mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
translated
This commit is contained in:
parent
4c511f090e
commit
8d5d157897
@ -1,40 +1,38 @@
|
||||
translating---geekpi
|
||||
|
||||
[DNS Infrastructure at GitHub][1]
|
||||
[GitHub 的 DNS 基础设施][1]
|
||||
============================================================
|
||||
|
||||
|
||||
At GitHub we recently revamped how we do DNS from the ground up. This included both how we [interact with external DNS providers][4] and how we serve records internally to our hosts. To do this, we had to design and build a new DNS infrastructure that could scale with GitHub’s growth and across many data centers.
|
||||
在 GitHub,我们最近从头改进了 DNS。这包括了我们[如何与外部 DNS 提供商交互][4]以及我们如何在内部向我们的主机提供记录。为此,我们必须设计和构建一个新的 DNS 基础设施,它可以随着 GitHub 的增长扩展并跨越多个数据中心。
|
||||
|
||||
Previously GitHub’s DNS infrastructure was fairly simple and straightforward. It included a local, forwarding only DNS cache on every server and a pair of hosts that acted as both caches and authorities used by all these hosts. These hosts were available both on the internal network as well as public internet. We configured zone stubs in the caching daemon to direct queries locally rather than recurse on the internet. We also had NS records set up at our DNS providers that pointed specific internal zones to the public IPs of this pair of hosts for queries external to our network.
|
||||
以前,GitHub 的 DNS 基础设施相当简单直接。它包括每台服务器上本地的,只进行转发的 DNS 缓存,以及被所有这些主机使用的一对缓存和权威主机。这些主机在内部网络以及公共互联网上都可用。我们在缓存守护程序中配置了域存根,以在本地进行查询,而不是在互联网上进行递归。我们还在我们的 DNS 提供商处设置了 NS 记录,它们将特定的内部域指向这对主机的公共 IP,以便我们网络外部的查询。
|
||||
|
||||
This configuration worked for many years but was not without its downsides. Many applications are highly sensitive to resolving DNS queries and any performance or availability issues we ran into would cause queuing and degraded performance at best and customer impacting outages at worst. Configuration and code changes can cause large unexpected changes in query rates. As such scaling beyond these two hosts became an issue. Due to the network configuration of these hosts we would just need to keep adding IPs and hosts which has its own problems. While attempting to fire fight and remediate these issues, the old system made it difficult to identify causes due to a lack of metrics and visibility. In many cases we resorted to `tcpdump` to identify traffic and queries in question. Another issue was running on public DNS servers we run the risk of leaking internal network information. As a result we decided to build something better and began to identify our requirements for the new system.
|
||||
这个配置使用了很多年,但并非没有它的缺点。许多程序对于解析 DNS 查询非常敏感,我们遇到的任何性能或可用性问题最好情况会导致排队和性能降级,最坏情况下客户会停机。配置和代码更改可能会导致查询率的大幅意外更改。因此超出这两台主机的扩展成为了一个问题。由于这些主机的网络配置,我们只需要继续添加有问题的 IP 和主机。在试图解决和补救这些问题的同时,由于缺乏指标和可见性,老旧的系统难以识别原因。在许多情况下,我们使用 `tcpdump` 来识别有问题的流量和查询。另一个问题是在公共 DNS 服务器上运行,我们冒着泄露内部网络信息的风险。因此,我们决定建立更好的东西,并开始确定我们对新系统的要求。
|
||||
|
||||
We set out to design a new DNS infrastructure that would improve the aforementioned operational issues including scaling and visibility, as well as introducing some additional requirements. We wanted to continue to run our public DNS zones via external DNS providers so whatever system we build needed to be vendor agnostic. Additionally, we wanted this system to be capable of serving both our internal and external zones, meaning internal zones were only available on our internal network unless specifically configured otherwise and external zones are resolvable without leaving our internal network. We wanted the new DNS architecture to allow both a [deploy-based workflow for making changes][5] as well as API access to our records for automated changes via our inventory and provisioning systems. The new system could not have any external dependencies; too much relies on DNS functioning for it to get caught in a cascading failure. This includes connectivity to other data centers and DNS services that may reside there. Our old system mixed the use of caches and authorities on the same host; we wanted to move to a tiered design with isolated roles. Lastly, we wanted a system that could support many data center environments whether it be EC2 or bare metal.
|
||||
我们着手设计一个新的 DNS 基础设施,以改善上述的操作问题,包括扩展和可见性,并引入了一些额外的要求。我们希望通过外部 DNS 提供商继续运行我们的公共 DNS 域,因此我们构建的系统需要与供应商无关。此外,我们希望该系统能够服务于我们的内部和外部域,这意味着内部域仅在我们的内部网络上可用,除非另有特别配置,否则外部域是可解析的,而不会离开我们的内部网络。我们希望新的 DNS 架构允许[更改基于部署的工作流][5],并通过我们的仓库和配置系统使用 API 自动更改记录。新系统不能有任何外部依赖,太依赖于 DNS 功能而被陷入级联故障。这包括连接到其他数据中心和其中可能有的 DNS 服务。我们的旧系统将缓存和权威在同一台主机上混合使用。我们想转到具有独立角色的分层设计。最后,我们希望系统能够支持多数据中心环境,无论是 EC2 还是裸机。
|
||||
|
||||
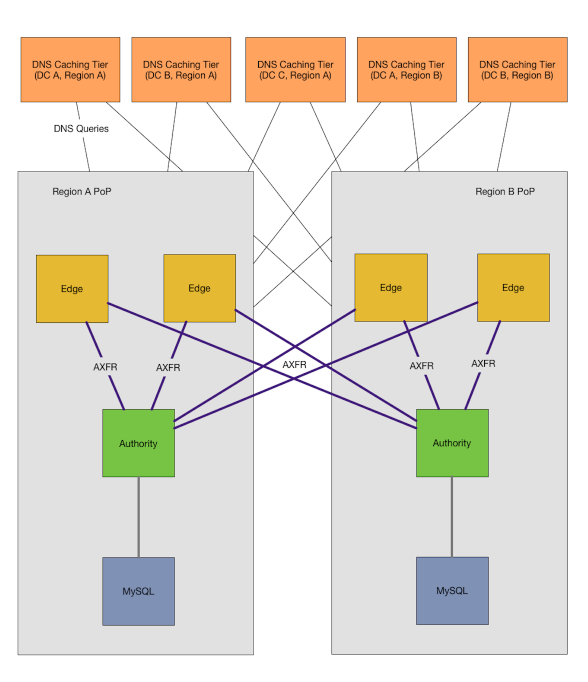
### Implementation
|
||||
### 实现
|
||||
|
||||
|
||||
|
||||
To build this system we identified three classes of hosts: caches, edges, and authorities. Caches serve as recursive resolvers and DNS “routers” caching responses from the edge tier. The edge tier, running a DNS authority daemon, responds to queries from the caching tier for zones it is configured to zone transfer from the authority tier. The authority tier serve as hidden DNS masters as our canonical source for DNS data, servicing zone transfers from the edge hosts as well as providing an HTTP API for creating, modifying or deleting records.
|
||||
为了构建这个系统,我们确定了三类主机:缓存主机、边缘主机和权威主机。缓存作为递归解析器和 DNS “路由器”缓存来自边缘层的响应。边缘层运行 DNS 权威守护程序,用于响应缓存层对权威层的响应。权威层作为隐藏的 DNS 主机是 DNS 数据的常规来源,为来自边缘主机的域传输服务,并提供用于创建、修改或删除记录的 HTTP API。
|
||||
|
||||
In our new configuration, caches live in each data center meaning application hosts don’t need to traverse a data center boundary to retrieve a record. The caches are configured to map zones to the edge hosts within their region in order to route our internal zones to our own hosts. Any zone that is not explicitly configured will recurse on the internet to resolve an answer.
|
||||
在我们的新配置中,缓存存在每个数据中心中,这意味着程序主机不需要遍历数据中心边界来检索记录。缓存被配置为将域映射到其域内的边缘主机,以便将我们的内部域路由到我们自己的主机。未明确配置的任何域将通过互联网递归解析。
|
||||
|
||||
The edge hosts are regional hosts, living in our network edge PoPs (Point of Presence). Our PoPs have one or more data centers that rely on them for external connectivity, without the PoP the data center can’t get to the internet and the internet can’t get to them. The edges perform zone transfers with all authorities regardless of what region or location they exist in and store those zones locally on their disk.
|
||||
边缘主机是区域主机,存在我们的网络边缘 PoP(存在点)。我们的 PoP 有一个或多个依赖于它们的数据中心进行外部连接,没有 PoP 数据中心无法访问互联网,互联网也无法访问它们。边缘对所有的权威执行区域传输,无论它们存在什么域或位置,并将这些域存在本地的磁盘上。
|
||||
|
||||
Our authorities are also regional hosts, only containing zones applicable to the region it is contained in. Our inventory and provisioning systems determine which regional authority a zone lives in and will create and delete records via an HTTP API as servers come and go. OctoDNS maps zones to regional authorities and uses the same API to create static records and to ensure dynamic sources are in sync. We have an additional separate authority for external domains, such as github.com, to allow us to query our external domains during a disruption to connectivity. All records are stored in MySQL.
|
||||
我们的权威主机也是区域主机,只包含适用于其所在区域的域。我们的仓库和配置系统决定区域权威存在哪里,通过 HTTP API 创建和删除服务器记录。 OctoDNS 将域映射到区域权威,并使用相同的 API 创建静态记录,并确保动态源处于同步状态。对于外部域 (如 github.com),我们有另外一个单独的权威,允许我们在连接中断期间查询我们的外部域。所有记录都存储在 MySQL 中。
|
||||
|
||||
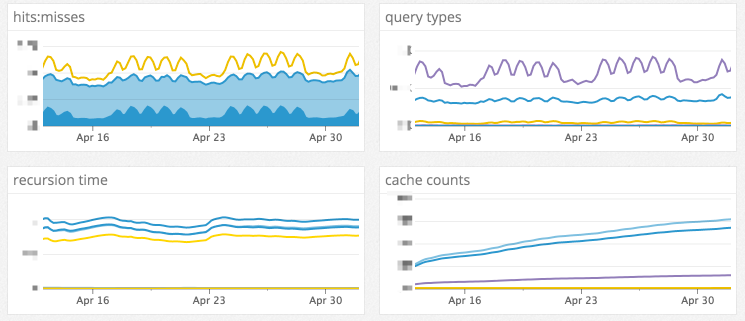
### Operability
|
||||
### 可操作性
|
||||
|
||||
|
||||
|
||||
One huge benefit of moving to a more modern DNS infrastructure is observability. Our old DNS system had little to no metrics and limited logging. A large factor in deciding which DNS servers to use was the breadth and depth of metrics they produce. We finalized on [Unbound][6] for the caches, [NSD][7] for the edge hosts and [PowerDNS][8] for the authorities, all of which have been proven in DNS infrastructures much larger than at GitHub.
|
||||
迁移到更现代的 DNS 基础设施的巨大好处是可观察性。我们的旧 DNS 系统几乎没有指标和有限的日志。决定使用哪些 DNS 服务器的一个重要因素是它们产生的指标的广度和深度。我们最终用 [Unbound][6] 作为缓存,[NSD][7] 作为边缘主机,[PowerDNS][8] 作为权威,所有这些都已在 DNS 基础架构中被证明比 GitHub 好很多。
|
||||
|
||||
When running in our bare metal data centers, caches are accessed via a private [anycast][9] IP resulting in it reaching the nearest available cache host. The caches have been deployed in a rack aware manner that provides some level of balanced load between them and isolation against some power and network failure modes. When a cache host fails, servers that would normally use it for lookups will now automatically be routed to the next closest cache, keeping latency low as well as providing tolerance to some failure modes. Anycast allows us to scale the number of caches behind a single IP address unlike our previous configuration, giving us the ability to run as many caching hosts as DNS demand requires.
|
||||
当在我们的裸机数据中心运行时,缓存通过私有[广播][9] IP 访问,从而到达最近的可用缓存主机。缓存已经以机架感知的方式部署,在它们之间提供一定程度的平衡负载,并且与一些电源和网络故障模式隔离。当缓存主机出现故障时,通常将其用于查找的服务器现在将自动路由到下一个最接近的缓存,保持低延迟并提供对某些故障模式的容错。广播允许我们扩展单个 IP 地址后面的缓存数量,这与先前的配置不同,使我们能够按 DNS 需求运行尽可能多的缓存主机。
|
||||
|
||||
Edge hosts perform zone transfers with the authority tier, regardless of region or location. Our zones are not large enough that keeping a copy of all of them in every region is a problem. This means for every zone, all caches will have access to a local edge server with a local copy of all zones even when a region is offline or upstream providers are having connectivity issues. This change alone has proven to be quite resilient in the face of connectivity issues and has helped keep GitHub available during failures that not long ago would have caused customer facing outages.
|
||||
无论区域或位置如何,边缘主机使用权威层进行域传输。我们的域不够大,在每个区域保留所有域的副本是一个问题。这意味着对于每个域,即使某个区域处于脱机状态,或者上游提供存在连接问题,所有缓存都可以访问具有所有域的本地副本的本地边缘服务器。这种变化在面对连接问题方面已被证明是相当有弹性的,并且在不久前会导致客户面临停机的故障期间帮助保持 GitHub 可用。
|
||||
|
||||
These zone transfers include both our internal and external zones from their respective authorities. As you might guess zones like github.com are external and zones like github.net are generally internal. The difference between them is only the types of use and data stored in them. Knowing which zones are internal and external gives us some flexibility in our configuration.
|
||||
这些域从它们相应的权威服务器同时转移内部和外部域。正如你可能会猜想像 github.com 这样的域是外部的,像 github.net 这样的域通常是内部的。它们之间的区别仅在于我们使用的类型和存储的数据。了解哪些域是内部和外部的,为我们在配置中提供了一些灵活性。
|
||||
|
||||
```
|
||||
$ dig +short github.com
|
||||
@ -43,7 +41,7 @@ $ dig +short github.com
|
||||
|
||||
```
|
||||
|
||||
Public zones are [sync’d][10] to external DNS providers and are records GitHub users use everyday. Addtionally, public zones are completely resolvable within our network without needing to communicate with our external providers. This means any service that needs to look up `api.github.com` can do so without needing to rely on external network connectivity. We also use the stub-first configuration option of Unbound which gives a lookup a second chance if our internal DNS service is down for some reason by looking it up externally when it fails.
|
||||
公共域被[同步][10]到外部 DNS 提供商,并且是 GitHub 用户每天使用的记录。另外,公共域在我们的网络中是完全可解析的,而不需要与我们的外部提供商进行通信。这意味着需要查询 `api.github.com`的任何服务都可以这样做,而无需依赖外部网络连接。我们还使用 Unbound 的 stub-first 配置选项,如果我们的内部 DNS 服务由于某些原因在外部查询失败,则可以进行第二次查找。
|
||||
|
||||
```
|
||||
$ dig +short time.github.net
|
||||
@ -51,20 +49,20 @@ $ dig +short time.github.net
|
||||
|
||||
```
|
||||
|
||||
Most of the `github.net` zone is completely private, inaccessible from the internet and only contains [RFC 1918][11] IP addresses. Private zones are split up per region and site. Each region and/or site has a set of sub-zones applicable to that location, sub-zones for management network, service discovery, specific service records and yet to be provisioned hosts that are in our inventory. Private zones also include reverse lookup zones for PTRs.
|
||||
`github.net` 域大部分是完全私有的,无法从互联网访问,它只包含 [RFC 1918][11] IP地址。每个区域和站点都划分了私有域。每个区域和/或站点都具有适用于该位置的一组子域,用于管理网络的子域、服务发现、特定服务记录,并且还包括在我们仓库中的配置主机。私有域还包括 PTR 反向查找域。
|
||||
|
||||
### Conclusion
|
||||
### 总结
|
||||
|
||||
Replacing an old system with a new one that is ready to serve millions of customers is never easy. Using a pragmatic, requirements based approach to designing and implementing our new DNS system resulted in a DNS infrastructure that was able to hit the ground running and will hopefully grow with GitHub into the future.
|
||||
用一个可以为数百万客户提供服务的新系统替换旧的系统并不容易。使用实用的,以需求为基础的方法来设计和实施我们的新 DNS 系统,来让 DNS 基础设施能迅速有效地运行,并有希望与 GitHub 一起成长。
|
||||
|
||||
Want to help the GitHub SRE team solve interesting problems like this? We’d love for you to join us. [Apply Here][12]
|
||||
想帮助 GitHub SRE 团队解决有趣的问题吗?我们很乐意你加入我们。[在这申请][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://githubengineering.com/dns-infrastructure-at-github/
|
||||
|
||||
作者:[Joe Williams ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Loading…
Reference in New Issue
Block a user