mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
Merge remote-tracking branch 'lctt/master' into 20181010
This commit is contained in:
commit
8a686fb691
@ -1,14 +1,15 @@
|
||||
三周内构建 JavaScript 全栈 web 应用
|
||||
============================================================
|
||||
===========
|
||||
|
||||
|
||||
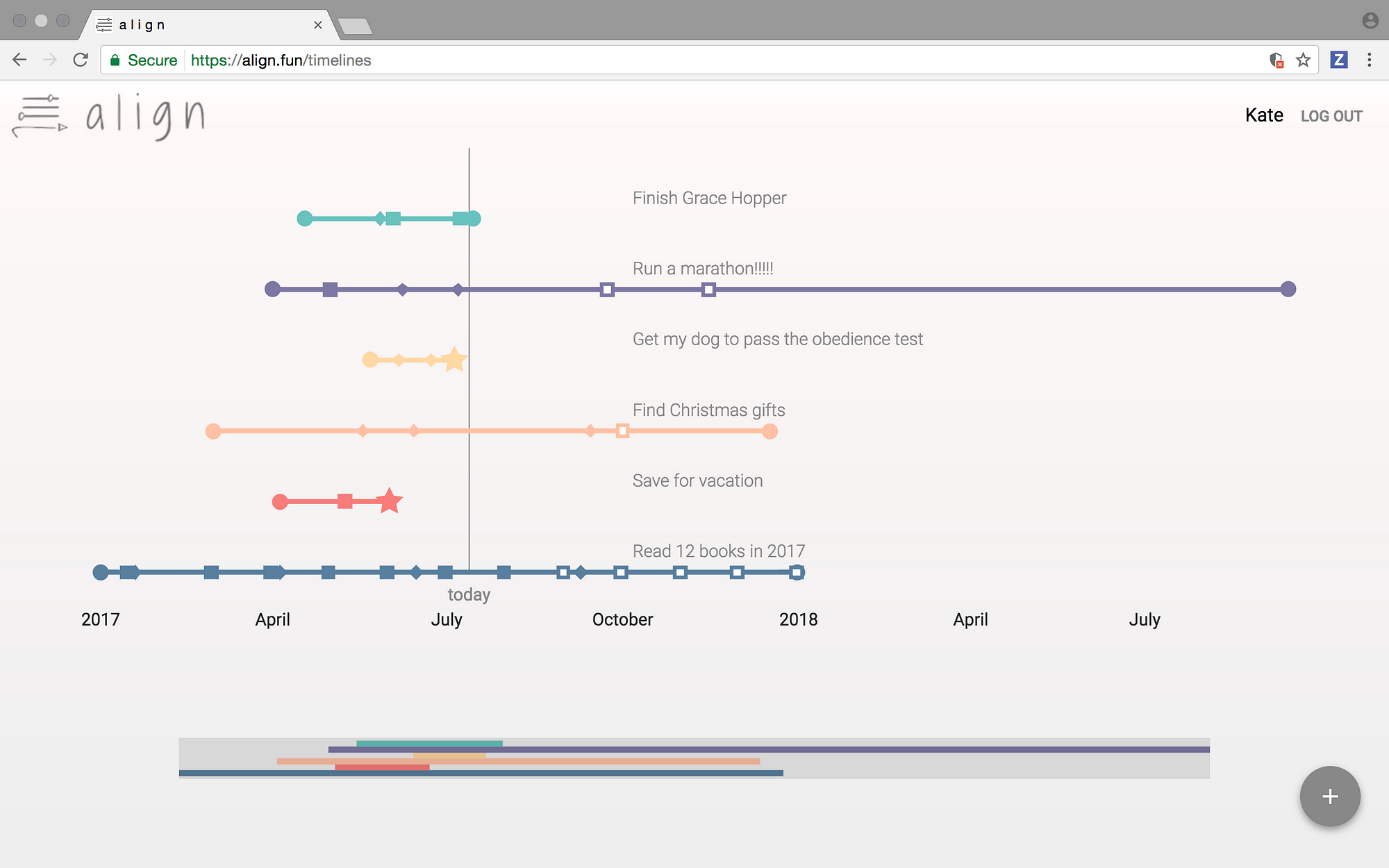
应用 Align 中,用户主页的控制面板
|
||||
|
||||
*应用 Align 中,用户主页的控制面板*
|
||||
|
||||
### 从构思到部署应用程序的简单分步指南
|
||||
|
||||
我在 Grace Hopper Program 为期三个月的编码训练营即将结束,实际上这篇文章的标题有些纰漏 —— 现在我已经构建了 _三个_ 全栈应用:[从零开始的电子商店(an e-commerce store from scratch)][3]、我个人的 [私人黑客马拉松项目(personal hackathon project)][4],还有这个“三周的结业项目”。这个项目是迄今为止强度最大的 —— 我和另外两名队友共同花费三周的时光 —— 而它也是我在训练营中最引以为豪的成就。这是我目前所构建和涉及的第一款稳定且复杂的应用。
|
||||
我在 Grace Hopper Program 为期三个月的编码训练营即将结束,实际上这篇文章的标题有些纰漏 —— 现在我已经构建了 _三个_ 全栈应用:[从零开始的电子商店][3]、我个人的 [私人黑客马拉松项目][4],还有这个“三周的结业项目”。这个项目是迄今为止强度最大的 —— 我和另外两名队友共同花费三周的时光 —— 而它也是我在训练营中最引以为豪的成就。这是我目前所构建和涉及的第一款稳定且复杂的应用。
|
||||
|
||||
如大多数开发者所知,即使你“知道怎么编写代码”,但真正要制作第一款全栈的应用却是非常困难的。JavaScript 生态系统出奇的大:有包管理器,模块,构建工具,转译器,数据库,库文件,还要对上述所有东西进行选择,难怪如此多的编程新手除了 Codecademy 的教程外,做不了任何东西。这就是为什么我想让你体验这个决策的分布教程,跟着我们队伍的脚印,构建可用的应用。
|
||||
如大多数开发者所知,即使你“知道怎么编写代码”,但真正要制作第一款全栈的应用却是非常困难的。JavaScript 生态系统出奇的大:有包管理器、模块、构建工具、转译器、数据库、库文件,还要对上述所有东西进行选择,难怪如此多的编程新手除了 Codecademy 的教程外,做不了任何东西。这就是为什么我想让你体验这个决策的分布教程,跟着我们队伍的脚印,构建可用的应用。
|
||||
|
||||
* * *
|
||||
|
||||
@ -38,12 +39,8 @@
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
这些骨架确保我们意见统一,提供了可预见的蓝图,让我们向着计划的方向努力。
|
||||
@ -53,35 +50,32 @@
|
||||
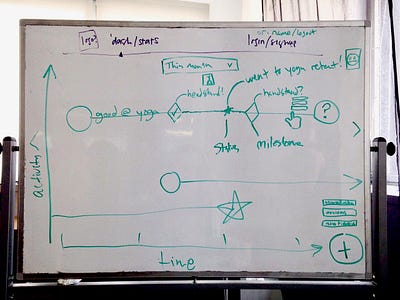
到了设计数据结构的时候。基于我们的示意图和用户故事,我们在 Google doc 中制作了一个清单,它包含我们将会需要的模型和每个模型应该包含的属性。我们知道需要 “目标(goal)” 模型、“用户(user)”模型、“里程碑(milestone)”模型、“记录(checkin)”模型还有最后的“资源(resource)”模型和“上传(upload)”模型,
|
||||
|
||||

|
||||
最初的数据模型结构
|
||||
|
||||
*最初的数据模型结构*
|
||||
|
||||
在正式确定好这些模型后,我们需要选择某种 _类型_ 的数据库:“关系型的”还是“非关系型的”(也就是“SQL”还是“NoSQL”)。由于基于表的 SQL 数据库需要预定义的格式,而基于文档的 NoSQL 数据库却可以用动态格式描述非结构化数据。
|
||||
|
||||
对于我们这个情况,用 SQL 型还是 No-SQL 型的数据库没多大影响,由于下列原因,我们最终选择了 Google 的 NoSQL 云数据库 Firebase:
|
||||
|
||||
1. 它能够把用户上传的图片保存在云端并存储起来
|
||||
|
||||
2. 它包含 WebSocket 功能,能够实时更新
|
||||
|
||||
3. 它能够处理用户验证,并且提供简单的 OAuth 功能。
|
||||
|
||||
我们确定了数据库后,就要理解数据模型之间的关系了。由于 Firebase 是 NoSQL 类型,我们无法创建联合表或者设置像 _"记录 (Checkins)属于目标(Goals)"_ 的从属关系。因此我们需要弄清楚 JSON 树是什么样的,对象是怎样嵌套的(或者不是嵌套的关系)。最终,我们构建了像这样的模型:
|
||||
|
||||
我们确定了数据库后,就要理解数据模型之间的关系了。由于 Firebase 是 NoSQL 类型,我们无法创建联合表或者设置像 _“记录 (Checkins)属于目标(Goals)”_ 的从属关系。因此我们需要弄清楚 JSON 树是什么样的,对象是怎样嵌套的(或者不是嵌套的关系)。最终,我们构建了像这样的模型:
|
||||
|
||||

|
||||
我们最终为目标(Goal)对象确定的 Firebase 数据格式。注意里程碑(Milestones)和记录(Checkins)对象嵌套在 Goals 中。
|
||||
|
||||
_(注意: 出于性能考虑,Firebase 更倾向于简单、常规的数据结构, 但对于我们这种情况,需要在数据中进行嵌套,因为我们不会从数据库中获取目标(Goal)却不获取相应的子对象里程碑(Milestones)和记录(Checkins)。)_
|
||||
*我们最终为目标(Goal)对象确定的 Firebase 数据格式。注意里程碑(Milestones)和记录(Checkins)对象嵌套在 Goals 中。*
|
||||
|
||||
_(注意: 出于性能考虑,Firebase 更倾向于简单、常规的数据结构, 但对于我们这种情况,需要在数据中进行嵌套,因为我们不会从数据库中获取目标(Goal)却不获取相应的子对象里程碑(Milestones)和记录(Checkins)。)_
|
||||
|
||||
### 第 4 步:设置好 Github 和敏捷开发工作流
|
||||
|
||||
我们知道,从一开始就保持井然有序、执行敏捷开发对我们有极大好处。我们设置好 Github 上的仓库,我们无法直接将代码合并到主(master)分支,这迫使我们互相审阅代码。
|
||||
|
||||
|
||||
|
||||
|
||||
我们还在 [Waffle.io][5] 网站上创建了敏捷开发的面板,它是免费的,很容易集成到 Github。我们在 Waffle 面板上罗列出所有用户故事以及需要我们去修复的 bugs。之后当我们开始编码时,我们每个人会为自己正在研究的每一个用户故事创建一个 git 分支,在完成工作后合并这一条条的分支。
|
||||
|
||||
我们还在 [Waffle.io][5] 网站上创建了敏捷开发的面板,它是免费的,很容易集成到 Github。我们在 Waffle 面板上罗列出所有用户故事以及需要我们去修复的 bug。之后当我们开始编码时,我们每个人会为自己正在研究的每一个用户故事创建一个 git 分支,在完成工作后合并这一条条的分支。
|
||||
|
||||
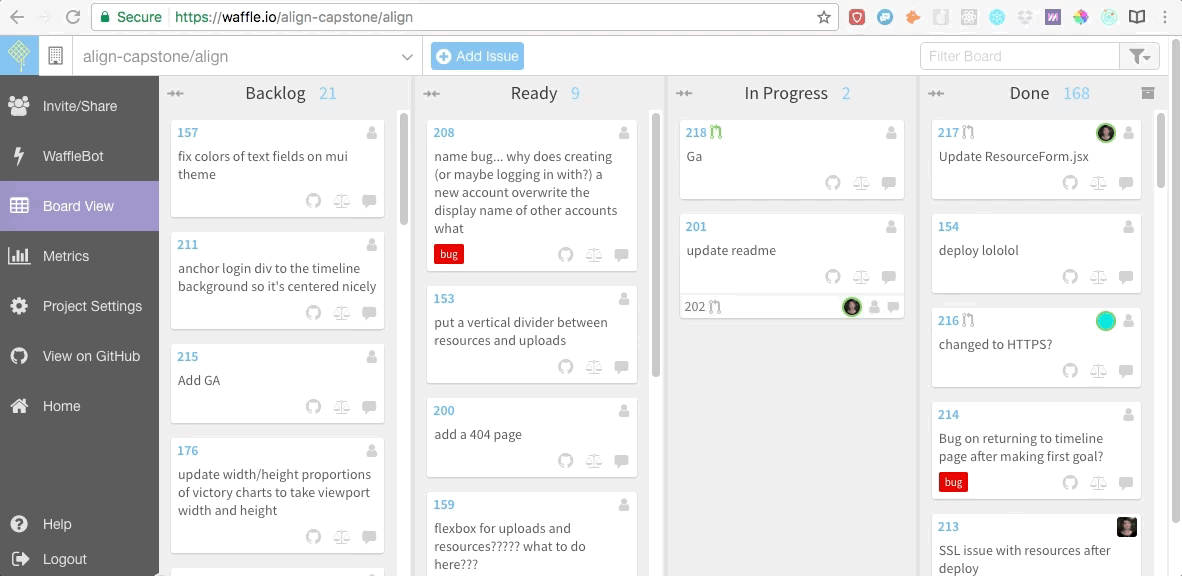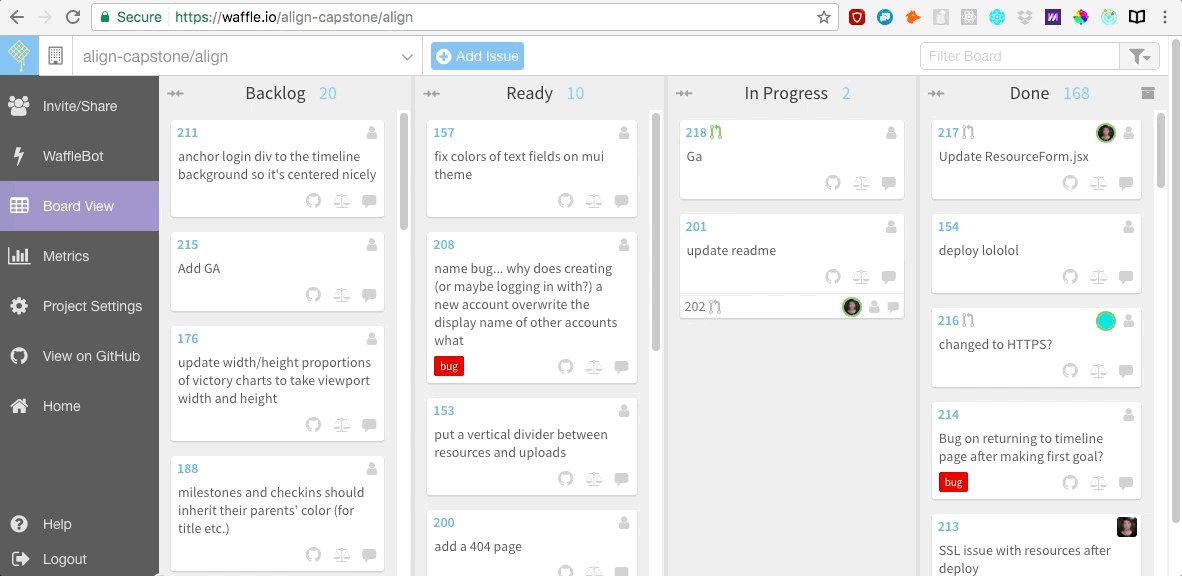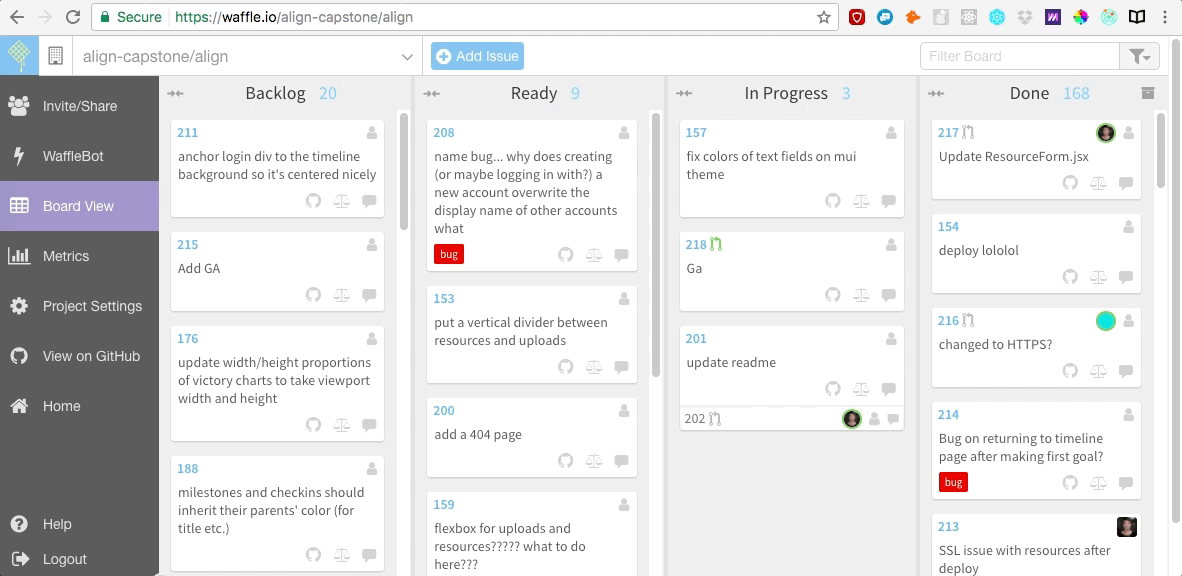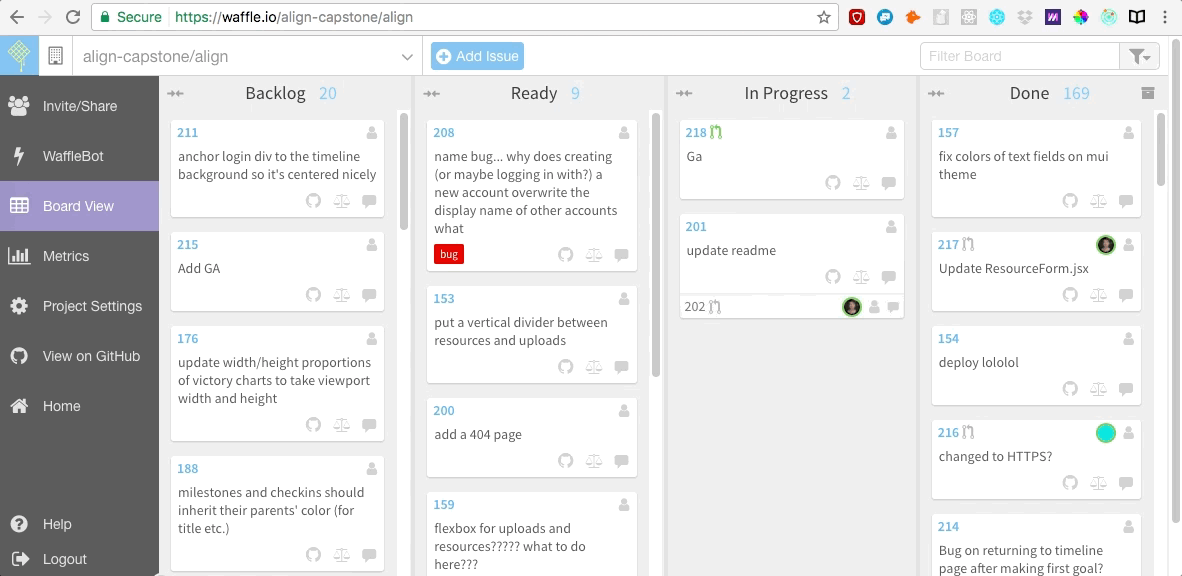
|
||||
|
||||
@ -103,9 +97,9 @@ _(注意: 出于性能考虑,Firebase 更倾向于简单、常规的数据结
|
||||
|
||||
接下来是为应用创建 “概念证明”,也可以说是实现起来最复杂的基本功能的原型,证明我们的应用 _可以_ 实现。对我们而言,这意味着要找个前端库来实现时间线的渲染,成功连接到 Firebase,显示数据库中的一些种子数据。
|
||||
|
||||
|
||||

|
||||
Victory.JS 绘制的简单时间线
|
||||
|
||||
*Victory.JS 绘制的简单时间线*
|
||||
|
||||
我们找到了基于 D3 构建的响应式库 Victory.JS,花了一天时间阅读文档,用 _VictoryLine_ 和 _VictoryScatter_ 组件实现了非常基础的示例,能够可视化地显示数据库中的数据。实际上,这很有用!我们可以开始构建了。
|
||||
|
||||
@ -113,26 +107,16 @@ Victory.JS 绘制的简单时间线
|
||||
|
||||
最后,是时候构建出应用中那些令人期待的功能了。取决于你要构建的应用,这一重要步骤会有些明显差异。我们根据所用的框架,编码出不同的用户故事并保存在 Waffle 上。常常需要同时接触前端和后端代码(比如,创建一个前端表格同时要连接到数据库)。我们实现了包含以下这些大大小小的功能:
|
||||
|
||||
* 能够创建新目标(goals)、里程碑(milestones)和记录(checkins)
|
||||
|
||||
* 能够创建新目标、里程碑和记录
|
||||
* 能够删除目标,里程碑和记录
|
||||
|
||||
* 能够更改时间线的名称,颜色和详细内容
|
||||
|
||||
* 能够缩放时间线
|
||||
|
||||
* 能够为资源添加链接
|
||||
|
||||
* 能够上传视频
|
||||
|
||||
* 在达到相关目标的里程碑和记录时弹出资源和视频
|
||||
|
||||
* 集成富文本编辑器
|
||||
|
||||
* 用户注册、验证、OAuth 验证
|
||||
|
||||
* 弹出查看时间线选项
|
||||
|
||||
* 加载画面
|
||||
|
||||
有各种原因,这一步花了我们很多时间 —— 这一阶段是产生最多优质代码的阶段,每当我们实现了一个功能,就会有更多的事情要完善。
|
||||
@ -142,7 +126,8 @@ Victory.JS 绘制的简单时间线
|
||||
当我们使用 MVP 架构实现了想要的功能,就可以开始清理,对它进行美化了。像表单,菜单和登陆栏等组件,我的团队用的是 Material-UI,不需要很多深层次的设计知识,它也能确保每个组件看上去都很圆润光滑。
|
||||
|
||||
|
||||
这是我制作的最喜爱功能之一了。它美得令人心旷神怡。
|
||||
|
||||
*这是我制作的最喜爱功能之一了。它美得令人心旷神怡。*
|
||||
|
||||
我们花了一点时间来选择颜色方案和编写 CSS ,这让我们在编程中休息了一段美妙的时间。期间我们还设计了 logo 图标,还上传了网站图标。
|
||||
|
||||
@ -169,15 +154,16 @@ Victory.JS 绘制的简单时间线
|
||||
但是,现在我们感到非常开心,不仅是因为成品,还因为我们从这个过程中获得了难以估量的知识和理解。点击 [这里][7] 查看 Align 应用!
|
||||
|
||||

|
||||
Align 团队:Sara Kladky (左), Melanie Mohn (中), 还有我自己.
|
||||
|
||||
*Align 团队:Sara Kladky(左),Melanie Mohn(中),还有我自己。*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/ladies-storm-hackathons/how-we-built-our-first-full-stack-javascript-web-app-in-three-weeks-8a4668dbd67c?imm_mid=0f581a&cmp=em-web-na-na-newsltr_20170816
|
||||
|
||||
作者:[Sophia Ciocca ][a]
|
||||
作者:[Sophia Ciocca][a]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,15 @@
|
||||
管理 Linux 系统中的用户
|
||||
管理 Linux 系统中的用户
|
||||
======
|
||||
|
||||

|
||||
|
||||
也许你的 Lniux 用户并不是愤怒的公牛,但是当涉及管理他们的账户的时候,能让他们一直开心也是一种挑战。监控他们当前正在访问的东西,追踪他们他们遇到问题时的解决方案,并且保证能把他们在使用系统时出现的重要变动记录下来。这里有一些方法和工具可以使这份工作轻松一点。
|
||||
也许你的 Linux 用户并不是愤怒的公牛,但是当涉及管理他们的账户的时候,能让他们一直满意也是一种挑战。你需要监控他们的访问权限,跟进他们遇到问题时的解决方案,并且把他们在使用系统时出现的重要变动记录下来。这里有一些方法和工具可以让这个工作轻松一点。
|
||||
|
||||
### 配置账户
|
||||
### 配置账户
|
||||
|
||||
添加和移除账户是管理用户中最简单的一项,但是这里面仍然有很多需要考虑的选项。无论你是用桌面工具或是命令行选项,这都是一个非常自动化的过程。你可以使用命令添加一个新用户,像是 `adduser jdoe`,这同时会触发一系列的事情。使用下一个可用的 UID 可以创建 John 的账户,或许还会被许多用以配置账户的文件所填充。当你运行 `adduser` 命令加一个新的用户名的时候,它将会提示一些额外的信息,同时解释这是在干什么。
|
||||
添加和删除账户是管理用户中比较简单的一项,但是这里面仍然有很多需要考虑的方面。无论你是用桌面工具或是命令行选项,这都是一个非常自动化的过程。你可以使用 `adduser jdoe` 命令添加一个新用户,同时会触发一系列的反应。在创建 John 这个账户时会自动使用下一个可用的 UID,并有很多自动生成的文件来完成这个工作。当你运行 `adduser` 后跟一个参数时(要创建的用户名),它会提示一些额外的信息,同时解释这是在干什么。
|
||||
|
||||
```
|
||||
```
|
||||
$ sudo adduser jdoe
|
||||
Adding user 'jdoe' ...
|
||||
Adding new group `jdoe' (1001) ...
|
||||
@ -20,21 +21,21 @@ Retype new UNIX password:
|
||||
passwd: password updated successfully
|
||||
Changing the user information for jdoe
|
||||
Enter the new value, or press ENTER for the default
|
||||
Full Name []: John Doe
|
||||
Room Number []:
|
||||
Work Phone []:
|
||||
Home Phone []:
|
||||
Other []:
|
||||
Full Name []: John Doe
|
||||
Room Number []:
|
||||
Work Phone []:
|
||||
Home Phone []:
|
||||
Other []:
|
||||
Is the information correct? [Y/n] Y
|
||||
```
|
||||
```
|
||||
|
||||
像你看到的那样,`adduser` 将添加用户的信息(到 `/etc/passwd` 和 `/etc/shadow` 文件中),创建新的家目录,并用 `/etc/skel` 里设置的文件填充家目录,提示你分配初始密码和认定信息,然后确认这些信息都是正确的,如果你在最后的提示 “Is the information correct” 处的答案是 “n”,它将回溯你之前所有的回答,允许修改任何你想要修改的地方。
|
||||
如你所见,`adduser` 会添加用户的信息(到 `/etc/passwd` 和 `/etc/shadow` 文件中),创建新的<ruby>家目录<rt>home directory</rt></ruby>,并用 `/etc/skel` 里设置的文件填充家目录,提示你分配初始密码和认证信息,然后确认这些信息都是正确的,如果你在最后的提示 “Is the information correct?” 处的回答是 “n”,它会回溯你之前所有的回答,允许修改任何你想要修改的地方。
|
||||
|
||||
创建好一个用户后,你可能会想要确认一下它是否是你期望的样子,更好的方法是确保在添加第一个帐户**之前**,“自动”选择与您想要查看的内容相匹配。默认有默认的好处,它对于你想知道他们定义在哪里有所用处,以防你想作出一些变动 —— 例如,你不想家目录在 `/home` 里,你不想用户 UID 从 1000 开始,或是你不想家目录下的文件被系统上的**每个人**都可读。
|
||||
创建好一个用户后,你可能会想要确认一下它是否是你期望的样子,更好的方法是确保在添加第一个帐户**之前**,“自动”选择与你想要查看的内容是否匹配。默认有默认的好处,它对于你想知道他们定义在哪里很有用,以便你想做出一些变动 —— 例如,你不想让用户的家目录在 `/home` 里,你不想让用户 UID 从 1000 开始,或是你不想让家目录下的文件被系统中的**每个人**都可读。
|
||||
|
||||
`adduser` 如何工作的一些细节设置在 `/etc/adduser.conf` 文件里。这个文件包含的一些设置决定了一个新的账户如何配置,以及它之后的样子。注意,注释和空白行将会在输出中被忽略,因此我们可以更加集中注意在设置上面。
|
||||
`adduser` 的一些配置细节设置在 `/etc/adduser.conf` 文件里。这个文件包含的一些配置项决定了一个新的账户如何配置,以及它之后的样子。注意,注释和空白行将会在输出中被忽略,因此我们更关注配置项。
|
||||
|
||||
```
|
||||
```
|
||||
$ cat /etc/adduser.conf | grep -v "^#" | grep -v "^$"
|
||||
DSHELL=/bin/bash
|
||||
DHOME=/home
|
||||
@ -55,45 +56,45 @@ DIR_MODE=0755
|
||||
SETGID_HOME=no
|
||||
QUOTAUSER=""
|
||||
SKEL_IGNORE_REGEX="dpkg-(old|new|dist|save)"
|
||||
```
|
||||
```
|
||||
|
||||
可以看到,我们有了一个默认的 shell(`DSHELL`),UID(`FIRST_UID`)的开始数值,家目录(`DHOME`)的位置,以及启动文件(`SKEL`)的来源位置。这个文件也会指定分配给家目录(`DIR_HOME`)的权限。
|
||||
可以看到,我们有了一个默认的 shell(`DSHELL`),UID(`FIRST_UID`)的起始值,家目录(`DHOME`)的位置,以及启动文件(`SKEL`)的来源位置。这个文件也会指定分配给家目录(`DIR_HOME`)的权限。
|
||||
|
||||
其中 `DIR_HOME` 是最重要的设置,它决定了每个家目录被使用的权限。这个设置分配给用户创建的目录权限是 `755`,家目录的权限将会设置为 `rwxr-xr-x`。用户可以读其他用户的文件,但是不能修改和移除他们。如果你想要更多的限制,你可以更改这个设置为 `750`(用户组外的任何人都不可访问)甚至是 `700`(除用户自己外的人都不可访问)。
|
||||
其中 `DIR_HOME` 是最重要的设置,它决定了每个家目录被使用的权限。这个设置分配给用户创建的目录权限是 755,家目录的权限将会设置为 `rwxr-xr-x`。用户可以读其他用户的文件,但是不能修改和移除它们。如果你想要更多的限制,你可以更改这个设置为 750(用户组外的任何人都不可访问)甚至是 700(除用户自己外的人都不可访问)。
|
||||
|
||||
任何用户账号在创建之前都可以进行手动修改。例如,你可以编辑 `/etc/passwd` 或者修改家目录的权限,开始在新服务器上添加用户之前配置 `/etc/adduser.conf` 可以确保一定的一致性,从长远来看可以节省时间和避免一些麻烦。
|
||||
任何用户账号在创建之前都可以进行手动修改。例如,你可以编辑 `/etc/passwd` 或者修改家目录的权限,开始在新服务器上添加用户之前配置 `/etc/adduser.conf` 可以确保一定的一致性,从长远来看可以节省时间和避免一些麻烦。
|
||||
|
||||
`/etc/adduser.conf` 的修改将会在之后创建的用户上生效。如果你想以不同的方式设置某个特定账户,除了用户名之外,你还可以选择使用 `adduser` 命令提供账户配置选项。或许你想为某些账户分配不同的 shell,请求特殊的 UID,完全禁用登录。`adduser` 的帮助页将会为你显示一些配置个人账户的选择。
|
||||
`/etc/adduser.conf` 的修改将会在之后创建的用户上生效。如果你想以不同的方式设置某个特定账户,除了用户名之外,你还可以选择使用 `adduser` 命令提供账户配置选项。或许你想为某些账户分配不同的 shell,分配特殊的 UID,或完全禁用该账户登录。`adduser` 的帮助页将会为你显示一些配置个人账户的选择。
|
||||
|
||||
```
|
||||
adduser [options] [--home DIR] [--shell SHELL] [--no-create-home]
|
||||
[--uid ID] [--firstuid ID] [--lastuid ID] [--ingroup GROUP | --gid ID]
|
||||
[--disabled-password] [--disabled-login] [--gecos GECOS]
|
||||
[--add_extra_groups] [--encrypt-home] user
|
||||
```
|
||||
```
|
||||
|
||||
每个 Linux 系统现在都会默认把每个用户放入对应的组中。作为一个管理员,你可能会选择以不同的方式去做事。你也许会发现把用户放在一个共享组中可以让你的站点工作的更好,这时,选择使用 `adduser` 的 `--gid` 选项去选择一个特定的组。当然,用户总是许多组的成员,因此也有一些选项去管理主要和次要的组。
|
||||
每个 Linux 系统现在都会默认把每个用户放入对应的组中。作为一个管理员,你可能会选择以不同的方式。你也许会发现把用户放在一个共享组中更适合你的站点,你就可以选择使用 `adduser` 的 `--gid` 选项指定一个特定的组。当然,用户总是许多组的成员,因此也有一些选项来管理主要和次要的组。
|
||||
|
||||
### 处理用户密码
|
||||
### 处理用户密码
|
||||
|
||||
一直以来,知道其他人的密码都是一个不好的念头,在设置账户时,管理员通常使用一个临时的密码,然后在用户第一次登录时会运行一条命令强制他修改密码。这里是一个例子:
|
||||
一直以来,知道其他人的密码都不是一件好事,在设置账户时,管理员通常使用一个临时密码,然后在用户第一次登录时运行一条命令强制他修改密码。这里是一个例子:
|
||||
|
||||
```
|
||||
$ sudo chage -d 0 jdoe
|
||||
```
|
||||
|
||||
当用户第一次登录的时候,会看到像这样的事情:
|
||||
当用户第一次登录时,会看到类似下面的提示:
|
||||
|
||||
```
|
||||
WARNING: Your password has expired.
|
||||
You must change your password now and login again!
|
||||
Changing password for jdoe.
|
||||
(current) UNIX password:
|
||||
```
|
||||
```
|
||||
|
||||
### 添加用户到副组
|
||||
### 添加用户到副组
|
||||
|
||||
添加用户到副组中,你可能会用如下所示的 `usermod` 命令 —— 添加用户到组中并确认已经做出变动。
|
||||
添加用户到副组中,你可能会用如下所示的 `usermod` 命令添加用户到组中并确认已经做出变动。
|
||||
|
||||
```
|
||||
$ sudo usermod -a -G sudo jdoe
|
||||
@ -101,54 +102,54 @@ $ sudo grep sudo /etc/group
|
||||
sudo:x:27:shs,jdoe
|
||||
```
|
||||
|
||||
记住在一些组,像是 `sudo` 或者 `wheel` 组中,意味着包含特权,一定要特别注意这一点。
|
||||
记住在一些组意味着特别的权限,如 sudo 或者 wheel 组,一定要特别注意这一点。
|
||||
|
||||
### 移除用户,添加组等
|
||||
### 移除用户,添加组等
|
||||
|
||||
Linux 系统也提供了移除账户,添加新的组,移除组等一些命令。例如,`deluser` 命令,将会从 `/etc/passwd` 和 `/etc/shadow` 中移除用户记录,但是会完整保留其家目录,除非你添加了 `--remove-home` 或者 `--remove-all-files` 选项。`addgroup` 命令会添加一个组,默认按目前组的次序分配下一个 id(在用户组范围内),除非你使用 `--gid` 选项指定 id。
|
||||
|
||||
Linux 系统也提供了命令去移除账户、添加新的组、移除组等。例如,`deluser` 命令,将会从 `/etc/passwd` 和 `/etc/shadow` 中移除用户登录入口,但是会完整保留他的家目录,除非你添加了 `--remove-home` 或者 `--remove-all-files` 选项。`addgroup` 命令会添加一个组,按目前组的次序给他下一个 ID(在用户组范围内),除非你使用 `--gid` 选项指定 ID。
|
||||
|
||||
```
|
||||
$ sudo addgroup testgroup --gid=131
|
||||
Adding group `testgroup' (GID 131) ...
|
||||
Done.
|
||||
```
|
||||
```
|
||||
|
||||
### 管理特权账户
|
||||
### 管理特权账户
|
||||
|
||||
一些 Linux 系统中有一个 wheel 组,它给组中成员赋予了像 root 一样运行命令的能力。在这种情况下,`/etc/sudoers` 将会引用该组。在 Debian 系统中,这个组被叫做 `sudo`,但是以相同的方式工作,你在 `/etc/sudoers` 中可以看到像这样的引用:
|
||||
一些 Linux 系统中有一个 wheel 组,它给组中成员赋予了像 root 一样运行命令的权限。在这种情况下,`/etc/sudoers` 将会引用该组。在 Debian 系统中,这个组被叫做 sudo,但是原理是相同的,你在 `/etc/sudoers` 中可以看到像这样的信息:
|
||||
|
||||
```
|
||||
%sudo ALL=(ALL:ALL) ALL
|
||||
```
|
||||
%sudo ALL=(ALL:ALL) ALL
|
||||
```
|
||||
|
||||
这个基础的设定意味着,任何在 wheel 或者 sudo 组中的成员,只要在他们运行的命令之前添加 `sudo`,就可以以 root 的权限去运行命令。
|
||||
这行基本的配置意味着任何在 wheel 或者 sudo 组中的成员只要在他们运行的命令之前添加 `sudo`,就可以以 root 的权限去运行命令。
|
||||
|
||||
你可以向 `sudoers` 文件中添加更多有限的特权 —— 也许给特定用户运行一两个 root 的命令。如果这样做,您还应定期查看 `/etc/sudoers` 文件以评估用户拥有的权限,以及仍然需要提供的权限。
|
||||
你可以向 sudoers 文件中添加更多有限的权限 —— 也许给特定用户几个能以 root 运行的命令。如果你是这样做的,你应该定期查看 `/etc/sudoers` 文件以评估用户拥有的权限,以及仍然需要提供的权限。
|
||||
|
||||
在下面显示的命令中,我们看到在 `/etc/sudoers` 中匹配到的行。在这个文件中最有趣的行是,包含能使用 `sudo` 运行命令的路径设置,以及两个允许通过 `sudo` 运行命令的组。像刚才提到的那样,单个用户可以通过包含在 `sudoers` 文件中来获得权限,但是更有实际意义的方法是通过组成员来定义各自的权限。
|
||||
在下面显示的命令中,我们过滤了 `/etc/sudoers` 中有效的配置行。其中最有意思的是,它包含了能使用 `sudo` 运行命令的路径设置,以及两个允许通过 `sudo` 运行命令的组。像刚才提到的那样,单个用户可以通过包含在 sudoers 文件中来获得权限,但是更有实际意义的方法是通过组成员来定义各自的权限。
|
||||
|
||||
```
|
||||
# cat /etc/sudoers | grep -v "^#" | grep -v "^$"
|
||||
Defaults env_reset
|
||||
Defaults mail_badpass
|
||||
Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
|
||||
root ALL=(ALL:ALL) ALL
|
||||
%admin ALL=(ALL) ALL <== admin group
|
||||
%sudo ALL=(ALL:ALL) ALL <== sudo group
|
||||
```
|
||||
root ALL=(ALL:ALL) ALL
|
||||
%admin ALL=(ALL) ALL <== admin group
|
||||
%sudo ALL=(ALL:ALL) ALL <== sudo group
|
||||
```
|
||||
|
||||
### 登录检查
|
||||
### 登录检查
|
||||
|
||||
你可以通过以下命令查看用户的上一次登录:
|
||||
你可以通过以下命令查看用户的上一次登录:
|
||||
|
||||
```
|
||||
# last jdoe
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 08:44 - 11:48 (00:04)
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 13:43 - 18:44 (00:00)
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:00)
|
||||
```
|
||||
```
|
||||
|
||||
如果你想查看每一个用户上一次的登录情况,你可以通过一个像这样的循环来运行 `last` 命令:
|
||||
如果你想查看每一个用户上一次的登录情况,你可以通过一个像这样的循环来运行 `last` 命令:
|
||||
|
||||
```
|
||||
$ for user in `ls /home`; do last $user | head -1; done
|
||||
@ -157,21 +158,21 @@ jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:03)
|
||||
|
||||
rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02 (00:00)
|
||||
shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged in
|
||||
```
|
||||
|
||||
此命令仅显示自当前 `wtmp` 文件变为活跃状态以来已登录的用户。空白行表示用户自那以后从未登录过,但没有将其调出。一个更好的命令是过滤掉在这期间从未登录过的用户的显示:
|
||||
|
||||
```
|
||||
$ for user in `ls /home`; do echo -n "$user ";last $user | head -1 | awk '{print substr($0,40)}'; done
|
||||
|
||||
此命令仅显示自当前 wtmp 文件登录过的用户。空白行表示用户自那以后从未登录过,但没有将他们显示出来。一个更好的命令可以明确地显示这期间从未登录过的用户:
|
||||
|
||||
```
|
||||
$ for user in `ls /home`; do echo -n "$user"; last $user | head -1 | awk '{print substr($0,40)}'; done
|
||||
dhayes
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43
|
||||
peanut pts/19 192.168.0.29 Mon Sep 11 09:15 - 17:11
|
||||
rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02
|
||||
shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged
|
||||
tsmith
|
||||
```
|
||||
```
|
||||
|
||||
这个命令会打印很多,但是可以通过一个脚本使它更加清晰易用。
|
||||
这个命令要打很多字,但是可以通过一个脚本使它更加清晰易用。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
@ -180,13 +181,13 @@ for user in `ls /home`
|
||||
do
|
||||
echo -n "$user ";last $user | head -1 | awk '{print substr($0,40)}'
|
||||
done
|
||||
```
|
||||
```
|
||||
|
||||
有时,此类信息可以提醒您用户角色的变动,表明他们可能不再需要相关帐户。
|
||||
有时这些信息可以提醒你用户角色的变动,表明他们可能不再需要相关帐户了。
|
||||
|
||||
### 与用户沟通
|
||||
### 与用户沟通
|
||||
|
||||
Linux 提供了许多方法和用户沟通。你可以向 `/etc/motd` 文件中添加信息,当用户从终端登录到服务器时,将会显示这些信息。你也可以通过例如 `write`(通知单个用户)或者 `wall`(`write` 给所有已登录的用户)命令发送通知。
|
||||
Linux 提供了许多和用户沟通的方法。你可以向 `/etc/motd` 文件中添加信息,当用户从终端登录到服务器时,将会显示这些信息。你也可以通过例如 `write`(通知单个用户)或者 `wall`(write 给所有已登录的用户)命令发送通知。
|
||||
|
||||
```
|
||||
$ wall System will go down in one hour
|
||||
@ -194,30 +195,30 @@ $ wall System will go down in one hour
|
||||
Broadcast message from shs@stinkbug (pts/17) (Thu Sep 14 14:04:16 2017):
|
||||
|
||||
System will go down in one hour
|
||||
```
|
||||
```
|
||||
|
||||
重要的通知应该通过多个管道传递,因为很难预测用户实际会注意到什么。mesage-of-the-day(motd),`wall` 和 email 通知可以吸引用户大部分的注意力。
|
||||
重要的通知应该通过多个渠道传达,因为很难预测用户实际会注意到什么。mesage-of-the-day(motd),`wall` 和 email 通知可以吸引用户大部分的注意力。
|
||||
|
||||
### 注意日志文件
|
||||
### 注意日志文件
|
||||
|
||||
更多地注意日志文件上也可以帮你理解用户活动。事实上,`/var/log/auth.log` 文件将会为你显示用户的登录和注销活动,组的创建等。`/var/log/message` 或者 `/var/log/syslog` 文件将会告诉你更多有关系统活动的事情。
|
||||
多注意日志文件也可以帮你理解用户的活动情况。尤其 `/var/log/auth.log` 文件将会显示用户的登录和注销活动,组的创建记录等。`/var/log/message` 或者 `/var/log/syslog` 文件将会告诉你更多有关系统活动的日志。
|
||||
|
||||
### 追踪问题和请求
|
||||
### 追踪问题和需求
|
||||
|
||||
无论你是否在 Linux 系统上安装了票务系统,跟踪用户遇到的问题以及他们提出的请求都非常重要。如果请求的一部分久久不见回应,用户必然不会高兴。即使是纸质日志也可能是有用的,或者更好的是,有一个电子表格,可以让你注意到哪些问题仍然悬而未决,以及问题的根本原因是什么。确保解决问题和请求非常重要,日志还可以帮助您记住你必须采取的措施来解决几个月甚至几年后重新出现的问题。
|
||||
无论你是否在 Linux 系统上安装了事件跟踪系统,跟踪用户遇到的问题以及他们提出的需求都非常重要。如果需求的一部分久久不见回应,用户必然不会高兴。即使是记录在纸上也是有用的,或者最好有个电子表格,这可以让你注意到哪些问题仍然悬而未决,以及问题的根本原因是什么。确认问题和需求非常重要,记录还可以帮助你记住你必须采取的措施来解决几个月甚至几年后重新出现的问题。
|
||||
|
||||
### 总结
|
||||
### 总结
|
||||
|
||||
在繁忙的服务器上管理用户帐户部分取决于从配置良好的默认值开始,部分取决于监控用户活动和遇到的问题。如果用户觉得你对他们的顾虑有所回应并且知道在需要系统升级时会发生什么,他们可能会很高兴。
|
||||
在繁忙的服务器上管理用户帐号,部分取决于配置良好的默认值,部分取决于监控用户活动和遇到的问题。如果用户觉得你对他们的顾虑有所回应并且知道在需要系统升级时会发生什么,他们可能会很高兴。
|
||||
|
||||
-----------
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3225109/linux/managing-users-on-linux-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)、[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
|
||||
@ -3,92 +3,90 @@
|
||||
|
||||

|
||||
|
||||
本教程将指导你在 Ubuntu 18.04 LTS 无头服务器上,一步一步地安装 **Oracle VirtualBox**。同时,本教程也将介绍如何使用 **phpVirtualBox** 去管理安装在无头服务器上的 **VirtualBox** 实例。**phpVirtualBox** 是 VirtualBox 的一个基于 Web 的后端工具。这个教程也可以工作在 Debian 和其它 Ubuntu 衍生版本上,如 Linux Mint。现在,我们开始。
|
||||
本教程将指导你在 Ubuntu 18.04 LTS 无头服务器上,一步一步地安装 **Oracle VirtualBox**。同时,本教程也将介绍如何使用 **phpVirtualBox** 去管理安装在无头服务器上的 **VirtualBox** 实例。**phpVirtualBox** 是 VirtualBox 的一个基于 Web 的前端工具。这个教程也可以工作在 Debian 和其它 Ubuntu 衍生版本上,如 Linux Mint。现在,我们开始。
|
||||
|
||||
### 前提条件
|
||||
|
||||
在安装 Oracle VirtualBox 之前,我们的 Ubuntu 18.04 LTS 服务器上需要满足如下的前提条件。
|
||||
|
||||
首先,逐个运行如下的命令来更新 Ubuntu 服务器。
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
|
||||
$ sudo apt upgrade
|
||||
|
||||
$ sudo apt dist-upgrade
|
||||
|
||||
```
|
||||
|
||||
接下来,安装如下的必需的包:
|
||||
|
||||
```
|
||||
$ sudo apt install build-essential dkms unzip wget
|
||||
|
||||
```
|
||||
|
||||
安装完成所有的更新和必需的包之后,重启动 Ubuntu 服务器。
|
||||
|
||||
```
|
||||
$ sudo reboot
|
||||
|
||||
```
|
||||
|
||||
### 在 Ubuntu 18.04 LTS 服务器上安装 VirtualBox
|
||||
|
||||
添加 Oracle VirtualBox 官方仓库。为此你需要去编辑 **/etc/apt/sources.list** 文件:
|
||||
添加 Oracle VirtualBox 官方仓库。为此你需要去编辑 `/etc/apt/sources.list` 文件:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/apt/sources.list
|
||||
|
||||
```
|
||||
|
||||
添加下列的行。
|
||||
|
||||
在这里,我将使用 Ubuntu 18.04 LTS,因此我添加下列的仓库。
|
||||
|
||||
```
|
||||
deb http://download.virtualbox.org/virtualbox/debian bionic contrib
|
||||
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
用你的 Ubuntu 发行版的代码名字替换关键字 **‘bionic’**,比如,**‘xenial’、‘vivid’、‘utopic’、‘trusty’、‘raring’、‘quantal’、‘precise’、‘lucid’、‘jessie’、‘wheezy’、或 ‘squeeze‘**。
|
||||
用你的 Ubuntu 发行版的代码名字替换关键字 ‘bionic’,比如,‘xenial’、‘vivid’、‘utopic’、‘trusty’、‘raring’、‘quantal’、‘precise’、‘lucid’、‘jessie’、‘wheezy’、或 ‘squeeze‘。
|
||||
|
||||
然后,运行下列的命令去添加 Oracle 公钥:
|
||||
|
||||
```
|
||||
$ wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
|
||||
|
||||
```
|
||||
|
||||
对于 VirtualBox 的老版本,添加如下的公钥:
|
||||
|
||||
```
|
||||
$ wget -q https://www.virtualbox.org/download/oracle_vbox.asc -O- | sudo apt-key add -
|
||||
|
||||
```
|
||||
|
||||
接下来,使用如下的命令去更新软件源:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
|
||||
```
|
||||
|
||||
最后,使用如下的命令去安装最新版本的 Oracle VirtualBox:
|
||||
|
||||
```
|
||||
$ sudo apt install virtualbox-5.2
|
||||
|
||||
```
|
||||
|
||||
### 添加用户到 VirtualBox 组
|
||||
|
||||
我们需要去创建并添加我们的系统用户到 **vboxusers** 组中。你也可以单独创建用户,然后将它分配到 **vboxusers** 组中,也可以使用已有的用户。我不想去创建新用户,因此,我添加已存在的用户到这个组中。请注意,如果你为 virtualbox 使用一个单独的用户,那么你必须注销当前用户,并使用那个特定的用户去登入,来完成剩余的步骤。
|
||||
我们需要去创建并添加我们的系统用户到 `vboxusers` 组中。你也可以单独创建用户,然后将它分配到 `vboxusers` 组中,也可以使用已有的用户。我不想去创建新用户,因此,我添加已存在的用户到这个组中。请注意,如果你为 virtualbox 使用一个单独的用户,那么你必须注销当前用户,并使用那个特定的用户去登入,来完成剩余的步骤。
|
||||
|
||||
我使用的是我的用户名 `sk`,因此,我运行如下的命令将它添加到 `vboxusers` 组中。
|
||||
|
||||
我使用的是我的用户名 **sk**,因此,我运行如下的命令将它添加到 **vboxusers** 组中。
|
||||
```
|
||||
$ sudo usermod -aG vboxusers sk
|
||||
|
||||
```
|
||||
|
||||
现在,运行如下的命令去检查 virtualbox 内核模块是否已加载。
|
||||
|
||||
```
|
||||
$ sudo systemctl status vboxdrv
|
||||
|
||||
```
|
||||
|
||||
![][3]
|
||||
@ -96,15 +94,15 @@ $ sudo systemctl status vboxdrv
|
||||
正如你在上面的截屏中所看到的,vboxdrv 模块已加载,并且是已运行的状态!
|
||||
|
||||
对于老的 Ubuntu 版本,运行:
|
||||
|
||||
```
|
||||
$ sudo /etc/init.d/vboxdrv status
|
||||
|
||||
```
|
||||
|
||||
如果 virtualbox 模块没有启动,运行如下的命令去启动它。
|
||||
|
||||
```
|
||||
$ sudo /etc/init.d/vboxdrv setup
|
||||
|
||||
```
|
||||
|
||||
很好!我们已经成功安装了 VirtualBox 并启动了 virtualbox 模块。现在,我们继续来安装 Oracle VirtualBox 的扩展包。
|
||||
@ -119,21 +117,19 @@ VirtualBox 扩展包为 VirtualBox 访客系统提供了如下的功能。
|
||||
* Intel PXE 引导 ROM
|
||||
* 对 Linux 宿主机上的 PCI 直通提供支持
|
||||
|
||||
从[这里][4]为 VirtualBox 5.2.x 下载最新版的扩展包。
|
||||
|
||||
|
||||
从[**这里**][4]为 VirtualBox 5.2.x 下载最新版的扩展包。
|
||||
```
|
||||
$ wget https://download.virtualbox.org/virtualbox/5.2.14/Oracle_VM_VirtualBox_Extension_Pack-5.2.14.vbox-extpack
|
||||
|
||||
```
|
||||
|
||||
使用如下的命令去安装扩展包:
|
||||
|
||||
```
|
||||
$ sudo VBoxManage extpack install Oracle_VM_VirtualBox_Extension_Pack-5.2.14.vbox-extpack
|
||||
|
||||
```
|
||||
|
||||
恭喜!我们已经成功地在 Ubuntu 18.04 LTS 服务器上安装了 Oracle VirtualBox 的扩展包。现在已经可以去部署虚拟机了。参考 [**virtualbox 官方指南**][5],在命令行中开始创建和管理虚拟机。
|
||||
恭喜!我们已经成功地在 Ubuntu 18.04 LTS 服务器上安装了 Oracle VirtualBox 的扩展包。现在已经可以去部署虚拟机了。参考 [virtualbox 官方指南][5],在命令行中开始创建和管理虚拟机。
|
||||
|
||||
然而,并不是每个人都擅长使用命令行。有些人可能希望在图形界面中去创建和使用虚拟机。不用担心!下面我们为你带来非常好用的 **phpVirtualBox** 工具!
|
||||
|
||||
@ -146,84 +142,82 @@ $ sudo VBoxManage extpack install Oracle_VM_VirtualBox_Extension_Pack-5.2.14.vbo
|
||||
由于它是基于 web 的工具,我们需要安装 Apache web 服务器、PHP 和一些 php 模块。
|
||||
|
||||
为此,运行如下命令:
|
||||
|
||||
```
|
||||
$ sudo apt install apache2 php php-mysql libapache2-mod-php php-soap php-xml
|
||||
|
||||
```
|
||||
|
||||
然后,从 [**下载页面**][6] 上下载 phpVirtualBox 5.2.x 版。请注意,由于我们已经安装了 VirtualBox 5.2 版,因此,同样的我们必须去安装 phpVirtualBox 的 5.2 版本。
|
||||
然后,从 [下载页面][6] 上下载 phpVirtualBox 5.2.x 版。请注意,由于我们已经安装了 VirtualBox 5.2 版,因此,同样的我们必须去安装 phpVirtualBox 的 5.2 版本。
|
||||
|
||||
运行如下的命令去下载它:
|
||||
|
||||
```
|
||||
$ wget https://github.com/phpvirtualbox/phpvirtualbox/archive/5.2-0.zip
|
||||
|
||||
```
|
||||
|
||||
使用如下命令解压下载的安装包:
|
||||
|
||||
```
|
||||
$ unzip 5.2-0.zip
|
||||
|
||||
```
|
||||
|
||||
这个命令将解压 5.2.0.zip 文件的内容到一个命名为 “phpvirtualbox-5.2-0” 的文件夹中。现在,复制或移动这个文件夹的内容到你的 apache web 服务器的根文件夹中。
|
||||
这个命令将解压 5.2.0.zip 文件的内容到一个名为 `phpvirtualbox-5.2-0` 的文件夹中。现在,复制或移动这个文件夹的内容到你的 apache web 服务器的根文件夹中。
|
||||
|
||||
```
|
||||
$ sudo mv phpvirtualbox-5.2-0/ /var/www/html/phpvirtualbox
|
||||
|
||||
```
|
||||
|
||||
给 phpvirtualbox 文件夹分配适当的权限。
|
||||
|
||||
```
|
||||
$ sudo chmod 777 /var/www/html/phpvirtualbox/
|
||||
|
||||
```
|
||||
|
||||
接下来,我们开始配置 phpVirtualBox。
|
||||
|
||||
像下面这样复制示例配置文件。
|
||||
|
||||
```
|
||||
$ sudo cp /var/www/html/phpvirtualbox/config.php-example /var/www/html/phpvirtualbox/config.php
|
||||
|
||||
```
|
||||
|
||||
编辑 phpVirtualBox 的 **config.php** 文件:
|
||||
编辑 phpVirtualBox 的 `config.php` 文件:
|
||||
|
||||
```
|
||||
$ sudo nano /var/www/html/phpvirtualbox/config.php
|
||||
|
||||
```
|
||||
|
||||
找到下列行,并且用你的系统用户名和密码去替换它(就是前面的“添加用户到 VirtualBox 组中”节中使用的用户名)。
|
||||
|
||||
在我的案例中,我的 Ubuntu 系统用户名是 **sk** ,它的密码是 **ubuntu**。
|
||||
在我的案例中,我的 Ubuntu 系统用户名是 `sk` ,它的密码是 `ubuntu`。
|
||||
|
||||
```
|
||||
var $username = 'sk';
|
||||
var $password = 'ubuntu';
|
||||
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
保存并关闭这个文件。
|
||||
|
||||
接下来,创建一个名为 **/etc/default/virtualbox** 的新文件:
|
||||
接下来,创建一个名为 `/etc/default/virtualbox` 的新文件:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/default/virtualbox
|
||||
|
||||
```
|
||||
|
||||
添加下列行。用你自己的系统用户替换 ‘sk’。
|
||||
添加下列行。用你自己的系统用户替换 `sk`。
|
||||
|
||||
```
|
||||
VBOXWEB_USER=sk
|
||||
|
||||
```
|
||||
|
||||
最后,重引导你的系统或重启下列服务去完成整个配置工作。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart vboxweb-service
|
||||
|
||||
$ sudo systemctl restart vboxdrv
|
||||
|
||||
$ sudo systemctl restart apache2
|
||||
|
||||
```
|
||||
|
||||
### 调整防火墙允许连接 Apache web 服务器
|
||||
@ -231,6 +225,7 @@ $ sudo systemctl restart apache2
|
||||
如果你在 Ubuntu 18.04 LTS 上启用了 UFW,那么在默认情况下,apache web 服务器是不能被任何远程系统访问的。你必须通过下列的步骤让 http 和 https 流量允许通过 UFW。
|
||||
|
||||
首先,我们使用如下的命令来查看在策略中已经安装了哪些应用:
|
||||
|
||||
```
|
||||
$ sudo ufw app list
|
||||
Available applications:
|
||||
@ -238,12 +233,12 @@ Apache
|
||||
Apache Full
|
||||
Apache Secure
|
||||
OpenSSH
|
||||
|
||||
```
|
||||
|
||||
正如你所见,Apache 和 OpenSSH 应该已经在 UFW 的策略文件中安装了。
|
||||
|
||||
如果你在策略中看到的是 **“Apache Full”**,说明它允许流量到达 **80** 和 **443** 端口:
|
||||
如果你在策略中看到的是 `Apache Full`,说明它允许流量到达 80 和 443 端口:
|
||||
|
||||
```
|
||||
$ sudo ufw app info "Apache Full"
|
||||
Profile: Apache Full
|
||||
@ -253,34 +248,33 @@ server.
|
||||
|
||||
Ports:
|
||||
80,443/tcp
|
||||
|
||||
```
|
||||
|
||||
现在,运行如下的命令去启用这个策略中的 HTTP 和 HTTPS 的入站流量:
|
||||
|
||||
```
|
||||
$ sudo ufw allow in "Apache Full"
|
||||
Rules updated
|
||||
Rules updated (v6)
|
||||
|
||||
```
|
||||
|
||||
如果你希望允许 https 流量,但是仅是 http (80) 的流量,运行如下的命令:
|
||||
|
||||
```
|
||||
$ sudo ufw app info "Apache"
|
||||
|
||||
```
|
||||
|
||||
### 访问 phpVirtualBox 的 Web 控制台
|
||||
|
||||
现在,用任意一台远程系统的 web 浏览器来访问。
|
||||
|
||||
在地址栏中,输入:**<http://IP-address-of-virtualbox-headless-server/phpvirtualbox>**。
|
||||
在地址栏中,输入:`http://IP-address-of-virtualbox-headless-server/phpvirtualbox`。
|
||||
|
||||
在我的案例中,我导航到这个链接 – **<http://192.168.225.22/phpvirtualbox>**
|
||||
在我的案例中,我导航到这个链接 – `http://192.168.225.22/phpvirtualbox`。
|
||||
|
||||
你将看到如下的屏幕输出。输入 phpVirtualBox 管理员用户凭据。
|
||||
|
||||
phpVirtualBox 的默认管理员用户名和密码是 **admin** / **admin**。
|
||||
phpVirtualBox 的默认管理员用户名和密码是 `admin` / `admin`。
|
||||
|
||||
![][8]
|
||||
|
||||
@ -303,7 +297,7 @@ via: https://www.ostechnix.com/install-oracle-virtualbox-ubuntu-16-04-headless-s
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,25 +3,28 @@
|
||||
|
||||

|
||||
|
||||
自我更新 Arch Linux 桌面以来已经有一个月了。今天我试着更新我的 Arch Linux 系统,然后遇到一个错误 **“error:failed to commit transaction (conflicting files) stfl:/usr/lib/libstfl.so.0 exists in filesystem”**。看起来是 pacman 无法更新一个已经存在于文件系统上的库 (/usr/lib/libstfl.so.0)。如果你也遇到了同样的问题,下面是一个快速解决方案。
|
||||
自我更新 Arch Linux 桌面以来已经有一个月了。今天我试着更新我的 Arch Linux 系统,然后遇到一个错误 “error:failed to commit transaction (conflicting files) stfl:/usr/lib/libstfl.so.0 exists in filesystem”。看起来是 pacman 无法更新一个已经存在于文件系统上的库 (/usr/lib/libstfl.so.0)。如果你也遇到了同样的问题,下面是一个快速解决方案。
|
||||
|
||||
### 解决 Arch Linux 中出现的 “error:failed to commit transaction (conflicting files)”
|
||||
|
||||
有三种方法。
|
||||
|
||||
1。简单在升级时忽略导致问题的 **stfl** 库并尝试再次更新系统。请参阅此指南以了解 [**如何在更新时忽略软件包 **][1]。
|
||||
1。简单在升级时忽略导致问题的 stfl 库并尝试再次更新系统。请参阅此指南以了解 [如何在更新时忽略软件包][1]。
|
||||
|
||||
2。使用命令覆盖这个包:
|
||||
|
||||
```
|
||||
$ sudo pacman -Syu --overwrite /usr/lib/libstfl.so.0
|
||||
```
|
||||
|
||||
3。手工删掉 stfl 库然后再次升级系统。请确保目标包不被其他任何重要的包所依赖。可以通过去 archlinux.org 查看是否有这种冲突。
|
||||
|
||||
```
|
||||
$ sudo rm /usr/lib/libstfl.so.0
|
||||
```
|
||||
|
||||
现在,尝试更新系统:
|
||||
|
||||
```
|
||||
$ sudo pacman -Syu
|
||||
```
|
||||
@ -41,7 +44,7 @@ via: https://www.ostechnix.com/how-to-solve-error-failed-to-commit-transaction-c
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,105 @@
|
||||
Talk over text: Conversational interface design and usability
|
||||
======
|
||||
To make conversational interfaces more human-centered, we must free our thinking from the trappings of web and mobile design.
|
||||
|
||||

|
||||
|
||||
Conversational interfaces are unique among the screen-based and physically manipulated user interfaces that characterize the range of digital experiences we encounter on a daily basis. As [Conversational Design][1] author Erika Hall eloquently writes, "Conversation is not a new interface. It's the oldest interface." And the conversation, the most human interaction of all, lies at the nexus of the aural and verbal rather than the visual and physical. This makes it particularly challenging for machines to meet the high expectations we tend to have when it comes to typical human conversations.
|
||||
|
||||
How do we design for conversational interfaces, which run the gamut from omnichannel chatbots on our websites and mobile apps to mono-channel voice assistants on physical devices such as the Amazon Echo and Google Home? What recommendations do other experts on conversational design and usability have when it comes to crafting the most robust chatbot or voice interface possible? In this overview, we focus on three areas: information architecture, design, and usability testing.
|
||||
|
||||
### Information architecture: Trees, not sitemaps
|
||||
|
||||
Consider the websites we visit and the visual interfaces we use regularly. Each has a navigational tool, whether it is a list of links or a series of buttons, that helps us gain some understanding of the interface. In a web-optimized information architecture, we can see the entire hierarchy of a website and its contents in the form of such navigation bars and sitemaps.
|
||||
|
||||
On the other hand, in a conversational information architecture—whether articulated in a chatbot or a voice assistant—the structure of our interactions must be provided to us in a simple and straightforward way. For instance, in lieu of a navigation bar that has links to pages like About, Menu, Order, and Locations with further links underneath, we can create a conversational means of describing how to navigate the options we wish to pursue.
|
||||
|
||||
Consider the differences between the two examples of navigation below.
|
||||
|
||||
| **Web-based navigation:** | **Conversational navigation:** |
|
||||
| Present all options in the navigation bar | Present only certain top-level options to access deeper options |
|
||||
|-------------------------------------------|-----------------------------------------------------------------|
|
||||
| • Floss's Pizza | • "To learn more about us, say About" |
|
||||
| • About | • "To hear our menu, say Menu" |
|
||||
| ◦ Team | • "To place an order, say Order" |
|
||||
| ◦ Our story | • "To find out where we are, say Where" |
|
||||
| • Menu | |
|
||||
| ◦ Pizzas | |
|
||||
| ◦ Pastas | |
|
||||
| ◦ Platters | |
|
||||
| • Order | |
|
||||
| ◦ Pickup | |
|
||||
| ◦ Delivery | |
|
||||
| • Where we are | |
|
||||
| ◦ Area map • "Welcome to Floss's Pizza!" | |
|
||||
|
||||
In a conversational context, an appropriate information architecture that focuses on decision trees is of paramount importance, because one of the biggest issues many conversational interfaces face is excessive verbosity. By avoiding information overload, prizing structural simplicity, and prescribing one-word directions, your users can traverse conversational interfaces without any additional visual aid.
|
||||
|
||||
### Design: Finessing flows and language
|
||||
|
||||
![Well-designed language example][3]
|
||||
|
||||
An example of well-designed language that encapsulates Hall's conversational key moments.
|
||||
|
||||
In her book Conversational Design, Hall emphasizes the need for all conversational interfaces to adhere to conversational maxims outlined by Paul Grice and advanced by Robin Lakoff. These conversational maxims highlight the characteristics every conversational interface should have to succeed: quantity (just enough information but not too much), quality (truthfulness), relation (relevance), manner (concision, orderliness, and lack of ambiguity), and politeness (Lakoff's addition).
|
||||
|
||||
In the process, Hall spotlights four key moments that build trust with users of conversational interfaces and give them all of the information they need to interact successfully with the conversational experience, whether it is a chatbot or a voice assistant.
|
||||
|
||||
* **Introduction:** Invite the user's interest and encourage trust with a friendly but brief greeting that welcomes them to an unfamiliar interface.
|
||||
|
||||
* **Orientation:** Offer system options, such as how to exit out of certain interactions, and provide a list of options that help the user achieve their goal.
|
||||
|
||||
* **Action:** After each response from the user, offer a new set of tasks and corresponding controls for the user to proceed with further interaction.
|
||||
|
||||
* **Guidance:** Provide feedback to the user after every response and give clear instructions.
|
||||
|
||||
|
||||
|
||||
|
||||
Taken as a whole, these key moments indicate that good conversational design obligates us to consider how we write machine utterances to be both inviting and informative and to structure our decision flows in such a way that they flow naturally to the user. In other words, rather than visual design chops or an eye for style, conversational design requires us to be good writers and thoughtful architects of decision trees.
|
||||
|
||||
![Decision flow example ][5]
|
||||
|
||||
An example decision flow that adheres to Hall's key moments.
|
||||
|
||||
One metaphor I use on a regular basis to conceive of each point in a conversational interface that presents a choice to the user is the dichotomous key. In tree science, dichotomous keys are used to identify trees in their natural habitat through certain salient characteristics. What makes dichotomous keys special, however, is the fact that each card in a dichotomous key only offers two choices (hence the moniker "dichotomous") with a clearly defined characteristic that cannot be mistaken for another. Eventually, after enough dichotomous choices have been made, we can winnow down the available options to the correct genus of tree.
|
||||
|
||||
We should design conversational interfaces in the same way, with particular attention given to disambiguation and decision-making that never verges on too much complexity. Because conversational interfaces require deeply nested hierarchical structures to reach certain outcomes, we can never be too helpful in the instructions and options we offer our users.
|
||||
|
||||
### Usability testing: Dialogues, not dialogs
|
||||
|
||||
Conversational usability is a relatively unexplored and less-understood area because it is frequently based on verbal and aural interactions rather than visual or physical ones. Whereas chatbots can be evaluated for their usability using traditional means such as think-aloud, voice assistants and other voice-driven interfaces have no such luxury.
|
||||
|
||||
For voice interfaces, we are unable to pursue approaches involving eye-tracking or think-aloud, since these interfaces are purely aural and users' utterances outside of responses to interface prompts can introduce bad data. For this reason, when our Acquia Labs team built [Ask GeorgiaGov][6], the first Alexa skill for residents of the state of Georgia, we chose retrospective probing (RP) for our usability tests.
|
||||
|
||||
In retrospective probing, the conversational interaction proceeds until the completion of the task, at which point the user is asked about their impressions of the interface. Retrospective probing is well-positioned for voice interfaces because it allows the conversation to proceed unimpeded by interruptions such as think-aloud feedback. Nonetheless, it does come with the disadvantage of suffering from our notoriously unreliable memories, as it forces us to recollect past interactions rather than ones we completed immediately before recollection.
|
||||
|
||||
### Challenges and opportunities
|
||||
|
||||
Conversational interfaces are here to stay in our rapidly expanding spectrum of digital experiences. Though they enrich the range of ways we have to engage users, they also present unprecedented challenges when it comes to information architecture, design, and usability testing. With the help of previous work such as Grice's conversational maxims and Hall's key moments, we can design and build effective conversational interfaces by focusing on strong writing and well-considered decision flows.
|
||||
|
||||
The fact that conversation is the oldest and most human of interfaces is also edifying when we approach other user interfaces that lack visual or physical manipulation. As Hall writes, "The ideal interface is an interface that's not noticeable at all." Whether or not we will eventually reach the utopian outcome of conversational interfaces that feel completely natural to the human ear, we can make conversational interfaces more human-centered by freeing our thinking from the trappings of web and mobile.
|
||||
|
||||
Preston So will present [Talk Over Text: Conversational Interface Design and Usability][7] at [All Things Open][8], October 21-23 in Raleigh, North Carolina.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/conversational-interface-design-and-usability
|
||||
|
||||
作者:[Preston So][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/prestonso
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://abookapart.com/products/conversational-design
|
||||
[2]: /file/411001
|
||||
[3]: https://opensource.com/sites/default/files/uploads/conversational-interfaces_1.png (Well-designed language example)
|
||||
[4]: /file/411006
|
||||
[5]: https://opensource.com/sites/default/files/uploads/conversational-interfaces_2.png (Decision flow example )
|
||||
[6]: https://www.acquia.com/blog/ask-georgiagov-alexa-skill-citizens-georgia-acquia-labs/12/10/2017/3312516
|
||||
[7]: https://allthingsopen.org/talk/talk-over-text-conversational-interface-design-and-usability/
|
||||
[8]: https://allthingsopen.org/
|
||||
@ -1,4 +1,3 @@
|
||||
imquanquan Translating
|
||||
Trying Other Go Versions
|
||||
============================================================
|
||||
|
||||
@ -110,4 +109,4 @@ via: https://pocketgophers.com/trying-other-versions/
|
||||
[8]:https://pocketgophers.com/trying-other-versions/#trying-a-specific-release
|
||||
[9]:https://pocketgophers.com/guide-to-json/
|
||||
[10]:https://pocketgophers.com/trying-other-versions/#trying-any-release
|
||||
[11]:https://pocketgophers.com/trying-other-versions/#trying-a-source-build-e-g-tip
|
||||
[11]:https://pocketgophers.com/trying-other-versions/#trying-a-source-build-e-g-tip
|
||||
@ -1,4 +1,3 @@
|
||||
Zafiry translating...
|
||||
Writing eBPF tracing tools in Rust
|
||||
============================================================
|
||||
|
||||
|
||||
201
sources/tech/20180907 6.828 lab tools guide.md
Normal file
201
sources/tech/20180907 6.828 lab tools guide.md
Normal file
@ -0,0 +1,201 @@
|
||||
6.828 lab tools guide
|
||||
======
|
||||
### 6.828 lab tools guide
|
||||
|
||||
Familiarity with your environment is crucial for productive development and debugging. This page gives a brief overview of the JOS environment and useful GDB and QEMU commands. Don't take our word for it, though. Read the GDB and QEMU manuals. These are powerful tools that are worth knowing how to use.
|
||||
|
||||
#### Debugging tips
|
||||
|
||||
##### Kernel
|
||||
|
||||
GDB is your friend. Use the qemu-gdb target (or its `qemu-gdb-nox` variant) to make QEMU wait for GDB to attach. See the GDB reference below for some commands that are useful when debugging kernels.
|
||||
|
||||
If you're getting unexpected interrupts, exceptions, or triple faults, you can ask QEMU to generate a detailed log of interrupts using the -d argument.
|
||||
|
||||
To debug virtual memory issues, try the QEMU monitor commands info mem (for a high-level overview) or info pg (for lots of detail). Note that these commands only display the _current_ page table.
|
||||
|
||||
(Lab 4+) To debug multiple CPUs, use GDB's thread-related commands like thread and info threads.
|
||||
|
||||
##### User environments (lab 3+)
|
||||
|
||||
GDB also lets you debug user environments, but there are a few things you need to watch out for, since GDB doesn't know that there's a distinction between multiple user environments, or between user and kernel.
|
||||
|
||||
You can start JOS with a specific user environment using make run- _name_ (or you can edit `kern/init.c` directly). To make QEMU wait for GDB to attach, use the run- _name_ -gdb variant.
|
||||
|
||||
You can symbolically debug user code, just like you can kernel code, but you have to tell GDB which symbol table to use with the symbol-file command, since it can only use one symbol table at a time. The provided `.gdbinit` loads the kernel symbol table, `obj/kern/kernel`. The symbol table for a user environment is in its ELF binary, so you can load it using symbol-file obj/user/ _name_. _Don't_ load symbols from any `.o` files, as those haven't been relocated by the linker (libraries are statically linked into JOS user binaries, so those symbols are already included in each user binary). Make sure you get the _right_ user binary; library functions will be linked at different EIPs in different binaries and GDB won't know any better!
|
||||
|
||||
(Lab 4+) Since GDB is attached to the virtual machine as a whole, it sees clock interrupts as just another control transfer. This makes it basically impossible to step through user code because a clock interrupt is virtually guaranteed the moment you let the VM run again. The stepi command works because it suppresses interrupts, but it only steps one assembly instruction. Breakpoints generally work, but watch out because you can hit the same EIP in a different environment (indeed, a different binary altogether!).
|
||||
|
||||
#### Reference
|
||||
|
||||
##### JOS makefile
|
||||
|
||||
The JOS GNUmakefile includes a number of phony targets for running JOS in various ways. All of these targets configure QEMU to listen for GDB connections (the `*-gdb` targets also wait for this connection). To start once QEMU is running, simply run gdb from your lab directory. We provide a `.gdbinit` file that automatically points GDB at QEMU, loads the kernel symbol file, and switches between 16-bit and 32-bit mode. Exiting GDB will shut down QEMU.
|
||||
|
||||
* make qemu
|
||||
Build everything and start QEMU with the VGA console in a new window and the serial console in your terminal. To exit, either close the VGA window or press `Ctrl-c` or `Ctrl-a x` in your terminal.
|
||||
* make qemu-nox
|
||||
Like `make qemu`, but run with only the serial console. To exit, press `Ctrl-a x`. This is particularly useful over SSH connections to Athena dialups because the VGA window consumes a lot of bandwidth.
|
||||
* make qemu-gdb
|
||||
Like `make qemu`, but rather than passively accepting GDB connections at any time, this pauses at the first machine instruction and waits for a GDB connection.
|
||||
* make qemu-nox-gdb
|
||||
A combination of the `qemu-nox` and `qemu-gdb` targets.
|
||||
* make run- _name_
|
||||
(Lab 3+) Run user program _name_. For example, `make run-hello` runs `user/hello.c`.
|
||||
* make run- _name_ -nox, run- _name_ -gdb, run- _name_ -gdb-nox,
|
||||
(Lab 3+) Variants of `run-name` that correspond to the variants of the `qemu` target.
|
||||
|
||||
|
||||
|
||||
The makefile also accepts a few useful variables:
|
||||
|
||||
* make V=1 ...
|
||||
Verbose mode. Print out every command being executed, including arguments.
|
||||
* make V=1 grade
|
||||
Stop after any failed grade test and leave the QEMU output in `jos.out` for inspection.
|
||||
* make QEMUEXTRA=' _args_ ' ...
|
||||
Specify additional arguments to pass to QEMU.
|
||||
|
||||
|
||||
|
||||
##### JOS obj/
|
||||
|
||||
The JOS GNUmakefile includes a number of phony targets for running JOS in various ways. All of these targets configure QEMU to listen for GDB connections (thetargets also wait for this connection). To start once QEMU is running, simply runfrom your lab directory. We provide afile that automatically points GDB at QEMU, loads the kernel symbol file, and switches between 16-bit and 32-bit mode. Exiting GDB will shut down QEMU.The makefile also accepts a few useful variables:
|
||||
|
||||
When building JOS, the makefile also produces some additional output files that may prove useful while debugging:
|
||||
|
||||
* `obj/boot/boot.asm`, `obj/kern/kernel.asm`, `obj/user/hello.asm`, etc.
|
||||
Assembly code listings for the bootloader, kernel, and user programs.
|
||||
* `obj/kern/kernel.sym`, `obj/user/hello.sym`, etc.
|
||||
Symbol tables for the kernel and user programs.
|
||||
* `obj/boot/boot.out`, `obj/kern/kernel`, `obj/user/hello`, etc
|
||||
Linked ELF images of the kernel and user programs. These contain symbol information that can be used by GDB.
|
||||
|
||||
|
||||
|
||||
##### GDB
|
||||
|
||||
See the [GDB manual][1] for a full guide to GDB commands. Here are some particularly useful commands for 6.828, some of which don't typically come up outside of OS development.
|
||||
|
||||
* Ctrl-c
|
||||
Halt the machine and break in to GDB at the current instruction. If QEMU has multiple virtual CPUs, this halts all of them.
|
||||
* c (or continue)
|
||||
Continue execution until the next breakpoint or `Ctrl-c`.
|
||||
* si (or stepi)
|
||||
Execute one machine instruction.
|
||||
* b function or b file:line (or breakpoint)
|
||||
Set a breakpoint at the given function or line.
|
||||
* b * _addr_ (or breakpoint)
|
||||
Set a breakpoint at the EIP _addr_.
|
||||
* set print pretty
|
||||
Enable pretty-printing of arrays and structs.
|
||||
* info registers
|
||||
Print the general purpose registers, `eip`, `eflags`, and the segment selectors. For a much more thorough dump of the machine register state, see QEMU's own `info registers` command.
|
||||
* x/ _N_ x _addr_
|
||||
Display a hex dump of _N_ words starting at virtual address _addr_. If _N_ is omitted, it defaults to 1. _addr_ can be any expression.
|
||||
* x/ _N_ i _addr_
|
||||
Display the _N_ assembly instructions starting at _addr_. Using `$eip` as _addr_ will display the instructions at the current instruction pointer.
|
||||
* symbol-file _file_
|
||||
(Lab 3+) Switch to symbol file _file_. When GDB attaches to QEMU, it has no notion of the process boundaries within the virtual machine, so we have to tell it which symbols to use. By default, we configure GDB to use the kernel symbol file, `obj/kern/kernel`. If the machine is running user code, say `hello.c`, you can switch to the hello symbol file using `symbol-file obj/user/hello`.
|
||||
|
||||
|
||||
|
||||
QEMU represents each virtual CPU as a thread in GDB, so you can use all of GDB's thread-related commands to view or manipulate QEMU's virtual CPUs.
|
||||
|
||||
* thread _n_
|
||||
GDB focuses on one thread (i.e., CPU) at a time. This command switches that focus to thread _n_ , numbered from zero.
|
||||
* info threads
|
||||
List all threads (i.e., CPUs), including their state (active or halted) and what function they're in.
|
||||
|
||||
|
||||
|
||||
##### QEMU
|
||||
|
||||
QEMU includes a built-in monitor that can inspect and modify the machine state in useful ways. To enter the monitor, press Ctrl-a c in the terminal running QEMU. Press Ctrl-a c again to switch back to the serial console.
|
||||
|
||||
For a complete reference to the monitor commands, see the [QEMU manual][2]. Here are some particularly useful commands:
|
||||
|
||||
* xp/ _N_ x _paddr_
|
||||
Display a hex dump of _N_ words starting at _physical_ address _paddr_. If _N_ is omitted, it defaults to 1. This is the physical memory analogue of GDB's `x` command.
|
||||
|
||||
* info registers
|
||||
Display a full dump of the machine's internal register state. In particular, this includes the machine's _hidden_ segment state for the segment selectors and the local, global, and interrupt descriptor tables, plus the task register. This hidden state is the information the virtual CPU read from the GDT/LDT when the segment selector was loaded. Here's the CS when running in the JOS kernel in lab 1 and the meaning of each field:
|
||||
```
|
||||
CS =0008 10000000 ffffffff 10cf9a00 DPL=0 CS32 [-R-]
|
||||
```
|
||||
|
||||
* `CS =0008`
|
||||
The visible part of the code selector. We're using segment 0x8. This also tells us we're referring to the global descriptor table (0x8 &4=0), and our CPL (current privilege level) is 0x8&3=0.
|
||||
* `10000000`
|
||||
The base of this segment. Linear address = logical address + 0x10000000.
|
||||
* `ffffffff`
|
||||
The limit of this segment. Linear addresses above 0xffffffff will result in segment violation exceptions.
|
||||
* `10cf9a00`
|
||||
The raw flags of this segment, which QEMU helpfully decodes for us in the next few fields.
|
||||
* `DPL=0`
|
||||
The privilege level of this segment. Only code running with privilege level 0 can load this segment.
|
||||
* `CS32`
|
||||
This is a 32-bit code segment. Other values include `DS` for data segments (not to be confused with the DS register), and `LDT` for local descriptor tables.
|
||||
* `[-R-]`
|
||||
This segment is read-only.
|
||||
* info mem
|
||||
(Lab 2+) Display mapped virtual memory and permissions. For example,
|
||||
```
|
||||
ef7c0000-ef800000 00040000 urw
|
||||
efbf8000-efc00000 00008000 -rw
|
||||
|
||||
```
|
||||
|
||||
tells us that the 0x00040000 bytes of memory from 0xef7c0000 to 0xef800000 are mapped read/write and user-accessible, while the memory from 0xefbf8000 to 0xefc00000 is mapped read/write, but only kernel-accessible.
|
||||
|
||||
* info pg
|
||||
(Lab 2+) Display the current page table structure. The output is similar to `info mem`, but distinguishes page directory entries and page table entries and gives the permissions for each separately. Repeated PTE's and entire page tables are folded up into a single line. For example,
|
||||
```
|
||||
VPN range Entry Flags Physical page
|
||||
[00000-003ff] PDE[000] -------UWP
|
||||
[00200-00233] PTE[200-233] -------U-P 00380 0037e 0037d 0037c 0037b 0037a ..
|
||||
[00800-00bff] PDE[002] ----A--UWP
|
||||
[00800-00801] PTE[000-001] ----A--U-P 0034b 00349
|
||||
[00802-00802] PTE[002] -------U-P 00348
|
||||
|
||||
```
|
||||
|
||||
This shows two page directory entries, spanning virtual addresses 0x00000000 to 0x003fffff and 0x00800000 to 0x00bfffff, respectively. Both PDE's are present, writable, and user and the second PDE is also accessed. The second of these page tables maps three pages, spanning virtual addresses 0x00800000 through 0x00802fff, of which the first two are present, user, and accessed and the third is only present and user. The first of these PTE's maps physical page 0x34b.
|
||||
|
||||
|
||||
|
||||
|
||||
QEMU also takes some useful command line arguments, which can be passed into the JOS makefile using the
|
||||
|
||||
* make QEMUEXTRA='-d int' ...
|
||||
Log all interrupts, along with a full register dump, to `qemu.log`. You can ignore the first two log entries, "SMM: enter" and "SMM: after RMS", as these are generated before entering the boot loader. After this, log entries look like
|
||||
```
|
||||
4: v=30 e=0000 i=1 cpl=3 IP=001b:00800e2e pc=00800e2e SP=0023:eebfdf28 EAX=00000005
|
||||
EAX=00000005 EBX=00001002 ECX=00200000 EDX=00000000
|
||||
ESI=00000805 EDI=00200000 EBP=eebfdf60 ESP=eebfdf28
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
The first line describes the interrupt. The `4:` is just a log record counter. `v` gives the vector number in hex. `e` gives the error code. `i=1` indicates that this was produced by an `int` instruction (versus a hardware interrupt). The rest of the line should be self-explanatory. See info registers for a description of the register dump that follows.
|
||||
|
||||
Note: If you're running a pre-0.15 version of QEMU, the log will be written to `/tmp` instead of the current directory.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labguide.html
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://sourceware.org/gdb/current/onlinedocs/gdb/
|
||||
[2]: http://wiki.qemu.org/download/qemu-doc.html#pcsys_005fmonitor
|
||||
247
sources/tech/20180911 Tools Used in 6.828.md
Normal file
247
sources/tech/20180911 Tools Used in 6.828.md
Normal file
@ -0,0 +1,247 @@
|
||||
Tools Used in 6.828
|
||||
======
|
||||
### Tools Used in 6.828
|
||||
|
||||
You'll use two sets of tools in this class: an x86 emulator, QEMU, for running your kernel; and a compiler toolchain, including assembler, linker, C compiler, and debugger, for compiling and testing your kernel. This page has the information you'll need to download and install your own copies. This class assumes familiarity with Unix commands throughout.
|
||||
|
||||
We highly recommend using a Debathena machine, such as athena.dialup.mit.edu, to work on the labs. If you use the MIT Athena machines that run Linux, then all the software tools you will need for this course are located in the 6.828 locker: just type 'add -f 6.828' to get access to them.
|
||||
|
||||
If you don't have access to a Debathena machine, we recommend you use a virtual machine with Linux. If you really want to, you can build and install the tools on your own machine. We have instructions below for Linux and MacOS computers.
|
||||
|
||||
It should be possible to get this development environment running under windows with the help of [Cygwin][1]. Install cygwin, and be sure to install the flex and bison packages (they are under the development header).
|
||||
|
||||
For an overview of useful commands in the tools used in 6.828, see the [lab tools guide][2].
|
||||
|
||||
#### Compiler Toolchain
|
||||
|
||||
A "compiler toolchain" is the set of programs, including a C compiler, assemblers, and linkers, that turn code into executable binaries. You'll need a compiler toolchain that generates code for 32-bit Intel architectures ("x86" architectures) in the ELF binary format.
|
||||
|
||||
##### Test Your Compiler Toolchain
|
||||
|
||||
Modern Linux and BSD UNIX distributions already provide a toolchain suitable for 6.828. To test your distribution, try the following commands:
|
||||
|
||||
```
|
||||
% objdump -i
|
||||
|
||||
```
|
||||
|
||||
The second line should say `elf32-i386`.
|
||||
|
||||
```
|
||||
% gcc -m32 -print-libgcc-file-name
|
||||
|
||||
```
|
||||
|
||||
The command should print something like `/usr/lib/gcc/i486-linux-gnu/version/libgcc.a` or `/usr/lib/gcc/x86_64-linux-gnu/version/32/libgcc.a`
|
||||
|
||||
If both these commands succeed, you're all set, and don't need to compile your own toolchain.
|
||||
|
||||
If the gcc command fails, you may need to install a development environment. On Ubuntu Linux, try this:
|
||||
|
||||
```
|
||||
% sudo apt-get install -y build-essential gdb
|
||||
|
||||
```
|
||||
|
||||
On 64-bit machines, you may need to install a 32-bit support library. The symptom is that linking fails with error messages like "`__udivdi3` not found" and "`__muldi3` not found". On Ubuntu Linux, try this to fix the problem:
|
||||
|
||||
```
|
||||
% sudo apt-get install gcc-multilib
|
||||
|
||||
```
|
||||
|
||||
##### Using a Virtual Machine
|
||||
|
||||
Otherwise, the easiest way to get a compatible toolchain is to install a modern Linux distribution on your computer. With platform virtualization, Linux can cohabitate with your normal computing environment. Installing a Linux virtual machine is a two step process. First, you download the virtualization platform.
|
||||
|
||||
* [**VirtualBox**][3] (free for Mac, Linux, Windows) — [Download page][3]
|
||||
* [VMware Player][4] (free for Linux and Windows, registration required)
|
||||
* [VMware Fusion][5] (Downloadable from IS&T for free).
|
||||
|
||||
|
||||
|
||||
VirtualBox is a little slower and less flexible, but free!
|
||||
|
||||
Once the virtualization platform is installed, download a boot disk image for the Linux distribution of your choice.
|
||||
|
||||
* [Ubuntu Desktop][6] is what we use.
|
||||
|
||||
|
||||
|
||||
This will download a file named something like `ubuntu-10.04.1-desktop-i386.iso`. Start up your virtualization platform and create a new (32-bit) virtual machine. Use the downloaded Ubuntu image as a boot disk; the procedure differs among VMs but is pretty simple. Type `objdump -i`, as above, to verify that your toolchain is now set up. You will do your work inside the VM.
|
||||
|
||||
##### Building Your Own Compiler Toolchain
|
||||
|
||||
This will take longer to set up, but give slightly better performance than a virtual machine, and lets you work in your own familiar environment (Unix/MacOS). Fast-forward to the end for MacOS instructions.
|
||||
|
||||
###### Linux
|
||||
|
||||
You can use your own tool chain by adding the following line to `conf/env.mk`:
|
||||
|
||||
```
|
||||
GCCPREFIX=
|
||||
|
||||
```
|
||||
|
||||
We assume that you are installing the toolchain into `/usr/local`. You will need a fair amount of disk space to compile the tools (around 1GiB). If you don't have that much space, delete each directory after its `make install` step.
|
||||
|
||||
Download the following packages:
|
||||
|
||||
+ ftp://ftp.gmplib.org/pub/gmp-5.0.2/gmp-5.0.2.tar.bz2
|
||||
+ https://www.mpfr.org/mpfr-3.1.2/mpfr-3.1.2.tar.bz2
|
||||
+ http://www.multiprecision.org/downloads/mpc-0.9.tar.gz
|
||||
+ http://ftpmirror.gnu.org/binutils/binutils-2.21.1.tar.bz2
|
||||
+ http://ftpmirror.gnu.org/gcc/gcc-4.6.4/gcc-core-4.6.4.tar.bz2
|
||||
+ http://ftpmirror.gnu.org/gdb/gdb-7.3.1.tar.bz2
|
||||
|
||||
(You may also use newer versions of these packages.) Unpack and build the packages. The `green bold` text shows you how to install into `/usr/local`, which is what we recommend. To install into a different directory, $PFX, note the differences in lighter type ([hide][7]). If you have problems, see below.
|
||||
|
||||
```
|
||||
export PATH=$PFX/bin:$PATH
|
||||
export LD_LIBRARY_PATH=$PFX/lib:$LD_LIBRARY_PATH
|
||||
|
||||
tar xjf gmp-5.0.2.tar.bz2
|
||||
cd gmp-5.0.2
|
||||
./configure --prefix=$PFX
|
||||
make
|
||||
make install # This step may require privilege (sudo make install)
|
||||
cd ..
|
||||
|
||||
tar xjf mpfr-3.1.2.tar.bz2
|
||||
cd mpfr-3.1.2
|
||||
./configure --prefix=$PFX --with-gmp=$PFX
|
||||
make
|
||||
make install # This step may require privilege (sudo make install)
|
||||
cd ..
|
||||
|
||||
tar xzf mpc-0.9.tar.gz
|
||||
cd mpc-0.9
|
||||
./configure --prefix=$PFX --with-gmp=$PFX --with-mpfr=$PFX
|
||||
make
|
||||
make install # This step may require privilege (sudo make install)
|
||||
cd ..
|
||||
|
||||
|
||||
tar xjf binutils-2.21.1.tar.bz2
|
||||
cd binutils-2.21.1
|
||||
./configure --prefix=$PFX --target=i386-jos-elf --disable-werror
|
||||
make
|
||||
make install # This step may require privilege (sudo make install)
|
||||
cd ..
|
||||
|
||||
i386-jos-elf-objdump -i
|
||||
# Should produce output like:
|
||||
# BFD header file version (GNU Binutils) 2.21.1
|
||||
# elf32-i386
|
||||
# (header little endian, data little endian)
|
||||
# i386...
|
||||
|
||||
|
||||
tar xjf gcc-core-4.6.4.tar.bz2
|
||||
cd gcc-4.6.4
|
||||
mkdir build # GCC will not compile correctly unless you build in a separate directory
|
||||
cd build
|
||||
../configure --prefix=$PFX --with-gmp=$PFX --with-mpfr=$PFX --with-mpc=$PFX \
|
||||
--target=i386-jos-elf --disable-werror \
|
||||
--disable-libssp --disable-libmudflap --with-newlib \
|
||||
--without-headers --enable-languages=c MAKEINFO=missing
|
||||
make all-gcc
|
||||
make install-gcc # This step may require privilege (sudo make install-gcc)
|
||||
make all-target-libgcc
|
||||
make install-target-libgcc # This step may require privilege (sudo make install-target-libgcc)
|
||||
cd ../..
|
||||
|
||||
i386-jos-elf-gcc -v
|
||||
# Should produce output like:
|
||||
# Using built-in specs.
|
||||
# COLLECT_GCC=i386-jos-elf-gcc
|
||||
# COLLECT_LTO_WRAPPER=/usr/local/libexec/gcc/i386-jos-elf/4.6.4/lto-wrapper
|
||||
# Target: i386-jos-elf
|
||||
|
||||
|
||||
tar xjf gdb-7.3.1.tar.bz2
|
||||
cd gdb-7.3.1
|
||||
./configure --prefix=$PFX --target=i386-jos-elf --program-prefix=i386-jos-elf- \
|
||||
--disable-werror
|
||||
make all
|
||||
make install # This step may require privilege (sudo make install)
|
||||
cd ..
|
||||
|
||||
```
|
||||
|
||||
###### Linux troubleshooting
|
||||
|
||||
* Q. I can't run `make install` because I don't have root permission on this machine.
|
||||
A. Our instructions assume you are installing into the `/usr/local` directory. However, this may not be allowed in your environment. If you can only install code into your home directory, that's OK. In the instructions above, replace `--prefix=/usr/local` with `--prefix=$HOME` (and [click here][7] to update the instructions further). You will also need to change your `PATH` and `LD_LIBRARY_PATH` environment variables, to inform your shell where to find the tools. For example:
|
||||
```
|
||||
export PATH=$HOME/bin:$PATH
|
||||
export LD_LIBRARY_PATH=$HOME/lib:$LD_LIBRARY_PATH
|
||||
```
|
||||
|
||||
Enter these lines in your `~/.bashrc` file so you don't need to type them every time you log in.
|
||||
|
||||
|
||||
|
||||
* Q. My build fails with an inscrutable message about "library not found".
|
||||
A. You need to set your `LD_LIBRARY_PATH`. The environment variable must include the `PREFIX/lib` directory (for instance, `/usr/local/lib`).
|
||||
|
||||
|
||||
|
||||
#### MacOS
|
||||
|
||||
First begin by installing developer tools on Mac OSX:
|
||||
`xcode-select --install`
|
||||
|
||||
First begin by installing developer tools on Mac OSX:
|
||||
|
||||
You can install the qemu dependencies from homebrew, however do not install qemu itself as you will need the 6.828 patched version.
|
||||
|
||||
`brew install $(brew deps qemu)`
|
||||
|
||||
The gettext utility does not add installed binaries to the path, so you will need to run
|
||||
|
||||
`PATH=${PATH}:/usr/local/opt/gettext/bin make install`
|
||||
|
||||
when installing qemu below.
|
||||
|
||||
### QEMU Emulator
|
||||
|
||||
[QEMU][8] is a modern and fast PC emulator. QEMU version 2.3.0 is set up on Athena for x86 machines in the 6.828 locker (`add -f 6.828`)
|
||||
|
||||
Unfortunately, QEMU's debugging facilities, while powerful, are somewhat immature, so we highly recommend you use our patched version of QEMU instead of the stock version that may come with your distribution. The version installed on Athena is already patched. To build your own patched version of QEMU:
|
||||
|
||||
1. Clone the IAP 6.828 QEMU git repository `git clone https://github.com/mit-pdos/6.828-qemu.git qemu`
|
||||
2. On Linux, you may need to install several libraries. We have successfully built 6.828 QEMU on Debian/Ubuntu 16.04 after installing the following packages: libsdl1.2-dev, libtool-bin, libglib2.0-dev, libz-dev, and libpixman-1-dev.
|
||||
3. Configure the source code (optional arguments are shown in square brackets; replace PFX with a path of your choice)
|
||||
1. Linux: `./configure --disable-kvm --disable-werror [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]`
|
||||
2. OS X: `./configure --disable-kvm --disable-werror --disable-sdl [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]` The `prefix` argument specifies where to install QEMU; without it QEMU will install to `/usr/local` by default. The `target-list` argument simply slims down the architectures QEMU will build support for.
|
||||
4. Run `make && make install`
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/tools.html
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.cygwin.com
|
||||
[2]: labguide.html
|
||||
[3]: http://www.oracle.com/us/technologies/virtualization/oraclevm/
|
||||
[4]: http://www.vmware.com/products/player/
|
||||
[5]: http://www.vmware.com/products/fusion/
|
||||
[6]: http://www.ubuntu.com/download/desktop
|
||||
[7]:
|
||||
[8]: http://www.nongnu.org/qemu/
|
||||
[9]: mailto:6828-staff@lists.csail.mit.edu
|
||||
[10]: https://i.creativecommons.org/l/by/3.0/us/88x31.png
|
||||
[11]: https://creativecommons.org/licenses/by/3.0/us/
|
||||
[12]: https://pdos.csail.mit.edu/6.828/2018/index.html
|
||||
@ -0,0 +1,616 @@
|
||||
Lab 1: PC Bootstrap and GCC Calling Conventions
|
||||
======
|
||||
### Lab 1: Booting a PC
|
||||
|
||||
#### Introduction
|
||||
|
||||
This lab is split into three parts. The first part concentrates on getting familiarized with x86 assembly language, the QEMU x86 emulator, and the PC's power-on bootstrap procedure. The second part examines the boot loader for our 6.828 kernel, which resides in the `boot` directory of the `lab` tree. Finally, the third part delves into the initial template for our 6.828 kernel itself, named JOS, which resides in the `kernel` directory.
|
||||
|
||||
##### Software Setup
|
||||
|
||||
The files you will need for this and subsequent lab assignments in this course are distributed using the [Git][1] version control system. To learn more about Git, take a look at the [Git user's manual][2], or, if you are already familiar with other version control systems, you may find this [CS-oriented overview of Git][3] useful.
|
||||
|
||||
The URL for the course Git repository is <https://pdos.csail.mit.edu/6.828/2018/jos.git>. To install the files in your Athena account, you need to _clone_ the course repository, by running the commands below. You must use an x86 Athena machine; that is, `uname -a` should mention `i386 GNU/Linux` or `i686 GNU/Linux` or `x86_64 GNU/Linux`. You can log into a public Athena host with `ssh -X athena.dialup.mit.edu`.
|
||||
|
||||
```
|
||||
athena% mkdir ~/6.828
|
||||
athena% cd ~/6.828
|
||||
athena% add git
|
||||
athena% git clone https://pdos.csail.mit.edu/6.828/2018/jos.git lab
|
||||
Cloning into lab...
|
||||
athena% cd lab
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
Git allows you to keep track of the changes you make to the code. For example, if you are finished with one of the exercises, and want to checkpoint your progress, you can _commit_ your changes by running:
|
||||
|
||||
```
|
||||
athena% git commit -am 'my solution for lab1 exercise 9'
|
||||
Created commit 60d2135: my solution for lab1 exercise 9
|
||||
1 files changed, 1 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
You can keep track of your changes by using the git diff command. Running git diff will display the changes to your code since your last commit, and git diff origin/lab1 will display the changes relative to the initial code supplied for this lab. Here, `origin/lab1` is the name of the git branch with the initial code you downloaded from our server for this assignment.
|
||||
|
||||
We have set up the appropriate compilers and simulators for you on Athena. To use them, run add -f 6.828. You must run this command every time you log in (or add it to your `~/.environment` file). If you get obscure errors while compiling or running `qemu`, double check that you added the course locker.
|
||||
|
||||
If you are working on a non-Athena machine, you'll need to install `qemu` and possibly `gcc` following the directions on the [tools page][4]. We've made several useful debugging changes to `qemu` and some of the later labs depend on these patches, so you must build your own. If your machine uses a native ELF toolchain (such as Linux and most BSD's, but notably _not_ OS X), you can simply install `gcc` from your package manager. Otherwise, follow the directions on the tools page.
|
||||
|
||||
##### Hand-In Procedure
|
||||
|
||||
You will turn in your assignments using the [submission website][5]. You need to request an API key from the submission website before you can turn in any assignments or labs.
|
||||
|
||||
The lab code comes with GNU Make rules to make submission easier. After committing your final changes to the lab, type make handin to submit your lab.
|
||||
|
||||
```
|
||||
athena% git commit -am "ready to submit my lab"
|
||||
[lab1 c2e3c8b] ready to submit my lab
|
||||
2 files changed, 18 insertions(+), 2 deletions(-)
|
||||
|
||||
athena% make handin
|
||||
git archive --prefix=lab1/ --format=tar HEAD | gzip > lab1-handin.tar.gz
|
||||
Get an API key for yourself by visiting https://6828.scripts.mit.edu/2018/handin.py/
|
||||
Please enter your API key: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 50199 100 241 100 49958 414 85824 --:--:-- --:--:-- --:--:-- 85986
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
make handin will store your API key in _myapi.key_. If you need to change your API key, just remove this file and let make handin generate it again ( _myapi.key_ must not include newline characters).
|
||||
|
||||
If use make handin and you have either uncomitted changes or untracked files, you will see output similar to the following:
|
||||
|
||||
```
|
||||
M hello.c
|
||||
?? bar.c
|
||||
?? foo.pyc
|
||||
Untracked files will not be handed in. Continue? [y/N]
|
||||
|
||||
```
|
||||
|
||||
Inspect the above lines and make sure all files that your lab solution needs are tracked i.e. not listed in a line that begins with ??.
|
||||
|
||||
In the case that make handin does not work properly, try fixing the problem with the curl or Git commands. Or you can run make tarball. This will make a tar file for you, which you can then upload via our [web interface][5].
|
||||
|
||||
You can run make grade to test your solutions with the grading program. The [web interface][5] uses the same grading program to assign your lab submission a grade. You should check the output of the grader (it may take a few minutes since the grader runs periodically) and ensure that you received the grade which you expected. If the grades don't match, your lab submission probably has a bug -- check the output of the grader (resp-lab*.txt) to see which particular test failed.
|
||||
|
||||
For Lab 1, you do not need to turn in answers to any of the questions below. (Do answer them for yourself though! They will help with the rest of the lab.)
|
||||
|
||||
#### Part 1: PC Bootstrap
|
||||
|
||||
The purpose of the first exercise is to introduce you to x86 assembly language and the PC bootstrap process, and to get you started with QEMU and QEMU/GDB debugging. You will not have to write any code for this part of the lab, but you should go through it anyway for your own understanding and be prepared to answer the questions posed below.
|
||||
|
||||
##### Getting Started with x86 assembly
|
||||
|
||||
If you are not already familiar with x86 assembly language, you will quickly become familiar with it during this course! The [PC Assembly Language Book][6] is an excellent place to start. Hopefully, the book contains mixture of new and old material for you.
|
||||
|
||||
_Warning:_ Unfortunately the examples in the book are written for the NASM assembler, whereas we will be using the GNU assembler. NASM uses the so-called _Intel_ syntax while GNU uses the _AT &T_ syntax. While semantically equivalent, an assembly file will differ quite a lot, at least superficially, depending on which syntax is used. Luckily the conversion between the two is pretty simple, and is covered in [Brennan's Guide to Inline Assembly][7].
|
||||
|
||||
Exercise 1. Familiarize yourself with the assembly language materials available on [the 6.828 reference page][8]. You don't have to read them now, but you'll almost certainly want to refer to some of this material when reading and writing x86 assembly.
|
||||
|
||||
We do recommend reading the section "The Syntax" in [Brennan's Guide to Inline Assembly][7]. It gives a good (and quite brief) description of the AT&T assembly syntax we'll be using with the GNU assembler in JOS.
|
||||
|
||||
Certainly the definitive reference for x86 assembly language programming is Intel's instruction set architecture reference, which you can find on [the 6.828 reference page][8] in two flavors: an HTML edition of the old [80386 Programmer's Reference Manual][9], which is much shorter and easier to navigate than more recent manuals but describes all of the x86 processor features that we will make use of in 6.828; and the full, latest and greatest [IA-32 Intel Architecture Software Developer's Manuals][10] from Intel, covering all the features of the most recent processors that we won't need in class but you may be interested in learning about. An equivalent (and often friendlier) set of manuals is [available from AMD][11]. Save the Intel/AMD architecture manuals for later or use them for reference when you want to look up the definitive explanation of a particular processor feature or instruction.
|
||||
|
||||
##### Simulating the x86
|
||||
|
||||
Instead of developing the operating system on a real, physical personal computer (PC), we use a program that faithfully emulates a complete PC: the code you write for the emulator will boot on a real PC too. Using an emulator simplifies debugging; you can, for example, set break points inside of the emulated x86, which is difficult to do with the silicon version of an x86.
|
||||
|
||||
In 6.828 we will use the [QEMU Emulator][12], a modern and relatively fast emulator. While QEMU's built-in monitor provides only limited debugging support, QEMU can act as a remote debugging target for the [GNU debugger][13] (GDB), which we'll use in this lab to step through the early boot process.
|
||||
|
||||
To get started, extract the Lab 1 files into your own directory on Athena as described above in "Software Setup", then type make (or gmake on BSD systems) in the `lab` directory to build the minimal 6.828 boot loader and kernel you will start with. (It's a little generous to call the code we're running here a "kernel," but we'll flesh it out throughout the semester.)
|
||||
|
||||
```
|
||||
athena% cd lab
|
||||
athena% make
|
||||
+ as kern/entry.S
|
||||
+ cc kern/entrypgdir.c
|
||||
+ cc kern/init.c
|
||||
+ cc kern/console.c
|
||||
+ cc kern/monitor.c
|
||||
+ cc kern/printf.c
|
||||
+ cc kern/kdebug.c
|
||||
+ cc lib/printfmt.c
|
||||
+ cc lib/readline.c
|
||||
+ cc lib/string.c
|
||||
+ ld obj/kern/kernel
|
||||
+ as boot/boot.S
|
||||
+ cc -Os boot/main.c
|
||||
+ ld boot/boot
|
||||
boot block is 380 bytes (max 510)
|
||||
+ mk obj/kern/kernel.img
|
||||
|
||||
```
|
||||
|
||||
(If you get errors like "undefined reference to `__udivdi3'", you probably don't have the 32-bit gcc multilib. If you're running Debian or Ubuntu, try installing the gcc-multilib package.)
|
||||
|
||||
Now you're ready to run QEMU, supplying the file `obj/kern/kernel.img`, created above, as the contents of the emulated PC's "virtual hard disk." This hard disk image contains both our boot loader (`obj/boot/boot`) and our kernel (`obj/kernel`).
|
||||
|
||||
```
|
||||
athena% make qemu
|
||||
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```
|
||||
athena% make qemu-nox
|
||||
|
||||
```
|
||||
|
||||
This executes QEMU with the options required to set the hard disk and direct serial port output to the terminal. Some text should appear in the QEMU window:
|
||||
|
||||
```
|
||||
Booting from Hard Disk...
|
||||
6828 decimal is XXX octal!
|
||||
entering test_backtrace 5
|
||||
entering test_backtrace 4
|
||||
entering test_backtrace 3
|
||||
entering test_backtrace 2
|
||||
entering test_backtrace 1
|
||||
entering test_backtrace 0
|
||||
leaving test_backtrace 0
|
||||
leaving test_backtrace 1
|
||||
leaving test_backtrace 2
|
||||
leaving test_backtrace 3
|
||||
leaving test_backtrace 4
|
||||
leaving test_backtrace 5
|
||||
Welcome to the JOS kernel monitor!
|
||||
Type 'help' for a list of commands.
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
Everything after '`Booting from Hard Disk...`' was printed by our skeletal JOS kernel; the `K>` is the prompt printed by the small _monitor_ , or interactive control program, that we've included in the kernel. If you used make qemu, these lines printed by the kernel will appear in both the regular shell window from which you ran QEMU and the QEMU display window. This is because for testing and lab grading purposes we have set up the JOS kernel to write its console output not only to the virtual VGA display (as seen in the QEMU window), but also to the simulated PC's virtual serial port, which QEMU in turn outputs to its own standard output. Likewise, the JOS kernel will take input from both the keyboard and the serial port, so you can give it commands in either the VGA display window or the terminal running QEMU. Alternatively, you can use the serial console without the virtual VGA by running make qemu-nox. This may be convenient if you are SSH'd into an Athena dialup. To quit qemu, type Ctrl+a x.
|
||||
|
||||
There are only two commands you can give to the kernel monitor, `help` and `kerninfo`.
|
||||
|
||||
```
|
||||
K> help
|
||||
help - display this list of commands
|
||||
kerninfo - display information about the kernel
|
||||
K> kerninfo
|
||||
Special kernel symbols:
|
||||
entry f010000c (virt) 0010000c (phys)
|
||||
etext f0101a75 (virt) 00101a75 (phys)
|
||||
edata f0112300 (virt) 00112300 (phys)
|
||||
end f0112960 (virt) 00112960 (phys)
|
||||
Kernel executable memory footprint: 75KB
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
The `help` command is obvious, and we will shortly discuss the meaning of what the `kerninfo` command prints. Although simple, it's important to note that this kernel monitor is running "directly" on the "raw (virtual) hardware" of the simulated PC. This means that you should be able to copy the contents of `obj/kern/kernel.img` onto the first few sectors of a _real_ hard disk, insert that hard disk into a real PC, turn it on, and see exactly the same thing on the PC's real screen as you did above in the QEMU window. (We don't recommend you do this on a real machine with useful information on its hard disk, though, because copying `kernel.img` onto the beginning of its hard disk will trash the master boot record and the beginning of the first partition, effectively causing everything previously on the hard disk to be lost!)
|
||||
|
||||
##### The PC's Physical Address Space
|
||||
|
||||
We will now dive into a bit more detail about how a PC starts up. A PC's physical address space is hard-wired to have the following general layout:
|
||||
|
||||
```
|
||||
+------------------+ <- 0xFFFFFFFF (4GB)
|
||||
| 32-bit |
|
||||
| memory mapped |
|
||||
| devices |
|
||||
| |
|
||||
/\/\/\/\/\/\/\/\/\/\
|
||||
|
||||
/\/\/\/\/\/\/\/\/\/\
|
||||
| |
|
||||
| Unused |
|
||||
| |
|
||||
+------------------+ <- depends on amount of RAM
|
||||
| |
|
||||
| |
|
||||
| Extended Memory |
|
||||
| |
|
||||
| |
|
||||
+------------------+ <- 0x00100000 (1MB)
|
||||
| BIOS ROM |
|
||||
+------------------+ <- 0x000F0000 (960KB)
|
||||
| 16-bit devices, |
|
||||
| expansion ROMs |
|
||||
+------------------+ <- 0x000C0000 (768KB)
|
||||
| VGA Display |
|
||||
+------------------+ <- 0x000A0000 (640KB)
|
||||
| |
|
||||
| Low Memory |
|
||||
| |
|
||||
+------------------+ <- 0x00000000
|
||||
|
||||
```
|
||||
|
||||
The first PCs, which were based on the 16-bit Intel 8088 processor, were only capable of addressing 1MB of physical memory. The physical address space of an early PC would therefore start at 0x00000000 but end at 0x000FFFFF instead of 0xFFFFFFFF. The 640KB area marked "Low Memory" was the _only_ random-access memory (RAM) that an early PC could use; in fact the very earliest PCs only could be configured with 16KB, 32KB, or 64KB of RAM!
|
||||
|
||||
The 384KB area from 0x000A0000 through 0x000FFFFF was reserved by the hardware for special uses such as video display buffers and firmware held in non-volatile memory. The most important part of this reserved area is the Basic Input/Output System (BIOS), which occupies the 64KB region from 0x000F0000 through 0x000FFFFF. In early PCs the BIOS was held in true read-only memory (ROM), but current PCs store the BIOS in updateable flash memory. The BIOS is responsible for performing basic system initialization such as activating the video card and checking the amount of memory installed. After performing this initialization, the BIOS loads the operating system from some appropriate location such as floppy disk, hard disk, CD-ROM, or the network, and passes control of the machine to the operating system.
|
||||
|
||||
When Intel finally "broke the one megabyte barrier" with the 80286 and 80386 processors, which supported 16MB and 4GB physical address spaces respectively, the PC architects nevertheless preserved the original layout for the low 1MB of physical address space in order to ensure backward compatibility with existing software. Modern PCs therefore have a "hole" in physical memory from 0x000A0000 to 0x00100000, dividing RAM into "low" or "conventional memory" (the first 640KB) and "extended memory" (everything else). In addition, some space at the very top of the PC's 32-bit physical address space, above all physical RAM, is now commonly reserved by the BIOS for use by 32-bit PCI devices.
|
||||
|
||||
Recent x86 processors can support _more_ than 4GB of physical RAM, so RAM can extend further above 0xFFFFFFFF. In this case the BIOS must arrange to leave a _second_ hole in the system's RAM at the top of the 32-bit addressable region, to leave room for these 32-bit devices to be mapped. Because of design limitations JOS will use only the first 256MB of a PC's physical memory anyway, so for now we will pretend that all PCs have "only" a 32-bit physical address space. But dealing with complicated physical address spaces and other aspects of hardware organization that evolved over many years is one of the important practical challenges of OS development.
|
||||
|
||||
##### The ROM BIOS
|
||||
|
||||
In this portion of the lab, you'll use QEMU's debugging facilities to investigate how an IA-32 compatible computer boots.
|
||||
|
||||
Open two terminal windows and cd both shells into your lab directory. In one, enter make qemu-gdb (or make qemu-nox-gdb). This starts up QEMU, but QEMU stops just before the processor executes the first instruction and waits for a debugging connection from GDB. In the second terminal, from the same directory you ran `make`, run make gdb. You should see something like this,
|
||||
|
||||
```
|
||||
athena% make gdb
|
||||
GNU gdb (GDB) 6.8-debian
|
||||
Copyright (C) 2008 Free Software Foundation, Inc.
|
||||
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
|
||||
This is free software: you are free to change and redistribute it.
|
||||
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
|
||||
and "show warranty" for details.
|
||||
This GDB was configured as "i486-linux-gnu".
|
||||
+ target remote localhost:26000
|
||||
The target architecture is assumed to be i8086
|
||||
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
|
||||
0x0000fff0 in ?? ()
|
||||
+ symbol-file obj/kern/kernel
|
||||
(gdb)
|
||||
|
||||
```
|
||||
|
||||
We provided a `.gdbinit` file that set up GDB to debug the 16-bit code used during early boot and directed it to attach to the listening QEMU. (If it doesn't work, you may have to add an `add-auto-load-safe-path` in your `.gdbinit` in your home directory to convince `gdb` to process the `.gdbinit` we provided. `gdb` will tell you if you have to do this.)
|
||||
|
||||
The following line:
|
||||
|
||||
```
|
||||
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
|
||||
|
||||
```
|
||||
|
||||
is GDB's disassembly of the first instruction to be executed. From this output you can conclude a few things:
|
||||
|
||||
* The IBM PC starts executing at physical address 0x000ffff0, which is at the very top of the 64KB area reserved for the ROM BIOS.
|
||||
* The PC starts executing with `CS = 0xf000` and `IP = 0xfff0`.
|
||||
* The first instruction to be executed is a `jmp` instruction, which jumps to the segmented address `CS = 0xf000` and `IP = 0xe05b`.
|
||||
|
||||
|
||||
|
||||
Why does QEMU start like this? This is how Intel designed the 8088 processor, which IBM used in their original PC. Because the BIOS in a PC is "hard-wired" to the physical address range 0x000f0000-0x000fffff, this design ensures that the BIOS always gets control of the machine first after power-up or any system restart - which is crucial because on power-up there _is_ no other software anywhere in the machine's RAM that the processor could execute. The QEMU emulator comes with its own BIOS, which it places at this location in the processor's simulated physical address space. On processor reset, the (simulated) processor enters real mode and sets CS to 0xf000 and the IP to 0xfff0, so that execution begins at that (CS:IP) segment address. How does the segmented address 0xf000:fff0 turn into a physical address?
|
||||
|
||||
To answer that we need to know a bit about real mode addressing. In real mode (the mode that PC starts off in), address translation works according to the formula: _physical address_ = 16 选题模板.txt 中文排版指北.md comic core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated _segment_ \+ _offset_. So, when the PC sets CS to 0xf000 and IP to 0xfff0, the physical address referenced is:
|
||||
|
||||
```
|
||||
16 * 0xf000 + 0xfff0 # in hex multiplication by 16 is
|
||||
= 0xf0000 + 0xfff0 # easy--just append a 0.
|
||||
= 0xffff0
|
||||
|
||||
```
|
||||
|
||||
`0xffff0` is 16 bytes before the end of the BIOS (`0x100000`). Therefore we shouldn't be surprised that the first thing that the BIOS does is `jmp` backwards to an earlier location in the BIOS; after all how much could it accomplish in just 16 bytes?
|
||||
|
||||
Exercise 2. Use GDB's si (Step Instruction) command to trace into the ROM BIOS for a few more instructions, and try to guess what it might be doing. You might want to look at [Phil Storrs I/O Ports Description][14], as well as other materials on the [6.828 reference materials page][8]. No need to figure out all the details - just the general idea of what the BIOS is doing first.
|
||||
|
||||
When the BIOS runs, it sets up an interrupt descriptor table and initializes various devices such as the VGA display. This is where the "`Starting SeaBIOS`" message you see in the QEMU window comes from.
|
||||
|
||||
After initializing the PCI bus and all the important devices the BIOS knows about, it searches for a bootable device such as a floppy, hard drive, or CD-ROM. Eventually, when it finds a bootable disk, the BIOS reads the _boot loader_ from the disk and transfers control to it.
|
||||
|
||||
#### Part 2: The Boot Loader
|
||||
|
||||
Floppy and hard disks for PCs are divided into 512 byte regions called _sectors_. A sector is the disk's minimum transfer granularity: each read or write operation must be one or more sectors in size and aligned on a sector boundary. If the disk is bootable, the first sector is called the _boot sector_ , since this is where the boot loader code resides. When the BIOS finds a bootable floppy or hard disk, it loads the 512-byte boot sector into memory at physical addresses 0x7c00 through 0x7dff, and then uses a `jmp` instruction to set the CS:IP to `0000:7c00`, passing control to the boot loader. Like the BIOS load address, these addresses are fairly arbitrary - but they are fixed and standardized for PCs.
|
||||
|
||||
The ability to boot from a CD-ROM came much later during the evolution of the PC, and as a result the PC architects took the opportunity to rethink the boot process slightly. As a result, the way a modern BIOS boots from a CD-ROM is a bit more complicated (and more powerful). CD-ROMs use a sector size of 2048 bytes instead of 512, and the BIOS can load a much larger boot image from the disk into memory (not just one sector) before transferring control to it. For more information, see the ["El Torito" Bootable CD-ROM Format Specification][15].
|
||||
|
||||
For 6.828, however, we will use the conventional hard drive boot mechanism, which means that our boot loader must fit into a measly 512 bytes. The boot loader consists of one assembly language source file, `boot/boot.S`, and one C source file, `boot/main.c` Look through these source files carefully and make sure you understand what's going on. The boot loader must perform two main functions:
|
||||
|
||||
1. First, the boot loader switches the processor from real mode to _32-bit protected mode_ , because it is only in this mode that software can access all the memory above 1MB in the processor's physical address space. Protected mode is described briefly in sections 1.2.7 and 1.2.8 of [PC Assembly Language][6], and in great detail in the Intel architecture manuals. At this point you only have to understand that translation of segmented addresses (segment:offset pairs) into physical addresses happens differently in protected mode, and that after the transition offsets are 32 bits instead of 16.
|
||||
2. Second, the boot loader reads the kernel from the hard disk by directly accessing the IDE disk device registers via the x86's special I/O instructions. If you would like to understand better what the particular I/O instructions here mean, check out the "IDE hard drive controller" section on [the 6.828 reference page][8]. You will not need to learn much about programming specific devices in this class: writing device drivers is in practice a very important part of OS development, but from a conceptual or architectural viewpoint it is also one of the least interesting.
|
||||
|
||||
|
||||
|
||||
After you understand the boot loader source code, look at the file `obj/boot/boot.asm`. This file is a disassembly of the boot loader that our GNUmakefile creates _after_ compiling the boot loader. This disassembly file makes it easy to see exactly where in physical memory all of the boot loader's code resides, and makes it easier to track what's happening while stepping through the boot loader in GDB. Likewise, `obj/kern/kernel.asm` contains a disassembly of the JOS kernel, which can often be useful for debugging.
|
||||
|
||||
You can set address breakpoints in GDB with the `b` command. For example, b *0x7c00 sets a breakpoint at address 0x7C00. Once at a breakpoint, you can continue execution using the c and si commands: c causes QEMU to continue execution until the next breakpoint (or until you press Ctrl-C in GDB), and si _N_ steps through the instructions _`N`_ at a time.
|
||||
|
||||
To examine instructions in memory (besides the immediate next one to be executed, which GDB prints automatically), you use the x/i command. This command has the syntax x/ _N_ i _ADDR_ , where _N_ is the number of consecutive instructions to disassemble and _ADDR_ is the memory address at which to start disassembling.
|
||||
|
||||
Exercise 3. Take a look at the [lab tools guide][16], especially the section on GDB commands. Even if you're familiar with GDB, this includes some esoteric GDB commands that are useful for OS work.
|
||||
|
||||
Set a breakpoint at address 0x7c00, which is where the boot sector will be loaded. Continue execution until that breakpoint. Trace through the code in `boot/boot.S`, using the source code and the disassembly file `obj/boot/boot.asm` to keep track of where you are. Also use the `x/i` command in GDB to disassemble sequences of instructions in the boot loader, and compare the original boot loader source code with both the disassembly in `obj/boot/boot.asm` and GDB.
|
||||
|
||||
Trace into `bootmain()` in `boot/main.c`, and then into `readsect()`. Identify the exact assembly instructions that correspond to each of the statements in `readsect()`. Trace through the rest of `readsect()` and back out into `bootmain()`, and identify the begin and end of the `for` loop that reads the remaining sectors of the kernel from the disk. Find out what code will run when the loop is finished, set a breakpoint there, and continue to that breakpoint. Then step through the remainder of the boot loader.
|
||||
|
||||
Be able to answer the following questions:
|
||||
|
||||
* At what point does the processor start executing 32-bit code? What exactly causes the switch from 16- to 32-bit mode?
|
||||
* What is the _last_ instruction of the boot loader executed, and what is the _first_ instruction of the kernel it just loaded?
|
||||
* _Where_ is the first instruction of the kernel?
|
||||
* How does the boot loader decide how many sectors it must read in order to fetch the entire kernel from disk? Where does it find this information?
|
||||
|
||||
|
||||
|
||||
##### Loading the Kernel
|
||||
|
||||
We will now look in further detail at the C language portion of the boot loader, in `boot/main.c`. But before doing so, this is a good time to stop and review some of the basics of C programming.
|
||||
|
||||
Exercise 4. Read about programming with pointers in C. The best reference for the C language is _The C Programming Language_ by Brian Kernighan and Dennis Ritchie (known as 'K &R'). We recommend that students purchase this book (here is an [Amazon Link][17]) or find one of [MIT's 7 copies][18].
|
||||
|
||||
Read 5.1 (Pointers and Addresses) through 5.5 (Character Pointers and Functions) in K&R. Then download the code for [pointers.c][19], run it, and make sure you understand where all of the printed values come from. In particular, make sure you understand where the pointer addresses in printed lines 1 and 6 come from, how all the values in printed lines 2 through 4 get there, and why the values printed in line 5 are seemingly corrupted.
|
||||
|
||||
There are other references on pointers in C (e.g., [A tutorial by Ted Jensen][20] that cites K&R heavily), though not as strongly recommended.
|
||||
|
||||
_Warning:_ Unless you are already thoroughly versed in C, do not skip or even skim this reading exercise. If you do not really understand pointers in C, you will suffer untold pain and misery in subsequent labs, and then eventually come to understand them the hard way. Trust us; you don't want to find out what "the hard way" is.
|
||||
|
||||
To make sense out of `boot/main.c` you'll need to know what an ELF binary is. When you compile and link a C program such as the JOS kernel, the compiler transforms each C source ('`.c`') file into an _object_ ('`.o`') file containing assembly language instructions encoded in the binary format expected by the hardware. The linker then combines all of the compiled object files into a single _binary image_ such as `obj/kern/kernel`, which in this case is a binary in the ELF format, which stands for "Executable and Linkable Format".
|
||||
|
||||
Full information about this format is available in [the ELF specification][21] on [our reference page][8], but you will not need to delve very deeply into the details of this format in this class. Although as a whole the format is quite powerful and complex, most of the complex parts are for supporting dynamic loading of shared libraries, which we will not do in this class. The [Wikipedia page][22] has a short description.
|
||||
|
||||
For purposes of 6.828, you can consider an ELF executable to be a header with loading information, followed by several _program sections_ , each of which is a contiguous chunk of code or data intended to be loaded into memory at a specified address. The boot loader does not modify the code or data; it loads it into memory and starts executing it.
|
||||
|
||||
An ELF binary starts with a fixed-length _ELF header_ , followed by a variable-length _program header_ listing each of the program sections to be loaded. The C definitions for these ELF headers are in `inc/elf.h`. The program sections we're interested in are:
|
||||
|
||||
* `.text`: The program's executable instructions.
|
||||
* `.rodata`: Read-only data, such as ASCII string constants produced by the C compiler. (We will not bother setting up the hardware to prohibit writing, however.)
|
||||
* `.data`: The data section holds the program's initialized data, such as global variables declared with initializers like `int x = 5;`.
|
||||
|
||||
|
||||
|
||||
When the linker computes the memory layout of a program, it reserves space for _uninitialized_ global variables, such as `int x;`, in a section called `.bss` that immediately follows `.data` in memory. C requires that "uninitialized" global variables start with a value of zero. Thus there is no need to store contents for `.bss` in the ELF binary; instead, the linker records just the address and size of the `.bss` section. The loader or the program itself must arrange to zero the `.bss` section.
|
||||
|
||||
Examine the full list of the names, sizes, and link addresses of all the sections in the kernel executable by typing:
|
||||
|
||||
```
|
||||
athena% objdump -h obj/kern/kernel
|
||||
|
||||
(If you compiled your own toolchain, you may need to use i386-jos-elf-objdump)
|
||||
|
||||
```
|
||||
|
||||
You will see many more sections than the ones we listed above, but the others are not important for our purposes. Most of the others are to hold debugging information, which is typically included in the program's executable file but not loaded into memory by the program loader.
|
||||
|
||||
Take particular note of the "VMA" (or _link address_ ) and the "LMA" (or _load address_ ) of the `.text` section. The load address of a section is the memory address at which that section should be loaded into memory.
|
||||
|
||||
The link address of a section is the memory address from which the section expects to execute. The linker encodes the link address in the binary in various ways, such as when the code needs the address of a global variable, with the result that a binary usually won't work if it is executing from an address that it is not linked for. (It is possible to generate _position-independent_ code that does not contain any such absolute addresses. This is used extensively by modern shared libraries, but it has performance and complexity costs, so we won't be using it in 6.828.)
|
||||
|
||||
Typically, the link and load addresses are the same. For example, look at the `.text` section of the boot loader:
|
||||
|
||||
```
|
||||
athena% objdump -h obj/boot/boot.out
|
||||
|
||||
```
|
||||
|
||||
The boot loader uses the ELF _program headers_ to decide how to load the sections. The program headers specify which parts of the ELF object to load into memory and the destination address each should occupy. You can inspect the program headers by typing:
|
||||
|
||||
```
|
||||
athena% objdump -x obj/kern/kernel
|
||||
|
||||
```
|
||||
|
||||
The program headers are then listed under "Program Headers" in the output of objdump. The areas of the ELF object that need to be loaded into memory are those that are marked as "LOAD". Other information for each program header is given, such as the virtual address ("vaddr"), the physical address ("paddr"), and the size of the loaded area ("memsz" and "filesz").
|
||||
|
||||
Back in boot/main.c, the `ph->p_pa` field of each program header contains the segment's destination physical address (in this case, it really is a physical address, though the ELF specification is vague on the actual meaning of this field).
|
||||
|
||||
The BIOS loads the boot sector into memory starting at address 0x7c00, so this is the boot sector's load address. This is also where the boot sector executes from, so this is also its link address. We set the link address by passing `-Ttext 0x7C00` to the linker in `boot/Makefrag`, so the linker will produce the correct memory addresses in the generated code.
|
||||
|
||||
Exercise 5. Trace through the first few instructions of the boot loader again and identify the first instruction that would "break" or otherwise do the wrong thing if you were to get the boot loader's link address wrong. Then change the link address in `boot/Makefrag` to something wrong, run make clean, recompile the lab with make, and trace into the boot loader again to see what happens. Don't forget to change the link address back and make clean again afterward!
|
||||
|
||||
Look back at the load and link addresses for the kernel. Unlike the boot loader, these two addresses aren't the same: the kernel is telling the boot loader to load it into memory at a low address (1 megabyte), but it expects to execute from a high address. We'll dig in to how we make this work in the next section.
|
||||
|
||||
Besides the section information, there is one more field in the ELF header that is important to us, named `e_entry`. This field holds the link address of the _entry point_ in the program: the memory address in the program's text section at which the program should begin executing. You can see the entry point:
|
||||
|
||||
```
|
||||
athena% objdump -f obj/kern/kernel
|
||||
|
||||
```
|
||||
|
||||
You should now be able to understand the minimal ELF loader in `boot/main.c`. It reads each section of the kernel from disk into memory at the section's load address and then jumps to the kernel's entry point.
|
||||
|
||||
Exercise 6. We can examine memory using GDB's x command. The [GDB manual][23] has full details, but for now, it is enough to know that the command x/ _N_ x _ADDR_ prints _`N`_ words of memory at _`ADDR`_. (Note that both '`x`'s in the command are lowercase.) _Warning_ : The size of a word is not a universal standard. In GNU assembly, a word is two bytes (the 'w' in xorw, which stands for word, means 2 bytes).
|
||||
|
||||
Reset the machine (exit QEMU/GDB and start them again). Examine the 8 words of memory at 0x00100000 at the point the BIOS enters the boot loader, and then again at the point the boot loader enters the kernel. Why are they different? What is there at the second breakpoint? (You do not really need to use QEMU to answer this question. Just think.)
|
||||
|
||||
#### Part 3: The Kernel
|
||||
|
||||
We will now start to examine the minimal JOS kernel in a bit more detail. (And you will finally get to write some code!). Like the boot loader, the kernel begins with some assembly language code that sets things up so that C language code can execute properly.
|
||||
|
||||
##### Using virtual memory to work around position dependence
|
||||
|
||||
When you inspected the boot loader's link and load addresses above, they matched perfectly, but there was a (rather large) disparity between the _kernel's_ link address (as printed by objdump) and its load address. Go back and check both and make sure you can see what we're talking about. (Linking the kernel is more complicated than the boot loader, so the link and load addresses are at the top of `kern/kernel.ld`.)
|
||||
|
||||
Operating system kernels often like to be linked and run at very high _virtual address_ , such as 0xf0100000, in order to leave the lower part of the processor's virtual address space for user programs to use. The reason for this arrangement will become clearer in the next lab.
|
||||
|
||||
Many machines don't have any physical memory at address 0xf0100000, so we can't count on being able to store the kernel there. Instead, we will use the processor's memory management hardware to map virtual address 0xf0100000 (the link address at which the kernel code _expects_ to run) to physical address 0x00100000 (where the boot loader loaded the kernel into physical memory). This way, although the kernel's virtual address is high enough to leave plenty of address space for user processes, it will be loaded in physical memory at the 1MB point in the PC's RAM, just above the BIOS ROM. This approach requires that the PC have at least a few megabytes of physical memory (so that physical address 0x00100000 works), but this is likely to be true of any PC built after about 1990.
|
||||
|
||||
In fact, in the next lab, we will map the _entire_ bottom 256MB of the PC's physical address space, from physical addresses 0x00000000 through 0x0fffffff, to virtual addresses 0xf0000000 through 0xffffffff respectively. You should now see why JOS can only use the first 256MB of physical memory.
|
||||
|
||||
For now, we'll just map the first 4MB of physical memory, which will be enough to get us up and running. We do this using the hand-written, statically-initialized page directory and page table in `kern/entrypgdir.c`. For now, you don't have to understand the details of how this works, just the effect that it accomplishes. Up until `kern/entry.S` sets the `CR0_PG` flag, memory references are treated as physical addresses (strictly speaking, they're linear addresses, but boot/boot.S set up an identity mapping from linear addresses to physical addresses and we're never going to change that). Once `CR0_PG` is set, memory references are virtual addresses that get translated by the virtual memory hardware to physical addresses. `entry_pgdir` translates virtual addresses in the range 0xf0000000 through 0xf0400000 to physical addresses 0x00000000 through 0x00400000, as well as virtual addresses 0x00000000 through 0x00400000 to physical addresses 0x00000000 through 0x00400000. Any virtual address that is not in one of these two ranges will cause a hardware exception which, since we haven't set up interrupt handling yet, will cause QEMU to dump the machine state and exit (or endlessly reboot if you aren't using the 6.828-patched version of QEMU).
|
||||
|
||||
Exercise 7. Use QEMU and GDB to trace into the JOS kernel and stop at the `movl %eax, %cr0`. Examine memory at 0x00100000 and at 0xf0100000. Now, single step over that instruction using the stepi GDB command. Again, examine memory at 0x00100000 and at 0xf0100000. Make sure you understand what just happened.
|
||||
|
||||
What is the first instruction _after_ the new mapping is established that would fail to work properly if the mapping weren't in place? Comment out the `movl %eax, %cr0` in `kern/entry.S`, trace into it, and see if you were right.
|
||||
|
||||
##### Formatted Printing to the Console
|
||||
|
||||
Most people take functions like `printf()` for granted, sometimes even thinking of them as "primitives" of the C language. But in an OS kernel, we have to implement all I/O ourselves.
|
||||
|
||||
Read through `kern/printf.c`, `lib/printfmt.c`, and `kern/console.c`, and make sure you understand their relationship. It will become clear in later labs why `printfmt.c` is located in the separate `lib` directory.
|
||||
|
||||
Exercise 8. We have omitted a small fragment of code - the code necessary to print octal numbers using patterns of the form "%o". Find and fill in this code fragment.
|
||||
|
||||
Be able to answer the following questions:
|
||||
|
||||
1. Explain the interface between `printf.c` and `console.c`. Specifically, what function does `console.c` export? How is this function used by `printf.c`?
|
||||
|
||||
2. Explain the following from `console.c`:
|
||||
```
|
||||
1 if (crt_pos >= CRT_SIZE) {
|
||||
2 int i;
|
||||
3 memmove(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) 选题模板.txt 中文排版指北.md comic core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated sizeof(uint16_t));
|
||||
4 for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++)
|
||||
5 crt_buf[i] = 0x0700 | ' ';
|
||||
6 crt_pos -= CRT_COLS;
|
||||
7 }
|
||||
|
||||
```
|
||||
|
||||
3. For the following questions you might wish to consult the notes for Lecture 2. These notes cover GCC's calling convention on the x86.
|
||||
|
||||
Trace the execution of the following code step-by-step:
|
||||
```
|
||||
int x = 1, y = 3, z = 4;
|
||||
cprintf("x %d, y %x, z %d\n", x, y, z);
|
||||
|
||||
```
|
||||
|
||||
* In the call to `cprintf()`, to what does `fmt` point? To what does `ap` point?
|
||||
* List (in order of execution) each call to `cons_putc`, `va_arg`, and `vcprintf`. For `cons_putc`, list its argument as well. For `va_arg`, list what `ap` points to before and after the call. For `vcprintf` list the values of its two arguments.
|
||||
4. Run the following code.
|
||||
```
|
||||
unsigned int i = 0x00646c72;
|
||||
cprintf("H%x Wo%s", 57616, &i);
|
||||
|
||||
```
|
||||
|
||||
What is the output? Explain how this output is arrived at in the step-by-step manner of the previous exercise. [Here's an ASCII table][24] that maps bytes to characters.
|
||||
|
||||
The output depends on that fact that the x86 is little-endian. If the x86 were instead big-endian what would you set `i` to in order to yield the same output? Would you need to change `57616` to a different value?
|
||||
|
||||
[Here's a description of little- and big-endian][25] and [a more whimsical description][26].
|
||||
|
||||
5. In the following code, what is going to be printed after `'y='`? (note: the answer is not a specific value.) Why does this happen?
|
||||
```
|
||||
cprintf("x=%d y=%d", 3);
|
||||
|
||||
```
|
||||
|
||||
6. Let's say that GCC changed its calling convention so that it pushed arguments on the stack in declaration order, so that the last argument is pushed last. How would you have to change `cprintf` or its interface so that it would still be possible to pass it a variable number of arguments?
|
||||
|
||||
|
||||
|
||||
|
||||
Challenge Enhance the console to allow text to be printed in different colors. The traditional way to do this is to make it interpret [ANSI escape sequences][27] embedded in the text strings printed to the console, but you may use any mechanism you like. There is plenty of information on [the 6.828 reference page][8] and elsewhere on the web on programming the VGA display hardware. If you're feeling really adventurous, you could try switching the VGA hardware into a graphics mode and making the console draw text onto the graphical frame buffer.
|
||||
|
||||
##### The Stack
|
||||
|
||||
In the final exercise of this lab, we will explore in more detail the way the C language uses the stack on the x86, and in the process write a useful new kernel monitor function that prints a _backtrace_ of the stack: a list of the saved Instruction Pointer (IP) values from the nested `call` instructions that led to the current point of execution.
|
||||
|
||||
Exercise 9. Determine where the kernel initializes its stack, and exactly where in memory its stack is located. How does the kernel reserve space for its stack? And at which "end" of this reserved area is the stack pointer initialized to point to?
|
||||
|
||||
The x86 stack pointer (`esp` register) points to the lowest location on the stack that is currently in use. Everything _below_ that location in the region reserved for the stack is free. Pushing a value onto the stack involves decreasing the stack pointer and then writing the value to the place the stack pointer points to. Popping a value from the stack involves reading the value the stack pointer points to and then increasing the stack pointer. In 32-bit mode, the stack can only hold 32-bit values, and esp is always divisible by four. Various x86 instructions, such as `call`, are "hard-wired" to use the stack pointer register.
|
||||
|
||||
The `ebp` (base pointer) register, in contrast, is associated with the stack primarily by software convention. On entry to a C function, the function's _prologue_ code normally saves the previous function's base pointer by pushing it onto the stack, and then copies the current `esp` value into `ebp` for the duration of the function. If all the functions in a program obey this convention, then at any given point during the program's execution, it is possible to trace back through the stack by following the chain of saved `ebp` pointers and determining exactly what nested sequence of function calls caused this particular point in the program to be reached. This capability can be particularly useful, for example, when a particular function causes an `assert` failure or `panic` because bad arguments were passed to it, but you aren't sure _who_ passed the bad arguments. A stack backtrace lets you find the offending function.
|
||||
|
||||
Exercise 10. To become familiar with the C calling conventions on the x86, find the address of the `test_backtrace` function in `obj/kern/kernel.asm`, set a breakpoint there, and examine what happens each time it gets called after the kernel starts. How many 32-bit words does each recursive nesting level of `test_backtrace` push on the stack, and what are those words?
|
||||
|
||||
Note that, for this exercise to work properly, you should be using the patched version of QEMU available on the [tools][4] page or on Athena. Otherwise, you'll have to manually translate all breakpoint and memory addresses to linear addresses.
|
||||
|
||||
The above exercise should give you the information you need to implement a stack backtrace function, which you should call `mon_backtrace()`. A prototype for this function is already waiting for you in `kern/monitor.c`. You can do it entirely in C, but you may find the `read_ebp()` function in `inc/x86.h` useful. You'll also have to hook this new function into the kernel monitor's command list so that it can be invoked interactively by the user.
|
||||
|
||||
The backtrace function should display a listing of function call frames in the following format:
|
||||
|
||||
```
|
||||
Stack backtrace:
|
||||
ebp f0109e58 eip f0100a62 args 00000001 f0109e80 f0109e98 f0100ed2 00000031
|
||||
ebp f0109ed8 eip f01000d6 args 00000000 00000000 f0100058 f0109f28 00000061
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
Each line contains an `ebp`, `eip`, and `args`. The `ebp` value indicates the base pointer into the stack used by that function: i.e., the position of the stack pointer just after the function was entered and the function prologue code set up the base pointer. The listed `eip` value is the function's _return instruction pointer_ : the instruction address to which control will return when the function returns. The return instruction pointer typically points to the instruction after the `call` instruction (why?). Finally, the five hex values listed after `args` are the first five arguments to the function in question, which would have been pushed on the stack just before the function was called. If the function was called with fewer than five arguments, of course, then not all five of these values will be useful. (Why can't the backtrace code detect how many arguments there actually are? How could this limitation be fixed?)
|
||||
|
||||
The first line printed reflects the _currently executing_ function, namely `mon_backtrace` itself, the second line reflects the function that called `mon_backtrace`, the third line reflects the function that called that one, and so on. You should print _all_ the outstanding stack frames. By studying `kern/entry.S` you'll find that there is an easy way to tell when to stop.
|
||||
|
||||
Here are a few specific points you read about in K&R Chapter 5 that are worth remembering for the following exercise and for future labs.
|
||||
|
||||
* If `int *p = (int*)100`, then `(int)p + 1` and `(int)(p + 1)` are different numbers: the first is `101` but the second is `104`. When adding an integer to a pointer, as in the second case, the integer is implicitly multiplied by the size of the object the pointer points to.
|
||||
* `p[i]` is defined to be the same as `*(p+i)`, referring to the i'th object in the memory pointed to by p. The above rule for addition helps this definition work when the objects are larger than one byte.
|
||||
* `&p[i]` is the same as `(p+i)`, yielding the address of the i'th object in the memory pointed to by p.
|
||||
|
||||
|
||||
|
||||
Although most C programs never need to cast between pointers and integers, operating systems frequently do. Whenever you see an addition involving a memory address, ask yourself whether it is an integer addition or pointer addition and make sure the value being added is appropriately multiplied or not.
|
||||
|
||||
Exercise 11. Implement the backtrace function as specified above. Use the same format as in the example, since otherwise the grading script will be confused. When you think you have it working right, run make grade to see if its output conforms to what our grading script expects, and fix it if it doesn't. _After_ you have handed in your Lab 1 code, you are welcome to change the output format of the backtrace function any way you like.
|
||||
|
||||
If you use `read_ebp()`, note that GCC may generate "optimized" code that calls `read_ebp()` _before_ `mon_backtrace()`'s function prologue, which results in an incomplete stack trace (the stack frame of the most recent function call is missing). While we have tried to disable optimizations that cause this reordering, you may want to examine the assembly of `mon_backtrace()` and make sure the call to `read_ebp()` is happening after the function prologue.
|
||||
|
||||
At this point, your backtrace function should give you the addresses of the function callers on the stack that lead to `mon_backtrace()` being executed. However, in practice you often want to know the function names corresponding to those addresses. For instance, you may want to know which functions could contain a bug that's causing your kernel to crash.
|
||||
|
||||
To help you implement this functionality, we have provided the function `debuginfo_eip()`, which looks up `eip` in the symbol table and returns the debugging information for that address. This function is defined in `kern/kdebug.c`.
|
||||
|
||||
Exercise 12. Modify your stack backtrace function to display, for each `eip`, the function name, source file name, and line number corresponding to that `eip`.
|
||||
|
||||
In `debuginfo_eip`, where do `__STAB_*` come from? This question has a long answer; to help you to discover the answer, here are some things you might want to do:
|
||||
|
||||
* look in the file `kern/kernel.ld` for `__STAB_*`
|
||||
* run objdump -h obj/kern/kernel
|
||||
* run objdump -G obj/kern/kernel
|
||||
* run gcc -pipe -nostdinc -O2 -fno-builtin -I. -MD -Wall -Wno-format -DJOS_KERNEL -gstabs -c -S kern/init.c, and look at init.s.
|
||||
* see if the bootloader loads the symbol table in memory as part of loading the kernel binary
|
||||
|
||||
|
||||
|
||||
Complete the implementation of `debuginfo_eip` by inserting the call to `stab_binsearch` to find the line number for an address.
|
||||
|
||||
Add a `backtrace` command to the kernel monitor, and extend your implementation of `mon_backtrace` to call `debuginfo_eip` and print a line for each stack frame of the form:
|
||||
|
||||
```
|
||||
K> backtrace
|
||||
Stack backtrace:
|
||||
ebp f010ff78 eip f01008ae args 00000001 f010ff8c 00000000 f0110580 00000000
|
||||
kern/monitor.c:143: monitor+106
|
||||
ebp f010ffd8 eip f0100193 args 00000000 00001aac 00000660 00000000 00000000
|
||||
kern/init.c:49: i386_init+59
|
||||
ebp f010fff8 eip f010003d args 00000000 00000000 0000ffff 10cf9a00 0000ffff
|
||||
kern/entry.S:70: <unknown>+0
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
Each line gives the file name and line within that file of the stack frame's `eip`, followed by the name of the function and the offset of the `eip` from the first instruction of the function (e.g., `monitor+106` means the return `eip` is 106 bytes past the beginning of `monitor`).
|
||||
|
||||
Be sure to print the file and function names on a separate line, to avoid confusing the grading script.
|
||||
|
||||
Tip: printf format strings provide an easy, albeit obscure, way to print non-null-terminated strings like those in STABS tables. `printf("%.*s", length, string)` prints at most `length` characters of `string`. Take a look at the printf man page to find out why this works.
|
||||
|
||||
You may find that some functions are missing from the backtrace. For example, you will probably see a call to `monitor()` but not to `runcmd()`. This is because the compiler in-lines some function calls. Other optimizations may cause you to see unexpected line numbers. If you get rid of the `-O2` from `GNUMakefile`, the backtraces may make more sense (but your kernel will run more slowly).
|
||||
|
||||
**This completes the lab.** In the `lab` directory, commit your changes with git commit and type make handin to submit your code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab1/
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.git-scm.com/
|
||||
[2]: http://www.kernel.org/pub/software/scm/git/docs/user-manual.html
|
||||
[3]: http://eagain.net/articles/git-for-computer-scientists/
|
||||
[4]: https://pdos.csail.mit.edu/6.828/2018/tools.html
|
||||
[5]: https://6828.scripts.mit.edu/2018/handin.py/
|
||||
[6]: https://pdos.csail.mit.edu/6.828/2018/readings/pcasm-book.pdf
|
||||
[7]: http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html
|
||||
[8]: https://pdos.csail.mit.edu/6.828/2018/reference.html
|
||||
[9]: https://pdos.csail.mit.edu/6.828/2018/readings/i386/toc.htm
|
||||
[10]: http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
|
||||
[11]: http://developer.amd.com/resources/developer-guides-manuals/
|
||||
[12]: http://www.qemu.org/
|
||||
[13]: http://www.gnu.org/software/gdb/
|
||||
[14]: http://web.archive.org/web/20040404164813/members.iweb.net.au/~pstorr/pcbook/book2/book2.htm
|
||||
[15]: https://pdos.csail.mit.edu/6.828/2018/readings/boot-cdrom.pdf
|
||||
[16]: https://pdos.csail.mit.edu/6.828/2018/labguide.html
|
||||
[17]: http://www.amazon.com/C-Programming-Language-2nd/dp/0131103628/sr=8-1/qid=1157812738/ref=pd_bbs_1/104-1502762-1803102?ie=UTF8&s=books
|
||||
[18]: http://library.mit.edu/F/AI9Y4SJ2L5ELEE2TAQUAAR44XV5RTTQHE47P9MKP5GQDLR9A8X-10422?func=item-global&doc_library=MIT01&doc_number=000355242&year=&volume=&sub_library=
|
||||
[19]: https://pdos.csail.mit.edu/6.828/2018/labs/lab1/pointers.c
|
||||
[20]: https://pdos.csail.mit.edu/6.828/2018/readings/pointers.pdf
|
||||
[21]: https://pdos.csail.mit.edu/6.828/2018/readings/elf.pdf
|
||||
[22]: http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[23]: https://sourceware.org/gdb/current/onlinedocs/gdb/Memory.html
|
||||
[24]: http://web.cs.mun.ca/~michael/c/ascii-table.html
|
||||
[25]: http://www.webopedia.com/TERM/b/big_endian.html
|
||||
[26]: http://www.networksorcery.com/enp/ien/ien137.txt
|
||||
[27]: http://rrbrandt.dee.ufcg.edu.br/en/docs/ansi/
|
||||
@ -1,90 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Boot Ubuntu 18.04 / Debian 9 Server in Rescue (Single User mode) / Emergency Mode
|
||||
======
|
||||
Booting a Linux Server into a single user mode or **rescue mode** is one of the important troubleshooting that a Linux admin usually follow while recovering the server from critical conditions. In Ubuntu 18.04 and Debian 9, single user mode is known as a rescue mode.
|
||||
|
||||
Apart from the rescue mode, Linux servers can be booted in **emergency mode** , the main difference between them is that, emergency mode loads a minimal environment with read only root file system file system, also it does not enable any network or other services. But rescue mode try to mount all the local file systems & try to start some important services including network.
|
||||
|
||||
In this article we will discuss how we can boot our Ubuntu 18.04 LTS / Debian 9 Server in rescue mode and emergency mode.
|
||||
|
||||
#### Booting Ubuntu 18.04 LTS Server in Single User / Rescue Mode:
|
||||
|
||||
Reboot your server and go to boot loader (Grub) screen and Select “ **Ubuntu** “, bootloader screen would look like below,
|
||||
|
||||

|
||||
|
||||
Press “ **e** ” and then go the end of line which starts with word “ **linux** ” and append “ **systemd.unit=rescue.target** “. Remove the word “ **$vt_handoff** ” if it exists.
|
||||
|
||||

|
||||
|
||||
Now Press Ctrl-x or F10 to boot,
|
||||
|
||||

|
||||
|
||||
Now press enter and then you will get the shell where all file systems will be mounted in read-write mode and do the troubleshooting. Once you are done with troubleshooting, you can reboot your server using “ **reboot** ” command.
|
||||
|
||||
#### Booting Ubuntu 18.04 LTS Server in emergency mode
|
||||
|
||||
Reboot the server and go the boot loader screen and select “ **Ubuntu** ” and then press “ **e** ” and go to the end of line which starts with word linux, and append “ **systemd.unit=emergency.target** ”
|
||||
|
||||

|
||||
|
||||
Now Press Ctlr-x or F10 to boot in emergency mode, you will get a shell and do the troubleshooting from there. As we had already discussed that in emergency mode, file systems will be mounted in read-only mode and also there will be no networking in this mode,
|
||||
|
||||

|
||||
|
||||
Use below command to mount the root file system in read-write mode,
|
||||
|
||||
```
|
||||
# mount -o remount,rw /
|
||||
|
||||
```
|
||||
|
||||
Similarly, you can remount rest of file systems in read-write mode .
|
||||
|
||||
#### Booting Debian 9 into Rescue & Emergency Mode
|
||||
|
||||
Reboot your Debian 9.x server and go to grub screen and select “ **Debian GNU/Linux** ”
|
||||
|
||||

|
||||
|
||||
Press “ **e** ” and go to end of line which starts with word linux and append “ **systemd.unit=rescue.target** ” to boot the system in rescue mode and to boot in emergency mode then append “ **systemd.unit=emergency.target** ”
|
||||
|
||||
#### Rescue mode :
|
||||
|
||||

|
||||
|
||||
Now press Ctrl-x or F10 to boot in rescue mode
|
||||
|
||||

|
||||
|
||||
Press Enter to get the shell and from there you can start troubleshooting.
|
||||
|
||||
#### Emergency Mode:
|
||||
|
||||

|
||||
|
||||
Now press ctrl-x or F10 to boot your system in emergency mode
|
||||
|
||||

|
||||
|
||||
Press enter to get the shell and use “ **mount -o remount,rw /** ” command to mount the root file system in read-write mode.
|
||||
|
||||
**Note:** In case root password is already set in Ubuntu 18.04 and Debian 9 Server then you must enter root password to get shell in rescue and emergency mode
|
||||
|
||||
That’s all from this article, please do share your feedback and comments in case you like this article.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/boot-ubuntu-18-04-debian-9-rescue-emergency-mode/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxtechi.com/author/pradeep/
|
||||
272
sources/tech/20180927 Lab 2- Memory Management.md
Normal file
272
sources/tech/20180927 Lab 2- Memory Management.md
Normal file
@ -0,0 +1,272 @@
|
||||
Lab 2: Memory Management
|
||||
======
|
||||
### Lab 2: Memory Management
|
||||
|
||||
#### Introduction
|
||||
|
||||
In this lab, you will write the memory management code for your operating system. Memory management has two components.
|
||||
|
||||
The first component is a physical memory allocator for the kernel, so that the kernel can allocate memory and later free it. Your allocator will operate in units of 4096 bytes, called _pages_. Your task will be to maintain data structures that record which physical pages are free and which are allocated, and how many processes are sharing each allocated page. You will also write the routines to allocate and free pages of memory.
|
||||
|
||||
The second component of memory management is _virtual memory_ , which maps the virtual addresses used by kernel and user software to addresses in physical memory. The x86 hardware's memory management unit (MMU) performs the mapping when instructions use memory, consulting a set of page tables. You will modify JOS to set up the MMU's page tables according to a specification we provide.
|
||||
|
||||
##### Getting started
|
||||
|
||||
In this and future labs you will progressively build up your kernel. We will also provide you with some additional source. To fetch that source, use Git to commit changes you've made since handing in lab 1 (if any), fetch the latest version of the course repository, and then create a local branch called `lab2` based on our lab2 branch, `origin/lab2`:
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab2 origin/lab2
|
||||
Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
|
||||
Switched to a new branch "lab2"
|
||||
athena%
|
||||
```
|
||||
|
||||
The git checkout -b command shown above actually does two things: it first creates a local branch `lab2` that is based on the `origin/lab2` branch provided by the course staff, and second, it changes the contents of your `lab` directory to reflect the files stored on the `lab2` branch. Git allows switching between existing branches using git checkout _branch-name_ , though you should commit any outstanding changes on one branch before switching to a different one.
|
||||
|
||||
You will now need to merge the changes you made in your `lab1` branch into the `lab2` branch, as follows:
|
||||
|
||||
```
|
||||
athena% git merge lab1
|
||||
Merge made by recursive.
|
||||
kern/kdebug.c | 11 +++++++++--
|
||||
kern/monitor.c | 19 +++++++++++++++++++
|
||||
lib/printfmt.c | 7 +++----
|
||||
3 files changed, 31 insertions(+), 6 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
In some cases, Git may not be able to figure out how to merge your changes with the new lab assignment (e.g. if you modified some of the code that is changed in the second lab assignment). In that case, the git merge command will tell you which files are _conflicted_ , and you should first resolve the conflict (by editing the relevant files) and then commit the resulting files with git commit -a.
|
||||
|
||||
Lab 2 contains the following new source files, which you should browse through:
|
||||
|
||||
* `inc/memlayout.h`
|
||||
* `kern/pmap.c`
|
||||
* `kern/pmap.h`
|
||||
* `kern/kclock.h`
|
||||
* `kern/kclock.c`
|
||||
|
||||
|
||||
|
||||
`memlayout.h` describes the layout of the virtual address space that you must implement by modifying `pmap.c`. `memlayout.h` and `pmap.h` define the `PageInfo` structure that you'll use to keep track of which pages of physical memory are free. `kclock.c` and `kclock.h` manipulate the PC's battery-backed clock and CMOS RAM hardware, in which the BIOS records the amount of physical memory the PC contains, among other things. The code in `pmap.c` needs to read this device hardware in order to figure out how much physical memory there is, but that part of the code is done for you: you do not need to know the details of how the CMOS hardware works.
|
||||
|
||||
Pay particular attention to `memlayout.h` and `pmap.h`, since this lab requires you to use and understand many of the definitions they contain. You may want to review `inc/mmu.h`, too, as it also contains a number of definitions that will be useful for this lab.
|
||||
|
||||
Before beginning the lab, don't forget to add -f 6.828 to get the 6.828 version of QEMU.
|
||||
|
||||
##### Lab Requirements
|
||||
|
||||
In this lab and subsequent labs, do all of the regular exercises described in the lab and _at least one_ challenge problem. (Some challenge problems are more challenging than others, of course!) Additionally, write up brief answers to the questions posed in the lab and a short (e.g., one or two paragraph) description of what you did to solve your chosen challenge problem. If you implement more than one challenge problem, you only need to describe one of them in the write-up, though of course you are welcome to do more. Place the write-up in a file called `answers-lab2.txt` in the top level of your `lab` directory before handing in your work.
|
||||
|
||||
##### Hand-In Procedure
|
||||
|
||||
When you are ready to hand in your lab code and write-up, add your `answers-lab2.txt` to the Git repository, commit your changes, and then run make handin.
|
||||
|
||||
```
|
||||
athena% git add answers-lab2.txt
|
||||
athena% git commit -am "my answer to lab2"
|
||||
[lab2 a823de9] my answer to lab2
|
||||
4 files changed, 87 insertions(+), 10 deletions(-)
|
||||
athena% make handin
|
||||
```
|
||||
|
||||
As before, we will be grading your solutions with a grading program. You can run make grade in the `lab` directory to test your kernel with the grading program. You may change any of the kernel source and header files you need to in order to complete the lab, but needless to say you must not change or otherwise subvert the grading code.
|
||||
|
||||
#### Part 1: Physical Page Management
|
||||
|
||||
The operating system must keep track of which parts of physical RAM are free and which are currently in use. JOS manages the PC's physical memory with _page granularity_ so that it can use the MMU to map and protect each piece of allocated memory.
|
||||
|
||||
You'll now write the physical page allocator. It keeps track of which pages are free with a linked list of `struct PageInfo` objects (which, unlike xv6, are not embedded in the free pages themselves), each corresponding to a physical page. You need to write the physical page allocator before you can write the rest of the virtual memory implementation, because your page table management code will need to allocate physical memory in which to store page tables.
|
||||
|
||||
Exercise 1. In the file `kern/pmap.c`, you must implement code for the following functions (probably in the order given).
|
||||
|
||||
`boot_alloc()`
|
||||
`mem_init()` (only up to the call to `check_page_free_list(1)`)
|
||||
`page_init()`
|
||||
`page_alloc()`
|
||||
`page_free()`
|
||||
|
||||
`check_page_free_list()` and `check_page_alloc()` test your physical page allocator. You should boot JOS and see whether `check_page_alloc()` reports success. Fix your code so that it passes. You may find it helpful to add your own `assert()`s to verify that your assumptions are correct.
|
||||
|
||||
This lab, and all the 6.828 labs, will require you to do a bit of detective work to figure out exactly what you need to do. This assignment does not describe all the details of the code you'll have to add to JOS. Look for comments in the parts of the JOS source that you have to modify; those comments often contain specifications and hints. You will also need to look at related parts of JOS, at the Intel manuals, and perhaps at your 6.004 or 6.033 notes.
|
||||
|
||||
#### Part 2: Virtual Memory
|
||||
|
||||
Before doing anything else, familiarize yourself with the x86's protected-mode memory management architecture: namely _segmentation_ and _page translation_.
|
||||
|
||||
Exercise 2. Look at chapters 5 and 6 of the [Intel 80386 Reference Manual][1], if you haven't done so already. Read the sections about page translation and page-based protection closely (5.2 and 6.4). We recommend that you also skim the sections about segmentation; while JOS uses the paging hardware for virtual memory and protection, segment translation and segment-based protection cannot be disabled on the x86, so you will need a basic understanding of it.
|
||||
|
||||
##### Virtual, Linear, and Physical Addresses
|
||||
|
||||
In x86 terminology, a _virtual address_ consists of a segment selector and an offset within the segment. A _linear address_ is what you get after segment translation but before page translation. A _physical address_ is what you finally get after both segment and page translation and what ultimately goes out on the hardware bus to your RAM.
|
||||
|
||||
```
|
||||
Selector +--------------+ +-----------+
|
||||
---------->| | | |
|
||||
| Segmentation | | Paging |
|
||||
Software | |-------->| |----------> RAM
|
||||
Offset | Mechanism | | Mechanism |
|
||||
---------->| | | |
|
||||
+--------------+ +-----------+
|
||||
Virtual Linear Physical
|
||||
|
||||
```
|
||||
|
||||
A C pointer is the "offset" component of the virtual address. In `boot/boot.S`, we installed a Global Descriptor Table (GDT) that effectively disabled segment translation by setting all segment base addresses to 0 and limits to `0xffffffff`. Hence the "selector" has no effect and the linear address always equals the offset of the virtual address. In lab 3, we'll have to interact a little more with segmentation to set up privilege levels, but as for memory translation, we can ignore segmentation throughout the JOS labs and focus solely on page translation.
|
||||
|
||||
Recall that in part 3 of lab 1, we installed a simple page table so that the kernel could run at its link address of 0xf0100000, even though it is actually loaded in physical memory just above the ROM BIOS at 0x00100000. This page table mapped only 4MB of memory. In the virtual address space layout you are going to set up for JOS in this lab, we'll expand this to map the first 256MB of physical memory starting at virtual address 0xf0000000 and to map a number of other regions of the virtual address space.
|
||||
|
||||
Exercise 3. While GDB can only access QEMU's memory by virtual address, it's often useful to be able to inspect physical memory while setting up virtual memory. Review the QEMU [monitor commands][2] from the lab tools guide, especially the `xp` command, which lets you inspect physical memory. To access the QEMU monitor, press Ctrl-a c in the terminal (the same binding returns to the serial console).
|
||||
|
||||
Use the xp command in the QEMU monitor and the x command in GDB to inspect memory at corresponding physical and virtual addresses and make sure you see the same data.
|
||||
|
||||
Our patched version of QEMU provides an info pg command that may also prove useful: it shows a compact but detailed representation of the current page tables, including all mapped memory ranges, permissions, and flags. Stock QEMU also provides an info mem command that shows an overview of which ranges of virtual addresses are mapped and with what permissions.
|
||||
|
||||
From code executing on the CPU, once we're in protected mode (which we entered first thing in `boot/boot.S`), there's no way to directly use a linear or physical address. _All_ memory references are interpreted as virtual addresses and translated by the MMU, which means all pointers in C are virtual addresses.
|
||||
|
||||
The JOS kernel often needs to manipulate addresses as opaque values or as integers, without dereferencing them, for example in the physical memory allocator. Sometimes these are virtual addresses, and sometimes they are physical addresses. To help document the code, the JOS source distinguishes the two cases: the type `uintptr_t` represents opaque virtual addresses, and `physaddr_t` represents physical addresses. Both these types are really just synonyms for 32-bit integers (`uint32_t`), so the compiler won't stop you from assigning one type to another! Since they are integer types (not pointers), the compiler _will_ complain if you try to dereference them.
|
||||
|
||||
The JOS kernel can dereference a `uintptr_t` by first casting it to a pointer type. In contrast, the kernel can't sensibly dereference a physical address, since the MMU translates all memory references. If you cast a `physaddr_t` to a pointer and dereference it, you may be able to load and store to the resulting address (the hardware will interpret it as a virtual address), but you probably won't get the memory location you intended.
|
||||
|
||||
To summarize:
|
||||
|
||||
C typeAddress type `T*` Virtual `uintptr_t` Virtual `physaddr_t` Physical
|
||||
|
||||
Question
|
||||
|
||||
1. Assuming that the following JOS kernel code is correct, what type should variable `x` have, `uintptr_t` or `physaddr_t`?
|
||||
|
||||
```
|
||||
mystery_t x;
|
||||
char* value = return_a_pointer();
|
||||
*value = 10;
|
||||
x = (mystery_t) value;
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
The JOS kernel sometimes needs to read or modify memory for which it knows only the physical address. For example, adding a mapping to a page table may require allocating physical memory to store a page directory and then initializing that memory. However, the kernel cannot bypass virtual address translation and thus cannot directly load and store to physical addresses. One reason JOS remaps all of physical memory starting from physical address 0 at virtual address 0xf0000000 is to help the kernel read and write memory for which it knows just the physical address. In order to translate a physical address into a virtual address that the kernel can actually read and write, the kernel must add 0xf0000000 to the physical address to find its corresponding virtual address in the remapped region. You should use `KADDR(pa)` to do that addition.
|
||||
|
||||
The JOS kernel also sometimes needs to be able to find a physical address given the virtual address of the memory in which a kernel data structure is stored. Kernel global variables and memory allocated by `boot_alloc()` are in the region where the kernel was loaded, starting at 0xf0000000, the very region where we mapped all of physical memory. Thus, to turn a virtual address in this region into a physical address, the kernel can simply subtract 0xf0000000. You should use `PADDR(va)` to do that subtraction.
|
||||
|
||||
##### Reference counting
|
||||
|
||||
In future labs you will often have the same physical page mapped at multiple virtual addresses simultaneously (or in the address spaces of multiple environments). You will keep a count of the number of references to each physical page in the `pp_ref` field of the `struct PageInfo` corresponding to the physical page. When this count goes to zero for a physical page, that page can be freed because it is no longer used. In general, this count should be equal to the number of times the physical page appears below `UTOP` in all page tables (the mappings above `UTOP` are mostly set up at boot time by the kernel and should never be freed, so there's no need to reference count them). We'll also use it to keep track of the number of pointers we keep to the page directory pages and, in turn, of the number of references the page directories have to page table pages.
|
||||
|
||||
Be careful when using `page_alloc`. The page it returns will always have a reference count of 0, so `pp_ref` should be incremented as soon as you've done something with the returned page (like inserting it into a page table). Sometimes this is handled by other functions (for example, `page_insert`) and sometimes the function calling `page_alloc` must do it directly.
|
||||
|
||||
##### Page Table Management
|
||||
|
||||
Now you'll write a set of routines to manage page tables: to insert and remove linear-to-physical mappings, and to create page table pages when needed.
|
||||
|
||||
Exercise 4. In the file `kern/pmap.c`, you must implement code for the following functions.
|
||||
|
||||
```
|
||||
|
||||
pgdir_walk()
|
||||
boot_map_region()
|
||||
page_lookup()
|
||||
page_remove()
|
||||
page_insert()
|
||||
|
||||
|
||||
```
|
||||
|
||||
`check_page()`, called from `mem_init()`, tests your page table management routines. You should make sure it reports success before proceeding.
|
||||
|
||||
#### Part 3: Kernel Address Space
|
||||
|
||||
JOS divides the processor's 32-bit linear address space into two parts. User environments (processes), which we will begin loading and running in lab 3, will have control over the layout and contents of the lower part, while the kernel always maintains complete control over the upper part. The dividing line is defined somewhat arbitrarily by the symbol `ULIM` in `inc/memlayout.h`, reserving approximately 256MB of virtual address space for the kernel. This explains why we needed to give the kernel such a high link address in lab 1: otherwise there would not be enough room in the kernel's virtual address space to map in a user environment below it at the same time.
|
||||
|
||||
You'll find it helpful to refer to the JOS memory layout diagram in `inc/memlayout.h` both for this part and for later labs.
|
||||
|
||||
##### Permissions and Fault Isolation
|
||||
|
||||
Since kernel and user memory are both present in each environment's address space, we will have to use permission bits in our x86 page tables to allow user code access only to the user part of the address space. Otherwise bugs in user code might overwrite kernel data, causing a crash or more subtle malfunction; user code might also be able to steal other environments' private data. Note that the writable permission bit (`PTE_W`) affects both user and kernel code!
|
||||
|
||||
The user environment will have no permission to any of the memory above `ULIM`, while the kernel will be able to read and write this memory. For the address range `[UTOP,ULIM)`, both the kernel and the user environment have the same permission: they can read but not write this address range. This range of address is used to expose certain kernel data structures read-only to the user environment. Lastly, the address space below `UTOP` is for the user environment to use; the user environment will set permissions for accessing this memory.
|
||||
|
||||
##### Initializing the Kernel Address Space
|
||||
|
||||
Now you'll set up the address space above `UTOP`: the kernel part of the address space. `inc/memlayout.h` shows the layout you should use. You'll use the functions you just wrote to set up the appropriate linear to physical mappings.
|
||||
|
||||
Exercise 5. Fill in the missing code in `mem_init()` after the call to `check_page()`.
|
||||
|
||||
Your code should now pass the `check_kern_pgdir()` and `check_page_installed_pgdir()` checks.
|
||||
|
||||
Question
|
||||
|
||||
2. What entries (rows) in the page directory have been filled in at this point? What addresses do they map and where do they point? In other words, fill out this table as much as possible:
|
||||
| Entry | Base Virtual Address | Points to (logically): |
|
||||
|-------|----------------------|---------------------------------------|
|
||||
| 1023 | ? | Page table for top 4MB of phys memory |
|
||||
| 1022 | ? | ? |
|
||||
| . | ? | ? |
|
||||
| . | ? | ? |
|
||||
| . | ? | ? |
|
||||
| 2 | 0x00800000 | ? |
|
||||
| 1 | 0x00400000 | ? |
|
||||
| 0 | 0x00000000 | [see next question] |
|
||||
3. We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel's memory? What specific mechanisms protect the kernel memory?
|
||||
4. What is the maximum amount of physical memory that this operating system can support? Why?
|
||||
5. How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
|
||||
6. Revisit the page table setup in `kern/entry.S` and `kern/entrypgdir.c`. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
|
||||
|
||||
|
||||
```
|
||||
Challenge! We consumed many physical pages to hold the page tables for the KERNBASE mapping. Do a more space-efficient job using the PTE_PS ("Page Size") bit in the page directory entries. This bit was _not_ supported in the original 80386, but is supported on more recent x86 processors. You will therefore have to refer to [Volume 3 of the current Intel manuals][3]. Make sure you design the kernel to use this optimization only on processors that support it!
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Extend the JOS kernel monitor with commands to:
|
||||
|
||||
* Display in a useful and easy-to-read format all of the physical page mappings (or lack thereof) that apply to a particular range of virtual/linear addresses in the currently active address space. For example, you might enter `'showmappings 0x3000 0x5000'` to display the physical page mappings and corresponding permission bits that apply to the pages at virtual addresses 0x3000, 0x4000, and 0x5000.
|
||||
* Explicitly set, clear, or change the permissions of any mapping in the current address space.
|
||||
* Dump the contents of a range of memory given either a virtual or physical address range. Be sure the dump code behaves correctly when the range extends across page boundaries!
|
||||
* Do anything else that you think might be useful later for debugging the kernel. (There's a good chance it will be!)
|
||||
```
|
||||
|
||||
|
||||
##### Address Space Layout Alternatives
|
||||
|
||||
The address space layout we use in JOS is not the only one possible. An operating system might map the kernel at low linear addresses while leaving the _upper_ part of the linear address space for user processes. x86 kernels generally do not take this approach, however, because one of the x86's backward-compatibility modes, known as _virtual 8086 mode_ , is "hard-wired" in the processor to use the bottom part of the linear address space, and thus cannot be used at all if the kernel is mapped there.
|
||||
|
||||
It is even possible, though much more difficult, to design the kernel so as not to have to reserve _any_ fixed portion of the processor's linear or virtual address space for itself, but instead effectively to allow user-level processes unrestricted use of the _entire_ 4GB of virtual address space - while still fully protecting the kernel from these processes and protecting different processes from each other!
|
||||
|
||||
```
|
||||
Challenge! Each user-level environment maps the kernel. Change JOS so that the kernel has its own page table and so that a user-level environment runs with a minimal number of kernel pages mapped. That is, each user-level environment maps just enough pages mapped so that the user-level environment can enter and leave the kernel correctly. You also have to come up with a plan for the kernel to read/write arguments to system calls.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Write up an outline of how a kernel could be designed to allow user environments unrestricted use of the full 4GB virtual and linear address space. Hint: do the previous challenge exercise first, which reduces the kernel to a few mappings in a user environment. Hint: the technique is sometimes known as " _follow the bouncing kernel_. " In your design, be sure to address exactly what has to happen when the processor transitions between kernel and user modes, and how the kernel would accomplish such transitions. Also describe how the kernel would access physical memory and I/O devices in this scheme, and how the kernel would access a user environment's virtual address space during system calls and the like. Finally, think about and describe the advantages and disadvantages of such a scheme in terms of flexibility, performance, kernel complexity, and other factors you can think of.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Since our JOS kernel's memory management system only allocates and frees memory on page granularity, we do not have anything comparable to a general-purpose `malloc`/`free` facility that we can use within the kernel. This could be a problem if we want to support certain types of I/O devices that require _physically contiguous_ buffers larger than 4KB in size, or if we want user-level environments, and not just the kernel, to be able to allocate and map 4MB _superpages_ for maximum processor efficiency. (See the earlier challenge problem about PTE_PS.)
|
||||
|
||||
Generalize the kernel's memory allocation system to support pages of a variety of power-of-two allocation unit sizes from 4KB up to some reasonable maximum of your choice. Be sure you have some way to divide larger allocation units into smaller ones on demand, and to coalesce multiple small allocation units back into larger units when possible. Think about the issues that might arise in such a system.
|
||||
```
|
||||
|
||||
**This completes the lab.** Make sure you pass all of the make grade tests and don't forget to write up your answers to the questions and a description of your challenge exercise solution in `answers-lab2.txt`. Commit your changes (including adding `answers-lab2.txt`) and type make handin in the `lab` directory to hand in your lab.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab2/
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pdos.csail.mit.edu/6.828/2018/readings/i386/toc.htm
|
||||
[2]: https://pdos.csail.mit.edu/6.828/2018/labguide.html#qemu
|
||||
[3]: https://pdos.csail.mit.edu/6.828/2018/readings/ia32/IA32-3A.pdf
|
||||
524
sources/tech/20181004 Lab 3- User Environments.md
Normal file
524
sources/tech/20181004 Lab 3- User Environments.md
Normal file
@ -0,0 +1,524 @@
|
||||
Lab 3: User Environments
|
||||
======
|
||||
### Lab 3: User Environments
|
||||
|
||||
#### Introduction
|
||||
|
||||
In this lab you will implement the basic kernel facilities required to get a protected user-mode environment (i.e., "process") running. You will enhance the JOS kernel to set up the data structures to keep track of user environments, create a single user environment, load a program image into it, and start it running. You will also make the JOS kernel capable of handling any system calls the user environment makes and handling any other exceptions it causes.
|
||||
|
||||
**Note:** In this lab, the terms _environment_ and _process_ are interchangeable - both refer to an abstraction that allows you to run a program. We introduce the term "environment" instead of the traditional term "process" in order to stress the point that JOS environments and UNIX processes provide different interfaces, and do not provide the same semantics.
|
||||
|
||||
##### Getting Started
|
||||
|
||||
Use Git to commit your changes after your Lab 2 submission (if any), fetch the latest version of the course repository, and then create a local branch called `lab3` based on our lab3 branch, `origin/lab3`:
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'changes to lab2 after handin'
|
||||
Created commit 734fab7: changes to lab2 after handin
|
||||
4 files changed, 42 insertions(+), 9 deletions(-)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab3 origin/lab3
|
||||
Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
|
||||
Switched to a new branch "lab3"
|
||||
athena% git merge lab2
|
||||
Merge made by recursive.
|
||||
kern/pmap.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
Lab 3 contains a number of new source files, which you should browse:
|
||||
|
||||
```
|
||||
inc/ env.h Public definitions for user-mode environments
|
||||
trap.h Public definitions for trap handling
|
||||
syscall.h Public definitions for system calls from user environments to the kernel
|
||||
lib.h Public definitions for the user-mode support library
|
||||
kern/ env.h Kernel-private definitions for user-mode environments
|
||||
env.c Kernel code implementing user-mode environments
|
||||
trap.h Kernel-private trap handling definitions
|
||||
trap.c Trap handling code
|
||||
trapentry.S Assembly-language trap handler entry-points
|
||||
syscall.h Kernel-private definitions for system call handling
|
||||
syscall.c System call implementation code
|
||||
lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
|
||||
entry.S Assembly-language entry-point for user environments
|
||||
libmain.c User-mode library setup code called from entry.S
|
||||
syscall.c User-mode system call stub functions
|
||||
console.c User-mode implementations of putchar and getchar, providing console I/O
|
||||
exit.c User-mode implementation of exit
|
||||
panic.c User-mode implementation of panic
|
||||
user/ * Various test programs to check kernel lab 3 code
|
||||
```
|
||||
|
||||
In addition, a number of the source files we handed out for lab2 are modified in lab3. To see the differences, you can type:
|
||||
|
||||
```
|
||||
$ git diff lab2
|
||||
|
||||
```
|
||||
|
||||
You may also want to take another look at the [lab tools guide][1], as it includes information on debugging user code that becomes relevant in this lab.
|
||||
|
||||
##### Lab Requirements
|
||||
|
||||
This lab is divided into two parts, A and B. Part A is due a week after this lab was assigned; you should commit your changes and make handin your lab before the Part A deadline, making sure your code passes all of the Part A tests (it is okay if your code does not pass the Part B tests yet). You only need to have the Part B tests passing by the Part B deadline at the end of the second week.
|
||||
|
||||
As in lab 2, you will need to do all of the regular exercises described in the lab and _at least one_ challenge problem (for the entire lab, not for each part). Write up brief answers to the questions posed in the lab and a one or two paragraph description of what you did to solve your chosen challenge problem in a file called `answers-lab3.txt` in the top level of your `lab` directory. (If you implement more than one challenge problem, you only need to describe one of them in the write-up.) Do not forget to include the answer file in your submission with git add answers-lab3.txt.
|
||||
|
||||
##### Inline Assembly
|
||||
|
||||
In this lab you may find GCC's inline assembly language feature useful, although it is also possible to complete the lab without using it. At the very least, you will need to be able to understand the fragments of inline assembly language ("`asm`" statements) that already exist in the source code we gave you. You can find several sources of information on GCC inline assembly language on the class [reference materials][2] page.
|
||||
|
||||
#### Part A: User Environments and Exception Handling
|
||||
|
||||
The new include file `inc/env.h` contains basic definitions for user environments in JOS. Read it now. The kernel uses the `Env` data structure to keep track of each user environment. In this lab you will initially create just one environment, but you will need to design the JOS kernel to support multiple environments; lab 4 will take advantage of this feature by allowing a user environment to `fork` other environments.
|
||||
|
||||
As you can see in `kern/env.c`, the kernel maintains three main global variables pertaining to environments:
|
||||
|
||||
```
|
||||
struct Env *envs = NULL; // All environments
|
||||
struct Env *curenv = NULL; // The current env
|
||||
static struct Env *env_free_list; // Free environment list
|
||||
|
||||
```
|
||||
|
||||
Once JOS gets up and running, the `envs` pointer points to an array of `Env` structures representing all the environments in the system. In our design, the JOS kernel will support a maximum of `NENV` simultaneously active environments, although there will typically be far fewer running environments at any given time. (`NENV` is a constant `#define`'d in `inc/env.h`.) Once it is allocated, the `envs` array will contain a single instance of the `Env` data structure for each of the `NENV` possible environments.
|
||||
|
||||
The JOS kernel keeps all of the inactive `Env` structures on the `env_free_list`. This design allows easy allocation and deallocation of environments, as they merely have to be added to or removed from the free list.
|
||||
|
||||
The kernel uses the `curenv` symbol to keep track of the _currently executing_ environment at any given time. During boot up, before the first environment is run, `curenv` is initially set to `NULL`.
|
||||
|
||||
##### Environment State
|
||||
|
||||
The `Env` structure is defined in `inc/env.h` as follows (although more fields will be added in future labs):
|
||||
|
||||
```
|
||||
struct Env {
|
||||
struct Trapframe env_tf; // Saved registers
|
||||
struct Env *env_link; // Next free Env
|
||||
envid_t env_id; // Unique environment identifier
|
||||
envid_t env_parent_id; // env_id of this env's parent
|
||||
enum EnvType env_type; // Indicates special system environments
|
||||
unsigned env_status; // Status of the environment
|
||||
uint32_t env_runs; // Number of times environment has run
|
||||
|
||||
// Address space
|
||||
pde_t *env_pgdir; // Kernel virtual address of page dir
|
||||
};
|
||||
```
|
||||
|
||||
Here's what the `Env` fields are for:
|
||||
|
||||
* **env_tf** :
|
||||
This structure, defined in `inc/trap.h`, holds the saved register values for the environment while that environment is _not_ running: i.e., when the kernel or a different environment is running. The kernel saves these when switching from user to kernel mode, so that the environment can later be resumed where it left off.
|
||||
* **env_link** :
|
||||
This is a link to the next `Env` on the `env_free_list`. `env_free_list` points to the first free environment on the list.
|
||||
* **env_id** :
|
||||
The kernel stores here a value that uniquely identifiers the environment currently using this `Env` structure (i.e., using this particular slot in the `envs` array). After a user environment terminates, the kernel may re-allocate the same `Env` structure to a different environment - but the new environment will have a different `env_id` from the old one even though the new environment is re-using the same slot in the `envs` array.
|
||||
* **env_parent_id** :
|
||||
The kernel stores here the `env_id` of the environment that created this environment. In this way the environments can form a “family tree,” which will be useful for making security decisions about which environments are allowed to do what to whom.
|
||||
* **env_type** :
|
||||
This is used to distinguish special environments. For most environments, it will be `ENV_TYPE_USER`. We'll introduce a few more types for special system service environments in later labs.
|
||||
* **env_status** :
|
||||
This variable holds one of the following values:
|
||||
* `ENV_FREE`:
|
||||
Indicates that the `Env` structure is inactive, and therefore on the `env_free_list`.
|
||||
* `ENV_RUNNABLE`:
|
||||
Indicates that the `Env` structure represents an environment that is waiting to run on the processor.
|
||||
* `ENV_RUNNING`:
|
||||
Indicates that the `Env` structure represents the currently running environment.
|
||||
* `ENV_NOT_RUNNABLE`:
|
||||
Indicates that the `Env` structure represents a currently active environment, but it is not currently ready to run: for example, because it is waiting for an interprocess communication (IPC) from another environment.
|
||||
* `ENV_DYING`:
|
||||
Indicates that the `Env` structure represents a zombie environment. A zombie environment will be freed the next time it traps to the kernel. We will not use this flag until Lab 4.
|
||||
* **env_pgdir** :
|
||||
This variable holds the kernel _virtual address_ of this environment's page directory.
|
||||
|
||||
|
||||
|
||||
Like a Unix process, a JOS environment couples the concepts of "thread" and "address space". The thread is defined primarily by the saved registers (the `env_tf` field), and the address space is defined by the page directory and page tables pointed to by `env_pgdir`. To run an environment, the kernel must set up the CPU with _both_ the saved registers and the appropriate address space.
|
||||
|
||||
Our `struct Env` is analogous to `struct proc` in xv6. Both structures hold the environment's (i.e., process's) user-mode register state in a `Trapframe` structure. In JOS, individual environments do not have their own kernel stacks as processes do in xv6. There can be only one JOS environment active in the kernel at a time, so JOS needs only a _single_ kernel stack.
|
||||
|
||||
##### Allocating the Environments Array
|
||||
|
||||
In lab 2, you allocated memory in `mem_init()` for the `pages[]` array, which is a table the kernel uses to keep track of which pages are free and which are not. You will now need to modify `mem_init()` further to allocate a similar array of `Env` structures, called `envs`.
|
||||
|
||||
```
|
||||
Exercise 1. Modify `mem_init()` in `kern/pmap.c` to allocate and map the `envs` array. This array consists of exactly `NENV` instances of the `Env` structure allocated much like how you allocated the `pages` array. Also like the `pages` array, the memory backing `envs` should also be mapped user read-only at `UENVS` (defined in `inc/memlayout.h`) so user processes can read from this array.
|
||||
```
|
||||
|
||||
You should run your code and make sure `check_kern_pgdir()` succeeds.
|
||||
|
||||
##### Creating and Running Environments
|
||||
|
||||
You will now write the code in `kern/env.c` necessary to run a user environment. Because we do not yet have a filesystem, we will set up the kernel to load a static binary image that is _embedded within the kernel itself_. JOS embeds this binary in the kernel as a ELF executable image.
|
||||
|
||||
The Lab 3 `GNUmakefile` generates a number of binary images in the `obj/user/` directory. If you look at `kern/Makefrag`, you will notice some magic that "links" these binaries directly into the kernel executable as if they were `.o` files. The `-b binary` option on the linker command line causes these files to be linked in as "raw" uninterpreted binary files rather than as regular `.o` files produced by the compiler. (As far as the linker is concerned, these files do not have to be ELF images at all - they could be anything, such as text files or pictures!) If you look at `obj/kern/kernel.sym` after building the kernel, you will notice that the linker has "magically" produced a number of funny symbols with obscure names like `_binary_obj_user_hello_start`, `_binary_obj_user_hello_end`, and `_binary_obj_user_hello_size`. The linker generates these symbol names by mangling the file names of the binary files; the symbols provide the regular kernel code with a way to reference the embedded binary files.
|
||||
|
||||
In `i386_init()` in `kern/init.c` you'll see code to run one of these binary images in an environment. However, the critical functions to set up user environments are not complete; you will need to fill them in.
|
||||
|
||||
```
|
||||
Exercise 2. In the file `env.c`, finish coding the following functions:
|
||||
|
||||
* `env_init()`
|
||||
Initialize all of the `Env` structures in the `envs` array and add them to the `env_free_list`. Also calls `env_init_percpu`, which configures the segmentation hardware with separate segments for privilege level 0 (kernel) and privilege level 3 (user).
|
||||
* `env_setup_vm()`
|
||||
Allocate a page directory for a new environment and initialize the kernel portion of the new environment's address space.
|
||||
* `region_alloc()`
|
||||
Allocates and maps physical memory for an environment
|
||||
* `load_icode()`
|
||||
You will need to parse an ELF binary image, much like the boot loader already does, and load its contents into the user address space of a new environment.
|
||||
* `env_create()`
|
||||
Allocate an environment with `env_alloc` and call `load_icode` to load an ELF binary into it.
|
||||
* `env_run()`
|
||||
Start a given environment running in user mode.
|
||||
|
||||
|
||||
|
||||
As you write these functions, you might find the new cprintf verb `%e` useful -- it prints a description corresponding to an error code. For example,
|
||||
|
||||
r = -E_NO_MEM;
|
||||
panic("env_alloc: %e", r);
|
||||
|
||||
will panic with the message "env_alloc: out of memory".
|
||||
```
|
||||
|
||||
Below is a call graph of the code up to the point where the user code is invoked. Make sure you understand the purpose of each step.
|
||||
|
||||
* `start` (`kern/entry.S`)
|
||||
* `i386_init` (`kern/init.c`)
|
||||
* `cons_init`
|
||||
* `mem_init`
|
||||
* `env_init`
|
||||
* `trap_init` (still incomplete at this point)
|
||||
* `env_create`
|
||||
* `env_run`
|
||||
* `env_pop_tf`
|
||||
|
||||
|
||||
|
||||
Once you are done you should compile your kernel and run it under QEMU. If all goes well, your system should enter user space and execute the `hello` binary until it makes a system call with the `int` instruction. At that point there will be trouble, since JOS has not set up the hardware to allow any kind of transition from user space into the kernel. When the CPU discovers that it is not set up to handle this system call interrupt, it will generate a general protection exception, find that it can't handle that, generate a double fault exception, find that it can't handle that either, and finally give up with what's known as a "triple fault". Usually, you would then see the CPU reset and the system reboot. While this is important for legacy applications (see [this blog post][3] for an explanation of why), it's a pain for kernel development, so with the 6.828 patched QEMU you'll instead see a register dump and a "Triple fault." message.
|
||||
|
||||
We'll address this problem shortly, but for now we can use the debugger to check that we're entering user mode. Use make qemu-gdb and set a GDB breakpoint at `env_pop_tf`, which should be the last function you hit before actually entering user mode. Single step through this function using si; the processor should enter user mode after the `iret` instruction. You should then see the first instruction in the user environment's executable, which is the `cmpl` instruction at the label `start` in `lib/entry.S`. Now use b *0x... to set a breakpoint at the `int $0x30` in `sys_cputs()` in `hello` (see `obj/user/hello.asm` for the user-space address). This `int` is the system call to display a character to the console. If you cannot execute as far as the `int`, then something is wrong with your address space setup or program loading code; go back and fix it before continuing.
|
||||
|
||||
##### Handling Interrupts and Exceptions
|
||||
|
||||
At this point, the first `int $0x30` system call instruction in user space is a dead end: once the processor gets into user mode, there is no way to get back out. You will now need to implement basic exception and system call handling, so that it is possible for the kernel to recover control of the processor from user-mode code. The first thing you should do is thoroughly familiarize yourself with the x86 interrupt and exception mechanism.
|
||||
|
||||
```
|
||||
Exercise 3. Read Chapter 9, Exceptions and Interrupts in the 80386 Programmer's Manual (or Chapter 5 of the IA-32 Developer's Manual), if you haven't already.
|
||||
```
|
||||
|
||||
In this lab we generally follow Intel's terminology for interrupts, exceptions, and the like. However, terms such as exception, trap, interrupt, fault and abort have no standard meaning across architectures or operating systems, and are often used without regard to the subtle distinctions between them on a particular architecture such as the x86. When you see these terms outside of this lab, the meanings might be slightly different.
|
||||
|
||||
##### Basics of Protected Control Transfer
|
||||
|
||||
Exceptions and interrupts are both "protected control transfers," which cause the processor to switch from user to kernel mode (CPL=0) without giving the user-mode code any opportunity to interfere with the functioning of the kernel or other environments. In Intel's terminology, an _interrupt_ is a protected control transfer that is caused by an asynchronous event usually external to the processor, such as notification of external device I/O activity. An _exception_ , in contrast, is a protected control transfer caused synchronously by the currently running code, for example due to a divide by zero or an invalid memory access.
|
||||
|
||||
In order to ensure that these protected control transfers are actually _protected_ , the processor's interrupt/exception mechanism is designed so that the code currently running when the interrupt or exception occurs _does not get to choose arbitrarily where the kernel is entered or how_. Instead, the processor ensures that the kernel can be entered only under carefully controlled conditions. On the x86, two mechanisms work together to provide this protection:
|
||||
|
||||
1. **The Interrupt Descriptor Table.** The processor ensures that interrupts and exceptions can only cause the kernel to be entered at a few specific, well-defined entry-points _determined by the kernel itself_ , and not by the code running when the interrupt or exception is taken.
|
||||
|
||||
The x86 allows up to 256 different interrupt or exception entry points into the kernel, each with a different _interrupt vector_. A vector is a number between 0 and 255. An interrupt's vector is determined by the source of the interrupt: different devices, error conditions, and application requests to the kernel generate interrupts with different vectors. The CPU uses the vector as an index into the processor's _interrupt descriptor table_ (IDT), which the kernel sets up in kernel-private memory, much like the GDT. From the appropriate entry in this table the processor loads:
|
||||
|
||||
* the value to load into the instruction pointer (`EIP`) register, pointing to the kernel code designated to handle that type of exception.
|
||||
* the value to load into the code segment (`CS`) register, which includes in bits 0-1 the privilege level at which the exception handler is to run. (In JOS, all exceptions are handled in kernel mode, privilege level 0.)
|
||||
2. **The Task State Segment.** The processor needs a place to save the _old_ processor state before the interrupt or exception occurred, such as the original values of `EIP` and `CS` before the processor invoked the exception handler, so that the exception handler can later restore that old state and resume the interrupted code from where it left off. But this save area for the old processor state must in turn be protected from unprivileged user-mode code; otherwise buggy or malicious user code could compromise the kernel.
|
||||
|
||||
For this reason, when an x86 processor takes an interrupt or trap that causes a privilege level change from user to kernel mode, it also switches to a stack in the kernel's memory. A structure called the _task state segment_ (TSS) specifies the segment selector and address where this stack lives. The processor pushes (on this new stack) `SS`, `ESP`, `EFLAGS`, `CS`, `EIP`, and an optional error code. Then it loads the `CS` and `EIP` from the interrupt descriptor, and sets the `ESP` and `SS` to refer to the new stack.
|
||||
|
||||
Although the TSS is large and can potentially serve a variety of purposes, JOS only uses it to define the kernel stack that the processor should switch to when it transfers from user to kernel mode. Since "kernel mode" in JOS is privilege level 0 on the x86, the processor uses the `ESP0` and `SS0` fields of the TSS to define the kernel stack when entering kernel mode. JOS doesn't use any other TSS fields.
|
||||
|
||||
|
||||
|
||||
|
||||
##### Types of Exceptions and Interrupts
|
||||
|
||||
All of the synchronous exceptions that the x86 processor can generate internally use interrupt vectors between 0 and 31, and therefore map to IDT entries 0-31. For example, a page fault always causes an exception through vector 14. Interrupt vectors greater than 31 are only used by _software interrupts_ , which can be generated by the `int` instruction, or asynchronous _hardware interrupts_ , caused by external devices when they need attention.
|
||||
|
||||
In this section we will extend JOS to handle the internally generated x86 exceptions in vectors 0-31. In the next section we will make JOS handle software interrupt vector 48 (0x30), which JOS (fairly arbitrarily) uses as its system call interrupt vector. In Lab 4 we will extend JOS to handle externally generated hardware interrupts such as the clock interrupt.
|
||||
|
||||
##### An Example
|
||||
|
||||
Let's put these pieces together and trace through an example. Let's say the processor is executing code in a user environment and encounters a divide instruction that attempts to divide by zero.
|
||||
|
||||
1. The processor switches to the stack defined by the `SS0` and `ESP0` fields of the TSS, which in JOS will hold the values `GD_KD` and `KSTACKTOP`, respectively.
|
||||
|
||||
2. The processor pushes the exception parameters on the kernel stack, starting at address `KSTACKTOP`:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20 <---- ESP
|
||||
+--------------------+
|
||||
|
||||
```
|
||||
|
||||
3. Because we're handling a divide error, which is interrupt vector 0 on the x86, the processor reads IDT entry 0 and sets `CS:EIP` to point to the handler function described by the entry.
|
||||
|
||||
4. The handler function takes control and handles the exception, for example by terminating the user environment.
|
||||
|
||||
|
||||
|
||||
|
||||
For certain types of x86 exceptions, in addition to the "standard" five words above, the processor pushes onto the stack another word containing an _error code_. The page fault exception, number 14, is an important example. See the 80386 manual to determine for which exception numbers the processor pushes an error code, and what the error code means in that case. When the processor pushes an error code, the stack would look as follows at the beginning of the exception handler when coming in from user mode:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20
|
||||
| error code | " - 24 <---- ESP
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
##### Nested Exceptions and Interrupts
|
||||
|
||||
The processor can take exceptions and interrupts both from kernel and user mode. It is only when entering the kernel from user mode, however, that the x86 processor automatically switches stacks before pushing its old register state onto the stack and invoking the appropriate exception handler through the IDT. If the processor is _already_ in kernel mode when the interrupt or exception occurs (the low 2 bits of the `CS` register are already zero), then the CPU just pushes more values on the same kernel stack. In this way, the kernel can gracefully handle _nested exceptions_ caused by code within the kernel itself. This capability is an important tool in implementing protection, as we will see later in the section on system calls.
|
||||
|
||||
If the processor is already in kernel mode and takes a nested exception, since it does not need to switch stacks, it does not save the old `SS` or `ESP` registers. For exception types that do not push an error code, the kernel stack therefore looks like the following on entry to the exception handler:
|
||||
|
||||
```
|
||||
+--------------------+ <---- old ESP
|
||||
| old EFLAGS | " - 4
|
||||
| 0x00000 | old CS | " - 8
|
||||
| old EIP | " - 12
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
For exception types that push an error code, the processor pushes the error code immediately after the old `EIP`, as before.
|
||||
|
||||
There is one important caveat to the processor's nested exception capability. If the processor takes an exception while already in kernel mode, and _cannot push its old state onto the kernel stack_ for any reason such as lack of stack space, then there is nothing the processor can do to recover, so it simply resets itself. Needless to say, the kernel should be designed so that this can't happen.
|
||||
|
||||
##### Setting Up the IDT
|
||||
|
||||
You should now have the basic information you need in order to set up the IDT and handle exceptions in JOS. For now, you will set up the IDT to handle interrupt vectors 0-31 (the processor exceptions). We'll handle system call interrupts later in this lab and add interrupts 32-47 (the device IRQs) in a later lab.
|
||||
|
||||
The header files `inc/trap.h` and `kern/trap.h` contain important definitions related to interrupts and exceptions that you will need to become familiar with. The file `kern/trap.h` contains definitions that are strictly private to the kernel, while `inc/trap.h` contains definitions that may also be useful to user-level programs and libraries.
|
||||
|
||||
Note: Some of the exceptions in the range 0-31 are defined by Intel to be reserved. Since they will never be generated by the processor, it doesn't really matter how you handle them. Do whatever you think is cleanest.
|
||||
|
||||
The overall flow of control that you should achieve is depicted below:
|
||||
|
||||
```
|
||||
IDT trapentry.S trap.c
|
||||
|
||||
+----------------+
|
||||
| &handler1 |---------> handler1: trap (struct Trapframe *tf)
|
||||
| | // do stuff {
|
||||
| | call trap // handle the exception/interrupt
|
||||
| | // ... }
|
||||
+----------------+
|
||||
| &handler2 |--------> handler2:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
.
|
||||
.
|
||||
.
|
||||
+----------------+
|
||||
| &handlerX |--------> handlerX:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
```
|
||||
|
||||
Each exception or interrupt should have its own handler in `trapentry.S` and `trap_init()` should initialize the IDT with the addresses of these handlers. Each of the handlers should build a `struct Trapframe` (see `inc/trap.h`) on the stack and call `trap()` (in `trap.c`) with a pointer to the Trapframe. `trap()` then handles the exception/interrupt or dispatches to a specific handler function.
|
||||
|
||||
```
|
||||
Exercise 4. Edit `trapentry.S` and `trap.c` and implement the features described above. The macros `TRAPHANDLER` and `TRAPHANDLER_NOEC` in `trapentry.S` should help you, as well as the T_* defines in `inc/trap.h`. You will need to add an entry point in `trapentry.S` (using those macros) for each trap defined in `inc/trap.h`, and you'll have to provide `_alltraps` which the `TRAPHANDLER` macros refer to. You will also need to modify `trap_init()` to initialize the `idt` to point to each of these entry points defined in `trapentry.S`; the `SETGATE` macro will be helpful here.
|
||||
|
||||
Your `_alltraps` should:
|
||||
|
||||
1. push values to make the stack look like a struct Trapframe
|
||||
2. load `GD_KD` into `%ds` and `%es`
|
||||
3. `pushl %esp` to pass a pointer to the Trapframe as an argument to trap()
|
||||
4. `call trap` (can `trap` ever return?)
|
||||
|
||||
|
||||
|
||||
Consider using the `pushal` instruction; it fits nicely with the layout of the `struct Trapframe`.
|
||||
|
||||
Test your trap handling code using some of the test programs in the `user` directory that cause exceptions before making any system calls, such as `user/divzero`. You should be able to get make grade to succeed on the `divzero`, `softint`, and `badsegment` tests at this point.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! You probably have a lot of very similar code right now, between the lists of `TRAPHANDLER` in `trapentry.S` and their installations in `trap.c`. Clean this up. Change the macros in `trapentry.S` to automatically generate a table for `trap.c` to use. Note that you can switch between laying down code and data in the assembler by using the directives `.text` and `.data`.
|
||||
```
|
||||
|
||||
```
|
||||
Questions
|
||||
|
||||
Answer the following questions in your `answers-lab3.txt`:
|
||||
|
||||
1. What is the purpose of having an individual handler function for each exception/interrupt? (i.e., if all exceptions/interrupts were delivered to the same handler, what feature that exists in the current implementation could not be provided?)
|
||||
2. Did you have to do anything to make the `user/softint` program behave correctly? The grade script expects it to produce a general protection fault (trap 13), but `softint`'s code says `int $14`. _Why_ should this produce interrupt vector 13? What happens if the kernel actually allows `softint`'s `int $14` instruction to invoke the kernel's page fault handler (which is interrupt vector 14)?
|
||||
```
|
||||
|
||||
|
||||
This concludes part A of the lab. Don't forget to add `answers-lab3.txt`, commit your changes, and run make handin before the part A deadline.
|
||||
|
||||
#### Part B: Page Faults, Breakpoints Exceptions, and System Calls
|
||||
|
||||
Now that your kernel has basic exception handling capabilities, you will refine it to provide important operating system primitives that depend on exception handling.
|
||||
|
||||
##### Handling Page Faults
|
||||
|
||||
The page fault exception, interrupt vector 14 (`T_PGFLT`), is a particularly important one that we will exercise heavily throughout this lab and the next. When the processor takes a page fault, it stores the linear (i.e., virtual) address that caused the fault in a special processor control register, `CR2`. In `trap.c` we have provided the beginnings of a special function, `page_fault_handler()`, to handle page fault exceptions.
|
||||
|
||||
```
|
||||
Exercise 5. Modify `trap_dispatch()` to dispatch page fault exceptions to `page_fault_handler()`. You should now be able to get make grade to succeed on the `faultread`, `faultreadkernel`, `faultwrite`, and `faultwritekernel` tests. If any of them don't work, figure out why and fix them. Remember that you can boot JOS into a particular user program using make run- _x_ or make run- _x_ -nox. For instance, make run-hello-nox runs the _hello_ user program.
|
||||
```
|
||||
|
||||
You will further refine the kernel's page fault handling below, as you implement system calls.
|
||||
|
||||
##### The Breakpoint Exception
|
||||
|
||||
The breakpoint exception, interrupt vector 3 (`T_BRKPT`), is normally used to allow debuggers to insert breakpoints in a program's code by temporarily replacing the relevant program instruction with the special 1-byte `int3` software interrupt instruction. In JOS we will abuse this exception slightly by turning it into a primitive pseudo-system call that any user environment can use to invoke the JOS kernel monitor. This usage is actually somewhat appropriate if we think of the JOS kernel monitor as a primitive debugger. The user-mode implementation of `panic()` in `lib/panic.c`, for example, performs an `int3` after displaying its panic message.
|
||||
|
||||
```
|
||||
Exercise 6. Modify `trap_dispatch()` to make breakpoint exceptions invoke the kernel monitor. You should now be able to get make grade to succeed on the `breakpoint` test.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Modify the JOS kernel monitor so that you can 'continue' execution from the current location (e.g., after the `int3`, if the kernel monitor was invoked via the breakpoint exception), and so that you can single-step one instruction at a time. You will need to understand certain bits of the `EFLAGS` register in order to implement single-stepping.
|
||||
|
||||
Optional: If you're feeling really adventurous, find some x86 disassembler source code - e.g., by ripping it out of QEMU, or out of GNU binutils, or just write it yourself - and extend the JOS kernel monitor to be able to disassemble and display instructions as you are stepping through them. Combined with the symbol table loading from lab 1, this is the stuff of which real kernel debuggers are made.
|
||||
```
|
||||
|
||||
```
|
||||
Questions
|
||||
|
||||
3. The break point test case will either generate a break point exception or a general protection fault depending on how you initialized the break point entry in the IDT (i.e., your call to `SETGATE` from `trap_init`). Why? How do you need to set it up in order to get the breakpoint exception to work as specified above and what incorrect setup would cause it to trigger a general protection fault?
|
||||
4. What do you think is the point of these mechanisms, particularly in light of what the `user/softint` test program does?
|
||||
```
|
||||
|
||||
|
||||
##### System calls
|
||||
|
||||
User processes ask the kernel to do things for them by invoking system calls. When the user process invokes a system call, the processor enters kernel mode, the processor and the kernel cooperate to save the user process's state, the kernel executes appropriate code in order to carry out the system call, and then resumes the user process. The exact details of how the user process gets the kernel's attention and how it specifies which call it wants to execute vary from system to system.
|
||||
|
||||
In the JOS kernel, we will use the `int` instruction, which causes a processor interrupt. In particular, we will use `int $0x30` as the system call interrupt. We have defined the constant `T_SYSCALL` to 48 (0x30) for you. You will have to set up the interrupt descriptor to allow user processes to cause that interrupt. Note that interrupt 0x30 cannot be generated by hardware, so there is no ambiguity caused by allowing user code to generate it.
|
||||
|
||||
The application will pass the system call number and the system call arguments in registers. This way, the kernel won't need to grub around in the user environment's stack or instruction stream. The system call number will go in `%eax`, and the arguments (up to five of them) will go in `%edx`, `%ecx`, `%ebx`, `%edi`, and `%esi`, respectively. The kernel passes the return value back in `%eax`. The assembly code to invoke a system call has been written for you, in `syscall()` in `lib/syscall.c`. You should read through it and make sure you understand what is going on.
|
||||
|
||||
```
|
||||
Exercise 7. Add a handler in the kernel for interrupt vector `T_SYSCALL`. You will have to edit `kern/trapentry.S` and `kern/trap.c`'s `trap_init()`. You also need to change `trap_dispatch()` to handle the system call interrupt by calling `syscall()` (defined in `kern/syscall.c`) with the appropriate arguments, and then arranging for the return value to be passed back to the user process in `%eax`. Finally, you need to implement `syscall()` in `kern/syscall.c`. Make sure `syscall()` returns `-E_INVAL` if the system call number is invalid. You should read and understand `lib/syscall.c` (especially the inline assembly routine) in order to confirm your understanding of the system call interface. Handle all the system calls listed in `inc/syscall.h` by invoking the corresponding kernel function for each call.
|
||||
|
||||
Run the `user/hello` program under your kernel (make run-hello). It should print "`hello, world`" on the console and then cause a page fault in user mode. If this does not happen, it probably means your system call handler isn't quite right. You should also now be able to get make grade to succeed on the `testbss` test.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Implement system calls using the `sysenter` and `sysexit` instructions instead of using `int 0x30` and `iret`.
|
||||
|
||||
The `sysenter/sysexit` instructions were designed by Intel to be faster than `int/iret`. They do this by using registers instead of the stack and by making assumptions about how the segmentation registers are used. The exact details of these instructions can be found in Volume 2B of the Intel reference manuals.
|
||||
|
||||
The easiest way to add support for these instructions in JOS is to add a `sysenter_handler` in `kern/trapentry.S` that saves enough information about the user environment to return to it, sets up the kernel environment, pushes the arguments to `syscall()` and calls `syscall()` directly. Once `syscall()` returns, set everything up for and execute the `sysexit` instruction. You will also need to add code to `kern/init.c` to set up the necessary model specific registers (MSRs). Section 6.1.2 in Volume 2 of the AMD Architecture Programmer's Manual and the reference on SYSENTER in Volume 2B of the Intel reference manuals give good descriptions of the relevant MSRs. You can find an implementation of `wrmsr` to add to `inc/x86.h` for writing to these MSRs [here][4].
|
||||
|
||||
Finally, `lib/syscall.c` must be changed to support making a system call with `sysenter`. Here is a possible register layout for the `sysenter` instruction:
|
||||
|
||||
eax - syscall number
|
||||
edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
|
||||
esi - return pc
|
||||
ebp - return esp
|
||||
esp - trashed by sysenter
|
||||
|
||||
GCC's inline assembler will automatically save registers that you tell it to load values directly into. Don't forget to either save (push) and restore (pop) other registers that you clobber, or tell the inline assembler that you're clobbering them. The inline assembler doesn't support saving `%ebp`, so you will need to add code to save and restore it yourself. The return address can be put into `%esi` by using an instruction like `leal after_sysenter_label, %%esi`.
|
||||
|
||||
Note that this only supports 4 arguments, so you will need to leave the old method of doing system calls around to support 5 argument system calls. Furthermore, because this fast path doesn't update the current environment's trap frame, it won't be suitable for some of the system calls we add in later labs.
|
||||
|
||||
You may have to revisit your code once we enable asynchronous interrupts in the next lab. Specifically, you'll need to enable interrupts when returning to the user process, which `sysexit` doesn't do for you.
|
||||
```
|
||||
|
||||
##### User-mode startup
|
||||
|
||||
A user program starts running at the top of `lib/entry.S`. After some setup, this code calls `libmain()`, in `lib/libmain.c`. You should modify `libmain()` to initialize the global pointer `thisenv` to point at this environment's `struct Env` in the `envs[]` array. (Note that `lib/entry.S` has already defined `envs` to point at the `UENVS` mapping you set up in Part A.) Hint: look in `inc/env.h` and use `sys_getenvid`.
|
||||
|
||||
`libmain()` then calls `umain`, which, in the case of the hello program, is in `user/hello.c`. Note that after printing "`hello, world`", it tries to access `thisenv->env_id`. This is why it faulted earlier. Now that you've initialized `thisenv` properly, it should not fault. If it still faults, you probably haven't mapped the `UENVS` area user-readable (back in Part A in `pmap.c`; this is the first time we've actually used the `UENVS` area).
|
||||
|
||||
```
|
||||
Exercise 8. Add the required code to the user library, then boot your kernel. You should see `user/hello` print "`hello, world`" and then print "`i am environment 00001000`". `user/hello` then attempts to "exit" by calling `sys_env_destroy()` (see `lib/libmain.c` and `lib/exit.c`). Since the kernel currently only supports one user environment, it should report that it has destroyed the only environment and then drop into the kernel monitor. You should be able to get make grade to succeed on the `hello` test.
|
||||
```
|
||||
|
||||
##### Page faults and memory protection
|
||||
|
||||
Memory protection is a crucial feature of an operating system, ensuring that bugs in one program cannot corrupt other programs or corrupt the operating system itself.
|
||||
|
||||
Operating systems usually rely on hardware support to implement memory protection. The OS keeps the hardware informed about which virtual addresses are valid and which are not. When a program tries to access an invalid address or one for which it has no permissions, the processor stops the program at the instruction causing the fault and then traps into the kernel with information about the attempted operation. If the fault is fixable, the kernel can fix it and let the program continue running. If the fault is not fixable, then the program cannot continue, since it will never get past the instruction causing the fault.
|
||||
|
||||
As an example of a fixable fault, consider an automatically extended stack. In many systems the kernel initially allocates a single stack page, and then if a program faults accessing pages further down the stack, the kernel will allocate those pages automatically and let the program continue. By doing this, the kernel only allocates as much stack memory as the program needs, but the program can work under the illusion that it has an arbitrarily large stack.
|
||||
|
||||
System calls present an interesting problem for memory protection. Most system call interfaces let user programs pass pointers to the kernel. These pointers point at user buffers to be read or written. The kernel then dereferences these pointers while carrying out the system call. There are two problems with this:
|
||||
|
||||
1. A page fault in the kernel is potentially a lot more serious than a page fault in a user program. If the kernel page-faults while manipulating its own data structures, that's a kernel bug, and the fault handler should panic the kernel (and hence the whole system). But when the kernel is dereferencing pointers given to it by the user program, it needs a way to remember that any page faults these dereferences cause are actually on behalf of the user program.
|
||||
2. The kernel typically has more memory permissions than the user program. The user program might pass a pointer to a system call that points to memory that the kernel can read or write but that the program cannot. The kernel must be careful not to be tricked into dereferencing such a pointer, since that might reveal private information or destroy the integrity of the kernel.
|
||||
|
||||
|
||||
|
||||
For both of these reasons the kernel must be extremely careful when handling pointers presented by user programs.
|
||||
|
||||
You will now solve these two problems with a single mechanism that scrutinizes all pointers passed from userspace into the kernel. When a program passes the kernel a pointer, the kernel will check that the address is in the user part of the address space, and that the page table would allow the memory operation.
|
||||
|
||||
Thus, the kernel will never suffer a page fault due to dereferencing a user-supplied pointer. If the kernel does page fault, it should panic and terminate.
|
||||
|
||||
```
|
||||
Exercise 9. Change `kern/trap.c` to panic if a page fault happens in kernel mode.
|
||||
|
||||
Hint: to determine whether a fault happened in user mode or in kernel mode, check the low bits of the `tf_cs`.
|
||||
|
||||
Read `user_mem_assert` in `kern/pmap.c` and implement `user_mem_check` in that same file.
|
||||
|
||||
Change `kern/syscall.c` to sanity check arguments to system calls.
|
||||
|
||||
Boot your kernel, running `user/buggyhello`. The environment should be destroyed, and the kernel should _not_ panic. You should see:
|
||||
|
||||
[00001000] user_mem_check assertion failure for va 00000001
|
||||
[00001000] free env 00001000
|
||||
Destroyed the only environment - nothing more to do!
|
||||
Finally, change `debuginfo_eip` in `kern/kdebug.c` to call `user_mem_check` on `usd`, `stabs`, and `stabstr`. If you now run `user/breakpoint`, you should be able to run backtrace from the kernel monitor and see the backtrace traverse into `lib/libmain.c` before the kernel panics with a page fault. What causes this page fault? You don't need to fix it, but you should understand why it happens.
|
||||
```
|
||||
|
||||
Note that the same mechanism you just implemented also works for malicious user applications (such as `user/evilhello`).
|
||||
|
||||
```
|
||||
Exercise 10. Boot your kernel, running `user/evilhello`. The environment should be destroyed, and the kernel should not panic. You should see:
|
||||
|
||||
[00000000] new env 00001000
|
||||
...
|
||||
[00001000] user_mem_check assertion failure for va f010000c
|
||||
[00001000] free env 00001000
|
||||
```
|
||||
|
||||
**This completes the lab.** Make sure you pass all of the make grade tests and don't forget to write up your answers to the questions and a description of your challenge exercise solution in `answers-lab3.txt`. Commit your changes and type make handin in the `lab` directory to submit your work.
|
||||
|
||||
Before handing in, use git status and git diff to examine your changes and don't forget to git add answers-lab3.txt. When you're ready, commit your changes with git commit -am 'my solutions to lab 3', then make handin and follow the directions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab3/
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pdos.csail.mit.edu/6.828/2018/labs/labguide.html
|
||||
[2]: https://pdos.csail.mit.edu/6.828/2018/labs/reference.html
|
||||
[3]: http://blogs.msdn.com/larryosterman/archive/2005/02/08/369243.aspx
|
||||
[4]: http://ftp.kh.edu.tw/Linux/SuSE/people/garloff/linux/k6mod.c
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Convert Screenshots of Equations into LaTeX Instantly With This Nifty Tool
|
||||
======
|
||||
**Mathpix is a nifty little tool that allows you to take screenshots of complex mathematical equations and instantly converts it into LaTeX editable text.**
|
||||
|
||||
@ -0,0 +1,183 @@
|
||||
Design faster web pages, part 1: Image compression
|
||||
======
|
||||
|
||||

|
||||
|
||||
Lots of web developers want to achieve fast loading web pages. As more page views come from mobile devices, making websites look better on smaller screens using responsive design is just one side of the coin. Browser Calories can make the difference in loading times, which satisfies not just the user but search engines that rank on loading speed. This article series covers how to slim down your web pages with tools Fedora offers.
|
||||
|
||||
### Preparation
|
||||
|
||||
Before you sart to slim down your web pages, you need to identify the core issues. For this, you can use [Browserdiet][1]. It’s a browser add-on available for Firefox, Opera and Chrome and other browsers. It analyzes the performance values of the actual open web page, so you know where to start slimming down.
|
||||
|
||||
Next you’ll need some pages to work on. The example screenshot shows a test of [getfedora.org][2]. At first it looks very simple and responsive.
|
||||
|
||||
![Browser Diet - values of getfedora.org][3]
|
||||
|
||||
However, BrowserDiet’s page analysis shows there are 1.8MB in files downloaded. Therefore, there’s some work to do!
|
||||
|
||||
### Web optimization
|
||||
|
||||
There are over 281 KB of JavaScript files, 203 KB more in CSS files, and 1.2 MB in images. Start with the biggest issue — the images. The tool set you need for this is GIMP, ImageMagick, and optipng. You can easily install them using the following command:
|
||||
|
||||
```
|
||||
sudo dnf install gimp imagemagick optipng
|
||||
|
||||
```
|
||||
|
||||
For example, take the [following file][4] which is 6.4 KB:
|
||||
|
||||
![][4]
|
||||
|
||||
First, use the file command to get some basic information about this image:
|
||||
|
||||
```
|
||||
$ file cinnamon.png
|
||||
cinnamon.png: PNG image data, 60 x 60, 8-bit/color RGBA, non-interlaced
|
||||
|
||||
```
|
||||
|
||||
The image — which is only in grey and white — is saved in 8-bit/color RGBA mode. That’s not as efficient as it could be.
|
||||
|
||||
Start GIMP so you can set a more appropriate color mode. Open cinnamon.png in GIMP. Then go to Image>Mode and set it to greyscale. Export the image as PNG with compression factor 9. All other settings in the export dialog should be the default.
|
||||
|
||||
```
|
||||
$ file cinnamon.png
|
||||
cinnamon.png: PNG image data, 60 x 60, 8-bit gray+alpha, non-interlaced
|
||||
|
||||
```
|
||||
|
||||
The output shows the file’s now in 8bit gray+alpha mode. The file size has shrunk from 6.4 KB to 2.8 KB. That’s already only 43.75% of the original size. But there’s more you can do!
|
||||
|
||||
You can also use the ImageMagick tool identify to provide more information about the image.
|
||||
|
||||
```
|
||||
$ identify cinnamon2.png
|
||||
cinnamon.png PNG 60x60 60x60+0+0 8-bit Grayscale Gray 2831B 0.000u 0:00.000
|
||||
|
||||
```
|
||||
|
||||
This tells you the file is 2831 bytes. Jump back into GIMP, and export the file. In the export dialog disable the storing of the time stamp and the alpha channel color values to reduce this a little more. Now the file output shows:
|
||||
|
||||
```
|
||||
$ identify cinnamon.png
|
||||
cinnamon.png PNG 60x60 60x60+0+0 8-bit Grayscale Gray 2798B 0.000u 0:00.000
|
||||
|
||||
```
|
||||
|
||||
Next, use optipng to losslessly optimize your PNG images. There are other tools that do similar things, including **advdef** (which is part of advancecomp), **pngquant** and **pngcrush.**
|
||||
|
||||
Run optipng on your file. Note that this will replace your original:
|
||||
|
||||
```
|
||||
$ optipng -o7 cinnamon.png
|
||||
** Processing: cinnamon.png
|
||||
60x60 pixels, 2x8 bits/pixel, grayscale+alpha
|
||||
Reducing image to 8 bits/pixel, grayscale
|
||||
Input IDAT size = 2720 bytes
|
||||
Input file size = 2812 bytes
|
||||
|
||||
Trying:
|
||||
zc = 9 zm = 8 zs = 0 f = 0 IDAT size = 1922
|
||||
zc = 9 zm = 8 zs = 1 f = 0 IDAT size = 1920
|
||||
|
||||
Selecting parameters:
|
||||
zc = 9 zm = 8 zs = 1 f = 0 IDAT size = 1920
|
||||
|
||||
Output IDAT size = 1920 bytes (800 bytes decrease)
|
||||
Output file size = 2012 bytes (800 bytes = 28.45% decrease)
|
||||
|
||||
```
|
||||
|
||||
The option -o7 is the slowest to process, but provides the best end results. You’ve knocked 800 more bytes off the file size, which is now 2012 bytes.
|
||||
|
||||
To resize all of the PNGs in a directory, use this command:
|
||||
|
||||
```
|
||||
$ optipng -o7 -dir=<directory> *.png
|
||||
|
||||
```
|
||||
|
||||
The option -dir lets you give a target directory for the output. If this option is not used, optipng would overwrite the original images.
|
||||
|
||||
### Choosing the right file format
|
||||
|
||||
When it comes to pictures for the usage in the internet, you have the choice between:
|
||||
|
||||
|
||||
+ [JPG or JPEG][9]
|
||||
+ [GIF][10]
|
||||
+ [PNG][11]
|
||||
+ [aPNG][12]
|
||||
+ [JPG-LS][13]
|
||||
+ [JPG 2000 or JP2][14]
|
||||
+ [SVG][15]
|
||||
|
||||
|
||||
JPG-LS and JPG 2000 are not widely used. Only a few digital cameras support these formats, so they can be ignored. aPNG is an animated PNG, and not widely used either.
|
||||
|
||||
You could save a few bytes more through changing the compression rate or choosing another file format. The first option you can’t do in GIMP, as it’s already using the highest compression rate. As there are no [alpha channels][5] in the picture, you can choose JPG as file format instead. For now use the default value of 90% quality — you could change it down to 85%, but then alias effects become visible. This saves a few bytes more:
|
||||
|
||||
```
|
||||
$ identify cinnamon.jpg
|
||||
cinnamon.jpg JPEG 60x60 60x60+0+0 8-bit sRGB 2676B 0.000u 0:00.000
|
||||
|
||||
```
|
||||
|
||||
Alone this conversion to the right color space and choosing JPG as file format brought down the file size from 23 KB to 12.3 KB, a reduction of nearly 50%.
|
||||
|
||||
|
||||
#### PNG vs. JPG: quality and compression rate
|
||||
|
||||
So what about the rest of the images? This method would work for all the other pictures, except the Fedora “flavor” logos and the logos for the four foundations. Those are presented on a white background.
|
||||
|
||||
One of the main differences between PNG and JPG is that JPG has no alpha channel. Therefore it can’t handle transparency. If you rework these images by using a JPG on a white background, you can reduce the file size from 40.7 KB to 28.3 KB.
|
||||
|
||||
Now there are four more images you can rework: the backgrounds. For the grey background, set the mode to greyscale again. With this bigger picture, the savings also is bigger. It shrinks from 216.2 KB to 51.0 KB — it’s now barely 25% of its original size. All in all, you’ve shrunk 481.1 KB down to 191.5 KB — only 39.8% of the starting size.
|
||||
|
||||
#### Quality vs. Quantity
|
||||
|
||||
Another difference between PNG and JPG is the quality. PNG is a lossless compressed raster graphics format. But JPG loses size through compression, and thus affects quality. That doesn’t mean you shouldn’t use JPG, though. But you have to find a balance between file size and quality.
|
||||
|
||||
### Achievement
|
||||
|
||||
This is the end of Part 1. After following the techniques described above, here are the results:
|
||||
|
||||
![][6]
|
||||
|
||||
You brought image size down to 488.9 KB versus 1.2MB at the start. That’s only about a third of the size, just through optimizing with optipng. This page can probably be made to load faster still. On the scale from snail to hypersonic, it’s not reached racing car speed yet!
|
||||
|
||||
Finally you can check the results in [Google Insights][7], for example:
|
||||
|
||||
![][8]
|
||||
|
||||
In the Mobile area the page gathered 10 points on scoring, but is still in the Medium sector. It looks totally different for the Desktop, which has gone from 62/100 to 91/100 and went up to Good. As mentioned before, this test isn’t the be all and end all. Consider scores such as these to help you go in the right direction. Keep in mind you’re optimizing for the user experience, and not for a search engine.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/design-faster-web-pages-part-1-image-compression/
|
||||
|
||||
作者:[Sirko Kemter][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/gnokii/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://browserdiet.com/calories/
|
||||
[2]: http://getfedora.org
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/02/ff-addon-diet.jpg
|
||||
[4]: https://getfedora.org/static/images/cinnamon.png
|
||||
[5]: https://www.webopedia.com/TERM/A/alpha_channel.html
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2018/02/ff-addon-diet-i.jpg
|
||||
[7]: https://developers.google.com/speed/pagespeed/insights/?url=getfedora.org&tab=mobile
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2018/02/PageSpeed_Insights.png
|
||||
[9]: https://en.wikipedia.org/wiki/JPEG
|
||||
[10]: https://en.wikipedia.org/wiki/GIF
|
||||
[11]: https://en.wikipedia.org/wiki/Portable_Network_Graphics
|
||||
[12]: https://en.wikipedia.org/wiki/APNG
|
||||
[13]: https://en.wikipedia.org/wiki/JPEG_2000
|
||||
[14]: https://en.wikipedia.org/wiki/JPEG_2000
|
||||
[15]: https://en.wikipedia.org/wiki/Scalable_Vector_Graphics
|
||||
@ -0,0 +1,289 @@
|
||||
How To List The Enabled/Active Repositories In Linux
|
||||
======
|
||||
There are many ways to list enabled repositories in Linux.
|
||||
|
||||
Here we are going to show you the easy methods to list active repositories.
|
||||
|
||||
It will helps you to know what are the repositories enabled on your system.
|
||||
|
||||
Once you have this information in handy then you can add any repositories that you want if it’s not already enabled.
|
||||
|
||||
Say for example, if you would like to enable `epel repository` then you need to check whether the epel repository is enabled or not. In this case this tutorial would help you.
|
||||
|
||||
### What Is Repository?
|
||||
|
||||
A software repository is a central place which stores the software packages for the particular application.
|
||||
|
||||
All the Linux distributions are maintaining their own repositories and they allow users to retrieve and install packages on their machine.
|
||||
|
||||
Each vendor offered a unique package management tool to manage their repositories such as search, install, update, upgrade, remove, etc.
|
||||
|
||||
Most of the Linux distributions comes as freeware except RHEL and SUSE. To access their repositories you need to buy a subscriptions.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [How To Add, Enable And Disable A Repository By Using The DNF/YUM Config Manager Command On Linux][1]
|
||||
**(#)** [How To List Installed Packages By Size (Largest) On Linux][2]
|
||||
**(#)** [How To View/List The Available Packages Updates In Linux][3]
|
||||
**(#)** [How To View A Particular Package Installed/Updated/Upgraded/Removed/Erased Date On Linux][4]
|
||||
**(#)** [How To View Detailed Information About A Package In Linux][5]
|
||||
**(#)** [How To Search If A Package Is Available On Your Linux Distribution Or Not][6]
|
||||
**(#)** [How To List An Available Package Groups In Linux][7]
|
||||
**(#)** [Newbies corner – A Graphical frontend tool for Linux Package Manager][8]
|
||||
**(#)** [Linux Expert should knows, list of Command line Package Manager & Usage][9]
|
||||
|
||||
### How To List The Enabled Repositories on RHEL/CentOS
|
||||
|
||||
RHEL & CentOS systems are using RPM packages hence we can use the `Yum Package Manager` to get this information.
|
||||
|
||||
YUM stands for Yellowdog Updater, Modified is an open-source command-line front-end package-management utility for RPM based systems such as Red Hat Enterprise Linux (RHEL) and CentOS.
|
||||
|
||||
Yum is the primary tool for getting, installing, deleting, querying, and managing RPM packages from distribution repositories, as well as other third-party repositories.
|
||||
|
||||
**Suggested Read :** [YUM Command To Manage Packages on RHEL/CentOS Systems][10]
|
||||
|
||||
RHEL based systems are mainly offering the below three major repositories. These repository will be enabled by default.
|
||||
|
||||
* **`base:`** It’s containing all the core packages and base packages.
|
||||
* **`extras:`** It provides additional functionality to CentOS without breaking upstream compatibility or updating base components. It is an upstream repository, as well as additional CentOS packages.
|
||||
* **`updates:`** It’s offering bug fixed packages, Security packages and Enhancement packages.
|
||||
|
||||
|
||||
|
||||
```
|
||||
# yum repolist
|
||||
or
|
||||
# yum repolist enabled
|
||||
|
||||
Loaded plugins: fastestmirror
|
||||
Determining fastest mirrors
|
||||
选题模板.txt 中文排版指北.md comic core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated epel: ewr.edge.kernel.org
|
||||
repo id repo name status
|
||||
!base/7/x86_64 CentOS-7 - Base 9,911
|
||||
!epel/x86_64 Extra Packages for Enterprise Linux 7 - x86_64 12,687
|
||||
!extras/7/x86_64 CentOS-7 - Extras 403
|
||||
!updates/7/x86_64 CentOS-7 - Updates 1,348
|
||||
repolist: 24,349
|
||||
|
||||
```
|
||||
|
||||
### How To List The Enabled Repositories on Fedora
|
||||
|
||||
DNF stands for Dandified yum. We can tell DNF, the next generation of yum package manager (Fork of Yum) using hawkey/libsolv library for backend. Aleš Kozumplík started working on DNF since Fedora 18 and its implemented/launched in Fedora 22 finally.
|
||||
|
||||
Dnf command is used to install, update, search & remove packages on Fedora 22 and later system. It automatically resolve dependencies and make it smooth package installation without any trouble.
|
||||
|
||||
Yum replaced by DNF due to several long-term problems in Yum which was not solved. Asked why ? he did not patches the Yum issues. Aleš Kozumplík explains that patching was technically hard and YUM team wont accept the changes immediately and other major critical, YUM is 56K lines but DNF is 29K lies. So, there is no option for further development, except to fork.
|
||||
|
||||
**Suggested Read :** [DNF (Fork of YUM) Command To Manage Packages on Fedora System][11]
|
||||
|
||||
Fedora system is mainly offering the below two major repositories. These repository will be enabled by default.
|
||||
|
||||
* **`fedora:`** It’s containing all the core packages and base packages.
|
||||
* **`updates:`** It’s offering bug fixed packages, Security packages and Enhancement packages from the stable release branch.
|
||||
|
||||
|
||||
|
||||
```
|
||||
# dnf repolist
|
||||
or
|
||||
# dnf repolist enabled
|
||||
|
||||
Last metadata expiration check: 0:02:56 ago on Wed 10 Oct 2018 06:12:22 PM IST.
|
||||
repo id repo name status
|
||||
docker-ce-stable Docker CE Stable - x86_64 6
|
||||
*fedora Fedora 26 - x86_64 53,912
|
||||
home_mhogomchungu mhogomchungu's Home Project (Fedora_25) 19
|
||||
home_moritzmolch_gencfsm Gnome Encfs Manager (Fedora_25) 5
|
||||
mystro256-gnome-redshift Copr repo for gnome-redshift owned by mystro256 6
|
||||
nodesource Node.js Packages for Fedora Linux 26 - x86_64 83
|
||||
rabiny-albert Copr repo for albert owned by rabiny 3
|
||||
*rpmfusion-free RPM Fusion for Fedora 26 - Free 536
|
||||
*rpmfusion-free-updates RPM Fusion for Fedora 26 - Free - Updates 278
|
||||
*rpmfusion-nonfree RPM Fusion for Fedora 26 - Nonfree 202
|
||||
*rpmfusion-nonfree-updates RPM Fusion for Fedora 26 - Nonfree - Updates 95
|
||||
*updates Fedora 26 - x86_64 - Updates 14,595
|
||||
|
||||
```
|
||||
|
||||
### How To List The Enabled Repositories on Debian/Ubuntu
|
||||
|
||||
Debian based systems are using APT/APT-GET package manager hence we can use the `APT/APT-GET Package Manager` to get this information.
|
||||
|
||||
APT stands for Advanced Packaging Tool (APT) which is replacement for apt-get, like how DNF came to picture instead of YUM. It’s feature rich command-line tools with included all the futures in one command (APT) such as apt-cache, apt-search, dpkg, apt-cdrom, apt-config, apt-key, etc..,. and several other unique features. For example we can easily install .dpkg packages through APT but we can’t do through Apt-Get similar more features are included into APT command. APT-GET replaced by APT Due to lock of futures missing in apt-get which was not solved.
|
||||
|
||||
Apt-Get stands for Advanced Packaging Tool (APT). apg-get is a powerful command-line tool which is used to automatically download and install new software packages, upgrade existing software packages, update the package list index, and to upgrade the entire Debian based systems.
|
||||
|
||||
```
|
||||
# apt-cache policy
|
||||
Package files:
|
||||
100 /var/lib/dpkg/status
|
||||
release a=now
|
||||
500 http://ppa.launchpad.net/peek-developers/stable/ubuntu artful/main amd64 Packages
|
||||
release v=17.10,o=LP-PPA-peek-developers-stable,a=artful,n=artful,l=Peek stable releases,c=main,b=amd64
|
||||
origin ppa.launchpad.net
|
||||
500 http://ppa.launchpad.net/notepadqq-team/notepadqq/ubuntu artful/main amd64 Packages
|
||||
release v=17.10,o=LP-PPA-notepadqq-team-notepadqq,a=artful,n=artful,l=Notepadqq,c=main,b=amd64
|
||||
origin ppa.launchpad.net
|
||||
500 http://dl.google.com/linux/chrome/deb stable/main amd64 Packages
|
||||
release v=1.0,o=Google, Inc.,a=stable,n=stable,l=Google,c=main,b=amd64
|
||||
origin dl.google.com
|
||||
500 https://download.docker.com/linux/ubuntu artful/stable amd64 Packages
|
||||
release o=Docker,a=artful,l=Docker CE,c=stable,b=amd64
|
||||
origin download.docker.com
|
||||
500 http://security.ubuntu.com/ubuntu artful-security/multiverse amd64 Packages
|
||||
release v=17.10,o=Ubuntu,a=artful-security,n=artful,l=Ubuntu,c=multiverse,b=amd64
|
||||
origin security.ubuntu.com
|
||||
500 http://security.ubuntu.com/ubuntu artful-security/universe amd64 Packages
|
||||
release v=17.10,o=Ubuntu,a=artful-security,n=artful,l=Ubuntu,c=universe,b=amd64
|
||||
origin security.ubuntu.com
|
||||
500 http://security.ubuntu.com/ubuntu artful-security/restricted i386 Packages
|
||||
release v=17.10,o=Ubuntu,a=artful-security,n=artful,l=Ubuntu,c=restricted,b=i386
|
||||
origin security.ubuntu.com
|
||||
.
|
||||
.
|
||||
origin in.archive.ubuntu.com
|
||||
500 http://in.archive.ubuntu.com/ubuntu artful/restricted amd64 Packages
|
||||
release v=17.10,o=Ubuntu,a=artful,n=artful,l=Ubuntu,c=restricted,b=amd64
|
||||
origin in.archive.ubuntu.com
|
||||
500 http://in.archive.ubuntu.com/ubuntu artful/main i386 Packages
|
||||
release v=17.10,o=Ubuntu,a=artful,n=artful,l=Ubuntu,c=main,b=i386
|
||||
origin in.archive.ubuntu.com
|
||||
500 http://in.archive.ubuntu.com/ubuntu artful/main amd64 Packages
|
||||
release v=17.10,o=Ubuntu,a=artful,n=artful,l=Ubuntu,c=main,b=amd64
|
||||
origin in.archive.ubuntu.com
|
||||
Pinned packages:
|
||||
|
||||
```
|
||||
|
||||
### How To List The Enabled Repositories on openSUSE
|
||||
|
||||
openSUSE system uses zypper package manager hence we can use the zypper Package Manager to get this information.
|
||||
|
||||
Zypper is a command line package manager for suse & openSUSE distributions. It’s used to install, update, search & remove packages & manage repositories, perform various queries, and more. Zypper command-line interface to ZYpp system management library (libzypp).
|
||||
|
||||
**Suggested Read :** [Zypper Command To Manage Packages On openSUSE & suse Systems][12]
|
||||
|
||||
```
|
||||
# zypper repos
|
||||
|
||||
# | Alias | Name | Enabled | GPG Check | Refresh
|
||||
--+-----------------------+-----------------------------------------------------+---------+-----------+--------
|
||||
1 | packman-repository | packman-repository | Yes | (r ) Yes | Yes
|
||||
2 | google-chrome | google-chrome | Yes | (r ) Yes | Yes
|
||||
3 | home_lazka0_ql-stable | Stable Quod Libet / Ex Falso Builds (openSUSE_42.1) | Yes | (r ) Yes | No
|
||||
4 | repo-non-oss | openSUSE-leap/42.1-Non-Oss | Yes | (r ) Yes | Yes
|
||||
5 | repo-oss | openSUSE-leap/42.1-Oss | Yes | (r ) Yes | Yes
|
||||
6 | repo-update | openSUSE-42.1-Update | Yes | (r ) Yes | Yes
|
||||
7 | repo-update-non-oss | openSUSE-42.1-Update-Non-Oss | Yes | (r ) Yes | Yes
|
||||
|
||||
```
|
||||
|
||||
List Repositories with URI.
|
||||
|
||||
```
|
||||
# zypper lr -u
|
||||
|
||||
# | Alias | Name | Enabled | GPG Check | Refresh | URI
|
||||
--+-----------------------+-----------------------------------------------------+---------+-----------+---------+---------------------------------------------------------------------------------
|
||||
1 | packman-repository | packman-repository | Yes | (r ) Yes | Yes | http://ftp.gwdg.de/pub/linux/packman/suse/openSUSE_Leap_42.1/
|
||||
2 | google-chrome | google-chrome | Yes | (r ) Yes | Yes | http://dl.google.com/linux/chrome/rpm/stable/x86_64
|
||||
3 | home_lazka0_ql-stable | Stable Quod Libet / Ex Falso Builds (openSUSE_42.1) | Yes | (r ) Yes | No | http://download.opensuse.org/repositories/home:/lazka0:/ql-stable/openSUSE_42.1/
|
||||
4 | repo-non-oss | openSUSE-leap/42.1-Non-Oss | Yes | (r ) Yes | Yes | http://download.opensuse.org/distribution/leap/42.1/repo/non-oss/
|
||||
5 | repo-oss | openSUSE-leap/42.1-Oss | Yes | (r ) Yes | Yes | http://download.opensuse.org/distribution/leap/42.1/repo/oss/
|
||||
6 | repo-update | openSUSE-42.1-Update | Yes | (r ) Yes | Yes | http://download.opensuse.org/update/leap/42.1/oss/
|
||||
7 | repo-update-non-oss | openSUSE-42.1-Update-Non-Oss | Yes | (r ) Yes | Yes | http://download.opensuse.org/update/leap/42.1/non-oss/
|
||||
|
||||
```
|
||||
|
||||
List Repositories by priority.
|
||||
|
||||
```
|
||||
# zypper lr -p
|
||||
|
||||
# | Alias | Name | Enabled | GPG Check | Refresh | Priority
|
||||
--+-----------------------+-----------------------------------------------------+---------+-----------+---------+---------
|
||||
1 | packman-repository | packman-repository | Yes | (r ) Yes | Yes | 99
|
||||
2 | google-chrome | google-chrome | Yes | (r ) Yes | Yes | 99
|
||||
3 | home_lazka0_ql-stable | Stable Quod Libet / Ex Falso Builds (openSUSE_42.1) | Yes | (r ) Yes | No | 99
|
||||
4 | repo-non-oss | openSUSE-leap/42.1-Non-Oss | Yes | (r ) Yes | Yes | 99
|
||||
5 | repo-oss | openSUSE-leap/42.1-Oss | Yes | (r ) Yes | Yes | 99
|
||||
6 | repo-update | openSUSE-42.1-Update | Yes | (r ) Yes | Yes | 99
|
||||
7 | repo-update-non-oss | openSUSE-42.1-Update-Non-Oss | Yes | (r ) Yes | Yes | 99
|
||||
|
||||
```
|
||||
|
||||
### How To List The Enabled Repositories on ArchLinux
|
||||
|
||||
Arch Linux based systems are using pacman package manager hence we can use the pacman Package Manager to get this information.
|
||||
|
||||
pacman stands for package manager utility (pacman). pacman is a command-line utility to install, build, remove and manage Arch Linux packages. pacman uses libalpm (Arch Linux Package Management (ALPM) library) as a back-end to perform all the actions.
|
||||
|
||||
**Suggested Read :** [Pacman Command To Manage Packages On Arch Linux Based Systems][13]
|
||||
|
||||
```
|
||||
# pacman -Syy
|
||||
:: Synchronizing package databases...
|
||||
core 132.6 KiB 1524K/s 00:00 [############################################] 100%
|
||||
extra 1859.0 KiB 750K/s 00:02 [############################################] 100%
|
||||
community 3.5 MiB 149K/s 00:24 [############################################] 100%
|
||||
multilib 182.7 KiB 1363K/s 00:00 [############################################] 100%
|
||||
|
||||
```
|
||||
|
||||
### How To List The Enabled Repositories on Linux using INXI Utility
|
||||
|
||||
inxi is a nifty tool to check hardware information on Linux and offers wide range of option to get all the hardware information on Linux system that i never found in any other utility which are available in Linux. It was forked from the ancient and mindbendingly perverse yet ingenius infobash, by locsmif.
|
||||
|
||||
inxi is a script that quickly shows system hardware, CPU, drivers, Xorg, Desktop, Kernel, GCC version(s), Processes, RAM usage, and a wide variety of other useful information, also used for forum technical support & debugging tool.
|
||||
|
||||
Additionally this utility will display all the distribution repository data information such as RHEL, CentOS, Fedora, Debain, Ubuntu, LinuxMint, ArchLinux, openSUSE, Manjaro, etc.,
|
||||
|
||||
**Suggested Read :** [inxi – A Great Tool to Check Hardware Information on Linux][14]
|
||||
|
||||
```
|
||||
# inxi -r
|
||||
Repos: Active apt sources in file: /etc/apt/sources.list
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety main restricted
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates main restricted
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety universe
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates universe
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety multiverse
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates multiverse
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-backports main restricted universe multiverse
|
||||
deb http://security.ubuntu.com/ubuntu yakkety-security main restricted
|
||||
deb http://security.ubuntu.com/ubuntu yakkety-security universe
|
||||
deb http://security.ubuntu.com/ubuntu yakkety-security multiverse
|
||||
Active apt sources in file: /etc/apt/sources.list.d/arc-theme.list
|
||||
deb http://download.opensuse.org/repositories/home:/Horst3180/xUbuntu_16.04/ /
|
||||
Active apt sources in file: /etc/apt/sources.list.d/snwh-ubuntu-pulp-yakkety.list
|
||||
deb http://ppa.launchpad.net/snwh/pulp/ubuntu yakkety main
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-list-the-enabled-active-repositories-in-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-config-manager-on-linux/
|
||||
[2]: https://www.2daygeek.com/how-to-list-installed-packages-by-size-largest-on-linux/
|
||||
[3]: https://www.2daygeek.com/how-to-view-list-the-available-packages-updates-in-linux/
|
||||
[4]: https://www.2daygeek.com/how-to-view-a-particular-package-installed-updated-upgraded-removed-erased-date-on-linux/
|
||||
[5]: https://www.2daygeek.com/how-to-view-detailed-information-about-a-package-in-linux/
|
||||
[6]: https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/
|
||||
[7]: https://www.2daygeek.com/how-to-list-an-available-package-groups-in-linux/
|
||||
[8]: https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
|
||||
[9]: https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
|
||||
[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[11]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[12]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[13]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[14]: https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
|
||||
@ -0,0 +1,186 @@
|
||||
A Front-end For Popular Package Managers
|
||||
======
|
||||
|
||||

|
||||
|
||||
Are you a distro-hopper who likes to try new Linux OSs every few days? If so, I have something for you. Say hello to **Sysget** , a front-end for popular package managers in Unix-like operating systems. You don’t need to learn about every package managers to do basic stuffs like installing, updating, upgrading and removing packages. You just need to remember one syntax for every package manager on every Unix-like operating systems. Sysget is a wrapper script for package managers and it is written in C++. The source code is freely available on GitHub.
|
||||
|
||||
Using Sysget, you can do all sorts of basic package management operations including the following:
|
||||
|
||||
* Install packages,
|
||||
* Update packages,
|
||||
* Upgrade packages,
|
||||
* Search for packages,
|
||||
* Remove packages,
|
||||
* Remove orphan packages,
|
||||
* Update database,
|
||||
* Upgrade system,
|
||||
* Clear package manager cache.
|
||||
|
||||
|
||||
|
||||
**An Important note to Linux learners:**
|
||||
|
||||
Sysget is not going to replace the package managers and definitely not suitable for everyone. If you’re a newbie who frequently switch to new Linux OS, Sysget may help. It is just wrapper script that helps the distro hoppers (or the new Linux users) who become frustrated when they have to learn new commands to install, update, upgrade, search and remove packages when using different package managers in different Linux distributions.
|
||||
|
||||
If you’re a Linux administrator or enthusiast who want to learn the internals of Linux, you should stick with your distribution’s package manager and learn to use it well.
|
||||
|
||||
### Installing Sysget
|
||||
|
||||
Installing sysget is trivial. Go to the [**releases page**][1] and download latest Sysget binary and install it as shown below. As of writing this guide, the latest version was 1.2.
|
||||
|
||||
```
|
||||
$ sudo wget -O /usr/local/bin/sysget https://github.com/emilengler/sysget/releases/download/v1.2/sysget
|
||||
|
||||
$ sudo mkdir -p /usr/local/share/sysget
|
||||
|
||||
$ sudo chmod a+x /usr/local/bin/sysget
|
||||
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
Sysget commands are mostly same as APT package manager, so it should be easy to use for the newbies.
|
||||
|
||||
When you run Sysget for the first time, you will be asked to choose the package manager you want to use. Since I am on Ubuntu, I chose **apt-get**.
|
||||
|
||||
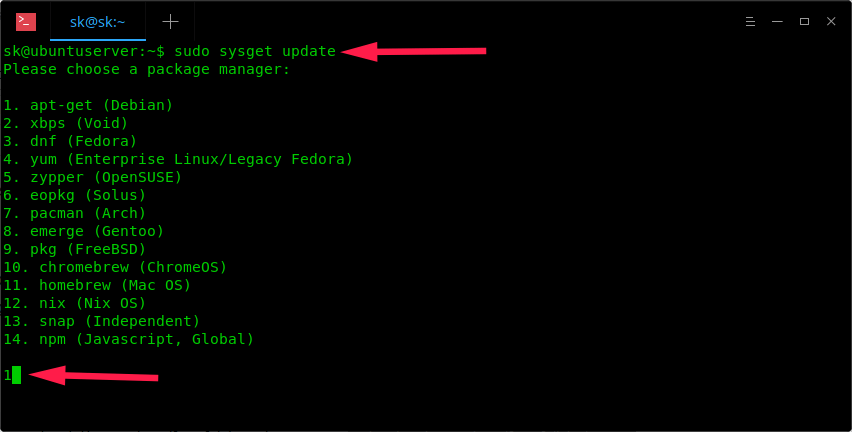
|
||||
|
||||
You must choose the right package manager depending upon the distribution you’re running. For instance, if you’re on Arch Linux, choose **pacman**. For CentOS, choose **yum**. For FreeBSD, choose **pkg**. The list of currently supported package managers are:
|
||||
|
||||
1. apt-get (Debian)
|
||||
2. xbps (Void)
|
||||
3. dnf (Fedora)
|
||||
4. yum (Enterprise Linux/Legacy Fedora)
|
||||
5. zypper (OpenSUSE)
|
||||
6. eopkg (Solus)
|
||||
7. pacman (Arch)
|
||||
8. emerge (Gentoo)
|
||||
9. pkg (FreeBSD)
|
||||
10. chromebrew (ChromeOS)
|
||||
11. homebrew (Mac OS)
|
||||
12. nix (Nix OS)
|
||||
13. snap (Independent)
|
||||
14. npm (Javascript, Global)
|
||||
|
||||
|
||||
|
||||
Just in case you assigned a wrong package manager, you can set a new package manager using the following command:
|
||||
|
||||
```
|
||||
$ sudo sysget set yum
|
||||
Package manager changed to yum
|
||||
|
||||
```
|
||||
|
||||
Just make sure you have chosen your native package manager.
|
||||
|
||||
Now, you can perform the package management operations as the way you do using your native package manager.
|
||||
|
||||
To install a package, for example Emacs, simply run:
|
||||
|
||||
```
|
||||
$ sudo sysget install emacs
|
||||
|
||||
```
|
||||
|
||||
The above command will invoke the native package manager (In my case it is “apt-get”) and install the given package.
|
||||
|
||||

|
||||
|
||||
Similarly, to remove a package, simply run:
|
||||
|
||||
```
|
||||
$ sudo sysget remove emacs
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
Update software repository (database):
|
||||
|
||||
```
|
||||
$ sudo sysget update
|
||||
|
||||
```
|
||||
|
||||
**Search for a specific package:**
|
||||
|
||||
```
|
||||
$ sudo sysget search emacs
|
||||
|
||||
```
|
||||
|
||||
**Upgrade a single package:**
|
||||
|
||||
```
|
||||
$ sudo sysget upgrade emacs
|
||||
|
||||
```
|
||||
|
||||
**Upgrade all packages:**
|
||||
|
||||
```
|
||||
$ sudo sysget upgrade
|
||||
|
||||
```
|
||||
|
||||
**Remove all orphaned packages:**
|
||||
|
||||
```
|
||||
$ sudo sysget autoremove
|
||||
|
||||
```
|
||||
|
||||
**Clear the package manager cache:**
|
||||
|
||||
```
|
||||
$ sudo sysget clean
|
||||
|
||||
```
|
||||
|
||||
For more details, refer the help section:
|
||||
|
||||
```
|
||||
$ sysget help
|
||||
Help of sysget
|
||||
sysget [OPTION] [ARGUMENT]
|
||||
|
||||
search [query] search for a package in the resporitories
|
||||
install [package] install a package from the repos
|
||||
remove [package] removes a package
|
||||
autoremove removes not needed packages (orphans)
|
||||
update update the database
|
||||
upgrade do a system upgrade
|
||||
upgrade [package] upgrade a specific package
|
||||
clean clean the download cache
|
||||
set [NEW MANAGER] set a new package manager
|
||||
|
||||
```
|
||||
|
||||
Please remember that the sysget syntax is same for all package managers in different Linux distributions. You don’t need to memorize the commands for each package manager.
|
||||
|
||||
Again, I must tell you Sysget isn’t a replacement for a package manager. It is just wrapper for popular package managers in Unix-like systems and it performs the basic package management operations only.
|
||||
|
||||
Sysget might be somewhat useful for newbies and distro-hoppers who are lazy to learn new commands for different package manager. Give it a try if you’re interested and see if it helps.
|
||||
|
||||
And, that’s all for now. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/sysget-a-front-end-for-popular-package-managers/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/emilengler/sysget/releases
|
||||
@ -0,0 +1,160 @@
|
||||
Getting started with Minikube: Kubernetes on your laptop
|
||||
======
|
||||
A step-by-step guide for running Minikube.
|
||||
|
||||

|
||||
|
||||
Minikube is advertised on the [Hello Minikube][1] tutorial page as a simple way to run Kubernetes for Docker. While that documentation is very informative, it is primarily written for MacOS. You can dig deeper for instructions for Windows or a Linux distribution, but they are not very clear. And much of the documentation—like one on [installing drivers for Minikube][2]—is targeted at Debian/Ubuntu users.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
1. You have [installed Docker][3].
|
||||
|
||||
2. Your computer is an RHEL/CentOS/Fedora-based workstation.
|
||||
|
||||
3. You have [installed a working KVM2 hypervisor][4].
|
||||
|
||||
4. You have a working **docker-machine-driver-kvm2**. The following commands will install the driver:
|
||||
|
||||
```
|
||||
curl -Lo docker-machine-driver-kvm2 https://storage.googleapis.com/minikube/releases/latest/docker-machine-driver-kvm2 \
|
||||
chmod +x docker-machine-driver-kvm2 \
|
||||
&& sudo cp docker-machine-driver-kvm2 /usr/local/bin/ \
|
||||
&& rm docker-machine-driver-kvm2
|
||||
```
|
||||
|
||||
### Download, install, and start Minikube
|
||||
|
||||
1. Create a directory for the two files you will download: [minikube][5] and [kubectl][6].
|
||||
|
||||
|
||||
2. Open a terminal window and run the following command to install minikube.
|
||||
|
||||
```
|
||||
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
|
||||
|
||||
```
|
||||
|
||||
Note that the minikube version (e.g., minikube-linux-amd64) may differ based on your computer's specs.
|
||||
|
||||
|
||||
|
||||
3. **chmod** to make it writable.
|
||||
|
||||
```
|
||||
chmod +x minikube
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
4. Move the file to the **/usr/local/bin** path so you can run it as a command.
|
||||
|
||||
```
|
||||
mv minikube /usr/local/bin
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
5. Install kubectl using the following command (similar to the minikube installation process).
|
||||
|
||||
```
|
||||
curl -Lo kubectl https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
|
||||
|
||||
```
|
||||
|
||||
Use the **curl** command to determine the latest version of Kubernetes.
|
||||
|
||||
|
||||
|
||||
6. **chmod** to make kubectl writable.
|
||||
|
||||
```
|
||||
chmod +x kubectl
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
7. Move kubectl to the **/usr/local/bin** path to run it as a command.
|
||||
|
||||
```
|
||||
mv kubectl /usr/local/bin
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
8. Run **minikube start**. To do so, you need to have a hypervisor available. I used KVM2, and you can also use Virtualbox. Make sure to run the following command as a user instead of root so the configuration will be stored for the user instead of root.
|
||||
|
||||
```
|
||||
minikube start --vm-driver=kvm2
|
||||
|
||||
```
|
||||
|
||||
It can take quite a while, so wait for it.
|
||||
|
||||
|
||||
|
||||
9. Minikube should download and start. Use the following command to make sure it was successful.
|
||||
|
||||
```
|
||||
cat ~/.kube/config
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
10. Execute the following command to run Minikube as the context. The context is what determines which cluster kubectl is interacting with. You can see all your available contexts in the ~/.kube/config file.
|
||||
|
||||
```
|
||||
kubectl config use-context minikube
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
11. Run the **config** file command again to check that context Minikube is there.
|
||||
|
||||
```
|
||||
cat ~/.kube/config
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
12. Finally, run the following command to open a browser with the Kubernetes dashboard.
|
||||
|
||||
```
|
||||
minikube dashboard
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
This guide aims to make things easier for RHEL/Fedora/CentOS-based operating system users.
|
||||
|
||||
Now that Minikube is up and running, read [Running Kubernetes Locally via Minikube][7] to start using it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/getting-started-minikube
|
||||
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://kubernetes.io/docs/tutorials/hello-minikube
|
||||
[2]: https://github.com/kubernetes/minikube/blob/master/docs/drivers.md
|
||||
[3]: https://docs.docker.com/install
|
||||
[4]: https://github.com/kubernetes/minikube/blob/master/docs/drivers.md#kvm2-driver
|
||||
[5]: https://github.com/kubernetes/minikube/releases
|
||||
[6]: https://kubernetes.io/docs/tasks/tools/install-kubectl/#install-kubectl-binary-using-curl
|
||||
[7]: https://kubernetes.io/docs/setup/minikube
|
||||
@ -0,0 +1,87 @@
|
||||
The First Beta of Haiku is Released After 16 Years of Development
|
||||
======
|
||||
There are a number of small operating systems out there that are designed to replicate the past. Haiku is one of those. We will look to see where Haiku came from and what the new release has to offer.
|
||||
|
||||
![Haiku OS desktop screenshot][1]Haiku desktop
|
||||
|
||||
### What is Haiku?
|
||||
|
||||
Haiku’s history begins with the now defunct [Be Inc][2]. Be Inc was founded by former Apple executive [Jean-Louis Gassée][3] after he was ousted by CEO [John Sculley][4]. Gassée wanted to create a new operating system from the ground up. BeOS was created with digital media work in mind and was designed to take advantage of the most modern hardware of the time. Originally, Be Inc attempted to create their own platform encompassing both hardware and software. The result was called the [BeBox][5]. After BeBox failed to sell well, Be turned their attention to BeOS.
|
||||
|
||||
In the 1990s, Apple was looking for a new operating system to replace the aging Classic Mac OS. The two contenders were Gassée’s BeOS and Steve Jobs’ NeXTSTEP. In the end, Apple went with NeXTSTEP. Be tried to license BeOS to hardware makers, but [in at least one case][6] Microsoft threatened to revoke a manufacturer’s Windows license if they sold BeOS machines. Eventually, Be Inc was sold to Palm in 2001 for $11 million. BeOS was subsequently discontinued.
|
||||
|
||||
Following the news of Palm’s purchase, a number of loyal fans decided they wanted to keep the operating system alive. The original name of the project was OpenBeOS, but was changed to Haiku to avoid infringing on Palm’s trademarks. The name is a reference to reference to the [haikus][7] used as error messages by many of the applications. Haiku is completely written from scratch and is compatible with BeOS.
|
||||
|
||||
### Why Haiku?
|
||||
|
||||
According to the project’s website, [Haiku][8] “is a fast, efficient, simple to use, easy to learn, and yet very powerful system for computer users of all levels”. Haiku comes with a kernel that have been customized for performance. Like FreeBSD, there is a “single team writing everything from the kernel, drivers, userland services, toolkit, and graphics stack to the included desktop applications and preflets”.
|
||||
|
||||
### New Features in Haiku Beta Release
|
||||
|
||||
A number of new features have been introduced since the release of Alpha 4.1. (Please note that Haiku is a passion project and all the devs are part-time, so some they can’t spend as much time working on Haiku as they would like.)
|
||||
|
||||
![Haiku OS software][9]
|
||||
HaikuDepot, Haiku’s package manager
|
||||
|
||||
One of the biggest features is the inclusion of a complete package management system. HaikuDepot allows you to sort through many applications. Many are built specifically for Haiku, but a number have been ported to the platform, such as [LibreOffice][10], [Otter Browser][11], and [Calligra][12]. Interestingly, each Haiku package is [“a special type of compressed filesystem image, which is ‘mounted’ upon installation”][13]. There is also a command line interface for package management named `pkgman`.
|
||||
|
||||
Another big feature is an upgraded browser. Haiku was able to hire a developer to work full-time for a year to improve the performance of WebPositive, the built-in browser. This included an update to a newer version of WebKit. WebPositive will now play Youtube videos properly.
|
||||
|
||||
![Haiku OS WebPositive browser][14]
|
||||
WebPositive, Haiku’s built-in browser
|
||||
|
||||
Other features include:
|
||||
|
||||
* A completely rewritten network preflet
|
||||
* User interface cleanup
|
||||
* Media subsystem improvements, including better streaming support, HDA driver improvements, and FFmpeg decoder plugin improvements
|
||||
* Native RemoteDesktop improved
|
||||
* Add EFI bootloader and GPT support
|
||||
* Updated Ethernet & WiFi drivers
|
||||
* Updated filesystem drivers
|
||||
* General system stabilization
|
||||
* Experimental Bluetooth stack
|
||||
|
||||
|
||||
|
||||
### Thoughts on Haiku OS
|
||||
|
||||
I have been following Haiku for many years. I’ve installed and played with the nightly builds a dozen times over the last couple of years. I even took some time to start learning one of its programming languages, so that I could write apps. But I got busy with other things.
|
||||
|
||||
I’m very conflicted about it. I like Haiku because it is a neat non-Linux project, but it is only just getting features that everyone else takes for granted, like a package manager.
|
||||
|
||||
If you’ve got a couple of minutes, download the [ISO][15] and install it on the virtual machine of your choice. You just might like it.
|
||||
|
||||
Have you ever used Haiku or BeOS? If so, what are your favorite features? Let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][16].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/haiku-os-release/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/haiku.jpg
|
||||
[2]: https://en.wikipedia.org/wiki/Be_Inc.
|
||||
[3]: https://en.wikipedia.org/wiki/Jean-Louis_Gass%C3%A9e
|
||||
[4]: https://en.wikipedia.org/wiki/John_Sculley
|
||||
[5]: https://en.wikipedia.org/wiki/BeBox
|
||||
[6]: https://birdhouse.org/beos/byte/30-bootloader/
|
||||
[7]: https://en.wikipedia.org/wiki/Haiku
|
||||
[8]: https://www.haiku-os.org/about/
|
||||
[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/haiku-depot.png
|
||||
[10]: https://www.libreoffice.org/
|
||||
[11]: https://itsfoss.com/otter-browser-review/
|
||||
[12]: https://www.calligra.org/
|
||||
[13]: https://www.haiku-os.org/get-haiku/release-notes/
|
||||
[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/webpositive.jpg
|
||||
[15]: https://www.haiku-os.org/get-haiku
|
||||
[16]: http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,88 @@
|
||||
如何在救援(单用户模式)/紧急模式下启动 Ubuntu 18.04/Debian 9 服务器
|
||||
======
|
||||
将 Linux 服务器引导到单用户模式或**救援模式**是 Linux 管理员在关键时刻恢复服务器时通常使用的重要故障排除方法之一。在 Ubuntu 18.04 和 Debian 9 中,单用户模式被称为救援模式。
|
||||
|
||||
除了救援模式外,Linux 服务器可以在**紧急模式**下启动,它们之间的主要区别在于,紧急模式加载了带有只读根文件系统文件系统的最小环境,也没有启用任何网络或其他服务。但救援模式尝试挂载所有本地文件系统并尝试启动一些重要的服务,包括网络。
|
||||
|
||||
在本文中,我们将讨论如何在救援模式和紧急模式下启动 Ubuntu 18.04 LTS/Debian 9 服务器。
|
||||
|
||||
#### 在单用户/救援模式下启动 Ubuntu 18.04 LTS 服务器:
|
||||
|
||||
重启服务器并进入启动加载程序 (Grub) 屏幕并选择 “**Ubuntu**”,启动加载器页面如下所示,
|
||||
|
||||

|
||||
|
||||
按下 “**e**”,然后移动到以 “**linux**” 开头的行尾,并添加 “**systemd.unit=rescue.target**”。如果存在单词 “**$vt_handoff**” 就删除它。
|
||||
|
||||

|
||||
|
||||
现在按 Ctrl-x 或 F10 启动,
|
||||
|
||||

|
||||
|
||||
现在按回车键,然后你将得到所有文件系统都以读写模式挂载的 shell 并进行故障排除。完成故障排除后,可以使用 “**reboot**” 命令重新启动服务器。
|
||||
|
||||
#### 在紧急模式下启动 Ubuntu 18.04 LTS 服务器
|
||||
|
||||
重启服务器并进入启动加载程序页面并选择 “**Ubuntu**”,然后按 “**e**” 并移动到以 linux 开头的行尾,并添加 “**systemd.unit=emergency.target**“。
|
||||
|
||||

|
||||
|
||||
现在按 Ctlr-x 或 F10 以紧急模式启动,你将获得一个 shell 并从那里进行故障排除。正如我们已经讨论过的那样,在紧急模式下,文件系统将以只读模式挂载,并且在这种模式下也不会有网络,
|
||||
|
||||

|
||||
|
||||
使用以下命令将根文件系统挂载到读写模式,
|
||||
|
||||
```
|
||||
# mount -o remount,rw /
|
||||
|
||||
```
|
||||
|
||||
同样,你可以在读写模式下重新挂载其余文件系统。
|
||||
|
||||
#### 将 Debian 9 引导到救援和紧急模式
|
||||
|
||||
重启 Debian 9.x 服务器并进入 grub页面选择 “**Debian GNU/Linux**”。
|
||||
|
||||

|
||||
|
||||
按下 “**e**” 并移动到 linux 开头的行尾并添加 “**systemd.unit=rescue.target**” 以在救援模式下启动系统, 要在紧急模式下启动,那就添加 “**systemd.unit=emergency.target**“
|
||||
|
||||
#### 救援模式:
|
||||
|
||||

|
||||
|
||||
现在按 Ctrl-x 或 F10 以救援模式启动
|
||||
|
||||

|
||||
|
||||
按下回车键以获取 shell,然后从这里开始故障排除。
|
||||
|
||||
#### 紧急模式:
|
||||
|
||||

|
||||
|
||||
现在按下 ctrl-x 或 F10 以紧急模式启动系统
|
||||
|
||||

|
||||
|
||||
按下回车获取 shell 并使用 “**mount -o remount,rw /**” 命令以读写模式挂载根文件系统。
|
||||
|
||||
**注意:**如果已经在 Ubuntu 18.04 和 Debian 9 Server 中设置了 root 密码,那么你必须输入 root 密码才能在救援和紧急模式下获得 shell
|
||||
|
||||
就是这些了,如果您喜欢这篇文章,请分享你的反馈和评论。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/boot-ubuntu-18-04-debian-9-rescue-emergency-mode/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxtechi.com/author/pradeep/
|
||||
Loading…
Reference in New Issue
Block a user