mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
8abb401eab
@ -0,0 +1,420 @@
|
||||
在 GitHub 上对编程语言与软件质量的一个大规模研究
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
编程语言对软件质量的影响是什么?这个问题在很长一段时间内成为一个引起了大量辩论的主题。在这项研究中,我们从 GitHub 上收集了大量的数据(728 个项目,6300 万行源代码,29000 位作者,150 万个提交,17 种编程语言),尝试在这个问题上提供一些实证。这个还算比较大的样本数量允许我们去使用一个混合的方法,结合多种可视化的回归模型和文本分析,去研究语言特性的影响,比如,在软件质量上,静态与动态类型和允许混淆与不允许混淆的类型。通过从不同的方法作三角测量研究(LCTT 译注:一种测量研究的方法),并且去控制引起混淆的因素,比如,团队大小、项目大小和项目历史,我们的报告显示,语言设计确实(对很多方面)有很大的影响,但是,在软件质量方面,语言的影响是非常有限的。最明显的似乎是,不允许混淆的类型比允许混淆的类型要稍微好一些,并且,在函数式语言中,静态类型也比动态类型好一些。值得注意的是,这些由语言设计所引起的轻微影响,绝大多数是由过程因素所主导的,比如,项目大小、团队大小和提交数量。但是,我们需要提示读者,即便是这些不起眼的轻微影响,也是由其它的无形的过程因素所造成的,例如,对某些函数类型、以及不允许类型混淆的静态语言的偏爱。
|
||||
|
||||
### 1 序言
|
||||
|
||||
在给定的编程语言是否是“适合这个工作的正确工具”的讨论期间,紧接着又发生了多种辩论。虽然一些辩论出现了带有宗教般狂热的色彩,但是大部分人都一致认为,编程语言的选择能够对编码过程和由此生成的结果都有影响。
|
||||
|
||||
主张强静态类型的人,倾向于认为静态方法能够在早期捕获到缺陷;他们认为,一点点的预防胜过大量的矫正。动态类型拥护者主张,保守的静态类型检查无论怎样都是非常浪费开发者资源的,并且,最好是依赖强动态类型检查来捕获错误类型。然而,这些辩论,大多数都是“纸上谈兵”,只靠“传说中”的证据去支持。
|
||||
|
||||
这些“传说”也许并不是没有道理的;考虑到影响软件工程结果的大量其它因素,获取这种经验性的证据支持是一项极具挑战性的任务,比如,代码质量、语言特征,以及应用领域。比如软件质量,考虑到它有大量的众所周知的影响因素,比如,代码数量, ^[6][1] 团队大小, ^[2][2] 和年龄/熟练程度。 ^[9][3]
|
||||
|
||||
受控实验是检验语言选择在面对如此令人气馁的混淆影响时的一种方法,然而,由于成本的原因,这种研究通常会引入一种它们自己的混淆,也就是说,限制了范围。在这种研究中,完整的任务是必须要受限制的,并且不能去模拟 _真实的世界_ 中的开发。这里有几个最近的这种大学本科生使用的研究,或者,通过一个实验因素去比较静态或动态类型的语言。^[7][4],[12][5],[15][6]
|
||||
|
||||
幸运的是,现在我们可以基于大量的真实世界中的软件项目去研究这些问题。GitHub 包含了多种语言的大量的项目,并且在大小、年龄、和开发者数量上有很大的差别。每个项目的仓库都提供一个详细的记录,包含贡献历史、项目大小、作者身份以及缺陷修复。然后,我们使用多种工具去研究语言特性对缺陷发生的影响。对我们的研究方法的最佳描述应该是“混合方法”,或者是三角测量法; ^[5][7] 我们使用文本分析、聚簇和可视化去证实和支持量化回归研究的结果。这个以经验为根据的方法,帮助我们去了解编程语言对软件质量的具体影响,因为,他们是被开发者非正式使用的。
|
||||
|
||||
### 2 方法
|
||||
|
||||
我们的方法是软件工程中典型的大范围观察研究法。我们首先大量的使用自动化方法,从几种数据源采集数据。然后使用预构建的统计分析模型对数据进行过滤和清洗。过滤器的选择是由一系列的因素共同驱动的,这些因素包括我们研究的问题的本质、数据质量和认为最适合这项统计分析研究的数据。尤其是,GitHub 包含了由大量的编程语言所写的非常多的项目。对于这项研究,我们花费大量的精力专注于收集那些用大多数的主流编程语言写的流行项目的数据。我们选择合适的方法来评估计数数据上的影响因素。
|
||||
|
||||
#### 2.1 数据收集
|
||||
|
||||
我们选择了 GitHub 上的排名前 19 的编程语言。剔除了 CSS、Shell 脚本、和 Vim 脚本,因为它们不是通用的编程语言。我们包含了 Typescript,它是 JavaScript 的超集。然后,对每个被研究的编程语言,我们检索出以它为主要编程语言的前 50 个项目。我们总共分析了 17 种不同的语言,共计 850 个项目。
|
||||
|
||||
我们的编程语言和项目的数据是从 _GitHub Archive_ 中提取的,这是一个记录所有活跃的公共 GitHub 项目的数据库。它记录了 18 种不同的 GitHub 事件,包括新提交、fork 事件、PR(拉取请求)、开发者信息和以每小时为基础的所有开源 GitHub 项目的问题跟踪。打包后的数据上传到 Google BigQuery 提供的交互式数据分析接口上。
|
||||
|
||||
**识别编程语言排名榜单**
|
||||
|
||||
我们基于它们的主要编程语言分类合计项目。然后,我们选择大多数的项目进行进一步分析,如 [表 1][48] 所示。一个项目可能使用多种编程语言;将它确定成单一的编程语言是很困难的。Github Archive 保存的信息是从 GitHub Linguist 上采集的,它使用项目仓库中源文件的扩展名来确定项目的发布语言是什么。源文件中使用数量最多的编程语言被确定为这个项目的 _主要编程语言_。
|
||||
|
||||
[][49]
|
||||
|
||||
*表 1 每个编程语言排名前三的项目*
|
||||
|
||||
**检索流行的项目**
|
||||
|
||||
对于每个选定的编程语言,我们先根据项目所使用的主要编程语言来选出项目,然后根据每个项目的相关 _星_ 的数量排出项目的流行度。 _星_ 的数量表示了有多少人主动表达对这个项目感兴趣,并且它是流行度的一个合适的代表指标。因此,在 C 语言中排名前三的项目是 linux、git、php-src;而对于 C++,它们则是 node-webkit、phantomjs、mongo ;对于 Java,它们则是 storm、elasticsearch、ActionBarSherlock 。每个编程语言,我们各选了 50 个项目。
|
||||
|
||||
为确保每个项目有足够长的开发历史,我们剔除了少于 28 个提交的项目(28 是候选项目的第一个四分位值数)。这样我们还剩下 728 个项目。[表 1][50] 展示了每个编程语言的前三个项目。
|
||||
|
||||
**检索项目演进历史**
|
||||
|
||||
对于 728 个项目中的每一个项目,我们下载了它们的非合并提交、提交记录、作者数据、作者使用 _git_ 的名字。我们从每个文件的添加和删除的行数中计算代码改动和每个提交的修改文件数量。我们以每个提交中修改的文件的扩展名所代表的编程语言,来检索出所使用的编程语言(一个提交可能有多个编程语言标签)。对于每个提交,我们通过它的提交日期减去这个项目的第一个提交的日期,来计算它的 _提交年龄_ 。我们也计算其它的项目相关的统计数据,包括项目的最大提交年龄和开发者总数,用于我们的回归分析模型的控制变量,它在第三节中会讨论到。我们通过在提交记录中搜索与错误相关的关键字,比如,`error`、`bug`、`fix`、`issue`、`mistake`、`incorrect`、`fault`、`defect`、`flaw`,来识别 bug 修复提交。这一点与以前的研究类似。^[18][8]
|
||||
|
||||
[表 2][51] 汇总了我们的数据集。因为一个项目可能使用多个编程语言,表的第二列展示了使用某种编程语言的项目的总数量。我们进一步排除了项目中该编程语言少于 20 个提交的那些编程语言。因为 20 是每个编程语言的每个项目的提交总数的第一个四分位值。例如,我们在 C 语言中共找到 220 项目的提交数量多于 20 个。这确保了每个“编程语言 – 项目”对有足够的活跃度。
|
||||
|
||||
[][52]
|
||||
|
||||
*表 2 研究主题*
|
||||
|
||||
总而言之,我们研究了最近 18 年以来,用了 17 种编程语言开发的,总共 728 个项目。总共包括了 29,000 个不同的开发者,157 万个提交,和 564,625 个 bug 修复提交。
|
||||
|
||||
#### 2.2 语言分类
|
||||
|
||||
我们基于影响语言质量的几种编程语言特性定义了语言类别,^[7][9],[8][10],[12][11] ,如 [表 3][53] 所示。
|
||||
|
||||
<ruby>编程范式<rt>Programming Paradigm</rt></ruby> 表示项目是以命令方式、脚本方式、还是函数语言所写的。在本文的下面部分,我们分别使用 <ruby>命令<rt>procedural</rt></ruby> 和 <ruby>脚本<rt>scripting</rt></ruby> 这两个术语去代表命令方式和脚本方式。
|
||||
|
||||
[][54]
|
||||
|
||||
*表 3. 语言分类的不同类型*
|
||||
|
||||
<ruby>类型检查<rt>Type Checking</rt></ruby> 代表静态或者动态类型。在静态类型语言中,在编译时进行类型检查,并且变量名是绑定到一个值和一个类型的。另外,(包含变量的)表达式是根据运行时,它们可能产生的值所符合的类型来分类的。在动态类型语言中,类型检查发生在运行时。因此,在动态类型语言中,它可能出现在同一个程序中,一个变量名可能会绑定到不同类型的对象上的情形。
|
||||
|
||||
<ruby>隐式类型转换<rt>Implicit Type Conversion</rt></ruby> 允许一个类型为 T1 的操作数,作为另一个不同的类型 T2 来访问,而无需进行显式的类型转换。这样的隐式类型转换在一些情况下可能会带来类型混淆,尤其是当它表示一个明确的 T1 类型的操作数时,把它再作为另一个不同的 T2 类型的情况下。因为,并不是所有的隐式类型转换都会立即出现问题,通过我们识别出的允许进行隐式类型转换的所有编程语言中,可能发生隐式类型转换混淆的例子来展示我们的定义。例如,在像 Perl、 JavaScript、CoffeeScript 这样的编程语言中,一个字符和一个数字相加是允许的(比如,`"5" + 2` 结果是 `"52"`)。但是在 Php 中,相同的操作,结果是 `7`。像这种操作在一些编程语言中是不允许的,比如 Java 和 Python,因为,它们不允许隐式转换。在强数据类型的 C 和 C++ 中,这种操作的结果是不可预料的,例如,`int x; float y; y=3.5; x=y`;是合法的 C 代码,并且对于 `x` 和 `y` 其结果是不同的值,具体是哪一个值,取决于含义,这可能在后面会产生问题。^[a][12] 在 `Objective-C` 中,数据类型 _id_ 是一个通用对象指针,它可以被用于任何数据类型的对象,而不管分类是什么。^[b][13] 像这种通用数据类型提供了很好的灵活性,它可能导致隐式的类型转换,并且也会出现不可预料的结果。^[c][14] 因此,我们根据它的编译器是否 _允许_ 或者 _不允许_ 如上所述的隐式类型转换,对编程语言进行分类;而不允许隐式类型转换的编程语言,会显式检测类型混淆,并报告类型不匹配的错误。
|
||||
|
||||
不允许隐式类型转换的编程语言,使用一个类型判断算法,比如,Hindley ^[10][15] 和 Milner,^[17][16] 或者,在运行时上使用一个动态类型检查器,可以在一个编译器(比如,使用 Java)中判断静态类型的结果。相比之下,一个类型混淆可能会悄无声息地发生,因为,它可能因为没有检测到,也可能是没有报告出来。无论是哪种方式,允许隐式类型转换在提供了灵活性的同时,最终也可能会出现很难确定原因的错误。为了简单起见,我们将用 <ruby>隐含<rt>implicit</rt></ruby> 代表允许隐式类型转换的编程语言,而不允许隐式类型转换的语言,我们用 <ruby>明确<rt>explicit</rt></ruby> 代表。
|
||||
|
||||
<ruby>内存分类<rt>Memory Class</rt></ruby> 表示是否要求开发者去管理内存。尽管 Objective-C 遵循了一个混合模式,我们仍将它放在非管理的分类中来对待,因为,我们在它的代码库中观察到很多的内存错误,在第 3 节的 RQ4 中会讨论到。
|
||||
|
||||
请注意,我们之所以使用这种方式对编程语言来分类和研究,是因为,这种方式在一个“真实的世界”中被大量的开发人员非正式使用。例如,TypeScript 被有意地分到静态编程语言的分类中,它不允许隐式类型转换。然而,在实践中,我们注意到,开发者经常(有 50% 的变量,并且跨 TypeScript —— 在我们的数据集中使用的项目)使用 `any` 类型,这是一个笼统的联合类型,并且,因此在实践中,TypeScript 允许动态地、隐式类型转换。为减少混淆,我们从我们的编程语言分类和相关的模型中排除了 TypeScript(查看 [表 3][55] 和 [7][56])。
|
||||
|
||||
#### 2.3 识别项目领域
|
||||
|
||||
我们基于编程语言的特性和功能,使用一个自动加手动的混合技术,将研究的项目分类到不同的领域。在 GitHub 上,项目使用 `project descriptions` 和 `README` 文件来描述它们的特性。我们使用一种文档主题生成模型(Latent Dirichlet Allocation,缩写为:LDA) ^[3][17] 去分析这些文本。提供一组文档给它,LDA 将生成不同的关键字,然后来识别可能的主题。对于每个文档,LDA 也估算每个主题分配的文档的概率。
|
||||
|
||||
我们检测到 30 个不同的领域(换句话说,就是主题),并且评估了每个项目从属于每个领域的概率。因为,这些自动检测的领域包含了几个具体项目的关键字,例如,facebook,很难去界定它的底层的常用功能。为了给每个领域分配一个有意义的名字,我们手动检查了 30 个与项目名字无关的用于识别领域的领域识别关键字。我们手动重命名了所有的 30 个自动检测的领域,并且找出了以下六个领域的大多数的项目:应用程序、数据库、代码分析、中间件、库,和框架。我们也找出了不符合以上任何一个领域的一些项目,因此,我们把这个领域笼统地标记为 _其它_ 。随后,我们研究组的另一名成员检查和确认了这种项目领域分类的方式。[表 4][57] 汇总了这个过程识别到的领域结果。
|
||||
|
||||
[][58]
|
||||
|
||||
*表 4 领域特征*
|
||||
|
||||
#### 2.4 bug 分类
|
||||
|
||||
尽管修复软件 bug 时,开发者经常会在提交日志中留下关于这个 bug 的原始的重要信息;例如,为什么会产生 bug,以及怎么去修复 bug。我们利用很多信息去分类 bug,与 Tan 的 _et al_ 类似。 ^[13][18],[24][19]
|
||||
|
||||
首先,我们基于 bug 的 <ruby>原因<rt>Cause</rt></ruby> 和 <ruby>影响<rt>Impact</rt></ruby> 进行分类。_ 原因 _ 进一步分解为不相关的错误子类:算法方面的、并发方面的、内存方面的、普通编程错误,和未知的。bug 的 _影响_ 也分成四个不相关的子类:安全、性能、失败、和其它的未知类。因此,每个 bug 修复提交也包含原因和影响的类型。[表 5][59] 展示了描述的每个 bug 分类。这个类别分别在两个阶段中被执行:
|
||||
|
||||
[][60]
|
||||
|
||||
*表 5 bug 分类和在整个数据集中的描述*
|
||||
|
||||
**(1) 关键字搜索** 我们随机选择了 10% 的 bug 修复信息,并且使用一个基于关键字的搜索技术去对它们进行自动化分类,作为可能的 bug 类型。我们对这两种类型(原因和影响)分别使用这个注释。我们选择了一个限定的关键字和习惯用语集,如 [表 5][61] 所展示的。像这种限定的关键字和习惯用语集可以帮我们降低误报。
|
||||
|
||||
**(2) 监督分类** 我们使用前面步骤中的有注释的 bug 修复日志作为训练数据,为监督学习分类技术,通过测试数据来矫正,去对剩余的 bug 修复信息进行分类。我们首先转换每个 bug 修复信息为一个词袋(LCTT 译注:bag-of-words,一种信息检索模型)。然后,删除在所有的 bug 修复信息中仅出现过一次的词。这样减少了具体项目的关键字。我们也使用标准的自然语言处理技术来解决这个问题。最终,我们使用支持向量机(LCTT 译注:Support Vector Machine,缩写为 SVM,在机器学习领域中,一种有监督的学习算法)去对测试数据进行分类。
|
||||
|
||||
为精确评估 bug 分类器,我们手动注释了 180 个随机选择的 bug 修复,平均分布在所有的分类中。然后,我们比较手动注释的数据集在自动分类器中的结果。最终处理后的,表现出的精确度是可接受的,性能方面的精确度最低,是 70%,并发错误方面的精确度最高,是 100%,平均是 84%。再次运行,精确度从低到高是 69% 到 91%,平均精确度还是 84%。
|
||||
|
||||
我们的 bug 分类的结果展示在 [表 5][62] 中。大多数缺陷的原因都与普通编程错误相关。这个结果并不意外,因为,在这个分类中涉及了大量的编程错误,比如,类型错误、输入错误、编写错误、等等。我们的技术并不能将在任何(原因或影响)分类中占比为 1.4% 的 bug 修复信息再次进行分类;我们将它归类为未知。
|
||||
|
||||
|
||||
#### 2.5 统计方法
|
||||
|
||||
我们使用回归模型对软件项目相关的其它因素中的有缺陷的提交数量进行了建模。所有的模型使用<ruby>负二项回归<rt>negative binomial regression</rt></ruby>(缩写为 NBR)(LCTT 译注:一种回归分析模型) 去对项目属性计数进行建模,比如,提交数量。NBR 是一个广义的线性模型,用于对非负整数进行响应建模。^[4][20]
|
||||
|
||||
在我们的模型中,我们对每个项目的编程语言,控制几个可能影响最终结果的因素。因此,在我们的回归分析中,每个(语言/项目)对是一个行,并且可以视为来自流行的开源项目中的样本。我们依据变量计数进行对象转换,以使变量保持稳定,并且提升了模型的适用度。^[4][21] 我们通过使用 AIC 和 Vuong 对非嵌套模型的测试比较来验证它们。
|
||||
|
||||
去检查那些过度的多重共线性(LCTT 译注:多重共线性是指,在线性回归模型中解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。)并不是一个问题,我们在所有的模型中使用一个保守的最大值 5,去计算每个依赖的变量的膨胀因子的方差。^[4][22] 我们通过对每个模型的残差和杠杆图进行视觉检查来移除高杠杆点,找出库克距离(LCTT 译注:一个统计学术语,用于诊断回归分析中是否存在异常数据)的分离值和最大值。
|
||||
|
||||
我们利用 _效果_ ,或者 _差异_ ,编码到我们的研究中,以提高编程语言回归系数的表现。^[4][23] 加权的效果代码允许我们将每种编程语言与所有编程语言的效果进行比较,同时弥补了跨项目使用编程语言的不均匀性。^[23][24] 去测试两种变量因素之间的联系,我们使用一个独立的卡方检验(LCTT 译注:Chi-square,一种统计学上的假设检验方法)测试。^[14][25] 在证实一个依赖之后,我们使用 Cramer 的 V,它是与一个 `r × c` 等价的正常数据的 `phi(φ)` 系数,去建立一个效果数据。
|
||||
|
||||
### 3 结果
|
||||
|
||||
我们从简单明了的问题开始,它非常直接地解决了人们坚信的一些核心问题,即:
|
||||
|
||||
#### 问题 1:一些编程语言相比其它语言来说更易于出现缺陷吗?
|
||||
|
||||
我们使用了回归分析模型,去比较每个编程语言对所有编程语言缺陷数量平均值的影响,以及对缺陷修复提交的影响(查看 [表 6][64])。
|
||||
|
||||
[][65]
|
||||
|
||||
*表 6. 一些语言的缺陷要少于其它语言*
|
||||
|
||||
我们包括了一些变量,作为对明确影响反应的控制因子。项目<ruby>年龄<rt>age</rt></ruby>也包括在内,因为,越老的项目生成的缺陷修复数量越大。<ruby>提交<rt>commits</rt></ruby>数量也会对项目反应有轻微的影响。另外,从事该项目的<ruby>开发人员<rt>dev</rt></ruby>的数量和项目的原始<ruby>大小<rt>size</rt></ruby>,都会随着项目的活跃而增长。
|
||||
|
||||
上述模型中估算系数的大小和符号(LCTT 译注:指 “+”或者“-”)与结果的预测因子有关。初始的四种变量是控制变量,并且,我们对这些变量对最终结果的影响不感兴趣,只是说它们都是积极的和有意义的。语言变量是指示变量,是每个项目的变化因子,该因子将每种编程语言与所有项目的编程语言的加权平均值进行比较。编程语言系数可以大体上分为三类。第一类是,那些在统计学上无关紧要的系数,并且在建模过程中这些系数不能从 0 中区分出来。这些编程语言的表现与平均值相似,或者它们也可能有更大的方差。剩余的系数是非常明显的,要么是正的,要么是负的。对于那些正的系数,我们猜测可能与这个编程语言有大量的缺陷修复相关。这些语言包括 C、C++、Objective-C、Php,以及 Python。所有的有一个负的系数的编程语言,比如 Clojure、Haskell、Ruby,和 Scala,暗示这些语言的缺陷修复提交可能小于平均值。
|
||||
|
||||
应该注意的是,虽然,从统计学的角度观察到编程语言与缺陷之间有明显的联系,但是,大家不要过高估计编程语言对于缺陷的影响,因为,这种影响效应是非常小的。异常分析的结果显示,这种影响小于总异常的 1%。
|
||||
|
||||
[][66]
|
||||
|
||||
我们可以这样去理解模型的系数,它代表一个预测因子在所有其它预测因子保持不变的情况下,这个预测因子一个<ruby>单位<rt>unit</rt></ruby>的变化,所反应出的预期的响应的对数变化;换句话说,对于一个系数 _β_<sub>i</sub> ,在 _β_<sub>i</sub> 中一个单位的变化,产生一个预期的 e^_β_<sub>i</sub> 响应的变化。对于可变因子,这个预期的变化是与所有编程语言的平均值进行比较。因此,如果对于一定数量的提交,用一个处于平均值的编程语言开发的特定项目有四个缺陷提交,那么,如果选择使用 C++ 来开发,意味着我们预计应该有一个额外的(LCTT 译注:相对于平均值 4,多 1 个)缺陷提交,因为 e^0.18 × 4 = 4.79。对于相同的项目,如果选择使用 Haskell 来开发,意味着我们预计应该少一个(LCTT 译注:同上,相对于平均值 4)缺陷提交。因为, e^−0.26 × 4 = 3.08。预测的精确度取决于剩余的其它因子都保持不变,除了那些微不足道的项目之外,所有的这些都是一个极具挑战性的命题。所有观察性研究都面临类似的局限性;我们将在第 5 节中详细解决这些事情。
|
||||
|
||||
**结论 1:一些编程语言相比其它编程语言有更高的缺陷相关度,不过,影响非常小。**
|
||||
|
||||
在这篇文章的剩余部分,我们会在基本结论的基础上详细阐述,通过考虑不同种类的应用程序、缺陷、和编程语言,可以进一步深入了解编程语言和缺陷倾向之间的关系。
|
||||
|
||||
软件 bug 通常落进两种宽泛的分类中:
|
||||
|
||||
1. _特定领域的 bug_ :特定于项目功能,并且不依赖于底层编程语言。
|
||||
2. _普通 bug_ :大多数的普通 bug 是天生的,并且与项目功能无关,比如,输入错误,并发错误、等等。
|
||||
|
||||
因此,在一个项目中,应用程序领域和编程语言相互作用可能会影响缺陷的数量,这一结论被认为是合理的。因为一些编程语言被认为在一些任务上相比其它语言表现更突出,例如,C 对于低级别的(底层)工作,或者,Java 对于用户应用程序,对于编程语言的一个不合适的选择,可能会带来更多的缺陷。为研究这种情况,我们将理想化地忽略领域特定的 bug,因为,普通 bug 更依赖于编程语言的特性。但是,因为一个领域特定的 bug 也可能出现在一个普通的编程错误中,这两者是很难区分的。一个可能的变通办法是在控制领域的同时去研究编程语言。从统计的角度来看,虽然,使用 17 种编程语言跨 7 个领域,在给定的样本数量中,理解大量的术语将是一个极大的挑战。
|
||||
|
||||
鉴于这种情况,我们首先考虑在一个项目中测试领域和编程语言使用之间的依赖关系,独立使用一个<ruby>卡方检验<rt>Chi-square</rt></ruby>测试。在 119 个单元中,是 46 个,也就是说是 39%,它在我们设定的保守值 5 以上,它太高了。这个数字不能超过 20%,应该低于 5。^[14][26] 我们在这里包含了完整有值; ^[d][27] 但是,通过 Cramer 的 V 测试的值是 0.191,是低相关度的,表明任何编程语言和领域之间的相关度是非常小的,并且,在回归模型中包含领域并不会产生有意义的结果。
|
||||
|
||||
去解决这种情况的一个选择是,去移除编程语言,或者混合领域,但是,我们现有的数据没有进行完全挑选。或者,我们混合编程语言;这个选择导致一个相关但略有不同的问题。
|
||||
|
||||
#### 问题 2: 哪些编程语言特性与缺陷相关?
|
||||
|
||||
我们按编程语言类别聚合它们,而不是考虑单独的编程语言,正如在第 2.2 节所描述的那样,然后去分析与缺陷的关系。总体上说,这些属性中的每一个都将编程语言按照在上下文中经常讨论的错误、用户辩论驱动、或者按以前工作主题来划分的。因此,单独的属性是高度相关的,我们创建了六个模型因子,将所有的单独因子综合到我们的研究中。然后,我们对六个不同的因子对缺陷数量的影响进行建模,同时控制我们在 _问题 1_ 节中使用的模型中的相同的基本协变量(LCTT 译注:协变量是指在实验中不能被人为操纵的独立变量)。
|
||||
|
||||
关于使用的编程语言(在前面的 [表 6][67]中),我们使用跨所有语言类的平均反应来比较编程语言 _类_ 。这个模型在 [表 7][68] 中表达了出来。很明显,`Script-Dynamic-Explicit-Managed` 类有最小的量级系数。这个系数是微不足道的,换句话说,对这个系数的 <ruby>Z 校验<rt>z-test</rt></ruby>(LCTT 译注:统计学上的一种平均值差异校验的方法) 并不能把它从 0 中区分出来。鉴于标准错误的量级,我们可以假设,在这个类别中的编程语言的行为是非常接近于所有编程语言行为的平均值。我们可以通过使用 `Proc-Static-Implicit-Unmanaged` 作为基本级并用于处理,或者使用基本级来虚假编码比较每个语言类,来证明这一点。在这种情况下,`Script-Dynamic-Explicit-Managed` 是明显不同于 _p_ = 0.00044 的。注意,虽然我们在这是选择了不同的编码方法,影响了系数和 Z 值,这个方法和所有其它的方面都是一样的。当我们改变了编码,我们调整系数去反应我们希望生成的对比。^[4][28] 将其它类的编程语言与总体平均数进行比较,`Proc-Static-Implicit-Unmanaged` 类编程语言更容易引起缺陷。这意味着与其它过程类编程语言相比,隐式类型转换或者管理内存会导致更多的缺陷倾向。
|
||||
|
||||
[][69]
|
||||
|
||||
*表 7. 函数式语言与缺陷的关联度和其它类语言相比要低,而过程类语言则大于或接近于平均值。*
|
||||
|
||||
在脚本类编程语言中,我们观察到类似于允许与不允许隐式类型转换的编程语言之间的关系,它们提供的一些证据表明,隐式类型转换(与显式类型转换相比)才是导致这种差异的原因,而不是内存管理。鉴于各种因素之间的相关性,我们并不能得出这个结论。但是,当它们与平均值进行比较时,作为一个组,那些不允许隐式类型转换的编程语言出现错误的倾向更低一些,而那些出现错误倾向更高的编程语言,出现错误的机率则相对更高。在函数式编程语言中静态和动态类型之间的差异也很明显。
|
||||
|
||||
函数式语言作为一个组展示了与平均值的很明显的差异。静态类型语言的系数要小很多,但是函数式语言类都有同样的标准错误。函数式静态编程语言出现错误的倾向要小于函数式动态编程语言,这是一个强有力的证据,尽管如此,Z 校验仅仅是检验系数是否能从 0 中区分出来。为了强化这个推论,我们使用处理编码,重新编码了上面的模型,并且观察到,`Functional-Static-Explicit-Managed` 编程语言类的错误倾向是明显小于 `Functional-Dynamic-Explicit-Managed` 编程语言类的 _p_ = 0.034。
|
||||
|
||||
[][70]
|
||||
|
||||
与编程语言和缺陷一样,编程语言类与缺陷之间关系的影响是非常小的。解释类编程语言的这种差异也是相似的,虽然很小,解释类编程语言的这种差异小于 1%。
|
||||
|
||||
我们现在重新回到应用领域这个问题。应用领域是否与语言类相互影响?怎么选择?例如,一个函数化编程语言,对特定的领域有一定的优势?与上面一样,对于这些因素和项目领域之间的关系做一个卡方检验,它的值是 99.05, _df_ = 30, _p_ = 2.622e–09,我们拒绝无意义假设,Cramer 的 V 产生的值是 0.133,表示一个弱关联。因此,虽然领域和编程语言之间有一些关联,但在这里应用领域和编程语言类之间仅仅是一个非常弱的关联。
|
||||
|
||||
**结论 2:在编程语言类与缺陷之间有一个很小但是很明显的关系。函数式语言与过程式或者脚本式语言相比,缺陷要少。**
|
||||
|
||||
这个结论有些不太令人满意的地方,因为,我们并没有一个强有力的证据去证明,在一个项目中编程语言或者语言类和应用领域之间的关联性。一个替代方法是,基于全部的编程语言和应用领域,忽略项目和缺陷总数,而去查看相同的数据。因为,这样不再产生不相关的样本,我们没有从统计学的角度去尝试分析它,而是使用一个描述式的、基于可视化的方法。
|
||||
|
||||
我们定义了 <ruby>缺陷倾向<rt>Defect Proneness</rt></ruby> 作为 bug 修复提交与每语言每领域总提交的比率。[图 1][71] 使用了一个热力图展示了应用领域与编程语言之间的相互作用,从亮到暗表示缺陷倾向在增加。我们研究了哪些编程语言因素影响了跨多种语言写的项目的缺陷修复提交。它引出了下面的研究问题:
|
||||
|
||||
[][72]
|
||||
|
||||
*图 1. 编程语言的缺陷倾向与应用领域之间的相互作用。对于一个给定的领域(列底部),热力图中的每个格子表示了一个编程语言的缺陷倾向(行头部)。“整体”列表示一个编程语言基于所有领域的缺陷倾向。用白色十字线标记的格子代表一个 null 值,换句话说,就是在那个格子里没有符合的提交。*
|
||||
|
||||
#### 问题 3: 编程语言的错误倾向是否取决于应用领域?
|
||||
|
||||
为了回答这个问题,我们首先在我们的回归模型中,以高杠杆点过滤掉认为是异常的项目,这种方法在这里是必要的,尽管这是一个非统计学的方法,一些关系可能影响可视化。例如,我们找到一个简单的项目,Google 的 v8,一个 JavaScript 项目,负责中间件中的所有错误。这对我们来说是一个惊喜,因为 JavaScript 通常不用于中间件。这个模式一直在其它应用领域中不停地重复着,因此,我们过滤出的项目的缺陷度都低于 10% 和高于 90%。这个结果在 [图 1][73] 中。
|
||||
|
||||
我们看到在这个热力图中仅有一个很小的差异,正如在问题 1 节中看到的那样,这个结果仅表示编程语言固有的错误倾向。为验证这个推论,我们测量了编程语言对每个应用领域和对全部应用领域的缺陷倾向。对于除了数据库以外的全部领域,关联性都是正向的,并且 p 值是有意义的(<0.01)。因此,关于缺陷倾向,在每个领域的语言排序与全部领域的语言排序是基本相同的。
|
||||
|
||||
[][74]
|
||||
|
||||
**结论 3: 应用领域和编程语言缺陷倾向之间总体上没有联系。**
|
||||
|
||||
我们证明了不同的语言产生了大量的缺陷,并且,这个关系不仅与特定的语言相关,也适用于一般的语言类;然而,我们发现,项目类型并不能在一定程度上协调这种关系。现在,我们转变我们的注意力到反应分类上,我想去了解,编程语言与特定种类的缺陷之间有什么联系,以及这种关系怎么与我们观察到的更普通的关系去比较。我们将缺陷分为不同的类别,如 [表 5][75] 所描述的那样,然后提出以下的问题:
|
||||
|
||||
#### 问题 4:编程语言与 bug 分类之间有什么关系?
|
||||
|
||||
我们使用了一个类似于问题 3 中所用的方法,去了解编程语言与 bug 分类之间的关系。首先,我们研究了 bug 分类和编程语言类之间的关系。一个热力图([图 2][76])展示了在编程语言类和 bug 类型之上的总缺陷数。去理解 bug 分类和语言之间的相互作用,我们对每个类别使用一个 NBR 回归模型。对于每个模型,我们使用了与问题 1 中相同的控制因素,以及使用加权效应编码后的语言,去预测缺陷修复提交。
|
||||
|
||||
[][77]
|
||||
|
||||
*图 2. bug 类别与编程语言类之间的关系。每个格子表示每语言类(行头部)每 bug 类别(列底部)的 bug 修复提交占全部 bug 修复提交的百分比。这个值是按列规范化的。*
|
||||
|
||||
结果和编程语言的方差分析值展示在 [表 8][78] 中。每个模型的整体异常是非常小的,并且对于特定的缺陷类型,通过语言所展示的比例在大多数类别中的量级是类似的。我们解释这种关系为,编程语言对于特定的 bug 类别的影响要大于总体的影响。尽管我们结论概括了全部的类别,但是,在接下来的一节中,我们对 [表 5][79] 中反应出来的 bug 数较多的 bug 类别做进一步研究。
|
||||
|
||||
[][80]
|
||||
|
||||
*表 8. 虽然编程语言对缺陷的影响因缺陷类别而不同,但是,编程语言对特定的类别的影响要大于一般的类别。*
|
||||
|
||||
**编程错误** 普通的编程错误占所有 bug 修复提交的 88.53% 左右,并且在所有的编程语言类中都有。因此,回归分析给出了一个与问题 1 中类似的结论(查看 [表 6][81])。所有的编程语言都会导致这种编程错误,比如,处理错误、定义错误、输入错误、等等。
|
||||
|
||||
**内存错误** 内存错误占所有 bug 修复提交的 5.44%。热力图 [图 2][82] 证明了在 `Proc-Static-Implicit-Unmanaged` 类和内存错误之间存在着非常紧密的联系。非管理内存的编程语言出现内存 bug,这是预料之中的。[表 8][83] 也证明了这一点,例如,C、C++、和 Objective-C 引发了很多的内存错误。在管理内存的语言中 Java 引发了更多的内存错误,尽管它少于非管理内存的编程语言。虽然 Java 自己做内存回收,但是,它出现内存泄露一点也不奇怪,因为对象引用经常阻止内存回收。^[11][29] 在我们的数据中,Java 的所有内存错误中,28.89% 是内存泄漏造成的。就数量而言,编程语言中内存缺陷相比其它类别的 _原因_ 造成的影响要大很多。
|
||||
|
||||
**并发错误** 在总的 bug 修复提交中,并发错误相关的修复提交占 1.99%。热力图显示,`Proc-Static-Implicit-Unmanaged` 是主要的错误类型。在这种错误中,C 和 C++ 分别占 19.15% 和 7.89%,并且它们分布在各个项目中。
|
||||
|
||||
[][84]
|
||||
|
||||
属于 `Static-Strong-Managed` 语言类的编程语言都被证实处于热力图中的暗区中,普通的静态语言相比其它语言产生更多的并发错误。在动态语言中,仅仅有 Erlang 有更多的并发错误倾向,或许与使用这种语言开发的并发应用程序非常多有关系。同样地,在 [表 8][85] 中的负的系数表明,用诸如 Ruby 和 `Php 这样的动态编程语言写的项目,并发错误要少一些。请注意,某些语言,如 JavaScript、CoffeeScript 和 TypeScript 是不支持并发的,在传统的惯例中,虽然 Php 具有有限的并发支持(取决于它的实现)。这些语言在我们的数据中引入了虚假的 0,因此,在 [表 8][86] 中这些语言的并发模型的系数,不能像其它的语言那样去解释。因为存在这些虚假的 0,所以在这个模型中所有语言的平均数非常小,它可能影响系数的大小,因此,她们给 w.r.t. 一个平均数,但是,这并不影响他们之间的相对关系,因为我们只关注它们的相对关系。
|
||||
|
||||
基于 bug 修复消息中高频词的文本分析表明,大多数的并发错误发生在一个条件争用、死锁、或者不正确的同步上,正如上面表中所示。遍历所有语言,条件争用是并发错误出现最多的原因,例如,在 Go 中占 92%。在 Go 中条件争用错误的改进,或许是因为使用了一个争用检测工具帮助开发者去定位争用。同步错误主要与消息传递接口(MPI)或者共享内存操作(SHM)相关。Erlang 和 Go 对线程间通讯使用 MPI ^[e][30] ,这就是为什么这两种语言没有发生任何 SHM 相关的错误的原因,比如共享锁、互斥锁等等。相比之下,为线程间通讯使用早期的 SHM 技术的语言写的项目,就可能存在锁相关的错误。
|
||||
|
||||
**安全和其它冲突错误** 在所有的 bug 修复提交中,与<ruby>冲突<rt>Impact</rt></ruby>错误相关的提交占了 7.33% 左右。其中,Erlang、C++、Python 与安全相关的错误要高于平均值([表 8][87])。Clojure 项目相关的安全错误较少([图 2][88])。从热力图上我们也可以看出来,静态语言一般更易于发生失败和性能错误,紧随其后的是 `Functional-Dynamic-Explicit-Managed` 语言,比如 Erlang。对异常结果的分析表明,编程语言与冲突失败密切相关。虽然安全错误在这个类别中是弱相关的,与残差相比,解释类语言的差异仍然比较大。
|
||||
|
||||
**结论 4: 缺陷类型与编程语言强相关;一些缺陷类型比如内存错误和并发错误也取决于早期的语言(所使用的技术)。对于特定类别,编程语言所引起的错误比整体更多。**
|
||||
|
||||
### 4. 相关工作
|
||||
|
||||
在编程语言比较之前做的工作分为以下三类:
|
||||
|
||||
#### (1) 受控实验
|
||||
|
||||
对于一个给定的任务,开发者使用不同的语言进行编程时受到监视。研究然后比较结果,比如,开发成果和代码质量。Hanenberg ^[7][31] 通过开发一个解析程序,对 48 位程序员监视了 27 小时,去比较了静态与动态类型。他发现这两者在代码质量方面没有显著的差异,但是,基于动态类型的语言花费了更短的开发时间。他们的研究是在一个实验室中,使用本科学生,设置了定制的语言和 IDE 来进行的。我们的研究正好相反,是一个实际的流行软件应用的研究。虽然我们只能够通过使用回归模型间接(和 _事后_ )控制混杂因素,我们的优势是样本数量大,并且更真实、使用更广泛的软件。我们发现在相同的条件下,静态化类型的语言比动态化类型的语言更少出现错误倾向,并且不允许隐式类型转换的语言要好于允许隐式类型转换的语言,其对结果的影响是非常小的。这是合理的,因为样本量非常大,所以这种非常小的影响在这个研究中可以看得到。
|
||||
|
||||
Harrison et al. ^[8][32] 比较了 C++ 与 SML,一个是过程化编程语言,一个是函数化编程语言,在总的错误数量上没有找到显著的差异,不过 SML 相比 C++ 有更高的缺陷密集度。SML 在我们的数据中并没有体现出来,不过,认为函数式编程语言相比过程化编程语言更少出现缺陷。另一个重点工作是比较跨不同语言的开发工作。^[12][33],[20][34] 不过,他们并不分析编程语言的缺陷倾向。
|
||||
|
||||
#### (2) 调查
|
||||
|
||||
Meyerovich 和 Rabkin ^[16][35] 调查了开发者对编程语言的观点,去研究为什么一些编程语言比其它的语言更流行。他们的报告指出,非编程语言的因素影响非常大:先前的编程语言技能、可用的开源工具、以及现有的老式系统。我们的研究也证明,可利用的外部工具也影响软件质量;例如,在 Go 中的并发 bug(请查看问题 4 节内容)。
|
||||
|
||||
#### (3) 对软件仓库的挖掘
|
||||
|
||||
Bhattacharya 和 Neamtiu ^[1][36] 研究了用 C 和 C++ 开发的四个项目,并且发现在 C++ 中开发的组件一般比在 C 中开发的组件更可靠。我们发现 C 和 C++ 的错误倾向要高于全部编程语言的平均值。但是,对于某些 bug 类型,像并发错误,C 的缺陷倾向要高于 C++(请查看第 3 节中的问题 4)。
|
||||
|
||||
### 5. 有效的风险
|
||||
|
||||
我们认为,我们的报告的结论几乎没有风险。首先,在识别 bug 修复提交方面,我们依赖的关键字是开发者经常用于表示 bug 修复的关键字。我们的选择是经过认真考虑的。在一个持续的开发过程中,我们去捕获那些开发者一直面对的问题,而不是他们报告的 bug。不过,这种选择存在过高估计的风险。我们对领域分类是为了去解释缺陷的倾向,而且,我们研究组中另外的成员验证过分类。此外,我们花费精力去对 bug 修复提交进行分类,也可能有被最初选择的关键字所污染的风险。每个项目在提交日志的描述上也不相同。为了缓解这些风险,我们像 2.4 节中描述的那样,利用手工注释评估了我们的类别。
|
||||
|
||||
我们判断文件所属的编程语言是基于文件的扩展名。如果使用不同的编程语言写的文件使用了我们研究的通用的编程语言文件的扩展名,这种情况下也容易出现错误倾向。为减少这种错误,我们使用一个随机样本文件集手工验证了我们的语言分类。
|
||||
|
||||
根据我们的数据集所显示的情形,2.2 节中的解释类编程语言,我们依据编程语言属性的主要用途作了一些假设。例如,我们将 Objective-C 分到非管理内存类型中,而不是混合类型。同样,我们将 Scala 注释为函数式编程语言,将 C# 作为过程化的编程语言,虽然,它们在设计的选择上两者都支持。 ^[19][37],[21][38] 在这项研究工作中,我们没有从过程化编程语言中分离出面向对象的编程语言(OOP),因为,它们没有清晰的区别,主要差异在于编程类型。我们将 C++ 分到允许隐式类型转换的类别中是因为,某些类型的内存区域可以通过使用指针操作被进行不同的处理, ^[22][39] 并且我们注意到大多数 C++ 编译器可以在编译时检测类型错误。
|
||||
|
||||
最后,我们将缺陷修复提交关联到编程语言属性上,它们可以反应出报告的风格或者其它开发者的属性。可用的外部工具或者<ruby>库<rt>library</rt></ruby>也可以影响一个相关的编程语言的 bug 数量。
|
||||
|
||||
### 6. 总结
|
||||
|
||||
我们对编程语言和使用进行了大规模的研究,因为它涉及到软件质量。我们使用的 Github 上的数据,具有很高的复杂性和多个维度上的差异的特性。我们的样本数量允许我们对编程语言效果以及在控制一些混杂因素的情况下,对编程语言、应用领域和缺陷类型之间的相互作用,进行一个混合方法的研究。研究数据显示,函数式语言是好于过程化语言的;不允许隐式类型转换的语言是好于允许隐式类型转换的语言的;静态类型的语言是好于动态类型的语言的;管理内存的语言是好于非管理的语言的。进一步讲,编程语言的缺陷倾向与软件应用领域并没有关联。另外,每个编程语言更多是与特定的 bug 类别有关联,而不是与全部 bug。
|
||||
|
||||
另一方面,即便是很大规模的数据集,它们被多种方法同时进行分割后,也变得很小且不全面。因此,随着依赖的变量越来越多,很难去回答某个变量所产生的影响有多大这种问题,尤其是在变量之间相互作用的情况下。因此,我们无法去量化编程语言在使用中的特定的效果。其它的方法,比如调查,可能对此有帮助。我们将在以后的工作中来解决这些挑战。
|
||||
|
||||
### 致谢
|
||||
|
||||
这个材料是在美国国家科学基金会(NSF)以及美国空军科学研究办公室(AFOSR)的授权和支持下完成的。授权号 1445079, 1247280, 1414172,1446683,FA955-11-1-0246。
|
||||
|
||||
### 参考资料
|
||||
|
||||
1. Bhattacharya, P., Neamtiu, I. Assessing programming language impact on development and maintenance: A study on C and C++. In _Proceedings of the 33rd International Conference on Software Engineering, ICSE'11_ (New York, NY USA, 2011). ACM, 171–180.
|
||||
2. Bird, C., Nagappan, N., Murphy, B., Gall, H., Devanbu, P. Don't touch my code! Examining the effects of ownership on software quality. In _Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering_ (2011). ACM, 4–14.
|
||||
3. Blei, D.M. Probabilistic topic models. _Commun. ACM 55_ , 4 (2012), 77–84.
|
||||
4. Cohen, J. _Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences._ Lawrence Erlbaum, 2003.
|
||||
5. Easterbrook, S., Singer, J., Storey, M.-A., Damian, D. Selecting empirical methods for software engineering research. In _Guide to Advanced Empirical Software Engineering_ (2008). Springer, 285–311.
|
||||
6. El Emam, K., Benlarbi, S., Goel, N., Rai, S.N. The confounding effect of class size on the validity of object-oriented metrics. _IEEE Trans. Softw. Eng. 27_ , 7 (2001), 630–650.
|
||||
7. Hanenberg, S. An experiment about static and dynamic type systems: Doubts about the positive impact of static type systems on development time. In _Proceedings of the ACM International Conference on Object Oriented Programming Systems Languages and Applications, OOPSLA'10_ (New York, NY, USA, 2010). ACM, 22–35.
|
||||
8. Harrison, R., Smaraweera, L., Dobie, M., Lewis, P. Comparing programming paradigms: An evaluation of functional and object-oriented programs. _Softw. Eng. J. 11_ , 4 (1996), 247–254.
|
||||
9. Harter, D.E., Krishnan, M.S., Slaughter, S.A. Effects of process maturity on quality, cycle time, and effort in software product development. _Manage. Sci. 46_ 4 (2000), 451–466.
|
||||
10. Hindley, R. The principal type-scheme of an object in combinatory logic. _Trans. Am. Math. Soc._ (1969), 29–60.
|
||||
11. Jump, M., McKinley, K.S. Cork: Dynamic memory leak detection for garbage-collected languages. In _ACM SIGPLAN Notices_ , Volume 42 (2007). ACM, 31–38.
|
||||
12. Kleinschmager, S., Hanenberg, S., Robbes, R., Tanter, É., Stefik, A. Do static type systems improve the maintainability of software systems? An empirical study. In _2012 IEEE 20th International Conference on Program Comprehension (ICPC)_ (2012). IEEE, 153–162.
|
||||
13. Li, Z., Tan, L., Wang, X., Lu, S., Zhou, Y., Zhai, C. Have things changed now? An empirical study of bug characteristics in modern open source software. In _ASID'06: Proceedings of the 1st Workshop on Architectural and System Support for Improving Software Dependability_ (October 2006).
|
||||
14. Marques De Sá, J.P. _Applied Statistics Using SPSS, Statistica and Matlab_ , 2003.
|
||||
15. Mayer, C., Hanenberg, S., Robbes, R., Tanter, É., Stefik, A. An empirical study of the influence of static type systems on the usability of undocumented software. In _ACM SIGPLAN Notices_ , Volume 47 (2012). ACM, 683–702.
|
||||
16. Meyerovich, L.A., Rabkin, A.S. Empirical analysis of programming language adoption. In _Proceedings of the 2013 ACM SIGPLAN International Conference on Object Oriented Programming Systems Languages & Applications_ (2013). ACM, 1–18.
|
||||
17. Milner, R. A theory of type polymorphism in programming. _J. Comput. Syst. Sci. 17_ , 3 (1978), 348–375.
|
||||
18. Mockus, A., Votta, L.G. Identifying reasons for software changes using historic databases. In _ICSM'00\. Proceedings of the International Conference on Software Maintenance_ (2000). IEEE Computer Society, 120.
|
||||
19. Odersky, M., Spoon, L., Venners, B. _Programming in Scala._ Artima Inc, 2008.
|
||||
20. Pankratius, V., Schmidt, F., Garretón, G. Combining functional and imperative programming for multicore software: An empirical study evaluating scala and java. In _Proceedings of the 2012 International Conference on Software Engineering_ (2012). IEEE Press, 123–133.
|
||||
21. Petricek, T., Skeet, J. _Real World Functional Programming: With Examples in F# and C#._ Manning Publications Co., 2009.
|
||||
22. Pierce, B.C. _Types and Programming Languages._ MIT Press, 2002.
|
||||
23. Posnett, D., Bird, C., Dévanbu, P. An empirical study on the influence of pattern roles on change-proneness. _Emp. Softw. Eng. 16_ , 3 (2011), 396–423.
|
||||
24. Tan, L., Liu, C., Li, Z., Wang, X., Zhou, Y., Zhai, C. Bug characteristics in open source software. _Emp. Softw. Eng._ (2013).
|
||||
|
||||
### 作者
|
||||
|
||||
**Baishakhi Ray** (rayb@virginia.edu), Department of Computer Science, University of Virginia, Charlottesville, VA.
|
||||
|
||||
**Daryl Posnett** (dpposnett@ucdavis.edu), Department of Computer Science, University of California, Davis, CA.
|
||||
|
||||
**Premkumar Devanbu** (devanbu@cs.ucdavis.edu), Department of Computer Science, University of California, Davis, CA.
|
||||
|
||||
**Vladimir Filkov** (filkov@cs.ucdavis.edu), Department of Computer Science, University of California, Davis, CA.
|
||||
|
||||
### 脚注
|
||||
|
||||
a. Wikipedia's article on type conversion, https://en.wikipedia.org/wiki/Type_conversion, has more examples of unintended behavior in C.
|
||||
|
||||
b. This Apple developer article describes the usage of "id" http://tinyurl.com/jkl7cby.
|
||||
|
||||
c. Some examples can be found here http://dobegin.com/objc-id-type/ and here http://tinyurl.com/hxv8kvg.
|
||||
|
||||
d. Chi-squared value of 243.6 with 96 df. and p = 8.394e–15
|
||||
|
||||
e. MPI does not require locking of shared resources.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007
|
||||
|
||||
作者:[Baishakhi Ray][a], [Daryl Posnett][b], [Premkumar Devanbu][c], [Vladimir Filkov ][d]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:rayb@virginia.edu
|
||||
[b]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:dpposnett@ucdavis.edu
|
||||
[c]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:devanbu@cs.ucdavis.edu
|
||||
[d]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:filkov@cs.ucdavis.edu
|
||||
[1]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R6
|
||||
[2]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R2
|
||||
[3]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R9
|
||||
[4]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7
|
||||
[5]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12
|
||||
[6]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R15
|
||||
[7]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R5
|
||||
[8]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R18
|
||||
[9]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7
|
||||
[10]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R8
|
||||
[11]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12
|
||||
[12]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNA
|
||||
[13]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNB
|
||||
[14]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNC
|
||||
[15]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R10
|
||||
[16]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R17
|
||||
[17]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R3
|
||||
[18]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R13
|
||||
[19]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R24
|
||||
[20]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[21]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[22]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[23]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[24]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R23
|
||||
[25]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R14
|
||||
[26]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R14
|
||||
[27]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FND
|
||||
[28]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[29]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R11
|
||||
[30]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNE
|
||||
[31]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7
|
||||
[32]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R8
|
||||
[33]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12
|
||||
[34]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R20
|
||||
[35]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R16
|
||||
[36]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R1
|
||||
[37]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R19
|
||||
[38]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R21
|
||||
[39]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R22
|
||||
[40]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#comments
|
||||
[41]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#
|
||||
[42]:https://cacm.acm.org/about-communications/mobile-apps/
|
||||
[43]:http://dl.acm.org/citation.cfm?id=3144574.3126905&coll=portal&dl=ACM
|
||||
[44]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/pdf
|
||||
[45]:http://dl.acm.org/ft_gateway.cfm?id=3126905&ftid=1909469&dwn=1
|
||||
[46]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[47]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[48]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg
|
||||
[49]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg
|
||||
[50]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg
|
||||
[51]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t2.jpg
|
||||
[52]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t2.jpg
|
||||
[53]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg
|
||||
[54]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg
|
||||
[55]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg
|
||||
[56]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg
|
||||
[57]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t4.jpg
|
||||
[58]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t4.jpg
|
||||
[59]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[60]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[61]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[62]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[63]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[64]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[65]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[66]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut1.jpg
|
||||
[67]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[68]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg
|
||||
[69]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg
|
||||
[70]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut2.jpg
|
||||
[71]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg
|
||||
[72]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg
|
||||
[73]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg
|
||||
[74]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut3.jpg
|
||||
[75]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[76]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[77]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[78]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[79]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[80]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[81]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[82]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[83]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[84]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut4.jpg
|
||||
[85]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[86]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[87]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[88]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[89]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[90]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[91]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[92]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[93]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
|
||||
|
||||
@ -1,16 +1,19 @@
|
||||
对可互换通证的通证 ERC 的比较 – Blockchainers
|
||||
对可互换通证(ERC-20 系列)的通证 ERC 的比较
|
||||
======
|
||||
“对于标准来说,最好的事情莫过于大量的人都去选择使用它。“ [_Andrew S. Tanenbaum_][1]
|
||||
|
||||
> “对于标准来说,最好的事情莫过于大量的人都去选择使用它。“
|
||||
|
||||
> —— [_Andrew S. Tanenbaum_][1]
|
||||
|
||||
### 通证标准的现状
|
||||
|
||||
在以太坊平台上,通证标准的现状出奇的简单:ERC-20 通证标准是通证接口中唯一被采用( [EIP-20][2])和接受的通证标准。
|
||||
在以太坊平台上,通证标准的现状出奇的简单:ERC-20 <ruby>通证<rt>token</rt></ruby>标准是通证接口中唯一被采用( [EIP-20][2])和接受的通证标准。
|
||||
|
||||
它在 2015 年被提出,最终接受是在 2017 年末。
|
||||
|
||||
在此期间,提出了许多解决 ERC-20 缺点的以太坊意见征集(ERC),其中的一部分是因为以太坊平台自身变更所导致的,比如,由 [EIP-150][3] 修复的重入(re-entrancy) bug。其它 ERC 提出的对 ERC-20 通证模型的强化。这些强化是通过采集大量的以太坊区块链和 ERC-20 通证标准的使用经验所确定的。ERC-20 通证接口的实际应用产生了新的要求和需要,比如像权限和操作方面的非功能性需求。
|
||||
在此期间,提出了许多解决 ERC-20 缺点的<ruby>以太坊意见征集<rt>Ethereum Requests for Comments</rt></ruby>(ERC),其中的一部分是因为以太坊平台自身变更所导致的,比如,由 [EIP-150][3] 修复的<ruby>重入<rt>re-entrancy</rt></ruby> bug。其它 ERC 提出的对 ERC-20 通证模型的强化。这些强化是通过收集大量的以太坊区块链和 ERC-20 通证标准的使用经验所确定的。ERC-20 通证接口的实际应用产生了新的要求和需要,比如像权限和操作方面的非功能性需求。
|
||||
|
||||
这篇文章将浅显但完整地对以太坊平台上提出的所有通证(类)标准进行简单概述。我将尽可能客观地去做比较,但不可避免地仍有一些不客观的地方。
|
||||
这篇文章将浅显但完整地对以太坊平台上提出的所有通证(类)的标准进行简单概述。我将尽可能客观地去做比较,但不可避免地仍有一些不客观的地方。
|
||||
|
||||
### 通证标准之母:ERC-20
|
||||
|
||||
@ -18,108 +21,90 @@
|
||||
|
||||
#### 提取模式
|
||||
|
||||
用户们尽可能地去理解 ERC-20 接口,尤其是从一个外部所有者帐户(EOA)_转账_ 通证的模式,即一个终端用户(“Alice”)到一个智能合约,很难去获得 approve/transferFrom 模式权利。
|
||||
用户不太好理解 ERC-20 接口,尤其是从一个<ruby>外部所有者帐户<rt>externally owned account</rt></ruby>(EOA)_转账_ 通证的模式,即一个终端用户(“Alice”)到一个智能合约的转账,很难正确理解 `approve`/`transferFrom` 模式。
|
||||
|
||||
![][5]
|
||||
|
||||
从软件工程师的角度看,这个提取模式非常类似于 [好莱坞原则][6] (“不要给我们打电话,我们会给你打电话的!”)。那个调用链的创意正好相反:在 ERC-20 通证转账中,通证不能调用合约,但是合约可以调用通证上的 `transferFrom`。
|
||||
从软件工程师的角度看,这个提取模式非常类似于 <ruby>[好莱坞原则][6]<rt>Hollywood Principle</rt></ruby> (“不要给我们打电话,我们会给你打电话的!”)。那个调用链的想法正好相反:在 ERC-20 通证转账中,通证不能调用合约,但是合约可以调用通证上的 `transferFrom`。
|
||||
|
||||
虽然好莱坞原则经常用于去实现关注点分离(SoC),但在以太坊中它是一个安全模式,目的是为了防止通证合约去调用外部合约上的未知的函数。这种行为是非常有必要的,因为 [Call Depth Attack][7] 直到 [EIP-150][3] 才被启用。在硬分叉之后,这个重入bug 将不再可能出现了,并且提取模式不提供任何比直接通证调用更好的安全性了。
|
||||
虽然好莱坞原则经常用于去实现<ruby>关注点分离<rt>Separation-of-Concerns</rt></ruby>(SoC),但在以太坊中它是一个安全模式,目的是为了防止通证合约去调用外部合约上的未知的函数。这种行为是非常有必要的,因为会出现 <ruby>[调用深度攻击][7]<rt>Call Depth Attack</rt></ruby>,直到 [EIP-150][3] 被启用才解决。在这个硬分叉之后,这个重入 bug 将不再可能出现了,并且提取模式也不能提供任何比直接通证调用更好的安全性。
|
||||
|
||||
但是,为什么现在它成了一个问题呢?可能是由于某些原因,它的用法设计有些欠佳,但是我们可以通过前端的 DApp 来修复这个问题,对吗?
|
||||
|
||||
因此,我们来看一看,如果一个用户使用 `transfer` 去转账一些通证到智能合约会发生什么事情。Alice 在带合约地址的通证合约上调用 `transfer`
|
||||
因此,我们来看一看,如果一个用户使用 `transfer` 去发送一些通证到智能合约会发生什么事情。Alice 对通证合约的合约地址进行转账,
|
||||
|
||||
**….aaaaand 它不见了!**
|
||||
**….啊啊啊,它不见了!**
|
||||
|
||||
是的,通证没有了。很有可能,没有任何人再能拿回通证了。但是像 Alice 的这种做法并不鲜见,正如 ERC-223 的发明者 Dexaran 所发现的,大约有 $400.000 的通证(由于 ETH 波动很大,我们只能说很多)是由于用户意外发送到智能合约中,并因此而丢失。
|
||||
|
||||
即便合约开发者是一个非常友好和无私的用户,他也不能创建一个合约以便将它收到的通证返还给你。因为合约并不会提示这类转账,并且事件仅在通证合约上发出。
|
||||
|
||||
从软件工程师的角度来看,那就是 ERC-20 的重大缺点。如果发生一个事件(为简单起见,我们现在假设以太坊交易是真实事件),对参与的当事人将有一个提示。但是,这个事件是在通证智能合约中触发的,合约接收方是无法知道它的。
|
||||
从软件工程师的角度来看,那就是 ERC-20 的重大缺点。如果发生一个事件(为简单起见,我们现在假设以太坊交易是真实事件),对参与的当事人应该有一个提示。但是,这个事件是在通证的智能合约中触发的,合约接收方是无法知道它的。
|
||||
|
||||
目前,还不能做到防止用户向智能合约发送通证,并且在 ERC-20 通证合约上使用不直观转账将导致这些发送的通证永远丢失。
|
||||
目前,还不能做到防止用户向智能合约发送通证,并且在 ERC-20 通证合约上使用这种不直观的转账将导致这些发送的通证永远丢失。
|
||||
|
||||
### 帝国反击战:ERC-223
|
||||
|
||||
[Dexaran][8] 第一个提出尝试去修复 ERC-20 的问题。这个提议通过将 EOA 和智能合约账户做不同的处理的方式来解决这个问题。
|
||||
第一个尝试去修复 ERC-20 的问题的提案是 [Dexaran][8] 提出来的。这个提议通过将 EOA 和智能合约账户做不同的处理的方式来解决这个问题。
|
||||
|
||||
强制的策略是去反转调用链(并且使用 [EIP-150][3] 解决它现在能做到了),并且在正接收的智能合约上使用一个预定义的回调(tokenFallback)。如果回调没有实现,转账将失败(将消耗掉发送方的汽油,这是 ERC-223 被批的最常见的一个地方)。
|
||||
强制的策略是去反转调用链(并且使用 [EIP-150][3] 解决它现在能做到了),并且在正在接收的智能合约上使用一个预定义的回调(`tokenFallback`)。如果回调没有实现,转账将失败(将消耗掉发送方的燃料,这是 ERC-223 最常被批评的一个地方)。
|
||||
|
||||
![][9]
|
||||
|
||||
#### 好处:
|
||||
|
||||
* 创建一个新接口,有意不遵守 ERC-20 关于弃权的功能
|
||||
**好处:**
|
||||
|
||||
* 创建一个新接口,有意使用这个废弃的函数来不遵守 ERC-20
|
||||
* 允许合约开发者去处理收到的通证(即:接受/拒绝)并因此遵守事件模式
|
||||
* 用一个交易来代替两个交易(`transfer` vs. `approve`/`transferFrom`)并且节省了燃料和区域链的存储空间
|
||||
|
||||
* 用一个交易来代替两个交易(transfer vs. approve/transferFrom)并且节省了汽油和区域链的存储空间
|
||||
|
||||
|
||||
|
||||
|
||||
#### 坏处:
|
||||
**坏处:**
|
||||
|
||||
* 如果 `tokenFallback` 不存在,那么合约的 `fallback` 功能将运行,这可能会产生意料之外的副作用
|
||||
|
||||
* 如果合约假设使用通证转账,比如,发送通证到一个特定的像多签名钱包一样的账户,这将使 ERC-223 通证失败,它将不能转移(即它们会丢失)。
|
||||
|
||||
* 假如合约使用通证转账功能的话,比如,发送通证到一个特定的像多签名钱包一样的账户,这将使 ERC-223 通证失败,它将不能转移(即它们会丢失)。
|
||||
|
||||
### 程序员修练之道:ERC-677
|
||||
|
||||
[ERC-667 transferAndCall 通证标准][10] 尝试将 ERC-20 和 ERC-223 结合起来。这个创意是在 ERC-20 中引入一个 `transferAndCall` 函数,并保持标准不变。ERC-223 有意不完全向后兼容,由于不再需要 approve/allowance 模式,并因此将它删除。
|
||||
[ERC-667:transferAndCall 通证标准][10] 尝试将 ERC-20 和 ERC-223 结合起来。这个创意是在 ERC-20 中引入一个 `transferAndCall` 函数,并保持标准不变。ERC-223 有意不完全向后兼容,由于不再需要 `approve`/`allowance` 模式,并因此将它删除。
|
||||
|
||||
ERC-667 的主要目标是向后兼容,为新合约向外部合约转账提供一个安全的方法。
|
||||
|
||||
![][11]
|
||||
|
||||
#### 好处:
|
||||
**好处:**
|
||||
|
||||
* 容易适用新的通证
|
||||
|
||||
* 兼容 ERC-20
|
||||
|
||||
* 为 ERC-20 设计的适配器用于安全使用 ERC-20
|
||||
|
||||
#### 坏处:
|
||||
**坏处:**
|
||||
|
||||
* 不是真正的新方法。只是一个 ERC-20 和 ERC-223 的折衷
|
||||
|
||||
* 目前实现 [尚未完成][12]
|
||||
|
||||
|
||||
### 重逢:ERC-777
|
||||
|
||||
[ERC-777 一个新的先进的通证标准][13],引入它是为了建立一个演进的通证标准,它是吸取了像带值的 `approve()` 以及上面提到的将通证发送到合约这样的错误观念的教训之后得来的演进后标准。
|
||||
[ERC-777:一个先进的新通证标准][13],引入它是为了建立一个演进的通证标准,它是吸取了像带值的 `approve()` 以及上面提到的将通证发送到合约这样的错误观念的教训之后得来的演进后标准。
|
||||
|
||||
另外,ERC-777 使用了新标准 [ERC-820:使用一个注册合约的伪内省][14],它允许为合约注册元数据以提供一个简单的内省类型。并考虑到了向后兼容和其它的功能扩展,这些取决于由一个 EIP-820 查找到的地址返回的 `ITokenRecipient`,和由目标合约实现的函数。
|
||||
|
||||
ERC-777 增加了许多使用 ERC-20 通证的经验,比如,白名单操作者、提供带 send(…) 的以太兼容的接口,为了向后兼容而使用 ERC-820 去覆盖和调整功能。
|
||||
ERC-777 增加了许多使用 ERC-20 通证的经验,比如,白名单操作者、提供带 `send(…)` 的以太兼容的接口,为了向后兼容而使用 ERC-820 去覆盖和调整功能。
|
||||
|
||||
![][15]
|
||||
|
||||
#### 好处:
|
||||
**好处:**
|
||||
|
||||
* 从 ERC-20 的使用经验上得来的、经过深思熟虑的、进化的通证接口
|
||||
|
||||
* 为内省要求 ERC-820 使用新标准,接受了增加的功能
|
||||
* 白名单操作者非常有用,而且比 `approve`/`allowance` 更有必要,它经常是无限的
|
||||
|
||||
* 白名单操作者非常有用,而且比 approve/allowance 更有必要,它经常是无限的
|
||||
|
||||
|
||||
#### 坏处:
|
||||
**坏处:**
|
||||
|
||||
* 刚刚才开始,复杂的依赖合约调用的结构
|
||||
|
||||
* 依赖导致出现安全问题的可能性增加:第一个安全问题并不是在 ERC-777 中 [确认(并解决的)][16],而是在最新的 ERC-820 中
|
||||
|
||||
|
||||
|
||||
|
||||
### (纯主观的)结论(轻喷)
|
||||
|
||||
目前为止,如果你想遵循 “行业标准”,你只能选择 ERC-20。它获得了最广泛的理解与支持。但是,它还是有缺陷的,最大的一个缺陷是因为非专业用户设计和规范问题导致的用户真实地损失金钱的问题。ERC-223 是非常好的,并且在理论上找到了 ERC-20 中这个问题的答案了,它应该被考虑为 ERC-20 的一个很好的替代标准。在一个新通证中实现这两个接口并不复杂,并且可以降低汽油的使用。
|
||||
目前为止,如果你想遵循 “行业标准”,你只能选择 ERC-20。它获得了最广泛的理解与支持。但是,它还是有缺陷的,最大的一个缺陷是因为非专业用户设计和规范问题导致的用户真实地损失金钱的问题。ERC-223 是非常好的,并且在理论上找到了 ERC-20 中这个问题的答案了,它应该被考虑为 ERC-20 的一个很好的替代标准。在一个新通证中实现这两个接口并不复杂,并且可以降低燃料的使用。
|
||||
|
||||
ERC-677 是事件和金钱丢失问题的一个务实的解决方案,但是它并没能提供足够多的新方法,以促使它成为一个标准。但是它可能是 ERC-20 2.0 的一个很好的候选者。
|
||||
|
||||
@ -127,13 +112,10 @@ ERC-777 是一个更先进的通证标准,它应该成为 ERC-20 的合法继
|
||||
|
||||
### 链接
|
||||
|
||||
[1] 在 ERC-20 中使用 approve/transferFrom-Pattern 的安全问题: <https://drive.google.com/file/d/0ByMtMw2hul0EN3NCaVFHSFdxRzA/view>
|
||||
|
||||
[2] ERC-20 中的无事件操作:<https://docs.google.com/document/d/1Feh5sP6oQL1-1NHi-X1dbgT3ch2WdhbXRevDN681Jv4>
|
||||
|
||||
[3] ERC-20 的故障及历史:<https://github.com/ethereum/EIPs/issues/223#issuecomment-317979258>
|
||||
|
||||
[4] ERC-20/223 的不同之处:<https://ethereum.stackexchange.com/questions/17054/erc20-vs-erc223-list-of-differences>
|
||||
1. 在 ERC-20 中使用 approve/transferFrom 模式的安全问题: <https://drive.google.com/file/d/0ByMtMw2hul0EN3NCaVFHSFdxRzA/view>
|
||||
2. ERC-20 中的无事件操作:<https://docs.google.com/document/d/1Feh5sP6oQL1-1NHi-X1dbgT3ch2WdhbXRevDN681Jv4>
|
||||
3. ERC-20 的故障及历史:<https://github.com/ethereum/EIPs/issues/223#issuecomment-317979258>
|
||||
4. ERC-20/223 的不同之处:<https://ethereum.stackexchange.com/questions/17054/erc20-vs-erc223-list-of-differences>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -142,7 +124,7 @@ via: http://blockchainers.org/index.php/2018/02/08/token-erc-comparison-for-fung
|
||||
作者:[Alexander Culum][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,119 @@
|
||||
学习用 Thonny 写代码: 一个面向初学者的Python IDE
|
||||
======
|
||||
|
||||

|
||||
|
||||
学习编程很难。即使当你最终怎么正确使用你的冒号和括号,但仍然有很大的可能你的程序不会如果所想的工作。 通常,这意味着你忽略了某些东西或者误解了语言结构,你需要在代码中找到你的期望与现实存在分歧的地方。
|
||||
|
||||
程序员通常使用被叫做<ruby>调试器<rt>debugger</rt></ruby>的工具来处理这种情况,它允许一步一步地运行他们的程序。不幸的是,大多数调试器都针对专业用途进行了优化,并假设用户已经很好地了解了语言结构的语义(例如:函数调用)。
|
||||
|
||||
Thonny 是一个适合初学者的 Python IDE,由爱沙尼亚的 [Tartu 大学][1] 开发,它采用了不同的方法,因为它的调试器是专为学习和教学编程而设计的。
|
||||
|
||||
虽然 Thonny 适用于像小白一样的初学者,但这篇文章面向那些至少具有 Python 或其他命令式语言经验的读者。
|
||||
|
||||
### 开始
|
||||
|
||||
从第 Fedora 27 开始,Thonny 就被包含在 Fedora 软件库中。 使用 `sudo dnf install thonny` 或者你选择的图形工具(比如“<ruby>软件<rt>Software</rt></ruby>”)安装它。
|
||||
|
||||
当第一次启动 Thonny 时,它会做一些准备工作,然后呈现一个空白的编辑器和 Python shell 。将下列程序文本复制到编辑器中,并将其保存到文件中(`Ctrl+S`)。
|
||||
|
||||
```
|
||||
n = 1
|
||||
while n < 5:
|
||||
print(n * "*")
|
||||
n = n + 1
|
||||
```
|
||||
|
||||
我们首先运行该程序。 为此请按键盘上的 `F5` 键。 你应该看到一个由星号组成的三角形出现在 shell 窗格中。
|
||||
|
||||
![一个简单的 Thonny 程序][2]
|
||||
|
||||
Python 分析了你的代码并理解了你想打印一个三角形了吗?让我们看看!
|
||||
|
||||
首先从“<ruby>查看<rt>View</rt></ruby>”菜单中选择“<ruby>变量<rt>Variables</rt></ruby>”。这将打开一张表格,向我们展示 Python 是如何管理程序的变量的。现在通过按 `Ctrl + F5`(在 XFCE 中是 `Ctrl + Shift + F5`)以调试模式运行程序。在这种模式下,Thonny 使 Python 在每一步所需的步骤之前暂停。你应该看到程序的第一行被一个框包围。我们将这称为焦点,它表明 Python 将接下来要执行的部分代码。
|
||||
|
||||
![ Thonny 调试器焦点 ][3]
|
||||
|
||||
你在焦点框中看到的一段代码段被称为赋值语句。 对于这种声明,Python 应该计算右边的表达式,并将值存储在左边显示的名称下。按 `F7` 进行下一步。你将看到 Python 将重点放在语句的正确部分。在这个例子中,表达式实际上很简单,但是为了通用性,Thonny 提供了表达式计算框,它允许将表达式转换为值。再次按 `F7` 将文字 `1` 转换为值 `1`。现在 Python 已经准备好执行实际的赋值—再次按 `F7`,你应该会看到变量 `n` 的值为 `1` 的变量出现在变量表中。
|
||||
|
||||
![Thonny 变量表][4]
|
||||
|
||||
继续按 `F7` 并观察 Python 如何以非常小的步骤前进。它看起来像是理解你的代码的目的或者更像是一个愚蠢的遵循简单规则的机器?
|
||||
|
||||
### 函数调用
|
||||
|
||||
<ruby>函数调用<rt>Function Call</rt></ruby>是一种编程概念,它常常给初学者带来很大的困惑。从表面上看,没有什么复杂的事情——给代码命名,然后在代码中的其他地方引用它(调用它)。传统的调试器告诉我们,当你进入调用时,焦点跳转到函数定义中(然后稍后神奇地返回到原来的位置)。这是整件事吗?这需要我们关心吗?
|
||||
|
||||
结果证明,“跳转模型” 只对最简单的函数是足够的。理解参数传递、局部变量、返回和递归都得理解堆栈框架的概念。幸运的是,Thonny 可以直观地解释这个概念,而无需在厚厚的掩盖下搜索重要的细节。
|
||||
|
||||
将以下递归程序复制到 Thonny 并以调试模式(`Ctrl+F5` 或 `Ctrl+Shift+F5`)运行。
|
||||
|
||||
```
|
||||
def factorial(n):
|
||||
if n == 0:
|
||||
return 1
|
||||
else:
|
||||
return factorial(n-1) * n
|
||||
|
||||
print(factorial(4))
|
||||
```
|
||||
|
||||
重复按 `F7`,直到你在对话框中看到表达式 `factorial(4)`。 当你进行下一步时,你会看到 Thonny 打开一个包含了函数代码、另一个变量表和另一个焦点框的新窗口(移动窗口以查看旧的焦点框仍然存在)。
|
||||
|
||||
![通过递归函数的 Thonny][5]
|
||||
|
||||
此窗口表示堆栈帧,即用于解析函数调用的工作区。几个放在彼此顶部的这样的窗口称为<ruby>调用堆栈<rt>call stack</rt></ruby>。注意调用位置的参数 `4` 与 “局部变量” 表中的输入 `n` 之间的关系。继续按 `F7` 步进, 观察在每次调用时如何创建新窗口并在函数代码完成时被销毁,以及如何用返回值替换了调用位置。
|
||||
|
||||
### 值与参考
|
||||
|
||||
现在,让我们在 Python shell 中进行一个实验。首先输入下面屏幕截图中显示的语句:
|
||||
|
||||
![Thonny shell 显示列表突变][6]
|
||||
|
||||
正如你所看到的, 我们追加到列表 `b`, 但列表 `a` 也得到了更新。你可能知道为什么会发生这种情况, 但是对初学者来说,什么才是最好的解释呢?
|
||||
|
||||
当教我的学生列表时,我告诉他们我一直欺骗了他们关于 Python 内存模型。实际上,它并不像变量表所显示的那样简单。我告诉他们重新启动解释器(工具栏上的红色按钮),从“<ruby>查看<rt>View</rt></ruby>”菜单中选择“<ruby>堆<rt>Heap</rt></ruby>”,然后再次进行相同的实验。如果这样做,你就会发现变量表不再包含值——它们实际上位于另一个名为“<ruby>堆<rt>Heap</rt></ruby>”的表中。变量表的作用实际上是将变量名映射到地址(或称 ID),地址又指向了<ruby>堆<rt>Heap</rt></ruby>表中的行。由于赋值仅更改变量表,因此语句 `b = a` 只复制对列表的引用,而不是列表本身。这解释了为什么我们通过这两个变量看到了变化。
|
||||
|
||||
![在堆模式中的 Thonny][7]
|
||||
|
||||
(为什么我要在教列表的主题之前推迟说出内存模型的事实?Python 存储的列表是否有所不同?请继续使用 Thonny 的堆模式来找出结果!在评论中告诉我你认为怎么样!)
|
||||
|
||||
如果要更深入地了解参考系统, 请将以下程序通过打开堆表复制到 Thonny 并进行小步调试(`F7`) 中。
|
||||
|
||||
```
|
||||
def do_something(lst, x):
|
||||
lst.append(x)
|
||||
|
||||
a = [1,2,3]
|
||||
n = 4
|
||||
do_something(a, n)
|
||||
print(a)
|
||||
```
|
||||
|
||||
即使“堆模式”向我们显示真实的图片,但它使用起来也相当不方便。 因此,我建议你现在切换回普通模式(取消选择“<ruby>查看<rt>View</rt></ruby>”菜单中的“<ruby>堆<rt>Heap</rt></ruby>”),但请记住,真实模型包含变量、参考和值。
|
||||
|
||||
### 结语
|
||||
|
||||
我在这篇文章中提及到的特性是创建 Thonny 的主要原因。很容易对函数调用和引用形成错误的理解,但传统的调试器并不能真正帮助减少混淆。
|
||||
|
||||
除了这些显著的特性,Thonny 还提供了其他几个初学者友好的工具。 请查看 [Thonny的主页][8] 以了解更多信息!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-code-thonny-python-ide-beginners/
|
||||
|
||||
作者:[Aivar Annamaa][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/
|
||||
[1]:https://www.ut.ee/en
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2017/12/scr1.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr2.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr3.png
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr4.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr5.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr6.png
|
||||
[8]:http://thonny.org
|
||||
@ -1,11 +1,15 @@
|
||||
可以考虑的 9 个开源 ERP 系统
|
||||
值得考虑的 9 个开源 ERP 系统
|
||||
======
|
||||
|
||||
> 有一些使用灵活、功能丰富而物有所值的开源 ERP 系统,这里有 9 个值得你看看。
|
||||
|
||||
|
||||
拥有一定数量员工的企业就需要大量的协调工作,包括价格、生产计划、帐务和财务、管理支出、管理存货等等。把一套截然不同的工具拼接到一起去处理这些工作,是一种粗制滥造和无价值的做法。
|
||||
|
||||
拥有一定数量员工的企业就需要大量的协调工作,包括制定价格、计划生产、会计和财务、管理支出、管理存货等等。把一套截然不同的工具拼接到一起去处理这些工作,是一种粗制滥造和无价值的做法。
|
||||
|
||||
那种方法没有任何弹性。并且那样在各种各样的自组织系统之间高效移动数据是非常困难的。同样,它也很难维护。
|
||||
|
||||
因此,大多数成长型企业都转而使用一个 [企业资源计划][1] (ERP) 系统。
|
||||
因此,大多数成长型企业都转而使用一个 [企业资源计划][1] (ERP)系统。
|
||||
|
||||
在这个行业中的大咖有 Oracle、SAP、以及 Microsoft Dynamics。它们都提供了一个综合的系统,但同时也很昂贵。如果你的企业支付不起如此昂贵的大系统,或者你仅需要一个简单的系统,怎么办呢?你可以使用开源的产品来作为替代。
|
||||
|
||||
@ -21,23 +25,23 @@
|
||||
|
||||
### ADempiere
|
||||
|
||||
像大多数其它开源 ERP 解决方案,[ADempiere][2] 的目标客户是中小企业。它已经存在一段时间了— 这个项目出现于 2006,它是 Compiere ERP 软件的一个分支。
|
||||
像大多数其它开源 ERP 解决方案,[ADempiere][2] 的目标客户是中小企业。它已经存在一段时间了 — 这个项目出现于 2006,它是 Compiere ERP 软件的一个分支。
|
||||
|
||||
它的意大利语名字的意思是“实现”或者“满足”,它“涉及多个方面”的 ERP 特性旨在帮企业去满足各种需求。它在 ERP 中增加了供应链管理(SCM)和客户关系管理(CRM)功能,能够让 ERP 套件在一个软件中去管理销售、采购、库存、以及帐务处理。它的最新版本是 v.3.9.0,更新了用户界面、销售点、人力资源、工资、以及其它的特性。
|
||||
它的意大利语名字的意思是“实现”或者“满足”,它“涉及多个方面”的 ERP 特性,旨在帮企业去满足各种需求。它在 ERP 中增加了供应链管理(SCM)和客户关系管理(CRM)功能,能够让该 ERP 套件在一个软件中去管理销售、采购、库存以及帐务处理。它的最新版本是 v.3.9.0,更新了用户界面、POS、人力资源、工资以及其它的特性。
|
||||
|
||||
因为是一个跨平台的、基于 Java 的云解决方案,ADempiere 可以运行在Linux、Unix、Windows、MacOS、智能手机、平板电脑上。它使用 [GPLv2][3] 授权。如果你想了解更多信息,这里有一个用于测试的 [demo][4],或者也可以在 GitHub 上查看它的 [源代码][5]。
|
||||
|
||||
### Apache OFBiz
|
||||
|
||||
[Apache OFBiz][6] 的业务相关的套件是构建在通用的架构上的,它允许企业根据自己的需要去定制 ERP。因此,它是有内部开发资源的大中型企业去修改和集成它到它们现有的 IT 和业务流程的最佳套件。
|
||||
[Apache OFBiz][6] 的业务相关的套件是构建在通用的架构上的,它允许企业根据自己的需要去定制 ERP。因此,它是有内部开发资源的大中型企业的最佳套件,可以去修改和集成它到它们现有的 IT 和业务流程。
|
||||
|
||||
OFBiz 是一个成熟的开源 ERP 系统;它的网站上说它是一个有十年历史的顶级 Apache 项目。可用的 [模块][7] 有帐务、生产制造、人力资源、存货管理、目录管理、客户关系管理、以及电子商务。你可以在它的 [demo 页面][8] 上试用电子商务的网上商店以及后端的 ERP 应用程序。
|
||||
OFBiz 是一个成熟的开源 ERP 系统;它的网站上说它是一个有十年历史的顶级 Apache 项目。可用的 [模块][7] 有会计、生产制造、人力资源、存货管理、目录管理、客户关系管理,以及电子商务。你可以在它的 [demo 页面][8] 上试用电子商务的网上商店以及后端的 ERP 应用程序。
|
||||
|
||||
Apache OFBiz 的源代码能够在它的 [项目仓库][9] 中找到。它是用 Java 写的,它在 [Apache 2.0 license][10] 下可用。
|
||||
|
||||
### Dolibarr
|
||||
|
||||
[Dolibarr][11] 提供了中小型企业端到端的业务管理,从发票跟踪、合同、存货、订单、以及支付,到文档管理和电子化 POS 系统支持。它的全部功能封装在一个清晰的界面中。
|
||||
[Dolibarr][11] 提供了中小型企业端到端的业务管理,从发票跟踪、合同、存货、订单,以及支付,到文档管理和电子化 POS 系统支持。它的全部功能封装在一个清晰的界面中。
|
||||
|
||||
如果你担心不会使用 Dolibarr,[这里有一些关于它的文档][12]。
|
||||
|
||||
@ -45,15 +49,15 @@ Apache OFBiz 的源代码能够在它的 [项目仓库][9] 中找到。它是用
|
||||
|
||||
### ERPNext
|
||||
|
||||
[ERPNext][17] 是这类开源项目中的其中一个;实际上它最初 [出现在 Opensource.com][18]。它被设计用于打破一个陈旧而昂贵的专用 ERP 系统的垄断局面。
|
||||
[ERPNext][17] 是这类开源项目中的其中一个;实际上它最初在 2014 年就被 [Opensource.com 推荐了][18]。它被设计用于打破一个陈旧而昂贵的专用 ERP 系统的垄断局面。
|
||||
|
||||
ERPNext 适合于中小型企业。它包含的模块有帐务、存货管理、销售、采购、以及项目管理。ERPNext 是表单驱动的应用程序 — 你可以在一组字段中填入信息,然后让应用程序去完成剩余部分。整个套件非常易用。
|
||||
ERPNext 适合于中小型企业。它包含的模块有会计、存货管理、销售、采购、以及项目管理。ERPNext 是表单驱动的应用程序 — 你可以在一组字段中填入信息,然后让应用程序去完成剩余部分。整个套件非常易用。
|
||||
|
||||
如果你感兴趣,在你考虑参与之前,你可以请求获取一个 [demo][19],去 [下载它][20] 或者在托管服务上 [购买一个订阅][21]。
|
||||
|
||||
### Metasfresh
|
||||
|
||||
[Metasfresh][22] 的名字表示它承诺软件的代码始终保持“新鲜”。它自 2015 年以来每周发行一个更新版本,那时,它的代码是由创始人从 ADempiere 项目中 fork 的。与 ADempiere 一样,它是一个基于 Java 的开源 ERP,目标客户是中小型企业。
|
||||
[Metasfresh][22] 的名字表示它承诺软件的代码始终保持“新鲜”。它自 2015 年以来每周发行一个更新版本,那时,它的代码是由创始人从 ADempiere 项目中分叉的。与 ADempiere 一样,它是一个基于 Java 的开源 ERP,目标客户是中小型企业。
|
||||
|
||||
虽然,相比在这里介绍的其它软件来说,它是一个很 “年青的” 项目,但是它早早就引起了一起人的注意,获得很多积极的评价,比如,被提名为“最佳开源”的 IT 创新奖入围者。
|
||||
|
||||
@ -71,7 +75,7 @@ Odoo 是基于 web 的工具。按单个模块来订阅的话,每个模块每
|
||||
|
||||
[Opentaps][30] 是专为大型业务设计的几个开源 ERP 解决方案之一,它的功能强大而灵活。这并不奇怪,因为它是在 Apache OFBiz 基础之上构建的。
|
||||
|
||||
你可以得到你所希望的模块组合,来帮你管理存货、生产制造、财务、以及采购。它也有分析功能,帮你去分析业务的各个方面。你可以借助这些信息让未来的计划做的更好。Opentaps 也包含一个强大的报表功能。
|
||||
你可以得到你所希望的模块组合,来帮你管理存货、生产制造、财务,以及采购。它也有分析功能,帮你去分析业务的各个方面。你可以借助这些信息让未来的计划做的更好。Opentaps 也包含一个强大的报表功能。
|
||||
|
||||
在它的基础之上,你还可以 [购买一些插件和附加模块][31] 去增强 Opentaps 的功能。包括与 Amazon Marketplace Services 和 FedEx 的集成等。在你 [下载 Opentaps][32] 之前,你可以到 [在线 demo][33] 上试用一下。它遵守 [GPLv3][34] 许可。
|
||||
|
||||
@ -87,7 +91,7 @@ WebERP 正在积极地进行开发,并且它有一个活跃的 [论坛][37],
|
||||
|
||||
如果你的生产制造、分销、电子商务业务已经从小规模业务成长起来了,并且正在寻找一个适合你的成长型企业的 ERP 系统,那么,你可以去了解一下 [xTuple PostBooks][41]。它是围绕核心 ERP 功能、帐务、以及可以添加存货、分销、采购、以及供应商报告等 CRM 功能构建的全面解决方案的系统。
|
||||
|
||||
xTuple 在通用公共属性许可证([CPAL][42])下使用,并且这个项目欢迎开发者去 fork 它,然后为基于存货的生产制造型企业开发其它的业务软件。它的基于 web 的核心是用 JavaScript 写的,它的 [源代码][43] 可以在 GitHub 上找到。你可以去在 xTuple 的网站上注册一个免费的 [demo][44] 去了解它。
|
||||
xTuple 在通用公共属性许可证([CPAL][42])下使用,并且这个项目欢迎开发者去分叉它,然后为基于存货的生产制造型企业开发其它的业务软件。它的基于 web 的核心是用 JavaScript 写的,它的 [源代码][43] 可以在 GitHub 上找到。你可以去在 xTuple 的网站上注册一个免费的 [demo][44] 去了解它。
|
||||
|
||||
还有许多其它的开源 ERP 可供你选择 — 另外你可以去了解的还有 [Tryton][45],它是用 Python 写的,并且使用的是 PostgreSQL 数据库引擎,或者基于 Java 的 [Axelor][46],它的好处是用户可以使用拖放界面来创建或者修改业务应用。如果还有在这里没有列出的你喜欢的开源 ERP 解决方案,请在下面的评论区共享出来。你也可以去查看我们的 [供应链管理工具][47] 榜单。
|
||||
|
||||
@ -98,9 +102,9 @@ xTuple 在通用公共属性许可证([CPAL][42])下使用,并且这个项
|
||||
via: https://opensource.com/tools/enterprise-resource-planning
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,76 +1,79 @@
|
||||
面向 Linux 和开源爱好者的书单(儿童版)
|
||||
让孩子爱上计算机和编程的 15 本书
|
||||
======
|
||||
|
||||
> 以及,还有三本是给宝宝的。
|
||||
|
||||

|
||||
|
||||
在工作之余,我听说不少技术专家透露出让他们自己的孩子学习更多关于 [Linux][1] 和 [开源][2]知识的意愿,他们中有的来自高管层,有的来自普通岗位。其中一些似乎时间比较充裕,伴随其孩子一步一步成长。另一些人可能没有充足的时间让他们的孩子看到为何 Linux 和 开源如此之酷。也许他们能抽出时间,但这不一定。在这个大世界中,有太多有趣、有价值的事物。
|
||||
|
||||
不论是哪种方式,如果你的或你认识的孩子愿意学习使用编程和硬件,实现游戏或机器人之类东西,那么这份书单很适合你。
|
||||
|
||||
### 面向儿童 Linux 和 开源爱好者的 15 本书
|
||||
|
||||
[零基础学 Raspberry Pi][3],作者 Carrie Anne Philbin
|
||||
**《[零基础学 Raspberry Pi][3]》,作者 Carrie Anne Philbin**
|
||||
|
||||
在对编程感兴趣的儿童和成人中,体积小小的、仅信用卡一般大的 Raspberry Pi 引起了强烈的反响。你台式机能做的事情它都能做,具备一定的基础编程技能后,你可以让它做更多的事情。本书操作简明、项目风趣、技能扎实,是一本儿童可用的终极编程指南。([Joshua Allen Holm][4] 推荐,评论节选于本书的内容提要)
|
||||
在对编程感兴趣的儿童和成人中,体积小小的、仅信用卡一般大的树莓派引起了强烈的反响。你台式机能做的事情它都能做,具备一定的基础编程技能后,你可以让它做更多的事情。本书操作简明、项目风趣、技能扎实,是一本儿童可用的终极编程指南。([Joshua Allen Holm][4] 推荐,评论节选于本书的内容提要)
|
||||
|
||||
[Python 编程快速上手:让繁琐工作自动化][5],作者 Al Sweigart
|
||||
**《[Python 编程快速上手:让繁琐工作自动化][5]》,作者 Al Sweigart**
|
||||
|
||||
这是一本经典的编程入门书,行文足够清晰,11 岁及以上的编程爱好者都可以读懂本书并从中受益。读者很快就会投入到真实且实用的任务中,在此过程中顺便掌握了优秀的编程实践。最好的一点是,如果你愿意,你可以在互联网上阅读本书。([DB Clinton][6] 推荐并评论)
|
||||
|
||||
[Scratch 游戏编程][7],作者 Jon Woodcock
|
||||
**《[Scratch 游戏编程][7]》,作者 Jon Woodcock**
|
||||
|
||||
本书适用于 8-12 岁没有或仅有有限编程经验的儿童。作为一本直观的可视化入门书,它使用有趣的图形和易于理解的操作,教导年轻的读者如何使用 Scratch 这款流行的自由编程语言构建他们自己的编程项目。([Joshua Allen Holm][4] 推荐,评论节选于本书的内容提要)
|
||||
|
||||
[用 Python 巧学数学][8],作者 Amit Saha
|
||||
**《[用 Python 巧学数学][8]》,作者 Amit Saha**
|
||||
|
||||
无论你是一名学生还是教师,只要你对使用 Python 学习数学感兴趣,不妨读读本书。在逻辑上,本书带领读者一步一步地从基础到更为复杂的操作,从最开始简单的 Python shell 数字运算,到使用类似 matplotlib 这样的 Python 库实现数据可视化,读者可以很容易跟上作者的思路。本书充分调动你的好奇心,感叹 Python 与 数学结合的威力。([Don Watkins][9] 推荐并评论)
|
||||
|
||||
[编程女生:学习编程,改变世界][10],作者 Reshma Saujani
|
||||
**《[编程女生:学习编程,改变世界][10]》,作者 Reshma Saujani**
|
||||
|
||||
作者是 Girls Who Code 运动的发起人,该运动得到 Sheryl Sandberg, Malala Yousafzai, and John Legend 支持。本书一部分是编程介绍,一部分女生赋能,这两部分都写得很有趣。本书包括动态艺术作品、零基础的编程原理讲解以及在 Pixar 和 NASA 等公司工作的女生的真实故事。这本书形象生动,向读者展示了计算机科学在我们生活中发挥的巨大作用以及其中的趣味。([Joshua Allen Holm][4] 推荐,评论节选于本书的内容提要)
|
||||
作者是 Girls Who Code 运动的发起人,该运动得到 Sheryl Sandberg、 Malala Yousafzai 和 John Legend 支持。本书一部分是编程介绍,一部分女生赋能,这两部分都写得很有趣。本书包括动态艺术作品、零基础的编程原理讲解以及在 Pixar 和 NASA 等公司工作的女生的真实故事。这本书形象生动,向读者展示了计算机科学在我们生活中发挥的巨大作用以及其中的趣味。([Joshua Allen Holm][4] 推荐,评论节选于本书的内容提要)
|
||||
|
||||
[Python 游戏编程快速上手][11],作者 Al Sweigart
|
||||
**《[Python 游戏编程快速上手][11]》,作者 Al Sweigart**
|
||||
|
||||
本书将让你学会如何使用流行的 Python 编程语言编写计算机游戏,不要求具有编程经验!入门阶段编写<ruby>刽子手<rt>Hangman</rt></ruby>,猜数字,<ruby>井字游戏<rt>Tic-Tac-Toe</rt></ruby>这样的经典游戏,后续更进一步编写高级一些的游戏,例如文字版寻宝游戏,以及带音效和动画的<ruby>碰撞与闪避<rt>collision-dodgoing</rt></ruby>游戏。([Joshua Allen Holm][4] 推荐,评论节选于本书的内容提要)
|
||||
|
||||
[Lauren Ipsum:关于计算机科学和一些不可思议事物的故事][12],作者 Carlos Bueno
|
||||
**《[Lauren Ipsum:关于计算机科学和一些不可思议事物的故事][12]》,作者 Carlos Bueno**
|
||||
|
||||
本书采用爱丽丝梦游仙境的风格,女主角 Lauren Ipsum 来到一个稍微具有魔幻色彩的世界。世界的自然法则是逻辑学和计算机科学,世界谜题只能通过学习计算机编程原理并编写代码完成。书中没有提及计算机,但其作为世界的核心存在。([DB Clinton][6] 推荐并评论)
|
||||
|
||||
[Java 轻松学][13],作者 Bryson Payne
|
||||
**《[Java 轻松学][13]》,作者 Bryson Payne**
|
||||
|
||||
Java 是全世界最流行的编程语言,但众所周知上手比较难。本书让 Java 学习不再困难,通过若干实操项目,让你马上学会构建真实可运行的应用。([Joshua Allen Holm][4] 推荐,评论节选于本书的内容提要)
|
||||
|
||||
[终身幼儿园][14],作者 Mitchell Resnick
|
||||
**《[终身幼儿园][14]》,作者 Mitchell Resnick**
|
||||
|
||||
幼儿园正变得越来越像学校。在本书中,学习专家 Mitchel Resnick 提出相反的看法:学校(甚至人的一生)应该更像幼儿园。要适应当今快速变化的世界,各个年龄段的人们都必须学会开创性思维和行动;想要达到这个目标,最好的方式就是更加专注于想象、创造、玩耍、分享和反馈,就像孩子在传统幼儿园中那样。基于在 MIT <ruby>媒体实验室<rt>Media Lab</rt></ruby> 30 多年的经历, Resnick 讨论了新的技术和策略,可以让年轻人拥有开创性的学习体验。([Don Watkins][9] 推荐,评论来自 Amazon 书评)
|
||||
|
||||
[趣学 Python:教孩子学编程][15],作者 Jason Briggs
|
||||
**《[趣学 Python:教孩子学编程][15]》,作者 Jason Briggs**
|
||||
|
||||
在本书中,Jason Briggs 将 Python 编程教学艺术提升到新的高度。我们可以很容易地将本书用作入门书,适用群体可以是教师/学生,也可以是父母/儿童。通过一步步引导的方式介绍复杂概念,让编程新手也可以成功完成,进一步激发学习欲望。本书是一本极为易读、寓教于乐但又强大的 Python 编程入门书。读者将学习基础数据结构,包括<ruby>元组<rt>turples</rt></ruby>、<ruby>列表<rt>lists</rt></ruby>和<ruby>映射<rt>maps</rt></ruby>等,学习如何创建函数、重用代码或者使用包括循环和条件语句在内的控制结构。孩子们还将学习如何创建游戏和动画,体验 Tkinter 的强大并创建高级图形。([Don Watkins][9] 推荐并评论)
|
||||
在本书中,Jason Briggs 将 Python 编程教学艺术提升到新的高度。我们可以很容易地将本书用作入门书,适用群体可以是教师/学生,也可以是父母/儿童。通过一步步引导的方式介绍复杂概念,让编程新手也可以成功完成,进一步激发学习欲望。本书是一本极为易读、寓教于乐但又强大的 Python 编程入门书。读者将学习基础数据结构,包括<ruby>元组<rt>turple</rt></ruby>、<ruby>列表<rt>list</rt></ruby>和<ruby>映射<rt>map</rt></ruby>等,学习如何创建函数、重用代码或者使用包括循环和条件语句在内的控制结构。孩子们还将学习如何创建游戏和动画,体验 Tkinter 的强大并创建高级图形。([Don Watkins][9] 推荐并评论)
|
||||
|
||||
[Scratch 编程园地][16],作者 Al Sweigart
|
||||
**《[Scratch 编程园地][16]》,作者 Al Sweigart**
|
||||
|
||||
Scratch 编程一般被视为一种寓教于乐的教年轻人编程的方式。在本书中,Al Sweigart 告诉我们 Scratch 是一种超出绝大多数人想象的强大编程语言。独特的风格,大师级的编写和呈现。Al 让孩子通过创造复杂图形和动画,短时间内认识到 Scratch 的强大之处。([Don Watkins][9] 推荐并评论)
|
||||
|
||||
[秘密编程者][17],作者 Gene Luen Yang,插图作者 Mike Holmes
|
||||
**《[秘密编程者][17]》,作者 Gene Luen Yang,插图作者 Mike Holmes**
|
||||
|
||||
Gene Luen Yang 是漫画小说超级巨星,也是一所高中的计算机编程教师。他推出了一个非常有趣的系列作品,将逻辑谜题、基础编程指令与引入入胜的解谜情节结合起来。故事发生在 Stately Academy 这所学校,其中充满有待解开的谜团。([Joshua Allen Holm][4] 推荐,评论节选于本书的内容提要)
|
||||
|
||||
[想成为编程者吗?编程、视频游戏制作、机器人等职业终极指南!][18],作者 Jane Bedell
|
||||
**《[想成为编程者吗?编程、视频游戏制作、机器人等职业终极指南!][18]》,作者 Jane Bedell**
|
||||
|
||||
酷爱编程?这本书易于理解,描绘了以编程为生的完整图景,激发你的热情,磨练你的专业技能。(Joshua Allen Holm][4] 推荐,评论节选于本书的内容提要)
|
||||
酷爱编程?这本书易于理解,描绘了以编程为生的完整图景,激发你的热情,磨练你的专业技能。([Joshua Allen Holm][4] 推荐,评论节选于本书的内容提要)
|
||||
|
||||
[教孩子编程][19],作者 Bryson Payne
|
||||
**《[教孩子编程][19]》,作者 Bryson Payne**
|
||||
|
||||
你是否在寻找一种寓教于乐的方式教你的孩子 Python 编程呢?Bryson Payne 已经写了这本大师级的书。本书通过乌龟图形打比方,引导你编写一些简单程序,为高级 Python 编程打下基础。如果你打算教年轻人编程,这本书不容错过。([Don Watkins][9] 推荐并评论)
|
||||
|
||||
[图解 Kubernetes(儿童版)][20],作者 Matt Butcher, 插画作者 Bailey Beougher
|
||||
**《[图解 Kubernetes(儿童版)][20]》,作者 Matt Butcher, 插画作者 Bailey Beougher**
|
||||
|
||||
介绍了 Phippy 这个勇敢的 PHP 小应用及其 Kubernetes 之旅。([Chris Short][21] 推荐,评论来自 [Matt Butcher 的博客][20])
|
||||
|
||||
### 给宝宝的福利书
|
||||
|
||||
[宝宝的 CSS][22],[宝宝的 Javascript][23],[宝宝的 HTML][24],作者 Sterling Children's
|
||||
**《[宝宝的 CSS][22]》、《[宝宝的 Javascript][23]》、《[宝宝的 HTML][24]》,作者 Sterling Children's**
|
||||
|
||||
这本概念书让宝宝熟悉图形和颜色的种类,这些是互联网编程语言的基石。这本漂亮的书用富有色彩的方式介绍了编程和互联网,对于技术人士的家庭而言,本书是一份绝佳的礼物。([Chris Short][21] 推荐,评论来自 Amazon 书评)
|
||||
|
||||
@ -83,7 +86,7 @@ via: https://opensource.com/article/18/5/books-kids-linux-open-source
|
||||
作者:[Jen Wike Huger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,23 @@
|
||||
如何在 Ubuntu Linux 上挂载和使用 exFAT 驱动器
|
||||
======
|
||||
**简介:本教程将向你展示如何在 Ubuntu 和其他基于 Ubuntu 的 Linux 发行版上启用 exFAT 文件系统支持。用此种方法在系统上挂载 exFAT 驱动器时,你将看不到任何错误。**
|
||||
|
||||
> 简介:本教程将向你展示如何在 Ubuntu 和其他基于 Ubuntu 的 Linux 发行版上启用 exFAT 文件系统支持。用此种方法在系统上挂载 exFAT 驱动器时,你将不会看到错误消息。
|
||||
|
||||
### 在 Ubuntu 上挂载 exFAT 磁盘时出现问题
|
||||
|
||||
有一天,我试图使用用 exFAT 格式化 的 U 盘,其中包含大小约为 10GB 的文件。只要我插入 U 盘,我的 Ubuntu 16.04 就会抛出一个错误说**无法挂载未知的文件系统类型 ‘exfat’**。
|
||||
有一天,我试图使用以 exFAT 格式化 的 U 盘,其中包含约为 10GB 大小的文件。只要我插入 U 盘,我的 Ubuntu 16.04 就会抛出一个错误说**无法挂载未知的文件系统类型 ‘exfat’**。
|
||||
|
||||
![Fix exfat drive mount error on Ubuntu Linux][1]
|
||||
|
||||
确切的错误信息是这样的:
|
||||
**Error mounting /dev/sdb1 at /media/abhishek/SHADI DATA: Command-line `mount -t “exfat” -o “uhelper=udisks2,nodev,nosuid,uid=1001,gid=1001,iocharset=utf8,namecase=0,errors=remount-ro,umask=0077” “/dev/sdb1” “/media/abhishek/SHADI DATA”‘ exited with non-zero exit status 32: mount: unknown filesystem type ‘exfat’**
|
||||
|
||||
### exFAT挂载错误的原因
|
||||
```
|
||||
Error mounting /dev/sdb1 at /media/abhishek/SHADI DATA: Command-line `mount -t "exfat" -o "uhelper=udisks2,nodev,nosuid,uid=1001,gid=1001,iocharset=utf8,namecase=0,errors=remount-ro,umask=0077" "/dev/sdb1" "/media/abhishek/SHADI DATA"` exited with non-zero exit status 32: mount: unknown filesystem type 'exfat'
|
||||
```
|
||||
|
||||
微软最喜欢的[ FAT 文件系统][2]仅限于最大 4GB 的文件。你不能将大于 4GB 的文件传输到 FAT 驱动器。为了克服 FAT 文件系统的限制,微软在 2006 年推出了 [exFAT][3] 文件系统。
|
||||
### exFAT 挂载错误的原因
|
||||
|
||||
微软最喜欢的 [FAT 文件系统][2]仅限于最大 4GB 的文件。你不能将大于 4GB 的文件传输到 FAT 驱动器。为了克服 FAT 文件系统的限制,微软在 2006 年推出了 [exFAT][3] 文件系统。
|
||||
|
||||
由于大多数微软相关的东西都是专有的,exFAT 文件格式也不例外。Ubuntu 和许多其他 Linux 发行版默认不提供专有的 exFAT 文件支持。这就是你看到 exFAT 文件出现挂载错误的原因。
|
||||
|
||||
@ -25,10 +29,10 @@
|
||||
|
||||
我将展示在 Ubuntu 中的命令,但这应该适用于其他基于 Ubuntu 的发行版,例如 [Linux Mint][5]、elementary OS 等。
|
||||
|
||||
打开终端(Ubuntu 中 Ctrl+Alt+T 快捷键)并使用以下命令:
|
||||
打开终端(Ubuntu 中 `Ctrl+Alt+T` 快捷键)并使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt install exfat-fuse exfat-utils
|
||||
|
||||
```
|
||||
|
||||
安装完这些软件包后,进入文件管理器并再次点击 U 盘来挂载它。无需重新插入 USB。它应该能直接挂载。
|
||||
@ -44,7 +48,7 @@ via: https://itsfoss.com/mount-exfat/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
(translating by runningwater)
|
||||
Microservices Explained
|
||||
======
|
||||
|
||||
@ -51,7 +52,7 @@ Learn more about cloud-native at [KubeCon + CloudNativeCon Europe][1], coming up
|
||||
via: https://www.linux.com/blog/2018/4/microservices-explained
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
|
||||
@ -1,138 +0,0 @@
|
||||
(translating by runningwater)
|
||||
A year as Android Engineer
|
||||
============================================================
|
||||
|
||||

|
||||
>Awesome drawing by [Miquel Beltran][0]
|
||||
|
||||
Two years ago I started my career in tech. I started as QA Tester and then transitioned into a developer role a year after. Not without a lot of effort and a lot of personal time invested.
|
||||
|
||||
You can find that part of the story in this post about [how I switch careers from Biology to tech][1] and how I [learned Android for a year][2]. Today I want to talk about how I started my first role as Android developer, how I switched companies and how my first year as Android Engineer has been overall.
|
||||
|
||||
### My first role
|
||||
|
||||
My first role as Android developer started out just a year ago. The company I was working at provided me with the opportunity to transition from QA to Android developer by dedicating half of the time to each role.
|
||||
|
||||
This transition was thanks to the time I invested learning Android on evenings and weekends. I went through the [Android Basics Nanodegree][3], the [Android Developer Nanodegree][4] and as well I got the [Google Developers Certification][5]. [That part of the story is explained in more detail here.][6]
|
||||
|
||||
After two months I switched to full time when they hired another QA. Here's were all the challenges began!
|
||||
|
||||
Transitioning someone into a developer role is a lot harder than just providing them with a laptop and a git account. And here I explain some of the roadblocks I got during that time:
|
||||
|
||||
#### Lack of expectations
|
||||
|
||||
The first problem I faced was not knowing the expectations that the company had on me. My thought was that they expected me to deliver since the very first day, probably not like my experienced colleagues, but deliver by doing small tasks. This feeling caused me a lot of pressure. By not having clear goals, I was constantly thinking I wasn't good enough and that I was an impostor.
|
||||
|
||||
#### Lack of mentorship
|
||||
|
||||
There was no concept of mentorship in the company and the environment didn’t allow us to work together. We barely did pair-programming, because there was always a deadline and the company wanted us to keep delivering. Luckily my colleagues were always willing to help! They sat with me to help me whenever I got stuck or asked for help.
|
||||
|
||||
#### Lack of feedback
|
||||
|
||||
I never got any feedback during that time. What was I doing well or bad? What could I improve? I didn't know since I didn’t have anyone whom to report.
|
||||
|
||||
#### Lack of learning culture
|
||||
|
||||
I think that in order to keep up to date we need to continue learning by reading blog posts, watching talks, attending conferences, trying new things, etc. The company didn’t offer learning hours during working time, which is unfortunately quite common as other devs told me. Without having learning time, I felt I wasn't entitled to spend even 10 minutes to read a blog post I found to be interesting and relevant for my job.
|
||||
|
||||
The problem was not only the lack of an explicit learning time allowance, but also that when I requested it, it got denied.
|
||||
|
||||
An example of that occurred when I finished my tasks for the sprint and we were already at the end of it, so I asked if I could spend the rest of the day learning Kotlin. This request got denied.
|
||||
|
||||
Another case was when I requested to attend an Android conference, and then I was asked to take days from my paid time off.
|
||||
|
||||
#### Impostor syndrome
|
||||
|
||||
The lack of expectations, the lack of feedback, and the lack of learning culture in the company made the first 9 months of my developer career even more challenging. I have the feeling that it contributed to increase my internal impostors syndrome.
|
||||
|
||||
One example of it was opening and reviewing pull requests. Sometimes I'd ask a colleague to check my code privately, rather than opening a pull request, to avoid showing my code to everyone.
|
||||
|
||||
Other times, when I was reviewing, I would spend minutes staring the "approve" button, worried of approving something that another colleague would have considered wrong.
|
||||
|
||||
And when I didn't agree on something, I was never speaking loud enough worried of a backslash due to my lack of knowledge.
|
||||
|
||||
> Sometimes I’d ask a colleague to check my code privately […] to avoid showing my code to everyone.
|
||||
|
||||
* * *
|
||||
|
||||
### New company, new challenges
|
||||
|
||||
Later on I got a new opportunity in my hands. I was invited to the hiring process for a Junior Android Engineer position at [Babbel][7] thanks to a friend who worked with me in the past.
|
||||
|
||||
I met the team while volunteering in a local meet-up that was hosted at their offices. That helped me a lot when deciding to apply. I loved the company's motto: learning for all. Also everyone was very friendly and looked happy working there! But I didn't apply straight away, because why would I apply if I though that I wasn't good enough?
|
||||
|
||||
Luckily my friend and my partner pushed me to do it. They gave me the strength I needed to send my CV. Shortly after I got into the interview process. It was fairly simple: I had to do a coding challenge in the form of a small app, and then later a technical interview with the team and team fit interview with the hiring manager.
|
||||
|
||||
#### Hiring process
|
||||
|
||||
I spent the weekend with the coding challenge and sent it right after on Monday. Soon after I got invited for an on-site interview.
|
||||
|
||||
The technical interview was about the coding challenge itself, we talked about good and bad things on Android, why did I implemented things in a way, how could it be improved, etc. It followed a short team fit interview with the hiring manager, where we talked about challenges I faced, how I solved this problems, and so on.
|
||||
|
||||
They offered me the job and I accepted the offer!
|
||||
|
||||
On my first year working as Android developer, I spent 9 months in a company and the next 3 with my current employer.
|
||||
|
||||
#### Learning environment
|
||||
|
||||
One big change for me is having 1:1 meetings with my Engineering Manager every two weeks. That way, it's clear for me what are our expectations.
|
||||
|
||||
We are getting constant feedback and ideas on what to improve and how to help and be helped. Beside the internal trainings they offer, I also have a weekly learning time allowance to learn anything I want. So far, I've been using it to improve my Kotlin and RxJava knowledge.
|
||||
|
||||
We also do pair-programming almost daily. There's always paper and pens nearby my desk to sketch ideas. And I keep a second chair by my side so my colleagues can sit with me :-)
|
||||
|
||||
However, I still struggle with the impostor syndrome.
|
||||
|
||||
#### Still the Impostor syndrome
|
||||
|
||||
I still struggle with it. For example, when doing pair-programming, if we reach a topic I don't quite understand, even when my colleagues have the patience to explain it to me many times, there are times I just can't get it.
|
||||
|
||||
After the second or third time I start feeling a big pressure on my chest. How come I don't get it? Why is it so difficult for me to understand? This situation creates me anxiety.
|
||||
|
||||
I realized I need to accept that I might not understand a given topic but that getting the idea is the first step! Sometimes we just require more time and practice so it finally "compiles in our brains" :-)
|
||||
|
||||
For example, I used to struggle with Java interfaces vs. abstract classes, I just couldn't understand them completely, no matter how many examples I saw. But then I started using them, and even if I could not explain how they worked, I knew how and when to use them.
|
||||
|
||||
#### Confidence
|
||||
|
||||
The learning environment in my current company helps me in building confidence. Even if I've been asking a lot of questions, there's always room for more!
|
||||
|
||||
Having less experience doesn't mean your opinions will be less valued. For example if a proposed solution seems too complex, I will challenge them to write it in a clearer way. Also, I provide a different set of experience and points of view, which has been helpful so far for polishing the app user experience.
|
||||
|
||||
### To improve
|
||||
|
||||
The engineer role isn't just coding, but rather a broad range of skills. I am still at the beginning of the journey, and on my way of mastering it, I want to focus on the following ideas:
|
||||
|
||||
* Communication: as English isn't my first language, sometimes I struggle to transmit an idea, which is essential for my job. I can work on that by writing, reading and talking more.
|
||||
|
||||
* Give constructive feedback: I want to give meaningful feedback to my colleagues so they can grow with me as well.
|
||||
|
||||
* Be proud of my achievements: I need to create a list to track all kind of achievements, small or big, and my overall progress, so I can look back and feel good when I struggle.
|
||||
|
||||
* Not being obsessed on what I don't know: hard to do when there's so many new things coming up, so keeping focused on the essentials, and what's required for my project in hand, is important.
|
||||
|
||||
* Share more knowledge with my colleagues! That I'm a junior doesn't mean I don't have anything to share! I need to keep sharing articles and talks I find interesting. I know my colleagues appreciate that.
|
||||
|
||||
* Be patient and constantly learn: keep learning as I am doing, but being more patient with myself.
|
||||
|
||||
* Self-care: take breaks whenever needed and don't be hard with myself. Relaxing is also productive.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://proandroiddev.com/a-year-as-android-engineer-55e2a428dfc8
|
||||
|
||||
作者:[Lara Martín][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://proandroiddev.com/@laramartin
|
||||
[0]:https://medium.com/@Miqubel
|
||||
[1]:https://medium.com/@laramartin/how-i-took-my-first-step-in-it-6e9233c4684d
|
||||
[2]:https://medium.com/udacity/a-year-of-android-ffba9f3e40b6
|
||||
[3]:https://de.udacity.com/course/android-basics-nanodegree-by-google--nd803
|
||||
[4]:https://de.udacity.com/course/android-developer-nanodegree-by-google--nd801
|
||||
[5]:https://developers.google.com/training/certification/
|
||||
[6]:https://medium.com/udacity/a-year-of-android-ffba9f3e40b6
|
||||
[7]:http://babbel.com/
|
||||
@ -0,0 +1,157 @@
|
||||
7 tips for promoting your project and community on Twitter
|
||||
======
|
||||
|
||||
|
||||
|
||||
Communicating in open source is about sharing information, engaging, and building community. Here I'll share techniques and best practices for using Twitter to reach your target audience. Whether you are just starting to use Twitter or have been playing around with it and need some new ideas, this article's got you covered.
|
||||
|
||||
This article is based on my [Lightning Talk at UpSCALE][1], a session at the Southern California Linux Expo ([SCALE][2]) in March 2018, held in partnership with Opensource.com. You can see a video of my five-minute talk on [Opensource.com's YouTube][3] page and access my slides on [Slideshare][4].
|
||||
|
||||
### Rule #1: Participate
|
||||
|
||||

|
||||
|
||||
My tech marketing colleague [Amanda Katona][5] and I were talking about the open source community and the ways successful people and organizations use social media. We came up with the meme above. Basically, you have to be part of the community—participate, go to events, engage on Twitter, and meet people. When you share something on Twitter, people see it. In turn, you become known and part of the community.
|
||||
|
||||
So, the Number 1 rule in marketing for open source projects is: You have to be a member of the community. You have to participate.
|
||||
|
||||
### Start with a goal
|
||||
|
||||
Starting with a goal helps you stay focused, instead of doing a lot of different things or jumping on the latest "good idea." Since this is marketing for open source projects, following the tenets of open source helps keep the communications focused on the community, transparency, and openness.
|
||||
|
||||
There is a broad spectrum of goals depending on what you are trying to accomplish for your community, your organization, and yourself. Some ideas:
|
||||
|
||||
* In general, grow the open source community.
|
||||
* Create awareness about the different open source projects going on by talking about and bringing attention to them.
|
||||
* Create a community around a new open source project.
|
||||
* Find things the community is sharing and share them further.
|
||||
* Talk about open source technologies.
|
||||
* Get your project into a foundation.
|
||||
* Build awareness of your project so you can get more users and/or contributors.
|
||||
* Work to be seen as an expert.
|
||||
* Take your existing community and grow it.
|
||||
|
||||
|
||||
|
||||
Above all, know why you are communicating and what you hope to accomplish. Otherwise, you might end up with a laundry list of things that dilute your focus, ultimately slowing progress towards your goals.
|
||||
|
||||
Goals help you stay focused on doing the most impactful things and even enable you to work less.
|
||||
|
||||
### Mix up your tweets
|
||||
|
||||
|
||||
Twitter is a great form of communication to reach a broad audience. There is a lot of content available that can help drive your goals: original content such as blogs and videos, third-party content from the community, and [engagement][6], which Twitter defines as the "total number of times a user interacted with a Tweet. Clicks anywhere on the tweet, including retweets, replies, follows, likes, links, cards, hashtags, embedded media, username, profile photo, or tweet expansion such as retweets and quote retweets."
|
||||
|
||||
When working in the open source community, weighing your Twitter posts toward 50% engagement and 20% community content is a good practice. It shows your expertise while being a good community member.
|
||||
|
||||
### Tweet throughout the day
|
||||
|
||||
There are many opinions on how often to tweet. My research turned up a wide variety of suggestions:
|
||||
|
||||
* Up to 15 times a day
|
||||
* Minimum of five
|
||||
* Maximum of five
|
||||
* Five to 20 times a day
|
||||
* Three to five tweets a day
|
||||
* More than three and engagement drops off
|
||||
* Engagement changes whether you do four to five a day or 11-15 a day
|
||||
* And on and on and on!
|
||||
|
||||
|
||||
|
||||
I looked at my engagement stats and how often the influencers I follow tweet to determine the "magic number" of five to eight tweets a day for a business account and three to five per day for my personal account.
|
||||
|
||||
There are days I tweet more—especially if there is a lot of good community content to share! Some days I tweet less, especially if I'm busy and don't have time to find good content to share. On days when I find more good content than I want to share in one day, I store the web links in a spreadsheet so I can share them throughout the week.
|
||||
|
||||
### Follow Twitter best practices
|
||||
|
||||
By tweeting, monitoring engagement, and watching what others in the community are doing, I came up with this list of Twitter best practices.
|
||||
|
||||
* Be consistently present on Twitter preferably daily or at least a couple of times a week.
|
||||
* Write your content to lead with what the community will find most interesting. For example, if you are sharing something about yourself and a community member, put the other person first in your tweet.
|
||||
* Whenever possible, give credit to the source by using their Twitter handle.
|
||||
* Use hashtags (#) as it makes sense to help the community find content.
|
||||
* Make sure all your tweets have an image.
|
||||
* Tweet like a community member or a person and not like a business. Let your personality show!
|
||||
* Put the most interesting part of the content at the beginning of a tweet.
|
||||
* Monitor Twitter for engagement opportunities:
|
||||
* Check your Twitter notifications tab daily.
|
||||
* Like and set up appropriate retweets and quote retweets.
|
||||
* Review your Twitter lists for engagement opportunities.
|
||||
* Check your numbers of followers, retweets, likes, comments, etc.
|
||||
|
||||
|
||||
|
||||
### Find your influencers
|
||||
|
||||
Knowing who the influencers in your industry are will help you find engagement opportunities and good content to share. Influencers can be technical, business-focused, inspirational, or even people posting pictures of dogs. The important thing is: Figure out who influences you.
|
||||
|
||||
Other ways to find your influencers:
|
||||
|
||||
* Ask your team and other people in the community.
|
||||
* Do a little snooping: Look at the Twitter handles the industry people you respect follow on Twitter.
|
||||
* Follow industry hashtags, especially event hashtags. People who are into the event are tweeting and sharing using the event hashtag. I always find someone who has something interesting to say!
|
||||
|
||||
|
||||
|
||||
When I manage Twitter for companies, I create an Influencer List, which is a spreadsheet that lists influencers' Twitter handles and hashtags. I use this to feed Twitter Lists, which help you organize the people you follow and find content to share. Creating an Influencer List and Twitter Lists takes some time, but it's worth it once you finish!
|
||||
|
||||
Need some inspiration? Check out [my Twitter Lists][7]. Feel free to subscribe to them, copy them, and use them. They are always a work in process as I add or remove people; if you have suggestions, let me know!
|
||||
|
||||
### Engage with the community
|
||||
|
||||
That's what it's all about—engaging with the community! I mentioned earlier that my goal is for 50% of my daily activity to be engagement. Here's my daily to-do list to hit that goal:
|
||||
|
||||
* Check my Notifications tab on Twitter
|
||||
* This is super important! If someone takes the time to respond on Twitter, I want to be prompt and respond to them.
|
||||
* Then I "like" the tweet and set up a retweet, a quote retweet, or a reply—whichever is the most appropriate.
|
||||
* Review my lists for engagement opportunities
|
||||
* See what the community is saying by reviewing tweets from my Twitter feed and my Lists
|
||||
* Check my list of hashtags common in the community to see what people are talking about
|
||||
|
||||
|
||||
|
||||
Based on the information I collect, I set up retweets and quote retweets throughout the day, using Twitter best practices, hashtags, and Twitter handles as it makes sense.
|
||||
|
||||
### More tips and tricks
|
||||
|
||||
There are many things you can do to promote your project, company, or yourself on Twitter. You don't have to do it all! Think hard about the time and other resources you have available—being consistent with your communications and your "community-first" message are most important.
|
||||
|
||||
Follow this checklist to ensure you're participating in the community—with your online presence, your outbound communications, or at events.
|
||||
|
||||
* **Set goals:** This doesn't need to be a monumental exercise or a full marketing strategy, but do set some goals for your online presence.
|
||||
* **Resources:** Know your resources and the limits of your (and your team's) time.
|
||||
* **Audience:** Define your audience—who you are talking to?
|
||||
* **Content:** Choose the content types that fit your goals and available resources.
|
||||
* **Community content:** Finding good community content to share is an excellent place to start.
|
||||
* **On Twitter:**
|
||||
* Have a good profile.
|
||||
* Decide on the right number and type of daily tweets.
|
||||
* Draft tweets using best practices.
|
||||
* Allocate time for engagement. Consistency is more important than the amount of time you spend.
|
||||
* At a minimum, check your Notifications tab and respond.
|
||||
* **Metrics:** While this is the most time-consuming thing to set up, once it's done, it's easy to keep up.
|
||||
|
||||
|
||||
|
||||
I hope this gives you some Twitter strategy ideas. I welcome your comments, questions, and invitations to talk about Twitter and social media in open source! Either leave a message in the comments below or reach out to me on Twitter [@kamcmahon][7]. Happy tweeting!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/promote-your-project-twitter
|
||||
|
||||
作者:[Kim McMahon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kimmcmahon
|
||||
[1]:https://opensource.com/article/18/5/promote-twitter-project
|
||||
[2]:https://www.socallinuxexpo.org/scale/16x
|
||||
[3]:https://www.youtube.com/watch?v=PnTJ4ZHRMuM&index=6&list=PL4jrq6cG7S45r6WC4MtODiwVMNQQVq9ny
|
||||
[4]:https://www.slideshare.net/KimMcMahon1/promoting-your-open-source-project-and-building-online-communities-using-social-media
|
||||
[5]:https://twitter.com/amanda_katona
|
||||
[6]:https://help.twitter.com/en/managing-your-account/using-the-tweet-activity-dashboard
|
||||
[7]:https://twitter.com/kamcmahon/lists
|
||||
@ -0,0 +1,89 @@
|
||||
5 open source puzzle games for Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but those games are often not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
|
||||
|
||||
So, can someone who only uses free and open source software find games that are polished enough to present a solid gaming experience without compromising their open source ideals? Absolutely. While open source games are unlikely ever to rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games, in many genres, that are fun to play and can be installed from the repositories of most major Linux distributions. Even if a particular game is not packaged for a particular distribution, it is usually easy to download the game from the project's website in order to install and play it.
|
||||
|
||||
This article looks at puzzle games. I have already written about [arcade-style games][1] and [board and card games][2]. In future articles, I plan to cover racing, role-playing, and strategy & simulation games.
|
||||
|
||||
### Atomix
|
||||
|
||||
[Atomix][3] is an open source clone of the [Atomix][4] puzzle game released in 1990 for Amiga, Commodore 64, MS-DOS, and other platforms. The goal of Atomix is to construct atomic molecules by connecting atoms. Individual atoms can be moved up, down, left, or right and will keep moving in that direction until the atom hits an obstacle—either the level's walls or another atom. This means that planning is needed to figure out where in the level to construct the molecule and in what order to move the individual pieces. The first level features a simple water molecule, which is made up of two hydrogen atoms and one oxygen atom, but later levels feature more complex molecules.
|
||||
|
||||
To install Atomix, run the following command:
|
||||
|
||||
* On Fedora: `dnf`` install ``atomix`
|
||||
* On Debian/Ubuntu: `apt install`
|
||||
|
||||
|
||||
|
||||
### Fish Fillets - Next Generation
|
||||

|
||||
[Fish Fillets - Next Generation][5] is a Linux port of the game Fish Fillets, which was released in 1998 for Windows, and the source code was released under the GPL in 2004. The game involves two fish trying to escape various levels by moving objects out of their way. The two fish have different attributes, so the player needs to pick the right fish for each task. The larger fish can move heavier objects but it is bigger, which means it cannot fit in smaller gaps. The smaller fish can fit in those smaller gaps, but it cannot move the heavier objects. Both fish will be crushed if an object is dropped on them from above, so the player needs to be careful when moving pieces.
|
||||
|
||||
To install Fish Fillets, run the following command:
|
||||
|
||||
* On Fedora: `dnf`` install fillets-ng`
|
||||
* On Debian/Ubuntu: `apt install fillets-ng`
|
||||
|
||||
|
||||
|
||||
### Frozen Bubble
|
||||
|
||||
[Frozen Bubble][6] is an arcade-style puzzle game that involves shooting bubbles from the bottom of the screen toward a collection of bubbles at the top of the screen. If three bubbles of the same color connect, they are removed from the screen. Any other bubbles that were connected below the removed bubbles but that were not connected to anything else are also removed. In puzzle mode, the design of the levels is fixed, and the player simply needs to remove the bubbles from the play area before the bubbles drop below a line near the bottom of the screen. The games arcade mode and multiplayer modes follow the same basic rules but provide some differences, which adds to the variety. Frozen Bubble is one of the iconic open source games, so if you have not played it before, check it out.
|
||||
|
||||
To install Frozen Bubble, run the following command:
|
||||
|
||||
* On Fedora: `dnf`` install frozen-bubble`
|
||||
* On Debian/Ubuntu: `apt install frozen-bubble`
|
||||
|
||||
|
||||
|
||||
### Hex-a-hop
|
||||
|
||||
[Hex-a-hop][7] is a hexagonal tile-based puzzle game in which the player needs to remove all the green tiles from the level. Tiles are removed by moving over them. Since tiles disappear after they are moved over, it is imperative to plan the optimal path through the level to remove all the tiles without getting stuck. However, there is an undo feature if the player uses a sub-optimal path. Later levels add extra complexity by including tiles that need to be crossed over multiple times and bouncing tiles that cause the player to jump over a certain number of hexes.
|
||||
|
||||
To install Hex-a-hop, run the following command:
|
||||
|
||||
* On Fedora: `dnf`` install hex-a-hop`
|
||||
* On Debian/Ubuntu: `apt install hex-a-hop`
|
||||
|
||||
|
||||
|
||||
### Pingus
|
||||
|
||||
[Pingus][8] is an open source clone of [Lemmings][9]. It is not an exact clone, but the game-play is very similar. Small creatures (lemmings in Lemmings, penguins in Pingus) enter the level through the level's entrance and start walking in a straight line. The player needs to use special abilities to make it so that the creatures can reach the level's exit without getting trapped or falling off a cliff. These abilities include things like digging or building a bridge. If a sufficient number of creatures make it to the exit, the level is successfully solved and the player can advance to the next level. Pingus adds a few extra features to the standard Lemmings features, including a world map and a few abilities not found in the original game, but fans of the classic Lemmings game should feel right at home in this open source variant.
|
||||
|
||||
To install Pingus, run the following command:
|
||||
|
||||
* On Fedora: `dnf`` install ``pingus`
|
||||
* On Debian/Ubuntu: `apt install ``pingus`
|
||||
|
||||
|
||||
|
||||
Did I miss one of your favorite open source puzzle games? Share it in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/puzzle-games-linux
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
[1]:https://opensource.com/article/18/1/arcade-games-linux
|
||||
[2]:https://opensource.com/article/18/3/card-board-games-linux
|
||||
[3]:https://wiki.gnome.org/action/raw/Apps/Atomix
|
||||
[4]:https://en.wikipedia.org/w/index.php?title=Atomix_(video_game)
|
||||
[5]:http://fillets.sourceforge.net/index.php
|
||||
[6]:http://www.frozen-bubble.org/home/
|
||||
[7]:http://hexahop.sourceforge.net/index.html
|
||||
[8]:https://pingus.seul.org/index.html
|
||||
[9]:http://en.wikipedia.org/wiki/Lemmings
|
||||
@ -0,0 +1,94 @@
|
||||
How to build a professional network when you work in a bazaar
|
||||
======
|
||||
|
||||

|
||||
|
||||
Professional social networking—creating interpersonal connections between work colleagues or professionals—can take many forms and span organizations across industries. Establishing professional networks takes time and effort, and when someone either joins or departs an organization, that person's networks often need to be rebuilt in a new work environment.
|
||||
|
||||
Professional social networks perform similar functions in different organizations—information sharing, mentorship, opportunities, work interests, and more—but the methods and reasons for making particular connections in an organization can vary between conventional and open organizations. And these differences make a difference: to the way colleagues relate, to how they build trust, to the amount and kinds of diversity within the organization, and to the forces that create collaboration. All these elements are interrelated, and they contribute to and shape the social networks people form.
|
||||
|
||||
An open organization's emphasis on inclusivity can produce networks more effective at solving business problems than those that emerge in conventional, hierarchical organizations. This notion has a long history in open source thinking. For example, in [The Cathedral and the Bazaar][1], Eric Raymond writes that "Sociologists years ago discovered that the averaged opinion of a mass of equally expert (or equally ignorant) observers is quite a bit more reliable a predictor than the opinion of a single randomly-chosen one of the observers." So let's examine how the structure and purpose of social networks impact what each type of organization values.
|
||||
|
||||
### Social networks in conventional organizations
|
||||
|
||||
When I worked in conventional organizations and would describe what I do for work, the first thing people asked me was how I was related to someone else, usually a director-level leader. "Is that under Hira?" they'd say. "Do you work for Malcolm?" That makes sense considering conventional organizations function in a "top-down" way; when trying to situate work or an employee, people wanted to understand the structure of the network from that top-down perspective.
|
||||
|
||||
In other words, in conventional organizations the social network depends upon the hierarchical structure, so they track one another. In fact, even figuring out where an employee exists within a network is a very "top-down organization" kind of concern.
|
||||
|
||||
But that isn't all that the underlying hierarchy does. It also vets associates. A focus on the top-down network can determine an employee's "value" in the network because the network itself is a system of ongoing power relations that grants people placed in its different locations varying levels of value. It downplays the value of individual talents and skills. Therefore, a person's connections in the conventional organization facilitate that person's ability to be proactive, heard, influential, and supported in their careers.
|
||||
|
||||
An open organization's emphasis on inclusivity can produce networks more effective at solving business problems than those that emerge in conventional, hierarchical organizations.
|
||||
|
||||
The conventional organization's formal structure defines employees' social networks in particular ways—some of which might be benefits, some of which might be disadvantages, depending on one's context—such as:
|
||||
|
||||
* It's easier to know "who's who" and see how people are related more quickly (often this builds trusted networks within the particular hierarchy).
|
||||
* Often, this increased understanding of relationships means there's less redundancy of work (projects have a clear owner embedded in a particular network) and communication (people know who is responsible for communicating what).
|
||||
* Associates can feel "stuck" in a power structure, or like they can't "break into" power structures that sometimes (too often?) don't work, diminishing meritocracy.
|
||||
* Crossing silos of work and effort is difficult and collaboration suffers.
|
||||
* Power transfers slowly; a person's ability to engage is determined more in alignment with network created by the hierarchical structure than by other factors (like individual abilities), reducing what is considered "community" and the benefits of its membership.
|
||||
* Competition seems more clear; understanding "who is vying for what" usually occurs within a recognized and delimited hierarchical structure (and the scarcity of positions in the power network increase competition so competition can be more fierce).
|
||||
* Adaptability can suffer when a more rigid network defines the limits of flexibility; what the network "wants" and the limits of collaboration can be affected this same way.
|
||||
* Execution occurs much more easily in rigid networks, where direction is clear and often leaders manage by overdirecting.
|
||||
* Risk is decreased when the social networks are less flexible; people know what needs to happen, how, and when (but this isn't always "bad" considering the wide range of work in an organization; some job functions require less risk, such as HR, mergers and acquisitions, legal, etc.).
|
||||
* Trust within the network is greater, especially when an employee is part of the formal network (when someone is not part of the network, exclusion can be particularly difficult to manage or to rectify).
|
||||
|
||||
|
||||
|
||||
### Social networks in open organizations
|
||||
|
||||
While open organizations can certainly have hierarchical structures, they don't operate only according to that network. Their professional networking structure is more flexible (or "all over and whenever").
|
||||
|
||||
An open organization is more associate-centric than leader-centric.
|
||||
|
||||
In an open organization, when I've described what I do for work virtually no one asks "for whom?" An open organization is more associate-centric than leader-centric. Open values like inclusivity and specific governance systems like meritocracy contribute to this; it's not who you know but rather it's what you know and how you use it (e.g., "bottom-up"). In an open organization, I don't feel like I'm fighting to show my value; my ideas are inherently valuable. I sometimes have to demonstrate how using my idea is more valuable than using someone else's idea―but that means I'm vetting myself within the community of my associates (including leadership), rather than being vetted solely by top-down leadership.
|
||||
|
||||
In this way, an open organization doesn't assess employees based on the network but rather on what they know of the associate as an individual. Does this person have good ideas? Does she work toward those ideas (lead them) by using the open organization values (that is, share those ideas and work across the organization to include others and work transparently, etc.)?
|
||||
|
||||
Open organizations also structure social networks in particular ways (which, again, could be advantageous or disadvantageous depending on one's goals and desires), including:
|
||||
|
||||
* People are more responsible for their networks, reputations, skills, and careers.
|
||||
* Competition (for resources, power, promotions, etc.) decreases because these organizations are by nature more collaborative (even during a "collision," the best outcome is negotiation, not winning, and competition hones the ideas instead of creating wedges between people).
|
||||
* Power is more fluid and dynamic, flowing from person to person (but this also means there can be a misunderstanding about accountability or responsibility and activities can go undone or unfinished because there is not a clear [sense of ownership][2]).
|
||||
* Trust is created "one associate at a time," rather than through the reputation of the network in which the person is situated.
|
||||
* Networks self-configure around a variety of work and activities, rising reactively around opportunity (this aids innovation but can add to confusion because who makes decisions, and who is in "control" is less clear).
|
||||
* Rate of execution can decrease in confusing contexts because what to do and how and when to do it requires leadership skills in setting direction and creating engaged and skilled associates.
|
||||
* Flexible social networks also increase innovation and risk; ideas circulate faster and are more novel, and execution is less assured.
|
||||
* Trust is based on associate relationships (as it should be!), rather than on sheer deference to structure.
|
||||
|
||||
|
||||
|
||||
### Making it work
|
||||
|
||||
If you're thinking of transitioning from one type of organizational structure to another, consider the following when building and maintaining your professional social networks.
|
||||
|
||||
#### Tips from conventional organizations
|
||||
|
||||
* Structure and control around decision-making isn't a bad thing; operational frameworks need to be clear and transparent, and decision-makers need to account for their decisions.
|
||||
* Excelling at execution requires managers to provide focus and the ability to provide sufficient context while filtering out anything that could distract or confuse.
|
||||
* Established networks help large groups of people work in concert and manage risk.
|
||||
|
||||
|
||||
|
||||
#### Tips from open organizations
|
||||
|
||||
* Strong leaders are those who can provide different levels of clarity and guidance according to the various styles and preferences of associates and teams without creating inflexible networks.
|
||||
* Great ideas win more, not established networks.
|
||||
* People are more responsible for their reputations.
|
||||
* The circulation of ideas and information is key to innovation. Loosening the networks in your organization can help these two elements occur with increased frequency and breadth.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/6/building-professional-social-networks-openly
|
||||
|
||||
作者:[Heidi Hess;von Ludewig][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/heidi-hess-von-ludewig
|
||||
[1]:http://www.catb.org/~esr/writings/cathedral-bazaar/cathedral-bazaar/ar01s04.html
|
||||
[2]:https://opensource.com/open-organization/18/4/rethinking-ownership-across-organization
|
||||
@ -0,0 +1,73 @@
|
||||
World Cup football on the command line
|
||||
======
|
||||
|
||||

|
||||
|
||||
Football is around us constantly. Even when domestic leagues have finished, there’s always a football score I want to know. Currently, it’s the biggest football tournament in the world, the Fifa World Cup 2018, hosted in Russia. Every World Cup there are some great football nations that don’t manage to qualify for the tournament. This time around the Italians and the Dutch missed out. But even in non-participating countries, it’s a rite of passage to keep track of the latest scores. I also like to keep abreast of the latest scores from the major leagues around the world without having to search different websites.
|
||||
|
||||
![Command-Line Interface][2]If you’re a big fan of the command-line, what better way to keep track of the latest World Cup scores and standings with a small command-line utility. Let’s take a look at one of the hottest trending football utilities available. It’s goes by the name football-cli.
|
||||
|
||||
If you’re a big fan of the command-line, what better way to keep track of the latest World Cup scores and standings with a small command-line utility. Let’s take a look at one of the hottest trending football utilities available. It’s goes by the name football-cli.
|
||||
|
||||
football-cli is not a groundbreaking app. Over the years, there’s been a raft of command line tools that let you keep you up-to-date with the latest football scores and league standings. For example, I am a heavy user of soccer-cli, a Python based tool, and App-Football, written in Perl. But I’m always looking on the look out for trending apps. And football-cli stands out from the crowd in a few ways.
|
||||
|
||||
football-cli is developed in JavaScript and written by Manraj Singh. It’s open source software, published under the MIT license. Installation is trivial with npm (the package manager for JavaScript), so let’s get straight into the action.
|
||||
|
||||
The utility offers commands that give scores of past and live fixtures, see upcoming and past fixtures of a league and team. It also displays standings of a particular league. There’s a command that lists the various supported competitions. Let’s start with the last command.
|
||||
|
||||
At a shell prompt.
|
||||
|
||||
`luke@ganges:~$ football lists`
|
||||
|
||||
![football-lists][3]
|
||||
|
||||
The World Cup is listed at the bottom. I missed yesterday’s games, so to catch up on the scores, I type at a shell prompt:
|
||||
|
||||
`luke@ganges:~$ football scores`
|
||||
|
||||
![football-wc-22][4]
|
||||
|
||||
Now I want to see the current World Cup group standings. That’s easy.
|
||||
|
||||
`luke@ganges:~$ football standings -l WC`
|
||||
|
||||
Here’s an excerpt of the output:
|
||||
|
||||
![football-wc-table][5]
|
||||
|
||||
The eagle-eyed among you may notice a bug here. Belgium is showing as the leader of Group G. But this is not correct. Belgium and England are (at the time of writing) both tied on points, goal difference, and goals scored. In this situation, the team with the better disciplinary record is ranked higher. England and Belgium have received 2 and 3 yellow cards respectively, so England top the group.
|
||||
|
||||
Suppose I want to find out Liverpool’s results in the Premiership going back 90 days from today.
|
||||
|
||||
`luke@ganges:~$ football fixtures -l PL -d 90 -t "Liverpool"`
|
||||
|
||||
![football-Liverpool][6]
|
||||
|
||||
I’m finding the utility really handy, displaying the scores and standings in a clear, uncluttered, and attractive way. When the European domestic games start up again, it’ll get heavy usage. (Actually, the 2018-19 Champions League is already underway)!
|
||||
|
||||
These few examples give a taster of the functionality available with football-cli. Read more about the utility from the developer’s **[GitHub page][7].** Football + command-line = football-cli
|
||||
|
||||
Like similar tools, the software retrieves its football data from football-data.org. This service provide football data for all major European leagues in a machine-readable way. This includes fixtures, teams, players, results and more. All this information is provided via an easy-to-use RESTful API in JSON representation.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxlinks.com/football-cli-world-cup-football-on-the-command-line/
|
||||
|
||||
作者:[Luke Baker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxlinks.com/author/luke-baker/
|
||||
[1]:https://www.linuxlinks.com/wp-content/plugins/jetpack/modules/lazy-images/images/1x1.trans.gif
|
||||
[2]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2017/12/CLI.png?resize=195%2C171&ssl=1
|
||||
[3]:https://i2.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-lists.png?resize=595%2C696&ssl=1
|
||||
[4]:https://i2.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-wc-22.png?resize=634%2C75&ssl=1
|
||||
[5]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-wc-table.png?resize=750%2C581&ssl=1
|
||||
[6]:https://i1.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-Liverpool.png?resize=749%2C131&ssl=1
|
||||
[7]:https://github.com/ManrajGrover/football-cli
|
||||
[8]:https://www.linuxlinks.com/links/Software/
|
||||
[9]:https://discord.gg/uN8Rqex
|
||||
@ -1,178 +0,0 @@
|
||||
10 Killer Tips To Speed Up Ubuntu Linux
|
||||
======
|
||||
**Brief** : Some practical **tips to speed up Ubuntu** Linux. Tips here are valid for most versions of Ubuntu and can also be applied in Linux Mint and other Ubuntu based distributions.
|
||||
|
||||
You might have experienced that after using Ubuntu for some time, the system starts running slow. In this article, we shall see several tweaks and **tips to make Ubuntu run faster**.
|
||||
|
||||
Before we see how to improve overall system performance in Ubuntu, first let’s ponder on why the system gets slower over time. There could be several reasons for it. You may have a humble computer with basic configuration. You might have installed several applications which are eating up resources at boot time. Endless reasons in fact.
|
||||
|
||||
Here I have listed several small tweaks that will help you speed up Ubuntu a little. There are some best practices as well which you can employ to get a smoother and improved system performance. You can choose to follow all or some of it. All of them adds up a little to give you a smoother, quicker and faster Ubuntu.
|
||||
|
||||
### Tips to make Ubuntu faster:
|
||||
|
||||
![Tips to speed up Ubuntu][1]
|
||||
|
||||
I have used these tweaks with an older version of Ubuntu but I believe that the same can be used in other Ubuntu versions as well as other Linux distributions which are based on Ubuntu such as Linux Mint, Elementary OS Luna etc.
|
||||
|
||||
#### 1\. Reduce the default grub load time:
|
||||
|
||||
The grub gives you 10 seconds to change between dual boot OS or to go in recovery etc. To me, it’s too much. It also means you will have to sit beside your computer and press the enter key to boot into Ubuntu as soon as possible. A little time taking, ain’t it? The first trick would be to change this boot time. If you are more comfortable with a GUI tool, read this article to [change grub time and boot order with Grub Customizer][2].
|
||||
|
||||
For the rest of us, you can simply use the following command to open grub configuration:
|
||||
```
|
||||
sudo gedit /etc/default/grub &
|
||||
|
||||
```
|
||||
|
||||
And change **GRUB_TIMEOUT=10** to **GRUB_TIMEOUT=2**. This will change the boot time to 2 seconds. Prefer not to put 0 here as you will lose the privilege to change between OS and recovery options. Once you have changed the grub configuration, use the following command to make the change count:
|
||||
```
|
||||
sudo update-grub
|
||||
|
||||
```
|
||||
|
||||
#### 2\. Manage startup applications:
|
||||
|
||||
Over the time you tend to start installing applications. If you are a regular It’s FOSS reader, you might have installed many apps from [App of the week][3] series.
|
||||
|
||||
Some of these apps are started at each startup and of course resources will be busy in running these applications. Result: a slow computer for a significant time duration at each boot. Go in Unity Dash and look for **Startup Applications** :
|
||||
|
||||

|
||||
In here, look at what applications are loaded at startup. Now think if there are any applications which you don’t require to be started up every time you boot in to Ubuntu. Feel free to remove them:
|
||||
|
||||

|
||||
But what if you don’t want to remove the applications from startup? For example, if you installed one of the [best indicator applets for Ubuntu][4], you will want them to be started automatically at each boot.
|
||||
|
||||
What you can do here is to delay some the start of some of the programs. This way you will free up the resource at boot time and your applications will be started automatically, after some time. In the previous picture click on Edit and change the run command with a sleep option.
|
||||
|
||||
For example, if you want to delay the running of Dropbox indicator for let’s say 20 seconds, you just need to **add a command** like this in the existing command:
|
||||
```
|
||||
sleep 10;
|
||||
|
||||
```
|
||||
|
||||
So, the command ‘ **dropbox start -i** ‘ changes to ‘ **sleep 20; drobox start -i** ‘. Which means that now Dropbox will start with a 20 seconds delay. You can change the start time of another start up applications in the similar fashion.
|
||||
|
||||

|
||||
|
||||
#### 3\. Install preload to speed up application load time:
|
||||
|
||||
Preload is a daemon that runs in the background and analyzes user behavior and frequently run applications. Open a terminal and use the following command to install preload:
|
||||
```
|
||||
sudo apt-get install preload
|
||||
|
||||
```
|
||||
|
||||
After installing it, restart your computer and forget about it. It will be working in the background. [Read more about preload.][5]
|
||||
|
||||
#### 4\. Choose the best mirror for software updates:
|
||||
|
||||
It’s good to verify that you are using the best mirror to update the software. Ubuntu software repository are mirrored across the globe and it is quite advisable to use the one which is nearest to you. This will result in a quicker system update as it reduces the time to get the packages from the server.
|
||||
|
||||
In **Software & Updates->Ubuntu Software tab->Download From** choose **Other** and thereafter click on **Select Best Server** :
|
||||
|
||||

|
||||
It will run a test and tell you which is the best mirror for you. Normally, the best mirror is already set but as I said, no harm in verifying it. Also, this may result in some delay in getting the updates if the nearest mirror where the repository is cached is not updated frequently. This is useful for people with a relatively slower internet connection. You can also these tips to [speed up wifi speed in Ubuntu][6].
|
||||
|
||||
#### 5\. Use apt-fast instead of apt-get for a speedy update:
|
||||
|
||||
apt-fast is a shell script wrapper for “apt-get” that improves updated and package download speed by downloading packages from multiple connections simultaneously. If you frequently use terminal and apt-get to install and update the packages, you may want to give apt-fast a try. Install apt-fast via official PPA using the following commands:
|
||||
```
|
||||
sudo add-apt-repository ppa:apt-fast/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install apt-fast
|
||||
|
||||
```
|
||||
|
||||
#### 6\. Remove language related ign from apt-get update:
|
||||
|
||||
Have you ever noticed the output of sudo apt-get update? There are three kinds of lines in it, **hit** , **ign** and **get**. You can read their meaning [here][7]. If you look at IGN lines, you will find that most of them are related to language translation. If you use all the applications, packages in English, there is absolutely no need for a translation of package database from English to English.
|
||||
|
||||
If you suppress this language related updates from apt-get, it will slightly increase the apt-get update speed. To do that, open the following file:
|
||||
```
|
||||
sudo gedit /etc/apt/apt.conf.d/00aptitude
|
||||
|
||||
```
|
||||
|
||||
And add the following line at the end of this file:
|
||||
```
|
||||
Acquire::Languages "none";
|
||||
|
||||
```
|
||||
[![speed up apt get update in Ubuntu][8]][9]
|
||||
|
||||
#### 7\. Reduce overheating:
|
||||
|
||||
Overheating is a common problem in computers these days. An overheated computer runs quite slow. It takes ages to open a program when your CPU fan is running like [Usain Bolt][10]. There are two tools which you can use to reduce overheating and thus get a better system performance in Ubuntu, TLP and CPUFREQ.
|
||||
|
||||
To install and use TLP, use the following commands in a terminal:
|
||||
```
|
||||
sudo add-apt-repository ppa:linrunner/tlp
|
||||
sudo apt-get update
|
||||
sudo apt-get install tlp tlp-rdw
|
||||
sudo tlp start
|
||||
|
||||
```
|
||||
|
||||
You don’t need to do anything after installing TLP. It works in the background.
|
||||
|
||||
To install CPUFREQ indicator use the following command:
|
||||
```
|
||||
sudo apt-get install indicator-cpufreq
|
||||
|
||||
```
|
||||
|
||||
Restart your computer and use the **Powersave** mode in it:
|
||||
|
||||

|
||||
|
||||
#### 8\. Tweak LibreOffice to make it faster:
|
||||
|
||||
If you are a frequent user of office product, then you may want to tweak the default LibreOffice a bit to make it faster. You will be tweaking memory option here. Open LibreOffice and go to **Tools- >Options**. In there, choose **Memory** from the left sidebar and enable **Systray Quickstarter** along with increasing memory allocation.
|
||||
|
||||

|
||||
You can read more about [how to speed up LibreOffice][11] in detail.
|
||||
|
||||
#### 9\. Use a lightweight desktop environment (if you can)
|
||||
|
||||
If you chose to install the default Unity of GNOME desktop environment, you may choose to opt for a lightweight desktop environment like [Xfce][12] or [LXDE][13].
|
||||
|
||||
These desktop environments use less RAM and consume less CPU. They also come with their own set of lightweight applications that further helps in running Ubuntu faster. You can refer to this detailed guide to learn [how to install Xfce on Ubuntu][14].
|
||||
|
||||
Of course, the desktop might not look as modern as Unity or GNOME. That’s a compromise you have to make.
|
||||
|
||||
#### 10\. Use lighter alternatives for different applications:
|
||||
|
||||
This is more of a suggestion and liking. Some of the default or popular applications are resource heavy and may not be suitable for a low-end computer. What you can do is to use some alternates to these applications. For example, use [AppGrid][15] instead of Ubuntu Software Center. Use [Gdebi][16] to install packages. Use AbiWord instead of LibreOffice Writer etc.
|
||||
|
||||
That concludes the collection of tips to make Ubuntu 14.04, 16.04 and other versions faster. I am sure these tips would provide overall a better system performance.
|
||||
|
||||
Do you have some tricks up your sleeves as well to **speed up Ubuntu**? Did these tips help you as well? Do share your views. Questions, suggestions are always welcomed. Feel free to drop to the comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/wp-content/uploads/2017/07/speed-up-ubuntu-featured-800x450.jpeg
|
||||
[2]:https://itsfoss.com/windows-default-os-dual-boot-ubuntu-1304-easy/ (Make Windows Default OS In Dual Boot With Ubuntu 13.04: The Easy Way)
|
||||
[3]:https://itsfoss.com/tag/app-of-the-week/
|
||||
[4]:https://itsfoss.com/best-indicator-applets-ubuntu/ (7 Best Indicator Applets For Ubuntu 13.10)
|
||||
[5]:https://itsfoss.com/improve-application-startup-speed-with-preload-in-ubuntu/ (Improve Application Startup Speed With Preload in Ubuntu)
|
||||
[6]:https://itsfoss.com/speed-up-slow-wifi-connection-ubuntu/ (Speed Up Slow WiFi Connection In Ubuntu 13.04)
|
||||
[7]:http://ubuntuforums.org/showthread.php?t=231300
|
||||
[8]:https://itsfoss.com/wp-content/uploads/2014/01/ign_language-apt_get_update-e1510129903529.jpeg
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2014/01/ign_language-apt_get_update.jpeg
|
||||
[10]:http://en.wikipedia.org/wiki/Usain_Bolt
|
||||
[11]:https://itsfoss.com/speed-libre-office-simple-trick/ (Speed Up LibreOffice With This Simple Trick)
|
||||
[12]:https://xfce.org/
|
||||
[13]:https://lxde.org/
|
||||
[14]:https://itsfoss.com/install-xfce-desktop-xubuntu/
|
||||
[15]:https://itsfoss.com/app-grid-lighter-alternative-ubuntu-software-center/ (App Grid: Lighter Alternative Of Ubuntu Software Center)
|
||||
[16]:https://itsfoss.com/install-deb-files-easily-and-quickly-in-ubuntu-12-10-quick-tip/ (Install .deb Files Easily And Quickly In Ubuntu 12.10 [Quick Tip])
|
||||
@ -0,0 +1,601 @@
|
||||
A Collection Of Useful BASH Scripts For Heavy Commandline Users
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, I have stumbled upon a collection of useful BASH scripts for heavy commandline users. These scripts, known as **Bash-Snippets** , might be quite helpful for those who live in Terminal all day. Want to check the weather of a place where you live? This script will do that for you. Wondering what is the Stock price? You can run the script that displays the current details of a stock. Feel bored? You can watch some youtube videos. All from commandline. You don’t need to install any heavy memory consumable GUI applications.
|
||||
|
||||
As of writing this, Bash-Snippets provides the following 19 useful tools:
|
||||
|
||||
1. **Cheat** – Linux Commands cheat sheet.
|
||||
2. **Cloudup** – A tool to backup your GitHub repositories to bitbucket.
|
||||
3. **Crypt** – Encrypt and decrypt files.
|
||||
4. **Cryptocurrency** – Converts Cryptocurrency based on realtime exchange rates of the top 10 cryptos.
|
||||
5. **Currency** – Currency converter.
|
||||
6. **Geo** – Provides the details of wan, lan, router, dns, mac, and ip.
|
||||
7. **Lyrics** – Grab lyrics for a given song quickly from the command line.
|
||||
8. **Meme** – Command line meme creator.
|
||||
9. **Movies** – Search and display a movie details.
|
||||
10. **Newton** – Performs numerical calculations all the way up to symbolic math parsing.
|
||||
11. **Qrify** – Turns the given string into a qr code.
|
||||
12. **Short** – URL Shortner
|
||||
13. **Siteciphers** – Check which ciphers are enabled / disabled for a given https site.
|
||||
14. **Stocks** – Provides certain Stock details.
|
||||
15. **Taste** – Recommendation engine that provides three similar items like the supplied item (The items can be books, music, artists, movies, and games etc).
|
||||
16. **Todo** – Command line todo manager.
|
||||
17. **Transfer** – Quickly transfer files from the command line.
|
||||
18. **Weather** – Displays weather details of your place.
|
||||
19. **Youtube-Viewer** – Watch YouTube from Terminal.
|
||||
|
||||
|
||||
|
||||
The author might add more utilities and/or features in future, so I recommend you to keep an eye on the project’s website or GitHub page for future updates.
|
||||
|
||||
### Bash-Snippets – A Collection Of Useful BASH Scripts For Heavy Commandline Users
|
||||
|
||||
#### Installation
|
||||
|
||||
You can install these scripts on any OS that supports BASH.
|
||||
|
||||
First, clone the GIT repository using command:
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
Go to the cloned directory:
|
||||
```
|
||||
$ cd Bash-Snippets/
|
||||
|
||||
```
|
||||
|
||||
Git checkout to the latest stable release:
|
||||
```
|
||||
$ git checkout v1.22.0
|
||||
|
||||
```
|
||||
|
||||
Finally, install the Bash-Snippets using command:
|
||||
```
|
||||
$ sudo ./install.sh
|
||||
|
||||
```
|
||||
|
||||
This will ask you which scripts to install. Just type **Y** and press ENTER key to install the respective script. If you don’t want to install a particular script, type **N** and hit ENTER.
|
||||
```
|
||||
Do you wish to install currency [Y/n]: y
|
||||
|
||||
```
|
||||
|
||||
To install all scripts, run:
|
||||
```
|
||||
$ sudo ./install.sh all
|
||||
|
||||
```
|
||||
|
||||
To install a specific script, say currency, run:
|
||||
```
|
||||
$ sudo ./install.sh currency
|
||||
|
||||
```
|
||||
|
||||
You can also install it using [**Linuxbrew**][1] package manager.
|
||||
|
||||
To installs all tools, run:
|
||||
```
|
||||
$ brew install bash-snippets
|
||||
|
||||
```
|
||||
|
||||
To install specific tools:
|
||||
```
|
||||
$ brew install bash-snippets --without-all-tools --with-newton --with-weather
|
||||
|
||||
```
|
||||
|
||||
Also, there is a PPA for Debian-based systems such as Ubuntu, Linux Mint.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:navanchauhan/bash-snippets
|
||||
$ sudo apt update
|
||||
$ sudo apt install bash-snippets
|
||||
|
||||
```
|
||||
|
||||
#### Usage
|
||||
|
||||
**An active Internet connection is required** to use these tools. The usage is fairly simple. Let us see how to use some of these scripts. I assume you have installed all scripts.
|
||||
|
||||
**1\. Currency – Currency Converter**
|
||||
|
||||
This script converts the currency based on realtime exchange rates. Enter the base currency code and the currency to exchange to, and the amount being exchanged one by one as shown below.
|
||||
```
|
||||
$ currency
|
||||
What is the base currency: INR
|
||||
What currency to exchange to: USD
|
||||
What is the amount being exchanged: 10
|
||||
|
||||
=========================
|
||||
| INR to USD
|
||||
| Rate: 0.015495
|
||||
| INR: 10
|
||||
| USD: .154950
|
||||
=========================
|
||||
|
||||
```
|
||||
|
||||
You can also pass all arguments in a single command as shown below.
|
||||
```
|
||||
$ currency INR USD 10
|
||||
|
||||
```
|
||||
|
||||
Refer the following screenshot.
|
||||
|
||||
[![Bash-Snippets][2]][3]
|
||||
|
||||
**2\. Stocks – Display stock price details**
|
||||
|
||||
If you want to check a stock price details, mention the stock item as shown below.
|
||||
```
|
||||
$ stocks Intel
|
||||
|
||||
INTC stock info
|
||||
=============================================
|
||||
| Exchange Name: NASDAQ
|
||||
| Latest Price: 34.2500
|
||||
| Close (Previous Trading Day): 34.2500
|
||||
| Price Change: 0.0000
|
||||
| Price Change Percentage: 0.00%
|
||||
| Last Updated: Jul 12, 4:00PM EDT
|
||||
=============================================
|
||||
|
||||
```
|
||||
|
||||
The above output the **Intel stock** details.
|
||||
|
||||
**3\. Weather – Display Weather details**
|
||||
|
||||
Let us check the Weather details by running the following command:
|
||||
```
|
||||
$ weather
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
![][4]
|
||||
|
||||
As you see in the above screenshot, it provides the 3 day weather forecast. Without any arguments, it will display the weather details based on your IP address. You can also bring the weather details of a particular city or country like below.
|
||||
```
|
||||
$ weather Chennai
|
||||
|
||||
```
|
||||
|
||||
Also, you can view the moon phase by entering the following command:
|
||||
```
|
||||
$ weather moon
|
||||
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
|
||||
![][5]
|
||||
|
||||
**4\. Crypt – Encrypt and Decrypt files**
|
||||
|
||||
This script is a wrapper for openssl that allows you to encrypt and decrypt files quickly and easily.
|
||||
|
||||
To encrypt a file, use the following command:
|
||||
```
|
||||
$ crypt -e [original file] [encrypted file]
|
||||
|
||||
```
|
||||
|
||||
For example, the following command will encrypt a file called **ostechnix.txt** , and save it as **encrypt_ostechnix.txt **in the current working directory.
|
||||
```
|
||||
$ crypt -e ostechnix.txt encrypt_ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
Enter the password for the file twice.
|
||||
```
|
||||
Encrypting ostechnix.txt...
|
||||
enter aes-256-cbc encryption password:
|
||||
Verifying - enter aes-256-cbc encryption password:
|
||||
Successfully encrypted
|
||||
|
||||
```
|
||||
|
||||
The above command will encrypt the given file using **AES 256 level encryption**. The password will not be saved in plain text. You can encrypt .pdf, .txt, .docx, .doc, .png, .jpeg type files.
|
||||
|
||||
To decrypt the file, use the following command:
|
||||
```
|
||||
$ crypt -d [encrypted file] [output file]
|
||||
|
||||
```
|
||||
|
||||
Example:
|
||||
```
|
||||
$ crypt -d encrypt_ostechnix.txt ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
Enter the password to decrypt.
|
||||
```
|
||||
Decrypting encrypt_ostechnix.txt...
|
||||
enter aes-256-cbc decryption password:
|
||||
Successfully decrypted
|
||||
|
||||
```
|
||||
|
||||
**5\. Movies – Find Movie details**
|
||||
|
||||
Using this script, you can find a movie details.
|
||||
|
||||
The following command displays the details of a movie called “mother”.
|
||||
```
|
||||
$ movies mother
|
||||
|
||||
==================================================
|
||||
| Title: Mother
|
||||
| Year: 2009
|
||||
| Tomato: 95%
|
||||
| Rated: R
|
||||
| Genre: Crime, Drama, Mystery
|
||||
| Director: Bong Joon Ho
|
||||
| Actors: Hye-ja Kim, Bin Won, Goo Jin, Je-mun Yun
|
||||
| Plot: A mother desperately searches for the killer who framed her son for a girl's horrific murder.
|
||||
==================================================
|
||||
|
||||
```
|
||||
|
||||
**6\. Display similar items like the supplied item**
|
||||
|
||||
To use this script, you need to get the API key **[here][6]**. No worries, it is completely FREE! Once the you got the API, add the following line to your **~/.bash_profile** : **export TASTE_API_KEY=”yourAPIKeyGoesHere”**``
|
||||
|
||||
Now, you can view the similar item like the supplied item as shown below:
|
||||
```
|
||||
$ taste -i Red Hot Chilli Peppers
|
||||
|
||||
```
|
||||
|
||||
**7\. Short – Shorten URLs**
|
||||
|
||||
This script shortens the given URL.
|
||||
```
|
||||
$ short <URL>
|
||||
|
||||
```
|
||||
|
||||
**8\. Geo – Display the details of your network**
|
||||
|
||||
This script helps you to find out the details of your network, such as wan, lan, router, dns, mac, and ip geolocation.
|
||||
|
||||
For example, to find out your LAN ip, run:
|
||||
```
|
||||
$ geo -l
|
||||
|
||||
```
|
||||
|
||||
Sample output from my system:
|
||||
```
|
||||
192.168.43.192
|
||||
|
||||
```
|
||||
|
||||
To find your Wan IP:
|
||||
```
|
||||
$ geo -w
|
||||
|
||||
```
|
||||
|
||||
For more details, just type ‘geo’ in the Terminal.
|
||||
```
|
||||
$ geo
|
||||
Geo
|
||||
Description: Provides quick access for wan, lan, router, dns, mac, and ip geolocation data
|
||||
Usage: geo [flag]
|
||||
-w Returns WAN IP
|
||||
-l Returns LAN IP(s)
|
||||
-r Returns Router IP
|
||||
-d Returns DNS Nameserver
|
||||
-m Returns MAC address for interface. Ex. eth0
|
||||
-g Returns Current IP Geodata
|
||||
Examples:
|
||||
geo -g
|
||||
geo -wlrdgm eth0
|
||||
Custom Geo Output =>
|
||||
[all] [query] [city] [region] [country] [zip] [isp]
|
||||
Example: geo -a 8.8.8.8 -o city,zip,isp
|
||||
-o [options] Returns Specific Geodata
|
||||
-a [address] For specific ip in -s
|
||||
-v Returns Version
|
||||
-h Returns Help Screen
|
||||
-u Updates Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
**9\. Cheat – Display cheatsheets of Linux commands**
|
||||
|
||||
Want to refer the cheatsheet of Linux command? Well, it is also possible. The following command will display the cheatsheet of **curl** command:
|
||||
```
|
||||
$ cheat curl
|
||||
|
||||
```
|
||||
|
||||
Just replace **curl** with the command of your choice to display its cheatsheet. This can be very useful for the quick reference to any command you want to use.
|
||||
|
||||
**10\. Youtube-Viewer – Watch YouTube videos**
|
||||
|
||||
Using this script, you can search or watch youtube videos right from the Terminal.
|
||||
|
||||
Let us watch some **Ed Sheeran** videos.
|
||||
```
|
||||
$ ytview Ed Sheeran
|
||||
|
||||
```
|
||||
|
||||
Choose the video you want to play from the list. The selected will play in your default media player.
|
||||
|
||||
![][7]
|
||||
|
||||
To view recent videos by an artist, you can use:
|
||||
```
|
||||
$ ytview -c [channel name]
|
||||
|
||||
```
|
||||
|
||||
To search for videos, just enter:
|
||||
```
|
||||
$ ytview -s [videoToSearch]
|
||||
|
||||
```
|
||||
|
||||
or just,
|
||||
```
|
||||
$ ytview [videoToSearch]
|
||||
|
||||
```
|
||||
|
||||
**11\. cloudup – Backup GitHub repositories to bitbucket**
|
||||
|
||||
Have you hosted any project on GitHub? Great! You can backup the GitHub repositories to **bitbucket** , a web-based hosting service used for source code and development projects, at any time.
|
||||
|
||||
You can either backup all github repositories of the designated user at once with the **-a** option. Or run it with no flags and backup individual repositories.
|
||||
|
||||
To backup GitHub repository, run:
|
||||
```
|
||||
$ cloudup
|
||||
|
||||
```
|
||||
|
||||
You will be asked to enter your GitHub username, name of the repository to backup, and bitbucket username and password etc.
|
||||
|
||||
**12\. Qrify – Convert Strings into QR code**
|
||||
|
||||
This script converts any given string of text into a QR code. This is useful for sending links or saving a string of commands to your phone
|
||||
```
|
||||
$ qrify convert this text into qr code
|
||||
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
|
||||
![][8]
|
||||
|
||||
Cool, isn’t it?
|
||||
|
||||
**13\. Cryptocurrency**
|
||||
|
||||
It displays the top ten cryptocurrencies realtime exchange rates.
|
||||
|
||||
Type the following command and hit ENTER to run it:
|
||||
```
|
||||
$ cryptocurrency
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
**14\. Lyrics**
|
||||
|
||||
This script grabs the lyrics for a given song quickly from the command line.
|
||||
|
||||
Say for example, I am going to fetch the lyrics of **“who is it”** song, a popular song sung by **Michael Jackson**.
|
||||
```
|
||||
$ lyrics -a michael jackson -s who is it
|
||||
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
**15\. Meme**
|
||||
|
||||
This script allows you to create simple memes from command line. It is quite faster than GUI-based meme generators.
|
||||
|
||||
To create a meme, just type:
|
||||
```
|
||||
$ meme -f mymeme
|
||||
Enter the name for the meme's background (Ex. buzz, doge, blb ): buzz
|
||||
Enter the text for the first line: THIS IS A
|
||||
Enter the text for the second line: MEME
|
||||
|
||||
```
|
||||
|
||||
This will create jpg file in your current working directory.
|
||||
|
||||
**16\. Newton**
|
||||
|
||||
Tired of solving complex Maths problems? Here you go. The Newton script will perform numerical calculations all the way up to symbolic math parsing.
|
||||
|
||||
![][11]
|
||||
|
||||
**17\. Siteciphers**
|
||||
|
||||
This script helps you to check which ciphers are enabled / disabled for a given https site.
|
||||
```
|
||||
$ siteciphers google.com
|
||||
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
**18\. Todo**
|
||||
|
||||
It allows you to create everyday tasks directly from the Terminal.
|
||||
|
||||
Let us create some tasks.
|
||||
```
|
||||
$ todo -a The first task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
|
||||
```
|
||||
|
||||
To add another task, simply re-run the above command with the task name.
|
||||
```
|
||||
$ todo -a The second task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). The second task Tue Jun 26 14:52:29 IST 2018
|
||||
|
||||
```
|
||||
|
||||
To view the list of tasks, run:
|
||||
```
|
||||
$ todo -g
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). A The second task Tue Jun 26 14:51:46 IST 2018
|
||||
|
||||
```
|
||||
|
||||
Once you completed a task, remove it from the list as shown below.
|
||||
```
|
||||
$ todo -r 2
|
||||
Sucessfully removed task number 2
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
|
||||
```
|
||||
|
||||
To clear all tasks, run:
|
||||
```
|
||||
$ todo -c
|
||||
Tasks cleared.
|
||||
|
||||
```
|
||||
|
||||
**19\. Transfer**
|
||||
|
||||
The transfer script allows you to quickly and easily transfer files and directories over Internet.
|
||||
|
||||
Let us upload a file.
|
||||
```
|
||||
$ transfer test.txt
|
||||
Uploading test.txt
|
||||
################################################################################################################################################ 100.0%
|
||||
Success!
|
||||
Transfer Download Command: transfer -d desiredOutputDirectory ivmfj test.txt
|
||||
Transfer File URL: https://transfer.sh/ivmfj/test.txt
|
||||
|
||||
```
|
||||
|
||||
The file will be uploaded to transfer.sh site. Transfer.sh allows you to upload files up to **10 GB** in one go. All shared files automatically expire after **14 days**. As you can see, anyone can download the file either by visiting the second URL via a web browser or using the transfer command (it is installed in his/her system, of course).
|
||||
|
||||
Now remove the file from your system.
|
||||
```
|
||||
$ rm -fr test.txt
|
||||
|
||||
```
|
||||
|
||||
Now, you can download the file from transfer.sh site at any time (within 14 days) like below.
|
||||
```
|
||||
$ transfer -d Downloads ivmfj test.txt
|
||||
|
||||
```
|
||||
|
||||
For more details about this utility, refer our following guide.
|
||||
|
||||
##### Getting help
|
||||
|
||||
If you don’t know how to use a particular script, just type that script’s name and press ENTER. You will see the usage details. The following example displays the help section of **Qrify** script.
|
||||
```
|
||||
$ qrify
|
||||
Qrify
|
||||
Usage: qrify [stringtoturnintoqrcode]
|
||||
Description: Converts strings or urls into a qr code.
|
||||
-u Update Bash-Snippet Tools
|
||||
-m Enable multiline support (feature not working yet)
|
||||
-h Show the help
|
||||
-v Get the tool version
|
||||
Examples:
|
||||
qrify this is a test string
|
||||
qrify -m two\\nlines
|
||||
qrify github.com # notice no http:// or https:// this will fail
|
||||
|
||||
```
|
||||
|
||||
#### Updating scripts
|
||||
|
||||
You can update the installed tools at any time suing -u option. The following command updates “weather” tool.
|
||||
```
|
||||
$ weather -u
|
||||
|
||||
```
|
||||
|
||||
#### Uninstall
|
||||
|
||||
You can uninstall these tools as shown below.
|
||||
|
||||
Git clone the repository:
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
Go to the Bash-Snippets directory:
|
||||
```
|
||||
$ cd Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
And uninstall the scripts by running the following command:
|
||||
```
|
||||
$ sudo ./uninstall.sh
|
||||
|
||||
```
|
||||
|
||||
Type **y** and hit ENTER to remove each script.
|
||||
```
|
||||
Do you wish to uninstall currency [Y/n]: y
|
||||
|
||||
```
|
||||
|
||||
**Also read: **
|
||||
|
||||
And, that’s all for now folks. I must admit that I’m very impressed when testing this scripts. I really liked the idea of combing all useful scripts into a single package. Kudos to the developer. Give it a try, you won’t be disappointed.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/collection-useful-bash-scripts-heavy-commandline-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_001.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_002-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_003.png
|
||||
[6]:https://tastedive.com/account/api_access
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/07/ytview-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_005.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/07/cryptocurrency.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/07/lyrics.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/07/newton.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/07/siteciphers.png
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
Why Python devs should use Pipenv
|
||||
======
|
||||
|
||||
|
||||
@ -1,154 +0,0 @@
|
||||
Translating by qhwdw
|
||||
The Cost of Cloud Computing
|
||||
============================================================
|
||||
|
||||
### A day in the life of two development teams
|
||||
|
||||
|
||||

|
||||
|
||||
Over the last few months, I’ve talked with a number people who are concerned about the cost of public cloud services in comparison to the price of traditional on-premises infrastructure. To provide some insights from the discussion, let’s follow two development teams within an enterprise — and compare how they would approach building a similar service.
|
||||
|
||||
The first team will deploy their application using traditional on-premises infrastructure, while the second will leverage some of the public cloud services available on AWS.
|
||||
|
||||
The two teams are being asked to develop a new service for a global enterprise company that currently serves millions of consumers worldwide. This new service will need to meet theses basic requirements:
|
||||
|
||||
1. The ability to scale to meet elastic demands
|
||||
|
||||
2. Provide resiliency in response to a datacenter failure
|
||||
|
||||
3. Ensure data is secure and protected
|
||||
|
||||
4. Provide in-depth debugging for troubleshooting
|
||||
|
||||
5. The project must be delivered quickly
|
||||
|
||||
6. The service be cost-efficient to build and maintain
|
||||
|
||||
As far as new services go, this seems to be a fairly standard set of requirements — nothing that would intrinsically favor either traditional on-premises infrastructure over the public cloud.
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
#### 1 —Scaling to meet customer demands
|
||||
|
||||
When it comes to scalability, this new service needs to scale to meet the variable demands of consumers. We can’t build a service that might drop requests and cost our company money and cause reputational risk.
|
||||
|
||||
The Traditional Team With on-premises infrastructure, the architectural approach dictates that compute capacity needs to be sized to match your peak data demands. For services that features a variable workload, this will leave you with a lot of excess and expensive compute capacity in times of low utilization.
|
||||
|
||||
This approach is wasteful — and the capital expense will eat into your profits. In addition, there is a heavy operational costs with maintaining your fleet of underutilized servers. This is a cost that is often overlooked — and I cannot emphasize enough how much money and time will be wasted supporting a rack of bare-metal servers for a single service.
|
||||
|
||||
The Cloud Team With a cloud-based autoscaling solution, your application scales up and down in-line with demand. This means that you’re only paying for the compute resources that you consume.
|
||||
|
||||
A well-architected cloud-based application enables the act of scaling up and down to be seamless — and automatic. The development team defines auto-scaling groups that spin up more instances of your application based on high-CPU utilization, or a large number of requests per second, and you can customize these rules to your heart’s content.
|
||||
|
||||
* * *
|
||||
|
||||
#### 2- Resiliency in response to failure
|
||||
|
||||
When it comes to resiliency, hosting a service on infrastructure that resides within the same four walls isn’t an option. If your application resides within a single datacenter — then you are stuffed when ( _not if_ ) something fails.
|
||||
|
||||
The Traditional Team To meet basic resiliency criteria for an on-premises solution, this team would a minimum of two servers for local resiliency — replicated in a second data center for geographic redundancy.
|
||||
|
||||
The development team will need to identify a load balancing solution that automatically redirects traffic between sites in the event of saturation or failure — and ensure that the mirror site is continually synchronized with the entire stack.
|
||||
|
||||
The Cloud Team Within each of their 50 regions worldwide, AWS provides multiple _availability zones_ . Each zone consists of one of more fault-tolerant data centers — with automated failover capabilities that can seamlessly transition AWS services to other zones within the region.
|
||||
|
||||
Defining your _ infrastructure as code_ within a CloudFormation template ensures your infrastructure resources remain consistent across the zones during autoscaling events — and the AWS load balancer service requires minimal effort to setup and manage the traffic flow.
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
#### 3 — Secure and protect your data
|
||||
|
||||
Security is be a fundamental requirement of any system being developed within an organization. You really don’t want to be one of the unfortunate companies dealing with fallout from a security breach.
|
||||
|
||||
The Traditional Team The traditional team will incur the ongoing costs of ensuring that the bare-metal servers that’s running their services is secure. This means investing in a team that is trying to monitor, identify, and patch security threats across multiple vendor solutions from a variety of unique data sources.
|
||||
|
||||
The Cloud Team Leveraging the public cloud does not exempt yourself from security. The cloud team still has to remain vigilant, but doesn’t have to worry about patching the underlying infrastructure. AWS actively works combat against zero-day exploits — most recently with Spectre and Meltdown.
|
||||
|
||||
Leveraging the identify management and encryption security services from AWS allows the cloud team to focus on their application — and not the undifferentiated security management. The API calls to AWS services are fully audited using CloudTrail, which provides transparent monitoring.
|
||||
|
||||
* * *
|
||||
|
||||
#### 4 — Monitoring and logging
|
||||
|
||||
Every infrastructure and application service being deployed need to be closely monitored with aggregated realtime data. The teams should have access to dashboards that provide alerts when thresholds are exceeded, and offer the ability to leverage logs for event correlation for troubleshooting.
|
||||
|
||||
The Traditional Team For traditional infrastructure, you will have to set up monitoring and alerting solutions across disparate vendors and snowflake solutions. Setting this up takes a hell of a lot of time — and effort and getting it right is incredibly difficult.
|
||||
|
||||
For many applications deployed on-premises, you may find yourself searching through log files stored on your server’s file-system in order to make sense of why your application is crashing. A lot of time will be wasted as teams need to ssh into the server, navigate to the unique directory of log files, and then grep through potentially hundreds of files. Having done this for an application that was deployed across 60 servers — I can tell you that this isn’t a pretty solution.
|
||||
|
||||
The Cloud Team Native AWS services such as CloudWatch and CloudTrail make monitoring cloud applications an absolute breeze. Without much setup, the development team can monitor a wide variety of different metrics for each of the deployed services — making the process of debugging issues an absolute dream.
|
||||
|
||||
With traditional infrastructure, teams need build their own solution, and configure their REST API or service to push log files to an aggregator. Getting this ‘out-of-the-box’ is an insane improvement fo productivity.
|
||||
|
||||
* * *
|
||||
|
||||
#### 5 — Accelerate the development
|
||||
|
||||
The ability to accelerate time-to-market is increasingly important in today’s business environment. The lost opportunity costs for delayed implementations can have a major impact on bottom-line profits.
|
||||
|
||||
The Traditional Team For most organizations, it takes a long time to purchase, configure and deploy hardware needed for new projects — and procuring extra capacity in advance leads to massive waste due to poor forecasting.
|
||||
|
||||
Most likely, the traditional development team will spend months working across the myriad of silos and hand-offs to create the services. Each step of the project will require a distinct work request to database, system, security, and network administrators.
|
||||
|
||||
The Cloud Team When it comes to developing new features in a timely manner, having a massive suite of production-ready services at the disposal of your keyboard is a developer’s paradise. Each of the AWS services is typically well documented and can be accessed programmatically via your language of choice.
|
||||
|
||||
With new cloud architectures such a serverless, development teams can build and deploy a scalable solution with minimal friction. For example, in just a couple of days I recently built a [serverless clone of Imgur][4] that features image recognition, a production-ready monitoring/logging solution built-in, and is incredibly resilient.
|
||||
|
||||

|
||||
|
||||
If I had to engineer the resiliency and scalability myself, I can guarantee you that I would still be developing this project — and the final product would have been nowhere near as good as it currently is.
|
||||
|
||||
Using serverless architecture, I experimented and delivered the solution in a less time that it takes to provision hardware in most companies. I simply glued together a series of AWS services with Lambda functions — and ta-da! I focused on developing the solution, while the undifferentiated scalability and resiliency is handled for me by AWS.
|
||||
|
||||
* * *
|
||||
|
||||
#### The cost verdict on cloud computing
|
||||
|
||||
When it comes to scalability, the cloud team is the clear winner with demand-drive elasticity — thus only paying for compute power that they need. The team no longer needs dedicated resources devoted to maintaining and patching the underlying physical infrastructure.
|
||||
|
||||
The cloud also provides development teams a resilient architecture with multiple availability zones, security features built into each service, consistent tools for logging and monitoring, pay-as-you-go services, and low-cost experimentation for accelerated delivery.
|
||||
|
||||
More often than not, the absolute cost of cloud will amount to less than the cost of buying, supporting, maintaining, and designing the on-premises infrastructure needed for your application to run — with minimal fuss.
|
||||
|
||||
By leveraging cloud we can move faster and with the minimal upfront capital investment needed. Overall, the economics of the cloud will actively work in your favor when developing and deploying your business services.
|
||||
|
||||
There will always be a couple of niche examples where the cost of cloud is prohibitively more expensive than traditional infrastructure, and a few situations where you end up forgetting that you have left some incredibly expensive test boxes running over the weekend.
|
||||
|
||||
[Dropbox saved almost $75 million over two years by building its own tech infrastructure
|
||||
After making the decision to roll its own infrastructure and reduce its dependence on Amazon Web Services, Dropbox…www.geekwire.com][5][][6]
|
||||
|
||||
However, these cases remain few and far between. Not to mention that Dropbox initially started out life on AWS — and it was only after they had reached a critical mass that they decided to migrate off the platform. Even now, they are overflowing into the cloud and retain 40% of their infrastructure on AWS and GCP.
|
||||
|
||||
The idea of comparing cloud services to traditional infrastructure-based of a single “cost” metric is incredibly naive — it blatantly disregards some of the major advantages the cloud offers development teams and your business.
|
||||
|
||||
In the rare cases when cloud services result in a greater absolute cost than your more traditional infrastructure offering — it still represents a better value in terms of developer productivity, speed, and innovation.
|
||||
|
||||

|
||||
|
||||
Customers don’t give a shit about your data centers
|
||||
|
||||
_I’m very interested in hearing your own experiences and feedback related to the true cost of developing in cloud! Please drop a comment below, on Twitter at _ [_@_ _Elliot_F_][7] _, or connect with me directly on _ [_LinkedIn_][8] _._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://read.acloud.guru/the-true-cost-of-cloud-a-comparison-of-two-development-teams-edc77d3dc6dc
|
||||
|
||||
作者:[Elliot Forbes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://read.acloud.guru/@elliot_f?source=post_header_lockup
|
||||
[1]:https://info.acloud.guru/faas-and-furious?utm_campaign=FaaS%20and%20Furious
|
||||
[2]:https://read.acloud.guru/building-an-imgur-clone-part-2-image-rekognition-and-a-dynamodb-backend-abc9af300123
|
||||
[3]:https://read.acloud.guru/customers-dont-give-a-shit-about-your-devops-pipeline-51a2342cc0f5
|
||||
[4]:https://read.acloud.guru/building-an-imgur-clone-part-2-image-rekognition-and-a-dynamodb-backend-abc9af300123
|
||||
[5]:https://www.geekwire.com/2018/dropbox-saved-almost-75-million-two-years-building-tech-infrastructure/
|
||||
[6]:https://www.geekwire.com/2018/dropbox-saved-almost-75-million-two-years-building-tech-infrastructure/
|
||||
[7]:https://twitter.com/Elliot_F
|
||||
[8]:https://www.linkedin.com/in/elliotforbes/
|
||||
82
sources/tech/20180313 Migrating to Linux- Using Sudo.md
Normal file
82
sources/tech/20180313 Migrating to Linux- Using Sudo.md
Normal file
@ -0,0 +1,82 @@
|
||||
Migrating to Linux: Using Sudo
|
||||
======
|
||||
|
||||

|
||||
|
||||
This article is the fifth in our series about migrating to Linux. If you missed earlier ones, you can catch up here:
|
||||
|
||||
[Part 1 - An Introduction][1]
|
||||
|
||||
[Part 2 - Disks, Files, and Filesystems][2]
|
||||
|
||||
[Part 3 - Graphical Environments][3]
|
||||
|
||||
[Part 4 - The Command Line][4]
|
||||
|
||||
You may have been wondering about Linux for a while. Perhaps it's used in your workplace and you'd be more efficient at your job if you used it on a daily basis. Or, perhaps you'd like to install Linux on some computer equipment you have at home. Whatever the reason, this series of articles is here to make the transition easier.
|
||||
|
||||
Linux, like many other operating systems supports multiple users. It even supports multiple users being logged in simultaneously.
|
||||
|
||||
User accounts are typically assigned a home directory where files can be stored. Usually this home directory is in:
|
||||
```
|
||||
/home/<login name>
|
||||
|
||||
```
|
||||
|
||||
This way, each user has their own separate location for their documents and other files.
|
||||
|
||||
### Admin Tasks
|
||||
|
||||
In a traditional Linux installation, regular user accounts don't have permissions to perform administrative tasks on the system. And instead of assigning rights to each user to perform various tasks, a typical Linux installation will require a user to log in as the admin to do certain tasks.
|
||||
|
||||
The administrator account on Linux is called root.
|
||||
|
||||
### Sudo Explained
|
||||
|
||||
Historically, to perform admin tasks, one would have to login as root, perform the task, and then log back out. This process was a bit tedious, so many folks logged in as root and worked all day long as the admin. This practice could lead to disastrous results, for example, accidentally deleting all the files in the system. The root user, of course, can do anything, so there are no protections to prevent someone from accidentally performing far-reaching actions.
|
||||
|
||||
The sudo facility was created to make it easier to login as your regular user account and occasionally perform admin tasks as root without having to login, do the task, and log back out. Specifically, sudo allows you to run a command as a different user. If you don't specify a specific user, it assumes you mean root.
|
||||
|
||||
Sudo can have complex settings to allow users certain permissions to use sudo for some commands but not for others. Typically, a desktop installation will make it so the first account created has full permissions in sudo, so you as the primary user can fully administer your Linux installation.
|
||||
|
||||
### Using Sudo
|
||||
|
||||
Some Linux installations set up sudo so that you still need to know the password for the root account to perform admin tasks. Others, set up sudo so that you type in your own password. There are different philosophies here.
|
||||
|
||||
When you try to perform an admin task in the graphical environment, it will usually open a dialog box asking for a password. Enter either your own password (e.g., on Ubuntu), or the root account's password (e.g., Red Hat).
|
||||
|
||||
When you try to perform an admin task in the command line, it will usually just give you a "permission denied" error. Then you would re-run the command with sudo in front. For example:
|
||||
```
|
||||
systemctl start vsftpd
|
||||
Failed to start vsftpd.service: Access denied
|
||||
|
||||
sudo systemctl start vsftpd
|
||||
[sudo] password for user1:
|
||||
|
||||
```
|
||||
|
||||
### When to Use Sudo
|
||||
|
||||
Running commands as root (under sudo or otherwise) is not always the best solution to get around permission errors. While will running as root will remove the "permission denied" errors, it's sometimes best to look for the root cause rather than just addressing the symptom. Sometimes files have the wrong owner and permissions.
|
||||
|
||||
Use sudo when you are trying to perform a task or run a program and the program requires root privileges to perform the operation. Don't use sudo if the file just happens to be owned by another user (including root). In this second case, it's better to set the permission on the file correctly.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][5]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/3/migrating-linux-using-sudo
|
||||
|
||||
作者:[John Bonesio][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction
|
||||
[2]:https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems
|
||||
[3]:https://www.linux.com/blog/learn/2017/12/migrating-linux-graphical-environments
|
||||
[4]:https://www.linux.com/blog/learn/2018/1/migrating-linux-command-line
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
55
sources/tech/20180606 6 Open Source AI Tools to Know.md
Normal file
55
sources/tech/20180606 6 Open Source AI Tools to Know.md
Normal file
@ -0,0 +1,55 @@
|
||||
6 Open Source AI Tools to Know
|
||||
======
|
||||
|
||||

|
||||
|
||||
In open source, no matter how original your own idea seems, it is always wise to see if someone else has already executed the concept. For organizations and individuals interested in leveraging the growing power of artificial intelligence (AI), many of the best tools are not only free and open source, but, in many cases, have already been hardened and tested.
|
||||
|
||||
At leading companies and non-profit organizations, AI is a huge priority, and many of these companies and organizations are open sourcing valuable tools. Here is a sampling of free, open source AI tools available to anyone.
|
||||
|
||||
**Acumos.** [Acumos AI][1] is a platform and open source framework that makes it easy to build, share, and deploy AI apps. It standardizes the infrastructure stack and components required to run an out-of-the-box general AI environment. This frees data scientists and model trainers to focus on their core competencies rather than endlessly customizing, modeling, and training an AI implementation.
|
||||
|
||||
Acumos is part of the[LF Deep Learning Foundation][2], an organization within The Linux Foundation that supports open source innovation in artificial intelligence, machine learning, and deep learning. The goal is to make these critical new technologies available to developers and data scientists, including those who may have limited experience with deep learning and AI. The LF Deep Learning Foundation just [recently approved a project lifecycle and contribution process][3] and is now accepting proposals for the contribution of projects.
|
||||
|
||||
**Facebook’s Framework.** Facebook[has open sourced][4] its central machine learning system designed for artificial intelligence tasks at large scale, and a series of other AI technologies. The tools are part of a proven platform in use at the company. Facebook has also open sourced a framework for deep learning and AI [called Caffe2][5].
|
||||
|
||||
**Speaking of Caffe.** Yahoo also released its key AI software under an open source license. The[CaffeOnSpark tool][6] is based on deep learning, a branch of artificial intelligence particularly useful in helping machines recognize human speech or the contents of a photo or video. Similarly, IBM’s machine learning program known as [SystemML][7] is freely available to share and modify through the Apache Software Foundation.
|
||||
|
||||
**Google’s Tools.** Google spent years developing its [TensorFlow][8] software framework to support its AI software and other predictive and analytics programs. TensorFlow is the engine behind several Google tools you may already use, including Google Photos and the speech recognition found in the Google app.
|
||||
|
||||
Two [AIY kits][9] open sourced by Google let individuals easily get hands-on with artificial intelligence. Focused on computer vision and voice assistants, the two kits come as small self-assembly cardboard boxes with all the components needed for use. The kits are currently available at Target in the United States, and are based on the open source Raspberry Pi platform — more evidence of how much is happening at the intersection of open source and AI.
|
||||
|
||||
**H2O.ai.** **** I[previously covered][10] H2O.ai, which has carved out a niche in the machine learning and artificial intelligence arena because its primary tools are free and open source. You can get the main H2O platform and Sparkling Water, which works with Apache Spark, simply by[downloading][11] them. These tools operate under the Apache 2.0 license, one of the most flexible open source licenses available, and you can even run them on clusters powered by Amazon Web Services (AWS) and others for just a few hundred dollars.
|
||||
|
||||
**Microsoft Onboard.** “Our goal is to democratize AI to empower every person and every organization to achieve more,” Microsoft CEO Satya Nadella[has said][12]. With that in mind, Microsoft is continuing to iterate its[Microsoft Cognitive Toolkit][13]. It’s an open source software framework that competes with tools such as TensorFlow and Caffe. Cognitive Toolkit works with both Windows and Linux on 64-bit platforms.
|
||||
|
||||
“Cognitive Toolkit enables enterprise-ready, production-grade AI by allowing users to create, train, and evaluate their own neural networks that can then scale efficiently across multiple GPUs and multiple machines on massive data sets,” reports the Cognitive Toolkit Team.
|
||||
|
||||
Learn more about AI in this new ebook from The Linux Foundation. [Open Source AI: Projects, Insights, and Trends by Ibrahim Haddad][14] surveys 16 popular open source AI projects – looking in depth at their histories, codebases, and GitHub contributions. [Download the free ebook now.][14]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/6-open-source-ai-tools-know
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.acumos.org/
|
||||
[2]:https://www.linuxfoundation.org/projects/deep-learning/
|
||||
[3]:https://www.linuxfoundation.org/blog/lf-deep-learning-foundation-announces-project-contribution-process/
|
||||
[4]:https://code.facebook.com/posts/1687861518126048/facebook-to-open-source-ai-hardware-design/
|
||||
[5]:https://venturebeat.com/2017/04/18/facebook-open-sources-caffe2-a-new-deep-learning-framework/
|
||||
[6]:http://yahoohadoop.tumblr.com/post/139916563586/caffeonspark-open-sourced-for-distributed-deep
|
||||
[7]:https://systemml.apache.org/
|
||||
[8]:https://www.tensorflow.org/
|
||||
[9]:https://www.techradar.com/news/google-assistant-sweetens-raspberry-pi-with-ai-voice-control
|
||||
[10]:https://www.linux.com/news/sparkling-water-bridging-open-source-machine-learning-and-apache-spark
|
||||
[11]:http://www.h2o.ai/download
|
||||
[12]:https://blogs.msdn.microsoft.com/uk_faculty_connection/2017/02/10/microsoft-cognitive-toolkit-cntk/
|
||||
[13]:https://www.microsoft.com/en-us/cognitive-toolkit/
|
||||
[14]:https://www.linuxfoundation.org/publications/open-source-ai-projects-insights-and-trends/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
3 journaling applications for the Linux desktop
|
||||
======
|
||||
|
||||
|
||||
@ -1,59 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
BLUI: An easy way to create game UI
|
||||
======
|
||||
|
||||

|
||||
|
||||
Game development engines have become increasingly accessible in the last few years. Engines like Unity, which has always been free to use, and Unreal, which recently switched from a subscription-based service to a free service, allow independent developers access to the same industry-standard tools used by AAA publishers. While neither of these engines is open source, each has enabled the growth of open source ecosystems around it.
|
||||
|
||||
Within these engines are plugins that allow developers to enhance the base capabilities of the engine by adding specific applications. These apps can range from simple asset packs to more complicated things, like artificial intelligence (AI) integrations. These plugins widely vary across creators. Some are offered by the engine development studios and others by individuals. Many of the latter are open source plugins.
|
||||
|
||||
### What is BLUI?
|
||||
|
||||
As part of an indie game development studio, I've experienced the perks of using open source plugins on proprietary game engines. One open source plugin, [BLUI][1] by Aaron Shea, has been instrumental in our team's development process. It allows us to create user interface (UI) components using web-based programming like HTML/CSS and JavaScript. We chose to use this open source plugin, even though Unreal Engine (our engine of choice) has a built-in UI editor that achieves a similar purpose. We chose to use open source alternatives for three main reasons: their accessibility, their ease of implementation, and the active, supportive online communities that accompany open source programs.
|
||||
|
||||
In Unreal Engine's earliest versions, the only means we had of creating UI in the game was either through the engine's native UI integration, by using Autodesk's Scaleform application, or via a few select subscription-based Unreal integrations spread throughout the Unreal community. In all those cases, the solutions were either incapable of providing a competitive UI solution for indie developers, too expensive for small teams, or exclusively for large-scale teams and AAA developers.
|
||||
|
||||
After commercial products and Unreal's native integration failed us, we looked to the indie community for solutions. There we discovered BLUI. It not only integrates with Unreal Engine seamlessly but also maintains a robust and active community that frequently pushes updates and ensures the documentation is easily accessible for indie developers. BLUI gives developers the ability to import HTML files into the Unreal Engine and program them even further while inside the program. This allows UI created through web languages to integrate with the game's code, assets, and other elements with the full power of HTML, CSS, JavaScript, and other web languages. It also provides full support for the open source [Chromium Embedded Framework][2].
|
||||
|
||||
### Installing and using BLUI
|
||||
|
||||
The basic process for using BLUI involves first creating the UI via HTML. Developers may use any tool at their disposal to achieve this, including bootstrapped JavaScript code, external APIs, or any database code. Once this HTML page is ready, you can install the plugin the same way you would install any Unreal plugin and load or create a project. Once the project is loaded, you can place a BLUI function anywhere within an Unreal UI blueprint or hardcoded via C++. Developers can call functions from within their HTML page or change variables easily using BLUI's internal functions.
|
||||
|
||||
![Integrating BLUI into Unreal Engine 4 blueprints][4]
|
||||
|
||||
Integrating BLUI into Unreal Engine 4 blueprints.
|
||||
|
||||
In our current project, we use BLUI to sync UI elements with the in-game soundtrack to provide visual feedback to the rhythm aspects of the game mechanics. It's easy to integrate custom engine programming with the BLUI plugin.
|
||||
|
||||
![Using BLUI to sync UI elements with the soundtrack.][6]
|
||||
|
||||
Using BLUI to sync UI elements with the soundtrack.
|
||||
|
||||
Implementing BLUI into Unreal Engine 4 is a trivial process thanks to the [documentation][7] on the BLUI GitHub page. There is also [a forum][8] populated with supportive Unreal Engine developers eager to both ask and answer questions regarding the plugin and any issues that appear when implementing the tool.
|
||||
|
||||
### Open source advantages
|
||||
|
||||
Open source plugins enable expanded creativity within the confines of proprietary game engines. They continue to lower the barrier of entry into game development and can produce in-game mechanics and assets no one has seen before. As access to proprietary game development engines continues to grow, the open source plugin community will become more important. Rising creativity will inevitably outpace proprietary software, and open source will be there to fill the gaps and facilitate the development of truly unique games. And that novelty is exactly what makes indie games so great!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/blui-game-development-plugin
|
||||
|
||||
作者:[Uwana lkaiddi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/uwikaiddi
|
||||
[1]:https://github.com/AaronShea/BLUI
|
||||
[2]:https://bitbucket.org/chromiumembedded/cef
|
||||
[3]:/file/400616
|
||||
[4]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-integratingblui.png (Integrating BLUI into Unreal Engine 4 blueprints)
|
||||
[5]:/file/400621
|
||||
[6]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-syncui.png (Using BLUI to sync UI elements with the soundtrack.)
|
||||
[7]:https://github.com/AaronShea/BLUI/wiki
|
||||
[8]:https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui
|
||||
@ -1,106 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to disable iptables firewall temporarily
|
||||
======
|
||||
|
||||
Learn how to disable iptables firewall in Linux temporarily for troubleshooting purpose. Also learn how to save policies and how to restore them back when you enable firewall back.
|
||||
|
||||
![How to disable iptables firewall temporarily][1]
|
||||
|
||||
Sometimes you have the requirement to turn off iptables firewall to do some connectivity troubleshooting and then you need to turn it back on. While doing it you also want to save all your [firewall policies][2] as well. In this article, we will walk you through how to save firewall policies and how to disable/enable iptables firewall. For more details about iptables firewall and policies [read our article][3] on it.
|
||||
|
||||
### Save iptables policies
|
||||
|
||||
The first step while disabling iptables firewall temporarily is to save existing firewall rules/policies. `iptables-save` command lists all your existing policies which you can save in a file on your server.
|
||||
|
||||
```
|
||||
root@kerneltalks # # iptables-save
|
||||
# Generated by iptables-save v1.4.21 on Tue Jun 19 09:54:36 2018
|
||||
*nat
|
||||
:PREROUTING ACCEPT [1:52]
|
||||
:INPUT ACCEPT [1:52]
|
||||
:OUTPUT ACCEPT [15:1140]
|
||||
:POSTROUTING ACCEPT [15:1140]
|
||||
:DOCKER - [0:0]
|
||||
---- output trucated----
|
||||
|
||||
root@kerneltalks # iptables-save > /root/firewall_rules.backup
|
||||
```
|
||||
|
||||
So iptables-save is the command with you can take iptables policy backup.
|
||||
|
||||
### Stop/disable iptables firewall
|
||||
|
||||
For older Linux kernels you have an option of stopping service iptables with `service iptables stop` but if you are on the new kernel, you just need to wipe out all the policies and allow all traffic through the firewall. This is as good as you are stopping the firewall.
|
||||
|
||||
Use below list of commands to do that.
|
||||
```
|
||||
root@kerneltalks # iptables -F
|
||||
root@kerneltalks # iptables -X
|
||||
root@kerneltalks # iptables -P INPUT ACCEPT
|
||||
root@kerneltalks # iptables -P OUTPUT ACCEPT
|
||||
root@kerneltalks # iptables -P FORWARD ACCEPT
|
||||
```
|
||||
|
||||
Where –
|
||||
|
||||
* -F : Flush all policy chains
|
||||
* -X : Delete user defined chains
|
||||
* -P INPUT/OUTPUT/FORWARD : Accept specified traffic
|
||||
|
||||
|
||||
|
||||
Once done, check current firewall policies. It should looks like below which means everything is accepted (as good as your firewall is disabled/stopped)
|
||||
|
||||
```
|
||||
# iptables -L
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
```
|
||||
|
||||
### Restore firewall policies
|
||||
|
||||
Once you are done with troubleshooting and you want to turn iptables back on with all its configurations. You need to first restore policies from the backup we took in first step.
|
||||
|
||||
```
|
||||
root@kerneltalks # iptables-restore </root/firewall_rules.backup
|
||||
```
|
||||
### Start iptables firewall
|
||||
|
||||
And then start iptables service in case you have stopped it in previous step using `service iptables start`. If you havnt stopped service then only restoring policies will do for you. Check if all policies are back in iptables firewall configurations :
|
||||
|
||||
```
|
||||
# iptables -L
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
Chain FORWARD (policy DROP)
|
||||
target prot opt source destination
|
||||
DOCKER-USER all -- anywhere anywhere
|
||||
DOCKER-ISOLATION-STAGE-1 all -- anywhere anywhere
|
||||
-----output truncated-----
|
||||
```
|
||||
|
||||
That’s it! You have successfully disabled and enabled firewall without loosing your policy rules.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/howto/how-to-disable-iptables-firewall-temporarily/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a2.kerneltalks.com/wp-content/uploads/2018/06/How-to-disable-iptables-firewall-temporarily.png
|
||||
[2]:https://kerneltalks.com/networking/configuration-of-iptables-policies/
|
||||
[3]:https://kerneltalks.com/networking/basics-of-iptables-linux-firewall/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Stop merging your pull requests manually
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,136 @@
|
||||
How to connect to a remote desktop from Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
A [remote desktop][1], according to Wikipedia, is "a software or operating system feature that allows a personal computer's desktop environment to be run remotely on one system (usually a PC, but the concept applies equally to a server), while being displayed on a separate client device."
|
||||
|
||||
In other words, a remote desktop is used to access an environment running on another computer. For example, the [ManageIQ/Integration tests][2] repository's pull request (PR) testing system exposes a Virtual Network Computing (VNC) connection port so I can remotely view my PRs being tested in real time. Remote desktops are also used to help customers solve computer problems: with the customer's permission, you can establish a VNC or Remote Desktop Protocol (RDP) connection to see or interactively access the computer to troubleshoot or repair the problem.
|
||||
|
||||
These connections are made using remote desktop connection software, and there are many options available. I use [Remmina][3] because I like its minimal, easy-to-use user interface (UI). It's written in GTK+ and is open source under the GNU GPL license.
|
||||
|
||||
In this article, I'll explain how to use the Remmina client to connect remotely from a Linux computer to a Windows 10 system and a Red Hat Enterprise Linux 7 system.
|
||||
|
||||
### Install Remmina on Linux
|
||||
|
||||
First, you need to install Remmina on the computer you'll use to access the other computer(s) remotely. If you're using Fedora, you can run the following command to install Remmina:
|
||||
```
|
||||
sudo dnf install -y remmina
|
||||
|
||||
```
|
||||
|
||||
If you want to install Remmina on a different Linux platform, follow these [installation instructions][4]. You should then find Remmina with your other apps (Remmina is selected in this image).
|
||||
|
||||
|
||||
|
||||
Launch Remmina by clicking on the icon. You should see a screen that resembles this:
|
||||
|
||||
|
||||
|
||||
Remmina offers several types of connections, including RDP, which is used to connect to Windows-based computers, and VNC, which is used to connect to Linux machines. As you can see in the top-left corner above, Remmina's default setting is RDP.
|
||||
|
||||
### Connecting to Windows 10
|
||||
|
||||
Before you can connect to a Windows 10 computer through RDP, you must change some permissions to allow remote desktop sharing and connections through your firewall.
|
||||
|
||||
[Note: Windows 10 Home has no RDP feature listed. ][5]
|
||||
|
||||
To enable remote desktop sharing, in **File Explorer** right-click on **My Computer → Properties → Remote Settings** and, in the pop-up that opens, check **Allow remote connections to this computer** , then select **Apply**.
|
||||
|
||||
|
||||
|
||||
Next, enable remote desktop connections through your firewall. First, search for **firewall settings** in the **Start** menu and select **Allow an app through Windows Firewall**.
|
||||
|
||||
|
||||
|
||||
In the window that opens, look for **Remote Desktop** under **Allowed apps and features**. Check the box(es) in the **Private **and/or **Public** columns, depending on the type of network(s) you will use to access this desktop. Click **OK**.
|
||||
|
||||
|
||||
|
||||
Go to the Linux computer you use to remotely access the Windows PC and launch Remmina. Enter the IP address of your Windows computer and hit the Enter key. (How do I locate my IP address [in Linux][6] and [Windows 10][7]?) When prompted, enter your username and password and click OK.
|
||||
|
||||
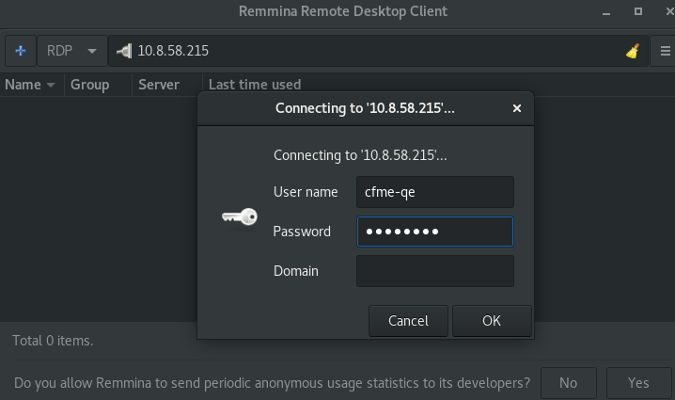
|
||||
|
||||
If you're asked to accept the certificate, select OK.
|
||||
|
||||
|
||||
|
||||
You should be able to see your Windows 10 computer's desktop.
|
||||
|
||||
|
||||
|
||||
### Connecting to Red Hat Enterprise Linux 7
|
||||
|
||||
To set permissions to enable remote access on your RHEL7 computer, open **All Settings** on the Linux desktop.
|
||||
|
||||
|
||||
|
||||
Click on the Sharing icon, and this window will open:
|
||||
|
||||
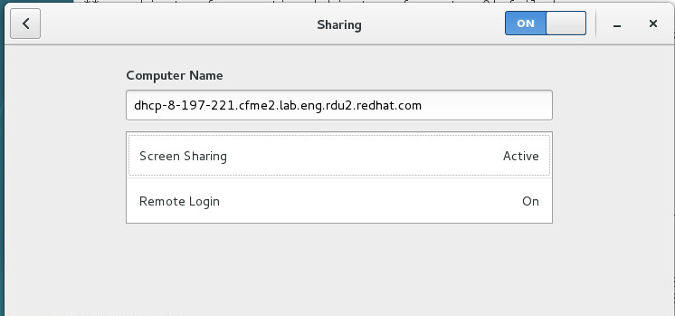
|
||||
|
||||
If **Screen Sharing** is off, click on it. A window will open, where you can slide it into the **On** position. If you want to allow remote connections to control the desktop, set **Allow Remote Control** to **On**. You can also select between two access options: one that prompts the computer's primary user to accept or deny the connection request, and another that allows connection authentication with a password. At the bottom of the window, select the network interface where connections are allowed, then close the window.
|
||||
|
||||
Next, open **Firewall Settings** from **Applications Menu → Sundry → Firewall**.
|
||||
|
||||
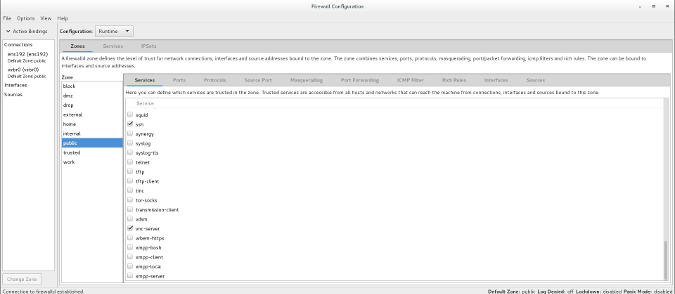
|
||||
|
||||
Check the box next to vnc-server (as shown above) and close the window. Then, head to Remmina on your remote computer, enter the IP address of the Linux desktop you want to connect with, select **VNC** as the protocol, and hit the **Enter** key.
|
||||
|
||||
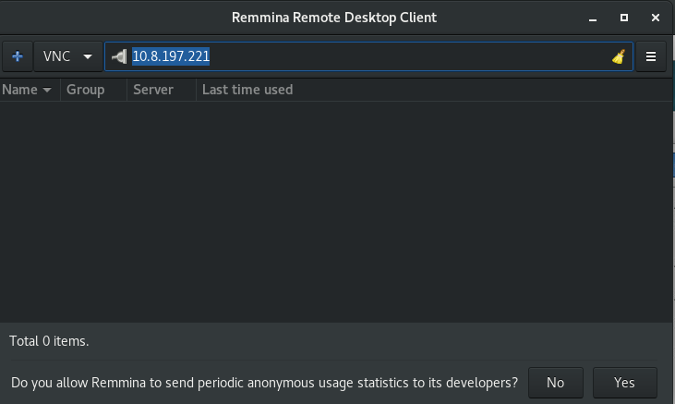
|
||||
|
||||
If you previously chose the authentication option **New connections must ask for access** , the RHEL system's user will see a prompt like this:
|
||||
|
||||
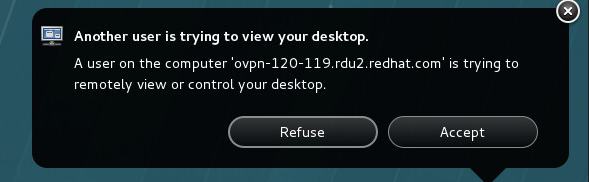
|
||||
|
||||
Select **Accept** for the remote connection to succeed.
|
||||
|
||||
If you chose the option to authenticate the connection with a password, Remmina will prompt you for the password.
|
||||
|
||||
|
||||
|
||||
Enter the password and hit **OK** , and you should be connected to the remote computer.
|
||||
|
||||
|
||||
|
||||
### Using Remmina
|
||||
|
||||
Remmina offers a tabbed UI, as shown in above picture, much like a web browser. In the top-left corner, as shown in the screenshot above, you can see two tabs: one for the previously established Windows 10 connection and a new one for the RHEL connection.
|
||||
|
||||
On the left-hand side of the window, there is a toolbar with options such as **Resize Window** , **Full-Screen Mode** , **Preferences** , **Screenshot** , **Disconnect** , and more. Explore them and see which ones work best for you.
|
||||
|
||||
You can also create saved connections in Remmina by clicking on the **+** (plus) sign in the top-left corner. Fill in the form with details specific to your connection and click **Save**. Here is an example Windows 10 RDP connection:
|
||||
|
||||
|
||||
|
||||
The next time you open Remmina, the connection will be available.
|
||||
|
||||
|
||||
|
||||
Just click on it, and your connection will be established without re-entering the details.
|
||||
|
||||
### Additional info
|
||||
|
||||
When you use remote desktop software, all the operations you perform take place on the remote desktop and use its resources—Remmina (or similar software) is just a way to interact with that desktop. You can also access a computer remotely through SSH, but it usually limits you to a text-only terminal to that computer.
|
||||
|
||||
You should also note that enabling remote connections with your computer could cause serious damage if an attacker uses this method to gain access to your computer. Therefore, it is wise to disallow remote desktop connections and block related services in your firewall when you are not actively using Remote Desktop.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/linux-remote-desktop
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kkulkarn
|
||||
[1]:https://en.wikipedia.org/wiki/Remote_desktop_software
|
||||
[2]:https://github.com/ManageIQ/integration_tests
|
||||
[3]:https://www.remmina.org/wp/
|
||||
[4]:https://www.tecmint.com/remmina-remote-desktop-sharing-and-ssh-client/
|
||||
[5]:https://superuser.com/questions/1019203/remote-desktop-settings-missing#1019212
|
||||
[6]:https://opensource.com/article/18/5/how-find-ip-address-linux
|
||||
[7]:https://www.groovypost.com/howto/find-windows-10-device-ip-address/
|
||||
179
sources/tech/20180621 Troubleshooting a Buildah script.md
Normal file
179
sources/tech/20180621 Troubleshooting a Buildah script.md
Normal file
@ -0,0 +1,179 @@
|
||||
Troubleshooting a Buildah script
|
||||
======
|
||||
|
||||

|
||||
|
||||
As both a father of teenagers and a software engineer, I spend most of my time dealing with problems. Whether the problem is large or small, many times you can't find the cause of an issue by looking directly at it. Instead, you need to step back and investigate the environment where the situation exists. I realized this recently, when a colleague who presents on container technologies, including [container managers][1] like [Buildah][2] and [Podman][3], asked me for help solving a problem with a demo script he was planning to show at a conference only a few days later.
|
||||
|
||||
The script had worked in the past but wasn't working now, and he was in a pinch. It's a demo script that creates a Fedora 28-based container [using Buildah][4] and installs the NGINX HTTPD server within it. Then it uses Podman to run the container and kick off the NGINX server. Finally, the script does a quick `curl` command to pull the index.html file to prove the server is up and responsive. All these commands had worked during setup and testing, but now the `curl` was failing. (By the way, if you want to learn about Buildah or run a demo, take a look at my colleague's [full script][5], as it is a great one to use.)
|
||||
|
||||
I talked to the folks on the Podman team, and they were not able to reproduce the issue, so I thought it might be a problem in Buildah. We did a flurry of debugging and checking in the config code to make sure the ports were being set up properly, the image was getting pulled correctly, and everything was saved. It all checked out. Prior run-throughs of the demo had all completed successfully: the NGINX server would serve up the index.html as expected. That was odd, and no recent changes to the Buildah code were likely to upset any of that.
|
||||
|
||||
With the deadline before the conference ticking away, I began investigating by shrinking the script down to the following.
|
||||
```
|
||||
cat ~/tom_nginx.sh
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
|
||||
# docker-compatibility-demo.sh
|
||||
|
||||
# author : demodude
|
||||
|
||||
# Assumptions install buildah, podman & docker
|
||||
|
||||
# Do NOT start the docker deamon
|
||||
|
||||
# Set some of the variables below
|
||||
|
||||
|
||||
|
||||
demoimg=dockercompatibilitydemo
|
||||
|
||||
quayuser=ipbabble
|
||||
|
||||
myname="Demo King"
|
||||
|
||||
distro=fedora
|
||||
|
||||
distrorelease=28
|
||||
|
||||
pkgmgr=dnf # switch to yum if using yum
|
||||
|
||||
|
||||
|
||||
#Setting up some colors for helping read the demo output
|
||||
|
||||
bold=$(tput bold)
|
||||
|
||||
red=$(tput setaf 1)
|
||||
|
||||
green=$(tput setaf 2)
|
||||
|
||||
yellow=$(tput setaf 3)
|
||||
|
||||
blue=$(tput setaf 4)
|
||||
|
||||
cyan=$(tput setaf 6)
|
||||
|
||||
reset=$(tput sgr0)
|
||||
|
||||
|
||||
|
||||
echo -e "Using ${green}GREEN${reset} to introduce Buildah steps"
|
||||
|
||||
echo -e "Using ${yellow}YELLOW${reset} to introduce code"
|
||||
|
||||
echo -e "Using ${blue}BLUE${reset} to introduce Podman steps"
|
||||
|
||||
echo -e "Using ${cyan}CYAN${reset} to introduce bash commands"
|
||||
|
||||
echo -e "Using ${red}RED${reset} to introduce Docker commands"
|
||||
|
||||
|
||||
|
||||
echo -e "Building an image called ${demoimg}"
|
||||
|
||||
|
||||
|
||||
set -x
|
||||
|
||||
newcontainer=$(buildah from ${distro})
|
||||
|
||||
buildah run $newcontainer -- ${pkgmgr} -y update && ${pkgmgr} -y clean all
|
||||
|
||||
buildah run $newcontainer -- ${pkgmgr} -y install nginx && ${pkgmgr} -y clean all
|
||||
|
||||
buildah run $newcontainer bash -c 'echo "daemon off;" >> /etc/nginx/nginx.conf'
|
||||
|
||||
buildah run $newcontainer bash -c 'echo "nginx on OCI Fedora image, built using Buildah" > /usr/share/nginx/html/index.html'
|
||||
|
||||
buildah config --port 80 --entrypoint /usr/sbin/nginx $newcontainer
|
||||
|
||||
buildah config --created-by "${quayuser}" $newcontainer
|
||||
|
||||
buildah config --author "${myname}" --label name=$demoimg $newcontainer
|
||||
|
||||
buildah inspect $newcontainer
|
||||
|
||||
buildah commit $newcontainer $demoimg
|
||||
|
||||
buildah images
|
||||
|
||||
containernum=$(podman run -d -p 80:80 $demoimg)
|
||||
|
||||
curl localhost # Failed
|
||||
|
||||
podman ps
|
||||
|
||||
podman stop $containernum
|
||||
|
||||
podman rm $containernum
|
||||
|
||||
```
|
||||
|
||||
### What the script is doing
|
||||
|
||||
Beginning in the `set -x` section, you can see the script creates a new Fedora container using `buildah from`. The next four steps use `buildah run` to do some configurations in the container: the first two use the DNF software package manager to do an update, install NGINX, and clean everything up; the third and fourth steps prepare NGINX to run—the third sets up the `/etc/nginx/nginx.conf` file and sets `daemon off`, and the `run` command in the fourth step creates the index.html file to be displayed.
|
||||
|
||||
The three `buildah config` commands that folllow do a little housekeeping within the container. They set up port 80, set the entry point to NGINX, and touch up the `created-by`, `author`, and `label` fields in the new container. At this point, the container is set up to run NGINX, and the `buildah inspect` command lets you walk through the container's fields and associated metadata to verify all of that.
|
||||
|
||||
This script uses Podman to run the container and the NGINX server. Podman is a new, open source utility for working with Linux containers and Kubernetes pods that emulates many features of the Docker command line but doesn't require a daemon as Docker does. For Podman to run the container, it must first be saved as an image—that's what the `buildah commit` line is doing.
|
||||
|
||||
Finally, the `podman run` line starts up the container and—due to the way we configured it with the entry point and setting up the ports—the NGINX server starts and is available for use. It's always nice to say the server is "running," but the proof is being able to interact with the server. So, the script executes a simple `curl localhost`; if it's working, index.html should contain:
|
||||
```
|
||||
nginx on OCI Fedora image, built using Buildah
|
||||
|
||||
```
|
||||
|
||||
However, with only hours before the next demo, it instead sent back:
|
||||
```
|
||||
curl: (7) Failed to connect to jappa.cos.redhat.com port 80: Connection refused
|
||||
|
||||
```
|
||||
|
||||
Now, that's not good.
|
||||
|
||||
### Diagnosing the problem
|
||||
|
||||
I was repeatedly having the problem on my development virtual machine (VM). I added debugging statements and still didn't find anything. Strangely, I found if I replaced `podman` with `docker` in the script, everything worked just fine. I'm not always very kind to my development VM, so I set up a new VM and installed everything nice and fresh and clean.
|
||||
|
||||
The script failed there as well, so it wasn't that my development VM was behaving badly by itself. I ran the script multiple times while I was thinking things through, hoping to pick up any clue from the output. My next thought was to get into the container and look around in there. I commented out the `stop` and `rm` lines and re-ran the script using:
|
||||
```
|
||||
podman exec --tty 129d4d33169f /bin/bash
|
||||
|
||||
```
|
||||
|
||||
where `129d4d33169f` was the `CONTAINER ID` value from the `podman ps` command for the container. I ran `curl localhost` there within the container and voilà! I received the correct output from index.html. I then exited the container and tried the `curl` command again from the host running the container, and this time it worked.
|
||||
|
||||
Finally, light dawned on marblehead. In past testing, I'd been playing with an Apache HTTPD server and trying to connect to it from another session. In those tests, if I went too quick, the server would reject me.
|
||||
|
||||
### Could it be that simple?
|
||||
|
||||
As it turns out, it was that simple. We added a `sleep 3` line between the `podman run` and the `curl localhost` commands, and everything worked as expected. What seemed to be happening was the `podman run` command was starting up the container and the NGINX server extremely quickly and returning to the command line. If you don't wait a few seconds, the NGINX server doesn't have time to start up and start accepting connection requests.
|
||||
|
||||
In our testing with Docker, this wasn't the case. I didn't dig into it deeply, but my assumption is the time Docker spends talking to the Docker daemon gives the NGINX server enough time to come up fully. This is what makes Buildah and Podman very useful and powerful: no daemon, less overhead. But you need to take that into account for demos!
|
||||
|
||||
Problems are indeed what engineers solve, and oftentimes the answer is not in the code itself. When looking at problems, it's good to step back a little bit and not get too focused on the bits and the bytes.
|
||||
|
||||
An earlier version of this article originally appeared on the [ProjectAtomic.io][6] blog.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/buildah-troubleshooting
|
||||
|
||||
作者:[Tom Sweeney][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tomsweeneyredhat
|
||||
[1]:https://opensource.com/article/18/1/history-low-level-container-runtimes
|
||||
[2]:https://github.com/projectatomic/buildah
|
||||
[3]:https://github.com/projectatomic/libpod/tree/master/cmd/podman
|
||||
[4]:https://opensource.com/article/18/6/getting-started-buildah
|
||||
[5]:https://github.com/projectatomic/buildah/blob/master/demos/buildah-bud-demo.sh
|
||||
[6]:https://www.projectatomic.io/blog/2018/06/problems-are-opportunities-in-disguise/
|
||||
@ -0,0 +1,83 @@
|
||||
Automatically Change Wallpapers in Linux with Little Simple Wallpaper Changer
|
||||
======
|
||||
|
||||
**Brief: Here is a tiny script that automatically changes wallpaper at regular intervals in your Linux desktop.**
|
||||
|
||||
As the name suggests, LittleSimpleWallpaperChanger is a small script that changes the wallpapers randomly at intervals.
|
||||
|
||||
Now I know that there is a random wallpaper option in the ‘Appearance’ or the ‘Change desktop background’ settings. But that randomly changes the pre-installed wallpapers and not the wallpapers that you add.
|
||||
|
||||
So in this article, we’ll be seeing how to set up a random desktop wallpaper setup consisting of your photos using LittleSimpleWallpaperChanger.
|
||||
|
||||
### Little Simple Wallpaper Changer (LSWC)
|
||||
|
||||
[LittleSimpleWallpaperChanger][1] or LSWC is a very lightweight script that runs in the background, changing the wallpapers from the user-specified folder. The wallpapers change at a random interval between 1 to 5 minutes. The software is rather simple to set up, and once set up, the user can just forget about it.
|
||||
|
||||
![Little Simple Wallpaper Changer to change wallpapers in Linux][2]
|
||||
|
||||
#### Installing LSWC
|
||||
|
||||
Download LSWC by [clicking on this link.][3] The zipped file is around 15 KB in size.
|
||||
|
||||
* Browse to the download location.
|
||||
* Right click on the downloaded .zip file and select ‘extract here’.
|
||||
* Open the extracted folder, right click and select ‘Open in terminal’.
|
||||
* Copy paste the command in the terminal and hit enter.
|
||||
`bash ./README_and_install.sh`
|
||||
* Now a dialogue box will pop up asking you to select the folder containing the wallpapers. Click on it and then select the folder that you’ve stored your wallpapers in.
|
||||
* That’s it. Reboot your computer.
|
||||
|
||||
|
||||
|
||||
![Little Simple Wallpaper Changer for Linux][4]
|
||||
|
||||
#### Using LSWC
|
||||
|
||||
On installation, LSWC asks you to select the folder containing your wallpapers. So I suggest you create a folder and move all the wallpapers you want to use there before we install LSWC. Or you can just use the ‘Wallpapers’ folder in the Pictures folder. **All the wallpapers need to be .jpg format.**
|
||||
|
||||
You can add more wallpapers or delete the current wallpapers from your selected folder. To change the wallpapers folder location, you can edit the location of the wallpapers in the
|
||||
following file.
|
||||
```
|
||||
.config/lswc/homepath.conf
|
||||
|
||||
```
|
||||
|
||||
#### To remove LSWC
|
||||
|
||||
Open a terminal and run the below command to stop LSWC
|
||||
```
|
||||
pkill lswc
|
||||
|
||||
```
|
||||
|
||||
Open home in your file manager and press ctrl+H to show hidden files, then delete the following files:
|
||||
|
||||
* ‘scripts’ folder from .local
|
||||
* ‘lswc’ folder from .config
|
||||
* ‘lswc.desktop’ file from .config/autostart
|
||||
|
||||
|
||||
|
||||
There you have it. How to create your own desktop background slideshow. LSWC is really lightweight and simple to use. Install it and then forget it.
|
||||
|
||||
LSWC is not very feature rich but that intentional. It does what it intends to do and that is to change wallpapers. If you want a tool that automatically downloads wallpapers try [WallpaperDownloader][5].
|
||||
|
||||
Do share your thoughts on this nifty little software in the comments section below. Don’t forget to share this article. Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/little-simple-wallpaper-changer/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://github.com/LittleSimpleWallpaperChanger/lswc
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/Little-simple-wallpaper-changer-2-800x450.jpg
|
||||
[3]:https://github.com/LittleSimpleWallpaperChanger/lswc/raw/master/Lswc.zip
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/Little-simple-wallpaper-changer-1-800x450.jpg
|
||||
[5]:https://itsfoss.com/wallpaperdownloader-linux/
|
||||
@ -0,0 +1,181 @@
|
||||
How to Check Disk Space on Linux from the Command Line
|
||||
======
|
||||
|
||||

|
||||
|
||||
Quick question: How much space do you have left on your drives? A little or a lot? Follow up question: Do you know how to find out? If you happen to use a GUI desktop (e.g., GNOME, KDE, Mate, Pantheon, etc.), the task is probably pretty simple. But what if you’re looking at a headless server, with no GUI? Do you need to install tools for the task? The answer is a resounding no. All the necessary bits are already in place to help you find out exactly how much space remains on your drives. In fact, you have two very easy-to-use options at the ready.
|
||||
|
||||
In this article, I’ll demonstrate these tools. I’ll be using [Elementary OS][1], which also includes a GUI option, but we’re going to limit ourselves to the command line. The good news is these command-line tools are readily available for every Linux distribution. On my testing system, there are a number of attached drives (both internal and external). The commands used are agnostic to where a drive is plugged in; they only care that the drive is mounted and visible to the operating system.
|
||||
|
||||
With that said, let’s take a look at the tools.
|
||||
|
||||
### df
|
||||
|
||||
The df command is the tool I first used to discover drive space on Linux, way back in the 1990s. It’s very simple in both usage and reporting. To this day, df is my go-to command for this task. This command has a few switches but, for basic reporting, you really only need one. That command is df -H. The -H switch is for human-readable format. The output of df -H will report how much space is used, available, percentage used, and the mount point of every disk attached to your system (Figure 1).
|
||||
|
||||
|
||||
![df output][3]
|
||||
|
||||
Figure 1: The output of df -H on my Elementary OS system.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
What if your list of drives is exceedingly long and you just want to view the space used on a single drive? With df, that is possible. Let’s take a look at how much space has been used up on our primary drive, located at /dev/sda1. To do that, issue the command:
|
||||
```
|
||||
df -H /dev/sda1
|
||||
|
||||
```
|
||||
|
||||
The output will be limited to that one drive (Figure 2).
|
||||
|
||||
|
||||
![disk usage][6]
|
||||
|
||||
Figure 2: How much space is on one particular drive?
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
You can also limit the reported fields shown in the df output. Available fields are:
|
||||
|
||||
* source — the file system source
|
||||
|
||||
* size — total number of blocks
|
||||
|
||||
* used — spaced used on a drive
|
||||
|
||||
* avail — space available on a drive
|
||||
|
||||
* pcent — percent of used space, divided by total size
|
||||
|
||||
* target — mount point of a drive
|
||||
|
||||
|
||||
|
||||
|
||||
Let’s display the output of all our drives, showing only the size, used, and avail (or availability) fields. The command for this would be:
|
||||
```
|
||||
df -H --output=size,used,avail
|
||||
|
||||
```
|
||||
|
||||
The output of this command is quite easy to read (Figure 3).
|
||||
|
||||
|
||||
![output][8]
|
||||
|
||||
Figure 3: Specifying what output to display for our drives.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
The only caveat here is that we don’t know the source of the output, so we’d want to include source like so:
|
||||
```
|
||||
df -H --output=source,size,used,avail
|
||||
|
||||
```
|
||||
|
||||
Now the output makes more sense (Figure 4).
|
||||
|
||||
![source][10]
|
||||
|
||||
Figure 4: We now know the source of our disk usage.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
### du
|
||||
|
||||
Our next command is du. As you might expect, that stands for disk usage. The du command is quite different to the df command, in that it reports on directories and not drives. Because of this, you’ll want to know the names of directories to be checked. Let’s say I have a directory containing virtual machine files on my machine. That directory is /media/jack/HALEY/VIRTUALBOX. If I want to find out how much space is used by that particular directory, I’d issue the command:
|
||||
```
|
||||
du -h /media/jack/HALEY/VIRTUALBOX
|
||||
|
||||
```
|
||||
|
||||
The output of the above command will display the size of every file in the directory (Figure 5).
|
||||
|
||||
![du command][12]
|
||||
|
||||
Figure 5: The output of the du command on a specific directory.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
So far, this command isn’t all that helpful. What if we want to know the total usage of a particular directory? Fortunately, du can handle that task. On the same directory, the command would be:
|
||||
```
|
||||
du -sh /media/jack/HALEY/VIRTUALBOX/
|
||||
|
||||
```
|
||||
|
||||
Now we know how much total space the files are using up in that directory (Figure 6).
|
||||
|
||||
![space used][14]
|
||||
|
||||
Figure 6: My virtual machine files are using 559GB of space.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
You can also use this command to see how much space is being used on all child directories of a parent, like so:
|
||||
```
|
||||
du -h /media/jack/HALEY
|
||||
|
||||
```
|
||||
|
||||
The output of this command (Figure 7) is a good way to find out what subdirectories are hogging up space on a drive.
|
||||
|
||||
![directories][16]
|
||||
|
||||
Figure 7: How much space are my subdirectories using?
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
The du command is also a great tool to use in order to see a list of directories that are using the most disk space on your system. The way to do this is by piping the output of du to two other commands: sort and head. The command to find out the top 10 directories eating space on a drive would look something like this:
|
||||
```
|
||||
du -a /media/jack | sort -n -r | head -n 10
|
||||
|
||||
```
|
||||
|
||||
The output would list out those directories, from largest to least offender (Figure 8).
|
||||
|
||||
![top users][18]
|
||||
|
||||
Figure 8: Our top ten directories using up space on a drive.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
### Not as hard as you thought
|
||||
|
||||
Finding out how much space is being used on your Linux-attached drives is quite simple. As long as your drives are mounted to the Linux system, both df and du will do an outstanding job of reporting the necessary information. With df you can quickly see an overview of how much space is used on a disk and with du you can discover how much space is being used by specific directories. These two tools in combination should be considered must-know for every Linux administrator.
|
||||
|
||||
And, in case you missed it, I recently showed how to [determine your memory usage on Linux][19]. Together, these tips will go a long way toward helping you successfully manage your Linux servers.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux"][20]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/6how-check-disk-space-linux-command-line
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://elementary.io/
|
||||
[2]:/files/images/diskspace1jpg
|
||||
[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_1.jpg?itok=aJa8AZAM (df output)
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:/files/images/diskspace2jpg
|
||||
[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_2.jpg?itok=_PAq3kxC (disk usage)
|
||||
[7]:/files/images/diskspace3jpg
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_3.jpg?itok=51m8I-Vu (output)
|
||||
[9]:/files/images/diskspace4jpg
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_4.jpg?itok=SuwgueN3 (source)
|
||||
[11]:/files/images/diskspace5jpg
|
||||
[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_5.jpg?itok=XfS4s7Zq (du command)
|
||||
[13]:/files/images/diskspace6jpg
|
||||
[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_6.jpg?itok=r71qICyG (space used)
|
||||
[15]:/files/images/diskspace7jpg
|
||||
[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_7.jpg?itok=PtDe4q5y (directories)
|
||||
[17]:/files/images/diskspace8jpg
|
||||
[18]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_8.jpg?itok=v9E1SFcC (top users)
|
||||
[19]:https://www.linux.com/learn/5-commands-checking-memory-usage-linux
|
||||
[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
215
sources/tech/20180622 Use LVM to Upgrade Fedora.md
Normal file
215
sources/tech/20180622 Use LVM to Upgrade Fedora.md
Normal file
@ -0,0 +1,215 @@
|
||||
Use LVM to Upgrade Fedora
|
||||
======
|
||||
|
||||

|
||||
|
||||
Most users find it simple to upgrade [from one Fedora release to the next][1] with the standard process. However, there are inevitably many special cases that Fedora can also handle. This article shows one way to upgrade using DNF along with Logical Volume Management (LVM) to keep a bootable backup in case of problems. This example upgrades a Fedora 26 system to Fedora 28.
|
||||
|
||||
The process shown here is more complex than the standard upgrade process. You should have a strong grasp of how LVM works before you use this process. Without proper skill and care, you could **lose data and/or be forced to reinstall your system!** If you don’t know what you’re doing, it is **highly recommended** you stick to the supported upgrade methods only.
|
||||
|
||||
### Preparing the system
|
||||
|
||||
Before you start, ensure your existing system is fully updated.
|
||||
```
|
||||
$ sudo dnf update
|
||||
$ sudo systemctl reboot # or GUI equivalent
|
||||
|
||||
```
|
||||
|
||||
Check that your root filesystem is mounted via LVM.
|
||||
```
|
||||
$ df /
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg_sdg-f26 20511312 14879816 4566536 77% /
|
||||
|
||||
$ sudo lvs
|
||||
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
|
||||
f22 vg_sdg -wi-ao---- 15.00g
|
||||
f24_64 vg_sdg -wi-ao---- 20.00g
|
||||
f26 vg_sdg -wi-ao---- 20.00g
|
||||
home vg_sdg -wi-ao---- 100.00g
|
||||
mockcache vg_sdg -wi-ao---- 10.00g
|
||||
swap vg_sdg -wi-ao---- 4.00g
|
||||
test vg_sdg -wi-a----- 1.00g
|
||||
vg_vm vg_sdg -wi-ao---- 20.00g
|
||||
|
||||
```
|
||||
|
||||
If you used the defaults when you installed Fedora, you may find the root filesystem is mounted on a LV named root. The name of your volume group will likely be different. Look at the total size of the root volume. In the example, the root filesystem is named f26 and is 20G in size.
|
||||
|
||||
Next, ensure you have enough free space in LVM.
|
||||
```
|
||||
$ sudo vgs
|
||||
VG #PV #LV #SN Attr VSize VFree
|
||||
vg_sdg 1 8 0 wz--n- 232.39g 42.39g
|
||||
|
||||
```
|
||||
|
||||
This system has enough free space to allocate a 20G logical volume for the upgraded Fedora 28 root. If you used the default install, there will be no free space in LVM. Managing LVM in general is beyond the scope of this article, but here are some possibilities:
|
||||
|
||||
1\. /home on its own LV, and lots of free space in /home
|
||||
|
||||
You can logout of the GUI and switch to a text console, logging in as root. Then you can unmount /home, and use lvreduce -r to resize and reallocate the /home LV. You might also boot from a Live image (so as not to use /home) and use the gparted GUI utility.
|
||||
|
||||
2\. Most of the LVM space allocated to a root LV, with lots of free space in the filesystem
|
||||
|
||||
You can boot from a Live image and use the gparted GUI utility to reduce the root LV. Consider moving /home to its own filesystem at this point, but that is beyond the scope of this article.
|
||||
|
||||
3\. Most of the file systems are full, but you have LVs you no longer need
|
||||
|
||||
You can delete the unneeded LVs, freeing space in the volume group for this operation.
|
||||
|
||||
### Creating a backup
|
||||
|
||||
First, allocate a new LV for the upgraded system. Make sure to use the correct name for your system’s volume group (VG). In this example it’s vg_sdg.
|
||||
```
|
||||
$ sudo lvcreate -L20G -n f28 vg_sdg
|
||||
Logical volume "f28" created.
|
||||
|
||||
```
|
||||
|
||||
Next, make a snapshot of your current root filesystem. This example creates a snapshot volume named f26_s.
|
||||
```
|
||||
$ sync
|
||||
$ sudo lvcreate -s -L1G -n f26_s vg_sdg/f26
|
||||
Using default stripesize 64.00 KiB.
|
||||
Logical volume "f26_s" created.
|
||||
|
||||
```
|
||||
|
||||
The snapshot can now be copied to the new LV. **Make sure you have the destination correct** when you substitute your own volume names. If you are not careful you could delete data irrevocably. Also, make sure you are copying from the snapshot of your root, **not** your live root.
|
||||
```
|
||||
$ sudo dd if=/dev/vg_sdg/f26_s of=/dev/vg_sdg/f28 bs=256k
|
||||
81920+0 records in
|
||||
81920+0 records out
|
||||
21474836480 bytes (21 GB, 20 GiB) copied, 149.179 s, 144 MB/s
|
||||
|
||||
```
|
||||
|
||||
Give the new filesystem copy a unique UUID. This is not strictly necessary, but UUIDs are supposed to be unique, so this avoids future confusion. Here is how for an ext4 root filesystem:
|
||||
```
|
||||
$ sudo e2fsck -f /dev/vg_sdg/f28
|
||||
$ sudo tune2fs -U random /dev/vg_sdg/f28
|
||||
|
||||
```
|
||||
|
||||
Then remove the snapshot volume which is no longer needed:
|
||||
```
|
||||
$ sudo lvremove vg_sdg/f26_s
|
||||
Do you really want to remove active logical volume vg_sdg/f26_s? [y/n]: y
|
||||
Logical volume "f26_s" successfully removed
|
||||
|
||||
```
|
||||
|
||||
You may wish to make a snapshot of /home at this point if you have it mounted separately. Sometimes, upgraded applications make changes that are incompatible with a much older Fedora version. If needed, edit the /etc/fstab file on the **old** root filesystem to mount the snapshot on /home. Remember that when the snapshot is full, it will disappear! You may also wish to make a normal backup of /home for good measure.
|
||||
|
||||
### Configuring to use the new root
|
||||
|
||||
First, mount the new LV and backup your existing GRUB settings:
|
||||
```
|
||||
$ sudo mkdir /mnt/f28
|
||||
$ sudo mount /dev/vg_sdg/f28 /mnt/f28
|
||||
$ sudo mkdir /mnt/f28/f26
|
||||
$ cd /boot/grub2
|
||||
$ sudo cp -p grub.cfg grub.cfg.old
|
||||
|
||||
```
|
||||
|
||||
Edit grub.conf and add this before the first menuentry, unless you already have it:
|
||||
```
|
||||
menuentry 'Old boot menu' {
|
||||
configfile /grub2/grub.cfg.old
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Edit grub.conf and change the default menuentry to activate and mount the new root filesystem. Change this line:
|
||||
```
|
||||
linux16 /vmlinuz-4.16.11-100.fc26.x86_64 root=/dev/mapper/vg_sdg-f26 ro rd.lvm.lv=vg_sdg/f26 rd.lvm.lv=vg_sdg/swap rhgb quiet LANG=en_US.UTF-8
|
||||
|
||||
```
|
||||
|
||||
So that it reads like this. Remember to use the correct names for your system’s VG and LV entries!
|
||||
```
|
||||
linux16 /vmlinuz-4.16.11-100.fc26.x86_64 root=/dev/mapper/vg_sdg-f28 ro rd.lvm.lv=vg_sdg/f28 rd.lvm.lv=vg_sdg/swap rhgb quiet LANG=en_US.UTF-8
|
||||
|
||||
```
|
||||
|
||||
Edit /mnt/f28/etc/default/grub and change the default root LV activated at boot:
|
||||
```
|
||||
GRUB_CMDLINE_LINUX="rd.lvm.lv=vg_sdg/f28 rd.lvm.lv=vg_sdg/swap rhgb quiet"
|
||||
|
||||
```
|
||||
|
||||
Edit /mnt/f28/etc/fstab to change the mounting of the root filesystem from the old volume:
|
||||
```
|
||||
/dev/mapper/vg_sdg-f26 / ext4 defaults 1 1
|
||||
|
||||
```
|
||||
|
||||
to the new one:
|
||||
```
|
||||
/dev/mapper/vg_sdg-f28 / ext4 defaults 1 1
|
||||
|
||||
```
|
||||
|
||||
Then, add a read-only mount of the old system for reference purposes:
|
||||
```
|
||||
/dev/mapper/vg_sdg-f26 /f26 ext4 ro,nodev,noexec 0 0
|
||||
|
||||
```
|
||||
|
||||
If your root filesystem is mounted by UUID, you will need to change this. Here is how if your root is an ext4 filesystem:
|
||||
```
|
||||
$ sudo e2label /dev/vg_sdg/f28 F28
|
||||
|
||||
```
|
||||
|
||||
Now edit /mnt/f28/etc/fstab to use the label. Change the mount line for the root file system so it reads like this:
|
||||
```
|
||||
LABEL=F28 / ext4 defaults 1 1
|
||||
|
||||
```
|
||||
|
||||
### Rebooting and upgrading
|
||||
|
||||
Reboot, and your system will be using the new root filesystem. It is still Fedora 26, but a copy with a new LV name, and ready for dnf system-upgrade! If anything goes wrong, use the Old Boot Menu to boot back into your working system, which this procedure avoids touching.
|
||||
```
|
||||
$ sudo systemctl reboot # or GUI equivalent
|
||||
...
|
||||
$ df / /f26
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg_sdg-f28 20511312 14903196 4543156 77% /
|
||||
/dev/mapper/vg_sdg-f26 20511312 14866412 4579940 77% /f26
|
||||
|
||||
```
|
||||
|
||||
You may wish to verify that using the Old Boot Menu does indeed get you back to having root mounted on the old root filesystem.
|
||||
|
||||
Now follow the instructions at [this wiki page][2]. If anything goes wrong with the system upgrade, you have a working system to boot back into.
|
||||
|
||||
### Future ideas
|
||||
|
||||
The steps to create a new LV and copy a snapshot of root to it could be automated with a generic script. It needs only the name of the new LV, since the size and device of the existing root are easy to determine. For example, one would be able to type this command:
|
||||
```
|
||||
$ sudo copyfs / f28
|
||||
|
||||
```
|
||||
|
||||
Supplying the mount-point to copy makes it clearer what is happening, and copying other mount-points like /home could be useful.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-lvm-upgrade-fedora/
|
||||
|
||||
作者:[Stuart D Gathman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/sdgathman/
|
||||
[1]:https://fedoramagazine.org/upgrading-fedora-27-fedora-28/
|
||||
[2]:https://fedoraproject.org/wiki/DNF_system_upgrade
|
||||
@ -0,0 +1,203 @@
|
||||
Don’t Install Yaourt! Use These Alternatives for AUR in Arch Linux
|
||||
======
|
||||
**Brief: Yaourt had been the most popular AUR helper, but it is not being developed anymore. In this article, we list out some of the best alternatives to Yaourt for Arch based Linux distributions. **
|
||||
|
||||
[Arch User Repository][1] popularly known as AUR is the community-driven software repository for Arch users. Debian/Ubuntu users can think of AUR as the equivalent of PPA.
|
||||
|
||||
It contains the packages that are not directly endorsed by [Arch Linux][2]. If someone develops a software or package for Arch Linux, it can be provided through this community repositories. This enables the end-user to access more software than what they get by default.
|
||||
|
||||
So, how do you use AUR then? Well, you need a different tool to install software from AUR. Arch’s package manager [pacman][3] doesn’t support it directly. These ‘special tools’ are called [AUR helpers][4].
|
||||
|
||||
Yaourt (Yet AnOther User Repository Tool) is/was a wrapper for pacman that helps to install AUR packages on Arch Linux. It uses the same syntax as pacman. Yaourt has great support for Arch User Repository for searching, installing, conflict resolution and dependency maintenance.
|
||||
|
||||
However, Yaourt development has been slow lately and is [listed][5] as “Discontinued or problematic” on Arch Wiki. [Many Arch User believe it’s not secure][6] and hence go towards a different AUR helper.
|
||||
|
||||
![AUR Helpers other than Yaourt][7]
|
||||
|
||||
In this article, we will see the best Yaourt alternatives that you can use for installing software from AUR.
|
||||
|
||||
### Best AUR helpers to use AUR
|
||||
|
||||
I am deliberating omitting some of the other popular AUR helpers like trizen or packer because they too have been flagged as ‘discontinued or problematic’.
|
||||
|
||||
#### 1\. aurman
|
||||
|
||||
[aurman][8] is one of the best AUR helpers and serves pretty well as an alternative to Yaourt. It has almost similar syntax to pacman with support for all pacman operations. You can search the AUR, resolve dependencies, check PKGBUILD content before a package build etc.
|
||||
|
||||
##### Features of aurman
|
||||
|
||||
* aurman supports all pacman operations and incorporates reliable dependency resolving, conflict detection and split package support.
|
||||
* Threaded sudo loop runs in the background saving you from entering your password each time.
|
||||
* Provides development package support and distincts between explictily and inlicitly installed packages.
|
||||
* Support for searching of AUR packages and repositories.
|
||||
* You can see and edit the PKGBUILDs before starting AUR package build.
|
||||
* It can also be used as a standalone [dependency solver][9].
|
||||
|
||||
|
||||
|
||||
##### Installing aurman
|
||||
```
|
||||
git clone https://aur.archlinux.org/aurman.git
|
||||
cd aurman
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### Using aurman
|
||||
|
||||
Searching for an application through aurman in Arch User Repository is done in the following manner:
|
||||
```
|
||||
aurman -Ss <package-name>
|
||||
|
||||
```
|
||||
|
||||
Installing an application using aurman:
|
||||
```
|
||||
aurman -S <package-name>
|
||||
|
||||
```
|
||||
|
||||
#### 2\. yay
|
||||
|
||||
[yay][10] is the next best AUR helper written in Go with the objective of providing an interface of pacman with minimal user input, yaourt like search and with almost no dependencies.
|
||||
|
||||
##### Features of yay
|
||||
|
||||
* yay provides AUR table completion and download the PKGBUILD from ABS or AUR.
|
||||
* Supports search narrowing and no sourcing of PKGBUILD.
|
||||
* The binary has no additional dependencies than pacman.
|
||||
* Provides advanced dependency solver and remove make dependencies at the end of the build process.
|
||||
* Supports colored output when you enable Color option in the /etc/pacman.conf file.
|
||||
* It can be made to support only AUR package or only repo packages.
|
||||
|
||||
|
||||
|
||||
##### Installing yay
|
||||
|
||||
You can install yay by cloning the git repo and building it. Use the below command to install yay in Arch Linux :
|
||||
```
|
||||
git clone https://aur.archlinux.org/yay.git
|
||||
cd yay
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### Using yay
|
||||
|
||||
Searching an application through Yay in AUR:
|
||||
```
|
||||
yay -Ss <package-name>
|
||||
|
||||
```
|
||||
|
||||
Installing an application:
|
||||
```
|
||||
yay -S <package-name>
|
||||
|
||||
```
|
||||
|
||||
#### 3\. pakku
|
||||
|
||||
[Pakku][11] is another pacman wrapper which is still in its initial stage. However, just because its new doesn’t mean its lacking any of the features supported by other AUR helper. It does its job pretty nice and along with searching and installing applications from AUR, it removes dependencies after a build.
|
||||
|
||||
##### Features of pakku
|
||||
|
||||
* Searching and installing packages from Arch User Repository.
|
||||
* Viewing files and changes between builds.
|
||||
* Building packages from official repositories and removing make dependencies after a build.
|
||||
* PKGBUILD retrieving and Pacman integration.
|
||||
* Pacman-like user interface and pacman options supports.
|
||||
* Pacman configuration supports and no PKGBUILD sourcing.
|
||||
|
||||
|
||||
|
||||
##### Installing pakku
|
||||
```
|
||||
git clone https://aur.archlinux.org/pakku.git
|
||||
cd pakku
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### Using pakku
|
||||
|
||||
You can search an application from AUR using below command.:
|
||||
```
|
||||
pakku -Ss spotify
|
||||
|
||||
```
|
||||
|
||||
And then the package can be installed similar to pacman:
|
||||
```
|
||||
pakku -S spotify
|
||||
|
||||
```
|
||||
|
||||
#### 4\. aurutils
|
||||
|
||||
[aurutils][12] is basically a collection of scripts that automates the usage of Arch User Repository. It can search AUR, check updates for different applications installed and settle up dependencies issues.
|
||||
|
||||
##### Features of aurutils
|
||||
|
||||
* aurutils uses a local repository which gives it a benefit of pacman file support, and all packages works with –asdeps.
|
||||
* There can be multiple repos for different tasks.
|
||||
* Update local repository in one go with aursync -u
|
||||
* pkgbase, long format and raw support for aursearch
|
||||
* Ability to ignore package
|
||||
|
||||
|
||||
|
||||
##### Installing aurutils
|
||||
```
|
||||
git clone https://aur.archlinux.org/aurutils.git
|
||||
cd aurutils
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### Using aurutils
|
||||
|
||||
Searching an application via aurutils:
|
||||
```
|
||||
aurutils -Ss <package-name>
|
||||
|
||||
```
|
||||
|
||||
Installing a package from AUR:
|
||||
```
|
||||
aurutils -S <package-name>
|
||||
|
||||
```
|
||||
|
||||
All of these packages can directly be installed if you are already using Yaourt or any other AUR helper.
|
||||
|
||||
#### Final Words on AUR helpers
|
||||
|
||||
Arch Linux has some [more AUR helper][4] that can automate certain tasks for the Arch User Repository. Many users are still using Yaourt for their AUR-work and
|
||||
|
||||
The choice differs for each user and we would like to know which one you use for your Arch Linux. Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-aur-helpers/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ambarish/
|
||||
[1]:https://wiki.archlinux.org/index.php/Arch_User_Repository
|
||||
[2]:https://www.archlinux.org/
|
||||
[3]:https://wiki.archlinux.org/index.php/pacman
|
||||
[4]:https://wiki.archlinux.org/index.php/AUR_helpers
|
||||
[5]:https://wiki.archlinux.org/index.php/AUR_helpers#Comparison_table
|
||||
[6]:https://www.reddit.com/r/archlinux/comments/4azqyb/whats_so_bad_with_yaourt/
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/no-yaourt-arch-800x450.jpeg
|
||||
[8]:https://github.com/polygamma/aurman
|
||||
[9]:https://github.com/polygamma/aurman/wiki/Using-aurman-as-dependency-solver
|
||||
[10]:https://github.com/Jguer/yay
|
||||
[11]:https://github.com/kitsunyan/pakku
|
||||
[12]:https://github.com/AladW/aurutils
|
||||
@ -0,0 +1,293 @@
|
||||
Intercepting and Emulating Linux System Calls with Ptrace « null program
|
||||
======
|
||||
|
||||
The `ptrace(2)` (“process trace”) system call is usually associated with debugging. It’s the primary mechanism through which native debuggers monitor debuggees on unix-like systems. It’s also the usual approach for implementing [strace][1] — system call trace. With Ptrace, tracers can pause tracees, [inspect and set registers and memory][2], monitor system calls, or even intercept system calls.
|
||||
|
||||
By intercept, I mean that the tracer can mutate system call arguments, mutate the system call return value, or even block certain system calls. Reading between the lines, this means a tracer can fully service system calls itself. This is particularly interesting because it also means **a tracer can emulate an entire foreign operating system**. This is done without any special help from the kernel beyond Ptrace.
|
||||
|
||||
The catch is that a process can only have one tracer attached at a time, so it’s not possible emulate a foreign operating system while also debugging that process with, say, GDB. The other issue is that emulated systems calls will have higher overhead.
|
||||
|
||||
For this article I’m going to focus on [Linux’s Ptrace][3] on x86-64, and I’ll be taking advantage of a few Linux-specific extensions. For the article I’ll also be omitting error checks, but the full source code listings will have them.
|
||||
|
||||
You can find runnable code for the examples in this article here:
|
||||
|
||||
**<https://github.com/skeeto/ptrace-examples>**
|
||||
|
||||
### strace
|
||||
|
||||
Before getting into the really interesting stuff, let’s start by reviewing a bare bones implementation of strace. It’s [no DTrace][4], but strace is still incredibly useful.
|
||||
|
||||
Ptrace has never been standardized. Its interface is similar across different operating systems, especially in its core functionality, but it’s still subtly different from system to system. The `ptrace(2)` prototype generally looks something like this, though the specific types may be different.
|
||||
```
|
||||
long ptrace(int request, pid_t pid, void *addr, void *data);
|
||||
|
||||
```
|
||||
|
||||
The `pid` is the tracee’s process ID. While a tracee can have only one tracer attached at a time, a tracer can be attached to many tracees.
|
||||
|
||||
The `request` field selects a specific Ptrace function, just like the `ioctl(2)` interface. For strace, only two are needed:
|
||||
|
||||
* `PTRACE_TRACEME`: This process is to be traced by its parent.
|
||||
* `PTRACE_SYSCALL`: Continue, but stop at the next system call entrance or exit.
|
||||
* `PTRACE_GETREGS`: Get a copy of the tracee’s registers.
|
||||
|
||||
|
||||
|
||||
The other two fields, `addr` and `data`, serve as generic arguments for the selected Ptrace function. One or both are often ignored, in which case I pass zero.
|
||||
|
||||
The strace interface is essentially a prefix to another command.
|
||||
```
|
||||
$ strace [strace options] program [arguments]
|
||||
|
||||
```
|
||||
|
||||
My minimal strace doesn’t have any options, so the first thing to do — assuming it has at least one argument — is `fork(2)` and `exec(2)` the tracee process on the tail of `argv`. But before loading the target program, the new process will inform the kernel that it’s going to be traced by its parent. The tracee will be paused by this Ptrace system call.
|
||||
```
|
||||
pid_t pid = fork();
|
||||
switch (pid) {
|
||||
case -1: /* error */
|
||||
FATAL("%s", strerror(errno));
|
||||
case 0: /* child */
|
||||
ptrace(PTRACE_TRACEME, 0, 0, 0);
|
||||
execvp(argv[1], argv + 1);
|
||||
FATAL("%s", strerror(errno));
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The parent waits for the child’s `PTRACE_TRACEME` using `wait(2)`. When `wait(2)` returns, the child will be paused.
|
||||
```
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
Before allowing the child to continue, we tell the operating system that the tracee should be terminated along with its parent. A real strace implementation may want to set other options, such as `PTRACE_O_TRACEFORK`.
|
||||
```
|
||||
ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_EXITKILL);
|
||||
|
||||
```
|
||||
|
||||
All that’s left is a simple, endless loop that catches on system calls one at a time. The body of the loop has four steps:
|
||||
|
||||
1. Wait for the process to enter the next system call.
|
||||
2. Print a representation of the system call.
|
||||
3. Allow the system call to execute and wait for the return.
|
||||
4. Print the system call return value.
|
||||
|
||||
|
||||
|
||||
The `PTRACE_SYSCALL` request is used in both waiting for the next system call to begin, and waiting for that system call to exit. As before, a `wait(2)` is needed to wait for the tracee to enter the desired state.
|
||||
```
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
When `wait(2)` returns, the registers for the thread that made the system call are filled with the system call number and its arguments. However, the operating system has not yet serviced this system call. This detail will be important later.
|
||||
|
||||
The next step is to gather the system call information. This is where it gets architecture specific. On x86-64, [the system call number is passed in `rax`][5], and the arguments (up to 6) are passed in `rdi`, `rsi`, `rdx`, `r10`, `r8`, and `r9`. Reading the registers is another Ptrace call, though there’s no need to `wait(2)` since the tracee isn’t changing state.
|
||||
```
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
long syscall = regs.orig_rax;
|
||||
|
||||
fprintf(stderr, "%ld(%ld, %ld, %ld, %ld, %ld, %ld)",
|
||||
syscall,
|
||||
(long)regs.rdi, (long)regs.rsi, (long)regs.rdx,
|
||||
(long)regs.r10, (long)regs.r8, (long)regs.r9);
|
||||
|
||||
```
|
||||
|
||||
There’s one caveat. For [internal kernel purposes][6], the system call number is stored in `orig_rax` rather than `rax`. All the other system call arguments are straightforward.
|
||||
|
||||
Next it’s another `PTRACE_SYSCALL` and `wait(2)`, then another `PTRACE_GETREGS` to fetch the result. The result is stored in `rax`.
|
||||
```
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
fprintf(stderr, " = %ld\n", (long)regs.rax);
|
||||
|
||||
```
|
||||
|
||||
The output from this simple program is very crude. There is no symbolic name for the system call and every argument is printed numerically, even if it’s a pointer to a buffer. A more complete strace would know which arguments are pointers and use `process_vm_readv(2)` to read those buffers from the tracee in order to print them appropriately.
|
||||
|
||||
However, this does lay the groundwork for system call interception.
|
||||
|
||||
### System call interception
|
||||
|
||||
Suppose we want to use Ptrace to implement something like OpenBSD’s [`pledge(2)`][7], in which [a process pledges to use only a restricted set of system calls][8]. The idea is that many programs typically have an initialization phase where they need lots of system access (opening files, binding sockets, etc.). After initialization they enter a main loop in which they processing input and only a small set of system calls are needed.
|
||||
|
||||
Before entering this main loop, a process can limit itself to the few operations that it needs. If [the program has a flaw][9] allowing it to be exploited by bad input, the pledge significantly limits what the exploit can accomplish.
|
||||
|
||||
Using the same strace model, rather than print out all system calls, we could either block certain system calls or simply terminate the tracee when it misbehaves. Termination is easy: just call `exit(2)` in the tracer. Since it’s configured to also terminate the tracee. Blocking the system call and allowing the child to continue is a little trickier.
|
||||
|
||||
The tricky part is that **there’s no way to abort a system call once it’s started**. When tracer returns from `wait(2)` on the entrance to the system call, the only way to stop a system call from happening is to terminate the tracee.
|
||||
|
||||
However, not only can we mess with the system call arguments, we can change the system call number itself, converting it to a system call that doesn’t exist. On return we can report a “friendly” `EPERM` error in `errno` [via the normal in-band signaling][10].
|
||||
```
|
||||
for (;;) {
|
||||
/* Enter next system call */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
/* Is this system call permitted? */
|
||||
int blocked = 0;
|
||||
if (is_syscall_blocked(regs.orig_rax)) {
|
||||
blocked = 1;
|
||||
regs.orig_rax = -1; // set to invalid syscall
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
|
||||
/* Run system call and stop on exit */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
if (blocked) {
|
||||
/* errno = EPERM */
|
||||
regs.rax = -EPERM; // Operation not permitted
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This simple example only checks against a whitelist or blacklist of system calls. And there’s no nuance, such as allowing files to be opened (`open(2)`) read-only but not as writable, allowing anonymous memory maps but not non-anonymous mappings, etc. There’s also no way to the tracee to dynamically drop privileges.
|
||||
|
||||
How could the tracee communicate to the tracer? Use an artificial system call!
|
||||
|
||||
### Creating an artificial system call
|
||||
|
||||
For my new pledge-like system call — which I call `xpledge()` to distinguish it from the real thing — I picked system call number 10000, a nice high number that’s unlikely to ever be used for a real system call.
|
||||
```
|
||||
#define SYS_xpledge 10000
|
||||
|
||||
```
|
||||
|
||||
Just for demonstration purposes, I put together a minuscule interface that’s not good for much in practice. It has little in common with OpenBSD’s `pledge(2)`, which uses a [string interface][11]. Actually designing robust and secure sets of privileges is really complicated, as the `pledge(2)` manpage shows. Here’s the entire interface and implementation of the system call for the tracee:
|
||||
```
|
||||
#define _GNU_SOURCE
|
||||
#include <unistd.h>
|
||||
|
||||
#define XPLEDGE_RDWR (1 << 0)
|
||||
#define XPLEDGE_OPEN (1 << 1)
|
||||
|
||||
#define xpledge(arg) syscall(SYS_xpledge, arg)
|
||||
|
||||
```
|
||||
|
||||
If it passes zero for the argument, only a few basic system calls are allowed, including those used to allocate memory (e.g. `brk(2)`). The `PLEDGE_RDWR` bit allows [various][12] read and write system calls (`read(2)`, `readv(2)`, `pread(2)`, `preadv(2)`, etc.). The `PLEDGE_OPEN` bit allows `open(2)`.
|
||||
|
||||
To prevent privileges from being escalated back, `pledge()` blocks itself — though this also prevents dropping more privileges later down the line.
|
||||
|
||||
In the xpledge tracer, I just need to check for this system call:
|
||||
```
|
||||
/* Handle entrance */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
register_pledge(regs.rdi);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The operating system will return `ENOSYS` (Function not implemented) since this isn’t a real system call. So on the way out I overwrite this with a success (0).
|
||||
```
|
||||
/* Handle exit */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
ptrace(PTRACE_POKEUSER, pid, RAX * 8, 0);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
I wrote a little test program that opens `/dev/urandom`, makes a read, tries to pledge, then tries to open `/dev/urandom` a second time, then confirms it can read from the original `/dev/urandom` file descriptor. Running without a pledge tracer, the output looks like this:
|
||||
```
|
||||
$ ./example
|
||||
fread("/dev/urandom")[1] = 0xcd2508c7
|
||||
XPledging...
|
||||
XPledge failed: Function not implemented
|
||||
fread("/dev/urandom")[2] = 0x0be4a986
|
||||
fread("/dev/urandom")[1] = 0x03147604
|
||||
|
||||
```
|
||||
|
||||
Making an invalid system call doesn’t crash an application. It just fails, which is a rather convenient fallback. When run under the tracer, it looks like this:
|
||||
```
|
||||
$ ./xpledge ./example
|
||||
fread("/dev/urandom")[1] = 0xb2ac39c4
|
||||
XPledging...
|
||||
fopen("/dev/urandom")[2]: Operation not permitted
|
||||
fread("/dev/urandom")[1] = 0x2e1bd1c4
|
||||
|
||||
```
|
||||
|
||||
The pledge succeeds but the second `fopen(3)` does not since the tracer blocked it with `EPERM`.
|
||||
|
||||
This concept could be taken much further, to, say, change file paths or return fake results. A tracer could effectively chroot its tracee, prepending some chroot path to the root of any path passed through a system call. It could even lie to the process about what user it is, claiming that it’s running as root. In fact, this is exactly how the [Fakeroot NG][13] program works.
|
||||
|
||||
### Foreign system emulation
|
||||
|
||||
Suppose you don’t just want to intercept some system calls, but all system calls. You’ve got [a binary intended to run on another operating system][14], so none of the system calls it makes will ever work.
|
||||
|
||||
You could manage all this using only what I’ve described so far. The tracer would always replace the system call number with a dummy, allow it to fail, then service the system call itself. But that’s really inefficient. That’s essentially three context switches for each system call: one to stop on the entrance, one to make the always-failing system call, and one to stop on the exit.
|
||||
|
||||
The Linux version of PTrace has had a more efficient operation for this technique since 2005: `PTRACE_SYSEMU`. PTrace stops only once per a system call, and it’s up to the tracer to service that system call before allowing the tracee to continue.
|
||||
```
|
||||
for (;;) {
|
||||
ptrace(PTRACE_SYSEMU, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
switch (regs.orig_rax) {
|
||||
case OS_read:
|
||||
/* ... */
|
||||
|
||||
case OS_write:
|
||||
/* ... */
|
||||
|
||||
case OS_open:
|
||||
/* ... */
|
||||
|
||||
case OS_exit:
|
||||
/* ... */
|
||||
|
||||
/* ... and so on ... */
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
To run binaries for the same architecture from any system with a stable (enough) system call ABI, you just need this `PTRACE_SYSEMU` tracer, a loader (to take the place of `exec(2)`), and whatever system libraries the binary needs (or only run static binaries).
|
||||
|
||||
In fact, this sounds like a fun weekend project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nullprogram.com/blog/2018/06/23/
|
||||
|
||||
作者:[Chris Wellons][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://nullprogram.com
|
||||
[1]:https://blog.plover.com/Unix/strace-groff.html
|
||||
[2]:http://nullprogram.com/blog/2016/09/03/
|
||||
[3]:http://man7.org/linux/man-pages/man2/ptrace.2.html
|
||||
[4]:http://nullprogram.com/blog/2018/01/17/
|
||||
[5]:http://nullprogram.com/blog/2015/05/15/
|
||||
[6]:https://stackoverflow.com/a/6469069
|
||||
[7]:https://man.openbsd.org/pledge.2
|
||||
[8]:http://www.openbsd.org/papers/hackfest2015-pledge/mgp00001.html
|
||||
[9]:http://nullprogram.com/blog/2017/07/19/
|
||||
[10]:http://nullprogram.com/blog/2016/09/23/
|
||||
[11]:https://www.tedunangst.com/flak/post/string-interfaces
|
||||
[12]:http://nullprogram.com/blog/2017/03/01/
|
||||
[13]:https://fakeroot-ng.lingnu.com/index.php/Home_Page
|
||||
[14]:http://nullprogram.com/blog/2017/11/30/
|
||||
@ -0,0 +1,85 @@
|
||||
8 reasons to use the Xfce Linux desktop environment
|
||||
======
|
||||
|
||||

|
||||
|
||||
For several reasons (including curiosity), a few weeks ago I started using [Xfce][1] as my Linux desktop. One reason was trouble with background daemons eating up all the CPU and I/O bandwidth on my very powerful main workstation. Of course, some of the instability may be due to my removal of some of the RPM packages that provide those background daemons. However, even before I removed the RPMs, the fact is KDE was unstable and causing performance and stability issues. I needed to use a different desktop to avoid these problems.
|
||||
|
||||
I realized in looking back over my series of articles on Linux desktops that I had neglected Xfce. This article is intended to rectify that oversight. I like Xfce a lot and am enjoying the speed and lightness of it more than I thought I would.
|
||||
|
||||
As part of my research, I googled to try to learn what Xfce means. There is a historical reference to XForms Common Environment, but Xfce no longer uses the XForms tools. Some years ago, I found a reference to "Xtra fine computing environment," and I like that a lot. I will use that (despite not being able to find the page reference again).
|
||||
|
||||
### Eight reasons for recommending Xfce
|
||||
|
||||
#### 1\. Lightweight construction
|
||||
|
||||
Xfce has a very small memory footprint and CPU usage compared to some other desktops, such as KDE and GNOME. On my system, the programs that make up the Xfce desktop take a tiny amount of memory for such a powerful desktop. Very low CPU usage is also a hallmark of the Xfce desktop. With such a small memory footprint, I am not especially surprised that Xfce is also very sparing of CPU cycles.
|
||||
|
||||
#### 2\. Simplicity
|
||||
|
||||
The Xfce desktop is simple and uncluttered with fluff. The basic desktop has two panels and a vertical line of icons on the left side. Panel 0 is at the bottom and consists of some basic application launchers, as well as the Applications icon, which provides access to all the applications on the system. Panel 1 is at the top and has an Applications launcher as well as a Workspace Switcher that allows the user to switch between multiple workspaces. The panels can be modified with additional items, such as new launchers, or by altering their height and width.
|
||||
|
||||
The icons down the left side of the desktop consist of the Home directory and Trash icons. It can also display icons for the complete filesystem directory tree and any connected pluggable USB storage devices. These icons can be used to mount and unmount the device, as well as to open the default file manager. They can also be hidden if you prefer, and the Filesystem, Trash, and Home directory icons are separately controllable. The removable drives can be hidden or displayed as a group.
|
||||
|
||||
#### 3\. File management
|
||||
|
||||
Thunar, Xfce's default file manager, is simple, easy to use and configure, and very easy to learn. While not as fancy as file managers like Konqueror or Dolphin, it is quite capable and very fast. Thunar can't create multiple panes in its window, but it does provide tabs so multiple directories can be open at the same time. Thunar also has a very nice sidebar that, like the desktop, shows the same icons for the complete filesystem directory tree and any connected USB storage devices. Devices can be mounted and unmounted, and removable media such as CDs can be ejected. Thunar can also use helper applications such as Ark to open archive files when they are clicked. Archives, such as ZIP, TAR, and RPM files, can be viewed, and individual files can be copied out of them.
|
||||
|
||||
|
||||
![Xfce desktop][3]
|
||||
|
||||
The Xfce desktop with Thunar and the Xfce terminal emulator.
|
||||
|
||||
Having used many different applications for my [series on file managers][4], I must say that I like Thunar for its simplicity and ease of use. It is easy to navigate the filesystem using the sidebar.
|
||||
|
||||
#### 4\. Stability
|
||||
|
||||
The Xfce desktop is very stable. New releases seem to be on a three-year cycle, although updates are provided as necessary. The current version is 4.12, which was released in February 2015. The rock-solid nature of the Xfce desktop is very reassuring after having issues with KDE. The Xfce desktop has never crashed for me, and it has never spawned daemons that gobbled up system resources. It just sits there and works—which is what I want.
|
||||
|
||||
#### 5\. Elegance
|
||||
|
||||
Xfce is simply elegant. In my new book, The Linux Philosophy for SysAdmins, which will be available this fall, I talk about the many advantages of simplicity, including the fact that simplicity is one of the hallmarks of elegance. Clearly, the programmers who write and maintain Xfce and its component applications are great fans of simplicity. This simplicity is very likely the reason that Xfce is so stable, but it also results in a clean look, a responsive interface, an easily navigable structure that feels natural, and an overall elegance that makes it a pleasure to use.
|
||||
|
||||
#### 6\. Terminal emulation
|
||||
|
||||
The Xfce4 terminal emulator is a powerful emulator that uses tabs to allow multiple terminals in a single window, like many other terminal emulators. This terminal emulator is simple compared to emulators like Tilix, Terminator, and Konsole, but it gets the job done. The tab names can be changed, and the tabs can be rearranged by drag and drop, using the arrow icons on the toolbar, or selecting the options on the menu bar. One thing I especially like about the tabs on the Xfce terminal emulator is that they display the name of the host to which they are connected regardless of how many other hosts are connected through to make that connection, e.g., `host1==>host2==>host3==>host4` properly shows `host4` in the tab. Other emulators show `host2` at best.
|
||||
|
||||
Other aspects of its function and appearance can be easily configured to suit your needs. Like other Xfce components, this terminal emulator uses very little in the way of system resources.
|
||||
|
||||
#### 7\. Configurability
|
||||
|
||||
Within its limits, Xfce is very configurable. While not offering as much configurability as a desktop like KDE, it is far more configurable (and more easily so) than GNOME, for example. I found that the Settings Manager is the doorway to everything needed to configure Xfce. The individual configuration apps are separately available, but the Settings Manager collects them all into one window for ease of access. All the important aspects of the desktop can be configured to meet my needs and preferences.
|
||||
|
||||
#### 8\. Modularity
|
||||
|
||||
Xfce has a number of individual projects that make up the whole, and not all parts of Xfce are necessarily installed by your distro. [Xfce's projects][5] page lists the main projects, so you can find additional parts you might want to install. The items that weren't installed on my Fedora 28 workstation when I installed the Xfce group were mostly the applications at the bottom of that page.
|
||||
|
||||
There is also a [documentation page][6], and a wiki called [Xfce Goodies Project][7] lists other Xfce-related projects that provide applications, artwork, and plugins for Thunar and the Xfce panels.
|
||||
|
||||
### Conclusions
|
||||
|
||||
The Xfce desktop is thin and fast with an overall elegance that makes it easy to figure out how to do things. Its lightweight construction conserves both memory and CPU cycles. This makes it ideal for older hosts with few resources to spare for a desktop. However, Xfce is flexible and powerful enough to satisfy my needs as a power user.
|
||||
|
||||
I've learned that changing to a new Linux desktop can take some work to configure it as I want—with all of my favorite application launchers on the panel, my preferred wallpaper, and much more. I have changed to new desktops or updates of old ones many times over the years. It takes some time and a bit of patience.
|
||||
|
||||
I think of it like when I've moved cubicles or offices at work. Someone carries my stuff from the old office to the new one, and I connect my computer, unpack the boxes, and place their contents in appropriate locations in my new office. Moving into the Xfce desktop was the easiest move I have ever made.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/xfce-desktop
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://xfce.org/
|
||||
[2]:/file/401856
|
||||
[3]:https://opensource.com/sites/default/files/uploads/xfce-desktop-01.png (Xfce desktop)
|
||||
[4]:https://opensource.com/sitewide-search?search_api_views_fulltext=David%20Both%20File%20managers
|
||||
[5]:https://xfce.org/projects
|
||||
[6]:https://docs.xfce.org/
|
||||
[7]:https://goodies.xfce.org/
|
||||
@ -0,0 +1,111 @@
|
||||
Checking out the notebookbar and other improvements in LibreOffice 6.0 – FOSS adventures
|
||||
======
|
||||
|
||||
With any new openSUSE release, I am interested in the improvements that the big applications have made. One of these big applications is LibreOffice. Ever since LibreOffice has forked from OpenOffice.org, there has been a constant delivery of new features and new fixes every 6 months. openSUSE Leap 15 brought us the upgrade from LibreOffice 5.3.3 to LibreOffice 6.0.4. In this post, I will highlight the improvements that I found most newsworthy.
|
||||
|
||||
### Notebookbar
|
||||
|
||||
One of the experimental features of LibreOffice 5.3 was the Notebookbar. In LibreOffice 6.0 this feature has matured a lot and has gained a new form: the groupedbar. Lets take a look at the 3 variants. You can enable the Notebookbar by clicking on View –> Toolbar Layout and then Notebookbar.
|
||||
|
||||
![][1]
|
||||
|
||||
Please be aware that switching back to the Default Toolbar Layout is a bit of a hassle. To list the tricks:
|
||||
|
||||
* The contextual groups notebookbar shows the menubar by default. Make sure that you don’t hide it. Change the Layout via the View menu in the menubar.
|
||||
* The tabbed notebookbar has a hamburger menu on the upper right side. Select menubar. Then change the Layout via the View menu in the menubar.
|
||||
* The groupedbar notebookbar has a menu dropdown menu on the upper right side. Make sure to maximize the window. Otherwise it might be hidden.
|
||||
|
||||
|
||||
|
||||
The most talked about version of the notebookbar is the tabbed version. This looks similar to the Microsoft Office 2007 ribbon. That fact alone is enough to ruffle some feathers in the open source community. In comparison to the ribbon, the tabs (other than Home) can feel rather empty. The reason for that is that the icons are not designed to be big and bold. Another reason is that there are no sub-sections in the tabs. In the Microsoft version of the ribbon, you have names of the sub-sections underneath the icons. This helps to fill the empty space. However, in terms of ease of use, this design does the job. It provides you with a lot of functions in an easy to understand interface.
|
||||
|
||||
![][2]
|
||||
|
||||
The most successful version of the notebookbar is in my opinion the groupedbar. It gives you all of the most needed functions in a single overview. And the dropdown menus (File / Edit / Styles / Format / Paragraph / Insert / Reference) all show useful functions that are not so often used.
|
||||
|
||||
![][3]
|
||||
|
||||
By the way, it also works great for Calc (Spreadsheets) and Impress (Presentations).
|
||||
|
||||
![][4]
|
||||
|
||||
![][5]
|
||||
|
||||
Finally there is the contextual groups version. The “groups” version is not very helpful. It shows a very limited number of basic functions. And it takes up a lot of space. If you want to use more advanced functions, you need to use the traditional menubar. The traditional menubar works perfectly, but in that case I rather combine it with the Default toolbar layout.
|
||||
|
||||
![][6]
|
||||
|
||||
The contextual single version is the better version. If you compare it to the “normal” single toolbar, it contains more functions and the order in which the functions are arranged is easier to use.
|
||||
|
||||
![][7]
|
||||
|
||||
There is no real need to make the switch to the notebookbar. But it provides you with choice. One of these user interfaces might just suit your taste.
|
||||
|
||||
### Microsoft Office compatibility
|
||||
|
||||
Microsoft Office compatibility (especially .docx, .xlsx and .pptx) is one of the things that I find very important. As a former Business Consultant I have created a lot of documents in the past. I have created 200+ page reports. They need to work flawless, including getting the page brakes right, which is incredibly difficult as the margins are never the same. Also the index, headers, footers, grouped drawings and SmartArt drawings need to display as originally composed. I have created large PowerPoint presentations with branded slides with +30 layouts, grouped drawings and SmartArt drawings. I need these to render perfectly in the slideshow. Furthermore, I have created large multi-tabbed Excel sheets with filters, pivot tables, graphs and conditional formatting. All of these need to be conserved when I open these files in LibreOffice.
|
||||
|
||||
And no, LibreOffice is still not perfect. But damn, it is close. This time I have seen no major problems when opening older documents. Which means that LibreOffice finally gets SmartArt drawings right. In Writer, the page breaks in different places compared to Microsoft Word. That has always been an issue. But I don’t see many other issues. In Calc, the rendering of the graphs is less beautiful. But it’s similar enough to Excel. In Impress, presentations can look strange, because sometimes you see bigger/smaller fonts in the same slide (and that is not on purpose). But I was very impressed to see branded slides with multiple sections render correctly. If I needed to score it, I would give LibreOffice a 7 out of 10 for Microsoft Office compatibility. A very solid score. Below some examples of compatibility done right.
|
||||
|
||||
![][8]
|
||||
|
||||
![][9]
|
||||
|
||||
![][10]
|
||||
|
||||
### Noteworthy features
|
||||
|
||||
Finally, there are the noteworthy features. I will only highlight the ones that I find cool. The first one is the ability to rotate images in any degree. Below is an example of me rotating a Gecko.
|
||||
|
||||
![][11]
|
||||
|
||||
The second cool feature is that the old collection of autoformat table styles are now replaced with a new collection of table styles. You can access these styles via the menubar: Table –> AutoFormat Styles. In the screenshots below, I show how to change a table from the Box List Green to the Box List Red format.
|
||||
|
||||
![][12]
|
||||
|
||||
![][13]
|
||||
|
||||
The third feature is the ability to copy-past unformatted text in Calc. This is something I will use a lot, making it a cool feature.
|
||||
|
||||
![][14]
|
||||
|
||||
The final feature is the new and improved LibreOffice Online help. This is not the same as the LibreOffice help (press F1 to see what I mean). That is still there (and as far as I know unchanged). But this is the online wiki that you will find on the LibreOffice.org website. Some contributors obviously put a lot of effort in this feature. It looks good, now also on a mobile device. Kudos!
|
||||
|
||||
![][15]
|
||||
|
||||
If you want to learn about all of the other introduced features, read the [release notes][16]. They are really well written.
|
||||
|
||||
### And that’s not all folks
|
||||
|
||||
I discussed LibreOffice on openSUSE Leap 15. However, LibreOffice is also available on Android and in the Cloud. You can get the Android version from the [Google Play Store][17]. And you can see the Cloud version in action if you go to the [Collabora website][18]. Check them out for yourselves.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossadventures.com/checking-out-the-notebookbar-and-other-improvements-in-libreoffice-6-0/
|
||||
|
||||
作者:[Martin De Boer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossadventures.com/author/martin_de_boer/
|
||||
[1]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice06.jpeg
|
||||
[2]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice09.jpeg
|
||||
[3]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice11.jpeg
|
||||
[4]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice10.jpeg
|
||||
[5]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice08.jpeg
|
||||
[6]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice07.jpeg
|
||||
[7]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice12.jpeg
|
||||
[8]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice14.jpeg
|
||||
[9]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice15.jpeg
|
||||
[10]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice16.jpeg
|
||||
[11]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice01.jpeg
|
||||
[12]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice02.jpeg
|
||||
[13]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice03.jpeg
|
||||
[14]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice04.jpeg
|
||||
[15]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice05.jpeg
|
||||
[16]:https://wiki.documentfoundation.org/ReleaseNotes/6.0
|
||||
[17]:https://play.google.com/store/apps/details?id=org.documentfoundation.libreoffice&hl=en
|
||||
[18]:https://www.collaboraoffice.com/press-releases/collabora-office-6-0-released/
|
||||
@ -0,0 +1,123 @@
|
||||
How To Upgrade Everything Using A Single Command In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
As we all know already, keeping our Linux system up-to-date involves invoking more than one package manager. Say for instance, in Ubuntu you can’t upgrade everything using “sudo apt update && sudo apt upgrade” command. This command will only upgrade the applications which are installed using APT package manager. There are chances that you might have installed some other applications using **cargo** , [**pip**][1], **npm** , **snap** , **flatpak** or [**Linuxbrew**][2] package managers. You need to use the respective package manager in order to keep them all updated. Not anymore! Say hello to **“topgrade”** , an utility to upgrade all the things in your system in one go.
|
||||
|
||||
You need not to run every package manager to update the packages. The topgrade tool resolves this problem by detecting the installed packages, tools, plugins and run their appropriate package manager to update everything in your Linux box with a single command. It is free, open source and written using **rust programming language**. It supports GNU/Linux and Mac OS X.
|
||||
|
||||
### Upgrade Everything Using A Single Command In Linux
|
||||
|
||||
The topgrade is available in AUR. So, you can install it using [**Yay**][3] helper program in any Arch-based systems.
|
||||
```
|
||||
$ yay -S topgrade
|
||||
|
||||
```
|
||||
|
||||
On other Linux distributions, you can install topgrade utility using **cargo** package manager. To install cargo package manager, refer the following link.
|
||||
|
||||
And, then run the following command to install topgrade.
|
||||
```
|
||||
$ cargo install topgrade
|
||||
|
||||
```
|
||||
|
||||
Once installed, run the topgrade to upgrade all the things in your Linux system.
|
||||
```
|
||||
$ topgrade
|
||||
|
||||
```
|
||||
|
||||
Once topgrade is invoked, it will perform the following tasks one by one. You will be asked to enter root/sudo user password wherever necessary.
|
||||
|
||||
1 Run your system’s package manager:
|
||||
|
||||
* Arch: Run **yay** or fall back to [**pacman**][4]
|
||||
* CentOS/RHEL: Run `yum upgrade`
|
||||
* Fedora – Run `dnf upgrade`
|
||||
* Debian/Ubuntu: Run `apt update && apt dist-upgrade`
|
||||
* Linux/macOS: Run `brew update && brew upgrade`
|
||||
|
||||
|
||||
|
||||
2\. Check if the following paths are tracked by Git. If so, pull them:
|
||||
|
||||
* ~/.emacs.d (Should work whether you use **Spacemacs** or a custom configuration)
|
||||
* ~/.zshrc
|
||||
* ~/.oh-my-zsh
|
||||
* ~/.tmux
|
||||
* ~/.config/fish/config.fish
|
||||
* Custom defined paths
|
||||
|
||||
|
||||
|
||||
3\. Unix: Run **zplug** update
|
||||
|
||||
4\. Unix: Upgrade **tmux** plugins with **TPM**
|
||||
|
||||
5\. Run **Cargo install-update**
|
||||
|
||||
6\. Upgrade **Emacs** packages
|
||||
|
||||
7\. Upgrade Vim packages. Works with the following plugin frameworks:
|
||||
|
||||
* NeoBundle
|
||||
* [**Vundle**][5]
|
||||
* Plug
|
||||
|
||||
|
||||
|
||||
8\. Upgrade [**NPM**][6] globally installed packages
|
||||
|
||||
9\. Upgrade **Atom** packages
|
||||
|
||||
10\. Update [**Flatpak**][7] packages
|
||||
|
||||
11\. Update [**snap**][8] packages
|
||||
|
||||
12\. **Linux:** Run **fwupdmgr** to show firmware upgrade. (View only. No upgrades will actually be performed)
|
||||
|
||||
13\. Run custom defined commands.
|
||||
|
||||
Finally, topgrade utility will run **needrestart** to restart all services. In Mac OS X, it will upgrade App Store applications.
|
||||
|
||||
Sample output from my Ubuntu 18.04 LTS test box:
|
||||
|
||||
![][10]
|
||||
|
||||
The good thing is if one task is failed, it will automatically run the next task and complete all other subsequent tasks. Finally, it will display the summary with details such as how many tasks did it run, how many succeeded and how many failed etc.
|
||||
|
||||
![][11]
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
Personally, I liked this idea of creating an utility like topgrade and upgrade everything installed with various package managers with a single command. I hope you find it useful too. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-upgrade-everything-using-a-single-command-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||
[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]:https://www.ostechnix.com/getting-started-pacman/
|
||||
[5]:https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
[6]:https://www.ostechnix.com/manage-nodejs-packages-using-npm/
|
||||
[7]:https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
[8]:https://www.ostechnix.com/install-snap-packages-arch-linux-fedora/
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-1.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-2.png
|
||||
93
sources/tech/20180625 How to install Pipenv on Fedora.md
Normal file
93
sources/tech/20180625 How to install Pipenv on Fedora.md
Normal file
@ -0,0 +1,93 @@
|
||||
How to install Pipenv on Fedora
|
||||
======
|
||||
|
||||

|
||||
|
||||
Pipenv aims to bring the best of all packaging worlds (bundler, composer, npm, cargo, yarn, etc.) to the Python world. It tries to solve a couple of problems and also simplify the whole management process.
|
||||
|
||||
Currently the management of Python application dependencies sometimes seems like a bit of a challenge. Developers usually create a [virtual environment][1] for each new project and install dependencies into it using [pip][2]. In addition they have to store the set of installed packages into the requirements.txt text file. We’ve seen many tools and wrappers that aim to automate this workflow. However, there was still necessity to combine multiple utilities and the requirements.txt format itself is not ideal for more complicated scenarios.
|
||||
|
||||
### One tol to rule them all
|
||||
|
||||
Pipenv manages complex inter-dependencies properly and it also provides manual documenting of installed packages. For example development, testing and production environments often require a different set of packages. It used to be necessary to maintain multiple requirements.txt per project. Pipenv introduces the new [Pipfile][3] format using [TOML][4] syntax. Thanks to this format, you can finally maintain multiple set of requirement for different environments in a single file.
|
||||
|
||||
Pipenv has become the officially recommended tool for managing Python application dependencies only a year after the first lines of code were committed into the project. Now it is finally available as an package in Fedora repositories as well.
|
||||
|
||||
### Installing Pipenv on Fedora
|
||||
|
||||
On clean installation of Fedora 28 and later you can simply install Pipenv by running this command at the terminal:
|
||||
```
|
||||
$ sudo dnf install pipenv
|
||||
|
||||
```
|
||||
|
||||
Your system is now ready to start working on your new Python 3 application with help of Pipenv.
|
||||
|
||||
The important point is that while this tool provides nice solution for the applications, it is not designed for dealing with library requirements. When writing a Python library, pinning dependencies is not desirable. You should rather specify install_requires in setup.py file.
|
||||
|
||||
### Basic dependencies management
|
||||
|
||||
Create a directory for your project first:
|
||||
```
|
||||
$ mkdir new-project && cd new-project
|
||||
|
||||
```
|
||||
|
||||
Another step is to create a virtual environment for this project:
|
||||
```
|
||||
$ pipenv --three
|
||||
|
||||
```
|
||||
|
||||
The –three option here sets the Python version of the virtual environment to Python 3.
|
||||
|
||||
Install dependencies:
|
||||
```
|
||||
$ pipenv install requests
|
||||
Installing requests…
|
||||
Adding requests to Pipfile's [packages]…
|
||||
Pipfile.lock not found, creating…
|
||||
Locking [dev-packages] dependencies…
|
||||
Locking [packages] dependencies…
|
||||
|
||||
```
|
||||
|
||||
Finally generate a lockfile:
|
||||
```
|
||||
$ pipenv lock
|
||||
Locking [dev-packages] dependencies…
|
||||
Locking [packages] dependencies…
|
||||
Updated Pipfile.lock (b14837)
|
||||
|
||||
```
|
||||
|
||||
You can also check a dependency graph:
|
||||
```
|
||||
$ pipenv graph
|
||||
- certifi [required: >=2017.4.17, installed: 2018.4.16]
|
||||
- chardet [required: <3.1.0,>=3.0.2, installed: 3.0.4]
|
||||
- idna [required: <2.8,>=2.5, installed: 2.7]
|
||||
- urllib3 [required: >=1.21.1,<1.24, installed: 1.23]
|
||||
|
||||
```
|
||||
|
||||
More details on Pipenv and it commands are available in the [documentation][5].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/install-pipenv-fedora/
|
||||
|
||||
作者:[Michal Cyprian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/mcyprian/
|
||||
[1]:https://packaging.python.org/tutorials/installing-packages/#creating-virtual-environments
|
||||
[2]:https://developer.fedoraproject.org/tech/languages/python/pypi-installation.html
|
||||
[3]:https://github.com/pypa/pipfile
|
||||
[4]:https://github.com/toml-lang/toml
|
||||
[5]:https://docs.pipenv.org/
|
||||
67
sources/tech/20180625 The life cycle of a software bug.md
Normal file
67
sources/tech/20180625 The life cycle of a software bug.md
Normal file
@ -0,0 +1,67 @@
|
||||
The life cycle of a software bug
|
||||
======
|
||||
|
||||

|
||||
|
||||
In 1947, the first computer bug was found—a moth trapped in a computer relay.
|
||||
|
||||
If only all bugs were as simple to uncover. As software has become more complex, so too has the process of testing and debugging. Today, the life cycle of a software bug can be lengthy—though the right technology and business processes can help. For open source software, developers use rigorous ticketing services and collaboration to find and mitigate bugs.
|
||||
|
||||
### Confirming a computer bug
|
||||
|
||||
During the process of testing, bugs are reported to the development team. Quality assurance testers describe the bug in as much detail as possible, reporting on their system state, the processes they were undertaking, and how the bug manifested itself.
|
||||
|
||||
Despite this, some bugs are never confirmed; they may be reported in testing but can never be reproduced in a controlled environment. In such cases they may not be resolved but are instead closed.
|
||||
|
||||
It can be difficult to confirm a computer bug due to the wide array of platforms in use and the many different types of user behavior. Some bugs only occur intermittently or under very specific situations, and others may occur seemingly at random.
|
||||
|
||||
Many people use and interact with open source software, and many bugs and issues may be non-repeatable or may not be adequately described. Still, because every user and developer also plays the role of quality assurance tester, at least in part, there is a good chance that bugs will be revealed.
|
||||
|
||||
When a bug is confirmed, work begins.
|
||||
|
||||
### Assigning a bug to be fixed
|
||||
|
||||
A confirmed bug is assigned to a developer or a development team to be addressed. At this stage, the bug needs to be reproduced, the issue uncovered, and the associated code fixed. Developers may categorize this bug as an issue to be fixed later if the bug is low-priority, or they may assign someone directly if it is high-priority. Either way, a ticket is opened during the process of development, and the bug becomes a known issue.
|
||||
|
||||
In open source solutions, developers may select from the bugs that they want to tackle, either choosing the areas of the program with which they are most familiar or working from the top priorities. Consolidated solutions such as [GitHub][1] make it easy for multiple developers to work on solutions without interfering with each other's work.
|
||||
|
||||
When assigning bugs to be fixed, reporters may also select a priority level for the bug. Major bugs may have a high priority level, whereas bugs related to appearance only, for example, may have a lower level. This priority level determines how and when the development team is assigned to resolve these issues. Either way, all bugs need to be resolved before a product can be considered complete. Using proper traceability back to prioritized requirements can also be helpful in this regard.
|
||||
|
||||
### Resolving the bug
|
||||
|
||||
Once a bug has been fixed, it is usually be sent back to Quality Assurance as a resolved bug. Quality Assurance then puts the product through its paces again to reproduce the bug. If the bug cannot be reproduced, Quality Assurance will assume that it has been properly resolved.
|
||||
|
||||
In open source situations, any changes are distributed—often as a tentative release that is being tested. This test release is distributed to users, who again fulfill the role of Quality Assurance and test the product.
|
||||
|
||||
If the bug occurs again, the issue is sent back to the development team. At this stage, the bug is reopened, and it is up to the development team to repeat the cycle of resolving the bug. This may occur multiple times, especially if the bug is unpredictable or intermittent. Intermittent bugs are notoriously difficult to resolve.
|
||||
|
||||
If the bug does not occur again, the issue will be marked as resolved. In some cases, the initial bug is resolved, but other bugs emerge as a result of the changes made. When this happens, new bug reports may need to be initiated, starting the process over again.
|
||||
|
||||
### Closing the bug
|
||||
|
||||
After a bug has been addressed, identified, and resolved, the bug is closed and developers can move on to other areas of software development and testing. A bug will also be closed if it was never found or if developers were never able to reproduce it—either way, the next stage of development and testing will begin.
|
||||
|
||||
Any changes made to the solution in the testing version will be rolled into the next release of the product. If the bug was a serious one, a patch or a hotfix may be provided for current users until the release of the next version. This is common for security issues.
|
||||
|
||||
Software bugs can be difficult to find, but by following set processes and procedures, developers can make the process faster, easier, and more consistent. Quality Assurance is an important part of this process, as QA testers must find and identify bugs and help developers reproduce them. Bugs cannot be closed and resolved until the error no longer occurs.
|
||||
|
||||
Open source solutions distribute the burden of quality assurance testing, development, and mitigation, which often leads to bugs being discovered and mitigated more quickly and comprehensively. However, because of the nature of open source technology, the speed and accuracy of this process often depends upon the popularity of the solution and the dedication of its maintenance and development team.
|
||||
|
||||
_Rich Butkevic is a PMP certified project manager, certified scum master, and runs[Project Zendo][2] , a website for project management professionals to discover strategies to simplify and improve their project results. Connect with Rich at [Richbutkevic.com][3] or on [LinkedIn][4]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/life-cycle-software-bug
|
||||
|
||||
作者:[Rich Butkevic][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rich-butkevic
|
||||
[1]:https://github.com/
|
||||
[2]:https://projectzendo.com
|
||||
[3]:https://richbutkevic.com
|
||||
[4]:https://www.linkedin.com/in/richbutkevic
|
||||
68
sources/tech/20180626 8 great pytest plugins.md
Normal file
68
sources/tech/20180626 8 great pytest plugins.md
Normal file
@ -0,0 +1,68 @@
|
||||
8 great pytest plugins
|
||||
======
|
||||
|
||||

|
||||
|
||||
We are big fans of [pytest][1] and use it as our default Python testing tool for work and open source projects. For this month's Python column, we're sharing why we love pytest and some of the plugins that make testing with pytest so much fun.
|
||||
|
||||
### What is pytest?
|
||||
|
||||
As the tool's website says, "The pytest framework makes it easy to write small tests, yet scales to support complex functional testing for applications and libraries."
|
||||
|
||||
`test_*.py` and as functions that begin with `test_*`. Pytest will then find all your tests, across your whole project, and run them automatically when you run `pytest` in your console. Pytest accepts `set_trace()` function that can be entered into your test; this will pause your tests and allow you to interact with your variables and otherwise "poke around" in the console to debug your project.
|
||||
|
||||
Pytest allows you to define your tests in any file calledand as functions that begin with. Pytest will then find all your tests, across your whole project, and run them automatically when you runin your console. Pytest accepts [flags and arguments][2] that can change when the testrunner stops, how it outputs results, which tests are run, and what information is included in the output. It also includes afunction that can be entered into your test; this will pause your tests and allow you to interact with your variables and otherwise "poke around" in the console to debug your project.
|
||||
|
||||
One of the best aspects of pytest is its robust plugin ecosystem. Because pytest is such a popular testing library, over the years many plugins have been created to extend, customize, and enhance its capabilities. These eight plugins are among our favorites.
|
||||
|
||||
### Great 8
|
||||
|
||||
**1.[pytest-sugar][3]**
|
||||
`pytest-sugar` changes the default look and feel of pytest, adds a progress bar, and shows failing tests instantly. It requires no configuration; just `pip install pytest-sugar`, run your tests with `pytest`, and enjoy the prettier, more useful output.
|
||||
|
||||
**2.[pytest-cov][4]**
|
||||
`pytest-cov` adds coverage support for pytest to show which lines of code have been tested and which have not. It will also include the percentage of test coverage for your project.
|
||||
|
||||
**3.[pytest-picked][5]**
|
||||
`pytest-picked` runs tests based on code that you have modified but not committed to `git` yet. Install the library and run your tests with `pytest --picked` to test only files that have been changed since your last commit.
|
||||
|
||||
**4.[pytest-instafail][6]**
|
||||
`pytest-instafail` modifies pytest's default behavior to show failures and errors immediately instead of waiting until pytest has finished running every test.
|
||||
|
||||
**5.[pytest-tldr][7]**
|
||||
A brand-new pytest plugin that limits the output to just the things you need. `pytest-tldr` (the `tldr` stands for "too long, didn't read"), like `pytest-sugar`, requires no configuration other than basic installation. Instead of pytest's default output, which is pretty verbose, `pytest-tldr`'s default limits the output to only tracebacks for failing tests and omits the color-coding that some find annoying. Adding a `-v` flag returns the more verbose output for those who prefer it.
|
||||
|
||||
**6.[pytest-xdist][8]**
|
||||
`pytest-xdist` allows you to run multiple tests in parallel via the `-n` flag: `pytest -n 2`, for example, would run your tests on two CPUs. This can significantly speed up your tests. It also includes the `--looponfail` flag, which will automatically re-run your failing tests.
|
||||
|
||||
**7.[pytest-django][9]**
|
||||
`pytest-django` adds pytest support to Django applications and projects. Specifically, `pytest-django` introduces the ability to test Django projects using pytest fixtures, omits the need to import `unittest` and copy/paste other boilerplate testing code, and runs faster than the standard Django test suite.
|
||||
|
||||
**8.[django-test-plus][10]**
|
||||
`django-test-plus` isn't specific to pytest, but it now supports pytest. It includes its own `TestCase` class that your tests can inherit from and enables you to use fewer keystrokes to type out frequent test cases, like checking for specific HTTP error codes.
|
||||
|
||||
The libraries we mentioned above are by no means your only options for extending your pytest usage. The landscape for useful pytest plugins is vast. Check out the [Pytest Plugins Compatibility][11] page to explore on your own. Which ones are your favorites?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/pytest-plugins
|
||||
|
||||
作者:[Jeff Triplett;Lacery Williams Henschel][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/sites/default/files/styles/byline_thumbnail/public/pictures/dcus-2017-bw.jpg?itok=s8PhD7Ok
|
||||
[1]:https://docs.pytest.org/en/latest/
|
||||
[2]:https://docs.pytest.org/en/latest/usage.html
|
||||
[3]:https://github.com/Frozenball/pytest-sugar
|
||||
[4]:https://github.com/pytest-dev/pytest-cov
|
||||
[5]:https://github.com/anapaulagomes/pytest-picked
|
||||
[6]:https://github.com/pytest-dev/pytest-instafail
|
||||
[7]:https://github.com/freakboy3742/pytest-tldr
|
||||
[8]:https://github.com/pytest-dev/pytest-xdist
|
||||
[9]:https://pytest-django.readthedocs.io/en/latest/
|
||||
[10]:https://django-test-plus.readthedocs.io/en/latest/
|
||||
[11]:https://plugincompat.herokuapp.com/
|
||||
@ -0,0 +1,347 @@
|
||||
How To Search If A Package Is Available On Your Linux Distribution Or Not
|
||||
======
|
||||
You can directly install the require package which you want if you know the package name.
|
||||
|
||||
In some cases, if you don’t know the exact package name or you want to search some packages then you can easily search that package with help of distribution package manager.
|
||||
|
||||
Searches automatically include both installed and available packages.
|
||||
|
||||
The format of the results depends upon the option. If the query produces no information, there are no packages matching the criteria.
|
||||
|
||||
This can be done through distribution package managers with variety of options.
|
||||
|
||||
I had added all the possible options in this article and you can select which is the best and suitable for you.
|
||||
|
||||
Alternatively we can achieve this through **whohas** command. This will search the given package to all the major distributions (such as Debian, Ubuntu, Fedora, etc.,) not only your own system distribution.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [List of Command line Package Managers For Linux & Usage][1]
|
||||
**(#)** [A Graphical frontend tool for Linux Package Manager][2]
|
||||
|
||||
### How to Search a Package in Debian/Ubuntu
|
||||
|
||||
We can use apt, apt-cache and aptitude package managers to find a given package on Debian based distributions. I had included vast of options with this package managers.
|
||||
|
||||
We can done this on three ways in Debian based systems.
|
||||
|
||||
* apt command
|
||||
* apt-cache command
|
||||
* aptitude command
|
||||
|
||||
|
||||
|
||||
### How to search a package using apt command
|
||||
|
||||
APT stands for Advanced Packaging Tool (APT) which is replacement for apt-get. It’s feature rich command-line tools with included all the futures in one command (APT) such as apt-cache, apt-search, dpkg, apt-cdrom, apt-config, apt-key, etc..,. and several other unique features.
|
||||
|
||||
APT is a powerful command-line tool for installing, downloading, removing, searching and managing as well as querying information about packages as a low-level access to all features of the libapt-pkg library. It’s contains some less used command-line utilities related to package management.
|
||||
```
|
||||
$ apt -q list nano vlc
|
||||
Listing...
|
||||
nano/artful,now 2.8.6-3 amd64 [installed]
|
||||
vlc/artful 2.2.6-6 amd64
|
||||
|
||||
```
|
||||
|
||||
Alternatively we can search a given package using below format.
|
||||
```
|
||||
$ apt search ^vlc
|
||||
Sorting... Done
|
||||
Full Text Search... Done
|
||||
vlc/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer
|
||||
|
||||
vlc-bin/artful 2.2.6-6 amd64
|
||||
binaries from VLC
|
||||
|
||||
vlc-data/artful,artful 2.2.6-6 all
|
||||
Common data for VLC
|
||||
|
||||
vlc-l10n/artful,artful 2.2.6-6 all
|
||||
Translations for VLC
|
||||
|
||||
vlc-plugin-access-extra/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer (extra access plugins)
|
||||
|
||||
vlc-plugin-base/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer (base plugins)
|
||||
|
||||
```
|
||||
|
||||
### How to search a package using apt-cache command
|
||||
|
||||
apt-cache performs a variety of operations on APT’s package cache. Displays information about the given packages. apt-cache does not manipulate the state of the system but does provide operations to search and generate interesting output from the package metadata.
|
||||
```
|
||||
$ apt-cache search nano | grep ^nano
|
||||
nano - small, friendly text editor inspired by Pico
|
||||
nano-tiny - small, friendly text editor inspired by Pico - tiny build
|
||||
nanoblogger - Small weblog engine for the command line
|
||||
nanoblogger-extra - Nanoblogger plugins
|
||||
nanoc - static site generator written in Ruby
|
||||
nanoc-doc - static site generator written in Ruby - documentation
|
||||
nanomsg-utils - nanomsg utilities
|
||||
nanopolish - consensus caller for nanopore sequencing data
|
||||
|
||||
```
|
||||
|
||||
Alternatively we can search a given package using below format.
|
||||
```
|
||||
$ apt-cache policy vlc
|
||||
vlc:
|
||||
Installed: (none)
|
||||
Candidate: 2.2.6-6
|
||||
Version table:
|
||||
2.2.6-6 500
|
||||
500 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 Packages
|
||||
|
||||
```
|
||||
|
||||
Alternatively we can search a given package using below format.
|
||||
```
|
||||
$ apt-cache pkgnames vlc
|
||||
vlc-bin
|
||||
vlc-plugin-video-output
|
||||
vlc-plugin-sdl
|
||||
vlc-plugin-svg
|
||||
vlc-plugin-samba
|
||||
vlc-plugin-fluidsynth
|
||||
vlc-plugin-qt
|
||||
vlc-plugin-skins2
|
||||
vlc-plugin-visualization
|
||||
vlc-l10n
|
||||
vlc-plugin-notify
|
||||
vlc-plugin-zvbi
|
||||
vlc-plugin-vlsub
|
||||
vlc-plugin-jack
|
||||
vlc-plugin-access-extra
|
||||
vlc
|
||||
vlc-data
|
||||
vlc-plugin-video-splitter
|
||||
vlc-plugin-base
|
||||
|
||||
```
|
||||
|
||||
### How to search a package using aptitude command
|
||||
|
||||
aptitude is a text-based interface to the Debian GNU/Linux package system. It allows the user to view the list of packages and to perform package management tasks such as installing, upgrading, and removing packages. Actions may be performed from a visual interface or from the command-line.
|
||||
```
|
||||
$ aptitude search ^vlc
|
||||
p vlc - multimedia player and streamer
|
||||
p vlc:i386 - multimedia player and streamer
|
||||
p vlc-bin - binaries from VLC
|
||||
p vlc-bin:i386 - binaries from VLC
|
||||
p vlc-data - Common data for VLC
|
||||
v vlc-data:i386 -
|
||||
p vlc-l10n - Translations for VLC
|
||||
v vlc-l10n:i386 -
|
||||
p vlc-plugin-access-extra - multimedia player and streamer (extra access plugins)
|
||||
p vlc-plugin-access-extra:i386 - multimedia player and streamer (extra access plugins)
|
||||
p vlc-plugin-base - multimedia player and streamer (base plugins)
|
||||
p vlc-plugin-base:i386 - multimedia player and streamer (base plugins)
|
||||
p vlc-plugin-fluidsynth - FluidSynth plugin for VLC
|
||||
p vlc-plugin-fluidsynth:i386 - FluidSynth plugin for VLC
|
||||
p vlc-plugin-jack - Jack audio plugins for VLC
|
||||
p vlc-plugin-jack:i386 - Jack audio plugins for VLC
|
||||
p vlc-plugin-notify - LibNotify plugin for VLC
|
||||
p vlc-plugin-notify:i386 - LibNotify plugin for VLC
|
||||
p vlc-plugin-qt - multimedia player and streamer (Qt plugin)
|
||||
p vlc-plugin-qt:i386 - multimedia player and streamer (Qt plugin)
|
||||
p vlc-plugin-samba - Samba plugin for VLC
|
||||
p vlc-plugin-samba:i386 - Samba plugin for VLC
|
||||
p vlc-plugin-sdl - SDL video and audio output plugin for VLC
|
||||
p vlc-plugin-sdl:i386 - SDL video and audio output plugin for VLC
|
||||
p vlc-plugin-skins2 - multimedia player and streamer (Skins2 plugin)
|
||||
p vlc-plugin-skins2:i386 - multimedia player and streamer (Skins2 plugin)
|
||||
p vlc-plugin-svg - SVG plugin for VLC
|
||||
p vlc-plugin-svg:i386 - SVG plugin for VLC
|
||||
p vlc-plugin-video-output - multimedia player and streamer (video output plugins)
|
||||
p vlc-plugin-video-output:i386 - multimedia player and streamer (video output plugins)
|
||||
p vlc-plugin-video-splitter - multimedia player and streamer (video splitter plugins)
|
||||
p vlc-plugin-video-splitter:i386 - multimedia player and streamer (video splitter plugins)
|
||||
p vlc-plugin-visualization - multimedia player and streamer (visualization plugins)
|
||||
p vlc-plugin-visualization:i386 - multimedia player and streamer (visualization plugins)
|
||||
p vlc-plugin-vlsub - VLC extension to download subtitles from opensubtitles.org
|
||||
p vlc-plugin-zvbi - VBI teletext plugin for VLC
|
||||
p vlc-plugin-zvbi:i386
|
||||
|
||||
```
|
||||
|
||||
### How to Search a Package in RHEL/CentOS
|
||||
|
||||
Yum (Yellowdog Updater Modified) is one of the package manager utility in Linux operating system. Yum command is used to install, update, search & remove packages on some Linux distributions based on RedHat.
|
||||
```
|
||||
# yum search ftpd
|
||||
Loaded plugins: fastestmirror, refresh-packagekit, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* base: centos.hyve.com
|
||||
* epel: mirrors.coreix.net
|
||||
* extras: centos.hyve.com
|
||||
* rpmforge: www.mirrorservice.org
|
||||
* updates: mirror.sov.uk.goscomb.net
|
||||
============================================================== N/S Matched: ftpd ===============================================================
|
||||
nordugrid-arc-gridftpd.x86_64 : ARC gridftp server
|
||||
pure-ftpd.x86_64 : Lightweight, fast and secure FTP server
|
||||
vsftpd.x86_64 : Very Secure Ftp Daemon
|
||||
|
||||
Name and summary matches only, use "search all" for everything.
|
||||
|
||||
```
|
||||
|
||||
Alternatively we can search the same using below command.
|
||||
```
|
||||
# yum list ftpd
|
||||
|
||||
```
|
||||
|
||||
### How to Search a Package in Fedora
|
||||
|
||||
DNF stands for Dandified yum. We can tell DNF, the next generation of yum package manager (Fork of Yum) using hawkey/libsolv library for backend. Aleš Kozumplík started working on DNF since Fedora 18 and its implemented/launched in Fedora 22 finally.
|
||||
```
|
||||
# dnf search ftpd
|
||||
Last metadata expiration check performed 0:42:28 ago on Tue Jun 9 22:52:44 2018.
|
||||
============================== N/S Matched: ftpd ===============================
|
||||
proftpd-utils.x86_64 : ProFTPD - Additional utilities
|
||||
pure-ftpd-selinux.x86_64 : SELinux support for Pure-FTPD
|
||||
proftpd-devel.i686 : ProFTPD - Tools and header files for developers
|
||||
proftpd-devel.x86_64 : ProFTPD - Tools and header files for developers
|
||||
proftpd-ldap.x86_64 : Module to add LDAP support to the ProFTPD FTP server
|
||||
proftpd-mysql.x86_64 : Module to add MySQL support to the ProFTPD FTP server
|
||||
proftpd-postgresql.x86_64 : Module to add PostgreSQL support to the ProFTPD FTP
|
||||
: server
|
||||
vsftpd.x86_64 : Very Secure Ftp Daemon
|
||||
proftpd.x86_64 : Flexible, stable and highly-configurable FTP server
|
||||
owfs-ftpd.x86_64 : FTP daemon providing access to 1-Wire networks
|
||||
perl-ftpd.noarch : Secure, extensible and configurable Perl FTP server
|
||||
pure-ftpd.x86_64 : Lightweight, fast and secure FTP server
|
||||
pyftpdlib.noarch : Python FTP server library
|
||||
nordugrid-arc-gridftpd.x86_64 : ARC gridftp server
|
||||
|
||||
```
|
||||
|
||||
Alternatively we can search the same using below command.
|
||||
```
|
||||
# dnf list proftpd
|
||||
Failed to synchronize cache for repo 'heikoada-terminix', disabling.
|
||||
Last metadata expiration check: 0:08:02 ago on Tue 26 Jun 2018 04:30:05 PM IST.
|
||||
Available Packages
|
||||
proftpd.x86_64
|
||||
|
||||
```
|
||||
|
||||
### How to Search a Package in Arch Linux
|
||||
|
||||
pacman stands for package manager utility (pacman). pacman is a command-line utility to install, build, remove and manage Arch Linux packages. pacman uses libalpm (Arch Linux Package Management (ALPM) library) as a back-end to perform all the actions.
|
||||
|
||||
In my case, i’m going to search chromium package.
|
||||
```
|
||||
# pacman -Ss chromium
|
||||
extra/chromium 48.0.2564.116-1
|
||||
The open-source project behind Google Chrome, an attempt at creating a safer, faster, and more stable browser
|
||||
extra/qt5-webengine 5.5.1-9 (qt qt5)
|
||||
Provides support for web applications using the Chromium browser project
|
||||
community/chromium-bsu 0.9.15.1-2
|
||||
A fast paced top scrolling shooter
|
||||
community/chromium-chromevox latest-1
|
||||
Causes the Chromium web browser to automatically install and update the ChromeVox screen reader extention. Note: This
|
||||
package does not contain the extension code.
|
||||
community/fcitx-mozc 2.17.2313.102-1
|
||||
Fcitx Module of A Japanese Input Method for Chromium OS, Windows, Mac and Linux (the Open Source Edition of Google Japanese
|
||||
Input)
|
||||
|
||||
```
|
||||
|
||||
By default `-s`‘s builtin ERE (Extended Regular Expressions) can cause a lot of unwanted results. Use the following format to match the package name only.
|
||||
```
|
||||
# pacman -Ss '^chromium-'
|
||||
|
||||
```
|
||||
|
||||
pkgfile is a tool for searching files from packages in the Arch Linux official repositories.
|
||||
```
|
||||
# pkgfile chromium
|
||||
|
||||
```
|
||||
|
||||
### How to Search a Package in openSUSE
|
||||
|
||||
Zypper is a command line package manager for suse & openSUSE distributions. It’s used to install, update, search & remove packages & manage repositories, perform various queries, and more. Zypper command-line interface to ZYpp system management library (libzypp).
|
||||
```
|
||||
# zypper search ftp
|
||||
or
|
||||
# zypper se ftp
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
S | Name | Summary | Type
|
||||
--+----------------+-----------------------------------------+--------
|
||||
| proftpd | Highly configurable GPL-licensed FTP -> | package
|
||||
| proftpd-devel | Development files for ProFTPD | package
|
||||
| proftpd-doc | Documentation for ProFTPD | package
|
||||
| proftpd-lang | Languages for package proftpd | package
|
||||
| proftpd-ldap | LDAP Module for ProFTPD | package
|
||||
| proftpd-mysql | MySQL Module for ProFTPD | package
|
||||
| proftpd-pgsql | PostgreSQL Module for ProFTPD | package
|
||||
| proftpd-radius | Radius Module for ProFTPD | package
|
||||
| proftpd-sqlite | SQLite Module for ProFTPD | package
|
||||
| pure-ftpd | A Lightweight, Fast, and Secure FTP S-> | package
|
||||
| vsftpd | Very Secure FTP Daemon - Written from-> | package
|
||||
|
||||
```
|
||||
|
||||
### How to Search a Package using whohas command
|
||||
|
||||
whohas command such a intelligent tools which search a given package to all the major distributions such as Debian, Ubuntu, Gentoo, Arch, AUR, Mandriva, Fedora, Fink, FreeBSD, NetBSD.
|
||||
```
|
||||
$ whohas nano
|
||||
Mandriva nano-debug 2.3.1-1mdv2010.2.x http://sophie.zarb.org/rpms/0b33dc73bca710749ad14bbc3a67e15a
|
||||
Mandriva nano-debug 2.2.4-1mdv2010.1.i http://sophie.zarb.org/rpms/d9dfb2567681e09287b27e7ac6cdbc05
|
||||
Mandriva nano-debug 2.2.4-1mdv2010.1.x http://sophie.zarb.org/rpms/3299516dbc1538cd27a876895f45aee4
|
||||
Mandriva nano 2.3.1-1mdv2010.2.x http://sophie.zarb.org/rpms/98421c894ee30a27d9bd578264625220
|
||||
Mandriva nano 2.3.1-1mdv2010.2.i http://sophie.zarb.org/rpms/cea07b5ef9aa05bac262fc7844dbd223
|
||||
Mandriva nano 2.2.4-1mdv2010.1.s http://sophie.zarb.org/rpms/d61f9341b8981e80424c39c3951067fa
|
||||
Mandriva spring-mod-nanoblobs 0.65-2mdv2010.0.sr http://sophie.zarb.org/rpms/74bb369d4cbb4c8cfe6f6028e8562460
|
||||
Mandriva nanoxml-lite 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/287a4c37bc2a39c0f277b0020df47502
|
||||
Mandriva nanoxml-manual-lite 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/17dc4f638e5e9964038d4d26c53cc9c6
|
||||
Mandriva nanoxml-manual 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/a1b5092cd01fc8bb78a0f3ca9b90370b
|
||||
Gentoo nano 9999 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 9999 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 2.9.8 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 2.9.7 http://packages.gentoo.org/package/app-editors/nano
|
||||
|
||||
```
|
||||
|
||||
If you want to search a given package to only current distribution repository, use the below format.
|
||||
```
|
||||
$ whohas -d Ubuntu vlc
|
||||
Ubuntu vlc 2.1.6-0ubuntu14.04 1M all http://packages.ubuntu.com/trusty/vlc
|
||||
Ubuntu vlc 2.1.6-0ubuntu14.04 1M all http://packages.ubuntu.com/trusty-updates/vlc
|
||||
Ubuntu vlc 2.2.2-5ubuntu0.16. 1M all http://packages.ubuntu.com/xenial/vlc
|
||||
Ubuntu vlc 2.2.2-5ubuntu0.16. 1M all http://packages.ubuntu.com/xenial-updates/vlc
|
||||
Ubuntu vlc 2.2.6-6 40K all http://packages.ubuntu.com/artful/vlc
|
||||
Ubuntu vlc 3.0.1-3build1 32K all http://packages.ubuntu.com/bionic/vlc
|
||||
Ubuntu vlc 3.0.2-0ubuntu0.1 32K all http://packages.ubuntu.com/bionic-updates/vlc
|
||||
Ubuntu vlc 3.0.3-1 33K all http://packages.ubuntu.com/cosmic/vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-2 55K all http://packages.ubuntu.com/trusty/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/xenial/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/artful/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/bionic/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/cosmic/browser-plugin-vlc
|
||||
Ubuntu libvlc-bin 2.2.6-6 27K all http://packages.ubuntu.com/artful/libvlc-bin
|
||||
Ubuntu libvlc-bin 3.0.1-3build1 17K all http://packages.ubuntu.com/bionic/libvlc-bin
|
||||
Ubuntu libvlc-bin 3.0.2-0ubuntu0.1 17K all http://packages.ubuntu.com/bionic-updates/libvlc-bin
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
|
||||
[2]:https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
|
||||
@ -0,0 +1,80 @@
|
||||
Historical inventory of collaborative editors
|
||||
======
|
||||
A quick inventory of major collaborative editor efforts, in chronological order.
|
||||
|
||||
As with any such list, it must start with an honorable mention to [the mother of all demos][25] during which [Doug Engelbart][26] presented what is basically an exhaustive list of all possible software written since 1968\. This includes not only a collaborative editor, but graphics, programming and math editor.
|
||||
|
||||
Everything else after that demo is just a slower implementation to compensate for the acceleration of hardware.
|
||||
|
||||
> Software gets slower faster than hardware gets faster. - Wirth's law
|
||||
|
||||
So without further ado, here is the list of notable collaborative editors that I could find. By "notable" i mean that they introduce a notable feature or implementation detail.
|
||||
|
||||
|
||||
| Project | Date | Platform | Notes |
|
||||
| --- | --- | --- | --- |
|
||||
| [SubEthaEdit][1] | 2003-2015? | Mac-only | first collaborative, real-time, multi-cursor editor I could find. [reverse-engineering attempt in Emacs][2] |
|
||||
| [DocSynch][3] | 2004-2007 | ? | built on top of IRC
|
||||

|
||||
|
|
||||
| [Gobby][4] | 2005-now | C, multi-platform | first open, solid and reliable implementation. still around! protocol ("[libinfinoted][5]") notoriously hard to port to other editors (e.g. [Rudel][6] failed to implement this in Emacs. 0.7 release in jan 2017 adds possible python bindings that might improve this. Interesting plugins: autosave to disk. |
|
||||
| [moonedit][7] | 2005-2008? | ? | Original website died. Other user's cursors visible and emulated keystrokes noises. Calculator and music sequencer. |
|
||||
| [synchroedit][8] | 2006-2007 | ? | First web app. |
|
||||
| [Etherpad][9] | 2008-now | Web | First solid webapp. Originally developped as a heavy Java app in 2008, acquired and opensourced by google in 2009, then rewritten in Node.js in 2011\. Widely used. |
|
||||
| [CRDT][10] | 2011 | Specification | Standard for replicating a document's datastructure among different computers reliably. |
|
||||
| [Operational transform][11] | 2013 | Specification | Similar to CRDT, yet, well, different. |
|
||||
| [Floobits][12] | 2013-now | ? | Commercial, but opensource plugins for different editors |
|
||||
| [HackMD][13] | 2015-now | ? | Commercial but [opensource][14]. Inspired by hackpad, which was bought up by Dropbox. |
|
||||
| [Cryptpad][15] | 2016-now | web? | spin-off of xwiki. encrypted, "zero-knowledge" on server |
|
||||
| [Prosemirror][16] | 2016-now | Web, Node.JS | "Tries to bridge the gap between Markdown text editing and classical WYSIWYG editors." Not really an editor, but something that can be used to build one. |
|
||||
| [Qill][17] | 2013-now | Web, Node.JS | Rich text editor, also javascript. Not sure it is really collaborative. |
|
||||
| [Nextcloud][18] | 2017-now | Web | Some sort of Google docs equivalent |
|
||||
| [Teletype][19] | 2017-now | WebRTC, Node.JS | For the GitHub's [Atom editor][20], introduces "portal" idea that makes guests follow what the host is doing across multiple docs. p2p with webRTC after visit to introduction server, CRDT based. |
|
||||
| [Tandem][21] | 2018-now | Node.JS? | Plugins for atom, vim, neovim, sublime... uses a relay to setup p2p connexions CRDT based. [Dubious license issues][22] were resolved thanks to the involvement of Debian developers, which makes it a promising standard to follow in the future. |
|
||||
|
||||
### Other lists
|
||||
|
||||
* [Emacs wiki][23]
|
||||
|
||||
* [Wikipedia][24]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://anarc.at/blog/2018-06-26-collaborative-editors-history/
|
||||
|
||||
作者:[Anacr][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://anarc.at
|
||||
[1]:https://www.codingmonkeys.de/subethaedit/
|
||||
[2]:https://www.emacswiki.org/emacs/SubEthaEmacs
|
||||
[3]:http://docsynch.sourceforge.net/
|
||||
[4]:https://gobby.github.io/
|
||||
[5]:http://infinote.0x539.de/libinfinity/API/libinfinity/
|
||||
[6]:https://www.emacswiki.org/emacs/Rudel
|
||||
[7]:https://web.archive.org/web/20060423192346/http://www.moonedit.com:80/
|
||||
[8]:http://www.synchroedit.com/
|
||||
[9]:http://etherpad.org/
|
||||
[10]:https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type
|
||||
[11]:http://operational-transformation.github.io/
|
||||
[12]:https://floobits.com/
|
||||
[13]:https://hackmd.io/
|
||||
[14]:https://github.com/hackmdio/hackmd
|
||||
[15]:https://cryptpad.fr/
|
||||
[16]:https://prosemirror.net/
|
||||
[17]:https://quilljs.com/
|
||||
[18]:https://nextcloud.com/collaboraonline/
|
||||
[19]:https://teletype.atom.io/
|
||||
[20]:https://atom.io
|
||||
[21]:http://typeintandem.com/
|
||||
[22]:https://github.com/typeintandem/tandem/issues/131
|
||||
[23]:https://www.emacswiki.org/emacs/CollaborativeEditing
|
||||
[24]:https://en.wikipedia.org/wiki/Collaborative_real-time_editor
|
||||
[25]:https://en.wikipedia.org/wiki/The_Mother_of_All_Demos
|
||||
[26]:https://en.wikipedia.org/wiki/Douglas_Engelbart
|
||||
137
translated/talk/20180514 A year as Android Engineer.md
Normal file
137
translated/talk/20180514 A year as Android Engineer.md
Normal file
@ -0,0 +1,137 @@
|
||||
Android 工程师的一年
|
||||
============================================================
|
||||
|
||||

|
||||
>妙绝的绘画来自 [Miquel Beltran][0]
|
||||
|
||||
我的技术生涯,从两年前算起。开始是 QA 测试员,一年后就转入开发人员角色。没怎么努力,也没有投入过多的个人时间。
|
||||
|
||||
你可以从[我为何从生物学转向技术][1]和我[学习 Android 的一年][2] 这两篇文章中找到些只言片语。今天,我想谈谈是自己是如何开始担任 Android 开发人员这个角色、如何换公司以及作为 Android 工程师的一年所得所失。
|
||||
|
||||
### 我的第一个职位角色
|
||||
|
||||
我的第一个职位角色, Android 开发者,开始于一年前。我工作的这家公司,可以花一半的时间去尝试其它角色的工作,这给我从 QA 职位转到 Android 开发者职位创造了机会。
|
||||
|
||||
这一转变归功于我在晚上和周末投入学习 Android 的时间。我通过了[ Android 基础纳米学位][3]、[Andriod 工程师纳米学位][4]课程,也获得了[ Google 开发者认证][5]。这部分的详细故事在[这儿][6]。
|
||||
|
||||
两个月后,公司雇佣了另一位 QA,我转向全职工作。挑战从此开始!
|
||||
|
||||
比起给他们提供一台笔记本电脑和一个 git 账号来说,要把某人转变为胜任的开发角色,显然困难重重。在这里我解释一下我在那段时间遇到的一些障碍:
|
||||
|
||||
#### 缺乏预期
|
||||
|
||||
我面临的第一个问题是不知道公司对我的期望。我认为他们希望我从第一天起就有交付物,虽然不会要求像那些经验丰富的同事一样,但也要完成一个小任务就交付。这种感觉让我压力山大。由于没有明确的目标,我一直认为自己不够好,而且是个伪劣的冒牌货。
|
||||
|
||||
#### 缺乏指导
|
||||
|
||||
在公司里没有导师的概念,环境也不允许我们一起工作。我们很少结对编程,因为总是在赶项目进度,公司要求我们持续交付。幸运的是,我的同事都乐于助人!无论何时我卡住或需要帮助,他们总是陪我一起解决。
|
||||
|
||||
#### 缺乏反馈
|
||||
|
||||
那段时间,我从来没有得到过任何的反馈。我做的好还是坏?我应该改进些什么?我不知道,因为我没有得到过任何人的评论。
|
||||
|
||||
#### 缺乏学习氛围
|
||||
|
||||
我认为,为了保持常新,我们应该通过阅读博客文章、观看演讲、参加会议、尝试新事物等方式持续学习。该公司在工作时间并没有安排学习时间,不幸的是,其它开发人员告诉我这很常见。由于没有学习时间,所以我觉得没有资格花费哪怕十分钟的时间来阅读与工作相关且很有意思的博客文章。
|
||||
|
||||
问题不仅在于缺乏明确的学习时间津贴,而且当我明确要求时,被拒绝了。
|
||||
|
||||
当我完成突击任务时,发生了一个例子,我们已经完成了任务,因此我询问是否可以用剩下的时间来学习 Kotlin。这个请求被拒绝了。
|
||||
|
||||
另外的例子是我想参加一个 Android 相关的研讨会,然后被要求从带薪年假中抽出时间。
|
||||
|
||||
#### 冒充者综合征
|
||||
|
||||
在这公司缺乏指导、缺乏反馈、缺乏学习氛围,使我的开发者职业生涯的前九个月更加煎熬。我有感觉到,我内心的冒充者综合征与日俱增。
|
||||
|
||||
一个例子就是拉取代码进行公开展示和代码审查。有是我会请同事私下检查我的代码,并不想被公开拉取,向任何人展示。
|
||||
|
||||
其他时候,当我做代码审查时,会花好几分钟盯着"批准"按纽犹豫不决,在担心审查通过的会被其他同事找出毛病。
|
||||
|
||||
当我在一些事上持反对意见时,由于缺乏相关知识,担心被坐冷板凳,从来没有大声说出来过。
|
||||
|
||||
> 某些时间我会请同事私下[...]检查我的代码,以避免被公开展示。
|
||||
|
||||
* * *
|
||||
|
||||
### 新的公司,新的挑战
|
||||
|
||||
后来,我手边有了个新的机会。感谢曾经和我共事的朋友,我被[ Babbel ][7]邀请去参加初级 Android 工程师职位的招聘流程。
|
||||
|
||||
我见到了他们的团队,同时自告奋勇的在他们办公室主持了一次本地会议。此事让我下定决心要申请这个职位。我喜欢公司的箴言:全民学习。其次,公司每个人都非常友善,在那儿工作看起来很愉快!但我没有马上申请,因为我认为自己不够好,所以为什么能申请呢?
|
||||
|
||||
还好我的朋友和搭档推动我这样做,他们给了我发送简历的力量和勇气。过后不久就进入了面试流程。这很简单:以很小的应该程序来进行编码挑战,随后是和团队一起的技术面试,之后是和招聘经理间关于团队合作的面试。
|
||||
|
||||
#### 招聘过程
|
||||
|
||||
我用周未的时间来完成编码挑战的项目,并在周一就立即发送过去。不久就受邀去当场面试。
|
||||
|
||||
技术面试是关于编程挑战本身,我们谈论了 Android 好的不好的、我为什么以这种方式实现这功能,以及如何改进等等。随后是招聘经理进行的一次简短的关于团队合作面试,也有涉及到编程挑战的事,我们谈到了我面临的挑战,我如何解决这些问题,等等。
|
||||
|
||||
最后,通过面试,得到 offer, 我授受了!
|
||||
|
||||
我的 Android 工程师生涯的第一年,有九个月在一个公司,后面三个月在当前的公司。
|
||||
|
||||
#### 学习环境
|
||||
|
||||
对我来说一个大的变化就是每两周会和工程经理进行面对面会谈。那样,我很清楚我们的目标和方向。
|
||||
|
||||
在需要如何改进、需要如何提供帮助及如何寻求帮助这些事情上,我们得到持续的反馈和想法。他们除了提供内部培训的的福利外,我还有每周学习时间的福利,可以学习任意想学的。到目前为止,我正利用这些时间来提高我的 Kotlin 和 RxJava 方面知识。
|
||||
|
||||
每日的大部分时间,我们也做结对编程。我的办公桌上总是备着纸和笔,以便记下想法。我旁边还配了第二把椅子,以方便同事就坐。:-)
|
||||
|
||||
但是,我仍然在与冒充者综合征斗争。
|
||||
|
||||
#### 仍然有冒充者综合征
|
||||
|
||||
我仍然在斗争。例如,在做结对编程时,当我对某个话题不太清楚时,即使我的同事很有耐心的一遍一遍为我解释,但有时我仍然还是不知道。
|
||||
|
||||
两次三次后,压力就堵到胸口。为什么我还不知道?为什么就那么难理解?这种状态让我焦虑万分。
|
||||
|
||||
我意识到我需要承认我确实不懂某个特定的主题,但第一步是要知道有这么个概念!有是,仅仅需要的就是更多的时间、更多的练习,最终会"在大脑中完全演绎" :-)
|
||||
|
||||
例如,我常常为 Java 的接口类和抽象类所困扰,不管看了多少的例子,还是不能完全明白他们之间的区别。但一旦我使用后,即使还不能解释其工作原理,也知道了怎么使用以及什么时候使用。
|
||||
|
||||
#### 自信
|
||||
|
||||
当前公司的学习氛围提升了我的自信心。即使我还在问很多问题,也开始如鱼得水了。
|
||||
|
||||
经验较少并不意味着您的意见将不会被重视。比如一个提出的解决方案似乎太复杂了,我会挑战自我以更清晰的方式来重写。此外,我提出了一套不同的体验和观点,目前,对公司的应用程序用户体验改进有着很大帮助。
|
||||
|
||||
### 提高
|
||||
|
||||
工程师的角色不仅仅是编码,而是广泛的技能。 我仍然处于旅程的起点,在掌握它的道路上,我想着重于以下几点:
|
||||
|
||||
* 交流:因为英文不是我的母语,所以有的时候我会努力传达我的想法,这在我工作中是至关重要的。我可以通过写作,阅读和交谈来解决这个问题。
|
||||
|
||||
* 提有建设性的反馈意见: 我想给同事有意义的反馈,这样我们一起共同发展。
|
||||
|
||||
* 为我的成就感到骄傲: 我需要创建一个列表来跟踪各种成就,无论大小,或整体进步,所以当我挣扎时我可以回顾并感觉良好。
|
||||
|
||||
* 不要着迷于不知道的事情: 当有很多新事物出现时很难做到都知道,所以只关注必须的,及手头项目需要的东西,这非常重要的。
|
||||
|
||||
* 多和同事分享知识。我是初级的并不意味着没有可以分享的!我需要持续分享我感兴趣的的文章及讨论话题。我知道同事们会感激我的。
|
||||
|
||||
* 耐心和持续学习: 和现在一样的保持不断学习,但对自己要有更多耐心。
|
||||
|
||||
* 自我保健: 随时注意休息,不要为难自己。 放松也富有成效。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://proandroiddev.com/a-year-as-android-engineer-55e2a428dfc8
|
||||
|
||||
作者:[Lara Martín][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://proandroiddev.com/@laramartin
|
||||
[0]:https://medium.com/@Miqubel
|
||||
[1]:https://medium.com/@laramartin/how-i-took-my-first-step-in-it-6e9233c4684d
|
||||
[2]:https://medium.com/udacity/a-year-of-android-ffba9f3e40b6
|
||||
[3]:https://de.udacity.com/course/android-basics-nanodegree-by-google--nd803
|
||||
[4]:https://de.udacity.com/course/android-developer-nanodegree-by-google--nd801
|
||||
[5]:https://developers.google.com/training/certification/
|
||||
[6]:https://medium.com/udacity/a-year-of-android-ffba9f3e40b6
|
||||
[7]:http://babbel.com/
|
||||
@ -0,0 +1,173 @@
|
||||
"翻译完成"
|
||||
10条加速Ubuntu Linux的杀手级贴士
|
||||
======
|
||||
**摘要** : 一些实际的**加速Ubuntu Linux的贴士**。 这里的贴士对于大多数版本的Ubuntu是有效的,也可以应用于Linux Mint以及其他的基于Ubuntu的发行版。
|
||||
|
||||
也许你经历过使用Ubuntu一段时间后系统开始运行缓慢的情况。 在这篇文章里,我们将看到几项调整以及**使Ubuntu运行更快的窍门**。
|
||||
|
||||
在我们了解如何提升Ubuntu的总体系统表现之前,首先让我们思考为什么系统逐渐变慢。这个问题可能有很多原因。也许你有一台只有基础配置的简陋的电脑;也许你安装了一些在启动时即耗尽资源的应用。事实上原因无穷无尽。
|
||||
|
||||
这里我列出一些能够帮助你稍微加速Ubuntu的小调整。也有一些你能够采用过来以获取一个更流畅、有所提升的系统表现的最好的尝试。你可以选择遵循全部或部分的建议。将各项调整一点一点的结合就能给你一个更流畅、更迅捷快速的Ubuntu。
|
||||
|
||||
### 使Ubuntu更快的贴士:
|
||||
|
||||
![Tips to speed up Ubuntu][1]
|
||||
我在一个较老版本的Ubuntu上使用了这些调整,但是我相信其他的Ubuntu版本以及其他的例如Linux Mint, Elementary OS Luna等基于Ubuntu的Linux版本也是同样适用的。
|
||||
|
||||
#### 1\. 减少默认的grub载入时间:
|
||||
|
||||
Grub给你10秒的时间以让你在多系统启动项或恢复模式之间改变。对我而言,它是多余的。它也意味着你将不得不坐在电脑旁,敲着Enter键以尽可能快的启动进入Ubuntu。这花了一点时间,不是吗? 第一个技巧便是改变这个启动时间。如果你使用图形工具更舒适,阅读这篇文章来[使用Grub定制器改变grub时间以及启动顺序][2].
|
||||
|
||||
如果更倾向于命令行,你可以简单地使用以下的命令来打开grub配置:
|
||||
```
|
||||
sudo gedit /etc/default/grub &
|
||||
|
||||
```
|
||||
|
||||
并且将**GRUB_TIMEOUT=10**改为**GRUB_TIMEOUT=2**.这将改变启动时间为2秒。最好不要将这里改为0,因为这样你将会失去在操作系统及恢复选项之间切换的机会。一旦你更改了grub配置,使用以下命令来使更改生效:
|
||||
```
|
||||
sudo update-grub
|
||||
|
||||
```
|
||||
|
||||
#### 2\. 管理开机启动的应用:
|
||||
渐渐地你倾向于开始安装应用。 如果你是日常的“It’s FOSS”读者, 你也许从[App of the week][3]系列安装了许多apps.
|
||||
|
||||
这些apps的其中一些在每次开机时都会启动,当然资源运行这些应用也会陷入繁忙。结果:一台电脑因为每次启动时的持续时间而变得缓慢。进入Unity Dash寻找**Startup Applications** :
|
||||
|
||||

|
||||
在这里,看看哪些应用在开机时被载入。现在考虑在你每次启动Ubuntu时是否有不需要启动的应用。尽管移除它们:
|
||||
|
||||

|
||||
但是要是你不想从启动里移除它们怎么办?举个例子,如果你安装了[Ubuntu最好的指示器程序][4]之一, 你将想要它们在每次开机时自动地启动。
|
||||
|
||||
这里你所能做的就是延迟一些程序的启动时间。这样你将能够释放开机启动时的资源,并且一段时间后你的应用将被自动启动。在上一张图片里点击Edit并使用sleep选项来更改运行命令。
|
||||
例如,如果你想要延迟Dropbox指示器的运行,我们指定时间20秒,你只需要在已有的命令里像这样**加入一个命令**:
|
||||
```
|
||||
sleep 20;
|
||||
|
||||
```
|
||||
|
||||
所以,命令‘ **dropbox start -i** ‘变为‘ **sleep 20; drobox start -i** ‘。这意味着现在Dropbox将延迟20秒启动。你可以通过相似的方法来改变另一个开机启动应用的启动时间。
|
||||

|
||||
|
||||
#### 3\. 安装preload来加速应用载入时间:
|
||||
|
||||
Preload是一个后台运行的守护进程,分析用户行为,频繁地运行应用。打开终端,使用如下的命令来安装preload:
|
||||
```
|
||||
sudo apt-get install preload
|
||||
|
||||
```
|
||||
|
||||
安装后,重启你的电脑就不用管它了。它将在后台工作。[阅读更多关于preload][5]
|
||||
|
||||
#### 4\. 选择最好的软件更新镜像:
|
||||
验证你正在使用最好的更新软件的镜像是很好的做法。Ubuntu的软件仓库镜像跨过全球, 使用离你最近的一个是相当明智的。随着从服务器获取包的时间减少,这将形成更快的系统更新。
|
||||
在**Software & Updates->Ubuntu Software tab->Download From**里选择**Other**紧接着点击**Select Best Server**:
|
||||
|
||||

|
||||
它将运行测试来告知你那个是最好的镜像。正常地,最好的镜像已经被设置,但是我说过,验证它没什么坏处。并且,如果仓库缓存的最近的镜像没有频繁更新的话,这将引起获取更新时的一些延迟。这对于网速相对慢的人们是有用的。你可以使用这些贴士来[加速Ubuntu的wifi][6].
|
||||
|
||||
#### 5\. 为了更快的更新,使用apt-fast而不是apt-get:
|
||||
|
||||
apt-fast是“apt-get”的一个shell脚本包装器,通过从多连接同时下载包来提升更新及包下载速度。 如果你经常使用终端以及apt-get来安装和更新包,你也许会想要试一试apt-fast。使用下面的命令来通过官方PPA安装apt-fast:
|
||||
```
|
||||
sudo add-apt-repository ppa:apt-fast/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install apt-fast
|
||||
|
||||
```
|
||||
|
||||
#### 6\. 从apt-get更新移除语言相关的ign:
|
||||
|
||||
你曾经注意过sudo apt-get更新的输出吗?其中有三种行,**hit**,**ign**和**get**. 你可以在[这里][7]阅读它们的意义。如果你看到IGN行,你会发现它们中的大多数都与语言翻译有关。如果你使用所有的英文应用及包,你将完全不需要英文向英文的包数据库的翻译。
|
||||
|
||||
如果你从apt-get制止语言相关的更新,它将略微地增加apt-get的更新速度。为了那样,打开如下的文件:
|
||||
```
|
||||
sudo gedit /etc/apt/apt.conf.d/00aptitude
|
||||
|
||||
```
|
||||
|
||||
然后在文件末尾添加如下行:
|
||||
```
|
||||
Acquire::Languages "none";
|
||||
|
||||
```
|
||||
[![speed up apt get update in Ubuntu][8]][9]
|
||||
|
||||
#### 7\. 减少过热:
|
||||
|
||||
现在过热是电脑普遍的问题。一台过热的电脑运行相当缓慢。当你的CPU风扇转得像[Usain Bolt][10],打开一个程序将花费很长的时间。有两个工具你可以用来极少过热,使Ubuntu获得更好的系统表现,即TLP和CPUFREQ。
|
||||
|
||||
在终端里使用以下命令来安装TLP:
|
||||
```
|
||||
sudo add-apt-repository ppa:linrunner/tlp
|
||||
sudo apt-get update
|
||||
sudo apt-get install tlp tlp-rdw
|
||||
sudo tlp start
|
||||
|
||||
```
|
||||
|
||||
安装完TLP后你不需要做任何事。它在后台工作。
|
||||
|
||||
使用如下命令来安装CPUFREQ indicator:
|
||||
```
|
||||
sudo apt-get install indicator-cpufreq
|
||||
|
||||
```
|
||||
|
||||
重启你的电脑并使用**Powersave**模式:
|
||||
|
||||

|
||||
|
||||
#### 8\. 调整LibreOffice来使它更快:
|
||||
|
||||
如果你是office产品频繁使用的用户, 那么你会想要稍微调整默认的LibreOffice使它更快。这里你将调整内存选项。打开Open LibreOffice,进入**Tools- >Options**。在那里,从左边的侧栏选择**Memory**并启用 **Systray Quickstarter** 以及增加内存分配。
|
||||
|
||||

|
||||
你可以阅读更多关于[如何提速LibreOffice][11]的细节。
|
||||
|
||||
#### 9\. 使用轻量级的桌面环境 (如果你可以):
|
||||
|
||||
如果你选择安装默认的Unity of GNOME桌面环境, 你也许会选择一个轻量级的桌面环境像[Xfce][12]或[LXDE][13]。
|
||||
|
||||
这些桌面环境使用更少的内存,消耗更少的CPU。它们也自带轻量应用集来更深入地帮助更快地使用Ubuntu。你可以参考这篇详细指南来学习[如何在Ubuntu上安装Ubuntu][14]。
|
||||
|
||||
当然,桌面也许没有Unity或GNOME看起来现代化。那是你必须做出的妥协。
|
||||
|
||||
#### 10\. 使用不同应用的更轻量可选:
|
||||
|
||||
这不仅仅是建议和喜好。一些默认的或者流行的应用是耗资源的且可能不适合低端的电脑。你能做的就是使用这些应用的一些替代品。例如,使用[AppGrid][15]而不是Ubuntu软件中心。使用[Gdebi][16]来安装包。使用 AbiWord而不是LibreOffice Writer等。
|
||||
|
||||
可以断定这些贴士的汇总使Ubuntu 14.04,16.04以及其他版本更快。我确定这些贴士会提供一个总体上更好的系统表现。
|
||||
|
||||
对于**加速Ubuntu**你也有妙计吗?这些贴士也帮到你了吗?分享你的观点。 问题,建议总是受欢迎的。请在评论区里提出来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/darsh8)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/wp-content/uploads/2017/07/speed-up-ubuntu-featured-800x450.jpeg
|
||||
[2]:https://itsfoss.com/windows-default-os-dual-boot-ubuntu-1304-easy/ (Make Windows Default OS In Dual Boot With Ubuntu 13.04: The Easy Way)
|
||||
[3]:https://itsfoss.com/tag/app-of-the-week/
|
||||
[4]:https://itsfoss.com/best-indicator-applets-ubuntu/ (7 Best Indicator Applets For Ubuntu 13.10)
|
||||
[5]:https://itsfoss.com/improve-application-startup-speed-with-preload-in-ubuntu/ (Improve Application Startup Speed With Preload in Ubuntu)
|
||||
[6]:https://itsfoss.com/speed-up-slow-wifi-connection-ubuntu/ (Speed Up Slow WiFi Connection In Ubuntu 13.04)
|
||||
[7]:http://ubuntuforums.org/showthread.php?t=231300
|
||||
[8]:https://itsfoss.com/wp-content/uploads/2014/01/ign_language-apt_get_update-e1510129903529.jpeg
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2014/01/ign_language-apt_get_update.jpeg
|
||||
[10]:http://en.wikipedia.org/wiki/Usain_Bolt
|
||||
[11]:https://itsfoss.com/speed-libre-office-simple-trick/ (Speed Up LibreOffice With This Simple Trick)
|
||||
[12]:https://xfce.org/
|
||||
[13]:https://lxde.org/
|
||||
[14]:https://itsfoss.com/install-xfce-desktop-xubuntu/
|
||||
[15]:https://itsfoss.com/app-grid-lighter-alternative-ubuntu-software-center/ (App Grid: Lighter Alternative Of Ubuntu Software Center)
|
||||
[16]:https://itsfoss.com/install-deb-files-easily-and-quickly-in-ubuntu-12-10-quick-tip/ (Install .deb Files Easily And Quickly In Ubuntu 12.10 [Quick Tip])
|
||||
@ -1,414 +0,0 @@
|
||||
在 GitHub 上对编程语言与软件质量的一个大规模研究
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
编程语言对软件质量的影响是什么?这个问题在很长一段时间内成为一个引起了大量辩论的主题。在这项研究中,我们从 GitHub 上收集了大量的数据(728 个项目,6300 万行源代码,29000 位作者,150 万个提交,17 种编程语言),尝试在这个问题上提供一些实证。这个还算比较大的样本数量允许我们去使用一个混合的方法,结合多种可视化的回归模型和文本分析,去研究语言特性的影响,比如,在软件质量上,静态与动态类型和允许混淆与不允许混淆的类型。通过从不同的方法作三角测量研究(译者注:一种测量研究的方法),并且去控制引起混淆的因素,比如,团队大小、项目大小、和项目历史,我们的报告显示,语言设计确实有很大的影响,但是,在软件质量方面,语言的影响是非常有限的。最明显的似乎是,不允许混淆的类型比允许混淆的类型要稍微好一些,并且,在函数式语言中,静态类型也比动态类型好一些。值得注意的是,这些由语言设计所引起的轻微影响,绝大多数是由过程因素所主导的,比如,项目大小,团队大小,和提交数量。但是,我们警告读者,即便是这些不起眼的轻微影响,也是由其它的无形的过程因素所造成的,例如,对某些函数类型、以及不允许类型混淆的静态语言的偏爱。
|
||||
|
||||
[Back to Top][46]
|
||||
|
||||
### 1 序言
|
||||
|
||||
在给定的编程语言是否是“适合这个工作的正确工具”的讨论期间,紧接着又发生了多种辩论。虽然一些辩论出现了带有宗教般狂热的色彩,但是大部分人都一致认为,编程语言的选择能够对编码过程和由此生成的结果都有影响。
|
||||
|
||||
主张强静态类型的人,倾向于认为静态方法能够在早期捕获到缺陷;他们认为,一点点的预防胜过大量的矫正。动态类型拥护者主张,保守的静态类型检查,无论怎样都是非常浪费开发者资源的,并且,最好是依赖强动态类型检查来捕获错误类型。然而,这些辩论,大多数都是“纸上谈兵”,只靠“传说中”的证据去支持。
|
||||
|
||||
这些“传说”也许并不是没有道理的;考虑到影响软件工程结果的大量其它因素,获取这种经验性的证据支持是一项极具挑战性的任务,比如,代码质量,语言特征,以及应用领域。比如软件质量,考虑到它有大量的众所周知的影响因素,比如,代码数量,[6][1] 团队大小,[2][2]和年龄/熟练程度[9][3]。
|
||||
|
||||
受控实验是检验语言选择在面对如此令人气馁的混淆影响时的一种方法,然而,由于成本的原因,这种研究通常会引入一种它们自己的混淆,也就是说,限制了范围。在这种研究中,完整的任务是必须要受限制的,并且不能去模拟 _真实的世界_ 中的开发。这里有几个最近的这种大学本科生使用的研究,或者,通过一个实验因素去比较静态或动态类型的语言。[7][4],[12][5],[15][6]
|
||||
|
||||
幸运的是,现在我们可以基于大量的真实世界中的软件项目去研究这些问题。GitHub 包含了多种语言的大量的项目,并且在大小、年龄、和开发者数量上有很大的差别。每个项目的仓库都提供一个详细的记录,包含贡献历史、项目大小、作者身份、以及缺陷修复。然后,我们使用多种工具去研究语言特性对缺陷发生的影响。对我们的研究方法的最佳描述应该是“混合方法”,或者是三角测量法 [5][7];我们使用文本分析、聚簇、和可视化去证实和支持量化回归研究的结果。这个以经验为根据的方法,帮助我们去了解编程语言对软件质量的具体影响,因为,他们是被开发者非正式使用的。
|
||||
|
||||
[Back to Top][47]
|
||||
|
||||
### 2 方法
|
||||
|
||||
我们的方法是软件工程中典型的大范围观察研究法。我们首先大量的使用自动化方法,从几种数据源采集数据。然后使用预构建的统计分析模型对数据进行过滤和清洗。过滤器的选择是由一系列的因素共同驱动的,这些因素包括我们研究的问题的本质、数据质量和认为最适合这项统计分析研究的数据。尤其是,GitHub 包含了由大量的编程语言所写的非常多的项目。对于这项研究,我们花费大量的精力专注于收集那些用大多数的主流编程语言写的流行的项目的数据。我们选择合适的方法来评估计数数据上的影响因素。
|
||||
|
||||

|
||||
**2.1 数据收集**
|
||||
|
||||
我们选择了 GitHub 上的排名前 19 的编程语言。剔除了 CSS、Shell script、和 Vim script,因为它们不是通用的编程语言。我们包含了 `Typescript`,它是 `JavaScript` 的超集。然后,对每个被研究的编程语言,我们检索出以它为主要编程语言的前 50 个项目。我们总共分析了 17 种不同的语言,共计 850 个项目。
|
||||
|
||||
我们的编程语言和项目的数据是从 _GitHub Archive_ 中提取的,这是一个记录所有活跃的公共 GitHub 项目的数据库。它记录了 18 种不同的 GitHub 事件,包括新提交(new commits)、fork 事件、PR(pull request)、开发者信息、和以每小时为基础的所有开源 GitHub 项目的问题跟踪(issue tracking)。打包后的数据上传到 Google BigQuery 提供的交互式数据分析接口上。
|
||||
|
||||
**识别编程语言排名榜单** 我们基于它们的主要编程语言分类合计项目。然后,我们选择大多数的项目进行进一步分析,如 [表 1][48] 所示。一个项目可能使用多种编程语言;将它确定成单一的编程语言是很困难的。Github 包保存的信息是从 GitHub Linguist 上采集的,它使用项目仓库中源文件的扩展名来确定项目的发布语言是什么。源文件中使用数量最多的编程语言被确定为这个项目的 _主要编程语言_。
|
||||
|
||||
[][49]
|
||||
**表 1 每个编程语言排名前三的项目**
|
||||
|
||||
**检索流行的项目** 对于每个选定的编程语言,我们先根据项目所使用的主要编程语言来选出项目,然后根据每个项目的相关 _星(stars)_ 的数量排出项目的流行度。 _星_ 的数量表示了在这个项目上有多少感兴趣的人在表达自己的意见,并且它是流行度的一个合适的代表指标。因此,在 C 语言中排名前三的项目是 _linux、git、php-src_ ;而对于 C++,它们则是 _node-webkit、phantomjs、mongo_ ;对于 `Java`,它们则是 _storm、elasticsearch、ActionBarSherlock_ 。每个编程语言,我们总共选了 50 个项目。
|
||||
|
||||
为确保每个项目有足够长的开发历史,我们剔除了少于 28 个提交的项目(28 是每个候选项目的第一个四分位值数)。这样我们还剩下 728 个项目。[表 1][50] 展示了每个编程语言的前三个项目。
|
||||
|
||||
**检索项目演进历史** 对于 728 个项目中的每一个项目,我们下载了它们的非合并提交、提交记录、作者数据、作者使用的 _git_ 名字。我们从每个文件的添加和删除的行数中计算代码改动和每个提交的修改文件数量。我们以每个提交中修改的文件的扩展名所代表的编程语言,来检索出所使用的编程语言(一个提交可能有多个编程语言标签)。对于每个提交,我们通过它的提交日期减去这个项目的第一个提交的日期,来计算它的 _commit age_ 。我们也计算其它的项目相关的统计数据,包括项目的最大 commit age 和开发者总数,用于我们的回归分析模型的控制变量,它在第三节中会讨论到。我们通过在提交记录中搜索与错误相关的关键字,比如,"error"、"bug"、"fix"、"issue"、"mistake"、"incorrect"、"fault"、"defect"、"flaw",来识别 bug 修复提交。这一点与以前的研究类似。[18][8]
|
||||
|
||||
[表 2][51] 汇总了我们的数据集。因为一个项目可能使用多个编程语言,表的第二列展示了使用某种编程语言的项目的总数量。我们进一步排除了该编程语言的项目中少于 20 个提交的那些编程语言。因为 20 是每个编程语言的每个项目的提交总数的第一个四分位值。例如,我们在 C 语言中共找到 220 项目的提交数量多于 20 个。这确保了每个“编程语言 – 项目”对有足够的活跃度。
|
||||
|
||||
[][52]
|
||||
**表 2 研究主题**
|
||||
|
||||
总而言之,我们研究了最近 18 年以来,用了 17 种编程语言开发的,总共 728 个项目。总共包括了 29,000 个不同的开发者,157 万个提交,和 564,625 个 bug 修复提交。
|
||||
|
||||

|
||||
**2.2 语言分类**
|
||||
|
||||
我们基于影响语言质量的几种编程语言特性定义了语言类别,[7][9],[8][10],[12][11],如 [表 3][53] 所示。 _编程范式_ 表示项目是否是以命令方式、脚本方式、或者函数语言所写的。在本文的下面部分,我们分别使用 _命令_ 和 _脚本_ 这两个术语去代表命令方式和脚本方式。
|
||||
|
||||
[][54]
|
||||
**表 3. 语言分类的不同类型**
|
||||
|
||||
_类型检查_ 代表静态或者动态类型。在静态类型语言中,在编译时进行类型检查,并且变量名是绑定到一个值和一个类型的。另外,(包含变量的)表达式是根据运行时,它们可能产生的值所符合的类型来分类的。在动态类型语言中,类型检查发生在运行时。因此,在动态类型语言中,它可能出现在同一个程序中,一个变量名可能会绑定到不同类型的对象上的情形。
|
||||
|
||||
_隐式类型转换_ 允许一个类型为 T1 的操作数,作为另一个不同的类型 T2 来访问,而无需进行显式的类型转换。这样的隐式类型转换在一些情况下可能会带来类型混淆,尤其是当它表示一个明确的 T1 类型的操作数时,把它再作为另一个不同的 T2 类型的情况下。因为,并不是所有的隐式类型转换都会立即出现问题,通过我们识别出的允许进行隐式类型转换的所有编程语言中,可能发生隐式类型转换混淆的例子来展示我们的定义。例如,在像 `Perl、 JavaScript、CoffeeScript` 这样的编程语言中,一个字符和一个数字相加是允许的(比如,"5" + 2 结果是 "52")。但是在 `Php` 中,相同的操作,结果是 7。像这种操作在一些编程语言中是不允许的,比如 `Java` 和 `Python`,因为,它们不允许隐式转换。在强数据类型的 C 和 C++ 中,这种操作的结果是不可预料的,例如,`int x;float y;y=3.5;x=y`;是合法的 C 代码,并且对于 x 和 y 其结果是不同的值,具体是哪一个值,取决于含义,这可能在后面会产生问题。[a][12] 在 `Objective-C` 中数据类型 _id_ 是一个通用对象指针,它可以被用于任何数据类型的对象,而不管分类是什么。[b][13] 像这种通用数据类型提供了很好的灵活性,它可能导致隐式的类型转换,并且也会出现不可预料的结果。[c][14] 因此,我们根据它的编译器是否 _允许_ 或者 _不允许_ 如上所述的隐式类型转换,对编程语言进行分类;而不允许隐式类型转换的编程语言,会显式检测类型混淆,并报告类型不匹配的错误。
|
||||
|
||||
不允许隐式类型转换的编程语言,使用一个类型判断算法,比如,Hindley[10][15] 和 Milner[17][16],或者,在运行时上使用一个动态类型检查器,可以在一个编译器(比如,使用 `Java`)中判断静态类型的结果。相比之下,一个类型混淆可能会悄无声息地发生,因为,它可能因为没有检测到,也可能是没有报告出来。无论是哪种方式,允许隐式类型转换在提供了灵活性的同时,最终也可能会出现很难确定原因的错误。为了简单起见,我们将用 _implicit_ 代表允许隐式类型转换的编程语言,而不允许隐式类型转换的语言,我们用 _explicit_ 代表。
|
||||
|
||||
_内存分类_ 表示是否要求开发者去管理内存。尽管 `Objective-C` 遵循了一个混合模式,我们仍将它在不托管的分类中来对待,因为,我们在它的代码库中观察到很多的内存错误,在第 3 节的 RQ4 中会讨论到。
|
||||
|
||||
请注意,我们之所以使用这种方式对编程语言来分类和研究,是因为,这种方式在一个“真实的世界”中被大量的开发人员非正式使用。例如,`TypeScript` 被有意地分到静态编程语言的分类中,它不允许隐式类型转换。然而,在实践中,我们注意到,开发者经常(有 50% 可变化,并且跨 `TypeScript` - 在我们的数据集中使用的项目)使用 `any` 类型,一个笼统的联合类型,并且,因此在实践中,`TypeScript` 允许动态地、隐式类型转换。为减少混淆,我们从我们的编程语言分类和相关的模型中排除了 `TypeScript`(查看 [表 3][55] 和 [7][56])。
|
||||
|
||||

|
||||
**2.3 识别项目领域**
|
||||
|
||||
我们基于编程语言的特性和功能,使用一个自动和手动的混合技术,将研究的项目分类到不同的领域。在 GitHub 上,项目使用 `project descriptions` 和 README 文件来描述它们的特性。我们使用文档主题生成模型(Latent Dirichlet Allocation,缩写为:LDA)[3][17] 去分析这些文本。提供一组文档给它,LDA 将生成不同的关键字,然后来识别可能的主题。对于每个文档,LDA 也估算每个主题分配的文档的概率。
|
||||
|
||||
我们检测到 30 个不同的领域,换句话说,就是主题,并且评估了每个项目从属于每个领域的概率。因为,这些自动检测的领域包含了几个具体项目的关键字,例如,facebook,很难去界定它的底层的常用功能。为了给每个领域分配一个有意义的名字,我们手动检查了识别到的、独立于项目名字的 30 个领域、领域识别关键字。我们手动重命名了所有的 30 个自动检测的领域,并且找出了以下六个领域的大多数的项目:应用程序、数据库、代码分析、中间件、库、和框架。我们也找出了不符合以上任何一个领域的一些项目,因此,我们把这个领域笼统地标记为 _其它_ 。随后,我们研究组的另一名成员检查和确认了这种项目领域分类的方式。[表 4][57] 汇总了这个过程识别到的领域结果。
|
||||
|
||||
[][58]
|
||||
**表 4 领域特征**
|
||||
|
||||

|
||||
**2.4 bugs 分类**
|
||||
|
||||
尽管修复软件 bugs 时,开发者经常会在提交日志中留下关于这个 bugs 的原始的重要信息;例如,为什么会产生 bugs,以及怎么去修复 bugs。我们利用很多信息去分类 bugs,与 Tan 的 _et al_ 类似 [13][18],[24][19]。
|
||||
|
||||
首先,我们基于 bugs 的 _原因_ 和 _影响_ 进行分类。_ 原因 _ 进一步分解为不相关的错误子类:算法方面的、并发方面的、内存方面的、普通编程错误、和未知的。bug 的 _影响_ 也分成四个不相关的子类:安全、性能、失败、和其它的未知类。因此,每个 bug 修复提交也包含原因和影响的类型。[表 5][59] 展示了描述的每个 bug 分类。这个类别分别在两个阶段中被执行:
|
||||
|
||||
[][60]
|
||||
**表 5 bugs 分类和在整个数据集中的描述**
|
||||
|
||||
**(1) 关键字搜索** 我们随机选择了 10% 的 bug 修复信息,并且使用一个关键字基于搜索技术去对它们进行自动化分类,作为可能的 bug 类型。我们对这两种类型(原因和影响),单独使用这个注释。我们选择了一个限定的关键字和习惯用语集,如 [表 5][61] 所展示的。像这种限定的关键字和习惯用语集可以帮我们降低误报。
|
||||
|
||||
**(2) 监督分类** 我们使用前面步骤中的有注释的 bug 修复日志作为训练数据,为监督学习分类技术,通过测试数据来矫正,去对剩余的 bug 修复信息进行分类。我们首先转换每个 bug 修复信息为一个词袋(译者注:bag-of-words,一种信息检索模型)。然后,删除在所有的 bug 修复信息中仅出现过一次的词。这样减少了具体项目的关键字。我们也使用标准的自然语言处理技术来解决这个问题。最终,我们使用支持向量机(译者注:Support Vector Machine,缩写为 SVM,在机器学习领域中,一种有监督的学习算法)去对测试数据进行分类。
|
||||
|
||||
为精确评估 bug 分类器,我们手动注释了 180 个随机选择的 bug 修复,平均分布在所有的分类中。然后,我们比较手动注释的数据集在自动分类器中的结果。最终处理后的,表现出的精确度是可接受的,性能方面的精确度最低,是 70%,并发错误方面的精确度最高,是 100%,平均是 84%。再次运行,精确度从低到高是 69% 到 91%,平均精确度还是 84%。
|
||||
|
||||
我们的 bug 分类的结果展示在 [表 5][62] 中。大多数缺陷的原因都与普通编程错误相关。这个结果并不意外,因为,在这个分类中涉及了大量的编程错误,比如,类型错误、输入错误、编写错误、等等。我们的技术并不能将在任何(原因或影响)分类中占比为 1.4% 的 bug 修复信息再次进行分类;我们将它归类为 Unknown。
|
||||
|
||||

|
||||
**2.5 统计方法**
|
||||
|
||||
我们使用回归模型对软件项目相关的其它因素中的有缺陷的提交数量进行了建模。所有的模型使用 _负二项回归(译者注:negative binomial regression,缩写为NBR,一种回归分析模型)_ 去对项目属性计数进行建模,比如,提交数量。NBR 是一个广义的线性模型,用于对非负整数进行响应建模。[4][20]
|
||||
|
||||
在我们的模型中,我们对每个项目的编程语言,控制几个可能影响最终结果的因素。因此,在我们的回归分析中,每个(语言、项目)对是一个行,并且可以视为来自流行的开源项目中的样本。我们依据变量计数进行对象转换,以使变量保持稳定,并且提升了模型的适用度。[4][21] 我们通过使用 AIC 和 Vuong 对非嵌套模型的测试比较来验证它们。
|
||||
|
||||
去检查那些过度的多重共线性(译者注:多重共线性是指,在线性回归模型中解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。)并不是一个问题,我们在所有的模型中使用一个保守的最大值 5,去计算每个依赖的变量的膨胀因子的方差。[4][22] 我们通过对每个模型的残差和杠杆图进行视觉检查来移除高杠杆点,找出库克距离(译者注:一个统计学术语,用于诊断回归分析中是否存在异常数据)的分离值和最大值。
|
||||
|
||||
我们利用 _效果_ ,或者 _差异_ ,编码到我们的研究中,以提高编程语言回归系数的表现。[4][23] 加权的效果代码允许我们将每种编程语言与所有编程语言的效果进行比较,同时弥补了跨项目使用编程语言的不均匀性。[23][24] 去测试两种变量因素之间的联系,我们使用一个独立的卡方检验(译者注:Chi-square,一种统计学上的假设检验方法)测试。[14][25] 在证实一个依赖之后,我们使用 Cramer 的 V,它是与一个 _r_ × _c_ 等价的正常数据的 phi(φ)系数,去建立一个效果数据。
|
||||
|
||||
[Back to Top][63]
|
||||
|
||||
### 3 结果
|
||||
|
||||
我们从简单明了的问题开始,它非常直接地解决了人们坚信的一些核心问题,即:
|
||||
|
||||
**RQ1. 一些编程语言相比其它语言来说更易于出现缺陷吗?**
|
||||
|
||||
我们使用了回归分析模型,去比较每个编程语言对所有编程语言缺陷数量平均值的影响,以及对缺陷修复提交的影响(查看 [表 6][64])。
|
||||
|
||||
[][65]
|
||||
**表 6. 一些语言的缺陷要少于其它语言**
|
||||
|
||||
我们包括了一些变量,作为对明确影响反应的控制。项目年龄(Project age)也包括在内,因为,越老的项目生成的缺陷修复数量越大。提交数量也会对项目反应有轻微的影响。另外,从事该项目的开发人员的数量和项目的原始大小,都会随着项目的活跃而增长。
|
||||
|
||||
上述模型中估算系数的大小和符号(译者注:指“+”或者“-”)与结果的预测因子有关。初始的四种变量是控制变量,并且,我们对这些变量对最终结果的影响不感兴趣,只是说它们都是积极的和有意义的。语言变量是指示变量,是每个项目的变化因子,该因子将每种编程语言与所有项目的编程语言的加权平均值进行比较。编程语言系数可以大体上分为三类。第一类是,那些在统计学上无关紧要的系数,并且在建模过程中这些系数不能从 0 中区分出来。这些编程语言的表现与平均值相似,或者它们也可能有更大的方差。剩余的系数是非常明显的,要么是正的,要么是负的。对于那些正的系数,我们猜测可能与这个编程语言有大量的缺陷修复相关。这些语言包括 `C、C++、Objective-C、Php`、以及 `Python`。所有的有一个负的系数的编程语言,比如 `Clojure、Haskell、Ruby`、和 `Scala`,暗示这些语言的缺陷修复提交可能小于平均值。
|
||||
|
||||
应该注意的是,虽然,从统计学的角度观察到编程语言与缺陷之间有明显的联系,但是,大家不要过高估计编程语言对于缺陷的影响,因为,这种影响效应是非常小的。异常分析的结果显示,这种影响小于总异常的 1%。
|
||||
|
||||
[][66]
|
||||
|
||||
我们可以这样去理解模型的系数,它代表一个预测因子在所有其它预测因子保持不变的情况下,这个预测因子一个单位(unit)的变化,所反应出的预期的响应的对数变化;换句话说,对于一个系数 _β<sub style="border: 0px; outline: 0px; font-size: smaller; vertical-align: sub; background: transparent;">i</sub>_ ,在 _β<sub style="border: 0px; outline: 0px; font-size: smaller; vertical-align: sub; background: transparent;">i</sub>_ 中一个单位的变化,产生一个预期的 e _βi_ 响应的变化。对于可变因子,这个预期的变化是与所有编程语言的平均值进行比较。因此,如果对于一定数量的提交,用一个处于平均值的编程语言开发的特定项目有四个缺陷提交,那么,如果选择使用 `C++` 来开发,意味着我们预计应该有一个额外的(译者注:相对于平均值 4,多 1 个)缺陷提交,因为 e0.18 × 4 = 4.79。对于相同的项目,如果选择使用 `Haskell` 来开发,意味着我们预计应该少一个(译者注:同上,相对于平均值 4)缺陷提交。因为, _e_ −0.26 × 4 = 3.08。预测的精确度取决于剩余的其它因子都保持不变,除了那些微不足道的项目之外,所有的这些都是一个极具挑战性的命题。所有观察性研究都面临类似的局限性;我们将在第 5 节中详细解决这些事情。
|
||||
|
||||
**结论 1:** _一些编程语言相比其它编程语言有更高的缺陷相关度,不过,影响非常小。_
|
||||
|
||||
在这篇文章的剩余部分,我们在基本结论的基础上详细阐述,通过考虑不同种类的应用程序、缺陷、和编程语言,可以进一步深入了解编程语言和缺陷倾向之间的关系。
|
||||
|
||||
软件 bugs 通常落进两种宽泛的分类中:(1) _特定领域的 bug_ :特定于项目功能,并且不依赖于底层编程语言。(2) _普通 bug_ :大多数的普通 bug 是天生的,并且与项目功能无关,比如,输入错误,并发错误、等等。
|
||||
|
||||
因此,在一个项目中,应用程序领域和编程语言相互作用可能会影响缺陷的数量,这一结论被认为是合理的。因为一些编程语言被认为在一些任务上相比其它语言表现更突出,例如,`C` 对于低级别的(底层)工作,或者,`Java` 对于用户应用程序,对于编程语言的一个不合适的选择,可能会带来更多的缺陷。为研究这种情况,我们将理想化地忽略领域特定的 bugs,因为,普通 bugs 更依赖于编程语言的特性。但是,因为一个领域特定的 bugs 也可能出现在一个普通的编程错误中,这两者是很难区分的。一个可能的变通办法是在控制领域的同时去研究编程语言。从统计的角度来看,虽然,使用 17 种编程语言跨 7 个领域,在给定的样本数量中,理解大量的术语将是一个极大的挑战。
|
||||
|
||||
鉴于这种情况,我们首先考虑在一个项目中测试领域和编程语言使用之间的依赖关系,独立使用一个卡方检验(Chi-square)测试。在 119 个单元中,是 46,也就是说是 39%,它在我们设定的保守值 5 以上,它太高了。这个数字不能超过 20%,应该低于 5。[14][26] 我们在这里包含了完整有值 [d][27];但是,通过 Cramer 的 V 测试的值是 0.191,是低相关度的,表明任何编程语言和领域之间的相关度是非常小的,并且,在回归模型中包含领域并不会产生有意义的结果。
|
||||
|
||||
去解决这种情况的一个选择是,去移除编程语言,或者混合领域,但是,我们现有的数据没有进行完全挑选。或者,我们混合编程语言;这个选择导致一个相关但略有不同的问题。
|
||||
|
||||
**RQ2. 哪些编程语言特性与缺陷相关?**
|
||||
|
||||
我们聚合它们为编程语言类别,而不是考虑单独的编程语言,正如在第 2.2 节所描述的那样,然后去分析与缺陷的关系。总体上说,这些属性中的每一个都将编程语言按照在上下文中经常讨论的错误、用户辩论驱动、或者按以前工作主题来划分的。因此,单独的属性是高度相关的,我们创建了六个模型因子,将所有的单独因子综合到我们的研究中。然后,我们对六个不同的因子对缺陷数量的影响进行建模,同时控制我们在 _RQ1_ 节中使用的模型中的相同的基本协变量(译者注:协变量是指在实验中不能被人为操纵的独立变量)。
|
||||
|
||||
关于使用的编程语言(在前面的 [表 6][67]中),我们使用跨所有语言类的平均反应来比较编程语言 _类_ 。这个模型在 [表 7][68] 中表达了出来。很明显,`Script-Dynamic-Explicit-Managed` 类有最小的量级系数。这个系数是微不足道的,换句话说,对这个系数的 Z 校验(z-test,译者注:统计学上的一种平均值差异校验的方法) 并不能把它从 0 中区分出来。鉴于标准错误的量级,我们可以假设,在这个类别中的编程语言的行为是非常接近于所有编程语言行为的平均值。我们可以通过使用 `Proc-Static-Implicit-Unmanaged` 作为基本级并用于处理,或者使用基本级来虚假编码比较每个语言类,来证明这一点。在这种情况下,`Script-Dynamic-Explicit-Managed` 是明显不同于 _p_ = 0.00044 的。注意,虽然我们在这是选择了不同的编码方法,影响了系数和 Z 值,这个方法和所有其它的方面都是一样的。当我们改变了编码,我们调整系数去反应我们希望生成的对比。[4][28] 将其它类的编程语言与总体平均数进行比较,`Proc-Static-Implicit-Unmanaged` 类编程语言更容易引起缺陷。这意味着与其它过程类编程语言相比,隐式类型转换或者内存托管会导致更多的缺陷倾向。
|
||||
|
||||
[][69]
|
||||
**表 7. 函数式语言与缺陷的关联度和其它类语言相比要低,而过程类语言则大于或接近于平均值。**
|
||||
|
||||
在脚本类编程语言中,我们观察到类似于允许与不允许隐式类型转换的编程语言之间的关系,它们提供的一些证据表明,隐式类型转换(与显示类型转换相比)才是导致这种差异的原因,而不是内存托管。鉴于各种因素之间的相关性,我们并不能得出这个结论。但是,当它们与平均值进行比较时,作为一个组,那些不允许隐式类型转换的编程语言出现错误的倾向更低一些,而那些出现错误倾向更高的编程语言,出现错误的机率则相对更高。在函数式编程语言中静态和动态类型之间的差异也很明显。
|
||||
|
||||
函数式语言作为一个组展示了与平均值的很明显的差异。静态类型语言的系数要小很多,但是函数式语言类都有同样的标准错误。函数式静态编程语言出现错误的倾向要小于函数式动态编程语言,这是一个强有力的证据,尽管如此,Z 校验仅仅是检验系数是否能从 0 中区分出来。为了强化这个推论,我们使用处理编码,重新编码了上面的模型,并且观察到,`Functional-Static-Explicit-Managed` 编程语言类的错误倾向是明显小于 `Functional-Dynamic-Explicit-Managed` 编程语言类的 _p_ = 0.034。
|
||||
|
||||
[][70]
|
||||
|
||||
与编程语言和缺陷一样,编程语言类与缺陷之间关系的影响是非常小的。解释类编程语言的这种差异也是相似的,虽然很小,解释类编程语言的这种差异小于 1%。
|
||||
|
||||
我们现在重新回到应用领域这个问题。应用领域是否与语言类相互影响?怎么选择?例如,一个函数化编程语言,对特定的领域有一定的优势?与上面一样,对于这些因素和项目领域之间的关系做一个卡方检验,它的值是 99.05, _df_ = 30, _p_ = 2.622e–09,我们拒绝无意义假设,Cramer 的 V 产生的值是 0.133,表示一个弱关联。因此,虽然领域和编程语言之间有一些关联,但在这里应用领域和编程语言类之间仅仅是一个非常弱的关联。
|
||||
|
||||
**结论 2:** _在编程语言类与缺陷之间有一个很小但是很明显的关系。函数式语言与过程式或者脚本式语言相比,缺陷要少。_
|
||||
|
||||
这个结论有些不太令人满意的地方,因为,我们并没有一个强有力的证据去证明,在一个项目中编程语言、或者语言类和应用领域之间的关联性。一个替代方法是,基于全部的编程语言和应用领域,忽略项目和缺陷总数,而去查看相同的数据。因为,这样不再产生不相关的样本,我们没有从统计学的角度去尝试分析它,而是使用一个描述式的、基于可视化的方法。
|
||||
|
||||
我们定义了 _缺陷倾向_ 作为 bug 修复提交与每语言每领域总提交的比率。[图 1][71] 使用了一个热力图展示了应用领域与编程语言之间的相互作用,从亮到暗表示缺陷倾向在增加。我们研究了哪些编程语言因素影响了跨多种语言写的项目的缺陷修复提交。它引出了下面的研究问题:
|
||||
|
||||
[][72]
|
||||
**图 1. 编程语言的缺陷倾向与应用领域之间的相互作用。对于一个给定的领域(列底部),热力图中的每个格子表示了一个编程语言的缺陷倾向(行头部)。“整体”列表示一个编程语言基于所有领域的缺陷倾向。用白色十字线标记的格子代表一个 null 值,换句话说,就是在那个格子里没有符合的提交。**
|
||||
|
||||
**RQ3. 编程语言的错误倾向是否取决于应用领域?**
|
||||
|
||||
为了回答这个问题,我们首先在我们的回归模型中,以高杠杆点过滤掉认为是异常的项目,这种方法在这里是必要的,尽管这是一个非统计学的方法,一些关系可能影响可视化。例如,我们找到一个简单的项目,Google 的 v8,一个 `JavaScript` 项目,负责中间件中的所有错误。这对我们来说是一个惊喜,因为 `JavaScript` 通常不用于中间件。这个模式一直在其它应用领域中不停地重复着,因此,我们过滤出的项目的缺陷度都低于 10% 和高于 90%。这个结果在 [图 1][73] 中。
|
||||
|
||||
我们看到在这个热力图中仅有一个很小的差异,正如在 RQ1 节中看到的那样,这个结果仅表示编程语言固有的错误倾向。为验证这个推论,我们测量了编程语言对每个应用领域和对全部应用领域的缺陷倾向。对于除了数据库以外的全部领域,关联性都是正向的,并且 p 值是有意义的(<0.01)。因此,关于缺陷倾向,在每个领域的语言排序与全部领域的语言排序是基本相同的。
|
||||
|
||||
[][74]
|
||||
|
||||
**结论 3:** _应用领域和编程语言缺陷倾向之间总体上没有联系_
|
||||
|
||||
我们证明了不同的语言产生了大量的缺陷,并且,这个关系不仅与特定的语言相关,也适用于一般的语言类;然而,我们发现,项目类型并不能在一定程度上协调这种关系。现在,我们转变我们的注意力到反应分类上,我想去了解,编程语言与特定种类的缺陷之间有什么联系,以及这种关系怎么与我们观察到的更普通的关系去比较。我们将缺陷分为不同的类别,如 [表 5][75] 所描述的那样,然后提出以下的问题:
|
||||
|
||||
**RQ4. 编程语言与 bug 分类之间有什么关系?**
|
||||
|
||||
我们使用了一个类似于 RQ3 中所用的方法,去了解编程语言与 bug 分类之间的关系。首先,我们研究了 bug 分类和编程语言类之间的关系。一个热力图([图 2][76])展示了在编程语言类和 bug 类型之上的总缺陷数。去理解 bug 分类和语言之间的相互作用,我们对每个类别使用一个 NBR 回归模型。对于每个模型,我们使用了与 RQ1 中相同的控制因素,以及使用加权效应编码后的语言,去预测缺陷修复提交。
|
||||
|
||||
[][77]
|
||||
**图 2. bug 类别与编程语言类之间的关系。每个格子表示每语言类(行头部)每 bug 类别(列底部)的 bug 修复提交占全部 bug 修复提交的百分比。这个值是按列规范化的。**
|
||||
|
||||
结果和编程语言的方差分析值展示在 [表 8][78] 中。每个模型的整体异常是非常小的,并且对于特定的缺陷类型,通过语言所展示的比例在大多数类别中的量级是类似的。我们解释这种关系为,编程语言对于特定的 bug 类别的影响要大于总体的影响。尽管我们结论概括了全部的类别,但是,在接下来的一节中,我们对 [表 5][79] 中反应出来的 bug 数较多的 bug 类别做进一步研究。
|
||||
|
||||
[][80]
|
||||
**表 8. 虽然编程语言对缺陷的影响因缺陷类别而不同,但是,编程语言对特定的类别的影响要大于一般的类别。**
|
||||
|
||||
**编程错误** 普通的编程错误占所有 bug 修复提交的 88.53% 左右,并且在所有的编程语言类中都有。因此,回归分析给出了一个与 RQ1 中类似的结论(查看 [表 6][81])。所有的编程语言都会导致这种编程错误,比如,处理错误、定义错误、输入错误、等等。
|
||||
|
||||
**内存错误** 内存错误占所有 bug 修复提交的 5.44%。热力图 [图 2][82] 证明了在 `Proc-Static-Implicit-Unmanaged` 类和内存错误之间存在着非常紧密的联系。非托管内存的编程语言出现内存 bug,这是预料之中的。[表 8][83] 也证明了这一点,例如,C、C++、和 `Objective-C` 引发了很多的内存错误。在托管内存的语言中 `Java` 引发了更多的内存错误,尽管它少于非托管的编程语言。虽然 `Java` 自己做内存回收,但是,它出现内存泄露一点也不奇怪,因为对象引用经常阻止内存回收。[11][29] 在我们的数据中,`Java` 的所有内存错误中,28.89% 是内存泄漏造成的。就数量而言,编程语言中内存缺陷相比其它类别的 _原因_ 造成的影响要大很多。
|
||||
|
||||
**并发错误** 在总的 bug 修复提交中,并发错误相关的修复提交占 1.99%。热力图显示,`Proc-Static-Implicit-Unmanaged` 是主要的错误类型。在这种错误中,C 和 C++ 分别占 19.15% 和 7.89%,并且它们分布在各个项目中。
|
||||
|
||||
[][84]
|
||||
|
||||
属于 `Static-Strong-Managed` 语言类的编程语言都被证实处于热力图中的暗区中,普通的静态语言相比其它语言产生更多的并发错误。在动态语言中,仅仅有 `Erlang` 更多的并发错误倾向,或许与使用这种语言开发的并发应用程序非常多有关系。同样地,在 [表 8][85] 中的负的系数表明,用诸如 `Ruby` 和 `Php` 这样的动态编程语言写的项目,并发错误要少一些。请注意,某些语言,如 `JavaScript、CoffeeScript`、和 `TypeScript` 是不支持并发的,在传统的惯例中,虽然 `Php` 具有有限的并发支持(取决于它的实现)。这些语言在我们的数据中引入了虚假的 0(zeros),因此,在 [表 8][86] 中这些语言的并发模型的系数,不能像其它的语言那样去解释。因为存在这些虚假的 0,所以在这个模型中所有语言的平均数非常小,它可能影响系数的大小,因此,她们给 w.r.t. 一个平均数,但是,这并不影响他们之间的相对关系,因为我们只关注它们的相对关系。
|
||||
|
||||
一个基于 bug 修复消息中高频词的文本分析表明,大多数的并发错误发生在一个条件争用、死锁、或者不正确的同步,正如上面表中所示。遍历所有语言,条件争用是并发错误出现最多的原因,例如,在 `Go` 中占 92%。在 `Go` 中条件争用错误的改进,或许是因为使用了一个争用检测工具帮助开发者去定位争用。同步错误主要与消息传递接口(MPI)或者共享内存操作(SHM)相关。`Erlang` 和 `Go` 对线程间通讯使用 MPI[e][30],这就是为什么这两种语言没有发生任何 SHM 相关的错误的原因,比如共享锁、互斥锁、等等。相比之下,为线程间通讯使用早期的 SHM 技术的语言写的项目,就可能存在锁相关的错误。
|
||||
|
||||
**安全和其它冲突(impact)错误** 在所有的 bug 修复提交中,与冲突错误相关的提交占了 7.33% 左右。其中,`Erlang、C++、Python` 与安全相关的错误要高于平均值([表 8][87])。`Clojure` 项目相关的安全错误较少([图 2][88])。从热力图上我们也可以看出来,`静态` 语言一般更易于发生失败和性能错误,紧随其后的是 `Functional-Dynamic-Explicit-Managed` 语言,比如 `Erlang`。对异常结果的分析表明,编程语言与冲突失败密切相关。虽然安全错误在这个类别中是弱相关的,与残差相比,解释类语言的差异仍然比较大。
|
||||
|
||||
**结论 4:** _缺陷类型与编程语言强相关;一些缺陷类型比如内存错误和并发错误也取决于早期的语言(所使用的技术)。对于特定类别,编程语言所引起的错误比整体更多。_
|
||||
|
||||
[Back to Top][89]
|
||||
|
||||
### 4. 相关工作
|
||||
|
||||
在编程语言比较之前做的工作分为以下三类:
|
||||
|
||||
**(1) _受控实验_** 对于一个给定的任务,开发者使用不同的语言进行编程时受到监视。研究然后比较结果,比如,开发成果和代码质量。Hanenberg[7][31]通过开发一个解析程序,对 27 h 监视了 48 位程序员,去比较了静态与动态类型。他发现这两者在代码质量方面没有显著的差异,但是,基于动态类型的语言花费了更短的开发时间。他们的研究是在一个实验室中,使用本科学生,设置了定制的语言和 IDE 来进行的。我们的研究正好相反,是一个实际的流行软件应用的研究。虽然我们只能够通过使用回归模型间接(和 _事后_ )控制混杂因素,我们的优势是样本数量大,并且更真实、使用更广泛的软件。我们发现在相同的条件下,静态化类型的语言比动态化类型的语言更少出现错误倾向,并且不允许隐式类型转换的语言要好于允许隐式类型转换的语言,其对结果的影响是非常小的。这是合理的,因为样本量非常大,所以这种非常小的影响在这个研究中可以看得到。
|
||||
|
||||
Harrison et al.[8][32] 比较了 C++ 与 `SML`,一个是过程化编程语言,一个是函数化编程语言,在总的错误数量上没有找到显著的差异,不过 `SML` 相比 C++ 有更高的缺陷密集度。`SML` 在我们的数据中并没有体现出来,不过,认为函数式编程语言相比过程化编程语言更少出现缺陷。另一个重点工作是比较跨不同语言的开发工作。[12][33],[20][34] 不过,他们并不分析编程语言的缺陷倾向。
|
||||
|
||||
**(2) _调查_** Meyerovich 和 Rabkin[16][35] 调查了开发者对编程语言的观点,去研究为什么一些编程语言比其它的语言更流行。他们的报告指出,非编程语言的因素影响非常大:先前的编程语言技能、可用的开源工具、以及现有的老式系统。我们的研究也证明,可利用的外部工具也影响软件质量;例如,在 `Go` 中的并发 bug(请查看 RQ4 节内容)。
|
||||
|
||||
**(3) _对软件仓库的挖掘_** Bhattacharya 和 Neamtiu[1][36] 研究了用 C 和 C++ 开发的四个项目,并且发现在 C++ 中开发的组件一般比在 C 中开发的组件更可靠。我们发现 C 和 C++ 的错误倾向要高于全部编程语言的平均值。但是,对于某些 bug 类型,像并发错误,C 的缺陷倾向要高于 C++(请查看第 3 节中的 RQ4)。
|
||||
|
||||
[Back to Top][90]
|
||||
|
||||
### 5. 有效的风险
|
||||
|
||||
我们认为,我们的报告的结论几乎没有风险。首先,在识别 bug 修复提交方面,我们依赖的关键字是开发者经常用于表示 bug 修复的关键字。我们的选择是经过认真考虑的。在一个持续的开发过程中,我们去捕获那些开发者一直面对的问题,而不是他们报告的 bug。不过,这种选择存在过高估计的风险。我们对领域分类是为了去解释缺陷的倾向,而且,我们研究组中另外的成员验证过分类。此外,我们花费精力去对 bug 修复提交进行分类,也可能有被最初选择的关键字所污染的风险。每个项目在提交日志的描述上也不相同。为了缓解这些风险,我们像 2.4 节中描述的那样,利用手工注释评估了我们的类别。
|
||||
|
||||
我们判断文件所属的编程语言是基于文件的扩展名。如果使用不同的编程语言写的文件使用了我们研究的通用的编程语言文件的扩展名,这种情况下也容易出现错误倾向。为减少这种错误,我们使用一个随机样本文件集手工验证了我们的语言分类。
|
||||
|
||||
根据我们的数据集所显示的情形,2.2 节中的解释类编程语言,我们依据编程语言属性的主要用途作了一些假设。例如,我们将 `Objective-C` 分到非托管内存类型中,而不是混合类型。同样,我们将 `Scala` 注释为函数式编程语言,将 C# 作为过程化的编程语言,虽然,它们在设计的选择上两者都支持[19][37],[21][38]。在这项研究工作中,我们没有从过程化编程语言中分离出面向对象的编程语言(OOP),因为,它们没有清晰的区别,主要差异在于编程类型。我们将 C++ 分到允许隐式类型转换的类别中是因为,某些类型的内存区域可以通过使用指针操作被进行不同的处理 [22][39],并且我们注意到大多数 C++ 编译器可以在编译时检测类型错误。
|
||||
|
||||
最后,我们将缺陷修复提交关联到编程语言属性上,它们可以反应出报告的风格或者其它开发者的属性。可用的外部工具或者库(library)也可以影响一个相关的编程语言的 bug 数量。
|
||||
|
||||
[Back to Top][91]
|
||||
|
||||
### 6. 总结
|
||||
|
||||
我们对编程语言和使用进行了大规模的研究,因为它涉及到软件质量。我们使用的 Github 上的数据,具有很高的复杂性和多个维度上的差异的特性。我们的样本数量允许我们对编程语言效果以及在控制一些混杂因素的情况下,对编程语言、应用领域和缺陷类型之间的相互作用,进行一个混合方法的研究。研究数据显示,函数式语言是好于过程化语言的;不允许隐式类型转换的语言是好于允许隐式类型转换的语言的;静态类型的语言是好于动态类型的语言的;内存托管的语言是好于非托管的语言的。进一步讲,编程语言的缺陷倾向与软件应用领域并没有关联。另外,每个编程语言更多是与特定的 bug 类别有关联,而不是与全部 bug。
|
||||
|
||||
另一方面,即便是很大规模的数据集,它们被多种方法同时进行分割后,也变得很小且不全面。因此,随着依赖的变量越来越多,很难去回答某个变量所产生的影响有多大这种问题,尤其是在变量之间相互作用的情况下。因此,我们无法去量化编程语言在使用中的特定的效果。其它的方法,比如调查,可能对此有帮助。我们将在以后的工作中来解决这些挑战。
|
||||
|
||||
[Back to Top][92]
|
||||
|
||||
### 致谢
|
||||
|
||||
这个材料是在美国国家科学基金会(NSF)以及美国空军科学研究办公室(AFOSR)的授权和支持下完成的。授权号 1445079, 1247280, 1414172,1446683,FA955-11-1-0246。
|
||||
|
||||
[Back to Top][93]
|
||||
|
||||
### 参考资料
|
||||
|
||||
1\. Bhattacharya, P., Neamtiu, I. Assessing programming language impact on development and maintenance: A study on C and C++. In _Proceedings of the 33rd International Conference on Software Engineering, ICSE'11_ (New York, NY USA, 2011). ACM, 171–180.
|
||||
|
||||
2\. Bird, C., Nagappan, N., Murphy, B., Gall, H., Devanbu, P. Don't touch my code! Examining the effects of ownership on software quality. In _Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering_ (2011). ACM, 4–14.
|
||||
|
||||
3\. Blei, D.M. Probabilistic topic models. _Commun. ACM 55_ , 4 (2012), 77–84.
|
||||
|
||||
4\. Cohen, J. _Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences._ Lawrence Erlbaum, 2003.
|
||||
|
||||
5\. Easterbrook, S., Singer, J., Storey, M.-A., Damian, D. Selecting empirical methods for software engineering research. In _Guide to Advanced Empirical Software Engineering_ (2008). Springer, 285–311.
|
||||
|
||||
6\. El Emam, K., Benlarbi, S., Goel, N., Rai, S.N. The confounding effect of class size on the validity of object-oriented metrics. _IEEE Trans. Softw. Eng. 27_ , 7 (2001), 630–650.
|
||||
|
||||
7\. Hanenberg, S. An experiment about static and dynamic type systems: Doubts about the positive impact of static type systems on development time. In _Proceedings of the ACM International Conference on Object Oriented Programming Systems Languages and Applications, OOPSLA'10_ (New York, NY, USA, 2010). ACM, 22–35.
|
||||
|
||||
8\. Harrison, R., Smaraweera, L., Dobie, M., Lewis, P. Comparing programming paradigms: An evaluation of functional and object-oriented programs. _Softw. Eng. J. 11_ , 4 (1996), 247–254.
|
||||
|
||||
9\. Harter, D.E., Krishnan, M.S., Slaughter, S.A. Effects of process maturity on quality, cycle time, and effort in software product development. _Manage. Sci. 46_ 4 (2000), 451–466.
|
||||
|
||||
10\. Hindley, R. The principal type-scheme of an object in combinatory logic. _Trans. Am. Math. Soc._ (1969), 29–60.
|
||||
|
||||
11\. Jump, M., McKinley, K.S. Cork: Dynamic memory leak detection for garbage-collected languages. In _ACM SIGPLAN Notices_ , Volume 42 (2007). ACM, 31–38.
|
||||
|
||||
12\. Kleinschmager, S., Hanenberg, S., Robbes, R., Tanter, É., Stefik, A. Do static type systems improve the maintainability of software systems? An empirical study. In _2012 IEEE 20th International Conference on Program Comprehension (ICPC)_ (2012). IEEE, 153–162.
|
||||
|
||||
13\. Li, Z., Tan, L., Wang, X., Lu, S., Zhou, Y., Zhai, C. Have things changed now? An empirical study of bug characteristics in modern open source software. In _ASID'06: Proceedings of the 1st Workshop on Architectural and System Support for Improving Software Dependability_ (October 2006).
|
||||
|
||||
14\. Marques De Sá, J.P. _Applied Statistics Using SPSS, Statistica and Matlab_ , 2003.
|
||||
|
||||
15\. Mayer, C., Hanenberg, S., Robbes, R., Tanter, É., Stefik, A. An empirical study of the influence of static type systems on the usability of undocumented software. In _ACM SIGPLAN Notices_ , Volume 47 (2012). ACM, 683–702.
|
||||
|
||||
16\. Meyerovich, L.A., Rabkin, A.S. Empirical analysis of programming language adoption. In _Proceedings of the 2013 ACM SIGPLAN International Conference on Object Oriented Programming Systems Languages & Applications_ (2013). ACM, 1–18.
|
||||
|
||||
17\. Milner, R. A theory of type polymorphism in programming. _J. Comput. Syst. Sci. 17_ , 3 (1978), 348–375.
|
||||
|
||||
18\. Mockus, A., Votta, L.G. Identifying reasons for software changes using historic databases. In _ICSM'00\. Proceedings of the International Conference on Software Maintenance_ (2000). IEEE Computer Society, 120.
|
||||
|
||||
19\. Odersky, M., Spoon, L., Venners, B. _Programming in Scala._ Artima Inc, 2008.
|
||||
|
||||
20\. Pankratius, V., Schmidt, F., Garretón, G. Combining functional and imperative programming for multicore software: An empirical study evaluating scala and java. In _Proceedings of the 2012 International Conference on Software Engineering_ (2012). IEEE Press, 123–133.
|
||||
|
||||
21\. Petricek, T., Skeet, J. _Real World Functional Programming: With Examples in F# and C#._ Manning Publications Co., 2009.
|
||||
|
||||
22\. Pierce, B.C. _Types and Programming Languages._ MIT Press, 2002.
|
||||
|
||||
23\. Posnett, D., Bird, C., Dévanbu, P. An empirical study on the influence of pattern roles on change-proneness. _Emp. Softw. Eng. 16_ , 3 (2011), 396–423.
|
||||
|
||||
24\. Tan, L., Liu, C., Li, Z., Wang, X., Zhou, Y., Zhai, C. Bug characteristics in open source software. _Emp. Softw. Eng._ (2013).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007
|
||||
|
||||
作者:[ Baishakhi Ray][a], [Daryl Posnett][b], [Premkumar Devanbu][c], [Vladimir Filkov ][d]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:rayb@virginia.edu
|
||||
[b]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:dpposnett@ucdavis.edu
|
||||
[c]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:devanbu@cs.ucdavis.edu
|
||||
[d]:http://delivery.acm.org/10.1145/3130000/3126905/mailto:filkov@cs.ucdavis.edu
|
||||
[1]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R6
|
||||
[2]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R2
|
||||
[3]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R9
|
||||
[4]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7
|
||||
[5]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12
|
||||
[6]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R15
|
||||
[7]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R5
|
||||
[8]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R18
|
||||
[9]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7
|
||||
[10]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R8
|
||||
[11]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12
|
||||
[12]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNA
|
||||
[13]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNB
|
||||
[14]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNC
|
||||
[15]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R10
|
||||
[16]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R17
|
||||
[17]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R3
|
||||
[18]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R13
|
||||
[19]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R24
|
||||
[20]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[21]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[22]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[23]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[24]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R23
|
||||
[25]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R14
|
||||
[26]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R14
|
||||
[27]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FND
|
||||
[28]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4
|
||||
[29]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R11
|
||||
[30]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNE
|
||||
[31]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7
|
||||
[32]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R8
|
||||
[33]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12
|
||||
[34]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R20
|
||||
[35]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R16
|
||||
[36]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R1
|
||||
[37]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R19
|
||||
[38]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R21
|
||||
[39]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R22
|
||||
[40]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#comments
|
||||
[41]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#
|
||||
[42]:https://cacm.acm.org/about-communications/mobile-apps/
|
||||
[43]:http://dl.acm.org/citation.cfm?id=3144574.3126905&coll=portal&dl=ACM
|
||||
[44]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/pdf
|
||||
[45]:http://dl.acm.org/ft_gateway.cfm?id=3126905&ftid=1909469&dwn=1
|
||||
[46]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[47]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[48]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg
|
||||
[49]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg
|
||||
[50]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg
|
||||
[51]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t2.jpg
|
||||
[52]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t2.jpg
|
||||
[53]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg
|
||||
[54]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg
|
||||
[55]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg
|
||||
[56]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg
|
||||
[57]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t4.jpg
|
||||
[58]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t4.jpg
|
||||
[59]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[60]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[61]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[62]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[63]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[64]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[65]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[66]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut1.jpg
|
||||
[67]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[68]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg
|
||||
[69]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg
|
||||
[70]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut2.jpg
|
||||
[71]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg
|
||||
[72]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg
|
||||
[73]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg
|
||||
[74]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut3.jpg
|
||||
[75]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[76]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[77]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[78]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[79]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg
|
||||
[80]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[81]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg
|
||||
[82]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[83]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[84]:http://deliveryimages.acm.org/10.1145/3130000/3126905/ut4.jpg
|
||||
[85]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[86]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[87]:http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg
|
||||
[88]:http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg
|
||||
[89]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[90]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[91]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[92]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
[93]:https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#PageTop
|
||||
|
||||
|
||||
@ -1,120 +0,0 @@
|
||||
学习用 Thonny 写代码 — 一个面向初学者的PythonIDE
|
||||
======
|
||||
|
||||

|
||||
学习编程很难。即使当你最终得到了你的冒号和括号是正确的,但仍然有很大的机会,程序不会做你想做的事情。 通常,这意味着你忽略了某些东西或者误解了语言结构,你需要在代码中找到你的期望与现实存在分歧的地方。
|
||||
|
||||
程序员通常使用被叫做调试器的工具来处理这种情况,它允许一步一步地运行他们的程序。不幸的是,大多数调试器都针对专业用途进行了优化,并假设用户已经很好地了解了语言结构的语义(例如:函数调用)。
|
||||
|
||||
Thonny 是一个适合初学者的 Python IDE,由爱沙尼亚的 [Tartu大学][1] 开发,它采用了不同的方法,因为它的调试器是专为学习和教学编程而设计的。
|
||||
|
||||
虽然Thonny 适用于像小白一样的初学者,但这篇文章面向那些至少具有 Python 或其他命令式语言经验的读者。
|
||||
|
||||
### 开始
|
||||
|
||||
从第27版开始,Thonny 就被包含在 Fedora 软件库中。 使用 sudo dnf 安装 thonny 或者你选择的图形工具(比如软件)安装它。
|
||||
|
||||
当第一次启动 Thonny 时,它会做一些准备工作,然后呈现一个空编辑器和 Pythonshell 。将下列程序文本复制到编辑器中,并将其保存到文件中(Ctrl+S)。
|
||||
```
|
||||
n = 1
|
||||
while n < 5:
|
||||
print(n * "*")
|
||||
n = n + 1
|
||||
|
||||
```
|
||||
我们首先运行该程序。 为此请按键盘上的 F5 键。 你应该看到一个由周期组成的三角形出现在外壳窗格中。
|
||||
|
||||
![一个简单的 Thonny 程序][2]
|
||||
|
||||
Python 只是分析了你的代码并理解了你想打印一个三角形吗?让我们看看!
|
||||
|
||||
首先从“查看”菜单中选择“变量”。这将打开一张表格,向我们展示 Python 是如何管理程序的变量的。现在通过按 Ctrl + F5(或 XFCE 中的 Ctrl + Shift + F5)以调试模式运行程序。在这种模式下,Thonny 使 Python 在每一步所需的步骤之前暂停。你应该看到程序的第一行被一个框包围。我们将这称为焦点,它表明 Python 将接下来要执行的部分代码。
|
||||
|
||||
|
||||
![ Thonny 调试器焦点 ][3]
|
||||
|
||||
你在焦点框中看到的一段代码段被称为赋值语句。 对于这种声明,Python 应该计算右边的表达式,并将值存储在左边显示的名称下。按 F7 进行下一步。你将看到 Python 将重点放在语句的正确部分。在这种情况下,表达式实际上很简单,但是为了通用性,Thonny 提供了表达式计算框,它允许将表达式转换为值。再次按 F7 将文字 1 转换为值 1。现在 Python 已经准备好执行实际的赋值—再次按 F7,你应该会看到变量 n 的值为 1 的变量出现在变量表中。
|
||||
|
||||
![Thonny 变量表][4]
|
||||
|
||||
继续按 F7 并观察 Python 如何以非常小的步骤前进。它看起来像是理解你的代码的目的或者更像是一个愚蠢的遵循简单规则的机器?
|
||||
|
||||
### 函数调用
|
||||
|
||||
函数调用(FunctionCall)是一种编程概念,它常常给初学者带来很大的困惑。从表面上看,没有什么复杂的事情--给代码命名,然后在代码中的其他地方引用它(调用它)。传统的调试器告诉我们,当你进入调用时,焦点跳转到函数定义中(然后神奇地返回到原来的位置)。这是整件事吗?这需要我们关心吗?
|
||||
|
||||
结果证明,“跳转模型” 只对最简单的函数是足够的。理解参数传递、局部变量、返回和递归都得益于堆栈框架的概念。幸运的是,Thonny 可以直观地解释这个概念,而无需在厚厚的一层下搜索重要的细节。
|
||||
|
||||
将以下递归程序复制到 Thonny 并以调试模式(Ctrl+F5 或 Ctrl+Shift+F5)运行。
|
||||
```
|
||||
def factorial(n):
|
||||
if n == 0:
|
||||
return 1
|
||||
else:
|
||||
return factorial(n-1) * n
|
||||
|
||||
print(factorial(4))
|
||||
|
||||
```
|
||||
|
||||
重复按 F7,直到你在对话框中看到表达式因式(4)。 当你进行下一步时,你会看到 Thonny 打开一个包含功能代码,另一个变量表和另一个焦点框的新窗口(移动窗口以查看旧的焦点框仍然存在)。
|
||||
|
||||
![通过递归函数的 Thonny][5]
|
||||
|
||||
此窗口表示堆栈帧, 即用于解析函数调用的工作区。在彼此顶部的几个这样的窗口称为调用堆栈。注意调用站点上的参数4与 "局部变量" 表中的输入 n 之间的关系。继续按 F7步进, 观察在每次调用时如何创建新窗口并在函数代码完成时被销毁, 以及如何用返回值替换调用站点。
|
||||
|
||||
|
||||
### 值与参考
|
||||
|
||||
现在,让我们在 Pythonshell 中进行一个实验。首先输入下面屏幕截图中显示的语句:
|
||||
|
||||
![Thonny 壳显示列表突变][6]
|
||||
|
||||
正如你所看到的, 我们追加到列表 b, 但列表 a 也得到了更新。你可能知道为什么会发生这种情况, 但是对初学者来说,什么才是最好的解释呢?
|
||||
|
||||
当教我的学生列表时,我告诉他们我一直在骗他们关于 Python 内存模型。实际上,它并不像变量表所显示的那样简单。我告诉他们重新启动解释器(工具栏上的红色按钮),从“视图”菜单中选择“堆”,然后再次进行相同的实验。如果这样做,你就会发现变量表不再包含值-它们实际上位于另一个名为“Heap”的表中。变量表的作用实际上是将变量名映射到地址(或ID-s),地址(或ID-s)引用堆表中的行。由于赋值仅更改变量表,因此语句 b = a 只复制对列表的引用,而不是列表本身。这解释了为什么我们通过这两个变量看到了变化。
|
||||
|
||||
|
||||
![在堆模式中的 Thonny][7]
|
||||
|
||||
(为什么我要在教列表的主题之前推迟说出内存模型的事实?Python存储的列表是否有所不同?请继续使用Thonny的堆模式来找出结果!在评论中告诉我你认为怎么样!)
|
||||
|
||||
如果要更深入地了解参考系统, 请将以下程序通过打开堆表复制到 Thonny 和小步骤 (F7) 中。
|
||||
```
|
||||
def do_something(lst, x):
|
||||
lst.append(x)
|
||||
|
||||
a = [1,2,3]
|
||||
n = 4
|
||||
do_something(a, n)
|
||||
print(a)
|
||||
|
||||
```
|
||||
|
||||
即使“堆模式”向我们显示真实的图片,但它使用起来也相当不方便。 因此,我建议你现在切换回普通模式(取消选择“查看”菜单中的“堆”),但请记住,真实模型包含变量,参考和值。
|
||||
|
||||
### 结语
|
||||
|
||||
我在这篇文章中提及到的特性是创建 Thonny 的主要原因。这很容易对函数调用和引用形成错误的理解,但传统的调试器并不能真正帮助减少混淆。
|
||||
|
||||
除了这些显著的特性,Thonny 还提供了其他几个初学者友好的工具。 请查看 [Thonny的主页][8] 以了解更多信息!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-code-thonny-python-ide-beginners/
|
||||
|
||||
作者:[Aivar Annamaa][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/
|
||||
[1]:https://www.ut.ee/en
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2017/12/scr1.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr2.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr3.png
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr4.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr5.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr6.png
|
||||
[8]:http://thonny.org
|
||||
151
translated/tech/20180301 The Cost of Cloud Computing.md
Normal file
151
translated/tech/20180301 The Cost of Cloud Computing.md
Normal file
@ -0,0 +1,151 @@
|
||||
云计算的成本
|
||||
============================================================
|
||||
|
||||
### 两个开发团队的一天
|
||||
|
||||
|
||||

|
||||
|
||||
几个月以前,我与一些人讨论过关于公共云服务成本与传统专用基础设施价格比较的话题。为给你提供一些见解,我们来跟踪一下一个企业中的两个开发团队 — 并比较他们构建类似服务的方式。
|
||||
|
||||
第一个团队将使用传统的专用基础设施来部署他们的应用,而第二个团队将使用 AWS 提供的公共云服务。
|
||||
|
||||
这两个团队被要求为一家全球化企业开发一个新的服务,该企业目前为全球数百万消费者提供服务。要开发的这项新服务需要满足以下基本需求:
|
||||
|
||||
1. 能够随时扩展以满足弹性需求
|
||||
|
||||
2. 具备应对数据中心故障的弹性
|
||||
|
||||
3. 确保数据安全以及数据受到保护
|
||||
|
||||
4. 为排错提供深入的调试功能
|
||||
|
||||
5. 项目必须能迅速分发
|
||||
|
||||
6. 服务构建和维护的性价比要高
|
||||
|
||||
就新服务来说,这看起来是非常标准的需求 — 从本质上看传统专用基础设备上没有什么东西可以超越公共云了。
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
#### 1 — 扩展以满足客户需求
|
||||
|
||||
当说到可扩展性时,这个新服务需要去满足客户变化无常的需求。我们构建的服务不可以拒绝任何请求,以防让公司遭受损失或者声誉受到影响。
|
||||
|
||||
传统的团队使用的是专用基础设施,架构体系的计算能力需要与峰值数据需求相匹配。对于负载变化无常的服务来说,大量昂贵的计算能力在低利用率的时间被浪费掉。
|
||||
|
||||
这是一种很浪费的方法 — 并且大量的资本支出会侵蚀掉你的利润。另外,这些未充分利用的庞大的服务器资源的维护也是一项很大的运营成本。这是一项你无法忽略的成本 — 我不得不再强调一下,为支持一个单一服务去维护一机柜的服务器是多么的浪费时间和金钱。
|
||||
|
||||
云团队使用的是基于云的自动伸缩解决方案,应用会按需要进行自动扩展和收缩。也就是说你只需要支付你所消费的计算资源的费用。
|
||||
|
||||
一个架构良好的基于云的应用可以实现无缝地伸缩 — 并且还是自动进行的。开发团队只需要定义好自动伸缩的资源组即可,即当你的应用 CPU 利用率达到某个高位、或者每秒有多大请求数时启动多少实例,并且你可以根据你的意愿去定制这些规则。
|
||||
|
||||
* * *
|
||||
|
||||
#### 2 — 应对故障的弹性
|
||||
|
||||
当说到弹性时,将托管服务的基础设施放在同一个房间里并不是一个好的选择。如果你的应用托管在一个单一的数据中心 — (不是如果)发生某些失败时(译者注:指坍塌、地震、洪灾等),你的所有的东西都被埋了。
|
||||
|
||||
传统的团队去满足这种基本需求的标准解决方案是,为实现局部弹性建立至少两个服务器 — 在地理上冗余的数据中心之间实施秒级复制。
|
||||
|
||||
开发团队需要一个负载均衡解决方案,以便于在发生饱合或者故障等事件时将流量转向到另一个节点 — 并且还要确保镜像节点之间,整个栈是持续完全同步的。
|
||||
|
||||
在全球 50 个区域中的每一个云团队,都由 AWS 提供多个_有效区域_。每个区域由多个容错数据中心组成 — 通过自动故障切换功能,AWS 可以在区域内将服务无缝地转移到其它的区中。
|
||||
|
||||
在一个 `CloudFormation` 模板中定义你的_基础设施即代码_,确保你的基础设施在自动伸缩事件中跨区保持一致 — 而对于流量的流向管理,AWS 负载均衡服务仅需要做很少的配置即可。
|
||||
|
||||
* * *
|
||||
|
||||
#### 3 — 安全和数据保护
|
||||
|
||||
安全是一个组织中任何一个系统的基本要求。我想你肯定不想成为那些不幸遭遇安全问题的公司之一的。
|
||||
|
||||
传统团队为保证运行他们服务的基础服务器安全,他们不得不持续投入成本。这意味着将不得不向监视、识别、以及为来自不同数据源的跨多个供应商解决方案的安全威胁打补丁的团队上投资。
|
||||
|
||||
使用公共云的团队并不能免除来自安全方面的责任。云团队仍然需要提高警惕,但是并不需要去担心为底层基础设施打补丁的问题。AWS 将积极地对付各种 0 日漏洞 — 最近的一次是 Spectre 和 Meltdown。
|
||||
|
||||
利用来自 AWS 的识别管理和加密安全服务,可以让云团队专注于他们的应用 — 而不是无差别的安全管理。使用 `CloudTrail` 对 API 到 AWS 服务的调用做全面审计,可以实现透明地监视。
|
||||
|
||||
* * *
|
||||
|
||||
#### 4 — 监视和日志
|
||||
|
||||
任何基础设施和部署为服务的应用都需要严密监视实时数据。团队应该有一个可以访问的仪表板,当超过指标阈值时仪表板会显示警报,并能够在排错时提供与事件相关的日志。
|
||||
|
||||
使用传统基础设施的传统团队,将不得不在跨不同供应商和“雪花状”的解决方案上配置监视和报告解决方案。配置这些“见鬼的”解决方案将花费你大量的时间和精力 — 并且能够正确地实现你的目的是相当困难的。
|
||||
|
||||
对于大多数部署在专用基础设施上的应用来说,为了搞清楚你的应用为什么崩溃,你可以通过搜索保存在你的服务器文件系统上的日志文件来找到答案。为此你的团队需要通过 SSH 进入服务器,导航到日志文件所在的目录,然后浪费大量的时间,通过 `grep` 在成百上千的日志文件中寻找。如果你在一个横跨 60 台服务器上部署的应用中这么做 — 我能负责任地告诉你,这是一个极差的解决方案。
|
||||
|
||||
云团队利用原生的 AWS 服务,如 CloudWatch 和 CloudTrail,来做云应用程序的监视是非常容易。不需要很多的配置,开发团队就可以监视部署的服务上的各种指标 — 问题的排除过程也不再是个恶梦了。
|
||||
|
||||
对于传统的基础设施,团队需要构建自己的解决方案,配置他们的 REST API 或者服务去推送日志到一个聚合器。而得到这个“开箱即用”的解决方案将对生产力有极大的提升。
|
||||
|
||||
* * *
|
||||
|
||||
#### 5 — 加速开发进程
|
||||
|
||||
现在的商业环境中,快速上市的能力越来越重要。由于实施延误所失去的机会成本,可能成为影响最终利润的一个主要因素。
|
||||
|
||||
大多数组织的这种传统团队,他们需要在新项目所需要的硬件采购、配置和部署上花费很长的时间 — 并且由于预测能力差,提前获得的额外的性能将造成大量的浪费。
|
||||
|
||||
而且还有可能的是,传统的开发团队在无数的“筒仓”中穿梭以及在移交创建的服务上花费数月的时间。项目的每一步都会在数据库、系统、安全、以及网络管理方面需要一个独立工作。
|
||||
|
||||
而云团队开发新特性时,拥有大量的随时可投入生产系统的服务套件供你使用。这是开发者的天堂。每个 AWS 服务一般都有非常好的文档并且可以通过你选择的语言以编程的方式去访问。
|
||||
|
||||
使用新的云架构,例如无服务器,开发团队可以在最小化冲突的前提下构建和部署一个可扩展的解决方案。比如,只需要几天时间就可以建立一个 [Imgur 的无服务器克隆][4],它具有图像识别的特性,内置一个产品级的监视/日志解决方案,并且它的弹性极好。
|
||||
|
||||

|
||||
|
||||
如果必须要我亲自去设计弹性和可伸缩性,我可以向你保证,我仍然在开发这个项目 — 而且最终的产品将远不如目前的这个好。
|
||||
|
||||
从我实践的情况来看,使用无服务器架构的交付时间远小于在大多数公司中提供硬件所花费的时间。我只是简单地将一系列 AWS 服务与 Lambda 功能 — 以及 ta-da 耦合到一起而已!我只专注于开发解决方案,而无差别的可伸缩性和弹性是由 AWS 为我处理的。
|
||||
|
||||
* * *
|
||||
|
||||
#### 关于云计算成本的结论
|
||||
|
||||
就弹性而言,云计算团队的按需扩展是当之无愧的赢家 — 因为他们仅为需要的计算能力埋单。而不需要为维护和底层的物理基础设施打补丁付出相应的资源。
|
||||
|
||||
云计算也为开发团队提供一个可使用多个有效区的弹性架构、为每个服务构建的安全特性、持续的日志和监视工具、随用随付的服务、以及低成本的加速分发实践。
|
||||
|
||||
大多数情况下,云计算的成本要远低于为你的应用运行所需要的购买、支持、维护和设计的按需基础架构的成本 — 并且云计算的麻烦事更少。
|
||||
|
||||
通过利用云计算,我们可以更少的先期投入而使业务快速开展。整体而言,当你开发和部署业务服务时,云计算的经济性可以让你的工作更赞。
|
||||
|
||||
也有一些云计算比传统基础设施更昂贵的例子,一些情况是在周末忘记关闭运行的一些极其昂贵的测试机器。
|
||||
|
||||
[Dropbox 在决定推出自己的基础设施并减少对 AWS 服务的依赖之后,在两年的时间内节省近 7500 万美元的费用,Dropbox…www.geekwire.com][5][][6]
|
||||
|
||||
即便如此,这样的案例仍然是非常少见的。更不用说当初 Dropbox 也是从 AWS 上开始它的业务的 — 并且当它的业务达到一个临界点时,才决定离开这个平台。即便到现在,他们也已经进入到云计算的领域了,并且还在 AWS 和 GCP 上保留了 40% 的基础设施。
|
||||
|
||||
将云服务与基于单一“成本”指标(译者注:此处的“成本”仅指物理基础设施的购置成本)的传统基础设施比较的想法是极其幼稚的 — 公然无视云为开发团队和你的业务带来的一些主要的优势。
|
||||
|
||||
在极少数的情况下,云服务比传统基础设施产生更多的绝对成本 — 它在开发团队的生产力、速度和创新方面仍然贡献着更好的价值。
|
||||
|
||||

|
||||
|
||||
客户才不在乎你的数据中心呢
|
||||
|
||||
_我非常乐意倾听你在云中开发的真实成本相关的经验和反馈!请在下面的评论区、Twitter _ [_@_ _Elliot_F_][7] 上、或者直接在 _ [_LinkedIn_][8] 上联系我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://read.acloud.guru/the-true-cost-of-cloud-a-comparison-of-two-development-teams-edc77d3dc6dc
|
||||
|
||||
作者:[Elliot Forbes][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://read.acloud.guru/@elliot_f?source=post_header_lockup
|
||||
[1]:https://info.acloud.guru/faas-and-furious?utm_campaign=FaaS%20and%20Furious
|
||||
[2]:https://read.acloud.guru/building-an-imgur-clone-part-2-image-rekognition-and-a-dynamodb-backend-abc9af300123
|
||||
[3]:https://read.acloud.guru/customers-dont-give-a-shit-about-your-devops-pipeline-51a2342cc0f5
|
||||
[4]:https://read.acloud.guru/building-an-imgur-clone-part-2-image-rekognition-and-a-dynamodb-backend-abc9af300123
|
||||
[5]:https://www.geekwire.com/2018/dropbox-saved-almost-75-million-two-years-building-tech-infrastructure/
|
||||
[6]:https://www.geekwire.com/2018/dropbox-saved-almost-75-million-two-years-building-tech-infrastructure/
|
||||
[7]:https://twitter.com/Elliot_F
|
||||
[8]:https://www.linkedin.com/in/elliotforbes/
|
||||
@ -0,0 +1,57 @@
|
||||
BLUI:创建游戏 UI 的简单方法
|
||||
======
|
||||
|
||||

|
||||
|
||||
游戏开发引擎在过去几年中变得越来越易于使用。像 Unity 这样一直免费使用的引擎,以及最近从基于订阅的服务切换到免费服务的 Unreal,允许独立开发者使用 AAA 发布商使用的相同行业标准工具。虽然这些引擎都不是开源的,但每个引擎都能够促进其周围的开源生态系统的发展。
|
||||
|
||||
这些引擎中包含的插件允许开发人员通过添加特定程序来增强引擎的基本功能。这些程序的范围可以从简单的资源包到更复杂的事物,如人工智能 (AI) 集成。这些插件来自不同的创作者。有些是由引擎开发工作室和有些是个人提供的。后者中的很多是开源插件。
|
||||
|
||||
### 什么是 BLUI?
|
||||
|
||||
作为独立游戏开发工作室的一部分,我体验到了在专有游戏引擎上使用开源插件的好处。Aaron Shea 开发的一个开源插件 [BLUI][1] 对我们团队的开发过程起到了重要作用。它允许我们使用基于 Web 的编程(如 HTML/CSS 和 JavaScript)创建用户界面 (UI) 组件。尽管虚幻引擎(我们选择的引擎)有一个内置的 UI 编辑器实现了类似目的,我们也选择使用这个开源插件。我们选择使用开源替代品有三个主要原因:它们的可访问性、易于实现以及伴随的开源程序活跃的、支持性好的在线社区。
|
||||
|
||||
在虚幻引擎的最早版本中,我们在游戏中创建 UI 的唯一方法是通过引擎的原生 UI 集成,使用 Autodesk 的 Scaleform 程序,或通过在虚幻社区中传播的一些选定的基于订阅的 Unreal 集成。在这些情况下,这些解决方案要么不能为独立开发者提供有竞争力的 UI 解决方案,要么对于小型团队来说太昂贵,要么只能为大型团队和 AAA 开发者提供。
|
||||
|
||||
在商业产品和 Unreal 的原生整合失败后,我们向独立社区寻求解决方案。我们在那里发现了 BLUI。它不仅与虚幻引擎无缝集成,而且还保持了一个强大且活跃的社区,经常推出更新并确保独立开发人员可以轻松访问文档。BLUI 使开发人员能够将 HTML 文件导入虚幻引擎,并在程序内部对其进行编程。这使得通过网络语言创建的 UI 能够集成到游戏的代码、资源和其他元素中,并拥有所有 HTML、CSS、Javascript 和其他网络语言的能力。它还为开源 [Chromium Embedded Framework][2] 提供全面支持。
|
||||
|
||||
### 安装和使用 BLUI
|
||||
|
||||
使用 BLUI 的基本过程包括首先通过 HTML 创建 UI。开发人员可以使用任何工具来实现此目的,包括自举 JavaScript 代码,外部 API 或任何数据库代码。一旦这个 HTML 页面完成,你可以像安装任何 Unreal 插件那样安装它并加载或创建一个项目。项目加载后,你可以将 BLUI 函数放在 Unreal UI 图纸中的任何位置,或者通过 C++ 进行硬编码。开发人员可以通过其 HTML 页面调用函数,或使用 BLUI 的内部函数轻松更改变量。
|
||||
|
||||
![Integrating BLUI into Unreal Engine 4 blueprints][4]
|
||||
|
||||
将 BLUI 集成到虚幻 4 图纸中。
|
||||
|
||||
在我们当前的项目中,我们使用 BLUI 将 UI 元素与游戏中的音轨同步,为游戏机制的节奏方面提供视觉反馈。将定制引擎编程与 BLUI 插件集成很容易。
|
||||
|
||||
![Using BLUI to sync UI elements with the soundtrack.][6]
|
||||
|
||||
使用 BLUI 将 UI 元素与音轨同步。
|
||||
|
||||
通过 BLUI GitHub 页面上的[文档][7],将 BLUI 集成到虚幻 4 中是一个微不足道的过程。还有一个由支援虚幻引擎开发人员组成的[论坛][8],他们乐于询问和回答关于插件以及实现该工具时出现的任何问题。
|
||||
|
||||
### 开源优势
|
||||
|
||||
开源插件可以在专有游戏引擎的范围内扩展创意。他们继续降低进入游戏开发的障碍,并且可以产生前所未有的游戏内机制和资源。随着对专有游戏开发引擎的访问持续增长,开源插件社区将变得更加重要。不断增长的创造力必将超过专有软件,开源代码将会填补这些空白,并促进开发真正独特的游戏。而这种新颖性正是让独立游戏如此美好的原因!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/blui-game-development-plugin
|
||||
|
||||
作者:[Uwana lkaiddi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/uwikaiddi
|
||||
[1]:https://github.com/AaronShea/BLUI
|
||||
[2]:https://bitbucket.org/chromiumembedded/cef
|
||||
[3]:/file/400616
|
||||
[4]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-integratingblui.png (Integrating BLUI into Unreal Engine 4 blueprints)
|
||||
[5]:/file/400621
|
||||
[6]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-syncui.png (Using BLUI to sync UI elements with the soundtrack.)
|
||||
[7]:https://github.com/AaronShea/BLUI/wiki
|
||||
[8]:https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui
|
||||
@ -0,0 +1,104 @@
|
||||
如何暂时禁用 iptables 防火墙
|
||||
======
|
||||
|
||||
了解如何在 Linux 中暂时禁用 iptables 防火墙来进行故障排除。还要学习如何保存策略以及如何在启用防火墙时恢复它们。
|
||||
|
||||
![How to disable iptables firewall temporarily][1]
|
||||
|
||||
有时你需要关闭 iptables 防火墙来做一些连接故障排除,然后你需要重新打开它。在执行此操作时,你还需要保存所有[防火墙策略][2]。在本文中,我们将引导你了解如何保存防火墙策略以及如何禁用/启用 iptables 防火墙。有关 iptables 防火墙和策略的更多详细信息[请阅读我们的文章][3]。
|
||||
|
||||
### 保存 iptables 策略
|
||||
|
||||
临时禁用 iptables 防火墙的第一步是保存现有的防火墙规则/策略。`iptables-save` 命令列出你可以保存到服务器中的所有现有策略。
|
||||
|
||||
```
|
||||
root@kerneltalks # # iptables-save
|
||||
# Generated by iptables-save v1.4.21 on Tue Jun 19 09:54:36 2018
|
||||
*nat
|
||||
:PREROUTING ACCEPT [1:52]
|
||||
:INPUT ACCEPT [1:52]
|
||||
:OUTPUT ACCEPT [15:1140]
|
||||
:POSTROUTING ACCEPT [15:1140]
|
||||
:DOCKER - [0:0]
|
||||
---- output trucated----
|
||||
|
||||
root@kerneltalks # iptables-save > /root/firewall_rules.backup
|
||||
```
|
||||
|
||||
因此,iptables-save 是可以用来备份 iptables 策略的命令。
|
||||
|
||||
### 停止/禁用 iptables 防火墙
|
||||
|
||||
对于较老的 Linux 内核,你可以选择使用 `service iptables stop` 停止 iptables 服务,但是如果你在用新内核,则只需清除所有策略并允许所有流量通过防火墙。这和你停止防火墙效果一样。
|
||||
|
||||
使用下面的命令列表来做到这一点。
|
||||
```
|
||||
root@kerneltalks # iptables -F
|
||||
root@kerneltalks # iptables -X
|
||||
root@kerneltalks # iptables -P INPUT ACCEPT
|
||||
root@kerneltalks # iptables -P OUTPUT ACCEPT
|
||||
root@kerneltalks # iptables -P FORWARD ACCEPT
|
||||
```
|
||||
|
||||
这里 –
|
||||
|
||||
* -F:删除所有策略链
|
||||
* -X:删除用户定义的链
|
||||
* -P INPUT/OUTPUT/FORWARD :接受指定的流量
|
||||
|
||||
|
||||
|
||||
完成后,检查当前的防火墙策略。它应该看起来像下面这样接受所有流量(和禁用/停止防火墙一样)
|
||||
|
||||
```
|
||||
# iptables -L
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
```
|
||||
|
||||
### 恢复防火墙策略
|
||||
|
||||
故障排除后,你想要重新打开 iptables 的所有配置。你需要先从我们在第一步中执行的备份中恢复策略。
|
||||
|
||||
```
|
||||
root@kerneltalks # iptables-restore </root/firewall_rules.backup
|
||||
```
|
||||
### 启动 iptables 防火墙
|
||||
|
||||
然后启动 iptables 服务,以防止你在上一步中使用 `service iptables start` 停止了它。如果你已经停止服务,那么只有恢复策略才能有用。检查所有策略是否恢复到 iptables 配置中:
|
||||
|
||||
```
|
||||
# iptables -L
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
Chain FORWARD (policy DROP)
|
||||
target prot opt source destination
|
||||
DOCKER-USER all -- anywhere anywhere
|
||||
DOCKER-ISOLATION-STAGE-1 all -- anywhere anywhere
|
||||
-----output truncated-----
|
||||
```
|
||||
|
||||
就是这些了!你已成功禁用并启用了防火墙,而不会丢失你的策略规则。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/howto/how-to-disable-iptables-firewall-temporarily/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a2.kerneltalks.com/wp-content/uploads/2018/06/How-to-disable-iptables-firewall-temporarily.png
|
||||
[2]:https://kerneltalks.com/networking/configuration-of-iptables-policies/
|
||||
[3]:https://kerneltalks.com/networking/basics-of-iptables-linux-firewall/
|
||||
Loading…
Reference in New Issue
Block a user