mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-01 21:50:13 +08:00
commit
867e236ef4
@ -0,0 +1,287 @@
|
||||
服务端 I/O 性能:Node、PHP、Java、Go 的对比
|
||||
============
|
||||
|
||||
了解应用程序的输入/输出(I/O)模型意味着理解应用程序处理其数据的载入差异,并揭示其在真实环境中表现。或许你的应用程序很小,在不承受很大的负载时,这并不是个严重的问题;但随着应用程序的流量负载增加,可能因为使用了低效的 I/O 模型导致承受不了而崩溃。
|
||||
|
||||
和大多数情况一样,处理这种问题的方法有多种方式,这不仅仅是一个择优的问题,而是对权衡的理解问题。 接下来我们来看看 I/O 到底是什么。
|
||||
|
||||

|
||||
|
||||
在本文中,我们将对 Node、Java、Go 和 PHP + Apache 进行对比,讨论不同语言如何构造其 I/O ,每个模型的优缺点,并总结一些基本的规律。如果你担心你的下一个 Web 应用程序的 I/O 性能,本文将给你最优的解答。
|
||||
|
||||
### I/O 基础知识: 快速复习
|
||||
|
||||
要了解 I/O 所涉及的因素,我们首先深入到操作系统层面复习这些概念。虽然看起来并不与这些概念直接打交道,但你会一直通过应用程序的运行时环境与它们间接接触。了解细节很重要。
|
||||
|
||||
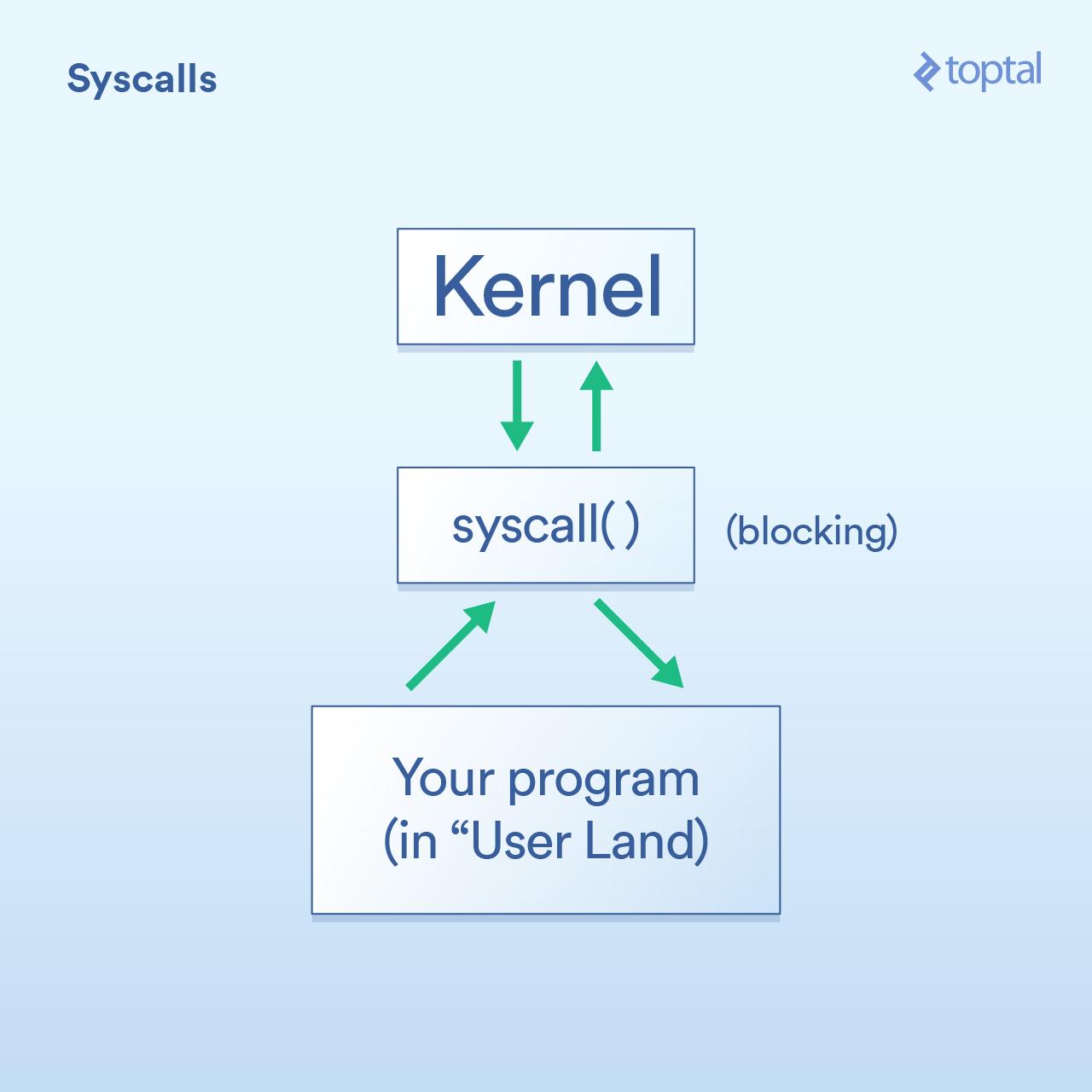
#### 系统调用
|
||||
|
||||
首先是系统调用,其被描述如下:
|
||||
|
||||
* 程序(所谓“<ruby>用户端<rt>user land</rt></ruby>”)必须请求操作系统内核代表它执行 I/O 操作。
|
||||
* “<ruby>系统调用<rt>syscall</rt></ruby>”是你的程序要求内核执行某些操作的方法。这些实现的细节在操作系统之间有所不同,但基本概念是相同的。有一些具体的指令会将控制权从你的程序转移到内核(类似函数调用,但是使用专门用于处理这种情况的专用方式)。一般来说,系统调用会被阻塞,这意味着你的程序会等待内核返回(控制权到)你的代码。
|
||||
* 内核在所需的物理设备( 磁盘、网卡等 )上执行底层 I/O 操作,并回应系统调用。在实际情况中,内核可能需要做许多事情来满足你的要求,包括等待设备准备就绪、更新其内部状态等,但作为应用程序开发人员,你不需要关心这些。这是内核的工作。
|
||||
|
||||
|
||||
|
||||
#### 阻塞与非阻塞
|
||||
|
||||
上面我们提到过,系统调用是阻塞的,一般来说是这样的。然而,一些调用被归类为“非阻塞”,这意味着内核会接收你的请求,将其放在队列或缓冲区之类的地方,然后立即返回而不等待实际的 I/O 发生。所以它只是在很短的时间内“阻塞”,只需要排队你的请求即可。
|
||||
|
||||
举一些 Linux 系统调用的例子可能有助于理解:
|
||||
|
||||
- `read()` 是一个阻塞调用 - 你传递一个句柄,指出哪个文件和缓冲区在哪里传送它所读取的数据,当数据就绪时,该调用返回。这种方式的优点是简单友好。
|
||||
- 分别调用 `epoll_create()`、`epoll_ctl()` 和 `epoll_wait()` ,你可以创建一组句柄来侦听、添加/删除该组中的处理程序、然后阻塞直到有任何事件发生。这允许你通过单个线程有效地控制大量的 I/O 操作,但是现在谈这个还太早。如果你需要这个功能当然好,但须知道它使用起来是比较复杂的。
|
||||
|
||||
了解这里的时间差异的数量级是很重要的。假设 CPU 内核运行在 3GHz,在没有进行 CPU 优化的情况下,那么它每秒执行 30 亿次<ruby>周期<rt>cycle</rt></ruby>(即每纳秒 3 个周期)。非阻塞系统调用可能需要几十个周期来完成,或者说 “相对少的纳秒” 时间完成。而一个被跨网络接收信息所阻塞的系统调用可能需要更长的时间 - 例如 200 毫秒(1/5 秒)。这就是说,如果非阻塞调用需要 20 纳秒,阻塞调用需要 2 亿纳秒。你的进程因阻塞调用而等待了 1000 万倍的时长!
|
||||
|
||||

|
||||
|
||||
内核既提供了阻塞 I/O (“从网络连接读取并给出数据”),也提供了非阻塞 I/O (“告知我何时这些网络连接具有新数据”)的方法。使用的是哪种机制对调用进程的阻塞时长有截然不同的影响。
|
||||
|
||||
#### 调度
|
||||
|
||||
关键的第三件事是当你有很多线程或进程开始阻塞时会发生什么。
|
||||
|
||||
根据我们的理解,线程和进程之间没有很大的区别。在现实生活中,最显著的性能相关的差异在于,由于线程共享相同的内存,而进程每个都有自己的内存空间,使得单独的进程往往占用更多的内存。但是当我们谈论<ruby>调度<rt>Scheduling</rt></ruby>时,它真正归结为一类事情(线程和进程类同),每个都需要在可用的 CPU 内核上获得一段执行时间。如果你有 300 个线程运行在 8 个内核上,则必须将时间分成几份,以便每个线程和进程都能分享它,每个运行一段时间,然后交给下一个。这是通过 “<ruby>上下文切换<rt>context switch</rt></ruby>” 完成的,可以使 CPU 从运行到一个线程/进程到切换下一个。
|
||||
|
||||
这些上下文切换也有相关的成本 - 它们需要一些时间。在某些快速的情况下,它可能小于 100 纳秒,但根据实际情况、处理器速度/体系结构、CPU 缓存等,偶见花费 1000 纳秒或更长时间。
|
||||
|
||||
而线程(或进程)越多,上下文切换就越多。当我们涉及数以千计的线程时,每个线程花费数百纳秒,就会变得很慢。
|
||||
|
||||
然而,非阻塞调用实质上是告诉内核“仅在这些连接之一有新的数据或事件时再叫我”。这些非阻塞调用旨在有效地处理大量 I/O 负载并减少上下文交换。
|
||||
|
||||
这些你明白了么?现在来到了真正有趣的部分:我们来看看一些流行的语言对那些工具的使用,并得出关于易用性和性能之间权衡的结论,以及一些其他有趣小东西。
|
||||
|
||||
声明,本文中显示的示例是零碎的(片面的,只能体现相关的信息); 数据库访问、外部缓存系统( memcache 等等)以及任何需要 I/O 的东西都将执行某种类型的 I/O 调用,其实质与上面所示的简单示例效果相同。此外,对于将 I/O 描述为“阻塞”( PHP、Java )的情况,HTTP 请求和响应读取和写入本身就是阻塞调用:系统中隐藏着更多 I/O 及其伴生的性能问题需要考虑。
|
||||
|
||||
为一个项目选择编程语言要考虑很多因素。甚至当你只考虑效率时,也有很多因素。但是,如果你担心你的程序将主要受到 I/O 的限制,如果 I/O 性能影响到项目的成败,那么这些是你需要了解的。
|
||||
|
||||
### “保持简单”方法:PHP
|
||||
|
||||
早在 90 年代,很多人都穿着 [Converse][1] 鞋,用 Perl 写着 CGI 脚本。然后 PHP 来了,就像一些人喜欢咒骂的一样,它使得动态网页更容易。
|
||||
|
||||
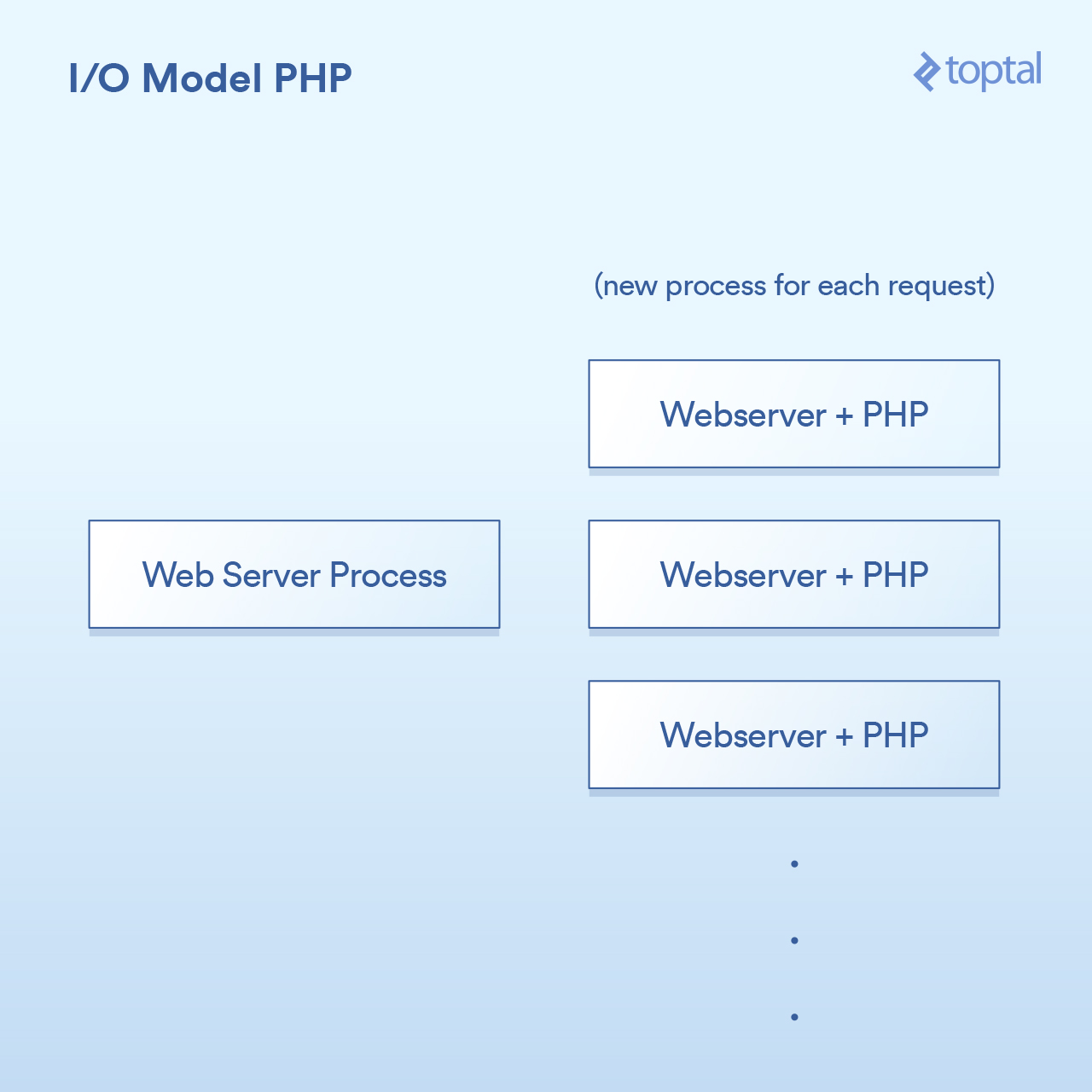
PHP 使用的模型相当简单。虽有一些出入,但你的 PHP 服务器基本上是这样:
|
||||
|
||||
HTTP 请求来自用户的浏览器,并访问你的 Apache Web 服务器。Apache 为每个请求创建一个单独的进程,有一些优化方式可以重新使用它们,以最大限度地减少创建次数( 相对而言,创建进程较慢 )。Apache 调用 PHP 并告诉它运行磁盘上合适的 `.php` 文件。PHP 代码执行并阻塞 I/O 调用。你在 PHP 中调用 `file_get_contents()` ,其底层会调用 `read()` 系统调用并等待结果。
|
||||
|
||||
当然,实际的代码是直接嵌入到你的页面,并且该操作被阻塞:
|
||||
|
||||
```
|
||||
<?php
|
||||
|
||||
// blocking file I/O
|
||||
$file_data = file_get_contents(‘/path/to/file.dat’);
|
||||
|
||||
// blocking network I/O
|
||||
$curl = curl_init('http://example.com/example-microservice');
|
||||
$result = curl_exec($curl);
|
||||
|
||||
// some more blocking network I/O
|
||||
$result = $db->query('SELECT id, data FROM examples ORDER BY id DESC limit 100');
|
||||
|
||||
?>
|
||||
|
||||
```
|
||||
|
||||
关于如何与系统集成,就像这样:
|
||||
|
||||
|
||||
|
||||
很简单:每个请求一个进程。 I/O 调用就阻塞。优点是简单可工作,缺点是,同时与 20,000 个客户端连接,你的服务器将会崩溃。这种方法不能很好地扩展,因为内核提供的用于处理大容量 I/O (epoll 等) 的工具没有被使用。 雪上加霜的是,为每个请求运行一个单独的进程往往会使用大量的系统资源,特别是内存,这通常是你在这样的场景中遇到的第一个问题。
|
||||
|
||||
_注意:Ruby 使用的方法与 PHP 非常相似,在大致的方面上,它们可以被认为是相同的。_
|
||||
|
||||
### 多线程方法: Java
|
||||
|
||||
就在你购买你的第一个域名,在某个句子后很酷地随机说出 “dot com” 的那个时候,Java 来了。而 Java 具有内置于该语言中的多线程功能,它非常棒(特别是在创建时)。
|
||||
|
||||
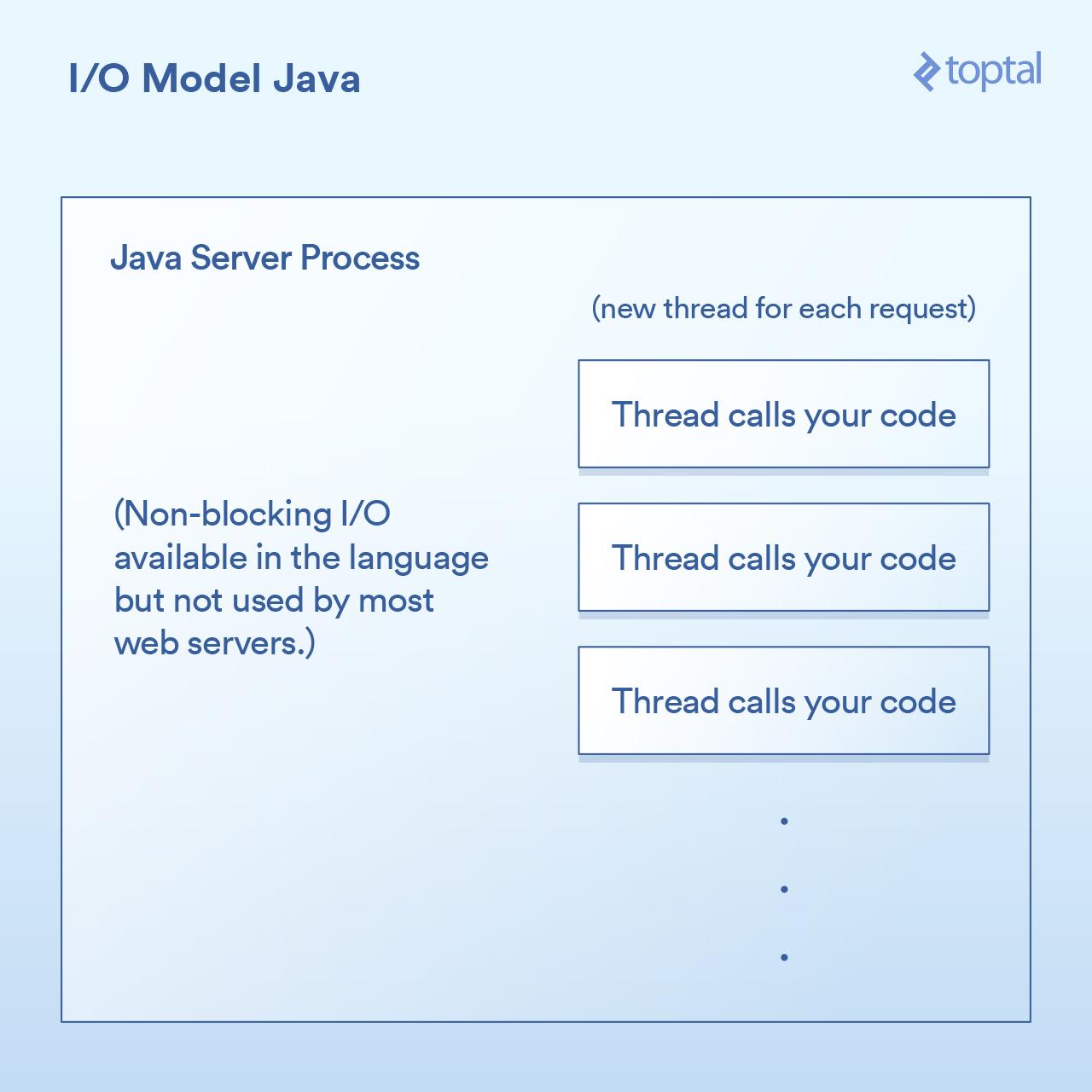
大多数 Java Web 服务器通过为每个请求启动一个新的执行线程,然后在该线程中最终调用你(作为应用程序开发人员)编写的函数。
|
||||
|
||||
在 Java Servlet 中执行 I/O 往往看起来像:
|
||||
|
||||
```
|
||||
public void doGet(HttpServletRequest request,
|
||||
HttpServletResponse response) throws ServletException, IOException
|
||||
{
|
||||
|
||||
// blocking file I/O
|
||||
InputStream fileIs = new FileInputStream("/path/to/file");
|
||||
|
||||
// blocking network I/O
|
||||
URLConnection urlConnection = (new URL("http://example.com/example-microservice")).openConnection();
|
||||
InputStream netIs = urlConnection.getInputStream();
|
||||
|
||||
// some more blocking network I/O
|
||||
out.println("...");
|
||||
}
|
||||
```
|
||||
|
||||
由于我们上面的 `doGet` 方法对应于一个请求,并且在其自己的线程中运行,而不是每个请求一个单独的进程,申请自己的内存。这样有一些好处,比如在线程之间共享状态、缓存数据等,因为它们可以访问彼此的内存,但是它与调度的交互影响与之前的 PHP 的例子几乎相同。每个请求获得一个新线程,该线程内的各种 I/O 操作阻塞在线程内,直到请求被完全处理为止。线程被池化以最小化创建和销毁它们的成本,但是数千个连接仍然意味着数千个线程,这对调度程序是不利的。
|
||||
|
||||
重要的里程碑出现在 Java 1.4 版本(以及 1.7 的重要升级)中,它获得了执行非阻塞 I/O 调用的能力。大多数应用程序、web 应用和其它用途不会使用它,但至少它是可用的。一些 Java Web 服务器尝试以各种方式利用这一点;然而,绝大多数部署的 Java 应用程序仍然如上所述工作。
|
||||
|
||||
|
||||
|
||||
肯定有一些很好的开箱即用的 I/O 功能,Java 让我们更接近,但它仍然没有真正解决当你有一个大量的 I/O 绑定的应用程序被数千个阻塞线程所压垮的问题。
|
||||
|
||||
### 无阻塞 I/O 作为一等公民: Node
|
||||
|
||||
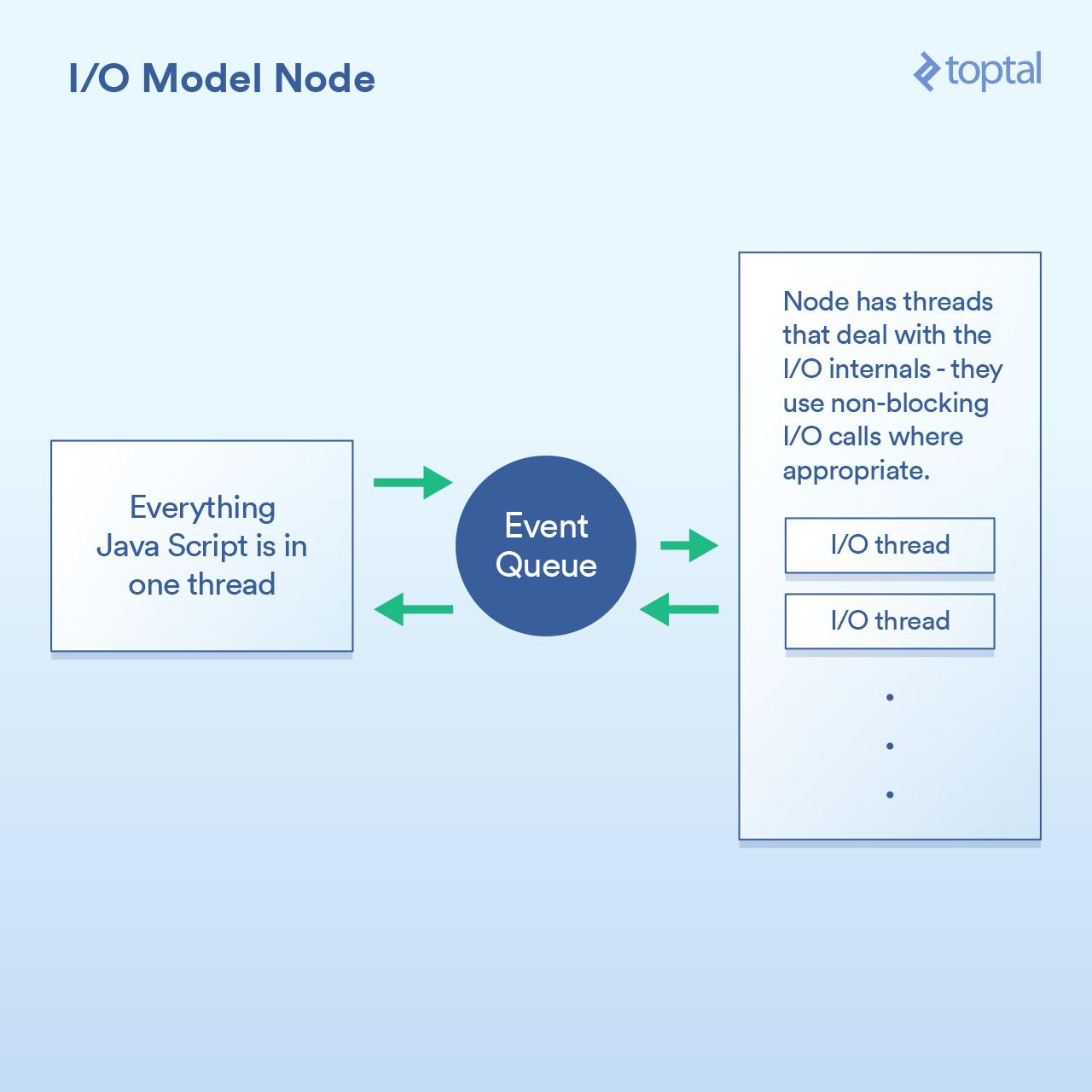
当更好的 I/O 模式来到 Node.js,阻塞才真正被解决。任何一个曾听过 Node 简单介绍的人都被告知这是“非阻塞”,可以有效地处理 I/O。这在一般意义上是正确的。但在细节中则不尽然,而且当在进行性能工程时,这种巫术遇到了问题。
|
||||
|
||||
Node 实现的范例基本上不是说 “在这里写代码来处理请求”,而是说 “在这里写代码来**开始**处理请求”。每次你需要做一些涉及到 I/O 的操作,你会创建一个请求并给出一个回调函数,Node 将在完成之后调用该函数。
|
||||
|
||||
在请求中执行 I/O 操作的典型 Node 代码如下所示:
|
||||
|
||||
```
|
||||
http.createServer(function(request, response) {
|
||||
fs.readFile('/path/to/file', 'utf8', function(err, data) {
|
||||
response.end(data);
|
||||
});
|
||||
});
|
||||
|
||||
```
|
||||
|
||||
你可以看到,这里有两个回调函数。当请求开始时,第一个被调用,当文件数据可用时,第二个被调用。
|
||||
|
||||
这样做的基本原理是让 Node 有机会有效地处理这些回调之间的 I/O 。一个更加密切相关的场景是在 Node 中进行数据库调用,但是我不会在这个例子中啰嗦,因为它遵循完全相同的原则:启动数据库调用,并给 Node 一个回调函数,它使用非阻塞调用单独执行 I/O 操作,然后在你要求的数据可用时调用回调函数。排队 I/O 调用和让 Node 处理它然后获取回调的机制称为“事件循环”。它工作的很好。
|
||||
|
||||
|
||||
|
||||
然而,这个模型有一个陷阱,究其原因,很多是与 V8 JavaScript 引擎(Node 用的是 Chrome 浏览器的 JS 引擎)如何实现的有关^注1 。你编写的所有 JS 代码都运行在单个线程中。你可以想想,这意味着当使用高效的非阻塞技术执行 I/O 时,你的 JS 可以在单个线程中运行计算密集型的操作,每个代码块都会阻塞下一个。可能出现这种情况的一个常见例子是以某种方式遍历数据库记录,然后再将其输出到客户端。这是一个示例,展示了其是如何工作:
|
||||
|
||||
```
|
||||
var handler = function(request, response) {
|
||||
|
||||
connection.query('SELECT ...', function (err, rows) {
|
||||
|
||||
if (err) { throw err };
|
||||
|
||||
for (var i = 0; i < rows.length; i++) {
|
||||
// do processing on each row
|
||||
}
|
||||
|
||||
response.end(...); // write out the results
|
||||
|
||||
})
|
||||
|
||||
};
|
||||
```
|
||||
|
||||
虽然 Node 确实有效地处理了 I/O ,但是上面的例子中 `for` 循环是在你的唯一的一个主线程中占用 CPU 周期。这意味着如果你有 10,000 个连接,则该循环可能会使你的整个应用程序像爬行般缓慢,具体取决于其会持续多久。每个请求必须在主线程中分享一段时间,一次一段。
|
||||
|
||||
这整个概念的前提是 I/O 操作是最慢的部分,因此最重要的是要有效地处理这些操作,即使这意味着要连续进行其他处理。这在某些情况下是正确的,但不是全部。
|
||||
|
||||
另一点是,虽然这只是一个观点,但是写一堆嵌套的回调可能是相当令人讨厌的,有些则认为它使代码更难以追踪。在 Node 代码中看到回调嵌套 4 层、5 层甚至更多层并不罕见。
|
||||
|
||||
我们再次来权衡一下。如果你的主要性能问题是 I/O,则 Node 模型工作正常。然而,它的关键是,你可以在一个处理 HTTP 请求的函数里面放置 CPU 密集型的代码,而且不小心的话会导致每个连接都很慢。
|
||||
|
||||
### 最自然的非阻塞:Go
|
||||
|
||||
在我进入 Go 部分之前,我应该披露我是一个 Go 的粉丝。我已经在许多项目中使用过它,我是一个其生产力优势的公开支持者,我在我的工作中使用它。
|
||||
|
||||
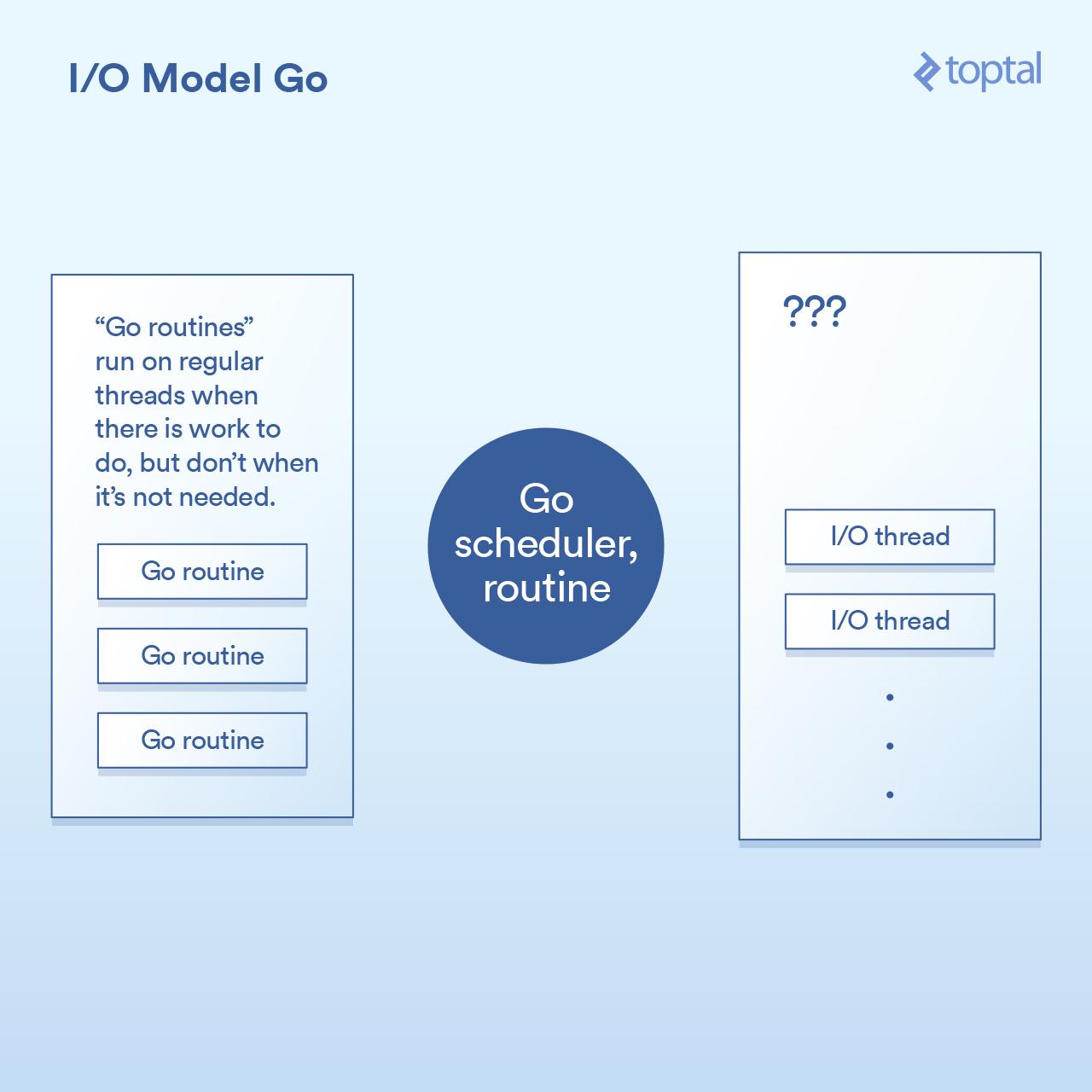
那么,让我们来看看它是如何处理 I/O 的。Go 语言的一个关键特征是它包含自己的调度程序。在 Go 中,不是每个执行线程对应于一个单一的 OS 线程,其通过一种叫做 “<ruby>协程<rt>goroutine</rt></ruby>” 的概念来工作。而 Go 的运行时可以将一个协程分配给一个 OS 线程,使其执行或暂停它,并且它不与一个 OS 线程相关联——这要基于那个协程正在做什么。来自 Go 的 HTTP 服务器的每个请求都在单独的协程中处理。
|
||||
|
||||
调度程序的工作原理如图所示:
|
||||
|
||||
|
||||
|
||||
在底层,这是通过 Go 运行时中的各个部分实现的,它通过对请求的写入/读取/连接等操作来实现 I/O 调用,将当前协程休眠,并当采取进一步动作时唤醒该协程。
|
||||
|
||||
从效果上看,Go 运行时做的一些事情与 Node 做的没有太大不同,除了回调机制是内置到 I/O 调用的实现中,并自动与调度程序交互。它也不会受到必须让所有处理程序代码在同一个线程中运行的限制,Go 将根据其调度程序中的逻辑自动将协程映射到其认为适当的 OS 线程。结果是这样的代码:
|
||||
|
||||
```
|
||||
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
|
||||
|
||||
// the underlying network call here is non-blocking
|
||||
rows, err := db.Query("SELECT ...")
|
||||
|
||||
for _, row := range rows {
|
||||
// do something with the rows,
|
||||
// each request in its own goroutine
|
||||
}
|
||||
|
||||
w.Write(...) // write the response, also non-blocking
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
如上所述,我们重构基本的代码结构为更简化的方式,并在底层仍然实现了非阻塞 I/O。
|
||||
|
||||
在大多数情况下,最终是“两全其美”的。非阻塞 I/O 用于所有重要的事情,但是你的代码看起来像是阻塞,因此更容易理解和维护。Go 调度程序和 OS 调度程序之间的交互处理其余部分。这不是完整的魔法,如果你建立一个大型系统,那么值得我们来看看有关它的工作原理的更多细节;但与此同时,你获得的“开箱即用”的环境可以很好地工作和扩展。
|
||||
|
||||
Go 可能有其缺点,但一般来说,它处理 I/O 的方式不在其中。
|
||||
|
||||
### 谎言,可恶的谎言和基准
|
||||
|
||||
对这些各种模式的上下文切换进行准确的定时是很困难的。我也可以认为这对你来说不太有用。相反,我会给出一些比较这些服务器环境的整个 HTTP 服务器性能的基本基准。请记住,影响整个端到端 HTTP 请求/响应路径的性能有很多因素,这里提供的数字只是我将一些样本放在一起进行基本比较的结果。
|
||||
|
||||
对于这些环境中的每一个,我写了适当的代码在一个 64k 文件中读取随机字节,在其上运行了一个 SHA-256 哈希 N 次( N 在 URL 的查询字符串中指定,例如 .../test.php?n=100),并打印出结果十六进制散列。我选择这样做,是因为使用一些一致的 I/O 和受控的方式来运行相同的基准测试是一个增加 CPU 使用率的非常简单的方法。
|
||||
|
||||
有关使用的环境的更多细节,请参阅 [基准说明][3] 。
|
||||
|
||||
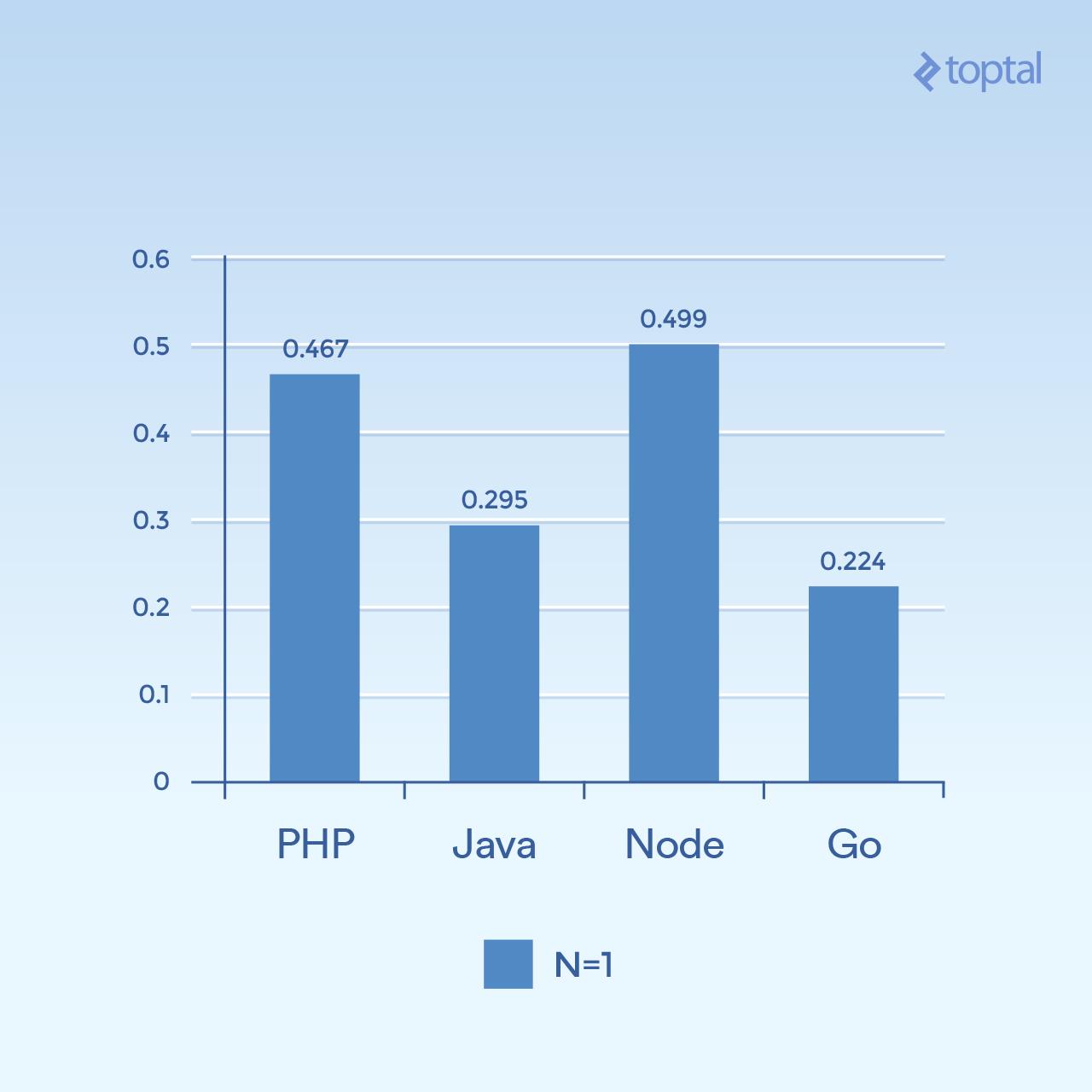
首先,我们来看一些低并发的例子。运行 2000 次迭代,300 个并发请求,每个请求只有一个散列(N = 1),结果如下:
|
||||
|
||||
|
||||
|
||||
*时间是在所有并发请求中完成请求的平均毫秒数。越低越好。*
|
||||
|
||||
仅从一张图很难得出结论,但是对我来说,似乎在大量的连接和计算量上,我们看到时间更多地与语言本身的一般执行有关,对于 I/O 更是如此。请注意,那些被视为“脚本语言”的语言(松散类型,动态解释)执行速度最慢。
|
||||
|
||||
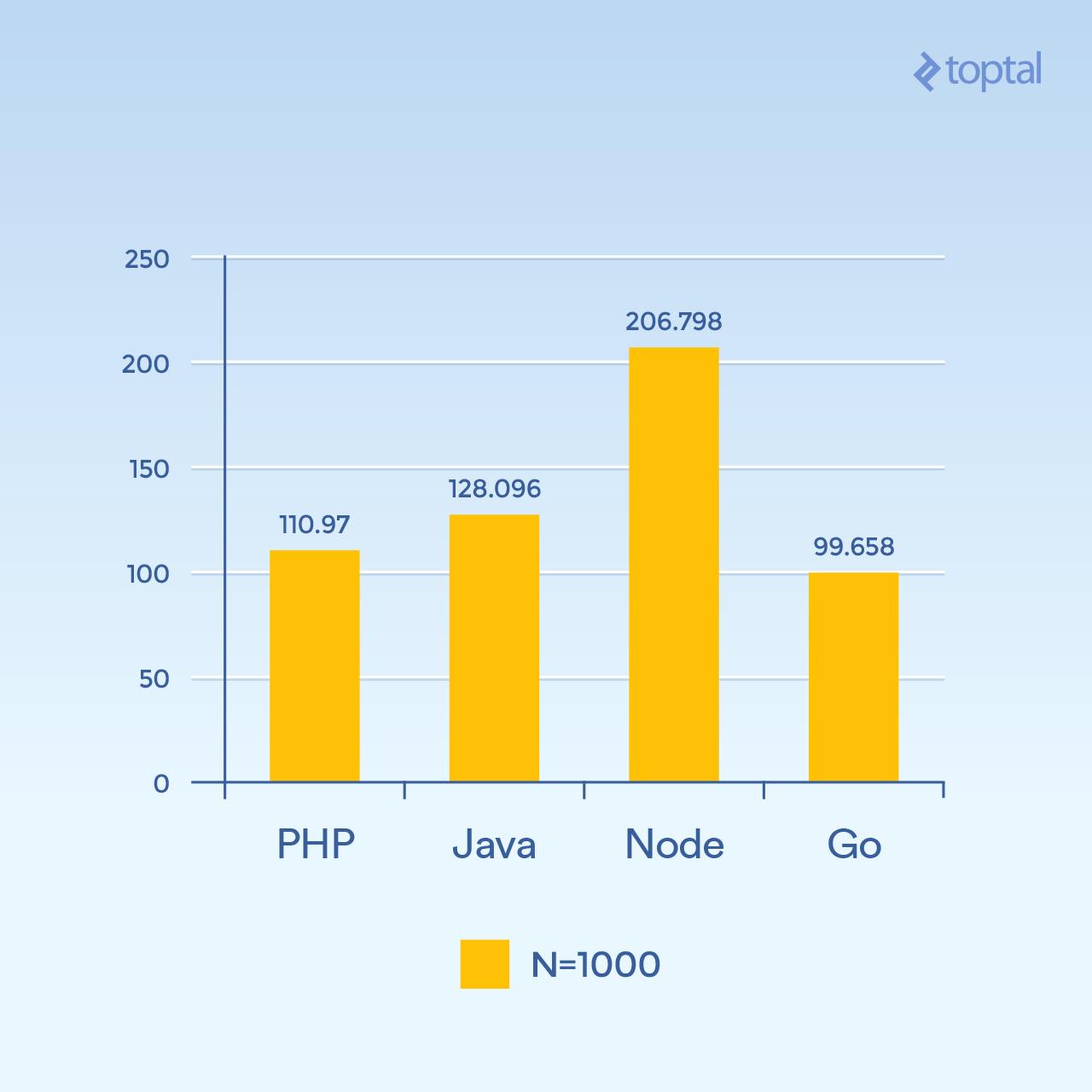
但是,如果我们将 N 增加到 1000,仍然有 300 个并发请求,相同的任务,但是哈希迭代是 1000 倍(显着增加了 CPU 负载):
|
||||
|
||||
|
||||
|
||||
*时间是在所有并发请求中完成请求的平均毫秒数。越低越好。*
|
||||
|
||||
突然间, Node 性能显著下降,因为每个请求中的 CPU 密集型操作都相互阻塞。有趣的是,在这个测试中,PHP 的性能要好得多(相对于其他的),并且打败了 Java。(值得注意的是,在 PHP 中,SHA-256 实现是用 C 编写的,在那个循环中执行路径花费了更多的时间,因为现在我们正在进行 1000 个哈希迭代)。
|
||||
|
||||
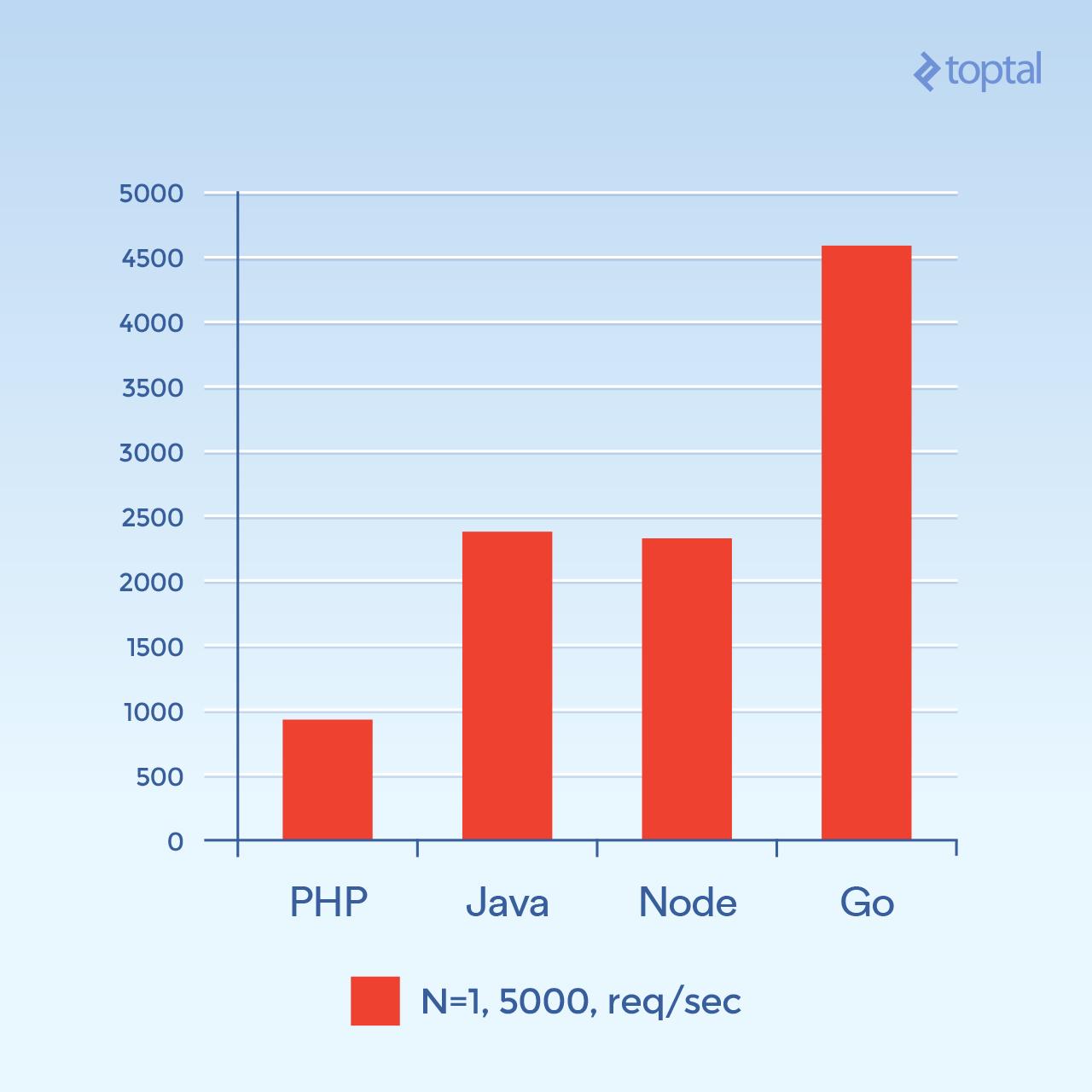
现在让我们尝试 5000 个并发连接(N = 1) - 或者是我可以发起的最大连接。不幸的是,对于大多数这些环境,故障率并不显着。对于这个图表,我们来看每秒的请求总数。 _越高越好_ :
|
||||
|
||||
|
||||
|
||||
*每秒请求数。越高越好。*
|
||||
|
||||
这个图看起来有很大的不同。我猜测,但是看起来像在高连接量时,产生新进程所涉及的每连接开销以及与 PHP + Apache 相关联的附加内存似乎成为主要因素,并阻止了 PHP 的性能。显然,Go 是这里的赢家,其次是 Java,Node,最后是 PHP。
|
||||
|
||||
虽然与你的整体吞吐量相关的因素很多,并且在应用程序之间也有很大的差异,但是你对底层发生什么的事情以及所涉及的权衡了解更多,你将会得到更好的结果。
|
||||
|
||||
### 总结
|
||||
|
||||
以上所有这一切,很显然,随着语言的发展,处理大量 I/O 的大型应用程序的解决方案也随之发展。
|
||||
|
||||
为了公平起见,PHP 和 Java,尽管这篇文章中的描述,确实 [实现了][4] 在 [ web 应用程序][7] 中 [可使用的][6] [ 非阻塞 I/O][5] 。但是这些方法并不像上述方法那么常见,并且需要考虑使用这种方法来维护服务器的随之而来的操作开销。更不用说你的代码必须以与这些环境相适应的方式进行结构化;你的 “正常” PHP 或 Java Web 应用程序通常不会在这样的环境中进行重大修改。
|
||||
|
||||
作为比较,如果我们考虑影响性能和易用性的几个重要因素,我们得出以下结论:
|
||||
|
||||
| 语言 | 线程与进程 | 非阻塞 I/O | 使用便捷性 |
|
||||
| --- | --- | --- | --- |
|
||||
| PHP | 进程 | 否 | |
|
||||
| Java | 线程 | 可用 | 需要回调 |
|
||||
| Node.js | 线程 | 是 | 需要回调 |
|
||||
| Go | 线程 (协程) | 是 | 不需要回调 |
|
||||
|
||||
线程通常要比进程有更高的内存效率,因为它们共享相同的内存空间,而进程则没有。结合与非阻塞 I/O 相关的因素,我们可以看到,至少考虑到上述因素,当我们从列表往下看时,与 I/O 相关的一般设置得到改善。所以如果我不得不在上面的比赛中选择一个赢家,那肯定会是 Go。
|
||||
|
||||
即使如此,在实践中,选择构建应用程序的环境与你的团队对所述环境的熟悉程度以及你可以实现的总体生产力密切相关。因此,每个团队都深入并开始在 Node 或 Go 中开发 Web 应用程序和服务可能就没有意义。事实上,寻找开发人员或你内部团队的熟悉度通常被认为是不使用不同语言和/或环境的主要原因。也就是说,过去十五年来,时代已经发生了变化。
|
||||
|
||||
希望以上内容可以帮助你更清楚地了解底层发生的情况,并为你提供如何处理应用程序的现实可扩展性的一些想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.toptal.com/back-end/server-side-io-performance-node-php-java-go
|
||||
|
||||
作者:[BRAD PEABODY][a]
|
||||
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.toptal.com/resume/brad-peabody
|
||||
[1]:https://www.pinterest.com/pin/414401603185852181/
|
||||
[2]:http://www.journaldev.com/7462/node-js-architecture-single-threaded-event-loop
|
||||
[3]:https://peabody.io/post/server-env-benchmarks/
|
||||
[4]:http://reactphp.org/
|
||||
[5]:http://amphp.org/
|
||||
[6]:http://undertow.io/
|
||||
[7]:https://netty.io/
|
||||
@ -1,88 +1,82 @@
|
||||
使用 Docker 构建你的 Serverless 树莓派集群
|
||||
============================================================
|
||||
|
||||
这篇博文将向你展示如何使用 Docker 和 [OpenFaaS][33] 框架构建你自己的 Serverless 树莓派集群。大家常常问我能用他们的集群来做些什么?而这个应用完美匹配卡片尺寸的设备——只需添加更多的树莓派就能获取更强的计算能力。
|
||||
|
||||
这篇博文将向你展示如何使用 Docker 和 [OpenFaaS][33] 框架构建你自己的 Serverless 树莓派集群。大家常常问我他们能用他们的集群来做些什么?这个应用完美匹配卡片尺寸的设备——只需添加更多的树莓派就能获取更强的计算能力。
|
||||
> “Serverless” (无服务器)是事件驱动架构的一种设计模式,与“桥接模式”、“外观模式”、“工厂模式”和“云”这些名词一样,都是一种抽象概念。
|
||||
|
||||
> “Serverless” 是事件驱动架构的一种设计模式,与“桥接模式”、“外观模式”、“工厂模式”和“云”这些名词一样,都是一种抽象概念。
|
||||

|
||||
|
||||
_图片:3 个 Raspberry Pi Zero_
|
||||
|
||||
这是我在本文中描述的集群,用黄铜支架分隔每个设备。
|
||||
|
||||
|
||||
|
||||
### Serverless 是什么?它为何重要?
|
||||
|
||||
行业对于“serverless”这个术语的含义有几种解释。在这篇博文中,我们就把它理解为一种事件驱动的架构模式,它能让你用自己喜欢的任何语言编写轻量可复用的功能。[更多关于 Serverless 的资料][22]。
|
||||
行业对于 “serverless” 这个术语的含义有几种解释。在这篇博文中,我们就把它理解为一种事件驱动的架构模式,它能让你用自己喜欢的任何语言编写轻量可复用的功能。[更多关于 Serverless 的资料][22]。
|
||||
|
||||
|
||||
_Serverless 架构也引出了“功能即服务服务”模式,简称 FaaS_
|
||||
|
||||
_Serverless 架构也引出了“功能即服务服务”模式,简称 FaaS_
|
||||
|
||||
Serverless 的“功能”可以做任何事,但通常用于处理给定的输入——例如来自 GitHub、Twitter、PayPal、Slack、Jenkins CI pipeline 的事件;或者以树莓派为例,处理像红外运动传感器、激光绊网、温度计等真实世界的传感器的输入。
|
||||
|
||||

|
||||
|
||||
|
||||
Serverless 功能能够更好地结合第三方的后端服务,使系统整体的能力大于各部分之和。
|
||||
|
||||
|
||||
了解更多背景信息,可以阅读我最近一偏博文:[Introducing Functions as a Service (FaaS)][34]。
|
||||
了解更多背景信息,可以阅读我最近一偏博文:[功能即服务(FaaS)简介][34]。
|
||||
|
||||
### 概述
|
||||
|
||||
我们将使用 [OpenFaaS][35], 它能够让主机或者集群作为支撑 Serverless 功能运行的后端。任何能够使用 Docker 部署的可执行二进制文件、脚本或者编程语言都能在 [OpenFaaS][36] 上运作,你可以根据速度和伸缩性选择部署的规模。另一个优点是,它还内建了用户界面和监控系统。
|
||||
我们将使用 [OpenFaaS][35],它能够让主机或者集群作为支撑 Serverless 功能运行的后端。任何能够使用 Docker 部署的可执行二进制文件、脚本或者编程语言都能在 [OpenFaaS][36] 上运作,你可以根据速度和伸缩性选择部署的规模。另一个优点是,它还内建了用户界面和监控系统。
|
||||
|
||||
这是我们要执行的步骤:
|
||||
|
||||
* 在一个或多个主机上配置 Docker (树莓派 2 或者 3);
|
||||
|
||||
* 利用 Docker Swarm 将它们连接;
|
||||
|
||||
* 部署 [OpenFaaS][23];
|
||||
|
||||
* 使用 Python 编写我们的第一个功能。
|
||||
|
||||
### Docker Swarm
|
||||
|
||||
Docker 是一项打包和部署应用的技术,支持集群上运行,有着安全的默认设置,而且在搭建集群时只需要一条命令。OpenFaaS 使用 Docker 和 Swarm 在你的可用树莓派上传递你的 Serverless 功能。
|
||||
|
||||

|
||||
_图片:3 个 Raspberry Pi Zero_
|
||||
|
||||
我推荐你在这个项目中使用带树莓派 2 或者 3,以太网交换机和[强大的 USB 多端口电源适配器][37]。
|
||||
|
||||
### 准备 Raspbian
|
||||
|
||||
把 [Raspbian Jessie Lite][38] 写入 SD 卡(8GB 容量就正常工作了,但还是推荐使用 16GB 的 SD 卡)。
|
||||
|
||||
_注意:不要下载成 Raspbian Stretch 了_
|
||||
_注意:不要下载成 Raspbian Stretch 了_
|
||||
|
||||
> 社区在努力让 Docker 支持 Raspbian Stretch,但是还未能做到完美运行。请从[树莓派基金会网站][24]下载 Jessie Lite 镜像。
|
||||
|
||||
我推荐使用 [Etcher.io][39] 烧写镜像。
|
||||
|
||||
> 在引导树莓派之前,你需要在引导分区创建名为“ssh”的空白文件。这样才能允许远程登录。
|
||||
> 在引导树莓派之前,你需要在引导分区创建名为 `ssh` 的空白文件。这样才能允许远程登录。
|
||||
|
||||
* 接通电源,然后修改主机名
|
||||
#### 接通电源,然后修改主机名
|
||||
|
||||
现在启动树莓派的电源并且使用`ssh`连接:
|
||||
现在启动树莓派的电源并且使用 `ssh` 连接:
|
||||
|
||||
```
|
||||
$ ssh pi@raspberrypi.local
|
||||
|
||||
```
|
||||
|
||||
> 默认密码是`raspberry`
|
||||
> 默认密码是 `raspberry`
|
||||
|
||||
使用 `raspi-config` 工具把主机名改为 `swarm-1` 或者类似的名字,然后重启。
|
||||
|
||||
当你到了这一步,你还可以把划分给 GPU (显卡)的内存设置为 16MB。
|
||||
|
||||
* 现在安装 Docker
|
||||
#### 现在安装 Docker
|
||||
|
||||
我们可以使用通用脚本来安装:
|
||||
|
||||
```
|
||||
$ curl -sSL https://get.docker.com | sh
|
||||
|
||||
```
|
||||
|
||||
> 这个安装方式在将来可能会发生变化。如上文所说,你的系统需要是 Jessie,这样才能得到一个确定的配置。
|
||||
@ -92,23 +86,21 @@ $ curl -sSL https://get.docker.com | sh
|
||||
```
|
||||
WARNING: raspbian is no longer updated @ https://get.docker.com/
|
||||
Installing the legacy docker-engine package...
|
||||
|
||||
```
|
||||
|
||||
之后,用下面这个命令确保你的用户帐号可以访问 Docker 客户端:
|
||||
|
||||
```
|
||||
$ usermod pi -aG docker
|
||||
|
||||
```
|
||||
|
||||
> 如果你的用户名不是 `pi`,那就把它替换成你的用户名。
|
||||
|
||||
* 修改默认密码
|
||||
#### 修改默认密码
|
||||
|
||||
输入 `$sudo passwd pi`,然后设置一个新密码,请不要跳过这一步!
|
||||
|
||||
* 重复以上步骤
|
||||
#### 重复以上步骤
|
||||
|
||||
现在为其它的树莓派重复上述步骤。
|
||||
|
||||
@ -128,9 +120,9 @@ To add a worker to this swarm, run the following command:
|
||||
|
||||
```
|
||||
|
||||
你会看到它显示了一个口令,以及其它结点加入集群的命令。接下来使用 `ssh` 登录每个树莓派,运行这个加入集群的命令。
|
||||
你会看到它显示了一个口令,以及其它节点加入集群的命令。接下来使用 `ssh` 登录每个树莓派,运行这个加入集群的命令。
|
||||
|
||||
等待连接完成后,在第一个树莓派上查看集群的结点:
|
||||
等待连接完成后,在第一个树莓派上查看集群的节点:
|
||||
|
||||
```
|
||||
$ docker node ls
|
||||
@ -143,15 +135,15 @@ y2p089bs174vmrlx30gc77h4o swarm4 Ready Active
|
||||
|
||||
恭喜你!你现在拥有一个树莓派集群了!
|
||||
|
||||
* _更多关于集群的内容_
|
||||
#### 更多关于集群的内容
|
||||
|
||||
你可以看到三个结点启动运行。这时只有一个结点是集群管理者。如果我们的管理结点_死机_了,集群就进入了不可修复的状态。我们可以通过添加冗余的管理结点解决这个问题。而且它们依然会运行工作负载,除非你明确设置了让你的服务只运作在工作结点上。
|
||||
你可以看到三个节点启动运行。这时只有一个节点是集群管理者。如果我们的管理节点_死机_了,集群就进入了不可修复的状态。我们可以通过添加冗余的管理节点解决这个问题。而且它们依然会运行工作负载,除非你明确设置了让你的服务只运作在工作节点上。
|
||||
|
||||
要把一个工作结点升级为管理结点,只需要在其中一个管理结点上运行 `docker node promote <node_name>` 命令。
|
||||
要把一个工作节点升级为管理节点,只需要在其中一个管理节点上运行 `docker node promote <node_name>` 命令。
|
||||
|
||||
> 注意: Swarm 命令,例如 `docker service ls` 或者 `docker node ls` 只能在管理结点上运行。
|
||||
> 注意: Swarm 命令,例如 `docker service ls` 或者 `docker node ls` 只能在管理节点上运行。
|
||||
|
||||
想深入了解管理结点与工作结点如何保持一致性,可以查阅 [Docker Swarm 管理指南][40]。
|
||||
想深入了解管理节点与工作节点如何保持一致性,可以查阅 [Docker Swarm 管理指南][40]。
|
||||
|
||||
### OpenFaaS
|
||||
|
||||
@ -159,9 +151,9 @@ y2p089bs174vmrlx30gc77h4o swarm4 Ready Active
|
||||
|
||||

|
||||
|
||||
> 如果你支持 [OpenFaaS][41],希望你能 **start** [OpenFaaS][25] 的 GitHub 仓库。
|
||||
> 如果你支持 [OpenFaaS][41],希望你能 **星标** [OpenFaaS][25] 的 GitHub 仓库。
|
||||
|
||||
登录你的第一个树莓派(你运行 `docker swarm init` 的结点),然后部署这个项目:
|
||||
登录你的第一个树莓派(你运行 `docker swarm init` 的节点),然后部署这个项目:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexellis/faas/
|
||||
@ -178,7 +170,7 @@ Creating service func_echoit
|
||||
|
||||
```
|
||||
|
||||
你的其它树莓派会收到 Docer Swarm 的指令,开始从网上拉取这个 Docker 镜像,并且解压到 SD 卡上。这些工作会分布到各个结点上,所以没有哪个结点产生过高的负载。
|
||||
你的其它树莓派会收到 Docer Swarm 的指令,开始从网上拉取这个 Docker 镜像,并且解压到 SD 卡上。这些工作会分布到各个节点上,所以没有哪个节点产生过高的负载。
|
||||
|
||||
这个过程会持续几分钟,你可以用下面指令查看它的完成状况:
|
||||
|
||||
@ -195,7 +187,7 @@ v9vsvx73pszz func_nodeinfo replicated 1/1
|
||||
|
||||
```
|
||||
|
||||
我们希望看到每个服务都显示“1/1”。
|
||||
我们希望看到每个服务都显示 “1/1”。
|
||||
|
||||
你可以根据服务名查看该服务被调度到哪个树莓派上:
|
||||
|
||||
@ -203,7 +195,6 @@ v9vsvx73pszz func_nodeinfo replicated 1/1
|
||||
$ docker service ps func_markdown
|
||||
ID IMAGE NODE STATE
|
||||
func_markdown.1 functions/markdownrender:latest-armhf swarm4 Running
|
||||
|
||||
```
|
||||
|
||||
状态一项应该显示 `Running`,如果它是 `Pending`,那么镜像可能还在下载中。
|
||||
@ -212,16 +203,15 @@ func_markdown.1 functions/markdownrender:latest-armhf swarm4 Running
|
||||
|
||||
```
|
||||
$ ifconfig
|
||||
|
||||
```
|
||||
|
||||
例如,如果你的 IP 地址是 192.168.0.100,那就访问 [http://192.168.0.100:8080][42]。
|
||||
例如,如果你的 IP 地址是 192.168.0.100,那就访问 http://192.168.0.100:8080 。
|
||||
|
||||
这是你会看到 FaaS UI(也叫 API 网关)。这是你定义、测试、调用功能的地方。
|
||||
|
||||
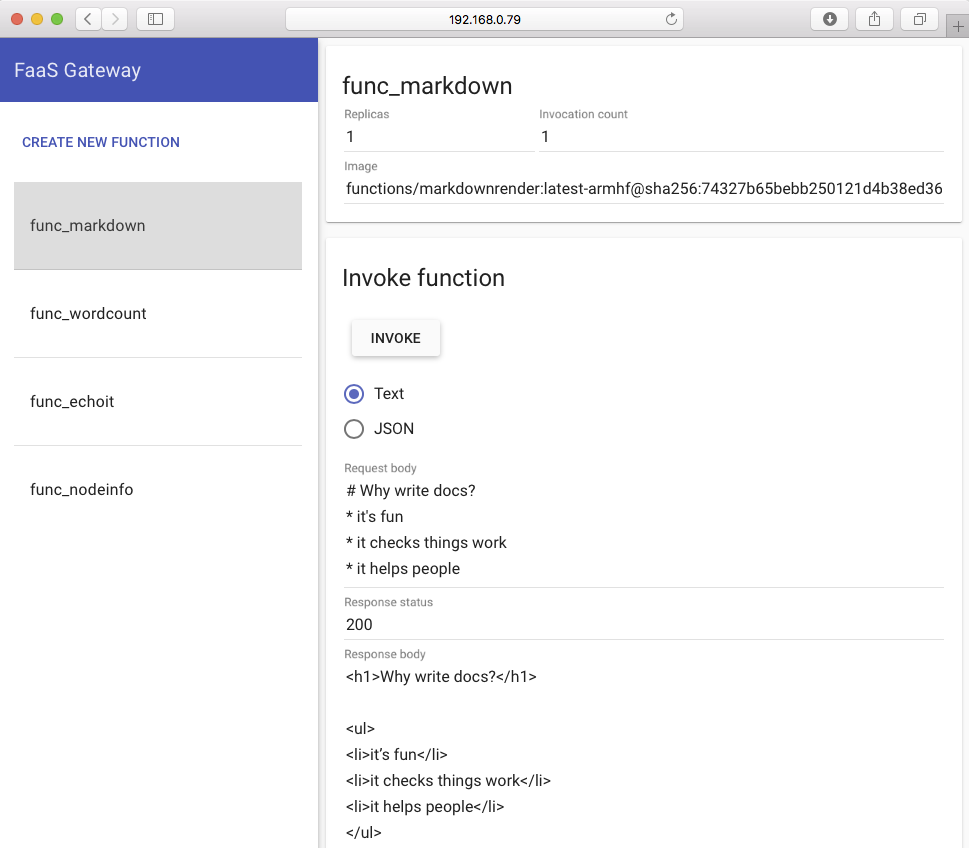
点击名称为 func_markdown 的 Markdown 转换功能,输入一些 Markdown(这是 Wikipedia 用来组织内容的语言)文本。
|
||||
点击名称为 “func_markdown” 的 Markdown 转换功能,输入一些 Markdown(这是 Wikipedia 用来组织内容的语言)文本。
|
||||
|
||||
然后点击 `invoke`。你会看到调用计数增加,屏幕下方显示功能调用的结果。
|
||||
然后点击 “invoke”。你会看到调用计数增加,屏幕下方显示功能调用的结果。
|
||||
|
||||
|
||||
|
||||
@ -229,53 +219,48 @@ $ ifconfig
|
||||
|
||||
这一节的内容已经有相关的教程,但是我们需要几个步骤来配置树莓派。
|
||||
|
||||
* 获取 FaaS-CLI:
|
||||
#### 获取 FaaS-CLI
|
||||
|
||||
```
|
||||
$ curl -sSL cli.openfaas.com | sudo sh
|
||||
armv7l
|
||||
Getting package https://github.com/alexellis/faas-cli/releases/download/0.4.5-b/faas-cli-armhf
|
||||
|
||||
```
|
||||
|
||||
* 下载样例:
|
||||
#### 下载样例
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexellis/faas-cli
|
||||
$ cd faas-cli
|
||||
|
||||
```
|
||||
|
||||
* 为树莓派修补样例:
|
||||
#### 为树莓派修补样例模版
|
||||
|
||||
我们临时修改我们的模版,让它们能在树莓派上工作:
|
||||
|
||||
```
|
||||
$ cp template/node-armhf/Dockerfile template/node/
|
||||
$ cp template/python-armhf/Dockerfile template/python/
|
||||
|
||||
```
|
||||
|
||||
这么做是因为树莓派和我们平时关注的大多数计算机使用不一样的处理器架构。
|
||||
|
||||
> 了解 Docker 在树莓派上的最新状况,请查阅: [5 Things you need to know][26]
|
||||
> 了解 Docker 在树莓派上的最新状况,请查阅: [你需要了解的五件事][26]。
|
||||
|
||||
现在你可以跟着下面为 PC,笔记本和云端所写的教程操作,但我们在树莓派上要先运行一些命令。
|
||||
现在你可以跟着下面为 PC、笔记本和云端所写的教程操作,但我们在树莓派上要先运行一些命令。
|
||||
|
||||
* [使用 OpenFaaS 运行你的第一个 Serverless Python 功能][27]
|
||||
|
||||
注意第 3 步:
|
||||
|
||||
* 把你的功能放到先前从 GitHub 下载的 `faas-cli` 文件夹中,而不是 `~/functinos/hello-python` 里。
|
||||
|
||||
* 同时,在 `stack.yml` 文件中把 `localhost` 替换成第一个树莓派的 IP 地址。
|
||||
|
||||
集群可能会花费几分钟把 Serverless 功能下载到相关的树莓派上。你可以用下面的命令查看你的服务,确保副本一项显示“1/1”:
|
||||
集群可能会花费几分钟把 Serverless 功能下载到相关的树莓派上。你可以用下面的命令查看你的服务,确保副本一项显示 “1/1”:
|
||||
|
||||
```
|
||||
$ watch 'docker service ls'
|
||||
pv27thj5lftz hello-python replicated 1/1 alexellis2/faas-hello-python-armhf:latest
|
||||
|
||||
```
|
||||
|
||||
**继续阅读教程:** [使用 OpenFaaS 运行你的第一个 Serverless Python 功能][43]
|
||||
@ -286,7 +271,7 @@ pv27thj5lftz hello-python replicated 1/1
|
||||
|
||||
既然使用 Serverless,你也不想花时间监控你的功能。幸运的是,OpenFaaS 内建了 [Prometheus][45] 指标检测,这意味着你可以追踪每个功能的运行时长和调用频率。
|
||||
|
||||
_指标驱动自动伸缩_
|
||||
#### 指标驱动自动伸缩
|
||||
|
||||
如果你给一个功能生成足够的负载,OpenFaaS 将自动扩展你的功能;当需求消失时,你又会回到单一副本的状态。
|
||||
|
||||
@ -298,31 +283,27 @@ pv27thj5lftz hello-python replicated 1/1
|
||||
|
||||
```
|
||||
http://192.168.0.25:9090/graph?g0.range_input=15m&g0.stacked=1&g0.expr=rate(gateway_function_invocation_total%5B20s%5D)&g0.tab=0&g1.range_input=1h&g1.expr=gateway_service_count&g1.tab=0
|
||||
|
||||
```
|
||||
|
||||
这些请求使用 PromQL(Prometheus 请求语言)编写。第一个请求返回功能调用的频率:
|
||||
|
||||
```
|
||||
rate(gateway_function_invocation_total[20s])
|
||||
|
||||
```
|
||||
|
||||
第二个请求显示每个功能的副本数量,最开始应该是每个功能只有一个副本。
|
||||
|
||||
```
|
||||
gateway_service_count
|
||||
|
||||
```
|
||||
|
||||
如果你想触发自动扩展,你可以在树莓派上尝试下面指令:
|
||||
|
||||
```
|
||||
$ while [ true ]; do curl -4 localhost:8080/function/func_echoit --data "hello world" ; done
|
||||
|
||||
```
|
||||
|
||||
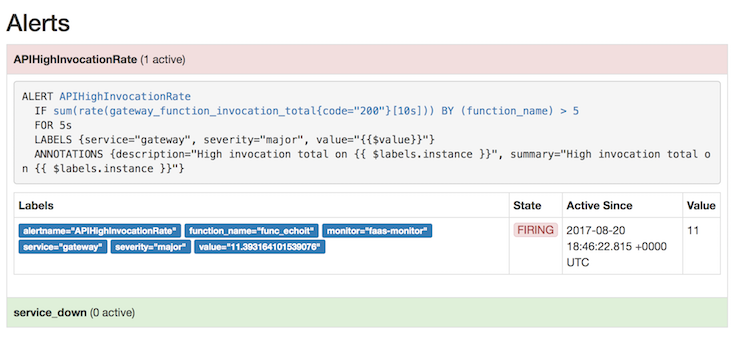
查看 Prometheus 的“alerts”页面,可以知道你是否产生足够的负载来触发自动扩展。如果没有,你可以尝试在多个终端同时运行上面的指令。
|
||||
查看 Prometheus 的 “alerts” 页面,可以知道你是否产生足够的负载来触发自动扩展。如果没有,你可以尝试在多个终端同时运行上面的指令。
|
||||
|
||||
|
||||
|
||||
@ -332,41 +313,33 @@ $ while [ true ]; do curl -4 localhost:8080/function/func_echoit --data "hello w
|
||||
|
||||
我们现在配置好了 Docker、Swarm, 并且让 OpenFaaS 运行代码,把树莓派像大型计算机一样使用。
|
||||
|
||||
> 希望大家支持这个项目,**Star** [FaaS 的 GitHub 仓库][28]。
|
||||
> 希望大家支持这个项目,**星标** [FaaS 的 GitHub 仓库][28]。
|
||||
|
||||
你是如何搭建好了自己的 Docker Swarm 集群并且运行 OpenFaaS 的呢?在 Twitter [@alexellisuk][46] 上分享你的照片或推文吧。
|
||||
|
||||
**观看我在 Dockercon 上关于 OpenFaaS 的视频**
|
||||
|
||||
我在 [Austin 的 Dockercon][47] 上展示了 OpenFaaS。——观看介绍和互动例子的视频:
|
||||
|
||||
** 此处有iframe,请手动处理 **
|
||||
我在 [Austin 的 Dockercon][47] 上展示了 OpenFaaS。——观看介绍和互动例子的视频: https://www.youtube.com/embed/-h2VTE9WnZs
|
||||
|
||||
有问题?在下面的评论中提出,或者给我发邮件,邀请我进入你和志同道合者讨论树莓派、Docker、Serverless 的 Slack channel。
|
||||
|
||||
**想要学习更多关于树莓派上运行 Docker 的内容?**
|
||||
|
||||
我建议从 [5 Things you need to know][48] 开始,它包含了安全性、树莓派和普通 PC 间微妙差别等话题。
|
||||
我建议从 [你需要了解的五件事][48] 开始,它包含了安全性、树莓派和普通 PC 间微妙差别等话题。
|
||||
|
||||
* [Dockercon tips: Docker & Raspberry Pi][18]
|
||||
|
||||
* [Control GPIO with Docker Swarm][19]
|
||||
|
||||
* [Is that a Docker Engine in your pocket??][20]
|
||||
|
||||
_在 Twitter 上分享_
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.alexellis.io/your-serverless-raspberry-pi-cluster/
|
||||
|
||||
作者:[Alex Ellis ][a]
|
||||
作者:[Alex Ellis][a]
|
||||
译者:[haoqixu](https://github.com/haoqixu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,204 @@
|
||||
每个安卓开发初学者应该了解的 12 个技巧
|
||||
====
|
||||
|
||||
> 一次掌握一个技巧,更好地学习安卓
|
||||
|
||||

|
||||
|
||||
距离安迪·鲁宾和他的团队着手开发一个希望颠覆传统手机操作模式的操作系统已经过去 12 年了,这套系统有可能让手机或者智能机给消费者以及软件开发人员带来全新的体验。之前的智能机仅限于收发短信和查看电子邮件(当然还可以打电话),给用户和开发者带来很大的限制。
|
||||
|
||||
安卓,作为打破这个枷锁的系统,拥有非常优秀的框架设计,给大家提供的不仅仅是一组有限的功能,更多的是自由的探索。有人会说 iPhone 才是手机产业的颠覆产品,不过我们说的不是 iPhone 有多么酷(或者多么贵,是吧?),它还是有限制的,而这是我们从来都不希望有的。
|
||||
|
||||
不过,就像本大叔说的,能力越大责任越大,我们也需要更加认真对待安卓应用的设计方式。我看到很多教程都忽略了向初学者传递这个理念,在动手之前请先充分理解系统架构。他们只是把一堆的概念和代码丢给读者,却没有解释清楚相关的优缺点,它们对系统的影响,以及该用什么不该用什么等等。
|
||||
|
||||
在这篇文章里,我们将介绍一些初学者以及中级开发人员都应该掌握的技巧,以帮助更好地理解安卓框架。后续我们还会在这个系列里写更多这样的关于实用技巧的文章。我们开始吧。
|
||||
|
||||
### 1、 `@+id` 和 `@id` 的区别
|
||||
|
||||
要在 Java 代码里访问一个图形控件(或组件),或者是要让它成为其他控件的依赖,我们需要一个唯一的值来引用它。这个唯一值用 `android:id` 属性来定义,本质上就是把用户提供的 id 附加到 `@+id/` 后面,写入到 _id 资源文件_,供其他控件使用。一个 Toolbar 的 id 可以这样定义,
|
||||
|
||||
```
|
||||
android:id="@+id/toolbar"
|
||||
```
|
||||
|
||||
然后这个 id 值就能被 `findViewById(…)` 识别,这个函数会在资源文件里查找 id,或者直接从 R.id 路径引用,然后返回所查找的 View 的类型。
|
||||
|
||||
而另一种,`@id`,和 `findViewById(…)` 行为一样 - 也会根据提供的 id 查找组件,不过仅限于布局时使用。一般用来布置相关控件。
|
||||
|
||||
```
|
||||
android:layout_below="@id/toolbar"
|
||||
```
|
||||
|
||||
### 2、 使用 `@string` 资源为 XML 提供字符串
|
||||
|
||||
简单来说,就是不要在 XML 里直接用字符串。原因很简单。当我们在 XML 里直接使用了字符串,我们一般会在其它地方再次用到同样的字符串。想像一下当我们需要在不同的地方调整同一个字符串的噩梦,而如果使用字符串资源就只改一个地方就够了。另一个好处是,使用资源文件可以提供多国语言支持,因为可以为不同的语言创建相应的字符串资源文件。
|
||||
|
||||
```
|
||||
android:text="My Awesome Application"
|
||||
```
|
||||
|
||||
当你直接使用字符串时,你会在 Android Studio 里收到警告,提示说应该把写死的字符串改成字符串资源。可以点击这个提示,然后按下 `ALT + ENTER` 打开字符串编辑。你也可以直接打开 `res` 目录下的 `values` 目录里的 `strings.xml` 文件,然后像下面这样声明一个字符串资源。
|
||||
|
||||
```
|
||||
<string name="app_name">My Awesome Application</string>
|
||||
```
|
||||
|
||||
然后用它来替换写死的字符串,
|
||||
|
||||
```
|
||||
android:text="@string/app_name"
|
||||
```
|
||||
|
||||
### 3、 使用 `@android` 和 `?attr` 常量
|
||||
|
||||
尽量使用系统预先定义的常量而不是重新声明。举个例子,在布局中有几个地方要用白色或者 #ffffff 颜色值。不要每次都直接用 #ffffff 数值,也不要自己为白色重新声明资源,我们可以直接用这个,
|
||||
|
||||
```
|
||||
@android:color/white
|
||||
```
|
||||
|
||||
安卓预先定义了很多常用的颜色常量,比如白色,黑色或粉色。最经典的应用场景是透明色:
|
||||
|
||||
```
|
||||
@android:color/transparent
|
||||
```
|
||||
|
||||
另一个引用常量的方式是 `?attr`,用来将预先定义的属性值赋值给不同的属性。举个自定义 Toolbar 的例子。这个 Toolbar 需要定义宽度和高度。宽度通常可以设置为 `MATCH_PARENT`,但高度呢?我们大多数人都没有注意设计指导,只是简单地随便设置一个看上去差不多的值。这样做不对。不应该随便自定义高度,而应该这样做,
|
||||
|
||||
```
|
||||
android:layout_height="?attr/actionBarSize"
|
||||
```
|
||||
|
||||
`?attr` 的另一个应用是点击视图时画水波纹效果。`SelectableItemBackground` 是一个预定义的 drawable,任何视图需要增加波纹效果时可以将它设为背景:
|
||||
|
||||
```
|
||||
android:background="?attr/selectableItemBackground"
|
||||
```
|
||||
|
||||
也可以用这个:
|
||||
|
||||
```
|
||||
android:background="?attr/selectableItemBackgroundBorderless"
|
||||
```
|
||||
|
||||
来显示无边框波纹。
|
||||
|
||||
### 4、 SP 和 DP 的区别
|
||||
|
||||
虽然这两个没有本质上的区别,但知道它们是什么以及在什么地方适合用哪个很重要。
|
||||
|
||||
SP 的意思是缩放无关像素,一般建议用于 TextView,首先文字不会因为显示密度不同而显示效果不一样,另外 TextView 的内容还需要根据用户设定做拉伸,或者只调整字体大小。
|
||||
|
||||
其他需要定义尺寸和位置的地方,可以使用 DP,也就是密度无关像素。之前说过,DP 和 SP 的性质是一样的,只是 DP 会根据显示密度自动拉伸,因为安卓系统会动态计算实际显示的像素,这样就可以让使用 DP 的组件在不同显示密度的设备上都可以拥有相同的显示效果。
|
||||
|
||||
### 5、 Drawable 和 Mipmap 的应用
|
||||
|
||||
这两个最让人困惑的是 - drawable 和 mipmap 有多少差异?
|
||||
|
||||
虽然这两个好像有同样的用途,但它们设计目的不一样。mipmap 是用来储存图标的,而 drawable 用于任何其他格式。我们可以看一下系统内部是如何使用它们的,就知道为什么不能混用了。
|
||||
|
||||
你可以看到你的应用里有几个 mipmap 和 drawable 目录,每一个分别代表不同的显示分辨率。当系统从 drawable 目录读取资源时,只会根据当前设备的显示密度选择确定的目录。然而,在读取 mipmap 时,系统会根据需要选择合适的目录,而不仅限于当前显示密度,主要是因为有些启动器会故意显示较大的图标,所以系统会使用较大分辨率的资源。
|
||||
|
||||
总之,用 mipmap 来存放图标或标记图片,可以在不同显示密度的设备上看到分辨率变化,而其它根据需要显示的图片资源都用 drawable。
|
||||
|
||||
比如说,Nexus 5 的显示分辨率是 xxhdpi。当我们把图标放到 `mipmap` 目录里时,所有 `mipmap` 目录都将读入内存。而如果放到 drawable 里,只有 `drawable-xxhdpi` 目录会被读取,其他目录都会被忽略。
|
||||
|
||||
### 6、 使用矢量图形
|
||||
|
||||
为了支持不同显示密度的屏幕,将同一个资源的多个版本(大小)添加到项目里是一个很常见的技巧。这种方式确实有用,不过它也会带来一定的性能开支,比如更大的 apk 文件以及额外的开发工作。为了消除这种影响,谷歌的安卓团队发布了新增的矢量图形。
|
||||
|
||||
矢量图形是用 XML 描述的 SVG(可拉伸矢量图形),是用点、直线和曲线组合以及填充颜色绘制出的图形。正因为矢量图形是由点和线动态画出来的,在不同显示密度下拉伸也不会损失分辨率。而矢量图形带来的另一个好处是更容易做动画。往一个 AnimatedVectorDrawable 文件里添加多个矢量图形就可以做出动画,而不用添加多张图片然后再分别处理。
|
||||
|
||||
```
|
||||
<vector xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
android:width="24dp"
|
||||
android:height="24dp"
|
||||
android:viewportWidth="24.0"
|
||||
android:viewportHeight="24.0">
|
||||
|
||||
<path android:fillColor="#69cdff" android:pathData="M3,18h18v-2L3,16v2zM3,13h18v-2L3,11v2zM3,6v2h18L21,6L3,6z"/>
|
||||
|
||||
</vector>
|
||||
```
|
||||
|
||||
上面的向量定义可以画出下面的图形,
|
||||
|
||||

|
||||
|
||||
要在你的安卓项目里添加矢量图形,可以右键点击你项目里的应用模块,然后选择 New >> Vector Assets。然后会打开 Assets Studio,你可以有两种方式添加矢量图形。第一种是从 Material 图标里选择,另一种是选择本地的 SVG 或 PSD 文件。
|
||||
|
||||
谷歌建议与应用相关都使用 Material 图标,来保持安卓的连贯性和统一体验。[这里][1]有全部图标,记得看一下。
|
||||
|
||||
### 7、 设定边界的开始和结束
|
||||
|
||||
这是人们最容易忽略的地方之一。边界!增加边界当然很简单,但是如果要考虑支持很旧的平台呢?
|
||||
|
||||
边界的“开始”和“结束”分别是“左”和“右”的超集,所以如果应用的 `minSdkVersion` 是 17 或更低,边界和填充的“开始”和“结束”定义是旧的“左”/“右”所需要的。在那些没有定义“开始”和“结束”的系统上,这两个定义可以被安全地忽略。可以像下面这样声明:
|
||||
|
||||
```
|
||||
android:layout_marginEnd="20dp"
|
||||
android:paddingStart="20dp"
|
||||
```
|
||||
|
||||
### 8、 使用 Getter/Setter 生成工具
|
||||
|
||||
在创建一个容器类(只是用来简单的存放一些变量数据)时很烦的一件事情是写多个 getter 和 setter,复制/粘贴该方法的主体再为每个变量重命名。
|
||||
|
||||
幸运的是,Android Studio 有一个解决方法。可以这样做,在类里声明你需要的所有变量,然后打开 Toolbar >> Code。快捷方式是 `ALT + Insert`。点击 Code 会显示 Generate,点击它会出来很多选项,里面有 Getter 和 Setter 选项。在保持焦点在你的类页面然后点击,就会为当前类添加所有的 getter 和 setter(有需要的话可以再去之前的窗口操作)。很爽吧。
|
||||
|
||||
### 9、 使用 Override/Implement 生成工具
|
||||
|
||||
这是另一个很好用的生成工具。自定义一个类然后再扩展很容易,但是如果要扩展你不熟悉的类呢。比如说 PagerAdapter,你希望用 ViewPager 来展示一些页面,那就需要定制一个 PagerAdapter 并实现它的重载方法。但是具体有哪些方法呢?Android Studio 非常贴心地为自定义类强行添加了一个构造函数,或者可以用快捷键(`ALT + Enter`),但是父类 PagerAdapter 里的其他(虚拟)方法需要自己手动添加,我估计大多数人都觉得烦。
|
||||
|
||||
要列出所有可以重载的方法,可以点击 Code >> Generate and Override methods 或者 Implement methods,根据你的需要。你还可以为你的类选择多个方法,只要按住 Ctrl 再选择方法,然后点击 OK。
|
||||
|
||||
### 10、 正确理解 Context
|
||||
|
||||
Context 有点恐怖,我估计许多初学者从没有认真理解过 Context 类的结构 - 它是什么,为什么到处都要用到它。
|
||||
|
||||
简单地说,它将你能从屏幕上看到的所有内容都整合在一起。所有的视图(或者它们的扩展)都通过 Context 绑定到当前的环境。Context 用来管理应用层次的资源,比如说显示密度,或者当前的关联活动。活动、服务和应用都实现了 Context 类的接口来为其他关联组件提供内部资源。举个添加到 MainActivity 的 TextView 的例子。你应该注意到了,在创建一个对象的时候,TextView 的构造函数需要 Context 参数。这是为了获取 TextView 里定义到的资源。比如说,TextView 需要在内部用到 Roboto 字体。这样的话,TextView 需要 Context。而且在我们将 Context(或者 `this`)传递给 TextView 的时候,也就是告诉它绑定当前活动的生命周期。
|
||||
|
||||
另一个 Context 的关键应用是初始化应用层次的操作,比如初始化一个库。库的生命周期和应用是不相关的,所以它需要用 `getApplicationContext()` 来初始化,而不是用 `getContext` 或 `this` 或 `getActivity()`。掌握正确使用不同 Context 类型非常重要,可以避免内存泄漏。另外,要用到 Context 来启动一个活动或服务。还记得 `startActivity(…)` 吗?当你需要在一个非活动类里切换活动时,你需要一个 Context 对象来调用 `startActivity` 方法,因为它是 Context 类的方法,而不是 Activity 类。
|
||||
|
||||
```
|
||||
getContext().startActivity(getContext(), SecondActivity.class);
|
||||
```
|
||||
|
||||
如果你想了解更多 Context 的行为,可以看看[这里][2]或[这里][3]。第一个是一篇关于 Context 的很好的文章,介绍了在哪些地方要用到它。而另一个是安卓关于 Context 的文档,全面介绍了所有的功能 - 方法,静态标识以及更多。
|
||||
|
||||
### 奖励 #1: 格式化代码
|
||||
|
||||
有人会不喜欢整齐,统一格式的代码吗?好吧,几乎我们每一个人,在写一个超过 1000 行的类的时候,都希望我们的代码能有合适的结构。而且,并不仅仅大的类才需要格式化,每一个小模块类也需要让代码保持可读性。
|
||||
|
||||
使用 Android Studio,或者任何 JetBrains IDE,你都不需要自己手动整理你的代码,像增加缩进或者 = 之前的空格。就按自己希望的方式写代码,在想要格式化的时候,如果是 Windows 系统可以按下 `ALT + CTRL + L`,Linux 系统按下 `ALT + CTRL + SHIFT + L`。*代码就自动格式化好了*
|
||||
|
||||
### 奖励 #2: 使用库
|
||||
|
||||
面向对象编程的一个重要原则是增加代码的可重用性,或者说减少重新发明轮子的习惯。很多初学者错误地遵循了这个原则。这条路有两个方向,
|
||||
|
||||
- 不用任何库,自己写所有的代码。
|
||||
- 用库来处理所有事情。
|
||||
|
||||
不管哪个方向走到底都是不对的。如果你彻底选择第一个方向,你将消耗大量的资源,仅仅是为了满足自己拥有一切的骄傲。很可能你的代码没有做过替代库那么多的测试,从而增加模块出问题的可能。如果资源有限,不要重复发明轮子。直接用经过测试的库,在有了明确目标以及充分的资源后,可以用自己的可靠代码来替换这个库。
|
||||
|
||||
而彻底走向另一个方向,问题更严重 - 别人代码的可靠性。不要习惯于所有事情都依赖于别人的代码。在不用太多资源或者自己能掌控的情况下尽量自己写代码。你不需要用库来自定义一个 TypeFaces(字体),你可以自己写一个。
|
||||
|
||||
所以要记住,在这两个极端中间平衡一下 - 不要重新创造所有事情,也不要过分依赖外部代码。保持中立,根据自己的能力写代码。
|
||||
|
||||
这篇文章最早发布在 [What’s That Lambda][4] 上。请访问网站阅读更多关于 Android、Node.js、Angular.js 等等类似文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://android.jlelse.eu/12-practices-every-android-beginner-should-know-cd43c3710027
|
||||
|
||||
作者:[Nilesh Singh][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://android.jlelse.eu/@nileshsingh?source=post_header_lockup
|
||||
[1]:https://material.io/icons/
|
||||
[2]:https://blog.mindorks.com/understanding-context-in-android-application-330913e32514
|
||||
[3]:https://developer.android.com/reference/android/content/Context.html
|
||||
[4]:https://www.whatsthatlambda.com/android/android-dev-101-things-every-beginner-must-know
|
||||
@ -1,26 +1,27 @@
|
||||
# IoT 网络安全:后备计划是什么?
|
||||
IoT 网络安全:后备计划是什么?
|
||||
=======
|
||||
|
||||
八月份,四名美国参议员提出了一项旨在改善物联网 (IoT) 安全性的法案。2017 年的“ 物联网网络安全改进法” 是一项小幅的立法。它没有规范物联网市场。它没有任何特别关注的行业,或强制任何公司做任何事情。甚至不修改嵌入式软件的法律责任。无论安全多么糟糕,公司可以继续销售物联网设备。
|
||||
八月份,四名美国参议员提出了一项旨在改善物联网(IoT)安全性的法案。2017 年的 “物联网网络安全改进法” 是一项小幅的立法。它没有规范物联网市场。它没有任何特别关注的行业,或强制任何公司做任何事情。甚至没有修改嵌入式软件的法律责任。无论安全多么糟糕,公司可以继续销售物联网设备。
|
||||
|
||||
法案的做法是利用政府的购买力推动市场:政府购买的任何物联网产品都必须符合最低安全标准。它要求供应商确保设备不仅可以打补丁,而且可以通过认证和及时的方式进行修补,没有不可更改的默认密码,并且没有已知的漏洞。这是一个你可以设置的低安全值,并且将大大提高安全性可以说明关于物联网安全性的当前状态。(全面披露:我帮助起草了一些法案的安全性要求。)
|
||||
法案的做法是利用政府的购买力推动市场:政府购买的任何物联网产品都必须符合最低安全标准。它要求供应商确保设备不仅可以打补丁,而且是以认证和及时的方式进行修补,没有不可更改的默认密码,并且没有已知的漏洞。这是一个你可以达到的低安全值,并且将大大提高安全性,可以说明关于物联网安全性的当前状态。(全面披露:我帮助起草了一些法案的安全性要求。)
|
||||
|
||||
该法案还将修改“计算机欺诈和滥用”和“数字千年版权”法案,以便安全研究人员研究政府购买的物联网设备的安全性。这比我们的行业需求要窄得多。但这是一个很好的第一步,这可能是对这个立法最好的事。
|
||||
|
||||
不过,这一步甚至不可能采取。我在八月份写这个专栏,毫无疑问,这个法案你在十月份或以后读的时候会没有了。如果听证会举行,它们无关紧要。该法案不会被任何委员会投票,不会在任何立法日程上。这个法案成为法律的可能性是零。这不仅仅是因为目前的政治 - 我在奥巴马政府下同样悲观。
|
||||
不过,这一步甚至不可能施行。我在八月份写这个专栏,毫无疑问,这个法案你在十月份或以后读的时候会没有了。如果听证会举行,它们无关紧要。该法案不会被任何委员会投票,不会在任何立法日程上。这个法案成为法律的可能性是零。这不仅仅是因为目前的政治 - 我在奥巴马政府下同样悲观。
|
||||
|
||||
但情况很严重。互联网是危险的 - 物联网不仅给了眼睛和耳朵,而且还给手脚。一旦有影响到位和字节的安全漏洞、利用和攻击现在会影响血肉和血肉。
|
||||
但情况很严重。互联网是危险的 - 物联网不仅给了眼睛和耳朵,而且还给手脚。一旦有影响到位和字节的安全漏洞、利用和攻击现在将会影响到其血肉。
|
||||
|
||||
正如我们在过去一个世纪一再学到的那样,市场是改善产品和服务安全的可怕机制。汽车、食品、餐厅、飞机、火灾和金融仪器安全都是如此。原因很复杂,但基本上卖家不会在安全方面进行竞争,因为买方无法根据安全考虑有效区分产品。市场使用的竞相降低门槛的机制价格降到最低的同时也将质量降至最低。没有政府干预,物联网仍然会很不安全。
|
||||
|
||||
美国政府对干预没有兴趣,所以我们不会看到严肃的安全和保障法规、新的联邦机构或更好的责任法。我们可能在欧盟有更好的机会。根据“通用数据保护条例”在数据隐私的规定,欧盟可能会在 5 年内通过类似的安全法。没有其他国家有足够的市场份额来做改变。
|
||||
|
||||
有时我们可以选择不使用物联网,但是这个选择变得越来越少见了。去年,我试着不连接网络购买新车但是失败了。再过几年, 就几乎不可能不连接到物联网。我们最大的安全风险将不会来自我们与之有市场关系的设备,而是来自其他人的汽车、照相机、路由器、无人机等等。
|
||||
有时我们可以选择不使用物联网,但是这个选择变得越来越少见了。去年,我试着不连接网络来购买新车但是失败了。再过几年, 就几乎不可能不连接到物联网。我们最大的安全风险将不会来自我们与之有市场关系的设备,而是来自其他人的汽车、照相机、路由器、无人机等等。
|
||||
|
||||
我们可以尝试为理想买单,并要求更多的安全性,但企业不会在物联网安全方面进行竞争 - 而且我们的安全专家不是一个足够大的市场力量来产生影响。
|
||||
我们可以尝试为理想买单,并要求更多的安全性,但企业不会在物联网安全方面进行竞争 - 而且我们的安全专家不是一个可以产生影响的足够大的市场力量。
|
||||
|
||||
我们需要一个后备计划,虽然我不知道是什么。如果你有任何想法请评论。
|
||||
|
||||
这篇文章以前出现在_ 9/10 月的 IEEE安全与隐私_上。
|
||||
这篇文章以前出现在 9/10 月的 《IEEE 安全与隐私》上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -35,7 +36,7 @@ via: https://www.schneier.com/blog/archives/2017/10/iot_cybersecuri.html
|
||||
|
||||
作者:[Bruce Schneier][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
157
published/201710/20171019 How to run DOS programs in Linux.md
Normal file
157
published/201710/20171019 How to run DOS programs in Linux.md
Normal file
@ -0,0 +1,157 @@
|
||||
怎么在 Linux 中运行 DOS 程序
|
||||
============================================================
|
||||
|
||||
> QEMU 和 FreeDOS 使得很容易在 Linux 中运行老的 DOS 程序
|
||||
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
传统的 DOS 操作系统支持的许多非常优秀的应用程序: 文字处理,电子表格,游戏和其它的程序。但是一个应用程序太老了,并不意味着它没用了。
|
||||
|
||||
如今有很多理由去运行一个旧的 DOS 应用程序。或许是从一个遗留的业务应用程序中提取一个报告,或者是想玩一个经典的 DOS 游戏,或者只是因为你对“传统计算机”很好奇。你不需要去双引导你的系统去运行 DOS 程序。取而代之的是,你可以在 Linux 中在一个 PC 仿真程序和 [FreeDOS][18] 的帮助下去正确地运行它们。
|
||||
|
||||
FreeDOS 是一个完整的、免费的、DOS 兼容的操作系统,你可以用它来玩经典的游戏、运行旧式业务软件,或者开发嵌入式系统。任何工作在 MS-DOS 中的程序也可以运行在 FreeDOS 中。
|
||||
|
||||
在那些“过去的时光”里,你安装的 DOS 是作为一台计算机上的独占操作系统。 而现今,它可以很容易地安装到 Linux 上运行的一台虚拟机中。 [QEMU][19] (<ruby>快速仿真程序<rt>Quick EMUlator</rt></ruby>的缩写) 是一个开源的虚拟机软件,它可以在 Linux 中以一个“<ruby>访客<rt>guest</rt></ruby>”操作系统来运行 DOS。许多流行的 Linux 系统都默认包含了 QEMU 。
|
||||
|
||||
通过以下四步,很容易地在 Linux 下通过使用 QEMU 和 FreeDOS 去运行一个老的 DOS 程序。
|
||||
|
||||
### 第 1 步:设置一个虚拟磁盘
|
||||
|
||||
你需要一个地方来在 QEMU 中安装 FreeDOS,为此你需要一个虚拟的 C: 驱动器。在 DOS 中,字母`A:` 和 `B:` 是分配给第一和第二个软盘驱动器的,而 `C:` 是第一个硬盘驱动器。其它介质,包括其它硬盘驱动器和 CD-ROM 驱动器,依次分配 `D:`、`E:` 等等。
|
||||
|
||||
在 QEMU 中,虚拟磁盘是一个镜像文件。要初始化一个用做虚拟 `C: ` 驱动器的文件,使用 `qemu-img` 命令。要创建一个大约 200 MB 的镜像文件,可以这样输入:
|
||||
|
||||
```
|
||||
qemu-img create dos.img 200M
|
||||
```
|
||||
|
||||
与现代计算机相比, 200MB 看起来非常小,但是早在 1990 年代, 200MB 是非常大的。它足够安装和运行 DOS。
|
||||
|
||||
### 第 2 步: QEMU 选项
|
||||
|
||||
与 PC 仿真系统 VMware 或 VirtualBox 不同,你需要通过 QEMU 命令去增加每个虚拟机的组件来 “构建” 你的虚拟系统 。虽然,这可能看起来很费力,但它实际并不困难。这些是我们在 QEMU 中用于去引导 FreeDOS 的参数:
|
||||
|
||||
| | |
|
||||
|:-- |:--|
|
||||
| `qemu-system-i386` | QEMU 可以仿真几种不同的系统,但是要引导到 DOS,我们需要有一个 Intel 兼容的 CPU。 为此,使用 i386 命令启动 QEMU。 |
|
||||
| `-m 16` | 我喜欢定义一个使用 16MB 内存的虚拟机。它看起来很小,但是 DOS 工作不需要很多的内存。在 DOS 时代,计算机使用 16MB 或者 8MB 内存是非常普遍的。 |
|
||||
| `-k en-us` | 从技术上说,这个 `-k` 选项是不需要的,因为 QEMU 会设置虚拟键盘去匹配你的真实键盘(在我的例子中, 它是标准的 US 布局的英语键盘)。但是我还是喜欢去指定它。 |
|
||||
| `-rtc base=localtime` | 每个传统的 PC 设备有一个实时时钟 (RTC) 以便于系统可以保持跟踪时间。我发现它是设置虚拟 RTC 匹配你的本地时间的最简单的方法。 |
|
||||
| `-soundhw sb16,adlib,pcspk` | 如果你需要声音,尤其是为了玩游戏时,我更喜欢定义 QEMU 支持 SoundBlaster 16 声音硬件和 AdLib 音乐。SoundBlaster 16 和 AdLib 是在 DOS 时代非常常见的声音硬件。一些老的程序也许使用 PC 喇叭发声; QEMU 也可以仿真这个。 |
|
||||
| `-device cirrus-vga` | 要使用图像,我喜欢去仿真一个简单的 VGA 视频卡。Cirrus VGA 卡是那时比较常见的图形卡, QEMU 可以仿真它。 |
|
||||
| `-display gtk` | 对于虚拟显示,我设置 QEMU 去使用 GTK toolkit,它可以将虚拟系统放到它自己的窗口内,并且提供一个简单的菜单去控制虚拟机。 |
|
||||
| `-boot order=` | 你可以告诉 QEMU 从多个引导源来引导虚拟机。从软盘驱动器引导(在 DOS 机器中一般情况下是 `A:` )指定 `order=a`。 从第一个硬盘驱动器引导(一般称为 `C:`) 使用 `order=c`。 或者去从一个 CD-ROM 驱动器(在 DOS 中经常分配为 `D:` ) 使用 `order=d`。 你可以使用组合字母去指定一个特定的引导顺序, 比如 `order=dc` 去第一个使用 CD-ROM 驱动器,如果 CD-ROM 驱动器中没有引导介质,然后使用硬盘驱动器。 |
|
||||
|
||||
### 第 3 步: 引导和安装 FreeDOS
|
||||
|
||||
现在 QEMU 已经设置好运行虚拟机,我们需要一个 DOS 系统来在那台虚拟机中安装和引导。 FreeDOS 做这个很容易。它的最新版本是 FreeDOS 1.2, 发行于 2016 年 12 月。
|
||||
|
||||
从 [FreeDOS 网站][20]上下载 FreeDOS 1.2 的发行版。 FreeDOS 1.2 CD-ROM “standard” 安装器 (`FD12CD.iso`) 可以很好地在 QEMU 上运行,因此,我推荐使用这个版本。
|
||||
|
||||
安装 FreeDOS 很简单。首先,告诉 QEMU 使用 CD-ROM 镜像并从其引导。 记住,第一个硬盘驱动器是 `C:` 驱动器,因此, CD-ROM 将以 `D:` 驱动器出现。
|
||||
|
||||
```
|
||||
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -display gtk -hda dos.img -cdrom FD12CD.iso -boot order=d
|
||||
```
|
||||
|
||||
正如下面的提示,你将在几分钟内安装完成 FreeDOS 。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
在你安装完成之后,关闭窗口退出 QEMU。
|
||||
|
||||
### 第 4 步:安装并运行你的 DOS 应用程序
|
||||
|
||||
一旦安装完 FreeDOS,你可以在 QEMU 中运行各种 DOS 应用程序。你可以在线上通过各种档案文件或其它[网站][21]找到老的 DOS 程序。
|
||||
|
||||
QEMU 提供了一个在 Linux 上访问本地文件的简单方法。比如说,想去用 QEMU 共享 `dosfiles/` 文件夹。 通过使用 `-drive` 选项,简单地告诉 QEMU 去使用这个文件夹作为虚拟的 FAT 驱动器。 QEMU 将像一个硬盘驱动器一样访问这个文件夹。
|
||||
|
||||
```
|
||||
-drive file=fat:rw:dosfiles/
|
||||
```
|
||||
|
||||
现在,你可以使用合适的选项去启动 QEMU,加上一个外部的虚拟 FAT 驱动器:
|
||||
|
||||
```
|
||||
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -display gtk -hda dos.img -drive file=fat:rw:dosfiles/ -boot order=c
|
||||
```
|
||||
|
||||
一旦你引导进入 FreeDOS,你保存在 `D:` 驱动器中的任何文件将被保存到 Linux 上的 `dosfiles/` 文件夹中。可以从 Linux 上很容易地直接去读取该文件;然而,必须注意的是,启动 QEMU 后,不能从 Linux 中去改变 `dosfiles/` 这个文件夹。 当你启动 QEMU 时,QEMU 一次性构建一个虚拟的 FAT 表,如果你在启动 QEMU 之后,在 `dosfiles/` 文件夹中增加或删除文件,仿真程序可能会很困惑。
|
||||
|
||||
我使用 QEMU 像这样运行一些我收藏的 DOS 程序, 比如 As-Easy-As 电子表格程序。这是一个在上世纪八九十年代非常流行的电子表格程序,它和现在的 Microsoft Excel 和 LibreOffice Calc 或和以前更昂贵的 Lotus 1-2-3 电子表格程序完成的工作是一样的。 As-Easy-As 和 Lotus 1-2-3 都保存数据为 WKS 文件,最新版本的 Microsoft Excel 不能读取它,但是,根据兼容性, LibreOffice Calc 可以支持它。
|
||||
|
||||

|
||||
|
||||
*As-Easy-As 电子表格程序*
|
||||
|
||||
我也喜欢在 QEMU中引导 FreeDOS 去玩一些收藏的 DOS 游戏,比如原版的 Doom。这些老的 DOS 游戏玩起来仍然非常有趣, 并且它们现在在 QEMU 上运行的非常好。
|
||||
|
||||

|
||||
|
||||
*Doom*
|
||||
|
||||

|
||||
|
||||
*Heretic*
|
||||
|
||||

|
||||
|
||||
*Jill of the Jungle*
|
||||
|
||||

|
||||
|
||||
*Commander Keen*
|
||||
|
||||
QEMU 和 FreeDOS 使得在 Linux 上运行老的 DOS 程序变得很容易。你一旦设置好了 QEMU 作为虚拟机仿真程序并安装了 FreeDOS,你将可以在 Linux 上运行你收藏的经典的 DOS 程序。
|
||||
|
||||
_所有图片要致谢 [FreeDOS.org][16]。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jim Hall 是一位开源软件的开发者和支持者,可能最广为人知的是他是 FreeDOS 的创始人和项目协调者。 Jim 也非常活跃于开源软件适用性领域,作为 GNOME Outreachy 适用性测试的导师,同时也作为一名兼职教授,教授一些开源软件适用性的课程,从 2016 到 2017, Jim 在 GNOME 基金会的董事会担任董事,在工作中, Jim 是本地政府部门的 CIO。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/run-dos-applications-linux
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/file/374821
|
||||
[7]:https://opensource.com/file/374771
|
||||
[8]:https://opensource.com/file/374776
|
||||
[9]:https://opensource.com/file/374781
|
||||
[10]:https://opensource.com/file/374761
|
||||
[11]:https://opensource.com/file/374786
|
||||
[12]:https://opensource.com/file/374791
|
||||
[13]:https://opensource.com/file/374796
|
||||
[14]:https://opensource.com/file/374801
|
||||
[15]:https://opensource.com/article/17/10/run-dos-applications-linux?rate=STdDX4LLLyyllTxAOD-CdfSwrZQ9D3FNqJTpMGE7v_8
|
||||
[16]:http://www.freedos.org/
|
||||
[17]:https://opensource.com/user/126046/feed
|
||||
[18]:http://www.freedos.org/
|
||||
[19]:https://www.qemu.org/
|
||||
[20]:http://www.freedos.org/
|
||||
[21]:http://www.freedos.org/links/
|
||||
[22]:https://opensource.com/users/jim-hall
|
||||
[23]:https://opensource.com/users/jim-hall
|
||||
[24]:https://opensource.com/article/17/10/run-dos-applications-linux#comments
|
||||
83
published/20171013 Best of PostgreSQL 10 for the DBA.md
Normal file
83
published/20171013 Best of PostgreSQL 10 for the DBA.md
Normal file
@ -0,0 +1,83 @@
|
||||
对 DBA 最重要的 PostgreSQL 10 新亮点
|
||||
============================================================
|
||||
|
||||
前段时间新的重大版本的 PostgreSQL 10 发布了! 强烈建议阅读[公告][3]、[发布说明][4]和“[新功能][5]”概述可以在[这里][3]、[这里][4]和[这里][5]。像往常一样,已经有相当多的博客覆盖了所有新的东西,但我猜每个人都有自己认为重要的角度,所以与 9.6 版一样我再次在这里列出我印象中最有趣/相关的功能。
|
||||
|
||||
与往常一样,升级或初始化一个新集群的用户将获得更好的性能(例如,更好的并行索引扫描、合并 join 和不相关的子查询,更快的聚合、远程服务器上更加智能的 join 和聚合),这些都开箱即用,但本文中我想讲一些不能开箱即用,实际上你需要采取一些步骤才能从中获益的内容。下面重点展示的功能是从 DBA 的角度来汇编的,很快也有一篇文章从开发者的角度讲述更改。
|
||||
|
||||
### 升级注意事项
|
||||
|
||||
首先有些从现有设置升级的提示 - 有一些小的事情会导致从 9.6 或更旧的版本迁移时引起问题,所以在真正的升级之前,一定要在单独的副本上测试升级,并遍历发行说明中所有可能的问题。最值得注意的缺陷是:
|
||||
|
||||
* 所有包含 “xlog” 的函数都被重命名为使用 “wal” 而不是 “xlog”。
|
||||
|
||||
后一个命名可能与正常的服务器日志混淆,因此这是一个“以防万一”的更改。如果使用任何第三方备份/复制/HA 工具,请检查它们是否为最新版本。
|
||||
* 存放服务器日志(错误消息/警告等)的 pg_log 文件夹已重命名为 “log”。
|
||||
|
||||
确保验证你的日志解析或 grep 脚本(如果有)可以工作。
|
||||
* 默认情况下,查询将最多使用 2 个后台进程。
|
||||
|
||||
如果在 CPU 数量较少的机器上在 `postgresql.conf` 设置中使用默认值 `10`,则可能会看到资源使用率峰值,因为默认情况下并行处理已启用 - 这是一件好事,因为它应该意味着更快的查询。如果需要旧的行为,请将 `max_parallel_workers_per_gather` 设置为 `0`。
|
||||
* 默认情况下,本地主机的复制连接已启用。
|
||||
|
||||
为了简化测试等工作,本地主机和本地 Unix 套接字复制连接现在在 `pg_hba.conf` 中以“<ruby>信任<rt>trust</rt></ruby>”模式启用(无密码)!因此,如果其他非 DBA 用户也可以访问真实的生产计算机,请确保更改配置。
|
||||
|
||||
### 从 DBA 的角度来看我的最爱
|
||||
|
||||
* 逻辑复制
|
||||
|
||||
这个期待已久的功能在你只想要复制一张单独的表、部分表或者所有表时只需要简单的设置而性能损失最小,这也意味着之后主要版本可以零停机升级!历史上(需要 Postgres 9.4+),这可以通过使用第三方扩展或缓慢的基于触发器的解决方案来实现。对我而言这是 10 最好的功能。
|
||||
* 声明分区
|
||||
|
||||
以前管理分区的方法通过继承并创建触发器来把插入操作重新路由到正确的表中,这一点很烦人,更不用说性能的影响了。目前支持的是 “range” 和 “list” 分区方案。如果有人在某些数据库引擎中缺少 “哈希” 分区,则可以使用带表达式的 “list” 分区来实现相同的功能。
|
||||
* 可用的哈希索引
|
||||
|
||||
哈希索引现在是 WAL 记录的,因此是崩溃安全的,并获得了一些性能改进,对于简单的搜索,它们比在更大的数据上的标准 B 树索引快。也支持更大的索引大小。
|
||||
|
||||
* 跨列优化器统计
|
||||
|
||||
这样的统计数据需要在一组表的列上手动创建,以指出这些值实际上是以某种方式相互依赖的。这将能够应对计划器认为返回的数据很少(概率的乘积通常会产生非常小的数字)从而导致在大量数据下性能不好的的慢查询问题(例如选择“嵌套循环” join)。
|
||||
* 副本上的并行快照
|
||||
|
||||
现在可以在 pg_dump 中使用多个进程(`-jobs` 标志)来极大地加快备用服务器上的备份。
|
||||
* 更好地调整并行处理 worker 的行为
|
||||
|
||||
参考 `max_parallel_workers` 和 `min_parallel_table_scan_size`/`min_parallel_index_scan_size` 参数。我建议增加一点后两者的默认值(8MB、512KB)。
|
||||
* 新的内置监控角色,便于工具使用
|
||||
|
||||
新的角色 `pg_monitor`、`pg_read_all_settings`、`pg_read_all_stats` 和 `pg_stat_scan_tables` 能更容易进行各种监控任务 - 以前必须使用超级用户帐户或一些 SECURITY DEFINER 包装函数。
|
||||
* 用于更安全的副本生成的临时 (每个会话) 复制槽
|
||||
* 用于检查 B 树索引的有效性的一个新的 Contrib 扩展
|
||||
|
||||
这两个智能检查发现结构不一致和页面级校验未覆盖的内容。希望不久的将来能更加深入。
|
||||
* Psql 查询工具现在支持基本分支(`if`/`elif`/`else`)
|
||||
|
||||
例如下面的将启用具有特定版本分支(对 pg_stat* 视图等有不同列名)的单个维护/监视脚本,而不是许多版本特定的脚本。
|
||||
|
||||
```
|
||||
SELECT :VERSION_NAME = '10.0' AS is_v10 \gset
|
||||
\if :is_v10
|
||||
SELECT 'yippee' AS msg;
|
||||
\else
|
||||
SELECT 'time to upgrade!' AS msg;
|
||||
\endif
|
||||
```
|
||||
|
||||
这次就这样了!当然有很多其他的东西没有列出,所以对于专职 DBA,我一定会建议你更全面地看发布记录。非常感谢那 300 多为这个版本做出贡献的人!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cybertec.at/best-of-postgresql-10-for-the-dba/
|
||||
|
||||
作者:[Kaarel Moppel][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cybertec.at/author/kaarel-moppel/
|
||||
[1]:http://www.cybertec.at/author/kaarel-moppel/
|
||||
[2]:http://www.cybertec.at/best-of-postgresql-10-for-the-dba/
|
||||
[3]:https://www.postgresql.org/about/news/1786/
|
||||
[4]:https://www.postgresql.org/docs/current/static/release-10.html
|
||||
[5]:https://wiki.postgresql.org/wiki/New_in_postgres_10
|
||||
242
published/20171015 Monitoring Slow SQL Queries via Slack.md
Normal file
242
published/20171015 Monitoring Slow SQL Queries via Slack.md
Normal file
@ -0,0 +1,242 @@
|
||||
通过 Slack 监视慢 SQL 查询
|
||||
==============
|
||||
|
||||
> 一个获得关于慢查询、意外错误和其它重要日志通知的简单 Go 秘诀。
|
||||
|
||||

|
||||
|
||||
我的 Slack bot 提示我一个运行了很长时间 SQL 查询。我应该尽快解决它。
|
||||
|
||||
**我们不能管理我们无法去测量的东西。**每个后台应用程序都需要我们去监视它在数据库上的性能。如果一个特定的查询随着数据量增长变慢,你必须在它变得太慢之前去优化它。
|
||||
|
||||
由于 Slack 已经成为我们工作的中心,它也在改变我们监视系统的方式。 虽然我们已经有非常不错的监视工具,如果在系统中任何东西有正在恶化的趋势,让 Slack 机器人告诉我们,也是非常棒的主意。比如,一个太长时间才完成的 SQL 查询,或者,在一个特定的 Go 包中发生一个致命的错误。
|
||||
|
||||
在这篇博客文章中,我们将告诉你,通过使用已经支持这些特性的[一个简单的日志系统][8] 和 [一个已存在的数据库库(database library)][9] 怎么去设置来达到这个目的。
|
||||
|
||||
### 使用记录器
|
||||
|
||||
[logger][10] 是一个为 Go 库和应用程序使用设计的小型库。在这个例子中我们使用了它的三个重要的特性:
|
||||
|
||||
* 它为测量性能提供了一个简单的定时器。
|
||||
* 支持复杂的输出过滤器,因此,你可以从指定的包中选择日志。例如,你可以告诉记录器仅从数据库包中输出,并且仅输出超过 500 ms 的定时器日志。
|
||||
* 它有一个 Slack 钩子,因此,你可以过滤并将日志输入到 Slack。
|
||||
|
||||
让我们看一下在这个例子中,怎么去使用定时器,稍后我们也将去使用过滤器:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"github.com/azer/logger"
|
||||
"time"
|
||||
)
|
||||
|
||||
var (
|
||||
users = logger.New("users")
|
||||
database = logger.New("database")
|
||||
)
|
||||
|
||||
func main () {
|
||||
users.Info("Hi!")
|
||||
|
||||
timer := database.Timer()
|
||||
time.Sleep(time.Millisecond * 250) // sleep 250ms
|
||||
timer.End("Connected to database")
|
||||
|
||||
users.Error("Failed to create a new user.", logger.Attrs{
|
||||
"e-mail": "foo@bar.com",
|
||||
})
|
||||
|
||||
database.Info("Just a random log.")
|
||||
|
||||
fmt.Println("Bye.")
|
||||
}
|
||||
```
|
||||
|
||||
运行这个程序没有输出:
|
||||
|
||||
```
|
||||
$ go run example-01.go
|
||||
Bye
|
||||
```
|
||||
|
||||
记录器是[缺省静默的][11],因此,它可以在库的内部使用。我们简单地通过一个环境变量去查看日志:
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
$ LOG=database@timer go run example-01.go
|
||||
01:08:54.997 database(250.095587ms): Connected to database.
|
||||
Bye
|
||||
```
|
||||
|
||||
上面的示例我们使用了 `database@timer` 过滤器去查看 `database` 包中输出的定时器日志。你也可以试一下其它的过滤器,比如:
|
||||
|
||||
* `LOG=*`: 所有日志
|
||||
* `LOG=users@error,database`: 所有来自 `users` 的错误日志,所有来自 `database` 的所有日志
|
||||
* `LOG=*@timer,database@info`: 来自所有包的定时器日志和错误日志,以及来自 `database` 的所有日志
|
||||
* `LOG=*,users@mute`: 除了 `users` 之外的所有日志
|
||||
|
||||
### 发送日志到 Slack
|
||||
|
||||
控制台日志是用于开发环境的,但是我们需要产品提供一个友好的界面。感谢 [slack-hook][12], 我们可以很容易地在上面的示例中,使用 Slack 去整合它:
|
||||
|
||||
```
|
||||
import (
|
||||
"github.com/azer/logger"
|
||||
"github.com/azer/logger-slack-hook"
|
||||
)
|
||||
|
||||
func init () {
|
||||
logger.Hook(&slackhook.Writer{
|
||||
WebHookURL: "https://hooks.slack.com/services/...",
|
||||
Channel: "slow-queries",
|
||||
Username: "Query Person",
|
||||
Filter: func (log *logger.Log) bool {
|
||||
return log.Package == "database" && log.Level == "TIMER" && log.Elapsed >= 200
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
我们来解释一下,在上面的示例中我们做了什么:
|
||||
|
||||
* 行 #5: 设置入站 webhook url。这个 URL [链接在这里][1]。
|
||||
* 行 #6: 选择流日志的入口通道。
|
||||
* 行 #7: 显示的发送者的用户名。
|
||||
* 行 #11: 使用流过滤器,仅输出时间超过 200 ms 的定时器日志。
|
||||
|
||||
希望这个示例能给你提供一个大概的思路。如果你有更多的问题,去看这个 [记录器][13]的文档。
|
||||
|
||||
### 一个真实的示例: CRUD
|
||||
|
||||
[crud][14] 是一个用于 Go 的数据库的 ORM 式的类库,它有一个隐藏特性是内部日志系统使用 [logger][15] 。这可以让我们很容易地去监视正在运行的 SQL 查询。
|
||||
|
||||
#### 查询
|
||||
|
||||
这有一个通过给定的 e-mail 去返回用户名的简单查询:
|
||||
|
||||
```
|
||||
func GetUserNameByEmail (email string) (string, error) {
|
||||
var name string
|
||||
if err := DB.Read(&name, "SELECT name FROM user WHERE email=?", email); err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
return name, nil
|
||||
}
|
||||
```
|
||||
|
||||
好吧,这个太短了, 感觉好像缺少了什么,让我们增加全部的上下文:
|
||||
|
||||
```
|
||||
import (
|
||||
"github.com/azer/crud"
|
||||
_ "github.com/go-sql-driver/mysql"
|
||||
"os"
|
||||
)
|
||||
|
||||
var db *crud.DB
|
||||
|
||||
func main () {
|
||||
var err error
|
||||
|
||||
DB, err = crud.Connect("mysql", os.Getenv("DATABASE_URL"))
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
username, err := GetUserNameByEmail("foo@bar.com")
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
fmt.Println("Your username is: ", username)
|
||||
}
|
||||
```
|
||||
|
||||
因此,我们有一个通过环境变量 `DATABASE_URL` 连接到 MySQL 数据库的 [crud][16] 实例。如果我们运行这个程序,将看到有一行输出:
|
||||
|
||||
```
|
||||
$ DATABASE_URL=root:123456@/testdb go run example.go
|
||||
Your username is: azer
|
||||
```
|
||||
|
||||
正如我前面提到的,日志是 [缺省静默的][17]。让我们看一下 crud 的内部日志:
|
||||
|
||||
```
|
||||
$ LOG=crud go run example.go
|
||||
22:56:29.691 crud(0): SQL Query Executed: SELECT username FROM user WHERE email='foo@bar.com'
|
||||
Your username is: azer
|
||||
```
|
||||
|
||||
这很简单,并且足够我们去查看在我们的开发环境中查询是怎么执行的。
|
||||
|
||||
#### CRUD 和 Slack 整合
|
||||
|
||||
记录器是为配置管理应用程序级的“内部日志系统”而设计的。这意味着,你可以通过在你的应用程序级配置记录器,让 crud 的日志流入 Slack :
|
||||
|
||||
```
|
||||
import (
|
||||
"github.com/azer/logger"
|
||||
"github.com/azer/logger-slack-hook"
|
||||
)
|
||||
|
||||
func init () {
|
||||
logger.Hook(&slackhook.Writer{
|
||||
WebHookURL: "https://hooks.slack.com/services/...",
|
||||
Channel: "slow-queries",
|
||||
Username: "Query Person",
|
||||
Filter: func (log *logger.Log) bool {
|
||||
return log.Package == "mysql" && log.Level == "TIMER" && log.Elapsed >= 250
|
||||
}
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
在上面的代码中:
|
||||
|
||||
* 我们导入了 [logger][2] 和 [logger-slack-hook][3] 库。
|
||||
* 我们配置记录器日志流入 Slack。这个配置覆盖了代码库中 [记录器][4] 所有的用法, 包括第三方依赖。
|
||||
* 我们使用了流过滤器,仅输出 MySQL 包中超过 250 ms 的定时器日志。
|
||||
|
||||
这种使用方法可以被扩展,而不仅是慢查询报告。我个人使用它去跟踪指定包中的重要错误, 也用于统计一些类似新用户登入或生成支付的日志。
|
||||
|
||||
### 在这篇文章中提到的包
|
||||
|
||||
* [crud][5]
|
||||
* [logger][6]
|
||||
* [logger-slack-hook][7]
|
||||
|
||||
[告诉我们][18] 如果你有任何的问题或建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/
|
||||
|
||||
作者:[Azer Koçulu][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://azer.bike/
|
||||
[1]:https://my.slack.com/services/new/incoming-webhook/
|
||||
[2]:https://github.com/azer/logger
|
||||
[3]:https://github.com/azer/logger-slack-hook
|
||||
[4]:https://github.com/azer/logger
|
||||
[5]:https://github.com/azer/crud
|
||||
[6]:https://github.com/azer/logger
|
||||
[7]:https://github.com/azer/logger
|
||||
[8]:http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/?utm_source=dbweekly&utm_medium=email#logger
|
||||
[9]:http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/?utm_source=dbweekly&utm_medium=email#crud
|
||||
[10]:https://github.com/azer/logger
|
||||
[11]:http://www.linfo.org/rule_of_silence.html
|
||||
[12]:https://github.com/azer/logger-slack-hook
|
||||
[13]:https://github.com/azer/logger
|
||||
[14]:https://github.com/azer/crud
|
||||
[15]:https://github.com/azer/logger
|
||||
[16]:https://github.com/azer/crud
|
||||
[17]:http://www.linfo.org/rule_of_silence.html
|
||||
[18]:https://twitter.com/afrikaradyo
|
||||
@ -1,26 +1,27 @@
|
||||
为什么要在 Docker 中使用 R? 一位 DevOps 的视角
|
||||
为什么要在 Docker 中使用 R? 一位 DevOps 的看法
|
||||
============================================================
|
||||
|
||||
[][11]
|
||||
|
||||
有几篇关于为什么要在 Docker 中使用 R 的文章。在这篇文章中,我将尝试加入一个 DevOps 的观点,并解释在 OpenCPU 系统的上下文中如何使用容器化 R 来构建和部署 R 服务器。
|
||||
> R 语言,一种自由软件编程语言与操作环境,主要用于统计分析、绘图、数据挖掘。R 内置多种统计学及数字分析功能。R 的另一强项是绘图功能,制图具有印刷的素质,也可加入数学符号。——引自维基百科。
|
||||
|
||||
> 有在 [#rstats][2] 世界的人真正地写*为什么*他们使用 Docker,而不是*如何*么?
|
||||
已经有几篇关于为什么要在 Docker 中使用 R 的文章。在这篇文章中,我将尝试加入一个 DevOps 的观点,并解释在 OpenCPU 系统的环境中如何使用容器化 R 来构建和部署 R 服务器。
|
||||
|
||||
> 有在 [#rstats][2] 世界的人真正地写过*为什么*他们使用 Docker,而不是*如何*么?
|
||||
>
|
||||
> — Jenny Bryan (@JennyBryan) [September 29, 2017][3]
|
||||
|
||||
### 1:轻松开发
|
||||
|
||||
OpenCPU 系统的旗舰是[ OpenCPU 服务器][12]:它是一个成熟且强大的 Linux 栈,用于在系统和应用程序中嵌入 R。因为 OpenCPU 是完全开源的,我们可以在 DockerHub 上构建和发布。可以使用以下命令启动(使用端口8004或80)一个可以立即使用的 OpenCPU 和 RStudio 的 Linux 服务器:
|
||||
OpenCPU 系统的旗舰是 [OpenCPU 服务器][12]:它是一个成熟且强大的 Linux 栈,用于在系统和应用程序中嵌入 R。因为 OpenCPU 是完全开源的,我们可以在 DockerHub 上构建和发布。可以使用以下命令启动一个可以立即使用的 OpenCPU 和 RStudio 的 Linux 服务器(使用端口 8004 或 80):
|
||||
|
||||
```
|
||||
docker run -t -p 8004:8004 opencpu/rstudio
|
||||
|
||||
```
|
||||
|
||||
现在只需在你的浏览器打开 [http://localhost:8004/ocpu/][13] 和 [http://localhost:8004/rstudio/][14]!在 rstudio 中用用户 `opencpu`(密码:`opencpu`)登录来构建或安装应用程序。有关详细信息,请参阅[自述文件][15]。
|
||||
现在只需在你的浏览器打开 http://localhost:8004/ocpu/ 和 http://localhost:8004/rstudio/ 即可!在 rstudio 中用用户 `opencpu`(密码:`opencpu`)登录来构建或安装应用程序。有关详细信息,请参阅[自述文件][15]。
|
||||
|
||||
Docker 让开始使用 OpenCPU 变得简单。容器给你一个充分灵活的 Linux,而无需在系统上安装任何东西。你可以通过 rstudio 服务器安装软件包或应用程序,也可以使用 `docker exec` 到正在运行的服务器中的 root shell 中:
|
||||
Docker 让开始使用 OpenCPU 变得简单。容器给你一个充分灵活的 Linux 机器,而无需在系统上安装任何东西。你可以通过 rstudio 服务器安装软件包或应用程序,也可以使用 `docker exec` 进入到正在运行的服务器的 root shell 中:
|
||||
|
||||
```
|
||||
# Lookup the container ID
|
||||
@ -28,52 +29,44 @@ docker ps
|
||||
|
||||
# Drop a shell
|
||||
docker exec -i -t eec1cdae3228 /bin/bash
|
||||
|
||||
```
|
||||
|
||||
你可以在服务器的 shell 中安装其他软件,自定义 apache2 httpd 配置(auth,代理等),调整 R 选项,通过预加载数据或包等来优化性能。
|
||||
你可以在服务器的 shell 中安装其他软件,自定义 apache2 的 httpd 配置(auth,代理等),调整 R 选项,通过预加载数据或包等来优化性能。
|
||||
|
||||
### 2: 通过 DockerHub 发布和部署
|
||||
|
||||
最强大的是,Docker 可以通过 Dockerhub 发布和部署。要创建一个完全独立的应用程序容器,只需使用标准[ opencpu 镜像][16]并添加你的程序。
|
||||
最强大的是,Docker 可以通过 DockerHub 发布和部署。要创建一个完全独立的应用程序容器,只需使用标准的 [opencpu 镜像][16]并添加你的程序。
|
||||
|
||||
为了本文的目的,我通过在每个仓库中添加一个非常简单的 “Dockerfile” 将一些[示例程序][17]打包为 docker 容器。例如:[nabel][18] 的 [Dockerfile][19] 包含以下内容:
|
||||
出于本文的目的,我通过在每个仓库中添加一个非常简单的 “Dockerfile”,将一些[示例程序][17]打包为 docker 容器。例如:[nabel][18] 的 [Dockerfile][19] 包含以下内容:
|
||||
|
||||
```
|
||||
FROM opencpu/base
|
||||
|
||||
RUN R -e 'devtools::install_github("rwebapps/nabel")'
|
||||
|
||||
```
|
||||
|
||||
它采用标准的 [opencpu/base][20] 镜像,并从 Github [仓库][21]安装 nabel。结果是一个完全隔离独立的程序。任何人可以使用下面这样的命令启动程序:
|
||||
它采用标准的 [opencpu/base][20] 镜像,并从 Github [仓库][21]安装 nabel。最终得到一个完全隔离、独立的程序。任何人可以使用下面这样的命令启动程序:
|
||||
|
||||
```
|
||||
docker run -d 8004:8004 rwebapps/nabel
|
||||
|
||||
```
|
||||
|
||||
`-d` 代表守护进程监听 8004 端口。很显然,你可以调整 `Dockerfile` 来安装任何其他的软件或设置你需要的程序。
|
||||
`-d` 代表守护进程监听 8004 端口。很显然,你可以调整 `Dockerfile` 来安装任何其它的软件或设置你需要的程序。
|
||||
|
||||
容器化部署展示了 Docker 的真正能力:它可以发布可以开箱即用的独立软件,而无需安装任何软件或依赖付费托管服务。如果你更喜欢专业的托管,那会有许多公司乐意在可扩展的基础设施上为你托管 docker 程序。
|
||||
容器化部署展示了 Docker 的真正能力:它可以发布可以开箱即用的独立软件,而无需安装任何软件或依赖付费托管的服务。如果你更喜欢专业的托管,那会有许多公司乐意在可扩展的基础设施上为你托管 docker 程序。
|
||||
|
||||
### 3: 跨平台构建
|
||||
|
||||
Docker用于OpenCPU的第三种方式。每次发布,我们都构建 6 个操作系统的 `opencpu-server` 安装包,它们在 [https://archive.opencpu.org][22] 上公布。这个过程已经使用 DockerHub 完全自动化了。以下镜像从源代码自动构建所有栈:
|
||||
还有 Docker 用于 OpenCPU 的第三种方式。每次发布,我们都构建 6 个操作系统的 `opencpu-server` 安装包,它们在 [https://archive.opencpu.org][22] 上公布。这个过程已经使用 DockerHub 完全自动化了。以下镜像从源代码自动构建所有栈:
|
||||
|
||||
* [opencpu/ubuntu-16.04][4]
|
||||
|
||||
* [opencpu/debian-9][5]
|
||||
|
||||
* [opencpu/fedora-25][6]
|
||||
|
||||
* [opencpu/fedora-26][7]
|
||||
|
||||
* [opencpu/centos-6][8]
|
||||
|
||||
* [opencpu/centos-7][9]
|
||||
|
||||
当 Github 上发布新版本时,DockerHub 会自动重建此镜像。要做的就是运行一个[脚本][23],它会取回镜像并将 `opencpu-server` 二进制复制到[归档服务器上][24]。
|
||||
当 GitHub 上发布新版本时,DockerHub 会自动重建此镜像。要做的就是运行一个[脚本][23],它会取回镜像并将 `opencpu-server` 二进制复制到[归档服务器上][24]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -81,7 +74,7 @@ via: https://www.r-bloggers.com/why-use-docker-with-r-a-devops-perspective/
|
||||
|
||||
作者:[Jeroen Ooms][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
71
published/20171016 Introducing CRI-O 1.0.md
Normal file
71
published/20171016 Introducing CRI-O 1.0.md
Normal file
@ -0,0 +1,71 @@
|
||||
CRI-O 1.0 简介
|
||||
=====
|
||||
|
||||
去年,Kubernetes 项目推出了<ruby>[容器运行时接口][11]<rt>Container Runtime Interface</rt></ruby>(CRI):这是一个插件接口,它让 kubelet(用于创建 pod 和启动容器的集群节点代理)有使用不同的兼容 OCI 的容器运行时的能力,而不需要重新编译 Kubernetes。在这项工作的基础上,[CRI-O][12] 项目([原名 OCID] [13])准备为 Kubernetes 提供轻量级的运行时。
|
||||
|
||||
那么这个**真正的**是什么意思?
|
||||
|
||||
CRI-O 允许你直接从 Kubernetes 运行容器,而不需要任何不必要的代码或工具。只要容器符合 OCI 标准,CRI-O 就可以运行它,去除外来的工具,并让容器做其擅长的事情:加速你的新一代原生云程序。
|
||||
|
||||
在引入 CRI 之前,Kubernetes 通过“[一个内部的][14][易失性][15][接口][16]”与特定的容器运行时相关联。这导致了上游 Kubernetes 社区以及在编排平台之上构建解决方案的供应商的大量维护开销。
|
||||
|
||||
使用 CRI,Kubernetes 可以与容器运行时无关。容器运行时的提供者不需要实现 Kubernetes 已经提供的功能。这是社区的胜利,因为它让项目独立进行,同时仍然可以共同工作。
|
||||
|
||||
在大多数情况下,我们不认为 Kubernetes 的用户(或 Kubernetes 的发行版,如 OpenShift)真的关心容器运行时。他们希望它工作,但他们不希望考虑太多。就像你(通常)不关心机器上是否有 GNU Bash、Korn、Zsh 或其它符合 POSIX 标准 shell。你只是要一个标准的方式来运行你的脚本或程序而已。
|
||||
|
||||
### CRI-O:Kubernetes 的轻量级容器运行时
|
||||
|
||||
这就是 CRI-O 提供的。该名称来自 CRI 和开放容器计划(OCI),因为 CRI-O 严格关注兼容 OCI 的运行时和容器镜像。
|
||||
|
||||
现在,CRI-O 支持 runc 和 Clear Container 运行时,尽管它应该支持任何遵循 OCI 的运行时。它可以从任何容器仓库中拉取镜像,并使用<ruby>[容器网络接口][17]<rt>Container Network Interface</rt></ruby>(CNI)处理网络,以便任何兼容 CNI 的网络插件可与该项目一起使用。
|
||||
|
||||
当 Kubernetes 需要运行容器时,它会与 CRI-O 进行通信,CRI-O 守护程序与 runc(或另一个符合 OCI 标准的运行时)一起启动容器。当 Kubernetes 需要停止容器时,CRI-O 会来处理。这没什么令人兴奋的,它只是在幕后管理 Linux 容器,以便用户不需要担心这个关键的容器编排。
|
||||
|
||||

|
||||
|
||||
### CRI-O 不是什么
|
||||
|
||||
值得花一点时间了解下 CRI-O _不是_什么。CRI-O 的范围是与 Kubernetes 一起工作来管理和运行 OCI 容器。这不是一个面向开发人员的工具,尽管该项目确实有一些面向用户的工具进行故障排除。
|
||||
|
||||
例如,构建镜像超出了 CRI-O 的范围,这些留给像 Docker 的构建命令、 [Buildah][18] 或 [OpenShift 的 Source-to-Image][19](S2I)这样的工具。一旦构建完镜像,CRI-O 将乐意运行它,但构建镜像留给其他工具。
|
||||
|
||||
虽然 CRI-O 包含命令行界面 (CLI),但它主要用于测试 CRI-O,而不是真正用于在生产环境中管理容器的方法。
|
||||
|
||||
### 下一步
|
||||
|
||||
现在 CRI-O 1.0 发布了,我们希望看到它作为一个稳定功能在下一个 Kubernetes 版本中发布。1.0 版本将与 Kubernetes 1.7.x 系列一起使用,即将发布的 CRI-O 1.8-rc1 适合 Kubernetes 1.8.x。
|
||||
|
||||
我们邀请您加入我们,以促进开源 CRI-O 项目的开发,并感谢我们目前的贡献者为达成这一里程碑而提供的帮助。如果你想贡献或者关注开发,就去 [CRI-O 项目的 GitHub 仓库][20],然后关注 [CRI-O 博客][21]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.redhat.com/en/blog/introducing-cri-o-10
|
||||
|
||||
作者:[Joe Brockmeier][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.redhat.com/en/blog/authors/joe-brockmeier
|
||||
[1]:https://www.redhat.com/en/blog/authors/joe-brockmeier
|
||||
[2]:https://www.redhat.com/en/blog/authors/senior-evangelist
|
||||
[3]:https://www.redhat.com/en/blog/authors/linux-containers
|
||||
[4]:https://www.redhat.com/en/blog/authors/red-hat-0
|
||||
[5]:https://www.redhat.com/en/blog
|
||||
[6]:https://www.redhat.com/en/blog/tag/community
|
||||
[7]:https://www.redhat.com/en/blog/tag/containers
|
||||
[8]:https://www.redhat.com/en/blog/tag/hybrid-cloud
|
||||
[9]:https://www.redhat.com/en/blog/tag/platform
|
||||
[10]:mailto:?subject=Check%20out%20this%20redhat.com%20page:%20Introducing%20CRI-O%201.0&body=I%20saw%20this%20on%20redhat.com%20and%20thought%20you%20might%20be%20interested.%20%20Click%20the%20following%20link%20to%20read:%20https://www.redhat.com/en/blog/introducing-cri-o-10https://www.redhat.com/en/blog/introducing-cri-o-10
|
||||
[11]:https://github.com/kubernetes/kubernetes/blob/242a97307b34076d5d8f5bbeb154fa4d97c9ef1d/docs/devel/container-runtime-interface.md
|
||||
[12]:http://cri-o.io/
|
||||
[13]:https://www.redhat.com/en/blog/running-production-applications-containers-introducing-ocid
|
||||
[14]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[15]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[16]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[17]:https://github.com/containernetworking/cni
|
||||
[18]:https://github.com/projectatomic/buildah
|
||||
[19]:https://github.com/openshift/source-to-image
|
||||
[20]:https://github.com/kubernetes-incubator/cri-o
|
||||
[21]:https://medium.com/cri-o
|
||||
@ -0,0 +1,136 @@
|
||||
记不住 Linux 命令?这三个工具可以帮你
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
*apropos 工具几乎默认安装在每个 Linux 发行版上,它可以帮你找到你所需的命令。*
|
||||
|
||||
Linux 桌面从开始的简陋到现在走了很长的路。在我早期使用 Linux 的那段日子里,掌握命令行是最基本的 —— 即使是在桌面版。不过现在变了,很多人可能从没用过命令行。但对于 Linux 系统管理员来说,可不能这样。实际上,对于任何 Linux 管理员(不管是服务器还是桌面),命令行仍是必须的。从管理网络到系统安全,再到应用和系统设定 —— 没有什么工具比命令行更强大。
|
||||
|
||||
但是,实际上……你可以在 Linux 系统里找到_非常多_命令。比如只看 `/usr/bin` 目录,你就可以找到很多命令执行文件(你可以运行 `ls/usr/bin/ | wc -l` 看一下你的系统里这个目录下到底有多少命令)。当然,它们并不全是针对用户的执行文件,但是可以让你感受下 Linux 命令数量。在我的 Elementary OS 系统里,目录 `/usr/bin` 下有 2029 个可执行文件。尽管我只会用到其中的一小部分,我要怎么才能记住这一部分呢?
|
||||
|
||||
幸运的是,你可以使用一些工具和技巧,这样你就不用每天挣扎着去记忆这些命令了。我想和大家分享几个这样的小技巧,希望能让你们能稍微有效地使用命令行(顺便节省点脑力)。
|
||||
|
||||
我们从一个系统内置的工具开始介绍,然后再介绍两个可以安装的非常实用的程序。
|
||||
|
||||
### Bash 命令历史
|
||||
|
||||
不管你知不知道,Bash(最流行的 Linux shell)会保留你执行过的命令的历史。想实际操作下看看吗?有两种方式。打开终端窗口然后按向上方向键。你应该可以看到会有命令出现,一个接一个。一旦你找到了想用的命令,不用修改的话,可以直接按 Enter 键执行,或者修改后再按 Enter 键。
|
||||
|
||||
要重新执行(或修改一下再执行)之前运行过的命令,这是一个很好的方式。我经常用这个功能。它不仅仅让我不用去记忆一个命令的所有细节,而且可以不用一遍遍重复地输入同样的命令。
|
||||
|
||||
说到 Bash 的命令历史,如果你执行命令 `history`,你可以列出你过去执行过的命令列表(图 1)。
|
||||
|
||||

|
||||
|
||||
*图 1: 你能找到我敲的命令里的错误吗?*
|
||||
|
||||
你的 Bash 命令历史保存的历史命令的数量可以在 `~/.bashrc` 文件里设置。在这个文件里,你可以找到下面两行:
|
||||
|
||||
```
|
||||
HISTSIZE=1000
|
||||
|
||||
HISTFILESIZE=2000
|
||||
```
|
||||
|
||||
`HISTSIZE` 是命令历史列表里记录的命令的最大数量,而 `HISTFILESIZE` 是命令历史文件的最大行数。
|
||||
|
||||
显然,默认情况下,Bash 会记录你的 1000 条历史命令。这已经很多了。有时候,这也被认为是一个安全漏洞。如果你在意的话,你可以随意减小这个数值,在安全性和实用性之间平衡。如果你不希望 Bash 记录你的命令历史,可以将 `HISTSIZE` 设置为 `0`。
|
||||
|
||||
如果你修改了 `~/.bashrc` 文件,记得要登出后再重新登录(否则改动不会生效)。
|
||||
|
||||
### apropos
|
||||
|
||||
这是第一个我要介绍的工具,可以帮助你记忆 Linux 命令。apropos (意即“关于”)能够搜索 Linux 帮助文档来帮你找到你想要的命令。比如说,你不记得你用的发行版用的什么防火墙工具了。你可以输入 `apropos “firewall” `,然后这个工具会返回相关的命令(图 2)。
|
||||
|
||||

|
||||
|
||||
*图 2: 你用的什么防火墙?*
|
||||
|
||||
再假如你需要一个操作目录的命令,但是完全不知道要用哪个呢?输入 `apropos “directory”` 就可以列出在帮助文档里包含了字符 “directory” 的所有命令(图 3)。
|
||||
|
||||

|
||||
|
||||
*图 3: 可以操作目录的工具有哪些呢?*
|
||||
|
||||
apropos 工具在几乎所有 Linux 发行版里都会默认安装。
|
||||
|
||||
### Fish
|
||||
|
||||
还有另一个能帮助你记忆命令的很好的工具。Fish 是 Linux/Unix/Mac OS 的一个命令行 shell,有一些很好用的功能。
|
||||
|
||||
* 自动推荐
|
||||
* VGA 颜色
|
||||
* 完美的脚本支持
|
||||
* 基于网页的配置
|
||||
* 帮助文档自动补全
|
||||
* 语法高亮
|
||||
* 以及更多
|
||||
|
||||
自动推荐功能让 fish 非常方便(特别是你想不起来一些命令的时候)。
|
||||
|
||||
你可能觉得挺好,但是 fish 没有被默认安装。对于 Ubuntu(以及它的衍生版),你可以用下面的命令安装:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:fish-shell/release-2
|
||||
sudo apt update
|
||||
sudo apt install fish
|
||||
```
|
||||
|
||||
对于类 CentOS 系统,可以这样安装 fish。用下面的命令增加仓库:
|
||||
|
||||
```
|
||||
sudo -s
|
||||
cd /etc/yum.repos.d/
|
||||
wget http://download.opensuse.org/repositories/shells:fish:release:2/CentOS_7/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
用下面的命令更新仓库:
|
||||
|
||||
```
|
||||
yum repolist
|
||||
yum update
|
||||
```
|
||||
|
||||
然后用下面的命令安装 fish:
|
||||
|
||||
```
|
||||
yum install fish
|
||||
```
|
||||
|
||||
fish 用起来可能没你想象的那么直观。记住,fish 是一个 shell,所以在使用命令之前你得先登录进去。在你的终端里,运行命令 fish 然后你就会看到自己已经打开了一个新的 shell(图 4)。
|
||||
|
||||

|
||||
|
||||
*图 4: fish 的交互式 shell。*
|
||||
|
||||
在开始输入命令的时候,fish 会自动补齐命令。如果推荐的命令不是你想要的,按下键盘的 Tab 键可以浏览更多选择。如果正好是你想要的,按下键盘的向右键补齐命令,然后按下 Enter 执行。在用完 fish 后,输入 exit 来退出 shell。
|
||||
|
||||
Fish 还可以做更多事情,但是这里只介绍用来帮助你记住命令,自动推荐功能足够了。
|
||||
|
||||
### 保持学习
|
||||
|
||||
Linux 上有太多的命令了。但你也不用记住所有命令。多亏有 Bash 命令历史以及像 apropos 和 fish 这样的工具,你不用消耗太多记忆来回忆那些帮你完成任务的命令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/3-tools-help-you-remember-linux-commands
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/files/images/commands1jpg
|
||||
[7]:https://www.linux.com/files/images/commands2jpg
|
||||
[8]:https://www.linux.com/files/images/commands3jpg
|
||||
[9]:https://www.linux.com/files/images/commands4jpg
|
||||
[10]:https://www.linux.com/files/images/commands-mainjpg
|
||||
[11]:http://download.opensuse.org/repositories/shells:fish:release:2/CentOS_7/shells:fish:release:2.repo
|
||||
@ -0,0 +1,71 @@
|
||||
在 Linux 图形栈上运行 Android
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
> 根据 Collabora 的 Linux 图形栈贡献者和软件工程师 Robert Foss 的说法,你现在可以在常规的 Linux 图形处理平台上运行 Android,这是非常强大的功能。了解更多关于他在欧洲嵌入式 Linux 会议上的演讲。[Creative Commons Zero][2] Pixabay
|
||||
|
||||
你现在可以在常规的 Linux 图形栈之上运行 Android。以前并不能这样,根据 Collabora 的 Linux 图形栈贡献者和软件工程师 Robert Foss 的说法,这是非常强大的功能。在即将举行的[欧洲 Linux 嵌入式会议][5]的讲话中,Foss 将会介绍这一领域的最新进展,并讨论这些变化如何让你可以利用内核中的新功能和改进。
|
||||
|
||||
在本文中,Foss 解释了更多内容,并提供了他的演讲的预览。
|
||||
|
||||
**Linux.com:你能告诉我们一些你谈论的图形栈吗?**
|
||||
|
||||
**Foss:** 传统的 Linux 图形系统(如 X11)大都没有使用<ruby>平面图形<rt>plane</rt></ruby>。但像 Android 和 Wayland 这样的现代图形系统可以充分利用它。
|
||||
|
||||
Android 在 HWComposer 中最成功实现了平面支持,其图形栈与通常的 Linux 桌面图形栈有所不同。在桌面上,典型的合成器只是使用 GPU 进行所有的合成,因为这是桌面上唯一有的东西。
|
||||
|
||||
大多数嵌入式和移动芯片都有为 Android 设计的专门的 2D 合成硬件。这是通过将显示的内容分成不同的图层,然后智能地将图层送到经过优化处理图层的硬件。这就可以释放 GPU 来处理你真正关心的事情,同时它让硬件更有效率地做最好一件事。
|
||||
|
||||
**Linux.com:当你说到 Android 时,你的意思是 Android 开源项目 (AOSP) 么?**
|
||||
|
||||
**Foss:** Android 开源项目(AOSP)是许多 Android 产品建立的基础,AOSP 和 Android 之间没有什么区别。
|
||||
|
||||
具体来说,我的工作已经在 AOSP 上完成,但没有什么可以阻止将此项工作加入到已经发货的 Android 产品中。
|
||||
|
||||
区别更多在于授权和满足 Google 对 Android 产品的要求,而不是代码。
|
||||
|
||||
**Linux.com: 谁想要运行它,为什么?有什么好处?**
|
||||
|
||||
**Foss:** AOSP 为你提供了大量免费的东西,例如针对可用性、低功耗和多样化硬件进行优化的软件栈。它比任何一家公司自行开发的更精致、更灵活, 而不需要投入大量资源。
|
||||
|
||||
作为制造商,它还为你提供了一个能够立即为你的平台开发的大量开发人员。
|
||||
|
||||
**Linux.com:有什么实际使用情况?**
|
||||
|
||||
** Foss:** 新的部分是在常规 Linux 图形栈上运行 Android 的能力。可以在主线/上游内核和驱动来做到这一点,让你可以利用内核中的新功能和改进,而不仅仅依赖于来自于你的供应商的大量分支的 BSP。
|
||||
|
||||
对于任何有合理标准的 Linux 支持的 GPU,你现在可以在上面运行 Android。以前并不能这样。而且这样做是非常强大的。
|
||||
|
||||
同样重要的是,它鼓励 GPU 设计者与上游的驱动一起工作。现在他们有一个简单的方法来提供适用于 Android 和 Linux 的驱动程序,而无需额外的努力。他们的成本将会降低,维护上游 GPU 驱动变得更有吸引力。
|
||||
|
||||
例如,我们希望看到主线内核支持高通 SOC,我们希望成为实现这一目标的一部分。
|
||||
|
||||
总而言之,这将有助于硬件生态系统获得更好的软件支持,软件生态系统有更多的硬件配合。
|
||||
|
||||
* 它改善了 SBC/开发板制造商的经济性:它们可以提供一个经过良好测试的栈,既可以在两者之间工作,而不必提供 “Linux 栈” 和 Android 栈。
|
||||
* 它简化了驱动程序开发人员的工作,因为只有一个优化和支持目标。
|
||||
* 它支持 Android 社区,因为在主线内核上运行的 Android 可以让他们分享上游的改进。
|
||||
* 这有助于上游,因为我们获得了一个产品级质量的栈,这些栈已经在硬件设计师的帮助下进行了测试和开发。
|
||||
|
||||
以前,Mesa 被视为二等栈,但现在它是最新的(完全符合 Vulkan 1.0、OpenGL 4.6、OpenGL ES 3.2)另外还有性能和产品质量。
|
||||
|
||||
这意味着驱动开发人员可以参与 Mesa,相信他们正在分享他人的辛勤工作,并且还有一个很好的基础。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/event/elce/2017/10/running-android-top-linux-graphics-stack
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[ ](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/robert-fosspng
|
||||
[4]:https://www.linux.com/files/images/linux-graphics-stackjpg
|
||||
[5]:http://events.linuxfoundation.org/events/embedded-linux-conference-europe
|
||||
66
published/20171024 Top 5 Linux pain points in 2017.md
Normal file
66
published/20171024 Top 5 Linux pain points in 2017.md
Normal file
@ -0,0 +1,66 @@
|
||||
2017 年 Linux 的五大痛点
|
||||
============================================================
|
||||
|
||||
> 目前为止糟糕的文档是 Linux 用户最头痛的问题。这里还有一些其他常见的问题。
|
||||
|
||||

|
||||
|
||||
图片提供: [Internet Archive Book Images][8]. Opensource.com 修改 [CC BY-SA 4.0][9]
|
||||
|
||||
正如我在 [2016 年开源年鉴][10]的“[故障排除提示:5 个最常见的 Linux 问题][11]”中所讨论的,对大多数用户而言 Linux 能安装并按照预期运行,但有些不可避免地会遇到问题。过去一年在这方面有什么变化?又一次,我将问题提交给 LinuxQuestions.org 和社交媒体,并分析了 LQ 回复情况。以下是更新后的结果。
|
||||
|
||||
### 1、 文档
|
||||
|
||||
文档及其不足是今年最大的痛点之一。尽管开源的方式产生了优秀的代码,但是制作高质量文档的重要性在最近才走到了前列。随着越来越多的非技术用户采用 Linux 和开源软件,文档的质量和数量将变得至关重要。如果你想为开源项目做出贡献,但不觉得你有足够的技术来提供代码,那么改进文档是参与的好方法。许多项目甚至将文档保存在其仓库中,因此你可以使用你的贡献来适应版本控制的工作流。
|
||||
|
||||
### 2、 软件/库版本不兼容
|
||||
|
||||
我对此感到惊讶,但软件/库版本不兼容性屡被提及。如果你没有运行某个主流发行版,这个问题似乎更加严重。我个人_许多_年来没有遇到这个问题,但是越来越多的诸如 [AppImage][15]、[Flatpak][16] 和 Snaps 等解决方案的采用让我相信可能确实存在这些情况。我有兴趣听到更多关于这个问题的信息。如果你最近遇到过,请在评论中告诉我。
|
||||
|
||||
### 3、 UEFI 和安全启动
|
||||
|
||||
尽管随着更多支持的硬件部署,这个问题在继续得到改善,但许多用户表示仍然存在 UEFI 和/或<ruby>安全启动<rt>secure boot</rt></ruby>问题。使用开箱即用完全支持 UEFI/安全启动的发行版是最好的解决方案。
|
||||
|
||||
### 4、 弃用 32 位
|
||||
|
||||
许多用户对他们最喜欢的发行版和软件项目中的 32 位支持感到失望。尽管如果 32 位支持是必须的,你仍然有很多选择,但可能会继续支持市场份额和心理份额不断下降的平台的项目越来越少。幸运的是,我们谈论的是开源,所以只要_有人_关心这个平台,你可能至少有几个选择。
|
||||
|
||||
### 5、 X 转发的支持和测试恶化
|
||||
|
||||
尽管 Linux 的许多长期和资深的用户经常使用 <ruby>X 转发<rt>X-forwarding</rt></ruby>,并将其视为关键功能,但随着 Linux 变得越来越主流,它看起来很少得到测试和支持,特别是对较新的应用程序。随着 Wayland 网络透明转发的不断发展,情况可能会进一步恶化。
|
||||
|
||||
### 对比去年的遗留和改进
|
||||
|
||||
视频(特别是视频加速器、最新的显卡、专有驱动程序、高效的电源管理)、蓝牙支持、特定 WiFi 芯片和打印机以及电源管理以及挂起/恢复,对许多用户来说仍然是麻烦的。更积极的一点的是,安装、HiDPI 和音频问题比一年前显著降低。
|
||||
|
||||
Linux 继续取得巨大的进步,而持续的、几乎必然的改进周期将会确保持续数年。然而,与任何复杂的软件一样,总会有问题。
|
||||
|
||||
那么说,你在 2017 年发现 Linux 最常见的技术问题是什么?让我在评论中知道它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/top-5-linux-painpoints
|
||||
|
||||
作者:[Jeremy Garcia][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jeremy-garcia
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/article/17/10/top-5-linux-painpoints?rate=p-SFnMtS8f6qYAt2xW-CYdGHottubCz2XoPptwCzSiU
|
||||
[7]:https://opensource.com/user/86816/feed
|
||||
[8]:https://www.flickr.com/photos/internetarchivebookimages/20570945848/in/photolist-xkMtw9-xA5zGL-tEQLWZ-wFwzFM-aNwxgn-aFdWBj-uyFKYv-7ZCCBU-obY1yX-UAPafA-otBzDF-ovdDo6-7doxUH-obYkeH-9XbHKV-8Zk4qi-apz7Ky-apz8Qu-8ZoaWG-orziEy-aNwxC6-od8NTv-apwpMr-8Zk4vn-UAP9Sb-otVa3R-apz6Cb-9EMPj6-eKfyEL-cv5mwu-otTtHk-7YjK1J-ovhxf6-otCg2K-8ZoaJf-UAPakL-8Zo8j7-8Zk74v-otp4Ls-8Zo8h7-i7xvpR-otSosT-9EMPja-8Zk6Zi-XHpSDB-hLkuF3-of24Gf-ouN1Gv-fJzkJS-icfbY9
|
||||
[9]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[10]:https://opensource.com/yearbook/2016
|
||||
[11]:https://linux.cn/article-8185-1.html
|
||||
[12]:https://opensource.com/users/jeremy-garcia
|
||||
[13]:https://opensource.com/users/jeremy-garcia
|
||||
[14]:https://opensource.com/article/17/10/top-5-linux-painpoints#comments
|
||||
[15]:https://appimage.org/
|
||||
[16]:http://flatpak.org/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by chao-zhi
|
||||
|
||||
Be a force for good in your community
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
zpl1025
|
||||
How to take screenshots on Linux using Scrot
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,216 +0,0 @@
|
||||
zpl1025 translating
|
||||
12 Practices every Android Development Beginner should know — Part 1
|
||||
============================================================
|
||||
|
||||
### One practice at a time to become a better Android beginner
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
It’s been more than 12 years since Andy Rubin and team started working on the idea of a mobile operating system that would change the way mobile phones, rather smartphones were seen by consumers as well as the people who developed software for it. Smartphones back then were limited to texting and checking emails (and of course, making phone calls), giving users and developers a boundary to work within.
|
||||
|
||||
Android, the breaker of chains, with its excellent framework design gave both the parties the freedom to explore more than just a limited set of functionalities. One would argue that the iPhone brought the revolution in the mobile industry, but the thing is no matter how cool (and pricey, eh?) an iPhone is, it again brings that boundary, that limitation we never wanted.
|
||||
|
||||
However, as Uncle Ben said — with great power comes great responsibility — we also need to be extra careful with our Android application design approach. I have often seen, in many courses offered, the negligence to teach beginners that value, the value to understand the architecture well enough before starting. We just throw things at people without correctly explaining what the upsides and downsides are, how they impact design or what to use, what not to.
|
||||
|
||||
In this post, we will see some of the practices that a beginner or an intermediate (if missed any) level developer should know in order to get better out of the Android framework. This post will be followed by more in this series of posts where we will talk about more such useful practices. Let’s begin.
|
||||
|
||||
* * *
|
||||
|
||||
### 1\. Difference between @+id and @id
|
||||
|
||||
In order to access a widget (or component) in Java or to make others dependent on it, we need a unique value to represent it. That unique value is provided by android:id attribute which essentially adds id provided as a suffix to @+id/ to the _id resource file_ for others to query. An id for Toolbar can be defined like this,
|
||||
|
||||
```
|
||||
android:id=”@+id/toolbar
|
||||
```
|
||||
|
||||
The following id can now be tracked by _findViewById(…)_ which looks for it in the res file for id, or simply R.id directory and returns the type of View in question.
|
||||
|
||||
The other one, @id, behaves the same as findViewById(…) — looks for the component by the id provided but is reserved for layouts only. The most general use of it is to place a component relative to the component it returns.
|
||||
|
||||
```
|
||||
android:layout_below=”@id/toolbar”
|
||||
```
|
||||
|
||||
### 2\. Using @string res for providing Strings in XML
|
||||
|
||||
In simpler words, don’t use hard coded strings in XML. The reason behind it is fairly simple. When we use hard coded string in XML, we often use the same word over and over again. Just imagine the nightmare of changing the same word at multiple places which could have been just one had it been a string resource. The other benefit it provides is multi-language support as different string resource files can be created for different languages.
|
||||
|
||||
```
|
||||
android:text=”My Awesome Application”
|
||||
```
|
||||
|
||||
When using hard coded strings, you will often see a warning over the use of such strings in Android Studio, offering to change that hard coded string into a string resource. Try clicking on them and then hitting ALT + ENTER to get the resource extractor. You can also go to strings.xml located in values folder under res and declare a string resource like this,
|
||||
|
||||
```
|
||||
<string name=”app_name”>My Awesome Application</string>
|
||||
```
|
||||
|
||||
and then use it in place of the hard coded string,
|
||||
|
||||
```
|
||||
android:text=”@string/app_name”
|
||||
```
|
||||
|
||||
### 3\. Using @android and ?attr constants
|
||||
|
||||
This is a fairly effective practice to use predefined constants instead of declaring new ones. Take an example of #ffffff or white color which is used several times in a layout. Now instead of writing #ffffff every single time, or declaring a color resource for white, we could directly use this,
|
||||
|
||||
```
|
||||
@android:color/white
|
||||
```
|
||||
|
||||
Android has several color constants declared mainly for general colors like white, black or pink. It’s best use case is setting transparent color with,
|
||||
|
||||
```
|
||||
@android:color/transparent
|
||||
```
|
||||
|
||||
Another constant holder is ?attr which is used for setting predefined attribute values to different attributes. Just take an example of a custom Toolbar. This Toolbar needs a defined width and height. The width can be normally set to MATCH_PARENT, but what about height? Most of us aren’t aware of the guidelines, and we simply set the desired height that seems fitting. That’s wrong practice. Instead of setting our own height, we should rather be using,
|
||||
|
||||
```
|
||||
android:layout_height=”?attr/actionBarSize”
|
||||
```
|
||||
|
||||
Another use of ?attr is to draw ripples on views when clicked. SelectableItemBackground is a predefined drawable that can be set as background to any view which needs ripple effect,
|
||||
|
||||
```
|
||||
android:background=”?attr/selectableItemBackground”
|
||||
```
|
||||
|
||||
or we can use
|
||||
|
||||
```
|
||||
android:background=”?attr/selectableItemBackgroundBorderless”
|
||||
```
|
||||
|
||||
to enable borderless ripple.
|
||||
|
||||
### 4\. Difference between SP and DP
|
||||
|
||||
While there’s no real difference between these two, it’s important to know what these two are, and where to use them to best results.
|
||||
|
||||
SP or Scale-independent pixels are recommended for use with TextViews which require the font size to not change with display (density). Instead, the content of a TextView needs to scale as per the needs of a user, or simply the font size preferred by the user.
|
||||
|
||||
With anything else that needs dimension or position, DP or Density-independent pixels can be used. As mentioned earlier, DP and SP are same things, it’s just that DP scales well with changing densities as the Android System dynamically calculates the pixels from it making it suitable for use on components that need to look and feel the same on different devices with different display densities.
|
||||
|
||||
### 5\. Use of Drawables and Mipmaps
|
||||
|
||||
This is the most confusing of them all — How are drawable and mipmap different?
|
||||
|
||||
While it may seem that both serve the same purpose, they are inherentaly different. Mipmaps are meant to be used for storing icons, where as drawables are for any other format. Let’s see how they are used by the system internally and why not to use one in place of the other.
|
||||
|
||||
You’ll notice that your application has several mipmap and drawable folders, each representing a different display resolution. When it comes to choosing from Drawable folder, the system chooses from the folder that belongs to current device density. However, with Mipmap, the system can choose an icon from any folder that fits the need mainly because some launchers display larger icons than intended, so system chooses the next size up.
|
||||
|
||||
In short, use mipmaps for icons or markers that see a change in resolution when used on different device densities and use drawable for other resource types that can be stripped out when required.
|
||||
|
||||
For example, a Nexus 5 is xxhdpi. Now when we put icons in mipmap folders, all the folders of mipmap will be retained. But when it comes to drawable, only drawable-xxhdpi will be retained, terming any other folder useless.
|
||||
|
||||
### 6\. Using Vector Drawables
|
||||
|
||||
It’s a very common practice to add multiple versions (sizes) of the same asset in order to support different screen densities. While this approach may work, it also adds certain performance overheads like larger apk size and extra development effort. To eliminate these overheads, Android team at Google announced the addition of Vector Drawables.
|
||||
|
||||
Vector Drawables are SVGs (scaled vector graphics) but in XML representing an image drawn using a set of dots, lines and curves with fill colors. The very fact that Vector Drawables are made of lines and dots, gives them the ability to scale at different densities without losing resolution. The other associated benefit with Vector Drawables is the ease of animation. Add multiple vector drawables in a single AnimatedVectorDrawable file and we’re good to go instead of adding multiple images and handling them separately.
|
||||
|
||||
```
|
||||
<vector xmlns:android=”http://schemas.android.com/apk/res/android"
|
||||
android:width=”24dp”
|
||||
android:height=”24dp”
|
||||
android:viewportWidth=”24.0"
|
||||
android:viewportHeight=”24.0">
|
||||
```
|
||||
|
||||
```
|
||||
<path android:fillColor=”#69cdff” android:pathData=”M3,18h18v-2L3,16v2zM3,13h18v-2L3,11v2zM3,6v2h18L21,6L3,6z”/>
|
||||
```
|
||||
|
||||
```
|
||||
</vector>
|
||||
```
|
||||
|
||||
The above vector definition will result in the following drawable,
|
||||
|
||||

|
||||
|
||||
To Add a vector drawable to your android project, right click on app module of your project, then New >> Vector Assets.This will get you Asset Studio which gives you two options to configure vector drawable. First, picking from Material Icons and second, choosing a local SVG or PSD file.
|
||||
|
||||
Google recommends using Material Icons for anything app related to maintain continuity and feel of Android. Be sure to check out all of the icons [here][1].
|
||||
|
||||
### 7\. Setting End/Start Margin
|
||||
|
||||
This is one of the easiest things people miss out on. Margin! Sure adding margin is easy but what about supporting older platforms?
|
||||
|
||||
Start and End are supersets of Left and Right respectively, so if the application has minSdkVersion 17 or less, start or end margin/padding is required with older left/right. On platforms where start and end are missing, these two can be safely ignored for left/right. Sample declaration looks like this,
|
||||
|
||||
```
|
||||
android:layout_marginEnd=”20dp”
|
||||
android:paddingStart=”20dp”
|
||||
```
|
||||
|
||||
### 8\. Using Getter/Setter Generator
|
||||
|
||||
One of the most frustrating things to do while creating a holder class (which simply holds variable data) is creating multiple getters and setters — Copy/paste method body and rename them for each variable.
|
||||
|
||||
Luckily, Android Studio has a solution for it. It goes like this — declare all the variables you need inside the class, and go to Toolbar >> Code. The Shortcut for it is ALT + Insert. Clicking Code will get you Generate, tap on it and among many other options, there will be Getter and Setter option. Tapping on it while maintaining focus on your class page will add all the getters and setters to the class (handle the previous window on your own). Neat, isn’t it?
|
||||
|
||||
### 9\. Using Override/Implement Generator
|
||||
|
||||
Another helpful generator. Writing custom classes and extending them is easy but what about classes you have little idea about. Take PagerAdapter for example. You want a ViewPager to show a few pages and for that, you will need a custom PagerAdapter that will work as you define inside its overridden methods. But where are those methods? Android Studio may be gracious enough to force you to add a constructor to your custom class or even to give a short cut for (that’s you ALT + Enter), but the rest of the (abstract) methods from parent PagerAdapter need to be added manually which I am sure is tiring for most of us.
|
||||
|
||||
To get a list of all the overridden methods available, go to Code >> Generate and Override method or Implement methods, which ever is your need. You can even choose to add multiple methods to your class, just hold Ctrl and select methods and hit OK.
|
||||
|
||||
### 10\. Understanding Contexts Properly
|
||||
|
||||
Context is scary and I believe a lot of beginners never care to understand the architecture of Context class — what it is, and why is it needed everywhere.
|
||||
|
||||
In simpler terms, it is the one that binds all that you see on the screen together. All the views (or their extensions) are tied to the current environment using Context. Context is responsible for allowing access to application level resources such as density or current activity associated with it. Activities, Services, and Application all implement Context interface to provide other to-be-associated components in-house resources. Take an example of a TextView which has to be added to MainActivity. You would notice while creating an object that the TextView constructor needs Context. This is to resolve any resources needed within TextView definition. Say TextView needs to internally load the Roboto font. For doing this, TextView needs Context. Also when we are providing context (or this) to TextView, we’re telling it to bind with the current activity’s lifecycle.
|
||||
|
||||
Another key use of Context is to initiate application level operations such as initiating a library. A library lives through out the application lifecycle and thus it needs to be initiated with getApplicationContext() instead of _getContext_ or _this_ or _getActivity()_ . It’s important to know the correct use of different Context types to avoid a memory leak. Other uses of Context includes starting an Activity or Service. Remember startActivity(…)? When you need to change Activity from a non-activity class, you will need a context object to access startActivity method since it belongs to the Context class, not Activity class.
|
||||
|
||||
```
|
||||
getContext().startActivity(getContext(), SecondActivity.class);
|
||||
```
|
||||
|
||||
If you want to know more about the behavior of Context, go [here][2] or [here][3]. The first one is a nice article on Contexts and where to use them while the latter is Android documentation for Context which has elaborately explained all of its available features — methods, static flags and more.
|
||||
|
||||
### Bonus #1: Formatting Code
|
||||
|
||||
Who doesn’t like clean, properly formatted code? Well, almost every one of us working on classes that tend to go up to 1000 lines in size want our code to stay structured. And it’s not that only larger classes need formatting, even smaller modular classes need to make sure code remains readable.
|
||||
|
||||
With Android Studio, or any of the JetBrains IDEs you don’t even need to care about manually structuring your code like adding indentation or space before =. Write code the way you want and when you feel like formatting it, just hit ALT + CTRL + L on Windows or ALT + CTRL + SHIFT + L on Linux. *Code Auto-Formatted*
|
||||
|
||||
### Bonus #2: Using Libraries
|
||||
|
||||
One of the key principles of Object Oriented Programming is to increase reuse of code or rather decrease the habit of reinventing the wheel. It’s a very common approach that a lot of beginners follow wrongly. The approach has two ends,
|
||||
|
||||
- Don’t use libraries, write every code on your own.
|
||||
|
||||
- Use a library for everything.
|
||||
|
||||
Going completely to either of the ends is wrong practice. If you go to the first end, you’re going to eat up a lot of resources just to live up to your pride to own everything. Plus chances are there that your code will be less tested than that library you should have gone with, increasing the chances of a buggy module. Don’t reinvent the wheel when there is a limited resource. Go with a tested library and when you’ve got the complete idea and resources, replace the library with your own reliable code.
|
||||
|
||||
With the second end, there is an even bigger issue — reliance on foreign code. Don’t get used to the idea of relying on others code for everything. Write your own code for things that need lesser resources or things that are within your reach. You don’t need a library that sets up custom TypeFaces (fonts) for you, that you can do on your own.
|
||||
|
||||
So remember, stay in the middle of the two ends — don’t reinvent everything but also don’t over-rely on foreign code. Stay neutral and code to your abilities.
|
||||
|
||||
* * *
|
||||
|
||||
This article was first published on [What’s That Lambda][4]. Be sure to visit for more articles like this one on Android, Node.js, Angular.js and more.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://android.jlelse.eu/12-practices-every-android-beginner-should-know-cd43c3710027
|
||||
|
||||
作者:[ Nilesh Singh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://android.jlelse.eu/@nileshsingh?source=post_header_lockup
|
||||
[1]:https://material.io/icons/
|
||||
[2]:https://blog.mindorks.com/understanding-context-in-android-application-330913e32514
|
||||
[3]:https://developer.android.com/reference/android/content/Context.html
|
||||
[4]:https://www.whatsthatlambda.com/android/android-dev-101-things-every-beginner-must-know
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Scaling the GitLab database
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
[Streams: a new general purpose data structure in Redis.][1]
|
||||
==================================
|
||||
|
||||
|
||||
@ -1,353 +0,0 @@
|
||||
Translating by Chao-zhi
|
||||
|
||||
8 best languages to blog about
|
||||
============================================================
|
||||
|
||||
|
||||
TL;DR: In this post we’re going to do some metablogging and analyze different blogs popularity against their ranking in Google. All the code is on [GitHub repo][38].
|
||||
|
||||
### The idea
|
||||
|
||||
I’ve been wondering, how many page views actually do different blogs get daily, as well as what programming languages are most popular today among blog reading audience. It was also interesting to me, whether Google ranking of websites directly correlates with their popularity.
|
||||
|
||||
In order to answer these questions, I decided to make a Scrapy project that will scrape some data and then perform certain Data Analysis and Data Visualization on the obtained information.
|
||||
|
||||
### Part I: Scraping
|
||||
|
||||
We will use [Scrapy][39] for our endeavors, as it provides clean and robust framework for scraping and managing feeds of processed requests. We’ll also use [Splash][40] in order to parse Javascript pages we’ll have to deal with. Splash uses its own Web server that acts like a proxy and processes the Javascript response before redirecting it further to our Spider process.
|
||||
|
||||
I don’t describe Scrapy project setup here as well as Splash integration. You can find example of Scrapy project backbone [here][34] and Scrapy+Splash guide [here][35].
|
||||
|
||||
### Getting relevant blogs
|
||||
|
||||
The first step is obviously getting the data. We’ll need Google search results about programming blogs. See, if we just start scraping Google itself with, let’s say query “Python”, we’ll get lots of other stuff besides blogs. What we need is some kind of filtering that leaves exclusively blogs in the results set. Luckily, there is a thing called [Google Custom Search Engine][41], that achieves exactly that. There’s also this website [www.blogsearchengine.org][42] that performs exactly what we need, delegating user requests to CSE, so we can look at its queries and repeat them.
|
||||
|
||||
So what we’re going to do is go to [www.blogsearchengine.org][43] and search for “python” having Network tab in Chrome Developer tools open by our side. Here’s the screenshot of what we’re going to see.
|
||||
|
||||

|
||||
|
||||
The highlighted query is the one that blogsearchengine delegates to Google, so we’re just going to copy it and use in our scraper.
|
||||
|
||||
The blog scraping spider class would then look like this:
|
||||
|
||||
```
|
||||
class BlogsSpider(scrapy.Spider):
|
||||
name = 'blogs'
|
||||
allowed_domains = ['cse.google.com']
|
||||
|
||||
def __init__(self, queries):
|
||||
super(BlogsSpider, self).__init__()
|
||||
self.queries = queries
|
||||
```
|
||||
|
||||
[view raw][3][blogs.py][4] hosted with
|
||||
|
||||
by [GitHub][5]
|
||||
|
||||
Unlike typical Scrapy spiders, ours has overridden `__init__` method that accepts additional argument `queries` that specifies the list of queries we want to perform.
|
||||
|
||||
Now, the most important part is the actual query building and execution. This process is performed in the `start_requests` Spider’s method, which we happily override as well:
|
||||
|
||||
|
||||
```
|
||||
def start_requests(self):
|
||||
params_dict = {
|
||||
'cx': ['partner-pub-9634067433254658:5laonibews6'],
|
||||
'cof': ['FORID:10'],
|
||||
'ie': ['ISO-8859-1'],
|
||||
'q': ['query'],
|
||||
'sa.x': ['0'],
|
||||
'sa.y': ['0'],
|
||||
'sa': ['Search'],
|
||||
'ad': ['n9'],
|
||||
'num': ['10'],
|
||||
'rurl': [
|
||||
'http://www.blogsearchengine.org/search.html?cx=partner-pub'
|
||||
'-9634067433254658%3A5laonibews6&cof=FORID%3A10&ie=ISO-8859-1&'
|
||||
'q=query&sa.x=0&sa.y=0&sa=Search'
|
||||
],
|
||||
'siteurl': ['http://www.blogsearchengine.org/']
|
||||
}
|
||||
|
||||
params = urllib.parse.urlencode(params_dict, doseq=True)
|
||||
url_template = urllib.parse.urlunparse(
|
||||
['https', self.allowed_domains[0], '/cse',
|
||||
'', params, 'gsc.tab=0&gsc.q=query&gsc.page=page_num'])
|
||||
for query in self.queries:
|
||||
for page_num in range(1, 11):
|
||||
url = url_template.replace('query', urllib.parse.quote(query))
|
||||
url = url.replace('page_num', str(page_num))
|
||||
yield SplashRequest(url, self.parse, endpoint='render.html',
|
||||
args={'wait': 0.5})
|
||||
```
|
||||
|
||||
[view raw][6][blogs.py][7] hosted with
|
||||
|
||||
by [GitHub][8]
|
||||
|
||||
Here you can see quite complex `params_dict` dictionary holding all the parameters of the Google CSE URL we found earlier. We then prepare `url_template` with everything but query and page number filled. We request 10 pages about each programming language, each page contains 10 links, so it’s 100 different blogs for each language to analyze.
|
||||
|
||||
On lines `42-43` we use special `SplashRequest` instead of Scrapy’s own Request class, which wraps internal redirect logic of Splash library, so we don’t have to worry about that. Neat.
|
||||
|
||||
Finally, here’s the parsing routine:
|
||||
|
||||
```
|
||||
def parse(self, response):
|
||||
urls = response.css('div.gs-title.gsc-table-cell-thumbnail') \
|
||||
.xpath('./a/@href').extract()
|
||||
gsc_fragment = urllib.parse.urlparse(response.url).fragment
|
||||
fragment_dict = urllib.parse.parse_qs(gsc_fragment)
|
||||
page_num = int(fragment_dict['gsc.page'][0])
|
||||
query = fragment_dict['gsc.q'][0]
|
||||
page_size = len(urls)
|
||||
for i, url in enumerate(urls):
|
||||
parsed_url = urllib.parse.urlparse(url)
|
||||
rank = (page_num - 1) * page_size + i
|
||||
yield {
|
||||
'rank': rank,
|
||||
'url': parsed_url.netloc,
|
||||
'query': query
|
||||
}
|
||||
```
|
||||
|
||||
[view raw][9][blogs.py][10] hosted with
|
||||
|
||||
by [GitHub][11]
|
||||
|
||||
The heart and soul of any scraper is parser’s logic. There are multiple ways to understand the response page structure and build the XPath query string. You can use [Scrapy shell][44] to try and adjust your XPath query on the fly, without running a spider. I prefer a more visual method though. It involves Google Chrome’s Developer console again. Simply right-click the element you want to get in your spider and press Inspect. It opens the console with HTML code set to the place where it’s being defined. In our case, we want to get the actual search result links. Their source location looks like this:
|
||||
|
||||

|
||||
|
||||
So, after looking at the element description we see that the <div> we’re searching for has `.gsc-table-cell-thumbnail` CSS class and is a child of the `.gs-title` <div>, so we put it into the `css`method of response object we have (line `46`). After that, we just need to get the URL of the blog post. It is easily achieved by `'./a/@href'` XPath string, which takes the `href` attribute of tag found as direct child of our <div>.
|
||||
|
||||
### Finding traffic data
|
||||
|
||||
The next task is estimating the number of views per day each of the blogs receives. There are [various options][45] to get such data, both free and paid. After quick googling I decided to stick to this simple and free to use website [www.statshow.com][46]. The Spider for this website should take as an input blog URLs we’ve obtained in the previous step, go through them and add traffic information. Spider initialization looks like this:
|
||||
|
||||
```
|
||||
class TrafficSpider(scrapy.Spider):
|
||||
name = 'traffic'
|
||||
allowed_domains = ['www.statshow.com']
|
||||
|
||||
def __init__(self, blogs_data):
|
||||
super(TrafficSpider, self).__init__()
|
||||
self.blogs_data = blogs_data
|
||||
```
|
||||
|
||||
[view raw][12][traffic.py][13] hosted with
|
||||
|
||||
by [GitHub][14]
|
||||
|
||||
`blogs_data` is expected to be list of dictionaries in the form: `{"rank": 70, "url": "www.stat.washington.edu", "query": "Python"}`.
|
||||
|
||||
Request building function looks like this:
|
||||
|
||||
```
|
||||
def start_requests(self):
|
||||
url_template = urllib.parse.urlunparse(
|
||||
['http', self.allowed_domains[0], '/www/{path}', '', '', ''])
|
||||
for blog in self.blogs_data:
|
||||
url = url_template.format(path=blog['url'])
|
||||
request = SplashRequest(url, endpoint='render.html',
|
||||
args={'wait': 0.5}, meta={'blog': blog})
|
||||
yield request
|
||||
```
|
||||
|
||||
[view raw][15][traffic.py][16] hosted with
|
||||
|
||||
by [GitHub][17]
|
||||
|
||||
It’s quite simple, we just add `/www/web-site-url/` string to the `'www.statshow.com'` url.
|
||||
|
||||
Now let’s see how does the parser look:
|
||||
|
||||
```
|
||||
def parse(self, response):
|
||||
site_data = response.xpath('//div[@id="box_1"]/span/text()').extract()
|
||||
views_data = list(filter(lambda r: '$' not in r, site_data))
|
||||
if views_data:
|
||||
blog_data = response.meta.get('blog')
|
||||
traffic_data = {
|
||||
'daily_page_views': int(views_data[0].translate({ord(','): None})),
|
||||
'daily_visitors': int(views_data[1].translate({ord(','): None}))
|
||||
}
|
||||
blog_data.update(traffic_data)
|
||||
yield blog_data
|
||||
```
|
||||
|
||||
[view raw][18][traffic.py][19] hosted with
|
||||
|
||||
by [GitHub][20]
|
||||
|
||||
Similarly to the blog parsing routine, we just make our way through the sample return page of the StatShow and track down the elements containing daily page views and daily visitors. Both of these parameters identify website popularity, so we’ll just pick page views for our analysis.
|
||||
|
||||
### Part II: Analysis
|
||||
|
||||
The next part is analyzing all the data we got after scraping. We then visualize the prepared data sets with the lib called [Bokeh][47]. I don’t give the runner/visualization code here but it can be found in the [GitHub repo][48] in addition to everything else you see in this post.
|
||||
|
||||
The initial result set has few outlying items representing websites with HUGE amount of traffic (such as google.com, linkedin.com, Oracle.com etc.). They obviously shouldn’t be considered. Even if some of those have blogs, they aren’t language specific. That’s why we filter the outliers based on the approach suggested in [this StackOverflow answer][36].
|
||||
|
||||
### Language popularity comparison
|
||||
|
||||
At first, let’s just make a head-to-head comparison of all the languages we have and see which one has most daily views among the top 100 blogs.
|
||||
|
||||
Here’s the function that can take care of such a task:
|
||||
|
||||
|
||||
```
|
||||
def get_languages_popularity(data):
|
||||
query_sorted_data = sorted(data, key=itemgetter('query'))
|
||||
result = {'languages': [], 'views': []}
|
||||
popularity = []
|
||||
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
|
||||
group = list(group)
|
||||
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
|
||||
total_page_views = sum(daily_page_views)
|
||||
popularity.append((group[0]['query'], total_page_views))
|
||||
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
|
||||
languages, views = zip(*sorted_popularity)
|
||||
result['languages'] = languages
|
||||
result['views'] = views
|
||||
return result
|
||||
|
||||
```
|
||||
|
||||
[view raw][21][analysis.py][22] hosted with
|
||||
|
||||
by [GitHub][23]
|
||||
|
||||
Here we first group our data by languages (‘query’ key in the dict) and then use python’s `groupby`wonderful function borrowed from SQL to generate groups of items from our data list, each representing some programming language. Afterwards, we calculate total page views for each language on line `14` and then add tuples of the form `('Language', rank)` in the `popularity`list. After the loop, we sort the popularity data based on the total views and unpack these tuples in 2 separate lists and return those in the `result` variable.
|
||||
|
||||
There was some huge deviation in the initial dataset. I checked what was going on and realized that if I make query “C” in the [blogsearchengine.org][37], I get lots of irrelevant links, containing “C” letter somewhere. So, I had to exclude C from the analysis. It almost doesn’t happen with “R” in contrast as well as other C-like names: “C++”, “C#”.
|
||||
|
||||
So, if we remove C from the consideration and look at other languages, we can see the following picture:
|
||||
|
||||
|
||||
|
||||
Evaluation. Java made it with over 4 million views daily, PHP and Go have over 2 million, R and JavaScript close up the “million scorers” list.
|
||||
|
||||
### Daily Page Views vs Google Ranking
|
||||
|
||||
Let’s now take a look at the connection between the number of daily views and Google ranking of blogs. Logically, less popular blogs should be further in ranking, It’s not so easy though, as other factors influence ranking as well, for example, if the article in the less popular blog is more recent, it’ll likely pop up first.
|
||||
|
||||
The data preparation is performed in the following fashion:
|
||||
|
||||
```
|
||||
def get_languages_popularity(data):
|
||||
query_sorted_data = sorted(data, key=itemgetter('query'))
|
||||
result = {'languages': [], 'views': []}
|
||||
popularity = []
|
||||
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
|
||||
group = list(group)
|
||||
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
|
||||
total_page_views = sum(daily_page_views)
|
||||
popularity.append((group[0]['query'], total_page_views))
|
||||
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
|
||||
languages, views = zip(*sorted_popularity)
|
||||
result['languages'] = languages
|
||||
result['views'] = views
|
||||
return result
|
||||
```
|
||||
|
||||
[view raw][24][analysis.py][25] hosted with
|
||||
|
||||
by [GitHub][26]
|
||||
|
||||
The function accepts scraped data and list of languages to consider. We sort the data in the same way we did for languages popularity. Afterwards, in a similar language grouping loop, we build `(rank, views_number)` tuples (with 1-based ranks) that are being converted to 2 separate lists. This pair of lists is then written to the resulting dictionary.
|
||||
|
||||
The results for the top 8 GitHub languages (except C) are the following:
|
||||
|
||||
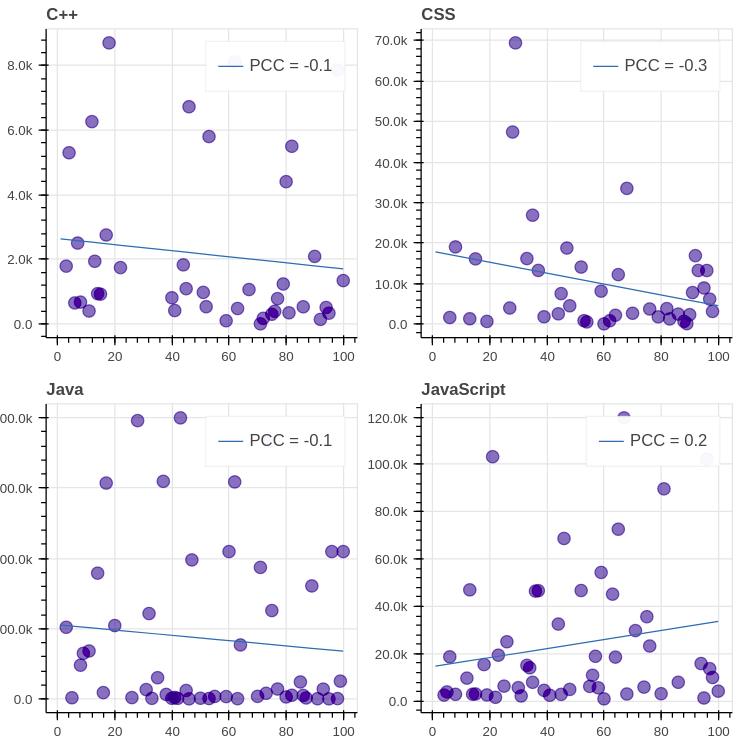
|
||||
|
||||
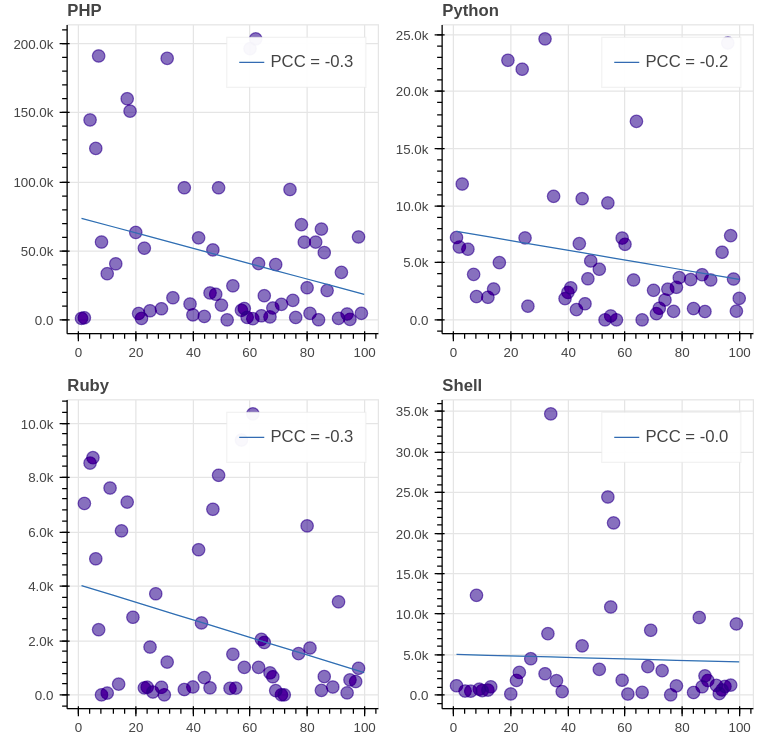
|
||||
|
||||
Evaluation. We see that the [PCC (Pearson correlation coefficient)][49] of all graphs is far from 1/-1, which signifies lack of correlation between the daily views and the ranking. It’s important to note though that in most of the graphs (7 out of 8) the correlation is negative, which means that decrease in ranking leads to decrease in views indeed.
|
||||
|
||||
### Conclusion
|
||||
|
||||
So, according to our analysis, Java is by far most popular programming language, followed by PHP, Go, R and JavaScript. Neither of top 8 languages has a strong correlation between daily views and ranking in Google, so you can definitely get high in search results even if you’re just starting your blogging path. What exactly is required for that top hit a topic for another discussion though.
|
||||
|
||||
These results are quite biased and can’t be taken into consideration without additional analysis. At first, it would be a good idea to collect more traffic feeds for an extended period of time and then analyze the mean (median?) values of daily views and rankings. Maybe I’ll return to it sometime in the future.
|
||||
|
||||
### References
|
||||
|
||||
1. Scraping:
|
||||
|
||||
1. [blog.scrapinghub.com: Handling Javascript In Scrapy With Splash][27]
|
||||
|
||||
2. [BlogSearchEngine.org][28]
|
||||
|
||||
3. [twingly.com: Twingly Real-Time Blog Search][29]
|
||||
|
||||
4. [searchblogspot.com: finding blogs on blogspot platform][30]
|
||||
|
||||
3. Traffic estimation:
|
||||
|
||||
1. [labnol.org: Find Out How Much Traffic a Website Gets][31]
|
||||
|
||||
2. [quora.com: What are the best free tools that estimate visitor traffic…][32]
|
||||
|
||||
3. [StatShow.com: The Stats Maker][33]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.databrawl.com/2017/10/08/blog-analysis/
|
||||
|
||||
作者:[Serge Mosin ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.databrawl.com/author/svmosingmail-com/
|
||||
[1]:https://bokeh.pydata.org/
|
||||
[2]:https://bokeh.pydata.org/
|
||||
[3]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||
[4]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||
[5]:https://github.com/
|
||||
[6]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||
[7]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||
[8]:https://github.com/
|
||||
[9]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||
[10]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||
[11]:https://github.com/
|
||||
[12]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||
[13]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||
[14]:https://github.com/
|
||||
[15]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||
[16]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||
[17]:https://github.com/
|
||||
[18]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||
[19]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||
[20]:https://github.com/
|
||||
[21]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/analysis.py
|
||||
[22]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-analysis-py
|
||||
[23]:https://github.com/
|
||||
[24]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/analysis.py
|
||||
[25]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-analysis-py
|
||||
[26]:https://github.com/
|
||||
[27]:https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/
|
||||
[28]:http://www.blogsearchengine.org/
|
||||
[29]:https://www.twingly.com/
|
||||
[30]:http://www.searchblogspot.com/
|
||||
[31]:https://www.labnol.org/internet/find-website-traffic-hits/8008/
|
||||
[32]:https://www.quora.com/What-are-the-best-free-tools-that-estimate-visitor-traffic-for-a-given-page-on-a-particular-website-that-you-do-not-own-or-operate-3rd-party-sites
|
||||
[33]:http://www.statshow.com/
|
||||
[34]:https://docs.scrapy.org/en/latest/intro/tutorial.html
|
||||
[35]:https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/
|
||||
[36]:https://stackoverflow.com/a/16562028/1573766
|
||||
[37]:http://blogsearchengine.org/
|
||||
[38]:https://github.com/Databrawl/blog_analysis
|
||||
[39]:https://scrapy.org/
|
||||
[40]:https://github.com/scrapinghub/splash
|
||||
[41]:https://en.wikipedia.org/wiki/Google_Custom_Search
|
||||
[42]:http://www.blogsearchengine.org/
|
||||
[43]:http://www.blogsearchengine.org/
|
||||
[44]:https://doc.scrapy.org/en/latest/topics/shell.html
|
||||
[45]:https://www.labnol.org/internet/find-website-traffic-hits/8008/
|
||||
[46]:http://www.statshow.com/
|
||||
[47]:https://bokeh.pydata.org/en/latest/
|
||||
[48]:https://github.com/Databrawl/blog_analysis
|
||||
[49]:https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
|
||||
[50]:https://www.databrawl.com/author/svmosingmail-com/
|
||||
[51]:https://www.databrawl.com/2017/10/08/
|
||||
@ -1,149 +0,0 @@
|
||||
Getting Started Analyzing Twitter Data in Apache Kafka through KSQL
|
||||
============================================================
|
||||
|
||||
[KSQL][8] is the open source streaming SQL engine for Apache Kafka. It lets you do sophisticated stream processing on Kafka topics, easily, using a simple and interactive SQL interface. In this short article we’ll see how easy it is to get up and running with a sandbox for exploring it, using everyone’s favourite demo streaming data source: Twitter. We’ll go from ingesting the raw stream of tweets, through to filtering it with predicates in KSQL, to building aggregates such as counting the number of tweets per user per hour.
|
||||
|
||||

|
||||
|
||||
First up, [go grab a copy of Confluent Platform][9]. I’m using the RPM but you can use [tar, zip, etc][10] if you want to. Start the Confluent stack up:
|
||||
|
||||
`$ confluent start`
|
||||
|
||||
(Here’s a [quick tutorial on the confluent CLI][11] if you’re interested!)
|
||||
|
||||
We’ll use Kafka Connect to pull the data from Twitter. The Twitter Connector can be found [on GitHub here][12]. To install it, simply do the following:
|
||||
|
||||
`# Clone the git repo
|
||||
cd /home/rmoff
|
||||
git clone https://github.com/jcustenborder/kafka-connect-twitter.git`
|
||||
|
||||
`# Compile the code
|
||||
cd kafka-connect-twitter
|
||||
mvn clean package`
|
||||
|
||||
To get Kafka Connect [to pick up the connector][13] that we’ve built, you’ll have to modify the configuration file. Since we’re using the Confluent CLI, the configuration file is actually `etc/schema-registry/connect-avro-distributed.properties`, so go modify that and add to it:
|
||||
|
||||
`plugin.path=/home/rmoff/kafka-connect-twitter/target/kafka-connect-twitter-0.2-SNAPSHOT.tar.gz`
|
||||
|
||||
Restart Kafka Connect:
|
||||
`confluent stop connect
|
||||
confluent start connect`
|
||||
|
||||
Once you’ve installed the plugin, you can easily configure it. You can use the Kafka Connect REST API directly, or create your configuration file, which is what I’ll do here. You’ll need to head over to [Twitter to grab your API keys first][14].
|
||||
|
||||
Assuming you’ve written this to `/home/rmoff/twitter-source.json`, you can now run:
|
||||
|
||||
`$ confluent load twitter_source -d /home/rmoff/twitter-source.json`
|
||||
|
||||
And then tweets from everyone’s favourite internet meme star start [rick]-rolling in…
|
||||
|
||||
Now let’s fire up KSQL! First off, download and build it:
|
||||
|
||||
`cd /home/rmoff `
|
||||
`git clone https://github.com/confluentinc/ksql.git `
|
||||
`cd /home/rmoff/ksql `
|
||||
`mvn clean compile install -DskipTests`
|
||||
|
||||
Once it’s built, let’s run it!
|
||||
|
||||
`./bin/ksql-cli local --bootstrap-server localhost:9092`
|
||||
|
||||
Using KSQL, we can take our data that’s held in Kafka topics and query it. First, we need to tell KSQL what the schema of the data in the topic is. A twitter message is actually a pretty huge JSON object, but for brevity let’s just pick a couple of columns to start with:
|
||||
|
||||
`ksql> CREATE STREAM twitter_raw (CreatedAt BIGINT, Id BIGINT, Text VARCHAR) WITH (KAFKA_TOPIC='twitter_json_01', VALUE_FORMAT='JSON');`
|
||||
`Message `
|
||||
`----------------`
|
||||
`Stream created`
|
||||
|
||||
With the schema defined, we can query the stream. To get KSQL to show data from the start of the topic (rather than the current point in time, which is the default), run:
|
||||
|
||||
`ksql> SET 'auto.offset.reset' = 'earliest'; `
|
||||
`Successfully changed local property 'auto.offset.reset' from 'null' to 'earliest'`
|
||||
|
||||
And now let’s see the data. We’ll select just one row using the LIMIT clause:
|
||||
|
||||
Now let’s redefine the stream with all the contents of the tweet payload now defined and available to us:
|
||||
|
||||
Now we can manipulate and examine our data more closely, using normal SQL queries:
|
||||
|
||||
Note that there’s no LIMIT clause, so you’ll see on screen the results of the _continuous query_ . Unlike a query on a relational table that returns a definite number of results, a continuous query is running on unbounded streaming data, so it always has the potential to return more records. Hit Ctrl-C to cancel and return to the KSQL prompt. In the above query we’re doing a few things:
|
||||
|
||||
* TIMESTAMPTOSTRING to convert the timestamp from epoch to a human-readable format
|
||||
|
||||
* EXTRACTJSONFIELD to show one of the nested user fields from the source, which looks like:
|
||||
|
||||
* Applying predicates to what’s shown, using pattern matching against the hashtag, forced to lower case with LCASE.
|
||||
|
||||
For a list of supported functions, see [the KSQL documentation][15].
|
||||
|
||||
We can create a derived stream from this data:
|
||||
|
||||
and query the derived stream:
|
||||
|
||||
Before we finish, let’s see how to do some aggregation.
|
||||
|
||||
You’ll probably get a screenful of results; this is because KSQL is actually emitting the aggregation values for the given hourly window each time it updates. Since we’ve set KSQL to read all messages on the topic (`SET 'auto.offset.reset' = 'earliest';`) it’s reading all of these messages at once and calculating the aggregation updates as it goes. There’s actually a subtlety in what’s going on here that’s worth digging into. Our inbound stream of tweets is just that—a stream. But now that we are creating aggregates, we have actually created a table. A table is a snapshot of a given key’s values at a given point in time. KSQL aggregates data based on the event time of the message, and handles late arriving data by simply restating that relevant window if it updates. Confused? We hope not, but let’s see if we can illustrate this with an example. We’ll declare our aggregate as an actual table:
|
||||
|
||||
Looking at the columns in the table, there are two implicit ones in addition to those we asked for:
|
||||
|
||||
`ksql> DESCRIBE user_tweet_count;
|
||||
|
||||
Field | Type
|
||||
-----------------------------------
|
||||
ROWTIME | BIGINT
|
||||
ROWKEY | VARCHAR(STRING)
|
||||
USER_SCREENNAME | VARCHAR(STRING)
|
||||
TWEET_COUNT | BIGINT
|
||||
ksql>`
|
||||
|
||||
Let’s see what’s in these:
|
||||
|
||||
The `ROWTIME` is the window start time, the `ROWKEY` is a composite of the `GROUP BY`(`USER_SCREENNAME`) plus the window. So we can tidy this up a bit by creating an additional derived table:
|
||||
|
||||
Now it’s easy to query and see the data that we’re interested in:
|
||||
|
||||
### Conclusion
|
||||
|
||||
So there we have it! We’re taking data from Kafka, and easily exploring it using KSQL. Not only can we explore and transform the data, we can use KSQL to easily build stream processing from streams and tables.
|
||||
|
||||

|
||||
|
||||
If you’re interested in what KSQL can do, check out:
|
||||
|
||||
* The [KSQL announcement blog post][1]
|
||||
|
||||
* [Our recent KSQL webinar][2] and [Kafka Summit keynote][3]
|
||||
|
||||
* The [clickstream demo][4] that’s available as part of [KSQL’s GitHub repo][5]
|
||||
|
||||
* A [presentation that I did recently][6] showing how KSQL can underpin a streaming ETL based platform.
|
||||
|
||||
Remember that KSQL is currently in developer preview. Feel free to raise any issues on the KSQL github repo, or come along to the #ksql channel on our [community Slack group][16].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.confluent.io/blog/using-ksql-to-analyse-query-and-transform-data-in-kafka
|
||||
|
||||
作者:[Robin Moffatt ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.confluent.io/blog/author/robin/
|
||||
[1]:https://www.confluent.io/blog/ksql-open-source-streaming-sql-for-apache-kafka/
|
||||
[2]:https://www.confluent.io/online-talk/ksql-streaming-sql-for-apache-kafka/
|
||||
[3]:https://www.confluent.io/kafka-summit-sf17/Databases-and-Stream-Processing-1
|
||||
[4]:https://www.youtube.com/watch?v=A45uRzJiv7I
|
||||
[5]:https://github.com/confluentinc/ksql
|
||||
[6]:https://speakerdeck.com/rmoff/look-ma-no-code-building-streaming-data-pipelines-with-apache-kafka
|
||||
[7]:https://www.confluent.io/blog/author/robin/
|
||||
[8]:https://github.com/confluentinc/ksql/
|
||||
[9]:https://www.confluent.io/download/
|
||||
[10]:https://docs.confluent.io/current/installation.html?
|
||||
[11]:https://www.youtube.com/watch?v=ZKqBptBHZTg
|
||||
[12]:https://github.com/jcustenborder/kafka-connect-twitter
|
||||
[13]:https://docs.confluent.io/current/connect/userguide.html#connect-installing-plugins
|
||||
[14]:https://apps.twitter.com/
|
||||
[15]:https://github.com/confluentinc/ksql/blob/0.1.x/docs/syntax-reference.md
|
||||
[16]:https://slackpass.io/confluentcommunity
|
||||
@ -1,277 +0,0 @@
|
||||
How to set up a Postgres database on a Raspberry Pi
|
||||
============================================================
|
||||
|
||||
### Install and configure the popular open source database system PostgreSQL and use it in your next Raspberry Pi project.
|
||||
|
||||

|
||||
Image credits : Raspberry Pi Foundation. [CC BY-SA 4.0][12].
|
||||
|
||||
Databases are a great way to add data persistence to your project or application. You can write data in one session and it'll be there the next time you want to look. A well-designed database can be efficient at looking up data in large datasets, and you won't have to worry about how it looks, just what you want it to find. It's fairly simple to set up a database for basic [CRUD][13] (create, record, update, delete) applications, which is a common pattern, and it is useful in many projects.
|
||||
|
||||
Why [PostgreSQL][14], commonly known as Postgres? It's considered to be the best open source database in terms of features and performance. It'll feel familiar if you've used MySQL, but when you need more advanced usage, you'll find the optimization in Postgres is far superior. It's easy to install, easy to use, easy to secure, and runs well on the Raspberry Pi 3.
|
||||
|
||||
This tutorial explains how to install Postgres on a Raspberry Pi; create a table; write simple queries; use the pgAdmin GUI on a Raspberry Pi, a PC, or a Mac; and interact with the database from Python.
|
||||
|
||||
Once you've learned the basics, you can take your application a lot further with complex queries joining multiple tables, at which point you need to think about optimization, best design practices, using primary and foreign keys, and more.
|
||||
|
||||
### Installation
|
||||
|
||||
To get started, you'll need to install Postgres and some other packages. Open a terminal window and run the following command while connected to the internet:
|
||||
|
||||
```
|
||||
sudo apt install postgresql libpq-dev postgresql-client
|
||||
postgresql-client-common -y
|
||||
```
|
||||
|
||||
### [postgres-install.png][1]
|
||||
|
||||

|
||||
|
||||
When that's complete, switch to the Postgres user to configure the database:
|
||||
|
||||
```
|
||||
sudo su postgres
|
||||
```
|
||||
|
||||
Now you can create a database user. If you create a user with the same name as one of your Unix user accounts, that user will automatically be granted access to the database. So, for the sake of simplicity in this tutorial, I'll assume you're using the default pi user. Run the **createuser** command to continue:
|
||||
|
||||
```
|
||||
createuser pi -P --interactive
|
||||
```
|
||||
|
||||
When prompted, enter a password (and remember what it is), select **n** for superuser, and **y** for the next two questions.
|
||||
|
||||
### [postgres-createuser.png][2]
|
||||
|
||||

|
||||
|
||||
Now connect to Postgres using the shell and create a test database:
|
||||
|
||||
```
|
||||
$ psql
|
||||
> create database test;
|
||||
```
|
||||
|
||||
Exit from the psql shell and again from the Postgres user by pressing Ctrl+D twice, and you'll be logged in as the pi user again. Since you created a Postgres user called pi, you can access the Postgres shell from here with no credentials:
|
||||
|
||||
```
|
||||
$ psql test
|
||||
```
|
||||
|
||||
You're now connected to the "test" database. The database is currently empty and contains no tables. You can create a simple table from the psql shell:
|
||||
|
||||
```
|
||||
test=> create table people (name text, company text);
|
||||
```
|
||||
|
||||
Now you can insert data into the table:
|
||||
|
||||
```
|
||||
test=> insert into people values ('Ben Nuttall', 'Raspberry Pi Foundation');
|
||||
|
||||
test=> insert into people values ('Rikki Endsley', 'Red Hat');
|
||||
```
|
||||
|
||||
And try a select query:
|
||||
|
||||
```
|
||||
test=> select * from people;
|
||||
|
||||
name | company
|
||||
---------------+-------------------------
|
||||
Ben Nuttall | Raspberry Pi Foundation
|
||||
Rikki Endsley | Red Hat
|
||||
(2 rows)
|
||||
```
|
||||
|
||||
### [postgres-query.png][3]
|
||||
|
||||

|
||||
|
||||
```
|
||||
test=> select name from people where company = 'Red Hat';
|
||||
|
||||
name | company
|
||||
---------------+---------
|
||||
Rikki Endsley | Red Hat
|
||||
(1 row)
|
||||
```
|
||||
|
||||
### pgAdmin
|
||||
|
||||
You might find it useful to use a graphical tool to access the database. PgAdmin is a full-featured PostgreSQL GUI that allows you to create and manage databases and users, create and modify tables, write and execute queries, and browse results in a more familiar view, similar to a spreadsheet. The psql command-line tool is fine for simple queries, and you'll find many power users stick with it for speed (and because they don't need the assistance the GUI gives), but midlevel users may find pgAdmin a more approachable way to learn and do more with a database.
|
||||
|
||||
Another useful thing about pgAdmin is that you can either use it directly on the Pi or on another computer that's remotely connected to the database on the Pi.
|
||||
|
||||
If you want to access it on the Raspberry Pi itself, you can just install it with **apt**:
|
||||
|
||||
```
|
||||
sudo apt install pgadmin3
|
||||
```
|
||||
|
||||
It's exactly the same if you're on a Debian-based system like Ubuntu; if you're on another distribution, try the equivalent command for your system. Alternatively, or if you're on Windows or macOS, try downloading pgAdmin from [pgAdmin.org][15]. Note that the version available in **apt** is pgAdmin3 and a newer version, pgAdmin4, is available from the website.
|
||||
|
||||
To connect to your database with pgAdmin on the same Raspberry Pi, simply open pgAdmin3 from the main menu, click the **new connection** icon, and complete the registration fields. In this case, all you'll need is a name (you choose the connection name, e.g. test), change the username to "pi," and leave the rest of the fields blank (or as they were). Click OK and you'll find a new connection in the side panel on the left.
|
||||
|
||||
### [pgadmin-connect.png][4]
|
||||
|
||||

|
||||
|
||||
To connect to your Pi's database with pgAdmin from another computer, you'll first need to edit the PostgreSQL configuration to allow remote connections:
|
||||
|
||||
1\. Edit the PostgreSQL config file **/etc/postgresql/9.6/main/postgresql.conf** to uncomment the **listen_addresses** line and change its value from **localhost** to *****. Save and exit.
|
||||
|
||||
2\. Edit the **pg_hba** config file **/etc/postgresql/9.6/main/postgresql.conf** to change **127.0.0.1/32** to **0.0.0.0/0** for IPv4 and **::1/128** to **::/0** for IPv6\. Save and exit.
|
||||
|
||||
3\. Restart the PostgreSQL service: **sudo service postgresql restart**.
|
||||
|
||||
Note the version number may be different if you're using an older Raspbian image or another distribution.
|
||||
|
||||
### [postgres-config.png][5]
|
||||
|
||||

|
||||
|
||||
Once that's done, open pgAdmin on your other computer and create a new connection. This time, in addition to giving the connection a name, enter the Pi's IP address as the host (this can be found by hovering over the WiFi icon in the taskbar or by typing **hostname -I** in a terminal).
|
||||
|
||||
### [pgadmin-remote.png][6]
|
||||
|
||||

|
||||
|
||||
Whether you connected locally or remotely, click to open **Server Groups > Servers > test > Schemas > public > Tables**, right-click the **people** table and select **View Data > View top 100 Rows**. You'll now see the data you entered earlier.
|
||||
|
||||
### [pgadmin-view.png][7]
|
||||
|
||||

|
||||
|
||||
You can now create and modify databases and tables, manage users, and write your own custom queries using the GUI. You might find this visual method more manageable than using the command line.
|
||||
|
||||
### Python
|
||||
|
||||
To connect to your database from a Python script, you'll need the [Psycopg2][16]Python package. You can install it with [pip][17]:
|
||||
|
||||
```
|
||||
sudo pip3 install psycopg2
|
||||
```
|
||||
|
||||
Now open a Python editor and write some code to connect to your database:
|
||||
|
||||
```
|
||||
import psycopg2
|
||||
|
||||
conn = psycopg2.connect('dbname=test')
|
||||
cur = conn.cursor()
|
||||
|
||||
cur.execute('select * from people')
|
||||
|
||||
results = cur.fetchall()
|
||||
|
||||
for result in results:
|
||||
print(result)
|
||||
```
|
||||
|
||||
Run this code to see the results of the query. Note that if you're connecting remotely, you'll need to supply more credentials in the connection string, for example, adding the host IP, username, and database password:
|
||||
|
||||
```
|
||||
conn = psycopg2.connect('host=192.168.86.31 user=pi
|
||||
password=raspberry dbname=test')
|
||||
```
|
||||
|
||||
You could even create a function to look up this query specifically:
|
||||
|
||||
```
|
||||
def get_all_people():
|
||||
query = """
|
||||
SELECT
|
||||
*
|
||||
FROM
|
||||
people
|
||||
"""
|
||||
cur.execute(query)
|
||||
return cur.fetchall()
|
||||
```
|
||||
|
||||
And one including a lookup:
|
||||
|
||||
```
|
||||
def get_people_by_company(company):
|
||||
query = """
|
||||
SELECT
|
||||
*
|
||||
FROM
|
||||
people
|
||||
WHERE
|
||||
company = %s
|
||||
"""
|
||||
values = (company, )
|
||||
cur.execute(query, values)
|
||||
return cur.fetchall()
|
||||
```
|
||||
|
||||
Or even a function for adding records:
|
||||
|
||||
```
|
||||
def add_person(name, company):
|
||||
query = """
|
||||
INSERT INTO
|
||||
people
|
||||
VALUES
|
||||
(%s, %s)
|
||||
"""
|
||||
values = (name, company)
|
||||
cur.execute(query, values)
|
||||
```
|
||||
|
||||
Note this uses a safe method of injecting strings into queries. You don't want to get caught out by [little bobby tables][18]!
|
||||
|
||||
### [python-postgres.png][8]
|
||||
|
||||

|
||||
|
||||
Now you know the basics. If you want to take Postgres further, check out this article on [Full Stack Python][19].
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ben Nuttall - Ben Nuttall is the Raspberry Pi Community Manager. In addition to his work for the Raspberry Pi Foundation, he's into free software, maths, kayaking, GitHub, Adventure Time, and Futurama. Follow Ben on Twitter [@ben_nuttall][10].
|
||||
|
||||
-------------
|
||||
|
||||
via: https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi
|
||||
|
||||
作者:[Ben Nuttall ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://opensource.com/file/374246
|
||||
[2]:https://opensource.com/file/374241
|
||||
[3]:https://opensource.com/file/374251
|
||||
[4]:https://opensource.com/file/374221
|
||||
[5]:https://opensource.com/file/374236
|
||||
[6]:https://opensource.com/file/374226
|
||||
[7]:https://opensource.com/file/374231
|
||||
[8]:https://opensource.com/file/374256
|
||||
[9]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021&rate=t-XUFUPa6mURgML4cfL1mjxsmFBG-VQTG4R39QvFVQA
|
||||
[10]:http://www.twitter.com/ben_nuttall
|
||||
[11]:https://opensource.com/user/26767/feed
|
||||
[12]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[13]:https://en.wikipedia.org/wiki/Create,_read,_update_and_delete
|
||||
[14]:https://www.postgresql.org/
|
||||
[15]:https://www.pgadmin.org/download/
|
||||
[16]:http://initd.org/psycopg/
|
||||
[17]:https://pypi.python.org/pypi/pip
|
||||
[18]:https://xkcd.com/327/
|
||||
[19]:https://www.fullstackpython.com/postgresql.html
|
||||
[20]:https://opensource.com/users/bennuttall
|
||||
[21]:https://opensource.com/users/bennuttall
|
||||
[22]:https://opensource.com/users/bennuttall
|
||||
[23]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021#comments
|
||||
[24]:https://opensource.com/tags/raspberry-pi
|
||||
[25]:https://opensource.com/tags/raspberry-pi-column
|
||||
[26]:https://opensource.com/tags/how-tos-and-tutorials
|
||||
[27]:https://opensource.com/tags/programming
|
||||
@ -1,95 +0,0 @@
|
||||
Best of PostgreSQL 10 for the DBA
|
||||
============================================================
|
||||
|
||||
|
||||
Last week a new PostgreSQL major version with the number 10 was released! Announcement, release notes and the „What’s new“ overview can be found from [here][3], [here][4]and [here][5] – it’s highly recommended reading, so check them out. As usual there have been already quite some blog postings covering all the new stuff, but I guess everyone has their own angle on what is important so as with version 9.6 I’m again throwing in my impressions on the most interesting/relevant features here.
|
||||
|
||||
As always, users who upgrade or initialize a fresh cluster, will enjoy huge performance wins (e.g. better parallelization with parallel index scans, merge joins and uncorrelated sub-queries, faster aggregations, smarter joins and aggregates on remote servers) out of the box without doing anything, but here I would like to look more at the things that you won’t get out of the box but you actually need to take some steps to start benefiting from them. List of below highlighted features is compiled from a DBA’s viewpoint here, soon a post on changes from a developer’s point of view will also follow.
|
||||
|
||||
### Upgrading considerations
|
||||
|
||||
First some hints on upgrading from an existing setup – this time there are some small things that could cause problems when migrating from 9.6 or even older versions, so before the real deal one should definitely test the upgrade on a separate replica and go through the full list of possible troublemakers from the release notes. Most likely pitfalls to watch out for:
|
||||
|
||||
* All functions containing „xlog“ have been renamed to use „wal“ instead of „xlog“
|
||||
|
||||
The latter naming could be confused with normal server logs so a „just in case“ change. If using any 3rd party backup/replication/HA tools check that they are all at latest versions.
|
||||
|
||||
* pg_log folder for server logs (error messages/warnings etc) has been renamed to just „log“
|
||||
|
||||
Make sure to verify that your log parsing/grepping scripts (if having any) work.
|
||||
|
||||
* By default queries will make use of up to 2 background processes
|
||||
|
||||
If using the default 10 postgresql.conf settings on a machine with low number of CPUs you may see resource usage spikes as parallel processing is enabled by default now – which is a good thing though as it should mean faster queries. Set max_parallel_workers_per_gather to 0 if old behaviour is needed.
|
||||
|
||||
* Replication connections from localhost are enabled now by default
|
||||
|
||||
To ease testing etc, localhost and local Unix socket replication connections are now enabled in „trust“ mode (without password) in pg_hba.conf! So if other non-DBA user also have access to real production machines, make sure you change the config.
|
||||
|
||||
### My favourites from a DBA’s point of view
|
||||
|
||||
* Logical replication
|
||||
|
||||
The long awaited feature enables easy setup and minimal performance penalties for application scenarios where you only want to replicate a single table or a subset of tables or all tables, meaning also zero downtime upgrades for following major versions! Historically (Postgres 9.4+ required) this could be achieved only by usage of a 3rd party extension or slowish trigger based solutions. The top feature of version 10 for me.
|
||||
|
||||
* Declarative partitioning
|
||||
|
||||
Old way of managing partitions via inheritance and creating triggers to re-route inserts to correct tables was bothersome to say the least, not to mention the performance impact. Currently supported are „range“ and „list“ partitioning schemes. If someone is missing „hash“ partitioning available in some DB engines, one could use „list“ partitioning with expressions to achieve the same.
|
||||
|
||||
* Usable Hash indexes
|
||||
|
||||
Hash indexes are now WAL-logged thus crash safe and received some performance improvements so that for simple searches they’re actually faster than standard B-tree indexes for bigger amounts of data. Bigger index size though too.
|
||||
|
||||
* Cross-column optimizer statistics
|
||||
|
||||
Such stats needs to be created manually on a set if columns of a table, to point out that the values are actually somehow dependent on each other. This will enable to counter slow query problems where the planner thinks there will be very little data returned (multiplication of probabilities yields very small numbers usually) and will choose for example a „nested loop“ join that does not perform well on bigger amounts of data.
|
||||
|
||||
* Parallel snapshots on replicas
|
||||
|
||||
Now one can use the pg_dump tool to speed up backups on standby servers enormously by using multiple processes (the –jobs flag).
|
||||
|
||||
* Better tuning of parallel processing worker behaviour
|
||||
|
||||
See max_parallel_workers and min_parallel_table_scan_size / min_parallel_index_scan_size parameters. The default values (8MB, 512KB) for the latter two I would recommend to increase a bit though.
|
||||
|
||||
* New built-in monitoring roles for easier tooling
|
||||
|
||||
New roles pg_monitor, pg_read_all_settings, pg_read_all_stats, and pg_stat_scan_tables make life a lot easier for all kinds of monitoring tasks – previously one had to use superuser accounts or some SECURITY DEFINER wrapper functions.
|
||||
|
||||
* Temporary (per session) replication slots for safer replica building
|
||||
|
||||
* A new Contrib extension for checking validity of B-tree indexes
|
||||
|
||||
Does couple of smart checks to discover structural inconsistencies and stuff not covered by page level checksums. Hope to check it out more deeply in nearer future.
|
||||
|
||||
* Psql query tool supports now basic branching (if/elif/else)
|
||||
|
||||
This would for example enable having a single maintenance/monitoring script with version specific branching (different column names for pg_stat* views etc) instead of many version specific scripts.
|
||||
|
||||
```
|
||||
SELECT :VERSION_NAME = '10.0' AS is_v10 \gset
|
||||
\if :is_v10
|
||||
SELECT 'yippee' AS msg;
|
||||
\else
|
||||
SELECT 'time to upgrade!' AS msg;
|
||||
\endif
|
||||
```
|
||||
|
||||
That’s it for this time! Lot of other stuff didn’t got listed of course, so for full time DBAs I’d definitely suggest to look at the notes more thoroughly. And a big thanks to those 300+ people who contributed their effort to this particularly exciting release!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cybertec.at/best-of-postgresql-10-for-the-dba/
|
||||
|
||||
作者:[ Kaarel Moppel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cybertec.at/author/kaarel-moppel/
|
||||
[1]:http://www.cybertec.at/author/kaarel-moppel/
|
||||
[2]:http://www.cybertec.at/best-of-postgresql-10-for-the-dba/
|
||||
[3]:https://www.postgresql.org/about/news/1786/
|
||||
[4]:https://www.postgresql.org/docs/current/static/release-10.html
|
||||
[5]:https://wiki.postgresql.org/wiki/New_in_postgres_10
|
||||
@ -1,260 +0,0 @@
|
||||
# Monitoring Slow SQL Queries via Slack
|
||||
|
||||
### A simple Go recipe for getting notified about slow SQL queries, unexpected errors and other important logs.
|
||||
|
||||
My Slack bot notifying me about a SQL query taking long time to execute. I should fix that soon.
|
||||
|
||||
We can't manage what we don't measure. Every backend application needs our eyes on the database performance. If a specific query gets slower as the data grows, you have to optimize it before it's too late.
|
||||
|
||||
As Slack has became a central to work, it's changing how we monitor our systems, too. Although there are quite nice monitoring tools existing, it's nice to have a Slack bot telling us if there is anything going wrong in the system; an SQL query taking too long to finish for example, or fatal errors in a specific Go package.
|
||||
|
||||
In this blog post, I'll tell how we can achieve this setup by using [a simple logging system][8], and [an existing database library][9] that already supports this feature.
|
||||
|
||||
Using Logger
|
||||
============================================================
|
||||
|
||||
[logger][10] is a tiny library designed for both Go libraries and applications. It has three important features useful for this case;
|
||||
|
||||
* It provides a simple timer for measuring performance.
|
||||
|
||||
* Supports complex output filters, so you can choose logs from specific packages. For example, you can tell logger to output only from database package, and only the timer logs which took more than 500ms.
|
||||
|
||||
* It has a Slack hook, so you can filter and stream logs into Slack.
|
||||
|
||||
Let's look at this example program to see how we use timers, later we'll get to filters, as well:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"github.com/azer/logger"
|
||||
"time"
|
||||
)
|
||||
|
||||
var (
|
||||
users = logger.New("users")
|
||||
database = logger.New("database")
|
||||
)
|
||||
|
||||
func main () {
|
||||
users.Info("Hi!")
|
||||
|
||||
timer := database.Timer()
|
||||
time.Sleep(time.Millisecond * 250) // sleep 250ms
|
||||
timer.End("Connected to database")
|
||||
|
||||
users.Error("Failed to create a new user.", logger.Attrs{
|
||||
"e-mail": "foo@bar.com",
|
||||
})
|
||||
|
||||
database.Info("Just a random log.")
|
||||
|
||||
fmt.Println("Bye.")
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Running this program will give no output:
|
||||
|
||||
```
|
||||
$ go run example-01.go
|
||||
Bye
|
||||
|
||||
```
|
||||
|
||||
Logger is [silent by default][11], so it can be used by libraries internally. We simply pass an environment variable to see the logs:
|
||||
|
||||
For example;
|
||||
|
||||
```
|
||||
$ LOG=database@timer go run example-01.go
|
||||
01:08:54.997 database(250.095587ms): Connected to database.
|
||||
Bye
|
||||
|
||||
```
|
||||
|
||||
The above example we used `database@timer` filter to see timer logs from `database` package. You can try different filters such as;
|
||||
|
||||
* `LOG=*`: enables all logs
|
||||
|
||||
* `LOG=users@error,database`: enables errors from `users`, all logs from `database`.
|
||||
|
||||
* `LOG=*@timer,database@info`: enables timer and error logs from all packages, any logs from `database`.
|
||||
|
||||
* `LOG=*,users@mute`: Enables all logs except from `users`.
|
||||
|
||||
### Sending Logs to Slack
|
||||
|
||||
Logging in console is useful in development environment, but we need a human-friendly interface for production. Thanks to the [slack-hook][12], we can easily integrate the above example with Slack:
|
||||
|
||||
```
|
||||
import (
|
||||
"github.com/azer/logger"
|
||||
"github.com/azer/logger-slack-hook"
|
||||
)
|
||||
|
||||
func init () {
|
||||
logger.Hook(&slackhook.Writer{
|
||||
WebHookURL: "https://hooks.slack.com/services/...",
|
||||
Channel: "slow-queries",
|
||||
Username: "Query Person",
|
||||
Filter: func (log *logger.Log) bool {
|
||||
return log.Package == "database" && log.Level == "TIMER" && log.Elapsed >= 200
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Let's explain what we've done in the above example:
|
||||
|
||||
* Line #5: Set the incoming webhook url. You can get this URL [here][1].
|
||||
|
||||
* Line #6: Choose the channel to stream the logs into.
|
||||
|
||||
* Line #7: The username that will appear as sender.
|
||||
|
||||
* Line #11: Filter for streaming only timer logs which took longer than 200ms.
|
||||
|
||||
Hope this gave you the general idea. Have a look at [logger][13]'s documentation if you got more questions.
|
||||
|
||||
# A Real-World Example: CRUD
|
||||
|
||||
One of the hidden features of [crud][14] -an ORM-ish database library for Go- is an internal logging system using [logger][15]. This allows us to monitor SQL queries being executed easily.
|
||||
|
||||
### Querying
|
||||
|
||||
Let's say you have a simple SQL query which returns username by given e-mail:
|
||||
|
||||
```
|
||||
func GetUserNameByEmail (email string) (string, error) {
|
||||
var name string
|
||||
if err := DB.Read(&name, "SELECT name FROM user WHERE email=?", email); err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
return name, nil
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Ok, this is too short, feels like something missing here. Let's add the full context:
|
||||
|
||||
```
|
||||
import (
|
||||
"github.com/azer/crud"
|
||||
_ "github.com/go-sql-driver/mysql"
|
||||
"os"
|
||||
)
|
||||
|
||||
var db *crud.DB
|
||||
|
||||
func main () {
|
||||
var err error
|
||||
|
||||
DB, err = crud.Connect("mysql", os.Getenv("DATABASE_URL"))
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
username, err := GetUserNameByEmail("foo@bar.com")
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
fmt.Println("Your username is: ", username)
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
So we have a [crud][16] instance that connects to the MySQL database passed through env variable `DATABASE_URL`. If we run this program, we'll see one-line output:
|
||||
|
||||
```
|
||||
$ DATABASE_URL=root:123456@/testdb go run example.go
|
||||
Your username is: azer
|
||||
|
||||
```
|
||||
|
||||
As I mentioned previously, logs are [silent by default][17]. Let's see internal logs of crud:
|
||||
|
||||
```
|
||||
$ LOG=crud go run example.go
|
||||
22:56:29.691 crud(0): SQL Query Executed: SELECT username FROM user WHERE email='foo@bar.com'
|
||||
Your username is: azer
|
||||
|
||||
```
|
||||
|
||||
This is simple and useful enough for seeing how our queries perform in our development environment.
|
||||
|
||||
### CRUD and Slack Integration
|
||||
|
||||
Logger is designed for configuring dependencies' internal logging systems from the application level. This means, you can stream crud's logs into Slack by configuring logger in your application level:
|
||||
|
||||
```
|
||||
import (
|
||||
"github.com/azer/logger"
|
||||
"github.com/azer/logger-slack-hook"
|
||||
)
|
||||
|
||||
func init () {
|
||||
logger.Hook(&slackhook.Writer{
|
||||
WebHookURL: "https://hooks.slack.com/services/...",
|
||||
Channel: "slow-queries",
|
||||
Username: "Query Person",
|
||||
Filter: func (log *logger.Log) bool {
|
||||
return log.Package == "mysql" && log.Level == "TIMER" && log.Elapsed >= 250
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
In the above code:
|
||||
|
||||
* We imported [logger][2] and [logger-slack-hook][3] libraries.
|
||||
|
||||
* We configured the logger library to stream some logs into Slack. This configuration covers all usages of [logger][4] in the codebase, including third-party dependencies.
|
||||
|
||||
* We used a filter to stream only timer logs taking longer than 250 in the MySQL package.
|
||||
|
||||
This usage can be extended beyond just slow query reports. I personally use it for tracking critical errors in specific packages, also statistical logs like a new user signs up or make payments.
|
||||
|
||||
### Packages I mentioned in this post:
|
||||
|
||||
* [crud][5]
|
||||
|
||||
* [logger][6]
|
||||
|
||||
* [logger-slack-hook][7]
|
||||
|
||||
[Let me know][18] if you have any questions or comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/
|
||||
|
||||
作者:[Azer Koçulu ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://azer.bike/
|
||||
[1]:https://my.slack.com/services/new/incoming-webhook/
|
||||
[2]:https://github.com/azer/logger
|
||||
[3]:https://github.com/azer/logger-slack-hook
|
||||
[4]:https://github.com/azer/logger
|
||||
[5]:https://github.com/azer/crud
|
||||
[6]:https://github.com/azer/logger
|
||||
[7]:https://github.com/azer/logger
|
||||
[8]:http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/?utm_source=dbweekly&utm_medium=email#logger
|
||||
[9]:http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/?utm_source=dbweekly&utm_medium=email#crud
|
||||
[10]:https://github.com/azer/logger
|
||||
[11]:http://www.linfo.org/rule_of_silence.html
|
||||
[12]:https://github.com/azer/logger-slack-hook
|
||||
[13]:https://github.com/azer/logger
|
||||
[14]:https://github.com/azer/crud
|
||||
[15]:https://github.com/azer/logger
|
||||
[16]:https://github.com/azer/crud
|
||||
[17]:http://www.linfo.org/rule_of_silence.html
|
||||
[18]:https://twitter.com/afrikaradyo
|
||||
@ -1,69 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
# Introducing CRI-O 1.0
|
||||
|
||||
Last year, the Kubernetes project introduced its [Container Runtime Interface][11] (CRI) -- a plugin interface that gives kubelet (a cluster node agent used to create pods and start containers) the ability to use different OCI-compliant container runtimes, without needing to recompile Kubernetes. Building on that work, the [CRI-O][12] project ([originally known as OCID][13]) is ready to provide a lightweight runtime for Kubernetes.
|
||||
|
||||
So what does this **really** mean?
|
||||
|
||||
CRI-O allows you to run containers directly from Kubernetes - without any unnecessary code or tooling. As long as the container is OCI-compliant, CRI-O can run it, cutting out extraneous tooling and allowing containers to do what they do best: fuel your next-generation cloud-native applications
|
||||
|
||||
Prior to the introduction of CRI, Kubernetes was tied to specific container runtimes through “[an internal and ][14][volatile ][15][interface][16].” This incurred a significant maintenance overhead for the upstream Kubernetes community as well as vendors building solutions on top of the orchestration platform.
|
||||
|
||||
With CRI, Kubernetes can be container runtime-agnostic. Providers of container runtimes don’t need to implement features that Kubernetes already provides. This is a win for the broad community, as it allows projects to move independently while still working well together.
|
||||
|
||||
For the most part, we don’t think users of Kubernetes (or distributions of Kubernetes, like OpenShift) really care a lot about the container runtime. They want it to work, but they don’t really want to think about it a great deal. Sort of like you don’t (usually) care if a machine has GNU Bash, Korn, Zsh, or another POSIX-compliant shell. You just want to have a standard way to run your script or application.
|
||||
|
||||
**CRI-O: A Lightweight Container Runtime for Kubernetes**
|
||||
And that’s what CRI-O provides. The name derives from CRI plus Open Container Initiative (OCI), because CRI-O is strictly focused on OCI-compliant runtimes and container images.
|
||||
|
||||
Today, CRI-O supports the runc and Clear Container runtimes, though it should support any OCI-conformant runtime. It can pull images from any container registry, and handles networking using the [Container Network Interface][17] (CNI) so that any CNI-compatible networking plugin will likely work with the project.
|
||||
|
||||
When Kubernetes needs to run a container, it talks to CRI-O and the CRI-O daemon works with runc (or another OCI-compliant runtime) to start the container. When Kubernetes needs to stop the container, CRI-O handles that. Nothing exciting, it just works behind the scenes to manage Linux containers so that users don’t need to worry about this crucial piece of container orchestration.
|
||||
|
||||

|
||||
|
||||
**What CRI-O isn’t**
|
||||
It’s worth spending a little time on what CRI-O _isn’t_ . The scope for CRI-O is to work with Kubernetes, to manage and run OCI containers. It’s not meant as a developer-facing tool, though the project does have some user-facing tools for troubleshooting.
|
||||
|
||||
Building images, for example, is out of scope for CRI-O and that’s left to tools like Docker’s build command, [Buildah][18], or [OpenShift’s Source-to-Image][19] (S2I). Once an image is built, CRI-O will happily consume it, but the building of images is left to other tools.
|
||||
|
||||
While CRI-O does include a command line interface (CLI), it’s provided mainly for testing CRI-O and not really as a method for managing containers in a production environment.
|
||||
|
||||
**Next steps**
|
||||
Now that CRI-O 1.0 is released, we’re hoping to see it included as a stable feature in the next release of Kubernetes. The 1.0 release will work with the Kubernetes 1.7.x series, a CRI-O 1.8-rc1 release for Kubernetes 1.8.x will be released soon.
|
||||
|
||||
We invite you to join us in furthering the development of the Open Source CRI-O project and we would like to thank our current contributors for their assistance in reaching this milestone. If you would like to contribute, or follow development, head to [CRI-O project’s GitHub repository][20] and follow the [CRI-O blog][21].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.redhat.com/en/blog/introducing-cri-o-10
|
||||
|
||||
作者:[Joe Brockmeier][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.redhat.com/en/blog/authors/joe-brockmeier
|
||||
[1]:https://www.redhat.com/en/blog/authors/joe-brockmeier
|
||||
[2]:https://www.redhat.com/en/blog/authors/senior-evangelist
|
||||
[3]:https://www.redhat.com/en/blog/authors/linux-containers
|
||||
[4]:https://www.redhat.com/en/blog/authors/red-hat-0
|
||||
[5]:https://www.redhat.com/en/blog
|
||||
[6]:https://www.redhat.com/en/blog/tag/community
|
||||
[7]:https://www.redhat.com/en/blog/tag/containers
|
||||
[8]:https://www.redhat.com/en/blog/tag/hybrid-cloud
|
||||
[9]:https://www.redhat.com/en/blog/tag/platform
|
||||
[10]:mailto:?subject=Check%20out%20this%20redhat.com%20page:%20Introducing%20CRI-O%201.0&body=I%20saw%20this%20on%20redhat.com%20and%20thought%20you%20might%20be%20interested.%20%20Click%20the%20following%20link%20to%20read:%20https://www.redhat.com/en/blog/introducing-cri-o-10https://www.redhat.com/en/blog/introducing-cri-o-10
|
||||
[11]:https://github.com/kubernetes/kubernetes/blob/242a97307b34076d5d8f5bbeb154fa4d97c9ef1d/docs/devel/container-runtime-interface.md
|
||||
[12]:http://cri-o.io/
|
||||
[13]:https://www.redhat.com/en/blog/running-production-applications-containers-introducing-ocid
|
||||
[14]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[15]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[16]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[17]:https://github.com/containernetworking/cni
|
||||
[18]:https://github.com/projectatomic/buildah
|
||||
[19]:https://github.com/openshift/source-to-image
|
||||
[20]:https://github.com/kubernetes-incubator/cri-o
|
||||
[21]:https://medium.com/cri-o
|
||||
@ -1,123 +0,0 @@
|
||||
# A tour of Postgres Index Types
|
||||
|
||||
At Citus we spend a lot of time working with customers on data modeling, optimizing queries, and adding [indexes][3] to make things snappy. My goal is to be as available for our customers as we need to be, in order to make you successful. Part of that is keeping your Citus cluster well tuned and [performant][4] which [we take care][5]of for you. Another part is helping you with everything you need to know about Postgres and Citus. After all a healthy and performant database means a fast performing app and who wouldn’t want that. Today we’re going to condense some of the information we’ve shared directly with customers about Postgres indexes.
|
||||
|
||||
Postgres has a number of index types, and with each new release seems to come with another new index type. Each of these indexes can be useful, but which one to use depends on 1\. the data type and then sometimes 2\. the underlying data within the table, and 3\. the types of lookups performed. In what follows we’ll look at a quick survey of the index types available to you in Postgres and when you should leverage each. Before we dig in, here’s a quick glimpse of the indexes we’ll walk you through:
|
||||
|
||||
* B-Tree
|
||||
|
||||
* Generalized Inverted Index (GIN)
|
||||
|
||||
* Generalized Inverted Seach Tree (GiST)
|
||||
|
||||
* Space partitioned GiST (SP-GiST)
|
||||
|
||||
* Block Range Indexes (BRIN)
|
||||
|
||||
* Hash
|
||||
|
||||
Now onto the indexing
|
||||
|
||||
### In Postgres, a B-Tree index is what you most commonly want
|
||||
|
||||
If you have a degree in Computer Science, then a B-tree index was likely the first one you learned about. A [B-tree index][6] creates a tree that will keep itself balanced and even. When it goes to look something up based on that index it will traverse down the tree to find the key the tree is split on and then return you the data you’re looking for. Using an index is much faster than a sequential scan because it may only have to read a few [pages][7] as opposed to sequentially scanning thousands of them (when you’re returning only a few records).
|
||||
|
||||
If you run a standard `CREATE INDEX` it creates a B-tree for you. B-tree indexes are valuable on the most common data types such as text, numbers, and timestamps. If you’re just getting started indexing your database and aren’t leveraging too many advanced Postgres features within your database, using standard B-Tree indexes is likely the path you want to take.
|
||||
|
||||
### GIN indexes, for columns with multiple values
|
||||
|
||||
Generalized Inverted Indexes, commonly referred to as [GIN][8], are most useful when you have data types that contain multiple values in a single column.
|
||||
|
||||
From the Postgres docs: _“GIN is designed for handling cases where the items to be indexed are composite values, and the queries to be handled by the index need to search for element values that appear within the composite items. For example, the items could be documents, and the queries could be searches for documents containing specific words.”_
|
||||
|
||||
The most common data types that fall into this bucket are:
|
||||
|
||||
* [hStore][1]
|
||||
|
||||
* Arrays
|
||||
|
||||
* Range types
|
||||
|
||||
* [JSONB][2]
|
||||
|
||||
One of the beautiful things about GIN indexes is that they are aware of the data within composite values. But because a GIN index has specific knowledge about the data structure support for each individual type needs to be added, as a result not all datatypes are supported.
|
||||
|
||||
### GiST indexes, for rows that overlap values
|
||||
|
||||
GiST indexes are most useful when you have data that can in some way overlap with the value of that same column but from another row. The best thing about GiST indexes: if you have say a geometry data type and you want to see if two polygons contained some point. In one case a specific point may be contained within box, while another point only exists within one polygon. The most common datatypes where you want to leverage GiST indexes are:
|
||||
|
||||
* Geometry types
|
||||
|
||||
* Text when dealing with full-text search
|
||||
|
||||
GiST indexes have some more fixed constraints around size, whereas GIN indexes can become quite large. As a result, GiST indexes are lossy. From the docs: _“A GiST index is lossy, meaning that the index might produce false matches, and it is necessary to check the actual table row to eliminate such false matches. (PostgreSQL does this automatically when needed.)”_ This doesn’t mean you’ll get wrong results, it just means Postgres has to do a little extra work to filter those false positives before giving your data back to you.
|
||||
|
||||
_Special note: GIN and GiST indexes can often be beneficial on the same column types. One can often boast better performance but larger disk footprint in the case of GIN and vice versa for GiST. When it comes to GIN vs. GiST there isn’t a perfect one size fits all, but the broad rules above apply_
|
||||
|
||||
### SP-GiST indexes, for larger data
|
||||
|
||||
Space partitioned GiST indexes leverage space partitioning trees that came out of some research from [Purdue][9]. SP-GiST indexes are most useful when your data has a natural clustering element to it, and is also not an equally balanced tree. A great example of this is phone numbers (at least US ones). They follow a format of:
|
||||
|
||||
* 3 digits for area code
|
||||
|
||||
* 3 digits for prefix (historically related to a phone carrier’s switch)
|
||||
|
||||
* 4 digits for line number
|
||||
|
||||
This means that you have some natural clustering around the first set of 3 digits, around the second set of 3 digits, then numbers may fan out in a more even distribution. But, with phone numbers some area codes have a much higher saturation than others. The result may be that the tree is very unbalanced. Because of that natural clustering up front and the unequal distribution of data–data like phone numbers could make a good case for SP-GiST.
|
||||
|
||||
### BRIN indexes, for larger data
|
||||
|
||||
Block range indexes can focus on some similar use cases to SP-GiST in that they’re best when there is some natural ordering to the data, and the data tends to be very large. Have a billion record table especially if it’s time series data? BRIN may be able to help. If you’re querying against a large set of data that is naturally grouped together such as data for several zip codes (which then roll up to some city) BRIN helps to ensure that similar zip codes are located near each other on disk.
|
||||
|
||||
When you have very large datasets that are ordered such as dates or zip codes BRIN indexes allow you to skip or exclude a lot of the unnecessary data very quickly. BRIN additionally are maintained as smaller indexes relative to the overall datasize making them a big win for when you have a large dataset.
|
||||
|
||||
### Hash indexes, finally crash safe
|
||||
|
||||
Hash indexes have been around for years within Postgres, but until Postgres 10 came with a giant warning that they were not WAL-logged. This meant if your server crashed and you failed over to a stand-by or recovered from archives using something like [wal-g][10] then you’d lose that index until you recreated it. With Postgres 10 they’re now WAL-logged so you can start to consider using them again, but the real question is should you?
|
||||
|
||||
Hash indexes at times can provide faster lookups than B-Tree indexes, and can boast faster creation times as well. The big issue with them is they’re limited to only equality operators so you need to be looking for exact matches. This makes hash indexes far less flexible than the more commonly used B-Tree indexes and something you won’t want to consider as a drop-in replacement but rather a special case.
|
||||
|
||||
### Which do you use?
|
||||
|
||||
We just covered a lot and if you’re a bit overwhelmed you’re not alone. If all you knew before was `CREATE INDEX` you’ve been using B-Tree indexes all along, and the good news is you’re still performing as well or better than most databases that aren’t Postgres :) As you start to use more Postgres features consider this a cheatsheet for when to use other Postgres types:
|
||||
|
||||
* B-Tree - For most datatypes and queries
|
||||
|
||||
* GIN - For JSONB/hstore/arrays
|
||||
|
||||
* GiST - For full text search and geospatial datatypes
|
||||
|
||||
* SP-GiST - For larger datasets with natural but uneven clustering
|
||||
|
||||
* BRIN - For really large datasets that line up sequentially
|
||||
|
||||
* Hash - For equality operations, and generally B-Tree still what you want here
|
||||
|
||||
If you have any questions or feedback about the post feel free to join us in our [slack channel][11].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
|
||||
作者:[Craig Kerstiens ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
[1]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||
[2]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||
[3]:https://www.citusdata.com/blog/2017/10/11/index-all-the-things-in-postgres/
|
||||
[4]:https://www.citusdata.com/blog/2017/09/29/what-performance-can-you-expect-from-postgres/
|
||||
[5]:https://www.citusdata.com/product/cloud
|
||||
[6]:https://en.wikipedia.org/wiki/B-tree
|
||||
[7]:https://www.8kdata.com/blog/postgresql-page-layout/
|
||||
[8]:https://www.postgresql.org/docs/10/static/gin.html
|
||||
[9]:https://www.cs.purdue.edu/spgist/papers/W87R36P214137510.pdf
|
||||
[10]:https://www.citusdata.com/blog/2017/08/18/introducing-wal-g-faster-restores-for-postgres/
|
||||
[11]:https://slack.citusdata.com/
|
||||
[12]:https://twitter.com/share?url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/&text=A%20tour%20of%20Postgres%20Index%20Types&via=citusdata
|
||||
[13]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
@ -0,0 +1,386 @@
|
||||
Learn how to program in Python by building a simple dice game
|
||||
============================================================
|
||||
|
||||
### Python is a good language for young and old, with or without any programming experience.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
[Python][9] is an all-purpose programming language that can be used to create desktop applications, 3D graphics, video games, and even websites. It's a great first programming language because it can be easy to learn and it's simpler than complex languages like C, C++, or Java. Even so, Python is powerful and robust enough to create advanced applications, and it's used in just about every industry that uses computers. This makes Python a good language for young and old, with or without any programming experience.
|
||||
|
||||
### Installing Python
|
||||
|
||||
Before learning Python, you may need to install it.
|
||||
|
||||
**Linux: **If you use Linux, Python is already included, but make sure that you have Python 3 specifically. To check which version is installed, open a terminal window and type:
|
||||
|
||||
```
|
||||
python3 -V
|
||||
```
|
||||
|
||||
If that command is not found, you'll need to install Python 3 from your package manager.
|
||||
|
||||
**MacOS:** If you're on a Mac, follow the instructions for Linux above to see if you have Python 3 installed. MacOS does not have a built-in package manager, so if Python 3 is not found, install it from [python.org/downloads/mac-osx][10]. Although macOS does have Python 2 installed, you should learn Python 3.
|
||||
|
||||
**Windows:** Microsoft Windows doesn't currently ship with Python. Install it from [python.org/downloads/windows][11]. Be sure to select **Add Python to PATH** in the install wizard.
|
||||
|
||||
### Running an IDE
|
||||
|
||||
To write programs in Python, all you really need is a text editor, but it's convenient to have an integrated development environment (IDE). An IDE integrates a text editor with some friendly and helpful Python features. IDLE 3 and NINJA-IDE are two options to consider.
|
||||
|
||||
### IDLE 3
|
||||
|
||||
Python comes with a basic IDE called IDLE.
|
||||
|
||||
### [idle3.png][2]
|
||||
|
||||

|
||||
|
||||
IDLE
|
||||
|
||||
It has keyword highlighting to help detect typos and a Run button to test code quickly and easily. To use it:
|
||||
|
||||
* On Linux or macOS, launch a terminal window and type **idle3**.
|
||||
|
||||
* On Windows, launch Python 3 from the Start menu.
|
||||
* If you don't see Python in the Start menu, launch the Windows command prompt by typing **cmd** in the Start menu, and type **C:\Windows\py.exe**.
|
||||
|
||||
* If that doesn't work, try reinstalling Python. Be sure to select **Add Python to PATH** in the install wizard. Refer to [docs.python.org/3/using/windows.html][1] for detailed instructions.
|
||||
|
||||
* If that still doesn't work, just use Linux. It's free and, as long as you save your Python files to a USB thumb drive, you don't even have to install it to use it.
|
||||
|
||||
### Ninja-IDE
|
||||
|
||||
[Ninja-IDE][12] is an excellent Python IDE. It has keyword highlighting to help detect typos, quotation and parenthesis completion to avoid syntax errors, line numbers (helpful when debugging), indentation markers, and a Run button to test code quickly and easily.
|
||||
|
||||
### [ninja.png][3]
|
||||
|
||||

|
||||
|
||||
Ninja-IDE
|
||||
|
||||
To use it:
|
||||
|
||||
1. Install Ninja-IDE. if you're using Linux, it's easiest to use your package manager; otherwise [download][7] the correct installer version from NINJA-IDE's website.
|
||||
|
||||
2. Launch Ninja-IDE.
|
||||
|
||||
3. Go to the Edit menu and select Preferences.
|
||||
|
||||
4. In the Preferences window, click the Execution tab.
|
||||
|
||||
5. In the Execution tab, change **python** to **python3**.
|
||||
|
||||
### [pref.png][4]
|
||||
|
||||

|
||||
|
||||
Python3 in Ninja-IDE
|
||||
|
||||
### Telling Python what to do
|
||||
|
||||
Keywords tell Python what you want it to do. In either IDLE or Ninja, go to the File menu and create a new file. Ninja users: Do not create a new project, just a new file.
|
||||
|
||||
In your new, empty file, type this into IDLE or Ninja:
|
||||
|
||||
```
|
||||
print("Hello world.")
|
||||
```
|
||||
|
||||
* If you are using IDLE, go to the Run menu and select Run module option.
|
||||
|
||||
* If you are using Ninja, click the Run File button in the left button bar.
|
||||
|
||||
### [ninja_run.png][5]
|
||||
|
||||

|
||||
|
||||
Run file in Ninja
|
||||
|
||||
The keyword **print** tells Python to print out whatever text you give it in parentheses and quotes.
|
||||
|
||||
That's not very exciting, though. At its core, Python has access to only basic keywords, like **print**, **help**, basic math functions, and so on.
|
||||
|
||||
Use the **import** keyword to load more keywords. Start a new file in IDLE or Ninja and name it **pen.py**.
|
||||
|
||||
**Warning**: Do not call your file **turtle.py**, because **turtle.py** is the name of the file that contains the turtle program you are controlling. Naming your file **turtle.py** will confuse Python, because it will think you want to import your own file.
|
||||
|
||||
Type this code into your file, and then run it:
|
||||
|
||||
```
|
||||
import turtle
|
||||
```
|
||||
|
||||
Turtle is a fun module to use. Try this:
|
||||
|
||||
```
|
||||
turtle.begin_fill()
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.end_fill()
|
||||
```
|
||||
|
||||
See what shapes you can draw with the turtle module.
|
||||
|
||||
To clear your turtle drawing area, use the **turtle.clear()** keyword. What do you think the keyword **turtle.color("blue")** does?
|
||||
|
||||
Try more complex code:
|
||||
|
||||
```
|
||||
import turtle as t
|
||||
import time
|
||||
|
||||
t.color("blue")
|
||||
t.begin_fill()
|
||||
|
||||
counter=0
|
||||
|
||||
while counter < 4:
|
||||
t.forward(100)
|
||||
t.left(90)
|
||||
counter = counter+1
|
||||
|
||||
t.end_fill()
|
||||
time.sleep(5)
|
||||
```
|
||||
|
||||
Once you have run your script, it's time to explore an even better module.
|
||||
|
||||
### Learning Python by making a game
|
||||
|
||||
To learn more about how Python works and prepare for more advanced programming with graphics, let's focus on game logic. In this tutorial, we'll also learn a bit about how computer programs are structured by making a text-based game in which the computer and the player roll a virtual die, and the one with the highest roll wins.
|
||||
|
||||
### Planning your game
|
||||
|
||||
Before writing code, it's important to think about what you intend to write. Many programmers [write simple documentation][13] _before_ they begin writing code, so they have a goal to program toward. Here's how the dice program might look if you shipped documentation along with the game:
|
||||
|
||||
1. Start the dice game and press Return or Enter to roll.
|
||||
|
||||
2. The results are printed out to your screen.
|
||||
|
||||
3. You are prompted to roll again or to quit.
|
||||
|
||||
It's a simple game, but the documentation tells you a lot about what you need to do. For example, it tells you that you need the following components to write this game:
|
||||
|
||||
* Player: You need a human to play the game.
|
||||
|
||||
* AI: The computer must roll a die, too, or else the player has no one to win or lose to.
|
||||
|
||||
* Random number: A common six-sided die renders a random number between 1 and 6.
|
||||
|
||||
* Operator: Simple math can compare one number to another to see which is higher.
|
||||
|
||||
* A win or lose message.
|
||||
|
||||
* A prompt to play again or quit.
|
||||
|
||||
### Making dice game alpha
|
||||
|
||||
Few programs start with all of their features, so the first version will only implement the basics. First a couple of definitions:
|
||||
|
||||
A **variable **is a value that is subject to change, and they are used a lot in Python. Whenever you need your program to "remember" something, you use a variable. In fact, almost all the information that code works with is stored in variables. For example, in the math equation **x + 5 = 20**, the variable is _x_ , because the letter _x_ is a placeholder for a value.
|
||||
|
||||
An **integer **is a number; it can be positive or negative. For example, 1 and -1 are both integers. So are 14, 21, and even 10,947.
|
||||
|
||||
Variables in Python are easy to create and easy to work with. This initial version of the dice game uses two variables: **player** and **ai**.
|
||||
|
||||
Type the following code into a new text file called **dice_alpha.py**:
|
||||
|
||||
```
|
||||
import random
|
||||
|
||||
player = random.randint(1,6)
|
||||
ai = random.randint(1,6)
|
||||
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
else:
|
||||
print("You lose")
|
||||
```
|
||||
|
||||
Launch your game to make sure it works.
|
||||
|
||||
This basic version of your dice game works pretty well. It accomplishes the basic goals of the game, but it doesn't feel much like a game. The player never knows what they rolled or what the computer rolled, and the game ends even if the player would like to play again.
|
||||
|
||||
This is common in the first version of software (called an alpha version). Now that you are confident that you can accomplish the main part (rolling a die), it's time to add to the program.
|
||||
|
||||
### Improving the game
|
||||
|
||||
In this second version (called a beta) of your game, a few improvements will make it feel more like a game.
|
||||
|
||||
#### 1\. Describe the results
|
||||
|
||||
Instead of just telling players whether they did or didn't win, it's more interesting if they know what they rolled. Try making these changes to your code:
|
||||
|
||||
```
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + player)
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolled " + ai)
|
||||
```
|
||||
|
||||
If you run the game now, it will crash because Python thinks you're trying to do math. It thinks you're trying to add the letters "You rolled" and whatever number is currently stored in the player variable.
|
||||
|
||||
You must tell Python to treat the numbers in the player and ai variables as if they were a word in a sentence (a string) rather than a number in a math equation (an integer).
|
||||
|
||||
Make these changes to your code:
|
||||
|
||||
```
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + str(player) )
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolled " + str(ai) )
|
||||
```
|
||||
|
||||
Run your game now to see the result.
|
||||
|
||||
#### 2\. Slow it down
|
||||
|
||||
Computers are fast. Humans sometimes can be fast, but in games, it's often better to build suspense. You can use Python's **time** function to slow your game down during the suspenseful parts.
|
||||
|
||||
```
|
||||
import random
|
||||
import time
|
||||
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + str(player) )
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolls...." )
|
||||
time.sleep(2)
|
||||
print("The computer has rolled a " + str(player) )
|
||||
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
else:
|
||||
print("You lose")
|
||||
```
|
||||
|
||||
Launch your game to test your changes.
|
||||
|
||||
#### 3\. Detect ties
|
||||
|
||||
If you play your game enough, you'll discover that even though your game appears to be working correctly, it actually has a bug in it: It doesn't know what to do when the player and the computer roll the same number.
|
||||
|
||||
To check whether a value is equal to another value, Python uses **==**. That's _two_ equal signs, not just one. If you use only one, Python thinks you're trying to create a new variable, but you're actually trying to do math.
|
||||
|
||||
When you want to have more than just two options (i.e., win or lose), you can using Python's keyword **elif**, which means _else if_ . This allows your code to check to see whether any one of _some _ results are true, rather than just checking whether _one_ thing is true.
|
||||
|
||||
Modify your code like this:
|
||||
|
||||
```
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
elif player == ai:
|
||||
print("Tie game.")
|
||||
else:
|
||||
print("You lose")
|
||||
```
|
||||
|
||||
Launch your game a few times to see if you can tie the computer's roll.
|
||||
|
||||
### Programming the final release
|
||||
|
||||
The beta release of your dice game is functional and feels more like a game than the alpha. For the final release, create your first Python **function**.
|
||||
|
||||
A function is a collection of code that you can call upon as a distinct unit. Functions are important because most applications have a lot of code in them, but not all of that code has to run at once. Functions make it possible to start an application and control what happens and when.
|
||||
|
||||
Change your code to this:
|
||||
|
||||
```
|
||||
import random
|
||||
import time
|
||||
|
||||
def dice():
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + str(player) )
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolls...." )
|
||||
time.sleep(2)
|
||||
print("The computer has rolled a " + str(player) )
|
||||
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
else:
|
||||
print("You lose")
|
||||
|
||||
print("Quit? Y/N")
|
||||
cont = input()
|
||||
|
||||
if cont == "Y" or cont == "y":
|
||||
exit()
|
||||
elif cont == "N" or cont == "n":
|
||||
pass
|
||||
else:
|
||||
print("I did not understand that. Playing again.")
|
||||
```
|
||||
|
||||
This version of the game asks the player whether they want to quit the game after they play. If they respond with a **Y** or **y**, Python's **exit** function is called and the game quits.
|
||||
|
||||
More importantly, you've created your own function called **dice**. The dice function doesn't run right away. In fact, if you try your game at this stage, it won't crash, but it doesn't exactly run, either. To make the **dice** function actually do something, you have to **call it** in your code.
|
||||
|
||||
Add this loop to the bottom of your existing code. The first two lines are only for context and to emphasize what gets indented and what does not. Pay close attention to indentation.
|
||||
|
||||
```
|
||||
else:
|
||||
print("I did not understand that. Playing again.")
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
print("Press return to roll your die.")
|
||||
roll = input()
|
||||
dice()
|
||||
```
|
||||
|
||||
The **while True** code block runs first. Because **True** is always true by definition, this code block always runs until Python tells it to quit.
|
||||
|
||||
The **while True** code block is a loop. It first prompts the user to start the game, then it calls your **dice** function. That's how the game starts. When the dice function is over, your loop either runs again or it exits, depending on how the player answered the prompt.
|
||||
|
||||
Using a loop to run a program is the most common way to code an application. The loop ensures that the application stays open long enough for the computer user to use functions within the application.
|
||||
|
||||
### Next steps
|
||||
|
||||
Now you know the basics of Python programming. The next article in this series will describe how to write a video game with [PyGame][14], a module that has more features than turtle, but is also a lot more complex.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Seth Kenlon - Seth Kenlon is an independent multimedia artist, free culture advocate, and UNIX geek. He has worked in the film and computing industry, often at the same time. He is one of the maintainers of the Slackware-based multimedia production project, http://slackermedia.info
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/python-101
|
||||
|
||||
作者:[Seth Kenlon ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:https://docs.python.org/3/using/windows.html
|
||||
[2]:https://opensource.com/file/374606
|
||||
[3]:https://opensource.com/file/374611
|
||||
[4]:https://opensource.com/file/374621
|
||||
[5]:https://opensource.com/file/374616
|
||||
[6]:https://opensource.com/article/17/10/python-101?rate=XlcW6PAHGbAEBboJ3z6P_4Sx-hyMDMlga9NfoauUA0w
|
||||
[7]:http://ninja-ide.org/downloads/
|
||||
[8]:https://opensource.com/user/15261/feed
|
||||
[9]:https://www.python.org/
|
||||
[10]:https://www.python.org/downloads/mac-osx/
|
||||
[11]:https://www.python.org/downloads/windows
|
||||
[12]:http://ninja-ide.org/
|
||||
[13]:https://opensource.com/article/17/8/doc-driven-development
|
||||
[14]:https://www.pygame.org/news
|
||||
[15]:https://opensource.com/users/seth
|
||||
[16]:https://opensource.com/users/seth
|
||||
[17]:https://opensource.com/article/17/10/python-101#comments
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Tips to Secure Your Network in the Wake of KRACK
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,188 +0,0 @@
|
||||
3 Simple, Excellent Linux Network Monitors
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Learn more about your network connections with the iftop, Nethogs, and vnstat tools.[Used with permission][3]
|
||||
|
||||
You can learn an amazing amount of information about your network connections with these three glorious Linux networking commands. iftop tracks network connections by process number, Nethogs quickly reveals what is hogging your bandwidth, and vnstat runs as a nice lightweight daemon to record your usage over time.
|
||||
|
||||
### iftop
|
||||
|
||||
The excellent [iftop][7] listens to the network interface that you specify, and displays connections in a top-style interface.
|
||||
|
||||
This is a great little tool for quickly identifying hogs, measuring speed, and also to maintain a running total of your network traffic. It is rather surprising to see how much bandwidth we use, especially for us old people who remember the days of telephone land lines, modems, screaming kilobits of speed, and real live bauds. We abandoned bauds a long time ago in favor of bit rates. Baud measures signal changes, which sometimes were the same as bit rates, but mostly not.
|
||||
|
||||
If you have just one network interface, run iftop with no options. iftop requires root permissions:
|
||||
|
||||
```
|
||||
$ sudo iftop
|
||||
```
|
||||
|
||||
When you have more than one, specify the interface you want to monitor:
|
||||
|
||||
```
|
||||
$ sudo iftop -i wlan0
|
||||
```
|
||||
|
||||
Just like top, you can change the display options while it is running.
|
||||
|
||||
* **h** toggles the help screen.
|
||||
|
||||
* **n** toggles name resolution.
|
||||
|
||||
* **s** toggles source host display, and **d** toggles the destination hosts.
|
||||
|
||||
* **s** toggles port numbers.
|
||||
|
||||
* **N** toggles port resolution; to see all port numbers toggle resolution off.
|
||||
|
||||
* **t** toggles the text interface. The default display requires ncurses. I think the text display is more readable and better-organized (Figure 1).
|
||||
|
||||
* **p** pauses the display.
|
||||
|
||||
* **q** quits the program.
|
||||
|
||||
### [fig-1.png][4]
|
||||
|
||||

|
||||
Figure 1: The text display is readable and organized.[Used with permission][1]
|
||||
|
||||
When you toggle the display options, iftop continues to measure all traffic. You can also select a single host to monitor. You need the host's IP address and netmask. I was curious how much of a load Pandora put on my sad little meager bandwidth cap, so first I used dig to find their IP address:
|
||||
|
||||
```
|
||||
$ dig A pandora.com
|
||||
[...]
|
||||
;; ANSWER SECTION:
|
||||
pandora.com. 267 IN A 208.85.40.20
|
||||
pandora.com. 267 IN A 208.85.40.50
|
||||
```
|
||||
|
||||
What's the netmask? [ipcalc][8] tells us:
|
||||
|
||||
```
|
||||
$ ipcalc -b 208.85.40.20
|
||||
Address: 208.85.40.20
|
||||
Netmask: 255.255.255.0 = 24
|
||||
Wildcard: 0.0.0.255
|
||||
=>
|
||||
Network: 208.85.40.0/24
|
||||
```
|
||||
|
||||
Now feed the address and netmask to iftop:
|
||||
|
||||
```
|
||||
$ sudo iftop -F 208.85.40.20/24 -i wlan0
|
||||
```
|
||||
|
||||
Is that not seriously groovy? I was surprised to learn that Pandora is easy on my precious bits, using around 500Kb per hour. And, like most streaming services, Pandora's traffic comes in spurts and relies on caching to smooth out the lumps and bumps.
|
||||
|
||||
You can do the same with IPv6 addresses, using the **-G** option. Consult the fine man page to learn the rest of iftop's features, including customizing your default options with a personal configuration file, and applying custom filters (see [PCAP-FILTER][9] for a filter reference).
|
||||
|
||||
### Nethogs
|
||||
|
||||
When you want to quickly learn who is sucking up your bandwidth, Nethogs is fast and easy. Run it as root and specify the interface to listen on. It displays the hoggy application and the process number, so that you may kill it if you so desire:
|
||||
|
||||
```
|
||||
$ sudo nethogs wlan0
|
||||
|
||||
NetHogs version 0.8.1
|
||||
|
||||
PID USER PROGRAM DEV SENT RECEIVED
|
||||
7690 carla /usr/lib/firefox wlan0 12.494 556.580 KB/sec
|
||||
5648 carla .../chromium-browser wlan0 0.052 0.038 KB/sec
|
||||
TOTAL 12.546 556.618 KB/sec
|
||||
```
|
||||
|
||||
Nethogs has few options: cycling between kb/s, kb, b, and mb, sorting by received or sent packets, and adjusting the delay between refreshes. See `man nethogs`, or run `nethogs -h`.
|
||||
|
||||
### vnstat
|
||||
|
||||
[vnstat][10] is the easiest network data collector to use. It is lightweight and does not need root permissions. It runs as a daemon and records your network statistics over time. The `vnstat` command displays the accumulated data:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan0
|
||||
Database updated: Tue Oct 17 08:36:38 2017
|
||||
|
||||
wlan0 since 10/17/2017
|
||||
|
||||
rx: 45.27 MiB tx: 3.77 MiB total: 49.04 MiB
|
||||
|
||||
monthly
|
||||
rx | tx | total | avg. rate
|
||||
------------------------+-------------+-------------+---------------
|
||||
Oct '17 45.27 MiB | 3.77 MiB | 49.04 MiB | 0.28 kbit/s
|
||||
------------------------+-------------+-------------+---------------
|
||||
estimated 85 MiB | 5 MiB | 90 MiB |
|
||||
|
||||
daily
|
||||
rx | tx | total | avg. rate
|
||||
------------------------+-------------+-------------+---------------
|
||||
today 45.27 MiB | 3.77 MiB | 49.04 MiB | 12.96 kbit/s
|
||||
------------------------+-------------+-------------+---------------
|
||||
estimated 125 MiB | 8 MiB | 133 MiB |
|
||||
```
|
||||
|
||||
By default it displays all network interfaces. Use the `-i` option to select a single interface. Merge the data of multiple interfaces this way:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan0+eth0+eth1
|
||||
```
|
||||
|
||||
You can filter the display in several ways:
|
||||
|
||||
* **-h** displays statistics by hours.
|
||||
|
||||
* **-d** displays statistics by days.
|
||||
|
||||
* **-w** and **-m** displays statistics by weeks and months.
|
||||
|
||||
* Watch live updates with the **-l** option.
|
||||
|
||||
This command deletes the database for wlan1 and stops watching it:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan1 --delete
|
||||
```
|
||||
|
||||
This command creates an alias for a network interface. This example uses one of the weird interface names from Ubuntu 16.04:
|
||||
|
||||
```
|
||||
$ vnstat -u -i enp0s25 --nick eth0
|
||||
```
|
||||
|
||||
By default vnstat monitors eth0\. You can change this in `/etc/vnstat.conf`, or create your own personal configuration file in your home directory. See `man vnstat` for a complete reference.
|
||||
|
||||
You can also install vnstati to create simple, colored graphs (Figure 2):
|
||||
|
||||
```
|
||||
$ vnstati -s -i wlx7cdd90a0a1c2 -o vnstat.png
|
||||
```
|
||||
|
||||
|
||||

|
||||
Figure 2: You can create simple colored graphs with vnstati.[Used with permission][2]
|
||||
|
||||
See `man vnstati` for complete options.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/3-simple-excellent-linux-network-monitors
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/files/images/fig-1png-8
|
||||
[5]:https://www.linux.com/files/images/fig-2png-5
|
||||
[6]:https://www.linux.com/files/images/bannerpng-3
|
||||
[7]:http://www.ex-parrot.com/pdw/iftop/
|
||||
[8]:https://www.linux.com/learn/intro-to-linux/2017/8/how-calculate-network-addresses-ipcalc
|
||||
[9]:http://www.tcpdump.org/manpages/pcap-filter.7.html
|
||||
[10]:http://humdi.net/vnstat/
|
||||
@ -1,147 +0,0 @@
|
||||
3 Tools to Help You Remember Linux Commands
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
The apropos tool, which is installed by default on nearly every Linux distribution, can help you find the command you need.[Used with permission][5]
|
||||
|
||||
The Linux desktop has come a very long way from its humble beginnings. Back in my early days of using Linux, knowledge of the command line was essential—even for the desktop. That’s no longer true. Many users might never touch the command line. For Linux system administrators, however, that’s not the case. In fact, for any Linux admin (be it server or desktop), the command line is a requirement. From managing networks, to security, to application and server settings—there’s nothing like the power of the good ol’ command line.
|
||||
|
||||
But, the thing is… there are a _lot_ of commands to be found on a Linux system. Consider _/usr/bin_ alone and you’ll find quite a lot of commands (you can issue _ls /usr/bin/ | wc -l_ to find out exactly how many you have). Of course, these aren’t all user-facing executables, but it gives you a good idea of the scope of Linux commands. On my Elementary OS system, there are 2029 executables within _/usr/bin_ . Even though I will use only a fraction of those commands, how am I supposed to remember even that amount?
|
||||
|
||||
Fortunately, there are various tricks and tools you can use, so that you’re not struggling on a daily basis to remember those commands. I want to offer up a few such tips that will go a long way to helping you work with the command line a bit more efficiently (and save a bit of brain power along the way).
|
||||
|
||||
We’ll start with a built-in tool and then illustrate two very handy applications that can be installed.
|
||||
|
||||
### Bash history
|
||||
|
||||
You may or may not know this, but Bash (the most popular Linux shell) retains a history of the commands you run. Want to see it in action? There are two ways. Open up a terminal window and tap the Up arrow key. You should see commands appear, one by one. Once you find the command you’re looking for, you can either use it as is, by hitting the Enter key, or modify it and then execute with the Enter key.
|
||||
|
||||
This is a great way to re-run (or modify and run) a command you’ve previously issued. I use this Linux feature regularly. It not only saves me from having to remember the minutiae of a command, it also saves me from having to type out the same command over and over.
|
||||
|
||||
Speaking of the Bash history, if you issue the command _history_ , you will be presented with a listing of commands you have run in the past (Figure 1).
|
||||
|
||||
|
||||

|
||||
Figure 1: Can you spot the mistake in one of my commands?[Used with permission][1]
|
||||
|
||||
The number of commands your Bash history holds is configured within the ~/.bashrc file. In that file, you’ll find two lines:
|
||||
|
||||
```
|
||||
HISTSIZE=1000
|
||||
|
||||
HISTFILESIZE=2000
|
||||
```
|
||||
|
||||
HISTSIZE is the maximum number of commands to remember on the history list, whereas HISTFILESIZE is the maximum number of lines contained in the history file.
|
||||
|
||||
Clearly, by default, Bash will retain 1000 commands in your history. That’s a lot. For some, this is considered an issue of security. If you’re concerned about that, you can shrink the number to whatever gives you the best ratio of security to practicality. If you don’t want Bash to remember your history, set HISTSIZE to 0.
|
||||
|
||||
If you make any changes to the ~/.bashrc file, make sure to log out and log back in (otherwise the changes won’t take effect).
|
||||
|
||||
### Apropos
|
||||
|
||||
This is the first of two tools that can be installed to assist you in recalling Linux commands. Apropos is able to search the Linux man pages to help you find the command you're looking for. Say, for instance, you don’t remember which firewall tool your distribution uses. You could type _apropos “firewall” _ and the tool would return any related command (Figure 2).
|
||||
|
||||
|
||||

|
||||
Figure 2: What is your firewall command?[Used with permission][2]
|
||||
|
||||
What if you needed a command to work with a directory, but had no idea what command was required? Type _apropos “directory” _ to see every command that contains the word “directory” in its man page (Figure 3).
|
||||
|
||||
|
||||

|
||||
Figure 3: What was that tool you used on a directory?[Used with permission][3]
|
||||
|
||||
The apropos tool is installed, by default, on nearly every Linux distribution.
|
||||
|
||||
### Fish
|
||||
|
||||
There’s another tool that does a great job of helping you recall commands. Fish is a command line shell for Linux, Unix, and Mac OS that has a few nifty tricks up its sleeve:
|
||||
|
||||
* Autosuggestions
|
||||
|
||||
* VGA Color
|
||||
|
||||
* Full scriptability
|
||||
|
||||
* Web Based configuration
|
||||
|
||||
* Man Page Completions
|
||||
|
||||
* Syntax highlighting
|
||||
|
||||
* And more
|
||||
|
||||
The autosuggestions make fish a really helpful tool (especially when you can’t recall those commands).
|
||||
|
||||
As you might expect, fish isn’t installed by default. For Ubuntu (and its derivatives), you can install fish with the following commands:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:fish-shell/release-2
|
||||
|
||||
sudo apt update
|
||||
|
||||
sudo apt install fish
|
||||
```
|
||||
|
||||
For the likes of CentOS, fish can be installed like so. Add the repository with the commands:
|
||||
|
||||
```
|
||||
sudo -s
|
||||
|
||||
cd /etc/yum.repos.d/
|
||||
|
||||
wget http://download.opensuse.org/repositories/shells:fish:release:2/CentOS_7/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
Update the repository list with the commands:
|
||||
|
||||
```
|
||||
yum repolist
|
||||
|
||||
yum update
|
||||
```
|
||||
|
||||
Install fish with the command:
|
||||
|
||||
```
|
||||
yum install fish
|
||||
```
|
||||
|
||||
Using fish isn’t quite as intuitive as you might expect. Remember, fish is a shell, so you have to enter the shell before using the command. From your terminal, issue the command fish and you will find yourself in the newly install shell (Figure 4).
|
||||
|
||||
|
||||

|
||||
Figure 4: The fish interactive shell.[Used with permission][4]
|
||||
|
||||
Start typing a command and fish will automatically complete the command. If the suggested command is not the one you’re looking for, hit the Tab key on your keyboard for more suggestions. If it is the command you want, type the right arrow key on your keyboard to complete the command and then hit Enter to execute. When you’re done using fish, type exit to leave that shell.
|
||||
|
||||
Fish does quite a bit more, but with regards to helping you remember your commands, the autosuggestions will go a very long way.
|
||||
|
||||
### Keep learning
|
||||
|
||||
There are so many commands to learn on Linux. But don’t think you have to commit every single one of them to memory. Thanks to the Bash history and tools like apropos and fish, you won’t have to strain your memory much to recall the commands you need to get your job done.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/3-tools-help-you-remember-linux-commands
|
||||
|
||||
作者:[JACK WALLEN ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/files/images/commands1jpg
|
||||
[7]:https://www.linux.com/files/images/commands2jpg
|
||||
[8]:https://www.linux.com/files/images/commands3jpg
|
||||
[9]:https://www.linux.com/files/images/commands4jpg
|
||||
[10]:https://www.linux.com/files/images/commands-mainjpg
|
||||
[11]:http://download.opensuse.org/repositories/shells:fish:release:2/CentOS_7/shells:fish:release:2.repo
|
||||
@ -0,0 +1,83 @@
|
||||
apply for translating
|
||||
|
||||
How Eclipse is advancing IoT development
|
||||
============================================================
|
||||
|
||||
### Open source organization's modular approach to development is a good match for the Internet of Things.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
[Eclipse][3] may not be the first open source organization that pops to mind when thinking about Internet of Things (IoT) projects. After all, the foundation has been around since 2001, long before IoT was a household word, supporting a community for commercially viable open source software development.
|
||||
|
||||
September's Eclipse IoT Day, held in conjunction with RedMonk's [ThingMonk 2017][4] event, emphasized the big role Eclipse is taking in [IoT development][5]. It currently hosts 28 projects that touch a wide range of IoT needs and projects. While at the conference, I talked with [Ian Skerritt][6], who heads marketing for Eclipse, about Eclipse's IoT projects and how Eclipse thinks about IoT more broadly.
|
||||
|
||||
### What's new about IoT?
|
||||
|
||||
I asked Ian how IoT is different from traditional industrial automation, given that sensors and tools have been connected in factories for the past several decades. Ian notes that many factories still are not connected.
|
||||
|
||||
Additionally, he says, "SCADA [supervisory control and data analysis] systems and even the factory floor technology are very proprietary, very siloed. It's hard to change it. It's hard to adapt to it… Right now, when you set up a manufacturing run, you need to manufacture hundreds of thousands of that piece, of that unit. What [manufacturers] want to do is to meet customer demand, to have manufacturing processes that are very flexible, that you can actually do a lot size of one." That's a big piece of what IoT is bringing to manufacturing.
|
||||
|
||||
### Eclipse's approach to IoT
|
||||
|
||||
He describes Eclipse's involvement in IoT by saying: "There's core fundamental technology that every IoT solution needs," and by using open source, "everyone can use it so they can get broader adoption." He says Eclipse see IoT as consisting of three connected software stacks. At a high level, these stacks mirror the (by now familiar) view that IoT can usually be described as spanning three layers. A given implementation may have even more layers, but they still generally map to the functions of this three-layer model:
|
||||
|
||||
* A stack of software for constrained devices (e.g., the device, endpoint, microcontroller unit (MCU), sensor hardware).
|
||||
|
||||
* Some type of gateway that aggregates information and data from the different sensors and sends it to the network. This layer also may take real-time actions based on what the sensors are observing.
|
||||
|
||||
* A software stack for the IoT platform on the backend. This backend cloud stores the data and can provide services based on collected data, such as analysis of historical trends and predictive analytics.
|
||||
|
||||
The three stacks are described in greater detail in Eclipse's whitepaper "[The Three Software Stacks Required for IoT Architectures][7]."
|
||||
|
||||
Ian says that, when developing a solution within those architectures, "there's very specific things that need to be built, but there's a lot of underlying technology that can be used, like messaging protocols, like gateway services. It needs to be a modular approach to scale up to the different use cases that are up there." This encapsulates Eclipse's activities around IoT: Developing modular open source components that can be used to build a range of business-specific services and solutions.
|
||||
|
||||
### Eclipse's IoT projects
|
||||
|
||||
Of Eclipse's many IoT projects currently in use, Ian says two of the most prominent relate to [MQTT][8], a machine-to-machine (M2M) messaging protocol for IoT. Ian describes it as "a publish‑subscribe messaging protocol that was designed specifically for oil and gas pipeline monitoring where power-management network latency is really important. MQTT has been a great success in terms of being a standard that's being widely adopted in IoT." [Eclipse Mosquitto][9] is MQTT's broker and [Eclipse Paho][10] its client.
|
||||
|
||||
[Eclipse Kura][11] is an IoT gateway that, in Ian's words, "provides northbound and southbound connectivity [for] a lot of different protocols" including Bluetooth, Modbus, controller-area network (CAN) bus, and OPC Unified Architecture, with more being added all the time. One benefit, he says, is "instead of you writing your own connectivity, Kura provides that and then connects you to the network via satellite, via Ethernet, or anything." In addition, it handles firewall configuration, network latency, and other functions. "If the network goes down, it will store messages until it comes back up," Ian says.
|
||||
|
||||
A newer project, [Eclipse Kapua][12], is taking a microservices approach to providing different services for an IoT cloud platform. For example, it handles aspects of connectivity, integration, management, storage, and analysis. Ian describes it as "up and coming. It's not being deployed yet, but Eurotech and Red Hat are very active in that."
|
||||
|
||||
Ian says [Eclipse hawkBit][13], which manages software updates, is one of the "most intriguing projects. From a security perspective, if you can't update your device, you've got a huge security hole." Most IoT security disasters are related to non-updated devices, he says. "HawkBit basically manages the backend of how you do scalable updates across your IoT system."
|
||||
|
||||
Indeed, the difficulty of updating software in IoT devices is regularly cited as one of its biggest security challenges. IoT devices aren't always connected and may be numerous, plus update processes for constrained devices can be hard to consistently get right. For this reason, projects relating to updating IoT software are likely to be important going forward.
|
||||
|
||||
### Why IoT is a good fit for Eclipse
|
||||
|
||||
One of the trends we've seen in IoT development has been around building blocks that are integrated and applied to solve particular business problems, rather than monolithic IoT platforms that apply across industries and companies. This is a good fit with Eclipse's approach to IoT, which focuses on a number of modular stacks; projects that provide specific and commonly needed functions; and brokers, gateways, and protocols that can tie together the components needed for a given implementation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gordon Haff - Gordon Haff is Red Hat’s cloud evangelist, is a frequent and highly acclaimed speaker at customer and industry events, and helps develop strategy across Red Hat’s full portfolio of cloud solutions. He is the author of Computing Next: How the Cloud Opens the Future in addition to numerous other publications. Prior to Red Hat, Gordon wrote hundreds of research notes, was frequently quoted in publications like The New York Times on a wide range of IT topics, and advised clients on product and...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/eclipse-and-iot
|
||||
|
||||
作者:[Gordon Haff ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://opensource.com/article/17/10/eclipse-and-iot?rate=u1Wr-MCMFCF4C45IMoSPUacCatoqzhdKz7NePxHOvwg
|
||||
[2]:https://opensource.com/user/21220/feed
|
||||
[3]:https://www.eclipse.org/home/
|
||||
[4]:http://thingmonk.com/
|
||||
[5]:https://iot.eclipse.org/
|
||||
[6]:https://twitter.com/ianskerrett
|
||||
[7]:https://iot.eclipse.org/resources/white-papers/Eclipse%20IoT%20White%20Paper%20-%20The%20Three%20Software%20Stacks%20Required%20for%20IoT%20Architectures.pdf
|
||||
[8]:http://mqtt.org/
|
||||
[9]:https://projects.eclipse.org/projects/technology.mosquitto
|
||||
[10]:https://projects.eclipse.org/projects/technology.paho
|
||||
[11]:https://www.eclipse.org/kura/
|
||||
[12]:https://www.eclipse.org/kapua/
|
||||
[13]:https://eclipse.org/hawkbit/
|
||||
[14]:https://opensource.com/users/ghaff
|
||||
[15]:https://opensource.com/users/ghaff
|
||||
[16]:https://opensource.com/article/17/10/eclipse-and-iot#comments
|
||||
@ -1,81 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Running Android on Top of a Linux Graphics Stack
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
>You can now run Android on top of a regular Linux graphics stack, which is hugely empowering, according to Robert Foss, a Linux graphic stack contributor and Software Engineer at Collabora. Learn more in this preview of his talk at Embedded Linux Conference Europe.[Creative Commons Zero][2]Pixabay
|
||||
|
||||
You can now run Android on top of a regular Linux graphics stack. This was not the case before, and according to Robert Foss, a Linux graphic stack contributor and Software Engineer at Collabora, this is hugely empowering. In his upcoming talk at [Embedded Linux Conference Europe,][5] Foss will cover recent developments in this area and discuss how these changes allow you to take advantage of new features and improvements in kernels.
|
||||
|
||||
|
||||

|
||||
|
||||
Robert Foss, Linux graphic stack contributor and Software Engineer at Collabora[Used with permission][1]
|
||||
|
||||
In this article, Foss explains more and offers a preview of his talk.
|
||||
|
||||
**Linux.com: Can you please tell us a bit about the graphics stack you’re talking about?**
|
||||
|
||||
**Foss: **Traditional Linux graphics systems (like X11) mostly did not use planes. But modern graphics systems like Android and Wayland can take full advantage of it.
|
||||
|
||||
Android has the most mature implementation of plane support in HWComposer, and its graphics stack is a bit different from the usual Linux desktop graphics stack. On desktops, the typical compositor just uses the GPU for all composition, because this is the only thing that exists on the desktop.
|
||||
|
||||
Most embedded and mobile chips have specialized 2D composition hardware that Android is designed around. The way this is done is by dividing the things that are displayed into layers, and then intelligently feeding the layers to hardware that is optimized to handle layers. This frees up the GPU to work on the things you actually care about, while at the same time, it lets hardware that is more efficient do what it does best.
|
||||
|
||||
**Linux.com: When you say Android, do you mean the Android Open Source Project (the AOSP)?**
|
||||
|
||||
**Foss: **The Android Open Source Project (the AOSP), is the base upon which many Android products is built, and there's not much of a distinction between AOSP and Android.
|
||||
|
||||
Specifically, my work has been done in the AOSP realm, but nothing is preventing this work from being pulled into a shipped Android product.
|
||||
|
||||
The distinction is more about licensing and fulfilling the requirements of Google for calling a product Android, than it is about code.
|
||||
|
||||
**Linux.com: Who would want to run that and why? What are some advantages?**
|
||||
|
||||
**Foss: **AOSP gives you a lot of things for free, such as a software stack optimized for usability, low power, and diverse hardware. It's a lot more polished and versatile than what any single company feasibly could develop on their own, without putting a lot of resources behind it.
|
||||
|
||||
As a manufacturer it also provides you with access to a large pool of developers that are immediately able to develop for your platform.
|
||||
|
||||
**Linux.com: What are some practical use cases?**
|
||||
|
||||
**Foss: **The new part here is the ability to run Android on top of the regular Linux graphics stack. Being able to do this with mainline/upstream kernels and drivers allows you to take advantage of new features and improvements in kernels as well, not just depend on whatever massively forked BSP you get from your vendor.
|
||||
|
||||
For any GPU that has reasonable standard Linux support, you are now able to run Android on top of it. This was not the case before. And in that way it is hugely enabling and empowering.
|
||||
|
||||
It also matter in the sense, that it incentivizes GPU designers to work with upstream for their drivers. Now there's a straightforward path for them to provide one driver that works for Android and Linux with no added effort. Their costs will be lower, and maintaining their GPU driver upstream is a lot more appealing.
|
||||
|
||||
For example, we would like to see mainline support Qualcomm SOCs, and we would like to be a part of making that a reality.
|
||||
|
||||
To summarize, this will help the hardware ecosystem get better software support and the software ecosystem have more hardware to work with.
|
||||
|
||||
* It improves the economy of SBC/devboard manufacturers: they can provide a single well-tested stack which works on both, rather than having to provide a "Linux stack" and an Android stack.
|
||||
|
||||
* It simplifies work for driver developers, since there's just a single target for optimisation and enablement.
|
||||
|
||||
* It enables the Android community, since Android running on mainline allows them to share the upstream improvements being made.
|
||||
|
||||
* It helps upstream, because we get a product-quality stack, that has been tested and developed with help from the designer of the hardware.
|
||||
|
||||
Previously, Mesa was looked upon as a second-class stack, but it's now shown that it is up-to-date (fully compliant with Vulkan 1.0, OpenGL 4.6, OpenGL ES 3.2 on release day), as well as performant, and product quality.
|
||||
|
||||
That means that driver developers can be involved in Mesa, and be confident that they're sharing in the hard work of others, and also getting a great base to build on.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/event/elce/2017/10/running-android-top-linux-graphics-stack
|
||||
|
||||
作者:[ SWAPNIL BHARTIYA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/robert-fosspng
|
||||
[4]:https://www.linux.com/files/images/linux-graphics-stackjpg
|
||||
[5]:http://events.linuxfoundation.org/events/embedded-linux-conference-europe
|
||||
@ -0,0 +1,141 @@
|
||||
# Why Did Ubuntu Drop Unity? Mark Shuttleworth Explains
|
||||
|
||||
[][6]
|
||||
|
||||
Mark Shuttleworth, found of Ubuntu
|
||||
|
||||
Ubuntu’s decision to ditch Unity took all of us — even me — by surprise when announced [back in April.][4]
|
||||
|
||||
Now Ubuntu founder [Mark Shuttleworth ][7]shares more details about why Ubuntu chose to drop Unity.
|
||||
|
||||
And the answer might surprise…
|
||||
|
||||
Actually, no; the answer probably _won’t_ surprise you.
|
||||
|
||||
Like, at all.
|
||||
|
||||
### Why Did Ubuntu Drop Unity?
|
||||
|
||||
Last week saw the [release of Ubuntu 17.10][8], the first release of Ubuntu to ship without the Unity desktop since it was [introduced back in 2011][9].
|
||||
|
||||
‘We couldn’t have on our books very substantial projects which have no commercial angle to them’
|
||||
|
||||
Naturally the mainstream press is curious about where Unity has gone. And so Mark Shuttleworth has [spoke to eWeek][10] to detail his decision to jettison Unity from the Ubuntu roadmap.
|
||||
|
||||
The _tl;dr_ he ejected Unity as part of a cost-saving pivot designed to put Canonical on the path toward an [initial public offering][11] (known as an “IPO”).
|
||||
|
||||
Yup: investors are coming.
|
||||
|
||||
But the full interview provides more context on the decision, and reveals just how difficult it was to let go of the desktop he helped nurture.
|
||||
|
||||
### “Ubuntu Has Moved In To The Mainstream”
|
||||
|
||||
Mark Shuttleworth, speaking to [Sean Michael Kerner,][12] starts by reminding us all how great Ubuntu is:
|
||||
|
||||
_“The beautiful thing about Ubuntu is that we created the possibility of a platform that is free of charge to its end users, with commercial services around it, in the dream that that might define the future in all sorts of different ways._
|
||||
|
||||
_We really have seen that Ubuntu has moved in to the mainstream in a bunch of areas.”_
|
||||
|
||||
‘We created a platform that is free of charge to its end users, with commercial services around it’
|
||||
|
||||
But being popular isn’t the same as being profitable, as Mark notes:
|
||||
|
||||
_“Some of the things that we were doing were clearly never going to be commercially sustainable, other things clearly will be commercially sustainable, or already are commercially sustainable. _
|
||||
|
||||
_As long as we stay a purely private company we have complete discretion whether we carry things that are not commercially sustainable.”_
|
||||
|
||||
Shuttleworth says he, along with the other ‘leads’ at Canonical, came to a consensual view that they should put the company on the path to becoming a public company.
|
||||
|
||||
‘In the last 7 years Ubuntu itself became completely sustainable’
|
||||
|
||||
And to appear attractive to potential investors the company has to focus on its areas of profitability — something Unity, Ubuntu phone, Unity 8 and convergence were not part of:
|
||||
|
||||
_“[The decision] meant that we couldn’t have on our books (effectively) very substantial projects which clearly have no commercial angle to them at all._
|
||||
|
||||
_It doesn’t mean that we would consider changing the terms of Ubuntu for example, because it’s foundational to everything we do. And we don’t have to, effectively.”_
|
||||
|
||||
‘I could get hit by a bus tomorrow and Ubuntu could continue’
|
||||
|
||||
#### ‘Ubuntu itself is now completely sustainable’
|
||||
|
||||
Money may have meant Unity’s demise but the wider Ubuntu project is in rude health. as Shuttleworth explains:
|
||||
|
||||
_“One of the things I’m most proud of is in the last 7 years is that Ubuntu itself became completely sustainable. _ _I could get hit by a bus tomorrow and Ubuntu could continue._
|
||||
|
||||
_It’s kind of magical, right? Here’s a platform that is a world class enterprise platform, that’s completely freely available, and yet it is sustainable._
|
||||
|
||||
_Jane Silber is largely to thank for that.”_
|
||||
|
||||
While it’s all-too-easy for desktop users to focus on, well, the desktop, there is far more to Canonical (the company) than the 6-monthly releases we look forward to.
|
||||
|
||||
Losing Unity may have been a big blow for desktop users but it helped to balance other parts of the company:
|
||||
|
||||
_“There are huge possibilities for us in the enterprise beyond that, in terms of really defining how cloud infrastructure is built, how cloud applications are operated, and so on. And, in IoT, looking at that next wave of possibility, innovators creating stuff on IoT._
|
||||
|
||||
_And all of that is ample for us to essentially put ourselves on course to IPO around that.”_
|
||||
|
||||
Dropping Unity wasn’t easy for Mark, though:
|
||||
|
||||
_“We had this big chunk of work, which was Unity, which I really loved._
|
||||
|
||||
_I think the engineering of Unity 8 was pretty spectacularly good, and the deep ideas of how you bring these different form factors together was pretty beautiful._
|
||||
|
||||
“I couldn’t make an argument for [Unity] to sit on Canonical’s books any longer”
|
||||
|
||||
_“But I couldn’t make an argument for that to sit on Canonical’s books any longer, if we were gonna go on a path to an IPO._
|
||||
|
||||
_So what you should see at some stage, and I think fairly soon, I think we’ll announce that we have broken even on all of the pieces that we do commercially, effectively, without Unity.“_
|
||||
|
||||
Soon after this he says the company will likely take its first round investment for growth, ahead of transitioning to a formal public company at a later date.
|
||||
|
||||
But Mark doesn’t want anyone to think that investors will ‘ruin the party’:
|
||||
|
||||
_“We’re not in a situation where we need to kind of flip flop based on what VCs might tell us to do. We’ve a pretty clear view of what our customers like, we’ve found good market traction and product fit both on cloud and on IoT.”_
|
||||
|
||||
Mark adds that the team at Canonical is ‘justifiably excited’ at this decision.
|
||||
|
||||
‘Emotionally I never want to go through a process like that again,’ Mark says
|
||||
|
||||
_“Emotionally I never want to go through a process like that again. I made some miscalculations around Unity. I really thought industry would rally to the idea of having a free platform that was independent._
|
||||
|
||||
_But then I also don’t regret having the will to go do that. Lots of people will complain about the options that they have and don’t go and create other options._
|
||||
|
||||
_It takes a bit of spine and, as it turns out, quite a lot of money to go and try and create those options.”_
|
||||
|
||||
#### OMG! IPO? NO!
|
||||
|
||||
Before anyone splits too many hairs over the notion of Canonical (possibly) becoming a public company let’s remember that Redhat has been a public company for 20 years. Both the GNOME desktop and Fedora are tickling along nicely, free of any ‘money making’ interventions.
|
||||
|
||||
If Canonical IPOs there is unlikely to be any sudden, dramatic change to Ubuntu because, as Shuttleworth himself has said, it’s the foundation on which everything else is built.
|
||||
|
||||
Ubuntu is established. It’s the number one OS on cloud. It’s the world’s most popular Linux distribution (in the world beyond [Distrowatch’s rankings][13]). And it’s apparently seeing great adoption in the Internet of Things space.
|
||||
|
||||
And Mark says Ubuntu is now totally sustainable.
|
||||
|
||||
With a [warm reception greeting the arrival of Ubuntu 17.10][14], and a new LTS on the horizon, things are looking pretty good…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/10/why-did-ubuntu-drop-unity-mark-shuttleworth-explains
|
||||
|
||||
作者:[ JOEY SNEDDON ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://trw.431.night8.win/yy.php/H5aIh_2F/ywcKfGz_/2BKS471c/l3mPrAOp/L1WrIpnn/GpPc4TFY/yHh6t5Cu/gk7ZPrW2/omFcT6ao/A9I_3D/b0/
|
||||
[2]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU38e9i0/RMyYqikJ/lzgv8Nfz/0gk_3D/b0/
|
||||
[3]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU38e9i0/RMyYqikO/nDs5/b0/
|
||||
[4]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3m/DJPe_2FH/MCjCI_2B/94yrj1PG/NeqgpjVN/F7WuA815/jIj6rCNO/KcNXKJ1Y/cEP_2BUn/_2Fb/b0/
|
||||
[5]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3m/DJLa_2FH/EIgGEu68/W3whyDb7/Om4zhPVa/LtGc511Z/WysilILZ/4JLodYKV/r1TGTQPz/vy99PlQJ/jKI1w_3D/b0/
|
||||
[6]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU3oaoGy/TM2etmgU/1jk67s77/0w3ZM_2F/fi_2BnMN/DP2NDdJ3/jL_2F3qj/xOKtYNKY/BYNRj6S2/w_3D/b0/
|
||||
[7]:https://trw.431.night8.win/yy.php/H5aIh_2B/myK6OBw_/2BSN4bVQ/2DSPs0u3/aQv0c4Oc/QtGBjFUI/jDg_2B7s/Tt2AyCaQ/_3D_3D/b0/
|
||||
[8]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3m/DJLa_2FH/MCjCI_2B/94yrgFPH/MeqhqzBY/W6GlQcZ5/wJjqrS1J/b0/
|
||||
[9]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3h/DJLa_2FH/MCjCI_2B/94yrhlPG/NeqmoDVJ/Q_2F_2Bk/CcZ91IDr/8ixfNdgO/KYI_3D/b0/
|
||||
[10]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7Gfze/iWqrJW1D/WFr1j9bB/Ltc9_2B0/DsKao3VP/mi0k7c_2/Fz1B_2Ba/LKi94yxc/TrrtGM8x/yJzw8ilJ/a8YYM5xY/KBvlVWLW/Mn6z_2B8/XgVNTHKF/zugKBoCH/NJcQJTvL/37D4mgxw/_3D_3D/b0/
|
||||
[11]:https://trw.431.night8.win/yy.php/H5aIh_2B/myK6OBw_/2BSN4bVQ/2DSPs0u3/aQv0c4OY/TcqeumcM/pjw_2F4M/3z1CGZZ6/G2vDVTXQ/_3D_3D/b0/
|
||||
[12]:https://trw.431.night8.win/yy.php/H5aIh_2F/irbKCczf/_2FT575U/lk6FokTS/cRftdM29/StCe/b0/
|
||||
[13]:https://trw.431.night8.win/yy.php/VoOIzOWv/caaH3_2B/yJ57kX2n/WN7lj5fA/76NNy5U5/yOunUUiy/Uo99Xz2B/DLdKWmoC/hI/b0/
|
||||
[14]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3m/DJLa_2FH/MCjCI_2B/94yrgFPH/MeqhqypU/X6XtHs9p/z4jqrw_3/D_3D/b0/
|
||||
@ -0,0 +1,229 @@
|
||||
How to roll your own backup solution with BorgBackup, Rclone, and Wasabi cloud storage
|
||||
============================================================
|
||||
|
||||
### Protect your data with an automated backup solution built on open source software and inexpensive cloud storage.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
For several years, I used CrashPlan to back up my family's computers, including machines belonging to my wife and siblings. The fact that CrashPlan was essentially "always on" and doing frequent backups without ever having to think about it was fantastic. Additionally, the ability to do point-in-time restores came in handy on several occasions. Because I'm generally the IT person for the family, I loved that the user interface was so easy to use that family members could recover their data without my help.
|
||||
|
||||
Recently [CrashPlan announced][5] that it was dropping its consumer subscriptions to focus on its enterprise customers. It makes sense, I suppose, as it wasn't making a lot of money off folks like me, and our family plan was using a whole lot of storage on its system.
|
||||
|
||||
I decided that the features I would need in a suitable replacement included:
|
||||
|
||||
* Cross-platform support for Linux and Mac
|
||||
|
||||
* Automation (so there's no need to remember to click "backup")
|
||||
|
||||
* Point-in-time recovery (or something close) so if you accidentally delete a file but don't notice until later, it's still recoverable
|
||||
|
||||
* Low cost
|
||||
|
||||
* Replicated data store for backup sets, so data exists in more than one place (i.e., not just backing up to a local USB drive)
|
||||
|
||||
* Encryption in case the backup files fall into the wrong hands
|
||||
|
||||
I searched around and asked my friends about services similar to CrashPlan. One was really happy with [Arq][6], but no Linux support meant it was no good for me. [Carbonite][7] is similar to CrashPlan but would be expensive, because I have multiple machines to back up. [Backblaze][8] offers unlimited backups at a good price (US$ 5/month), but its backup client doesn't support Linux. [BackupPC][9] was a strong contender, but I had already started testing my solution before I remembered it. None of the other options I looked at matched everything I was looking for. That meant I had to figure out a way to replicate what CrashPlan delivered for me and my family.
|
||||
|
||||
I knew there were lots of good options for backing up files on Linux systems. In fact, I've been using [rdiff-backup][10] for at least 10 years, usually for saving snapshots of remote filesystems locally. I had hopes of finding something that would do a better job of deduplicating backup data though, because I knew there were going to be some things (like music libraries and photos) that were stored on multiple computers.
|
||||
|
||||
I think what I worked out came pretty close to meeting my goals.
|
||||
|
||||
### My backup solution
|
||||
|
||||
### [backup-diagram.png][1]
|
||||
|
||||

|
||||
|
||||
Ultimately, I landed on a combination of [BorgBackup][11], [Rclone][12], and [Wasabi cloud storage][13], and I couldn't be happier with my decision. Borg fits all my criteria and has a pretty healthy [community of users and contributors][14]. It offers deduplication and compression, and works great on PC, Mac, and Linux. I use Rclone to synchronize the backup repositories from the Borg host to S3-compatible storage on Wasabi. Any S3-compatible storage will work, but I chose Wasabi because its price can't be beat and it outperforms Amazon's S3\. With this setup, I can restore files from the local Borg host or from Wasabi.
|
||||
|
||||
Installing Borg on my machine was as simple as **sudo apt install borgbackup**. My backup host is a Linux machine that's always on with a 1.5TB USB drive attached to it. This backup host could be something as lightweight as a Raspberry Pi if you don't have a machine available. Just make sure all the client machines can reach this server over SSH and you are good to go.
|
||||
|
||||
On the backup host, initialize a new backup repository with:
|
||||
|
||||
```
|
||||
$ borg init /mnt/backup/repo1
|
||||
```
|
||||
|
||||
Depending on what you're backing up, you might choose to make multiple repositories per machine, or possibly one big repository for all your machines. Because Borg deduplicates, if you have identical data on many computers, sending backups from all those machines to the same repository might make sense.
|
||||
|
||||
Installing Borg on the Linux client machines was straightforward. On Mac OS X I needed to install XCode and Homebrew first. I followed a [how-to][15] to install the command-line tools, then used **pip3 install borgbackup**.
|
||||
|
||||
### Backing up
|
||||
|
||||
Each machine has a **backup.sh** script (see below) that is kicked off by **cron** at regular intervals; it will make only one backup set per day, but it doesn't hurt to try a few times in the same day. The laptops are set to try every two hours, because there's no guarantee they will be on at a certain time, but it's very likely they'll be on during one of those times. This could be improved by writing a daemon that's always running and triggers a backup attempt anytime the laptop wakes up. For now, I'm happy with the way things are working.
|
||||
|
||||
I could skip the cron job and provide a relatively easy way for each user to trigger a backup using [BorgWeb][16], but I really don't want anyone to have to remember to back things up. I tend to forget to click that backup button until I'm in dire need of a restoration (at which point it's way too late!).
|
||||
|
||||
The backup script I'm using came from the Borg [quick start][17] docs, plus I added a little check at the top to see if Borg is already running, which will exit the script if the previous backup run is still in progress. This script makes a new backup set and labels it with the hostname and current date. It then prunes old backup sets with an easy retention schedule.
|
||||
|
||||
Here is my **backup.sh** script:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
REPOSITORY=borg@borgserver:/mnt/backup/repo1
|
||||
|
||||
#Bail if borg is already running, maybe previous run didn't finish
|
||||
if pidof -x borg >/dev/null; then
|
||||
echo "Backup already running"
|
||||
exit
|
||||
fi
|
||||
|
||||
# Setting this, so you won't be asked for your repository passphrase:
|
||||
export BORG_PASSPHRASE='thisisnotreallymypassphrase'
|
||||
# or this to ask an external program to supply the passphrase:
|
||||
export BORG_PASSCOMMAND='pass show backup'
|
||||
|
||||
# Backup all of /home and /var/www except a few
|
||||
# excluded directories
|
||||
borg create -v --stats \
|
||||
$REPOSITORY::'{hostname}-{now:%Y-%m-%d}' \
|
||||
/home/doc \
|
||||
--exclude '/home/doc/.cache' \
|
||||
--exclude '/home/doc/.minikube' \
|
||||
--exclude '/home/doc/Downloads' \
|
||||
--exclude '/home/doc/Videos' \
|
||||
--exclude '/home/doc/Music' \
|
||||
|
||||
# Use the `prune` subcommand to maintain 7 daily, 4 weekly and 6 monthly
|
||||
# archives of THIS machine. The '{hostname}-' prefix is very important to
|
||||
# limit prune's operation to this machine's archives and not apply to
|
||||
# other machine's archives also.
|
||||
borg prune -v --list $REPOSITORY --prefix '{hostname}-' \
|
||||
--keep-daily=7 --keep-weekly=4 --keep-monthly=6
|
||||
```
|
||||
|
||||
The output from a backup run looks like this:
|
||||
|
||||
```
|
||||
------------------------------------------------------------------------------
|
||||
Archive name: x250-2017-10-05
|
||||
Archive fingerprint: xxxxxxxxxxxxxxxxxxx
|
||||
Time (start): Thu, 2017-10-05 03:09:03
|
||||
Time (end): Thu, 2017-10-05 03:12:11
|
||||
Duration: 3 minutes 8.12 seconds
|
||||
Number of files: 171150
|
||||
------------------------------------------------------------------------------
|
||||
Original size Compressed size Deduplicated size
|
||||
This archive: 27.75 GB 27.76 GB 323.76 MB
|
||||
All archives: 3.08 TB 3.08 TB 262.76 GB
|
||||
|
||||
Unique chunks Total chunks
|
||||
Chunk index: 1682989 24007828
|
||||
------------------------------------------------------------------------------
|
||||
[...]
|
||||
Keeping archive: x250-2017-09-17 Sun, 2017-09-17 03:09:02
|
||||
Pruning archive: x250-2017-09-28 Thu, 2017-09-28 03:09:02
|
||||
```
|
||||
|
||||
Once I had all the machines backing up to the host, I followed [the instructions for installing a precompiled Rclone binary][18] and set it up to access my Wasabi account.
|
||||
|
||||
This script runs each night to synchronize any changes to the backup sets:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
repos=( repo1 repo2 repo3 )
|
||||
|
||||
#Bail if rclone is already running, maybe previous run didn't finish
|
||||
if pidof -x rclone >/dev/null; then
|
||||
echo "Process already running"
|
||||
exit
|
||||
fi
|
||||
|
||||
for i in "${repos[@]}"
|
||||
do
|
||||
#Lets see how much space is used by directory to back up
|
||||
#if directory is gone, or has gotten small, we will exit
|
||||
space=`du -s /mnt/backup/$i|awk '{print $1}'`
|
||||
|
||||
if (( $space < 34500000 )); then
|
||||
echo "EXITING - not enough space used in $i"
|
||||
exit
|
||||
fi
|
||||
|
||||
/usr/bin/rclone -v sync /mnt/backup/$i wasabi:$i >> /home/borg/wasabi-sync.log 2>&1
|
||||
done
|
||||
```
|
||||
|
||||
The first synchronization of the backup set to Wasabi with Rclone took several days, but it was around 400GB of new data, and my outbound connection is not super-fast. But the daily delta is very small and completes in just a few minutes.
|
||||
|
||||
### Restoring files
|
||||
|
||||
Restoring files is not as easy as it was with CrashPlan, but it is relatively straightforward. The fastest approach is to restore from the backup stored on the Borg backup server. Here are some example commands used to restore:
|
||||
|
||||
```
|
||||
#List which backup sets are in the repo
|
||||
$ borg list borg@borgserver:/mnt/backup/repo1
|
||||
Remote: Authenticated with partial success.
|
||||
Enter passphrase for key ssh://borg@borgserver/mnt/backup/repo1:
|
||||
x250-2017-09-17 Sun, 2017-09-17 03:09:02
|
||||
#List contents of a backup set
|
||||
$ borg list borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 | less
|
||||
#Restore one file from the repo
|
||||
$ borg extract borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 home/doc/somefile.jpg
|
||||
#Restore a whole directory
|
||||
$ borg extract borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 home/doc
|
||||
```
|
||||
|
||||
If something happens to the local Borg server or the USB drive holding all the backup repositories, I can also easily restore directly from Wasabi. If the machine has Rclone installed, using **[rclone mount][3]** I can mount the remote storage bucket as though it were a local filesystem:
|
||||
|
||||
```
|
||||
#Mount the S3 store and run in the background
|
||||
$ rclone mount wasabi:repo1 /mnt/repo1 &
|
||||
#List archive contents
|
||||
$ borg list /mnt/repo1
|
||||
#Extract a file
|
||||
$ borg extract /mnt/repo1::x250-2017-09-17 home/doc/somefile.jpg
|
||||
```
|
||||
|
||||
### How it's working
|
||||
|
||||
Now that I've been using this backup approach for a few weeks, I can say I'm really happy with it. Setting everything up and getting it running was a lot more complicated than just installing CrashPlan of course, but that's the difference between rolling your own solution and using a service. I will have to watch closely to be sure backups continue to run and the data is properly synchronized to Wasabi.
|
||||
|
||||
But, overall, replacing CrashPlan with something offering comparable backup coverage at a really reasonable price turned out to be a little easier than I expected. If you see room for improvement please let me know.
|
||||
|
||||
_This was originally published on _ [_Local Conspiracy_][19] _ and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Christopher Aedo - Christopher Aedo has been working with and contributing to open source software since his college days. Most recently he can be found leading an amazing team of upstream developers at IBM who are also developer advocates. When he’s not at work or speaking at a conference, he’s probably using a RaspberryPi to brew and ferment a tasty homebrew in Portland OR.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/backing-your-machines-borg
|
||||
|
||||
作者:[ Christopher Aedo ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/docaedo
|
||||
[1]:https://opensource.com/file/375066
|
||||
[2]:https://opensource.com/article/17/10/backing-your-machines-borg?rate=Aa1IjkXuXy95tnvPGLWcPQJCKBih4Wo9hNPxhDs-mbQ
|
||||
[3]:https://rclone.org/commands/rclone_mount/
|
||||
[4]:https://opensource.com/user/145976/feed
|
||||
[5]:https://www.crashplan.com/en-us/consumer/nextsteps/
|
||||
[6]:https://www.arqbackup.com/
|
||||
[7]:https://www.carbonite.com/
|
||||
[8]:https://www.backblaze.com/
|
||||
[9]:http://backuppc.sourceforge.net/BackupPCServerStatus.html
|
||||
[10]:http://www.nongnu.org/rdiff-backup/
|
||||
[11]:https://www.borgbackup.org/
|
||||
[12]:https://rclone.org/
|
||||
[13]:https://wasabi.com/
|
||||
[14]:https://github.com/borgbackup/borg/
|
||||
[15]:http://osxdaily.com/2014/02/12/install-command-line-tools-mac-os-x/
|
||||
[16]:https://github.com/borgbackup/borgweb
|
||||
[17]:https://borgbackup.readthedocs.io/en/stable/quickstart.html
|
||||
[18]:https://rclone.org/install/
|
||||
[19]:http://localconspiracy.com/2017/10/backup-everything.html
|
||||
[20]:https://opensource.com/users/docaedo
|
||||
[21]:https://opensource.com/users/docaedo
|
||||
[22]:https://opensource.com/article/17/10/backing-your-machines-borg#comments
|
||||
102
sources/tech/20171026 But I dont know what a container is.md
Normal file
102
sources/tech/20171026 But I dont know what a container is.md
Normal file
@ -0,0 +1,102 @@
|
||||
But I don't know what a container is
|
||||
============================================================
|
||||
|
||||
### Here's how containers are both very much like — and very much unlike — virtual machines.
|
||||
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
I've been speaking about security in DevOps—also known as "DevSecOps"[*][9]—at a few conferences and seminars recently, and I've started to preface the discussion with a quick question: "Who here understands what a container is?" Usually I don't see many hands going up,[**][10] so I've started briefly explaining what containers[***][11] are before going much further.
|
||||
|
||||
To be clear: You _can_ do DevOps without containers, and you _can_ do DevSecOps without containers. But containers lend themselves so well to the DevOps approach—and to DevSecOps, it turns out—that even though it's possible to do DevOps without them, I'm going to assume that most people will use containers.
|
||||
|
||||
### What is a container?
|
||||
|
||||
Linux Containers
|
||||
|
||||
* [What are Linux containers?][1]
|
||||
|
||||
* [What is Docker?][2]
|
||||
|
||||
* [What is Kubernetes?][3]
|
||||
|
||||
* [An introduction to container terminology][4]
|
||||
|
||||
I was in a meeting with colleagues a few months ago, and one of them was presenting on containers. Not everybody around the table was an expert on the technology, so he started simply. He said something like, "There's no mention of containers in the Linux kernel source code." This, it turned out, was a dangerous statement to make in this particular group, and within a few seconds, both my boss (sitting next to me) and I were downloading the recent kernel source tarballs and performing a count of the exact number of times that the word "container" occurred. It turned out that his statement wasn't entirely correct. To give you an idea, I just tried it on an old version (4.9.2) I have on a laptop—it turns out 15,273 lines in that version include the word "container."[****][16] My boss and I had a bit of a smirk and ensured we corrected him at the next break.
|
||||
|
||||
What my colleague meant to say—and clarified later—is that the concept of a container doesn't really exist as a clear element within the Linux kernel. In other words, containers use a number of abstractions, components, tools, and mechanisms from the Linux kernel, but there's nothing very special about these; they can also be used for other purposes. So, there's "no such thing as a container, according to the Linux kernel."
|
||||
|
||||
What, then, is a container? Well, I come from a virtualization—hypervisor and virtual machine (VM)—background, and, in my mind, containers are both very much like and very much unlike VMs. I realize that this may not sound very helpful, but let me explain.
|
||||
|
||||
### How is a container like a VM?
|
||||
|
||||
The main way in which a container is like a VM is that it's a unit of execution. You bundle something up—an image—which you can then run on a suitably equipped host platform. Like a VM, it's a workload on a host, and like a VM, it runs at the mercy of that host. Beyond providing workloads with the resources they need to do their job (CPU cycles, networking, storage access, etc.), the host has a couple of jobs that it needs to do:
|
||||
|
||||
1. Protect workloads from each other, and make sure that a malicious, compromised, or poorly written workload cannot affect the operation of any others.
|
||||
|
||||
2. Protect itself (the host) from workloads, and make sure that a malicious, compromised, or poorly written workload cannot affect the operation of the host.
|
||||
|
||||
The ways VMs and containers achieve this isolation are fundamentally different, with VMs isolated by hypervisors making use of hardware capabilities, and containers isolated via software controls provided by the Linux kernel.[******][12]These controls revolve around various "namespaces" that ensure one container can't see other containers' files, users, network connections, etc.—nor those of the host. These can be supplemented by tools such as SELinux, which provide capabilities controls for further isolation of containers.
|
||||
|
||||
### How is a container unlike a VM?
|
||||
|
||||
The problem with the description above is that if you're even vaguely hypervisor-aware, you probably think that a container is just like a VM, and it _really_ isn't.
|
||||
|
||||
A container, first and foremost,[*******][6] is a packaging format. "WHAT?" you say, "but you just said it was something that was executed." Well, yes, but the main reason containers are so interesting is that it's very easy to create the images from which they're instantiated, and those images are typically much, _much_ smaller than for VMs. For this reason, they take up very little memory and can be spun up and spun down very, very quickly. Having a container that sits around for just a few minutes or even seconds (OK, milliseconds, if you like) is an entirely sensible and feasible idea. For VMs, not so much.
|
||||
|
||||
Given that containers are so lightweight and easy to replace, people are using them to create microservices—minimal components split out of an application that can be used by one or many other microservices to build into whatever you want. Given that you plan to put only what you need for a particular function or service within a container, you're now free to make it very small, which means that writing new ones and throwing away the old ones becomes very practicable. I'll follow up on this and some of the impacts this might have on security, and hence DevSecOps, in a future article.
|
||||
|
||||
Hopefully this has been a useful intro to containers, and you're motivated to learn more about DevSecOps. (And if you aren't, just pretend.)
|
||||
|
||||
* * *
|
||||
|
||||
* I think SecDevOps reads oddly, and DevOpsSec tends to get pluralized, and then you're on an entirely different topic.
|
||||
|
||||
** I should note that this isn't just with British audiences, who are reserved and don't like drawing attention to themselves. This also happens with Canadian and U.S. audiences who, well … are different in that regard.
|
||||
|
||||
*** I'm going to be talking about Linux containers. I'm aware there's history here, so it's worth noting. In case of pedantry.
|
||||
|
||||
**** I used **grep -ir container linux-4.9.2 | wc -l** in case you're interested.[*****][13]
|
||||
|
||||
***** To be fair, at a quick glance, a number of those uses have nothing to do with containers in the way we're discussing them as "Linux containers," but refer to abstractions, which can be said to contain other elements, and are, therefore, logically referred to as containers.
|
||||
|
||||
****** There are clever ways to combine VMs and containers to benefit from the strengths of each. I'm not going into those today.
|
||||
|
||||
_*******_Well, apart from the execution bit that we just covered, obviously.
|
||||
|
||||
_This article originally appeared on [Alice, Eve, and Bob—a security blog][7] and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Mike Bursell - I've been in and around Open Source since around 1997, and have been running (GNU) Linux as my main desktop at home and work since then: not always easy... I'm a security bod and architect, and am currently employed as Chief Security Architect for Red Hat. I have a blog - "Alice, Eve & Bob" - where I write (sometimes rather parenthetically) about security. I live in the UK and like single malts.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/what-are-containers
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://opensource.com/resources/what-are-linux-containers?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[2]:https://opensource.com/resources/what-docker?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[4]:https://developers.redhat.com/blog/2016/01/13/a-practical-introduction-to-docker-container-terminology/?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[5]:https://opensource.com/article/17/10/what-are-containers?rate=sPHuhiD4Z3D3vJ6ZqDT-wGp8wQjcQDv-iHf2OBG_oGQ
|
||||
[6]:https://opensource.com/article/17/10/what-are-containers#*******
|
||||
[7]:https://aliceevebob.wordpress.com/2017/07/04/but-i-dont-know-what-a-container-is/
|
||||
[8]:https://opensource.com/user/105961/feed
|
||||
[9]:https://opensource.com/article/17/10/what-are-containers#*
|
||||
[10]:https://opensource.com/article/17/10/what-are-containers#**
|
||||
[11]:https://opensource.com/article/17/10/what-are-containers#***
|
||||
[12]:https://opensource.com/article/17/10/what-are-containers#******
|
||||
[13]:https://opensource.com/article/17/10/what-are-containers#*****
|
||||
[14]:https://opensource.com/users/mikecamel
|
||||
[15]:https://opensource.com/users/mikecamel
|
||||
[16]:https://opensource.com/article/17/10/what-are-containers#****
|
||||
83
sources/tech/20171026 Why is Kubernetes so popular.md
Normal file
83
sources/tech/20171026 Why is Kubernetes so popular.md
Normal file
@ -0,0 +1,83 @@
|
||||
translating---geekpi
|
||||
|
||||
Why is Kubernetes so popular?
|
||||
============================================================
|
||||
|
||||
### The Google-developed container management system has quickly become one of the biggest success stories in open source history.
|
||||
|
||||

|
||||
Image credits : RIkki Endsley. [CC BY-SA 4.0][7]
|
||||
|
||||
[Kubernetes][8], an open source container management system, has surged in popularity in the past several years. Used by the largest enterprises in a wide range of industries for mission-critical tasks, it has become one of the biggest success stories in open source. How did that happen? And what is it about Kubernetes that explains its widespread adoption?
|
||||
|
||||
### Kubernetes' backstory: Origins in Google's Borg system
|
||||
|
||||
As the computing world became more distributed, more network-based, and more about cloud computing, we saw large, monolithic apps slowly transform into multiple, agile microservices. These microservices allowed users to individually scale key functions of an application and handle millions and millions of customers. On top of this paradigm change, we saw technologies like Docker containers emerge in the enterprise, creating a consistent, portable, and easy way for users to quickly build these microservices.
|
||||
|
||||
Linux Containers
|
||||
|
||||
* [What are Linux containers?][1]
|
||||
|
||||
* [What is Docker?][2]
|
||||
|
||||
* [What is Kubernetes?][3]
|
||||
|
||||
* [An introduction to container terminology][4]
|
||||
|
||||
While Docker continued to thrive, managing these microservices and containers became a paramount requirement. That's when Google, which had been running container-based infrastructure for many years, made the bold decision to open source an in-house project called [Borg][15]. The Borg system was key to running Google's services, such as Google Search and Gmail. This decision by Google to open source its infrastructure has created a way for any company in the world to run its infrastructure like one of the top companies in the world.
|
||||
|
||||
### One of the biggest open source communities
|
||||
|
||||
After its open source release, Kubernetes found itself competing with other container-management systems, namely Docker Swarm and Apache Mesos. One of the reasons Kubernetes surged past these other systems in recent months is the community and support behind the system: It's one of the largest open source communities (more than 27,000+ stars on GitHub); has contributions from thousands of organizations (1,409 contributors); and is housed within a large, neutral open source foundation, the [Cloud Native Computing Foundation][9] (CNCF).
|
||||
|
||||
The CNCF, which is also part of the larger Linux Foundation, has some of the top enterprise companies as members, including Microsoft, Google, and Amazon Web Services. Additionally, the ranks of enterprise members in CNCF continue to grow, with SAP and Oracle joining as Platinum members within the past couple of months. These companies joining the CNCF, where the Kubernetes project is front and center, is a testament to how much these enterprises are betting on the community to deliver a portion of their cloud strategy.
|
||||
|
||||
The enterprise community around Kubernetes has also surged, with vendors providing enterprise versions with added security, manageability, and support. Red Hat, CoreOS, and Platform 9 are some of the few that have made Enterprise Kubernetes offerings key to their strategy going forward and have invested heavily in ensuring the open source project continues to be maintained.
|
||||
|
||||
### Delivering the benefits of the hybrid cloud
|
||||
|
||||
Yet another reason why enterprises are adopting Kubernetes at such a breakneck pace is that Kubernetes can work in any cloud. With most enterprises sharing assets between their existing on-premises datacenters and the public cloud, the need for hybrid cloud technologies is critical.
|
||||
|
||||
Kubernetes can be deployed in a company's pre-existing datacenter on premises, in one of the many public cloud environments, and even run as a service. Because Kubernetes abstracts the underlying infrastructure layer, developers can focus on building applications, then deploy them to any of those environments. This helps accelerate a company's Kubernetes adoption, because it can run Kubernetes on-premises while continuing to build out its cloud strategy.
|
||||
|
||||
### Real-world use cases
|
||||
|
||||
Another reason Kubernetes continues to surge is that major corporations are using the technology to tackle some of the industry's largest challenges. Capital One, Pearson Education, and Ancestry.com are just a few of the companies that have published Kubernetes [use cases][10].
|
||||
|
||||
[Pokemon Go][11] is one of the most-popular publicized use cases showing the power of Kubernetes. Before its release, the online multiplayer game was expected to be reasonably popular. But as soon as it launched, it took off like a rocket, garnering 50 times the expected traffic. By using Kubernetes as the infrastructure overlay on top of Google Cloud, Pokemon Go could scale massively to keep up with the unexpected demand.
|
||||
|
||||
What started out as an open source project from Google—backed by 15 years of experience running Google services and a heritage from Google Borg—Kubernetes is now open source software that is part of a big foundation (CNCF) with many enterprise members. It continues to grow in popularity and is being widely used with mission-critical apps in finance, in massive multiplayer online games like Pokemon Go, and by educational companies and traditional enterprise IT. Considered together, all signs point to Kubernetes continuing to grow in popularity and remaining one of the biggest success stories in open source.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
Anurag Gupta - Anurag Gupta is a Product Manager at Treasure Data driving the development of the unified logging layer, Fluentd Enterprise. Anurag has worked on large data technologies including Azure Log Analytics, and enterprise IT services such as Microsoft System Center.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/why-kubernetes-so-popular
|
||||
|
||||
作者:[Anurag Gupta ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/anuraggupta
|
||||
[1]:https://opensource.com/resources/what-are-linux-containers?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[2]:https://opensource.com/resources/what-docker?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[4]:https://developers.redhat.com/blog/2016/01/13/a-practical-introduction-to-docker-container-terminology/?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[5]:https://opensource.com/article/17/10/why-kubernetes-so-popular?rate=LM949RNFmORuG0I79_mgyXiVXrdDqSxIQjOReJ9_SbE
|
||||
[6]:https://opensource.com/user/171186/feed
|
||||
[7]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[8]:https://kubernetes.io/
|
||||
[9]:https://www.cncf.io/
|
||||
[10]:https://kubernetes.io/case-studies/
|
||||
[11]:https://cloudplatform.googleblog.com/2016/09/bringing-Pokemon-GO-to-life-on-Google-Cloud.html
|
||||
[12]:https://opensource.com/users/anuraggupta
|
||||
[13]:https://opensource.com/users/anuraggupta
|
||||
[14]:https://opensource.com/article/17/10/why-kubernetes-so-popular#comments
|
||||
[15]:http://queue.acm.org/detail.cfm?id=2898444
|
||||
@ -1,287 +0,0 @@
|
||||
服务端 I/O 性能: Node , PHP , Java , Go 的对比
|
||||
============
|
||||
|
||||
了解应用程序的输入/输出(I / O)模型意味着处理其所受负载的应用程序之间的差异,以及遇到真实环境的例子。或许你的应用程序很小,承受不了很大的负载;但随着应用程序的流量负载增加,可能因为使用低效的 I / O 模型导致承受不了而崩溃。
|
||||
|
||||
和大多数情况一样,处理这种问题的方法是多种的,这不仅仅是一个择优的问题,而是理解权衡的问题。 接下来我们来看看 I / O 到底是什么。
|
||||
|
||||

|
||||
|
||||
在本文中,我们将对 Node,Java,Go 和 PHP 与 Apache 进行对比,讨论不同语言如何模拟其 I / O ,每个模型的优缺点,并总结一些基本的规律。如果您担心下一个 Web 应用程序的 I / O 性能,本文将给您最优的解答。
|
||||
|
||||
### I/O 基础知识: 快速复习
|
||||
|
||||
要了解 I / O 涉及的因素,我们首先在操作系统层面检查这些概念。虽然不可能直接处理这些概念,但您可以通过应用程序的运行时环境间接处理它们。细节很重要。
|
||||
|
||||
### 系统调用
|
||||
|
||||
首先是系统调用,我们的描述如下:
|
||||
|
||||
* 您的程序(在“用户本地”中)说,它们必须要求操作系统内核代表它执行 I / O 操作。
|
||||
|
||||
* “系统调用”是您的程序要求内核执行某些操作的方法。这些实现的细节在操作系统之间有所不同,但基本概念是相同的。将有一些具体的指令将控制从您的程序转移到内核(如函数调用,但是使用专门用于处理这种情况的专用调剂)。一般来说,系统调用会阻塞,这意味着你的程序会等待内核返回你的代码。
|
||||
|
||||
* 内核在有问题的物理设备( 磁盘,网卡等 )上执行底层的I / O 操作,并回复系统调用。在现实世界中,内核可能需要做许多事情来满足您的要求,包括等待设备准备就绪,更新其内部状态等,但作为应用程序开发人员,您不在乎这些。这是内核该做的工作。
|
||||
|
||||

|
||||
|
||||
### 阻塞与非阻塞
|
||||
|
||||
现在,我刚刚在上面说过,系统调用是阻塞的,一般来说是这样。然而,一些调用被分为“非阻塞”,这意味着内核会接收您的请求,将其放在某个地方的队列或缓冲区中,然后立即返回而不等待实际的 I / O 发生。所以它只是在很短的时间内“阻挡”,只需要排队你的请求。
|
||||
|
||||
一些例子(Linux系统调用)可能有助于理解: - `read()` 是一个阻塞调用 - 你传递一个句柄,指出哪个文件和缓冲区在哪里传送它读取的数据,当数据在那里时,该调用返回。这具有简单的优点。- `epoll_create()`, `epoll_ctl()` 和 `epoll_wait()` 是分别调用的,您可以创建一组句柄来侦听,添加/删除该组中的处理程序,然后阻止直到有任何活动。这允许您通过单个线程有效地控制大量的 I / O 操作。
|
||||
|
||||
了解这里的时间差异的数量级是很重要的。如果 CPU 内核运行在 3GHz,而不用进行 CPU 优化,那么它每秒执行 30 亿次周期(或每纳秒 3 个周期)。非阻塞系统调用可能需要 10 秒的周期来完成或者 “相对较少的纳秒” 的时间完成。阻止通过网络接收信息的调用可能需要更长的时间 - 例如 200 毫秒(1/5秒)。比方说,非阻塞电话需要 20 纳秒,阻塞电话就需要 2 亿个纳秒。您的进程只是等待了 1000 万次的阻塞调用。
|
||||
|
||||

|
||||
内核提供了阻塞 I / O (“从此网络连接读取并给出数据”)和非阻塞 I / O (“告知我何时这些网络连接具有新数据”)的方法。使用哪种机制将阻止调用过程显示不同的时间长度。
|
||||
|
||||
### 调度
|
||||
|
||||
关键的第三件事是当你有很多线程或进程开始阻止时会发生什么。
|
||||
|
||||
根据我们的理解,线程和进程之间没有很大的区别。在现实生活中,最显著的性能相关差异在于,由于线程共享相同的内存,而进程每个都有自己的内存空间,使得单独的进程往往占用更多的内存。但是当我们谈论调度时,它真正归结为一系列事情(线程和进程),每个都需要在可用的 CPU 内核上获得一段执行时间。如果您有 300 个线程运行在 8 个内核上,则必须将时间分成几个,以便每个内核获取其共享,每个内核运行一段时间,然后移动到下一个线程。这是通过 “上下文切换” 完成的,使 CPU 从一个线程/进程运行到下一个。
|
||||
|
||||
这些上下文切换具有与它们相关联的成本 - 它们需要一些时间。在一些快速的情况下,它可能小于 100 纳秒,但根据实际情况,处理器速度/体系结构,CPU缓存等,采取 1000 纳秒或更长时间并不常见。
|
||||
|
||||
而更多的线程(或进程),更多的上下文切换。当我们谈论数以千计的线程时,每个线程数百纳秒,事情就会变得很慢。
|
||||
|
||||
然而,非阻塞调用告诉内核“只有在这些连接中有一些新的数据或事件时才会给我”。这些非阻塞调用旨在有效地处理大量 I / O 负载并减少上下文交换。
|
||||
|
||||
到目前为止,我们现在看有趣的部分:我们来看看一些流行的语言使用,并得出关于易用性和性能与其他有趣的事情之间的权衡的结论。
|
||||
|
||||
声明,本文中显示的示例是微不足道的(部分的,只显示相关的信息); 数据库访问,外部缓存系统( memcache 等等)和任何需要 I / O 的东西都将执行某种类型的 I / O 调用,这将与所示的简单示例具有相同的效果。此外,对于将 I / O 描述为“阻塞”( PHP,Java )的情况,HTTP 请求和响应读取和写入本身就是阻止调用:系统中隐藏更多 I / O 及其伴随考虑到的性能问题。
|
||||
|
||||
选择一个项目的编程语言有很多因素。当你只考虑效率时,还有很多其它的因素。但是,如果您担心您的程序将主要受到 I/O 的限制,如果 I/O 性能是对项目的成败,那么这些是您需要了解的。## “保持简单”方法:PHP
|
||||
|
||||
早在90年代,很多人都穿着 [Converse][1] 鞋,并在 Perl 中编写了 CGI 脚本。然后 PHP 来了,就像一些人喜欢涂抹一样,它使得动态网页更容易。
|
||||
|
||||
PHP使用的模型相当简单。有一些变化,但您的平均 PHP 服务器来看:
|
||||
|
||||
HTTP请求来自用户的浏览器,并且访问您的 Apache Web 服务器。 Apache 为每个请求创建一个单独的进程,通过一些优化来重新使用它们,以最大限度地减少它需要执行的次数( 相对而言,创建进程较慢 )。Apache 调用 PHP 并告诉它 `.php` 在磁盘上运行相应的文件。PHP 代码执行并阻止 I / O 调用。你调用 `file_get_contents()` , PHP 并在引擎盖下使 read() 系统调用并等待结果。
|
||||
|
||||
当然,实际的代码只是直接嵌入你的页面,并且操作被阻止:
|
||||
|
||||
```
|
||||
<?php
|
||||
|
||||
// blocking file I/O
|
||||
$file_data = file_get_contents(‘/path/to/file.dat’);
|
||||
|
||||
// blocking network I/O
|
||||
$curl = curl_init('http://example.com/example-microservice');
|
||||
$result = curl_exec($curl);
|
||||
|
||||
// some more blocking network I/O
|
||||
$result = $db->query('SELECT id, data FROM examples ORDER BY id DESC limit 100');
|
||||
|
||||
?>
|
||||
|
||||
```
|
||||
|
||||
关于如何与系统集成,就像这样:
|
||||
|
||||

|
||||
|
||||
很简单:每个请求一个进程。 I / O 只是阻塞。优点是简单,缺点是,同时与20,000个客户端连接,您的服务器将会崩溃。这种方法不能很好地扩展,因为内核提供的用于处理大容量 I / O (epoll等) 的工具没有被使用。 为了增加人数,为每个请求运行一个单独的过程往往会使用大量的系统资源,特别是内存,这通常是您在这样一个场景中遇到的第一件事情。
|
||||
|
||||
_注意: Ruby使用的方法与PHP非常相似,在广泛而普遍的手工波浪方式下,它们可以被认为是相同的。_
|
||||
|
||||
### 多线程方法: Java
|
||||
|
||||
所以 Java 来了,就是你购买你的第一个域名的时候,在一个句子后随机说出 “dot com” 很酷。而 Java 具有内置于该语言中的多线程(特别是在创建时)非常棒。
|
||||
|
||||
大多数 Java Web 服务器通过为每个请求启动一个新的执行线程,然后在该线程中最终调用您作为应用程序开发人员编写的函数。
|
||||
|
||||
在 Java Servlet 中执行 I / O 往往看起来像:
|
||||
|
||||
```
|
||||
public void doGet(HttpServletRequest request,
|
||||
HttpServletResponse response) throws ServletException, IOException
|
||||
{
|
||||
|
||||
// blocking file I/O
|
||||
InputStream fileIs = new FileInputStream("/path/to/file");
|
||||
|
||||
// blocking network I/O
|
||||
URLConnection urlConnection = (new URL("http://example.com/example-microservice")).openConnection();
|
||||
InputStream netIs = urlConnection.getInputStream();
|
||||
|
||||
// some more blocking network I/O
|
||||
out.println("...");
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
由于我们 `doGet` 上面的方法对应于一个请求并且在其自己的线程中运行,而不是需要自己内存每个请求单独进程,我们有一个单独的线程。这样有一些好的优点,就像能够在线程之间共享状态,缓存的数据等,因为它们可以访问对方的内存,但是它与调度的交互影响与 PHP 中的内容几乎相同以前的例子。每个请求获得一个新线程和该线程内的各种 I / O 操作块,直到请求被完全处理为止。线程被汇集以最小化创建和销毁它们的成本,但是仍然有数千个连接意味着数千个线程,这对调度程序是不利的。
|
||||
|
||||
重要的里程碑中,在1.4版本的Java(和 1.7 中的重要升级)中,获得了执行非阻塞 I / O 调用的能力。大多数应用程序,网络和其他,不使用它,但至少它是可用的。一些 Java Web 服务器尝试以各种方式利用这一点; 然而,绝大多数部署的 Java 应用程序仍然如上所述工作。
|
||||
|
||||

|
||||
|
||||
Java 让我们更接近,肯定有一些很好的开箱即用的 I / O 功能,但它仍然没有真正解决当你有一个大量的 I / O 绑定的应用程序被捣毁时会发生什么的问题,有数千个阻塞线程?。
|
||||
|
||||
<form action="https://www.toptal.com/blog/subscription" class="embeddable_form" data-entity="blog_subscription" data-remote="" data-view="form#form" method="post" style="border: 0px; vertical-align: baseline; min-height: 0px; min-width: 0px;">喜欢你正在阅读什么?首先获取最新的更新。Like what you're reading?Get the latest updates first.<input autocomplete="off" class="input is-medium" data-role="email" name="blog_subscription[email]" placeholder="Enter your email address..." type="text" style="-webkit-appearance: none; background: rgb(250, 250, 250); border-radius: 4px; border-width: 1px; border-style: solid; border-color: rgb(238, 238, 238); color: rgb(60, 60, 60); font-family: proxima-nova, Arial, sans-serif; font-size: 14px; padding: 15px 12px; transition: all 0.2s; width: 799.36px;"><input class="button is-green_candy is-default is-full_width" data-loader-text="Subscribing..." data-role="submit" type="submit" value="Get Exclusive Updates" style="-webkit-appearance: none; font-weight: 600; border-radius: 4px; transition: background 150ms; background: linear-gradient(rgb(67, 198, 146), rgb(57, 184, 133)); border-width: 1px; border-style: solid; border-color: rgb(31, 124, 87); box-shadow: rgb(79, 211, 170) 0px 1px inset; color: rgb(255, 255, 255); position: relative; text-shadow: rgb(28, 143, 61) 0px 1px 0px; font-size: 14px; padding: 15px 20px; width: 549.32px;">没有垃圾邮件。只是伟大的工程职位。</form>
|
||||
|
||||
### 无阻塞 I / O 作为一流公民: Node
|
||||
|
||||
操作块更好的 I / O 是 Node.js. 曾经对 Node 的最简单的介绍的人都被告知这是“非阻塞”,它有效地处理 I / O。这在一般意义上是正确的。但魔鬼的细节和这个巫术的实现手段在涉及演出时是重要的。
|
||||
|
||||
Node实现的范例基本上不是说 “在这里写代码来处理请求”,而是说 “在这里编写代码来开始处理请求”。每次你需要做一些涉及到 I / O ,您提出请求并给出一个回调函数,Node 将在完成之后调用该函数。
|
||||
|
||||
在请求中执行 I / O 操作的典型节点代码如下所示:
|
||||
|
||||
```
|
||||
http.createServer(function(request, response) {
|
||||
fs.readFile('/path/to/file', 'utf8', function(err, data) {
|
||||
response.end(data);
|
||||
});
|
||||
});
|
||||
|
||||
```
|
||||
|
||||
你可以看到,这里有两个回调函数。当请求开始时,第一个被调用,当文件数据可用时,第二个被调用。
|
||||
|
||||
这样做的基本原理是让 Node 有机会有效地处理这些回调之间的 I / O 。在 Node 中进行数据库调用的方式更为相关,但是我不会在这个例子中啰嗦,因为它是完全相同的原则:启动数据库调用,并给 Node 一个回调函数使用非阻塞调用单独执行 I / O 操作,然后在您要求的数据可用时调用回调函数。排队 I / O 调用和让 Node 处理它然后获取回调的机制称为“事件循环”。它的工作原理很好。
|
||||
|
||||

|
||||
|
||||
然而,这个模型的要点是在引擎盖下,其原因有很多更多的是如何在 V8 JavaScript 引擎(即使用节点 Chrome 浏览器的 JS 引擎)实现 [<sup style="border: 0px; vertical-align: super; min-height: 0px; min-width: 0px;">1</sup>][2] 比什么都重要。您编写的所有 JS 代码都运行在单个线程中。想一会儿 这意味着当使用高效的非阻塞技术执行 I / O 时,您的 JS 可以在单个线程中运行 CPU 绑定操作,每个代码块阻止下一个。可能出现这种情况的一个常见例子是在数据库记录之前循环,以某种方式处理它们,然后再将其输出到客户端。这是一个示例,显示如何工作:
|
||||
|
||||
```
|
||||
var handler = function(request, response) {
|
||||
|
||||
connection.query('SELECT ...', function (err, rows) {
|
||||
|
||||
if (err) { throw err };
|
||||
|
||||
for (var i = 0; i < rows.length; i++) {
|
||||
// do processing on each row
|
||||
}
|
||||
|
||||
response.end(...); // write out the results
|
||||
|
||||
})
|
||||
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
虽然 Node 确实有效地处理了 I / O ,但是 `for` 上面的例子中的循环是在你的一个主线程中使用 CPU 周期。这意味着如果您有 10,000 个连接,则该循环可能会使您的整个应用程序进行爬网,具体取决于需要多长时间。每个请求必须在主线程中共享一段时间,一次一个。
|
||||
|
||||
这个整体概念的前提是 I / O 操作是最慢的部分,因此最重要的是要有效地处理这些操作,即使这意味着连续进行其他处理。这在某些情况下是正确的,但不是全部。
|
||||
|
||||
另一点是,虽然这只是一个意见,但是写一堆嵌套回调可能是相当令人讨厌的,有些则认为它使代码更难以遵循。看到回调在 Node 代码中嵌套甚至更多级别并不罕见。
|
||||
|
||||
我们再回到权衡。如果您的主要性能问题是 I / O,则 Node 模型工作正常。然而,它的跟腱是,您可以进入处理 HTTP 请求的功能,并放置 CPU 密集型代码,并将每个连接都抓取。
|
||||
|
||||
### 最自然的非阻塞: Go
|
||||
|
||||
在我进入Go部分之前,我应该披露我是一个Go的粉丝。我已经使用它为许多项目,我公开表示其生产力优势的支持者,我看到他们在我的工作中。
|
||||
|
||||
也就是说,我们来看看它如何处理 I / O 。Go 语言的一个关键特征是它包含自己的调度程序。而不是每个线程的执行对应于一个单一的 OS 线程,它的作用与 “goroutines” 的概念。而 Go 运行时可以将一个 goroutine 分配给一个 OS 线程,并使其执行或暂停它,并且它不与一个 OS 线程,基于 goroutine 正在做什么。来自 Go 的 HTTP 服务器的每个请求都在单独的 Goroutine 中处理。
|
||||
|
||||
调度程序的工作原理如图所示:
|
||||
|
||||

|
||||
|
||||
在引擎下,通过 Go 执行程序中的各个点实现的,通过使当前的 goroutine 进入睡眠状态,通过将请求写入/读取/连接等来实现 I / O 调用,通过将信息唤醒回来可采取进一步行动。
|
||||
|
||||
实际上,Go 运行时正在做一些与 Node 正在做的不太相似的事情,除了回调机制内置到 I / O 调用的实现中,并自动与调度程序交互。它也不会受到必须让所有处理程序代码在同一个线程中运行的限制,Go 将根据其调度程序中的逻辑自动将 Goroutines 映射到其认为适当的 OS 线程。结果是这样的代码:
|
||||
|
||||
```
|
||||
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
|
||||
|
||||
// the underlying network call here is non-blocking
|
||||
rows, err := db.Query("SELECT ...")
|
||||
|
||||
for _, row := range rows {
|
||||
// do something with the rows,
|
||||
// each request in its own goroutine
|
||||
}
|
||||
|
||||
w.Write(...) // write the response, also non-blocking
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
如上所述,我们正在做的类似于更简单的方法的基本代码结构,并且在引擎下实现了非阻塞 I / O。
|
||||
|
||||
在大多数情况下,最终都是“两个世界最好的”。非阻塞 I / O 用于所有重要的事情,但是您的代码看起来像是阻塞,因此更容易理解和维护。Go 调度程序和OS调度程序之间的交互处理其余部分。这不是完整的魔法,如果你建立一个大型系统,那么值得我们来看看有关它的工作原理的更多细节; 但与此同时,您获得的“开箱即用”的环境可以很好地工作和扩展。
|
||||
|
||||
Go 可能有其缺点,但一般来说,它处理 I / O 的方式不在其中。
|
||||
|
||||
### 谎言,可恶的谎言和基准
|
||||
|
||||
对这些各种模式的上下文切换进行准确的定时是很困难的。我也可以认为这对你来说不太有用。相反,我会给出一些比较这些服务器环境的 HTTP 服务器性能的基本基准。请记住,整个端到端 HTTP 请求/响应路径的性能有很多因素,这里提供的数字只是我将一些样本放在一起进行基本比较。
|
||||
|
||||
对于这些环境中的每一个,我写了适当的代码以随机字节读取 64k 文件,在其上运行了一个 SHA-256 哈希 N 次( N 在 URL 的查询字符串中指定,例如 .../test.php?n=100),并打印出结果十六进制散列 我选择了这一点,因为使用一些一致的 I / O 和受控的方式来运行相同的基准测试是一个非常简单的方法来增加 CPU 使用率。
|
||||
|
||||
有关使用的环境的更多细节,请参阅 [基准笔记][3] 。
|
||||
|
||||
首先,我们来看一些低并发的例子。运行 2000 次迭代,具有 300 个并发请求,每个请求只有一个散列(N = 1)给我们这样:
|
||||
|
||||

|
||||
|
||||
时间是在所有并发请求中完成请求的平均毫秒数。低于更好。
|
||||
|
||||
很难从这个图中得出结论,但是对我来说,似乎在这个连接和计算量上,我们看到时间更多地与语言本身的一般执行有关,这样更多的是 I / O。请注意,被认为是“脚本语言”(松散类型,动态解释)的语言执行速度最慢。
|
||||
|
||||
但是,如果我们将 N 增加到 1000,仍然有 300 个并发请求,则会发生相同的负载,但是更多的哈希迭代是 100 倍(显着增加了 CPU 负载):
|
||||
|
||||

|
||||
|
||||
时间是在所有并发请求中完成请求的平均毫秒数。低于更好。
|
||||
|
||||
突然间,节点性能显着下降,因为每个请求中的 CPU 密集型操作都相互阻塞。有趣的是,在这个测试中,PHP 的性能要好得多(相对于其他的),并且打败了 Java。(值得注意的是,在 PHP 中,SHA-256 实现是用 C 编写的,执行路径在这个循环中花费更多的时间,因为现在我们正在进行 1000 个哈希迭代)。
|
||||
|
||||
现在让我们尝试 5000 个并发连接(N = 1) - 或者接近我可以来的连接。不幸的是,对于大多数这些环境,故障率并不显着。对于这个图表,我们来看每秒的请求总数。 _越高越好_ :
|
||||
|
||||

|
||||
|
||||
每秒请求总数。越高越好。
|
||||
|
||||
而且这张照片看起来有很大的不同 这是一个猜测,但是看起来像在高连接量时,产生新进程所涉及的每连接开销以及与 PHP + Apache 相关联的附加内存似乎成为主要因素,并阻止了 PHP 的性能。显然,Go 是这里的赢家,其次是 Java,Node 和 PHP。
|
||||
|
||||
虽然与您的整体吞吐量相关的因素很多,并且在应用程序之间也有很大的差异,但是您了解更多关于发生什么的事情以及所涉及的权衡,您将会越有效。
|
||||
|
||||
### 总结
|
||||
|
||||
以上所有这一切,很显然,随着语言的发展,处理大量 I / O 的大型应用程序的解决方案也随之发展。
|
||||
|
||||
为了公平起见,PHP 和 Java,尽管这篇文章中的描述,确实有 [实现][4] [ 非阻塞I / O][5] 和 [可使用][6] [ web 应用程序][7] 。但是这些方法并不像上述方法那么常见,并且需要考虑使用这种方法来维护服务器的随之而来的操作开销。更不用说您的代码必须以与这些环境相适应的方式进行结构化; 您的 “正常” PHP 或 Java Web 应用程序通常不会在这样的环境中进行重大修改。
|
||||
|
||||
作为比较,如果我们考虑影响性能和易用性的几个重要因素,我们得出以下结论:
|
||||
|
||||
| 语言 | 线程与进程 | 非阻塞 I/O | 使用便捷性 |
|
||||
| --- | --- | --- | --- |
|
||||
| PHP | 进程 | No | |
|
||||
| Java | 线程 | Available | 需要回调 |
|
||||
| Node.js | 线程 | Yes | 需要回调 |
|
||||
| Go | 线程 (Goroutines) | Yes | 不需要回调 |
|
||||
|
||||
线程通常要比进程更高的内存效率,因为它们共享相同的内存空间,而进程没有进程。结合与非阻塞 I / O 相关的因素,我们可以看到,至少考虑到上述因素,当我们向下移动列表时,与 I / O 相关的一般设置得到改善。所以如果我不得不在上面的比赛中选择一个赢家,那肯定会是 Go。
|
||||
|
||||
即使如此,在实践中,选择构建应用程序的环境与您的团队对所述环境的熟悉程度以及您可以实现的总体生产力密切相关。因此,每个团队只需潜入并开始在 Node 或 Go 中开发 Web 应用程序和服务可能就没有意义。事实上,寻找开发人员或您内部团队的熟悉度通常被认为是不使用不同语言和/或环境的主要原因。也就是说,过去十五年来,时代已经发生了变化。
|
||||
|
||||
希望以上内容可以帮助您更清楚地了解引擎下发生的情况,并为您提供如何处理应用程序的现实可扩展性的一些想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.toptal.com/back-end/server-side-io-performance-node-php-java-go
|
||||
|
||||
作者:[ BRAD PEABODY][a]
|
||||
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.toptal.com/resume/brad-peabody
|
||||
[1]:https://www.pinterest.com/pin/414401603185852181/
|
||||
[2]:http://www.journaldev.com/7462/node-js-architecture-single-threaded-event-loop
|
||||
[3]:https://peabody.io/post/server-env-benchmarks/
|
||||
[4]:http://reactphp.org/
|
||||
[5]:http://amphp.org/
|
||||
[6]:http://undertow.io/
|
||||
[7]:https://netty.io/
|
||||
349
translated/tech/20171008 8 best languages to blog about.md
Normal file
349
translated/tech/20171008 8 best languages to blog about.md
Normal file
@ -0,0 +1,349 @@
|
||||
博客中最好的 8 种语言
|
||||
============================================================
|
||||
|
||||
|
||||
长文示警:这篇文章我们将对一些各种各样的博客的流行度相对于他们在谷歌上的排名进行一个分析。所有代码可以在 [github][38] 上找到.
|
||||
|
||||
### 想法来源
|
||||
|
||||
我一直在想,各种各样的博客每天到底都有多少页面浏览量,以及在博客阅读中最受欢迎的是什么编程语言。我也很感兴趣的是,它们在谷歌的网站排名是否与它们的受欢迎程度直接相关。
|
||||
|
||||
为了回答这些问题,我决定做一个 Scrapy 项目,它将收集一些数据,然后对所获得的信息执行特定的数据分析和数据可视化。
|
||||
|
||||
### 第一部分:Scrapy
|
||||
|
||||
我们将使用 [Scrapy][39] 为我们的工作,因为它为抓取和管理处理请求的反馈提供了干净和健壮的框架。我们还将使用 [Splash][40] 来解析需要处理的 Javascript 页面。Splash 使用自己的 Web 服务器充当代理,并处理 Javascript 响应,然后再将其重定向到我们的爬虫进程。
|
||||
|
||||
我这里没有描述 Scrapy 的设置,也没有描述 Splash 的集成。你可以在[这里][34]找到 Scrapy 的示例,而[这里][35]还有 Scrapy+Splash 指南。
|
||||
|
||||
#### 获得相关的博客
|
||||
|
||||
第一步显然是获取数据。我们需要谷歌关于编程博客的搜索结果。你看,如果我们开始仅仅用谷歌自己来搜索,比如说查询 “Python”,除了博客,我们还会得到很多其他的东西。我们需要的是做一些过滤,只留下特定的博客。幸运的是,有一种叫做 [Google 自定义搜索引擎][41]的东西,它能做到这一点。还有一个网站 [www.blogsearchengine.org][42],它可以执行我们需要的东西,将用户请求委托给 CSE,这样我们就可以查看它的查询并重复它们。
|
||||
|
||||
所以,我们要做的是到 [www.blogsearchengine.org][43] 网站,搜索 “python”,在网络标签页旁边将打开一个Chrome开发者工具。这截图是我们将要看到的。
|
||||
|
||||

|
||||
|
||||
突出显示的搜索请求是博客搜索引擎向谷歌委派的,所以我们将复制它并在我们的 scraper 中使用。
|
||||
|
||||
这个博客抓取爬行器类会是如下这样的:
|
||||
|
||||
```
|
||||
class BlogsSpider(scrapy.Spider):
|
||||
name = 'blogs'
|
||||
allowed_domains = ['cse.google.com']
|
||||
|
||||
def __init__(self, queries):
|
||||
super(BlogsSpider, self).__init__()
|
||||
self.queries = queries
|
||||
```
|
||||
|
||||
[view raw][3] [blogs.py][4] 代码托管于
|
||||
|
||||
[GitHub][5]
|
||||
|
||||
与典型的 Scrapy 爬虫不同,我们的方法覆盖了 `__init__` 方法,它接受额外的参数 `queries`,它指定了我们想要执行的查询列表。
|
||||
|
||||
现在,最重要的部分是构建和执行这个实际的查询。这个过程是在执行 `start_requests` 爬虫的方法,我们愉快地覆盖下来:
|
||||
|
||||
```
|
||||
def start_requests(self):
|
||||
params_dict = {
|
||||
'cx': ['partner-pub-9634067433254658:5laonibews6'],
|
||||
'cof': ['FORID:10'],
|
||||
'ie': ['ISO-8859-1'],
|
||||
'q': ['query'],
|
||||
'sa.x': ['0'],
|
||||
'sa.y': ['0'],
|
||||
'sa': ['Search'],
|
||||
'ad': ['n9'],
|
||||
'num': ['10'],
|
||||
'rurl': [
|
||||
'http://www.blogsearchengine.org/search.html?cx=partner-pub'
|
||||
'-9634067433254658%3A5laonibews6&cof=FORID%3A10&ie=ISO-8859-1&'
|
||||
'q=query&sa.x=0&sa.y=0&sa=Search'
|
||||
],
|
||||
'siteurl': ['http://www.blogsearchengine.org/']
|
||||
}
|
||||
|
||||
params = urllib.parse.urlencode(params_dict, doseq=True)
|
||||
url_template = urllib.parse.urlunparse(
|
||||
['https', self.allowed_domains[0], '/cse',
|
||||
'', params, 'gsc.tab=0&gsc.q=query&gsc.page=page_num'])
|
||||
for query in self.queries:
|
||||
for page_num in range(1, 11):
|
||||
url = url_template.replace('query', urllib.parse.quote(query))
|
||||
url = url.replace('page_num', str(page_num))
|
||||
yield SplashRequest(url, self.parse, endpoint='render.html',
|
||||
args={'wait': 0.5})
|
||||
```
|
||||
|
||||
[view raw][6] [blogs.py][7] 代码托管于
|
||||
|
||||
[GitHub][8]
|
||||
|
||||
在这里你可以看到相当复杂的 `params_dict` 字典持有所有我们之前找到的 Google CSE URL 的参数。然后我们准备 `url_template` 一切,除了已经填好的查询和页码。我们对每种编程语言请求10页,每一页包含10个链接,所以是每种语言有100个不同的博客用来分析。
|
||||
|
||||
在 `42-43` 行,我使用一个特殊的类 `SplashRequest` 来代替 Scrapy 自带的 Request 类。它可以抓取 Splash 库中的重定向逻辑,所以我们无需为此担心。十分整洁。
|
||||
|
||||
最后,这是解析程序:
|
||||
|
||||
```
|
||||
def parse(self, response):
|
||||
urls = response.css('div.gs-title.gsc-table-cell-thumbnail') \
|
||||
.xpath('./a/@href').extract()
|
||||
gsc_fragment = urllib.parse.urlparse(response.url).fragment
|
||||
fragment_dict = urllib.parse.parse_qs(gsc_fragment)
|
||||
page_num = int(fragment_dict['gsc.page'][0])
|
||||
query = fragment_dict['gsc.q'][0]
|
||||
page_size = len(urls)
|
||||
for i, url in enumerate(urls):
|
||||
parsed_url = urllib.parse.urlparse(url)
|
||||
rank = (page_num - 1) * page_size + i
|
||||
yield {
|
||||
'rank': rank,
|
||||
'url': parsed_url.netloc,
|
||||
'query': query
|
||||
}
|
||||
```
|
||||
|
||||
[view raw][9] [blogs.py][10] 代码托管于
|
||||
|
||||
[GitHub][11]
|
||||
|
||||
所有 scraper 的心脏和灵魂就是解析器的逻辑。可以有多种方法来理解响应页面结构和构建 XPath 查询字符串。您可以使用 [Scrapy shell][44] 尝试和调整你的 XPath 查询在没有运行爬虫的 fly 上。不过我更喜欢可视化的方法。它再次涉及到谷歌 Chrome 的开发人员控制台。只需右键单击你想要用在你的爬虫里的元素,然后按下 Inspect。控制台将定位到你指定位置的 HTML 代码。在本例中,我们想要得到实际的搜索结果链接。他们的源位置是这样的:
|
||||
|
||||

|
||||
|
||||
在查看这个元素的描述后我们看到所找到的 `<div>` 有一个 `.gsc-table-cell-thumbnail` 类,它是 `.gs-title` 的子类,所以我们把它放到响应对象的 `css` 方法(`46` 行)。然后,我们只需要得到博客文章的 URL。它很容易通过`'./a/@href'` XPath 字符串来获得,它能从我们的 `<div>` 子类中将 `href` 属性的标签找到。
|
||||
|
||||
#### 发现流量数据
|
||||
|
||||
下一个任务是估测每个博客每天接收到的查看 数量。有[各种各样的选择][45],可以获得免费和付费的数据。在快速搜索之后,我决定坚持使用这个简单且免费的网站 [www.statshow.com][46]。我们在前一步获得的博客的 URL 将用作这个网站的爬虫,通过它们并添加流量信息。爬虫的初始化是这样的:
|
||||
|
||||
```
|
||||
class TrafficSpider(scrapy.Spider):
|
||||
name = 'traffic'
|
||||
allowed_domains = ['www.statshow.com']
|
||||
|
||||
def __init__(self, blogs_data):
|
||||
super(TrafficSpider, self).__init__()
|
||||
self.blogs_data = blogs_data
|
||||
```
|
||||
|
||||
[view raw][12][traffic.py][13] 代码托管于
|
||||
|
||||
[GitHub][14]
|
||||
|
||||
`blogs_data` 将被格式化为词典的列表项:`{"rank": 70, "url": "www.stat.washington.edu", "query": "Python"}`.
|
||||
|
||||
请求构建函数如下:
|
||||
|
||||
```
|
||||
def start_requests(self):
|
||||
url_template = urllib.parse.urlunparse(
|
||||
['http', self.allowed_domains[0], '/www/{path}', '', '', ''])
|
||||
for blog in self.blogs_data:
|
||||
url = url_template.format(path=blog['url'])
|
||||
request = SplashRequest(url, endpoint='render.html',
|
||||
args={'wait': 0.5}, meta={'blog': blog})
|
||||
yield request
|
||||
```
|
||||
|
||||
[view raw][15][traffic.py][16] 代码托管于
|
||||
|
||||
[GitHub][17]
|
||||
|
||||
它相当的简单,我们只是添加了字符串 `/www/web-site-url/` 到 `'www.statshow.com'` URL 中。
|
||||
|
||||
现在让我们看一下语法解析器是什么样子的:
|
||||
|
||||
```
|
||||
def parse(self, response):
|
||||
site_data = response.xpath('//div[@id="box_1"]/span/text()').extract()
|
||||
views_data = list(filter(lambda r: '$' not in r, site_data))
|
||||
if views_data:
|
||||
blog_data = response.meta.get('blog')
|
||||
traffic_data = {
|
||||
'daily_page_views': int(views_data[0].translate({ord(','): None})),
|
||||
'daily_visitors': int(views_data[1].translate({ord(','): None}))
|
||||
}
|
||||
blog_data.update(traffic_data)
|
||||
yield blog_data
|
||||
```
|
||||
|
||||
[view raw][18][traffic.py][19] 代码托管于
|
||||
|
||||
[GitHub][20]
|
||||
|
||||
与博客解析程序类似,我们只是通过 StatShow 示例的返回页面,并跟踪包含每日页面查看 和每日访问者的元素。这两个参数都确定了网站的受欢迎程度,所以我们只需要为我们的分析选择页面查看 。
|
||||
|
||||
### 第二部分:分析
|
||||
|
||||
这部分是分析我们搜集到的所有数据。然后,我们用名为 [Bokeh][47] 的库来可视化准备好的数据集。我在这里没有给出其他的可视化代码,但是它可以在 [GitHub repo][48] 中找到,包括你在这篇文章中看到的和其他一切东西。
|
||||
|
||||
最初的结果集含有少许偏离中心过大的数据,(如 google.com、linkedin.com、Oracle.com 等)。它们显然不应该被考虑。即使有些人有博客,他们也不是特定的语言。这就是为什么我们基于这个 [this StackOverflow answer][36] 中所建议的方法来过滤异常值。
|
||||
|
||||
#### 语言流行度比较
|
||||
|
||||
首先,让我们对所有的语言进行直接的比较,看看哪一种语言在前 100 个博客中有最多的浏览量。
|
||||
|
||||
这是能进行这个任务的函数:
|
||||
|
||||
```
|
||||
def get_languages_popularity(data):
|
||||
query_sorted_data = sorted(data, key=itemgetter('query'))
|
||||
result = {'languages': [], 'views': []}
|
||||
popularity = []
|
||||
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
|
||||
group = list(group)
|
||||
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
|
||||
total_page_views = sum(daily_page_views)
|
||||
popularity.append((group[0]['query'], total_page_views))
|
||||
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
|
||||
languages, views = zip(*sorted_popularity)
|
||||
result['languages'] = languages
|
||||
result['views'] = views
|
||||
return result
|
||||
|
||||
```
|
||||
|
||||
[view raw][21][analysis.py][22] 代码托管于
|
||||
|
||||
[GitHub][23]
|
||||
|
||||
在这里,我们首先使用语言(词典中的关键字“query”)来分组我们的数据,然后使用 python 的 `groupby` 函数,这是一个从 SQL 中借来的奇妙函数,从我们的数据列表中生成一组条目,每个条目都表示一些编程语言。然后,在第 `14` 行我们计算的每一种语言的总页面查看 ,然后添加表单的元组`('Language', rank)`到 `popularity` 列表中。在循环之后,我们根据总查看 对流行数据进行排序,并将这些元组解压缩到两个单独的列表中,并在 `result` 变量中返回这些元组。
|
||||
|
||||
最初的数据集有很大的偏差。我检查了到底发生了什么,并意识到如果我在 [blogsearchengine.org][37] 上查询“C”,我就会得到很多无关的链接,其中包含了 “C” 的字母。因此,我必须将 C 排除在分析之外。它几乎不会在“R”和其他类似 C 的名称中出现:“C++”,“C”。
|
||||
|
||||
因此,如果我们将 C 从考虑中移除并查看其他语言,我们可以看到如下图:
|
||||
|
||||

|
||||
|
||||
据评估。Java 每天有超过 400 万的浏览量,PHP 和 Go 有超过 200 万,R 和 JavaScript 也突破了百万大关。
|
||||
|
||||
#### 每日网页浏览量与谷歌排名
|
||||
|
||||
现在让我们来看看每日访问量的数量和谷歌的博客排名之间的联系。从逻辑上来说,不那么受欢迎的博客应该排名靠后,但这并不容易,因为其他因素也会影响排名,例如,如果在人气较低的博客上的文章是最近的,那么它很可能会首先出现。
|
||||
|
||||
数据准备工作以下列方式进行:
|
||||
|
||||
```
|
||||
def get_languages_popularity(data):
|
||||
query_sorted_data = sorted(data, key=itemgetter('query'))
|
||||
result = {'languages': [], 'views': []}
|
||||
popularity = []
|
||||
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
|
||||
group = list(group)
|
||||
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
|
||||
total_page_views = sum(daily_page_views)
|
||||
popularity.append((group[0]['query'], total_page_views))
|
||||
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
|
||||
languages, views = zip(*sorted_popularity)
|
||||
result['languages'] = languages
|
||||
result['views'] = views
|
||||
return result
|
||||
```
|
||||
|
||||
[view raw][24][analysis.py][25] 代码托管于
|
||||
|
||||
[GitHub][26]
|
||||
|
||||
该函数需要考虑接受爬到的数据和语言列表。我们对这些数据进行排序,就像我们对语言的受欢迎程度一样。后来,在类似的语言分组循环中,我们构建了 `(rank, views_number)` 元组(以1为基础)被转换为 2 个单独的列表。然后将这一对列表写入到生成的字典中。
|
||||
|
||||
前 8 位 GitHub 语言(除了 C)是如下这些:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
据评估。我们看到,[PCC (皮尔逊相关系数)][49]的所有图都远离 1/-1,这表示每日查看 与排名之间缺乏相关性。值得注意的是,在大多数图表(7/8)中,相关性是负的,这意味着排名的下降会导致查看的减少。
|
||||
|
||||
### 结论
|
||||
|
||||
因此,根据我们的分析,Java 是目前最流行的编程语言,其次是 PHP、Go、R 和 JavaScript。在谷歌的日常浏览和排名中,排名前 8 的语言都没有很强的相关性,所以即使你刚刚开始写博客,你也可以在搜索结果中获得很高的评价。不过,成为热门博客究竟需要什么,可以留待下次讨论。
|
||||
|
||||
这些结果是相当有偏差的,如果没有额外的分析,就不能过分的考虑这些结果。首先,在较长的一段时间内收集更多的流量信息,然后分析每日查看和排名的平均值(中值)值是一个好主意。也许我以后还会再回来讨论这个。
|
||||
|
||||
### 引用
|
||||
|
||||
1. Scraping:
|
||||
|
||||
2. [blog.scrapinghub.com: Handling Javascript In Scrapy With Splash][27]
|
||||
|
||||
3. [BlogSearchEngine.org][28]
|
||||
|
||||
4. [twingly.com: Twingly Real-Time Blog Search][29]
|
||||
|
||||
5. [searchblogspot.com: finding blogs on blogspot platform][30]
|
||||
|
||||
6. Traffic estimation:
|
||||
|
||||
7. [labnol.org: Find Out How Much Traffic a Website Gets][31]
|
||||
|
||||
8. [quora.com: What are the best free tools that estimate visitor traffic…][32]
|
||||
|
||||
9. [StatShow.com: The Stats Maker][33]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.databrawl.com/2017/10/08/blog-analysis/
|
||||
|
||||
作者:[Serge Mosin ][a]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.databrawl.com/author/svmosingmail-com/
|
||||
[1]:https://bokeh.pydata.org/
|
||||
[2]:https://bokeh.pydata.org/
|
||||
[3]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||
[4]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||
[5]:https://github.com/
|
||||
[6]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||
[7]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||
[8]:https://github.com/
|
||||
[9]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||
[10]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||
[11]:https://github.com/
|
||||
[12]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||
[13]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||
[14]:https://github.com/
|
||||
[15]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||
[16]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||
[17]:https://github.com/
|
||||
[18]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||
[19]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||
[20]:https://github.com/
|
||||
[21]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/analysis.py
|
||||
[22]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-analysis-py
|
||||
[23]:https://github.com/
|
||||
[24]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/analysis.py
|
||||
[25]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-analysis-py
|
||||
[26]:https://github.com/
|
||||
[27]:https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/
|
||||
[28]:http://www.blogsearchengine.org/
|
||||
[29]:https://www.twingly.com/
|
||||
[30]:http://www.searchblogspot.com/
|
||||
[31]:https://www.labnol.org/internet/find-website-traffic-hits/8008/
|
||||
[32]:https://www.quora.com/What-are-the-best-free-tools-that-estimate-visitor-traffic-for-a-given-page-on-a-particular-website-that-you-do-not-own-or-operate-3rd-party-sites
|
||||
[33]:http://www.statshow.com/
|
||||
[34]:https://docs.scrapy.org/en/latest/intro/tutorial.html
|
||||
[35]:https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/
|
||||
[36]:https://stackoverflow.com/a/16562028/1573766
|
||||
[37]:http://blogsearchengine.org/
|
||||
[38]:https://github.com/Databrawl/blog_analysis
|
||||
[39]:https://scrapy.org/
|
||||
[40]:https://github.com/scrapinghub/splash
|
||||
[41]:https://en.wikipedia.org/wiki/Google_Custom_Search
|
||||
[42]:http://www.blogsearchengine.org/
|
||||
[43]:http://www.blogsearchengine.org/
|
||||
[44]:https://doc.scrapy.org/en/latest/topics/shell.html
|
||||
[45]:https://www.labnol.org/internet/find-website-traffic-hits/8008/
|
||||
[46]:http://www.statshow.com/
|
||||
[47]:https://bokeh.pydata.org/en/latest/
|
||||
[48]:https://github.com/Databrawl/blog_analysis
|
||||
[49]:https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
|
||||
[50]:https://www.databrawl.com/author/svmosingmail-com/
|
||||
[51]:https://www.databrawl.com/2017/10/08/
|
||||
@ -0,0 +1,149 @@
|
||||
在 Apache Kafka 中通过 KSQL 分析 Twitter 数据入门
|
||||
============================================================
|
||||
|
||||
[KSQL][8] 是 Apache Kafka 中的开源的流式 SQL 引擎。它可以让你在 Kafka 主题(topics)上,使用一个简单的并且是交互式的SQL接口,很容易地做一些复杂的流处理。在这个短文中,我们将看到怎么去很容易地配置并运行在一个沙箱中去探索它,使用大家都喜欢的一个演示数据库源: Twitter。我们将去从 teewts 的行流中获取,通过使用 KSQL 中的条件去过滤它。去构建一个合计,如统计 tweets 每个用户每小时的数量。
|
||||
|
||||

|
||||
|
||||
首先, [抓取一个汇总平台的拷贝][9]。我使用的是 RPM 但是,如果你想去使用的话,你也可以使用 [tar, zip, etc][10] 。启动 Confluent:
|
||||
|
||||
`$ confluent start`
|
||||
|
||||
(如果你感兴趣,这是一个 [在Confluent CLI 上的快速教程][11] )
|
||||
|
||||
我们将使用 Kafka 连接去从 Twitter 上拖数据。 Twitter 连接器可以在 [on GitHub here][12]上找到。去安装它,像下面这样操作:
|
||||
|
||||
`# Clone the git repo
|
||||
cd /home/rmoff
|
||||
git clone https://github.com/jcustenborder/kafka-connect-twitter.git`
|
||||
|
||||
`# Compile the code
|
||||
cd kafka-connect-twitter
|
||||
mvn clean package`
|
||||
|
||||
从我们建立的 [连接器][13] 上建立连接, 你要去修改配置文件.自从我们使用 Confluent CLI, 真实的配置文件是 `etc/schema-registry/connect-avro-distributed.properties`, 因此去修改它并增加如下内容:
|
||||
|
||||
`plugin.path=/home/rmoff/kafka-connect-twitter/target/kafka-connect-twitter-0.2-SNAPSHOT.tar.gz`
|
||||
|
||||
重启动 Kafka 连接:
|
||||
`confluent stop connect
|
||||
confluent start connect`
|
||||
|
||||
一旦你安装了插件,你可以很容易地去配置它。你可以直接使用 Kafka Connect REST API ,或者创建你的配置文件,这就是我要在这里做的。如果你需要全部的方法查看 [Twitter to grab your API keys first][14]。
|
||||
|
||||
假设你写这些到 `/home/rmoff/twitter-source.json`,你可以现在运行:
|
||||
|
||||
`$ confluent load twitter_source -d /home/rmoff/twitter-source.json`
|
||||
|
||||
然后 tweets 从大家都喜欢的网络明星 [rick]-rolling in…开始
|
||||
|
||||
现在我们从 KSQL 开始 ! 马上去下载并构建它:
|
||||
|
||||
`cd /home/rmoff `
|
||||
`git clone https://github.com/confluentinc/ksql.git `
|
||||
`cd /home/rmoff/ksql `
|
||||
`mvn clean compile install -DskipTests`
|
||||
|
||||
构建完成后,让我们来运行它:
|
||||
|
||||
`./bin/ksql-cli local --bootstrap-server localhost:9092`
|
||||
|
||||
使用 KSQL, 我们可以让我们的数据保留在 Kafka 话题上并可以查询它。首先,我们需要去告诉 KSQL 主题上的数据模式(schema)是什么,一个 twitter 消息是一个真实的非常好的巨大的 JSON 对象, 但是,为了简洁,我们只好选出几个行去开始它:
|
||||
|
||||
`ksql> CREATE STREAM twitter_raw (CreatedAt BIGINT, Id BIGINT, Text VARCHAR) WITH (KAFKA_TOPIC='twitter_json_01', VALUE_FORMAT='JSON');`
|
||||
`Message `
|
||||
`----------------`
|
||||
`Stream created`
|
||||
|
||||
在定义的模式中,我们可以查询这些流。使用 KSQL 去展示从开始的主题中取得的数据 (而不是当前时间点,它是缺省的),运行:
|
||||
|
||||
`ksql> SET 'auto.offset.reset' = 'earliest'; `
|
||||
`Successfully changed local property 'auto.offset.reset' from 'null' to 'earliest'`
|
||||
|
||||
现在,让我们看看这些数据,我们将使用 LIMIT 从句仅检索一行:
|
||||
|
||||
现在,让我们使用刚才定义的可用的 tweet 负荷的全部内容重新定义流:
|
||||
|
||||
现在,我们可以操作和检查更多的最近的数据,使用一般的 SQL 查询:
|
||||
|
||||
注意这里没有 LIMIT 从句,因此,你将在屏幕上看到 _continuous query_ 的结果。不像关系表中返回一个确定数量结果的查询,一个运行在无限的流式数据上的持续查询, 因此,它总是可能返回更多的记录。点击 Ctrl-C 去中断燕返回到 KSQL 提示符。在以上的查询中我们做了一些事情:
|
||||
|
||||
* TIMESTAMPTOSTRING 去转换时间戳从 epoch 到人类可读格式。(译者注: epoch 指的是一个特定的时间 1970-01-01 00:00:00 UTC)
|
||||
|
||||
* EXTRACTJSONFIELD 去展示源中嵌套的用户域中的一个,它看起来像:
|
||||
|
||||
* 应用谓语去展示内容,对#(hashtag)使用模式匹配, 使用 LCASE 去强制小写字母。(译者注:hashtag,twitter中用来标注线索主题的标签)
|
||||
|
||||
关于支持的功能列表,查看 [the KSQL documentation][15]。
|
||||
|
||||
我们可以创建一个从这个数据中得到的流:
|
||||
|
||||
并且查询这个得到的流:
|
||||
|
||||
在我们完成之前,让我们去看一下怎么去做一些聚合。
|
||||
|
||||
你将可能得到满屏幕的结果;这是因为 KSQL 在每次给定的时间窗口更新时实际发出聚合值。自从我们设置 KSQL 去读取在主题 (`SET 'auto.offset.reset' = 'earliest';`) 上的全部消息,它是一次性读取这些所有的消息并计算聚合更新。这里有一个微妙之处值得去深入研究。我们的入站 tweets 流正好就是一个流。但是,现有它不能创建聚合,我们实际上是创建了一个表。一个表是在给定时间点的给定键的值的一个快照。 KSQL 聚合数据基于消息事件的时间,并且如果它更新了,通过简单的相关窗口重申去操作后面到达的数据。困惑了吗? 我希望没有,但是,让我们看一下,如果我们可以用这个例子去说明。 我们将申明我们的聚合作为一个真实的表:
|
||||
|
||||
看表中的列,这里除了我们要求的外,还有两个隐含列:
|
||||
|
||||
`ksql> DESCRIBE user_tweet_count;
|
||||
|
||||
Field | Type
|
||||
-----------------------------------
|
||||
ROWTIME | BIGINT
|
||||
ROWKEY | VARCHAR(STRING)
|
||||
USER_SCREENNAME | VARCHAR(STRING)
|
||||
TWEET_COUNT | BIGINT
|
||||
ksql>`
|
||||
|
||||
我们看一下这些是什么:
|
||||
|
||||
`ROWTIME` 是窗口开始时间, `ROWKEY` 是 `GROUP BY`(`USER_SCREENNAME`) 加上窗口的组合。因此,我们可以通过创建另外一个衍生的表来整理一下:
|
||||
|
||||
现在它更易于查询和查看我们感兴趣的数据:
|
||||
|
||||
### 结论
|
||||
|
||||
所以我们有了它! 我们可以从 Kafka 中取得数据, 并且很容易使用 KSQL 去探索它。 而不仅是去浏览和转换数据,我们可以很容易地使用 KSQL 从流和表中建立流处理。
|
||||
|
||||

|
||||
|
||||
如果你对 KSQL 能够做什么感兴趣,去查看:
|
||||
|
||||
* [KSQL announcement blog post][1]
|
||||
|
||||
* [Our recent KSQL webinar][2] 和 [Kafka Summit keynote][3]
|
||||
|
||||
* [clickstream demo][4] 它可用于 [KSQL’s GitHub repo][5] 的一部分
|
||||
|
||||
* [presentation that I did recently][6] 展示了 KSQL 如何去支持基于流的 ETL 平台
|
||||
|
||||
记住,KSQL 现在正处于开发者预览版中。 欢迎在 KSQL github repo 上提出任何问题, 或者去我们的 [community Slack group][16] 的 #KSQL通道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.confluent.io/blog/using-ksql-to-analyse-query-and-transform-data-in-kafka
|
||||
|
||||
作者:[Robin Moffatt ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.confluent.io/blog/author/robin/
|
||||
[1]:https://www.confluent.io/blog/ksql-open-source-streaming-sql-for-apache-kafka/
|
||||
[2]:https://www.confluent.io/online-talk/ksql-streaming-sql-for-apache-kafka/
|
||||
[3]:https://www.confluent.io/kafka-summit-sf17/Databases-and-Stream-Processing-1
|
||||
[4]:https://www.youtube.com/watch?v=A45uRzJiv7I
|
||||
[5]:https://github.com/confluentinc/ksql
|
||||
[6]:https://speakerdeck.com/rmoff/look-ma-no-code-building-streaming-data-pipelines-with-apache-kafka
|
||||
[7]:https://www.confluent.io/blog/author/robin/
|
||||
[8]:https://github.com/confluentinc/ksql/
|
||||
[9]:https://www.confluent.io/download/
|
||||
[10]:https://docs.confluent.io/current/installation.html?
|
||||
[11]:https://www.youtube.com/watch?v=ZKqBptBHZTg
|
||||
[12]:https://github.com/jcustenborder/kafka-connect-twitter
|
||||
[13]:https://docs.confluent.io/current/connect/userguide.html#connect-installing-plugins
|
||||
[14]:https://apps.twitter.com/
|
||||
[15]:https://github.com/confluentinc/ksql/blob/0.1.x/docs/syntax-reference.md
|
||||
[16]:https://slackpass.io/confluentcommunity
|
||||
@ -0,0 +1,277 @@
|
||||
怎么在一台树莓派上安装 Postgres 数据库
|
||||
============================================================
|
||||
|
||||
### 在你的下一个树莓派项目上安装和配置流行的开源数据库 Postgres 并去使用它。
|
||||
|
||||

|
||||
Image credits : Raspberry Pi Foundation. [CC BY-SA 4.0][12].
|
||||
|
||||
保存你的项目或应用程序持续增加的数据,数据库是一种很好的方式。你可以在一个会话中将数据写入到数据库,并且在下次你需要查找的时候找到它。一个设计良好的数据库可以在巨大的数据集中高效地找到数据,只要告诉它你想去找什么,而不用去考虑它是如何查找的。为一个基本的 [CRUD][13] (创建、记录、更新、删除) 应用程序安装一个数据库是非常简单的, 它是一个很通用的模式,并且也适用于很多项目。
|
||||
|
||||
为什么 [PostgreSQL][14],一般被为 Postgres? 它被认为是在功能和性能方面最好的开源数据库。如果你使用过 MySQL,它们是很相似的。但是,如果你希望使用它更高级的功能,你会发现优化 Postgres 是比较容易的。它便于安装、容易使用、方便安全, 而且在树莓派 3 上运行的非常好。
|
||||
|
||||
本教程介绍了怎么在一个树莓派上去安装 Postgres;创建一个表;写简单查询;在树莓派上使用 pgAdmin 图形用户界面, 一台 PC,或者一台 Mac,从 Python 中与数据库互相配合。
|
||||
|
||||
你掌握了这些基础知识后,你可以让你的应用程序使用复合查询连接多个表,那个时候你需要考虑的是,怎么去使用主键或外键优化及最佳实践等等。
|
||||
|
||||
### 安装
|
||||
|
||||
一开始,你将需要去安装 Postgres 和一些其它的包。打开一个终端窗口并连接到因特网,然后运行以下命令:
|
||||
|
||||
```
|
||||
sudo apt install postgresql libpq-dev postgresql-client
|
||||
postgresql-client-common -y
|
||||
```
|
||||
|
||||
### [postgres-install.png][1]
|
||||
|
||||

|
||||
|
||||
当安装完成后,切换到 Postgres 用户去配置数据库:
|
||||
|
||||
```
|
||||
sudo su postgres
|
||||
```
|
||||
|
||||
现在,你可以创建一个数据库用户。如果你创建了一个与你的 Unix 用户帐户相同名字的用户,那个用户将被自动授权访问数据库。因此在本教程中,为简单起见,我们将假设你使用了一个缺省的 pi 用户。继续去运行 **createuser** 命令:
|
||||
|
||||
```
|
||||
createuser pi -P --interactive
|
||||
```
|
||||
|
||||
当提示时,输入一个密码 (并记住它), 选择 **n** 使它成为一个超级用户,接下来两个问题选择 **y** 。
|
||||
|
||||
### [postgres-createuser.png][2]
|
||||
|
||||

|
||||
|
||||
现在,使用 shell 连接到 Postgres 去创建一个测试数据库:
|
||||
|
||||
```
|
||||
$ psql
|
||||
> create database test;
|
||||
```
|
||||
|
||||
退出 psql shell,然后,按下 Ctrl+D 两次从 Postgres 中退出,再次以 pi 用户登入。从你创建了一个名为 pi 的 Postgres 用户后,你可以从这里无需登陆凭据访问 Postgres shell:
|
||||
|
||||
```
|
||||
$ psql test
|
||||
```
|
||||
|
||||
你现在已经连接到 "test" 数据库。这个数据库当前是空的,不包含任何表。你可以从 psql shell 上创建一个简单的表:
|
||||
|
||||
```
|
||||
test=> create table people (name text, company text);
|
||||
```
|
||||
|
||||
现在你可插入数据到表中:
|
||||
|
||||
```
|
||||
test=> insert into people values ('Ben Nuttall', 'Raspberry Pi Foundation');
|
||||
|
||||
test=> insert into people values ('Rikki Endsley', 'Red Hat');
|
||||
```
|
||||
|
||||
然后尝试进行查询:
|
||||
|
||||
```
|
||||
test=> select * from people;
|
||||
|
||||
name | company
|
||||
---------------+-------------------------
|
||||
Ben Nuttall | Raspberry Pi Foundation
|
||||
Rikki Endsley | Red Hat
|
||||
(2 rows)
|
||||
```
|
||||
|
||||
### [postgres-query.png][3]
|
||||
|
||||

|
||||
|
||||
```
|
||||
test=> select name from people where company = 'Red Hat';
|
||||
|
||||
name | company
|
||||
---------------+---------
|
||||
Rikki Endsley | Red Hat
|
||||
(1 row)
|
||||
```
|
||||
|
||||
### pgAdmin
|
||||
|
||||
如果希望使用一个图形工具去访问数据库,你可以找到它。 PgAdmin 是一个全功能的 PostgreSQL GUI,它允许你去创建和管理数据库和用户、创建和修改表、执行查询,和在熟悉的视图中像电子表格一样浏览结果。psql 命令行工具可以很好地进行简单查询,并且你会发现很多高级用户一直在使用它,因为它的执行速度很快 (并且因为他们不需要借助 GUI),但是,一般用户学习和操作数据库,使用 pgAdmin 是一个更适合的方式。
|
||||
|
||||
关于 pgAdmin 可以做的其它事情:你可以用它在树莓派上直接连接数据库,或者用它在其它的电脑上远程连接到树莓派上的数据库。
|
||||
|
||||
如果你想去访问树莓派,你可以用 **apt** 去安装它:
|
||||
|
||||
```
|
||||
sudo apt install pgadmin3
|
||||
```
|
||||
|
||||
它是和基于 Debian 的系统如 Ubuntu 是完全相同的;如果你在其它分发版上安装,尝试与你的系统相关的等价的命令。 或者,如果你在 Windows 或 macOS 上,尝试从 [pgAdmin.org][15] 上下载 pgAdmin。注意,在 **apt** 上的可用版本是 pgAdmin3,而最新的版本 pgAdmin4,在网站上可以找到。
|
||||
|
||||
在同一台树莓派上使用 pgAdmin 连接到你的数据库,从主菜单上简单地打开 pgAdmin3 ,点击 **new connection** 图标,然后完成注册,这时,你将需要一个名字(选择连接名,比如 test),改变用户为 "pi",然后剩下的输入框留空 (或者像他们一样)。点击 OK,然后你在左侧的侧面版中将发现一个连接。
|
||||
|
||||
### [pgadmin-connect.png][4]
|
||||
|
||||

|
||||
|
||||
从另外一台电脑上使用 pgAdmin 连接到你的树莓派数据库上,你首先需要编辑 PostgreSQL 配置允许远程连接:
|
||||
|
||||
1\. 编辑 PostgreSQL 配置文件 **/etc/postgresql/9.6/main/postgresql.conf** ,去取消注释 **listen_addresses** 行并改变它的值,从 **localhost** 到 *****。然后保存并退出。
|
||||
|
||||
2\. 编辑 **pg_hba** 配置文件 **/etc/postgresql/9.6/main/postgresql.conf** ,去改变 **127.0.0.1/32** 到 **0.0.0.0/0** (对于IPv4)和 **::1/128** 到 **::/0** (对于IPv6)。然后保存并退出。
|
||||
|
||||
3\. 重启 PostgreSQL 服务: **sudo service postgresql restart**。
|
||||
|
||||
注意,如果你使用一个旧的 Raspbian image 或其它分发版,版本号可能不一样。
|
||||
|
||||
### [postgres-config.png][5]
|
||||
|
||||

|
||||
|
||||
做完这些之后,在其它的电脑上打开 pgAdmin 并创建一个新的连接。这时,需要提供一个连接名,输入树莓派的 IP 地址作为主机 (这可以在任务栏的 WiFi 图标上或者在一个终端中输入 **hostname -I** 找到)。
|
||||
|
||||
### [pgadmin-remote.png][6]
|
||||
|
||||

|
||||
|
||||
不论你连接的是本地的还是远程的数据库,点击打开 **Server Groups > Servers > test > Schemas > public > Tables**,右键单击 **people** 表,然后选择 **View Data > View top 100 Rows**。你现在将看到你前面输入的数据。
|
||||
|
||||
### [pgadmin-view.png][7]
|
||||
|
||||

|
||||
|
||||
你现在可以创建和修改数据库和表、管理用户,和使用 GUI 去写你自己的查询。你可能会发现这种可视化方法比命令行更易于管理。
|
||||
|
||||
### Python
|
||||
|
||||
从一个 Python 脚本连接到你的数据库,你将需要 [Psycopg2][16] 这个 Python 包。你可以用 [pip][17] 来安装它:
|
||||
|
||||
```
|
||||
sudo pip3 install psycopg2
|
||||
```
|
||||
|
||||
现在打开一个 Python 编辑器写一些代码连接到你的数据库:
|
||||
|
||||
```
|
||||
import psycopg2
|
||||
|
||||
conn = psycopg2.connect('dbname=test')
|
||||
cur = conn.cursor()
|
||||
|
||||
cur.execute('select * from people')
|
||||
|
||||
results = cur.fetchall()
|
||||
|
||||
for result in results:
|
||||
print(result)
|
||||
```
|
||||
|
||||
运行这个代码去看查询结果。注意,如果你连接的是远程数据库,在连接字符串中你将提供更多的凭据,比如,增加主机 IP、用户名,和数据库密码:
|
||||
|
||||
```
|
||||
conn = psycopg2.connect('host=192.168.86.31 user=pi
|
||||
password=raspberry dbname=test')
|
||||
```
|
||||
|
||||
你甚至可以创建一个函数去查找特定的查询:
|
||||
|
||||
```
|
||||
def get_all_people():
|
||||
query = """
|
||||
SELECT
|
||||
*
|
||||
FROM
|
||||
people
|
||||
"""
|
||||
cur.execute(query)
|
||||
return cur.fetchall()
|
||||
```
|
||||
|
||||
和一个包含的查询:
|
||||
|
||||
```
|
||||
def get_people_by_company(company):
|
||||
query = """
|
||||
SELECT
|
||||
*
|
||||
FROM
|
||||
people
|
||||
WHERE
|
||||
company = %s
|
||||
"""
|
||||
values = (company, )
|
||||
cur.execute(query, values)
|
||||
return cur.fetchall()
|
||||
```
|
||||
|
||||
或者甚至是一个增加记录的函数:
|
||||
|
||||
```
|
||||
def add_person(name, company):
|
||||
query = """
|
||||
INSERT INTO
|
||||
people
|
||||
VALUES
|
||||
(%s, %s)
|
||||
"""
|
||||
values = (name, company)
|
||||
cur.execute(query, values)
|
||||
```
|
||||
|
||||
注意,这里使用了一个注入字符串到查询的安全的方法, 你不希望通过 [little bobby tables][18] 被抓住!
|
||||
|
||||
### [python-postgres.png][8]
|
||||
|
||||

|
||||
|
||||
现在你知道了这些基础知识,如果你想去进一步掌握 Postgres ,查看在 [Full Stack Python][19] 上的文章。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ben Nuttall - 树莓派社区的管理者。除了它为树莓派基金会所做的工作之外 ,他也投入开源软件、数学、皮艇运动、GitHub、探险活动和Futurama。在 Twitter [@ben_nuttall][10] 上关注他。
|
||||
|
||||
-------------
|
||||
|
||||
via: https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi
|
||||
|
||||
作者:[Ben Nuttall ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://opensource.com/file/374246
|
||||
[2]:https://opensource.com/file/374241
|
||||
[3]:https://opensource.com/file/374251
|
||||
[4]:https://opensource.com/file/374221
|
||||
[5]:https://opensource.com/file/374236
|
||||
[6]:https://opensource.com/file/374226
|
||||
[7]:https://opensource.com/file/374231
|
||||
[8]:https://opensource.com/file/374256
|
||||
[9]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021&rate=t-XUFUPa6mURgML4cfL1mjxsmFBG-VQTG4R39QvFVQA
|
||||
[10]:http://www.twitter.com/ben_nuttall
|
||||
[11]:https://opensource.com/user/26767/feed
|
||||
[12]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[13]:https://en.wikipedia.org/wiki/Create,_read,_update_and_delete
|
||||
[14]:https://www.postgresql.org/
|
||||
[15]:https://www.pgadmin.org/download/
|
||||
[16]:http://initd.org/psycopg/
|
||||
[17]:https://pypi.python.org/pypi/pip
|
||||
[18]:https://xkcd.com/327/
|
||||
[19]:https://www.fullstackpython.com/postgresql.html
|
||||
[20]:https://opensource.com/users/bennuttall
|
||||
[21]:https://opensource.com/users/bennuttall
|
||||
[22]:https://opensource.com/users/bennuttall
|
||||
[23]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021#comments
|
||||
[24]:https://opensource.com/tags/raspberry-pi
|
||||
[25]:https://opensource.com/tags/raspberry-pi-column
|
||||
[26]:https://opensource.com/tags/how-tos-and-tutorials
|
||||
[27]:https://opensource.com/tags/programming
|
||||
123
translated/tech/20171017 A tour of Postgres Index Types.md
Normal file
123
translated/tech/20171017 A tour of Postgres Index Types.md
Normal file
@ -0,0 +1,123 @@
|
||||
# Postgres 索引类型探索之旅
|
||||
|
||||
在 Citus上,为让事情做的更好,我们与客户一起在数据建模、优化查询、和增加 [索引][3]上花了一些时间。我的目标是为客户需要提供更好的服务,让你更成功。部分原因是[我们持续][5]为你的 Citus 集群保持良好的优化和 [高性能][4]。 另外部分是帮你了解你所需要的关于 Postgres and Citus的一切。毕竟,一个健康和高性能的数据库意味着 app 执行的更快,并且谁不愿意这样呢? 今天,我们简化一些内容,与客户仅分享关于 Postgres 索引的一些信息。
|
||||
|
||||
Postgres 有几种索引类型, 并且每个新版本都似乎增加一些新的索引类型。每个索引类型都是有用的,但是使用那种类型取决于 1\. (有时是)数据类型 2\. 表中的底层数据、和 3\. 执行的查找类型。 接下来的内容我们将介绍在 Postgres 中你可用的索引类型,以及你何时使用何种索引类型。在开始之前,这里有一个我们将带你亲历的索引类型列表:
|
||||
|
||||
* B-Tree
|
||||
|
||||
* Generalized Inverted Index (GIN)
|
||||
|
||||
* Generalized Inverted Seach Tree (GiST)
|
||||
|
||||
* Space partitioned GiST (SP-GiST)
|
||||
|
||||
* Block Range Indexes (BRIN)
|
||||
|
||||
* Hash
|
||||
|
||||
现在开始介绍索引
|
||||
|
||||
### 在 Postgres 中, 一个 B-Tree 索引是你使用的最普遍的索引
|
||||
|
||||
如果你有一个计算机科学的学位,那么 B-Tree 索引可能是你学会的第一个索引。一个 [B-tree 索引][6] 创建一个保持自身平衡的一棵树。当它根据索引去查找某个东西时,它会遍历这棵树去找到键,然后返回你要查找的数据。使用一个索引是大大快于顺序扫描的,因为相对于顺序扫描成千上万的记录,它可以仅需要读几个 [页][7] (当你仅返回几个记录时)。
|
||||
|
||||
如果你运行一个标准的 `CREATE INDEX` ,它将为你创建一个 B-tree 索引。 B-tree 索引在大多数的数据类型上是很有价值的,比如 text、numbers、和 timestamps。如果你正好在你的数据库中使用索引, 并且不在你的数据库上使用太多的 Postgres 的高级特性,使用标准的 B-Tree 索引可能是你最好的选择。
|
||||
|
||||
### GIN 索引,用于多值列
|
||||
|
||||
Generalized Inverted Indexes,一般称为 [GIN][8],大多适用于当单个列中包含多个值的数据类型
|
||||
|
||||
在 Postgres 文档中: _“GIN 是设计用于处理被索引的条目是复合值的情况的, 并且由索引处理的查询需要搜索在复合条目中出现的值。例如,这个条目可能是文档,并且查询可以搜索文档中包含的指定字符。”_
|
||||
|
||||
包含在这个范围内的最常见的数据类型有:
|
||||
|
||||
* [hStore][1]
|
||||
|
||||
* Arrays
|
||||
|
||||
* Range types
|
||||
|
||||
* [JSONB][2]
|
||||
|
||||
关于 GIN 索引中最让人满意的一件事是,它们知道索引的数据在复合值中。但是,因为一个 GIN 索引有一个关于对需要被添加的每个单独的类型支持的数据结构的特定的知识,因此,GIN 索引并不是支持所有的数据类型。
|
||||
|
||||
### GiST 索引, 用于有重叠值的行
|
||||
|
||||
GiST 索引多适用于当你的数据与同一列的其它行数据重叠时。关于 GiST 索引最好的用处是:如果你声明一个几何数据类型,并且你希望去看两个多边型包含的一些点。在一个例子中一个特定的点可能被包含在一个 box 中,而与此同时,其它的点仅存在于一个多边形中。你想去使用 GiST 索引的常见数据类型有:
|
||||
|
||||
* 几何类型
|
||||
|
||||
* 当需要进行全文搜索的文本类型
|
||||
|
||||
GiST 索引在大小上有很多的限制,否则,GiST 索引可能会变的特别大。最后导致 GiST 索引产生损害。从官方文档中: _“一个 GiST 索引是有损害的,意味着索引可能产生虚假的匹配,并且需要去检查真实的表行去消除虚假的匹配。 (当需要时 PostgreSQL 会自动执行这个动作)”_ 这并不意味着你会得到一个错误的结果,它正好说明了在 Postgres 给你返回数据之前,做了一个很小的额外的工作去过滤这些虚假结果。
|
||||
|
||||
_特别提示: GIN 和 GiST 索引可能经常在相同的数据类型上有益处的。其中之一是可能经常有很好的性能表现,但是,使用 GIN 可能占用很大的磁盘空间,并且对于 GiST 反之亦然。说到 GIN vs. GiST 的比较,并没有一个完美的大小去适用所有案例,但是,以上规则应用于大部分常见情况。_
|
||||
|
||||
### SP-GiST 索引,用于大的数据
|
||||
|
||||
空间分区的 GiST 索引利用来自 [Purdue][9] 研究的一些空间分区树。 SP-GiST 索引经常用于,当你的数据有一个天然的聚集因素并且还不是一个平衡树的时候。 电话号码是一个非常好的例子 (至少 US 的电话号码是)。 它们有如下的格式:
|
||||
|
||||
* 3 位数字的区域号
|
||||
|
||||
* 3 位数字的前缀号 (与以前的电话交换机有关)
|
||||
|
||||
* 4 位的线路号
|
||||
|
||||
这意味着第一组前三位处有一个天然的聚集因素, 接着是第二组三位, 然后的数字才是一个均匀的分布。但是,在电话号码的一些区域号中,存在一个比其它区域号更高的饱合状态。结果可能导致树非常的不平衡。因为前面有一个天然的聚集因素,并且像电话号码一样数据到数据的不对等分布,可能会是 SP-GiST 的一个很好的案例。
|
||||
|
||||
### BRIN 索引, 用于大的数据
|
||||
|
||||
BRIN 索引可以专注于一些类似使用 SP-GiST 的案例,当数据有一些自然的排序,并且往往数据量很大时,它们的性能表现是最好的。如果有一个以时间为序的 10 亿条的记录, BRIN 可能对它很有帮助。如果你正在查询一组很大的有自然分组的数据,如有几个 zip 代码的数据,BRIN 能帮你确保类似的 zip 代码在磁盘上位于它们彼此附近。
|
||||
|
||||
当你有一个非常大的比如以日期或 zip 代码排序的数据库, BRIN 索引可以允许你非常快的去跳过或排除一些不需要的数据。此外,与整体数据量大小相比,BRIN 索引相对较小,因此,当你有一个大的数据集时,BRIN 索引就可以表现出较好的性能。
|
||||
|
||||
### Hash 索引, 总算崩溃安全了
|
||||
|
||||
Hash 索引在 Postgres 中已经存在多年了,但是,在 Postgres 10 发布之前,它们一直有一个巨大的警告,不能使用 WAL-logged。这意味着如果你的服务器崩溃,并且你无法使用如 [wal-g][10] 故障转移到备机或从存档中恢复,那么你将丢失那个索引,直到你重建它。 随着 Postgres 10 发布,它们现在可以使用 WAL-logged,因此,你可以再次考虑使用它们 ,但是,真正的问题是,你应该这样做吗?
|
||||
|
||||
Hash 索引有时会提供比 B-Tree 索引更快的查找,并且创建也很快。最大的问题是它们被限制仅用于相等的比较操作,因此你只能用于精确匹配的查找。这使得 hash 索引的灵活性远不及通常使用的 B-Tree 索引,并且,你不能把它看成是一种替代,而是一种使用于特殊情况的索引。
|
||||
|
||||
### 你该使用哪个?
|
||||
|
||||
我们刚才介绍了很多,如果你有点被吓到,也很正常。 如果在你知道这些之前, `CREATE INDEX` ,将始终为你创建使用 B-Tree 索引,并且有一个好消息是,对于大多数的 Postgres 数据库,你做的一直很好或非常好。 :) 从你开始使用更多的 Postgres 特性的角度来说,下面是一个当你使用其它 Postgres 索引类型的备忘清单:
|
||||
|
||||
* B-Tree - 适用于大多数的数据类型和查询
|
||||
|
||||
* GIN - 适用于 JSONB/hstore/arrays
|
||||
|
||||
* GiST - 适用于全文搜索和几何数据类型
|
||||
|
||||
* SP-GiST - 适用于有天然的聚集因素但是分布不均匀的大数据集
|
||||
|
||||
* BRIN - 适用于有顺序排列的真正的大数据集
|
||||
|
||||
* Hash - 适用于等式操作,而且,通常情况下 B-Tree 索引仍然是你所需要的。
|
||||
|
||||
如果你有关于这篇文章的任何问题或反馈,欢迎加入我们的 [slack channel][11]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
|
||||
作者:[Craig Kerstiens ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
[1]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||
[2]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||
[3]:https://www.citusdata.com/blog/2017/10/11/index-all-the-things-in-postgres/
|
||||
[4]:https://www.citusdata.com/blog/2017/09/29/what-performance-can-you-expect-from-postgres/
|
||||
[5]:https://www.citusdata.com/product/cloud
|
||||
[6]:https://en.wikipedia.org/wiki/B-tree
|
||||
[7]:https://www.8kdata.com/blog/postgresql-page-layout/
|
||||
[8]:https://www.postgresql.org/docs/10/static/gin.html
|
||||
[9]:https://www.cs.purdue.edu/spgist/papers/W87R36P214137510.pdf
|
||||
[10]:https://www.citusdata.com/blog/2017/08/18/introducing-wal-g-faster-restores-for-postgres/
|
||||
[11]:https://slack.citusdata.com/
|
||||
[12]:https://twitter.com/share?url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/&text=A%20tour%20of%20Postgres%20Index%20Types&via=citusdata
|
||||
[13]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
@ -0,0 +1,188 @@
|
||||
3 个简单、优秀的 Linux 网络监视器
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
用 iftop、Nethogs 和 vnstat 了解更多关于你的网络连接。[经许可使用][3]
|
||||
|
||||
你可以通过这三个 Linux 网络命令,了解有关你网络连接的大量信息。iftop 通过进程编号跟踪网络连接,Nethogs 可以快速显示哪个在占用你的带宽,而 vnstat 作为一个很好的轻量级守护进程运行,可以随时随地记录你的使用情况。
|
||||
|
||||
### iftop
|
||||
|
||||
[iftop][7] 监听你指定的网络接口,并以 top 的形式展示连接。
|
||||
|
||||
这是一个很好的小工具,用于快速识别占用、测量速度,并保持网络流量的总体运行。看到我们使用了多少带宽是非常令人惊讶的,特别是对于我们这些记得使用电话线、调制解调器、让人尖叫的 Kbit 速度和真实的实时波特率的老年人来说。我们很久以前就放弃了波特, 转而使用比特率。波特测量信号变化,有时与比特率相同,但大多数情况下不是。
|
||||
|
||||
如果你只有一个网络接口,不带选项运行 iftop。iftop 需要 root 权限:
|
||||
|
||||
```
|
||||
$ sudo iftop
|
||||
```
|
||||
|
||||
当你有多个接口时,指定要监控的接口:
|
||||
|
||||
```
|
||||
$ sudo iftop -i wlan0
|
||||
```
|
||||
|
||||
就像 top 一样,你可以在运行时更改显示选项。
|
||||
|
||||
* **h** 切换帮助屏幕。
|
||||
|
||||
* **n** 切换名称解析。
|
||||
|
||||
* **s** 切换源主机显示,**d** 切换目标主机。
|
||||
|
||||
* **s** 切换端口号。
|
||||
|
||||
* **N** 切换端口分辨率。要查看所有端口号,请关闭分辨率。
|
||||
|
||||
* **t** 切换文本界面。默认显示需要 ncurses。我认为文本显示更易于阅读和更好的组织(图1)。
|
||||
|
||||
* **p** 暂停显示。
|
||||
|
||||
* **q** 退出程序。
|
||||
|
||||
### [fig-1.png][4]
|
||||
|
||||

|
||||
图 1:文本显示是可读的和可组织的。[经许可使用][1]
|
||||
|
||||
当你切换显示选项时,iftop 继续测量所有流量。你还可以选择要监控的单个主机。你需要主机的 IP 地址和网络掩码。我很好奇,Pandora 在我那可怜的带宽中占用了多少,所以我先用 dig 找到它们的 IP 地址:
|
||||
|
||||
```
|
||||
$ dig A pandora.com
|
||||
[...]
|
||||
;; ANSWER SECTION:
|
||||
pandora.com. 267 IN A 208.85.40.20
|
||||
pandora.com. 267 IN A 208.85.40.50
|
||||
```
|
||||
|
||||
网络掩码是什么? [ipcalc][8] 告诉我们:
|
||||
|
||||
```
|
||||
$ ipcalc -b 208.85.40.20
|
||||
Address: 208.85.40.20
|
||||
Netmask: 255.255.255.0 = 24
|
||||
Wildcard: 0.0.0.255
|
||||
=>
|
||||
Network: 208.85.40.0/24
|
||||
```
|
||||
|
||||
现在将地址和网络掩码提供给 iftop:
|
||||
|
||||
```
|
||||
$ sudo iftop -F 208.85.40.20/24 -i wlan0
|
||||
```
|
||||
|
||||
这不是真的吗?我很惊讶地发现,Pandora 在我珍贵的带宽中很轻松,每小时使用大约使用 500Kb。而且,像大多数流媒体服务一样,Pandora 的流量也是出乎意料的,而且依赖于缓存来缓解阻塞。
|
||||
|
||||
你可以使用 **-G** 选项对 IPv6 地址执行相同操作。请参阅手册页了解 iftop 的其他功能,包括使用自定义配置文件定制默认选项,并应用自定义过滤器(请参阅 [PCAP-FILTER][9] 作为过滤器参考)。
|
||||
|
||||
### Nethogs
|
||||
|
||||
当你想要快速了解谁占用了你的带宽时,Nethogs 是快速和容易的。以 root 身份运行,并指定要监听的接口。它显示了空闲的应用程序和进程号,以便如果你愿意的话,你可以杀死它:
|
||||
|
||||
```
|
||||
$ sudo nethogs wlan0
|
||||
|
||||
NetHogs version 0.8.1
|
||||
|
||||
PID USER PROGRAM DEV SENT RECEIVED
|
||||
7690 carla /usr/lib/firefox wlan0 12.494 556.580 KB/sec
|
||||
5648 carla .../chromium-browser wlan0 0.052 0.038 KB/sec
|
||||
TOTAL 12.546 556.618 KB/sec
|
||||
```
|
||||
|
||||
Nethogs 有很少的选项:在 kb/s、kb、b 和 mb 之间循环,通过接收或发送的数据包进行排序,并调整刷新之间的延迟。请参阅 `man nethogs`,或者运行 `nethogs -h`。
|
||||
|
||||
### vnstat
|
||||
|
||||
[vnstat][10] 是使用最简单的网络数据收集器。它是轻量级的,不需要 root 权限。它作为守护进程运行,并记录你网络统计信息。`vnstat` 命令显示累计的数据:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan0
|
||||
Database updated: Tue Oct 17 08:36:38 2017
|
||||
|
||||
wlan0 since 10/17/2017
|
||||
|
||||
rx: 45.27 MiB tx: 3.77 MiB total: 49.04 MiB
|
||||
|
||||
monthly
|
||||
rx | tx | total | avg. rate
|
||||
------------------------+-------------+-------------+---------------
|
||||
Oct '17 45.27 MiB | 3.77 MiB | 49.04 MiB | 0.28 kbit/s
|
||||
------------------------+-------------+-------------+---------------
|
||||
estimated 85 MiB | 5 MiB | 90 MiB |
|
||||
|
||||
daily
|
||||
rx | tx | total | avg. rate
|
||||
------------------------+-------------+-------------+---------------
|
||||
today 45.27 MiB | 3.77 MiB | 49.04 MiB | 12.96 kbit/s
|
||||
------------------------+-------------+-------------+---------------
|
||||
estimated 125 MiB | 8 MiB | 133 MiB |
|
||||
```
|
||||
|
||||
它默认显示所有的网络接口。使用 `-i` 选项选择单个接口。以这种方式合并多个接口的数据:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan0+eth0+eth1
|
||||
```
|
||||
|
||||
你可以通过以下几种方式过滤显示:
|
||||
|
||||
* **-h** 以小时显示统计数据。
|
||||
|
||||
* **-d** 以天数显示统计数据。
|
||||
|
||||
* **-w** 和 **-m** 按周和月显示统计数据。
|
||||
|
||||
* 使用 **-l** 选项查看实时更新。
|
||||
|
||||
此命令删除 wlan1 的数据库,并停止监控它:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan1 --delete
|
||||
```
|
||||
|
||||
此命令为网络接口创建别名。此例使用 Ubuntu 16.04 中的一个奇怪的接口名称:
|
||||
|
||||
```
|
||||
$ vnstat -u -i enp0s25 --nick eth0
|
||||
```
|
||||
|
||||
默认情况下,vnstat 监视 eth0。你可以在 `/etc/vnstat.conf` 中更改此内容,或在主目录中创建自己的个人配置文件。请参见 `man vnstat` 以获得完整的参考。
|
||||
|
||||
你还可以安装 vnstati 创建简单的彩色图(图2):
|
||||
|
||||
```
|
||||
$ vnstati -s -i wlx7cdd90a0a1c2 -o vnstat.png
|
||||
```
|
||||
|
||||
|
||||

|
||||
图 2:你可以使用 vnstati 创建简单的彩色图表。[经许可使用][2]
|
||||
|
||||
有关完整选项,请参见 `man vnstati`。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/3-simple-excellent-linux-network-monitors
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/files/images/fig-1png-8
|
||||
[5]:https://www.linux.com/files/images/fig-2png-5
|
||||
[6]:https://www.linux.com/files/images/bannerpng-3
|
||||
[7]:http://www.ex-parrot.com/pdw/iftop/
|
||||
[8]:https://www.linux.com/learn/intro-to-linux/2017/8/how-calculate-network-addresses-ipcalc
|
||||
[9]:http://www.tcpdump.org/manpages/pcap-filter.7.html
|
||||
[10]:http://humdi.net/vnstat/
|
||||
Loading…
Reference in New Issue
Block a user