mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
commit
874e69ad33
@ -0,0 +1,74 @@
|
||||
使用 Python 和 Asyncio 编写在线多人游戏(一)
|
||||
===================================================================
|
||||
|
||||
你在 Python 中用过异步编程吗?本文中我会告诉你怎样做,而且用一个[能工作的例子][1]来展示它:这是一个流行的贪吃蛇游戏,而且是为多人游戏而设计的。
|
||||
|
||||
- [游戏入口在此,点此体验][2]。
|
||||
|
||||
###1、简介
|
||||
|
||||
在技术和文化领域,大规模多人在线游戏(MMO)毋庸置疑是我们当今世界的潮流之一。很长时间以来,为一个 MMO 游戏写一个服务器这件事总是会涉及到大量的预算与复杂的底层编程技术,不过在最近这几年,事情迅速发生了变化。基于动态语言的现代框架允许在中档的硬件上面处理大量并发的用户连接。同时,HTML5 和 WebSockets 标准使得创建基于实时图形的游戏的直接运行至浏览器上的客户端成为可能,而不需要任何的扩展。
|
||||
|
||||
对于创建可扩展的非堵塞性的服务器来说,Python 可能不是最受欢迎的工具,尤其是和在这个领域里最受欢迎的 Node.js 相比而言。但是最近版本的 Python 正在改变这种现状。[asyncio][3] 的引入和一个特别的 [async/await][4] 语法使得异步代码看起来像常规的阻塞代码一样,这使得 Python 成为了一个值得信赖的异步编程语言,所以我将尝试利用这些新特点来创建一个多人在线游戏。
|
||||
|
||||
###2、异步
|
||||
|
||||
一个游戏服务器应该可以接受尽可能多的用户并发连接,并实时处理这些连接。一个典型的解决方案是创建线程,然而在这种情况下并不能解决这个问题。运行上千的线程需要 CPU 在它们之间不停的切换(这叫做上下文切换),这将导致开销非常大,效率很低下。更糟糕的是使用进程来实现,因为,不但如此,它们还会占用大量的内存。在 Python 中,甚至还有一个问题,Python 的解释器(CPython)并不是针对多线程设计的,相反它主要针对于单线程应用实现最大的性能。这就是为什么它使用 GIL(global interpreter lock),这是一个不允许同时运行多线程 Python 代码的架构,以防止同一个共享对象出现使用不可控。正常情况下,在当前线程正在等待的时候,解释器会转换到另一个线程,通常是等待一个 I/O 的响应(举例说,比如等待 Web 服务器的响应)。这就允许在你的应用中实现非阻塞 I/O 操作,因为每一个操作仅仅阻塞一个线程而不是阻塞整个服务器。然而,这也使得通常的多线程方案变得几近无用,因为它不允许你并发执行 Python 代码,即使是在多核心的 CPU 上也是这样。而与此同时,在一个单一线程中拥有非阻塞 I/O 是完全有可能的,因而消除了经常切换上下文的需要。
|
||||
|
||||
实际上,你可以用纯 Python 代码来实现一个单线程的非阻塞 I/O。你所需要的只是标准的 [select][5] 模块,这个模块可以让你写一个事件循环来等待未阻塞的 socket 的 I/O。然而,这个方法需要你在一个地方定义所有 app 的逻辑,用不了多久,你的 app 就会变成非常复杂的状态机。有一些框架可以简化这个任务,比较流行的是 [tornade][6] 和 [twisted][7]。它们被用来使用回调方法实现复杂的协议(这和 Node.js 比较相似)。这种框架运行在它自己的事件循环中,按照定义的事件调用你的回调函数。并且,这或许是一些情况的解决方案,但是它仍然需要使用回调的方式编程,这使你的代码变得碎片化。与写同步代码并且并发地执行多个副本相比,这就像我们在普通的线程上做的一样。在单个线程上这为什么是不可能的呢?
|
||||
|
||||
这就是为什么出现微线程(microthread)概念的原因。这个想法是为了在一个线程上并发执行任务。当你在一个任务中调用阻塞的方法时,有一个叫做“manager” (或者“scheduler”)的东西在执行事件循环。当有一些事件准备处理的时候,一个 manager 会转移执行权给一个任务,并等着它执行完毕。任务将一直执行,直到它遇到一个阻塞调用,然后它就会将执行权返还给 manager。
|
||||
|
||||
> 微线程也称为轻量级线程(lightweight threads)或绿色线程(green threads)(来自于 Java 中的一个术语)。在伪线程中并发执行的任务叫做 tasklets、greenlets 或者协程(coroutines)。
|
||||
|
||||
Python 中的微线程最早的实现之一是 [Stackless Python][8]。它之所以这么知名是因为它被用在了一个叫 [EVE online][9] 的非常有名的在线游戏中。这个 MMO 游戏自称说在一个持久的“宇宙”中,有上千个玩家在做不同的活动,这些都是实时发生的。Stackless 是一个独立的 Python 解释器,它代替了标准的函数栈调用,并且直接控制程序运行流程来减少上下文切换的开销。尽管这非常有效,这个解决方案不如在标准解释器中使用“软”库更流行,像 [eventlet][10] 和 [gevent][11] 的软件包配备了修补过的标准 I/O 库,I/O 函数会将执行权传递到内部事件循环。这使得将正常的阻塞代码转变成非阻塞的代码变得简单。这种方法的一个缺点是从代码上看这并不分明,它的调用是非阻塞的。新版本的 Python 引入了本地协程作为生成器的高级形式。在 Python 的 3.4 版本之后,引入了 asyncio 库,这个库依赖于本地协程来提供单线程并发。但是仅仅到了 Python 3.5 ,协程就变成了 Python 语言的一部分,使用新的关键字 async 和 await 来描述。这是一个简单的例子,演示了使用 asyncio 来运行并发任务。
|
||||
|
||||
```
|
||||
import asyncio
|
||||
|
||||
async def my_task(seconds):
|
||||
print("start sleeping for {} seconds".format(seconds))
|
||||
await asyncio.sleep(seconds)
|
||||
print("end sleeping for {} seconds".format(seconds))
|
||||
|
||||
all_tasks = asyncio.gather(my_task(1), my_task(2))
|
||||
loop = asyncio.get_event_loop()
|
||||
loop.run_until_complete(all_tasks)
|
||||
loop.close()
|
||||
```
|
||||
|
||||
我们启动了两个任务,一个睡眠 1 秒钟,另一个睡眠 2 秒钟,输出如下:
|
||||
|
||||
```
|
||||
start sleeping for 1 seconds
|
||||
start sleeping for 2 seconds
|
||||
end sleeping for 1 seconds
|
||||
end sleeping for 2 seconds
|
||||
```
|
||||
|
||||
正如你所看到的,协程不会阻塞彼此——第二个任务在第一个结束之前启动。这发生的原因是 asyncio.sleep 是协程,它会返回执行权给调度器,直到时间到了。
|
||||
|
||||
在下一节中,我们将会使用基于协程的任务来创建一个游戏循环。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[xinglianfly](https://github.com/xinglianfly)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: http://snakepit-game.com/
|
||||
[3]: https://docs.python.org/3/library/asyncio.html
|
||||
[4]: https://docs.python.org/3/whatsnew/3.5.html#whatsnew-pep-492
|
||||
[5]: https://docs.python.org/2/library/select.html
|
||||
[6]: http://www.tornadoweb.org/
|
||||
[7]: http://twistedmatrix.com/
|
||||
[8]: http://www.stackless.com/
|
||||
[9]: http://www.eveonline.com/
|
||||
[10]: http://eventlet.net/
|
||||
[11]: http://www.gevent.org/
|
||||
464
published/20160608 Simple Python Framework from Scratch.md
Normal file
464
published/20160608 Simple Python Framework from Scratch.md
Normal file
@ -0,0 +1,464 @@
|
||||
从零构建一个简单的 Python 框架
|
||||
===================================
|
||||
|
||||
为什么你想要自己构建一个 web 框架呢?我想,原因有以下几点:
|
||||
|
||||
- 你有一个新奇的想法,觉得将会取代其他的框架
|
||||
- 你想要获得一些名气
|
||||
- 你遇到的问题很独特,以至于现有的框架不太合适
|
||||
- 你对 web 框架是如何工作的很感兴趣,因为你想要成为一位更好的 web 开发者。
|
||||
|
||||
接下来的笔墨将着重于最后一点。这篇文章旨在通过对设计和实现过程一步一步的阐述告诉读者,我在完成一个小型的服务器和框架之后学到了什么。你可以在这个[代码仓库][1]中找到这个项目的完整代码。
|
||||
|
||||
我希望这篇文章可以鼓励更多的人来尝试,因为这确实很有趣。它让我知道了 web 应用是如何工作的,而且这比我想的要容易的多!
|
||||
|
||||
### 范围
|
||||
|
||||
框架可以处理请求-响应周期、身份认证、数据库访问、模板生成等部分工作。Web 开发者使用框架是因为,大多数的 web 应用拥有大量相同的功能,而对每个项目都重新实现同样的功能意义不大。
|
||||
|
||||
比较大的的框架如 Rails 和 Django 实现了高层次的抽象,或者说“自备电池”(“batteries-included”,这是 Python 的口号之一,意即所有功能都自足。)。而实现所有的这些功能可能要花费数千小时,因此在这个项目上,我们重点完成其中的一小部分。在开始写代码前,我先列举一下所需的功能以及限制。
|
||||
|
||||
功能:
|
||||
|
||||
- 处理 HTTP 的 GET 和 POST 请求。你可以在[这篇 wiki][2] 中对 HTTP 有个大致的了解。
|
||||
- 实现异步操作(我*喜欢* Python 3 的 asyncio 模块)。
|
||||
- 简单的路由逻辑以及参数撷取。
|
||||
- 像其他微型框架一样,提供一个简单的用户级 API 。
|
||||
- 支持身份认证,因为学会这个很酷啊(微笑)。
|
||||
|
||||
限制:
|
||||
|
||||
- 将只支持 HTTP 1.1 的一个小子集,不支持传输编码(transfer-encoding)、HTTP 认证(http-auth)、内容编码(content-encoding,如 gzip)以及[持久化连接][3]等功能。
|
||||
- 不支持对响应内容的 MIME 判断 - 用户需要手动指定。
|
||||
- 不支持 WSGI - 仅能处理简单的 TCP 连接。
|
||||
- 不支持数据库。
|
||||
|
||||
我觉得一个小的用例可以让上述内容更加具体,也可以用来演示这个框架的 API:
|
||||
|
||||
```
|
||||
from diy_framework import App, Router
|
||||
from diy_framework.http_utils import Response
|
||||
|
||||
|
||||
# GET simple route
|
||||
async def home(r):
|
||||
rsp = Response()
|
||||
rsp.set_header('Content-Type', 'text/html')
|
||||
rsp.body = '<html><body><b>test</b></body></html>'
|
||||
return rsp
|
||||
|
||||
|
||||
# GET route + params
|
||||
async def welcome(r, name):
|
||||
return "Welcome {}".format(name)
|
||||
|
||||
# POST route + body param
|
||||
async def parse_form(r):
|
||||
if r.method == 'GET':
|
||||
return 'form'
|
||||
else:
|
||||
name = r.body.get('name', '')[0]
|
||||
password = r.body.get('password', '')[0]
|
||||
|
||||
return "{0}:{1}".format(name, password)
|
||||
|
||||
# application = router + http server
|
||||
router = Router()
|
||||
router.add_routes({
|
||||
r'/welcome/{name}': welcome,
|
||||
r'/': home,
|
||||
r'/login': parse_form,})
|
||||
|
||||
app = App(router)
|
||||
app.start_server()
|
||||
```
|
||||
'
|
||||
用户需要定义一些能够返回字符串或 `Response` 对象的异步函数,然后将这些函数与表示路由的字符串配对,最后通过一个函数调用(`start_server`)开始处理请求。
|
||||
|
||||
完成设计之后,我将它抽象为几个我需要编码的部分:
|
||||
|
||||
- 接受 TCP 连接以及调度一个异步函数来处理这些连接的部分
|
||||
- 将原始文本解析成某种抽象容器的部分
|
||||
- 对于每个请求,用来决定调用哪个函数的部分
|
||||
- 将上述部分集中到一起,并为开发者提供一个简单接口的部分
|
||||
|
||||
我先编写一些测试,这些测试被用来描述每个部分的功能。几次重构后,整个设计被分成若干部分,每个部分之间是相对解耦的。这样就非常好,因为每个部分可以被独立地研究学习。以下是我上文列出的抽象的具体体现:
|
||||
|
||||
- 一个 HTTPServer 对象,需要一个 Router 对象和一个 http_parser 模块,并使用它们来初始化。
|
||||
- HTTPConnection 对象,每一个对象表示一个单独的客户端 HTTP 连接,并且处理其请求-响应周期:使用 http_parser 模块将收到的字节流解析为一个 Request 对象;使用一个 Router 实例寻找并调用正确的函数来生成一个响应;最后将这个响应发送回客户端。
|
||||
- 一对 Request 和 Response 对象为用户提供了一种友好的方式,来处理实质上是字节流的字符串。用户不需要知道正确的消息格式和分隔符是怎样的。
|
||||
- 一个包含“路由:函数”对应关系的 Router 对象。它提供一个添加配对的方法,可以根据 URL 路径查找到相应的函数。
|
||||
- 最后,一个 App 对象。它包含配置信息,并使用它们实例化一个 HTTPServer 实例。
|
||||
|
||||
让我们从 `HTTPConnection` 开始来讲解各个部分。
|
||||
|
||||
### 模拟异步连接
|
||||
|
||||
为了满足上述约束条件,每一个 HTTP 请求都是一个单独的 TCP 连接。这使得处理请求的速度变慢了,因为建立多个 TCP 连接需要相对高的花销(DNS 查询,TCP 三次握手,[慢启动][4]等等的花销),不过这样更加容易模拟。对于这一任务,我选择相对高级的 [asyncio-stream][5] 模块,它建立在 [asyncio 的传输和协议][6]的基础之上。我强烈推荐你读一读标准库中的相应代码,很有意思!
|
||||
|
||||
一个 `HTTPConnection` 的实例能够处理多个任务。首先,它使用 `asyncio.StreamReader` 对象以增量的方式从 TCP 连接中读取数据,并存储在缓存中。每一个读取操作完成后,它会尝试解析缓存中的数据,并生成一个 `Request` 对象。一旦收到了这个完整的请求,它就生成一个回复,并通过 `asyncio.StreamWriter` 对象发送回客户端。当然,它还有两个任务:超时连接以及错误处理。
|
||||
|
||||
你可以在[这里][7]浏览这个类的完整代码。我将分别介绍代码的每一部分。为了简单起见,我移除了代码文档。
|
||||
|
||||
```
|
||||
class HTTPConnection(object):
|
||||
def init(self, http_server, reader, writer):
|
||||
self.router = http_server.router
|
||||
self.http_parser = http_server.http_parser
|
||||
self.loop = http_server.loop
|
||||
|
||||
self._reader = reader
|
||||
self._writer = writer
|
||||
self._buffer = bytearray()
|
||||
self._conn_timeout = None
|
||||
self.request = Request()
|
||||
```
|
||||
|
||||
这个 `init` 方法没啥意思,它仅仅是收集了一些对象以供后面使用。它存储了一个 `router` 对象、一个 `http_parser` 对象以及 `loop` 对象,分别用来生成响应、解析请求以及在事件循环中调度任务。
|
||||
|
||||
然后,它存储了代表一个 TCP 连接的读写对,和一个充当原始字节缓冲区的空[字节数组][8]。`_conn_timeout` 存储了一个 [asyncio.Handle][9] 的实例,用来管理超时逻辑。最后,它还存储了 `Request` 对象的一个单一实例。
|
||||
|
||||
下面的代码是用来接受和发送数据的核心功能:
|
||||
|
||||
```
|
||||
async def handle_request(self):
|
||||
try:
|
||||
while not self.request.finished and not self._reader.at_eof():
|
||||
data = await self._reader.read(1024)
|
||||
if data:
|
||||
self._reset_conn_timeout()
|
||||
await self.process_data(data)
|
||||
if self.request.finished:
|
||||
await self.reply()
|
||||
elif self._reader.at_eof():
|
||||
raise BadRequestException()
|
||||
except (NotFoundException,
|
||||
BadRequestException) as e:
|
||||
self.error_reply(e.code, body=Response.reason_phrases[e.code])
|
||||
except Exception as e:
|
||||
self.error_reply(500, body=Response.reason_phrases[500])
|
||||
|
||||
self.close_connection()
|
||||
```
|
||||
|
||||
所有内容被包含在 `try-except` 代码块中,这样在解析请求或响应期间抛出的异常可以被捕获到,然后一个错误响应会发送回客户端。
|
||||
|
||||
在 `while` 循环中不断读取请求,直到解析器将 `self.request.finished` 设置为 True ,或者客户端关闭连接所触发的信号使得 `self._reader_at_eof()` 函数返回值为 True 为止。这段代码尝试在每次循环迭代中从 `StreamReader` 中读取数据,并通过调用 `self.process_data(data)` 函数以增量方式生成 `self.request`。每次循环读取数据时,连接超时计数器被重置。
|
||||
|
||||
这儿有个错误,你发现了吗?稍后我们会再讨论这个。需要注意的是,这个循环可能会耗尽 CPU 资源,因为如果没有读取到东西 `self._reader.read()` 函数将会返回一个空的字节对象 `b''`。这就意味着循环将会不断运行,却什么也不做。一个可能的解决方法是,用非阻塞的方式等待一小段时间:`await asyncio.sleep(0.1)`。我们暂且不对它做优化。
|
||||
|
||||
还记得上一段我提到的那个错误吗?只有从 `StreamReader` 读取数据时,`self._reset_conn_timeout()` 函数才会被调用。这就意味着,**直到第一个字节到达时**,`timeout` 才被初始化。如果有一个客户端建立了与服务器的连接却不发送任何数据,那就永远不会超时。这可能被用来消耗系统资源,从而导致拒绝服务式攻击(DoS)。修复方法就是在 `init` 函数中调用 `self._reset_conn_timeout()` 函数。
|
||||
|
||||
当请求接受完成或连接中断时,程序将运行到 `if-else` 代码块。这部分代码会判断解析器收到完整的数据后是否完成了解析。如果是,好,生成一个回复并发送回客户端。如果不是,那么请求信息可能有错误,抛出一个异常!最后,我们调用 `self.close_connection` 执行清理工作。
|
||||
|
||||
解析请求的部分在 `self.process_data` 方法中。这个方法非常简短,也易于测试:
|
||||
|
||||
```
|
||||
async def process_data(self, data):
|
||||
self._buffer.extend(data)
|
||||
|
||||
self._buffer = self.http_parser.parse_into(
|
||||
self.request, self._buffer)
|
||||
```
|
||||
|
||||
每一次调用都将数据累积到 `self._buffer` 中,然后试着用 `self.http_parser` 来解析已经收集的数据。这里需要指出的是,这段代码展示了一种称为[依赖注入(Dependency Injection)][10]的模式。如果你还记得 `init` 函数的话,应该知道我们传入了一个包含 `http_parser` 对象的 `http_server` 对象。在这个例子里,`http_parser` 对象是 `diy_framework` 包中的一个模块。不过它也可以是任何含有 `parse_into` 函数的类,这个 `parse_into` 函数接受一个 `Request` 对象以及字节数组作为参数。这很有用,原因有二:一是,这意味着这段代码更易扩展。如果有人想通过一个不同的解析器来使用 `HTTPConnection`,没问题,只需将它作为参数传入即可。二是,这使得测试更加容易,因为 `http_parser` 不是硬编码的,所以使用虚假数据或者 [mock][11] 对象来替代是很容易的。
|
||||
|
||||
下一段有趣的部分就是 `reply` 方法了:
|
||||
|
||||
```
|
||||
async def reply(self):
|
||||
request = self.request
|
||||
handler = self.router.get_handler(request.path)
|
||||
|
||||
response = await handler.handle(request)
|
||||
|
||||
if not isinstance(response, Response):
|
||||
response = Response(code=200, body=response)
|
||||
|
||||
self._writer.write(response.to_bytes())
|
||||
await self._writer.drain()
|
||||
```
|
||||
|
||||
这里,一个 `HTTPConnection` 的实例使用了 `HTTPServer` 中的 `router` 对象来得到一个生成响应的对象。一个路由可以是任何一个拥有 `get_handler` 方法的对象,这个方法接收一个字符串作为参数,返回一个可调用的对象或者抛出 `NotFoundException` 异常。而这个可调用的对象被用来处理请求以及生成响应。处理程序由框架的使用者编写,如上文所说的那样,应该返回字符串或者 `Response` 对象。`Response` 对象提供了一个友好的接口,因此这个简单的 if 语句保证了无论处理程序返回什么,代码最终都得到一个统一的 `Response` 对象。
|
||||
|
||||
接下来,被赋值给 `self._writer` 的 `StreamWriter` 实例被调用,将字节字符串发送回客户端。函数返回前,程序在 `await self._writer.drain()` 处等待,以确保所有的数据被发送给客户端。只要缓存中还有未发送的数据,`self._writer.close()` 方法就不会执行。
|
||||
|
||||
`HTTPConnection` 类还有两个更加有趣的部分:一个用于关闭连接的方法,以及一组用来处理超时机制的方法。首先,关闭一条连接由下面这个小函数完成:
|
||||
|
||||
```
|
||||
def close_connection(self):
|
||||
self._cancel_conn_timeout()
|
||||
self._writer.close()
|
||||
```
|
||||
|
||||
每当一条连接将被关闭时,这段代码首先取消超时,然后把连接从事件循环中清除。
|
||||
|
||||
超时机制由三个相关的函数组成:第一个函数在超时后给客户端发送错误消息并关闭连接;第二个函数用于取消当前的超时;第三个函数调度超时功能。前两个函数比较简单,我将详细解释第三个函数 `_reset_cpmm_timeout()` 。
|
||||
|
||||
```
|
||||
def _conn_timeout_close(self):
|
||||
self.error_reply(500, 'timeout')
|
||||
self.close_connection()
|
||||
|
||||
def _cancel_conn_timeout(self):
|
||||
if self._conn_timeout:
|
||||
self._conn_timeout.cancel()
|
||||
|
||||
def _reset_conn_timeout(self, timeout=TIMEOUT):
|
||||
self._cancel_conn_timeout()
|
||||
self._conn_timeout = self.loop.call_later(
|
||||
timeout, self._conn_timeout_close)
|
||||
```
|
||||
|
||||
每当 `_reset_conn_timeout` 函数被调用时,它会先取消之前所有赋值给 `self._conn_timeout` 的 `asyncio.Handle` 对象。然后,使用 [BaseEventLoop.call_later][12] 函数让 `_conn_timeout_close` 函数在超时数秒(`timeout`)后执行。如果你还记得 `handle_request` 函数的内容,就知道每当接收到数据时,这个函数就会被调用。这就取消了当前的超时并且重新安排 `_conn_timeout_close` 函数在超时数秒(`timeout`)后执行。只要接收到数据,这个循环就会不断地重置超时回调。如果在超时时间内没有接收到数据,最后函数 `_conn_timeout_close` 就会被调用。
|
||||
|
||||
### 创建连接
|
||||
|
||||
我们需要创建 `HTTPConnection` 对象,并且正确地使用它们。这一任务由 `HTTPServer` 类完成。`HTTPServer` 类是一个简单的容器,可以存储着一些配置信息(解析器,路由和事件循环实例),并使用这些配置来创建 `HTTPConnection` 实例:
|
||||
|
||||
```
|
||||
class HTTPServer(object):
|
||||
def init(self, router, http_parser, loop):
|
||||
self.router = router
|
||||
self.http_parser = http_parser
|
||||
self.loop = loop
|
||||
|
||||
async def handle_connection(self, reader, writer):
|
||||
connection = HTTPConnection(self, reader, writer)
|
||||
asyncio.ensure_future(connection.handle_request(), loop=self.loop)
|
||||
```
|
||||
|
||||
`HTTPServer` 的每一个实例能够监听一个端口。它有一个 `handle_connection` 的异步方法来创建 `HTTPConnection` 的实例,并安排它们在事件循环中运行。这个方法被传递给 [asyncio.start_server][13] 作为一个回调函数。也就是说,每当一个 TCP 连接初始化时(以 `StreamReader` 和 `StreamWriter` 为参数),它就会被调用。
|
||||
|
||||
```
|
||||
self._server = HTTPServer(self.router, self.http_parser, self.loop)
|
||||
self._connection_handler = asyncio.start_server(
|
||||
self._server.handle_connection,
|
||||
host=self.host,
|
||||
port=self.port,
|
||||
reuse_address=True,
|
||||
reuse_port=True,
|
||||
loop=self.loop)
|
||||
```
|
||||
|
||||
这就是构成整个应用程序工作原理的核心:`asyncio.start_server` 接受 TCP 连接,然后在一个预配置的 `HTTPServer` 对象上调用一个方法。这个方法将处理一条 TCP 连接的所有逻辑:读取、解析、生成响应并发送回客户端、以及关闭连接。它的重点是 IO 逻辑、解析和生成响应。
|
||||
|
||||
讲解了核心的 IO 部分,让我们继续。
|
||||
|
||||
### 解析请求
|
||||
|
||||
这个微型框架的使用者被宠坏了,不愿意和字节打交道。它们想要一个更高层次的抽象 —— 一种更加简单的方法来处理请求。这个微型框架就包含了一个简单的 HTTP 解析器,能够将字节流转化为 Request 对象。
|
||||
|
||||
这些 Request 对象是像这样的容器:
|
||||
|
||||
```
|
||||
class Request(object):
|
||||
def init(self):
|
||||
self.method = None
|
||||
self.path = None
|
||||
self.query_params = {}
|
||||
self.path_params = {}
|
||||
self.headers = {}
|
||||
self.body = None
|
||||
self.body_raw = None
|
||||
self.finished = False
|
||||
```
|
||||
|
||||
它包含了所有需要的数据,可以用一种容易理解的方法从客户端接受数据。哦,不包括 cookie ,它对身份认证是非常重要的,我会将它留在第二部分。
|
||||
|
||||
每一个 HTTP 请求都包含了一些必需的内容,如请求路径和请求方法。它们也包含了一些可选的内容,如请求体、请求头,或是 URL 参数。随着 REST 的流行,除了 URL 参数,URL 本身会包含一些信息。比如,"/user/1/edit" 包含了用户的 id 。
|
||||
|
||||
一个请求的每个部分都必须被识别、解析,并正确地赋值给 Request 对象的对应属性。HTTP/1.1 是一个文本协议,事实上这简化了很多东西。(HTTP/2 是一个二进制协议,这又是另一种乐趣了)
|
||||
|
||||
解析器不需要跟踪状态,因此 `http_parser` 模块其实就是一组函数。调用函数需要用到 `Request` 对象,并将它连同一个包含原始请求信息的字节数组传递给 `parse_into` 函数。然后解析器会修改 `Request` 对象以及充当缓存的字节数组。字节数组的信息被逐渐地解析到 request 对象中。
|
||||
|
||||
`http_parser` 模块的核心功能就是下面这个 `parse_into` 函数:
|
||||
|
||||
```
|
||||
def parse_into(request, buffer):
|
||||
_buffer = buffer[:]
|
||||
if not request.method and can_parse_request_line(_buffer):
|
||||
(request.method, request.path,
|
||||
request.query_params) = parse_request_line(_buffer)
|
||||
remove_request_line(_buffer)
|
||||
|
||||
if not request.headers and can_parse_headers(_buffer):
|
||||
request.headers = parse_headers(_buffer)
|
||||
if not has_body(request.headers):
|
||||
request.finished = True
|
||||
|
||||
remove_intro(_buffer)
|
||||
|
||||
if not request.finished and can_parse_body(request.headers, _buffer):
|
||||
request.body_raw, request.body = parse_body(request.headers, _buffer)
|
||||
clear_buffer(_buffer)
|
||||
request.finished = True
|
||||
return _buffer
|
||||
```
|
||||
|
||||
从上面的代码中可以看到,我把解析的过程分为三个部分:解析请求行(这行像这样:GET /resource HTTP/1.1),解析请求头以及解析请求体。
|
||||
|
||||
请求行包含了 HTTP 请求方法以及 URL 地址。而 URL 地址则包含了更多的信息:路径、url 参数和开发者自定义的 url 参数。解析请求方法和 URL 还是很容易的 - 合适地分割字符串就好了。函数 `urlparse.parse` 可以用来解析 URL 参数。开发者自定义的 URL 参数可以通过正则表达式来解析。
|
||||
|
||||
接下来是 HTTP 头部。它们是一行行由键值对组成的简单文本。问题在于,可能有多个 HTTP 头有相同的名字,却有不同的值。一个值得关注的 HTTP 头部是 `Content-Length`,它描述了请求体的字节长度(不是整个请求,仅仅是请求体)。这对于决定是否解析请求体有很重要的作用。
|
||||
|
||||
最后,解析器根据 HTTP 方法和头部来决定是否解析请求体。
|
||||
|
||||
### 路由!
|
||||
|
||||
在某种意义上,路由就像是连接框架和用户的桥梁,用户用合适的方法创建 `Router` 对象并为其设置路径/函数对,然后将它赋值给 App 对象。而 App 对象依次调用 `get_handler` 函数生成相应的回调函数。简单来说,路由就负责两件事,一是存储路径/函数对,二是返回需要的路径/函数对
|
||||
|
||||
`Router` 类中有两个允许最终开发者添加路由的方法,分别是 `add_routes` 和 `add_route`。因为 `add_routes` 就是 `add_route` 函数的一层封装,我们将主要讲解 `add_route` 函数:
|
||||
|
||||
```
|
||||
def add_route(self, path, handler):
|
||||
compiled_route = self.class.build_route_regexp(path)
|
||||
if compiled_route not in self.routes:
|
||||
self.routes[compiled_route] = handler
|
||||
else:
|
||||
raise DuplicateRoute
|
||||
```
|
||||
|
||||
首先,这个函数使用 `Router.build_router_regexp` 的类方法,将一条路由规则(如 '/cars/{id}' 这样的字符串),“编译”到一个已编译的正则表达式对象。这些已编译的正则表达式用来匹配请求路径,以及解析开发者自定义的 URL 参数。如果已经存在一个相同的路由,程序就会抛出一个异常。最后,这个路由/处理程序对被添加到一个简单的字典`self.routes`中。
|
||||
|
||||
下面展示 Router 是如何“编译”路由的:
|
||||
|
||||
```
|
||||
@classmethod
|
||||
def build_route_regexp(cls, regexp_str):
|
||||
"""
|
||||
Turns a string into a compiled regular expression. Parses '{}' into
|
||||
named groups ie. '/path/{variable}' is turned into
|
||||
'/path/(?P<variable>[a-zA-Z0-9_-]+)'.
|
||||
|
||||
:param regexp_str: a string representing a URL path.
|
||||
:return: a compiled regular expression.
|
||||
"""
|
||||
def named_groups(matchobj):
|
||||
return '(?P<{0}>[a-zA-Z0-9_-]+)'.format(matchobj.group(1))
|
||||
|
||||
re_str = re.sub(r'{([a-zA-Z0-9_-]+)}', named_groups, regexp_str)
|
||||
re_str = ''.join(('^', re_str, '$',))
|
||||
return re.compile(re_str)
|
||||
```
|
||||
|
||||
这个方法使用正则表达式将所有出现的 `{variable}` 替换为 `(?P<variable>)`。然后在字符串头尾分别添加 `^` 和 `$` 标记,最后编译正则表达式对象。
|
||||
|
||||
完成了路由存储仅成功了一半,下面是如何得到路由对应的函数:
|
||||
|
||||
```
|
||||
def get_handler(self, path):
|
||||
logger.debug('Getting handler for: {0}'.format(path))
|
||||
for route, handler in self.routes.items():
|
||||
path_params = self.class.match_path(route, path)
|
||||
if path_params is not None:
|
||||
logger.debug('Got handler for: {0}'.format(path))
|
||||
wrapped_handler = HandlerWrapper(handler, path_params)
|
||||
return wrapped_handler
|
||||
|
||||
raise NotFoundException()
|
||||
```
|
||||
|
||||
一旦 `App` 对象获得一个 `Request` 对象,也就获得了 URL 的路径部分(如 /users/15/edit)。然后,我们需要匹配函数来生成一个响应或者 404 错误。`get_handler` 函数将路径作为参数,循环遍历路由,对每条路由调用 `Router.match_path` 类方法检查是否有已编译的正则对象与这个请求路径匹配。如果存在,我们就调用 `HandleWrapper` 来包装路由对应的函数。`path_params` 字典包含了路径变量(如 '/users/15/edit' 中的 '15'),若路由没有指定变量,字典就为空。最后,我们将包装好的函数返回给 `App` 对象。
|
||||
|
||||
如果遍历了所有的路由都找不到与路径匹配的,函数就会抛出 `NotFoundException` 异常。
|
||||
|
||||
这个 `Route.match` 类方法挺简单:
|
||||
|
||||
```
|
||||
def match_path(cls, route, path):
|
||||
match = route.match(path)
|
||||
try:
|
||||
return match.groupdict()
|
||||
except AttributeError:
|
||||
return None
|
||||
```
|
||||
|
||||
它使用正则对象的 [match 方法][14]来检查路由是否与路径匹配。若果不匹配,则返回 None 。
|
||||
|
||||
最后,我们有 `HandleWraapper` 类。它的唯一任务就是封装一个异步函数,存储 `path_params` 字典,并通过 `handle` 方法对外提供一个统一的接口。
|
||||
|
||||
```
|
||||
class HandlerWrapper(object):
|
||||
def init(self, handler, path_params):
|
||||
self.handler = handler
|
||||
self.path_params = path_params
|
||||
self.request = None
|
||||
|
||||
async def handle(self, request):
|
||||
return await self.handler(request, **self.path_params)
|
||||
```
|
||||
|
||||
### 组合到一起
|
||||
|
||||
框架的最后部分就是用 `App` 类把所有的部分联系起来。
|
||||
|
||||
`App` 类用于集中所有的配置细节。一个 `App` 对象通过其 `start_server` 方法,使用一些配置数据创建一个 `HTTPServer` 的实例,然后将它传递给 [asyncio.start_server 函数][15]。`asyncio.start_server` 函数会对每一个 TCP 连接调用 `HTTPServer` 对象的 `handle_connection` 方法。
|
||||
|
||||
```
|
||||
def start_server(self):
|
||||
if not self._server:
|
||||
self.loop = asyncio.get_event_loop()
|
||||
self._server = HTTPServer(self.router, self.http_parser, self.loop)
|
||||
self._connection_handler = asyncio.start_server(
|
||||
self._server.handle_connection,
|
||||
host=self.host,
|
||||
port=self.port,
|
||||
reuse_address=True,
|
||||
reuse_port=True,
|
||||
loop=self.loop)
|
||||
|
||||
logger.info('Starting server on {0}:{1}'.format(
|
||||
self.host, self.port))
|
||||
self.loop.run_until_complete(self._connection_handler)
|
||||
|
||||
try:
|
||||
self.loop.run_forever()
|
||||
except KeyboardInterrupt:
|
||||
logger.info('Got signal, killing server')
|
||||
except DiyFrameworkException as e:
|
||||
logger.error('Critical framework failure:')
|
||||
logger.error(e.traceback)
|
||||
finally:
|
||||
self.loop.close()
|
||||
else:
|
||||
logger.info('Server already started - {0}'.format(self))
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
如果你查看源码,就会发现所有的代码仅 320 余行(包括测试代码的话共 540 余行)。这么少的代码实现了这么多的功能,让我有点惊讶。这个框架没有提供模板、身份认证以及数据库访问等功能(这些内容也很有趣哦)。这也让我知道,像 Django 和 Tornado 这样的框架是如何工作的,而且我能够快速地调试它们了。
|
||||
|
||||
这也是我按照测试驱动开发完成的第一个项目,整个过程有趣而有意义。先编写测试用例迫使我思考设计和架构,而不仅仅是把代码放到一起,让它们可以运行。不要误解我的意思,有很多时候,后者的方式更好。不过如果你想给确保这些不怎么维护的代码在之后的几周甚至几个月依然工作,那么测试驱动开发正是你需要的。
|
||||
|
||||
我研究了下[整洁架构][16]以及依赖注入模式,这些充分体现在 `Router` 类是如何作为一个更高层次的抽象的(实体?)。`Router` 类是比较接近核心的,像 `http_parser` 和 `App` 的内容比较边缘化,因为它们只是完成了极小的字符串和字节流、或是中层 IO 的工作。测试驱动开发(TDD)迫使我独立思考每个小部分,这使我问自己这样的问题:方法调用的组合是否易于理解?类名是否准确地反映了我正在解决的问题?我的代码中是否很容易区分出不同的抽象层?
|
||||
|
||||
来吧,写个小框架,真的很有趣:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://mattscodecave.com/posts/simple-python-framework-from-scratch.html
|
||||
|
||||
作者:[Matt][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://mattscodecave.com/hire-me.html
|
||||
[1]: https://github.com/sirMackk/diy_framework
|
||||
[2]:https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
|
||||
[3]: https://en.wikipedia.org/wiki/HTTP_persistent_connection
|
||||
[4]: https://en.wikipedia.org/wiki/TCP_congestion-avoidance_algorithm#Slow_start
|
||||
[5]: https://docs.python.org/3/library/asyncio-stream.html
|
||||
[6]: https://docs.python.org/3/library/asyncio-protocol.html
|
||||
[7]: https://github.com/sirMackk/diy_framework/blob/88968e6b30e59504251c0c7cd80abe88f51adb79/diy_framework/http_server.py#L46
|
||||
[8]: https://docs.python.org/3/library/functions.html#bytearray
|
||||
[9]: https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.Handle
|
||||
[10]: https://en.wikipedia.org/wiki/Dependency_injection
|
||||
[11]: https://docs.python.org/3/library/unittest.mock.html
|
||||
[12]: https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.BaseEventLoop.call_later
|
||||
[13]: https://docs.python.org/3/library/asyncio-stream.html#asyncio.start_server
|
||||
[14]: https://docs.python.org/3/library/re.html#re.match
|
||||
[15]: https://docs.python.org/3/library/asyncio-stream.html?highlight=start_server#asyncio.start_server
|
||||
[16]: https://blog.8thlight.com/uncle-bob/2012/08/13/the-clean-architecture.html
|
||||
@ -0,0 +1,111 @@
|
||||
使用 HTTP/2 服务端推送技术加速 Node.js 应用
|
||||
=========================================================
|
||||
|
||||
四月份,我们宣布了对 [HTTP/2 服务端推送技术][3]的支持,我们是通过 HTTP 的 [Link 头部](https://www.w3.org/wiki/LinkHeader)来实现这项支持的。我的同事 John 曾经通过一个例子演示了[在 PHP 里支持服务端推送功能][4]是多么的简单。
|
||||
|
||||

|
||||
|
||||
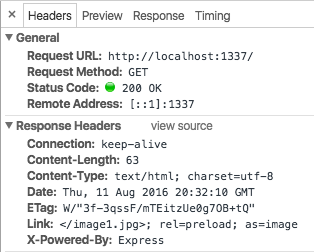
我们想让现今使用 Node.js 构建的网站能够更加轻松的获得性能提升。为此,我们开发了 [netjet][1] 中间件,它可以解析应用生成的 HTML 并自动添加 Link 头部。当在一个示例的 Express 应用中使用这个中间件时,我们可以看到应用程序的输出多了如下 HTTP 头:
|
||||
|
||||
|
||||
|
||||
[本博客][5]是使用 [Ghost](https://ghost.org/)(LCTT 译注:一个博客发布平台)进行发布的,因此如果你的浏览器支持 HTTP/2,你已经在不知不觉中享受了服务端推送技术带来的好处了。接下来,我们将进行更详细的说明。
|
||||
|
||||
netjet 使用了带有定制插件的 [PostHTML](https://github.com/posthtml/posthtml) 来解析 HTML。目前,netjet 用它来查找图片、脚本和外部 CSS 样式表。你也可以用其它的技术来实现这个。
|
||||
|
||||
在响应过程中增加 HTML 解析器有个明显的缺点:这将增加页面加载的延时(到加载第一个字节所花的时间)。大多数情况下,所新增的延时被应用里的其他耗时掩盖掉了,比如数据库访问。为了解决这个问题,netjet 包含了一个可调节的 LRU 缓存,该缓存以 HTTP 的 ETag 头部作为索引,这使得 netjet 可以非常快的为已经解析过的页面插入 Link 头部。
|
||||
|
||||
不过,如果我们现在从头设计一款全新的应用,我们就应该考虑把页面内容和页面中的元数据分开存放,从而整体地减少 HTML 解析和其它可能增加的延时了。
|
||||
|
||||
任意的 Node.js HTML 框架,只要它支持类似 Express 这样的中间件,netjet 都是能够兼容的。只要把 netjet 像下面这样加到中间件加载链里就可以了。
|
||||
|
||||
```javascript
|
||||
var express = require('express');
|
||||
var netjet = require('netjet');
|
||||
var root = '/path/to/static/folder';
|
||||
|
||||
express()
|
||||
.use(netjet({
|
||||
cache: {
|
||||
max: 100
|
||||
}
|
||||
}))
|
||||
.use(express.static(root))
|
||||
.listen(1337);
|
||||
```
|
||||
|
||||
稍微加点代码,netjet 也可以摆脱 HTML 框架,独立工作:
|
||||
|
||||
```javascript
|
||||
var http = require('http');
|
||||
var netjet = require('netjet');
|
||||
|
||||
var port = 1337;
|
||||
var hostname = 'localhost';
|
||||
var preload = netjet({
|
||||
cache: {
|
||||
max: 100
|
||||
}
|
||||
});
|
||||
|
||||
var server = http.createServer(function (req, res) {
|
||||
preload(req, res, function () {
|
||||
res.statusCode = 200;
|
||||
res.setHeader('Content-Type', 'text/html');
|
||||
res.end('<!doctype html><h1>Hello World</h1>');
|
||||
});
|
||||
});
|
||||
|
||||
server.listen(port, hostname, function () {
|
||||
console.log('Server running at http://' + hostname + ':' + port+ '/');
|
||||
});
|
||||
```
|
||||
|
||||
[netjet 文档里][1]有更多选项的信息。
|
||||
|
||||
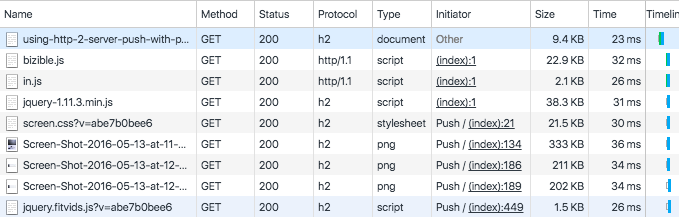
### 查看推送了什么数据
|
||||
|
||||
|
||||
|
||||
访问[本文][5]时,通过 Chrome 的开发者工具,我们可以轻松的验证网站是否正在使用服务器推送技术(LCTT 译注: Chrome 版本至少为 53)。在“Network”选项卡中,我们可以看到有些资源的“Initiator”这一列中包含了`Push`字样,这些资源就是服务器端推送的。
|
||||
|
||||
不过,目前 Firefox 的开发者工具还不能直观的展示被推送的资源。不过我们可以通过页面响应头部里的`cf-h2-pushed`头部看到一个列表,这个列表包含了本页面主动推送给浏览器的资源。
|
||||
|
||||
希望大家能够踊跃为 netjet 添砖加瓦,我也乐于看到有人正在使用 netjet。
|
||||
|
||||
### Ghost 和服务端推送技术
|
||||
|
||||
Ghost 真是包罗万象。在 Ghost 团队的帮助下,我把 netjet 也集成到里面了,而且作为测试版内容可以在 Ghost 的 0.8.0 版本中用上它。
|
||||
|
||||
如果你正在使用 Ghost,你可以通过修改 config.js、并在`production`配置块中增加 `preloadHeaders` 选项来启用服务端推送。
|
||||
|
||||
```javascript
|
||||
production: {
|
||||
url: 'https://my-ghost-blog.com',
|
||||
preloadHeaders: 100,
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
Ghost 已经为其用户整理了[一篇支持文档][2]。
|
||||
|
||||
### 总结
|
||||
|
||||
使用 netjet,你的 Node.js 应用也可以使用浏览器预加载技术。并且 [CloudFlare][5] 已经使用它在提供了 HTTP/2 服务端推送了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.cloudflare.com/accelerating-node-js-applications-with-http-2-server-push/
|
||||
|
||||
作者:[Terin Stock][a]
|
||||
译者:[echoma](https://github.com/echoma)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.cloudflare.com/author/terin-stock/
|
||||
[1]: https://www.npmjs.com/package/netjet
|
||||
[2]: http://support.ghost.org/preload-headers/
|
||||
[3]: https://www.cloudflare.com/http2/server-push/
|
||||
[4]: https://blog.cloudflare.com/using-http-2-server-push-with-php/
|
||||
[5]: https://blog.cloudflare.com/accelerating-node-js-applications-with-http-2-server-push/
|
||||
@ -0,0 +1,48 @@
|
||||
百度运用 FPGA 方法大规模加速 SQL 查询
|
||||
===================================================================
|
||||
|
||||
尽管我们对百度今年工作焦点的关注集中在这个中国搜索巨头在深度学习方面的举措上,许多其他的关键的,尽管不那么前沿的应用表现出了大数据带来的挑战。
|
||||
|
||||
正如百度的欧阳剑在本周 Hot Chips 大会上谈论的,百度坐拥超过 1 EB 的数据,每天处理大约 100 PB 的数据,每天更新 100 亿的网页,每 24 小时更新处理超过 1 PB 的日志更新,这些数字和 Google 不分上下,正如人们所想象的。百度采用了类似 Google 的方法去大规模地解决潜在的瓶颈。
|
||||
|
||||
正如刚刚我们谈到的,Google 寻找一切可能的方法去打败摩尔定律,百度也在进行相同的探索,而令人激动的、使人着迷的机器学习工作是迷人的,业务的核心关键任务的加速同样也是,因为必须如此。欧阳提到,公司基于自身的数据提供高端服务的需求和 CPU 可以承载的能力之间的差距将会逐渐增大。
|
||||
|
||||
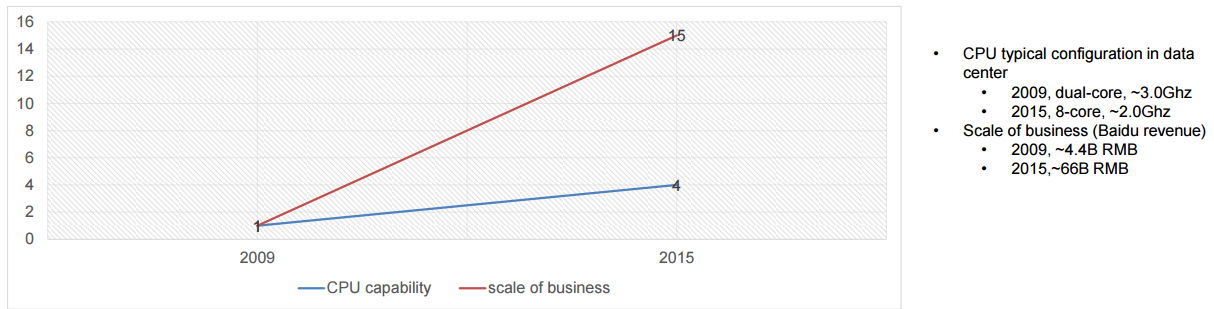
|
||||
|
||||
对于百度的百亿亿级问题,在所有数据的接受端是一系列用于数据分析的框架和平台,从该公司的海量知识图谱,多媒体工具,自然语言处理框架,推荐引擎,和点击流分析都是这样。简而言之,大数据的首要问题就是这样的:一系列各种应用和与之匹配的具有压倒性规模的数据。
|
||||
|
||||
当谈到加速百度的大数据分析,所面临的几个挑战,欧阳谈到抽象化运算核心去寻找一个普适的方法是困难的。“大数据应用的多样性和变化的计算类型使得这成为一个挑战,把所有这些整合成为一个分布式系统是困难的,因为有多变的平台和编程模型(MapReduce,Spark,streaming,user defined,等等)。将来还会有更多的数据类型和存储格式。”
|
||||
|
||||
尽管存在这些障碍,欧阳讲到他们团队找到了(它们之间的)共同线索。如他所指出的那样,那些把他们的许多数据密集型的任务相连系在一起的就是传统的 SQL。“我们的数据分析任务大约有 40% 是用 SQL 写的,而其他的用 SQL 重写也是可用做到的。” 更进一步,他讲道他们可以享受到现有的 SQL 系统的好处,并可以和已有的框架相匹配,比如 Hive,Spark SQL,和 Impala 。下一步要做的事情就是 SQL 查询加速,百度发现 FPGA 是最好的硬件。
|
||||
|
||||

|
||||
|
||||
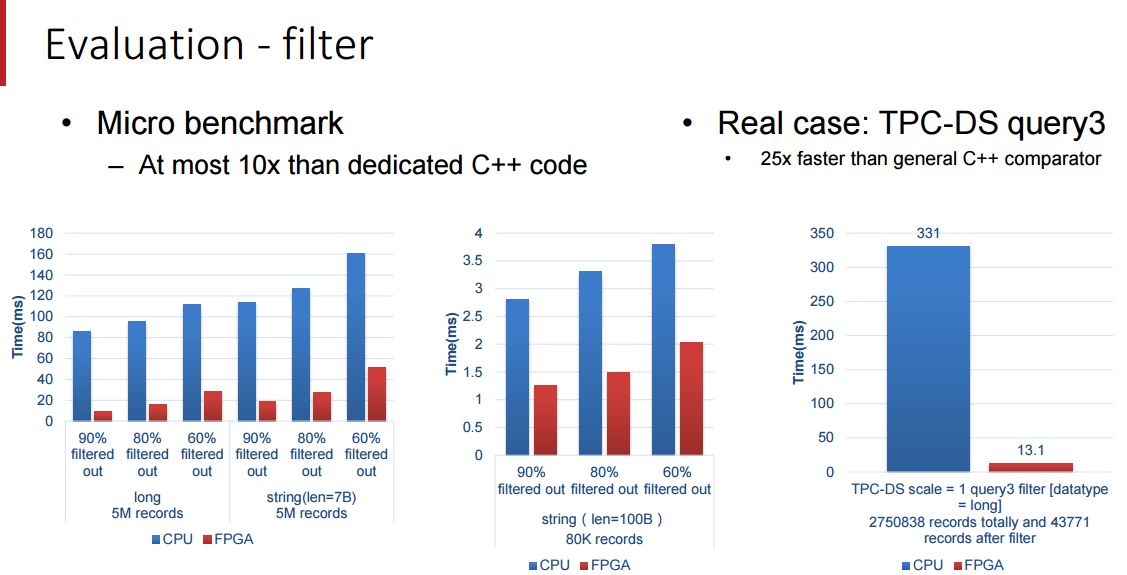
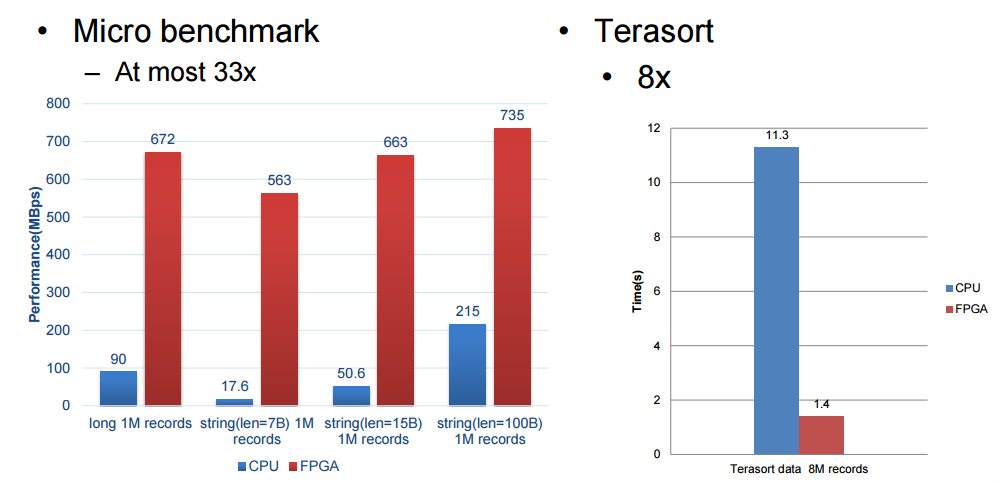
这些主板,被称为处理单元( 下图中的 PE ),当执行 SQL 时会自动地处理关键的 SQL 功能。这里所说的都是来自演讲,我们不承担责任。确切的说,这里提到的 FPGA 有点神秘,或许是故意如此。如果百度在基准测试中得到了如下图中的提升,那这可是一个有竞争力的信息。后面我们还会继续介绍这里所描述的东西。简单来说,FPGA 运行在数据库中,当其收到 SQL 查询的时候,该团队设计的软件就会与之紧密结合起来。
|
||||
|
||||
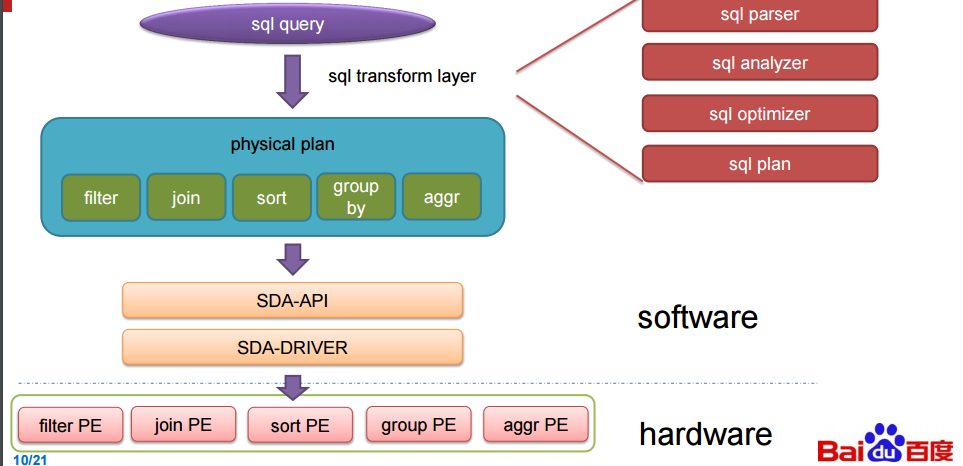
|
||||
|
||||
欧阳提到了一件事,他们的加速器受限于 FPGA 的带宽,不然性能表现本可以更高,在下面的评价中,百度安装了 2 块12 核心,主频 2.0 GHz 的 intl E26230 CPU,运行在 128G 内存。SDA 具有 5 个处理单元,(上图中的 300MHz FPGA 主板)每个分别处理不同的核心功能(筛选(filter),排序(sort),聚合(aggregate),联合(join)和分组(group by))
|
||||
|
||||
为了实现 SQL 查询加速,百度针对 TPC-DS 的基准测试进行了研究,并且创建了称做处理单元(PE)的特殊引擎,用于在基准测试中加速 5 个关键功能,这包括筛选(filter),排序(sort),聚合(aggregate),联合(join)和分组(group by),(我们并没有把这些单词都像 SQL 那样大写)。SDA 设备使用卸载模型,具有多个不同种类的处理单元的加速卡在 FPGA 中组成逻辑,SQL 功能的类型和每张卡的数量由特定的工作量决定。由于这些查询在百度的系统中执行,用来查询的数据被以列格式推送到加速卡中(这会使得查询非常快速),而且通过一个统一的 SDA API 和驱动程序,SQL 查询工作被分发到正确的处理单元而且 SQL 操作实现了加速。
|
||||
|
||||
SDA 架构采用一种数据流模型,加速单元不支持的操作被退回到数据库系统然后在那里本地运行,比其他任何因素,百度开发的 SQL 加速卡的性能被 FPGA 卡的内存带宽所限制。加速卡跨整个集群机器工作,顺便提一下,但是数据和 SQL 操作如何分发到多个机器的准确原理没有被百度披露。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
我们受限与百度所愿意披露的细节,但是这些基准测试结果是十分令人鼓舞的,尤其是 Terasort 方面,我们将在 Hot Chips 大会之后跟随百度的脚步去看看我们是否能得到关于这是如何连接到一起的和如何解决内存带宽瓶颈的细节。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.nextplatform.com/2016/08/24/baidu-takes-fpga-approach-accelerating-big-sql/
|
||||
|
||||
作者:[Nicole Hemsoth][a]
|
||||
译者:[LinuxBars](https://github.com/LinuxBars)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.nextplatform.com/author/nicole/
|
||||
[1]: http://www.nextplatform.com/?s=baidu+deep+learning
|
||||
[2]: http://www.hotchips.org/wp-content/uploads/hc_archives/hc26/HC26-12-day2-epub/HC26.12-5-FPGAs-epub/HC26.12.545-Soft-Def-Acc-Ouyang-baidu-v3--baidu-v4.pdf
|
||||
@ -0,0 +1,77 @@
|
||||
QOwnNotes:一款记录笔记和待办事项的应用,集成 ownCloud 云服务
|
||||
===============
|
||||
|
||||
[QOwnNotes][1] 是一款自由而开源的笔记记录和待办事项的应用,可以运行在 Linux、Windows 和 mac 上。
|
||||
|
||||
这款程序将你的笔记保存为纯文本文件,它支持 Markdown 支持,并与 ownCloud 云服务紧密集成。
|
||||
|
||||
|
||||
|
||||
QOwnNotes 的亮点就是它集成了 ownCloud 云服务(当然是可选的)。在 ownCloud 上用这款 APP,你就可以在网路上记录和搜索你的笔记,也可以在移动设备上使用(比如一款像 CloudNotes 的软件[2])。
|
||||
|
||||
不久以后,用你的 ownCloud 账户连接上 QOwnNotes,你就可以从你 ownCloud 服务器上分享笔记和查看或恢复之前版本记录的笔记(或者丢到垃圾箱的笔记)。
|
||||
|
||||
同样,QOwnNotes 也可以与 ownCloud 任务或者 Tasks Plus 应用程序相集成。
|
||||
|
||||
如果你不熟悉 [ownCloud][3] 的话,这是一款替代 Dropbox、Google Drive 和其他类似商业性的网络服务的自由软件,它可以安装在你自己的服务器上。它有一个网络界面,提供了文件管理、日历、照片、音乐、文档浏览等等功能。开发者同样提供桌面同步客户端以及移动 APP。
|
||||
|
||||
因为笔记被保存为纯文本,它们可以在不同的设备之间通过云存储服务进行同步,比如 Dropbox,Google Drive 等等,但是在这些应用中不能完全替代 ownCloud 的作用。
|
||||
|
||||
我提到的上述特点,比如恢复之前的笔记,只能在 ownCloud 下可用(尽管 Dropbox 和其他类似的也提供恢复以前的文件的服务,但是你不能在 QOwnnotes 中直接访问到)。
|
||||
|
||||
鉴于 QOwnNotes 有这么多优点,它支持 Markdown 语言(内置了 Markdown 预览模式),可以标记笔记,对标记和笔记进行搜索,在笔记中加入超链接,也可以插入图片:
|
||||
|
||||
|
||||
|
||||
标记嵌套和笔记文件夹同样支持。
|
||||
|
||||
代办事项管理功能比较基本还可以做一些改进,它现在打开在一个单独的窗口里,它也不用和笔记一样的编辑器,也不允许添加图片或者使用 Markdown 语言。
|
||||
|
||||
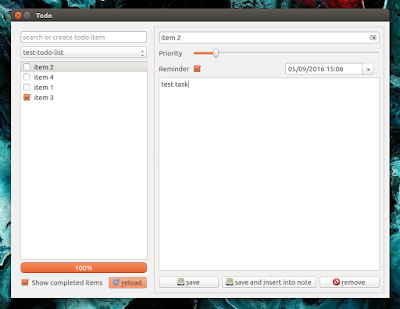
|
||||
|
||||
它可以让你搜索你代办事项,设置事项优先级,添加提醒和显示完成的事项。此外,待办事项可以加入笔记中。
|
||||
|
||||
这款软件的界面是可定制的,允许你放大或缩小字体,切换窗格等等,也支持无干扰模式。
|
||||
|
||||

|
||||
|
||||
从程序的设置里,你可以开启黑夜模式(这里有个 bug,在 Ubuntu 16.04 里有些工具条图标消失了),改变状态条大小,字体和颜色方案(白天和黑夜):
|
||||
|
||||
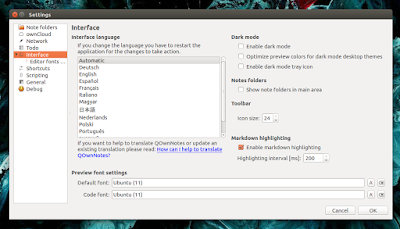
|
||||
|
||||
其他的特点有支持加密(笔记只能在 QOwnNotes 中加密),自定义键盘快捷键,输出笔记为 pdf 或者 Markdown,自定义笔记自动保存间隔等等。
|
||||
|
||||
访问 [QOwnNotes][11] 主页查看完整的特性。
|
||||
|
||||
### 下载 QOwnNotes
|
||||
|
||||
如何安装,请查看安装页(支持 Debian、Ubuntu、Linux Mint、openSUSE、Fedora、Arch Linux、KaOS、Gentoo、Slackware、CentOS 以及 Mac OSX 和 Windows)。
|
||||
|
||||
QOwnNotes 的 [snap][5] 包也是可用的,在 Ubuntu 16.04 或更新版本中,你可以通过 Ubuntu 的软件管理器直接安装它。
|
||||
|
||||
为了集成 QOwnNotes 到 ownCloud,你需要有 [ownCloud 服务器][6],同样也需要 [Notes][7]、[QOwnNotesAPI][8]、[Tasks][9]、[Tasks Plus][10] 等 ownColud 应用。这些可以从 ownCloud 的 Web 界面上安装,不需要手动下载。
|
||||
|
||||
请注意 QOenNotesAPI 和 Notes ownCloud 应用是实验性的,你需要“启用实验程序”来发现并安装他们,可以从 ownCloud 的 Web 界面上进行设置,在 Apps 菜单下,在左下角点击设置按钮。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.webupd8.org/2016/09/qownnotes-is-note-taking-and-todo-list.html
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.webupd8.org/p/about.html
|
||||
[1]: http://www.qownnotes.org/
|
||||
[2]: http://peterandlinda.com/cloudnotes/
|
||||
[3]: https://owncloud.org/
|
||||
[4]: http://www.qownnotes.org/installation
|
||||
[5]: https://uappexplorer.com/app/qownnotes.pbek
|
||||
[6]: https://download.owncloud.org/download/repositories/stable/owncloud/
|
||||
[7]: https://github.com/owncloud/notes
|
||||
[8]: https://github.com/pbek/qownnotesapi
|
||||
[9]: https://apps.owncloud.com/content/show.php/Tasks?content=164356
|
||||
[10]: https://apps.owncloud.com/content/show.php/Tasks+Plus?content=170561
|
||||
[11]: http://www.qownnotes.org/
|
||||
@ -1,3 +1,5 @@
|
||||
LinuxBars translating
|
||||
|
||||
Torvalds 2.0: Patricia Torvalds on computing, college, feminism, and increasing diversity in tech
|
||||
================================================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Chao-zhi
|
||||
|
||||
Ubuntu’s Snap, Red Hat’s Flatpak And Is ‘One Fits All’ Linux Packages Useful?
|
||||
=================================================================================
|
||||
|
||||
|
||||
@ -1,101 +0,0 @@
|
||||
Tips for managing your project's issue tracker
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
Issue-tracking systems are important for many open source projects, and there are many open source tools that provide this functionality but many projects opt to use GitHub's built-in issue tracker.
|
||||
|
||||
Its simple structure makes it easy for others to weigh in, but issues are really only as good as you make them.
|
||||
|
||||
Without a process, your repository can become unwieldy, overflowing with duplicate issues, vague feature requests, or confusing bug reports. Project maintainers can become burdened by the organizational load, and it can become difficult for new contributors to understand where priorities lie.
|
||||
|
||||
In this article, I'll discuss how to take your GitHub issues from good to great.
|
||||
|
||||
### The issue as user story
|
||||
|
||||
My team spoke with open source expert [Jono Bacon][1]—author of [The Art of Community][2], a strategy consultant, and former Director of Community at GitHub—who said that high-quality issues are at the core of helping a projects succeed. He says that while some see issues as merely a big list of problems you have to tend to, well-managed, triaged, and labeled issues can provide incredible insight into your code, your community, and where the problem spots are.
|
||||
|
||||
"At the point of submission of an issue, the user likely has little patience or interest in providing expansive detail. As such, you should make it as easy as possible to get the most useful information from them in the shortest time possible," Jono Bacon said.
|
||||
|
||||
A consistent structure can take a lot of burden off project maintainers, particularly for open source projects. We've found that encouraging a user story approach helps make clarity a constant. The common structure for a user story addresses the "who, what, and why" of a feature: As a [user type], I want to [task] so that [goal].
|
||||
|
||||
Here's what that looks like in practice:
|
||||
|
||||
>As a customer, I want to create an account so that I can make purchases.
|
||||
|
||||
We suggest sticking that user story in the issue's title. You can also set up [issue templates][3] to keep things consistent.
|
||||
|
||||
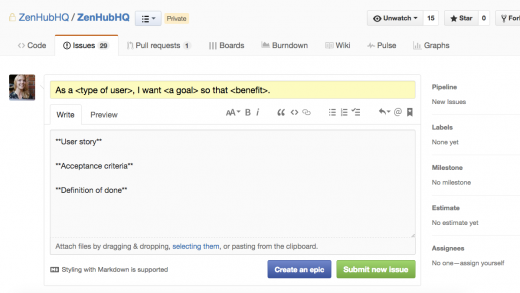
|
||||
> Issue templates bring consistency to feature requests.
|
||||
|
||||
The point is to make the issue well-defined for everyone involved: it identifies the audience (or user), the action (or task), and the outcome (or goal) as simply as possible. There's no need to obsess over this structure, though; as long as the what and why of a story are easy to spot, you're good.
|
||||
|
||||
### Qualities of a good issue
|
||||
|
||||
Not all issues are created equal—as any OSS contributor or maintainer can attest. A well-formed issue meets these qualities outlined in [The Agile Samurai][4].
|
||||
|
||||
Ask yourself if it is...
|
||||
|
||||
- something of value to customers
|
||||
- avoids jargon or mumbo jumbo; a non-expert should be able to understand it
|
||||
- "slices the cake," which means it goes end-to-end to deliver something of value
|
||||
- independent from other issues if possible; dependent issues reduce flexibility of scope
|
||||
- negotiable, meaning there are usually several ways to get to the stated goal
|
||||
- small and easily estimable in terms of time and resources required
|
||||
- measurable; you can test for results
|
||||
|
||||
### What about everything else? Working with constraints
|
||||
|
||||
If an issue is difficult to measure or doesn't seem feasible to complete within a short time period, you can still work with it. Some people call these "constraints."
|
||||
|
||||
For example, "the product needs to be fast" doesn't fit the story template, but it is non-negotiable. But how fast is fast? Vague requirements don't meet the criteria of a "good issue", but if you further define these concepts—for example, "the product needs to be fast" can be "each page needs to load within 0.5 seconds"—you can work with it more easily. Constraints can be seen as internal metrics of success, or a landmark to shoot for. Your team should test for them periodically.
|
||||
|
||||
### What's inside your issue?
|
||||
|
||||
In agile, user stories typically include acceptance criteria or requirements. In GitHub, I suggest using markdown checklists to outline any tasks that make up an issue. Issues should get more detail as they move up in priority.
|
||||
|
||||
Say you're creating an issue around a new homepage for a website. The sub-tasks for that task might look something like this.
|
||||
|
||||
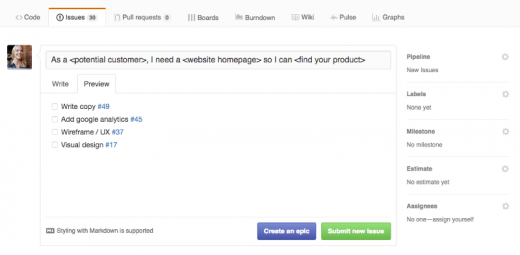
|
||||
>Use markdown checklists to split a complicated issue into several parts.
|
||||
|
||||
If necessary, link to other issues to further define a task. (GitHub makes this really easy.)
|
||||
|
||||
Defining features as granularly as possible makes it easier to track progress, test for success, and ultimately ship valuable code more frequently.
|
||||
|
||||
Once you've gathered some data points in the form of issues, you can use APIs to glean deeper insight into the health of your project.
|
||||
|
||||
"The GitHub API can be hugely helpful here in identifying patterns and trends in your issues," Bacon said. "With some creative data science, you can identify problem spots in your code, active members of your community, and other useful insights."
|
||||
|
||||
Some issue management tools provide APIs that add additional context, like time estimates or historical progress.
|
||||
|
||||
### Getting others on board
|
||||
|
||||
Once your team decides on an issue structure, how do you get others to buy in? Think of your repo's ReadMe.md file as your project's "how-to." It should clearly define what your project does (ideally using searchable language) and explain how others can contribute (by submitting requests, bug reports, suggestions, or by contributing code itself.)
|
||||
|
||||
|
||||
>Edit your ReadMe file with clear instructions for new collaborators.
|
||||
|
||||
This is the perfect spot to share your GitHub issue guidelines. If you want feature requests to follow the user story format, share that here. If you use a tracking tool to organize your product backlog, share the badge so others can gain visibility.
|
||||
|
||||
"Issue templates, sensible labels, documentation for how to file issues, and ensuring your issues get triaged and responded to quickly are all important" for your open source project, Bacon said.
|
||||
|
||||
Remember: It's not about adding process for the process' sake. It's about setting up a structure that makes it easy for others to discover, understand, and feel confident contributing to your community.
|
||||
|
||||
"Focus your community growth efforts not just on growing the number of programmers, but also [on] people interested in helping issues be accurate, up to date, and a source of active conversation and productive problem solving," Bacon said.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/how-take-your-projects-github-issues-good-great
|
||||
|
||||
作者:[Matt Butler][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mattzenhub
|
||||
[1]: http://www.jonobacon.org/
|
||||
[2]: http://www.artofcommunityonline.org/
|
||||
[3]: https://help.github.com/articles/creating-an-issue-template-for-your-repository/
|
||||
[4]: https://www.amazon.ca/Agile-Samurai-Masters-Deliver-Software/dp/1934356581
|
||||
@ -1,234 +0,0 @@
|
||||
chunyang-wen translating
|
||||
Writing online multiplayer game with python and asyncio - Part 2
|
||||
==================================================================
|
||||
|
||||

|
||||
|
||||
Have you ever made an asynchronous Python app? Here I’ll tell you how to do it and in the next part, show it on a [working example][1] - a popular Snake game, designed for multiple players.
|
||||
|
||||
see the intro and theory about how to [Get Asynchronous [part 1]][2]
|
||||
|
||||
[Play the game][3]
|
||||
|
||||
### 3. Writing game loop
|
||||
|
||||
The game loop is a heart of every game. It runs continuously to get player's input, update state of the game and render the result on the screen. In online games the loop is divided into client and server parts, so basically there are two loops which communicate over the network. Usually, client role is to get player's input, such as keypress or mouse movement, pass this data to a server and get back the data to render. The server side is processing all the data coming from players, updating game's state, doing necessary calculations to render next frame and passes back the result, such as new placement of game objects. It is very important not to mix client and server roles without a solid reason. If you start doing game logic calculations on the client side, you can easily go out of sync with other clients, and your game can also be created by simply passing any data from the client side.
|
||||
|
||||
A game loop iteration is often called a tick. Tick is an event meaning that current game loop iteration is over and the data for the next frame(s) is ready.
|
||||
In the next examples we will use the same client, which connects to a server from a web page using WebSocket. It runs a simple loop which passes pressed keys' codes to the server and displays all messages that come from the server. [Client source code is located here][4].
|
||||
|
||||
#### Example 3.1: Basic game loop
|
||||
|
||||
[Example 3.1 source code][5]
|
||||
|
||||
We will use [aiohttp][6] library to create a game server. It allows creating web servers and clients based on asyncio. A good thing about this library is that it supports normal http requests and websockets at the same time. So we don't need other web servers to render game's html page.
|
||||
|
||||
Here is how we run the server:
|
||||
|
||||
```
|
||||
app = web.Application()
|
||||
app["sockets"] = []
|
||||
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
|
||||
app.router.add_route('GET', '/connect', wshandler)
|
||||
app.router.add_route('GET', '/', handle)
|
||||
|
||||
web.run_app(app)
|
||||
```
|
||||
|
||||
web.run_app is a handy shortcut to create server's main task and to run asyncio event loop with it's run_forever() method. I suggest you check the source code of this method to see how the server is actually created and terminated.
|
||||
|
||||
An app is a dict-like object which can be used to share data between connected clients. We will use it to store a list of connected sockets. This list is then used to send notification messages to all connected clients. A call to asyncio.ensure_future() will schedule our main game_loop task which sends 'tick' message to clients every 2 seconds. This task will run concurrently in the same asyncio event loop along with our web server.
|
||||
|
||||
There are 2 web request handlers: handle just serves a html page and wshandler is our main websocket server's task which handles interaction with game clients. With every connected client a new wshandler task is launched in the event loop. This task adds client's socket to the list, so that game_loop task may send messages to all the clients. Then it echoes every keypress back to the client with a message.
|
||||
|
||||
In the launched tasks we are running worker loops over the main event loop of asyncio. A switch between tasks happens when one of them uses await statement to wait for a coroutine to finish. For instance, asyncio.sleep just passes execution back to a scheduler for a given amount of time, and ws.receive() is waiting for a message from websocket, while the scheduler may switch to some other task.
|
||||
|
||||
After you open the main page in a browser and connect to the server, just try to press some keys. Their codes will be echoed back from the server and every 2 seconds this message will be overwritten by game loop's 'tick' message which is sent to all clients.
|
||||
|
||||
So we have just created a server which is processing client's keypresses, while the main game loop is doing some work in the background and updates all clients periodically.
|
||||
|
||||
#### Example 3.2: Starting game loop by request
|
||||
|
||||
[Example 3.2 source code][7]
|
||||
|
||||
In the previous example a game loop was running continuously all the time during the life of the server. But in practice, there is usually no sense to run game loop when no one is connected. Also, there may be different game "rooms" running on one server. In this concept one player "creates" a game session (a match in a multiplayer game or a raid in MMO for example) so other players may join it. Then a game loop runs while the game session continues.
|
||||
|
||||
In this example we use a global flag to check if a game loop is running, and we start it when the first player connects. In the beginning, a game loop is not running, so the flag is set to False. A game loop is launched from the client's handler:
|
||||
|
||||
```
|
||||
if app["game_is_running"] == False:
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
This flag is then set to True at the start of game loop() and then back to False in the end, when all clients are disconnected.
|
||||
|
||||
#### Example 3.3: Managing tasks
|
||||
|
||||
[Example 3.3 source code][8]
|
||||
|
||||
This example illustrates working with task objects. Instead of storing a flag, we store game loop's task directly in our application's global dict. This may be not an optimal thing to do in a simple case like this, but sometimes you may need to control already launched tasks.
|
||||
```
|
||||
if app["game_loop"] is None or \
|
||||
app["game_loop"].cancelled():
|
||||
app["game_loop"] = asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
Here ensure_future() returns a task object that we store in a global dict; and when all users disconnect, we cancel it with
|
||||
|
||||
```
|
||||
app["game_loop"].cancel()
|
||||
```
|
||||
|
||||
This cancel() call tells scheduler not to pass execution to this coroutine anymore and sets its state to cancelled which then can be checked by cancelled() method. And here is one caveat worth to mention: when you have external references to a task object and exception happens in this task, this exception will not be raised. Instead, an exception is set to this task and may be checked by exception() method. Such silent fails are not useful when debugging a code. Thus, you may want to raise all exceptions instead. To do so you need to call result() method of unfinished task explicitly. This can be done in a callback:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result())
|
||||
```
|
||||
|
||||
Also if we are going to cancel this task in our code and we don't want to have CancelledError exception, it has a point checking its "cancelled" state:
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result()
|
||||
if not t.cancelled() else None)
|
||||
```
|
||||
|
||||
Note that this is required only if you store a reference to your task objects. In the previous examples all exceptions are raised directly without additional callbacks.
|
||||
|
||||
#### Example 3.4: Waiting for multiple events
|
||||
|
||||
[Example 3.4 source code][9]
|
||||
|
||||
In many cases, you need to wait for multiple events inside client's handler. Beside a message from a client, you may need to wait for different types of things to happen. For instance, if your game's time is limited, you may wait for a signal from timer. Or, you may wait for a message from other process using pipes. Or, for a message from a different server in the network, using a distributed messaging system.
|
||||
|
||||
This example is based on example 3.1 for simplicity. But in this case we use Condition object to synchronize game loop with connected clients. We do not keep a global list of sockets here as we are using sockets only within the handler. When game loop iteration ends, we notify all clients using Condition.notify_all() method. This method allows implementing publish/subscribe pattern within asyncio event loop.
|
||||
|
||||
To wait for two events in the handler, first, we wrap awaitable objects in a task using ensure_future()
|
||||
|
||||
```
|
||||
if not recv_task:
|
||||
recv_task = asyncio.ensure_future(ws.receive())
|
||||
if not tick_task:
|
||||
await tick.acquire()
|
||||
tick_task = asyncio.ensure_future(tick.wait())
|
||||
```
|
||||
|
||||
Before we can call Condition.wait(), we need to acquire a lock behind it. That is why, we call tick.acquire() first. This lock is then released after calling tick.wait(), so other coroutines may use it too. But when we get a notification, a lock will be acquired again, so we need to release it calling tick.release() after received notification.
|
||||
|
||||
We are using asyncio.wait() coroutine to wait for two tasks.
|
||||
|
||||
```
|
||||
done, pending = await asyncio.wait(
|
||||
[recv_task,
|
||||
tick_task],
|
||||
return_when=asyncio.FIRST_COMPLETED)
|
||||
```
|
||||
|
||||
It blocks until either of tasks from the list is completed. Then it returns 2 lists: tasks which are done and tasks which are still running. If the task is done, we set it to None so it may be created again on the next iteration.
|
||||
|
||||
#### Example 3.5: Combining with threads
|
||||
|
||||
[Example 3.5 source code][10]
|
||||
|
||||
In this example we combine asyncio loop with threads by running the main game loop in a separate thread. As I mentioned before, it's not possible to perform real parallel execution of python code with threads because of GIL. So it is not a good idea to use other thread to do heavy calculations. However, there is one reason to use threads with asyncio: this is the case when you need to use other libraries which do not support asyncio. Using these libraries in the main thread will simply block execution of the loop, so the only way to use them asynchronously is to run in a different thread.
|
||||
|
||||
We run game loop using run_in_executor() method of asyncio loop and ThreadPoolExecutor. Note that game_loop() is not a coroutine anymore. It is a function that is executed in another thread. However, we need to interact with the main thread to notify clients on the game events. And while asyncio itself is not threadsafe, it has methods which allow running your code from another thread. These are call_soon_threadsafe() for normal functions and run_coroutine_threadsafe() for coroutines. We will put a code which notifies clients about game's tick to notify() coroutine and runs it in the main event loop from another thread.
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
print("Game loop thread id {}".format(threading.get_ident()))
|
||||
async def notify():
|
||||
print("Notify thread id {}".format(threading.get_ident()))
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
while 1:
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
# blocking the thread
|
||||
sleep(1)
|
||||
# make sure the task has finished
|
||||
task.result()
|
||||
```
|
||||
|
||||
When you launch this example, you will see that "Notify thread id" is equal to "Main thread id", this is because notify() coroutine is executed in the main thread. While sleep(1) call is executed in another thread, and, as a result, it will not block the main event loop.
|
||||
|
||||
#### Example 3.6: Multiple processes and scaling up
|
||||
|
||||
[Example 3.6 source code][11]
|
||||
|
||||
One threaded server may work well, but it is limited to one CPU core. To scale the server beyond one core, we need to run multiple processes containing their own event loops. So we need a way for processes to interact with each other by exchanging messages or sharing game's data. Also in games, it is often required to perform heavy calculations, such as path finding and alike. These tasks are sometimes not possible to complete quickly within one game tick. It is not recommended to perform time-consuming calculations in coroutines, as it will block event processing, so in this case, it may be reasonable to pass the heavy task to other process running in parallel.
|
||||
|
||||
The easiest way to utilize multiple cores is to launch multiple single core servers, like in the previous examples, each on a different port. You can do this with supervisord or similar process-controller system. Then, you may use a load balancer, such as HAProxy, to distribute connecting clients between the processes. There are different ways for processes to interact wich each other. One is to use network-based systems, which allows you to scale to multiple servers as well. There are already existing adapters to use popular messaging and storage systems with asyncio. Here are some examples:
|
||||
|
||||
- [aiomcache][12] for memcached client
|
||||
- [aiozmq][13] for zeroMQ
|
||||
- [aioredis][14] for Redis storage and pub/sub
|
||||
|
||||
You can find many other packages like this on github and pypi, most of them have "aio" prefix.
|
||||
|
||||
Using network services may be effective to store persistent data and exchange some kind of messages. But its performance may be not enough if you need to perform real-time data processing that involves inter-process communications. In this case, a more appropriate way may be using standard unix pipes. asyncio has support for pipes and there is a [very low-level example of the server which uses pipes][15] in aiohttp repository.
|
||||
|
||||
In the current example, we will use python's high-level [multiprocessing][16] library to instantiate new process to perform heavy calculations on a different core and to exchange messages with this process using multiprocessing.Queue. Unfortunately, the current implementation of multiprocessing is not compatible with asyncio. So every blocking call will block the event loop. But this is exactly the case where threads will be helpful because if we run multiprocessing code in a different thread, it will not block our main thread. All we need is to put all inter-process communications to another thread. This example illustrates this technique. It is very similar to multi-threading example above, but we create a new process from a thread.
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
# coroutine to run in main thread
|
||||
async def notify():
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
queue = Queue()
|
||||
|
||||
# function to run in a different process
|
||||
def worker():
|
||||
while 1:
|
||||
print("doing heavy calculation in process {}".format(os.getpid()))
|
||||
sleep(1)
|
||||
queue.put("calculation result")
|
||||
|
||||
Process(target=worker).start()
|
||||
|
||||
while 1:
|
||||
# blocks this thread but not main thread with event loop
|
||||
result = queue.get()
|
||||
print("getting {} in process {}".format(result, os.getpid()))
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
task.result()
|
||||
```
|
||||
|
||||
Here we run worker() function in another process. It contains a loop doing heavy calculations and putting results to the queue, which is an instance of multiprocessing.Queue. Then we get the results and notify clients in the main event loop from a different thread, exactly as in the example 3.5. This example is very simplified, it doesn't have a proper termination of the process. Also, in a real game, we would probably use the second queue to pass data to the worker.
|
||||
|
||||
There is a project called [aioprocessing][17], which is a wrapper around multiprocessing that makes it compatible with asyncio. However, it uses exactly the same approach as described in this example - creating processes from threads. It will not give you any advantage, other than hiding these tricks behind a simple interface. Hopefully, in the next versions of Python, we will get a multiprocessing library based on coroutines and supports asyncio.
|
||||
|
||||
>Important! If you are going to run another asyncio event loop in a different thread or sub-process created from main thread/process, you need to create a loop explicitly, using asyncio.new_event_loop(), otherwise, it will not work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[3]: http://snakepit-game.com/
|
||||
[4]: https://github.com/7WebPages/snakepit-game/blob/master/simple/index.html
|
||||
[5]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_basic.py
|
||||
[6]: http://aiohttp.readthedocs.org/
|
||||
[7]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_handler.py
|
||||
[8]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_global.py
|
||||
[9]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_wait.py
|
||||
[10]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_thread.py
|
||||
[11]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_process.py
|
||||
[12]: https://github.com/aio-libs/aiomcache
|
||||
[13]: https://github.com/aio-libs/aiozmq
|
||||
[14]: https://github.com/aio-libs/aioredis
|
||||
[15]: https://github.com/KeepSafe/aiohttp/blob/master/examples/mpsrv.py
|
||||
[16]: https://docs.python.org/3.5/library/multiprocessing.html
|
||||
[17]: https://github.com/dano/aioprocessing
|
||||
@ -1,138 +0,0 @@
|
||||
chunyang-wen translating
|
||||
Writing online multiplayer game with python and asyncio - Part 3
|
||||
=================================================================
|
||||
|
||||

|
||||
|
||||
In this series, we are making an asynchronous Python app on the example of a multiplayer [Snake game][1]. The previous article focused on [Writing Game Loop][2] and Part 1 was covering how to [Get Asynchronous][3].
|
||||
|
||||
You can find the code [here][4].
|
||||
|
||||
### 4. Making a complete game
|
||||
|
||||

|
||||
|
||||
#### 4.1 Project's overview
|
||||
|
||||
In this part, we will review a design of a complete online game. It is a classic snake game with added multiplayer. You can try it yourself at (<http://snakepit-game.com>). A source code is located [in github repository][5]. The game consists of the following files:
|
||||
|
||||
- [server.py][6] - a server handling main game loop and connections.
|
||||
- [game.py][7] - a main Game class, which implements game's logic and most of the game's network protocol.
|
||||
- [player.py][8] - Player class, containing individual player's data and snake's representation. This one is responsible for getting player's input and moving the snake accordingly.
|
||||
- [datatypes.py][9] - basic data structures.
|
||||
- [settings.py][10] - game settings, and it has descriptions in commentaries.
|
||||
- [index.html][11] - all html and javascript client part in one file.
|
||||
|
||||
#### 4.2 Inside a game loop
|
||||
|
||||
Multiplayer snake game is a good example to learn because of its simplicity. All snakes move to one position every single frame, and frames are changing at a very slow rate, allowing you to watch how game engine is working actually. There is no instant reaction to player's keypresses because of the slow speed. A pressed key is remembered and then taken into account while calculating the next frame at the end of game loop's iteration.
|
||||
|
||||
> Modern action games are running at much higher frame rates and often frame rates of server and client are not equal. Client frame rate usually depends on the client hardware performance, while server frame rate is fixed. A client may render several frames after getting the data corresponding to one "game tick". This allows to create smooth animations, which are only limited by client's performance. In this case, a server should pass not only current positions of the objects but also their moving directions, speeds and velocities. And while client frame rate is called FPS (frames per second), sever frame rate is called TPS (ticks per second). In this snake game example both values are equal, and one frame displayed by a client is calculated within one server's tick.
|
||||
|
||||
We will use textmode-like play field, which is, in fact, a html table with one-char cells. All objects of the game are displayed with characters of different colors placed in table's cells. Most of the time client passes pressed keys' codes to the server and gets back play field updates with every "tick". An update from server consists of messages representing characters to render along with their coordinates and colors. So we are keeping all game logic on the server and we are sending to client only rendering data. In addition, we minimize the possibilities to hack the game by substituting its information sent over the network.
|
||||
|
||||
#### 4.3 How does it work?
|
||||
|
||||
The server in this game is close to Example 3.2 for simplicity. But instead of having a global list of connected websockets, we have one server-wide Game object. A Game instance contains a list of Player objects (inside self._players attribute) which represents players connected to this game, their personal data and websocket objects. Having all game-related data in a Game object also allows us to have multiple game rooms if we want to add such feature. In this case, we need to maintain multiple Game objects, one per game started.
|
||||
|
||||
All interactions between server and clients are done with messages encoded in json. Message from the client containing only a number is interpreted as a code of the key pressed by the player. Other messages from client are sent in the following format:
|
||||
|
||||
```
|
||||
[command, arg1, arg2, ... argN ]
|
||||
```
|
||||
|
||||
Messages from server are sent as a list because there is often a bunch of messages to send at once (rendering data mostly):
|
||||
|
||||
```
|
||||
[[command, arg1, arg2, ... argN ], ... ]
|
||||
```
|
||||
|
||||
At the end of every game loop iteration, the next frame is calculated and sent to all the clients. Of course, we are not sending complete frame every time, but only a list of changes for the next frame.
|
||||
|
||||
Note that players are not joining the game immediately after connecting to the server. The connection starts in "spectator" mode, so one can watch how others are playing. if the game is already started, or a "game over" screen from the previous game session. Then a player may press "Join" button to join the existing game or to create a new game if the game is not currently running (no other active players). In the later case, the play field is cleared before the start.
|
||||
|
||||
The play field is stored in Game._world attribute, which is a 2d array made of nested lists. It is used to keep game field's state internally. Each element of an array represents a field's cell which is then rendered to a html table cell. It has a type of Char, which is a namedtuple consisting of a character and color. It is important to keep play field in sync with all the connected clients, so all updates to the play field should be made only along with sending corresponding messages to the clients. This is performed by Game.apply_render() method. It receives a list of Draw objects, which is then used to update play field internally and also to send render message to clients.
|
||||
|
||||
We are using namedtuple not only because it is a good way to represent simple data structures, but also because it takes less space comparing to dict when sending in a json message. If you are sending complex data structures in a real game app, it is recommended to serialize them into a plain and shorter format or even pack in a binary format (such as bson instead of json) to minimize network traffic.
|
||||
|
||||
ThePlayer object contains snake's representation in a deque object. This data type is similar to a list but is more effective for adding and removing elements on its sides, so it is ideal to represent a moving snake. The main method of the class is Player.render_move(), it returns rendering data to move player's snake to the next position. Basically, it renders snake's head in the new position and removes the last element where the tail was in the previous frame. In case the snake has eaten a digit and has to grow, a tail is not moving for a corresponding number of frames. The snake rendering data is used in Game.next_frame() method of the main class, which implements all game logic. This method renders all snake moves and checks for obstacles in front of every snake and also spawns digits and "stones". It is called directly from game_loop() to generate the next frame at every "tick".
|
||||
|
||||
In case there is an obstacle in front of snake's head, a Game.game_over() method is called from Game.next_frame(). It notifies all connected clients about the dead snake (which is turned into stones by player.render_game_over() method) and updates top scores table. Player object's alive flag is set to False, so this player will be skipped when rendering the next frames, until joining the game once again. In case there are no more snakes alive, a "game over" message is rendered at the game field. Also, the main game loop will stop and set game.running flag to False, which will cause a game field to be cleared when some player will press "Join" button next time.
|
||||
|
||||
Spawning of digits and stones is also happening while rendering every next frame, and it is determined by random values. A chance to spawn a digit or a stone can be changed in settings.py along with some other values. Note that digit spawning is happening for every live snake in the play field, so the more snakes are there, the more digits will appear, and they all will have enough food to consume.
|
||||
|
||||
#### 4.4 Network protocol
|
||||
List of messages sent from client
|
||||
|
||||
Command | Parameters |Description
|
||||
:-- |:-- |:--
|
||||
new_player | [name] |Setting player's nickname
|
||||
join | |Player is joining the game
|
||||
|
||||
|
||||
List of messages sent from server
|
||||
|
||||
Command | Parameters |Description
|
||||
:-- |:-- |:--
|
||||
handshake |[id] |Assign id to a player
|
||||
world |[[(char, color), ...], ...] |Initial play field (world) map
|
||||
reset_world | |Clean up world map, replacing all characters with spaces
|
||||
render |[x, y, char, color] |Display character at position
|
||||
p_joined |[id, name, color, score] |New player joined the game
|
||||
p_gameover |[id] |Game ended for a player
|
||||
p_score |[id, score] |Setting score for a player
|
||||
top_scores |[[name, score, color], ...] |Update top scores table
|
||||
|
||||
Typical messages exchange order
|
||||
|
||||
Client -> Server |Server -> Client |Server -> All clients |Commentaries
|
||||
:-- |:-- |:-- |:--
|
||||
new_player | | |Name passed to server
|
||||
|handshake | |ID assigned
|
||||
|world | |Initial world map passed
|
||||
|top_scores | |Recent top scores table passed
|
||||
join | | |Player pressed "Join", game loop started
|
||||
| |reset_world |Command clients to clean up play field
|
||||
| |render, render, ... |First game tick, first frame rendered
|
||||
(key code) | | |Player pressed a key
|
||||
| |render, render, ... |Second frame rendered
|
||||
| |p_score |Snake has eaten a digit
|
||||
| |render, render, ... |Third frame rendered
|
||||
| | |... Repeat for a number of frames ...
|
||||
| |p_gameover |Snake died when trying to eat an obstacle
|
||||
| |top_scores |Updated top scores table (if updated)
|
||||
|
||||
### 5. Conclusion
|
||||
|
||||
To tell the truth, I really enjoy using the latest asynchronous capabilities of Python. The new syntax really makes a difference, so async code is now easily readable. It is obvious which calls are non-blocking and when the green thread switching is happening. So now I can claim with confidence that Python is a good tool for asynchronous programming.
|
||||
|
||||
SnakePit has become very popular at 7WebPages team, and if you decide to take a break at your company, please, don’t forget to leave a feedback for us, say, on [Twitter][12] or [Facebook][13] .
|
||||
|
||||
Get to know more from:
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-part-3/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-part-3/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
[3]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[4]: https://github.com/7WebPages/snakepit-game
|
||||
[5]: https://github.com/7WebPages/snakepit-game
|
||||
[6]: https://github.com/7WebPages/snakepit-game/blob/master/server.py
|
||||
[7]: https://github.com/7WebPages/snakepit-game/blob/master/game.py
|
||||
[8]: https://github.com/7WebPages/snakepit-game/blob/master/player.py
|
||||
[9]: https://github.com/7WebPages/snakepit-game/blob/master/datatypes.py
|
||||
[10]: https://github.com/7WebPages/snakepit-game/blob/master/settings.py
|
||||
[11]: https://github.com/7WebPages/snakepit-game/blob/master/index.html
|
||||
[12]: https://twitter.com/7WebPages
|
||||
[13]: https://www.facebook.com/7WebPages/
|
||||
@ -1,407 +0,0 @@
|
||||
Backup Photos While Traveling With an Ipad Pro and a Raspberry Pi
|
||||
===================================================================
|
||||
|
||||

|
||||
>Backup Photos While Traveling - Gear.
|
||||
|
||||
### Introduction
|
||||
|
||||
I’ve been on a quest to finding the ideal travel photo backup solution for a long time. Relying on just tossing your SD cards in your camera bag after they are full during a trip is a risky move that leaves you too exposed: SD cards can be lost or stolen, data can get corrupted or cards can get damaged in transit. Backing up to another medium - even if it’s just another SD card - and leaving that in a safe(r) place while traveling is the best practice. Ideally, backing up to a remote location would be the way to go, but that may not be practical depending on where you are traveling to and Internet availability in the region.
|
||||
|
||||
My requirements for the ideal backup procedure are:
|
||||
|
||||
1. Use an iPad to manage the process instead of a laptop. I like to travel light and since most of my trips are business related (i.e. non-photography related), I’d hate to bring my personal laptop along with my business laptop. My iPad, however; is always with me, so using it as a tool just makes sense.
|
||||
2. Use as few hardware devices as practically possible.
|
||||
3. Connection between devices should be secure. I’ll be using this setup in hotels and airports, so closed and encrypted connection between devices is ideal.
|
||||
4. The whole process should be sturdy and reliable. I’ve tried other options using router/combo devices and [it didn’t end up well][1].
|
||||
|
||||
### The Setup
|
||||
|
||||
I came up with a setup that meets the above criteria and is also flexible enough to expand on it in the future. It involves the use of the following gear:
|
||||
|
||||
1. [iPad Pro 9.7][2] inches. It’s the most powerful, small and lightweight iOS device at the time of writing. Apple pencil is not really needed, but it’s part of my gear as I so some editing on the iPad Pro while on the road. All the heavy lifting will be done by the Raspberry Pi, so any other device capable of connecting through SSH would fit the bill.
|
||||
2. [Raspberry Pi 3][3] with Raspbian installed.
|
||||
3. [Micro SD card][4] for Raspberry Pi and a Raspberry Pi [box/case][5].
|
||||
5. [128 GB Pen Drive][6]. You can go bigger, but 128 GB is enough for my user case. You can also get a portable external hard drive like [this one][7], but the Raspberry Pi may not provide enough power through its USB port, which means you would have to get a [powered USB hub][8], along with the needed cables, defeating the purpose of having a lightweight and minimalistic setup.
|
||||
6. [SD card reader][9]
|
||||
7. [SD Cards][10]. I use several as I don’t wait for one to fill up before using a different one. That allows me to spread photos I take on a single trip amongst several cards.
|
||||
|
||||
The following diagram shows how these devices will be interacting with each other.
|
||||
|
||||

|
||||
>Backup Photos While Traveling - Process Diagram.
|
||||
|
||||
The Raspberry Pi will be configured to act as a secured Hot Spot. It will create its own WPA2-encrypted WiFi network to which the iPad Pro will connect. Although there are many online tutorials to create an Ad Hoc (i.e. computer-to-computer) connection with the Raspberry Pi, which is easier to setup; that connection is not encrypted and it’s relatively easy for other devices near you to connect to it. Therefore, I decided to go with the WiFi option.
|
||||
|
||||
The camera’s SD card will be connected to one of the Raspberry Pi’s USB ports through an SD card reader. Additionally, a high capacity Pen Drive (128 GB in my case) will be permanently inserted in one of the USB ports on the Raspberry Pi. I picked the [Sandisk Ultra Fit][11] because of its tiny size. The main idea is to have the Raspberry Pi backup the photos from the SD Card to the Pen Drive with the help of a Python script. The backup process will be incremental, meaning that only changes (i.e. new photos taken) will be added to the backup folder each time the script runs, making the process really fast. This is a huge advantage if you take a lot of photos or if you shoot in RAW format. The iPad will be used to trigger the Python script and to browse the SD Card and Pen Drive as needed.
|
||||
|
||||
As an added benefit, if the Raspberry Pi is connected to Internet through a wired connection (i.e. through the Ethernet port), it will be able to share the Internet connection with the devices connected to its WiFi network.
|
||||
|
||||
### 1. Raspberry Pi Configuration
|
||||
|
||||
This is the part where we roll up our sleeves and get busy as we’ll be using Raspbian’s command-line interface (CLI) . I’ll try to be as descriptive as possible so it’s easy to go through the process.
|
||||
|
||||
#### Install and Configure Raspbian
|
||||
|
||||
Connect a keyboard, mouse and an LCD monitor to the Raspberry Pi. Insert the Micro SD in the Raspberry Pi’s slot and proceed to install Raspbian per the instructions in the [official site][12].
|
||||
|
||||
After the installation is done, go to the CLI (Terminal in Raspbian) and type:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
```
|
||||
|
||||
This will upgrade all software on the machine. I configured the Raspberry Pi to connect to the local network and changed the default password as a safety measure.
|
||||
|
||||
By default SSH is enabled on Raspbian, so all sections below can be done from a remote machine. I also configured RSA authentication, but that’s optional. More info about it [here][13].
|
||||
|
||||
This is a screenshot of the SSH connection to the Raspberry Pi from [iTerm][14] on Mac:
|
||||
|
||||
##### Creating Encrypted (WPA2) Access Point
|
||||
|
||||
The installation was made based on [this][15] article, it was optimized for my user case.
|
||||
|
||||
##### 1. Install Packages
|
||||
|
||||
We need to type the following to install the required packages:
|
||||
|
||||
```
|
||||
sudo apt-get install hostapd
|
||||
sudo apt-get install dnsmasq
|
||||
```
|
||||
|
||||
hostapd allows to use the built-in WiFi as an access point. dnsmasq is a combined DHCP and DNS server that’s easy to configure.
|
||||
|
||||
##### 2. Edit dhcpcd.conf
|
||||
|
||||
Connect to the Raspberry Pi through Ethernet. Interface configuration on the Raspbery Pi is handled by dhcpcd, so first we tell it to ignore wlan0 as it will be configured with a static IP address.
|
||||
|
||||
Open up the dhcpcd configuration file with sudo nano `/etc/dhcpcd.conf` and add the following line to the bottom of the file:
|
||||
|
||||
```
|
||||
denyinterfaces wlan0
|
||||
```
|
||||
|
||||
Note: This must be above any interface lines that may have been added.
|
||||
|
||||
##### 3. Edit interfaces
|
||||
|
||||
Now we need to configure our static IP. To do this, open up the interface configuration file with sudo nano `/etc/network/interfaces` and edit the wlan0 section so that it looks like this:
|
||||
|
||||
```
|
||||
allow-hotplug wlan0
|
||||
iface wlan0 inet static
|
||||
address 192.168.1.1
|
||||
netmask 255.255.255.0
|
||||
network 192.168.1.0
|
||||
broadcast 192.168.1.255
|
||||
# wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
```
|
||||
|
||||
Also, the wlan1 section was edited to be:
|
||||
|
||||
```
|
||||
#allow-hotplug wlan1
|
||||
#iface wlan1 inet manual
|
||||
# wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
```
|
||||
|
||||
Important: Restart dhcpcd with sudo service dhcpcd restart and then reload the configuration for wlan0 with `sudo ifdown eth0; sudo ifup wlan0`.
|
||||
|
||||
##### 4. Configure Hostapd
|
||||
|
||||
Next, we need to configure hostapd. Create a new configuration file with `sudo nano /etc/hostapd/hostapd.conf with the following contents:
|
||||
|
||||
```
|
||||
interface=wlan0
|
||||
|
||||
# Use the nl80211 driver with the brcmfmac driver
|
||||
driver=nl80211
|
||||
|
||||
# This is the name of the network
|
||||
ssid=YOUR_NETWORK_NAME_HERE
|
||||
|
||||
# Use the 2.4GHz band
|
||||
hw_mode=g
|
||||
|
||||
# Use channel 6
|
||||
channel=6
|
||||
|
||||
# Enable 802.11n
|
||||
ieee80211n=1
|
||||
|
||||
# Enable QoS Support
|
||||
wmm_enabled=1
|
||||
|
||||
# Enable 40MHz channels with 20ns guard interval
|
||||
ht_capab=[HT40][SHORT-GI-20][DSSS_CCK-40]
|
||||
|
||||
# Accept all MAC addresses
|
||||
macaddr_acl=0
|
||||
|
||||
# Use WPA authentication
|
||||
auth_algs=1
|
||||
|
||||
# Require clients to know the network name
|
||||
ignore_broadcast_ssid=0
|
||||
|
||||
# Use WPA2
|
||||
wpa=2
|
||||
|
||||
# Use a pre-shared key
|
||||
wpa_key_mgmt=WPA-PSK
|
||||
|
||||
# The network passphrase
|
||||
wpa_passphrase=YOUR_NEW_WIFI_PASSWORD_HERE
|
||||
|
||||
# Use AES, instead of TKIP
|
||||
rsn_pairwise=CCMP
|
||||
```
|
||||
|
||||
Now, we also need to tell hostapd where to look for the config file when it starts up on boot. Open up the default configuration file with `sudo nano /etc/default/hostapd` and find the line `#DAEMON_CONF=""` and replace it with `DAEMON_CONF="/etc/hostapd/hostapd.conf"`.
|
||||
|
||||
##### 5. Configure Dnsmasq
|
||||
|
||||
The shipped dnsmasq config file contains tons of information on how to use it, but we won’t be using all the options. I’d recommend moving it (rather than deleting it), and creating a new one with
|
||||
|
||||
```
|
||||
sudo mv /etc/dnsmasq.conf /etc/dnsmasq.conf.orig
|
||||
sudo nano /etc/dnsmasq.conf
|
||||
```
|
||||
|
||||
Paste the following into the new file:
|
||||
|
||||
```
|
||||
interface=wlan0 # Use interface wlan0
|
||||
listen-address=192.168.1.1 # Explicitly specify the address to listen on
|
||||
bind-interfaces # Bind to the interface to make sure we aren't sending things elsewhere
|
||||
server=8.8.8.8 # Forward DNS requests to Google DNS
|
||||
domain-needed # Don't forward short names
|
||||
bogus-priv # Never forward addresses in the non-routed address spaces.
|
||||
dhcp-range=192.168.1.50,192.168.1.100,12h # Assign IP addresses in that range with a 12 hour lease time
|
||||
```
|
||||
|
||||
##### 6. Set up IPV4 forwarding
|
||||
|
||||
One of the last things that we need to do is to enable packet forwarding. To do this, open up the sysctl.conf file with `sudo nano /etc/sysctl.conf`, and remove the # from the beginning of the line containing `net.ipv4.ip_forward=1`. This will enable it on the next reboot.
|
||||
|
||||
We also need to share our Raspberry Pi’s internet connection to our devices connected over WiFi by the configuring a NAT between our wlan0 interface and our eth0 interface. We can do this by writing a script with the following lines.
|
||||
|
||||
```
|
||||
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
|
||||
sudo iptables -A FORWARD -i eth0 -o wlan0 -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
sudo iptables -A FORWARD -i wlan0 -o eth0 -j ACCEPT
|
||||
```
|
||||
|
||||
I named the script hotspot-boot.sh and made it executable with:
|
||||
|
||||
```
|
||||
sudo chmod 755 hotspot-boot.sh
|
||||
```
|
||||
|
||||
The script should be executed when the Raspberry Pi boots. There are many ways to accomplish this, and this is the way I went with:
|
||||
|
||||
1. Put the file in `/home/pi/scripts`.
|
||||
2. Edit the rc.local file by typing `sudo nano /etc/rc.local` and place the call to the script before the line that reads exit 0 (more information [here][16]).
|
||||
|
||||
This is how the rc.local file looks like after editing it.
|
||||
|
||||
```
|
||||
#!/bin/sh -e
|
||||
#
|
||||
# rc.local
|
||||
#
|
||||
# This script is executed at the end of each multiuser runlevel.
|
||||
# Make sure that the script will "exit 0" on success or any other
|
||||
# value on error.
|
||||
#
|
||||
# In order to enable or disable this script just change the execution
|
||||
# bits.
|
||||
#
|
||||
# By default this script does nothing.
|
||||
|
||||
# Print the IP address
|
||||
_IP=$(hostname -I) || true
|
||||
if [ "$_IP" ]; then
|
||||
printf "My IP address is %s\n" "$_IP"
|
||||
fi
|
||||
|
||||
sudo /home/pi/scripts/hotspot-boot.sh &
|
||||
|
||||
exit 0
|
||||
|
||||
```
|
||||
|
||||
#### Installing Samba and NTFS Compatibility.
|
||||
|
||||
We also need to install the following packages to enable the Samba protocol and allow the File Browser App to see the connected devices to the Raspberry Pi as shared folders. Also, ntfs-3g provides NTFS compatibility in case we decide to connect a portable hard drive to the Raspberry Pi.
|
||||
|
||||
```
|
||||
sudo apt-get install ntfs-3g
|
||||
sudo apt-get install samba samba-common-bin
|
||||
```
|
||||
|
||||
You can follow [this][17] article for details on how to configure Samba.
|
||||
|
||||
Important Note: The referenced article also goes through the process of mounting external hard drives on the Raspberry Pi. We won’t be doing that because, at the time of writing, the current version of Raspbian (Jessie) auto-mounts both the SD Card and the Pendrive to `/media/pi/` when the device is turned on. The article also goes over some redundancy features that we won’t be using.
|
||||
|
||||
### 2. Python Script
|
||||
|
||||
Now that the Raspberry Pi has been configured, we need to work on the script that will actually backup/copy our photos. Note that this script just provides certain degree of automation to the backup process. If you have a basic knowledge of using the Linux/Raspbian CLI, you can just SSH into the Raspberry Pi and copy yourself all photos from one device to the other by creating the needed folders and using either the cp or the rsync command. We’ll be using the rsync method on the script as it’s very reliable and allows for incremental backups.
|
||||
|
||||
This process relies on two files: the script itself and the configuration file `backup_photos.conf`. The latter just have a couple of lines indicating where the destination drive (Pendrive) is mounted and what folder has been mounted to. This is what it looks like:
|
||||
|
||||
```
|
||||
mount folder=/media/pi/
|
||||
destination folder=PDRIVE128GB
|
||||
```
|
||||
|
||||
Important: Do not add any additional spaces between the `=` symbol and the words to both sides of it as the script will break (definitely an opportunity for improvement).
|
||||
|
||||
Below is the Python script, which I named `backup_photos.py` and placed in `/home/pi/scripts/`. I included comments in between the lines of code to make it easier to follow.
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
|
||||
import os
|
||||
import sys
|
||||
from sh import rsync
|
||||
|
||||
'''
|
||||
The script copies an SD Card mounted on /media/pi/ to a folder with the same name
|
||||
created in the destination drive. The destination drive's name is defined in
|
||||
the .conf file.
|
||||
|
||||
|
||||
Argument: label/name of the mounted SD Card.
|
||||
'''
|
||||
|
||||
CONFIG_FILE = '/home/pi/scripts/backup_photos.conf'
|
||||
ORIGIN_DEV = sys.argv[1]
|
||||
|
||||
def create_folder(path):
|
||||
|
||||
print ('attempting to create destination folder: ',path)
|
||||
if not os.path.exists(path):
|
||||
try:
|
||||
os.mkdir(path)
|
||||
print ('Folder created.')
|
||||
except:
|
||||
print ('Folder could not be created. Stopping.')
|
||||
return
|
||||
else:
|
||||
print ('Folder already in path. Using that instead.')
|
||||
|
||||
|
||||
|
||||
confFile = open(CONFIG_FILE,'rU')
|
||||
#IMPORTANT: rU Opens the file with Universal Newline Support,
|
||||
#so \n and/or \r is recognized as a new line.
|
||||
|
||||
confList = confFile.readlines()
|
||||
confFile.close()
|
||||
|
||||
|
||||
for line in confList:
|
||||
line = line.strip('\n')
|
||||
|
||||
try:
|
||||
name , value = line.split('=')
|
||||
|
||||
if name == 'mount folder':
|
||||
mountFolder = value
|
||||
elif name == 'destination folder':
|
||||
destDevice = value
|
||||
|
||||
|
||||
except ValueError:
|
||||
print ('Incorrect line format. Passing.')
|
||||
pass
|
||||
|
||||
|
||||
destFolder = mountFolder+destDevice+'/'+ORIGIN_DEV
|
||||
create_folder(destFolder)
|
||||
|
||||
print ('Copying files...')
|
||||
|
||||
# Comment out to delete files that are not in the origin:
|
||||
# rsync("-av", "--delete", mountFolder+ORIGIN_DEV, destFolder)
|
||||
rsync("-av", mountFolder+ORIGIN_DEV+'/', destFolder)
|
||||
|
||||
print ('Done.')
|
||||
```
|
||||
|
||||
### 3. iPad Pro Configuration
|
||||
|
||||
Since all the heavy-lifting will be done on the Raspberry Pi and no files will be transferred through the iPad Pro, which was a huge disadvantage in [one of the workflows I tried before][18]; we just need to install [Prompt 2][19] on the iPad to access the Raspeberry Pi through SSH. Once connected, you can either run the Python script or copy the files manually.
|
||||
|
||||

|
||||
>SSH Connection to Raspberry Pi From iPad Using Prompt.
|
||||
|
||||
Since we installed Samba, we can access USB devices connected to the Raspberry Pi in a more graphical way. You can stream videos, copy and move files between devices. [File Browser][20] is perfect for that.
|
||||
|
||||
### 4. Putting it All Together
|
||||
|
||||
Let’s suppose that `SD32GB-03` is the label of an SD card connected to one of the USB ports on the Raspberry Pi. Also, let’s suppose that `PDRIVE128GB` is the label of the Pendrive, also connected to the device and defined on the `.conf` file as indicated above. If we wanted to backup the photos on the SD Card, we would need to go through the following steps:
|
||||
|
||||
1. Turn on Raspberry Pi so that drives are mounted automatically.
|
||||
2. Connect to the WiFi network generated by the Raspberry Pi.
|
||||
3. Connect to the Raspberry Pi through SSH using the [Prompt][21] App.
|
||||
4. Type the following once you are connected:
|
||||
|
||||
```
|
||||
python3 backup_photos.py SD32GB-03
|
||||
```
|
||||
|
||||
The first backup my take some minutes depending on how much of the card is used. That means you need to keep the connection alive to the Raspberry Pi from the iPad. You can get around this by using the [nohup][22] command before running the script.
|
||||
|
||||
```
|
||||
nohup python3 backup_photos.py SD32GB-03 &
|
||||
```
|
||||
|
||||

|
||||
>iTerm Screenshot After Running Python Script.
|
||||
|
||||
### Further Customization
|
||||
|
||||
I installed a VNC server to access Raspbian’s graphical interface from another computer or the iPad through [Remoter App][23]. I’m looking into installing [BitTorrent Sync][24] for backing up photos to a remote location while on the road, which would be the ideal setup. I’ll expand this post once I have a workable solution.
|
||||
|
||||
Feel free to either include your comments/questions below or reach out to me. My contact info is at the footer of this page.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.movingelectrons.net/blog/2016/06/26/backup-photos-while-traveling-with-a-raspberry-pi.html
|
||||
|
||||
作者:[Editor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.movingelectrons.net/blog/2016/06/26/backup-photos-while-traveling-with-a-raspberry-pi.html
|
||||
[1]: http://bit.ly/1MVVtZi
|
||||
[2]: http://www.amazon.com/dp/B01D3NZIMA/?tag=movinelect0e-20
|
||||
[3]: http://www.amazon.com/dp/B01CD5VC92/?tag=movinelect0e-20
|
||||
[4]: http://www.amazon.com/dp/B010Q57T02/?tag=movinelect0e-20
|
||||
[5]: http://www.amazon.com/dp/B01F1PSFY6/?tag=movinelect0e-20
|
||||
[6]: http://amzn.to/293kPqX
|
||||
[7]: http://amzn.to/290syFY
|
||||
[8]: http://amzn.to/290syFY
|
||||
[9]: http://amzn.to/290syFY
|
||||
[10]: http://amzn.to/290syFY
|
||||
[11]: http://amzn.to/293kPqX
|
||||
[12]: https://www.raspberrypi.org/downloads/noobs/
|
||||
[13]: https://www.raspberrypi.org/documentation/remote-access/ssh/passwordless.md
|
||||
[14]: https://www.iterm2.com/
|
||||
[15]: https://frillip.com/using-your-raspberry-pi-3-as-a-wifi-access-point-with-hostapd/
|
||||
[16]: https://www.raspberrypi.org/documentation/linux/usage/rc-local.md
|
||||
[17]: http://www.howtogeek.com/139433/how-to-turn-a-raspberry-pi-into-a-low-power-network-storage-device/
|
||||
[18]: http://bit.ly/1MVVtZi
|
||||
[19]: https://itunes.apple.com/us/app/prompt-2/id917437289?mt=8&uo=4&at=11lqkH
|
||||
[20]: https://itunes.apple.com/us/app/filebrowser-access-files-on/id364738545?mt=8&uo=4&at=11lqkH
|
||||
[21]: https://itunes.apple.com/us/app/prompt-2/id917437289?mt=8&uo=4&at=11lqkH
|
||||
[22]: https://en.m.wikipedia.org/wiki/Nohup
|
||||
[23]: https://itunes.apple.com/us/app/remoter-pro-vnc-ssh-rdp/id519768191?mt=8&uo=4&at=11lqkH
|
||||
[24]: https://getsync.com/
|
||||
@ -1,225 +0,0 @@
|
||||
translating by maywanting
|
||||
|
||||
How to build your own Git server
|
||||
====================
|
||||
|
||||

|
||||
|
||||
Now we will learn how to build a Git server, and how to write custom Git hooks to trigger specific actions on certain events (such as notifications), and publishing your code to a website.
|
||||
|
||||
Up until now, the focus has been interacting with Git as a user. In this article I'll discuss the administration of Git, and the design of a flexible Git infrastructure. You might think it sounds like a euphemism for "advanced Git techniques" or "only read this if you're a super-nerd", but actually none of these tasks require advanced knowledge or any special training beyond an intermediate understanding of how Git works, and in some cases a little bit of knowledge about Linux.
|
||||
|
||||
### Shared Git server
|
||||
|
||||
Creating your own shared Git server is surprisingly simple, and in many cases well worth the trouble. Not only does it ensure that you always have access to your code, it also opens doors to stretching the reach of Git with extensions such as personal Git hooks, unlimited data storage, and continuous integration and deployment.
|
||||
|
||||
If you know how to use Git and SSH, then you already know how to create a Git server. The way Git is designed, the moment you create or clone a repository, you have already set up half the server. Then enable SSH access to the repository, and anyone with access can use your repo as the basis for a new clone.
|
||||
|
||||
However, that's a little ad hoc. With some planning a you can construct a well-designed Git server with about the same amount of effort, but with better scalability.
|
||||
|
||||
First things first: identify your users, both current and in the future. If you're the only user then no changes are necessary, but if you intend to invite contributors aboard, then you should allow for a dedicated shared system user for your developers.
|
||||
|
||||
Assuming that you have a server available (if not, that's not exactly a problem Git can help with, but CentOS on a Raspberry Pi 3 is a good start), then the first step is to enable SSH logins using only SSH key authorization. This is much stronger than password logins because it is immune to brute-force attacks, and disabling a user is as simple as deleting their key.
|
||||
|
||||
Once you have SSH key authorization enabled, create the gituser. This is a shared user for all of your authorized users:
|
||||
|
||||
```
|
||||
$ su -c 'adduser gituser'
|
||||
```
|
||||
|
||||
Then switch over to that user, and create an ~/.ssh framework with the appropriate permissions. This is important, because for your own protection SSH will default to failure if you set the permissions too liberally.
|
||||
|
||||
```
|
||||
$ su - gituser
|
||||
$ mkdir .ssh && chmod 700 .ssh
|
||||
$ touch .ssh/authorized_keys
|
||||
$ chmod 600 .ssh/authorized_keys
|
||||
```
|
||||
|
||||
The authorized_keys file holds the SSH public keys of all developers you give permission to work on your Git project. Your developers must create their own SSH key pairs and send you their public keys. Copy the public keys into the gituser's authorized_keys file. For instance, for a developer called Bob, run these commands:
|
||||
|
||||
```
|
||||
$ cat ~/path/to/id_rsa.bob.pub >> \
|
||||
/home/gituser/.ssh/authorized_keys
|
||||
```
|
||||
|
||||
As long as developer Bob has the private key that matches the public key he sent you, Bob can access the server as gituser.
|
||||
|
||||
However, you don't really want to give your developers access to your server, even if only as gituser. You only want to give them access to the Git repository. For this very reason, Git provides a limited shell called, appropriately, git-shell. Run these commands as root to add git-shell to your system, and then make it the default shell for your gituser:
|
||||
|
||||
```
|
||||
# grep git-shell /etc/shells || su -c \
|
||||
"echo `which git-shell` >> /etc/shells"
|
||||
# su -c 'usermod -s git-shell gituser'
|
||||
```
|
||||
|
||||
Now the gituser can only use SSH to push and pull Git repositories, and cannot access a login shell. You should add yourself to the corresponding group for the gituser, which in our example server is also gituser.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
# usermod -a -G gituser seth
|
||||
```
|
||||
|
||||
The only step remaining is to make a Git repository. Since no one is going to interact with it directly on the server (that is, you're not going to SSH to the server and work directly in this repository), make it a bare repository. If you want to use the repo on the server to get work done, you'll clone it from where it lives and work on it in your home directory.
|
||||
|
||||
Strictly speaking, you don't have to make this a bare repository; it would work as a normal repo. However, a bare repository has no *working tree* (that is, no branch is ever in a `checkout` state). This is important because remote users are not permitted to push to an active branch (how would you like it if you were working in a `dev` branch and suddenly someone pushed changes into your workspace?). Since a bare repo can have no active branch, that won't ever be an issue.
|
||||
|
||||
You can place this repository anywhere you please, just as long as the users and groups you want to grant permission to access it can do so. You do NOT want to store the directory in a user's home directory, for instance, because the permissions there are pretty strict, but in a common shared location, such as /opt or /usr/local/share.
|
||||
|
||||
Create a bare repository as root:
|
||||
|
||||
```
|
||||
# git init --bare /opt/jupiter.git
|
||||
# chown -R gituser:gituser /opt/jupiter.git
|
||||
# chmod -R 770 /opt/jupiter.git
|
||||
```
|
||||
|
||||
Now any user who is either authenticated as gituser or is in the gituser group can read from and write to the jupiter.git repository. Try it out on a local machine:
|
||||
|
||||
```
|
||||
$ git clone gituser@example.com:/opt/jupiter.git jupiter.clone
|
||||
Cloning into 'jupiter.clone'...
|
||||
Warning: you appear to have cloned an empty repository.
|
||||
```
|
||||
|
||||
Remember: developers MUST have their public SSH key entered into the authorized_keys file of gituser, or if they have accounts on the server (as you would), then they must be members of the gituser group.
|
||||
|
||||
### Git hooks
|
||||
|
||||
One of the nice things about running your own Git server is that it makes Git hooks available. Git hosting services sometimes provide a hook-like interface, but they don't give you true Git hooks with access to the file system. A Git hook is a script that gets executed at some point during a Git process; a hook can be executed when a repository is about to receive a commit, or after it has accepted a commit, or before it receives a push, or after a push, and so on.
|
||||
|
||||
It is a simple system: any executable script placed in the .git/hooks directory, using a standard naming scheme, is executed at the designated time. When a script should be executed is determined by the name; a pre-push script is executed before a push, a post-receive script is executed after a commit has been received, and so on. It's more or less self-documenting.
|
||||
|
||||
Scripts can be written in any language; if you can execute a language's hello world script on your system, then you can use that language to script a Git hook. By default, Git ships with some samples but does not have any enabled.
|
||||
|
||||
Want to see one in action? It's easy to get started. First, create a Git repository if you don't already have one:
|
||||
|
||||
```
|
||||
$ mkdir jupiter
|
||||
$ cd jupiter
|
||||
$ git init .
|
||||
```
|
||||
|
||||
Then write a "hello world" Git hook. Since I use tcsh at work for legacy support, I'll stick with that as my scripting language, but feel free to use your preferred language (Bash, Python, Ruby, Perl, Rust, Swift, Go) instead:
|
||||
|
||||
```
|
||||
$ echo "#\!/bin/tcsh" > .git/hooks/post-commit
|
||||
$ echo "echo 'POST-COMMIT SCRIPT TRIGGERED'" >> \
|
||||
~/jupiter/.git/hooks/post-commit
|
||||
$ chmod +x ~/jupiter/.git/hooks/post-commit
|
||||
```
|
||||
|
||||
Now test it out:
|
||||
|
||||
```
|
||||
$ echo "hello world" > foo.txt
|
||||
$ git add foo.txt
|
||||
$ git commit -m 'first commit'
|
||||
! POST-COMMIT SCRIPT TRIGGERED
|
||||
[master (root-commit) c8678e0] first commit
|
||||
1 file changed, 1 insertion(+)
|
||||
create mode 100644 foo.txt
|
||||
```
|
||||
|
||||
And there you have it: your first functioning Git hook.
|
||||
|
||||
### The famous push-to-web hook
|
||||
|
||||
A popular use of Git hooks is to automatically push changes to a live, in-production web server directory. It is a great way to ditch FTP, retain full version control of what is in production, and integrate and automate publication of content.
|
||||
|
||||
If done correctly, it works brilliantly and is, in a way, exactly how web publishing should have been done all along. It is that good. I don't know who came up with the idea initially, but the first I heard of it was from my Emacs- and Git- mentor, Bill von Hagen at IBM. His article remains the definitive introduction to the process: [Git changes the game of distributed Web development][1].
|
||||
|
||||
### Git variables
|
||||
|
||||
Each Git hook gets a different set of variables relevant to the Git action that triggered it. You may or may not need to use those variables; it depends on what you're writing. If all you want is a generic email alerting you that someone pushed something, then you don't need specifics, and probably don't even need to write the script as the existing samples may work for you. If you want to see the commit message and author of a commit in that email, then your script becomes more demanding.
|
||||
|
||||
Git hooks aren't run by the user directly, so figuring out how to gather important information can be confusing. In fact, a Git hook script is just like any other script, accepting arguments from stdin in the same way that BASH, Python, C++, and anything else does. The difference is, we aren't providing that input ourselves, so to use it you need to know what to expect.
|
||||
|
||||
Before writing a Git hook, look at the samples that Git provides in your project's .git/hooks directory. The pre-push.sample file, for instance, states in the comments section:
|
||||
|
||||
```
|
||||
# $1 -- Name of the remote to which the push is being done
|
||||
# $2 -- URL to which the push is being done
|
||||
# If pushing without using a named remote those arguments will be equal.
|
||||
#
|
||||
# Information about commit is supplied as lines
|
||||
# to the standard input in this form:
|
||||
# <local ref> <local sha1> <remote ref> <remote sha1>
|
||||
```
|
||||
|
||||
Not all samples are that clear, and documentation on what hook gets what variable is still a little sparse (unless you want to read the source code of Git), but if in doubt, you can learn a lot from the [trials of other users][2] online, or just write a basic script and echo $1, $2, $3, and so on.
|
||||
|
||||
### Branch detection example
|
||||
|
||||
I have found that a common requirement in production instances is a hook that triggers specific events based on what branch is being affected. Here is an example of how to tackle such a task.
|
||||
|
||||
First of all, Git hooks are not, themselves, version controlled. That is, Git doesn't track its own hooks because a Git hook is part of Git, not a part of your repository. For that reason, a Git hook that oversees commits and pushes probably make most sense living in a bare repository on your Git server, rather than as a part of your local repositories.
|
||||
|
||||
Let's write a hook that runs upon post-receive (that is, after a commit has been received). The first step is to identify the branch name:
|
||||
|
||||
```
|
||||
#!/bin/tcsh
|
||||
|
||||
foreach arg ( $< )
|
||||
set argv = ( $arg )
|
||||
set refname = $1
|
||||
end
|
||||
```
|
||||
|
||||
This for-loop reads in the first arg ($1) and then loops again to overwrite that with the value of the second ($2), and then again with the third ($3). There is a better way to do that in Bash: use the read command and put the values into an array. However, this being tcsh and the variable order being predictable, it's safe to hack through it.
|
||||
|
||||
When we have the refname of what is being commited, we can use Git to discover the human-readable name of the branch:
|
||||
|
||||
```
|
||||
set branch = `git rev-parse --symbolic --abbrev-ref $refname`
|
||||
echo $branch #DEBUG
|
||||
```
|
||||
|
||||
And then compare the branch name to the keywords we want to base the action on:
|
||||
|
||||
```
|
||||
if ( "$branch" == "master" ) then
|
||||
echo "Branch detected: master"
|
||||
git \
|
||||
--work-tree=/path/to/where/you/want/to/copy/stuff/to \
|
||||
checkout -f $branch || echo "master fail"
|
||||
else if ( "$branch" == "dev" ) then
|
||||
echo "Branch detected: dev"
|
||||
Git \
|
||||
--work-tree=/path/to/where/you/want/to/copy/stuff/to \
|
||||
checkout -f $branch || echo "dev fail"
|
||||
else
|
||||
echo "Your push was successful."
|
||||
echo "Private branch detected. No action triggered."
|
||||
endif
|
||||
```
|
||||
|
||||
Make the script executable:
|
||||
|
||||
```
|
||||
$ chmod +x ~/jupiter/.git/hooks/post-receive
|
||||
```
|
||||
|
||||
Now when a user commits to the server's master branch, the code is copied to an in-production directory, a commit to the dev branch get copied someplace else, and any other branch triggers no action.
|
||||
|
||||
It's just as simple to create a pre-commit script that, for instance, checks to see if someone is trying to push to a branch that they should not be pushing to, or to parse commit messages for approval strings, and so on.
|
||||
|
||||
Git hooks can get complex, and they can be confusing due to the level of abstraction that working through Git imposes, but they're a powerful system that allows you to design all manner of actions in your Git infrastructure. They're worth dabbling in, if only to become familiar with the process, and worth mastering if you're a serious Git user or full-time Git admin.
|
||||
|
||||
In our next and final article in this series, we will learn how to use Git to manage non-text binary blobs, such as audio and graphics files.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: http://www.ibm.com/developerworks/library/wa-git/
|
||||
[2]: https://www.analysisandsolutions.com/code/git-hooks-summary-cheat-sheet.htm
|
||||
@ -1,116 +0,0 @@
|
||||
echoma 翻译中
|
||||
|
||||
Accelerating Node.js applications with HTTP/2 Server Push
|
||||
=========================================================
|
||||
|
||||
In April, we [announced support for HTTP/2 Server][3] Push via the HTTP Link header. My coworker John has demonstrated how easy it is to [add Server Push to an example PHP application][4].
|
||||
|
||||

|
||||
|
||||
We wanted to make it easy to improve the performance of contemporary websites built with Node.js. we developed the netjet middleware to parse the generated HTML and automatically add the Link headers. When used with an example Express application you can see the headers being added:
|
||||
|
||||

|
||||
|
||||
We use Ghost to power this blog, so if your browser supports HTTP/2 you have already benefited from Server Push without realizing it! More on that below.
|
||||
|
||||
In netjet, we use the PostHTML project to parse the HTML with a custom plugin. Right now it is looking for images, scripts and external stylesheets. You can implement this same technique in other environments too.
|
||||
|
||||
Putting an HTML parser in the response stack has a downside: it will increase the page load latency (or "time to first byte"). In most cases, the added latency will be overshadowed by other parts of your application, such as database access. However, netjet includes an adjustable LRU cache keyed by ETag headers, allowing netjet to insert Link headers quickly on pages already parsed.
|
||||
|
||||
If you are designing a brand new application, however, you should consider storing metadata on embedded resources alongside your content, eliminating the HTML parse, and possible latency increase, entirely.
|
||||
|
||||
Netjet is compatible with any Node.js HTML framework that supports Express-like middleware. Getting started is as simple as adding netjet to the beginning of your middleware chain.
|
||||
|
||||
```
|
||||
var express = require('express');
|
||||
var netjet = require('netjet');
|
||||
var root = '/path/to/static/folder';
|
||||
|
||||
express()
|
||||
.use(netjet({
|
||||
cache: {
|
||||
max: 100
|
||||
}
|
||||
}))
|
||||
.use(express.static(root))
|
||||
.listen(1337);
|
||||
```
|
||||
|
||||
With a little more work, you can even use netjet without frameworks.
|
||||
|
||||
```
|
||||
var http = require('http');
|
||||
var netjet = require('netjet');
|
||||
|
||||
var port = 1337;
|
||||
var hostname = 'localhost';
|
||||
var preload = netjet({
|
||||
cache: {
|
||||
max: 100
|
||||
}
|
||||
});
|
||||
|
||||
var server = http.createServer(function (req, res) {
|
||||
preload(req, res, function () {
|
||||
res.statusCode = 200;
|
||||
res.setHeader('Content-Type', 'text/html');
|
||||
res.end('<!doctype html><h1>Hello World</h1>');
|
||||
});
|
||||
});
|
||||
|
||||
server.listen(port, hostname, function () {
|
||||
console.log('Server running at http://' + hostname + ':' + port+ '/');
|
||||
});
|
||||
```
|
||||
|
||||
See the [netjet documentation][1] for more information on the supported options.
|
||||
|
||||
### Seeing what’s pushed
|
||||
|
||||

|
||||
|
||||
Chrome's Developer Tools makes it easy to verify that your site is using Server Push. The Network tab shows pushed assets with "Push" included as part of the initiator.
|
||||
|
||||
Unfortunately, Firefox's Developers Tools don't yet directly expose if the resource pushed. You can, however, check for the cf-h2-pushed header in the page's response headers, which contains a list of resources that CloudFlare offered browsers over Server Push.
|
||||
|
||||
Contributions to improve netjet or the documentation are greatly appreciated. I'm excited to hear where people are using netjet.
|
||||
|
||||
### Ghost and Server Push
|
||||
|
||||
Ghost is one such exciting integration. With the aid of the Ghost team, I've integrated netjet, and it has been available as an opt-in beta since version 0.8.0.
|
||||
|
||||
If you are running a Ghost instance, you can enable Server Push by modifying the server's config.js file and add the preloadHeaders option to the production configuration block.
|
||||
|
||||
|
||||
```
|
||||
production: {
|
||||
url: 'https://my-ghost-blog.com',
|
||||
preloadHeaders: 100,
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
Ghost has put together [a support article][2] for Ghost(Pro) customers.
|
||||
|
||||
### Conclusion
|
||||
|
||||
With netjet, your Node.js applications can start to use browser preloading and, when used with CloudFlare, HTTP/2 Server Push today.
|
||||
|
||||
At CloudFlare, we're excited to make tools to help increase the performance of websites. If you find this interesting, we are hiring in Austin, Texas; Champaign, Illinois; London; San Francisco; and Singapore.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.cloudflare.com/accelerating-node-js-applications-with-http-2-server-push/?utm_source=nodeweekly&utm_medium=email
|
||||
|
||||
作者:[Terin Stock][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.cloudflare.com/author/terin-stock/
|
||||
[1]: https://www.npmjs.com/package/netjet
|
||||
[2]: http://support.ghost.org/preload-headers/
|
||||
[3]: https://www.cloudflare.com/http2/server-push/
|
||||
[4]: https://blog.cloudflare.com/using-http-2-server-push-with-php/
|
||||
@ -1,62 +0,0 @@
|
||||
LinuxBars Translating
|
||||
LinuxBars 翻译中
|
||||
|
||||
Baidu Takes FPGA Approach to Accelerating SQL at Scale
|
||||
===================
|
||||
|
||||

|
||||
|
||||
While much of the work at Baidu we have focused on this year has centered on the Chinese search giant’s [deep learning initiatives][1], many other critical, albeit less bleeding edge applications present true big data challenges.
|
||||
|
||||
As Baidu’s Jian Ouyang detailed this week at the Hot Chips conference, Baidu sits on over an exabyte of data, processes around 100 petabytes per day, updates 10 billion webpages daily, and handles over a petabyte of log updates every 24 hours. These numbers are on par with Google and as one might imagine, it takes a Google-like approach to problem solving at scale to get around potential bottlenecks.
|
||||
|
||||
Just as we have described Google looking for any way possible to beat Moore’s Law, Baidu is on the same quest. While the exciting, sexy machine learning work is fascinating, acceleration of the core mission-critical elements of the business is as well—because it has to be. As Ouyang notes, there is a widening gap between the company’s need to deliver top-end services based on their data and what CPUs are capable of delivering.
|
||||
|
||||

|
||||
|
||||
As for Baidu’s exascale problems, on the receiving end of all of this data are a range of frameworks and platforms for data analysis; from the company’s massive knowledge graph, multimedia tools, natural language processing frameworks, recommendation engines, and click stream analytics. In short, the big problem of big data is neatly represented here—a diverse array of applications matched with overwhelming data volumes.
|
||||
|
||||
When it comes to acceleration for large-scale data analytics at Baidu, there are several challenges. Ouyang says it is difficult to abstract the computing kernels to find a comprehensive approach. “The diversity of big data applications and variable computing types makes this a challenge. It is also difficult to integrate all of this into a distributed system because there are also variable platforms and program models (MapReduce, Spark, streaming, user defined, and so on). Further there is more variance in data types and storage formats.”
|
||||
|
||||
Despite these barriers, Ouyang says teams looked for the common thread. And as it turns out, that string that ties together many of their data-intensive jobs is good old SQL. “Around 40% of our data analysis jobs are already written in SQL and rewriting others to match it can be done.” Further, he says they have the benefit of using existing SQL system that mesh with existing frameworks like Hive, Spark SQL, and Impala. The natural thing to do was to look for SQL acceleration—and Baidu found no better hardware than an FPGA.
|
||||
|
||||

|
||||
|
||||
These boards, called processing elements (PE on coming slides), automatically handle key SQL functions as they come in. With that said, a disclaimer note here about what we were able to glean from the presentation. Exactly what the FPGA is talking to is a bit of a mystery and so by design. If Baidu is getting the kinds of speedups shown below in their benchmarks, this is competitive information. Still, we will share what was described. At its simplest, the FPGAs are running in the database and when it sees SQL queries coming it, the software the team designed ([and presented at Hot Chips two years ago][2] related to DNNs) kicks into gear.
|
||||
|
||||

|
||||
|
||||
One thing Ouyang did note about the performance of their accelerator is that their performance could have been higher but they were bandwidth limited with the FPGA. In the evaluation below, Baidu setup with a 12-core 2.0 Ghz Intel E26230 X2 sporting 128 GB of memory. The SDA had five processing elements (the 300 MHzFPGA boards seen above) each of which handles core functions (filter, sort, aggregate, join and group by.).
|
||||
|
||||
To make the SQL accelerator, Baidu picked apart the TPC-DS benchmark and created special engines, called processing elements, that accelerate the five key functions in that benchmark test. These include filter, sort, aggregate, join, and group by SQL functions. (And no, we are not going to put these in all caps to shout as SQL really does.) The SDA setup employs an offload model, with the accelerator card having multiple processing elements of varying kinds shaped into the FPGA logic, with the type of SQL function and the number per card shaped by the specific workload. As these queries are being performed on Baidu’s systems, the data for the queries is pushed to the accelerator card in columnar format (which is blazingly fast for queries) and through a unified SDA API and driver, the SQL work is pushed to the right processing elements and the SQL operations are accelerated.
|
||||
|
||||
The SDA architecture uses a data flow model, and functions not supported by the processing elements are pushed back to the database systems and run natively there. More than any other factor, the performance of the SQL accelerator card developed by Baidu is limited by the memory bandwidth of the FPGA card. The accelerator works across clusters of machines, by the way, but the precise mechanism of how data and SQL operations are parsed out to multiple machines was not disclosed by Baidu.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
We’re limited in some of the details Baidu was willing to share but these benchmark results are quite impressive, particularly for Terasort. We will follow up with Baidu after Hot Chips to see if we can get more detail about how this is hooked together and how to get around the memory bandwidth bottlenecks.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.nextplatform.com/2016/08/24/baidu-takes-fpga-approach-accelerating-big-sql/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[Nicole Hemsoth][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.nextplatform.com/author/nicole/
|
||||
[1]: http://www.nextplatform.com/?s=baidu+deep+learning
|
||||
[2]: http://www.hotchips.org/wp-content/uploads/hc_archives/hc26/HC26-12-day2-epub/HC26.12-5-FPGAs-epub/HC26.12.545-Soft-Def-Acc-Ouyang-baidu-v3--baidu-v4.pdf
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by ucasFL
|
||||
|
||||
Ohm: JavaScript Parser that Creates a Language in 200 Lines of Code
|
||||
===========
|
||||
|
||||
|
||||
@ -1,80 +0,0 @@
|
||||
QOWNNOTES IS A NOTE TAKING AND TODO LIST APP THAT INTEGRATES WITH OWNCLOUD
|
||||
===============
|
||||
|
||||
[QOwnNotes][1] is a free, open source note taking and todo list application available for Linux, Windows, and Mac.
|
||||
|
||||
The application saves your notes as plain-text files, and it features Markdown support and tight ownCloud integration.
|
||||
|
||||

|
||||
|
||||
What makes QOwnNotes stand out is its ownCloud integration (which is optional). Using the ownCloud Notes app, you are able to edit and search notes from the web, or from mobile devices (by using an app like [CloudNotes][2]).
|
||||
|
||||
Furthermore, connecting QOwnNotes with your ownCloud account allows you to share notes and access / restore previous versions (or trashed files) of your notes from the ownCloud server.
|
||||
|
||||
In the same way, QOwnNotes can also integrate with the ownCloud tasks or Tasks Plus apps.
|
||||
|
||||
In case you're not familiar with [ownCloud][3], this is a free software alternative to proprietary web services such as Dropbox, Google Drive, and others, which can be installed on your own server. It comes with a web interface that provides access to file management, calendar, image gallery, music player, document viewer, and much more. The developers also provide desktop sync clients, as well as mobile apps.
|
||||
|
||||
Since the notes are saved as plain text, they can be synchronized across devices using other cloud storage services, like Dropbox, Google Drive, and so on, but this is not done directly from within the application.
|
||||
|
||||
As a result, the features I mentioned above, like restoring previous note versions, are only available with ownCloud (although Dropbox, and others, do provide access to previous file revisions, but you won't be able to access this directly from QOwnNotes).
|
||||
|
||||
As for the QOwnNotes note taking features, the app supports Markdown (with a built-in Markdown preview mode), tagging notes, searching in tags and notes, adding links to notes, and inserting images:
|
||||
|
||||

|
||||
|
||||
Hierarchical note tagging and note subfolders are also supported.
|
||||
|
||||
The todo manager feature is pretty basic and could use some improvements, as it currently opens in a separate window, and it doesn't use the same editor as the notes, not allowing you to insert images, or use Markdown.
|
||||
|
||||

|
||||
|
||||
It does allow you to search your todo items, set item priority, add reminders, and show completed items. Also, todo items can be inserted into notes.
|
||||
|
||||
The application user interface is customizable, allowing you to increase or decrease the font size, toggle panes (Markdown preview, note edit and tag panes), and more. A distraction-free mode is also available:
|
||||
|
||||

|
||||
|
||||
From the application settings, you can enable the dark mode (this was buggy in my test under Ubuntu 16.04 - some toolbar icons were missing), change the toolbar icon size, fonts, and color scheme (light or dark):
|
||||
|
||||

|
||||
|
||||
Other QOwnNotes features include encryption support (notes can only be decrypted in QOwnNotes), customizable keyboard shortcuts, export notes to PDF or Markdown, customizable note saving interval, and more.
|
||||
|
||||
Check out the QOwnNotes [homepage][11] for a complete list of features.
|
||||
|
||||
|
||||
### Download QOwnNotes
|
||||
|
||||
|
||||
For how to install QownNotes, see its [installation][4] page (packages / repositories available for Debian, Ubuntu, Linux Mint, openSUSE, Fedora, Arch Linux, KaOS, Gentoo, Slakware, CentOS, as well as Mac OSX and Windows).
|
||||
|
||||
A QOwnNotes [snap][5] package is also available (in Ubuntu 16.04 and newer, you should be able to install it directly from Ubuntu Software).
|
||||
|
||||
To integrate QOwnNotes with ownCloud you'll need [ownCloud server][6], as well as [Notes][7], [QOwnNotesAPI][8], and [Tasks][9] or [Tasks Plus][10] ownCloud apps. These can be installed from the ownCloud web interface, without having to download anything manually.
|
||||
|
||||
Note that the QOenNotesAPI and Notes ownCloud apps are listed as experimental, so you'll need to enable experimental apps to be able to find and install them. This can be done from the ownCloud web interface, under Apps, by clicking on the settings icon in the lower left-hand side corner.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.webupd8.org/2016/09/qownnotes-is-note-taking-and-todo-list.html
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.webupd8.org/p/about.html
|
||||
[1]: http://www.qownnotes.org/
|
||||
[2]: http://peterandlinda.com/cloudnotes/
|
||||
[3]: https://owncloud.org/
|
||||
[11]: http://www.qownnotes.org/
|
||||
[4]: http://www.qownnotes.org/installation
|
||||
[5]: https://uappexplorer.com/app/qownnotes.pbek
|
||||
[6]: https://download.owncloud.org/download/repositories/stable/owncloud/
|
||||
[7]: https://github.com/owncloud/notes
|
||||
[8]: https://github.com/pbek/qownnotesapi
|
||||
[9]: https://apps.owncloud.com/content/show.php/Tasks?content=164356
|
||||
[10]: https://apps.owncloud.com/content/show.php/Tasks+Plus?content=170561
|
||||
@ -0,0 +1,101 @@
|
||||
几个小窍门帮你管理项目的问题追踪器
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
对于大多数开源项目来讲,问题追踪系统是至关重要的。虽然市面上有非常多的开源工具提供了这样的功能,但是大量项目还是选择了GitHub自带的问题追踪器(Issue Tracker)。
|
||||
|
||||
它结构简单,因此其他人可以非常轻松地参与进来,但这才刚刚开始。
|
||||
|
||||
如果没有适当的处理,你的代码仓库会挤满重复的问题单、模糊不明的特性需求单、混淆不清的bug报告单。项目维护者会被大量的组织内协调工作压得喘不过气来,新的贡献者也搞不清楚项目当前的重点工作是什么。
|
||||
|
||||
接下来,我们一起研究下,如何玩转GitHub的问题单。
|
||||
|
||||
### 问题单就是用户的故事
|
||||
|
||||
我的团队曾经和开源专家[Jono Bacon][1]做过一次对话,他是[The Art of Community][2]的作者、GitHub的战略顾问和前社区总监。他告诉我们,高质量的问题单是项目成功的关键。尽管有些人把问题单仅仅看作是一堆难题的列表,但是他认为这个难题列表是我们必须要时刻关注、完善管理并进行分类的。他还认为,给问题单打上标签的做法,会令人意想不到的提升我们对代码和社区的了解程度,也让我们更清楚问题的关键点在哪里。
|
||||
|
||||
“在提交问题单时,用户不太会有耐心或者有兴趣把问题的细节描述清楚。在这种情况下,你应当努力花最短的时间,尽量多的获取有用的信息。”,Jono Bacon说。
|
||||
|
||||
统一的问题单模板可以大大减轻项目维护者的负担,尤其是开源项目的维护者。我们发现,让用户讲故事的方法总是可以把问题描述的非常清楚。用户讲故事时需要说明“是谁,做了什么,为什么而做”,也就是:我是【何种用户】,为了【达到何种目的】,我要【做何种操作】。
|
||||
|
||||
实际操作起来,大概是这样的:
|
||||
|
||||
>我是一名顾客,我想付钱,所以我想创建个账户。
|
||||
|
||||
我们建议,问题单的标题始终使用这样的用户故事形式。你可以设置[问题单模板][3]来保证这点。
|
||||
|
||||

|
||||
> 问题单模板让特性需求单保持统一的形式
|
||||
|
||||
这个做法的核心点在于,问题单要被清晰的呈现给它涉及的每一个人:它要尽量简单的指明受众(或者说用户),操作(或者说任务),和收益(或者说目标)。你不需要拘泥于这个具体的模板,只要能把故事里的是什么事情或者是什么原因搞清楚,就达到目的了。
|
||||
|
||||
### 高质量的问题单
|
||||
|
||||
问题单的质量是参差不齐的,这一点任何一个开源软件的贡献者或维护者都能证实。具有良好格式的问题单所应具备的素质在[The Agile Samurai][4]有过概述。
|
||||
|
||||
问题单需要满足如下条件:
|
||||
|
||||
- 客户价值所在
|
||||
- 避免使用术语或晦涩的文字,就算不是专家也能看懂
|
||||
- 可以切分,也就是说我们可以一小步一小步的对最终价值进行交付
|
||||
- 尽量跟其他问题单没有瓜葛,这会降低我们在问题范围上的灵活性
|
||||
- 可以协商,也就说我们有好几种办法达到目标
|
||||
- 问题足够小,可以非常容易的评估出所需时间和资源
|
||||
- 可衡量,我们可以对结果进行测试
|
||||
|
||||
### 那其他的呢? 要有约束
|
||||
|
||||
如果一个问题单很难衡量,或者很难在短时间内完成,你也一样有办法搞定它。有些人把这种办法叫做”约束“。
|
||||
|
||||
例如,”这个软件要快“,这种问题单是不符合我们的故事模板的,而且是没办法协商的。多快才是快呢?这种模糊的需求没有达到”好问题单“的标准,但是如果你把一些概念进一步定义一下,例如”每个页面都需要在0.5秒内加载完“,那我们就能更轻松的解决它了。我们可以把”约束“看作是成功的标尺,或者是里程碑。每个团队都应该定期的对”约束“进行测试。
|
||||
|
||||
### 问题单里面有什么?
|
||||
|
||||
敏捷方法中,用户的故事里通常要包含验收指标或者标准。如果是在GitHub里,建议大家使用markdown的清单来概述完成这个问题单需要完成的任务。优先级越高的问题单应当包含更多的细节。
|
||||
|
||||
比如说,你打算提交一个问题单,关于网站的新版主页的。那这个问题单的子任务列表可能就是这样的:
|
||||
|
||||

|
||||
>使用markdown的清单把复杂问题拆分成多个部分
|
||||
|
||||
在必要的情况下,你还可以链接到其他问题单,那些问题单每个都是一个要完成的任务。(GitHub里做这个挺方便的)
|
||||
|
||||
将特性进行细粒度的拆分,这样更轻松的跟踪整体的进度和测试,要能更高频的发布有价值的代码。
|
||||
|
||||
一旦以问题单的形式收到数据,我们还可以用API更深入的了解软件的健康度。
|
||||
|
||||
”在统计问题单的类型和趋势时,GitHub的API可以发挥巨大作用“,Bacon告诉我们,”如果再做些数据挖掘工作,你就能发现代码里的问题点,谁是社区的活跃成员,或者其他有用的信息。“
|
||||
|
||||
有些问题单管理工具提供了API,通过API可以增加额外的信息,比如预估时间或者历史进度。
|
||||
|
||||
### 让大伙都上车
|
||||
|
||||
一旦你的团队决定使用某种问题单模板,你要想办法让所有人都按照模板来。代码仓库里的ReadMe.md其实也可以是项目的”How-to“文档。这个文档会描述清除这个项目是做什么的(最好是用可以搜索的语言),并且解释其他贡献者应当如何参与进来(比如提交需求单、bug报告、建议,或者直接贡献代码)
|
||||
|
||||

|
||||
>为新来的合作者在ReadMe文件里增加清晰的说明
|
||||
|
||||
ReadMe文件是提供”问题单指引“的完美场所。如果你希望特性需求单遵循”用户讲故事“的格式,那就把格式写在ReadMe里。如果你使用某种跟踪工具来管理待办事项,那就标记在ReadMe里,这样别人也能看到。
|
||||
|
||||
”问题单模板,合理的标签,如何提交问题单的文档,确保问题单被分类,所有的问题单都及时做出回复,这些对于开源项目都至关重要“,Bacon说。
|
||||
|
||||
记住一点:这不是为了完成工作而做的工作。这时让其他人更轻松的发现、了解、融入你的社区而设立的规则。
|
||||
|
||||
"关注社区的成长,不仅要关注参与开发者的的数量增长,也要关注那些在问题单上帮助我们的人,他们让问题单更加明确、保持更新,这是活跃沟通和高效解决问题的力量源泉",Bacon说。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/how-take-your-projects-github-issues-good-great
|
||||
|
||||
作者:[Matt Butler][a]
|
||||
译者:[echoma](https://github.com/echoma)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mattzenhub
|
||||
[1]: http://www.jonobacon.org/
|
||||
[2]: http://www.artofcommunityonline.org/
|
||||
[3]: https://help.github.com/articles/creating-an-issue-template-for-your-repository/
|
||||
[4]: https://www.amazon.ca/Agile-Samurai-Masters-Deliver-Software/dp/1934356581
|
||||
@ -1,71 +0,0 @@
|
||||
使用python 和asyncio编写在线多人游戏 - 第1部分
|
||||
===================================================================
|
||||
|
||||
你曾经把async和python关联起来过吗?在这里我将告诉你怎样做,而且在[working example][1]这个例子里面展示-一个流行的贪吃蛇游戏,这是为多人游戏而设计的。
|
||||
[Play game][2]
|
||||
|
||||
###1.简介
|
||||
|
||||
在技术和文化领域,大量的多人在线游戏毋庸置疑是我们这个世界的主流之一。同时,为一个MMO游戏写一个服务器一般和大量的预算与低水平的编程技术相关,在最近这几年,事情发生了很大的变化。基于动态语言的现代框架允许在稳健的硬件上面处理大量并发的用户连接。同时,HTML5 和 WebSockets 标准允许基于实时的图形游戏直接在web浏览器上创建客户端,而不需要任何的扩展。
|
||||
|
||||
对于创建可扩展非堵塞的服务器,Python可能不是最受欢迎的工具,尤其是和在这个领域最受欢迎的node.js相比。但是最近版本的python打算改变这种现状。[asyncio][3]的介绍和一个特别的[async/await][4] 语法使得异步代码看起来像常规的阻塞代码,这使得python成为一个值得信赖的异步编程语言。所以我将尝试利用这些新特点来创建一个多人在线游戏。
|
||||
|
||||
###2.异步
|
||||
一个游戏服务器应该处理最大数量的用户的并发连接和实时处理这些连接。一个典型的解决方案----创建线程,然而在这种情况下并不能解决这个问题。运行上千的线程需要CPU在它们之间不停的切换(这叫做上下文切换),这将开销非常大,效率很低下。更糟糕的是,因为,此外,它们会占用大量的内存。在python中,还有一个问题,python的解释器(CPython)并不是针对多线程设计的,它主要针对于单线程实现最大数量的行为。这就是为什么它使用GIL(global interpreter lock),一个不允许同时运行多线程python代码的架构,来防止共享物体的不可控用法。正常情况下当当前线程正在等待的时候,解释器转换到另一个线程,通常是一个I/O的响应(像一个服务器的响应一样)。这允许在你的应用中有非阻塞I/O,因为每一个操作仅仅堵塞一个线程而不是堵塞整个服务器。然而,这也使得通常的多线程变得无用,因为它不允许你并发执行python代码,即使是在多核心的cpu上。同时在单线程中拥有非阻塞IO是完全有可能的,因而消除了经常切换上下文的需要。
|
||||
|
||||
实际上,你可以用纯python代码来实现一个单线程的非阻塞IO。你所需要的只是标准的[select][5]模块,这个模块可以让你写一个事件循环来等待未阻塞的socket的io。然而,这个方法需要你在一个地方定义所有app的逻辑,不久之后,你的app就会变成非常复杂的状态机。有一些框架可以简化这个任务,比较流行的是[tornade][6] 和 [twisted][7]。他们被用来使用回调方法实现复杂的协议(这和node.js比较相似)。这个框架运行在他自己的事件循环中,这个事件在定义的事件上调用你的回调。并且,这或许是一些情况的解决方案,但是它仍然需要使用回调的方式编程,这使你的代码碎片化。和写同步代码并且并发执行多个副本相比,就像我们会在普通的线程上做一样。这为什么在单个线程上是不可能的呢?
|
||||
|
||||
这就是为什么microthread出现的原因。这个想法是为了在一个线程上并发执行任务。当你在一个任务中调用阻塞的方法时,有一个叫做"manager" (或者“scheduler”)的东西在执行事件循环。当有一些事件准备处理的时候,一个manager会让等这个事件的“任务”单元去执行,直到自己停了下来。然后执行完之后就返回那个管理器(manager)。
|
||||
|
||||
>Microthreads are also called lightweight threads or green threads (a term which came from Java world). Tasks which are running concurrently in pseudo-threads are called tasklets, greenlets or coroutines.(Microthreads 也会被称为lightweight threads 或者 green threads(java中的一个术语)。在伪线程中并发执行的任务叫做tasklets,greenlets或者coroutines).
|
||||
|
||||
microthreads的其中一种实现在python中叫做[Stackless Python][8]。这个被用在了一个叫[EVE online][9]的非常有名的在线游戏中,所以它变得非常有名。这个MMO游戏自称说在一个持久的宇宙中,有上千个玩家在做不同的活动,这些都是实时发生的。Stackless 是一个单独的python解释器,它代替了标准的栈调用并且直接控制流来减少上下文切换的开销。尽管这非常有效,这个解决方案不如使用标准解释器的“soft”库有名。像[eventlet][10]和[gevent][11] 的方式配备了标准的I / O库的补丁的I / O功能在内部事件循环执行。这使得将正常的阻塞代码转变成非阻塞的代码变得简单。这种方法的一个缺点是从代码看这并不明显,这被称为非阻塞。Python的新的版本介绍了本地协同程序作为生成器的高级形式。在Python 的3.4版本中,引入了asyncio库,这个库依赖于本地协同程序来提供单线程并发。但是在Python 3.5 协同程序变成了Python语言的一部分,使用新的关键字 async 和 await 来描述。这是一个简单的例子,这表明了使用asyncio来运行 并发任务。
|
||||
|
||||
```
|
||||
import asyncio
|
||||
|
||||
async def my_task(seconds):
|
||||
print("start sleeping for {} seconds".format(seconds))
|
||||
await asyncio.sleep(seconds)
|
||||
print("end sleeping for {} seconds".format(seconds))
|
||||
|
||||
all_tasks = asyncio.gather(my_task(1), my_task(2))
|
||||
loop = asyncio.get_event_loop()
|
||||
loop.run_until_complete(all_tasks)
|
||||
loop.close()
|
||||
```
|
||||
|
||||
我们启动了两个任务,一个睡眠1秒钟,另一个睡眠2秒钟,输出如下:
|
||||
|
||||
```
|
||||
start sleeping for 1 seconds
|
||||
start sleeping for 2 seconds
|
||||
end sleeping for 1 seconds
|
||||
end sleeping for 2 seconds
|
||||
```
|
||||
|
||||
正如你所看到的,协同程序不会阻塞彼此-----第二个任务在第一个结束之前启动。这发生的原因是asyncio.sleep是协同程序,它会返回一个调度器的执行直到时间过去。在下一节中,
|
||||
我们将会使用coroutine-based的任务来创建一个游戏循环。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[xinglianfly](https://github.com/xinglianfly)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: http://snakepit-game.com/
|
||||
[3]: https://docs.python.org/3/library/asyncio.html
|
||||
[4]: https://docs.python.org/3/whatsnew/3.5.html#whatsnew-pep-492
|
||||
[5]: https://docs.python.org/2/library/select.html
|
||||
[6]: http://www.tornadoweb.org/
|
||||
[7]: http://twistedmatrix.com/
|
||||
[8]: http://www.stackless.com/
|
||||
[9]: http://www.eveonline.com/
|
||||
[10]: http://eventlet.net/
|
||||
[11]: http://www.gevent.org/
|
||||
@ -0,0 +1,234 @@
|
||||
使用 Python 和 asyncio 编写在线多用人游戏 - 第2部分
|
||||
==================================================================
|
||||
|
||||

|
||||
|
||||
你曾经写过异步的 Python 程序吗?这里我将告诉你如果如何做,而且在接下来的部分用一个[实例][1] - 专为多玩家设计的、受欢迎的贪吃蛇游戏来演示。
|
||||
|
||||
介绍和理论部分参见第一部分[异步化[第1部分]][2]。
|
||||
|
||||
试玩游戏[3]。
|
||||
|
||||
### 3. 编写游戏循环主体
|
||||
|
||||
游戏循环是每一个游戏的核心。它持续地读取玩家的输入,更新游戏的状态,并且在屏幕上渲染游戏结果。在在线游戏中,游戏循环分为客户端和服务端两部分,所以一般有两个循环通过网络通信。通常客户端的角色是获取玩家输入,比如按键或者鼠标移动,将数据传输给服务端,然后接收需要渲染的数据。服务端处理来自玩家的所有数据,更新游戏的状态,执行渲染下一帧的必要计算,然后将结果传回客户端,例如游戏中对象的位置。如果没有可靠的理由,不混淆客户端和服务端的角色很重要。如果你在客户端执行游戏逻辑的计算,很容易就会和其它客户端失去同步,其实你的游戏也可以通过简单地传递客户端的数据来创建。
|
||||
|
||||
游戏循环的一次迭代称为一个嘀嗒。嘀嗒表示当前游戏循环的迭代已经结束,下一帧(或者多帧)的数据已经就绪。在后面的例子中,我们使用相同的客户端,使用 WebSocket 连接服务端。它执行一个简单的循环,将按键码发送给服务端,显示来自服务端的所有信息。[客户端代码戳这里][4]。
|
||||
|
||||
#### 例子3.1:基本游戏循环
|
||||
|
||||
[例子3.1源码][5]。
|
||||
|
||||
我们使用 [aiohttp][6] 库来创建游戏服务器。它可以通过 asyncio 创建网页服务器和客户端。这个库的一个优势是它同时支持普通 http 请求和 websocket。所以我们不用其他网页服务器来渲染游戏的 html 页面。
|
||||
|
||||
下面是启动服务器的方法:
|
||||
|
||||
```
|
||||
app = web.Application()
|
||||
app["sockets"] = []
|
||||
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
|
||||
app.router.add_route('GET', '/connect', wshandler)
|
||||
app.router.add_route('GET', '/', handle)
|
||||
|
||||
web.run_app(app)
|
||||
```
|
||||
|
||||
`web.run_app` 是创建服务主任务的快捷方法,通过他的 `run_forever()` 方法来执行 asyncio 事件循环。建议你查看这个方法的源码,弄清楚服务器到底是如何创建和结束的。
|
||||
|
||||
`app` 变量就是一个类似于字典的对象,它可以在所连接的客户端之间共享数据。我们使用它来存储连接套接字的列表。随后会用这个列表来给所有连接的客户端发送消息。`asyncio.ensure_future()` 调用会启动主游戏循环的任务,每隔2s向客户端发送嘀嗒消息。这个任务会在同样的 asyncio 事件循环中和网页服务器并行执行。
|
||||
|
||||
有两个网页请求处理器:提供 html 页面的处理器 (`handle`);`wshandler` 是主要的 websocket 服务器任务,处理和客户端之间的交互。在事件循环中,每一个连接的客户端都会创建一个新的 `wshandler`。
|
||||
|
||||
在启动的任务中,我们在 asyncio 的主事件循环中启动 worker 循环。任务之间的切换发生在他们任何一个使用 `await`语句来等待某个协程结束。例如 `asyncio.sleep` 仅仅是将程序执行权交给调度器指定的时间;`ws.receive` 等待 websocket 的消息,此时调度器可能切换到其它任务。
|
||||
|
||||
在浏览器中打开主页,连接上服务器后,试试随便按下键。他们的键值会从服务端返回,每隔2秒这个数字会被游戏循环发给所有客户端的嘀嗒消息覆盖。
|
||||
|
||||
我们刚刚创建了一个处理客户端按键的服务器,主游戏循环在后台做一些处理,周期性地同时更新所有的客户端。
|
||||
|
||||
#### 例子 3.2: 根据请求启动游戏
|
||||
|
||||
[例子 3.2的源码][7]
|
||||
|
||||
在前一个例子中,在服务器的生命周期内,游戏循环一直运行着。但是现实中,如果没有一个人连接服务器,空运行游戏循环通常是不合理的。而且,同一个服务器上可能有不同的’游戏房间‘。在这种假设下,每一个玩家创建一个游戏会话(多人游戏中的一个比赛或者大型多人游戏中的副本),这样其他用户可以加入其中。当游戏会话开始时,游戏循环才开始执行。
|
||||
|
||||
在这个例子中,我们使用一个全局标记来检测游戏循环是否在执行。当第一个用户发起连接时,启动它。最开始,游戏循环不在执行,标记设置为 `False`。游戏循环是通过客户端的处理方法启动的。
|
||||
|
||||
```
|
||||
if app["game_is_running"] == False:
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
当游戏的循环(`loop()`)运行时,这个标记设置为 `True`;当所有客户端都断开连接时,其又被设置为 `False`。
|
||||
|
||||
#### 例子 3.3:管理任务
|
||||
|
||||
[例子3.3源码][8]
|
||||
|
||||
这个例子用来解释如何和任务对象协同工作。我们把游戏循环的任务直接存储在游戏循环的全局字典中,代替标记的使用。在这个简单例子中并不一定是最优的,但是有时候你可能需要控制所有已经启动的任务。
|
||||
|
||||
```
|
||||
if app["game_loop"] is None or \
|
||||
app["game_loop"].cancelled():
|
||||
app["game_loop"] = asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
这里 `ensure_future()` 返回我们存放在全局字典中的任务对象,当所有用户都断开连接时,我们使用下面方式取消任务:
|
||||
|
||||
```
|
||||
app["game_loop"].cancel()
|
||||
```
|
||||
|
||||
这个 `cancel()` 调用将通知所有的调度器不要向这个协程提交任何执行任务,而且将它的状态设置为已取消,之后可以通过 `cancelled()` 方法来检查是否已取消。这里有一个值得一提的小注意点:当你持有一个任务对象的外部引用时,而这个任务执行中抛出了异常,这个异常不会抛出。取而代之的是为这个任务设置一个异常状态,可以通过 `exception()` 方法来检查是否出现了异常。这种悄无声息地失败在调试时不是很有用。所以,你可能想用抛出所有异常来取代这种做法。你可以对所有未完成的任务显示地调用 `result()` 来实现。可以通过如下的回调来实现:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result())
|
||||
```
|
||||
|
||||
如果我们打算在我们代码中取消任务,但是又不想产生 `CancelError` 异常,有一个检查 `cancelled` 状态的点:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result()
|
||||
if not t.cancelled() else None)
|
||||
```
|
||||
|
||||
注意仅当你持有任务对象的引用时必须要这么做。在前一个例子,所有的异常都是没有额外的回调,直接抛出所有异常。
|
||||
|
||||
#### 例子 3.4:等待多个事件
|
||||
|
||||
[例子 3.4 源码][9]
|
||||
|
||||
在许多场景下,在客户端的处理方法中你需要等待多个事件的发生。除了客户端的消息,你可能需要等待不同类型事件的发生。比如,如果你的游戏时间有限制,那么你可能需要等一个来自定时器的信号。或者你需要使用管道来等待来自其它进程的消息。亦或者是使用分布式消息系统网络中其它服务器的信息。
|
||||
|
||||
为了简单起见,这个例子是基于例子 3.1。但是这个例子中我们使用 `Condition` 对象来保证已连接客户端游戏循环的同步。我们不保存套接字的全局列表,因为只在方法中使用套接字。当游戏循环停止迭代时,我们使用 `Condition.notify_all()` 方法来通知所有的客户端。这个方法允许在 `asyncio` 的事件循环中使用发布/订阅的模式。
|
||||
|
||||
为了等待两个事件,首先我们使用 `ensure_future()` 来封装任务中可以等待的对象。
|
||||
|
||||
```
|
||||
if not recv_task:
|
||||
recv_task = asyncio.ensure_future(ws.receive())
|
||||
if not tick_task:
|
||||
await tick.acquire()
|
||||
tick_task = asyncio.ensure_future(tick.wait())
|
||||
```
|
||||
|
||||
在我们调用 `Condition.wait()` 之前,我们需要在背后获取一把锁。这就是我们为什么先调用 `tick.acquire()` 的原因。在调用 `tick.wait()` 之后,锁会被释放,这样其他的协程也可以使用它。但是当我们收到通知时,会重新获取锁,所以在收到通知后需要调用 `tick.release()` 来释放它。
|
||||
|
||||
我们使用 `asyncio.wait()` 协程来等待两个任务。
|
||||
|
||||
```
|
||||
done, pending = await asyncio.wait(
|
||||
[recv_task,
|
||||
tick_task],
|
||||
return_when=asyncio.FIRST_COMPLETED)
|
||||
```
|
||||
|
||||
程序会阻塞,直到列表中的任意一个任务完成。然后它返回两个列表:执行完成的任务列表和仍然在执行的任务列表。如果任务执行完成了,其对应变量赋值为 `None`,所以在下一个迭代时,它可能会被再次创建。
|
||||
|
||||
#### 例子 3.5: 结合多个线程
|
||||
|
||||
[例子 3.5 源码][10]
|
||||
|
||||
在这个例子中,我们结合 asyncio 循环和线程,在一个单独的线程中执行主游戏循环。我之前提到过,由于 `GIL` 的存在,Python 代码的真正并行执行是不可能的。所以使用其它线程来执行复杂计算并不是一个好主意。然而,在使用 `asyncio` 时结合线程有原因的:当我们使用的其它库不支持 `asyncio` 时。在主线程中调用这些库会阻塞循环的执行,所以异步使用他们的唯一方法是在不同的线程中使用他们。
|
||||
|
||||
在 asyncio 的循环和 `ThreadPoolExecutor` 中,我们通过 `run_in_executor()` 方法来执行游戏循环。注意 `game_loop()` 已经不再是一个协程了。它是一个由其它线程执行的函数。然而我们需要和主线程交互,在游戏事件到来时通知客户端。asyncio 本身不是线程安全的,它提供了可以在其它线程中执行你的代码的方法。普通函数有 `call_soon_threadsafe()`, 协程有 `run_coroutine_threadsafe()`。我们在 `notify()` 协程中增加代码通知客户端游戏的嘀嗒,然后通过另外一个线程执行主事件循环。
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
print("Game loop thread id {}".format(threading.get_ident()))
|
||||
async def notify():
|
||||
print("Notify thread id {}".format(threading.get_ident()))
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
while 1:
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
# blocking the thread
|
||||
sleep(1)
|
||||
# make sure the task has finished
|
||||
task.result()
|
||||
```
|
||||
|
||||
当你执行这个例子时,你会看到 "Notify thread id" 和 "Main thread id" 相等,因为 `notify()` 协程在主线程中执行。与此同时 `sleep(1)` 在另外一个线程中执行,因此它不会阻塞主事件循环。
|
||||
|
||||
#### 例子 3.6:多进程和扩展
|
||||
|
||||
[例子 3.6 源码][11]
|
||||
|
||||
单线程的服务器可能运行得很好,但是它只能使用一个CPU核。为了将服务扩展到多核,我们需要执行多个进程,每个进程执行各自的事件循环。这样我们需要在进程间交互信息或者共享游戏的数据。而且在一个游戏中经常需要进行复杂的计算,例如路径查找。这些任务有时候在一个游戏嘀嗒中没法快速完成。在协程中不推荐进行费时的计算,因为它会阻塞事件的处理。在这种情况下,将这个复杂任务交给并行执行地其它进程可能更合理。
|
||||
|
||||
最简单的使用多个核的方法是启动多个使用单核的服务器,就像之前的例子中一样,每个服务器占用不同的端口。你可以使用 `supervisord` 或者其它进程控制的系统。这个时候你需要一个负载均衡器,像 `HAProxy`,使得连接的客户端在多个进程间均匀分布。有一些适配 asyncio 消息系统和存储系统。例如:
|
||||
|
||||
- [aiomcache][12] for memcached client
|
||||
- [aiozmq][13] for zeroMQ
|
||||
- [aioredis][14] for Redis storage and pub/sub
|
||||
|
||||
你可以在 github 或者 pypi 上找到其它的安装包,大部分以 `aio` 开头。
|
||||
|
||||
使用网络服务在存储持久状态和交互信息时可能比较有效。但是如果你需要进行进程通信的实时处理,它的性能可能不足。此时,使用标准的 unix 管道可能更合适。asyncio 支持管道,这个仓库有个 [使用pipe且比较底层的例子][15]
|
||||
|
||||
在当前的例子中,我们使用 Python 的高层库 [multiprocessing][16] 来在不同的核上启动复杂的计算,使用 `multiprocessing.Queue` 来进行进程间的消息交互。不幸的是,当前的 multiprocessing 实现与 asyncio 不兼容。所以每一个阻塞方法的调用都会阻塞事件循环。但是此时线程正好可以起到帮助作用,因为如果在不同线程里面执行 multiprocessing 的代码,它就不会阻塞主线程。所有我们需要做的就是把所有进程间的通信放到另外一个线程中去。这个例子会解释如何使用这个方法。和上面的多线程例子非常类似,但是我们从线程中创建的是一个新的进程。
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
# coroutine to run in main thread
|
||||
async def notify():
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
queue = Queue()
|
||||
|
||||
# function to run in a different process
|
||||
def worker():
|
||||
while 1:
|
||||
print("doing heavy calculation in process {}".format(os.getpid()))
|
||||
sleep(1)
|
||||
queue.put("calculation result")
|
||||
|
||||
Process(target=worker).start()
|
||||
|
||||
while 1:
|
||||
# blocks this thread but not main thread with event loop
|
||||
result = queue.get()
|
||||
print("getting {} in process {}".format(result, os.getpid()))
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
task.result()
|
||||
```
|
||||
|
||||
这里我们在另外一个进程中运行 `worker()` 函数。它包括一个执行复杂计算的循环,然后把计算结果放到 `queue` 中,这个 `queue` 是 `multiprocessing.Queue` 的实例。然后我们就可以在另外一个线程的主事件循环中获取结果并通知客户端,就是例子 3.5 一样。这个例子已经非常简化了,它没有合理的结束进程。而且在真实的游戏中,我们可能需要另外一个队列来将数据传递给 `worker`。
|
||||
|
||||
有一个项目叫 [aioprocessing][17],它封装了 multiprocessing,使得它可以和 asyncio 兼容。但是实际上它只是和上面例子使用了完全一样的方法:从线程中创建进程。它并没有给你带来任何方便,除了它使用了简单的接口隐藏了后面的这些技巧。希望在 Python 的下一个版本中,我们能有一个基于协程且支持 asyncio 的 multiprocessing 库。
|
||||
|
||||
> 注意!如果你从主线程或者主进程中创建了一个不同的线程或者子进程来运行另外一个 asyncio 事件循环,你需要显示地使用 `asyncio.new_event_loop()` 来创建循环,不然的话可能程序不会正常工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[3]: http://snakepit-game.com/
|
||||
[4]: https://github.com/7WebPages/snakepit-game/blob/master/simple/index.html
|
||||
[5]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_basic.py
|
||||
[6]: http://aiohttp.readthedocs.org/
|
||||
[7]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_handler.py
|
||||
[8]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_global.py
|
||||
[9]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_wait.py
|
||||
[10]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_thread.py
|
||||
[11]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_process.py
|
||||
[12]: https://github.com/aio-libs/aiomcache
|
||||
[13]: https://github.com/aio-libs/aiozmq
|
||||
[14]: https://github.com/aio-libs/aioredis
|
||||
[15]: https://github.com/KeepSafe/aiohttp/blob/master/examples/mpsrv.py
|
||||
[16]: https://docs.python.org/3.5/library/multiprocessing.html
|
||||
[17]: https://github.com/dano/aioprocessing
|
||||
@ -0,0 +1,138 @@
|
||||
使用 Python 和 asyncio 来编写在线多人游戏 - 第3部分
|
||||
=================================================================
|
||||
|
||||

|
||||
|
||||
在这个系列中,我们基于多人游戏 [贪吃蛇][1] 来制作一个异步的 Python 程序。前一篇文章聚焦于[编写游戏循环][2]上,而本系列第1部分涵盖了 [异步化][3]。
|
||||
|
||||
代码戳[这里][4]
|
||||
|
||||
### 4. 制作一个完成的游戏
|
||||
|
||||

|
||||
|
||||
#### 4.1 工程概览
|
||||
#### 4.1 Project's overview
|
||||
|
||||
在此部分,我们将回顾一个完整在线游戏的设计。这是一个经典的贪吃蛇游戏,增加了多玩家支持。你可以自己在 (<http://snakepit-game.com>) 亲自试玩。源码在 Github的这个[仓库][5]。游戏包括下列文件:
|
||||
|
||||
- [server.py][6] - 处理主游戏循环和连接服务器。
|
||||
- [game.py][7] - 主要 `Game` 类。实现游戏的逻辑和游戏的大部分通信协议。
|
||||
- [player.py][8] - `Player` 类,包括每一个独立玩家的数据和蛇的表示。这个类负责获取玩家的输入以及根据输入相应地移动蛇。
|
||||
- [datatypes.py][9] - 基本数据结构。
|
||||
- [settings.py][10] - 游戏设置,在注释中有相关的说明。
|
||||
- [index.html][11] - 一个文件中包括客户端所有的 html 和 javascript代码。
|
||||
|
||||
#### 4.2 游戏循环内窥
|
||||
|
||||
多人的贪吃蛇游戏是个十分好的例子,因为它简单。所有的蛇在每个帧中移动到一个位置,而且帧之间的变化频率较低,这样你就可以一探一个游戏引擎到底是如何工作的。因为速度慢,对于玩家的按键不会立马响应。按键先是记录下来,然后在一个游戏迭代的最后计算下一帧时使用。
|
||||
|
||||
> 现代的动作游戏帧频率更高,而且服务端和客户端的帧频率不相等。客户端的帧频率通常依赖于客户端的硬件性能,而服务端的帧频率是固定的。一个客户端可能根据一个游戏嘀嗒的数据渲染多个帧。这样就可以创建平滑的动画,这个受限于客户端的性能。在这个例子中,服务器不仅传输物体的当前位置,也要传输他们的移动方向,速度和加速度。客户端的帧频率称之为 FPS(frames per second),服务端的帧频率称之为 TPS(ticks per second)。在这个贪吃蛇游戏的例子中,二者的值是相等的,客户端帧的展现和服务端的嘀嗒是同步的。
|
||||
|
||||
我们使用文本模式一样的游戏区域,事实上是 html 表格中的一个字符宽的小格。游戏中的所有对象都是通过表格中的不同颜色字符来表示。大部分时候,客户端将按键码发送至服务器,然后每个 tick 更新游戏区域。服务端一次更新包括需要更新字符的坐标和颜色。所以我们将所有游戏逻辑放置在服务端,只将需要渲染的数据发送给客户端。此外,我们通过替换网络上发送的数据来最小化游戏被破解的概率。
|
||||
|
||||
#### 4.3 它是如何运行的?
|
||||
|
||||
这个游戏中的服务端出于简化的目的,它和例子 3.2 类似。但是我们用一个所有服务器都可访问的 Game 对象来代替之前保存所有已连接 websocket 的全局列表。一个 Game 实例包括玩家的列表 (self._players),表示连接到此游戏的玩家,他们的个人数据和 websocket 对象。将所有游戏相关的数据存储在一个 Game 对象中,会方便我们增加多个游戏房间这个功能。这样的话,我们只要维护多个 Game 对象,每个游戏开始时创建相应的 Game 对象。
|
||||
|
||||
客户端和服务端的所有交互都是通过编码成 json 的消息来完成。来自客户端的消息仅包含玩家所按下键对应的编码。其它来自客户端消息使用如下格式:
|
||||
|
||||
```
|
||||
[command, arg1, arg2, ... argN ]
|
||||
```
|
||||
|
||||
来自服务端的消息以列表的形式发送,因为通常一次要发送多个消息 (大多数情况下是渲染的数据):
|
||||
|
||||
```
|
||||
[[command, arg1, arg2, ... argN ], ... ]
|
||||
```
|
||||
|
||||
在每次游戏循环迭代的最后会计算下一帧,并且将数据发送给所有的客户端。当然,每次不是发送完整的帧,而是发送两帧之间的变化列表。
|
||||
|
||||
注意玩家连接上服务器后不是立马加入游戏。连接开始时是观望者 (spectator) 模式,玩家可以观察其它玩家如何玩游戏。如果游戏已经开始或者上一个游戏会话已经在屏幕上显示 "game over" (游戏结束),用户此时可以按下 "Join" (参与),加入一个已经存在的游戏或者如果游戏不在运行(没有其它玩家)则创建一个新的游戏。后一种情况,游戏区域在开始前会被先清空。
|
||||
|
||||
游戏区域存储在 `Game._field` 这个属性中,它是二维的嵌套列表,用于内部存储游戏区域的状态。数组中的每一个元素表示区域中的一个小格,最终小格会被渲染成 html 表格的格子。如果它的类型是 Char,它是一个 `namedtuple` ,包括一个字符和颜色。在所有连接的客户端之间保证游戏区域的同步很重要,所以所有游戏区域的更新都必须依据发送到客户端的相应的信息。这是通过 `Game.apply_render()` 来实现的。它接受一个 `Draw` 对象的列表,其用于内部更新游戏区域和发送渲染消息给客户端。
|
||||
|
||||
我们使用 `namedtuple` 不仅因为它表示简单数据结构很方便,也因为用它生成 json 格式的消息时相对于字典更省空间。如果你在一个真实的游戏循环中需要发送完整的数据结构,建议先将它们序列化成一个简单的,更短的格式,甚至打包成二进制格式(例如 bson,而不是 json),以减少网络传输。
|
||||
|
||||
`ThePlayer` 对象包括用双端队列表示的蛇。这种数据类型和列表相似,但是在两端增加和删除元素时效率更高,用它来表示蛇很理想。它的主要方法是 `Player.render_move()`,它返回移动玩家蛇至下一个位置的渲染数据。一般来说它在新的位置渲染蛇的头部,移除上一帧中表示蛇的尾巴元素。如果蛇吃了一个数字,需要增长,在相应的多个帧中尾巴是不需要移动的。蛇的渲染数据在主要类的 `Game.next_frame()` 中使用,该方法中实现所有的游戏逻辑。这个方法渲染所有蛇的移动,检查每一个蛇前面的障碍物,而且生成数字和石头。每一个嘀嗒,`game_loop()` 都会直接调用它来生成下一帧。
|
||||
|
||||
如果蛇头前面有障碍物,在 `Game.next_frame()` 中会调用 `Game.game_over()`。所有的客户端都会收到那个蛇死掉的通知 (会调用 `player.render_game_over()` 方法将其变成石头),然后更新表中的分数排行榜。`Player` 的存活标记被置为 `False`,当渲染下一帧时,这个玩家会被跳过,除非他重新加入游戏。当没有蛇存活时,游戏区域会显示 "game over" (游戏结束) 。而且,主游戏循环会停止,设置 `game.running` 标记为 `False`。当某个玩家下次按下 "Join" (加入) 时,游戏区域会被清空。
|
||||
|
||||
在渲染游戏的每个下一帧时都会产生数字和石头,他们是由随机值决定的。产生数字或者石头的概率可以在 settings.py 中修改。注意数字是针对游戏区域每一个活的蛇产生的,所以蛇越多,产生的数字就越多,这样他们都有足够的食物来消费。
|
||||
|
||||
#### 4.4 网络协议
|
||||
#### 4.4 Network protocol
|
||||
|
||||
从客户端发送消息的列表:
|
||||
|
||||
Command | Parameters |Description
|
||||
:-- |:-- |:--
|
||||
new_player | [name] |Setting player's nickname
|
||||
join | |Player is joining the game
|
||||
|
||||
|
||||
从服务端发送消息的列表
|
||||
|
||||
Command | Parameters |Description
|
||||
:-- |:-- |:--
|
||||
handshake |[id] |Assign id to a player
|
||||
world |[[(char, color), ...], ...] |Initial play field (world) map
|
||||
reset_world | |Clean up world map, replacing all characters with spaces
|
||||
render |[x, y, char, color] |Display character at position
|
||||
p_joined |[id, name, color, score] |New player joined the game
|
||||
p_gameover |[id] |Game ended for a player
|
||||
p_score |[id, score] |Setting score for a player
|
||||
top_scores |[[name, score, color], ...] |Update top scores table
|
||||
|
||||
典型的消息交换顺序
|
||||
|
||||
Client -> Server |Server -> Client |Server -> All clients |Commentaries
|
||||
:-- |:-- |:-- |:--
|
||||
new_player | | |Name passed to server
|
||||
|handshake | |ID assigned
|
||||
|world | |Initial world map passed
|
||||
|top_scores | |Recent top scores table passed
|
||||
join | | |Player pressed "Join", game loop started
|
||||
| |reset_world |Command clients to clean up play field
|
||||
| |render, render, ... |First game tick, first frame rendered
|
||||
(key code) | | |Player pressed a key
|
||||
| |render, render, ... |Second frame rendered
|
||||
| |p_score |Snake has eaten a digit
|
||||
| |render, render, ... |Third frame rendered
|
||||
| | |... Repeat for a number of frames ...
|
||||
| |p_gameover |Snake died when trying to eat an obstacle
|
||||
| |top_scores |Updated top scores table (if updated)
|
||||
|
||||
### 5. 总结
|
||||
|
||||
说实话,我十分享受 Python 最新的异步特性。新的语法很友善,所以异步代码很容易阅读。可以明显看出哪些调用是非阻塞的,什么时候发生 greenthread 的切换。所以现在我可以宣称 Python 是异步编程的好工具。
|
||||
|
||||
SnakePit 在 7WebPages 团队中非常受欢迎。如果你在公司想休息一下,不要忘记给我们在 [Twitter][12] 或者 [Facebook][13] 留下反馈。
|
||||
|
||||
更多详见:
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-part-3/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-part-3/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
[3]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[4]: https://github.com/7WebPages/snakepit-game
|
||||
[5]: https://github.com/7WebPages/snakepit-game
|
||||
[6]: https://github.com/7WebPages/snakepit-game/blob/master/server.py
|
||||
[7]: https://github.com/7WebPages/snakepit-game/blob/master/game.py
|
||||
[8]: https://github.com/7WebPages/snakepit-game/blob/master/player.py
|
||||
[9]: https://github.com/7WebPages/snakepit-game/blob/master/datatypes.py
|
||||
[10]: https://github.com/7WebPages/snakepit-game/blob/master/settings.py
|
||||
[11]: https://github.com/7WebPages/snakepit-game/blob/master/index.html
|
||||
[12]: https://twitter.com/7WebPages
|
||||
[13]: https://www.facebook.com/7WebPages/
|
||||
@ -1,466 +0,0 @@
|
||||
从零构建一个简单的 Python 框架
|
||||
===================================
|
||||
|
||||
为什么你想要自己构建一个 web 框架呢?我想,原因有以下几点:
|
||||
|
||||
- 你有一个新奇的想法,觉得将会取代其他的框架
|
||||
- 你想要获得一些名气
|
||||
- 你的问题领域很独特,以至于现有的框架不太合适
|
||||
- 你对 web 框架是如何工作的很感兴趣,因为你想要成为一位更好的 web 开发者。
|
||||
|
||||
接下来的笔墨将着重于最后一点。这篇文章旨在通过对设计和实现过程一步一步的阐述告诉读者,我在完成一个小型的服务器和框架之后学到了什么。你可以在这个[代码仓库][1]中找到这个项目的完整代码。
|
||||
|
||||
我希望这篇文章可以鼓励更多的人来尝试,因为这确实很有趣。它让我知道了 web 应用是如何工作的,而且这比我想的要容易的多!
|
||||
|
||||
### 范围
|
||||
|
||||
框架可以处理请求-响应周期,身份认证,数据库访问,模板生成等。Web 开发者使用框架是因为,大多数的 web 应用拥有大量相同的功能,而对每个项目都重新实现同样的功能意义不大。
|
||||
|
||||
比较大的的框架如 Rails 和 Django 实现了高层次的抽象,开箱即用功能齐备。而实现所有的这些功能可能要花费数千小时,因此在这个项目上,我们重点完成其中的一小部分。在开始写代码前,我先列举一下所需的功能以及限制。
|
||||
|
||||
功能:
|
||||
|
||||
- 处理 HTTP 的 GET 和 POST 请求。你可以在[这篇 wiki][2] 中对 HTTP 有个大致的了解。
|
||||
- 实现异步操作(我喜欢 Python 3 的 asyncio 模块)。
|
||||
- 简单的路由逻辑以及参数捕获。
|
||||
- 像其他微型框架一样,提供一个简单的用户级 API 。
|
||||
- 支持身份认证,因为学会这个很酷啊(微笑)。
|
||||
|
||||
限制:
|
||||
|
||||
- 将只支持 HTTP 1.1 的一个小子集,不支持传输编码,http-auth,内容编码(gzip)以及[持久化连接][3]。
|
||||
- 不支持对响应的 MIME 判断 - 用户需要手动设置。
|
||||
- 不支持 WSGI - 仅能处理简单的 TCP 连接。
|
||||
- 不支持数据库。
|
||||
|
||||
我觉得一个小的用例可以让上述内容更加具体,也可以用来演示这个框架的 API:
|
||||
|
||||
```
|
||||
from diy_framework import App, Router
|
||||
from diy_framework.http_utils import Response
|
||||
|
||||
|
||||
# GET simple route
|
||||
async def home(r):
|
||||
rsp = Response()
|
||||
rsp.set_header('Content-Type', 'text/html')
|
||||
rsp.body = '<html><body><b>test</b></body></html>'
|
||||
return rsp
|
||||
|
||||
|
||||
# GET route + params
|
||||
async def welcome(r, name):
|
||||
return "Welcome {}".format(name)
|
||||
|
||||
# POST route + body param
|
||||
async def parse_form(r):
|
||||
if r.method == 'GET':
|
||||
return 'form'
|
||||
else:
|
||||
name = r.body.get('name', '')[0]
|
||||
password = r.body.get('password', '')[0]
|
||||
|
||||
return "{0}:{1}".format(name, password)
|
||||
|
||||
# application = router + http server
|
||||
router = Router()
|
||||
router.add_routes({
|
||||
r'/welcome/{name}': welcome,
|
||||
r'/': home,
|
||||
r'/login': parse_form,})
|
||||
|
||||
app = App(router)
|
||||
app.start_server()
|
||||
```
|
||||
'
|
||||
用户需要定义一些能够返回字符串或响应对象的异步函数,然后将这些函数与表示路由的字符串配对,最后通过一个函数(start_server)调用开始处理请求。
|
||||
|
||||
|
||||
完成设计之后,我将它抽象为几个我需要编码的部分:
|
||||
|
||||
- 接受 TCP 连接以及调度一个异步函数来处理这些连接的部分
|
||||
- 将原始文本解析成某种抽象容器的部分
|
||||
- 对于每个请求,用来决定调用哪个函数的部分
|
||||
- 将上述部分集中到一起,并为开发者提供一个简单接口的部分
|
||||
|
||||
我先编写一些测试,这些测试被用来描述每个部分的功能。几次重构后,整个设计被分成若干部分,每个部分之间是相对解耦的。这样就非常好,因为每个部分可以被独立地研究学习。以下是我上文列出的抽象的具体体现:
|
||||
|
||||
- 一个 HTTPServer 对象,需要一个 Router 对象和一个 http_parser 模块,并使用它们来初始化。
|
||||
- HTTPConnection 对象,每一个对象表示一个单独的客户端 HTTP 连接,并且处理其请求-响应周期:使用 http_parser 模块将收到的字节流解析为一个 Request 对象;使用一个 Router 实例寻找并调用正确的函数来生成一个响应; 最后将这个响应发送回客户端。
|
||||
- 一对 Request 和 Response 对象为用户提供了一种友好的方式,来处理实质上是字节流的字符串。用户不需要知道正确的消息格式和分隔符。
|
||||
- 一个 Router 对象包含路由:函数对。它提供一个添加配对的方法,还有一个根据 URL 路径查找相应函数的方法。
|
||||
- 最后,一个 App 对象。它包含配置信息,并使用它们实例化一个 HTTPServer 实例。
|
||||
|
||||
让我们从 HTTPConnection 开始来讲解各个部分。
|
||||
|
||||
### 模拟异步连接
|
||||
|
||||
为了满足约束条件,每一个 HTTP 请求都是一个单独的 TCP 连接。这使得处理请求的速度变慢了,因为建立多个 TCP 连接需要相对高的花销(DNS 查询,TCP 三次握手,[慢启动][4]的花销等等),不过这样更加容易模拟。对于这一任务,我选择相对高级的 [asyncio-stream][5] 模块,它建立在 asyncio 的传输和协议的基础之上。我强烈推荐阅读标准库中的相应代码!
|
||||
|
||||
一个 HTTPConnection 的实例能够处理多个任务。首先,它使用 asyncio.StreamReader 对象以增量的方式从 TCP 连接中读取数据,并存储在缓存中。每一个读取操作完成后,它会尝试解析缓存中的数据,并生成一个 Request 对象。一旦收到了完整的请求,它就生成一个回复,并通过 asyncio.StreamWriter 对象发送回客户端。当然,它还有两个任务:超时连接以及错误处理。
|
||||
|
||||
你可以在[这里][7]浏览这个类的完整代码。我将分别介绍代码的每一部分。为了简单起见,我移除了代码文档。
|
||||
|
||||
```
|
||||
class HTTPConnection(object):
|
||||
def init(self, http_server, reader, writer):
|
||||
self.router = http_server.router
|
||||
self.http_parser = http_server.http_parser
|
||||
self.loop = http_server.loop
|
||||
|
||||
self._reader = reader
|
||||
self._writer = writer
|
||||
self._buffer = bytearray()
|
||||
self._conn_timeout = None
|
||||
self.request = Request()
|
||||
```
|
||||
|
||||
这个 init 方法仅仅收集了一些对象以供后面使用。它存储了一个 router 对象,一个 http_parser 对象以及 loop 对象,分别用来生成响应,解析请求以及在事件循环中调度任务。
|
||||
|
||||
然后,它存储了代表一个 TCP 连接的读写对,和一个充当缓冲区的空[字节数组][8]。_conn_timeout 存储了一个 [asyncio.Handle][9] 的实例,用来管理超时逻辑。最后,它还存储了一个 Request 对象的实例。
|
||||
|
||||
下面的代码是用来接受和发送数据的核心功能:
|
||||
|
||||
```
|
||||
async def handle_request(self):
|
||||
try:
|
||||
while not self.request.finished and not self._reader.at_eof():
|
||||
data = await self._reader.read(1024)
|
||||
if data:
|
||||
self._reset_conn_timeout()
|
||||
await self.process_data(data)
|
||||
if self.request.finished:
|
||||
await self.reply()
|
||||
elif self._reader.at_eof():
|
||||
raise BadRequestException()
|
||||
except (NotFoundException,
|
||||
BadRequestException) as e:
|
||||
self.error_reply(e.code, body=Response.reason_phrases[e.code])
|
||||
except Exception as e:
|
||||
self.error_reply(500, body=Response.reason_phrases[500])
|
||||
|
||||
self.close_connection()
|
||||
```
|
||||
|
||||
所有内容被包含在 try-except 代码块中,在解析请求或响应期间抛出的异常可以被捕获,然后一个错误响应会发送回客户端。
|
||||
|
||||
在 while 循环中不断读取请求,直到解析器将 self.request.finished 设置为 True 或者客户端关闭连接,使得 self._reader_at_eof() 函数返回值为 True 为止。这段代码尝试在每次循环迭代中从 StreamReader 中读取数据,并通过调用 self.process_data(data) 函数以增量方式生成 self.request 。每次循环读取数据时,连接超时计数器被重值。
|
||||
|
||||
这儿有个错误,你发现了吗?稍后我们会再讨论这个。需要注意的是,这个循环可能会耗尽 CPU 资源,因为如果没有消息读取 self._reader.read() 函数将会返回一个空的字节对象。这就意味着循环将会不断运行,却什么也不做。一个可能的解决方法是,用非阻塞的方式等待一小段时间:await asyncio.sleep(0.1)。我们暂且不对它做优化。
|
||||
|
||||
还记得上一段我提到的那个错误吗?只有 StreamReader 读取数据时,self._reset_conn_timeout() 函数才会被调用。这就意味着,直到第一个字节到达时,timeout 才被初始化。如果有一个客户端建立了与服务器的连接却不发送任何数据,那就永远不会超时。这可能被用来消耗系统资源,或导致拒绝式服务攻击。修复方法就是在 init 函数中调用 self._reset_conn_timeout() 函数。
|
||||
|
||||
当请求接受完成或连接中断时,程序将运行到 if-else 代码块。这部分代码会判断解析器收到完整的数据后是否完成了解析。如果是,好,生成一个回复并发送回客户端。如果不是,那么请求信息可能有错误,抛出一个异常!最后,我们调用 self.close_connection 执行清理工作。
|
||||
|
||||
解析请求的部分在 self.process_data 方法中。这个方法非常简短,也易于测试:
|
||||
|
||||
```
|
||||
async def process_data(self, data):
|
||||
self._buffer.extend(data)
|
||||
|
||||
self._buffer = self.http_parser.parse_into(
|
||||
self.request, self._buffer)
|
||||
```
|
||||
|
||||
每一次调用都将数据累积到 self._buffer 中,然后试着用 self.http_parser 来解析已经收集的数据。这里需要指出的是,这段代码展示了一种称为[依赖注入][10]的模式。如果你还记得 init 函数的话,应该知道我们传入了一个包含 http_parser 的 http_server 对象。在这个例子里,http_parser 对象是 diy_framework 包中的一个模块。不过它也可以是任何含有 parse_into 函数的类。这个 parse_into 函数接受一个 Request 对象以及字节数组作为参数。这很有用,原因有二。一是,这意味着这段代码更易扩展。如果有人想通过一个不同的解析器来使用 HTTPConnection,没问题,只需将它作为参数传入即可。二是,这使得测试更加容易,因为 http_parser 不是硬编码的,所以使用虚假数据或者 [mock][11] 对象来替代是很容易的。
|
||||
|
||||
下一段有趣的部分就是 reply 方法了:
|
||||
|
||||
```
|
||||
async def reply(self):
|
||||
request = self.request
|
||||
handler = self.router.get_handler(request.path)
|
||||
|
||||
response = await handler.handle(request)
|
||||
|
||||
if not isinstance(response, Response):
|
||||
response = Response(code=200, body=response)
|
||||
|
||||
self._writer.write(response.to_bytes())
|
||||
await self._writer.drain()
|
||||
```
|
||||
|
||||
这里,一个 HTTPConnection 的实例使用了 HTTPServer 中的路由对象来得到一个生成响应的对象。一个路由可以是任何一个拥有 get_handler 方法的对象,这个方法接收一个字符串作为参数,返回一个可调用的对象或者抛出 NotFoundException 异常。而这个可调用的对象被用来处理请求以及生成响应。处理程序由框架的使用者编写,如上文所说的那样,应该返回字符串或者 Response 对象。Response 对象提供了一个友好的接口,因此这个简单的 if 语句保证了无论处理程序返回什么,代码最终都得到一个统一的 Response 对象。
|
||||
|
||||
接下来,赋值给 self._writer 的 StreamWriter 实例被调用,将字节字符串发送回客户端。函数返回前,程序在 self._writer.drain() 处等待,以确保所有的数据被发送给客户端。只要缓存中还有未发送的数据,self._writer.close() 方法就不会执行。
|
||||
|
||||
HTTPConnection 类还有两个更加有趣的部分:一个用于关闭连接的方法,以及一组用来处理超时机制的方法。首先,关闭一条连接由下面这个小函数完成:
|
||||
|
||||
```
|
||||
def close_connection(self):
|
||||
self._cancel_conn_timeout()
|
||||
self._writer.close()
|
||||
```
|
||||
|
||||
每当一条连接将被关闭时,这段代码首先取消超时,然后把连接从事件循环中清除。
|
||||
|
||||
超时框架由三个有关的函数组成:第一个函数在超时后给客户端发送错误消息并关闭连接; 第二个函数取消当前的超时; 第三个函数调度超时功能。前两个函数比较简单,我将详细解释第三个函数 _reset_cpmm_timeout() 。
|
||||
|
||||
```
|
||||
def _conn_timeout_close(self):
|
||||
self.error_reply(500, 'timeout')
|
||||
self.close_connection()
|
||||
|
||||
def _cancel_conn_timeout(self):
|
||||
if self._conn_timeout:
|
||||
self._conn_timeout.cancel()
|
||||
|
||||
def _reset_conn_timeout(self, timeout=TIMEOUT):
|
||||
self._cancel_conn_timeout()
|
||||
self._conn_timeout = self.loop.call_later(
|
||||
timeout, self._conn_timeout_close)
|
||||
```
|
||||
|
||||
每当 _reset_conn_timeout 函数被调用时,它会先取消之前所有赋值给 self._conn_timeout 的 asyncio.Handle 对象。然后,使用 BaseEventLoop.call_later 函数让 _conn_timeout_close 函数在超时数秒后执行。如果你还记得 handle_request 函数的内容,就知道每当接收到数据时,这个函数就会被调用。这就取消了当前的超时并且重新安排 _conn_timeout_close 函数在超时数秒后执行。只要接收到数据,这个循环就会不断地重置超时回调。如果在超时时间内没有接收到数据,最后函数 _conn_timeout_close 就会被调用。
|
||||
|
||||
### 创建连接
|
||||
|
||||
我们需要创建 HTTPConnection 对象,并且正确地使用它们。这一任务由 HTTPServer 类完成。HTTPServer 类是一个简单的容器,可以存储着一些配置信息(解析器,路由和事件循环实例),并使用这些配置来创建 HTTPConnection 实例:
|
||||
|
||||
```
|
||||
class HTTPServer(object):
|
||||
def init(self, router, http_parser, loop):
|
||||
self.router = router
|
||||
self.http_parser = http_parser
|
||||
self.loop = loop
|
||||
|
||||
async def handle_connection(self, reader, writer):
|
||||
connection = HTTPConnection(self, reader, writer)
|
||||
asyncio.ensure_future(connection.handle_request(), loop=self.loop)
|
||||
```
|
||||
|
||||
HTTPServer 的每一个实例能够监听一个端口。它有一个 handle_connection 的异步方法来创建 HTTPConnection 的实例,并安排它们在事件循环中运行。这个方法被传递给 [asyncio.start_server][12] 作为一个回调函数。也就是说,每当一个 TCP 连接初始化时,它就会被调用。
|
||||
|
||||
```
|
||||
self._server = HTTPServer(self.router, self.http_parser, self.loop)
|
||||
self._connection_handler = asyncio.start_server(
|
||||
self._server.handle_connection,
|
||||
host=self.host,
|
||||
port=self.port,
|
||||
reuse_address=True,
|
||||
reuse_port=True,
|
||||
loop=self.loop)
|
||||
```
|
||||
|
||||
这就是整个应用程序工作原理的核心:asyncio.start_server 接受 TCP 连接,然后在预配置的 HTTPServer 对象上调用一个方法。这个方法将处理一条 TCP 连接的所有逻辑:读取,解析,生成响应并发送回客户端,以及关闭连接。它的重点是 IO 逻辑,解析和生成响应。
|
||||
|
||||
讲解了核心的 IO 部分,让我们继续。
|
||||
|
||||
### 解析请求
|
||||
|
||||
这个微型框架的使用者被宠坏了,不愿意和字节打交道。它们想要一个更高层次的抽象 - 一种更加简单的方法来处理请求。这个微型框架就包含了一个简单的 HTTP 解析器,能够将字节流转化为 Request 对象。
|
||||
|
||||
这些 Request 对象是像这样的容器:
|
||||
|
||||
```
|
||||
class Request(object):
|
||||
def init(self):
|
||||
self.method = None
|
||||
self.path = None
|
||||
self.query_params = {}
|
||||
self.path_params = {}
|
||||
self.headers = {}
|
||||
self.body = None
|
||||
self.body_raw = None
|
||||
self.finished = False
|
||||
```
|
||||
|
||||
它包含了所有需要的数据,可以用一种容易理解的方法从客户端接受数据。哦,不包括 cookie ,它对身份认证是非常重要的,我会将它留在第二部分。
|
||||
|
||||
每一个 HTTP 请求都包含了一些必需的内容,如请求路径和请求方法。它们也包含了一些可选的内容,如请求体,请求头,或是 URL 参数。随着 REST 的流行,除了 URL 参数,URL 本身会包含一些信息。比如,"/user/1/edit" 包含了用户的 id 。
|
||||
|
||||
一个请求的每个部分都必须被识别,解析,并正确地赋值给 Request 对象的对应属性。HTTP/1.1 是一个文本协议,这简化了很多。(HTTP/2 是一个二进制协议,这又是另一种乐趣了)
|
||||
|
||||
The http_parser module is a group of functions inside because the parser does not need to keep track of state. Instead, the calling code has to manage a Request object and pass it into the parse_into function along with a bytearray containing the raw bytes of a request. To this end, the parser modifies both the request object as well as the bytearray buffer passed to it. The request object gets fuller and fuller while the bytearray buffer gets emptier and emptier.
|
||||
|
||||
解析器不需要跟踪状态,因此 http_parser 模块其实就是一组函数。调用函数需要用到 Request 对象,并将它连同一个包含原始请求信息的字节数组传递给 parse_into 函数。然后解析器会修改 request 对象以及充当缓存的字节数组。字节数组的信息被逐渐地解析到 request 对象中。
|
||||
|
||||
http_parser 模块的核心功能就是下面这个 parse_into 函数:
|
||||
|
||||
```
|
||||
def parse_into(request, buffer):
|
||||
_buffer = buffer[:]
|
||||
if not request.method and can_parse_request_line(_buffer):
|
||||
(request.method, request.path,
|
||||
request.query_params) = parse_request_line(_buffer)
|
||||
remove_request_line(_buffer)
|
||||
|
||||
if not request.headers and can_parse_headers(_buffer):
|
||||
request.headers = parse_headers(_buffer)
|
||||
if not has_body(request.headers):
|
||||
request.finished = True
|
||||
|
||||
remove_intro(_buffer)
|
||||
|
||||
if not request.finished and can_parse_body(request.headers, _buffer):
|
||||
request.body_raw, request.body = parse_body(request.headers, _buffer)
|
||||
clear_buffer(_buffer)
|
||||
request.finished = True
|
||||
return _buffer
|
||||
```
|
||||
|
||||
从上面的代码中可以看到,我把解析的过程分为三个部分:解析请求行(请求行有这样的格式:GET /resource HTTP/1.1),解析请求头以及解析请求体。
|
||||
|
||||
请求行包含了 HTTP 请求方法以及 URL 地址。而 URL 地址则包含了更多的信息:路径,url 参数和开发者自定义的 url 参数。解析请求方法和 URL 还是很容易的 - 合适地分割字符串就好了。函数 urlparse.parse 可以用来解析 URL 参数。开发者自定义的 URL 参数可以通过正则表达式来解析。
|
||||
|
||||
接下来是 HTTP 头部。它们是一行行由键值对组成的简单文本。问题在于,可能有多个 HTTP 头有相同的名字,却有不同的值。一个值得关注的 HTTP 头部是 Content-Length,它描述了请求体的字节长度(仅仅是请求体)。这对于决定是否解析请求体有很重要的作用。
|
||||
|
||||
最后,解析器根据 HTTP 方法和头部来决定是否解析请求体。
|
||||
|
||||
### 路由!
|
||||
|
||||
在某种意义上,路由就像是连接框架和用户的桥梁,用户用合适的方法创建 Router 对象并为其设置路径/函数对,然后将它赋值给 App 对象。而 App 对象依次调用 get_handler 函数生成相应的回调函数。简单来说,路由就负责两件事,一是存储路径/函数对,二是返回需要的路径/函数对
|
||||
|
||||
Router 类中有两个允许开发者添加路由的方法,分别是 add_routes 和 add_route。因为 add_routes 就是 add_route 函数的一层封装,我们将主要讲解 add_route 函数:
|
||||
|
||||
```
|
||||
def add_route(self, path, handler):
|
||||
compiled_route = self.class.build_route_regexp(path)
|
||||
if compiled_route not in self.routes:
|
||||
self.routes[compiled_route] = handler
|
||||
else:
|
||||
raise DuplicateRoute
|
||||
```
|
||||
|
||||
首先,这个函数使用 Router.build_router_regexp 的类方法,将一条路由规则(如 '/cars/{id}' 这样的字符串),“编译”到一个已编译的正则表达式对象。这些已编译的正则表达式用来匹配请求路径,以及解析开发者自定义的 URL 参数。如果存在一个相同的路由,程序就会抛出一个异常。最后,这个路由/处理程序对被添加到一个简单的字典(self.routes)中。
|
||||
|
||||
下面展示 Router 是如何“编译”路由的:
|
||||
|
||||
```
|
||||
@classmethod
|
||||
def build_route_regexp(cls, regexp_str):
|
||||
"""
|
||||
Turns a string into a compiled regular expression. Parses '{}' into
|
||||
named groups ie. '/path/{variable}' is turned into
|
||||
'/path/(?P<variable>[a-zA-Z0-9_-]+)'.
|
||||
|
||||
:param regexp_str: a string representing a URL path.
|
||||
:return: a compiled regular expression.
|
||||
"""
|
||||
def named_groups(matchobj):
|
||||
return '(?P<{0}>[a-zA-Z0-9_-]+)'.format(matchobj.group(1))
|
||||
|
||||
re_str = re.sub(r'{([a-zA-Z0-9_-]+)}', named_groups, regexp_str)
|
||||
re_str = ''.join(('^', re_str, '$',))
|
||||
return re.compile(re_str)
|
||||
```
|
||||
|
||||
The method uses regular expressions to substitute all occurrences of "{variable}" with named regexp groups: "(?P<variable>...)". Then it adds the ^ and $ regexp signifiers at the beginning and end of the resulting string, and finally compiles regexp object out of it.
|
||||
|
||||
这个方法使用正则表达式将所有出现的 "{variable}" 替换为 "(?P<variable>)"。然后在字符串头尾分别添加 ^ 和 $ 标记,最后编译正则表达式对象。
|
||||
|
||||
完成了路由存储仅成功了一半,下面是如何得到路由对应的函数:
|
||||
|
||||
```
|
||||
def get_handler(self, path):
|
||||
logger.debug('Getting handler for: {0}'.format(path))
|
||||
for route, handler in self.routes.items():
|
||||
path_params = self.class.match_path(route, path)
|
||||
if path_params is not None:
|
||||
logger.debug('Got handler for: {0}'.format(path))
|
||||
wrapped_handler = HandlerWrapper(handler, path_params)
|
||||
return wrapped_handler
|
||||
|
||||
raise NotFoundException()
|
||||
```
|
||||
|
||||
一旦 App 对象获得一个 Request 对象,也就获得了 URL 的路径部分(如 /users/15/edit)。然后,我们需要匹配函数来生成一个响应或者 404 错误。get_handler 函数将路径作为参数,循环遍历路由,对每条路由调用 Router.match_path 类方法检查是否有已编译的正则对象与这个请求路径匹配。如果存在,我们就调用 HandleWrapper 来包装路由对应的函数。path_params 字典包含了路径变量(如 '/users/15/edit' 中的 '15'),若路由没有指定变量,字典就为空。最后,我们将包装好的函数返回给 App 对象。
|
||||
|
||||
如果遍历了所有的路由都找不到与路径匹配的,函数就会抛出 NotFoundException 异常。
|
||||
|
||||
这个 Route.match 类方法挺简单:
|
||||
|
||||
```
|
||||
def match_path(cls, route, path):
|
||||
match = route.match(path)
|
||||
try:
|
||||
return match.groupdict()
|
||||
except AttributeError:
|
||||
return None
|
||||
```
|
||||
|
||||
它使用正则对象的 match 方法来检查路由是否与路径匹配。若果不匹配,则返回 None 。
|
||||
|
||||
最后,我们有 HandleWraapper 类。它的唯一任务就是封装一个异步函数,存储 path_params 字典,并通过 handle 方法对外提供一个统一的接口。
|
||||
|
||||
```
|
||||
class HandlerWrapper(object):
|
||||
def init(self, handler, path_params):
|
||||
self.handler = handler
|
||||
self.path_params = path_params
|
||||
self.request = None
|
||||
|
||||
async def handle(self, request):
|
||||
return await self.handler(request, **self.path_params)
|
||||
```
|
||||
|
||||
### 合并到一起
|
||||
|
||||
框架的最后部分就是用 App 类把所有的部分联系起来。
|
||||
|
||||
App 类用于集中所有的配置细节。一个 App 对象通过其 start_server 方法,使用一些配置数据创建一个 HTTPServer 的实例,然后将它传递给 asyncio.start_server 函数。asyncio.start_server 函数会对每一个 TCP 连接调用 HTTPServer 对象的 handle_connection 方法。
|
||||
|
||||
```
|
||||
def start_server(self):
|
||||
if not self._server:
|
||||
self.loop = asyncio.get_event_loop()
|
||||
self._server = HTTPServer(self.router, self.http_parser, self.loop)
|
||||
self._connection_handler = asyncio.start_server(
|
||||
self._server.handle_connection,
|
||||
host=self.host,
|
||||
port=self.port,
|
||||
reuse_address=True,
|
||||
reuse_port=True,
|
||||
loop=self.loop)
|
||||
|
||||
logger.info('Starting server on {0}:{1}'.format(
|
||||
self.host, self.port))
|
||||
self.loop.run_until_complete(self._connection_handler)
|
||||
|
||||
try:
|
||||
self.loop.run_forever()
|
||||
except KeyboardInterrupt:
|
||||
logger.info('Got signal, killing server')
|
||||
except DiyFrameworkException as e:
|
||||
logger.error('Critical framework failure:')
|
||||
logger.error(e.traceback)
|
||||
finally:
|
||||
self.loop.close()
|
||||
else:
|
||||
logger.info('Server already started - {0}'.format(self))
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
如果你查看源码,就会发现所有的代码仅 320 余行(包括测试代码共 540 余行)。这么少的代码实现了这么多的功能,让我有点惊讶。这个框架没有提供模板,身份认证以及数据库访问等功能(这些内容也很有趣哦)。这也让我知道,像 Django 和 Tornado 这样的框架是如何工作的,而且我能够快速地调试它们了。
|
||||
|
||||
这也是我按照测试驱动开发完成的第一个项目,整个过程有趣而有意义。先编写测试用例迫使我思考设计和架构,而不仅仅是把代码放到一起,让它们可以运行。不要误解我的意思,有很多时候,后者的方式更好。不过如果你想给确保这些不怎么维护的代码在之后的几周甚至几个月依然工作,那么测试驱动开发正是你需要的。
|
||||
|
||||
我研究了下[整洁架构][13]以及依赖注入模式,这些充分体现在 Router 类是如何作为一个更高层次的抽象的。Router 类是比较接近核心的,像 http_parser 和 App 的内容比较边缘化,因为它们只是完成了极小的字符串和字节流,或是中层 IO 的工作。测试驱动开发迫使我独立思考每个小部分,这使我问自己这样的问题:方法调用的组合是否易于理解?类名是否准确地反映了我正在解决的问题?我的代码中是否很容易区分出不同的抽象层?
|
||||
|
||||
来吧,写个小框架,真的很有趣:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://mattscodecave.com/posts/simple-python-framework-from-scratch.html
|
||||
|
||||
作者:[Matt][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://mattscodecave.com/hire-me.html
|
||||
[1]: https://github.com/sirMackk/diy_framework
|
||||
[2]:https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
|
||||
[3]: https://en.wikipedia.org/wiki/HTTP_persistent_connection
|
||||
[4]: https://en.wikipedia.org/wiki/TCP_congestion-avoidance_algorithm#Slow_start
|
||||
[5]: https://docs.python.org/3/library/asyncio-stream.html
|
||||
[6]: https://docs.python.org/3/library/asyncio-protocol.html
|
||||
[7]: https://github.com/sirMackk/diy_framework/blob/88968e6b30e59504251c0c7cd80abe88f51adb79/diy_framework/http_server.py#L46
|
||||
[8]: https://docs.python.org/3/library/functions.html#bytearray
|
||||
[9]: https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.Handle
|
||||
[10]: https://en.wikipedia.org/wiki/Dependency_injection
|
||||
[11]: https://docs.python.org/3/library/unittest.mock.html
|
||||
[12]: https://docs.python.org/3/library/asyncio-stream.html#asyncio.start_server
|
||||
[13]: https://blog.8thlight.com/uncle-bob/2012/08/13/the-clean-architecture.html
|
||||
@ -0,0 +1,405 @@
|
||||
旅行时通过树莓派和iPad Pro备份图片
|
||||
===================================================================
|
||||
|
||||

|
||||
>旅行中备份图片 - Gear.
|
||||
|
||||
### 介绍
|
||||
|
||||
我在很长的时间内一直在寻找一个旅行中备份图片的理想方法,把SD卡放进你的相机包是比较危险和暴露的,SD卡可能丢失或者被盗,数据可能损坏或者在传输过程中失败。比较好的一个选择是复制到另外一个设备即使它也是个SD卡,并且将它放到一个比较安全的地方去,备份到远端也是一个可行的办法,但是如果去了一个没有网络的地方就不太可行了。
|
||||
|
||||
我理想的备份步骤需要下面的工具:
|
||||
|
||||
1. 用一台iPad pro而不是一台笔记本。我喜欢简便的旅行,我的旅行大部分是商务的而不是拍摄休闲的,这很显然我为什么选择了iPad Pro
|
||||
2. 用尽可能少的设备
|
||||
3. 设备之间的连接需要很安全。我需要在旅馆和机场使用,所以设备之间的连接需要时封闭的加密的。
|
||||
4. 整个过程应该是稳定的安全的,我还用过其他的移动设备,但是效果不太理想[1].
|
||||
|
||||
### 设置
|
||||
|
||||
我制定了一个满足上面条件并且在未来可以扩充的设定,它包含下面这些部件的使用:
|
||||
|
||||
1. [2]9.7寸写作时最棒的又小又轻便的IOS系统的iPad Pro,苹果笔不是不许的,但是当我在路上进行一些编辑的时候依然需要,所有的重活由树莓派做 ,其他设备通过ssh连接设备
|
||||
2. [3] 树莓派3包含Raspbian系统
|
||||
3. [4]Mini SD卡 [box/case][5].
|
||||
5. [6]128G的优盘,对于我是够用了,你可以买个更大的,你也可以买个移动硬盘,但是树莓派没办法给移动硬盘供电,你需要额外准备一个供电的hub,当然优质的线缆能提供可靠便捷的安装和连接。
|
||||
6. [9]SD读卡器
|
||||
7. [10]另外的sd卡,SD卡我在用满之前就会立即换一个,这样就会让我的照片分布在不同的sd卡上
|
||||
|
||||
下图展示了这些设备之间如何相互连接.
|
||||
|
||||

|
||||
>旅行时照片的备份-过程表格.
|
||||
|
||||
树莓派会作为一个热点. 它会创建一个WIFI网络,当然也可以建立一个Ad Hoc网络,更简单一些,但是它不会加密设备之间的连接,因此我选择创建WIFI网络。
|
||||
|
||||
SD卡放进SD读卡器插到树莓派USB端口上,128G的大容量优盘一直插在树莓派的USB端口上,我选择了一款闪迪的体积比较小。主要的思路就是通过脚本把SD卡的图片备份到优盘上,脚本是增量备份,而且脚本会自动运行,使备份特别快,如果你有很多的照片或者拍摄了很多没压缩的照片,这个任务量就比较大,用ipad来运行Python脚本,而且用来浏览SD卡和优盘的文件。
|
||||
|
||||
如果给树莓派连上一根能上网的网线,那样连接树莓派wifi的设备就可以上网啦!
|
||||
|
||||
### 1. 树莓派的设置
|
||||
|
||||
这部分要用到命令行模式,我会尽可能详细的介绍,方便大家进行下去。
|
||||
|
||||
#### 安装和配置Raspbian
|
||||
|
||||
给树莓派连接鼠标键盘和显示器,将SD卡插到树莓派上,在官网按步骤安装Raspbian [12].
|
||||
|
||||
安装完后执行下面的命令:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
```
|
||||
|
||||
升级机器上所有的软件到最新,我将树莓派连接到本地网络,而且为了安全更改了默认的密码。
|
||||
|
||||
Raspbian默认开启了SSH,这样所有的设置可以在一个远程的设备上完成。我也设置了RSA验证,那是个可选的功能,查看能多信息 [这里][13].
|
||||
|
||||
这是一个在MAC上建立SSH连接到树莓派上的截图[14]:
|
||||
|
||||
##### 建立WPA2验证的WIFI
|
||||
|
||||
这个安装过程是基于这篇文章,只适用于我自己做的例子[15].
|
||||
|
||||
##### 1. 安装软件包
|
||||
|
||||
我们需要安装下面的软件包:
|
||||
|
||||
```
|
||||
sudo apt-get install hostapd
|
||||
sudo apt-get install dnsmasq
|
||||
```
|
||||
|
||||
hostapd用来创建wifi,dnsmasp用来做dhcp和dns服务,很容易设置.
|
||||
|
||||
##### 2. 编辑dhcpcd.conf
|
||||
|
||||
通过网络连接树莓派,网络设置树莓派需要dhcpd,首先我们将wlan0设置为一个静态的IP。
|
||||
|
||||
用sudo nano `/etc/dhcpcd.conf`命令打开配置文件,在最后一行添加上如下信息:
|
||||
|
||||
```
|
||||
denyinterfaces wlan0
|
||||
```
|
||||
|
||||
注意: 必须先配置这个接口才能配置其他接口.
|
||||
|
||||
##### 3. 编辑端口
|
||||
|
||||
现在设置静态IP,sudo nano `/etc/network/interfaces`打开端口配置文件按照如下信息编辑wlan0选项:
|
||||
|
||||
```
|
||||
allow-hotplug wlan0
|
||||
iface wlan0 inet static
|
||||
address 192.168.1.1
|
||||
netmask 255.255.255.0
|
||||
network 192.168.1.0
|
||||
broadcast 192.168.1.255
|
||||
# wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
```
|
||||
|
||||
同样, 然后添加wlan1信息:
|
||||
|
||||
```
|
||||
#allow-hotplug wlan1
|
||||
#iface wlan1 inet manual
|
||||
# wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
```
|
||||
|
||||
重要: sudo service dhcpcd restart命令重启dhcpd服务`sudo ifdown eth0; sudo ifup wlan0`命令用来关闭eth0端口再开启用来生效配置文件.
|
||||
|
||||
##### 4. 配置Hostapd
|
||||
|
||||
接下来我们配置hostapd,`sudo nano /etc/hostapd/hostapd.conf` 用这个命令创建并填写配置信息到文件中:
|
||||
|
||||
```
|
||||
interface=wlan0
|
||||
|
||||
# Use the nl80211 driver with the brcmfmac driver
|
||||
driver=nl80211
|
||||
|
||||
# This is the name of the network
|
||||
ssid=YOUR_NETWORK_NAME_HERE
|
||||
|
||||
# Use the 2.4GHz band
|
||||
hw_mode=g
|
||||
|
||||
# Use channel 6
|
||||
channel=6
|
||||
|
||||
# Enable 802.11n
|
||||
ieee80211n=1
|
||||
|
||||
# Enable QoS Support
|
||||
wmm_enabled=1
|
||||
|
||||
# Enable 40MHz channels with 20ns guard interval
|
||||
ht_capab=[HT40][SHORT-GI-20][DSSS_CCK-40]
|
||||
|
||||
# Accept all MAC addresses
|
||||
macaddr_acl=0
|
||||
|
||||
# Use WPA authentication
|
||||
auth_algs=1
|
||||
|
||||
# Require clients to know the network name
|
||||
ignore_broadcast_ssid=0
|
||||
|
||||
# Use WPA2
|
||||
wpa=2
|
||||
|
||||
# Use a pre-shared key
|
||||
wpa_key_mgmt=WPA-PSK
|
||||
|
||||
# The network passphrase
|
||||
wpa_passphrase=YOUR_NEW_WIFI_PASSWORD_HERE
|
||||
|
||||
# Use AES, instead of TKIP
|
||||
rsn_pairwise=CCMP
|
||||
```
|
||||
|
||||
配置完成后,我们需要运行 `sudo nano /etc/default/hostapd` 命令打开这个配置文件然后找到`#DAEMON_CONF=""` 替换成`DAEMON_CONF="/etc/hostapd/hostapd.conf"`以便hostapd服务能够找到对应的配置文件.
|
||||
|
||||
##### 5. 配置Dnsmasq
|
||||
|
||||
dnsmasp配置文件包含很多信息方便你使用它,但是我们不需要那么多选项,我建议用下面两条命令把它放到别的地方,不要删除它,然后自己创建一个文件
|
||||
|
||||
```
|
||||
sudo mv /etc/dnsmasq.conf /etc/dnsmasq.conf.orig
|
||||
sudo nano /etc/dnsmasq.conf
|
||||
```
|
||||
|
||||
粘贴下面的信息到新文件中:
|
||||
|
||||
```
|
||||
interface=wlan0 # Use interface wlan0
|
||||
listen-address=192.168.1.1 # Explicitly specify the address to listen on
|
||||
bind-interfaces # Bind to the interface to make sure we aren't sending things elsewhere
|
||||
server=8.8.8.8 # Forward DNS requests to Google DNS
|
||||
domain-needed # Don't forward short names
|
||||
bogus-priv # Never forward addresses in the non-routed address spaces.
|
||||
dhcp-range=192.168.1.50,192.168.1.100,12h # Assign IP addresses in that range with a 12 hour lease time
|
||||
```
|
||||
|
||||
##### 6. 设置IPv4转发
|
||||
|
||||
最后我们需要做的事就是配置包转发,用`sudo nano /etc/sysctl.conf`命令打开sysctl.conf文件,将containing `net.ipv4.ip_forward=1`之前的#号删除,然后重启生效
|
||||
|
||||
我们还需要给连接树莓派的设备通过WIFI分享一个网络连接,做一个wlan0和eth0的NAT,我们可以参照下面的脚本来实现。
|
||||
|
||||
```
|
||||
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
|
||||
sudo iptables -A FORWARD -i eth0 -o wlan0 -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
sudo iptables -A FORWARD -i wlan0 -o eth0 -j ACCEPT
|
||||
```
|
||||
|
||||
我命名了一个hotspot-boot.sh的脚本然后让它可以运行:
|
||||
|
||||
```
|
||||
sudo chmod 755 hotspot-boot.sh
|
||||
```
|
||||
|
||||
脚本会在树莓派启动的时候运行,有很多方法实现,下面是我实现的方式:
|
||||
|
||||
1. 把文件放到`/home/pi/scripts`目录下.
|
||||
2. 编辑rc.local文件,输入`sudo nano /etc/rc.local`命令将运行脚本命令放到exit0之前[16]).
|
||||
|
||||
下面是实例.
|
||||
|
||||
```
|
||||
#!/bin/sh -e
|
||||
#
|
||||
# rc.local
|
||||
#
|
||||
# This script is executed at the end of each multiuser runlevel.
|
||||
# Make sure that the script will "exit 0" on success or any other
|
||||
# value on error.
|
||||
#
|
||||
# In order to enable or disable this script just change the execution
|
||||
# bits.
|
||||
#
|
||||
# By default this script does nothing.
|
||||
|
||||
# Print the IP address
|
||||
_IP=$(hostname -I) || true
|
||||
if [ "$_IP" ]; then
|
||||
printf "My IP address is %s\n" "$_IP"
|
||||
fi
|
||||
|
||||
sudo /home/pi/scripts/hotspot-boot.sh &
|
||||
|
||||
exit 0
|
||||
|
||||
```
|
||||
|
||||
#### 安装Samba服务和NTFS兼容驱动.
|
||||
|
||||
我们要安装下面几个软件使我们能够访问树莓派分享的文件夹,ntfs-3g可以使我们能够方位ntfs文件系统的文件.
|
||||
|
||||
```
|
||||
sudo apt-get install ntfs-3g
|
||||
sudo apt-get install samba samba-common-bin
|
||||
```
|
||||
|
||||
你可以参照这些文档来配置Samba[17] .
|
||||
|
||||
重要提示,推荐的文档要先挂在外置硬盘,我们不这样做,因为在这篇文章写作的时候树莓派在启动时的auto-mounts功能同时将sd卡和优盘挂载到`/media/pi/`上,这篇文章有一些多余的功能我们也不会采用。
|
||||
|
||||
### 2. Python脚本
|
||||
|
||||
树莓派配置好后,我们需要让脚本拷贝和备份照片的时候真正的起作用,脚本只提供了特定的自动化备份进程,如果你有基本的cli操作的技能,你可以ssh进树莓派,然后拷贝你自己的照片从一个设备到另外一个设备用cp或者rsync命令。在脚本里我们用rsync命令,这个命令比较可靠而且支持增量备份。
|
||||
|
||||
这个过程依赖两个文件,脚本文件自身和`backup_photos.conf`这个配置文件,后者只有几行包含已挂载的目的驱动器和应该挂载到哪个目录,它看起来是这样的:
|
||||
|
||||
```
|
||||
mount folder=/media/pi/
|
||||
destination folder=PDRIVE128GB
|
||||
```
|
||||
|
||||
重要提示: 在这个符号`=`前后不要添加多余的空格,否则脚本会失效.
|
||||
|
||||
下面是这个Python脚本,我把它命名为`backup_photos.py`,把它放到了`/home/pi/scripts/`目录下,我在每行都做了注释可以方便的查看各行的功能.
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
|
||||
import os
|
||||
import sys
|
||||
from sh import rsync
|
||||
|
||||
'''
|
||||
脚本将挂载到/media/pi的sd卡上的内容复制到一个目的磁盘的同名目录下,目的驱动器的名字在.conf文件里定义好了.
|
||||
|
||||
|
||||
Argument: label/name of the mounted SD Card.
|
||||
'''
|
||||
|
||||
CONFIG_FILE = '/home/pi/scripts/backup_photos.conf'
|
||||
ORIGIN_DEV = sys.argv[1]
|
||||
|
||||
def create_folder(path):
|
||||
|
||||
print ('attempting to create destination folder: ',path)
|
||||
if not os.path.exists(path):
|
||||
try:
|
||||
os.mkdir(path)
|
||||
print ('Folder created.')
|
||||
except:
|
||||
print ('Folder could not be created. Stopping.')
|
||||
return
|
||||
else:
|
||||
print ('Folder already in path. Using that instead.')
|
||||
|
||||
|
||||
|
||||
confFile = open(CONFIG_FILE,'rU')
|
||||
#IMPORTANT: rU Opens the file with Universal Newline Support,
|
||||
#so \n and/or \r is recognized as a new line.
|
||||
|
||||
confList = confFile.readlines()
|
||||
confFile.close()
|
||||
|
||||
|
||||
for line in confList:
|
||||
line = line.strip('\n')
|
||||
|
||||
try:
|
||||
name , value = line.split('=')
|
||||
|
||||
if name == 'mount folder':
|
||||
mountFolder = value
|
||||
elif name == 'destination folder':
|
||||
destDevice = value
|
||||
|
||||
|
||||
except ValueError:
|
||||
print ('Incorrect line format. Passing.')
|
||||
pass
|
||||
|
||||
|
||||
destFolder = mountFolder+destDevice+'/'+ORIGIN_DEV
|
||||
create_folder(destFolder)
|
||||
|
||||
print ('Copying files...')
|
||||
|
||||
# Comment out to delete files that are not in the origin:
|
||||
# rsync("-av", "--delete", mountFolder+ORIGIN_DEV, destFolder)
|
||||
rsync("-av", mountFolder+ORIGIN_DEV+'/', destFolder)
|
||||
|
||||
print ('Done.')
|
||||
```
|
||||
|
||||
### 3.iPad Pro的配置
|
||||
|
||||
树莓派做了最重的活,而且iPad Pro根本没参与传输文件,我们在iPad上只需要安装上Prompt2来通过ssh连接树莓派就行了,这样你既可以运行Python脚本也可以复制文件了。[18]; [19].
|
||||
|
||||

|
||||
>iPad用prompt通过SSH连接树莓派.
|
||||
|
||||
我们安装了Samba,我们可以通过图形方式通过树莓派连接到USB设备,你可以看视频,在不同的设备之间复制和移动文件,文件浏览器是必须的[20] .
|
||||
|
||||
### 4. 将它们都放到一起
|
||||
|
||||
我们假设`SD32GB-03`是连接到树莓派的SD卡名字,`PDRIVE128GB`是那个优盘通过事先的配置文件挂载好,如果我们想要备份SD卡上的图片,我们需要这么做:
|
||||
|
||||
1. 让树莓派先正常运行,将设备挂载好.
|
||||
2. 连接树莓派配置好的WIFI网络.
|
||||
3. 用prompt这个app通过ssh连接树莓派[21].
|
||||
4. 连接好后输入下面的命令:
|
||||
|
||||
```
|
||||
python3 backup_photos.py SD32GB-03
|
||||
```
|
||||
|
||||
首次备份需要一些时间基于SD卡的容量,你需要保持好设备之间的连接,在脚本运行之前你可以通过下面这个命令绕过.
|
||||
|
||||
```
|
||||
nohup python3 backup_photos.py SD32GB-03 &
|
||||
```
|
||||
|
||||

|
||||
>运行完成的脚本如图所示.
|
||||
|
||||
### 未来的定制
|
||||
|
||||
我在树莓派上安装了vnc服务,这样我可以通过ipad连接树莓派的图形界面,我安装了bittorrent用来远端备份我的图片,当然需要先设置好,我会放出这些当我完成这些工作后[23[24]。
|
||||
|
||||
你可以在下面发表你的评论和问题,我会在此页下面回复。.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.movingelectrons.net/blog/2016/06/26/backup-photos-while-traveling-with-a-raspberry-pi.html
|
||||
|
||||
作者:[Editor][a]
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.movingelectrons.net/blog/2016/06/26/backup-photos-while-traveling-with-a-raspberry-pi.html
|
||||
[1]: http://bit.ly/1MVVtZi
|
||||
[2]: http://www.amazon.com/dp/B01D3NZIMA/?tag=movinelect0e-20
|
||||
[3]: http://www.amazon.com/dp/B01CD5VC92/?tag=movinelect0e-20
|
||||
[4]: http://www.amazon.com/dp/B010Q57T02/?tag=movinelect0e-20
|
||||
[5]: http://www.amazon.com/dp/B01F1PSFY6/?tag=movinelect0e-20
|
||||
[6]: http://amzn.to/293kPqX
|
||||
[7]: http://amzn.to/290syFY
|
||||
[8]: http://amzn.to/290syFY
|
||||
[9]: http://amzn.to/290syFY
|
||||
[10]: http://amzn.to/290syFY
|
||||
[11]: http://amzn.to/293kPqX
|
||||
[12]: https://www.raspberrypi.org/downloads/noobs/
|
||||
[13]: https://www.raspberrypi.org/documentation/remote-access/ssh/passwordless.md
|
||||
[14]: https://www.iterm2.com/
|
||||
[15]: https://frillip.com/using-your-raspberry-pi-3-as-a-wifi-access-point-with-hostapd/
|
||||
[16]: https://www.raspberrypi.org/documentation/linux/usage/rc-local.md
|
||||
[17]: http://www.howtogeek.com/139433/how-to-turn-a-raspberry-pi-into-a-low-power-network-storage-device/
|
||||
[18]: http://bit.ly/1MVVtZi
|
||||
[19]: https://itunes.apple.com/us/app/prompt-2/id917437289?mt=8&uo=4&at=11lqkH
|
||||
[20]: https://itunes.apple.com/us/app/filebrowser-access-files-on/id364738545?mt=8&uo=4&at=11lqkH
|
||||
[21]: https://itunes.apple.com/us/app/prompt-2/id917437289?mt=8&uo=4&at=11lqkH
|
||||
[22]: https://en.m.wikipedia.org/wiki/Nohup
|
||||
[23]: https://itunes.apple.com/us/app/remoter-pro-vnc-ssh-rdp/id519768191?mt=8&uo=4&at=11lqkH
|
||||
[24]: https://getsync.com/
|
||||
222
translated/tech/20160809 How to build your own Git server.md
Normal file
222
translated/tech/20160809 How to build your own Git server.md
Normal file
@ -0,0 +1,222 @@
|
||||
如何搭建你自己的 Git 服务器
|
||||
====================
|
||||
|
||||

|
||||
|
||||
现在我们将要学习如何搭建 git 服务器,如何编写自定义的 Git 钩子来在特定的事件触发相应的动作(例如通知),或者是发布你的代码到一个站点。
|
||||
|
||||
直到现在,作为一个使用者注意力还是被 Git 影响。这篇文章中我将讨论 Git 的管理,并且设计一个灵活的 Git 框架。你可能会觉得这听起来是 “高阶 Git 技术” 或者 “只有狂热粉才能阅读”的一句委婉的说法,但是事实是这里面的每个任务都不需要很深的知识或者其他特殊的训练,就能立刻理解 Git 的工作原理,有可能需要一丁点关于 Linux 的知识
|
||||
|
||||
### 共享 Git 服务器
|
||||
|
||||
创建你自己的共享 Git 服务器意外地简单,而且遇到各方面的问题时都很值得。不仅仅是因为它保证你有权限查看自己的代码,它还对于利用扩展来维持 Git 的通信敞开了一扇大门,例如个人 Git 钩子,无限制的数据存储,和持续的整合与发布
|
||||
|
||||
如果你知道如何使用 Git 和 SSH,那么你已经知道怎么创建一个 Git 服务器了。Git 的设计方式,就是让你在创建或者 clone 一个仓库的时候,就完成了一半服务器的搭建。然后允许用 SSH 访问仓库,而且任何有权限访问的人都可以使用你的仓库,作为 clone 的新仓库的基础。
|
||||
|
||||
但是,这是一个小的自组织。按照一些计划你可以以同样的效果创建一些设计优良的 Git 服务器,同时有更好的拓展性。
|
||||
|
||||
首要之事:确认你的用户们,现在的用户以及之后的用户都要考虑。如果你是唯一的用户那么没有任何改动的必要。但是如果你试图邀请其他的代码贡献者,那么你应该允许一个专门的分享系统用户给你的开发者们。
|
||||
|
||||
假定你有一个可用的服务器(如果没有,这不成问题,Git 会帮忙解决,CentOS 的 Raspberry Pi 3 是个不错的开始),然后第一步就是只允许使用 SSH 密钥认证的 SSH 登录。
|
||||
|
||||
一旦你启用了 SSH 密钥认证,创建 gituser 用户。这是给你的所有确认的开发者们的公共用户。
|
||||
|
||||
```
|
||||
$ su -c 'adduser gituser'
|
||||
```
|
||||
|
||||
然后切换到刚创建的 gituser 用户,创建一个 `~/.ssh` 的框架,并设置好合适的权限。这很重要,如果权限设置得太开放会使自己受保护的 SSH 默认失败。
|
||||
|
||||
```
|
||||
$ su - gituser
|
||||
$ mkdir .ssh && chmod 700 .ssh
|
||||
$ touch .ssh/authorized_keys
|
||||
$ chmod 600 .ssh/authorized_keys
|
||||
```
|
||||
|
||||
`authorized_keys` 文件里包含所有你的开发者们的 SSH 公钥,你开放权限允许他们可以在你的 Git 项目上工作。他们必须创建他们自己的 SSH 密钥对然后把他们的公钥给你。复制公钥到 gituser 用户下的 `authorized_keys` 文件中。例如,为一个叫 Bob 的开发者,执行以下命令:
|
||||
|
||||
```
|
||||
$ cat ~/path/to/id_rsa.bob.pub >> \
|
||||
/home/gituser/.ssh/authorized_keys
|
||||
```
|
||||
|
||||
只要开发者 Bob 有私钥并且把相对应的公钥给你,Bob 就可以用 gituser 用户访问服务器。
|
||||
|
||||
但是,你并不是想让你的开发者们能使用服务器,即使只是以 gituser 的身份访问。你只是想给他们访问 Git 仓库的权限。因为这个特殊的原因,Git 提供了一个限制的 shell,准确的说是 git-shell。以 root 身份执行以下命令,把 git-shell 添加到你的系统中,然后设置成 gituser 用户默认的shell。
|
||||
|
||||
```
|
||||
# grep git-shell /etc/shells || su -c \
|
||||
"echo `which git-shell` >> /etc/shells"
|
||||
# su -c 'usermod -s git-shell gituser'
|
||||
```
|
||||
|
||||
现在 gituser 用户只能使用 SSH 来 push 或者 pull Git 仓库,并且无法使用任何一个可以登录的 shell。你应该把你自己添加到和 gituser 一样的组中,在我们的样例服务器中仍是这个组的名字仍是 gituser。
|
||||
|
||||
举个例子:
|
||||
|
||||
```
|
||||
# usermod -a -G gituser seth
|
||||
```
|
||||
|
||||
仅剩下的一步就是创建一个 Git 仓库。因为没有人能在服务器上与 Git 交互(也就是说,你之后不能 SSH 到服务器然后直接操作这个仓库),创一个最原始的仓库 。如果你想使用位于服务器上的仓库来完成工作,你可以从它的所在处 clone 下来然后直接在你的 home 目录下工作。
|
||||
|
||||
说白了,你不需要让它变成一个空的仓库,你需要像工作在一个正常的仓库一样。但是,一个空的仓库没有 *working tree* (也就是说,使用 `checkout` 并没有任何分支显示)。这很重要,因为远程使用者们并不被允许 push 一个有效的分支(如果你正在 `dev` 分支工作然后突然有人把一些变更 push 到你的工作分支,你会有怎么样的感受?)。因为一个空的仓库可以没有有效的分支,这不会成为一个问题。
|
||||
|
||||
你可以把这个仓库放到任何你想放的地方,只要你想要放开权限给用户和用户组,让他们可以在仓库下工作。千万不要保存目录到例如一个用户的 home 目录下,因为有严格的权限控制。保存到一个常规的共享地址,例如 `/opt` 或者 `/usr/local/share`。
|
||||
|
||||
以 root 身份创建一个空的仓库:
|
||||
|
||||
```
|
||||
# git init --bare /opt/jupiter.git
|
||||
# chown -R gituser:gituser /opt/jupiter.git
|
||||
# chmod -R 770 /opt/jupiter.git
|
||||
```
|
||||
|
||||
现在任何一个用户,只要他被认证为 gituser 或者在 gituser 组中,就可以从 jupiter.git 库中读取或者写入。在本地机器尝试以下操作。
|
||||
|
||||
```
|
||||
$ git clone gituser@example.com:/opt/jupiter.git jupiter.clone
|
||||
Cloning into 'jupiter.clone'...
|
||||
Warning: you appear to have cloned an empty repository.
|
||||
```
|
||||
|
||||
谨记:开发者们一定要把他们的 SSH 公钥加入到 gituser 用户下的 `authorized_keys` 文件里,或者说,如果他们有服务器上的用户(如果你给了他们用户),那么他们的用户必须属于 gituser 用户组。
|
||||
|
||||
### Git 钩子
|
||||
|
||||
将自己的 Git 服务器跑起来,很赞的一件事就是可以使用 Git 钩子。支持 Git 的设备有时提供一个类钩子接口,但是并没有给你真正的 Git 钩子来访问文件系统。Git 钩子是一个脚本,它将在一个 Git 过程的某些点运行;当一个仓库即将接收一个 commit,或者接受一个 commit 之后,或者即将接收一次 push,或者一次 push 之后等等
|
||||
|
||||
这是一个简单的系统:任何放在 `.git/hooks` 目录下的脚本,使用标准的命名体系,就可按设计好的时间运行。一个脚本是否应该被运行取决于它的名字; pre-push 脚本在 push 之前运行,post-received 脚本在 push 之后运行,post-receive 脚本在接受 commit 之后运行等等。
|
||||
|
||||
脚本可以用任何语言写;如果在你的系统上有可以执行的脚本语言,例如输出 ‘hello world’ ,那么你就用这个语言来写 Git 钩子脚本。Git 默认会给出一些例子,但是并不能用。
|
||||
|
||||
想要动手试一个?这很简单。如果你没有现成的 Git 仓库,首先创建一个 Git 仓库:
|
||||
|
||||
```
|
||||
$ mkdir jupiter
|
||||
$ cd jupiter
|
||||
$ git init .
|
||||
```
|
||||
|
||||
然后写一个功能为输出 “hello world” 的 Git 钩子。因为我使用 tsch 作为传统系统的长期支持 shell,所以我仍然用它作为我的脚本语言,你可以自由的使用自己喜欢的语言(Bash,Python,Ruby,Perl,Rust,Swift,Go):
|
||||
|
||||
```
|
||||
$ echo "#\!/bin/tcsh" > .git/hooks/post-commit
|
||||
$ echo "echo 'POST-COMMIT SCRIPT TRIGGERED'" >> \
|
||||
~/jupiter/.git/hooks/post-commit
|
||||
$ chmod +x ~/jupiter/.git/hooks/post-commit
|
||||
```
|
||||
|
||||
现在测试它的输出:
|
||||
|
||||
```
|
||||
$ echo "hello world" > foo.txt
|
||||
$ git add foo.txt
|
||||
$ git commit -m 'first commit'
|
||||
! POST-COMMIT SCRIPT TRIGGERED
|
||||
[master (root-commit) c8678e0] first commit
|
||||
1 file changed, 1 insertion(+)
|
||||
create mode 100644 foo.txt
|
||||
```
|
||||
|
||||
然后你已经实现了:你的第一个有功能的 Git 钩子
|
||||
|
||||
### 有名的 push-to-web 钩子
|
||||
|
||||
Git 钩子最流行的用法就是自动 push 更改的代码到一个正在使用中的网络服务器目录下。这是摆脱 FTP 的很好的方式,对于正在使用的产品保留完整的版本控制,自动整合发布的内容
|
||||
|
||||
如果操作正确,在一直以来的网站发布维护中 Git 会完成的很好,而且在某种程度上,很精准。Git 真的好棒。我不知道谁最初想到这个主意,但是我第一次听到它是从 Emacs 和 Git 方面的专家,IBM 的 Bill von Hagen。他的文章包含一系列明确的介绍:[Git 改变了分布式网页开发的游戏规则][1]。
|
||||
|
||||
### Git 变量
|
||||
|
||||
每一个 Git 钩子都有一系列不同的变量对应触发钩子的不同 Git 行为。你需不需要这些变量,主要取决于你写的程序。如果你需要一个当某人 push 代码时候的通用邮件通知,那么你就不需要特殊化,并且甚至也不需要编写额外的脚本,因为已经有现成的适合你的脚本。如果你想在邮件里查看 commit 信息和 commit 的作者,那么你的脚本就会变得相对棘手些。
|
||||
|
||||
Git 钩子并不是被用户直接执行,所以要弄清楚如何收集可能会误解的重要信息。事实上,Git 钩子脚本就像其他的脚本一样,像 BASH, Python, C++ 等等,从标准输入读取参数。不同的是,我们不会给它提供这个输入,所以,你在使用的时候,需要知道可能的输入参数。
|
||||
|
||||
在写 Git 钩子之前,看一下 Git 在你的项目目录下 `.git/hooks` 目录中提供的一些例子。举个例子,在这个 `pre-push.sample` 文件里,注释部分说明了如下内容:
|
||||
|
||||
```
|
||||
# $1 -- 即将 push 的远方仓库的名字
|
||||
# $2 -- 即将 push 的远方仓库的 URL
|
||||
# 如果 push 的时候,并没有一个命名的远方仓库,那么这两个参数将会一样。
|
||||
#
|
||||
# 对于这个表单的标准输入,
|
||||
# 参数通过行的形式输入
|
||||
# <local ref> <local sha1> <remote ref> <remote sha1>
|
||||
```
|
||||
|
||||
并不是所有的例子都是这么清晰,而且关于钩子获取变量的文档依旧缺乏(除非你去读 Git 的源码)。但是,如果你有疑问,你可以从[其他用户的尝试中][2]学习,或者你只是写一些基本的脚本,比如 `echo $1, $2, $3` 等等。
|
||||
|
||||
### 分支检测示例
|
||||
|
||||
我发现,对于生产环境来说有一个共同的需求,就是需要一个只有在特定分支被修改之后,才会触发事件的钩子。以下就是如何跟踪分支的示例。
|
||||
|
||||
首先,Git 钩子本身是不受版本控制的。 Git 并不会跟踪他自己的钩子,因为对于钩子来说,他是 Git 的一部分,而不是你仓库的一部分。所以,Git 钩子可以监控你的 Git 服务器上的 Git 仓库的 commit 记录和 push 记录,而不是你本地仓库的一部分。
|
||||
|
||||
我们来写一个 post-receive(也就是说,在 commit 被接受之后触发)钩子。第一步就是需要确定分支名:
|
||||
|
||||
```
|
||||
#!/bin/tcsh
|
||||
|
||||
foreach arg ( $< )
|
||||
set argv = ( $arg )
|
||||
set refname = $1
|
||||
end
|
||||
```
|
||||
|
||||
这个 for 循环用来读入第一个参数 `arg($1)` 然后循环用第二个参数 `($2)` 去重写,然后用第三个参数 `($3)` 。在 Bash 中有一个更好的方法,使用 read 命令,并且把值放入数组里。但是,这里是 tcsh,并且变量的顺序可以预测的,所以,这个方法也是可行的。
|
||||
|
||||
当我们有了 commit 记录的 refname,我们就能使用 Git 去找到这个分支的人类能读的名字:
|
||||
|
||||
```
|
||||
set branch = `git rev-parse --symbolic --abbrev-ref $refname`
|
||||
echo $branch #DEBUG
|
||||
```
|
||||
|
||||
然后把这个分支名和我们想要触发的事件的分支名关键字进行比较。
|
||||
|
||||
```
|
||||
if ( "$branch" == "master" ) then
|
||||
echo "Branch detected: master"
|
||||
git \
|
||||
--work-tree=/path/to/where/you/want/to/copy/stuff/to \
|
||||
checkout -f $branch || echo "master fail"
|
||||
else if ( "$branch" == "dev" ) then
|
||||
echo "Branch detected: dev"
|
||||
Git \
|
||||
--work-tree=/path/to/where/you/want/to/copy/stuff/to \
|
||||
checkout -f $branch || echo "dev fail"
|
||||
else
|
||||
echo "Your push was successful."
|
||||
echo "Private branch detected. No action triggered."
|
||||
endif
|
||||
```
|
||||
|
||||
给这个脚本分配可执行权限:
|
||||
|
||||
```
|
||||
$ chmod +x ~/jupiter/.git/hooks/post-receive
|
||||
```
|
||||
|
||||
现在,当一个用户在服务器的 master 分支 commit 代码,这个代码就会被复制到一个生产环境的目录,dev 分支的一个 commit 记录也会被复制到其他地方,其他分支将不会触发这些操作。
|
||||
|
||||
同时,创造一个 pre-commit 脚本也很简单。比如,判断一个用户是否在他们不该 push 的分支上 push 代码,或者对 commit 信息进行解析等等。
|
||||
|
||||
Git 钩子也可以变得复杂,而且他们因为 Git 的工作流的抽象层次不同而变得难以理解,但是他们确实是一个强大的系统,让你能够在你的 Git 基础设施上针对所有的行为进行对应的操作。如果你是一个 Git 重度用户,或者一个全职 Git 管理员,那么 Git 钩子是值得学习的。
|
||||
|
||||
在我们这个系列之后和最后的文章,我们将会学习如何使用 Git 来管理非文本的二进制数据,比如音频和图片。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[maywanting](https://github.com/maywanting)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: http://www.ibm.com/developerworks/library/wa-git/
|
||||
[2]: https://www.analysisandsolutions.com/code/git-hooks-summary-cheat-sheet.htm
|
||||
Loading…
Reference in New Issue
Block a user