mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
Merge pull request #9169 from amwps290/master
20180525 How to clean up your data in the command line.md-translated
This commit is contained in:
commit
89b809dee8
@ -1,3 +1,4 @@
|
||||
translating by amwps290
|
||||
How To Convert DEB Packages Into Arch Linux Packages
|
||||
======
|
||||

|
||||
|
||||
@ -1,115 +0,0 @@
|
||||
translating by amwps290
|
||||
How to clean up your data in the command line
|
||||
======
|
||||

|
||||
|
||||
I work part-time as a data auditor. Think of me as a proofreader who works with tables of data rather than pages of prose. The tables are exported from relational databases and are usually fairly modest in size: 100,000 to 1,000,000 records and 50 to 200 fields.
|
||||
|
||||
I haven't seen an error-free data table, ever. The messiness isn't limited, as you might think, to duplicate records, spelling and formatting errors, and data items placed in the wrong field. I also find:
|
||||
|
||||
* broken records spread over several lines because data items had embedded line breaks
|
||||
* data items in one field disagreeing with data items in another field, in the same record
|
||||
* records with truncated data items, often because very long strings were shoehorned into fields with 50- or 100-character limits
|
||||
* character encoding failures producing the gibberish known as [mojibake][1]
|
||||
* invisible [control characters][2], some of which can cause data processing errors
|
||||
* [replacement characters][3] and mysterious question marks inserted by the last program that failed to understand the data's character encoding
|
||||
|
||||
|
||||
|
||||
Cleaning up these problems isn't hard, but there are non-technical obstacles to finding them. The first is everyone's natural reluctance to deal with data errors. Before I see a table, the data owners or managers may well have gone through all five stages of Data Grief:
|
||||
|
||||
1. There are no errors in our data.
|
||||
2. Well, maybe there are a few errors, but they're not that important.
|
||||
3. OK, there are a lot of errors; we'll get our in-house people to deal with them.
|
||||
4. We've started fixing a few of the errors, but it's time-consuming; we'll do it when we migrate to the new database software.
|
||||
5. We didn't have time to clean the data when moving to the new database; we could use some help.
|
||||
|
||||
|
||||
|
||||
The second progress-blocking attitude is the belief that data cleaning requires dedicated applications—either expensive proprietary programs or the excellent open source program [OpenRefine][4]. To deal with problems that dedicated applications can't solve, data managers might ask a programmer for help—someone good with [Python][5] or [R][6].
|
||||
|
||||
But data auditing and cleaning generally don't require dedicated applications. Plain-text data tables have been around for many decades, and so have text-processing tools. Open up a Bash shell and you have a toolbox loaded with powerful text processors like `grep`, `cut`, `paste`, `sort`, `uniq`, `tr`, and `awk`. They're fast, reliable, and easy to use.
|
||||
|
||||
I do all my data auditing on the command line, and I've put many of my data-auditing tricks on a ["cookbook" website][7]. Operations I do regularly get stored as functions and shell scripts (see the example below).
|
||||
|
||||
Yes, a command-line approach requires that the data to be audited have been exported from the database. And yes, the audit results need to be edited later within the database, or (database permitting) the cleaned data items need to be imported as replacements for the messy ones.
|
||||
|
||||
But the advantages are remarkable. `awk` will process a few million records in seconds on a consumer-grade desktop or laptop. Uncomplicated regular expressions will find all the data errors you can imagine. And all of this will happen safely outside the database structure: Command-line auditing cannot affect the database, because it works with data liberated from its database prison.
|
||||
|
||||
Readers who trained on Unix will be smiling smugly at this point. They remember manipulating data on the command line many years ago in just these ways. What's happened since then is that processing power and RAM have increased spectacularly, and the standard command-line tools have been made substantially more efficient. Data auditing has never been faster or easier. And now that Microsoft Windows 10 can run Bash and GNU/Linux programs, Windows users can appreciate the Unix and Linux motto for dealing with messy data: Keep calm and open a terminal.
|
||||
|
||||
|
||||
![Tshirt, Keep Calm and Open A Terminal][9]
|
||||
|
||||
Photo by Robert Mesibov, CC BY
|
||||
|
||||
### An example
|
||||
|
||||
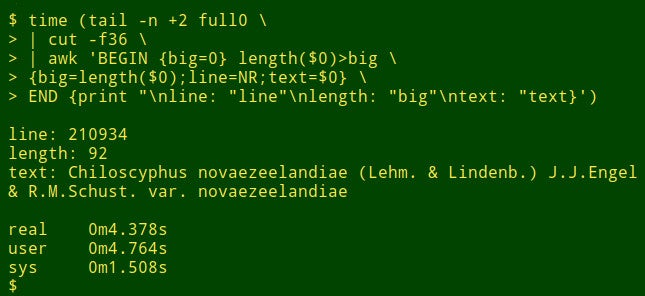
Suppose I want to find the longest data item in a particular field of a big table. That's not really a data auditing task, but it will show how shell tools work. For demonstration purposes, I'll use the tab-separated table `full0`, which has 1,122,023 records (plus a header line) and 49 fields, and I'll look in field number 36. (I get field numbers with a function explained [on my cookbook site][10].)
|
||||
|
||||
The command begins by using `tail` to remove the header line from `full0`. The result is piped to `cut`, which extracts the decapitated field 36. Next in the pipeline is `awk`. Here the variable `big` is initialized to a value of 0; then `awk` tests the length of the data item in the first record. If the length is bigger than 0, `awk` resets `big` to the new length and stores the line number (NR) in the variable `line` and the whole data item in the variable `text`. `awk` then processes each of the remaining 1,122,022 records in turn, resetting the three variables when it finds a longer data item. Finally, it prints out a neatly separated list of line numbers, length of data item, and full text of the longest data item. (In the following code, the commands have been broken up for clarity onto several lines.)
|
||||
```
|
||||
<code>tail -n +2 full0 \
|
||||
|
||||
> | cut -f36 \
|
||||
|
||||
> | awk 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
> {big=length($0);line=NR;text=$0} \
|
||||
|
||||
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
|
||||
|
||||
```
|
||||
|
||||
How long does this take? About 4 seconds on my desktop (core i5, 8GB RAM):
|
||||
|
||||
|
||||
|
||||
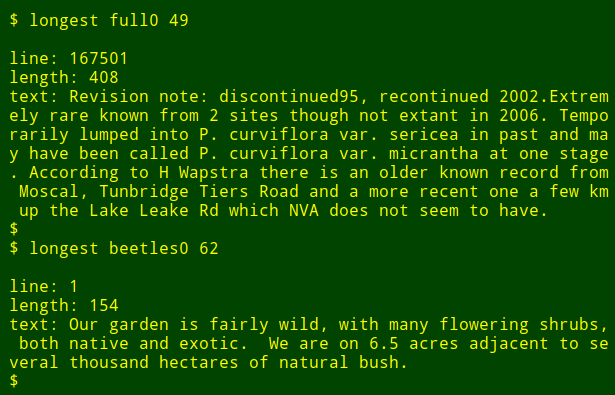
Now for the neat part: I can pop that long command into a shell function, `longest`, which takes as its arguments the filename `($1)` and the field number `($2)`:
|
||||

|
||||
|
||||
I can then re-run the command as a function, finding longest data items in other fields and in other files without needing to remember how the command is written:
|
||||
|
||||
|
||||
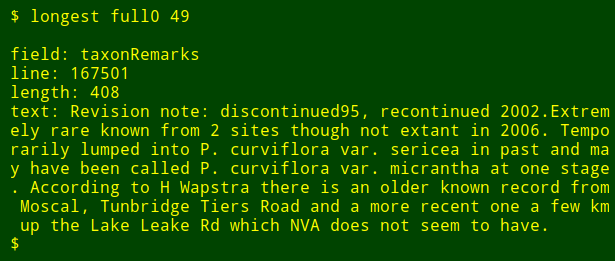
As a final tweak, I can add to the output the name of the numbered field I'm searching. To do this, I use `head` to extract the header line of the table, pipe that line to `tr` to convert tabs to new lines, and pipe the resulting list to `tail` and `head` to print the `$2th` field name on the list, where `$2` is the field number argument. The field name is stored in the shell variable `field` and passed to `awk` for printing as the internal `awk` variable `fld`.
|
||||
```
|
||||
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
|
||||
|
||||
tail -n +2 "$1" \
|
||||
|
||||
| cut -f"$2" | \
|
||||
|
||||
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
{big=length($0);line=NR;text=$0}
|
||||
|
||||
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code>
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
Note that if I'm looking for the longest data item in a number of different fields, all I have to do is press the Up Arrow key to get the last `longest` command, then backspace the field number and enter a new one.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/command-line-data-auditing
|
||||
|
||||
作者:[Bob Mesibov][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bobmesibov
|
||||
[1]:https://en.wikipedia.org/wiki/Mojibake
|
||||
[2]:https://en.wikipedia.org/wiki/Control_character
|
||||
[3]:https://en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_character
|
||||
[4]:http://openrefine.org/
|
||||
[5]:https://www.python.org/
|
||||
[6]:https://www.r-project.org/about.html
|
||||
[7]:https://www.polydesmida.info/cookbook/index.html
|
||||
[8]:/file/399116
|
||||
[9]:https://opensource.com/sites/default/files/uploads/terminal_tshirt.jpg (Tshirt, Keep Calm and Open A Terminal)
|
||||
[10]:https://www.polydesmida.info/cookbook/functions.html#fields
|
||||
@ -0,0 +1,115 @@
|
||||
# 在命令行中整理数据
|
||||
|
||||

|
||||
|
||||
我兼职做数据审计。把我想象成一个校对者,处理数据表格而不是一页一页的文章。这些表是从关系数据库导出的,并且规模相当小:100,000 到 1,000,000条记录,50 到 200个字段。
|
||||
|
||||
我从来没有见过没有错误的数据表。您可能认为,这种混乱并不局限于重复记录、拼写和格式错误以及放置在错误字段中的数据项。我还发现:
|
||||
|
||||
* 损坏的记录分布在几行上,因为数据项具有内嵌的换行符
|
||||
* 在同一记录中一个字段中的数据项与另一个字段中的数据项不一致
|
||||
* 使用截断数据项的记录,通常是因为非常长的字符串被硬塞到具有50或100字符限制的字段中
|
||||
* 字符编码失败产生称为[乱码][1]
|
||||
* 不可见的[控制字符][2],其中一些会导致数据处理错误
|
||||
* 由上一个程序插入的[替换字符][3]和神秘的问号,这导致了不知道数据的编码是什么
|
||||
|
||||
解决这些问题并不困难,但找到它们存在非技术障碍。首先,每个人都不愿处理数据错误。在我看到表格之前,数据所有者或管理人员可能已经经历了数据悲伤的所有五个阶段:
|
||||
|
||||
1. 我们的数据没有错误。
|
||||
|
||||
1. 好吧,也许有一些错误,但它们并不重要。
|
||||
2. 好的,有很多错误; 我们会让我们的内部人员处理它们。
|
||||
3. 我们已经开始修复一些错误,但这很耗时间; 我们将在迁移到新的数据库软件时执行此操作。
|
||||
4. 1.移至新数据库时,我们没有时间整理数据; 我们可以使用一些帮助。
|
||||
|
||||
第二个阻碍进展的是相信数据整理需要专用的应用程序——要么是昂贵的专有程序,要么是优秀的开源程序 [OpenRefine][4] 。为了解决专用应用程序无法解决的问题,数据管理人员可能会向程序员寻求帮助,比如擅长 [Python][5] 或 [R][6] 的人。
|
||||
|
||||
但是数据审计和整理通常不需要专用的应用程序。纯文本数据表已经存在了几十年,文本处理工具也是如此。打开 Bash shell,您将拥有一个工具箱,其中装载了强大的文本处理器,如 `grep`、`cut`、`paste`、`sort`、`uniq`、`tr` 和 `awk`。它们快速、可靠、易于使用。
|
||||
|
||||
我在命令行上执行所有的数据审计工作,并且在 “[cookbook][7]” 网站上发布了许多数据审计技巧。我经常将操作存储为函数和 shell 脚本(参见下面的示例)。
|
||||
|
||||
是的,命令行方法要求将要审计的数据从数据库中导出。 是的,审计结果需要稍后在数据库中进行编辑,或者(数据库允许)整理的数据项作为替换杂乱的数据项导入其中。
|
||||
|
||||
但其优势是显著的。awk 将在普通的台式机或笔记本电脑上以几秒钟的时间处理数百万条记录。不复杂的正则表达式将找到您可以想象的所有数据错误。所有这些都将安全地发生在数据库结构之外:命令行审计不会影响数据库,因为它使用从数据库中释放的数据。
|
||||
|
||||
受过 Unix 培训的读者此时会沾沾自喜。他们还记得许多年前用这些方法操纵命令行上的数据。从那时起,计算机的处理能力和 RAM 得到了显著提高,标准命令行工具的效率大大提高。数据审计从来都不是更快或更容易的。现在微软的 Windows 10 可以运行 Bash 和 GNU/Linux 程序了,Windows 用户也可以用 Unix 和 Linux 的座右铭来处理混乱的数据:保持冷静,打开一个终端。
|
||||
|
||||
|
||||
![Tshirt, Keep Calm and Open A Terminal][9]
|
||||
|
||||
图片:Robert Mesibov,CC BY
|
||||
|
||||
### 例子:
|
||||
|
||||
假设我想在一个大的表中的特定字段中找到最长的数据项。 这不是一个真正的数据审计任务,但它会显示 shell 工具的工作方式。 为了演示目的,我将使用制表符分隔的表 `full0` ,它有 1,122,023 条记录(加上一个标题行)和 49 个字段,我会查看 36 号字段.(我得到字段编号的函数在我的[网站][10]上有解释)
|
||||
|
||||
首先,使用 `tail` 命令从表 `full0` 移除标题行,结果管道至 `cut` 命令,截取第 36 个字段,接下来,管道至 `awk` ,这里有一个初始化为 0 的变量 `big` ,然后 `awk` 开始检测第一行数据项的长度,如果长度大于 0 , `awk` 将会设置 `big` 变量为新的长度,同时存储行数到变量 `line` 中。整个数据项存储在变量 `text` 中。然后 `awk` 开始轮流处理剩余的 1,122,022 记录项。同时,如果发现更长的数据项时,更新 3 个变量。最后,它打印出行号,数据项的长度,以及最长数据项的内容。(在下面的代码中,为了清晰起见,将代码分为几行)
|
||||
|
||||
```
|
||||
<code>tail -n +2 full0 \
|
||||
|
||||
> | cut -f36 \
|
||||
|
||||
> | awk 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
> {big=length($0);line=NR;text=$0} \
|
||||
|
||||
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
|
||||
|
||||
```
|
||||
|
||||
大约花了多长时间?我的电脑大约用了 4 秒钟(core i5,8GB RAM);
|
||||
|
||||

|
||||
|
||||
现在我可以将这个长长的命令封装成一个 shell 函数,`longest`,它把第一个参数认为是文件名,第二个参数认为是字段号:
|
||||
|
||||

|
||||
|
||||
现在,我重新运行这个命令,在另一个文件中找另一个字段中最长的数据项而不需要去记忆命令是如何写的:
|
||||
|
||||

|
||||
|
||||
最后调整一下,我还可以输出我要查询字段的名称,我只需要使用 `head` 命令抽取表格第一行的标题行,然后将结果管道至 `tr` 命令,将制表位转换为换行,然后将结果管道至 `tail` 和 `head` 命令,打印出第二个参数在列表中名称,第二个参数就是字段号。字段的名字就存储到变量 `field` 中,然后将他传向 `awk` ,通过变量 `fld` 打印出来。(译者注:按照下面的代码,编号的方式应该是从右向左)
|
||||
|
||||
```
|
||||
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
|
||||
|
||||
tail -n +2 "$1" \
|
||||
|
||||
| cut -f"$2" | \
|
||||
|
||||
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
{big=length($0);line=NR;text=$0}
|
||||
|
||||
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code>
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
注意,如果我在多个不同的字段中查找最长的数据项,我所要做的就是按向上箭头来获得最后一个最长的命令,然后删除字段号并输入一个新的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/command-line-data-auditing
|
||||
|
||||
作者:[Bob Mesibov][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bobmesibov
|
||||
[1]:https://en.wikipedia.org/wiki/Mojibake
|
||||
[2]:https://en.wikipedia.org/wiki/Control_character
|
||||
[3]:https://en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_character
|
||||
[4]:http://openrefine.org/
|
||||
[5]:https://www.python.org/
|
||||
[6]:https://www.r-project.org/about.html
|
||||
[7]:https://www.polydesmida.info/cookbook/index.html
|
||||
[8]:/file/399116
|
||||
[9]:https://opensource.com/sites/default/files/uploads/terminal_tshirt.jpg "Tshirt, Keep Calm and Open A Terminal"
|
||||
[10]:https://www.polydesmida.info/cookbook/functions.html#fields
|
||||
Loading…
Reference in New Issue
Block a user