mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
8ab3d04b2d
@ -0,0 +1,126 @@
|
||||
An introduction to the DomTerm terminal emulator for Linux
|
||||
======
|
||||

|
||||
|
||||
[DomTerm][1] is a modern terminal emulator that uses a browser engine as a "GUI toolkit." This enables some neat features, such as embeddable graphics and links, HTML rich text, and foldable (show/hide) commands. Otherwise it looks and feels like a feature-full, standalone terminal emulator, with excellent xterm compatibility (including mouse handling and 24-bit color), and appropriate "chrome" (menus). In addition, there is built-in support for session management and sub-windows (as in `tmux` and `GNU screen`), basic input editing (as in `readline`), and paging (as in `less`).
|
||||
|
||||
|
||||
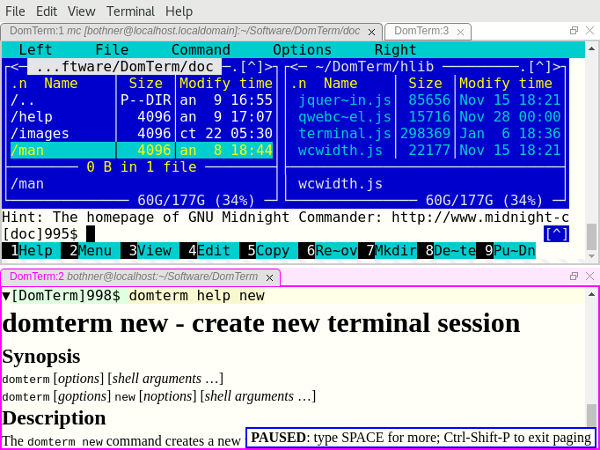
Image 1: The DomTerminal terminal emulator. View larger image.
|
||||
|
||||
Below we'll look more at these features. We'll assume you have `domterm` installed (skip to the end of this article if you need to get and build DomTerm). First, though, here's a quick overview of the technology.
|
||||
|
||||
### Frontend vs. backend
|
||||
|
||||
Most of DomTerm is written in JavaScript and runs in a browser engine. This can be a desktop web browser, such as Chrome or Firefox (see image 3), or it can be an embedded browser. Using a general web browser works fine, but the user experience isn't as nice (as the menus are designed for general browsing, not for a terminal emulator), and the security model gets in the way, so using an embedded browser is nicer.
|
||||
|
||||
The following are currently supported:
|
||||
|
||||
* `qtdomterm`, which uses the Qt toolkit and `QtWebEngine`
|
||||
* An `[Electron][2]` embedding (see image 1)
|
||||
* `atom-domterm` runs DomTerm as a package in the [Atom text editor][3] (which is also based on Electron) and integrates with the Atom pane system (see image 2)
|
||||
* A wrapper for JavaFX's `WebEngine`, which is useful for code written in Java (see image 4)
|
||||
* Previously, the preferred frontend used [Firefox-XUL][4], but Mozilla has since dropped XUL
|
||||
|
||||
|
||||
|
||||
![DomTerm terminal panes in Atom editor][6]
|
||||
|
||||
Image 2: DomTerm terminal panes in Atom editor. [View larger image.][7]
|
||||
|
||||
Currently, the Electron frontend is probably the nicest option, closely followed by the Qt frontend. If you use Atom, `atom-domterm` works pretty well.
|
||||
|
||||
The backend server is written in C. It manages pseudo terminals (PTYs) and sessions. It is also an HTTP server that provides the JavaScript and other files to the frontend. The `domterm` command starts terminal jobs and performs other requests. If there is no server running, `domterm` daemonizes itself. Communication between the backend and the server is normally done using WebSockets (with [libwebsockets][8] on the server). However, the JavaFX embedding uses neither WebSockets nor the DomTerm server; instead Java applications communicate directly using the Java-JavaScript bridge.
|
||||
|
||||
### A solid xterm-compatible terminal emulator
|
||||
|
||||
DomTerm looks and feels like a modern terminal emulator. It handles mouse events, 24-bit color, Unicode, double-width (CJK) characters, and input methods. DomTerm does a very good job on the [vttest testsuite][9].
|
||||
|
||||
Unusual features include:
|
||||
|
||||
**Show/hide buttons ("folding"):** The little triangles (seen in image 2 above) are buttons that hide/show the corresponding output. To create the buttons, just add certain [escape sequences][10] in the [prompt text][11].
|
||||
|
||||
**Mouse-click support for`readline` and similar input editors:** If you click in the (yellow) input area, DomTerm will send the right sequence of arrow-key keystrokes to the application. (This is enabled by escape sequences in the prompt; you can also force it using Alt+Click.)
|
||||
|
||||
**Style the terminal using CSS:** This is usually done in `~/.domterm/settings.ini`, which is automatically reloaded when saved. For example, in image 2, terminal-specific background colors were set.
|
||||
|
||||
### A better REPL console
|
||||
|
||||
A classic terminal emulator works on rectangular grids of character cells. This works for a REPL (command shell), but it is not ideal. Here are some DomTerm features useful for REPLs that are not typically found in terminal emulators:
|
||||
|
||||
**A command can "print" an image, a graph, a mathematical formula, or a set of clickable links:** An application can send an escape sequence containing almost any HTML. (The HTML is scrubbed to remove JavaScript and other dangerous features.)
|
||||
|
||||
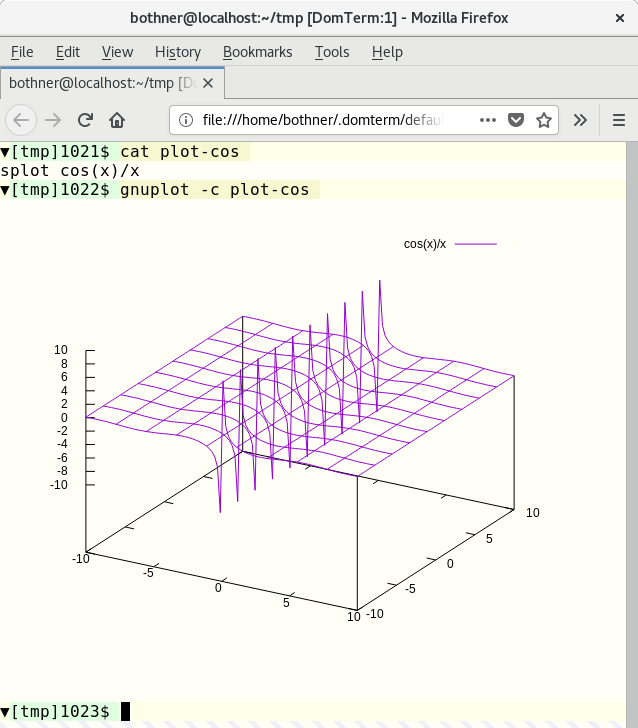
The image 3 shows a fragment from a [`gnuplot`][12] session. Gnuplot (2.1 or later) supports `domterm` as a terminal type. Graphical output is converted to an [SVG image][13], which is then printed to the terminal. My blog post [Gnuplot display on DomTerm][14] provides more information on this.
|
||||
|
||||
|
||||
Image 3: Gnuplot screenshot. View larger image.
|
||||
|
||||
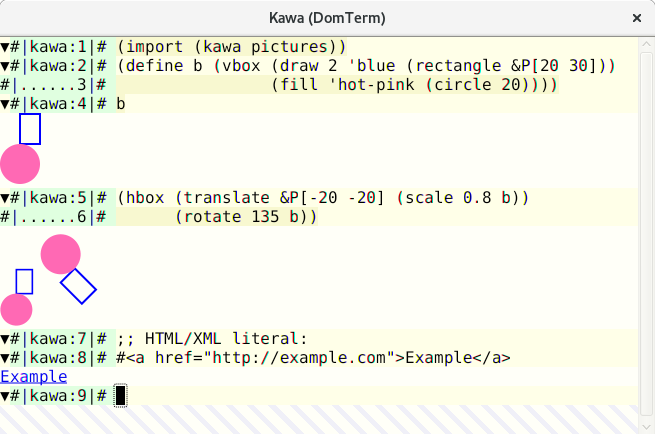
The [Kawa][15] language has a library for creating and transforming [geometric picture values][16]. If you print such a picture value to a DomTerm terminal, the picture is converted to SVG and embedded in the output.
|
||||
|
||||
|
||||
Image 4: Computable geometry in Kawa. View larger image.
|
||||
|
||||
**Rich text in output:** Help messages are more readable and look nicer with HTML styling. The lower pane of image 1 shows the ouput from `domterm help`. (The output is plaintext if not running under DomTerm.) Note the `PAUSED` message from the built-in pager.
|
||||
|
||||
**Error messages can include clickable links:** DomTerm recognizes the syntax `filename:line:column:` and turns it into a link that opens the file and line in a configurable text editor. (This works for relative filenames if you use `PROMPT_COMMAND` or similar to track directories.)
|
||||
|
||||
A compiler can detect that it is running under DomTerm and directly emit file links in an escape sequence. This is more robust than depending on DomTerm's pattern matching, as it handles spaces and other special characters, and it does not depend on directory tracking. In image 4, you can see error messages from the [Kawa compiler][15]. Hovering over the file position causes it to be underlined, and the `file:` URL shows in the `atom-domterm` message area (bottom of the window). (When not using `atom-domterm`, such messages are shown in an overlay box, as seen for the `PAUSED` message in image 1.)
|
||||
|
||||
The action when clicking on a link is configurable. The default action for a `file:` link with a `#position` suffix is to open the file in a text editor.
|
||||
|
||||
**Structured internal representation:** The following are all represented in the internal node structure: Commands, prompts, input lines, normal and error output, tabs, and preserving the structure if you "Save as HTML." The HTML file is compatible with XML, so you can use XML tools to search or transform the output. The command `domterm view-saved` opens a saved HTML file in a way that enables command folding (show/hide buttons are active) and reflow on window resize.
|
||||
|
||||
**Built-in Lisp-style pretty-printing:** You can include pretty-printing directives (e.g., grouping) in the output such that line breaks are recalculated on window resize. See my article [Dynamic pretty-printing in DomTerm][17] for a deeper discussion.
|
||||
|
||||
**Basic built-in line editing** with history (like `GNU readline`): This uses the browser's built-in editor, so it has great mouse and selection handling. You can switch between normal character-mode (most characters typed are sent directly to the process); or line-mode (regular characters are inserted while control characters cause editing actions, with Enter sending the edited line to the process). The default is automatic mode, where DomTerm switches between character-mode and line-mode depending on whether the PTY is in raw or canonical mode.
|
||||
|
||||
**A built-in pager** (like a simplified `less`): Keyboard shortcuts will control scrolling. In "paging mode," the output pauses after each new screen (or single line, if you move forward line-by-line). The paging mode is unobtrusive and smart about user input, so you can (if you wish) run it without it interfering with interactive programs.
|
||||
|
||||
### Multiplexing and sessions
|
||||
|
||||
**Tabs and tiling:** Not only can you create multiple terminal tabs, you can also tile them. You can use either the mouse or a keyboard shortcut to move between panes and tabs as well as create new ones. They can be rearranged and resized with the mouse. This is implemented using the [GoldenLayout][18] JavaScript library. [Image 1][19] shows a window with two panes. The top one has two tabs, with one running [Midnight Commander][20]; the bottom pane shows `domterm help` output as HTML. However, on Atom we instead use its built-in draggable tiles and tabs; you can see this in image 2.
|
||||
|
||||
**Detaching and reattaching to sessions:** DomTerm supports sessions arrangement, similar to `tmux` and GNU `screen`. You can even attach multiple windows or panes to the same session. This supports multi-user session sharing and remote connections. (For security, all sessions of the same server need to be able to read a Unix domain socket and a local file containing a random key. This restriction will be lifted when we have a good, safe remote-access story.)
|
||||
|
||||
**The** **`domterm`** **command** is also like `tmux` or GNU `screen` in that has multiple options for controlling or starting a server that manages one or more sessions. The major difference is that, if it's not already running under DomTerm, the `domterm` command creates a new top-level window, rather than running in the existing terminal.
|
||||
|
||||
The `domterm` command has a number of sub-commands, similar to `tmux` or `git`. Some sub-commands create windows or sessions. Others (such as "printing" an image) only work within an existing DomTerm session.
|
||||
|
||||
The command `domterm browse` opens a window or pane for browsing a specified URL, such as when browsing documentation.
|
||||
|
||||
### Getting and installing DomTerm
|
||||
|
||||
DomTerm is available from its [GitHub repository][21]. Currently, there are no prebuilt packages, but there are [detailed instructions][22]. All prerequisites are available on Fedora 27, which makes it especially easy to build.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/introduction-domterm-terminal-emulator
|
||||
|
||||
作者:[Per Bothner][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/perbothner
|
||||
[1]:http://domterm.org/
|
||||
[2]:https://electronjs.org/
|
||||
[3]:https://atom.io/
|
||||
[4]:https://en.wikipedia.org/wiki/XUL
|
||||
[5]:/file/385346
|
||||
[6]:https://opensource.com/sites/default/files/images/dt-atom1.png (DomTerm terminal panes in Atom editor)
|
||||
[7]:https://opensource.com/sites/default/files/images/dt-atom1.png
|
||||
[8]:https://libwebsockets.org/
|
||||
[9]:http://invisible-island.net/vttest/
|
||||
[10]:http://domterm.org/Wire-byte-protocol.html
|
||||
[11]:http://domterm.org/Shell-prompts.html
|
||||
[12]:http://www.gnuplot.info/
|
||||
[13]:https://developer.mozilla.org/en-US/docs/Web/SVG
|
||||
[14]:http://per.bothner.com/blog/2016/gnuplot-in-domterm/
|
||||
[15]:https://www.gnu.org/software/kawa/
|
||||
[16]:https://www.gnu.org/software/kawa/Composable-pictures.html
|
||||
[17]:http://per.bothner.com/blog/2017/dynamic-prettyprinting/
|
||||
[18]:https://golden-layout.com/
|
||||
[19]:https://opensource.com/sites/default/files/u128651/domterm1.png
|
||||
[20]:https://midnight-commander.org/
|
||||
[21]:https://github.com/PerBothner/DomTerm
|
||||
[22]:http://domterm.org/Downloading-and-building.html
|
||||
212
sources/talk/20180130 Introduction to AWS for Data Scientists.md
Normal file
212
sources/talk/20180130 Introduction to AWS for Data Scientists.md
Normal file
@ -0,0 +1,212 @@
|
||||
Introduction to AWS for Data Scientists
|
||||
======
|
||||
![sky-690293_1920][1]
|
||||
|
||||
These days, many businesses use cloud based services; as a result various companies have started building and providing such services. Amazon [began the trend][2], with Amazon Web Services (AWS). While AWS began in 2006 as a side business, it now makes [$14.5 billion in revenue each year][3].
|
||||
|
||||
Other leaders in this area include:
|
||||
|
||||
* Google--Google Cloud Platform (GCP)
|
||||
* Microsoft--Azure Cloud Services
|
||||
* IBM--IBM Cloud
|
||||
|
||||
|
||||
|
||||
Cloud services are useful to businesses of all sizes--small companies benefit from the low cost, as compared to buying servers. Larger companies gain reliability and productivity, with less cost, since the services run on optimum energy and maintenance.
|
||||
|
||||
These services are also powerful tools that you can use to ease your work. Setting up a Hadoop cluster to work with Spark manually could take days if it's your first time, but AWS sets that up for you in minutes.
|
||||
|
||||
We are going to focus on AWS here because it comes with more products relevant to data scientists. In general, we can say familiarity with AWS helps data scientists to:
|
||||
|
||||
1. Prepare the infrastructure they need for their work (e.g. Hadoop clusters) with ease
|
||||
2. Easily set up necessary tools (e.g. Spark)
|
||||
3. Decrease expenses significantly--such as by paying for huge Hadoop clusters only when needed
|
||||
4. Spend less time on maintenance, as there's no need for tasks like manually backing up data
|
||||
5. Develop products and features that are ready to launch without needing help from engineers (or, at least, needing very little help)
|
||||
|
||||
|
||||
|
||||
In this post, I'll give an overview of useful AWS services for data scientists -- what they are, why they're useful, and how much they cost.
|
||||
|
||||
### Elastic Compute Cloud (EC2)
|
||||
|
||||
Many other AWS services are built around EC2, making it a core piece of AWS. EC2s are in fact (virtual) servers that you can rent from Amazon and set up or run any program/application on it. These servers come in different operating systems and Amazon charges you based on the computing power and capacity of the server (i.e. Hard Drive capacity, CPU, Memory, etc.) and the duration the server been up.
|
||||
|
||||
#### EC2 benefits
|
||||
|
||||
For example, you can rent a Linux or Windows server with computation power and storage capacity that fits your specific needs and Amazon charges you based on these specifications and the duration you use the server. Note that previously AWS charged at least for one hour for each instance you run, but they recently changed their policy to [per-second billing][4].
|
||||
|
||||
One of the good things about EC2 is its scalability--by changing memory, number of vCPUs, bandwidth, and so on, you can easily scale your system up or down. Therefore, if you think a system doesn't have enough power for running a specific task or a calculation in your project is taking too long, you can scale up to finish your work and later scale down again to reduce the cost. EC2 is also very reliable, since Amazon takes care of the maintenance.
|
||||
|
||||
#### EC2 cost
|
||||
|
||||
EC2 instances are relatively low-cost, and there are different types of instances for different use cases. For example, there are instances that are optimized for computation and those have relatively lower cost on CPU usage. Or those optimized for memory have lower cost on memory usage.
|
||||
|
||||
To give you an idea on EC2 cost, a general purpose medium instance with 2 vCPUs and 4 GIG of memory (at the time of writing this article) costs $0.0464 per hour for a linux server, see [Amazon EC2 Pricing][5] for prices and more information. AWS also now has [spot instance pricing][6], which calculates the price based on supply/demand at the time and provides up to a 90% discount for short term usages depending on the time you want to use the instance. For example, the same instance above costs $0.0173 per hour on spot pricing plan.
|
||||
|
||||
Note that you have to add storage costs to the above as well. Most EC2 instances use Elastic Block Store (EBS) systems, which cost around $0.1/GIG/month; see the prices [here][7]. [Storage optimized instances][8] use Solid State Drive (SSD) systems, which are more expensive.
|
||||
|
||||
![Ec2cost][9]
|
||||
|
||||
EBS acts like an external hard drive. You can attach it to an instance, de-attach it, and re-attach it to another instance. You can also stop or terminate an instance after your work is done and not pay for the instance when it is idle.
|
||||
|
||||
If you stop an instance, AWS will still keep the EBS live and as a result the data you have on the hard drive will remain intact (it's like powering off your computer). Later you can restart stopped instances and get access to the data you generated, or even tools you installed there in the previous sessions. However, when you stop an instance instead of terminating it, Amazon will still charge you for the attached EBS (~$0.1/GIG/month). If you terminate the instance, the EBS will get cleaned so you will lose all the data on that instance, but you no longer need to pay for the EBS.
|
||||
|
||||
If you need to keep the data on EBS for your future use (let's say you have custom tools installed on that instance and you don't want to redo your work again later) you can make a snapshot of the EBS and can later restore it in a new EBS and attach it to a new instance.
|
||||
|
||||
Snapshots get stored on S3 (Amazon's cheap storage system; we will get to it later) so it will cost you less ($0.05 per GB-month) to keep the data in EBS like that. However, it takes time (depending on the size of the EBS) to get snapshot and restoring it. Besides, reattaching a restored EBS to EC2 instance is not that straight forward, so it only make sense to use a snapshot like that if you know you are not going to use that EBS for a while.
|
||||
|
||||
Note that to scale an instance up or down, you have to first stop the instance and then change the instance specifications. You can't decrease the EBS size, only increase it, and it's more difficult. You have to:
|
||||
|
||||
1. Stop the instance
|
||||
2. Make a snapshot out of the EBS
|
||||
3. Restore the snapshot in an EBS with the new size
|
||||
4. De-attach previous EBS
|
||||
5. Attach the new one.
|
||||
|
||||
|
||||
|
||||
### Simple Storage Service (S3)
|
||||
|
||||
S3 is AWS object (file) storage service. S3 is like Dropbox or Google drive, but way more scalable and is made particularly to work with codes and applications.
|
||||
|
||||
S3 doesn't provide a user friendly interface since it is designed to work with online applications, not the end user. Therefore, working with S3 through APIs is easier than through its web console and there are many libraries and APIs developed (in various languages) to work with this service. For example, [Boto3][10] is a S3 library written in Python (in fact Boto3 is suitable for working with many other AWS services as well) .
|
||||
|
||||
S3 stores files based on `bucket`s and `key`s. Buckets are similar to root folders, and keys are similar to subfolders and files. So if you store a file named `my_file.txt` on s3 like `myproject/mytextfiles/my_file.txt`, then "myproject" is the bucket you are using and then `mytextfiles/my_file.txt` is the key to that file. This is important to know since APIs will ask for the bucket and key separately when you want to retrieve your file from s3.
|
||||
|
||||
#### S3 benefits
|
||||
|
||||
There is no limit on the size of data you can store on S3--you just have to pay for the storage based on the size you need per month.
|
||||
|
||||
S3 is also very reliable and "[it is designed to deliver 99.999999999% durability][11]". However, the service may not be always up. On February 28th, 2017 some of s3 servers went down for couple of hours and that disrupted many applications such as Slack, Trello, etc. see [these][12] [articles][13] for more information on this incident.
|
||||
|
||||
#### S3 cost
|
||||
|
||||
The cost is low, starting at $0.023 per GB per month for standard access, if you want to get access to these files regularly. It could go down even lower if you don't need to load data too frequently. See [Amazon S3 Pricing][14] for more information.
|
||||
|
||||
AWS may charge you for other S3 related actions such as requests through APIs, but the cost for those are insignificant (less than $0.05 per 1,000 requests in most cases).
|
||||
|
||||
### Relational Database Service (RDS)
|
||||
|
||||
AWS RDS is a relational database service in the cloud. RDS currently supports SQL Server, MySQL, PostgreSQL, ORACLE, and a couple of other SQL-based frameworks. AWS sets up the system you need and configures the parameters so you can have a relational database up and running in minutes. RDS also handles backup, recovery, software patching, failure detection, and repairs by itself so you don't need to maintain the system.
|
||||
|
||||
#### RDS benefits
|
||||
|
||||
RDS is scalable, both computing power and the storage capacity can be scaled up or down easily. RDS system runs on EC2 servers (as I mentioned EC2 servers are the core of most of AWS services, including RDS service) so by computing power here we mean the computing power of the EC2 server our RDS service is running on, and you can scale up the computing power of this system up to 32 vCPUs and 244 GiB of RAM and changing the scale would not take more than few minutes.
|
||||
|
||||
Scaling the storage requirements up or down is also possible. [Amazon Aurora][15] is a version of MySQL and PostgreSQL with some additional features, and can automatically scale up when more storage space is needed (you can define the maximum). The MySQL, MariaDB, Oracle, and PostgreSQL engines allow you to scale up on the fly without downtime.
|
||||
|
||||
#### RDS cost
|
||||
|
||||
The [cost of RDS servers][16] is based on three factors: computational power, storage, and data transfer.
|
||||
|
||||
![RDSpricing][17]
|
||||
|
||||
For example, a PostgreSQL system with medium computational power (2 vCPUs and 8 gig of memory) costs $0.182 per hour; you can pay less if you go under a one- or three-year contract.
|
||||
|
||||
For storage, there are a [variety of options and prices][18]. If you choose single availability zone General Purpose SSD Storage (gp2), a good option for data scientists, the cost for a server in north Virginia at the time of writing this article is $0.115 per GB-month, and you can select from 5 GB to 16 TB of SSD.
|
||||
|
||||
For data transfer, the cost varies a little based on the source and destination of data (one of which is RDS). For example, all data transferred from the internet into RDS is free. The first gig of data transferred from RDS to the internet is free as well, and for the next 10 terabytes of data in a month it costs $0.09 per GB; the cost decreases for transfering more data than that.
|
||||
|
||||
### Redshift
|
||||
|
||||
Redshift is Amazon's data warehouse service; it is a distributed system (something like the Hadoop framework) which lets you store huge amounts of data and get queries. The difference between this service and RDS is its high capacity and ability to work with big data (terabytes and petabytes). You can use simple SQL queries on Redshift as well.
|
||||
|
||||
Redshift works on a distributed framework--data is distributed on different nodes (servers) connected on a cluster. Simply put, queries on a distributed system run in parallel on all the nodes and then the results get collected from each node and get summarized.
|
||||
|
||||
#### Redshift benefits
|
||||
|
||||
Redshift is highly scalable, meaning in theory (depending on the query, network structure and design, service specification, etc.) the speed of getting query out of 1 terabyte of data and 1 petabyte of data can match by scaling up (adding more cluster to) the system.
|
||||
|
||||
When you create a table on Redshift, you can choose one of three distribution styles: EVEN, KEY, or ALL.
|
||||
|
||||
* EVEN means the table rows will get distributed over all the nodes evenly. Then queries involving that table get distributed over the cluster and run in parallel, summarized at the end. Per Amazon's documentation, "[EVEN distribution is appropriate when a table does not participate in joins][19]".
|
||||
|
||||
* ALL means that on each node there will be a copy of this table, so if you query for a join on that table, the table is already there on all the nodes and there is no need for copying the required data across the network from node to node. The problem is "[ALL distribution multiplies the storage required by the number of nodes in the cluster, and so it takes much longer to load, update, or insert data into multiple tables][19]".
|
||||
|
||||
* In the KEY style, distribution rows of the table are distributed based on the values in one column, in an attempt to keep the rows with the same value of that column in the same node. Physically storing matching values on the same nodes make joining on that specific column faster in parallel systems, see more information [here][19].
|
||||
|
||||
|
||||
|
||||
|
||||
#### Redshift cost
|
||||
|
||||
Redshift has two types of instances: Dense Compute or Dense Storage. Dense Compute is optimized for fast querying and it is cost effective for less than 500GB of data in size (~$5,500/TB/Year for a three-year contract with partial upfront).
|
||||
|
||||
Dense Storage is optimized for high size storage (~$1,000/TB/Year for a three-year contract with partial upfront) and is cost effective for +500GB, but it is slower. You can find more general pricing [here][20].
|
||||
|
||||
You can also save a large amount of data on S3 and use [Amazon Redshift Spectrum][21] to run SQL query on that data. For Redshift Spectrum, AWS charges you by the number of bytes scanned by Redshift Spectrum per query; and $5 per terabyte of data scanned (10 megabyte minimum per query).
|
||||
|
||||
### Elastic MapReduce (EMR)
|
||||
|
||||
EMR is suitable for setting up Hadoop clusters with Spark and other distributed type applications. A Hadoop cluster can be used as a compute engine or a (distributed) storage system. However, if the data is so big that you need a distributed system to handle it, Redshift is more suitable and way cheaper than storing in EMR.
|
||||
|
||||
There are three types of [nodes][22] on a cluster:
|
||||
|
||||
* The master node (you only have one) is responsible for managing the cluster. It distributes the workloads to the core and task nodes, tracks the status of tasks, and monitors the health of the cluster.
|
||||
* Core nodes run tasks and store the data.
|
||||
* Task nodes can only run tasks.
|
||||
|
||||
|
||||
|
||||
#### EMR benefits
|
||||
|
||||
Since you can set EMR to install Apache Spark, this service is good for for cleaning, reformatting, and analyzing big data. You can use EMR on-demand, meaning you can set it to grab the code and data from a source (e.g. S3 for the code, and S3 or RDS for the data), run the task on the cluster, and store the results somewhere (again s3, RDS, or Redshift) and terminate the cluster.
|
||||
|
||||
By using the service in such a way, you can reduce the cost of your cluster significantly. In my opinion, EMR is one of the most useful AWS services for data scientists.
|
||||
|
||||
To setup an EMR cluster, you need to first configure applications you want to have on the cluster. Note that different versions of EMR come with different versions of the applications. For example, if you configure EMR version 5.10.0 to install Spark, the default version of the Spark for this version is 2.2.0. So if your code works only on Spark 1.6, you need to run EMR on the 4.x version. EMR will set up the network and configures all the nodes on the cluster along with needed tools.
|
||||
|
||||
An EMR cluster comes with one master instance and a number of core nodes (slave instances). You can choose the number of core nodes, and can even select to have no core node and only use the master server for your work. Like other services, you can choose the computational power of the servers and the storage size available on each node. You can use autoscale option for your core nodes, meaning you can add rules to the system to add/remove core node (up to a maximum number you choose) if needed while running your code. See [Using Automatic Scaling in Amazon EMR][23] for more information on auto scaling.
|
||||
|
||||
#### EMR pricing
|
||||
|
||||
EMR pricing is based on the computational power you choose for different instances (master, core and task nodes). Basically, it is the cost of the EC2 servers plus the cost of EMR. You can find detailed pricing [here][24].
|
||||
|
||||
![EMRpricing][25]
|
||||
|
||||
### Conclusion
|
||||
|
||||
I have developed many end-to-end data-driven products (including reporting, machine learning models, and product health checking systems) for our company using Python and Spark on AWS, which later became good sources of income for the company.
|
||||
|
||||
Experience working with cloud services, especially a well-known one like AWS, is a huge plus in your data scientist career. Many companies depend on these services now and use them constantly, so you being familiar with these services will give them the confidence that you need less training to get on board. With more and more people moving into data science, you want your resume to stand out as much as possible.
|
||||
|
||||
Do you have cloud tips to add? [Let us know][26].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.dataquest.io/blog/introduction-to-aws-for-data-scientists/
|
||||
|
||||
作者:[Read More][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.dataquest.io/blog/author/armin/
|
||||
[1]:/blog/content/images/2018/01/sky-690293_1920.jpg
|
||||
[2]:http://www.computerweekly.com/feature/A-history-of-cloud-computing
|
||||
[3]:https://www.forbes.com/sites/bobevans1/2017/07/28/ibm-beats-amazon-in-12-month-cloud-revenue-15-1-billion-to-14-5-billion/#53c3e14c39d6
|
||||
[4]:https://aws.amazon.com/blogs/aws/new-per-second-billing-for-ec2-instances-and-ebs-volumes/
|
||||
[5]:https://aws.amazon.com/ec2/pricing/on-demand/
|
||||
[6]:https://aws.amazon.com/ec2/spot/pricing/
|
||||
[7]:https://aws.amazon.com/ebs/pricing/
|
||||
[8]:https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/storage-optimized-instances.html
|
||||
[9]:/blog/content/images/2018/01/Ec2cost.png
|
||||
[10]:https://boto3.readthedocs.io
|
||||
[11]:https://aws.amazon.com/s3/
|
||||
[12]:https://aws.amazon.com/message/41926/
|
||||
[13]:https://venturebeat.com/2017/02/28/aws-is-investigating-s3-issues-affecting-quora-slack-trello/
|
||||
[14]:https://aws.amazon.com/s3/pricing/
|
||||
[15]:https://aws.amazon.com/rds/aurora/
|
||||
[16]:https://aws.amazon.com/rds/postgresql/pricing/
|
||||
[17]:/blog/content/images/2018/01/RDSpricing.png
|
||||
[18]:https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_Storage.html
|
||||
[19]:http://docs.aws.amazon.com/redshift/latest/dg/c_choosing_dist_sort.html
|
||||
[20]:https://aws.amazon.com/redshift/pricing/
|
||||
[21]:https://aws.amazon.com/redshift/spectrum/
|
||||
[22]:http://docs.aws.amazon.com/emr/latest/DeveloperGuide/emr-nodes.html
|
||||
[23]:https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-automatic-scaling.html
|
||||
[24]:https://aws.amazon.com/emr/pricing/
|
||||
[25]:/blog/content/images/2018/01/EMRpricing.png
|
||||
[26]:https://twitter.com/dataquestio
|
||||
@ -0,0 +1,51 @@
|
||||
An old DOS BBS in a Docker container
|
||||
======
|
||||
Awhile back, I wrote about [my Debian Docker base images][1]. I decided to extend this concept a bit further: to running DOS applications in Docker.
|
||||
|
||||
But first, a screenshot:
|
||||
|
||||
![][2]
|
||||
|
||||
It turns out this is possible, but difficult. I went through all three major DOS emulators available (dosbox, qemu, and dosemu). I got them all running inside the Docker container, but had a number of, er, fun issues to resolve.
|
||||
|
||||
The general thing one has to do here is present a fake modem to the DOS environment. This needs to be exposed outside the container as a TCP port. That much is possible in various ways -- I wound up using tcpser. dosbox had a TCP modem interface, but it turned out to be too buggy for this purpose.
|
||||
|
||||
The challenge comes in where you want to be able to accept more than one incoming telnet (or TCP) connection at a time. DOS was not a multitasking operating system, so there were any number of hackish solutions back then. One might have had multiple physical computers, one for each incoming phone line. Or they might have run multiple pseudo-DOS instances under a multitasking layer like [DESQview][3], OS/2, or even Windows 3.1.
|
||||
|
||||
(Side note: I just learned of [DESQview/X][4], which integrated DESQview with X11R5 and [replaced the Windows 3 drivers][5] to allow running Windows as an X application).
|
||||
|
||||
For various reasons, I didn't want to try running one of those systems inside Docker. That left me with emulating the original multiple physical node setup. In theory, pretty easy -- spin up a bunch of DOS boxes, each using at most 1MB of emulated RAM, and go to town. But here came the challenge.
|
||||
|
||||
In a multiple-physical-node setup, you need some sort of file sharing, because your nodes have to access the shared message and file store. There were a myriad of clunky ways to do this in the old DOS days - [Netware][6], [LAN manager][7], even some PC NFS clients. I didn't have access to Netware. I tried the Microsoft LM client in DOS, talking to a Samba server running inside the Docker container. This I got working, but the LM client used so much RAM that, even with various high memory tricks, BBS software wasn't going to run. I couldn't just mount an underlying filesystem in multiple dosbox instances either, because dosbox did caching that wasn't going to be compatible.
|
||||
|
||||
This is why I wound up using dosemu. Besides being a more complete emulator than dosbox, it had a way of sharing the host's filesystems that was going to work.
|
||||
|
||||
So, all of this wound up with this: [jgoerzen/docker-bbs-renegade][8].
|
||||
|
||||
I also prepared building blocks for others that want to do something similar: [docker-dos-bbs][9] and the lower-level [docker-dosemu][10].
|
||||
|
||||
As a side bonus, I also attempted running this under Joyent's Triton (SmartOS, Solaris-based). I was pleasantly impressed that I got it all almost working there. So yes, a Renegade DOS BBS running under a Linux-based DOS emulator in a container on a Solaris machine.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9836-an-old-dos-bbs-in-a-docker-container
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://changelog.complete.org/archives/9794-fixing-the-problems-with-docker-images
|
||||
[2]:https://raw.githubusercontent.com/jgoerzen/docker-bbs-renegade/master/renegade-login.png
|
||||
[3]:https://en.wikipedia.org/wiki/DESQview
|
||||
[4]:http://toastytech.com/guis/dvx.html
|
||||
[5]:http://toastytech.com/guis/dvx3.html
|
||||
[6]:https://en.wikipedia.org/wiki/NetWare
|
||||
[7]:https://en.wikipedia.org/wiki/LAN_Manager
|
||||
[8]:https://github.com/jgoerzen/docker-bbs-renegade
|
||||
[9]:https://github.com/jgoerzen/docker-dos-bbs
|
||||
[10]:https://github.com/jgoerzen/docker-dosemu
|
||||
@ -0,0 +1,160 @@
|
||||
Linux Find Out Last System Reboot Time and Date Command
|
||||
======
|
||||
So, how do you find out your Linux or UNIX-like system was last rebooted? How do you display the system shutdown date and time? The last utility will either list the sessions of specified users, ttys, and hosts, in reverse time order, or list the users logged in at a specified date and time. Each line of output contains the user name, the tty from which the session was conducted, any hostname, the start and stop times for the session, and the duration of the session. To view Linux or Unix system reboot and shutdown date and time stamp using the following commands:
|
||||
|
||||
* last command
|
||||
* who command
|
||||
|
||||
|
||||
|
||||
### Use who command to find last system reboot time/date
|
||||
|
||||
You need to use the [who command][1], to print who is logged on. It also displays the time of last system boot. Use the last command to display system reboot and shutdown date and time, run:
|
||||
`$ who -b`
|
||||
Sample outputs:
|
||||
```
|
||||
system boot 2017-06-20 17:41
|
||||
```
|
||||
|
||||
Use the last command to display listing of last logged in users and system last reboot time and date, enter:
|
||||
`$ last reboot | less`
|
||||
Sample outputs:
|
||||
[![Fig.01: last command in action][2]][2]
|
||||
Or, better try:
|
||||
`$ last reboot | head -1`
|
||||
Sample outputs:
|
||||
```
|
||||
reboot system boot 4.9.0-3-amd64 Sat Jul 15 19:19 still running
|
||||
```
|
||||
|
||||
The last command searches back through the file /var/log/wtmp and displays a list of all users logged in (and out) since that file was created. The pseudo user reboot logs in each time the system is rebooted. Thus last reboot command will show a log of all reboots since the log file was created.
|
||||
|
||||
### Finding systems last shutdown date and time
|
||||
|
||||
To display last shutdown date and time use the following command:
|
||||
`$ last -x|grep shutdown | head -1`
|
||||
Sample outputs:
|
||||
```
|
||||
shutdown system down 2.6.15.4 Sun Apr 30 13:31 - 15:08 (01:37)
|
||||
```
|
||||
|
||||
Where,
|
||||
|
||||
* **-x** : Display the system shutdown entries and run level changes.
|
||||
|
||||
|
||||
|
||||
Here is another session from my last command:
|
||||
```
|
||||
$ last
|
||||
$ last -x
|
||||
$ last -x reboot
|
||||
$ last -x shutdown
|
||||
```
|
||||
Sample outputs:
|
||||
![Fig.01: How to view last Linux System Reboot Date/Time ][3]
|
||||
|
||||
### Find out Linux system up since…
|
||||
|
||||
Another option as suggested by readers in the comments section below is to run the following command:
|
||||
`$ uptime -s`
|
||||
Sample outputs:
|
||||
```
|
||||
2017-06-20 17:41:51
|
||||
```
|
||||
|
||||
### OS X/Unix/FreeBSD find out last reboot and shutdown time command examples
|
||||
|
||||
Type the following command:
|
||||
`$ last reboot`
|
||||
Sample outputs from OS X unix:
|
||||
```
|
||||
reboot ~ Fri Dec 18 23:58
|
||||
reboot ~ Mon Dec 14 09:54
|
||||
reboot ~ Wed Dec 9 23:21
|
||||
reboot ~ Tue Nov 17 21:52
|
||||
reboot ~ Tue Nov 17 06:01
|
||||
reboot ~ Wed Nov 11 12:14
|
||||
reboot ~ Sat Oct 31 13:40
|
||||
reboot ~ Wed Oct 28 15:56
|
||||
reboot ~ Wed Oct 28 11:35
|
||||
reboot ~ Tue Oct 27 00:00
|
||||
reboot ~ Sun Oct 18 17:28
|
||||
reboot ~ Sun Oct 18 17:11
|
||||
reboot ~ Mon Oct 5 09:35
|
||||
reboot ~ Sat Oct 3 18:57
|
||||
|
||||
|
||||
wtmp begins Sat Oct 3 18:57
|
||||
```
|
||||
|
||||
To see shutdown date and time, enter:
|
||||
`$ last shutdown`
|
||||
Sample outputs:
|
||||
```
|
||||
shutdown ~ Fri Dec 18 23:57
|
||||
shutdown ~ Mon Dec 14 09:53
|
||||
shutdown ~ Wed Dec 9 23:20
|
||||
shutdown ~ Tue Nov 17 14:24
|
||||
shutdown ~ Mon Nov 16 21:15
|
||||
shutdown ~ Tue Nov 10 13:15
|
||||
shutdown ~ Sat Oct 31 13:40
|
||||
shutdown ~ Wed Oct 28 03:10
|
||||
shutdown ~ Sun Oct 18 17:27
|
||||
shutdown ~ Mon Oct 5 09:23
|
||||
|
||||
|
||||
wtmp begins Sat Oct 3 18:57
|
||||
```
|
||||
|
||||
### How do I find who rebooted/shutdown the Linux box?
|
||||
|
||||
You need [to enable psacct service and run the following command to see info][4] about executed commands including user name. Type the following [lastcomm command][5] to see
|
||||
```
|
||||
# lastcomm userNameHere
|
||||
# lastcomm commandNameHere
|
||||
# lastcomm | more
|
||||
# lastcomm reboot
|
||||
# lastcomm shutdown
|
||||
### OR see both reboot and shutdown time
|
||||
# lastcomm | egrep 'reboot|shutdown'
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
reboot S X root pts/0 0.00 secs Sun Dec 27 23:49
|
||||
shutdown S root pts/1 0.00 secs Sun Dec 27 23:45
|
||||
```
|
||||
|
||||
So root user rebooted the box from 'pts/0' on Sun, Dec, 27th at 23:49 local time.
|
||||
|
||||
### See also
|
||||
|
||||
* For more information read last(1) and [learn how to use the tuptime command on Linux server to see the historical and statistical uptime][6].
|
||||
|
||||
|
||||
|
||||
### about the author
|
||||
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][7], [Facebook][8], [Google+][9].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-last-reboot-time-and-date-find-out.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/unix-linux-who-command-examples-syntax-usage/ (See Linux/Unix who command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/tips/wp-content/uploads/2006/04/last-reboot.jpg
|
||||
[3]:https://www.cyberciti.biz/media/new/tips/2006/04/check-last-time-system-was-rebooted.jpg
|
||||
[4]:https://www.cyberciti.biz/tips/howto-log-user-activity-using-process-accounting.html
|
||||
[5]:https://www.cyberciti.biz/faq/linux-unix-lastcomm-command-examples-usage-syntax/ (See Linux/Unix lastcomm command examples for more info)
|
||||
[6]:https://www.cyberciti.biz/hardware/howto-see-historical-statistical-uptime-on-linux-server/
|
||||
[7]:https://twitter.com/nixcraft
|
||||
[8]:https://facebook.com/nixcraft
|
||||
[9]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Monitoring network bandwidth with iftop command
|
||||
======
|
||||
System Admins are required to monitor IT infrastructure to make sure that everything is up & running. We have to monitor performance of hardware i.e memory, hdds & CPUs etc & so does we have to monitor our network. We need to make sure that our network is not being over utilised or our applications, websites might not work. In this tutorial, we are going to learn to use IFTOP utility.
|
||||
|
||||
@ -1,158 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Ansible Tutorial: Intorduction to simple Ansible commands
|
||||
======
|
||||
In our earlier Ansible tutorial, we discussed [**the installation & configuration of Ansible**][1]. Now in this ansible tutorial, we will learn some basic examples of ansible commands that we will use to manage our infrastructure. So let us start by looking at the syntax of a complete ansible command,
|
||||
|
||||
```
|
||||
$ ansible <group> -m <module> -a <arguments>
|
||||
```
|
||||
|
||||
Here, we can also use a single host or all in place of <group> & <arguments> are optional to provide. Now let's look at some basic commands to use with ansible,
|
||||
|
||||
### Check connectivity of hosts
|
||||
|
||||
We have used this command in our previous tutorial also. The command to check connectivity of hosts is
|
||||
|
||||
```
|
||||
$ ansible <group> -m ping
|
||||
```
|
||||
|
||||
### Rebooting hosts
|
||||
|
||||
```
|
||||
$ ansible <group> -a "/sbin/reboot"
|
||||
```
|
||||
|
||||
### Checking host 's system information
|
||||
|
||||
Ansible collects the system's information for all the hosts connected to it. To display the information of hosts, run
|
||||
|
||||
```
|
||||
$ ansible <group> -m setup | less
|
||||
```
|
||||
|
||||
Secondly, to check a particular info from the collected information by passing an argument,
|
||||
|
||||
```
|
||||
$ ansible <group> -m setup -a "filter=ansible_distribution"
|
||||
```
|
||||
|
||||
### Transfering files
|
||||
|
||||
For transferring files we use a module 'copy' & complete command that is used is
|
||||
|
||||
```
|
||||
$ ansible <group> -m copy -a "src=/home/dan dest=/tmp/home"
|
||||
```
|
||||
|
||||
### Manging users
|
||||
|
||||
So to manage the users on the connected hosts, we use a module named 'user' & comamnds to use it are as follows,
|
||||
|
||||
#### Creating a new user
|
||||
|
||||
```
|
||||
$ ansible <group> -m user -a "name=testuser password=<encrypted password>"
|
||||
```
|
||||
|
||||
#### Deleting a user
|
||||
|
||||
```
|
||||
$ ansible <group> -m user -a "name=testuser state=absent"
|
||||
```
|
||||
|
||||
**Note:-** To create an encrypted password, use the 'mkpasswd -method=sha-512' command.
|
||||
|
||||
### Changing permissions & ownership
|
||||
|
||||
So for changing ownership of files of connected hosts, we use module named 'file' & commands used are
|
||||
|
||||
### Changing permission of a file
|
||||
|
||||
```
|
||||
$ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777"
|
||||
```
|
||||
|
||||
### Changing ownership of a file
|
||||
|
||||
```
|
||||
$ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777 owner=dan group=dan"
|
||||
```
|
||||
|
||||
### Managing Packages
|
||||
|
||||
So, we can manage the packages installed on all the hosts connected to ansible by using 'yum' & 'apt' modules & the complete commands used are
|
||||
|
||||
#### Check if package is installed & update it
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=latest"
|
||||
```
|
||||
|
||||
#### Check if package is installed & don't update it
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=present"
|
||||
```
|
||||
|
||||
#### Check if package is at a specific version
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name= ntp-1.8 state=present"
|
||||
```
|
||||
|
||||
#### Check if package is not installed
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=absent"
|
||||
```
|
||||
|
||||
### Managing services
|
||||
|
||||
So to manage services with ansible, we use a modules 'service' & complete commands that are used are,
|
||||
|
||||
#### Starting a service
|
||||
|
||||
```
|
||||
$ansible <group> -m service -a "name=httpd state=started"
|
||||
```
|
||||
|
||||
#### Stopping a service
|
||||
|
||||
```
|
||||
$ ansible <group> -m service -a "name=httpd state=stopped"
|
||||
```
|
||||
|
||||
#### Restarting a service
|
||||
|
||||
```
|
||||
$ ansible <group> -m service -a "name=httpd state=restarted"
|
||||
```
|
||||
|
||||
So this completes our tutorial of some simple, one line commands that can be used with ansible. Also, for our future tutorials, we will learn to create plays & playbooks that help us manage our hosts more easliy & efficiently.
|
||||
|
||||
If you think we have helped you or just want to support us, please consider these :-
|
||||
|
||||
Connect to us: [Facebook][2] | [Twitter][3] | [Google Plus][4]
|
||||
|
||||
Become a Supporter - [Make a contribution via PayPal][5]
|
||||
|
||||
Linux TechLab is thankful for your continued support.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/ansible-tutorial-simple-commands/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/create-first-ansible-server-automation-setup/
|
||||
[2]:https://www.facebook.com/linuxtechlab/
|
||||
[3]:https://twitter.com/LinuxTechLab
|
||||
[4]:https://plus.google.com/+linuxtechlab
|
||||
[5]:http://linuxtechlab.com/contact-us-2/
|
||||
@ -1,266 +0,0 @@
|
||||
Translating by MjSeven
|
||||
How To Install And Setup Vagrant
|
||||
======
|
||||
Vagrant is a powerful tool when it comes to virtual machines, here we will look at how to setup and use Vagrant with Virtualbox on Ubuntu to provision reproducible virtual machines.
|
||||
|
||||
## Virtual Machines, not all that complex
|
||||
|
||||
For years, developers have been using virtual machines as part of their workflow, allowing them to swap and change environments that the software is running in, this is generally to prevent conflicts between projects such as project A needing php 5.3 and project b needing php 5.4.
|
||||
|
||||
Also, using Virtual Machines means you only ever need the computer you're working on, you don't need dedicated hardware to mirror the production environment.
|
||||
|
||||
It also comes in handy when multiple developers are working on one project, they can all run an environment which contains all of its requirements, but it can be hard maintaining multiple machines and ensuring all have the same versions of all the requirements, this is where Vagrant comes in.
|
||||
|
||||
### The benefits of using Virtual Machines
|
||||
|
||||
* Your vm is separate from your host environment
|
||||
* You can have a vm tailor for the requirements of your code
|
||||
* Anything done in one vm does not effect another VM
|
||||
* You can run programs in a vm which your host may not be able to run, such as running some windows only software in a - windows vm on top of ubuntu
|
||||
|
||||
|
||||
|
||||
## What is Vagrant
|
||||
|
||||
In short, it's a tool that works with virtual box to allow you to automate the creation and removal of a virtual machines.
|
||||
|
||||
It revolves around a Config File Called the VagrantFile, which tells vagrant what version of what os you want to install, and some other options such as the IP and Directory Syncing. You can also add a provisioning script of commands to run on the virtual machine.
|
||||
|
||||
By Sharing this VagrantFile around, all developers on a project. You will all be using the exact same virtual machine.
|
||||
|
||||
## Installing the Requirements
|
||||
|
||||
### Install VirtualBox
|
||||
|
||||
VirtualBox is the program which will run the Virtual Machine and is available in the Ubuntu Repos
|
||||
```
|
||||
sudo apt-get install virtualbox
|
||||
```
|
||||
|
||||
### Install Vagrant
|
||||
|
||||
For vagrant itself, you need to head to <https://www.vagrantup.com/downloads.html> and install the package for your OS.
|
||||
|
||||
### Install Guest Additions
|
||||
|
||||
If you intend to sharing any folders with virtual machine, you need to install the following plugin.
|
||||
```
|
||||
vagrant plugin install vagrant-vbguest
|
||||
```
|
||||
|
||||
## Setting Up Vagrant
|
||||
|
||||
### First we need to create an area for vagrant setups.
|
||||
```
|
||||
mkdir ~/Vagrant/test-vm
|
||||
cd ~/Vagrant/test-vm
|
||||
```
|
||||
|
||||
### Create the VagrantFile
|
||||
```
|
||||
vagrant init
|
||||
```
|
||||
|
||||
### Start the Virtual Machine
|
||||
```
|
||||
vagrant up
|
||||
```
|
||||
|
||||
### Login to the Machine
|
||||
```
|
||||
vagrant-ssh
|
||||
```
|
||||
|
||||
By this point you will have the basic vagrant box, and a file called VagrantFile.
|
||||
|
||||
## Customising
|
||||
|
||||
The VagrantFile created in the steps above will look similar to the following
|
||||
|
||||
**VagrantFile**
|
||||
|
||||
```
|
||||
# -*- mode: ruby -*-
|
||||
# vi: set ft=ruby :
|
||||
# All Vagrant configuration is done below. The "2" in Vagrant.configure
|
||||
# configures the configuration version (we support older styles for
|
||||
# backwards compatibility). Please don't change it unless you know what
|
||||
# you're doing.
|
||||
Vagrant.configure("2") do |config|
|
||||
# The most common configuration options are documented and commented below.
|
||||
# For a complete reference, please see the online documentation at
|
||||
# https://docs.vagrantup.com.
|
||||
|
||||
# Every Vagrant development environment requires a box. You can search for
|
||||
# boxes at https://vagrantcloud.com/search.
|
||||
config.vm.box = "base"
|
||||
|
||||
# Disable automatic box update checking. If you disable this, then
|
||||
# boxes will only be checked for updates when the user runs
|
||||
# `vagrant box outdated`. This is not recommended.
|
||||
# config.vm.box_check_update = false
|
||||
|
||||
# Create a forwarded port mapping which allows access to a specific port
|
||||
# within the machine from a port on the host machine. In the example below,
|
||||
# accessing "localhost:8080" will access port 80 on the guest machine.
|
||||
# NOTE: This will enable public access to the opened port
|
||||
# config.vm.network "forwarded_port", guest: 80, host: 8080
|
||||
|
||||
# Create a forwarded port mapping which allows access to a specific port
|
||||
# within the machine from a port on the host machine and only allow access
|
||||
# via 127.0.0.1 to disable public access
|
||||
# config.vm.network "forwarded_port", guest: 80, host: 8080, host_ip: "127.0.0.1"
|
||||
|
||||
# Create a private network, which allows host-only access to the machine
|
||||
# using a specific IP.
|
||||
# config.vm.network "private_network", ip: "192.168.33.10"
|
||||
|
||||
# Create a public network, which generally matched to bridged network.
|
||||
# Bridged networks make the machine appear as another physical device on
|
||||
# your network.
|
||||
# config.vm.network "public_network"
|
||||
|
||||
# Share an additional folder to the guest VM. The first argument is
|
||||
# the path on the host to the actual folder. The second argument is
|
||||
# the path on the guest to mount the folder. And the optional third
|
||||
# argument is a set of non-required options.
|
||||
# config.vm.synced_folder "../data", "/vagrant_data"
|
||||
|
||||
# Provider-specific configuration so you can fine-tune various
|
||||
# backing providers for Vagrant. These expose provider-specific options.
|
||||
# Example for VirtualBox:
|
||||
#
|
||||
# config.vm.provider "virtualbox" do |vb|
|
||||
# # Display the VirtualBox GUI when booting the machine
|
||||
# vb.gui = true
|
||||
#
|
||||
# # Customize the amount of memory on the VM:
|
||||
# vb.memory = "1024"
|
||||
# end
|
||||
#
|
||||
# View the documentation for the provider you are using for more
|
||||
# information on available options.
|
||||
|
||||
# Enable provisioning with a shell script. Additional provisioners such as
|
||||
# Puppet, Chef, Ansible, Salt, and Docker are also available. Please see the
|
||||
# documentation for more information about their specific syntax and use.
|
||||
# config.vm.provision "shell", inline: <<-SHELL
|
||||
# apt-get update
|
||||
# apt-get install -y apache2
|
||||
# SHELL
|
||||
end
|
||||
```
|
||||
|
||||
Now this VagrantFile wll create the basic virtual machine. But the concept behind vagrant is to have the virtual machines set up for our specific tasks. So lets remove the comments and tweak the config.
|
||||
|
||||
**VagrantFile**
|
||||
```
|
||||
# -*- mode: ruby -*-
|
||||
# vi: set ft=ruby :
|
||||
|
||||
Vagrant.configure("2") do |config|
|
||||
# Set the Linux Version to Debian Jessie
|
||||
config.vm.box = "debian/jessie64"
|
||||
# Set the IP of the Box
|
||||
config.vm.network "private_network", ip: "192.168.33.10"
|
||||
# Sync Our Projects Directory with the WWW directory
|
||||
config.vm.synced_folder "~/Projects", "/var/www/"
|
||||
# Run the following to Provision
|
||||
config.vm.provision "shell", path: "install.sh"
|
||||
end
|
||||
```
|
||||
|
||||
Now we have a simple VagrantFile, Which sets the box to debian jessie, sets an IP for us to use, syncs the folders we are interested in, and finally runs an install.sh, which is where our shell commands can go.
|
||||
|
||||
**install.sh**
|
||||
```
|
||||
#! /usr/bin/env bash
|
||||
# Variables
|
||||
DBHOST=localhost
|
||||
DBNAME=dbname
|
||||
DBUSER=dbuser
|
||||
DBPASSWD=test123
|
||||
|
||||
echo "[ Provisioning machine ]"
|
||||
echo "1) Update APT..."
|
||||
apt-get -qq update
|
||||
|
||||
echo "1) Install Utilities..."
|
||||
apt-get install -y tidy pdftk curl xpdf imagemagick openssl vim git
|
||||
|
||||
echo "2) Installing Apache..."
|
||||
apt-get install -y apache2
|
||||
|
||||
echo "3) Installing PHP and packages..."
|
||||
apt-get install -y php5 libapache2-mod-php5 libssh2-php php-pear php5-cli php5-common php5-curl php5-dev php5-gd php5-imagick php5-imap php5-intl php5-mcrypt php5-memcached php5-mysql php5-pspell php5-xdebug php5-xmlrpc
|
||||
#php5-suhosin-extension, php5-mysqlnd
|
||||
|
||||
echo "4) Installing MySQL..."
|
||||
debconf-set-selections <<< "mysql-server mysql-server/root_password password secret"
|
||||
debconf-set-selections <<< "mysql-server mysql-server/root_password_again password secret"
|
||||
apt-get install -y mysql-server
|
||||
mysql -uroot -p$DBPASSWD -e "CREATE DATABASE $DBNAME"
|
||||
mysql -uroot -p$DBPASSWD -e "grant all privileges on $DBNAME.* to '$DBUSER'@'localhost' identified by '$DBPASSWD'"
|
||||
|
||||
echo "5) Generating self signed certificate..."
|
||||
mkdir -p /etc/ssl/localcerts
|
||||
openssl req -new -x509 -days 365 -nodes -subj "/C=US/ST=Denial/L=Springfield/O=Dis/CN=www.example.com" -out /etc/ssl/localcerts/apache.pem -keyout /etc/ssl/localcerts/apache.key
|
||||
chmod 600 /etc/ssl/localcerts/apache*
|
||||
|
||||
echo "6) Setup Apache..."
|
||||
a2enmod rewrite
|
||||
> /etc/apache2/sites-enabled/000-default.conf
|
||||
echo "
|
||||
<VirtualHost *:80>
|
||||
ServerAdmin [[email protected]][1]
|
||||
DocumentRoot /var/www/
|
||||
ErrorLog ${APACHE_LOG_DIR}/error.log
|
||||
CustomLog ${APACHE_LOG_DIR}/access.log combined
|
||||
</VirtualHost>
|
||||
|
||||
" >> /etc/apache2/sites-enabled/000-default.conf
|
||||
service apache2 restart
|
||||
|
||||
echo "7) Composer Install..."
|
||||
curl --silent https://getcomposer.org/installer | php
|
||||
mv composer.phar /usr/local/bin/composer
|
||||
|
||||
echo "8) Install NodeJS..."
|
||||
curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash -
|
||||
apt-get -qq update
|
||||
apt-get -y install nodejs
|
||||
|
||||
echo "9) Install NPM Packages..."
|
||||
npm install -g gulp gulp-cli
|
||||
|
||||
echo "Provisioning Completed"
|
||||
```
|
||||
|
||||
By having the above VagrantFile and Install.sh in your directory, running vagrant up will do the following
|
||||
|
||||
* Create a Virtual Machine Using Debian Jessie
|
||||
* Set the Machines IP to 192.168.33.10
|
||||
* Sync ~/Projects with /var/www/
|
||||
* Install and Setup Apache, Mysql, PHP, Git, Vim
|
||||
* Install and Run Composer
|
||||
* Install Nodejs and gulp
|
||||
* Create A MySQL Database
|
||||
* Create Self Sign Certificates
|
||||
|
||||
|
||||
|
||||
By sharing the VagrantFile and install.sh with others, you can work on the exact same environment, on two different machines.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.chris-shaw.com/blog/how-to-install-and-setup-vagrant
|
||||
|
||||
作者:[Christopher Shaw][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.chris-shaw.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by cncuckoo
|
||||
|
||||
Rediscovering make: the power behind rules
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by cncuckoo
|
||||
|
||||
Linux mv Command Explained for Beginners (8 Examples)
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,179 @@
|
||||
Graphics and music tools for game development
|
||||
======
|
||||
|
||||

|
||||
|
||||
In early October, our club, [Geeks and Gadgets][1] from Marshall University, participated in the inaugural [Open Jam][2], a game jam that celebrated the best of open source tools. Game jams are events where participants work as teams to develop computer games for fun. Jams tend to be very short--only three days long--and very exhausting. Opensource.com [announced][3] Open Jam in late August, and more than [three dozen games][4] were entered into the competition.
|
||||
|
||||
Our club likes to create and use open source software in our projects, so Open Jam was naturally the jam we wanted to participate in. Our submission was an experimental game called [Mark My Words][5]. We used a variety of free and open source (FOSS) tools to develop it; in this article we'll discuss some of the tools we used and potential stumbling blocks to be aware of.
|
||||
|
||||
### Audio tools
|
||||
|
||||
#### MilkyTracker
|
||||
|
||||
[MilkyTracker][6] is one of the best software packages available for composing old-style video game music. It is an example of a [music tracker][7], a powerful MOD and XM file creator with a characteristic grid-based pattern editor. We used it to compose most of the musical pieces in our game. One of the great things about this program is that it consumed much less disk space and RAM than most of our other tools. Even so, MilkyTracker is still extremely powerful.
|
||||
|
||||
|
||||
|
||||
The user interface took a while to get used to, so here are some pointers for any musician who wants to try out MilkyTracker:
|
||||
|
||||
* Go to Config > Misc. and set the edit mode control style to "MilkyTracker." This will give you modern keyboard shortcuts for almost everything
|
||||
* Undo with Ctrl+Z
|
||||
* Redo with Ctrl+Y
|
||||
* Toggle pattern-edit mode with the Spacebar
|
||||
* Delete the previous note with the Backspace key
|
||||
* Insert a row with the Insert key
|
||||
* By default, a note will continue playing until it is replaced on that channel. You can end a note explicitly by inserting a KeyOff note with the backquote (`) key
|
||||
* You will have to create or find samples before you can start composing. We recommend finding [Creative Commons][8] licensed samples at websites such as [Freesound][9] or [ccMixter][10]
|
||||
|
||||
|
||||
|
||||
In addition, keep the [MilkyTracker documentation page][11] handy. It contains links to numerous tutorials and manuals. A good starting point is the [MilkyTracker Guide][12] on the project's wiki.
|
||||
|
||||
#### LMMS
|
||||
|
||||
Two of our musicians used the versatile and modern music creation tool [LMMS][13]. It comes with a library of cool samples and effects, plus a variety of flexible plugins for generating unique sounds. The learning curve for LMMS was surprisingly low, in part due to the nice beat/bassline editor.
|
||||
|
||||
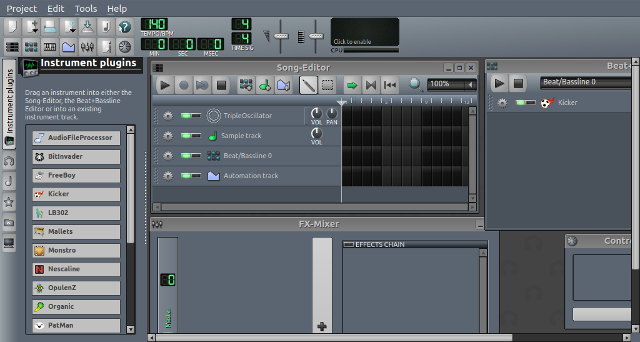
|
||||
|
||||
We have one suggestion for musicians trying out LMMS: Use the plugins. For [chiptune][14]-style music, we recommend [sfxr][15], [BitInvader][16], and [FreeBoy][17]. For other styles, [ZynAddSubFX][18] is a good choice. It comes with a wide range of synthesized instruments that can be altered however you see fit.
|
||||
|
||||
### Graphics tools
|
||||
|
||||
#### Tiled
|
||||
|
||||
[Tiled][19] is a popular tilemap editor in open source game development. We used it to assemble consistent, retro-looking backgrounds for our in-game scenes.
|
||||
|
||||
|
||||
|
||||
Tiled can export maps as XML, JSON, or as flattened images. It is stable and cross-platform.
|
||||
|
||||
One of Tiled's features, which we did not use during the jam, allows you to define and place arbitrary game objects, such as coins and powerups, onto the map. All you have to do is load the object's graphics as a tileset, then place them using Insert Tile.
|
||||
|
||||
Overall, Tiled is a stellar piece of software that we recommend for any project that needs a map editor.
|
||||
|
||||
#### Piskel
|
||||
|
||||
[Piskel][20] is a pixel art editor whose source code is licensed under the [Apache License, Version 2.0][21]. We used Piskel for almost all our graphical assets during the jam, and we will certainly be using it in future projects as well.
|
||||
|
||||
Two features of Piskel that helped us immensely during the jam are onion skin and spritesheet exporting.
|
||||
|
||||
##### Onion skin
|
||||
|
||||
The onion skin feature will make Piskel show a ghostly overlay of the previous and next frames of your animation as you edit, like this:
|
||||
|
||||
|
||||
|
||||
Onion skin is handy because it serves as a drawing guide and helps you maintain consistent shapes and volumes on your characters throughout the animation process. To enable it, just click the onion-shaped icon underneath the preview window on the top-right of the screen.
|
||||
|
||||
|
||||
|
||||
##### Spritesheet exporting
|
||||
|
||||
Piskel's ability to export animations as a spritesheet was also very helpful. A spritesheet is a single raster image that contains all the frames of an animation. For example, here is a spritesheet we exported from Piskel:
|
||||
|
||||

|
||||
|
||||
The spritesheet consists of two frames. One frame is in the top half of the image and the other frame is in the bottom half of the image. Spritesheets greatly simplify a game's code by enabling an entire animation to be loaded from a single file. Here is an animated version of the above spritesheet:
|
||||
|
||||

|
||||
|
||||
##### Unpiskel.py
|
||||
|
||||
There were several times during the jam when we wanted to batch convert Piskel files into PNGs. Since the Piskel file format is based on JSON, we wrote a small GPLv3-licensed Python script called [unpiskel.py][22] to do the conversion.
|
||||
|
||||
It is invoked like this:
|
||||
```
|
||||
|
||||
|
||||
python unpiskel.py input.piskel
|
||||
```
|
||||
|
||||
The script will extract the PNG data frames and layers from a Piskel file (here `input.piskel`) and store them in their own files. The files follow the pattern `NAME_XX_YY.png` where `NAME` is the truncated name of the Piskel file, `XX` is the frame number, and `YY` is the layer number.
|
||||
|
||||
Because the script can be invoked from a shell, it can be used on a whole list of files.
|
||||
```
|
||||
for f in *.piskel; do python unpiskel.py "$f"; done
|
||||
```
|
||||
|
||||
### Python, Pygame, and cx_Freeze
|
||||
|
||||
#### Python and Pygame
|
||||
|
||||
We used the [Python][23] language to make our game. It is a scripting language that is commonly used for text processing and desktop app development. It can also be used for game development, as projects like [Angry Drunken Dwarves][24] and [Ren'Py][25] have shown. Both of these projects use a Python library called [Pygame][26] to display graphics and produce sound, so we decided to use this library in Open Jam, too.
|
||||
|
||||
Pygame turned out to be both stable and featureful, and it was great for the arcade-style game we were creating. The library's speed was fast enough at low resolutions, but its CPU-only rendering starts to slow down at higher resolutions. This is because Pygame does not use hardware-accelerated rendering. However, the infrastructure is there for developers to take full advantage of OpenGL.
|
||||
|
||||
If you're looking for a good 2D game programming library, Pygame is one to keep your eye on. Its website has [a good tutorial][27] to get started. Be sure to check it out!
|
||||
|
||||
#### cx_Freeze
|
||||
|
||||
Prepping our game for distribution was interesting. We knew that Windows users were unlikely to have a Python installation, and asking them to install it would have been too much. On top of that, they would have had to also install Pygame, which is not an intuitive task on Windows.
|
||||
|
||||
One thing was clear: We had to put our game into a more convenient form. Many of the other Open Jam participants used the proprietary game engine Unity, which enabled their games to be played in the web browser. This made them extremely convenient to play. Convenience was one thing our game didn't have even a sliver of. But, thanks to a vibrant Python ecosystem, we had options. Tools exist to help Python programmers prepare their programs for distribution on Windows. The two that we considered were [cx_Freeze][28] and [Pygame2exe][29] (which uses [py2exe][30]). We decided on cx_Freeze because it was cross-platform.
|
||||
|
||||
In cx_Freeze, you can pack a single-script game for distribution just by running a command like this in the shell:
|
||||
```
|
||||
cxfreeze main.py --target-dir dist
|
||||
```
|
||||
|
||||
This invocation of `cxfreeze` will take your script (here `main.py`) and the Python interpreter on your system and bundle them up into the `dist` directory. Once this is done, all you have to do is manually copy your game's data files into the `dist` directory. You will find that the `dist` directory contains an executable file that can be run to start your game.
|
||||
|
||||
There is a more involved way to use cx_Freeze that allows you to automate the copying of data files, but we found the straightforward invocation of `cxfreeze` to be good enough for our needs. Thanks to this tool, we made our game a little more convenient to play.
|
||||
|
||||
### Celebrating open source
|
||||
|
||||
Open Jam is important because it celebrates the open source model of software development. This is an opportunity to analyze the current state of open source tools and what we need to work on in the future. Game jams are perhaps the best time for game devs to try to push their tools to the limit, to learn what must be improved for the good of future game devs.
|
||||
|
||||
Open source tools enable people to explore their creativity without compromising their freedom and without investing money upfront. Although we might not become professional game developers, we were still able to get a small taste of it with our short, experimental game called [Mark My Words][5]. It is a linguistically themed game that depicts the evolution of a fictional writing system throughout its history. There were many other delightful submissions to Open Jam, and they are all worth checking out. Really, [go look][31]!
|
||||
|
||||
Before closing, we would like to thank all the [club members who participated][32] and made this experience truly worthwhile. We would also like to thank [Michael Clayton][33], [Jared Sprague][34], and [Opensource.com][35] for hosting Open Jam. It was a blast.
|
||||
|
||||
Now, we have some questions for readers. Are you a FOSS game developer? What are your tools of choice? Be sure to leave a comment below!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/graphics-music-tools-game-dev
|
||||
|
||||
作者:[Charlie Murphy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rsg167
|
||||
[1]:http://mugeeks.org/
|
||||
[2]:https://itch.io/jam/open-jam-1
|
||||
[3]:https://opensource.com/article/17/8/open-jam-announcement
|
||||
[4]:https://opensource.com/article/17/11/open-jam
|
||||
[5]:https://mugeeksalpha.itch.io/mark-omy-words
|
||||
[6]:http://milkytracker.titandemo.org/
|
||||
[7]:https://en.wikipedia.org/wiki/Music_tracker
|
||||
[8]:https://creativecommons.org/
|
||||
[9]:https://freesound.org/
|
||||
[10]:http://ccmixter.org/view/media/home
|
||||
[11]:http://milkytracker.titandemo.org/documentation/
|
||||
[12]:https://github.com/milkytracker/MilkyTracker/wiki/MilkyTracker-Guide
|
||||
[13]:https://lmms.io/
|
||||
[14]:https://en.wikipedia.org/wiki/Chiptune
|
||||
[15]:https://github.com/grimfang4/sfxr
|
||||
[16]:https://lmms.io/wiki/index.php?title=BitInvader
|
||||
[17]:https://lmms.io/wiki/index.php?title=FreeBoy
|
||||
[18]:http://zynaddsubfx.sourceforge.net/
|
||||
[19]:http://www.mapeditor.org/
|
||||
[20]:https://www.piskelapp.com/
|
||||
[21]:https://github.com/piskelapp/piskel/blob/master/LICENSE
|
||||
[22]:https://raw.githubusercontent.com/MUGeeksandGadgets/MarkMyWords/master/tools/unpiskel.py
|
||||
[23]:https://www.python.org/
|
||||
[24]:https://www.sacredchao.net/~piman/angrydd/
|
||||
[25]:https://renpy.org/
|
||||
[26]:https://www.Pygame.org/
|
||||
[27]:http://Pygame.org/docs/tut/PygameIntro.html
|
||||
[28]:https://anthony-tuininga.github.io/cx_Freeze/
|
||||
[29]:https://Pygame.org/wiki/Pygame2exe
|
||||
[30]:http://www.py2exe.org/
|
||||
[31]:https://itch.io/jam/open-jam-1/entries
|
||||
[32]:https://github.com/MUGeeksandGadgets/MarkMyWords/blob/3e1e8aed12ebe13acccf0d87b06d4f3bd124b9db/README.md#credits
|
||||
[33]:https://twitter.com/mwcz
|
||||
[34]:https://twitter.com/caramelcode
|
||||
[35]:https://opensource.com/
|
||||
@ -0,0 +1,119 @@
|
||||
Linux ln Command Tutorial for Beginners (5 Examples)
|
||||
======
|
||||
|
||||
Sometimes, while working on the command line, you need to create links between files. This can be achieved using a dedicated command, dubbed **ln**. In this tutorial, we will discuss the basics of this tool using some easy to understand examples. But before we do that, it's worth mentioning that all examples here have been tested on an Ubuntu 16.04 machine.
|
||||
|
||||
### Linux ln command
|
||||
|
||||
As you'd have understood by now, the ln command lets you make links between files. Following is the syntax (or rather different syntax available) for this tool:
|
||||
|
||||
```
|
||||
ln [OPTION]... [-T] TARGET LINK_NAME (1st form)
|
||||
ln [OPTION]... TARGET (2nd form)
|
||||
ln [OPTION]... TARGET... DIRECTORY (3rd form)
|
||||
ln [OPTION]... -t DIRECTORY TARGET... (4th form)
|
||||
```
|
||||
|
||||
And here's how the tool's man page explains it:
|
||||
```
|
||||
In the 1st form, create a link to TARGET with the name LINK_NAME. In the 2nd form, create a link
|
||||
to TARGET in the current directory. In the 3rd and 4th forms, create links to each TARGET in
|
||||
DIRECTORY. Create hard links by default, symbolic links with --symbolic. By default, each
|
||||
destination (name of new link) should not already exist. When creating hard links, each TARGET
|
||||
must exist. Symbolic links can hold arbitrary text; if later resolved, a relative link is
|
||||
interpreted in relation to its parent directory.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples will give you a better idea on how the ln command works. But before that, it's good you get a understanding of what's the [difference between hard links and soft links][1].
|
||||
|
||||
### Q1. How to create a hard link using ln?
|
||||
|
||||
That's pretty straightforward - all you have to do is to use the ln command in the following way:
|
||||
|
||||
```
|
||||
ln [file] [hard-link-to-file]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
ln test.txt test_hard_link.txt
|
||||
```
|
||||
|
||||
[![How to create a hard link using ln][2]][3]
|
||||
|
||||
So you can see a hard link was created with the name test_hard_link.txt.
|
||||
|
||||
### Q2. How to create soft/symbolic link using ln?
|
||||
|
||||
For this, use the -s command line option.
|
||||
|
||||
```
|
||||
ln -s [file] [soft-link-to-file]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
ln -s test.txt test_soft_link.txt
|
||||
```
|
||||
|
||||
[![How to create soft/symbolic link using ln][4]][5]
|
||||
|
||||
The test_soft_link.txt file is a soft/symbolic link, as [confirmed][6] by its sky blue text color.
|
||||
|
||||
### Q3. How to make ln remove existing destination files of same name?
|
||||
|
||||
By default, ln won't let you create a link if a file of the same name already exists in the destination directory.
|
||||
|
||||
[![ln command example][7]][8]
|
||||
|
||||
However, if you want, you can make ln override this behavior by using the **-f** command line option.
|
||||
|
||||
[![How to make ln remove existing destination files of same name][9]][10]
|
||||
|
||||
**Note** : You can use the **-i** command line option if you want to make all this deletion process interactive.
|
||||
|
||||
### Q4. How to make ln create backup of existing files with same name?
|
||||
|
||||
If you don't want ln to delete existing files of same name, you can make it create backup of these files. This can be achieved using the **-b** command line option. Backup files created this way will contain a tilde (~) towards the end of their name.
|
||||
|
||||
[![How to make ln create backup of existing files with same name][11]][12]
|
||||
|
||||
A particular destination directory (other than the current one) can be specified using the **-t** command line option. For example:
|
||||
|
||||
```
|
||||
ls test* | xargs ln -s -t /home/himanshu/Desktop/
|
||||
```
|
||||
|
||||
The aforementioned command will create links to all test* files (present in the current directory) and put them in the Desktop directory.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Agreed, **ln** isn't something that you'll require on daily basis, especially if you're a newbie. But it's a helpful command to know about, as you never know when it'd save your day. We've discussed some useful command line options the tool offers. Once you're done with these, you can learn more about ln by heading to its [man page][13].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-ln-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://medium.com/meatandmachines/explaining-the-difference-between-hard-links-symbolic-links-using-bruce-lee-32828832e8d3
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/ln-hard-link.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/big/ln-hard-link.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/ln-soft-link.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/big/ln-soft-link.png
|
||||
[6]:https://askubuntu.com/questions/17299/what-do-the-different-colors-mean-in-ls
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/ln-file-exists.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/ln-file-exists.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/ln-f-option.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/ln-f-option.png
|
||||
[11]:https://www.howtoforge.com/images/command-tutorial/ln-b-option.png
|
||||
[12]:https://www.howtoforge.com/images/command-tutorial/big/ln-b-option.png
|
||||
[13]:https://linux.die.net/man/1/ln
|
||||
110
sources/tech/20180130 Use of du - df commands (with examples).md
Normal file
110
sources/tech/20180130 Use of du - df commands (with examples).md
Normal file
@ -0,0 +1,110 @@
|
||||
Use of du & df commands (with examples)
|
||||
======
|
||||
In this article I will discuss du & df commands. Both du & df commands are important utilities of Linux system & shows disk usage of Linux filesystem. Here we will share usage of both commands with some examples.
|
||||
|
||||
**(Recommended Read:[Files transfer using scp & rsync commands][1])**
|
||||
|
||||
**(Also Read:[Cloning Disks using dd & cat commands for Linux systems][2])**
|
||||
|
||||
### du COMMAND
|
||||
|
||||
du command (short for disk usage) is useful command which is used to find disk usage for files & directories. du command when used with various options provides results in many formats.
|
||||
|
||||
Some of the examples are mentioned below:-
|
||||
|
||||
**1- To find out summary of disk usage for a directory with all its sub-directories**
|
||||
|
||||
```
|
||||
$ du /home
|
||||
```
|
||||
|
||||
![du command][4]
|
||||
|
||||
Output of the command shows all the files & directories in /home with block size.
|
||||
|
||||
**2- Disk usage with file/directory sizes in human readable format I.e. in kb, mb etc**
|
||||
|
||||
```
|
||||
$ du -h /home
|
||||
```
|
||||
|
||||
![du command][6]
|
||||
|
||||
**3- Total disk size of a directory**
|
||||
|
||||
```
|
||||
$ du -s /home
|
||||
```
|
||||
|
||||
![du command][8]
|
||||
|
||||
It will total size of /home directory.
|
||||
|
||||
### df COMMAND
|
||||
|
||||
df command (short for disk filesystem) is used to show disk utilization for a Linux system.
|
||||
|
||||
Some examples are shared below.
|
||||
|
||||
**1- To display information of device name, total blocks, total disk space, used disk space, available disk space and mount points on a file system.**
|
||||
|
||||
```
|
||||
$ df
|
||||
```
|
||||
|
||||
|
||||
![df command][10]
|
||||
|
||||
**2- Information in human readable format**
|
||||
|
||||
```
|
||||
$ df -h
|
||||
```
|
||||
|
||||
![df command][12]
|
||||
|
||||
Above command displays information in human readable format.
|
||||
|
||||
**3- Display information of a particular partition**
|
||||
|
||||
```
|
||||
$ df -hT /etc
|
||||
```
|
||||
|
||||
![df command][14]
|
||||
|
||||
Using -hT with a target directory will show information of /etc/ in human readable format.
|
||||
|
||||
Though there are many more options that can be used with du & df commands, but these should get you started. If you don't find what you are looking for here then you can always refer to man pages for the concerned command.
|
||||
|
||||
Also, read my other posts [**HERE**][15] where i have shared some other important & frequently used Linux.
|
||||
|
||||
And as always your comments/queries are really appreciated, so please leave your comments/queries down below & I will get back to you.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/du-df-commands-examples/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/files-transfer-scp-rsync-commands/
|
||||
[2]:http://linuxtechlab.com/linux-cloning-disks-using-dd-cat-commands/
|
||||
[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=453%2C162
|
||||
[4]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/du1.jpg?resize=453%2C162
|
||||
[5]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=491%2C163
|
||||
[6]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/du2.jpg?resize=491%2C163
|
||||
[7]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=584%2C61
|
||||
[8]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/du3.jpg?resize=584%2C61
|
||||
[9]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=638%2C157
|
||||
[10]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/df1.jpg?resize=638%2C157
|
||||
[11]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=641%2C149
|
||||
[12]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/df2.jpg?resize=641%2C149
|
||||
[13]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=638%2C62
|
||||
[14]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/df3-1.jpg?resize=638%2C62
|
||||
[15]:http://linuxtechlab.com/tips-tricks/
|
||||
@ -0,0 +1,86 @@
|
||||
How to access/view Python help when using vim
|
||||
======
|
||||
|
||||
I am a new Vim text editor user. I am writing Python code. Is there is a way to see Python documentation within vim and without visiting the Internet? Say my cursor is under the print Python keyword, and I press F1. I want to look at the help for the print keyword. How do I show python help() inside vim? How do I call pydoc3/pydoc to seek help without leaving vim?
|
||||
|
||||
The pydoc or pydoc3 command show text documentation on the name of a Python keyword, topic, function, module, or package, or a dotted reference to a class or function within a module or module in a package. You can call pydoc from vim itself. Let us see how to access Python documentation using pydoc within vim text editor.
|
||||
|
||||
### Access python help using pydoc
|
||||
|
||||
The syntax is:
|
||||
```
|
||||
pydoc keyword
|
||||
pydoc3 keyword
|
||||
pydoc len
|
||||
pydoc print
|
||||
```
|
||||
Edit your ~/.vimrc:
|
||||
`$ vim ~/.vimrc`
|
||||
Append the following configuration for pydoc3 (python v3.x docs). Create a mapping for H key that works in normal mode:
|
||||
```
|
||||
nnoremap <buffer> H :<C-u>execute "!pydoc3 " . expand("<cword>")<CR>
|
||||
```
|
||||
|
||||
|
||||
Save and close the file. Open vim text editor:
|
||||
`$ vim file.py`
|
||||
Write some code:
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
x=5
|
||||
y=10
|
||||
z=x+y
|
||||
print(z)
|
||||
print("Hello world")
|
||||
```
|
||||
|
||||
Position cursor under the print Python keyword and press Shift followed by H. You will see output as follows:
|
||||
|
||||
[![Access Python Help Within Vim][1]][1]
|
||||
Gif.01: Press H to view help for the print Python keyword
|
||||
|
||||
### How to view python help when using vim
|
||||
|
||||
[jedi-vim][2] is a VIM binding to the autocompletion library Jed. It can do many things including display help for keyword when you press Shift followed by K i.e. press capital K.
|
||||
|
||||
#### How to install jedi-vim on Linux or Unix-like system
|
||||
|
||||
Use [pathogen][3], [vim-plug][4] or [Vundle][5] to install jedi-vim. I am using Vim-Plug. Add the following line in ~/vimrc:
|
||||
`Plug 'davidhalter/jedi-vim'`
|
||||
Save and close the file. Start vim and type:
|
||||
`PlugInstall`
|
||||
On Arch Linux, you can also install jedi-vim from official repositories as vim-jedi using pacman command:
|
||||
`$ sudo pacman -S vim-jedi`
|
||||
It is also available on Debian (?8) and Ubuntu (?14.04) as vim-python-jedi using [apt command][6]/[apt-get command][7]:
|
||||
`$ sudo apt install vim-python-jedi`
|
||||
On Fedora Linux, it is available as vim-jedi using dnf command:
|
||||
`$ sudo dnf install vim-jedi`
|
||||
Jedi is by default automatically initialized. So no further configuration needed on your part. To see Documentation/Pydoc press K. It shows a popup with assignments:
|
||||
[![How to view python help when using vim][8]][8]
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][9], [Facebook][10], [Google+][11].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-access-view-python-help-when-using-vim/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/01/Access-Python-Help-Within-Vim.gif
|
||||
[2]:https://github.com/davidhalter/jedi-vim
|
||||
[3]:https://github.com/tpope/vim-pathogen
|
||||
[4]:https://www.cyberciti.biz/programming/vim-plug-a-beautiful-and-minimalist-vim-plugin-manager-for-unix-and-linux-users/
|
||||
[5]:https://github.com/gmarik/vundle
|
||||
[6]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[7]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[8]:https://www.cyberciti.biz/media/new/faq/2018/01/How-to-view-Python-Documentation-using-pydoc-within-vim-on-Linux-Unix.jpg
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
@ -0,0 +1,223 @@
|
||||
Migrating the debichem group subversion repository to Git - Part 1: svn-all-fast-export basics
|
||||
======
|
||||
With the [deprecation of alioth.debian.org][1] the subversion service hosted there will be shut down too. [According to lintian][2] the estimated date is May 1st 2018 and there are currently more then 1500 source packages affected. In the [debichem group][3] we've used the subversion service since 2006. Our repository contains around 7500 commits done by around 20 different alioth user accounts and the packaging history of around 70 to 80 packages, including packaging attempts. I've spent the last days to prepare the Git migration, comparing different tools, controlling the created repositories and testing possibilities to automate the process as much as possible. The resulting scripts can currently be found [here][4].
|
||||
|
||||
Of course I began as described at the [Debian Wiki][5]. But following this guide, using `git-svn` and converting the tags with the script supplied under rubric Convert remote tags and branches to local one gave me really weird results. The tags were pointing to the wrong commit-IDs. I thought, that `git-svn` was to blame and reported this as [bug #887881][6]. In the following mail exchange Andreas Kaesorg explained to me, that the issue is caused by so-called mixed-revision-tags in our repository as shown in the following example:
|
||||
```
|
||||
$ svn log -v -r7405
|
||||
------------------------------------------------------------------------
|
||||
r7405 | dleidert | 2018-01-17 18:14:57 +0100 (Mi, 17. Jan 2018) | 1 Zeile
|
||||
Geanderte Pfade:
|
||||
A /tags/shelxle/1.0.888-1 (von /unstable/shelxle:7396)
|
||||
R /tags/shelxle/1.0.888-1/debian/changelog (von /unstable/shelxle/debian/changelog:7404)
|
||||
R /tags/shelxle/1.0.888-1/debian/control (von /unstable/shelxle/debian/control:7403)
|
||||
D /tags/shelxle/1.0.888-1/debian/patches/qt5.patch
|
||||
R /tags/shelxle/1.0.888-1/debian/patches/series (von /unstable/shelxle/debian/patches/series:7402)
|
||||
R /tags/shelxle/1.0.888-1/debian/rules (von /unstable/shelxle/debian/rules:7403)
|
||||
|
||||
[svn-buildpackage] Tagging shelxle 1.0.888-1
|
||||
------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
|
||||
Looking into the git log, the tags deteremined by git-svn are really not in their right place in the history line, even before running the script to convert the branches into real Git tags. So IMHO git-svn is not able to cope with this kind of situation. Because it also cannot handle our branch model, where we use /branch/package/, I began to look for different tools and found [svn-all-fast-export][7], a tool created (by KDE?) to convert even large subversion repositories based on a ruleset. My attempt using this tool was so successful (not to speak of, how fast it is), that I want to describe it more. Maybe it will prove to be useful for others as well and it won't hurt to give some more information about this poorly documented tool :)
|
||||
|
||||
### Step 1: Setting up a local subversion mirror
|
||||
|
||||
First I suggest setting up a local copy of the subversion repository to migrate, that is kept in sync with the remote repository. This can be achieved using the svnsync command. There are several howtos for this, so I won't describe this step here. Please check out [this guide][8]. In my case I have such a copy in /srv/svn/debichem.
|
||||
|
||||
### Step 2: Creating the identity map
|
||||
|
||||
svn-all-fast-export needs at least two files to work. One is the so called identity map. This file contains the mapping between subversion user IDs (login names) and the (Git) committer info, like real name and mail address. The format is the same as used by git-svn:
|
||||
```
|
||||
loginname = author name <mail address>
|
||||
```
|
||||
|
||||
e.g.
|
||||
```
|
||||
dleidert = Daniel Leidert <dleidert@debian.org>
|
||||
```
|
||||
|
||||
The list of subversion user IDs can be obtained the same way as [described in the Wiki][9]:
|
||||
```
|
||||
svn log SVN_URL | awk -F'|' '/^r[0-9]+/ { print $2 }' | sort -u
|
||||
```
|
||||
|
||||
Just replace the placeholder SVN_URL with your subversion URL. [Here][10] is the complete file for the debichem group.
|
||||
|
||||
### Step 3: Creating the rules
|
||||
|
||||
The most important thing is the second file, which contains the processing rules. There is really not much documentation out there. So when in doubt, one has to read the source file [src/ruleparser.cpp][11]. I'll describe, what I already found out. If you are impatient, [here][12] is my result so far.
|
||||
|
||||
The basic rules are:
|
||||
```
|
||||
create repository REPOSITORY
|
||||
...
|
||||
end repository
|
||||
|
||||
```
|
||||
|
||||
and
|
||||
```
|
||||
match PATTERN
|
||||
...
|
||||
end match
|
||||
|
||||
```
|
||||
|
||||
The first rule creates a bare git repository with the name you've chosen (above represented by REPOSITORY). It can have one child, that is the repository description to be put into the repositories description file. There are AFAIK no other elements allowed here. So in case of e.g. ShelXle the rule might look like this:
|
||||
```
|
||||
create repository shelxle
|
||||
description packaging of ShelXle, a graphical user interface for SHELXL
|
||||
end repository
|
||||
|
||||
```
|
||||
|
||||
You'll have to create every repository, before you can put something into it. Else svn-all-fast-export will exit with an error. JFTR: It won't complain, if you create a repository, but don't put anything into it. You will just end up with an empty Git repository.
|
||||
|
||||
Now the second type of rule is the most important one. Based on regular expression match patterns (above represented by PATTERN), one can define actions, including the possibility to limit these actions to repositories, branches and revisions. **The patterns are applied in their order of appearance. Thus if a matching pattern is found, other patterns matching but appearing later in the rules file, won't apply!** So a special rule should always be put above a general rule. The patterns, that can be used, seem to be of type [QRegExp][13] and seem like basic Perl regular expressions including e.g. capturing, backreferences and lookahead capabilities. For a multi-package subversion repository with standard layout (that is /PACKAGE/{trunk,tags,branches}/), clean naming and subversion history, the rules could be:
|
||||
```
|
||||
match /([^/]+)/trunk/
|
||||
repository \1
|
||||
branch master
|
||||
end match
|
||||
|
||||
match /([^/]+)/tags/([^/]+)/
|
||||
repository \1
|
||||
branch refs/tags/debian/\2
|
||||
annotated true
|
||||
end match
|
||||
|
||||
match /([^/]+)/branches/([^/]+)/
|
||||
repository \1
|
||||
branch \2
|
||||
end match
|
||||
|
||||
```
|
||||
|
||||
The first rule captures the (source) package name from the path and puts it into the backreference `\1`. It applies to the trunk directory history and will put everything it finds there into the repository named after the directory - here we simply use the backreference `\1` to that name - and there into the master branch. Note, that svn-all-fast-export will error out, if it tries to access a repository, which has not been created. So make sure, all repositories are created as shown with the `create repository` rule. The second rule captures the (source) package name from the path too and puts it into the backreference `\1`. But in backreference `\2` it further captures (and applies to) all the tag directories under the /tags/ directory. Usually these have a Debian package version as name. With the branch statement as shown in this rule, the tags, which are really just branches in subversion, are automatically converted to [annotated][14] Git tags (another advantage of svn-all-fast-export over git-svn). Without enabling the `annotated` statement, the tags created will be [lightweight tags][15]. So the tag name (here: debian/VERSION) is determined via backreference `\2`. The third rule is almost the same, except that everything found in the matching path will be pushed into a Git branch named after the top-level directory captured from the subversion path.
|
||||
|
||||
Now in an ideal world, this might be enough and the actual conversion can be done. The command should only be executed in an empty directory. I'll assume, that the identity map is called authors and the rules file is called rules and that both are in the parent directory. I'll also assume, that the local subversion mirror of the packaging repository is at /srv/svn/mymirror. So ...
|
||||
```
|
||||
svn-all-fast-export --stats --identity-map=../authors.txt --rules=../debichem.rules --stats /srv/svn/mymirror
|
||||
```
|
||||
|
||||
... will create one or more **bare** Git repositories (depending on your rules file) in the current directory. After the command succeeded, you can test the results ...
|
||||
```
|
||||
git -C REPOSITORY/ --bare show-ref
|
||||
git -C REPOSITORY/ --bare log --all --graph
|
||||
|
||||
```
|
||||
|
||||
... and you will find your repositories description (if you added one to the rules file) in REPOSITORY/description:
|
||||
```
|
||||
cat REPOSITORY/description
|
||||
```
|
||||
|
||||
**Please note, that not all the debian version strings are[well formed Git reference names][16] and therefor need fixing. There might also be gaps shown in the Git history log. Or maybe the command didn't even suceed or complained (without you noticing it) or you ended up with an empty repository, although the matching rules applied. I encountered all of these issues and I'll describe the cause and fixes in the next blog article.**
|
||||
|
||||
But if everything went well (you have no history gaps, the tags are in their right place within the linearized history and the repository looks fine) and you can and want to proceed, you might want to skip to the next step.
|
||||
|
||||
In the debichem group we used a different layout. The packaging directories were under /{unstable,experimental,wheezy,lenny,non-free}/PACKAGE/. This translates to [/unstable/][17]PACKAGE/ and [/non-free/][18]PACKAGE/ being the trunk directories and the [others][19] being the branches. The tags are in [/tags/][20]PACKAGE/. And packages, that are yet to upload are located in [/wnpp/][21]PACKAGE/. With this layout, the basic rules are:
|
||||
```
|
||||
# trunk handling
|
||||
# e.g. /unstable/espresso/
|
||||
# e.g. /non-free/molden/
|
||||
match /(?:unstable|non-free)/([^/]+)/
|
||||
repository \1
|
||||
branch master
|
||||
end match
|
||||
|
||||
# handling wnpp
|
||||
# e.g. /wnpp/osra/
|
||||
match /(wnpp)/([^/]+)/
|
||||
repository \2
|
||||
branch \1
|
||||
end match
|
||||
|
||||
# branch handling
|
||||
# e.g. /wheezy/espresso/
|
||||
match /(lenny|wheezy|experimental)/([^/]+)/
|
||||
repository \2
|
||||
branch \1
|
||||
end match
|
||||
|
||||
# tags handling
|
||||
# e.g. /tags/espresso/VERSION/
|
||||
match /tags/([^/]+)/([^/]+)/
|
||||
repository \1
|
||||
annotated true
|
||||
branch refs/tags/debian/\2
|
||||
substitute branch s/~/_/
|
||||
substitute branch s/:/_/
|
||||
end match
|
||||
|
||||
```
|
||||
|
||||
In the first rule, there is a non-capturing expression (?: ... ), which simply means, that the rule applies to /unstable/ and /non-free/. Thus the backreference `\1` refers to second part of the path, the package directory name. The contents found are pushed to the master branch. In the second rule, the contents from the wnpp directory are not pushed to master, but instead to a branch called wnpp. This was necessary because of overlaps between /unstable/ and /wnpp/ history and already shows, that the repositories history makes things complicated. In the third rule, the first backreference `\1` determines the branch (note the capturing expression in contrast to the first rule) and the second backreference `\2` the package repository to act on. The last rule is similar, but now `\1` determines the package repository and `\2` the tag name (debian package version) based on the matching path. The example also shows another issue, which I'd like to explain more in the next article: some characters we use in debian package versions, e.g. the tilde sign and the colon, are not allowed within Git tag names and must therefor be substituted, which is done by the `substitute branch EXPRESSION` instructions.
|
||||
|
||||
### Step 4: Cleaning the bare repository
|
||||
|
||||
The [tool documentation][27] suggests to run ...
|
||||
```
|
||||
git -C REPOSITORY/ repack -a -d -f
|
||||
```
|
||||
|
||||
... before you upload this bare repository to another location. But [Stuart Prescott told me on the debichem list][28], that this might not be enough and still leave some garbage behind. I'm not experienved enough to judge here, but his suggestion is, to clone the repository, either a bare clone or clone and init a new bare. I used the first approach:
|
||||
```
|
||||
git -C REPOSITORY/ --bare clone --bare REPOSITORY.git
|
||||
git -C REPOSITORY.git/ repack -a -d -f
|
||||
|
||||
```
|
||||
|
||||
**Please note, that this won't copy the repositories description file. You'll have to copy it manually, if you wanna keep it.** The resulting bare repository can be uploaded (e.g. to [git.debian.org as personal repository][29]:
|
||||
```
|
||||
cp REPOSITORY/description REPOSITORY.git/description
|
||||
touch REPOSITORY.git/git-daemon-export-ok
|
||||
rsync -avz REPOSITORY.git git.debian.org:~/public_git/
|
||||
|
||||
```
|
||||
|
||||
Or you clone the repository, add a remote origin and push everything there. It is even possible to use the gitlab API at salsa.debian.org to create a project and push there. I'll save the latter for another post. If you are hasty, you'll find a script [here][30].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.wgdd.de/2018/01/migrating-debichem-group-subversion.html
|
||||
|
||||
作者:[Daniel Leidert][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.blogger.com/profile/17052464961644858181
|
||||
[1]:https://wiki.debian.org/Alioth#Deprecation_of_Alioth
|
||||
[2]:https://lintian.debian.org/tags/vcs-deprecated-in-debian-infrastructure.html
|
||||
[3]:https://debichem.alioth.debian.org/
|
||||
[4]:https://anonscm.debian.org/viewvc/debichem/tools/svn2git/
|
||||
[5]:https://wiki.debian.org/de/Alioth/Git#Convert_a_SVN_Alioth_repository_to_Git
|
||||
[6]:https://bugs.debian.org/887881
|
||||
[7]:https://github.com/svn-all-fast-export/svn2git
|
||||
[8]:http://www.microhowto.info/howto/mirror_a_subversion_repository.html
|
||||
[9]:https://wiki.debian.org/de/Alioth/Git#Create_the_author_file
|
||||
[10]:https://anonscm.debian.org/viewvc/debichem/tools/svn2git/authors.txt?view=co&content-type=text%2Fplain
|
||||
[11]:https://raw.githubusercontent.com/svn-all-fast-export/svn2git/master/src/ruleparser.cpp
|
||||
[12]:https://anonscm.debian.org/viewvc/debichem/tools/svn2git/debichem.rules?view=co&content-type=text%2Fplain
|
||||
[13]:http://doc.qt.io/qt-5/qregexp.html#introduction
|
||||
[14]:https://git-scm.com/book/en/v2/Git-Basics-Tagging#_annotated_tags
|
||||
[15]:https://git-scm.com/book/en/v2/Git-Basics-Tagging#_lightweight_tags
|
||||
[16]:https://git-scm.com/docs/git-check-ref-format
|
||||
[17]:https://anonscm.debian.org/viewvc/debichem/unstable/
|
||||
[18]:https://anonscm.debian.org/viewvc/debichem/non-free/
|
||||
[19]:https://anonscm.debian.org/viewvc/debichem/experimental/
|
||||
[20]:https://anonscm.debian.org/viewvc/debichem/tags/
|
||||
[21]:https://anonscm.debian.org/viewvc/debichem/wnpp/
|
||||
[22]:https://anonscm.debian.org/viewvc/debichem/unstable/espresso/
|
||||
[23]:https://anonscm.debian.org/viewvc/debichem/non-free/molden/
|
||||
[24]:https://anonscm.debian.org/viewvc/debichem/wnpp/osra/
|
||||
[25]:https://anonscm.debian.org/viewvc/debichem/wheezy/espresso/
|
||||
[26]:https://anonscm.debian.org/viewvc/debichem/tags/espresso/
|
||||
[27]:https://techbase.kde.org/Projects/MoveToGit/UsingSvn2Git#Checking_for_proper_history_in_the_new_git_repository
|
||||
[28]:http://lists.alioth.debian.org/pipermail/debichem-devel/2018-January/008816.html
|
||||
[29]:https://wiki.debian.org/de/Alioth/Git#Using_personal_Git_repositories
|
||||
[30]:https://anonscm.debian.org/viewvc/debichem/tools/svn2git/gitimport.sh?view=co&content-type=text%2Fplain
|
||||
@ -0,0 +1,157 @@
|
||||
Ansible 教程:简单 Ansible 命令介绍
|
||||
======
|
||||
在我们之前的 Ansible 教程中,我们讨论了[ **Ansible** 的安装和配置][1]。在这个 ansible 教程中,我们将学习一些基本的 ansible 命令的例子,我们将用它来管理基础设施。所以让我们先看看一个完整的 ansible 命令的语法:
|
||||
|
||||
```
|
||||
$ ansible <group> -m <module> -a <arguments>
|
||||
```
|
||||
|
||||
在这里,我们可以用单个主机或用 <group> 代替全部主机,<arguments> 代表可以提供的选项。现在我们来看看一些 ansible 的基本命令。
|
||||
|
||||
### 检查主机的连通性
|
||||
|
||||
我们在之前的教程中也使用了这个命令。检查主机连接的命令是:
|
||||
|
||||
```
|
||||
$ ansible <group> -m ping
|
||||
```
|
||||
|
||||
### 重启主机
|
||||
|
||||
```
|
||||
$ ansible <group> -a "/sbin/reboot"
|
||||
```
|
||||
|
||||
### 检查主机的系统信息
|
||||
|
||||
Ansible 收集所有连接到它主机的信息。要显示主机的信息,请运行:
|
||||
|
||||
```
|
||||
$ ansible <group> -m setup | less
|
||||
```
|
||||
|
||||
其次,通过传递参数来从收集的信息中检查特定的信息:
|
||||
|
||||
```
|
||||
$ ansible <group> -m setup -a "filter=ansible_distribution"
|
||||
```
|
||||
|
||||
### 传输文件
|
||||
|
||||
对于传输文件,我们使用模块 “copy” ,完整的命令是这样的:
|
||||
|
||||
```
|
||||
$ ansible <group> -m copy -a "src=/home/dan dest=/tmp/home"
|
||||
```
|
||||
|
||||
### 管理用户
|
||||
|
||||
要管理已连接主机上的用户,我们使用一个名为 “user” 的模块,并如下使用它。
|
||||
|
||||
#### 创建新用户
|
||||
|
||||
```
|
||||
$ ansible <group> -m user -a "name=testuser password=<encrypted password>"
|
||||
```
|
||||
|
||||
#### 删除用户
|
||||
|
||||
```
|
||||
$ ansible <group> -m user -a "name=testuser state=absent"
|
||||
```
|
||||
|
||||
**注意:** 要创建加密密码,请使用 ”mkpasswd -method=sha-512“。
|
||||
|
||||
### 更改权限和所有者
|
||||
|
||||
要改变已连接主机文件的所有者,我们使用名为 ”file“ 的模块,使用如下。
|
||||
|
||||
### 更改文件权限
|
||||
|
||||
```
|
||||
$ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777"
|
||||
```
|
||||
|
||||
### 更改文件的所有者
|
||||
|
||||
```
|
||||
$ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777 owner=dan group=dan"
|
||||
```
|
||||
|
||||
### 管理软件包
|
||||
|
||||
我们可以通过使用 ”yum“ 和 ”apt“ 模块来管理所有已连接主机的软件包,完整的命令如下:
|
||||
|
||||
#### 检查包是否已安装并更新
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=latest"
|
||||
```
|
||||
|
||||
#### 检查包是否已安装,但不更新
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=present"
|
||||
```
|
||||
|
||||
#### 检查包是否是特定的版本
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name= ntp-1.8 state=present"
|
||||
```
|
||||
|
||||
#### 检查包是否没有安装
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=absent"
|
||||
```
|
||||
|
||||
### 管理服务
|
||||
|
||||
要管理服务,我们使用模块 “service” ,完整命令如下:
|
||||
|
||||
#### 启动服务
|
||||
|
||||
```
|
||||
$ansible <group> -m service -a "name=httpd state=started"
|
||||
```
|
||||
|
||||
#### 停止服务
|
||||
|
||||
```
|
||||
$ ansible <group> -m service -a "name=httpd state=stopped"
|
||||
```
|
||||
|
||||
#### 重启服务
|
||||
|
||||
```
|
||||
$ ansible <group> -m service -a "name=httpd state=restarted"
|
||||
```
|
||||
|
||||
这样我们简单的,只有一行的 ansible 命令的教程就完成了。此外,在未来的教程中,我们将学习创建 playbook,来帮助我们更轻松高效地管理主机。
|
||||
|
||||
If you think we have helped you or just want to support us, please consider these :-
|
||||
如果你认为我们帮助到您,或者只是想支持我们,请考虑这些:
|
||||
|
||||
关注我们:[Facebook][2] | [Twitter][3] | [Google Plus][4]
|
||||
|
||||
成为支持者 - [通过 PayPal 捐助][5]
|
||||
|
||||
Linux TechLab 感谢你的持续支持。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/ansible-tutorial-simple-commands/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/create-first-ansible-server-automation-setup/
|
||||
[2]:https://www.facebook.com/linuxtechlab/
|
||||
[3]:https://twitter.com/LinuxTechLab
|
||||
[4]:https://plus.google.com/+linuxtechlab
|
||||
[5]:http://linuxtechlab.com/contact-us-2/
|
||||
252
translated/tech/20170915 How To Install And Setup Vagrant.md
Normal file
252
translated/tech/20170915 How To Install And Setup Vagrant.md
Normal file
@ -0,0 +1,252 @@
|
||||
如何安装并设置 Vagrant
|
||||
=============================
|
||||
|
||||
Vagrant 对于虚拟机来说是一个强大的工具,在这里我们将研究如何在 Ubuntu 上设置和使用 Virtualbox 的 Vagrant 来提供可重复的虚拟机。
|
||||
|
||||
##虚拟机,并不复杂
|
||||
|
||||
多年来,开发人员一直使用虚拟机作为其工作流程的一部分,允许他们交换和更改运行软件的环境,这通常是为了防止项目之间的冲突,例如需要 php 5.3 的项目 A 和需要 php 5.4 的项目 B。
|
||||
|
||||
并且使用虚拟机意味着你只需要你正在使用的计算机,不需要专用硬件来镜像生产环境。
|
||||
|
||||
当多个开发人员在一个项目上工作时,它也很方便,他们都可以运行一个包含所有需求的环境,但是维护多台机器并确保所有的需求都具有相同的版本是非常困难的,这时 Vagrant 就能派上用场了。
|
||||
|
||||
###使用虚拟机的好处
|
||||
|
||||
- 你的虚拟机与主机环境是分开的
|
||||
- 可以根据你代码的要求有一个定制的虚拟机
|
||||
- 不会影响其他虚拟机
|
||||
- 可以运行在你的主机上无法运行的程序,例如在 Ubuntu 中运行一些只能在 Windows 运行的软件
|
||||
|
||||
##什么是 Vagrant
|
||||
|
||||
简而言之,这是一个与虚拟机一起工作的工具,可以让你自动创建和删除虚拟机。
|
||||
|
||||
它围绕一个名为 VagrantFile 的配置文件进行,这个配置文件告诉 Vagrant 你想要安装的操作系统,以及一些其他选项,如 IP 和同步目录。 你还可以在虚拟机上添加一个命令的配置脚本。
|
||||
|
||||
一个项目的所有开发人员通过共享这个 VagrantFile,你们将全部使用完全相同的虚拟机。
|
||||
|
||||
##安装要求
|
||||
|
||||
###安装 VirtualBox
|
||||
|
||||
VirtualBox 是运行虚拟机的程序,它可以在 Ubuntu Repos 中使用。
|
||||
|
||||
sudo apt-get install virtualbox
|
||||
|
||||
|
||||
###安装 Vagrant
|
||||
|
||||
对于 Vagrant 本身,你要前往 [https://www.vagrantup.com/downloads.html ](https://www.vagrantup.com/downloads.html) 查看并为你的 OS 安装软件包。
|
||||
|
||||
###安装增强功能
|
||||
|
||||
如果你打算与虚拟机共享任何文件夹,则需要安装以下插件。
|
||||
|
||||
|
||||
vagrant plugin install vagrant-vbguest
|
||||
|
||||
|
||||
##配置 Vagrant
|
||||
|
||||
###首先我们需要为 Vagrant 的配置创建一个文件夹
|
||||
|
||||
|
||||
mkdir ~/Vagrant/test-vm
|
||||
cd ~/Vagrant/test-vm
|
||||
|
||||
|
||||
###创建 VagrantFile
|
||||
|
||||
vagrant init
|
||||
|
||||
|
||||
###开启虚拟机
|
||||
|
||||
vagrant up
|
||||
|
||||
|
||||
###登录机器
|
||||
|
||||
vagrant-ssh
|
||||
|
||||
|
||||
此时,你将拥有一个基本的 vagrant box,以及一个名为 VagrantFile 的文件。
|
||||
|
||||
##定制
|
||||
|
||||
在上面的步骤中创建的 VagrantFile 看起来类似于以下内容
|
||||
|
||||
**VagrantFile**
|
||||
|
||||
# -*- mode: ruby -*-
|
||||
# vi: set ft=ruby :
|
||||
# All Vagrant configuration is done below. The "2" in Vagrant.configure
|
||||
# configures the configuration version (we support older styles for
|
||||
# backwards compatibility). Please don't change it unless you know what
|
||||
# you're doing.
|
||||
Vagrant.configure("2") do |config|
|
||||
# The most common configuration options are documented and commented below.
|
||||
# For a complete reference, please see the online documentation at
|
||||
# https://docs.vagrantup.com.
|
||||
|
||||
# Every Vagrant development environment requires a box. You can search for
|
||||
# boxes at https://vagrantcloud.com/search.
|
||||
config.vm.box = "base"
|
||||
|
||||
# Disable automatic box update checking. If you disable this, then
|
||||
# boxes will only be checked for updates when the user runs
|
||||
# `vagrant box outdated`. This is not recommended.
|
||||
# config.vm.box_check_update = false
|
||||
|
||||
# Create a forwarded port mapping which allows access to a specific port
|
||||
# within the machine from a port on the host machine. In the example below,
|
||||
# accessing "localhost:8080" will access port 80 on the guest machine.
|
||||
# NOTE: This will enable public access to the opened port
|
||||
# config.vm.network "forwarded_port", guest: 80, host: 8080
|
||||
|
||||
# Create a forwarded port mapping which allows access to a specific port
|
||||
# within the machine from a port on the host machine and only allow access
|
||||
# via 127.0.0.1 to disable public access
|
||||
# config.vm.network "forwarded_port", guest: 80, host: 8080, host_ip: "127.0.0.1"
|
||||
|
||||
# Create a private network, which allows host-only access to the machine
|
||||
# using a specific IP.
|
||||
# config.vm.network "private_network", ip: "192.168.33.10"
|
||||
|
||||
# Create a public network, which generally matched to bridged network.
|
||||
# Bridged networks make the machine appear as another physical device on
|
||||
# your network.
|
||||
# config.vm.network "public_network"
|
||||
|
||||
# Share an additional folder to the guest VM. The first argument is
|
||||
# the path on the host to the actual folder. The second argument is
|
||||
# the path on the guest to mount the folder. And the optional third
|
||||
# argument is a set of non-required options.
|
||||
# config.vm.synced_folder "../data", "/vagrant_data"
|
||||
|
||||
# Provider-specific configuration so you can fine-tune various
|
||||
# backing providers for Vagrant. These expose provider-specific options.
|
||||
# Example for VirtualBox:
|
||||
#
|
||||
# config.vm.provider "virtualbox" do |vb|
|
||||
# # Display the VirtualBox GUI when booting the machine
|
||||
# vb.gui = true
|
||||
#
|
||||
# # Customize the amount of memory on the VM:
|
||||
# vb.memory = "1024"
|
||||
# end
|
||||
#
|
||||
# View the documentation for the provider you are using for more
|
||||
# information on available options.
|
||||
|
||||
# Enable provisioning with a shell script. Additional provisioners such as
|
||||
# Puppet, Chef, Ansible, Salt, and Docker are also available. Please see the
|
||||
# documentation for more information about their specific syntax and use.
|
||||
# config.vm.provision "shell", inline: <<-SHELL
|
||||
# apt-get update
|
||||
# apt-get install -y apache2
|
||||
# SHELL
|
||||
end
|
||||
|
||||
现在这个 VagrantFile 将创建基本的虚拟机。但 Vagrant 背后的理念是让虚拟机设置我们的特定任务,所以我们删除注释和调整配置。
|
||||
|
||||
**VagrantFile**
|
||||
|
||||
# -*- mode: ruby -*-
|
||||
# vi: set ft=ruby :
|
||||
|
||||
Vagrant.configure("2") do |config|
|
||||
# Set the Linux Version to Debian Jessie
|
||||
config.vm.box = "debian/jessie64"
|
||||
# Set the IP of the Box
|
||||
config.vm.network "private_network", ip: "192.168.33.10"
|
||||
# Sync Our Projects Directory with the WWW directory
|
||||
config.vm.synced_folder "~/Projects", "/var/www/"
|
||||
# Run the following to Provision
|
||||
config.vm.provision "shell", path: "install.sh"
|
||||
end
|
||||
|
||||
现在我们有一个简单的 VagrantFile,它将 Linux 版本设置为 debian jessie,设置一个 IP 给我们使用,同步我们感兴趣的文件夹,最后运行 install.sh,这是我们的 shell 命令可以使用的地方。
|
||||
|
||||
**install.sh**
|
||||
|
||||
#! /usr/bin/env bash
|
||||
# Variables
|
||||
DBHOST=localhost
|
||||
DBNAME=dbname
|
||||
DBUSER=dbuser
|
||||
DBPASSWD=test123
|
||||
|
||||
echo "[ Provisioning machine ]"
|
||||
echo "1) Update APT..."
|
||||
apt-get -qq update
|
||||
|
||||
echo "1) Install Utilities..."
|
||||
apt-get install -y tidy pdftk curl xpdf imagemagick openssl vim git
|
||||
|
||||
echo "2) Installing Apache..."
|
||||
apt-get install -y apache2
|
||||
|
||||
echo "3) Installing PHP and packages..."
|
||||
apt-get install -y php5 libapache2-mod-php5 libssh2-php php-pear php5-cli php5-common php5-curl php5-dev php5-gd php5-imagick php5-imap php5-intl php5-mcrypt php5-memcached php5-mysql php5-pspell php5-xdebug php5-xmlrpc
|
||||
#php5-suhosin-extension, php5-mysqlnd
|
||||
|
||||
echo "4) Installing MySQL..."
|
||||
debconf-set-selections <<< "mysql-server mysql-server/root_password password secret"
|
||||
debconf-set-selections <<< "mysql-server mysql-server/root_password_again password secret"
|
||||
apt-get install -y mysql-server
|
||||
mysql -uroot -p$DBPASSWD -e "CREATE DATABASE $DBNAME"
|
||||
mysql -uroot -p$DBPASSWD -e "grant all privileges on $DBNAME.* to '$DBUSER'@'localhost' identified by '$DBPASSWD'"
|
||||
|
||||
echo "5) Generating self signed certificate..."
|
||||
mkdir -p /etc/ssl/localcerts
|
||||
openssl req -new -x509 -days 365 -nodes -subj "/C=US/ST=Denial/L=Springfield/O=Dis/CN=www.example.com" -out /etc/ssl/localcerts/apache.pem -keyout /etc/ssl/localcerts/apache.key
|
||||
chmod 600 /etc/ssl/localcerts/apache*
|
||||
|
||||
echo "6) Setup Apache..."
|
||||
a2enmod rewrite
|
||||
> /etc/apache2/sites-enabled/000-default.conf
|
||||
echo "
|
||||
<VirtualHost *:80>
|
||||
ServerAdmin [[email protected]][1]
|
||||
DocumentRoot /var/www/
|
||||
ErrorLog ${APACHE_LOG_DIR}/error.log
|
||||
CustomLog ${APACHE_LOG_DIR}/access.log combined
|
||||
</VirtualHost>
|
||||
|
||||
" >> /etc/apache2/sites-enabled/000-default.conf
|
||||
service apache2 restart
|
||||
|
||||
echo "7) Composer Install..."
|
||||
curl --silent https://getcomposer.org/installer | php
|
||||
mv composer.phar /usr/local/bin/composer
|
||||
|
||||
echo "8) Install NodeJS..."
|
||||
curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash -
|
||||
apt-get -qq update
|
||||
apt-get -y install nodejs
|
||||
|
||||
echo "9) Install NPM Packages..."
|
||||
npm install -g gulp gulp-cli
|
||||
|
||||
echo "Provisioning Completed"
|
||||
|
||||
通过上面的步骤,在你的目录中会有 VagrantFile 和 Install.sh,运行 vagrant 会做下面的事情
|
||||
|
||||
- 采用 Debian Jessie 来创建虚拟机
|
||||
- 将机器的 IP 设置为 192.168.33.10
|
||||
- 同步 ~/Projects 和 /var/www/ 目录
|
||||
- 安装并设置 Apache, Mysql, PHP, Git, Vim
|
||||
- 安装并运行 Composer
|
||||
- 安装 Nodejs 和 gulp
|
||||
- 创建一个 MySQL 数据库
|
||||
- 创建自签名证书
|
||||
|
||||
通过与其他人共享 VagrantFile 和 install.sh,你可以在两台不同的机器上使用完全相同的环境。
|
||||
|
||||
via: [https://www.chris-shaw.com/blog/how-to-install-and-setup-vagrant)](https://www.chris-shaw.com/blog/how-to-install-and-setup-vagrant)
|
||||
|
||||
作者:[Christopher Shaw](a) 译者:[MjSeven](https://github.com/MjSeven) 校对:[校对者 ID](a)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user