mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
8b51948c34
77
published/201309/20190204 7 Best VPN Services For 2019.md
Normal file
77
published/201309/20190204 7 Best VPN Services For 2019.md
Normal file
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Modrisco)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10691-1.html)
|
||||
[#]: subject: (7 Best VPN Services For 2019)
|
||||
[#]: via: (https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/)
|
||||
[#]: author: (Editor https://www.ostechnix.com/author/editor/)
|
||||
|
||||
2019 年最好的 7 款虚拟私人网络服务
|
||||
======
|
||||
|
||||
在过去三年中,全球至少有 67% 的企业面临着数据泄露,亿万用户受到影响。研究表明,如果事先对数据安全采取最基本的保护措施,那么预计有 93% 的安全问题是可以避免的。
|
||||
|
||||
糟糕的数据安全会带来极大的代价,特别是对企业而言。它会大致大规模的破坏并影响你的品牌声誉。尽管有些企业可以艰难地收拾残局,但仍有一些企业无法从事故中完全恢复。不过现在,你很幸运地可以得到数据及网络安全软件。
|
||||
|
||||

|
||||
|
||||
到了 2019 年,你可以通过**虚拟私人网络**,也就是我们熟知的 **VPN** 来保护你免受网络攻击。当涉及到在线隐私和安全时,常常存在许多不确定因素。有数百个不同的 VPN 提供商,选择合适的供应商也同时意味着在定价、服务和易用性之间谋取恰当的平衡。
|
||||
|
||||
如果你正在寻找一个可靠的 100% 经过测试和安全的 VPN,你可能需要进行详尽的调查并作出最佳选择。这里为你提供在 2019 年 7 款最好用并经过测试的 VPN 服务。
|
||||
|
||||
### 1、Vpnunlimitedapp
|
||||
|
||||
通过 VPN Unlimited,你的数据安全将得到全面的保障。此 VPN 允许你连接任何 WiFi ,而无需担心你的个人数据可能被泄露。你的数据通过 AES-256 算法加密,保护你不受第三方和黑客的窥探。无论你身处何处,这款 VPN 都可确保你在所有网站上保持匿名且不受跟踪。它提供 7 天的免费试用和多种协议支持:openvpn、IKEv2 和 KeepSolidWise。有特殊需求的用户会获得特殊的额外服务,如个人服务器、终身 VPN 订阅和个人 IP 选项。
|
||||
|
||||
### 2、VPN Lite
|
||||
|
||||
VPN Lite 是一款易于使用而且**免费**的用于上网的 VPN 服务。你可以通过它在网络上保持匿名并保护你的个人隐私。它会模糊你的 IP 并加密你的数据,这意味着第三方无法跟踪你的所有线上活动。你还可以访问网络上的全部内容。使用 VPN Lite,你可以访问在被拦截的网站。你还放心地可以访问公共 WiFi 而不必担心敏感信息被间谍软件窃取和来自黑客的跟踪和攻击。
|
||||
|
||||
### 3、HotSpot Shield
|
||||
|
||||
这是一款在 2005 年推出的大受欢迎的 VPN。这套 VPN 协议至少被全球 70% 的数据安全公司所集成,并在全球有数千台服务器。它提供两种免费模式:一种为完全免费,但会有线上广告;另一种则为七天试用。它提供军事级的数据加密和恶意软件防护。HotSpot Shield 保证网络安全并保证高速网络。
|
||||
|
||||
### 4、TunnelBear
|
||||
|
||||
如果你是一名 VPN 新手,那么 TunnelBear 将是你的最佳选择。它带有一个用户友好的界面,并配有动画熊引导。你可以在 TunnelBear 的帮助下以极快的速度连接至少 22 个国家的服务器。它使用 **AES 256-bit** 加密算法,保证无日志记录,这意味着你的数据将得到保护。你还可以在最多五台设备上获得无限流量。
|
||||
|
||||
### 5、ProtonVPN
|
||||
|
||||
这款 VPN 为你提供强大的优质服务。你的连接速度可能会受到影响,但你也可以享受到无限流量。它具有易于使用的用户界面,提供多平台兼容。 ProtonVPN 的服务据说是因为为种子下载提供了优化因而无法访问 Netflix。你可以获得如协议和加密等安全功能来保证你的网络安全。
|
||||
|
||||
### 6、ExpressVPN
|
||||
|
||||
ExpressVPN 被认为是最好的用于接触封锁和保护隐私的离岸 VPN。凭借强大的客户支持和快速的速度,它已成为全球顶尖的 VPN 服务。它提供带有浏览器扩展和自定义固件的路由。 ExpressVPN 拥有一系列令人赞叹高质量应用程序,配有大量的服务器,并且最多只能支持三台设备。
|
||||
|
||||
ExpressVPN 并不是完全免费的,恰恰相反,正是由于它所提供的高质量服务而使之成为了市场上最贵的 VPN 之一。ExpressVPN 有 30 天内退款保证,因此你可以免费试用一个月。好消息是,这是完全没有风险的。例如,如果你在短时间内需要 VPN 来绕过在线审查,这可能是你的首选解决方案。用过它之后,你就不会随意想给一个会发送垃圾邮件、缓慢的免费的程序当成试验品。
|
||||
|
||||
ExpressVPN 也是享受在线流媒体和户外安全的最佳方式之一。如果你需要继续使用它,你只需要续订或取消你的免费试用。ExpressVPN 在 90 多个国家架设有 2000 多台服务器,可以解锁 Netflix,提供快速连接,并为用户提供完全隐私。
|
||||
|
||||
### 7、PureVPN
|
||||
|
||||
虽然 PureVPN 可能不是完全免费的,但它却是此列表中最实惠的一个。用户可以注册获得 7 天的免费试用,并在之后选择任一付费计划。通过这款 VPN,你可以访问到至少 140 个国家中的 750 余台服务器。它还可以在几乎所有设备上轻松安装。它的所有付费特性仍然可以在免费试用期间使用。包括无限数据流量、IP 泄漏保护和 ISP 不可见性。它支持的系统有 iOS、Android、Windows、Linux 和 macOS。
|
||||
|
||||
### 总结
|
||||
|
||||
如今,可用的免费 VPN 服务越来越多,为什么不抓住这个机会来保护你自己和你的客户呢?在了解到有那么多优秀的 VPN 服务后,我们知道即使是最安全的免费服务也不一定就完全没有风险。你可能需要付费升级到高级版以增强保护。高级版的 VPN 为你提供了免费试用,提供无风险退款保证。无论你打算花钱购买 VPN 还是准备使用免费 VPN,我们都强烈建议你使用一个。
|
||||
|
||||
**关于作者:**
|
||||
|
||||
**Renetta K. Molina** 是一个技术爱好者和健身爱好者。她撰写有关技术、应用程序、 WordPress 和其他任何领域的文章。她喜欢在空余时间打高尔夫球和读书。她喜欢学习和尝试新事物。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/
|
||||
|
||||
作者:[Editor][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Modrisco](https://github.com/Modrisco)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,482 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (ezio)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10676-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 10 Input01)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
计算机实验室之树莓派:课程 10 输入01
|
||||
======
|
||||
|
||||
欢迎进入输入课程系列。在本系列,你将会学会如何使用键盘接收输入给树莓派。我们将会从揭示输入开始本课,然后转向更传统的文本提示符。
|
||||
|
||||
这是第一堂输入课,会教授一些关于驱动和链接的理论,同样也包含键盘的知识,最后以在屏幕上显示文本结束。
|
||||
|
||||
### 1、开始
|
||||
|
||||
希望你已经完成了 OK 系列课程,这会对你完成屏幕系列课程很有帮助。很多 OK 课程上的文件会被使用而不会做解释。如果你没有这些文件,或者希望使用一个正确的实现,可以从该堂课的[下载页][1]下载模板。如果你使用你自己的实现,请删除调用了 `SetGraphicsAddress` 之后全部的代码。
|
||||
|
||||
### 2、USB
|
||||
|
||||
如你所知,树莓派 B 型有两个 USB 接口,通常用来连接一个鼠标和一个键盘。这是一个非常好的设计决策,USB 是一个非常通用的接口,很多种设备都可以使用它。这就很容易为它设计新外设,很容易为它编写设备驱动,而且通过 USB 集线器可以非常容易扩展。还能更好吗?当然是不能,实际上对一个操作系统开发者来说,这就是我们的噩梦。USB 标准太大了。我是说真的,在你思考如何连接设备之前,它的文档将近 700 页。
|
||||
|
||||
> USB 标准的设计目的是通过复杂的软件来简化硬件交互。
|
||||
|
||||
我和很多爱好操作系统的开发者谈过这些,而他们全部都说几句话:不要抱怨。“实现这个需要花费很久时间”,“你不可能写出关于 USB 的教程”,“收益太小了”。在很多方面,他们是对的,我不可能写出一个关于 USB 标准的教程,那得花费几周时间。我同样不能教授如何为全部所有的设备编写外设驱动,所以使用自己写的驱动是没什么用的。然而,即便不能做到最好,我仍然可以获取一个正常工作的 USB 驱动,拿一个键盘驱动,然后教授如何在操作系统中使用它们。我开始寻找可以运行在一个甚至不知道文件是什么的操作系统的自由驱动,但是我一个都找不到,它们都太高层了,所以我尝试写一个。大家说的都对,这耗费了我几周时间。然而我可以高兴的说我做的这些工作没有获取操作系统以外的帮助,并且可以和鼠标和键盘通信。这绝不是完整的、高效的,或者正确的,但是它能工作。驱动是以 C 编写的,而且有兴趣的可以在下载页找到全部源代码。
|
||||
|
||||
所以,这一个教程不会是 USB 标准的课程(一点也没有)。实际上我们将会看到如何使用其他人的代码。
|
||||
|
||||
### 3、链接
|
||||
|
||||
既然我们要引进外部代码到操作系统,我们就需要谈一谈<ruby>链接<rt>linking</rt></ruby>。链接是一种过程,可以在程序或者操作系统中链接函数。这意味着当一个程序生成之后,我们不必要编写每一个函数(几乎可以肯定,实际上并非如此)。链接就是我们做的用来把我们程序和别人代码中的函数连结在一起。这个实际上已经在我们的操作系统进行了,因为链接器把所有不同的文件链接在一起,每个都是分开编译的。
|
||||
|
||||
> 链接允许我们制作可重用的代码库,所有人都可以在他们的程序中使用。
|
||||
|
||||
有两种链接方式:静态和动态。静态链接就像我们在制作自己的操作系统时进行的。链接器找到全部函数的地址,然后在链接结束前,将这些地址都写入代码中。动态链接是在程序“完成”之后。当程序加载后,动态链接器检查程序,然后在操作系统的库找到所有不在程序里的函数。这就是我们的操作系统最终应该能够完成的一项工作,但是现在所有东西都将是静态链接的。
|
||||
|
||||
> 程序经常调用调用库,这些库会调用其它的库,直到最终调用了我们写的操作系统的库。
|
||||
|
||||
我编写的 USB 驱动程序适合静态编译。这意味着我给你的是每个文件的编译后的代码,然后链接器找到你的代码中的那些没有实现的函数,就将这些函数链接到我的代码。在本课的 [下载页][1] 是一个 makefile 和我的 USB 驱动,这是接下来需要的。下载并使用这个 makefile 替换你的代码中的 makefile, 同事将驱动放在和这个 makefile 相同的文件夹。
|
||||
|
||||
### 4、键盘
|
||||
|
||||
为了将输入传给我们的操作系统,我们需要在某种程度上理解键盘是如何实际工作的。键盘有两种按键:普通键和修饰键。普通按键是字母、数字、功能键,等等。它们构成了键盘上几乎全部按键。修饰键是多达 8 个的特殊键。它们是左 shift、右 shift、左 ctrl、右 ctrl、左 alt、右 alt、左 GUI 和右 GUI。键盘可以检测出所有的组合中那个修饰键被按下了,以及最多 6 个普通键。每次一个按钮变化了(例如,是按下了还是释放了),键盘就会报告给电脑。通常,键盘也会有 3 个 LED 灯,分别指示大写锁定,数字键锁定,和滚动锁定,这些都是由电脑控制的,而不是键盘自己。键盘也可能有更多的灯,比如电源、静音,等等。
|
||||
|
||||
对于标准 USB 键盘,有一个按键值的表,每个键盘按键都一个唯一的数字,每个可能的 LED 也类似。下面的表格列出了前 126 个值。
|
||||
|
||||
表 4.1 USB 键盘值
|
||||
|
||||
| 序号 | 描述 | 序号 | 描述 | 序号 | 描述 | 序号 | 描述 |
|
||||
| ------ | ---------------------- | ------ | -------------------- | ----------- | ----------------------- | -------- | ---------------------- |
|
||||
| 4 | `a` 和 `A` | 5 | `b` 和 `B` | 6 | `c` 和 `C` | 7 | `d` 和 `D` |
|
||||
| 8 | `e` 和 `E` | 9 | `f` 和 `F` | 10 | `g` 和 `G` | 11 | `h` 和 `H` |
|
||||
| 12 | `i` 和 `I` | 13 | `j` 和 `J` | 14 | `k` 和 `K` | 15 | `l` 和 `L` |
|
||||
| 16 | `m` 和 `M` | 17 | `n` 和 `N` | 18 | `o` 和 `O` | 19 | `p` 和 `P` |
|
||||
| 20 | `q` 和 `Q` | 21 | `r` 和 `R` | 22 | `s` 和 `S` | 23 | `t` 和 `T` |
|
||||
| 24 | `u` 和 `U` | 25 | `v` 和 `V` | 26 | `w` 和 `W` | 27 | `x` 和 `X` |
|
||||
| 28 | `y` 和 `Y` | 29 | `z` 和 `Z` | 30 | `1` 和 `!` | 31 | `2` 和 `@` |
|
||||
| 32 | `3` 和 `#` | 33 | `4` 和 `$` | 34 | `5` 和 `%` | 35 | `6` 和 `^` |
|
||||
| 36 | `7` 和 `&` | 37 | `8` 和 `*` | 38 | `9` 和 `(` | 39 | `0` 和 `)` |
|
||||
| 40 | `Return`(`Enter`) | 41 | `Escape` | 42 | `Delete`(`Backspace`) | 43 | `Tab` |
|
||||
| 44 | `Spacebar` | 45 | `-` 和 `_` | 46 | `=` 和 `+` | 47 | `[` 和 `{` |
|
||||
| 48 | `]` 和 `}` | 49 | `\` 和 `|` | 50 | `#` 和 `~` | 51 | `;` 和 `:` |
|
||||
| 52 | `'` 和 `"` | 53 | \` 和 `~` | 54 | `,` 和 `<` | 55 | `.` 和 `>` |
|
||||
| 56 | `/` 和 `?` | 57 | `Caps Lock` | 58 | `F1` | 59 | `F2` |
|
||||
| 60 | `F3` | 61 | `F4` | 62 | `F5` | 63 | `F6` |
|
||||
| 64 | `F7` | 65 | `F8` | 66 | `F9` | 67 | `F10` |
|
||||
| 68 | `F11` | 69 | `F12` | 70 | `Print Screen` | 71 | `Scroll Lock` |
|
||||
| 72 | `Pause` | 73 | `Insert` | 74 | `Home` | 75 | `Page Up` |
|
||||
| 76 | `Delete forward` | 77 | `End` | 78 | `Page Down` | 79 | `Right Arrow` |
|
||||
| 80 | `Left Arrow` | 81 | `Down Arrow` | 82 | `Up Arrow` | 83 | `Num Lock` |
|
||||
| 84 | 小键盘 `/` | 85 | 小键盘 `*` | 86 | 小键盘 `-` | 87 | 小键盘 `+` |
|
||||
| 88 | 小键盘 `Enter` | 89 | 小键盘 `1` 和 `End` | 90 | 小键盘 `2` 和 `Down Arrow` | 91 | 小键盘 `3` 和 `Page Down` |
|
||||
| 92 | 小键盘 `4` 和 `Left Arrow` | 93 | 小键盘 `5` | 94 | 小键盘 `6` 和 `Right Arrow` | 95 | 小键盘 `7` 和 `Home` |
|
||||
| 96 | 小键盘 `8` 和 `Up Arrow` | 97 | 小键盘 `9` 和 `Page Up` | 98 | 小键盘 `0` 和 `Insert` | 99 | 小键盘 `.` 和 `Delete` |
|
||||
| 100 | `\` 和 `|` | 101 | `Application` | 102 | `Power` | 103 | 小键盘 `=` |
|
||||
| 104 | `F13` | 105 | `F14` | 106 | `F15` | 107 | `F16` |
|
||||
| 108 | `F17` | 109 | `F18` | 110 | `F19` | 111 | `F20` |
|
||||
| 112 | `F21` | 113 | `F22` | 114 | `F23` | 115 | `F24` |
|
||||
| 116 | `Execute` | 117 | `Help` | 118 | `Menu` | 119 | `Select` |
|
||||
| 120 | `Stop` | 121 | `Again` | 122 | `Undo` | 123 | `Cut` |
|
||||
| 124 | `Copy` | 125 | `Paste` | 126 | `Find` | 127 | `Mute` |
|
||||
| 128 | `Volume Up` | 129 | `Volume Down` | | | | |
|
||||
|
||||
完全列表可以在[HID 页表 1.12][2]的 53 页,第 10 节找到。
|
||||
|
||||
### 5、车轮后的螺母
|
||||
|
||||
通常,当你使用其他人的代码,他们会提供一份自己代码的总结,描述代码都做了什么,粗略介绍了是如何工作的,以及什么情况下会出错。下面是一个使用我的 USB 驱动的相关步骤要求。
|
||||
|
||||
> 这些总结和代码的描述组成了一个 API - 应用程序产品接口。
|
||||
|
||||
表 5.1 CSUD 中和键盘相关的函数
|
||||
|
||||
| 函数 | 参数 | 返回值 | 描述 |
|
||||
| ----------------------- | ----------------------- | ----------------------- | -----------------------|
|
||||
| `UsbInitialise` | 无 | `r0` 是结果码 | 这个方法是一个集多种功能于一身的方法,它加载 USB 驱动程序,枚举所有设备并尝试与它们通信。这种方法通常需要大约一秒钟的时间来执行,但是如果插入几个 USB 集线器,执行时间会明显更长。在此方法完成之后,键盘驱动程序中的方法就可用了,不管是否确实插入了键盘。返回代码如下解释。|
|
||||
| `UsbCheckForChange` | 无 | 无 | 本质上提供与 `UsbInitialise` 相同的效果,但不提供相同的一次初始化。该方法递归地检查每个连接的集线器上的每个端口,如果已经添加了新设备,则添加它们。如果没有更改,这应该是非常快的,但是如果连接了多个设备的集线器,则可能需要几秒钟的时间。|
|
||||
| `KeyboardCount` | 无 | `r0` 是计数 | 返回当前连接并检测到的键盘数量。`UsbCheckForChange` 可能会对此进行更新。默认情况下最多支持 4 个键盘。可以通过这个驱动程序访问多达这么多的键盘。|
|
||||
| `KeyboardGetAddress` | `r0` 是索引 | `r0` 是地址 | 检索给定键盘的地址。所有其他函数都需要一个键盘地址,以便知道要访问哪个键盘。因此,要与键盘通信,首先要检查计数,然后检索地址,然后使用其他方法。注意,在调用 `UsbCheckForChange` 之后,此方法返回的键盘顺序可能会改变。|
|
||||
| `KeyboardPoll` | `r0` 是地址 | `r0` 是结果码 | 从键盘读取当前键状态。这是通过直接轮询设备来操作的,与最佳实践相反。这意味着,如果没有频繁地调用此方法,可能会错过一个按键。所有读取方法只返回上次轮询时的值。|
|
||||
| `KeyboardGetModifiers` | `r0` 是地址 | `r0` 是修饰键状态 | 检索上次轮询时修饰键的状态。这是两边的 `shift` 键、`alt` 键和 `GUI` 键。这回作为一个位字段返回,这样,位 0 中的 1 表示左控件被保留,位 1 表示左 `shift`,位 2 表示左 `alt` ,位 3 表示左 `GUI`,位 4 到 7 表示前面几个键的右版本。如果有问题,`r0` 包含 0。|
|
||||
| `KeyboardGetKeyDownCount` | `r0` 是地址 | `r0` 是计数 | 检索当前按下键盘的键数。这排除了修饰键。这通常不能超过 6。如果有错误,这个方法返回 0。|
|
||||
| `KeyboardGetKeyDown` | `r0` 是地址,`r1` 键号 | `r0` 是扫描码 | 检索特定按下键的扫描码(见表 4.1)。通常,要计算出哪些键是按下的,可以调用 `KeyboardGetKeyDownCount`,然后多次调用 `KeyboardGetKeyDown` ,将 `r1` 的值递增,以确定哪些键是按下的。如果有问题,返回 0。可以(但不建议这样做)在不调用 `KeyboardGetKeyDownCount` 的情况下调用此方法将 0 解释为没有按下的键。注意,顺序或扫描代码可以随机更改(有些键盘按数字排序,有些键盘按时间排序,没有任何保证)。|
|
||||
| `KeyboardGetKeyIsDown` | `r0` 是地址,`r1` 扫描码 | `r0` 是状态 | 除了 `KeyboardGetKeyDown` 之外,还可以检查按下的键中是否有特定的扫描码。如果没有,返回 0;如果有,返回一个非零值。当检测特定的扫描码(例如寻找 `ctrl+c`)时更快。出错时,返回 0。|
|
||||
| `KeyboardGetLedSupport` | `r0` 是地址 | `r0` 是 LED | 检查特定键盘支持哪些 LED。第 0 位代表数字锁定,第 1 位代表大写锁定,第 2 位代表滚动锁定,第 3 位代表合成,第 4 位代表假名,第 5 位代表电源,第 6 位代表 Shift ,第 7 位代表静音。根据 USB 标准,这些 LED 都不是自动更新的(例如,当检测到大写锁定扫描代码时,必须手动设置大写锁定 LED)。|
|
||||
| `KeyboardSetLeds` | `r0` 是地址, `r1` 是 LED | `r0` 是结果码 | 试图打开/关闭键盘上指定的 LED 灯。查看下面的结果代码值。参见 `KeyboardGetLedSupport` 获取 LED 的值。|
|
||||
|
||||
有几种方法返回“返回值”。这些都是 C 代码的老生常谈了,就是用数字代表函数调用发生了什么。通常情况, 0 总是代表操作成功。下面的是驱动用到的返回值。
|
||||
|
||||
> 返回值是一种处理错误的简单方法,但是通常更优雅的解决途径会出现于更高层次的代码。
|
||||
|
||||
表 5.2 - CSUD 返回值
|
||||
|
||||
| 代码 | 描述 |
|
||||
| ---- | ----------------------------------------------------------------------- |
|
||||
| 0 | 方法成功完成。 |
|
||||
| -2 | 参数:函数调用了无效参数。 |
|
||||
| -4 | 设备:设备没有正确响应请求。 |
|
||||
| -5 | 不匹配:驱动不适用于这个请求或者设备。 |
|
||||
| -6 | 编译器:驱动没有正确编译,或者被破坏了。 |
|
||||
| -7 | 内存:驱动用尽了内存。 |
|
||||
| -8 | 超时:设备没有在预期的时间内响应请求。 |
|
||||
| -9 | 断开连接:被请求的设备断开连接,或者不能使用。 |
|
||||
|
||||
驱动的通常用法如下:
|
||||
|
||||
1. 调用 `UsbInitialise`
|
||||
2. 调用 `UsbCheckForChange`
|
||||
3. 调用 `KeyboardCount`
|
||||
4. 如果返回 0,重复步骤 2。
|
||||
5. 针对你支持的每个键盘:
|
||||
1. 调用 `KeyboardGetAddress`
|
||||
2. 调用 `KeybordGetKeyDownCount`
|
||||
3. 针对每个按下的按键:
|
||||
1. 检查它是否已经被按下了
|
||||
2. 保存按下的按键
|
||||
4. 针对每个保存的按键:
|
||||
3. 检查按键是否被释放了
|
||||
4. 如果释放了就删除
|
||||
6. 根据按下/释放的案件执行操作
|
||||
7. 重复步骤 2
|
||||
|
||||
最后,你可以对键盘做所有你想做的任何事了,而这些方法应该允许你访问键盘的全部功能。在接下来的两节课,我们将会着眼于完成文本终端的输入部分,类似于大部分的命令行电脑,以及命令的解释。为了做这些,我们将需要在更有用的形式下得到一个键盘输入。你可能注意到我的驱动是(故意的)没有太大帮助,因为它并没有方法来判断是否一个按键刚刚按下或释放了,它只有方法来判断当前那个按键是按下的。这就意味着我们需要自己编写这些方法。
|
||||
|
||||
### 6、可用更新
|
||||
|
||||
首先,让我们实现一个 `KeyboardUpdate` 方法,检查第一个键盘,并使用轮询方法来获取当前的输入,以及保存最后一个输入来对比。然后我们可以使用这个数据和其它方法来将扫描码转换成按键。这个方法应该按照下面的说明准确操作:
|
||||
|
||||
> 重复检查更新被称为“轮询”。这是针对驱动 IO 中断而言的,这种情况下设备在准备好后会发一个信号。
|
||||
|
||||
1. 提取一个保存好的键盘地址(初始值为 0)。
|
||||
2. 如果不是 0 ,进入步骤 9.
|
||||
3. 调用 `UsbCheckForChange` 检测新键盘。
|
||||
4. 调用 `KeyboardCount` 检测有几个键盘在线。
|
||||
5. 如果返回 0,意味着没有键盘可以让我们操作,只能退出了。
|
||||
6. 调用 `KeyboardGetAddress` 参数是 0,获取第一个键盘的地址。
|
||||
7. 保存这个地址。
|
||||
8. 如果这个值是 0,那么退出,这里应该有些问题。
|
||||
9. 调用 `KeyboardGetKeyDown` 6 次,获取每次按键按下的值并保存。
|
||||
10. 调用 `KeyboardPoll`
|
||||
11. 如果返回值非 0,进入步骤 3。这里应该有些问题(比如键盘断开连接)。
|
||||
|
||||
要保存上面提到的值,我们将需要下面 `.data` 段的值。
|
||||
|
||||
```
|
||||
.section .data
|
||||
.align 2
|
||||
KeyboardAddress:
|
||||
.int 0
|
||||
KeyboardOldDown:
|
||||
.rept 6
|
||||
.hword 0
|
||||
.endr
|
||||
```
|
||||
|
||||
```
|
||||
.hword num 直接将半字的常数插入文件。
|
||||
```
|
||||
|
||||
```
|
||||
.rept num [commands] .endr 复制 `commands` 命令到输出 num 次。
|
||||
```
|
||||
|
||||
试着自己实现这个方法。对此,我的实现如下:
|
||||
|
||||
1、我们加载键盘的地址。
|
||||
|
||||
```
|
||||
.section .text
|
||||
.globl KeyboardUpdate
|
||||
KeyboardUpdate:
|
||||
push {r4,r5,lr}
|
||||
|
||||
kbd .req r4
|
||||
ldr r0,=KeyboardAddress
|
||||
ldr kbd,[r0]
|
||||
```
|
||||
|
||||
2、如果地址非 0,就说明我们有一个键盘。调用 `UsbCheckForChanges` 慢,所以如果一切正常,我们要避免调用这个函数。
|
||||
|
||||
```
|
||||
teq kbd,#0
|
||||
bne haveKeyboard$
|
||||
```
|
||||
|
||||
3、如果我们一个键盘都没有,我们就必须检查新设备。
|
||||
|
||||
```
|
||||
getKeyboard$:
|
||||
bl UsbCheckForChange
|
||||
```
|
||||
|
||||
4、如果有新键盘添加,我们就会看到这个。
|
||||
|
||||
```
|
||||
bl KeyboardCount
|
||||
```
|
||||
|
||||
5、如果没有键盘,我们就没有键盘地址。
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
ldreq r1,=KeyboardAddress
|
||||
streq r0,[r1]
|
||||
beq return$
|
||||
```
|
||||
|
||||
6、让我们获取第一个键盘的地址。你可能想要支持更多键盘。
|
||||
|
||||
```
|
||||
mov r0,#0
|
||||
bl KeyboardGetAddress
|
||||
```
|
||||
|
||||
7、保存键盘地址。
|
||||
|
||||
```
|
||||
ldr r1,=KeyboardAddress
|
||||
str r0,[r1]
|
||||
```
|
||||
|
||||
8、如果我们没有键盘地址,这里就没有其它活要做了。
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
beq return$
|
||||
mov kbd,r0
|
||||
```
|
||||
|
||||
9、循环查询全部按键,在 `KeyboardOldDown` 保存下来。如果我们询问的太多了,返回 0 也是正确的。
|
||||
|
||||
```
|
||||
saveKeys$:
|
||||
mov r0,kbd
|
||||
mov r1,r5
|
||||
bl KeyboardGetKeyDown
|
||||
|
||||
ldr r1,=KeyboardOldDown
|
||||
add r1,r5,lsl #1
|
||||
strh r0,[r1]
|
||||
add r5,#1
|
||||
cmp r5,#6
|
||||
blt saveKeys$
|
||||
```
|
||||
|
||||
10、现在我们得到了新的按键。
|
||||
|
||||
```
|
||||
mov r0,kbd
|
||||
bl KeyboardPoll
|
||||
```
|
||||
|
||||
11、最后我们要检查 `KeyboardOldDown` 是否工作了。如果没工作,那么我们可能是断开连接了。
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
bne getKeyboard$
|
||||
|
||||
return$:
|
||||
pop {r4,r5,pc}
|
||||
.unreq kbd
|
||||
```
|
||||
|
||||
有了我们新的 `KeyboardUpdate` 方法,检查输入变得简单,固定周期调用这个方法就行,而它甚至可以检查键盘是否断开连接,等等。这是一个有用的方法,因为我们实际的按键处理会根据条件不同而有所差别,所以能够用一个函数调以它的原始方式获取当前的输入是可行的。下一个方法我们希望它是 `KeyboardGetChar`,简单的返回下一个按下的按钮的 ASCII 字符,或者如果没有按键按下就返回 0。这可以扩展到支持如果它按下一个特定时间当做多次按下按键,也支持锁定键和修饰键。
|
||||
|
||||
如果我们有一个 `KeyWasDown` 方法可以使这个方法有用起来,如果给定的扫描代码不在 `KeyboardOldDown` 值中,它只返回 0,否则返回一个非零值。你可以自己尝试一下。与往常一样,可以在下载页面找到解决方案。
|
||||
|
||||
### 7、查找表
|
||||
|
||||
`KeyboardGetChar` 方法如果写得不好,可能会非常复杂。有 100 多种扫描码,每种代码都有不同的效果,这取决于 shift 键或其他修饰符的存在与否。并不是所有的键都可以转换成一个字符。对于一些字符,多个键可以生成相同的字符。在有如此多可能性的情况下,一个有用的技巧是查找表。查找表与物理意义上的查找表非常相似,它是一个值及其结果的表。对于一些有限的函数,推导出答案的最简单方法就是预先计算每个答案,然后通过检索返回正确的答案。在这种情况下,我们可以在内存中建立一个序列的值,序列中第 n 个值就是扫描代码 n 的 ASCII 字符代码。这意味着如果一个键被按下,我们的方法只需要检测到,然后从表中检索它的值。此外,我们可以为当按住 shift 键时的值单独创建一个表,这样按下 shift 键就可以简单地换个我们用的表。
|
||||
|
||||
> 在编程的许多领域,程序越大,速度越快。查找表很大,但是速度很快。有些问题可以通过查找表和普通函数的组合来解决。
|
||||
|
||||
在 `.section .data` 命令之后,复制下面的表:
|
||||
|
||||
```
|
||||
.align 3
|
||||
KeysNormal:
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 'a', 'b', 'c', 'd'
|
||||
.byte 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l'
|
||||
.byte 'm', 'n', 'o', 'p', 'q', 'r', 's', 't'
|
||||
.byte 'u', 'v', 'w', 'x', 'y', 'z', '1', '2'
|
||||
.byte '3', '4', '5', '6', '7', '8', '9', '0'
|
||||
.byte '\n', 0x0, '\b', '\t', ' ', '-', '=', '['
|
||||
.byte ']', '\\\', '#', ';', '\'', '`', ',', '.'
|
||||
.byte '/', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
|
||||
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
|
||||
.byte '8', '9', '0', '.', '\\\', 0x0, 0x0, '='
|
||||
|
||||
.align 3
|
||||
KeysShift:
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 'A', 'B', 'C', 'D'
|
||||
.byte 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L'
|
||||
.byte 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T'
|
||||
.byte 'U', 'V', 'W', 'X', 'Y', 'Z', '!', '"'
|
||||
.byte '£', '$', '%', '^', '&', '*', '(', ')'
|
||||
.byte '\n', 0x0, '\b', '\t', ' ', '_', '+', '{'
|
||||
.byte '}', '|', '~', ':', '@', '¬', '<', '>'
|
||||
.byte '?', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
|
||||
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
|
||||
.byte '8', '9', '0', '.', '|', 0x0, 0x0, '='
|
||||
```
|
||||
|
||||
这些表直接将前 104 个扫描码映射到 ASCII 字符作为一个字节表。我们还有一个单独的表来描述 `shift` 键对这些扫描码的影响。我使用 ASCII `null` 字符(`0`)表示所有没有直接映射的 ASCII 键(例如功能键)。退格映射到 ASCII 退格字符(8 表示 `\b`),`enter` 映射到 ASCII 新行字符(10 表示 `\n`), `tab` 映射到 ASCII 水平制表符(9 表示 `\t`)。
|
||||
|
||||
> `.byte num` 直接插入字节常量 num 到文件。
|
||||
|
||||
.
|
||||
|
||||
> 大部分的汇编器和编译器识别转义序列;如 `\t` 这样的字符序列会插入该特殊字符。
|
||||
|
||||
`KeyboardGetChar` 方法需要做以下工作:
|
||||
|
||||
1. 检查 `KeyboardAddress` 是否返回 `0`。如果是,则返回 0。
|
||||
2. 调用 `KeyboardGetKeyDown` 最多 6 次。每次:
|
||||
1. 如果按键是 0,跳出循环。
|
||||
2. 调用 `KeyWasDown`。 如果返回是,处理下一个按键。
|
||||
3. 如果扫描码超过 103,进入下一个按键。
|
||||
4. 调用 `KeyboardGetModifiers`
|
||||
5. 如果 `shift` 是被按着的,就加载 `KeysShift` 的地址,否则加载 `KeysNormal` 的地址。
|
||||
6. 从表中读出 ASCII 码值。
|
||||
7. 如果是 0,进行下一个按键,否则返回 ASCII 码值并退出。
|
||||
3. 返回 0。
|
||||
|
||||
|
||||
试着自己实现。我的实现展示在下面:
|
||||
|
||||
1、简单的检查我们是否有键盘。
|
||||
|
||||
```
|
||||
.globl KeyboardGetChar
|
||||
KeyboardGetChar:
|
||||
ldr r0,=KeyboardAddress
|
||||
ldr r1,[r0]
|
||||
teq r1,#0
|
||||
moveq r0,#0
|
||||
moveq pc,lr
|
||||
```
|
||||
|
||||
2、`r5` 将会保存按键的索引,`r4` 保存键盘的地址。
|
||||
|
||||
```
|
||||
push {r4,r5,r6,lr}
|
||||
kbd .req r4
|
||||
key .req r6
|
||||
mov r4,r1
|
||||
mov r5,#0
|
||||
keyLoop$:
|
||||
mov r0,kbd
|
||||
mov r1,r5
|
||||
bl KeyboardGetKeyDown
|
||||
```
|
||||
|
||||
2.1、 如果扫描码是 0,它要么意味着有错,要么说明没有更多按键了。
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
beq keyLoopBreak$
|
||||
```
|
||||
|
||||
2.2、如果按键已经按下了,那么他就没意义了,我们只想知道按下的按键。
|
||||
|
||||
```
|
||||
mov key,r0
|
||||
bl KeyWasDown
|
||||
teq r0,#0
|
||||
bne keyLoopContinue$
|
||||
```
|
||||
|
||||
|
||||
2.3、如果一个按键有个超过 104 的扫描码,它将会超出我们的表,所以它是无关的按键。
|
||||
|
||||
```
|
||||
cmp key,#104
|
||||
bge keyLoopContinue$
|
||||
```
|
||||
|
||||
2.4、我们需要知道修饰键来推断字符。
|
||||
|
||||
```
|
||||
mov r0,kbd
|
||||
bl KeyboardGetModifiers
|
||||
```
|
||||
|
||||
5. 当将字符更改为其 shift 变体时,我们要同时检测左 `shift` 键和右 `shift` 键。记住,`tst` 指令计算的是逻辑和,然后将其与 0 进行比较,所以当且仅当移位位都为 0 时,它才等于 0。
|
||||
|
||||
```
|
||||
tst r0,#0b00100010
|
||||
ldreq r0,=KeysNormal
|
||||
ldrne r0,=KeysShift
|
||||
```
|
||||
|
||||
2.6、现在我们可以从查找表加载按键了。
|
||||
|
||||
```
|
||||
ldrb r0,[r0,key]
|
||||
```
|
||||
|
||||
2.7、如果查找码包含一个 0,我们必须继续。为了继续,我们要增加索引,并检查是否到 6 次了。
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
bne keyboardGetCharReturn$
|
||||
keyLoopContinue$:
|
||||
add r5,#1
|
||||
cmp r5,#6
|
||||
blt keyLoop$
|
||||
```
|
||||
|
||||
|
||||
3、在这里我们返回我们的按键,如果我们到达 `keyLoopBreak$` ,然后我们就知道这里没有按键被握住,所以返回 0。
|
||||
|
||||
```
|
||||
keyLoopBreak$:
|
||||
mov r0,#0
|
||||
keyboardGetCharReturn$:
|
||||
pop {r4,r5,r6,pc}
|
||||
.unreq kbd
|
||||
.unreq key
|
||||
```
|
||||
|
||||
### 8、记事本操作系统
|
||||
|
||||
现在我们有了 `KeyboardGetChar` 方法,可以创建一个操作系统,只打印出用户对着屏幕所写的内容。为了简单起见,我们将忽略所有非常规的键。在 `main.s`,删除 `bl SetGraphicsAddress` 之后的所有代码。调用 `UsbInitialise`,将 `r4` 和 `r5` 设置为 0,然后循环执行以下命令:
|
||||
|
||||
1. 调用 `KeyboardUpdate`
|
||||
2. 调用 `KeyboardGetChar`
|
||||
3. 如果返回 0,跳转到步骤 1
|
||||
4. 复制 `r4` 和 `r5` 到 `r1` 和 `r2` ,然后调用 `DrawCharacter`
|
||||
5. 把 `r0` 加到 `r4`
|
||||
6. 如果 `r4` 是 1024,将 `r1` 加到 `r5`,然后设置 `r4` 为 0。
|
||||
7. 如果 `r5` 是 768,设置 `r5` 为0
|
||||
8. 跳转到步骤 1
|
||||
|
||||
现在编译,然后在树莓派上测试。你几乎可以立即开始在屏幕上输入文本。如果没有工作,请参阅我们的故障排除页面。
|
||||
|
||||
当它工作时,祝贺你,你已经实现了与计算机的接口。现在你应该开始意识到,你几乎已经拥有了一个原始的操作系统。现在,你可以与计算机交互、发出命令,并在屏幕上接收反馈。在下一篇教程[输入02][3]中,我们将研究如何生成一个全文本终端,用户在其中输入命令,然后计算机执行这些命令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads/hut1_12v2.pdf
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html
|
||||
@ -0,0 +1,197 @@
|
||||
iWant:一个去中心化的点对点共享文件的命令行工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
不久之前,我们编写了一个指南,内容是一个文件共享实用程序,名为 [transfer.sh][1],它是一个免费的 Web 服务,允许你在 Internet 上轻松快速地共享文件,还有 [PSiTransfer][2],一个简单的开源自托管文件共享解决方案。今天,我们将看到另一个名为 “iWant” 的文件共享实用程序。它是一个基于命令行的自由开源的去中心化点对点文件共享应用程序。
|
||||
|
||||
你可能想知道,它与其它文件共享应用程序有什么不同?以下是 iWant 的一些突出特点。
|
||||
|
||||
* 它是一个命令行应用程序。这意味着你不需要消耗内存来加载 GUI 实用程序。你只需要一个终端。
|
||||
* 它是去中心化的。这意味着你的数据不会在任何中心位置存储。因此,不会因为中心点失败而失败。
|
||||
* iWant 允许中断下载,你可以在以后随时恢复。你不需要从头开始下载,它会从你停止的位置恢复下载。
|
||||
* 共享目录中文件所作的任何更改(如删除、添加、修改)都会立即反映在网络中。
|
||||
* 就像种子一样,iWant 从多个节点下载文件。如果任何节点离开群组或未能响应,它将继续从另一个节点下载。
|
||||
* 它是跨平台的,因此你可以在 GNU/Linux、MS Windows 或者 Mac OS X 中使用它。
|
||||
|
||||
### 安装 iWant
|
||||
|
||||
iWant 可以使用 PIP 包管理器轻松安装。确保你在 Linux 发行版中安装了 pip。如果尚未安装,参考以下指南。
|
||||
|
||||
[如何使用 Pip 管理 Python 包](https://www.ostechnix.com/manage-python-packages-using-pip/)
|
||||
|
||||
安装 pip 后,确保你有以下依赖项:
|
||||
|
||||
* libffi-dev
|
||||
* libssl-dev
|
||||
|
||||
比如说,在 Ubuntu 上,你可以使用以下命令安装这些依赖项:
|
||||
|
||||
```
|
||||
$ sudo apt-get install libffi-dev libssl-dev
|
||||
```
|
||||
|
||||
安装完所有依赖项后,使用以下命令安装 iWant:
|
||||
|
||||
```
|
||||
$ sudo pip install iwant
|
||||
```
|
||||
|
||||
现在我们的系统中已经有了 iWant,让我们来看看如何使用它来通过网络传输文件。
|
||||
|
||||
### 用法
|
||||
|
||||
首先,使用以下命令启动 iWant 服务器:
|
||||
|
||||
(LCTT 译注:虽然这个软件是叫 iWant,但是其命令名为 `iwanto`,另外这个软件至少一年没有更新了。)
|
||||
|
||||
```
|
||||
$ iwanto start
|
||||
```
|
||||
|
||||
第一次启动时,iWant 会询问想要分享和下载文件夹的位置,所以需要输入两个文件夹的位置。然后,选择要使用的网卡。
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Shared/Download folder details looks empty..
|
||||
Note: Shared and Download folder cannot be the same
|
||||
SHARED FOLDER(absolute path):/home/sk/myshare
|
||||
DOWNLOAD FOLDER(absolute path):/home/sk/mydownloads
|
||||
Network interface available
|
||||
1. lo => 127.0.0.1
|
||||
2. enp0s3 => 192.168.43.2
|
||||
Enter index of the interface:2
|
||||
now scanning /home/sk/myshare
|
||||
[Adding] /home/sk/myshare 0.0
|
||||
Updating Leader 56f6d5e8-654e-11e7-93c8-08002712f8c1
|
||||
[Adding] /home/sk/myshare 0.0
|
||||
connecting to 192.168.43.2:1235 for hashdump
|
||||
```
|
||||
|
||||
如果你看到类似上面的输出,你可以立即开始使用 iWant 了。
|
||||
|
||||
同样,在网络中的所有系统上启动 iWant 服务,指定有效的分享和下载文件夹的位置,并选择合适的网卡。
|
||||
|
||||
iWant 服务将继续在当前终端窗口中运行,直到你按下 `CTRL+C` 退出为止。你需要打开一个新选项卡或新的终端窗口来使用 iWant。
|
||||
|
||||
iWant 的用法非常简单,它的命令很少,如下所示。
|
||||
|
||||
* `iwanto start` – 启动 iWant 服务。
|
||||
* `iwanto search <name>` – 查找文件。
|
||||
* `iwanto download <hash>` – 下载一个文件。
|
||||
* `iwanto share <path>` – 更改共享文件夹的位置。
|
||||
* `iwanto download to <destination>` – 更改下载文件夹位置。
|
||||
* `iwanto view config` – 查看共享和下载文件夹。
|
||||
* `iwanto –version` – 显示 iWant 版本。
|
||||
* `iwanto -h` – 显示帮助信息。
|
||||
|
||||
让我向你展示一些例子。
|
||||
|
||||
#### 查找文件
|
||||
|
||||
要查找一个文件,运行:
|
||||
|
||||
```
|
||||
$ iwanto search <filename>
|
||||
|
||||
```
|
||||
|
||||
请注意,你无需指定确切的名称。
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ iwanto search command
|
||||
```
|
||||
|
||||
上面的命令将搜索包含 “command” 字符串的所有文件。
|
||||
|
||||
我的 Ubuntu 系统会输出:
|
||||
|
||||
```
|
||||
Filename Size Checksum
|
||||
------------------------------------------- ------- --------------------------------
|
||||
/home/sk/myshare/THE LINUX COMMAND LINE.pdf 3.85757 efded6cc6f34a3d107c67c2300459911
|
||||
```
|
||||
|
||||
#### 下载文件
|
||||
|
||||
你可以在你的网络上的任何系统下载文件。要下载文件,只需提供文件的哈希(校验和),如下所示。你可以使用 `iwanto search` 命令获取共享的哈希值。
|
||||
|
||||
```
|
||||
$ iwanto download efded6cc6f34a3d107c67c2300459911
|
||||
```
|
||||
|
||||
文件将保存在你的下载位置,在本文中是 `/home/sk/mydownloads/` 位置。
|
||||
|
||||
```
|
||||
Filename: /home/sk/mydownloads/THE LINUX COMMAND LINE.pdf
|
||||
Size: 3.857569 MB
|
||||
```
|
||||
|
||||
#### 查看配置
|
||||
|
||||
要查看配置,例如共享和下载文件夹的位置,运行:
|
||||
|
||||
```
|
||||
$ iwanto view config
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Shared folder:/home/sk/myshare
|
||||
Download folder:/home/sk/mydownloads
|
||||
```
|
||||
|
||||
#### 更改共享和下载文件夹的位置
|
||||
|
||||
你可以更改共享文件夹和下载文件夹。
|
||||
|
||||
```
|
||||
$ iwanto share /home/sk/ostechnix
|
||||
```
|
||||
|
||||
现在,共享位置已更改为 `/home/sk/ostechnix`。
|
||||
|
||||
同样,你可以使用以下命令更改下载位置:
|
||||
|
||||
```
|
||||
$ iwanto download to /home/sk/Downloads
|
||||
```
|
||||
|
||||
要查看所做的更改,运行命令:
|
||||
|
||||
```
|
||||
$ iwanto view config
|
||||
```
|
||||
|
||||
#### 停止 iWant
|
||||
|
||||
一旦你不想用 iWant 了,可以按下 `CTRL+C` 退出。
|
||||
|
||||
如果它不起作用,那可能是由于防火墙或你的路由器不支持多播。你可以在 `~/.iwant/.iwant.log` 文件中查看所有日志。有关更多详细信息,参阅最后提供的项目的 GitHub 页面。
|
||||
|
||||
差不多就是全部了。希望这个工具有所帮助。下次我会带着另一个有趣的指南再次来到这里。
|
||||
|
||||
干杯!
|
||||
|
||||
### 资源
|
||||
|
||||
-[iWant GitHub](https://github.com/nirvik/iWant)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/iwant-decentralized-peer-peer-file-sharing-commandline-application/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/easy-fast-way-share-files-internet-command-line/
|
||||
[2]:https://www.ostechnix.com/psitransfer-simple-open-source-self-hosted-file-sharing-solution/
|
||||
101
published/20180118 Rediscovering make- the power behind rules.md
Normal file
101
published/20180118 Rediscovering make- the power behind rules.md
Normal file
@ -0,0 +1,101 @@
|
||||
重新发现 make: 规则背后的力量
|
||||
======
|
||||
|
||||

|
||||
|
||||
我过去认为 makefile 只是一种将一组组的 shell 命令列出来的简便方法;过了一段时间我了解到它们是有多么的强大、灵活以及功能齐全。这篇文章带你领略其中一些有关规则的特性。
|
||||
|
||||
> 备注:这些全是针对 GNU Makefile 的,如果你希望支持 BSD Makefile ,你会发现有些新的功能缺失。感谢 [zge][5] 指出这点。
|
||||
|
||||
### 规则
|
||||
|
||||
<ruby>规则<rt>rule</rt></ruby>是指示 `make` 应该如何并且何时构建一个被称作为<ruby>目标<rt>target</rt></ruby>的文件的指令。目标可以依赖于其它被称作为<ruby>前提<rt>prerequisite</rt></ruby>的文件。
|
||||
|
||||
你会指示 `make` 如何按<ruby>步骤<rt>recipe</rt></ruby>构建目标,那就是一套按照出现顺序一次执行一个的 shell 命令。语法像这样:
|
||||
|
||||
```
|
||||
target_name : prerequisites
|
||||
recipe
|
||||
```
|
||||
|
||||
一但你定义好了规则,你就可以通过从命令行执行以下命令构建目标:
|
||||
|
||||
```
|
||||
$ make target_name
|
||||
```
|
||||
|
||||
目标一经构建,除非前提改变,否则 `make` 会足够聪明地不再去运行该步骤。
|
||||
|
||||
### 关于前提的更多信息
|
||||
|
||||
前提表明了两件事情:
|
||||
|
||||
* 当目标应当被构建时:如果其中一个前提比目标更新,`make` 假定目的应当被构建。
|
||||
* 执行的顺序:鉴于前提可以反过来在 makefile 中由另一套规则所构建,它们同样暗示了一个执行规则的顺序。
|
||||
|
||||
如果你想要定义一个顺序但是你不想在前提改变的时候重新构建目标,你可以使用一种特别的叫做“<ruby>唯顺序<rt>order only</rt></ruby>”的前提。这种前提可以被放在普通的前提之后,用管道符(`|`)进行分隔。
|
||||
|
||||
### 样式
|
||||
|
||||
为了便利,`make` 接受目标和前提的样式。通过包含 `%` 符号可以定义一种样式。这个符号是一个可以匹配任何长度的文字符号或者空隔的通配符。以下有一些示例:
|
||||
|
||||
* `%`:匹配任何文件
|
||||
* `%.md`:匹配所有 `.md` 结尾的文件
|
||||
* `prefix%.go`:匹配所有以 `prefix` 开头以 `.go` 结尾的文件
|
||||
|
||||
### 特殊目标
|
||||
|
||||
有一系列目标名字,它们对于 `make` 来说有特殊的意义,被称作<ruby>特殊目标<rt>special target</rt></ruby>。
|
||||
|
||||
你可以在这个[文档][1]发现全套特殊目标。作为一种经验法则,特殊目标以点开始后面跟着大写字母。
|
||||
|
||||
以下是几个有用的特殊目标:
|
||||
|
||||
- `.PHONY`:向 `make` 表明此目标的前提可以被当成伪目标。这意味着 `make` 将总是运行,无论有那个名字的文件是否存在或者上次被修改的时间是什么。
|
||||
- `.DEFAULT`:被用于任何没有指定规则的目标。
|
||||
- `.IGNORE`:如果你指定 `.IGNORE` 为前提,`make` 将忽略执行步骤中的错误。
|
||||
|
||||
### 替代
|
||||
|
||||
当你需要以你指定的改动方式改变一个变量的值,<ruby>替代<rt>substitution</rt></ruby>就十分有用了。
|
||||
|
||||
替代的格式是 `$(var:a=b)`,它的意思是获取变量 `var` 的值,用值里面的 `b` 替代词末尾的每个 `a` 以代替最终的字符串。例如:
|
||||
|
||||
```
|
||||
foo := a.o
|
||||
bar : = $(foo:.o=.c) # sets bar to a.c
|
||||
```
|
||||
|
||||
注意:特别感谢 [Luis Lavena][2] 让我们知道替代的存在。
|
||||
|
||||
### 档案文件
|
||||
|
||||
档案文件是用来一起将多个数据文档(类似于压缩文件的概念)收集成一个文件。它们由 `ar` Unix 工具所构建。`ar` 可以用于为任何目的创建档案,但除了[静态库][3],它已经被 `tar` 大量替代。
|
||||
|
||||
在 `make` 中,你可以使用一个档案文件中的单独一个成员作为目标或者前提,就像这样:
|
||||
|
||||
```
|
||||
archive(member) : prerequisite
|
||||
recipe
|
||||
```
|
||||
|
||||
### 最后的想法
|
||||
|
||||
关于 `make` 还有更多可探索的,但是至少这是一个起点,我强烈鼓励你去查看[文档][4],创建一个笨拙的 makefile 然后就可以探索它了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://monades.roperzh.com/rediscovering-make-power-behind-rules/
|
||||
|
||||
作者:[Roberto Dip][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://monades.roperzh.com
|
||||
[1]:https://www.gnu.org/software/make/manual/make.html#Special-Targets
|
||||
[2]:https://twitter.com/luislavena/
|
||||
[3]:http://tldp.org/HOWTO/Program-Library-HOWTO/static-libraries.html
|
||||
[4]:https://www.gnu.org/software/make/manual/make.html
|
||||
[5]:https://lobste.rs/u/zge
|
||||
229
published/20180205 Rancher - Container Management Application.md
Normal file
229
published/20180205 Rancher - Container Management Application.md
Normal file
@ -0,0 +1,229 @@
|
||||
Rancher:一个全面的可用于产品环境的容器管理平台
|
||||
======
|
||||
|
||||
Docker 作为一款容器化应用的新兴软件,被大多数 IT 公司使用来减少基础设施平台的成本。
|
||||
|
||||
通常,没有 GUI 的 Docker 软件对于 Linux 管理员来说很容易,但是对于开发者来就有点困难。当把它搬到生产环境上来,那么它对 Linux 管理员来说也相当不友好。那么,轻松管理 Docker 的最佳解决方案是什么呢?
|
||||
|
||||
唯一的办法就是提供 GUI。Docker API 允许第三方应用接入 Docker。在市场上有许多 Docker GUI 应用。我们已经写过一篇关于 Portainer 应用的文章。今天我们来讨论另一个应用,Rancher。
|
||||
|
||||
容器让软件开发更容易,让开发者更快的写代码、更好的运行它们。但是,在生产环境上运行容器却很困难。
|
||||
|
||||
**推荐阅读:** [Portainer:一个简单的 Docker 管理图形工具][1]
|
||||
|
||||
### Rancher 简介
|
||||
|
||||
[Rancher][2] 是一个全面的容器管理平台,它可以让容器在各种基础设施平台的生产环境上部署和运行更容易。它提供了诸如多主机网络、全局/本地负载均衡和卷快照等基础设施服务。它整合了原生 Docker 的管理能力,如 Docker Machine 和 Docker Swarm。它提供了丰富的用户体验,让 DevOps 管理员在更大规模的生产环境上运行 Docker。
|
||||
|
||||
访问以下文章可以了解 Linux 系统上安装 Docker。
|
||||
|
||||
**推荐阅读:**
|
||||
|
||||
- [如何在 Linux 上安装 Docker][3]
|
||||
- [如何在 Linux 上使用 Docker 镜像][4]
|
||||
- [如何在 Linux 上使用 Docker 容器][5]
|
||||
- [如何在 Docker 容器内安装和运行应用][6]
|
||||
|
||||
### Rancher 特性
|
||||
|
||||
* 可以在两分钟内安装 Kubernetes。
|
||||
* 一键启动应用(90 个流行的 Docker 应用)。
|
||||
* 部署和管理 Docker 更容易。
|
||||
* 全面的生产级容器管理平台。
|
||||
* 可以在生产环境上快速部署容器。
|
||||
* 强大的自动部署和运营容器技术。
|
||||
* 模块化基础设施服务。
|
||||
* 丰富的编排工具。
|
||||
* Rancher 支持多种认证机制。
|
||||
|
||||
### 怎样安装 Rancher
|
||||
|
||||
由于 Rancher 是以轻量级的 Docker 容器方式运行,所以它的安装非常简单。Rancher 是由一组 Docker 容器部署的。只需要简单的启动两个容器就能运行 Rancher。一个容器用作管理服务器,另一个容器在各个节点上作为代理。在 Linux 系统下简单的运行下列命令就能部署 Rancher。
|
||||
|
||||
Rancher 服务器提供了两个不同的安装包标签如 `stable` 和 `latest`。下列命令将会拉取适合的 Rancher 镜像并安装到你的操作系统上。Rancher 服务器仅需要两分钟就可以启动。
|
||||
|
||||
* `latest`:这个标签是他们的最新开发构建。这些构建将通过 Rancher CI 的自动化框架进行验证,不建议在生产环境使用。
|
||||
* `stable`:这是最新的稳定发行版本,推荐在生产环境使用。
|
||||
|
||||
Rancher 的安装方法有多种。在这篇教程中我们仅讨论两种方法。
|
||||
|
||||
* 以单一容器的方式安装 Rancher(内嵌 Rancher 数据库)
|
||||
* 以单一容器的方式安装 Rancher(外部数据库)
|
||||
|
||||
### 方法 - 1
|
||||
|
||||
运行下列命令以单一容器的方式安装 Rancher 服务器(内嵌数据库)
|
||||
|
||||
```
|
||||
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:stable
|
||||
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:latest
|
||||
```
|
||||
|
||||
### 方法 - 2
|
||||
|
||||
你可以在启动 Rancher 服务器时指向外部数据库,而不是使用自带的内部数据库。首先创建所需的数据库,数据库用户为同一个。
|
||||
|
||||
```
|
||||
> CREATE DATABASE IF NOT EXISTS cattle COLLATE = 'utf8_general_ci' CHARACTER SET = 'utf8';
|
||||
> GRANT ALL ON cattle.* TO 'cattle'@'%' IDENTIFIED BY 'cattle';
|
||||
> GRANT ALL ON cattle.* TO 'cattle'@'localhost' IDENTIFIED BY 'cattle';
|
||||
```
|
||||
|
||||
运行下列命令启动 Rancher 去连接外部数据库。
|
||||
|
||||
```
|
||||
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server \
|
||||
--db-host myhost.example.com --db-port 3306 --db-user username --db-pass password --db-name cattle
|
||||
```
|
||||
|
||||
如果你想测试 Rancher 2.0,使用下列的命令去启动。
|
||||
|
||||
```
|
||||
$ sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/server:preview
|
||||
```
|
||||
|
||||
### 通过 GUI 访问 & 安装 Rancher
|
||||
|
||||
浏览器输入 `http://hostname:8080` 或 `http://server_ip:8080` 去访问 rancher GUI.
|
||||
|
||||
![][8]
|
||||
|
||||
### 怎样注册主机
|
||||
|
||||
注册你的主机 URL 允许它连接到 Rancher API。这是一次性设置。
|
||||
|
||||
接下来,点击主菜单下面的 “Add a Host” 链接或者点击主菜单上的 “INFRASTRUCTURE >> Add Hosts”,点击 “Save” 按钮。
|
||||
|
||||
![][9]
|
||||
|
||||
默认情况下,Rancher 里的访问控制认证禁止了访问,因此我们首先需要通过一些方法打开访问控制认证,否则任何人都不能访问 GUI。
|
||||
|
||||
点击 “>> Admin >> Access Control”,输入下列的值最后点击 “Enable Authentication” 按钮去打开它。在我这里,是通过 “local authentication” 的方式打开的。
|
||||
|
||||
* “Login UserName”: 输入你期望的登录名
|
||||
* “Full Name”: 输入你的全名
|
||||
* “Password”: 输入你期望的密码
|
||||
* “Confirm Password”: 再一次确认密码
|
||||
|
||||
![][10]
|
||||
|
||||
注销然后使用新的登录凭证重新登录:
|
||||
|
||||
![][11]
|
||||
|
||||
现在,我能看到本地认证已经被打开。
|
||||
|
||||
![][12]
|
||||
|
||||
### 怎样添加主机
|
||||
|
||||
注册你的主机后,它将带你进入下一个页面,在那里你能选择不同云服务提供商的 Linux 主机。我们将添加一个主机运行 Rancher 服务,因此选择“custom”选项然后输入必要的信息。
|
||||
|
||||
在第 4 步输入你服务器的公有 IP,运行第 5 步列出的命令,最后点击 “close” 按钮。
|
||||
|
||||
```
|
||||
$ sudo docker run -e CATTLE_AGENT_IP="192.168.56.2" --rm --privileged -v /var/run/docker.sock:/var/run/docker.sock -v /var/lib/rancher:/var/lib/rancher rancher/agent:v1.2.11 http://192.168.56.2:8080/v1/scripts/16A52B9BE2BAB87BB0F5:1546214400000:ODACe3sfis5V6U8E3JASL8jQ
|
||||
|
||||
INFO: Running Agent Registration Process, CATTLE_URL=http://192.168.56.2:8080/v1
|
||||
INFO: Attempting to connect to: http://192.168.56.2:8080/v1
|
||||
INFO: http://192.168.56.2:8080/v1 is accessible
|
||||
INFO: Configured Host Registration URL info: CATTLE_URL=http://192.168.56.2:8080/v1 ENV_URL=http://192.168.56.2:8080/v1
|
||||
INFO: Inspecting host capabilities
|
||||
INFO: Boot2Docker: false
|
||||
INFO: Host writable: true
|
||||
INFO: Token: xxxxxxxx
|
||||
INFO: Running registration
|
||||
INFO: Printing Environment
|
||||
INFO: ENV: CATTLE_ACCESS_KEY=9946BD1DCBCFEF3439F8
|
||||
INFO: ENV: CATTLE_AGENT_IP=192.168.56.2
|
||||
INFO: ENV: CATTLE_HOME=/var/lib/cattle
|
||||
INFO: ENV: CATTLE_REGISTRATION_ACCESS_KEY=registrationToken
|
||||
INFO: ENV: CATTLE_REGISTRATION_SECRET_KEY=xxxxxxx
|
||||
INFO: ENV: CATTLE_SECRET_KEY=xxxxxxx
|
||||
INFO: ENV: CATTLE_URL=http://192.168.56.2:8080/v1
|
||||
INFO: ENV: DETECTED_CATTLE_AGENT_IP=172.17.0.1
|
||||
INFO: ENV: RANCHER_AGENT_IMAGE=rancher/agent:v1.2.11
|
||||
INFO: Launched Rancher Agent: e83b22afd0c023dabc62404f3e74abb1fa99b9a178b05b1728186c9bfca71e8d
|
||||
```
|
||||
|
||||
![][13]
|
||||
|
||||
等待几秒钟后新添加的主机将会出现。点击 “Infrastructure >> Hosts” 页面。
|
||||
|
||||
![][14]
|
||||
|
||||
### 怎样查看容器
|
||||
|
||||
只需要点击下列位置就能列出所有容器。点击 “Infrastructure >> Containers” 页面。
|
||||
|
||||
![][15]
|
||||
|
||||
### 怎样创建容器
|
||||
|
||||
非常简单,只需点击下列位置就能创建容器。
|
||||
|
||||
点击 “Infrastructure >> Containers >> Add Container” 然后输入每个你需要的信息。为了测试,我将创建一个 `latest` 标签的 CentOS 容器。
|
||||
|
||||
![][16]
|
||||
|
||||
在同样的列表位置,点击 “ Infrastructure >> Containers”。
|
||||
|
||||
![][17]
|
||||
|
||||
点击容器名展示容器的性能信息,如 CPU、内存、网络和存储。
|
||||
|
||||
![][18]
|
||||
|
||||
选择特定容器,然后点击最右边的“三点”按钮或者点击“Actions”按钮对容器进行管理,如停止、启动、克隆、重启等。
|
||||
|
||||
![][19]
|
||||
|
||||
如果你想控制台访问容器,只需要点击 “Actions” 按钮中的 “Execute Shell” 选项即可。
|
||||
|
||||
![][20]
|
||||
|
||||
### 怎样从应用目录部署容器
|
||||
|
||||
Rancher 提供了一个应用模版目录,让部署变的很容易,只需要单击一下就可以。
|
||||
它维护了多数流行应用,这些应用由 Rancher 社区贡献。
|
||||
|
||||
![][21]
|
||||
|
||||
点击 “Catalog >> All >> Choose the required application”,最后点击 “Launch” 去部署。
|
||||
|
||||
![][22]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/rancher-a-complete-container-management-platform-for-production-environment/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/portainer-a-simple-docker-management-gui/
|
||||
[2]:http://rancher.com/
|
||||
[3]:https://www.2daygeek.com/install-docker-on-centos-rhel-fedora-ubuntu-debian-oracle-archi-scentific-linux-mint-opensuse/
|
||||
[4]:https://www.2daygeek.com/list-search-pull-download-remove-docker-images-on-linux/
|
||||
[5]:https://www.2daygeek.com/create-run-list-start-stop-attach-delete-interactive-daemonized-docker-containers-on-linux/
|
||||
[6]:https://www.2daygeek.com/install-run-applications-inside-docker-containers/
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-1.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-2.png
|
||||
[10]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-3.png
|
||||
[11]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-3a.png
|
||||
[12]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-4.png
|
||||
[13]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-5.png
|
||||
[14]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-6.png
|
||||
[15]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-7.png
|
||||
[16]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-8.png
|
||||
[17]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-9.png
|
||||
[18]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-10.png
|
||||
[19]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-11.png
|
||||
[20]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-12.png
|
||||
[21]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-13.png
|
||||
[22]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-14.png
|
||||
@ -0,0 +1,132 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10683-1.html)
|
||||
[#]: subject: (Oomox – Customize And Create Your Own GTK2, GTK3 Themes)
|
||||
[#]: via: (https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/)
|
||||
[#]: author: (EDITOR https://www.ostechnix.com/author/editor/)
|
||||
|
||||
Oomox:定制和创建你自己的 GTK2、GTK3 主题
|
||||
======
|
||||
|
||||

|
||||
|
||||
主题和可视化定制是 Linux 的主要优势之一。由于所有代码都是开源的,因此你可以比 Windows/Mac OS 更大程度上地改变 Linux 系统的外观和行为方式。GTK 主题可能是人们定制 Linux 桌面的最流行方式。GTK 工具包被各种桌面环境使用,如 Gnome、Cinnamon、Unity、XFC E和 budgie。这意味着为 GTK 制作的单个主题只需很少的修改就能应用于任何这些桌面环境。
|
||||
|
||||
有很多非常高品质的流行 GTK 主题,例如 **Arc**、**Numix** 和 **Adapta**。但是如果你想自定义这些主题并创建自己的视觉设计,你可以使用 **Oomox**。
|
||||
|
||||
Oomox 是一个图形应用,可以完全使用自己的颜色、图标和终端风格自定义和创建自己的 GTK 主题。它自带几个预设,你可以在 Numix、Arc 或 Materia 主题样式上创建自己的 GTK 主题。
|
||||
|
||||
### 安装 Oomox
|
||||
|
||||
在 Arch Linux 及其衍生版中:
|
||||
|
||||
Oomox 可以在 [AUR][1] 中找到,所以你可以使用任何 AUR 助手程序安装它,如 [yay][2]。
|
||||
|
||||
```
|
||||
$ yay -S oomox
|
||||
```
|
||||
|
||||
在 Debian/Ubuntu/Linux Mint 中,在[这里][3]下载 `oomox.deb` 包并按如下所示进行安装。在写本指南时,最新版本为 `oomox_1.7.0.5.deb`。
|
||||
|
||||
```
|
||||
$ sudo dpkg -i oomox_1.7.0.5.deb
|
||||
$ sudo apt install -f
|
||||
```
|
||||
|
||||
在 Fedora 上,Oomox 可以在第三方 **COPR** 仓库中找到。
|
||||
|
||||
```
|
||||
$ sudo dnf copr enable tcg/themes
|
||||
$ sudo dnf install oomox
|
||||
```
|
||||
|
||||
Oomox 也有 [Flatpak 应用][4]。确保已按照[本指南][5]中的说明安装了 Flatpak。然后,使用以下命令安装并运行 Oomox:
|
||||
|
||||
```
|
||||
$ flatpak install flathub com.github.themix_project.Oomox
|
||||
$ flatpak run com.github.themix_project.Oomox
|
||||
```
|
||||
|
||||
对于其他 Linux 发行版,请进入 Github 上的 Oomox 项目页面(本指南末尾给出链接),并从源代码手动编译和安装。
|
||||
|
||||
### 自定义并创建自己的 GTK2、GTK3 主题
|
||||
|
||||
#### 主题定制
|
||||
|
||||
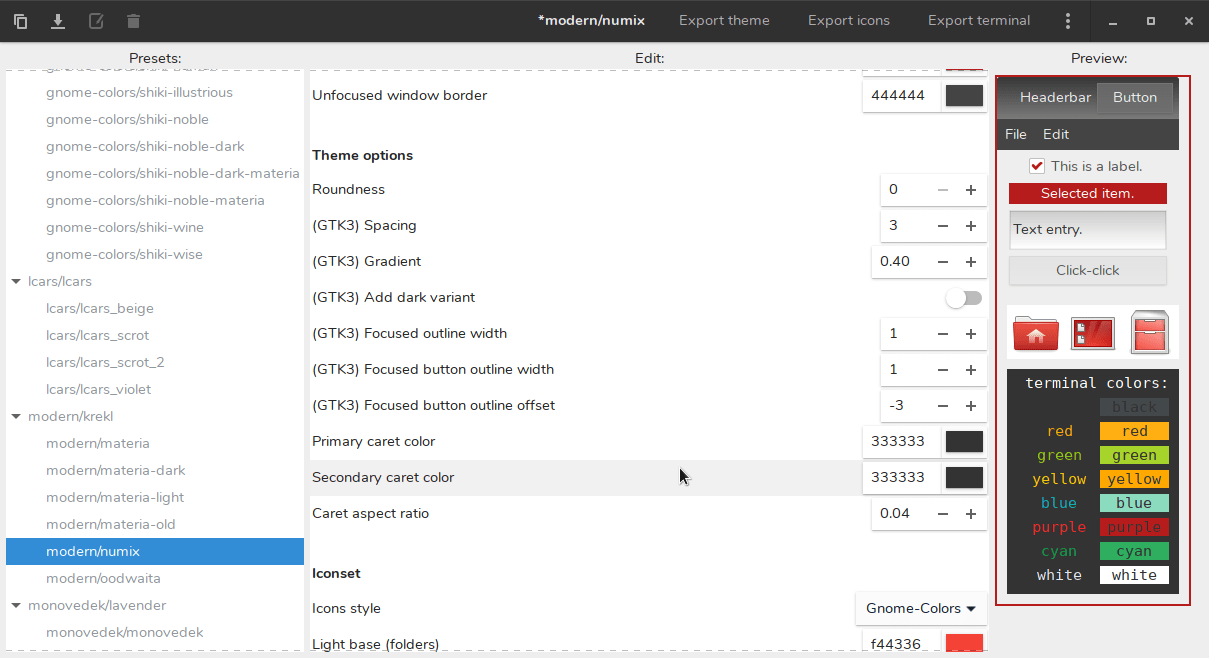
|
||||
|
||||
你可以更改几乎每个 UI 元素的颜色,例如:
|
||||
|
||||
1. 标题
|
||||
2. 按钮
|
||||
3. 标题内的按钮
|
||||
4. 菜单
|
||||
5. 选定的文字
|
||||
|
||||
在左边,有许多预设主题,如汽车主题、现代主题,如 Materia 和 Numix,以及复古主题。在窗口的顶部,有一个名为**主题样式**的选项,可让你设置主题的整体视觉样式。你可以在 Numix、Arc 和 Materia 之间进行选择。
|
||||
|
||||
使用某些像 Numix 这样的样式,你甚至可以更改标题渐变,边框宽度和面板透明度等内容。你还可以为主题添加黑暗模式,该模式将从默认主题自动创建。
|
||||
|
||||
|
||||
|
||||
#### 图标集定制
|
||||
|
||||
你可以自定义用于主题图标的图标集。有两个选项:Gnome Colors 和 Archdroid。你可以更改图标集的基础和笔触颜色。
|
||||
|
||||
#### 终端定制
|
||||
|
||||
你还可以自定义终端颜色。该应用有几个预设,但你可以为每个颜色,如红色,绿色,黑色等自定义确切的颜色代码。你还可以自动交换前景色和背景色。
|
||||
|
||||
#### Spotify 主题
|
||||
|
||||
这个应用的一个独特功能是你可以根据喜好定义 spotify 主题。你可以更改 spotify 的前景色、背景色和强调色来匹配整体的 GTK 主题。
|
||||
|
||||
然后,只需按下“应用 Spotify 主题”按钮,你就会看到这个窗口:
|
||||
|
||||
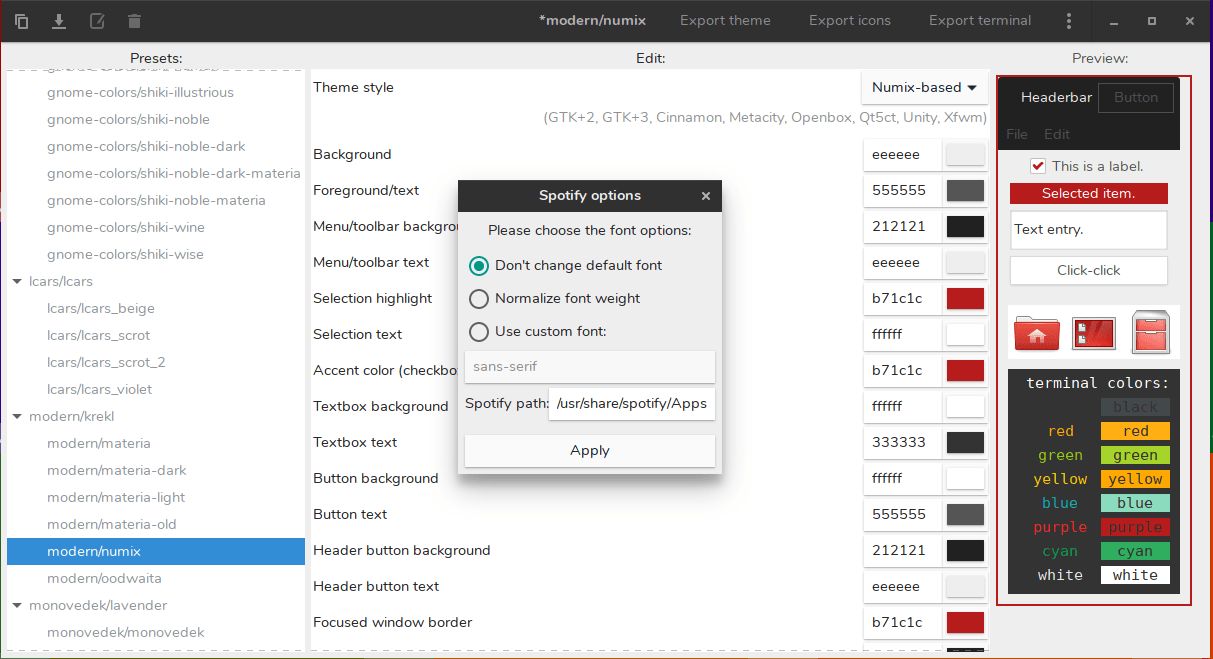
|
||||
|
||||
点击应用即可。
|
||||
|
||||
#### 导出主题
|
||||
|
||||
根据自己的喜好自定义主题后,可以通过单击左上角的重命名按钮重命名主题:
|
||||
|
||||

|
||||
|
||||
然后,只需点击“导出主题”将主题导出到你的系统。
|
||||
|
||||
|
||||
|
||||
你也可以只导出图标集或终端主题。
|
||||
|
||||
之后你可以打开桌面环境中的任何可视化自定义应用,例如基于 Gnome 桌面的 Tweaks,或者 “XFCE 外观设置”。选择你导出的 GTK 或者 shell 主题。
|
||||
|
||||
### 总结
|
||||
|
||||
如果你是一个 Linux 主题迷,并且你确切知道系统中的每个按钮、每个标题应该怎样,Oomox 值得一试。 对于极致的定制者,它可以让你几乎更改系统外观的所有内容。对于那些只想稍微调整现有主题的人来说,它有很多很多预设,所以你可以毫不费力地得到你想要的东西。
|
||||
|
||||
你试过吗? 你对 Oomox 有什么看法? 请在下面留言!
|
||||
|
||||
### 资源
|
||||
|
||||
- [Oomox GitHub 仓库](https://github.com/themix-project/oomox)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://aur.archlinux.org/packages/oomox/
|
||||
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[3]: https://github.com/themix-project/oomox/releases
|
||||
[4]: https://flathub.org/apps/details/com.github.themix_project.Oomox
|
||||
[5]: https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
212
published/20181108 My Google-free Android life.md
Normal file
212
published/20181108 My Google-free Android life.md
Normal file
@ -0,0 +1,212 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LuuMing)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10677-1.html)
|
||||
[#]: subject: (My Google-free Android life)
|
||||
[#]: via: (https://lushka.al/my-android-setup/)
|
||||
[#]: author: (Anxhelo Lushka https://lushka.al/)
|
||||
|
||||
我的去 Google 化的安卓之旅
|
||||
======
|
||||
> 一篇介绍如何在你的生活中和设备里去 Google 化的文章。
|
||||
|
||||
最近人们经常问我有关我手机的事情,比如安卓怎么安装,怎样绕过 Google Service 使用手机。好吧,这篇文章就来详细的解决那些问题。我尽可能让这篇文章适合初学者,因此我会慢慢介绍,一个一个来讲并且附上截图,你就能更好地看到它是怎样运作的。
|
||||
|
||||
首先我会告诉你为什么 Google Services(在我看来)对你的设备不好。我可以一言以概之,并让你看 [Richard Stallman][2] 写的这篇[文章][1],但我决定抓住几个要点附在这。
|
||||
|
||||
* 要用<ruby>非自由软件<rt>Nonfree software</rt></ruby>
|
||||
* 大体上,大多数 Google Services 需要运行在非自由的 Javascript 代码之上。现如今,如果禁用掉 Javascript,什么都没有了,甚至 Google 帐号都需要运行非自由软件(由站点发送的 JavaScript),对于登录也是。
|
||||
* 被监视
|
||||
* Google 悄悄地把它的<ruby>广告跟踪方式<rt>ad-tracking profiles</rt></ruby>与浏览方式结合在一起,并存储了每个用户的大量数据。
|
||||
* 服务条款
|
||||
* Google 会终止转卖了 Pixel 手机的用户账户。他们无法访问帐户下保存在 Google Services 中的所有邮件和文档。
|
||||
* 审查
|
||||
* Amazon 和 Google 切断了<ruby>域前置<rt>domain-fronting</rt></ruby>,该技术能使身处某些国家的人们访问到在那里禁止的通信系统。
|
||||
* Google 已经同意为巴基斯坦政府执行特殊的 Youtube 审查,删除对立观点。这将有助于压制异议。
|
||||
* Youtube 的“content ID”会自动删除已发布的视频,这并不包含在版权法中。
|
||||
|
||||
这只是几个原因,你可以阅读上面我提到的 RMS 的文章,他详细解释了这几点。尽管听起来骇人听闻,但这些行为在现实生活中已经每天在发生。
|
||||
|
||||
### 下一步,我的搭建教程
|
||||
|
||||
我有一款[小米红米 Note 5 Pro][3] 智能手机(代号 whyred),生产于中国的[小米][4]。它是 4 个月之前(距写这篇文章的时候)我花了大约 185 欧元买的。
|
||||
|
||||
现在你也许会想,“但你为什么买中国品牌,他们不可靠”。是的,它不是通常你所期望的(品牌)所生产的,例如三星(人们通常会将它和安卓联系在一起,这显然是错的)、一加、诺基亚等。但你应当知道几乎所有的手机都生产于中国。
|
||||
|
||||
我选择这款手机有几个原因,首先当然是价格。它是一款<ruby>性价比<rt>budget-friendly</rt></ruby>相当高的产品,大多数人都能买得起。下一个原因是说明书上的规格(不仅仅是),在这个<ruby>价位<rt>price tag</rt></ruby>上相当合适。拥有 6 英尺屏幕(<ruby>全高清分辨率<rt>Full HD resolution</rt></ruby>),4000 毫安电池(一流的电池寿命),4GB RAM,64GB 存储,双后摄像头(12 MP + 5 MP),一个带闪光灯的前摄像头(13 MP)和一个高性能的<ruby>骁龙<rt>Snapdragon</rt></ruby> 636,它可能是那时候最好的选择。
|
||||
|
||||
随之而来的问题是 [MIUI][5],大多数小米设备所附带的安卓外壳(除了 Android One 项目设备)。是的,它没有那么可怕,它有一些额外的功能,但问题在更深的地方。小米设备如此便宜(据我所知销售利润仅有 5-10%)的一个原因是**他们在系统里伴随 MIUI 添加了数据挖掘和广告**。这样的话,系统应用需要额外不必要的权限来获取你的数据并且进行广告轰炸,从中获取利润。
|
||||
|
||||
更有趣的是,所包含的“天气”应用想要访问我的联系人并且拨打电话,如果它仅是显示天气的话为什么需要访问联系人呢。另一个例子是“录音机”应用,它也需要联系人和网络权限,可能想把录音发送回小米。
|
||||
|
||||
为了解决它,我不得不格式化手机并且摆脱 MIUI。在市场上近来的手机上这就变得极为艰难。
|
||||
|
||||
格式化手机的想法很简单,删除掉现有的系统然后安装一个新的喜欢的系统(这次是原生安卓)。为了实现它,你先得解锁 [bootloader][6]。
|
||||
|
||||
> bootloader 是一个在计算机完成自检后为其加载操作系统或者运行环境的计算机程序。—[维基百科][7]
|
||||
|
||||
问题是小米关于解锁 bootloader 有明确的政策。几个月之前,流程就像这样:你需向小米[申请][8]解锁代码,并提供真实的原因,但不是每次都成功,因为他们可以拒绝你的请求并且不提供理由。
|
||||
|
||||
现在,流程变了。你要从小米那下载一个软件,叫做 [Mi Unlock][9],在 Windows 电脑上安装它,在手机的[开发者模式中打开调试选项][10],重启到 bootloader 模式(关机状态下长按向下音量键 + 电源键)并将手机连接到电脑上,开始一个叫做“许可”的流程。这个过程会在小米的服务器上启动一个定时器,允许你**在 15 天之后解锁手机**(在一些少数情况下或者一个月,完全随机)。
|
||||
|
||||
![Mi Unlock app][11]
|
||||
|
||||
15 天过去后,重新连接手机并重复之前的步骤,这时候按下解锁键,你的 bootloader 就会解锁,并且能够安装其他 ROM(系统)。**注意,确保你已经备份好了数据,因为解锁 bootloader 会清空手机。**
|
||||
|
||||
下一步就是找一个兼容的系统([ROM][12])。我在 [XDA 开发者论坛上][13]找了个遍,它是 Android 开发者和用户们交流想法、应用等东西的地方。幸运的是,我的手机相当流行,因此论坛上有它[专门的版块][14]。在那儿,我略过一些流行的 ROM 并决定使用 [AOSiP ROM][15]。(AOSiP 代表<ruby>安卓开源 illusion 项目<rt>Android Open Source illusion Project</rt></ruby>)
|
||||
|
||||
> **校订**:有人发邮件告诉我说文章里写的就是[/e/][16]的目的与所做的事情。我想说谢谢你的帮助,但完全不是这样。我关于 /e/ 的看法背后的原因可以见此[网站][17],但我仍会在此列出一些原因。
|
||||
|
||||
> eelo 是一个从 Kickstarter 和 IndieGoGo 上集资并超过 200K € 的“基金会”,承诺创造一个开放、安全且保护隐私的移动 OS 和网页服务器。
|
||||
|
||||
> 1. 他们的 OS 基于 LineageOS 14.1 (Android 7.1) 且搭载 microG 和其他开源应用,此系统已经存在很长一段时间了并且现在叫做 [Lineage for microG][18]。
|
||||
> 2. 所有的应用程序并非从源代码构建,而是从 [APKPure][19] 上下载安装包并推送进 ROM,不知道那些安装包中是否包含<ruby>专有代码<rt>proprietary code</rt></ruby>或<ruby>恶意软件<rt>malware</rt></ruby>。
|
||||
> 3. 有一段时间,它们就那样随意地从代码中删除 Lineage 的<ruby>版权标头<rt>copyright header</rt></ruby>并加入自己的。
|
||||
> 4. 他们喜欢删除负面反馈并且监视用户 Telegram 群聊中的舆论。
|
||||
|
||||
> 总而言之,我**不建议使用 /e/** ROM。(至少现在)
|
||||
|
||||
另一件你有可能要做的事情是获取手机的 [root 权限][20],让它真正的成为你的手机,并且修改系统中的文件,例如使用系统范围的 adblocker 等。为了实现它,我决定使用 [Magisk][21],一个天赐的应用,它由一个学生开发,可以帮你获取设备的 root 权限并安装一种叫做[模块][22]的东西,基本上是软件。
|
||||
|
||||
下载 ROM 和 Magisk 之后,我得在手机上安装它们。为了完成安装,我将文件移动到了 SD 卡上。现在,若要安装系统,我需要使用 [恢复系统][23]。我用的是较为普遍的 [TWRP][24](代表 TeamWin Recovery Project)。
|
||||
|
||||
要安装恢复系统(听起来有点难,我知道),我需要将文件[烧录][20]进手机。为了完成烧录,我将手机用一个叫做 [ADB 的工具][25]连接上电脑(Fedora Linux 系统)。使用命令让自己定制的恢复系统覆盖掉原先的。
|
||||
|
||||
```
|
||||
fastboot flash recovery twrp.img
|
||||
```
|
||||
|
||||
完成之后,我关掉手机并按住音量上和电源键,直到 TWRP 界面显示。这意味着我进行顺利,并且它已经准备好接收我的指令。
|
||||
|
||||
![TWRP screen][26]
|
||||
|
||||
下一步是**发送擦除命令**,在你第一次为手机安装自定义 ROM 时是必要的。如上图所示,擦除命令会清除掉<ruby>数据<rt>Data</rt></ruby>,<ruby>缓存<rt>Cache</rt></ruby>和 Dalvik 。(这里也有高级选项让我们可以勾选以删除掉系统,如果我们不再需要旧系统的话)
|
||||
|
||||
这需要几分钟去完成,之后,你的手机基本上就干净了。现在是时候**安装系统了**。通过按下主屏幕上的安装按钮,我们选择之前添加进的 zip 文件(ROM 文件)并滑动屏幕安装它。下一步,我们需要安装 Magisk,它可以给我们访问设备的 root 权限。
|
||||
|
||||
> **校订**:一些有经验的安卓用户或发烧友也许注意到了,手机上不包含 [GApps](谷歌应用)。这在安卓世界里称之为 GApps-less,一个 GAps 应用也不安装。
|
||||
|
||||
> 注意有一个不好之处在于若不安装 Google Services 有的应用无法正常工作,例如它们的通知也许会花更长的时间到达或者根本不起作用。(对我来说这一点是最影响应用程序使用的)原因是这些应用使用了 [Google Cloud Messaging][28](现在叫做 [Firebase][29])唤醒手机并推送通知。
|
||||
|
||||
> 你可以通过安装使用 [microG][30](部分地)解决它,microG 提供一些 Google Services 的特性且允许你拥有更多的控制。我不建议使用它,因为它仍然有助于 Google Services 并且你不一定信任它。但是,如果你没法<ruby>立刻放弃使用<rt>go cold turkey on it</rt><ruby>,只想慢慢地退出谷歌,这便是一个好的开始。
|
||||
|
||||
都成功地安装之后,现在我们重启手机,就进入了主屏幕。
|
||||
|
||||
### 下一个部分,安装应用并配置一切
|
||||
|
||||
事情开始变得简单了。为了安装应用,我使用了 [F-Droid][31],一个可替代的应用商店,里面**只包含自由及开源应用**。如果这里没有你要的应用,你可以使用 [Aurora Store][32],一个从应用商店里下载应用且不需要使用谷歌帐号或被追踪的客户端。
|
||||
|
||||
F-Droid 里面有名为 repos 的东西,它是一个包含你可以安装应用的“仓库”。我使用默认的仓库,并从 [IzzyOnDroid][33] 添加了另一个,它有更多默认仓库中没有的应用,并且它更新地更频繁。
|
||||
|
||||
![My repos][34]
|
||||
|
||||
从下面你可以发现我所安装的应用清单,它们替代的应用与用途。
|
||||
|
||||
- [AdAway](https://f-droid.org/en/packages/org.adaway) > 系统广告拦截器,使用 hosts 文件拦截所有的广告
|
||||
- [AfWall+](https://f-droid.org/en/packages/dev.ukanth.ufirewall) > 一个防火墙,可以阻止不想要的连接
|
||||
- [Amaze](https://f-droid.org/en/packages/com.amaze.filemanager) > 替代系统的文件管理器,允许文件的 root 访问权限,并且拥有 zip/unzip 功能
|
||||
- [Ameixa](https://f-droid.org/en/packages/org.xphnx.ameixa) > 大多数应用的图标包
|
||||
- [andOTP](https://f-droid.org/en/packages/org.shadowice.flocke.andotp) > 替代谷歌验证器/Authy,一个可以用来登录启用了<ruby>双因子验证<rt>2FA</rt></ruby>的网站账户的 TOTP 应用,可以使用 PIN 码备份和锁定
|
||||
- [AnySoftKeyboard/AOSP Keyboard](https://f-droid.org/packages/com.menny.android.anysoftkeyboard/) > 开源键盘,它有许多主题和语言包,我也是该[项目](https://anysoftkeyboard.github.io/)的一员
|
||||
- [Audio Recorder](https://f-droid.org/en/packages/com.github.axet.audiorecorder) > 如其名字,允许你从麦克风录制不同格式的音频文件
|
||||
- [Battery Charge Limit](https://f-droid.org/en/packages/com.slash.batterychargelimit) > 当到 80% 时自动停止充电,降低<ruby>电池磨损<rt>battery wear</rt></ruby>并增加寿命
|
||||
- [DAVx5](https://f-droid.org/en/packages/at.bitfire.davdroid) > 这是我最常用的应用之一,对我来说它基本上替代了谷歌联系人、谷歌日历和谷歌 Tasks,它连接着我的 Nextcloud 环境可以让我完全控制自己的数据
|
||||
- [Document Viewer](https://f-droid.org/en/packages/org.sufficientlysecure.viewer) > 一个可以打开数百种文件格式的查看器应用,快速、轻量
|
||||
- [Deezloader Remix](https://gitlab.com/Nick80835/DeezLoader-Android/) > 让我可以在 Deezer 上下载高质量 MP3 的应用
|
||||
- [Easy xkcd](https://f-droid.org/en/packages/de.tap.easy_xkcd) > xkcd 漫画阅读器,我喜欢这些 xkcd 漫画
|
||||
- [Etar](https://f-droid.org/en/packages/ws.xsoh.etar) > 日历应用,替代谷歌日历,与 DAVx5 一同工作
|
||||
- [FastHub-Libre](https://f-droid.org/en/packages/com.fastaccess.github.libre) > 一个 GitHub 客户端,完全 FOSS(自由及开源软件),非常实用如果你像我一样喜欢使用 Github 的话
|
||||
- [Fennec F-Droid](https://f-droid.org/en/packages/org.mozilla.fennec_fdroid) > 替代谷歌 Chrome 和其他类似的应用,一个为 F-Droid 打造的火狐浏览器,不含专有二进制代码并允许安装扩展提升浏览体验
|
||||
- [Gadgetbridge](https://f-droid.org/en/packages/nodomain.freeyourgadget.gadgetbridge) > 替代小米运动,可以用来配对小米硬件的应用,追踪你的健康、步数、睡眠等。
|
||||
- [K-9 Mail](https://f-droid.org/en/packages/com.fsck.k9) > 邮件客户端,替代 GMail 应用,可定制并可以添加多个账户
|
||||
- [Lawnchair](https://f-droid.org/en/packages/ch.deletescape.lawnchair.plah) > 启动器,可以替代 Nova Launcher 或 Pixel Launcher,允许自定义和各种改变,也支持图标包
|
||||
- [Mattermost](https://f-droid.org/en/packages/com.mattermost.mattermost) > 可以连接 Mattermost 服务器的应用。Mattermost 是一个 Slack 替代品
|
||||
- [NewPipe](https://f-droid.org/en/packages/org.schabi.newpipe) > 最好的 YouTube 客户端(我认为),可以替代 YoubTube,它完全是 FOSS,免除 YouTube 广告,占用更少空间,允许背景播放,允许下载视频/音频等。试一试吧
|
||||
- [Nextcloud SMS](https://f-droid.org/en/packages/fr.unix_experience.owncloud_sms) > 允许备份/同步 SMS 到我的 Nextcloud 环境
|
||||
- [Nextcloud Notes](https://f-droid.org/en/packages/it.niedermann.owncloud.notes) > 允许我创建,修改,删除,分享笔记并同步/备份到 Nextcloud 环境
|
||||
- [OpenTasks](https://f-droid.org/en/packages/org.dmfs.tasks) > 允许我创建、修改、删除任务并同步到我的 Nextcloud 环境
|
||||
- [OsmAnd~](https://f-droid.org/en/packages/net.osmand.plus) > 一个地图应用,使用 [OpenStreetMap](https://openstreetmap.org/),允许下载离线地图和导航
|
||||
- [QKSMS](https://f-droid.org/en/packages/com.moez.QKSMS) > 我最喜欢的短信应用,可以替代原来的 Messaging 应用,拥有漂亮的界面,拥有备份、个性化、延迟发送等特性。
|
||||
- [Resplash/Mysplash](https://f-droid.org/en/packages/com.wangdaye.mysplash) > 允许你无限地从 [Unsplash](https://unsplash.com/) 下载无数的漂亮壁纸,全都可以免费使用和修改。
|
||||
- [ScreenCam](https://f-droid.org/en/packages/com.orpheusdroid.screenrecorder) > 一个录屏工具,允许各样的自定义和录制模式,没有广告并且免费
|
||||
- [SecScanQR](https://f-droid.org/en/packages/de.t_dankworth.secscanqr) > 二维码识别应用,快速轻量
|
||||
- [Send Reduced Free](https://f-droid.org/en/packages/mobi.omegacentauri.SendReduced) > 这个应用可以在发送之前通过移除 PII(<ruby>个人识别信息<rt>personally identifiable information</rt></ruby>)和减小尺寸,让你立即分享大图
|
||||
- [Slide](https://f-droid.org/en/packages/me.ccrama.redditslide/) > 开源 Reddit 客户端
|
||||
- [Telegram FOSS](https://f-droid.org/en/packages/org.telegram.messenger) > 没有追踪和 Google Services 的纯净版 Telegram 安卓客户端
|
||||
- [TrebleShot](https://f-droid.org/en/packages/com.genonbeta.TrebleShot) > 这个天才般的应用可以让你通过 WIFI 分享文件给其它设备,真的超快,甚至无需连接网络
|
||||
- [Tusky](https://f-droid.org/en/packages/com.keylesspalace.tusky) > Tusky 是 [Mastodon](https://joinmastodon.org/) 平台的客户端(替代 Twitter)
|
||||
- [Unit Converter Ultimate](https://f-droid.org/en/packages/com.physphil.android.unitconverterultimate) > 这款应用可以一键在 200 种单位之间来回转换,非常快并且完全离线
|
||||
- [Vinyl Music Player](https://f-droid.org/en/packages/com.poupa.vinylmusicplayer) > 我首选的音乐播放器,可以替代谷歌音乐播放器或其他你已经安装的音乐播放器,它有漂亮的界面和许多特性
|
||||
- [VPN Hotspot](https://f-droid.org/en/packages/be.mygod.vpnhotspot) > 这款应用可以让我打开热点的时候分享 VPN,因此我可以在笔记本上什么都不用做就可以安全地浏览网页
|
||||
|
||||
这些差不多就是我列出的一张**最实用的 F-Droid 应用**清单,但不巧,这些并不是所有应用。我使用的专有应用如下(我知道,我也许听起来是一个伪君子,但并不是所有的应用都可以替代,至少现在不是):
|
||||
|
||||
* Google Camera(与 Camera API 2 结合起来,需要 F-Droid 的基本的 microG 才能工作)
|
||||
* Instagram
|
||||
* MyVodafoneAL (运营商应用)
|
||||
* ProtonMail (email 应用)
|
||||
* Titanium Backup(备份应用数据,wifi 密码,通话记录等)
|
||||
* WhatsApp (专有的端到端聊天应用,几乎我认识的所有人都有它)
|
||||
|
||||
差不多就是这样,这就是我用的手机上所有的应用。**配置非常简单明了,我可以给几点提示**。
|
||||
|
||||
1. 仔细阅读和检查应用的权限,不要无脑地点“安装”。
|
||||
2. 尽可能多地使用开源应用,它们即尊重你的隐私又是免费的(且自由)。
|
||||
3. 尽可能地使用 VPN,找一个有名气的,别用免费的,否则你将被收割数据然后成为产品。
|
||||
4. 不要一直打开 WIFI/移动数据/定位,有可能引起安全隐患。
|
||||
5. 不要只依赖指纹解锁,或者尽可能只用 PIN/密码/模式解锁,因为生物数据可以被克隆后针对你,例如解锁你的手机盗取你的数据。
|
||||
|
||||
作为坚持读到这儿的奖励,**一张主屏幕的截图奉上**
|
||||
|
||||
![Screenshot][35]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lushka.al/my-android-setup/
|
||||
|
||||
作者:[Anxhelo Lushka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuuMing](https://github.com/luuming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://lushka.al/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://stallman.org/google.html
|
||||
[2]: https://en.wikipedia.org/wiki/Richard_Stallman
|
||||
[3]: https://www.gsmarena.com/xiaomi_redmi_note_5_pro-8893.php
|
||||
[4]: https://en.wikipedia.org/wiki/Xiaomi
|
||||
[5]: https://en.wikipedia.org/wiki/MIUI
|
||||
[6]: https://forum.xda-developers.com/wiki/Bootloader
|
||||
[7]: https://en.wikipedia.org/wiki/Booting
|
||||
[8]: https://en.miui.com/unlock/
|
||||
[9]: http://www.miui.com/unlock/apply.php
|
||||
[10]: https://www.youtube.com/watch?v=7zhEsJlivFA
|
||||
[11]: https://lushka.al//assets/img/posts/mi-unlock.png
|
||||
[12]: https://www.xda-developers.com/what-is-custom-rom-android/
|
||||
[13]: https://forum.xda-developers.com/
|
||||
[14]: https://forum.xda-developers.com/redmi-note-5-pro
|
||||
[15]: https://forum.xda-developers.com/redmi-note-5-pro/development/rom-aosip-8-1-t3804473
|
||||
[16]: https://e.foundation
|
||||
[17]: https://ewwlo.xyz/evil
|
||||
[18]: https://lineage.microg.org/
|
||||
[19]: https://apkpure.com/
|
||||
[20]: https://lifehacker.com/5789397/the-always-up-to-date-guide-to-rooting-any-android-phone
|
||||
[21]: https://forum.xda-developers.com/apps/magisk/official-magisk-v7-universal-systemless-t3473445
|
||||
[22]: https://forum.xda-developers.com/apps/magisk
|
||||
[23]: http://www.smartmobilephonesolutions.com/content/android-system-recovery
|
||||
[24]: https://dl.twrp.me/whyred/
|
||||
[25]: https://developer.android.com/studio/command-line/adb
|
||||
[26]: https://lushka.al//assets/img/posts/android-twrp.png
|
||||
[27]: https://opengapps.org/
|
||||
[28]: https://developers.google.com/cloud-messaging/
|
||||
[29]: https://firebase.google.com/docs/cloud-messaging/
|
||||
[30]: https://microg.org/
|
||||
[31]: https://f-droid.org/
|
||||
[32]: https://f-droid.org/en/packages/com.dragons.aurora/
|
||||
[33]: https://android.izzysoft.de/repo
|
||||
[34]: https://lushka.al//assets/img/posts/android-fdroid-repos.jpg
|
||||
[35]: https://lushka.al//assets/img/posts/android-screenshot.jpg
|
||||
[36]: https://creativecommons.org/licenses/by-nc-sa/4.0/
|
||||
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10688-1.html)
|
||||
[#]: subject: (Secure Email Service Tutanota Has a Desktop App Now)
|
||||
[#]: via: (https://itsfoss.com/tutanota-desktop)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
加密邮件服务 Tutanota 现在有桌面应用了
|
||||
======
|
||||
|
||||
![][18]
|
||||
|
||||
[Tutanota][1] 最近[宣布][2]发布针对其电子邮件服务的桌面应用。该 Beta 版适用于 Linux、Windows 和 macOS。
|
||||
|
||||
### 什么是 Tutanota?
|
||||
|
||||
网上有大量免费的、带有广告的电子邮件服务。但是,大多数电子邮件服务并不完全安全或在意隐私。在这个后[斯诺登][3]世界中,[Tutanota][4] 提供了免费、安全的电子邮件服务,它专注于隐私。
|
||||
|
||||
Tutanota 有许多引人注目的功能,例如:
|
||||
|
||||
* 端到端加密邮箱
|
||||
* 端到端加密地址簿
|
||||
* 用户之间自动端到端加密邮件
|
||||
* 通过分享密码将端到端加密电子邮件发送到任何电子邮件地址
|
||||
* 安全密码重置,使 Tutanota 完全无法访问
|
||||
* 从发送和接收的电子邮件中去除 IP 地址
|
||||
* 运行 Tutanota 的代码是[开源][5]的
|
||||
* 双因子身份验证
|
||||
* 专注于隐私
|
||||
* 加盐的密码,并本地使用 Bcrypt 哈希
|
||||
* 位于德国的安全服务器
|
||||
* 支持 PFS、DMARC、DKIM、DNSSEC 和 DANE 的 TLS
|
||||
* 本地执行加密数据的全文搜索
|
||||
|
||||
![][6]
|
||||
|
||||
*web 中的 Tutanota*
|
||||
|
||||
你可以[免费注册一个帐户][7]。你还可以升级帐户获取其他功能,例如自定义域、自定义域登录、域规则、额外的存储和别名。他们还提供企业帐户。
|
||||
|
||||
Tutanota 也可以在移动设备上使用。事实上,它的 [Android 应用也是开源的][8]。
|
||||
|
||||
这家德国公司计划扩展邮件之外的其他业务。他们希望提供加密的日历和云存储。你可以通过 PayPal 和加密货币[捐赠][9]帮助他们实现目标。
|
||||
|
||||
### Tutanota 的新桌面应用
|
||||
|
||||
Tutanota 在去年圣诞节前宣布了桌面应用的 [Beta 版][2]。该应用基于 [Electron][10]。
|
||||
|
||||
![][11]
|
||||
|
||||
*Tutanota 桌面应用*
|
||||
|
||||
他们选择 Electron 的原因:
|
||||
|
||||
* 以最小的成本支持三个主流操作系统。
|
||||
* 快速调整新桌面客户端,使其与添加到网页客户端的新功能一致。
|
||||
* 将开发时间留给桌面功能,例如离线可用、电子邮件导入,将同时在所有三个桌面客户端中提供。
|
||||
|
||||
由于这是 Beta 版,因此应用中缺少一些功能。Tutanota 的开发团队正在努力添加以下功能:
|
||||
|
||||
* 电子邮件导入和与外部邮箱同步。这将“使 Tutanota 能够从外部邮箱导入电子邮件,并在将数据存储在 Tutanota 服务器上之前在设备本地加密数据。”
|
||||
* 电子邮件的离线可用
|
||||
* 双因子身份验证
|
||||
|
||||
### 如何安装 Tutanota 桌面客户端?
|
||||
|
||||
![][12]
|
||||
|
||||
*在 Tutanota 中写邮件*
|
||||
|
||||
你可以直接从 Tutanota 的网站[下载][2] Beta 版应用。它们有[适用于 Linux 的 AppImage 文件][13]、适用于 Windows 的 .exe 文件和适用于 macOS 的 .app 文件。你可以将你遇到的任何 bug 发布到 Tutanota 的 [GitHub 帐号中][14]。
|
||||
|
||||
为了证明应用的安全性,Tutanota 签名了每个版本。“签名确保桌面客户端以及任何更新直接来自我们且未被篡改。”你可以使用 Tutanota 的 [GitHub 页面][15]来验证签名。
|
||||
|
||||
请记住,你需要先创建一个 Tutanota 帐户才能使用它。该邮件客户端设计上只能用在 Tutanota。
|
||||
|
||||
### 总结
|
||||
|
||||
我在 Linux Mint MATE 上测试了 Tutanota 的邮件应用。正如所料,它是网络应用的镜像。同时,我发现桌面应用和 Web 应用程序之间没有任何区别。我目前觉得使用该应用的唯一场景是在自己的窗口中使用。
|
||||
|
||||
你曾经使用过 [Tutanota][16] 么?如果没有,你最喜欢的关心隐私的邮件服务是什么?请在下面的评论中告诉我们。
|
||||
|
||||
如果你觉得这篇文章很有趣,请花些时间在社交媒体上分享。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/tutanota-desktop
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/tutanota-review/
|
||||
[2]: https://tutanota.com/blog/posts/desktop-clients/
|
||||
[3]: https://en.wikipedia.org/wiki/Edward_Snowden
|
||||
[4]: https://tutanota.com/
|
||||
[5]: https://tutanota.com/blog/posts/open-source-email
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/tutanota2.jpg?resize=800%2C490&ssl=1
|
||||
[7]: https://tutanota.com/pricing
|
||||
[8]: https://itsfoss.com/tutanota-fdroid-release/
|
||||
[9]: https://tutanota.com/community
|
||||
[10]: https://electronjs.org/
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/tutanota-app1.png?fit=800%2C486&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/tutanota1.jpg?resize=800%2C405&ssl=1
|
||||
[13]: https://itsfoss.com/use-appimage-linux/
|
||||
[14]: https://github.com/tutao/tutanota
|
||||
[15]: https://github.com/tutao/tutanota/blob/master/buildSrc/installerSigner.js
|
||||
[16]: https://tutanota.com/polo/
|
||||
[17]: http://reddit.com/r/linuxusersgroup
|
||||
[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/02/tutanota-featured.png?fit=800%2C450&ssl=1
|
||||
@ -1,15 +1,16 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10682-1.html)
|
||||
[#]: subject: (Emulators and Native Linux games on the Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/play-games-raspberry-pi)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
|
||||
|
||||
树莓派上的模拟器和原生 Linux 游戏
|
||||
树莓派使用入门:树莓派上的模拟器和原生 Linux 游戏
|
||||
======
|
||||
树莓派是一个很棒的游戏平台。在我们的系列文章的第九篇中学习如何开始使用树莓派。
|
||||
|
||||
> 树莓派是一个很棒的游戏平台。在我们的系列文章的第九篇中学习如何开始使用树莓派。
|
||||
|
||||

|
||||
|
||||
@ -17,13 +18,13 @@
|
||||
|
||||
### 使用模拟器玩游戏
|
||||
|
||||
模拟器是一种能让你在树莓派上玩不同系统,不同年代游戏的软件。在如今众多的模拟器中,[RetroPi][2] 是树莓派中最受欢迎的。你可以用它来玩 Apple II、Amiga、Atari 2600、Commodore 64、Game Boy Advance 和[其他许多][3]游戏。
|
||||
模拟器是一种能让你在树莓派上玩不同系统、不同年代游戏的软件。在如今众多的模拟器中,[RetroPi][2] 是树莓派中最受欢迎的。你可以用它来玩 Apple II、Amiga、Atari 2600、Commodore 64、Game Boy Advance 和[其他许多][3]游戏。
|
||||
|
||||
如果 RetroPi 听起来有趣,请阅读[这些说明][4]开始使用,玩得开心!
|
||||
|
||||
### 原生 Linux 游戏
|
||||
|
||||
树莓派的操作系统 Raspbian 上也有很多原生 Linux 游戏。“Make Use Of” 有一篇关于如何在树莓派上[玩 10 个老经典游戏][5]如 Doom 和 Nuke Dukem 3D 的文章。
|
||||
树莓派的操作系统 Raspbian 上也有很多原生 Linux 游戏。“Make Use Of” 有一篇关于如何在树莓派上[玩 10 个老经典游戏][5],如 Doom 和 Nuke Dukem 3D 的文章。
|
||||
|
||||
你也可以将树莓派用作[游戏服务器][6]。例如,你可以在树莓派上安装 Terraria、Minecraft 和 QuakeWorld 服务器。
|
||||
|
||||
@ -34,13 +35,13 @@ via: https://opensource.com/article/19/3/play-games-raspberry-pi
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/19/3/teach-kids-program-raspberry-pi
|
||||
[1]: https://linux.cn/article-10653-1.html
|
||||
[2]: https://retropie.org.uk/
|
||||
[3]: https://retropie.org.uk/about/systems
|
||||
[4]: https://opensource.com/article/19/1/retropie
|
||||
@ -1,28 +1,30 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10687-1.html)
|
||||
[#]: subject: (Let's get physical: How to use GPIO pins on the Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/gpio-pins-raspberry-pi)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
|
||||
|
||||
进入物理世界:如何使用树莓派的 GPIO 针脚
|
||||
树莓派使用入门:进入物理世界 —— 如何使用树莓派的 GPIO 针脚
|
||||
======
|
||||
在树莓派使用入门的第十篇文章中,我们将学习如何使用 GPIO。
|
||||
|
||||
> 在树莓派使用入门的第十篇文章中,我们将学习如何使用 GPIO。
|
||||
|
||||

|
||||
|
||||
到目前为止,本系列文章主要专注于树莓派的软件方面,而今天我们将学习硬件。在树莓派最初发布时,最让我感兴趣的主要特性之一就是它的 [通用输入输出][1](GPIO)针脚。GPIO 可以让你的树莓派程序与连接到它上面的传感器、继电器、和其它类型的电子元件与物理世界来交互。
|
||||
|
||||

|
||||
|
||||
树莓派上的每个 GPIO 针脚要么有一个预定义的功能,要么被设计为通用的。另外,不同的树莓派型号要么 26 个,要么有 40 个 GPIO 针脚是你可以随意使用的。在维基百科上有一个 [关于每个针脚的非常详细的说明][2] 以及它的功能介绍。
|
||||
树莓派上的每个 GPIO 针脚要么有一个预定义的功能,要么被设计为通用的。另外,不同的树莓派型号要么 26 个,要么有 40 个 GPIO 针脚,你可以根据情况使用的。在维基百科上有一个 [关于每个针脚的非常详细的说明][2] 以及它的功能介绍。
|
||||
|
||||
你可以使用树莓派的 GPIO 针脚做更多的事情。关于它的 GPIO 的使用我写过一些文章,包括使用树莓派来控制节日彩灯的三篇文章([第一篇][3]、 [第二篇][4]、和 [第三篇][5]),在这些文章中我通过使用开源程序让灯光随着音乐起舞。
|
||||
|
||||
树莓派社区在不同编程语言上创建不同的库方面做了非常好的一些工作,因此,你能够使用 [C][6]、[Python][7]、 [Scratch][8]、和其它语言与 GPIO 进行交互。
|
||||
树莓派社区在用不同编程语言创建不同的库方面做了非常好的一些工作,因此,你能够使用 [C][6]、[Python][7]、 [Scratch][8] 和其它语言与 GPIO 进行交互。
|
||||
|
||||
另外,如果你想在树莓派与物理世界交互方面获得更好的体验,你可以选用 [Raspberry Pi Sense Hat][9],它是插入树莓派 GPIO 针脚上的一个很便宜的电路板,借助它你可以通过程序与 LED、驾驶杆、气压计、温度计、温度计、 陀螺仪、加速度计、以及磁力仪来交互。
|
||||
另外,如果你想在树莓派与物理世界交互方面获得更好的体验,你可以选用 [Raspberry Pi Sense Hat][9],它是插入树莓派 GPIO 针脚上的一个很便宜的电路板,借助它你可以通过程序与 LED、驾驶杆、气压计、温度计、温度计、 陀螺仪、加速度计以及磁力仪来交互。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -31,7 +33,7 @@ via: https://opensource.com/article/19/3/gpio-pins-raspberry-pi
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (sanfusu)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10689-1.html)
|
||||
[#]: subject: (Blockchain 2.0: Redefining Financial Services [Part 3])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-redefining-financial-services/)
|
||||
[#]: author: (ostechnix https://www.ostechnix.com/author/editor/)
|
||||
|
||||
区块链 2.0:重新定义金融服务(三)
|
||||
======
|
||||
|
||||

|
||||
|
||||
[本系列的前一篇文章][1]侧重于建立背景,以阐明为什么将现有的金融系统向充满未来主义的[区块链][2]体系迈进是“货币”改革的下一个自然步骤。我们将继续了解哪些区块链特性将有助于这一迁移。但是,金融市场十分复杂,并且人们的交易由众多组成部分组成,而不仅仅是货币。
|
||||
|
||||
本部分将探索哪些区块链特性能够让金融机构向区块链平台迁移,并将传统银行和金融系统与其合并。如之前讨论证明的那样,如果有足够的人参与到给定的区块链网络并且支持交易协议,则赋给“代币”的面值将提升并变得更稳定。以比特币(BTC)为例,就和我们习惯使用的纸币一样,像比特币和以太币这样的加密货币,都可以用于所有前者的目的,从购买食物到船只,乃至贷款和购买保险。
|
||||
|
||||
事实上,你所涉及的银行或其他金融机构很可能已经[利用了区块链分类账本技术][r1]。金融行业中区块链技术最显著的用途是建立支付基础设施、基金交易技术和数字身份管理。传统上,后两者是由金融服务业传统的系统处理的。但由于区块链处理上的效率,这些系统正逐渐的向区块链迁移合并。区块链还为这些金融服务业的公司提供了高质量的数据分析解决方案,这一方面之所以能够快速的得到重视,主要得益于最近的数据科学的发展。
|
||||
|
||||
从这一领域前沿阵地的初创企业和项目入手考察,区块链似乎能有所保证,因为这些企业或项目的产品已经开始在市场上扩展开来。
|
||||
|
||||
PayPal,这是一家创建于 1998 年的在线支付公司,现为此类平台中最大的一个,常被视作运营和技术能力的基准。PayPal 很大程度上派生自现有的货币体系。它的创新贡献来自于如何收集并利用消费者数据,以提供即时的在线服务。如今,在线交易已被认为是理所当然的事,其所基于的技术方面,在该行业里的创新极少。拥有坚实的基础是一件好事,但在快速发展的 IT 行业里并不能提供任何竞争力,毕竟每天都有新的标准和新的技术。2014 年,PayPal 子公司 **Braintree** [宣布][r2]与流行的加密货币支付方案解决商 [Coinbase][r3] 和 **GoCoin** 建立了合作关系,以便逐步将比特币和其它加密货币整合到它们的服务平台上。这基本上给了加密货币支付方案解决商的消费者在 PayPal 可靠且熟悉的平台下探索和体验的一个机会。事实上,打车公司 **Uber** 和 Braintree 具有独家合作关系,允许消费者在打车的时候使用比特币。
|
||||
|
||||
**瑞波(Ripple)** 正在让人们在多个区块链之间的操作变得更简单。瑞波已经成为美国各地区银行向前发展的头条新闻,比如,在不需要第三方中介的情况下,将资金双边转移给其他地区银行,从而降低了成本和时间管理费用。[瑞波的 Codius 平台][r4]允许区块链之间互相操作,并为智能合约编入系统提供了方便之门,以最大限度地减少篡改和混乱。建立在这种先进、安全并且可根据需要扩展的平台上,瑞波拥有像瑞银和[渣打银行][r5] 在内的客户列表,更多的银行客户也在期待加入。
|
||||
|
||||
**Kraken**,是一个在全球各地运营的美国加密货币交易所,因其可靠的**加密货币量**估算而闻名,甚至向彭博终端实时提供比特币定价数据。在 2015 年,[他们与菲多尔银行][r6]合作建立世界上第一个提供银行业务和加密货币交易的加密货币银行。
|
||||
|
||||
另一家金融科技公司 [Circle][r7] 则是目前同类公司中规模最大的一家,允许用户投资和交易加密货币衍生资产,类似于传统的货币市场资产。
|
||||
|
||||
如今,像 [Wyre][r8] 和 **Stellar** 这样的公司已经将国际电汇的提前期从平均 3 天降到了 6 小时。有人声称,一旦建立了适当的监管体系,同样的 6 小时可以缩短至几秒钟。
|
||||
|
||||
虽然现在上述内容集中在相关的初创项目上,但是不应忽视更受尊敬的老派金融机构的影响力和能力。这些全球范围内交易量达数十亿美元,已经存在了数十年乃至上百年的机构,在利用区块链及其潜力上有着相当的兴趣。
|
||||
|
||||
前面的文章中我们已经提到,**摩根大通**最近披露了他们在开发加密货币和企业级别的区块链基础分类帐本上的计划。该项目被称为 [Quorum][r9],被定义为 **“企业级分布式分类帐和智能合约平台”**。这一平台的主要目标是将大量的银行操作逐渐的迁移到 Quorum 中,从而削减像摩根大通这样的公司在保证隐私、安全和透明度上的重大开销。他们声称自己是行业中唯一完整拥有全部的区块链、协议和代币系统的玩家。他们也发布了一个称为 **JPM 硬币** 的加密货币,用于大额即时结算。JPM 硬币是由摩根大通等主要银行支持的首批“稳定币”。稳定币是其价格与现存主要货币系统相关联的加密货币。Quorum 也因其每秒几近 100 次远高于同行的交易量而倍受吹捧,这远远领先于同时代。
|
||||
|
||||
据报道,英国跨国金融巨头巴克莱已经[注册了两项基于区块链的专利][r10],旨在简化资金转移和 KYC 规程。巴克莱更多的是旨在提高自身的银行操作效率。其中一个应用是创建一个私有区块链网络,用于存储客户的 KYC 信息。经过验证、存储和确认后,这些详细信息将不可变,并且无需再进一步验证。若能实施这一应用,该协议将取消对 KYC 信息多次验证的需求。像印度这样有着高密度人口的发展中国家,其中大部分人口的 KYC 信息尚未被引入正式的银行系统中,若能引入这种具有革新意义的 KYC 系统,将有助于减少随机错误并减少交付时间。据传,巴克莱同时也在探索区块链系统的功能,以便解决信用状态评级和保险赔偿问题。
|
||||
|
||||
这种以区块链作支撑的系统,被用来消除不必要的维护成本,并利用智能合约来为那些需要慎重、安全和速度的企业在行业内赢得竞争力。这些企业产品建立在一个能够确保完整交易以及合同隐私的协议之上,同时建立了可使腐败和贿赂无效的共识机制。
|
||||
|
||||
[普华永道 2017 年的全球金融科技报告][r11] 表示到 2020 年,所有金融科技公司中约有 77% 将转向基于区块链的技术和流程。高达 90% 的受访者表示他们计划在 2020 年之前将区块链技术作为生产系统的一部分。他们的判断没错,因为从监管的角度来看,通过转移到基于区块链的系统上,可以确保显著的成本节约和透明度增加。
|
||||
|
||||
由于区块链平台默认内置了监管能力,因此企业从传统系统迁移到运行区块链分类账本的现代网络也是行业监管机构所欢迎的举措。交易和贸易运动可以一劳永逸地进行验证和跟踪。从长远来看,这可能会带来更好的监管和风险管理,更不用说改善了公司和个人的责任。
|
||||
|
||||
虽然对跨越式创新的投资是由企业进行的大量投资顺带所致,但如果认为这些措施不会渗透到最终用户的利益中是具有误导性的。随着银行和金融机构开始采用区块链,这将为他们带来更多的成本节约和效率,而这最终也将对终端消费者有利。透明度和欺诈保护带来的额外好处将改善客户的感受,更重要的是提高人们对银行和金融系统的信任。通过区块链及其与传统服务的整合,金融服务行业急需的革命将成为可能。 在本系列的下一部分中,我们将讨论[房地产中的区块链][3]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-redefining-financial-services/
|
||||
|
||||
作者:[ostechnix][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[sanfusu](https://github.com/sanfusu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10668-1.html
|
||||
[2]: https://linux.cn/article-10650-1.html
|
||||
[3]: https://www.ostechnix.com/blockchain-2-0-blockchain-in-real-estate/
|
||||
[r1]: https://www.forbes.com/sites/bernardmarr/2018/01/22/35-amazing-real-world-examples-of-how-blockchain-is-changing-our-world/#170df8de43b5
|
||||
[r2]: https://publicpolicy.paypal-corp.com/issues/blockchain
|
||||
[r3]: https://blog.coinbase.com/coinbase-adds-support-for-paypal-and-credit-cards-21968661d508
|
||||
[r4]: http://fortune.com/2018/06/06/ripple-codius/
|
||||
[r5]: https://www.finextra.com/newsarticle/32048/standard-chartered-to-extend-use-of-ripplenet-to-more-countries
|
||||
[r6]: https://99bitcoins.com/fidor-and-kraken-team-up-for-cryptocurrency-bank/
|
||||
[r7]: https://www.bloomberg.com/research/stocks/private/snapshot.asp?privcapId=249292386
|
||||
[r8]: https://www.forbes.com/sites/julianmitchell/2018/07/31/wyre-the-blockchain-platform-taking-the-lead-in-cross-border-transactions/#6bc69ade69d7
|
||||
[r9]: https://www.jpmorgan.com/global/Quorum
|
||||
[r10]: https://cointelegraph.com/news/barclays-files-two-digital-currency-and-blockchain-patents-with-u-s-patent-office
|
||||
[r11]: https://www.pwc.com/jg/en/media-release/global-fintech-survey-2017.html
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10690-1.html)
|
||||
[#]: subject: (Learn about computer security with the Raspberry Pi and Kali Linux)
|
||||
[#]: via: (https://opensource.com/article/19/3/computer-security-raspberry-pi)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
|
||||
|
||||
树莓派使用入门:通过树莓派和 kali Linux 学习计算机安全
|
||||
======
|
||||
|
||||
> 树莓派是学习计算机安全的一个好方法。在我们这个系列的第十一篇文章中会进行学习。
|
||||
|
||||

|
||||
|
||||
在技术方面是否有比保护你的计算机更热门的话题?一些专家会告诉你,没有绝对安全的系统。他们开玩笑说,如果你想要你的服务器或者应用程序真正的安全,就关掉你的服务器,从网络上断线,然后把它放在一个安全的地方。但问题是显而易见的:没人能用的应用程序或者服务器有什么用?
|
||||
|
||||
这是围绕安全的一个难题,我们如何才能在保证安全性的同时,让服务器或应用程序依然可用且有价值?我无论如何都不是一个安全专家,虽然我希望有一天我能是。因此,分享可以用树莓派来做些什么以学习计算机安全的知识,我认为是有意义的。
|
||||
|
||||
我要提示一下,就像本系列中其他写给树莓派初学者的文章一样,我的目标不是深入研究,而是起个头,让你有兴趣去了解更多与这些主题相关的东西。
|
||||
|
||||
### Kali Linux
|
||||
|
||||
当我们谈到“做一些安全方面的事”的时候,出现在脑海中的一个 Linux 发行版就是 [Kali Linux][1]。Kali Linux 的开发主要集中在调查取证和渗透测试方面。它有超过 600 个已经预先安装好了的用来测试你的计算机的安全性的[渗透测试工具][2],还有一个[取证模式][3],它可以避免自身接触到被检查系统的内部的硬盘驱动器或交换空间。
|
||||
|
||||
|
||||
|
||||
就像 Raspbian 一样,Kali Linux 基于 Debian 的发行版,你可以在 Kali 的主要[文档门户][4]的网页上找到将它安装在树莓派上的文档。如果你已经在你的树莓派上安装了 Raspbian 或者是其它的 Linux 发行版。那么你装 Kali 应该是没问题的,Kali 的创造者甚至将[培训、研讨会和职业认证][5]整合到了一起,以此来帮助提升你在安全领域内的职业生涯。
|
||||
|
||||
### 其他的 Linux 发行版
|
||||
|
||||
大多数的标准 Linux 发行版,比如 Raspbian、Ubuntu 和 Fedora 这些,在它们的仓库里同样也有[很多可用的安全工具][6]。一些很棒的探测工具你可以试试,包括 [Nmap][7]、[Wireshark][8]、[auditctl][9],和 [SELinux][10]。
|
||||
|
||||
### 项目
|
||||
|
||||
你可以在树莓派上运行很多其他的安全相关的项目,例如[蜜罐][11],[广告拦截器][12]和 [USB 清洁器][13]。花些时间了解它们!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/computer-security-raspberry-pi
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.kali.org/
|
||||
[2]: https://en.wikipedia.org/wiki/Kali_Linux#Development
|
||||
[3]: https://docs.kali.org/general-use/kali-linux-forensics-mode
|
||||
[4]: https://docs.kali.org/kali-on-arm/install-kali-linux-arm-raspberry-pi
|
||||
[5]: https://www.kali.org/penetration-testing-with-kali-linux/
|
||||
[6]: https://linuxblog.darkduck.com/2019/02/9-best-linux-based-security-tools.html
|
||||
[7]: https://nmap.org/
|
||||
[8]: https://www.wireshark.org/
|
||||
[9]: https://linux.die.net/man/8/auditctl
|
||||
[10]: https://opensource.com/article/18/7/sysadmin-guide-selinux
|
||||
[11]: https://trustfoundry.net/honeypi-easy-honeypot-raspberry-pi/
|
||||
[12]: https://pi-hole.net/
|
||||
[13]: https://www.circl.lu/projects/CIRCLean/
|
||||
325
published/20190318 10 Python image manipulation tools.md
Normal file
325
published/20190318 10 Python image manipulation tools.md
Normal file
@ -0,0 +1,325 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10679-1.html)
|
||||
[#]: subject: (10 Python image manipulation tools)
|
||||
[#]: via: (https://opensource.com/article/19/3/python-image-manipulation-tools)
|
||||
[#]: author: (Parul Pandey https://opensource.com/users/parul-pandey)
|
||||
|
||||
10 个 Python 图像编辑工具
|
||||
======
|
||||
|
||||
> 以下提到的这些 Python 工具在编辑图像、操作图像底层数据方面都提供了简单直接的方法。
|
||||
|
||||
![][1]
|
||||
|
||||
当今的世界充满了数据,而图像数据就是其中很重要的一部分。但只有经过处理和分析,提高图像的质量,从中提取出有效地信息,才能利用到这些图像数据。
|
||||
|
||||
常见的图像处理操作包括显示图像,基本的图像操作,如裁剪、翻转、旋转;图像的分割、分类、特征提取;图像恢复;以及图像识别等等。Python 作为一种日益风靡的科学编程语言,是这些图像处理操作的最佳选择。同时,在 Python 生态当中也有很多可以免费使用的优秀的图像处理工具。
|
||||
|
||||
下文将介绍 10 个可以用于图像处理任务的 Python 库,它们在编辑图像、查看图像底层数据方面都提供了简单直接的方法。
|
||||
|
||||
### 1、scikit-image
|
||||
|
||||
[scikit-image][2] 是一个结合 [NumPy][3] 数组使用的开源 Python 工具,它实现了可用于研究、教育、工业应用的算法和应用程序。即使是对于刚刚接触 Python 生态圈的新手来说,它也是一个在使用上足够简单的库。同时它的代码质量也很高,因为它是由一个活跃的志愿者社区开发的,并且通过了<ruby>同行评审<rt>peer review</rt></ruby>。
|
||||
|
||||
#### 资源
|
||||
|
||||
scikit-image 的[文档][4]非常完善,其中包含了丰富的用例。
|
||||
|
||||
#### 示例
|
||||
|
||||
可以通过导入 `skimage` 使用,大部分的功能都可以在它的子模块中找到。
|
||||
|
||||
<ruby>图像滤波<rt>image filtering</rt></ruby>:
|
||||
|
||||
```
|
||||
import matplotlib.pyplot as plt
|
||||
%matplotlib inline
|
||||
|
||||
from skimage import data,filters
|
||||
|
||||
image = data.coins() # ... or any other NumPy array!
|
||||
edges = filters.sobel(image)
|
||||
plt.imshow(edges, cmap='gray')
|
||||
```
|
||||
|
||||
![Image filtering in scikit-image][6]
|
||||
|
||||
使用 [match_template()][7] 方法实现<ruby>模板匹配<rt>template matching</rt></ruby>:
|
||||
|
||||
![Template matching in scikit-image][9]
|
||||
|
||||
在[展示页面][10]可以看到更多相关的例子。
|
||||
|
||||
### 2、NumPy
|
||||
|
||||
[NumPy][11] 提供了对数组的支持,是 Python 编程的一个核心库。图像的本质其实也是一个包含像素数据点的标准 NumPy 数组,因此可以通过一些基本的 NumPy 操作(例如切片、<ruby>掩膜<rt>mask</rt></ruby>、<ruby>花式索引<rt>fancy indexing</rt></ruby>等),就可以从像素级别对图像进行编辑。通过 NumPy 数组存储的图像也可以被 skimage 加载并使用 matplotlib 显示。
|
||||
|
||||
#### 资源
|
||||
|
||||
在 NumPy 的[官方文档][11]中提供了完整的代码文档和资源列表。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 NumPy 对图像进行<ruby>掩膜<rt>mask</rt></ruby>操作:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
from skimage import data
|
||||
import matplotlib.pyplot as plt
|
||||
%matplotlib inline
|
||||
|
||||
image = data.camera()
|
||||
type(image)
|
||||
numpy.ndarray #Image is a NumPy array:
|
||||
|
||||
mask = image < 87
|
||||
image[mask]=255
|
||||
plt.imshow(image, cmap='gray')
|
||||
```
|
||||
|
||||
![NumPy][13]
|
||||
|
||||
### 3、SciPy
|
||||
|
||||
像 NumPy 一样,[SciPy][14] 是 Python 的一个核心科学计算模块,也可以用于图像的基本操作和处理。尤其是 SciPy v1.1.0 中的 [scipy.ndimage][15] 子模块,它提供了在 n 维 NumPy 数组上的运行的函数。SciPy 目前还提供了<ruby>线性和非线性滤波<rt>linear and non-linear filtering</rt></ruby>、<ruby>二值形态学<rt>binary morphology</rt></ruby>、<ruby>B 样条插值<rt>B-spline interpolation</rt></ruby>、<ruby>对象测量<rt>object measurements</rt></ruby>等方面的函数。
|
||||
|
||||
#### 资源
|
||||
|
||||
在[官方文档][16]中可以查阅到 `scipy.ndimage` 的完整函数列表。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 SciPy 的[高斯滤波][17]对图像进行模糊处理:
|
||||
|
||||
```
|
||||
from scipy import misc,ndimage
|
||||
|
||||
face = misc.face()
|
||||
blurred_face = ndimage.gaussian_filter(face, sigma=3)
|
||||
very_blurred = ndimage.gaussian_filter(face, sigma=5)
|
||||
|
||||
#Results
|
||||
plt.imshow(<image to be displayed>)
|
||||
```
|
||||
|
||||
![Using a Gaussian filter in SciPy][19]
|
||||
|
||||
### 4、PIL/Pillow
|
||||
|
||||
PIL (Python Imaging Library) 是一个免费 Python 编程库,它提供了对多种格式图像文件的打开、编辑、保存的支持。但在 2009 年之后 PIL 就停止发布新版本了。幸运的是,还有一个 PIL 的积极开发的分支 [Pillow][20],它的安装过程比 PIL 更加简单,支持大部分主流的操作系统,并且还支持 Python 3。Pillow 包含了图像的基础处理功能,包括像素点操作、使用内置卷积内核进行滤波、颜色空间转换等等。
|
||||
|
||||
#### 资源
|
||||
|
||||
Pillow 的[官方文档][21]提供了 Pillow 的安装说明自己代码库中每一个模块的示例。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 Pillow 中的 ImageFilter 模块实现图像增强:
|
||||
|
||||
```
|
||||
from PIL import Image,ImageFilter
|
||||
#Read image
|
||||
im = Image.open('image.jpg')
|
||||
#Display image
|
||||
im.show()
|
||||
|
||||
from PIL import ImageEnhance
|
||||
enh = ImageEnhance.Contrast(im)
|
||||
enh.enhance(1.8).show("30% more contrast")
|
||||
```
|
||||
|
||||
![Enhancing an image in Pillow using ImageFilter][23]
|
||||
|
||||
- [源码][24]
|
||||
|
||||
### 5、OpenCV-Python
|
||||
|
||||
OpenCV(Open Source Computer Vision 库)是计算机视觉领域最广泛使用的库之一,[OpenCV-Python][25] 则是 OpenCV 的 Python API。OpenCV-Python 的运行速度很快,这归功于它使用 C/C++ 编写的后台代码,同时由于它使用了 Python 进行封装,因此调用和部署的难度也不大。这些优点让 OpenCV-Python 成为了计算密集型计算机视觉应用程序的一个不错的选择。
|
||||
|
||||
#### 资源
|
||||
|
||||
入门之前最好先阅读 [OpenCV2-Python-Guide][26] 这份文档。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 OpenCV-Python 中的<ruby>金字塔融合<rt>Pyramid Blending</rt></ruby>将苹果和橘子融合到一起:
|
||||
|
||||
|
||||
![Image blending using Pyramids in OpenCV-Python][28]
|
||||
|
||||
- [源码][29]
|
||||
|
||||
### 6、SimpleCV
|
||||
|
||||
[SimpleCV][30] 是一个开源的计算机视觉框架。它支持包括 OpenCV 在内的一些高性能计算机视觉库,同时不需要去了解<ruby>位深度<rt>bit depth</rt></ruby>、文件格式、<ruby>色彩空间<rt>color space</rt></ruby>之类的概念,因此 SimpleCV 的学习曲线要比 OpenCV 平缓得多,正如它的口号所说,“将计算机视觉变得更简单”。SimpleCV 的优点还有:
|
||||
|
||||
* 即使是刚刚接触计算机视觉的程序员也可以通过 SimpleCV 来实现一些简易的计算机视觉测试
|
||||
* 录像、视频文件、图像、视频流都在支持范围内
|
||||
|
||||
#### 资源
|
||||
|
||||
[官方文档][31]简单易懂,同时也附有大量的学习用例。
|
||||
|
||||
#### 示例
|
||||
|
||||
![SimpleCV][33]
|
||||
|
||||
### 7、Mahotas
|
||||
|
||||
[Mahotas][34] 是另一个 Python 图像处理和计算机视觉库。在图像处理方面,它支持滤波和形态学相关的操作;在计算机视觉方面,它也支持<ruby>特征计算<rt>feature computation</rt></ruby>、<ruby>兴趣点检测<rt>interest point detection</rt></ruby>、<ruby>局部描述符<rt>local descriptors</rt></ruby>等功能。Mahotas 的接口使用了 Python 进行编写,因此适合快速开发,而算法使用 C++ 实现,并针对速度进行了优化。Mahotas 尽可能做到代码量少和依赖项少,因此它的运算速度非常快。可以参考[官方文档][35]了解更多详细信息。
|
||||
|
||||
#### 资源
|
||||
|
||||
[文档][36]包含了安装介绍、示例以及一些 Mahotas 的入门教程。
|
||||
|
||||
#### 示例
|
||||
|
||||
Mahotas 力求使用少量的代码来实现功能。例如这个 [Finding Wally][37] 游戏:
|
||||
|
||||
![Finding Wally problem in Mahotas][39]
|
||||
|
||||
![Finding Wally problem in Mahotas][42]
|
||||
|
||||
- [源码][40]
|
||||
|
||||
### 8、SimpleITK
|
||||
|
||||
[ITK][43](Insight Segmentation and Registration Toolkit)是一个为开发者提供普适性图像分析功能的开源、跨平台工具套件,[SimpleITK][44] 则是基于 ITK 构建出来的一个简化层,旨在促进 ITK 在快速原型设计、教育、解释语言中的应用。SimpleITK 作为一个图像分析工具包,它也带有[大量的组件][45],可以支持常规的滤波、图像分割、<ruby>图像配准<rt>registration</rt></ruby>功能。尽管 SimpleITK 使用 C++ 编写,但它也支持包括 Python 在内的大部分编程语言。
|
||||
|
||||
#### 资源
|
||||
|
||||
有很多 [Jupyter Notebooks][46] 用例可以展示 SimpleITK 在教育和科研领域中的应用,通过这些用例可以看到如何使用 Python 和 R 利用 SimpleITK 来实现交互式图像分析。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 Python + SimpleITK 实现的 CT/MR 图像配准过程:
|
||||
|
||||
![SimpleITK animation][48]
|
||||
|
||||
- [源码][49]
|
||||
|
||||
### 9、pgmagick
|
||||
|
||||
[pgmagick][50] 是使用 Python 封装的 GraphicsMagick 库。[GraphicsMagick][51] 通常被认为是图像处理界的瑞士军刀,因为它强大而又高效的工具包支持对多达 88 种主流格式图像文件的读写操作,包括 DPX、GIF、JPEG、JPEG-2000、PNG、PDF、PNM、TIFF 等等。
|
||||
|
||||
#### 资源
|
||||
|
||||
pgmagick 的 [GitHub 仓库][52]中有相关的安装说明、依赖列表,以及详细的[使用指引][53]。
|
||||
|
||||
#### 示例
|
||||
|
||||
图像缩放:
|
||||
|
||||
![Image scaling in pgmagick][55]
|
||||
|
||||
- [源码][56]
|
||||
|
||||
边缘提取:
|
||||
|
||||
![Edge extraction in pgmagick][58]
|
||||
|
||||
- [源码][59]
|
||||
|
||||
### 10、Pycairo
|
||||
|
||||
[Cairo][61] 是一个用于绘制矢量图的二维图形库,而 [Pycairo][60] 是用于 Cairo 的一组 Python 绑定。矢量图的优点在于做大小缩放的过程中不会丢失图像的清晰度。使用 Pycairo 可以在 Python 中调用 Cairo 的相关命令。
|
||||
|
||||
#### 资源
|
||||
|
||||
Pycairo 的 [GitHub 仓库][62]提供了关于安装和使用的详细说明,以及一份简要介绍 Pycairo 的[入门指南][63]。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 Pycairo 绘制线段、基本图形、<ruby>径向渐变<rt>radial gradients</rt></ruby>:
|
||||
|
||||
![Pycairo][65]
|
||||
|
||||
- [源码][66]
|
||||
|
||||
### 总结
|
||||
|
||||
以上就是 Python 中的一些有用的图像处理库,无论你有没有听说过、有没有使用过,都值得试用一下并了解它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/python-image-manipulation-tools
|
||||
|
||||
作者:[Parul Pandey][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/parul-pandey
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/daisy_gimp_art_design.jpg?itok=6kCxAKWO
|
||||
[2]: https://scikit-image.org/
|
||||
[3]: http://docs.scipy.org/doc/numpy/reference/index.html#module-numpy
|
||||
[4]: http://scikit-image.org/docs/stable/user_guide.html
|
||||
[5]: /file/426206
|
||||
[6]: https://opensource.com/sites/default/files/uploads/1-scikit-image.png "Image filtering in scikit-image"
|
||||
[7]: http://scikit-image.org/docs/dev/auto_examples/features_detection/plot_template.html#sphx-glr-auto-examples-features-detection-plot-template-py
|
||||
[8]: /file/426211
|
||||
[9]: https://opensource.com/sites/default/files/uploads/2-scikit-image.png "Template matching in scikit-image"
|
||||
[10]: https://scikit-image.org/docs/dev/auto_examples
|
||||
[11]: http://www.numpy.org/
|
||||
[12]: /file/426216
|
||||
[13]: https://opensource.com/sites/default/files/uploads/3-numpy.png "NumPy"
|
||||
[14]: https://www.scipy.org/
|
||||
[15]: https://docs.scipy.org/doc/scipy/reference/ndimage.html#module-scipy.ndimage
|
||||
[16]: https://docs.scipy.org/doc/scipy/reference/tutorial/ndimage.html#correlation-and-convolution
|
||||
[17]: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.gaussian_filter.html
|
||||
[18]: /file/426221
|
||||
[19]: https://opensource.com/sites/default/files/uploads/4-scipy.png "Using a Gaussian filter in SciPy"
|
||||
[20]: https://python-pillow.org/
|
||||
[21]: https://pillow.readthedocs.io/en/3.1.x/index.html
|
||||
[22]: /file/426226
|
||||
[23]: https://opensource.com/sites/default/files/uploads/5-pillow.png "Enhancing an image in Pillow using ImageFilter"
|
||||
[24]: http://sipi.usc.edu/database/
|
||||
[25]: https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_setup/py_intro/py_intro.html
|
||||
[26]: https://github.com/abidrahmank/OpenCV2-Python-Tutorials
|
||||
[27]: /file/426236
|
||||
[28]: https://opensource.com/sites/default/files/uploads/6-opencv.jpeg "Image blending using Pyramids in OpenCV-Python"
|
||||
[29]: https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_pyramids/py_pyramids.html#pyramids
|
||||
[30]: http://simplecv.org/
|
||||
[31]: http://examples.simplecv.org/en/latest/
|
||||
[32]: /file/426241
|
||||
[33]: https://opensource.com/sites/default/files/uploads/7-_simplecv.png "SimpleCV"
|
||||
[34]: https://mahotas.readthedocs.io/en/latest/
|
||||
[35]: https://openresearchsoftware.metajnl.com/articles/10.5334/jors.ac/
|
||||
[36]: https://mahotas.readthedocs.io/en/latest/install.html
|
||||
[37]: https://blog.clarifai.com/wheres-waldo-using-machine-learning-to-find-all-the-waldos
|
||||
[38]: /file/426246
|
||||
[39]: https://opensource.com/sites/default/files/uploads/8-mahotas.png "Finding Wally problem in Mahotas"
|
||||
[40]: https://mahotas.readthedocs.io/en/latest/wally.html
|
||||
[41]: /file/426251
|
||||
[42]: https://opensource.com/sites/default/files/uploads/9-mahotas.png "Finding Wally problem in Mahotas"
|
||||
[43]: https://itk.org/
|
||||
[44]: http://www.simpleitk.org/
|
||||
[45]: https://itk.org/ITK/resources/resources.html
|
||||
[46]: http://insightsoftwareconsortium.github.io/SimpleITK-Notebooks/
|
||||
[47]: /file/426256
|
||||
[48]: https://opensource.com/sites/default/files/uploads/10-simpleitk.gif "SimpleITK animation"
|
||||
[49]: https://github.com/InsightSoftwareConsortium/SimpleITK-Notebooks/blob/master/Utilities/intro_animation.py
|
||||
[50]: https://pypi.org/project/pgmagick/
|
||||
[51]: http://www.graphicsmagick.org/
|
||||
[52]: https://github.com/hhatto/pgmagick
|
||||
[53]: https://pgmagick.readthedocs.io/en/latest/
|
||||
[54]: /file/426261
|
||||
[55]: https://opensource.com/sites/default/files/uploads/11-pgmagick.png "Image scaling in pgmagick"
|
||||
[56]: https://pgmagick.readthedocs.io/en/latest/cookbook.html#scaling-a-jpeg-image
|
||||
[57]: /file/426266
|
||||
[58]: https://opensource.com/sites/default/files/uploads/12-pgmagick.png "Edge extraction in pgmagick"
|
||||
[59]: https://pgmagick.readthedocs.io/en/latest/cookbook.html#edge-extraction
|
||||
[60]: https://pypi.org/project/pycairo/
|
||||
[61]: https://cairographics.org/
|
||||
[62]: https://github.com/pygobject/pycairo
|
||||
[63]: https://pycairo.readthedocs.io/en/latest/tutorial.html
|
||||
[64]: /file/426271
|
||||
[65]: https://opensource.com/sites/default/files/uploads/13-pycairo.png "Pycairo"
|
||||
[66]: http://zetcode.com/gfx/pycairo/basicdrawing/
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "FSSlc"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-10675-1.html"
|
||||
[#]: subject: "3 Ways To Check Whether A Port Is Open On The Remote Linux System?"
|
||||
[#]: via: "https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/"
|
||||
[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
|
||||
@ -10,11 +10,7 @@
|
||||
查看远程 Linux 系统中某个端口是否开启的 3 种方法
|
||||
======
|
||||
|
||||
这是一个很重要的话题,不仅对 Linux 管理员而言,对于我们大家而言也非常有帮助。
|
||||
|
||||
我的意思是说对于工作在 IT 基础设施行业的用户来说,了解这个话题也是非常有用的。
|
||||
|
||||
他们需要在执行下一步操作前,检查 Linux 服务器上某个端口是否开启。
|
||||
这是一个很重要的话题,不仅对 Linux 管理员而言,对于我们大家而言也非常有帮助。我的意思是说对于工作在 IT 基础设施行业的用户来说,了解这个话题也是非常有用的。他们需要在执行下一步操作前,检查 Linux 服务器上某个端口是否开启。
|
||||
|
||||
假如这个端口没有被开启,则他们会直接找 Linux 管理员去开启它。如果这个端口已经开启了,则我们需要和应用团队来商量下一步要做的事。
|
||||
|
||||
@ -22,21 +18,21 @@
|
||||
|
||||
这个目标可以使用下面的 Linux 命令来达成:
|
||||
|
||||
* **`nc:`** `netcat` 是一个简单的 Unix 工具,它使用 TCP 或 UDP 协议去读写网络连接间的数据。
|
||||
* **`nmap:`** `nmap`(“Network Mapper”) 是一个用于网络探索和安全审计的开源工具,被设计用来快速地扫描大规模网络。
|
||||
* **`telnet:`** `telnet` 命令被用来交互地通过 TELNET 协议与另一台主机通信。
|
||||
* `nc`:netcat 是一个简单的 Unix 工具,它使用 TCP 或 UDP 协议去读写网络连接间的数据。
|
||||
* `nmap`:(“Network Mapper”)是一个用于网络探索和安全审计的开源工具,被设计用来快速地扫描大规模网络。
|
||||
* `telnet`:被用来交互地通过 TELNET 协议与另一台主机通信。
|
||||
|
||||
### 如何使用 nc(netcat)命令来查看远程 Linux 系统中某个端口是否开启?
|
||||
|
||||
`nc` 即 `netcat`。 `netcat` 是一个简单的 Unix 工具,它使用 TCP 或 UDP 协议去读写网络连接间的数据。
|
||||
`nc` 即 `netcat`。`netcat` 是一个简单的 Unix 工具,它使用 TCP 或 UDP 协议去读写网络连接间的数据。
|
||||
|
||||
它被设计成为一个可信赖的后端工具,可被直接使用或者轻易地被其他程序或脚本调用。
|
||||
它被设计成为一个可信赖的后端工具,可被直接使用或者简单地被其他程序或脚本调用。
|
||||
|
||||
与此同时,它也是一个富含功能的网络调试和探索工具,因为它可以创建你所需的几乎所有类型的连接,并且还拥有几个内置的有趣功能。
|
||||
|
||||
netcat 有三类功能模式,它们分别为连接模式、监听模式和隧道模式。
|
||||
`netcat` 有三类功能模式,它们分别为连接模式、监听模式和隧道模式。
|
||||
|
||||
**nc(netcat)命令的一般语法:**
|
||||
`nc`(`netcat`)命令的一般语法:
|
||||
|
||||
```
|
||||
$ nc [-options] [HostName or IP] [PortNumber]
|
||||
@ -51,14 +47,14 @@ $ nc [-options] [HostName or IP] [PortNumber]
|
||||
Connection to 192.168.1.8 22 port [tcp/ssh] succeeded!
|
||||
```
|
||||
|
||||
**命令详解:**
|
||||
命令详解:
|
||||
|
||||
* **`nc:`** 即执行的命令主体;
|
||||
* **`z:`** zero-I/O 模式(被用来扫描);
|
||||
* **`v:`** 显式地输出;
|
||||
* **`w3:`** 设置超时时间为 3 秒;
|
||||
* **`192.168.1.8:`** 目标系统的 IP 地址;
|
||||
* **`22:`** 需要验证的端口。
|
||||
* `nc`:即执行的命令主体;
|
||||
* `z`:零 I/O 模式(被用来扫描);
|
||||
* `v`:显式地输出;
|
||||
* `w3`:设置超时时间为 3 秒;
|
||||
* `192.168.1.8`:目标系统的 IP 地址;
|
||||
* `22`:需要验证的端口。
|
||||
|
||||
当检测到端口没有开启,你将获得如下输出:
|
||||
|
||||
@ -69,13 +65,13 @@ nc: connect to 192.168.1.95 port 22 (tcp) failed: Connection refused
|
||||
|
||||
### 如何使用 nmap 命令来查看远程 Linux 系统中某个端口是否开启?
|
||||
|
||||
`nmap`(“Network Mapper”) 是一个用于网络探索和安全审计的开源工具,被设计用来快速地扫描大规模网络,尽管对于单个主机它也同样能够正常工作。
|
||||
`nmap`(“Network Mapper”)是一个用于网络探索和安全审计的开源工具,被设计用来快速地扫描大规模网络,尽管对于单个主机它也同样能够正常工作。
|
||||
|
||||
nmap 以一种新颖的方式,使用裸 IP 包来决定网络中的主机是否可达,这些主机正提供什么服务(应用名和版本号),它们运行的操作系统(系统的版本),它们正在使用的是什么包过滤软件或者防火墙,以及其他额外的特性。
|
||||
`nmap` 以一种新颖的方式,使用裸 IP 包来决定网络中的主机是否可达,这些主机正提供什么服务(应用名和版本号),它们运行的操作系统(系统的版本),它们正在使用的是什么包过滤软件或者防火墙,以及其他额外的特性。
|
||||
|
||||
尽管 nmap 通常被用于安全审计,许多系统和网络管理员发现在一些日常任务(例如罗列网络资产、管理服务升级的计划、监视主机或者服务是否正常运行)中,它也同样十分有用。
|
||||
尽管 `nmap` 通常被用于安全审计,许多系统和网络管理员发现在一些日常任务(例如罗列网络资产、管理服务升级的计划、监视主机或者服务是否正常运行)中,它也同样十分有用。
|
||||
|
||||
**nmap 的一般语法:**
|
||||
`nmap` 的一般语法:
|
||||
|
||||
```
|
||||
$ nmap [-options] [HostName or IP] [-p] [PortNumber]
|
||||
@ -113,7 +109,7 @@ Nmap done: 1 IP address (1 host up) scanned in 13.07 seconds
|
||||
|
||||
`telnet` 命令被用来交互地通过 TELNET 协议与另一台主机通信。
|
||||
|
||||
**telnet 命令的一般语法:**
|
||||
`telnet` 命令的一般语法:
|
||||
|
||||
```
|
||||
$ telnet [HostName or IP] [PortNumber]
|
||||
@ -148,7 +144,7 @@ via: https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (mokshal)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (5 reasons to give Linux for the holidays)
|
||||
|
||||
@ -0,0 +1,97 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Managing changes in open source projects)
|
||||
[#]: via: (https://opensource.com/article/19/3/managing-changes-open-source-projects)
|
||||
[#]: author: (Ben Cotton (Red Hat, Community Moderator) https://opensource.com/users/bcotton)
|
||||
|
||||
Managing changes in open source projects
|
||||
======
|
||||
|
||||
Here's how to create a visible change process to support the community around an open source project.
|
||||
|
||||
![scrabble letters: "time for change"][1]
|
||||
|
||||
Why bother having a process for proposing changes to your open source project? Why not just let people do what they're doing and merge the features when they're ready? Well, you can certainly do that if you're the only person on the project. Or maybe if it's just you and a few friends.
|
||||
|
||||
But if the project is large, you might need to coordinate how some of the changes land. Or, at the very least, let people know a change is coming so they can adjust if it affects the parts they work on. A visible change process is also helpful to the community. It allows them to give feedback that can improve your idea. And if nothing else, it lets people know what's coming so that they can get excited, and maybe get you a little bit of coverage on Opensource.com or the like. Basically, it's "here's what I'm going to do" instead of "here's what I did," and it might save you some headaches as you scramble to QA right before your release.
|
||||
|
||||
So let's say I've convinced you that having a change process is a good idea. How do you build one?
|
||||
|
||||
**[Watch my talk on this topic]**
|
||||
<https://www.youtube.com/embed/cVV1K3Junkc>
|
||||
|
||||
### Right-size your change process
|
||||
|
||||
Before we start talking about what a change process looks like, I want to make it very clear that this is not a one-size-fits-all situation. The smaller your project is—mainly in the number of contributors—the less process you'll probably need. As [Richard Hackman says][2], the number of communication channels in a team goes up exponentially with the number of people on the team. In community-driven projects, this becomes even more complicated as people come and go, and even your long-time contributors might not be checking in every day. So the change process consolidates those communication channels into a single area where people can quickly check to see if they care and then get back to whatever it is they do.
|
||||
|
||||
At one end of the scale, there's the command-line Twitter client I maintain. The change process there is, "I pick something I want to work on, probably make a Git branch for it but I might forget that, merge it, and tag a release when I'm out of stuff that I can/want to do." At the other end is Fedora. Fedora isn't really a single project; it's a program of related projects that mostly move in the same direction. More than 200 people a week touch Fedora in a technical sense: spec file maintenance, build submission, etc. This doesn't even include the untold number of people who are working on the upstreams. And these upstreams all have their own release schedules and their own processes for how features land and when. Nobody can keep up with everything on their own, so the change process brings important changes to light.
|
||||
|
||||
### Decide who needs to review changes
|
||||
|
||||
One of the first things you need to consider when putting together a change process for your community is: "who needs to review changes?" This isn't necessarily approving the changes; we'll come to that shortly. But are there people who should take a look early in the process? Maybe your release engineering or infrastructure teams need to review them to make sure they don't require changes to build infrastructure. Maybe you have a legal review process to make sure licenses are in order. Or maybe you just have a change wrangler who looks to make sure all the required information is included. Or you may choose to do none of these and have change proposals go directly to the community.
|
||||
|
||||
But this brings up the next step. Do you want full community feedback or only a select group to provide feedback? My preference, and what we do in Fedora, is to publish changes to the community before they're approved. But the structure of your community may fit a model where some approval body signs off on the change before it is sent to the community as an announcement.
|
||||
|
||||
### Determine who approves changes
|
||||
|
||||
Even if you lack any sort of organizational structure, someone ends up approving changes. This should reflect the norms and values of your community. The simplest form of approval is the person who proposed the change implements it. Easy peasy! In loosely organized communities, that might work. Fully democratic communities might put it to a community-wide vote. If a certain number or proportion of members votes in favor, the change is approved. Other communities may give that power to an individual or group. They could be responsible for the entire project or certain subsections.
|
||||
|
||||
In Fedora, change approval is the role of the Fedora Engineering Steering Committee (FESCo). This is a nine-person body elected by community members. This gives the community the ability to remove members who are not acting in the best interests of the project but also enables relatively quick decisions without large overhead.
|
||||
|
||||
In much of this article, I am simply presenting information, but I'm going to take a moment to be opinionated. For any project with a significant contributor base, a model where a small body makes approval decisions is the right approach. A pure democracy can be pretty messy. People who may have no familiarity with the technical ramifications of a change will be able to cast a binding vote. And that process is subject to "brigading," where someone brings along a large group of otherwise-uninterested people to support their position. Think about what it might look like if someone proposed changing the default text editor. Would the decision process be rational?
|
||||
|
||||
### Plan how to enforce changes
|
||||
|
||||
The other advantage of having a defined approval body is it can mediate conflicts between changes. What happens if two proposed changes conflict? Or if a change turns out to have a negative impact? Someone needs to have the authority to say "this isn't going in after all" or make sure conflicting changes are brought into agreement. Your QA team and processes will be a part of this, and maybe they're the ones who will make the final call.
|
||||
|
||||
It's relatively straightforward to come up with a plan if a change doesn't work as expected or is incomplete by the deadline. If you require a contingency plan as part of the change process, then you implement that plan. The harder part is: what happens if someone makes a change that doesn't go through your change process? Here's a secret your friendly project manager doesn't want you to know: you can't force people to go through your process, particularly in community projects.
|
||||
|
||||
So if something sneaks in and you don't discover it until you have a release candidate, you have a couple of options: you can let it in, or you can get someone to forcibly remove it. In either case, you'll have someone who is very unhappy. Either the person who made the change, because you kicked their work out, or the people who had to deal with the breakage it caused. (If it snuck in without anyone noticing, then it's probably not that big of a deal.)
|
||||
|
||||
The answer, in either case, is going to be social pressure to follow the process. Processes are sometimes painful to follow, but a well-designed and well-maintained process will give more benefit than it costs. In this case, the benefit may be identifying breakages sooner or giving other developers a chance to take advantage of new features that are offered. And it can help prevent slips in the release schedule or hero effort from your QA team.
|
||||
|
||||
### Implement your change process
|
||||
|
||||
So we've thought about the life of a change proposal in your project. Throw in some deadlines that make sense for your release cadence, and you can now come up with the policy—but how do you implement it?
|
||||
|
||||
First, you'll want to identify the required information for a change proposal. At a minimum, I'd suggest the following. You may have more requirements depending on the specifics of what your community is making and how it operates.
|
||||
|
||||
* Name and summary
|
||||
* Benefit to the project
|
||||
* Scope
|
||||
* Owner
|
||||
* Test plan
|
||||
* Dependencies and impacts
|
||||
* Contingency plan
|
||||
|
||||
|
||||
|
||||
You'll also want one or several change wranglers. These aren't gatekeepers so much as shepherds. They may not have the ability to approve or reject change proposals, but they are responsible for moving the proposals through the process. They check the proposal for completeness, submit it to the appropriate bodies, make appropriate announcements, etc. You can have people wrangle their own changes, but this can be a specialized task and will generally benefit from a dedicated person who does this regularly, instead of making community members do it less frequently.
|
||||
|
||||
And you'll need some tooling to manage these changes. This could be a wiki page, a kanban board, a ticket tracker, something else, or a combination of these. But basically, you want to be able to track their state and provide some easy reporting on the status of changes. This makes it easier to know what is complete, what is at risk, and what needs to be deferred to a later release. You can use whatever works best for you, but in general, you'll want to minimize copy-and-pasting and maximize scriptability.
|
||||
|
||||
### Remember to iterate
|
||||
|
||||
Your change process may seem perfect. Then people will start using it. You'll discover edge cases you didn't consider. You'll find that the community hates a certain part of it. Decisions that were once valid will become invalid over time as technology and society change. In Fedora, our Features process revealed itself to be ambiguous and burdensome, so it was refined into the [Changes][3] process we use today. Even though the Changes process is much better than its predecessor, we still adjust it here and there to make sure it's best meeting the needs of the community.
|
||||
|
||||
When designing your process, make sure it fits the size and values of your community. Consider who gets a voice and who gets a vote in approving changes. Come up with a plan for how you'll handle incomplete changes and other exceptions. Decide who will guide the changes through the process and how they'll be tracked. And once you design your change policy, write it down in a place that's easy for your community to find so that they can follow it. But most of all, remember that the process is here to serve the community; the community is not here to serve the process.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/managing-changes-open-source-projects
|
||||
|
||||
作者:[Ben Cotton (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bcotton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/change_words_scrabble_letters.jpg?itok=mbRFmPJ1 (scrabble letters: "time for change")
|
||||
[2]: https://hbr.org/2009/05/why-teams-dont-work
|
||||
[3]: https://fedoraproject.org/wiki/Changes/Policy
|
||||
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why DevOps is the most important tech strategy today)
|
||||
[#]: via: (https://opensource.com/article/19/3/devops-most-important-tech-strategy)
|
||||
[#]: author: (Kelly AlbrechtWilly-Peter Schaub https://opensource.com/users/ksalbrecht/users/brentaaronreed/users/wpschaub/users/wpschaub/users/ksalbrecht)
|
||||
|
||||
Why DevOps is the most important tech strategy today
|
||||
======
|
||||
Clearing up some of the confusion about DevOps.
|
||||
![CICD with gears][1]
|
||||
|
||||
Many people first learn about [DevOps][2] when they see one of its outcomes and ask how it happened. It's not necessary to understand why something is part of DevOps to implement it, but knowing that—and why a DevOps strategy is important—can mean the difference between being a leader or a follower in an industry.
|
||||
|
||||
Maybe you've heard some the incredible outcomes attributed to DevOps, such as production environments that are so resilient they can handle thousands of releases per day while a "[Chaos Monkey][3]" is running around randomly unplugging things. This is impressive, but on its own, it's a weak business case, essentially burdened with [proving a negative][4]: The DevOps environment is resilient because a serious failure hasn't been observed… yet.
|
||||
|
||||
There is a lot of confusion about DevOps and many people are still trying to make sense of it. Here's an example from someone in my LinkedIn feed:
|
||||
|
||||
> Recently attended few #DevOps sessions where some speakers seemed to suggest #Agile is a subset of DevOps. Somehow, my understanding was just the opposite.
|
||||
>
|
||||
> Would like to hear your thoughts. What do you think is the relationship between Agile and DevOps?
|
||||
>
|
||||
> 1. DevOps is a subset of Agile
|
||||
> 2. Agile is a subset of DevOps
|
||||
> 3. DevOps is an extension of Agile, starts where Agile ends
|
||||
> 4. DevOps is the new version of Agile
|
||||
>
|
||||
|
||||
|
||||
Tech industry professionals have been weighing in on the LinkedIn post with a wide range of answers. How would you respond?
|
||||
|
||||
### DevOps' roots in lean and agile
|
||||
|
||||
DevOps makes a lot more sense if we start with the strategies of Henry Ford and the Toyota Production System's refinements of Ford's model. Within this history is the birthplace of lean manufacturing, which has been well studied. In [_Lean Thinking_][5], James P. Womack and Daniel T. Jones distill it into five principles:
|
||||
|
||||
1. Specify the value desired by the customer
|
||||
2. Identify the value stream for each product providing that value and challenge all of the wasted steps currently necessary to provide it
|
||||
3. Make the product flow continuously through the remaining value-added steps
|
||||
4. Introduce pull between all steps where continuous flow is possible
|
||||
5. Manage toward perfection so that the number of steps and the amount of time and information needed to serve the customer continually falls
|
||||
|
||||
|
||||
|
||||
Lean seeks to continuously remove waste and increase the flow of value to the customer. This is easily recognizable and understood through a core tenet of lean: single piece flow. We can do a number of activities to learn why moving single pieces at a time is magnitudes faster than batches of many pieces; the [Penny Game][6] and the [Airplane Game][7] are two of them. In the Penny Game, if a batch of 20 pennies takes two minutes to get to the customer, they get the whole batch after waiting two minutes. If you move one penny at a time, the customer gets the first penny in about five seconds and continues getting pennies until the 20th penny arrives approximately 25 seconds later.
|
||||
|
||||
This is a huge difference, but not everything in life is as simple and predictable as the penny in the Penny Game. This is where agile comes in. We certainly see lean principles on high-performing agile teams, but these teams need more than lean to do what they do.
|
||||
|
||||
To be able to handle the unpredictability and variance of typical software development tasks, agile methodology focuses on awareness, deliberation, decision, and action to adjust course in the face of a constantly changing reality. For example, agile frameworks (like scrum) increase awareness with ceremonies like the daily standup and the sprint review. If the scrum team becomes aware of a new reality, the framework allows and encourages them to adjust course if necessary.
|
||||
|
||||
For teams to make these types of decisions, they need to be self-organizing in a high-trust environment. High-performing agile teams working this way achieve a fast flow of value while continuously adjusting course, removing the waste of going in the wrong direction.
|
||||
|
||||
### Optimal batch size
|
||||
|
||||
To understand the power of DevOps in software development, it helps to understand the economics of batch size. Consider the following U-curve optimization illustration from Donald Reinertsen's _[Principles of Product Development Flow][8]:_
|
||||
|
||||
![U-curve optimization illustration of optimal batch size][9]
|
||||
|
||||
This can be explained with an analogy about grocery shopping. Suppose you need to buy some eggs and you live 30 minutes from the store. Buying one egg (far left on the illustration) at a time would mean a 30-minute trip each time. This is your _transaction cost_. The _holding cost_ might represent the eggs spoiling and taking up space in your refrigerator over time. The _total cost_ is the _transaction cost_ plus your _holding cost_. This U-curve explains why, for most people, buying a dozen eggs at a time is their _optimal batch size_. If you lived next door to the store, it'd cost you next to nothing to walk there, and you'd probably buy a smaller carton each time to save room in your refrigerator and enjoy fresher eggs.
|
||||
|
||||
This U-curve optimization illustration can shed some light on why productivity increases significantly in successful agile transformations. Consider the effect of agile transformation on decision making in an organization. In traditional hierarchical organizations, decision-making authority is centralized. This leads to larger decisions made less frequently by fewer people. An agile methodology will effectively reduce an organization's transaction cost for making decisions by decentralizing the decisions to where the awareness and information is the best known: across the high-trust, self-organizing agile teams.
|
||||
|
||||
The following animation shows how reducing transaction cost shifts the optimal batch size to the left. You can't understate the value to an organization in making faster decisions more frequently.
|
||||
|
||||
![U-curve optimization illustration][10]
|
||||
|
||||
### Where does DevOps fit in?
|
||||
|
||||
Automation is one of the things DevOps is most known for. The previous illustration shows the value of automation in great detail. Through automation, we reduce our transaction costs to nearly zero, essentially getting our testing and deployments for free. This lets us take advantage of smaller and smaller batch sizes of work. Smaller batches of work are easier to understand, commit to, test, review, and know when they are done. These smaller batch sizes also contain less variance and risk, making them easier to deploy and, if something goes wrong, to troubleshoot and recover from. With automation combined with a solid agile practice, we can get our feature development very close to single piece flow, providing value to customers quickly and continuously.
|
||||
|
||||
More traditionally, DevOps is understood as a way to knock down the walls of confusion between the dev and ops teams. In this model, development teams develop new features, while operations teams keep the system stable and running smoothly. Friction occurs because new features from development introduce change into the system, increasing the risk of an outage, which the operations team doesn't feel responsible for—but has to deal with anyway. DevOps is not just trying to get people working together, it's more about trying to make more frequent changes safely in a complex environment.
|
||||
|
||||
We can look to [Ron Westrum][11] for research about achieving safety in complex organizations. In researching why some organizations are safer than others, he found that an organization's culture is predictive of its safety. He identified three types of culture: Pathological, Bureaucratic, and Generative. He found that the Pathological culture was predictive of less safety and the Generative culture was predictive of more safety (e.g., far fewer plane crashes or accidental hospital deaths in his main areas of research).
|
||||
|
||||
![Three types of culture identified by Ron Westrum][12]
|
||||
|
||||
Effective DevOps teams achieve a Generative culture with lean and agile practices, showing that speed and safety are complementary, or two sides of the same coin. By reducing the optimal batch sizes of decisions and features to become very small, DevOps achieves a faster flow of information and value while removing waste and reducing risk.
|
||||
|
||||
In line with Westrum's research, change can happen easily with safety and reliability improving at the same time. When an agile DevOps team is trusted to make its own decisions, we get the tools and techniques DevOps is most known for today: automation and continuous delivery. Through this automation, transaction costs are reduced further than ever, and a near single piece lean flow is achieved, creating the potential for thousands of decisions and releases per day, as we've seen happen in high-performing DevOps organizations.
|
||||
|
||||
### Flow, feedback, learning
|
||||
|
||||
DevOps doesn't stop there. We've mainly been talking about DevOps achieving a revolutionary flow, but lean and agile practices are further amplified through similar efforts that achieve faster feedback loops and faster learning. In the [_DevOps Handbook_][13], the authors explain in detail how, beyond its fast flow, DevOps achieves telemetry across its entire value stream for fast and continuous feedback. Further, leveraging the [kaizen][14] bursts of lean and the [retrospectives][15] of scrum, high-performing DevOps teams will continuously drive learning and continuous improvement deep into the foundations of their organizations, achieving a lean manufacturing revolution in the software product development industry.
|
||||
|
||||
### Start with a DevOps assessment
|
||||
|
||||
The first step in leveraging DevOps is, either after much study or with the help of a DevOps consultant and coach, to conduct an assessment across a suite of dimensions consistently found in high-performing DevOps teams. The assessment should identify weak or non-existent team norms that need improvement. Evaluate the assessment's results to find quick wins—focus areas with high chances for success that will produce high-impact improvement. Quick wins are important for gaining the momentum needed to tackle more challenging areas. The teams should generate ideas that can be tried quickly and start to move the needle on the DevOps transformation.
|
||||
|
||||
After some time, the team should reassess on the same dimensions to measure improvements and identify new high-impact focus areas, again with fresh ideas from the team. A good coach will consult, train, mentor, and support as needed until the team owns its own continuous improvement and achieves near consistency on all dimensions by continually reassessing, experimenting, and learning.
|
||||
|
||||
In the [second part][16] of this article, we'll look at results from a DevOps survey in the Drupal community and see where the quick wins are most likely to be found.
|
||||
|
||||
* * *
|
||||
|
||||
_Rob_ _Bayliss and Kelly Albrecht will present[DevOps: Why, How, and What][17] and host a follow-up [Birds of a][18]_ [_Feather_][18] _[discussion][18] at [DrupalCon 2019][19] in Seattle, April 8-12._
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/devops-most-important-tech-strategy
|
||||
|
||||
作者:[Kelly AlbrechtWilly-Peter Schaub][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksalbrecht/users/brentaaronreed/users/wpschaub/users/wpschaub/users/ksalbrecht
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc (CICD with gears)
|
||||
[2]: https://opensource.com/resources/devops
|
||||
[3]: https://github.com/Netflix/chaosmonkey
|
||||
[4]: https://en.wikipedia.org/wiki/Burden_of_proof_(philosophy)#Proving_a_negative
|
||||
[5]: https://www.amazon.com/dp/B0048WQDIO/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
|
||||
[6]: https://youtu.be/5t6GhcvKB8o?t=54
|
||||
[7]: https://www.shmula.com/paper-airplane-game-pull-systems-push-systems/8280/
|
||||
[8]: https://www.amazon.com/dp/B00K7OWG7O/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
|
||||
[9]: https://opensource.com/sites/default/files/uploads/batch_size_optimal_650.gif (U-curve optimization illustration of optimal batch size)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/batch_size_650.gif (U-curve optimization illustration)
|
||||
[11]: https://en.wikipedia.org/wiki/Ron_Westrum
|
||||
[12]: https://opensource.com/sites/default/files/uploads/information_flow.png (Three types of culture identified by Ron Westrum)
|
||||
[13]: https://www.amazon.com/DevOps-Handbook-World-Class-Reliability-Organizations/dp/1942788002/ref=sr_1_3?keywords=DevOps+handbook&qid=1553197361&s=books&sr=1-3
|
||||
[14]: https://en.wikipedia.org/wiki/Kaizen
|
||||
[15]: https://www.scrum.org/resources/what-is-a-sprint-retrospective
|
||||
[16]: https://opensource.com/article/19/3/where-drupal-community-stands-devops-adoption
|
||||
[17]: https://events.drupal.org/seattle2019/sessions/devops-why-how-and-what
|
||||
[18]: https://events.drupal.org/seattle2019/bofs/devops-getting-started
|
||||
[19]: https://events.drupal.org/seattle2019
|
||||
@ -0,0 +1,115 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Continuous response: The essential process we're ignoring in DevOps)
|
||||
[#]: via: (https://opensource.com/article/19/3/continuous-response-devops)
|
||||
[#]: author: (Randy Bias https://opensource.com/users/randybias)
|
||||
|
||||
Continuous response: The essential process we're ignoring in DevOps
|
||||
======
|
||||
You probably practice CI and CD, but if you aren't thinking about
|
||||
continuous response, you aren't really doing DevOps.
|
||||
![CICD with gears][1]
|
||||
|
||||
Continuous response (CR) is an overlooked link in the DevOps process chain. The two other major links—[continuous integration (CI) and continuous delivery (CD)][2]—are well understood, but CR is not. Yet, CR is the essential element of follow-through required to make customers happy and fulfill the promise of greater speed and agility. At the heart of the DevOps movement is the need for greater velocity and agility to bring businesses into our new digital age. CR plays a pivotal role in enabling this.
|
||||
|
||||
### Defining CR
|
||||
|
||||
We need a crisp definition of CR to move forward with breaking it down. To put it into context, let's revisit the definitions of continuous integration (CI) and continuous delivery (CD). Here are Gartner's definitions when I wrote this them down in 2017:
|
||||
|
||||
> [Continuous integration][3] is the practice of integrating, building, testing, and delivering functional software on a scheduled, repeatable, and automated basis.
|
||||
>
|
||||
> Continuous delivery is a software engineering approach where teams keep producing valuable software in short cycles while ensuring that the software can be reliably released at any time.
|
||||
|
||||
I propose the following definition for CR:
|
||||
|
||||
> Continuous response is a practice where developers and operators instrument, measure, observe, and manage their deployed software looking for changes in performance, resiliency, end-user behavior, and security posture and take corrective actions as necessary.
|
||||
|
||||
We can argue about whether these definitions are 100% correct. They are good enough for our purposes, which is framing the definition of CR in rough context so we can understand it is really just the last link in the chain of a holistic cycle.
|
||||
|
||||
![The holistic DevOps cycle][4]
|
||||
|
||||
What is this multi-colored ring, you ask? It's the famous [OODA Loop][5]. Before continuing, let's touch on what the OODA Loop is and why it's relevant to DevOps. We'll keep it brief though, as there is already a long history between the OODA Loop and DevOps.
|
||||
|
||||
#### A brief aside: The OODA Loop
|
||||
|
||||
At the heart of core DevOps thinking is using the OODA Loop to create a proactive process for evolving and responding to changing environments. A quick [web search][6] makes it easy to learn the long history between the OODA Loop and DevOps, but if you want the deep dive, I highly recommend [The Tao of Boyd: How to Master the OODA Loop][7].
|
||||
|
||||
Here is the "evolved OODA Loop" presented by John Boyd:
|
||||
|
||||
![OODA Loop][8]
|
||||
|
||||
The most important thing to understand about the OODA Loop is that it's a cognitive process for adapting to and handling changing circumstances.
|
||||
|
||||
The second most important thing to understand about the OODA Loop is, since it is a thought process that is meant to evolve, it depends on driving feedback back into the earlier parts of the cycle as you iterate.
|
||||
|
||||
As you can see in the diagram above, CI, CD, and CR are all their own isolated OODA Loops within the overall DevOps OODA Loop. The key here is that each OODA Loop is an evolving thought process for how test, release, and success are measured. Simply put, those who can execute on the OODA Loop fastest will win.
|
||||
|
||||
Put differently, DevOps wants to drive speed (executing the OODA Loop faster) combined with agility (taking feedback and using it to constantly adjust the OODA Loop). This is why CR is a vital piece of the DevOps process. We must drive production feedback into the DevOps maturation process. The DevOps notion of Culture, Automation, Measurement, and Sharing ([CAMS][9]) partially but inadequately captures this, whereas CR provides a much cleaner continuation of CI/CD in my mind.
|
||||
|
||||
### Breaking CR down
|
||||
|
||||
CR has more depth and breadth than CI or CD. This is natural, given that what we're categorizing is the post-deployment process by which our software is taking a variety of actions from autonomic responses to analytics of customer experience. I think, when it's broken down, there are three key buckets that CR components fall into. Each of these three areas forms a complete OODA Loop; however, the level of automation throughout the OODA Loop varies significantly.
|
||||
|
||||
The following table will help clarify the three areas of CR:
|
||||
|
||||
CR Type | Purpose | Examples
|
||||
---|---|---
|
||||
Real-time | Autonomics for availability and resiliency | Auto-scaling, auto-healing, developer-in-the-loop automated responses to real-time failures, automated root-cause analysis
|
||||
Analytic | Feature/fix pipeline | A/B testing, service response times, customer interaction models
|
||||
Predictive | History-based planning | Capacity planning, hardware failure prediction models, cost-basis analysis
|
||||
|
||||
_Real-time CR_ is probably the best understood of the three. This kind of CR is where our software has been instrumented for known issues and can take an immediate, automated response (autonomics). Examples of known issues include responding to high or low demand (e.g., elastic auto-scaling), responding to expected infrastructure resource failures (e.g., auto-healing), and responding to expected distributed application failures (e.g., circuit breaker pattern). In the future, we will see machine learning (ML) and similar technologies applied to automated root-cause analysis and event correlation, which will then provide a path towards "no ops" or "zero ops" operational models.
|
||||
|
||||
_Analytic CR_ is still the most manual of the CR processes. This kind of CR is focused primarily on observing end-user experience and providing feedback to the product development cycle to add features or fix existing functionality. Examples of this include traditional A/B website testing, measuring page-load times or service-response times, post-mortems of service failures, and so on.
|
||||
|
||||
_Predictive CR_ , due to the resurgence of AI and ML, is one of the innovation areas in CR. It uses historical data to predict future needs. ML techniques are allowing this area to become more fully automated. Examples include automated and predictive capacity planning (primarily for the infrastructure layer), automated cost-basis analysis of service delivery, and real-time reallocation of infrastructure resources to resolve capacity and hardware failure issues before they impact the end-user experience.
|
||||
|
||||
### Diving deeper on CR
|
||||
|
||||
CR, like CI or CD, is a DevOps process supported by a set of underlying tools. CI and CD are not Jenkins, unit tests, or automated deployments alone. They are a process flow. Similarly, CR is a process flow that begins with the delivery of new code via CD, which open source tools like [Spinnaker][10] give us. CR is not monitoring, machine learning, or auto-scaling, but a diverse set of processes that occur after code deployment, supported by a variety of tools. CR is also different in two specific ways.
|
||||
|
||||
First, it is different because, by its nature, it is broader. The general software development lifecycle (SDLC) process means that most [CI/CD processes][11] are similar. However, code running in production differs from app to app or service to service. This means that CR differs as well.
|
||||
|
||||
Second, CR is different because it is nascent. Like CI and CD before it, the process and tools existed before they had a name. Over time, CI/CD became more normalized and easier to scope. CR is new, hence there is lots of room to discuss what's in or out. I welcome your comments in this regard and hope you will run with these ideas.
|
||||
|
||||
### CR: Closing the loop on DevOps
|
||||
|
||||
DevOps arose because of the need for greater service delivery velocity and agility. Essentially, DevOps is an extension of agile software development practices to an operational mindset. It's a direct response to the flexibility and automation possibilities that cloud computing affords. However, much of the thinking on DevOps to date has focused on deploying the code to production and ends there. But our jobs don't end there. As professionals, we must also make certain our code is behaving as expected, we are learning as it runs in production, and we are taking that learning back into the product development process.
|
||||
|
||||
This is where CR lives and breathes. DevOps without CR is the same as saying there is no OODA Loop around the DevOps process itself. It's like saying that operators' and developers' jobs end with the code being deployed. We all know this isn't true. Customer experience is the ultimate measurement of our success. Can people use the software or service without hiccups or undue friction? If not, we need to fix it. CR is the final link in the DevOps chain that enables delivering the truest customer experience.
|
||||
|
||||
If you aren't thinking about continuous response, you aren't doing DevOps. Share your thoughts on CR, and tell me what you think about the concept and the definition.
|
||||
|
||||
* * *
|
||||
|
||||
_This article is based on[The Essential DevOps Process We're Ignoring: Continuous Response][12], which originally appeared on the Cloudscaling blog under a [CC BY 4.0][13] license and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/continuous-response-devops
|
||||
|
||||
作者:[Randy Bias][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/randybias
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc (CICD with gears)
|
||||
[2]: https://opensource.com/article/18/8/what-cicd
|
||||
[3]: https://www.gartner.com/doc/3187420/guidance-framework-continuous-integration-continuous
|
||||
[4]: https://opensource.com/sites/default/files/uploads/holistic-devops-cycle-smaller.jpeg (The holistic DevOps cycle)
|
||||
[5]: https://en.wikipedia.org/wiki/OODA_loop
|
||||
[6]: https://www.google.com/search?q=site%3Ablog.b3k.us+ooda+loop&rlz=1C5CHFA_enUS730US730&oq=site%3Ablog.b3k.us+ooda+loop&aqs=chrome..69i57j69i58.8660j0j4&sourceid=chrome&ie=UTF-8#q=devops+ooda+loop&*
|
||||
[7]: http://www.artofmanliness.com/2014/09/15/ooda-loop/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/ooda-loop-2-1.jpg (OODA Loop)
|
||||
[9]: https://itrevolution.com/devops-culture-part-1/
|
||||
[10]: https://www.spinnaker.io
|
||||
[11]: https://opensource.com/article/18/12/cicd-tools-sysadmins
|
||||
[12]: http://cloudscaling.com/blog/devops/the-essential-devops-process-were-ignoring-continuous-response/
|
||||
[13]: https://creativecommons.org/licenses/by/4.0/
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why do organizations have open secrets?)
|
||||
[#]: via: (https://opensource.com/open-organization/19/3/open-secrets-bystander-effect)
|
||||
[#]: author: (Laura Hilliger https://opensource.com/users/laurahilliger/users/maryjo)
|
||||
|
||||
Why do organizations have open secrets?
|
||||
======
|
||||
Everyone sees something, but no one says anything—that's the bystander
|
||||
effect. And it's damaging your organizational culture.
|
||||
![][1]
|
||||
|
||||
[The five characteristics of an open organization][2] must work together to ensure healthy and happy communities inside our organizations. Even the most transparent teams, departments, and organizations require equal doses of additional open principles—like inclusivity and collaboration—to avoid dysfunction.
|
||||
|
||||
The "open secrets" phenomenon illustrates the limitations of transparency when unaccompanied by additional open values. [A recent article in Harvard Business Review][3] explored the way certain organizational issues—widely apparent but seemingly impossible to solve—lead to discomfort in the workforce. Authors Insiya Hussain and Subra Tangirala performed a number of studies, and found that the more people in an organization who knew about a particular "secret," be it a software bug or a personnel issue, the less likely any one person would be to report the issue or otherwise _do_ something about it.
|
||||
|
||||
Hussain and Tangirala explain that so-called "open secrets" are the result of a [bystander effect][4], which comes into play when people think, "Well, if _everyone_ knows, surely _I_ don't need to be the one to point it out." The authors mention several causes of this behavior, but let's take a closer look at why open secrets might be circulating in your organization—with an eye on what an open leader might do to [create a safe space for whistleblowing][5].
|
||||
|
||||
### 1\. Fear
|
||||
|
||||
People don't want to complain about a known problem only to have their complaint be the one that initiates the quality assurance, integrity, or redress process. What if new information emerges that makes their report irrelevant? What if they are simply _wrong_?
|
||||
|
||||
At the root of all bystander behavior is fear—fear of repercussions, fear of losing reputation or face, or fear that the very thing you've stood up against turns out to be a non-issue for everyone else. Going on record as "the one who reported" carries with it a reputational risk that is very intimidating.
|
||||
|
||||
The first step to ensuring that your colleagues report malicious behavior, code, or _whatever_ needs reporting is to create a fear-free workplace. We're inundated with the idea that making a mistake is bad or wrong. We're taught that we have to "protect" our reputations. However, the qualities of a good and moral character are _always_ subjective.
|
||||
|
||||
_Tip for leaders_ : Reward courage and strength every time you see it, regardless of whether you deem it "necessary." For example, if in a meeting where everyone except one person agrees on something, spend time on that person's concerns. Be patient and kind in helping that person change their mind, and be open minded about that person being able to change yours. Brains work in different ways; never forget that one person might have a perspective that changes the lay of the land.
|
||||
|
||||
### 2\. Policies
|
||||
|
||||
Usually, complaint procedures and policies are designed to ensure fairness towards all parties involved in the complaint. Discouraging false reporting and ensuring such fairness in situations like these is certainly a good idea. But policies might actually deter people from standing up—because a victim might be discouraged from reporting an experience if the formal policy for reporting doesn't make them feel protected. Standing up to someone in a position of power and saying "Your behavior is horrid, and I'm not going to take it" isn't easy for anyone, but it's particularly difficult for marginalized groups.
|
||||
|
||||
The "open secrets" phenomenon illustrates the limitations of transparency when unaccompanied by additional open values.
|
||||
|
||||
To ensure fairness to all parties, we need to adjust for victims. As part of making the decision to file a report, a victim will be dealing with a variety of internal fears. They'll wonder what might happen to their self-worth if they're put in a situation where they have to talk to someone about their experience. They'll wonder if they'll be treated differently if they're the one who stands up, and how that will affect their future working environments and relationships. Especially in a situation involving an open secret, asking a victim to be strong is asking them to have to trust that numerous other people will back them up. This fear shouldn't be part of their workplace experience; it's just not fair.
|
||||
|
||||
Remember that if one feels responsible for a problem (e.g., "Crap, that's _my code_ that's bringing down the whole server!"), then that person might feel fear at pointing out the mistake. _The important thing is dealing with the situation, not finding someone to blame._ Policies that make people feel personally protected—no matter what the situation—are absolutely integral to ensuring the organization deals with open secrets.
|
||||
|
||||
_Tip for leaders_ : Make sure your team's or organization's policy regarding complaints makes anonymous reporting possible. Asking a victim to "go on record" puts them in the position of having to defend their perspective. If they feel they're the victim of harassment, they're feeling as if they are harassed _and_ being asked to defend their experience. This means they're doing double the work of the perpetrator, who only has to defend themselves.
|
||||
|
||||
### 3\. Marginalization
|
||||
|
||||
Women, LGBTQ people, racial minorities, people with physical disabilities, people who are neuro-atypical, and other marginalized groups often find themselves in positions that them feel routinely dismissed, disempowered, disrespected—and generally dissed. These feelings are valid (and shouldn't be too surprising to anyone who has spent some time looking at issues of diversity and inclusion). Our emotional safety matters, and we tend to be quite protective of it—even if it means letting open secrets go unaddressed.
|
||||
|
||||
Marginalized groups have enough worries weighing on them, even when they're _not_ running the risk of damaging their relationships with others at work. Being seen and respected in both an organization and society more broadly is difficult enough _without_ drawing potentially negative attention.
|
||||
|
||||
Policies that make people feel personally protected—no matter what the situation—are absolutely integral to ensuring the organization deals with open secrets.
|
||||
|
||||
Luckily, in recent years attitudes towards marginalized groups have become visible, and we as a society have begun to talk about our experiences as "outliers." We've also come to realize that marginalized groups aren't actually "outliers" at all; we can thank the colorful, beautiful internet for that.
|
||||
|
||||
_Tip for leaders_ : Diversity and inclusion plays a role in dispelling open secrets. Make sure your diversity and inclusion practices and policies truly encourage a diverse workplace.
|
||||
|
||||
### Model the behavior
|
||||
|
||||
The best way to create a safe workplace and give people the ability to call attention to pervasive problems found within it is to _model the behaviors that you want other people to display_. Dysfunction occurs in cultures that don't pay attention to and value the principles upon which they are built. In order to discourage bystander behavior, transparent, inclusive, adaptable and collaborative communities must create policies that support calling attention to open secrets and then empathetically dealing with whatever the issue may be.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/3/open-secrets-bystander-effect
|
||||
|
||||
作者:[Laura Hilliger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/laurahilliger/users/maryjo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_secret_ingredient_520x292.png?itok=QbKzJq-N
|
||||
[2]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
[3]: https://hbr.org/2019/01/why-open-secrets-exist-in-organizations
|
||||
[4]: https://www.psychologytoday.com/us/basics/bystander-effect
|
||||
[5]: https://opensource.com/open-organization/19/2/open-leaders-whistleblowers
|
||||
@ -0,0 +1,139 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (9 open source tools for building a fault-tolerant system)
|
||||
[#]: via: (https://opensource.com/article/19/3/tools-fault-tolerant-system)
|
||||
[#]: author: (Bryant Son (Red Hat, Community Moderator) https://opensource.com/users/brson)
|
||||
|
||||
9 open source tools for building a fault-tolerant system
|
||||
======
|
||||
|
||||
Maximize uptime and minimize problems with these open source tools.
|
||||
|
||||
![magnifying glass on computer screen, finding a bug in the code][1]
|
||||
|
||||
I've always been interested in web development and software architecture because I like to see the broader picture of a working system. Whether you are building a mobile app or a web application, it has to be connected to the internet to exchange data among different modules, which means you need a web service.
|
||||
|
||||
If you use a cloud system as your application's backend, you can take advantage of greater computing power, as the backend service will scale horizontally and vertically and orchestrate different services. But whether or not you use a cloud backend, it's important to build a _fault-tolerant system_ —one that is resilient, stable, fast, and safe.
|
||||
|
||||
To understand fault-tolerant systems, let's use Facebook, Amazon, Google, and Netflix as examples. Millions and billions of users access these platforms simultaneously while transmitting enormous amounts of data via peer-to-peer and user-to-server networks, and you can be sure there are also malicious users with bad intentions, like hacking or denial-of-service (DoS) attacks. Even so, these platforms can operate 24 hours a day and 365 days a year without downtime.
|
||||
|
||||
Although machine learning and smart algorithms are the backbones of these systems, the fact that they achieve consistent service without a single minute of downtime is praiseworthy. Their expensive hardware and gigantic datacenters certainly matter, but the elegant software designs supporting the services are equally important. And the fault-tolerant system is one of the principles to build such an elegant system.
|
||||
|
||||
### Two behaviors that cause problems in production
|
||||
|
||||
Here's another way to think of a fault-tolerant system. When you run your application service locally, everything seems to be fine. Great! But when you promote your service to the production environment, all hell breaks loose. In a situation like this, a fault-tolerant system helps by addressing two problems: Fail-stop behavior and Byzantine behavior.
|
||||
|
||||
#### Fail-stop behavior
|
||||
|
||||
Fail-stop behavior is when a running system suddenly halts or a few parts of the system fail. Server downtime and database inaccessibility fall under this category. For example, in the diagram below, Service 1 can't communicate with Service 2 because Service 2 is inaccessible:
|
||||
|
||||
![Fail-stop behavior due to Service 2 downtime][2]
|
||||
|
||||
But the problem can also occur if there is a network problem between the services, like this:
|
||||
|
||||
![Fail-stop behavior due to network failure][3]
|
||||
|
||||
#### Byzantine behavior
|
||||
|
||||
Byzantine behavior is when the system continuously runs but doesn't produce the expected behavior (e.g., wrong data or an invalid value).
|
||||
|
||||
Byzantine failure can happen if Service 2 has corrupted data or values, even though the service looks to be operating just fine, like in this example:
|
||||
|
||||
![Byzantine failure due to corrupted service][4]
|
||||
|
||||
Or, there can be a malicious middleman intercepting between the services and injecting unwanted data:
|
||||
|
||||
![Byzantine failure due to malicious middleman][5]
|
||||
|
||||
Neither fail-stop nor Byzantine behavior is a desired situation, so we need ways to prevent or fix them. That's where fault-tolerant systems come into play. Following are eight open source tools that can help you address these problems.
|
||||
|
||||
### Tools for building a fault-tolerant system
|
||||
|
||||
Although building a truly practical fault-tolerant system touches upon in-depth _distributed computing theory_ and complex computer science principles, there are many software tools—many of them, like the following, open source—to alleviate undesirable results by building a fault-tolerant system.
|
||||
|
||||
#### Circuit-breaker pattern: Hystrix and Resilience4j
|
||||
|
||||
The [circuit-breaker pattern][6] is a technique that helps to return a prepared dummy response or a simple response when a service fails:
|
||||
|
||||
![Circuit breaker pattern][7]
|
||||
|
||||
Netflix's open source **[Hystrix][8]** is the most popular implementation of the circuit-breaker pattern.
|
||||
|
||||
Many companies where I've worked previously are leveraging this wonderful tool. Surprisingly, Netflix announced that it will no longer update Hystrix. (Yeah, I know.) Instead, Netflix recommends using an alternative solution like [**Resilence4j**][9], which supports Java 8 and functional programming, or an alternative practice like [Adaptive Concurrency Limit][10].
|
||||
|
||||
#### Load balancing: Nginx and HaProxy
|
||||
|
||||
Load balancing is one of the most fundamental concepts in a distributed system and must be present to have a production-quality environment. To understand load balancers, we first need to understand the concept of _redundancy_. Every production-quality web service has multiple servers that provide redundancy to take over and maintain services when servers go down.
|
||||
|
||||
![Load balancer][11]
|
||||
|
||||
Think about modern airplanes: their dual engines provide redundancy that allows them to land safely even if an engine catches fire. (It also helps that most commercial airplanes have state-of-art, automated systems.) But, having multiple engines (or servers) means that there must be some kind of scheduling mechanism to effectively route the system when something fails.
|
||||
|
||||
A load balancer is a device or software that optimizes heavy traffic transactions by balancing multiple server nodes. For instance, when thousands of requests come in, the load balancer acts as the middle layer to route and evenly distribute traffic across different servers. If a server goes down, the load balancer forwards requests to the other servers that are running well.
|
||||
|
||||
There are many load balancers available, but the two best-known ones are Nginx and HaProxy.
|
||||
|
||||
[**Nginx**][12] is more than a load balancer. It is an HTTP and reverse proxy server, a mail proxy server, and a generic TCP/UDP proxy server. Companies like Groupon, Capital One, Adobe, and NASA use it.
|
||||
|
||||
[**HaProxy**][13] is also popular, as it is a free, very fast and reliable solution offering high availability, load balancing, and proxying for TCP and HTTP-based applications. Many large internet companies, including GitHub, Reddit, Twitter, and Stack Overflow, use HaProxy. Oh and yes, Red Hat Enterprise Linux also supports HaProxy configuration.
|
||||
|
||||
#### Actor model: Akka
|
||||
|
||||
The [actor model][14] is a concurrency design pattern that delegates responsibility when an _actor_ , which is a primitive unit of computation, receives a message. An actor can create even more actors and delegate the message to them.
|
||||
|
||||
[**Akka**][15] is one of the most well-known tools for the actor model implementation. The framework supports Java and Scala, which are both based on JVM.
|
||||
|
||||
#### Asynchronous, non-blocking I/O using messaging queue: Kafka and RabbitMQ
|
||||
|
||||
Multi-threaded development has been popular in the past, but this practice has been discouraged and replaced with asynchronous, non-blocking I/O patterns. For Java, this is explicitly stated in its [Enterprise Java Bean (EJB) specifications][16]:
|
||||
|
||||
> "An enterprise bean must not use thread synchronization primitives to synchronize execution of multiple instances.
|
||||
>
|
||||
> "The enterprise bean must not attempt to manage threads. The enterprise bean must not attempt to start, stop, suspend, or resume a thread, or to change a thread's priority or name. The enterprise bean must not attempt to manage thread groups."
|
||||
|
||||
Now, there are other practices like stream APIs and actor models. But messaging queues like [**Kafka**][17] and [**RabbitMQ**][18] offer the out-of-box support for asynchronous and non-blocking IO features, and they are powerful open source tools that can be replacements for threads by handling concurrent processes.
|
||||
|
||||
#### Other options: Eureka and Chaos Monkey
|
||||
|
||||
Other useful tools for fault-tolerant systems include monitoring tools, such as Netflix's **[Eureka][19]** , and stress-testing tools, like **[Chaos Monkey][20]**. They aim to discover potential issues earlier by testing in lower environments, like integration (INT), quality assurance (QA), and user acceptance testing (UAT), to prevent potential problems before moving to the production environment.
|
||||
|
||||
* * *
|
||||
|
||||
What open source tools are you using for building a fault-tolerant system? Please share your favorites in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/tools-fault-tolerant-system
|
||||
|
||||
作者:[Bryant Son (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/mistake_bug_fix_find_error.png?itok=PZaz3dga (magnifying glass on computer screen, finding a bug in the code)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/1_errordowntimeservice.jpg (Fail-stop behavior due to Service 2 downtime)
|
||||
[3]: https://opensource.com/sites/default/files/uploads/2_errordowntimenetwork.jpg (Fail-stop behavior due to network failure)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/3_byzantinefailuremalicious.jpg (Byzantine failure due to corrupted service)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/4_byzantinefailuremiddleman.jpg (Byzantine failure due to malicious middleman)
|
||||
[6]: https://martinfowler.com/bliki/CircuitBreaker.html
|
||||
[7]: https://opensource.com/sites/default/files/uploads/5_circuitbreakerpattern.jpg (Circuit breaker pattern)
|
||||
[8]: https://github.com/Netflix/Hystrix/wiki
|
||||
[9]: https://github.com/resilience4j/resilience4j
|
||||
[10]: https://medium.com/@NetflixTechBlog/performance-under-load-3e6fa9a60581
|
||||
[11]: https://opensource.com/sites/default/files/uploads/7_loadbalancer.jpg (Load balancer)
|
||||
[12]: https://www.nginx.com
|
||||
[13]: https://www.haproxy.org
|
||||
[14]: https://en.wikipedia.org/wiki/Actor_model
|
||||
[15]: https://akka.io
|
||||
[16]: https://jcp.org/aboutJava/communityprocess/final/jsr220/index.html
|
||||
[17]: https://kafka.apache.org
|
||||
[18]: https://www.rabbitmq.com
|
||||
[19]: https://github.com/Netflix/eureka
|
||||
[20]: https://github.com/Netflix/chaosmonkey
|
||||
@ -0,0 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How Kubeflow is evolving without ksonnet)
|
||||
[#]: via: (https://opensource.com/article/19/4/kubeflow-evolution)
|
||||
[#]: author: (Jonathan Gershater (Red Hat) https://opensource.com/users/jgershat/users/jgershat)
|
||||
|
||||
How Kubeflow is evolving without ksonnet
|
||||
======
|
||||
There are big differences in how open source communities handle change compared to closed source vendors.
|
||||
![Chat bubbles][1]
|
||||
|
||||
Many software projects depend on modules that are run as separate open source projects. When one of those modules loses support (as is inevitable), the community around the main project must determine how to proceed.
|
||||
|
||||
This situation is happening right now in the [Kubeflow][2] community. Kubeflow is an evolving open source platform for developing, orchestrating, deploying, and running scalable and portable machine learning workloads on [Kubernetes][3]. Recently, the primary supporter of the Kubeflow component [ksonnet][4] announced that it would [no longer support][5] the software.
|
||||
|
||||
When a piece of software loses support, the decision-making process (and the outcome) differs greatly depending on whether the software is open source or closed source.
|
||||
|
||||
### A cellphone analogy
|
||||
|
||||
To illustrate the differences in how an open source community and a closed source/single software vendor proceed when a component loses support, let's use an example from hardware design.
|
||||
|
||||
Suppose you buy cellphone Model A and it stops working. When you try to get it repaired, you discover the manufacturer is out of business and no longer offering support. Since the cellphone's design is proprietary and closed, no other manufacturers can support it.
|
||||
|
||||
Now, suppose you buy cellphone Model B, it stops working, and its manufacturer is also out of business and no longer offering support. However, Model B's design is open, and another company is in business manufacturing, repairing and upgrading Model B cellphones.
|
||||
|
||||
This illustrates one difference between software written using closed and open source principles. If the vendor of a closed source software solution goes out of business, support disappears with the vendor, unless the vendor sells the software's design and intellectual property. But, if the vendor of an open source solution goes out of business, there is no intellectual property to sell. By the principles of open source, the source code is available for anyone to use and modify, under license, so another vendor can continue to maintain the software.
|
||||
|
||||
### How Kubeflow is evolving without ksonnet
|
||||
|
||||
The ramification of ksonnet's backers' decision to cease development illustrates Kubeflow's open and collaborative design process. Kubeflow's designers have several options, such as replacing ksonnet, adopting and developing ksonnet, etc. Because Kubeflow is an open source project, all options are discussed in the open on the Kubeflow mailing list. Some of the community's suggestions include:
|
||||
|
||||
> * Should we look at projects that are CNCF/Apache projects e.g. [helm][6]
|
||||
> * I would opt for back to the basics. KISS. How about plain old jsonnet + kubectl + makefile/scripts ? Thats how e.g. the coreos [prometheus operator][7] does it. It would also lower the entry barrier (no new tooling) and let vendors of k8s (gke, openshift, etc) easily build on top of that.
|
||||
> * I vote for using a simple, _programmatic_ context, be it manual jsonnet + kubectl, or simple Python scripts + Python K8s client, or any tool be can build on top of these.
|
||||
>
|
||||
|
||||
|
||||
The members of the mailing list are discussing and debating alternatives to ksonnet and will arrive at a decision to continue development. What I love about the open source way of adapting is that it's done communally. Unlike closed source software, which is often designed by one vendor, the organizations that are members of an open source project can collaboratively steer the project in the direction they best see fit. As Kubeflow evolves, it will benefit from an open, collaborative decision-making framework.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/kubeflow-evolution
|
||||
|
||||
作者:[Jonathan Gershater (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jgershat/users/jgershat
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_communication_team.png?itok=CYfZ_gE7 (Chat bubbles)
|
||||
[2]: https://www.kubeflow.org/
|
||||
[3]: https://github.com/kubernetes
|
||||
[4]: https://ksonnet.io/
|
||||
[5]: https://blogs.vmware.com/cloudnative/2019/02/05/welcoming-heptio-open-source-projects-to-vmware/
|
||||
[6]: https://landscape.cncf.io
|
||||
[7]: https://github.com/coreos/prometheus-operator/tree/master/contrib/kube-prometheus
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Making computer science curricula as adaptable as our code)
|
||||
[#]: via: (https://opensource.com/open-organization/19/4/adaptable-curricula-computer-science)
|
||||
[#]: author: (Amarachi Achonu https://opensource.com/users/amarach1/users/johnsontanner3)
|
||||
|
||||
Making computer science curricula as adaptable as our code
|
||||
======
|
||||
No two computer science students are alike—so teachers need curricula
|
||||
that are open and adaptable.
|
||||
![][1]
|
||||
|
||||
Educators in elementary computer science face a lack of adaptable curricula. Calls for more modifiable, non-rigid curricula are therefore enticing—assuming that such curricula could benefit teachers by increasing their ability to mold resources for individual classrooms and, ultimately, produce better teaching experiences and learning outcomes.
|
||||
|
||||
Our team at [CSbyUs][2] noticed this scarcity, and we've created an open source web platform to facilitate more flexible, adaptable, and tested curricula for computer science educators. The mission of the CSbyUs team has always been utilizing open source technology to improve pedagogy in computer science, which includes increasing support for teachers. Therefore, this project primarily seeks to use open source principles—and the benefits inherent in them—to expand the possibilities of modern curriculum-making and support teachers by increasing access to more adaptable curricula.
|
||||
|
||||
### Rigid, monotonous, mundane
|
||||
|
||||
Why is the lack of adaptable curricula a problem for computer science education? Rigid curricula dominates most classrooms today, primarily through monotonous and routinely distributed lesson plans. Many of these plans are developed without the capacity for dynamic use and application to different classroom atmospheres. In contrast, an _adaptable_ curriculum is one that would _account_ for dynamic and changing classroom environments.
|
||||
|
||||
An adaptable curriculum means freedom and more options for educators. This is especially important in elementary-level classrooms, where instructors are introducing students to computer science for the first time, and in classrooms with higher populations of groups typically underrepresented in the field of computer science. Here especially, it's advantageous for instructors to have access to curricula that explicitly consider diverse classroom landscapes and grants the freedom necessary to adapt to specific student populations.
|
||||
|
||||
### Making it adaptable
|
||||
|
||||
This kind of adaptability is certainly at work at CSbyUs. Hayley Barton—a member of both the organization's curriculum-making team and its teaching team, and a senior at Duke University majoring in Economics and minoring in Computer Science and Spanish—recently demonstrated the benefits of adaptable curricula during an engagement in the field. Reflecting on her teaching experiences, Barton describes a major reason why curriculum adaptation is necessary in computer science classrooms. "We are seeing the range of students that we work with," she says, "and trying to make the curriculum something that can be tailored to different students."
|
||||
|
||||
An adaptable curriculum means freedom and more options for educators.
|
||||
|
||||
A more adaptable curriculum is necessary for truly challenging students, Barton continues.
|
||||
|
||||
The need for change became most evident to Barton when working students to make their own preliminary apps. Barton collaborated with students who appeared to be at different levels of focus and attention. On the one hand, a group of more advanced students took well to the style of a demonstrative curriculum and remained attentive and engaged to the task. On the other hand, another group of students seemed to have more trouble focusing in the classroom or even being motivated to engage with topics of computer science skills. Witnessing this difference among students, it became important that curriculum would need to be adaptable in multiple ways to be able to engage more students at their level.
|
||||
|
||||
"We want to challenge every student without making it too challenging for any individual student," Barton says. "Thinking about those things definitely feeds into how I'm thinking about the curriculum in terms of making it accessible for all the students."
|
||||
|
||||
As a curriculum-maker, she subsequently uses experiences like this to make changes to the original curriculum.
|
||||
|
||||
"If those other students have one-on-one time themselves, they could be doing even more amazing things with their apps," says Barton.
|
||||
|
||||
Taking this advice, Barton would potentially incorporate into the curriculum more emphasis on cultivating students' sense of ownership in computer science, since this is important to their focus and productivity. For this, students may be afforded that sense of one-on-one time. The result will affect the next round of teachers who use the curriculum.
|
||||
|
||||
For these changes to be effective, the onus is on teachers to notice the dynamics of the classroom. In the future, curriculum adaptation may depend on paying particular attention to and identifying these subtle differences of style of curriculum. Identifying and commenting about these subtleties allows the possibility of applying a different strategy, and these are the changes that are applied to the curriculum.
|
||||
|
||||
Curriculum adaptation should be iterative, as it involves learning from experience, returning to the drawing board, making changes, and finally, utilizing the curriculum again.
|
||||
|
||||
"We've gone through a lot of stages of development," Barton says. "The goal is to have this kind of back and forth, where the curriculum is something that's been tested, where we've used our feedback, and also used other research that we've done, to make it something that's actually impactful."
|
||||
|
||||
Hayley's "back and forth" process is an iterative process of curriculum-making. Between utilizing curricula and modifying curricula, instructors like Hayley can take a once-rigid curriculum and mold it to any degree that the user sees fit—again and again. This iterative process depends on tests performed first in the classroom, and it depends on the teacher's rationale and reflection on how curricula uniquely pans out for them.
|
||||
|
||||
Adaptability of curriculum is the most important principle on which the CSbyUs platform is built. Much like Hayley's process of curriculum-making, curriculum adaptation should be _iterative_ , as it involves learning from experience, returning to the drawing board, making changes, and finally, utilizing the curriculum again. Once launched, the CSbyUS website will document this iterative process.
|
||||
|
||||
The open-focused pedagogy behind the CSByUs platform, then, brings to life the flexibility inherent in the process of curriculum adaptation. First, it invites and collects the valuable first-hand perspectives of real educators working with real curricula to produce real learning. Next, it capitalizes on an iterative processes of development—one familiar to open source programmers—to enable modifications to curriculum (and the documentation of those modifications). Finally, it transforms the way teachers encounter curricula by helping them make selections from different versions of both modified curriculum and "the original." Our platform's open source strategy is crucial to cultivating a hub of flexible curricula for educators.
|
||||
|
||||
Open source practices can be a key difference in making rigid curricula more moldable for educators. Furthermore, since this approach effectively melds open source technologies with open-focused pedagogy, open pedagogy can potentially provide flexibility for educators teaching various curriculum across disciplines.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/4/adaptable-curricula-computer-science
|
||||
|
||||
作者:[Amarachi Achonu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/amarach1/users/johnsontanner3
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003588_01_rd3os.combacktoschoolserieshe_rh_051x_0.png?itok=gIzbmxuI
|
||||
[2]: https://csbyus.herokuapp.com/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (liujing97)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Moelf translating
|
||||
Myths about /dev/urandom
|
||||
======
|
||||
|
||||
|
||||
@ -1,203 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
iWant – The Decentralized Peer To Peer File Sharing Commandline Application
|
||||
======
|
||||
|
||||

|
||||
|
||||
A while ago, we have written a guide about two file sharing utilities named [**transfer.sh**][1], a free web service that allows you to share files over Internet easily and quickly, and [**PSiTransfer**][2], a simple open source self-hosted file sharing solution. Today, we will see yet another file sharing utility called **“iWant”**. It is a free and open source CLI-based decentralized peer to peer file sharing application.
|
||||
|
||||
What’s makes it different from other file sharing applications? You might wonder. Here are some prominent features of iWant.
|
||||
|
||||
* It’s commandline application. You don’t need any memory consuming GUI utilities. You need only the Terminal.
|
||||
* It is decentralized. That means your data will not be stored in any central location. So, there is no central point of failure.
|
||||
* iWant allows you to pause the download and you can resume it later when you want. You don’t need to download it from beginning, it just resumes the downloads from where you left off.
|
||||
* Any changes made in the files in the shared directory (such as deletion, addition, modification) will be reflected instantly in the network.
|
||||
* Just like torrents, iWant downloads the files from multiple peers. If any seeder left the group or failed to respond, it will continue the download from another seeder.
|
||||
* It is cross-platform, so, you can use it in GNU/Linux, MS Windows, and Mac OS X.
|
||||
|
||||
|
||||
|
||||
### iWant – A CLI-based Decentralized Peer To Peer File Sharing Solution
|
||||
|
||||
#### Install iWant
|
||||
|
||||
iWant can be easily installed using PIP package manager. Make sure you have pip installed in your Linux distribution. if it is not installed yet, refer the following guide.
|
||||
|
||||
[How To Manage Python Packages Using Pip](https://www.ostechnix.com/manage-python-packages-using-pip/)
|
||||
|
||||
After installing PIP, make sure you have installed the the following dependencies:
|
||||
|
||||
* libffi-dev
|
||||
* libssl-dev
|
||||
|
||||
|
||||
|
||||
Say for example, on Ubuntu, you can install these dependencies using command:
|
||||
```
|
||||
$ sudo apt-get install libffi-dev libssl-dev
|
||||
|
||||
```
|
||||
|
||||
Once all dependencies installed, install iWant using the following command:
|
||||
```
|
||||
$ sudo pip install iwant
|
||||
|
||||
```
|
||||
|
||||
We have now iWant in our system. Let us go ahead and see how to use it to transfer files over network.
|
||||
|
||||
#### Usage
|
||||
|
||||
First, start iWant server using command:
|
||||
```
|
||||
$ iwanto start
|
||||
|
||||
```
|
||||
|
||||
At the first time, iWant will ask the Shared and Download folder’s location. Enter the actual location of both folders. Then, choose which interface you want to use:
|
||||
|
||||
Sample output would be:
|
||||
```
|
||||
Shared/Download folder details looks empty..
|
||||
Note: Shared and Download folder cannot be the same
|
||||
SHARED FOLDER(absolute path):/home/sk/myshare
|
||||
DOWNLOAD FOLDER(absolute path):/home/sk/mydownloads
|
||||
Network interface available
|
||||
1. lo => 127.0.0.1
|
||||
2. enp0s3 => 192.168.43.2
|
||||
Enter index of the interface:2
|
||||
now scanning /home/sk/myshare
|
||||
[Adding] /home/sk/myshare 0.0
|
||||
Updating Leader 56f6d5e8-654e-11e7-93c8-08002712f8c1
|
||||
[Adding] /home/sk/myshare 0.0
|
||||
connecting to 192.168.43.2:1235 for hashdump
|
||||
|
||||
```
|
||||
|
||||
If you see an output something like above, you can start using iWant right away.
|
||||
|
||||
Similarly, start iWant service on all systems in the network, assign valid Shared and Downloads folder’s location, and select the network interface card.
|
||||
|
||||
The iWant service will keep running in the current Terminal window until you press **CTRL+C** to quit it. You need to open a new tab or new Terminal window to use iWant.
|
||||
|
||||
iWant usage is very simple. It has few commands as listed below.
|
||||
|
||||
* **iwanto start** – Starts iWant server.
|
||||
* **iwanto search <name>** – Search for files.
|
||||
* **iwanto download <hash>** – Download a file.
|
||||
* **iwanto share <path>** – Change the Shared folder’s location.
|
||||
* **iwanto download to <destination>** – Change the Download folder’s location.
|
||||
* **iwanto view config** – View Shared and Download folders.
|
||||
* **iwanto –version** – Displays the iWant version.
|
||||
* **iwanto -h** – Displays the help section.
|
||||
|
||||
|
||||
|
||||
Allow me to show you some examples.
|
||||
|
||||
**Search files**
|
||||
|
||||
To search for a file, run:
|
||||
```
|
||||
$ iwanto search <filename>
|
||||
|
||||
```
|
||||
|
||||
Please note that you don’t need to specify the accurate name.
|
||||
|
||||
Example:
|
||||
```
|
||||
$ iwanto search command
|
||||
|
||||
```
|
||||
|
||||
The above command will search for any files that contains the string “command”.
|
||||
|
||||
Sample output from my Ubuntu system:
|
||||
```
|
||||
Filename Size Checksum
|
||||
------------------------------------------- ------- --------------------------------
|
||||
/home/sk/myshare/THE LINUX COMMAND LINE.pdf 3.85757 efded6cc6f34a3d107c67c2300459911
|
||||
|
||||
```
|
||||
|
||||
**Download files**
|
||||
|
||||
You can download the files from any system on your network. To download a file, just mention the hash (checksum) of the file as shown below. You can get hash value of a share using “iwanto search” command.
|
||||
```
|
||||
$ iwanto download efded6cc6f34a3d107c67c2300459911
|
||||
|
||||
```
|
||||
|
||||
The file will be saved in your Download location (/home/sk/mydownloads/ in my case).
|
||||
```
|
||||
Filename: /home/sk/mydownloads/THE LINUX COMMAND LINE.pdf
|
||||
Size: 3.857569 MB
|
||||
|
||||
```
|
||||
|
||||
**View configuration**
|
||||
|
||||
To view the configuration i.e the Shared and Download folders, run:
|
||||
```
|
||||
$ iwanto view config
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
Shared folder:/home/sk/myshare
|
||||
Download folder:/home/sk/mydownloads
|
||||
|
||||
```
|
||||
|
||||
**Change Shared and Download folder’s location**
|
||||
|
||||
You can change the Shared folder and Download folder location to some other path like below.
|
||||
```
|
||||
$ iwanto share /home/sk/ostechnix
|
||||
|
||||
```
|
||||
|
||||
Now, the Shared location has been changed to /home/sk/ostechnix location.
|
||||
|
||||
Also, you can change the Downloads location using command:
|
||||
```
|
||||
$ iwanto download to /home/sk/Downloads
|
||||
|
||||
```
|
||||
|
||||
To view the changes made, run the config command:
|
||||
```
|
||||
$ iwanto view config
|
||||
|
||||
```
|
||||
|
||||
**Stop iWant**
|
||||
|
||||
Once you done with iWant, you can quit it by pressing **CTRL+C**.
|
||||
|
||||
If it is not working by any chance, it might be due to Firewall or your router doesn’t support multicast. You can view all logs in** ~/.iwant/.iwant.log** file. For more details, refer the project’s GitHub page provided at the end.
|
||||
|
||||
And, that’s all. Hope this tool helps. I will be here again with another interesting guide. Till then, stay tuned with OSTechNix!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/iwant-decentralized-peer-peer-file-sharing-commandline-application/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/easy-fast-way-share-files-internet-command-line/
|
||||
[2]:https://www.ostechnix.com/psitransfer-simple-open-source-self-hosted-file-sharing-solution/
|
||||
@ -1,3 +1,4 @@
|
||||
FSSlc translating
|
||||
5 open source fonts ideal for programmers
|
||||
======
|
||||
|
||||
@ -102,7 +103,7 @@ Whichever typeface you select, you will most likely spend hours each day immerse
|
||||
via: https://opensource.com/article/17/11/how-select-open-source-programming-font
|
||||
|
||||
作者:[Andrew Lekashman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
104
sources/tech/20171226 The shell scripting trap.md
Normal file
104
sources/tech/20171226 The shell scripting trap.md
Normal file
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The shell scripting trap)
|
||||
[#]: via: (https://arp242.net/weblog/shell-scripting-trap.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
The shell scripting trap
|
||||
======
|
||||
|
||||
|
||||
Shell scripting is great. It is amazingly simple to create something very useful. Even a simple no-brainer command such as:
|
||||
|
||||
```
|
||||
# Official way of naming Go-related things:
|
||||
$ grep -i ^go /usr/share/dict/american-english /usr/share/dict/british /usr/share/dict/british-english /usr/share/dict/catala /usr/share/dict/catalan /usr/share/dict/cracklib-small /usr/share/dict/finnish /usr/share/dict/french /usr/share/dict/german /usr/share/dict/italian /usr/share/dict/ngerman /usr/share/dict/ogerman /usr/share/dict/spanish /usr/share/dict/usa /usr/share/dict/words | cut -d: -f2 | sort -R | head -n1
|
||||
goldfish
|
||||
```
|
||||
|
||||
Takes several lines of code and a lot more brainpower in many programming languages. For example in Ruby:
|
||||
|
||||
```
|
||||
puts(Dir['/usr/share/dict/*-english'].map do |f|
|
||||
File.open(f)
|
||||
.readlines
|
||||
.select { |l| l[0..1].downcase == 'go' }
|
||||
end.flatten.sample.chomp)
|
||||
```
|
||||
|
||||
The Ruby version isn’t that long, or even especially complicated. But the shell script version was so simple that I didn’t even need to actually test it to make sure it is correct, whereas I did have to test the Ruby version to ensure I didn’t make a mistake. It’s also twice as long and looks a lot more dense.
|
||||
|
||||
This is why people use shell scripts, it’s so easy to make something useful. Here’s is another example:
|
||||
|
||||
```
|
||||
curl https://nl.wikipedia.org/wiki/Lijst_van_Nederlandse_gemeenten |
|
||||
grep '^<li><a href=' |
|
||||
sed -r 's|<li><a href="/wiki/.+" title=".+">(.+)</a>.*</li>|\1|' |
|
||||
grep -Ev '(^Tabel van|^Lijst van|Nederland)'
|
||||
```
|
||||
|
||||
This gets a list of all Dutch municipalities. I actually wrote this as a quick one-shot script to populate a database years ago, but it still works fine today, and it took me a minimum of effort to make it. Doing this in e.g. Ruby would take a lot more effort.
|
||||
|
||||
But there’s a downside, as your script grows it will become increasingly harder to maintain, but you also don’t really want to rewrite it to something else, as you’ve already spent so much time on the shell script version.
|
||||
|
||||
This is what I call ‘the shell script trap’, which is a special case of the [sunk cost fallacy][1].
|
||||
|
||||
And many scripts do grow beyond their original intended size, and often you will spend a lot more time than you should on “fixing that one bug”, or “adding just one small feature”. Rinse, repeat.
|
||||
|
||||
If you had written it in Python or Ruby or another similar language from the start, you would have spent some more time writing the original version, but would have spent much less time maintaining it, while almost certainly having fewer bugs.
|
||||
|
||||
Take my [packman.vim][2] script for example. It started out as a simple `for` loop over all directories and a `git pull` and has grown from there. At about 200 lines it’s hardly the most complex script, but had I written it in Go as I originally planned then it would have been much easier to add support for printing out the status or cloning new repos from a config file. It would also be almost trivial to add support for parallel clones, which is hard (though not impossible) to do correct in a shell script. In hindsight, I would have saved time, and gotten a better result to boot.
|
||||
|
||||
I regret writing most shell scripts I’ve written for similar reasons, and my 2018 new year’s pledge will be to not write any more.
|
||||
|
||||
#### Appendix: the problems
|
||||
|
||||
And to be clear, shell scripting does come with some real limitation. Some examples:
|
||||
|
||||
* Dealing with filenames that contain spaces or other ‘special’ characters requires careful attention to detail. The vast majority of scripts get this wrong, even when written by experienced authors who care about such things (e.g. me), because it’s so easy to do it wrong. [Adding quotes is not enough][3].
|
||||
|
||||
* There are many “right” and “wrong” ways to do things. Should you use `which` or `command`? Should you use `$@` or `$*`, and should that be quoted? Should you use `cmd $arg` or `cmd "$arg"`? etc. etc.
|
||||
|
||||
* You cannot store any NULL bytes (0x00) in variables; it is very hard to make shell scripts deal with binary data.
|
||||
|
||||
* While you can make something very useful very quickly, implementing more complex algorithms can be very painful – if not nigh-impossible – even when using the ksh/zsh/bash extensions. My ad-hoc HTML parsing in the example above was okay for a quick one-off script, but you really don’t want to do things like that in a production-script.
|
||||
|
||||
* It can be hard to write shell scripts that work well on all platforms. `/bin/sh` could be `dash` or `bash`, and will behave different. External tools such as `grep`, `sed`, etc. may or may not support certain flags. Are you sure that your script works on all versions (past, present, and future) of Linux, macOS, and Windows equally well?
|
||||
|
||||
* Debugging shell scripts can be hard, especially as the syntax can get fairly obscure quite fast, and not everyone is equally well versed in shell scripting.
|
||||
|
||||
* Error handling can be tricky (check `$?` or `set -e`), and doing something more advanced beyond “an error occurred” is practically impossible.
|
||||
|
||||
* Undefined variables are not an error unless you use `set -u`, leading to “fun stuff” like `rm -r ~/$undefined` deleting user’s home dir ([not a theoretical problem][4]).
|
||||
|
||||
* Everything is a string. Some shells add arrays, which works but the syntax is obscure and ugly. Numeric computations with fractions remain tricky and rely on external tools such as `bc` or `dc` (`$(( .. ))` expansion only works for integers).
|
||||
|
||||
|
||||
|
||||
|
||||
**Feedback**
|
||||
|
||||
You can mail me at [martin@arp242.net][5] or [create a GitHub issue][6] for feedback, questions, etc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/shell-scripting-trap.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://youarenotsosmart.com/2011/03/25/the-sunk-cost-fallacy/
|
||||
[2]: https://github.com/Carpetsmoker/packman.vim
|
||||
[3]: https://dwheeler.com/essays/filenames-in-shell.html
|
||||
[4]: https://github.com/ValveSoftware/steam-for-linux/issues/3671
|
||||
[5]: mailto:martin@arp242.net
|
||||
[6]: https://github.com/Carpetsmoker/arp242.net/issues/new
|
||||
@ -1,100 +0,0 @@
|
||||
Rediscovering make: the power behind rules
|
||||
======
|
||||
|
||||

|
||||
|
||||
I used to think makefiles were just a convenient way to list groups of shell commands; over time I've learned how powerful, flexible, and full-featured they are. This post brings to light over some of those features related to rules.
|
||||
|
||||
### Rules
|
||||
|
||||
Rules are instructions that indicate `make` how and when a file called the target should be built. The target can depend on other files called prerequisites.
|
||||
|
||||
You instruct `make` how to build the target in the recipe, which is no more than a set of shell commands to be executed, one at a time, in the order they appear. The syntax looks like this:
|
||||
```
|
||||
target_name : prerequisites
|
||||
recipe
|
||||
```
|
||||
|
||||
Once you have defined a rule, you can build the target from the command line by executing:
|
||||
```
|
||||
$ make target_name
|
||||
```
|
||||
|
||||
Once the target is built, `make` is smart enough to not run the recipe ever again unless at least one of the prerequisites has changed.
|
||||
|
||||
### More on prerequisites
|
||||
|
||||
Prerequisites indicate two things:
|
||||
|
||||
* When the target should be built: if a prerequisite is newer than the target, `make` assumes that the target should be built.
|
||||
* An order of execution: since prerequisites can, in turn, be built by another rule on the makefile, they also implicitly set an order on which rules are executed.
|
||||
|
||||
|
||||
|
||||
If you want to define an order, but you don't want to rebuild the target if the prerequisite changes, you can use a special kind of prerequisite called order only, which can be placed after the normal prerequisites, separated by a pipe (`|`)
|
||||
|
||||
### Patterns
|
||||
|
||||
For convenience, `make` accepts patterns for targets and prerequisites. A pattern is defined by including the `%` character, a wildcard that matches any number of literal characters or an empty string. Here are some examples:
|
||||
|
||||
* `%`: match any file
|
||||
* `%.md`: match all files with the `.md` extension
|
||||
* `prefix%.go`: match all files that start with `prefix` that have the `.go` extension
|
||||
|
||||
|
||||
|
||||
### Special targets
|
||||
|
||||
There's a set of target names that have special meaning for `make` called special targets.
|
||||
|
||||
You can find the full list of special targets in the [documentation][1]. As a rule of thumb, special targets start with a dot followed by uppercase letters.
|
||||
|
||||
Here are a few useful ones:
|
||||
|
||||
**.PHONY** : Indicates `make` that the prerequisites of this target are considered to be phony targets, which means that `make` will always run it's recipe regardless of whether a file with that name exists or what its last-modification time is.
|
||||
|
||||
**.DEFAULT** : Used for any target for which no rules are found.
|
||||
|
||||
**.IGNORE** : If you specify prerequisites for `.IGNORE`, `make` will ignore errors in execution of their recipes.
|
||||
|
||||
### Substitutions
|
||||
|
||||
Substitutions are useful when you need to modify the value of a variable with alterations that you specify.
|
||||
|
||||
A substitution has the form `$(var:a=b)` and its meaning is to take the value of the variable `var`, replace every `a` at the end of a word with `b` in that value, and substitute the resulting string. For example:
|
||||
```
|
||||
foo := a.o
|
||||
bar : = $(foo:.o=.c) # sets bar to a.c
|
||||
```
|
||||
|
||||
note: special thanks to [Luis Lavena][2] for letting me know about the existence of substitutions.
|
||||
|
||||
### Archive Files
|
||||
|
||||
Archive files are used to collect multiple data files together into a single file (same concept as a zip file), they are built with the `ar` Unix utility. `ar` can be used to create archives for any purpose, but has been largely replaced by `tar` for any other purposes than [static libraries][3].
|
||||
|
||||
In `make`, you can use an individual member of an archive file as a target or prerequisite as follows:
|
||||
```
|
||||
archive(member) : prerequisite
|
||||
recipe
|
||||
```
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
There's a lot more to discover about make, but at least this counts as a start, I strongly encourage you to check the [documentation][4], create a dumb makefile, and just play with it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://monades.roperzh.com/rediscovering-make-power-behind-rules/
|
||||
|
||||
作者:[Roberto Dip][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://monades.roperzh.com
|
||||
[1]:https://www.gnu.org/software/make/manual/make.html#Special-Targets
|
||||
[2]:https://twitter.com/luislavena/
|
||||
[3]:http://tldp.org/HOWTO/Program-Library-HOWTO/static-libraries.html
|
||||
[4]:https://www.gnu.org/software/make/manual/make.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating by robsean
|
||||
|
||||
12 Best GTK Themes for Ubuntu and other Linux Distributions
|
||||
======
|
||||
**Brief: Let’s have a look at some of the beautiful GTK themes that you can use not only in Ubuntu but other Linux distributions that use GNOME.**
|
||||
|
||||
@ -1,137 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Oomox – Customize And Create Your Own GTK2, GTK3 Themes)
|
||||
[#]: via: (https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/)
|
||||
[#]: author: (EDITOR https://www.ostechnix.com/author/editor/)
|
||||
|
||||
Oomox – Customize And Create Your Own GTK2, GTK3 Themes
|
||||
======
|
||||
|
||||

|
||||
|
||||
Theming and Visual customization is one of the main advantages of Linux. Since all the code is open, you can change how your Linux system looks and behaves to a greater degree than you ever could with Windows/Mac OS. GTK theming is perhaps the most popular way in which people customize their Linux desktops. The GTK toolkit is used by a wide variety of desktop environments like Gnome, Cinnamon, Unity, XFCE, and budgie. This means that a single theme made for GTK can be applied to any of these Desktop Environments with little changes.
|
||||
|
||||
There are a lot of very high quality popular GTK themes out there, such as **Arc** , **Numix** , and **Adapta**. But if you want to customize these themes and create your own visual design, you can use **Oomox**.
|
||||
|
||||
The Oomox is a graphical app for customizing and creating your own GTK theme complete with your own color, icon and terminal style. It comes with several presets, which you can apply on a Numix, Arc, or Materia style theme to create your own GTK theme.
|
||||
|
||||
### Installing Oomox
|
||||
|
||||
On Arch Linux and its variants:
|
||||
|
||||
Oomox is available on [**AUR**][1], so you can install it using any AUR helper programs like [**Yay**][2].
|
||||
|
||||
```
|
||||
$ yay -S oomox
|
||||
|
||||
```
|
||||
|
||||
On Debian/Ubuntu/Linux Mint, download `oomox.deb`package from [**here**][3] and install it as shown below. As of writing this guide, the latest version was **oomox_1.7.0.5.deb**.
|
||||
|
||||
```
|
||||
$ sudo dpkg -i oomox_1.7.0.5.deb
|
||||
$ sudo apt install -f
|
||||
|
||||
```
|
||||
|
||||
On Fedora, Oomox is available in third-party **COPR** repository.
|
||||
|
||||
```
|
||||
$ sudo dnf copr enable tcg/themes
|
||||
$ sudo dnf install oomox
|
||||
|
||||
```
|
||||
|
||||
Oomox is also available as a [**Flatpak app**][4]. Make sure you have installed Flatpak as described in [**this guide**][5]. And then, install and run Oomox using the following commands:
|
||||
|
||||
```
|
||||
$ flatpak install flathub com.github.themix_project.Oomox
|
||||
|
||||
$ flatpak run com.github.themix_project.Oomox
|
||||
|
||||
```
|
||||
|
||||
For other Linux distributions, go to the Oomox project page (Link is given at the end of this guide) on Github and compile and install it manually from source.
|
||||
|
||||
### Customize And Create Your Own GTK2, GTK3 Themes
|
||||
|
||||
**Theme Customization**
|
||||
|
||||

|
||||
|
||||
You can change the colour of practically every UI element, like:
|
||||
|
||||
1. Headers
|
||||
2. Buttons
|
||||
3. Buttons inside Headers
|
||||
4. Menus
|
||||
5. Selected Text
|
||||
|
||||
|
||||
|
||||
To the left, there are a number of presets, like the Cars theme, modern themes like Materia, and Numix, and retro themes. Then, at the top of the main window, there’s an option called **Theme Style** , that lets you set the overall visual style of the theme. You can choose from between Numix, Arc, and Materia.
|
||||
|
||||
With certain styles like Numix, you can even change things like the Header Gradient, Outline Width and Panel Opacity. You can also add a Dark Mode for your theme that will be automatically created from the default theme.
|
||||
|
||||

|
||||
|
||||
**Iconset Customization**
|
||||
|
||||
You can customize the iconset that will be used for the theme icons. There are 2 options – Gnome Colors and Archdroid. You an change the base, and stroke colours of the iconset.
|
||||
|
||||
**Terminal Customization**
|
||||
|
||||
You can also customize the terminal colours. The app has several presets for this, but you can customize the exact colour code for each colour value like red, green,black, and so on. You can also auto swap the foreground and background colours.
|
||||
|
||||
**Spotify Theme**
|
||||
|
||||
A unique feature this app has is that you can theme the spotify app to your liking. You can change the foreground, background, and accent color of the spotify app to match the overall GTK theme.
|
||||
|
||||
Then, just press the **Apply Spotify Theme** button, and you’ll get this window:
|
||||
|
||||

|
||||
|
||||
Just hit apply, and you’re done.
|
||||
|
||||
**Exporting your Theme**
|
||||
|
||||
Once you’re done customizing the theme to your liking, you can rename it by clicking the rename button at the top left:
|
||||
|
||||

|
||||
|
||||
And then, just hit **Export Theme** to export the theme to your system.
|
||||
|
||||

|
||||
|
||||
You can also just export just the Iconset or the terminal theme.
|
||||
|
||||
After this, you can open any Visual Customization app for your Desktop Environment, like Tweaks for Gnome based DEs, or the **XFCE Appearance Settings** , and select your exported GTK and Shell theme.
|
||||
|
||||
### Verdict
|
||||
|
||||
If you are a Linux theme junkie, and you know exactly how each button, how each header in your system should look like, Oomox is worth a look. For extreme customizers, it lets you change virtually everything about how your system looks. For people who just want to tweak an existing theme a little bit, it has many, many presets so you can get what you want without a lot of effort.
|
||||
|
||||
Have you tried it? What are your thoughts on Oomox? Put them in the comments below!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://aur.archlinux.org/packages/oomox/
|
||||
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[3]: https://github.com/themix-project/oomox/releases
|
||||
[4]: https://flathub.org/apps/details/com.github.themix_project.Oomox
|
||||
[5]: https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
@ -1,191 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LuuMing)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (My Google-free Android life)
|
||||
[#]: via: (https://lushka.al/my-android-setup/)
|
||||
[#]: author: (Anxhelo Lushka https://lushka.al/)
|
||||
|
||||
My Google-free Android life
|
||||
======
|
||||
|
||||
People have been asking me a lot lately about my phone, my Android setup and how I manage to use my smartphone without Google Services. Well, this is a post that aims to address precisely that. I would like to make this article really beginner-friendly so I’ll try to go slow, going through things one by one and including screenshots so you can have a better view on how things happen and work like.
|
||||
|
||||
At first I’ll start with why Google Services are (imo) bad for your device. I could cut it short and guide you to this [post][1] by [Richard Stallman][2], but I’m grabbing a few main points from it and adding them here.
|
||||
|
||||
* Nonfree software required
|
||||
* In general, most Google services require running nonfree Javascript code. Nowadays, nothing whatsoever appears if Javascript is disabled, even making a Google account requires running nonfree software (Javascript sent by the site), same thing for logging in.
|
||||
* Surveillance
|
||||
* Google quietly combines its ad-tracking profiles with its browsing profiles and stores a huge amount of data on each user.
|
||||
* Terms of Service
|
||||
* Google cuts off accounts for users that resell Pixel phones. They lose access to all of their mail and documents stored in Google servers under that account.
|
||||
* Censorship
|
||||
* Amazon and Google have cut off domain-fronting, a feature used to enable people in tyrannical countries to reach communication systems that are banned there.
|
||||
* Google has agreed to perform special censorship of Youtube for the government of Pakistan, deleting views that the state opposes. This will help the illiberal Pakistani state suppress dissent.
|
||||
* Youtube’s “content ID” automatically deletes posted videos in a way copyright law does not require.
|
||||
|
||||
|
||||
|
||||
These are just a few reasons, but you can read the post by RMS I linked above in which he tries to explain these points in detail. Although it may look like a tinfoil hat reaction to you, all these actions already happen everyday in real life.
|
||||
|
||||
### Next on the list, my setup and a tutorial on how I achieved it
|
||||
|
||||
I own a **[Xiaomi Redmi Note 5 Pro][3]** smartphone (codename **whyred** ), produced in China by [Xiaomi][4], which I bought for around 185 EUR 4 months ago (from the time of writing this post).
|
||||
|
||||
Now you might be thinking, ‘but why did you buy a Chinese brand, they are not reliable’. Yes, it is not made from the usuals as you would expect, such as Samsung (which people often associate with Android, which is plain wrong), OnePlus, Nokia etc, but you should know almost every phone is produced in China.
|
||||
|
||||
There were a few reasons I chose this phone, first one of course being the price. It is a quite **budget-friendly** device, so most people are able to afford it. Next one would be the specs, which on paper (not only) are pretty decents for the price tag. With a 6 inch screen (Full HD resolution), a **4000 mAh battery** (superb battery life), 4GB of RAM, 64GB of storage, dual back cameras (12MP + 5MP), a front camera with flash (13MP) and a decent efficient Snapdragon 636, it was probably the best choice at that moment.
|
||||
|
||||
The issue with it was that it came with [MIUI][5], the Android skin that Xiaomi ships with most of its devices (except the Android One project devices). Yes, it is not that horrible, it has some extra features, but the problems lie deeper within. One of the reasons these devices from Xiaomi are so cheap (afaik they only have 5-10% win margin from sales) is that **they include data mining and ads in the system altogether with MIUI**. In this way, the system apps requires extra unnecessary permissions that mine your data and bombard you with ads, from which Xiaomi earns money.
|
||||
|
||||
Funnily enough, the Weather app included wanted access to my contacts and to make calls, why would it need that if it would just show the weather? Another case was with the Recorder app, it also required contacts and internet permissions, probably to send those recordings back to Xiaomi.
|
||||
|
||||
To fix this, I’d have to format the phone and get rid of MIUI. This has become increasingly difficult with the latest phones in the market.
|
||||
|
||||
The concept of formatting a phone is simple, you remove the existing system and install a new one of your preference (Android-only in this case). To do that, you have to have your [bootloader][6] unlocked.
|
||||
|
||||
> A bootloader is a computer program that loads an operating system (OS) or runtime environment for the computer after completion of the self-tests. — [Wikipedia][7]
|
||||
|
||||
The problem here is that Xiaomi has a specific policy about the bootloader unlocking. A few months ago, the process was like this. You would have to [make a request][8] to Xiaomi to obtain an unlock code for your phone, by giving a valid reason, but this would not always work, as they could just refuse your request without reason and explanation.
|
||||
|
||||
Now, that process has changed. You’ll have to download a specific software from Xiaomi, called [Mi Unlock][9], install it in your Windows PC, [activate Debugging Settings in Developer Options][10] on your phone, reboot to the bootloader mode (by holding the Volume Down + Power button while the phone is off) and connect the phone to your computer to start a process called “Approval”. This process starts a timer on the Xiaomi servers that will allow you to **unlock the phone only after a period of 15 days** (or a month in some rare cases, totally random) goes by.
|
||||
|
||||
![Mi Unlock app][11]
|
||||
|
||||
After this period of 15 days has passed, you have to re-connect your phone and do the same procedure as above, then by pressing the Unlock button your bootloader will be unlocked and this will allow you to install other ROM-s (systems). **Careful, make sure to backup your data because unlocking the bootloader deletes everything in the phone**.
|
||||
|
||||
The next step would be finding a system ([ROM][12]) that works for your device. I searched through the [XDA Developers Forum][13], which is a place where Android developers and users exchange ideas, apps etc. Fortunately, my phone is quite popular so it had [its own forum category][14]. There, I skimmed through some popular ROM-s for my device and decided to use the [AOSiP ROM][15] (AOSiP standing for Android Open Source illusion Project).
|
||||
|
||||
**EDIT** : Someone emailed me to say that my article is exactly what [/e/][16] does and is targeted to. I wanted to say thank you for reaching out but that is not true at all. The reasoning behind my opinion about /e/ can also be found in this [website][17], but I’ll list a few of the reasons here.
|
||||
|
||||
eelo is a “foundation” that got over 200K € in funding from Kickstarter and IndieGoGo, promising to create a mobile OS and web services that are open and secure and protect your privacy.
|
||||
|
||||
1. Their OS is based on LineageOS 14.1 (Android 7.1) with microG and other open source apps with it, which already exists for a long time now and it’s called [Lineage for microG][18].
|
||||
2. Instead of building all apps from the source code, they download the APKs from [APKPure][19] and put them in the ROM, without knowing if those APKs contain proprietary code/malware in them.
|
||||
3. At one point, they were literally just removing the Lineage copyright header from their code and adding theirs.
|
||||
4. They love to delete negative feedback and censor their users’ opinions in their Telegram group chat.
|
||||
|
||||
|
||||
|
||||
In conclusion, I **don’t recommend using /e/** ROM-s (at least until now).
|
||||
|
||||
Another thing you would likely want to do is have [root access][20] to your phone, to make it truly yours and modify files in the system, such as use a system-wide adblocker etc. To do this, I decided to use [Magisk][21], a godsend app developed by a student to help you gain root access on your device and install what are called [modules][22], basically software.
|
||||
|
||||
After downloading the ROM and Magisk, I had to install them on my phone. To do that, I moved the files to my SD card on the phone. Now, to install the system, I had to use something called a [recovery system][23]. The one I use is called [TWRP][24] (standing for TeamWin Recovery Project), a popular solution.
|
||||
|
||||
To install the recovery system (sounds hard, I know), I had to [flash][20] the file on the phone. To do that, I connected my phone with the computer (Fedora Linux system) and with something called [ADB Tools][25] I issued a command that overwrites the system recovery with the custom one I had.
|
||||
|
||||
> fastboot flash recovery twrp.img
|
||||
|
||||
After this was done, I turned off the phone and kept Volume Up + Power button pressed until I saw the TWRP screen show up. That meant I was good to go and it was ready to receive my commands.
|
||||
|
||||
![TWRP screen][26]
|
||||
|
||||
Next step was to **issue a Wipe command** , necessary when you first install a custom ROM on your phone. As you can see from the image above, the Wipe command clears the Data, Cache and Dalvik (there is also an advanced option that allows us to tick a box to delete the System one too, as we don’t need the old one anymore).
|
||||
|
||||
This takes a few moments and after that, your phone is basically clean. Now it’s time to **install the system**. By pressing the Install button on the main screen, we select the zip file we added there before (the ROM file) and swipe the screen to install it. Next, we have to install Magisk, which gives us root access to the device.
|
||||
|
||||
**EDIT** : As some more experienced/power Android users might have noticed until now, there is no [GApps][27] (Google Apps) included. This is what we call GApps-less in the Android world, not having those packages installed at all.
|
||||
|
||||
Note that one of the downsides of not having Google Services installed is that some of your apps might not work, for example their notifications might take longer to arrive or might not even work at all (this is what happens with Mattermost app for me). This happens because these apps use [Google Cloud Messaging][28] (now called [Firebase][29]) to wake the phone and push notifications to your phone.
|
||||
|
||||
You can solve this (partially) by installing and using [microG][30] which provides some features of Google Services but allows for more control on your side. I don’t recommend using this because it still helps Google Services and you don’t really give up on them, but it’s a good start if you want to quit Google slowly and not go cold turkey on it.
|
||||
|
||||
After successfully installing both, now we reboot the phone and **tada** 🎉, we are in the main screen.
|
||||
|
||||
### Next part, installing the apps and configuring everything
|
||||
|
||||
This is where things start to get easier. To install the apps, I use [F-Droid][31], an alternative app store that includes **only free and open source apps**. If you need apps that are not available there, you can use [Aurora Store][32], a client to download apps from the Play Store without using your Google account or getting tracked.
|
||||
|
||||
F-Droid has what are called repos, a “storehouse” that contains apps you can install. I use the default ones and have added another one from [IzzyOnDroid][33], that contains some more apps not available from the default F-Droid repo and is updated more often.
|
||||
|
||||
![My repos][34]
|
||||
|
||||
Below you will find a list of the apps I have installed, what they replace and their use.
|
||||
|
||||
This is pretty much **my list of the most useful F-Droid apps** I use, but unfortunately these are NOT the only apps I use. The proprietary apps I use (I know, I might sound a hypocrite, but not everything is replaceable, not yet at least) are as below:
|
||||
|
||||
* AliExpress
|
||||
* Boost for Reddit
|
||||
* Google Camera (coupled with Camera API 2, this app allows me to take wonderful pictures with a 185 EUR phone, it’s just too impressive)
|
||||
* Instagram
|
||||
* MediaBox HD (allows me to stream movies)
|
||||
* Mi Fit (an app that pairs with my Mi Band 2)
|
||||
* MyVodafoneAL (the carrier app)
|
||||
* ProtonMail (email app)
|
||||
* Shazam Encore (to find those songs you usually listen in coffee shops)
|
||||
* Snapseed (photo editing app, really simple, powerful and quite good)
|
||||
* Spotify (music streaming)
|
||||
* Titanium Backup (to backup my app data, wifi passwords, calls log etc.)
|
||||
* ViPER4Android FX (music equalizer)
|
||||
* VSCO (photo editing, never use it really)
|
||||
* WhatsApp (E2E proprietary messaging app, almost everyone I know has it)
|
||||
* WiFi Map (mapped hotspots that are available, handy when abroad)
|
||||
|
||||
|
||||
|
||||
This is pretty much it, all the apps I use on my phone. **The configs are then pretty simple and straightforward and I can give a few tips**.
|
||||
|
||||
1. Read and check the permissions of apps carefully, don’t click ‘Install’ mindlessly.
|
||||
2. Try to use as many open source apps as possible, they both respect your privacy and are free (as in both free beer and freedom).
|
||||
3. Use a VPN as much as you can, find a reputable one and don’t use free ones, otherwise you get to be the product and you’ll get your data harvested.
|
||||
4. Don’t keep your WiFi/mobile data/location on all the time, it might be a security risk.
|
||||
5. Try not to rely on fingerprint unlock only, or better yet use only PIN/password/pattern unlock, as biometric data can be cloned and used against you, for example to unlock your phone and steal your data.
|
||||
|
||||
|
||||
|
||||
And as a bonus for reading far down here, **a screenshot of my home screen** right now.
|
||||
|
||||
![Screenshot][35]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lushka.al/my-android-setup/
|
||||
|
||||
作者:[Anxhelo Lushka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://lushka.al/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://stallman.org/google.html
|
||||
[2]: https://en.wikipedia.org/wiki/Richard_Stallman
|
||||
[3]: https://www.gsmarena.com/xiaomi_redmi_note_5_pro-8893.php
|
||||
[4]: https://en.wikipedia.org/wiki/Xiaomi
|
||||
[5]: https://en.wikipedia.org/wiki/MIUI
|
||||
[6]: https://forum.xda-developers.com/wiki/Bootloader
|
||||
[7]: https://en.wikipedia.org/wiki/Booting
|
||||
[8]: https://en.miui.com/unlock/
|
||||
[9]: http://www.miui.com/unlock/apply.php
|
||||
[10]: https://www.youtube.com/watch?v=7zhEsJlivFA
|
||||
[11]: https://lushka.al//assets/img/posts/mi-unlock.png
|
||||
[12]: https://www.xda-developers.com/what-is-custom-rom-android/
|
||||
[13]: https://forum.xda-developers.com/
|
||||
[14]: https://forum.xda-developers.com/redmi-note-5-pro
|
||||
[15]: https://forum.xda-developers.com/redmi-note-5-pro/development/rom-aosip-8-1-t3804473
|
||||
[16]: https://e.foundation
|
||||
[17]: https://ewwlo.xyz/evil
|
||||
[18]: https://lineage.microg.org/
|
||||
[19]: https://apkpure.com/
|
||||
[20]: https://lifehacker.com/5789397/the-always-up-to-date-guide-to-rooting-any-android-phone
|
||||
[21]: https://forum.xda-developers.com/apps/magisk/official-magisk-v7-universal-systemless-t3473445
|
||||
[22]: https://forum.xda-developers.com/apps/magisk
|
||||
[23]: http://www.smartmobilephonesolutions.com/content/android-system-recovery
|
||||
[24]: https://dl.twrp.me/whyred/
|
||||
[25]: https://developer.android.com/studio/command-line/adb
|
||||
[26]: https://lushka.al//assets/img/posts/android-twrp.png
|
||||
[27]: https://opengapps.org/
|
||||
[28]: https://developers.google.com/cloud-messaging/
|
||||
[29]: https://firebase.google.com/docs/cloud-messaging/
|
||||
[30]: https://microg.org/
|
||||
[31]: https://f-droid.org/
|
||||
[32]: https://f-droid.org/en/packages/com.dragons.aurora/
|
||||
[33]: https://android.izzysoft.de/repo
|
||||
[34]: https://lushka.al//assets/img/posts/android-fdroid-repos.jpg
|
||||
[35]: https://lushka.al//assets/img/posts/android-screenshot.jpg
|
||||
[36]: https://creativecommons.org/licenses/by-nc-sa/4.0/
|
||||
@ -1,214 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Auk7F7)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Arch-Wiki-Man – A Tool to Browse The Arch Wiki Pages As Linux Man Page from Offline)
|
||||
[#]: via: (https://www.2daygeek.com/arch-wiki-man-a-tool-to-browse-the-arch-wiki-pages-as-linux-man-page-from-offline/)
|
||||
[#]: author: ([Prakash Subramanian](https://www.2daygeek.com/author/prakash/))
|
||||
[#]: url: ( )
|
||||
|
||||
Arch-Wiki-Man – A Tool to Browse The Arch Wiki Pages As Linux Man Page from Offline
|
||||
======
|
||||
|
||||
Getting internet is not a big deal now a days, however there will be a limitation on technology.
|
||||
|
||||
I was really surprise to see the technology growth but in the same time there will be fall in everywhere.
|
||||
|
||||
Whenever you search anything about other Linux distributions most of the time you will get a third party links in the first place but for Arch Linux every time you would get the Arch Wiki page for your results.
|
||||
|
||||
As Arch Wiki has most of the solution other than third party websites.
|
||||
|
||||
As of now, you might used web browser to get a solution for your Arch Linux system but you no need to do the same for now.
|
||||
|
||||
There is a solution is available in command line to perform this action much faster way and the utility called arch-wiki-man. If you are Arch Linux lover, i would suggest you to read **[Arch Linux Post Installation guide][1]** which helps you to tweak your system for day to day use.
|
||||
|
||||
### What is arch-wiki-man?
|
||||
|
||||
[arch-wiki-man][2] tool allows user to search the arch wiki pages right from the command line (CLI) instantly without internet connection. It allows user to access and search an entire wiki pages as a Linux man page.
|
||||
|
||||
Also, you no need to switch to GUI. Updates are pushed automatically every two days so, your local copy of the Arch Wiki pages will be upto date. The tool name is `awman`. awman stands for Arch Wiki Man.
|
||||
|
||||
We had already wrote similar kind of topic called **[Arch Wiki Command Line Utility][3]** (arch-wiki-cli) which allows user search Arch Wiki from command line but make sure you should have internet to use this utility.
|
||||
|
||||
### How to Install arch-wiki-man tool?
|
||||
|
||||
arch-wiki-man utility is available in AUR repository so, we need to use AUR helper to install it. There are many AUR helper is available and we had wrote an article about **[Yaourt AUR helper][4]** and **[Packer AUR helper][5]** which are very famous AUR helper.
|
||||
|
||||
```
|
||||
$ yaourt -S arch-wiki-man
|
||||
|
||||
or
|
||||
|
||||
$ packer -S arch-wiki-man
|
||||
```
|
||||
|
||||
Alternatively we can install it using npm package manager. Make sure, you should have installed **[NodeJS][6]** on your system. If so, run the following command to install it.
|
||||
|
||||
```
|
||||
$ npm install -g arch-wiki-man
|
||||
```
|
||||
|
||||
### How to Update the local Arch Wiki copy?
|
||||
|
||||
As updated previously, updates are pushed automatically every two days and it can be done by running the following command.
|
||||
|
||||
```
|
||||
$ sudo awman-update
|
||||
[sudo] password for daygeek:
|
||||
[email protected] /usr/lib/node_modules/arch-wiki-man
|
||||
└── [email protected]
|
||||
|
||||
arch-wiki-md-repo has been successfully updated or reinstalled.
|
||||
```
|
||||
|
||||
awman-update is faster and more convenient method to get the update. However, you can get the updates by reinstalling this package using the following command.
|
||||
|
||||
```
|
||||
$ yaourt -S arch-wiki-man
|
||||
|
||||
or
|
||||
|
||||
$ packer -S arch-wiki-man
|
||||
```
|
||||
|
||||
### How to Use Arch Wiki from command line?
|
||||
|
||||
It’s very simple interface and easy to use. To search anything, just run `awman` followed by the search term. The general syntax is as follow.
|
||||
|
||||
```
|
||||
$ awman Search-Term
|
||||
```
|
||||
|
||||
### How to Search Multiple Matches?
|
||||
|
||||
If you would like to list all the results titles comes with `installation` string, run the following command format. If the output comes with multiple results then you will get a selection menu to navigate each item.
|
||||
|
||||
```
|
||||
$ awman installation
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
Detailed page screenshot.
|
||||
![][9]
|
||||
|
||||
### Search a given string in Titles & Descriptions
|
||||
|
||||
The `-d` or `--desc-search` option allow users to search a given string in titles and descriptions.
|
||||
|
||||
```
|
||||
$ awman -d mirrors
|
||||
|
||||
or
|
||||
|
||||
$ awman --desc-search mirrors
|
||||
? Select an article: (Use arrow keys)
|
||||
❯ [1/3] Mirrors: Related articles
|
||||
[2/3] DeveloperWiki-NewMirrors: Contents
|
||||
[3/3] Powerpill: Powerpill is a pac
|
||||
```
|
||||
|
||||
### Search a given string in Contents
|
||||
|
||||
The `-k` or `--apropos` option allow users to search a given string in content as well. Make a note, this option significantly slower your search as this scan entire wiki page content.
|
||||
|
||||
```
|
||||
$ awman -k openjdk
|
||||
|
||||
or
|
||||
|
||||
$ awman --apropos openjdk
|
||||
? Select an article: (Use arrow keys)
|
||||
❯ [1/26] Hadoop: Related articles
|
||||
[2/26] XDG Base Directory support: Related articles
|
||||
[3/26] Steam-Game-specific troubleshooting: See Steam/Troubleshooting first.
|
||||
[4/26] Android: Related articles
|
||||
[5/26] Elasticsearch: Elasticsearch is a search engine based on Lucene. It provides a distributed, mul..
|
||||
[6/26] LibreOffice: Related articles
|
||||
[7/26] Browser plugins: Related articles
|
||||
(Move up and down to reveal more choices)
|
||||
```
|
||||
|
||||
### Open the search results in a web browser
|
||||
|
||||
The `-w` or `--web` option allow users to open the search results in a web browser.
|
||||
|
||||
```
|
||||
$ awman -w AUR helper
|
||||
|
||||
or
|
||||
|
||||
$ awman --web AUR helper
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
### Search in other languages
|
||||
|
||||
The `-w` or `--web` option allow users to open the search results in a web browser. To see a list of supported language, run the following command.
|
||||
|
||||
```
|
||||
$ awman --list-languages
|
||||
arabic
|
||||
bulgarian
|
||||
catalan
|
||||
chinesesim
|
||||
chinesetrad
|
||||
croatian
|
||||
czech
|
||||
danish
|
||||
dutch
|
||||
english
|
||||
esperanto
|
||||
finnish
|
||||
greek
|
||||
hebrew
|
||||
hungarian
|
||||
indonesian
|
||||
italian
|
||||
korean
|
||||
lithuanian
|
||||
norwegian
|
||||
polish
|
||||
portuguese
|
||||
russian
|
||||
serbian
|
||||
slovak
|
||||
spanish
|
||||
swedish
|
||||
thai
|
||||
ukrainian
|
||||
```
|
||||
|
||||
Run the awman command with your preferred language to see the results with different language other than English.
|
||||
|
||||
```
|
||||
$ awman -l chinesesim deepin
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/arch-wiki-man-a-tool-to-browse-the-arch-wiki-pages-as-linux-man-page-from-offline/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/arch-linux-post-installation-30-things-to-do-after-installing-arch-linux/
|
||||
[2]: https://github.com/greg-js/arch-wiki-man
|
||||
[3]: https://www.2daygeek.com/search-arch-wiki-website-command-line-terminal/
|
||||
[4]: https://www.2daygeek.com/install-yaourt-aur-helper-on-arch-linux/
|
||||
[5]: https://www.2daygeek.com/install-packer-aur-helper-on-arch-linux/
|
||||
[6]: https://www.2daygeek.com/install-nodejs-on-ubuntu-centos-debian-fedora-mint-rhel-opensuse/
|
||||
[7]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]: https://www.2daygeek.com/wp-content/uploads/2018/11/arch-wiki-man-%E2%80%93-A-Tool-to-Browse-The-Arch-Wiki-Pages-As-Linux-Man-page-from-Offline-1.png
|
||||
[9]: https://www.2daygeek.com/wp-content/uploads/2018/11/arch-wiki-man-%E2%80%93-A-Tool-to-Browse-The-Arch-Wiki-Pages-As-Linux-Man-page-from-Offline-2.png
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2018/11/arch-wiki-man-%E2%80%93-A-Tool-to-Browse-The-Arch-Wiki-Pages-As-Linux-Man-page-from-Offline-3.png
|
||||
[11]: https://www.2daygeek.com/wp-content/uploads/2018/11/arch-wiki-man-%E2%80%93-A-Tool-to-Browse-The-Arch-Wiki-Pages-As-Linux-Man-page-from-Offline-4.png
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,119 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Secure Email Service Tutanota Has a Desktop App Now)
|
||||
[#]: via: (https://itsfoss.com/tutanota-desktop)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
Secure Email Service Tutanota Has a Desktop App Now
|
||||
======
|
||||
|
||||
[Tutanota][1] recently [announced][2] the release of a desktop app for their email service. The beta is available for Linux, Windows, and macOS.
|
||||
|
||||
### What is Tutanota?
|
||||
|
||||
There are plenty of free, ad-supported email services available online. However, the majority of those email services are not exactly secure or privacy-minded. In this post-[Snowden][3] world, [Tutanota][4] offers a free, secure email service with a focus on privacy.
|
||||
|
||||
Tutanota has a number of eye-catching features, such as:
|
||||
|
||||
* End-to-end encrypted mailbox
|
||||
* End-to-end encrypted address book
|
||||
* Automatic end-to-end encrypted emails between users
|
||||
* End-to-end encrypted emails to any email address with a shared password
|
||||
* Secure password reset that gives Tutanota absolutely no access
|
||||
* Strips IP addresses from emails sent and received
|
||||
* The code that runs Tutanota is [open source][5]
|
||||
* Two-factor authentication
|
||||
* Focus on privacy
|
||||
* Passwords are salted and hashed locally with Bcrypt
|
||||
* Secure servers located in Germany
|
||||
* TLS with support for PFS, DMARC, DKIM, DNSSEC, and DANE
|
||||
* Full-text search of encrypted data executed locally
|
||||
|
||||
|
||||
|
||||
![][6]
|
||||
Tutanota on the web
|
||||
|
||||
You can [sign up for an account for free][7]. You can also upgrade your account to get extra features, such as custom domains, custom domain login, domain rules, extra storage, and aliases. They also have accounts available for businesses.
|
||||
|
||||
Tutanota is also available on mobile devices. In fact, it’s [Android app is open source as well][8].
|
||||
|
||||
This German company is planning to expand beyond email. They hope to offer an encrypted calendar and cloud storage. You can help them reach their goals by [donating][9] via PayPal and cryptocurrency.
|
||||
|
||||
### The New Desktop App from Tutanota
|
||||
|
||||
Tutanota announced the [beta release][2] of the desktop app right before Christmas. They based this app on [Electron][10].
|
||||
|
||||
![][11]
|
||||
Tutanota desktop app
|
||||
|
||||
They went the Electron route:
|
||||
|
||||
* to support all three major operating systems with minimum effort.
|
||||
* to quickly adapt the new desktop clients so that they match new features added to the webmail client.
|
||||
* to allocate development time to particular desktop features, e.g. offline availability, email import, that will simultaneously be available in all three desktop clients.
|
||||
|
||||
|
||||
|
||||
Because this is a beta, there are several features missing from the app. The development team at Tutanota is working to add the following features:
|
||||
|
||||
* Email import and synchronization with external mailboxes. This will “enable Tutanota to import emails from external mailboxes and encrypt the data locally on your device before storing it on the Tutanota servers.”
|
||||
* Offline availability of emails
|
||||
* Two-factor authentication
|
||||
|
||||
|
||||
|
||||
### How to Install the Tutanota desktop client?
|
||||
|
||||
![][12]Composing email in Tutanota
|
||||
|
||||
You can [download][2] the beta app directly from Tutanota’s website. They have an [AppImage file for Linux][13], a .exe file for Windows, and a .app file for macOS. You can post any bugs that you encounter to the Tutanota [GitHub account][14].
|
||||
|
||||
To prove the security of the app, Tutanota signed each version. “The signatures make sure that the desktop clients as well as any updates come directly from us and have not been tampered with.” You can verify the signature using from Tutanota’s [GitHub page][15].
|
||||
|
||||
Remember, you will need to create a Tutanota account before you can use it. This is email client is designed to work solely with Tutanota.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
I tested out the Tutanota email app on Linux Mint MATE. As to be expected, it was a mirror image of the web app. At this point in time, I don’t see any difference between the desktop app and the web app. The only use case that I can see to use the app now is to have Tutanota in its own window.
|
||||
|
||||
Have you ever used [Tutanota][16]? If not, what is your favorite privacy conscience email service? Let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][17].
|
||||
|
||||
![][18]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/tutanota-desktop
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/tutanota-review/
|
||||
[2]: https://tutanota.com/blog/posts/desktop-clients/
|
||||
[3]: https://en.wikipedia.org/wiki/Edward_Snowden
|
||||
[4]: https://tutanota.com/
|
||||
[5]: https://tutanota.com/blog/posts/open-source-email
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/tutanota2.jpg?resize=800%2C490&ssl=1
|
||||
[7]: https://tutanota.com/pricing
|
||||
[8]: https://itsfoss.com/tutanota-fdroid-release/
|
||||
[9]: https://tutanota.com/community
|
||||
[10]: https://electronjs.org/
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/tutanota-app1.png?fit=800%2C486&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/tutanota1.jpg?resize=800%2C405&ssl=1
|
||||
[13]: https://itsfoss.com/use-appimage-linux/
|
||||
[14]: https://github.com/tutao/tutanota
|
||||
[15]: https://github.com/tutao/tutanota/blob/master/buildSrc/installerSigner.js
|
||||
[16]: https://tutanota.com/polo/
|
||||
[17]: http://reddit.com/r/linuxusersgroup
|
||||
[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/02/tutanota-featured.png?fit=800%2C450&ssl=1
|
||||
@ -1,77 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Modrisco)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (7 Best VPN Services For 2019)
|
||||
[#]: via: (https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/)
|
||||
[#]: author: (Editor https://www.ostechnix.com/author/editor/)
|
||||
|
||||
7 Best VPN Services For 2019
|
||||
======
|
||||
|
||||
At least 67 percent of global businesses in the past three years have faced data breaching. The breaching has been reported to expose hundreds of millions of customers. Studies show that an estimated 93 percent of these breaches would have been avoided had data security fundamentals been considered beforehand.
|
||||
|
||||
Understand that poor data security can be extremely costly, especially to a business and could quickly lead to widespread disruption and possible harm to your brand reputation. Although some businesses can pick up the pieces the hard way, there are still those that fail to recover. Today however, you are fortunate to have access to data and network security software.
|
||||
|
||||

|
||||
|
||||
As you start 2019, keep off cyber-attacks by investing in a **V** irtual **P** rivate **N** etwork commonly known as **VPN**. When it comes to online privacy and security, there are many uncertainties. There are hundreds of different VPN providers, and picking the right one means striking just the right balance between pricing, services, and ease of use.
|
||||
|
||||
If you are looking for a solid 100 percent tested and secure VPN, you might want to do your due diligence and identify the best match. Here are the top 7 Best tried and tested VPN services For 2019.
|
||||
|
||||
### 1. Vpnunlimitedapp
|
||||
|
||||
With VPN Unlimited, you have total security. This VPN allows you to use any WIFI without worrying that your personal data can be leaked. With AES-256, your data is encrypted and protected against prying third-parties and hackers. This VPN ensures you stay anonymous and untracked on all websites no matter the location. It offers a 7-day trial and a variety of protocol options: OpenVPN, IKEv2, and KeepSolid Wise. Demanding users are entitled to special extras such as a personal server, lifetime VPN subscription, and personal IP options.
|
||||
|
||||
### 2. VPN Lite
|
||||
|
||||
VPN Lite is an easy-to-use and **free VPN service** that allows you to browse the internet at no charges. You remain anonymous and your privacy is protected. It obscures your IP and encrypts your data meaning third parties are not able to track your activities on all online platforms. You also get to access all online content. With VPN Lite, you get to access blocked sites in your state. You can also gain access to public WIFI without the worry of having sensitive information tracked and hacked by spyware and hackers.
|
||||
|
||||
### 3. HotSpot Shield
|
||||
|
||||
Launched in 2005, this is a popular VPN embraced by the majority of users. The VPN protocol here is integrated by at least 70 percent of the largest security companies globally. It is also known to have thousands of servers across the globe. It comes with two free options. One is completely free but supported by online advertisements, and the second one is a 7-day trial which is the flagship product. It contains military grade data encryption and protects against malware. HotSpot Shield guaranteed secure browsing and offers lightning-fast speeds.
|
||||
|
||||
### 4. TunnelBear
|
||||
|
||||
This is the best way to start if you are new to VPNs. It comes to you with a user-friendly interface complete with animated bears. With the help of TunnelBear, users are able to connect to servers in at least 22 countries at great speeds. It uses **AES 256-bit encryption** guaranteeing no data logging meaning your data stays protected. You also get unlimited data for up to five devices.
|
||||
|
||||
### 5. ProtonVPN
|
||||
|
||||
This VPN offers you a strong premium service. You may suffer from reduced connection speeds, but you also get to enjoy its unlimited data. It features an intuitive interface easy to use, and comes with a multi-platform compatibility. Proton’s servers are said to be specifically optimized for torrenting and thus cannot give access to Netflix. You get strong security features such as protocols and encryptions meaning your browsing activities remain secure.
|
||||
|
||||
### 6. ExpressVPN
|
||||
|
||||
This is known as the best offshore VPN for unblocking and privacy. It has gained recognition for being the top VPN service globally resulting from solid customer support and fast speeds. It offers routers that come with browser extensions and custom firmware. ExpressVPN also has an admirable scope of quality apps, plenty of servers, and can only support up to three devices.
|
||||
|
||||
It’s not entirely free, and happens to be one of the most expensive VPNs on the market today because it is fully packed with the most advanced features. With it comes a 30-day money-back guarantee, meaning you can freely test this VPN for a month. Good thing is; it is completely risk-free. If you need a VPN for a short duration to bypass online censorship for instance, this could, be your go-to solution. You don’t want to give trials to a spammy, slow, free program.
|
||||
|
||||
It is also one of the best ways to enjoy online streaming as well as outdoor security. Should you need to continue using it, you only have to renew or cancel your free trial if need be. Express VPN has over 2000 servers across 90 countries, unblocks Netflix, gives lightning fast connections, and gives users total privacy.
|
||||
|
||||
### 7. PureVPN
|
||||
|
||||
While this VPN may not be completely free, it falls under the most budget-friendly services on this list. Users can sign up for a free seven days trial and later choose one of its paid plans. With this VPN, you get to access 750-plus servers in at least 140 countries. There is also access to easy installation on almost all devices. All its paid features can still be accessed within the free trial window. That includes unlimited data transfers, IP leakage protection, and ISP invisibility. The supproted operating systems are iOS, Android, Windows, Linux, and macOS.
|
||||
|
||||
### Summary
|
||||
|
||||
With the large variety of available freemium VPN services today, why not take that opportunity to protect yourself and your customers? Understand that there are some great VPN services. Even the most secure free service however, cannot be touted as risk free. You might want to upgrade to a premium one for increased protection. Premium VPN allows you to test freely offering risk-free money-back guarantee. Whether you plan to sign up for a paid VPN or commit to a free one, it is highly advisable to have a VPN.
|
||||
|
||||
**About the author:**
|
||||
|
||||
**Renetta K. Molina** is a tech enthusiast and fitness enthusiast. She writes about technology, apps, WordPress and a variety of other topics. In her free time, she likes to play golf and read books. She loves to learn and try new things.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/
|
||||
|
||||
作者:[Editor][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,63 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (sanfusu)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Blockchain 2.0: Redefining Financial Services [Part 3])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-redefining-financial-services/)
|
||||
[#]: author: (EDITOR https://www.ostechnix.com/author/editor/)
|
||||
|
||||
Blockchain 2.0: Redefining Financial Services [Part 3]
|
||||
======
|
||||
|
||||

|
||||
|
||||
The [**previous article of this series**][1] focused on building context to bring forth why moving our existing monetary system to a futuristic [**blockchain**][2] system is the next natural step in the evolution of “money”. We looked at the features of a blockchain platform which would aid in such a move. However, the financial markets are far more complex and composed of numerous other instruments that people trade rather than just a currency.
|
||||
|
||||
This part will explore the features of blockchain which will enable institutions to transform and interlace traditional banking and financing systems with it. As previously discussed, and proved, if enough people participate in a given blockchain network and support the protocols for transactions, the nominal value that can be attributed to the “token” increases and becomes more stable. Take, for instance, Bitcoin (BTC). Like the simple paper currency, we’re all used to, cryptocurrencies such as Bitcoin and Ether can be utilized for all the former’s purposes from buying food to ships and from loaning money to insurance.
|
||||
|
||||
Chances are you are already involved with a bank or any other financial institution that makes use of blockchain ledger technology. The most significant uses of blockchain tech in the finance industry will be in setting up payments infrastructure, fund transfer technologies, and digital identity management. The latter two have traditionally been handled by legacy systems in the financial services industry. These systems are slowly being migrated to blockchain systems owing to their efficiency in handling work like this. The blockchain also offers high-quality data analytics solutions to these firms, an aspect that is quickly gaining prominence because of recent developments in data sciences.[1]
|
||||
|
||||
Considering the start-ups and projects at the cutting edge of innovation in this space first seems warranted due to their products or services already doing the rounds in the market today.
|
||||
|
||||
Starting with PayPal, an online payments company started in 1998, and now among the largest of such platforms, it is considered to be a benchmark in terms of operations and technical prowess. PayPal derives largely from the existing monetary system. Its contribution to innovation came by how it collected and leveraged consumer data to provide services online at instantaneous speeds. Online transactions are taken for granted today with minimal innovation in the industry in terms of the tech that it’s based on. Having a solid foundation is a good thing, but that won’t give anyone an edge over their competition in this fast-paced IT world with new standards and technology being pioneered every other day. In 2014 PayPal subsidiary, **Braintree** announced partnerships with popular cryptocurrency payment solutions including **Coinbase** and **GoCoin** , in a bid to gradually integrate Bitcoin and other popular cryptocurrencies into its service platform. This basically gave its consumers a chance to explore and experience the side of what’s to come under the familiar umbrella cover and reliability of PayPal. In fact, ride-hailing company **Uber** had an exclusive partnership with Braintree to allow customers to pay for rides using Bitcoin.[2][3]
|
||||
|
||||
**Ripple** is making it easier for people to operate between multiple blockchains. Ripple has been in the headlines for moving ahead with regional banks in the US, for instance, to facilitate transferring money bilaterally to other regional banks without the need for a 3rd party intermediary resulting in reduced cost and time overheads. Ripple’s **Codius platform** allows for interoperability between blockchains and opens the doors to smart contracts programmed into the system for minimal tampering and confusion. Built on technology that is highly advanced, secure and scalable to suit needs, Ripple’s platform currently has names such as UBS and Standard Chartered on their client’s list. Many more are expected to join in.[4][5]
|
||||
|
||||
**Kraken** , a US-based cryptocurrency exchange operating in locations around the globe is known for their reliable **crypto quant** estimates even providing Bitcoin pricing data real time to the Bloomberg terminal. In 2015, they partnered with **Fidor Bank** to form what was then the world’s first Cryptocurrency Bank offering customers banking services and products which dealt with cryptocurrencies.[6]
|
||||
|
||||
**Circle** , another FinTech company is currently among the largest of its sorts involved with allowing users to invest and trade in cryptocurrency derived assets, similar to traditional money market assets.[7]
|
||||
|
||||
Companies such as **Wyre** and **Stellar** today have managed to bring down the lead time involved in international wire transfers from an average of 3 days to under 6 hours. Claims have been made saying that once a proper regulatory system is in place the same 6 hours can be brought down to a matter of seconds.[8]
|
||||
|
||||
Now while all of the above have focused on the start-up projects involved, it has to be remembered that the reach and capabilities of the older more respectable financial institutions should not be ignored. Institutions that have existed for decades if not centuries moving billions of dollars worldwide are equally interested in leveraging the blockchain and its potential.
|
||||
|
||||
As we already mentioned in the previous article, **JP Morgan** recently unveiled their plans to exploit cryptocurrencies and the underlying ledger like the functionality of the blockchain for enterprises. The project, called **Quorum** , is defined as an **“Enterprise-ready distributed ledger and smart contract platform”**. The main goal being that gradually the bulk of the bank’s operations would one day be migrated to Quorum thus cutting significant investments that firms such as JP Morgan need to make in order to guarantee privacy, security, and transparency. They’re claimed to be the only player in the industry now to have complete ownership over the whole stack of the blockchain, protocol, and token system. They also released a cryptocurrency called **JPM Coin** meant to be used in transacting high volume settlements instantaneously. JPM coin is among the first “stable coins” to be backed by a major bank such as JP Morgan. A stable coin is a cryptocurrency whose price is linked to an existing major monetary system. Quorum is also touted for its capabilities to process almost 100 transactions a second which is leaps and bounds ahead of its contemporaries.[9]
|
||||
|
||||
**Barclay’s** , a British multinational financial giant is reported to have registered two blockchain-based patents supposedly with the aim of streamlining fund transfers and KYC procedures. Barclay’s proposals though are more aimed toward improving their banking operations’ efficiency. One of the application deals with creating a private blockchain network for storing KYC details of consumers. Once verified, stored and confirmed, these details are immutable and nullifies the need for further verifications down the line. If implemented the protocol will do away with the need for multiple verifications of KYC details. Developing and densely populated countries such as India where a bulk of the population is yet to be inducted into a formal banking system will find the innovative KYC system useful in reducing random errors and lead times involved in the process[10]. Barclay’s is also rumored to be exploring the capabilities of a blockchain system to address credit status ratings and insurance claims.
|
||||
|
||||
Such blockchain backed systems are designed to eliminate needless maintenance costs and leverage the power of smart contracts for enterprises which operate in industries where discretion, security, and speed determine competitive advantage. Being enterprise products, they’re built on protocols that ensure complete transaction and contract privacy along with a consensus mechanism which essentially nullifies corruption and bribery.
|
||||
|
||||
**PwC’s Global Fintech Report** from 2017 states that by 2020, an estimated 77% of all Fintech companies are estimated to switch to blockchain based technologies and processes concerning their operations. A whopping 90 percent of their respondents said that they were planning to adopt blockchain technology as part of an in-production system by 2020. Their judgments are not misplaced as significant cost savings and transparency gains from a regulatory point of view are guaranteed by moving to a blockchain based system.[11]
|
||||
|
||||
Since regulatory capabilities are built into the blockchain platform by default the migration of firms from legacy systems to modern networks running blockchain ledgers is a welcome move for industry regulators as well. Transactions and trade movements can be verified and tracked on the fly once and for all rather than after. This, in the long run, will likely result in better regulation and risk management. Not to mention improved accountability from the part of firms and individuals alike.[11]
|
||||
|
||||
While considerable investments in the space and leaping innovations are courtesy of large investments by established corporates it is misleading to think that such measures wouldn’t permeate the benefits to the end user. As banks and financial institutions start to adopt the blockchain, it will result in increased cost savings and efficiency for them which will ultimately mean good for the end consumer too. The added benefits of transparency and fraud protection will improve customer sentiments and more importantly improve the trust that people place on the banking and financial system. A much-needed revolution in the financial services industry is possible with blockchains and their integration into traditional services.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-redefining-financial-services/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/blockchain-2-0-revolutionizing-the-financial-system/
|
||||
[2]: https://www.ostechnix.com/blockchain-2-0-an-introduction/
|
||||
@ -1,77 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (14 days of celebrating the Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/happy-pi-day)
|
||||
[#]: author: (Anderson Silva (Red Hat) https://opensource.com/users/ansilva)
|
||||
|
||||
14 days of celebrating the Raspberry Pi
|
||||
======
|
||||
|
||||
In the 14th and final article in our series on getting started with the Raspberry Pi, take a look back at all the things we've learned.
|
||||
|
||||
![][1]
|
||||
|
||||
**Happy Pi Day!**
|
||||
|
||||
Every year on March 14th, we geeks celebrate Pi Day. In the way we abbreviate dates—MMDD—March 14 is written 03/14, which numerically reminds us of 3.14, or the first three numbers of [pi][2]. What many Americans don't realize is that virtually no other country in the world uses this [date format][3], so Pi Day pretty much only works in the US, though it is celebrated globally.
|
||||
|
||||
Wherever you are in the world, let's celebrate the Raspberry Pi and wrap up this series by reviewing the topics we've covered in the past two weeks:
|
||||
|
||||
* Day 1: [Which Raspberry Pi should you choose?][4]
|
||||
* Day 2: [How to buy a Raspberry Pi][5]
|
||||
* Day 3: [How to boot up a new Raspberry Pi][6]
|
||||
* Day 4: [Learn Linux with the Raspberry Pi][7]
|
||||
* Day 5: [5 ways to teach kids to program with Raspberry Pi][8]
|
||||
* Day 6: [3 popular programming languages you can learn with Raspberry Pi][9]
|
||||
* Day 7: [How to keep your Raspberry Pi updated][10]
|
||||
* Day 8: [How to use your Raspberry Pi for entertainment][11]
|
||||
* Day 9: [Play games on the Raspberry Pi][12]
|
||||
* Day 10: [Let's get physical: How to use GPIO pins on the Raspberry Pi][13]
|
||||
* Day 11: [Learn about computer security with the Raspberry Pi][14]
|
||||
* Day 12: [Do advanced math with Mathematica on the Raspberry Pi][15]
|
||||
* Day 13: [Contribute to the Raspberry Pi community][16]
|
||||
|
||||
|
||||
|
||||
![Pi Day illustration][18]
|
||||
|
||||
I'll end this series by thanking everyone who was brave enough to follow along and especially those who learned something from it during these past 14 days! I also want to encourage everyone to keep expanding their knowledge about the Raspberry Pi and all of the open (and closed) source technology that has been built around it.
|
||||
|
||||
I also encourage you to learn about other cultures, philosophies, religions, and worldviews. What makes us human is this amazing (and sometimes amusing) ability that we have to adapt not only to external environmental circumstances—but also intellectual ones.
|
||||
|
||||
No matter what you do, keep learning!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/happy-pi-day
|
||||
|
||||
作者:[Anderson Silva (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/raspberry-pi-juggle.png?itok=oTgGGSRA
|
||||
[2]: https://www.piday.org/million/
|
||||
[3]: https://en.wikipedia.org/wiki/Date_format_by_country
|
||||
[4]: https://opensource.com/article/19/3/which-raspberry-pi-choose
|
||||
[5]: https://opensource.com/article/19/3/how-buy-raspberry-pi
|
||||
[6]: https://opensource.com/article/19/3/how-boot-new-raspberry-pi
|
||||
[7]: https://opensource.com/article/19/3/learn-linux-raspberry-pi
|
||||
[8]: https://opensource.com/article/19/3/teach-kids-program-raspberry-pi
|
||||
[9]: https://opensource.com/article/19/3/programming-languages-raspberry-pi
|
||||
[10]: https://opensource.com/article/19/3/how-raspberry-pi-update
|
||||
[11]: https://opensource.com/article/19/3/raspberry-pi-entertainment
|
||||
[12]: https://opensource.com/article/19/3/play-games-raspberry-pi
|
||||
[13]: https://opensource.com/article/19/3/gpio-pins-raspberry-pi
|
||||
[14]: https://opensource.com/article/19/3/learn-about-computer-security-raspberry-pi
|
||||
[15]: https://opensource.com/article/19/3/do-math-raspberry-pi
|
||||
[16]: https://opensource.com/article/19/3/contribute-raspberry-pi-community
|
||||
[17]: /file/426561
|
||||
[18]: https://opensource.com/sites/default/files/uploads/raspberrypi_14_piday.jpg (Pi Day illustration)
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
301
sources/tech/20190317 How To Configure sudo Access In Linux.md
Normal file
301
sources/tech/20190317 How To Configure sudo Access In Linux.md
Normal file
@ -0,0 +1,301 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Configure sudo Access In Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-configure-sudo-access-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Configure sudo Access In Linux?
|
||||
======
|
||||
|
||||
The root user has all the controls in Linux system.
|
||||
|
||||
root user is the most powerful user in the Linux system and can perform any action in the system.
|
||||
|
||||
If any users wants to perform some actions, don’t provide the root access to anybody because if he/she done anything wrong there is no option/way to rectify it.
|
||||
|
||||
To fix this, what will be the solution?
|
||||
|
||||
We can grant sudo permission to the corresponding user to overcome this situation.
|
||||
|
||||
The sudo command offers a mechanism for providing trusted users with administrative access to a system without sharing the password of the root user.
|
||||
|
||||
They can perform most of the administrative operations but not all operations like root.
|
||||
|
||||
### What Is sudo?
|
||||
|
||||
sudo is a program, which can be used by a normal users to execute a command as the super user or another user, as specified by the security policy.
|
||||
|
||||
sudo users access is controlled by `/etc/sudoers` file.
|
||||
|
||||
### What Is An Advantage Of sudo Users?
|
||||
|
||||
sudo is a safe way to run a command in Linux system if you are not familiar on it.
|
||||
|
||||
* The Linux system keeps a logs into the `/var/log/secure` and `/var/log/auth.log` file where you can verify what actions was made by the sudo user.
|
||||
* Every time, it will prompt a password to perform the current action. So, you will be getting a time to verify the action, which you are going to perform. If you feel it’s not a correct action then you can safely exit there itself without perform the current action.
|
||||
|
||||
|
||||
|
||||
It’s different for RHEL based systems such as Redhat (RHEL), CentOS and Oracle Enterprise Linux (OEL) and Debian based systems such as Debian, Ubuntu and LinuxMint.
|
||||
|
||||
We will tech you, how to perform this on both the distributions in this article.
|
||||
|
||||
It can be done in three ways in both the distributions.
|
||||
|
||||
* Add a user into corresponding groups. For RHEL based system, we need to add a user into `wheel` group. For Debian based system, we need to add a user into `sudo` or `admin` groups.
|
||||
* Add a user into `/etc/group` file manually.
|
||||
* Add a user into `/etc/sudoers` file using visudo.
|
||||
|
||||
|
||||
|
||||
### How To Configure sudo Access In RHEL/CentOS/OEL Systems?
|
||||
|
||||
It can be done on RHEL based systems such as Redhat (RHEL), CentOS and Oracle Enterprise Linux (OEL) using following three methods.
|
||||
|
||||
### Method-1: How To Grant The Super User Access To A Normal User In Linux Using wheel Group?
|
||||
|
||||
Wheel is a special group in the RHEL based systems that provides additional privileges that empower a user to execute restricted commands as the super user.
|
||||
|
||||
Make a note that the `wheel` group should be enabled in the `/etc/sudoers` file to gain this access.
|
||||
|
||||
```
|
||||
# grep -i wheel /etc/sudoers
|
||||
|
||||
## Allows people in group wheel to run all commands
|
||||
%wheel ALL=(ALL) ALL
|
||||
# %wheel ALL=(ALL) NOPASSWD: ALL
|
||||
```
|
||||
|
||||
I assume that we had already created an user account to perform this. In my case, I’m going to use `daygeek` user account.
|
||||
|
||||
Run the following command to add an user into wheel group.
|
||||
|
||||
```
|
||||
# usermod -aG wheel daygeek
|
||||
```
|
||||
|
||||
We can doube confirm this by running the following command.
|
||||
|
||||
```
|
||||
# getent group wheel
|
||||
wheel:x:10:daygeek
|
||||
```
|
||||
|
||||
I’m going to check whether `daygeek` user can access a file which is owned by the root user.
|
||||
|
||||
```
|
||||
$ tail -5 /var/log/secure
|
||||
tail: cannot open _/var/log/secure_ for reading: Permission denied
|
||||
```
|
||||
|
||||
I was getting an error when i try to access the `/var/log/secure` file as a normal user. I’m going to access the same file with sudo, let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo tail -5 /var/log/secure
|
||||
[sudo] password for daygeek:
|
||||
Mar 17 07:01:56 CentOS7 sudo: daygeek : TTY=pts/0 ; PWD=/home/daygeek ; USER=root ; COMMAND=/bin/tail -5 /var/log/secure
|
||||
Mar 17 07:01:56 CentOS7 sudo: pam_unix(sudo:session): session opened for user root by daygeek(uid=0)
|
||||
Mar 17 07:01:56 CentOS7 sudo: pam_unix(sudo:session): session closed for user root
|
||||
Mar 17 07:05:10 CentOS7 sudo: daygeek : TTY=pts/0 ; PWD=/home/daygeek ; USER=root ; COMMAND=/bin/tail -5 /var/log/secure
|
||||
Mar 17 07:05:10 CentOS7 sudo: pam_unix(sudo:session): session opened for user root by daygeek(uid=0)
|
||||
```
|
||||
|
||||
### Method-2: How To Grant The Super User Access To A Normal User In RHEL/CentOS/OEL using /etc/group file?
|
||||
|
||||
We can manually add an user into the wheel group by editing the `/etc/group` file.
|
||||
|
||||
Just open the file then append the corresponding user in the appropriate group to achieve this.
|
||||
|
||||
```
|
||||
$ grep -i wheel /etc/group
|
||||
wheel:x:10:daygeek,user1
|
||||
```
|
||||
|
||||
In this example, I’m going to use `user1` user account.
|
||||
|
||||
I’m going to check whether `user1` user has sudo access or not by restarting the `Apache` service in the system. let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart httpd
|
||||
[sudo] password for user1:
|
||||
|
||||
$ sudo grep -i user1 /var/log/secure
|
||||
[sudo] password for user1:
|
||||
Mar 17 07:09:47 CentOS7 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/bin/systemctl restart httpd
|
||||
Mar 17 07:10:40 CentOS7 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/bin/systemctl restart httpd
|
||||
Mar 17 07:12:35 CentOS7 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/bin/grep -i httpd /var/log/secure
|
||||
```
|
||||
|
||||
### Method-3: How To Grant The Super User Access To A Normal User In Linux Using /etc/sudoers file?
|
||||
|
||||
sudo users access is controlled by `/etc/sudoers` file. So, simply add an user into the sudoers file under wheel group.
|
||||
|
||||
Just append the desired user into /etc/suoders file by using visudo command.
|
||||
|
||||
```
|
||||
# grep -i user2 /etc/sudoers
|
||||
user2 ALL=(ALL) ALL
|
||||
```
|
||||
|
||||
In this example, I’m going to use `user2` user account.
|
||||
|
||||
I’m going to check whether `user2` user has sudo access or not by restarting the `MariaDB` service in the system. let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart mariadb
|
||||
[sudo] password for user2:
|
||||
|
||||
$ sudo grep -i mariadb /var/log/secure
|
||||
[sudo] password for user2:
|
||||
Mar 17 07:23:10 CentOS7 sudo: user2 : TTY=pts/0 ; PWD=/home/user2 ; USER=root ; COMMAND=/bin/systemctl restart mariadb
|
||||
Mar 17 07:26:52 CentOS7 sudo: user2 : TTY=pts/0 ; PWD=/home/user2 ; USER=root ; COMMAND=/bin/grep -i mariadb /var/log/secure
|
||||
```
|
||||
|
||||
### How To Configure sudo Access In Debian/Ubuntu Systems?
|
||||
|
||||
It can be done on Debian based systems such as Debian based systems such as Debian, Ubuntu and LinuxMint using following three methods.
|
||||
|
||||
### Method-1: How To Grant The Super User Access To A Normal User In Linux Using sudo or admin Groups?
|
||||
|
||||
sudo or admin is a special group in the Debian based systems that provides additional privileges that empower a user to execute restricted commands as the super user.
|
||||
|
||||
Make a note that the `sudo` or `admin` group should be enabled in the `/etc/sudoers` file to gain this access.
|
||||
|
||||
```
|
||||
# grep -i 'sudo\|admin' /etc/sudoers
|
||||
|
||||
# Members of the admin group may gain root privileges
|
||||
%admin ALL=(ALL) ALL
|
||||
|
||||
# Allow members of group sudo to execute any command
|
||||
%sudo ALL=(ALL:ALL) ALL
|
||||
```
|
||||
|
||||
I assume that we had already created an user account to perform this. In my case, I’m going to use `2gadmin` user account.
|
||||
|
||||
Run the following command to add an user into sudo group.
|
||||
|
||||
```
|
||||
# usermod -aG sudo 2gadmin
|
||||
```
|
||||
|
||||
We can doube confirm this by running the following command.
|
||||
|
||||
```
|
||||
# getent group sudo
|
||||
sudo:x:27:2gadmin
|
||||
```
|
||||
|
||||
I’m going to check whether `2gadmin` user can access a file which is owned by the root user.
|
||||
|
||||
```
|
||||
$ less /var/log/auth.log
|
||||
/var/log/auth.log: Permission denied
|
||||
```
|
||||
|
||||
I was getting an error when i try to access the `/var/log/auth.log` file as a normal user. I’m going to access the same file with sudo, let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo tail -5 /var/log/auth.log
|
||||
[sudo] password for 2gadmin:
|
||||
Mar 17 20:39:47 Ubuntu18 sudo: 2gadmin : TTY=pts/0 ; PWD=/home/2gadmin ; USER=root ; COMMAND=/bin/bash
|
||||
Mar 17 20:39:47 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by 2gadmin(uid=0)
|
||||
Mar 17 20:40:23 Ubuntu18 sudo: pam_unix(sudo:session): session closed for user root
|
||||
Mar 17 20:40:48 Ubuntu18 sudo: 2gadmin : TTY=pts/0 ; PWD=/home/2gadmin ; USER=root ; COMMAND=/usr/bin/tail -5 /var/log/auth.log
|
||||
Mar 17 20:40:48 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by 2gadmin(uid=0)
|
||||
```
|
||||
|
||||
Alternatively we can perform the same by adding an user to `admin` group.
|
||||
|
||||
Run the following command to add an user into sudo group.
|
||||
|
||||
```
|
||||
# usermod -aG admin user1
|
||||
```
|
||||
|
||||
We can doube confirm this by running the following command.
|
||||
|
||||
```
|
||||
# getent group admin
|
||||
admin:x:1011:user1
|
||||
```
|
||||
|
||||
Let’s see the output.
|
||||
|
||||
```
|
||||
$ sudo tail -2 /var/log/auth.log
|
||||
[sudo] password for user1:
|
||||
Mar 17 20:53:36 Ubuntu18 sudo: user1 : TTY=pts/0 ; PWD=/home/user1 ; USER=root ; COMMAND=/usr/bin/tail -2 /var/log/auth.log
|
||||
Mar 17 20:53:36 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by user1(uid=0)
|
||||
```
|
||||
|
||||
### Method-2: How To Grant The Super User Access To A Normal User In Debian/Ubuntu using /etc/group file?
|
||||
|
||||
We can manually add an user into the sudo or admin group by editing the `/etc/group` file.
|
||||
|
||||
Just open the file then append the corresponding user in the appropriate group to achieve this.
|
||||
|
||||
```
|
||||
$ grep -i sudo /etc/group
|
||||
sudo:x:27:2gadmin,user2
|
||||
```
|
||||
|
||||
In this example, I’m going to use `user2` user account.
|
||||
|
||||
I’m going to check whether `user2` user has sudo access or not by restarting the `Apache` service in the system. let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart apache2
|
||||
[sudo] password for user2:
|
||||
|
||||
$ sudo tail -f /var/log/auth.log
|
||||
[sudo] password for user2:
|
||||
Mar 17 21:01:04 Ubuntu18 systemd-logind[559]: New session 22 of user user2.
|
||||
Mar 17 21:01:04 Ubuntu18 systemd: pam_unix(systemd-user:session): session opened for user user2 by (uid=0)
|
||||
Mar 17 21:01:33 Ubuntu18 sudo: user2 : TTY=pts/0 ; PWD=/home/user2 ; USER=root ; COMMAND=/bin/systemctl restart apache2
|
||||
```
|
||||
|
||||
### Method-3: How To Grant The Super User Access To A Normal User In Linux Using /etc/sudoers file?
|
||||
|
||||
sudo users access is controlled by `/etc/sudoers` file. So, simply add an user into the sudoers file under sudo or admin group.
|
||||
|
||||
Just append the desired user into /etc/suoders file by using visudo command.
|
||||
|
||||
```
|
||||
# grep -i user3 /etc/sudoers
|
||||
user3 ALL=(ALL:ALL) ALL
|
||||
```
|
||||
|
||||
In this example, I’m going to use `user3` user account.
|
||||
|
||||
I’m going to check whether `user3` user has sudo access or not by restarting the `MariaDB` service in the system. let’s see the magic.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart mariadb
|
||||
[sudo] password for user3:
|
||||
|
||||
$ sudo tail -f /var/log/auth.log
|
||||
[sudo] password for user3:
|
||||
Mar 17 21:12:32 Ubuntu18 systemd-logind[559]: New session 24 of user user3.
|
||||
Mar 17 21:12:49 Ubuntu18 sudo: user3 : TTY=pts/0 ; PWD=/home/user3 ; USER=root ; COMMAND=/bin/systemctl restart mariadb
|
||||
Mar 17 21:12:49 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by user3(uid=0)
|
||||
Mar 17 21:12:53 Ubuntu18 sudo: pam_unix(sudo:session): session closed for user root
|
||||
Mar 17 21:13:08 Ubuntu18 sudo: user3 : TTY=pts/0 ; PWD=/home/user3 ; USER=root ; COMMAND=/usr/bin/tail -f /var/log/auth.log
|
||||
Mar 17 21:13:08 Ubuntu18 sudo: pam_unix(sudo:session): session opened for user root by user3(uid=0)
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-configure-sudo-access-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,331 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (10 Python image manipulation tools)
|
||||
[#]: via: (https://opensource.com/article/19/3/python-image-manipulation-tools)
|
||||
[#]: author: (Parul Pandey https://opensource.com/users/parul-pandey)
|
||||
|
||||
10 Python image manipulation tools
|
||||
======
|
||||
|
||||
These Python libraries provide an easy and intuitive way to transform images and make sense of the underlying data.
|
||||
|
||||
![][1]
|
||||
|
||||
Today's world is full of data, and images form a significant part of this data. However, before they can be used, these digital images must be processed—analyzed and manipulated in order to improve their quality or extract some information that can be put to use.
|
||||
|
||||
Common image processing tasks include displays; basic manipulations like cropping, flipping, rotating, etc.; image segmentation, classification, and feature extractions; image restoration; and image recognition. Python is an excellent choice for these types of image processing tasks due to its growing popularity as a scientific programming language and the free availability of many state-of-the-art image processing tools in its ecosystem.
|
||||
|
||||
This article looks at 10 of the most commonly used Python libraries for image manipulation tasks. These libraries provide an easy and intuitive way to transform images and make sense of the underlying data.
|
||||
|
||||
### 1\. scikit-image
|
||||
|
||||
**[**scikit** -image][2]** is an open source Python package that works with [NumPy][3] arrays. It implements algorithms and utilities for use in research, education, and industry applications. It is a fairly simple and straightforward library, even for those who are new to Python's ecosystem. The code is high-quality, peer-reviewed, and written by an active community of volunteers.
|
||||
|
||||
#### Resources
|
||||
|
||||
scikit-image is very well [documented][4] with a lot of examples and practical use cases.
|
||||
|
||||
#### Usage
|
||||
|
||||
The package is imported as **skimage** , and most functions are found within the submodules.
|
||||
|
||||
Image filtering:
|
||||
|
||||
```
|
||||
import matplotlib.pyplot as plt
|
||||
%matplotlib inline
|
||||
|
||||
from skimage import data,filters
|
||||
|
||||
image = data.coins() # ... or any other NumPy array!
|
||||
edges = filters.sobel(image)
|
||||
plt.imshow(edges, cmap='gray')
|
||||
```
|
||||
|
||||
![Image filtering in scikit-image][6]
|
||||
|
||||
Template matching using the [match_template][7] function:
|
||||
|
||||
![Template matching in scikit-image][9]
|
||||
|
||||
You can find more examples in the [gallery][10].
|
||||
|
||||
### 2\. NumPy
|
||||
|
||||
[**NumPy**][11] is one of the core libraries in Python programming and provides support for arrays. An image is essentially a standard NumPy array containing pixels of data points. Therefore, by using basic NumPy operations, such as slicing, masking, and fancy indexing, you can modify the pixel values of an image. The image can be loaded using **skimage** and displayed using Matplotlib.
|
||||
|
||||
#### Resources
|
||||
|
||||
A complete list of resources and documentation is available on NumPy's [official documentation page][11].
|
||||
|
||||
#### Usage
|
||||
|
||||
Using Numpy to mask an image:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
from skimage import data
|
||||
import matplotlib.pyplot as plt
|
||||
%matplotlib inline
|
||||
|
||||
image = data.camera()
|
||||
type(image)
|
||||
numpy.ndarray #Image is a NumPy array:
|
||||
|
||||
mask = image < 87
|
||||
image[mask]=255
|
||||
plt.imshow(image, cmap='gray')
|
||||
```
|
||||
|
||||
![NumPy][13]
|
||||
|
||||
### 3\. SciPy
|
||||
|
||||
**[SciPy][14]** is another of Python's core scientific modules (like NumPy) and can be used for basic image manipulation and processing tasks. In particular, the submodule [**scipy.ndimage**][15] (in SciPy v1.1.0) provides functions operating on n-dimensional NumPy arrays. The package currently includes functions for linear and non-linear filtering, binary morphology, B-spline interpolation, and object measurements.
|
||||
|
||||
#### Resources
|
||||
|
||||
For a complete list of functions provided by the **scipy.ndimage** package, refer to the [documentation][16].
|
||||
|
||||
#### Usage
|
||||
|
||||
Using SciPy for blurring using a [Gaussian filter][17]:
|
||||
```
|
||||
from scipy import misc,ndimage
|
||||
|
||||
face = misc.face()
|
||||
blurred_face = ndimage.gaussian_filter(face, sigma=3)
|
||||
very_blurred = ndimage.gaussian_filter(face, sigma=5)
|
||||
|
||||
#Results
|
||||
plt.imshow(<image to be displayed>)
|
||||
```
|
||||
|
||||
![Using a Gaussian filter in SciPy][19]
|
||||
|
||||
### 4\. PIL/Pillow
|
||||
|
||||
**PIL** (Python Imaging Library) is a free library for the Python programming language that adds support for opening, manipulating, and saving many different image file formats. However, its development has stagnated, with its last release in 2009. Fortunately, there is [**Pillow**][20], an actively developed fork of PIL, that is easier to install, runs on all major operating systems, and supports Python 3. The library contains basic image processing functionality, including point operations, filtering with a set of built-in convolution kernels, and color-space conversions.
|
||||
|
||||
#### Resources
|
||||
|
||||
The [documentation][21] has instructions for installation as well as examples covering every module of the library.
|
||||
|
||||
#### Usage
|
||||
|
||||
Enhancing an image in Pillow using ImageFilter:
|
||||
|
||||
```
|
||||
from PIL import Image,ImageFilter
|
||||
#Read image
|
||||
im = Image.open('image.jpg')
|
||||
#Display image
|
||||
im.show()
|
||||
|
||||
from PIL import ImageEnhance
|
||||
enh = ImageEnhance.Contrast(im)
|
||||
enh.enhance(1.8).show("30% more contrast")
|
||||
```
|
||||
|
||||
![Enhancing an image in Pillow using ImageFilter][23]
|
||||
|
||||
[Image source code][24]
|
||||
|
||||
### 5\. OpenCV-Python
|
||||
|
||||
**OpenCV** (Open Source Computer Vision Library) is one of the most widely used libraries for computer vision applications. [**OpenCV-Python**][25] is the Python API for OpenCV. OpenCV-Python is not only fast, since the background consists of code written in C/C++, but it is also easy to code and deploy (due to the Python wrapper in the foreground). This makes it a great choice to perform computationally intensive computer vision programs.
|
||||
|
||||
#### Resources
|
||||
|
||||
The [OpenCV2-Python-Guide][26] makes it easy to get started with OpenCV-Python.
|
||||
|
||||
#### Usage
|
||||
|
||||
Using _Image Blending using Pyramids_ in OpenCV-Python to create an "Orapple":
|
||||
|
||||
|
||||
![Image blending using Pyramids in OpenCV-Python][28]
|
||||
|
||||
[Image source code][29]
|
||||
|
||||
### 6\. SimpleCV
|
||||
|
||||
[**SimpleCV**][30] is another open source framework for building computer vision applications. It offers access to several high-powered computer vision libraries such as OpenCV, but without having to know about bit depths, file formats, color spaces, etc. Its learning curve is substantially smaller than OpenCV's, and (as its tagline says), "it's computer vision made easy." Some points in favor of SimpleCV are:
|
||||
|
||||
* Even beginning programmers can write simple machine vision tests
|
||||
* Cameras, video files, images, and video streams are all interoperable
|
||||
|
||||
|
||||
|
||||
#### Resources
|
||||
|
||||
The official [documentation][31] is very easy to follow and has tons of examples and use cases to follow.
|
||||
|
||||
#### Usage
|
||||
|
||||
### [7-_simplecv.png][32]
|
||||
|
||||
![SimpleCV][33]
|
||||
|
||||
### 7\. Mahotas
|
||||
|
||||
**[Mahotas][34]** is another computer vision and image processing library for Python. It contains traditional image processing functions such as filtering and morphological operations, as well as more modern computer vision functions for feature computation, including interest point detection and local descriptors. The interface is in Python, which is appropriate for fast development, but the algorithms are implemented in C++ and tuned for speed. Mahotas' library is fast with minimalistic code and even minimum dependencies. Read its [official paper][35] for more insights.
|
||||
|
||||
#### Resources
|
||||
|
||||
The [documentation][36] contains installation instructions, examples, and even some tutorials to help you get started using Mahotas easily.
|
||||
|
||||
#### Usage
|
||||
|
||||
The Mahotas library relies on simple code to get things done. For example, it does a good job with the [Finding Wally][37] problem with a minimum amount of code.
|
||||
|
||||
Solving the Finding Wally problem:
|
||||
|
||||
![Finding Wally problem in Mahotas][39]
|
||||
|
||||
[Image source code][40]
|
||||
|
||||
![Finding Wally problem in Mahotas][42]
|
||||
|
||||
[Image source code][40]
|
||||
|
||||
### 8\. SimpleITK
|
||||
|
||||
[**ITK**][43] (Insight Segmentation and Registration Toolkit) is an "open source, cross-platform system that provides developers with an extensive suite of software tools for image analysis. **[SimpleITK][44]** is a simplified layer built on top of ITK, intended to facilitate its use in rapid prototyping, education, [and] interpreted languages." It's also an image analysis toolkit with a [large number of components][45] supporting general filtering operations, image segmentation, and registration. SimpleITK is written in C++, but it's available for a large number of programming languages including Python.
|
||||
|
||||
#### Resources
|
||||
|
||||
There are a large number of [Jupyter Notebooks][46] illustrating the use of SimpleITK for educational and research activities. The notebooks demonstrate using SimpleITK for interactive image analysis using the Python and R programming languages.
|
||||
|
||||
#### Usage
|
||||
|
||||
Visualization of a rigid CT/MR registration process created with SimpleITK and Python:
|
||||
|
||||
![SimpleITK animation][48]
|
||||
|
||||
[Image source code][49]
|
||||
|
||||
### 9\. pgmagick
|
||||
|
||||
[**pgmagick**][50] is a Python-based wrapper for the GraphicsMagick library. The [**GraphicsMagick**][51] image processing system is sometimes called the Swiss Army Knife of image processing. Its robust and efficient collection of tools and libraries supports reading, writing, and manipulating images in over 88 major formats including DPX, GIF, JPEG, JPEG-2000, PNG, PDF, PNM, and TIFF.
|
||||
|
||||
#### Resources
|
||||
|
||||
pgmagick's [GitHub repository][52] has installation instructions and requirements. There is also a detailed [user guide][53].
|
||||
|
||||
#### Usage
|
||||
|
||||
Image scaling:
|
||||
|
||||
![Image scaling in pgmagick][55]
|
||||
|
||||
[Image source code][56]
|
||||
|
||||
Edge extraction:
|
||||
|
||||
![Edge extraction in pgmagick][58]
|
||||
|
||||
[Image source code][59]
|
||||
|
||||
### 10\. Pycairo
|
||||
|
||||
[**Pycairo**][60] is a set of Python bindings for the [Cairo][61] graphics library. Cairo is a 2D graphics library for drawing vector graphics. Vector graphics are interesting because they don't lose clarity when resized or transformed. Pycairo can call Cairo commands from Python.
|
||||
|
||||
#### Resources
|
||||
|
||||
The Pycairo [GitHub repository][62] is a good resource with detailed instructions on installation and usage. There is also a [getting started guide][63], which has a brief tutorial on Pycairo.
|
||||
|
||||
#### Usage
|
||||
|
||||
Drawing lines, basic shapes, and radial gradients with Pycairo:
|
||||
|
||||
![Pycairo][65]
|
||||
|
||||
[Image source code][66]
|
||||
|
||||
### Conclusion
|
||||
|
||||
These are some of the useful and freely available image processing libraries in Python. Some are well known and others may be new to you. Try them out to get to know more about them!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/python-image-manipulation-tools
|
||||
|
||||
作者:[Parul Pandey][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/parul-pandey
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/daisy_gimp_art_design.jpg?itok=6kCxAKWO
|
||||
[2]: https://scikit-image.org/
|
||||
[3]: http://docs.scipy.org/doc/numpy/reference/index.html#module-numpy
|
||||
[4]: http://scikit-image.org/docs/stable/user_guide.html
|
||||
[5]: /file/426206
|
||||
[6]: https://opensource.com/sites/default/files/uploads/1-scikit-image.png (Image filtering in scikit-image)
|
||||
[7]: http://scikit-image.org/docs/dev/auto_examples/features_detection/plot_template.html#sphx-glr-auto-examples-features-detection-plot-template-py
|
||||
[8]: /file/426211
|
||||
[9]: https://opensource.com/sites/default/files/uploads/2-scikit-image.png (Template matching in scikit-image)
|
||||
[10]: https://scikit-image.org/docs/dev/auto_examples
|
||||
[11]: http://www.numpy.org/
|
||||
[12]: /file/426216
|
||||
[13]: https://opensource.com/sites/default/files/uploads/3-numpy.png (NumPy)
|
||||
[14]: https://www.scipy.org/
|
||||
[15]: https://docs.scipy.org/doc/scipy/reference/ndimage.html#module-scipy.ndimage
|
||||
[16]: https://docs.scipy.org/doc/scipy/reference/tutorial/ndimage.html#correlation-and-convolution
|
||||
[17]: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.gaussian_filter.html
|
||||
[18]: /file/426221
|
||||
[19]: https://opensource.com/sites/default/files/uploads/4-scipy.png (Using a Gaussian filter in SciPy)
|
||||
[20]: https://python-pillow.org/
|
||||
[21]: https://pillow.readthedocs.io/en/3.1.x/index.html
|
||||
[22]: /file/426226
|
||||
[23]: https://opensource.com/sites/default/files/uploads/5-pillow.png (Enhancing an image in Pillow using ImageFilter)
|
||||
[24]: http://sipi.usc.edu/database/
|
||||
[25]: https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_setup/py_intro/py_intro.html
|
||||
[26]: https://github.com/abidrahmank/OpenCV2-Python-Tutorials
|
||||
[27]: /file/426236
|
||||
[28]: https://opensource.com/sites/default/files/uploads/6-opencv.jpeg (Image blending using Pyramids in OpenCV-Python)
|
||||
[29]: https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_pyramids/py_pyramids.html#pyramids
|
||||
[30]: http://simplecv.org/
|
||||
[31]: http://examples.simplecv.org/en/latest/
|
||||
[32]: /file/426241
|
||||
[33]: https://opensource.com/sites/default/files/uploads/7-_simplecv.png (SimpleCV)
|
||||
[34]: https://mahotas.readthedocs.io/en/latest/
|
||||
[35]: https://openresearchsoftware.metajnl.com/articles/10.5334/jors.ac/
|
||||
[36]: https://mahotas.readthedocs.io/en/latest/install.html
|
||||
[37]: https://blog.clarifai.com/wheres-waldo-using-machine-learning-to-find-all-the-waldos
|
||||
[38]: /file/426246
|
||||
[39]: https://opensource.com/sites/default/files/uploads/8-mahotas.png (Finding Wally problem in Mahotas)
|
||||
[40]: https://mahotas.readthedocs.io/en/latest/wally.html
|
||||
[41]: /file/426251
|
||||
[42]: https://opensource.com/sites/default/files/uploads/9-mahotas.png (Finding Wally problem in Mahotas)
|
||||
[43]: https://itk.org/
|
||||
[44]: http://www.simpleitk.org/
|
||||
[45]: https://itk.org/ITK/resources/resources.html
|
||||
[46]: http://insightsoftwareconsortium.github.io/SimpleITK-Notebooks/
|
||||
[47]: /file/426256
|
||||
[48]: https://opensource.com/sites/default/files/uploads/10-simpleitk.gif (SimpleITK animation)
|
||||
[49]: https://github.com/InsightSoftwareConsortium/SimpleITK-Notebooks/blob/master/Utilities/intro_animation.py
|
||||
[50]: https://pypi.org/project/pgmagick/
|
||||
[51]: http://www.graphicsmagick.org/
|
||||
[52]: https://github.com/hhatto/pgmagick
|
||||
[53]: https://pgmagick.readthedocs.io/en/latest/
|
||||
[54]: /file/426261
|
||||
[55]: https://opensource.com/sites/default/files/uploads/11-pgmagick.png (Image scaling in pgmagick)
|
||||
[56]: https://pgmagick.readthedocs.io/en/latest/cookbook.html#scaling-a-jpeg-image
|
||||
[57]: /file/426266
|
||||
[58]: https://opensource.com/sites/default/files/uploads/12-pgmagick.png (Edge extraction in pgmagick)
|
||||
[59]: https://pgmagick.readthedocs.io/en/latest/cookbook.html#edge-extraction
|
||||
[60]: https://pypi.org/project/pycairo/
|
||||
[61]: https://cairographics.org/
|
||||
[62]: https://github.com/pygobject/pycairo
|
||||
[63]: https://pycairo.readthedocs.io/en/latest/tutorial.html
|
||||
[64]: /file/426271
|
||||
[65]: https://opensource.com/sites/default/files/uploads/13-pycairo.png (Pycairo)
|
||||
[66]: http://zetcode.com/gfx/pycairo/basicdrawing/
|
||||
@ -0,0 +1,157 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with Jaeger to build an Istio service mesh)
|
||||
[#]: via: (https://opensource.com/article/19/3/getting-started-jaeger)
|
||||
[#]: author: (Daniel Oh (Red Hat) https://opensource.com/users/daniel-oh)
|
||||
|
||||
Getting started with Jaeger to build an Istio service mesh
|
||||
======
|
||||
|
||||
Improve monitoring and tracing of cloud-native apps on a distributed networking system.
|
||||
|
||||
![Mesh networking connected dots][1]
|
||||
|
||||
[Service mesh][2] provides a dedicated network for service-to-service communication in a transparent way. [Istio][3] aims to help developers and operators address service mesh features such as dynamic service discovery, mutual transport layer security (TLS), circuit breakers, rate limiting, and tracing. [Jaeger][4] with Istio augments monitoring and tracing of cloud-native apps on a distributed networking system. This article explains how to get started with Jaeger to build an Istio service mesh on the Kubernetes platform.
|
||||
|
||||
### Spinning up a Kubernetes cluster
|
||||
|
||||
[Minikube][5] allows you to run a single-node Kubernetes cluster based on a virtual machine such as [KVM][6], [VirtualBox][7], or [HyperKit][8] on your local machine. [Install Minikube][9] and use the following shell script to run it:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
export MINIKUBE_PROFILE_NAME=istio-jaeger
|
||||
minikube profile $MINIKUBE_PROFILE_NAME
|
||||
minikube config set cpus 3
|
||||
minikube config set memory 8192
|
||||
|
||||
# You need to replace appropriate VM driver on your local machine
|
||||
minikube config set vm-driver hyperkit
|
||||
|
||||
minikube start
|
||||
```
|
||||
|
||||
In the above script, replace the **\--vm-driver=xxx** option with the appropriate virtual machine driver on your operating system (OS).
|
||||
|
||||
### Deploying Istio service mesh with Jaeger
|
||||
|
||||
Download the Istio installation file for your OS from the [Istio release page][10]. In the Istio package directory, you will find the Kubernetes installation YAML files in **install/** and the sample applications in **sample/**. Use the following commands:
|
||||
|
||||
```
|
||||
$ curl -L <https://git.io/getLatestIstio> | sh -
|
||||
$ cd istio-1.0.5
|
||||
$ export PATH=$PWD/bin:$PATH
|
||||
```
|
||||
|
||||
The easiest way to deploy Istio with Jaeger on your Kubernetes cluster is to use [Custom Resource Definitions][11]. Install Istio with mutual TLS authentication between sidecars with these commands:
|
||||
|
||||
```
|
||||
$ kubectl apply -f install/kubernetes/helm/istio/templates/crds.yaml
|
||||
$ kubectl apply -f install/kubernetes/istio-demo-auth.yaml
|
||||
```
|
||||
|
||||
Check if all pods of Istio on your Kubernetes cluster are deployed and running correctly by using the following command and review the output:
|
||||
|
||||
```
|
||||
$ kubectl get pods -n istio-system
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
grafana-59b8896965-p2vgs 1/1 Running 0 3h
|
||||
istio-citadel-856f994c58-tk8kq 1/1 Running 0 3h
|
||||
istio-cleanup-secrets-mq54t 0/1 Completed 0 3h
|
||||
istio-egressgateway-5649fcf57-n5ql5 1/1 Running 0 3h
|
||||
istio-galley-7665f65c9c-wx8k7 1/1 Running 0 3h
|
||||
istio-grafana-post-install-nh5rw 0/1 Completed 0 3h
|
||||
istio-ingressgateway-6755b9bbf6-4lf8m 1/1 Running 0 3h
|
||||
istio-pilot-698959c67b-d2zgm 2/2 Running 0 3h
|
||||
istio-policy-6fcb6d655f-lfkm5 2/2 Running 0 3h
|
||||
istio-security-post-install-st5xc 0/1 Completed 0 3h
|
||||
istio-sidecar-injector-768c79f7bf-9rjgm 1/1 Running 0 3h
|
||||
istio-telemetry-664d896cf5-wwcfw 2/2 Running 0 3h
|
||||
istio-tracing-6b994895fd-h6s9h 1/1 Running 0 3h
|
||||
prometheus-76b7745b64-hzm27 1/1 Running 0 3h
|
||||
servicegraph-5c4485945b-mk22d 1/1 Running 1 3h
|
||||
```
|
||||
|
||||
### Building sample microservice apps
|
||||
|
||||
You can use the [Bookinfo][12] app to learn about Istio's features. Bookinfo consists of four microservice apps: _productpage_ , _details_ , _reviews_ , and _ratings_ deployed independently on Minikube. Each microservice will be deployed with an Envoy sidecar via Istio by using the following commands:
|
||||
|
||||
```
|
||||
// Enable sidecar injection automatically
|
||||
$ kubectl label namespace default istio-injection=enabled
|
||||
$ kubectl apply -f samples/bookinfo/platform/kube/bookinfo.yaml
|
||||
|
||||
// Export the ingress IP, ports, and gateway URL
|
||||
$ kubectl apply -f samples/bookinfo/networking/bookinfo-gateway.yaml
|
||||
|
||||
$ export INGRESS_PORT=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.spec.ports[?(@.name=="http2")].nodePort}')
|
||||
$ export SECURE_INGRESS_PORT=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.spec.ports[?(@.name=="https")].nodePort}')
|
||||
$ export INGRESS_HOST=$(minikube ip)
|
||||
|
||||
$ export GATEWAY_URL=$INGRESS_HOST:$INGRESS_PORT
|
||||
```
|
||||
|
||||
### Accessing the Jaeger dashboard
|
||||
|
||||
To view tracing information for each HTTP request, create some traffic by running the following commands at the command line:
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
$ while true; do
|
||||
curl -s http://${GATEWAY_URL}/productpage > /dev/null
|
||||
echo -n .;
|
||||
sleep 0.2
|
||||
done
|
||||
|
||||
You can access the Jaeger dashboard through a web browser with [http://localhost:16686][13] if you set up port forwarding as follows:
|
||||
|
||||
```
|
||||
kubectl port-forward -n istio-system $(kubectl get pod -n istio-system -l app=jaeger -o jsonpath='{.items[0].metadata.name}') 16686:16686 &
|
||||
```
|
||||
|
||||
You can explore all traces by clicking "Find Traces" after selecting the _productpage_ service. Your dashboard will look similar to this:
|
||||
|
||||
![Find traces in Jaeger][14]
|
||||
|
||||
You can also view more details about each trace to dig into performance issues or elapsed time by clicking on a certain trace.
|
||||
|
||||
![Viewing details about a trace][15]
|
||||
|
||||
### Conclusion
|
||||
|
||||
A distributed tracing platform allows you to understand what happened from service to service for individual ingress/egress traffic. Istio sends individual trace information automatically to Jaeger, the distributed tracing platform, even if your modern applications aren't aware of Jaeger at all. In the end, this capability helps developers and operators do troubleshooting easier and quicker at scale.
|
||||
|
||||
* * *
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/getting-started-jaeger
|
||||
|
||||
作者:[Daniel Oh (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/daniel-oh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/mesh_networking_dots_connected.png?itok=ovINTRR3 (Mesh networking connected dots)
|
||||
[2]: https://blog.buoyant.io/2017/04/25/whats-a-service-mesh-and-why-do-i-need-one/
|
||||
[3]: https://istio.io/docs/concepts/what-is-istio/
|
||||
[4]: https://www.jaegertracing.io/docs/1.9/
|
||||
[5]: https://opensource.com/article/18/10/getting-started-minikube
|
||||
[6]: https://www.linux-kvm.org/page/Main_Page
|
||||
[7]: https://www.virtualbox.org/wiki/Downloads
|
||||
[8]: https://github.com/moby/hyperkit
|
||||
[9]: https://kubernetes.io/docs/tasks/tools/install-minikube/
|
||||
[10]: https://github.com/istio/istio/releases
|
||||
[11]: https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/#customresourcedefinitions
|
||||
[12]: https://github.com/istio/istio/tree/master/samples/bookinfo
|
||||
[13]: http://localhost:16686/
|
||||
[14]: https://opensource.com/sites/default/files/uploads/traces_productpages.png (Find traces in Jaeger)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/traces_performance.png (Viewing details about a trace)
|
||||
@ -0,0 +1,96 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (4 ways to jumpstart productivity at work)
|
||||
[#]: via: (https://opensource.com/article/19/3/guide-being-more-productive)
|
||||
[#]: author: (Sarah Wall https://opensource.com/users/sarahwall)
|
||||
|
||||
4 ways to jumpstart productivity at work
|
||||
======
|
||||
|
||||
This article includes six open source productivity tools.
|
||||
|
||||
![][1]
|
||||
|
||||
Time poverty—the idea that there's not enough time to do all the work we need to do—is it a perception or a reality?
|
||||
|
||||
The truth is you'll never get more than 24 hours out of any day. Working longer hours doesn't help. Your productivity actually decreases the longer you work in a given day. Your perception, or intuitive understanding of your time, is what matters. One key to managing productivity is how you use the time you've got.
|
||||
|
||||
You have lots of time that you can use more efficiently, including time lost to ineffective meetings, distractions, and context switching between tasks. By spending your time more wisely, you can get more done and achieve higher overall job performance. You will also have a higher level of job satisfaction and feel lower levels of stress.
|
||||
|
||||
### Jumpstart your productivity
|
||||
|
||||
#### 1\. Eliminate distractions
|
||||
|
||||
When you have too many things vying for your attention, it slows you down and decreases your productivity. Do your best to remove every distraction that pulls you off tasks.
|
||||
|
||||
Cellphones, email, and messaging apps are the most common drains on productivity. Set the ringer on your phone to vibrate, set specific times for checking email, and close irrelevant browser tabs. With this approach, your work will be interrupted less throughout the day.
|
||||
|
||||
#### 2\. Make your to-do list _verb-oriented_
|
||||
|
||||
To-do lists are a great way to help you focus on exactly what you need to accomplish each day. Some people do best with a physical list, like a notebook, and others do better with digital tools. Check out these suggestions for [open source productivity tools][2] to help you manage your workflow. Or check these six open source tools to stay organized:
|
||||
|
||||
* [Joplin, a note-taking app][3]
|
||||
* [Wekan, an open source kanban board][4]
|
||||
* [TaskBoard, a lightweight kanban board][5]
|
||||
* [Go For It, a flexible to-do list application][6]
|
||||
* [Org mode without Emacs][7]
|
||||
* [Freeplane, an open source mind-mapping application][8]
|
||||
|
||||
|
||||
|
||||
Your list can be as sophisticated or as simple as you like, but just making a list is not enough. What goes on your list makes all the difference. Every item that goes on your list should be actionable. The trick is to make sure there's a verb. For example, "Smith project" is not actionable enough. "Outline key deliverables on Smith project" gives you a more concrete task to complete.
|
||||
|
||||
#### 3\. Stick to the 10-minute rule
|
||||
|
||||
Overwhelmed by an unclear or unwieldy task? Break it into 10-minute mini-tasks instead. This can be a great way to take something unmanageable and turn it into something achievable.
|
||||
|
||||
The beauty of 10-minute tasks is they can be fit into many parts of your day. When you get into the office in the morning and are feeling fresh, kick off your day with a burst of productivity with a few 10-minute tasks. Losing momentum in the afternoon? A 10-minute job can help you regain speed.
|
||||
|
||||
Ten-minute tasks are also a good way to identify tasks that can be delegated to others. The ability to delegate work is often one of the most effective management techniques. By finding a simple task that can be accomplished by another member of your team, you can make short work of a big job.
|
||||
|
||||
#### 4\. Take a break
|
||||
|
||||
Another drain on productivity is the urge to keep pressing ahead on a task to complete it without taking a break. Suddenly you feel really fatigued or hungry, and you realize you haven't gone to the bathroom in hours! Your concentration is affected, and therefore your productivity decreases.
|
||||
|
||||
Set benchmarks for taking breaks and stick to them. For example, commit to once per hour to get up and move around for five minutes. If you're pressed for time, stand up and stretch for two minutes. Changing your body position and focusing on the present moment will help relieve any mental tension that has built up.
|
||||
|
||||
Hydrate your mind with a glass of water. When your body is not properly hydrated, it can put increased stress on your brain. As little as a one to three percent decrease in hydration can negatively affect your memory, concentration, and decision-making.
|
||||
|
||||
### Don't fall into the time-poverty trap
|
||||
|
||||
Time is limited and time poverty is just an idea. How you choose to spend the time you have each day is what's important. When you develop new, healthy habits, you can increase your productivity and direct your time in the ways that give the most value.
|
||||
|
||||
* * *
|
||||
|
||||
_This article was adapted from "[The Keys to Productivity][9]" on ImageX's blog._
|
||||
|
||||
_Sarah Wall will present_ [_Mindless multitasking: a dummy's guide to productivity_][10], _at_ [_DrupalCon_][11] _in Seattle, April 8-12, 2019._
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/guide-being-more-productive
|
||||
|
||||
作者:[Sarah Wall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sarahwall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_commun_4604_02_mech_connections_rhcz0.5x.png?itok=YPPU4dMj
|
||||
[2]: https://opensource.com/article/16/11/open-source-productivity-hacks
|
||||
[3]: https://opensource.com/article/19/1/productivity-tool-joplin
|
||||
[4]: https://opensource.com/article/19/1/productivity-tool-wekan
|
||||
[5]: https://opensource.com/article/19/1/productivity-tool-taskboard
|
||||
[6]: https://opensource.com/article/19/1/productivity-tool-go-for-it
|
||||
[7]: https://opensource.com/article/19/1/productivity-tool-org-mode
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-freeplane
|
||||
[9]: https://imagexmedia.com/managing-productivity
|
||||
[10]: https://events.drupal.org/seattle2019/sessions/mindless-multitasking-dummy%E2%80%99s-guide-productivity
|
||||
[11]: https://events.drupal.org/seattle2019
|
||||
@ -0,0 +1,188 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Check If A Port Is Open On Multiple Remote Linux System Using Shell Script With nc Command?)
|
||||
[#]: via: (https://www.2daygeek.com/check-a-open-port-on-multiple-remote-linux-server-using-nc-command/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Check If A Port Is Open On Multiple Remote Linux System Using Shell Script With nc Command?
|
||||
======
|
||||
|
||||
We had recently written an article to check if a port is open on the remote Linux server. It will help you to check for single server.
|
||||
|
||||
If you want to check for five servers then no issues, you can use any of the one following command such as nc (netcat), nmap and telnet.
|
||||
|
||||
If you would like to check for 50+ servers then what will be the solution?
|
||||
|
||||
It’s not easy to check all servers, if you do the same then there is no point and you will be wasting a lots of time unnecessarily.
|
||||
|
||||
To overcome this situation, i had coded a small shell script using nc command that will allow us to scan any number of servers with given port.
|
||||
|
||||
If you are looking for a single server scan then you have multiple options, to know more about it. Simply navigate to the following URL to **[Check Whether A Port Is Open On The Remote Linux System?][1]**
|
||||
|
||||
There are two scripts available in this tutorial and both the scripts are useful.
|
||||
|
||||
Both scripts are used for different purpose, which you can easily understand by reading a head line.
|
||||
|
||||
I will ask you few questions before you are reading this article, just answer yourself if you know or you can get it by reading this article.
|
||||
|
||||
How to check, if a port is open on the remote Linux server?
|
||||
|
||||
How to check, if a port is open on the multiple remote Linux server?
|
||||
|
||||
How to check, if multiple ports are open on the multiple remote Linux server?
|
||||
|
||||
### What Is nc (netcat) Command?
|
||||
|
||||
nc stands for netcat. Netcat is a simple Unix utility which reads and writes data across network connections, using TCP or UDP protocol.
|
||||
|
||||
It is designed to be a reliable “back-end” tool that can be used directly or easily driven by other programs and scripts.
|
||||
|
||||
At the same time, it is a feature-rich network debugging and exploration tool, since it can create almost any kind of connection you would need and has several interesting built-in capabilities.
|
||||
|
||||
Netcat has three main modes of functionality. These are the connect mode, the listen mode, and the tunnel mode.
|
||||
|
||||
**Common Syntax for nc (netcat):**
|
||||
|
||||
```
|
||||
$ nc [-options] [HostName or IP] [PortNumber]
|
||||
```
|
||||
|
||||
### How To Check If A Port Is Open On Multiple Remote Linux Server?
|
||||
|
||||
Use the following shell script if you would like to check the given port is open on multiple remote Linux servers or not.
|
||||
|
||||
In my case, we are going to check whether the port 22 is open in the following remote servers or not? Make sure you have to update your servers list in the file instead of us.
|
||||
|
||||
Make sure you have to update the servers list into `server-list.txt file`. Each server should be in separate line.
|
||||
|
||||
```
|
||||
# cat server-list.txt
|
||||
192.168.1.2
|
||||
192.168.1.3
|
||||
192.168.1.4
|
||||
192.168.1.5
|
||||
192.168.1.6
|
||||
192.168.1.7
|
||||
```
|
||||
|
||||
Use the following script to achieve this.
|
||||
|
||||
```
|
||||
# vi port_scan.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
#echo $i
|
||||
nc -zvw3 $server 22
|
||||
done
|
||||
```
|
||||
|
||||
Set an executable permission to `port_scan.sh` file.
|
||||
|
||||
```
|
||||
$ chmod +x port_scan.sh
|
||||
```
|
||||
|
||||
Finally run the script to achieve this.
|
||||
|
||||
```
|
||||
# sh port_scan.sh
|
||||
|
||||
Connection to 192.168.1.2 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.3 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.4 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.5 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.6 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.7 22 port [tcp/ssh] succeeded!
|
||||
```
|
||||
|
||||
### How To Check If Multiple Ports Are Open On Multiple Remote Linux Server?
|
||||
|
||||
Use the following script if you want to check the multiple ports in multiple servers.
|
||||
|
||||
In my case, we are going to check whether the port 22 and 80 is open or not in the given servers. Make sure you have to replace your required ports and servers name instead of us.
|
||||
|
||||
Make sure you have to update the port lists into `port-list.txt` file. Each port should be in a separate line.
|
||||
|
||||
```
|
||||
# cat port-list.txt
|
||||
22
|
||||
80
|
||||
```
|
||||
|
||||
Make sure you have to update the servers list into `server-list.txt` file. Each server should be in separate line.
|
||||
|
||||
```
|
||||
# cat server-list.txt
|
||||
192.168.1.2
|
||||
192.168.1.3
|
||||
192.168.1.4
|
||||
192.168.1.5
|
||||
192.168.1.6
|
||||
192.168.1.7
|
||||
```
|
||||
|
||||
Use the following script to achieve this.
|
||||
|
||||
```
|
||||
# vi multiple_port_scan.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
for port in `more port-list.txt`
|
||||
do
|
||||
#echo $server
|
||||
nc -zvw3 $server $port
|
||||
echo ""
|
||||
done
|
||||
done
|
||||
```
|
||||
|
||||
Set an executable permission to `multiple_port_scan.sh` file.
|
||||
|
||||
```
|
||||
$ chmod +x multiple_port_scan.sh
|
||||
```
|
||||
|
||||
Finally run the script to achieve this.
|
||||
|
||||
```
|
||||
# sh multiple_port_scan.sh
|
||||
Connection to 192.168.1.2 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.2 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.3 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.3 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.4 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.4 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.5 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.5 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.6 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.6 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.7 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.7 80 port [tcp/http] succeeded!
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/check-a-open-port-on-multiple-remote-linux-server-using-nc-command/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/
|
||||
@ -0,0 +1,540 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to use Spark SQL: A hands-on tutorial)
|
||||
[#]: via: (https://opensource.com/article/19/3/apache-spark-and-dataframes-tutorial)
|
||||
[#]: author: (Dipanjan (DJ) Sarkar (Red Hat) https://opensource.com/users/djsarkar)
|
||||
|
||||
How to use Spark SQL: A hands-on tutorial
|
||||
======
|
||||
|
||||
This tutorial explains how to leverage relational databases at scale using Spark SQL and DataFrames.
|
||||
|
||||
![Team checklist and to dos][1]
|
||||
|
||||
In the [first part][2] of this series, we looked at advances in leveraging the power of relational databases "at scale" using [Apache Spark SQL and DataFrames][3]. We will now do a simple tutorial based on a real-world dataset to look at how to use Spark SQL. We will be using Spark DataFrames, but the focus will be more on using SQL. In a separate article, I will cover a detailed discussion around Spark DataFrames and common operations.
|
||||
|
||||
I love using cloud services for my machine learning, deep learning, and even big data analytics needs, instead of painfully setting up my own Spark cluster. I will be using the Databricks Platform for my Spark needs. Databricks is a company founded by the creators of Apache Spark that aims to help clients with cloud-based big data processing using Spark.
|
||||
|
||||
![Apache Spark and Databricks][4]
|
||||
|
||||
The simplest (and free of charge) way is to go to the [Try Databricks page][5] and [sign up for a community edition][6] account. You get a cloud-based cluster, which is a single-node cluster with 6GB and unlimited notebooks—not bad for a free version! I recommend using the Databricks Platform if you have serious needs for analyzing big data.
|
||||
|
||||
Let's get started with our case study now. Feel free to create a new notebook from your home screen in Databricks or your own Spark cluster.
|
||||
|
||||
![Create a notebook][7]
|
||||
|
||||
You can also import my notebook containing the entire tutorial, but please make sure to run every cell and play around and explore with it, instead of just reading through it. Unsure of how to use Spark on Databricks? Follow [this short but useful tutorial][8].
|
||||
|
||||
This tutorial will familiarize you with essential Spark capabilities to deal with structured data often obtained from databases or flat files. We will explore typical ways of querying and aggregating relational data by leveraging concepts of DataFrames and SQL using Spark. We will work on an interesting dataset from the [KDD Cup 1999][9] and try to query the data using high-level abstractions like the dataframe that has already been a hit in popular data analysis tools like R and Python. We will also look at how easy it is to build data queries using the SQL language and retrieve insightful information from our data. This also happens at scale without us having to do a lot more since Spark distributes these data structures efficiently in the backend, which makes our queries scalable and as efficient as possible. We'll start by loading some basic dependencies.
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
import matplotlib.pyplot as plt
|
||||
plt.style.use('fivethirtyeight')
|
||||
```
|
||||
|
||||
#### Data retrieval
|
||||
|
||||
The [KDD Cup 1999][9] dataset was used for the Third International Knowledge Discovery and Data Mining Tools Competition, which was held in conjunction with KDD-99, the Fifth International Conference on Knowledge Discovery and Data Mining. The competition task was to build a network-intrusion detector, a predictive model capable of distinguishing between _bad connections_ , called intrusions or attacks, and _good, normal connections_. This database contains a standard set of data to be audited, which includes a wide variety of intrusions simulated in a military network environment.
|
||||
|
||||
We will be using the reduced dataset **kddcup.data_10_percent.gz** that contains nearly a half-million network interactions. We will download this Gzip file from the web locally and then work on it. If you have a good, stable internet connection, feel free to download and work with the full dataset, **kddcup.data.gz**.
|
||||
|
||||
#### Working with data from the web
|
||||
|
||||
Dealing with datasets retrieved from the web can be a bit tricky in Databricks. Fortunately, we have some excellent utility packages like **dbutils** that help make our job easier. Let's take a quick look at some essential functions for this module.
|
||||
|
||||
```
|
||||
dbutils.help()
|
||||
```
|
||||
|
||||
```
|
||||
This module provides various utilities for users to interact with the rest of Databricks.
|
||||
|
||||
fs: DbfsUtils -> Manipulates the Databricks filesystem (DBFS) from the console
|
||||
meta: MetaUtils -> Methods to hook into the compiler (EXPERIMENTAL)
|
||||
notebook: NotebookUtils -> Utilities for the control flow of a notebook (EXPERIMENTAL)
|
||||
preview: Preview -> Utilities under preview category
|
||||
secrets: SecretUtils -> Provides utilities for leveraging secrets within notebooks
|
||||
widgets: WidgetsUtils -> Methods to create and get bound value of input widgets inside notebooks
|
||||
```
|
||||
|
||||
#### Retrieve and store data in Databricks
|
||||
|
||||
We will now leverage the Python **urllib** library to extract the KDD Cup 99 data from its web repository, store it in a temporary location, and move it to the Databricks filesystem, which can enable easy access to this data for analysis
|
||||
|
||||
> **Note:** If you skip this step and download the data directly, you may end up getting a **InvalidInputException: Input path does not exist** error.
|
||||
|
||||
```
|
||||
import urllib
|
||||
urllib.urlretrieve("<http://kdd.ics.uci.edu/databases/kddcup99/kddcup.data\_10\_percent.gz>", "/tmp/kddcup_data.gz")
|
||||
dbutils.fs.mv("file:/tmp/kddcup_data.gz", "dbfs:/kdd/kddcup_data.gz")
|
||||
display(dbutils.fs.ls("dbfs:/kdd"))
|
||||
```
|
||||
|
||||
![Spark Job kddcup_data.gz][10]
|
||||
|
||||
#### Build the KDD dataset
|
||||
|
||||
Now that we have our data stored in the Databricks filesystem, let's load up our data from the disk into Spark's traditional abstracted data structure, the [Resilient Distributed Dataset][11] (RDD).
|
||||
|
||||
```
|
||||
data_file = "dbfs:/kdd/kddcup_data.gz"
|
||||
raw_rdd = sc.textFile(data_file).cache()
|
||||
raw_rdd.take(5)
|
||||
```
|
||||
|
||||
![Data in Resilient Distributed Dataset \(RDD\)][12]
|
||||
|
||||
You can also verify the type of data structure of our data (RDD) using the following code.
|
||||
|
||||
```
|
||||
type(raw_rdd)
|
||||
```
|
||||
|
||||
![output][13]
|
||||
|
||||
#### Build a Spark DataFrame on our data
|
||||
|
||||
A Spark DataFrame is an interesting data structure representing a distributed collecion of data. Typically the entry point into all SQL functionality in Spark is the **SQLContext** class. To create a basic instance of this call, all we need is a **SparkContext** reference. In Databricks, this global context object is available as **sc** for this purpose.
|
||||
|
||||
```
|
||||
from pyspark.sql import SQLContext
|
||||
sqlContext = SQLContext(sc)
|
||||
sqlContext
|
||||
```
|
||||
|
||||
![output][14]
|
||||
|
||||
#### Split the CSV data
|
||||
|
||||
Each entry in our RDD is a comma-separated line of data, which we first need to split before we can parse and build our dataframe.
|
||||
|
||||
```
|
||||
csv_rdd = raw_rdd.map(lambda row: row.split(","))
|
||||
print(csv_rdd.take(2))
|
||||
print(type(csv_rdd))
|
||||
```
|
||||
|
||||
![Splitting RDD entries][15]
|
||||
|
||||
#### Check the total number of features (columns)
|
||||
|
||||
We can use the following code to check the total number of potential columns in our dataset.
|
||||
|
||||
```
|
||||
len(csv_rdd.take(1)[0])
|
||||
|
||||
Out[57]: 42
|
||||
```
|
||||
|
||||
#### Understand and parse data
|
||||
|
||||
The KDD 99 Cup data consists of different attributes captured from connection data. You can obtain the [full list of attributes in the data][16] and further details pertaining to the [description for each attribute/column][17]. We will just be using some specific columns from the dataset, the details of which are specified as follows.
|
||||
|
||||
feature num | feature name | description | type
|
||||
---|---|---|---
|
||||
1 | duration | length (number of seconds) of the connection | continuous
|
||||
2 | protocol_type | type of the protocol, e.g., tcp, udp, etc. | discrete
|
||||
3 | service | network service on the destination, e.g., http, telnet, etc. | discrete
|
||||
4 | src_bytes | number of data bytes from source to destination | continuous
|
||||
5 | dst_bytes | number of data bytes from destination to source | continuous
|
||||
6 | flag | normal or error status of the connection | discrete
|
||||
7 | wrong_fragment | number of "wrong" fragments | continuous
|
||||
8 | urgent | number of urgent packets | continuous
|
||||
9 | hot | number of "hot" indicators | continuous
|
||||
10 | num_failed_logins | number of failed login attempts | continuous
|
||||
11 | num_compromised | number of "compromised" conditions | continuous
|
||||
12 | su_attempted | 1 if "su root" command attempted; 0 otherwise | discrete
|
||||
13 | num_root | number of "root" accesses | continuous
|
||||
14 | num_file_creations | number of file creation operations | continuous
|
||||
|
||||
We will be extracting the following columns based on their positions in each data point (row) and build a new RDD as follows.
|
||||
|
||||
```
|
||||
from pyspark.sql import Row
|
||||
|
||||
parsed_rdd = csv_rdd.map(lambda r: Row(
|
||||
duration=int(r[0]),
|
||||
protocol_type=r[1],
|
||||
service=r[2],
|
||||
flag=r[3],
|
||||
src_bytes=int(r[4]),
|
||||
dst_bytes=int(r[5]),
|
||||
wrong_fragment=int(r[7]),
|
||||
urgent=int(r[8]),
|
||||
hot=int(r[9]),
|
||||
num_failed_logins=int(r[10]),
|
||||
num_compromised=int(r[12]),
|
||||
su_attempted=r[14],
|
||||
num_root=int(r[15]),
|
||||
num_file_creations=int(r[16]),
|
||||
label=r[-1]
|
||||
)
|
||||
)
|
||||
parsed_rdd.take(5)
|
||||
```
|
||||
|
||||
![Extracting columns][18]
|
||||
|
||||
#### Construct the DataFrame
|
||||
|
||||
Now that our data is neatly parsed and formatted, let's build our DataFrame!
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
df = sqlContext.createDataFrame(parsed_rdd)
|
||||
display(df.head(10))
|
||||
|
||||
![DataFrame][19]
|
||||
|
||||
You can also now check out the schema of our DataFrame using the following code.
|
||||
|
||||
```
|
||||
df.printSchema()
|
||||
```
|
||||
|
||||
![Dataframe schema][20]
|
||||
|
||||
#### Build a temporary table
|
||||
|
||||
We can leverage the **registerTempTable()** function to build a temporary table to run SQL commands on our DataFrame at scale! A point to remember is that the lifetime of this temp table is tied to the session. It creates an in-memory table that is scoped to the cluster in which it was created. The data is stored using Hive's highly optimized, in-memory columnar format.
|
||||
|
||||
You can also check out **saveAsTable()** , which creates a permanent, physical table stored in S3 using the Parquet format. This table is accessible to all clusters. The table metadata, including the location of the file(s), is stored within the Hive metastore.
|
||||
|
||||
```
|
||||
help(df.registerTempTable)
|
||||
```
|
||||
|
||||
![help\(df.registerTempTable\)][21]
|
||||
|
||||
```
|
||||
df.registerTempTable("connections")
|
||||
```
|
||||
|
||||
### Execute SQL at Scale
|
||||
|
||||
Let's look at a few examples of how we can run SQL queries on our table based off of our dataframe. We will start with some simple queries and then look at aggregations, filters, sorting, sub-queries, and pivots in this tutorial.
|
||||
|
||||
#### Connections based on the protocol type
|
||||
|
||||
Let's look at how we can get the total number of connections based on the type of connectivity protocol. First, we will get this information using normal DataFrame DSL syntax to perform aggregations.
|
||||
|
||||
```
|
||||
display(df.groupBy('protocol_type')
|
||||
.count()
|
||||
.orderBy('count', ascending=False))
|
||||
```
|
||||
|
||||
![Total number of connections][22]
|
||||
|
||||
Can we also use SQL to perform the same aggregation? Yes, we can leverage the table we built earlier for this!
|
||||
|
||||
```
|
||||
protocols = sqlContext.sql("""
|
||||
SELECT protocol_type, count(*) as freq
|
||||
FROM connections
|
||||
GROUP BY protocol_type
|
||||
ORDER BY 2 DESC
|
||||
""")
|
||||
display(protocols)
|
||||
```
|
||||
|
||||
![protocol type and frequency][23]
|
||||
|
||||
You can clearly see that you get the same results and don't need to worry about your background infrastructure or how the code is executed. Just write simple SQL!
|
||||
|
||||
#### Connections based on good or bad (attack types) signatures
|
||||
|
||||
We will now run a simple aggregation to check the total number of connections based on good (normal) or bad (intrusion attacks) types.
|
||||
|
||||
```
|
||||
labels = sqlContext.sql("""
|
||||
SELECT label, count(*) as freq
|
||||
FROM connections
|
||||
GROUP BY label
|
||||
ORDER BY 2 DESC
|
||||
""")
|
||||
display(labels)
|
||||
```
|
||||
|
||||
![Connection by type][24]
|
||||
|
||||
We have a lot of different attack types. We can visualize this in the form of a bar chart. The simplest way is to use the excellent interface options in the Databricks notebook.
|
||||
|
||||
![Databricks chart types][25]
|
||||
|
||||
This gives us a nice-looking bar chart, which you can customize further by clicking on **Plot Options**.
|
||||
|
||||
![Bar chart][26]
|
||||
|
||||
Another way is to write the code to do it. You can extract the aggregated data as a Pandas DataFrame and plot it as a regular bar chart.
|
||||
|
||||
```
|
||||
labels_df = pd.DataFrame(labels.toPandas())
|
||||
labels_df.set_index("label", drop=True,inplace=True)
|
||||
labels_fig = labels_df.plot(kind='barh')
|
||||
|
||||
plt.rcParams["figure.figsize"] = (7, 5)
|
||||
plt.rcParams.update({'font.size': 10})
|
||||
plt.tight_layout()
|
||||
display(labels_fig.figure)
|
||||
```
|
||||
|
||||
![Bar chart][27]
|
||||
|
||||
### Connections based on protocols and attacks
|
||||
|
||||
Let's look at which protocols are most vulnerable to attacks by using the following SQL query.
|
||||
|
||||
```
|
||||
|
||||
attack_protocol = sqlContext.sql("""
|
||||
SELECT
|
||||
protocol_type,
|
||||
CASE label
|
||||
WHEN 'normal.' THEN 'no attack'
|
||||
ELSE 'attack'
|
||||
END AS state,
|
||||
COUNT(*) as freq
|
||||
FROM connections
|
||||
GROUP BY protocol_type, state
|
||||
ORDER BY 3 DESC
|
||||
""")
|
||||
display(attack_protocol)
|
||||
```
|
||||
|
||||
![Protocols most vulnerable to attacks][28]
|
||||
|
||||
Well, it looks like ICMP connections, followed by TCP connections have had the most attacks.
|
||||
|
||||
#### Connection stats based on protocols and attacks
|
||||
|
||||
Let's take a look at some statistical measures pertaining to these protocols and attacks for our connection requests.
|
||||
|
||||
```
|
||||
attack_stats = sqlContext.sql("""
|
||||
SELECT
|
||||
protocol_type,
|
||||
CASE label
|
||||
WHEN 'normal.' THEN 'no attack'
|
||||
ELSE 'attack'
|
||||
END AS state,
|
||||
COUNT(*) as total_freq,
|
||||
ROUND(AVG(src_bytes), 2) as mean_src_bytes,
|
||||
ROUND(AVG(dst_bytes), 2) as mean_dst_bytes,
|
||||
ROUND(AVG(duration), 2) as mean_duration,
|
||||
SUM(num_failed_logins) as total_failed_logins,
|
||||
SUM(num_compromised) as total_compromised,
|
||||
SUM(num_file_creations) as total_file_creations,
|
||||
SUM(su_attempted) as total_root_attempts,
|
||||
SUM(num_root) as total_root_acceses
|
||||
FROM connections
|
||||
GROUP BY protocol_type, state
|
||||
ORDER BY 3 DESC
|
||||
""")
|
||||
display(attack_stats)
|
||||
```
|
||||
|
||||
![Statistics pertaining to protocols and attacks][29]
|
||||
|
||||
Looks like the average amount of data being transmitted in TCP requests is much higher, which is not surprising. Interestingly, attacks have a much higher average payload of data being transmitted from the source to the destination.
|
||||
|
||||
#### Filtering connection stats based on the TCP protocol by service and attack type
|
||||
|
||||
Let's take a closer look at TCP attacks, given that we have more relevant data and statistics for the same. We will now aggregate different types of TCP attacks based on service and attack type and observe different metrics.
|
||||
|
||||
```
|
||||
tcp_attack_stats = sqlContext.sql("""
|
||||
SELECT
|
||||
service,
|
||||
label as attack_type,
|
||||
COUNT(*) as total_freq,
|
||||
ROUND(AVG(duration), 2) as mean_duration,
|
||||
SUM(num_failed_logins) as total_failed_logins,
|
||||
SUM(num_file_creations) as total_file_creations,
|
||||
SUM(su_attempted) as total_root_attempts,
|
||||
SUM(num_root) as total_root_acceses
|
||||
FROM connections
|
||||
WHERE protocol_type = 'tcp'
|
||||
AND label != 'normal.'
|
||||
GROUP BY service, attack_type
|
||||
ORDER BY total_freq DESC
|
||||
""")
|
||||
display(tcp_attack_stats)
|
||||
```
|
||||
|
||||
![TCP attack data][30]
|
||||
|
||||
There are a lot of attack types, and the preceding output shows a specific section of them.
|
||||
|
||||
#### Filtering connection stats based on the TCP protocol by service and attack type
|
||||
|
||||
We will now filter some of these attack types by imposing some constraints in our query based on duration, file creations, and root accesses.
|
||||
|
||||
```
|
||||
tcp_attack_stats = sqlContext.sql("""
|
||||
SELECT
|
||||
service,
|
||||
label as attack_type,
|
||||
COUNT(*) as total_freq,
|
||||
ROUND(AVG(duration), 2) as mean_duration,
|
||||
SUM(num_failed_logins) as total_failed_logins,
|
||||
SUM(num_file_creations) as total_file_creations,
|
||||
SUM(su_attempted) as total_root_attempts,
|
||||
SUM(num_root) as total_root_acceses
|
||||
FROM connections
|
||||
WHERE (protocol_type = 'tcp'
|
||||
AND label != 'normal.')
|
||||
GROUP BY service, attack_type
|
||||
HAVING (mean_duration >= 50
|
||||
AND total_file_creations >= 5
|
||||
AND total_root_acceses >= 1)
|
||||
ORDER BY total_freq DESC
|
||||
""")
|
||||
display(tcp_attack_stats)
|
||||
```
|
||||
|
||||
![Filtered by attack type][31]
|
||||
|
||||
It's interesting to see that [multi-hop attacks][32] can get root accesses to the destination hosts!
|
||||
|
||||
#### Subqueries to filter TCP attack types based on service
|
||||
|
||||
Let's try to get all the TCP attacks based on service and attack type such that the overall mean duration of these attacks is greater than zero ( **> 0** ). For this, we can do an inner query with all aggregation statistics and extract the relevant queries and apply a mean duration filter in the outer query, as shown below.
|
||||
|
||||
```
|
||||
tcp_attack_stats = sqlContext.sql("""
|
||||
SELECT
|
||||
t.service,
|
||||
t.attack_type,
|
||||
t.total_freq
|
||||
FROM
|
||||
(SELECT
|
||||
service,
|
||||
label as attack_type,
|
||||
COUNT(*) as total_freq,
|
||||
ROUND(AVG(duration), 2) as mean_duration,
|
||||
SUM(num_failed_logins) as total_failed_logins,
|
||||
SUM(num_file_creations) as total_file_creations,
|
||||
SUM(su_attempted) as total_root_attempts,
|
||||
SUM(num_root) as total_root_acceses
|
||||
FROM connections
|
||||
WHERE protocol_type = 'tcp'
|
||||
AND label != 'normal.'
|
||||
GROUP BY service, attack_type
|
||||
ORDER BY total_freq DESC) as t
|
||||
WHERE t.mean_duration > 0
|
||||
""")
|
||||
display(tcp_attack_stats)
|
||||
```
|
||||
|
||||
![TCP attacks based on service and attack type][33]
|
||||
|
||||
This is nice! Now another interesting way to view this data is to use a pivot table, where one attribute represents rows and another one represents columns. Let's see if we can leverage Spark DataFrames to do this!
|
||||
|
||||
#### Build a pivot table from aggregated data
|
||||
|
||||
We will build upon the previous DataFrame object where we aggregated attacks based on type and service. For this, we can leverage the power of Spark DataFrames and the DataFrame DSL.
|
||||
|
||||
```
|
||||
display((tcp_attack_stats.groupby('service')
|
||||
.pivot('attack_type')
|
||||
.agg({'total_freq':'max'})
|
||||
.na.fill(0))
|
||||
)
|
||||
```
|
||||
|
||||
![Pivot table][34]
|
||||
|
||||
We get a nice, neat pivot table showing all the occurrences based on service and attack type!
|
||||
|
||||
### Next steps
|
||||
|
||||
I would encourage you to go out and play with Spark SQL and DataFrames. You can even [import my notebook][35] and play with it in your own account.
|
||||
|
||||
Feel free to refer to [my GitHub repository][36] also for all the code and notebooks used in this article. It covers things we didn't cover here, including:
|
||||
|
||||
* Joins
|
||||
* Window functions
|
||||
* Detailed operations and transformations of Spark DataFrames
|
||||
|
||||
|
||||
|
||||
You can also access my tutorial as a [Jupyter Notebook][37], in case you want to use it offline.
|
||||
|
||||
There are plenty of articles and tutorials available online, so I recommend you check them out. One useful resource is Databricks' complete [guide to Spark SQL][38].
|
||||
|
||||
Thinking of working with JSON data but unsure of using Spark SQL? Databricks supports it! Check out this excellent guide to [JSON support in Spark SQL][39].
|
||||
|
||||
Interested in advanced concepts like window functions and ranks in SQL? Take a look at "[Introducing Window Functions in Spark SQL][40]."
|
||||
|
||||
I will write another article covering some of these concepts in an intuitive way, which should be easy for you to understand. Stay tuned!
|
||||
|
||||
In case you have any feedback or queries, you can reach out to me on [LinkedIn][41].
|
||||
|
||||
* * *
|
||||
|
||||
*This article originally appeared on Medium's [Towards Data Science][42] channel and is republished with permission. *
|
||||
|
||||
* * *
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/apache-spark-and-dataframes-tutorial
|
||||
|
||||
作者:[Dipanjan (DJ) Sarkar (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/djsarkar
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/todo_checklist_team_metrics_report.png?itok=oB5uQbzf (Team checklist and to dos)
|
||||
[2]: https://opensource.com/article/19/3/sql-scale-apache-spark-sql-and-dataframes
|
||||
[3]: https://spark.apache.org/sql/
|
||||
[4]: https://opensource.com/sites/default/files/uploads/13_spark-databricks.png (Apache Spark and Databricks)
|
||||
[5]: https://databricks.com/try-databricks
|
||||
[6]: https://databricks.com/signup#signup/community
|
||||
[7]: https://opensource.com/sites/default/files/uploads/14_create-notebook.png (Create a notebook)
|
||||
[8]: https://databricks.com/spark/getting-started-with-apache-spark
|
||||
[9]: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
|
||||
[10]: https://opensource.com/sites/default/files/uploads/15_dbfs-kdd-kddcup_data-gz.png (Spark Job kddcup_data.gz)
|
||||
[11]: https://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-distributed-datasets-rdds
|
||||
[12]: https://opensource.com/sites/default/files/uploads/16_rdd-data.png (Data in Resilient Distributed Dataset (RDD))
|
||||
[13]: https://opensource.com/sites/default/files/uploads/16a_output.png (output)
|
||||
[14]: https://opensource.com/sites/default/files/uploads/16b_output.png (output)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/17_split-csv.png (Splitting RDD entries)
|
||||
[16]: http://kdd.ics.uci.edu/databases/kddcup99/kddcup.names
|
||||
[17]: http://kdd.ics.uci.edu/databases/kddcup99/task.html
|
||||
[18]: https://opensource.com/sites/default/files/uploads/18_extract-columns.png (Extracting columns)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/19_build-dataframe.png (DataFrame)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/20_dataframe-schema.png (Dataframe schema)
|
||||
[21]: https://opensource.com/sites/default/files/uploads/21_registertemptable.png (help(df.registerTempTable))
|
||||
[22]: https://opensource.com/sites/default/files/uploads/22_number-of-connections.png (Total number of connections)
|
||||
[23]: https://opensource.com/sites/default/files/uploads/23_sql.png (protocol type and frequency)
|
||||
[24]: https://opensource.com/sites/default/files/uploads/24_intrusion-type.png (Connection by type)
|
||||
[25]: https://opensource.com/sites/default/files/uploads/25_chart-interface.png (Databricks chart types)
|
||||
[26]: https://opensource.com/sites/default/files/uploads/26_plot-options-chart.png (Bar chart)
|
||||
[27]: https://opensource.com/sites/default/files/uploads/27_pandas-barchart.png (Bar chart)
|
||||
[28]: https://opensource.com/sites/default/files/uploads/28_most-attacked.png (Protocols most vulnerable to attacks)
|
||||
[29]: https://opensource.com/sites/default/files/uploads/29_data-transmissions.png (Statistics pertaining to protocols and attacks)
|
||||
[30]: https://opensource.com/sites/default/files/uploads/30_tcp-attack-metrics.png (TCP attack data)
|
||||
[31]: https://opensource.com/sites/default/files/uploads/31_attack-type.png (Filtered by attack type)
|
||||
[32]: https://attack.mitre.org/techniques/T1188/
|
||||
[33]: https://opensource.com/sites/default/files/uploads/32_tcp-attack-types.png (TCP attacks based on service and attack type)
|
||||
[34]: https://opensource.com/sites/default/files/uploads/33_pivot-table.png (Pivot table)
|
||||
[35]: https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/3137082781873852/3704545280501166/1264763342038607/latest.html
|
||||
[36]: https://github.com/dipanjanS/data_science_for_all/tree/master/tds_spark_sql_intro
|
||||
[37]: http://nbviewer.jupyter.org/github/dipanjanS/data_science_for_all/blob/master/tds_spark_sql_intro/Working%20with%20SQL%20at%20Scale%20-%20Spark%20SQL%20Tutorial.ipynb
|
||||
[38]: https://docs.databricks.com/spark/latest/spark-sql/index.html
|
||||
[39]: https://databricks.com/blog/2015/02/02/an-introduction-to-json-support-in-spark-sql.html
|
||||
[40]: https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html
|
||||
[41]: https://www.linkedin.com/in/dipanzan/
|
||||
[42]: https://towardsdatascience.com/sql-at-scale-with-apache-spark-sql-and-dataframes-concepts-architecture-and-examples-c567853a702f
|
||||
177
sources/tech/20190322 Printing from the Linux command line.md
Normal file
177
sources/tech/20190322 Printing from the Linux command line.md
Normal file
@ -0,0 +1,177 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Printing from the Linux command line)
|
||||
[#]: via: (https://www.networkworld.com/article/3373502/printing-from-the-linux-command-line.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Printing from the Linux command line
|
||||
======
|
||||
|
||||
There's a lot more to printing from the Linux command line than the lp command. Check out some of the many available options.
|
||||
|
||||
![Sherry \(CC BY 2.0\)][1]
|
||||
|
||||
Printing from the Linux command line is easy. You use the **lp** command to request a print, and **lpq** to see what print jobs are in the queue, but things get a little more complicated when you want to print double-sided or use portrait mode. And there are lots of other things you might want to do — such as printing multiple copies of a document or canceling a print job. Let's check out some options for getting your printouts to look just the way you want them to when you're printing from the command line.
|
||||
|
||||
### Displaying printer settings
|
||||
|
||||
To view your printer settings from the command line, use the **lpoptions** command. The output should look something like this:
|
||||
|
||||
```
|
||||
$ lpoptions
|
||||
copies=1 device-uri=dnssd://HP%20Color%20LaserJet%20CP2025dn%20(F47468)._pdl-datastream._tcp.local/ finishings=3 job-cancel-after=10800 job-hold-until=no-hold job-priority=50 job-sheets=none,none marker-change-time=1553023232 marker-colors=#000000,#00FFFF,#FF00FF,#FFFF00 marker-levels=18,62,62,63 marker-names='Black\ Cartridge\ HP\ CC530A,Cyan\ Cartridge\ HP\ CC531A,Magenta\ Cartridge\ HP\ CC533A,Yellow\ Cartridge\ HP\ CC532A' marker-types=toner,toner,toner,toner number-up=1 printer-commands=none printer-info='HP Color LaserJet CP2025dn (F47468)' printer-is-accepting-jobs=true printer-is-shared=true printer-is-temporary=false printer-location printer-make-and-model='HP Color LaserJet cp2025dn pcl3, hpcups 3.18.7' printer-state=3 printer-state-change-time=1553023232 printer-state-reasons=none printer-type=167964 printer-uri-supported=ipp://localhost/printers/Color-LaserJet-CP2025dn sides=one-sided
|
||||
```
|
||||
|
||||
This output is likely to be a little more human-friendly if you turn its blanks into carriage returns. Notice how many settings are listed.
|
||||
|
||||
NOTE: In the output below, some lines have been reconnected to make this output more readable.
|
||||
|
||||
```
|
||||
$ lpoptions | tr " " '\n'
|
||||
copies=1
|
||||
device-uri=dnssd://HP%20Color%20LaserJet%20CP2025dn%20(F47468)._pdl-datastream._tcp.local/
|
||||
finishings=3
|
||||
job-cancel-after=10800
|
||||
job-hold-until=no-hold
|
||||
job-priority=50
|
||||
job-sheets=none,none
|
||||
marker-change-time=1553023232
|
||||
marker-colors=#000000,#00FFFF,#FF00FF,#FFFF00
|
||||
marker-levels=18,62,62,63
|
||||
marker-names='Black\ Cartridge\ HP\ CC530A,
|
||||
Cyan\ Cartridge\ HP\ CC531A,
|
||||
Magenta\ Cartridge\ HP\ CC533A,
|
||||
Yellow\ Cartridge\ HP\ CC532A'
|
||||
marker-types=toner,toner,toner,toner
|
||||
number-up=1
|
||||
printer-commands=none
|
||||
printer-info='HP Color LaserJet CP2025dn (F47468)'
|
||||
printer-is-accepting-jobs=true
|
||||
printer-is-shared=true
|
||||
printer-is-temporary=false
|
||||
printer-location
|
||||
printer-make-and-model='HP Color LaserJet cp2025dn pcl3, hpcups 3.18.7'
|
||||
printer-state=3
|
||||
printer-state-change-time=1553023232
|
||||
printer-state-reasons=none
|
||||
printer-type=167964
|
||||
printer-uri-supported=ipp://localhost/printers/Color-LaserJet-CP2025dn
|
||||
sides=one-sided
|
||||
```
|
||||
|
||||
With the **-v** option, the **lpinfo** command will list drivers and related information.
|
||||
|
||||
```
|
||||
$ lpinfo -v
|
||||
network ipp
|
||||
network https
|
||||
network socket
|
||||
network beh
|
||||
direct hp
|
||||
network lpd
|
||||
file cups-brf:/
|
||||
network ipps
|
||||
network http
|
||||
direct hpfax
|
||||
network dnssd://HP%20Color%20LaserJet%20CP2025dn%20(F47468)._pdl-datastream._tcp.local/ <== printer
|
||||
network socket://192.168.0.23 <== printer IP
|
||||
```
|
||||
|
||||
The lpoptions command will show the settings of your default printer. Use the **-p** option to specify one of a number of available printers.
|
||||
|
||||
```
|
||||
$ lpoptions -p LaserJet
|
||||
```
|
||||
|
||||
The **lpstat -p** command displays the status of a printer while **lpstat -p -d** also lists available printers.
|
||||
|
||||
```
|
||||
$ lpstat -p -d
|
||||
printer Color-LaserJet-CP2025dn is idle. enabled since Tue 19 Mar 2019 05:07:45 PM EDT
|
||||
system default destination: Color-LaserJet-CP2025dn
|
||||
```
|
||||
|
||||
### Useful commands
|
||||
|
||||
To print a document on the default printer, just use the **lp** command followed by the name of the file you want to print. If the filename includes blanks (rare on Linux systems), either put the name in quotes or start entering the file name and press the tab key to invoke file completion (as shown in the second example below).
|
||||
|
||||
```
|
||||
$ lp "never leave home angry"
|
||||
$ lp never\ leave\ home\ angry
|
||||
```
|
||||
|
||||
The **lpq** command displays the print queue.
|
||||
|
||||
```
|
||||
$ lpq
|
||||
Color-LaserJet-CP2025dn is ready and printing
|
||||
Rank Owner Job File(s) Total Size
|
||||
active shs 234 agenda 2048 bytes
|
||||
```
|
||||
|
||||
With the **-n** option, the lp command allows you to specify the number of copies of a printout you want.
|
||||
|
||||
```
|
||||
$ lp -n 11 agenda
|
||||
```
|
||||
|
||||
To cancel a print job, you can use the **cancel** or **lprm** command. If you don't act quickly, you might see this:
|
||||
|
||||
```
|
||||
$ cancel 229
|
||||
cancel: cancel-job failed: Job #229 is already completed - can't cancel.
|
||||
```
|
||||
|
||||
### Two-sided printing
|
||||
|
||||
To print in two-sided mode, you can issue your lp command with a **sides** option that says both to print on both sides of the paper and which edge to turn the paper on. This setting represents the normal way that you would expect two-sided portrait documents to look.
|
||||
|
||||
```
|
||||
$ lp -o sides=two-sided-long-edge Notes.pdf
|
||||
```
|
||||
|
||||
If you want all of your documents to print in two-side mode, you can change your lp settings by using the **lpoptions** command to change the setting for **sides**.
|
||||
|
||||
```
|
||||
$ lpoptions -o sides=two-sided-short-edge
|
||||
```
|
||||
|
||||
To revert to single-sided printing, you would use a command like this one:
|
||||
|
||||
```
|
||||
$ lpoptions -o sides=one-sided
|
||||
```
|
||||
|
||||
#### Printing in landscape mode
|
||||
|
||||
To print in landscape mode, you would use the **landscape** option with the lp command.
|
||||
|
||||
```
|
||||
$ lp -o landscape penguin.jpg
|
||||
```
|
||||
|
||||
### CUPS
|
||||
|
||||
The print system used on Linux systems is the standards-based, open source printing system called CUPS, originally standing for **Common Unix Printing System**. It allows a computer to act as a print server.
|
||||
|
||||
Join the Network World communities on [Facebook][2] and [LinkedIn][3] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3373502/printing-from-the-linux-command-line.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/03/printouts-paper-100791390-large.jpg
|
||||
[2]: https://www.facebook.com/NetworkWorld/
|
||||
[3]: https://www.linkedin.com/company/network-world
|
||||
314
sources/tech/20190325 Backup on Fedora Silverblue with Borg.md
Normal file
314
sources/tech/20190325 Backup on Fedora Silverblue with Borg.md
Normal file
@ -0,0 +1,314 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Backup on Fedora Silverblue with Borg)
|
||||
[#]: via: (https://fedoramagazine.org/backup-on-fedora-silverblue-with-borg/)
|
||||
[#]: author: (Steven Snow https://fedoramagazine.org/author/jakfrost/)
|
||||
|
||||
Backup on Fedora Silverblue with Borg
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
When it comes to backing up a Fedora Silverblue system, some of the traditional tools may not function as expected. BorgBackup (Borg) is an alternative available that can provide backup capability for your Silverblue based systems. This how-to explains the steps for using BorgBackup 1.1.8 as a layered package to back up Fedora Silverblue 29 system.
|
||||
|
||||
On a normal Fedora Workstation system, _dnf_ is used to install a package. However, on Fedora Silverblue, _rpm-ostree install_ is used to install new software. This is termed layering on the Silverblue system, since the core ostree is an immutable image and the rpm package is layered onto the core system during the install process resulting in a new local image with the layered package.
|
||||
|
||||
> “BorgBackup (short: Borg) is a deduplicating backup program. Optionally, it supports compression and authenticated encryption.”
|
||||
>
|
||||
> From the Borg website
|
||||
|
||||
Additionally, the main way to interact with Borg is via the command line. Reading the Quick Start guide it becomes apparent that Borg is well suited to scripting. In fact, it is pretty much necessary to use some form of shell script when performing repeated thorough backup’s of a system. A basic script is provided in the [Borg Quick Start guide][2] , as a point to get started.
|
||||
|
||||
### Installing Borg
|
||||
|
||||
In a terminal, type the following command to install BorgBackup as a layered package:
|
||||
|
||||
```
|
||||
$rpm-ostree install borgbackup
|
||||
```
|
||||
This installs BorgBackup to the Fedora Silverblue system. To use it, reboot into the new ostree with:
|
||||
|
||||
```
|
||||
$systemctl reboot
|
||||
```
|
||||
|
||||
Now Borg is installed, and ready to use.
|
||||
|
||||
### Some notes about Silverblue and its file system, layered packages and flatpaks
|
||||
|
||||
#### The file system
|
||||
|
||||
Silverblue is an immutable operating system based on ostree, with support for layering rpm’s through the use of rpm-ostree. At the user level, this means the path that appears as _/home_ in a flatpak, will actually be _/var/home_ to the system. For programs like Borg, and other backup tools this is important to remember since they often require the actual path, so in this example that would be _/var/home_ instead of just _/home_.
|
||||
|
||||
Before starting a backup it’s a good idea to understand where potential data could be stored, and then if that data should be backed up. Silverblue’s file system layout is very specific with respect to what is writable and what is not. On Silverblue _/etc_ and _/var_ are the only places that are not immutable, therefore writable. On a single user system, typically the user home directory would be a likely choice for data backup. Normally excluding Downloads, but including Documents and more. Also, _/etc_ is a logical choice for some configuration options you don’t want to go through again. Take notes of what to exclude from your home directory and from _/etc_. Some files and subdirectories of /etc you need root or sudo privileges to access.
|
||||
|
||||
#### Flatpaks
|
||||
|
||||
Flatpak applications store data in your home directory under _$HOME/.var/app/flatpakapp_ , regardless of whether they were installed as user or system. If installed at a user level, there is also data found in _$HOME/.local/share/flatpak/app/_ , or if installed at a system level it will be found in _/var/lib/flatpak/app_ For the purposes of this article, it was enough to list the flatpak’s installed and redirect the output to a file for backing up. Reasoning that if there is a need to reinstall them (flatpaks) the list file could be used to do it from. For a more robust approach, examining the flatpak file system layouts can be done [here.][3]
|
||||
|
||||
#### Layering and rpm-ostree
|
||||
|
||||
There is no easy way for a user to retrieve the layered package information aside from the
|
||||
|
||||
$rpm-ostree status
|
||||
|
||||
command. Which shows the current and previous ostree commit’s layered packages, and if any commits are pinned they would be listed too. Below is the output on my system, note the LayeredPackages label at the end of each commit listing.
|
||||
|
||||
![][4]
|
||||
|
||||
The command
|
||||
|
||||
$ostree log
|
||||
|
||||
is useful to retrieve a history of commits for the system. Type it in your terminal to see the output.
|
||||
|
||||
### Preparing the backup repo
|
||||
|
||||
In order to use Borg to back up a system, you need to first initialize a Borg repo. Before initializing, the decision must be made to use encryption (or not) and if so, what mode.
|
||||
|
||||
With Borg the data can be protected using 256-bit AES encryption. The integrity and authenticity of the data, which is encrypted on the clientside, is verified using HMAC-SHA256. The encryption modes are listed below.
|
||||
|
||||
#### Encryption modes
|
||||
|
||||
Hash/MAC | Not encrypted no auth | Not encrypted, but authenticated | Encrypted (AEAD w/ AES) and authenticated
|
||||
---|---|---|---
|
||||
SHA-256 | none | authenticated | repokey keyfile
|
||||
BLAKE2b | n/a | authenticated-blake2 | repokey-blake2 keyfile-blake2
|
||||
|
||||
The encryption mode decided on was keyfile-blake2, which requires a passphrase to be entered as well as the keyfile being needed.
|
||||
|
||||
Borg can use the following compression types which you can specify at backup creation time.
|
||||
|
||||
* lz4 (super fast, low compression)
|
||||
* zstd (wide range from high speed and low compression to high compression and lower speed)
|
||||
* zlib (medium speed and compression)
|
||||
* lzma (low speed, high compression)
|
||||
|
||||
|
||||
|
||||
For compression lzma was chosen at setting 6, the highest sensible compression level. The initial backup took 4 minutes 59.98 seconds to complete, while subsequent ones have taken less than 20 seconds as a rule.
|
||||
|
||||
#### Borg init
|
||||
|
||||
To be able to perform backups with Borg, first, create a directory for your Borg repo:
|
||||
|
||||
```
|
||||
$mkdir borg_testdir
|
||||
```
|
||||
|
||||
and then change to it.
|
||||
|
||||
```
|
||||
$cd borg_testdir
|
||||
```
|
||||
|
||||
Next, initialize the Borg repo with the borg init command:
|
||||
|
||||
```
|
||||
$borg init -e=keyfile-blake2 .
|
||||
```
|
||||
|
||||
Borg will prompt for your passphrase, which is case sensitive, and at creation must be entered twice. A suitable passphrase of alpha-numeric characters and symbols, and of a reasonable length should be created. It can be changed later on if needed without affecting the keyfile, or your encrypted data. The keyfile can be exported and should be for backup purposes, along with the passphrase, and stored somewhere secure.
|
||||
|
||||
#### Creating a backup
|
||||
|
||||
Next, create a test backup of the Documents directory, remember on Silverblue the actual path to the user Documents directory is _/var/home/username/Documents_. In practice on Silverblue, it is suitable to use _~/_ or _$HOME_ to indicate your home directory. The distinction between the actual path and environment variables being the real path does not change whereas the environment variable can be changed. From within the Borg repo, type the following command
|
||||
|
||||
```
|
||||
$borg create .::borgtest /var/home/username/Documents
|
||||
```
|
||||
|
||||
and that will create a backup of the Documents directory named **borgtest**. To break down the command a bit; **create** requires a **repo location** , in this case **.** since we are in the **top level** of the **repo**. That makes the path **.::borgtest** for the backup name. Finally **/var/home/username/Documents** is the location of the data we are backing up.
|
||||
|
||||
The following command
|
||||
|
||||
```
|
||||
$borg list
|
||||
```
|
||||
|
||||
returns a listing of your backups, after a few days it look similar to this:
|
||||
|
||||
![Output of borg list command in my backup repo.][5]
|
||||
|
||||
To delete the test backup, type the following in the terminal
|
||||
|
||||
```
|
||||
$borg delete .::borgtest
|
||||
```
|
||||
|
||||
at this time Borg will prompt for the encryption passphrase in order to delete the backup.
|
||||
|
||||
### Pulling it together into a shell script
|
||||
|
||||
As mentioned Borg is an eminently script friendly tool. The Borg documentation links provided are great places to find out more about BorgBackup, and there is more. The example script provided by Borg was modified to suit this article. Below is a version with the basic parts that others could use as a starting point if desired. It tries to capture the three information pieces of the system and apps mentioned earlier. The output of _flatpak list_ , _rpm-ostree status_ , and _ostree log_ as human readable files given the same names each time so overwritten each time. The repo setup had to be changed since the original example is for a remote server login with ssh, and this was intended to be used locally. The other changes mostly involved correcting directory paths, tailoring the excluded content to suit this systems home directory, and choosing the compression.
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
|
||||
|
||||
# This gets the ostree commit data, this file is overwritten each time
|
||||
|
||||
sudo ostree log fedora-workstation:fedora/29/x86_64/silverblue > ostree.log
|
||||
|
||||
|
||||
|
||||
rpm-ostree status > rpm-ostree-status.lst
|
||||
|
||||
|
||||
|
||||
# Flatpaks get listed too
|
||||
|
||||
flatpak list > flatpak.lst
|
||||
|
||||
|
||||
|
||||
# Setting this, so the repo does not need to be given on the commandline:
|
||||
|
||||
export BORG_REPO=/var/home/usernamehere/borg_testdir
|
||||
|
||||
|
||||
|
||||
# Setting this, so you won't be asked for your repository passphrase:(Caution advised!)
|
||||
|
||||
export BORG_PASSPHRASE='usercomplexpassphrasehere'
|
||||
|
||||
|
||||
|
||||
# some helpers and error handling:
|
||||
|
||||
info() { printf "\n%s %s\n\n" "$( date )" "$*" >&2; }
|
||||
|
||||
trap 'echo $( date ) Backup interrupted >&2; exit 2' INT TERM
|
||||
|
||||
|
||||
|
||||
info "Starting backup"
|
||||
|
||||
|
||||
|
||||
# Backup the most important directories into an archive named after
|
||||
|
||||
# the machine this script is currently running on:
|
||||
|
||||
borg create \
|
||||
|
||||
--verbose \
|
||||
|
||||
--filter AME \
|
||||
|
||||
--list \
|
||||
|
||||
--stats \
|
||||
|
||||
--show-rc \
|
||||
|
||||
--compression auto,lzma,6 \
|
||||
|
||||
--exclude-caches \
|
||||
|
||||
--exclude '/var/home/*/borg_testdir'\
|
||||
|
||||
--exclude '/var/home/*/Downloads/'\
|
||||
|
||||
--exclude '/var/home/*/.var/' \
|
||||
|
||||
--exclude '/var/home/*/Desktop/'\
|
||||
|
||||
--exclude '/var/home/*/bin/' \
|
||||
|
||||
\
|
||||
|
||||
::'{hostname}-{now}' \
|
||||
|
||||
/etc \
|
||||
|
||||
/var/home/ssnow \
|
||||
|
||||
|
||||
|
||||
backup_exit=$?
|
||||
|
||||
|
||||
|
||||
info "Pruning repository"
|
||||
|
||||
|
||||
|
||||
# Use the `prune` subcommand to maintain 7 daily, 4 weekly and 6 monthly
|
||||
|
||||
# archives of THIS machine. The '{hostname}-' prefix is very important to
|
||||
|
||||
# limit prune's operation to this machine's archives and not apply to
|
||||
|
||||
# other machines' archives also:
|
||||
|
||||
|
||||
|
||||
borg prune \
|
||||
|
||||
--list \
|
||||
|
||||
--prefix '{hostname}-' \
|
||||
|
||||
--show-rc \
|
||||
|
||||
--keep-daily 7 \
|
||||
|
||||
--keep-weekly 4 \
|
||||
|
||||
--keep-monthly 6 \
|
||||
|
||||
|
||||
|
||||
prune_exit=$?
|
||||
|
||||
|
||||
|
||||
# use highest exit code as global exit code
|
||||
|
||||
global_exit=$(( backup_exit > prune_exit ? backup_exit : prune_exit ))
|
||||
|
||||
|
||||
|
||||
if [ ${global_exit} -eq 0 ]; then
|
||||
|
||||
info "Backup and Prune finished successfully"
|
||||
|
||||
elif [ ${global_exit} -eq 1 ]; then
|
||||
|
||||
info "Backup and/or Prune finished with warnings"
|
||||
|
||||
else
|
||||
|
||||
info "Backup and/or Prune finished with errors"
|
||||
|
||||
fi
|
||||
|
||||
|
||||
|
||||
exit ${global_exit}
|
||||
```
|
||||
|
||||
This listing is missing some more excludes that were specific to the test system setup and backup intentions, and is very basic with room for customization and improvement. For this test to write an article it wasn’t a problem having the passphrase inside of a shell script file. Under normal use it is better to enter the passphrase each time when performing the backup.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/backup-on-fedora-silverblue-with-borg/
|
||||
|
||||
作者:[Steven Snow][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/jakfrost/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/borg-816x345.jpg
|
||||
[2]: https://borgbackup.readthedocs.io/en/stable/quickstart.html
|
||||
[3]: https://github.com/flatpak/flatpak/wiki/Filesystem
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-18-17-11-21-1024x285.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-18-18-56-03.png
|
||||
222
sources/tech/20190325 Getting started with Vim- The basics.md
Normal file
222
sources/tech/20190325 Getting started with Vim- The basics.md
Normal file
@ -0,0 +1,222 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Modrisco)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with Vim: The basics)
|
||||
[#]: via: (https://opensource.com/article/19/3/getting-started-vim)
|
||||
[#]: author: (Bryant Son (Red Hat, Community Moderator) https://opensource.com/users/brson)
|
||||
|
||||
Getting started with Vim: The basics
|
||||
======
|
||||
|
||||
Learn to use Vim enough to get by at work or for a new project.
|
||||
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
I remember the very first time I encountered Vim. I was a university student, and the computers in the computer science department's lab were installed with Ubuntu Linux. While I had been exposed to different Linux variations (like RHEL) even before my college years (Red Hat sold its CDs at Best Buy!), this was the first time I needed to use the Linux operating system regularly, because my classes required me to do so. Once I started using Linux, like many others before and after me, I began to feel like a "real programmer."
|
||||
|
||||
![Real Programmers comic][2]
|
||||
|
||||
Real Programmers, by [xkcd][3]
|
||||
|
||||
Students could use a graphical text editor like [Kate][4], which was installed on the lab computers by default. For students who could use the shell but weren't used to the console-based editor, the popular choice was [Nano][5], which provided good interactive menus and an experience similar to Windows' graphical text editor.
|
||||
|
||||
I used Nano sometimes, but I heard awesome things about [Vi/Vim][6] and [Emacs][7] and really wanted to give them a try (mainly because they looked cool, and I was also curious to see what was so great about them). Using Vim for the first time scared me—I did not want to mess anything up! But once I got the hang of it, things became much easier and I could appreciate the editor's powerful capabilities. As for Emacs, well, I sort of gave up, but I'm happy I stuck with Vim.
|
||||
|
||||
In this article, I will walk through Vim (based on my personal experience) just enough so you can get by with it as an editor on a Linux system. This will neither make you an expert nor even scratch the surface of many of Vim's powerful capabilities. But the starting point always matters, and I want to make the beginning experience as easy as possible, and you can explore the rest on your own.
|
||||
|
||||
### Step 0: Open a console window
|
||||
|
||||
Before jumping into Vim, you need to do a little preparation. Open a console terminal from your Linux operating system. (Since Vim is also available on MacOS, Mac users can use these instructions, also.)
|
||||
|
||||
Once a terminal window is up, type the **ls** command to list the current directory. Then, type **mkdir Tutorial** to create a new directory called **Tutorial**. Go inside the directory by typing **cd Tutorial**.
|
||||
|
||||
![Create a folder][8]
|
||||
|
||||
That's it for preparation. Now it's time to move on to the fun part—starting to use Vim.
|
||||
|
||||
### Step 1: Create and close a Vim file without saving
|
||||
|
||||
Remember when I said I was scared to use Vim at first? Well, the scary part was thinking, "what if I change an existing file and mess things up?" After all, several computer science assignments required me to work on existing files by modifying them. I wanted to know: _How can I open and close a file without saving my changes?_
|
||||
|
||||
The good news is you can use the same command to create or open a file in Vim: **vim <FILE_NAME**>, where **< FILE_NAME>** represents the target file name you want to create or modify. Let's create a file named **HelloWorld.java** by typing **vim HelloWorld.java**.
|
||||
|
||||
Hello, Vim! Now, here is a very important concept in Vim, possibly the most important to remember: Vim has multiple modes. Here are three you need to know to do Vim basics:
|
||||
|
||||
Mode | Description
|
||||
---|---
|
||||
Normal | Default; for navigation and simple editing
|
||||
Insert | For explicitly inserting and modifying text
|
||||
Command Line | For operations like saving, exiting, etc.
|
||||
|
||||
Vim has other modes, like Visual, Select, and Ex-Mode, but Normal, Insert, and Command Line modes are good enough for us.
|
||||
|
||||
You are now in Normal mode. If you have text, you can move around with your arrow keys or other navigation keystrokes (which you will see later). To make sure you are in Normal mode, simply hit the **Esc** (Escape) key.
|
||||
|
||||
> **Tip:** **Esc** switches to Normal mode. Even though you are already in Normal mode, hit **Esc** just for practice's sake.
|
||||
|
||||
Now, this will be interesting. Press **:** (the colon key) followed by **q!** (i.e., **:q!** ). Your screen will look like this:
|
||||
|
||||
![Editing Vim][9]
|
||||
|
||||
Pressing the colon in Normal mode switches Vim to Command Line mode, and the **:q!** command quits the Vim editor without saving. In other words, you are abandoning all changes. You can also use **ZQ** ; choose whichever option is more convenient.
|
||||
|
||||
Once you hit **Enter** , you should no longer be in Vim. Repeat the exercise a few times, just to get the hang of it. Once you've done that, move on to the next section to learn how to make a change to this file.
|
||||
|
||||
### Step 2: Make and save modifications in Vim
|
||||
|
||||
Reopen the file by typing **vim HelloWorld.java** and pressing the **Enter** key. Insert mode is where you can make changes to a file. First, hit **Esc** to make sure you are in Normal mode, then press **i** to go into Insert mode. (Yes, that is the letter **i**.)
|
||||
|
||||
In the lower-left, you should see **\-- INSERT --**. This means you are in Insert mode.
|
||||
|
||||
![Vim insert mode][10]
|
||||
|
||||
Type some Java code. You can type anything you want, but here is an example for you to follow. Your screen will look like this:
|
||||
|
||||
|
||||
```
|
||||
public class HelloWorld {
|
||||
public static void main([String][11][] args) {
|
||||
}
|
||||
}
|
||||
```
|
||||
Very pretty! Notice how the text is highlighted in Java syntax highlight colors. Because you started the file in Java, Vim will detect the syntax color.
|
||||
|
||||
Save the file. Hit **Esc** to leave Insert mode and enter Command Line mode. Type **:** and follow that with **x!** (i.e., a colon followed by x and !). Hit **Enter** to save the file. You can also type **wq** to perform the same operation.
|
||||
|
||||
Now you know how to enter text using Insert mode and save the file using **:x!** or **:wq**.
|
||||
|
||||
### Step 3: Basic navigation in Vim
|
||||
|
||||
While you can always use your friendly Up, Down, Left, and Right arrow buttons to move around a file, that would be very difficult in a large file with almost countless lines. It's also helpful to be able to be able to jump around within a line. Although Vim has a ton of awesome navigation features, the first one I want to show you is how to go to a specific line.
|
||||
|
||||
Press the **Esc** key to make sure you are in Normal mode, then type **:set number** and hit **Enter** .
|
||||
|
||||
Voila! You see line numbers on the left side of each line.
|
||||
|
||||
![Showing Line Numbers][12]
|
||||
|
||||
OK, you may say, "that's cool, but how do I jump to a line?" Again, make sure you are in Normal mode, then press **: <LINE_NUMBER>**, where **< LINE_NUMBER>** is the number of the line you want to go to, and press **Enter**. Try moving to line 2.
|
||||
|
||||
```
|
||||
:2
|
||||
```
|
||||
|
||||
Now move to line 3.
|
||||
|
||||
![Jump to line 3][13]
|
||||
|
||||
But imagine a scenario where you are dealing with a file that is 1,000 lines long and you want to go to the end of the file. How do you get there? Make sure you are in Normal mode, then type **:$** and press **Enter**.
|
||||
|
||||
You will be on the last line!
|
||||
|
||||
Now that you know how to jump among the lines, as a bonus, let's learn how to move to the end of a line. Make sure you are on a line with some text, like line 3, and type **$**.
|
||||
|
||||
![Go to the last character][14]
|
||||
|
||||
You're now at the last character on the line. In this example, the open curly brace is highlighted to show where your cursor moved to, and the closing curly brace is highlighted because it is the opening curly brace's matching character.
|
||||
|
||||
That's it for basic navigation in Vim. Wait, don't exit the file, though. Let's move to basic editing in Vim. Feel free to grab a cup of coffee or tea, though.
|
||||
|
||||
### Step 4: Basic editing in Vim
|
||||
|
||||
Now that you know how to navigate around a file by hopping onto the line you want, you can use that skill to do some basic editing in Vim. Switch to Insert mode. (Remember how to do that, by hitting the **i** key?) Sure, you can edit by using the keyboard to delete or insert characters, but Vim offers much quicker ways to edit files.
|
||||
|
||||
Move to line 3, where it shows **public static void main(String[] args) {**. Quickly hit the **d** key twice in succession. Yes, that is **dd**. If you did it successfully, you will see a screen like this, where line 3 is gone, and every following line moved up by one (i.e., line 4 became line 3).
|
||||
|
||||
![Deleting A Line][15]
|
||||
|
||||
That's the _delete_ command. Don't fear! Hit **u** and you will see the deleted line recovered. Whew. This is the _undo_ command.
|
||||
|
||||
![Undoing a change in Vim][16]
|
||||
|
||||
The next lesson is learning how to copy and paste text, but first, you need to learn how to highlight text in Vim. Press **v** and move your Left and Right arrow buttons to select and deselect text. This feature is also very useful when you are showing code to others and want to identify the code you want them to see.
|
||||
|
||||
![Highlighting text in Vim][17]
|
||||
|
||||
Move to line 4, where it says **System.out.println("Hello, Opensource");**. Highlight all of line 4. Done? OK, while line 4 is still highlighted, press **y**. This is called _yank_ mode, and it will copy the text to the clipboard. Next, create a new line underneath by entering **o**. Note that this will put you into Insert mode. Get out of Insert mode by pressing **Esc** , then hit **p** , which stands for _paste_. This will paste the copied text from line 3 to line 4.
|
||||
|
||||
![Pasting in Vim][18]
|
||||
|
||||
As an exercise, repeat these steps but also modify the text on your newly created lines. Also, make sure the lines are aligned well.
|
||||
|
||||
> **Hint:** You need to switch back and forth between Insert mode and Command Line mode to accomplish this task.
|
||||
|
||||
Once you are finished, save the file with the **x!** command. That's all for basic editing in Vim.
|
||||
|
||||
### Step 5: Basic searching in Vim
|
||||
|
||||
Imagine your team lead wants you to change a text string in a project. How can you do that quickly? You might want to search for the line using a certain keyword.
|
||||
|
||||
Vim's search functionality can be very useful. Go into the Command Line mode by (1) pressing **Esc** key, then (2) pressing colon **:** ****key. We can search a keyword by entering : **/ <SEARCH_KEYWORD>**, where **< SEARCH_KEYWORD>** is the text string you want to find. Here we are searching for the keyword string "Hello." In the image below, the colon is missing but required.
|
||||
|
||||
![Searching in Vim][19]
|
||||
|
||||
However, a keyword can appear more than once, and this may not be the one you want. So, how do you navigate around to find the next match? You simply press the **n** key, which stands for _next_. Make sure that you aren't in Insert mode when you do this!
|
||||
|
||||
### Bonus step: Use split mode in Vim
|
||||
|
||||
That pretty much covers all the Vim basics. But, as a bonus, I want to show you a cool Vim feature called _split mode_.
|
||||
|
||||
Get out of _HelloWorld.java_ and create a new file. In a terminal window, type **vim GoodBye.java** and hit **Enter** to create a new file named _GoodBye.java_.
|
||||
|
||||
Enter any text you want; I decided to type "Goodbye." Save the file. (Remember you can use **:x!** or **:wq** in Command Line mode.)
|
||||
|
||||
In Command Line mode, type **:split HelloWorld.java** , and see what happens.
|
||||
|
||||
![Split mode in Vim][20]
|
||||
|
||||
Wow! Look at that! The **split** command created horizontally divided windows with _HelloWorld.java_ above and _GoodBye.java_ below. How can you switch between the windows? Hold **Control** (on a Mac) or **CTRL** (on a PC) then hit **ww** (i.e., **w** twice in succession).
|
||||
|
||||
As a final exercise, try to edit _GoodBye.java_ to match the screen below by copying and pasting from _HelloWorld.java_.
|
||||
|
||||
![Modify GoodBye.java file in Split Mode][21]
|
||||
|
||||
Save both files, and you are done!
|
||||
|
||||
> **TIP 1:** If you want to arrange the files vertically, use the command **:vsplit <FILE_NAME>** (instead of **:split <FILE_NAME>**, where **< FILE_NAME>** is the name of the file you want to open in Split mode.
|
||||
>
|
||||
> **TIP 2:** You can open more than two files by calling as many additional **split** or **vsplit** commands as you want. Try it and see how it looks.
|
||||
|
||||
### Vim cheat sheet
|
||||
|
||||
In this article, you learned how to use Vim just enough to get by for work or a project. But this is just the beginning of your journey to unlock Vim's powerful capabilities. Be sure to check out other great tutorials and tips on Opensource.com.
|
||||
|
||||
To make things a little easier, I've summarized everything you've learned into [a handy cheat sheet][22].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/getting-started-vim
|
||||
|
||||
作者:[Bryant Son (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/1_xkcdcartoon.jpg (Real Programmers comic)
|
||||
[3]: https://xkcd.com/378/
|
||||
[4]: https://kate-editor.org
|
||||
[5]: https://www.nano-editor.org
|
||||
[6]: https://www.vim.org
|
||||
[7]: https://www.gnu.org/software/emacs
|
||||
[8]: https://opensource.com/sites/default/files/uploads/2_createtestfolder.jpg (Create a folder)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/4_existingvim.jpg (Editing Vim)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/6_insertionmode.jpg (Vim insert mode)
|
||||
[11]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||
[12]: https://opensource.com/sites/default/files/uploads/10_setnumberresult_0.jpg (Showing Line Numbers)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/12_jumpintoline3.jpg (Jump to line 3)
|
||||
[14]: https://opensource.com/sites/default/files/uploads/14_gotolastcharacter.jpg (Go to the last character)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/15_deletinglines.jpg (Deleting A Line)
|
||||
[16]: https://opensource.com/sites/default/files/uploads/16_undoingtheline.jpg (Undoing a change in Vim)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/17_highlighting.jpg (Highlighting text in Vim)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/19_pasting.jpg (Pasting in Vim)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/22_searchmode.jpg (Searching in Vim)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/26_copytonewfiles.jpg (Split mode in Vim)
|
||||
[21]: https://opensource.com/sites/default/files/uploads/27_exercise.jpg (Modify GoodBye.java file in Split Mode)
|
||||
[22]: https://opensource.com/downloads/cheat-sheet-vim
|
||||
@ -0,0 +1,166 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Reducing sysadmin toil with Kubernetes controllers)
|
||||
[#]: via: (https://opensource.com/article/19/3/reducing-sysadmin-toil-kubernetes-controllers)
|
||||
[#]: author: (Paul Czarkowski https://opensource.com/users/paulczar)
|
||||
|
||||
Reducing sysadmin toil with Kubernetes controllers
|
||||
======
|
||||
|
||||
Controllers can ease a sysadmin's workload by handling things like creating and managing DNS addresses and SSL certificates.
|
||||
|
||||
![][1]
|
||||
|
||||
Kubernetes is a platform for reducing toil cunningly disguised as a platform for running containers. The element that allows for both running containers and reducing toil is the Kubernetes concept of a **Controller**.
|
||||
|
||||
Most resources in Kubernetes are managed by **kube-controller-manager** , or "controller" for short. A [controller][2] is defined as "a control loop that watches the shared state of a cluster … and makes changes attempting to move the current state toward the desired state." Think of it like this: A Kubernetes controller is to a microservice as a Chef recipe (or an Ansible playbook) is to a monolith.
|
||||
|
||||
Each Kubernetes resource is controlled by its own control loop. This is a step forward from previous systems like Chef or Puppet, which both have control loops at the server level, but not the resource level. A controller is a fairly simple piece of code that creates a control loop over a single resource to ensure the resource is behaving correctly. These control loops can stack together to create complex functionality with simple interfaces.
|
||||
|
||||
The canonical example of this in action is in how we manage Pods in Kubernetes. A Pod is effectively a running copy of an application that a specific worker node is asked to run. If that application crashes, the kubelet running on that node will start it again. However, if that node crashes, the Pod is not recovered, as the control loop (via the kubelet process) responsible for the resource no longer exists. To make applications more resilient, Kubernetes has the ReplicaSet controller.
|
||||
|
||||
The ReplicaSet controller is bundled inside the Kubernetes **controller-manager** , which runs on the Kubernetes master node and contains the controllers for these more advanced resources. The ReplicaSet controller is responsible for ensuring that a set number of copies of your application is always running. To do this, the ReplicaSet controller requests that a given number of Pods is created. It then routinely checks that the correct number of Pods is still running and will request more Pods or destroy existing Pods to do so.
|
||||
|
||||
By requesting a ReplicaSet from Kubernetes, you get a self-healing deployment of your application. You can further add lifecycle management to your workload by requesting [a Deployment][3], which is a controller that manages ReplicaSets and provides rolling upgrades by managing multiple versions of your application's ReplicaSets.
|
||||
|
||||
These controllers are great for managing Kubernetes resources and fantastic for managing resources outside of Kubernetes. The [Cloud Controller Manager][4] is a grouping of Kubernetes controllers that acts on resources external to Kubernetes, specifically resources that provide functionality to Kubernetes on the underlying cloud infrastructure. This is what drives Kubernetes' ability to do things like having a **LoadBalancer** [Service][5] type create and manage a cloud-specific load-balancer (e.g., an Elastic Load Balancer on AWS).
|
||||
|
||||
Furthermore, you can extend Kubernetes by writing a controller that watches for events and annotations and performs extra work, acting on Kubernetes resources or external resources that have some form of programmable API.
|
||||
|
||||
To review:
|
||||
|
||||
* Controllers are a fundamental building block of Kubernetes' functionality.
|
||||
* A controller forms a control loop to ensure that the state of a given resource matches the requested state.
|
||||
* Kubernetes provides controllers via Controller Manager and Cloud Controller Manager processes that provide additional resilience and functionality.
|
||||
* The ReplicaSet controller adds resiliency to pods by ensuring the correct number of replicas is running.
|
||||
* A Deployment controller adds rolling upgrade capabilities to ReplicaSets.
|
||||
* You can extend Kubernetes' functionality by writing your own controllers.
|
||||
|
||||
|
||||
|
||||
### Controllers reduce sysadmin toil
|
||||
|
||||
Some of the most common tickets in a sysadmin's queue are for fairly simple tasks that should be automated, but for various reasons are not. For example, creating or updating a DNS record generally requires updating a [zone file][6], but one bad entry and you can take down your entire DNS infrastructure. Or how about those tickets that look like _[SYSAD-42214] Expired SSL Certificate - Production is down_?
|
||||
|
||||
[![DNS Haiku][7]][8]
|
||||
|
||||
DNS haiku, image by HasturHasturHamster
|
||||
|
||||
What if I told you that Kubernetes could manage these things for you by running some additional controllers?
|
||||
|
||||
Imagine a world where asking Kubernetes to run applications for you would automatically create and manage DNS addresses and SSL certificates. What a world we live in!
|
||||
|
||||
#### Example: External DNS controller
|
||||
|
||||
The **[external-dns][9]** controller is a perfect example of Kubernetes treating operations as a microservice. You configure it with your DNS provider, and it will watch resources including Services and Ingress controllers. When one of those resources changes, it will inspect them for annotations that will tell it when it needs to perform an action.
|
||||
|
||||
With the **external-dns** controller running in your cluster, you can add the following annotation to a service, and it will go out and create a matching [DNS A record][10] for that resource:
|
||||
```
|
||||
kubectl annotate service nginx \
|
||||
"external-dns.alpha.kubernetes.io/hostname=nginx.example.org."
|
||||
```
|
||||
You can change other characteristics, such as the DNS record's TTL value:
|
||||
```
|
||||
kubectl annotate service nginx \
|
||||
"external-dns.alpha.kubernetes.io/ttl=10"
|
||||
```
|
||||
Just like that, you now have automatic DNS management for your applications and services in Kubernetes that reacts to any changes in your cluster to ensure your DNS is correct.
|
||||
|
||||
#### Example: Certificate manager operator
|
||||
|
||||
Like the **external-dns** controller, the [**cert-manager**][11] will react to changes in resources, but it also comes with a custom resource definition (CRD) that will allow you to request certificates as a resource on their own, not just as a byproduct of an annotation.
|
||||
|
||||
**cert-manager** works with [Let's Encrypt][12] and other sources of certificates to request valid, signed Transport Layer Security (TLS) certificates. You can even use it in combination with **external-dns** , like in the following example, which registers **web.example.com** , retrieves a TLS certificate from Let's Encrypt, and stores it in a Secret.
|
||||
|
||||
```
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Ingress
|
||||
metadata:
|
||||
annotations:
|
||||
certmanager.k8s.io/acme-http01-edit-in-place: "true"
|
||||
certmanager.k8s.io/cluster-issuer: letsencrypt-prod
|
||||
kubernetes.io/tls-acme: "true"
|
||||
name: example
|
||||
spec:
|
||||
rules:
|
||||
- host: web.example.com
|
||||
http:
|
||||
paths:
|
||||
- backend:
|
||||
serviceName: example
|
||||
servicePort: 80
|
||||
path: /*
|
||||
tls:
|
||||
- hosts:
|
||||
- web.example.com
|
||||
secretName: example-tls
|
||||
```
|
||||
|
||||
You can also request a certificate directly from the **cert-manager** CRD, like in the following example. As in the above, it will result in a certificate key pair stored in a Kubernetes Secret:
|
||||
```
|
||||
apiVersion: certmanager.k8s.io/v1alpha1
|
||||
kind: Certificate
|
||||
metadata:
|
||||
name: example-com
|
||||
namespace: default
|
||||
spec:
|
||||
secretName: example-com-tls
|
||||
issuerRef:
|
||||
name: letsencrypt-staging
|
||||
commonName: example.com
|
||||
dnsNames:
|
||||
- www.example.com
|
||||
acme:
|
||||
config:
|
||||
- http01:
|
||||
ingressClass: nginx
|
||||
domains:
|
||||
- example.com
|
||||
- http01:
|
||||
ingress: my-ingress
|
||||
domains:
|
||||
- www.example.com
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
This was a quick look at one way Kubernetes is helping enable a new wave of changes in how we operate software. This is one of my favorite topics, and I look forward to sharing more on [Opensource.com][14] and my [blog][15]. I'd also like to hear how you use controllers—message me on Twitter [@pczarkowski][16].
|
||||
|
||||
* * *
|
||||
|
||||
_This article is based on[Cloud Native Operations - Kubernetes Controllers][17] originally published on Paul Czarkowski's blog._
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/reducing-sysadmin-toil-kubernetes-controllers
|
||||
|
||||
作者:[Paul Czarkowski][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/paulczar
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/ship_wheel_gear_devops_kubernetes.png?itok=xm4a74Kv
|
||||
[2]: https://kubernetes.io/docs/reference/command-line-tools-reference/kube-controller-manager/
|
||||
[3]: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
|
||||
[4]: https://kubernetes.io/docs/tasks/administer-cluster/running-cloud-controller/
|
||||
[5]: https://kubernetes.io/docs/concepts/services-networking/service/#publishing-services-service-types
|
||||
[6]: https://en.wikipedia.org/wiki/Zone_file
|
||||
[7]: https://opensource.com/sites/default/files/uploads/dns_haiku.png (DNS Haiku)
|
||||
[8]: https://www.reddit.com/r/sysadmin/comments/4oj7pv/network_solutions_haiku/
|
||||
[9]: https://github.com/kubernetes-incubator/external-dns
|
||||
[10]: https://en.wikipedia.org/wiki/List_of_DNS_record_types#Resource_records
|
||||
[11]: http://docs.cert-manager.io/en/latest/
|
||||
[12]: https://letsencrypt.org/
|
||||
[13]: http://www.example.com
|
||||
[14]: http://Opensource.com
|
||||
[15]: https://tech.paulcz.net/blog/
|
||||
[16]: https://twitter.com/pczarkowski
|
||||
[17]: https://tech.paulcz.net/blog/cloud-native-operations-k8s-controllers/
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bringing Kubernetes to the bare-metal edge)
|
||||
[#]: via: (https://opensource.com/article/19/3/bringing-kubernetes-bare-metal-edge)
|
||||
[#]: author: (John Studarus https://opensource.com/users/studarus)
|
||||
|
||||
Bringing Kubernetes to the bare-metal edge
|
||||
======
|
||||
New Kubespray features enable Kubernetes clusters to be deployed across
|
||||
next-generation edge locations.
|
||||
![cubes coming together to create a larger cube][1]
|
||||
|
||||
[Kubespray][2], a community project that provides Ansible playbooks for the deployment and management of Kubernetes clusters, recently added support for the bare-metal cloud [Packet][3]. This allows Kubernetes clusters to be deployed across next-generation edge locations, including [cell-tower based micro datacenters][4].
|
||||
|
||||
Packet, which is unique in its bare-metal focus, expands Kubespray's support beyond the usual clouds—Amazon Web Services, Google Compute Engine, Azure, OpenStack, vSphere, and Oracle Cloud Infrastructure. Kubespray removes the complexities of standing up a Kubernetes cluster through automation using Terraform and Ansible. Terraform provisions the infrastructure and installs the prerequisites for the Ansible installation. Terraform provider plugins enable support for a variety of different cloud providers. The Ansible playbook then deploys and configures Kubernetes.
|
||||
|
||||
Since there are already [detailed instructions online][5] for deploying with Kubespray on Packet, I'll focus on why bare-metal support is important for Kubernetes and what's required to make it happen.
|
||||
|
||||
### Why bare metal?
|
||||
|
||||
Historically, Kubernetes deployments relied upon the "creature comforts" of a public cloud or a fully managed private cloud to provide virtual machines and networking infrastructure for running Kubernetes. This adds a layer of abstraction (e.g., a hypervisor with virtual machines) that Kubernetes doesn't necessarily need. In fact, Kubernetes began its life on bare metal as Google's Borg.
|
||||
|
||||
As we move workloads closer to the end user (in the form of edge computing) and deploy to more diverse environments (including hybrid and on-premises infrastructure of different architectures and sizes), relying on a homogenous public cloud substrate isn't always possible or ideal. For instance, with edge locations being resource constrained, it is more efficient and practical to run Kubernetes directly on bare metal.
|
||||
|
||||
### Mind the gaps
|
||||
|
||||
Without a full-featured public cloud underneath a bare-metal cluster, some traditional capabilities, such as load balancing and storage orchestration, will need to be managed directly within the Kubernetes cluster. Luckily there are projects, such as [MetalLB][6] and [Rook][7], that provide this support for Kubernetes.
|
||||
|
||||
MetalLB, a Layer 2 and Layer 3 load balancer, is integrated into Kubespray, and it's easy to install support for Rook, which orchestrates Ceph to provide distributed and replicated storage for a Kubernetes cluster, on a bare-metal cluster. In addition to enabling full functionality, this "bring your own" approach to storage and load balancing removes reliance upon specific cloud services, helping you avoid lock-in with an approach that can be installed anywhere.
|
||||
|
||||
Kubespray has support for ARM64 processors. The ARM architecture (which is starting to show up regularly in datacenter-grade hardware, SmartNICs, and other custom accelerators) has a long history in mobile and embedded devices, making it well-suited for edge deployments.
|
||||
|
||||
Going forward, I hope to see deeper integration with MetalLB and Rook as well as bare-metal continuous integration (CI) of daily builds atop a number of different hardware configurations. Access to automated bare metal at Packet enables testing and maintaining support across various processor types, storage options, and networking setups. This will help ensure that Kubespray-powered Kubernetes can be deployed and managed confidently across public clouds, bare metal, and edge environments.
|
||||
|
||||
### It takes a village
|
||||
|
||||
Kubespray is an open source project driven by the community, indebted to its core developers and contributors as well as the folks that assisted with the Packet integration. Contributors include [Maxime Guyot][8] and [Aivars Sterns][9] for the initial commits and code reviews, [Rong Zhang][10] and [Ed Vielmetti][11] for document reviews, as well as [Tomáš Karásek][12] (who maintains the Packet Go library and Terraform provider).
|
||||
|
||||
* * *
|
||||
|
||||
_John Studarus will present[The Open Micro Edge Data Center][13] at the [Open Infrastructure Summit][14], April 29-May 1 in Denver._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/bringing-kubernetes-bare-metal-edge
|
||||
|
||||
作者:[John Studarus][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/studarus
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cube_innovation_process_block_container.png?itok=vkPYmSRQ (cubes coming together to create a larger cube)
|
||||
[2]: https://kubespray.io/
|
||||
[3]: https://www.packet.com/
|
||||
[4]: https://twitter.com/packethost/status/1062147355108085760
|
||||
[5]: https://github.com/kubernetes-sigs/kubespray/blob/master/docs/packet.md
|
||||
[6]: https://metallb.universe.tf/
|
||||
[7]: https://rook.io/
|
||||
[8]: https://twitter.com/Miouge
|
||||
[9]: https://github.com/Atoms
|
||||
[10]: https://github.com/riverzhang
|
||||
[11]: https://twitter.com/vielmetti
|
||||
[12]: https://t0mk.github.io/
|
||||
[13]: https://www.openstack.org/summit/denver-2019/summit-schedule/events/23153/the-open-micro-edge-data-center
|
||||
[14]: https://openstack.org/summit
|
||||
229
sources/tech/20190326 How to use NetBSD on a Raspberry Pi.md
Normal file
229
sources/tech/20190326 How to use NetBSD on a Raspberry Pi.md
Normal file
@ -0,0 +1,229 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to use NetBSD on a Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/netbsd-raspberry-pi)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
How to use NetBSD on a Raspberry Pi
|
||||
======
|
||||
|
||||
Experiment with NetBSD, an open source OS with direct lineage back to the original UNIX source code, on your Raspberry Pi.
|
||||
|
||||
![][1]
|
||||
|
||||
Do you have an old Raspberry Pi lying around gathering dust, maybe after a recent Pi upgrade? Are you curious about [BSD Unix][2]? If you answered "yes" to both of these questions, you'll be pleased to know that the first is the solution to the second, because you can run [NetBSD][3], as far back as the very first release, on a Raspberry Pi.
|
||||
|
||||
BSD is the Berkley Software Distribution of [Unix][4]. In fact, it's the only open source Unix with direct lineage back to the original source code written by Dennis Ritchie and Ken Thompson at Bell Labs. Other modern versions are either proprietary (such as AIX and Solaris) or clever re-implementations (such as Minix and GNU/Linux). If you're used to Linux, you'll feel mostly right at home with BSD, but there are plenty of new commands and conventions to discover. If you're still relatively new to open source, trying BSD is a good way to experience a traditional Unix.
|
||||
|
||||
Admittedly, NetBSD isn't an operating system that's perfectly suited for the Pi. It's a minimal install compared to many Linux distributions designed specifically for the Pi, and not all components of recent Pi models are functional under NetBSD yet. However, it's arguably an ideal OS for the older Pi models, since it's lightweight and lovingly maintained. And if nothing else, it's a lot of fun for any die-hard Unix geek to experience another side of the [POSIX][5] world.
|
||||
|
||||
### Download NetBSD
|
||||
|
||||
There are different versions of BSD. NetBSD has cultivated a reputation for being lightweight and versatile (its website features the tagline "Of course it runs NetBSD"). It offers an image of the latest version of the OS for every version of the Raspberry Pi since the original. To download a version for your Pi, you must first [determine what variant of the ARM architecture your Pi uses][6]. Some information about this is available on the NetBSD site, but for a comprehensive overview, you can also refer to [RPi Hardware History][7].
|
||||
|
||||
The Pi I used for this article is, as far as I can tell, a Raspberry Pi Model B Rev 2.0 (with two USB ports and no mounting holes). According to the [Raspberry Pi FAQ][8], this means the architecture is ARMv6, which translates to **earmv6hf** in NetBSD's architecture notation.
|
||||
|
||||
![NetBSD on Raspberry Pi][9]
|
||||
|
||||
If you're not sure what kind of Pi you have, the good news is that there are only two Pi images, so try **earmv7hf** first; if it doesn't work, fall back to **earmv6hf**.
|
||||
|
||||
For the easiest and quickest install, use the binary image instead of an installer. Using the image is the most common method of getting an OS onto your Pi: you copy the image to your SD card and boot it up. There's no install necessary, because the image is a generic installation of the OS, and you've just copied it, bit for bit, onto the media that the Pi uses as its boot drive.
|
||||
|
||||
The image files are found in the **binary > gzimg** directories of the NetBSD installation media server, which you can reach from the [front page][3] of NetBSD.org. The image is **rpi.img.gz** , a compressed **.img** file. Download it to your hard drive.
|
||||
|
||||
Once you have downloaded the entire image, extract it. If you're running Linux, BSD, or MacOS, you can use the **gunzip** command:
|
||||
|
||||
```
|
||||
$ gunzip ~/Downloads/rpi.img.gz
|
||||
```
|
||||
|
||||
If you're working on Windows, you can install the open source [7-Zip][10] archive utility.
|
||||
|
||||
### Copy the image to your SD card
|
||||
|
||||
Once the image file is uncompressed, you must copy it to your Pi's SD card. There are two ways to do this, so use the one that works best for you.
|
||||
|
||||
#### 1\. Using Etcher
|
||||
|
||||
Etcher is a cross-platform application specifically designed to copy OS images to USB drives and SD cards. Download it from [Etcher.io][11] and launch it.
|
||||
|
||||
In the Etcher interface, select the image file on your hard drive and the SD card you want to flash, then click the Flash button.
|
||||
|
||||
![Etcher][12]
|
||||
|
||||
That's it.
|
||||
|
||||
#### 2\. Using the dd command
|
||||
|
||||
On Linux, BSD, or MacOS, you can use the **dd** command to copy the image to your SD card.
|
||||
|
||||
1. First, insert your SD card into a card reader. Don't mount the card to your system because **dd** needs the device to be disengaged to copy data onto it.
|
||||
|
||||
2. Run **dmesg | tail** to find out where the card is located without it being mounted. On MacOS, use **diskutil list**.
|
||||
|
||||
3. Copy the image file to the SD card:
|
||||
|
||||
```
|
||||
$ sudo dd if=~/Downloads/rpi.img of=/dev/mmcblk0 bs=2M status=progress
|
||||
```
|
||||
|
||||
Before doing this, you _must be sure_ you have the correct location of the SD card. If you copy the image file to the incorrect device, you could lose data. If you are at all unsure about this, use Etcher instead!
|
||||
|
||||
|
||||
|
||||
|
||||
When either **dd** or Etcher has written the image to the SD card, place the card in your Pi and power it on.
|
||||
|
||||
### First boot
|
||||
|
||||
The first time it's booted, NetBSD detects that the SD card's filesystem does not occupy all the free space available and resizes the filesystem accordingly.
|
||||
|
||||
![Booting NetBSD on Raspberry Pi][13]
|
||||
|
||||
Once that's finished, the Pi reboots and presents a login prompt. Log into your NetBSD system using **root** as the user name. No password is required.
|
||||
|
||||
### Set up a user account
|
||||
|
||||
First, set a password for the root user:
|
||||
|
||||
```
|
||||
# passwd
|
||||
```
|
||||
|
||||
Then create a user account for yourself with the **-m** option to prompt NetBSD to create a home directory and the **-G wheel** option to add your account to the wheel group so that you can become the administrative user (root) as needed:
|
||||
|
||||
```
|
||||
# useradd -m -G wheel seth
|
||||
```
|
||||
|
||||
Use the **passwd** command again to set a password for your user account:
|
||||
|
||||
```
|
||||
# passwd seth
|
||||
```
|
||||
|
||||
Log out, and then log back in with your new credentials.
|
||||
|
||||
### Add software to NetBSD
|
||||
|
||||
If you've ever used a Pi, you probably know that the way to add more software to your system is with a special command like **apt** or **dnf** (depending on whether you prefer to run [Raspbian][14] or [FedBerry][15] on your Pi). On NetBSD, use the **pkg_add** command. But some setup is required before the command knows where to go to get the packages you want to install.
|
||||
|
||||
There are ready-made (pre-compiled) packages for NetBSD on NetBSD's servers using the scheme **<[ftp://ftp.netbsd.org/pub/pkgsrc/packages/NetBSD/[PORT]/[VERSION]/All>][16]**. Replace PORT with the architecture you are using, either **earmv6hf** or **earmv7hf**. Replace VERSION with the NetBSD release you are using; at the time of this writing, that's **8.0**.
|
||||
|
||||
Place this value in a file called **/etc/pkg_install.conf**. Since that's a system file outside your user folder, you must invoke root privileges to create it:
|
||||
|
||||
```
|
||||
$ su -
|
||||
<password>
|
||||
# echo "PKG_PATH=<ftp://ftp.NetBSD.org/pub/pkgsrc/packages/NetBSD/earmv6hf/8.0/All/>" >> /etc/pkg_install.conf
|
||||
```
|
||||
|
||||
Now you can install packages from the NetBSD software distribution. A good first candidate is Bash, commonly the default shell on a Linux (and Mac) system. Also, if you're not already a Vi text editor user, you may want to try something more intuitive such as [Jove][17] or [Nano][18]:
|
||||
|
||||
```
|
||||
# pkg_add -v bash jove nano
|
||||
# exit
|
||||
$
|
||||
```
|
||||
|
||||
Unlike many Linux distributions ([Slackware][19] being a notable exception), NetBSD does very little configuration on your behalf, and this is considered a feature. So, to use Bash, Jove, or Nano as your default toolset, you must set the configuration yourself.
|
||||
|
||||
You can set many of your preferences dynamically using environment variables, which are special variables that your whole system can access. For instance, most applications in Unix know that if there is a **VISUAL** or **EDITOR** variable set, the value of those variables should be used as the default text editor. You can set these two variables temporarily, just for your current login session:
|
||||
|
||||
```
|
||||
$ export EDITOR=nano
|
||||
# export VISUAL=nano
|
||||
```
|
||||
|
||||
Or you can make them permanent by adding them to the default NetBSD **.profile** file:
|
||||
|
||||
```
|
||||
$ sed -i 's/EDITOR=vi/EDITOR=nano/' ~/.profile
|
||||
```
|
||||
|
||||
Load your new settings:
|
||||
|
||||
```
|
||||
$ . ~/.profile
|
||||
```
|
||||
|
||||
To make Bash your default shell, use the **chsh** (change shell) command, which now loads into your preferred editor. Before running **chsh** , though, make sure you know where Bash is located:
|
||||
|
||||
```
|
||||
$ which bash
|
||||
/usr/pkg/bin/bash
|
||||
```
|
||||
|
||||
Set the value for **shell** in the **chsh** entry to **/usr/pkg/bin/bash** , then save the document.
|
||||
|
||||
### Add sudo
|
||||
|
||||
The **pkg_add** command is a privileged command, which means to use it, you must become the root user with the **su** command. If you prefer, you can also set up the **sudo** command, which allows certain users to use their own password to execute administrative tasks.
|
||||
|
||||
First, install it:
|
||||
|
||||
```
|
||||
# pkg_add -v sudo
|
||||
```
|
||||
|
||||
And then use the **visudo** command to edit its configuration file. You must use the **visudo** command to edit the **sudo** configuration, and it must be run as root:
|
||||
|
||||
```
|
||||
$ su
|
||||
# SUDO_EDITOR=nano visudo
|
||||
```
|
||||
|
||||
Once you are in the editor, find the line allowing members of the wheel group to execute any command, and uncomment it (by removing **#** from the beginning of the line):
|
||||
|
||||
```
|
||||
### Uncomment to allow members of group wheel to execute any command
|
||||
%wheel ALL=(ALL) ALL
|
||||
```
|
||||
|
||||
Save the document as described in Nano's bottom menu panel and exit the root shell.
|
||||
|
||||
Now you can use **pkg_add** with **sudo** instead of becoming root:
|
||||
|
||||
```
|
||||
$ sudo pkg_add -v fluxbox
|
||||
```
|
||||
|
||||
### Net gain
|
||||
|
||||
NetBSD is a full-featured Unix operating system, and now that you have it set up on your Pi, you can explore every nook and cranny. It happens to be a pretty lightweight OS, so even an old Pi with a 700mHz processor and 256MB of RAM can run it with ease. If this article has sparked your interest and you have an old Pi sitting in a drawer somewhere, try it out!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/netbsd-raspberry-pi
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_development_programming.png?itok=4OM29-82
|
||||
[2]: https://en.wikipedia.org/wiki/Berkeley_Software_Distribution
|
||||
[3]: http://netbsd.org/
|
||||
[4]: https://en.wikipedia.org/wiki/Unix
|
||||
[5]: https://en.wikipedia.org/wiki/POSIX
|
||||
[6]: http://wiki.netbsd.org/ports/evbarm/raspberry_pi
|
||||
[7]: https://elinux.org/RPi_HardwareHistory
|
||||
[8]: https://www.raspberrypi.org/documentation/faqs/
|
||||
[9]: https://opensource.com/sites/default/files/uploads/pi.jpg (NetBSD on Raspberry Pi)
|
||||
[10]: https://www.7-zip.org/
|
||||
[11]: https://www.balena.io/etcher/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/etcher_0.png (Etcher)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/boot.png (Booting NetBSD on Raspberry Pi)
|
||||
[14]: http://raspbian.org/
|
||||
[15]: http://fedberry.org/
|
||||
[16]: ftp://ftp.netbsd.org/pub/pkgsrc/packages/NetBSD/%5BPORT%5D/%5BVERSION%5D/All%3E
|
||||
[17]: https://opensource.com/article/17/1/jove-lightweight-alternative-vim
|
||||
[18]: https://www.nano-editor.org/
|
||||
[19]: http://www.slackware.com/
|
||||
154
sources/tech/20190326 Using Square Brackets in Bash- Part 1.md
Normal file
154
sources/tech/20190326 Using Square Brackets in Bash- Part 1.md
Normal file
@ -0,0 +1,154 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using Square Brackets in Bash: Part 1)
|
||||
[#]: via: (https://www.linux.com/blog/2019/3/using-square-brackets-bash-part-1)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Using Square Brackets in Bash: Part 1
|
||||
======
|
||||
|
||||
![square brackets][1]
|
||||
|
||||
This tutorial tackle square brackets and how they are used in different contexts at the command line.
|
||||
|
||||
[Creative Commons Zero][2]
|
||||
|
||||
After taking a look at [how curly braces (`{}`) work on the command line][3], now it’s time to tackle brackets (`[]`) and see how they are used in different contexts.
|
||||
|
||||
### Globbing
|
||||
|
||||
The first and easiest use of square brackets is in _globbing_. You have probably used globbing before without knowing it. Think of all the times you have listed files of a certain type, say, you wanted to list JPEGs, but not PNGs:
|
||||
|
||||
```
|
||||
ls *.jpg
|
||||
```
|
||||
|
||||
Using wildcards to get all the results that fit a certain pattern is precisely what we call globbing.
|
||||
|
||||
In the example above, the asterisk means " _zero or more characters_ ". There is another globbing wildcard, `?`, which means " _exactly one character_ ", so, while
|
||||
|
||||
```
|
||||
ls d*k*
|
||||
```
|
||||
|
||||
will list files called _darkly_ and _ducky_ (and _dark_ and _duck_ \-- remember `*` can also be zero characters),
|
||||
|
||||
```
|
||||
ls d*k?
|
||||
```
|
||||
|
||||
will not list _darkly_ (or _dark_ or _duck_ ), but it will list _ducky_.
|
||||
|
||||
Square brackets are used in globbing for sets of characters. To see what this means, make directory in which to carry out tests, `cd` into it and create a bunch of files like this:
|
||||
|
||||
```
|
||||
touch file0{0..9}{0..9}
|
||||
```
|
||||
|
||||
(If you don't know why that works, [take a look at the last installment that explains curly braces `{}`][3]).
|
||||
|
||||
This will create files _file000_ , _file001_ , _file002_ , etc., through _file097_ , _file098_ and _file099_.
|
||||
|
||||
Then, to list the files in the 70s and 80s, you can do this:
|
||||
|
||||
```
|
||||
ls file0[78]?
|
||||
```
|
||||
|
||||
To list _file022_ , _file027_ , _file028_ , _file052_ , _file057_ , _file058_ , _file092_ , _file097_ , and _file98_ you can do this:
|
||||
|
||||
```
|
||||
ls file0[259][278]
|
||||
```
|
||||
|
||||
Of course, you can use globbing (and square brackets for sets) for more than just `ls`. You can use globbing with any other tool for listing, removing, moving, or copying files, although the last two may require a bit of lateral thinking.
|
||||
|
||||
Let's say you want to create duplicates of files _file010_ through _file029_ and call the copies _archive010_ , _archive011_ , _archive012_ , etc..
|
||||
|
||||
You can't do:
|
||||
|
||||
```
|
||||
cp file0[12]? archive0[12]?
|
||||
```
|
||||
|
||||
Because globbing is for matching against existing files and directories and the _archive..._ files don't exist yet.
|
||||
|
||||
Doing this:
|
||||
|
||||
```
|
||||
cp file0[12]? archive0[1..2][0..9]
|
||||
```
|
||||
|
||||
won't work either, because `cp` doesn't let you copy many files to other many new files. Copying many files only works if you are copying them to a directory, so this:
|
||||
|
||||
```
|
||||
mkdir archive
|
||||
|
||||
cp file0[12]? archive
|
||||
```
|
||||
|
||||
would work, but it would copy the files, using their same names, into a directory called _archive/_. This is not what you set out to do.
|
||||
|
||||
However, if you look back at [the article on curly braces (`{}`)][3], you will remember how you can use `%` to lop off the end of a string contained in a variable.
|
||||
|
||||
Of course, there is a way you can also lop of the beginning of string contained in a variable. Instead of `%`, you use `#`.
|
||||
|
||||
For practice, you can try this:
|
||||
|
||||
```
|
||||
myvar="Hello World"
|
||||
|
||||
echo Goodbye Cruel ${myvar#Hello}
|
||||
```
|
||||
|
||||
It prints " _Goodbye Cruel World_ " because `#Hello` gets rid of the _Hello_ part at the beginning of the string stored in `myvar`.
|
||||
|
||||
You can use this feature alongside your globbing tools to make your _archive_ duplicates:
|
||||
|
||||
```
|
||||
for i in file0[12]?;\
|
||||
|
||||
do\
|
||||
|
||||
cp $i archive${i#file};\
|
||||
|
||||
done
|
||||
```
|
||||
|
||||
The first line tells the Bash interpreter that you want to loop through all the files that contain the string _file0_ followed by the digits _1_ or _2_ , and then one other character, which can be anything. The second line `do` indicates that what follows is the instruction or list of instructions you want the interpreter to loop through.
|
||||
|
||||
Line 3 is where the actually copying happens, and you use the contents of the loop variable _`i`_ **twice: First, straight out, as the first parameter of the `cp` command, and then you add _archive_ to its contents, while at the same time cutting of _file_. So, if _`i`_ contains, say, _file019_...
|
||||
|
||||
```
|
||||
"archive" + "file019" - "file" = "archive019"
|
||||
```
|
||||
|
||||
the `cp` line is expanded to this:
|
||||
|
||||
```
|
||||
cp file019 archive019
|
||||
```
|
||||
|
||||
Finally, notice how you can use the backslash `\` to split a chain of commands over several lines for clarity.
|
||||
|
||||
In part two, we’ll look at more ways to use square brackets. Stay tuned.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2019/3/using-square-brackets-bash-part-1
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/square-gabriele-diwald-475007-unsplash.jpg?itok=cKmysLfd (square brackets)
|
||||
[2]: https://www.linux.com/LICENSES/CATEGORY/CREATIVE-COMMONS-ZERO
|
||||
[3]: https://www.linux.com/blog/learn/2019/2/all-about-curly-braces-bash
|
||||
235
sources/tech/20190327 How to make a Raspberry Pi gamepad.md
Normal file
235
sources/tech/20190327 How to make a Raspberry Pi gamepad.md
Normal file
@ -0,0 +1,235 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to make a Raspberry Pi gamepad)
|
||||
[#]: via: (https://opensource.com/article/19/3/gamepad-raspberry-pi)
|
||||
[#]: author: (Leon Anavi https://opensource.com/users/leon-anavi)
|
||||
|
||||
How to make a Raspberry Pi gamepad
|
||||
======
|
||||
|
||||
This DIY retro video game controller for the Raspberry Pi is fun and not difficult to build but requires some time.
|
||||
|
||||
![Raspberry Pi Gamepad device][1]
|
||||
|
||||
From time to time, I get nostalgic about the video games I played during my childhood in the late '80s and the '90s. Although most of my old computers and game consoles are long gone, my Raspberry Pi can fulfill my retro-gaming fix. I enjoy the simple games included in Raspbian, and the open source RetroPie project helped me turn my Raspberry Pi into an advanced retro-gaming machine.
|
||||
|
||||
But, for a more authentic experience, like back in the "old days," I needed a gamepad. There are a lot of options on the market for USB gamepads and joysticks, but as an open source enthusiast, maker, and engineer, I prefer doing it the hard way. So, I made my own simple open source hardware gamepad, which I named the [ANAVI Play pHAT][2]. I designed it as an add-on board for Raspberry Pi using an [EEPROM][3] and a devicetree binary overlay I created for mapping the keys.
|
||||
|
||||
### Get the gamepad buttons and EEPROM
|
||||
|
||||
There are a huge variety of gamepads available for purchase, and some of them are really complex. However, it's not hard to make a gamepad similar to the iconic NES controller using the design I created.
|
||||
|
||||
The gamepad uses eight "momentary" buttons (i.e., switches that are active only while they're pushed): four tactile (tact) switches for movement (Up, Down, Left, Right), two tact buttons for A and B, and two smaller tact buttons for Select and Start. I used [through-hole][4] tact switches: six 6x6x4.3mm switches for movement and the A and B buttons, and two 3x6x4.3mm switches for the Start and Select buttons.
|
||||
|
||||
While the gamepad's primary purpose is to play retro games, the add-on board is large enough to include home-automation features, such as monitoring temperature, humidity, light, or barometric pressure, that you can use when you're not playing games. I added three slots for attaching [I2C][5] sensors to the primary I2C bus on physical pins 3 and 5.
|
||||
|
||||
The most interesting and important part of the hardware design is the EEPROM (electrically erasable programmable read-only memory). A through-hole mounted EEPROM is easier to flash on a breadboard and solder to the gamepad. An article in the [MagPi magazine][6] recommends CAT24C32 EEPROM; if that model isn't available, try to find a model with similar technical specifications. All Raspberry Pi models and versions released after 2014 (Raspberry Pi B+ and newer) have a secondary I2C bus on physical pins 27 and 28.
|
||||
|
||||
Once you have this hardware, use a breadboard to check that it works.
|
||||
|
||||
### Create the printed circuit board
|
||||
|
||||
The next step is to create a printed circuit board (PCB) design and have it manufactured. As an open source enthusiast, I believe that free and open source software should be used for creating open source hardware. I rely on [KiCad][7], electronic design automation (EDA) software available under the GPLv3+ license. KiCad works on Windows, MacOS, and GNU/Linux. (I use KiCad version 5 on Ubuntu 18.04.)
|
||||
|
||||
KiCad allows you to create PCBs with up to 32 copper layers plus 14 fixed-purpose technical layers. It also has an integrated 3D viewer. It's actively developed, including many contributions by CERN developers, and used for industrial applications; for example, Olimex uses KiCad to design complex PCBs with multiple layers, like the one in its [TERES-I][8] DIY open source hardware laptop.
|
||||
|
||||
The KiCad workflow includes three major steps:
|
||||
|
||||
* Designing the schematics in the schematic layout editor
|
||||
* Drawing the edge cuts, placing the components, and routing the tracks in the PCB layout editor
|
||||
* Exporting Gerber and drill files for manufacture
|
||||
|
||||
|
||||
|
||||
If you haven't designed PCBs before, keep in mind there is a steep learning curve. Go through the [examples and user's guides][9] provided by KiCad to learn how to work with the schematic and the PCB layout editor. (If you are not in the mood to do everything from scratch, you can just clone the ANAVI Play pHAT project in my [GitHub repository][10].)
|
||||
|
||||
![KiCad schematic][11]
|
||||
|
||||
In KiCad's schematic layout editor, connect the Raspberry Pi's GPIOs to the buttons, the slots for sensors to the primary I2C, and the EEPROM to the secondary I2C. Assign an appropriate footprint to each component. Perform an electrical rule check and, if there are no errors, generate the [netlist][12], which describes an electronic circuit's connectivity.
|
||||
|
||||
Open the PCB layout editor. It contains several layers. Read the netlist. All components and tracks must be on the front and bottom copper layers (F.Cu and B.Cu), and the board's form must be created in the Edge.Cuts layer. Any text, including button labels, must be on the silkscreen layers.
|
||||
|
||||
![Printable circuit board design][13]
|
||||
|
||||
Finally, export the Gerber and drill files that you'll send to the company that will produce your PCB. The Gerber format is the de facto industry standard for PCBs. It is an open ASCII vector format for 2D binary images; simply explained, it is like a PDF for PCB manufacturing.
|
||||
|
||||
There are numerous companies that can make a simple two-layer board like the gamepad's. For a few prototypes, you can count on [OSHPark in the US][14] or [Aisler in Europe][15]. There are also a lot of Chinese manufacturers, such as JLCPCB, PCBWay, ALLPCB, Seeed Studio, and many more. Alternatively, if you prefer to skip the hassle of PCB manufacturing and sourcing components, you can order the [ANAVI Play pHAT maker kit from Crowd Supply][2] and solder all the through-hole components on your own.
|
||||
|
||||
### Understanding devicetree
|
||||
|
||||
[Devicetree][16] is a specification for a software data structure that describes the hardware components. Its purpose is to allow the compiled Linux kernel to handle a variety of different hardware configurations within a wider architecture family. The bootloader loads the devicetree into memory and passes it to the Linux kernel.
|
||||
|
||||
The devicetree includes three components:
|
||||
|
||||
* Devicetree source (DTS)
|
||||
* Devicetree blob (DTB) and overlay (DTBO)
|
||||
* Devicetree compiler (DTC)
|
||||
|
||||
|
||||
|
||||
The DTC creates binaries from a textual source. Devicetree overlays allow a central DTB to be overlaid on the devicetree. Overlays include a number of fragments.
|
||||
|
||||
For several years, a devicetree has been required for all new ARM systems on a chip (SoCs), including Broadcom SoCs in all Raspberry Pi models and versions. With the default bootloader in Raspberry Pi's popular Raspbian distribution, DTO can be set in the configuration file ( **config.txt** ) on the FAT partition of a bootable microSD card using the keyword **device_tree=**.
|
||||
|
||||
Since 2014, the Raspberry Pi's pin header has been extended to 40 pins. Pins 27 and 28 are dedicated for a secondary I2C bus. This way, the DTBO can be automatically loaded from an EEPROM attached to these pins. Furthermore, additional system information can be saved in the EEPROM. This feature is among the Raspberry Pi Foundation's requirements for any Raspberry Pi HAT (hardware attached on top) add-on board. On Raspbian and other GNU/Linux distributions for Raspberry Pi, the information from the EEPROM can be seen from userspace at **/proc/device-tree/hat/** after booting.
|
||||
|
||||
In my opinion, the devicetree is one of the most fascinating features added in the Linux ecosystem over the past decade. Creating devicetree blobs and overlays is an advanced task and requires some background knowledge. However, it's possible to create a devicetree binary overlay for the Raspberry Pi add-on board and flash it on an appropriate EEPROM. The device binary overlay defines the Linux key codes for each key of the gamepad. The result is a gamepad for Raspberry Pi with keys that work as soon as you boot Raspbian.
|
||||
|
||||
#### Creating the DTBO
|
||||
|
||||
There are three major steps to create a devicetree binary overlay for the gamepad:
|
||||
|
||||
* Creating the devicetree source with mapping for the keys based on the Linux key codes
|
||||
* Compiling the devicetree binary overlay using the devicetree compiles
|
||||
* Creating an **.eep** file and flashing it on an EEPROM using the open source tools provided by the Raspberry Pi Foundation
|
||||
|
||||
|
||||
|
||||
Linux key codes are defined in the file **/usr/include/linux/input-event-codes.h**. The device source file should describe which Raspberry Pi GPIO pin is connected to which hardware button and which Linux key code should be triggered when the button is pressed. In this gamepad, GPIO17 (pin 11) is connected to the tactile button for Right, GPIO4 (pin 7) to Left, GPIO22 (pin 15) to Up, GPIO27 (pin 13) to Down, GPIO5 (pin 29) to Start, GPIO6 (pin 31) to Select, GPIO19 (pin 35) to A, and GPIO26 (pin 37) to B.
|
||||
|
||||
Please note there is a difference between the GPIO numbers and the physical position of the pin on the header. For convenience, all pins are located on the second row of the Raspberry Pi's 40-pin header. This approach makes it easier to route the printed circuit board in KiCad.
|
||||
|
||||
The entire devicetree source for the gamepad is [available on GitHub][17]. As an example, the following is a short code snippet that demonstrates how GPIO17, corresponding to physical pin 11 on the Raspberry Pi, is mapped to the tact button for Right:
|
||||
|
||||
```
|
||||
button@17 {
|
||||
label = "right";
|
||||
linux,code = <106>;
|
||||
gpios = <&gpio 17 1>;
|
||||
};
|
||||
```
|
||||
|
||||
To compile the DTS directly on the Raspberry Pi, install the devicetree compiler on Raspbian by executing the following command in the terminal:
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get install device-tree-compiler
|
||||
```
|
||||
Run DTC and provide as arguments the name of the output DTBO and the path to the source file. For example:
|
||||
|
||||
```
|
||||
dtc -I dts -O dtb -o anavi-play-phat.dtbo anavi-play-phat.dts
|
||||
```
|
||||
|
||||
The Raspberry Pi Foundation provides a [GitHub repository with the mechanical, hardware, and software specifications for HATs][18]. It also includes three very convenient tools:
|
||||
|
||||
* **eepmake:** Creates an **.eep** file from a text file with settings
|
||||
* **eepdump:** Useful for debugging, as it dumps a binary **.eep** file as human-readable text
|
||||
* **eepflash:** Writes or reads an **.eep** binary image to/from an EEPROM
|
||||
|
||||
|
||||
|
||||
The **eeprom_settings.txt** file can be used as a template. [The Raspberry Pi Foundation][19] and [MagPi magazine][6] have helpful articles and tutorials, so I won't go into too many details. As I wrote above, the recommended EEPROM is CAT24C32, but it can be replaced with any other EEPROM with the same technical specifications. Using an EEPROM with an eight-pin, through-hole, dual in-line (DIP) package is easier for hobbyists to flash because it can be done with a breadboard. The following example command creates a file ready to be flashed on the EEPROM using the **eepmake** tool from the Raspberry Pi GitHub repository:
|
||||
|
||||
```
|
||||
./eepmake settings.txt settings.eep anavi-play-phat.dtbo
|
||||
```
|
||||
|
||||
Before proceeding with flashing, ensure that the EEPROM is connected properly to the primary I2C bus (pins 3 and 5) on the Raspberry Pi. (You can consult the MagPi magazine article linked above for a discussion on wiring schematics.) Then run the following command and follow the onscreen instructions to flash the **.eep** file on the EEPROM:
|
||||
|
||||
```
|
||||
sudo ./eepflash.sh -w -f=settings.eep -t=24c32
|
||||
```
|
||||
|
||||
Before soldering the EEPROM to the printed circuit board, move it to the secondary I2C bus on the breadboard and test it to ensure it works as expected. If you detect any issues while testing the EEPROM on the breadboard, correct the settings files, move it back to the primary I2C bus, and flash it again.
|
||||
|
||||
### Testing the gamepad
|
||||
|
||||
Now comes the fun part! It is time to test the add-on board using Raspbian, which you can [download][20] from RaspberryPi.org. After booting, open a terminal and enter the following commands:
|
||||
|
||||
```
|
||||
cat /proc/device-tree/hat/product
|
||||
cat /proc/device-tree/hat/vendor
|
||||
```
|
||||
|
||||
The output should be similar to this:
|
||||
|
||||
![Testing output][21]
|
||||
|
||||
If it is, congratulations! The data from the EEPROM has been read successfully.
|
||||
|
||||
The next step is to verify that the keys on the Play pHAT are set properly and working. In a terminal or a text editor, press each of the eight buttons and verify they are acting as configured.
|
||||
|
||||
Finally, it is time to play games! By default, Raspbian's desktop includes [Python Games][22]. Launch them from the application menu. Make an audio output selection and pick a game from the list. My favorite is Wormy, a Snake-like game. As a former Symbian mobile application developer, I find playing Wormy brings back memories of the glorious days of Nokia.
|
||||
|
||||
### Retro gaming with RetroPie
|
||||
|
||||
![RetroPie with the Play pHAT][23]
|
||||
|
||||
Raspbian is amazing, but [RetroPie][24] offers so much more for retro games fans. It is a GNU/Linux distribution optimized for playing retro games and combines the open source projects RetroArch and Emulation Station. It's available for Raspberry Pi, the [Odroid][25] C1/C2, and personal computers running Debian or Ubuntu. It provides emulators for loading ROMs—the digital versions of game cartridges. Keep in mind that no ROMs are included in RetroPie due to copyright issues. You will have to [find appropriate ROMs and copy them][26] to the Raspberry Pi after booting RetroPie.
|
||||
|
||||
The open source hardware gamepad works fine in RetroPie's menus, but I discovered that the keys fail after launching some games and emulators. After debugging, I found a solution to ensuring they work in the game emulators: add a Python script for additional software emulation of the keys. [The script is available on GitHub.][27] Here's how to get it and install Python on RetroPie:
|
||||
|
||||
```
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get install -y python-pip
|
||||
sudo pip install evdev
|
||||
cd ~
|
||||
git clone <https://github.com/AnaviTechnology/anavi-examples.git>
|
||||
```
|
||||
|
||||
Finally, add the following line to **/etc/rc.local** so it will be executed automatically when RetroPie boots:
|
||||
|
||||
```
|
||||
sudo python /home/pi/anavi-examples/anavi-play-phat/anavi-play-gamepad.py &
|
||||
```
|
||||
|
||||
That's it! After following these steps, you can create an entirely open source hardware gamepad as an add-on board for any Raspberry Pi model with a 40-pin header and use it with Raspbian and RetroPie!
|
||||
|
||||
### What's next?
|
||||
|
||||
Combining free and open source software with open source hardware is fun and not difficult, but it requires a significant amount of time. After creating the open source hardware gamepad in my spare time, I ran a modest crowdfunding campaign at [Crowd Supply][2] for low-volume manufacturing in my hometown in Plovdiv, Bulgaria. [The Open Source Hardware Association][28] certified the ANAVI Play pHAT as an open source hardware project under [BG000007][29]. Even [the acrylic enclosures][30] that protect the board from dust are open source hardware created with the free and open source software OpenSCAD.
|
||||
|
||||
![Game pad in acrylic enclosure][31]
|
||||
|
||||
If you enjoyed reading this article, I encourage you to try creating your own open source hardware add-on board for Raspberry Pi with KiCad. If you don't have enough spare time, you can order an [ANAVI Play pHAT maker kit][2], grab your soldering iron, and assemble the through-hole components. If you're not comfortable with the soldering iron, you can just order a fully assembled version.
|
||||
|
||||
Happy retro gaming everybody! Next time someone irritably asks what you can learn from playing vintage computer games, tell them about Raspberry Pi, open source hardware, Linux, and devicetree.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/gamepad-raspberry-pi
|
||||
|
||||
作者:[Leon Anavi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/leon-anavi
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/gamepad_raspberrypi_hardware.jpg?itok=W16gOnay (Raspberry Pi Gamepad device)
|
||||
[2]: https://www.crowdsupply.com/anavi-technology/anavi-play-phat
|
||||
[3]: https://en.wikipedia.org/wiki/EEPROM
|
||||
[4]: https://en.wikipedia.org/wiki/Through-hole_technology
|
||||
[5]: https://en.wikipedia.org/wiki/I%C2%B2C
|
||||
[6]: https://www.raspberrypi.org/magpi/make-your-own-hat/
|
||||
[7]: http://kicad-pcb.org/
|
||||
[8]: https://www.olimex.com/Products/DIY-Laptop/
|
||||
[9]: http://kicad-pcb.org/help/getting-started/
|
||||
[10]: https://github.com/AnaviTechnology/anavi-play-phat
|
||||
[11]: https://opensource.com/sites/default/files/uploads/kicad-schematic.png (KiCad schematic)
|
||||
[12]: https://en.wikipedia.org/wiki/Netlist
|
||||
[13]: https://opensource.com/sites/default/files/uploads/circuitboard.png (Printable circuit board design)
|
||||
[14]: https://oshpark.com/
|
||||
[15]: https://aisler.net/
|
||||
[16]: https://www.devicetree.org/
|
||||
[17]: https://github.com/AnaviTechnology/hats/blob/anavi/eepromutils/anavi-play-phat.dts
|
||||
[18]: https://github.com/raspberrypi/hats
|
||||
[19]: https://www.raspberrypi.org/blog/introducing-raspberry-pi-hats/
|
||||
[20]: https://www.raspberrypi.org/downloads/
|
||||
[21]: https://opensource.com/sites/default/files/uploads/testing-output.png (Testing output)
|
||||
[22]: https://www.raspberrypi.org/documentation/usage/python-games/
|
||||
[23]: https://opensource.com/sites/default/files/uploads/retropie.jpg (RetroPie with the Play pHAT)
|
||||
[24]: https://retropie.org.uk/
|
||||
[25]: https://www.hardkernel.com/product-category/odroid-board/
|
||||
[26]: https://opensource.com/article/19/1/retropie
|
||||
[27]: https://github.com/AnaviTechnology/anavi-examples/blob/master/anavi-play-phat/anavi-play-gamepad.py
|
||||
[28]: https://www.oshwa.org/
|
||||
[29]: https://certification.oshwa.org/bg000007.html
|
||||
[30]: https://github.com/AnaviTechnology/anavi-cases/tree/master/anavi-play-phat
|
||||
[31]: https://opensource.com/sites/default/files/uploads/gamepad-acrylic.jpg (Game pad in acrylic enclosure)
|
||||
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Setting kernel command line arguments with Fedora 30)
|
||||
[#]: via: (https://fedoramagazine.org/setting-kernel-command-line-arguments-with-fedora-30/)
|
||||
[#]: author: (Laura Abbott https://fedoramagazine.org/makes-fedora-kernel/)
|
||||
|
||||
Setting kernel command line arguments with Fedora 30
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Adding options to the kernel command line is a common task when debugging or experimenting with the kernel. The upcoming Fedora 30 release made a change to use Bootloader Spec ([BLS][2]). Depending on how you are used to modifying kernel command line options, your workflow may now change. Read on for more information.
|
||||
|
||||
To determine if your system is running with BLS or the older layout, look in the file
|
||||
|
||||
```
|
||||
/etc/default/grub
|
||||
```
|
||||
|
||||
If you see
|
||||
|
||||
```
|
||||
GRUB_ENABLE_BLSCFG=true
|
||||
```
|
||||
|
||||
in there, you are running with the BLS setup and you may need to change how you set kernel command line arguments.
|
||||
|
||||
If you only want to modify a single kernel entry (for example, to temporarily work around a display problem) you can use a grubby command
|
||||
|
||||
```
|
||||
$ grubby --update-kernel /boot/vmlinuz-5.0.1-300.fc30.x86_64 --args="amdgpu.dc=0"
|
||||
```
|
||||
|
||||
To remove a kernel argument, you can use the
|
||||
|
||||
```
|
||||
--remove-args
|
||||
```
|
||||
argument to grubby
|
||||
|
||||
```
|
||||
$ grubby --update-kernel /boot/vmlinuz-5.0.1-300.fc30.x86_64 --remove-args="amdgpu.dc=0"
|
||||
```
|
||||
|
||||
If there is an option that should be added to every kernel command line (for example, you always want to disable the use of the rdrand instruction for random number generation) you can run a grubby command:
|
||||
|
||||
```
|
||||
$ grubby --update-kernel=ALL --args="nordrand"
|
||||
```
|
||||
|
||||
This will update the command line of all kernel entries and save the option to the saved kernel command line for future entries.
|
||||
|
||||
If you later want to remove the option from all kernels, you can again use
|
||||
|
||||
```
|
||||
--remove-args
|
||||
```
|
||||
with
|
||||
|
||||
```
|
||||
--update-kernel=ALL
|
||||
```
|
||||
|
||||
```
|
||||
$ grubby --update-kernel=ALL --remove-args="nordrand"
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/setting-kernel-command-line-arguments-with-fedora-30/
|
||||
|
||||
作者:[Laura Abbott][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/f30-kernel-1-816x345.jpg
|
||||
[2]: https://fedoraproject.org/wiki/Changes/BootLoaderSpecByDefault
|
||||
@ -0,0 +1,347 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Standardizing WASI: A system interface to run WebAssembly outside the web)
|
||||
[#]: via: (https://hacks.mozilla.org/2019/03/standardizing-wasi-a-webassembly-system-interface/)
|
||||
[#]: author: (Lin Clark https://twitter.com/linclark)
|
||||
|
||||
Standardizing WASI: A system interface to run WebAssembly outside the web
|
||||
======
|
||||
|
||||
Today, we announce the start of a new standardization effort — WASI, the WebAssembly system interface.
|
||||
|
||||
**Why:** Developers are starting to push WebAssembly beyond the browser, because it provides a fast, scalable, secure way to run the same code across all machines.
|
||||
|
||||
But we don’t yet have a solid foundation to build upon. Code outside of a browser needs a way to talk to the system — a system interface. And the WebAssembly platform doesn’t have that yet.
|
||||
|
||||
**What:** WebAssembly is an assembly language for a conceptual machine, not a physical one. This is why it can be run across a variety of different machine architectures.
|
||||
|
||||
Just as WebAssembly is an assembly language for a conceptual machine, WebAssembly needs a system interface for a conceptual operating system, not any single operating system. This way, it can be run across all different OSs.
|
||||
|
||||
This is what WASI is — a system interface for the WebAssembly platform.
|
||||
|
||||
We aim to create a system interface that will be a true companion to WebAssembly and last the test of time. This means upholding the key principles of WebAssembly — portability and security.
|
||||
|
||||
**Who:** We are chartering a WebAssembly subgroup to focus on standardizing [WASI][1]. We’ve already gathered interested partners, and are looking for more to join.
|
||||
|
||||
Here are some of the reasons that we, our partners, and our supporters think this is important:
|
||||
|
||||
### Sean White, Chief R&D Officer of Mozilla
|
||||
|
||||
“WebAssembly is already transforming the way the web brings new kinds of compelling content to people and empowers developers and creators to do their best work on the web. Up to now that’s been through browsers, but with WASI we can deliver the benefits of WebAssembly and the web to more users, more places, on more devices, and as part of more experiences.”
|
||||
|
||||
### Tyler McMullen, CTO of Fastly
|
||||
|
||||
“We are taking WebAssembly beyond the browser, as a platform for fast, safe execution of code in our edge cloud. Despite the differences in environment between our edge and browsers, WASI means WebAssembly developers won’t have to port their code to each different platform.”
|
||||
|
||||
### Myles Borins, Node Technical Steering committee director
|
||||
|
||||
“WebAssembly could solve one of the biggest problems in Node — how to get close-to-native speeds and reuse code written in other languages like C and C++ like you can with native modules, while still remaining portable and secure. Standardizing this system interface is the first step towards making that happen.”
|
||||
|
||||
### Laurie Voss, co-founder of npm
|
||||
|
||||
“npm is tremendously excited by the potential WebAssembly holds to expand the capabilities of the npm ecosystem while hugely simplifying the process of getting native code to run in server-side JavaScript applications. We look forward to the results of this process.”
|
||||
|
||||
So that’s the big news! 🎉
|
||||
|
||||
There are currently 3 implementations of WASI:
|
||||
|
||||
|
||||
+ [wasmtime](https://github.com/CraneStation/wasmtime), Mozilla’s WebAssembly runtime
|
||||
+ [Lucet](https://www.fastly.com/blog/announcing-lucet-fastly-native-webassembly-compiler-runtime), Fastly’s WebAssembly runtime
|
||||
+ [a browser polyfill](https://wasi.dev/polyfill/)
|
||||
|
||||
|
||||
You can see WASI in action in this video:
|
||||
|
||||
<https://www.youtube.com/embed/ggtEJC0Jv8A>
|
||||
|
||||
And if you want to learn more about our proposal for how this system interface should work, keep reading.
|
||||
|
||||
### What’s a system interface?
|
||||
|
||||
Many people talk about languages like C giving you direct access to system resources. But that’s not quite true.
|
||||
|
||||
These languages don’t have direct access to do things like open or create files on most systems. Why not?
|
||||
|
||||
Because these system resources — such as files, memory, and network connections— are too important for stability and security.
|
||||
|
||||
If one program unintentionally messes up the resources of another, then it could crash the program. Even worse, if a program (or user) intentionally messes with the resources of another, it could steal sensitive data.
|
||||
|
||||
[![A frowning terminal window indicating a crash, and a file with a broken lock indicating a data leak][2]][3]
|
||||
|
||||
So we need a way to control which programs and users can access which resources. People figured this out pretty early on, and came up with a way to provide this control: protection ring security.
|
||||
|
||||
With protection ring security, the operating system basically puts a protective barrier around the system’s resources. This is the kernel. The kernel is the only thing that gets to do operations like creating a new file or opening a file or opening a network connection.
|
||||
|
||||
The user’s programs run outside of this kernel in something called user mode. If a program wants to do anything like open a file, it has to ask the kernel to open the file for it.
|
||||
|
||||
[![A file directory structure on the left, with a protective barrier in the middle containing the operating system kernel, and an application knocking for access on the right][4]][5]
|
||||
|
||||
This is where the concept of the system call comes in. When a program needs to ask the kernel to do one of these things, it asks using a system call. This gives the kernel a chance to figure out which user is asking. Then it can see if that user has access to the file before opening it.
|
||||
|
||||
On most devices, this is the only way that your code can access the system’s resources — through system calls.
|
||||
|
||||
[![An application asking the operating system to put data into an open file][6]][7]
|
||||
|
||||
The operating system makes the system calls available. But if each operating system has its own system calls, wouldn’t you need a different version of the code for each operating system? Fortunately, you don’t.
|
||||
|
||||
How is this problem solved? Abstraction.
|
||||
|
||||
Most languages provide a standard library. While coding, the programmer doesn’t need to know what system they are targeting. They just use the interface.
|
||||
|
||||
Then, when compiling, your toolchain picks which implementation of the interface to use based on what system you’re targeting. This implementation uses functions from the operating system’s API, so it’s specific to the system.
|
||||
|
||||
This is where the system interface comes in. For example, `printf` being compiled for a Windows machine could use the Windows API to interact with the machine. If it’s being compiled for Mac or Linux, it will use POSIX instead.
|
||||
|
||||
[![The interface for putc being translated into two different implementations, one implemented using POSIX and one implemented using Windows APIs][8]][9]
|
||||
|
||||
This poses a problem for WebAssembly, though.
|
||||
|
||||
With WebAssembly, you don’t know what kind of operating system you’re targeting even when you’re compiling. So you can’t use any single OS’s system interface inside the WebAssembly implementation of the standard library.
|
||||
|
||||
[![an empty implementation of putc][10]][11]
|
||||
|
||||
I’ve talked before about how WebAssembly is [an assembly language for a conceptual machine][12], not a real machine. In the same way, WebAssembly needs a system interface for a conceptual operating system, not a real operating system.
|
||||
|
||||
But there are already runtimes that can run WebAssembly outside the browser, even without having this system interface in place. How do they do it? Let’s take a look.
|
||||
|
||||
### How is WebAssembly running outside the browser today?
|
||||
|
||||
The first tool for producing WebAssembly was Emscripten. It emulates a particular OS system interface, POSIX, on the web. This means that the programmer can use functions from the C standard library (libc).
|
||||
|
||||
To do this, Emscripten created its own implementation of libc. This implementation was split in two — part was compiled into the WebAssembly module, and the other part was implemented in JS glue code. This JS glue would then call into the browser, which would then talk to the OS.
|
||||
|
||||
[![A Rube Goldberg machine showing how a call goes from a WebAssembly module, into Emscripten's JS glue code, into the browser, into the kernel][13]][14]
|
||||
|
||||
Most of the early WebAssembly code was compiled with Emscripten. So when people started wanting to run WebAssembly without a browser, they started by making Emscripten-compiled code run.
|
||||
|
||||
So these runtimes needed to create their own implementations for all of these functions that were in the JS glue code.
|
||||
|
||||
There’s a problem here, though. The interface provided by this JS glue code wasn’t designed to be a standard, or even a public facing interface. That wasn’t the problem it was solving.
|
||||
|
||||
For example, for a function that would be called something like `read` in an API that was designed to be a public interface, the JS glue code instead uses `_system3(which, varargs)`.
|
||||
|
||||
[![A clean interface for read, vs a confusing one for system3][15]][16]
|
||||
|
||||
The first parameter, `which`, is an integer which is always the same as the number in the name (so 3 in this case).
|
||||
|
||||
The second parameter, `varargs`, are the arguments to use. It’s called `varargs` because you can have a variable number of them. But WebAssembly doesn’t provide a way to pass in a variable number of arguments to a function. So instead, the arguments are passed in via linear memory. This isn’t type safe, and it’s also slower than it would be if the arguments could be passed in using registers.
|
||||
|
||||
That was fine for Emscripten running in the browser. But now runtimes are treating this as a de facto standard, implementing their own versions of the JS glue code. They are emulating an internal detail of an emulation layer of POSIX.
|
||||
|
||||
This means they are re-implementing choices (like passing arguments in as heap values) that made sense based on Emscripten’s constraints, even though these constraints don’t apply in their environments.
|
||||
|
||||
[![A more convoluted Rube Goldberg machine, with the JS glue and browser being emulated by a WebAssembly runtime][17]][18]
|
||||
|
||||
If we’re going to build a WebAssembly ecosystem that lasts for decades, we need solid foundations. This means our de facto standard can’t be an emulation of an emulation.
|
||||
|
||||
But what principles should we apply?
|
||||
|
||||
### What principles does a WebAssembly system interface need to uphold?
|
||||
|
||||
There are two important principles that are baked into WebAssembly :
|
||||
|
||||
* portability
|
||||
* security
|
||||
|
||||
|
||||
|
||||
We need to maintain these key principles as we move to outside-the-browser use cases.
|
||||
|
||||
As it is, POSIX and Unix’s Access Control approach to security don’t quite get us there. Let’s look at where they fall short.
|
||||
|
||||
### Portability
|
||||
|
||||
POSIX provides source code portability. You can compile the same source code with different versions of libc to target different machines.
|
||||
|
||||
[![One C source file being compiled to multiple binaries][19]][20]
|
||||
|
||||
But WebAssembly needs to go one step beyond this. We need to be able to compile once and run across a whole bunch of different machines. We need portable binaries.
|
||||
|
||||
[![One C source file being compiled to a single binary][21]][22]
|
||||
|
||||
This kind of portability makes it much easier to distribute code to users.
|
||||
|
||||
For example, if Node’s native modules were written in WebAssembly, then users wouldn’t need to run node-gyp when they install apps with native modules, and developers wouldn’t need to configure and distribute dozens of binaries.
|
||||
|
||||
### Security
|
||||
|
||||
When a line of code asks the operating system to do some input or output, the OS needs to determine if it is safe to do what the code asks.
|
||||
|
||||
Operating systems typically handle this with access control that is based on ownership and groups.
|
||||
|
||||
For example, the program might ask the OS to open a file. A user has a certain set of files that they have access to.
|
||||
|
||||
When the user starts the program, the program runs on behalf of that user. If the user has access to the file — either because they are the owner or because they are in a group with access — then the program has that same access, too.
|
||||
|
||||
[![An application asking to open a file that is relevant to what it's doing][23]][24]
|
||||
|
||||
This protects users from each other. That made a lot of sense when early operating systems were developed. Systems were often multi-user, and administrators controlled what software was installed. So the most prominent threat was other users taking a peek at your files.
|
||||
|
||||
That has changed. Systems now are usually single user, but they are running code that pulls in lots of other, third party code of unknown trustworthiness. Now the biggest threat is that the code that you yourself are running will turn against you.
|
||||
|
||||
For example, let’s say that the library you’re using in an application gets a new maintainer (as often happens in open source). That maintainer might have your interest at heart… or they might be one of the bad guys. And if they have access to do anything on your system — for example, open any of your files and send them over the network — then their code can do a lot of damage.
|
||||
|
||||
[![An evil application asking for access to the users bitcoin wallet and opening up a network connection][25]][26]
|
||||
|
||||
This is why using third-party libraries that can talk directly to the system can be dangerous.
|
||||
|
||||
WebAssembly’s way of doing security is different. WebAssembly is sandboxed.
|
||||
|
||||
This means that code can’t talk directly to the OS. But then how does it do anything with system resources? The host (which might be a browser, or might be a wasm runtime) puts functions in the sandbox that the code can use.
|
||||
|
||||
This means that the host can limit what a program can do on a program-by-program basis. It doesn’t just let the program act on behalf of the user, calling any system call with the user’s full permissions.
|
||||
|
||||
Just having a mechanism for sandboxing doesn’t make a system secure in and of itself — the host can still put all of the capabilities into the sandbox, in which case we’re no better off — but it at least gives hosts the option of creating a more secure system.
|
||||
|
||||
[![A runtime placing safe functions into the sandbox with an application][27]][28]
|
||||
|
||||
In any system interface we design, we need to uphold these two principles. Portability makes it easier to develop and distribute software, and providing the tools for hosts to secure themselves or their users is an absolute must.,
|
||||
|
||||
### What should this system interface look like?
|
||||
|
||||
Given those two key principles, what should the design of the WebAssembly system interface be?
|
||||
|
||||
That’s what we’ll figure out through the standardization process. We do have a proposal to start with, though:
|
||||
|
||||
* Create a modular set of standard interfaces
|
||||
* Start with standardizing the most fundamental module, wasi-core
|
||||
|
||||
|
||||
|
||||
[![Multiple modules encased in the WASI standards effort][29]][30]
|
||||
|
||||
What will be in wasi-core?
|
||||
|
||||
wasi-core will contain the basics that all programs need. It will cover much of the same ground as POSIX, including things such as files, network connections, clocks, and random numbers.
|
||||
|
||||
And it will take a very similar approach to POSIX for many of these things. For example, it will use POSIX’s file-oriented approach, where you have system calls such as open, close, read, and write and everything else basically provides augmentations on top.
|
||||
|
||||
But wasi-core won’t cover everything that POSIX does. For example, the process concept does not map clearly onto WebAssembly. And beyond that, it doesn’t make sense to say that every WebAssembly engine needs to support process operations like `fork`. But we also want to make it possible to standardize `fork`.
|
||||
|
||||
This is where the modular approach comes in. This way, we can get good standardization coverage while still allowing niche platforms to use only the parts of WASI that make sense for them.
|
||||
|
||||
[![Modules filled in with possible areas for standardization, such as processes, sensors, 3D graphics, etc][31]][32]
|
||||
|
||||
Languages like Rust will use wasi-core directly in their standard libraries. For example, Rust’s `open` is implemented by calling `__wasi_path_open` when it’s compiled to WebAssembly.
|
||||
|
||||
For C and C++, we’ve created a [wasi-sysroot][33] that implements libc in terms of wasi-core functions.
|
||||
|
||||
[![The Rust and C implementations of openat with WASI][34]][35]
|
||||
|
||||
We expect compilers like Clang to be ready to interface with the WASI API, and complete toolchains like the Rust compiler and Emscripten to use WASI as part of their system implementations
|
||||
|
||||
How does the user’s code call these WASI functions?
|
||||
|
||||
The runtime that is running the code passes the wasi-core functions in as imports.
|
||||
|
||||
[![A runtime placing an imports object into the sandbox][36]][37]
|
||||
|
||||
This gives us portability, because each host can have their own implementation of wasi-core that is specifically written for their platform — from WebAssembly runtimes like Mozilla’s wasmtime and Fastly’s Lucet, to Node, or even the browser.
|
||||
|
||||
It also gives us sandboxing because the host can choose which wasi-core functions to pass in — so, which system calls to allow — on a program-by-program basis. This preserves security.
|
||||
|
||||
[
|
||||
][38][![Three runtimes—wastime, Node, and the browser—passing their own implementations of wasi_fd_open into the sandbox][39]][40]
|
||||
|
||||
WASI gives us a way to extend this security even further. It brings in more concepts from capability-based security.
|
||||
|
||||
Traditionally, if code needs to open a file, it calls `open` with a string, which is the path name. Then the OS does a check to see if the code has permission (based on the user who started the program).
|
||||
|
||||
With WASI, if you’re calling a function that needs to access a file, you have to pass in a file descriptor, which has permissions attached to it. This could be for the file itself, or for a directory that contains the file.
|
||||
|
||||
This way, you can’t have code that randomly asks to open `/etc/passwd`. Instead, the code can only operate on the directories that are passed in to it.
|
||||
|
||||
[![Two evil apps in sandboxes. The one on the left is using POSIX and succeeds at opening a file it shouldn't have access to. The other is using WASI and can't open the file.][41]][42]
|
||||
|
||||
This makes it possible to safely give sandboxed code more access to different system calls — because the capabilities of these system calls can be limited.
|
||||
|
||||
And this happens on a module-by-module basis. By default, a module doesn’t have any access to file descriptors. But if code in one module has a file descriptor, it can choose to pass that file descriptor to functions it calls in other modules. Or it can create more limited versions of the file descriptor to pass to the other functions.
|
||||
|
||||
So the runtime passes in the file descriptors that an app can use to the top level code, and then file descriptors get propagated through the rest of the system on an as-needed basis.
|
||||
|
||||
[![The runtime passing a directory to the app, and then then app passing a file to a function][43]][44]
|
||||
|
||||
This gets WebAssembly closer to the principle of least privilege, where a module can only access the exact resources it needs to do its job.
|
||||
|
||||
These concepts come from capability-oriented systems, like CloudABI and Capsicum. One problem with capability-oriented systems is that it is often hard to port code to them. But we think this problem can be solved.
|
||||
|
||||
If code already uses `openat` with relative file paths, compiling the code will just work.
|
||||
|
||||
If code uses `open` and migrating to the `openat` style is too much up-front investment, WASI can provide an incremental solution. With [libpreopen][45], you can create a list of file paths that the application legitimately needs access to. Then you can use `open`, but only with those paths.
|
||||
|
||||
### What’s next?
|
||||
|
||||
We think wasi-core is a good start. It preserves WebAssembly’s portability and security, providing a solid foundation for an ecosystem.
|
||||
|
||||
But there are still questions we’ll need to address after wasi-core is fully standardized. Those questions include:
|
||||
|
||||
* asynchronous I/O
|
||||
* file watching
|
||||
* file locking
|
||||
|
||||
|
||||
|
||||
This is just the beginning, so if you have ideas for how to solve these problems, [join us][1]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hacks.mozilla.org/2019/03/standardizing-wasi-a-webassembly-system-interface/
|
||||
|
||||
作者:[Lin Clark][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/linclark
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://wasi.dev/
|
||||
[2]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/01-01_crash-data-leak-1-500x220.png
|
||||
[3]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/01-01_crash-data-leak-1.png
|
||||
[4]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/01-02-protection-ring-sec-1-500x298.png
|
||||
[5]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/01-02-protection-ring-sec-1.png
|
||||
[6]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/01-03-syscall-1-500x227.png
|
||||
[7]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/01-03-syscall-1.png
|
||||
[8]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/02-01-implementations-1-500x267.png
|
||||
[9]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/02-01-implementations-1.png
|
||||
[10]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/02-02-implementations-1-500x260.png
|
||||
[11]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/02-02-implementations-1.png
|
||||
[12]: https://hacks.mozilla.org/2017/02/creating-and-working-with-webassembly-modules/
|
||||
[13]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/03-01-emscripten-1-500x329.png
|
||||
[14]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/03-01-emscripten-1.png
|
||||
[15]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/03-02-system3-1-500x179.png
|
||||
[16]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/03-02-system3-1.png
|
||||
[17]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/03-03-emulation-1-500x341.png
|
||||
[18]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/03-03-emulation-1.png
|
||||
[19]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/04-01-portability-1-500x375.png
|
||||
[20]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/04-01-portability-1.png
|
||||
[21]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/04-02-portability-1-500x484.png
|
||||
[22]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/04-02-portability-1.png
|
||||
[23]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/04-03-access-control-1-500x224.png
|
||||
[24]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/04-03-access-control-1.png
|
||||
[25]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/04-04-bitcoin-1-500x258.png
|
||||
[26]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/04-04-bitcoin-1.png
|
||||
[27]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/04-05-sandbox-1-500x278.png
|
||||
[28]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/04-05-sandbox-1.png
|
||||
[29]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-01-wasi-1-500x419.png
|
||||
[30]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-01-wasi-1.png
|
||||
[31]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-02-wasi-1-500x251.png
|
||||
[32]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-02-wasi-1.png
|
||||
[33]: https://github.com/CraneStation/wasi-sysroot
|
||||
[34]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-03-open-imps-1-500x229.png
|
||||
[35]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-03-open-imps-1.png
|
||||
[36]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-04-imports-1-500x285.png
|
||||
[37]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-04-imports-1.png
|
||||
[38]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-05-sec-port-1.png
|
||||
[39]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-05-sec-port-2-500x705.png
|
||||
[40]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-05-sec-port-2.png
|
||||
[41]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-06-openat-path-1-500x192.png
|
||||
[42]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-06-openat-path-1.png
|
||||
[43]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-07-file-perms-1-500x423.png
|
||||
[44]: https://2r4s9p1yi1fa2jd7j43zph8r-wpengine.netdna-ssl.com/files/2019/03/05-07-file-perms-1.png
|
||||
[45]: https://github.com/musec/libpreopen
|
||||
108
sources/tech/20190328 How to run PostgreSQL on Kubernetes.md
Normal file
108
sources/tech/20190328 How to run PostgreSQL on Kubernetes.md
Normal file
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to run PostgreSQL on Kubernetes)
|
||||
[#]: via: (https://opensource.com/article/19/3/how-run-postgresql-kubernetes)
|
||||
[#]: author: (Jonathan S. Katz https://opensource.com/users/jkatz05)
|
||||
|
||||
How to run PostgreSQL on Kubernetes
|
||||
======
|
||||
Create uniformly managed, cloud-native production deployments with the
|
||||
flexibility to deploy a personalized database-as-a-service.
|
||||
![cubes coming together to create a larger cube][1]
|
||||
|
||||
By running a [PostgreSQL][2] database on [Kubernetes][3], you can create uniformly managed, cloud-native production deployments with the flexibility to deploy a personalized database-as-a-service tailored to your specific needs.
|
||||
|
||||
Using an Operator allows you to provide additional context to Kubernetes to [manage a stateful application][4]. An Operator is also helpful when using an open source database like PostgreSQL to help with actions including provisioning, scaling, high availability, and user management.
|
||||
|
||||
Let's explore how to get PostgreSQL up and running on Kubernetes.
|
||||
|
||||
### Set up the PostgreSQL operator
|
||||
|
||||
The first step to using PostgreSQL with Kubernetes is installing an Operator. You can get up and running with the open source [Crunchy PostgreSQL Operator][5] on any Kubernetes-based environment with the help of Crunchy's [quickstart script][6] for Linux.
|
||||
|
||||
The quickstart script has a few prerequisites:
|
||||
|
||||
* The [Wget][7] utility installed
|
||||
* [kubectl][8] installed
|
||||
* A [StorageClass][9] defined on your Kubernetes cluster
|
||||
* Access to a Kubernetes user account with cluster-admin privileges. This is required to install the Operator [RBAC][10] rules
|
||||
* A [namespace][11] to hold the PostgreSQL Operator
|
||||
|
||||
|
||||
|
||||
Executing the script will give you a default PostgreSQL Operator deployment that assumes [dynamic storage][12] and a StorageClass named **standard**. User-provided values are allowed by the script to override these defaults.
|
||||
|
||||
You can download the quickstart script and set it to be executable with the following commands:
|
||||
|
||||
```
|
||||
wget <https://raw.githubusercontent.com/CrunchyData/postgres-operator/master/examples/quickstart.sh>
|
||||
chmod +x ./quickstart.sh
|
||||
```
|
||||
|
||||
Then you can execute the quickstart script:
|
||||
|
||||
```
|
||||
./examples/quickstart.sh
|
||||
```
|
||||
|
||||
After the script prompts you for some basic information about your Kubernetes cluster, it performs the following operations:
|
||||
|
||||
* Downloads the Operator configuration files
|
||||
* Sets the **$HOME/.pgouser** file to default settings
|
||||
* Deploys the Operator as a Kubernetes [Deployment][13]
|
||||
* Sets your **.bashrc** to include the Operator environmental variables
|
||||
* Sets your **$HOME/.bash_completion** file to be the **pgo bash_completion** file
|
||||
|
||||
|
||||
|
||||
During the quickstart's execution, you'll be prompted to set up the RBAC rules for your Kubernetes cluster. In a separate terminal, execute the command the quickstart command tells you to use.
|
||||
|
||||
Once the script completes, you'll get information on setting up a port forward to the PostgreSQL Operator pod. In a separate terminal, execute the port forward; this will allow you to begin executing commands to the PostgreSQL Operator! Try creating a cluster by entering:
|
||||
|
||||
```
|
||||
pgo create cluster mynewcluster
|
||||
```
|
||||
|
||||
You can test that your cluster is up and running with by entering:
|
||||
|
||||
```
|
||||
pgo test mynewcluster
|
||||
```
|
||||
|
||||
You can now manage your PostgreSQL databases in your Kubernetes environment! You can find a full reference to commands, including those for scaling, high availability, backups, and more, in the [documentation][14].
|
||||
|
||||
* * *
|
||||
|
||||
_Parts of this article are based on[Get Started Running PostgreSQL on Kubernetes][15] that the author wrote for the Crunchy blog._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/how-run-postgresql-kubernetes
|
||||
|
||||
作者:[Jonathan S. Katz][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jkatz05
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cube_innovation_process_block_container.png?itok=vkPYmSRQ (cubes coming together to create a larger cube)
|
||||
[2]: https://www.postgresql.org/
|
||||
[3]: https://kubernetes.io/
|
||||
[4]: https://opensource.com/article/19/2/scaling-postgresql-kubernetes-operators
|
||||
[5]: https://github.com/CrunchyData/postgres-operator
|
||||
[6]: https://crunchydata.github.io/postgres-operator/stable/installation/#quickstart-script
|
||||
[7]: https://www.gnu.org/software/wget/
|
||||
[8]: https://kubernetes.io/docs/tasks/tools/install-kubectl/
|
||||
[9]: https://kubernetes.io/docs/concepts/storage/storage-classes/
|
||||
[10]: https://kubernetes.io/docs/reference/access-authn-authz/rbac/
|
||||
[11]: https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
|
||||
[12]: https://kubernetes.io/docs/concepts/storage/dynamic-provisioning/
|
||||
[13]: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
|
||||
[14]: https://crunchydata.github.io/postgres-operator/stable/#documentation
|
||||
[15]: https://info.crunchydata.com/blog/get-started-runnning-postgresql-on-kubernetes
|
||||
@ -0,0 +1,102 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to submit a bug report with Bugzilla)
|
||||
[#]: via: (https://opensource.com/article/19/3/bug-reporting)
|
||||
[#]: author: (David Both (Community Moderator) https://opensource.com/users/dboth)
|
||||
|
||||
How to submit a bug report with Bugzilla
|
||||
======
|
||||
|
||||
Submitting bug reports is an easy way to give back and it helps everyone.
|
||||
|
||||
![][1]
|
||||
|
||||
I spend a lot of time doing research for my books and [Opensource.com][2] articles. Sometimes this leads me to discover bugs in the software I use, including Fedora and the Linux kernel. As a long-time Linux user and sysadmin, I have benefited greatly from GNU/Linux, and I like to give back. I am not a C language programmer, so I don't create fixes and submit them with bug reports, as some people do. But a way I can return some value to the Linux community is by reporting bugs.
|
||||
|
||||
Product maintainers use a lot of tools to let their users search for existing bugs and report new ones. Bugzilla is a popular tool, and I use the Red Hat [Bugzilla][3] website to report Fedora-related bugs because I primarily use Fedora on the systems I'm responsible for. It's an easy process, but it may seem daunting if you have never done it before. So let's start with the basics.
|
||||
|
||||
### Start with a search
|
||||
|
||||
Even though it's tempting, never assume that seemingly anomalous behavior is the result of a bug. I always start with a search of relevant websites, such as the [Fedora wiki][4], the [CentOS wiki][5], and the documentation for the distro I'm using. I also try to check the various distro listservs.
|
||||
|
||||
If it appears that no one has encountered this problem before (or if they have, they haven't reported it as a bug), I go to the Red Hat Bugzilla site and begin searching for a bug report that might come close to matching the symptoms I encountered.
|
||||
|
||||
You can search the Red Hat Bugzilla site without an account. Go to the Bugzilla site and click on the [Advanced Search tab][6].
|
||||
|
||||
![Searching for a bug][7]
|
||||
|
||||
For example, if you want to search for bug reports related to Fedora's Rescue mode kernel, enter the following data in the Advanced Search form.
|
||||
|
||||
Field | Logic | Data or Selection
|
||||
---|---|---
|
||||
Summary | Contains the string | Rescue mode kernel
|
||||
Classification | | Fedora
|
||||
Product | | Fedora
|
||||
Component | | grub2
|
||||
Status | | New + Assigned
|
||||
|
||||
Then press **Search**. This returns a list of one bug with the ID 1654337 (which happens to be a bug I reported).
|
||||
|
||||
![Bug report list][8]
|
||||
|
||||
Click on the ID to view my bug report details. I entered as much relevant data as possible in the top section of the report. In the comments, I described the problem and included supporting files, other relevant comments (such as the fact that the problem occurred on multiple motherboards), and the steps to reproduce the problem.
|
||||
|
||||
![Bug report details][9]
|
||||
|
||||
The more information you can provide here that pertains to the bug, such as symptoms, the hardware and software environments (if they are applicable), other software that was running at the time, kernel and distro release levels, and so on, the easier it will be to determine where to assign your bug. In this case, I originally chose the kernel component, but it was quickly changed to the GRUB2 component because the problem occurred before the kernel loaded.
|
||||
|
||||
### How to submit a bug report
|
||||
|
||||
The Red Hat [Bugzilla][3] website requires an account to submit new bugs or comment on old ones. It is easy to sign up. On Bugzilla's main page, click **Open a New Account** and fill in the requested information. After you verify your email address, you can fill in the rest of the information to create your account.
|
||||
|
||||
_**Advisory:**_ _Bugzilla is a working website that people count on for support. I strongly suggest not creating an account unless you intend to submit bug reports or comment on existing bugs._
|
||||
|
||||
To demonstrate how to submit a bug report, I'll use a fictional example of creating a bug against the Xfce4-terminal emulator in Fedora. _Please do not do this unless you have a real bug to report._
|
||||
|
||||
Log into your account and click on **New** in the menu bar or the **File a Bug** button. You'll need to select a classification for the bug to continue the process. This will narrow down some of the choices on the next page.
|
||||
|
||||
The following image shows how I filled out the required fields (and a couple of others that are not required).
|
||||
|
||||
![Reporting a bug][10]
|
||||
|
||||
When you type a short problem description in the **Summary** field, Bugzilla displays a list of other bugs that might match yours. If one matches, click **Add Me to the CC List** to receive emails when changes are made to the bug.
|
||||
|
||||
If none match, fill in the information requested in the **Description** field. Add as much information as you can, including error messages and screen captures that illustrate the problem. Be sure to describe the exact steps needed to reproduce the problem and how reproducible it is: does it fail every time, every second, third, fourth, random time, or whatever. If it happened only once, it's very unlikely anyone will be able to reproduce the problem you observed.
|
||||
|
||||
When you finish adding as much information as you can, press **Submit Bug**.
|
||||
|
||||
### Be kind
|
||||
|
||||
Bug reporting websites are not for asking questions—they are for searching and reporting bugs. That means you must have performed some work on your own to conclude that there really is a bug. There are many wikis, listservs, and Q&A websites that are appropriate for asking questions. Use sites like Bugzilla to search for existing bug reports on the problem you have found.
|
||||
|
||||
Be sure you submit your bugs on the correct bug reporting website. For example, only submit bugs about Red Hat products on the Red Hat Bugzilla, and submit bugs about LibreOffice by following [LibreOffice's instructions][11].
|
||||
|
||||
Reporting bugs is not difficult, and it is an important way to participate.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/bug-reporting
|
||||
|
||||
作者:[David Both (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bug-insect-butterfly-diversity-inclusion-2.png?itok=TcC9eews
|
||||
[2]: http://Opensource.com
|
||||
[3]: https://bugzilla.redhat.com/
|
||||
[4]: https://fedoraproject.org/wiki/
|
||||
[5]: https://wiki.centos.org/
|
||||
[6]: https://bugzilla.redhat.com/query.cgi?format=advanced
|
||||
[7]: https://opensource.com/sites/default/files/uploads/bugreporting-1.png (Searching for a bug)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/bugreporting-2.png (Bug report list)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/bugreporting-4.png (Bug report details)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/bugreporting-3.png (Reporting a bug)
|
||||
[11]: https://wiki.documentfoundation.org/QA/BugReport
|
||||
@ -0,0 +1,176 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (ShadowReader: Serverless load tests for replaying production traffic)
|
||||
[#]: via: (https://opensource.com/article/19/3/shadowreader-serverless)
|
||||
[#]: author: (Yuki Sawa https://opensource.com/users/yukisawa1/users/yongsanchez)
|
||||
|
||||
ShadowReader: Serverless load tests for replaying production traffic
|
||||
======
|
||||
This open source tool recreates serverless production conditions to
|
||||
pinpoint causes of memory leaks and other errors that aren't visible in
|
||||
the QA environment.
|
||||
![Traffic lights at night][1]
|
||||
|
||||
While load testing has become more accessible, configuring load tests that faithfully re-create production conditions can be difficult. A good load test must use a set of URLs that are representative of production traffic and achieve request rates that mimic real users. Even performing distributed load tests requires the upkeep of a fleet of servers.
|
||||
|
||||
[ShadowReader][2] aims to solve these problems. It gathers URLs and request rates straight from production logs and replays them using AWS Lambda. Being serverless, it is more cost-efficient and performant than traditional distributed load tests; in practice, it has scaled beyond 50,000 requests per minute.
|
||||
|
||||
At Edmunds, we have been able to utilize these capabilities to solve problems, such as Node.js memory leaks that were happening only in production, by recreating the same conditions in our QA environment. We're also using it daily to generate load for pre-production canary deployments.
|
||||
|
||||
The memory leak problem we faced in our Node.js application confounded our engineering team; as it was only occurring in our production environment; we could not reproduce it in QA until we introduced ShadowReader to replay production traffic into QA.
|
||||
|
||||
### The incident
|
||||
|
||||
On Christmas Eve 2017, we suffered an incident where there was a jump in response time across the board with error rates tripling and impacting many users of our website.
|
||||
|
||||
![Christmas Eve 2017 incident][3]
|
||||
|
||||
![Christmas Eve 2017 incident][4]
|
||||
|
||||
Monitoring during the incident helped identify and resolve the issue quickly, but we still needed to understand the root cause.
|
||||
|
||||
At Edmunds, we leverage a robust continuous delivery (CD) pipeline that releases new updates to production multiple times a day. We also dynamically scale up our applications to accommodate peak traffic and scale down to save costs. Unfortunately, this had the side effect of masking a memory leak.
|
||||
|
||||
In our investigation, we saw that the memory leak had existed for weeks, since early December. Memory usage would climb to 60%, along with a slow increase in 99th percentile response time.
|
||||
|
||||
Between our CD pipeline and autoscaling events, long-running containers were frequently being shut down and replaced by newer ones. This inadvertently masked the memory leak until December, when we decided to stop releasing software to ensure stability during the holidays.
|
||||
|
||||
![Slow increase in 99th percentile response time][5]
|
||||
|
||||
### Our CD pipeline
|
||||
|
||||
At a glance, Edmunds' CD pipeline looks like this:
|
||||
|
||||
1. Unit test
|
||||
2. Build a Docker image for the application
|
||||
3. Integration test
|
||||
4. Load test/performance test
|
||||
5. Canary release
|
||||
|
||||
|
||||
|
||||
The solution is fully automated and requires no manual cutover. The final step is a canary deployment directly into the live website, allowing us to release multiple times a day.
|
||||
|
||||
For our load testing, we leveraged custom tooling built on top of JMeter. It takes random samples of production URLs and can simulate various percentages of traffic. Unfortunately, however, our load tests were not able to reproduce the memory leak in any of our pre-production environments.
|
||||
|
||||
### Solving the memory leak
|
||||
|
||||
When looking at the memory patterns in QA, we noticed there was a very healthy pattern. Our initial hypothesis was that our JMeter load testing in QA was unable to simulate production traffic in a way that allows us to predict how our applications will perform.
|
||||
|
||||
While the load test takes samples from production URLs, it can't precisely simulate the URLs customers use and the exact frequency of calls (i.e., the burst rate).
|
||||
|
||||
Our first step was to re-create the problem in QA. We used a new tool called ShadowReader, a project that evolved out of our hackathons. While many projects we considered were product-focused, this was the only operations-centric one. It is a load-testing tool that runs on AWS Lambda and can replay production traffic and usage patterns against our QA environment.
|
||||
|
||||
The results it returned were immediate:
|
||||
|
||||
![QA results in ShadowReader][6]
|
||||
|
||||
Knowing that we could re-create the problem in QA, we took the additional step to point ShadowReader to our local environment, as this allowed us to trigger Node.js heap dumps. After analyzing the contents of the dumps, it was obvious the memory leak was coming from two excessively large objects containing only strings. At the time the snapshot dumped, these objects contained 373MB and 63MB of strings!
|
||||
|
||||
![Heap dumps show source of memory leak][7]
|
||||
|
||||
We found that both objects were temporary lookup caches containing metadata to be used on the client side. Neither of these caches was ever intended to be persisted on the server side. The user's browser cached only its own metadata, but on the server side, it cached the metadata for all users. This is why we were unable to reproduce the leak with synthetic testing. Synthetic tests always resulted in the same fixed set of metadata in the server-side caches. The leak surfaced only when we had a sufficient amount of unique metadata being generated from a variety of users.
|
||||
|
||||
Once we identified the problem, we were able to remove the large caches that we observed in the heap dumps. We've since instrumented the application to start collecting metrics that can help detect issues like this faster.
|
||||
|
||||
![Collecting metrics][8]
|
||||
|
||||
After making the fix in QA, we saw that the memory usage was constant and the leak was plugged.
|
||||
|
||||
![Graph showing memory leak fixed][9]
|
||||
|
||||
### What is ShadowReader?
|
||||
|
||||
ShadowReader is a serverless load-testing framework powered by AWS Lambda and S3 to replay production traffic. It mimics real user traffic by replaying URLs from production at the same rate as the live website. We are happy to announce that after months of internal usage, we have released it as open source!
|
||||
|
||||
#### Features
|
||||
|
||||
* ShadowReader mimics real user traffic by replaying user requests (URLs). It can also replay certain headers, such as True-Client-IP and User-Agent, along with the URL.
|
||||
|
||||
|
||||
* It is more efficient cost- and performance-wise than traditional distributed load tests that run on a fleet of servers. Managing a fleet of servers for distributed load testing can cost $1,000 or more per month; with a serverless stack, it can be reduced to $100 per month by provisioning compute resources on demand.
|
||||
|
||||
|
||||
* We've scaled it up to 50,000 requests per minute, but it should be able to handle more than 100,000 reqs/min.
|
||||
|
||||
|
||||
* New load tests can be spun up and stopped instantly, unlike traditional load-testing tools, which can take many minutes to generate the test plan and distribute the test data to the load-testing servers.
|
||||
|
||||
|
||||
* It can ramp traffic up or down by a percentage value to function as a more traditional load test.
|
||||
|
||||
|
||||
* Its plugin system enables you to switch out plugins to change its behavior. For instance, you can switch from past replay (i.e., replays past requests) to live replay (i.e., replays requests as they come in).
|
||||
|
||||
|
||||
* Currently, it can replay logs from the [Application Load Balancer][10] and [Classic Load Balancer][11] Elastic Load Balancers (ELBs), and support for other load balancers is coming soon.
|
||||
|
||||
|
||||
|
||||
### How it works
|
||||
|
||||
ShadowReader is composed of four different Lambdas: a Parser, an Orchestrator, a Master, and a Worker.
|
||||
|
||||
![ShadowReader architecture][12]
|
||||
|
||||
When a user visits a website, a load balancer (in this case, an ELB) typically routes the request. As the ELB routes the request, it will log the event and ship it to S3.
|
||||
|
||||
Next, ShadowReader triggers a Parser Lambda every minute via a CloudWatch event, which parses the latest access (ELB) logs on S3 for that minute, then ships the parsed URLs into another S3 bucket.
|
||||
|
||||
On the other side of the system, ShadowReader also triggers an Orchestrator lambda every minute. This Lambda holds the configurations and state of the system.
|
||||
|
||||
The Orchestrator then invokes a Master Lambda function. From the Orchestrator, the Master receives information on which time slice to replay and downloads the respective data from the S3 bucket of parsed URLs (deposited there by the Parser).
|
||||
|
||||
The Master Lambda divides the load-test URLs into smaller batches, then invokes and passes each batch into a Worker Lambda. If 800 requests must be sent out, then eight Worker Lambdas will be invoked, each one handling 100 URLs.
|
||||
|
||||
Finally, the Worker receives the URLs passed from the Master and starts load-testing the chosen test environment.
|
||||
|
||||
### The bigger picture
|
||||
|
||||
The challenge of reproducibility in load testing serverless infrastructure becomes increasingly important as we move from steady-state application sizing to on-demand models. While ShadowReader is designed and used with Edmunds' infrastructure in mind, any application leveraging ELBs can take full advantage of it. Soon, it will have support to replay the traffic of any service that generates traffic logs.
|
||||
|
||||
As the project moves forward, we would love to see it evolve to be compatible with next-generation serverless runtimes such as Knative. We also hope to see other open source communities build similar toolchains for their infrastructure as serverless becomes more prevalent.
|
||||
|
||||
### Getting started
|
||||
|
||||
If you would like to test drive ShadowReader, check out the [GitHub repo][2]. The README contains how-to guides and a batteries-included [demo][13] that will deploy all the necessary resources to try out live replay in your AWS account.
|
||||
|
||||
We would love to hear what you think and welcome contributions. See the [contributing guide][14] to get started!
|
||||
|
||||
* * *
|
||||
|
||||
_This article is based on "[How we fixed a Node.js memory leak by using ShadowReader to replay production traffic into QA][15]," published on the_ _Edmunds Tech Blog_ _with the help of Carlos Macasaet, Sharath Gowda, and Joey Davis._ _Yuki_ _Sawa_ _also presented this_ as* [ShadowReader—Serverless load tests for replaying production traffic][16] at ([SCaLE 17x][17]) March 7-10 in Pasadena, Calif.*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/shadowreader-serverless
|
||||
|
||||
作者:[Yuki Sawa][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/yukisawa1/users/yongsanchez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/traffic-light-go.png?itok=nC_851ys (Traffic lights at night)
|
||||
[2]: https://github.com/edmunds/shadowreader
|
||||
[3]: https://opensource.com/sites/default/files/uploads/shadowreader_incident1_0.png (Christmas Eve 2017 incident)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/shadowreader_incident2.png (Christmas Eve 2017 incident)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/shadowreader_99thpercentile.png (Slow increase in 99th percentile response time)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/shadowreader_qa.png (QA results in ShadowReader)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/shadowreader_heapdumps.png (Heap dumps show source of memory leak)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/shadowreader_code.png (Collecting metrics)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/shadowreader_leakplugged.png (Graph showing memory leak fixed)
|
||||
[10]: https://docs.aws.amazon.com/elasticloadbalancing/latest/application/introduction.html
|
||||
[11]: https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/introduction.html
|
||||
[12]: https://opensource.com/sites/default/files/uploads/shadowreader_architecture.png (ShadowReader architecture)
|
||||
[13]: https://github.com/edmunds/shadowreader#live-replay
|
||||
[14]: https://github.com/edmunds/shadowreader/blob/master/CONTRIBUTING.md
|
||||
[15]: https://technology.edmunds.com/2018/08/25/Investigating-a-Memory-Leak-and-Introducing-ShadowReader/
|
||||
[16]: https://www.socallinuxexpo.org/scale/17x/speakers/yuki-sawa
|
||||
[17]: https://www.socallinuxexpo.org/
|
||||
@ -0,0 +1,126 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to build a mobile particulate matter sensor with a Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/mobile-particulate-matter-sensor)
|
||||
[#]: author: (Stephan Tetzel https://opensource.com/users/stephan)
|
||||
|
||||
How to build a mobile particulate matter sensor with a Raspberry Pi
|
||||
======
|
||||
|
||||
Monitor your air quality with a Raspberry Pi, a cheap sensor, and an inexpensive display.
|
||||
|
||||
![Team communication, chat][1]
|
||||
|
||||
About a year ago, I wrote about [measuring air quality][2] using a Raspberry Pi and a cheap sensor. We've been using this project in our school and privately for a few years now. However, it has one disadvantage: It is not portable because it depends on a WLAN network or a wired network connection to work. You can't even access the sensor's measurements if the Raspberry Pi and the smartphone or computer are not on the same network.
|
||||
|
||||
To overcome this limitation, we added a small screen to the Raspberry Pi so we can read the values directly from the device. Here's how we set up and configured a screen for our mobile fine particulate matter sensor.
|
||||
|
||||
### Setting up the screen for the Raspberry Pi
|
||||
|
||||
There is a wide range of Raspberry Pi displays available from [Amazon][3], AliExpress, and other sources. They range from ePaper screens to LCDs with touch function. We chose an inexpensive [3.5″ LCD][4] with touch and a resolution of 320×480 pixels that can be plugged directly into the Raspberry Pi's GPIO pins. It's also nice that a 3.5″ display is about the same size as a Raspberry Pi.
|
||||
|
||||
The first time you turn on the screen and start the Raspberry Pi, the screen will remain white because the driver is missing. You have to install [the appropriate drivers][5] for the display first. Log in with SSH and execute the following commands:
|
||||
|
||||
```
|
||||
$ rm -rf LCD-show
|
||||
$ git clone <https://github.com/goodtft/LCD-show.git>
|
||||
$ chmod -R 755 LCD-show
|
||||
$ cd LCD-show/
|
||||
```
|
||||
|
||||
Execute the appropriate command for your screen to install the drivers. For example, this is the command for our model MPI3501 screen:
|
||||
|
||||
```
|
||||
$ sudo ./LCD35-show
|
||||
```
|
||||
|
||||
This command installs the appropriate drivers and restarts the Raspberry Pi.
|
||||
|
||||
### Installing PIXEL desktop and setting up autostart
|
||||
|
||||
Here is what we want our project to do: If the Raspberry Pi boots up, we want to display a small website with our air quality measurements.
|
||||
|
||||
First, install the Raspberry Pi's [PIXEL desktop environment][6]:
|
||||
|
||||
```
|
||||
$ sudo apt install raspberrypi-ui-mods
|
||||
```
|
||||
|
||||
Then install the Chromium browser to display the website:
|
||||
|
||||
```
|
||||
$ sudo apt install chromium-browser
|
||||
```
|
||||
|
||||
Autologin is required for the measured values to be displayed directly after startup; otherwise, you will just see the login screen. However, autologin is not configured for the "pi" user by default. You can configure autologin with the **raspi-config** tool:
|
||||
|
||||
```
|
||||
$ sudo raspi-config
|
||||
```
|
||||
|
||||
In the menu, select: **3 Boot Options → B1 Desktop / CLI → B4 Desktop Autologin**.
|
||||
|
||||
There is a step missing to start Chromium with our website right after boot. Create the folder **/home/pi/.config/lxsession/LXDE-pi/** :
|
||||
|
||||
```
|
||||
$ mkdir -p /home/pi/config/lxsession/LXDE-pi/
|
||||
```
|
||||
|
||||
Then create the **autostart** file in this folder:
|
||||
|
||||
```
|
||||
$ nano /home/pi/.config/lxsession/LXDE-pi/autostart
|
||||
```
|
||||
|
||||
and paste the following code:
|
||||
|
||||
```
|
||||
#@unclutter
|
||||
@xset s off
|
||||
@xset -dpms
|
||||
@xset s noblank
|
||||
|
||||
# Open Chromium in Full Screen Mode
|
||||
@chromium-browser --incognito --kiosk <http://localhost>
|
||||
```
|
||||
|
||||
If you want to hide the mouse pointer, you have to install the package **unclutter** and remove the comment character at the beginning of the **autostart** file:
|
||||
|
||||
```
|
||||
$ sudo apt install unclutter
|
||||
```
|
||||
|
||||
![Mobile particulate matter sensor][7]
|
||||
|
||||
I've made a few small changes to the code in the last year. So, if you set up the air quality project before, make sure to re-download the script and files for the AQI website using the instructions in the [original article][2].
|
||||
|
||||
By adding the touch screen, you now have a mobile particulate matter sensor! We use it at our school to check the quality of the air in the classrooms or to do comparative measurements. With this setup, you are no longer dependent on a network connection or WLAN. You can use the small measuring station everywhere—you can even use it with a power bank to be independent of the power grid.
|
||||
|
||||
* * *
|
||||
|
||||
_This article originally appeared on[Open School Solutions][8] and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/mobile-particulate-matter-sensor
|
||||
|
||||
作者:[Stephan Tetzel][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/stephan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://opensource.com/article/18/3/how-measure-particulate-matter-raspberry-pi
|
||||
[3]: https://www.amazon.com/gp/search/ref=as_li_qf_sp_sr_tl?ie=UTF8&tag=openschoolsol-20&keywords=lcd%20raspberry&index=aps&camp=1789&creative=9325&linkCode=ur2&linkId=51d6d7676e10d6c7db203c4a8b3b529a
|
||||
[4]: https://amzn.to/2CcvgpC
|
||||
[5]: https://github.com/goodtft/LCD-show
|
||||
[6]: https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc
|
||||
[7]: https://opensource.com/sites/default/files/uploads/mobile-aqi-sensor.jpg (Mobile particulate matter sensor)
|
||||
[8]: https://openschoolsolutions.org/mobile-particulate-matter-sensor/
|
||||
70
sources/tech/20190401 3 cool text-based email clients.md
Normal file
70
sources/tech/20190401 3 cool text-based email clients.md
Normal file
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 cool text-based email clients)
|
||||
[#]: via: (https://fedoramagazine.org/3-cool-text-based-email-clients/)
|
||||
[#]: author: (Clément Verna https://fedoramagazine.org/author/cverna/)
|
||||
|
||||
3 cool text-based email clients
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Writing and receiving email is a big part of everyone’s daily routine and choosing an email client is usually a major decision. The Fedora OS provides a large choice of email clients and among these are text-based email applications.
|
||||
|
||||
### Mutt
|
||||
|
||||
Mutt is probably one of the most popular text-based email clients. It supports all the common features that one would expect from an email client. Color coding, mail threading, POP3, and IMAP are all supported by Mutt. But one of its best features is it’s highly configurable. Indeed, the user can easily change the keybindings, and create macros to adapt the tool to a particular workflow.
|
||||
|
||||
To give Mutt a try, install it [using sudo][2] and dnf:
|
||||
|
||||
```
|
||||
$ sudo dnf install mutt
|
||||
```
|
||||
|
||||
To help newcomers get started, Mutt has a very comprehensive [wiki][3] full of macro examples and configuration tricks.
|
||||
|
||||
### Alpine
|
||||
|
||||
Alpine is also among the most popular text-based email clients. It’s more beginner friendly than Mutt, and you can configure most of Alpine via the application itself — no need to edit a configuration file. One powerful feature of Alpine is the ability to score emails. This is particularly interesting for users that are registered to a high volume mailing list like Fedora’s [devel list][4]. Using scores, Alpine can sort the email based on the user’s interests, showing emails with a high score first.
|
||||
|
||||
Alpine is also available to install from Fedora’s repository using dnf.
|
||||
|
||||
```
|
||||
$ sudo dnf install alpine
|
||||
```
|
||||
|
||||
While using Alpine, you can easily access the documentation by pressing the _Ctrl+G_ key combination.
|
||||
|
||||
### nmh
|
||||
|
||||
nmh (new Mail Handling) follows the UNIX tools philosophy. It provides a collection of single purpose programs to send, receive, save, retrieve, and manipulate e-mail messages. This lets you swap the _nmh_ command with other programs, or create scripts around _nmh_ to create more customized tools. For example, you can use Mutt with nmh.
|
||||
|
||||
nmh can be easily installed using dnf.
|
||||
|
||||
```
|
||||
$ sudo dnf install nmh
|
||||
```
|
||||
|
||||
To learn more about nmh and mail handling in general you can read this GPL licenced [book][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/3-cool-text-based-email-clients/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/cverna/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2018/07/email-clients-816x345.png
|
||||
[2]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[3]: https://gitlab.com/muttmua/mutt/wikis/home
|
||||
[4]: https://lists.fedoraproject.org/archives/list/devel@lists.fedoraproject.org/
|
||||
[5]: https://rand-mh.sourceforge.io/book/
|
||||
226
sources/tech/20190401 Build and host a website with Git.md
Normal file
226
sources/tech/20190401 Build and host a website with Git.md
Normal file
@ -0,0 +1,226 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Build and host a website with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/building-hosting-website-git)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
Build and host a website with Git
|
||||
======
|
||||
Publishing your own website is easy if you let Git help you out. Learn
|
||||
how in the first article in our series about little-known Git uses.
|
||||
![web development and design, desktop and browser][1]
|
||||
|
||||
[Git][2] is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git.
|
||||
|
||||
Creating a website used to be both sublimely simple and a form of black magic all at once. Back in the old days of Web 1.0 (that's not what anyone actually called it), you could just open up any website, view its source code, and reverse engineer the HTML—with all its inline styling and table-based layout—and you felt like a programmer after an afternoon or two. But there was still the matter of getting the page you created on the internet, which meant dealing with servers and FTP and webroot directories and file permissions. While the modern web has become far more complex since then, self-publication can be just as easy (or easier!) if you let Git help you out.
|
||||
|
||||
### Create a website with Hugo
|
||||
|
||||
[Hugo][3] is an open source static site generator. Static sites are what the web used to be built on (if you go back far enough, it was _all_ the web was). There are several advantages to static sites: they're relatively easy to write because you don't have to code them, they're relatively secure because there's no code executed on the pages, and they can be quite fast because there's no processing aside from transferring whatever you have on the page.
|
||||
|
||||
Hugo isn't the only static site generator out there. [Grav][4], [Pico][5], [Jekyll][6], [Podwrite][7], and many others provide an easy way to create a full-featured website with minimal maintenance. Hugo happens to be one with GitLab integration built in, which means you can generate and host your website with a free GitLab account.
|
||||
|
||||
Hugo has some pretty big fans, too. For instance, if you've ever gone to the Let's Encrypt website, then you've used a site built with Hugo.
|
||||
|
||||
![Let's Encrypt website][8]
|
||||
|
||||
#### Install Hugo
|
||||
|
||||
Hugo is cross-platform, and you can find installation instructions for MacOS, Windows, Linux, OpenBSD, and FreeBSD in [Hugo's getting started resources][9].
|
||||
|
||||
If you're on Linux or BSD, it's easiest to install Hugo from a software repository or ports tree. The exact command varies depending on what your distribution provides, but on Fedora you would enter:
|
||||
|
||||
```
|
||||
$ sudo dnf install hugo
|
||||
```
|
||||
|
||||
Confirm you have installed it correctly by opening a terminal and typing:
|
||||
|
||||
```
|
||||
$ hugo help
|
||||
```
|
||||
|
||||
This prints all the options available for the **hugo** command. If you don't see that, you may have installed Hugo incorrectly or need to [add the command to your path][10].
|
||||
|
||||
#### Create your site
|
||||
|
||||
To build a Hugo site, you must have a specific directory structure, which Hugo will generate for you by entering:
|
||||
|
||||
```
|
||||
$ hugo new site mysite
|
||||
```
|
||||
|
||||
You now have a directory called **mysite** , and it contains the default directories you need to build a Hugo website.
|
||||
|
||||
Git is your interface to get your site on the internet, so change directory to your new **mysite** folder and initialize it as a Git repository:
|
||||
|
||||
```
|
||||
$ cd mysite
|
||||
$ git init .
|
||||
```
|
||||
|
||||
Hugo is pretty Git-friendly, so you can even use Git to install a theme for your site. Unless you plan on developing the theme you're installing, you can use the **\--depth** option to clone the latest state of the theme's source:
|
||||
|
||||
```
|
||||
$ git clone --depth 1 \
|
||||
<https://github.com/darshanbaral/mero.git\\>
|
||||
themes/mero
|
||||
```
|
||||
|
||||
|
||||
Now create some content for your site:
|
||||
|
||||
```
|
||||
$ hugo new posts/hello.md
|
||||
```
|
||||
|
||||
Use your favorite text editor to edit the **hello.md** file in the **content/posts** directory. Hugo accepts Markdown files and converts them to themed HTML files at publication, so your content must be in [Markdown format][11].
|
||||
|
||||
If you want to include images in your post, create a folder called **images** in the **static** directory. Place your images into this folder and reference them in your markup using the absolute path starting with **/images**. For example:
|
||||
|
||||
```
|
||||

|
||||
```
|
||||
|
||||
#### Choose a theme
|
||||
|
||||
You can find more themes at [themes.gohugo.io][12], but it's best to stay with a basic theme while testing. The canonical Hugo test theme is [Ananke][13]. Some themes have complex dependencies, and others don't render pages the way you might expect without complex configuration. The Mero theme used in this example comes bundled with a detailed **config.toml** configuration file, but (for the sake of simplicity) I'll provide just the basics here. Open the file called **config.toml** in a text editor and add three configuration parameters:
|
||||
|
||||
```
|
||||
|
||||
languageCode = "en-us"
|
||||
title = "My website on the web"
|
||||
theme = "mero"
|
||||
|
||||
[params]
|
||||
author = "Seth Kenlon"
|
||||
description = "My hugo demo"
|
||||
```
|
||||
|
||||
#### Preview your site
|
||||
|
||||
You don't have to put anything on the internet until you're ready to publish it. While you work, you can preview your site by launching the local-only web server that ships with Hugo.
|
||||
|
||||
```
|
||||
$ hugo server --buildDrafts --disableFastRender
|
||||
```
|
||||
|
||||
Open a web browser and navigate to **<http://localhost:1313>** to see your work in progress.
|
||||
|
||||
### Publish with Git to GitLab
|
||||
|
||||
To publish and host your site on GitLab, create a repository for the contents of your site.
|
||||
|
||||
To create a repository in GitLab, click on the **New Project** button in your GitLab Projects page. Create an empty repository called **yourGitLabUsername.gitlab.io** , replacing **yourGitLabUsername** with your GitLab user name or group name. You must use this scheme as the name of your project. If you want to add a custom domain later, you can.
|
||||
|
||||
Do not include a license or a README file (because you've started a project locally, adding these now would make pushing your data to GitLab more complex, and you can always add them later).
|
||||
|
||||
Once you've created the empty repository on GitLab, add it as the remote location for the local copy of your Hugo site, which is already a Git repository:
|
||||
|
||||
```
|
||||
$ git remote add origin git@gitlab.com:skenlon/mysite.git
|
||||
```
|
||||
|
||||
Create a GitLab site configuration file called **.gitlab-ci.yml** and enter these options:
|
||||
|
||||
```
|
||||
image: monachus/hugo
|
||||
|
||||
variables:
|
||||
GIT_SUBMODULE_STRATEGY: recursive
|
||||
|
||||
pages:
|
||||
script:
|
||||
- hugo
|
||||
artifacts:
|
||||
paths:
|
||||
- public
|
||||
only:
|
||||
- master
|
||||
```
|
||||
|
||||
The **image** parameter defines a containerized image that will serve your site. The other parameters are instructions telling GitLab's servers what actions to execute when you push new code to your remote repository. For more information on GitLab's CI/CD (Continuous Integration and Delivery) options, see the [CI/CD section of GitLab's docs][14].
|
||||
|
||||
#### Set the excludes
|
||||
|
||||
Your Git repository is configured, the commands to build your site on GitLab's servers are set, and your site ready to publish. For your first Git commit, you must take a few extra precautions so you're not version-controlling files you don't intend to version-control.
|
||||
|
||||
First, add the **/public** directory that Hugo creates when building your site to your **.gitignore** file. You don't need to manage the finished site in Git; all you need to track are your source Hugo files.
|
||||
|
||||
```
|
||||
$ echo "/public" >> .gitignore
|
||||
```
|
||||
|
||||
You can't maintain a Git repository within a Git repository without creating a Git submodule. For the sake of keeping this simple, move the embedded **.git** directory so that the theme is just a theme.
|
||||
|
||||
Note that you _must_ add your theme files to your Git repository so GitLab will have access to the theme. Without committing your theme files, your site cannot successfully build.
|
||||
|
||||
```
|
||||
$ mv themes/mero/.git ~/.local/share/Trash/files/
|
||||
```
|
||||
|
||||
Alternately, use a **trash** command such as [Trashy][15]:
|
||||
|
||||
```
|
||||
$ trash themes/mero/.git
|
||||
```
|
||||
|
||||
Now you can add all the contents of your local project directory to Git and push it to GitLab:
|
||||
|
||||
```
|
||||
$ git add .
|
||||
$ git commit -m 'hugo init'
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
### Go live with GitLab
|
||||
|
||||
Once your code has been pushed to GitLab, take a look at your project page. An icon indicates GitLab is processing your build. It might take several minutes the first time you push your code, so be patient. However, don't be _too_ patient, because the icon doesn't always update reliably.
|
||||
|
||||
![GitLab processing your build][16]
|
||||
|
||||
While you're waiting for GitLab to assemble your site, go to your project settings and find the **Pages** panel. Once your site is ready, its URL will be provided for you. The URL is **yourGitLabUsername.gitlab.io/yourProjectName**. Navigate to that address to view the fruits of your labor.
|
||||
|
||||
![Previewing Hugo site][17]
|
||||
|
||||
If your site fails to assemble correctly, GitLab provides insight into the CI/CD pipeline logs. Review the error message for an indication of what went wrong.
|
||||
|
||||
### Git and the web
|
||||
|
||||
Hugo (or Jekyll or similar tools) is just one way to leverage Git as your web publishing tool. With server-side Git hooks, you can design your own Git-to-web pipeline with minimal scripting. With the community edition of GitLab, you can self-host your own GitLab instance or you can use an alternative like [Gitolite][18] or [Gitea][19] and use this article as inspiration for a custom solution. Have fun!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/building-hosting-website-git
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web_browser_desktop_devlopment_design_system_computer.jpg?itok=pfqRrJgh (web development and design, desktop and browser)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: http://gohugo.io
|
||||
[4]: http://getgrav.org
|
||||
[5]: http://picocms.org/
|
||||
[6]: https://jekyllrb.com
|
||||
[7]: http://slackermedia.info/podwrite/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/letsencrypt-site.jpg (Let's Encrypt website)
|
||||
[9]: https://gohugo.io/getting-started/installing
|
||||
[10]: https://opensource.com/article/17/6/set-path-linux
|
||||
[11]: https://commonmark.org/help/
|
||||
[12]: https://themes.gohugo.io/
|
||||
[13]: https://themes.gohugo.io/gohugo-theme-ananke/
|
||||
[14]: https://docs.gitlab.com/ee/ci/#overview
|
||||
[15]: http://slackermedia.info/trashy
|
||||
[16]: https://opensource.com/sites/default/files/uploads/hugo-gitlab-cicd.jpg (GitLab processing your build)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/hugo-demo-site.jpg (Previewing Hugo site)
|
||||
[18]: http://gitolite.com
|
||||
[19]: http://gitea.io
|
||||
@ -0,0 +1,168 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (liujing97)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to create a filesystem on a Linux partition or logical volume)
|
||||
[#]: via: (https://opensource.com/article/19/4/create-filesystem-linux-partition)
|
||||
[#]: author: (Kedar Vijay Kulkarni (Red Hat) https://opensource.com/users/kkulkarn)
|
||||
|
||||
How to create a filesystem on a Linux partition or logical volume
|
||||
======
|
||||
Learn to create a filesystem and mount it persistently or
|
||||
non-persistently in your system.
|
||||
![Filing papers and documents][1]
|
||||
|
||||
In computing, a filesystem controls how data is stored and retrieved and helps organize the files on the storage media. Without a filesystem, information in storage would be one large block of data, and you couldn't tell where one piece of information stopped and the next began. A filesystem helps manage all of this by providing names to files that store data and maintaining a table of files and directories—along with their start/end location, total size, etc.—on disks within the filesystem.
|
||||
|
||||
In Linux, when you create a hard disk partition or a logical volume, the next step is usually to create a filesystem by formatting the partition or logical volume. This how-to assumes you know how to create a partition or a logical volume, and you just want to format it to contain a filesystem and mount it.
|
||||
|
||||
### Create a filesystem
|
||||
|
||||
Imagine you just added a new disk to your system and created a partition named **/dev/sda1** on it.
|
||||
|
||||
1. To verify that the Linux kernel can see the partition, you can **cat** out **/proc/partitions** like this:
|
||||
|
||||
```
|
||||
[root@localhost ~]# cat /proc/partitions
|
||||
major minor #blocks name
|
||||
|
||||
253 0 10485760 vda
|
||||
253 1 8192000 vda1
|
||||
11 0 1048575 sr0
|
||||
11 1 374 sr1
|
||||
8 0 10485760 sda
|
||||
8 1 10484736 sda1
|
||||
252 0 3145728 dm-0
|
||||
252 1 2097152 dm-1
|
||||
252 2 1048576 dm-2
|
||||
8 16 1048576 sdb
|
||||
```
|
||||
|
||||
|
||||
2. Decide what kind of filesystem you want to create, such as ext4, XFS, or anything else. Here are a few options:
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkfs.<tab><tab>
|
||||
mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.minix mkfs.xfs
|
||||
```
|
||||
|
||||
|
||||
3. For the purposes of this exercise, choose ext4. (I like ext4 because it allows you to shrink the filesystem if you need to, a thing that isn't as straightforward with XFS.) Here's how it can be done (the output may differ based on device name/sizes):
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkfs.ext4 /dev/sda1
|
||||
mke2fs 1.42.9 (28-Dec-2013)
|
||||
Filesystem label=
|
||||
OS type: Linux
|
||||
Block size=4096 (log=2)
|
||||
Fragment size=4096 (log=2)
|
||||
Stride=0 blocks, Stripe width=8191 blocks
|
||||
194688 inodes, 778241 blocks
|
||||
38912 blocks (5.00%) reserved for the super user
|
||||
First data block=0
|
||||
Maximum filesystem blocks=799014912
|
||||
24 block groups
|
||||
32768 blocks per group, 32768 fragments per group
|
||||
8112 inodes per group
|
||||
Superblock backups stored on blocks:
|
||||
32768, 98304, 163840, 229376, 294912
|
||||
|
||||
Allocating group tables: done
|
||||
Writing inode tables: done
|
||||
Creating journal (16384 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
```
|
||||
|
||||
4. In the previous step, if you want to create a different kind of filesystem, use a different **mkfs** command variation.
|
||||
|
||||
|
||||
|
||||
### Mount a filesystem
|
||||
|
||||
After you create your filesystem, you can mount it in your operating system.
|
||||
|
||||
1. First, identify the UUID of your new filesystem. Issue the **blkid** command to list all known block storage devices and look for **sda1** in the output:
|
||||
|
||||
```
|
||||
[root@localhost ~]# blkid
|
||||
/dev/vda1: UUID="716e713d-4e91-4186-81fd-c6cfa1b0974d" TYPE="xfs"
|
||||
/dev/sr1: UUID="2019-03-08-16-17-02-00" LABEL="config-2" TYPE="iso9660"
|
||||
/dev/sda1: UUID="wow9N8-dX2d-ETN4-zK09-Gr1k-qCVF-eCerbF" TYPE="LVM2_member"
|
||||
/dev/mapper/test-test1: PTTYPE="dos"
|
||||
/dev/sda1: UUID="ac96b366-0cdd-4e4c-9493-bb93531be644" TYPE="ext4"
|
||||
[root@localhost ~]#
|
||||
```
|
||||
|
||||
|
||||
2. Run the following command to mount the **/dev/sd1** device :
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkdir /mnt/mount_point_for_dev_sda1
|
||||
[root@localhost ~]# ls /mnt/
|
||||
mount_point_for_dev_sda1
|
||||
[root@localhost ~]# mount -t ext4 /dev/sda1 /mnt/mount_point_for_dev_sda1/
|
||||
[root@localhost ~]# df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/vda1 7.9G 920M 7.0G 12% /
|
||||
devtmpfs 443M 0 443M 0% /dev
|
||||
tmpfs 463M 0 463M 0% /dev/shm
|
||||
tmpfs 463M 30M 434M 7% /run
|
||||
tmpfs 463M 0 463M 0% /sys/fs/cgroup
|
||||
tmpfs 93M 0 93M 0% /run/user/0
|
||||
/dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1
|
||||
[root@localhost ~]#
|
||||
```
|
||||
The **df -h** command shows which filesystem is mounted on which mount point. Look for **/dev/sd1**. The mount command above used the device name **/dev/sda1**. Substitute it with the UUID identified in the **blkid** command. Also, note that a new directory was created to mount **/dev/sda1** under **/mnt**.
|
||||
|
||||
|
||||
|
||||
3. A problem with using the mount command directly on the command line (as in the previous step) is that the mount won't persist across reboots. To mount the filesystem persistently, edit the **/etc/fstab** file to include your mount information:
|
||||
|
||||
```
|
||||
UUID=ac96b366-0cdd-4e4c-9493-bb93531be644 /mnt/mount_point_for_dev_sda1/ ext4 defaults 0 0
|
||||
```
|
||||
|
||||
|
||||
|
||||
4. After you edit **/etc/fstab** , you can **umount /mnt/mount_point_for_dev_sda1** and run the command **mount -a** to mount everything listed in **/etc/fstab**. If everything went right, you can still list **df -h** and see your filesystem mounted:
|
||||
|
||||
```
|
||||
root@localhost ~]# umount /mnt/mount_point_for_dev_sda1/
|
||||
[root@localhost ~]# mount -a
|
||||
[root@localhost ~]# df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/vda1 7.9G 920M 7.0G 12% /
|
||||
devtmpfs 443M 0 443M 0% /dev
|
||||
tmpfs 463M 0 463M 0% /dev/shm
|
||||
tmpfs 463M 30M 434M 7% /run
|
||||
tmpfs 463M 0 463M 0% /sys/fs/cgroup
|
||||
tmpfs 93M 0 93M 0% /run/user/0
|
||||
/dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1
|
||||
```
|
||||
|
||||
5. You can also check whether the filesystem was mounted:
|
||||
|
||||
```
|
||||
[root@localhost ~]# mount | grep ^/dev/sd
|
||||
/dev/sda1 on /mnt/mount_point_for_dev_sda1 type ext4 (rw,relatime,seclabel,stripe=8191,data=ordered)
|
||||
```
|
||||
|
||||
|
||||
|
||||
Now you know how to create a filesystem and mount it persistently or non-persistently within your system.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/create-filesystem-linux-partition
|
||||
|
||||
作者:[Kedar Vijay Kulkarni (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kkulkarn
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/documents_papers_file_storage_work.png?itok=YlXpAqAJ (Filing papers and documents)
|
||||
@ -0,0 +1,90 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Announcing the release of Fedora 30 Beta)
|
||||
[#]: via: (https://fedoramagazine.org/announcing-the-release-of-fedora-30-beta/)
|
||||
[#]: author: (Ben Cotton https://fedoramagazine.org/author/bcotton/)
|
||||
|
||||
Announcing the release of Fedora 30 Beta
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
The Fedora Project is pleased to announce the immediate availability of Fedora 30 Beta, the next big step on our journey to the exciting Fedora 30 release.
|
||||
|
||||
Download the prerelease from our Get Fedora site:
|
||||
|
||||
* [Get Fedora 30 Beta Workstation][2]
|
||||
* [Get Fedora 30 Beta Server][3]
|
||||
* [Get Fedora 30 Beta Silverblue][4]
|
||||
|
||||
|
||||
|
||||
Or, check out one of our popular variants, including KDE Plasma, Xfce, and other desktop environments, as well as images for ARM devices like the Raspberry Pi 2 and 3:
|
||||
|
||||
* [Get Fedora 30 Beta Spins][5]
|
||||
* [Get Fedora 30 Beta Labs][6]
|
||||
* [Get Fedora 30 Beta ARM][7]
|
||||
|
||||
|
||||
|
||||
### Beta Release Highlights
|
||||
|
||||
#### New desktop environment options
|
||||
|
||||
Fedora 30 Beta includes two new options for desktop environment. [DeepinDE][8] and [Pantheon Desktop][9] join GNOME, KDE Plasma, Xfce, and others as options for users to customize their Fedora experience.
|
||||
|
||||
#### DNF performance improvements
|
||||
|
||||
All dnf repository metadata for Fedora 30 Beta is compressed with the zchunk format in addition to xz or gzip. zchunk is a new compression format designed to allow for highly efficient deltas. When Fedora’s metadata is compressed using zchunk, dnf will download only the differences between any earlier copies of the metadata and the current version.
|
||||
|
||||
#### GNOME 3.32
|
||||
|
||||
Fedora 30 Workstation Beta includes GNOME 3.32, the latest version of the popular desktop environment. GNOME 3.32 features updated visual style, including the user interface, the icons, and the desktop itself. For a full list of GNOME 3.32 highlights, see the [release notes][10].
|
||||
|
||||
#### Other updates
|
||||
|
||||
Fedora 30 Beta also includes updated versions of many popular packages like Golang, the Bash shell, the GNU C Library, Python, and Perl. For a full list, see the [Change set][11] on the Fedora Wiki. In addition, many Python 2 packages are removed in preparation for Python 2 end-of-life on 2020-01-01.
|
||||
|
||||
#### Testing needed
|
||||
|
||||
Since this is a Beta release, we expect that you may encounter bugs or missing features. To report issues encountered during testing, contact the Fedora QA team via the mailing list or in #fedora-qa on Freenode. As testing progresses, common issues are tracked on the [Common F30 Bugs page][12].
|
||||
|
||||
For tips on reporting a bug effectively, read [how to file a bug][13].
|
||||
|
||||
#### What is the Beta Release?
|
||||
|
||||
A Beta release is code-complete and bears a very strong resemblance to the final release. If you take the time to download and try out the Beta, you can check and make sure the things that are important to you are working. Every bug you find and report doesn’t just help you, it improves the experience of millions of Fedora users worldwide! Together, we can make Fedora rock-solid. We have a culture of coordinating new features and pushing fixes upstream as much as we can. Your feedback improves not only Fedora, but Linux and free software as a whole.
|
||||
|
||||
#### More information
|
||||
|
||||
For more detailed information about what’s new on Fedora 30 Beta release, you can consult the [Fedora 30 Change set][11]. It contains more technical information about the new packages and improvements shipped with this release.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/announcing-the-release-of-fedora-30-beta/
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/bcotton/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/f30-beta-816x345.jpg
|
||||
[2]: https://getfedora.org/workstation/prerelease/
|
||||
[3]: https://getfedora.org/server/prerelease/
|
||||
[4]: https://silverblue.fedoraproject.org/download
|
||||
[5]: https://spins.fedoraproject.org/prerelease
|
||||
[6]: https://labs.fedoraproject.org/prerelease
|
||||
[7]: https://arm.fedoraproject.org/prerelease
|
||||
[8]: https://www.deepin.org/en/dde/
|
||||
[9]: https://www.fosslinux.com/4652/pantheon-everything-you-need-to-know-about-the-elementary-os-desktop.htm
|
||||
[10]: https://help.gnome.org/misc/release-notes/3.32/
|
||||
[11]: https://fedoraproject.org/wiki/Releases/30/ChangeSet
|
||||
[12]: https://fedoraproject.org/wiki/Common_F30_bugs
|
||||
[13]: https://docs.fedoraproject.org/en-US/quick-docs/howto-file-a-bug/
|
||||
94
sources/tech/20190402 Automate password resets with PWM.md
Normal file
94
sources/tech/20190402 Automate password resets with PWM.md
Normal file
@ -0,0 +1,94 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Automate password resets with PWM)
|
||||
[#]: via: (https://opensource.com/article/19/4/automate-password-resets-pwm)
|
||||
[#]: author: (James Mawson https://opensource.com/users/dxmjames)
|
||||
|
||||
Automate password resets with PWM
|
||||
======
|
||||
PWM puts responsibility for password resets in users' hands, freeing IT
|
||||
for more pressing tasks.
|
||||
![Password][1]
|
||||
|
||||
One of the things that can be "death by a thousand cuts" for any IT team's sanity and patience is constantly being asked to reset passwords.
|
||||
|
||||
The best way we've found to handle this is to ditch your hashing algorithms and store your passwords in plaintext so that your users can retrieve them at any time.
|
||||
|
||||
Ha! I am, of course, kidding. That's a terrible idea.
|
||||
|
||||
When your users forget their passwords, you'll still need to reset them. But is there a way to break free from the monotonous, repetitive task of doing it manually?
|
||||
|
||||
### PWM puts password resets in users' hands
|
||||
|
||||
[PWM][2] is an open source ([GPLv2][3]) [JavaServer Pages][4] application that provides a webpage where users can submit their own password resets. If certain conditions are met—which you can configure—PWM will send a password reset instruction to whichever directory service you've connected it to.
|
||||
|
||||
![PWM password reset screen][5]
|
||||
|
||||
One thing that's great about PWM is it's very easy to add it to an existing network. If you're largely happy with what you've already built—just sick of processing password requests manually—you can just throw PWM into the mix.
|
||||
|
||||
PWM works with any implementation of [LDAP][6] and written to run on [Apache Tomcat][7]. Once you get it up and running, you can administer it through a browser-based dashboard.
|
||||
|
||||
### Why PWM is better than Microsoft SSPR
|
||||
|
||||
As much as our team prefers open source, we still have to deal with Windows networks. Of course, Microsoft has its own password-reset tool, called Self Service Password Reset (SSPR). But I prefer PWM, and not just because of a general preference for open source. I believe PWM is better for my use case for the following reasons:
|
||||
|
||||
* **SSPR has a very complex licensing system**. You need different products depending on what servers you're running and whose metal they're running on. This is a constraint on your flexibility and a whole extra pain in the neck when it's time to move to new architecture. For [the busy admin who wants to go home on time][8], it's extra bureaucracy to get the purchase approved. PWM just works on what it's configured to work on at no cost.
|
||||
|
||||
* **PWM is not just for Windows**. It works with any kind of LDAP server. So, it's one less part you need to worry about if you ever stop using Windows for a certain role. It also means that, once you've gotten the hang of it, you have something in your bag of tricks that you can use in many different environments.
|
||||
|
||||
* **PWM is easy to install**. If you know how to install Linux as a virtual machine—and, let's face it, if you're running a network, you probably do—then you're already most of the way there.
|
||||
|
||||
|
||||
|
||||
|
||||
PWM can run on Windows, but we prefer to include it in a Windows network by running it on a Linux virtual machine, [for example, Ubuntu Server 16.04][9].
|
||||
|
||||
### Risks and rewards of automation
|
||||
|
||||
Password resets are an attack vector, so be thoughtful about where and how you use PWM. Automating your password resets can mean an attacker is potentially just one unencrypted email connection away from resetting a password.
|
||||
|
||||
To some extent, automating your password resets trades a bit of security for some convenience. So maybe this isn't the right way to handle C-suite user accounts that approve large payments.
|
||||
|
||||
On the other hand, manual resets are not 100% secure either—they can be gamed with targeted attacks like spear phishing and social engineering. It's much easier to fall for these scams if your team gets frequent reset requests and is sick of dealing with them. You may benefit from automating the bulk of lower-risk requests so you can focus on protecting the higher-risk accounts manually; this is possible given the time you can save using PWM.
|
||||
|
||||
Some of the risks associated with shifting resets to users can be mitigated with PWM's built-in features, such as insisting users verify their password reset request by email or SMS. You can also make PWM accessible only on the intranet.
|
||||
|
||||
![PWM configuration options][10]
|
||||
|
||||
PWM doesn't store any passwords, so that's one less headache. It does, however, store answers to users' secret questions in a MySQL database that can be configured to be stored locally or on a separate server, depending on your preference.
|
||||
|
||||
There are a ton of ways to make PWM look and feel like a polished part of your team's infrastructure. With a little bit of CSS know-how, you can customize the user interface for your business' branding. There are also more options for implementation than you can shake a stick at.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
PWM is a great open source project, it's actively developed, and it has a helpful online community. It's a great alternative to Microsoft's Azure SSPR solution for small to midsized businesses that have to keep a tight grip on the purse strings, and it slots in neatly to any existing Active Directory infrastructure. It also saves IT's time by outsourcing this mundane task to users.
|
||||
|
||||
I advise every network admin to dive in and have a look at the cool stuff PWM offers. Check out the [getting started resources][11] and reach out to the community if you have any questions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/automate-password-resets-pwm
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dxmjames
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/password.jpg?itok=ec6z6YgZ (Password)
|
||||
[2]: https://github.com/pwm-project/pwm
|
||||
[3]: https://github.com/pwm-project/pwm/blob/master/LICENSE
|
||||
[4]: https://www.oracle.com/technetwork/java/index-jsp-138231.html
|
||||
[5]: https://opensource.com/sites/default/files/uploads/pwm_password-reset.png (PWM password reset screen)
|
||||
[6]: https://opensource.com/business/14/5/top-4-open-source-ldap-implementations
|
||||
[7]: http://tomcat.apache.org/
|
||||
[8]: https://opensource.com/article/18/7/tools-admin
|
||||
[9]: https://blog.dxmtechsupport.com.au/adding-pwm-password-reset-tool-to-windows-network/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/pwm-configuration.png (PWM configuration options)
|
||||
[11]: https://github.com/pwm-project/pwm#links
|
||||
@ -0,0 +1,202 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Install and Configure Plex on Ubuntu Linux)
|
||||
[#]: via: (https://itsfoss.com/install-plex-ubuntu)
|
||||
[#]: author: (Chinmay https://itsfoss.com/author/chinmay/)
|
||||
|
||||
How to Install and Configure Plex on Ubuntu Linux
|
||||
======
|
||||
|
||||
When you are a media hog and have a big collection of movies, photos or music, the below capabilities would be very handy.
|
||||
|
||||
* Share media with family and other people.
|
||||
* Access media from different devices and platforms.
|
||||
|
||||
|
||||
|
||||
Plex ticks all of those boxes and more. Plex is a client-server media player system with additional features. Plex supports a wide array of platforms, both for the server and the player. No wonder it is considered one of the [best media servers for Linux][1].
|
||||
|
||||
Note: Plex is not a completely open source media player. We have covered it because this is one of the frequently [requested tutorial][2].
|
||||
|
||||
### Install Plex on Ubuntu
|
||||
|
||||
For this guide I am installing Plex on Elementary OS, an Ubuntu based distribution. You can still follow along if you are installing it on a headless Linux machine.
|
||||
|
||||
Go to the Plex [downloads][3] page, select Ubuntu 64-bit (I would not recommend installing it on a 32-bit CPU) and download the .deb file.
|
||||
|
||||
![][4]
|
||||
|
||||
[Download Plex][3]
|
||||
|
||||
You can [install the .deb file][5] by just clicking on the package. If it does not work, you can use an installer like **Eddy** or **[GDebi][6].**
|
||||
|
||||
You can also install it via the terminal using dpkg as shown below.
|
||||
|
||||
Install Plex on a headless Linux system
|
||||
|
||||
For a [headless system][7], you can use **wget** to download the .deb package. This example uses the current link for Ubuntu, at the time of writing. Be sure to use the up-to-date version supplied on the Plex website.
|
||||
|
||||
```
|
||||
wget https://downloads.plex.tv/plex-media-server-new/1.15.1.791-8bec0f76c/debian/plexmediaserver_1.15.1.791-8bec0f76c_amd64.deb
|
||||
```
|
||||
|
||||
The above command downloads the 64-bit .deb package. Once downloaded install the package using the following command.
|
||||
|
||||
```
|
||||
dpkg -i plexmediaserver*.deb
|
||||
```
|
||||
|
||||
Enable version upgrades for Plex
|
||||
|
||||
The .deb installation does create an entry in sources.d, but [repository updates][8] are not enabled by default and the contents of _plexmediaserver.list_ are commented out. This means that if there is a new Plex version available, your system will not be able to update your Plex install.
|
||||
|
||||
To enable repository updates you can either remove the # from the line starting with deb or run the following commands.
|
||||
|
||||
```
|
||||
echo deb https://downloads.plex.tv/repo/deb public main | sudo tee /etc/apt/sources.list.d/plexmediaserver.list
|
||||
```
|
||||
|
||||
The above command updates the entry in sources.d directory.
|
||||
|
||||
We also need to add Plex’s public key to facilitate secure and safe downloads. You can try running the command below, unfortunately this **did not work for me** and the [GPG][9] key was not added.
|
||||
|
||||
```
|
||||
curl https://downloads.plex.tv/plex-keys/PlexSign.key | sudo apt-key add -
|
||||
```
|
||||
|
||||
To fix this issue I found out the key hash for from the error message after running _sudo apt-get update._
|
||||
|
||||
![][10]
|
||||
|
||||
```
|
||||
97203C7B3ADCA79D
|
||||
```
|
||||
|
||||
The above hash can be used to add the key from the key-server. Run the below commands to add the key.
|
||||
|
||||
```
|
||||
gpg --keyserver https://downloads.plex.tv/plex-keys/PlexSign.key --recv-keys 97203C7B3ADCA79D
|
||||
```
|
||||
|
||||
```
|
||||
gpg --export --armor 97203C7B3ADCA79D|sudo apt-key add -
|
||||
```
|
||||
|
||||
You should see an **OK** once the key is added.
|
||||
|
||||
Run the below command to verify that the repository is added to the sources list successfully.
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
To update Plex to the newest version available on the repository, run the below [apt-get command][11].
|
||||
|
||||
```
|
||||
sudo apt-get --only-upgrade install plexmediaserver
|
||||
```
|
||||
|
||||
Once installed the Plex service automatically starts running. You can check if its running by running the this command in a terminal.
|
||||
|
||||
```
|
||||
systemctl status plexmediaserver
|
||||
```
|
||||
|
||||
If the service is running properly you should see something like this.
|
||||
|
||||
![Check the status of Plex Server][12]
|
||||
|
||||
### Configuring Plex as a Media Server
|
||||
|
||||
The Plex server is accessible on the ports 32400 and 32401. Navigate to **localhost:32400** or **localhost:32401** using a browser. You should replace the ‘localhost’ with the IP address of the machine running Plex server if you are going headless.
|
||||
|
||||
The first time you are required to sign up or log in to your Plex account.
|
||||
|
||||
![Plex Login Page][13]
|
||||
|
||||
Now you can go ahead and give a friendly name to your Plex Server. This name will be used to identify the server over the network. You can also have multiple Plex servers identified by different names on the same network.
|
||||
|
||||
![Plex Server Setup][14]
|
||||
|
||||
Now it is finally time to add all your collections to the Plex library. Here your collections will be automatically get indexed and organized.
|
||||
|
||||
You can click the add library button to add all your collections.
|
||||
|
||||
![Add Media Library][15]
|
||||
|
||||
![][16]
|
||||
|
||||
Navigate to the location of the media you want to add to Plex .
|
||||
|
||||
![][17]
|
||||
|
||||
You can add multiple folders and different types of media.
|
||||
|
||||
When you are done, you are taken to a very slick looking Plex UI. You can already see the contents of your libraries showing up on the home screen. It also automatically selects a thumbnail and also fills the metadata.
|
||||
|
||||
![][18]
|
||||
|
||||
You can head over to the settings and configure some of the settings. You can create new users( **only with Plex Pass** ), adjust the transcoding settings set scheduled library updates and more.
|
||||
|
||||
If you have a public IP assigned to your router by the ISP you can also enable Remote Access. This means that you can be traveling and still access your libraries at home, considering you have your Plex server running all the time.
|
||||
|
||||
Now you are all set up and ready, but how do you access your media? Yes you can access through your browser but Plex has a presence in almost all platforms you can think of including Android Auto.
|
||||
|
||||
### Accessing Your Media and Plex Pass
|
||||
|
||||
You can access you media either by using the web browser (the same address you used earlier) or Plex’s suite of apps. The web browser experience is pretty good on computers and can be better on phones.
|
||||
|
||||
Plex apps provide a much better experience. But, the iOS and Android apps need to be activated with a [Plex Pass][19]. Without activation you are limited to 1 minute of video playback and images are watermarked.
|
||||
|
||||
Plex Pass is a premium subscription service which activates the mobile apps and enables more features. You can also individually activate your apps tied to a particular phone for a cheaper price. You can also create multiple users and set permissions with the Plex Pass which is a very handy feature.
|
||||
|
||||
You can check out all the benefits of Plex Pass [here][19].
|
||||
|
||||
_Note: Plex Meida Player is free on all platforms other than Android and iOS App._
|
||||
|
||||
**Conclusion**
|
||||
|
||||
That’s about all things you need to know for the first time configuration, go ahead and explore the Plex UI, it also gives you access to free online content like podcasts and music through Tidal.
|
||||
|
||||
There are alternatives to Plex like [Jellyfin][20] which is free but native apps are in beta and on road to be published on the App stores.You can also use a NAS with any of the freely available media centers like Kodi, OpenELEC or even VLC media player.
|
||||
|
||||
Here is an article listing the [best Linux media servers.][1]
|
||||
|
||||
Let us know your experience with Plex and what you use for your media sharing needs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-plex-ubuntu
|
||||
|
||||
作者:[Chinmay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/chinmay/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-linux-media-server/
|
||||
[2]: https://itsfoss.com/request-tutorial/
|
||||
[3]: https://www.plex.tv/media-server-downloads/
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/downloads-plex.png?ssl=1
|
||||
[5]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[6]: https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[7]: https://www.lions-wing.net/lessons/servers/home-server.html
|
||||
[8]: https://itsfoss.com/ubuntu-repositories/
|
||||
[9]: https://www.gnupg.org/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/Screenshot-from-2019-03-26-07-21-05-1.png?ssl=1
|
||||
[11]: https://itsfoss.com/apt-get-linux-guide/
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/check-plex-service.png?ssl=1
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/plex-home-page.png?ssl=1
|
||||
[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/Plex-server-setup.png?ssl=1
|
||||
[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/add-library.png?ssl=1
|
||||
[16]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/add-plex-library.png?ssl=1
|
||||
[17]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/add-plex-folder.png?ssl=1
|
||||
[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/Screenshot-from-2019-03-17-22-27-56.png?ssl=1
|
||||
[19]: https://www.plex.tv/plex-pass/
|
||||
[20]: https://jellyfin.readthedocs.io/en/latest/
|
||||
240
sources/tech/20190402 Manage your daily schedule with Git.md
Normal file
240
sources/tech/20190402 Manage your daily schedule with Git.md
Normal file
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Manage your daily schedule with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/calendar-git)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
Manage your daily schedule with Git
|
||||
======
|
||||
Treat time like source code and maintain your calendar with the help of
|
||||
Git.
|
||||
![website design image][1]
|
||||
|
||||
[Git][2] is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git. Today, we'll look at using Git to keep track of your calendar.
|
||||
|
||||
### Keep track of your schedule with Git
|
||||
|
||||
What if time itself was but source code that could be managed and version controlled? While proving or disproving such a theory is probably beyond the scope of this article, it happens that you can treat time like source code and manage your daily schedule with the help of Git.
|
||||
|
||||
The reigning champion for calendaring is the [CalDAV][3] protocol, which drives popular open source calendaring applications like [NextCloud][4] as well as popular closed source ones. There's nothing wrong with CalDAV (commenters, take heed). But it's not for everyone, and besides there's nothing less inspiring than a mono-culture.
|
||||
|
||||
Because I have no interest in becoming invested in largely GUI-dependent CalDAV clients (although if you're looking for a good terminal CalDAV viewer, see [khal][5]), I started investigating text-based alternatives. Text-based calendaring has all the usual benefits of working in [plaintext][6]. It's lightweight, it's highly portable, and as long as it's structured, it's easy to parse and beautify (whatever _beauty_ means to you).
|
||||
|
||||
And best of all, it's exactly what Git was designed to manage.
|
||||
|
||||
### Org mode not in a scary way
|
||||
|
||||
If you don't impose structure on your plaintext, it quickly falls into a pandemonium of off-the-cuff thoughts and devil-may-care notation. Luckily, a markup syntax exists for calendaring, and it's contained in the venerable productivity Emacs mode, [Org mode][7] (which, admit it, you've been meaning to start using anyway).
|
||||
|
||||
The amazing thing about Org mode that many people don't realize is [you don't need to know or even use Emacs][8] to take advantage of conventions established by Org mode. You get a lot of great features if you _do_ use Emacs, but if Emacs intimidates you, then you can implement a Git-based Org-mode calendaring system without so much as installing Emacs.
|
||||
|
||||
The only part of Org mode that you need to know is its syntax. Org-mode syntax is low-maintenance and fairly intuitive. The biggest difference in calendaring with Org mode instead of a GUI calendaring app is the workflow: instead of going to a calendar and finding the day you want to schedule a task, you create a list of tasks and then assign each one a day and time.
|
||||
|
||||
Lists in Org mode use asterisks (*) as bullets. Here's my gaming task list: ****
|
||||
|
||||
```
|
||||
* Gaming
|
||||
** Build Stardrifter character
|
||||
** Read Stardrifter rules
|
||||
** Stardrifter playtest
|
||||
|
||||
** Blue Planet @ Mike's
|
||||
|
||||
** Run Rappan Athuk
|
||||
*** Purchase hard copy
|
||||
*** Skim Rappan Athuk
|
||||
*** Build Rappan Athuk maps in maptool
|
||||
*** Sort Rappan Athuk tokens
|
||||
```
|
||||
|
||||
If you're familiar with [CommonMark][9] or Markdown, you'll notice that instead of using whitespace to create a subtask, Org mode favors the more explicit use of additional bullets. Whatever your background with lists, this is an intuitive and easy way to build a list, and it obviously is not inherently tied to Emacs (although using Emacs provides you with shortcuts so you can rearrange your list quickly).
|
||||
|
||||
To turn your list into scheduled tasks or events in a calendar, go back through and add the keywords **SCHEDULED** and, optionally, **:CATEGORY:**.
|
||||
|
||||
```
|
||||
* Gaming
|
||||
:CATEGORY: Game
|
||||
** Build Stardrifter character
|
||||
SCHEDULED: <2019-03-22 18:00-19:00>
|
||||
** Read Stardrifter rules
|
||||
SCHEDULED: <2019-03-22 19:00-21:00>
|
||||
** Stardrifter playtest
|
||||
SCHEDULED: <2019-03-25 0900-1300>
|
||||
** Blue Planet @ Mike's
|
||||
SCHEDULED: <2019-03-18 18:00-23:00 +1w>
|
||||
|
||||
and so on...
|
||||
```
|
||||
|
||||
The **SCHEDULED** keyword marks the entry as an event that you expect to be notified about and the optional **:CATEGORY:** keyword is an arbitrary tagging system for your own use (and in Emacs, you can color-code entries according to category).
|
||||
|
||||
For a repeating event, you can use notation such as **+1w** to create a weekly event or **+2w** for a fortnightly event, and so on.
|
||||
|
||||
All the fancy markup available for Org mode is [documented][10], so don't hesitate to find more tricks to help it fit your needs.
|
||||
|
||||
### Put it into Git
|
||||
|
||||
Without Git, your Org-mode appointments are just a file on your local machine. It's the 21st century, though, so you at least need your calendar on your mobile phone, if not on all of your personal computers. You can use Git to publish your calendar for yourself and others.
|
||||
|
||||
First, create a directory for your **.org** files. I store mine in **~/cal**.
|
||||
|
||||
```
|
||||
$ mkdir ~/cal
|
||||
```
|
||||
|
||||
Change into your directory and make it a Git repository:
|
||||
|
||||
```
|
||||
$ cd cal
|
||||
$ git init
|
||||
```
|
||||
|
||||
Move your **.org** file to your local Git repo. In practice, I maintain one **.org** file per category.
|
||||
|
||||
```
|
||||
$ mv ~/*.org ~/cal
|
||||
$ ls
|
||||
Game.org Meal.org Seth.org Work.org
|
||||
```
|
||||
|
||||
Stage and commit your files:
|
||||
|
||||
```
|
||||
$ git add *.org
|
||||
$ git commit -m 'cal init'
|
||||
```
|
||||
|
||||
### Create a Git remote
|
||||
|
||||
To make your calendar available from anywhere, you must have a Git repository on the internet. Your calendar is plaintext, so any Git repository will do. You can put your calendar on [GitLab][11] or any other public Git hosting service (even proprietary ones), and as long as your host allows it, you can even mark the repository as private. If you don't want to post your calendar to a server you don't control, it's easy to host a Git repository yourself, either using a bare repository for a single user or using a frontend service like [Gitolite][12] or [Gitea][13].
|
||||
|
||||
In the interest of simplicity, I'll assume a self-hosted bare Git repository. You can create a bare remote repository on any server you have SSH access to with one Git command:
|
||||
```
|
||||
$ ssh -p 22122 [seth@example.com][14]
|
||||
[remote]$ mkdir cal.git
|
||||
[remote]$ cd cal.git
|
||||
[remote]$ git init --bare
|
||||
[remote]$ exit
|
||||
```
|
||||
|
||||
This bare repository can serve as your calendar's home on the internet.
|
||||
|
||||
Set it as the remote source for your local (on your computer, not your server) Git repository:
|
||||
|
||||
```
|
||||
$ git remote add origin seth@example.com:/home/seth/cal.git
|
||||
```
|
||||
|
||||
And then push your calendar data to the server:
|
||||
|
||||
```
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
With your calendar in a Git repository, it's available to you on any device running Git. That means you can make updates and changes to your schedule and push your changes upstream so it updates everywhere.
|
||||
|
||||
I use this method to keep my calendar in sync between my work laptop and my home workstation. Since I use Emacs every day for most of the day, being able to view and edit my calendar in Emacs is a major convenience. The same is true for most people with a mobile device, so the next step is to set up an Org-mode calendaring system on a mobile.
|
||||
|
||||
### Mobile Git
|
||||
|
||||
Since your calendar data is in plaintext, strictly speaking, you can "use" it on any device that can read a text file. That's part of the beauty of this system; you're never without, at the very least, your raw data. But to integrate your calendar on a mobile device the way you'd expect a modern calendar to work, you need two components: a mobile Git client and a mobile Org-mode viewer.
|
||||
|
||||
#### Git client for mobile
|
||||
|
||||
[MGit][15] is a good Git client for Android. There are Git clients for iOS, as well.
|
||||
|
||||
Once you've installed MGit (or a similar Git client), you must clone your calendar repository so your phone has a copy. To access your server from your mobile device, you must set up an SSH key for authentication. MGit can generate and store a key for you, which you must add to your server's **~/.ssh/authorized_keys** file or to your SSH keys in the settings of your hosted Git account.
|
||||
|
||||
You must do this manually. MGit does not have an interface to log into your server or hosted Git account. If you do not do this, your mobile device cannot access your server to access your calendar data.
|
||||
|
||||
I did it by copying the key file I generated in MGit to my laptop over [KDE Connect][16] (but you can do the same over Bluetooth, or with an SD card reader, or a USB cable, depending on your preferred method of accessing data on your phone). I copied the key (a file called **calkey** to my server with this command:
|
||||
|
||||
```
|
||||
$ cat calkey | ssh seth@example.com "cat >> /home/seth/.ssh/authorized_keys"
|
||||
```
|
||||
|
||||
You may have a different way of doing it, but if you ever set your server up for passwordless login, this is exactly the same process. If you're using a hosted Git service like GitLab, you must copy and paste the contents of your key file into your user account's SSH Key panel.
|
||||
|
||||
![Adding key file data to GitLab][17]
|
||||
|
||||
Once that's done, your mobile device can authorize to your server, but it still needs to know where to go to find your calendar data. Different apps may use different notation, but MGit uses plain old Git-over-SSH. That means if you're using a non-standard SSH port, you must specify the SSH port to use:
|
||||
|
||||
```
|
||||
$ git clone ssh://seth@example.com:22122//home/seth/git/cal.git
|
||||
```
|
||||
|
||||
![Specifying SSH port in MGit][18]
|
||||
|
||||
If you use a different app, it may use a different syntax that allows you to provide a port in a special field or drop the **ssh://** prefix. Refer to the app documentation if you experience issues.
|
||||
|
||||
Clone the repository to your phone.
|
||||
|
||||
![Cloned repositories][19]
|
||||
|
||||
Few Git apps are set to automatically update the repository. There are a few apps you can use to automate pulls, or you can set up Git hooks to push updates from your server—but I won't get into that here. For now, after you make an update to your calendar, be sure to pull new changes manually in MGit (or if you change events on your phone, push the changes to your server).
|
||||
|
||||
![MGit push/pull settings][20]
|
||||
|
||||
#### Mobile calendar
|
||||
|
||||
There are a few different apps that provide frontends for Org mode on a mobile device. [Orgzly][21] is a great open source Android app that provides an interface for Org mode's greatest features, from the Agenda mode to the TODO lists. Install and launch it.
|
||||
|
||||
From the Main menu, choose Setting Sync Repositories and select the directory containing your calendar files (i.e., the Git repository you cloned from your server).
|
||||
|
||||
Give Orgzly a moment to import the data, then use Orgzly's [hamburger][22] menu to select the Agenda view.
|
||||
|
||||
![Orgzly's agenda view][23]
|
||||
|
||||
In Orgzly's Settings Reminders menu, you can choose which event types trigger a notification on your phone. You can get notifications for **SCHEDULED** tasks, **DEADLINE** tasks, or anything with an event time assigned to it. If you use your phone as your taskmaster, you'll never miss an event with Org mode and Orgzly.
|
||||
|
||||
![Orgzly notification][24]
|
||||
|
||||
Orgzly isn't just a parser. You can edit and update events, and even mark events **DONE**.
|
||||
|
||||
![Orgzly to-do list][25]
|
||||
|
||||
### Designed for and by you
|
||||
|
||||
The important thing to understand about using Org mode and Git is that both applications are highly flexible, and it's expected that you'll customize how and what they do so they will adapt to your needs. If something in this article is an affront to how you organize your life or manage your weekly schedule, but you like other parts of what this proposal offers, then throw out the part you don't like. You can use Org mode in Emacs if you want, or you can just use it as calendar markup. You can set your phone to pull Git data right off your computer at the end of the day instead of a server on the internet, or you can configure your computer to sync calendars whenever your phone is plugged in, or you can manage it daily as you load up your phone with all the stuff you need for the workday. It's up to you, and that's the most significant thing about Git, about Org mode, and about open source.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/calendar-git
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web-design-monitor-website.png?itok=yUK7_qR0 (website design image)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: https://tools.ietf.org/html/rfc4791
|
||||
[4]: http://nextcloud.com
|
||||
[5]: https://github.com/pimutils/khal
|
||||
[6]: https://plaintextproject.online/
|
||||
[7]: https://orgmode.org
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-org-mode
|
||||
[9]: https://commonmark.org/
|
||||
[10]: https://orgmode.org/manual/
|
||||
[11]: http://gitlab.com
|
||||
[12]: http://gitolite.com/gitolite/index.html
|
||||
[13]: https://gitea.io/en-us/
|
||||
[14]: mailto:seth@example.com
|
||||
[15]: https://f-droid.org/en/packages/com.manichord.mgit
|
||||
[16]: https://community.kde.org/KDEConnect
|
||||
[17]: https://opensource.com/sites/default/files/uploads/gitlab-add-key.jpg (Adding key file data to GitLab)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/mgit-0.jpg (Specifying SSH port in MGit)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/mgit-1.jpg (Cloned repositories)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/mgit-2.jpg (MGit push/pull settings)
|
||||
[21]: https://f-droid.org/en/packages/com.orgzly/
|
||||
[22]: https://en.wikipedia.org/wiki/Hamburger_button
|
||||
[23]: https://opensource.com/sites/default/files/uploads/orgzly-agenda.jpg (Orgzly's agenda view)
|
||||
[24]: https://opensource.com/sites/default/files/uploads/orgzly-cal-notify.jpg (Orgzly notification)
|
||||
[25]: https://opensource.com/sites/default/files/uploads/orgzly-cal-todo.jpg (Orgzly to-do list)
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Parallel computation in Python with Dask)
|
||||
[#]: via: (https://opensource.com/article/19/4/parallel-computation-python-dask)
|
||||
[#]: author: (Moshe Zadka (Community Moderator) https://opensource.com/users/moshez)
|
||||
|
||||
Parallel computation in Python with Dask
|
||||
======
|
||||
The Dask library scales Python computation to multiple cores or even to
|
||||
multiple machines.
|
||||
![Pair programming][1]
|
||||
|
||||
One frequent complaint about Python performance is the [global interpreter lock][2] (GIL). Because of GIL, only one thread can execute Python byte code at a time. As a consequence, using threads does not speed up computation—even on modern, multi-core machines.
|
||||
|
||||
But when you need to parallelize to many cores, you don't need to stop using Python: the **[Dask][3]** library will scale computation to multiple cores or even to multiple machines. Some setups configure Dask on thousands of machines, each with multiple cores; while there are scaling limits, they are not easy to hit.
|
||||
|
||||
While Dask has many built-in array operations, as an example of something not built-in, we can calculate the [skewness][4]:
|
||||
```
|
||||
import numpy
|
||||
import dask
|
||||
from dask import array as darray
|
||||
|
||||
arr = dask.from_array(numpy.array(my_data), chunks=(1000,))
|
||||
mean = darray.mean()
|
||||
stddev = darray.std(arr)
|
||||
unnormalized_moment = darry.mean(arr * arr * arr)
|
||||
## See formula in wikipedia:
|
||||
skewness = ((unnormalized_moment - (3 * mean * stddev ** 2) - mean ** 3) /
|
||||
stddev ** 3)
|
||||
```
|
||||
|
||||
Notice that each operation will use as many cores as needed. This will parallelize across all cores, even when calculating across billions of elements.
|
||||
|
||||
Of course, it is not always the case that our operations can be parallelized by the library; sometimes we need to implement parallelism on our own.
|
||||
|
||||
For that, Dask has a "delayed" functionality:
|
||||
```
|
||||
import dask
|
||||
|
||||
def is_palindrome(s):
|
||||
return s == s[::-1]
|
||||
|
||||
palindromes = [dask.delayed(is_palindrome)(s) for s in string_list]
|
||||
total = dask.delayed(sum)(palindromes)
|
||||
result = total.compute()
|
||||
```
|
||||
|
||||
This will calculate whether strings are palindromes in parallel and will return a count of the palindromic ones.
|
||||
|
||||
While Dask was created for data scientists, it is by no means limited to data science. Whenever we need to parallelize tasks in Python, we can turn to Dask—GIL or no GIL.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/parallel-computation-python-dask
|
||||
|
||||
作者:[Moshe Zadka (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/collab-team-pair-programming-code-keyboard.png?itok=kBeRTFL1 (Pair programming)
|
||||
[2]: https://wiki.python.org/moin/GlobalInterpreterLock
|
||||
[3]: https://github.com/dask/dask
|
||||
[4]: https://en.wikipedia.org/wiki/Skewness#Definition
|
||||
@ -0,0 +1,189 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What are Ubuntu Repositories? How to enable or disable them?)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-repositories)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
What are Ubuntu Repositories? How to enable or disable them?
|
||||
======
|
||||
|
||||
_**This detailed article tells you about various repositories like universe, multiverse in Ubuntu and how to enable or disable them.**_
|
||||
|
||||
So, you are trying to follow a tutorial from the web and installing a software using apt-get command and it throws you an error:
|
||||
|
||||
```
|
||||
E: Unable to locate package xyz
|
||||
```
|
||||
|
||||
You are surprised because others the package should be available. You search on the internet and come across a solution that you have to enable universe or multiverse repository to install that package.
|
||||
|
||||
**You can enable universe and multiverse repositories in Ubuntu using the commands below:**
|
||||
|
||||
```
|
||||
sudo add-apt-repository universe multiverse
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
You installed the universe and multiverse repository but do you know what are these repositories? How do they play a role in installing packages? Why there are several repositories?
|
||||
|
||||
I’ll explain all these questions in detail here.
|
||||
|
||||
### The concept of repositories in Ubuntu
|
||||
|
||||
Okay, so you already know that to [install software in Ubuntu][1], you can use the [apt command][2]. This is the same [APT package manager][3] that Ubuntu Software Center utilizes underneath. So all the software (except Snap packages) that you see in the Software Center are basically from APT.
|
||||
|
||||
Have you ever wondered where does the apt program install the programs from? How does it know which packages are available and which are not?
|
||||
|
||||
Apt basically works on the repository. A repository is nothing but a server that contains a set of software. Ubuntu provides a set of repositories so that you won’t have to search on the internet for the installation file of various software of your need. This centralized way of providing software is one of the main strong points of using Linux.
|
||||
|
||||
The APT package manager gets the repository information from the /etc/apt/sources.list file and files listed in /etc/apt/sources.list.d directory. Repository information is usually in the following format:
|
||||
|
||||
```
|
||||
deb http://us.archive.ubuntu.com/ubuntu/ bionic main
|
||||
```
|
||||
|
||||
In fact, you can [go to the above server address][4] and see how the repository is structured.
|
||||
|
||||
When you [update Ubuntu using the apt update command][5], the apt package manager gets the information about the available packages (and their version info) from the repositories and stores them in local cache. You can see this in /var/lib/apt/lists directory.
|
||||
|
||||
Keeping this information locally speeds up the search process because you don’t have to go through the network and search the database of available packages just to check if a certain package is available or not.
|
||||
|
||||
Now you know how repositories play an important role, let’s see why there are several repositories provided by Ubuntu.
|
||||
|
||||
### Ubuntu Repositories: Main, Universe, Multiverse, Restricted and Partner
|
||||
|
||||
![][6]
|
||||
|
||||
Software in Ubuntu repository are divided into five categories: main, universe, multiverse, restricted and partner.
|
||||
|
||||
Why Ubuntu does that? Why not put all the software into one single repository? To answer this question, let’s see what are these repositories:
|
||||
|
||||
#### **Main**
|
||||
|
||||
When you install Ubuntu, this is the repository enabled by default. The main repository consists of only FOSS (free and open source software) that can be distributed freely without any restrictions.
|
||||
|
||||
Software in this repository are fully supported by the Ubuntu developers. This is what Ubuntu will provide with security updates until your system reaches end of life.
|
||||
|
||||
#### **Universe**
|
||||
|
||||
This repository also consists free and open source software but Ubuntu doesn’t guarantee of regular security updates to software in this category.
|
||||
|
||||
Software in this category are packaged and maintained by the community. The Universe repository has a vast amount of open source software and thus it enables you to have access to a huge number of software via apt package manager.
|
||||
|
||||
#### **Multiverse**
|
||||
|
||||
Multiverse contains the software that are not FOSS. Due to licensing and legal issues, Ubuntu cannot enable this repository by default and cannot provide fix and updates.
|
||||
|
||||
It’s up to you to decide if you want to use Multiverse repository and check if you have the right to use the software.
|
||||
|
||||
#### **Restricted**
|
||||
|
||||
Ubuntu tries to provide only free and open source software but that’s not always possible specially when it comes to supporting hardware.
|
||||
|
||||
The restricted repositories consists of proprietary drivers.
|
||||
|
||||
#### **Partner**
|
||||
|
||||
This repository consist of proprietary software packaged by Ubuntu for their partners. Earlier, Ubuntu used to provide Skype trough this repository.
|
||||
|
||||
#### Third party repositories and PPA (Not provided by Ubuntu)
|
||||
|
||||
The above five repositories are provided by Ubuntu. You can also add third party repositories (it’s up to you if you want to do it) to access more software or to access newer version of a software (as Ubuntu might provide old version of the same software).
|
||||
|
||||
For example, if you add the repository provided by [VirtualBox][7], you can get the latest version of VurtualBox. It will add a new entry in your sources.list.
|
||||
|
||||
You can also install additional application using PPA (Personal Package Archive). I have written about [what is PPA and how it works][8] in detail so please read that article.
|
||||
|
||||
Tip
|
||||
|
||||
Try NOT adding anything other than Ubuntu’s repositories in your sources.list file. You should keep this file in pristine condition because if you mess it up, you won’t be able to update your system or (at times) even install new packages.
|
||||
|
||||
### Add universe, multiverse and other repositories
|
||||
|
||||
As I had mentioned earlier, only the Main repository is enabled by default when you install Ubuntu. To access more software, you can add the additional repositories.
|
||||
|
||||
Let me show you how to do it in command line first and then I’ll show you the GUI ways as well.
|
||||
|
||||
To enable Universe repository, use:
|
||||
|
||||
```
|
||||
sudo add-apt-repository universe
|
||||
```
|
||||
|
||||
To enable Restricted repository, use:
|
||||
|
||||
```
|
||||
sudo add-apt-repository restricted
|
||||
```
|
||||
|
||||
To enable Multiverse repository, use this command:
|
||||
|
||||
```
|
||||
sudo add-apt-repository multiverse
|
||||
```
|
||||
|
||||
You must use sudo apt update command after adding the repository so that you system creates the local cache with package information.
|
||||
|
||||
If you want to **remove a repository** , simply add -r like **sudo add-apt-repository -r universe**.
|
||||
|
||||
Graphically, go to Software & Updates and you can enable the repositories here:
|
||||
|
||||
![Adding Universe, Restricted and Multiverse repositories][9]
|
||||
|
||||
You’ll find the option to enable partner repository in the Other Software tab.
|
||||
|
||||
![Adding Partner repository][10]
|
||||
|
||||
To disable a repository, simply uncheck the box.
|
||||
|
||||
### Bonus Tip: How to know which repository a package belongs to?
|
||||
|
||||
Ubuntu has a dedicated website that provides you with information about all the packages available in the Ubuntu archive. Go to Ubuntu Packages website.
|
||||
|
||||
[Ubuntu Packages][11]
|
||||
|
||||
You can search for a package name in the search field. You can select if you are looking for a particular Ubuntu release or a particular repository. I prefer using ‘any’ option in both fields.
|
||||
|
||||
![][12]
|
||||
|
||||
It will show you all the matching packages, Ubuntu releases and the repository information.
|
||||
|
||||
![][13]
|
||||
|
||||
As you can see above the package tor is available in the Universe repository for various Ubuntu releases.
|
||||
|
||||
**Conclusion**
|
||||
|
||||
I hope this article helped you in understanding the concept of repositories in Ubuntu.
|
||||
|
||||
If you have any questions or suggestions, please feel free to leave a comment below. If you liked the article, please share it on social media sites like Reddit and Hacker News.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-repositories
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/remove-install-software-ubuntu/
|
||||
[2]: https://itsfoss.com/apt-command-guide/
|
||||
[3]: https://wiki.debian.org/Apt
|
||||
[4]: http://us.archive.ubuntu.com/ubuntu/
|
||||
[5]: https://itsfoss.com/update-ubuntu/
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/ubuntu-repositories.png?resize=800%2C450&ssl=1
|
||||
[7]: https://itsfoss.com/install-virtualbox-ubuntu/
|
||||
[8]: https://itsfoss.com/ppa-guide/
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/enable-repositories-ubuntu.png?resize=800%2C490&ssl=1
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/enable-partner-repository-ubuntu.png?resize=800%2C490&ssl=1
|
||||
[11]: https://packages.ubuntu.com
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/search-packages-ubuntu-archive.png?ssl=1
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/search-packages-ubuntu-archive-1.png?resize=800%2C454&ssl=1
|
||||
124
sources/tech/20190403 5 useful open source log analysis tools.md
Normal file
124
sources/tech/20190403 5 useful open source log analysis tools.md
Normal file
@ -0,0 +1,124 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 useful open source log analysis tools)
|
||||
[#]: via: (https://opensource.com/article/19/4/log-analysis-tools)
|
||||
[#]: author: (Sam Bocetta https://opensource.com/users/sambocetta)
|
||||
|
||||
5 useful open source log analysis tools
|
||||
======
|
||||
Monitoring network activity is as important as it is tedious. These
|
||||
tools can make it easier.
|
||||
![People work on a computer server][1]
|
||||
|
||||
Monitoring network activity can be a tedious job, but there are good reasons to do it. For one, it allows you to find and investigate suspicious logins on workstations, devices connected to networks, and servers while identifying sources of administrator abuse. You can also trace software installations and data transfers to identify potential issues in real time rather than after the damage is done.
|
||||
|
||||
Those logs also go a long way towards keeping your company in compliance with the [General Data Protection Regulation][2] (GDPR) that applies to any entity operating within the European Union. If you have a website that is viewable in the EU, you qualify.
|
||||
|
||||
Logging—both tracking and analysis—should be a fundamental process in any monitoring infrastructure. A transaction log file is necessary to recover a SQL server database from disaster. Further, by tracking log files, DevOps teams and database administrators (DBAs) can maintain optimum database performance or find evidence of unauthorized activity in the case of a cyber attack. For this reason, it's important to regularly monitor and analyze system logs. It's a reliable way to re-create the chain of events that led up to whatever problem has arisen.
|
||||
|
||||
There are quite a few open source log trackers and analysis tools available today, making choosing the right resources for activity logs easier than you think. The free and open source software community offers log designs that work with all sorts of sites and just about any operating system. Here are five of the best I've used, in no particular order.
|
||||
|
||||
### Graylog
|
||||
|
||||
[Graylog][3] started in Germany in 2011 and is now offered as either an open source tool or a commercial solution. It is designed to be a centralized log management system that receives data streams from various servers or endpoints and allows you to browse or analyze that information quickly.
|
||||
|
||||
![Graylog screenshot][4]
|
||||
|
||||
Graylog has built a positive reputation among system administrators because of its ease in scalability. Most web projects start small but can grow exponentially. Graylog can balance loads across a network of backend servers and handle several terabytes of log data each day.
|
||||
|
||||
IT administrators will find Graylog's frontend interface to be easy to use and robust in its functionality. Graylog is built around the concept of dashboards, which allows you to choose which metrics or data sources you find most valuable and quickly see trends over time.
|
||||
|
||||
When a security or performance incident occurs, IT administrators want to be able to trace the symptoms to a root cause as fast as possible. Search functionality in Graylog makes this easy. It has built-in fault tolerance that can run multi-threaded searches so you can analyze several potential threats together.
|
||||
|
||||
### Nagios
|
||||
|
||||
[Nagios][5] started with a single developer back in 1999 and has since evolved into one of the most reliable open source tools for managing log data. The current version of Nagios can integrate with servers running Microsoft Windows, Linux, or Unix.
|
||||
|
||||
![Nagios Core][6]
|
||||
|
||||
Its primary product is a log server, which aims to simplify data collection and make information more accessible to system administrators. The Nagios log server engine will capture data in real-time and feed it into a powerful search tool. Integrating with a new endpoint or application is easy thanks to the built-in setup wizard.
|
||||
|
||||
Nagios is most often used in organizations that need to monitor the security of their local network. It can audit a range of network-related events and help automate the distribution of alerts. Nagios can even be configured to run predefined scripts if a certain condition is met, allowing you to resolve issues before a human has to get involved.
|
||||
|
||||
As part of network auditing, Nagios will filter log data based on the geographic location where it originates. That means you can build comprehensive dashboards with mapping technology to understand how your web traffic is flowing.
|
||||
|
||||
### Elastic Stack (the "ELK Stack")
|
||||
|
||||
[Elastic Stack][7], often called the ELK Stack, is one of the most popular open source tools among organizations that need to sift through large sets of data and make sense of their system logs (and it's a personal favorite, too).
|
||||
|
||||
![ELK Stack][8]
|
||||
|
||||
Its primary offering is made up of three separate products: Elasticsearch, Kibana, and Logstash:
|
||||
|
||||
* As its name suggests, _**Elasticsearch**_ is designed to help users find matches within datasets using a wide range of query languages and types. Speed is this tool's number one advantage. It can be expanded into clusters of hundreds of server nodes to handle petabytes of data with ease.
|
||||
|
||||
* _**Kibana**_ is a visualization tool that runs alongside Elasticsearch to allow users to analyze their data and build powerful reports. When you first install the Kibana engine on your server cluster, you will gain access to an interface that shows statistics, graphs, and even animations of your data.
|
||||
|
||||
* The final piece of ELK Stack is _**Logstash**_ , which acts as a purely server-side pipeline into the Elasticsearch database. You can integrate Logstash with a variety of coding languages and APIs so that information from your websites and mobile applications will be fed directly into your powerful Elastic Stalk search engine.
|
||||
|
||||
|
||||
|
||||
|
||||
A unique feature of ELK Stack is that it allows you to monitor applications built on open source installations of WordPress. In contrast to most out-of-the-box security audit log tools that [track admin and PHP logs][9] but little else, ELK Stack can sift through web server and database logs.
|
||||
|
||||
Poor log tracking and database management are one of the [most common causes of poor website performance][10]. Failure to regularly check, optimize, and empty database logs can not only slow down a site but could lead to a complete crash as well. Thus, the ELK Stack is an excellent tool for every WordPress developer's toolkit.
|
||||
|
||||
### LOGalyze
|
||||
|
||||
[LOGalyze][11] is an organization based in Hungary that builds open source tools for system administrators and security experts to help them manage server logs and turn them into useful data points. Its primary product is available as a free download for either personal or commercial use.
|
||||
|
||||
![LOGalyze][12]
|
||||
|
||||
LOGalyze is designed to work as a massive pipeline in which multiple servers, applications, and network devices can feed information using the Simple Object Access Protocol (SOAP) method. It provides a frontend interface where administrators can log in to monitor the collection of data and start analyzing it.
|
||||
|
||||
From within the LOGalyze web interface, you can run dynamic reports and export them into Excel files, PDFs, or other formats. These reports can be based on multi-dimensional statistics managed by the LOGalyze backend. It can even combine data fields across servers or applications to help you spot trends in performance.
|
||||
|
||||
LOGalyze is designed to be installed and configured in less than an hour. It has prebuilt functionality that allows it to gather audit data in formats required by regulatory acts. For example, LOGalyze can easily run different HIPAA reports to ensure your organization is adhering to health regulations and remaining compliant.
|
||||
|
||||
### Fluentd
|
||||
|
||||
If your organization has data sources living in many different locations and environments, your goal should be to centralize them as much as possible. Otherwise, you will struggle to monitor performance and protect against security threats.
|
||||
|
||||
[Fluentd][13] is a robust solution for data collection and is entirely open source. It does not offer a full frontend interface but instead acts as a collection layer to help organize different pipelines. Fluentd is used by some of the largest companies worldwide but can be implemented in smaller organizations as well.
|
||||
|
||||
![Fluentd architecture][14]
|
||||
|
||||
The biggest benefit of Fluentd is its compatibility with the most common technology tools available today. For example, you can use Fluentd to gather data from web servers like Apache, sensors from smart devices, and dynamic records from MongoDB. What you do with that data is entirely up to you.
|
||||
|
||||
Fluentd is based around the JSON data format and can be used in conjunction with [more than 500 plugins][15] created by reputable developers. This allows you to extend your logging data into other applications and drive better analysis from it with minimal manual effort.
|
||||
|
||||
### The bottom line
|
||||
|
||||
If you aren't already using activity logs for security reasons, governmental compliance, and measuring productivity, commit to changing that. There are plenty of plugins on the market that are designed to work with multiple environments and platforms, even on your internal network. Don't wait for a serious incident to justify taking a proactive approach to logs maintenance and oversight.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/log-analysis-tools
|
||||
|
||||
作者:[Sam Bocetta][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sambocetta
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux11x_cc.png?itok=XMDOouJR (People work on a computer server)
|
||||
[2]: https://opensource.com/article/18/4/gdpr-impact
|
||||
[3]: https://www.graylog.org/products/open-source
|
||||
[4]: https://opensource.com/sites/default/files/uploads/graylog-data.png (Graylog screenshot)
|
||||
[5]: https://www.nagios.org/downloads/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/nagios_core_4.0.8.png (Nagios Core)
|
||||
[7]: https://www.elastic.co/products
|
||||
[8]: https://opensource.com/sites/default/files/uploads/elk-stack.png (ELK Stack)
|
||||
[9]: https://www.wpsecurityauditlog.com/benefits-wordpress-activity-log/
|
||||
[10]: https://websitesetup.org/how-to-speed-up-wordpress/
|
||||
[11]: http://www.logalyze.com/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/logalyze.jpg (LOGalyze)
|
||||
[13]: https://www.fluentd.org/
|
||||
[14]: https://opensource.com/sites/default/files/uploads/fluentd-architecture.png (Fluentd architecture)
|
||||
[15]: https://opensource.com/article/18/9/open-source-log-aggregation-tools
|
||||
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to rebase to Fedora 30 Beta on Silverblue)
|
||||
[#]: via: (https://fedoramagazine.org/how-to-rebase-to-fedora-30-beta-on-silverblue/)
|
||||
[#]: author: (Michal Konečný https://fedoramagazine.org/author/zlopez/)
|
||||
|
||||
How to rebase to Fedora 30 Beta on Silverblue
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Silverblue is [an operating system for your desktop built on Fedora][2]. It’s excellent for daily use, development, and container-based workflows. It offers [numerous advantages][3] such as being able to roll back in case of any problems. If you want to test Fedora 30 on your Silverblue system, this article tells you how. It not only shows you what to do, but also how to revert back if anything unforeseen happens.
|
||||
|
||||
### Switching to Fedora 30 branch
|
||||
|
||||
Switching to Fedora 30 on Silverblue is easy. First, check if the _30_ branch is available, which should be true now:
|
||||
|
||||
```
|
||||
ostree remote refs fedora-workstation
|
||||
```
|
||||
|
||||
You should see the following in the output:
|
||||
|
||||
```
|
||||
fedora-workstation:fedora/30/x86_64/silverblue
|
||||
```
|
||||
|
||||
Next, import the GPG key for the Fedora 30 branch. Without this step, you won’t be able to rebase.
|
||||
|
||||
```
|
||||
sudo ostree remote gpg-import fedora-workstation -k /etc/pki/rpm-gpg/RPM-GPG-KEY-fedora-30-primary
|
||||
```
|
||||
|
||||
Next, rebase your system to the Fedora 30 branch.
|
||||
|
||||
```
|
||||
rpm-ostree rebase fedora-workstation:fedora/30/x86_64/silverblue
|
||||
```
|
||||
|
||||
Finally, the last thing to do is restart your computer and boot to Fedora 30.
|
||||
|
||||
### How to revert things back
|
||||
|
||||
Remember that Fedora 30’s still in beta testing phase, so there could still be some issues. If anything bad happens — for instance, if you can’t boot to Fedora 30 at all — it’s easy to go back. Just pick the previous entry in GRUB, and your system will start in its previous state before switching to Fedora 30. To make this change permanent, use the following command:
|
||||
|
||||
```
|
||||
rpm-ostree rollback
|
||||
```
|
||||
|
||||
That’s it. Now you know how to rebase to Fedora 30 and back. So why not test it today? 🙂
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/how-to-rebase-to-fedora-30-beta-on-silverblue/
|
||||
|
||||
作者:[Michal Konečný][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/zlopez/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/silverblue-f30beta-816x345.jpg
|
||||
[2]: https://docs.fedoraproject.org/en-US/fedora-silverblue/
|
||||
[3]: https://fedoramagazine.org/give-fedora-silverblue-a-test-drive/
|
||||
141
sources/tech/20190403 Use Git as the backend for chat.md
Normal file
141
sources/tech/20190403 Use Git as the backend for chat.md
Normal file
@ -0,0 +1,141 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use Git as the backend for chat)
|
||||
[#]: via: (https://opensource.com/article/19/4/git-based-chat)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
Use Git as the backend for chat
|
||||
======
|
||||
GIC is a prototype chat application that showcases a novel way to use Git.
|
||||
![Team communication, chat][1]
|
||||
|
||||
[Git][2] is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git. Today, we'll look at GIC, a Git-based chat application
|
||||
|
||||
### Meet GIC
|
||||
|
||||
While the authors of Git probably expected frontends to be created for Git, they undoubtedly never expected Git would become the backend for, say, a chat client. Yet, that's exactly what developer Ephi Gabay did with his experimental proof-of-concept [GIC][3]: a chat client written in [Node.js][4] using Git as its backend database.
|
||||
|
||||
GIC is by no means intended for production use. It's purely a programming exercise, but it's one that demonstrates the flexibility of open source technology. What's astonishing is that the client consists of just 300 lines of code, excluding the Node libraries and Git itself. And that's one of the best things about the chat client and about open source; the ability to build upon existing work. Seeing is believing, so you should give GIC a look for yourself.
|
||||
|
||||
### Get set up
|
||||
|
||||
GIC uses Git as its engine, so you need an empty Git repository to serve as its chatroom and logger. The repository can be hosted anywhere, as long as you and anyone who needs access to the chat service has access to it. For instance, you can set up a Git repository on a free Git hosting service like GitLab and grant chat users contributor access to the Git repository. (They must be able to make commits to the repository, because each chat message is a literal commit.)
|
||||
|
||||
If you're hosting it yourself, create a centrally located bare repository. Each user in the chat must have an account on the server where the bare repository is located. You can create accounts specific to Git with Git hosting software like [Gitolite][5] or [Gitea][6], or you can give them individual user accounts on your server, possibly using **git-shell** to restrict their access to Git.
|
||||
|
||||
Performance is best on a self-hosted instance. Whether you host your own or you use a hosting service, the Git repository you create must have an active branch, or GIC won't be able to make commits as users chat because there is no Git HEAD. The easiest way to ensure that a branch is initialized and active is to commit a README or license file upon creation. If you don't do that, you can create and commit one after the fact:
|
||||
|
||||
```
|
||||
$ echo "chat logs" > README
|
||||
$ git add README
|
||||
$ git commit -m 'just creating a HEAD ref'
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
### Install GIC
|
||||
|
||||
Since GIC is based on Git and written in Node.js, you must first install Git, Node.js, and the Node package manager, npm (which should be bundled with Node). The command to install these differs depending on your Linux or BSD distribution, but here's an example command on Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install git nodejs
|
||||
```
|
||||
|
||||
If you're not running Linux or BSD, follow the installation instructions on [git-scm.com][7] and [nodejs.org][8].
|
||||
|
||||
There's no install process, as such, for GIC. Each user (Alice and Bob, in this example) must clone the repository to their hard drive:
|
||||
|
||||
```
|
||||
$ git cone https://github.com/ephigabay/GIC GIC
|
||||
```
|
||||
|
||||
Change directory into the GIC directory and install the Node.js dependencies with **npm** :
|
||||
|
||||
```
|
||||
$ cd GIC
|
||||
$ npm install
|
||||
```
|
||||
|
||||
Wait for the Node modules to download and install.
|
||||
|
||||
### Configure GIC
|
||||
|
||||
The only configuration GIC requires is the location of your Git chat repository. Edit the **config.js** file:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
gitRepo: '[seth@example.com][9]:/home/gitchat/chatdemo.git',
|
||||
messageCheckInterval: 500,
|
||||
branchesCheckInterval: 5000
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
Test your connection to the Git repository before trying GIC, just to make sure your configuration is sane:
|
||||
|
||||
```
|
||||
$ git clone --quiet seth@example.com:/home/gitchat/chatdemo.git > /dev/null
|
||||
```
|
||||
|
||||
Assuming you receive no errors, you're ready to start chatting.
|
||||
|
||||
### Chat with Git
|
||||
|
||||
From within the GIC directory, start the chat client:
|
||||
|
||||
```
|
||||
$ npm start
|
||||
```
|
||||
|
||||
When the client first launches, it must clone the chat repository. Since it's nearly an empty repository, it won't take long. Type your message and press Enter to send a message.
|
||||
|
||||
![GIC][10]
|
||||
|
||||
A Git-based chat client. What will they think of next?
|
||||
|
||||
As the greeting message says, a branch in Git serves as a chatroom or channel in GIC. There's no way to create a new branch from within the GIC UI, but if you create one in another terminal session or in a web UI, it shows up immediately in GIC. It wouldn't take much to patch some IRC-style commands into GIC.
|
||||
|
||||
After chatting for a while, take a look at your Git repository. Since the chat happens in Git, the repository itself is also a chat log:
|
||||
|
||||
```
|
||||
$ git log --pretty=format:"%p %cn %s"
|
||||
4387984 Seth Kenlon Hey Chani, did you submit a talk for All Things Open this year?
|
||||
36369bb Chani No I didn't get a chance. Did you?
|
||||
[...]
|
||||
```
|
||||
|
||||
### Exit GIC
|
||||
|
||||
Not since Vim has there been an application as difficult to stop as GIC. You see, there is no way to stop GIC. It will continue to run until it is killed. When you're ready to stop GIC, open another terminal tab or window and issue this command:
|
||||
|
||||
```
|
||||
$ kill `pgrep npm`
|
||||
```
|
||||
|
||||
GIC is a novelty. It's a great example of how an open source ecosystem encourages and enables creativity and exploration and challenges us to look at applications from different angles. Try GIC out. Maybe it will give you ideas. At the very least, it's a great excuse to spend an afternoon with Git.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/git-based-chat
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: https://github.com/ephigabay/GIC
|
||||
[4]: https://nodejs.org/en/
|
||||
[5]: http://gitolite.com
|
||||
[6]: http://gitea.io
|
||||
[7]: http://git-scm.com
|
||||
[8]: http://nodejs.org
|
||||
[9]: mailto:seth@example.com
|
||||
[10]: https://opensource.com/sites/default/files/uploads/gic.jpg (GIC)
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Command line quick tips: Cutting content out of files)
|
||||
[#]: via: (https://fedoramagazine.org/command-line-quick-tips-cutting-content-out-of-files/)
|
||||
[#]: author: (Stephen Snow https://fedoramagazine.org/author/jakfrost/)
|
||||
|
||||
Command line quick tips: Cutting content out of files
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
The Fedora distribution is a full featured operating system with an excellent graphical desktop environment. A user can point and click their way through just about any typical task easily. All of this wonderful ease of use masks the details of a powerful command line under the hood. This article is part of a series that shows you some common command line utilities. So let’s drop into the shell, and have a look at **cut**.
|
||||
|
||||
Often when you work in the command line, you are working with text files. Sometimes these files may be quite long. Reading them in their entirety, while feasible, can be time consuming and prone to errors. In this installment you’ll learn how to extract content from text files, and get the information you want from them.
|
||||
|
||||
It’s important to recognize that there are many ways to accomplish similar command line tasks in Fedora. The Fedora repositories include entire language systems for parsing and working with text, as an example. Also, there are multiple command line utilities available for just about any purpose conceivable in the shell. This article will only focus on using a few of those utility choices, to extract some information from a file and present it in a readable format.
|
||||
|
||||
### Making the cut
|
||||
|
||||
To illustrate this example use a standard sizable file on the system like _/etc/passwd_. As seen in a prior article in this series, you can execute the _cat_ command to view an entire file:
|
||||
|
||||
```
|
||||
$ cat /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
bin:x:1:1:bin:/bin:/sbin/nologin
|
||||
daemon:x:2:2:daemon:/sbin:/sbin/nologin
|
||||
adm:x:3:4:adm:/var/adm:/sbin/nologin
|
||||
...
|
||||
```
|
||||
|
||||
This file contains information on all accounts present on the system. It has a specific format:
|
||||
|
||||
```
|
||||
name:password:user-id:group-id:comment:home-directory:shell
|
||||
```
|
||||
|
||||
Imagine that you want to simply have a list of all the account names on the system. If you could only cut out the _name_ value from each line. This is where the _cut_ command comes in handy! This command treats any input one line at a time, and extracts a specific part of the line.
|
||||
|
||||
The _cut_ command provides options for selecting parts of a line differently, and in this example two of them are needed, _-d_ which is an option to specify a delimiter type to use, and _-f_ which is an option to specify which field of the line to cut. The _-d_ option lets you declare the _delimiter_ that separates values in a line. In this case a colon (:) is used to separate values. The _-f_ option lets you choose which field value or values to extract. So for this example the command entered would be:
|
||||
|
||||
```
|
||||
$ cut -d: -f1 /etc/passwd
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
...
|
||||
```
|
||||
|
||||
That’s great, it worked! But you get the printout to the standard output, which in a terminal session at least means the screen. What if you needed the information for another task to be done later? It would be really nice if there was a way to put the output of the _cut_ command into a text file to save it. There is an easy builtin shell function for such a task, the redirect function ( _>_ ).
|
||||
|
||||
```
|
||||
$ cut -d: -f1 /etc/passwd > names.txt
|
||||
```
|
||||
|
||||
This will place the output of cut into a file called _names.txt_ and you can check the contents with _cat:_
|
||||
|
||||
```
|
||||
$ cat names.txt
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
...
|
||||
```
|
||||
|
||||
With two commands and one shell function, it was easy to identify using _cat_ , extract using _cut_ , and redirect the extracted information from one file, saving it to another file for later use.
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by _[ _Joel Mbugua_][2]_ on _[_Unsplash_][3]_._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/command-line-quick-tips-cutting-content-out-of-files/
|
||||
|
||||
作者:[Stephen Snow][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/jakfrost/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/commandline-cutting-816x345.jpg
|
||||
[2]: https://unsplash.com/photos/tA5eSY_hay8?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]: https://unsplash.com/search/photos/command-line?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -1,506 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (ezio )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 10 Input01)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
|
||||
计算机实验课 – 树莓派: 课程 10 输入01
|
||||
======
|
||||
|
||||
欢迎进入输入课程系列。在本系列,你将会学会如何使用键盘接收输入给树莓派。我们将会从揭示输入开始本课,然后开始传统的文本命令。
|
||||
|
||||
这是第一堂输入课,会教授一些关于驱动和链接的理论,同样也包含键盘的知识,最后以在屏幕上显示文本结束。
|
||||
|
||||
### 1 开始
|
||||
|
||||
希望你已经完成了 OK 系列课程, 这会对你完成屏幕系列课程很有帮助。很多 OK 课程上的文件会被使用而不会做解释。如果你没有这些文件,或者希望使用一个正确的实现, 可以从该堂课的[下载页][1]下载模板。如果你使用你自己的实现,请删除调用了 `SetGraphicsAddress` 之后全部的代码。
|
||||
|
||||
### 2 USB
|
||||
|
||||
```
|
||||
USB 标准的设计目的是通过复杂的硬件来简化硬件。
|
||||
```
|
||||
|
||||
如你所知,树莓派 B 型有两个 USB 接口,通常用来连接一个鼠标和一个键盘。这是一个非常好的设计决策,USB 是一个非常通用的接口, 很多种设备都可以使用它。这就很容易为它设计新外设,很容易为它编写设备驱动, 而且通过 USB 集线器可以非常容易扩展。还能更好吗?当然是不能,实际上对一个操作系统开发者来说,这就是我们的噩梦。USB 标准太大了。 我是真的,在你思考如何连接设备之前,它的文档将近 700 页。
|
||||
|
||||
我和很多爱好操作系统的开发者谈过这些,而他们全部都说几句话:不要抱怨。“实现这个需要花费很久时间”,“你不可能写出关于 USB 的教程”,“收益太小了”。在很多方面,他们是对的,我不可能写出一个关于 USB 标准的教程, 那得花费几周时间。我同样不能教授如何为全部所有的设备编写外设驱动,所以使用自己写的驱动是没什么用的。然而,我可以做仅次于最好的事情是获取一个正常工作的 USB 驱动,拿一个键盘驱动,然后教授如何在操作系统中使用它们。我开始寻找可以运行在一个甚至不知道文件是什么的操作系统的自由驱动,但是我一个都找不到。他们都太高层了。所以我尝试写一个。每个人都是对的,这耗费了我几周时间。然而我高兴的说我我做这些工作没有获取操作系统以外的帮助,并且可以和鼠标和键盘通信。这句不是完整的,高效的,或者正确的,但是它能工作。驱动是以 C 编写的,而且有兴趣的可以在下载页找到全部源代码。
|
||||
|
||||
所以,这一个教程不会是 USB 标准的课程(一点也没有)。实际上我们将会看到如何使用其他人的代码。
|
||||
|
||||
### 3 链接
|
||||
|
||||
```
|
||||
链接允许我们制作可重用的代码库,所有人都可以在他们的程序中使用。
|
||||
```
|
||||
|
||||
既然我们要引进外部代码到操作系统,我们就需要谈一谈链接。链接是一种过程,可以在程序或者操作系统中链接函数。这意味着当一个程序生成之后,我们不必要编写每一个函数(几乎可以肯定,实际上并非如此)。链接就是我们做的用来把我们程序和别人代码中的函数连结在一起。这个实际上已经在我们的操作系统进行了,因为链接器吧所有不同的文件链接在一起,每个都是分开编译的。
|
||||
|
||||
|
||||
```
|
||||
程序经常知识调用库,这些库会调用其它的库,知道最终调用了我们写的操作系统。
|
||||
```
|
||||
|
||||
有两种链接:静态和动态。静态链接就像我们在制作自己的操作系统时进行的。链接器找到全部函数的地址,然后在链接结束前,将这些地址都写入代码中。动态链接是在程序“完成”之后。当程序加载后,动态链接器检查程序,然后在操作系统的库找到所有不在程序里的函数。这就是我们的操作系统最终应该能够完成的一项工作,但是现在所有东西都将是静态链接的。
|
||||
|
||||
我编写的 USB 驱动程序适合静态编译。这意味着我给你我的每个文件的编译后的代码,然后链接器找到你的代码中的那些没有实现的函数,就将这些函数链接到我的代码。在本课的 [下载页][1] 是一个 makefile 和我的 USB 驱动,这是接下来需要的。下载并使用这 makefile 替换你的代码中的 makefile, 同事将驱动放在和这个 makefile 相同的文件夹。
|
||||
|
||||
### 4 键盘
|
||||
|
||||
为了将输入传给我们的操作系统,我们需要在某种程度上理解键盘是如何实际工作的。键盘有两种按键:普通键和修饰键。普通按键是字母、数字、功能键,等等。他们构成了键盘上几乎每一个按键。修饰键是最多 8 个特殊键。他们是左 shift , 右 shift, 左 ctrl,右 ctrl,左 alt, 右 alt,左 GUI 和右 GUI。键盘可以检测出所有的组合中那个修饰键被按下了,以及最多 6 个普通键。每次一个按钮变化了(i.e. 是按下了还是释放了),键盘就会报告给电脑。通常,键盘也会有 3 个 LED 灯,分别指示 Caps 锁定,Num 锁定,和 Scroll 锁定,这些都是由电脑控制的,而不是键盘自己。键盘也可能由更多的灯,比如电源、静音,等等。
|
||||
|
||||
为了帮助标准 USB 键盘,产生了一个按键值的表,每个键盘按键都一个唯一的数字,每个可能的 LED 也类似。下面的表格列出了前 126 个值。
|
||||
|
||||
Table 4.1 USB 键盘值
|
||||
|
||||
| 序号 | 描述 | 序号 | 描述 | 序号 | 描述 | 序号 | 描述 | |
|
||||
| ------ | ---------------- | ------- | ---------------------- | -------- | -------------- | --------------- | -------------------- |----|
|
||||
| 4 | a and A | 5 | b and B | 6 | c and C | 7 | d and D | |
|
||||
| 8 | e and E | 9 | f and F | 10 | g and G | 11 | h and H | |
|
||||
| 12 | i and I | 13 | j and J | 14 | k and K | 15 | l and L | |
|
||||
| 16 | m and M | 17 | n and N | 18 | o and O | 19 | p and P | |
|
||||
| 20 | q and Q | 21 | r and R | 22 | s and S | 23 | t and T | |
|
||||
| 24 | u and U | 25 | v and V | 26 | w and W | 27 | x and X | |
|
||||
| 28 | y and Y | 29 | z and Z | 30 | 1 and ! | 31 | 2 and @ | |
|
||||
| 32 | 3 and # | 33 | 4 and $ | 34 | 5 and % | 35 | 6 and ^ | |
|
||||
| 36 | 7 and & | 37 | 8 and * | 38 | 9 and ( | 39 | 0 and ) | |
|
||||
| 40 | Return (Enter) | 41 | Escape | 42 | Delete (Backspace) | 43 | Tab | |
|
||||
| 44 | Spacebar | 45 | - and _ | 46 | = and + | 47 | [ and { | |
|
||||
| 48 | ] and } | 49 | \ and | 50 | # and ~ | 51 | ; and : |
|
||||
| 52 | ' and " | 53 | ` and ~ | 54 | , and < | 55 | . and > | |
|
||||
| 56 | / and ? | 57 | Caps Lock | 58 | F1 | 59 | F2 | |
|
||||
| 60 | F3 | 61 | F4 | 62 | F5 | 63 | F6 | |
|
||||
| 64 | F7 | 65 | F8 | 66 | F9 | 67 | F10 | |
|
||||
| 68 | F11 | 69 | F12 | 70 | Print Screen | 71 | Scroll Lock | |
|
||||
| 72 | Pause | 73 | Insert | 74 | Home | 75 | Page Up | |
|
||||
| 76 | Delete forward | 77 | End | 78 | Page Down | 79 | Right Arrow | |
|
||||
| 80 | Left Arrow | 81 | Down Arrow | 82 | Up Arrow | 83 | Num Lock | |
|
||||
| 84 | Keypad / | 85 | Keypad * | 86 | Keypad - | 87 | Keypad + | |
|
||||
| 88 | Keypad Enter | 89 | Keypad 1 and End | 90 | Keypad 2 and Down Arrow | 91 | Keypad 3 and Page Down | |
|
||||
| 92 | Keypad 4 and Left Arrow | 93 | Keypad 5 | 94 | Keypad 6 and Right Arrow | 95 | Keypad 7 and Home | |
|
||||
| 96 | Keypad 8 and Up Arrow | 97 | Keypad 9 and Page Up | 98 | Keypad 0 and Insert | 99 | Keypad . and Delete | |
|
||||
| 100 | \ and | 101 | Application | 102 | Power | 103 | Keypad = |
|
||||
| 104 | F13 | 105 | F14 | 106 | F15 | 107 | F16 | |
|
||||
| 108 | F17 | 109 | F18 | 110 | F19 | 111 | F20 | |
|
||||
| 112 | F21 | 113 | F22 | 114 | F23 | 115 | F24 | |
|
||||
| 116 | Execute | 117 | Help | 118 | Menu | 119 | Select | |
|
||||
| 120 | Stop | 121 | Again | 122 | Undo | 123 | Cut | |
|
||||
| 124 | Copy | 125 | Paste | 126 | Find | 127 | Mute | |
|
||||
| 128 | Volume Up | 129 | Volume Down | | | | | |
|
||||
|
||||
完全列表可以在[HID 页表 1.12][2]的 53 页,第 10 节找到
|
||||
|
||||
### 5 车轮后的螺母
|
||||
|
||||
```
|
||||
这些总结和代码的描述组成了一个 API - 应用程序产品接口。
|
||||
|
||||
```
|
||||
|
||||
通常,当你使用其他人的代码,他们会提供一份自己代码的总结,描述代码都做了什么,粗略介绍了是如何工作的,以及什么情况下会出错。下面是一个使用我的 USB 驱动的相关步骤要求。
|
||||
|
||||
Table 5.1 CSUD 中和键盘相关的函数
|
||||
| 函数 | 参数 | 返回值 | 描述 |
|
||||
| ----------------------- | ----------------------- | ----------------------- | -----------------------|
|
||||
| UsbInitialise | None | r0 is result code | 这个方法是一个集多种功能于一身的方法,它加载USB驱动程序,枚举所有设备并尝试与它们通信。这种方法通常需要大约一秒钟的时间来执行,但是如果插入几个USB集线器,执行时间会明显更长。在此方法完成之后,键盘驱动程序中的方法就可用了,不管是否确实插入了键盘。返回代码如下解释。|
|
||||
| UsbCheckForChange | None | None | 本质上提供与 `usbinitialization` 相同的效果,但不提供相同的一次初始化。该方法递归地检查每个连接的集线器上的每个端口,如果已经添加了新设备,则添加它们。如果没有更改,这应该是非常快的,但是如果连接了多个设备的集线器,则可能需要几秒钟的时间。|
|
||||
| KeyboardCount | None | r0 is count | 返回当前连接并检测到的键盘数量。`UsbCheckForChange` 可能会对此进行更新。默认情况下最多支持4个键盘。多达这么多的键盘可以通过这个驱动程序访问。|
|
||||
| KeyboardGetAddress | r0 is index | r0 is address | 检索给定键盘的地址。所有其他函数都需要一个键盘地址,以便知道要访问哪个键盘。因此,要与键盘通信,首先要检查计数,然后检索地址,然后使用其他方法。注意,在调用 `UsbCheckForChange` 之后,此方法返回的键盘顺序可能会改变。
|
||||
|
|
||||
| KeyboardPoll | r0 is address | r0 is result code | 从键盘读取当前键状态。这是通过直接轮询设备来操作的,与最佳实践相反。这意味着,如果没有频繁地调用此方法,可能会错过一个按键。所有读取方法只返回上次轮询时的值。
|
||||
|
|
||||
| KeyboardGetModifiers | r0 is address | r0 is modifier state | 检索上次轮询时修饰符键的状态。这是两边的 `shift` 键、`alt` 键和 `GUI` 键。这回作为一个位字段返回,这样,位0中的1表示左控件被保留,位1表示左 `shift`,位2表示左 `alt` ,位3表示左 `GUI`,位4到7表示前几位的右版本。如果有问题,`r0` 包含0。|
|
||||
| KeyboardGetKeyDownCount | r0 is address | r0 is count | 检索当前按下键盘的键数。这排除了修饰键。这通常不能超过6次。如果有错误,这个方法返回0。|
|
||||
| KeyboardGetKeyDown | r0 is address, r1 is key number | r0 is scan code | 检索特定下拉键的扫描代码(见表4.1)。通常,要计算出哪些键是关闭的,可以调用 `KeyboardGetKeyDownCount`,然后多次调用 `KeyboardGetKeyDown` ,将 `r1` 的值递增,以确定哪些键是关闭的。如果有问题,返回0。在不调用 `KeyboardGetKeyDownCount` 并将0解释为未持有的键的情况下调用此方法是安全的(但不建议这样做)。注意,顺序或扫描代码可以随机更改(有些键盘按数字排序,有些键盘按时间排序,没有任何保证)。|
|
||||
| KeyboardGetKeyIsDown | r0 is address, r1 is scan code | r0 is status | 除了 `KeyboardGetKeyDown` 之外,还可以检查下拉键中是否有特定的扫描代码。如果不是,返回0;如果是,返回一个非零值。当检测特定的扫描代码(例如寻找ctrl+c)更快。出错时,返回0。
|
||||
|
|
||||
| KeyboardGetLedSupport | r0 is address | r0 is LEDs | 检查特定键盘支持哪些led。第0位代表数字锁定,第1位代表大写锁定,第2位代表滚动锁定,第3位代表合成,第4位代表假名,第5位代表能量,第6位代表静音,第7位代表合成。根据USB标准,这些led都不是自动更新的(例如,当检测到大写锁定扫描代码时,必须手动设置大写锁定)。|
|
||||
| KeyboardSetLeds | r0 is address, r1 is LEDs | r0 is result code | 试图打开/关闭键盘上指定的 LED 灯。查看下面的结果代码值。参见 `KeyboardGetLedSupport` 获取 LED 的值。
|
||||
|
|
||||
|
||||
```
|
||||
返回值是一种处理错误的简单方法,但是通常更优雅的解决途径存在于更高层次的代码。
|
||||
```
|
||||
|
||||
有几种方法返回 ‘返回值’。这些都是 C 代码的老生常谈了,就是用数字代表函数调用发生了什么。通常情况, 0 总是代表操作成功。下面的是驱动用到的返回值。
|
||||
|
||||
Table 5.2 - CSUD 返回值
|
||||
|
||||
| 代码 | 描述 |
|
||||
| ---- | ----------------------------------------------------------------------- |
|
||||
| 0 | 方法成功完成。 |
|
||||
| -2 | 参数: 函数调用了无效参数。 |
|
||||
| -4 | 设备: 设备没有正确响应请求。 |
|
||||
| -5 | 不匹配: 驱动不适用于这个请求或者设备。 |
|
||||
| -6 | 编译器: 驱动没有正确编译,或者被破坏了。 |
|
||||
| -7 | 内存: 驱动用尽了内存。 |
|
||||
| -8 | 超时: 设备没有在预期的时间内响应请求。 |
|
||||
| -9 | 断开连接: 被请求的设备断开连接,或者不能使用。 |
|
||||
|
||||
驱动的通常用法如下:
|
||||
|
||||
1. 调用 `UsbInitialise`
|
||||
2. 调用 `UsbCheckForChange`
|
||||
3. 调用 `KeyboardCount`
|
||||
4. 如果返回 0,重复步骤 2。
|
||||
5. 针对你支持的每种键盘:
|
||||
1. 调用 ·KeyboardGetAddress·
|
||||
2. 调用 ·KeybordGetKeyDownCount·
|
||||
3. 针对每个按下的按键:
|
||||
1. 检查它是否已经被按下了
|
||||
2. 保存按下的按键
|
||||
4. 针对每个保存的按键:
|
||||
3. 检查按键是否被释放了
|
||||
4. 如果释放了就删除
|
||||
6. 根据按下/释放的案件执行操作
|
||||
7. 重复步骤 2.
|
||||
|
||||
|
||||
最后,你可能做所有你想对键盘做的事,而这些方法应该允许你访问键盘的全部功能。在接下来的两节课,我们将会着眼于完成文本终端的输入部分,类似于大部分的命令行电脑,以及命令的解释。为了做这些,我们将需要在更有用的形式下得到一个键盘输入。你可能注意到我的驱动是(故意)没有太大帮助,因为它并没有方法来判断是否一个案件刚刚按下或释放了,它只有芳芳来判断当前那个按键是按下的。这就意味着我们需要自己编写这些方法。
|
||||
|
||||
### 6 可用更新
|
||||
|
||||
重复检查更新被称为 ‘轮询’。这是针对驱动 IO 中断而言的,这种情况下设备在准备好后会发一个信号。
|
||||
|
||||
首先,让我们实现一个 `KeyboardUpdate` 方法,检查第一个键盘,并使用轮询方法来获取当前的输入,以及保存最后一个输入来对比。然后我们可以使用这个数据和其它方法来将扫描码转换成按键。这个方法应该按照下面的说明准确操作:
|
||||
|
||||
1. 提取一个保存好的键盘地址(初始值为 0)。
|
||||
2. 如果不是0 ,进入步骤9.
|
||||
3. 调用 `UsbCheckForChange` 检测新键盘。
|
||||
4. 调用 `KeyboardCount` 检测有几个键盘在线。
|
||||
5. 如果返回0,意味着没有键盘可以让我们操作,只能退出了。
|
||||
6. 调用 `KeyboardGetAddress` 参数是 0,获取第一个键盘的地址。
|
||||
7. 保存这个地址。
|
||||
8. 如果这个值是0,那么退出,这里应该有些问题。
|
||||
9. 调用 `KeyboardGetKeyDown` 6 次,获取每次按键按下的值并保存。
|
||||
10. 调用 `KeyboardPoll`
|
||||
11. 如果返回值非 0,进入步骤 3。这里应该有些问题(比如键盘断开连接)。
|
||||
|
||||
要保存上面提到的值,我们将需要下面 `.data` 段的值。
|
||||
|
||||
```
|
||||
.section .data
|
||||
.align 2
|
||||
KeyboardAddress:
|
||||
.int 0
|
||||
KeyboardOldDown:
|
||||
.rept 6
|
||||
.hword 0
|
||||
.endr
|
||||
```
|
||||
|
||||
```
|
||||
.hword num 直接将半字的常数插入文件。
|
||||
```
|
||||
|
||||
```
|
||||
.rept num [commands] .endr 复制 `commands` 命令到输出 num 次。
|
||||
```
|
||||
|
||||
试着自己实现这个方法。对此,我的实现如下:
|
||||
|
||||
1.
|
||||
```
|
||||
.section .text
|
||||
.globl KeyboardUpdate
|
||||
KeyboardUpdate:
|
||||
push {r4,r5,lr}
|
||||
|
||||
kbd .req r4
|
||||
ldr r0,=KeyboardAddress
|
||||
ldr kbd,[r0]
|
||||
```
|
||||
我们加载键盘的地址。
|
||||
|
||||
2.
|
||||
```
|
||||
teq kbd,#0
|
||||
bne haveKeyboard$
|
||||
```
|
||||
如果地址非0,就说明我们有一个键盘。调用 `UsbCheckForChanges` 慢,所以如果全部事情都起作用,我们要避免调用这个函数。
|
||||
|
||||
3.
|
||||
```
|
||||
getKeyboard$:
|
||||
bl UsbCheckForChange
|
||||
```
|
||||
如果我们一个键盘都没有,我们就必须检查新设备。
|
||||
|
||||
4.
|
||||
```
|
||||
bl KeyboardCount
|
||||
```
|
||||
如果有心键盘添加,我们就会看到这个。
|
||||
|
||||
5.
|
||||
```
|
||||
teq r0,#0
|
||||
ldreq r1,=KeyboardAddress
|
||||
streq r0,[r1]
|
||||
beq return$
|
||||
```
|
||||
如果没有键盘,我们就没有键盘地址。
|
||||
|
||||
6.
|
||||
```
|
||||
mov r0,#0
|
||||
bl KeyboardGetAddress
|
||||
```
|
||||
让我们获取第一个键盘的地址。你可能想要更多。
|
||||
|
||||
7.
|
||||
```
|
||||
ldr r1,=KeyboardAddress
|
||||
str r0,[r1]
|
||||
```
|
||||
保存键盘地址。
|
||||
|
||||
8.
|
||||
```
|
||||
teq r0,#0
|
||||
beq return$
|
||||
mov kbd,r0
|
||||
```
|
||||
如果我们没有地址,这里就没有其它活要做了。
|
||||
|
||||
9.
|
||||
```
|
||||
saveKeys$:
|
||||
mov r0,kbd
|
||||
mov r1,r5
|
||||
bl KeyboardGetKeyDown
|
||||
|
||||
ldr r1,=KeyboardOldDown
|
||||
add r1,r5,lsl #1
|
||||
strh r0,[r1]
|
||||
add r5,#1
|
||||
cmp r5,#6
|
||||
blt saveKeys$
|
||||
```
|
||||
Loop through all the keys, storing them in KeyboardOldDown. If we ask for too many, this returns 0 which is fine.
|
||||
查询遍全部按键,在 `KeyboardOldDown` 保存下来。如果我们询问的太多了,返回 0 也是正确的。
|
||||
|
||||
10.
|
||||
```
|
||||
mov r0,kbd
|
||||
bl KeyboardPoll
|
||||
```
|
||||
现在哦我们得到了新的按键。
|
||||
|
||||
11.
|
||||
```
|
||||
teq r0,#0
|
||||
bne getKeyboard$
|
||||
|
||||
return$:
|
||||
pop {r4,r5,pc}
|
||||
.unreq kbd
|
||||
```
|
||||
最后我们要检查 `KeyboardOldDown` 是否工作了。如果没工作,那么我们可能是断开连接了。
|
||||
|
||||
有了我们新的 `KeyboardUpdate` 方法,检查输入变得简单到固定周期调用这个方法,而它甚至可以检查断开连接,等等。这是一个有用的方法,因为我们实际的按键处理会根据条件不同而有所差别,所以能够用一个函数调以它的原始方式获取当前的输入是可行的。下一个方法我们理想希望的是 `KeyboardGetChar`,简单的返回下一个按下的按钮的 ASCII 字符,或者如果没有按键按下就返回 0。这可以扩展到支持将一个按键多次按下,如果它保持了一个特定时间,也支持‘锁定’键和修饰键。
|
||||
|
||||
要使这个方法有用,如果我们有一个 `KeyWasDown` 方法,如果给定的扫描代码不在keyboard dolddown值中,它只返回0,否则返回一个非零值。你可以自己尝试一下。与往常一样,可以在下载页面找到解决方案。
|
||||
|
||||
### 7 查找表
|
||||
|
||||
```
|
||||
在编程的许多领域,程序越大,速度越快。查找表很大,但是速度很快。有些问题可以通过查找表和普通函数的组合来解决。
|
||||
```
|
||||
|
||||
`KeyboardGetChar`方法如果写得不好,可能会非常复杂。有 100 多种扫描代码,每种代码都有不同的效果,这取决于 shift 键或其他修饰符的存在与否。并不是所有的键都可以转换成一个字符。对于一些字符,多个键可以生成相同的字符。在有如此多可能性的情况下,一个有用的技巧是查找表。查找表与物理意义上的查找表非常相似,它是一个值及其结果的表。对于一些有限的函数,推导出答案的最简单方法就是预先计算每个答案,然后通过检索返回正确的答案。在这种情况下,我们可以建立一个序列的值在内存中,n值序列的ASCII字符代码扫描代码n。这意味着我们的方法只会发现如果一个键被按下,然后从表中检索它的值。此外,当按住shift键时,我们可以为值创建一个单独的表,这样shift键就可以简单地更改正在处理的表。
|
||||
|
||||
在 `.section` `.data` 命令之后,复制下面的表:
|
||||
|
||||
```
|
||||
.align 3
|
||||
KeysNormal:
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 'a', 'b', 'c', 'd'
|
||||
.byte 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l'
|
||||
.byte 'm', 'n', 'o', 'p', 'q', 'r', 's', 't'
|
||||
.byte 'u', 'v', 'w', 'x', 'y', 'z', '1', '2'
|
||||
.byte '3', '4', '5', '6', '7', '8', '9', '0'
|
||||
.byte '\n', 0x0, '\b', '\t', ' ', '-', '=', '['
|
||||
.byte ']', '\\\', '#', ';', '\'', '`', ',', '.'
|
||||
.byte '/', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
|
||||
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
|
||||
.byte '8', '9', '0', '.', '\\\', 0x0, 0x0, '='
|
||||
|
||||
.align 3
|
||||
KeysShift:
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 'A', 'B', 'C', 'D'
|
||||
.byte 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L'
|
||||
.byte 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T'
|
||||
.byte 'U', 'V', 'W', 'X', 'Y', 'Z', '!', '"'
|
||||
.byte '£', '$', '%', '^', '&', '*', '(', ')'
|
||||
.byte '\n', 0x0, '\b', '\t', ' ', '_', '+', '{'
|
||||
.byte '}', '|', '~', ':', '@', '¬', '<', '>'
|
||||
.byte '?', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
|
||||
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
|
||||
.byte '8', '9', '0', '.', '|', 0x0, 0x0, '='
|
||||
```
|
||||
|
||||
```
|
||||
.byte num 直接插入字节常量 num 到文件。
|
||||
```
|
||||
|
||||
```
|
||||
大部分的汇编器和编译器识别转义序列;插入特殊字符的字符序列,如\t。
|
||||
```
|
||||
|
||||
这些表直接将前 104 个扫描代码映射到 ASCII 字符,作为一个字节表。我们还有一个单独的表来描述 `shift` 键对这些扫描代码的影响。我使用 ASCII `null`字符(0)表示所有没有直接映射的 ASCII 键(例如函数键)。退格映射到ASCII退格字符(8表示 `\b` ), `enter` 映射到ASCII新行字符(10表示 `\n`), `tab` 映射到ASCII水平制表符(9表示 `\t` )。
|
||||
|
||||
|
||||
`KeyboardGetChar` 方法需要做以下工作:
|
||||
1. 检查 `KeyboardAddress` 是否返回 0。如果是,则返回0。
|
||||
2. 调用 `KeyboardGetKeyDown` 最多 6 次。每次:
|
||||
1. 如果按键时0,跳出循环。
|
||||
2. 调用 `KeyWasDown`。 如果返回是,处理下一个按键。
|
||||
3. 如果扫描码超过 103,进入下一个按键。
|
||||
4. 调用 `KeyboardGetModifiers`
|
||||
5. 如果 `shift` 是被按着的,就加载 `KeysShift` 的地址。否则加载 `KeysNormal` 的地址。
|
||||
6. 从表中读出 ASCII 码值。
|
||||
7. 如果是 0,进行下一个按键,否则返回 ASCII 码值并退出。
|
||||
3. 返回0。
|
||||
|
||||
|
||||
试着自己实现。我的实现展示在下面:
|
||||
|
||||
1.
|
||||
```
|
||||
.globl KeyboardGetChar
|
||||
KeyboardGetChar:
|
||||
ldr r0,=KeyboardAddress
|
||||
ldr r1,[r0]
|
||||
teq r1,#0
|
||||
moveq r0,#0
|
||||
moveq pc,lr
|
||||
```
|
||||
简单的检查我们是否有键盘。
|
||||
|
||||
2.
|
||||
```
|
||||
push {r4,r5,r6,lr}
|
||||
kbd .req r4
|
||||
key .req r6
|
||||
mov r4,r1
|
||||
mov r5,#0
|
||||
keyLoop$:
|
||||
mov r0,kbd
|
||||
mov r1,r5
|
||||
bl KeyboardGetKeyDown
|
||||
```
|
||||
r5 will hold the index of the key, r4 holds the keyboard address.
|
||||
`r5` 将会保存按键的索引, `r4` 保存键盘的地址。
|
||||
|
||||
1.
|
||||
```
|
||||
teq r0,#0
|
||||
beq keyLoopBreak$
|
||||
```
|
||||
如果扫描码是0,它要么意味着有错,要么说明没有更多按键了。
|
||||
|
||||
2.
|
||||
```
|
||||
mov key,r0
|
||||
bl KeyWasDown
|
||||
teq r0,#0
|
||||
bne keyLoopContinue$
|
||||
```
|
||||
如果按键已经按下了,那么他就没意思了,我们只想知道按下的按键。
|
||||
|
||||
3.
|
||||
```
|
||||
cmp key,#104
|
||||
bge keyLoopContinue$
|
||||
```
|
||||
如果一个按键有个超过 104 的扫描码,他将会超出我们的表,所以它是无关的按键。
|
||||
|
||||
4.
|
||||
```
|
||||
mov r0,kbd
|
||||
bl KeyboardGetModifiers
|
||||
```
|
||||
我们需要知道修饰键来推断字符。
|
||||
|
||||
5.
|
||||
```
|
||||
tst r0,#0b00100010
|
||||
ldreq r0,=KeysNormal
|
||||
ldrne r0,=KeysShift
|
||||
```
|
||||
当将字符更改为其移位变体时,我们要同时检测左 `shift` 键和右 `shift` 键。记住,`tst` 指令计算的是逻辑和,然后将其与 0 进行比较,所以当且仅当移位位都为 0 时,它才等于0。
|
||||
|
||||
|
||||
1.
|
||||
```
|
||||
ldrb r0,[r0,key]
|
||||
```
|
||||
现在我们可以从查找表加载按键了。
|
||||
|
||||
1.
|
||||
```
|
||||
teq r0,#0
|
||||
bne keyboardGetCharReturn$
|
||||
keyLoopContinue$:
|
||||
add r5,#1
|
||||
cmp r5,#6
|
||||
blt keyLoop$
|
||||
```
|
||||
如果查找码包含一个 0,我们必须继续。为了继续,我们要增加索引,并检查是否到 6 次了。
|
||||
|
||||
1.
|
||||
```
|
||||
keyLoopBreak$:
|
||||
mov r0,#0
|
||||
keyboardGetCharReturn$:
|
||||
pop {r4,r5,r6,pc}
|
||||
.unreq kbd
|
||||
.unreq key
|
||||
```
|
||||
在这里我们返回我们的按键,如果我们到达 `keyLoopBreak$` ,然后我们就知道这里没有按键被握住,所以返回0。
|
||||
|
||||
### 8 记事本操作系统
|
||||
|
||||
现在我们有了 `KeyboardGetChar` 方法,可以创建一个操作系统,只输入用户对着屏幕所写的内容。为了简单起见,我们将忽略所有不寻常的键。在 `main.s` ,删除`bl SetGraphicsAddress` 之后的所有代码。调用 `UsbInitialise`,将 `r4` 和 `r5` 设置为 0,然后循环执行以下命令:
|
||||
|
||||
1. 调用 `KeyboardUpdate`
|
||||
2. 调用 `KeyboardGetChar`
|
||||
3. 如果返回 0,跳转到步骤1
|
||||
4. 复制 `r4` 和 `r5` 到 `r1` 和 `r2` ,然后调用 `DrawCharacter`
|
||||
5. 把 `r0` 加到 `r4`
|
||||
6. 如果 `r4` 是 1024,将 `r1` 加到 `r5`,然后设置 `r4` 为 0。
|
||||
7. 如果 `r5` 是 768,设置 `r5` 为0
|
||||
8. 跳转到步骤1
|
||||
|
||||
|
||||
|
||||
现在编译这个,然后在 PI 上测试。您几乎可以立即开始在屏幕上输入文本。如果没有,请参阅我们的故障排除页面。
|
||||
|
||||
当它工作时,祝贺您,您已经实现了与计算机的接口。现在您应该开始意识到,您几乎已经拥有了一个原始的操作系统。现在,您可以与计算机交互,发出命令,并在屏幕上接收反馈。在下一篇教程[输入02][3]中,我们将研究如何生成一个全文本终端,用户在其中输入命令,然后计算机执行这些命令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads/hut1_12v2.pdf
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html
|
||||
@ -1,225 +0,0 @@
|
||||
|
||||
Rancher - 容器管理平台
|
||||
======
|
||||
Docker作为一款容器化应用的新兴软件, 被大多数IT公司使用来减少基础设施平台建设的成本。
|
||||
|
||||
通常,没有GUI的docker软件对于Linux管理员很友好,但是对于开发者来说很不友好。当把它搬到生产环境上来,那么它对Linux管理员来说也相当不友好。那么,什么最佳解决方案可以轻松的管理docker。
|
||||
|
||||
仅有的方式那就是提供GUI。Docker API允许第三方平台接入Docker。在市场上有许多docker GUI应用可用。我们已经写了一篇关于Portainer应用的文章。今天我们来讨论另一个应用,Rancher。
|
||||
|
||||
容器让软件开发更容易,让开发者写代码更快且更好的运行它们。但是,在生产环境上运行容器却很困难。
|
||||
|
||||
**推荐阅读 :** [Portainer – A Simple Docker Management GUI][1]
|
||||
|
||||
### What is Rancher
|
||||
[Rancher][2]是一个完整的容器管理平台,在任意基础设施平台的生产环境上,它让容器的部署和运行更容易。它提供了诸如多主机网络,全局、局部负载均衡和卷快照等基础设施服务。它整合原生Docker的管理能力,如Docker Machine和Docker Swarm。它提供了丰富的用户体验,让devops管理员以一个更大的规模在生产环境上运行Docker。
|
||||
|
||||
以下文章导航到在Linux系统上安装Docker。
|
||||
|
||||
**推荐阅读 :**
|
||||
**(#)** [How to install Docker in Linux][3]
|
||||
**(#)** [How to play with Docker images on Linux][4]
|
||||
**(#)** [How to play with Docker containers on Linux][5]
|
||||
**(#)** [How to Install, Run Applications inside Docker Containers][6]
|
||||
|
||||
### Rancher 特性
|
||||
|
||||
* 在两分钟内安装Kubernetes。
|
||||
* 单机启动应用(90个流行的Docker应用)。
|
||||
* 部署和管理Docker更容易。
|
||||
* 全面的生产级容器管理平台。
|
||||
* 在生产环境上快速部署容器。
|
||||
* 强大的自动部署和运营容器技术。
|
||||
* 模块化基础设施服务。
|
||||
* 丰富的编排工具。
|
||||
* Rancher支持多种认证机制。
|
||||
|
||||
|
||||
|
||||
### 怎样安装Rancher
|
||||
|
||||
由于Rancher是以轻量级的Docker容器方式运行,所以它的安装非常简单。Rancher是由一组Docker容器部署。只需要简单的启动两个容器就能运行Rancher。一个容器用作管理服务,另一个容器在各个节点上作为代理。在Linux系统下简单的运行下列命令就能部署Rancher。
|
||||
|
||||
Rancher服务提供了两个不同的安装包标签如`stable`和`latest`。下列命令将会拉去适合的rancher镜像并安装到你的操作系统上。Rancher server仅需要几分钟就可以启动。
|
||||
|
||||
* `latest` : 这个标签是他们的最新开发构建。这些构建将通过rancher CI的自动化框架进行验证,不建议在生产环境使用。
|
||||
* `stable` : 这是最新的稳定发行版本,推荐在生产环境使用。
|
||||
|
||||
|
||||
Rancher的安装方法有多种。在这边教程中我们仅讨论两种方法。
|
||||
|
||||
* 以单一容器的方式安装Rancher(内嵌Rancher数据库)
|
||||
* 以单一容器的方式安装Rancher(外部数据库)
|
||||
|
||||
|
||||
|
||||
### 方法-1
|
||||
|
||||
运行下列命令以单一容器的方式安装rancher服务(内嵌数据库)
|
||||
```
|
||||
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:stable
|
||||
|
||||
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:latest
|
||||
|
||||
```
|
||||
|
||||
### 方法-2
|
||||
|
||||
你可以开始Rancher服务时指向外部数据库,而不是使用内部数据库。首先创建所需的数据库,数据库用户为同一个。
|
||||
```
|
||||
> CREATE DATABASE IF NOT EXISTS cattle COLLATE = 'utf8_general_ci' CHARACTER SET = 'utf8';
|
||||
> GRANT ALL ON cattle.* TO 'cattle'@'%' IDENTIFIED BY 'cattle';
|
||||
> GRANT ALL ON cattle.* TO 'cattle'@'localhost' IDENTIFIED BY 'cattle';
|
||||
|
||||
```
|
||||
|
||||
运行下列命令开始Rancher去连接外部数据库。
|
||||
```
|
||||
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server \
|
||||
--db-host myhost.example.com --db-port 3306 --db-user username --db-pass password --db-name cattle
|
||||
|
||||
```
|
||||
如果你想测试Rancher 2.0,使用下列的命令去开始。
|
||||
```
|
||||
$ sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/server:preview
|
||||
|
||||
```
|
||||
|
||||
### 通过GUI访问 & 安装Rancher
|
||||
|
||||
浏览器输入 `http://hostname:8080` or `http://server_ip:8080` 去访问 rancher GUI.
|
||||

|
||||
|
||||
|
||||
### 怎样注册主机
|
||||
|
||||
注册你的主机URL允许去连接到Rancher API。这是一次性设置。
|
||||
|
||||
接下来,点击主菜单下面的`Add a Host`链接或者点击主菜单上的INFRASTRUCTURE >> Add Hosts,点击保存按钮。
|
||||

|
||||
|
||||
|
||||
在rancher里默认访问控制认证机制是没有打开的,因此我们首先需要通过一些方法打开访问控制认证,否则任何人都不能访问GUI。
|
||||
|
||||
点击 >> Admin >> Access Control , 输入下列的值最后点击`打开认证`按钮去打开它。以我的案例,我通过`本地认证`的方式打开。
|
||||
|
||||
* **`Login UserName`** 输入你期望的登录名
|
||||
* **`Full Name`** 输入你的全名
|
||||
* **`Password`** 输入你期望的密码
|
||||
* **`Confirm Password`** 再一次确认密码
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
注销然后使用新的登录凭证重新登陆
|
||||

|
||||
|
||||
现在,我能看到本地认证已经被打开。
|
||||

|
||||
|
||||
|
||||
### 怎样添加主机
|
||||
|
||||
点击注册你的主机后,它将带你进入下一个页面,在那里你能选择不同云服务提供商的Linux主机。我们将添加一个主机运行Rancher服务,因此选择`自定义`选项然后输入必要的信息。
|
||||
|
||||
在第四部输入你服务器的公有IP,运行第5步列出的命令,最后点击`close`按钮。
|
||||

|
||||
```
|
||||
|
||||
$ sudo docker run -e CATTLE_AGENT_IP="192.168.56.2" --rm --privileged -v /var/run/docker.sock:/var/run/docker.sock -v /var/lib/rancher:/var/lib/rancher rancher/agent:v1.2.11 http://192.168.56.2:8080/v1/scripts/16A52B9BE2BAB87BB0F5:1546214400000:ODACe3sfis5V6U8E3JASL8jQ
|
||||
|
||||
INFO: Running Agent Registration Process, CATTLE_URL=http://192.168.56.2:8080/v1
|
||||
INFO: Attempting to connect to: http://192.168.56.2:8080/v1
|
||||
INFO: http://192.168.56.2:8080/v1 is accessible
|
||||
INFO: Configured Host Registration URL info: CATTLE_URL=http://192.168.56.2:8080/v1 ENV_URL=http://192.168.56.2:8080/v1
|
||||
INFO: Inspecting host capabilities
|
||||
INFO: Boot2Docker: false
|
||||
INFO: Host writable: true
|
||||
INFO: Token: xxxxxxxx
|
||||
INFO: Running registration
|
||||
INFO: Printing Environment
|
||||
INFO: ENV: CATTLE_ACCESS_KEY=9946BD1DCBCFEF3439F8
|
||||
INFO: ENV: CATTLE_AGENT_IP=192.168.56.2
|
||||
INFO: ENV: CATTLE_HOME=/var/lib/cattle
|
||||
INFO: ENV: CATTLE_REGISTRATION_ACCESS_KEY=registrationToken
|
||||
INFO: ENV: CATTLE_REGISTRATION_SECRET_KEY=xxxxxxx
|
||||
INFO: ENV: CATTLE_SECRET_KEY=xxxxxxx
|
||||
INFO: ENV: CATTLE_URL=http://192.168.56.2:8080/v1
|
||||
INFO: ENV: DETECTED_CATTLE_AGENT_IP=172.17.0.1
|
||||
INFO: ENV: RANCHER_AGENT_IMAGE=rancher/agent:v1.2.11
|
||||
INFO: Launched Rancher Agent: e83b22afd0c023dabc62404f3e74abb1fa99b9a178b05b1728186c9bfca71e8d
|
||||
|
||||
```
|
||||
|
||||
等待几秒钟后新添加的主机将会出现。点击INFRASTRUCTURE >> Hosts 页面。
|
||||

|
||||
|
||||
### 怎样查看容器
|
||||
|
||||
只需要点击下列位置就能列出所有容器。点击 >> INFRASTRUCTURE >> Containers
|
||||

|
||||
|
||||
|
||||
### 怎样创建容器
|
||||
|
||||
非常简单, 只需点击下列位置就能创建容器。
|
||||
|
||||
点击 >> INFRASTRUCTURE >> Containers >> “Add Container” 然后输入每个你需要的信息。 方便测试, 我将创建一个latest标签的Centos容器。
|
||||

|
||||
|
||||
在同样的列表位置,点击 INFRASTRUCTURE >> Containers
|
||||

|
||||
|
||||
点击`Container`名展示容器的性能信息,如CPU,内存,网络和存储。
|
||||

|
||||
|
||||
选择特定容器,然后点击最右边的`三点`按钮或者点击`Actions`按钮对容器进行管理,如停止,启动,克隆,重启等。
|
||||

|
||||
|
||||
如果你想控制台访问容器,只需要点击action按钮中的`Execute Shell`选项即可。
|
||||

|
||||
|
||||
### 怎样从应用目录部署容器
|
||||
|
||||
Rancher 提供了一个应用模版目录,让部署变的很容易,只需要单击一下就可以。
|
||||
它维护了多数流行应用,这些应用由Rancher社区贡献。
|
||||

|
||||
|
||||
点击 >> Catalog >> All >> 选择你需要的应用 >> 最后点击运行去部署。
|
||||

|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
浏览: https://www.2daygeek.com/rancher-a-complete-container-management-platform-for-production-environment/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/portainer-a-simple-docker-management-gui/
|
||||
[2]:http://rancher.com/
|
||||
[3]:https://www.2daygeek.com/install-docker-on-centos-rhel-fedora-ubuntu-debian-oracle-archi-scentific-linux-mint-opensuse/
|
||||
[4]:https://www.2daygeek.com/list-search-pull-download-remove-docker-images-on-linux/
|
||||
[5]:https://www.2daygeek.com/create-run-list-start-stop-attach-delete-interactive-daemonized-docker-containers-on-linux/
|
||||
[6]:https://www.2daygeek.com/install-run-applications-inside-docker-containers/
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-1.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-2.png
|
||||
[10]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-3.png
|
||||
[11]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-3a.png
|
||||
[12]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-4.png
|
||||
[13]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-5.png
|
||||
[14]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-6.png
|
||||
[15]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-7.png
|
||||
[16]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-8.png
|
||||
[17]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-9.png
|
||||
[18]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-10.png
|
||||
[19]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-11.png
|
||||
[20]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-12.png
|
||||
[21]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-13.png
|
||||
[22]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-14.png
|
||||
@ -0,0 +1,215 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: subject: "Arch-Wiki-Man – A Tool to Browse The Arch Wiki Pages As Linux Man Page from Offline"
|
||||
[#]: via: "https://www.2daygeek.com/arch-wiki-man-a-tool-to-browse-the-arch-wiki-pages-as-linux-man-page-from-offline/"
|
||||
[#]: author: "[Prakash Subramanian](https://www.2daygeek.com/author/prakash/)"
|
||||
[#]: url: " "
|
||||
|
||||
Arch-Wiki-Man – 一个以 Linux Man 手册样式离线浏览 Arch Wiki 的工具
|
||||
======
|
||||
|
||||
现在上网已经很方便了,但技术上会有限制。
|
||||
|
||||
看到技术的发展,我很惊讶,但与此同时,各个地方都会出现衰退。
|
||||
|
||||
当你搜索有关其他 Linux 发型版本的某些东西时,大多数时候你会首先得到一个第三方的链接,但是对于 Arch Linux 来说,每次你都会得到 Arch Wiki 页面的结果。
|
||||
|
||||
因为 Arch Wiki 提供了除第三方网站以外的大多数解决方案。
|
||||
|
||||
到目前为止,你也许可以使用 Web 浏览器为你的 Arch Linux 系统找到一个解决方案,但现在你可以不用这么做了。
|
||||
|
||||
一个名为 arch-wiki-man 的工具t提供了一个在命令行中更快地执行这个操作的方案。如果你是一个 Arch Linux 爱好者,我建议你阅读 **[Arch Linux 安装后指南][1]** ,它可以帮助你调整你的系统以供日常使用。
|
||||
|
||||
### arch-wiki-man 是什么?
|
||||
|
||||
[arch-wiki-man][2] 工具允许用户在离线的时候从命令行(CLI)中搜索 Arch Wiki 页面。它允许用户以 Linux Man 手册样式访问和搜索整个 Wiki 页面。
|
||||
|
||||
而且,你无需切换到GUI。更新将每两天自动推送一次,因此,你的 Arch Wiki 本地副本页面将是最新的。这个工具的名字是`awman`, `awman` 是 Arch Wiki Man 的缩写。
|
||||
|
||||
我们已经写出了名为 **[Arch Wiki 命令行实用程序][3]** (arch-wiki-cli)的类似工具。它允许用户从互联网上搜索 Arch Wiki。但确保你因该在线使用这个实用程序。
|
||||
|
||||
### 如何安装 arch-wiki-man 工具?
|
||||
|
||||
arch-wiki-man 工具可以在 AUR 仓库(LCTT译者注:AUR 即 Arch 用户软件仓库(Archx User Repository))中获得,因此,我们需要使用 AUR 工具来安装它。有许多 AUR 工具可用,而且我们曾写了一篇有关非常著名的 AUR 工具: **[Yaourt AUR helper][4]** 和 **[Packer AUR helper][5]** 的文章,
|
||||
|
||||
```
|
||||
$ yaourt -S arch-wiki-man
|
||||
|
||||
or
|
||||
|
||||
$ packer -S arch-wiki-man
|
||||
```
|
||||
|
||||
或者,我们可以使用 npm 包管理器来安装它,确保你已经在你的系统上安装了 **[NodeJS][6]** 。然后运行以下命令来安装它。
|
||||
|
||||
```
|
||||
$ npm install -g arch-wiki-man
|
||||
```
|
||||
|
||||
### 如何更新 Arch Wiki 本地副本?
|
||||
|
||||
正如前面更新的那样,更新每两天自动推送一次,也可以通过运行以下命令来完成更新。
|
||||
|
||||
```
|
||||
$ sudo awman-update
|
||||
[sudo] password for daygeek:
|
||||
[email protected] /usr/lib/node_modules/arch-wiki-man
|
||||
└── [email protected]
|
||||
|
||||
arch-wiki-md-repo has been successfully updated or reinstalled.
|
||||
```
|
||||
|
||||
awman-update 是一种更快更方便的更新方法。但是,你也可以通过运行以下命令重新安装arch-wiki-man 来获取更新。
|
||||
|
||||
```
|
||||
$ yaourt -S arch-wiki-man
|
||||
|
||||
or
|
||||
|
||||
$ packer -S arch-wiki-man
|
||||
```
|
||||
|
||||
### 如何在终端中使用 Arch Wiki ?
|
||||
|
||||
它有着简易的接口且易于使用。想要搜索,只需要运行 `awman` 加搜索项目。一般语法如下所示。
|
||||
|
||||
```
|
||||
$ awman Search-Term
|
||||
```
|
||||
|
||||
### 如何搜索多个匹配项?
|
||||
|
||||
如果希望列出包含`installation`字符串的所有结果的标题,运行以下格式的命令,如果输出有多个结果,那么你将会获得一个选择菜单来浏览每个项目。
|
||||
|
||||
```
|
||||
$ awman installation
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
详细页面的截屏
|
||||
|
||||
![][9]
|
||||
|
||||
### 在标题和描述中搜索给定的字符串
|
||||
|
||||
`-d` 或 `--desc-search` 选项允许用户在标题和描述中搜索给定的字符串。
|
||||
|
||||
```
|
||||
$ awman -d mirrors
|
||||
|
||||
or
|
||||
|
||||
$ awman --desc-search mirrors
|
||||
? Select an article: (Use arrow keys)
|
||||
❯ [1/3] Mirrors: Related articles
|
||||
[2/3] DeveloperWiki-NewMirrors: Contents
|
||||
[3/3] Powerpill: Powerpill is a pac
|
||||
```
|
||||
|
||||
### 在内容中搜索给定的字符串
|
||||
|
||||
`-k` 或 `--apropos` 选项也允许用户在内容中搜索给定的字符串。但须注意,此选项会显著降低搜索速度,因为此选项会扫描整个 Wiki 页面的内容。
|
||||
|
||||
```
|
||||
$ awman -k openjdk
|
||||
|
||||
or
|
||||
|
||||
$ awman --apropos openjdk
|
||||
? Select an article: (Use arrow keys)
|
||||
❯ [1/26] Hadoop: Related articles
|
||||
[2/26] XDG Base Directory support: Related articles
|
||||
[3/26] Steam-Game-specific troubleshooting: See Steam/Troubleshooting first.
|
||||
[4/26] Android: Related articles
|
||||
[5/26] Elasticsearch: Elasticsearch is a search engine based on Lucene. It provides a distributed, mul..
|
||||
[6/26] LibreOffice: Related articles
|
||||
[7/26] Browser plugins: Related articles
|
||||
(Move up and down to reveal more choices)
|
||||
```
|
||||
|
||||
### 在浏览器中打开搜索结果
|
||||
|
||||
`-w` 或 `--web` 选项允许用户在 Web 浏览器中打开搜索结果。
|
||||
|
||||
```
|
||||
$ awman -w AUR helper
|
||||
|
||||
or
|
||||
|
||||
$ awman --web AUR helper
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
### 以其他语言搜索
|
||||
|
||||
`-w` 或 `--web` 选项允许用户在 Web 浏览器中打开搜索结果。想要查看支持的语言列表,请运行以下命令。
|
||||
|
||||
```
|
||||
$ awman --list-languages
|
||||
arabic
|
||||
bulgarian
|
||||
catalan
|
||||
chinesesim
|
||||
chinesetrad
|
||||
croatian
|
||||
czech
|
||||
danish
|
||||
dutch
|
||||
english
|
||||
esperanto
|
||||
finnish
|
||||
greek
|
||||
hebrew
|
||||
hungarian
|
||||
indonesian
|
||||
italian
|
||||
korean
|
||||
lithuanian
|
||||
norwegian
|
||||
polish
|
||||
portuguese
|
||||
russian
|
||||
serbian
|
||||
slovak
|
||||
spanish
|
||||
swedish
|
||||
thai
|
||||
ukrainian
|
||||
```
|
||||
|
||||
使用你的首选语言运行 `awman` 命令以查看除英语以外的其他语言的结果。
|
||||
|
||||
```
|
||||
$ awman -l chinesesim deepin
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/arch-wiki-man-a-tool-to-browse-the-arch-wiki-pages-as-linux-man-page-from-offline/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/arch-linux-post-installation-30-things-to-do-after-installing-arch-linux/
|
||||
[2]: https://github.com/greg-js/arch-wiki-man
|
||||
[3]: https://www.2daygeek.com/search-arch-wiki-website-command-line-terminal/
|
||||
[4]: https://www.2daygeek.com/install-yaourt-aur-helper-on-arch-linux/
|
||||
[5]: https://www.2daygeek.com/install-packer-aur-helper-on-arch-linux/
|
||||
[6]: https://www.2daygeek.com/install-nodejs-on-ubuntu-centos-debian-fedora-mint-rhel-opensuse/
|
||||
[7]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]: https://www.2daygeek.com/wp-content/uploads/2018/11/arch-wiki-man-%E2%80%93-A-Tool-to-Browse-The-Arch-Wiki-Pages-As-Linux-Man-page-from-Offline-1.png
|
||||
[9]: https://www.2daygeek.com/wp-content/uploads/2018/11/arch-wiki-man-%E2%80%93-A-Tool-to-Browse-The-Arch-Wiki-Pages-As-Linux-Man-page-from-Offline-2.png
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2018/11/arch-wiki-man-%E2%80%93-A-Tool-to-Browse-The-Arch-Wiki-Pages-As-Linux-Man-page-from-Offline-3.png
|
||||
[11]: https://www.2daygeek.com/wp-content/uploads/2018/11/arch-wiki-man-%E2%80%93-A-Tool-to-Browse-The-Arch-Wiki-Pages-As-Linux-Man-page-from-Offline-4.png
|
||||
@ -1,62 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Learn about computer security with the Raspberry Pi and Kali Linux)
|
||||
[#]: via: (https://opensource.com/article/19/3/computer-security-raspberry-pi)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
|
||||
|
||||
通过树莓派和 kali Linux 学习计算机安全
|
||||
======
|
||||
树莓派是学习计算机安全的一个好方法。在我们入门系列的第 11 篇文章中会进行学习。
|
||||

|
||||
|
||||
是否有比保护你的计算机更热门的技术?一些专家会告诉你,没有绝对安全的系统。他们开玩笑说,如果你想要你的服务器或者应用程序真正的安全,就关掉你的服务器,从网络上断线,然后把它放在一个安全的地方。但问题是显而易见的:没人能用的应用程序或者服务器有什么用?
|
||||
|
||||
这是围绕安全的一个难题,我们如何才能在保证安全性的同时,让服务器或应用程序依然可用且有价值?我无论如何都不是一个安全专家,虽然我希望有一天我能是。考虑到这一点,对于你能用树莓派做什么,分享和这有关的想法来学习计算机安全,我认为是有意义的。
|
||||
|
||||
我会注意到,就像本系列中其他写给树莓派初学者的文章一样,我的目标不是深入研究,而是起个头,让你有兴趣去了解更多与这些主题相关的东西。
|
||||
|
||||
### Kali Linux
|
||||
|
||||
当我们谈到“做一些安全方面的事”的时候,出现在脑海中的一个 Linux 发行版就是 Kali Linux。kali Linux 的开发主要集中在调查取证和渗透测试方面。它有超过 600 个已经预先安装好了的渗透测试工具来测试你的计算机的安全性,以及取证模式,它可以防止自己接触到内部的硬盘驱动器或是被检查系统的交换空间。
|
||||
|
||||

|
||||
|
||||
就像 Raspbian 一样,Kali Linux 基于 Debian 的发行版,你可以在 kali 的主文档门户网页上找到将它安装在树莓派上的文档(译者注:截至到翻译时,该网页是这个:https://docs.kali.org/kali-on-arm/install-kali-linux-arm-raspberry-pi)。如果你已经在你的树莓派上安装了 Raspbian 或者是其他的 Linux 发行版。那么你装 Kali 应该是没问题的,Kali 的创造者甚至将培训、研讨会和职业认证整合到了一起,以此来帮助提升你在安全领域内的职业生涯。
|
||||
|
||||
### 其他的 Linux 发行版
|
||||
|
||||
大多数的标准 Linux 发行版,比如 Raspbian,Ubuntu 和 Fedora 这些,在它们的仓库里同样也有很多可用的安全工具。一些很棒的探测工具包括 Nmap,Wireshark,auditctl,和 SELinux。
|
||||
|
||||
### 项目
|
||||
|
||||
你可以在树莓派上运行很多其他的安全相关的项目,例如蜜罐,广告拦截器和 USB 清洁器。花些时间了解它们!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/computer-security-raspberry-pi
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.kali.org/
|
||||
[2]: https://en.wikipedia.org/wiki/Kali_Linux#Development
|
||||
[3]: https://docs.kali.org/general-use/kali-linux-forensics-mode
|
||||
[4]: https://docs.kali.org/kali-on-arm/install-kali-linux-arm-raspberry-pi
|
||||
[5]: https://www.kali.org/penetration-testing-with-kali-linux/
|
||||
[6]: https://linuxblog.darkduck.com/2019/02/9-best-linux-based-security-tools.html
|
||||
[7]: https://nmap.org/
|
||||
[8]: https://www.wireshark.org/
|
||||
[9]: https://linux.die.net/man/8/auditctl
|
||||
[10]: https://opensource.com/article/18/7/sysadmin-guide-selinux
|
||||
[11]: https://trustfoundry.net/honeypi-easy-honeypot-raspberry-pi/
|
||||
[12]: https://pi-hole.net/
|
||||
[13]: https://www.circl.lu/projects/CIRCLean/
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (14 days of celebrating the Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/happy-pi-day)
|
||||
[#]: author: (Anderson Silva (Red Hat) https://opensource.com/users/ansilva)
|
||||
|
||||
庆祝 Raspberry Pi 的 14 天
|
||||
======
|
||||
|
||||
在我们关于树莓派入门系列的第 14 篇也是最后一篇文章中,回顾一下我们学到的所有东西。
|
||||
|
||||
![][1]
|
||||
|
||||
**派节快乐!**
|
||||
|
||||
每年的 3 月 14 日,我们这些极客都会庆祝派节。我们用这种方式缩写日期 MMDD,March 14 于是写成 03/14,它的数字上提醒我们 3.14,或者说 [π][2] 的前三位数字。许多美国人没有意识到的是,世界上几乎没有其他国家使用这种[日期格式][3],因此派节几乎只适用于美国,尽管它在全球范围内得到了庆祝。
|
||||
|
||||
无论你身在何处,让我们一起庆祝树莓派,并通过回顾过去两周我们所涉及的主题来结束本系列:
|
||||
|
||||
* 第 1 天:[你应该选择哪种树莓派?][4]
|
||||
* 第 2 天:[如何购买树莓派][5]
|
||||
* 第 3 天:[如何启动新的树莓派][6]
|
||||
* 第 4 天:[用树莓派学习 Linux][7]
|
||||
* 第 5 天:[5 种教孩子用树莓派编程的方法][8]
|
||||
* 第 6 天:[你可以用树莓派学习的 3 种流行编程语言][9]
|
||||
* 第 7 天:[如何更新树莓派][10]
|
||||
* 第 8 天:[如何使用树莓派娱乐][11]
|
||||
* 第 9 天:[在树莓派上玩游戏][12]
|
||||
* 第 10 天:[让我们实物化:如何在树莓派上使用 GPIO 引脚][13]
|
||||
* 第 11 天:[通过树莓派了解计算机安全][14]
|
||||
* 第 12 天:[在树莓派上使用 Mathematica 进行高级数学运算][15]
|
||||
* 第 13 天:[为树莓派社区做出贡献][16]
|
||||
|
||||
|
||||
|
||||
![Pi Day illustration][18]
|
||||
|
||||
我将结束本系列,感谢所有关注的人,尤其是那些在过去 14 天里从中学到了东西的人!我还想鼓励大家不断扩展他们对树莓派以及围绕它构建的所有开源(和闭源)技术的了解。
|
||||
|
||||
我还鼓励你了解其他文化、哲学、宗教和世界观。让我们成为人类的是这种惊人的 (有时是有趣的) 能力,我们不仅要适应外部环境,而且要适应智力环境。
|
||||
|
||||
不管你做什么,保持学习!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/happy-pi-day
|
||||
|
||||
作者:[Anderson Silva (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/raspberry-pi-juggle.png?itok=oTgGGSRA
|
||||
[2]: https://www.piday.org/million/
|
||||
[3]: https://en.wikipedia.org/wiki/Date_format_by_country
|
||||
[4]: https://opensource.com/article/19/3/which-raspberry-pi-choose
|
||||
[5]: https://opensource.com/article/19/3/how-buy-raspberry-pi
|
||||
[6]: https://opensource.com/article/19/3/how-boot-new-raspberry-pi
|
||||
[7]: https://opensource.com/article/19/3/learn-linux-raspberry-pi
|
||||
[8]: https://opensource.com/article/19/3/teach-kids-program-raspberry-pi
|
||||
[9]: https://opensource.com/article/19/3/programming-languages-raspberry-pi
|
||||
[10]: https://opensource.com/article/19/3/how-raspberry-pi-update
|
||||
[11]: https://opensource.com/article/19/3/raspberry-pi-entertainment
|
||||
[12]: https://opensource.com/article/19/3/play-games-raspberry-pi
|
||||
[13]: https://opensource.com/article/19/3/gpio-pins-raspberry-pi
|
||||
[14]: https://opensource.com/article/19/3/learn-about-computer-security-raspberry-pi
|
||||
[15]: https://opensource.com/article/19/3/do-math-raspberry-pi
|
||||
[16]: https://opensource.com/article/19/3/contribute-raspberry-pi-community
|
||||
[17]: /file/426561
|
||||
[18]: https://opensource.com/sites/default/files/uploads/raspberrypi_14_piday.jpg (Pi Day illustration)
|
||||
@ -0,0 +1,188 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Quickly Go Back To A Specific Parent Directory Using bd Command In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/bd-quickly-go-back-to-a-specific-parent-directory-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
在 Linux 中使用 bd 命令快速返回到特定的父目录
|
||||
======
|
||||
|
||||
<to 校正:我在 ubuntu 上似乎没有按照这个教程成功使用 bd 命令,难道我的姿势不对?>
|
||||
|
||||
两天前我们写了一篇关于 `autocd` 的文章,它是一个内置的 `shell` 变量,可以帮助我们在**[没有 `cd` 命令的情况下导航到目录中][1]**.
|
||||
|
||||
如果你想回到上一级目录,那么你需要输入 `cd ..`。
|
||||
|
||||
如果你想回到上两级目录,那么你需要输入 `cd ../..`。
|
||||
|
||||
这在 Linux 中是正常的,但如果你想从第九个目录回到第三个目录,那么使用 cd 命令是很糟糕的。
|
||||
|
||||
有什么解决方案呢?
|
||||
|
||||
是的,在 Linux 中有一个解决方案。我们可以使用 bd 命令来轻松应对这种情况。
|
||||
|
||||
### 什么是 bd 命令?
|
||||
|
||||
bd 命令允许用户快速返回 Linux 中的父目录,而不是反复输入 `cd ../../..`。
|
||||
|
||||
你可以列出给定目录的内容,而不用提供完整路径 `ls `bd Directory_Name``。它支持以下其它命令,如 ls、ln、echo、zip、tar 等。
|
||||
|
||||
另外,它还允许我们执行 shell 文件而不用提供完整路径 `bd p`/shell_file.sh``。
|
||||
|
||||
### 如何在 Linux 中安装 bd 命令?
|
||||
|
||||
除了 Debian/Ubuntu 之外,bd 没有官方发行包。因此,我们需要手动执行方法。
|
||||
|
||||
对于 **`Debian/Ubuntu`** 系统,使用 **[APT-GET 命令][2]**或**[APT 命令][3]**来安装 bd。
|
||||
|
||||
```
|
||||
$ sudo apt install bd
|
||||
```
|
||||
|
||||
对于其它 Linux 发行版,使用 **[wget 命令][4]**下载 bd 可执行二进制文件。
|
||||
|
||||
```
|
||||
$ sudo wget --no-check-certificate -O /usr/local/bin/bd https://raw.github.com/vigneshwaranr/bd/master/bd
|
||||
```
|
||||
|
||||
设置 bd 二进制文件的可执行权限。
|
||||
|
||||
```
|
||||
$ sudo chmod +rx /usr/local/bin/bd
|
||||
```
|
||||
|
||||
在 `.bashrc` 文件中添加以下值。
|
||||
|
||||
```
|
||||
$ echo 'alias bd=". bd -si"' >> ~/.bashrc
|
||||
```
|
||||
|
||||
运行以下命令以使更改生效。
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
要启用自动完成,执行以下两个步骤。
|
||||
```
|
||||
$ sudo wget -O /etc/bash_completion.d/bd https://raw.github.com/vigneshwaranr/bd/master/bash_completion.d/bd
|
||||
$ sudo source /etc/bash_completion.d/bd
|
||||
```
|
||||
|
||||
我们已经在系统上成功安装并配置了 bd 实用程序,现在是时候测试一下了。
|
||||
|
||||
我将使用下面的目录路径进行测试。
|
||||
|
||||
运行 `pwd` 命令或 `dirs` 命令,亦或是 `tree` 命令来了解你当前的路径。
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ pwd
|
||||
或者
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ dirs
|
||||
|
||||
/usr/share/icons/Adwaita/256x256/apps
|
||||
```
|
||||
|
||||
我现在在 `/usr/share/icons/Adwaita/256x256/apps` 目录,如果我想快速跳转到 `icons` 目录,那么只需输入以下命令即可。
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ bd icons
|
||||
/usr/share/icons/
|
||||
daygeek@Ubuntu18:/usr/share/icons$
|
||||
```
|
||||
|
||||
甚至,你不需要输入完整的目录名称,也可以输入几个字母。
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ bd i
|
||||
/usr/share/icons/
|
||||
daygeek@Ubuntu18:/usr/share/icons$
|
||||
```
|
||||
|
||||
`注意:` 如果层次结构中有多个同名的目录,bd 会将你带到最近的目录。(不考虑直接的父目录)
|
||||
|
||||
如果要列出给定的目录内容,使用以下格式。它会打印出 `/usr/share/icons/` 的内容。
|
||||
|
||||
```
|
||||
$ ls -lh `bd icons`
|
||||
or
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ ls -lh `bd i`
|
||||
total 64K
|
||||
drwxr-xr-x 12 root root 4.0K Jul 25 2018 Adwaita
|
||||
lrwxrwxrwx 1 root root 51 Feb 25 14:32 communitheme -> /snap/communitheme/current/share/icons/communitheme
|
||||
drwxr-xr-x 2 root root 4.0K Jul 25 2018 default
|
||||
drwxr-xr-x 3 root root 4.0K Jul 25 2018 DMZ-Black
|
||||
drwxr-xr-x 3 root root 4.0K Jul 25 2018 DMZ-White
|
||||
drwxr-xr-x 9 root root 4.0K Jul 25 2018 gnome
|
||||
drwxr-xr-x 3 root root 4.0K Jul 25 2018 handhelds
|
||||
drwxr-xr-x 20 root root 4.0K Mar 9 14:52 hicolor
|
||||
drwxr-xr-x 9 root root 4.0K Jul 25 2018 HighContrast
|
||||
drwxr-xr-x 12 root root 4.0K Jul 25 2018 Humanity
|
||||
drwxr-xr-x 7 root root 4.0K Jul 25 2018 Humanity-Dark
|
||||
drwxr-xr-x 4 root root 4.0K Jul 25 2018 locolor
|
||||
drwxr-xr-x 3 root root 4.0K Feb 25 15:46 LoginIcons
|
||||
drwxr-xr-x 3 root root 4.0K Jul 25 2018 redglass
|
||||
drwxr-xr-x 10 root root 4.0K Feb 25 15:46 ubuntu-mono-dark
|
||||
drwxr-xr-x 10 root root 4.0K Feb 25 15:46 ubuntu-mono-light
|
||||
drwxr-xr-x 3 root root 4.0K Jul 25 2018 whiteglass
|
||||
```
|
||||
|
||||
如果要在父目录中的某个位置执行文件,使用以下格式。它将运行 shell 文件 `/usr/share/icons/users-list.sh`。
|
||||
|
||||
```
|
||||
$ `bd i`/users-list.sh
|
||||
or
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ `bd icon`/users-list.sh
|
||||
daygeek
|
||||
thanu
|
||||
renu
|
||||
2gadmin
|
||||
testuser
|
||||
demouser
|
||||
sudha
|
||||
suresh
|
||||
user1
|
||||
user2
|
||||
user3
|
||||
```
|
||||
|
||||
如果你位于 `/usr/share/icons/Adwaita/256x256/apps` 中,想要导航到不同的父目录,使用以下格式。以下命令将导航到 `/usr/share/icons/gnome` 目录。
|
||||
|
||||
```
|
||||
$ cd `bd i`/gnome
|
||||
or
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ cd `bd icon`/gnome
|
||||
daygeek@Ubuntu18:/usr/share/icons/gnome$
|
||||
```
|
||||
|
||||
如果你位于 `/usr/share/icons/Adwaita/256x256/apps` ,你想在 `/usr/share/icons/` 下创建一个新目录,使用以下格式。
|
||||
|
||||
```
|
||||
$ daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ sudo mkdir `bd icons`/2g
|
||||
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ ls -ld `bd icon`/2g
|
||||
drwxr-xr-x 2 root root 4096 Mar 16 05:44 /usr/share/icons//2g
|
||||
```
|
||||
|
||||
本教程允许你快速返回到特定的父目录,但没有快速前进的选项。
|
||||
|
||||
我们有另一个解决方案,很快就会提出新的解决方案,请跟我们保持联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/bd-quickly-go-back-to-a-specific-parent-directory-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/navigate-switch-directory-without-using-cd-command-in-linux/
|
||||
[2]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[3]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/wget-command-line-download-utility-tool/
|
||||
Loading…
Reference in New Issue
Block a user