` 加上 `div` 标签,注意生成的段落是自动缩进的。
+
+```
+
+
Vim plugins are awesome !
+
+```
+
+Vim Surround 有很多其它选项,你可以参照 [GitHub][7] 上的说明尝试它们。
+
+### 4. Vim Gitgutter
+
+[Vim Gitgutter][8] 插件对使用 Git 作为版本控制工具的人来说非常有用。它会在 Vim 显示行号的列旁 `git diff` 的差异标记。假设你有如下已提交过的代码:
+
+```
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+ 5 func main() {
+ 6 x := true
+ 7 items := []string{"tv", "pc", "tablet"}
+ 8
+ 9 if x {
+ 10 for _, i := range items {
+ 11 fmt.Println(i)
+ 12 }
+ 13 }
+ 14 }
+```
+
+当你做出一些修改后,Vim Gitgutter 会显示如下标记:
+
+```
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+_ 5 func main() {
+ 6 items := []string{"tv", "pc", "tablet"}
+ 7
+~ 8 if len(items) > 0 {
+ 9 for _, i := range items {
+ 10 fmt.Println(i)
++ 11 fmt.Println("------")
+ 12 }
+ 13 }
+ 14 }
+```
+
+`-` 标记表示在第 5 行和第 6 行之间删除了一行。`~` 表示第 8 行有修改,`+` 表示新增了第 11 行。
+
+另外,Vim Gitgutter 允许你用 `[c` 和 `]c` 在多个有修改的块之间跳转,甚至可以用 `Leader+hs` 来暂存某个变更集。
+
+这个插件提供了对变更的即时视觉反馈,如果你用 Git 的话,有了它简直是如虎添翼。
+
+### 5. VIM Fugitive
+
+[Vim Fugitive][9] 是另一个超棒的将 Git 工作流集成到 Vim 中的插件。它对 Git 做了一些封装,可以让你在 Vim 里直接执行 Git 命令并将结果集成在 Vim 界面里。这个插件有超多的特性,更多信息请访问它的 [GitHub][10] 项目页面。
+
+这里有一个使用 Vim Fugitive 的基础 Git 工作流示例。设想我们已经对下面的 Go 代码做出修改,你可以用 `:Gblame` 调用 `git blame` 来查看每行最后的提交信息:
+
+```
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 1 package main
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 2
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 3 import "fmt"
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 4
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│_ 5 func main() {
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 6 items := []string{"tv", "pc", "tablet"}
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 7
+00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│~ 8 if len(items) > 0 {
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 9 for _, i := range items {
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 10 fmt.Println(i)
+00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│+ 11 fmt.Println("------")
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 12 }
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 13 }
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 14 }
+```
+
+可以看到第 8 行和第 11 行显示还未提交。用 `:Gstatus` 命令检查仓库当前的状态:
+
+```
+ 1 # On branch master
+ 2 # Your branch is up to date with 'origin/master'.
+ 3 #
+ 4 # Changes not staged for commit:
+ 5 # (use "git add
..." to update what will be committed)
+ 6 # (use "git checkout -- ..." to discard changes in working directory)
+ 7 #
+ 8 # modified: vim-5plugins/examples/test1.go
+ 9 #
+ 10 no changes added to commit (use "git add" and/or "git commit -a")
+--------------------------------------------------------------------------------------------------------
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+_ 5 func main() {
+ 6 items := []string{"tv", "pc", "tablet"}
+ 7
+~ 8 if len(items) > 0 {
+ 9 for _, i := range items {
+ 10 fmt.Println(i)
++ 11 fmt.Println("------")
+ 12 }
+ 13 }
+ 14 }
+```
+
+Vim Fugitive 在分割的窗口里显示 `git status` 的输出结果。你可以在某文件名所在的行用 `-` 键暂存这个文件,再按一次 `-` 可以取消暂存。这个信息会随着你的操作自动更新:
+
+```
+ 1 # On branch master
+ 2 # Your branch is up to date with 'origin/master'.
+ 3 #
+ 4 # Changes to be committed:
+ 5 # (use "git reset HEAD ..." to unstage)
+ 6 #
+ 7 # modified: vim-5plugins/examples/test1.go
+ 8 #
+--------------------------------------------------------------------------------------------------------
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+_ 5 func main() {
+ 6 items := []string{"tv", "pc", "tablet"}
+ 7
+~ 8 if len(items) > 0 {
+ 9 for _, i := range items {
+ 10 fmt.Println(i)
++ 11 fmt.Println("------")
+ 12 }
+ 13 }
+ 14 }
+```
+
+现在你可以用 `:Gcommit` 来提交修改了。Vim Fugitive 会打开另一个分割窗口让你输入提交信息:
+
+```
+ 1 vim-5plugins: Updated test1.go example file
+ 2 # Please enter the commit message for your changes. Lines starting
+ 3 # with '#' will be ignored, and an empty message aborts the commit.
+ 4 #
+ 5 # On branch master
+ 6 # Your branch is up to date with 'origin/master'.
+ 7 #
+ 8 # Changes to be committed:
+ 9 # modified: vim-5plugins/examples/test1.go
+ 10 #
+```
+
+按 `:wq` 保存文件完成提交:
+
+```
+[master c3bf80f] vim-5plugins: Updated test1.go example file
+ 1 file changed, 2 insertions(+), 2 deletions(-)
+Press ENTER or type command to continue
+```
+
+然后你可以再用 `:Gstatus` 检查结果并用 `:Gpush` 把新的提交推送到远程。
+
+```
+ 1 # On branch master
+ 2 # Your branch is ahead of 'origin/master' by 1 commit.
+ 3 # (use "git push" to publish your local commits)
+ 4 #
+ 5 nothing to commit, working tree clean
+```
+
+Vim Fugitive 的 GitHub 项目主页有很多屏幕录像展示了它的更多功能和工作流,如果你喜欢它并想多学一些,快去看看吧。
+
+### 接下来?
+
+这些 Vim 插件都是程序开发者的神器!还有其它几类开发者常用的插件:自动完成插件和语法检查插件。它些大都是和具体的编程语言相关的,以后我会在一些文章中介绍它们。
+
+你在写代码时是否用到一些其它 Vim 插件?请在评论区留言分享。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/vim-plugins-developers
+
+作者:[Ricardo Gerardi][a]
+选题:[lujun9972][b]
+译者:[pityonline](https://github.com/pityonline)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/rgerardi
+[b]: https://github.com/lujun9972
+[1]: https://www.vim.org/
+[2]: https://www.vim.org/scripts/script.php?script_id=3599
+[3]: https://github.com/jiangmiao/auto-pairs
+[4]: https://github.com/scrooloose/nerdcommenter
+[5]: http://vim.wikia.com/wiki/Filetype.vim
+[6]: https://www.vim.org/scripts/script.php?script_id=1697
+[7]: https://github.com/tpope/vim-surround
+[8]: https://github.com/airblade/vim-gitgutter
+[9]: https://www.vim.org/scripts/script.php?script_id=2975
+[10]: https://github.com/tpope/vim-fugitive
diff --git a/translated/tech/20190124 Get started with LogicalDOC, an open source document management system.md b/translated/tech/20190124 Get started with LogicalDOC, an open source document management system.md
new file mode 100644
index 0000000000..b49933414c
--- /dev/null
+++ b/translated/tech/20190124 Get started with LogicalDOC, an open source document management system.md
@@ -0,0 +1,62 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get started with LogicalDOC, an open source document management system)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-logicaldoc)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
+
+开始使用 LogicalDOC,一个开源文档管理系统
+======
+使用 LogicalDOC 更好地跟踪文档版本,这是我们开源工具系列中的第 12 个工具,它将使你在 2019 年更高效。
+
+
+
+每年年初似乎都有疯狂的冲动,想方设法提高工作效率。新年的决议,开始一年的权利,当然,“与旧的,与新的”的态度都有助于实现这一目标。通常的一轮建议严重偏向封闭源和专有软件。它不一定是这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 12 个工具来帮助你在 2019 年更有效率。
+
+### LogicalDOC
+
+高效的一部分是能够在你需要时找到你需要的东西。我们都看到过充满类似名称文件的目录, 这是每次更改文档时为跟踪所有版本而重命名这些文件的结果。例如,我的妻子是一名作家,她在将文档发送给审稿人之前,她经常使用新名称保存文档修订版。
+
+
+
+程序员对此一个自然的解决方案是 Git 或者其他版本控制器,这个不适用于文档作者,因为用于代码的系统通常不能很好地兼容商业文本编辑器使用的格式。之前有人说,“只是更改格式”,[这不是每个人的选择][1]。同样,许多版本控制工具对于非技术人员来说并不是非常友好。在大型组织中,有一些工具可以解决此问题,但它们还需要大型组织的资源来运行、管理和支持它们。
+
+
+
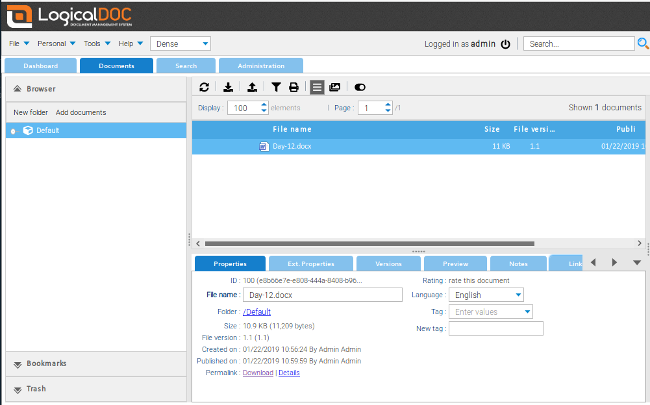
+[LogicalDOC CE][2] 是为解决此问题而编写的开源文档管理系统。它允许用户签入、签出、查看版本、搜索和锁定文档,并保留版本历史记录,类似于程序员使用的版本控制工具。
+
+LogicalDOC 可在 Linux、MacOS 和 Windows 上[安装][3],使用基于 Java 的安装程序。在安装中,系统将提示你提供数据库存储文职,并提供仅限本地文件存储的选项。你将获得访问服务器的 URL 和默认用户名和密码,以及保存用于自动安装脚本选项。
+
+登录后,LogicalDOC 的默认页面会列出你已标记、签出的文档以及有关它们的最新说明。切换到“文档”选项卡将显示你有权访问的文件。你可以在界面中选择文件或使用拖放来上传文档。如果你上传 ZIP 文件,LogicalDOC 会解压它,并将其中的文件添加到仓库中。
+
+
+
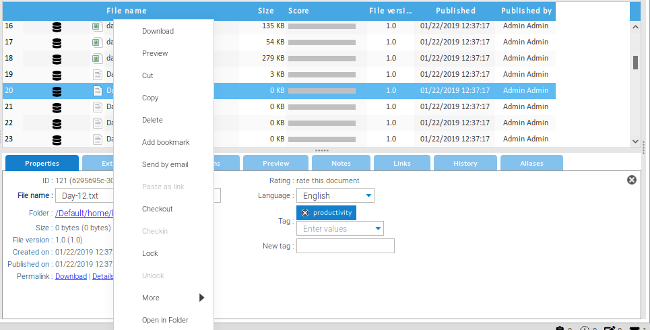
+右键单击文件将显示一个菜单选项,包括检出文件、锁定文件以防止更改,以及执行大量其他操作。签出文件会将其下载到用于编辑的本地计算机。在重新签入之前,其他任何人都无法修改签出文件。当重新签入文件时(使用相同的菜单),用户可以向版本添加标签,并且需要评论对其执行的操作。
+
+
+
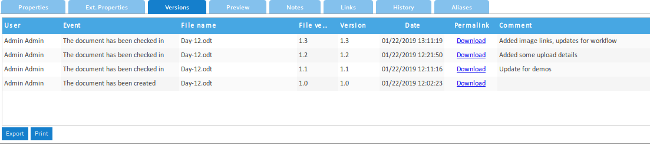
+查看早期版本只需在“版本”页面下载就行。对于某些第三方服务,它还有导入和导出选项,内置 [Dropbox][4] 支持。
+
+文档管理不仅仅是对能够负担得起昂贵解决方案的大公司。LogicalDOC 可帮助你追踪文档的版本历史,并为难以管理的文档提供了安全的仓库。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-logicaldoc
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: http://www.antipope.org/charlie/blog-static/2013/10/why-microsoft-word-must-die.html
+[2]: https://www.logicaldoc.com/download-logicaldoc-community
+[3]: https://docs.logicaldoc.com/en/installation
+[4]: https://dropbox.com
diff --git a/translated/tech/20190129 Get started with gPodder, an open source podcast client.md b/translated/tech/20190129 Get started with gPodder, an open source podcast client.md
new file mode 100644
index 0000000000..429189b926
--- /dev/null
+++ b/translated/tech/20190129 Get started with gPodder, an open source podcast client.md
@@ -0,0 +1,64 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get started with gPodder, an open source podcast client)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-gpodder)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用 gPodder,一个开源播客客户端
+======
+使用 gPodder 将你的播客同步到你的设备上,gPodder 是我们开源工具系列中的第 17 个工具,它将在 2019 年提高你的工作效率。
+
+
+
+每年年初似乎都有疯狂的冲动,想方设法提高工作效率。新年的决议,开始一年的权利,当然,“与旧的,与新的”的态度都有助于实现这一目标。通常的一轮建议严重偏向封闭源和专有软件。它不一定是这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 17 个工具来帮助你在 2019 年更有效率。
+
+### gPodder
+
+我喜欢播客。哎呀,我非常喜欢他们,因此我录制了其中的三个(你可以在[我的个人资料][1]中找到它们的链接)。我从播客那里学到了很多东西,并在我工作时在后台播放它们。但是,在多台桌面和移动设备之间保持同步可能会带来一些挑战。
+
+[gPodder][2] 是一个简单的跨平台播客下载器、播放器和同步工具。它支持 RSS feed、[FeedBurner][3]、[YouTube][4] 和 [SoundCloud][5],它还有一个开源同步服务,你可以根据需要运行它。gPodder 不直接播放播客。相反, 它使用你选择的音频或视频播放器。
+
+
+
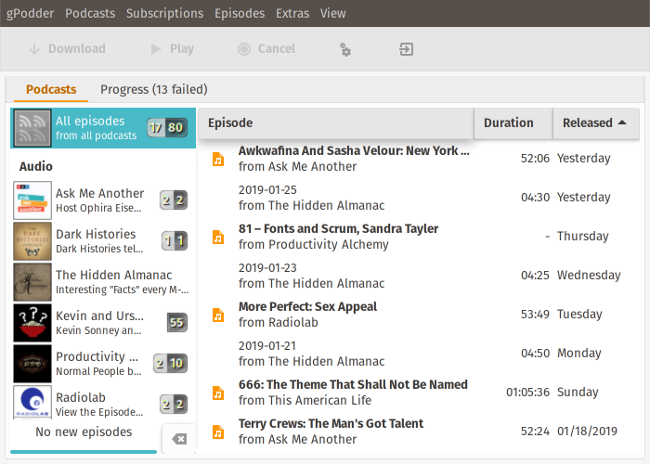
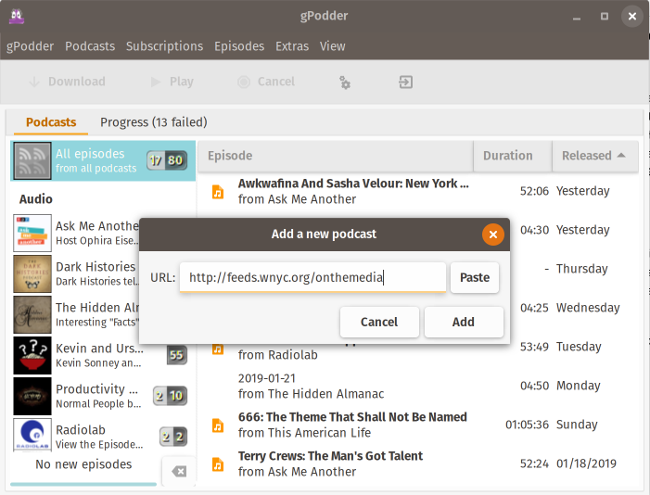
+安装 gPodder 非常简单。安装程序适用于 Windows 和 MacOS,同时包可用于主要的 Linux 发行版。如果你的发行版中没有它,你可以直接从 Git 下载运行。通过 “Add Podcasts via URL” 菜单,你可以输入播客的 RSS 源 URL 或其他服务的“特殊” URL。gPodder 将获取节目列表并显示一个对话框,你可以在其中选择要下载的节目或在列表上标记旧节目。
+
+
+
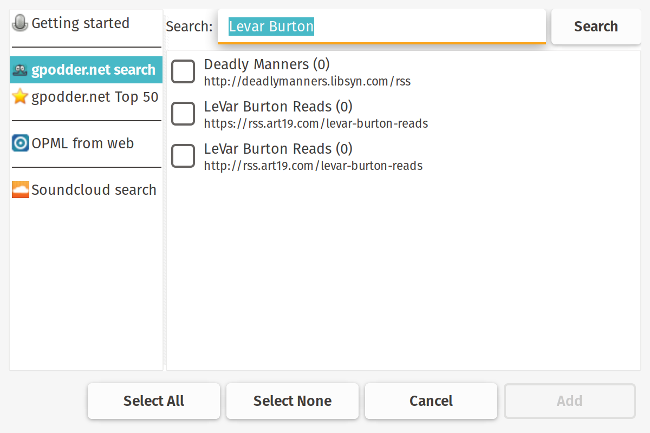
+它一个更好的功能是,如果 URL 已经在你的剪贴板中,gPodder 会自动将它放入播放 URL 中,这样你就可以很容易地将新的播客添加到列表中。如果你已有播客 feed 的 OPML 文件,那么可以上传并导入它。还有一个发现选项,让你可搜索 [gPodder.net][6] 上的播客,这是由编写和维护 gPodder 的人员提供的免费和开源播客列表网站。
+
+
+
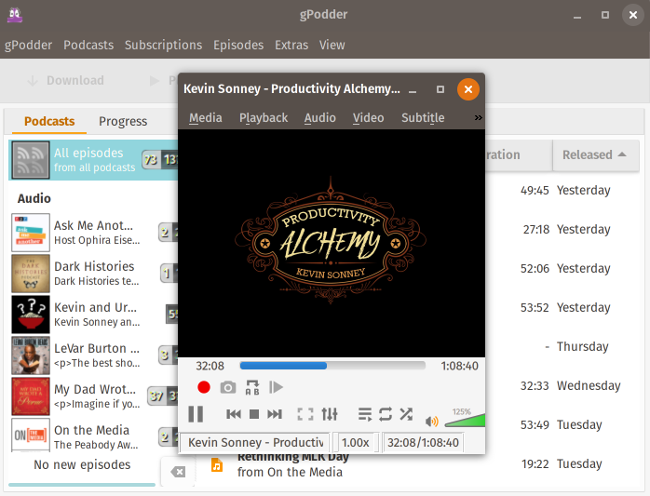
+[mygpo][7] 服务器在设备之间同步播客。gPodder 默认使用 [gPodder.net][8] 的服务器,但是如果你想要运行自己的服务器,那么可以在配置文件中更改它(请注意,你需要直接修改配置文件)。同步能让你在桌面和移动设备之间保持列表一致。如果你在多个设备上收听播客(例如,我在我的工作电脑、家用电脑和手机上收听),这会非常有用,因为这意味着无论你身在何处,你都拥有最近的播客和节目列表而无需一次又一次地设置。
+
+
+
+单击播客节目将显示与其关联的文本,单击“播放”将启动设备的默认音频或视频播放器。如果要使用默认之外的其他播放器,可以在 gPodder 的配置设置中更改此设置。
+
+通过 gPodder,你可以轻松查找、下载和收听播客,在设备之间同步这些播客,在易于使用的界面中访问许多其他功能。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-gpodder
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/users/ksonney
+[2]: https://gpodder.github.io/
+[3]: https://feedburner.google.com/
+[4]: https://youtube.com
+[5]: https://soundcloud.com/
+[6]: http://gpodder.net
+[7]: https://github.com/gpodder/mygpo
+[8]: http://gPodder.net
diff --git a/translated/tech/20190130 Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro.md b/translated/tech/20190130 Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro.md
new file mode 100644
index 0000000000..93f73664a6
--- /dev/null
+++ b/translated/tech/20190130 Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro.md
@@ -0,0 +1,101 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro)
+[#]: via: (https://itsfoss.com/olive-video-editor)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+Olive 是一个新的开源视频编辑器,一款类似 Final Cut Pro 的工具
+======
+
+[Olive][1] 是一个正在开发的新开源视频编辑器。这个非线性视频编辑器旨在提供高端专业视频编辑软件的免费替代品。目标高么?我认为是的。
+
+如果你读过我们的 [Linux 中的最佳视频编辑器][2]这篇文章,你可能已经注意到大多数“专业级”视频编辑器(如 [Lightworks][3] 或 DaVinciResolve)既不免费也不开源。
+
+[Kdenlive][4] 和 Shotcut 也出现在了文章中,但它通常无法达到专业视频编辑的标准(这是许多 Linux 用户说的)。
+
+爱好者和专业视频编辑之间的这种差距促使 Olive 的开发人员启动了这个项目。
+
+![Olive Video Editor][5]Olive Video Editor Interface
+
+Libre Graphics World 中有一篇详细的[关于 Olive 的评论][6]。实际上,这是我第一次知道 Olive 的地方。如果你有兴趣了解更多信息,请阅读该文章。
+
+### 在 Linux 中安装 Olive 视频编辑器
+
+提醒你一下。Olive 正处于发展的早期阶段。你会发现很多 bug 和缺失/不完整的功能。你不应该把它当作你的主要视频编辑器。
+
+如果你想测试 Olive,有几种方法可以在 Linux 上安装它。
+
+#### 通过 PPA 在基于 Ubuntu 的发行版中安装 Olive
+
+你可以在 Ubuntu、Mint 和其他基于 Ubuntu 的发行版使用官方 PPA 安装 Olive。
+
+```
+sudo add-apt-repository ppa:olive-editor/olive-editor
+sudo apt-get update
+sudo apt-get install olive-editor
+```
+
+#### 通过 Snap 安装 Olive
+
+如果你的 Linux 发行版支持 Snap,则可以使用以下命令进行安装。
+
+```
+sudo snap install --edge olive-editor
+```
+
+#### 通过 Flatpak 安装 Olive
+
+如果你的 [Linux 发行版支持 Flatpak][7],你可以通过 Flatpak 安装 Olive 视频编辑器。
+
+#### 通过 AppImage 使用 Olive
+
+不想安装吗?下载 [AppImage][8] 文件,将其设置为可执行文件并运行它。
+
+32 位和 64 位 AppImage 文件都有。你应该下载相应的文件。
+
+Olive 也可用于 Windows 和 macOS。你可以从它的[下载页面][9]获得它。
+
+### 想要支持 Olive 视频编辑器的开发吗?
+
+如果你喜欢 Olive 尝试实现的功能,并且想要支持它,那么你可以通过以下几种方式。
+
+如果你在测试 Olive 时发现一些 bug,请到它们的 GitHub 仓库中报告。
+
+如果你是程序员,请浏览 Olive 的源代码,看看你是否可以通过编码技巧帮助项目。
+
+在经济上为项目做贡献是另一种可以帮助开发开源软件的方法。你可以通过成为赞助人来支持 Olive。
+
+如果你没有支持 Olive 的金钱或编码技能,你仍然可以帮助它。在社交媒体或你经常访问的 Linux/软件相关论坛和群组中分享这篇文章或 Olive 的网站。一点微小的口碑都能间接地帮助它。
+
+### 你如何看待 Olive?
+
+评判 Olive 还为时过早。我希望能够持续快速开发,并且在年底之前发布 Olive 的稳定版(如果我没有过于乐观的话)。
+
+你如何看待 Olive?你是否认同开发人员针对专业用户的目标?你希望 Olive 拥有哪些功能?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/olive-video-editor
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://www.olivevideoeditor.org/
+[2]: https://itsfoss.com/best-video-editing-software-linux/
+[3]: https://www.lwks.com/
+[4]: https://kdenlive.org/en/
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/olive-video-editor-interface.jpg?resize=800%2C450&ssl=1
+[6]: http://libregraphicsworld.org/blog/entry/introducing-olive-new-non-linear-video-editor
+[7]: https://itsfoss.com/flatpak-guide/
+[8]: https://itsfoss.com/use-appimage-linux/
+[9]: https://www.olivevideoeditor.org/download.php
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/olive-video-editor-interface.jpg?fit=800%2C450&ssl=1
diff --git a/translated/tech/20190131 Will quantum computing break security.md b/translated/tech/20190131 Will quantum computing break security.md
new file mode 100644
index 0000000000..a4b3792e6f
--- /dev/null
+++ b/translated/tech/20190131 Will quantum computing break security.md
@@ -0,0 +1,93 @@
+[#]: collector: (lujun9972)
+[#]: translator: (HankChow)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Will quantum computing break security?)
+[#]: via: (https://opensource.com/article/19/1/will-quantum-computing-break-security)
+[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
+
+量子计算会打破现有的安全体系吗?
+======
+
+> 你会希望黑客冒充成你的银行吗?
+
+
+
+近年来,量子计算机已经出现在大众的视野当中。量子计算机被认为是第六类计算机,这六类计算机包括:
+
+1. **人力:** 在人造的计算工具出现之前,人类只能使用人力去进行计算。而承担计算工作的人,只能被称为“计算者”。
+
+2. **模拟计算工具:** 由人类制造的一些模拟计算过程的小工具,例如[安提凯希拉装置][1]、星盘、计算尺等等。
+
+3. **机械工具:** 在这一个类别中包括了运用到离散数学但未使用电子技术进行计算的工具,例如算盘、Charles Babbage 的差分机等等。
+
+4. **电子模拟计算工具:** 这一个类别的计算机多数用于军事方面的用途,例如炸弹瞄准器、枪炮瞄准装置等等。
+
+5. **电子计算机:** 这个类别包含的种类就太多了,几乎包含现代所有的电子设备,从移动电话到超级计算机,都在这个类别当中。
+
+6. **量子计算机:** 即将进入我们的生活,而且与之前的几类完全不同。
+
+
+### 什么是量子计算?
+
+量子计算的概念来源于量子力学,因此使用的计算方式和我们平常使用的普通计算并不相同。如果想要深入理解,建议从参考[维基百科上的定义][2]开始。对我们来说,最重要的是理解这一点:量子计算机使用量子位进行计算。在这样的前提下,对于很多数学算法和运算操作,量子计算机的计算速度会比普通计算机要快得多。
+
+这里的“快得多”是按数量级来说的“快得多”。在某些情况下,一个计算任务如果由普通计算机来执行,可能要耗费几年或者几十年才能完成,但如果由量子计算机来执行,就只需要几秒钟。这样的速度甚至令人感到可怕。因为量子计算机会非常擅长信息的加密解密计算,即使在没有密钥的情况下,也能快速完成繁重的计算任务。
+
+这意味着,如果拥有足够强大的量子计算机,那么你的所有信息都会被一览无遗,任何被加密的数据都可以被正确解密出来,甚至伪造数字签名也会成为可能。这确实是一个严重的问题。毕竟谁也不想被黑客冒充成自己在用的银行,更不希望自己在区块链上的交易被篡改得面目全非。
+
+### 好消息
+
+尽管上面的提到的问题非常可怕,但也不需要太担心。
+
+首先,如果要实现上面提到的能力,一台可以操作大量量子位的量子计算机是必不可少的,而这个硬件上的要求就是一个很高的门槛。目前普遍认为,规模大得足以有效破解经典加密算法的量子计算机在最近几年还不可能出现。
+
+其次,除了攻击现有的加密算法需要大量的量子位以外,还需要很多量子位来保证容错性。
+
+还有,尽管确实有一些理论上的模型阐述了量子计算机如何对一些现有的算法作出攻击,但是要让这样的理论模型实际运作起来的难度会比我们想象中大得多。事实上,有一些攻击手段也是未被完全确认是可行的,又或者这些攻击手段还需要继续耗费很多年的改进才能到达如斯恐怖的程度。
+
+最后,还有很多专业人士正在研究能够防御量子计算的算法(这样的算法也被称为“后量子算法”)。如果这些防御算法经过测试以后投入使用,我们就可以使用这些算法进行加密,来对抗量子计算了。
+
+总而言之,很多专家都认为,我们现有的加密方式在未来 5 年甚至未来 10 年内都是安全的,不需要过分担心。
+
+### 也有坏消息
+
+但我们也并不是高枕无忧了,以下两个问题就值得我们关注:
+
+1. 人们在设计应用系统的时候仍然没有对量子计算作出太多的考量。如果设计的系统可能会使用 10 年以上,又或者数据存储和加密的时间跨度在 10 年以上,那么就必须考虑量子计算在未来会不会对系统造成不利的影响。
+
+2. 新出现的防御量子计算的算法可能会是专有的。也就是说,如果基于这些防御量子计算的算法来设计系统,那么在系统落地的时候,可能会需要为此付费。尽管我是支持开源的,尤其是[开源密码学][3],但我最担心的就是这方面的内容无法被开源。而且,在建立新的协议标准时,无论是故意的,无意的,还是别无选择,都很可能不会使用开源的专有算法。
+
+
+
+
+### 我们要怎样做?
+
+幸运的是,针对上述两个问题,我们还是有应对措施的。首先,在整个系统的设计阶段,就需要考虑到它是否会受到量子计算的影响,并作出相应的规划。当然了,不需要现在就立即采取行动,因为当前的技术水平也没法实现有效的方案,但至少也要[在加密方面保持敏捷性][4],以便在任何需要的时候为你的协议和系统更换更有效的加密算法。
+
+其次是参与开源运动。尽可能鼓励密码学方面的有识之士团结起来,支持开放标准,并投入对非专有的防御量子计算的算法研究当中去。这一点也算是当务之急,因为号召更多的人重视起来并加入研究,比研究本身更为重要。
+
+
+
+本文首发于《[Alice, Eve, and Bob][5]》,并在作者同意下重新发表。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/will-quantum-computing-break-security
+
+作者:[Mike Bursell][a]
+选题:[lujun9972][b]
+译者:[HankChow](https://github.com/HankChow)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mikecamel
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Antikythera_mechanism
+[2]: https://en.wikipedia.org/wiki/Quantum_computing
+[3]: https://opensource.com/article/17/10/many-eyes
+[4]: https://aliceevebob.com/2017/04/04/disbelieving-the-many-eyes-hypothesis/
+[5]: https://aliceevebob.com/2019/01/08/will-quantum-computing-break-security/
+
diff --git a/translated/tech/20190217 How to Change User Password in Ubuntu -Beginner-s Tutorial.md b/translated/tech/20190217 How to Change User Password in Ubuntu -Beginner-s Tutorial.md
new file mode 100644
index 0000000000..a2dfb77515
--- /dev/null
+++ b/translated/tech/20190217 How to Change User Password in Ubuntu -Beginner-s Tutorial.md
@@ -0,0 +1,129 @@
+[#]: collector: (lujun9972)
+[#]: translator: (An-DJ)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Change User Password in Ubuntu [Beginner’s Tutorial])
+[#]: via: (https://itsfoss.com/change-password-ubuntu)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+Ubuntu下如何修改用户密码 [新手教程]
+======
+**想要在Ubuntu下修改root用户的密码?那我们来学习下如何在Ubuntu Linux下修改任意用户的密码。我们会讨论在终端下修改和在图形界面(GUI)修改两种做法**
+
+那么,在Ubuntu下什么时候会需要修改密码呢?这里我给出如下两种场景。
+
+当你刚安装[Ubuntu][1]系统时,你会创建一个用户并且为之设置一个密码。这个初始密码可能安全性较弱或者太过于复杂,你会想要对它做出修改。
+
+如果你是系统管理员,你可能需要去修改在你管理的系统内其他用户的密码。
+
+当然,你可能会有其他的一些原因做这样的一件事。不过现在问题来了,我们到底如何在Ubuntu或Linux系统下修改单个用户的密码呢?
+
+在这个快速教程中,我将会展示给你在Ubuntu中如何使用命令行和图形界面(GUI)两种方式修改密码。
+
+### 在Ubuntu中修改用户密码[通过命令行]
+
+![如何在Ubuntu Linux下修改用户密码][2]
+
+在Ubuntu下修改用户密码其实非常简单。事实上,在任何Linux发行版上修改的方式都是一样的,因为你要使用的是叫做 passwd 的普通Linux命令来达到此目的。
+
+如果你想要修改你的当前密码,只需要简单地在终端执行此命令:
+
+```
+passwd
+```
+
+系统会要求你输入当前密码和两次新的密码。
+
+在键入密码时,你不会从屏幕上看到任何东西。这在UNIX和Linux系统中是非常正常的表现。
+
+```
+passwd
+
+Changing password for abhishek.
+
+(current) UNIX password:
+
+Enter new UNIX password:
+
+Retype new UNIX password:
+
+passwd: password updated successfully
+```
+
+由于这是你的管理员账户,你刚刚修改了Ubuntu下sudo的密码,但你甚至没有意识到这个操作。
+
+![在Linux命令行中修改用户密码][3]
+
+如果你想要修改其他用户的密码,你也可以使用passwd命令来做。但是在这种情况下,你将不得不使用sudo。
+
+```
+sudo passwd
+```
+
+如果你对密码已经做出了修改,不过之后忘记了,不要担心。你可以[很容易地在Ubuntu下重置密码][4].
+
+### 修改Ubuntu下root用户密码
+
+默认情况下,Ubuntu中root用户是没有密码的。不必惊讶,你并不是在Ubuntu下一直使用root用户。不太懂?让我快速地给你解释下。
+
+当[安装Ubuntu][5]时,你会被强制创建一个用户。这个用户拥有管理员访问权限。这个管理员用户可以通过sudo命令获得root访问权限。但是,该用户使用的是自身的密码,而不是root账户的密码(因为就没有)。
+
+你可以使用**passwd**命令来设置或修改root用户的密码。然而,在大多数情况下,你并不需要它,而且你不应该去做这样的事。
+
+你将不得不使用sudo命令(对于拥有管理员权限的账户)。如果root用户的密码之前没有被设置,它会要求你设置。另外,你可以使用已有的root密码对它进行修改。
+
+```
+sudo password root
+```
+
+### 在Ubuntu下使用图形界面(GUI)修改密码
+
+我这里使用的是GNOME桌面环境,Ubuntu版本为18.04。这些步骤对于其他桌面环境和Ubuntu版本应该差别不大。
+
+打开菜单(按下Windows/Super键)并搜索Settings。
+
+在Settings中,向下滚动一段距离打开进入Details。
+
+![在Ubuntu GNOME Settings中进入Details][6]
+
+在这里,点击Users获取系统下可见的所有用户。
+
+![Ubuntu下用户设置][7]
+
+你可以选择任一你想要的用户,包括你的主要管理员账户。你需要先解锁用户并点击密码(password)区域。
+
+![Ubuntu下修改用户密码][8]
+
+你会被要求设置密码。如果你正在修改的是你自己的密码,你将必须也输入当前使用的密码。
+
+![Ubuntu下修改用户密码][9]
+
+做好这些后,点击上面的Change按钮,这样就完成了。你已经成功地在Ubuntu下修改了用户密码。
+
+我希望这篇快速精简的小教程能够帮助你在Ubuntu下修改用户密码。如果你对此还有一些问题或建议,请在下方留下评论。
+
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/change-password-ubuntu
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[An-DJ](https://github.com/An-DJ)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://www.ubuntu.com/
+[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-password-ubuntu-linux.png?resize=800%2C450&ssl=1
+[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-user-password-linux-1.jpg?resize=800%2C253&ssl=1
+[4]: https://itsfoss.com/how-to-hack-ubuntu-password/
+[5]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
+[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-user-password-ubuntu-gui-2.jpg?resize=800%2C484&ssl=1
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-user-password-ubuntu-gui-3.jpg?resize=800%2C488&ssl=1
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-user-password-ubuntu-gui-4.jpg?resize=800%2C555&ssl=1
+[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-user-password-ubuntu-gui-1.jpg?ssl=1
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-password-ubuntu-linux.png?fit=800%2C450&ssl=1
diff --git a/translated/tech/20190219 How to List Installed Packages on Ubuntu and Debian -Quick Tip.md b/translated/tech/20190219 How to List Installed Packages on Ubuntu and Debian -Quick Tip.md
new file mode 100644
index 0000000000..cba74fd894
--- /dev/null
+++ b/translated/tech/20190219 How to List Installed Packages on Ubuntu and Debian -Quick Tip.md
@@ -0,0 +1,180 @@
+[#]: collector: (lujun9972)
+[#]: translator: (guevaraya)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to List Installed Packages on Ubuntu and Debian [Quick Tip])
+[#]: via: (https://itsfoss.com/list-installed-packages-ubuntu)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+如何索引 Ubuntu 和 Debian 上已安装的软件包 [快速提示]
+======
+
+当你安装了 [Ubuntu 并想好好用一用][1]。但在将来某个时候,你肯定会遇到忘记曾经安装了那些软件包。
+
+这个是完全正常。没有人要求你把系统里所有已安装的软件包都记住。但是问题是,如何才能知道已经安装了哪些软件包?如何查看安装过的软件包呢?
+
+### 索引 Ubuntu 和 Debian 上已安装的软件包
+
+![索引已安装的软件包][2]
+
+如果你经常用 [apt 命令][3],你可能会注意到 apt 可以索引已安装的软件包。这里说对了一点。
+
+
+[apt-get 命令] 没有类似索引已安装软件包的简单的选项,但是 apt 有一个这样的命令:
+```
+apt list --installed
+```
+这个会显示 apt 命令安装的所有的软件包。同时也会包含由于依赖被安装的软件包。也就是说不仅会包含你曾经安装的程序,而且会包含大量库文件和间接安装的软件包。
+
+![用 atp 命令索引显示已安装的软件包][5] 用 atp 命令索引显示已安装的软件包
+
+由于索引出来的已安装的软件包太多,用 grep 过滤特定的软件包是一个比较好的办法。
+```
+apt list --installed | grep program_name
+```
+
+如上命令也可以检索出 .deb 格式的软件包文件。是不是很酷?不是吗?
+
+如果你阅读过 [apt 与 apt-get 对比][7]的文章,你可能已经知道 apt 和 apt-get 命令都是基于 [dpkg][8]。也就是说用 dpkg 命令可以索引 Debian 系统的所有已经安装的软件包。
+
+```
+dpkg-query -l
+```
+你可以用 grep 命令检索指定的软件包。
+
+![用 dpkg 命令索引显示已经安装的软件包][9]![用 dpkg 命令索引显示已经安装的软件包][9]用 dpkg 命令索引显示已经安装的软件包
+
+
+现在你可以搞定索引 Debian 的软件包管理器安装的应用了。那 Snap 和 Flatpak 这个两种应用呢?如何索引他们?因为他们不能被 apt 和 dpkg 访问。
+
+显示系统里所有已经安装的 [Snap 软件包][10],可以这个命令:
+
+```
+snap list
+```
+Snap 可以用绿色勾号索引显示经过认证的发布者。
+![索引已经安装的 Snap 软件包][11]索引已经安装的 Snap 软件包
+
+显示系统里所有已安装的 [Flatpak 软件包][12],可以用这个命令:
+
+```
+flatpak list
+```
+
+让我来个汇总:
+
+
+用 apt 命令显示已安装软件包:
+
+**apt** **list –installed**
+
+用 dpkg 命令显示已安装软件包:
+
+**dpkg-query -l**
+
+索引系统里 Snap 已安装软件包:
+
+**snap list**
+
+索引系统里 Flatpak 已安装软件包:
+
+**flatpak list**
+
+### 显示最近安装的软件包
+
+现在你已经看过以字母顺序索引的已经安装软件包了。如何显示最近已经安装的软件包?
+
+幸运的是,Linux 系统保存了所有发生事件的日志。你可以参考最近安装软件包的日志。
+
+有两个方法可以来做。用 dpkg 命令的日志或者 apt 命令的日志。
+
+你仅仅需要用 grep 命令过滤已经安装的软件包日志。
+
+```
+grep " install " /var/log/dpkg.log
+```
+
+这会显示所有的软件安装包,其中包括最近安装的过程中被依赖的软件包。
+
+```
+2019-02-12 12:41:42 install ubuntu-make:all 16.11.1ubuntu1
+2019-02-13 21:03:02 install xdg-desktop-portal:amd64 0.11-1
+2019-02-13 21:03:02 install libostree-1-1:amd64 2018.8-0ubuntu0.1
+2019-02-13 21:03:02 install flatpak:amd64 1.0.6-0ubuntu0.1
+2019-02-13 21:03:02 install xdg-desktop-portal-gtk:amd64 0.11-1
+2019-02-14 11:49:10 install qml-module-qtquick-window2:amd64 5.9.5-0ubuntu1.1
+2019-02-14 11:49:10 install qml-module-qtquick2:amd64 5.9.5-0ubuntu1.1
+2019-02-14 11:49:10 install qml-module-qtgraphicaleffects:amd64 5.9.5-0ubuntu1
+```
+
+你也可以查看 apt历史命令日志。这个仅会显示用 apt 命令安装的的程序。但不会显示被依赖安装的软件包,详细的日志在日志里可以看到。有时你只是想看看对吧?
+
+```
+grep " install " /var/log/apt/history.log
+```
+
+具体的显示如下:
+
+```
+Commandline: apt install pinta
+Commandline: apt install pinta
+Commandline: apt install tmux
+Commandline: apt install terminator
+Commandline: apt install moreutils
+Commandline: apt install ubuntu-make
+Commandline: apt install flatpak
+Commandline: apt install cool-retro-term
+Commandline: apt install ubuntu-software
+```
+
+![显示最近已安装的软件包][13]显示最近已安装的软件包
+
+apt 的历史日志非常有用。因为他显示了什么时候执行了 apt 命令,哪个用户执行的命令以及安装的软件包名
+
+### 小贴士: 在软件中心显示已安装的程序包名
+
+如果你觉得终端和命令行交互不友好,可以有一个方法查看系统的程序名。
+
+可以打开软件中心,然后点击已安装标签。你可以看到系统上已经安装的程序包名
+
+![Ubuntu 软件中心显示已安装的软件包][14] 在软件中心显示已安装的软件包
+
+这个不会显示库和其他命令行的东西,有可能你也不想看到他们,因为你是大量交互都是在 GUI,相反你可以一直用 Synaptic 软件包管理器。
+
+**结束语**
+
+我希望这个简易的教程可以帮你查看 Ubuntu 和 基于 Debian 的发行版的已安装软件包。
+
+如果你对本文有什么问题或建议,请在下面留言。
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/list-installed-packages-ubuntu
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[guevaraya](https://github.com/guevaraya)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/getting-started-with-ubuntu/
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages.png?resize=800%2C450&ssl=1
+[3]: https://itsfoss.com/apt-command-guide/
+[4]: https://itsfoss.com/apt-get-linux-guide/
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages-in-ubuntu-with-apt.png?resize=800%2C407&ssl=1
+[6]: https://itsfoss.com/install-deb-files-ubuntu/
+[7]: https://itsfoss.com/apt-vs-apt-get-difference/
+[8]: https://wiki.debian.org/dpkg
+[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages-with-dpkg.png?ssl=1
+[10]: https://itsfoss.com/use-snap-packages-ubuntu-16-04/
+[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-snap-packages.png?ssl=1
+[12]: https://itsfoss.com/flatpak-guide/
+[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/apt-list-recently-installed-packages.png?resize=800%2C187&ssl=1
+[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/installed-software-ubuntu.png?ssl=1
+[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages.png?fit=800%2C450&ssl=1