT | Javascript
+
+现在 DevOps 流水线差不多能用了,干得好!
+
+![Web application server][44]
+
+尽管你可以在这里停下来并进行进一步的集成,但是代码质量对于应用开发者来说是一件非常重要的事情。
+
+### 第五步:代码覆盖测试
+
+实现代码测试件可能是另一个麻烦的需求,但是开发者需要尽早地捕捉程序中的所有错误并提升代码质量来保证最终用户满意度。幸运的是,这里有许多开源工具来测试你的代码并提出改善质量的建议。甚至更好的,大部分 CI/CD 工具能够集成这些工具并将测试过程自动化进行。
+
+代码测试分为两个部分:“代码测试框架”帮助进行编写与运行测试,“代码质量改进工具”帮助提升代码的质量。
+
+#### 代码测试框架
+
+名称 | 许可证 | 编程语言
+---|---|---
+[JUnit][45] | Eclipse Public License | Java
+[EasyMock][46] | Apache | Java
+[Mockito][47] | MIT | Java
+[PowerMock][48] | Apache 2.0 | Java
+[Pytest][49] | MIT | Python
+[Hypothesis][50] | Mozilla | Python
+[Tox][51] | MIT | Python
+
+#### 代码质量改进工具
+
+名称 | 许可证 | 编程语言
+---|---|---
+[Cobertura][52] | GNU | Java
+[CodeCover][53] | Eclipse Public (EPL) | Java
+[Coverage.py][54] | Apache 2.0 | Python
+[Emma][55] | Common Public License | Java
+[JaCoCo][56] | Eclipse Public License | Java
+[Hypothesis][50] | Mozilla | Python
+[Tox][51] | MIT | Python
+[Jasmine][57] | MIT | JavaScript
+[Karma][58] | MIT | JavaScript
+[Mocha][59] | MIT | JavaScript
+[Jest][60] | MIT | JavaScript
+
+注意,之前提到的大多数工具和框架都是为 Java、Python、JavaScript 写的,因为 C++ 和 C# 是专有编程语言(尽管 GCC 是开源的)。
+
+现在你已经运用了代码覆盖测试工具,你的 DevOps 流水线应该就像教程开始那幅图中展示的那样了。
+
+### 可选步骤
+
+#### 容器
+
+正如我之前所说,你可以在虚拟机(VM)或服务器上发布你的应用,但是容器是一个更好的解决方法。
+
+[什么是容器][61]?简要的介绍就是 VM 需要占用操作系统大量的资源,它提升了应用程序的大小,而容器仅仅需要一些库和配置来运行应用程序。显然,VM 仍有重要的用途,但容器对于发布应用(包括应用程序服务器)来说是一个更为轻量的解决方式。
+
+尽管对于容器来说也有其他的选择,但是 Docker 和 Kubernetes 更为广泛。
+
+名称 | 许可证
+---|---
+[Docker][62] | Apache 2.0
+[Kubernetes][63] | Apache 2.0
+
+了解更多信息,请查看 [Opensource.com][64] 上关于 Docker 和 Kubernetes 的其它文章:
+
+ * [什么是 Docker?][65]
+ * [Docker 简介][66]
+ * [什么是 Kubernetes?][67]
+ * [从零开始的 Kubernetes 实践][68]
+
+#### 中间件自动化工具
+
+我们的 DevOps 流水线大部分集中在协作构建与部署应用上,但你也可以用 DevOps 工具完成许多其他的事情。其中之一便是利用它实现基础设施管理(IaC)工具,这也是熟知的中间件自动化工具。这些工具帮助完成中间件的自动化安装、管理和其他任务。例如,自动化工具可以用正确的配置下拉应用程序,例如网页服务器、数据库和监控工具,并且部署它们到应用服务器上。
+
+这里有几个开源的中间件自动化工具值得考虑:
+
+名称 | 许可证
+---|---
+[Ansible][69] | GNU Public
+[SaltStack][70] | Apache 2.0
+[Chef][71] | Apache 2.0
+[Puppet][72] | Apache or GPL
+
+获取更多中间件自动化工具,查看 [Opensource.com][64] 上的其它文章:
+
+ * [Ansible 快速入门指南][73]
+ * [Ansible 自动化部署策略][74]
+ * [配置管理工具 Top 5][75]
+
+### 之后的发展
+
+这只是一个完整 DevOps 流水线的冰山一角。从 CI/CD 工具开始并且探索其他可以自动化的东西来使你的团队更加轻松的工作。并且,寻找[开源通讯工具][76]可以帮助你的团队一起工作的更好。
+
+发现更多见解,这里有一些非常棒的文章来介绍 DevOps :
+
+ * [什么是 DevOps][77]
+ * [掌握 5 件事成为 DevOps 工程师][78]
+ * [所有人的 DevOps][79]
+ * [在 DevOps 中开始使用预测分析][80]
+
+使用开源 agile 工具来集成 DevOps 也是一个很好的主意:
+
+ * [什么是 agile ?][81]
+ * [4 步成为一个了不起的 agile 开发者][82]
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/4/devops-pipeline
+
+作者:[Bryant Son][a]
+选题:[lujun9972][b]
+译者:[LuMing](https://github.com/LuuMing)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/brson/users/milindsingh/users/milindsingh/users/dscripter
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/network_team_career_hand.png?itok=_ztl2lk_ (Shaking hands, networking)
+[2]: https://www.amazon.com/dp/B078Y98RG8/
+[3]: https://en.wikipedia.org/wiki/Pareto_principle
+[4]: https://opensource.com/sites/default/files/uploads/1_finaldevopspipeline.jpg (Complete DevOps pipeline)
+[5]: https://github.com/jenkinsci/jenkins
+[6]: https://github.com/travis-ci/travis-ci
+[7]: http://cruisecontrol.sourceforge.net
+[8]: https://github.com/buildbot/buildbot
+[9]: https://gump.apache.org
+[10]: http://cabie.tigris.org
+[11]: https://opensource.com/sites/default/files/uploads/2_runningjenkins.jpg (CI/CD tool)
+[12]: https://git-scm.com
+[13]: https://subversion.apache.org
+[14]: http://savannah.nongnu.org/projects/cvs
+[15]: http://www.vestasys.org
+[16]: https://www.mercurial-scm.org
+[17]: https://opensource.com/sites/default/files/uploads/3_sourcecontrolmanagement.jpg (Source control management)
+[18]: https://maven.apache.org
+[19]: https://ant.apache.org
+[20]: https://gradle.org/
+[21]: https://bazel.build
+[22]: https://www.gnu.org/software/make
+[23]: https://gruntjs.com
+[24]: https://gulpjs.com
+[25]: http://buildr.apache.org
+[26]: https://github.com/ruby/rake
+[27]: http://www.a-a-p.org
+[28]: https://www.scons.org
+[29]: https://www.yoctoproject.org/software-item/bitbake
+[30]: https://github.com/cake-build/cake
+[31]: https://common-lisp.net/project/asdf
+[32]: https://www.haskell.org/cabal
+[33]: https://opensource.com/sites/default/files/uploads/4_buildtools.jpg (Build automation tool)
+[34]: https://tomcat.apache.org
+[35]: https://www.eclipse.org/jetty/
+[36]: http://wildfly.org
+[37]: https://javaee.github.io/glassfish
+[38]: https://www.djangoproject.com/
+[39]: http://www.tornadoweb.org/en/stable
+[40]: https://gunicorn.org
+[41]: https://github.com/cdent/paste
+[42]: https://rubyonrails.org
+[43]: https://nodejs.org/en
+[44]: https://opensource.com/sites/default/files/uploads/5_applicationserver.jpg (Web application server)
+[45]: https://junit.org/junit5
+[46]: http://easymock.org
+[47]: https://site.mockito.org
+[48]: https://github.com/powermock/powermock
+[49]: https://docs.pytest.org
+[50]: https://hypothesis.works
+[51]: https://github.com/tox-dev/tox
+[52]: http://cobertura.github.io/cobertura
+[53]: http://codecover.org/
+[54]: https://github.com/nedbat/coveragepy
+[55]: http://emma.sourceforge.net
+[56]: https://github.com/jacoco/jacoco
+[57]: https://jasmine.github.io
+[58]: https://github.com/karma-runner/karma
+[59]: https://github.com/mochajs/mocha
+[60]: https://jestjs.io
+[61]: /resources/what-are-linux-containers
+[62]: https://www.docker.com
+[63]: https://kubernetes.io
+[64]: http://Opensource.com
+[65]: https://opensource.com/resources/what-docker
+[66]: https://opensource.com/business/15/1/introduction-docker
+[67]: https://opensource.com/resources/what-is-kubernetes
+[68]: https://opensource.com/article/17/11/kubernetes-lightning-talk
+[69]: https://www.ansible.com
+[70]: https://www.saltstack.com
+[71]: https://www.chef.io
+[72]: https://puppet.com
+[73]: https://opensource.com/article/19/2/quickstart-guide-ansible
+[74]: https://opensource.com/article/19/1/automating-deployment-strategies-ansible
+[75]: https://opensource.com/article/18/12/configuration-management-tools
+[76]: https://opensource.com/alternatives/slack
+[77]: https://opensource.com/resources/devops
+[78]: https://opensource.com/article/19/2/master-devops-engineer
+[79]: https://opensource.com/article/18/11/how-non-engineer-got-devops
+[80]: https://opensource.com/article/19/1/getting-started-predictive-analytics-devops
+[81]: https://opensource.com/article/18/10/what-agile
+[82]: https://opensource.com/article/19/2/steps-agile-developer
diff --git a/published/20190524 Spell Checking Comments.md b/published/20190524 Spell Checking Comments.md
new file mode 100644
index 0000000000..d48358c2a9
--- /dev/null
+++ b/published/20190524 Spell Checking Comments.md
@@ -0,0 +1,40 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11294-1.html)
+[#]: subject: (Spell Checking Comments)
+[#]: via: (https://emacsredux.com/blog/2019/05/24/spell-checking-comments/)
+[#]: author: (Bozhidar Batsov https://emacsredux.com)
+
+Emacs 注释中的拼写检查
+======
+
+我出了名的容易拼错单词(特别是在播客当中)。谢天谢地 Emacs 内置了一个名为 `flyspell` 的超棒模式来帮助像我这样的可怜的打字员。flyspell 会在你输入时突出显示拼错的单词 (也就是实时的) 并提供有用的快捷键来快速修复该错误。
+
+大多输入通常会对派生自 `text-mode`(比如 `markdown-mode`,`adoc-mode` )的主模式启用 `flyspell`,但是它对程序员也有所帮助,可以指出他在注释中的错误。所需要的只是启用 `flyspell-prog-mode`。我通常在所有的编程模式中(至少在 `prog-mode` 派生的模式中)都启用它:
+
+```
+(add-hook 'prog-mode-hook #'flyspell-prog-mode)
+```
+
+现在当你在注释中输入错误时,就会得到即时反馈了。要修复单词只需要将光标置于单词后,然后按下 `C-c $` (`M-x flyspell-correct-word-before-point`)。(还有许多其他方法可以用 `flyspell` 来纠正拼写错误的单词,但为了简单起见,我们暂时忽略它们。)
+
+![flyspell_prog_mode.gif][1]
+
+今天的分享就到这里!我要继续修正这些讨厌的拼写错误了!
+
+--------------------------------------------------------------------------------
+
+via: https://emacsredux.com/blog/2019/05/24/spell-checking-comments/
+
+作者:[Bozhidar Batsov][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://emacsredux.com
+[b]: https://github.com/lujun9972
+[1]: https://emacsredux.com/assets/images/flyspell_prog_mode.gif
diff --git a/published/20190701 Get modular with Python functions.md b/published/20190701 Get modular with Python functions.md
new file mode 100644
index 0000000000..37124c8e2b
--- /dev/null
+++ b/published/20190701 Get modular with Python functions.md
@@ -0,0 +1,322 @@
+[#]: collector: (lujun9972)
+[#]: translator: (MjSeven)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11295-1.html)
+[#]: subject: (Get modular with Python functions)
+[#]: via: (https://opensource.com/article/19/7/get-modular-python-functions)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth/users/xd-deng/users/nhuntwalker/users/don-watkins)
+
+使用 Python 函数进行模块化
+======
+
+> 使用 Python 函数来最大程度地减少重复任务编码工作量。
+
+
+
+你是否对函数、类、方法、库和模块等花哨的编程术语感到困惑?你是否在与变量作用域斗争?无论你是自学成才的还是经过正式培训的程序员,代码的模块化都会令人困惑。但是类和库鼓励模块化代码,因为模块化代码意味着只需构建一个多用途代码块集合,就可以在许多项目中使用它们来减少编码工作量。换句话说,如果你按照本文对 [Python][2] 函数的研究,你将找到更聪明的工作方法,这意味着更少的工作。
+
+本文假定你对 Python 很熟(LCTT 译注:稍微熟悉就可以),并且可以编写和运行一个简单的脚本。如果你还没有使用过 Python,请首先阅读我的文章:[Python 简介][3]。
+
+### 函数
+
+函数是迈向模块化过程中重要的一步,因为它们是形式化的重复方法。如果在你的程序中,有一个任务需要反复执行,那么你可以将代码放入一个函数中,根据需要随时调用该函数。这样,你只需编写一次代码,就可以随意使用它。
+
+以下一个简单函数的示例:
+
+```
+#!/usr/bin/env python3
+import time
+
+def Timer():
+ print("Time is " + str(time.time() ))
+```
+
+创建一个名为 `mymodularity` 的目录,并将以上函数代码保存为该目录下的 `timestamp.py`。
+
+除了这个函数,在 `mymodularity` 目录中创建一个名为 `__init__.py` 的文件,你可以在文件管理器或 bash shell 中执行此操作:
+
+```
+$ touch mymodularity/__init__.py
+```
+
+现在,你已经创建了属于你自己的 Python 库(Python 中称为“模块”),名为 `mymodularity`。它不是一个特别有用的模块,因为它所做的只是导入 `time` 模块并打印一个时间戳,但这只是一个开始。
+
+要使用你的函数,像对待任何其他 Python 模块一样对待它。以下是一个小应用,它使用你的 `mymodularity` 软件包来测试 Python `sleep()` 函数的准确性。将此文件保存为 `sleeptest.py`,注意要在 `mymodularity` 文件夹 *之外*,因为如果你将它保存在 `mymodularity` *里面*,那么它将成为你的包中的一个模块,你肯定不希望这样。
+
+```
+#!/usr/bin/env python3
+
+import time
+from mymodularity import timestamp
+
+print("Testing Python sleep()...")
+
+# modularity
+timestamp.Timer()
+time.sleep(3)
+timestamp.Timer()
+```
+
+在这个简单的脚本中,你从 `mymodularity` 包中调用 `timestamp` 模块两次。从包中导入模块时,通常的语法是从包中导入你所需的模块,然后使用 *模块名称 + 一个点 + 要调用的函数名*(例如 `timestamp.Timer()`)。
+
+你调用了两次 `Timer()` 函数,所以如果你的 `timestamp` 模块比这个简单的例子复杂些,那么你将节省大量重复代码。
+
+保存文件并运行:
+
+```
+$ python3 ./sleeptest.py
+Testing Python sleep()...
+Time is 1560711266.1526039
+Time is 1560711269.1557732
+```
+
+根据测试,Python 中的 `sleep` 函数非常准确:在三秒钟等待之后,时间戳成功且正确地增加了 3,在微秒单位上差距很小。
+
+Python 库的结构看起来可能令人困惑,但其实它并不是什么魔法。Python *被编程* 为一个包含 Python 代码的目录,并附带一个 `__init__.py` 文件,那么这个目录就会被当作一个包,并且 Python 会首先在当前目录中查找可用模块。这就是为什么语句 `from mymodularity import timestamp` 有效的原因:Python 在当前目录查找名为 `mymodularity` 的目录,然后查找 `timestamp.py` 文件。
+
+你在这个例子中所做的功能和以下这个非模块化的版本是一样的:
+
+```
+#!/usr/bin/env python3
+
+import time
+from mymodularity import timestamp
+
+print("Testing Python sleep()...")
+
+# no modularity
+print("Time is " + str(time.time() ) )
+time.sleep(3)
+print("Time is " + str(time.time() ) )
+```
+
+对于这样一个简单的例子,其实没有必要以这种方式编写测试,但是对于编写自己的模块来说,最佳实践是你的代码是通用的,可以将它重用于其他项目。
+
+通过在调用函数时传递信息,可以使代码更通用。例如,假设你想要使用模块来测试的不是 *系统* 的 `sleep` 函数,而是 *用户自己实现* 的 `sleep` 函数,更改 `timestamp` 代码,使它接受一个名为 `msg` 的传入变量,它将是一个字符串,控制每次调用 `timestamp` 时如何显示:
+
+```
+#!/usr/bin/env python3
+
+import time
+
+# 更新代码
+def Timer(msg):
+ print(str(msg) + str(time.time() ) )
+```
+
+现在函数比以前更抽象了。它仍会打印时间戳,但是它为用户打印的内容 `msg` 还是未定义的。这意味着你需要在调用函数时定义它。
+
+`Timer` 函数接受的 `msg` 参数是随便命名的,你可以使用参数 `m`、`message` 或 `text`,或是任何对你来说有意义的名称。重要的是,当调用 `timestamp.Timer` 函数时,它接收一个文本作为其输入,将接收到的任何内容放入 `msg` 变量中,并使用该变量完成任务。
+
+以下是一个测试测试用户正确感知时间流逝能力的新程序:
+
+```
+#!/usr/bin/env python3
+
+from mymodularity import timestamp
+
+print("Press the RETURN key. Count to 3, and press RETURN again.")
+
+input()
+timestamp.Timer("Started timer at ")
+
+print("Count to 3...")
+
+input()
+timestamp.Timer("You slept until ")
+```
+
+将你的新程序保存为 `response.py`,运行它:
+
+```
+$ python3 ./response.py
+Press the RETURN key. Count to 3, and press RETURN again.
+
+Started timer at 1560714482.3772075
+Count to 3...
+
+You slept until 1560714484.1628013
+```
+
+### 函数和所需参数
+
+新版本的 `timestamp` 模块现在 *需要* 一个 `msg` 参数。这很重要,因为你的第一个应用程序将无法运行,因为它没有将字符串传递给 `timestamp.Timer` 函数:
+
+```
+$ python3 ./sleeptest.py
+Testing Python sleep()...
+Traceback (most recent call last):
+ File "./sleeptest.py", line 8, in <module>
+ timestamp.Timer()
+TypeError: Timer() missing 1 required positional argument: 'msg'
+```
+
+你能修复你的 `sleeptest.py` 应用程序,以便它能够与更新后的模块一起正确运行吗?
+
+### 变量和函数
+
+通过设计,函数限制了变量的范围。换句话说,如果在函数内创建一个变量,那么这个变量 *只* 在这个函数内起作用。如果你尝试在函数外部使用函数内部出现的变量,就会发生错误。
+
+下面是对 `response.py` 应用程序的修改,尝试从 `timestamp.Timer()` 函数外部打印 `msg` 变量:
+
+```
+#!/usr/bin/env python3
+
+from mymodularity import timestamp
+
+print("Press the RETURN key. Count to 3, and press RETURN again.")
+
+input()
+timestamp.Timer("Started timer at ")
+
+print("Count to 3...")
+
+input()
+timestamp.Timer("You slept for ")
+
+print(msg)
+```
+
+试着运行它,查看错误:
+
+```
+$ python3 ./response.py
+Press the RETURN key. Count to 3, and press RETURN again.
+
+Started timer at 1560719527.7862902
+Count to 3...
+
+You slept for 1560719528.135406
+Traceback (most recent call last):
+ File "./response.py", line 15, in <module>
+ print(msg)
+NameError: name 'msg' is not defined
+```
+
+应用程序返回一个 `NameError` 消息,因为没有定义 `msg`。这看起来令人困惑,因为你编写的代码定义了 `msg`,但你对代码的了解比 Python 更深入。调用函数的代码,不管函数是出现在同一个文件中,还是打包为模块,都不知道函数内部发生了什么。一个函数独立地执行它的计算,并返回你想要它返回的内容。这其中所涉及的任何变量都只是 *本地的*:它们只存在于函数中,并且只存在于函数完成其目的所需时间内。
+
+#### Return 语句
+
+如果你的应用程序需要函数中特定包含的信息,那么使用 `return` 语句让函数在运行后返回有意义的数据。
+
+时间就是金钱,所以修改 `timestamp` 函数,以使其用于一个虚构的收费系统:
+
+```
+#!/usr/bin/env python3
+
+import time
+
+def Timer(msg):
+ print(str(msg) + str(time.time() ) )
+ charge = .02
+ return charge
+```
+
+现在,`timestamp` 模块每次调用都收费 2 美分,但最重要的是,它返回每次调用时所收取的金额。
+
+以下一个如何使用 `return` 语句的演示:
+
+```
+#!/usr/bin/env python3
+
+from mymodularity import timestamp
+
+print("Press RETURN for the time (costs 2 cents).")
+print("Press Q RETURN to quit.")
+
+total = 0
+
+while True:
+ kbd = input()
+ if kbd.lower() == "q":
+ print("You owe $" + str(total) )
+ exit()
+ else:
+ charge = timestamp.Timer("Time is ")
+ total = total+charge
+```
+
+在这个示例代码中,变量 `charge` 为 `timestamp.Timer()` 函数的返回,它接收函数返回的任何内容。在本例中,函数返回一个数字,因此使用一个名为 `total` 的新变量来跟踪已经进行了多少更改。当应用程序收到要退出的信号时,它会打印总花费:
+
+```
+$ python3 ./charge.py
+Press RETURN for the time (costs 2 cents).
+Press Q RETURN to quit.
+
+Time is 1560722430.345412
+
+Time is 1560722430.933996
+
+Time is 1560722434.6027434
+
+Time is 1560722438.612629
+
+Time is 1560722439.3649364
+q
+You owe $0.1
+```
+
+#### 内联函数
+
+函数不必在单独的文件中创建。如果你只是针对一个任务编写一个简短的脚本,那么在同一个文件中编写函数可能更有意义。唯一的区别是你不必导入自己的模块,但函数的工作方式是一样的。以下是时间测试应用程序的最新迭代:
+
+```
+#!/usr/bin/env python3
+
+import time
+
+total = 0
+
+def Timer(msg):
+ print(str(msg) + str(time.time() ) )
+ charge = .02
+ return charge
+
+print("Press RETURN for the time (costs 2 cents).")
+print("Press Q RETURN to quit.")
+
+while True:
+ kbd = input()
+ if kbd.lower() == "q":
+ print("You owe $" + str(total) )
+ exit()
+ else:
+ charge = Timer("Time is ")
+ total = total+charge
+```
+
+它没有外部依赖(Python 发行版中包含 `time` 模块),产生与模块化版本相同的结果。它的优点是一切都位于一个文件中,缺点是你不能在其他脚本中使用 `Timer()` 函数,除非你手动复制和粘贴它。
+
+#### 全局变量
+
+在函数外部创建的变量没有限制作用域,因此它被视为 *全局* 变量。
+
+全局变量的一个例子是在 `charge.py` 中用于跟踪当前花费的 `total` 变量。`total` 是在函数之外创建的,因此它绑定到应用程序而不是特定函数。
+
+应用程序中的函数可以访问全局变量,但要将变量传入导入的模块,你必须像发送 `msg` 变量一样将变量传入模块。
+
+全局变量很方便,因为它们似乎随时随地都可用,但也很难跟踪它们,很难知道哪些变量不再需要了但是仍然在系统内存中停留(尽管 Python 有非常好的垃圾收集机制)。
+
+但是,全局变量很重要,因为不是所有的变量都可以是函数或类的本地变量。现在你知道了如何向函数传入变量并获得返回,事情就变得容易了。
+
+### 总结
+
+你已经学到了很多关于函数的知识,所以开始将它们放入你的脚本中 —— 如果它不是作为单独的模块,那么作为代码块,你不必在一个脚本中编写多次。在本系列的下一篇文章中,我将介绍 Python 类。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/get-modular-python-functions
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth/users/xd-deng/users/nhuntwalker/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/openstack_python_vim_1.jpg?itok=lHQK5zpm
+[2]: https://www.python.org/
+[3]: https://opensource.com/article/17/10/python-10
diff --git a/published/20190705 Learn object-oriented programming with Python.md b/published/20190705 Learn object-oriented programming with Python.md
new file mode 100644
index 0000000000..1d2767d601
--- /dev/null
+++ b/published/20190705 Learn object-oriented programming with Python.md
@@ -0,0 +1,305 @@
+[#]: collector: (lujun9972)
+[#]: translator: (MjSeven)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11317-1.html)
+[#]: subject: (Learn object-oriented programming with Python)
+[#]: via: (https://opensource.com/article/19/7/get-modular-python-classes)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+使用 Python 学习面对对象的编程
+======
+
+> 使用 Python 类使你的代码变得更加模块化。
+
+
+
+在我上一篇文章中,我解释了如何通过使用函数、创建模块或者两者一起来[使 Python 代码更加模块化][2]。函数对于避免重复多次使用的代码非常有用,而模块可以确保你在不同的项目中复用代码。但是模块化还有另一种方法:类。
+
+如果你已经听过面对对象编程(OOP)这个术语,那么你可能会对类的用途有一些概念。程序员倾向于将类视为一个虚拟对象,有时与物理世界中的某些东西直接相关,有时则作为某种编程概念的表现形式。无论哪种表示,当你想要在程序中为你或程序的其他部分创建“对象”时,你都可以创建一个类来交互。
+
+### 没有类的模板
+
+假设你正在编写一个以幻想世界为背景的游戏,并且你需要这个应用程序能够涌现出各种坏蛋来给玩家的生活带来一些刺激。了解了很多关于函数的知识后,你可能会认为这听起来像是函数的一个教科书案例:需要经常重复的代码,但是在调用时可以考虑变量而只编写一次。
+
+下面一个纯粹基于函数的敌人生成器实现的例子:
+
+```
+#!/usr/bin/env python3
+
+import random
+
+def enemy(ancestry,gear):
+ enemy=ancestry
+ weapon=gear
+ hp=random.randrange(0,20)
+ ac=random.randrange(0,20)
+ return [enemy,weapon,hp,ac]
+
+def fight(tgt):
+ print("You take a swing at the " + tgt[0] + ".")
+ hit=random.randrange(0,20)
+ if hit > tgt[3]:
+ print("You hit the " + tgt[0] + " for " + str(hit) + " damage!")
+ tgt[2] = tgt[2] - hit
+ else:
+ print("You missed.")
+
+
+foe=enemy("troll","great axe")
+print("You meet a " + foe[0] + " wielding a " + foe[1])
+print("Type the a key and then RETURN to attack.")
+
+while True:
+ action=input()
+
+ if action.lower() == "a":
+ fight(foe)
+
+ if foe[2] < 1:
+ print("You killed your foe!")
+ else:
+ print("The " + foe[0] + " has " + str(foe[2]) + " HP remaining")
+```
+
+`enemy` 函数创造了一个具有多个属性的敌人,例如谱系、武器、生命值和防御等级。它返回每个属性的列表,表示敌人全部特征。
+
+从某种意义上说,这段代码创建了一个对象,即使它还没有使用类。程序员将这个 `enemy` 称为*对象*,因为该函数的结果(本例中是一个包含字符串和整数的列表)表示游戏中一个单独但复杂的*东西*。也就是说,列表中字符串和整数不是任意的:它们一起描述了一个虚拟对象。
+
+在编写描述符集合时,你可以使用变量,以便随时使用它们来生成敌人。这有点像模板。
+
+在示例代码中,当需要对象的属性时,会检索相应的列表项。例如,要获取敌人的谱系,代码会查询 `foe[0]`,对于生命值,会查询 `foe[2]`,以此类推。
+
+这种方法没有什么不妥,代码按预期运行。你可以添加更多不同类型的敌人,创建一个敌人类型列表,并在敌人创建期间从列表中随机选择,等等,它工作得很好。实际上,[Lua][3] 非常有效地利用这个原理来近似了一个面对对象模型。
+
+然而,有时候对象不仅仅是属性列表。
+
+### 使用对象
+
+在 Python 中,一切都是对象。你在 Python 中创建的任何东西都是某个预定义模板的*实例*。甚至基本的字符串和整数都是 Python `type` 类的衍生物。你可以在这个交互式 Python shell 中见证:
+
+```
+>>> foo=3
+>>> type(foo)
+
+>>> foo="bar"
+>>> type(foo)
+
+```
+
+当一个对象由一个类定义时,它不仅仅是一个属性的集合,Python 类具有各自的函数。从逻辑上讲,这很方便,因为只涉及某个对象类的操作包含在该对象的类中。
+
+在示例代码中,`fight` 的代码是主应用程序的功能。这对于一个简单的游戏来说是可行的,但对于一个复杂的游戏来说,世界中不仅仅有玩家和敌人,还可能有城镇居民、牲畜、建筑物、森林等等,它们都不需要使用战斗功能。将战斗代码放在敌人的类中意味着你的代码更有条理,在一个复杂的应用程序中,这是一个重要的优势。
+
+此外,每个类都有特权访问自己的本地变量。例如,敌人的生命值,除了某些功能之外,是不会改变的数据。游戏中的随机蝴蝶不应该意外地将敌人的生命值降低到 0。理想情况下,即使没有类,也不会发生这种情况。但是在具有大量活动部件的复杂应用程序中,确保不需要相互交互的部件永远不会发生这种情况,这是一个非常有用的技巧。
+
+Python 类也受垃圾收集的影响。当不再使用类的实例时,它将被移出内存。你可能永远不知道这种情况会什么时候发生,但是你往往知道什么时候它不会发生,因为你的应用程序占用了更多的内存,而且运行速度比较慢。将数据集隔离到类中可以帮助 Python 跟踪哪些数据正在使用,哪些不在需要了。
+
+### 优雅的 Python
+
+下面是一个同样简单的战斗游戏,使用了 `Enemy` 类:
+
+```
+#!/usr/bin/env python3
+
+import random
+
+class Enemy():
+ def __init__(self,ancestry,gear):
+ self.enemy=ancestry
+ self.weapon=gear
+ self.hp=random.randrange(10,20)
+ self.ac=random.randrange(12,20)
+ self.alive=True
+
+ def fight(self,tgt):
+ print("You take a swing at the " + self.enemy + ".")
+ hit=random.randrange(0,20)
+
+ if self.alive and hit > self.ac:
+ print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
+ self.hp = self.hp - hit
+ print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
+ else:
+ print("You missed.")
+
+ if self.hp < 1:
+ self.alive=False
+
+# 游戏开始
+foe=Enemy("troll","great axe")
+print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
+
+# 主函数循环
+while True:
+
+ print("Type the a key and then RETURN to attack.")
+
+ action=input()
+
+ if action.lower() == "a":
+ foe.fight(foe)
+
+ if foe.alive == False:
+ print("You have won...this time.")
+ exit()
+```
+
+这个版本的游戏将敌人作为一个包含相同属性(谱系、武器、生命值和防御)的对象来处理,并添加一个新的属性来衡量敌人时候已被击败,以及一个战斗功能。
+
+类的第一个函数是一个特殊的函数,在 Python 中称为 `init` 或初始化的函数。这类似于其他语言中的[构造器][4],它创建了类的一个实例,你可以通过它的属性和调用类时使用的任何变量来识别它(示例代码中的 `foe`)。
+
+### Self 和类实例
+
+类的函数接受一种你在类之外看不到的新形式的输入:`self`。如果不包含 `self`,那么当你调用类函数时,Python 无法知道要使用的类的*哪个*实例。这就像在一间充满兽人的房间里说:“我要和兽人战斗”,向一个兽人发起。没有人知道你指的是谁,所有兽人就都上来了。
+
+![Image of an Orc, CC-BY-SA by Buch on opengameart.org][5]
+
+*CC-BY-SA by Buch on opengameart.org*
+
+类中创建的每个属性都以 `self` 符号作为前缀,该符号将变量标识为类的属性。一旦派生出类的实例,就用表示该实例的变量替换掉 `self` 前缀。使用这个技巧,你可以在一间满是兽人的房间里说:“我要和谱系是 orc 的兽人战斗”,这样来挑战一个兽人。当 orc 听到 “gorblar.orc” 时,它就知道你指的是谁(他自己),所以你得到是一场公平的战斗而不是斗殴。在 Python 中:
+
+```
+gorblar=Enemy("orc","sword")
+print("The " + gorblar.enemy + " has " + str(gorblar.hp) + " remaining.")
+```
+
+通过检索类属性(`gorblar.enemy` 或 `gorblar.hp` 或你需要的任何对象的任何值)而不是查询 `foe[0]`(在函数示例中)或 `gorblar[0]` 来寻找敌人。
+
+### 本地变量
+
+如果类中的变量没有以 `self` 关键字作为前缀,那么它就是一个局部变量,就像在函数中一样。例如,无论你做什么,你都无法访问 `Enemy.fight` 类之外的 `hit` 变量:
+
+```
+>>> print(foe.hit)
+Traceback (most recent call last):
+ File "./enclass.py", line 38, in
+ print(foe.hit)
+AttributeError: 'Enemy' object has no attribute 'hit'
+
+>>> print(foe.fight.hit)
+Traceback (most recent call last):
+ File "./enclass.py", line 38, in
+ print(foe.fight.hit)
+AttributeError: 'function' object has no attribute 'hit'
+```
+
+`hit` 变量包含在 Enemy 类中,并且只能“存活”到在战斗中发挥作用。
+
+### 更模块化
+
+本例使用与主应用程序相同的文本文档中的类。在一个复杂的游戏中,我们更容易将每个类看作是自己独立的应用程序。当多个开发人员处理同一个应用程序时,你会看到这一点:一个开发人员负责一个类,另一个开发人员负责主程序,只要他们彼此沟通这个类必须具有什么属性,就可以并行地开发这两个代码块。
+
+要使这个示例游戏模块化,可以把它拆分为两个文件:一个用于主应用程序,另一个用于类。如果它是一个更复杂的应用程序,你可能每个类都有一个文件,或每个逻辑类组有一个文件(例如,用于建筑物的文件,用于自然环境的文件,用于敌人或 NPC 的文件等)。
+
+将只包含 `Enemy` 类的一个文件保存为 `enemy.py`,将另一个包含其他内容的文件保存为 `main.py`。
+
+以下是 `enemy.py`:
+
+```
+import random
+
+class Enemy():
+ def __init__(self,ancestry,gear):
+ self.enemy=ancestry
+ self.weapon=gear
+ self.hp=random.randrange(10,20)
+ self.stg=random.randrange(0,20)
+ self.ac=random.randrange(0,20)
+ self.alive=True
+
+ def fight(self,tgt):
+ print("You take a swing at the " + self.enemy + ".")
+ hit=random.randrange(0,20)
+
+ if self.alive and hit > self.ac:
+ print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
+ self.hp = self.hp - hit
+ print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
+ else:
+ print("You missed.")
+
+ if self.hp < 1:
+ self.alive=False
+```
+
+以下是 `main.py`:
+
+```
+#!/usr/bin/env python3
+
+import enemy as en
+
+# game start
+foe=en.Enemy("troll","great axe")
+print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
+
+# main loop
+while True:
+
+ print("Type the a key and then RETURN to attack.")
+
+ action=input()
+
+ if action.lower() == "a":
+ foe.fight(foe)
+
+ if foe.alive == False:
+ print("You have won...this time.")
+ exit()
+```
+
+导入模块 `enemy.py` 使用了一条特别的语句,引用类文件名称而不用带有 `.py` 扩展名,后跟你选择的命名空间指示符(例如,`import enemy as en`)。这个指示符是在你调用类时在代码中使用的。你需要在导入时添加指示符,例如 `en.Enemy`,而不是只使用 `Enemy()`。
+
+所有这些文件名都是任意的,尽管在原则上不要使用罕见的名称。将应用程序的中心命名为 `main.py` 是一个常见约定,和一个充满类的文件通常以小写形式命名,其中的类都以大写字母开头。是否遵循这些约定不会影响应用程序的运行方式,但它确实使经验丰富的 Python 程序员更容易快速理解应用程序的工作方式。
+
+在如何构建代码方面有一些灵活性。例如,使用该示例代码,两个文件必须位于同一目录中。如果你只想将类打包为模块,那么必须创建一个名为 `mybad` 的目录,并将你的类移入其中。在 `main.py` 中,你的 `import` 语句稍有变化:
+
+```
+from mybad import enemy as en
+```
+
+两种方法都会产生相同的结果,但如果你创建的类足够通用,你认为其他开发人员可以在他们的项目中使用它们,那么后者更好。
+
+无论你选择哪种方式,都可以启动游戏的模块化版本:
+
+```
+$ python3 ./main.py
+You meet a troll wielding a great axe
+Type the a key and then RETURN to attack.
+a
+You take a swing at the troll.
+You missed.
+Type the a key and then RETURN to attack.
+a
+You take a swing at the troll.
+You hit the troll for 8 damage!
+The troll has 4 HP remaining
+Type the a key and then RETURN to attack.
+a
+You take a swing at the troll.
+You hit the troll for 11 damage!
+The troll has -7 HP remaining
+You have won...this time.
+```
+
+游戏启动了,它现在更加模块化了。现在你知道了面对对象的应用程序意味着什么,但最重要的是,当你向兽人发起决斗的时候,你知道是哪一个。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/get-modular-python-classes
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming.png?itok=M_QDcgz5 (Developing code.)
+[2]: https://linux.cn/article-11295-1.html
+[3]: https://opensource.com/article/17/4/how-program-games-raspberry-pi
+[4]: https://opensource.com/article/19/6/what-java-constructor
+[5]: https://opensource.com/sites/default/files/images/orc-buch-opengameart_cc-by-sa.jpg (CC-BY-SA by Buch on opengameart.org)
diff --git a/published/20171113 IT disaster recovery- Sysadmins vs. natural disasters - HPE.md b/published/201908/20171113 IT disaster recovery- Sysadmins vs. natural disasters - HPE.md
similarity index 100%
rename from published/20171113 IT disaster recovery- Sysadmins vs. natural disasters - HPE.md
rename to published/201908/20171113 IT disaster recovery- Sysadmins vs. natural disasters - HPE.md
diff --git a/published/20171216 Sysadmin 101- Troubleshooting.md b/published/201908/20171216 Sysadmin 101- Troubleshooting.md
similarity index 100%
rename from published/20171216 Sysadmin 101- Troubleshooting.md
rename to published/201908/20171216 Sysadmin 101- Troubleshooting.md
diff --git a/published/20180104 How allowing myself to be vulnerable made me a better leader.md b/published/201908/20180104 How allowing myself to be vulnerable made me a better leader.md
similarity index 100%
rename from published/20180104 How allowing myself to be vulnerable made me a better leader.md
rename to published/201908/20180104 How allowing myself to be vulnerable made me a better leader.md
diff --git a/published/20180116 Command Line Heroes- Season 1- OS Wars.md b/published/201908/20180116 Command Line Heroes- Season 1- OS Wars.md
similarity index 100%
rename from published/20180116 Command Line Heroes- Season 1- OS Wars.md
rename to published/201908/20180116 Command Line Heroes- Season 1- OS Wars.md
diff --git a/published/20180119 Two great uses for the cp command Bash shortcuts.md b/published/201908/20180119 Two great uses for the cp command Bash shortcuts.md
similarity index 100%
rename from published/20180119 Two great uses for the cp command Bash shortcuts.md
rename to published/201908/20180119 Two great uses for the cp command Bash shortcuts.md
diff --git a/published/20180131 How to test Webhooks when youre developing locally.md b/published/201908/20180131 How to test Webhooks when youre developing locally.md
similarity index 100%
rename from published/20180131 How to test Webhooks when youre developing locally.md
rename to published/201908/20180131 How to test Webhooks when youre developing locally.md
diff --git a/published/20180622 Use LVM to Upgrade Fedora.md b/published/201908/20180622 Use LVM to Upgrade Fedora.md
similarity index 100%
rename from published/20180622 Use LVM to Upgrade Fedora.md
rename to published/201908/20180622 Use LVM to Upgrade Fedora.md
diff --git a/published/20180720 A brief history of text-based games and open source.md b/published/201908/20180720 A brief history of text-based games and open source.md
similarity index 100%
rename from published/20180720 A brief history of text-based games and open source.md
rename to published/201908/20180720 A brief history of text-based games and open source.md
diff --git a/published/20180727 4 Ways to Customize Xfce and Give it a Modern Look.md b/published/201908/20180727 4 Ways to Customize Xfce and Give it a Modern Look.md
similarity index 100%
rename from published/20180727 4 Ways to Customize Xfce and Give it a Modern Look.md
rename to published/201908/20180727 4 Ways to Customize Xfce and Give it a Modern Look.md
diff --git a/published/20180928 Quiet log noise with Python and machine learning.md b/published/201908/20180928 Quiet log noise with Python and machine learning.md
similarity index 100%
rename from published/20180928 Quiet log noise with Python and machine learning.md
rename to published/201908/20180928 Quiet log noise with Python and machine learning.md
diff --git a/published/20181011 Exploring the Linux kernel- The secrets of Kconfig-kbuild.md b/published/201908/20181011 Exploring the Linux kernel- The secrets of Kconfig-kbuild.md
similarity index 100%
rename from published/20181011 Exploring the Linux kernel- The secrets of Kconfig-kbuild.md
rename to published/201908/20181011 Exploring the Linux kernel- The secrets of Kconfig-kbuild.md
diff --git a/published/20181029 Create animated, scalable vector graphic images with MacSVG.md b/published/201908/20181029 Create animated, scalable vector graphic images with MacSVG.md
similarity index 100%
rename from published/20181029 Create animated, scalable vector graphic images with MacSVG.md
rename to published/201908/20181029 Create animated, scalable vector graphic images with MacSVG.md
diff --git a/published/20181029 DF-SHOW - A Terminal File Manager Based On An Old DOS Application.md b/published/201908/20181029 DF-SHOW - A Terminal File Manager Based On An Old DOS Application.md
similarity index 100%
rename from published/20181029 DF-SHOW - A Terminal File Manager Based On An Old DOS Application.md
rename to published/201908/20181029 DF-SHOW - A Terminal File Manager Based On An Old DOS Application.md
diff --git a/published/20181030 Podman- A more secure way to run containers.md b/published/201908/20181030 Podman- A more secure way to run containers.md
similarity index 100%
rename from published/20181030 Podman- A more secure way to run containers.md
rename to published/201908/20181030 Podman- A more secure way to run containers.md
diff --git a/published/20181202 How To Customize The GNOME 3 Desktop.md b/published/201908/20181202 How To Customize The GNOME 3 Desktop.md
similarity index 100%
rename from published/20181202 How To Customize The GNOME 3 Desktop.md
rename to published/201908/20181202 How To Customize The GNOME 3 Desktop.md
diff --git a/published/20181213 Podman and user namespaces- A marriage made in heaven.md b/published/201908/20181213 Podman and user namespaces- A marriage made in heaven.md
similarity index 100%
rename from published/20181213 Podman and user namespaces- A marriage made in heaven.md
rename to published/201908/20181213 Podman and user namespaces- A marriage made in heaven.md
diff --git a/published/20181220 Getting started with Prometheus.md b/published/201908/20181220 Getting started with Prometheus.md
similarity index 100%
rename from published/20181220 Getting started with Prometheus.md
rename to published/201908/20181220 Getting started with Prometheus.md
diff --git a/published/20181222 How to detect automatically generated emails.md b/published/201908/20181222 How to detect automatically generated emails.md
similarity index 100%
rename from published/20181222 How to detect automatically generated emails.md
rename to published/201908/20181222 How to detect automatically generated emails.md
diff --git a/translated/tech/20190225 How to Install VirtualBox on Ubuntu -Beginner-s Tutorial.md b/published/201908/20190225 How to Install VirtualBox on Ubuntu -Beginner-s Tutorial.md
similarity index 72%
rename from translated/tech/20190225 How to Install VirtualBox on Ubuntu -Beginner-s Tutorial.md
rename to published/201908/20190225 How to Install VirtualBox on Ubuntu -Beginner-s Tutorial.md
index e23d9c3f0e..8d83afa0dd 100644
--- a/translated/tech/20190225 How to Install VirtualBox on Ubuntu -Beginner-s Tutorial.md
+++ b/published/201908/20190225 How to Install VirtualBox on Ubuntu -Beginner-s Tutorial.md
@@ -1,18 +1,20 @@
[#]: collector: (lujun9972)
[#]: translator: (beamrolling)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11282-1.html)
[#]: subject: (How to Install VirtualBox on Ubuntu [Beginner’s Tutorial])
[#]: via: (https://itsfoss.com/install-virtualbox-ubuntu)
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
-如何在 Ubuntu 上安装 VirtualBox [新手教程]
+如何在 Ubuntu 上安装 VirtualBox
======
-**本新手教程解释了在 Ubuntu 和其他基于 Debian 的 Linux 发行版上安装 VirtualBox 的各种方法。**
+> 本新手教程解释了在 Ubuntu 和其他基于 Debian 的 Linux 发行版上安装 VirtualBox 的各种方法。
-Oracle 公司的免费开源产品 [VirtualBox][1] 是一款出色的虚拟化工具,专门用于桌面操作系统。和 [Linux 上的 VMWare Workstation][2] — 另一款虚拟化工具,相比起来,我更喜欢它。
+
+
+Oracle 公司的自由开源产品 [VirtualBox][1] 是一款出色的虚拟化工具,专门用于桌面操作系统。与另一款虚拟化工具 [Linux 上的 VMWare Workstation][2] 相比起来,我更喜欢它。
你可以使用 VirtualBox 等虚拟化软件在虚拟机中安装和使用其他操作系统。
@@ -20,25 +22,29 @@ Oracle 公司的免费开源产品 [VirtualBox][1] 是一款出色的虚拟化
你也可以用 VirtualBox 在你当前的 Linux 系统中安装别的 Linux 发行版。事实上,这就是我用它的原因。如果我听说了一个不错的 Linux 发行版,我会在虚拟机上测试它,而不是安装在真实的系统上。当你想要在安装之前尝试一下别的发行版时,用虚拟机会很方便。
-![Linux installed inside Linux using VirtualBox][5]安装在 Ubuntu 18.04 内的 Ubuntu 18.10
+![Linux installed inside Linux using VirtualBox][5]
+
+*安装在 Ubuntu 18.04 内的 Ubuntu 18.10*
在本新手教程中,我将向你展示在 Ubuntu 和其他基于 Debian 的 Linux 发行版上安装 VirtualBox 的各种方法。
### 在 Ubuntu 和基于 Debian 的 Linux 发行版上安装 VirtualBox
-这里提出的安装方法也适用于其他基于 Debian 和 Ubuntu 的 Linux 发行版,如 Linux Mint,elementar OS 等。
+这里提出的安装方法也适用于其他基于 Debian 和 Ubuntu 的 Linux 发行版,如 Linux Mint、elementar OS 等。
#### 方法 1:从 Ubuntu 仓库安装 VirtualBox
-**优点** : 安装简便
+**优点**:安装简便
-**缺点** : 下载旧版本
+**缺点**:较旧版本
在 Ubuntu 上下载 VirtualBox 最简单的方法可能是从软件中心查找并下载。
-![VirtualBox in Ubuntu Software Center][6]VirtualBox 在 Ubuntu 软件中心提供
+![VirtualBox in Ubuntu Software Center][6]
-你也可以使用该条命令从命令行安装:
+*VirtualBox 在 Ubuntu 软件中心提供*
+
+你也可以使用这条命令从命令行安装:
```
sudo apt install virtualbox
@@ -50,27 +56,27 @@ sudo apt install virtualbox
#### 方法 2:使用 Oracle 网站上的 Deb 文件安装 VirtualBox
-**优点** : 容易安装最新版本
+**优点**:安装简便,最新版本
-**缺点** : 不能更新
+**缺点**:不能更新
如果你想要在 Ubuntu 上使用 VirtualBox 的最新版本,最简单的方法就是[使用 Deb 文件][9]。
-建议阅读[如何在 Ubuntu Linux 上下载 GNOME](https://itsfoss.com/fix-white-screen-login-arch-linux/great )
-
-Oracle 为 VirtiualBox 版本提供了开箱可用的二进制文件。如果查看其下载页面,你将看到为 Ubuntu 和其他发行版下载 deb 安装程序的选项。
+Oracle 为 VirtiualBox 版本提供了开箱即用的二进制文件。如果查看其下载页面,你将看到为 Ubuntu 和其他发行版下载 deb 安装程序的选项。
![VirtualBox Linux Download][10]
你只需要下载 deb 文件并双击它即可安装。就是这么简单。
+- [下载 virtualbox for Ubuntu](https://www.virtualbox.org/wiki/Linux_Downloads)
+
然而,这种方法的问题在于你不能自动更新到最新的 VirtualBox 版本。唯一的办法是移除现有版本,下载最新版本并再次安装。不太方便,是吧?
#### 方法 3:用 Oracle 的仓库安装 VirtualBox
-**优点** : 自动更新
+**优点**:自动更新
-**缺点** : 安装略微复杂
+**缺点**:安装略微复杂
现在介绍的是命令行安装方法,它看起来可能比较复杂,但与前两种方法相比,它更具有优势。你将获得 VirtualBox 的最新版本,并且未来它还将自动更新到更新的版本。我想那就是你想要的。
@@ -82,13 +88,13 @@ Oracle 为 VirtiualBox 版本提供了开箱可用的二进制文件。如果查
wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
```
-```
-Mint 用户请注意:
+> Mint 用户请注意:
-下一步只适用于 Ubuntu。如果你使用的是 Linux Mint 或其他基于 Ubuntu 的发行版,请将命令行中的 $(lsb_release -cs) 替换成你当前版本所基于的 Ubuntu 版本。例如,Linux Mint 19 系列用户应该使用 bionic,Mint 18 系列用户应该使用 xenial,像这样:
+> 下一步只适用于 Ubuntu。如果你使用的是 Linux Mint 或其他基于 Ubuntu 的发行版,请将命令行中的 `$(lsb_release -cs)` 替换成你当前版本所基于的 Ubuntu 版本。例如,Linux Mint 19 系列用户应该使用 bionic,Mint 18 系列用户应该使用 xenial,像这样:
-sudo add-apt-repository “deb [arch=amd64] **bionic** contrib“
-```
+> ```
+> sudo add-apt-repository “deb [arch=amd64] **bionic** contrib“`
+> ```
现在用以下命令来将 Oracle VirtualBox 仓库添加到仓库列表中:
@@ -96,9 +102,9 @@ sudo add-apt-repository “deb [arch=amd64] 无论你是刚毕业的大学生,还是想在职业中寻求进步的经验丰富的 IT 专家,这些提示都可以帮你成为 DevOps 工程师。
+
+
+
+DevOps 工程是一个备受称赞的热门职业。不管你是刚毕业正在找第一份工作,还是在利用之前的行业经验的同时寻求学习新技能的机会,本指南都能帮你通过正确的步骤成为 [DevOps 工程师][2]。
+
+### 让自己沉浸其中
+
+首先学习 [DevOps][3] 的基本原理、实践以及方法。在使用工具之前,先了解 DevOps 背后的“为什么”。DevOps 工程师的主要目标是在整个软件开发生命周期(SDLC)中提高速度并保持或提高质量,以提供最大的业务价值。阅读文章、观看 YouTube 视频、参加当地小组聚会或者会议 —— 成为热情的 DevOps 社区中的一员,在那里你将从先行者的错误和成功中学习。
+
+### 考虑你的背景
+
+如果你有从事技术工作的经历,例如软件开发人员、系统工程师、系统管理员、网络运营工程师或者数据库管理员,那么你已经拥有了广泛的见解和有用的经验,它们可以帮助你在未来成为 DevOps 工程师。如果你在完成计算机科学或任何其他 STEM(LCTT 译注:STEM 是科学、技术、工程和数学四个学科的首字母缩略字)领域的学业后刚开始职业生涯,那么你将拥有在这个过渡期间需要的一些基本踏脚石。
+
+DevOps 工程师的角色涵盖了广泛的职责。以下是企业最有可能使用他们的三种方向:
+
+* **偏向于开发(Dev)的 DevOps 工程师**,在构建应用中扮演软件开发的角色。他们日常工作的一部分是利用持续集成 / 持续交付(CI/CD)、共享仓库、云和容器,但他们不一定负责构建或实施工具。他们了解基础架构,并且在成熟的环境中,能将自己的代码推向生产环境。
+* **偏向于运维技术(Ops)的 DevOps 工程师**,可以与系统工程师或系统管理员相比较。他们了解软件的开发,但并不会把一天的重心放在构建应用上。相反,他们更有可能支持软件开发团队实现手动流程的自动化,并提高人员和技术系统的效率。这可能意味着分解遗留代码,并用不太繁琐的自动化脚本来运行相同的命令,或者可能意味着安装、配置或维护基础结构和工具。他们确保为任何有需要的团队安装可使用的工具。他们也会通过教团队如何利用 CI / CD 和其他 DevOps 实践来帮助他们。
+* **网站可靠性工程师(SRE)**,就像解决运维和基础设施的软件工程师。SRE 专注于创建可扩展、高可用且可靠的软件系统。
+
+在理想的世界中,DevOps 工程师将了解以上所有领域;这在成熟的科技公司中很常见。然而,顶级银行和许多财富 500 强企业的 DevOps 职位通常会偏向开发(Dev)或运营(Ops)。
+
+### 要学习的技术
+
+DevOps 工程师需要了解各种技术才能有效完成工作。无论你的背景如何,请从作为 DevOps 工程师需要使用和理解的基本技术开始。
+
+#### 操作系统
+
+操作系统是一切运行的地方,拥有相关的基础知识十分重要。[Linux][4] 是你最有可能每天使用的操作系统,尽管有的组织会使用 Windows 操作系统。要开始使用,你可以在家中安装 Linux,在那里你可以随心所欲地中断,并在此过程中学习。
+
+#### 脚本
+
+接下来,选择一门语言来学习脚本编程。有很多语言可供选择,包括 Python、Go、Java、Bash、PowerShell、Ruby 和 C / C++。我建议[从 Python 开始][5],因为它相对容易学习和解释,是最受欢迎的语言之一。Python 通常是遵循面向对象编程(OOP)的准则编写的,可用于 Web 开发、软件开发以及创建桌面 GUI 和业务应用程序。
+
+#### 云
+
+学习了 [Linux][4] 和 [Python][5] 之后,我认为下一个该学习的是云计算。基础设施不再只是“运维小哥”的事情了,因此你需要接触云平台,例如 AWS 云服务、Azure 或者谷歌云平台。我会从 AWS 开始,因为它有大量免费学习工具,可以帮助你降低作为开发人员、运维人员,甚至面向业务的部门的任何障碍。事实上,你可能会被它提供的东西所淹没。考虑从 EC2、S3 和 VPC 开始,然后看看你从其中想学到什么。
+
+#### 编程语言
+
+如果你对 DevOps 的软件开发充满热情,请继续提高你的编程技能。DevOps 中的一些优秀和常用的编程语言和你用于脚本编程的相同:Python、Go、Java、Bash、PowerShell、Ruby 和 C / C++。你还应该熟悉 Jenkins 和 Git / Github,你将会在 CI / CD 过程中经常使用到它们。
+
+#### 容器
+
+最后,使用 Docker 和编排平台(如 Kubernetes)等工具开始学习[容器化][6]。网上有大量的免费学习资源,大多数城市都有本地的线下小组,你可以在友好的环境中向有经验的人学习(还有披萨和啤酒哦!)。
+
+#### 其他的呢?
+
+如果你缺乏开发经验,你依然可以通过对自动化的热情,提高效率,与他人协作以及改进自己的工作来[参与 DevOps][3]。我仍然建议学习上述工具,但重点不要放在编程 / 脚本语言上。了解基础架构即服务、平台即服务、云平台和 Linux 会非常有用。你可能会设置工具并学习如何构建具有弹性和容错能力的系统,并在编写代码时利用它们。
+
+### 找一份 DevOps 的工作
+
+求职过程会有所不同,具体取决于你是否一直从事技术工作,是否正在进入 DevOps 领域,或者是刚开始职业生涯的毕业生。
+
+#### 如果你已经从事技术工作
+
+如果你正在从一个技术领域转入 DevOps 角色,首先尝试在你当前的公司寻找机会。你能通过和其他的团队一起工作来重新掌握技能吗?尝试跟随其他团队成员,寻求建议,并在不离开当前工作的情况下获得新技能。如果做不到这一点,你可能需要换另一家公司。如果你能从上面列出的一些实践、工具和技术中学习,你将能在面试时展示相关知识从而占据有利位置。关键是要诚实,不要担心失败。大多数招聘主管都明白你并不知道所有的答案;如果你能展示你一直在学习的东西,并解释你愿意学习更多,你应该有机会获得 DevOps 的工作。
+
+#### 如果你刚开始职业生涯
+
+申请雇用初级 DevOps 工程师的公司的空缺机会。不幸的是,许多公司表示他们希望寻找更富有经验的人,并建议你在获得经验后再申请该职位。这是“我们需要经验丰富的人”的典型,令人沮丧的场景,并且似乎没人愿意给你第一次机会。
+
+然而,并不是所有求职经历都那么令人沮丧;一些公司专注于培训和提升刚从大学毕业的学生。例如,我工作的 [MThree][7] 会聘请应届毕业生并且对其进行 8 周的培训。当完成培训后,参与者们可以充分了解到整个 SDLC,并充分了解它在财富 500 强公司环境中的运用方式。毕业生被聘为 MThree 的客户公司的初级 DevOps 工程师 —— MThree 在前 18 - 24 个月内支付全职工资和福利,之后他们将作为直接雇员加入客户。这是弥合从大学到技术职业的间隙的好方法。
+
+### 总结
+
+转职成 DevOps 工程师的方法有很多种。这是一条非常有益的职业路线,可能会让你保持繁忙和挑战 — 并增加你的收入潜力。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/how-transition-career-devops-engineer
+
+作者:[Conor Delanbanque][a]
+选题:[lujun9972][b]
+译者:[beamrolling](https://github.com/beamrolling)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/hiring_talent_resume_job_career.png?itok=Ci_ulYAH (technical resume for hiring new talent)
+[2]: https://opensource.com/article/19/7/devops-vs-sysadmin
+[3]: https://opensource.com/resources/devops
+[4]: https://opensource.com/resources/linux
+[5]: https://opensource.com/resources/python
+[6]: https://opensource.com/article/18/8/sysadmins-guide-containers
+[7]: https://www.mthreealumni.com/
diff --git a/published/20190725 Introduction to GNU Autotools.md b/published/201908/20190725 Introduction to GNU Autotools.md
similarity index 100%
rename from published/20190725 Introduction to GNU Autotools.md
rename to published/201908/20190725 Introduction to GNU Autotools.md
diff --git a/published/20190726 Manage your passwords with Bitwarden and Podman.md b/published/201908/20190726 Manage your passwords with Bitwarden and Podman.md
similarity index 100%
rename from published/20190726 Manage your passwords with Bitwarden and Podman.md
rename to published/201908/20190726 Manage your passwords with Bitwarden and Podman.md
diff --git a/published/20190729 Command line quick tips- More about permissions.md b/published/201908/20190729 Command line quick tips- More about permissions.md
similarity index 100%
rename from published/20190729 Command line quick tips- More about permissions.md
rename to published/201908/20190729 Command line quick tips- More about permissions.md
diff --git a/published/20190729 Top 8 Things to do after Installing Debian 10 (Buster).md b/published/201908/20190729 Top 8 Things to do after Installing Debian 10 (Buster).md
similarity index 100%
rename from published/20190729 Top 8 Things to do after Installing Debian 10 (Buster).md
rename to published/201908/20190729 Top 8 Things to do after Installing Debian 10 (Buster).md
diff --git a/published/20190730 How to create a pull request in GitHub.md b/published/201908/20190730 How to create a pull request in GitHub.md
similarity index 100%
rename from published/20190730 How to create a pull request in GitHub.md
rename to published/201908/20190730 How to create a pull request in GitHub.md
diff --git a/published/20190730 OpenHMD- Open Source Project for VR Development.md b/published/201908/20190730 OpenHMD- Open Source Project for VR Development.md
similarity index 100%
rename from published/20190730 OpenHMD- Open Source Project for VR Development.md
rename to published/201908/20190730 OpenHMD- Open Source Project for VR Development.md
diff --git a/published/20190731 Bash aliases you can-t live without.md b/published/201908/20190731 Bash aliases you can-t live without.md
similarity index 100%
rename from published/20190731 Bash aliases you can-t live without.md
rename to published/201908/20190731 Bash aliases you can-t live without.md
diff --git a/published/20190801 5 Free Partition Managers for Linux.md b/published/201908/20190801 5 Free Partition Managers for Linux.md
similarity index 100%
rename from published/20190801 5 Free Partition Managers for Linux.md
rename to published/201908/20190801 5 Free Partition Managers for Linux.md
diff --git a/published/20190801 Bash Script to Send a Mail When a New User Account is Created in System.md b/published/201908/20190801 Bash Script to Send a Mail When a New User Account is Created in System.md
similarity index 100%
rename from published/20190801 Bash Script to Send a Mail When a New User Account is Created in System.md
rename to published/201908/20190801 Bash Script to Send a Mail When a New User Account is Created in System.md
diff --git a/published/20190802 Linux Smartphone Librem 5 is Available for Preorder.md b/published/201908/20190802 Linux Smartphone Librem 5 is Available for Preorder.md
similarity index 100%
rename from published/20190802 Linux Smartphone Librem 5 is Available for Preorder.md
rename to published/201908/20190802 Linux Smartphone Librem 5 is Available for Preorder.md
diff --git a/published/20190802 Use Postfix to get email from your Fedora system.md b/published/201908/20190802 Use Postfix to get email from your Fedora system.md
similarity index 100%
rename from published/20190802 Use Postfix to get email from your Fedora system.md
rename to published/201908/20190802 Use Postfix to get email from your Fedora system.md
diff --git a/published/20190803 The fastest open source CPU ever, Facebook shares AI algorithms fighting harmful content, and more news.md b/published/201908/20190803 The fastest open source CPU ever, Facebook shares AI algorithms fighting harmful content, and more news.md
similarity index 100%
rename from published/20190803 The fastest open source CPU ever, Facebook shares AI algorithms fighting harmful content, and more news.md
rename to published/201908/20190803 The fastest open source CPU ever, Facebook shares AI algorithms fighting harmful content, and more news.md
diff --git a/published/20190805 4 cool new projects to try in COPR for August 2019.md b/published/201908/20190805 4 cool new projects to try in COPR for August 2019.md
similarity index 100%
rename from published/20190805 4 cool new projects to try in COPR for August 2019.md
rename to published/201908/20190805 4 cool new projects to try in COPR for August 2019.md
diff --git a/published/20190805 Find The Linux Distribution Name, Version And Kernel Details.md b/published/201908/20190805 Find The Linux Distribution Name, Version And Kernel Details.md
similarity index 100%
rename from published/20190805 Find The Linux Distribution Name, Version And Kernel Details.md
rename to published/201908/20190805 Find The Linux Distribution Name, Version And Kernel Details.md
diff --git a/published/20190805 GameMode - A Tool To Improve Gaming Performance On Linux.md b/published/201908/20190805 GameMode - A Tool To Improve Gaming Performance On Linux.md
similarity index 100%
rename from published/20190805 GameMode - A Tool To Improve Gaming Performance On Linux.md
rename to published/201908/20190805 GameMode - A Tool To Improve Gaming Performance On Linux.md
diff --git a/published/20190805 How To Add ‘New Document- Option In Right Click Context Menu In Ubuntu 18.04.md b/published/201908/20190805 How To Add ‘New Document- Option In Right Click Context Menu In Ubuntu 18.04.md
similarity index 100%
rename from published/20190805 How To Add ‘New Document- Option In Right Click Context Menu In Ubuntu 18.04.md
rename to published/201908/20190805 How To Add ‘New Document- Option In Right Click Context Menu In Ubuntu 18.04.md
diff --git a/published/20190805 How To Find Hardware Specifications On Linux.md b/published/201908/20190805 How To Find Hardware Specifications On Linux.md
similarity index 100%
rename from published/20190805 How To Find Hardware Specifications On Linux.md
rename to published/201908/20190805 How To Find Hardware Specifications On Linux.md
diff --git a/published/20190805 How To Set Up Time Synchronization On Ubuntu.md b/published/201908/20190805 How To Set Up Time Synchronization On Ubuntu.md
similarity index 100%
rename from published/20190805 How To Set Up Time Synchronization On Ubuntu.md
rename to published/201908/20190805 How To Set Up Time Synchronization On Ubuntu.md
diff --git a/published/20190805 How To Verify ISO Images In Linux.md b/published/201908/20190805 How To Verify ISO Images In Linux.md
similarity index 100%
rename from published/20190805 How To Verify ISO Images In Linux.md
rename to published/201908/20190805 How To Verify ISO Images In Linux.md
diff --git a/published/20190806 Microsoft finds Russia-backed attacks that exploit IoT devices.md b/published/201908/20190806 Microsoft finds Russia-backed attacks that exploit IoT devices.md
similarity index 100%
rename from published/20190806 Microsoft finds Russia-backed attacks that exploit IoT devices.md
rename to published/201908/20190806 Microsoft finds Russia-backed attacks that exploit IoT devices.md
diff --git a/published/20190806 Unboxing the Raspberry Pi 4.md b/published/201908/20190806 Unboxing the Raspberry Pi 4.md
similarity index 100%
rename from published/20190806 Unboxing the Raspberry Pi 4.md
rename to published/201908/20190806 Unboxing the Raspberry Pi 4.md
diff --git a/published/20190808 Find Out How Long Does it Take To Boot Your Linux System.md b/published/201908/20190808 Find Out How Long Does it Take To Boot Your Linux System.md
similarity index 100%
rename from published/20190808 Find Out How Long Does it Take To Boot Your Linux System.md
rename to published/201908/20190808 Find Out How Long Does it Take To Boot Your Linux System.md
diff --git a/published/20190808 How to manipulate PDFs on Linux.md b/published/201908/20190808 How to manipulate PDFs on Linux.md
similarity index 100%
rename from published/20190808 How to manipulate PDFs on Linux.md
rename to published/201908/20190808 How to manipulate PDFs on Linux.md
diff --git a/published/20190809 Copying files in Linux.md b/published/201908/20190809 Copying files in Linux.md
similarity index 100%
rename from published/20190809 Copying files in Linux.md
rename to published/201908/20190809 Copying files in Linux.md
diff --git a/published/20190809 Use a drop-down terminal for fast commands in Fedora.md b/published/201908/20190809 Use a drop-down terminal for fast commands in Fedora.md
similarity index 100%
rename from published/20190809 Use a drop-down terminal for fast commands in Fedora.md
rename to published/201908/20190809 Use a drop-down terminal for fast commands in Fedora.md
diff --git a/published/20190811 How to measure the health of an open source community.md b/published/201908/20190811 How to measure the health of an open source community.md
similarity index 100%
rename from published/20190811 How to measure the health of an open source community.md
rename to published/201908/20190811 How to measure the health of an open source community.md
diff --git a/published/201908/20190812 How Hexdump works.md b/published/201908/20190812 How Hexdump works.md
new file mode 100644
index 0000000000..81c499affb
--- /dev/null
+++ b/published/201908/20190812 How Hexdump works.md
@@ -0,0 +1,228 @@
+[#]: collector: (lujun9972)
+[#]: translator: (0x996)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11288-1.html)
+[#]: subject: (How Hexdump works)
+[#]: via: (https://opensource.com/article/19/8/dig-binary-files-hexdump)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Hexdump 如何工作
+======
+
+> Hexdump 能帮助你查看二进制文件的内容。让我们来学习 Hexdump 如何工作。
+
+
+
+Hexdump 是个用十六进制、十进制、八进制数或 ASCII 码显示二进制文件内容的工具。它是个用于检查的工具,也可用于[数据恢复][2]、逆向工程和编程。
+
+### 学习基本用法
+
+Hexdump 让你毫不费力地得到输出结果,依你所查看文件的尺寸,输出结果可能会非常多。本文中我们会创建一个 1x1 像素的 PNG 文件。你可以用图像处理应用如 [GIMP][3] 或 [Mtpaint][4] 来创建该文件,或者也可以在终端内用 [ImageMagick][5] 创建。
+
+用 ImagiMagick 生成 1x1 像素 PNG 文件的命令如下:
+
+```
+$ convert -size 1x1 canvas:black pixel.png
+```
+
+你可以用 `file` 命令确认此文件是 PNG 格式:
+
+```
+$ file pixel.png
+pixel.png: PNG image data, 1 x 1, 1-bit grayscale, non-interlaced
+```
+
+你可能好奇 `file` 命令是如何判断文件是什么类型。巧的是,那正是 `hexdump` 将要揭示的原理。眼下你可以用你常用的图像查看软件来看看你的单一像素图片(它看上去就像这样:`.`),或者你可以用 `hexdump` 查看文件内部:
+
+```
+$ hexdump pixel.png
+0000000 5089 474e 0a0d 0a1a 0000 0d00 4849 5244
+0000010 0000 0100 0000 0100 0001 0000 3700 f96e
+0000020 0024 0000 6704 4d41 0041 b100 0b8f 61fc
+0000030 0005 0000 6320 5248 004d 7a00 0026 8000
+0000040 0084 fa00 0000 8000 00e8 7500 0030 ea00
+0000050 0060 3a00 0098 1700 9c70 51ba 003c 0000
+0000060 6202 474b 0044 dd01 138a 00a4 0000 7407
+0000070 4d49 0745 07e3 081a 3539 a487 46b0 0000
+0000080 0a00 4449 5441 d708 6063 0000 0200 0100
+0000090 21e2 33bc 0000 2500 4574 7458 6164 6574
+00000a0 633a 6572 7461 0065 3032 3931 302d 2d37
+00000b0 3532 3254 3a30 3735 353a 2b33 3231 303a
+00000c0 ac30 5dcd 00c1 0000 7425 5845 6474 7461
+00000d0 3a65 6f6d 6964 7966 3200 3130 2d39 3730
+00000e0 322d 5435 3032 353a 3a37 3335 312b 3a32
+00000f0 3030 90dd 7de5 0000 0000 4549 444e 42ae
+0000100 8260
+0000102
+```
+
+透过一个你以前可能从未用过的视角,你所见的是该示例 PNG 文件的内容。它和你在图像查看软件中看到的是完全一样的数据,只是用一种你或许不熟悉的方式编码。
+
+### 提取熟悉的字符串
+
+尽管默认的数据输出结果看上去毫无意义,那并不意味着其中没有有价值的信息。你可以用 `--canonical` 选项将输出结果,或至少是其中可翻译的部分,翻译成更加熟悉的字符集:
+
+```
+$ hexdump --canonical foo.png
+00000000 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 |.PNG........IHDR|
+00000010 00 00 00 01 00 00 00 01 01 00 00 00 00 37 6e f9 |.............7n.|
+00000020 24 00 00 00 04 67 41 4d 41 00 00 b1 8f 0b fc 61 |$....gAMA......a|
+00000030 05 00 00 00 20 63 48 52 4d 00 00 7a 26 00 00 80 |.... cHRM..z&...|
+00000040 84 00 00 fa 00 00 00 80 e8 00 00 75 30 00 00 ea |...........u0...|
+00000050 60 00 00 3a 98 00 00 17 70 9c ba 51 3c 00 00 00 |`..:....p..Q<...|
+00000060 02 62 4b 47 44 00 01 dd 8a 13 a4 00 00 00 07 74 |.bKGD..........t|
+00000070 49 4d 45 07 e3 07 1a 08 39 35 87 a4 b0 46 00 00 |IME.....95...F..|
+00000080 00 0a 49 44 41 54 08 d7 63 60 00 00 00 02 00 01 |..IDAT..c`......|
+00000090 e2 21 bc 33 00 00 00 25 74 45 58 74 64 61 74 65 |.!.3...%tEXtdate|
+000000a0 3a 63 72 65 61 74 65 00 32 30 31 39 2d 30 37 2d |:create.2019-07-|
+000000b0 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a 30 |25T20:57:53+12:0|
+000000c0 30 ac cd 5d c1 00 00 00 25 74 45 58 74 64 61 74 |0..]....%tEXtdat|
+000000d0 65 3a 6d 6f 64 69 66 79 00 32 30 31 39 2d 30 37 |e:modify.2019-07|
+000000e0 2d 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a |-25T20:57:53+12:|
+000000f0 30 30 dd 90 e5 7d 00 00 00 00 49 45 4e 44 ae 42 |00...}....IEND.B|
+00000100 60 82 |`.|
+00000102
+```
+
+在右侧的列中,你看到的是和左侧一样的数据,但是以 ASCII 码展现的。如果你仔细看,你可以从中挑选出一些有用的信息,如文件格式(PNG)以及文件创建、修改日期和时间(向文件底部寻找一下)。
+
+`file` 命令通过头 8 个字节获取文件类型。程序员会参考 [libpng 规范][6] 来知晓需要查看什么。具体而言,那就是你能在该图像文件的头 8 个字节中看到的字符串 `PNG`。这个事实显而易见,因为它揭示了 `file` 命令是如何知道要报告的文件类型。
+
+你也可以控制 `hexdump` 显示多少字节,这在处理大于一个像素的文件时很实用:
+
+```
+$ hexdump --length 8 pixel.png
+0000000 5089 474e 0a0d 0a1a
+0000008
+```
+
+`hexdump` 不只限于查看 PNG 或图像文件。你也可以用 `hexdump` 查看你日常使用的二进制文件,如 [ls][7]、[rsync][8],或你想检查的任何二进制文件。
+
+### 用 hexdump 实现 cat 命令
+
+阅读 PNG 规范的时候你可能会注意到头 8 个字节中的数据与 `hexdump` 提供的结果看上去不一样。实际上,那是一样的数据,但以一种不同的转换方式展现出来。所以 `hexdump` 的输出是正确的,但取决于你在寻找的信息,其输出结果对你而言不总是直接了当的。出于这个原因,`hexdump` 有一些选项可供用于定义格式和转化其转储的原始数据。
+
+转换选项可以很复杂,所以用无关紧要的东西练习会比较实用。下面这个简易的介绍,通过重新实现 [cat][9] 命令来演示如何格式化 `hexdump` 的输出。首先,对一个文本文件运行 `hexdump` 来查看其原始数据。通常你可以在硬盘上某处找到 [GNU 通用许可证][10](GPL)的一份拷贝,也可以用你手头的任何文本文件。你的输出结果可能不同,但下面是如何在你的系统中找到一份 GPL(或至少其部分)的拷贝:
+
+```
+$ find /usr/share/doc/ -type f -name "COPYING" | tail -1
+/usr/share/doc/libblkid-devel/COPYING
+```
+
+对其运行 `hexdump`:
+
+```
+$ hexdump /usr/share/doc/libblkid-devel/COPYING
+0000000 6854 7369 6c20 6269 6172 7972 6920 2073
+0000010 7266 6565 7320 666f 7774 7261 3b65 7920
+0000020 756f 6320 6e61 7220 6465 7369 7274 6269
+0000030 7475 2065 7469 6120 646e 6f2f 0a72 6f6d
+0000040 6964 7966 6920 2074 6e75 6564 2072 6874
+0000050 2065 6574 6d72 2073 666f 7420 6568 4720
+0000060 554e 4c20 7365 6573 2072 6547 656e 6172
+0000070 206c 7550 6c62 6369 4c0a 6369 6e65 6573
+0000080 6120 2073 7570 6c62 7369 6568 2064 7962
+[...]
+```
+
+如果该文件输出结果很长,用 `--length`(或短选项 `-n`)来控制输出长度使其易于管理。
+
+原始数据对你而言可能没什么意义,但你已经知道如何将其转换为 ASCII 码:
+
+```
+hexdump --canonical /usr/share/doc/libblkid-devel/COPYING
+00000000 54 68 69 73 20 6c 69 62 72 61 72 79 20 69 73 20 |This library is |
+00000010 66 72 65 65 20 73 6f 66 74 77 61 72 65 3b 20 79 |free software; y|
+00000020 6f 75 20 63 61 6e 20 72 65 64 69 73 74 72 69 62 |ou can redistrib|
+00000030 75 74 65 20 69 74 20 61 6e 64 2f 6f 72 0a 6d 6f |ute it and/or.mo|
+00000040 64 69 66 79 20 69 74 20 75 6e 64 65 72 20 74 68 |dify it under th|
+00000050 65 20 74 65 72 6d 73 20 6f 66 20 74 68 65 20 47 |e terms of the G|
+00000060 4e 55 20 4c 65 73 73 65 72 20 47 65 6e 65 72 61 |NU Lesser Genera|
+00000070 6c 20 50 75 62 6c 69 63 0a 4c 69 63 65 6e 73 65 |l Public.License|
+[...]
+```
+
+这个输出结果有帮助但太累赘且难于阅读。要将 `hexdump` 的输出结果转换为其选项不支持的其他格式,可组合使用 `--format`(或 `-e`)和专门的格式代码。用来自定义格式的代码和 `printf` 命令使用的类似,所以如果你熟悉 `printf` 语句,你可能会觉得 `hexdump` 自定义格式不难学会。
+
+在 `hexdump` 中,字符串 `%_p` 告诉 `hexdump` 用你系统的默认字符集输出字符。`--format` 选项的所有格式符号必须以*单引号*包括起来:
+
+```
+$ hexdump -e'"%_p"' /usr/share/doc/libblkid-devel/COPYING
+This library is fre*
+ software; you can redistribute it and/or.modify it under the terms of the GNU Les*
+er General Public.License as published by the Fre*
+ Software Foundation; either.version 2.1 of the License, or (at your option) any later.version..*
+The complete text of the license is available in the..*
+/Documentation/licenses/COPYING.LGPL-2.1-or-later file..
+```
+
+这次的输出好些了,但依然不方便阅读。传统上 UNIX 文本文件假定 80 个字符的输出宽度(因为很久以前显示器一行只能显示 80 个字符)。
+
+尽管这个输出结果未被自定义格式限制输出宽度,你可以用附加选项强制 `hexdump` 一次处理 80 字节。具体而言,通过 80 除以 1 这种形式,你可以告诉 `hexdump` 将 80 字节作为一个单元对待:
+
+```
+$ hexdump -e'80/1 "%_p"' /usr/share/doc/libblkid-devel/COPYING
+This library is free software; you can redistribute it and/or.modify it under the terms of the GNU Lesser General Public.License as published by the Free Software Foundation; either.version 2.1 of the License, or (at your option) any later.version...The complete text of the license is available in the.../Documentation/licenses/COPYING.LGPL-2.1-or-later file..
+```
+
+现在该文件被分割成 80 字节的块处理,但没有任何换行。你可以用 `\n` 字符自行添加换行,在 UNIX 中它代表换行:
+
+```
+$ hexdump -e'80/1 "%_p""\n"'
+This library is free software; you can redistribute it and/or.modify it under th
+e terms of the GNU Lesser General Public.License as published by the Free Softwa
+re Foundation; either.version 2.1 of the License, or (at your option) any later.
+version...The complete text of the license is available in the.../Documentation/
+licenses/COPYING.LGPL-2.1-or-later file..
+```
+
+现在你已经(大致上)用 `hexdump` 自定义格式实现了 `cat` 命令。
+
+### 控制输出结果
+
+实际上自定义格式是让 `hexdump` 变得有用的方法。现在你已经(至少是原则上)熟悉 `hexdump` 自定义格式,你可以让 `hexdump -n 8` 的输出结果跟 `libpng` 官方规范中描述的 PNG 文件头相匹配了。
+
+首先,你知道你希望 `hexdump` 以 8 字节的块来处理 PNG 文件。此外,你可能通过识别这些整数从而知道 PNG 格式规范是以十进制数表述的,根据 `hexdump` 文档,十进制用 `%d` 来表示:
+
+```
+$ hexdump -n8 -e'8/1 "%d""\n"' pixel.png
+13780787113102610
+```
+
+你可以在每个整数后面加个空格使输出结果变得完美:
+
+```
+$ hexdump -n8 -e'8/1 "%d ""\n"' pixel.png
+137 80 78 71 13 10 26 10
+```
+
+现在输出结果跟 PNG 规范完美匹配了。
+
+### 好玩又有用
+
+Hexdump 是个迷人的工具,不仅让你更多地领会计算机如何处理和转换信息,而且让你了解文件格式和编译的二进制文件如何工作。日常工作时你可以随机地试着对不同文件运行 `hexdump`。你永远不知道你会发现什么样的信息,或是什么时候具有这种洞察力会很实用。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/dig-binary-files-hexdump
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[0x996](https://github.com/0x996)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
+[2]: https://www.redhat.com/sysadmin/find-lost-files-scalpel
+[3]: http://gimp.org
+[4]: https://opensource.com/article/17/2/mtpaint-pixel-art-animated-gifs
+[5]: https://opensource.com/article/17/8/imagemagick
+[6]: http://www.libpng.org/pub/png/spec/1.2/PNG-Structure.html
+[7]: https://opensource.com/article/19/7/master-ls-command
+[8]: https://opensource.com/article/19/5/advanced-rsync
+[9]: https://opensource.com/article/19/2/getting-started-cat-command
+[10]: https://en.wikipedia.org/wiki/GNU_General_Public_License
diff --git a/published/20190812 How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS.md b/published/201908/20190812 How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS.md
similarity index 100%
rename from published/20190812 How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS.md
rename to published/201908/20190812 How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS.md
diff --git a/published/20190814 How to Reinstall Ubuntu in Dual Boot or Single Boot Mode.md b/published/201908/20190814 How to Reinstall Ubuntu in Dual Boot or Single Boot Mode.md
similarity index 100%
rename from published/20190814 How to Reinstall Ubuntu in Dual Boot or Single Boot Mode.md
rename to published/201908/20190814 How to Reinstall Ubuntu in Dual Boot or Single Boot Mode.md
diff --git a/published/20190815 Fix ‘E- The package cache file is corrupted, it has the wrong hash- Error In Ubuntu.md b/published/201908/20190815 Fix ‘E- The package cache file is corrupted, it has the wrong hash- Error In Ubuntu.md
similarity index 100%
rename from published/20190815 Fix ‘E- The package cache file is corrupted, it has the wrong hash- Error In Ubuntu.md
rename to published/201908/20190815 Fix ‘E- The package cache file is corrupted, it has the wrong hash- Error In Ubuntu.md
diff --git a/published/20190815 How To Change Linux Console Font Type And Size.md b/published/201908/20190815 How To Change Linux Console Font Type And Size.md
similarity index 100%
rename from published/20190815 How To Change Linux Console Font Type And Size.md
rename to published/201908/20190815 How To Change Linux Console Font Type And Size.md
diff --git a/translated/tech/20190815 How To Fix -Kernel driver not installed (rc--1908)- VirtualBox Error In Ubuntu.md b/published/201908/20190815 How To Fix -Kernel driver not installed (rc--1908)- VirtualBox Error In Ubuntu.md
similarity index 89%
rename from translated/tech/20190815 How To Fix -Kernel driver not installed (rc--1908)- VirtualBox Error In Ubuntu.md
rename to published/201908/20190815 How To Fix -Kernel driver not installed (rc--1908)- VirtualBox Error In Ubuntu.md
index b7eddc11fb..0abdba8e6d 100644
--- a/translated/tech/20190815 How To Fix -Kernel driver not installed (rc--1908)- VirtualBox Error In Ubuntu.md
+++ b/published/201908/20190815 How To Fix -Kernel driver not installed (rc--1908)- VirtualBox Error In Ubuntu.md
@@ -1,8 +1,8 @@
[#]: collector: (lujun9972)
[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11283-1.html)
[#]: subject: (How To Fix “Kernel driver not installed (rc=-1908)” VirtualBox Error In Ubuntu)
[#]: via: (https://www.ostechnix.com/how-to-fix-kernel-driver-not-installed-rc-1908-virtualbox-error-in-ubuntu/)
[#]: author: (sk https://www.ostechnix.com/author/sk/)
@@ -26,7 +26,7 @@ where: suplibOsInit what: 3 VERR_VM_DRIVER_NOT_INSTALLED (-1908) - The support d
![][2]
-Ubuntu 中的 “Kernel driver not installed (rc=-1908)” 错误
+*Ubuntu 中的 “Kernel driver not installed (rc=-1908)” 错误*
我点击了 OK 关闭消息框,然后在后台看到了另一条消息。
@@ -45,7 +45,7 @@ IMachine {85cd948e-a71f-4289-281e-0ca7ad48cd89}
![][3]
-启动期间虚拟机意外终止,退出代码为 1(0x1)
+*启动期间虚拟机意外终止,退出代码为 1(0x1)*
我不知道该先做什么。我运行以下命令来检查是否有用。
@@ -61,7 +61,7 @@ modprobe: FATAL: Module vboxdrv not found in directory /lib/modules/5.0.0-23-gen
仔细阅读这两个错误消息后,我意识到我应该更新 Virtualbox 程序。
-如果你在 Ubuntu 及其衍生版(如 Linux Mint)中遇到此错误,你只需使用以下命令重新安装或更新 **“virtualbox-dkms”** 包:
+如果你在 Ubuntu 及其衍生版(如 Linux Mint)中遇到此错误,你只需使用以下命令重新安装或更新 `virtualbox-dkms` 包:
```
$ sudo apt install virtualbox-dkms
@@ -82,7 +82,7 @@ via: https://www.ostechnix.com/how-to-fix-kernel-driver-not-installed-rc-1908-vi
作者:[sk][a]
选题:[lujun9972][b]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20190815 How To Set up Automatic Security Update (Unattended Upgrades) on Debian-Ubuntu.md b/published/201908/20190815 How To Set up Automatic Security Update (Unattended Upgrades) on Debian-Ubuntu.md
similarity index 100%
rename from published/20190815 How To Set up Automatic Security Update (Unattended Upgrades) on Debian-Ubuntu.md
rename to published/201908/20190815 How To Set up Automatic Security Update (Unattended Upgrades) on Debian-Ubuntu.md
diff --git a/published/20190815 How To Setup Multilingual Input Method On Ubuntu.md b/published/201908/20190815 How To Setup Multilingual Input Method On Ubuntu.md
similarity index 100%
rename from published/20190815 How To Setup Multilingual Input Method On Ubuntu.md
rename to published/201908/20190815 How To Setup Multilingual Input Method On Ubuntu.md
diff --git a/published/20190815 SSLH - Share A Same Port For HTTPS And SSH.md b/published/201908/20190815 SSLH - Share A Same Port For HTTPS And SSH.md
similarity index 100%
rename from published/20190815 SSLH - Share A Same Port For HTTPS And SSH.md
rename to published/201908/20190815 SSLH - Share A Same Port For HTTPS And SSH.md
diff --git a/published/20190817 GNOME and KDE team up on the Linux desktop, docs for Nvidia GPUs open up, a powerful new way to scan for firmware vulnerabilities, and more news.md b/published/201908/20190817 GNOME and KDE team up on the Linux desktop, docs for Nvidia GPUs open up, a powerful new way to scan for firmware vulnerabilities, and more news.md
similarity index 100%
rename from published/20190817 GNOME and KDE team up on the Linux desktop, docs for Nvidia GPUs open up, a powerful new way to scan for firmware vulnerabilities, and more news.md
rename to published/201908/20190817 GNOME and KDE team up on the Linux desktop, docs for Nvidia GPUs open up, a powerful new way to scan for firmware vulnerabilities, and more news.md
diff --git a/published/20190817 LiVES Video Editor 3.0 is Here With Significant Improvements.md b/published/201908/20190817 LiVES Video Editor 3.0 is Here With Significant Improvements.md
similarity index 100%
rename from published/20190817 LiVES Video Editor 3.0 is Here With Significant Improvements.md
rename to published/201908/20190817 LiVES Video Editor 3.0 is Here With Significant Improvements.md
diff --git a/published/20190820 A guided tour of Linux file system types.md b/published/201908/20190820 A guided tour of Linux file system types.md
similarity index 100%
rename from published/20190820 A guided tour of Linux file system types.md
rename to published/201908/20190820 A guided tour of Linux file system types.md
diff --git a/published/20190823 How to Delete Lines from a File Using the sed Command.md b/published/201908/20190823 How to Delete Lines from a File Using the sed Command.md
similarity index 100%
rename from published/20190823 How to Delete Lines from a File Using the sed Command.md
rename to published/201908/20190823 How to Delete Lines from a File Using the sed Command.md
diff --git a/published/20190823 Managing credentials with KeePassXC.md b/published/201908/20190823 Managing credentials with KeePassXC.md
similarity index 100%
rename from published/20190823 Managing credentials with KeePassXC.md
rename to published/201908/20190823 Managing credentials with KeePassXC.md
diff --git a/published/20190825 Happy birthday to the Linux kernel- What-s your favorite release.md b/published/201908/20190825 Happy birthday to the Linux kernel- What-s your favorite release.md
similarity index 100%
rename from published/20190825 Happy birthday to the Linux kernel- What-s your favorite release.md
rename to published/201908/20190825 Happy birthday to the Linux kernel- What-s your favorite release.md
diff --git a/translated/tech/20190825 How to Install Ansible (Automation Tool) on Debian 10 (Buster).md b/published/201908/20190825 How to Install Ansible (Automation Tool) on Debian 10 (Buster).md
similarity index 52%
rename from translated/tech/20190825 How to Install Ansible (Automation Tool) on Debian 10 (Buster).md
rename to published/201908/20190825 How to Install Ansible (Automation Tool) on Debian 10 (Buster).md
index 64ad4a25c7..be4bbb0a36 100644
--- a/translated/tech/20190825 How to Install Ansible (Automation Tool) on Debian 10 (Buster).md
+++ b/published/201908/20190825 How to Install Ansible (Automation Tool) on Debian 10 (Buster).md
@@ -1,32 +1,30 @@
[#]: collector: (lujun9972)
[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11286-1.html)
[#]: subject: (How to Install Ansible (Automation Tool) on Debian 10 (Buster))
[#]: via: (https://www.linuxtechi.com/install-ansible-automation-tool-debian10/)
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
-如何在 Debian 10(Buster)上安装 Ansible(自动化工具)
+如何在 Debian 10 上安装 Ansible
======
-在如今的 IT 领域,自动化一个是热门话题,每个组织都开始采用自动化工具,像 **Puppet**、**Ansible**、**Chef**、**CFEngine**、**Foreman** 和 **Katello**。在这些工具中,Ansible 是几乎所有 IT 组织中管理 UNIX 和 Linux 系统的首选。在本文中,我们将演示如何在 Debian 10 Sever 上安装和使用 ansible。
+在如今的 IT 领域,自动化一个是热门话题,每个组织都开始采用自动化工具,像 Puppet、Ansible、Chef、CFEngine、Foreman 和 Katello。在这些工具中,Ansible 是几乎所有 IT 组织中管理 UNIX 和 Linux 系统的首选。在本文中,我们将演示如何在 Debian 10 Sever 上安装和使用 Ansible。
-[![Ansible-Install-Debian10][1]][2]
-
-我的实验室细节:
-
- * Debian 10 – Ansible 服务器/ 控制节点 – 192.168.1.14
- * CentOS 7 – Ansible 主机 (Web 服务器)– 192.168.1.15
- * CentOS 7 – Ansible 主机(DB 服务器)– 192.169.1.17
+![Ansible-Install-Debian10][2]
+我的实验室环境:
+* Debian 10 – Ansible 服务器/ 控制节点 – 192.168.1.14
+* CentOS 7 – Ansible 主机 (Web 服务器)– 192.168.1.15
+* CentOS 7 – Ansible 主机(DB 服务器)– 192.169.1.17
我们还将演示如何使用 Ansible 服务器管理 Linux 服务器
### 在 Debian 10 Server 上安装 Ansible
-我假设你的 Debian 10 中有一个拥有 root 或 sudo 权限的用户。在我这里,我有一个名为 “pkumar” 的本地用户,它拥有 sudo 权限。
+我假设你的 Debian 10 中有一个拥有 root 或 sudo 权限的用户。在我这里,我有一个名为 `pkumar` 的本地用户,它拥有 sudo 权限。
Ansible 2.7 包存在于 Debian 10 的默认仓库中,在命令行中运行以下命令安装 Ansible,
@@ -35,13 +33,13 @@ root@linuxtechi:~$ sudo apt update
root@linuxtechi:~$ sudo apt install ansible -y
```
-运行以下命令验证 ansible 版本,
+运行以下命令验证 Ansible 版本,
```
root@linuxtechi:~$ sudo ansible --version
```
-![ansible-version][1]
+
要安装最新版本的 Ansible 2.8,首先我们必须设置 Ansible 仓库。
@@ -55,15 +53,15 @@ root@linuxtechi:~$ sudo apt install ansible -y
root@linuxtechi:~$ sudo ansible --version
```
-![latest-ansible-version][1]
+
### 使用 Ansible 管理 Linux 服务器
-请参考以下步骤,使用 Ansible 控制器节点管理类似 Linux 的服务器,
+请参考以下步骤,使用 Ansible 控制器节点管理 Linux 类的服务器,
-### 步骤 1:在 Ansible 服务器及其主机之间交换 SSH 密钥
+#### 步骤 1:在 Ansible 服务器及其主机之间交换 SSH 密钥
-在 ansible 服务器生成 ssh 密钥并在 ansible 主机之间共享密钥。
+在 Ansible 服务器生成 ssh 密钥并在 Ansible 主机之间共享密钥。
```
root@linuxtechi:~$ sudo -i
@@ -72,11 +70,11 @@ root@linuxtechi:~# ssh-copy-id root@linuxtechi
root@linuxtechi:~# ssh-copy-id root@linuxtechi
```
-### 步骤 2:创建 Ansible 主机清单
+#### 步骤 2:创建 Ansible 主机清单
-安装 ansible 后会自动创建 /etc/hosts,在此文件中我们可以编辑 ansible 主机或其客户端。我们还可以在家目录中创建自己的 ansible 主机清单,
+安装 Ansible 后会自动创建 `/etc/ansible/hosts`,在此文件中我们可以编辑 Ansible 主机或其客户端。我们还可以在家目录中创建自己的 Ansible 主机清单,
-运行以下命令在我们的家目录中创建 ansible 主机清单。
+运行以下命令在我们的家目录中创建 Ansible 主机清单。
```
root@linuxtechi:~$ vi $HOME/hosts
@@ -87,27 +85,27 @@ root@linuxtechi:~$ vi $HOME/hosts
192.168.1.17
```
-保存并退出文件
+保存并退出文件。
-**注意:**在上面的 hosts 文件中,我们也可以使用主机名或 FQDN,但为此我们必须确保 ansible 主机可以通过主机名或者 fqdn 访问。。
+注意:在上面的主机文件中,我们也可以使用主机名或 FQDN,但为此我们必须确保 Ansible 主机可以通过主机名或者 FQDN 访问。
-### 步骤 3:测试和使用默认的ansible模块
+#### 步骤 3:测试和使用默认的 Ansible 模块
-Ansible 附带了许多可在 ansible 命令中使用的默认模块,示例如下所示。
+Ansible 附带了许多可在 `ansible` 命令中使用的默认模块,示例如下所示。
语法:
-# ansible -i <host_file> -m <module> <host>
+```
+# ansible -i -m
+```
这里:
- * **-i ~/hosts**:包含 ansible 主机列表
- * **-m:** 在 -m 之后指定 ansible 模块,如 ping 和 shell
- * **<host>:** 我们要运行 ansible 模块的 Ansible 主机
+ * `-i ~/hosts`:包含 Ansible 主机列表
+ * `-m`:在之后指定 Ansible 模块,如 ping 和 shell
+ * ``:我们要运行 Ansible 模块的 Ansible 主机
-
-
-使用 ansible ping 模块验证 ping 连接
+使用 Ansible ping 模块验证 ping 连接,
```
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping all
@@ -117,12 +115,15 @@ root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping DB
命令输出如下所示:
-![Ansible-ping-module-examples][1]
+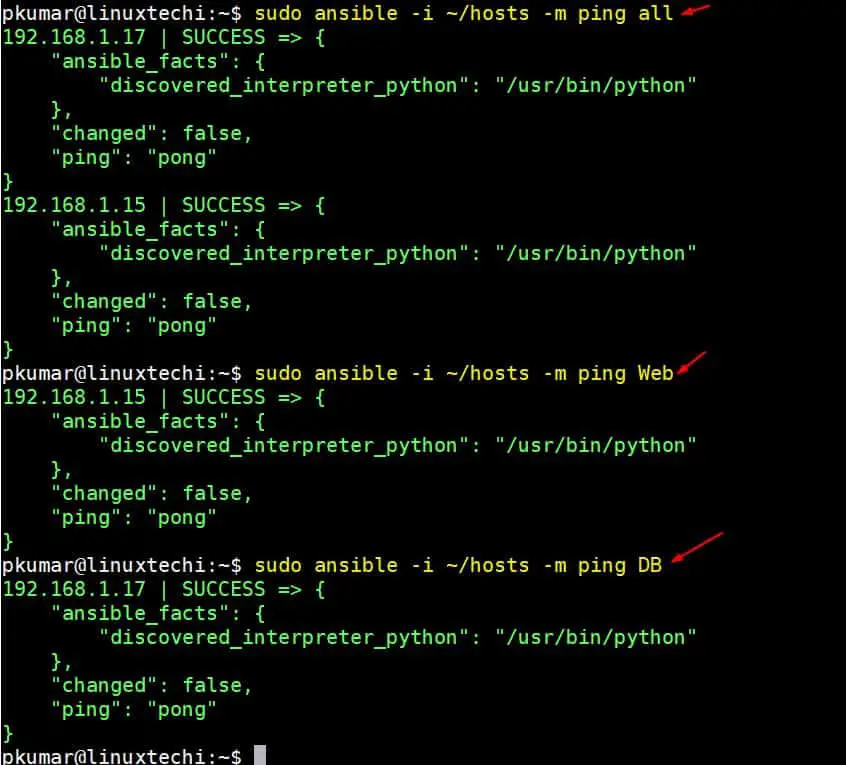
-Running shell commands on ansible hosts using shell module
-使用 shell 模块在 ansible 主机上运行 shell 命令
+使用 shell 模块在 Ansible 主机上运行 shell 命令
-**语法:** # ansible -i <hosts_file> -m shell -a <shell_commands> <host>
+语法:
+
+```
+ansible -i -m shell -a
+```
例子:
@@ -145,9 +146,9 @@ Filesystem Type Size Used Avail Use% Mounted on
root@linuxtechi:~$
```
-上面的命令输出表明我们已成功设置 ansible 控制器节点。
+上面的命令输出表明我们已成功设置 Ansible 控制器节点。
-让我们创建一个示例 NGINX 安装 playbook,下面的 playbook 将在所有服务器上安装 nginx,这些服务器是 Web 主机组的一部分,但在这里,我的主机组下只有一台 centos 7 机器。
+让我们创建一个安装 nginx 的示例剧本,下面的剧本将在所有服务器上安装 nginx,这些服务器是 Web 主机组的一部分,但在这里,我的主机组下只有一台 centos 7 机器。
```
root@linuxtechi:~$ vi nginx.yaml
@@ -162,17 +163,19 @@ root@linuxtechi:~$ vi nginx.yaml
state: started
```
-现在使用以下命令执行 playbook。
+现在使用以下命令执行剧本。
```
root@linuxtechi:~$ sudo ansible-playbook -i ~/hosts nginx.yaml
```
-上面命令的输出类似下面这样。
+上面命令的输出类似下面这样,
-![nginx-installation-playbook-debian10][1]
+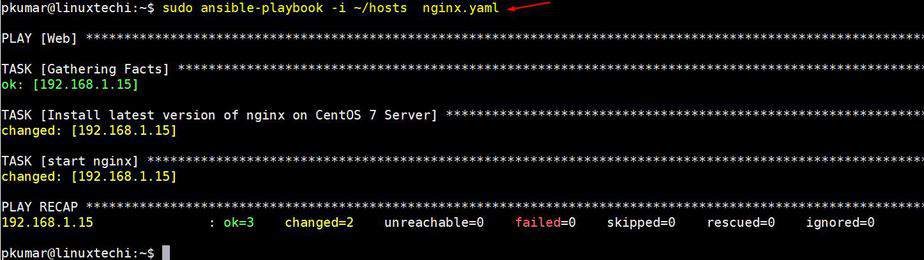
-这表明 Ansible playbook 成功执行了。本文就是这些了,请分享你的反馈和评论。
+这表明 Ansible 剧本成功执行了。
+
+本文就是这些了,请分享你的反馈和评论。
--------------------------------------------------------------------------------
@@ -181,11 +184,11 @@ via: https://www.linuxtechi.com/install-ansible-automation-tool-debian10/
作者:[Pradeep Kumar][a]
选题:[lujun9972][b]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]: https://www.linuxtechi.com/author/pradeep/
[b]: https://github.com/lujun9972
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[2]: https://www.linuxtechi.com/wp-content/uploads/2019/08/Ansible-Install-Debian10.jpg
\ No newline at end of file
+[2]: https://www.linuxtechi.com/wp-content/uploads/2019/08/Ansible-Install-Debian10.jpg
diff --git a/published/20190827 A dozen ways to learn Python.md b/published/201908/20190827 A dozen ways to learn Python.md
similarity index 100%
rename from published/20190827 A dozen ways to learn Python.md
rename to published/201908/20190827 A dozen ways to learn Python.md
diff --git a/published/201908/20190830 11 surprising ways you use Linux every day.md b/published/201908/20190830 11 surprising ways you use Linux every day.md
new file mode 100644
index 0000000000..df3bfb043b
--- /dev/null
+++ b/published/201908/20190830 11 surprising ways you use Linux every day.md
@@ -0,0 +1,108 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11289-1.html)
+[#]: subject: (11 surprising ways you use Linux every day)
+[#]: via: (https://opensource.com/article/19/8/everyday-tech-runs-linux)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+
+你可能意识不到的使用 Linux 的 11 种方式
+======
+
+> 什么技术运行在 Linux 上?你可能会惊讶于日常生活中使用 Linux 的频率。
+
+
+
+现在 Linux 几乎可以运行每样东西,但很多人都没有意识到这一点。有些人可能知道 Linux,可能听说过超级计算机运行着这个操作系统。根据 [Top500][2],Linux 现在驱动着世界上最快的 500 台计算机。你可以转到他们的网站并[搜索“Linux”][3]自己查看一下结果。
+
+### NASA 运行在 Linux 之上
+
+你可能不知道 Linux 为 NASA(美国国家航空航天局)提供支持。NASA 的 [Pleiades][4] 超级计算机运行着 Linux。由于操作系统的可靠性,国际空间站六年前[从 Windows 切换到了 Linux][5]。NASA 甚至最近给国际空间站部署了三台[运行着 Linux][6] 的“Astrobee”机器人。
+
+### 电子书运行在 Linux 之上
+
+我读了很多书,我的首选设备是亚马逊 Kindle Paperwhite,它运行 Linux(虽然大多数人完全没有意识到这一点)。如果你使用亚马逊的任何服务,从[亚马逊弹性计算云(Amazon EC2)][7] 到 Fire TV,你就是在 Linux 上运行。当你问 Alexa 现在是什么时候,或者你最喜欢的运动队得分时,你也在使用 Linux,因为 Alexa 由 [Fire OS][8](基于 Android 的操作系统)提供支持。实际上,[Android][9] 是由谷歌开发的用于移动手持设备的 Linux,而且占据了当今移动电话的[76% 的市场][10]。
+
+### 电视运行在 Linux 之上
+
+如果你有一台 [TiVo][11],那么你也在运行 Linux。如果你是 Roku 用户,那么你也在使用 Linux。[Roku OS][12] 是专为 Roku 设备定制的 Linux 版本。你可以选择使用在 Linux 上运行的 Chromecast 看流媒体。不过,Linux 不只是为机顶盒和流媒体设备提供支持。它也可能运行着你的智能电视。LG 使用 webOS,它是基于 Linux 内核的。Panasonic 使用 Firefox OS,它也是基于 Linux 内核的。三星、菲利普斯以及更多厂商都使用基于 Linux 的操作系统支持其设备。
+
+### 智能手表和平板电脑运行在 Linux 之上
+
+如果你拥有智能手表,它可能正在运行 Linux。世界各地的学校系统一直在实施[一对一系统][13],让每个孩子都有自己的笔记本电脑。越来越多的机构为学生配备了 Chromebook。这些轻巧的笔记本电脑使用 [Chrome OS][14],它基于 Linux。
+
+### 汽车运行在 Linux 之上
+
+你驾驶的汽车可能正在运行 Linux。 [汽车级 Linux(AGL)][15] 是一个将 Linux 视为汽车标准代码库的项目,它列入了丰田、马自达、梅赛德斯-奔驰和大众等汽车制造商。你的[车载信息娱乐(IVI)][16]系统也可能运行 Linux。[GENIVI 联盟][17]在其网站称,它开发了“用于集成在集中连接的车辆驾驶舱中的操作系统和中间件的标准方法”。
+
+### 游戏运行在 Linux 之上
+
+如果你是游戏玩家,那么你可能正在使用 [SteamOS][18],这是一个基于 Linux 的操作系统。此外,如果你使用 Google 的众多服务,那么你也运行在 Linux上。
+
+### 社交媒体运行在 Linux 之上
+
+当你刷屏和评论时,你可能会意识到这些平台正在做的很多工作。也许 Instagram、Facebook、YouTube 和 Twitter 都在 Linux 上运行并不令人惊讶。
+
+此外,社交媒体的新浪潮,去中心化的联合社区的联盟节点,如 [Mastodon][19]、[GNU Social][20]、[Nextcloud][21](类似 Twitter 的微博平台)、[Pixelfed][22](分布式照片共享)和[Peertube][23](分布式视频共享)至少默认情况下在 Linux 上运行。由于开源,它们可以在任何平台上运行,这本身就是一个强大的优先级。
+
+### 商业和政务运行在 Linux 之上
+
+与五角大楼一样,纽约证券交易所也在 Linux 上运行。美国联邦航空管理局每年处理超过 1600 万次航班,他们在 Linux 上运营。美国国会图书馆、众议院、参议院和白宫都使用 Linux。
+
+### 零售运行在 Linux 之上
+
+最新航班座位上的娱乐系统很可能在 Linux 上运行。你最喜欢的商店的 POS 机可能正运行在 Linux 上。基于 Linux 的 [Tizen OS][24] 为智能家居和其他智能设备提供支持。许多公共图书馆现在在 [Evergreen][25] 和 [Koha][26] 上托管他们的综合图书馆系统。这两个系统都在 Linux 上运行。
+
+### Apple 运行在 Linux 之上
+
+如果你是使用 [iCloud][27] 的 iOS 用户,那么你也在使用运行在 Linux 上的系统。Apple 公司的网站在 Linux 上运行。如果你想知道在 Linux 上运行的其他网站,请务必使用 [Netcraft][28] 并检查“该网站运行在什么之上?”的结果。
+
+### 路由器运行在 Linux 之上
+
+在你家里将你连接到互联网的路由器可能正运行在 Linux 上。如果你当前的路由器没有运行 Linux 而你想改变它,那么这里有一个[优秀的方法][29]。
+
+如你所见,Linux 从许多方面为今天的世界提供动力。还有什么运行在 Linux 之上的东西是人们还没有意识到的?请让我们在评论中知道。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/everyday-tech-runs-linux
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/truck_steering_wheel_drive_car_kubernetes.jpg?itok=0TOzve80 (Truck steering wheel and dash)
+[2]: https://www.top500.org/
+[3]: https://www.top500.org/statistics/sublist/
+[4]: https://www.nas.nasa.gov/hecc/resources/pleiades.html
+[5]: https://www.extremetech.com/extreme/155392-international-space-station-switches-from-windows-to-linux-for-improved-reliability
+[6]: https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20180003515.pdf
+[7]: https://aws.amazon.com/amazon-linux-ami/
+[8]: https://en.wikipedia.org/wiki/Fire_OS
+[9]: https://en.wikipedia.org/wiki/Android_(operating_system)
+[10]: https://gs.statcounter.com/os-market-share/mobile/worldwide/
+[11]: https://tivo.pactsafe.io/legal.html#open-source-software
+[12]: https://en.wikipedia.org/wiki/Roku
+[13]: https://en.wikipedia.org/wiki/One-to-one_computing
+[14]: https://en.wikipedia.org/wiki/Chrome_OS
+[15]: https://opensource.com/life/16/8/agl-provides-common-open-code-base
+[16]: https://opensource.com/business/16/5/interview-alison-chaiken-steven-crumb
+[17]: https://www.genivi.org/faq
+[18]: https://store.steampowered.com/steamos/
+[19]: https://opensource.com/article/17/4/guide-to-mastodon
+[20]: https://www.gnu.org/software/social/
+[21]: https://apps.nextcloud.com/apps/social
+[22]: https://pixelfed.org/
+[23]: https://joinpeertube.org/en/
+[24]: https://wiki.tizen.org/Devices
+[25]: https://evergreen-ils.org/
+[26]: https://koha-community.org/
+[27]: https://toolbar.netcraft.com/site_report?url=https://www.icloud.com/
+[28]: https://www.netcraft.com/
+[29]: https://opensource.com/life/16/6/why-i-built-my-own-linux-router
diff --git a/published/20190805 Is your enterprise software committing security malpractice.md b/published/20190805 Is your enterprise software committing security malpractice.md
new file mode 100644
index 0000000000..8418098906
--- /dev/null
+++ b/published/20190805 Is your enterprise software committing security malpractice.md
@@ -0,0 +1,72 @@
+[#]: collector: (lujun9972)
+[#]: translator: (hopefully2333)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11305-1.html)
+[#]: subject: (Is your enterprise software committing security malpractice?)
+[#]: via: (https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html)
+[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
+
+你的企业安全软件是否在背后偷传数据?
+======
+
+> ExtraHop 发现一些企业安全和分析软件正在“私下回拨”,悄悄地将信息上传到客户网络外的服务器上。
+
+![Getty Images][1]
+
+当这个博客专注于微软的一切事情时,我常常抱怨、反对 Windows 10 的间谍活动方面。嗯,显然,这些跟企业安全、分析和硬件管理工具所做的相比,都不算什么。
+
+一家叫做 ExtraHop 的分析公司检查了其客户的网络,并发现客户的安全和分析软件悄悄地将信息上传到客户网络外的服务器上。这家公司上周发布了一份[报告来进行警示][2]。
+
+ExtraHop 特意选择不对这四个例子中的企业安全工具进行点名,这些工具在没有警告用户或使用者的情况发送了数据。这家公司的一位发言人通过电子邮件告诉我,“ExtraHop 希望关注报告的这个趋势,我们已经多次观察到了这种令人担心的情况。这个严重的问题需要企业的更多关注,而只是关注几个特定的软件会削弱这个严重的问题需要得到更多关注的观点。”
+
+### 产品在安全提交传输方面玩忽职守,并且偷偷地传输数据到异地
+
+[ExtraHop 的报告][6]中称发现了一系列的产品在偷偷地传输数据回自己的服务器上,包括终端安全软件、医院设备管理软件、监控摄像头、金融机构使用的安全分析软件等。报告中同样指出,这些应用涉嫌违反了欧洲的[通用数据隐私法规(GDPR)][7]。
+
+在每个案例里,ExtraHop 都提供了这些软件传输数据到异地的证据,在其中一个案例中,一家公司注意到,大约每隔 30 分钟,一台连接了网络的设备就会发送 UDP 数据包给一个已知的恶意 IP 地址。有问题的是一台某国制造的安全摄像头,这个摄像头正在偷偷联系一个和某国有联系的已知的恶意 IP 地址。
+
+该摄像头很可能由其办公室的一名员工出于其个人安全的用途独自设置的,这显示出影子 IT 的缺陷。
+
+而对于医院设备的管理工具和金融公司的分析工具,这些工具违反了数据安全法,公司面临着法律风险——即使公司不知道这个事。
+
+该医院的医疗设备管理产品应该只使用医院的 WiFi 网络,以此来确保患者的数据隐私和 HIPAA 合规。ExtraHop 注意到管理初始设备部署的工作站正在打开加密的 ssl:443 来连接到供应商自己的云存储服务器,这是一个重要的 HIPAA 违规。
+
+ExtraHop 指出,尽管这些例子中可能没有任何恶意活动。但它仍然违反了法律规定,管理员需要密切关注他们的网络,以此来监视异常活动的流量。
+
+“要明确的是,我们不知道供应商为什么要把数据偷偷传回自己的服务器。这些公司都是受人尊敬的安全和 IT 供应商,并且很有可能,这些数据是由他们的程序框架设计用于合法目的的,或者是错误配置的结果”,报告中说。
+
+### 如何减轻数据外传的安全风险
+
+为了解决这种安全方面玩忽职守的问题,ExtraHop 建议公司做下面这五件事:
+
+* 监视供应商的活动:在你的网络上密切注意供应商的非正常活动,无论他们是活跃供应商、以前的供应商,还是评估后的供应商。
+* 监控出口流量:了解出口流量,尤其是来自域控制器等敏感资产的出口流量。当检测到出口流量时,始终将其与核准的应用程序和服务进行匹配。
+* 跟踪部署:在评估过程中,跟踪软件代理的部署。
+* 理解监管方面的考量因素:了解数据跨越政治、地理边界的监管和合规考量因素。
+* 理解合同协议:跟踪数据的使用是否符合供应商合同上的协议。
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html
+
+作者:[Andy Patrizio][a]
+选题:[lujun9972][b]
+译者:[hopefully2333](https://github.com/hopefully2333)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Andy-Patrizio/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2018/03/cybersecurity_eye-with-binary_face-recognition_abstract-eye-100751589-large.jpg
+[2]: https://www.extrahop.com/company/press-releases/2019/extrahop-issues-warning-about-phoning-home/
+[3]: https://www.networkworld.com/article/3254185/internet-of-things/tips-for-securing-iot-on-your-network.html#nww-fsb
+[4]: https://www.networkworld.com/article/3269184/10-best-practices-to-minimize-iot-security-vulnerabilities#nww-fsb
+[5]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
+[6]: https://www.extrahop.com/resources/whitepapers/eh-security-advisory-calling-home-success/
+[7]: https://www.csoonline.com/article/3202771/general-data-protection-regulation-gdpr-requirements-deadlines-and-facts.html
+[8]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
+[9]: https://www.networkworld.com/article/3269165/internet-of-things/a-corporate-guide-to-addressing-iot-security-concerns.html
+[10]: https://www.facebook.com/NetworkWorld/
+[11]: https://www.linkedin.com/company/network-world
diff --git a/published/20190810 How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina).md b/published/20190810 How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina).md
new file mode 100644
index 0000000000..20ea79975d
--- /dev/null
+++ b/published/20190810 How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina).md
@@ -0,0 +1,237 @@
+[#]: collector: (lujun9972)
+[#]: translator: (robsean)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11298-1.html)
+[#]: subject: (How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina)?)
+[#]: via: (https://www.2daygeek.com/upgrade-linux-mint-19-1-tessa-to-linux-mint-19-2-tina/)
+[#]: author: (2daygeek http://www.2daygeek.com/author/2daygeek/)
+
+如何升级 Linux Mint 19.1 为 Linux Mint 19.2
+======
+
+
+
+Linux Mint 19.2 “Tina” 在 2019 年 8 月 2 日发布,它是一个基于 Ubuntu 18.04 LTS (Bionic Beaver) 的长期支持版本。它将被支持到 2023 年。它带来更新的软件和精细的改进和很多新的特色来使你的桌面使用地更舒适。
+
+Linux Mint 19.2 特色有 Cinnamon 4.2 、Linux 内核 4.15 和 Ubuntu 18.04 基础软件包。
+
+**注意:** 不要忘记备份你的重要数据。如果一些东西出错,在最新的安装后,你可以从备份中恢复数据。
+
+备份可以通过 rsnapshot 或 timeshift 完成。
+
+Linux Mint 19.2 “Tina” 发布日志可以在下面的链接中找到。
+
+* [Linux Mint 19.2 (Tina) 发布日志][1]
+
+这里有三种方法,能让我们升级为 Linux Mint 19.2 “Tina”。
+
+ * 使用本地方法升级 Linux Mint 19.2 (Tina)
+ * 使用 Mintupgrade 实用程序方法升级 Linux Mint 19.2 (Tina)
+ * 使用 GUI 升级 Linux Mint 19.2 (Tina)
+
+### 如何从 Linux Mint 19.1 (Tessa) 升级为 Linux Mint 19.2 (Tina)?
+
+升级 Linux Mint 系统是一项简单轻松的任务。有三种方法可以完成。
+
+### 方法-1:使用本地方法升级 Linux Mint 19.2 (Tina)
+
+这是执行升级 Linux Mint 系统的本地和标准的方法之一。为做到这点,遵循下面的程序步骤。
+
+确保你当前 Linux Mint 系统是最新的。使用下面的命令来更新你现在的软件为最新可用版本。
+
+#### 步骤-1:
+
+通过运行下面的命令来刷新存储库索引。
+
+```
+$ sudo apt update
+```
+
+运行下面的命令来在系统上安装可用的更新。
+
+```
+$ sudo apt upgrade
+```
+
+运行下面的命令来在版本中执行可用的次要更新。
+
+```
+$ sudo apt full-upgrade
+```
+
+默认情况下,它将通过上面的命令来移除过时的软件包。但是,我建议你运行下面的命令。
+
+```
+$ sudo apt autoremove
+$ sudo apt clean
+```
+
+如果安装一个新的内核,你可能需要重启系统。如果是这样,运行下面的命令。
+
+```
+$ sudo shutdown -r now
+```
+
+最后检查当前安装的版本。
+
+```
+$ lsb_release -a
+
+No LSB modules are available.
+Distributor ID: Linux Mint
+Description: Linux Mint 19.1 (Tessa)
+Release: 19.1
+Codename: Tessa
+```
+
+#### 步骤-2:更新/修改 /etc/apt/sources.list 文件
+
+在重启后,修改 `sources.list` 文件,并从 Linux Mint 19.1 (Tessa) 指向 Linux Mint 19.2 (Tina)。
+
+首先,使用 `cp` 命令备份下面的配置文件。
+
+```
+$ sudo cp /etc/apt/sources.list /root
+$ sudo cp -r /etc/apt/sources.list.d/ /root
+```
+
+修改 `sources.list` 文件,并指向 Linux Mint 19.2 (Tina)。
+
+```
+$ sudo sed -i 's/tessa/tina/g' /etc/apt/sources.list
+$ sudo sed -i 's/tessa/tina/g' /etc/apt/sources.list.d/*
+```
+
+通过运行下面的命令来刷新存储库索引。
+
+```
+$ sudo apt update
+```
+
+运行下面的命令来在系统上安装可用的更新。在升级过程中,你可用需要确认服务重启和配置文件替换,因此,只需遵循屏幕上的指令。
+
+升级可能花费一些时间,具体依赖于更新的数量和你的网络速度。
+
+```
+$ sudo apt upgrade
+```
+
+运行下面的命令来执行一次完整的系统升级。
+
+```
+$ sudo apt full-upgrade
+```
+
+默认情况下,上面的命令将移除过时的软件包。但是,我建议你再次运行下面的命令。
+
+```
+$ sudo apt autoremove
+$ sudo apt clean
+```
+
+最后重启系统来启动 Linux Mint 19.2 (Tina)。
+
+```
+$ sudo shutdown -r now
+```
+
+升级后的 Linux Mint 版本可以通过运行下面的命令验证。
+
+```
+$ lsb_release -a
+
+No LSB modules are available.
+Distributor ID: Linux Mint
+Description: Linux Mint 19.2 (Tina)
+Release: 19.2
+Codename: Tina
+```
+
+### 方法-2:使用 Mintupgrade 实用程序升级 Linux Mint 19.2 (Tina)
+
+这是 Mint 官方实用程序,它允许我们对 Linux Mint 系统执行平滑升级。
+
+使用下面的命令来安装 mintupgrade 软件包。
+
+```
+$ sudo apt install mintupgrade
+```
+
+确保你已经安装 mintupgrade 软件包的最新版本。
+
+```
+$ apt version mintupgrade
+```
+
+以一个普通用户来运行下面的命令以模拟一次升级,遵循屏幕上的指令。
+
+```
+$ mintupgrade check
+```
+
+使用下面的命令来下载需要的软件包来升级为 Linux Mint 19.2 (Tina) ,遵循屏幕上的指令。
+
+```
+$ mintupgrade download
+```
+
+运行下面的命令来运用升级,最新屏幕上的指令。
+
+```
+$ mintupgrade upgrade
+```
+
+在成功升级后,重启系统,并检查升级后的版本。
+
+```
+$ lsb_release -a
+
+No LSB modules are available.
+Distributor ID: Linux Mint
+Description: Linux Mint 19.2 (Tina)
+Release: 19.2
+Codename: Tina
+```
+
+### 方法-3:使用 GUI 升级 Linux Mint 19.2 (Tina)
+
+或者,我们可以通过 GUI 执行升级。
+
+#### 步骤-1:
+
+通过 Timeshift 创建一个系统快照。如果一些东西出错,你可以简单地恢复你的操作系统到它先前状态。
+
+#### 步骤-2:
+
+打开更新管理器,单击刷新按钮来检查 mintupdate 和 mint-upgrade-info 的任何新版本。如果有这些软件包的更新,应用它们。
+
+通过单击 “编辑-> 升级到 Linux Mint 19.2 Tina”来启动系统升级。
+
+![][3]
+
+遵循屏幕上的指令。如果被询问是否保留或替换配置文件,选择替换它们。
+
+![][4]
+
+#### 步骤-3:
+
+在升级完成后,重启你的电脑。
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/upgrade-linux-mint-19-1-tessa-to-linux-mint-19-2-tina/
+
+作者:[2daygeek][a]
+选题:[lujun9972][b]
+译者:[robsean](https://github.com/robsean)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: http://www.2daygeek.com/author/2daygeek/
+[b]: https://github.com/lujun9972
+[1]: https://www.linuxtechnews.com/linux-mint-19-2-tina-released-check-what-is-new-feature/
+[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[3]: https://www.2daygeek.com/wp-content/uploads/2019/08/linux-mint-19-2-tina-mintupgrade.png
+[4]: https://www.2daygeek.com/wp-content/uploads/2019/08/linux-mint-19-2-tina-mintupgrade-1.png
diff --git a/published/20190821 Getting Started with Go on Fedora.md b/published/20190821 Getting Started with Go on Fedora.md
new file mode 100644
index 0000000000..25cff871be
--- /dev/null
+++ b/published/20190821 Getting Started with Go on Fedora.md
@@ -0,0 +1,120 @@
+[#]: collector: "lujun9972"
+[#]: translator: "hello-wn"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-11293-1.html"
+[#]: subject: "Getting Started with Go on Fedora"
+[#]: via: "https://fedoramagazine.org/getting-started-with-go-on-fedora/"
+[#]: author: "Clément Verna https://fedoramagazine.org/author/cverna/"
+
+在 Fefora 上开启 Go 语言之旅
+======
+
+![][1]
+
+[Go][2] 编程语言于 2009 年首次公开发布,此后被广泛使用。特别是,Go 已经成为云基础设施领域的一种代表性语言,例如 [Kubernetes][3]、[OpenShift][4] 或 [Terraform][5] 等大型项目都使用了 Go。
+
+Go 越来越受欢迎的原因是性能好、易于编写高并发的程序、语法简单和编译快。
+
+让我们来看看如何在 Fedora 上开始 Go 语言编程吧。
+
+### 在 Fedora 上安装 Go
+
+Fedora 可以通过官方库简单快速地安装 Go 语言。
+
+```
+$ sudo dnf install -y golang
+$ go version
+go version go1.12.7 linux/amd64
+```
+
+既然装好了 Go ,让我们来写个简单的程序,编译并运行。
+
+### 第一个 Go 程序
+
+让我们来用 Go 语言写一波 “Hello, World!”。首先创建 `main.go` 文件,然后输入或者拷贝以下内容。
+
+```
+package main
+
+import "fmt"
+
+func main() {
+ fmt.Println("Hello, World!")
+}
+```
+
+运行这个程序很简单。
+
+```
+$ go run main.go
+Hello, World!
+```
+
+Go 会在临时目录将 `main.go` 编译成二进制文件并执行,然后删除临时目录。这个命令非常适合在开发过程中快速运行程序,它还凸显了 Go 的编译速度。
+
+编译一个可执行程序就像运行它一样简单。
+
+```
+$ go build main.go
+$ ./main
+Hello, World!
+```
+
+### 使用 Go 的模块
+
+Go 1.11 和 1.12 引入了对模块的初步支持。模块可用于管理应用程序的各种依赖包。Go 通过 `go.mod` 和 `go.sum` 这两个文件,显式地定义依赖包的版本。
+
+为了演示如何使用模块,让我们为 `hello world` 程序添加一个依赖。
+
+在更改代码之前,需要初始化模块。
+
+```
+$ go mod init helloworld
+go: creating new go.mod: module helloworld
+$ ls
+go.mod main main.go
+```
+
+然后按照以下内容修改 `main.go` 文件。
+
+```
+package main
+
+import "github.com/fatih/color"
+
+func main () {
+ color.Blue("Hello, World!")
+}
+```
+
+在修改后的 `main.go` 中,不再使用标准库 `fmt` 来打印 “Hello, World!” ,而是使用第三方库打印出有色字体。
+
+让我们来跑一下新版的程序吧。
+
+```
+$ go run main.go
+Hello, World!
+```
+
+因为程序依赖于 `github.com/fatih/color` 库,它需要在编译前下载所有依赖包。 然后把依赖包都添加到 `go.mod` 中,并将它们的版本号和哈希值记录在 `go.sum` 中。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/getting-started-with-go-on-fedora/
+
+作者:[Clément Verna][a]
+选题:[lujun9972][b]
+译者:[hello-wn](https://github.com/hello-wn)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/cverna/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/go-article-816x345.jpg
+[2]: https://golang.org/
+[3]: https://kubernetes.io/
+[4]: https://www.openshift.com/
+[5]: https://www.terraform.io/
+
diff --git a/published/20190823 How To Check Your IP Address in Ubuntu -Beginner-s Tip.md b/published/20190823 How To Check Your IP Address in Ubuntu -Beginner-s Tip.md
new file mode 100644
index 0000000000..33084aaa52
--- /dev/null
+++ b/published/20190823 How To Check Your IP Address in Ubuntu -Beginner-s Tip.md
@@ -0,0 +1,112 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11308-1.html)
+[#]: subject: (How To Check Your IP Address in Ubuntu [Beginner’s Tip])
+[#]: via: (https://itsfoss.com/check-ip-address-ubuntu/)
+[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
+
+如何在 Ubuntu 中检查你的 IP 地址
+======
+
+不知道你的 IP 地址是什么?以下是在 Ubuntu 和其他 Linux 发行版中检查 IP 地址的几种方法。
+
+![][1]
+
+### 什么是 IP 地址?
+
+**互联网协议地址**(通常称为 **IP 地址**)是分配给连接到计算机网络的每个设备(使用互联网协议)的数字标签。IP 地址用于识别和定位机器。
+
+**IP 地址**在网络中是*唯一的*,使得所有连接设备能够通信。
+
+你还应该知道有两种**类型的 IP 地址**:**公有**和**私有**。**公有 IP 地址**是用于互联网通信的地址,这与你用于邮件的物理地址相同。但是,在本地网络(例如使用路由器的家庭)的环境中,会为每个设备分配在该子网内唯一的**私有 IP 地址**。这在本地网络中使用,而不直接暴露公有 IP(路由器用它与互联网通信)。
+
+另外还有区分 **IPv4** 和 **IPv6** 协议。**IPv4** 是经典的 IP 格式,它由基本的 4 部分结构组成,四个字节用点分隔(例如 127.0.0.1)。但是,随着设备数量的增加,IPv4 很快就无法提供足够的地址。这就是 **IPv6** 被发明的原因,它使用 **128 位地址**的格式(与 **IPv4** 使用的 **32 位地址**相比)。
+
+### 在 Ubuntu 中检查你的 IP 地址(终端方式)
+
+检查 IP 地址的最快和最简单的方法是使用 `ip` 命令。你可以按以下方式使用此命令:
+
+```
+ip addr show
+```
+
+它将同时显示 IPv4 和 IPv6 地址:
+
+![Display IP Address in Ubuntu Linux][2]
+
+实际上,你可以进一步缩短这个命令 `ip a`。它会给你完全相同的结果。
+
+```
+ip a
+```
+
+如果你希望获得最少的细节,也可以使用 `hostname`:
+
+```
+hostname -I
+```
+
+还有一些[在 Linux 中检查 IP 地址的方法][3],但是这两个命令足以满足这个目的。
+
+`ifconfig` 如何?
+
+老用户可能会想要使用 `ifconfig`(net-tools 软件包的一部分),但该程序已被弃用。一些较新的 Linux 发行版不再包含此软件包,如果你尝试运行它,你将看到 ifconfig 命令未找到的错误。
+
+### 在 Ubuntu 中检查你的 IP 地址(GUI 方式)
+
+如果你对命令行不熟悉,你还可以使用图形方式检查 IP 地址。
+
+打开 Ubuntu 应用菜单(在屏幕左下角**显示应用**)并搜索**Settings**,然后单击图标:
+
+![Applications Menu Settings][5]
+
+这应该会打开**设置菜单**。进入**网络**:
+
+![Network Settings Ubuntu][6]
+
+按下连接旁边的**齿轮图标**会打开一个窗口,其中包含更多设置和有关你网络链接的信息,其中包括你的 IP 地址:
+
+![IP Address GUI Ubuntu][7]
+
+### 额外提示:检查你的公共 IP 地址(适用于台式计算机)
+
+首先,要检查你的**公有 IP 地址**(用于与服务器通信),你可以[使用 curl 命令][8]。打开终端并输入以下命令:
+
+```
+curl ifconfig.me
+```
+
+这应该只会返回你的 IP 地址而没有其他多余信息。我建议在分享这个地址时要小心,因为这相当于公布你的个人地址。
+
+**注意:** 如果 `curl` 没有安装,只需使用 `sudo apt install curl -y` 来解决问题,然后再试一次。
+
+另一种可以查看公共 IP 地址的简单方法是在 Google 中搜索 “ip address”。
+
+### 总结
+
+在本文中,我介绍了在 Uuntu Linux 中找到 IP 地址的不同方法,并向你概述了 IP 地址的用途以及它们对我们如此重要的原因。
+
+我希望你喜欢这篇文章。如果你觉得文章有用,请在评论栏告诉我们!
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/check-ip-address-ubuntu/
+
+作者:[Sergiu][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/sergiu/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/checking-ip-address-ubuntu.png?resize=800%2C450&ssl=1
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/ip_addr_show.png?fit=800%2C493&ssl=1
+[3]: https://linuxhandbook.com/find-ip-address/
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/applications_menu_settings.jpg?fit=800%2C309&ssl=1
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/network_settings_ubuntu.jpg?fit=800%2C591&ssl=1
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/ip_address_gui_ubuntu.png?fit=800%2C510&ssl=1
+[8]: https://linuxhandbook.com/curl-command-examples/
diff --git a/published/20190825 Top 5 IoT networking security mistakes.md b/published/20190825 Top 5 IoT networking security mistakes.md
new file mode 100644
index 0000000000..237d81b266
--- /dev/null
+++ b/published/20190825 Top 5 IoT networking security mistakes.md
@@ -0,0 +1,62 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Morisun029)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11299-1.html)
+[#]: subject: (Top 5 IoT networking security mistakes)
+[#]: via: (https://www.networkworld.com/article/3433476/top-5-iot-networking-security-mistakes.html)
+[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
+
+五大物联网网络安全错误
+======
+
+> IT 供应商兄弟国际公司分享了五种最常见的物联网安全错误,这是从它们的打印机和多功能设备买家中看到的。
+
+![Getty Images][1]
+
+尽管[兄弟国际公司][2]是许多 IT 产品的供应商,从[机床][3]到[头戴式显示器][4]再到[工业缝纫机][5],但它最知名的产品是打印机。在当今世界,这些打印机不再是独立的设备,而是物联网的组成部分。
+
+这也是我为什么对罗伯特•伯内特提供的这份列表感兴趣的原因。伯内特是兄弟公司的总监,负责 B2B 产品和提供解决方案。基本上是该公司负责大客户实施的关键人物。所以他对打印机相关的物联网安全错误非常关注,并且分享了兄弟国际公司对于处理这五大错误的建议。
+
+### #5:不控制访问和授权
+
+伯内特说:“过去,成本控制是管理谁可以使用机器、何时结束工作背后的推动力。”当然,这在今天也仍然很重要,但他指出安全性正迅速成为管理控制打印和扫描设备的关键因素。这不仅适用于大型企业,也适用于各种规模的企业。
+
+### #4:无法定期更新固件
+
+让我们来面对这一现实,大多数 IT 专业人员都忙于保持服务器和其他网络基础设施设备的更新,确保其基础设施尽可能的安全高效。“在这日常的流程中,像打印机这样的设备经常被忽视。”但过时的固件可能会使基础设施面临新的威胁。
+
+### #3:设备意识不足
+
+伯内特说:“正确理解谁在使用什么设备,以及整套设备中所有连接设备的功能是什么,这是至关重要的。使用端口扫描技术、协议分析和其他检测技术检查这些设备应作为你的网络基础设施整体安全审查中的一部分。 他常常提醒人们说:“处理打印设备的方法是:如果没有损坏,就不要修理!”但即使是可靠运行多年的设备也应该成为安全审查的一部分。这是因为旧设备可能无法提供更强大的安全设置,或者可能需要更新其配置才能满足当今更高的安全要求,这其中包括设备的监控/报告功能。
+
+### #2:用户培训不足
+
+“应该把培训团队在工作过程中管理文档的最佳实践作为强有力的安全计划中的一部分。”伯内特说道,“然而,事实却是,无论你如何努力地去保护物联网设备,人为因素通常是一家企业在保护重要和敏感信息方面最薄弱的环节。像这些简单的事情,如无意中将重要文件留在打印机上供任何人查看,或者将文件扫描到错误的目的地,不仅会给企业带来经济损失和巨大的负面影响,还会影响企业的知识产权、声誉,引起合规性/监管问题。”
+
+### #1:使用默认密码
+
+“只是因为它很方便并不意味着它不重要!”伯内特说,“保护打印机和多功能设备免受未经授权的管理员访问不仅有助于保护敏感的机器配置设置和报告信息,还可以防止访问个人信息,例如,像可能用于网络钓鱼攻击的用户名。”
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3433476/top-5-iot-networking-security-mistakes.html
+
+作者:[Fredric Paul][a]
+选题:[lujun9972][b]
+译者:[Morisun029](https://github.com/Morisun029)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Fredric-Paul/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2019/02/iot_security_tablet_conference_digital-100787102-large.jpg
+[2]: https://www.brother-usa.com/business
+[3]: https://www.brother-usa.com/machinetool/default?src=default
+[4]: https://www.brother-usa.com/business/hmd#sort=%40productcatalogsku%20ascending
+[5]: https://www.brother-usa.com/business/industrial-sewing
+[6]: https://www.networkworld.com/article/2855207/internet-of-things/5-ways-to-prepare-for-internet-of-things-security-threats.html#tk.nww-infsb
+[7]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
+[8]: https://www.facebook.com/NetworkWorld/
+[9]: https://www.linkedin.com/company/network-world
diff --git a/published/20190826 5 ops tasks to do with Ansible.md b/published/20190826 5 ops tasks to do with Ansible.md
new file mode 100644
index 0000000000..de7916b81d
--- /dev/null
+++ b/published/20190826 5 ops tasks to do with Ansible.md
@@ -0,0 +1,95 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11312-1.html)
+[#]: subject: (5 ops tasks to do with Ansible)
+[#]: via: (https://opensource.com/article/19/8/ops-tasks-ansible)
+[#]: author: (Mark Phillips https://opensource.com/users/markphttps://opensource.com/users/adminhttps://opensource.com/users/alsweigarthttps://opensource.com/users/belljennifer43)
+
+5 个 Ansible 运维任务
+======
+
+> 让 DevOps 少一点,OpsDev 多一点。
+
+![gears and lightbulb to represent innovation][1]
+
+在这个 DevOps 世界中,看起来开发(Dev)这一半成为了关注的焦点,而运维(Ops)则是这个关系中被遗忘的另一半。这几乎就好像是领头的开发告诉尾随的运维做什么,几乎所有的“运维”都是开发说要做的。因此,运维被抛到后面,降级到了替补席上。
+
+我想看到更多的 OpsDev。因此,让我们来看看 Ansible 在日常的运维中可以帮助你什么。
+
+![Job templates][2]
+
+我选择在 [Ansible Tower][3] 中展示这些方案,因为我认为用户界面 (UI) 可以增色大多数的任务。如果你想模拟测试,你可以在 Tower 的上游开源版本 [AWX][4] 中测试它。
+
+### 管理用户
+
+在大规模环境中,你的用户将集中在活动目录或 LDAP 等系统中。但我敢打赌,仍然存在许多包含大量的静态用户的全负荷环境。Ansible 可以帮助你将这些分散的环境集中到一起。*社区*已为我们解决了这个问题。看看 [Ansible Galaxy][5] 中的 [users][6] 角色。
+
+这个角色的聪明之处在于它允许我们通过*数据*管理用户,而无需更改运行逻辑。
+
+![User data][7]
+
+通过简单的数据结构,我们可以在系统上添加、删除和修改静态用户。这很有用。
+
+### 管理 sudo
+
+提权有[多种形式][8],但最流行的是 [sudo][9]。通过每个 `user`、`group` 等离散文件来管理 sudo 相对容易。但一些人对给予特权感到紧张,并倾向于有时限地给予提权。因此[下面是一种方案][10],它使用简单的 `at` 命令对授权访问设置时间限制。
+
+![Managing sudo][11]
+
+### 管理服务
+
+给入门级运维团队提供[菜单][12]以便他们可以重启某些服务不是很好吗?看下面!
+
+![Managing services][13]
+
+### 管理磁盘空间
+
+这有[一个简单的角色][14],可在特定目录中查找字节大于某个大小的文件。在 Tower 中这么做时,启用[回调][15]有额外的好处。想象一下,你的监控方案发现文件系统已超过 X% 并触发 Tower 中的任务以找出是什么文件导致的。
+
+![Managing disk space][16]
+
+### 调试系统性能问题
+
+[这个角色][17]相当简单:它运行一些命令并打印输出。细节在最后输出,让你 —— 系统管理员快速浏览一眼。另外可以使用 [正则表达式][18] 在输出中找到某些条件(比如说 CPU 占用率超过 80%)。
+
+![Debugging system performance][19]
+
+### 总结
+
+我已经录制了这五个任务的简短视频。你也可以在 Github 上找到[所有代码][20]!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/ops-tasks-ansible
+
+作者:[Mark Phillips][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/markphttps://opensource.com/users/adminhttps://opensource.com/users/alsweigarthttps://opensource.com/users/belljennifer43
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/innovation_lightbulb_gears_devops_ansible.png?itok=TSbmp3_M (gears and lightbulb to represent innovation)
+[2]: https://opensource.com/sites/default/files/uploads/00_templates.png (Job templates)
+[3]: https://www.ansible.com/products/tower
+[4]: https://github.com/ansible/awx
+[5]: https://galaxy.ansible.com
+[6]: https://galaxy.ansible.com/singleplatform-eng/users
+[7]: https://opensource.com/sites/default/files/uploads/01_users_data.png (User data)
+[8]: https://docs.ansible.com/ansible/latest/plugins/become.html
+[9]: https://www.sudo.ws/intro.html
+[10]: https://github.com/phips/ansible-demos/tree/master/roles/sudo
+[11]: https://opensource.com/sites/default/files/uploads/02_sudo.png (Managing sudo)
+[12]: https://docs.ansible.com/ansible-tower/latest/html/userguide/job_templates.html#surveys
+[13]: https://opensource.com/sites/default/files/uploads/03_services.png (Managing services)
+[14]: https://github.com/phips/ansible-demos/tree/master/roles/disk
+[15]: https://docs.ansible.com/ansible-tower/latest/html/userguide/job_templates.html#provisioning-callbacks
+[16]: https://opensource.com/sites/default/files/uploads/04_diskspace.png (Managing disk space)
+[17]: https://github.com/phips/ansible-demos/tree/master/roles/gather_debug
+[18]: https://docs.ansible.com/ansible/latest/user_guide/playbooks_filters.html#regular-expression-filters
+[19]: https://opensource.com/sites/default/files/uploads/05_debug.png (Debugging system performance)
+[20]: https://github.com/phips/ansible-demos
diff --git a/published/20190826 How to rename a group of files on Linux.md b/published/20190826 How to rename a group of files on Linux.md
new file mode 100644
index 0000000000..e80d1bc31d
--- /dev/null
+++ b/published/20190826 How to rename a group of files on Linux.md
@@ -0,0 +1,128 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11300-1.html)
+[#]: subject: (How to rename a group of files on Linux)
+[#]: via: (https://www.networkworld.com/article/3433865/how-to-rename-a-group-of-files-on-linux.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+如何在 Linux 上重命名一组文件
+======
+
+> 要用单个命令重命名一组文件,请使用 rename 命令。它需要使用正则表达式,并且可以在开始前告诉你会有什么更改。
+
+
+
+几十年来,Linux 用户一直使用 `mv` 命令重命名文件。它很简单,并且能做到你要做的。但有时你需要重命名一大组文件。在这种情况下,`rename` 命令可以使这个任务更容易。它只需要一些正则表达式的技巧。
+
+与 `mv` 命令不同,`rename` 不允许你简单地指定旧名称和新名称。相反,它使用类似于 Perl 中的正则表达式。在下面的例子中,`s` 指定我们将第一个字符串替换为第二个字符串(旧的),从而将 `this.new` 变为 `this.old`。
+
+```
+$ rename 's/new/old/' this.new
+$ ls this*
+this.old
+```
+
+使用 `mv this.new this.old` 可以更容易地进行更改一个,但是将字符串 `this` 变成通配符 `*`,你可以用一条命令将所有的 `*.new` 文件重命名为 `*.old`:
+
+```
+$ ls *.new
+report.new schedule.new stats.new this.new
+$ rename 's/new/old/' *.new
+$ ls *.old
+report.old schedule.old stats.old this.old
+```
+
+正如你所料,`rename` 命令不限于更改文件扩展名。如果你需要将名为 `report.*` 的文件更改为 `review.*`,那么可以使用以下命令做到:
+
+```
+$ rename 's/report/review/' *
+```
+
+正则表达式中的字符串可以更改文件名的任何部分,无论是文件名还是扩展名。
+
+```
+$ rename 's/123/124/' *
+$ ls *124*
+status.124 report124.txt
+```
+
+如果你在 `rename` 命令中添加 `-v` 选项,那么该命令将提供一些反馈,以便你可以看到所做的更改,或许会包含你没注意的。这让你注意到并按需还原更改。
+
+```
+$ rename -v 's/123/124/' *
+status.123 renamed as status.124
+report123.txt renamed as report124.txt
+```
+
+另一方面,使用 `-n`(或 `--nono`)选项会使 `rename` 命令告诉你将要做的但不会实际做的更改。这可以让你免于执行不不想要的操作,然后再还原更改。
+
+```
+$ rename -n 's/old/save/' *
+rename(logger.man-old, logger.man-save)
+rename(lyrics.txt-old, lyrics.txt-save)
+rename(olderfile-, saveerfile-)
+rename(oldfile, savefile)
+rename(review.old, review.save)
+rename(schedule.old, schedule.save)
+rename(stats.old, stats.save)
+rename(this.old, this.save)
+```
+
+如果你对这些更改满意,那么就可以运行不带 `-n` 选项的命令来更改文件名。
+
+但请注意,正则表达式中的 `.` **不会**被视为句点,而是作为匹配任何字符的通配符。上面和下面的示例中的一些更改可能不是输入命令的人希望的。
+
+```
+$ rename -n 's/.old/.save/' *
+rename(logger.man-old, logger.man.save)
+rename(lyrics.txt-old, lyrics.txt.save)
+rename(review.old, review.save)
+rename(schedule.old, schedule.save)
+rename(stats.old, stats.save)
+rename(this.old, this.save)
+```
+
+为确保句点按照字面意思执行,请在它的前面加一个反斜杠。这将使其不被解释为通配符并匹配任何字符。请注意,进行此更改时,仅选择了 `.old` 文件。
+
+```
+$ rename -n 's/\.old/.save/' *
+rename(review.old, review.save)
+rename(schedule.old, schedule.save)
+rename(stats.old, stats.save)
+rename(this.old, this.save)
+```
+
+下面的命令会将文件名中的所有大写字母更改为小写,除了使用 `-n` 选项来确保我们在命令执行之前检查将做的修改。注意在正则表达式中使用了 `y`,这是改变大小写所必需的。
+
+```
+$ rename -n 'y/A-Z/a-z/' W*
+rename(WARNING_SIGN.pdf, warning_sign.pdf)
+rename(Will_Gardner_buttons.pdf, will_gardner_buttons.pdf)
+rename(Wingding_Invites.pdf, wingding_invites.pdf)
+rename(WOW-buttons.pdf, wow-buttons.pdf)
+```
+
+在上面的例子中,我们将所有大写字母更改为了小写,但这仅对以大写字母 `W` 开头的文件名。
+
+### 总结
+
+当你需要重命名大量文件时,`rename` 命令非常有用。请注意不要做比预期更多的更改。请记住,`-n`(或者 `--nono`)选项可以帮助你避免耗时的错误。
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3433865/how-to-rename-a-group-of-files-on-linux.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2019/08/card-catalog-machester_city_library-100809242-large.jpg
+[4]: https://www.facebook.com/NetworkWorld/
+[5]: https://www.linkedin.com/company/network-world
diff --git a/published/20190829 Three Ways to Exclude Specific-Certain Packages from Yum Update.md b/published/20190829 Three Ways to Exclude Specific-Certain Packages from Yum Update.md
new file mode 100644
index 0000000000..f0d1ba9087
--- /dev/null
+++ b/published/20190829 Three Ways to Exclude Specific-Certain Packages from Yum Update.md
@@ -0,0 +1,138 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11315-1.html)
+[#]: subject: (Three Ways to Exclude Specific/Certain Packages from Yum Update)
+[#]: via: (https://www.2daygeek.com/redhat-centos-yum-update-exclude-specific-packages/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+从 Yum 更新中排除特定/某些包的三种方法
+======
+
+
+
+作为系统更新的一部分,你也许需要在基于 Red Hat 系统中由于应用依赖排除一些软件包。
+
+如果是,如何排除?可以采取多少种方式?有三种方式可以做到,我们会在本篇中教你这三种方法。
+
+包管理器是一组工具,它允许用户在 Linux 系统中轻松管理包。它能让用户在 Linux 系统中安装、更新/升级、删除、查询、重新安装和搜索软件包。
+
+对于基于 Red Hat 的系统,我们使用 [yum 包管理器][1] 和 [rpm 包管理器][2] 进行包管理。
+
+### 什么是 yum?
+
+yum 代表 “Yellowdog Updater, Modified”。Yum 是用于 rpm 系统的自动更新程序和包安装/卸载器。
+
+它在安装包时自动解决依赖关系。
+
+### 什么是 rpm?
+
+rpm 代表 “Red Hat Package Manager”,它是一款用于 Red Hat 系统的功能强大的包管理工具。
+
+RPM 指的是 `.rpm` 文件格式,它包含已编译的软件和必要的库。
+
+你可能有兴趣阅读以下与本主题相关的文章。如果是的话,请进入相应的链接。
+
+ * [如何检查 Red Hat(RHEL)和 CentOS 系统上的可用安全更新][3]
+ * [在 Red Hat(RHEL)和 CentOS 系统上安装安全更新的四种方法][4]
+ * [在 Redhat(RHEL)和 CentOS 系统上检查或列出已安装的安全更新的两种方法][5]
+
+### 方法 1:手动或临时用 yum 命令排除包
+
+我们可以在 yum 中使用 `--exclude` 或 `-x` 开关来阻止 yum 命令获取特定包的更新。
+
+我可以说,这是一种临时方法或按需方法。如果你只想将特定包排除一次,那么我们可以使用此方法。
+
+以下命令将更新除 kernel 之外的所有软件包。
+
+要排除单个包:
+
+```
+# yum update --exclude=kernel
+或者
+# yum update -x 'kernel'
+```
+
+要排除多个包。以下命令将更新除 kernel 和 php 之外的所有软件包。
+
+```
+# yum update --exclude=kernel* --exclude=php*
+或者
+# yum update --exclude httpd,php
+```
+
+### 方法 2:在 yum 命令中永久排除软件包
+
+这是永久性方法,如果你经常执行修补程序更新,那么可以使用此方法。
+
+为此,请在 `/etc/yum.conf` 中添加相应的软件包以永久禁用软件包更新。
+
+添加后,每次运行 `yum update` 命令时都不需要指定这些包。此外,这可以防止任何意外更新这些包。
+
+```
+# vi /etc/yum.conf
+
+[main]
+cachedir=/var/cache/yum/$basearch/$releasever
+keepcache=0
+debuglevel=2
+logfile=/var/log/yum.log
+exactarch=1
+obsoletes=1
+gpgcheck=1
+plugins=1
+installonly_limit=3
+exclude=kernel* php*
+```
+
+### 方法 3:使用 Yum versionlock 插件排除包
+
+这也是与上面类似的永久方法。Yum versionlock 插件允许用户通过 `yum` 命令锁定指定包的更新。
+
+为此,请运行以下命令。以下命令将从 `yum update` 中排除 freetype 包。
+
+或者,你可以直接在 `/etc/yum/pluginconf.d/versionlock.list` 中添加条目。
+
+```
+# yum versionlock add freetype
+
+Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
+Adding versionlock on: 0:freetype-2.8-12.el7
+versionlock added: 1
+```
+
+运行以下命令来检查被 versionlock 插件锁定的软件包列表。
+
+```
+# yum versionlock list
+
+Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
+0:freetype-2.8-12.el7.*
+versionlock list done
+```
+
+运行以下命令清空该列表。
+
+```
+# yum versionlock clear
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/redhat-centos-yum-update-exclude-specific-packages/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
+[2]: https://www.2daygeek.com/rpm-command-examples/
+[3]: https://www.2daygeek.com/check-list-view-find-available-security-updates-on-redhat-rhel-centos-system/
+[4]: https://www.2daygeek.com/install-security-updates-on-redhat-rhel-centos-system/
+[5]: https://www.2daygeek.com/check-installed-security-updates-on-redhat-rhel-and-centos-system/
diff --git a/published/20190830 Change your Linux terminal color theme.md b/published/20190830 Change your Linux terminal color theme.md
new file mode 100644
index 0000000000..321dc40997
--- /dev/null
+++ b/published/20190830 Change your Linux terminal color theme.md
@@ -0,0 +1,86 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11310-1.html)
+[#]: subject: (Change your Linux terminal color theme)
+[#]: via: (https://opensource.com/article/19/8/add-color-linux-terminal)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+如何更改 Linux 终端颜色主题
+======
+
+> 你可以用丰富的选项来定义你的终端主题。
+
+
+
+如果你大部分时间都盯着终端,那么你很自然地希望它看起来能赏心悦目。美与不美,全在观者,自 CRT 串口控制台以来,终端已经经历了很多变迁。因此,你的软件终端窗口有丰富的选项,可以用来定义你看到的主题,不管你如何定义美,这总是件好事。
+
+### 设置
+
+包括 GNOME、KDE 和 Xfce 在内的流行的软件终端应用,它们都提供了更改其颜色主题的选项。调整主题就像调整应用首选项一样简单。Fedora、RHEL 和 Ubuntu 默认使用 GNOME,因此本文使用该终端作为示例,但对 Konsole、Xfce 终端和许多其他终端的设置流程类似。
+
+首先,进入到应用的“首选项”或“设置”面板。在 GNOME 终端中,你可以通过屏幕顶部或窗口右上角的“应用”菜单访问它。
+
+在“首选项”中,单击“配置文件” 旁边的加号(“+”)来创建新的主题配置文件。在新配置文件中,单击“颜色”选项卡。
+
+![GNOME Terminal preferences][2]
+
+在“颜色”选项卡中,取消选择“使用系统主题中的颜色”选项,以使窗口的其余部分变为可选状态。最开始,你可以选择内置的颜色方案。这些包括浅色主题,它有明亮的背景和深色的前景文字;还有深色主题,它有深色背景和浅色前景文字。
+
+当没有其他设置(例如 `dircolors` 命令的设置)覆盖它们时,“默认颜色”色板将同时定义前景色和背景色。“调色板”设置 `dircolors` 命令定义的颜色。这些颜色由终端以 `LS_COLORS` 环境变量的形式使用,以在 [ls][3] 命令的输出中添加颜色。如果这些颜色不吸引你,请在此更改它们。
+
+如果对主题感到满意,请关闭“首选项”窗口。
+
+要将终端更改为新的配置文件,请单击“应用”菜单,然后选择“配置文件”。选择新的配置文件,接着享受自定义主题。
+
+![GNOME Terminal profile selection][4]
+
+### 命令选项
+
+如果你的终端没有合适的设置窗口,它仍然可以在启动命令中提供颜色选项。xterm 和 rxvt 终端(旧的和启用 Unicode 的变体,有时称为 urxvt 或 rxvt-unicode)都提供了这样的选项,因此即使没有桌面环境和大型 GUI 框架,你仍然可以设置终端模拟器的主题。
+
+两个明显的选项是前景色和背景色,分别用 `-fg` 和 `-bg` 定义。每个选项的参数是*颜色名*而不是它的 ANSI 编号。例如:
+
+```
+$ urxvt -bg black -fg green
+```
+
+这些会设置默认的前景和背景。如果有任何其他规则会控制特定文件或设备类型的颜色,那么就使用这些颜色。有关如何设置它们的信息,请参阅 [dircolors][5] 命令。
+
+你还可以使用 `-cr` 设置文本光标(而不是鼠标光标)的颜色:
+
+```
+$ urxvt -bg black -fg green -cr teal
+```
+
+![Setting color in urxvt][6]
+
+你的终端模拟器可能还有更多选项,如边框颜色(rxvt 中的 `-bd`)、光标闪烁(urxvt 中的 `-bc` 和 `+bc`),甚至背景透明度。请参阅终端的手册页,了解更多的功能。
+
+要使用你选择的颜色启动终端,你可以将选项添加到用于启动终端的命令或菜单中(例如,在你的 Fluxbox 菜单文件、`$HOME/.local/share/applications` 目录中的 `.desktop` 或者类似的)。或者,你可以使用 [xrdb][7] 工具来管理与 X 相关的资源(但这超出了本文的范围)。
+
+### 家是可定制的地方
+
+自定义 Linux 机器并不意味着你需要学习如何编程。你可以而且应该进行小而有意义的更改,来使你的数字家庭感觉更舒适。而且没有比终端更好的起点了!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/add-color-linux-terminal
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/terminal_command_linux_desktop_code.jpg?itok=p5sQ6ODE (Terminal command prompt on orange background)
+[2]: https://opensource.com/sites/default/files/uploads/gnome-terminal-preferences.jpg (GNOME Terminal preferences)
+[3]: https://opensource.com/article/19/7/master-ls-command
+[4]: https://opensource.com/sites/default/files/uploads/gnome-terminal-profile-select.jpg (GNOME Terminal profile selection)
+[5]: http://man7.org/linux/man-pages/man1/dircolors.1.html
+[6]: https://opensource.com/sites/default/files/uploads/urxvt-color.jpg (Setting color in urxvt)
+[7]: https://www.x.org/releases/X11R7.7/doc/man/man1/xrdb.1.xhtml
diff --git a/published/20190831 Google opens Android speech transcription and gesture tracking, Twitter-s telemetry tooling, Blender-s growing adoption, and more news.md b/published/20190831 Google opens Android speech transcription and gesture tracking, Twitter-s telemetry tooling, Blender-s growing adoption, and more news.md
new file mode 100644
index 0000000000..c6370eb975
--- /dev/null
+++ b/published/20190831 Google opens Android speech transcription and gesture tracking, Twitter-s telemetry tooling, Blender-s growing adoption, and more news.md
@@ -0,0 +1,88 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11292-1.html)
+[#]: subject: (Google opens Android speech transcription and gesture tracking, Twitter's telemetry tooling, Blender's growing adoption, and more news)
+[#]: via: (https://opensource.com/19/8/news-august-31)
+[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
+
+开源新闻综述:谷歌开源 Android 语音转录和手势追踪、Twitter 的遥测工具
+======
+
+> 不要错过两周以来最大的开源头条新闻。
+
+![Weekly news roundup with TV][1]
+
+在本期的开源新闻综述中,我们来看看谷歌发布的两个开源软件、Twitter 的最新可观测性工具、动漫工作室对 Blender 的采用在增多等等新闻!
+
+### 谷歌的开源双响炮
+
+搜索引擎巨头谷歌的开发人员最近一直忙于开源。在过去的两周里,他们以开源的方式发布了两个截然不同的软件。
+
+第一个是 Android 的语音识别和转录工具 Live Transcribe 的[语音引擎][2],它可以“在移动设备上使用机器学习算法将音频变成实时字幕”。谷歌的声明称,它正在开源 Live Transcribe 以“让所有开发人员可以为长篇对话提供字幕”。你可以[在 GitHub 上][3]浏览或下载 Live Transcribe 的源代码。
+
+谷歌还为 Android 和 iOS 开源了[手势跟踪软件][4],它建立在其 [MediaPipe][5] 机器学习框架之上。该软件结合了三种人工智能组件:手掌探测器、“返回 3D 手点”的模型和手势识别器。据谷歌研究人员称,其目标是改善“跨各种技术领域和平台的用户体验”。该软件的源代码和文档[可在 GitHub 上获得][6]。
+
+### Twitter 开源 Rezolus 遥测工具
+
+当想到网络中断时,我们想到的是影响站点或服务性能的大崩溃或减速。让我们感到惊讶的是性能慢慢被吃掉的小尖峰的重要性。为了更容易地检测这些尖峰,Twitter 开发了一个名为 Rezolus 的工具,该公司[已将其开源][7]。
+
+> 我们现有的按分钟采样的遥测技术未能反映出这些异常现象。这是因为相对于该异常发生的长度,较低的采样率掩盖了这些持续时间大约为 10 秒的异常。这使得很难理解正在发生的事情并调整系统以获得更高的性能。
+
+Rezolus 旨在检测“非常短暂但有时显著的性能异常”——仅持续几秒钟。Twitter 已经运行了 Rezolus 大约一年,并且一直在使用它收集的内容“与后端服务日志来确定峰值的来源”。
+
+如果你对将 Rezolus 添加到可观测性堆栈中的结果感到好奇,请查看 Twitter 的 [GitHub 存储库][8]中的源代码。
+
+### 日本的 Khara 动画工作室采用 Blender
+
+Blender 被认为是开源的动画和视觉效果软件的黄金标准。它被几家制作公司采用,其中最新的是[日本动漫工作室 Khara][9]。
+
+Khara 正在使用 Blender 开发 Evangelion: 3.0+1.0,这是基于流行动漫系列《Neon Genesis Evangelion》的电影系列的最新版本。虽然该电影的工作不能在 Blender 中全部完成,但 Khara 的员工“将从 2020 年 6 月开始使用 Blender 进行大部分工作”。为了强调其对 Blender 和开源的承诺,“Khara 宣布它将作为企业会员加入 Blender 基金会的发展基金。“
+
+### NSA 分享其固件安全工具
+
+继澳大利亚同行[共享他们的一个工具][10]之后,美国国家安全局(NSA)正在[提供][11]的一个项目的成果“可以更好地保护机器免受固件攻击“。这个最新的软件以及其他保护固件的开源工作可以在 [Coreboot Gerrit 存储库][12]下找到。
+
+这个名为“具有受保护执行的 SMI 传输监视器”(STM-PE)的软件“将与运行 Coreboot 的 x86 处理器配合使用”以防止固件攻击。根据 NSA 高级网络安全实验室的 Eugene Meyers 的说法,STM-PE 采用低级操作系统代码“并将其置于一个盒子中,以便它只能访问它需要访问的设备系统”。这有助于防止篡改,Meyers 说,“这将提高系统的安全性。”
+
+### 其它新闻
+
+* [Linux 内核中的 exFAT?是的!][13]
+* [瓦伦西亚继续支持 Linux 学校发行版][14]
+* [西班牙首个开源卫星][15]
+* [Western Digital 从开放标准到开源芯片的长途旅行][16]
+* [用于自动驾驶汽车多模传感器的 Waymo 开源数据集][17]
+
+一如既往地感谢 Opensource.com 的工作人员和主持人本周的帮助。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/19/8/news-august-31
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i (Weekly news roundup with TV)
+[2]: https://venturebeat.com/2019/08/16/google-open-sources-live-transcribes-speech-engine/
+[3]: https://github.com/google/live-transcribe-speech-engine
+[4]: https://venturebeat.com/2019/08/19/google-open-sources-gesture-tracking-ai-for-mobile-devices/
+[5]: https://github.com/google/mediapipe
+[6]: https://github.com/google/mediapipe/blob/master/mediapipe/docs/hand_tracking_mobile_gpu.md
+[7]: https://blog.twitter.com/engineering/en_us/topics/open-source/2019/introducing-rezolus.html
+[8]: https://github.com/twitter/rezolus
+[9]: https://www.neowin.net/news/anime-studio-khara-is-planning-to-use-open-source-blender-software/
+[10]: https://linux.cn/article-11241-1.html
+[11]: https://www.cyberscoop.com/nsa-firmware-open-source-coreboot-stm-pe-eugene-myers/
+[12]: https://review.coreboot.org/admin/repos
+[13]: https://cloudblogs.microsoft.com/opensource/2019/08/28/exfat-linux-kernel/
+[14]: https://joinup.ec.europa.eu/collection/open-source-observatory-osor/news/120000-lliurex-desktops
+[15]: https://hackaday.com/2019/08/15/spains-first-open-source-satellite/
+[16]: https://www.datacenterknowledge.com/open-source/western-digitals-long-trip-open-standards-open-source-chips
+[17]: https://venturebeat.com/2019/08/21/waymo-open-sources-data-set-for-autonomous-vehicle-multimodal-sensors/
diff --git a/published/20190903 5 open source speed-reading applications.md b/published/20190903 5 open source speed-reading applications.md
new file mode 100644
index 0000000000..ef922bf1e8
--- /dev/null
+++ b/published/20190903 5 open source speed-reading applications.md
@@ -0,0 +1,93 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11316-1.html)
+[#]: subject: (5 open source speed-reading applications)
+[#]: via: (https://opensource.com/article/19/8/speed-reading-open-source)
+[#]: author: (Jaouhari Youssef https://opensource.com/users/jaouhari)
+
+5 个开源的速读应用
+======
+
+> 使用这五个应用训练自己更快地阅读文本。
+
+
+
+英国散文家和政治家 [Joseph Addison][2] 曾经说过,“读书益智,运动益体。”如今,我们大多数人(如果不是全部)都是通过计算机显示器、电视屏幕、移动设备、街道标志、报纸、杂志上阅读,以及在工作场所和学校阅读论文来训练我们的大脑。
+
+鉴于我们每天都会收到大量的书面信息,通过做一些挑战我们经典的阅读习惯并教会我们吸收更多内容和数据的特定练习,来训练我们的大脑以便更快地阅读似乎是有利的。学习这些技能的目的不仅仅是浏览文本,因为没有理解的阅读就是浪费精力。目标是提高你的阅读速度,同时仍然达到高水平的理解。
+
+### 阅读和处理输入
+
+在深入探讨速读之前,让我们来看看阅读过程。根据法国眼科医生 Louis Emile Javal 的说法,阅读分为三个步骤:
+
+ 1. 固定
+ 2. 处理
+ 3. [扫视][3]
+
+在第一步,我们确定文本中的固定点,称为最佳识别点。在第二步中,我们在眼睛固定的同时引入(处理)新信息。最后,我们改变注视点的位置,这是一种称为扫视的操作,此时未获取任何新信息。
+
+在实践中,阅读更快的读者之间的主要差异是固定时间短于平均值,更长距离扫视,重读更少。
+
+### 阅读练习
+
+阅读不是人类的自然过程,因为它是人类生存跨度中一个相当新的发展。第一个书写系统是在大约 5000 年前创建的,它不足以让人们发展成为阅读机器。因此,我们必须运用我们的阅读技巧,在这项沟通的基本任务中变得更加娴熟和高效。
+
+第一项练习包括减少默读,也被称为无声语音,这是一种在阅读时内部发音的习惯。它是一个减慢阅读速度的自然过程,因为阅读速度限于语速。减少默读的关键是只说出一些阅读的单词。一种方法是用其他任务来占据内部声音,例如用口香糖。
+
+第二个练习包括减少回归,或称为重读。回归是一种懒惰的机制,因为我们的大脑可以随时重读任何材料,从而降低注意力。
+
+### 5 个开源应用来训练你的大脑
+
+有几个有趣的开源应用可用于锻炼你的阅读速度。
+
+一个是 [Gritz][4],它是一个开源文件阅读器,它一次一个地弹出单词,以减少回归。它适用于 Linux、Windows 和 MacOS,并在 GPL 许可证下发布,因此你可以随意使用它。
+
+其他选择包括 [Spray Speed-Reader][5],一个用 JavaScript 编写的开源速读应用,以及 [Sprits-it!][6],一个开源 Web 应用,可以快速阅读网页。
+
+对于 Android 用户,[Comfort Reader][7] 是一个开源的速读应用。它可以在 [F-droid][8] 和 [Google Play][9] 应用商店中找到。
+
+我最喜欢的应用是 [Speedread][10],它是一个简单的终端程序,它可以在最佳阅读点逐字显示文本。要安装它,请在你的设备上克隆 Github 仓库,然后输入相应的命令来选择以喜好的每分钟字数 (WPM)来阅读文档。默认速率为 250 WPM。例如,要以 400 WPM 阅读 `your_text_file.txt`,你应该输入:
+
+```
+`cat your_text_file.txt | ./speedread -w 400`
+```
+
+下面是该程序的运行界面:
+
+![Speedread demo][11]
+
+由于你可能不会只阅读[纯文本][12],因此可以使用 [Pandoc][13] 将文件从标记格式转换为文本格式。你还可以使用 Android 终端模拟器 [Termux][14] 在 Android 设备上运行 Speedread。
+
+### 其他方案
+
+对于开源社区来说,构建一个解决方案是一个有趣的项目,它仅为了通过使用特定练习来提高阅读速度,以此改进如默读和重读。我相信这个项目会非常有益,因为在当今信息丰富的环境中,提高阅读速度非常有价值。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/speed-reading-open-source
+
+作者:[Jaouhari Youssef][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jaouhari
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/books_stack_library_reading.jpg?itok=uulcS8Sw (stack of books)
+[2]: https://en.wikipedia.org/wiki/Joseph_Addison
+[3]: https://en.wikipedia.org/wiki/Saccade
+[4]: https://github.com/jeffkowalski/gritz
+[5]: https://github.com/chaimpeck/spray
+[6]: https://github.com/the-happy-hippo/sprits-it
+[7]: https://github.com/mschlauch/comfortreader
+[8]: https://f-droid.org/packages/com.mschlauch.comfortreader/
+[9]: https://play.google.com/store/apps/details?id=com.mschlauch.comfortreader
+[10]: https://github.com/pasky/speedread
+[11]: https://opensource.com/sites/default/files/uploads/speedread_demo.gif (Speedread demo)
+[12]: https://plaintextproject.online/
+[13]: https://opensource.com/article/18/9/intro-pandoc
+[14]: https://termux.com/
diff --git a/published/20190903 The birth of the Bash shell.md b/published/20190903 The birth of the Bash shell.md
new file mode 100644
index 0000000000..8102b01097
--- /dev/null
+++ b/published/20190903 The birth of the Bash shell.md
@@ -0,0 +1,102 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11314-1.html)
+[#]: subject: (The birth of the Bash shell)
+[#]: via: (https://opensource.com/19/9/command-line-heroes-bash)
+[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberg)
+
+Bash shell 的诞生
+======
+
+> 本周的《代码英雄》播客深入研究了最广泛使用的、已经成为事实标准的脚本语言,它来自于自由软件基金会及其作者的早期灵感。
+
+![Listen to the Command Line Heroes Podcast][1]
+
+对于任何从事于系统管理员方面的人来说,Shell 脚本编程是一门必不可少的技能,而如今人们编写脚本的主要 shell 是 Bash。Bash 是几乎所有的 Linux 发行版和现代 MacOS 版本的默认配置,也很快就会成为 [Windows 终端][2]的原生部分。你可以说 Bash 无处不在。
+
+那么它是如何做到这一点的呢?本周的《[代码英雄][3]》播客将通过询问编写那些代码的人来深入研究这个问题。
+
+### 肇始于 Unix
+
+像所有编程方面的东西一样,我们必须追溯到 Unix。shell 的简短历史是这样的:1971 年,Ken Thompson 发布了第一个 Unix shell:Thompson shell。但是,脚本用户所能做的存在严重限制,这意味着严重制约了自动化以及整个 IT 运营领域。
+
+这个[奇妙的研究][4]概述了早期尝试脚本的挑战:
+
+> 类似于它在 Multics 中的前身,这个 shell(`/bin/sh`)是一个在内核外执行的独立用户程序。诸如通配(参数扩展的模式匹配,例如 `*.txt`)之类的概念是在一个名为 `glob` 的单独的实用程序中实现的,就像用于计算条件表达式的 `if` 命令一样。这种分离使 shell 变得更小,才不到 900 行的 C 源代码。
+>
+> shell 引入了紧凑的重定向(`<`、`>` 和 `>>`)和管道(`|` 或 `^`)语法,它们已经存在于现代 shell 中。你还可以找到对调用顺序命令(`;`)和异步命令(`&`)的支持。
+>
+> Thompson shell 缺少的是编写脚本的能力。它的唯一目的是作为一个交互式 shell(命令解释器)来调用命令和查看结果。
+
+随着对终端使用的增长,对自动化的兴趣随之增长。
+
+### Bourne shell 前进一步
+
+在 Thompson 发布 shell 六年后,1977 年,Stephen Bourne 发布了 Bourne shell,旨在解决Thompson shell 中的脚本限制。(Chet Ramey 是自 1990 年以来 Bash 语言的主要维护者,在这一集的《代码英雄》中讨论了它)。作为 Unix 系统的一部分,这是这个来自贝尔实验室的技术的自然演变。
+
+Bourne 打算做什么不同的事情?[研究员 M. Jones][4] 很好地概述了它:
+
+> Bourne shell 有两个主要目标:作为命令解释器以交互方式执行操作系统的命令,和用于脚本编程(编写可通过 shell 调用的可重用脚本)。除了替换 Thompson shell,Bourne shell 还提供了几个优于其前辈的优势。Bourne 将控制流、循环和变量引入脚本,提供了更具功能性的语言来(以交互式和非交互式)与操作系统交互。该 shell 还允许你使用 shell 脚本作为过滤器,为处理信号提供集成支持,但它缺乏定义函数的能力。最后,它结合了我们今天使用的许多功能,包括命令替换(使用后引号)和 HERE 文档(以在脚本中嵌入保留的字符串文字)。
+
+Bourne 在[之前的一篇采访中][5]这样描述它:
+
+> 最初的 shell (编程语言)不是一种真正的语言;它是一种记录 —— 一种从文件中线性执行命令序列的方法,唯一的控制流的原语是 `GOTO` 到一个标签。Ken Thompson 所编写的这个最初的 shell 的这些限制非常重要。例如,你无法简单地将命令脚本用作过滤器,因为命令文件本身是标准输入。而在过滤器中,标准输入是你从父进程继承的,不是命令文件。
+>
+> 最初的 shell 很简单,但随着人们开始使用 Unix 进行应用程序开发和脚本编写,它就太有限了。它没有变量、它没有控制流,而且它的引用能力非常不足。
+
+对于脚本编写者来说,这个新 shell 是一个巨大的进步,但前提是你可以使用它。
+
+### 以自由软件来重新构思 Bourne Shell
+
+在此之前,这个占主导地位的 shell 是由贝尔实验室拥有和管理的专有软件。幸运的话,你的大学可能有权访问 Unix shell。但这种限制性访问远非自由软件基金会(FSF)想要实现的世界。
+
+Richard Stallman 和一群志同道合的开发人员那时正在编写所有的 Unix 功能,其带有可以在 GNU 许可证下免费获得的许可。其中一个开发人员的任务是制作一个 shell,那位开发人员是 Brian Fox。他对他的任务的讲述十分吸引我。正如他在播客上所说:
+
+> 它之所以如此具有挑战性,是因为我们必须忠实地模仿 Bourne shell 的所有行为,同时允许扩展它以使其成为一个供人们使用的更好工具。
+
+而那时也恰逢人们在讨论 shell 标准是什么的时候。在这一历史背景和将来的竞争前景下,流行的 Bourne shell 被重新构想,并再次重生。
+
+### 重新打造 Bourne Shell
+
+自由软件的使命和竞争这两个催化剂使重制的 Bourne shell(Bash)具有了生命。和之前不同的是,Fox 并没有把 shell 放到自己的名字之后命名,他专注于从 Unix 到自由软件的演变。(虽然 Fox Shell 这个名字看起来要比 Fish shell 更适合作为 fsh 命令 #missedopportunity)。这个命名选择似乎符合他的个性。正如 Fox 在剧集中所说,他甚至对个人的荣耀也不感兴趣;他只是试图帮助编程文化发展。然而,他并不是一个优秀的双关语。
+
+而 Bourne 也并没有因为他命名 shell 的文字游戏而感到被轻视。Bourne 讲述了一个故事,有人走到他面前,并在会议上给了他一件 Bash T 恤,而那个人是 Brian Fox。
+
+Shell | 发布于 | 创造者
+---|---|---
+Thompson Shell | 1971 | Ken Thompson
+Bourne Shell | 1977 | Stephen Bourne
+Bourne-Again Shell | 1989 | Brian Fox
+
+随着时间的推移,Bash 逐渐成长。其他工程师开始使用它并对其设计进行改进。事实上,多年后,Fox 坚定地认为学会放弃控制 Bash 是他一生中最重要的事情之一。随着 Unix 让位于 Linux 和开源软件运动,Bash 成为开源世界的至关重要的脚本语言。这个伟大的项目似乎超出了单一一个人的愿景范围。
+
+### 我们能从 shell 中学到什么?
+
+shell 是一项技术,它是笔记本电脑日常使用中的一个组成部分,你很容易忘记它也需要发明出来。从 Thompson 到 Bourne 再到 Bash,shell 的故事为我们描绘了一些熟悉的结论:
+
+* 有动力的人可以在正确的使命中取得重大进展。
+* 我们今天所依赖的大部分内容都建立在我们行业中仍然活着的那些传奇人物打下的基础之上。
+* 能够生存下来的软件超越了其原始创作者的愿景。
+
+代码英雄在全部的第三季中讲述了编程语言,并且正在接近它的尾声。[请务必订阅,来了解你想知道的有关编程语言起源的各种内容][3],我很乐意在下面的评论中听到你的 shell 故事。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/19/9/command-line-heroes-bash
+
+作者:[Matthew Broberg][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberg
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/commnad_line_hereoes_ep6_blog-header-292x521.png?itok=Bs1RlwoW (Listen to the Command Line Heroes Podcast)
+[2]: https://devblogs.microsoft.com/commandline/introducing-windows-terminal/
+[3]: https://www.redhat.com/en/command-line-heroes
+[4]: https://developer.ibm.com/tutorials/l-linux-shells/
+[5]: https://www.computerworld.com.au/article/279011/-z_programming_languages_bourne_shell_sh
diff --git a/sources/news/20190831 Endless Grants -500,000 Fund To GNOME Foundation-s Coding Education Challenge.md b/sources/news/20190831 Endless Grants -500,000 Fund To GNOME Foundation-s Coding Education Challenge.md
new file mode 100644
index 0000000000..1ab956abc6
--- /dev/null
+++ b/sources/news/20190831 Endless Grants -500,000 Fund To GNOME Foundation-s Coding Education Challenge.md
@@ -0,0 +1,65 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Endless Grants $500,000 Fund To GNOME Foundation’s Coding Education Challenge)
+[#]: via: (https://itsfoss.com/endless-gnome-coding-education-challenge/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Endless Grants $500,000 Fund To GNOME Foundation’s Coding Education Challenge
+======
+
+The [GNOME foundation][1] recently announced the “**Coding Education Challenge**“, which is a three-stage competition to offer educators and students the opportunity to share their innovative ideas (projects) to teach coding with free and open-source software.
+
+For the funding (that covers the reward), [Endless][2] has issued a $500,000 (half a million) grant to support the competition and attract more educators/students from across the world. Yes, that is a whole lot of money to be awarded to the team (or individual) that wins the competition.
+
+In case you didn’t know about **Endless**, here’s a background for you – _they work on increasing digital access to children and help them to make the most out of it while also educating them about it_. Among other projects, they have [Endless OS Linux distribution][3]. They also have [inexpensive mini PCs running Linux][4] to help their educational projects.
+
+In the [press release][5], **Neil McGovern**, Executive Director, GNOME Foundation mentioned:
+
+> “We’re very grateful that Endless has come forward to provide more opportunities for individuals to learn about free and open-source ”
+
+He also added:
+
+> “We’re excited to see what can be achieved when we empower the creativity and imagination of our global community. We hope to make powerful partnerships between students and educators to explore the possibilities of our rich and diverse software ecosystem. Reaching the next generation of developers is crucial to ensuring that free software continues for many years in the future.”
+
+**Matt Dalio**, founder of Endless, also shared his thoughts about this competition:
+
+> “We fully believe in GNOME’s mission of making technology available and providing the tools of digital agency to all. What’s so unique about the GNOME Project is that it delivers a fully-working personal computer system, which is a powerful real-world vehicle to teach kids to code. There are so many potential ways for this competition to build flourishing ecosystems that empower the next generation to create, learn and build.”
+
+In addition to the announcement of competition and the grant, we do not have more details. However, anyone can submit a proposal for the competition (an individual or a team). Also, it has been decided that there will be 20 winners for the first round and will be rewarded **$6500** each for their ideas.
+
+[][6]
+
+Suggested read StationX Announces New Laptop Customized for Manjaro Linux
+
+For the second stage of the competition, the winners will be asked to provide a working prototype from which 5 winners will be filtered to get **$25,000** each as the prize money.
+
+In the final stage will involve making an end-product where only two winners will be selected. The runners up shall get **$25,000** and the winner walks away with **$100,000**.
+
+_**Wrapping Up**_
+
+I’d love to watch out for more details on ‘Coding Education Challenge’ by GNOME Foundation. We shall update this article for more details on the competition.
+
+While the grant makes it look like a great initiative by GNOME Foundation, what do you think about it? Feel free to share your thoughts in the comments below.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/endless-gnome-coding-education-challenge/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://www.gnome.org/
+[2]: https://endlessnetwork.com/
+[3]: https://endlessos.com/home/
+[4]: https://endlessos.com/computers/
+[5]: https://www.gnome.org/news/2019/08/gnome-foundation-launches-coding-education-challenge/
+[6]: https://itsfoss.com/stationx-manjaro-linux/
diff --git a/sources/news/20190905 Exploit found in Supermicro motherboards could allow for remote hijacking.md b/sources/news/20190905 Exploit found in Supermicro motherboards could allow for remote hijacking.md
new file mode 100644
index 0000000000..6d2b48755b
--- /dev/null
+++ b/sources/news/20190905 Exploit found in Supermicro motherboards could allow for remote hijacking.md
@@ -0,0 +1,72 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Exploit found in Supermicro motherboards could allow for remote hijacking)
+[#]: via: (https://www.networkworld.com/article/3435123/exploit-found-in-supermicro-motherboards-could-allow-for-remote-hijacking.html)
+[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
+
+Exploit found in Supermicro motherboards could allow for remote hijacking
+======
+The vulnerability impacts three models of Supermicro motherboards. Fortunately, a fix is already available.
+IDG / Thinkstock
+
+A security group discovered a vulnerability in three models of Supermicro motherboards that could allow an attacker to remotely commandeer the server. Fortunately, a fix is already available.
+
+Eclypsium, which specializes in firmware security, announced in its blog that it had found a set of flaws in the baseboard management controller (BMC) for three different models of Supermicro server boards: the X9, X10, and X11.
+
+**[ Also see: [What to consider when deploying a next-generation firewall][1] | Get regularly scheduled insights: [Sign up for Network World newsletters][2] ]**
+
+BMCs are designed to permit administrators remote access to the computer so they can do maintenance and other updates, such as firmware and operating system patches. It’s meant to be a secure port into the computer while at the same time walled off from the rest of the server.
+
+Normally BMCs are locked down within the network in order to prevent this kind of malicious access in the first place. In some cases, BMCs are left open to the internet so they can be accessed from a web browser, and those interfaces are not terribly secure. That’s what Eclypsium found.
+
+For its BMC management console, Supermicro uses an app called virtual media application. This application allows admins to remotely mount images from USB devices and CD or DVD-ROM drives.
+
+When accessed remotely, the virtual media service allows for plaintext authentication, sends most of the traffic unencrypted, uses a weak encryption algorithm for the rest, and is susceptible to an authentication bypass, [according to Eclypsium][3].
+
+Eclypsium was more diplomatic than I, so I’ll say it: Supermicro was sloppy.
+
+**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][4] ]**
+
+These issues allow an attacker to easily gain access to a server, either by capturing a legitimate user’s authentication packet, using default credentials, and in some cases, without any credentials at all.
+
+"This means attackers can attack the server in the same way as if they had physical access to a USB port, such as loading a new operating system image or using a keyboard and mouse to modify the server, implant malware, or even disable the device entirely," Eclypsium wrote in its blog post.
+
+All told, the team found four different flaws within the virtual media service of the BMC's web control interface.
+
+### How an attacker could exploit the Supermicro flaws
+
+According to Eclypsium, the easiest way to attack the virtual media flaws is to find a server with the default login or brute force an easily guessed login (root or admin). In other cases, the flaws would have to be targeted.
+
+Normally, access to the virtual media service is conducted by a small Java application served on the BMC’s web interface. This application then connects to the virtual media service listening on TCP port 623 on the BMC. A scan by Eclypsium on port 623 turned up 47,339 exposed BMCs around the world.
+
+Eclypsium did the right thing and contacted Supermicro and waited for the vendor to release [an update to fix the vulnerabilities][5] before going public. Supermicro thanked Eclypsium for not only bringing this issue to its attention but also helping validate the fixes.
+
+Eclypsium is on quite the roll. In July it disclosed BMC [vulnerabilities in motherboards from Lenovo, Gigabyte][6] and other vendors, and last month it [disclosed flaws in 40 device drivers][7] from 20 vendors that could be exploited to deploy malware.
+
+Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3435123/exploit-found-in-supermicro-motherboards-could-allow-for-remote-hijacking.html
+
+作者:[Andy Patrizio][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Andy-Patrizio/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html
+[2]: https://www.networkworld.com/newsletters/signup.html
+[3]: https://eclypsium.com/2019/09/03/usbanywhere-bmc-vulnerability-opens-servers-to-remote-attack/
+[4]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
+[5]: https://www.supermicro.com/support/security_BMC_virtual_media.cfm
+[6]: https://eclypsium.com/2019/07/16/vulnerable-firmware-in-the-supply-chain-of-enterprise-servers/
+[7]: https://eclypsium.com/2019/08/10/screwed-drivers-signed-sealed-delivered/
+[8]: https://www.facebook.com/NetworkWorld/
+[9]: https://www.linkedin.com/company/network-world
diff --git a/sources/news/20190905 USB4 gets final approval, offers Ethernet-like speed.md b/sources/news/20190905 USB4 gets final approval, offers Ethernet-like speed.md
new file mode 100644
index 0000000000..5c17746eb5
--- /dev/null
+++ b/sources/news/20190905 USB4 gets final approval, offers Ethernet-like speed.md
@@ -0,0 +1,59 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (USB4 gets final approval, offers Ethernet-like speed)
+[#]: via: (https://www.networkworld.com/article/3435113/usb4-gets-final-approval-offers-ethernet-like-speed.html)
+[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
+
+USB4 gets final approval, offers Ethernet-like speed
+======
+USB4 could be a unifying interface that eliminates bulky cables and oversized plugs and provides throughput that satisfies everyone laptop users to server administrators.
+Intel
+
+The USB Implementers Forum (USB-IF), the industry consortium behind the development of the Universal Serial Bus (USB) specification, announced this week it has finalized the technical specifications for USB4, the next generation of the spec.
+
+One of the most important aspects of USB4 (they have dispensed with the space between the acronym and the version number with this release) is that it merges USB with Thunderbolt 3, an Intel-designed interface that hasn’t really caught on outside of laptops despite its potential. For that reason, Intel gave the Thunderbolt spec to the USB consortium.
+
+Unfortunately, Thunderbolt 3 is listed as an option for USB4 devices, so some will have it and some won’t. This will undoubtedly cause headaches, and hopefully all device makers will include Thunderbolt 3.
+
+**[ Also read: [Your hardware order is ready. Do you want cables with that?][1] ]**
+
+USB4 will use the same form factor as USB type-C, the small plug used in all modern Android phones and by Thunderbolt 3. It will be backwards compatible with USB 3.2, USB 2.0, as well as Thunderbolt. So, just about any existing USB type-C device can connect to a machine featuring a USB4 bus but will run at the connecting cable’s rated speed.
+
+### USB4: Less bulk, more speed
+
+Because it supports Thunderbolt 3, the new connection will support both data and display protocols, so this could mean the small USB-C port replacing the big, bulky DVI port on monitors, and monitors coming with multiple USB4 ports to act as a hub.
+
+Which gets to the main point of the new standard: It offers dual-lane 40Gbps transfer speed, double the rate of USB 3.2, which is the current spec, and eight times that of USB 3. That’s Ethernet speed and should be more than enough to keep your high-definition monitor fed with plenty of bandwidth for other data movement.
+
+USB4 also has better resource allocation for video, so if you use a USB4 port to move video and data at the same time, the port will allocate bandwidth accordingly. This will allow a computer to use both an external GPU in a self-contained case, which have come to market only because of Thunderbolt 3, and an external SSD.
+
+**[ [Get certified as an Apple Technical Coordinator with this seven-part online course from PluralSight.][2] ]**
+
+This could open up all kinds of new server designs because large, bulky devices, such as GPUs or other cards that won’t go easily into a 1U or 2U case, can now be externally attached and run at speeds comparable to an internal device.
+
+Of course, it will be a while before we see PCs with USB4 ports, never mind servers. It took years to get USB 3 into PCs, and uptake for USB-C has been very slow. USB 2 thumb drives are still the bulk of the market for those devices, and motherboards are still shipping with USB 2 on them.
+
+Still, USB4 has the potential to be a unifying interface that gets rid of bulky cables that have oversized plugs and provides throughput that can satisfy everyone from a laptop user to a server administrator.
+
+Join the Network World communities on [Facebook][3] and [LinkedIn][4] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3435113/usb4-gets-final-approval-offers-ethernet-like-speed.html
+
+作者:[Andy Patrizio][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Andy-Patrizio/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3278052/your-hardware-order-is-ready-do-you-want-cables-with-that.html
+[2]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
+[3]: https://www.facebook.com/NetworkWorld/
+[4]: https://www.linkedin.com/company/network-world
diff --git a/sources/news/20190906 Great News- Firefox 69 Blocks Third-Party Cookies, Autoplay Videos - Cryptominers by Default.md b/sources/news/20190906 Great News- Firefox 69 Blocks Third-Party Cookies, Autoplay Videos - Cryptominers by Default.md
new file mode 100644
index 0000000000..1cb11a5e59
--- /dev/null
+++ b/sources/news/20190906 Great News- Firefox 69 Blocks Third-Party Cookies, Autoplay Videos - Cryptominers by Default.md
@@ -0,0 +1,96 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Great News! Firefox 69 Blocks Third-Party Cookies, Autoplay Videos & Cryptominers by Default)
+[#]: via: (https://itsfoss.com/firefox-69/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Great News! Firefox 69 Blocks Third-Party Cookies, Autoplay Videos & Cryptominers by Default
+======
+
+If you’re using [Mozilla Firefox][1] and haven’t updated yet to the latest version, you are missing a lot of new and important features.
+
+### Awesome new features in Firefox 69 release
+
+To start with, Mozilla Firefox 69 enforces stronger security and privacy options by default. Here are some of the major highlights of the new release.
+
+#### Firefox 69 blocks autoplay videos
+
+![][2]
+
+A lot of websites offer auto-play videos nowadays. No matter whether it is a pop-up video or a video embedded in an article set to autoplay, it is blocked by default (or you may be prompted about it).
+
+The [Block Autoplay][3] feature gives users to block any video playing automatically.
+
+#### No more third party tracking cookies
+
+By default, as part of the Enhanced Tracking Protection feature, it will now block third-party tracking cookies and crypto miners. This is a very useful change to enhance privacy protection while using Mozilla Firefox.
+
+There are two kind of cookies: first party and third party. The first party cookies are owned by the website itself. These are the ‘good cookies’ that improve your browsing experience by keeping you logged in, remembering your password or entry fields etc. The third party cookies are owned by domains other than the website you visit. Ad servers use these cookies to track you and serve you tracking ads on all the website you visit. Firefox 69 aims to block these.
+
+You will observe the shield icon in the address bar when it’s active. You may choose to disable it for specific websites.
+
+![Firefox Blocking Tracking][4]
+
+#### No more cryptomining off your CPU
+
+![][5]
+
+The lust for cryptocurrency has plagued the world. The cost of GPU has gone high because the professional cryptominers use them for mining cryptocurrency.
+
+People are using computers at work to secretly mine cryptocurrency. And when I say work, I don’t necessarily mean an IT company. Only this year, [people got caught mining cryptocurency at a nuclear plant in Ukrain][6][.][6]
+
+That’s not it. If you visit some websites, they run scripts and use your computer’s CPU to mine cryptocurrency. This is called [cryptojacking][7] in IT terms.
+
+The good thing is that Firefox 69 will automatically blocking cryptominers. So websites should not be able to exploit your system resources for cryptojacking.
+
+#### Stronger Privacy with Firefox 69
+
+![][8]
+
+If you take it up a notch with a stricter setting, it will block fingerprinters as well. So, you won’t have to worry about sharing your computer’s configuration info via [fingerprinters][9] when you choose the strict privacy setting in Firefox 69.
+
+In the [official blog post about the release][10], Mozilla mentions that with this release, they expect to provide protection for 100% of our users by default.
+
+#### Performance Improvements
+
+Even though Linux hasn’t been mentioned in the changelog – it mentions performance, UI, and battery life improvements for systems running on Windows 10/mac OS. If you observe any performance improvements, do mention it in comments.
+
+**Wrapping Up**
+
+In addition to all these, there’s a lot of under-the-hood improvements as well. You can check out the details in the [release notes][11].
+
+Firefox 69 is an impressive update for users concerned about their privacy. Similar to our recommendation on some of the [secure email services][12] recently, we recommend you to update your browser to get the best out of it. The new update is already available in most Linux distributions. You just have to update your system.
+
+If you are interested in browsers that block ads and tracking cookies, try [open source Brave browser][13]. They are even giving you their own cryptocurrency for using their web browser. You can use it to reward your favorite publishers.
+
+What do you think about this release? Let us know your thoughts in the comments below.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/firefox-69/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/why-firefox/
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/auto-block-firefox.png?ssl=1
+[3]: https://support.mozilla.org/en-US/kb/block-autoplay
+[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/firefox-blocking-tracking.png?ssl=1
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/firefox-shield.png?ssl=1
+[6]: https://thenextweb.com/hardfork/2019/08/22/ukrainian-nuclear-powerplant-mine-cryptocurrency-state-secrets/
+[7]: https://hackernoon.com/cryptojacking-in-2019-is-not-dead-its-evolving-984b97346d16
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/firefox-secure.jpg?ssl=1
+[9]: https://clearcode.cc/blog/device-fingerprinting/
+[10]: https://blog.mozilla.org/blog/2019/09/03/todays-firefox-blocks-third-party-tracking-cookies-and-cryptomining-by-default/
+[11]: https://www.mozilla.org/en-US/firefox/69.0/releasenotes/
+[12]: https://itsfoss.com/secure-private-email-services/
+[13]: https://itsfoss.com/brave-web-browser/
diff --git a/sources/talk/20190805 Is your enterprise software committing security malpractice.md b/sources/talk/20190805 Is your enterprise software committing security malpractice.md
deleted file mode 100644
index 9ab039b6e9..0000000000
--- a/sources/talk/20190805 Is your enterprise software committing security malpractice.md
+++ /dev/null
@@ -1,80 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (hopefully2333)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Is your enterprise software committing security malpractice?)
-[#]: via: (https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html)
-[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
-
-Is your enterprise software committing security malpractice?
-======
-ExtraHop discovered enterprise security and analytic software are "phoning home" and quietly uploading information to servers outside of customers' networks.
-![Getty Images][1]
-
-Back when this blog was dedicated to all things Microsoft I routinely railed against the spying aspects of Windows 10. Well, apparently that’s nothing compared to what enterprise security, analytics, and hardware management tools are doing.
-
-An analytics firm called ExtraHop examined the networks of its customers and found that their security and analytic software was quietly uploading information to servers outside of the customer's network. The company issued a [report and warning][2] last week.
-
-ExtraHop deliberately chose not to name names in its four examples of enterprise security tools that were sending out data without warning the customer or user. A spokesperson for the company told me via email, “ExtraHop wants the focus of the report to be the trend, which we have observed on multiple occasions and find alarming. Focusing on a specific group would detract from the broader point that this important issue requires more attention from enterprises.”
-
-**[ For more on IoT security, read [tips to securing IoT on your network][3] and [10 best practices to minimize IoT security vulnerabilities][4]. | Get regularly scheduled insights by [signing up for Network World newsletters][5]. ]**
-
-### Products committing security malpractice and secretly transmitting data offsite
-
-[ExtraHop's report][6] found a pretty broad range of products secretly phoning home, including endpoint security software, device management software for a hospital, surveillance cameras, and security analytics software used by a financial institution. It also noted the applications may run afoul of Europe’s [General Data Privacy Regulation (GDPR)][7].
-
-In every case, ExtraHop provided evidence that the software was transmitting data offsite. In one case, a company noticed that approximately every 30 minutes, a network-connected device was sending UDP traffic out to a known bad IP address. The device in question was a Chinese-made security camera that was phoning home to a known malicious IP address with ties to China.
-
-And the camera was likely set up independently by an employee at their office for personal security purposes, showing the downside to shadow IT.
-
-In the cases of the hospital's device management tool and the financial firm's analytics tool, those were violations of data security laws and could expose the company to legal risks even though it was happening without their knowledge.
-
-**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][8] ]**
-
-The hospital’s medical device management product was supposed to use the hospital’s Wi-Fi network to only ensure patient data privacy and HIPAA compliance. ExtraHop noticed traffic from the workstation that was managing initial device rollout was opening encrypted SSL:443 connections to vendor-owned cloud storage, a major HIPAA violation.
-
-ExtraHop notes that while there may not be any malicious activity in these examples, it is still in violation of the law, and administrators need to keep an eye on their networks to monitor traffic for unusual activity.
-
-"To be clear, we don’t know why these vendors are phoning home data. The companies are all respected security and IT vendors, and in all likelihood, their phoning home of data was either for a legitimate purpose given their architecture design or the result of a misconfiguration," the report says.
-
-### How to mitigate phoning-home security risks
-
-To address this security malpractice problem, ExtraHop suggests companies do these five things:
-
- * Monitor for vendor activity: Watch for unexpected vendor activity on your network, whether they are an active vendor, a former vendor or even a vendor post-evaluation.
- * Monitor egress traffic: Be aware of egress traffic, especially from sensitive assets such as domain controllers. When egress traffic is detected, always match it to approved applications and services.
- * Track deployment: While under evaluation, track deployments of software agents.
- * Understand regulatory considerations: Be informed about the regulatory and compliance considerations of data crossing political and geographic boundaries.
- * Understand contract agreements: Track whether data is used in compliance with vendor contract agreements.
-
-
-
-**[ Now read this: [Network World's corporate guide to addressing IoT security][9] ]**
-
-Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
-
---------------------------------------------------------------------------------
-
-via: https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html
-
-作者:[Andy Patrizio][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.networkworld.com/author/Andy-Patrizio/
-[b]: https://github.com/lujun9972
-[1]: https://images.idgesg.net/images/article/2018/03/cybersecurity_eye-with-binary_face-recognition_abstract-eye-100751589-large.jpg
-[2]: https://www.extrahop.com/company/press-releases/2019/extrahop-issues-warning-about-phoning-home/
-[3]: https://www.networkworld.com/article/3254185/internet-of-things/tips-for-securing-iot-on-your-network.html#nww-fsb
-[4]: https://www.networkworld.com/article/3269184/10-best-practices-to-minimize-iot-security-vulnerabilities#nww-fsb
-[5]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
-[6]: https://www.extrahop.com/resources/whitepapers/eh-security-advisory-calling-home-success/
-[7]: https://www.csoonline.com/article/3202771/general-data-protection-regulation-gdpr-requirements-deadlines-and-facts.html
-[8]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
-[9]: https://www.networkworld.com/article/3269165/internet-of-things/a-corporate-guide-to-addressing-iot-security-concerns.html
-[10]: https://www.facebook.com/NetworkWorld/
-[11]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190825 Top 5 IoT networking security mistakes.md b/sources/talk/20190825 Top 5 IoT networking security mistakes.md
deleted file mode 100644
index 7620ceae62..0000000000
--- a/sources/talk/20190825 Top 5 IoT networking security mistakes.md
+++ /dev/null
@@ -1,68 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (Morisun029)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Top 5 IoT networking security mistakes)
-[#]: via: (https://www.networkworld.com/article/3433476/top-5-iot-networking-security-mistakes.html)
-[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
-
-Top 5 IoT networking security mistakes
-======
-IT supplier Brother International shares five of the most common internet-of-things security errors it sees among buyers of its printers and multi-function devices.
-![Getty Images][1]
-
-Even though [Brother International][2] is a supplier of many IT products, from [machine tools][3] to [head-mounted displays][4] to [industrial sewing machines][5], it’s best known for printers. And in today’s world, those printers are no longer stand-alone devices, but components of the internet of things.
-
-That’s why I was interested in this list from Robert Burnett, Brother’s director, B2B product & solution – basically, the company’s point man for large customer implementations. Not surprisingly, Burnett focuses on IoT security mistakes related to printers and also shares Brother’s recommendations for dealing with the top five.
-
-## #5: Not controlling access and authorization
-
-“In the past,” Burnett says, “cost control was the driving force behind managing who can use a machine and when their jobs are released.” That’s still important, of course, but Burnett says security is quickly becoming the key reason to put management controls on print and scan devices. That’s true not just for large enterprises, he notes, but for businesses of all sizes.
-
-[INSIDER: 5 ways to prepare for Internet of Things security threats][6]
-
-## #4: Failure to update firmware regularly
-
-Let’s face it, most IT professionals stay plenty busy keeping servers and other network infrastructure devices up to date and ensuring their infrastructure is as secure and efficient as possible. “In this day-to-day process,” Burnett says, “devices like printers are very often overlooked.” But out-of-date firmware could expose the infrastructure to new threats.
-
-## #3: Inadequate device awareness
-
-It’s critical, Burnett says, to properly understand who is using what, and the capabilities of all the connected devices in the fleet. Reviewing these devices using port scanning, protocol analysis and other detection techniques should be part of the overall security reviews of your network infrastructure. Too often, he warns, “the approach to print devices is ‘if it’s not broke, don’t fix it!’” But even devices that have been running reliably for years should be part of security reviews. That’s because older devices may not have the capability to offer stronger security settings or you may need to update their configuration to meet today’s greater security demands. This includes the monitoring/reporting capabilities of a device.
-
-## #2: Inadequate user training
-
-“Training your team on best practices for managing documents within the workflow must be part of a strong security plan,” Burnett says. The fact is, no matter how hard you work to secure IoT devices, “the human factor is often the weakest link in securing important and sensitive information within a business. Items as simple as leaving important documents on the printer for anyone to see, or scanning documents to the wrong destination by accident, can have a huge, negative impact on a business not just financially, but also to its IP, reputation, and cause compliance/regulation issues.”
-
-## #1: Using default passwords**
-
-**
-
-“Just because it’s easy doesn’t mean it’s not important!” Burnett says. Securing printer and multi-function devices from unauthorized admin access not only helps protect sensitive machine-configuration settings and report information, Burnett says, but also prevents access to personal information, such as user names that could be used in phishing attacks, for example.
-
-**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][7] ]**
-
-Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
-
---------------------------------------------------------------------------------
-
-via: https://www.networkworld.com/article/3433476/top-5-iot-networking-security-mistakes.html
-
-作者:[Fredric Paul][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.networkworld.com/author/Fredric-Paul/
-[b]: https://github.com/lujun9972
-[1]: https://images.idgesg.net/images/article/2019/02/iot_security_tablet_conference_digital-100787102-large.jpg
-[2]: https://www.brother-usa.com/business
-[3]: https://www.brother-usa.com/machinetool/default?src=default
-[4]: https://www.brother-usa.com/business/hmd#sort=%40productcatalogsku%20ascending
-[5]: https://www.brother-usa.com/business/industrial-sewing
-[6]: https://www.networkworld.com/article/2855207/internet-of-things/5-ways-to-prepare-for-internet-of-things-security-threats.html#tk.nww-infsb
-[7]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
-[8]: https://www.facebook.com/NetworkWorld/
-[9]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190828 VMware touts hyperscale SD-WAN.md b/sources/talk/20190828 VMware touts hyperscale SD-WAN.md
new file mode 100644
index 0000000000..77c42a98b5
--- /dev/null
+++ b/sources/talk/20190828 VMware touts hyperscale SD-WAN.md
@@ -0,0 +1,88 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (VMware touts hyperscale SD-WAN)
+[#]: via: (https://www.networkworld.com/article/3434619/vmware-touts-hyperscale-sd-wan.html)
+[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
+
+VMware touts hyperscale SD-WAN
+======
+VMware is teaming up with Dell/EMC to offer a hardware/software package rolled up into a managed SD-WAN service.
+BlueBay2014 / Getty Images
+
+SAN FRANCISCO – VMware teamed with Dell/EMC this week to deliver an SD-WAN service that promises to greatly simplify setting up and supporting wide-area-network connectivity.
+
+The Dell EMC SD-WAN Solution is a package of VMware software with Dell hardware and software that will be managed by Dell and sold as a package by both companies and their partners.
+
+The package, introduced at the [VMworld event][1] here, includes VMware SD-WAN by VeloCloud software available as a subscription coupled with appliances available in multiple configurations capable of handling 10Mbps to 10Gbps of traffic, depending on customer need, said [Sanjay Uppal,][2] vice president and general manager of VMware’s VeloCloud Business Unit.
+
+**More about SD-WAN**
+
+ * [How to buy SD-WAN technology: Key questions to consider when selecting a supplier][3]
+ * [How to pick an off-site data-backup method][4]
+ * [SD-Branch: What it is and why you’ll need it][5]
+ * [What are the options for security SD-WAN?][6]
+
+
+
+“The package is a much simpler way for customers to quickly set up a modern SD-WAN, especially for those customers who don’t have a lot of IT personnel to handle setting up and configuring an SD-WAN,” Uppal said. “Branch office networking can be complex and expensive, and this package uses subscription pricing, and supports cloud-like capabilities and economics.”
+
+Dell EMC and VMware also announced SmartFabric Director, software that can be part of the service offering. Director enables data-center operators to build, operate and monitor an open network-underlay fabric based on Dell EMC PowerSwitch switches.
+
+Accoding to Dell, organizations that have embraced overlay software-defined networks need to make sure their physical, underlay networks are tuned to work with the SDN. "A lack of visibility between the two layers can lead to provisioning and configuration errors, hampering network performance,” Dell stated.
+
+The Director also supports flexible streaming telemetry to gather key operational data and statistics from the fabric switches it oversees, so customers can use it in security and other day-to-day operations, Dell said.
+
+Analysts said the key to the VMware/Dell package isn’t so much the technology but the fact that it can be sold by so many of Dell and VMware’s partners.
+
+"Dell will lead on the sales motion with an SD-WAN-as-a-Service offering leveraging its [customer premises equipment] platforms and global service and support capabilities, leveraging SD-WAN technology from VMware/VeloCloud,” said Rohit Mehra, vice president, Network Infrastructure for IDC.
+
+VMware also used its VMworld event to say its VeloCloud SD-WAN platform and aggregate data gathered from customer networks will let the company offer more powerful network-health and control mechanisms in the future.
+
+“The SD-WAN VMware/VeloCloud has actually achieved a milestone we think is significant across multiple dimensions, one is architecture. We have proven that we can get to tens of thousands of edges with a single network. In the aggregate, we are crossing 150,000 gateways, over 120 points-of-presence,” Uppal said.
+
+VMware/Velocloud supports gateways across major cloud providers including Amazon Web Services, Microsoft Azure, Google Cloud Platform, and IBM Cloud as well as multiple carrier underlay networks.
+
+“From all of those endpoints we can see how the underlay network is performing, what applications are running on it and security threat information. Right now we can use that information to help IT intervene and fix problems manually,” Uppal said. Long-term, the goal is to use the data to train algorithms that VMware is developing to promote self-healing networks that could, for example, detect outages and automatically reroute traffic around them.
+
+The amount of data VMware gathers from cloud, branch-office and SD-WAN endpoints amounts to a treasure trove. “That is all part of the hyperscale idea," Uppal said.
+
+There are a number of trends driving the increased use of SD-WAN technologies, Uppal said, a major one being the increased use of containers and cloud-based applications that need access from the edge. “The scope of clients needing SD-WAN service access to the data center or cloud resources is growing and changing rapidly,” he said.
+
+In the most recent IDC [SD-WAN Infrastructure Forecast][7] report, Mehra wrote about a number of other factors driving SD-WAN evolution. For example:
+
+ * Traditional enterprise WANs are increasingly not meeting the needs of today's modern digital businesses, especially as it relates to supporting SaaS apps and multi- and hybrid-cloud usage.
+ * Enterprises are interested in easier management of multiple connection types across their WAN to improve application performance and end-user experience.
+
+
+
+“Combined with the rapid embrace of SD-WAN by leading communications service providers globally, these trends continue to drive deployments of SD-WAN, providing enterprises with dynamic management of hybrid WAN connections and the ability to guarantee high levels of quality of service on a per-application basis,” Mehra wrote in the report.
+
+The report also said that the SD-WAN infrastructure market continues to be highly competitive with sales increasing 64.9% in 2018 to $1.37 billion. IDC stated Cisco holds the largest share of the SD-WAN infrastructure market, with VMware coming in second followed by Silver Peak, Nokia-Nuage, and Riverbed.
+
+Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3434619/vmware-touts-hyperscale-sd-wan.html
+
+作者:[Michael Cooney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Michael-Cooney/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3434576/vmware-boosts-load-balancing-security-intelligence-analytics.html
+[2]: https://www.networkworld.com/article/3387641/beyond-sd-wan-vmwares-vision-for-the-network-edge.html
+[3]: https://www.networkworld.com/article/3323407/sd-wan/how-to-buy-sd-wan-technology-key-questions-to-consider-when-selecting-a-supplier.html
+[4]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
+[5]: https://www.networkworld.com/article/3250664/lan-wan/sd-branch-what-it-is-and-why-youll-need-it.html
+[6]: https://www.networkworld.com/article/3285728/sd-wan/what-are-the-options-for-securing-sd-wan.html?nsdr=true
+[7]: https://www.idc.com/getdoc.jsp?containerId=prUS45380319
+[8]: https://www.facebook.com/NetworkWorld/
+[9]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190829 Data center-specific AI completes tasks twice as fast.md b/sources/talk/20190829 Data center-specific AI completes tasks twice as fast.md
new file mode 100644
index 0000000000..61505ddebe
--- /dev/null
+++ b/sources/talk/20190829 Data center-specific AI completes tasks twice as fast.md
@@ -0,0 +1,59 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Data center-specific AI completes tasks twice as fast)
+[#]: via: (https://www.networkworld.com/article/3434597/data-center-specific-ai-completes-tasks-twice-as-fast.html)
+[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
+
+Data center-specific AI completes tasks twice as fast
+======
+Researchers at MIT have developed an artificial intelligence-powered system based on reinforcement learning that could revolutionize data center operations.
+Matejmo / Getty Images
+
+Data centers running artificial intelligence (AI) will be significantly more efficient than those operating with hand-edited algorithm schedules, say experts at MIT. The researchers there say they have developed an automated scheduler that speeds cluster jobs by up to 20 or 30 percent, and even faster (2x) in peak periods.
+
+The school’s AI job scheduler works on a type of AI called “reinforcement learning” (RL). That’s a trial-and-error-based machine-learning method that modifies scheduling decisions depending on actual workloads in a specific cluster. AI, when done right, could supersede the current state-of-the-art method, which is algorithms. They often must be fine-tuned by humans, introducing inefficiency.
+
+“The system could enable data centers to handle the same workload at higher speeds, using fewer resources,” [the school says in a news article related to the tech][1]. The MIT researchers say the data center-adapted form of RL could revolutionize operations.
+
+**Also read: [AI boosts data center availability and efficiency][2]**
+
+“If you have a way of doing trial and error using machines, they can try different ways of scheduling jobs and automatically figure out which strategy is better than others,” says Hongzi Mao, a student in the university’s Department of Electrical Engineering and Computer Science, in the article. “Any slight improvement in utilization, even 1%, can save millions of dollars and a lot of energy.”
+
+### What's wrong with today's data center algorithms
+
+The problem with the current algorithms for running tasks on thousands of servers at the same time is that they’re not very efficient. Theoretically, they should be, but because workloads (combinations of tasks) are varied, humans get involved in tweaking the performance—a resource, say, might need to be shared between jobs, or some jobs might need to be performed faster than others—but humans can’t handle the range or scope of the edits; the job is just too big.
+
+Unfathomable permutations for humans in the manually edited scheduling can include the fact that a lower node (smaller computational task) can’t start work until an upper node (larger, more power-requiring computational task) has completed its work. It gets highly complicated allocating the computational resources, the scientists explain.
+
+Decima, MIT’s system, can process dynamic graphs (representations) of nodes and edges (edges connect nodes, linking tasks), the school says. That hasn’t been possible before with RL because RL hasn’t been able to understand the graphs well enough at scale.
+
+“Traditional RL systems are not accustomed to processing such dynamic graphs,” MIT says.
+
+MIT’s graph-oriented AI is different than other forms of AI that are more commonly used with images. Robots, for example, learn the difference between objects in different scenarios by processing images and getting reward signals when they get it right.
+
+Similar, though, to presenting images to robots, workloads in the Decima system are mimicked until the system, through the receipt of AI reward signals, improves its decisions. A special kind of baselining (comparison to history) then helps Decima figure out which actions are good and which ones are bad, even when the workload sequences only supply poor reward signals due to the complication of the job structures slowing everything down. That baselining is a key differentiator in the MIT system.
+
+“Decima can find opportunities for [scheduling] optimization that are simply too onerous to realize via manual design/tuning processes,” says Aditya Akella, a professor at University of Wisconsin at Madison, in the MIT article. The team there has developed a number of high-performance schedulers. “Decima can go a step further,” Akella says.
+
+Join the Network World communities on [Facebook][3] and [LinkedIn][4] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3434597/data-center-specific-ai-completes-tasks-twice-as-fast.html
+
+作者:[Patrick Nelson][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Patrick-Nelson/
+[b]: https://github.com/lujun9972
+[1]: http://news.mit.edu/2019/decima-data-processing-0821
+[2]: https://www.networkworld.com/article/3274654/ai-boosts-data-center-availability-efficiency.html
+[3]: https://www.facebook.com/NetworkWorld/
+[4]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190829 Rating IoT devices to gauge their impact on your network.md b/sources/talk/20190829 Rating IoT devices to gauge their impact on your network.md
new file mode 100644
index 0000000000..9da7cd573d
--- /dev/null
+++ b/sources/talk/20190829 Rating IoT devices to gauge their impact on your network.md
@@ -0,0 +1,81 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Rating IoT devices to gauge their impact on your network)
+[#]: via: (https://www.networkworld.com/article/3435136/rating-iot-devices-to-gauge-their-impact-on-your-network.html)
+[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
+
+Rating IoT devices to gauge their impact on your network
+======
+With the wide range of internet of things devices being connected to business networks, there’s no cookie-cutter solution to building networks to support them, but assessing their needs can help.
+Natalya Burova / Getty Images
+
+One difficulty designing [IoT][1] implementations is the large number of moving parts. Most IoT setups are built out of components from many different manufacturers – one company’s sensors here, another’s there, someone else handling the networking and someone else again making the backend.
+
+To help you get a ballpark sense of what any given implementation will demand from your network, we’ve come up with a basic taxonomy for rating IoT endpoints. It’s got three main axes: delay tolerance, data throughput and processing power. Here is an explainer for each. (Terminology note: We’ll use “IoT setup” or “IoT implementation” to refer to the entirety of the IoT infrastructure being used by a given organization.)
+
+**Learn about edge networking**
+
+ * [How edge networking and IoT will reshape data centers][2]
+ * [Edge computing best practices][3]
+ * [How edge computing can help secure the IoT][4]
+
+
+
+### Delay tolerance
+
+Many IoT implementation don’t require the millisecond-scale delay tolerance that traditional enterprise networks can provide, so that opens up a lot of network-connectivity options and means that going for a lower-priced choice could prove very successful.
+
+For example, a connected parking meter doesn’t need to report its status to the city more than once a minute or so (if that), so a delay-inducing wireless option like [LoRaWAN][5] might be perfectly acceptable. Some systems of that type even use standard cellular SMS services to send updates back to central hubs.
+
+For less delay-tolerant applications, like a production line or oil and gas extraction, industrial Ethernet or particularly low-latency wireless links should be used. Older-generation orchestration systems usually have the actual handling of instructions and coordination between machines well in hand, but adding real-time analytics data to the mix can increase network demands.
+
+### Data throughput
+
+Again, networking pros used to dealing with nothing less than megabits per second should adjust their expectations here, as there are plenty of IoT devices that require as little as a few kilobits per second or even less.
+
+Devices with low-bandwidth requirements include smart-building devices such as connected door locks and light switches that mostly say “open” or “closed” or “on” or “off.”
+
+Fewer demands on a given data link opens up the possibility of using less-capable wireless technology. Low-power WAN and Sigfox might not have the bandwidth to handle large amounts of traffic, but they are well suited for connections that don’t need to move large amounts of data in the first place, and they can cover significant areas. The range of Sigfox is 3 to 50 km depending on the terrain, and for Bluetooth, it’s 100 meters to 1,000 meters, depending on the class of Bluetooth being used.
+
+Conversely, an IoT setup such as multiple security cameras connected to a central hub to a backend for image analysis will require many times more bandwidth. In such a case the networking piece of the puzzle will have to be more capable and, consequently, more expensive. Widely distributed devices could demand a dedicated [LTE][6] connection, for example, or perhaps even a microcell of their own for coverage.
+
+Network World / IDG
+
+### Processing power
+
+The degree to which an IoT device is capable of doing its own processing is a somewhat indirect measurement of its impact on your network, to be sure, but it’s still relevant in terms of comparing it to other devices that perform a similar function. A device that’s constantly streaming raw data onto the network, without performing any meaningful analysis or shaping of its own, can be a bigger traffic burden than one that’s doing at least some of the work.
+
+That’s not always the case, of course. Many less-capable devices won’t generate a lot of data with which to clog up whatever network connection they have, while some more-capable ones (let’s say industrial robots with a lot of inbuilt power to processing data they collect) might still generate plenty of traffic.
+
+But the onboard computing power of a device is still relevant when comparing it to others that perform similar jobs, particularly in sectors like manufacturing and energy extraction where a lot of analysis has to be performed somewhere, whether it’s on the device, at the edge or at the back end.
+
+It’s even more relevant in the context of an edge setup, where some or all of the data analysis is done on an [edge-gateway device][7] located close to the endpoints. These gateways can be a good choice when fairly complicated analysis has to be performed as close to real-time as possible. But edge gateways don’t have the same resources available as a full-on [data center][8] or cloud so the amount of work that can be done on the endpoint itself remains a crucial concern. Synthesizing raw information into analysis can mean less traffic that has to go on the network.
+
+Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3435136/rating-iot-devices-to-gauge-their-impact-on-your-network.html
+
+作者:[Jon Gold][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Jon-Gold/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
+[2]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
+[3]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
+[4]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
+[5]: https://www.networkworld.com/article/3235124/internet-of-things-definitions-a-handy-guide-to-essential-iot-terms.html
+[6]: https://www.networkworld.com/article/3432938/when-private-lte-is-better-than-wi-fi.html
+[7]: https://www.networkworld.com/article/3327197/edge-gateways-flexible-rugged-iot-enablers.html
+[8]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
+[9]: https://www.facebook.com/NetworkWorld/
+[10]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190829 SparkFun continues to innovate thanks to open source hardware.md b/sources/talk/20190829 SparkFun continues to innovate thanks to open source hardware.md
new file mode 100644
index 0000000000..ed48ba62f1
--- /dev/null
+++ b/sources/talk/20190829 SparkFun continues to innovate thanks to open source hardware.md
@@ -0,0 +1,69 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (SparkFun continues to innovate thanks to open source hardware)
+[#]: via: (https://opensource.com/article/19/8/sparkfun-creator-nathan-seidle)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+
+SparkFun continues to innovate thanks to open source hardware
+======
+SparkFun founder Nathan Seidle says companies built around patents
+become "intellectually unfit" to innovate. Artemis, his new
+microprocessor for low-power devices, is just one example of the
+company's nimbleness.
+![SparkFun Redboard with Artemis][1]
+
+When [SparkFun Electronics][2] founder and CEO Nathan Seidle was an engineering student at the University of Colorado, he was taught, "Real engineers come up with an idea and patent that idea." However, his experience with SparkFun, which he founded from his college apartment in 2003, is quite the opposite.
+
+All 600 "SparkFun original" components are for sale on the site in addition to 1000+ resell products. All of the company's schematics and code are licensed under [CC BY-SA][3], with some firmware [CC0][4], and its design files are available on [public GitHub repos][5]. In addition, some of the company's designs are Open Source Hardware Association ([OSHWA][6]) certified.
+
+Contrary to his college professor's lesson, Nathan sees patents as an anachronism that provide no guarantees to the companies and individuals who hold them. As he explained in a 2013 [TEDx Boulder talk][7], "If your idea can be sold, it will be," even if you have a patent.
+
+"When a company relies too much on their intellectual property, they become intellectually unfit—they suffer from IP obesity," he says. "There have been numerous companies in history that have had long periods of prosperity only to be quickly left behind when technology shifted. Cloners are going to clone regardless of your business plan."
+
+### Openness leads to innovation
+
+Nathan says building a business on open hardware enables companies like SparkFun to innovate faster than those that are more concerned with defending their patents than developing new ideas.
+
+Nathan says, "At the end of the day, by not relying on IP and patents, we've gotten stronger, more nimble, and built a more enduring business because of open source hardware." Nathan and SparkFun's 100 employees would rather spend their time innovating than litigating, he says.
+
+His latest innovation is [Artemis][8], a new type of microprocessor module and the most complex thing he has ever designed.
+
+![SparkFun and Artemis][9]
+
+He hopes Artemis will enable users to design consumer-grade products and run anything from an Arduino sketch down to a bare-metal model for voice recognition.
+
+"The Apollo 3 [integrated circuit] that powers Artemis is exceptionally powerful but also mind-bogglingly low power," he says. "At 0.5mA at 48MHz, it really changes the way you think about microcontrollers and low-power devices. Combine that low power with the push by Google to deploy TensorFlow light onto Artemis, and you've got the potential for battery-powered devices that can run machine learning algorithms for weeks on a single coin cell. It's all a bit mind-bending. We created a custom Arduino port from scratch in order to allow users to program Artemis with Arduino but not be limited to any toolchain."
+
+### Building a sustainable business on open hardware
+
+Because all of SparkFun's designs and hardware are open source, anyone can take the source files and copy, modify, sell, or do anything they like with them. SparkFun appreciates that people can take its innovations and use them in even more innovative ways, he says.
+
+"Where many companies bury or open-wash themselves with the 'open source' banner, we like to brag we're two clicks away from the source files: a link on the product page will take you to the repo where you can immediately clone the repo and begin benefiting from our designs," Nathan says.
+
+You may be wondering how a company can survive when everything is open and available. Nathan believes that open source is more than sustainable. He says it is a necessity given the rapid pace of change. A culture of sharing and openness can mitigate a lot of problems that more closed companies suffer. He says, "We need to avoid the mistakes that others have made, and the only way to do that is to talk openly and share in our mistakes."
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/sparkfun-creator-nathan-seidle
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/sparkfun_redboard_artemis.jpg?itok=XGRU-VUF (SparkFun Redboard with Artemis)
+[2]: https://www.sparkfun.com/
+[3]: https://creativecommons.org/licenses/by-sa/2.0/
+[4]: https://creativecommons.org/publicdomain/zero/1.0/
+[5]: https://github.com/sparkfun
+[6]: https://www.oshwa.org/
+[7]: https://www.youtube.com/watch?v=xGhj_lLNtd0
+[8]: https://www.sparkfun.com/artemis
+[9]: https://opensource.com/sites/default/files/uploads/sparkfun_artemis_module_-_low_power_machine_learning_ble_cortex-m4f.jpg (SparkFun and Artemis)
diff --git a/sources/talk/20190830 7 rules for remote-work sanity.md b/sources/talk/20190830 7 rules for remote-work sanity.md
new file mode 100644
index 0000000000..7e282d02a5
--- /dev/null
+++ b/sources/talk/20190830 7 rules for remote-work sanity.md
@@ -0,0 +1,94 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (7 rules for remote-work sanity)
+[#]: via: (https://opensource.com/article/19/8/rules-remote-work-sanity)
+[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
+
+7 rules for remote-work sanity
+======
+These rules don't describe my complete practice, but they are an
+important summary of what I try to do and what keeps me (relatively)
+sane.
+![Coding on a computer][1]
+
+I work remotely and have done so on and off for a good percentage of the past 10 to 15 years. I'm lucky that I'm in a role where this suits my responsibilities, and in a company that is set up for it. Not all roles—those with many customer onsite meetings or those with a major service component—are suited to remote working, of course. But it's clear that an increasing number of organisations are considering having at least some of their workers doing so remotely.
+
+I've carefully avoided using the phrase either "working from home" or "working at home" above. I've seen discussions that the latter gives a better "vibe" for some reason, but it's not accurate for many remote workers. In fact, it doesn't describe my role perfectly, either. My role is remote, in that I have no company-provided "base"—with a chair, desk, meeting rooms, phone, internet access, etc.—but I don't spend all of my time at home. I spend maybe one-and-a-half weeks a month, on average, travelling—to attend or speak at conferences, to have face-to-face ("F2F") meetings, etc. During these times, I'm generally expected to be contactable and to keep at least vaguely up-to-date on email—although the exact nature of the activities in which I'm engaged, and the urgency of the contacts and email, may increase or reduce my engagement.
+
+### Open source
+
+One of the reasons I can work remotely is that I work for a company that works with open source software. I'm currently involved in a very exciting project called [Enarx][2] (which I [announced][3] in May). We have contributors in Europe and the US and interest from further abroad. Our stand-ups are all virtual, and we default to turning on video. At least two of our regulars participate from a treadmill, I will typically stand at my desk. We use GitHub for all our code (it's all open source, of course), and there's basically no reason for us to meet in person very often. We try to celebrate together—agreeing to get cake, wherever we are, to mark special occasions, for instance—and have laptop stickers to brand ourselves and help team unity. We have a shared chat and IRC channel and spend a lot of time communicating via different channels. We're still quite a small team, but it works for now.
+
+If you're looking for more tips about how to manage, coordinate, and work in remote teams, particularly around open source projects, you'll find lots of [information][4] online.
+
+### The environment
+
+When I'm not travelling around the place, I'm based at home. There, I have a commute—depending on weather conditions—of around 30-45 seconds, which is generally pretty bearable. My office is separate from the rest of the house (set in the garden) and outfitted with an office chair, desk, laptop dock, monitor, webcam, phone, keyboard, and printer; these are the obvious work-related items in the room.
+
+Equally important, however, are the other accoutrements that make for a good working environment. These will vary from person to person, but I also have:
+
+ * A Sonos attached to an amplifier and good speakers
+ * A sofa, often occupied by my dog and sometimes one of the cats
+ * A bookshelf where the books that aren't littering the floor reside
+ * Tea-making facilities (I'm British; this is important)
+ * A fridge filled with milk (for the tea), beer, and wine (don't worry: I don't drink these during work hours, and it's more that the fridge is good for "overflow" from our main kitchen one)
+ * Wide-opening windows and blinds for the summer (we have no air-conditioning; I'm British, remember?)
+ * Underfloor heating _and_ a wood-burning stove for the winter (the former to keep the room above freezing until I get the latter warmed up)
+ * A "[NUC][5]" computer and monitor for activities that aren't specifically work-related
+ * A few spiders
+
+
+
+What you have will depend on your work style, but these "non-work" items are important (bar the spiders, possibly) to my comfort and work practice. For instance, I often like to listen to music to help me concentrate; I often sit on the sofa with the dog and cats to read long documents; and without the fridge and tea-making facilities, I might as well be American.[1][6]
+
+### My rules
+
+How does it work, then? Well, first of all, most of us like human contact from time to time. Some remote workers rent space in a shared work environment and work there most of the time; they prefer an office environment or don't have a dedicated space for working at home. Others will mainly work in coffee shops or on their boat,[2][7] or they may spend half of the year in the office and the other half working from a second home. Whatever you do, finding something that works for you is important. Here's what I tend to do, and why:
+
+ 1. **I try to have fairly rigid work hours.** Officially (and as advertised on our intranet for the information of colleagues), I work 10am-6pm UK time. This gives me a good overlap with the US (where many of my colleagues are based) and time in the morning to go for a run or a cycle and/or to walk the dog (see below). I don't always manage these times, but when I flex outward in one direction, I attempt to pull some time back the other way, as otherwise I know I'll just work ridiculous hours.
+ 2. **I ensure that I get up and have a cup of tea.** In an office environment, I would typically be interrupted from time to time by conversations, invitations to get tea, physical meetings in meeting rooms, lunch trips, etc. This doesn't happen at home, so it's important to keep moving, or you'll be stuck at your desk frequently for three to four hours at a time. This isn't good for your health or often for your productivity (and I enjoy drinking tea).
+ 3. **I have an app that tells me when I've been inactive.** This is new for me, but I like it. If I've basically not moved for an hour, my watch (could be a phone or laptop) tells me to do some exercise. It even suggests something, but I'll often ignore that and get up for some tea, for instance.[3][8]
+ 4. **I use my standing desk's up/down capability.** I try to vary my position through the day from standing to sitting and back again. It's good for posture and keeps me more alert.
+ 5. **I walk the dog.** If I need to get out of my office and do some deep thinking (or just escape a particularly painful email thread!), I'll take the dog for a walk. Even if I'm not thinking about work for the entire time, I know it'll make me more productive, and if it's a longish walk, I'll make sure I compensate by spending extra time working (which is always easy).
+ 6. **I have family rules.** The family knows that when I'm in my office, I'm at work. They can message me on my phone (which I may ignore) or may come to the window to see if I'm available, but if I'm not, I'm not. Emergencies (lack of milk for tea, for example) can be negotiated on a case-by-case basis.
+ 7. **I go for tea (and usually cake) at a cafe.** Sometimes, I need to get into a different environment and have a chat with actual people. For me, popping into the car for 10 minutes and going to a cafe is the way to do this. I've found one that makes good cakes (and tea).
+
+
+
+These rules don't describe my complete practice, but they are an important summary of what I try to do and what keeps me (relatively) sane. Your rules will be different, but I think it's really important to _have_ rules and to make it clear to yourself, your colleagues, your friends, and your family what they are. Remote working is not always easy and requires discipline—but that discipline, more often than not, is in giving yourself some slack, rather than making yourself sit down for eight hours a day.
+
+* * *
+
+1\. I realise that many people, including many of my readers, are American. That's fine: you be you. I actively _like_ tea, however (and know how to make it properly, which seems to be an issue when I visit the US).
+2\. I know a couple of these: lucky, lucky people!
+3\. Can you spot a pattern?
+
+* * *
+
+_This article was originally published on [Alice, Eve, and Bob][9] and is reprinted with the author's permission._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/rules-remote-work-sanity
+
+作者:[Mike Bursell][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mikecamel
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
+[2]: https://enarx.io/
+[3]: https://opensource.com/article/19/5/enarx-security
+[4]: https://opensource.com/sitewide-search?search_api_views_fulltext=remote%20work
+[5]: https://en.wikipedia.org/wiki/Next_Unit_of_Computing
+[6]: tmp.S5SfsQZWG4#1
+[7]: tmp.S5SfsQZWG4#2
+[8]: tmp.S5SfsQZWG4#3
+[9]: https://aliceevebob.com/2019/08/13/my-7-rules-for-remote-work-sanity/
diff --git a/sources/talk/20190830 Bluetooth finds a role in the industrial internet of things.md b/sources/talk/20190830 Bluetooth finds a role in the industrial internet of things.md
new file mode 100644
index 0000000000..1bdc34a5fb
--- /dev/null
+++ b/sources/talk/20190830 Bluetooth finds a role in the industrial internet of things.md
@@ -0,0 +1,113 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Bluetooth finds a role in the industrial internet of things)
+[#]: via: (https://www.networkworld.com/article/3434526/bluetooth-finds-a-role-in-the-industrial-internet-of-things.html)
+[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
+
+Bluetooth finds a role in the industrial internet of things
+======
+Market awareness and penetration, plus new technological advancements, are making Bluetooth—yes, Bluetooth—a key networking technology for the IIoT.
+Michael Brown / IDG
+
+Like most people, I think of Bluetooth as a useful but consumer-oriented technology that lets me make easy wireless connections from my smartphone to various headsets, portable speakers, automobile, and other devices. And, of course, billions of people rely on Bluetooth for exactly those capabilities. But according to [Chuck Sabin][1], senior director of market development for the [Bluetooth SIG][2], the technology is growing into a key role in the industrial internet of things (IIoT).
+
+Sabin says, Bluetooth “technology is actually well-suited for both consumer and enterprise markets.” He cites Bluetooth’s easy-to-implement low-power connections. More importantly, though, Bluetooth is ubiquitous, enjoying 90% global awareness and global, multi-vendor interoperability.
+
+Bluetooth offers low deployment costs and massive economies of scale because it’s already built into virtually every new smartphone, tablet, and personal computer, not to mention a wide variety of wearables, smart speakers, and other devices, notes Sabin. That means IIoT deployments leveraging Bluetooth may be able to avoid having to build a completely proprietary solution to start using wireless systems in smart-building and smart-industry environments.
+
+**[ Learn more [Download a PDF bundle of five essential articles about IoT in the enterprise][3] ]**
+
+### 3 things driving Bluetooth adoption in IIoT?
+
+In addition to Bluetooth’s deep market penetration, Sabin cites three notable technical advancements that are driving Bluetooth adoption in industrial and enterprise IoT applications:
+
+ 1. **“The introduction of [Bluetooth 5][4] in 2016 was all about flexibility,”** Sabin explains. Bluetooth 5’s longer range and higher speeds provide the crucial flexibility necessary to support more reliable connections in a wide variety of large, noisy environments, like those of industrial or commercial spaces. For example, Sabin says, “a warehouse is a much different environment than the basement of a nuclear power plant. One is open and requires long-range connections, and the other is a more complex environment with a lot of interference, requiring a reliable connection or device network that can deliver information despite the noise.”
+
+ 2. **[Bluetooth mesh][5], released In July of 2017, extends the [Bluetooth Core Specification][6] to enable “industrial-grade” many-to-many communication,** Sabin says, where tens, hundreds, and even thousands of devices can reliably and securely communicate with one another. “Bluetooth mesh networks are ideally suited for control, monitoring, and automation systems,” Sabin claims, and can also reduce latency and improve security.
+
+ 3. **More recently, the Bluetooth SIG announced a new [direction-finding feature][7]** **for Bluetooth,** bringing even greater precision to location-services systems used in industrial and enterprise settings. [Bluetooth low energy][8] introduced the ability to roughly determine the location of a Bluetooth device by comparing signal strength between the device being located and the tracking device, at what Sabin calls a “fairly broad—“the device is in this room”—level of accuracy. This led to inexpensive, mass-market indoor location and asset tracking solutions.
+
+The new direction-finding feature makes this much more precise: “Not only is the device in a specific room, but it’s in the back, left corner,” he says. And the Bluetooth SIG is working to add distance to this feature, so users will know whether “the device is in this specific room, in the back, left the corner, and 30 feet from me right now.” This level of precision will enable new applications, including monitoring for safety and security, Sabin says: for example, helping keep workers out of a toxic environment.
+
+
+
+
+### IioT Bluetooth use cases
+
+Put all those developments together, and you enable device networks, Sabin says, where interconnected networks of devices are used to control lighting systems, sensor networks, and asset management solutions.
+
+The Bluetooth SIG divides smart buildings and smart industry into three primary categories:
+
+ 1. **Building automation:** The centralized automation of a factory’s essential systems—including lighting, heating, ventilation, and air conditioning (HVAC) and security—which can help conserve energy, lower operating costs, and improve the life cycle of a building’s core systems.
+ 2. **Condition monitoring:** Bluetooth sensor networks deployed across a factory floor or throughout an office building enable real-time monitoring of system performance to make maintenance, updating, and overall management more efficient.
+ 3. **Location services:** This can take on many forms, from wayfinding to asset tracking/management to indoor positioning and location and logistics solutions.
+
+
+
+Use cases in manufacturing include helping manufacturers better monitor location, availability, and condition of equipment and output across the supply chain, Sabin says. Using enterprise wearables is helping manufacturers improve material management and process flow. Bluetooth location services are employing beacons to boost safety and security in chemical and manufacturing plants by creating geo-fences for restricted access and tracking numbers of employees in critical areas.
+
+**[ [Take this mobile device management course from PluralSight and learn how to secure devices in your company without degrading the user experience.][9] ]**
+
+Bluetooth Mesh was actually designed with connected lighting in mind, Sabin says, enabling everything from connected lighting in building automation to what he called [Lighting-as-a Platform (LaaP)][10] for deploying these services.
+
+### Fast growth for Bluetooth in the IIoT
+
+Based on these trends and advancements, the Bluetooth SIG’s recent [Bluetooth Market Update][11] predicts a 7x growth in annual shipments of Bluetooth smart-building location services devices by 2023, with 374 million Bluetooth smart-building devices shipping that year. The update also sees a 5x growth in annual shipments of Bluetooth smart-industry devices by 2023. These shipments are growing at of 47% a year, Sabin says, and will account for 70% of market shipments in 2023. The report also forecasts a 3.5x increase in shipments of Bluetooth enterprise wearables for smart industry use cases by 2023, with a 28% annual growth rate over the next five years.
+
+That’s only if everything goes as planned, of course. Sabin warns that industrial and enterprise organizations often adopt new technology relatively slowly, looking for clear ROIs that may not always be fully fleshed out for new technologies. And, yes, no doubt some decision makers still think of Bluetooth as a short-range, point-to-point, consumer-grade technology not ready for enterprise and industrial environments.
+
+**More about IoT:**
+
+ * [What is the IoT? How the internet of things works][12]
+ * [What is edge computing and how it’s changing the network][13]
+ * [Most powerful Internet of Things companies][14]
+ * [10 Hot IoT startups to watch][15]
+ * [The 6 ways to make money in IoT][16]
+ * [What is digital twin technology? [and why it matters]][17]
+ * [Blockchain, service-centric networking key to IoT success][18]
+ * [Getting grounded in IoT networking and security][3]
+ * [Building IoT-ready networks must become a priority][19]
+ * [What is the Industrial IoT? [And why the stakes are so high]][20]
+
+
+
+Join the Network World communities on [Facebook][21] and [LinkedIn][22] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3434526/bluetooth-finds-a-role-in-the-industrial-internet-of-things.html
+
+作者:[Fredric Paul][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Fredric-Paul/
+[b]: https://github.com/lujun9972
+[1]: https://www.linkedin.com/in/chucksabin/
+[2]: https://www.bluetooth.com/about-us/
+[3]: https://www.networkworld.com/article/3269736/internet-of-things/getting-grounded-in-iot-networking-and-security.html
+[4]: https://www.bluetooth.com/bluetooth-resources/bluetooth-5-go-faster-go-further/
+[5]: https://www.bluetooth.com/media/mesh-kit/
+[6]: https://www.bluetooth.com/specifications/bluetooth-core-specification/
+[7]: https://www.bluetooth.com/media/location-services/
+[8]: https://en.wikipedia.org/wiki/Bluetooth_Low_Energy
+[9]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
+[10]: https://www.bluetooth.com/blog/lighting-as-a-platform-part-1/
+[11]: https://www.bluetooth.com/bluetooth-resources/2019-bluetooth-market-update/?utm_campaign=bmu&utm_source=internal&utm_medium=pr&utm_content=2019bmu-pr-outreach-ink
+[12]: https://www.networkworld.com/article/3207535/internet-of-things/what-is-the-iot-how-the-internet-of-things-works.html
+[13]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
+[14]: https://www.networkworld.com/article/2287045/internet-of-things/wireless-153629-10-most-powerful-internet-of-things-companies.html
+[15]: https://www.networkworld.com/article/3270961/internet-of-things/10-hot-iot-startups-to-watch.html
+[16]: https://www.networkworld.com/article/3279346/internet-of-things/the-6-ways-to-make-money-in-iot.html
+[17]: https://www.networkworld.com/article/3280225/internet-of-things/what-is-digital-twin-technology-and-why-it-matters.html
+[18]: https://www.networkworld.com/article/3276313/internet-of-things/blockchain-service-centric-networking-key-to-iot-success.html
+[19]: https://www.networkworld.com/article/3276304/internet-of-things/building-iot-ready-networks-must-become-a-priority.html
+[20]: https://www.networkworld.com/article/3243928/internet-of-things/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html
+[21]: https://www.facebook.com/NetworkWorld/
+[22]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190831 Why support open source- Strategies from around the world.md b/sources/talk/20190831 Why support open source- Strategies from around the world.md
new file mode 100644
index 0000000000..9b142b5c9c
--- /dev/null
+++ b/sources/talk/20190831 Why support open source- Strategies from around the world.md
@@ -0,0 +1,57 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Why support open source? Strategies from around the world)
+[#]: via: (https://opensource.com/article/19/8/open-source-large-series)
+[#]: author: (Karl Fogel https://opensource.com/users/kfogelhttps://opensource.com/users/jamesvasile)
+
+Why support open source? Strategies from around the world
+======
+A new series on open source strategy digs into using open source
+investments to support the overall mission.
+![World locations with red dots with a sun burst background][1]
+
+There are many excellent resources available to teach you how to run an open source project—how to set up the collaboration tools, how to get the community engaged, etc. But there is much less out there about open source _strategy_; that is, about how to use well-considered open source investments to support an overall mission.
+
+Thus, while "How can we integrate new contributors?" is a project management concern, the strategic question it grows from has wider implications: "What are the long-term returns we expect from engaging with others, who are those others, and how do we structure our investments to achieve those returns?"
+
+As we work with different clients, we've been gradually publishing reports that approach open source strategy from various directions. Two examples are our work with Mozilla on [open source archetypes][2] and with the World Bank on its [investment strategy for the GeoNode project][3].
+
+Now we have a chance to have this discussion in a more regular and complete way: Microsoft has asked us to do a series of blog posts about open source, and the request was essentially _"help organizations get better at open source"_ (not a direct quote, but a reasonable summary). They were very clear about the series being independent; they did not want editorial control and specifically did not want to be involved in any pre-approval before we publish a post. It goes without saying, but we'll say it anyway, just so there's no doubt, that the views we express in the series may or may not be shared by Microsoft.
+
+We're calling the series [Open Source At Large][4], and it focuses on open source strategy. The first three posts in the series are already up:
+
+ * [What is open source strategy?][5]
+ * [Open source goal setting][6]
+ * [Ecosystem mapping][7]
+
+
+
+Our clients will recognize some of the material—our advice tends to be consistent over time—but the series will also cover ideas we have not discussed widely before.
+
+Strategy is not just for executives and managers, by the way. We can most effectively support strategies we understand, and every person on a team can use strategic awareness to improve performance. Our target audience is the managers and organization leaders who make decisions about open source investments and also developers who can benefit from a strategic viewpoint.
+
+We hope that offering techniques for strategic analysis will be useful for newcomers to open source, and we also look forward to engaging colleagues in a wide-ranging discussion about best practices and considered approaches to strategy.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/open-source-large-series
+
+作者:[Karl Fogel][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/kfogelhttps://opensource.com/users/jamesvasile
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/world_remote_teams.png?itok=Wk1yBFv6 (World locations with red dots with a sun burst background)
+[2]: https://blog.opentechstrategies.com/2018/05/field-guide-to-open-source-project-archetypes/
+[3]: https://blog.opentechstrategies.com/2017/06/geonode-report/
+[4]: https://blog.opentechstrategies.com/category/open-source-at-large/
+[5]: https://blog.opentechstrategies.com/2019/05/what-is-open-source-strategy/
+[6]: https://blog.opentechstrategies.com/2019/05/open-source-goal-setting/
+[7]: https://blog.opentechstrategies.com/2019/06/ecosystem-mapping/
diff --git a/sources/talk/20190902 Top take-aways from DevOps World 2019.md b/sources/talk/20190902 Top take-aways from DevOps World 2019.md
new file mode 100644
index 0000000000..d85b944b56
--- /dev/null
+++ b/sources/talk/20190902 Top take-aways from DevOps World 2019.md
@@ -0,0 +1,76 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Top take-aways from DevOps World 2019)
+[#]: via: (https://opensource.com/article/19/9/devops-world-2019)
+[#]: author: (Patrick Housley https://opensource.com/users/patrickhousley)
+
+Top take-aways from DevOps World 2019
+======
+Some of the biggest announcements from August's major DevOps event.
+![Globe up in the clouds][1]
+
+In August, I had the opportunity to join more than 2,000 people gathered in San Francisco for DevOps World 2019. Following are some of the most newsworthy announcements from the 150 breakout sessions and 16 workshops held over the four-day event.
+
+### Standardizing CI/CD
+
+The greatest advantage and sometimes the most difficult challenge for our industry is the number of options we have for solving problems. Both are true for continuous integration and continuous development (CI/CD); it seems as though there's a new product or tool every week. This means we have amazing flexibility and control in how we implement CI/CD for our products and organizations. It also means we have a flood of opinions about how CI/CD _should_ be implemented. While there are some agreed-upon concepts (like shift-left), there is not much in the way of standards or best practices. That's not surprising. Continuously integrating features and bug fixes and continuously delivering those to a production environment for customer consumption are still fairly new.
+
+Our struggles have not gone unnoticed, and in March, the Linux Foundation announced the formation of the [Continuous Delivery Foundation][2]. The CD Foundation's goals are to provide a vendor-neutral home for many of the tools we rely on and to provide support to DevOps practitioners around learning and developing industry best practices. To do this, the CD Foundation is bringing together some of the most-used and fastest-growing open source projects with the companies and users using their solutions. The first projects to join the foundation include Jenkins, Jenkins X, Spinnaker, and Tekton, and its members include CapitalOne, CircleCI, CloudBees, Google, Huawei, Netflix, and many more.
+
+### Creating a BOK for CI/CD
+
+One of the most significant contributors to the success of agile and the [theory of constraints][3] is having a body of knowledge (BOK). A BOK is a collection of industry learnings that embody the principles of a professional domain. For example, the CD Foundation's focus will not be on standardizing the tools we use for CI/CD but on standardizing the collective knowledge about how to implement those tools and CI/CD in general.
+
+To that end, I want to give a special shout-out to the [DevOps Institute][4], a new member of the CD Foundation. Technology tools and practices can be complex, difficult to learn, and even harder to stay up-to-date on. The DevOps Institute is trying to tackle this by providing training and learning resources to help us stay skilled-up. Even better, it is launching an [Ambassador Program][5] to help spread its reach around the world. I encourage everyone to take a look and consider signing up.
+
+### Integrating DevOps metrics and reporting
+
+It's doubtful we will see any slowdown around the release of new CI/CD tools, and the CD Foundation's and DevOps Institute's valuable initiatives won't affect that. I am also sure we will continue to find innovative ways to move code from our developers' laptops to our production systems (hopefully with some quality checks in between). So, how can we follow the flow of that code from laptop to production? Can we follow new code from a twinkle in a customer's eye to when we release their idea (and see their jumps for joy when we do)?
+
+In today's DevOps, we use multiple tools to track our work. It usually starts with some type of issue tracker, like Jira or Trello. We work in a feature branch in our code repository and eventually merge to the trunk branch with a pull request. Along the way, our CI tools (like Jenkins) build, test, and scan our code to make sure we didn't fat-finger something, and eventually, our CD tooling deploys our code into pre-production and production environments.
+
+Even if all these tools are operating perfectly and our CI/CD implementation is the best in the world, we still have one piece missing: How can leadership, product owners, and developers take all the data these tools are generating and construct some knowledge from it? How can these individuals get a bird's-eye view of what features and bug fixes went out in the last 24 hours? How can they monitor the lead time for those changes?
+
+We can use something along the lines of an [ELK Stack][6] to centralize our data collection and create pretty dashboards. We could also use custom shell scripts to drive our CI/CD instead of Jenkins, but I wouldn't advocate for that. Not that there is anything wrong with ELK, but I'm not a big data engineer, and trying to find what ties the logs of two completely different tools together does not sound fun to me.
+
+There is a clear gap in tools that can do this off the shelf, and I hope we will see some new offerings in this area soon.
+
+### Learning with new book releases
+
+If like me, you like to learn through reading, following are some new books I picked up at DevOps World that you may want to acquire to further your DevOps knowledge.
+
+ * [_Epic Failures in DevSecOps: Volume 1_][7] edited by Mark Miller
+ * [_Effective Feature Management_][8] by John Kodumal
+ * [_The Continuous Application Security Handbook_][9] by Contrast Security
+ * [_Engineering DevOps_][10] by Marc Hornbeek
+ * [_The Unicorn Project_][11] by Gene Kim
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/devops-world-2019
+
+作者:[Patrick Housley][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/patrickhousley
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cloud-globe.png?itok=_drXt4Tn (Globe up in the clouds)
+[2]: https://cd.foundation/
+[3]: https://en.wikipedia.org/wiki/Theory_of_constraints
+[4]: https://devopsinstitute.com/
+[5]: https://devopsinstitute.com/become-a-community-member/devops-institute-ambassador/
+[6]: https://www.elastic.co/what-is/elk-stack
+[7]: https://www.amazon.com/Epic-Failures-DevSecOps-Mark-Miller/dp/1728806992
+[8]: https://launchdarkly.com/effective-feature-management-ebook/
+[9]: https://www.contrastsecurity.com/continuous-app-sec-cas
+[10]: https://engineeringdevops.com/
+[11]: https://www.amazon.com/gp/product/1942788762
diff --git a/sources/talk/20190902 Why I use Java.md b/sources/talk/20190902 Why I use Java.md
new file mode 100644
index 0000000000..6b6d8b8eab
--- /dev/null
+++ b/sources/talk/20190902 Why I use Java.md
@@ -0,0 +1,106 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Why I use Java)
+[#]: via: (https://opensource.com/article/19/9/why-i-use-java)
+[#]: author: (Chris Hermansen https://opensource.com/users/clhermansen)
+
+Why I use Java
+======
+There are probably better languages than Java, depending on work
+requirements. But I haven't seen anything yet to pull me away.
+![Coffee beans][1]
+
+I believe I started using Java in 1997, not long after [Java 1.1 saw the light of day][2]. Since that time, by and large, I've really enjoyed programming in Java; although I confess these days, I'm as likely to be found writing [Groovy][3] scripts as "serious code" in Java.
+
+Coming from a background in [FORTRAN][4], [PL/1][5], [Pascal][6], and finally [C][7], I found a lot of things to like about Java. Java was my first significant hands-on experience with [object-oriented programming][8]. By then, I had been programming for about 20 years, and it's probably safe to say I had some ideas about what mattered and what didn't.
+
+### Debugging as a key language feature
+
+I really hated wasting time tracking down obscure bugs caused by my code carelessly iterating off the end of an array, especially back in the days of programming in FORTRAN on IBM mainframes. Another subtle problem that cropped up from time to time was calling a subroutine with a four-byte integer argument that was expecting two bytes; on small-endian architecture, this was often a benign bug, but on big-endian machines, the value of the top two bytes was usually, but not always, zero.
+
+Debugging in that batch environment was pretty awkward, too—poring through core dumps or inserting print statements, which themselves could move bugs around or even make them disappear.
+
+So my early experiences with Pascal, first on [MTS][9], then using the same MTS compiler on [IBM OS/VS1][10], made my life a lot easier. Pascal's [strong and static typing][11] were a big part of the win here, and every Pascal compiler I have used inserts run-time checks on array bounds and ranges, so bugs are detected at the point of occurrence. When we moved most of our work to a Unix system in the early 1980s, porting the Pascal code was a straightforward task.
+
+### Finding the right amount of syntax
+
+But for all the things I liked about Pascal, my code was wordy, and the syntax seemed to have a tendency to slightly obscure the code; for example, using:
+
+
+```
+`if … then begin … end else … end`
+```
+
+instead of:
+
+
+```
+`if (…) { … } else { … }`
+```
+
+in C and similar languages. Also, some things were quite hard to do in Pascal and much easier to do in C. But, as I began to use C more and more, I found myself running into the same kind of errors I used to commit in FORTRAN—running off the end of arrays, for example—that were not detected at the point of the original error, but only through their adverse effects later in the program's execution. Fortunately, I was no longer living in the batch environment and had great debugging tools at hand. Still, C gave me a little too much flexibility for my own good.
+
+When I discovered [awk][12], I found I had a nice counterpoint to C. At that time, a lot of my work involved transforming field data and creating reports. I found I could do a surprising amount of that with awk, coupled with other Unix command-line tools like sort, sed, cut, join, paste, comm, and so on. Essentially, these tools gave me something a lot like a relational database manager for text files that had a column-oriented structure, which was the way a lot of our field data came in. Or, if not exactly in that format, most of the time the data could be unloaded from a relational database or from some kind of binary format into that column-oriented structure.
+
+String handling, [regular expressions][13], and [associative arrays][14] supported by awk, as well as the basic nature of awk (it's really a data-transformation pipeline), fit my needs very well. When confronted with binary data files, complicated data structuring, and absolute performance needs, I would still revert to C; but as I used awk more and more, I found C's very basic string support more and more frustrating. As time went on, more and more often I would end up using C only when I had to—and probably overusing awk the rest of the time.
+
+### Java is the right level of abstraction
+
+And then along came Java. It looked pretty good right out of the gate—a relatively terse syntax reminiscent of C, or at least, more so than Pascal or any of those other earlier experiences. It was strongly typed, so a lot of programming errors would get caught at compile time. It didn't seem to require too much object-oriented learning to get going, which was a good thing, as I was barely familiar with [OOP design patterns][15] at the time. But even in the earliest days, I liked the ideas behind its simplified [inheritance model][16]. (Java allows for single inheritance with interfaces provided to enrich the paradigm somewhat.)
+
+And it seemed to come with a rich library of functionality (the concept of "batteries included") that worked at the right level to directly meet my needs. Finally, I found myself rapidly coming to like the idea of both data and behavior being grouped together in objects. This seemed like a great way to explicitly control interactions among data—much better than enormous parameter lists or uncontrolled access to global variables.
+
+Since then, Java has grown to be the Helvetic military knife in my programming toolbox. I will still write stuff occasionally in awk or use Linux command-line utilities like cut, sort, or sed when they're obviously and precisely the straightforward way to solve the problem at hand. I doubt if I've written 50 lines of C in the last 20 years, though; Java has completely replaced C for my needs.
+
+In addition, Java has been improving over time. First of all, it's become much more performant. And it's added some really useful capabilities, like [try with resources][17], which very nicely cleans up verbose and somewhat messy code dealing with error handling during file I/O, for example; or [lambdas][18], which provide the ability to declare functions and pass them as parameters, instead of the old approach, which required creating classes or interfaces to "host" those functions; or [streams][19], which encapsulate iterative behavior in functions, creating an efficient data-transformation pipeline materialized in the form of chained function calls.
+
+### Java is getting better and better
+
+A number of language designers have looked at ways to radically improve the Java experience. For me, most of these aren't yet of great interest; again, that's more a reflection of my typical workflow and (much) less a function of the features those languages bring. But one of these evolutionary steps has become an indispensable part of my programming arsenal: [Groovy][20]. Groovy has become my go-to solution when I run into a small problem that needs a small solution. Moreover, it's highly compatible with Java. For me, Groovy fills the same niche that Python fills for a lot of other people—it's compact, DRY (don't repeat yourself), and expressive (lists and dictionaries have full language support). I also make use of [Grails][21], which uses Groovy to provide a streamlined web framework for very performant and useful Java web applications.
+
+### But is Java still open source?
+
+Recently, growing support for [OpenJDK][22] has further improved my comfort level with Java. A number of companies are supporting OpenJDK in various ways, including [AdoptOpenJDK, Amazon, and Red Hat][23]. In one of my bigger and longer-term projects, we use AdoptOpenJDK to [generate customized runtimes on several desktop platforms][24].
+
+Are there better languages than Java? I'm sure there are, depending on your work needs. But I'm still a very happy Java user, and I haven't seen anything yet that threatens to pull me away.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/why-i-use-java
+
+作者:[Chris Hermansen][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/clhermansen
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/java-coffee-beans.jpg?itok=3hkjX5We (Coffee beans)
+[2]: https://en.wikipedia.org/wiki/Java_version_history
+[3]: https://en.wikipedia.org/wiki/Apache_Groovy
+[4]: https://en.wikipedia.org/wiki/Fortran
+[5]: https://en.wikipedia.org/wiki/PL/I
+[6]: https://en.wikipedia.org/wiki/Pascal_(programming_language)
+[7]: https://en.wikipedia.org/wiki/C_(programming_language)
+[8]: https://en.wikipedia.org/wiki/Object-oriented_programming
+[9]: https://en.wikipedia.org/wiki/Michigan_Terminal_System
+[10]: https://en.wikipedia.org/wiki/OS/VS1
+[11]: https://stackoverflow.com/questions/11889602/difference-between-strong-vs-static-typing-and-weak-vs-dynamic-typing
+[12]: https://en.wikipedia.org/wiki/AWK
+[13]: https://en.wikipedia.org/wiki/Regular_expression
+[14]: https://en.wikipedia.org/wiki/Associative_array
+[15]: https://opensource.com/article/19/7/understanding-software-design-patterns
+[16]: https://www.w3schools.com/java/java_inheritance.asp
+[17]: https://www.baeldung.com/java-try-with-resources
+[18]: https://www.baeldung.com/java-8-lambda-expressions-tips
+[19]: https://www.tutorialspoint.com/java8/java8_streams
+[20]: https://groovy-lang.org/
+[21]: https://grails.org/
+[22]: https://openjdk.java.net/
+[23]: https://en.wikipedia.org/wiki/OpenJDK
+[24]: https://opensource.com/article/19/4/java-se-11-removing-jnlp
diff --git a/sources/talk/20190903 IT Leaders Need to Get Aggressive with SD-WAN.md b/sources/talk/20190903 IT Leaders Need to Get Aggressive with SD-WAN.md
new file mode 100644
index 0000000000..67f2bc4a5c
--- /dev/null
+++ b/sources/talk/20190903 IT Leaders Need to Get Aggressive with SD-WAN.md
@@ -0,0 +1,47 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (IT Leaders Need to Get Aggressive with SD-WAN)
+[#]: via: (https://www.networkworld.com/article/3435119/it-leaders-need-to-get-aggressive-with-sd-wan.html)
+[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
+
+IT Leaders Need to Get Aggressive with SD-WAN
+======
+
+grynold
+
+Late last year I moderated a MicroScope roundtable in the UK on the challenges and opportunities of [SD-WAN][1]. The representatives included 12 leading SD-WAN vendors, including Michael O’Brien, vice president of worldwide channel sales for [Silver Peak][2]. I started off the discussion by introducing a data point from a TechTarget survey (TechTarget owns MicroScope) that only 26 percent of companies surveyed had an SD-WAN deployment underway. This spans any stage of the deployment cycle, including testing. Given the hype around SD-WAN and how many conversations I have with IT leaders about it, this number seemed low to me, so I wanted to get a better feel for what the leading vendors thought about it.
+
+Going into the roundtable, I wasn’t sure if the vendor community would think this number was too high or too low, but I did expect to get uniformity in their responses. Instead, their responses that were all over the map. The most pessimistic view came from a smaller and relatively new entrant into the market who felt that less than five percent of companies had an SD-WAN deployment underway. The most optimistic was Silver Peak’s O’Brien who felt that the number was a bit low and should be closer to around one third. Another industry leader supported O’Brien when he said that 55 percent of its customers plan to make an SD-WAN decision in the next nine months. Everyone else provided a perspective that fell somewhere in the middle.
+
+Based on my own research and anecdotal discussions, I think 26 percent is just about right. The smaller vendor’s outlook on the industry is more a reflection of their late entry into the market. As a corollary to this, Silver Peak jumped into the space early and would have an overly positive opinion of customer adoption. The other industry leader is an interesting case as now that they finally have a viable offering, they’ll be pushing their install base hard, which should create a “rising tide” for all vendors.
+
+So, what does all this data tell us? Whether the number is five percent or 33 percent (I’m not including the 55% number here as it’s a projection), the fact is, given the strong value proposition and maturity of SD-WAN technology, it’s something all businesses should carefully evaluate. Not for the cost savings, but rather the increased network agility that enables tighter alignment with digital transformation initiatives.
+
+The next obvious question is, “Why haven’t more companies adopted SD-WAN?”. The answer to this is likely that many network engineers are still clinging to the past and aren’t ready to make the shift. Most current SD-WAN solutions are built on the concept of simplicity and use high amounts of automation, enabling the network to learn and adapt to changing requirements to ensure the highest levels of performance of an organizations’ users and applications. For example, the Silver Peak [Unity EdgeConnect™][3] SD-WAN edge platform is constantly monitoring network and application performance, applying a number of optimization techniques to maintain application performance and availability. In the past, network professionals would endlessly fiddle with network configurations to accomplish the same thing. That worked in the past when traffic volumes were lower and there were only a few applications that were dependent on the network. Today, due to the rise of cloud and mobility, almost all applications require a reliable, high quality network connection to deliver a high quality of experience to users.
+
+Based on the results of the TechTarget survey and the feedback from the MicroScope roundtable, I’m appealing to all CIOs and IT leaders. If your company isn’t at least piloting an SD-WAN, why not? Several senior IT people I have talked to tell me that’s a decision left in the hands of the network engineers. But that’s like asking a traditional auto mechanic if people should buy an electric car. Of course, a router jockey whose livelihood is tied up in hunting and pecking on a command line all day is going to be resistant to change.
+
+If the network team isn’t ready to modernize the network, it will hold the company back so it’s really up to IT leadership to mandate the change. Again, not because of cost, but because it’s too risky to sit idle while your competitors get jiggy with SD-WAN and are able to do things your business can’t. Instead, it makes far more sense to be aggressive and leapfrog the field to maintain a competitive edge. SD-WAN is the biggest evolutionary step in the WAN since the invention of the WAN and the time to move is now.
+
+**Silver Peak was named a leader in Gartner’s 2018 Magic Quadrant for WAN Edge Infrastructure. If you are rethinking your WAN edge (and we believe you should be), this [report][4] is a must-read.**
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3435119/it-leaders-need-to-get-aggressive-with-sd-wan.html
+
+作者:[Zeus Kerravala][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Zeus-Kerravala/
+[b]: https://github.com/lujun9972
+[1]: https://www.silver-peak.com/sd-wan/sd-wan-explained
+[2]: https://www.silver-peak.com/
+[3]: https://www.silver-peak.com/products/unity-edge-connect
+[4]: https://www.silver-peak.com/sd-wan-edge-gartner-magic-quadrant-2018
diff --git a/sources/talk/20190903 IoT security essentials- Physical, network, software.md b/sources/talk/20190903 IoT security essentials- Physical, network, software.md
new file mode 100644
index 0000000000..8264591faf
--- /dev/null
+++ b/sources/talk/20190903 IoT security essentials- Physical, network, software.md
@@ -0,0 +1,64 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (IoT security essentials: Physical, network, software)
+[#]: via: (https://www.networkworld.com/article/3435108/iot-security-essentials-physical-network-software.html)
+[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
+
+IoT security essentials: Physical, network, software
+======
+Internet of things devices present unique security problems due to being spread out, exposed to physical attacks and often lacking processor power.
+Thinkstock
+
+Even in the planning stages of a deployment, IoT security is one of the chief stumbling blocks to successful adoption of the technology.
+
+And while the problem is vastly complicated, there are three key angles to think about when laying out how IoT sensors will be deployed in any given setup: How secure are the device themselves, how many are there and can they receive security patches.
+
+### Physical access
+
+Physical access is an important but, generally, straightforward consideration for traditional IT security. Data centers can be carefully secured, and routers and switches are often located in places where they’re either difficult to fiddle with discreetly or difficult to access in the first place.
+
+Where IoT is concerned, however, best security practices aren’t as fleshed out. Some types of IoT implementation could be relatively simple to secure – a bad actor could find it comparatively difficult to tinker with a piece of complex diagnostic equipment in a well-secured hospital, or a big piece of sophisticated robotic manufacturing equipment on an access-controlled factory floor. Compromises can happen, certainly, but a bad actor trying to get into a secure area is still a well-understood security threat.
+
+By contrast, smart city equipment scattered across a metropolis – traffic cameras, smart parking meters, noise sensors and the like – is readily accessible by the general public, to say nothing of anybody able to look convincing in a hard hat and hazard vest. The same issue applies to soil sensors in rural areas and any other technology deployed to a sufficiently remote location.
+
+The solutions to this problem vary. Cases and enclosures could deter some attackers, but they might not be practical in some instances. The same goes for video surveillance of the devices, which could become a target itself. The IoT Security Foundation recommends disabling all ports on a device that aren’t strictly necessary for it perform its function, implementing tamper-proofing on circuit boards, and even embedding those circuits entirely in resin.
+
+### Discovery and networking
+
+Securing the connections between IoT sensors and the backend is arguably the toughest part to solve, in part because an alarming number of organizations aren’t even aware of all the devices on their network at any given time. Hence, device discovery remains a critically important part of network security for IoT.
+
+**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][1] ]**
+
+The main reason for this lack of visibility is that the nature of IoT as an operational technology, rather than one that’s solely administered by IT staff, means that line-of-business personnel will sometimes connect helpful devices to the network without telling the people in charge of keeping the network secure. For network **operations** people, used to having a clear sense of the entire network’s topology, this can be an unaccustomed headache.
+
+Beyond IT personnel working closely with the operational side of the business to ensure all devices connected to the network are properly provisioned and monitored, network scanners can discover connected devices on a network automatically, whether that’s via network traffic analysis, device profiles, whitelists or other techniques.
+
+### Software patching
+
+Many IoT sensors don’t have a lot of built-in computing capability, so some of those devices aren’t able to run a security-software agent nor accept updates and patches remotely.
+
+That is a huge worry, because there are software vulnerabilities being discovered every day that target the IoT. An inability to patch those holes when they’re discovered is a serious problem.
+
+Moreover, certain devices simply won’t be able to be properly secured and made patchable. The only solution might be to find a different product that accomplishes the functional task yet has better security.
+
+Join the Network World communities on [Facebook][2] and [LinkedIn][3] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3435108/iot-security-essentials-physical-network-software.html
+
+作者:[Jon Gold][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Jon-Gold/
+[b]: https://github.com/lujun9972
+[1]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
+[2]: https://www.facebook.com/NetworkWorld/
+[3]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190903 Peanuts, paper towels, and other important considerations on community.md b/sources/talk/20190903 Peanuts, paper towels, and other important considerations on community.md
new file mode 100644
index 0000000000..80b9bb89db
--- /dev/null
+++ b/sources/talk/20190903 Peanuts, paper towels, and other important considerations on community.md
@@ -0,0 +1,65 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Peanuts, paper towels, and other important considerations on community)
+[#]: via: (https://opensource.com/open-organization/19/9/peanuts-community-reciprocity)
+[#]: author: (Jim Whitehurst https://opensource.com/users/jwhitehurst)
+
+Peanuts, paper towels, and other important considerations on community
+======
+Red Hat president and CEO Jim Whitehurst explains that even the smallest
+gestures can impact how an organization sees itself—and how it sustains
+itself.
+![People working together to build ][1]
+
+The most powerful aspects of an organization's culture live in the smallest individual gestures—sometimes no bigger than a peanut.
+
+Not long ago, as I was sitting in the Dallas airport waiting for a delayed flight, I watched another passenger munch on some peanuts. Their shells fell all over the floor and, after a few minutes, the passenger kicked them into the aisle, presumably for the airport cleaning staff to collect later.
+
+I hadn't given those peanuts shells much thought until a recent internal Red Hat event, when someone asked me about my pet peeves. I started thinking about the way I notice paper towels on the floors in Red Hat bathrooms. Whenever I see them, I pick them up and put them in the trash.
+
+I'll admit: it's a tiny gesture. But the longer I work at Red Hat, the more I realize just how great an impact those seemingly inconsequential moments can have on a community.
+
+I've always done my best to put others before myself (my mother was a nurse, and I think I inherited that attitude from her). But working at Red Hat has made me care even more about the importance of community. Community is critical not only [to our business][2] but also to how we operate as an open organization.
+
+In a well-functioning open organization, you'll often see people doing things simply because they benefit the organization itself—even if those actions don't immediately benefit the individual. People tend to prioritize the well-being of the group over the agendas of the few.
+
+At the same time, you'll also encounter people working to keep that spirit in place (I'm thinking of the Red Hatters who take pictures of vehicles occupying more than one parking space in our company lot and post them to the all-building mailing list). Maybe they're extra conscientious about ending their meetings on time, so others waiting for the room can get started right away. Maybe they refill the printer paper even if they haven't used the last sheet. Maybe they schedule an early-morning call so their colleagues overseas don't need to stay up late. Regardless, in an open organization, you'll hear "let me help with that" much more than you'll hear "that's not my responsibility."
+
+For these folks, a paper towel is more than a paper towel. It's a tangible representation of someone's investment in the organization.
+
+In a well-functioning open organization, you'll often see people doing things simply because they benefit the organization itself—even if those actions don't immediately benefit the individual.
+
+That sense of reciprocity at the heart of a community-focused organization—the idea that I might do something because it strengthens the critical social bonds that keep our group from falling apart—is important. We can't underestimate the power of that kind of social cohesion, not only in our organizations but in our societies more broadly.
+
+In fact, writer and historian Paul Collier attributes the United States' growth and success after World War II to it. "The escape from the Depression by means of the Second World War had been far more than an inadvertent stimulus package," he writes [in _The Future of Capitalism_][3]. "Its legacy was to turn each nation into a gigantic community, a society with a strong sense of shared identity, obligation and reciprocity." Collier goes on to assess the current state of that shared identity and sense of reciprocity in today's seemingly fragmented political landscape.
+
+He also explains how leadership practices also shifted during this time, especially in organizations:
+
+> Gradually, many organizations learned that it was more effective to soften hierarchy, creating interdependent roles that had a clear sense of purpose, and giving people the autonomy and responsibility to perform them. The change from hierarchy run through power, to interdependence run through purpose, implies a corresponding change in leadership. Instead of being the commander-in-chief, the leader became the communicator-in-chief. Carrots and sticks evolved into narratives.
+
+I love this passage, because it describes how my own thinking about leadership has changed since I joined Red Hat. Being a "communicator-in-chief" is now the most important job a leader can have. That means creating a sense of common purpose, shared values, and what Collier calls "mutual obligation" among people empowered with the [context and resources they need to do their best work][4].
+
+We tell stories through actions, not just words. Open leaders should take opportunities to reinforce the kinds of communal, reciprocity-generating behaviors they want to see in other people.
+
+It's why I always pick up the paper towels.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/open-organization/19/9/peanuts-community-reciprocity
+
+作者:[Jim Whitehurst][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jwhitehurst
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_buildtogether.png?itok=9Tvz64K5 (People working together to build )
+[2]: https://www.redhat.com/en/about/development-model
+[3]: https://www.harpercollins.com/9780062748652/the-future-of-capitalism/
+[4]: https://opensource.com/open-organization/16/3/what-it-means-be-open-source-leader
diff --git a/sources/talk/20190904 A guide to human communication for sysadmins.md b/sources/talk/20190904 A guide to human communication for sysadmins.md
new file mode 100644
index 0000000000..eaa25203c8
--- /dev/null
+++ b/sources/talk/20190904 A guide to human communication for sysadmins.md
@@ -0,0 +1,60 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (A guide to human communication for sysadmins)
+[#]: via: (https://opensource.com/article/19/9/communication-sysadmins)
+[#]: author: (Maxim Burgerhout https://opensource.com/users/wzzrdhttps://opensource.com/users/rikki-endsley)
+
+A guide to human communication for sysadmins
+======
+The best way to increase your value to an organization is to get to know
+the people around you.
+![People work on a computer server with devices][1]
+
+Not too long ago, I spoke at a tech event in the Netherlands to an audience mostly made up of sysadmins. One of my topics was how sysadmins can increase the value they deliver to the organization they work for. I believe that among the most important factors for delivering value is for everyone to know the overall organization's priorities and goals, as well as the priorities and goals of the organization's development teams.
+
+This all sounds obvious, but in many organizations, silos almost completely block the inter-team communication needed to understand each other's priorities. Even in large organizations that pat themselves on the back for having gone full DevOps (or aspire to go full DevOps), knowledge of the priorities and goals of other teams is not ubiquitous. When I asked the couple hundred people in my audience whether they knew their development teams and what drives those teams, very few hands came up.
+
+You could argue that if you claim to have gone full DevOps, yet your people don't know the goals and priorities of the teams they work directly with, you are doing it wrong. And you would probably have a point. But put that aside for a moment. Even in a traditional organization—one that is only beginning its DevOps journey, has implemented some parts of the DevOps philosophy, or implemented DevOps only in certain parts of the organization (I have seen them all)—I would heartily recommend getting to know your co-workers. I would _especially_ recommend getting to know the ones outside your team that work with (or on) the platform that you build and maintain.
+
+Sit down for an hour or so with one of the people that develop applications on your platform or with someone who maintains commercial, off-the-shelf software on it. Have them explain to you how your platform and your services make their lives easier and how they make their lives harder. What could you and your team do to improve that situation?
+
+Talking to each other, learning from each other, debating problems _and_ solutions—especially with people whose immediate goals might initially differ from your own—helps everyone move forward together and build something that benefits an entire community.
+
+We see this happening in open source communities around the world all the time. Broad communities that are built from different companies and different people with (potentially) different or even conflicting goals, work. Successful open source communities are usually diverse, and members communicate to meet a broad range of goals, to find compromises, and to accommodate everyone.
+
+There is an obvious parallel between a broad open source community and working with "neighboring teams" in your organization to make your platform fit their interests and goals better. It's just a matter of taking that first step and starting a conversation with them.
+
+At this point, you may be asking, "But this is what I have my architects or service owners for, right?" Well, yeah, of course, they play a role in this. As do many others. And so do you!
+
+As an example, imagine your organization sets a target for your team to deliver a service within one week of the initial request. If the service is delivered within the week, the service-level agreements (SLAs) are met, and all is good, right? In reality, that is only sometimes true.
+
+Imagine your goal is to automatically (upon a self-service request) deliver a new virtual machine (VM) within a day and with a success rate of at least 95%. Now imagine a development team requests dozens of temporary VMs per day for CI/CD purposes, and 95% of them are delivered correctly. Your goal has been met, your SLA has been achieved—but no one is happy with the situation, because the CI/CD pipeline has broken on multiple occasions due to misconfigured VMs.
+
+**[More to read: [10 ways to have better conversations][2]]**
+
+In this example, the goals and SLAs need to be re-evaluated as soon as possible. But having a regular conversation with your developer teams or application maintainers, even in an organization that is pretty siloed, could make experiences like this much less common (and much easier to solve if they occur). Small annoyances and small problems would be unearthed at an early stage; small improvements would be suggested, and small improvements would be made _before_ large deployments of shadow IT happen.
+
+At the end of the day, nothing beats human-to-human communication. Nothing breaks barriers like knowing which face goes with which name. Nothing makes it easier to talk to people than knowing they want to support you in being successful! So, go and talk to your neighboring teams. Have coffee with them. Go build a broad community in your organization!
+
+P.S. Odds are your developer teams will talk to you about cloud and continuous integration and delivery. Those are topics for a potential future follow-up to this article. Stay tuned!
+
+It takes developers, sales, marketing, and product people to take this open source thing and turn...
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/communication-sysadmins
+
+作者:[Maxim Burgerhout][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/wzzrdhttps://opensource.com/users/rikki-endsley
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux11x_cc.png?itok=XMDOouJR (People work on a computer server with devices)
+[2]: https://enterprisersproject.com/article/2019/7/leadership-10-tips-better-conversations
diff --git a/sources/talk/20190904 Geeks in Cyberspace- A documentary about Linux nerds and the web that was.md b/sources/talk/20190904 Geeks in Cyberspace- A documentary about Linux nerds and the web that was.md
new file mode 100644
index 0000000000..df6726fb56
--- /dev/null
+++ b/sources/talk/20190904 Geeks in Cyberspace- A documentary about Linux nerds and the web that was.md
@@ -0,0 +1,71 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Geeks in Cyberspace: A documentary about Linux nerds and the web that was)
+[#]: via: (https://opensource.com/article/19/9/geeks-cyberspace)
+[#]: author: (Michael Stevenson https://opensource.com/users/mstevenson)
+
+Geeks in Cyberspace: A documentary about Linux nerds and the web that was
+======
+Film explores how a group of friends helped usher in our present age of
+social media, inventing now-familiar conventions that we use every day.
+![An old-fashioned video camera][1]
+
+"We invented blogging, we invented podcasting, we invented the LIKE button…"
+
+Rob Malda is only half-joking when he makes these claims in the closing minutes of my new documentary, _Geeks in Cyberspace_. Together with his friends Jeff Bates, Nate Oostendorp, and Kurt Demaagd, Malda helped usher in our present age of social media, inventing now-familiar conventions that we use every day on Reddit, Wikipedia, Facebook, and elsewhere.
+
+### Slashdot's success
+
+Malda created [Slashdot.org][2] more than 20 years ago, in 1997, and his friends helped him turn his proto-blog into an engine of participation. The site was powered by an incredibly rich suite of Linux, Apache, MySQL, and clever Perl hacks, as well as a community of readers who would submit stories, comment on them, then moderate those comments to bring the best bits to the top. _Wired_ called this "open-source journalism" in 1999, and the site would directly influence the creation of Digg and later Reddit.
+
+Slashdot's massive influence in the open source community coincided with what could be termed the open source bubble of the late 1990s, when Linux companies set records on Wall Street, and Microsoft recognized it had a real competitor in projects that were giving their source code away for free. Malda and his friends profited from the speculative craze, albeit modestly in comparison to later social media entrepreneurs. They sold Slashdot to Andover.net in the summer of 1999 for several million dollars in cash and stock options.
+
+### Everything2 and PerlMonks
+
+With some of the profits from Slashdot's sale, the friends looked to reproduce their success with [Everything2][3] (E2), another community website. E2 evolved out of a side project that Oostendorp built in 1998, one that in some ways was even more creative than Slashdot. Called "Everything," the project was to be a user-contributed information database that covered, well, everything—from _The Simpsons_ and beer brands to historical events and computer companies. Sound familiar? Conceived several years before Wikipedia launched, Everything was different from the collaborative encyclopedia we all use today. Rather than a "neutral point of view," it promoted something like "multiple points of view," and it had what could be considered an early ancestor of the ubiquitous "Like" button (as well as a counterpart "I don't like this" button).
+
+E2 launched in 1999 and took on a life of its own. Although its audience was small in comparison to Slashdot, the site's community was tight-knit and dedicated. The E2 community’s story is central to the documentary; it is striking because it reminds us that even in the footnotes of internet history, there are fascinating human stories that are worth recounting.
+
+Technologically, Everything2 was notable for being the first site run on The Everything Engine, software that would now be called a content management system or even an early web framework. As fellow geek chromatic [wrote][4], the Everything Engine was ahead of its time in many ways, if not as robust as the technologies it foreshadowed. The engine was also used to create [PerlMonks][5], the question-and-answer programming site that prefigured Stack Overflow and others.
+
+### Looking back, looking forward
+
+When I look at the history of Slashdot, E2, and PerlMonks, I don't simply see predecessors to today's social media landscape. For one thing, there were many other initiatives that shaped what was to come. More importantly, the value of such history is found in its specificity and how it can help us ask new questions about contemporary social media and imagine future platforms that will eventually challenge today's major players.
+
+With that in mind, I draw two key lessons from the work that Malda and company did at the turn of the century.
+
+First, they showed that getting these things off the ground requires not just a mix of hard work and luck but also an inspired mode of production. Chromatic rightly described the joy and sense of purpose they felt in terms of "momentum" and "a movement." A similar mix of joy and purpose can be found in waves across the cultural spectrum: think, for example, of the emerging scene of [chiptunes][6] artists, whose music I drew on heavily for this documentary, or a (hypothetical) group of journalists who seek to retake the news industry from commercial and political interests. Money certainly matters, as does circumstance. But time and again, for culture to renew itself, inspiration is key.
+
+Second, in the case of social media, an inspired outlook must translate to its community of users in tangible ways. For Slashdot, and even more so for E2 and PerlMonks, community members felt connected to _their_ site's purpose and had a real say in determining daily operations and overall direction.
+
+When real ownership is given, and a community works together to manage complex tasks of maintenance and government, social media becomes much more than a communications infrastructure. As E2 user and documentary subject Dana McNabb wrote many years ago about E2: "Everything is people. I married a noder, some of my best friends are noders, I continue to make new noding friends. Don't tell me this website is just a website."
+
+Although it is hard to imagine something similar ever being said about a platform the size of Facebook or Instagram, I believe such lessons can nonetheless figure into improving our current social media or in our attempts to provide alternatives.
+
+### Acknowledgments
+
+"Geeks in Cyberspace" and this article came out of my research project "The web that was," which also includes [this open access article][7]. The project is funded by the Dutch Research Council, project number 275-45-006. Most of all, thanks are due to Rob Malda, Nate Oostendorp, Kurt Demaagd, Jeff Bates, Tim Vroom, Ryan Postma, chromatic, Dana McNabb, and Cliff Lampe for generously giving their time for this project.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/geeks-cyberspace
+
+作者:[Michael Stevenson][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mstevenson
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LIFE_film.png?itok=aElrLLrw (An old-fashioned video camera)
+[2]: https://slashdot.org/
+[3]: https://www.everything2.com/
+[4]: https://www.perl.com/pub/2010/08/rethinking-perl-web.html
+[5]: https://www.perlmonks.org/
+[6]: https://en.wikipedia.org/wiki/Chiptune
+[7]: https://www.tandfonline.com/doi/full/10.1080/24701475.2018.1495810
diff --git a/sources/talk/20190905 10 pitfalls to avoid when implementing DevOps.md b/sources/talk/20190905 10 pitfalls to avoid when implementing DevOps.md
new file mode 100644
index 0000000000..2d66534959
--- /dev/null
+++ b/sources/talk/20190905 10 pitfalls to avoid when implementing DevOps.md
@@ -0,0 +1,126 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (10 pitfalls to avoid when implementing DevOps)
+[#]: via: (https://opensource.com/article/19/9/pitfalls-avoid-devops)
+[#]: author: (Mehul Rajput https://opensource.com/users/mehulrajputhttps://opensource.com/users/daniel-ohhttps://opensource.com/users/genekimhttps://opensource.com/users/ghaff)
+
+10 pitfalls to avoid when implementing DevOps
+======
+Make your DevOps implementation journey smoother by avoiding the
+mistakes others have made.
+![old postcard highway ][1]
+
+In companies of every size, software is increasingly providing business value because of a shift in how technology teams define success. More than ever, they are defined by how the applications they build bring value to their customers. Tickets and stability at the cost of saying no are no longer the key value of IT. It's now about increasing developer velocity by partnering with the business.
+
+In order to keep up with this faster pace, leading technology professionals are building software with precision and embracing standards of continuous delivery, integration, and DevOps. According to [Shanhong Liu][2], "As of 2018, only nine percent of technology professionals responsible for the development and quality of web and mobile applications stated that they had not adopted DevOps and had no plans to do so."
+
+A significant value in a [DevOps culture][3] is to accept failure as a part of the journey toward value. For software, the journey comes in the form of [continuous delivery][4] with the expectation that we regularly release code. The fast pace ensures failure, but it also ensures that when you do fail, you learn from your mistakes and adapt quickly. This is how you grow as a business: you get more insights and let them guide you toward success.
+
+Since those who have already adopted DevOps have made mistakes, you can use their experience to learn and avoid repeating the same mistakes. In the spirit of DevOps and open source—rapid iteration, building upon the work (and mistakes) of those who have gone before—following are some of the most common mistakes businesses encounter on their DevOps journey and how to work through them.
+
+### 1\. Out-of-order delivery
+
+Sometimes, developers will perform continuous delivery (CD) and continuous integration (CI) simultaneously to accelerate automated testing and feedback cycles. CI/CD as a practice has a lot of benefits when it comes to the pace of software delivery. The risk is that incorrect code configurations may be delivered to production environments without enough exploration on their impact, negating the value of automated testing before expansion.
+
+I believe manual confirmation is still essential before code goes all the way through the software delivery cycle. There must be a pre-production stage—a layer of deployment and testing before production—that allows developers to correct and rectify errors that users could face if the code were pushed directly to production.
+
+![Software delivery cycle][5]
+
+It is extremely important to put monitoring in place before code reaches the end user. For instance, structuring the CD pipelines so testing is done alongside development will ensure that changes are not deployed automatically.
+
+While DevOps standards declare that teams must expand beyond silos, deployment should always be validated by those familiar with the code that comes out at the end of the pipeline. This mandates a thorough examination before code reaches customers.
+
+### 2\. Misunderstanding the DevOps title
+
+Some organizations are bewildered about the DevOps title. They believe a DevOps engineer's object is to solve all problems associated with DevOps—even when DevOps means collaboration across Developers and Operators.
+
+The way DevOps integrates development and operations roles can be a difficult career progression. Developers require more understanding of how their application runs in order to keep it running and potentially be on call for support if it goes down. Operations must become an expert on how to scale and understand the metrics that fit inside a larger [monitoring and observability strategy][6].
+
+DevOps, in practice, helps companies accelerate time-consuming tasks in IT operations. For example, automating testing provides developers with faster feedback, and automating integration incorporates developers' changes more quickly into the codebase. DevOps may also be asked to automate procedures around collecting, expanding, and running apps.
+
+Your organization's fundamental needs dictate whether your DevOps professionals' skill sets need to be stronger in operations or development, and this information must align with how you select or hire your DevOps team. For instance, it is important to prioritize past software development and scripting skills when automation is key (instead of requiring expertise around containerization). Hire for your unique DevOps experience needs, and let people learn the other skills on the job. If you hire people who are ready to learn, you will build the best possible team for your organization.
+
+### 3\. Inflexibility around DevOps procedures
+
+While DevOps principles provide a foundation, each organization must be ready to customize their journey for their desired outcomes. Companies need to make sure that, while the core DevOps pillars stay steady during implementation, they create internal modifications that are essential in measuring their predicted results.
+
+It is important to master the fundamentals of DevOps, especially the [CALMS][7] (Culture, Automation, Lean, Measurement, and Sharing) pillars, to build a foundation for technology advancement. But there is no one-size-fits-all DevOps implementation. By recognizing that, the DevOps team can build a plan to address the key reason for the initiative and build from past failed results. Teams should be ready to modify their plan while staying within the recommendations of the fundamental DevOps principles.
+
+### 4\. Selecting speed over quality
+
+Many companies concentrate on product delivery without paying enough attention to product quality. If the effort's key performance indicators (KPIs) center only on time to production, it is easy for quality to fall off in the process. Endpoints that could monitor performance are left for future versions, and software that is not production-ready is seen as a success because it was pushed rapidly forward.
+
+In a fast-paced market, teams can't afford to provide the best product quality with the time requirements dictated by either the customer or internal demand. Many companies are hurrying to get and finish as many DevOps projects as possible within a shorter time span to keep their position in a competitive market. That may sound like a good idea, but expecting DevOps to be a quick journey may result in more pain than gain.
+
+Achieving both speed and quality improvement is an essential DevOps value. It is not achieved easily and requires operators and developers to write testing in new and improved ways. When done well, quality and speed improve simultaneously.
+
+### 5\. Building a dedicated DevOps team
+
+Theoretically, it makes sense to build a dedicated team to concentrate on training the newest professionals in IT. The movement to complete a DevOps journey must be hassle-free and seamless, right? But two issues quickly arise:
+
+ * Existing quality assurance (QA), operations, and development team members feel overlooked and may try to hinder the new team's efforts.
+ * This new team becomes another silo, providing new technology but not advancing the company's goals on a DevOps journey.
+
+
+
+It is better to have a mix of new team members and current employees from QA, ops, and dev who are excited to join the DevOps initiative. The latter group has a lot of institutional knowledge that is valuable as you roll out such a large initiative.
+
+### 6\. Overlooking databases
+
+The database is one of the most essential technology areas overlooked while building out DevOps. New, ephemeral applications can fly through a DevOps pipeline at a speed unlike any application before. But data-hungry applications don't see the same ease of deployment.
+
+Data snapshots in separate environments can and will drift toward inaccuracy without a concentrated effort to automate them effectively. Experts stress constant integration and code handling but fail in automating the database. Database management should be done properly, particularly for data-centric apps. The database plays an important role in such apps and may require separate expertise to automate it alongside other applications.
+
+### 7\. Insufficient incident-handling procedures
+
+In case something goes wrong (and it will), DevOps teams should have incident-handling procedures in place. Incident handling should be a continuous and active procedure clearly outlined for consistency and to avoid error. This means that in order for an incident-handling process to be documented, you must capture and describe the incident-response requirements. There is a lot of research into runbook documentation and [blameless post-mortems][8] that is important to learn to be successful.
+
+### 8\. Insufficient knowledge of DevOps
+
+Although acceptance of DevOps has expanded rapidly in recent years, application experts may be working without precise quality-control procedures. The team's ability to do all the technical, cultural, and process changes needed to succeed in DevOps sometimes falls short.
+
+It's a wise move to adopt DevOps practices, but success requires ample experience and preparation. In some cases, getting the right expertise to meet your requirements means hiring outside experts (disclaimer: I manage a DevOps consultancy). These trained experts should have certifications in the required technologies, and companies should abstain from making rapid DevOps decisions without having a good handle on outcomes.
+
+### 9\. Neglecting security
+
+Security and DevOps should move side-by-side. Many organizations dismiss security guidelines because it's hard, and a DevOps journey can be hard enough. This leads to issues, such as initially maximizing the output of developers and later realizing that they neglected to secure those applications. Take security seriously, and look into [DevSecOps][9] to see if it makes sense to your organization.
+
+### 10\. Getting fatigued while implementing DevOps
+
+If you start a DevOps team with the goal to go from one product deployment a year to 10 pushes in a week, it will likely fail. The path to get to an arbitrary metric that looks good in a presentation will not motivate the team. DevOps is not a simple technology movement; it's a huge cultural upgrade.
+
+The larger the enterprise, the longer it may take to get DevOps practices to stick. You should apply your DevOps methodology in a phased and measured approach with realistic results as milestones to celebrate. Train your employees, and schedule ample breaks before starting the initial round of application deployments. The first DevOps pipeline can be slow to achieve. That's what continuous improvement looks like in real life.
+
+### The bottom line
+
+Companies are rapidly moving towards DevOps to keep pace with their competition but make common mistakes in their implementations. To avoid these pitfalls, plan precisely and apply the right strategies to achieve a more successful DevOps outcome.
+
+Just as with any transformational and disruptive movement, DevOps can be misunderstood or...
+
+Is DevOps fundamentally about changing culture in an IT organization? That seemingly simple...
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/pitfalls-avoid-devops
+
+作者:[Mehul Rajput][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mehulrajputhttps://opensource.com/users/daniel-ohhttps://opensource.com/users/genekimhttps://opensource.com/users/ghaff
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/road2.jpeg?itok=chTVOSil (old postcard highway )
+[2]: https://www.statista.com/statistics/673505/worldwide-software-development-survey-devops-adoption/
+[3]: https://www.linkedin.com/pulse/10-facts-stats-every-devops-enthusiast-must-know-pavan-belagatti-/
+[4]: https://opensource.com/article/19/4/devops-pipeline
+[5]: https://opensource.com/sites/default/files/uploads/devopsmistakes_pipeline.png (Software delivery cycle)
+[6]: https://opensource.com/article/18/8/now-available-open-source-guide-devops-monitoring-tools
+[7]: https://whatis.techtarget.com/definition/CALMS
+[8]: https://opensource.com/article/19/4/psychology-behind-blameless-retrospective
+[9]: https://opensource.com/article/19/1/what-devsecops
diff --git a/sources/talk/20190905 6 years of tech evolution, revolution and radical change.md b/sources/talk/20190905 6 years of tech evolution, revolution and radical change.md
new file mode 100644
index 0000000000..f08cb34071
--- /dev/null
+++ b/sources/talk/20190905 6 years of tech evolution, revolution and radical change.md
@@ -0,0 +1,106 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (6 years of tech evolution, revolution and radical change)
+[#]: via: (https://www.networkworld.com/article/3435857/6-years-of-tech-evolution-revolution-and-radical-change.html)
+[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
+
+6 years of tech evolution, revolution and radical change
+======
+In his farewell TechWatch post, Fredric Paul looks back at how technology has changed in the six years he’s been writing for Network World—and what to expect over the next six years.
+Peshkov / Getty Images
+
+Exactly six years ago today—Sept. 5, 2013—Network World published my very first [TechWatch][1] blog post. It addressed the introduction of [Samsung's Galaxy Gear and the problem with smartwatches][2].
+
+Since then, I’ve written hundreds of blog posts on a dizzying array of technology topics, ranging from [net neutrality][3] to phablets to cloud computing to big data to the internet of things (IoT)—and many, many more. It’s been a great ride, and I will be forever grateful to my amazing editors at Network World and everyone who’s taken the time to read my work. But all good things must come to an end, and this will be my last TechWatch post for Network World.
+
+You see, writing for Network World is not my day job. For the last five and a half years, I have been editor in chief of [New Relic][4], a leader in the enterprise observability space. But this week, I’ve taken a new position at director of content for [Redis Labs][5], the home of the fast Redis database. I’m super excited about the opportunity, but here’s the thing: Redis Labs has a number of products in the IoT space, which could raise thorny conflict-of-interest questions for many blog posts I might write.
+
+**[ Find out how [5G wireless could change networking as we know it][6] and [how to deal with networking IoT][7]. | Get regularly scheduled insights by [signing up for Network World newsletters][8]. ]**
+
+### Looking back: What technology has changed and what hasn’t
+
+So, for this good-bye post, I want to look back at some of the topics I’ve touched on over the years—and especially that first year—and see how far we’ve come, and maybe get a sense of what’s coming next.
+
+Obviously, there’s no time or space to revisit everything. But I do want to touch on six key themes.
+
+#### **1\. Wearable tech**
+
+Back when I wrote that first post on [Samsung's Galaxy Gear][2], it seemed like wearable technology was about to change everything. Smartwatches and fitness trackers were being introduced by everyone from tech companies to sporting goods manufacturers to fashion brands and [luxury watch companies][9]. The [epic failure of Google Glass][10] hadn’t yet set the category back a decade by permanently creeping out folks around the world.
+
+Today, things look very different. [The Apple Watch is thriving in a limited role][11] as a fitness and health tracking device, trailed by a variety of simpler, cheaper options. [Google Glass and its ilk are niche products looking for industrial applications.][12] And my grand vision of wearable tech fundamentally reshaping the technology landscape? Yeah, we’re still waiting for that.
+
+**[ [Take this mobile device management course from PluralSight and learn how to secure devices in your company without degrading the user experience.][13] ]**
+
+#### 2\. Phones & phablets & tablets
+
+Six years ago, I had a lot of phun making puns about the rise of “phablets,” those giant phones (or miniature tablets) threatening to take over the mobile world. Well, that happened. In fact, it happened so thoroughly that no one even talks about increasingly ginormous phones as phablets anymore. They’re just… phones.
+
+**[ Also on Network World: [Phablets are the phuture, no phoolin'][14] ]**
+
+#### 3\. BYOD and shadow IT
+
+Back in 2013, shadow IT was still mostly thought of as [Bring Your Own Device][15], but increasingly powerful online services have expanded the concept far beyond enterprise workers using their own phones on the corporate network. Now, shadow IT includes everything from computing power and storage in the cloud to virtually Everything-as-a-Service. And with the rise of Shadow IoT, the situation is only getting more complicated for IT teams. How do you maintain order and security while also empowering users with maximum productivity?
+
+**[ Also on Network World: [Don’t worry about shadow IT. Shadow IoT is much worse.][16] ]**
+
+#### 4\. Net neutrality
+
+Hoo-boy. After endless arguments rooted in deeply differing versions of what freedom really means, ideological conflicts, all-out business battles between communications companies and online services, net neutrality was finally settled as official U.S. policy. And then, suddenly, [all that was changed by a new administration and a new FCC leader][17]. At least for now. Probably. Ahhh, who are we kidding? We’re going to be arguing over net neutrality forever.
+
+**[ Also on Network World: [Why even ISPs will regret the end of net neutrality][18] ]**
+
+#### 5\. The cloud
+
+When I started writing TechWatch, the cloud was still a good idea looking to find its rightful place in a world still dominated by private data centers. Today, everything has flipped. [The cloud is now pretty much the default for new IT infrastructure workloads][19], and it is slowly but surely chipping away at all those legacy, mission-critical apps and systems. Sure, key questions around cost, security, compliance and reliability remain, but as 2019 begins to wind down, the cloud’s promise of radical improvements in development speed and agility can no longer be questioned. As [cloud providers keep growing like weeds on steroids][19], modern IT leaders increasingly have to justify _not_doing things in the cloud.
+
+**[ Also on Network World: [The week cloud computing took over the world][20] ]**
+
+#### 6\. The internet of things
+
+TechWatch has been interested in the IoT for a while now (see [How the Internet of Things will – and won't – change IT][21]), but for the last couple years it has been the dominant topic for TechWatch. Over that time, the IoT has evolved from a concept with tremendous promise but limited real-world applications to one of the most important technologies on the planet, on pace to disrupt everything from brushing your teeth to driving (or not driving) your car to [maintaining jet airplanes][22]. It’s been a wild ride, but serious barriers remain. IoT security concerns, especially on the consumer side, still threaten IoT adoption. Lack of interoperability and unclear ROI continue to slow IoT installations.
+
+But those are just speed bumps. Like it or not, the IoT is going to keep growing. And that growth won’t always come in nicely defined, easily understood and controlled ways. In many cases, IoT devices and networks are being deployed without established goals, metrics, controls, and contingency plans. It may be a recipe for trouble, but it’s also how just about every important technology rolls out. [The winners will be the organizations that figure out how to maximize the IoT’s value while avoiding its pitfalls.][23] I will be watching closely to see what happens!
+
+Join the Network World communities on [Facebook][24] and [LinkedIn][25] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3435857/6-years-of-tech-evolution-revolution-and-radical-change.html
+
+作者:[Fredric Paul][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Fredric-Paul/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/blog/techwatch/
+[2]: https://www.networkworld.com/article/2225307/samsung-s-galaxy-gear-and-the-problem-with-smartwatches.html
+[3]: https://www.networkworld.com/article/3238016/will-the-end-of-net-neutrality-crush-the-internet-of-things.html
+[4]: https://newrelic.com/
+[5]: https://redislabs.com/
+[6]: https://www.networkworld.com/cms/article/https:/www.networkworld.com/article/3203489/lan-wan/what-is-5g-wireless-networking-benefits-standards-availability-versus-lte.html
+[7]: https://www.networkworld.com/cms/article/https:/www.networkworld.com/article/3258993/internet-of-things/how-to-deal-with-networking-iot-devices.html
+[8]: https://www.networkworld.com/newsletters/signup.html
+[9]: https://www.networkworld.com/article/2882057/would-you-buy-a-smartwatch-from-a-watch-company.html
+[10]: https://www.networkworld.com/article/2364501/how-google-glass-set-wearable-computing-back-10-years.html
+[11]: https://www.networkworld.com/article/3305812/the-new-apple-watch-4-represents-an-epic-fail-for-smartwatches.html
+[12]: https://www.networkworld.com/article/2955708/google-glass-returning-enterprise-business-users.html
+[13]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
+[14]: https://www.networkworld.com/article/2225569/phablets-are-the-phuture--no-phoolin-.html
+[15]: https://www.networkworld.com/article/2225741/5-disturbing-byod-lessons-from-the-faa-s-in-flight-electronics-announcement.html
+[16]: https://www.networkworld.com/article/3433496/dont-worry-about-shadow-it-shadow-iot-is-much-worse.html
+[17]: https://www.networkworld.com/article/3166611/the-end-of-net-neutrality-is-nighheres-whats-likely-to-happen.html
+[18]: https://www.networkworld.com/article/2226155/why-even-isps-will-regret-the-end-of-net-neutrality.html
+[19]: https://www.networkworld.com/article/3391465/another-strong-cloud-computing-quarter-puts-pressure-on-data-centers.html
+[20]: https://www.networkworld.com/article/2914880/the-week-cloud-computing-took-over-the-world-microsoft-amazon.html
+[21]: https://www.networkworld.com/article/2454225/how-the-internet-of-things-will-and-wont-change-it.html
+[22]: https://www.networkworld.com/article/3340132/why-predictive-maintenance-hasn-t-taken-off-as-expected.html
+[23]: https://www.networkworld.com/article/3211438/is-iot-really-driving-enterprise-digital-transformation.html
+[24]: https://www.facebook.com/NetworkWorld/
+[25]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190905 Data center cooling- Electricity-free system sends excess building heat into space.md b/sources/talk/20190905 Data center cooling- Electricity-free system sends excess building heat into space.md
new file mode 100644
index 0000000000..e87065de21
--- /dev/null
+++ b/sources/talk/20190905 Data center cooling- Electricity-free system sends excess building heat into space.md
@@ -0,0 +1,66 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Data center cooling: Electricity-free system sends excess building heat into space)
+[#]: via: (https://www.networkworld.com/article/3435769/data-center-cooling-electricity-free-system-sends-excess-building-heat-into-space.html)
+[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
+
+Data center cooling: Electricity-free system sends excess building heat into space
+======
+A polymer and aluminum film solar shelter that transmits heat into space without using electricity could drastically cut data center cooling costs.
+University at Buffalo
+
+We all know that blocking incoming sunlight helps cool buildings and that indoor thermal conditions can be improved with the added shade. More recently, though, scientists have been experimenting with ways to augment that passive cooling by capturing any superfluous, unwanted solar heat and expelling it, preferably into outer space, where it can’t add to global warming.
+
+Difficulties in getting that kind of radiative cooling to work are two-fold. First, directing the heat optimally is hard.
+
+“Normally, thermal emissions travel in all directions,” says Qiaoqiang Gan, an associate professor of electrical engineering at University at Buffalo, in a [news release][1]. The school is working on radiative concepts. That’s bad for heat spill-over and can send the thermal energy where it’s not wanted—like into other buildings.
+
+**[ Learn [how server disaggregation can boost data center efficiency][2] and [how Windows Server 2019 embraces hyperconverged data centers][3] . | Get regularly scheduled insights by [signing up for Network World newsletters][4]. ]**
+
+But the school says it has recently figured out how to “beam the emissions in a narrow direction.”
+
+Second, radiative cooling is a night-time effect. It can be best described in the analogy of a blacktop road surface, which absorbs the sun’s rays during the day and emits that captured heat overnight as the surrounding air cools.
+
+But University at Buffalo's system works during the day, the researchers say. It is made up of building-installed rooftop boxes that have a polymer combination aluminum film affixed to the bottom (pictured above). The film stops the area around the roof from getting hot through a form of heat absorption. The polymer absorbs warmth from the air in the box and transmits “that energy through the Earth’s atmosphere into outer space.” The box, when installed en massse, potentially shelters the entire roof from sunlight “while also beaming thermal radiation emitted from the film into the sky.” The polymer itself stays cool.
+
+That directionality also solves the problem of how to get the application to function within a city—the heat is beamed straight up in this case, rather than being allowed to disperse side to side and potentially infiltrate neighboring buildings.
+
+University at Buffalo’s box is about 18 inches by 10 inches. Multiple boxes would be affixed to cover a rooftop, augmenting the air conditioning.
+
+### Stanford University also has a cooling system
+
+I’ve written before about passive, radiative cooling systems that could be used in data center environments. A few years ago, [Stanford University suggested using the sky as one giant heatsink][5]. It reckons cost savings for cooling could be in the order of 21%. That system used mirror-like panels and, like the University at Buffalo solution, tries to solve the second major problem involved with radiative heating: How to get it to work during the day when the sun is beating down on the surfaces and the ambient air is warm—you need cool air to absorb the hot air.
+
+Stanford’s solution is to reflect the sunlight away from the panels during the day so the stored heat can radiate, even during the day. Researchers at University at Buffalo, however, say their approach, which uses special materials, is better.
+
+“Daytime cooling is a challenge because the sun is shining. In this situation, you need to find strategies to prevent rooftops from heating up. You also need to find emissive materials that don’t absorb solar energy. Our system address these challenges,” says Haomin Song, Ph.D., UB assistant professor of research in electrical engineering, in the news release.
+
+University at Buffalo’s directional aspect is interesting, too.
+
+“If you look at the headlight of your car, it has a certain structure that allows it to direct the light in a certain direction,” Gan says. “We follow this kind of a design. The structure of our beam-shaping system increases our access to the sky.”
+
+Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3435769/data-center-cooling-electricity-free-system-sends-excess-building-heat-into-space.html
+
+作者:[Patrick Nelson][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Patrick-Nelson/
+[b]: https://github.com/lujun9972
+[1]: http://www.buffalo.edu/news/releases/2019/08/003.html
+[2]: https://www.networkworld.com/article/3266624/how-server-disaggregation-could-make-cloud-datacenters-more-efficient.html
+[3]: https://www.networkworld.com/article/3263718/software/windows-server-2019-embraces-hybrid-cloud-hyperconverged-data-centers-linux.html
+[4]: https://www.networkworld.com/newsletters/signup.html
+[5]: https://www.networkworld.com/article/3222850/space-radiated-cooling-cuts-power-use-21.html
+[6]: https://www.facebook.com/NetworkWorld/
+[7]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190905 HPE-s vision for the intelligent edge.md b/sources/talk/20190905 HPE-s vision for the intelligent edge.md
new file mode 100644
index 0000000000..44161337ba
--- /dev/null
+++ b/sources/talk/20190905 HPE-s vision for the intelligent edge.md
@@ -0,0 +1,88 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (HPE's vision for the intelligent edge)
+[#]: via: (https://www.networkworld.com/article/3435790/hpes-vision-for-the-intelligent-edge.html)
+[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
+
+HPE's vision for the intelligent edge
+======
+HPE plans to incorporate segmentation, artificial intelligence and automation into its wired and wireless gear in order to deal with the increased network challenges imposed by IoT and SD-WAN.
+HPE
+
+It’s not just speeds and feeds anymore, it's intelligent software, integrated security and automation that will drive the networks of the future.
+
+That about sums up the networking areas that Keerti Melkote, HPE's President, Intelligent Edge, thinks are ripe for innovation in the next few years.He has a broad perspective because his role puts him in charge of the company's networking products, both wired and wireless.
+
+[Now see how AI can boost data-center availability and efficiency][1]
+
+“On the wired side, we are seeing an evolution in terms of manageability," said Melkote, who founded Aruba, now part of HPE. "I think the last couple of decades of wired networking have been about faster connectivity. How do you go from a 10G to 100G Ethernet inside data centers? That will continue, but the bigger picture that we’re beginning to see is really around automation.”
+
+[For an edited version of Network World\\\\\'s wide-ranging inerview with Merkote click here.][2]
+
+The challenge is how to inject automation into areas such as [data centers][3], [IoT][4] and granting network access to endpoints. In the past, automation and manageability were afterthoughts, he said. “The wired network world never really enabled native management monitoring and automation from the get-go.”
+
+Melkote said HPE is changing that world with its next generation of switches and apps, starting with a switching line the company introduced a little over a year ago, the Core Switch 8400 series, which puts the the ability to monitor, manage and automate right at the heart of the network itself, he said.
+
+In addition to providing the network fabric, it also provides deep visibility, deep penetrability and deep automation capabilities. "That is where we see the wide network foundation evolving," he said.
+
+In the wireless world, speeds and capacity have also increased over time, but there remains the need to improve network efficiency for high-density deployments, Melkote said. Improvements with the latest generation of wireless, [Wi-Fi 6][5], address this by focusing on efficiency and reliability and high-density connectivity, which are necessary given the explosion of wireless devices, including IoT gear, he said.
+
+**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][6] ]**
+
+Artificial intelligence will also play a major role in how networks are managed, he said. “Behind the scenes, across both wired and wireless, AI and AI operations are going to be at the heart of how the vision of manageability and automation is going to be realized,” Melkote said.
+
+AI operations are fundamentally about collecting large amounts of data from network devices and gaining insights from the data to predict when and where the network is going to face capacity and congestion problems that could kill performance, and to discover security issues, he said.
+
+“Any one of those insights being able to proactively give our customers a view into what’s happening so they can solve a problem before it really becomes a big issue is a huge area of research and development for us,” Melkote said.
+
+And that includes AI in wireless networks. “Even more than Wi-Fi 6, I see the evolution of AI behind the Wi-Fi 6 network or the next-generation wired network being really the enabler of the next evolution of efficiency, the next level of insights into the operations of the network,” he said.
+
+From a security perspective, IoT poses a particular challenge that can be addressed in part via network features. “The big risk with IoT is that these devices are not secured with traditional operating systems. They don’t run Windows; they don’t run [Linux][7]; they don’t run an OS,” Melkote said. As a result, they are susceptible to attacks, "and if a hacker is able to jump onto your video camera or your IoT sensor, it can then use that to attack the rest of the internal network.”
+
+That creates a need for access control and network segmentation that isolates these devices and provides a level of visibility and control that is integrated into the network architecture itself. HPE regards this as a massive shift from what enterprise networks have been used for historically – connecting users and taking them from Point A to Point B with high quality of service, Melkote said.
+
+"The segmentation is, I think, the next big evolution for all the new use cases that are emerging,” Melkote said. “The segmentation not only happens inside a LAN context with Wi-Fi and wired technology but in a WAN context, too. You need to be able to extend it across a wide area network, which itself is changing from a traditional [MPLS][8] network to a software-defined WAN, [SD-WAN][9].”
+
+SD-WAN is one of the core technologies for enabling edge-to-cloud efficiency, an ever-more-important consideration given the migration of applications from private data centers to public cloud, Melkote said. SD-WAN also extends to branch offices that not only need to connect to data centers, but directly to the cloud using a combination of internet links and private circuits, he said.
+
+“What we are doing is basically integrating the security and the WAN functionality into the architecture so you don’t have to rely on technology from third parties to provide that additional level of security or additional segmentation on the network itself,” Melkote said.
+
+The edge of the network – or the intelligent edge – is also brings with it its own challenges. HPE says the intelligent edge entails analysis of data where it is generated to reduce latency, security risk and costs. It breaks intelligent edge types into three groups: operational technology, IT and IoT edges.
+
+Part of the intelligent edge will include micro data centers that will be deployed at the point where data gets created, he said. "That’s not to say that the on-prem data center goes away or the cloud data center goes away," Melkote said. "Those two will continue to be served, and we will continue to serve those through our switching/networking products as well as our traditional compute and storage products."
+
+The biggest challenge will be bringing these technologies to customers to deploy them quickly. "We are still in the early days of the intelligent-edge explosion. I think in a decade we’ll be talking about the edge in the same way we talk about mobility and cloud today, which is in the past tense – and they’re massive trends. The edge is going to be very similar, and I think we don’t say that yet simply because I don’t think we have enough critical mass and use cases yet.”
+
+But ultimately, individual industustries will glean advantages from the intelligent edge, and it will spread, Melkote said.
+
+“A lot of the early work that we’re doing is taking these building blocks of connectivity, security, manageability and analytics and packaging them in a manner that is consumable for retail use cases, for energy use cases, for healthcare use cases, for education use cases and workplace use cases," he said. Every vertical has its own unique way to derive value out of this package. We are in the early days figuring that out."
+
+Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3435790/hpes-vision-for-the-intelligent-edge.html
+
+作者:[Michael Cooney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Michael-Cooney/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3274654/ai-boosts-data-center-availability-efficiency.html
+[2]: https://www.networkworld.com/article/3435206/hpe-s-keerti-melkote-dissects-future-of-mobility-the-role-of-the-data-center-and-data-intelligence.html
+[3]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
+[4]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
+[5]: https://www.networkworld.com/article/3356838/how-to-determine-if-wi-fi-6-is-right-for-you.html
+[6]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
+[7]: https://www.networkworld.com/article/3215226/what-is-linux-uses-featres-products-operating-systems.html
+[8]: https://www.networkworld.com/article/2297171/network-security-mpls-explained.html
+[9]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
+[10]: https://www.facebook.com/NetworkWorld/
+[11]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190906 How to open source your academic work in 7 steps.md b/sources/talk/20190906 How to open source your academic work in 7 steps.md
new file mode 100644
index 0000000000..a233d8131d
--- /dev/null
+++ b/sources/talk/20190906 How to open source your academic work in 7 steps.md
@@ -0,0 +1,114 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to open source your academic work in 7 steps)
+[#]: via: (https://opensource.com/article/19/9/how-open-source-academic-work)
+[#]: author: (Joshua Pearce https://opensource.com/users/jmpearcehttps://opensource.com/users/ianwellerhttps://opensource.com/users/edunham)
+
+How to open source your academic work in 7 steps
+======
+Open source technology and academia are the perfect match. Find out how
+to meet tenure requirements while benefiting the whole community.
+![Document sending][1]
+
+Academic work fits nicely into the open source ethos: The higher the value of what you give away, the greater your academic prestige and earnings. Professors accomplish this by sharing their best ideas for free in journal articles in peer-reviewed literature. This is our currency, without a strong publishing record not only would our ability to progress in our careers degrade, but even our jobs could be lost (and the ability to get any other job).
+
+This situation makes attribution or credit for developing new ideas and technologies critical to an academic, and it must be done in the peer-reviewed literature. Many young academics struggle with how to pull this off while working with an open source community and keeping their academic publishing record strong. There does not need to be a conflict. In fact, by fully embracing open source, there are distinct advantages (e.g., it is hard to get scooped by unethical reviewers when you have a time- and date-stamped open access preprint published for all the world to see).
+
+The following seven steps provide the best practices for making an academic’s work open source. Start by using best practices (e.g., [General Design Procedure for Free and Open-Source Hardware for Scientific Equipment][2]), then when your work is ready to share, do the first three steps simultaneously.
+
+**Note:** Academics should not be concerned about working in open source at all at this point, as open source is now mainstream academia in software and has even been [embraced by the hardware community][3].
+
+### Step 1: Select a relevant peer-reviewed journal
+
+Your work should first be published as a technology paper in a peer-reviewed journal with a good reputation (e.g., by [Impact Factor][4] or [CiteScore][5], which is a measure reflecting the yearly average number of citations to recent articles published in that journal). If yours is a hardware project, then choose journals such as:
+
+ * _[HardwareX][6]_ (CiteScore: 4.42)
+ * _[Sensors][7]_ (CiteScore: 3.72)
+ * _[PLOS ONE][8]_ (CiteScore: 3.02)
+ * _[The Journal of Open Hardware][9]_ (new)
+
+
+
+You could also choose a discipline-specific journal that publishes hardware.
+
+Or, if your project is software, then the following journals may be of interest:
+
+ * _[SoftwareX][10]_ (CiteScore: 11.56)
+ * _[The Journal of Open Source Software][11]_ (new)
+ * _[The Journal of Open Research Software][12]_ (new)
+
+
+
+### Step 2: Post your source code
+
+When submitting your work to a peer-reviewed journal, you will need to post your source code and cite it in your paper. For software papers, you would post your actual code, but for hardware papers, you would post aspects like the bill of materials, CAD designs, build instructions, etc.
+
+Use common websites for sharing code like [GitLab][13], or websites meant specifically for academia like the [Open Science Framework][14].
+
+### Step 3: Publish an open access pre-print
+
+When your paper is complete and you submit it to the journal, publish an open-access preprint as well. Doing so protects you against others scooping or patenting your ideas, while at the same time opening all of your work including the paper itself.
+
+Almost all major publishers allow preprints. There are a lot of pre-print servers for every discipline (e.g., [arXiv][15], [preprints.org][16]).
+
+### Step 4: Start (or select) a company
+
+The next step is not strictlly mandatory, but it is useful to either commercialize your work or provide support for your open source software. Start a spin-off company (or have a student do it), or work with an existing open source company. This step is recommended because although some people will fabricate your device from open source plans or compile your code, the vast majority would rather buy a reasonably priced version that is both open source so they control it, but also assembled or compiled, ready to use, and supported.
+
+### Step 5: Certify your project
+
+As soon as the paper is accepted, send it in for certification. See: [The trials of certifying open source software][17], or the perhaps more straightforward [OSHWA open hardware certification][18], for more information. You could do this step earlier, but publishing outside of a preprint server runs risks of being auto-rejected due to the plagiarism checks run by some journals.
+
+### Step 6: Prepare a press release
+
+As soon as certification comes through, organize a press release between the company and the university—and embargo it to the date of the academic paper’s official publication. This action spreads information about your open source technology and its benefits as far as possible.
+
+### Step 7: Use your own technology
+
+Last, but not least—use your open source technology in future research. From here on out, an academic can publish normally (e.g., do a scientific study using the open hardware and publish in a discipline-specific journal). Of course, preference should be given to [open access journals][19].
+
+### Step up
+
+These seven steps are reasonably straightforward for new open source technology projects. When it comes to academics working on _existing_ open source projects, it’s a bit different. They need to carve out an area such as an upgrade to existing open hardware, or a new feature for free and open source software (FOSS), that they can publish on independently. They can then follow the same steps as above while integrating their work back into the community’s code (e.g., back in Step 2).
+
+Following these steps enables academics to more than meet the academic requirements they need for tenure and promotion while developing open source technology for everyone’s benefit.
+
+A few months ago, opensource.com ran a story on a textbook for college students learning...
+
+When academia and open source collaborate, everybody wins. Open source projects get new...
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/how-open-source-academic-work
+
+作者:[Joshua Pearce][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jmpearcehttps://opensource.com/users/ianwellerhttps://opensource.com/users/edunham
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/email_paper_envelope_document.png?itok=uPj_kouJ (Document sending)
+[2]: http://www.mdpi.com/2411-9660/2/1/2/htm
+[3]: https://opensource.com/article/18/4/mainstream-academia-embraces-open-source-hardware
+[4]: https://en.wikipedia.org/wiki/Impact_factor
+[5]: https://en.wikipedia.org/wiki/CiteScore
+[6]: https://www.journals.elsevier.com/hardwarex
+[7]: https://www.mdpi.com/journal/sensors
+[8]: https://journals.plos.org/plosone/
+[9]: https://openhardware.metajnl.com/
+[10]: https://www.journals.elsevier.com/softwarex
+[11]: https://joss.theoj.org/
+[12]: https://openresearchsoftware.metajnl.com/
+[13]: https://about.gitlab.com/
+[14]: https://osf.io/
+[15]: https://arxiv.org/
+[16]: https://www.preprints.org/
+[17]: https://opensource.com/business/16/2/certified-good-software
+[18]: https://certification.oshwa.org/
+[19]: https://doaj.org/
diff --git a/sources/tech/20180704 BASHing data- Truncated data items.md b/sources/tech/20180704 BASHing data- Truncated data items.md
deleted file mode 100644
index 33a9dd636b..0000000000
--- a/sources/tech/20180704 BASHing data- Truncated data items.md
+++ /dev/null
@@ -1,107 +0,0 @@
-BASHing data: Truncated data items
-======
-### Truncated data items
-
-**truncated** (adj.): abbreviated, abridged, curtailed, cut off, clipped, cropped, trimmed...
-
-One way to truncate a data item is to enter it into a database field that has a character limit shorter than the data item. For example, the string
-
->Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE of Yermo CA
-
-is 60 characters long. If you enter it into a "Locality" field with a 50-character limit, you get
-
->Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE #Ends with a whitespace
-
-Truncations can also be data entry errors. You meant to enter
-
->Sally Ann Hunter (aka Sally Cleveland)
-
-but you forgot the closing bracket
-
->Sally Ann Hunter (aka Sally Cleveland
-
-leaving the data user to wonder whether Sally has other aliases that were trimmed off the data item.
-
-Truncated data items are very difficult to detect. When auditing data I use three different methods to find possible truncations, but I probably miss some.
-
-**Item length distribution.** The first method catches most of the truncations I find in individual fields. I pass the field to an AWK command that tallies up data items by field width, then I use **sort** to print the tallies in reverse order of width. For example, to check field 33 in the tab-separated file "midges":
-
-```
-awk -F"\t" 'NR>1 {a[length($33)]++} \
-END {for (i in a) print i FS a[i]}' midges | sort -nr
-```
-
-![distro1][1]
-
-The longest entries have exactly 50 characters, which is suspicious, and there's a "bulge" of data items at that width, which is even more suspicious. Inspection of those 50-character-wide items reveals truncations:
-
-![distro2][2]
-
-Other tables I've checked this way had bulges at 100, 200 and 255 characters. In each case the bulges contained apparent truncations.
-
-**Unmatched brackets**. The second method looks for data items like "...(Sally Cleveland" above. A good starting point is a tally of all the punctuation in the data table. Here I'm checking the file "mag2":
-
-grep -o "[[:punct:]]" file | sort | uniqc
-
-![punct][3]
-
-Note that the numbers of opening and closing round brackets in "mag2" aren't equal. To see what's going on, I use the function "unmatched", which takes three arguments and checks all fields in a data table. The first argument is the filename and the second and third are the opening and closing brackets, enclosed in quotes.
-
-```
-unmatched()
-{
-awk -F"\t" -v start="$2" -v end="$3" \
-'{for (i=1;i<=NF;i++) \
-if (split($i,a,start) != split($i,b,end)) \
-print "line "NR", field "i":\n"$i}' "$1"
-
-}
-```
-
-"unmatched" reports line number and field number if it finds a mismatch between opening and closing brackets in the field. It relies on AWK's **split** function, which returns the number of elements (including blank space) separated by the splitting character. This number will always be one more than the number of splitters:
-
-![split][4]
-
-Here "ummatched" checks the round brackets in "mag2" and finds some likely truncations:
-
-![unmatched][5]
-
-I use "unmatched" to locate unmatched round brackets (), square brackets [], curly brackets {} and arrows <>, but the function can be used for any paired punctuation characters.
-
-**Unexpected endings**. The third method looks for data items that end in a trailing space or a non-terminal punctuation mark, like a comma or a hyphen. This can be done on a single field with **cut** piped to **grep** , or in one step with AWK. Here I'm checking field 47 of the tab-separated table "herp5", and pulling out suspect data items and their line numbers:
-
-```
-cut -f47 herp5 | grep -n "[ ,;:-]$"
-
-awk -F"\t" '$47 ~ /[ ,;:-]$/ {print NR": "$47}' herp5
-```
-
-![herps5][6]
-
-The all-fields version of the AWK command for a tab-separated file is:
-
-```
-awk -F"\t" '{for (i=1;i<=NF;i++) if ($i ~ /[ ,;:-]$/) \
-print "line "NR", field "i":\n"$i}' file
-```
-
-**Cautionary thoughts**. Truncations also appear during the validation tests I do on fields. For example, I might be checking for plausible 4-digit entries in a "Year" field, and there's a 198 that hints at 198n. Or is it 1898? Truncated data items with their lost characters are mysteries. As a data auditor I can only report (possible) character losses and suggest that the (possibly) missing characters be restored by the data compilers or managers.
-
---------------------------------------------------------------------------------
-
-via: https://www.polydesmida.info/BASHing/2018-07-04.html
-
-作者:[polydesmida][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.polydesmida.info/
-[1]:https://www.polydesmida.info/BASHing/img1/2018-07-04_1.png
-[2]:https://www.polydesmida.info/BASHing/img1/2018-07-04_2.png
-[3]:https://www.polydesmida.info/BASHing/img1/2018-07-04_3.png
-[4]:https://www.polydesmida.info/BASHing/img1/2018-07-04_4.png
-[5]:https://www.polydesmida.info/BASHing/img1/2018-07-04_5.png
-[6]:https://www.polydesmida.info/BASHing/img1/2018-07-04_6.png
diff --git a/sources/tech/20180802 Top 5 CAD Software Available for Linux in 2018.md b/sources/tech/20180802 Top 5 CAD Software Available for Linux in 2018.md
deleted file mode 100644
index ec02690b6e..0000000000
--- a/sources/tech/20180802 Top 5 CAD Software Available for Linux in 2018.md
+++ /dev/null
@@ -1,143 +0,0 @@
-Top 5 CAD Software Available for Linux in 2018
-======
-[Computer Aided Design (CAD)][1] is an essential part of many streams of engineering. CAD is professionally used is architecture, auto parts design, space shuttle research, aeronautics, bridge construction, interior design, and even clothing and jewelry.
-
-A number of professional grade CAD software like SolidWorks and Autodesk AutoCAD are not natively supported on the Linux platform. So today we will be having a look at the top CAD software available for Linux. Let’s dive right in.
-
-### Best CAD Software available for Linux
-
-![CAD Software for Linux][2]
-
-Before you see the list of CAD software for Linux, you should keep one thing in mind that not all the applications listed here are open source. We included some non-FOSS CAD software to help average Linux user.
-
-Installation instructions of Ubuntu-based Linux distributions have been provided. You may check the respective websites to learn the installation procedure for other distributions.
-
-The list is not any specific order. CAD application at number one should not be considered better than the one at number three and so on.
-
-#### 1\. FreeCAD
-
-For 3D Modelling, FreeCAD is an excellent option which is both free (beer and speech) and open source. FreeCAD is built with keeping mechanical engineering and product design as target purpose. FreeCAD is multiplatform and is available on Windows, Mac OS X+ along with Linux.
-
-![freecad][3]
-
-Although FreeCAD has been the choice of many Linux users, it should be noted that FreeCAD is still on version 0.17 and therefore, is not suitable for major deployment. But the development has picked up pace recently.
-
-[FreeCAD][4]
-
-FreeCAD does not focus on direct 2D drawings and animation of organic shapes but it’s great for design related to mechanical engineering. FreeCAD version 0.15 is available in the Ubuntu repositories. You can install it by running the below command.
-```
-sudo apt install freecad
-
-```
-
-To get newer daily builds (0.17 at the moment), open a terminal (ctrl+alt+t) and run the commands below one by one.
-```
-sudo add-apt-repository ppa:freecad-maintainers/freecad-daily
-
-sudo apt update
-
-sudo apt install freecad-daily
-
-```
-
-#### 2\. LibreCAD
-
-LibreCAD is a free, opensource, 2D CAD solution. Generally, CAD tends to be a resource-intensive task, and if you have a rather modest hardware, then I’d suggest you go for LibreCAD as it is really lightweight in terms of resource usage. LibreCAD is a great candidate for geometric constructions.
-
-![librecad][5]
-As a 2D tool, LibreCAD is good but it cannot work on 3D models and renderings. It might be unstable at times but it has a dependable autosave which won’t let your work go wasted.
-
-[LibreCAD][6]
-
-You can install LibreCAD by running the following command
-```
-sudo apt install librecad
-
-```
-
-#### 3\. OpenSCAD
-
-OpenSCAD is a free 3D CAD software. OpenSCAD is very lightweight and flexible. OpenSCAD is not interactive. You need to ‘program’ the model and OpenSCAD interprets that code to render a visual model. It is a compiler in a sense. You cannot draw the model. You describe the model.
-
-![openscad][7]
-
-OpenSCAD is the most complicated tool on this list but once you get to know it, it provides an enjoyable work experience.
-
-[OpenSCAD][8]
-
-You can use the following commands to install OpenSCAD.
-```
-sudo apt-get install openscad
-
-```
-
-#### 4\. BRL-CAD
-
-BRL-CAD is one of the oldest CAD tools out there. It also has been loved by Linux/UNIX users as it aligns itself with *nix philosophies of modularity and freedom.
-
-![BRL-CAD rendering by Sean][9]
-
-BRL-CAD was started in 1979, and it is still developed actively. Now, BRL-CAD is not AutoCAD but it is still a great choice for transport studies such as thermal and ballistic penetration. BRL-CAD underlies CSG instead of boundary representation. You might need to keep that in mind while opting for BRL-CAD. You can download BRL-CAD from its official website.
-
-[BRL-CAD][10]
-
-#### 5\. DraftSight (not open source)
-
-If You’re used to working on AutoCAD, then DraftSight would be the perfect alternative for you.
-
-DraftSight is a great CAD tool available on Linux. It has a rather similar workflow to AutoCAD, which makes migrating easier. It even provides a similar look and feel. DrafSight is also compatible with the .dwg file format of AutoCAD. But DrafSight is a 2D CAD software. It does not support 3D CAD as of yet.
-
-![draftsight][11]
-
-Although DrafSight is a commercial software with a starting price of $149. A free version is also made available on the[DraftSight website][12]. You can download the .deb package and install it on Ubuntu based distributions. need to register your free copy using your email ID to start using DraftSight.
-
-[DraftSight][12]
-
-#### Honorary mentions
-
- * With a huge growth in cloud computing technologies, cloud CAD solutions like [OnShape][13] have been getting popular day by day.
- * [SolveSpace][14] is another open-source project worth mentioning. It supports 3D modeling.
- * Siemens NX is an industrial grade CAD solution available on Windows, Mac OS and Linux, but it is ridiculously expensive, so omitted in this list.
- * Then you have [LeoCAD][15], which is a CAD software where you use LEGO blocks to build stuff. What you do with this information is up to you.
-
-
-
-#### CAD on Linux, in my opinion
-
-Although gaming on Linux has picked up, I always tell my hardcore gaming friends to stick to Windows. Similarly, if You are an engineering student with CAD in your curriculum, I’d recommend that you use the software that your college prescribes (AutoCAD, SolidEdge, Catia), which generally tend to run on Windows only.
-
-And for the advanced professionals, these tools are simply not up to the mark when we’re talking about industry standards.
-
-For those of you thinking about running AutoCAD in WINE, although some older versions of AutoCAD can be installed on WINE, they simply do not perform, with glitches and crashes ruining the experience.
-
-That being said, I highly respect the work that has been put by the developers of the above-listed software. They have enriched the FOSS world. And it’s great to see software like FreeCAD developing with an accelerated pace in the recent years.
-
-Well, that’s it for today. Do share your thoughts with us using the comments section below and don’t forget to share this article. Cheers.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/cad-software-linux/
-
-作者:[Aquil Roshan][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/aquil/
-[1]:https://en.wikipedia.org/wiki/Computer-aided_design
-[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/cad-software-linux.jpeg
-[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freecad.jpg
-[4]:https://www.freecadweb.org/
-[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/librecad.jpg
-[6]:https://librecad.org/
-[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/openscad.jpg
-[8]:http://www.openscad.org/
-[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/brlcad.jpg
-[10]:https://brlcad.org/
-[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/draftsight.jpg
-[12]:https://www.draftsight2018.com/
-[13]:https://www.onshape.com/
-[14]:http://solvespace.com/index.pl
-[15]:https://www.leocad.org/
diff --git a/sources/tech/20190129 Create an online store with this Java-based framework.md b/sources/tech/20190129 Create an online store with this Java-based framework.md
index b72a8551de..6fb9bc5a6b 100644
--- a/sources/tech/20190129 Create an online store with this Java-based framework.md
+++ b/sources/tech/20190129 Create an online store with this Java-based framework.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (laingke)
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
diff --git a/sources/tech/20190401 Build and host a website with Git.md b/sources/tech/20190401 Build and host a website with Git.md
deleted file mode 100644
index 32a07d3490..0000000000
--- a/sources/tech/20190401 Build and host a website with Git.md
+++ /dev/null
@@ -1,226 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Build and host a website with Git)
-[#]: via: (https://opensource.com/article/19/4/building-hosting-website-git)
-[#]: author: (Seth Kenlon https://opensource.com/users/seth)
-
-Build and host a website with Git
-======
-Publishing your own website is easy if you let Git help you out. Learn
-how in the first article in our series about little-known Git uses.
-![web development and design, desktop and browser][1]
-
-[Git][2] is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git.
-
-Creating a website used to be both sublimely simple and a form of black magic all at once. Back in the old days of Web 1.0 (that's not what anyone actually called it), you could just open up any website, view its source code, and reverse engineer the HTML—with all its inline styling and table-based layout—and you felt like a programmer after an afternoon or two. But there was still the matter of getting the page you created on the internet, which meant dealing with servers and FTP and webroot directories and file permissions. While the modern web has become far more complex since then, self-publication can be just as easy (or easier!) if you let Git help you out.
-
-### Create a website with Hugo
-
-[Hugo][3] is an open source static site generator. Static sites are what the web used to be built on (if you go back far enough, it was _all_ the web was). There are several advantages to static sites: they're relatively easy to write because you don't have to code them, they're relatively secure because there's no code executed on the pages, and they can be quite fast because there's no processing aside from transferring whatever you have on the page.
-
-Hugo isn't the only static site generator out there. [Grav][4], [Pico][5], [Jekyll][6], [Podwrite][7], and many others provide an easy way to create a full-featured website with minimal maintenance. Hugo happens to be one with GitLab integration built in, which means you can generate and host your website with a free GitLab account.
-
-Hugo has some pretty big fans, too. For instance, if you've ever gone to the Let's Encrypt website, then you've used a site built with Hugo.
-
-![Let's Encrypt website][8]
-
-#### Install Hugo
-
-Hugo is cross-platform, and you can find installation instructions for MacOS, Windows, Linux, OpenBSD, and FreeBSD in [Hugo's getting started resources][9].
-
-If you're on Linux or BSD, it's easiest to install Hugo from a software repository or ports tree. The exact command varies depending on what your distribution provides, but on Fedora you would enter:
-
-```
-$ sudo dnf install hugo
-```
-
-Confirm you have installed it correctly by opening a terminal and typing:
-
-```
-$ hugo help
-```
-
-This prints all the options available for the **hugo** command. If you don't see that, you may have installed Hugo incorrectly or need to [add the command to your path][10].
-
-#### Create your site
-
-To build a Hugo site, you must have a specific directory structure, which Hugo will generate for you by entering:
-
-```
-$ hugo new site mysite
-```
-
-You now have a directory called **mysite** , and it contains the default directories you need to build a Hugo website.
-
-Git is your interface to get your site on the internet, so change directory to your new **mysite** folder and initialize it as a Git repository:
-
-```
-$ cd mysite
-$ git init .
-```
-
-Hugo is pretty Git-friendly, so you can even use Git to install a theme for your site. Unless you plan on developing the theme you're installing, you can use the **\--depth** option to clone the latest state of the theme's source:
-
-```
-$ git clone --depth 1 \
-
-themes/mero
-```
-
-
-Now create some content for your site:
-
-```
-$ hugo new posts/hello.md
-```
-
-Use your favorite text editor to edit the **hello.md** file in the **content/posts** directory. Hugo accepts Markdown files and converts them to themed HTML files at publication, so your content must be in [Markdown format][11].
-
-If you want to include images in your post, create a folder called **images** in the **static** directory. Place your images into this folder and reference them in your markup using the absolute path starting with **/images**. For example:
-
-```
-
-```
-
-#### Choose a theme
-
-You can find more themes at [themes.gohugo.io][12], but it's best to stay with a basic theme while testing. The canonical Hugo test theme is [Ananke][13]. Some themes have complex dependencies, and others don't render pages the way you might expect without complex configuration. The Mero theme used in this example comes bundled with a detailed **config.toml** configuration file, but (for the sake of simplicity) I'll provide just the basics here. Open the file called **config.toml** in a text editor and add three configuration parameters:
-
-```
-
-languageCode = "en-us"
-title = "My website on the web"
-theme = "mero"
-
-[params]
- author = "Seth Kenlon"
- description = "My hugo demo"
-```
-
-#### Preview your site
-
-You don't have to put anything on the internet until you're ready to publish it. While you work, you can preview your site by launching the local-only web server that ships with Hugo.
-
-```
-$ hugo server --buildDrafts --disableFastRender
-```
-
-Open a web browser and navigate to **** to see your work in progress.
-
-### Publish with Git to GitLab
-
-To publish and host your site on GitLab, create a repository for the contents of your site.
-
-To create a repository in GitLab, click on the **New Project** button in your GitLab Projects page. Create an empty repository called **yourGitLabUsername.gitlab.io** , replacing **yourGitLabUsername** with your GitLab user name or group name. You must use this scheme as the name of your project. If you want to add a custom domain later, you can.
-
-Do not include a license or a README file (because you've started a project locally, adding these now would make pushing your data to GitLab more complex, and you can always add them later).
-
-Once you've created the empty repository on GitLab, add it as the remote location for the local copy of your Hugo site, which is already a Git repository:
-
-```
-$ git remote add origin git@gitlab.com:skenlon/mysite.git
-```
-
-Create a GitLab site configuration file called **.gitlab-ci.yml** and enter these options:
-
-```
-image: monachus/hugo
-
-variables:
- GIT_SUBMODULE_STRATEGY: recursive
-
-pages:
- script:
- - hugo
- artifacts:
- paths:
- - public
- only:
- - master
-```
-
-The **image** parameter defines a containerized image that will serve your site. The other parameters are instructions telling GitLab's servers what actions to execute when you push new code to your remote repository. For more information on GitLab's CI/CD (Continuous Integration and Delivery) options, see the [CI/CD section of GitLab's docs][14].
-
-#### Set the excludes
-
-Your Git repository is configured, the commands to build your site on GitLab's servers are set, and your site ready to publish. For your first Git commit, you must take a few extra precautions so you're not version-controlling files you don't intend to version-control.
-
-First, add the **/public** directory that Hugo creates when building your site to your **.gitignore** file. You don't need to manage the finished site in Git; all you need to track are your source Hugo files.
-
-```
-$ echo "/public" >> .gitignore
-```
-
-You can't maintain a Git repository within a Git repository without creating a Git submodule. For the sake of keeping this simple, move the embedded **.git** directory so that the theme is just a theme.
-
-Note that you _must_ add your theme files to your Git repository so GitLab will have access to the theme. Without committing your theme files, your site cannot successfully build.
-
-```
-$ mv themes/mero/.git ~/.local/share/Trash/files/
-```
-
-Alternately, use a **trash** command such as [Trashy][15]:
-
-```
-$ trash themes/mero/.git
-```
-
-Now you can add all the contents of your local project directory to Git and push it to GitLab:
-
-```
-$ git add .
-$ git commit -m 'hugo init'
-$ git push -u origin HEAD
-```
-
-### Go live with GitLab
-
-Once your code has been pushed to GitLab, take a look at your project page. An icon indicates GitLab is processing your build. It might take several minutes the first time you push your code, so be patient. However, don't be _too_ patient, because the icon doesn't always update reliably.
-
-![GitLab processing your build][16]
-
-While you're waiting for GitLab to assemble your site, go to your project settings and find the **Pages** panel. Once your site is ready, its URL will be provided for you. The URL is **yourGitLabUsername.gitlab.io/yourProjectName**. Navigate to that address to view the fruits of your labor.
-
-![Previewing Hugo site][17]
-
-If your site fails to assemble correctly, GitLab provides insight into the CI/CD pipeline logs. Review the error message for an indication of what went wrong.
-
-### Git and the web
-
-Hugo (or Jekyll or similar tools) is just one way to leverage Git as your web publishing tool. With server-side Git hooks, you can design your own Git-to-web pipeline with minimal scripting. With the community edition of GitLab, you can self-host your own GitLab instance or you can use an alternative like [Gitolite][18] or [Gitea][19] and use this article as inspiration for a custom solution. Have fun!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/4/building-hosting-website-git
-
-作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/seth
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web_browser_desktop_devlopment_design_system_computer.jpg?itok=pfqRrJgh (web development and design, desktop and browser)
-[2]: https://git-scm.com/
-[3]: http://gohugo.io
-[4]: http://getgrav.org
-[5]: http://picocms.org/
-[6]: https://jekyllrb.com
-[7]: http://slackermedia.info/podwrite/
-[8]: https://opensource.com/sites/default/files/uploads/letsencrypt-site.jpg (Let's Encrypt website)
-[9]: https://gohugo.io/getting-started/installing
-[10]: https://opensource.com/article/17/6/set-path-linux
-[11]: https://commonmark.org/help/
-[12]: https://themes.gohugo.io/
-[13]: https://themes.gohugo.io/gohugo-theme-ananke/
-[14]: https://docs.gitlab.com/ee/ci/#overview
-[15]: http://slackermedia.info/trashy
-[16]: https://opensource.com/sites/default/files/uploads/hugo-gitlab-cicd.jpg (GitLab processing your build)
-[17]: https://opensource.com/sites/default/files/uploads/hugo-demo-site.jpg (Previewing Hugo site)
-[18]: http://gitolite.com
-[19]: http://gitea.io
diff --git a/sources/tech/20190408 A beginner-s guide to building DevOps pipelines with open source tools.md b/sources/tech/20190408 A beginner-s guide to building DevOps pipelines with open source tools.md
deleted file mode 100644
index b5650680bc..0000000000
--- a/sources/tech/20190408 A beginner-s guide to building DevOps pipelines with open source tools.md
+++ /dev/null
@@ -1,352 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (luming)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (A beginner's guide to building DevOps pipelines with open source tools)
-[#]: via: (https://opensource.com/article/19/4/devops-pipeline)
-[#]: author: (Bryant Son https://opensource.com/users/brson/users/milindsingh/users/milindsingh/users/dscripter)
-
-A beginner's guide to building DevOps pipelines with open source tools
-======
-If you're new to DevOps, check out this five-step process for building
-your first pipeline.
-![Shaking hands, networking][1]
-
-DevOps has become the default answer to fixing software development processes that are slow, siloed, or otherwise dysfunctional. But that doesn't mean very much when you're new to DevOps and aren't sure where to begin. This article explores what a DevOps pipeline is and offers a five-step process to create one. While this tutorial is not comprehensive, it should give you a foundation to start on and expand later. But first, a story.
-
-### My DevOps journey
-
-I used to work for the cloud team at Citi Group, developing an Infrastructure-as-a-Service (IaaS) web application to manage Citi's cloud infrastructure, but I was always interested in figuring out ways to make the development pipeline more efficient and bring positive cultural change to the development team. I found my answer in a book recommended by Greg Lavender, who was the CTO of Citi's cloud architecture and infrastructure engineering, called _[The Phoenix Project][2]_. The book reads like a novel while it explains DevOps principles.
-
-A table at the back of the book shows how often different companies deploy to the release environment:
-
-Company | Deployment Frequency
----|---
-Amazon | 23,000 per day
-Google | 5,500 per day
-Netflix | 500 per day
-Facebook | 1 per day
-Twitter | 3 per week
-Typical enterprise | 1 every 9 months
-
-How are the frequency rates of Amazon, Google, and Netflix even possible? It's because these companies have figured out how to make a nearly perfect DevOps pipeline.
-
-This definitely wasn't the case before we implemented DevOps at Citi. Back then, my team had different staged environments, but deployments to the development server were very manual. All developers had access to just one development server based on IBM WebSphere Application Server Community Edition. The problem was the server went down whenever multiple users simultaneously tried to make deployments, so the developers had to let each other know whenever they were about to make a deployment, which was quite a pain. In addition, there were problems with low code test coverages, cumbersome manual deployment processes, and no way to track code deployments with a defined task or a user story.
-
-I realized something had to be done, and I found a colleague who felt the same way. We decided to collaborate to build an initial DevOps pipeline—he set up a virtual machine and a Tomcat application server while I worked on Jenkins, integrating with Atlassian Jira and BitBucket, and code testing coverages. This side project was hugely successful: we almost fully automated the development pipeline, we achieved nearly 100% uptime on our development server, we could track and improve code testing coverage, and the Git branch could be associated with the deployment and Jira task. And most of the tools we used to construct our DevOps pipeline were open source.
-
-I now realize how rudimentary our DevOps pipeline was, as we didn't take advantage of advanced configurations like Jenkins files or Ansible. However, this simple process worked well, maybe due to the [Pareto][3] principle (also known as the 80/20 rule).
-
-### A brief introduction to DevOps and the CI/CD pipeline
-
-If you ask several people, "What is DevOps? you'll probably get several different answers. DevOps, like agile, has evolved to encompass many different disciplines, but most people will agree on a few things: DevOps is a software development practice or a software development lifecycle (SDLC) and its central tenet is cultural change, where developers and non-developers all breathe in an environment where formerly manual things are automated; everyone does what they are best at; the number of deployments per period increases; throughput increases; and flexibility improves.
-
-While having the right software tools is not the only thing you need to achieve a DevOps environment, some tools are necessary. A key one is continuous integration and continuous deployment (CI/CD). This pipeline is where the environments have different stages (e.g., DEV, INT, TST, QA, UAT, STG, PROD), manual things are automated, and developers can achieve high-quality code, flexibility, and numerous deployments.
-
-This article describes a five-step approach to creating a DevOps pipeline, like the one in the following diagram, using open source tools.
-
-![Complete DevOps pipeline][4]
-
-Without further ado, let's get started.
-
-### Step 1: CI/CD framework
-
-The first thing you need is a CI/CD tool. Jenkins, an open source, Java-based CI/CD tool based on the MIT License, is the tool that popularized the DevOps movement and has become the de facto standard.
-
-So, what is Jenkins? Imagine it as some sort of a magical universal remote control that can talk to many many different services and tools and orchestrate them. On its own, a CI/CD tool like Jenkins is useless, but it becomes more powerful as it plugs into different tools and services.
-
-Jenkins is just one of many open source CI/CD tools that you can leverage to build a DevOps pipeline.
-
-Name | License
----|---
-[Jenkins][5] | Creative Commons and MIT
-[Travis CI][6] | MIT
-[CruiseControl][7] | BSD
-[Buildbot][8] | GPL
-[Apache Gump][9] | Apache 2.0
-[Cabie][10] | GNU
-
-Here's what a DevOps process looks like with a CI/CD tool.
-
-![CI/CD tool][11]
-
-You have a CI/CD tool running in your localhost, but there is not much you can do at the moment. Let's follow the next step of DevOps journey.
-
-### Step 2: Source control management
-
-The best (and probably the easiest) way to verify that your CI/CD tool can perform some magic is by integrating with a source control management (SCM) tool. Why do you need source control? Suppose you are developing an application. Whenever you build an application, you are programming—whether you are using Java, Python, C++, Go, Ruby, JavaScript, or any of the gazillion programming languages out there. The programming codes you write are called source codes. In the beginning, especially when you are working alone, it's probably OK to put everything in your local directory. But when the project gets bigger and you invite others to collaborate, you need a way to avoid merge conflicts while effectively sharing the code modifications. You also need a way to recover a previous version—and the process of making a backup and copying-and-pasting gets old. You (and your teammates) want something better.
-
-This is where SCM becomes almost a necessity. A SCM tool helps by storing your code in repositories, versioning your code, and coordinating among project members.
-
-Although there are many SCM tools out there, Git is the standard and rightly so. I highly recommend using Git, but there are other open source options if you prefer.
-
-Name | License
----|---
-[Git][12] | GPLv2 & LGPL v2.1
-[Subversion][13] | Apache 2.0
-[Concurrent Versions System][14] (CVS) | GNU
-[Vesta][15] | LGPL
-[Mercurial][16] | GNU GPL v2+
-
-Here's what the DevOps pipeline looks like with the addition of SCM.
-
-![Source control management][17]
-
-The CI/CD tool can automate the tasks of checking in and checking out source code and collaborating across members. Not bad? But how can you make this into a working application so billions of people can use and appreciate it?
-
-### Step 3: Build automation tool
-
-Excellent! You can check out the code and commit your changes to the source control, and you can invite your friends to collaborate on the source control development. But you haven't yet built an application. To make it a web application, it has to be compiled and put into a deployable package format or run as an executable. (Note that an interpreted programming language like JavaScript or PHP doesn't need to be compiled.)
-
-Enter the build automation tool. No matter which build tool you decide to use, all build automation tools have a shared goal: to build the source code into some desired format and to automate the task of cleaning, compiling, testing, and deploying to a certain location. The build tools will differ depending on your programming language, but here are some common open source options to consider.
-
-Name | License | Programming Language
----|---|---
-[Maven][18] | Apache 2.0 | Java
-[Ant][19] | Apache 2.0 | Java
-[Gradle][20] | Apache 2.0 | Java
-[Bazel][21] | Apache 2.0 | Java
-[Make][22] | GNU | N/A
-[Grunt][23] | MIT | JavaScript
-[Gulp][24] | MIT | JavaScript
-[Buildr][25] | Apache | Ruby
-[Rake][26] | MIT | Ruby
-[A-A-P][27] | GNU | Python
-[SCons][28] | MIT | Python
-[BitBake][29] | GPLv2 | Python
-[Cake][30] | MIT | C#
-[ASDF][31] | Expat (MIT) | LISP
-[Cabal][32] | BSD | Haskell
-
-Awesome! You can put your build automation tool configuration files into your source control management and let your CI/CD tool build it.
-
-![Build automation tool][33]
-
-Everything is good, right? But where can you deploy it?
-
-### Step 4: Web application server
-
-So far, you have a packaged file that might be executable or deployable. For any application to be truly useful, it has to provide some kind of a service or an interface, but you need a vessel to host your application.
-
-For a web application, a web application server is that vessel. An application server offers an environment where the programming logic inside the deployable package can be detected, render the interface, and offer the web services by opening sockets to the outside world. You need an HTTP server as well as some other environment (like a virtual machine) to install your application server. For now, let's assume you will learn about this along the way (although I will discuss containers below).
-
-There are a number of open source web application servers available.
-
-Name | License | Programming Language
----|---|---
-[Tomcat][34] | Apache 2.0 | Java
-[Jetty][35] | Apache 2.0 | Java
-[WildFly][36] | GNU Lesser Public | Java
-[GlassFish][37] | CDDL & GNU Less Public | Java
-[Django][38] | 3-Clause BSD | Python
-[Tornado][39] | Apache 2.0 | Python
-[Gunicorn][40] | MIT | Python
-[Python Paste][41] | MIT | Python
-[Rails][42] | MIT | Ruby
-[Node.js][43] | MIT | Javascript
-
-Now the DevOps pipeline is almost usable. Good job!
-
-![Web application server][44]
-
-Although it's possible to stop here and integrate further on your own, code quality is an important thing for an application developer to be concerned about.
-
-### Step 5: Code testing coverage
-
-Implementing code test pieces can be another cumbersome requirement, but developers need to catch any errors in an application early on and improve the code quality to ensure end users are satisfied. Luckily, there are many open source tools available to test your code and suggest ways to improve its quality. Even better, most CI/CD tools can plug into these tools and automate the process.
-
-There are two parts to code testing: _code testing frameworks_ that help write and run the tests, and _code quality suggestion tools_ that help improve code quality.
-
-#### Code test frameworks
-
-Name | License | Programming Language
----|---|---
-[JUnit][45] | Eclipse Public License | Java
-[EasyMock][46] | Apache | Java
-[Mockito][47] | MIT | Java
-[PowerMock][48] | Apache 2.0 | Java
-[Pytest][49] | MIT | Python
-[Hypothesis][50] | Mozilla | Python
-[Tox][51] | MIT | Python
-
-#### Code quality suggestion tools
-
-Name | License | Programming Language
----|---|---
-[Cobertura][52] | GNU | Java
-[CodeCover][53] | Eclipse Public (EPL) | Java
-[Coverage.py][54] | Apache 2.0 | Python
-[Emma][55] | Common Public License | Java
-[JaCoCo][56] | Eclipse Public License | Java
-[Hypothesis][50] | Mozilla | Python
-[Tox][51] | MIT | Python
-[Jasmine][57] | MIT | JavaScript
-[Karma][58] | MIT | JavaScript
-[Mocha][59] | MIT | JavaScript
-[Jest][60] | MIT | JavaScript
-
-Note that most of the tools and frameworks mentioned above are written for Java, Python, and JavaScript, since C++ and C# are proprietary programming languages (although GCC is open source).
-
-Now that you've implemented code testing coverage tools, your DevOps pipeline should resemble the DevOps pipeline diagram shown at the beginning of this tutorial.
-
-### Optional steps
-
-#### Containers
-
-As I mentioned above, you can host your application server on a virtual machine or a server, but containers are a popular solution.
-
-[What are][61] [containers][61]? The short explanation is that a VM needs the huge footprint of an operating system, which overwhelms the application size, while a container just needs a few libraries and configurations to run the application. There are clearly still important uses for a VM, but a container is a lightweight solution for hosting an application, including an application server.
-
-Although there are other options for containers, Docker and Kubernetes are the most popular.
-
-Name | License
----|---
-[Docker][62] | Apache 2.0
-[Kubernetes][63] | Apache 2.0
-
-To learn more, check out these other [Opensource.com][64] articles about Docker and Kubernetes:
-
- * [What Is Docker?][65]
- * [An introduction to Docker][66]
- * [What is Kubernetes?][67]
- * [From 0 to Kubernetes][68]
-
-
-
-#### Middleware automation tools
-
-Our DevOps pipeline mostly focused on collaboratively building and deploying an application, but there are many other things you can do with DevOps tools. One of them is leveraging Infrastructure as Code (IaC) tools, which are also known as middleware automation tools. These tools help automate the installation, management, and other tasks for middleware software. For example, an automation tool can pull applications, like a web application server, database, and monitoring tool, with the right configurations and deploy them to the application server.
-
-Here are several open source middleware automation tools to consider:
-
-Name | License
----|---
-[Ansible][69] | GNU Public
-[SaltStack][70] | Apache 2.0
-[Chef][71] | Apache 2.0
-[Puppet][72] | Apache or GPL
-
-For more on middleware automation tools, check out these other [Opensource.com][64] articles:
-
- * [A quickstart guide to Ansible][73]
- * [Automating deployment strategies with Ansible][74]
- * [Top 5 configuration management tools][75]
-
-
-
-### Where can you go from here?
-
-This is just the tip of the iceberg for what a complete DevOps pipeline can look like. Start with a CI/CD tool and explore what else you can automate to make your team's job easier. Also, look into [open source communication tools][76] that can help your team work better together.
-
-For more insight, here are some very good introductory articles about DevOps:
-
- * [What is DevOps][77]
- * [5 things to master to be a DevOps engineer][78]
- * [DevOps is for everyone][79]
- * [Getting started with predictive analytics in DevOps][80]
-
-
-
-Integrating DevOps with open source agile tools is also a good idea:
-
- * [What is agile?][81]
- * [4 steps to becoming an awesome agile developer][82]
-
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/4/devops-pipeline
-
-作者:[Bryant Son (Red Hat, Community Moderator)][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/brson/users/milindsingh/users/milindsingh/users/dscripter
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/network_team_career_hand.png?itok=_ztl2lk_ (Shaking hands, networking)
-[2]: https://www.amazon.com/dp/B078Y98RG8/
-[3]: https://en.wikipedia.org/wiki/Pareto_principle
-[4]: https://opensource.com/sites/default/files/uploads/1_finaldevopspipeline.jpg (Complete DevOps pipeline)
-[5]: https://github.com/jenkinsci/jenkins
-[6]: https://github.com/travis-ci/travis-ci
-[7]: http://cruisecontrol.sourceforge.net
-[8]: https://github.com/buildbot/buildbot
-[9]: https://gump.apache.org
-[10]: http://cabie.tigris.org
-[11]: https://opensource.com/sites/default/files/uploads/2_runningjenkins.jpg (CI/CD tool)
-[12]: https://git-scm.com
-[13]: https://subversion.apache.org
-[14]: http://savannah.nongnu.org/projects/cvs
-[15]: http://www.vestasys.org
-[16]: https://www.mercurial-scm.org
-[17]: https://opensource.com/sites/default/files/uploads/3_sourcecontrolmanagement.jpg (Source control management)
-[18]: https://maven.apache.org
-[19]: https://ant.apache.org
-[20]: https://gradle.org/
-[21]: https://bazel.build
-[22]: https://www.gnu.org/software/make
-[23]: https://gruntjs.com
-[24]: https://gulpjs.com
-[25]: http://buildr.apache.org
-[26]: https://github.com/ruby/rake
-[27]: http://www.a-a-p.org
-[28]: https://www.scons.org
-[29]: https://www.yoctoproject.org/software-item/bitbake
-[30]: https://github.com/cake-build/cake
-[31]: https://common-lisp.net/project/asdf
-[32]: https://www.haskell.org/cabal
-[33]: https://opensource.com/sites/default/files/uploads/4_buildtools.jpg (Build automation tool)
-[34]: https://tomcat.apache.org
-[35]: https://www.eclipse.org/jetty/
-[36]: http://wildfly.org
-[37]: https://javaee.github.io/glassfish
-[38]: https://www.djangoproject.com/
-[39]: http://www.tornadoweb.org/en/stable
-[40]: https://gunicorn.org
-[41]: https://github.com/cdent/paste
-[42]: https://rubyonrails.org
-[43]: https://nodejs.org/en
-[44]: https://opensource.com/sites/default/files/uploads/5_applicationserver.jpg (Web application server)
-[45]: https://junit.org/junit5
-[46]: http://easymock.org
-[47]: https://site.mockito.org
-[48]: https://github.com/powermock/powermock
-[49]: https://docs.pytest.org
-[50]: https://hypothesis.works
-[51]: https://github.com/tox-dev/tox
-[52]: http://cobertura.github.io/cobertura
-[53]: http://codecover.org/
-[54]: https://github.com/nedbat/coveragepy
-[55]: http://emma.sourceforge.net
-[56]: https://github.com/jacoco/jacoco
-[57]: https://jasmine.github.io
-[58]: https://github.com/karma-runner/karma
-[59]: https://github.com/mochajs/mocha
-[60]: https://jestjs.io
-[61]: /resources/what-are-linux-containers
-[62]: https://www.docker.com
-[63]: https://kubernetes.io
-[64]: http://Opensource.com
-[65]: https://opensource.com/resources/what-docker
-[66]: https://opensource.com/business/15/1/introduction-docker
-[67]: https://opensource.com/resources/what-is-kubernetes
-[68]: https://opensource.com/article/17/11/kubernetes-lightning-talk
-[69]: https://www.ansible.com
-[70]: https://www.saltstack.com
-[71]: https://www.chef.io
-[72]: https://puppet.com
-[73]: https://opensource.com/article/19/2/quickstart-guide-ansible
-[74]: https://opensource.com/article/19/1/automating-deployment-strategies-ansible
-[75]: https://opensource.com/article/18/12/configuration-management-tools
-[76]: https://opensource.com/alternatives/slack
-[77]: https://opensource.com/resources/devops
-[78]: https://opensource.com/article/19/2/master-devops-engineer
-[79]: https://opensource.com/article/18/11/how-non-engineer-got-devops
-[80]: https://opensource.com/article/19/1/getting-started-predictive-analytics-devops
-[81]: https://opensource.com/article/18/10/what-agile
-[82]: https://opensource.com/article/19/2/steps-agile-developer
diff --git a/sources/tech/20190701 Get modular with Python functions.md b/sources/tech/20190701 Get modular with Python functions.md
deleted file mode 100644
index 57d363f4e6..0000000000
--- a/sources/tech/20190701 Get modular with Python functions.md
+++ /dev/null
@@ -1,337 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (MjSeven)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Get modular with Python functions)
-[#]: via: (https://opensource.com/article/19/7/get-modular-python-functions)
-[#]: author: (Seth Kenlon https://opensource.com/users/seth/users/xd-deng/users/nhuntwalker/users/don-watkins)
-
-Get modular with Python functions
-======
-Minimize your coding workload by using Python functions for repeating
-tasks.
-![OpenStack source code \(Python\) in VIM][1]
-
-Are you confused by fancy programming terms like functions, classes, methods, libraries, and modules? Do you struggle with the scope of variables? Whether you're a self-taught programmer or a formally trained code monkey, the modularity of code can be confusing. But classes and libraries encourage modular code, and modular code can mean building up a collection of multipurpose code blocks that you can use across many projects to reduce your coding workload. In other words, if you follow along with this article's study of [Python][2] functions, you'll find ways to work smarter, and working smarter means working less.
-
-This article assumes enough Python familiarity to write and run a simple script. If you haven't used Python, read my [intro to Python][3] article first.
-
-### Functions
-
-Functions are an important step toward modularity because they are formalized methods of repetition. If there is a task that needs to be done again and again in your program, you can group the code into a function and call the function as often as you need it. This way, you only have to write the code once, but you can use it as often as you like.
-
-Here is an example of a simple function:
-
-
-```
-#!/usr/bin/env python3
-
-import time
-
-def Timer():
- print("Time is " + str(time.time() ) )
-```
-
-Create a folder called **mymodularity** and save the function code as **timestamp.py**.
-
-In addition to this function, create a file called **__init__.py** in the **mymodularity** directory. You can do this in a file manager or a Bash shell:
-
-
-```
-`$ touch mymodularity/__init__.py`
-```
-
-You have now created your own Python library (a "module," in Python lingo) in your Python package called **mymodularity**. It's not a very useful module, because all it does is import the **time** module and print a timestamp, but it's a start.
-
-To use your function, treat it just like any other Python module. Here's a small application that tests the accuracy of Python's **sleep()** function, using your **mymodularity** package for support. Save this file as **sleeptest.py** _outside_ the **mymodularity** directory (if you put this _into_ **mymodularity**, then it becomes a module in your package, and you don't want that).
-
-
-```
-#!/usr/bin/env python3
-
-import time
-from mymodularity import timestamp
-
-print("Testing Python sleep()...")
-
-# modularity
-timestamp.Timer()
-time.sleep(3)
-timestamp.Timer()
-```
-
-In this simple script, you are calling your **timestamp** module from your **mymodularity** package (twice). When you import a module from a package, the usual syntax is to import the module you want from the package and then use the _module name + a dot + the name of the function you want to call_ (e.g., **timestamp.Timer()**).
-
-You're calling your **Timer()** function twice, so if your **timestamp** module were more complicated than this simple example, you'd be saving yourself quite a lot of repeated code.
-
-Save the file and run it:
-
-
-```
-$ python3 ./sleeptest.py
-Testing Python sleep()...
-Time is 1560711266.1526039
-Time is 1560711269.1557732
-```
-
-According to your test, the sleep function in Python is pretty accurate: after three seconds of sleep, the timestamp was successfully and correctly incremented by three, with a little variance in microseconds.
-
-The structure of a Python library might seem confusing, but it's not magic. Python is _programmed_ to treat a folder full of Python code accompanied by an **__init__.py** file as a package, and it's programmed to look for available modules in its current directory _first_. This is why the statement **from mymodularity import timestamp** works: Python looks in the current directory for a folder called **mymodularity**, then looks for a **timestamp** file ending in **.py**.
-
-What you have done in this example is functionally the same as this less modular version:
-
-
-```
-#!/usr/bin/env python3
-
-import time
-from mymodularity import timestamp
-
-print("Testing Python sleep()...")
-
-# no modularity
-print("Time is " + str(time.time() ) )
-time.sleep(3)
-print("Time is " + str(time.time() ) )
-```
-
-For a simple example like this, there's not really a reason you wouldn't write your sleep test that way, but the best part about writing your own module is that your code is generic so you can reuse it for other projects.
-
-You can make the code more generic by passing information into the function when you call it. For instance, suppose you want to use your module to test not the _computer's_ sleep function, but a _user's_ sleep function. Change your **timestamp** code so it accepts an incoming variable called **msg**, which will be a string of text controlling how the **timestamp** is presented each time it is called:
-
-
-```
-#!/usr/bin/env python3
-
-import time
-
-# updated code
-def Timer(msg):
- print(str(msg) + str(time.time() ) )
-```
-
-Now your function is more abstract than before. It still prints a timestamp, but what it prints for the user is undefined. That means you need to define it when calling the function.
-
-The **msg** parameter your **Timer** function accepts is arbitrarily named. You could call the parameter **m** or **message** or **text** or anything that makes sense to you. The important thing is that when the **timestamp.Timer** function is called, it accepts some text as its input, places whatever it receives into a variable, and uses the variable to accomplish its task.
-
-Here's a new application to test the user's ability to sense the passage of time correctly:
-
-
-```
-#!/usr/bin/env python3
-
-from mymodularity import timestamp
-
-print("Press the RETURN key. Count to 3, and press RETURN again.")
-
-input()
-timestamp.Timer("Started timer at ")
-
-print("Count to 3...")
-
-input()
-timestamp.Timer("You slept until ")
-```
-
-Save your new application as **response.py** and run it:
-
-
-```
-$ python3 ./response.py
-Press the RETURN key. Count to 3, and press RETURN again.
-
-Started timer at 1560714482.3772075
-Count to 3...
-
-You slept until 1560714484.1628013
-```
-
-### Functions and required parameters
-
-The new version of your timestamp module now _requires_ a **msg** parameter. That's significant because your first application is broken because it doesn't pass a string to the **timestamp.Timer** function:
-
-
-```
-$ python3 ./sleeptest.py
-Testing Python sleep()...
-Traceback (most recent call last):
- File "./sleeptest.py", line 8, in <module>
- timestamp.Timer()
-TypeError: Timer() missing 1 required positional argument: 'msg'
-```
-
-Can you fix your **sleeptest.py** application so it runs correctly with the updated version of your module?
-
-### Variables and functions
-
-By design, functions limit the scope of variables. In other words, if a variable is created within a function, that variable is available to _only_ that function. If you try to use a variable that appears in a function outside the function, an error occurs.
-
-Here's a modification of the **response.py** application, with an attempt to print the **msg** variable from the **timestamp.Timer()** function:
-
-
-```
-#!/usr/bin/env python3
-
-from mymodularity import timestamp
-
-print("Press the RETURN key. Count to 3, and press RETURN again.")
-
-input()
-timestamp.Timer("Started timer at ")
-
-print("Count to 3...")
-
-input()
-timestamp.Timer("You slept for ")
-
-print(msg)
-```
-
-Try running it to see the error:
-
-
-```
-$ python3 ./response.py
-Press the RETURN key. Count to 3, and press RETURN again.
-
-Started timer at 1560719527.7862902
-Count to 3...
-
-You slept for 1560719528.135406
-Traceback (most recent call last):
- File "./response.py", line 15, in <module>
- print(msg)
-NameError: name 'msg' is not defined
-```
-
-The application returns a **NameError** message because **msg** is not defined. This might seem confusing because you wrote code that defined **msg**, but you have greater insight into your code than Python does. Code that calls a function, whether the function appears within the same file or if it's packaged up as a module, doesn't know what happens inside the function. A function independently performs its calculations and returns what it has been programmed to return. Any variables involved are _local_ only: they exist only within the function and only as long as it takes the function to accomplish its purpose.
-
-#### Return statements
-
-If your application needs information contained only in a function, use a **return** statement to have the function provide meaningful data after it runs.
-
-They say time is money, so modify your timestamp function to allow for an imaginary charging system:
-
-
-```
-#!/usr/bin/env python3
-
-import time
-
-def Timer(msg):
- print(str(msg) + str(time.time() ) )
- charge = .02
- return charge
-```
-
-The **timestamp** module now charges two cents for each call, but most importantly, it returns the amount charged each time it is called.
-
-Here's a demonstration of how a return statement can be used:
-
-
-```
-#!/usr/bin/env python3
-
-from mymodularity import timestamp
-
-print("Press RETURN for the time (costs 2 cents).")
-print("Press Q RETURN to quit.")
-
-total = 0
-
-while True:
- kbd = input()
- if kbd.lower() == "q":
- print("You owe $" + str(total) )
- exit()
- else:
- charge = timestamp.Timer("Time is ")
- total = total+charge
-```
-
-In this sample code, the variable **charge** is assigned as the endpoint for the **timestamp.Timer()** function, so it receives whatever the function returns. In this case, the function returns a number, so a new variable called **total** is used to keep track of how many changes have been made. When the application receives the signal to quit, it prints the total charges:
-
-
-```
-$ python3 ./charge.py
-Press RETURN for the time (costs 2 cents).
-Press Q RETURN to quit.
-
-Time is 1560722430.345412
-
-Time is 1560722430.933996
-
-Time is 1560722434.6027434
-
-Time is 1560722438.612629
-
-Time is 1560722439.3649364
-q
-You owe $0.1
-```
-
-#### Inline functions
-
-Functions don't have to be created in separate files. If you're just writing a short script specific to one task, it may make more sense to just write your functions in the same file. The only difference is that you don't have to import your own module, but otherwise the function works the same way. Here's the latest iteration of the time test application as one file:
-
-
-```
-#!/usr/bin/env python3
-
-import time
-
-total = 0
-
-def Timer(msg):
- print(str(msg) + str(time.time() ) )
- charge = .02
- return charge
-
-print("Press RETURN for the time (costs 2 cents).")
-print("Press Q RETURN to quit.")
-
-while True:
- kbd = input()
- if kbd.lower() == "q":
- print("You owe $" + str(total) )
- exit()
- else:
- charge = Timer("Time is ")
- total = total+charge
-```
-
-It has no external dependencies (the **time** module is included in the Python distribution), and produces the same results as the modular version. The advantage is that everything is located in one file, and the disadvantage is that you cannot use the **Timer()** function in some other script you are writing unless you copy and paste it manually.
-
-#### Global variables
-
-A variable created outside a function has nothing limiting its scope, so it is considered a _global_ variable.
-
-An example of a global variable is the **total** variable in the **charge.py** example used to track current charges. The running total is created outside any function, so it is bound to the application rather than to a specific function.
-
-A function within the application has access to your global variable, but to get the variable into your imported module, you must send it there the same way you send your **msg** variable.
-
-Global variables are convenient because they seem to be available whenever and wherever you need them, but it can be difficult to keep track of their scope and to know which ones are still hanging around in system memory long after they're no longer needed (although Python generally has very good garbage collection).
-
-Global variables are important, though, because not all variables can be local to a function or class. That's easy now that you know how to send variables to functions and get values back.
-
-### Wrapping up functions
-
-You've learned a lot about functions, so start putting them into your scripts—if not as separate modules, then as blocks of code you don't have to write multiple times within one script. In the next article in this series, I'll get into Python classes.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/7/get-modular-python-functions
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/seth/users/xd-deng/users/nhuntwalker/users/don-watkins
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/openstack_python_vim_1.jpg?itok=lHQK5zpm (OpenStack source code (Python) in VIM)
-[2]: https://www.python.org/
-[3]: https://opensource.com/article/17/10/python-101
diff --git a/sources/tech/20190810 How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina).md b/sources/tech/20190810 How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina).md
deleted file mode 100644
index cd5e3dac06..0000000000
--- a/sources/tech/20190810 How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina).md
+++ /dev/null
@@ -1,245 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (robsean)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina)?)
-[#]: via: (https://www.2daygeek.com/upgrade-linux-mint-19-1-tessa-to-linux-mint-19-2-tina/)
-[#]: author: (2daygeek http://www.2daygeek.com/author/2daygeek/)
-
-How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina)?
-======
-
-Linux Mint 19.2 “Tina” was released on Aug 02nd 2019, it is a long term support release, which is based on Ubuntu 18.04 LTS (Bionic Beaver).
-
-It will be supported until 2023. It comes with updated software and brings refinements and many new features to make your desktop even more comfortable to use.
-
-Linux Mint 19.2 features with Cinnamon 4.2, Linux kernel 4.15, and Ubuntu 18.04 package base.
-
-**`Note:`**` ` Don’t forget to take backup of your important data. If something goes wrong you can restore the data from the backup after fresh installation.
-
-Backup can be done either rsnapshot or timeshift.
-
-Linux Mint 19.2 “Tina” Release notes can be found in the following link.
-
- * **[Linux Mint 19.2 (Tina) Release Notes][1]**
-
-
-
-There are three ways that we can upgrade to Linux Mint 19.2 “Tina”.
-
- * Upgrade Linux Mint 19.2 (Tina) Using Native Method
- * Upgrade Linux Mint 19.2 (Tina) Using Mintupgrade Utility
- * Upgrade Linux Mint 19.2 (Tina) Using GUI
-
-
-
-### How to Perform The Upgrade from Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina)?
-
-Upgrading the Linux Mint system is an easy and painless task. It can be done three ways.
-
-### Method-1: Upgrade Linux Mint 19.2 (Tina) Using Native Method
-
-This is one of the native and standard method to perform the upgrade for Linux Mint system.
-
-To do so, follow the below procedures.
-
-Make sure that your current Linux Mint system is up-to-date.
-
-Update your existing software to latest available version using the following commands.
-
-### Step-1:
-
-Refresh the repositories index by running the following command.
-
-```
-$ sudo apt update
-```
-
-Run the following command to install the available updates on system.
-
-```
-$ sudo apt upgrade
-```
-
-Run the following command to perform the available minor upgrade with in version.
-
-```
-$ sudo apt full-upgrade
-```
-
-By default, it will remove obsolete packages by running the above command. However, i advise you to run the below commands.
-
-```
-$ sudo apt autoremove
-
-$ sudo apt clean
-```
-
-You may need to reboot the system, if a new kernel is installed. If so, run the following command.
-
-```
-$ sudo shutdown -r now
-```
-
-Finally check the currently installed version.
-
-```
-$ lsb_release -a
-
-No LSB modules are available.
-Distributor ID: Linux Mint
-Description: Linux Mint 19.1 (Tessa)
-Release: 19.1
-Codename: Tessa
-```
-
-### Step-2: Update/Modify the /etc/apt/sources.list file
-
-After reboot, modify the sources.list file and point from Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina).
-
-First backup the below config files using the cp command.
-
-```
-$ sudo cp /etc/apt/sources.list /root
-$ sudo cp -r /etc/apt/sources.list.d/ /root
-```
-
-Modify the “sources.list” file and point to Linux Mint 19.1 (Tina).
-
-```
-$ sudo sed -i 's/tessa/tina/g' /etc/apt/sources.list
-$ sudo sed -i 's/tessa/tina/g' /etc/apt/sources.list.d/*
-```
-
-Refresh the repositories index by running the following command.
-
-```
-$ sudo apt update
-```
-
-Run the following command to install the available updates on system. During the upgrade you may need to confirm for service restart and config file replace so, just follow on-screen instructions.
-
-The upgrade may take some time depending on the number of updates and your Internet speed.
-
-```
-$ sudo apt upgrade
-```
-
-Run the following command to perform a complete upgrade of the system.
-
-```
-$ sudo apt full-upgrade
-```
-
-By default, the above command will remove obsolete packages. However, i advise you to run the below commands once again.
-
-```
-$ sudo apt autoremove
-
-$ sudo apt clean
-```
-
-Finally reboot the system to boot with Linux Mint 19.2 (Tina).
-
-```
-$ sudo shutdown -r now
-```
-
-The upgraded Linux Mint version can be verified by running the following command.
-
-```
-$ lsb_release -a
-
-No LSB modules are available.
-Distributor ID: Linux Mint
-Description: Linux Mint 19.2 (Tina)
-Release: 19.2
-Codename: Tina
-```
-
-### Method-2: Upgrade Linux Mint 19.2 (Tina) Using Mintupgrade Utility
-
-This is Mint official utility that allow us to perform the smooth upgrade for Linux Mint system.
-
-Use the below command to install mintupgrade package.
-
-```
-$ sudo apt install mintupgrade
-```
-
-Make sure you have installed the latest version of mintupgrade package.
-
-```
-$ apt version mintupgrade
-```
-
-Run the below command as a normal user to simulate an upgrade and follow on-screen instructions.
-
-```
-$ mintupgrade check
-```
-
-Use the below command to download the packages necessary to upgrade to Linux Mint 19.2 (Tina) and follow on screen instructions.
-
-```
-$ mintupgrade download
-```
-
-Run the following command to apply the upgrades and follow on-screen instructions.
-
-```
-$ mintupgrade upgrade
-```
-
-Once upgrade done successfully, Reboot the system and check the upgraded version.
-
-```
-$ lsb_release -a
-
-No LSB modules are available.
-Distributor ID: Linux Mint
-Description: Linux Mint 19.2 (Tina)
-Release: 19.2
-Codename: Tina
-```
-
-### Method-3: Upgrade Linux Mint 19.2 (Tina) Using GUI
-
-Alternatively, we can perform the upgrade through GUI.
-
-### Step-1:
-
-Create a system snapshot through Timeshift. If anything goes wrong, you can easily restore your operating system to its previous state.
-
-### Step-2:
-
-Open the Update Manager, click on the Refresh button to check for any new version of mintupdate and mint-upgrade-info. If there are updates for these packages, apply them.
-
-Launch the System Upgrade by clicking on “Edit->Upgrade to Linux Mint 19.2 Tina”.
-[![][2]![][2]][3]
-
-Follow the instructions on the screen. If asked whether to keep or replace configuration files, choose to replace them.
-[![][2]![][2]][4]
-
-### Step-3:
-
-Once the upgrade is finished, reboot your computer.
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/upgrade-linux-mint-19-1-tessa-to-linux-mint-19-2-tina/
-
-作者:[2daygeek][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: http://www.2daygeek.com/author/2daygeek/
-[b]: https://github.com/lujun9972
-[1]: https://www.linuxtechnews.com/linux-mint-19-2-tina-released-check-what-is-new-feature/
-[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[3]: https://www.2daygeek.com/wp-content/uploads/2019/08/linux-mint-19-2-tina-mintupgrade.png
-[4]: https://www.2daygeek.com/wp-content/uploads/2019/08/linux-mint-19-2-tina-mintupgrade-1.png
diff --git a/sources/tech/20190812 How Hexdump works.md b/sources/tech/20190812 How Hexdump works.md
deleted file mode 100644
index 25907fe05f..0000000000
--- a/sources/tech/20190812 How Hexdump works.md
+++ /dev/null
@@ -1,240 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (0x996)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How Hexdump works)
-[#]: via: (https://opensource.com/article/19/8/dig-binary-files-hexdump)
-[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/shishz)
-
-How Hexdump works
-======
-Hexdump helps you investigate the contents of binary files. Learn how
-hexdump works.
-![Magnifying glass on code][1]
-
-Hexdump is a utility that displays the contents of binary files in hexadecimal, decimal, octal, or ASCII. It’s a utility for inspection and can be used for [data recovery][2], reverse engineering, and programming.
-
-### Learning the basics
-
-Hexdump provides output with very little effort on your part and depending on the size of the file you’re looking at, there can be a lot of output. For the purpose of this article, create a 1x1 PNG file. You can do this with a graphics application such as [GIMP][3] or [Mtpaint][4], or you can create it in a terminal with [ImageMagick][5].
-
-Here’s a command to generate a 1x1 pixel PNG with ImageMagick:
-
-
-```
-$ convert -size 1x1 canvas:black pixel.png
-```
-
-You can confirm that this file is a PNG with the **file** command:
-
-
-```
-$ file pixel.png
-pixel.png: PNG image data, 1 x 1, 1-bit grayscale, non-interlaced
-```
-
-You may wonder how the **file** command is able to determine what kind of file it is. Coincidentally, that’s what **hexdump** will reveal. For now, you can view your one-pixel graphic in the image viewer of your choice (it looks like this: **.** ), or you can view what’s inside the file with **hexdump**:
-
-
-```
-$ hexdump pixel.png
-0000000 5089 474e 0a0d 0a1a 0000 0d00 4849 5244
-0000010 0000 0100 0000 0100 0001 0000 3700 f96e
-0000020 0024 0000 6704 4d41 0041 b100 0b8f 61fc
-0000030 0005 0000 6320 5248 004d 7a00 0026 8000
-0000040 0084 fa00 0000 8000 00e8 7500 0030 ea00
-0000050 0060 3a00 0098 1700 9c70 51ba 003c 0000
-0000060 6202 474b 0044 dd01 138a 00a4 0000 7407
-0000070 4d49 0745 07e3 081a 3539 a487 46b0 0000
-0000080 0a00 4449 5441 d708 6063 0000 0200 0100
-0000090 21e2 33bc 0000 2500 4574 7458 6164 6574
-00000a0 633a 6572 7461 0065 3032 3931 302d 2d37
-00000b0 3532 3254 3a30 3735 353a 2b33 3231 303a
-00000c0 ac30 5dcd 00c1 0000 7425 5845 6474 7461
-00000d0 3a65 6f6d 6964 7966 3200 3130 2d39 3730
-00000e0 322d 5435 3032 353a 3a37 3335 312b 3a32
-00000f0 3030 90dd 7de5 0000 0000 4549 444e 42ae
-0000100 8260
-0000102
-```
-
-What you’re seeing is the contents of the sample PNG file through a lens you may have never used before. It’s the exact same data you see in an image viewer, encoded in a way that’s probably unfamiliar to you.
-
-### Extracting familiar strings
-
-Just because the default data dump seems meaningless, that doesn’t mean it’s devoid of valuable information. You can translate this output or at least the parts that actually translate, to a more familiar character set with the **\--canonical** option:
-
-
-```
-$ hexdump --canonical foo.png
-00000000 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 |.PNG........IHDR|
-00000010 00 00 00 01 00 00 00 01 01 00 00 00 00 37 6e f9 |.............7n.|
-00000020 24 00 00 00 04 67 41 4d 41 00 00 b1 8f 0b fc 61 |$....gAMA......a|
-00000030 05 00 00 00 20 63 48 52 4d 00 00 7a 26 00 00 80 |.... cHRM..z&...|
-00000040 84 00 00 fa 00 00 00 80 e8 00 00 75 30 00 00 ea |...........u0...|
-00000050 60 00 00 3a 98 00 00 17 70 9c ba 51 3c 00 00 00 |`..:....p..Q<...|
-00000060 02 62 4b 47 44 00 01 dd 8a 13 a4 00 00 00 07 74 |.bKGD..........t|
-00000070 49 4d 45 07 e3 07 1a 08 39 35 87 a4 b0 46 00 00 |IME.....95...F..|
-00000080 00 0a 49 44 41 54 08 d7 63 60 00 00 00 02 00 01 |..IDAT..c`......|
-00000090 e2 21 bc 33 00 00 00 25 74 45 58 74 64 61 74 65 |.!.3...%tEXtdate|
-000000a0 3a 63 72 65 61 74 65 00 32 30 31 39 2d 30 37 2d |:create.2019-07-|
-000000b0 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a 30 |25T20:57:53+12:0|
-000000c0 30 ac cd 5d c1 00 00 00 25 74 45 58 74 64 61 74 |0..]....%tEXtdat|
-000000d0 65 3a 6d 6f 64 69 66 79 00 32 30 31 39 2d 30 37 |e:modify.2019-07|
-000000e0 2d 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a |-25T20:57:53+12:|
-000000f0 30 30 dd 90 e5 7d 00 00 00 00 49 45 4e 44 ae 42 |00...}....IEND.B|
-00000100 60 82 |`.|
-00000102
-```
-
-In the right column, you see the same data that’s on the left but presented as ASCII. If you look carefully, you can pick out some useful information, such as the file’s format (PNG) and—toward the bottom—the date and time the file was created and last modified. The dots represent symbols that aren’t present in the ASCII character set, which is to be expected because binary formats aren’t restricted to mundane letters and numbers.
-
-The **file** command knows from the first 8 bytes what this file is. The [libpng specification][6] alerts programmers what to look for. You can see that within the first 8 bytes of this image file, specifically, is the string **PNG**. That fact is significant because it reveals how the **file** command knows what kind of file to report.
-
-You can also control how many bytes **hexdump** displays, which is useful with files larger than one pixel:
-
-
-```
-$ hexdump --length 8 pixel.png
-0000000 5089 474e 0a0d 0a1a
-0000008
-```
-
-You don’t have to limit **hexdump** to PNG or graphic files. You can run **hexdump** against binaries you run on a daily basis as well, such as [ls][7], [rsync][8], or any binary format you want to inspect.
-
-### Implementing cat with hexdump
-
-If you read the PNG spec, you may notice that the data in the first 8 bytes looks different than what **hexdump** provides. Actually, it’s the same data, but it’s presented using a different conversion. So, the output of **hexdump** is true, but not always directly useful to you, depending on what you’re looking for. For that reason, **hexdump** has options to format and convert the raw data it dumps.
-
-The conversion options can get complex, so it’s useful to practice with something trivial first. Here’s a gentle introduction to formatting **hexdump** output by reimplementing the [**cat**][9] command. First, run **hexdump** on a text file to see its raw data. You can usually find a copy of the [GNU General Public License (GPL)][10] license somewhere on your hard drive, or you can use any text file you have handy. Your output may differ, but here’s how to find a copy of the GPL on your system (or at least part of it):
-
-
-```
-$ find /usr/share/doc/ -type f -name "COPYING" | tail -1
-/usr/share/doc/libblkid-devel/COPYING
-```
-
-Run **hexdump** against it:
-
-
-```
-$ hexdump /usr/share/doc/libblkid-devel/COPYING
-0000000 6854 7369 6c20 6269 6172 7972 6920 2073
-0000010 7266 6565 7320 666f 7774 7261 3b65 7920
-0000020 756f 6320 6e61 7220 6465 7369 7274 6269
-0000030 7475 2065 7469 6120 646e 6f2f 0a72 6f6d
-0000040 6964 7966 6920 2074 6e75 6564 2072 6874
-0000050 2065 6574 6d72 2073 666f 7420 6568 4720
-0000060 554e 4c20 7365 6573 2072 6547 656e 6172
-0000070 206c 7550 6c62 6369 4c0a 6369 6e65 6573
-0000080 6120 2073 7570 6c62 7369 6568 2064 7962
-[...]
-```
-
-If the file’s output is very long, use the **\--length** (or **-n** for short) to make it manageable for yourself.
-
-The raw data probably means nothing to you, but you already know how to convert it to ASCII:
-
-
-```
-hexdump --canonical /usr/share/doc/libblkid-devel/COPYING
-00000000 54 68 69 73 20 6c 69 62 72 61 72 79 20 69 73 20 |This library is |
-00000010 66 72 65 65 20 73 6f 66 74 77 61 72 65 3b 20 79 |free software; y|
-00000020 6f 75 20 63 61 6e 20 72 65 64 69 73 74 72 69 62 |ou can redistrib|
-00000030 75 74 65 20 69 74 20 61 6e 64 2f 6f 72 0a 6d 6f |ute it and/or.mo|
-00000040 64 69 66 79 20 69 74 20 75 6e 64 65 72 20 74 68 |dify it under th|
-00000050 65 20 74 65 72 6d 73 20 6f 66 20 74 68 65 20 47 |e terms of the G|
-00000060 4e 55 20 4c 65 73 73 65 72 20 47 65 6e 65 72 61 |NU Lesser Genera|
-00000070 6c 20 50 75 62 6c 69 63 0a 4c 69 63 65 6e 73 65 |l Public.License|
-[...]
-```
-
-That output is helpful but unwieldy and difficult to read. To format **hexdump**’s output beyond what’s offered by its own options, use **\--format** (or **-e**) along with specialized formatting codes. The shorthand used for formatting is similar to what the **printf** command uses, so if you are familiar with **printf** statements, you may find **hexdump** formatting easier to learn.
-
-In **hexdump**, the character sequence **%_p** tells **hexdump** to print a character in your system’s default character set. All formatting notation for the **\--format** option must be enclosed in _single quotes_:
-
-
-```
-$ hexdump -e'"%_p"' /usr/share/doc/libblkid-devel/COPYING
-This library is fre*
- software; you can redistribute it and/or.modify it under the terms of the GNU Les*
-er General Public.License as published by the Fre*
- Software Foundation; either.version 2.1 of the License, or (at your option) any later.version..*
-The complete text of the license is available in the..*
-/Documentation/licenses/COPYING.LGPL-2.1-or-later file..
-```
-
-This output is better, but still inconvenient to read. Traditionally, UNIX text files assume an 80-character output width (because long ago, monitors tended to fit only 80 characters across).
-
-While this output isn’t bound by formatting, you can force **hexdump** to process 80 bytes at a time with additional options. Specifically, by dividing 80 by one, you can tell **hexdump** to treat 80 bytes as one unit:
-
-
-```
-$ hexdump -e'80/1 "%_p"' /usr/share/doc/libblkid-devel/COPYING
-This library is free software; you can redistribute it and/or.modify it under the terms of the GNU Lesser General Public.License as published by the Free Software Foundation; either.version 2.1 of the License, or (at your option) any later.version...The complete text of the license is available in the.../Documentation/licenses/COPYING.LGPL-2.1-or-later file..
-```
-
-Now the file is processed in 80-byte chunks, but it’s lost any sense of new lines. You can add your own with the **\n** character, which in UNIX represents a new line:
-
-
-```
-$ hexdump -e'80/1 "%_p""\n"'
-This library is free software; you can redistribute it and/or.modify it under th
-e terms of the GNU Lesser General Public.License as published by the Free Softwa
-re Foundation; either.version 2.1 of the License, or (at your option) any later.
-version...The complete text of the license is available in the.../Documentation/
-licenses/COPYING.LGPL-2.1-or-later file..
-```
-
-You have now (approximately) implemented the **cat** command with **hexdump** formatting.
-
-### Controlling the output
-
-Formatting is, realistically, how you make **hexdump** useful. Now that you’re familiar, in principle at least, with **hexdump** formatting, you can make the output of **hexdump -n 8** match the output of the PNG header as described by the official **libpng** spec.
-
-First, you know that you want **hexdump** to process the PNG file in 8-byte chunks. Furthermore, you may know by integer recognition that the PNG spec is documented in decimal, which is represented by **%d** according to the **hexdump** documentation:
-
-
-```
-$ hexdump -n8 -e'8/1 "%d""\n"' pixel.png
-13780787113102610
-```
-
-You can make the output perfect by adding a blank space after each integer:
-
-
-```
-$ hexdump -n8 -e'8/1 "%d ""\n"' pixel.png
-137 80 78 71 13 10 26 10
-```
-
-The output is now a perfect match to the PNG specification.
-
-### Hexdumping for fun and profit
-
-Hexdump is a fascinating tool that not only teaches you more about how computers process and convert information, but also about how file formats and compiled binaries function. You should try running **hexdump** on files at random throughout the day as you work. You never know what kinds of information you may find, nor when having that insight may be useful.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/dig-binary-files-hexdump
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/sethhttps://opensource.com/users/shishz
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
-[2]: https://www.redhat.com/sysadmin/find-lost-files-scalpel
-[3]: http://gimp.org
-[4]: https://opensource.com/article/17/2/mtpaint-pixel-art-animated-gifs
-[5]: https://opensource.com/article/17/8/imagemagick
-[6]: http://www.libpng.org/pub/png/spec/1.2/PNG-Structure.html
-[7]: https://opensource.com/article/19/7/master-ls-command
-[8]: https://opensource.com/article/19/5/advanced-rsync
-[9]: https://opensource.com/article/19/2/getting-started-cat-command
-[10]: https://en.wikipedia.org/wiki/GNU_General_Public_License
diff --git a/sources/tech/20190819 Moving files on Linux without mv.md b/sources/tech/20190819 Moving files on Linux without mv.md
deleted file mode 100644
index 6bf44ff584..0000000000
--- a/sources/tech/20190819 Moving files on Linux without mv.md
+++ /dev/null
@@ -1,189 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Moving files on Linux without mv)
-[#]: via: (https://opensource.com/article/19/8/moving-files-linux-without-mv)
-[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/seth)
-
-Moving files on Linux without mv
-======
-Sometimes the mv command isn't the best option when you need to move a
-file. So how else do you do it?
-![Hand putting a Linux file folder into a drawer][1]
-
-The humble **mv** command is one of those useful tools you find on every POSIX box you encounter. Its job is clearly defined, and it does it well: Move a file from one place in a file system to another. But Linux is nothing if not flexible, and there are other options for moving files. Using different tools can provide small advantages that fit perfectly with a specific use case.
-
-Before straying too far from **mv**, take a look at this command’s default results. First, create a directory and generate some files with permissions set to 777:
-
-
-```
-$ mkdir example
-$ touch example/{foo,bar,baz}
-$ for i in example/*; do ls /bin > "${i}"; done
-$ chmod 777 example/*
-```
-
-You probably don't think about it this way, but files exist as entries, called index nodes (commonly known as **inodes**), in a [filesystem][2]. You can see what inode a file occupies with the [ls command][3] and its **\--inode** option:
-
-
-```
-$ ls --inode example/foo
-7476868 example/foo
-```
-
-As a test, move that file from the example directory to your current directory and then view the file’s attributes:
-
-
-```
-$ mv example/foo .
-$ ls -l -G -g --inode
-7476868 -rwxrwxrwx. 1 29545 Aug 2 07:28 foo
-```
-
-As you can see, the original file—along with its existing permissions—has been "moved", but its inode has not changed.
-
-That’s the way the **mv** tool is programmed to move a file: Leave the inode unchanged (unless the file is being moved to a different filesystem), and preserve its ownership and permissions.
-
-Other tools provide different options.
-
-### Copy and remove
-
-On some systems, the move action is a true move action: Bits are removed from one point in the file system and reassigned to another. This behavior has largely fallen out of favor. Move actions are now either attribute reassignments (an inode now points to a different location in your file organization) or amalgamations of a copy action followed by a remove action.
-The philosophical intent of this design is to ensure that, should a move fail, a file is not left in pieces.
-
-The **cp** command, unlike **mv**, creates a brand new data object in your filesystem. It has a new inode location, and it is subject to your active umask. You can mimic a move using the **cp** and **rm** (or [trash][4] if you have it) commands:
-
-
-```
-$ cp example/foo .
-$ ls -l -G -g --inode
-7476869 -rwxrwxr-x. 29545 Aug 2 11:58 foo
-$ trash example/foo
-```
-
-The new **foo** file in this example got 775 permissions because the location’s umask specifically excludes write permissions:
-
-
-```
-$ umask
-0002
-```
-
-For more information about umask, read Alex Juarez’s article about [file permissions][5].
-
-### Cat and remove
-
-Similar to a copy and remove, using the [cat][6] (or **tac**, for that matter) command assigns different permissions when your "moved" file is created. Assuming a fresh test environment with no **foo** in the current directory:
-
-
-```
-$ cat example/foo > foo
-$ ls -l -G -g --inode
-7476869 -rw-rw-r--. 29545 Aug 8 12:21 foo
-$ trash example/foo
-```
-
-This time, a new file was created with no prior permissions set. The result is entirely subject to the umask setting, which blocks no permission bit for the user and group (the executable bit is not granted for new files regardless of umask), but it blocks the write (value two) bit from others. The result is a file with 664 permission.
-
-### Rsync
-
-The **rsync** command is a robust multipurpose tool to send files between hosts and file system locations. This command has many options available to it, including the ability to make its destination mirror its source.
-
-You can copy and then remove a file with **rsync** using the **\--remove-source-files** option, along with whatever other option you choose to perform the synchronization (a common, general-purpose one is **\--archive**):
-
-
-```
-$ rsync --archive --remove-source-files example/foo .
-$ ls example
-bar baz
-$ ls -lGgi
-7476870 -rwxrwxrwx. 1 seth users 29545 Aug 8 12:23 foo
-```
-
-Here you can see that file permission and ownership was retained, the timestamp was updated, and the source file was removed.
-
-**A word of warning:** Do not confuse this option for **\--delete**, which removes files from your _destination_ directory. Misusing **\--delete** can wipe out most of your data, and it’s recommended that you avoid this option except in a test environment.
-
-You can override some of these defaults, changing permission and modification settings:
-
-
-```
-$ rsync --chmod=666 --times \
-\--remove-source-files example/foo .
-$ ls example
-bar baz
-$ ls -lGgi
-7476871 -rw-rw-r--. 1 seth users 29545 Aug 8 12:55 foo
-```
-
-Here, the destination’s umask is respected, so the **\--chmod=666** option results in a file with 664 permissions.
-
-The benefits go beyond just permissions, though. The **rsync** command has [many][7] useful [options][8] (not the least of which is the **\--exclude** flag so you can exempt items from a large move operation) that make it a more robust tool than the simple **mv** command. For example, to exclude all backup files while moving a collection of files:
-
-
-```
-$ rsync --chmod=666 --times \
-\--exclude '*~' \
-\--remove-source-files example/foo .
-```
-
-### Set permissions with install
-
-The **install** command is a copy command specifically geared toward developers and is mostly invoked as part of the install routine of software compiling. It’s not well known among users (and I do often wonder why it got such an intuitive name, leaving mere acronyms and pet names for package managers), but **install** is actually a useful way to put files where you want them.
-
-There are many options for the **install** command, including **\--backup** and **\--compare** command (to avoid "updating" a newer copy of a file).
-
-Unlike **cp** and **cat**, but exactly like **mv**, the **install** command can copy a file while preserving its timestamp:
-
-
-```
-$ install --preserve-timestamp example/foo .
-$ ls -l -G -g --inode
-7476869 -rwxr-xr-x. 1 29545 Aug 2 07:28 foo
-$ trash example/foo
-```
-
-Here, the file was copied to a new inode, but its **mtime** did not change. The permissions, however, were set to the **install** default of **755**.
-
-You can use **install** to set the file’s permissions, owner, and group:
-
-
-```
-$ install --preserve-timestamp \
-\--owner=skenlon \
-\--group=dialout \
-\--mode=666 example/foo .
-$ ls -li
-7476869 -rw-rw-rw-. 1 skenlon dialout 29545 Aug 2 07:28 foo
-$ trash example/foo
-```
-
-### Move, copy, and remove
-
-Files contain data, and the really important files contain _your_ data. Learning to manage them wisely is important, and now you have the toolkit to ensure that your data is handled in exactly the way you want.
-
-Do you have a different way of managing your data? Tell us your ideas in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/moving-files-linux-without-mv
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/sethhttps://opensource.com/users/seth
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
-[2]: https://opensource.com/article/18/11/partition-format-drive-linux#what-is-a-filesystem
-[3]: https://opensource.com/article/19/7/master-ls-command
-[4]: https://gitlab.com/trashy
-[5]: https://opensource.com/article/19/8/linux-permissions-101#umask
-[6]: https://opensource.com/article/19/2/getting-started-cat-command
-[7]: https://opensource.com/article/19/5/advanced-rsync
-[8]: https://opensource.com/article/17/1/rsync-backup-linux
diff --git a/sources/tech/20190821 Getting Started with Go on Fedora.md b/sources/tech/20190821 Getting Started with Go on Fedora.md
deleted file mode 100644
index 8dee1048bb..0000000000
--- a/sources/tech/20190821 Getting Started with Go on Fedora.md
+++ /dev/null
@@ -1,117 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (hello-wn)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Getting Started with Go on Fedora)
-[#]: via: (https://fedoramagazine.org/getting-started-with-go-on-fedora/)
-[#]: author: (Clément Verna https://fedoramagazine.org/author/cverna/)
-
-Getting Started with Go on Fedora
-======
-
-![][1]
-
-The [Go][2] programming language was first publicly announced in 2009, since then the language has become widely adopted. In particular Go has become a reference in the world of cloud infrastructure with big projects like [Kubernetes][3], [OpenShift][4] or [Terraform][5] for example.
-
-Some of the main reasons for Go’s increasing popularity are the performances, the ease to write fast concurrent application, the simplicity of the language and fast compilation time. So let’s see how to get started with Go on Fedora.
-
-### Install Go in Fedora
-
-Fedora provides an easy way to install the Go programming language via the official repository.
-
-```
-$ sudo dnf install -y golang
-$ go version
-go version go1.12.7 linux/amd64
-```
-
-Now that Go is installed, let’s write a simple program, compile it and execute it.
-
-### First program in Go
-
-Let’s write the traditional “Hello, World!” program in Go. First create a _main.go_ file and type or copy the following.
-
-```
-package main
-
-import "fmt"
-
-func main() {
- fmt.Println("Hello, World!")
-}
-```
-
-Running this program is quite simple.
-
-```
-$ go run main.go
-Hello, World!
-```
-
-This will build a binary from main.go in a temporary directory, execute the binary, then delete the temporary directory. This command is really great to quickly run the program during development and it also highlights the speed of Go compilation.
-
-Building an executable of the program is as simple as running it.
-
-```
-$ go build main.go
-$ ./main
-Hello, World!
-```
-
-### Using Go modules
-
-Go 1.11 and 1.12 introduce preliminary support for modules. Modules are a solution to manage application dependencies. This solution is based on 2 files _go.mod_ and _go.sum_ used to explicitly define the version of the dependencies.
-
-To show how to use modules, let’s add a dependency to the hello world program.
-
-Before changing the code, the module needs to be initialized.
-
-```
-$ go mod init helloworld
-go: creating new go.mod: module helloworld
-$ ls
-go.mod main main.go
-```
-
-Next modify the main.go file as follow.
-
-```
-package main
-
-import "github.com/fatih/color"
-
-func main () {
- color.Blue("Hello, World!")
-}
-```
-
-In the modified main.go, instead of using the standard library “_fmt_” to print the “Hello, World!”. The application uses an external library which makes it easy to print text in color.
-
-Let’s run this version of the application.
-
-```
-$ go run main.go
-Hello, World!
-```
-
-Now that the application is depending on the _github.com/fatih/color_ library, it needs to download all the dependencies before compiling it. The list of dependencies is then added to _go.mod_ and the exact version and commit hash of these dependencies is recorded in _go.sum_.
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/getting-started-with-go-on-fedora/
-
-作者:[Clément Verna][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fedoramagazine.org/author/cverna/
-[b]: https://github.com/lujun9972
-[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/go-article-816x345.jpg
-[2]: https://golang.org/
-[3]: https://kubernetes.io/
-[4]: https://www.openshift.com/
-[5]: https://www.terraform.io/
diff --git a/sources/tech/20190823 How To Check Your IP Address in Ubuntu -Beginner-s Tip.md b/sources/tech/20190823 How To Check Your IP Address in Ubuntu -Beginner-s Tip.md
deleted file mode 100644
index d4662b0228..0000000000
--- a/sources/tech/20190823 How To Check Your IP Address in Ubuntu -Beginner-s Tip.md
+++ /dev/null
@@ -1,117 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How To Check Your IP Address in Ubuntu [Beginner’s Tip])
-[#]: via: (https://itsfoss.com/check-ip-address-ubuntu/)
-[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
-
-How To Check Your IP Address in Ubuntu [Beginner’s Tip]
-======
-
-Wonder what’s your IP address? Here are several ways to check IP address in Ubuntu and other Linux distributions.
-
-![][1]
-
-### What is an IP Address?
-
-An **Internet Protocol address** (commonly referred to as **IP address**) is a numerical label assigned to each device connected to a computer network (using the Internet Protocol). An IP address serves both the purpose of identification and localisation of a machine.
-
-The **IP address** is _unique_ within the network, allowing the communication between all connected devices.
-
-You should also know that there are two **types of IP addresses**: **public** and **private**. The **public IP address** is the address used to communicate over the Internet, the same way your physical address is used for postal mail. However, in the context of a local network (such as a home where are router is used), each device is assigned a **private IP address** unique within this sub-network. This is used inside this local network, without directly exposing the public IP (which is used by the router to communicate with the Internet).
-
-Another distinction can be made between **IPv4** and **IPv6** protocol. **IPv4** is the classic IP format,consisting of a basic 4 part structure, with four bytes separated by dots (e.g. 127.0.0.1). However, with the growing number of devices, IPv4 will soon be unable to offer enough addresses. This is why **IPv6** was invented, a format using **128-bit addresses** (compared to the **32-bit addresses** used by **IPv4**).
-
-## Checking your IP Address in Ubuntu [Terminal Method]
-
-The fastest and the simplest way to check your IP address is by using the ip command. You can use this command in the following fashion:
-
-```
-ip addr show
-```
-
-It will show you both IPv4 and IPv6 addresses:
-
-![Display IP Address in Ubuntu Linux][2]
-
-Actually, you can further shorten this command to just `ip a`. It will give you the exact same result.
-
-```
-ip a
-```
-
-If you prefer to get minimal details, you can also use **hostname**:
-
-```
-hostname -I
-```
-
-There are some other [ways to check IP address in Linux][3] but these two commands are more than enough to serve the purpose.
-
-[][4]
-
-Suggested read How to Disable IPv6 on Ubuntu Linux
-
-What about ifconfig?
-
-Long-time users might be tempted to use ifconfig (part of net-tools), but that program is deprecated. Some newer Linux distributions don’t include this package anymore and if you try running it, you’ll see ifconfig command not found error.
-
-## Checking IP address in Ubuntu [GUI Method]
-
-If you are not comfortable with the command line, you can also check IP address graphically.
-
-Open up the Ubuntu Applications Menu (**Show Applications** in the bottom-left corner of the screen) and search for **Settings** and click on the icon:
-
-![Applications Menu Settings][5]
-
-This should open up the **Settings Menu**. Go to **Network**:
-
-![Network Settings Ubuntu][6]
-
-Pressing on the **gear icon** next to your connection should open up a window with more settings and information about your link to the network, including your IP address:
-
-![IP Address GUI Ubuntu][7]
-
-## Bonus Tip: Checking your Public IP Address (for desktop computers)
-
-First of all, to check your **public IP address** (used for communicating with servers etc.) you can [use curl command][8]. Open up a terminal and enter the following command:
-
-```
-curl ifconfig.me
-```
-
-This should simply return your IP address with no additional bulk information. I would recommend being careful when sharing this address, since it is the equivalent to giving out your personal address.
-
-**Note:** _If **curl** isn’t installed on your system, simply use **sudo apt install curl -y** to solve the problem, then try again._
-
-Another simple way you can see your public IP address is by searching for **ip address** on Google.
-
-**Summary**
-
-In this article I went through the different ways you can find your IP address in Uuntu Linux, as well as giving you a basic overview of what IP addresses are used for and why they are so important for us.
-
-I hope you enjoyed this quick guide. Let us know if you found this explanation helpful in the comments section!
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/check-ip-address-ubuntu/
-
-作者:[Sergiu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/sergiu/
-[b]: https://github.com/lujun9972
-[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/checking-ip-address-ubuntu.png?resize=800%2C450&ssl=1
-[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/ip_addr_show.png?fit=800%2C493&ssl=1
-[3]: https://linuxhandbook.com/find-ip-address/
-[4]: https://itsfoss.com/disable-ipv6-ubuntu-linux/
-[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/applications_menu_settings.jpg?fit=800%2C309&ssl=1
-[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/network_settings_ubuntu.jpg?fit=800%2C591&ssl=1
-[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/ip_address_gui_ubuntu.png?fit=800%2C510&ssl=1
-[8]: https://linuxhandbook.com/curl-command-examples/
diff --git a/sources/tech/20190826 5 ops tasks to do with Ansible.md b/sources/tech/20190826 5 ops tasks to do with Ansible.md
deleted file mode 100644
index 9748ce55e9..0000000000
--- a/sources/tech/20190826 5 ops tasks to do with Ansible.md
+++ /dev/null
@@ -1,97 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (5 ops tasks to do with Ansible)
-[#]: via: (https://opensource.com/article/19/8/ops-tasks-ansible)
-[#]: author: (Mark Phillips https://opensource.com/users/markphttps://opensource.com/users/adminhttps://opensource.com/users/alsweigarthttps://opensource.com/users/belljennifer43)
-
-5 ops tasks to do with Ansible
-======
-Less DevOps, more OpsDev.
-![gears and lightbulb to represent innovation][1]
-
-In this DevOps world, it sometimes appears the Dev half gets all the limelight, with Ops the forgotten half in the relationship. It's almost as if the leading Dev tells the trailing Ops what to do, with almost everything "Ops" being whatever Dev says it should be. Ops, therefore, gets left behind, punted to the back, relegated to the bench.
-
-I'd like to see more OpsDev happening. So let's look at a handful of things Ansible can help you do with your day-to-day Ops life.
-
-![Job templates][2]
-
-I've chosen to present these solutions within [Ansible Tower][3] because I think a user interface (UI) adds value to most of these tasks. If you want to emulate this, you can test it out in [AWX][4], the upstream open source version of Tower.
-
-### Manage users
-
-In a large-scale environment, your users would be centralised in a system like Active Directory or LDAP. But I bet there are still a whole load of environments with lots of static users in them, too. Ansible can help you centralise that decentralised problem. And _the community_ has already solved it for us. Meet the [Ansible Galaxy][5] role **[users][6]**.
-
-What's clever about this role is it allows us to manage users via *data—*no changes to play logic required.
-
-![User data][7]
-
-With simple data structures, we can add, remove and modify static users on a system. Very useful.
-
-### Manage sudo
-
-Privilege escalation comes [in many forms][8], but one of the most popular is [sudo][9]. It's relatively easy to manage sudo through discrete files per user, group, etc. But some folk get nervous about giving privilege escalation willy-nilly and prefer it to be time-bound. So [here's a take on that][10], using the simple **at** command to put a time limit on the granted access.
-
-![Managing sudo][11]
-
-### Manage services
-
-Wouldn't it be great to give a [menu][12] to an entry-level ops team so they could just restart certain services? Voila!
-
-![Managing services][13]
-
-### Manage disk space
-
-Here's [a simple role][14] that can be used to look for files larger than size _N_ in a particular directory. Doing this in Tower, we have the bonus of enabling [callbacks][15]. Imagine your monitoring solution spotting a filesystem going over X% full and triggering a job in Tower to go find out what files are the cause.
-
-![Managing disk space][16]
-
-### Debug a system performance problem
-
-[This role][17] is fairly simple: it runs some commands and prints the output. The details are printed at the end of the run for you, sysadmin, to cast your skilled eyes over. Bonus homework: use [regexs][18] to find certain conditions in the output (CPU hog over 80%, say).
-
-![Debugging system performance][19]
-
-### Summary
-
-I've recorded a short video of these five tasks in action. You can find all [the code on GitHub][20] too!
-
-Michael DeHaan is the guy who created, in his own words, "that Ansible thing." A lot of the things...
-
-A little bit of coding knowledge can let anyone write small scripts to do these tasks and save them...
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/ops-tasks-ansible
-
-作者:[Mark Phillips][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/markphttps://opensource.com/users/adminhttps://opensource.com/users/alsweigarthttps://opensource.com/users/belljennifer43
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/innovation_lightbulb_gears_devops_ansible.png?itok=TSbmp3_M (gears and lightbulb to represent innovation)
-[2]: https://opensource.com/sites/default/files/uploads/00_templates.png (Job templates)
-[3]: https://www.ansible.com/products/tower
-[4]: https://github.com/ansible/awx
-[5]: https://galaxy.ansible.com
-[6]: https://galaxy.ansible.com/singleplatform-eng/users
-[7]: https://opensource.com/sites/default/files/uploads/01_users_data.png (User data)
-[8]: https://docs.ansible.com/ansible/latest/plugins/become.html
-[9]: https://www.sudo.ws/intro.html
-[10]: https://github.com/phips/ansible-demos/tree/master/roles/sudo
-[11]: https://opensource.com/sites/default/files/uploads/02_sudo.png (Managing sudo)
-[12]: https://docs.ansible.com/ansible-tower/latest/html/userguide/job_templates.html#surveys
-[13]: https://opensource.com/sites/default/files/uploads/03_services.png (Managing services)
-[14]: https://github.com/phips/ansible-demos/tree/master/roles/disk
-[15]: https://docs.ansible.com/ansible-tower/latest/html/userguide/job_templates.html#provisioning-callbacks
-[16]: https://opensource.com/sites/default/files/uploads/04_diskspace.png (Managing disk space)
-[17]: https://github.com/phips/ansible-demos/tree/master/roles/gather_debug
-[18]: https://docs.ansible.com/ansible/latest/user_guide/playbooks_filters.html#regular-expression-filters
-[19]: https://opensource.com/sites/default/files/uploads/05_debug.png (Debugging system performance)
-[20]: https://github.com/phips/ansible-demos
diff --git a/sources/tech/20190826 How to rename a group of files on Linux.md b/sources/tech/20190826 How to rename a group of files on Linux.md
deleted file mode 100644
index 15e62bb4c4..0000000000
--- a/sources/tech/20190826 How to rename a group of files on Linux.md
+++ /dev/null
@@ -1,134 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to rename a group of files on Linux)
-[#]: via: (https://www.networkworld.com/article/3433865/how-to-rename-a-group-of-files-on-linux.html)
-[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
-
-How to rename a group of files on Linux
-======
-To rename a group of files with a single command, use the rename command. It requires the use of regular expressions and can tell you what changes will be made before making them.
-![Manchester City Library \(CC BY-SA 2.0\)][1]
-
-For decades, Linux users have been renaming files with the **mv** command. It’s easy, and the command does just what you expect. Yet sometimes you need to rename a large group of files. When that is the case, the **rename** command can make the task a lot easier. It just requires a little finesse with regular expressions.
-
-**[ Two-Minute Linux Tips: [Learn how to master a host of Linux commands in these 2-minute video tutorials][2] ]**
-
-Unlike the **mv** command, **rename** isn’t going to allow you to simply specify the old and new names. Instead, it uses a regular expression like those you'd use with Perl. In the example below, the "s" specifies that we're substituting the second string (old) for the first, thus changing **this.new** to **this.old**.
-
-```
-$ rename 's/new/old/' this.new
-$ ls this*
-this.old
-```
-
-A change as simple as that would be easier using **mv this.new this.old**, but change the literal string “this” to the wild card “*” and you would rename all of your *.new files to *.old files with a single command:
-
-```
-$ ls *.new
-report.new schedule.new stats.new this.new
-$ rename 's/new/old/' *.new
-$ ls *.old
-report.old schedule.old stats.old this.old
-```
-
-As you might expect, the **rename** command isn’t restricted to changing file extensions. If you needed to change files named “report.*” to “review.*”, you could manage that with a command like this:
-
-```
-$ rename 's/report/review/' *
-```
-
-The strings supplied in the regular expressions can make changes to any portion of a file name — whether file names or extensions.
-
-```
-$ rename 's/123/124/' *
-$ ls *124*
-status.124 report124.txt
-```
-
-If you add the **-v** option to a **rename** command, the command will provide some feedback so that you can see the changes you made, maybe including any you didn’t intend — making it easier to notice and revert changes as needed.
-
-```
-$ rename -v 's/123/124/' *
-status.123 renamed as status.124
-report123.txt renamed as report124.txt
-```
-
-On the other hand, using the **-n** (or **\--nono**) option makes the **rename** command tell you the changes that it would make without actually making them. This can save you from making changes you may not be intending to make and then having to revert those changes.
-
-```
-$ rename -n 's/old/save/' *
-rename(logger.man-old, logger.man-save)
-rename(lyrics.txt-old, lyrics.txt-save)
-rename(olderfile-, saveerfile-)
-rename(oldfile, savefile)
-rename(review.old, review.save)
-rename(schedule.old, schedule.save)
-rename(stats.old, stats.save)
-rename(this.old, this.save)
-```
-
-If you're then happy with those changes, you can then run the command without the **-n** option to make the file name changes.
-
-Notice, however, that the “.” within the regular expressions will not be treated as a period, but as a wild card that will match any character. Some of the changes in the examples above and below are likely not what was intended by the person typing the command.
-
-```
-$ rename -n 's/.old/.save/' *
-rename(logger.man-old, logger.man.save)
-rename(lyrics.txt-old, lyrics.txt.save)
-rename(review.old, review.save)
-rename(schedule.old, schedule.save)
-rename(stats.old, stats.save)
-rename(this.old, this.save)
-```
-
-To ensure that a period is taken literally, put a backslash in front of it. This will keep it from being interpreted as a wild card and matching any character. Notice that only the “.old” files are selected when this change is made.
-
-```
-$ rename -n 's/\.old/.save/' *
-rename(review.old, review.save)
-rename(schedule.old, schedule.save)
-rename(stats.old, stats.save)
-rename(this.old, this.save)
-```
-
-A command like the one below would change all uppercase letters in file names to lowercase except that the -n option is being used to make sure we review the changes that would be made before we run the command to make the changes. Notice the use of the “y” in the regular expression; it’s required for making the case changes.
-
-```
-$ rename -n 'y/A-Z/a-z/' W*
-rename(WARNING_SIGN.pdf, warning_sign.pdf)
-rename(Will_Gardner_buttons.pdf, will_gardner_buttons.pdf)
-rename(Wingding_Invites.pdf, wingding_invites.pdf)
-rename(WOW-buttons.pdf, wow-buttons.pdf)
-```
-
-In the example above, we're changing all uppercase letters to lowercase, but only in file names that begin with an uppercase W.
-
-### Wrap-up
-
-The **rename** command is very helpful when you need to rename a lot of files. Just be careful not to make more changes than you intended. Keep in mind that the **-n** (or spelled out as **\--nono**) option can help you avoid time-consuming mistakes.
-
-**[Now read this: [Linux hardening: A 15-step checklist for a secure Linux server][3] ]**
-
-Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
-
---------------------------------------------------------------------------------
-
-via: https://www.networkworld.com/article/3433865/how-to-rename-a-group-of-files-on-linux.html
-
-作者:[Sandra Henry-Stocker][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
-[b]: https://github.com/lujun9972
-[1]: https://images.idgesg.net/images/article/2019/08/card-catalog-machester_city_library-100809242-large.jpg
-[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
-[3]: http://www.networkworld.com/article/3143050/linux/linux-hardening-a-15-step-checklist-for-a-secure-linux-server.html
-[4]: https://www.facebook.com/NetworkWorld/
-[5]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20190829 Getting started with HTTPie for API testing.md b/sources/tech/20190829 Getting started with HTTPie for API testing.md
new file mode 100644
index 0000000000..a7e4f7d32a
--- /dev/null
+++ b/sources/tech/20190829 Getting started with HTTPie for API testing.md
@@ -0,0 +1,341 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Getting started with HTTPie for API testing)
+[#]: via: (https://opensource.com/article/19/8/getting-started-httpie)
+[#]: author: (Moshe Zadka https://opensource.com/users/moshezhttps://opensource.com/users/mkalindepauleduhttps://opensource.com/users/jamesf)
+
+Getting started with HTTPie for API testing
+======
+Debug API clients with HTTPie, an easy-to-use command-line tool written
+in Python.
+![Raspberry pie with slice missing][1]
+
+[HTTPie][2] is a delightfully easy to use and easy to upgrade HTTP client. Pronounced "aitch-tee-tee-pie" and run as **http**, it is a command-line tool written in Python to access the web.
+
+Since this how-to is about an HTTP client, you need an HTTP server to try it out; in this case, [httpbin.org][3], a simple, open source HTTP request-and-response service. The httpbin.org site is a powerful way to test to test web API clients and carefully manage and show details in requests and responses, but for now we will focus on the power of HTTPie.
+
+### An alternative to Wget and cURL
+
+You might have heard of the venerable [Wget][4] or the slightly newer [cURL][5] tools that allow you to access the web from the command line. They were written to access websites, whereas HTTPie is for accessing _web APIs_.
+
+Website requests are designed to be between a computer and an end user who is reading and responding to what they see. This doesn't depend much on structured responses. However, API requests make _structured_ calls between two computers. The human is not part of the picture, and the parameters of a command-line tool like HTTPie handle this effectively.
+
+### Install HTTPie
+
+There are several ways to install HTTPie. You can probably get it as a package for your package manager, whether you use **brew**, **apt**, **yum**, or **dnf**. However, if you have configured [virtualenvwrapper][6], you can own your own installation:
+
+
+```
+$ mkvirtualenv httpie
+...
+(httpie) $ pip install httpie
+...
+(httpie) $ deactivate
+$ alias http=~/.virtualenvs/httpie/bin/http
+$ http -b GET
+{
+ "args": {},
+ "headers": {
+ "Accept": "*/*",
+ "Accept-Encoding": "gzip, deflate",
+ "Host": "httpbin.org",
+ "User-Agent": "HTTPie/1.0.2"
+ },
+ "origin": "104.220.242.210, 104.220.242.210",
+ "url": ""
+}
+```
+
+By aliasing **http** directly to the command inside the virtual environment, you can run it even when the virtual environment is not active. You can put the **alias** command in **.bash_profile** or **.bashrc** so you can upgrade HTTPie with the command:
+
+
+```
+`$ ~/.virtualenvs/httpie/bin/pip install -U pip`
+```
+
+### Query a website with HTTPie
+
+HTTPie can simplify querying and testing an API. One option for running it, **-b** (also known as **\--body**), was used above. Without it, HTTPie will print the entire response, including the headers, by default:
+
+
+```
+$ http GET
+HTTP/1.1 200 OK
+Access-Control-Allow-Credentials: true
+Access-Control-Allow-Origin: *
+Connection: keep-alive
+Content-Encoding: gzip
+Content-Length: 177
+Content-Type: application/json
+Date: Fri, 09 Aug 2019 20:19:47 GMT
+Referrer-Policy: no-referrer-when-downgrade
+Server: nginx
+X-Content-Type-Options: nosniff
+X-Frame-Options: DENY
+X-XSS-Protection: 1; mode=block
+
+{
+ "args": {},
+ "headers": {
+ "Accept": "*/*",
+ "Accept-Encoding": "gzip, deflate",
+ "Host": "httpbin.org",
+ "User-Agent": "HTTPie/1.0.2"
+ },
+ "origin": "104.220.242.210, 104.220.242.210",
+ "url": ""
+}
+```
+
+This is crucial when debugging an API service because a lot of information is sent in the headers. For example, it is often important to see which cookies are being sent. Httpbin.org provides options to set cookies (for testing purposes) through the URL path. The following sets a cookie titled **opensource** to the value **awesome**:
+
+
+```
+$ http GET
+HTTP/1.1 302 FOUND
+Access-Control-Allow-Credentials: true
+Access-Control-Allow-Origin: *
+Connection: keep-alive
+Content-Length: 223
+Content-Type: text/html; charset=utf-8
+Date: Fri, 09 Aug 2019 20:22:39 GMT
+Location: /cookies
+Referrer-Policy: no-referrer-when-downgrade
+Server: nginx
+Set-Cookie: opensource=awesome; Path=/
+X-Content-Type-Options: nosniff
+X-Frame-Options: DENY
+X-XSS-Protection: 1; mode=block
+
+<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
+<title>Redirecting...</title>
+<h1>Redirecting...</h1>
+<p>You should be redirected automatically to target URL:
+<a href="/cookies">/cookies</a>. If not click the link.
+```
+
+Notice the **Set-Cookie: opensource=awesome; Path=/** header. This shows the cookie you expected to be set is set correctly and with a **/** path. Also notice that, even though you got a **302** redirect, **http** did not follow it. If you want to follow redirects, you need to ask for it explicitly with the **\--follow** flag:
+
+
+```
+$ http --follow GET
+HTTP/1.1 200 OK
+Access-Control-Allow-Credentials: true
+Access-Control-Allow-Origin: *
+Connection: keep-alive
+Content-Encoding: gzip
+Content-Length: 66
+Content-Type: application/json
+Date: Sat, 10 Aug 2019 01:33:34 GMT
+Referrer-Policy: no-referrer-when-downgrade
+Server: nginx
+X-Content-Type-Options: nosniff
+X-Frame-Options: DENY
+X-XSS-Protection: 1; mode=block
+
+{
+ "cookies": {
+ "opensource": "awesome"
+ }
+}
+```
+
+But now you cannot see the original **Set-Cookie** header. In order to see intermediate replies, you need to use **\--all**:
+
+
+```
+$ http --headers --all --follow \
+GET
+HTTP/1.1 302 FOUND
+Access-Control-Allow-Credentials: true
+Access-Control-Allow-Origin: *
+Content-Type: text/html; charset=utf-8
+Date: Sat, 10 Aug 2019 01:38:40 GMT
+Location: /cookies
+Referrer-Policy: no-referrer-when-downgrade
+Server: nginx
+Set-Cookie: opensource=awesome; Path=/
+X-Content-Type-Options: nosniff
+X-Frame-Options: DENY
+X-XSS-Protection: 1; mode=block
+Content-Length: 223
+Connection: keep-alive
+
+HTTP/1.1 200 OK
+Access-Control-Allow-Credentials: true
+Access-Control-Allow-Origin: *
+Content-Encoding: gzip
+Content-Type: application/json
+Date: Sat, 10 Aug 2019 01:38:41 GMT
+Referrer-Policy: no-referrer-when-downgrade
+Server: nginx
+X-Content-Type-Options: nosniff
+X-Frame-Options: DENY
+X-XSS-Protection: 1; mode=block
+Content-Length: 66
+Connection: keep-alive
+```
+
+Printing the body is uninteresting because you are mostly interested in the cookies. If you want to see the headers from the intermediate request but the body from the final request, you can do that with:
+
+
+```
+$ http --print hb --history-print h --all --follow \
+GET
+HTTP/1.1 302 FOUND
+Access-Control-Allow-Credentials: true
+Access-Control-Allow-Origin: *
+Content-Type: text/html; charset=utf-8
+Date: Sat, 10 Aug 2019 01:40:56 GMT
+Location: /cookies
+Referrer-Policy: no-referrer-when-downgrade
+Server: nginx
+Set-Cookie: opensource=awesome; Path=/
+X-Content-Type-Options: nosniff
+X-Frame-Options: DENY
+X-XSS-Protection: 1; mode=block
+Content-Length: 223
+Connection: keep-alive
+
+HTTP/1.1 200 OK
+Access-Control-Allow-Credentials: true
+Access-Control-Allow-Origin: *
+Content-Encoding: gzip
+Content-Type: application/json
+Date: Sat, 10 Aug 2019 01:40:56 GMT
+Referrer-Policy: no-referrer-when-downgrade
+Server: nginx
+X-Content-Type-Options: nosniff
+X-Frame-Options: DENY
+X-XSS-Protection: 1; mode=block
+Content-Length: 66
+Connection: keep-alive
+
+{
+ "cookies": {
+ "opensource": "awesome"
+ }
+}
+```
+
+You can control exactly what is being printed with **\--print** and override what is printed for intermediate requests with **\--history-print**.
+
+### Download binary files with HTTPie
+
+Sometimes the body is non-textual and needs to be sent to a file that can be opened by a different application:
+
+
+```
+$ http GET
+HTTP/1.1 200 OK
+Access-Control-Allow-Credentials: true
+Access-Control-Allow-Origin: *
+Connection: keep-alive
+Content-Length: 35588
+Content-Type: image/jpeg
+Date: Fri, 09 Aug 2019 20:25:49 GMT
+Referrer-Policy: no-referrer-when-downgrade
+Server: nginx
+X-Content-Type-Options: nosniff
+X-Frame-Options: DENY
+X-XSS-Protection: 1; mode=block
+
++-----------------------------------------+
+| NOTE: binary data not shown in terminal |
++-----------------------------------------+
+```
+
+To get the right image, you need to save it to a file:
+
+
+```
+$ http --download GET
+HTTP/1.1 200 OK
+Access-Control-Allow-Credentials: true
+Access-Control-Allow-Origin: *
+Connection: keep-alive
+Content-Length: 35588
+Content-Type: image/jpeg
+Date: Fri, 09 Aug 2019 20:28:13 GMT
+Referrer-Policy: no-referrer-when-downgrade
+Server: nginx
+X-Content-Type-Options: nosniff
+X-Frame-Options: DENY
+X-XSS-Protection: 1; mode=block
+
+Downloading 34.75 kB to "jpeg.jpe"
+Done. 34.75 kB in 0.00068s (50.05 MB/s)
+```
+
+Try it! The picture is adorable.
+
+### Sending custom requests with HTTPie
+
+You can also send specific headers. This is useful for custom web APIs that require a non-standard header:
+
+
+```
+$ http GET X-Open-Source-Com:Awesome
+{
+ "headers": {
+ "Accept": "*/*",
+ "Accept-Encoding": "gzip, deflate",
+ "Host": "httpbin.org",
+ "User-Agent": "HTTPie/1.0.2",
+ "X-Open-Source-Com": "Awesome"
+ }
+}
+```
+
+Finally, if you want to send JSON fields (although it is possible to specify exact content), for many less-nested inputs, you can use a shortcut:
+
+
+```
+$ http --body PUT open-source=awesome author=moshez
+{
+ "args": {},
+ "data": "{\"open-source\": \"awesome\", \"author\": \"moshez\"}",
+ "files": {},
+ "form": {},
+ "headers": {
+ "Accept": "application/json, */*",
+ "Accept-Encoding": "gzip, deflate",
+ "Content-Length": "46",
+ "Content-Type": "application/json",
+ "Host": "httpbin.org",
+ "User-Agent": "HTTPie/1.0.2"
+ },
+ "json": {
+ "author": "moshez",
+ "open-source": "awesome"
+ },
+ "method": "PUT",
+ "origin": "73.162.254.113, 73.162.254.113",
+ "url": ""
+}
+```
+
+The next time you are debugging a web API, whether your own or someone else's, put down your cURL and reach for HTTPie, the command-line client for web APIs.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/getting-started-httpie
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshezhttps://opensource.com/users/mkalindepauleduhttps://opensource.com/users/jamesf
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/pie-raspberry-bake-make-food.png?itok=QRV_R8Fa (Raspberry pie with slice missing)
+[2]: https://httpie.org/
+[3]: https://github.com/postmanlabs/httpbin
+[4]: https://en.wikipedia.org/wiki/Wget
+[5]: https://en.wikipedia.org/wiki/CURL
+[6]: https://opensource.com/article/19/6/virtual-environments-python-macos
diff --git a/sources/tech/20190829 Three Ways to Exclude Specific-Certain Packages from Yum Update.md b/sources/tech/20190829 Three Ways to Exclude Specific-Certain Packages from Yum Update.md
deleted file mode 100644
index 2f6a35780b..0000000000
--- a/sources/tech/20190829 Three Ways to Exclude Specific-Certain Packages from Yum Update.md
+++ /dev/null
@@ -1,146 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Three Ways to Exclude Specific/Certain Packages from Yum Update)
-[#]: via: (https://www.2daygeek.com/redhat-centos-yum-update-exclude-specific-packages/)
-[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
-
-Three Ways to Exclude Specific/Certain Packages from Yum Update
-======
-
-As part of system update, you may need to exclude few of the packages due to application dependency in Red Hat based system.
-
-If yes, how to exclude, how many ways that can be done.
-
-Yes, it can be done in three ways, we will teach you all three methods in this article.
-
-A package manager is a collection of tools that allow users to easily manage packages in Linux system.
-
-It allows users to install, update/upgrade, remove, query, re-install, and search packages in Linux system.
-
-For Red Hat and it’s clone, we uses **[yum Package Manager][1]** and **[rpm Package Manager][2]** for package management.
-
-### What’s yum?
-
-yum stands for Yellowdog Updater, Modified. Yum is an automatic updater and package installer/remover for rpm systems.
-
-It automatically resolve dependencies when installing a package.
-
-### What’s rpm?
-
-rpm stands for Red Hat Package Manager is a powerful package management tool for Red Hat system.
-
-The name RPM refers to `.rpm` file format that containing compiled software’s and necessary libraries for the package.
-
-You may interested to read the following articles, which is related to this topic. If so, navigate to appropriate links.
-
- * **[How To Check Available Security Updates On Red Hat (RHEL) And CentOS System][3]**
- * **[Four Ways To Install Security Updates On Red Hat (RHEL) And CentOS Systems][4]**
- * **[Two Methods To Check Or List Installed Security Updates on Redhat (RHEL) And CentOS System][5]**
-
-
-
-### Method-1: Exclude Packages with yum Command Manually or Temporarily
-
-We can use `--exclude or -x` switch with yum command to exclude specific packages from getting updated through yum command.
-
-I can say, this is a temporary method or On-Demand method. If you want to exclude specific package only once then we can go with this method.
-
-The below command will update all packages except kernel.
-
-To exclude single package.
-
-```
-# yum update --exclude=kernel
-
-or
-
-# yum update -x 'kernel'
-```
-
-To exclude multiple packages. The below command will update all packages except kernel and php.
-
-```
-# yum update --exclude=kernel* --exclude=php*
-
-or
-
-# yum update --exclude httpd,php
-```
-
-### Method-2: Exclude Packages with yum Command Permanently
-
-This is permanent method and you can use this, if you are frequently performing the patch update.
-
-To do so, add the required packages in /etc/yum.conf to disable packages updates permanently.
-
-Once you add an entry, you don’t need to specify these package each time you run yum update command. Also, this prevent packages from any accidental update.
-
-```
-# vi /etc/yum.conf
-
-[main]
-cachedir=/var/cache/yum/$basearch/$releasever
-keepcache=0
-debuglevel=2
-logfile=/var/log/yum.log
-exactarch=1
-obsoletes=1
-gpgcheck=1
-plugins=1
-installonly_limit=3
-exclude=kernel* php*
-```
-
-### Method-3: Exclude Packages Using Yum versionlock plugin
-
-This is also permanent method similar to above. Yum versionlock plugin allow users to lock specified packages from being updated through yum command.
-
-To do so, run the following command. The below command will exclude the freetype package from yum update.
-
-Alternatively, you can add the package entry directly in “/etc/yum/pluginconf.d/versionlock.list” file.
-
-```
-# yum versionlock add freetype
-
-Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
-Adding versionlock on: 0:freetype-2.8-12.el7
-versionlock added: 1
-```
-
-Run the following command to check the list of packages locked by versionlock plugin.
-
-```
-# yum versionlock list
-
-Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
-0:freetype-2.8-12.el7.*
-versionlock list done
-```
-
-Run the following command to discards the list.
-
-```
-# yum versionlock clear
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/redhat-centos-yum-update-exclude-specific-packages/
-
-作者:[Magesh Maruthamuthu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.2daygeek.com/author/magesh/
-[b]: https://github.com/lujun9972
-[1]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
-[2]: https://www.2daygeek.com/rpm-command-examples/
-[3]: https://www.2daygeek.com/check-list-view-find-available-security-updates-on-redhat-rhel-centos-system/
-[4]: https://www.2daygeek.com/install-security-updates-on-redhat-rhel-centos-system/
-[5]: https://www.2daygeek.com/check-installed-security-updates-on-redhat-rhel-and-centos-system/
diff --git a/sources/tech/20190829 Variables in PowerShell.md b/sources/tech/20190829 Variables in PowerShell.md
new file mode 100644
index 0000000000..6d522610c1
--- /dev/null
+++ b/sources/tech/20190829 Variables in PowerShell.md
@@ -0,0 +1,138 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Variables in PowerShell)
+[#]: via: (https://opensource.com/article/19/8/variables-powershell)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Variables in PowerShell
+======
+In our miniseries Variables in Shells, learn how to handle local
+variables in PowerShell.
+![Shells in a competition][1]
+
+In computer science (and casual computing), a variable is a location in memory that holds arbitrary information for later use. In other words, it’s a temporary storage container for you to put data into and get data out of. In the Bash shell, that data can be a word (a _string_, in computer lingo) or a number (an _integer_).
+
+You may have never (knowingly) used a variable before on your computer, but you probably have used a variable in another area of your life. When you say things like "give me that" or "look at this," you’re using grammatical variables (you think of them as _pronouns_). The meaning of "this" and "that" depends on whatever you’re picturing in your mind, or whatever you’re pointing to as an indicator for your audience to know what you’re referring to. When you do math, you use variables to stand in for unknown values, even though you probably don’t call them variables.
+
+This article addresses variables in [PowerShell][2], which runs on Windows, Linux, or Mac. Users of the open source [Bash][3] shell should refer to my article about variables in the Bash shell instead (although you can run PowerShell on Linux, and it is open source, so you can still follow along with this article).
+
+**Note:** The examples in this article are from a PowerShell session running on the open source operating system Linux, so if you’re on Windows or Mac the file paths will differ. However, Windows converts **/** to **\** automatically, and all examples work across all platforms, provided that you substitute obvious differences (for instance, it is statistically unlikely that your username is **seth**).
+
+### What are variables for?
+
+Whether you need variables in PowerShell depends on what you do in a terminal. For some users, variables are an essential means of managing data, while for others they’re minor and temporary conveniences, or for some, they may as well not exist.
+
+Ultimately, variables are a tool. You can use them when you find a use for them, or leave them alone in the comfort of knowing they’re managed by your OS. Knowledge is power, though, and understanding how variables work in Bash can lead you to all kinds of unexpected creative problem-solving.
+
+### Set a variable
+
+You don’t need special permissions to create a variable. They’re free to create, free to use, and generally harmless. In PowerShell, you create a variable by defining a variable name and then setting its value with the **Set-Variable** command. The example below creates a new variable called **FOO** and sets its value to the string **$HOME/Documents**:
+
+
+```
+`PS> Set-Variable -Name FOO -Value "$HOME/Documents"`
+```
+
+Success is eerily silent, so you may not feel confident that your variable got set. You can see the results for yourself with the **Get-Variable** (**gv** for short) command. To ensure that the variable is read exactly as you defined it, you can also wrap it in quotes. Doing so preserves any special characters that might appear in the variable; in this example, that doesn’t apply, but it’s still a good habit to form:
+
+
+```
+PS> Get-Variable "FOO" -valueOnly
+/home/seth/Documents
+```
+
+Notice that the contents of **FOO** aren’t exactly what you set. The literal string you set for the variable was **$HOME/Documents**, but now it’s showing up as **/home/seth/Documents**. This happened because you can nest variables. The **$HOME** variable points to the current user’s home directory, whether it’s in **C:\Users** on Windows, **/home** on Linux, or **/Users** on Mac. Since **$HOME** was embedded in **FOO**, that variable gets _expanded_ when recalled. Using default variables in this way helps you write portable scripts that operate across platforms.
+
+Variables usually are meant to convey information from one system to another. In this simple example, your variable is not very useful, but it can still communicate information. For instance, because the content of the **FOO** variable is a [file path][4], you can use **FOO** as a shortcut to the directory its value references.
+
+To reference the variable **FOO**’s _contents_ and not the variable itself, prepend the variable with a dollar sign (**$**):
+
+
+```
+PS> pwd
+/home/seth
+PS> cd "$FOO"
+PS> pwd
+/home/seth/Documents
+```
+
+### Clear a variable
+
+You can remove a variable with the **Remove-Variable** command:
+
+
+```
+PS> Remove-Variable -Name "FOO"
+PS> gv "FOO"
+gv : Cannot find a variable with the name 'FOO'.
+[...]
+```
+
+In practice, removing a variable is not usually necessary. Variables are relatively "cheap," so you can create them and forget them when you don’t need them anymore. However, there may be times you want to ensure a variable is empty to avoid conveying unwanted information to another process that might read that variable.
+
+### Create a new variable with collision protection
+
+Sometimes, you may have reason to believe a variable was already set by you or some other process. If you would rather not override it, you can either use **New-Variable**, which is designed to fail if a variable with the same name already exists, or you can use a conditional statement to check for a variable first:
+
+
+```
+PS> New-Variable -Name FOO -Value "example"
+New-Variable : A variable with name 'FOO' already exists.
+```
+
+**Note:** In these examples, assume that **FOO** is set to **/home/seth/Documents**.
+
+Alternately, you can construct a simple **if** statement to check for an existing variable:
+
+
+```
+PS> if ( $FOO )
+>> { gv FOO } else
+>> { Set-Variable -Name "FOO" -Value "quux" }
+```
+
+### Add to a variable
+
+Instead of overwriting a variable, you can add to an existing one. In PowerShell, variables have diverse types, including string, integer, and array. When choosing to create a variable with, essentially, more than one value, you must decide whether you need a [character-delimited string][5] or an [array][6]. You may not care one way or the other, but the application receiving the variable’s data may expect one or the other, so make your choice based on your target.
+
+To append data to a string variable, use the **=+** syntax:
+
+
+```
+PS> gv FOO
+foo
+PS> $FOO =+ "$FOO,bar"
+PS> gv FOO
+foo,bar
+PS> $FOO.getType().Name
+String
+```
+
+Arrays are special types of variables in PowerShell and require an ArrayList object. That’s out of scope for this article, as it requires delving deeper into PowerShell’s .NET internals.
+
+### Go global with environment variables
+
+So far the variables created in this article have been _local_, meaning that they apply only to the PowerShell session you create them in. To create variables that are accessible to other processes, you can create environment variables, which will be covered in a future article.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/variables-powershell
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/shelloff.png?itok=L8pjHXjW (Shells in a competition)
+[2]: https://en.wikipedia.org/wiki/PowerShell
+[3]: https://www.gnu.org/software/bash/
+[4]: https://opensource.com/article/19/8/understanding-file-paths-linux
+[5]: https://en.wikipedia.org/wiki/Delimiter
+[6]: https://en.wikipedia.org/wiki/Array_data_structure
diff --git a/sources/tech/20190829 What is an Object in Java.md b/sources/tech/20190829 What is an Object in Java.md
new file mode 100644
index 0000000000..033fdd5403
--- /dev/null
+++ b/sources/tech/20190829 What is an Object in Java.md
@@ -0,0 +1,202 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (What is an Object in Java?)
+[#]: via: (https://opensource.com/article/19/8/what-object-java)
+[#]: author: (Chris Hermansen https://opensource.com/users/clhermansenhttps://opensource.com/users/mdowdenhttps://opensource.com/users/sethhttps://opensource.com/users/drmjghttps://opensource.com/users/jamesfhttps://opensource.com/users/clhermansen)
+
+What is an Object in Java?
+======
+Java's approach to object-oriented programming is the basis for almost
+everything in the language. Here's what you need to know.
+![Coffee beans and a cup of coffee][1]
+
+Java is an object-oriented programming language, which views the world as a collection of objects that have both _properties_ and _behavior_. Java's version of object-orientedness is pretty straightforward, and it's the basis for almost everything in the language. Because it's so essential to Java, I'll explain a bit about what's under the covers to help anyone new to the language.
+
+### Inheritance
+
+In general, all [Cartesian geometric objects][2], like circles, squares, triangles, lines, and points, have basic properties, like location and extension. Objects with zero extension, like points, usually don't have anything more than that. Objects like lines have more—e.g., the start and endpoint of a line segment or two points along a line (if it's a "true line"). Objects like squares or triangles have still more—the corner points, for example—whereas circles may have a center and radius.
+
+We can see there is a simple hierarchy at work here: The general geometric object can be _extended_ into specific geometric objects, like points, lines, squares, etc. Each specific geometric object _inherits_ the basic geometric properties of location and extension and adds its own properties.
+
+This is an example of _single inheritance_. Java's original object-oriented model allowed only single inheritance, where objects cannot belong to more than one inheritance hierarchy. This design decision comes out of the kinds of ambiguities programmers found themselves facing in [complex multiple-inheritance scenarios][3], typically in cases where "interesting design decisions" led to several possible implementations of the function **foo()** as defined (and re-defined) in the hierarchy.
+
+Since Java 8, there has been a limited multiple inheritance structure in place that requires specific actions on behalf of the programmer to ensure there are no ambiguities.
+
+### Strong and static typing
+
+Java is _strongly_ and _statically_ typed. What does this mean?
+
+A _statically_ typed language is one where the type of a variable is known at compile time. In this situation, it is not possible to assign a value of type B to a variable whose declared type is A, unless there is a conversion mechanism to turn a value of type B into a value of type A. An example of this type of conversion is turning an integer value, like 1, 2, or 42, into a floating-point value, like 1.0, 2.0, or 42.0.
+
+A _strongly_ typed language is one where very few (or perhaps no) type conversions are applied automatically. For example, whereas a strongly typed language might permit automatic conversion of _integer_ to _real_, it will never permit automatic conversion of _real_ to _integer_ since that conversion requires either rounding or truncation in the general case.
+
+### Primitive types, classes, and objects
+
+Java provides a number of primitive types: _byte_ (an eight-bit signed integer); _short_ (a 16-bit signed integer); _int_ (a 32-bit signed integer); _long_ (a 64-bit signed integer); _float_ (a single precision 32-bit IEEE floating-point number); _double_ (a double precision 64-bit IEEE floating-point number); _boolean_ (true or false); and _char_ (a 16-bit Unicode character).
+
+Beyond those primitive types, Java allows the programmer to create new types using _class declarations_. Class declarations are used to define object templates, including their properties and behavior. Once a class is declared, _instances_ of that class can generally be created using the **new** keyword. These instances correspond directly to the "objects" we have been discussing. Java comes with a library of useful class definitions, including some simple basic classes such as _String_, which is used to hold a sequence of characters like "Hello, world."
+
+Let's define a simple message class that contains the name of the sender as well as the message text:
+
+
+```
+class Message {
+ [String][4] sender;
+ [String][4] text;
+ public Message([String][4] sender, [String][4] text) {
+ this.sender = sender;
+ this.text = text;
+ }
+}
+```
+
+There are several important things to note in this class declaration:
+
+ 1. The class is (by convention) always declared with a leading capital letter.
+ 2. The **Message** class contains two properties (or fields):
+– a String field called **sender**
+– a String field called **text**
+Properties or fields are (by convention) always declared with a leading lower-case letter.
+ 3. There is some kind of thing that starts with **public Message**.
+– It is a _method_ (methods define the behavior of an object).
+– It is used to _construct_ instances of the class **Message**.
+– Constructor methods always take the same name as the class and are understood to return an instance of the class once it's constructed.
+– Other methods are (by convention) always declared with a leading lower-case letter.
+– This constructor is "public," meaning any caller can access it.
+ 4. As part of the construction process, some lines start with **this**.
+– **this** refers to the present instance of the class.
+– Thus **this.sender** refers to the sender property of the object.
+– Whereas plain **sender** refers to the parameter of the **Message** constructor method.
+– Therefore, these two lines are copying the values provided in the call to the constructor into the fields of the object itself.
+
+
+
+So we have the **Method** class definition. How do we use it? The following code excerpt shows one possible way:
+
+
+```
+`Message message = new Message("system", "I/O error");`
+```
+
+Here we see:
+
+ 1. The declaration of the variable **message** of type **Message**
+ 2. The creation of a new instance of the **Message** class with **sender** set to "system" and **text** set to "I/O error"
+ 3. The assignment of that new instance of **Message** to the variable **message**
+ 4. If later in the code, the variable **message** is assigned a different value (another instance of **Message**) and no other variable was created that referred to this instance of **Message**, then this instance is no longer used by anything and can be garbage-collected.
+
+
+
+The key thing happening here is that we are creating an object of type **Message** and keeping a reference to that object in the variable **message**.
+
+We can now use that message; for instance, we can print the values in the **sender** and **text** properties, like this:
+
+
+```
+[System][5].out.println("message sender = " + message.sender);
+[System][5].out.println("message text = " + message.text);
+```
+
+This is a very simple and unsophisticated class definition. We can modify this class definition in a number of ways:
+
+ 1. We can make the implementation details of properties invisible to callers by using the keyword **private** in front of the declarations, allowing us to change the implementation without affecting callers.
+ 2. If we choose to conceal properties in the class, we would then typically define procedures for _getting_ and _setting_ those properties; by convention in Java these would be defined as:
+– **public String getSender()**
+– **public String getText()**
+– **public void setSender(String sender)**
+– **public void setText(String text)**
+ 3. In some cases, we may wish to have "read-only" properties; in those cases, we would not define setters for such properties.
+ 4. We can make the constructor of the class invisible to callers by using the **private** keyword instead of **public**. We might wish to do this when we have another class whose responsibility is creating and managing a pool of messages (possibly executing in another process or even on another system).
+
+
+
+Now, suppose we want a kind of message that records when it was generated. We could declare it this like:
+
+
+```
+class TimedMessage extends Message {
+ long creationTime;
+ public TimedMessage([String][4] sender, [String][4] text) {
+ super(sender, text);
+ this.creationTime = [System][5].currentTimeMillis();
+ }
+}
+```
+
+Here we see some new things:
+
+ 1. **TimedMessage** is _extending_ the **Message** class—that is, **TimedMessage** is inheriting properties and behavior from **Message**.
+ 2. The constructor calls the constructor in its parent, or _superclass_, with the values of **sender** and **text** passed in, as **super(sender, text)**, in order to make sure its inherited properties are properly initialized.
+ 3. **TimedMessage** adds a new property, **creationTime**, and the constructor sets it to be the current system time in milliseconds.
+ 4. Time in milliseconds in Java is kept as a long (64-bit) value (0 is 1 January, 1970 00:00:00 UTC).
+ 5. As a bit of an aside, the name **creationTime** suggests it should be a read-only property, which also suggests that the other properties be read-only; that is, **TimedMessage** instances should probably not be reused nor have their properties altered.
+
+
+
+### The Object class
+
+"The Object class" sounds like a kind of contradiction in terms, doesn't it? But notice that the first class we defined, **Message**, did not _appear_ to extend anything—but it _actually_ did. All classes that don't specifically extend another class have the class **Object** as their immediate and only parent; therefore, all classes have the **Object** class as their ultimate superclass.
+
+You can [learn more about the **Object** class][6] in Java's docs. Let's (briefly) review some interesting details:
+
+ 1. **Object** has the constructor **Object()**, that is, with no parameters.
+ 2. **Object** provides some useful methods to all of its subclasses, including:
+– **clone()**, which creates and returns a copy of the instance at hand
+– **equals(Object anotherObject)**, which determines whether **anotherObject** is equal to the instance of **Object** at hand
+– **finalize()**, which is used to garbage-collect the instance at hand when it is no longer used (see above)
+– **getClass()**, which returns the class used to declare the instance at hand
+— The value returned by this is an instance of the [**Class** class][7], which permits learning about the declaring class at runtime—a process referred to _introspection_.
+ 3. **hashCode()** is an integer value that gives a nearly unique value for the instance at hand.
+– If the hash codes of two distinct instances are equal, then they may be equal; a detailed comparison of the properties (and perhaps methods) is necessary to determine complete equality;
+– If the hash codes are not equal, then the instances are also not equal.
+– Therefore, hash codes can speed up equality tests.
+– A hash code can also be used to create a [**HashMap**][8] (a map is an associative array or dictionary that uses the hash code to speed up lookups) and a [**HashSet**][9] (a set is a collection of objects; the programmer can test whether an instance is in a set or not; hash codes are used to speed up the test).
+ 4. **notify()**, **notifyAll()**, **wait()**, **wait(long timeout)**, and **wait(long timeout, int nanos)** communicate between collaborating instances executing on separate threads.
+ 5. **toString()** produces a printable version of the instance.
+
+
+
+### Concluding thoughts
+
+We've touched on some important aspects of object-oriented programming, Java-style. There are six important, related topics that will be covered in future articles:
+
+ * Namespaces and packages
+ * Overriding methods in subclasses—for instance, the String class has its own specific **hashCode()** method that recognizes its meaning as an array of characters; this is accomplished by overriding the **hashCode()** method inherited from Object
+ * Interfaces, which permit describing behavior that must be provided by a class that implements the interface; instances of classes that implement a given interface can be referred to by that interface when the only thing of interest is that specific behavior
+ * Arrays of primitives or classes and collections of classes (such as lists, maps, and sets)
+ * Overloading of methods—where several methods with the same name and similar behavior have different parameters
+ * Using libraries that don't come with the Java distribution
+
+
+
+Is there anything you would like to read next? Let us know in the comments and stay tuned!
+
+Michael Dowden takes a look at four Java web frameworks built for scalability.
+
+Optimizing your Java code requires an understanding of how the different elements in Java interact...
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/what-object-java
+
+作者:[Chris Hermansen][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/clhermansenhttps://opensource.com/users/mdowdenhttps://opensource.com/users/sethhttps://opensource.com/users/drmjghttps://opensource.com/users/jamesfhttps://opensource.com/users/clhermansen
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/java-coffee-mug.jpg?itok=Bj6rQo8r (Coffee beans and a cup of coffee)
+[2]: https://en.wikipedia.org/wiki/Analytic_geometry
+[3]: https://en.wikipedia.org/wiki/Multiple_inheritance
+[4]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
+[5]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
+[6]: https://docs.oracle.com/javase/8/docs/api/java/lang/Object.html
+[7]: https://docs.oracle.com/javase/8/docs/api/java/lang/Class.html
+[8]: https://docs.oracle.com/javase/8/docs/api/java/util/HashMap.html
+[9]: https://docs.oracle.com/javase/8/docs/api/java/util/HashSet.html
diff --git a/sources/tech/20190830 Command line quick tips- Using pipes to connect tools.md b/sources/tech/20190830 Command line quick tips- Using pipes to connect tools.md
new file mode 100644
index 0000000000..7781fb5a16
--- /dev/null
+++ b/sources/tech/20190830 Command line quick tips- Using pipes to connect tools.md
@@ -0,0 +1,110 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Command line quick tips: Using pipes to connect tools)
+[#]: via: (https://fedoramagazine.org/command-line-quick-tips-using-pipes-to-connect-tools/)
+[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
+
+Command line quick tips: Using pipes to connect tools
+======
+
+![][1]
+
+One of the most powerful concepts of Linux is carried on from its predecessor, UNIX. Your Fedora system has a bunch of useful, single-purpose utilities available for all sorts of simple operations. Like building blocks, you can attach them in creative and complex ways. _Pipes_ are key to this concept.
+
+Before you hear about pipes, though, it’s helpful to know the basic concept of input and output. Many utilities in your Fedora system can operate against files. But they can often take input not stored on a disk. You can think of input flowing freely into a process such as a utility as its _standard input_ (also sometimes called _stdin_).
+
+Similarly, a tool or process can display information to the screen by default. This is often because its default output is connected to the terminal. You can think of the free-flowing output of a process as its _standard output_ (or _stdout_ — go figure!).
+
+### Examples of standard input and output
+
+Often when you run a tool, it outputs to the terminal. Take for instance this simple sequence command using the _seq_ tool:
+
+```
+$ seq 1 6
+1
+2
+3
+4
+5
+6
+```
+
+The output, which is simply to count integers up from 1 to 6, one number per line, comes to the screen. But you could also send it to a file using the **>** character. The shell interpreter uses this character to mean “redirect _standard output_ to a file whose name follows.” So as you can guess, this command puts the output into a file called _six.txt:_
+
+```
+$ seq 1 6 > six.txt
+```
+
+Notice nothing comes to the screen. You’ve sent the ouptut into a file instead. If you run the command _cat six.txt_ you can verify that.
+
+You probably remember the simple use of the _grep_ command [from a previous article][2]. You could ask _grep_ to search for a pattern in a file by simply declaring the file name. But that’s simply a convenience feature in _grep_. Technically it’s built to take _standard input_, and search that.
+
+The shell uses the **<** character similarly to mean “redirect _standard input_ from a file whose name follows.” So you could just as well search for the number **4** in the file _six.txt_ this way:
+
+```
+$ grep 4 < six.txt
+4
+```
+
+Of course the output here is, by default, the content of any line with a match. So _grep_ finds the digit **4** in the file and outputs that line to _standard output_.
+
+### Introducing pipes
+
+Now imagine: what if you took the standard output of one tool, and instead of sending it to the terminal, you sent it into another tool’s standard input? This is the essence of the pipe.
+
+Your shell uses the vertical bar character **|** to represent a pipe between two commands. You can find it on most keyboard above the backslash **\** character. It’s used like this:
+
+```
+$ command1 | command2
+```
+
+For most simple utilities, you wouldn’t use an output filename option on _command1_, nor an input file option on _command2_. (You might use other options, though.) Instead of using files, you’re sending the output of _command1_ directly into _command2_. You can use as many pipes in a row as needed, creating complex pipelines of several commands in a row.
+
+This (relatively useless) example combines the commands above:
+
+```
+$ seq 1 6 | grep 4
+4
+```
+
+What happened here? The _seq_ command outputs the integers 1 through 6, one line at a time. The _grep_ command processes that output line by line, searching for a match on the digit **4**, and outputs any matching line.
+
+Here’s a slightly more useful example. Let’s say you want to find out if TCP port 22, the _ssh_ port, is open on your system. You could find this out using the _ss_ command* by looking through its copious output. Or you could figure out its filter language and use that. Or you could use pipes. For example, pipe it through _grep_ looking for the _ssh_ port label:
+
+```
+$ ss -tl | grep ssh
+LISTEN 0 128 0.0.0.0:ssh 0.0.0.0:*
+LISTEN 0 128 [::]:ssh [::]:*
+```
+
+_* Those readers familiar with the venerable_ netstat _command may note it is mostly obsolete, as stated in its [man page][3]._
+
+That’s a lot easier than reading through many lines of output. And of course, you can combine redirectors and pipes, for instance:
+
+```
+$ ss -tl | grep ssh > ssh-listening.txt
+```
+
+This is barely scratching the surface of pipes. Let your imagination run wild. Have fun piping!
+
+* * *
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/command-line-quick-tips-using-pipes-to-connect-tools/
+
+作者:[Paul W. Frields][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/pfrields/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2018/10/commandlinequicktips-816x345.jpg
+[2]: https://fedoramagazine.org/command-line-quick-tips-searching-with-grep/
+[3]: https://linux.die.net/man/8/netstat
diff --git a/sources/tech/20190830 How to Create and Use Swap File on Linux.md b/sources/tech/20190830 How to Create and Use Swap File on Linux.md
new file mode 100644
index 0000000000..bfda3bcdbe
--- /dev/null
+++ b/sources/tech/20190830 How to Create and Use Swap File on Linux.md
@@ -0,0 +1,261 @@
+[#]: collector: (lujun9972)
+[#]: translator: (hello-wn)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Create and Use Swap File on Linux)
+[#]: via: (https://itsfoss.com/create-swap-file-linux/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+How to Create and Use Swap File on Linux
+======
+
+This tutorial discusses the concept of swap file in Linux, why it is used and its advantages over the traditional swap partition. You’ll learn how to create swap file or resize it.
+
+### What is a swap file in Linux?
+
+A swap file allows Linux to simulate the disk space as RAM. When your system starts running out of RAM, it uses the swap space to and swaps some content of the RAM on to the disk space. This frees up the RAM to serve more important processes. When the RAM is free again, it swaps back the data from the disk. I recommend [reading this article to learn more about swap on Linux][1].
+
+Traditionally, swap space is used as a separate partition on the disk. When you install Linux, you create a separate partition just for swap. But this trend has changed in the recent years.
+
+With swap file, you don’t need a separate partition anymore. You create a file under root and tell your system to use it as the swap space.
+
+With dedicated swap partition, resizing the swap space is a nightmare and an impossible task in many cases. But with swap files, you can resize them as you like.
+
+Recent versions of Ubuntu and some other Linux distributions have started [using the swap file by default][2]. Even if you don’t create a swap partition, Ubuntu creates a swap file of around 1 GB on its own.
+
+Let’s see some more on swap files.
+
+![][3]
+
+### Check swap space in Linux
+
+Before you go and start adding swap space, it would be a good idea to check whether you have swap space already available in your system.
+
+You can check it with the [free command in Linux][4]. In my case, my [Dell XPS][5] has 14GB of swap.
+
+```
+free -h
+ total used free shared buff/cache available
+Mem: 7.5G 4.1G 267M 971M 3.1G 2.2G
+Swap: 14G 0B 14G
+```
+
+The free command gives you the size of the swap space but it doesn’t tell you if it’s a real swap partition or a swap file. The swapon command is better in this regard.
+
+```
+swapon --show
+NAME TYPE SIZE USED PRIO
+/dev/nvme0n1p4 partition 14.9G 0B -2
+```
+
+As you can see, I have 14.9 GB of swap space and it’s on a separate partition. If it was a swap file, the type would have been file instead of partition.
+
+```
+swapon --show
+NAME TYPE SIZE USED PRIO
+/swapfile file 2G 0B -2
+```
+
+If you don’ have a swap space on your system, it should show something like this:
+
+```
+free -h
+ total used free shared buff/cache available
+Mem: 7.5G 4.1G 267M 971M 3.1G 2.2G
+Swap: 0B 0B 0B
+```
+
+The swapon command won’t show any output.
+
+### Create swap file on Linux
+
+If your system doesn’t have swap space or if you think the swap space is not adequate enough, you can create swap file on Linux. You can create multiple swap files as well.
+
+[][6]
+
+Suggested read Fix Missing System Settings In Ubuntu 14.04 [Quick Tip]
+
+Let’s see how to create swap file on Linux. I am using Ubuntu 18.04 in this tutorial but it should work on other Linux distributions as well.
+
+#### Step 1: Make a new swap file
+
+First thing first, create a file with the size of swap space you want. Let’s say that I want to add 1 GB of swap space to my system. Use the fallocate command to create a file of size 1 GB.
+
+```
+sudo fallocate -l 1G /swapfile
+```
+
+It is recommended to allow only root to read and write to the swap file. You’ll even see warning like “insecure permissions 0644, 0600 suggested” when you try to use this file for swap area.
+
+```
+sudo chmod 600 /swapfile
+```
+
+Do note that the name of the swap file could be anything. If you need multiple swap spaces, you can give it any appropriate name like swap_file_1, swap_file_2 etc. It’s just a file with a predefined size.
+
+#### Step 2: Mark the new file as swap space
+
+Your need to tell the Linux system that this file will be used as swap space. You can do that with [mkswap][7] tool.
+
+```
+sudo mkswap /swapfile
+```
+
+You should see an output like this:
+
+```
+Setting up swapspace version 1, size = 1024 MiB (1073737728 bytes)
+no label, UUID=7e1faacb-ea93-4c49-a53d-fb40f3ce016a
+```
+
+#### Step 3: Enable the swap file
+
+Now your system knows that the file swapfile can be used as swap space. But it is not done yet. You need to enable the swap file so that your system can start using this file as swap.
+
+```
+sudo swapon /swapfile
+```
+
+Now if you check the swap space, you should see that your Linux system recognizes and uses it as the swap area:
+
+```
+swapon --show
+NAME TYPE SIZE USED PRIO
+/swapfile file 1024M 0B -2
+```
+
+#### Step 4: Make the changes permanent
+
+Whatever you have done so far is temporary. Reboot your system and all the changes will disappear.
+
+You can make the changes permanent by adding the newly created swap file to /etc/fstab file.
+
+It’s always a good idea to make a backup before you make any changes to the /etc/fstab file.
+
+```
+sudo cp /etc/fstab /etc/fstab.back
+```
+
+Now you can add the following line to the end of /etc/fstab file:
+
+```
+/swapfile none swap sw 0 0
+```
+
+You can do it manually using a [command line text editor][8] or you just use the following command:
+
+```
+echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
+```
+
+Now you have everything in place. Your swap file will be used even after you reboot your Linux system.
+
+### Adjust swappiness
+
+The swappiness parameters determines how often the swap space should be used. The swappiness value ranges from 0 to 100. Higher value means the swap space will be used more frequently.
+
+The default swappiness in Ubuntu desktop is 60 while in server it is 1. You can check the swappiness with the following command:
+
+```
+cat /proc/sys/vm/swappiness
+```
+
+Why servers should use a low swappiness? Because swap is slower than RAM and for a better performance, the RAM should be utilized as much as possible. On servers, the performance factor is crucial and hence the swappinness is as low as possible.
+
+[][9]
+
+Suggested read How to Replace One Linux Distribution With Another From Dual Boot [Keeping Home Partition]
+
+You can change the swappiness on the fly using the following systemd command:
+
+```
+sudo sysctl vm.swappiness=25
+```
+
+This change it only temporary though. If you want to make it permanent, you can edit the /etc/sysctl.conf file and add the swappiness value in the end of the file:
+
+```
+vm.swappiness=25
+```
+
+### Resizing swap space on Linux
+
+There are a couple of ways you can resize the swap space on Linux. But before you see that, you should learn a few things around it.
+
+When you ask your system to stop using a swap file for swap area, it transfers all the data (pages to be precise) back to RAM. So you should have enough free RAM before you swap off.
+
+This is why a good practice is to create and enable another temporary swap file. This way, when you swap off the original swap area, your system will use the temporary swap file. Now you can resize the original swap space. You can manually remove the temporary swap file or leave it as it is and it will be automatically deleted on the next boot.
+
+If you have enough free RAM or if you created a temporary swap space, swapoff your original file.
+
+```
+sudo swapoff /swapfile
+```
+
+Now you can use fallocate command to change the size of the file. Let’s say, you change it to 2 GB in size:
+
+```
+sudo fallocate -l 2G /swapfile
+```
+
+Now mark the file as swap space again:
+
+```
+sudo mkswap /swapfile
+```
+
+And turn the swap on again:
+
+```
+sudo swapon /swapfile
+```
+
+You may also choose to have multiple swap files at the same time.
+
+### Removing swap file in Linux
+
+You may have your reasons for not using swap file on Linux. If you want to remove it, the process is similar to what you just saw in resizing the swap.
+
+First, make sure that you have enough free RAM. Now swap off the file:
+
+```
+sudo swapoff /swapfile
+```
+
+The next step is to remove the respective entry from the /etc/fstab file.
+
+And in the end, you can remove the file to free up the space:
+
+```
+sudo rm /swapfile
+```
+
+**Do you swap?**
+
+I think you now have a good understanding of swap file concept in Linux. You can now easily create swap file or resize them as per your need.
+
+If you have anything to add on this topic or if you have any doubts, please leave a comment below.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/create-swap-file-linux/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/swap-size/
+[2]: https://help.ubuntu.com/community/SwapFaq
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/swap-file-linux.png?resize=800%2C450&ssl=1
+[4]: https://linuxhandbook.com/free-command/
+[5]: https://itsfoss.com/dell-xps-13-ubuntu-review/
+[6]: https://itsfoss.com/fix-missing-system-settings-ubuntu-1404-quick-tip/
+[7]: http://man7.org/linux/man-pages/man8/mkswap.8.html
+[8]: https://itsfoss.com/command-line-text-editors-linux/
+[9]: https://itsfoss.com/replace-linux-from-dual-boot/
diff --git a/sources/tech/20190830 How to Install Linux on Intel NUC.md b/sources/tech/20190830 How to Install Linux on Intel NUC.md
new file mode 100644
index 0000000000..86d73c5ddc
--- /dev/null
+++ b/sources/tech/20190830 How to Install Linux on Intel NUC.md
@@ -0,0 +1,191 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Install Linux on Intel NUC)
+[#]: via: (https://itsfoss.com/install-linux-on-intel-nuc/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+How to Install Linux on Intel NUC
+======
+
+The previous week, I got myself an [Intel NUC][1]. Though it is a tiny device, it is equivalent to a full-fledged desktop CPU. Most of the [Linux-based mini PCs][2] are actually built on top of the Intel NUC devices.
+
+I got the ‘barebone’ NUC with 8th generation Core i3 processor. Barebone means that the device has no RAM, no hard disk and obviously, no operating system. I added an [8GB RAM from Crucial][3] (around $33) and a [240 GB Western Digital SSD][4] (around $45).
+
+Altogether, I had a desktop PC ready in under $400. I already have a screen and keyboard-mouse pair so I am not counting them in the expense.
+
+![A brand new Intel NUC NUC8i3BEH at my desk with Raspberry Pi 4 lurking behind][5]
+
+The main reason why I got Intel NUC is that I want to test and review various Linux distributions on real hardware. I have a [Raspberry Pi 4][6] which works as an entry-level desktop but it’s an [ARM][7] device and thus there are only a handful of Linux distributions available for Raspberry Pi.
+
+_The Amazon links in the article are affiliate links. Please read our [affiliate policy][8]._
+
+### Installing Linux on Intel NUC
+
+I started with Ubuntu 18.04 LTS version because that’s what I had available at the moment. You can follow this tutorial for other distributions as well. The steps should remain the same at least till the partition step which is the most important one in the entire procedure.
+
+#### Step 1: Create a live Linux USB
+
+Download Ubuntu 18.04 from its website. Use another computer to [create a live Ubuntu USB][9]. You can use a tool like [Rufus][10] or [Etcher][11]. On Ubuntu, you can use the default Startup Disk Creator tool.
+
+#### Step 2: Make sure the boot order is correct
+
+Insert your USB and power on the NUC. As soon as you see the Intel NUC written on the screen, press F2 to go to BIOS settings.
+
+![BIOS Settings in Intel NUC][12]
+
+In here, just make sure that boot order is set to boot from USB first. If not, change the boot order.
+
+If you had to make any changes, press F10 to save and exit. Else, use Esc to exit the BIOS.
+
+#### Step 3: Making the correct partition to install Linux
+
+Now when it boots again, you’ll see the familiar Grub screen that allows you to try Ubuntu live or install it. Choose to install it.
+
+[][13]
+
+Suggested read 3 Ways to Check Linux Kernel Version in Command Line
+
+First few installation steps are simple. You choose the keyboard layout, and the network connection (if any) and other simple steps.
+
+![Choose the keyboard layout while installing Ubuntu Linux][14]
+
+You may go with the normal installation that has a handful of useful applications installed by default.
+
+![][15]
+
+The interesting screen comes next. You have two options:
+
+ * **Erase disk and install Ubuntu**: Simplest option that will install Ubuntu on the entire disk. If you want to use only one operating system on the Intel NUC, choose this option and Ubuntu will take care of the rest.
+ * **Something Else**: This is the advanced option if you want to take control of things. In my case, I want to install multiple Linux distribution on the same SSD. So I am opting for this advanced option.
+
+
+
+![][16]
+
+_**If you opt for “Erase disk and install Ubuntu”, click continue and go to the step 4.**_
+
+If you are going with the advanced option, follow the rest of the step 3.
+
+Select the SSD disk and click on New Partition Table.
+
+![][17]
+
+It will show you a warning. Just hit Continue.
+
+![][18]
+
+Now you’ll see a free space of the size of your SSD disk. My idea is to create an EFI System Partition for the EFI boot loader, a root partition and a home partition. I am not creating a [swap partition][19]. Ubuntu creates a swap file on its own and if the need be, I can extend the swap by creating additional swap files.
+
+I’ll leave almost 200 GB of free space on the disk so that I could install other Linux distributions here. You can utilize all of it for your home partitions. Keeping separate root and home partitions help you when you want to save reinstall the system
+
+Select the free space and click on the plus sign to add a partition.
+
+![][20]
+
+Usually 100 MB is sufficient for the EFI but some distributions may need more space so I am going with 500 MB of EFI partition.
+
+![][21]
+
+Next, I am using 20 GB of root space. If you are going to use only one distributions, you can increase it to 40 GB easily.
+
+Root is where the system files are kept. Your program cache and installed applications keep some files under the root directory. I recommend [reading about the Linux filesystem hierarchy][22] to get more knowledge on this topic.
+
+[][23]
+
+Suggested read Share Folders On Local Network Between Ubuntu And Windows
+
+Provide the size, choose Ext4 file system and use / as the mount point.
+
+![][24]
+
+The next is to create a home partition. Again, if you want to use only one Linux distribution, go for the remaining free space. Else, choose a suitable disk space for the Home partition.
+
+Home is where your personal documents, pictures, music, download and other files are stored.
+
+![][25]
+
+Now that you have created EFI, root and home partitions, you are ready to install Ubuntu Linux. Hit the Install Now button.
+
+![][26]
+
+It will give you a warning about the new changes being written to the disk. Hit continue.
+
+![][27]
+
+#### Step 4: Installing Ubuntu Linux
+
+Things are pretty straightforward from here onward. Choose your time zone right now or change it later.
+
+![][28]
+
+On the next screen, choose a username, hostname and the password.
+
+![][29]
+
+It’s a wait an watch game for next 7-8 minutes.
+
+![][30]
+
+Once the installation is over, you’ll be prompted for a restart.
+
+![][31]
+
+When you restart, you should remove the live USB otherwise you’ll boot into the installation media again.
+
+That’s all you need to do to install Linux on an Intel NUC device. Quite frankly, you can use the same procedure on any other system.
+
+**Intel NUC and Linux: how do you use it?**
+
+I am loving the Intel NUC. It doesn’t take space on the desk and yet it is powerful enough to replace the regular bulky desktop CPU. You can easily upgrade it to 32GB of RAM. You can install two SSD on it. Altogether, it provides some scope of configuration and upgrade.
+
+If you are looking to buy a desktop computer, I highly recommend [Intel NUC][1] mini PC. If you are not comfortable installing the OS on your own, you can [buy one of the Linux-based mini PCs][2].
+
+Do you own an Intel NUC? How’s your experience with it? Do you have any tips to share it with us? Do leave a comment below.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/install-linux-on-intel-nuc/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://www.amazon.com/Intel-NUC-Mainstream-Kit-NUC8i3BEH/dp/B07GX4X4PW?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07GX4X4PW (Intel NUC)
+[2]: https://itsfoss.com/linux-based-mini-pc/
+[3]: https://www.amazon.com/Crucial-Single-PC4-19200-SODIMM-260-Pin/dp/B01BIWKP58?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01BIWKP58 (8GB RAM from Crucial)
+[4]: https://www.amazon.com/Western-Digital-240GB-Internal-WDS240G1G0B/dp/B01M9B2VB7?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01M9B2VB7 (240 GB Western Digital SSD)
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/intel-nuc.jpg?resize=800%2C600&ssl=1
+[6]: https://itsfoss.com/raspberry-pi-4/
+[7]: https://en.wikipedia.org/wiki/ARM_architecture
+[8]: https://itsfoss.com/affiliate-policy/
+[9]: https://itsfoss.com/create-live-usb-of-ubuntu-in-windows/
+[10]: https://rufus.ie/
+[11]: https://www.balena.io/etcher/
+[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/boot-screen-nuc.jpg?ssl=1
+[13]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
+[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-1_tutorial.jpg?ssl=1
+[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-2_tutorial.jpg?ssl=1
+[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-3_tutorial.jpg?ssl=1
+[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-4_tutorial.jpg?ssl=1
+[18]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-5_tutorial.jpg?ssl=1
+[19]: https://itsfoss.com/swap-size/
+[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-6_tutorial.jpg?ssl=1
+[21]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-7_tutorial.jpg?ssl=1
+[22]: https://linuxhandbook.com/linux-directory-structure/
+[23]: https://itsfoss.com/share-folders-local-network-ubuntu-windows/
+[24]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-8_tutorial.jpg?ssl=1
+[25]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-9_tutorial.jpg?ssl=1
+[26]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-10_tutorial.jpg?ssl=1
+[27]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-11_tutorial.jpg?ssl=1
+[28]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-12_tutorial.jpg?ssl=1
+[29]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-13_tutorial.jpg?ssl=1
+[30]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-14_tutorial.jpg?ssl=1
+[31]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-15_tutorial.jpg?ssl=1
diff --git a/sources/tech/20190901 Best Linux Distributions For Everyone in 2019.md b/sources/tech/20190901 Best Linux Distributions For Everyone in 2019.md
new file mode 100644
index 0000000000..6959b35d60
--- /dev/null
+++ b/sources/tech/20190901 Best Linux Distributions For Everyone in 2019.md
@@ -0,0 +1,392 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Best Linux Distributions For Everyone in 2019)
+[#]: via: (https://itsfoss.com/best-linux-distributions/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Best Linux Distributions For Everyone in 2019
+======
+
+_**Brief: Which is the best Linux distribution? There is no definite answer to that question. This is why we have compiled this list of best Linux in various categories.**_
+
+There are a lot of Linux distributions. I can’t even think of coming up with an exact number because you would find loads of Linux distros that differ from one another in one way or the other.
+
+Some of them just turn out to be a clone of one another while some of them tend to be unique. So, it’s kind of a mess – but that is the beauty of Linux.
+
+Fret not, even though there are thousands of distributions around, in this article, I have compiled a list of the best Linux distros available right now. Of course, the list can be subjective. But, here, we try to categorize the distros – so there’s something for everyone.
+
+ * [Best distribution for new Linux users][1]
+ * [Best Linux distros for servers][2]
+ * [Best Linux distros that can run on old computers][3]
+ * [Best distributions for advanced Linux users][4]
+ * [Best evergreen Linux distributions][5]
+
+
+
+**Note:** _The list is in no particular order of ranking._
+
+### Best Linux Distributions for Beginners
+
+In this category, we aim to list the distros which are easy-to-use out of the box. You do not need to dig deeper, you can just start using it right away after installation without needing to know any commands or tips.
+
+#### Ubuntu
+
+![][6]
+
+Ubuntu is undoubtedly one of the most popular Linux distributions. You can even find it pre-installed on a lot of laptops available.
+
+The user interface is easy to get comfortable with. If you play around, you can easily customize the look of it as per your requirements. In either case, you can opt to install a theme as well. You can learn more about [how to install themes in Ubuntu][7] to get started.
+
+In addition to what it offers, you will find a huge online community of Ubuntu users. So, if you face an issue – head to any of the forums (or a subreddit) to ask for help. If you are looking for direct solutions in no time, you should check out our coverage on [Ubuntu][8] (where we have a lot of tutorials and recommendations for Ubuntu).
+
+[Ubuntu][9]
+
+#### Linux Mint
+
+![Linux Mint 19 Cinnamon desktop screenshot][10]
+
+Linux Mint Cinnamon is another popular Linux distribution among beginners. The default Cinnamon desktop resembles Windows XP and this is why many users opted for it when Windows XP was discontinued.
+
+Linux Mint is based on Ubuntu and thus it has all the applications available for Ubuntu. The simplicity and ease of use is why it has become a prominent choice for new Linux users.
+
+[Linux Mint][11]
+
+#### elementary OS
+
+![][12]
+
+elementary OS is one of the most beautiful Linux distros I’ve ever used. The UI resembles that of Mac OS – so if you have already used a Mac-powered system, it’s easy to get comfortable with.
+
+This distribution is based on Ubuntu and focuses to deliver a user-friendly Linux environment which looks as pretty as possible while keeping the performance in mind. If you choose to install elementary OS, a list of [11 things to do after installing elementary OS][13] should come in handy.
+
+[elementary OS][14]
+
+#### MX Linux
+
+![][15]
+
+MX Linux came in the limelight almost a year ago. Now (at the time of publishing this), it is the most popular Linux distro on [DistroWatch.com][16]. If you haven’t used it yet – you will be surprised when you get to use it.
+
+Unlike Ubuntu, MX Linux is a [rolling release distribution][17] based on Debian with Xfce as its desktop environment. In addition to its impeccable stability – it comes packed with a lot of GUI tools which makes it easier for any user comfortable with Windows/Mac originally.
+
+Also, the package manager is perfectly tailored to facilitate one-click installations. You can even search for [Flatpak][18] packages and install it in no time (Flathub is available by default in the package manager as one of the sources).
+
+[MX Linux][19]
+
+#### Zorin OS
+
+![][20]
+
+Zorin OS is yet another Ubuntu-based distribution which happens to be one of the most good-looking and intuitive OS for desktop. Especially, after [Zorin OS 15 release][21] – I would definitely recommend it for users without any Linux background. A lot of GUI-based applications comes baked in as well.
+
+You can also install it on older PCs – however, make sure to choose the “Lite” edition. In addition, you have “Core”, “Education” & “Ultimate” editions. You can choose to install the Core edition for free – but if you want to support the developers and help improve Zorin, consider getting the Ultimate edition.
+
+Zorin OS was started by two teenagers based in Ireland. You may [read their story here][22].
+
+[Zorin OS][23]
+
+**Other Options**
+
+[Deepin][24] and other flavors of Ubuntu (like Kubuntu, Xubuntu) could also be some of the preferred choices for beginners. You can take a look at them if you want to explore more options.
+
+If you want a challenge, you can indeed try Fedora over Ubuntu – but make sure to follow our article on [Ubuntu vs Fedora][25] to make a better decision from the desktop point of view.
+
+### Best Linux Server Distributions
+
+For servers, the choice of a Linux distro comes down to stability, performance, and enterprise support. If you are just experimenting, you can try any distro you want.
+
+But, if you are installing it for a web server or anything vital – you should take a look at some of our recommendations.
+
+#### Ubuntu Server
+
+Depending on where you want it, Ubuntu provides different options for your server. If you are looking for an optimized solution to run on AWS, Azure, Google Cloud Platform, etc., [Ubuntu Cloud][26] is the way to go.
+
+In either case, you can opt for Ubuntu Server packages and have it installed on your server. Nevertheless, Ubuntu is the most popular Linux distro when it comes to deployment on the cloud (judging by the numbers – [source 1][27], [source 2][28]).
+
+Do note that we recommend you to go for the LTS editions – unless you have specific requirements.
+
+[Ubuntu Server][29]
+
+#### Red Hat Enterprise Linux
+
+Red Hat Enterprise Linux is a top-notch Linux platform for businesses and organizations. If we go by the numbers, Red Hat may not be the most popular choice for servers. But, there’s a significant group of enterprise users who rely on RHEL (like Lenovo).
+
+Technically, Fedora and Red Hat are related. Whatever Red Hat supports – gets tested on Fedora before making it available for RHEL. I’m not an expert on server distributions for tailored requirements – so you should definitely check out their [official documentation][30] to know if it’s suitable for you.
+
+[Red Hat Enterprise Linux][31]
+
+#### SUSE Linux Enterprise Server
+
+![Suse Linux Enterprise \(Image: Softpedia\)][32]
+
+Fret not, do not confuse this with OpenSUSE. Everything comes under a common brand “SUSE” – but OpenSUSE is an open-source distro targeted and yet, maintained by the community.
+
+SUSE Linux Enterprise Server is one of the most popular solutions for cloud-based servers. You will have to opt for a subscription in order to get priority support and assistance to manage your open source solution.
+
+[SUSE Linux Enterprise Server][33]
+
+#### CentOS
+
+![][34]
+
+As I mentioned, you need a subscription for RHEL. But, CentOS is more like a community edition of RHEL because it has been derived from the sources of Red Hat Enterprise Linux. And, it is open source and free as well. Even though the number of hosting providers using CentOS is significantly less compared to the last few years – it still is a great choice.
+
+CentOS may not come loaded with the latest software packages – but it is considered as one of the most stable distros. You should find CentOS images on a variety of cloud platforms. If you don’t, you can always opt for the self-hosted image that CentOS provides.
+
+[CentOS][35]
+
+**Other Options**
+
+You can also try exploring [Fedora Server][36] or [Debian][37] as alternatives to some of the distros mentioned above.
+
+![Coding][38]
+
+![Coding][38]
+
+If you are into programming and software development check out the list of
+
+[Best Linux Distributions for Programmers][39]
+
+![Hacking][40]
+
+![Hacking][40]
+
+Interested in learning and practicing cyber security? Check out the list of
+
+[Best Linux Distribution for Hacking and Pen-Testing][41]
+
+### Best Linux Distributions for Older Computers
+
+If you have an old PC laying around or if you didn’t really need to upgrade your system – you can still try some of the best Linux distros available.
+
+We’ve already talked about some of the [best lightweight Linux distributions][42] in details. Here, we shall only mention what really stands out from that list (and some new additions).
+
+#### Puppy Linux
+
+![][43]
+
+Puppy Linux is literally one of the smallest distribution there is. When I first started to explore Linux, my friend recommended me to experiment with Puppy Linux because it can run on older hardware configurations with ease.
+
+It’s worth checking it out if you want a snappy experience on your good old PC. Over the years, the user experience has improved along with the addition of several new useful features.
+
+[Puppy Linux][44]
+
+#### Solus Budgie
+
+![][45]
+
+After a recent major release – [Solus 4 Fortitude][46] – it is an impressive lightweight desktop OS. You can opt for desktop environments like GNOME or MATE. However, Solus Budgie happens to be one of my favorites as a full-fledged Linux distro for beginners while being light on system resources.
+
+[Solus][47]
+
+#### Bodhi
+
+![][48]
+
+Bodhi Linux is built on top of Ubuntu. However, unlike Ubuntu – it does run well on older configurations.
+
+The main highlight of this distro is its [Moksha Desktop][49] (which is a continuation of Enlightenment 17 desktop). The user experience is intuitive and screaming fast. Even though it’s not something for my personal use – you should give it a try on your older systems.
+
+[Bodhi Linux][50]
+
+#### antiX
+
+![][51]
+
+antiX – which is also partially responsible for MX Linux is a lightweight Linux distribution tailored for old and new computers. The UI isn’t impressive – but it works as expected.
+
+It is based on Debian and can be utilized as a live CD distribution without needing to install it. antiX also provides live bootloaders. In contrast to some other distros, you get to save the settings so that you don’t lose it with every reboot. Not just that, you can also save changes to the root directory with its “Live persistence” feature.
+
+So, if you are looking for a live-USB distro to provide a snappy user experience on old hardware – antiX is the way to go.
+
+[antiX][52]
+
+#### Sparky Linux
+
+![][53]
+
+Sparky Linux is based on Debian which turns out to be a perfect Linux distro for low-end systems. Along with a screaming fast experience, Sparky Linux offers several special editions (or varieties) for different users.
+
+For example, it provides a stable release (with varieties) and rolling releases specific to a group of users. Sparky Linux GameOver edition is quite popular for gamers because it includes a bunch of pre-installed games. You can check out our list of [best Linux Gaming distributions][54] – if you also want to play games on your system.
+
+#### Other Options
+
+You can also try [Linux Lite][55], [Lubuntu][56], and [Peppermint][57] as some of the lightweight Linux distributions.
+
+### Best Linux Distro for Advanced Users
+
+Once you get comfortable with the variety of package managers and commands to help troubleshoot your way to resolve any issue, you can start exploring Linux distros which are tailored for Advanced users only.
+
+Of course, if you are a professional – you will have a set of specific requirements. However, if you’ve been using Linux for a while as a common user – these distros are worth checking out.
+
+#### Arch Linux
+
+![Image Credits: Samiuvic / Deviantart][58]
+
+Arch Linux is itself a simple yet powerful distribution with a huge learning curve. Unlike others, you won’t have everything pre-installed in one go. You have to configure the system and add packages as needed.
+
+Also, when installing Arch Linux, you will have to follow a set of commands (without GUI). To know more about it, you can follow our guide on [how to install Arch Linux][59]. If you are going to install it, you should also know about some of the [essential things to do after installing Arch Linux][60]. It will help you get a jump start.
+
+In addition to all the versatility and simplicity, it’s worth mentioning that the community behind Arch Linux is very active. So, if you run into a problem, you don’t have to worry.
+
+[Arch Linux][61]
+
+#### Gentoo
+
+![Gentoo Linux][62]
+
+If you know how to compile the source code, Gentoo Linux is a must-try for you. It is also a lightweight distribution – however, you need to have the required technical knowledge to make it work.
+
+Of course, the [official handbook][63] provides a lot of information that you need to know. But, if you aren’t sure what you’re doing – it will take a lot of your time to figure out how to make the most out of it.
+
+[Gentoo Linux][64]
+
+#### Slackware
+
+![Image Credits: thundercr0w / Deviantart][65]
+
+Slackware is one of the oldest Linux distribution that still matters. If you are willing to compile or develop software to set up a perfect environment for yourself – Slackware is the way to go.
+
+In case you’re curious about some of the oldest Linux distros, we have an article on the [earliest linux distributions][66] – go check it out.
+
+Even though the number of users/developers utilizing it has significantly decreased, it is still a fantastic choice for advanced users. Also, with the recent news of [Slackware getting a Patreon page][67] – we hope that Slackware continues to exist as one of the best Linux distros out there.
+
+[Slackware][68]
+
+### Best Multi-purpose Linux Distribution
+
+There are certain Linux distros which you can utilize as a beginner-friendly / advanced OS for both desktops and servers. Hence, we thought of compiling a separate section for such distributions.
+
+If you don’t agree with us (or have suggestions to add here) – feel free to let us know in the comments. Here’s what we think could come in handy for every user:
+
+#### Fedora
+
+![][69]
+
+Fedora offers two separate editions – one for desktops/laptops and the other for servers (Fedora Workstation and Fedora Server respectively).
+
+So, if you are looking for a snappy desktop OS – with a potential learning curve while being user-friendly – Fedora is an option. In either case, if you are looking for a Linux OS for your server – that’s a good choice as well.
+
+[Fedora][70]
+
+#### Manjaro
+
+![][71]
+
+Manjaro is based on [Arch Linux][72]. Fret not, while Arch Linux is tailored for advanced users, Manjaro makes it easy for a newcomer. It is a simple and beginner-friendly Linux distro. The user interface is good enough and offers a bunch of useful GUI applications built-in.
+
+You get options to choose a [desktop environment][73] for Manjaro while downloading it. Personally, I like the KDE desktop for Manjaro.
+
+[Manjaro Linux][74]
+
+### Debian
+
+![Image Credits: mrneilypops / Deviantart][75]
+
+Well, Ubuntu’s based on Debian – so it must be a darn good distribution itself. Debian is an ideal choice for both desktop and servers.
+
+It may not be the best beginner-friendly OS – but you can easily get started by going through the [official documentation][76]. The recent release of [Debian 10 Buster][77] introduces a lot of changes and necessary improvements. So, you must give it a try!
+
+**Wrapping Up**
+
+Overall, these are the best Linux distributions that we recommend you to try. Yes, there are a lot of other Linux distributions that deserve the mention – but to each of their own, depending on personal preferences – the choices will be subjective.
+
+But, we also have a separate list of distros for [Windows users][78], [hackers and pen testers][41], [gamers][54], [programmers][39], and [privacy buffs.][79] So, if that interest you – do go through them.
+
+If you think we missed listing one of your favorites that deserves as one of the best Linux distributions out there, let us know your thoughts in the comments below and we’ll keep the article up-to-date accordingly.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/best-linux-distributions/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: tmp.NoRXbIWHkg#for-beginners
+[2]: tmp.NoRXbIWHkg#for-servers
+[3]: tmp.NoRXbIWHkg#for-old-computers
+[4]: tmp.NoRXbIWHkg#for-advanced-users
+[5]: tmp.NoRXbIWHkg#general-purpose
+[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/install-google-chrome-ubuntu-10.jpg?ssl=1
+[7]: https://itsfoss.com/install-themes-ubuntu/
+[8]: https://itsfoss.com/tag/ubuntu/
+[9]: https://ubuntu.com/download/desktop
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/linux-Mint-19-desktop.jpg?ssl=1
+[11]: https://www.linuxmint.com/
+[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/elementary-os-juno-feat.jpg?ssl=1
+[13]: https://itsfoss.com/things-to-do-after-installing-elementary-os-5-juno/
+[14]: https://elementary.io/
+[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/mx-linux.jpg?ssl=1
+[16]: https://distrowatch.com/
+[17]: https://en.wikipedia.org/wiki/Linux_distribution#Rolling_distributions
+[18]: https://flatpak.org/
+[19]: https://mxlinux.org/
+[20]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/zorin-os-15.png?ssl=1
+[21]: https://itsfoss.com/zorin-os-15-release/
+[22]: https://itsfoss.com/zorin-os-interview/
+[23]: https://zorinos.com/
+[24]: https://www.deepin.org/en/
+[25]: https://itsfoss.com/ubuntu-vs-fedora/
+[26]: https://ubuntu.com/download/cloud
+[27]: https://w3techs.com/technologies/details/os-linux/all/all
+[28]: https://thecloudmarket.com/stats
+[29]: https://ubuntu.com/download/server
+[30]: https://developers.redhat.com/products/rhel/docs-and-apis
+[31]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
+[32]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/SUSE-Linux-Enterprise.jpg?ssl=1
+[33]: https://www.suse.com/products/server/
+[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/centos.png?ssl=1
+[35]: https://www.centos.org/
+[36]: https://getfedora.org/en/server/
+[37]: https://www.debian.org/distrib/
+[38]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/coding.jpg?ssl=1
+[39]: https://itsfoss.com/best-linux-distributions-progammers/
+[40]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/hacking.jpg?ssl=1
+[41]: https://itsfoss.com/linux-hacking-penetration-testing/
+[42]: https://itsfoss.com/lightweight-linux-beginners/
+[43]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/puppy-linux-bionic.jpg?ssl=1
+[44]: http://puppylinux.com/
+[45]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/solus-4-featured.jpg?resize=800%2C450&ssl=1
+[46]: https://itsfoss.com/solus-4-release/
+[47]: https://getsol.us/home/
+[48]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/bodhi-linux.png?fit=800%2C436&ssl=1
+[49]: http://www.bodhilinux.com/moksha-desktop/
+[50]: http://www.bodhilinux.com/
+[51]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/10/antix-linux-screenshot.jpg?ssl=1
+[52]: https://antixlinux.com/
+[53]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/sparky-linux.jpg?ssl=1
+[54]: https://itsfoss.com/linux-gaming-distributions/
+[55]: https://www.linuxliteos.com/
+[56]: https://lubuntu.me/
+[57]: https://peppermintos.com/
+[58]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/arch_linux_screenshot.jpg?ssl=1
+[59]: https://itsfoss.com/install-arch-linux/
+[60]: https://itsfoss.com/things-to-do-after-installing-arch-linux/
+[61]: https://www.archlinux.org
+[62]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/gentoo-linux.png?ssl=1
+[63]: https://wiki.gentoo.org/wiki/Handbook:Main_Page
+[64]: https://www.gentoo.org
+[65]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/slackware-screenshot.jpg?ssl=1
+[66]: https://itsfoss.com/earliest-linux-distros/
+[67]: https://distrowatch.com/dwres.php?resource=showheadline&story=8743
+[68]: http://www.slackware.com/
+[69]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/fedora-overview.png?ssl=1
+[70]: https://getfedora.org/
+[71]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/manjaro-gnome.jpg?ssl=1
+[72]: https://www.archlinux.org/
+[73]: https://itsfoss.com/glossary/desktop-environment/
+[74]: https://manjaro.org/
+[75]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/debian-screenshot.png?ssl=1
+[76]: https://www.debian.org/releases/stable/installmanual
+[77]: https://itsfoss.com/debian-10-buster/
+[78]: https://itsfoss.com/windows-like-linux-distributions/
+[79]: https://itsfoss.com/privacy-focused-linux-distributions/
diff --git a/sources/tech/20190901 Different Ways to Configure Static IP Address in RHEL 8.md b/sources/tech/20190901 Different Ways to Configure Static IP Address in RHEL 8.md
new file mode 100644
index 0000000000..2f8f6ba711
--- /dev/null
+++ b/sources/tech/20190901 Different Ways to Configure Static IP Address in RHEL 8.md
@@ -0,0 +1,250 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Different Ways to Configure Static IP Address in RHEL 8)
+[#]: via: (https://www.linuxtechi.com/configure-static-ip-address-rhel8/)
+[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
+
+Different Ways to Configure Static IP Address in RHEL 8
+======
+
+While Working on **Linux Servers**, assigning Static IP address on NIC / Ethernet cards is one of the common tasks that every Linux engineer do. If one configures the **Static IP address** correctly on a Linux server then he/she can access it remotely over network. In this article we will demonstrate what are different ways to assign Static IP address on RHEL 8 Server’s NIC.
+
+[![Configure-Static-IP-RHEL8][1]][2]
+
+Following are the ways to configure Static IP on a NIC,
+
+ * nmcli (command line tool)
+ * Network Scripts files(ifcfg-*)
+ * nmtui (text based user interface)
+
+
+
+### Configure Static IP Address using nmcli command line tool
+
+Whenever we install RHEL 8 server then ‘**nmcli**’, a command line tool is installed automatically, nmcli is used by network manager and allows us to configure static ip address on Ethernet cards.
+
+Run the below ip addr command to list Ethernet cards on your RHEL 8 server
+
+```
+[root@linuxtechi ~]# ip addr
+```
+
+![ip-addr-command-rhel8][1]
+
+As we can see in above command output, we have two NICs enp0s3 & enp0s8. Currently ip address assigned to the NIC is via dhcp server.
+
+Let’s assume we want to assign the static IP address on first NIC (enp0s3) with the following details,
+
+ * IP address = 192.168.1.4
+ * Netmask = 255.255.255.0
+ * Gateway= 192.168.1.1
+ * DNS = 8.8.8.8
+
+
+
+Run the following nmcli commands one after the another to configure static ip,
+
+List currently active Ethernet cards using “**nmcli connection**” command,
+
+```
+[root@linuxtechi ~]# nmcli connection
+NAME UUID TYPE DEVICE
+enp0s3 7c1b8444-cb65-440d-9bf6-ea0ad5e60bae ethernet enp0s3
+virbr0 3020c41f-6b21-4d80-a1a6-7c1bd5867e6c bridge virbr0
+[root@linuxtechi ~]#
+```
+
+Use beneath nmcli command to assign static ip on enp0s3,
+
+**Syntax:**
+
+# nmcli connection modify <interface_name> ipv4.address <ip/prefix>
+
+**Note:** In short form, we usually replace connection with ‘con’ keyword and modify with ‘mod’ keyword in nmcli command.
+
+Assign ipv4 (192.168.1.4) to enp0s3 interface,
+
+```
+[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.addresses 192.168.1.4/24
+[root@linuxtechi ~]#
+```
+
+Set the gateway using below nmcli command,
+
+```
+[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.gateway 192.168.1.1
+[root@linuxtechi ~]#
+```
+
+Set the manual configuration (from dhcp to static),
+
+```
+[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.method manual
+[root@linuxtechi ~]#
+```
+
+Set DNS value as “8.8.8.8”,
+
+```
+[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.dns "8.8.8.8"
+[root@linuxtechi ~]#
+```
+
+To save the above changes and to reload the interface execute the beneath nmcli command,
+
+```
+[root@linuxtechi ~]# nmcli con up enp0s3
+Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
+[root@linuxtechi ~]#
+```
+
+Above command output confirms that interface enp0s3 has been configured successfully.Whatever the changes we have made using above nmcli commands, those changes is saved permanently under the file “etc/sysconfig/network-scripts/ifcfg-enp0s3”
+
+```
+[root@linuxtechi ~]# cat /etc/sysconfig/network-scripts/ifcfg-enp0s3
+```
+
+![ifcfg-enp0s3-file-rhel8][1]
+
+To Confirm whether IP address has been to enp0s3 interface use the below ip command,
+
+```
+[root@linuxtechi ~]#ip addr show enp0s3
+```
+
+### Configure Static IP Address manually using network-scripts (ifcfg-) files
+
+We can configure the static ip address to an ethernet card using its network-script or ‘ifcfg-‘ files. Let’s assume we want to assign the static ip address on our second Ethernet card ‘enp0s8’.
+
+ * IP= 192.168.1.91
+ * Netmask / Prefix = 24
+ * Gateway=192.168.1.1
+ * DNS1=4.2.2.2
+
+
+
+Go to the directory “/etc/sysconfig/network-scripts” and look for the file ‘ifcfg- enp0s8’, if it does not exist then create it with following content,
+
+```
+[root@linuxtechi ~]# cd /etc/sysconfig/network-scripts/
+[root@linuxtechi network-scripts]# vi ifcfg-enp0s8
+TYPE="Ethernet"
+DEVICE="enp0s8"
+BOOTPROTO="static"
+ONBOOT="yes"
+NAME="enp0s8"
+IPADDR="192.168.1.91"
+PREFIX="24"
+GATEWAY="192.168.1.1"
+DNS1="4.2.2.2"
+```
+
+Save and exit the file and then restart network manager service to make above changes into effect,
+
+```
+[root@linuxtechi network-scripts]# systemctl restart NetworkManager
+[root@linuxtechi network-scripts]#
+```
+
+Now use below ip command to verify whether ip address is assigned to nic or not,
+
+```
+[root@linuxtechi ~]# ip add show enp0s8
+3: enp0s8: mtu 1500 qdisc fq_codel state UP group default qlen 1000
+ link/ether 08:00:27:7c:bb:cb brd ff:ff:ff:ff:ff:ff
+ inet 192.168.1.91/24 brd 192.168.1.255 scope global noprefixroute enp0s8
+ valid_lft forever preferred_lft forever
+ inet6 fe80::a00:27ff:fe7c:bbcb/64 scope link
+ valid_lft forever preferred_lft forever
+[root@linuxtechi ~]#
+```
+
+Above output confirms that static ip address has been configured successfully on the NIC ‘enp0s8’
+
+### Configure Static IP Address using ‘nmtui’ utility
+
+nmtui is a text based user interface for controlling network manager, when we execute nmtui, it will open a text base user interface through which we can add, modify and delete connections. Apart from this nmtui can also be used to set hostname of your system.
+
+Let’s assume we want to assign static ip address to interface enp0s3 with following details,
+
+ * IP address = 10.20.0.72
+ * Prefix = 24
+ * Gateway= 10.20.0.1
+ * DNS1=4.2.2.2
+
+
+
+Run nmtui and follow the screen instructions, example is show
+
+```
+[root@linuxtechi ~]# nmtui
+```
+
+[![nmtui-rhel8][1]][3]
+
+Select the first option ‘**Edit a connection**‘ and then choose the interface as ‘enp0s3’
+
+[![Choose-interface-nmtui-rhel8][1]][4]
+
+Choose Edit and then specify the IP address, Prefix, Gateway and DNS Server ip,
+
+[![set-ip-nmtui-rhel8][1]][5]
+
+Choose OK and hit enter. In the next window Choose ‘**Activate a connection**’
+
+[![Activate-option-nmtui-rhel8][1]][6]
+
+Select **enp0s3**, Choose **Deactivate** & hit enter
+
+[![Deactivate-interface-nmtui-rhel8][1]][7]
+
+Now choose **Activate** & hit enter,
+
+[![Activate-interface-nmtui-rhel8][1]][8]
+
+Select Back and then select Quit,
+
+[![Quit-Option-nmtui-rhel8][1]][9]
+
+Use below IP command to verify whether ip address has been assigned to interface enp0s3
+
+```
+[root@linuxtechi ~]# ip add show enp0s3
+2: enp0s3: mtu 1500 qdisc fq_codel state UP group default qlen 1000
+ link/ether 08:00:27:53:39:4d brd ff:ff:ff:ff:ff:ff
+ inet 10.20.0.72/24 brd 10.20.0.255 scope global noprefixroute enp0s3
+ valid_lft forever preferred_lft forever
+ inet6 fe80::421d:5abf:58bd:c47e/64 scope link noprefixroute
+ valid_lft forever preferred_lft forever
+[root@linuxtechi ~]#
+```
+
+Above output confirms that we have successfully assign the static IP address to interface enp0s3 using nmtui utility.
+
+That’s all from this tutorial, we have covered three different ways to configure ipv4 address to an Ethernet card on RHEL 8 system. Please do not hesitate to share feedback and comments in comments section below.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxtechi.com/configure-static-ip-address-rhel8/
+
+作者:[Pradeep Kumar][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linuxtechi.com/author/pradeep/
+[b]: https://github.com/lujun9972
+[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Configure-Static-IP-RHEL8.jpg
+[3]: https://www.linuxtechi.com/wp-content/uploads/2019/09/nmtui-rhel8.jpg
+[4]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Choose-interface-nmtui-rhel8.jpg
+[5]: https://www.linuxtechi.com/wp-content/uploads/2019/09/set-ip-nmtui-rhel8.jpg
+[6]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Activate-option-nmtui-rhel8.jpg
+[7]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Deactivate-interface-nmtui-rhel8.jpg
+[8]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Activate-interface-nmtui-rhel8.jpg
+[9]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Quit-Option-nmtui-rhel8.jpg
diff --git a/sources/tech/20190902 How RPM packages are made- the spec file.md b/sources/tech/20190902 How RPM packages are made- the spec file.md
new file mode 100644
index 0000000000..c5dace0332
--- /dev/null
+++ b/sources/tech/20190902 How RPM packages are made- the spec file.md
@@ -0,0 +1,299 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How RPM packages are made: the spec file)
+[#]: via: (https://fedoramagazine.org/how-rpm-packages-are-made-the-spec-file/)
+[#]: author: (Ankur Sinha "FranciscoD" https://fedoramagazine.org/author/ankursinha/)
+
+How RPM packages are made: the spec file
+======
+
+![][1]
+
+In the [previous article on RPM package building][2], you saw that source RPMS include the source code of the software, along with a “spec” file. This post digs into the spec file, which contains instructions on how to build the RPM. Again, this article uses _fpaste_ as an example.
+
+### Understanding the source code
+
+Before you can start writing a spec file, you need to have some idea of the software that you’re looking to package. Here, you’re looking at fpaste, a very simple piece of software. It is written in Python, and is a one file script. When a new version is released, it’s provided here on Pagure:
+
+The current version, as the archive shows, is 0.3.9.2. Download it so you can see what’s in the archive:
+
+```
+$ wget https://pagure.io/releases/fpaste/fpaste-0.3.9.2.tar.gz
+$ tar -tvf fpaste-0.3.9.2.tar.gz
+drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/
+-rw-rw-r-- root/root 25 2018-07-25 02:58 fpaste-0.3.9.2/.gitignore
+-rw-rw-r-- root/root 3672 2018-07-25 02:58 fpaste-0.3.9.2/CHANGELOG
+-rw-rw-r-- root/root 35147 2018-07-25 02:58 fpaste-0.3.9.2/COPYING
+-rw-rw-r-- root/root 444 2018-07-25 02:58 fpaste-0.3.9.2/Makefile
+-rw-rw-r-- root/root 1656 2018-07-25 02:58 fpaste-0.3.9.2/README.rst
+-rw-rw-r-- root/root 658 2018-07-25 02:58 fpaste-0.3.9.2/TODO
+drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/
+drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/
+drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/en/
+-rw-rw-r-- root/root 3867 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/en/fpaste.1
+-rwxrwxr-x root/root 24884 2018-07-25 02:58 fpaste-0.3.9.2/fpaste
+lrwxrwxrwx root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/fpaste.py -> fpaste
+```
+
+The files you want to install are:
+
+ * _fpaste.py_: which should go be installed to /usr/bin/.
+ * _docs/man/en/fpaste.1_: the manual, which should go to /usr/share/man/man1/.
+ * _COPYING_: the license text, which should go to /usr/share/license/fpaste/.
+ * _README.rst, TODO_: miscellaneous documentation that goes to /usr/share/doc/fpaste.
+
+
+
+Where these files are installed depends on the Filesystem Hierarchy Standard. To learn more about it, you can either read here: or look at the man page on your Fedora system:
+
+```
+$ man hier
+```
+
+#### Part 1: What are we building?
+
+Now that we know what files we have in the source, and where they are to go, let’s look at the spec file. You can see the full file here:
+
+Here is the first part of the spec file:
+
+```
+Name: fpaste
+Version: 0.3.9.2
+Release: 3%{?dist}
+Summary: A simple tool for pasting info onto sticky notes instances
+BuildArch: noarch
+License: GPLv3+
+URL: https://pagure.io/fpaste
+Source0: https://pagure.io/releases/fpaste/fpaste-0.3.9.2.tar.gz
+
+Requires: python3
+
+%description
+It is often useful to be able to easily paste text to the Fedora
+Pastebin at http://paste.fedoraproject.org and this simple script
+will do that and return the resulting URL so that people may
+examine the output. This can hopefully help folks who are for
+some reason stuck without X, working remotely, or any other
+reason they may be unable to paste something into the pastebin
+```
+
+_Name_, _Version_, and so on are called _tags_, and are defined in RPM. This means you can’t just make up tags. RPM won’t understand them if you do! The tags to keep an eye out for are:
+
+ * _Source0_: tells RPM where the source archive for this software is located.
+ * _Requires_: lists run-time dependencies for the software. RPM can automatically detect quite a few of these, but in some cases they must be mentioned manually. A run-time dependency is a capability (often a package) that must be on the system for this package to function. This is how _[dnf][3]_ detects whether it needs to pull in other packages when you install this package.
+ * _BuildRequires_: lists the build-time dependencies for this software. These must generally be determined manually and added to the spec file.
+ * _BuildArch_: the computer architectures that this software is being built for. If this tag is left out, the software will be built for all supported architectures. The value _noarch_ means the software is architecture independent (like fpaste, which is written purely in Python).
+
+
+
+This section provides general information about fpaste: what it is, which version is being made into an RPM, its license, and so on. If you have fpaste installed, and look at its metadata, you can see this information included in the RPM:
+
+```
+$ sudo dnf install fpaste
+$ rpm -qi fpaste
+Name : fpaste
+Version : 0.3.9.2
+Release : 2.fc30
+...
+```
+
+RPM adds a few extra tags automatically that represent things that it knows.
+
+At this point, we have the general information about the software that we’re building an RPM for. Next, we start telling RPM what to do.
+
+#### Part 2: Preparing for the build
+
+The next part of the spec is the preparation section, denoted by _%prep_:
+
+```
+%prep
+%autosetup
+```
+
+For fpaste, the only command here is %autosetup. This simply extracts the tar archive into a new folder and keeps it ready for the next section where we build it. You can do more here, like apply patches, modify files for different purposes, and so on. If you did look at the contents of the source rpm for Python, you would have seen lots of patches there. These are all applied in this section.
+
+Typically anything in a spec file with the **%** prefix is a macro or label that RPM interprets in a special way. Often these will appear with curly braces, such as _%{example}_.
+
+#### Part 3: Building the software
+
+The next section is where the software is built, denoted by “%build”. Now, since fpaste is a simple, pure Python script, it doesn’t need to be built. So, here we get:
+
+```
+%build
+#nothing required
+```
+
+Generally, though, you’d have build commands here, like:
+
+```
+configure; make
+```
+
+The build section is often the hardest section of the spec, because this is where the software is being built from source. This requires you to know what build system the tool is using, which could be one of many: Autotools, CMake, Meson, Setuptools (for Python) and so on. Each has its own commands and style. You need to know these well enough to get the software to build correctly.
+
+#### Part 4: Installing the files
+
+Once the software is built, it needs to be installed in the _%install_ section:
+
+```
+%install
+mkdir -p %{buildroot}%{_bindir}
+make install BINDIR=%{buildroot}%{_bindir} MANDIR=%{buildroot}%{_mandir}
+```
+
+RPM doesn’t tinker with your system files when building RPMs. It’s far too risky to add, remove, or modify files to a working installation. What if something breaks? So, instead RPM creates an artificial file system and works there. This is referred to as the _buildroot_. So, here in the buildroot, we create _/usr/bin_, represented by the macro _%{_bindir}_, and then install the files to it using the provided Makefile.
+
+At this point, we have a built version of fpaste installed in our artificial buildroot.
+
+#### Part 5: Listing all files to be included in the RPM
+
+The last section of the spec file is the files section, _%files_. This is where we tell RPM what files to include in the archive it creates from this spec file. The fpaste file section is quite simple:
+
+```
+%files
+%{_bindir}/%{name}
+%doc README.rst TODO
+%{_mandir}/man1/%{name}.1.gz
+%license COPYING
+```
+
+Notice how, here, we do not specify the buildroot. All of these paths are relative to it. The _%doc_ and _%license_ commands simply do a little more—they create the required folders and remember that these files must go there.
+
+RPM is quite smart. If you’ve installed files in the _%install_ section, but not listed them, it’ll tell you this, for example.
+
+#### Part 6: Document all changes in the change log
+
+Fedora is a community based project. Lots of contributors maintain and co-maintain packages. So it is imperative that there’s no confusion about what changes have been made to a package. To ensure this, the spec file contains the last section, the Changelog, _%changelog_:
+
+```
+%changelog
+* Thu Jul 25 2019 Fedora Release Engineering < ...> - 0.3.9.2-3
+- Rebuilt for https://fedoraproject.org/wiki/Fedora_31_Mass_Rebuild
+
+* Thu Jan 31 2019 Fedora Release Engineering < ...> - 0.3.9.2-2
+- Rebuilt for https://fedoraproject.org/wiki/Fedora_30_Mass_Rebuild
+
+* Tue Jul 24 2018 Ankur Sinha - 0.3.9.2-1
+- Update to 0.3.9.2
+
+* Fri Jul 13 2018 Fedora Release Engineering < ...> - 0.3.9.1-4
+- Rebuilt for https://fedoraproject.org/wiki/Fedora_29_Mass_Rebuild
+
+* Wed Feb 07 2018 Fedora Release Engineering < ..> - 0.3.9.1-3
+- Rebuilt for https://fedoraproject.org/wiki/Fedora_28_Mass_Rebuild
+
+* Sun Sep 10 2017 Vasiliy N. Glazov < ...> - 0.3.9.1-2
+- Cleanup spec
+
+* Fri Sep 08 2017 Ankur Sinha - 0.3.9.1-1
+- Update to latest release
+- fixes rhbz 1489605
+...
+....
+```
+
+There must be a changelog entry for _every_ change to the spec file. As you see here, while I’ve updated the spec as the maintainer, others have too. Having the changes documented clearly helps everyone know what the current status of the spec is. For all packages installed on your system, you can use rpm to see their changelogs:
+
+```
+$ rpm -q --changelog fpaste
+```
+
+### Building the RPM
+
+Now we are ready to build the RPM. If you want to follow along and run the commands below, please ensure that you followed the steps [in the previous post][2] to set your system up for building RPMs.
+
+We place the fpaste spec file in _~/rpmbuild/SPECS_, the source code archive in _~/rpmbuild/SOURCES/_ and can now create the source RPM:
+
+```
+$ cd ~/rpmbuild/SPECS
+$ wget https://src.fedoraproject.org/rpms/fpaste/raw/master/f/fpaste.spec
+
+$ cd ~/rpmbuild/SOURCES
+$ wget https://pagure.io/fpaste/archive/0.3.9.2/fpaste-0.3.9.2.tar.gz
+
+$ cd ~/rpmbuild/SOURCES
+$ rpmbuild -bs fpaste.spec
+Wrote: /home/asinha/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpm
+```
+
+Let’s have a look at the results:
+
+```
+$ ls ~/rpmbuild/SRPMS/fpaste*
+/home/asinha/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpm
+
+$ rpm -qpl ~/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpm
+fpaste-0.3.9.2.tar.gz
+fpaste.spec
+```
+
+There we are — the source rpm has been built. Let’s build both the source and binary rpm together:
+
+```
+$ cd ~/rpmbuild/SPECS
+$ rpmbuild -ba fpaste.spec
+..
+..
+..
+```
+
+RPM will show you the complete build output, with details on what it is doing in each section that we saw before. This “build log” is extremely important. When builds do not go as expected, we packagers spend lots of time going through them, tracing the complete build path to see what went wrong.
+
+That’s it really! Your ready-to-install RPMs are where they should be:
+
+```
+$ ls ~/rpmbuild/RPMS/noarch/
+fpaste-0.3.9.2-3.fc30.noarch.rpm
+```
+
+### Recap
+
+We’ve covered the basics of how RPMs are built from a spec file. This is by no means an exhaustive document. In fact, it isn’t documentation at all, really. It only tries to explain how things work under the hood. Here’s a short recap:
+
+ * RPMs are of two types: _source_ and _binary_.
+ * Binary RPMs contain the files to be installed to use the software.
+ * Source RPMs contain the information needed to build the binary RPMs: the complete source code, and the instructions on how to build the RPM in the spec file.
+ * The spec file has various sections, each with its own purpose.
+
+
+
+Here, we’ve built RPMs locally, on our Fedora installations. While this is the basic process, the RPMs we get from repositories are built on dedicated servers with strict configurations and methods to ensure correctness and security. This Fedora packaging pipeline will be discussed in a future post.
+
+Would you like to get started with building packages, and help the Fedora community maintain the massive amount of software we provide? You can [start here by joining the package collection maintainers][4].
+
+For any queries, post to the [Fedora developers mailing list][5]—we’re always happy to help!
+
+### References
+
+Here are some useful references to building RPMs:
+
+ *
+ *
+ *
+ *
+
+
+
+* * *
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/how-rpm-packages-are-made-the-spec-file/
+
+作者:[Ankur Sinha "FranciscoD"][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/ankursinha/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/06/rpm.png-816x345.jpg
+[2]: https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/
+[3]: https://fedoramagazine.org/managing-packages-fedora-dnf/
+[4]: https://fedoraproject.org/wiki/Join_the_package_collection_maintainers
+[5]: https://lists.fedoraproject.org/archives/list/devel@lists.fedoraproject.org/
diff --git a/sources/tech/20190903 An introduction to Hyperledger Fabric.md b/sources/tech/20190903 An introduction to Hyperledger Fabric.md
new file mode 100644
index 0000000000..80e421ae79
--- /dev/null
+++ b/sources/tech/20190903 An introduction to Hyperledger Fabric.md
@@ -0,0 +1,117 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (An introduction to Hyperledger Fabric)
+[#]: via: (https://opensource.com/article/19/9/introduction-hyperledger-fabric)
+[#]: author: (Matt Zand https://opensource.com/users/mattzandhttps://opensource.com/users/ron-mcfarlandhttps://opensource.com/users/wonderchook)
+
+An introduction to Hyperledger Fabric
+======
+Hyperledger is a set of open source tools aiming to build a robust,
+business-driven blockchain framework.
+![Chain image][1]
+
+One of the biggest projects in the blockchain industry, [Hyperledger][2], is comprised of a set of open source tools and subprojects. It's a global collaboration hosted by The Linux Foundation and includes leaders in different sectors who are aiming to build a robust, business-driven blockchain framework.
+
+There are three main types of blockchain networks: public blockchains, consortiums or federated blockchains, and private blockchains. Hyperledger is a blockchain framework that aims to help companies build private or consortium permissioned blockchain networks where multiple organizations can share the control and permission to operate a node within the network.
+
+Since a blockchain is a transparent, immutable, and secure decentralized system, it is considered a game-changing solution for traditional supply chain industries. It can support an effective supply chain system by:
+
+ * Tracking the products in the entire chain
+ * Verifying and authenticating the products in the chain
+ * Sharing the entire chain's information between supply chain actors
+ * Providing auditability
+
+
+
+This article uses the example of a food supply chain to explain how a Hyperledger blockchain can transform a traditional supply chain.
+
+### Food industry supply chains
+
+The main reason for classic supply chain inefficiency is lack of transparency, leading to unreliable reporting and competitive disadvantage.
+
+In traditional supply chain models, information about an entity is not fully transparent to others in the chain, which leads to inaccurate reports and a lack of interoperability. Emails and printed documents provide some information, but they can't contain fully detailed visibility data because the products are hard to trace across the entire supply chain. This also makes it nearly impossible for a consumer to know the true value and origin of a product.
+
+The food industry's supply chain is a difficult landscape, where multiple actors need to coordinate to deliver goods to their final destination, the customers. The following diagram shows the key actors in a food supply chain (multi-echelon) network.
+
+![Typical food supply chain][3]
+
+Every stage of the chain introduces potential security vulnerabilities, integration problems, and other inefficiency issues. The main growing threat in current food supply chains remains counterfeit food and food fraud.
+
+A food-tracking system based on the Hyperledger blockchain enables full visibility, tracking, and traceability. More importantly, it ensures the authenticity of food by recording a product's details in an immutable and viable way. By sharing a product's details over an immutable framework, the end user can self-verify a product's authenticity.
+
+### Hyperledger Fabric
+
+Hyperledger Fabric is the cornerstone of the Hyperledger project. It is a permission-based blockchain, or more accurately a distributed ledger technology (DLT), which was originally created by IBM and Digital Asset. It is designed as a modular framework with different components (outlined below). It is also a flexible solution offering a pluggable consensus model, although it currently only provides permissioned, voting-based consensus (with the assumption that today's Hyperledger networks operate in a partially trustworthy environment).
+
+Given this, there is no need for anonymous miners to validate transactions nor for an associated currency to act as an incentive. All participants must be authenticated to participate and transact on the blockchain. Like with Ethereum, Hyperledger Fabric supports smart contracts, called Chaincodes in Hyperledger, and these contracts describe and execute the system's application logic.
+
+Unlike Ethereum, however, Hyperledger Fabric doesn't require expensive mining computations to commit transactions, so it can help build blockchains that can scale up with less latency.
+
+Hyperledger Fabric is different from blockchains such as Ethereum or Bitcoin, not only in its type or because it is currency-agnostic, but also in terms of its internal machinery. Following are the key elements of a typical Hyperledger network:
+
+ * **Ledgers** store a chain of blocks that keep all immutable historical records of all state transitions.
+ * **Nodes** are the logical entities of the blockchain. There are three types:
+– **Clients** are applications that act on behalf of a user to submit transactions to the network.
+– **Peers** are entities that commit transactions and maintain the ledger state.
+– **Orderers** create a shared communication channel between clients and peers; they also package blockchain transactions into blocks and send them to committing peers
+
+
+
+Along with these elements, Hyperledger Fabric is based on the following key design features:
+
+ * **Chaincode** is similar to a smart contract in other networks, such as Ethereum. It is a program written in a higher-level language that executes against the ledger's current-state database.
+ * **Channels** are private communication subnets for sharing confidential information between multiple network members. Each transaction is executed on a channel that is visible only to the authenticated and authorized parties.
+ * **Endorsers** validate transactions, invoke Chaincode, and send the endorsed transaction results back to the calling applications.
+ * **Membership Services Providers** (MSPs) provide identity validation and authentication processes by issuing and validating certificates. An MSP identifies which certification authorities (CAs) are trusted to define the members of a trust domain and determines the specific roles an actor might play (member, admin, and so on).
+
+
+
+### How transactions are validated
+
+Exploring how a transaction gets validated is a good way to understand how Hyperledger Fabric works under the hood. This diagram shows the end-to-end system flow for processing a transaction in a typical Hyperledger network:
+
+![Hyperledger transaction validation flow][4]
+
+First, the client initiates a transaction by sending a request to a Hyperledger Fabric-based application client, which submits the transaction proposal to endorsing peers. These peers simulate the transaction by executing the Chaincode (using a local copy of the state) specified by the transaction and sending the results back to the application. At this point, the application combines the transaction with the endorsements and broadcasts it to the Ordering Service. The Ordering Service checks the endorsements and creates a block of transactions for each channel before broadcasting them to all peers in the channel. Peers then verify the transactions and commit them.
+
+The Hyperledger Fabric blockchain can connect food supply chain participants through a transparent, permanent, and shared record of food-origin data, processing data, shipping details, and more. The Chaincode is invoked by authorized participants in the food supply chain. All executed transaction records are permanently saved in the ledger, and all entities can look up this information.
+
+### Hyperledger Composer
+
+Alongside blockchain frameworks such as Fabric or Iroha, the Hyperledger project provides tools such as Composer, Hyperledger Explorer, and Cello. Hyperledger Composer provides a toolset to help build blockchain applications more easily. It consists of:
+
+ * CTO, a modeling language
+ * Playground, a browser-based development tool for rapid testing and deployment
+ * A command-line interface (CLI) tool
+
+
+
+Composer supports the Hyperledger Fabric runtime and infrastructure, and internally the composer's API utilizes the underlying Fabric API. Composer runs on Fabric, meaning the business networks generated by Composer can be deployed to Hyperledger Fabric for execution.
+
+To learn more about Hyperledger, visit the [project's website][2], where you can view the members, access training and tutorials, or find out how you can contribute.
+
+* * *
+
+_This article is adapted from [Coding Bootcamp's article Building A Blockchain Supply Chain Using Hyperledger Fabric and Composer][5] and is used with permission._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/introduction-hyperledger-fabric
+
+作者:[Matt Zand][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mattzandhttps://opensource.com/users/ron-mcfarlandhttps://opensource.com/users/wonderchook
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/chain.png?itok=sgAjswFf (Chain image)
+[2]: https://www.hyperledger.org/
+[3]: https://opensource.com/sites/default/files/uploads/foodindustrysupplychain.png (Typical food supply chain)
+[4]: https://opensource.com/sites/default/files/uploads/hyperledger-fabric-transaction-flow.png (Hyperledger transaction validation flow)
+[5]: https://coding-bootcamps.com/ultimate-guide-for-building-a-blockchain-supply-chain-using-hyperledger-fabric-and-composer.html
diff --git a/sources/tech/20190903 Get a Preconfigured Tiling Window Manager on Ubuntu With Regolith.md b/sources/tech/20190903 Get a Preconfigured Tiling Window Manager on Ubuntu With Regolith.md
new file mode 100644
index 0000000000..10811483db
--- /dev/null
+++ b/sources/tech/20190903 Get a Preconfigured Tiling Window Manager on Ubuntu With Regolith.md
@@ -0,0 +1,152 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get a Preconfigured Tiling Window Manager on Ubuntu With Regolith)
+[#]: via: (https://itsfoss.com/regolith-linux-desktop/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+Get a Preconfigured Tiling Window Manager on Ubuntu With Regolith
+======
+
+_**Brief: Using tiling window manager in Linux can be tricky with all those configuration. Regolith gives you an out of box i3wm experience within Ubuntu.**_
+
+Perhaps you have come across desktop screenshot like the one below in some forums. If you haven’t, try checking this [subreddit][1]. You might have wondered how could people make their Linux desktop look so beautiful.
+
+![Linux Ricing Example | Image Source][2]
+
+Of course, you can make your own desktop look good by changing the icon, theme and wallpaper but you might still not achieve the same result.
+
+In majority of cases, a tiling window manager is used instead of the regular floating window manager. Ahmm! what’s a tiling window manager? Let me quickly explain it to you.
+
+### Tiling window manager
+
+The concept of tiling window manager is simple. Instead of stacking new program window over the other programs, it tiles the programs side by side. So the first program takes up the entire screen. The next one is tiled to its side either horizontally or vertically and so on.
+
+![AwesomeWM Tiling Window Manager][3]
+
+Sounds good but what happens when you have tens of programs open? It will be unusable won’t it? This is where the workspaces save your day. You can switch to new workspace and open new programs here. Switching between workspaces is just one or two keystroke away.
+
+Tiling window manager can be overwhelming for you if you have never used it. It requires you to remember keyboard shortcuts to use it efficiently. But that’s not the end of trouble. Even if you install a tiling window manager like [i3wm][4] or [awesome][5], you won’t get a beautiful desktop out of the box. In fact, it could even look uglier than before.
+
+You see, all those mesmerizing desktops are result of personal customization. The [tiling window managers are highly configurable but you need to learn to customize them][6]. That’s not very comforting specially for someone who has never used a tiling window manager.
+
+If you are one of those people who wanted to have a good looking desktop with tiling window manager but could never configured them properly, the Linux ricing gods have heard your prayers.
+
+### Regolith is dream come true for tiling window noobs
+
+![Regolith Linux Desktop][7]
+
+[Regolith][8] is a Linux distribution that brings Ubuntu’s simplicity, GNOME’s configuration and i3wm’s tiling interface together.
+
+Wait! Don’t we already have enough of Ubuntu-based distributions that change nothing more than the theme and wallpaper? Regolith doesn’t want to be that kind of distribution. In fact, Regolith doesn’t pretend to be a standalone distribution.
+
+Its [developer experimented with i3wm][9], tweaked it to his liking but soon realized that he had to do it all over again on all the systems he used. That’s when he decided to package it so that he could use it easily on new system. And hence Regolith Linux was born as a customized version of Ubuntu.
+
+The developer totally understands that not everyone would be willing to replace their existing Ubuntu system just to get a tiling window manager and this is why he has made it available as a desktop as well. This means if you are already running Ubuntu, you can install Regolith desktop and use it beside your regular desktop environment.
+
+### Install Regolith desktop on Ubuntu
+
+Regolith desktop is available through [PPA in Ubuntu][10] 18.04 and higher versions. You can install it using the following commands:
+
+```
+sudo add-apt-repository -y ppa:kgilmer/regolith-stable
+sudo apt install regolith-desktop
+```
+
+Once you have installed it, reboot your system. At the user login screen, click the username and you should see a gear symbol, Click on it and it would give you the option to change the desktop environment.
+
+![Switch to Regolith Desktop][11]
+
+### Using tiling window manager with Regolith
+
+When you log in to the Regolith desktop, you’ll see a plain simple screen with some keyboard shortcuts displayed on the right side, a thin bottom panel with only a few system information. You can find the keyboard shortcut information on [this page][12] as well.
+
+The keyboard shortcut will help you get started. You can search for an application or settings by pressing Super (Windows) and space key.
+
+![Regolith App Launcher][13]
+
+By default, the new program windows are tiled vertically. You can toggle that with Super+Backspace key. Do note that the tiling and toggling is related to the program window in focus. If you have three program windows and you are using the first program window, the next program will be tiled (vertically or horizontally) after it, not after the third program window. It takes some time in getting used to this concept.
+
+![Multiple Program Windows in Regolith Desktop][14]
+
+If you don’t like the layout of the windows, you can move them around using the Super+Shift+Arrow keys. You can move between the application windows using Super and Arrow keys.
+
+If your screen is filled with applications and you want to breath fresh, press Super key and 2 (or 3 or 4, depending upon number of workspaces in use) and start afresh with a new workspace. The new workspace has the keyboard shortcut on the display. You can toggle it with Super+Shift+? key combination.
+
+Regolith uses GNOME underneath so you can still use GNOME tools to change the system settings.
+
+Regolith comes with four different color themes with solarized dark being the default. It uses Arc icon themes. Changing the icon theme is same as Ubuntu but if you want to change the color, you need to do some minor tweaking in the configuration file. You can find the configuration information on [this page][15].
+
+![Regolith Desktop With Nord Color Scheme][16]
+
+You can log out of Regolith using the Super+Shift+E key combination. The keyboard shortcuts displayed on the desktop is not correct for logging out.
+
+Since I have never used i3wm or any other tiling window manager, I find it weird that there is no shutdown option here. You’ll have to use [command line to shutdown Ubuntu here][17].
+
+You can find some [useful information to get started with Regolith desktop here][18].
+
+### Getting rid of Regolith desktop
+
+I can understand if you didn’t like Regolith enough to use it as your main desktop. Tiling window manager is not everyone’s cup of tea (or coffee). The good thing is that you can go back to your regular desktop environment the same way you switch to Regolith.
+
+Log out of your account. Click on the username and you’ll see the gear icon. Click on it and select the desktop environment you want to use.
+
+Once you are back to the other desktop environment, you may even choose to remove Regolith completely. Note that you MUST be using some other desktop environment while removing Regolith.
+
+Open a terminal and use the following commands:
+
+```
+sudo apt remove regolith-desktop
+```
+
+You can [remove the PPA][19] as well:
+
+```
+sudo add-apt-repository --remove ppa:kgilmer/regolith-stable
+```
+
+### To tile, or not to tile, that is the question
+
+![Regolith Desktop on my Ubuntu 18.04 LTS][20]
+
+Personally, I am happy to have discovered Regolith desktop. I have been fascinated by the tiling window managers but I didn’t want to spend time on figuring out the configuration. Regolith gives me the comfort of using i3wm out of the box with my main distribution, Ubuntu.
+
+I like it more as a desktop than a distribution. It gives the opportunity to try out tiling window manager without a lot of hassle.
+
+Do you like the concept of Regolith desktop? Are you willing to give it a try? How’s your experience with tiling window manager (if any)? Do share your views in the comment section.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/regolith-linux-desktop/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://www.reddit.com/r/unixporn/
+[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/linux-ricing-example.jpg?ssl=1
+[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/awesome-window-anager.jpg?resize=800%2C450&ssl=1
+[4]: https://i3wm.org/
+[5]: https://awesomewm.org/
+[6]: https://fedoramagazine.org/getting-started-i3-window-manager/
+[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/regolith-linux-desktop-screenshot-apps.jpg?ssl=1
+[8]: https://regolith-linux.org/
+[9]: https://regolith-linux.org/motivations.html
+[10]: https://itsfoss.com/ppa-guide/
+[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/change-to-regolith-desktop.jpg?resize=800%2C400&ssl=1
+[12]: https://regolith-linux.org/keybindings.html
+[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/regolith-app-launcher.jpg?ssl=1
+[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/regolith-desktop-tiled-windows.jpg?ssl=1
+[15]: https://regolith-linux.org/configuring.html
+[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/regolith-desktop-with-nord-color-scheme.jpg?ssl=1
+[17]: https://itsfoss.com/schedule-shutdown-ubuntu/
+[18]: https://regolith-linux.org/getting_started.html
+[19]: https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
+[20]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/regolith-desktop-screenshot.jpg?ssl=1
diff --git a/sources/tech/20190903 Humbleness key to open source success, Kubernetes security struggles, and more industry trends.md b/sources/tech/20190903 Humbleness key to open source success, Kubernetes security struggles, and more industry trends.md
new file mode 100644
index 0000000000..b5626f9abb
--- /dev/null
+++ b/sources/tech/20190903 Humbleness key to open source success, Kubernetes security struggles, and more industry trends.md
@@ -0,0 +1,73 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Humbleness key to open source success, Kubernetes security struggles, and more industry trends)
+[#]: via: (https://opensource.com/article/19/9/kubernetes-security-struggles-and-more)
+[#]: author: (Tim Hildred https://opensource.com/users/thildred)
+
+Humbleness key to open source success, Kubernetes security struggles, and more industry trends
+======
+A weekly look at open source community and industry trends.
+![Person standing in front of a giant computer screen with numbers, data][1]
+
+As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
+
+## [How will open source deal with success?][2]
+
+> “The old school model is quarterly growth and never over-extend yourself,” Wright explained. “The newer model is very different. You look at it as a big upfront investment and then capture the most mindshare or market share that you possibly can and growth is more important than profitability. If you flip that from a business context to an open source community context, if the metrics are all about growth and not about sustainability then you are going to incentive the wrong kind of behavior and that’s the thing that worries me.”
+
+**The impact:** The importance of this could easily be summarized as "be humble." A hot streak can easily change the thinking from "we can do anything together" to "nothing can stop this" and of course pride comes before the fall.
+
+## [10 Quarkus videos to get you up to speed with supersonic, subatomic Java][3]
+
+> Maybe you’ve heard about [Quarkus][4], also known as supersonic, subatomic Java. According to [Quarkus.io][5], it’s a [Kubernetes][6]-native Java stack tailored for GraalVM and OpenJDK HotSpot, crafted from the best of breed Java libraries and standards.
+>
+> To help you learn more, we’ve rounded up 10 talks showing Quarkus in action. These videos will take your Quarkus knowledge to the next level.
+
+**The impact**: The promise of the second sentence is to help you understand what the first one means. Videos 4 (Taste of serverless application development) and 9 (Build Eclipse MicroProfile apps quickly with Quarkus) are probably the most practical.
+
+## [exFAT in the Linux kernel? Yes!][7]
+
+> It’s important to us that the Linux community can make use of exFAT included in the Linux kernel with confidence. To this end, we will be making Microsoft’s technical specification for exFAT publicly available to facilitate development of conformant, interoperable implementations. We also support the eventual inclusion of a Linux kernel with exFAT support in a future revision of the Open Invention Network’s Linux System Definition, where, once accepted, the code will benefit from the defensive patent commitments of OIN’s 3040+ members and licensees.
+
+**The impact**: exFAT is a lowest common denominator filesystem (your microwave can probably read exFAT-formatted USB drives). At the very least, Apple no longer has to license the format. Open sourcing it could just be a good way to squeeze out the last little bit of juice.
+
+## [Announcing the CNCF Kubernetes Project Journey Report][8]
+
+> We wanted to create a series of reports that help explain our nurturing efforts and some of the positive trends and outcomes we see developing around our hosted projects. This report attempts to objectively assess the state of the Kubernetes project and how the CNCF has impacted the progress and growth of Kubernetes. We recognize that it’s impossible to sort out correlation and causation but this report attempts to document correlations. For the report, we pulled data from multiple sources, particularly CNCF’s own [DevStats tool][9], which provides detailed development statistics for all CNCF projects.
+
+**The impact**: On the one hand the CNCF clearly has an interest in making donor organizations feel like their money is being well spent. On the other hand, the money is clearly being well spent: the year-on-year stats improvement is incredible.
+
+## [The continuing rise of Kubernetes analysed: Security struggles and lifecycle learnings][10]
+
+> In an early sign of Kubernetes going mainstream, in 2016 Niantic released the massively popular mobile game Pokémon Go, which was built on Kubernetes and deployed in Google Container Engine. At launch, the game experienced usability issues caused by a massive user interest in U.S—the number of users logging in ended up being 50x the original estimation, and 10x the prediction for worst case scenario. By using the inherent scalability advantages of Kubernetes, Pokémon Go went on to successfully launch in Japan two weeks later despite traffic tripling what was experienced during the U.S launch.
+
+**The impact**: Two things stood out to me: 1) Kubernetes powers Pokemon (!?!) and 2) 2016 seems like so long ago. Sure, the stuff about containers and Kubernetes pushing organizations to adopt new security approaches and the bit about their biggest security concerns (misconfiguration) is interesting but... Pokemon!
+
+_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/kubernetes-security-struggles-and-more
+
+作者:[Tim Hildred][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/thildred
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
+[2]: https://www.sdxcentral.com/articles/opinion-editorial/how-will-open-source-deal-with-success/2019/08/
+[3]: https://developers.redhat.com/blog/2019/08/26/10-quarkus-videos-to-get-you-up-to-speed-with-supersonic-subatomic-java/
+[4]: https://developers.redhat.com/blog/2019/05/09/create-your-first-quarkus-project-with-eclipse-ide-red-hat-codeready-studio/
+[5]: https://quarkus.io/
+[6]: https://developers.redhat.com/topics/kubernetes/
+[7]: https://cloudblogs.microsoft.com/opensource/2019/08/28/exfat-linux-kernel/
+[8]: https://www.cncf.io/blog/2019/08/29/announcing-the-cncf-kubernetes-project-journey-report/
+[9]: https://k8s.devstats.cncf.io/d/12/dashboards?orgId=1&refresh=15m
+[10]: https://www.cloudcomputing-news.net/news/2019/aug/29/continuing-rise-kubernetes-analysed-security-struggles-and-lifecycle-learnings/
diff --git a/sources/tech/20190904 Environment variables in PowerShell.md b/sources/tech/20190904 Environment variables in PowerShell.md
new file mode 100644
index 0000000000..9345aa0230
--- /dev/null
+++ b/sources/tech/20190904 Environment variables in PowerShell.md
@@ -0,0 +1,196 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Environment variables in PowerShell)
+[#]: via: (https://opensource.com/article/19/9/environment-variables-powershell)
+[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/seth)
+
+Environment variables in PowerShell
+======
+Up your PowerShell game with environment variables, in Part 2.5 of the
+"Variables in shells" miniseries.
+![Hands programming][1]
+
+Environment variables are global settings for your Linux, Mac, or Windows computer, stored for the system shell to use when executing commands. Many are set by default during installation or user creation.
+
+For instance, your home directory is set as an environment variable when you log in. How it looks in PowerShell depends on your operating system.
+
+On Windows:
+
+
+```
+PS C:\Users\bogus> Get-Variable HOME -valueOnly
+C:\Users\bogus
+```
+
+On Linux:
+
+
+```
+pwsh> Get-Variable HOME -valueOnly
+HOME=/home/seth
+```
+
+On a Mac:
+
+
+```
+pwsh> Get-Variable HOME -valueOnly
+HOME=/Users/bogus
+```
+
+You usually don’t use environment variables directly, but they’re referenced by individual applications and daemons as needed. However, environment variables can be useful when you want to override default settings, or when you need to manage new settings that your system has no reason to create on its own.
+
+This article is about environment variables in the open source PowerShell environment, and so it’s applicable to PowerShell running on Windows, Linux, and Mac. Users of the Bash shell should refer to my article about [Bash environment variables][2].
+
+For this article, I ran PowerShell on the open source operating system Linux. The commands are the same regardless of your platform, although the output will differ (for instance, it is statistically unlikely that your username is **seth**).
+
+### What are environment variables?
+
+Environment variables in PowerShell are special kinds of variables that provide the system with information about the operating system environment. With environment variables, you can view and change variables in the Windows registry, as well as variables set for a particular session.
+
+In PowerShell, environment variables are stored in the **Env:** "drive", accessible through the _PowerShell environment provider_, a subsystem of PowerShell. This isn’t a physical drive, but a virtual file system.
+
+Because environment variables exist in the **Env:** drive, you must prepend **Env:** to the variable name when you reference them. Alternatively, you can set your working location to the **Env:** drive with the **Set-Location** command so you can treat all environment variables as local variables:
+
+
+```
+PS> Set-Location Env:
+PS> pwd
+
+Path
+\----
+Env:/
+```
+
+Environment variables convey information about your login session to your computer. For instance, when an application needs to determine where to save a data file by default, it usually calls upon the **HOME** environment variable. You probably never set the **HOME** variable yourself, and yet it exists because most environment variables are managed by your operating system.
+
+You can view all environment variables set on your system with the **Get-ChildItem** command from within the **Env:** drive. The list is long, so pipe the output through **out-host -paging** to make it easy to read:
+
+
+```
+PS> Get-ChildItem | out-host -paging
+LOGNAME seth
+LS_COLORS rs=0:mh=00:bd=48;5;232;38;5;
+MAIL /var/spool/mail/seth
+MODULEPATH /etc/scl/modulefiles:/etc/scl/modulefiles
+MODULESHOME /usr/share/Modules
+OLDPWD /home/seth
+PATH /opt/microsoft/powershell/6:/usr/share/Modules/bin
+PSModulePath /home/seth/.local/share/powershell/Modules
+PWD /home/seth
+[...]
+```
+
+If you’re not in the **Env:** drive, then you can do the same thing by adding **Env: **to your command:
+
+
+```
+PS> Get-ChildItem Env: | out-host -paging
+LOGNAME seth
+LS_COLORS rs=0:mh=00:bd=48;5;232;38;5;
+MAIL /var/spool/mail/seth
+MODULEPATH /etc/scl/modulefiles:/etc/scl/modulefiles
+```
+
+Environment variables can be set, recalled, and cleared with some of the same syntax used for normal variables. Like other variables, anything you set during a session only applies to that particular session.
+
+If you want to make permanent changes to a variable, you must change them in Windows Registry on Windows, or in a shell configuration file (such as **~/.bashrc**) on Linux or Mac. If you’re not familiar with using variables in PowerShell, read my [variables in PowerShell][3] article before continuing.
+
+### What are environment variables used for?
+
+Different environment variables get used by several different systems within your computer. Your **PATH** variable is vital to your shell, for instance, but a lot less significant to, say, Java (which also has paths, but they’re paths to important Java libraries rather than general system folders). However, the **USER** variable is used by several different processes to identify who is requesting a service.
+
+An installer wizard, like the open source [Nullsoft Scriptable Install System (NSIS)][4] framework, updates your environment variables when you’re installing a new application. Sometimes, when you’re installing something outside of your operating system’s intended toolset, you may have to manage an environment variable yourself. Or, you might choose to add an environment variable to suit your preferences.
+
+### How are they different from regular variables?
+
+When you create a normal variable, the variable is considered local, meaning that it’s not defined outside of the shell that created it.
+
+For example, create a variable:
+
+
+```
+PS> Set-Variable -Name VAR -Value "example"
+PS> gv VAR -valueOnly
+example
+```
+
+Launch a new shell, even from within your current shell:
+
+
+```
+PS> pwsh
+PS c:\> gv VAR -valueOnly
+gv : Cannot find a variable with the name 'example'.
+```
+
+Environment variables, on the other hand, are meant to be global in scope. They exist separately from the shell that created them and are available to other processes.
+
+### How do you set an environment variable?
+
+When setting an environment variable, you should be explicit that it is an environment variable by using the **$Env:** notation:
+
+
+```
+PS Env:/> $Env:FOO = "hello world"
+PS Env:/> Get-ChildItem FOO
+hello world
+```
+
+As a test, launch a new session and access the variable you’ve just created. Because the variable is an environment variable, though, you must prepend it with **$Env:**:
+
+
+```
+PS Env:/> pwsh
+PS c:\> $Env.FOO
+hello world
+```
+
+Even though you’ve made a variable available to child processes, it’s still just a temporary variable. It works, you can verify that it exists, you can use it from any process, but it is destroyed when the shell that created it is closed.
+
+### How do you set environment variables in your profile?
+
+To force an environment variable to persist across sessions, you must add it to your PowerShell profile, such as your **CurrentUser,AllHosts** profile, located in **HOME/Documents/Profile.ps1**:
+
+
+```
+PS> Add-Content -Path $Profile.CurrentUserAllHosts -Value '$Env:FOO = "hello world"'
+```
+
+With this line added, any PowerShell session launched instantiates the **FOO** environment variable and sets its value to **hello world**.
+
+There are currently six default profiles controlling PowerShell sessions, so refer to the [Microsoft dev blog][5] for more information.
+
+### How do you discover new environment variables?
+
+You can create and manipulate environment variables at will, and some applications do just that. This fact means that many of your environment variables aren’t used by most of your applications, and if you add your own arbitrary variables then some could be used by nothing at all.
+
+So the question is: How do you find out which environment variables are meaningful? The answer lies in an application’s documentation.
+
+Python, for instance, offers to add the appropriate Python path to your **Path** environment variable during install. **[Note: PATH?]** If you decline, you can set the value yourself now that you know how to modify environment variables.
+
+The same is true for any application you install: The installer is expected to add the appropriate variables to your environment, so you should never need to modify **Env:** manually. If you’re developing an application, then your installer should do the same for your users.
+
+To discover significant variables for individual applications, refer to their user and developer documentation.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/environment-variables-powershell
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sethhttps://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop.png?itok=pGfEfu2S (Hands programming)
+[2]: https://opensource.com/article/19/8/what-are-environment-variables
+[3]: https://opensource.com/article/19/8/variables-powershell
+[4]: https://sourceforge.net/projects/nsis/
+[5]: https://devblogs.microsoft.com/scripting/understanding-the-six-powershell-profiles
diff --git a/sources/tech/20190904 How to build Fedora container images.md b/sources/tech/20190904 How to build Fedora container images.md
new file mode 100644
index 0000000000..fc443c8bf1
--- /dev/null
+++ b/sources/tech/20190904 How to build Fedora container images.md
@@ -0,0 +1,103 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to build Fedora container images)
+[#]: via: (https://fedoramagazine.org/how-to-build-fedora-container-images/)
+[#]: author: (Clément Verna https://fedoramagazine.org/author/cverna/)
+
+How to build Fedora container images
+======
+
+![][1]
+
+With the rise of containers and container technology, all major Linux distributions nowadays provide a container base image. This article presents how the Fedora project builds its base image. It also shows you how to use it to create a layered image.
+
+### Base and layered images
+
+Before we look at how the Fedora container base image is built, let’s define a base image and a layered image. A simple way to define a base image is an image that has no parent layer. But what does that concretely mean? It means a base image usually contains only the root file system (_rootfs_) of an operating system. The base image generally provides the tools needed to install software in order to create layered images.
+
+A layered image adds a collections of layers on top of the base image in order to install, configure, and run an application. Layered images reference base images in a _Dockerfile_ using the _FROM_ instruction:
+
+```
+FROM fedora:latest
+```
+
+### How to build a base image
+
+Fedora has a full suite of tools available to build container images. [This includes][2] _[podman][2]_, which does not require running as the root user.
+
+#### Building a rootfs
+
+A base image comprises mainly a [tarball][3]. This tarball contains a rootfs. There are different ways to build this rootfs. The Fedora project uses the [kickstart][4] installation method coupled with [imagefactory][5] software to create these tarballs.
+
+The kickstart file used during the creation of the Fedora base image is available in Fedora’s build system [Koji][6]. The _[Fedora-Container-Base][7]_ package regroups all the base image builds. If you select a build, it gives you access to all the related artifacts, including the kickstart files. Looking at an [example][8], the _%packages_ section at the end of the file defines all the packages to install. This is how you make software available in the base image.
+
+#### Using a rootfs to build a base image
+
+Building a base image is easy, once a rootfs is available. It requires only a Dockerfile with the following instructions:
+
+```
+FROM scratch
+ADD layer.tar /
+CMD ["/bin/bash"]
+```
+
+The important part here is the _FROM scratch_ instruction, which is creating an empty image. The following instructions then add the rootfs to the image, and set the default command to be executed when the image is run.
+
+Let’s build a base image using a Fedora rootfs built in Koji:
+
+```
+$ curl -o fedora-rootfs.tar.xz https://kojipkgs.fedoraproject.org/packages/Fedora-Container-Base/Rawhide/20190902.n.0/images/Fedora-Container-Base-Rawhide-20190902.n.0.x86_64.tar.xz
+$ tar -xJvf fedora-rootfs.tar.xz 51c14619f9dfd8bf109ab021b3113ac598aec88870219ff457ba07bc29f5e6a2/layer.tar
+$ mv 51c14619f9dfd8bf109ab021b3113ac598aec88870219ff457ba07bc29f5e6a2/layer.tar layer.tar
+$ printf "FROM scratch\nADD layer.tar /\nCMD [\"/bin/bash\"]" > Dockerfile
+$ podman build -t my-fedora .
+$ podman run -it --rm my-fedora cat /etc/os-release
+```
+
+The _layer.tar_ file which contains the rootfs needs to be extracted from the downloaded archive. This is only needed because Fedora generates images that are ready to be consumed by a container run-time.
+
+So using Fedora’s generated image, it’s even easier to get a base image. Let’s see how that works:
+
+```
+$ curl -O https://kojipkgs.fedoraproject.org/packages/Fedora-Container-Base/Rawhide/20190902.n.0/images/Fedora-Container-Base-Rawhide-20190902.n.0.x86_64.tar.xz
+$ podman load --input Fedora-Container-Base-Rawhide-20190902.n.0.x86_64.tar.xz
+$ podman run -it --rm localhost/fedora-container-base-rawhide-20190902.n.0.x86_64:latest cat /etc/os-release
+```
+
+### Building a layered image
+
+To build a layered image that uses the Fedora base image, you only need to specify _fedora_ in the _FROM_ line instruction:
+
+```
+FROM fedora:latest
+```
+
+The _latest_ tag references the latest active Fedora release (Fedora 30 at the time of writing). But it is possible to get other versions using the image tag. For example, _FROM fedora:31_ will use the Fedora 31 base image.
+
+Fedora supports building and releasing software as containers. This means you can maintain a Dockerfile to make your software available to others. For more information about becoming a container image maintainer in Fedora, check out the [Fedora Containers Guidelines][9].
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/how-to-build-fedora-container-images/
+
+作者:[Clément Verna][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/cverna/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/fedoracontainers-816x345.jpg
+[2]: https://fedoramagazine.org/running-containers-with-podman/
+[3]: https://en.wikipedia.org/wiki/Tar_(computing)
+[4]: https://en.wikipedia.org/wiki/Kickstart_(Linux)
+[5]: http://imgfac.org/
+[6]: https://koji.fedoraproject.org/koji/
+[7]: https://koji.fedoraproject.org/koji/packageinfo?packageID=26387
+[8]: https://kojipkgs.fedoraproject.org//packages/Fedora-Container-Base/30/20190902.0/images/koji-f30-build-37420478-base.ks
+[9]: https://docs.fedoraproject.org/en-US/containers/guidelines/guidelines/
diff --git a/sources/tech/20190905 Building CI-CD pipelines with Jenkins.md b/sources/tech/20190905 Building CI-CD pipelines with Jenkins.md
new file mode 100644
index 0000000000..44b4d6cd24
--- /dev/null
+++ b/sources/tech/20190905 Building CI-CD pipelines with Jenkins.md
@@ -0,0 +1,255 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Building CI/CD pipelines with Jenkins)
+[#]: via: (https://opensource.com/article/19/9/intro-building-cicd-pipelines-jenkins)
+[#]: author: (Bryant Son https://opensource.com/users/brson)
+
+Building CI/CD pipelines with Jenkins
+======
+Build continuous integration and continuous delivery (CI/CD) pipelines
+with this step-by-step Jenkins tutorial.
+![pipelines][1]
+
+In my article [_A beginner's guide to building DevOps pipelines with open source tools_][2], I shared a story about building a DevOps pipeline from scratch. The core technology driving that initiative was [Jenkins][3], an open source tool to build continuous integration and continuous delivery (CI/CD) pipelines.
+
+At Citi, there was a separate team that provided dedicated Jenkins pipelines with a stable master-slave node setup, but the environment was only used for quality assurance (QA), staging, and production environments. The development environment was still very manual, and our team needed to automate it to gain as much flexibility as possible while accelerating the development effort. This is the reason we decided to build a CI/CD pipeline for DevOps. And the open source version of Jenkins was the obvious choice due to its flexibility, openness, powerful plugin-capabilities, and ease of use.
+
+In this article, I will share a step-by-step walkthrough on how you can build a CI/CD pipeline using Jenkins.
+
+### What is a pipeline?
+
+Before jumping into the tutorial, it's helpful to know something about CI/CD pipelines.
+
+To start, it is helpful to know that Jenkins itself is not a pipeline. Just creating a new Jenkins job does not construct a pipeline. Think about Jenkins like a remote control—it's the place you click a button. What happens when you do click a button depends on what the remote is built to control. Jenkins offers a way for other application APIs, software libraries, build tools, etc. to plug into Jenkins, and it executes and automates the tasks. On its own, Jenkins does not perform any functionality but gets more and more powerful as other tools are plugged into it.
+
+A pipeline is a separate concept that refers to the groups of events or jobs that are connected together in a sequence:
+
+> A **pipeline** is a sequence of events or jobs that can be executed.
+
+The easiest way to understand a pipeline is to visualize a sequence of stages, like this:
+
+![Pipeline example][4]
+
+Here, you should see two familiar concepts: _Stage_ and _Step_.
+
+ * **Stage:** A block that contains a series of steps. A stage block can be named anything; it is used to visualize the pipeline process.
+ * **Step:** A task that says what to do. Steps are defined inside a stage block.
+
+
+
+In the example diagram above, Stage 1 can be named "Build," "Gather Information," or whatever, and a similar idea is applied for the other stage blocks. "Step" simply says what to execute, and this can be a simple print command (e.g., **echo "Hello, World"**), a program-execution command (e.g., **java HelloWorld**), a shell-execution command (e.g., **chmod 755 Hello**), or any other command—as long as it is recognized as an executable command through the Jenkins environment.
+
+The Jenkins pipeline is provided as a _codified script_ typically called a **Jenkinsfile**, although the file name can be different. Here is an example of a simple Jenkins pipeline file.
+
+
+```
+// Example of Jenkins pipeline script
+
+pipeline {
+ stages {
+ stage("Build") {
+ steps {
+ // Just print a Hello, Pipeline to the console
+ echo "Hello, Pipeline!"
+ // Compile a Java file. This requires JDKconfiguration from Jenkins
+ javac HelloWorld.java
+ // Execute the compiled Java binary called HelloWorld. This requires JDK configuration from Jenkins
+ java HelloWorld
+ // Executes the Apache Maven commands, clean then package. This requires Apache Maven configuration from Jenkins
+ mvn clean package ./HelloPackage
+ // List the files in current directory path by executing a default shell command
+ sh "ls -ltr"
+ }
+ }
+ // And next stages if you want to define further...
+ } // End of stages
+} // End of pipeline
+```
+
+It's easy to see the structure of a Jenkins pipeline from this sample script. Note that some commands, like **java**, **javac**, and **mvn**, are not available by default, and they need to be installed and configured through Jenkins. Therefore:
+
+> A **Jenkins pipeline** is the way to execute a Jenkins job sequentially in a defined way by codifying it and structuring it inside multiple blocks that can include multiple steps containing tasks.
+
+OK. Now that you understand what a Jenkins pipeline is, I'll show you how to create and execute a Jenkins pipeline. At the end of the tutorial, you will have built a Jenkins pipeline like this:
+
+![Final Result][5]
+
+### How to build a Jenkins pipeline
+
+To make this tutorial easier to follow, I created a sample [GitHub repository][6] and a video tutorial.
+
+Before starting this tutorial, you'll need:
+
+ * **Java Development Kit:** If you don't already have it, install a JDK and add it to the environment path so a Java command (like **java jar**) can be executed through a terminal. This is necessary to leverage the Java Web Archive (WAR) version of Jenkins that is used in this tutorial (although you can use any other distribution).
+ * **Basic computer operations:** You should know how to type some code, execute basic Linux commands through the shell, and open a browser.
+
+
+
+Let's get started.
+
+#### Step 1: Download Jenkins
+
+Navigate to the [Jenkins download page][7]. Scroll down to **Generic Java package (.war)** and click on it to download the file; save it someplace where you can locate it easily. (If you choose another Jenkins distribution, the rest of tutorial steps should be pretty much the same, except for Step 2.) The reason to use the WAR file is that it is a one-time executable file that is easily executable and removable.
+
+![Download Jenkins as Java WAR file][8]
+
+#### Step 2: Execute Jenkins as a Java binary
+
+Open a terminal window and enter the directory where you downloaded Jenkins with **cd <your path>**. (Before you proceed, make sure JDK is installed and added to the environment path.) Execute the following command, which will run the WAR file as an executable binary:
+
+
+```
+`java -jar ./jenkins.war`
+```
+
+If everything goes smoothly, Jenkins should be up and running at the default port 8080.
+
+![Execute as an executable JAR binary][9]
+
+#### Step 3: Create a new Jenkins job
+
+Open a web browser and navigate to **localhost:8080**. Unless you have a previous Jenkins installation, it should go straight to the Jenkins dashboard. Click **Create New Jobs**. You can also click **New Item** on the left.
+
+![Create New Job][10]
+
+#### Step 4: Create a pipeline job
+
+In this step, you can select and define what type of Jenkins job you want to create. Select **Pipeline** and give it a name (e.g., TestPipeline). Click **OK** to create a pipeline job.
+
+![Create New Pipeline Job][11]
+
+You will see a Jenkins job configuration page. Scroll down to find** Pipeline section**. There are two ways to execute a Jenkins pipeline. One way is by _directly writing a pipeline script_ on Jenkins, and the other way is by retrieving the _Jenkins file from SCM_ (source control management). We will go through both ways in the next two steps.
+
+#### Step 5: Configure and execute a pipeline job through a direct script
+
+To execute the pipeline with a direct script, begin by copying the contents of the [sample Jenkinsfile][6] from GitHub. Choose **Pipeline script** as the **Destination** and paste the **Jenkinsfile** contents in **Script**. Spend a little time studying how the Jenkins file is structured. Notice that there are three Stages: Build, Test, and Deploy, which are arbitrary and can be anything. Inside each Stage, there are Steps; in this example, they just print some random messages.
+
+Click **Save** to keep the changes, and it should automatically take you back to the Job Overview.
+
+![Configure to Run as Jenkins Script][12]
+
+To start the process to build the pipeline, click **Build Now**. If everything works, you will see your first pipeline (like the one below).
+
+![Click Build Now and See Result][13]
+
+To see the output from the pipeline script build, click any of the Stages and click **Log**. You will see a message like this.
+
+![Visit sample GitHub with Jenkins get clone link][14]
+
+#### Step 6: Configure and execute a pipeline job with SCM
+
+Now, switch gears: In this step, you will Deploy the same Jenkins job by copying the **Jenkinsfile** from a source-controlled GitHub. In the same [GitHub repository][6], pick up the repository URL by clicking **Clone or download** and copying its URL.
+
+![Checkout from GitHub][15]
+
+Click **Configure** to modify the existing job. Scroll to the **Advanced Project Options** setting, but this time, select the **Pipeline script from SCM** option in the **Destination** dropdown. Paste the GitHub repo's URL in the **Repository URL**, and type **Jenkinsfile** in the **Script Path**. Save by clicking the **Save** button.
+
+![Change to Pipeline script from SCM][16]
+
+To build the pipeline, once you are back to the Task Overview page, click **Build Now** to execute the job again. The result will be the same as before, except you have one additional stage called **Declaration: Checkout SCM**.
+
+![Build again and verify][17]
+
+To see the pipeline's output from the SCM build, click the Stage and view the **Log** to check how the source control cloning process went.
+
+![Verify Checkout Procedure][18]
+
+### Do more than print messages
+
+Congratulations! You've built your first Jenkins pipeline!
+
+"But wait," you say, "this is very limited. I cannot really do anything with it except print dummy messages." That is OK. So far, this tutorial provided just a glimpse of what a Jenkins pipeline can do, but you can extend its capabilities by integrating it with other tools. Here are a few ideas for your next project:
+
+ * Build a multi-staged Java build pipeline that takes from the phases of pulling dependencies from JAR repositories like Nexus or Artifactory, compiling Java codes, running the unit tests, packaging into a JAR/WAR file, and deploying to a cloud server.
+ * Implement the advanced code testing dashboard that will report back the health of the project based on the unit test, load test, and automated user interface test with Selenium.
+ * Construct a multi-pipeline or multi-user pipeline automating the tasks of executing Ansible playbooks while allowing for authorized users to respond to task in progress.
+ * Design a complete end-to-end DevOps pipeline that pulls the infrastructure resource files and configuration files stored in SCM like GitHub and executing the scripts through various runtime programs.
+
+
+
+Follow any of the tutorials at the end of this article to get into these more advanced cases.
+
+#### Manage Jenkins
+
+From the main Jenkins dashboard, click **Manage Jenkins**.
+
+![Manage Jenkins][19]
+
+#### Global tool configuration
+
+There are many options available, including managing plugins, viewing the system log, etc. Click **Global Tool Configuration**.
+
+![Global Tools Configuration][20]
+
+#### Add additional capabilities
+
+Here, you can add the JDK path, Git, Gradle, and so much more. After you configure a tool, it is just a matter of adding the command into your Jenkinsfile or executing it through your Jenkins script.
+
+![See Various Options for Plugin][21]
+
+### Where to go from here?
+
+This article put you on your way to creating a CI/CD pipeline using Jenkins, a cool open source tool. To find out about many of the other things you can do with Jenkins, check out these other articles on Opensource.com:
+
+ * [Getting started with Jenkins X][22]
+ * [Install an OpenStack cloud with Jenkins][23]
+ * [Running Jenkins builds in containers][24]
+ * [Getting started with Jenkins pipelines][25]
+ * [How to run JMeter with Jenkins][26]
+ * [Integrating OpenStack into your Jenkins workflow][27]
+
+
+
+You may be interested in some of the other articles I've written to supplement your open source journey:
+
+ * [9 open source tools for building a fault-tolerant system][28]
+ * [Understanding software design patterns][29]
+ * [A beginner's guide to building DevOps pipelines with open source tools][2]
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/intro-building-cicd-pipelines-jenkins
+
+作者:[Bryant Son][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/brson
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/pipe-pipeline-grid.png?itok=kkpzKxKg (pipelines)
+[2]: https://opensource.com/article/19/4/devops-pipeline
+[3]: https://jenkins.io/
+[4]: https://opensource.com/sites/default/files/uploads/diagrampipeline.jpg (Pipeline example)
+[5]: https://opensource.com/sites/default/files/uploads/0_endresultpreview_0.jpg (Final Result)
+[6]: https://github.com/bryantson/CICDPractice
+[7]: https://jenkins.io/download/
+[8]: https://opensource.com/sites/default/files/uploads/2_downloadwar.jpg (Download Jenkins as Java WAR file)
+[9]: https://opensource.com/sites/default/files/uploads/3_runasjar.jpg (Execute as an executable JAR binary)
+[10]: https://opensource.com/sites/default/files/uploads/4_createnewjob.jpg (Create New Job)
+[11]: https://opensource.com/sites/default/files/uploads/5_createpipeline.jpg (Create New Pipeline Job)
+[12]: https://opensource.com/sites/default/files/uploads/6_runaspipelinescript.jpg (Configure to Run as Jenkins Script)
+[13]: https://opensource.com/sites/default/files/uploads/7_buildnow4script.jpg (Click Build Now and See Result)
+[14]: https://opensource.com/sites/default/files/uploads/8_seeresult4script.jpg (Visit sample GitHub with Jenkins get clone link)
+[15]: https://opensource.com/sites/default/files/uploads/9_checkoutfromgithub.jpg (Checkout from GitHub)
+[16]: https://opensource.com/sites/default/files/uploads/10_runsasgit.jpg (Change to Pipeline script from SCM)
+[17]: https://opensource.com/sites/default/files/uploads/11_seeresultfromgit.jpg (Build again and verify)
+[18]: https://opensource.com/sites/default/files/uploads/12_verifycheckout.jpg (Verify Checkout Procedure)
+[19]: https://opensource.com/sites/default/files/uploads/13_managingjenkins.jpg (Manage Jenkins)
+[20]: https://opensource.com/sites/default/files/uploads/14_globaltoolsconfiguration.jpg (Global Tools Configuration)
+[21]: https://opensource.com/sites/default/files/uploads/15_variousoptions4plugin.jpg (See Various Options for Plugin)
+[22]: https://opensource.com/article/18/11/getting-started-jenkins-x
+[23]: https://opensource.com/article/18/4/install-OpenStack-cloud-Jenkins
+[24]: https://opensource.com/article/18/4/running-jenkins-builds-containers
+[25]: https://opensource.com/article/18/4/jenkins-pipelines-with-cucumber
+[26]: https://opensource.com/life/16/7/running-jmeter-jenkins-continuous-delivery-101
+[27]: https://opensource.com/business/15/5/interview-maish-saidel-keesing-cisco
+[28]: https://opensource.com/article/19/3/tools-fault-tolerant-system
+[29]: https://opensource.com/article/19/7/understanding-software-design-patterns
diff --git a/sources/tech/20190905 Don-t force allocations on the callers of your API.md b/sources/tech/20190905 Don-t force allocations on the callers of your API.md
new file mode 100644
index 0000000000..eca6cc3732
--- /dev/null
+++ b/sources/tech/20190905 Don-t force allocations on the callers of your API.md
@@ -0,0 +1,79 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Don’t force allocations on the callers of your API)
+[#]: via: (https://dave.cheney.net/2019/09/05/dont-force-allocations-on-the-callers-of-your-api)
+[#]: author: (Dave Cheney https://dave.cheney.net/author/davecheney)
+
+Don’t force allocations on the callers of your API
+======
+
+This is a post about performance. Most of the time when worrying about the performance of a piece of code the overwhelming advice should be (with apologies to Brendan Gregg) _don’t worry about it, yet._ However there is one area where I counsel developers to think about the performance implications of a design, and that is API design.
+
+Because of the high cost of retrofitting a change to an API’s signature to address performance concerns, it’s worthwhile considering the performance implications of your API’s design on its caller.
+
+### A tale of two API designs
+
+Consider these two `Read` methods:
+
+```
+func (r *Reader) Read(buf []byte) (int, error)
+func (r *Reader) Read() ([]byte, error)
+```
+
+The first method takes a `[]byte` buffer and returns the number of bytes read into that buffer and possibly an `error` that occurred while reading. The second takes no arguments and returns some data as a `[]byte` or an `error`.
+
+This first method should be familiar to any Go programmer, it’s `io.Reader.Read`. As ubiquitous as `io.Reader` is, it’s not the most convenient API to use. Consider for a moment that `io.Reader` is the only Go interface in widespread use that returns _both_ a result _and_ an error. Meditate on this for a moment. The standard Go idiom, checking the error and iff it is `nil` is it safe to consult the other return values, does not apply to `Read`. In fact the caller must do the opposite. First they must record the number of bytes read into the buffer, reslice the buffer, process that data, and only then, consult the error. This is an unusual API for such a common operation and one that frequently catches out newcomers.
+
+### A trap for young players?
+
+Why is it so? Why is one of the central APIs in Go’s standard library written like this? A superficial answer might be `io.Reader`‘s signature is a reflection of the underlying `read(2)` syscall, which is indeed true, but misses the point of this post.
+
+If we compare the API of `io.Reader` to our alternative, `func Read() ([]byte, error)`, this API seems easier to use. Each call to `Read()` will return the data that was read, no need to reslice buffers, no need to remember the special case to do this before checking the error. Yet this is not the signature of `io.Reader.Read`. Why would one of Go’s most pervasive interfaces choose such an awkward API? The answer, I believe, lies in the performance implications of the APIs signature on the _caller_.
+
+Consider again our alternative `Read` function, `func Read() ([]byte, error)`. On each call `Read` will read some data into a buffer[1][1] and return the buffer to the caller. Where does this buffer come from? Who allocates it? The answer is the buffer is allocated _inside_ `Read`. Therefore each call to `Read` is guaranteed to allocate a buffer which would escape to the heap. The more the program reads, the faster it reads data, the more streams of data it reads concurrently, the more pressure it places on the garbage collector.
+
+The standard libraries’ `io.Reader.Read` forces the caller to supply a buffer because if the caller is concerned with the number of allocations their program is making this is precisely the kind of thing they want to control. Passing a buffer into `Read` puts the control of the allocations into the caller’s hands. If they aren’t concerned about allocations they can use higher level helpers like `ioutil.ReadAll` to read the contents into a `[]byte`, or `bufio.Scanner` to stream the contents instead.
+
+The opposite, starting with a method like our alternative `func Read() ([]byte, error)` API, prevents callers from pooling or reusing allocations–no amount of helper methods can fix this. As an API author, if the API cannot be changed you’ll be forced to add a second form to your API taking a supplied buffer and reimplementing your original API in terms of the newer form. Consider, for example, `io.CopyBuffer`. Other examples of retrofitting APIs for performance reasons are the `fmt` [package][2] and the `net/http` [package][3] which drove the introduction of the `sync.Pool` type precisely because the Go 1 guarantee prevented the APIs of those packages from changing.
+
+* * *
+
+If you want to commit to an API for the long run, consider how its design will impact the size and frequency of allocations the caller will have to make to use it.
+
+ 1. This API has other problems, such as, _how much data should be read?_ or _should it try to read as much as possible, or return promptly if the read would block?_[][4]
+
+
+
+#### Related posts:
+
+ 1. [Friday pop quiz: the smallest buffer][5]
+ 2. [Constant errors][6]
+ 3. [Simple test coverage with Go 1.2][7]
+ 4. [Struct composition with Go][8]
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://dave.cheney.net/2019/09/05/dont-force-allocations-on-the-callers-of-your-api
+
+作者:[Dave Cheney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://dave.cheney.net/author/davecheney
+[b]: https://github.com/lujun9972
+[1]: tmp.9E95iAQGkb#easy-footnote-bottom-1-3821 (This API has other problems, such as, how much data should be read? or should it try to read as much as possible, or return promptly if the read would block?)
+[2]: https://golang.org/cl/43990043
+[3]: https://golang.org/cl/44080043
+[4]: tmp.9E95iAQGkb#easy-footnote-1-3821
+[5]: https://dave.cheney.net/2015/06/05/friday-pop-quiz-the-smallest-buffer (Friday pop quiz: the smallest buffer)
+[6]: https://dave.cheney.net/2016/04/07/constant-errors (Constant errors)
+[7]: https://dave.cheney.net/2013/10/07/simple-test-coverage-with-go-1-2 (Simple test coverage with Go 1.2)
+[8]: https://dave.cheney.net/2015/05/22/struct-composition-with-go (Struct composition with Go)
diff --git a/sources/tech/20190905 How to Change Themes in Linux Mint.md b/sources/tech/20190905 How to Change Themes in Linux Mint.md
new file mode 100644
index 0000000000..c01cad9a73
--- /dev/null
+++ b/sources/tech/20190905 How to Change Themes in Linux Mint.md
@@ -0,0 +1,103 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Change Themes in Linux Mint)
+[#]: via: (https://itsfoss.com/install-themes-linux-mint/)
+[#]: author: (It's FOSS Community https://itsfoss.com/author/itsfoss/)
+
+How to Change Themes in Linux Mint
+======
+
+Using Linux Mint is, from the start, a unique experience for its main Desktop Environment: Cinnamon. This is one of the main [features why I love Linux Mint][1].
+
+Since Mint’s dev team [started to take design more serious][2], “Themes” applet became an important way not only to choose new themes, icons, buttons, window borders and mouse pointers, but also to install new themes directly from it. Interested? Let’s jump into it.
+
+### How to change themes in Linux Mint
+
+Search for themes in the Menu and open the Themes applet.
+
+![Theme Applet provides an easy way of installing and changing themes][3]
+
+At the applet there’s a “Add/Remove” button, pretty simple, huh? And, clicking on it, you and I can see Cinnamon Spices (Cinnamon’s official addons repository) themes ordered first by popularity.
+
+![Installing new themes in Linux Mint Cinnamon][4]
+
+To install one, all it’s needed to do is click on yours preferred one and wait for it to download. After that, the theme will be available at the “Desktop” option on the first page of the applet. Just double click on one of the installed themes to start using it.
+
+![Changing themes in Linux Mint Cinnamon][5]
+
+Here’s the default Linux Mint look:
+
+![Linux Mint Default Theme][6]
+
+And here’s after I change the theme:
+
+![Linux Mint with Carta Theme][7]
+
+All the themes are also available at the Cinnamon Spices site for more information and bigger screenshots so you can take a better look on how your system will look.
+
+[Browse Cinnamon Themes][8]
+
+### Installing third party themes in Linux Mint
+
+_“I saw this amazing theme on another site and it is not available at Cinnamon Spices…”_
+
+Cinnamon Spices has a good collection of themes but you’ll still find that the theme you saw some place else is not available on the official Cinnamon website.
+
+Well, it would be nice if there was another way, huh? You might imagine that there is (I’m mean…obviously there is). So, first things first, there are other websites where you and I can find new cool themes.
+
+I’ll recommend going to Cinnamon Look and browse themes there. If you like something download it.
+
+[Get more themes at Cinnamon Look][9]
+
+After the preferred theme is downloaded, you will have a compressed file now with all you need for the installation. Extract it and save at ~/.themes. Confused? The “~” file path is actually your home folder: /home/{YOURUSER}/.themes.
+
+[][10]
+
+Suggested read Fix "Failed To Start Session" At Login In Ubuntu 16.04
+
+So go to the your Home directory. Press Ctrl+H to [show hidden files in Linux][11]. If you don’t see a .themes folder, create a new folder and name .themes. Remember that the dot at the beginning of the folder name is important.
+
+Copy the extracted theme folder from your Downloads directory to the .themes folder in your Home.
+
+After that, look for the installed theme at the applet above mentioned.
+
+Note
+
+Remember that the themes must be made to work on Cinnamon, even though it is a fork from GNOME, not all themes made for GNOME works at Cinnamon.
+
+Changing theme is one part of Cinnamon customization. You can also [change the looks of Linux Mint by changing the icons][12].
+
+I hope you now you know how to change themes in Linux Mint. Which theme are you going to use?
+
+### João Gondim
+
+Linux enthusiast from Brasil.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/install-themes-linux-mint/
+
+作者:[It's FOSS Community][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/itsfoss/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/tiny-features-linux-mint-cinnamon/
+[2]: https://itsfoss.com/linux-mint-new-design/
+[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/install-theme-linux-mint-1.jpg?resize=800%2C625&ssl=1
+[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/install-theme-linux-mint-2.jpg?resize=800%2C625&ssl=1
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/install-theme-linux-mint-3.jpg?resize=800%2C450&ssl=1
+[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/09/linux-mint-default-theme.jpg?resize=800%2C450&ssl=1
+[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/09/linux-mint-carta-theme.jpg?resize=800%2C450&ssl=1
+[8]: https://cinnamon-spices.linuxmint.com/themes
+[9]: https://www.cinnamon-look.org/
+[10]: https://itsfoss.com/failed-to-start-session-ubuntu-14-04/
+[11]: https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
+[12]: https://itsfoss.com/install-icon-linux-mint/
diff --git a/sources/tech/20190905 How to Get Average CPU and Memory Usage from SAR Reports Using the Bash Script.md b/sources/tech/20190905 How to Get Average CPU and Memory Usage from SAR Reports Using the Bash Script.md
new file mode 100644
index 0000000000..c53b7440e3
--- /dev/null
+++ b/sources/tech/20190905 How to Get Average CPU and Memory Usage from SAR Reports Using the Bash Script.md
@@ -0,0 +1,232 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Get Average CPU and Memory Usage from SAR Reports Using the Bash Script)
+[#]: via: (https://www.2daygeek.com/linux-get-average-cpu-memory-utilization-from-sar-data-report/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+How to Get Average CPU and Memory Usage from SAR Reports Using the Bash Script
+======
+
+Most Linux administrator monitor system performance with **[SAR report][1]** because it collect performance data for a week.
+
+But you can easily extend this to four weeks by making changes to the “/etc/sysconfig/sysstat” file.
+
+Also, this period can be extended beyond one month. If the value exceeds 28, the log files are placed in multiple directories, one for each month.
+
+To extend the coverage period to 28 days, make the following change to the “/etc/sysconfig/sysstat” file.
+
+Edit the sysstat file and change HISTORY=7 to HISTORY=28.
+
+In this article we have added three bash scripts that will help you to easily view each data file averages in one place.
+
+We have added many useful shell scripts in the past. If you want to check out that collection, go to the link below.
+
+ * **[How to automate daily operations using shell script][2]**
+
+
+
+These scripts are simple and straightforward. For testing purposes, we have included only two performance metrics, namely CPU and memory.
+
+You can modify other performance metrics in the script to suit your needs.
+
+### Script-1: Bash Script to Get Average CPU Utilization from SAR Reports
+
+This bash script collects the CPU average from each data file and display it on one page.
+
+Since this is a month end, it shows 28 days data for August 2019.
+
+```
+# vi /opt/scripts/sar-cpu-avg.sh
+
+#!/bin/sh
+
+echo "+----------------------------------------------------------------------------------+"
+echo "|Average: CPU %user %nice %system %iowait %steal %idle |"
+echo "+----------------------------------------------------------------------------------+"
+
+for file in `ls -tr /var/log/sa/sa* | grep -v sar`
+
+do
+
+dat=`sar -f $file | head -n 1 | awk '{print $4}'`
+
+echo -n $dat
+
+sar -f $file | grep -i Average | sed "s/Average://"
+
+done
+
+echo "+----------------------------------------------------------------------------------+"
+```
+
+Once you run the script, you will get an output like the one below.
+
+```
+# sh /opt/scripts/sar-cpu-avg.sh
+
++----------------------------------------------------------------------------------+
+|Average: CPU %user %nice %system %iowait %steal %idle |
++----------------------------------------------------------------------------------+
+08/01/2019 all 0.70 0.00 1.19 0.00 0.00 98.10
+08/02/2019 all 1.73 0.00 3.16 0.01 0.00 95.10
+08/03/2019 all 1.73 0.00 3.16 0.01 0.00 95.11
+08/04/2019 all 1.02 0.00 1.80 0.00 0.00 97.18
+08/05/2019 all 0.68 0.00 1.08 0.01 0.00 98.24
+08/06/2019 all 0.71 0.00 1.17 0.00 0.00 98.12
+08/07/2019 all 1.79 0.00 3.17 0.01 0.00 95.03
+08/08/2019 all 1.78 0.00 3.14 0.01 0.00 95.08
+08/09/2019 all 1.07 0.00 1.82 0.00 0.00 97.10
+08/10/2019 all 0.38 0.00 0.50 0.00 0.00 99.12
+.
+.
+.
+08/29/2019 all 1.50 0.00 2.33 0.00 0.00 96.17
+08/30/2019 all 2.32 0.00 3.47 0.01 0.00 94.20
++----------------------------------------------------------------------------------+
+```
+
+### Script-2: Bash Script to Get Average Memory Utilization from SAR Reports
+
+This bash script will collect memory averages from each data file and display it on one page.
+
+Since this is a month end, it shows 28 days data for August 2019.
+
+```
+# vi /opt/scripts/sar-memory-avg.sh
+
+#!/bin/sh
+
+echo "+-------------------------------------------------------------------------------------------------------------------+"
+echo "|Average: kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty |"
+echo "+-------------------------------------------------------------------------------------------------------------------+"
+
+for file in `ls -tr /var/log/sa/sa* | grep -v sar`
+
+do
+
+dat=`sar -f $file | head -n 1 | awk '{print $4}'`
+
+echo -n $dat
+
+sar -r -f $file | grep -i Average | sed "s/Average://"
+
+done
+
+echo "+-------------------------------------------------------------------------------------------------------------------+"
+```
+
+Once you run the script, you will get an output like the one below.
+
+```
+# sh /opt/scripts/sar-memory-avg.sh
+
++--------------------------------------------------------------------------------------------------------------------+
+|Average: kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty |
++--------------------------------------------------------------------------------------------------------------------+
+08/01/2019 1492331 2388461 61.55 29888 1152142 1560615 12.72 1693031 380472 6
+08/02/2019 1493126 2387666 61.53 29888 1147811 1569624 12.79 1696387 373346 3
+08/03/2019 1489582 2391210 61.62 29888 1147076 1581711 12.89 1701480 370325 3
+08/04/2019 1490403 2390389 61.60 29888 1148206 1569671 12.79 1697654 373484 4
+08/05/2019 1484506 2396286 61.75 29888 1152409 1563804 12.75 1702424 374628 4
+08/06/2019 1473593 2407199 62.03 29888 1151137 1577491 12.86 1715426 371000 8
+08/07/2019 1467150 2413642 62.19 29888 1155639 1596653 13.01 1716900 372574 13
+08/08/2019 1451366 2429426 62.60 29888 1162253 1604672 13.08 1725931 376998 5
+08/09/2019 1451191 2429601 62.61 29888 1158696 1582192 12.90 1728819 371025 4
+08/10/2019 1450050 2430742 62.64 29888 1160916 1579888 12.88 1729975 370844 5
+.
+.
+.
+08/29/2019 1365699 2515093 64.81 29888 1198832 1593567 12.99 1781733 376157 15
+08/30/2019 1361920 2518872 64.91 29888 1200785 1595105 13.00 1784556 375641 8
++-------------------------------------------------------------------------------------------------------------------+
+```
+
+### Script-3: Bash Script to Get Average CPU & Memory Utilization from SAR Reports
+
+This bash script collects the CPU & memory averages from each data file and displays them on a page.
+
+This bash script is slightly different compared to the above script. It shows the average of both (CPU & Memory) in one location, not the other data.
+
+```
+# vi /opt/scripts/sar-cpu-mem-avg.sh
+
+#!/bin/bash
+
+for file in `ls -tr /var/log/sa/sa* | grep -v sar`
+
+do
+
+ sar -f $file | head -n 1 | awk '{print $4}'
+
+ echo "-----------"
+
+ sar -u -f $file | awk '/Average:/{printf("CPU Average: %.2f%\n"), 100 - $8}'
+
+ sar -r -f $file | awk '/Average:/{printf("Memory Average: %.2f%\n"),(($3-$5-$6)/($2+$3)) * 100 }'
+
+ printf "\n"
+
+done
+```
+
+Once you run the script, you will get an output like the one below.
+
+```
+# sh /opt/scripts/sar-cpu-mem-avg.sh
+
+08/01/2019
+-----------
+CPU Average: 1.90%
+Memory Average: 31.09%
+
+08/02/2019
+-----------
+CPU Average: 4.90%
+Memory Average: 31.18%
+
+08/03/2019
+-----------
+CPU Average: 4.89%
+Memory Average: 31.29%
+
+08/04/2019
+-----------
+CPU Average: 2.82%
+Memory Average: 31.24%
+
+08/05/2019
+-----------
+CPU Average: 1.76%
+Memory Average: 31.28%
+.
+.
+.
+08/29/2019
+-----------
+CPU Average: 3.83%
+Memory Average: 33.15%
+
+08/30/2019
+-----------
+CPU Average: 5.80%
+Memory Average: 33.19%
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-get-average-cpu-memory-utilization-from-sar-data-report/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/sar-system-performance-monitoring-command-tool-linux/
+[2]: https://www.2daygeek.com/category/shell-script/
diff --git a/sources/tech/20190906 6 Open Source Paint Applications for Linux Users.md b/sources/tech/20190906 6 Open Source Paint Applications for Linux Users.md
new file mode 100644
index 0000000000..d1523f33c3
--- /dev/null
+++ b/sources/tech/20190906 6 Open Source Paint Applications for Linux Users.md
@@ -0,0 +1,234 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (6 Open Source Paint Applications for Linux Users)
+[#]: via: (https://itsfoss.com/open-source-paint-apps/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+6 Open Source Paint Applications for Linux Users
+======
+
+As a child, when I started using computer (with Windows XP), my favorite application was Paint. I spent hours doodling on it. Surprisingly, children still love the paint apps. And not just children, the simple paint app comes handy in a number of situations.
+
+You will find a bunch of applications that let you draw/paint or manipulate images. However, some of them are proprietary. While you’re a Linux user – why not focus on open source paint applications?
+
+In this article, we are going to list some of the best open source paint applications which are worthy alternatives to proprietary painting software available on Linux.
+
+### Open Source paint & drawing applications
+
+![][1]
+
+**Note:** _The list is in no particular order of ranking._
+
+#### 1\. Pinta
+
+![][2]
+
+Key Highlights:
+
+ * Great alternative to Paint.NET / MS Paint
+ * Add-on support (WebP Image support available)
+ * Layer Support
+
+
+
+[Pinta][3] is an impressive open-source paint application which is perfect for drawing and basic image editing. In other words, it is a simple paint application with some fancy features.
+
+You may consider [Pinta][4] as an alternative to MS Paint on Linux – but with layer support and more. Not just MS Paint, but it acts as a Linux replacement for Paint.NET software available for Windows. Even though Paint.NET is better – Pinta seems to be a decent alternative to it.
+
+A couple of add-ons can be utilized to enhance the functionality, like the [support for WebP images on Linux][5]. In addition to the layer support, you can easily resize the images, add effects, make adjustments (brightness, contrast, etc.), and also adjust the quality when exporting the image.
+
+#### How to install Pinta?
+
+You should be able to easily find it in the Software Center / App Center / Package Manager. Just type in “**Pinta**” and get started installing it. In either case, try the [Flatpak][6] package.
+
+Or, you can enter the following command in the terminal (Ubuntu/Debian):
+
+```
+sudo apt install pinta
+```
+
+For more information on the download packages and installation instructions, refer the [official download page][7].
+
+#### 2\. Krita
+
+![][8]
+
+Key Highlights:
+
+ * HDR Painting
+ * PSD Support
+ * Layer Support
+ * Brush stabilizers
+ * 2D Animation
+
+
+
+Krita is one of the most advanced open source paint applications for Linux. Of course, for this article, it helps you draw sketches and wreak havoc upon the canvas. But, in addition to that, it offers a whole lot of features.
+
+[][9]
+
+Suggested read Things To Do After Installing Fedora 24
+
+For instance, if you have a shaky hand, it can help you stabilize the brush strokes. You also get built-in vector tools to create comic panels and other interesting things. If you are looking for a full-fledged color management support, drawing assistants, and layer management, Krita should be your preferred choice.
+
+#### How to install Krita?
+
+Similar to pinta, you should be able to find it listed in the Software Center/App Center or the package manager. It’s also available in the [Flatpak repository][10].
+
+Thinking to install it via terminal? Type in the following command:
+
+```
+sudo apt install krita
+```
+
+In either case, you can head down to their [official download page][11] to get the **AppImage** file and run it.
+
+If you have no idea on AppImage files, check out our guide on – [how to use AppImage][12].
+
+#### 3\. Tux Paint
+
+![][13]
+
+Key Highlights:
+
+ * A no-nonsense paint application for kids
+
+
+
+I’m not kidding, Tux Paint is one of the best open-source paint applications for kids between 3-12 years of age. Of course, you do not want options when you want to just scribble. So, Tux Paint seems to be the best option in that case (even for adults!).
+
+#### How to install Tuxpaint?
+
+Tuxpaint can be downloaded from the Software Center or Package manager. In either case, to install it on Ubuntu/Debian, type in the following command in the terminal:
+
+```
+sudo apt install tuxpaint
+```
+
+For more information on it, head to the [official site][14].
+
+#### 4\. Drawpile
+
+![][15]
+
+Key Highlights:
+
+ * Collaborative Drawing
+ * Built-in chat to interact with other users
+ * Layer support
+ * Record drawing sessions
+
+
+
+Drawpile is an interesting open-source paint application where you get to collaborate with other users in real-time. To be precise, you can simultaneously draw in a single canvas. In addition to this unique feature, you have the layer support, ability to record your drawing session, and even a chat facility to interact with the users collaborating.
+
+You can host/join a public session or start a private session with your friend which requires a code. By default, the server will be your computer. But, if you want a remote server, you can select it as well.
+
+Do note, that you will need to [sign up for a Drawpile account][16] in order to collaborate.
+
+#### How to install Drawpile?
+
+As far as I’m aware of, you can only find it listed in the [Flatpak repository][17].
+
+[][18]
+
+Suggested read OCS Store: One Stop Shop All of Your Linux Software Customization Needs
+
+#### 5\. MyPaint
+
+![][19]
+
+Key Highlights:
+
+ * Easy-to-use tool for digital painters
+ * Layer management support
+ * Lots of options to tweak your brush and drawing
+
+
+
+[MyPaint][20] is a simple yet powerful tool for digital painters. It features a lot of options to tweak in order to make the perfect digital brush stroke. I’m not much of a digital artist (but a scribbler) but I observed quite a few options to adjust the brush, the colors, and an option to add a scratchpad panel.
+
+It also supports layer management – in case you want that. The latest stable version hasn’t been updated for a few years now, but the recent alpha build (which I tested) works just fine. If you are looking for an open source paint application on Linux – do give this a try.
+
+#### How to install MyPaint?
+
+MyPaint is available in the official repository. However, that’s the old version. If you still want to proceed, you can search for it in the Software Center or type the following command in the terminal:
+
+```
+sudo apt install mypaint
+```
+
+You can head to its official [GitHub release page][21] for the latest alpha build and get the [AppImage file][12] (any version) to make it executable and launch the app.
+
+#### 6\. KolourPaint
+
+![][22]
+
+Key Highlights:
+
+ * A simple alternative to MS Paint on Linux
+ * No layer management support
+
+
+
+If you aren’t looking for any Layer management support and just want an open source paint application to draw stuff – this is it.
+
+[KolourPaint][23] is originally tailored for KDE desktop environments but it works flawlessly on others too.
+
+#### How to install KolourPaint?
+
+You can install KolourPaint right from the Software Center or via the terminal using the following command:
+
+```
+sudo apt install kolourpaint4
+```
+
+In either case, you can utilize [Flathub][24] as well.
+
+**Wrapping Up**
+
+If you are wondering about applications like GIMP/Inkscape, we have those listed in another separate article on the [best Linux Tools for digital artists][25]. If you’re curious about more options, I recommend you to check that out.
+
+Here, we try to compile a list of best open source paint applications available for Linux. If you think we missed something, feel free to tell us about it in the comments section below!
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/open-source-paint-apps/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/09/open-source-paint-apps.png?resize=800%2C450&ssl=1
+[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/pinta.png?ssl=1
+[3]: https://pinta-project.com/pintaproject/pinta/
+[4]: https://itsfoss.com/pinta-1-6-ubuntu-linux-mint/
+[5]: https://itsfoss.com/webp-ubuntu-linux/
+[6]: https://www.flathub.org/apps/details/com.github.PintaProject.Pinta
+[7]: https://pinta-project.com/pintaproject/pinta/releases
+[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/09/krita-paint.png?ssl=1
+[9]: https://itsfoss.com/things-to-do-after-installing-fedora-24/
+[10]: https://www.flathub.org/apps/details/org.kde.krita
+[11]: https://krita.org/en/download/krita-desktop/
+[12]: https://itsfoss.com/use-appimage-linux/
+[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/tux-paint.jpg?ssl=1
+[14]: http://www.tuxpaint.org/
+[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/drawpile.png?ssl=1
+[16]: https://drawpile.net/accounts/signup/
+[17]: https://flathub.org/apps/details/net.drawpile.drawpile
+[18]: https://itsfoss.com/ocs-store/
+[19]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/mypaint.png?ssl=1
+[20]: https://mypaint.org/
+[21]: https://github.com/mypaint/mypaint/releases
+[22]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/kolourpaint.png?ssl=1
+[23]: http://kolourpaint.org/
+[24]: https://flathub.org/apps/details/org.kde.kolourpaint
+[25]: https://itsfoss.com/best-linux-graphic-design-software/
diff --git a/sources/tech/20190906 How to change the color of your Linux terminal.md b/sources/tech/20190906 How to change the color of your Linux terminal.md
new file mode 100644
index 0000000000..bb418a6ded
--- /dev/null
+++ b/sources/tech/20190906 How to change the color of your Linux terminal.md
@@ -0,0 +1,211 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to change the color of your Linux terminal)
+[#]: via: (https://opensource.com/article/19/9/linux-terminal-colors)
+[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/jason-bakerhttps://opensource.com/users/tlaihttps://opensource.com/users/amjithhttps://opensource.com/users/greg-phttps://opensource.com/users/marcobravo)
+
+How to change the color of your Linux terminal
+======
+Make Linux as colorful (or as monochromatic) as you want.
+![4 different color terminal windows with code][1]
+
+You can add color to your Linux terminal using special ANSI encoding settings, either dynamically in a terminal command or in configuration files, or you can use ready-made themes in your terminal emulator. Either way, the nostalgic green or amber text on a black screen is wholly optional. This article demonstrates how you can make Linux as colorful (or as monochromatic) as you want.
+
+### Terminal capabilities
+
+Modern systems usually default to at least xterm-256color, but if you try to add color to your terminal without success, you should check your TERM setting.
+
+Historically, Unix terminals were literally that: physical points at the literal endpoint (termination) of a shared computer system where users could type in commands. They were unique from the teletype machines (which is why we still have /dev/tty devices in Linux today) that were often used to issue commands remotely. Terminals had CRT monitors built-in, so users could sit at a terminal in their office to interact directly with the mainframe. CRT monitors were expensive—both to manufacture and to control; it was easier to have a computer spit out crude ASCII text than to worry about anti-aliasing and other niceties that modern computerists take for granted. However, developments in technology happened fast even then, and it quickly became apparent that as new video display terminals were designed, they needed new capabilities to be available on an optional basis.
+
+For instance, the fancy new VT100 released in 1978 supported ANSI color, so if a user identified the terminal type as vt100, then a computer could deliver color output, while a basic serial device might not have such an option. The same principle applies today, and it's set by the TERM [environment variable][2]. You can check your TERM definition with **echo**:
+
+
+```
+$ echo $TERM
+xterm-256color
+```
+
+The obsolete (but still maintained on some systems in the interest of backward compatibility) /etc/termcap file defined the capabilities of terminals and printers. The modern version of that is terminfo, located in either /etc or /usr/share, depending on your distribution. These files list features available in different kinds of terminals, many of which are defined by historical hardware: there are definitions for vt100 through vt220, as well as for modern software emulators like xterm and Xfce. Most software doesn't care what terminal type you're using; in rare instances, you might get a warning or error about an incorrect terminal type when logging into a server that checks for compatible features. If your terminal is set to a profile with very few features, but you know the emulator you use is capable of more, then you can change your setting by defining the TERM environment variable. You can do this by exporting the TERM variable in your ~/.bashrc configuration file:
+
+
+```
+`export TERM=xterm-256color`
+```
+
+Save the file, and reload your settings:
+
+
+```
+`$ source ~/.bashrc`
+```
+
+### ANSI color codes
+
+Modern terminals have inherited ANSI escape sequences for "meta" features. These are special sequences of characters that a terminal interprets as actions instead of characters. For instance, this sequence clears the screen up to the next prompt:
+
+
+```
+`$ printf `\033[2J``
+```
+
+It doesn't clear your history; it just clears up the screen in your terminal emulator, so it's a safe and demonstrative ANSI escape sequence.
+
+ANSI also has sequences to set the color of your terminal. For example, typing this code changes the subsequent text to green:
+
+
+```
+`$ printf '\033[32m'`
+```
+
+As long as you see color the same way your computer does, you could use color to help you remember what system you're logged into. For example, if you regularly SSH into your server, you can set your server prompt to green to help you differentiate it at a glance from your local prompt. For a green prompt, use the ANSI code for green before your prompt character and end it with the code representing your normal default color:
+
+
+```
+`export PS1=`printf "\033[32m$ \033[39m"``
+```
+
+### Foreground and background
+
+You're not limited to setting the color of your text. With ANSI codes, you can control the background color of your text as well as do some rudimentary styling.
+
+For instance, with **\033[4m**, you can cause text to be underlined, or with **\033[5m** you can set it to blink. That might seem silly at first—because you're probably not going to set your terminal to underline all text and blink all day—but it can be useful for select functions. For instance, you might set an urgent error produced by a shell script to blink (as an alert for your user), or you might underline a URL.
+
+For your reference, here are the foreground and background color codes. Foreground colors are in the 30 range, while background colors are in the 40 range:
+
+Color | Foreground | Background
+---|---|---
+Black | \033[30m | \033[40m
+Red | \033[31m | \033[41m
+Green | \033[32m | \033[42m
+Orange | \033[33m | \033[43m
+Blue | \033[34m | \033[44m
+Magenta | \033[35m | \033[45m
+Cyan | \033[36m | \033[46m
+Light gray | \033[37m | \033[47m
+Fallback to distro's default | \033[39m | \033[49m
+
+There are some additional colors available for the background:
+
+Color | Background
+---|---
+Dark gray | \033[100m
+Light red | \033[101m
+Light green | \033[102m
+Yellow | \033[103m
+Light blue | \033[104m
+Light purple | \033[105m
+Teal | \033[106m
+White | \033[107m
+
+### Permanency
+
+Setting colors in your terminal session is only temporary and relatively unconditional. Sometimes the effect lasts for a few lines; that's because this method of setting colors relies on a printf statement to set a mode that lasts only until something else overrides it.
+
+The way a terminal emulator typically gets instructions on what colors to use is from the settings of the LS_COLORS environment variable, which is in turn populated by the settings of dircolors. You can view your current settings with an echo statement:
+
+
+```
+$ echo $LS_COLORS
+rs=0:di=38;5;33:ln=38;5;51:mh=00:pi=40;
+38;5;11:so=38;5;13:do=38;5;5:bd=48;5;
+232;38;5;11:cd=48;5;232;38;5;3:or=48;
+5;232;38;5;9:mi=01;05;37;41:su=48;5;
+196;38;5;15:sg=48;5;11;38;5;16:ca=48;5;
+196;38;5;226:tw=48;5;10;38;5;16:ow=48;5;
+[...]
+```
+
+Or you can use dircolors directly:
+
+
+```
+$ dircolors --print-database
+[...]
+# image formats
+.jpg 01;35
+.jpeg 01;35
+.mjpg 01;35
+.mjpeg 01;35
+.gif 01;35
+.bmp 01;35
+.pbm 01;35
+.tif 01;35
+.tiff 01;35
+[...]
+```
+
+If that looks cryptic, it's because it is. The first digit after a file type is the attribute code, and it has six options:
+
+ * 00 none
+ * 01 bold
+ * 04 underscore
+ * 05 blink
+ * 07 reverse
+ * 08 concealed
+
+
+
+The next digit is the color code in a simplified form. You can get the color code by taking the final digit of the ANSII code (32 for green foreground, 42 for green background; 31 or 41 for red, and so on).
+
+Your distribution probably sets LS_COLORS globally, so all users on your system inherit the same colors. If you want a customized set of colors, you can use dircolors for that. First, generate a local copy of your color settings:
+
+
+```
+`$ dircolors --print-database > ~/.dircolors`
+```
+
+Edit your local list as desired. When you're happy with your choices, save the file. Your color settings are just a database and can't be used directly by [ls][3], but you can use dircolors to get shellcode you can use to set LS_COLORS:
+
+
+```
+$ dircolors --bourne-shell ~/.dircolors
+LS_COLORS='rs=0:di=01;34:ln=01;36:mh=00:
+pi=40;33:so=01;35:do=01;35:bd=40;33;01:
+cd=40;33;01:or=40;31;01:mi=00:su=37;41:
+sg=30;43:ca=30;41:tw=30;42:ow=34;
+[...]
+export LS_COLORS
+```
+
+Copy and paste that output into your ~/.bashrc file and reload. Alternatively, you can dump that output straight into your .bashrc file and reload.
+
+
+```
+$ dircolors --bourne-shell ~/.dircolors >> ~/.bashrc
+$ source ~/.bashrc
+```
+
+You can also make Bash resolve .dircolors upon launch instead of doing the conversion manually. Realistically, you're probably not going to change colors often, so this may be overly aggressive, but it's an option if you plan on changing your color scheme a lot. In your .bashrc file, add this rule:
+
+
+```
+`[[ -e $HOME/.dircolors ]] && eval "`dircolors --sh $HOME/.dircolors`"`
+```
+
+Should you have a .dircolors file in your home directory, Bash evaluates it upon launch and sets LS_COLORS accordingly.
+
+### Color
+
+Colors in your terminal are an easy way to give yourself a quick visual reference for specific information. However, you might not want to lean on them too heavily. After all, colors aren't universal, so if someone else uses your system, they may not see the colors the same way you do. Furthermore, if you use a variety of tools to interact with computers, you might also find that some terminals or remote connections don't provide the colors you expect (or colors at all).
+
+Those warnings aside, colors can be useful and fun in some workflows, so create a .dircolor database and customize it to your heart's content.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/linux-terminal-colors
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sethhttps://opensource.com/users/jason-bakerhttps://opensource.com/users/tlaihttps://opensource.com/users/amjithhttps://opensource.com/users/greg-phttps://opensource.com/users/marcobravo
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/freedos.png?itok=aOBLy7Ky (4 different color terminal windows with code)
+[2]: https://opensource.com/article/19/8/what-are-environment-variables
+[3]: https://opensource.com/article/19/7/master-ls-command
diff --git a/sources/tech/20190906 Introduction to monitoring with Pandora FMS.md b/sources/tech/20190906 Introduction to monitoring with Pandora FMS.md
new file mode 100644
index 0000000000..2c88ffc6e5
--- /dev/null
+++ b/sources/tech/20190906 Introduction to monitoring with Pandora FMS.md
@@ -0,0 +1,221 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Introduction to monitoring with Pandora FMS)
+[#]: via: (https://opensource.com/article/19/9/introduction-monitoring-pandora-fms)
+[#]: author: (Sancho Lerena https://opensource.com/users/slerenahttps://opensource.com/users/jimmyolanohttps://opensource.com/users/alanfdoss)
+
+Introduction to monitoring with Pandora FMS
+======
+Open source, all-purpose monitoring software monitors network equipment,
+servers, virtual environments, applications, and much more.
+![A network diagram][1]
+
+Pandora Flexible Monitoring Solution (FMS) is all-purpose monitoring software, which means it can control network equipment, servers (Linux and Windows), virtual environments, applications, databases, and a lot more. It can do both remote monitoring and monitoring based on agents installed on the servers. You can get collected data in reports and graphs and raise alerts if something goes wrong.
+
+Pandora FMS is offered in two versions: the [open source community edition][2] is aimed at private users and organizations of any size and is fully functional and totally free, while the [enterprise version][3] is designed to facilitate the work of companies, as it has support services and special features for large environments. Both versions are updated every month and accessible directly from the console.
+
+### Installing Pandora FMS
+
+#### Getting started
+
+Linux is the Pandora FMS's preferred operating system, but it also works perfectly under Windows. CentOS 7 is the recommended distribution, and there are installation packages in Debian/Ubuntu and SUSE Linux. If you feel brave, you can install it from source on other distros or FreeBSD or Solaris, but professional support is available only in Linux.
+
+For a small test, you will need a server with at least 4GB of RAM and about 20GB of free disk space. With this environment, you can monitor 200 to 300 servers easily. Pandora FMS has different ways to scale, and it can monitor several thousand servers in a single instance. By combining several instances, clients with even 100,000 devices can be monitored.
+
+#### ISO installation
+
+The easiest way to install Pandora FMS is to use the ISO image, which contains a CentOS 7 version with all the dependencies. The following steps will get Pandora FMS ready to use in just five minutes.
+
+ 1. [Download][4] the ISO from Pandora FMS's website.
+ 2. Burn it onto a DVD or USB stick, or boot it from your virtual infrastructure manager (e.g., VMware, Xen, VirtualBox).
+ 3. Boot the image and proceed to the guided setup (a standard CentOS setup process). Set a unique password for the root user.
+ 4. Identify the IP address of your new system.
+ 5. Access the Pandora FMS console, using the IP address of the system where you installed Pandora FMS. Open a web browser and enter **http://<pandora_ip_address>/pandora_console** and log in as **admin** using the default password **pandora**.
+
+
+
+Congratulations, you're in! You can skip the other installation methods and [jump ahead][5] to start monitoring something real.
+
+#### Docker installation
+
+ 1. First, launch Pandora FMS with this command: [code]`curl -sSL http://pandorafms.org/getpandora | sh`[/code] You can also run Pandora FMS as a container by executing: [code] docker run --rm -ti -p 80:80 -p 443:443 \
+ --name pandorafms pandorafms/pandorafms:latest
+```
+ 2. Once Pandora FMS is running, open your browser and enter
+**http://<ip address>/pandora_console**. Log in as **admin** with the default password **pandora**.
+
+
+
+The Docker container is at [hub.docker.com/r/pandorafms/pandorafms][6].
+
+### Yum installation
+
+You can install Pandora FMS for Red Hat Enterprise Linux or CentOS 7 in just five steps.
+
+ 1. Activate CentOS Updates, CentOS Extras, and EPEL in [your repository's library][7].
+
+ 2. Add the official Pandora FMS repo to your system: [code] [artica_pandorafms]
+
+name=CentOS7 - PandoraFMS official repo
+baseurl=
+gpgcheck=0
+enabled=1
+```
+
+ 3. Install the packages from the repo and solve all dependencies: [code]`yum install pandorafms_console pandorafms_server mariadb-server`
+```
+ 4. Reload services if you need to install Apache or MySQL/MariaDB: [code] service httpd reload (or equivalent)
+
+service mysqld reload (or equivalent)
+```
+
+ 5. Open your browser and enter **http://<ip address>/pandora_console**. Proceed with the setup process. After accepting the license and doing a few pre-checks, you should see something like this:
+
+
+
+
+![Pandora FMS environment and database setup][8]
+
+This screen is only needed when you install using the RPM, DEB, or source code (Git, tarball, etc.). This step of the console configuration uses MySQL credentials (which you need to know) to create a database and a username and password for Pandora FMS console and server. You need to set up the server password manually (yep! Vim or Nano?) by editing the **/etc/pandora/pandora_server.conf** file (follow the [instructions in the documentation][9]).
+
+Restart the Pandora FMS server, and everything should be ready.
+
+#### Other ways to install Pandora FMS
+
+If none of these installation methods work with your setup, other options include a Git checkout, tarball with sources, DEB package (with the .deb online repo), and SUSE RPM. You can learn more about these installation methods in the [installing wiki][10].
+
+Grabbing the code is pretty easy with Git:
+
+
+```
+`git clone https://github.com/pandorafms/pandorafms.git`
+```
+
+### Monitoring with Pandora FMS
+
+When you log into the console, you will see a welcome screen.
+
+![Pandora FMS welcome screen][11]
+
+#### Monitoring something connected to the network
+
+Let's begin with the most simple thing to do: ping to a host. First, create an agent by selecting **Resources** then **Manage Agents** from the menu.
+
+![Locating the Manage Agents menu][12]
+
+Click on **Create** at the bottom of the page, and fill the basic information (don't go crazy, just add your IP address and name).
+
+![Enter basic data in the Agent Manager][13]
+
+Go to the **Modules** tab and create a network module.
+
+![Create a network module][14]
+
+Use the Module component (which comes from an internal library pre-defined in Pandora FMS) to choose the ping by selecting **Network Management** and entering **Host Alive**.
+
+![Choosing Host Alive ping][15]
+
+Click on **Save** and go back to the "view" interface by clicking the "eye" icon on the right.
+
+![Menu bar with "eye" icon][16]
+
+Congratulations! Your ping is running (you know it because it's green).
+
+![Console showing ping is running][17]
+
+This is the manual way; you can also use the wizard to grab an entire Simple Network Management Protocol (SNMP) device to show interfaces, or you can use a bulk operation to copy a configuration from one device to another, or you can use the command-line interface (CLI) API to do configurations automatically. Review the [online wiki][18], with over 1200 articles of documentation, to learn more.
+
+The following shows an old Sonicwall NSA 250M Firewall monitored with the SNMP wizard. It shows data on status interfaces, active connections, CPU usage, active VPN, and a lot more.
+
+![Console showing firewall monitoring][19]
+
+Remote monitoring supports SNMP v.1, 2, and 3; Windows Management Instrumentation (WMI); remote SSH calls; SNMP trap capturing; and NetFlow monitoring.
+
+#### Monitoring a server with an agent
+
+Installing a Linux agent in Red Hat/CentOS is simple. Enter:
+
+
+```
+`yum install pandorafms_agent_unix`
+```
+
+Edit **/etc/pandora/pandora_agent.conf** and set up the IP address of your Pandora FMS server:
+
+
+```
+`server_ip `
+```
+
+Restart the agent and wait a few seconds for the console to show the data.
+
+![Console monitoring a Linux agent][20]
+
+In the main agent view, you can see events, data, and history; define the threshold for status change; and set up alerts to warn you when something is wrong. Months worth of data is available for graphs, reports, and service-level agreement (SLA) compliance.
+
+Installing a Windows agent is even easier because the installer supports automation for unattended setups. Start by downloading the agent and doing some usual routines. At some point, it will ask you for your server IP and the name for the agent, but that's all.
+
+![Pandora FMS Windows setup screen][21]
+
+Windows agents support grabbing service status and processes, executing local commands to get information, getting Windows events, native WMI calls, obtaining performance counters directly from the system, and providing a lot more information than the basic CPU/RAM/disk stuff. It uses the same configuration file as the Linux version (pandora_agent.conf), which you can edit with a text editor like Notepad. Editing is very easy; you should be able to add your own checks in less than a minute.
+
+### Creating graphs, reports, and SLA checks
+
+Pandora FMS has lots of options for graphs and reports, including on SLA compliance, in both the open source and enterprise versions.
+
+![Pandora FMS SLA compliance report][22]
+
+Pandora FMS's Visual Map feature allows you to create a map of information that combines status, data, graphs, icons, and more. You can edit it using an online editor. Pandora FMS is 100% operable from the console; no desktop application or Java is needed, nor do you need to execute commands from the console.
+
+Here are three examples.
+
+![Pandora FMS support ticket graph][23]
+
+![Pandora FMS network status graph][24]
+
+![Pandora FMS server status graph][25]
+
+If you would like to learn more about Pandora FMS, visit the [website][2] or ask questions in the [forum][26].
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/introduction-monitoring-pandora-fms
+
+作者:[Sancho Lerena][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/slerenahttps://opensource.com/users/jimmyolanohttps://opensource.com/users/alanfdoss
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LAW_fedora_cla.png?itok=O927VLkU (A network diagram)
+[2]: https://pandorafms.org/
+[3]: https://pandorafms.com/
+[4]: http://pandorafms.org/features/free-download-monitoring-software/
+[5]: tmp.jGrBq9KQnv#Monitoring
+[6]: https://hub.docker.com/r/pandorafms/pandorafms
+[7]: https://pandorafms.com/docs/index.php?title=Pandora:Documentation_en:Installing#Installation_in_Red_Hat_Enterprise_Linux_.2F_Fedora_.2F_CentOS
+[8]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-1.png (Pandora FMS environment and database setup)
+[9]: https://pandorafms.com/docs/index.php?title=Pandora:Documentation_en:Installing#Server_Initialization_and_Basic_Configuration
+[10]: https://pandorafms.com/docs/index.php?title=Pandora:Documentation_en:Installing
+[11]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-2.png (Pandora FMS welcome screen)
+[12]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-3.png (Locating the Manage Agents menu)
+[13]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-4.png (Enter basic data in the Agent Manager)
+[14]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-5.png (Create a network module)
+[15]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-6.png (Choosing Host Alive ping)
+[16]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-7.png (Menu bar with "eye" icon)
+[17]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-8.png (Console showing ping is running)
+[18]: https://pandorafms.com/docs/index.php?title=Main_Page
+[19]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-9.png (Console showing firewall monitoring)
+[20]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-10.png (Console monitoring a Linux agent)
+[21]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-11.png (Pandora FMS Windows setup screen)
+[22]: https://opensource.com/sites/default/files/uploads/installing-pandora-fms-12.png (Pandora FMS SLA compliance report)
+[23]: https://opensource.com/sites/default/files/uploads/pandora-fms-visual-console-1.jpg (Pandora FMS support ticket graph)
+[24]: https://opensource.com/sites/default/files/uploads/pandora-fms-visual-console-2.jpg (Pandora FMS network status graph)
+[25]: https://opensource.com/sites/default/files/uploads/pandora-fms-visual-console-3.png (Pandora FMS server status graph)
+[26]: https://pandorafms.org/forum/
diff --git a/sources/tech/20190906 Performing storage management tasks in Cockpit.md b/sources/tech/20190906 Performing storage management tasks in Cockpit.md
new file mode 100644
index 0000000000..133d1437a9
--- /dev/null
+++ b/sources/tech/20190906 Performing storage management tasks in Cockpit.md
@@ -0,0 +1,100 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Performing storage management tasks in Cockpit)
+[#]: via: (https://fedoramagazine.org/performing-storage-management-tasks-in-cockpit/)
+[#]: author: (Shaun Assam https://fedoramagazine.org/author/sassam/)
+
+Performing storage management tasks in Cockpit
+======
+
+![][1]
+
+In the [previous article][2] we touched upon some of the new features introduced to Cockpit over the years. This article will look into some of the tools within the UI to perform everyday storage management tasks. To access these functionalities, install the _cockpit-storaged_ package:
+
+```
+sudo dnf install cockpit-storaged
+```
+
+From the main screen, click the **Storage** menu option in the left column. Everything needed to observe and manage disks is available on the main Storage screen. Also, the top of the page displays two graphs for the disk’s reading and writing performance with the local filesystem’s information below. In addition, the options to add or modify RAID devices, volume groups, iSCSI devices, and drives are available as well. In addition, scrolling down will reveal a summary of recent logs. This allows admins to catch any errors that require immediate attention.
+
+![][3]
+
+### Filesystems
+
+This section lists the system’s mounted partitions. Clicking on a partition will display information and options for that mounted drive. Growing and shrinking partitions are available in the **Volume** sub-section. There’s also a filesystem subsection that allows you to change the label and configure the mount.
+
+If it’s part of a volume group, other logical volumes in that group will also be available. Each standard partition has the option to delete and format. Also, logical volumes have an added option to deactivate the partition.
+
+![][4]
+
+### RAID devices
+
+Cockpit makes it super-easy to manage RAID drives. With a few simple clicks the RAID drive is created, formatted, encrypted, and mounted. For details, or a how-to on creating a RAID device from the CLI check out the article [Managing RAID arrays with mdadm][5].
+
+To create a RAID device, start by clicking the add (**+**) button. Enter a name, select the type of RAID level and the available drives, then click **Create**. The RAID section will show the newly created device. Select it to create the partition table and format the drive(s). You can always remove the device by clicking the **Stop** and **Delete** buttons in the top-right corner.
+
+![][6]
+
+### Logical volumes
+
+By default, the Fedora installation uses LVM when creating the partition scheme. This allows users to create groups, and add volumes from different disks to those groups. The article, [Use LVM to Upgrade Fedora][7], has some great tips and explanations on how it works in the command-line.
+
+Start by clicking the add (**+**) button next to “Volume Groups”. Give the group a name, select the disk(s) for the volume group, and click **Create**. The new group is available in the Volume Groups section. The example below demonstrates a new group named “vgraiddemo”.
+
+Now, click the newly made group then select the option to **Create a New Logical Volume**. Give the LV a name and select the purpose: Block device for filesystems, or pool for thinly provisioning volumes. Adjust the amount of storage, if necessary, and click the **Format** button to finalize the creation.
+
+![][8]
+
+Cockpit can also configure current volume groups. To add a drive to an existing group, click the name of the volume group, then click the add (**+**) button next to “Physical Volumes”. Select the disk from the list and click the **Add** button. In one shot, not only has a new PV, been created, but it’s also added to the group. From here, we can add the available storage to a partition, or create a new LV. The example below demonstrates how the additional space is used to grow the root filesystem.
+
+![][9]
+
+### iSCSI targets
+
+Connecting to an iSCSI server is a quick process and requires two things, the initiator’s name, which is assigned to the client, and the name or IP of the server, or target. Therefore we will need to change the initiator’s name on the system to match the configurations on the target server.
+
+To change the initiator’s name, click the button with the pencil icon, enter the name, and click **Change**.
+
+To add the iSCSI target, click the add (**+**) button, enter the server’s address, the username and password, if required, and click **Next**. Select the target — verify the name, address, and port, — and click **Add** to finalize the process.
+
+To remove a target, click the “checkmark” button. A red trashcan will appear beside the target(s). Click it to remove the target from the setup list.
+
+![][10]
+
+### NFS mount
+
+Cockpit even allows sysadmins to configure NFS shares within the UI. To add NFS shares, click the add (**+**) button in the NFS mounts section. Enter the server’s address, the path of the share on the server, and a location on the local machine to mount the share. Adjust the mount options if needed and click **Add** to view information about the share. We also have the options to unmount, edit, and remove the share. The example below demonstrates how the NFS share on SERVER02 is mounted to the _/mnt_ directory.
+
+![][11]
+
+### Conclusion
+
+As we’ve seen in this article, a lot of the storage-related tasks that require lengthy, and multiple, lines of commands can be easily done within the web UI with just a few clicks. Cockpit is continuously evolving and every new feature makes the project better and better. In the next article we’ll explore the features and components on the networking side of things.
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/performing-storage-management-tasks-in-cockpit/
+
+作者:[Shaun Assam][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/sassam/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-storage-816x345.png
+[2]: https://fedoramagazine.org/cockpit-and-the-evolution-of-the-web-user-interface/
+[3]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-storage-main-screen.png
+[4]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-filesystem.png
+[5]: https://fedoramagazine.org/managing-raid-arrays-with-mdadm/
+[6]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-raid.gif
+[7]: https://fedoramagazine.org/use-lvm-upgrade-fedora/
+[8]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-lvm-volgroup.gif.gif
+[9]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-lvm-pv_lv.gif.gif
+[10]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-iscsi-storage.gif
+[11]: https://fedoramagazine.org/wp-content/uploads/2019/08/cockpit-nfs-storage.gif
diff --git a/translated/talk/20180116 Command Line Heroes- Season 1- OS Wars_2.md b/translated/talk/20180116 Command Line Heroes- Season 1- OS Wars_2.md
deleted file mode 100644
index 040a2d2836..0000000000
--- a/translated/talk/20180116 Command Line Heroes- Season 1- OS Wars_2.md
+++ /dev/null
@@ -1,162 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (lujun9972)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Command Line Heroes: Season 1: OS Wars)
-[#]: via: (https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux)
-[#]: author: (redhat https://www.redhat.com)
-
-代码英雄:第一季:操作系统大战(第二部分 Linux 崛起)
-======
-Saron Yitbarek: 这玩意开着的吗?让我们进一段史诗般的星球大战的开幕吧,开始了。
-
-配音:[00:00:30] 第二集 :Linux® 的崛起。微软帝国控制着 90% 的桌面用户。操作系统的全面标准化似乎是板上钉钉的事了。然而,互联网的出现将战争的焦点从桌面转向了企业,在该领域,所有商业组织都争相构建自己的服务器。与此同时,一个不太可能的英雄出现在开源反叛组织中。固执,戴着眼镜的 Linus Torvalds 免费发布了他的 Linux 系统。微软打了个趔趄-并且开始重组。
-
-Saron Yitbarek: [00:01:00] 哦,我们书呆子就是喜欢那样。上一次我们讲到哪了?苹果和微软互相攻伐,试图在一场争夺桌面用户的战争中占据主导地位。在第一集的结尾,我们看到微软获得了大部分的市场份额。很快,由于互联网的兴起以及随之而来的开发者大军,整个市场都经历了一场地震。互联网将战场从在家庭和办公室中的个人电脑用户转移到拥有数百台服务器的大型商业客户中。
-
-[00:01:30] 这意味着巨量资源的迁移。突然间,所有相关企业不仅被迫为服务器空间和网站建设付费,而且还必须集成软件来进行资源跟踪和数据库监控等工作。你需要很多开发人员来帮助你。至少那时候大家都是这么做的。
-
-在操作系统之战的第二部分,我们将看到优先级的巨大转变,以及像 Linus Torvalds 和 Richard Stallman 这样的开源叛逆者是如何成功地在微软和整个软件行业的核心地带引起恐惧的。
-
-[00:02:00] 我是 Saron Yitbarek,您现在收听的是代码英雄,一款红帽公司原创的播客节目。每一集,我们都会给您带来“从码开始”改变技术的人的故事。
-
-[00:02:30] 好。假设你是 1991 年的微软。你自我感觉良好,对吧?满怀信心。确定全球主导的地位感觉不错。你已经掌握了与其他企业合作的艺术,但是仍然将大部分开发人员、程序员和系统管理员排除在联盟之外,而他们才是真正的步兵。这是出现了个叫 Linus Torvalds 的芬兰极客。他和他的开源程序员团队正在开始发布 Linux,其操作系统内核是由他们一起编写出来的。
-
-[00:03:00] 坦白地说,如果你是微软公司,你并不会太在意 Linux,甚至是一般意义上的开源运动,但是最终,Linux 的规模变得如此之大,以至于微软不可能不注意到。Linux 第一个版本出现在 1991 年,当时大概有 10000 行代码。十年后,变成了 300 万行代码。如果你想知道,今天则是 2000 万行代码。
-
-[00:03:30] 让我们停留在 90 年代初一会儿。那是 Linux 还没有成为我们现在所知道的庞然大物。只是这个奇怪的病毒式的操作系统正在这个星球上蔓延,全世界的极客和黑客都爱上了它。那时候我还太年轻,但依然希望加入他们。在那个时候,发现 Linux 就如同进入了一个秘密社会一样。程序员与朋友分享 Linux CD 集,就像其他人分享地下音乐混音带一样。
-
-Developer Tristram Oaten [00:03:40] 讲讲了你 16 岁时第一次接触 Linux 的故事吧。
-
-Tristram Oaten: [00:04:00] 我和我的家人去了 Red Sea 上的 Hurghada 潜水度假。那是一个美丽的地方,强烈推荐。第一天,我喝了自来水。也许,我妈妈跟我说过不要这么做。我整个星期都病得很厉害,没有离开旅馆房间。当时我只带了一台新安装了 Slackware Linux 的笔记本电脑,我听说过这玩意并且正在尝试使用它。这台笔记本上没有额外的应用程序,只有 8 张 cd。出于必要,整个星期我所做的就是去了解这个外星一般的系统。我阅读手册,摆弄着终端。我记得当时我甚至我不知道一个点(表示当前目录)和两个点(表示前一个目录)之间的区别。
-
-[00:04:30] 我一点头绪都没有。犯过很多错误,但慢慢地,在这种强迫的孤独中,我突破了障碍,开始理解并明白命令行到底是怎么回事。假期结束时,我没有看过金字塔、尼罗河等任何埃及遗址,但我解锁了现代世界的一个奇迹。我解锁了 Linux,接下来的事大家都知道了。
-
-Saron Yitbarek: 你可以从很多人那里听到关于这个故事的不同说法。访问 Linux 命令行是一种革命性的体验。
-
-David Cantrell: 它给了我源代码。我当时的感觉是,"太神奇了。"
-
-Saron Yitbarek: 我们正在参加一个名为 Flock to Fedora 的 2017 年 Linux 开发者大会。
-
-David Cantrell: .。. 非常有吸引力。我觉得我对这个系统有了更多的控制力,它越来越吸引我。我想,从那时起,1995 年我第一次编译 Linux 内核时,我就迷上了它。
-
-Saron Yitbarek: 开发者 David Cantrell 与 Joe Brockmire。
-
-Joe Brockmeier: 我寻遍了便宜软件最终找到一套四张 CD 的 Slackware Linux。它看起来来非常令人兴奋而且很有趣,所以我把它带回家,安装在第二台电脑上,开始摆弄它,并为两件事情感到兴奋。一个是,我运行的不是 Windows,另一个我 Linux 的开源特性。
-
-Saron Yitbarek: [00:06:00] 某种程度上来说,对命令行的访问总是存在的。在开源真正开始流行还要早几十年前,人们(至少在开发人员中是这样)总是希望能够做到完全控制。让我们回到操作系统大战之前的那个时代,在苹果和微软他们的 GUI 而战之前。那时也有代码英雄。保罗·琼斯 (Paul Jones) 教授(在线图书馆 ibiblio.org 负责人)在那个古老的时代,就是一名开发人员。
-
-Paul Jones: [00:07:00] 从本质上讲,互联网在那个时候比较少是客户端-服务器架构的,而是更多是点对点架构的。讲真,当我们说,某种 VAX 到 VAX,某科学工作站,科学工作站。这并不意味着没有客户端与服务端的关系以及没有应用程序,但这的确意味着,最初的设计是思考如何实现点对点,它与 IBM 一直在做的东西相对立。IBM 给你的只有哑终端,这种终端只能让你管理用户界面,却无法让你像真正的终端一样为所欲为。
-
-Saron Yitbarek: 图形用户界面在普通用户中普及的同时,在工程师和开发人员中总是存在和一股相反的力量。早在 20 世纪 70 年代和 80 年代的 Linux 出现之前,这股力量就存在于 EMAX 和 GNU 中。有了斯托尔曼的自由软件基金会后,总有某些人想要使用命令行,但上世纪 90 年代的 Linux 的交付方式是独一无二的。
-
-[00:07:30] Linux 和其他开源软件的早期爱好者是都是先驱。我正站在他们的肩膀上。我们都是。
-
-您现在收听的是代码英雄,一款由红帽公司原创的播客。这是操作系统大战的第二部分:Linux 崛起。
-
-Steven Vaughan-Nichols: 1998 年的时候,情况发生了变化。
-
-Saron Yitbarek: Steven Vaughan-Nichols 是 zdnet.com 的特约编辑,他已经写了几十年关于技术商业方面的文章了。他将向我们讲述 Linux 是如何慢慢变得越来越流行,直到自愿贡献者的数量远远超过了在 Windows 上工作的微软开发人员的数量的。不过,Linux 从来没有真正关注过微软的台式机客户,这也许就是微软最开始时忽略了 Linux 及其开发者的原因。Linux 真正大放光彩的地方是在服务器机房。当企业开始线上业务时,每个企业都需要一个独特的编程解决方案来满足其需求。
-
-[00:08:30] WindowsNT 于 1993 年问世,当时它已经在与其他的服务器操作系统展开竞争了,但是许多开发人员都在想,“既然我可以通过 Apache 构建出基于 Linux 的廉价系统,那我为什么要购买 AIX 设备或大型 Windows 设备呢?”关键点在于,Linux 代码已经开始渗透到几乎所有在线的东西中。
-
-Steven Vaughan-Nichols: [00:09:00] 令微软感到惊讶的是,它开始意识到,Linux 实际上已经开始有一些商业应用,不是在桌面环境,而是在商业服务器上。因此,他们发起了一场运动,我们称之为 FUD- 恐惧、不确定和怀疑 (fear,uncertainty 和 double)。他们说,“哦,Linux 这玩意,真的没有那么好。它不太可靠。你一点都不能相信它”。
-
-Saron Yitbarek: [00:09:30] 这种软宣传式的攻击持续了一段时间。微软也不是唯一一个对 Linux 感到紧张的公司。这其实是整个行业在对抗这个奇怪新人的挑战。例如,任何与 UNIX 有利害关系的人都可能将 Linux 视为篡夺者。有一个案例很著名,那就是 SCO 组织(它发行过一种版本的 UNIX) 在过去 10 多年里发起一系列的诉讼,试图阻止 Linux 的传播。SCO 最终失败而且破产了。与此同时,微软一直在寻找机会。他们势在必行。只不过目前还不清楚具体要怎么做。
-
-Steven Vaughan-Nichols: [00:10:30] 让微软真正担心的是,第二年,在 2000 年的时候,IBM 宣布,他们将于 2001 年投资 10 亿美元在 Linux 上。现在,IBM 已经不再涉足个人电脑业务。他们还没有走出去,但他们正朝着这个方向前进,他们将 Linux 视为服务器和大型计算机的未来,在这一点上,剧透警告,IBM 是正确的。Linux 将主宰服务器世界。
-
-Saron Yitbarek: 这已经不再仅仅是一群黑客喜欢命令行的 Jedi 式的控制了。金钱的投入对 Linux 助力极大。Linux 国际的执行董事 John "Mad Dog" Hall 有一个故事可以解释为什么会这样。我们通过电话与他取得了联系。
-
-John Hall: [00:11:30] 我的一个朋友名叫 Dirk Holden[00:10:56],他是德国德意志银行的一名系统管理员,他也参与了个人电脑上早期 X Windows 系统的图形项目中的工作。有一天我去银行拜访他,我说 :“Dirk,你银行里有 3000 台服务器,用的都是 Linux。为什么不用 Microsoft NT 呢?”他看着我说:“是的,我有 3000 台服务器,如果使用微软的 Windows NT 系统,我需要 2999 名系统管理员。”他继续说道:“而使用 Linux,我只需要四个。”这真是完美的答案。
-
-Saron Yitbarek: [00:12:00] 程序员们着迷的这些东西恰好对大公司也极具吸引力。但由于 FUD 的作用,一些企业对此持谨慎态度。他们听到开源,就想:"开源。这看起来不太可靠,很混乱,充满了 BUG"。但正如那位银行经理所指出的,金钱听过一种有趣的方式,说服人们克服困境。甚至那些需要网站的小公司也加入了 Linux 阵营。与一些昂贵的专有选择相比,使用一个廉价的 Linux 系统在成本上是无法比拟的。如果您是一家雇佣专业人员来构建网站的商店,那么您很定想让他们使用 Linux。
-
-[00:12:30] 让我们快进几年。Linux 运行每个人的网站上。Linux 已经征服了服务器世界,然后智能手机也随之诞生。当然,苹果和他们的 iPhone 占据了相当大的市场份额,而且微软也希望能进入这个市场,但令人惊讶的是,Linux 也在那,已经做好准备了,迫不及待要大展拳脚。
-
-作家兼记者 James Allworth。
-
-James Allworth: [00:13:00] 当然还有容纳第二个竞争者的空间,那本可以是微软,但是实际上却是 Android,而 Andrid 基本上是基于 Linux 的。众所周知,Android 被谷歌所收购,现在运行在世界上大部分的智能手机上,谷歌在 Linux 的基础上创建了 Android。Linux 使他们能够以零成本从一个非常复杂的操作系统开始。他们成功地实现了这一目标,最终将微软挡在了下一代设备之外,至少从操作系统的角度来看是这样。
-
-Saron Yitbarek: [00:13:30] 天崩地裂了,很大程度上,微软有被埋没的风险。John Gossman 是微软 Azure 团队的首席架构师。他还记得当时困扰公司的困惑。
-
-John Gossman: [00:14:00] 像许多公司一样,微软也非常担心知识产权污染。他们认为,如果允许开发人员使用开源代码,那么很可能只是复制并粘贴一些代码到某些产品中,就会让某种病毒式的许可证生效从而引发未知的风险…,我认为,这跟公司文化有关,很多公司,包括微软,都对开源开发的意义和商业模式之间的分歧感到困惑。有一种观点认为,开源意味着你所有的软件都是免费的,人们永远不会付钱。
-
-Saron Yitbarek: [00:14:30] 任何投资于旧的、专有软件模型的人都会觉得这里发生的一切对他们构成了威胁。当你威胁到像微软这样的大公司时,是的,他们一定会做出反应。他们推动所有这些 FUD(fear,uncertainty,doubt)- 恐惧,不确定性和怀疑是有道理的。当时,商业运作的方式基本上就是相互竞争。不过,如果他们是其他公司的话 (If they'd been any other company,看不懂什么意思),他们可能还会怀恨在心,抱着旧有的想法,但到了 2013 年,一切都变了。
-
-[00:15:00] 微软的云计算服务 Azure 上线了,令人震惊的是,它从第一天开始就提供了 Linux 虚拟机。Steve Ballmer,这位把 Linux 称为癌症的首席执行官,已经离开了,代替他的是一位新的有远见的首席执行官 Satya Nadella。
-
-John Gossman: Satya 有不同的看法。他属于另一个世代。比 Paul,Bill 和 Steve 更年轻的世代,他对开源有不同的看法。
-
-Saron Yitbarek: John Gossman,再说一次,来自于 微软的 Azure 团队。
-
-John Gossman: [00:16:00] 大约四年前,处于实际需要,我们在 Azure 中添加了 Linux 支持。如果访问任何一家企业客户,你都会发现他们并没有试图决定是使用 Windows 还是使用 Linux、 使用 .net 还是使用 Java TM。他们在很久以前就做出了决定——大约 15 年前才有这样的一些争论。现在,我见过的每一家公司都混合了 Linux 和 Java、Windows 和 .net、SQL Server、Oracle 和 MySQL—— 基于专有源代码的产品和开放源代码的产品。
-
-如果你正在运维着一个云,允许这些公司在云上运行他们的业务,那么你就不能简单地告诉他们,“你可以使用这个软件,但你不能使用那个软件。”
-
-Saron Yitbarek: [00:16:30] 这正是 Satya Nadella 采纳的哲学思想。2014 年秋季,他站在舞台上,希望传递一个重要信息。微软爱 Linux。他接着说,Azure 20% 的业务量已经是 Linux 了,微软将始终对 Linux 发行版提供一流的支持。没有哪怕一丝对开源的宿怨。
-
-为了说明这一点,在他们的背后有一个巨大的标志,上面写着 :“Microsoft hearts Linux”。哇哇哇。对我们中的一些人来说,这种转变有点令人震惊,但实际上,无需如此震惊。下面是 Steven Levy,一名科技记者兼作家。
-
-Steven Levy: [00:17:30] 当你在踢足球的时候,如果草坪变滑了,那么你也许会换一种不同的鞋子。他们当初就是这么做的。他们不能否认现实而且他们之间也有有聪明人,所以他们必须意识到,这就是世界的运行方式,不管他们早些时候说了什么,即使他们对之前的言论感到尴尬,但是让他们之前关于开源多么可怕的言论影响到现在明智的决策那才真的是疯了。
-
-Saron Yitbarek: [00:18:00] 微软低下了它高傲的头。你可能还记得苹果公司,经过多年的孤立无援,最终转向与微软构建合作伙伴关系。现在轮到微软进行 180 度转变了。经过多年的与开源方法的战斗后,他们正在重塑自己。要么改变,要么死亡。Steven Vaughan-Nichols。
-
-Steven Vaughan-Nichols: [00:18:30] 即使是像微软这样规模的公司也无法与成千上万的开源开发者竞争,这些开发者开发这包括 Linux 在内的其他大项目。很长时间以来他们都不愿意这么做。前微软首席执行官史蒂夫·鲍尔默 (SteveBallmer) 对 Linux 深恶痛绝。由于它的 GPL 许可证,让 Linux 称为一种癌症,但一旦鲍尔默被扫地出门,新的微软领导层说,“这就好像试图命令潮流不要过来,但潮水依然会不断涌进来。我们应该与 Linux 合作,而不是与之对抗。”
-
-Saron Tiebreak: [00:19:00] 真的,在线技术历史上最大的胜利之一就是微软能够做出这样的转变,当他们最终决定这么做的时候。当然,当微软出现在开源的桌子上时,老的、铁杆 Linux 支持者是相当怀疑的。他们不确定自己是否能接受这些家伙,但正如沃恩-尼科尔斯所指出的,今天的微软根本不是你父母的微软。事实上,互联网技术历史上最大的胜利之一就是让微软最终做出如此转变。当然,当微软出现在开源桌上时,老一代的、铁杆 Linux 支持者是相当怀疑的。他们不确定自己是否能接受这些家伙,但正如 Vaughan-Nichols 所指出的,今天的微软已经不是你父母那一代时的微软了。
-
-Steven Vaughan-Nichols : [00:19:30] 2017 年的微软既不是史蒂夫•鲍尔默 (Steve Ballmer) 的微软,也不是比尔•盖茨 (Bill Gates) 的微软。这是一家完全不同的公司,有着完全不同的方法,而且,开源软件一旦被放出,就无法被收回。开源已经吞噬了整个技术世界。从未听说过 Linux 的人可能对它并不了解,但是每次他们访问 Facebook,他们都在运行 Linux。每次执行谷歌搜索时,你都在运行 Linux。
-
-[00:20:00] 每次你用 Android 手机,你都在运行 Linux。它确实无处不在,微软无法阻止它,我认为以为微软可以以某种方式接管它的想法,太天真了。
-
-Saron Yitbarek: [00:20:30] 开源支持者可能一直担心微软会像混入羊群中的狼一样,但事实是,开源软件的本质保护了它无法被完全控制。没有一家公司能够拥有 Linux 并以某种特定的方式控制它。Greg Kroah-Hartman 是 Linux 基金会的一名成员。
-
-Greg Kroah-Hartman: 每个公司和个人都以自私的方式为 Linux 做出贡献。他们之所以这样做是因为他们想要解决他们所面临的问题,可能是硬件无法工作,或者是他们想要添加一个新功能来做其他事情,又或者想在他们的产品中使用它。这很棒,因为他们会把代码贡献回去,此后每个人都会从中受益,这样每个人都可以用到这份代码。正是因为这种自私,所有的公司,所有的人,所有的人都能从中受益。
-
-Saron Yitbarek: [00:21:30] 微软已经意识到,在即将到来的云战争中,与 Linux 作战就像与空气作战一样。Linux 和开源不是敌人,它们是一种氛围。今天,微软以白金会员的身份加入了 Linux 基金会。他们成为 GitHub 开源项目的头号贡献者。2017 年 9 月,他们甚至加入了 Open Source Initiative 组织。现在,微软在开放许可下发布了很多代码。微软的 John Gossman 描述了他们开源 .net 时所发生的事情。起初,他们并不认为自己能得到什么回报。
-
-John Gossman: [00:22:00] 我们本没有指望来自社区的贡献,然而,三年后,超过 50% 的对 .net 框架库的贡献来自于微软之外。这包括大量的代码。三星为 .net 提供了 ARM 支持。Intel 和 ARM 以及其他一些芯片厂商已经为 .net 框架贡献了特定于他们处理器的代码生成,以及数量惊人的修复、性能改进等等——既有单个贡献者也有社区。
-
-Saron Yitbarek: 直到几年前,我们今天拥有的这个微软,这个开放的微软,还是不可想象的。
-
-[00:23:00] 我是 Saron Yitbarek,这里是代码英雄。好吧,我们已经看到了为了赢得数百万桌面用户的爱而战的激烈场面。我们已经看到开源软件在私有巨头的背后悄然崛起,并攫取了巨大的市场份额。我们已经看到了一批批的代码英雄将编程领域变成了我你现在看到的这个样子。今天,大企业正在吸收开源软件,通过这一切,每个人都从他人那里受益。
-
-[00:23:30] 在狂野的西方科技界,一贯如此。苹果受到施乐的启发,微软受到苹果的启发,Linux 受到 UNIX 的启发。进化,借鉴,不断成长。如果比喻成大卫和歌利亚(西方经典的以弱胜强战争中的两个主角)的话,开源软件不再是大卫,但是,你知道吗?它也不是歌利亚。开源已经超越了传统。它已经成为其他人战斗的战场。随着开源变得不可避免,新的战争,那些在云计算中进行的战争,那些在开源战场上进行的战争,都在增加。
-
-这是 Steven Levy,他是一名作者。
-
-Steven Levy: [00:24:00] 基本上,到目前为止,包括微软在内,我们有四到五家公司,正以各种方式努力把自己打造成为我们的工作平台,比如人工智能领域。你能看到智能助手之间的战争,你猜怎么着?苹果有一个智能助手,叫 Siri。微软有一个,叫 Cortana。谷歌有谷歌助手。三星也有一个智能助手。亚马逊也有一个,叫 Alexa。我们看到这些战斗遍布各地。也许,你可以说,最热门的人工智能平台将控制我们生活中所有的东西,而这五家公司就是在为此而争斗。
-
-Saron Yitbarek: 现在很难再找到另一个反叛者,它就像 Linux 奇袭微软那样,偷偷潜入 Facebook、 谷歌或亚马逊,攻其不备。因为正如作家 James Allworth 所指出的,成为一个真正的反叛者者只会变得越来越难。
-
-James Allworth: [00:25:30] 规模一直以来都是一种优势,但规模优势本质上……怎么说呢,我认为以前它们在本质上是线性的,现在它们在本质上是指数型的了,所以,一旦你开始以某种方法走在前面,另一个新玩家要想赶上来就变得越来越难了。我认为在互联网时代这大体来说来说是正确的,无论是因为规模,还是数据赋予组织的重要性和优势,就其竞争能力而言。一旦你走在前面,你就会吸引更多的客户,这就给了你更多的数据,让你能做得更好,这之后,客户还有什么理由选择排名第二的公司呢,难道是因为因为他们落后了这么远么?我认为在云的时代这个逻辑也不会有什么不同。
-
-Saron Yitbarek: [00:26:00] 这个故事始于史蒂夫•乔布斯 (Steve Jobs) 和比尔•盖茨 (Bill Gates) 这样的非凡的英雄,但科技的进步已经呈现出一种众包、有机的感觉。我认为据说我们的开源英雄 Linus Torvalds 在第一次发明 Linux 内核时甚至没有一个真正的计划。他无疑是一位才华横溢的年轻开发者,但他也像潮汐前的一滴水一样。变革是不可避免的。据估计,对于一家私有专利公司来说,用他们老式的、专有的方式创建一个 Linux 发行版将花费他们超过 100 亿美元。这说明了开源的力量。
-
-[00:26:30] 最后,这并不是一个专利模型所能与之竞争的东西。成功的公司必须保持开放。这是最大、最终极的教训。还有一点要记住:当我们连接在一起的时候,我们在已有基础上成长和建设的能力是无限的。不管这些公司有多大,我们都不必坐等他们给我们更好的东西。想想那些为了纯粹的创造乐趣而学习编码的新开发者,那些自己动手丰衣足食的人。
-
-未来的优秀程序员无管来自何方,只要能够访问代码,他们就能构建下一个大项目。
-
-[00:27:30] 以上就是我们关于操作系统战争的两个故事。这场战争塑造了我们的数字生活。争夺主导地位的斗争从桌面转移到了服务器室,最终进入了云计算领域。过去的敌人难以置信地变成了盟友,众包的未来让一切都变得开放。听着,我知道,在这段历史之旅中,还有很多英雄我们没有提到,所以给我们写信吧。分享你的故事。Redhat.com/commandlineheroes。我恭候佳音。
-
-在本季剩下的时间里,我们将学习今天的英雄们在创造什么,以及他们要经历什么样的战斗才能将他们的创造变为现实。让我们从艰苦卓绝的编程一线回来看看更多的传奇故事吧。我们每两周放一集新的博客。几周后,我们将为您带来第三集:敏捷革命。
-
-[00:28:00] 命令行英雄是一款红帽公司原创的播客。要想免费自动获得新一集的代码英雄,请订阅我们的节目。只要在苹果播客 、Spotify、 谷歌 Play,或其他应用中搜索“代码英雄”。然后点击“订阅”。这样你就会第一个知道什么时候有新剧集了。
-
-我是 Saron Yitbarek。感谢收听。继续编码。
-
---------------------------------------------------------------------------------
-
-via: https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux
-
-作者:[redhat][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.redhat.com
-[b]: https://github.com/lujun9972
diff --git a/translated/talk/20190725 How to transition into a career as a DevOps engineer.md b/translated/talk/20190725 How to transition into a career as a DevOps engineer.md
deleted file mode 100644
index 9735ee727c..0000000000
--- a/translated/talk/20190725 How to transition into a career as a DevOps engineer.md
+++ /dev/null
@@ -1,101 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (beamrolling)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to transition into a career as a DevOps engineer)
-[#]: via: (https://opensource.com/article/19/7/how-transition-career-devops-engineer)
-[#]: author: (Conor Delanbanque https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque)
-
-如何转职为 DevOps 工程师
-======
-无论你是刚毕业的大学生,还是想在职业中寻求进步的经验丰富的 IT 专家,这些提示都可以帮你成为 DevOps 工程师。
-
-![technical resume for hiring new talent][1]
-
-DevOps 工程是一个备受称赞的热门职业。不管你是刚毕业正在找第一份工作,还是在利用之前的行业经验的同时寻求学习新技能的机会,本指南都能帮你通过正确的步骤成为[ DevOps 工程师][2].
-
-### 让自己沉浸其中
-
-首先学习 [DevOps][3] 的基本原理,实践以及方法。在使用工具之前,先了解 DevOps 背后的“为什么”。DevOps 工程师的主要目标是在整个软件开发生命周期(SDLC)中提高速度并保持或提高质量,以提供最大的业务价值。阅读文章,观看 YouTube 视频,参加当地小组聚会或者会议 — 成为热情的 DevOps 社区中的一员,在那里你将从先行者的错误和成功中学习。
-
-### 考虑你的背景
-
-如果你有从事技术工作的经历,例如软件开发人员,系统工程师,系统管理员,网络运营工程师或者数据库管理员,那么你已经拥有了广泛的见解和有用的经验,它们可以帮助你在未来成为 DevOps 工程师。如果你在完成计算机科学或任何其他 STEM(译者注,STEM 是科学 Science,技术 Technology,工程 Engineering 和数学 Math四个学科的首字母缩略字)领域的学业后刚开始职业生涯,那么你将拥有在这个过渡期间需要的一些基本踏脚石。
-
-DevOps 工程师的角色涵盖了广泛的职责。以下是企业最有可能使用他们的三种方向:
-
-* **偏向于开发(Dev)的 DevOps 工程师**在构建应用中扮演软件开发的角色。他们日常工作的一部分是利用持续集成 / 持续交付(CI/CD),共享仓库,云和容器,但他们不一定负责构建或实施工具。他们了解基础架构,并且在成熟的环境中,能将自己的代码推向生产环境。
-* **偏向于运维技术(Ops)的 DevOps 工程师**可以与系统工程师或系统管理员进行比较。他们了解软件的开发,但并不会把一天的重心放在构建应用上。相反,他们更有可能支持软件开发团队将手动流程自动化的过程,并提高人员和技术系统的效率。这可能意味着分解遗留代码并用较少繁琐的自动化脚本来运行相同的命令,或者可能意味着安装,配置或维护基础结构和工具。他们确保为任何有需要的团队安装可使用的工具。他们也会通过教授如何利用 CI / CD 和其他 DevOps 实践来帮助团队。
-* **网站可靠性工程师(SRE)** 就像解决运维和基础设施的软件工程师。SRE 专注于创建可扩展,高度可用且可靠的软件系统。
-
-
-
-在理想的世界中,DevOps 工程师将了解以上所有领域;这在成熟的科技公司中很常见。然而,顶级银行和许多财富 500 强企业的 DevOps 职位通常会偏向开发(Dev)或运营(Ops)。
-
-### 要学习的技术
-
-DevOps 工程师需要了解各种技术才能有效完成工作。无论你的背景如何,请从作为 DevOps 工程师使用和理解的基础技术入手。
-
-#### 操作系统
-
-操作系统是所有东西运行的地方,拥有相关的基础知识十分重要。 [Linux ][4]是你最有可能每天使用的操作系统,尽管有的组织会使用 Windows 操作系统。要开始使用,你可以在家中安装 Linux,在那里你可以随心所欲地打破并学习。
-
-#### 脚本
-
-接下来,选择一门语言来学习脚本。有很多语言可供选择,包括 Python,Go,Java,Bash,PowerShell,Ruby,和 C / C++。我建议[从 Python 开始][5],因为它相对容易学习和解释,是最受欢迎的语言之一。Python 通常是为了遵循面向对象编程(OOP)的基础而写的,可用于 Web 开发,软件开发以及创建桌面 GUI 和业务应用程序。
-
-#### 云
-
-学习了 [Linux][4] 和 [Python][5] 之后,我认为下一个该学习的是云计算。基础设施不再只是“运维小哥”的事情了,因此你需要接触云平台,例如 AWS 云服务,Azure 或者谷歌云平台。我会从 AWS 开始,因为它有大量免费学习工具,可以帮助你降低作为开发人员,运维,甚至面向业务的组件的任何障碍。事实上,你可能会被它提供的东西所淹没。考虑从 EC2, S3 和 VPC 开始,然后看看你从其中想学到什么。
-
-#### 编程语言
-
-如果你带着对软件开发的热情来到 DevOps,请继续提高你的编程技能。DevOps 中的一些优秀和常用语言与脚本相同:Python,Go,Java,Bash,PowerShell,Ruby 和 C / C++。你还应该熟悉 Jenkins 和 Git / Github,你将会在 CI / CD 过程中经常使用到它们。
-
-#### 容器
-
-最后,使用 Docker 和编排平台(如 Kubernetes)等工具开始学习[容器化][6]。网上有大量的免费学习资源,大多数城市都有本地的线下小组,你可以在友好的环境中向有经验的人学习(还有披萨和啤酒哦!)。
-
-#### 其他的呢?
-
-如果你缺乏开发经验,你依然可以通过对自动化的热情,效率的提高,与他人协作以及改进自己的工作[参与到 DevOps 中][3]来。我仍然建议学习上述工具,但重点不要放在编程 / 脚本语言上。了解基础架构即服务,平台即服务,云平台和 Linux 会非常有用。你可能正在设置工具并学习如何构建有弹性和容错性的系统,并在写代码时利用它们。
-
-### 找一份 DevOps 的工作
-
-求职过程会有所不同,具体取决于你是否一直从事技术工作,并且正在进入 DevOps 领域,或者你是刚开始职业生涯的毕业生。
-
-#### 如果你已经从事技术工作
-
-如果你正在从一个技术领域转入 DevOps 角色,首先尝试在你当前的公司寻找机会。你可以和其他的团队一起工作吗?尝试影响其他团队成员,寻求建议,并在不离开当前工作的情况下获得新技能。如果做不到这一点,你可能需要换另一家公司。如果你能从上面列出的一些实践,工具和技术中学习,你将能在面试时展示相关知识中占据有利位置。关键是要诚实,不要让自己陷入失败中。大多数招聘主管都了解你不知道所有的答案;如果你能展示你所学到的东西,并解释你愿意学习更多,你应该有机会获得 DevOps 的工作。
-
-#### 如果你刚开始职业生涯
-
-申请雇用初级 DevOps 工程师的公司的开放机会。不幸的是,许多公司表示他们希望寻找更富有经验的人,并建议你在获得经验后再申请该职位。这是“我们需要经验丰富的人”的典型,令人沮丧的场景,并且似乎没人愿意给你第一次机会。
-
-然而,并不是所有求职经历都那么令人沮丧;一些公司专注于培训和提升刚从大学毕业的学生。例如,我工作的 [MThree][7] 聘请来应届毕业生并且对其进行了 8 周的培训。当完成培训后,参与者们可以充分了解到整个 SDLC,并很好地了解它在财富 500 强公司相关环境中的应用。毕业生被聘为 MThree 的客户公司的初级 DevOps 工程师 — MThree 在前 18 - 24 个月内支付全职工资和福利,之后他们将作为直接雇员加入客户。这是弥合从大学到技术职业的间隙的好方法。
-
-### 总结
-
-转换成 DevOps 工程师的方法有很多种。这是一条非常有益的职业路线,可能会让你保持繁忙和挑战 — 并增加你的收入潜力。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/7/how-transition-career-devops-engineer
-
-作者:[Conor Delanbanque][a]
-选题:[lujun9972][b]
-译者:[beamrolling](https://github.com/beamrolling)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/hiring_talent_resume_job_career.png?itok=Ci_ulYAH (technical resume for hiring new talent)
-[2]: https://opensource.com/article/19/7/devops-vs-sysadmin
-[3]: https://opensource.com/resources/devops
-[4]: https://opensource.com/resources/linux
-[5]: https://opensource.com/resources/python
-[6]: https://opensource.com/article/18/8/sysadmins-guide-containers
-[7]: https://www.mthreealumni.com/
diff --git a/translated/tech/20180802 Top 5 CAD Software Available for Linux in 2018.md b/translated/tech/20180802 Top 5 CAD Software Available for Linux in 2018.md
new file mode 100644
index 0000000000..f27407bc51
--- /dev/null
+++ b/translated/tech/20180802 Top 5 CAD Software Available for Linux in 2018.md
@@ -0,0 +1,143 @@
+2018年前5名的 Linux 可用 CAD 软件
+======
+[计算机辅助设计 (CAD)][1] 是很多工程流的必不可少的部分。CAD 被专业地使用于建筑,汽车零部件设计,航天飞机研究,航空,桥梁施工,室内设计,甚至服装和珠宝设计。
+
+在 Linux 上,一些专业级 CAD 软件,像 SolidWorks 和 Autodesk AutoCAD ,不是本地支持的。因此,今天,我们将看看排名靠前的 Linux 可用的 CAD 软件。我们马上进去看看。
+
+### Linux 可用的最好的 CAD 软件
+
+![CAD Software for Linux][2]
+
+在我们看 Linux 的 CAD 软件列表前,你应该记住一件事,在这里不是所有的应用程序都是开源软件。我们包含一些非自由和开源软件的 CAD 软件来帮助平常的 Linux 用户。
+
+基于 Ubuntu 的 Linux 发行版已经提供安装操作指南。你可以检查各自的网站来学习其它发行版的安装程序步骤。
+
+列表没有任何特殊顺序。在第一顺位的 CAD 应用程序不能认为比在第三顺位的好,以此类推。
+
+#### 1\. FreeCAD
+
+对于 3D 建模,FreeCAD 是一个极好的选项,它是自由 (啤酒和演讲) 和开源软件。 FreeCAD 以构建坚持机械工程和产品设计为目标目的。FreeCAD 是多平台的,可用于 Windows,Mac OS X+ ,以及 Linux。
+
+![freecad][3]
+
+尽管 FreeCAD 已经是很多 Linux 用户的选择,应该注意到,FreeCAD 仍然是 0.17 版本,因此,不适用于重要的部署。但是最近开发加速了。
+
+[FreeCAD][4]
+
+FreeCAD 不专注于 2D 直接绘图和统一形状动画,但是它对机械工程相关的设计极好。FreeCAD 的 0.15 版本在 Ubuntu 存储库中可用。你可以通过运行下面的命令安装。
+```
+sudo apt install freecad
+
+```
+
+为获取新的每日构建(目前0.17),打开一个终端(ctrl+alt+t),并逐个运行下面的命令。
+```
+sudo add-apt-repository ppa:freecad-maintainers/freecad-daily
+
+sudo apt update
+
+sudo apt install freecad-daily
+
+```
+
+#### 2\. LibreCAD
+
+LibreCAD 是一个自由,开源,2D CAD 解决方案。一般来说,CAD 倾向于一个资源密集型任务,如果你有一个相当普通的硬件,那么我建议你使用 LibreCAD ,因为它在资源使用方面真的轻量化。LibreCAD 是几何图形结构方面的一个极好的候选者。
+
+![librecad][5]
+作为一个 2D 工具,LibreCAD 是好的,但是它不能在 3D 模型和渲染上工作。它有时可能不稳定,但是,它有一个可靠的自动保存,它不会让你的工作浪费。
+
+[LibreCAD][6]
+
+你可以通过运行下面的命令安装 LibreCAD
+```
+sudo apt install librecad
+
+```
+
+#### 3\. OpenSCAD
+
+OpenSCAD 是一个自由的 3D CAD 软件。OpenSCAD 非常轻量和灵活。OpenSCAD 不是交互式的。你需要‘编程’模型,OpenSCAD 解释这些代码来渲染一个可视化模型。在某种意义上说,它是一个编译器。你不能直接绘制模型,而是你描述模型。
+
+![openscad][7]
+
+OpenSCAD 是这个列表上最复杂的工具,但是,一旦你了解它,它将提供一个令人愉快的工作经历。
+
+[OpenSCAD][8]
+
+你可以使用下面的命令来安装 OpenSCAD。
+```
+sudo apt-get install openscad
+
+```
+
+#### 4\. BRL-CAD
+
+BRL-CAD 是最老的 CAD 工具之一。它也深受 Linux/UNIX 用户喜爱,因为它与模块化和自由的 *nix 哲学相一致。
+
+![BRL-CAD rendering by Sean][9]
+
+BRL-CAD 始于1979年,并且,它仍然在积极开发。现在,BRL-CAD 不是 AutoCAD ,但是对于像热穿透和弹道穿透等等的运输研究仍然是一个极好的选择。BRL-CAD 构成 CSG 的基础,而不是边界表示。在选择 BRL-CAD 是,你可能需要记住这一点。你可以从它的官方网站下载 BRL-CAD 。
+
+[BRL-CAD][10]
+
+#### 5\. DraftSight (非开源)
+
+如果你习惯在 AutoCAD 上作业。那么, DraftSight 将是完美的替代。
+
+DraftSight 是一个在 Linux 上可用的极好的 CAD 工具。 它有相当类似于 AutoCAD 的工作流,这使得迁移更容易。它甚至提供一种类似的外观和感觉。DrafSight 也兼容 AutoCAD 的 .dwg 文件格式。 但是,DrafSight 是一个 2D CAD 软件。截至当前,它不支持 3D CAD 。
+
+![draftsight][11]
+
+尽管 DrafSight 是一款起价149美元的商业软件。在 [DraftSight 网站][12]上可获得一个免费版本。你可以下载 .deb 软件包,并在基于 Ubuntu 的发行版上安装它。为了开始使用 DraftSight ,你需要使用你的电子邮件 ID 来注册你的免费版本 。
+
+[DraftSight][12]
+
+#### 荣誉提名
+
+ * 随着云计算技术的巨大发展,像 [OnShape][13] 的云 CAD 解决方案已经变得日渐流行。
+ * [SolveSpace][14] 是另一个值得一提的开源软件项目。它支持 3D 模型。
+ * 西门子 NX 是一个在 Windows,Mac OS 及 Linux 上可用的工业级 CAD 解决方案,但是它贵得离谱,所以,在这个列表中被忽略。
+ * 接下来,你有 [LeoCAD][15],它是一个 CAD 软件,在软件中你使用乐高积木来构建东西。你使用这些信息做些什么取决于你。
+
+
+
+#### 在 Linux 上的 CAD ,以我的看法
+
+尽管在 Linux 上游戏变得流行,我总是告诉我的铁杆游戏朋友坚持使用 Windows 。 类似地,如果你是一名在你是课程中使用 CAD 的工科学生,我建议你使用学校规定的软件 (AutoCAD,SolidEdge,Catia),这些软件通常只在 Windows 上运行。
+
+对于高级专业人士来说,当我们讨论行业标准时,这些工具根本达不到标准。
+
+对于想在 WINE 中运行 AutoCAD 的那些人来说,尽管一些较旧版本的 AutoCAD 可以安装在 WINE 上,它们根本不执行工作,小故障和崩溃严重损害这些体验。
+
+话虽如此,我高度尊重上述列表中软件的开发者的工作。他们丰富了 FOSS 世界。很高兴看到像 FreeCAD 一样的软件在近些年中加速开发速度。
+
+好了,今天到此为止。使用下面的评论区与我们分享你的想法,不用忘记分享这篇文章。谢谢。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/cad-software-linux/
+
+作者:[Aquil Roshan][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[robsean](https://github.com/robsean)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://itsfoss.com/author/aquil/
+[1]:https://en.wikipedia.org/wiki/Computer-aided_design
+[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/cad-software-linux.jpeg
+[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freecad.jpg
+[4]:https://www.freecadweb.org/
+[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/librecad.jpg
+[6]:https://librecad.org/
+[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/openscad.jpg
+[8]:http://www.openscad.org/
+[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/brlcad.jpg
+[10]:https://brlcad.org/
+[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/draftsight.jpg
+[12]:https://www.draftsight2018.com/
+[13]:https://www.onshape.com/
+[14]:http://solvespace.com/index.pl
+[15]:https://www.leocad.org/
diff --git a/translated/tech/20190705 Learn object-oriented programming with Python.md b/translated/tech/20190705 Learn object-oriented programming with Python.md
deleted file mode 100644
index 01f6902ad8..0000000000
--- a/translated/tech/20190705 Learn object-oriented programming with Python.md
+++ /dev/null
@@ -1,302 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (MjSeven)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Learn object-oriented programming with Python)
-[#]: via: (https://opensource.com/article/19/7/get-modular-python-classes)
-[#]: author: (Seth Kenlon https://opensource.com/users/seth)
-
-使用 Python 学习面对对象的编程
-======
-使用 Python 类使你的代码变得更加模块化。
-![Developing code.][1]
-
-在我上一篇文章中,我解释了如何通过使用函数、创建模块或者两者一起来[使 Python 代码更加模块化][2]。函数对于避免重复多次使用的代码非常有用,而模块可以确保你在不同的项目中复用代码。但是模块化还有另一种方法:类。
-
-如果你已经听过 _面对对象编程_ 这个术语,那么你可能会对类的用途有一些概念。程序员倾向于将类视为一个虚拟对象,有时与物理世界中的某些东西直接相关,有时则作为某种编程概念的表现形式。无论哪种表示,当你想要在程序中为你或程序的其他部分创建“对象”时,你都可以创建一个类来交互。
-
-### 没有类的模板
-
-假设你正在编写一个以幻想世界为背景的游戏,并且你需要这个应用程序能够涌现出各种坏蛋来给玩家的生活带来一些刺激。了解了很多关于函数的知识后,你可能会认为这听起来像是函数的一个教科书案例:需要经常重复的代码,但是在调用时可以考虑变量而只编写一次。
-
-下面一个纯粹基于函数的敌人生成器实现的例子:
-
-```
-#!/usr/bin/env python3
-
-import random
-
-def enemy(ancestry,gear):
- enemy=ancestry
- weapon=gear
- hp=random.randrange(0,20)
- ac=random.randrange(0,20)
- return [enemy,weapon,hp,ac]
-
-def fight(tgt):
- print("You take a swing at the " + tgt[0] + ".")
- hit=random.randrange(0,20)
- if hit > tgt[3]:
- print("You hit the " + tgt[0] + " for " + str(hit) + " damage!")
- tgt[2] = tgt[2] - hit
- else:
- print("You missed.")
-
-foe=enemy("troll","great axe")
-print("You meet a " + foe[0] + " wielding a " + foe[1])
-print("Type the a key and then RETURN to attack.")
-
-while True:
- action=input()
-
- if action.lower() == "a":
- fight(foe)
-
- if foe[2] < 1:
- print("You killed your foe!")
- else:
- print("The " + foe[0] + " has " + str(foe[2]) + " HP remaining")
-```
-
-**enemy** 函数创造了一个具有多个属性的敌人,例如祖先、武器、生命值和防御等级。它返回每个属性的列表,表示敌人全部特征。
-
-从某种意义上说,这段代码创建了一个对象,即使它还没有使用类。程序员将这个 "enemy" 称为 _对象_,因为该函数的结果(本例中是一个包含字符串和整数的列表)表示游戏中一个单独但复杂的 _东西_。也就是说,列表中字符串和整数不是任意的:它们一起描述了一个虚拟对象。
-
-在编写描述符集合时,你可以使用变量,以便随时使用它们来生成敌人。这有点像模板。
-
-在示例代码中,当需要对象的属性时,会检索相应的列表项。例如,要获取敌人的祖先,代码会查询 **foe[0]**,对于生命值,会查询 **foe[2]**,以此类推。
-
-这种方法没有什么不妥,代码按预期运行。你可以添加更多不同类型的敌人,创建一个敌人类型列表,并在敌人创建期间从列表中随机选择,等等,它工作得很好。实际上,[Lua][3] 非常有效地利用这个原理来近似面对对象模型。
-
-然而,有时候对象不仅仅是属性列表。
-
-### 使用对象
-
-在 Python 中,一切都是对象。你在 Python 中创建的任何东西都是某个预定义模板的 _实例_。甚至基本的字符串和整数都是 Python **type** 类的衍生物。你可以在这个交互式 Python shell 中见证:
-
-```
->>> foo=3
->>> type(foo)
-<class 'int'>
->>> foo="bar"
->>> type(foo)
-<class 'str'>
-```
-
-当一个对象由一个类定义时,它不仅仅是一个属性的集合,Python 类具有各自的函数。从逻辑上讲,这很方便,因为只涉及某个对象类的操作包含在该对象的类中。
-
-在示例代码中,fight 代码是主应用程序的功能。这对于一个简单的游戏来说是可行的,但对于一个复杂的游戏来说,世界中不仅仅有玩家和敌人,还可能有城镇居民、牲畜、建筑物、森林等等,他们都不需要使用战斗功能。将战斗代码放在敌人的类中意味着你的代码更有条理,在一个复杂的应用程序中,这是一个重要的优势。
-
-此外,每个类都有特权访问自己的本地变量。例如,敌人的生命值,除了某些功能之外,是不会改变的数据。游戏中的随机蝴蝶不应该意外地将敌人的生命值降低到 0。理想情况下,即使没有类,也不会发生这种情况。但是在具有大量活动部件的复杂应用程序中,确保不需要相互交互的部件永远不会发生这种情况,这是一个非常有用的技巧。
-
-Python 类也受垃圾收集的影响。当不再使用类的实例时,它将被移出内存。你可能永远不知道这种情况会什么时候发生,但是你往往知道什么时候它不会发生,因为你的应用程序占用了更多的内存,而且运行速度比较慢。将数据集隔离到类中可以帮助 Python 跟踪哪些数据正在使用,哪些不在需要了。
-
-### 优雅的 Python
-
-下面是一个同样简单的战斗游戏,使用了 Enemy 类:
-
-```
-#!/usr/bin/env python3
-
-import random
-
-class Enemy():
- def __init__(self,ancestry,gear):
- self.enemy=ancestry
- self.weapon=gear
- self.hp=random.randrange(10,20)
- self.ac=random.randrange(12,20)
- self.alive=True
-
- def fight(self,tgt):
- print("You take a swing at the " + self.enemy + ".")
- hit=random.randrange(0,20)
-
- if self.alive and hit > self.ac:
- print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
- self.hp = self.hp - hit
- print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
- else:
- print("You missed.")
-
- if self.hp < 1:
- self.alive=False
-
-# 游戏开始
-foe=Enemy("troll","great axe")
-print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
-
-# 主函数循环
-while True:
-
- print("Type the a key and then RETURN to attack.")
-
- action=input()
-
- if action.lower() == "a":
- foe.fight(foe)
-
- if foe.alive == False:
- print("You have won...this time.")
- exit()
-```
-
-这个版本的游戏将敌人作为一个包含相同属性(祖先,武器,生命值和防御)的对象来处理,并添加一个新的属性来衡量敌人时候已被击败,以及一个战斗功能。
-
-类的第一个函数是一个特殊的函数,在 Python 中称为 \_init\_ 或初始化函数。这类似于其他语言中的[构造器][4],它创建了类的一个实例,你可以通过它的属性和调用类时使用的任何变量来识别它(示例代码中的 **foe**)。
-
-### Self 和类实例
-
-类的函数接受一种你在类之外看不到的新形式的输入:**self**。如果不包含 **self**,那么当你调用类函数时,Python 无法知道要使用的类的 _哪个_ 实例。这就像在一间充满兽人的房间里说:“我要和兽人战斗”,向一个兽人发起。没有人知道你指的是谁,所以坏事就发生了。
-
-![Image of an Orc, CC-BY-SA by Buch on opengameart.org][5]
-
-CC-BY-SA by Buch on opengameart.org
-
-类中创建的每个属性都以 **self** 符号作为前缀,该符号将变量标识为类的属性。一旦派生出类的实例,就用表示该实例的变量替换掉 **self** 前缀。使用这个技巧,你可以在一间满是兽人的房间里说:“我要和祖先是 orc 的兽人战斗”,这样来挑战一个兽人。当 orc 听到 "gorblar.orc" 时,它就知道你指的是谁(他自己),所以你得到是一场公平的战斗而不是争吵。在 Python 中:
-
-```
-gorblar=Enemy("orc","sword")
-print("The " + gorblar.enemy + " has " + str(gorblar.hp) + " remaining.")
-```
-
-通过检索类属性而不是查询 **foe[0]**(在函数示例中)或 **gorblar[0]** 来寻找敌人(**gorblar.enemy** 或 **gorblar.hp** 或你需要的任何对象的任何值)。
-
-### 本地变量
-
-如果类中的变量没有以 **self** 关键字作为前缀,那么它就是一个局部变量,就像在函数中一样。例如,无论你做什么,你都无法访问 **Enemy.fight** 类之外的 **hit** 变量:
-
-```
->>> print(foe.hit)
-Traceback (most recent call last):
- File "./enclass.py", line 38, in <module>
- print(foe.hit)
-AttributeError: 'Enemy' object has no attribute 'hit'
-
->>> print(foe.fight.hit)
-Traceback (most recent call last):
- File "./enclass.py", line 38, in <module>
- print(foe.fight.hit)
-AttributeError: 'function' object has no attribute 'hit'
-```
-
-**hi** 变量包含在 Enemy 类中,并且只能“存活”到在战斗种发挥作用。
-
-### 更模块化
-
-本例使用与主应用程序相同的文本文档中的类。在一个复杂的游戏中,我们更容易将每个类看作是自己独立的应用程序。当多个开发人员处理同一个应用程序时,你会看到这一点:一个开发人员处理一个类,另一个开发主程序,只要他们彼此沟通这个类必须具有什么属性,就可以并行地开发这两个代码块。
-
-要使这个示例游戏模块化,可以把它拆分为两个文件:一个用于主应用程序,另一个用于类。如果它是一个更复杂的应用程序,你可能每个类都有一个文件,或每个逻辑类组有一个文件(例如,用于建筑物的文件,用于自然环境的文件,用于敌人或 NPC 的文件等)。
-
-将只包含 Enemy 类的一个文件保存为 **enemy.py**,将另一个包含其他内容的文件保存为 **main.py**。
-
-以下是 **enemy.py**:
-
-```
-import random
-
-class Enemy():
- def __init__(self,ancestry,gear):
- self.enemy=ancestry
- self.weapon=gear
- self.hp=random.randrange(10,20)
- self.stg=random.randrange(0,20)
- self.ac=random.randrange(0,20)
- self.alive=True
-
- def fight(self,tgt):
- print("You take a swing at the " + self.enemy + ".")
- hit=random.randrange(0,20)
-
- if self.alive and hit > self.ac:
- print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
- self.hp = self.hp - hit
- print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
- else:
- print("You missed.")
-
- if self.hp < 1:
- self.alive=False
-```
-
-以下是 **main.py**:
-
-```
-#!/usr/bin/env python3
-
-import enemy as en
-
-# game start
-foe=en.Enemy("troll","great axe")
-print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
-
-# main loop
-while True:
-
- print("Type the a key and then RETURN to attack.")
-
- action=input()
-
- if action.lower() == "a":
- foe.fight(foe)
-
- if foe.alive == False:
- print("You have won...this time.")
- exit()
-```
-
-导入模块 **enemy.py** 使用了一条特别的语句,将类文件名称作为引用而不是 **.py** 扩展名,后跟你选择的命名空间指示符(例如,**import enemy as en**)。这个指示符是在你调用类时在代码中使用的。你需要在导入时添加指定符,例如 **en.Enemy**,而不是只使用 **Enemy()**。
-
-所有这些文件名都是任意的,尽管在原则上并不罕见。将应用程序的中心命名为 **main.py** 是一个常见约定,和一个充满类的文件通常以小写形式命名,其中的类都以大写字母开头。是否遵循这些约定不会影响应用程序的运行方式,但它确实使经验丰富的 Python 程序员更容易快速理解应用程序的工作方式。
-
-在如何构建代码方面有一些灵活性。例如,使用代码示例,两个文件必须位于同一目录中。如果你只想将类打包为模块,那么必须创建一个名为 **mybad** 的目录,并将你的类移入其中。在 **main.py** 中,你的 import 语句稍有变化:
-
-```
-from mybad import enemy as en
-```
-
-两种方法都会产生相同的结果,但如果你创建的类足够通用,你认为其他开发人员可以在他们的项目中使用它们,那么后者是更好的。
-
-无论你选择哪种方式,都可以启动游戏的模块化版本:
-
-```
-$ python3 ./main.py
-You meet a troll wielding a great axe
-Type the a key and then RETURN to attack.
-a
-You take a swing at the troll.
-You missed.
-Type the a key and then RETURN to attack.
-a
-You take a swing at the troll.
-You hit the troll for 8 damage!
-The troll has 4 HP remaining
-Type the a key and then RETURN to attack.
-a
-You take a swing at the troll.
-You hit the troll for 11 damage!
-The troll has -7 HP remaining
-You have won...this time.
-```
-
-游戏启动了,它现在更加模块化了。现在你知道了面对对象的应用程序意味着什么,但最重要的是,当你向兽人发起决斗的时候,你要想清楚。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/7/get-modular-python-classes
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[MjSeven](https://github.com/MjSeven)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/seth
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming.png?itok=M_QDcgz5 (Developing code.)
-[2]: https://opensource.com/article/19/6/get-modular-python-functions
-[3]: https://opensource.com/article/17/4/how-program-games-raspberry-pi
-[4]: https://opensource.com/article/19/6/what-java-constructor
-[5]: https://opensource.com/sites/default/files/images/orc-buch-opengameart_cc-by-sa.jpg (CC-BY-SA by Buch on opengameart.org)
diff --git a/translated/tech/20190819 Moving files on Linux without mv.md b/translated/tech/20190819 Moving files on Linux without mv.md
new file mode 100644
index 0000000000..82657644c1
--- /dev/null
+++ b/translated/tech/20190819 Moving files on Linux without mv.md
@@ -0,0 +1,171 @@
+[#]: collector: (lujun9972)
+[#]: translator: (MjSeven)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Moving files on Linux without mv)
+[#]: via: (https://opensource.com/article/19/8/moving-files-linux-without-mv)
+[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/seth)
+
+在不使用 mv 命令的情况下移动文件
+======
+有时当你需要移动一个文件时,mv 命令似乎不是最佳选项,那么你会如何做呢?
+![Hand putting a Linux file folder into a drawer][1]
+
+不起眼的 **mv** 命令是在你见过的每个 POSIX 系统中都能找到的有用工具之一。它的作用是明确定义的,并且做得很好:将文件从文件系统中的一个位置移动到另一个位置。但是 Linux 非常灵活,还有其他移动文件的办法。使用不同的工具可以完美匹配一些特殊用例,这算一个小优势。
+
+在远离 **mv** 之前,先看看这个命令的默认结果。首先,创建一个目录并生成一些权限为 777 的文件:
+```
+$ mkdir example
+$ touch example/{foo,bar,baz}
+$ for i in example/*; do ls /bin > "${i}"; done
+$ chmod 777 example/*
+```
+
+你可能不会这么认为,但是文件在一个[文件系统][2]中作为条目存在,称为索引节点(通常称为 **inode**),你可以使用 [ls 命令][3]及其 **\--inode** 选项查看一个文件占用的 inode:
+
+```
+$ ls --inode example/foo
+7476868 example/foo
+```
+
+作为测试,将文件从示例目录移动到当前目录,然后查看文件的属性:
+```
+$ mv example/foo .
+$ ls -l -G -g --inode
+7476868 -rwxrwxrwx. 1 29545 Aug 2 07:28 foo
+```
+
+如你所见,原始文件及权限已经被“移动”,但它的 inode 没有变化。
+
+这就是 **mv** 工具用来移动的方式:保持 inode 不变(除非文件被移动到不同的文件系统),并保留其所有权和权限。
+
+其他工具提供了不同的选项。
+
+### 复制和删除
+
+在某些系统上,move 操作是一个真正的移动操作:比特从文件系统中的某个位置删除并重新分配给另一个位置。这种行为在很大程度上已经失宠。现在,move 操作要么是属性重新分配(inode 现在指向文件组织中的不同位置),要么是复制和删除操作的组合。这种设计的哲学意图是确保在移动失败时,文件不会碎片化。
+
+与 **mv** 不同,**cp** 命令会在文件系统中创建一个全新的数据对象,它有一个新的 inode 位置,并取决于 umask。你可以使用 **cp** 和 **rm**(或 [trash][4](译注:它是一个命令行回收站工具),如果有的话)命令来模仿 mv 命令。
+```
+$ cp example/foo .
+$ ls -l -G -g --inode
+7476869 -rwxrwxr-x. 29545 Aug 2 11:58 foo
+$ trash example/foo
+```
+
+示例中的新 **foo** 文件获得了 755 权限,因为此处的 umask 明确排除了写入权限。
+```
+$ umask
+0002
+```
+
+有关 umask 的更多信息,阅读 Alex Juarez 这篇关于[文件权限][5]的文章。
+
+### 查看和删除
+
+与复制和删除类似,使用 [cat][6](或 **tac**)命令在创建“移动”文件时分配不同的权限。假设当前目录中是一个没有 **foo** 的新测试环境:
+
+```
+$ cat example/foo > foo
+$ ls -l -G -g --inode
+7476869 -rw-rw-r--. 29545 Aug 8 12:21 foo
+$ trash example/foo
+```
+
+这次,创建了一个没有事先设置权限的新文件,所以文件最终权限完全取决于 umask 设置,它不会阻止用户和组的权限位(无论 umask 是什么,都不会为新文件授予可执行权限),但它会阻止其他人的写入(值为 2)。所以结果是一个权限是 664 的文件。
+
+### Rsync
+
+**rsync** 命令是一个强大的多功能工具,用于在主机和文件系统位置之间发送文件。此命令有许多可用选项,包括使其目标镜像成为源。
+
+你可以使用 **\--remove-source-files** 选项复制,然后删除带有 **rsync** 的文件,以及你选择执行同步的任何其他选项(常见的通用选项是 **\--archive**):
+
+```
+$ rsync --archive --remove-source-files example/foo .
+$ ls example
+bar baz
+$ ls -lGgi
+7476870 -rwxrwxrwx. 1 seth users 29545 Aug 8 12:23 foo
+```
+
+在这里,你可以看到保留了文件权限和所有权,只是更新了时间戳,并删除了源文件。
+
+**警告**:不要将此选项与 **\--delete** 混淆,后者会从 _目标_ 目录中删除文件。误用 **\--delete** 可以清除很多数据,建议你不要使用此选项,除非是在测试环境中。
+
+你可以覆盖其中一些默认值,更改权限和修改设置:
+
+```
+$ rsync --chmod=666 --times \
+\--remove-source-files example/foo .
+$ ls example
+bar baz
+$ ls -lGgi
+7476871 -rw-rw-r--. 1 seth users 29545 Aug 8 12:55 foo
+```
+
+这里,目标的 umask 会生效,因此 **\--chmod=666** 选项会产生一个权限为 644 的文件。
+
+好处不仅仅是权限,与简单的 **mv** 命令相比,**rsync** 命令有[很多][7]有用的[选项][8](其中最重要的是 **\--exclude** 选项,这样你可以在一个大型移动操作中排除某些项目),这使它成为一个更强大的工具。例如,要在移动文件集合时排除所有备份文件:
+```
+$ rsync --chmod=666 --times \
+\--exclude '*~' \
+\--remove-source-files example/foo .
+```
+
+### 使用 install 设置权限
+
+**install** 命令是一个专门面向开发人员的复制命令,主要是作为软件编译安装例程的一部分调用。它并不为用户所知(我经常想知道为什么它有这么一个直观的名字,只给包管理器留下缩写和昵称),但是 **install** 实际上是一种将文件放在你想要地方的有用方法。
+
+**install** 命令有很多选项,包括 **\--backup** 和 **\--compare** 命令(以避免**更新**文件的新副本)。
+
+与 **cp** 和 **cat** 命令不同,但与 **mv** 完全相同,**install** 命令可以复制文件,同时保留其时间戳:
+
+```
+$ install --preserve-timestamp example/foo .
+$ ls -l -G -g --inode
+7476869 -rwxr-xr-x. 1 29545 Aug 2 07:28 foo
+$ trash example/foo
+```
+
+在这里,文件被复制到一个新的 inode,但它的 **mtime(修改时间)** 没有改变。但权限被设置为 **install** 的默认值 **755**。
+
+你可以使用 **install** 来设置文件的权限,所有者和组:
+
+```
+$ install --preserve-timestamp \
+\--owner=skenlon \
+\--group=dialout \
+\--mode=666 example/foo .
+$ ls -li
+7476869 -rw-rw-rw-. 1 skenlon dialout 29545 Aug 2 07:28 foo
+$ trash example/foo
+```
+
+### 移动、复制和删除
+
+文件包含数据,而真正重要的文件包含 _你_ 的数据。学会聪明地管理它们是很重要的,现在你有确保以你想要的方式来处理数据的工具包。
+
+你是否有不同的数据管理方式?在评论中告诉我们你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/moving-files-linux-without-mv
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sethhttps://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
+[2]: https://opensource.com/article/18/11/partition-format-drive-linux#what-is-a-filesystem
+[3]: https://opensource.com/article/19/7/master-ls-command
+[4]: https://gitlab.com/trashy
+[5]: https://opensource.com/article/19/8/linux-permissions-101#umask
+[6]: https://opensource.com/article/19/2/getting-started-cat-command
+[7]: https://opensource.com/article/19/5/advanced-rsync
+[8]: https://opensource.com/article/17/1/rsync-backup-linux