mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-10 22:21:11 +08:00
commit
867c27e370
@ -60,6 +60,7 @@ LCTT 的组成
|
|||||||
* 2017/03/13 制作了 LCTT 主页、成员列表和成员主页,LCTT 主页将移动至 https://linux.cn/lctt 。
|
* 2017/03/13 制作了 LCTT 主页、成员列表和成员主页,LCTT 主页将移动至 https://linux.cn/lctt 。
|
||||||
* 2017/03/16 提升 GHLandy、bestony、rusking 为新的 Core 成员。创建 Comic 小组。
|
* 2017/03/16 提升 GHLandy、bestony、rusking 为新的 Core 成员。创建 Comic 小组。
|
||||||
* 2017/04/11 启用头衔制,为各位重要成员颁发头衔。
|
* 2017/04/11 启用头衔制,为各位重要成员颁发头衔。
|
||||||
|
* 2017/11/21 鉴于 qhwdw 快速而上佳的翻译质量,提升 qhwdw 为新的 Core 成员。
|
||||||
|
|
||||||
核心成员
|
核心成员
|
||||||
-------------------------------
|
-------------------------------
|
||||||
@ -86,6 +87,7 @@ LCTT 的组成
|
|||||||
- 核心成员 @Locez,
|
- 核心成员 @Locez,
|
||||||
- 核心成员 @ucasFL,
|
- 核心成员 @ucasFL,
|
||||||
- 核心成员 @rusking,
|
- 核心成员 @rusking,
|
||||||
|
- 核心成员 @qhwdw,
|
||||||
- 前任选题 @DeadFire,
|
- 前任选题 @DeadFire,
|
||||||
- 前任校对 @reinoir222,
|
- 前任校对 @reinoir222,
|
||||||
- 前任校对 @PurlingNayuki,
|
- 前任校对 @PurlingNayuki,
|
||||||
|
|||||||
@ -0,0 +1,347 @@
|
|||||||
|
理解多区域配置中的 firewalld
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
现在的新闻里充斥着服务器被攻击和数据失窃事件。对于一个阅读过安全公告博客的人来说,通过访问错误配置的服务器,利用最新暴露的安全漏洞或通过窃取的密码来获得系统控制权,并不是件多困难的事情。在一个典型的 Linux 服务器上的任何互联网服务都可能存在漏洞,允许未经授权的系统访问。
|
||||||
|
|
||||||
|
因为在应用程序层面上强化系统以防范任何可能的威胁是不可能做到的事情,而防火墙可以通过限制对系统的访问提供了安全保证。防火墙基于源 IP、目标端口和协议来过滤入站包。因为这种方式中,仅有几个 IP/端口/协议的组合与系统交互,而其它的方式做不到过滤。
|
||||||
|
|
||||||
|
Linux 防火墙是通过 netfilter 来处理的,它是内核级别的框架。这十几年来,iptables 被作为 netfilter 的用户态抽象层(LCTT 译注: userland,一个基本的 UNIX 系统是由 kernel 和 userland 两部分构成,除 kernel 以外的称为 userland)。iptables 将包通过一系列的规则进行检查,如果包与特定的 IP/端口/协议的组合匹配,规则就会被应用到这个包上,以决定包是被通过、拒绝或丢弃。
|
||||||
|
|
||||||
|
Firewalld 是最新的 netfilter 用户态抽象层。遗憾的是,由于缺乏描述多区域配置的文档,它强大而灵活的功能被低估了。这篇文章提供了一个示例去改变这种情况。
|
||||||
|
|
||||||
|
### Firewalld 的设计目标
|
||||||
|
|
||||||
|
firewalld 的设计者认识到大多数的 iptables 使用案例仅涉及到几个单播源 IP,仅让每个符合白名单的服务通过,而其它的会被拒绝。这种模式的好处是,firewalld 可以通过定义的源 IP 和/或网络接口将入站流量分类到不同<ruby>区域<rt>zone</rt></ruby>。每个区域基于指定的准则按自己配置去通过或拒绝包。
|
||||||
|
|
||||||
|
另外的改进是基于 iptables 进行语法简化。firewalld 通过使用服务名而不是它的端口和协议去指定服务,使它更易于使用,例如,是使用 samba 而不是使用 UDP 端口 137 和 138 和 TCP 端口 139 和 445。它进一步简化语法,消除了 iptables 中对语句顺序的依赖。
|
||||||
|
|
||||||
|
最后,firewalld 允许交互式修改 netfilter,允许防火墙独立于存储在 XML 中的永久配置而进行改变。因此,下面的的临时修改将在下次重新加载时被覆盖:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd <some modification>
|
||||||
|
```
|
||||||
|
|
||||||
|
而,以下的改变在重加载后会永久保存:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --permanent <some modification>
|
||||||
|
# firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
### 区域
|
||||||
|
|
||||||
|
在 firewalld 中最上层的组织是区域。如果一个包匹配区域相关联的网络接口或源 IP/掩码 ,它就是区域的一部分。可用的几个预定义区域:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --get-zones
|
||||||
|
block dmz drop external home internal public trusted work
|
||||||
|
```
|
||||||
|
|
||||||
|
任何配置了一个**网络接口**和/或一个**源**的区域就是一个<ruby>活动区域<rt>active zone</rt></ruby>。列出活动的区域:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --get-active-zones
|
||||||
|
public
|
||||||
|
interfaces: eno1 eno2
|
||||||
|
```
|
||||||
|
|
||||||
|
**Interfaces** (接口)是系统中的硬件和虚拟的网络适配器的名字,正如你在上面的示例中所看到的那样。所有的活动的接口都将被分配到区域,要么是默认的区域,要么是用户指定的一个区域。但是,一个接口不能被分配给多于一个的区域。
|
||||||
|
|
||||||
|
在缺省配置中,firewalld 设置所有接口为 public 区域,并且不对任何区域设置源。其结果是,`public` 区域是唯一的活动区域。
|
||||||
|
|
||||||
|
**Sources** (源)是入站 IP 地址的范围,它也可以被分配到区域。一个源(或重叠的源)不能被分配到多个区域。这样做的结果是产生一个未定义的行为,因为不清楚应该将哪些规则应用于该源。
|
||||||
|
|
||||||
|
因为指定一个源不是必需的,任何包都可以通过接口匹配而归属于一个区域,而不需要通过源匹配来归属一个区域。这表示通过使用优先级方式,优先到达多个指定的源区域,稍后将详细说明这种情况。首先,我们来检查 `public` 区域的配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --zone=public --list-all
|
||||||
|
public (default, active)
|
||||||
|
interfaces: eno1 eno2
|
||||||
|
sources:
|
||||||
|
services: dhcpv6-client ssh
|
||||||
|
ports:
|
||||||
|
masquerade: no
|
||||||
|
forward-ports:
|
||||||
|
icmp-blocks:
|
||||||
|
rich rules:
|
||||||
|
# firewall-cmd --permanent --zone=public --get-target
|
||||||
|
default
|
||||||
|
```
|
||||||
|
|
||||||
|
逐行说明如下:
|
||||||
|
|
||||||
|
* `public (default, active)` 表示 `public` 区域是默认区域(当接口启动时会自动默认),并且它是活动的,因为,它至少有一个接口或源分配给它。
|
||||||
|
* `interfaces: eno1 eno2` 列出了这个区域上关联的接口。
|
||||||
|
* `sources:` 列出了这个区域的源。现在这里什么都没有,但是,如果这里有内容,它们应该是这样的格式 xxx.xxx.xxx.xxx/xx。
|
||||||
|
* `services: dhcpv6-client ssh` 列出了允许通过这个防火墙的服务。你可以通过运行 `firewall-cmd --get-services` 得到一个防火墙预定义服务的详细列表。
|
||||||
|
* `ports:` 列出了一个允许通过这个防火墙的目标端口。它是用于你需要去允许一个没有在 firewalld 中定义的服务的情况下。
|
||||||
|
* `masquerade: no` 表示这个区域是否允许 IP 伪装。如果允许,它将允许 IP 转发,它可以让你的计算机作为一个路由器。
|
||||||
|
* `forward-ports:` 列出转发的端口。
|
||||||
|
* `icmp-blocks:` 阻塞的 icmp 流量的黑名单。
|
||||||
|
* `rich rules:` 在一个区域中优先处理的高级配置。
|
||||||
|
* `default` 是目标区域,它决定了与该区域匹配而没有由上面设置中显式处理的包的动作。
|
||||||
|
|
||||||
|
### 一个简单的单区域配置示例
|
||||||
|
|
||||||
|
如果只是简单地锁定你的防火墙。简单地在删除公共区域上当前允许的服务,并重新加载:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --permanent --zone=public --remove-service=dhcpv6-client
|
||||||
|
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||||
|
# firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
在下面的防火墙上这些命令的结果是:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --zone=public --list-all
|
||||||
|
public (default, active)
|
||||||
|
interfaces: eno1 eno2
|
||||||
|
sources:
|
||||||
|
services:
|
||||||
|
ports:
|
||||||
|
masquerade: no
|
||||||
|
forward-ports:
|
||||||
|
icmp-blocks:
|
||||||
|
rich rules:
|
||||||
|
# firewall-cmd --permanent --zone=public --get-target
|
||||||
|
default
|
||||||
|
```
|
||||||
|
|
||||||
|
本着尽可能严格地保证安全的精神,如果发生需要在你的防火墙上临时开放一个服务的情况(假设是 ssh),你可以增加这个服务到当前会话中(省略 `--permanent`),并且指示防火墙在一个指定的时间之后恢复修改:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --zone=public --add-service=ssh --timeout=5m
|
||||||
|
```
|
||||||
|
|
||||||
|
这个 `timeout` 选项是一个以秒(`s`)、分(`m`)或小时(`h`)为单位的时间值。
|
||||||
|
|
||||||
|
### 目标
|
||||||
|
|
||||||
|
当一个区域处理它的源或接口上的一个包时,但是,没有处理该包的显式规则时,这时区域的<ruby>目标<rt>target</rt></ruby>决定了该行为:
|
||||||
|
|
||||||
|
* `ACCEPT`:通过这个包。
|
||||||
|
* `%%REJECT%%`:拒绝这个包,并返回一个拒绝的回复。
|
||||||
|
* `DROP`:丢弃这个包,不回复任何信息。
|
||||||
|
* `default`:不做任何事情。该区域不再管它,把它踢到“楼上”。
|
||||||
|
|
||||||
|
在 firewalld 0.3.9 中有一个 bug (已经在 0.3.10 中修复),对于一个目标是除了“default”以外的源区域,不管允许的服务是什么,这的目标都会被应用。例如,一个使用目标 `DROP` 的源区域,将丢弃所有的包,甚至是白名单中的包。遗憾的是,这个版本的 firewalld 被打包到 RHEL7 和它的衍生版中,使它成为一个相当常见的 bug。本文中的示例避免了可能出现这种行为的情况。
|
||||||
|
|
||||||
|
### 优先权
|
||||||
|
|
||||||
|
活动区域中扮演两个不同的角色。关联接口行为的区域作为接口区域,并且,关联源行为的区域作为源区域(一个区域能够扮演两个角色)。firewalld 按下列顺序处理一个包:
|
||||||
|
|
||||||
|
1. 相应的源区域。可以存在零个或一个这样的区域。如果这个包满足一个<ruby>富规则<rt>rich rule</rt></ruby>、服务是白名单中的、或者目标没有定义,那么源区域处理这个包,并且在这里结束。否则,向上传递这个包。
|
||||||
|
2. 相应的接口区域。肯定有一个这样的区域。如果接口处理这个包,那么到这里结束。否则,向上传递这个包。
|
||||||
|
3. firewalld 默认动作。接受 icmp 包并拒绝其它的一切。
|
||||||
|
|
||||||
|
这里的关键信息是,源区域优先于接口区域。因此,对于多区域的 firewalld 配置的一般设计模式是,创建一个优先源区域来允许指定的 IP 对系统服务的提升访问,并在一个限制性接口区域限制其它访问。
|
||||||
|
|
||||||
|
### 一个简单的多区域示例
|
||||||
|
|
||||||
|
为演示优先权,让我们在 `public` 区域中将 `http` 替换成 `ssh`,并且为我们喜欢的 IP 地址,如 1.1.1.1,设置一个默认的 `internal` 区域。以下的命令完成这个任务:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||||
|
# firewall-cmd --permanent --zone=public --add-service=http
|
||||||
|
# firewall-cmd --permanent --zone=internal --add-source=1.1.1.1
|
||||||
|
# firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
这些命令的结果是生成如下的配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --zone=public --list-all
|
||||||
|
public (default, active)
|
||||||
|
interfaces: eno1 eno2
|
||||||
|
sources:
|
||||||
|
services: dhcpv6-client http
|
||||||
|
ports:
|
||||||
|
masquerade: no
|
||||||
|
forward-ports:
|
||||||
|
icmp-blocks:
|
||||||
|
rich rules:
|
||||||
|
# firewall-cmd --permanent --zone=public --get-target
|
||||||
|
default
|
||||||
|
# firewall-cmd --zone=internal --list-all
|
||||||
|
internal (active)
|
||||||
|
interfaces:
|
||||||
|
sources: 1.1.1.1
|
||||||
|
services: dhcpv6-client mdns samba-client ssh
|
||||||
|
ports:
|
||||||
|
masquerade: no
|
||||||
|
forward-ports:
|
||||||
|
icmp-blocks:
|
||||||
|
rich rules:
|
||||||
|
# firewall-cmd --permanent --zone=internal --get-target
|
||||||
|
default
|
||||||
|
```
|
||||||
|
|
||||||
|
在上面的配置中,如果有人尝试从 1.1.1.1 去 `ssh`,这个请求将会成功,因为这个源区域(`internal`)被首先应用,并且它允许 `ssh` 访问。
|
||||||
|
|
||||||
|
如果有人尝试从其它的地址,如 2.2.2.2,去访问 `ssh`,它不是这个源区域的,因为和这个源区域不匹配。因此,这个请求被直接转到接口区域(`public`),它没有显式处理 `ssh`,因为,public 的目标是 `default`,这个请求被传递到默认动作,它将被拒绝。
|
||||||
|
|
||||||
|
如果 1.1.1.1 尝试进行 `http` 访问会怎样?源区域(`internal`)不允许它,但是,目标是 `default`,因此,请求将传递到接口区域(`public`),它被允许访问。
|
||||||
|
|
||||||
|
现在,让我们假设有人从 3.3.3.3 拖你的网站。要限制从那个 IP 的访问,简单地增加它到预定义的 `drop` 区域,正如其名,它将丢弃所有的连接:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --permanent --zone=drop --add-source=3.3.3.3
|
||||||
|
# firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
下一次 3.3.3.3 尝试去访问你的网站,firewalld 将转发请求到源区域(`drop`)。因为目标是 `DROP`,请求将被拒绝,并且它不会被转发到接口区域(`public`)。
|
||||||
|
|
||||||
|
### 一个实用的多区域示例
|
||||||
|
|
||||||
|
假设你为你的组织的一台服务器配置防火墙。你希望允许全世界使用 `http` 和 `https` 的访问,你的组织(1.1.0.0/16)和工作组(1.1.1.0/8)使用 `ssh` 访问,并且你的工作组可以访问 `samba` 服务。使用 firewalld 中的区域,你可以用一个很直观的方式去实现这个配置。
|
||||||
|
|
||||||
|
`public` 这个命名,它的逻辑似乎是把全世界访问指定为公共区域,而 `internal` 区域用于为本地使用。从在 `public` 区域内设置使用 `http` 和 `https` 替换 `dhcpv6-client` 和 `ssh` 服务来开始:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --permanent --zone=public --remove-service=dhcpv6-client
|
||||||
|
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||||
|
# firewall-cmd --permanent --zone=public --add-service=http
|
||||||
|
# firewall-cmd --permanent --zone=public --add-service=https
|
||||||
|
```
|
||||||
|
|
||||||
|
然后,取消 `internal` 区域的 `mdns`、`samba-client` 和 `dhcpv6-client` 服务(仅保留 `ssh`),并增加你的组织为源:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --permanent --zone=internal --remove-service=mdns
|
||||||
|
# firewall-cmd --permanent --zone=internal --remove-service=samba-client
|
||||||
|
# firewall-cmd --permanent --zone=internal --remove-service=dhcpv6-client
|
||||||
|
# firewall-cmd --permanent --zone=internal --add-source=1.1.0.0/16
|
||||||
|
```
|
||||||
|
|
||||||
|
为容纳你提升的 `samba` 的权限,增加一个富规则:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --permanent --zone=internal --add-rich-rule='rule family=ipv4 source address="1.1.1.0/8" service name="samba" accept'
|
||||||
|
```
|
||||||
|
|
||||||
|
最后,重新加载,把这些变化拉取到会话中:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
仅剩下少数的细节了。从一个 `internal` 区域以外的 IP 去尝试通过 `ssh` 到你的服务器,结果是回复一个拒绝的消息。它是 firewalld 默认的。更为安全的作法是去显示不活跃的 IP 行为并丢弃该连接。改变 `public` 区域的目标为 `DROP`,而不是 `default` 来实现它:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --permanent --zone=public --set-target=DROP
|
||||||
|
# firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
但是,等等,你不再可以 ping 了,甚至是从内部区域!并且 icmp (ping 使用的协议)并不在 firewalld 可以列入白名单的服务列表中。那是因为,icmp 是第 3 层的 IP 协议,它没有端口的概念,不像那些捆绑了端口的服务。在设置公共区域为 `DROP` 之前,ping 能够通过防火墙是因为你的 `default` 目标通过它到达防火墙的默认动作(default),即允许它通过。但现在它已经被删除了。
|
||||||
|
|
||||||
|
为恢复内部网络的 ping,使用一个富规则:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --permanent --zone=internal --add-rich-rule='rule protocol value="icmp" accept'
|
||||||
|
# firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
结果如下,这里是两个活动区域的配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
# firewall-cmd --zone=public --list-all
|
||||||
|
public (default, active)
|
||||||
|
interfaces: eno1 eno2
|
||||||
|
sources:
|
||||||
|
services: http https
|
||||||
|
ports:
|
||||||
|
masquerade: no
|
||||||
|
forward-ports:
|
||||||
|
icmp-blocks:
|
||||||
|
rich rules:
|
||||||
|
# firewall-cmd --permanent --zone=public --get-target
|
||||||
|
DROP
|
||||||
|
# firewall-cmd --zone=internal --list-all
|
||||||
|
internal (active)
|
||||||
|
interfaces:
|
||||||
|
sources: 1.1.0.0/16
|
||||||
|
services: ssh
|
||||||
|
ports:
|
||||||
|
masquerade: no
|
||||||
|
forward-ports:
|
||||||
|
icmp-blocks:
|
||||||
|
rich rules:
|
||||||
|
rule family=ipv4 source address="1.1.1.0/8" service name="samba" accept
|
||||||
|
rule protocol value="icmp" accept
|
||||||
|
# firewall-cmd --permanent --zone=internal --get-target
|
||||||
|
default
|
||||||
|
```
|
||||||
|
|
||||||
|
这个设置演示了一个三层嵌套的防火墙。最外层,`public`,是一个接口区域,包含全世界的访问。紧接着的一层,`internal`,是一个源区域,包含你的组织,它是 `public` 的一个子集。最后,一个富规则增加到最内层,包含了你的工作组,它是 `internal` 的一个子集。
|
||||||
|
|
||||||
|
这里的关键信息是,当在一个场景中可以突破到嵌套层,最外层将使用接口区域,接下来的将使用一个源区域,并且在源区域中额外使用富规则。
|
||||||
|
|
||||||
|
### 调试
|
||||||
|
|
||||||
|
firewalld 采用直观范式来设计防火墙,但比它的前任 iptables 更容易产生歧义。如果产生无法预料的行为,或者为了更好地理解 firewalld 是怎么工作的,则可以使用 iptables 描述 netfilter 是如何配置操作的。前一个示例的输出如下,为了简单起见,将输出和日志进行了修剪:
|
||||||
|
|
||||||
|
```
|
||||||
|
# iptables -S
|
||||||
|
-P INPUT ACCEPT
|
||||||
|
... (forward and output lines) ...
|
||||||
|
-N INPUT_ZONES
|
||||||
|
-N INPUT_ZONES_SOURCE
|
||||||
|
-N INPUT_direct
|
||||||
|
-N IN_internal
|
||||||
|
-N IN_internal_allow
|
||||||
|
-N IN_internal_deny
|
||||||
|
-N IN_public
|
||||||
|
-N IN_public_allow
|
||||||
|
-N IN_public_deny
|
||||||
|
-A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
|
||||||
|
-A INPUT -i lo -j ACCEPT
|
||||||
|
-A INPUT -j INPUT_ZONES_SOURCE
|
||||||
|
-A INPUT -j INPUT_ZONES
|
||||||
|
-A INPUT -p icmp -j ACCEPT
|
||||||
|
-A INPUT -m conntrack --ctstate INVALID -j DROP
|
||||||
|
-A INPUT -j REJECT --reject-with icmp-host-prohibited
|
||||||
|
... (forward and output lines) ...
|
||||||
|
-A INPUT_ZONES -i eno1 -j IN_public
|
||||||
|
-A INPUT_ZONES -i eno2 -j IN_public
|
||||||
|
-A INPUT_ZONES -j IN_public
|
||||||
|
-A INPUT_ZONES_SOURCE -s 1.1.0.0/16 -g IN_internal
|
||||||
|
-A IN_internal -j IN_internal_deny
|
||||||
|
-A IN_internal -j IN_internal_allow
|
||||||
|
-A IN_internal_allow -p tcp -m tcp --dport 22 -m conntrack --ctstate NEW -j ACCEPT
|
||||||
|
-A IN_internal_allow -s 1.1.1.0/8 -p udp -m udp --dport 137 -m conntrack --ctstate NEW -j ACCEPT
|
||||||
|
-A IN_internal_allow -s 1.1.1.0/8 -p udp -m udp --dport 138 -m conntrack --ctstate NEW -j ACCEPT
|
||||||
|
-A IN_internal_allow -s 1.1.1.0/8 -p tcp -m tcp --dport 139 -m conntrack --ctstate NEW -j ACCEPT
|
||||||
|
-A IN_internal_allow -s 1.1.1.0/8 -p tcp -m tcp --dport 445 -m conntrack --ctstate NEW -j ACCEPT
|
||||||
|
-A IN_internal_allow -p icmp -m conntrack --ctstate NEW -j ACCEPT
|
||||||
|
-A IN_public -j IN_public_deny
|
||||||
|
-A IN_public -j IN_public_allow
|
||||||
|
-A IN_public -j DROP
|
||||||
|
-A IN_public_allow -p tcp -m tcp --dport 80 -m conntrack --ctstate NEW -j ACCEPT
|
||||||
|
-A IN_public_allow -p tcp -m tcp --dport 443 -m conntrack --ctstate NEW -j ACCEPT
|
||||||
|
```
|
||||||
|
|
||||||
|
在上面的 iptables 输出中,新的链(以 `-N` 开始的行)是被首先声明的。剩下的规则是附加到(以 `-A` 开始的行) iptables 中的。已建立的连接和本地流量是允许通过的,并且入站包被转到 `INPUT_ZONES_SOURCE` 链,在那里如果存在相应的区域,IP 将被发送到那个区域。从那之后,流量被转到 `INPUT_ZONES` 链,从那里它被路由到一个接口区域。如果在那里它没有被处理,icmp 是允许通过的,无效的被丢弃,并且其余的都被拒绝。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
firewalld 是一个文档不足的防火墙配置工具,它的功能远比大多数人认识到的更为强大。以创新的区域范式,firewalld 允许系统管理员去分解流量到每个唯一处理它的分类中,简化了配置过程。因为它直观的设计和语法,它在实践中不但被用于简单的单一区域中也被用于复杂的多区域配置中。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linuxjournal.com/content/understanding-firewalld-multi-zone-configurations?page=0,0
|
||||||
|
|
||||||
|
作者:[Nathan Vance][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linuxjournal.com/users/nathan-vance
|
||||||
|
[1]:https://www.linuxjournal.com/tag/firewalls
|
||||||
|
[2]:https://www.linuxjournal.com/tag/howtos
|
||||||
|
[3]:https://www.linuxjournal.com/tag/networking
|
||||||
|
[4]:https://www.linuxjournal.com/tag/security
|
||||||
|
[5]:https://www.linuxjournal.com/tag/sysadmin
|
||||||
|
[6]:https://www.linuxjournal.com/users/william-f-polik
|
||||||
|
[7]:https://www.linuxjournal.com/users/nathan-vance
|
||||||
@ -1,36 +1,28 @@
|
|||||||
Translating By LHRchina
|
使用 LXD 容器运行 Ubuntu Core
|
||||||
|
|
||||||
|
|
||||||
Ubuntu Core in LXD containers
|
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
### Share or save
|
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### What’s Ubuntu Core?
|
### Ubuntu Core 是什么?
|
||||||
|
|
||||||
Ubuntu Core is a version of Ubuntu that’s fully transactional and entirely based on snap packages.
|
Ubuntu Core 是完全基于 snap 包构建,并且完全事务化的 Ubuntu 版本。
|
||||||
|
|
||||||
Most of the system is read-only. All installed applications come from snap packages and all updates are done using transactions. Meaning that should anything go wrong at any point during a package or system update, the system will be able to revert to the previous state and report the failure.
|
该系统大部分是只读的,所有已安装的应用全部来自 snap 包,完全使用事务化更新。这意味着不管在系统更新还是安装软件的时候遇到问题,整个系统都可以回退到之前的状态并且记录这个错误。
|
||||||
|
|
||||||
The current release of Ubuntu Core is called series 16 and was released in November 2016.
|
最新版是在 2016 年 11 月发布的 Ubuntu Core 16。
|
||||||
|
|
||||||
Note that on Ubuntu Core systems, only snap packages using confinement can be installed (no “classic” snaps) and that a good number of snaps will not fully work in this environment or will require some manual intervention (creating user and groups, …). Ubuntu Core gets improved on a weekly basis as new releases of snapd and the “core” snap are put out.
|
注意,Ubuntu Core 限制只能够安装 snap 包(而非 “传统” 软件包),并且有相当数量的 snap 包在当前环境下不能正常运行,或者需要人工干预(创建用户和用户组等)才能正常运行。随着新版的 snapd 和 “core” snap 包发布,Ubuntu Core 每周都会得到改进。
|
||||||
|
|
||||||
### Requirements
|
### 环境需求
|
||||||
|
|
||||||
As far as LXD is concerned, Ubuntu Core is just another Linux distribution. That being said, snapd does require unprivileged FUSE mounts and AppArmor namespacing and stacking, so you will need the following:
|
就 LXD 而言,Ubuntu Core 仅仅相当于另一个 Linux 发行版。也就是说,snapd 需要挂载无特权的 FUSE 和 AppArmor 命名空间以及软件栈,像下面这样:
|
||||||
|
|
||||||
* An up to date Ubuntu system using the official Ubuntu kernel
|
* 一个新版的使用 Ubuntu 官方内核的系统
|
||||||
|
* 一个新版的 LXD
|
||||||
|
|
||||||
* An up to date version of LXD
|
### 创建一个 Ubuntu Core 容器
|
||||||
|
|
||||||
### Creating an Ubuntu Core container
|
当前 Ubuntu Core 镜像发布在社区的镜像服务器。你可以像这样启动一个新的容器:
|
||||||
|
|
||||||
The Ubuntu Core images are currently published on the community image server.
|
|
||||||
You can launch a new container with:
|
|
||||||
|
|
||||||
```
|
```
|
||||||
stgraber@dakara:~$ lxc launch images:ubuntu-core/16 ubuntu-core
|
stgraber@dakara:~$ lxc launch images:ubuntu-core/16 ubuntu-core
|
||||||
@ -38,9 +30,9 @@ Creating ubuntu-core
|
|||||||
Starting ubuntu-core
|
Starting ubuntu-core
|
||||||
```
|
```
|
||||||
|
|
||||||
The container will take a few seconds to start, first executing a first stage loader that determines what read-only image to use and setup the writable layers. You don’t want to interrupt the container in that stage and “lxc exec” will likely just fail as pretty much nothing is available at that point.
|
这个容器启动需要一点点时间,它会先执行第一阶段的加载程序,加载程序会确定使用哪一个镜像(镜像是只读的),并且在系统上设置一个可读层,你不要在这一阶段中断容器执行,这个时候什么都没有,所以执行 `lxc exec` 将会出错。
|
||||||
|
|
||||||
Seconds later, “lxc list” will show the container IP address, indicating that it’s booted into Ubuntu Core:
|
几秒钟之后,执行 `lxc list` 将会展示容器的 IP 地址,这表明已经启动了 Ubuntu Core:
|
||||||
|
|
||||||
```
|
```
|
||||||
stgraber@dakara:~$ lxc list
|
stgraber@dakara:~$ lxc list
|
||||||
@ -51,7 +43,7 @@ stgraber@dakara:~$ lxc list
|
|||||||
+-------------+---------+----------------------+----------------------------------------------+------------+-----------+
|
+-------------+---------+----------------------+----------------------------------------------+------------+-----------+
|
||||||
```
|
```
|
||||||
|
|
||||||
You can then interact with that container the same way you would any other:
|
之后你就可以像使用其他的交互一样和这个容器进行交互:
|
||||||
|
|
||||||
```
|
```
|
||||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||||
@ -63,11 +55,11 @@ pc-kernel 4.4.0-45-4 37 canonical -
|
|||||||
root@ubuntu-core:~#
|
root@ubuntu-core:~#
|
||||||
```
|
```
|
||||||
|
|
||||||
### Updating the container
|
### 更新容器
|
||||||
|
|
||||||
If you’ve been tracking the development of Ubuntu Core, you’ll know that those versions above are pretty old. That’s because the disk images that are used as the source for the Ubuntu Core LXD images are only refreshed every few months. Ubuntu Core systems will automatically update once a day and then automatically reboot to boot onto the new version (and revert if this fails).
|
如果你一直关注着 Ubuntu Core 的开发,你应该知道上面的版本已经很老了。这是因为被用作 Ubuntu LXD 镜像的代码每隔几个月才会更新。Ubuntu Core 系统在重启时会检查更新并进行自动更新(更新失败会回退)。
|
||||||
|
|
||||||
If you want to immediately force an update, you can do it with:
|
如果你想现在强制更新,你可以这样做:
|
||||||
|
|
||||||
```
|
```
|
||||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||||
@ -81,7 +73,7 @@ series 16
|
|||||||
root@ubuntu-core:~#
|
root@ubuntu-core:~#
|
||||||
```
|
```
|
||||||
|
|
||||||
And then reboot the system and check the snapd version again:
|
然后重启一下 Ubuntu Core 系统,然后看看 snapd 的版本。
|
||||||
|
|
||||||
```
|
```
|
||||||
root@ubuntu-core:~# reboot
|
root@ubuntu-core:~# reboot
|
||||||
@ -95,7 +87,7 @@ series 16
|
|||||||
root@ubuntu-core:~#
|
root@ubuntu-core:~#
|
||||||
```
|
```
|
||||||
|
|
||||||
You can get an history of all snapd interactions with
|
你也可以像下面这样查看所有 snapd 的历史记录:
|
||||||
|
|
||||||
```
|
```
|
||||||
stgraber@dakara:~$ lxc exec ubuntu-core snap changes
|
stgraber@dakara:~$ lxc exec ubuntu-core snap changes
|
||||||
@ -105,9 +97,9 @@ ID Status Spawn Ready Summary
|
|||||||
3 Done 2017-01-31T05:21:30Z 2017-01-31T05:22:45Z Refresh all snaps in the system
|
3 Done 2017-01-31T05:21:30Z 2017-01-31T05:22:45Z Refresh all snaps in the system
|
||||||
```
|
```
|
||||||
|
|
||||||
### Installing some snaps
|
### 安装 Snap 软件包
|
||||||
|
|
||||||
Let’s start with the simplest snaps of all, the good old Hello World:
|
以一个最简单的例子开始,经典的 Hello World:
|
||||||
|
|
||||||
```
|
```
|
||||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||||
@ -117,7 +109,7 @@ root@ubuntu-core:~# hello-world
|
|||||||
Hello World!
|
Hello World!
|
||||||
```
|
```
|
||||||
|
|
||||||
And then move on to something a bit more useful:
|
接下来让我们看一些更有用的:
|
||||||
|
|
||||||
```
|
```
|
||||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||||
@ -125,9 +117,9 @@ root@ubuntu-core:~# snap install nextcloud
|
|||||||
nextcloud 11.0.1snap2 from 'nextcloud' installed
|
nextcloud 11.0.1snap2 from 'nextcloud' installed
|
||||||
```
|
```
|
||||||
|
|
||||||
Then hit your container over HTTP and you’ll get to your newly deployed Nextcloud instance.
|
之后通过 HTTP 访问你的容器就可以看到刚才部署的 Nextcloud 实例。
|
||||||
|
|
||||||
If you feel like testing the latest LXD straight from git, you can do so with:
|
如果你想直接通过 git 测试最新版 LXD,你可以这样做:
|
||||||
|
|
||||||
```
|
```
|
||||||
stgraber@dakara:~$ lxc config set ubuntu-core security.nesting true
|
stgraber@dakara:~$ lxc config set ubuntu-core security.nesting true
|
||||||
@ -156,7 +148,7 @@ What IPv6 address should be used (CIDR subnet notation, “auto” or “none”
|
|||||||
LXD has been successfully configured.
|
LXD has been successfully configured.
|
||||||
```
|
```
|
||||||
|
|
||||||
And because container inception never gets old, lets run Ubuntu Core 16 inside Ubuntu Core 16:
|
已经设置过的容器不能回退版本,但是可以在 Ubuntu Core 16 中运行另一个 Ubuntu Core 16 容器:
|
||||||
|
|
||||||
```
|
```
|
||||||
root@ubuntu-core:~# lxc launch images:ubuntu-core/16 nested-core
|
root@ubuntu-core:~# lxc launch images:ubuntu-core/16 nested-core
|
||||||
@ -170,28 +162,29 @@ root@ubuntu-core:~# lxc list
|
|||||||
+-------------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
+-------------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||||
```
|
```
|
||||||
|
|
||||||
### Conclusion
|
### 写在最后
|
||||||
|
|
||||||
If you ever wanted to try Ubuntu Core, this is a great way to do it. It’s also a great tool for snap authors to make sure their snap is fully self-contained and will work in all environments.
|
如果你只是想试用一下 Ubuntu Core,这是一个不错的方法。对于 snap 包开发者来说,这也是一个不错的工具来测试你的 snap 包能否在不同的环境下正常运行。
|
||||||
|
|
||||||
Ubuntu Core is a great fit for environments where you want to ensure that your system is always up to date and is entirely reproducible. This does come with a number of constraints that may or may not work for you.
|
如果你希望你的系统总是最新的,并且整体可复制,Ubuntu Core 是一个很不错的方案,不过这也会带来一些相应的限制,所以可能不太适合你。
|
||||||
|
|
||||||
And lastly, a word of warning. Those images are considered as good enough for testing, but aren’t officially supported at this point. We are working towards getting fully supported Ubuntu Core LXD images on the official Ubuntu image server in the near future.
|
最后是一个警告,对于测试来说,这些镜像是足够的,但是当前并没有被正式的支持。在不久的将来,官方的 Ubuntu server 可以完整的支持 Ubuntu Core LXD 镜像。
|
||||||
|
|
||||||
### Extra information
|
### 附录
|
||||||
|
|
||||||
The main LXD website is at: [https://linuxcontainers.org/lxd][2] Development happens on Github at: [https://github.com/lxc/lxd][3]
|
- LXD 主站:[https://linuxcontainers.org/lxd][2]
|
||||||
Mailing-list support happens on: [https://lists.linuxcontainers.org][4]
|
- Github:[https://github.com/lxc/lxd][3]
|
||||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
- 邮件列表:[https://lists.linuxcontainers.org][4]
|
||||||
Try LXD online: [https://linuxcontainers.org/lxd/try-it][5]
|
- IRC:#lxcontainers on irc.freenode.net
|
||||||
|
- 在线试用:[https://linuxcontainers.org/lxd/try-it][5]
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
via: https://insights.ubuntu.com/2017/02/27/ubuntu-core-in-lxd-containers/
|
via: https://insights.ubuntu.com/2017/02/27/ubuntu-core-in-lxd-containers/
|
||||||
|
|
||||||
作者:[Stéphane Graber ][a]
|
作者:[Stéphane Graber][a]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[aiwhj](https://github.com/aiwhj)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,48 @@
|
|||||||
|
肯特·贝克:改变人生的代码整理魔法
|
||||||
|
==========
|
||||||
|
|
||||||
|
> 本文作者<ruby>肯特·贝克<rt>Kent Beck</rt></ruby>,是最早研究软件开发的模式和重构的人之一,是敏捷开发的开创者之一,更是极限编程和测试驱动开发的创始人,同时还是 Smalltalk 和 JUnit 的作者,对当今世界的软件开发影响深远。现在 Facebook 工作。
|
||||||
|
|
||||||
|
本周我一直在整理 Facebook 代码,而且我喜欢这个工作。我的职业生涯中已经整理了数千小时的代码,我有一套使这种整理更加安全、有趣和高效的规则。
|
||||||
|
|
||||||
|
整理工作是通过一系列短小而安全的步骤进行的。事实上,规则一就是**如果这很难,那就不要去做**。我以前在晚上做填字游戏。如果我卡住那就去睡觉,第二天晚上那些没有发现的线索往往很容易发现。与其想要一心搞个大的,不如在遇到阻力的时候停下来。
|
||||||
|
|
||||||
|
整理会陷入这样一种感觉:你错失的要比你从一个个成功中获得的更多(稍后会细说)。第二条规则是**当你充满活力时开始,当你累了时停下来**。起来走走。如果还没有恢复精神,那这一天的工作就算做完了。
|
||||||
|
|
||||||
|
只有在仔细追踪其它变化的时候(我把它和最新的差异搞混了),整理工作才可以与开发同步进行。第三条规则是**立即完成每个环节的工作**。与功能开发所不同的是,功能开发只有在完成一大块工作时才有意义,而整理是基于时间一点点完成的。
|
||||||
|
|
||||||
|
整理在任何步骤中都只需要付出不多的努力,所以我会在任何步骤遇到麻烦的时候放弃。所以,规则四是**两次失败后恢复**。如果我整理代码,运行测试,并遇到测试失败,那么我会立即修复它。如果我修复失败,我会立即恢复到上次已知最好的状态。
|
||||||
|
|
||||||
|
即便没有闪亮的新设计的愿景,整理也是有用的。不过,有时候我想看看事情会如何发展,所以第五条就是**实践**。执行一系列的整理和还原。第二次将更快,你会更加熟悉避免哪些坑。
|
||||||
|
|
||||||
|
只有在附带损害的风险较低,审查整理变化的成本也较低的时候整理才有用。规则六是**隔离整理**。如果你错过了在编写代码中途整理的机会,那么接下来可能很困难。要么完成并接着整理,要么还原、整理并进行修改。
|
||||||
|
|
||||||
|
试试这些。将临时申明的变量移动到它第一次使用的位置,简化布尔表达式(`return expression == True`?),提取一个 helper,将逻辑或状态的范围缩小到实际使用的位置。
|
||||||
|
|
||||||
|
### 规则
|
||||||
|
|
||||||
|
- 规则一、 如果这很难,那就不要去做
|
||||||
|
- 规则二、 当你充满活力时开始,当你累了时停下来
|
||||||
|
- 规则三、 立即完成每个环节工作
|
||||||
|
- 规则四、 两次失败后恢复
|
||||||
|
- 规则五、 实践
|
||||||
|
- 规则六、 隔离整理
|
||||||
|
|
||||||
|
### 尾声
|
||||||
|
|
||||||
|
我通过严格地整理改变了架构、提取了框架。这种方式可以安全地做出重大改变。我认为这是因为,虽然每次整理的成本是不变的,但回报是指数级的,但我需要数据和模型来解释这个假说。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.facebook.com/notes/kent-beck/the-life-changing-magic-of-tidying-up-code/1544047022294823/
|
||||||
|
|
||||||
|
作者:[KENT BECK][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.facebook.com/kentlbeck
|
||||||
|
[1]:https://www.facebook.com/notes/kent-beck/the-life-changing-magic-of-tidying-up-code/1544047022294823/?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#
|
||||||
|
[2]:https://www.facebook.com/kentlbeck
|
||||||
|
[3]:https://www.facebook.com/notes/kent-beck/the-life-changing-magic-of-tidying-up-code/1544047022294823/
|
||||||
@ -0,0 +1,33 @@
|
|||||||
|
Let’s Encrypt :2018 年 1 月发布通配证书
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
Let’s Encrypt 将于 2018 年 1 月开始发放通配证书。通配证书是一个经常需要的功能,并且我们知道在一些情况下它可以使 HTTPS 部署更简单。我们希望提供通配证书有助于加速网络向 100% HTTPS 进展。
|
||||||
|
|
||||||
|
Let’s Encrypt 目前通过我们的全自动 DV 证书颁发和管理 API 保护了 4700 万个域名。自从 Let's Encrypt 的服务于 2015 年 12 月发布以来,它已经将加密网页的数量从 40% 大大地提高到了 58%。如果你对通配证书的可用性以及我们达成 100% 的加密网页的使命感兴趣,我们请求你为我们的[夏季筹款活动][1](LCTT 译注:之前的夏季活动,原文发布于今年夏季)做出贡献。
|
||||||
|
|
||||||
|
通配符证书可以保护基本域的任何数量的子域名(例如 *.example.com)。这使得管理员可以为一个域及其所有子域使用单个证书和密钥对,这可以使 HTTPS 部署更加容易。
|
||||||
|
|
||||||
|
通配符证书将通过我们[即将发布的 ACME v2 API 终端][2]免费提供。我们最初只支持通过 DNS 进行通配符证书的基础域验证,但是随着时间的推移可能会探索更多的验证方式。我们鼓励人们在我们的[社区论坛][3]上提出任何关于通配证书支持的问题。
|
||||||
|
|
||||||
|
我们决定在夏季筹款活动中宣布这一令人兴奋的进展,因为我们是一个非营利组织,这要感谢使用我们服务的社区的慷慨支持。如果你想支持一个更安全和保密的网络,[现在捐赠吧][4]!
|
||||||
|
|
||||||
|
我们要感谢我们的[社区][5]和我们的[赞助者][6],使我们所做的一切成为可能。如果你的公司或组织能够赞助 Let's Encrypt,请发送电子邮件至 [sponsor@letsencrypt.org][7]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://letsencrypt.org/2017/07/06/wildcard-certificates-coming-jan-2018.html
|
||||||
|
|
||||||
|
作者:[Josh Aas][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://letsencrypt.org/2017/07/06/wildcard-certificates-coming-jan-2018.html
|
||||||
|
[1]:https://letsencrypt.org/donate/
|
||||||
|
[2]:https://letsencrypt.org/2017/06/14/acme-v2-api.html
|
||||||
|
[3]:https://community.letsencrypt.org/
|
||||||
|
[4]:https://letsencrypt.org/donate/
|
||||||
|
[5]:https://letsencrypt.org/getinvolved/
|
||||||
|
[6]:https://letsencrypt.org/sponsors/
|
||||||
|
[7]:mailto:sponsor@letsencrypt.org
|
||||||
@ -0,0 +1,149 @@
|
|||||||
|
Linux 用户的手边工具:Guide to Linux
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> “Guide to Linux” 这个应用并不完美,但它是一个非常好的工具,可以帮助你学习 Linux 命令。
|
||||||
|
|
||||||
|
还记得你初次使用 Linux 时的情景吗?对于有些人来说,他的学习曲线可能有些挑战性。比如,在 `/usr/bin` 中能找到许多命令。在我目前使用的 Elementary OS 系统中,命令的数量是 1944 个。当然,这并不全是真实的命令(或者,我会使用到的命令数量),但这个数目是很多的。
|
||||||
|
|
||||||
|
正因为如此(并且不同平台不一样),现在,新用户(和一些已经熟悉的用户)需要一些帮助。
|
||||||
|
|
||||||
|
对于每个管理员来说,这些技能是必须具备的:
|
||||||
|
|
||||||
|
* 熟悉平台
|
||||||
|
* 理解命令
|
||||||
|
* 编写 Shell 脚本
|
||||||
|
|
||||||
|
当你寻求帮助时,有时,你需要去“阅读那些该死的手册”(Read the Fine/Freaking/Funky Manual,LCTT 译注:一个网络用语,简写为 RTFM),但是当你自己都不知道要找什么的时候,它就没办法帮到你了。在那个时候,你就会为你拥有像 [Guide to Linux][15] 这样的手机应用而感到高兴。
|
||||||
|
|
||||||
|
不像你在 Linux.com 上看到的那些大多数的内容,这篇文章只是介绍一个 Android 应用的。为什么呢?因为这个特殊的 应用是用来帮助用户学习 Linux 的。
|
||||||
|
|
||||||
|
而且,它做的很好。
|
||||||
|
|
||||||
|
关于这个应用我清楚地告诉你 —— 它并不完美。Guide to Linux 里面充斥着很烂的英文,糟糕的标点符号,并且(如果你是一个纯粹主义者),它从来没有提到过 GNU。在这之上,它有一个特别的功能(通常它对用户非常有用)功能不是很有用(LCTT 译注:是指终端模拟器,后面会详细解释)。除此之外,我敢说 Guide to Linux 可能是 Linux 平台上最好的一个移动端的 “口袋指南”。
|
||||||
|
|
||||||
|
对于这个应用,你可能会喜欢它的如下特性:
|
||||||
|
|
||||||
|
* 离线使用
|
||||||
|
* Linux 教程
|
||||||
|
* 基础的和高级的 Linux 命令的详细介绍
|
||||||
|
* 包含了命令示例和语法
|
||||||
|
* 专用的 Shell 脚本模块
|
||||||
|
|
||||||
|
除此以外,Guide to Linux 是免费提供的(尽管里面有一些广告)。如果你想去除广告,它有一个应用内的购买,($2.99 USD/年)可以去消除广告。
|
||||||
|
|
||||||
|
让我们来安装这个应用,来看一看它的构成。
|
||||||
|
|
||||||
|
### 安装
|
||||||
|
|
||||||
|
像所有的 Android 应用一样,安装 Guide to Linux 是非常简单的。按照以下简单的几步就可以安装它了:
|
||||||
|
|
||||||
|
1. 打开你的 Android 设备上的 Google Play 商店
|
||||||
|
2. 搜索 Guide to Linux
|
||||||
|
3. 找到 Essence Infotech 的那个,并轻触进入
|
||||||
|
4. 轻触 Install
|
||||||
|
5. 允许安装
|
||||||
|
|
||||||
|
安装完成后,你可以在你的<ruby>应用抽屉<rt>App Drawer</rt></ruby>或主屏幕上(或者两者都有)上找到它去启动 Guide to Linux 。轻触图标去启动这个应用。
|
||||||
|
|
||||||
|
### 使用
|
||||||
|
|
||||||
|
让我们看一下 Guide to Linux 的每个功能。我发现某些功能比其它的更有帮助,或许你的体验会不一样。在我们分别讲解之前,我将重点提到其界面。开发者在为这个应用创建一个易于使用的界面方面做的很好。
|
||||||
|
|
||||||
|
从主窗口中(图 1),你可以获取四个易于访问的功能。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 1: The Guide to Linux 主窗口。[已获授权][1]*
|
||||||
|
|
||||||
|
轻触四个图标中的任何一个去启动一个功能,然后,准备去学习。
|
||||||
|
|
||||||
|
### 教程
|
||||||
|
|
||||||
|
让我们从这个应用教程的最 “新手友好” 的功能开始。打开“Tutorial”功能,然后,将看到该教程的欢迎部分,“Linux 操作系统介绍”(图 2)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 2:教程开始。[已获授权][2]*
|
||||||
|
|
||||||
|
如果你轻触 “汉堡包菜单” (左上角的三个横线),显示了内容列表(图 3),因此,你可以在教程中选择任何一个可用部分。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 3:教程的内容列表。[已获授权][3]*
|
||||||
|
|
||||||
|
如果你现在还没有注意到,Guide to Linux 教程部分是每个主题的一系列短文的集合。短文包含图片和链接(有时候),链接将带你到指定的 web 网站(根据主题的需要)。这里没有交互,仅仅只能阅读。但是,这是一个很好的起点,由于开发者在描述各个部分方面做的很好(虽然有语法问题)。
|
||||||
|
|
||||||
|
尽管你可以在窗口的顶部看到一个搜索选项,但是,我还是没有发现这一功能的任何效果 —— 但是,你可以试一下。
|
||||||
|
|
||||||
|
对于 Linux 新手来说,如果希望获得 Linux 管理的技能,你需要去阅读整个教程。完成之后,转到下一个主题。
|
||||||
|
|
||||||
|
### 命令
|
||||||
|
|
||||||
|
命令功能类似于手机上的 man 页面一样,是大量的频繁使用的 Linux 命令。当你首次打开它,欢迎页面将详细解释使用命令的益处。
|
||||||
|
|
||||||
|
读完之后,你可以轻触向右的箭头(在屏幕底部)或轻触 “汉堡包菜单” ,然后从侧边栏中选择你想去学习的其它命令。(图 4)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 4:命令侧边栏允许你去查看列出的命令。[已获授权][4]*
|
||||||
|
|
||||||
|
轻触任意一个命令,你可以阅读这个命令的解释。每个命令解释页面和它的选项都提供了怎么去使用的示例。
|
||||||
|
|
||||||
|
### Shell 脚本
|
||||||
|
|
||||||
|
在这个时候,你开始熟悉 Linux 了,并对命令已经有一定程序的掌握。现在,是时候去熟悉 shell 脚本了。这个部分的设置方式与教程部分和命令部分相同。
|
||||||
|
|
||||||
|
你可以打开内容列表的侧边栏,然后打开包含 shell 脚本教程的任意部分(图 5)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 5:Shell 脚本节看上去很熟悉。[已获授权][5]*
|
||||||
|
|
||||||
|
开发者在解释如何最大限度地利用 shell 脚本方面做的很好。对于任何有兴趣学习 shell 脚本细节的人来说,这是个很好的起点。
|
||||||
|
|
||||||
|
### 终端
|
||||||
|
|
||||||
|
现在我们到了一个新的地方,开发者在这个应用中包含了一个终端模拟器。遗憾的是,当你在一个没有 “root” 权限的 Android 设备上安装这个应用时,你会发现你被限制在一个只读文件系统中,在那里,大部分命令根本无法工作。但是,我在一台 Pixel 2 (通过 Android 应用商店)安装的 Guide to Linux 中,可以使用更多的这个功能(还只是较少的一部分)。在一台 OnePlus 3 (非 root 过的)上,不管我改变到哪个目录,我都是得到相同的错误信息 “permission denied”,甚至是一个简单的命令也如此。
|
||||||
|
|
||||||
|
在 Chromebook 上,不管怎么操作,它都是正常的(图 6)。可以说,它可以一直很好地工作在一个只读操作系统中(因此,你不能用它进行真正的工作或创建新文件)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 6: 可以完美地(可以这么说)用一个终端模拟器去工作。[已获授权][6]*
|
||||||
|
|
||||||
|
记住,这并不是真实的成熟终端,但却是一个新用户去熟悉终端是怎么工作的一种方法。遗憾的是,大多数用户只会发现自己对这个工具的终端功能感到沮丧,仅仅是因为,它们不能使用他们在其它部分学到的东西。开发者可能将这个终端功能打造成了一个 Linux 文件系统沙箱,因此,用户可以真实地使用它去学习。每次用户打开那个工具,它将恢复到原始状态。这只是我一个想法。
|
||||||
|
|
||||||
|
### 写在最后…
|
||||||
|
|
||||||
|
尽管终端功能被一个只读文件系统所限制(几乎到了没法使用的程序),Guide to Linux 仍然是一个新手学习 Linux 的好工具。在 guide to Linux 中,你将学习关于 Linux、命令、和 shell 脚本的很多知识,以便在你安装你的第一个发行版之前,让你学习 Linux 有一个好的起点。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linux.com/learn/intro-to-linux/2017/8/guide-linux-app-handy-tool-every-level-linux-user
|
||||||
|
|
||||||
|
作者:[JACK WALLEN][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linux.com/users/jlwallen
|
||||||
|
[1]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[2]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[3]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[4]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[5]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[6]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[7]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[8]:https://www.linux.com/files/images/guidetolinux1jpg
|
||||||
|
[9]:https://www.linux.com/files/images/guidetolinux2jpg
|
||||||
|
[10]:https://www.linux.com/files/images/guidetolinux3jpg-0
|
||||||
|
[11]:https://www.linux.com/files/images/guidetolinux4jpg
|
||||||
|
[12]:https://www.linux.com/files/images/guidetolinux-5-newjpg
|
||||||
|
[13]:https://www.linux.com/files/images/guidetolinux6jpg-0
|
||||||
|
[14]:https://www.linux.com/files/images/guide-linuxpng
|
||||||
|
[15]:https://play.google.com/store/apps/details?id=com.essence.linuxcommands
|
||||||
|
[16]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||||
|
[17]:https://www.addtoany.com/share#url=https%3A%2F%2Fwww.linux.com%2Flearn%2Fintro-to-linux%2F2017%2F8%2Fguide-linux-app-handy-tool-every-level-linux-user&title=Guide%20to%20Linux%20App%20Is%20a%20Handy%20Tool%20for%20Every%20Level%20of%20Linux%20User
|
||||||
@ -0,0 +1,85 @@
|
|||||||
|
放弃你的代码,而不是你的时间
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
作为软件开发人员,我认为我们可以认同开源代码^注1 已经[改变了世界][9]。它的公共性质去除了壁垒,可以让软件可以变的最好。但问题是,太多有价值的项目由于领导者的精力耗尽而停滞不前:
|
||||||
|
|
||||||
|
>“我没有时间和精力去投入开源了。我在开源上没有得到任何收入,所以我在那上面花的时间,我可以用在‘生活上的事’,或者写作上……正因为如此,我决定现在结束我所有的开源工作。”
|
||||||
|
>
|
||||||
|
>—[Ryan Bigg,几个 Ruby 和 Elixir 项目的前任维护者][1]
|
||||||
|
>
|
||||||
|
>“这也是一个巨大的机会成本,由于我无法同时学习或者完成很多事情,FubuMVC 占用了我很多的时间,这是它现在必须停下来的主要原因。”
|
||||||
|
>
|
||||||
|
>—[前 FubuMVC 项目负责人 Jeremy Miller][2]
|
||||||
|
>
|
||||||
|
>“当我们决定要孩子的时候,我可能会放弃开源,我预计最终解决我问题的方案将是:核武器。”
|
||||||
|
>
|
||||||
|
>—[Nolan Lawson,PouchDB 的维护者之一][3]
|
||||||
|
|
||||||
|
我们需要的是一种新的行业规范,即项目领导者将_总是_能获得(其付出的)时间上的补偿。我们还需要抛弃的想法是, 任何提交问题或合并请求的开发人员都自动会得到维护者的注意。
|
||||||
|
|
||||||
|
我们先来回顾一下开源代码在市场上的作用。它是一个积木。它是[实用软件][10],是企业为了在别处获利而必须承担的成本。如果用户能够理解该代码的用途并且发现它比替代方案(闭源专用、定制的内部解决方案等)更有价值,那么围绕该软件的社区就会不断增长。它可以更好,更便宜,或两者兼而有之。
|
||||||
|
|
||||||
|
如果一个组织需要改进该代码,他们可以自由地聘请任何他们想要的开发人员。通常情况下[为了他们的利益][11]会将改进贡献给社区,因为由于代码合并的复杂性,这是他们能够轻松地从其他用户获得未来改进的唯一方式。这种“引力”倾向于把社区聚集在一起。
|
||||||
|
|
||||||
|
但是它也会加重项目维护者的负担,因为他们必须对这些改进做出反应。他们得到了什么回报?最好的情况是,这些社区贡献可能是他们将来可以使用的东西,但现在不是。最坏的情况下,这只不过是一个带着利他主义面具的自私请求罢了。
|
||||||
|
|
||||||
|
有一类开源项目避免了这个陷阱。Linux、MySQL、Android、Chromium 和 .NET Core 除了有名,有什么共同点么?他们都对一个或多个大型企业具有_战略性重要意义_,因为它们满足了这些利益。[聪明的公司商品化他们的商品][12],没有什么比开源软件便宜的商品了。红帽需要那些使用 Linux 的公司来销售企业级 Linux,Oracle 使用 MySQL 作为销售 MySQL Enterprise 的引子,谷歌希望世界上每个人都拥有电话和浏览器,而微软则试图将开发者锁定在平台上然后将它们拉入 Azure 云。这些项目全部由各自公司直接资助。
|
||||||
|
|
||||||
|
但是那些其他的项目呢,那些不是大玩家核心战略的项目呢?
|
||||||
|
|
||||||
|
如果你是其中一个项目的负责人,请向社区成员收取年费。_开放的源码,封闭的社区_。给用户的信息应该是“尽你所愿地使用代码,但如果你想影响项目的未来,请_为我们的时间支付_。”将非付费用户锁定在论坛和问题跟踪之外,并忽略他们的电子邮件。不支付的人应该觉得他们错过了派对。
|
||||||
|
|
||||||
|
还要向贡献者收取合并非普通的合并请求的时间花费。如果一个特定的提交不会立即给你带来好处,请为你的时间收取全价。要有原则并[记住 YAGNI][13]。
|
||||||
|
|
||||||
|
这会导致一个极小的社区和更多的分支么?绝对。但是,如果你坚持不懈地构建自己的愿景,并为其他人创造价值,他们会尽快为要做的贡献而支付。_合并贡献的意愿是[稀缺资源][4]_。如果没有它,用户必须反复地将它们的变化与你发布的每个新版本进行协调。
|
||||||
|
|
||||||
|
如果你想在代码库中保持高水平的[概念完整性][14],那么限制社区是特别重要的。有[自由贡献政策][15]的无领导者项目没有必要收费。
|
||||||
|
|
||||||
|
为了实现更大的愿景,而不是单独为自己的业务支付成本,而是可能使其他人受益,去[众筹][16]吧。有许多成功的故事:
|
||||||
|
|
||||||
|
- [Font Awesome 5][5]
|
||||||
|
- [Ruby enVironment Management (RVM)][6]
|
||||||
|
- [Django REST framework 3][7]
|
||||||
|
|
||||||
|
[众筹有局限性][17]。它[不适合][18][大型项目][19]。但是,开源代码也是实用软件,它不需要雄心勃勃、冒险的破局者。它已经一点点地[渗透到每个行业][20]。
|
||||||
|
|
||||||
|
这些观点代表着一条可持续发展的道路,也可以解决[开源的多样性问题][21],这可能源于其历史上无偿的性质。但最重要的是,我们要记住,[我们一生中只留下那么多的按键次数][22],而且我们总有一天会后悔那些我们浪费的东西。
|
||||||
|
|
||||||
|
- 注 1 :当我说“开源”时,我的意思是代码[许可][8]以某种方式来构建专有的东西。这通常意味着一个宽松许可证(MIT 或 Apache 或 BSD),但并非总是如此。Linux 是当今科技行业的核心,但是是以 GPL 授权的。_
|
||||||
|
|
||||||
|
感谢 Jason Haley、Don McNamara、Bryan Hogan 和 Nadia Eghbal 阅读了这篇文章的草稿。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://wgross.net/essays/give-away-your-code-but-never-your-time
|
||||||
|
|
||||||
|
作者:[William Gross][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://wgross.net/#about-section
|
||||||
|
[1]:http://ryanbigg.com/2015/11/open-source-work
|
||||||
|
[2]:https://jeremydmiller.com/2014/04/03/im-throwing-in-the-towel-in-fubumvc/
|
||||||
|
[3]:https://nolanlawson.com/2017/03/05/what-it-feels-like-to-be-an-open-source-maintainer/
|
||||||
|
[4]:https://hbr.org/2010/11/column-to-win-create-whats-scarce
|
||||||
|
[5]:https://www.kickstarter.com/projects/232193852/font-awesome-5
|
||||||
|
[6]:https://www.bountysource.com/teams/rvm/fundraiser
|
||||||
|
[7]:https://www.kickstarter.com/projects/tomchristie/django-rest-framework-3
|
||||||
|
[8]:https://choosealicense.com/
|
||||||
|
[9]:https://www.wired.com/insights/2013/07/in-a-world-without-open-source/
|
||||||
|
[10]:https://martinfowler.com/bliki/UtilityVsStrategicDichotomy.html
|
||||||
|
[11]:https://tessel.io/blog/67472869771/monetizing-open-source
|
||||||
|
[12]:https://www.joelonsoftware.com/2002/06/12/strategy-letter-v/
|
||||||
|
[13]:https://martinfowler.com/bliki/Yagni.html
|
||||||
|
[14]:http://wiki.c2.com/?ConceptualIntegrity
|
||||||
|
[15]:https://opensource.com/life/16/5/growing-contributor-base-modern-open-source
|
||||||
|
[16]:https://poststatus.com/kickstarter-open-source-project/
|
||||||
|
[17]:http://blog.felixbreuer.net/2013/04/24/crowdfunding-for-open-source.html
|
||||||
|
[18]:https://www.indiegogo.com/projects/geary-a-beautiful-modern-open-source-email-client#/
|
||||||
|
[19]:http://www.itworld.com/article/2708360/open-source-tools/canonical-misses-smartphone-crowdfunding-goal-by--19-million.html
|
||||||
|
[20]:http://www.infoworld.com/article/2914643/open-source-software/rise-and-rise-of-open-source.html
|
||||||
|
[21]:http://readwrite.com/2013/12/11/open-source-diversity/
|
||||||
|
[22]:http://keysleft.com/
|
||||||
|
[23]:http://wgross.net/essays/give-away-your-code-but-never-your-time
|
||||||
98
published/20170928 3 Python web scrapers and crawlers.md
Normal file
98
published/20170928 3 Python web scrapers and crawlers.md
Normal file
@ -0,0 +1,98 @@
|
|||||||
|
三种 Python 网络内容抓取工具与爬虫
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 运用这些很棒的 Python 爬虫工具来获取你需要的数据。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在一个理想的世界里,你需要的所有数据都将以公开而文档完备的格式清晰地展现,你可以轻松地下载并在任何你需要的地方使用。
|
||||||
|
|
||||||
|
然而,在真实世界里,数据是凌乱的,极少被打包成你需要的样子,要么经常是过期的。
|
||||||
|
|
||||||
|
你所需要的信息经常是潜藏在一个网站里。相比一些清晰地、有调理地呈现数据的网站,更多的网站则不是这样的。<ruby>[爬取数据][33]<rt>crawling</rt></ruby>、<ruby>[挖掘数据][34]<rt>scraping</rt></ruby>、加工数据、整理数据这些是获取整个网站结构来绘制网站拓扑来收集数据所必须的活动,这些可以是以网站的格式储存的或者是储存在一个专有数据库中。
|
||||||
|
|
||||||
|
也许在不久的将来,你需要通过爬取和挖掘来获得一些你需要的数据,当然你几乎肯定需要进行一点点的编程来正确的获取。你要怎么做取决于你自己,但是我发现 Python 社区是一个很好的提供者,它提供了工具、框架以及文档来帮助你从网站上获取数据。
|
||||||
|
|
||||||
|
在我们进行之前,这里有一个小小的请求:在你做事情之前请思考,以及请耐心。抓取这件事情并不简单。不要把网站爬下来只是复制一遍,并其它人的工作当成是你自己的东西(当然,没有许可)。要注意版权和许可,以及你所爬行的内容应用哪一个标准。尊重 [robots.txt][15] 文件。不要频繁的针对一个网站,这将导致真实的访问者会遇到访问困难的问题。
|
||||||
|
|
||||||
|
在知晓这些警告之后,这里有一些很棒的 Python 网站爬虫工具,你可以用来获得你需要的数据。
|
||||||
|
|
||||||
|
### Pyspider
|
||||||
|
|
||||||
|
让我们先从 [pyspider][16] 开始介绍。这是一个带有 web 界面的网络爬虫,让与使之容易跟踪多个爬虫。其具有扩展性,支持多个后端数据库和消息队列。它还具有一些方便的特性,从优先级到再次访问抓取失败的页面,此外还有通过时间顺序来爬取和其他的一些特性。Pyspider 同时支持 Python 2 和 Python 3。为了实现一个更快的爬取,你可以在分布式的环境下一次使用多个爬虫进行爬取。
|
||||||
|
|
||||||
|
Pyspyder 的基本用法都有良好的 [文档说明][17] ,包括简单的代码片段。你能通过查看一个 [在线的样例][18] 来体验用户界面。它在 Apache 2 许可证下开源,Pyspyder 仍然在 GitHub 上积极地开发。
|
||||||
|
|
||||||
|
### MechanicalSoup
|
||||||
|
|
||||||
|
[MechanicalSoup][19] 是一个基于极其流行而异常多能的 HTML 解析库 [Beautiful Soup][20] 建立的爬虫库。如果你的爬虫需要相当的简单,但是又要求检查一些选择框或者输入一些文字,而你又不想为这个任务单独写一个爬虫,那么这会是一个值得考虑的选择。
|
||||||
|
|
||||||
|
MechanicalSoup 在 MIT 许可证下开源。查看 GitHub 上该项目的 [example.py][21] 样例文件来获得更多的用法。不幸的是,到目前为止,这个项目还没有一个很好的文档。
|
||||||
|
|
||||||
|
### Scrapy
|
||||||
|
|
||||||
|
[Scrapy][22] 是一个有着活跃社区支持的抓取框架,在那里你可以建造自己的抓取工具。除了爬取和解析工具,它还能将它收集的数据以 JSON 或者 CSV 之类的格式轻松输出,并存储在一个你选择的后端数据库。它还有许多内置的任务扩展,例如 cookie 处理、代理欺骗、限制爬取深度等等,同时还可以建立你自己附加的 API。
|
||||||
|
|
||||||
|
要了解 Scrapy,你可以查看[网上的文档][23]或者是访问它诸多的[社区][24]资源,包括一个 IRC 频道、Reddit 子版块以及关注他们的 StackOverflow 标签。Scrapy 的代码在 3 句版 BSD 许可证下开源,你可以在 [GitHub][25] 上找到它们。
|
||||||
|
|
||||||
|
如果你完全不熟悉编程,[Portia][26] 提供了一个易用的可视化的界面。[scrapinghub.com][27] 则提供一个托管的版本。
|
||||||
|
|
||||||
|
### 其它
|
||||||
|
|
||||||
|
* [Cola][6] 自称它是个“高级的分布式爬取框架”,如果你在寻找一个 Python 2 的方案,这也许会符合你的需要,但是注意它已经有超过两年没有更新了。
|
||||||
|
* [Demiurge][7] 是另一个可以考虑的潜在候选者,它同时支持 Python 2和 Python 3,虽然这个项目的发展较为缓慢。
|
||||||
|
* 如果你要解析一些 RSS 和 Atom 数据,[Feedparser][8] 或许是一个有用的项目。
|
||||||
|
* [Lassie][9] 让从网站检索像说明、标题、关键词或者是图片一类的基本内容变得简单。
|
||||||
|
* [RoboBrowser][10] 是另一个简单的库,它基于 Python 2 或者 Python 3,它具有按钮点击和表格填充的基本功能。虽然它有一段时间没有更新了,但是它仍然是一个不错的选择。
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
这远不是一个完整的列表,当然,如果你是一个编程专家,你可以选择采取你自己的方法而不是使用这些框架中的一个。或者你发现一个用其他语言编写的替代品。例如 Python 编程者可能更喜欢 [Python 附带的][28] [Selenium][29],它可以在不使用实际浏览器的情况下进行爬取。如果你有喜欢的爬取和挖掘工具,请在下面评论让我们知道。
|
||||||
|
|
||||||
|
(题图:[You as a Machine][13]. Modified by Rikki Endsley. [CC BY-SA 2.0][14])
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/resources/python/web-scraper-crawler
|
||||||
|
|
||||||
|
作者:[Jason Baker][a]
|
||||||
|
译者:[ZH1122](https://github.com/ZH1122)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/jason-baker
|
||||||
|
[1]:https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
|
||||||
|
[2]:https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
|
||||||
|
[3]:https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
|
||||||
|
[4]:https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
|
||||||
|
[5]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ
|
||||||
|
[6]:https://github.com/chineking/cola
|
||||||
|
[7]:https://github.com/matiasb/demiurge
|
||||||
|
[8]:https://github.com/kurtmckee/feedparser
|
||||||
|
[9]:https://github.com/michaelhelmick/lassie
|
||||||
|
[10]:https://github.com/jmcarp/robobrowser
|
||||||
|
[11]:https://opensource.com/resources/python/web-scraper-crawler?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007&rate=Wn1vUb9FpPK-IGQ1waRzgdIsDN3pXBH6rO2xnjoK_t4
|
||||||
|
[12]:https://opensource.com/user/19894/feed
|
||||||
|
[13]:https://www.flickr.com/photos/youasamachine/8025582590/in/photolist-decd6C-7pkccp-aBfN9m-8NEffu-3JDbWb-aqf5Tx-7Z9MTZ-rnYTRu-3MeuPx-3yYwA9-6bSLvd-irmvxW-5Asr4h-hdkfCA-gkjaSQ-azcgct-gdV5i4-8yWxCA-9G1qDn-5tousu-71V8U2-73D4PA-iWcrTB-dDrya8-7GPuxe-5pNb1C-qmnLwy-oTxwDW-3bFhjL-f5Zn5u-8Fjrua-bxcdE4-ddug5N-d78G4W-gsYrFA-ocrBbw-pbJJ5d-682rVJ-7q8CbF-7n7gDU-pdfgkJ-92QMx2-aAmM2y-9bAGK1-dcakkn-8rfyTz-aKuYvX-hqWSNP-9FKMkg-dyRPkY
|
||||||
|
[14]:https://creativecommons.org/licenses/by/2.0/
|
||||||
|
[15]:http://www.robotstxt.org/
|
||||||
|
[16]:https://github.com/binux/pyspider
|
||||||
|
[17]:http://docs.pyspider.org/en/latest/
|
||||||
|
[18]:http://demo.pyspider.org/
|
||||||
|
[19]:https://github.com/hickford/MechanicalSoup
|
||||||
|
[20]:https://www.crummy.com/software/BeautifulSoup/
|
||||||
|
[21]:https://github.com/hickford/MechanicalSoup/blob/master/example.py
|
||||||
|
[22]:https://scrapy.org/
|
||||||
|
[23]:https://doc.scrapy.org/en/latest/
|
||||||
|
[24]:https://scrapy.org/community/
|
||||||
|
[25]:https://github.com/scrapy/scrapy
|
||||||
|
[26]:https://github.com/scrapinghub/portia
|
||||||
|
[27]:https://portia.scrapinghub.com/
|
||||||
|
[28]:https://selenium-python.readthedocs.io/
|
||||||
|
[29]:https://github.com/SeleniumHQ/selenium
|
||||||
|
[30]:https://opensource.com/users/jason-baker
|
||||||
|
[31]:https://opensource.com/users/jason-baker
|
||||||
|
[32]:https://opensource.com/resources/python/web-scraper-crawler?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#comments
|
||||||
|
[33]:https://en.wikipedia.org/wiki/Web_crawler
|
||||||
|
[34]:https://en.wikipedia.org/wiki/Web_scraping
|
||||||
95
published/201710/20160511 LEDE and OpenWrt.md
Normal file
95
published/201710/20160511 LEDE and OpenWrt.md
Normal file
@ -0,0 +1,95 @@
|
|||||||
|
LEDE 和 OpenWrt 分裂之争
|
||||||
|
===================
|
||||||
|
|
||||||
|
对于家用 WiFi 路由器和接入点来说,[OpenWrt][1] 项目可能是最广为人知的 Linux 发行版;在 12 年以前,它产自现在有名的 Linksys WRT54G 路由器的源代码。(2016 年)五月初,当一群 OpenWrt 核心开发者 [宣布][2] 他们将开始着手 OpenWrt 的一个副产品 (或者,可能算一个分支)叫 [Linux 嵌入开发环境][3] (LEDE)时,OpenWrt 用户社区陷入一片巨大的混乱中。为什么产生分裂对公众来说并不明朗,而且 LEDE 宣言惊到了一些其他 OpenWrt 开发者也暗示这团队的内部矛盾。
|
||||||
|
|
||||||
|
LEDE 宣言被 Jo-Philipp Wich 于五月三日发往所有 OpenWrt 开发者列表和新 LEDE 开发者列表。它将 LEDE 描述为“OpenWrt 社区的一次重启” 和 “OpenWrt 项目的一个副产品” ,希望产生一个 “注重透明性、合作和权利分散”的 Linux 嵌入式开发社区。
|
||||||
|
|
||||||
|
给出的重启的原因是 OpenWrt 遭受着长期以来存在且不能从内部解决的问题 —— 换句话说,关于内部处理方式和政策。例如,宣言称,开发者的数目在不断减少,却没有接纳新开发者的方式(而且貌似没有授权委托访问给新开发者的方法)。宣言说到,项目的基础设施不可靠(例如,去年服务器挂掉在这个项目中也引发了相当多的矛盾),但是内部不合和单点错误阻止了修复它。内部和从这个项目到外面世界也存在着“交流、透明度和合作”的普遍缺失。最后,一些技术缺陷被引述:不充分的测试、缺乏常规维护,以及窘迫的稳固性与文档。
|
||||||
|
|
||||||
|
该宣言继续描述 LEDE 重启将怎样解决这些问题。所有交流频道都会打开供公众使用,决策将在项目范围内的投票决出,合并政策将放宽等等。更详细的说明可以在 LEDE 站点的[规则][4]页找到。其他细节中,它说贡献者将只有一个阶级(也就是,没有“核心开发者”这样拥有额外权利的群体),简单的少数服从多数投票作出决定,并且任何被这个项目管理的基础设施必须有三个以上管理员账户。在 LEDE 邮件列表, Hauke Mehrtens [补充][5]到,该项目将会努力把补丁投递到上游项目 —— 这是过去 OpenWrt 被批判的一点,尤其是对 Linux 内核。
|
||||||
|
|
||||||
|
除了 Wich,这个宣言被 OpenWrt 贡献者 John Crispin、 Daniel Golle、 Felix Fietkau、 Mehrtens、 Matthias Schiffer 和 Steven Barth 共同签署,并以给其他有兴趣参与的人访问 LEDE 站点的邀请作为了宣言结尾。
|
||||||
|
|
||||||
|
### 回应和问题
|
||||||
|
|
||||||
|
有人可能会猜想 LEDE 组织者预期他们的宣言会有或积极或消极的反响。毕竟,细读宣言中批判 OpenWrt 项目暗示了 LEDE 阵营发现有一些 OpenWrt 项目成员难以共事(例如,“单点错误” 或 “内部不和”阻止了基础设施的修复)。
|
||||||
|
|
||||||
|
并且,确实,有很多消极回应。OpenWrt 创立者之一 Mike Baker [回应][6] 了一些警告,反驳所有 LEDE 宣言中的结论并称“像‘重启’这样的词语都是含糊不清的,且具有误导性的,而且 LEDE 项目未能揭晓其真实本质。”与此同时,有人关闭了那些在 LEDE 宣言上署名的开发者的 @openwrt.org 邮件入口;当 Fietkau [提出反对][7], Baker [回复][8]账户“暂时停用”是因为“还不确定 LEDE 能不能代表 OpenWrt。” 另一个 OpenWrt 核心成员 Imre Kaloz [写][9]到,他们现在所抱怨的 OpenWrt 的“大多数[破]事就是 LEDE 团队弄出来的”。
|
||||||
|
|
||||||
|
但是大多数 OpenWrt 列表的回应对该宣言表示困惑。邮件列表成员不明确 LEDE 团队是否将对 OpenWrt [继续贡献][10],或导致了这次分裂的架构和内部问题的[确切本质][11]是什么。 Baker 的第一反应是对宣言中引述的那些问题缺乏公开讨论表示难过:“我们意识到当前的 OpenWrt 项目遭受着许多的问题,”但“我们希望有机会去讨论并尝试着解决”它们。 Baker 作出结论:
|
||||||
|
|
||||||
|
> 我们想强调,我们确实希望能够公开的讨论,并解决掉手头事情。我们的目标是与所有能够且希望对 OpenWrt 作出贡献的参与者共事,包括 LEDE 团队。
|
||||||
|
|
||||||
|
除了有关新项目的初心的问题之外,一些邮件列表订阅者提出了 LEDE 是否与 OpenWrt 有相同的使用场景定位,给新项目取一个听起来更一般的名字的疑惑。此外,许多人,像 Roman Yeryomin,对为什么这些问题需要 LEDE 团队的离开(来解决)[表示了疑惑][12],特别是,与此同时,LEDE 团队由大部分活跃核心 OpenWrt 开发者构成。一些列表订阅者,像 Michael Richardson,甚至不清楚[谁还会继续开发][13] OpenWrt。
|
||||||
|
|
||||||
|
### 澄清
|
||||||
|
|
||||||
|
LEDE 团队尝试着深入阐释他们的境况。在 Fietkau 给 Baker 的回复中,他说在 OpenWrt 内部关于有目的地改变的讨论会很快变得“有毒,”因此导致没有进展。而且:
|
||||||
|
|
||||||
|
> 这些讨论的要点在于那些掌握着基础设施关键部分的人精力有限却拒绝他人的加入和帮助,甚至是面对无法及时解决的重要问题时也是这样。
|
||||||
|
|
||||||
|
> 这种像单点错误一样的事已经持续了很多年了,没有任何有意义的进展来解决它。
|
||||||
|
|
||||||
|
Wich 和 Fietkau 都没有明显指出具体的人,虽然在列表的其他人可能会想到这个基础设施和 OpenWrt 的内部决策问题要归咎于某些人。 Daniel Dickinson [陈述][14]到:
|
||||||
|
|
||||||
|
> 我的印象是 Kaloz (至少) 以基础设施为胁来保持控制,并且根本性的问题是 OpenWrt 是*不*民主的,而且忽视那些真正在 OpenWrt 工作的人想要的是什么,无视他们的愿望,因为他/他们把控着要害。
|
||||||
|
|
||||||
|
另一方面, Luka Perkov [指出][15] 很多 OpemWrt 开发者想从 Subversion 转移到 Git,但 Fietkau 却阻止这种变化。
|
||||||
|
|
||||||
|
看起来是 OpenWrt 的管理结构并非如预期般发挥作用,其结果导致个人冲突爆发,而且由于没有完好定义的流程,某些人能够简单的忽视或阻止提议的变化。明显,这不是一个能长期持续的模式。
|
||||||
|
|
||||||
|
五月六日,Crispin 在一个新的帖子中[写给][16] OpenWrt 列表,尝试着重构 LEDE 项目宣言。他说,这并不是意味着“敌对或分裂”行为,只是与结构失衡的 OpenWrt 做个清晰的划分并以新的方式开始。问题在于“不要归咎于一次单独的事件、一个人或者一次口水战”,他说,“我们想与过去自己造成的错误和多次作出的错误管理决定分开”。 Crispin 也承认宣言没有把握好,说 LEDE 团队 “弄糟了发起纲领。”
|
||||||
|
|
||||||
|
Crispin 的邮件似乎没能使 Kaloz 满意,她[坚持认为][17] Crispin(作为发行经理)和 Fietkau(作为领头开发者)可以轻易地在 OpenWrt 内部作出想要的改变。但是讨论的下文后来变得沉寂;之后 LEDE 或者 OpenWrt 哪边会发生什么还有待观察。
|
||||||
|
|
||||||
|
### 目的
|
||||||
|
|
||||||
|
对于那些想要探究 LEDE 所认为有问题的事情的更多细节的 OpenWrt 成员来说,有更多的信息来源可以为这个问题提供线索。在公众宣言之前,LEDE 组织花了几周谈论他们的计划,会议的 IRC 日志现已[发布][18]。特别有趣的是,三月三十日的[会议][19]包含了这个项目目标的细节讨论。
|
||||||
|
|
||||||
|
其中包括一些针对 OpenWrt 的基础设施的抱怨,像项目的 Trac 工单追踪器的缺点。它充斥着不完整的漏洞报告和“我也是”的评论,Wich 说,结果几乎没有贡献者使用它。此外,他们也在 Github 上追踪 bug,人们对这件事感到困惑,这使得工单应该在哪里讨论不明了。
|
||||||
|
|
||||||
|
这些 IRC 讨论也定下了开发流程本身。LEDE 团队想作出些改变,以使用会合并到主干的阶段开发分支为开端,与 OpenWrt 所使用的“直接提交到主干”方式不同。该项目也将提供基于时间的发行版,并通过只发行已被成功测试的二进制模块来鼓励用户测试,由社区而不是核心开发者在实际的硬件上进行测试。
|
||||||
|
|
||||||
|
最后,这些 IRC 讨论也确定了 LEDE 团队的目的不是用它的宣言吓唬 OpenWrt。Crispin 提到 LEDE 首先是“半公开的”并渐渐做得更公开。 Wich 解释说他希望 LEDE 是“中立的、专业的,并打开大门欢迎 OpenWrt 以便将来的合并”。不幸的是,前期发起工作并不是做得很好。
|
||||||
|
|
||||||
|
在一封邮件中, Fietkau 补充到 OpenWrt 核心开发者确实在任务中遇到瓶颈,像补丁复审和基础设施维护这些事情让他们完成不了其他工作,比如配置下载镜像和改良构建系统。在 LEDE 宣言之后短短几天内,他说,团队成功解决了镜像和构建系统任务,而这些已被搁置多年。
|
||||||
|
|
||||||
|
> 我们在 LEDE 所做的事情很多是基于转移到 Github 的去中心化软件包开发经验,并放弃了软件包应如何被维护的许多控制。这样最终有效减少了我们的工作量,而且我们有了很多更活跃的开发者。
|
||||||
|
|
||||||
|
> 我们真的希望为核心开发做一些类似的事,但是基于我们想作出更大改变的经验,我们觉得在 OpenWrt 项目内做不到。
|
||||||
|
|
||||||
|
修复基础设施也将收获其他好处,他说,就比如改进了用于管理签署发布版本的密码的系统。团队正在考虑在某些情况下非上游补丁的规则,像需要补丁的描述和为什么没有发送到上游的解释。他也提到很多留下的 OpenWrt 开发者表示有兴趣加入 LEDE,相关当事人正试图弄清楚他们是否会重新合并该项目。
|
||||||
|
|
||||||
|
有人希望 LEDE 更为扁平的管理模式和更为透明的分工会在困扰 OpenWrt 的方面取得成功。解决最初的宣言中被诟病的沟通方面的问题会是最大的障碍。如果那个过程处理得好,那么,未来 LEDE 和 OpenWrt 可能能够求同存异并协作。否则,之后两个团队可能一起被迫发展到比以前拥有更少资源的方向,这也许不是开发者或用户想看到的。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://lwn.net/Articles/686767/
|
||||||
|
|
||||||
|
作者:[Nathan Willis][a]
|
||||||
|
译者:[XYenChi](https://github.com/XYenChi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://lwn.net/Articles/686767/
|
||||||
|
[1]:https://openwrt.org/
|
||||||
|
[2]:https://lwn.net/Articles/686180/
|
||||||
|
[3]:https://www.lede-project.org/
|
||||||
|
[4]:https://www.lede-project.org/rules.html
|
||||||
|
[5]:http://lists.infradead.org/pipermail/lede-dev/2016-May/000080.html
|
||||||
|
[6]:https://lwn.net/Articles/686988/
|
||||||
|
[7]:https://lwn.net/Articles/686989/
|
||||||
|
[8]:https://lwn.net/Articles/686990/
|
||||||
|
[9]:https://lwn.net/Articles/686991/
|
||||||
|
[10]:https://lwn.net/Articles/686995/
|
||||||
|
[11]:https://lwn.net/Articles/686996/
|
||||||
|
[12]:https://lwn.net/Articles/686992/
|
||||||
|
[13]:https://lwn.net/Articles/686993/
|
||||||
|
[14]:https://lwn.net/Articles/686998/
|
||||||
|
[15]:https://lwn.net/Articles/687001/
|
||||||
|
[16]:https://lwn.net/Articles/687003/
|
||||||
|
[17]:https://lwn.net/Articles/687004/
|
||||||
|
[18]:http://meetings.lede-project.org/lede-adm/2016/?C=M;O=A
|
||||||
|
[19]:http://meetings.lede-project.org/lede-adm/2016/lede-adm.2016-03-30-11.05.log.html
|
||||||
File diff suppressed because one or more lines are too long
@ -0,0 +1,56 @@
|
|||||||
|
如何像 NASA 顶级程序员一样编程 —— 10 条重要原则
|
||||||
|
===
|
||||||
|
|
||||||
|
[][1]
|
||||||
|
|
||||||
|
> 引言: 你知道 NASA 顶级程序员如何编写关键任务代码么?为了确保代码更清楚、更安全、且更容易理解,NASA 的喷气推进实验室制定了 10 条编码规则。
|
||||||
|
|
||||||
|
NASA 的开发者是编程界最有挑战性的工作之一。他们编写代码并将开发安全的关键任务应用程序作为其主要关注点。
|
||||||
|
|
||||||
|
在这种情形下,遵守一些严格的编码规则是重要的。这些规则覆盖软件开发的多个方面,例如软件应该如何编码、应该使用哪些语言特性等。
|
||||||
|
|
||||||
|
尽管很难就一个好的编码标准达成共识,NASA 的喷气推进实验室(JPL)遵守一个[编码规则][2],其名为“十的次方:开发安全的关键代码的规则”。
|
||||||
|
|
||||||
|
由于 JPL 长期使用 C 语言,这个规则主要是针对于 C 程序语言编写。但是这些规则也可以很容地应用到其它的程序语言。
|
||||||
|
|
||||||
|
该规则由 JPL 的首席科学家 Gerard J. Holzmann 制定,这些严格的编码规则主要是聚焦于安全。
|
||||||
|
|
||||||
|
NASA 的 10 条编写关键任务代码的规则:
|
||||||
|
|
||||||
|
1. 限制所有代码为极为简单的控制流结构 — 不用 `goto` 语句、`setjmp` 或 `longjmp` 结构,不用间接或直接的递归调用。
|
||||||
|
2. 所有循环必须有一个固定的上限值。必须可以被某个检测工具静态证实,该循环不能达到预置的迭代上限值。如果该上限值不能被静态证实,那么可以认为违背该原则。
|
||||||
|
3. 在初始化后不要使用动态内存分配。
|
||||||
|
4. 如果一个语句一行、一个声明一行的标准格式来参考,那么函数的长度不应该比超过一张纸。通常这意味着每个函数的代码行不能超过 60。
|
||||||
|
5. 代码中断言的密度平均低至每个函数 2 个断言。断言被用于检测那些在实际执行中不可能发生的情况。断言必须没有副作用,并应该定义为布尔测试。当一个断言失败时,应该执行一个明确的恢复动作,例如,把错误情况返回给执行该断言失败的函数调用者。对于静态工具来说,任何能被静态工具证实其永远不会失败或永远不能触发的断言违反了该规则(例如,通过增加无用的 `assert(true)` 语句是不可能满足这个规则的)。
|
||||||
|
6. 必须在最小的范围内声明数据对象。
|
||||||
|
7. 非 void 函数的返回值在每次函数调用时都必须检查,且在每个函数内其参数的有效性必须进行检查。
|
||||||
|
8. 预处理器的使用仅限制于包含头文件和简单的宏定义。符号拼接、可变参数列表(省略号)和递归宏调用都是不允许的。所有的宏必须能够扩展为完整的语法单元。条件编译指令的使用通常是晦涩的,但也不总是能够避免。这意味着即使在一个大的软件开发中超过一两个条件编译指令也要有充足的理由,这超出了避免多次包含头文件的标准做法。每次在代码中这样做的时候必须有基于工具的检查器进行标记,并有充足的理由。
|
||||||
|
9. 应该限制指针的使用。特别是不应该有超过一级的解除指针引用。解除指针引用操作不可以隐含在宏定义或类型声明中。还有,不允许使用函数指针。
|
||||||
|
10. 从开发的第一天起,必须在编译器开启最高级别警告选项的条件下对代码进行编译。在此设置之下,代码必须零警告编译通过。代码必须利用源代码静态分析工具每天至少检查一次或更多次,且零警告通过。
|
||||||
|
|
||||||
|
关于这些规则,NASA 是这么评价的:
|
||||||
|
|
||||||
|
> 这些规则就像汽车中的安全带一样,刚开始你可能感到有一点不适,但是一段时间后就会养成习惯,你会无法想象不使用它们的日子。
|
||||||
|
|
||||||
|
此文是否对你有帮助?不要忘了在下面的评论区写下你的反馈。
|
||||||
|
|
||||||
|
---
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Adarsh Verma 是 Fossbytes 的共同创始人,他是一个令人尊敬的企业家,他一直对开源、技术突破和完全保持密切关注。可以通过邮件联系他 — [adarsh.verma@fossbytes.com](mailto:adarsh.verma@fossbytes.com)
|
||||||
|
|
||||||
|
------------------
|
||||||
|
|
||||||
|
via: https://fossbytes.com/nasa-coding-programming-rules-critical/
|
||||||
|
|
||||||
|
作者:[Adarsh Verma][a]
|
||||||
|
译者:[penghuster](https://github.com/penghuster)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://fossbytes.com/author/adarsh/
|
||||||
|
[1]:http://fossbytes.com/wp-content/uploads/2016/06/rules-of-coding-nasa.jpg
|
||||||
|
[2]:http://pixelscommander.com/wp-content/uploads/2014/12/P10.pdf
|
||||||
|
[3]:https://fossbytes.com/wp-content/uploads/2016/12/learn-to-code-banner-ad-content-1.png
|
||||||
|
[4]:http://pixelscommander.com/wp-content/uploads/2014/12/P10.pdf
|
||||||
@ -1,59 +1,59 @@
|
|||||||
用户报告:Steam Machines 与 SteamOS 发布一周年记
|
回顾 Steam Machines 与 SteamOS
|
||||||
====
|
====
|
||||||
|
|
||||||
去年今日,在非常符合 Valve 风格的跳票之后大众迎来了 [Steam Machine 的发布][2]。即使是在 Linux 桌面环境对于游戏的支持大步进步的今天,Steam Machines 作为一个平台依然没有飞跃,而 SteamOS 似乎也止步不前。这些由 Valve 发起的项目究竟怎么了?这些项目为何被发起,又是如何失败的?一些改进又是否曾有机会挽救这些项目的成败?
|
去年今日(LCTT 译注:本文发表于 2016 年),在非常符合 Valve 风格的跳票之后,大众迎来了 [Steam Machines 的发布][2]。即使是在 Linux 桌面环境对于游戏的支持大步进步的今天,Steam Machines 作为一个平台依然没有飞跃,而 SteamOS 似乎也止步不前。这些由 Valve 发起的项目究竟怎么了?这些项目为何被发起,又是如何失败的?一些改进又是否曾有机会挽救这些项目的成败?
|
||||||
|
|
||||||
**行业环境**
|
### 行业环境
|
||||||
|
|
||||||
在 2012 年 Windows 8 发布的时候,微软像 iOS 与 Android 那样,为 Windows 集成了一个应用商店。在微软试图推广对触摸体验友好的界面时,为了更好的提供 “Metro” UI 语言指导下的沉浸式触摸体验,他们同时推出了一系列叫做 “WinRT” 的 API。然而为了能够使用这套 API,应用开发者们必须把应用程序通过 Windows 应用商城发布,并且正如其他应用商城那样,微软从中抽成30%。对于 Valve 的 CEO,Gabe Newell (G胖) 而言,这种限制发布平台和抽成行为是让人无法接受的,而且他前瞻地看到了微软利用行业龙头地位来推广 Windows 商店和 Metro 应用对于 Valve 潜在的危险,正如当年微软用 IE 浏览器击垮 Netscape 浏览器一样。
|
在 2012 年 Windows 8 发布的时候,微软像 iOS 与 Android 那样,为 Windows 集成了一个应用商店。在微软试图推广对触摸体验友好的界面时,为了更好的提供 “Metro” UI 语言指导下的沉浸式触摸体验,他们同时推出了一系列叫做 “WinRT” 的 API。然而为了能够使用这套 API,应用开发者们必须把应用程序通过 Windows 应用商城发布,并且正如其它应用商城那样,微软从中抽成 30%。对于 Valve 的 CEO,Gabe Newell (G 胖) 而言,这种限制发布平台和抽成行为是让人无法接受的,而且他前瞻地看到了微软利用行业龙头地位来推广 Windows 商店和 Metro 应用对于 Valve 潜在的危险,正如当年微软用 IE 浏览器击垮 Netscape 浏览器一样。
|
||||||
|
|
||||||
对于 Valve 来说,运行 Windows 的 PC 的优势在于任何人都可以不受操作系统和硬件方的限制运行各种软件。当像 Windows 这样的专有平台对像 Steam 这样的第三方软件限制越来越严格时,应用开发者们自然会想要寻找一个对任何人都更开放和自由的替代品,他们很自然的会想到 Linux 。Linux 本质上只是一套内核,但你可以轻易地使用 GNU 组件,Gnnome 等软件在这套内核上开发出一个操作系统,比如 Ubuntu 就是这么来的。推行 Ubuntu 或者其他 Linux 发行版自然可以为 Valve 提供一个无拘无束的平台,以防止微软或者苹果变成 Valve 作为第三方平台之路上的的敌人,但 Linux 甚至给了 Valve 一个创造新的操作系统平台的机会。
|
对于 Valve 来说,运行 Windows 的 PC 的优势在于任何人都可以不受操作系统和硬件方的限制运行各种软件。当像 Windows 这样的专有平台对像 Steam 这样的第三方软件限制越来越严格时,应用开发者们自然会想要寻找一个对任何人都更开放和自由的替代品,他们很自然的会想到 Linux 。Linux 本质上只是一套内核,但你可以轻易地使用 GNU 组件、Gnome 等软件在这套内核上开发出一个操作系统,比如 Ubuntu 就是这么来的。推行 Ubuntu 或者其他 Linux 发行版自然可以为 Valve 提供一个无拘无束的平台,以防止微软或者苹果变成 Valve 作为第三方平台之路上的的敌人,但 Linux 甚至给了 Valve 一个创造新的操作系统平台的机会。
|
||||||
|
|
||||||
**概念化**
|
### 概念化
|
||||||
|
|
||||||
如果我们把 Steam Machines 叫做主机的话,Valve 当时似乎认定了主机平台是一个机会。为了迎合用户对于电视主机平台用户界面的审美期待,同时也为了让玩家更好地从稍远的距离上在电视上玩游戏,Valve 为 Steam 推出了 Big Picture 模式。Steam Machines 的核心要点是开放性;比方说所有的软件都被设计成可以脱离 Windows 工作,又比如说 Steam Machines 手柄的 CAD 图纸也被公布出来以便支持玩家二次创作。
|
如果我们把 Steam Machines 叫做主机的话,Valve 当时似乎认定了主机平台是一个机会。为了迎合用户对于电视主机平台用户界面的审美期待,同时也为了让玩家更好地从稍远的距离上在电视上玩游戏,Valve 为 Steam 推出了 Big Picture 模式。Steam Machines 的核心要点是开放性;比方说所有的软件都被设计成可以脱离 Windows 工作,又比如说 Steam Machines 手柄的 CAD 图纸也被公布出来以便支持玩家二次创作。
|
||||||
|
|
||||||
原初计划中,Valve 打算设计一款官方的 Steam Machine 作为旗舰机型。但最终,这些机型只在 2013 年的时候作为原型机给与了部分测试者用于测试。Valve 后来也允许像戴尔这样的 OEM 厂商们制造 Steam Machines,并且也赋予了他们定制价格和配置规格的权利。有一家叫做 “Xi3” 的公司展示了他们设计的 Steam Machine 小型机型,那款机型小到可以放在手掌上,这一新闻创造了围绕 Steam Machines 的更多热烈讨论。最终,Valve 决定不自己设计知道 Steam Machines,而全权交给 OEM 合作厂商们。
|
原初计划中,Valve 打算设计一款官方的 Steam Machine 作为旗舰机型。但最终,这些机型只在 2013 年的时候作为原型机给与了部分测试者用于测试。Valve 后来也允许像戴尔这样的 OEM 厂商们制造 Steam Machines,并且也赋予了他们制定价格和配置规格的权利。有一家叫做 “Xi3” 的公司展示了他们设计的 Steam Machine 小型机型,那款机型小到可以放在手掌上,这一新闻创造了围绕 Steam Machines 的更多热烈讨论。最终,Valve 决定不自己设计制造 Steam Machines,而全权交给 OEM 合作厂商们。
|
||||||
|
|
||||||
这一过程中还有很多天马行空的创意被列入考量,比如在手柄上加入生物识别技术,眼球追踪以及动作控制等。在这些最初的想法里,陀螺仪被加入了 Steam Controller 手柄,HTC Vive 的手柄也有各种动作追踪仪器;这些想法可能最初都来源于 Steam 手柄的设计过程中。手柄最初还有些更激进的设计,比如在中心放置一块可定制化并且会随着游戏内容变化的触摸屏。但最后的最后,发布会上的手柄偏向保守了许多,但也有诸如双触摸板和内置软件等黑科技。Valve 也考虑过制作面向笔记本类型硬件的 Steam Machines 和 SteamOS。这个企划最终没有任何成果,但也许 “Smach Z” 手持游戏机会是发展的方向之一。
|
这一过程中还有很多天马行空的创意被列入考量,比如在手柄上加入生物识别技术、眼球追踪以及动作控制等。在这些最初的想法里,陀螺仪被加入了 Steam Controller 手柄,HTC Vive 的手柄也有各种动作追踪仪器;这些想法可能最初都来源于 Steam 手柄的设计过程中。手柄最初还有些更激进的设计,比如在中心放置一块可定制化并且会随着游戏内容变化的触摸屏。但最后的最后,发布会上的手柄偏向保守了许多,但也有诸如双触摸板和内置软件等黑科技。Valve 也考虑过制作面向笔记本类型硬件的 Steam Machines 和 SteamOS。这个企划最终没有任何成果,但也许 “Smach Z” 手持游戏机会是发展的方向之一。
|
||||||
|
|
||||||
在 [2013年九月][3],Valve 对外界宣布了 Steam Machines 和 SteamOS, 并且预告会在 2014 年中发布。前述的 300 台原型机在当年 12 月被分发给了测试者们,随后次年 1 月,2000 台原型机又被分发给了开发者们。SteamOS 也在那段时间被分发给有 Linux 经验的测试者们试用。根据当时的测试反馈,Valve 最终决定把产品发布延期到 2015 年 11 月。
|
在 [2013 年九月][3],Valve 对外界宣布了 Steam Machines 和 SteamOS, 并且预告会在 2014 年中发布。前述的 300 台原型机在当年 12 月分发给了测试者们,随后次年 1 月,又分发给了开发者们 2000 台原型机。SteamOS 也在那段时间分发给有 Linux 经验的测试者们试用。根据当时的测试反馈,Valve 最终决定把产品发布延期到 2015 年 11 月。
|
||||||
|
|
||||||
SteamOS 的延期跳票给合作伙伴带来了问题;戴尔的 Steam Machine 由于早发售了一年结果不得不改为搭配了额外软件甚至运行着 Windows 操作系统的 Alienware Alpha。
|
SteamOS 的延期跳票给合作伙伴带来了问题;戴尔的 Steam Machine 由于早发售了一年,结果不得不改为搭配了额外软件、甚至运行着 Windows 操作系统的 Alienware Alpha。
|
||||||
|
|
||||||
**正式发布**
|
### 正式发布
|
||||||
|
|
||||||
在最终的正式发布会上,Valve 和 OEM 合作商们发布了 Steam Machines,同时 Valve 还推出了 Steam Controller 手柄和 Steam Link 串流游戏设备。Valve 也在线下零售行业比如 GameStop 里开辟了货架空间。在发布会前,有几家 OEM 合作商退出了与 Valve 的合作;比如 Origin PC 和 Falcon Northwest 这两家高端精品主机设计商。他们宣称 Steam 生态的性能问题和一些限制迫使他们决定弃用 SteamOS。
|
在最终的正式发布会上,Valve 和 OEM 合作商们发布了 Steam Machines,同时 Valve 还推出了 Steam Controller 手柄和 Steam Link 串流游戏设备。Valve 也在线下零售行业比如 GameStop 里开辟了货架空间。在发布会前,有几家 OEM 合作商退出了与 Valve 的合作;比如 Origin PC 和 Falcon Northwest 这两家高端精品主机设计商。他们宣称 Steam 生态的性能问题和一些限制迫使他们决定弃用 SteamOS。
|
||||||
|
|
||||||
Steam Machines 在发布后收到了褒贬不一的评价。另一方面 Steam Link 则普遍受到好评,很多人表示愿意在客厅电视旁为他们已有的 PC 系统购买 Steam Link, 而不是购置一台全新的 Steam Machine。Steam Controller 手柄则受到其丰富功能伴随而来的陡峭学习曲线影响,评价一败涂地。然而针对 Steam Machines 的批评则是最猛烈的。诸如 LinusTechTips 这样的评测团体 (译者:YouTube硬件界老大,个人也经常看他们节目) 注意到了主机的明显的不足,其中甚至不乏性能为题。很多厂商的 Machines 都被批评为性价比极低,特别是经过和玩家们自己组装的同配置机器或者电视主机做对比之后。SteamOS 而被批评为兼容性有问题,Bugs 太多,以及性能不及 Windows。在所有 Machines 里,戴尔的 Alienware Alpha 被评价为最有意思的一款,主要是由于品牌价值和机型外观极小的缘故。
|
Steam Machines 在发布后收到了褒贬不一的评价。另一方面 Steam Link 则普遍受到好评,很多人表示愿意在客厅电视旁为他们已有的 PC 系统购买 Steam Link, 而不是购置一台全新的 Steam Machine。Steam Controller 手柄则受到其丰富功能伴随而来的陡峭学习曲线影响,评价一败涂地。然而针对 Steam Machines 的批评则是最猛烈的。诸如 LinusTechTips 这样的评测团体 (LCTT 译注:YouTube 硬件界老大,个人也经常看他们节目)注意到了主机的明显的不足,其中甚至不乏性能为题。很多厂商的 Machines 都被批评为性价比极低,特别是经过和玩家们自己组装的同配置机器或者电视主机做对比之后。SteamOS 而被批评为兼容性有问题,Bug 太多,以及性能不及 Windows。在所有 Machines 里,戴尔的 Alienware Alpha 被评价为最有意思的一款,主要是由于品牌价值和机型外观极小的缘故。
|
||||||
|
|
||||||
通过把 Debian Linux 操作系统作为开发基础,Valve 得以为 SteamOS 平台找到很多原本就存在与 Steam 平台上的 Linux 兼容游戏来作为“首发游戏”。所以起初大家认为在“首发游戏”上 Steam Machines 对比其他新发布的主机优势明显。然而,很多宣称会在新平台上发布的游戏要么跳票要么被中断了。Rocket League 和 Mad Max 在宣布支持新平台整整一年后才真正发布,而 巫师3 和蝙蝠侠:阿克汉姆骑士 甚至从来没有发布在新平台上。就 巫师3 的情况而言,他们的开发者 CD Projekt Red 拒绝承认他们曾经说过要支持新平台;然而他们的游戏曾在宣布支持 Linux 和 SteamOS 的游戏列表里赫然醒目。雪上加霜的是,很多 AAA 级的大作甚至没被宣布移植,虽然最近这种情况稍有所好转了。
|
通过把 Debian Linux 操作系统作为开发基础,Valve 得以为 SteamOS 平台找到很多原本就存在与 Steam 平台上的 Linux 兼容游戏来作为“首发游戏”。所以起初大家认为在“首发游戏”上 Steam Machines 对比其他新发布的主机优势明显。然而,很多宣称会在新平台上发布的游戏要么跳票要么被中断了。Rocket League 和 Mad Max 在宣布支持新平台整整一年后才真正发布,而《巫师 3》和《蝙蝠侠:阿克汉姆骑士》甚至从来没有发布在新平台上。就《巫师 3》的情况而言,他们的开发者 CD Projekt Red 拒绝承认他们曾经说过要支持新平台;然而他们的游戏曾在宣布支持 Linux 和 SteamOS 的游戏列表里赫然醒目。雪上加霜的是,很多 AAA 级的大作甚至没宣布移植,虽然最近这种情况稍有所好转了。
|
||||||
|
|
||||||
**被忽视的**
|
### 被忽视的
|
||||||
|
|
||||||
在 Stame Machines 发售后,Valve 的开发者们很快转移到了其他项目的工作中去了。在当时,VR 项目最为被内部所重视,6 月份的时候大约有 1/3 的员工都在相关项目上工作。Valve 把 VR 视为亟待开发的一片领域,而他们的 Steam 则应该作为分发 VR 内容的生态环境。通过与 HTC 合作生产,Valve 设计并制造出了他们自己的 VR 头戴和手柄,并计划在将来更新换代。然而与此同时,Linux 和 Steam Machines 都渐渐淡出了视野。SteamVR 甚至直到最近才刚刚支持 Linux (其实还没对普通消费者开放使用,只在 SteamDevDays 上展示过对 Linux 的支持),而这一点则让我们怀疑 Valve 在 Stame Machines 和 Linux 的开发上是否下定了足够的决心。
|
在 Stame Machines 发售后,Valve 的开发者们很快转移到了其他项目的工作中去了。在当时,VR 项目最为内部所重视,6 月份的时候大约有 1/3 的员工都在相关项目上工作。Valve 把 VR 视为亟待开发的一片领域,而他们的 Steam 则应该作为分发 VR 内容的生态环境。通过与 HTC 合作生产,Valve 设计并制造出了他们自己的 VR 头戴和手柄,并计划在将来更新换代。然而与此同时,Linux 和 Steam Machines 都渐渐淡出了视野。SteamVR 甚至直到最近才刚刚支持 Linux (其实还没对普通消费者开放使用,只在 SteamDevDays 上展示过对 Linux 的支持),而这一点则让我们怀疑 Valve 在 Stame Machines 和 Linux 的开发上是否下定了足够的决心。
|
||||||
|
|
||||||
SteamOS 自发布以来几乎止步不前。SteamOS 2.0 作为上一个大版本号更新,几乎只是同步了 Debian 上游的变化,而且还需要用户重新安装整个系统,而之后的小补丁也只是在做些上游更新的配合。当 Valve 在其他事关性能和用户体验的项目,例如 Mesa,上进步匪浅的时候,针对 Steam Machines 的相关项目则少有顾及。
|
SteamOS 自发布以来几乎止步不前。SteamOS 2.0 作为上一个大版本号更新,几乎只是同步了 Debian 上游的变化,而且还需要用户重新安装整个系统,而之后的小补丁也只是在做些上游更新的配合。当 Valve 在其他事关性能和用户体验的项目(例如 Mesa)上进步匪浅的时候,针对 Steam Machines 的相关项目则少有顾及。
|
||||||
|
|
||||||
很多原本应有的功能都从未完成。Steam 的内置功能,例如聊天和直播,都依然处于较弱的状态,而且这种落后会影响所有平台上的 Steam 用户体验。更具体来说,Steam 没有像其他主流主机平台一样把诸如 Netflix,Twitch 和 Spotify 之类的服务集成到客户端里,而通过 Steam 内置的浏览器使用这些服务则体验极差,甚至无法使用;而如果要使用第三方软件则需要开启 Terminal,而且很多软件甚至无法支持控制手柄 —— 无论从哪方面讲这样的用户界面体验都糟糕透顶。
|
很多原本应有的功能都从未完成。Steam 的内置功能,例如聊天和直播,都依然处于较弱的状态,而且这种落后会影响所有平台上的 Steam 用户体验。更具体来说,Steam 没有像其他主流主机平台一样把诸如 Netflix、Twitch 和 Spotify 之类的服务集成到客户端里,而通过 Steam 内置的浏览器使用这些服务则体验极差,甚至无法使用;而如果要使用第三方软件则需要开启 Terminal,而且很多软件甚至无法支持控制手柄 —— 无论从哪方面讲这样的用户界面体验都糟糕透顶。
|
||||||
|
|
||||||
Valve 同时也几乎没有花任何力气去推广他们的新平台而选择把一切都交由 OEM 厂商们去做。然而,几乎所有 OEM 合作商们要么是高端主机定制商,要么是电脑生产商,要么是廉价电脑公司(译者:简而言之没有一家有大型宣传渠道)。在所有 OEM 中,只有戴尔是 PC 市场的大碗,也只有他们真正给 Steam Machines 做了广告宣传。
|
Valve 同时也几乎没有花任何力气去推广他们的新平台,而选择把一切都交由 OEM 厂商们去做。然而,几乎所有 OEM 合作商们要么是高端主机定制商,要么是电脑生产商,要么是廉价电脑公司(LCTT 译注:简而言之没有一家有大型宣传渠道)。在所有 OEM 中,只有戴尔是 PC 市场的大碗,也只有他们真正给 Steam Machines 做了广告宣传。
|
||||||
|
|
||||||
最终销量也不尽人意。截至 2016 年 6 月,7 个月间 Steam Controller 手柄的销量在包括捆绑销售的情况下仅销售 500,000 件。这让 Steam Machines 的零售情况差到只能被归类到十万俱乐部的最底部。对比已经存在的巨大 PC 和主机游戏平台,可以说销量极低。
|
最终销量也不尽人意。截至 2016 年 6 月,7 个月间 Steam Controller 手柄的销量在包括捆绑销售的情况下仅销售 500,000 件。这让 Steam Machines 的零售情况差到只能被归类到十万俱乐部的最底部。对比已经存在的巨大 PC 和主机游戏平台,可以说销量极低。
|
||||||
|
|
||||||
**事后诸葛亮**
|
### 事后诸葛亮
|
||||||
|
|
||||||
既然知道了 Steam Machines 的历史,我们又能否总结出失败的原因以及可能存在的翻身改进呢?
|
既然知道了 Steam Machines 的历史,我们又能否总结出失败的原因以及可能存在的翻身改进呢?
|
||||||
|
|
||||||
_视野与目标_
|
#### 视野与目标
|
||||||
|
|
||||||
Steam Machines 从来没搞清楚他们在市场里的定位究竟是什么,也从来没说清楚他们具体有何优势。从 PC 市场的角度来说,自己搭建台式机已经非常普及并且往往让电脑的可以匹配玩家自己的目标,同时升级性也非常好。从主机平台的角度来说,Steam Machines 又被主机本身的相对廉价所打败,虽然算上游戏可能稍微便宜一些,但主机上的用户体验也直白很多。
|
Steam Machines 从来没搞清楚他们在市场里的定位究竟是什么,也从来没说清楚他们具体有何优势。从 PC 市场的角度来说,自己搭建台式机已经非常普及,并且往往可以让电脑可以匹配玩家自己的目标,同时升级性也非常好。从主机平台的角度来说,Steam Machines 又被主机本身的相对廉价所打败,虽然算上游戏可能稍微便宜一些,但主机上的用户体验也直白很多。
|
||||||
|
|
||||||
PC 用户会把多功能性看得很重,他们不仅能用电脑打游戏,也一样能办公和做各种各样的事情。即使 Steam Machines 也是跑着的 SteamOS 操作系统的自由的 Linux 电脑,但操作系统和市场宣传加固了 PC 玩家们对 Steam Machines 是不可定制硬件,低价的更接近主机的印象。即使这些 PC 用户能接受在客厅里购置一台 Steam Machines,他们也有 Steam Link 可以选择,而且很多更小型机比如 NUC 和 Mini-ITX 主板定制机可以让他们搭建更适合放在客厅里的电脑。SteamOS 软件也允许把这些硬件转变为 Steam Machines,但寻求灵活性和兼容性的用户通常都会使用一般 Linux 发行版或者 Windows。二矿最近的 Windows 和 Linux 桌面环境都让维护一般用户的操作系统变得自动化和简单了。
|
PC 用户会把多功能性看得很重,他们不仅能用电脑打游戏,也一样能办公和做各种各样的事情。即使 Steam Machines 也是跑着的 SteamOS 操作系统的自由的 Linux 电脑,但操作系统和市场宣传加深了 PC 玩家们对 Steam Machines 是不可定制的硬件、低价的、更接近主机的印象。即使这些 PC 用户能接受在客厅里购置一台 Steam Machines,他们也有 Steam Link 可以选择,而且很多更小型机比如 NUC 和 Mini-ITX 主板定制机可以让他们搭建更适合放在客厅里的电脑。SteamOS 软件也允许把这些硬件转变为 Steam Machines,但寻求灵活性和兼容性的用户通常都会使用一般 Linux 发行版或者 Windows。何况最近的 Windows 和 Linux 桌面环境都让维护一般用户的操作系统变得自动化和简单了。
|
||||||
|
|
||||||
电视主机用户们则把易用性放在第一。虽然近年来主机的功能也逐渐扩展,比如可以播放视频或者串流,但总体而言用户还是把即插即用即玩,不用担心兼容性和性能问题和低门槛放在第一。主机的使用寿命也往往较常,一般在 4-7 年左右,而统一固定的硬件也让游戏开发者们能针对其更好的优化和调试软件。现在刚刚新起的中代升级,例如天蝎和 PS 4 Pro 则可能会打破这样统一的游戏体验,但无论如何厂商还是会要求开发者们需要保证游戏在原机型上的体验。为了提高用户粘性,主机也会有自己的社交系统和独占游戏。而主机上的游戏也有实体版,以便将来重用或者二手转卖,这对零售商和用户都是好事儿。Steam Machines 则完全没有这方面的保证;即使长的像一台客厅主机,他们却有 PC 高昂的价格和复杂的硬件情况。
|
电视主机用户们则把易用性放在第一。虽然近年来主机的功能也逐渐扩展,比如可以播放视频或者串流,但总体而言用户还是把即插即用即玩、不用担心兼容性和性能问题和低门槛放在第一。主机的使用寿命也往往较长,一般在 4-7 年左右,而统一固定的硬件也让游戏开发者们能针对其更好的优化和调试软件。现在刚刚兴起的中生代升级,例如天蝎和 PS 4 Pro 则可能会打破这样统一的游戏体验,但无论如何厂商还是会要求开发者们需要保证游戏在原机型上的体验。为了提高用户粘性,主机也会有自己的社交系统和独占游戏。而主机上的游戏也有实体版,以便将来重用或者二手转卖,这对零售商和用户都是好事儿。Steam Machines 则完全没有这方面的保证;即使长的像一台客厅主机,他们却有 PC 高昂的价格和复杂的硬件情况。
|
||||||
|
|
||||||
_妥协_
|
#### 妥协
|
||||||
|
|
||||||
综上所述,Steam Machines 可以说是“集大成者”,吸取了两边的缺点,又没有自己明确的定位。更糟糕的是 Steam Machines 还展现了 PC 和主机都没有的毛病,比如没有 AAA 大作,又没有 Netflix 这样的客户端。抛开这些不说,Valve 在提高他们产品这件事上几乎没有出力,甚至没有尝试着解决 PC 和主机两头定位矛盾这一点。
|
综上所述,Steam Machines 可以说是“集大成者”,吸取了两边的缺点,又没有自己明确的定位。更糟糕的是 Steam Machines 还展现了 PC 和主机都没有的毛病,比如没有 AAA 大作,又没有 Netflix 这样的客户端。抛开这些不说,Valve 在提高他们产品这件事上几乎没有出力,甚至没有尝试着解决 PC 和主机两头定位矛盾这一点。
|
||||||
|
|
||||||
@ -61,35 +61,35 @@ _妥协_
|
|||||||
|
|
||||||
而最复杂的是 Steam Machines 多变的硬件情况,这使得用户不仅要考虑价格还要考虑配置,还要考虑这个价格下和别的系统(PC 和主机)比起来划算与否。更关键的是,Valve 无论如何也应该做出某种自动硬件检测机制,这样玩家才能知道是否能玩某个游戏,而且这个测试既得简单明了,又要能支持 Steam 上几乎所有游戏。同时,Valve 还要操心未来游戏对配置需求的变化,比如2016 年的 "A" 等主机三年后该给什么评分呢?
|
而最复杂的是 Steam Machines 多变的硬件情况,这使得用户不仅要考虑价格还要考虑配置,还要考虑这个价格下和别的系统(PC 和主机)比起来划算与否。更关键的是,Valve 无论如何也应该做出某种自动硬件检测机制,这样玩家才能知道是否能玩某个游戏,而且这个测试既得简单明了,又要能支持 Steam 上几乎所有游戏。同时,Valve 还要操心未来游戏对配置需求的变化,比如2016 年的 "A" 等主机三年后该给什么评分呢?
|
||||||
|
|
||||||
_Valve, 个人努力与公司结构_
|
#### Valve, 个人努力与公司结构
|
||||||
|
|
||||||
尽管 Valve 在 Steam 上创造了辉煌,但其公司的内部结构可能对于开发一个像 Steam Machines 一样的平台是有害的。他们几乎没有领导的自由办公结构,以及所有人都可以自由移动到想要工作的项目组里决定了他们具有极大的创新,研发,甚至开发能力。据说 Valve 只愿意招他们眼中的的 "顶尖人才",通过极其严格的筛选标准,并通过让他们在自己认为“有意义”的项目里工作以保持热情。然而这种思路很可能是错误的;拉帮结派总是存在,而 G胖 的话或许比公司手册上写的还管用,而又有人时不时会由于特殊原因被雇佣或解雇。
|
尽管 Valve 在 Steam 上创造了辉煌,但其公司的内部结构可能对于开发一个像 Steam Machines 一样的平台是有害的。他们几乎没有领导的自由办公结构,以及所有人都可以自由移动到想要工作的项目组里决定了他们具有极大的创新,研发,甚至开发能力。据说 Valve 只愿意招他们眼中的的 “顶尖人才”,通过极其严格的筛选标准,并通过让他们在自己认为“有意义”的项目里工作以保持热情。然而这种思路很可能是错误的;拉帮结派总是存在,而 G胖的话或许比公司手册上写的还管用,而又有人时不时会由于特殊原因被雇佣或解雇。
|
||||||
|
|
||||||
正因为如此,很多虽不闪闪发光甚至维护起来有些无聊但又需要大量时间的项目很容易枯萎。Valve 的客服已是被人诟病已久的毛病,玩家经常觉得被无视了,而 Valve 则经常不到万不得已法律要求的情况下绝不行动:例如自动退款系统,就是在澳大利亚和欧盟法律的要求下才被加入的;更有目前还没结案的华盛顿州 CS:GO 物品在线赌博网站一案。
|
正因为如此,很多虽不闪闪发光甚至维护起来有些无聊但又需要大量时间的项目很容易枯萎。Valve 的客服已是被人诟病已久的毛病,玩家经常觉得被无视了,而 Valve 则经常不到万不得已、法律要求的情况下绝不行动:例如自动退款系统,就是在澳大利亚和欧盟法律的要求下才被加入的;更有目前还没结案的华盛顿州 CS:GO 物品在线赌博网站一案。
|
||||||
|
|
||||||
各种因素最后也反映在 Steam Machines 这一项目上。Valve 方面的跳票迫使一些合作方做出了尴尬的决定,比如戴尔提前一年发布了 Alienware Alpha 外观的 Steam Machine 就在一年后的正式发布时显得硬件状况落后了。跳票很可能也导致了游戏数量上的问题。开发者和硬件合作商的对跳票和最终毫无轰动的发布也不明朗。Valve 的 VR 平台干脆直接不支持 Linux,而直到最近,SteamVR 都风风火火迭代了好几次之后,SteamOS 和 Linux 依然不支持 VR。
|
各种因素最后也反映在 Steam Machines 这一项目上。Valve 方面的跳票迫使一些合作方做出了尴尬的决定,比如戴尔提前一年发布了 Alienware Alpha 外观的 Steam Machine 就在一年后的正式发布时显得硬件状况落后了。跳票很可能也导致了游戏数量上的问题。开发者和硬件合作商的对跳票和最终毫无轰动的发布也不明朗。Valve 的 VR 平台干脆直接不支持 Linux,而直到最近,SteamVR 都风风火火迭代了好几次之后,SteamOS 和 Linux 依然不支持 VR。
|
||||||
|
|
||||||
_“长线钓鱼”_
|
#### “长线钓鱼”
|
||||||
|
|
||||||
尽管 Valve 方面对未来的规划毫无透露,有些人依然认为 Valve 在 Steam Machine 和 SteamOS 上是放长线钓大鱼。他们论点是 Steam 本身也是这样的项目 —— 一开始作为游戏补丁平台出现,到现在无敌的游戏零售和玩家社交网络。虽然 Valve 的独占游戏比如 Half-Life 2 和 CS 也帮助了 Steam 平台的传播。但现今我们完全无法看到 Valve 像当初对 Steam 那样上心 Steam Machines。同时现在 Steam Machines 也面临着 Steam 从没碰到过的激烈竞争。而这些竞争里自然也包含 Valve 自己的那些把 Windows 作为平台的 Steam 客户端。
|
尽管 Valve 方面对未来的规划毫无透露,有些人依然认为 Valve 在 Steam Machine 和 SteamOS 上是放长线钓大鱼。他们论点是 Steam 本身也是这样的项目 —— 一开始作为游戏补丁平台出现,到现在无敌的游戏零售和玩家社交网络。虽然 Valve 的独占游戏比如《半条命 2》和 《CS》 也帮助了 Steam 平台的传播。但现今我们完全无法看到 Valve 像当初对 Steam 那样上心 Steam Machines。同时现在 Steam Machines 也面临着 Steam 从没碰到过的激烈竞争。而这些竞争里自然也包含 Valve 自己的那些把 Windows 作为平台的 Steam 客户端。
|
||||||
|
|
||||||
_真正目的_
|
#### 真正目的
|
||||||
|
|
||||||
介于投入在 Steam Machines 上的努力如此之少,有些人怀疑整个产品平台是不是仅仅作为某种博弈的筹码才被开发出来。原初 Steam Machines 就发家于担心微软和苹果通过自己的应用市场垄断游戏的反制手段当中,Valve 寄希望于 Steam Machines 可以在不备之时脱离那些操作系统的支持而运行,同时也是提醒开发者们,也许有一日整个 Steam 平台会独立出来。而当微软和苹果等方面的风口没有继续收紧的情况下,Valve 自然就放慢了开发进度。然而我不这样认为;Valve 其实已经花了不少精力与硬件商和游戏开发者们共同推行这件事,不可能仅仅是为了吓吓他人就终止项目。你可以把这件事想成,微软和 Valve 都在吓唬对方 —— 微软推出了突然收紧的 Windows 8 而 Valve 则展示了一下可以独立门户的能力。
|
鉴于投入在 Steam Machines 上的努力如此之少,有些人怀疑整个产品平台是不是仅仅作为某种博弈的筹码才被开发出来。原初 Steam Machines 就发家于担心微软和苹果通过自己的应用市场垄断游戏的反制手段当中,Valve 寄希望于 Steam Machines 可以在不备之时脱离那些操作系统的支持而运行,同时也是提醒开发者们,也许有一日整个 Steam 平台会独立出来。而当微软和苹果等方面的风口没有继续收紧的情况下,Valve 自然就放慢了开发进度。然而我不这样认为;Valve 其实已经花了不少精力与硬件商和游戏开发者们共同推行这件事,不可能仅仅是为了吓吓他人就终止项目。你可以把这件事想成,微软和 Valve 都在吓唬对方 —— 微软推出了突然收紧的 Windows 8 ,而 Valve 则展示了一下可以独立门户的能力。
|
||||||
|
|
||||||
但即使如此,谁能保证开发者不会愿意跟着微软的封闭环境跑了呢?万一微软最后能提供更好的待遇和用户群体呢?更何况,微软现在正大力推行 Xbox 和 Windows 的交叉和整合,甚至 Xbox 独占游戏也出现在 Windows 上,这一切都没有损害 Windows 原本的平台性定位 —— 谁还能说微软方面不是 Steam 的直接竞争对手呢?
|
但即使如此,谁能保证开发者不会愿意跟着微软的封闭环境跑了呢?万一微软最后能提供更好的待遇和用户群体呢?更何况,微软现在正大力推行 Xbox 和 Windows 的交叉和整合,甚至 Xbox 独占游戏也出现在 Windows 上,这一切都没有损害 Windows 原本的平台性定位 —— 谁还能说微软方面不是 Steam 的直接竞争对手呢?
|
||||||
|
|
||||||
还会有人说这一切一切都是为了推进 Linux 生态环境尽快接纳 PC 游戏,而 Steam Machines 只是想为此大力推一把。但如果是这样,那这个目的实在是性价比极低,因为本愿意支持 Linux 的自然会开发,而 Steam Machines 这一出甚至会让开发者对平台期待额落空从而伤害到他们。
|
还会有人说这一切一切都是为了推进 Linux 生态环境尽快接纳 PC 游戏,而 Steam Machines 只是想为此大力推一把。但如果是这样,那这个目的实在是性价比极低,因为本愿意支持 Linux 的自然会开发,而 Steam Machines 这一出甚至会让开发者对平台期待额落空从而伤害到他们。
|
||||||
|
|
||||||
**大家眼中 Valve 曾经的机会**
|
### 大家眼中 Valve 曾经的机会
|
||||||
|
|
||||||
我认为 Steam Machines 的创意还是很有趣的,而也有一个与之匹配的市场,但就结果而言 Valve 投入的创意和努力还不够多,而定位模糊也伤害了这个产品。我认为 Steam Machines 的优势在于能砍掉 PC 游戏传统的复杂性,比如硬件问题,整机寿命和维护等;但又能拥有游戏便宜,可以打 Mod 等好处,而且也可以做各种定制化以满足用户需求。但他们必须要让产品的核心内容:价格,市场营销,机型产品线还有软件的质量有所保证才行。
|
我认为 Steam Machines 的创意还是很有趣的,而也有一个与之匹配的市场,但就结果而言 Valve 投入的创意和努力还不够多,而定位模糊也伤害了这个产品。我认为 Steam Machines 的优势在于能砍掉 PC 游戏传统的复杂性,比如硬件问题、整机寿命和维护等;但又能拥有游戏便宜,可以打 Mod 等好处,而且也可以做各种定制化以满足用户需求。但他们必须要让产品的核心内容:价格、市场营销、机型产品线还有软件的质量有所保证才行。
|
||||||
|
|
||||||
我认为 Steam Machines 可以做出一点妥协,比如硬件升级性(尽管这一点还是有可能被保留下来的 —— 但也要极为小心整个过程对用户体验的影响)和产品选择性,来减少摩擦成本。PC 一直会是一个并列的选项。想给用户产品可选性带来的只有一个困境,成吨的质量低下的 Steam Machines 根本不能解决。Valve 得自己造一台旗舰机型来指明 Steam Machines 的方向。毫无疑问,Alienware 的产品是最接近理想目标的,但他说到底也不是 Valve 的官方之作。Valve 内部不乏优秀的工业设计人才,如果他们愿意投入足够多的重视,我认为结果也许会值得他们努力。而像戴尔和 HTC 这样的公司则可以用他们丰富的经验帮 Valve 制造成品。直接钦定 Steam Machines 的硬件周期,并且在期间只推出 1-2 台机型也有助于帮助解决问题,更不用说他们还可以依次和开发商们确立性能的基准线。我不知道 OEM 合作商们该怎么办;如果 Valve 专注于自己的几台设备里,OEM 们很可能会变得多余甚至拖平台后腿。
|
我认为 Steam Machines 可以做出一点妥协,比如硬件升级性(尽管这一点还是有可能被保留下来的 —— 但也要极为小心整个过程对用户体验的影响)和产品选择性,来减少摩擦成本。PC 一直会是一个并列的选项。想给用户产品可选性带来的只有一个困境,成吨的质量低下的 Steam Machines 根本不能解决。Valve 得自己造一台旗舰机型来指明 Steam Machines 的方向。毫无疑问,Alienware 的产品是最接近理想目标的,但它说到底也不是 Valve 的官方之作。Valve 内部不乏优秀的工业设计人才,如果他们愿意投入足够多的重视,我认为结果也许会值得他们努力。而像戴尔和 HTC 这样的公司则可以用他们丰富的经验帮 Valve 制造成品。直接钦定 Steam Machines 的硬件周期,并且在期间只推出 1-2 台机型也有助于帮助解决问题,更不用说他们还可以依次和开发商们确立性能的基准线。我不知道 OEM 合作商们该怎么办;如果 Valve 专注于自己的几台设备里,OEM 们很可能会变得多余甚至拖平台后腿。
|
||||||
|
|
||||||
我觉得修复软件问题是最关键的。很多问题在严重拖着 Steam Machines 的后退,比如缺少主机上遍地都是,又能轻易安装在 PC 上的的 Netflix 和 Twitch,即使做好了客厅体验问题依然是严重的败笔。即使 Valve 已经在逐步购买电影的版权以便在 Steam 上发售,我觉得用户还是会倾向于去使用已经在市场上建立口碑的一些串流服务。这些问题需要被严肃地对待,因为玩家日益倾向于把主机作为家庭影院系统的一部分。同时,修复 Steam 客户端和平台的问题也很重要,和更多第三方服务商合作增加内容应该会是个好主意。性能问题和 Linux 下的显卡问题也很严重,不过好在他们最近在慢慢进步。移植游戏也是个问题。类似 Feral Interactive 或者 Aspyr Media 这样的游戏移植商可以帮助扩展 Steam 的商店游戏数量,但联系开发者和出版社可能会有问题,而且这两家移植商经常在移植的容器上搞自己的花样。Valve 已经在帮助游戏工作室自己移植游戏了,比如 Rocket League,不过这种情况很少见,而且就算 Valve 去帮忙了,也是非常符合 Valve 风格的拖拉。而 AAA 大作这一块内容也绝不应该被忽略 —— 近来这方面的情况已经有极大好转了,虽然 Linux 平台的支持好了很多,但在玩家数量不够以及 Valve 为 Steam Machines 提供的开发帮助甚少的情况下,Bethesda 这样的开发商依然不愿意移植游戏;同时,也有像 Denuvo 一样缺乏数字版权管理的公司难以向 Steam Machines 移植游戏。
|
我觉得修复软件问题是最关键的。很多问题在严重拖着 Steam Machines 的后腿,比如缺少主机上遍地都是、又能轻易安装在 PC 上的的 Netflix 和 Twitch,那么即使做好了客厅体验问题依然是严重的败笔。即使 Valve 已经在逐步购买电影的版权以便在 Steam 上发售,我觉得用户还是会倾向于去使用已经在市场上建立口碑的一些流媒体服务。这些问题需要被严肃地对待,因为玩家日益倾向于把主机作为家庭影院系统的一部分。同时,修复 Steam 客户端和平台的问题也很重要,和更多第三方服务商合作增加内容应该会是个好主意。性能问题和 Linux 下的显卡问题也很严重,不过好在他们最近在慢慢进步。移植游戏也是个问题。类似 Feral Interactive 或者 Aspyr Media 这样的游戏移植商可以帮助扩展 Steam 的商店游戏数量,但联系开发者和出版社可能会有问题,而且这两家移植商经常在移植的容器上搞自己的花样。Valve 已经在帮助游戏工作室自己移植游戏了,比如 Rocket League,不过这种情况很少见,而且就算 Valve 去帮忙了,也是非常符合 Valve 拖拉的风格。而 AAA 大作这一块内容也绝不应该被忽略 —— 近来这方面的情况已经有极大好转了,虽然 Linux 平台的支持好了很多,但在玩家数量不够以及 Valve 为 Steam Machines 提供的开发帮助甚少的情况下,Bethesda 这样的开发商依然不愿意移植游戏;同时,也有像 Denuvo 一样缺乏数字版权管理的公司难以向 Steam Machines 移植游戏。
|
||||||
|
|
||||||
在我看来 Valve 需要在除了软件和硬件的地方也多花些功夫。如果他们只有一个机型的话,他们可以很方便的在硬件生产上贴点钱。这样 Steam Machines 的价格就能跻身主机的行列,而且还能比自己组装 PC 要便宜。针对正确的市场群体做营销也很关键,即便我们还不知道目标玩家应该是谁(我个人会对这样的 Steam Machines 感兴趣,而且我有一整堆已经在 Steam 上以相当便宜的价格买好的游戏)。最后,我觉得零售商们其实不会对 Valve 的计划很感冒,毕竟他们要靠卖和倒卖实体游戏赚钱。
|
在我看来 Valve 需要在除了软件和硬件的地方也多花些功夫。如果他们只有一个机型的话,他们可以很方便的在硬件生产上贴点钱。这样 Steam Machines 的价格就能跻身主机的行列,而且还能比自己组装 PC 要便宜。针对正确的市场群体做营销也很关键,即便我们还不知道目标玩家应该是谁(我个人会对这样的 Steam Machines 感兴趣,而且我有一整堆已经在 Steam 上以相当便宜的价格买下的游戏)。最后,我觉得零售商们其实不会对 Valve 的计划很感冒,毕竟他们要靠卖和倒卖实体游戏赚钱。
|
||||||
|
|
||||||
就算 Valve 在产品和平台上采纳过这些改进,我也不知道怎样才能激活 Steam Machines 的全市场潜力。总的来说,Valve 不仅得学习自己的经验教训,还应该参考曾经有过类似尝试的厂商们,比如尝试依靠开放平台的 3DO 和 Pippin;又或者那些从台式机体验的竞争力退赛的那些公司,其实 Valve 如今的情况和他们也有几分相似。亦或者他们也可以观察一下任天堂 Switch —— 毕竟任天堂也在尝试跨界的创新。
|
就算 Valve 在产品和平台上采纳过这些改进,我也不知道怎样才能激活 Steam Machines 的全市场潜力。总的来说,Valve 不仅得学习自己的经验教训,还应该参考曾经有过类似尝试的厂商们,比如尝试依靠开放平台的 3DO 和 Pippin;又或者那些从台式机体验的竞争力退赛的那些公司,其实 Valve 如今的情况和他们也有几分相似。亦或者他们也可以观察一下任天堂 Switch —— 毕竟任天堂也在尝试跨界的创新。
|
||||||
|
|
||||||
@ -103,7 +103,7 @@ via: https://www.gamingonlinux.com/articles/user-editorial-steam-machines-steamo
|
|||||||
|
|
||||||
作者:[calvin][a]
|
作者:[calvin][a]
|
||||||
译者:[Moelf](https://github.com/Moelf)
|
译者:[Moelf](https://github.com/Moelf)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,17 +1,17 @@
|
|||||||
Android 在物联网方面能否像在移动终端一样成功?
|
Android 在物联网方面能否像在移动终端一样成功?
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
*Android Things 让 IoT 如虎添翼*
|
*Android Things 让 IoT 如虎添翼*
|
||||||
|
|
||||||
### 我 在Android Things 上的最初 24 小时
|
### 我在 Android Things 上的最初 24 小时
|
||||||
|
|
||||||
正当我在开发一个基于 Android 的运行在树莓派 3 的物联网商业项目时,一些令人惊喜的事情发生了。谷歌发布了[Android Things][1] 的第一个预览版本,他们的 SDK 专门(目前)针对 3 个 SBC(单板计算机) - 树莓派 3、英特尔 Edison 和恩智浦 Pico。说我一直在挣扎似乎有些轻描淡写 - 没有成功的移植树莓派 Android 可以参照,我们在理想丰满,但是实践漏洞百出的内测版本上叫苦不迭。其中一个问题,同时也是不可原谅的问题是,它不支持触摸屏,甚至连 [Element14][2] 官方销售的也不支持。曾经我认为 Android 已经支持树莓派,更早时候 [commi tto AOSP project from Google][3] 提到过树莓派曾让所有人兴奋不已。所以当 2016 年 12 月 12 日谷歌发布 “Android Things” 和其 SDK 的时候,我马上闭门谢客,全身心地去研究了……
|
正当我在开发一个基于 Android 的运行在树莓派 3 的物联网商业项目时,一些令人惊喜的事情发生了。谷歌发布了[Android Things][1] 的第一个预览版本,他们的 SDK 专门(目前)针对 3 个 SBC(单板计算机) —— 树莓派 3、英特尔 Edison 和恩智浦 Pico。说我一直在挣扎似乎有些轻描淡写 —— 树莓派上甚至没有一个成功的 Android 移植版本,我们在理想丰满,但是实践漏洞百出的内测版本上叫苦不迭。其中一个问题,同时也是不可原谅的问题是,它不支持触摸屏,甚至连 [Element14][2] 官方销售的也不支持。曾经我认为 Android 已经支持树莓派,更早时候 “[谷歌向 AOSP 项目发起提交][3]” 中提到过树莓派曾让所有人兴奋不已。所以当 2016 年 12 月 12 日谷歌发布 “Android Things” 及其 SDK 的时候,我马上闭门谢客,全身心地去研究了……
|
||||||
|
|
||||||
### 问题?
|
### 问题?
|
||||||
|
|
||||||
关于树莓派上的谷歌 Android 我遇到很多问题,我以前用 Android 做过许多开发,也做过一些树莓派项目,包括之前提到过的一个真正参与的。未来我会尝试解决它们,但是首先最重要的问题得到了解决 - 有完整的 Android Studio 支持,树莓派成为你手里的另一个常规的 ADB 可寻址设备。好极了。Android Studio 强大而便利、十分易用的功能包括布局预览、调试系统、源码检查器、自动化测试等都可以真正的应用在 IoT 硬件上。这些好处怎么说都不过分。到目前为止,我在树莓派上的大部分工作都是通过 SSH 使用运行在树莓派上的编辑器(MC,如果你真的想知道)借助 Python 完成的。这是有效的,毫无疑问铁杆的 Pi/Python 粉丝或许会有更好的工作方式,而不是当前这种像极了 80 年代码农的软件开发模式。我的项目需要在控制树莓派的手机上编写 Android 软件,这真有点痛不欲生 - 我使用 Android Studio 做“真正的” Android 开发,借助 SSH 做剩下的。但是有了“Android Things”之后,一切都结束了。
|
关于树莓派上的谷歌 Android 我遇到很多问题,我以前用 Android 做过许多开发,也做过一些树莓派项目,包括之前提到过的一个真正参与的。未来我会尝试解决这些问题,但是首先最重要的问题得到了解决 —— 有完整的 Android Studio 支持,树莓派成为你手里的另一个常规的 ADB 可寻址设备。好极了。Android Studio 强大而便利、十分易用的功能包括布局预览、调试系统、源码检查器、自动化测试等都可以真正的应用在 IoT 硬件上。这些好处怎么说都不过分。到目前为止,我在树莓派上的大部分工作都是通过 SSH 使用运行在树莓派上的编辑器(MC,如果你真的想知道)借助 Python 完成的。这是有效的,毫无疑问铁杆的 Pi/Python 粉丝或许会有更好的工作方式,而不是当前这种像极了 80 年代码农的软件开发模式。我的项目需要在控制树莓派的手机上编写 Android 软件,这真有点痛不欲生 —— 我使用 Android Studio 做“真正的” Android 开发,借助 SSH 做剩下的。但是有了“Android Things”之后,一切都结束了。
|
||||||
|
|
||||||
所有的示例代码都适用于这三种 SBC,树莓派只是其中之一。 `Build.DEVICE` 常量可以在运行时确定是哪一个,所以你会看到很多如下代码:
|
所有的示例代码都适用于这三种 SBC,树莓派只是其中之一。 `Build.DEVICE` 常量可以在运行时确定是哪一个,所以你会看到很多如下代码:
|
||||||
|
|
||||||
@ -32,7 +32,7 @@
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
我对 GPIO 处理有浓厚的兴趣。 由于我只熟悉树莓派,我只能假定其他 SBC 工作方式相同,GPIO 只是一组引脚,可以定义为输入/输出,是连接物理外部世界的主要接口。 基于 Linux 的树莓派操作系统通过 Python 中的读取和写入方法提供了完整和便捷的支持,但对于 Android,您必须使用 NDK 编写 C++ 驱动程序,并通过 JNI 在 Java 中与这些驱动程序对接。 不是那么困难,但需要在你的构建链中维护额外的一些东西。 树莓派还为 I2C 指定了 2 个引脚:时钟和数据,因此需要额外的工作来处理它们。I2C 是真正酷的总线寻址系统,它通过串行化将许多独立的数据引脚转换成一个。 所以这里的优势是 - Android Things 已经帮你完成了所有这一切。 你只需要 `read()` 和 `write() ` 你需要的任何 GPIO 引脚,I2C 同样容易:
|
我对 GPIO 处理有浓厚的兴趣。 由于我只熟悉树莓派,我只能假定其它 SBC 工作方式相同,GPIO 只是一组引脚,可以定义为输入/输出,是连接物理外部世界的主要接口。 基于 Linux 的树莓派操作系统通过 Python 中的读取和写入方法提供了完整和便捷的支持,但对于 Android,您必须使用 NDK 编写 C++ 驱动程序,并通过 JNI 在 Java 中与这些驱动程序对接。 不是那么困难,但需要在你的构建链中维护额外的一些东西。 树莓派还为 I2C 指定了 2 个引脚:时钟和数据,因此需要额外的工作来处理它们。I2C 是真正酷的总线寻址系统,它通过串行化将许多独立的数据引脚转换成一个。 所以这里的优势是 —— Android Things 已经帮你完成了所有这一切。 你只需要 `read()` 和 `write() ` 你需要的任何 GPIO 引脚,I2C 同样容易:
|
||||||
|
|
||||||
```
|
```
|
||||||
public class HomeActivity extends Activity {
|
public class HomeActivity extends Activity {
|
||||||
@ -73,11 +73,11 @@ public class HomeActivity extends Activity {
|
|||||||
|
|
||||||
### Android Things 基于 Android 的哪个版本?
|
### Android Things 基于 Android 的哪个版本?
|
||||||
|
|
||||||
看起来是 Android 7.0,这样很好,因为我们可以继承 Android 所有以前版本的平板设计 UI、优化,安全加固等。它也带来了一个有趣的问题 - 与应用程序必须单独管理不同,未来的平台应如何更新升级?请记住,这些设备可能无法连接到互联网。我们可能不便于连接蜂窝/ WiFi ,即便之前这些连接能用,但是有时不那么可靠。
|
看起来是 Android 7.0,这样很好,因为我们可以继承 Android 所有以前版本的平板设计 UI、优化,安全加固等。它也带来了一个有趣的问题 —— 与应用程序必须单独管理不同,未来的平台应如何更新升级?请记住,这些设备可能无法连接到互联网。我们可能不便于连接蜂窝 / WiFi ,即便之前这些连接能用,但是有时不那么可靠。
|
||||||
|
|
||||||
另一个担心是,Android Things 仅仅是一个名字不同的 Android 分支版本,大部分都是一样的,和已经发布的 Arduino 一样,更像为了市场营销而出现,而不是作为操作系统。不过可以放心,实际上通过[样例][4]可以看到,其中一些样例甚至使用了 SVG 图形作为资源,而不是传统的基于位图的图形(当然也能轻松处理) ——这是一个非常新的 Android 创新。
|
另一个担心是,Android Things 仅仅是一个名字不同的 Android 分支版本,大部分都是一样的,和已经发布的 Arduino 一样,更像是为了市场营销而出现,而不是作为操作系统。不过可以放心,实际上通过[样例][4]可以看到,其中一些样例甚至使用了 SVG 图形作为资源,而不是传统的基于位图的图形(当然也能轻松处理) —— 这是一个非常新的 Android 创新。
|
||||||
|
|
||||||
不可避免地,与 Android Things 相比,普通的 Android 会有些不同。例如,权限问题。因为 Android Things 为固定硬件设计,在构建好之后,用户通常不会在这种设备上安装应用,所以在一定程序上减轻了这个问题,尽管当设备要求权限时是个问题——因为它们没有 UI。解决方案是当应用在安装时给予所有需要的权限。 通常,这些设备只有一个应用,并且该应用从设备上电的那一刻就开始运行。
|
不可避免地,与 Android Things 相比,普通的 Android 会有些不同。例如,权限问题。因为 Android Things 为固定硬件设计,在构建好之后,用户通常不会在这种设备上安装应用,所以在一定程序上减轻了这个问题,尽管当设备要求权限时是个问题 —— 因为它们没有 UI。解决方案是当应用在安装时给予所有需要的权限。 通常,这些设备只有一个应用,并且该应用从设备上电的那一刻就开始运行。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -87,35 +87,35 @@ Brillo 是谷歌以前的 IoT 操作系统的代号,听起来很像 Android Th
|
|||||||
|
|
||||||
### UI 指南?
|
### UI 指南?
|
||||||
|
|
||||||
谷歌针对 Android 智能手机和平板电脑应用发布了大量指南,例如屏幕按钮间距等。 当然,你最好在可行的情况下遵循这些,但这已经不是本文应该考虑的范畴了。 缺省情况下什么也没有 - 应用程序作者决定一切,这包括顶部状态栏,底部导航栏 - 绝对是一切。 多年来谷歌一直在告诉 Android 应用程序的作者们绝不要在屏幕上放置返回按钮,因为平台将提供一个,因为 Android Things [可能甚至没有 UI!] [5]
|
谷歌针对 Android 智能手机和平板电脑应用发布了大量指南,例如屏幕按钮间距等。 当然,你最好在可行的情况下遵循这些,但这已经不是本文应该考虑的范畴了。 缺省情况下什么也没有 —— 应用程序作者决定一切,这包括顶部状态栏,底部导航栏 —— 绝对是一切。 多年来谷歌一直在告诉 Android 应用程序的作者们绝不要在屏幕上放置返回按钮,因为平台将提供一个,因为 Android Things [可能甚至没有 UI!][5]。
|
||||||
|
|
||||||
### 智能手机上会有多少谷歌服务?
|
### 智能手机上会有多少谷歌服务?
|
||||||
|
|
||||||
有一些,但不是所有。第一个预览版本没有蓝牙支持、没有NFC,这两者都对物联网革命有重大贡献。 SBC 支持它们,所以我们应该不会等待太久。由于没有通知栏,因此不支持任何通知。没有地图。缺省没有软键盘,你必须自己安装一个键盘。由于没有 Play 商店,你只能难受地通过 ADB 做这个和许多其他操作。
|
有一些,但不是所有。第一个预览版本没有蓝牙支持、没有 NFC,这两者都对物联网革命有重大贡献。 SBC 支持它们,所以我们应该不会等待太久。由于没有通知栏,因此不支持任何通知。没有地图。缺省没有软键盘,你必须自己安装一个键盘。由于没有 Play 商店,你只能艰难地通过 ADB 做这个和许多其他操作。
|
||||||
|
|
||||||
当为 Android Things 开发时,我试图为运行在手机上和树莓派上使用同一个 APK。这引发了一个错误,阻止它安装在除 Android Things 设备之外的任何设备:库 `com.google.android.things` 不存在。 这有点用,因为只有 Android Things 设备需要这个,但它似乎是个限制,因为不仅智能手机或平板电脑上没有,连模拟器上也没有。似乎只能在物理 Android Things 设备上运行和测试您的 Android Things 应用程序……直到谷歌在 [G+ 谷歌的 IoT 开发人员社区][6]组中回答了我的问题,并提供了规避方案。但是,躲过初一,躲不过十五。
|
当为 Android Things 开发时,我试图为运行在手机上和树莓派上使用同一个 APK。这引发了一个错误,阻止它安装在除 Android Things 设备之外的任何设备:`com.google.android.things` 库不存在。 这有点用,因为只有 Android Things 设备需要这个,但它似乎是个限制,因为不仅智能手机或平板电脑上没有,连模拟器上也没有。似乎只能在物理 Android Things 设备上运行和测试您的 Android Things 应用程序……直到谷歌在 [G+ 谷歌的 IoT 开发人员社区][6]组中回答了我的问题,并提供了规避方案。但是,躲过初一,躲不过十五。
|
||||||
|
|
||||||
### 可以期待 Android Thing 生态演进到什么程度?
|
### 可以期待 Android Thing 生态演进到什么程度?
|
||||||
|
|
||||||
我期望看到移植更多传统的基于 Linux 服务器的应用程序,将 Android 限制在智能手机和平板电脑上没有意义。例如,Web 服务器突然变得非常有用。已经有一些了,但没有像重量级的 Apache 或 Nginx。物联网设备可以没有本地 UI,但通过浏览器管理它们当然是可行的,因此需要用这种方式呈现 Web 面板。类似的那些如雷贯耳的通讯应用程序 - 它需要的仅是一个麦克风和扬声器,而且在理论上任何视频通话应用程序,如 Duo、Skype、FB 等都可行。这个演变能走多远目前只能猜测。会有 Play 商店吗?它们会展示广告吗?我们能够确保它们不会窥探我们,或被黑客控制它们么?从消费者的角度来看,物联网应该是具有触摸屏的网络连接设备,因为每个人都已经习惯于通过智能手机工作。
|
我期望看到移植更多传统的基于 Linux 服务器的应用程序,将 Android 限制在智能手机和平板电脑上没有意义。例如,Web 服务器突然变得非常有用。已经有一些了,但没有像重量级的 Apache 或 Nginx 的。物联网设备可以没有本地 UI,但通过浏览器管理它们当然是可行的,因此需要用这种方式呈现 Web 面板。类似的那些如雷贯耳的通讯应用程序 —— 它需要的仅是一个麦克风和扬声器,而且在理论上任何视频通话应用程序,如 Duo、Skype、FB 等都可行。这个演变能走多远目前只能猜测。会有 Play 商店吗?它们会展示广告吗?我们能够确保它们不会窥探我们,或被黑客控制它们么?从消费者的角度来看,物联网应该是具有触摸屏的网络连接设备,因为每个人都已经习惯于通过智能手机工作。
|
||||||
|
|
||||||
我还期望看到硬件的迅速发展 - 特别是有更多的 SBC 拥有更低的成本。看看惊人的 5 美元 树莓派 Zero,不幸的是,由于其有限的 CPU 和内存,几乎可以肯定不能运行 Android Things。多久之后像这样的设备才能运行 Android Things?这是很明显的,标杆已经设定,任何有追求的 SBC 制造商将瞄准 Android Things 的兼容性,规模经济也将波及到外围设备,如 23 美元的触摸屏。没人会购买不会播放 YouTube 的微波炉,你的洗碗机会在 eBay 上购买更多的清洁粉,因为它注意到你很少使用它……
|
我还期望看到硬件的迅速发展 —— 特别是有更多的 SBC 拥有更低的成本。看看惊人的 5 美元树莓派 Zero,不幸的是,由于其有限的 CPU 和内存,几乎可以肯定不能运行 Android Things。多久之后像这样的设备才能运行 Android Things?这是很明显的,标杆已经设定,任何有追求的 SBC 制造商将瞄准 Android Things 的兼容性,规模经济也将波及到外围设备,如 23 美元的触摸屏。没人会购买不会播放 YouTube 的微波炉,你的洗碗机会在 eBay 上购买更多的清洁粉,因为它注意到你很少使用它……
|
||||||
|
|
||||||
然而,我不认为我们会过于冲昏头脑。了解一点 Android 架构有助于将其视为一个包罗万象的物联网操作系统。它仍然使用 Java,其垃圾回收机制导致的所有时序问题在过去几乎把它搞死。这仅仅是问题最少的部分。真正的实时操作系统依赖于可预测、准确和坚如磐石的时序,或者它不能被用于“关键任务”。想想医疗应用、安全监视器,工业控制器等。使用 Android,如果宿主操作系统认为它需要,理论上可以在任何时候杀死您的活动/服务。这在手机上没那么糟糕 - 用户可以重新启动应用程序,杀死其他应用程序,或重新启动手机。但心脏监视器就完全是另一码事。如果前台的活动/服务正在监视一个 GPIO 引脚,而这个信号没有被准确地处理,我们就完了。必须要做一些相当根本的改变让 Android 来支持这一点,到目前为止还没有迹象表明它已经在计划之中了。
|
然而,我不认为我们会过于冲昏头脑。了解一点 Android 架构有助于将其视为一个包罗万象的物联网操作系统。它仍然使用 Java,其垃圾回收机制导致的所有时序问题在过去几乎把它搞死。这仅仅是问题最少的部分。真正的实时操作系统依赖于可预测、准确和坚如磐石的时序,要么它就不能被用于“关键任务”。想想医疗应用、安全监视器,工业控制器等。使用 Android,如果宿主操作系统认为它需要,理论上可以在任何时候杀死您的活动/服务。这在手机上没那么糟糕 —— 用户可以重新启动应用程序,杀死其他应用程序,或重新启动手机。但心脏监视器就完全是另一码事。如果前台的活动/服务正在监视一个 GPIO 引脚,而这个信号没有被准确地处理,我们就完了。必须要做一些相当根本的改变让 Android 来支持这一点,到目前为止还没有迹象表明它已经在计划之中了。
|
||||||
|
|
||||||
###这 24 小时
|
### 这 24 小时
|
||||||
|
|
||||||
所以,回到我的项目。 我认为我会接管我已经完成和尽力能为的工作,等待不可避免的路障,并向 G+ 社区寻求帮助。 除了一些在非 Android Things 设备上如何运行程序的问题之外,没有其他问题。 它运行得很好! 这个项目也使用了一些奇怪的东西,如自定义字体、高精定时器 - 所有这些都在 Android Studio 中完美地展现。对我而言,可以打满分 - 至少我能够开始做出实际原型,而不只是视频和截图。
|
所以,回到我的项目。 我认为我会接管我已经完成和尽力能为的工作,等待不可避免的路障,并向 G+ 社区寻求帮助。 除了一些在非 Android Things 设备上如何运行程序的问题之外,没有其他问题。它运行得很好! 这个项目也使用了一些奇怪的东西,如自定义字体、高精定时器 —— 所有这些都在 Android Studio 中完美地展现。对我而言,可以打满分 —— 至少我能够开始做出实际原型,而不只是视频和截图。
|
||||||
|
|
||||||
### 蓝图
|
### 蓝图
|
||||||
|
|
||||||
今天的物联网操作系统环境看起来非常零碎。 显然没有市场领导者,尽管炒作之声沸反连天,物联网仍然在草创阶段。 谷歌 Android 物联网能否像它在移动端那样取得成功?现在 Android 在移动方面的主导地位非常接近 90%。我相信如果真的如此,Android Things 的推出正是重要的一步。
|
今天的物联网操作系统环境看起来非常零碎。 显然没有市场领导者,尽管炒作之声沸反连天,物联网仍然在草创阶段。 谷歌 Android 物联网能否像它在移动端那样取得成功?现在 Android 在移动方面的主导地位几近达到 90%。我相信如果真的如此,Android Things 的推出正是重要的一步。
|
||||||
|
|
||||||
记住所有的关于开放和封闭软件的战争,它们主要发生在从不授权的苹果和一直担心免费还不够充分的谷歌之间。那个老梗又来了,因为让苹果推出一个免费的物联网操作系统的构想就像让他们免费赠送下一代 iPhone 一样遥不可及。
|
记住所有的关于开放和封闭软件的战争,它们主要发生在从不授权的苹果和一直担心免费还不够充分的谷歌之间。那个老梗又来了,因为让苹果推出一个免费的物联网操作系统的构想就像让他们免费赠送下一代 iPhone 一样遥不可及。
|
||||||
|
|
||||||
物联网操作系统游戏是开放的,大家机遇共享,不过这个时候,封闭派甚至不会公布它们的开发工具箱……
|
物联网操作系统游戏是开放的,大家机遇共享,不过这个时候,封闭派甚至不会公布它们的开发工具箱……
|
||||||
|
|
||||||
转到 [Developer Preview][7]网站,立即获取 Android Things SDK 的副本。
|
前往 [Developer Preview][7]网站,立即获取 Android Things SDK 的副本。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -0,0 +1,35 @@
|
|||||||
|
Ciao:云集成高级编排器
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
<ruby>云集成高级编排器<rt>Cloud Integrated Advanced Orchestrator</rt></ruby> (Ciao) 是一个新的负载调度程序,用来解决当前云操作系统项目的局限性。Ciao 提供了一个轻量级,完全基于 TLS 的最小配置。它是
|
||||||
|
工作量无关的、易于更新、具有优化速度的调度程序,目前已针对 OpenStack 进行了优化。
|
||||||
|
|
||||||
|
其设计决策和创新方法在对安全性、可扩展性、可用性和可部署性的要求下进行:
|
||||||
|
|
||||||
|
- **可扩展性:** 初始设计目标是伸缩超过 5,000 个节点。因此,调度器架构用新的形式实现:
|
||||||
|
- 在 ciao 中,决策制定是去中心化的。它基于拉取模型,允许计算节点从调度代理请求作业。调度程序总能知道启动器的容量,而不要求进行数据更新,并且将调度决策时间保持在最小。启动器异步向调度程序发送容量。
|
||||||
|
- 持久化状态跟踪与调度程序决策制定相分离,它让调度程序保持轻量级。这种分离增加了可靠性、可扩展性和性能。结果是调度程序让出了权限并且这不是瓶颈。
|
||||||
|
- **可用性:** 虚拟机、容器和裸机集成到一个调度器中。所有的负载都被视为平等公民。为了更易于使用,网络通过一个组件间最小化的异步协议进行简化,只需要最少的配置。Ciao 还包括一个新的、简单的 UI。所有的这些功能都集成到一起来简化安装、配置、维护和操作。
|
||||||
|
- **轻松部署:** 升级应该是预期操作,而不是例外情况。这种新的去中心化状态的体系结构能够无缝升级。为了确保基础设施(例如 OpenStack)始终是最新的,它实现了持续集成/持续交付(CI/CD)模型。Ciao 的设计使得它可以立即杀死任何 Ciao 组件,更换它,并重新启动它,对可用性影响最小。
|
||||||
|
- **安全性是必需的:** 与调度程序的连接总是加密的:默认情况下 SSL 是打开的,而不是关闭的。加密是从端到端:所有外部连接都需要 HTTPS,组件之间的内部通信是基于 TLS 的。网络支持的一体化保障了租户分离。
|
||||||
|
|
||||||
|
初步结果证明是显著的:在 65 秒内启动一万个 Docker 容器和五千个虚拟机。进一步优化还在进行。
|
||||||
|
|
||||||
|
- 文档:[https://clearlinux.org/documentation/ciao/ciao.html][3]
|
||||||
|
- Github 链接: [https://github.com/01org/ciao(link is external)][1]
|
||||||
|
- 邮件列表链接: [https://lists.clearlinux.org/mailman/listinfo/ciao-devel][2]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://clearlinux.org/ciao
|
||||||
|
|
||||||
|
作者:[ciao][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://clearlinux.org/ciao
|
||||||
|
[1]:https://github.com/01org/ciao
|
||||||
|
[2]:https://lists.clearlinux.org/mailman/listinfo/ciao-devel
|
||||||
|
[3]:https://clearlinux.org/documentation/ciao/ciao.html
|
||||||
@ -0,0 +1,287 @@
|
|||||||
|
服务端 I/O 性能:Node、PHP、Java、Go 的对比
|
||||||
|
============
|
||||||
|
|
||||||
|
了解应用程序的输入/输出(I/O)模型意味着理解应用程序处理其数据的载入差异,并揭示其在真实环境中表现。或许你的应用程序很小,在不承受很大的负载时,这并不是个严重的问题;但随着应用程序的流量负载增加,可能因为使用了低效的 I/O 模型导致承受不了而崩溃。
|
||||||
|
|
||||||
|
和大多数情况一样,处理这种问题的方法有多种方式,这不仅仅是一个择优的问题,而是对权衡的理解问题。 接下来我们来看看 I/O 到底是什么。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在本文中,我们将对 Node、Java、Go 和 PHP + Apache 进行对比,讨论不同语言如何构造其 I/O ,每个模型的优缺点,并总结一些基本的规律。如果你担心你的下一个 Web 应用程序的 I/O 性能,本文将给你最优的解答。
|
||||||
|
|
||||||
|
### I/O 基础知识: 快速复习
|
||||||
|
|
||||||
|
要了解 I/O 所涉及的因素,我们首先深入到操作系统层面复习这些概念。虽然看起来并不与这些概念直接打交道,但你会一直通过应用程序的运行时环境与它们间接接触。了解细节很重要。
|
||||||
|
|
||||||
|
#### 系统调用
|
||||||
|
|
||||||
|
首先是系统调用,其被描述如下:
|
||||||
|
|
||||||
|
* 程序(所谓“<ruby>用户端<rt>user land</rt></ruby>”)必须请求操作系统内核代表它执行 I/O 操作。
|
||||||
|
* “<ruby>系统调用<rt>syscall</rt></ruby>”是你的程序要求内核执行某些操作的方法。这些实现的细节在操作系统之间有所不同,但基本概念是相同的。有一些具体的指令会将控制权从你的程序转移到内核(类似函数调用,但是使用专门用于处理这种情况的专用方式)。一般来说,系统调用会被阻塞,这意味着你的程序会等待内核返回(控制权到)你的代码。
|
||||||
|
* 内核在所需的物理设备( 磁盘、网卡等 )上执行底层 I/O 操作,并回应系统调用。在实际情况中,内核可能需要做许多事情来满足你的要求,包括等待设备准备就绪、更新其内部状态等,但作为应用程序开发人员,你不需要关心这些。这是内核的工作。
|
||||||
|
|
||||||
|
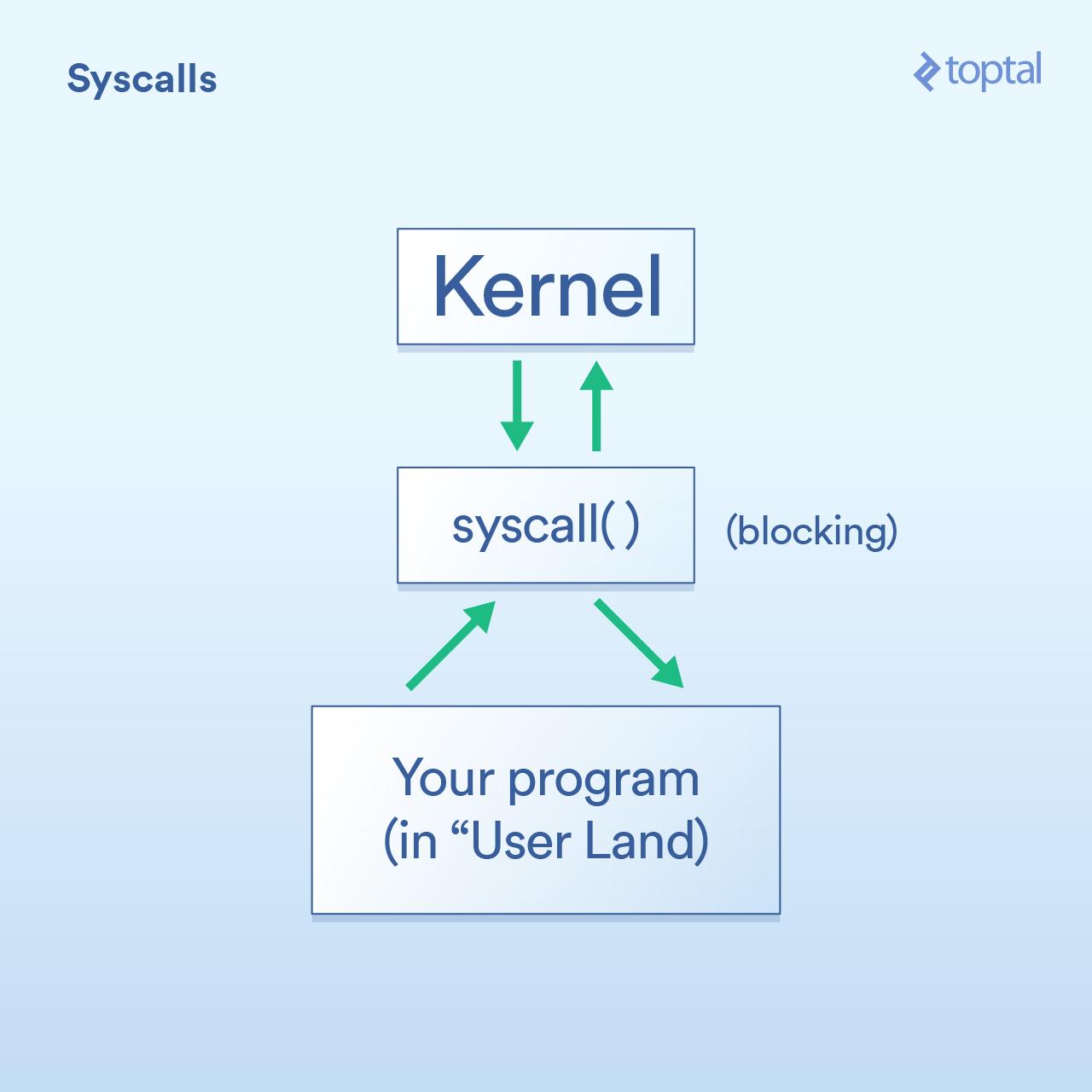
|
||||||
|
|
||||||
|
#### 阻塞与非阻塞
|
||||||
|
|
||||||
|
上面我们提到过,系统调用是阻塞的,一般来说是这样的。然而,一些调用被归类为“非阻塞”,这意味着内核会接收你的请求,将其放在队列或缓冲区之类的地方,然后立即返回而不等待实际的 I/O 发生。所以它只是在很短的时间内“阻塞”,只需要排队你的请求即可。
|
||||||
|
|
||||||
|
举一些 Linux 系统调用的例子可能有助于理解:
|
||||||
|
|
||||||
|
- `read()` 是一个阻塞调用 - 你传递一个句柄,指出哪个文件和缓冲区在哪里传送它所读取的数据,当数据就绪时,该调用返回。这种方式的优点是简单友好。
|
||||||
|
- 分别调用 `epoll_create()`、`epoll_ctl()` 和 `epoll_wait()` ,你可以创建一组句柄来侦听、添加/删除该组中的处理程序、然后阻塞直到有任何事件发生。这允许你通过单个线程有效地控制大量的 I/O 操作,但是现在谈这个还太早。如果你需要这个功能当然好,但须知道它使用起来是比较复杂的。
|
||||||
|
|
||||||
|
了解这里的时间差异的数量级是很重要的。假设 CPU 内核运行在 3GHz,在没有进行 CPU 优化的情况下,那么它每秒执行 30 亿次<ruby>周期<rt>cycle</rt></ruby>(即每纳秒 3 个周期)。非阻塞系统调用可能需要几十个周期来完成,或者说 “相对少的纳秒” 时间完成。而一个被跨网络接收信息所阻塞的系统调用可能需要更长的时间 - 例如 200 毫秒(1/5 秒)。这就是说,如果非阻塞调用需要 20 纳秒,阻塞调用需要 2 亿纳秒。你的进程因阻塞调用而等待了 1000 万倍的时长!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
内核既提供了阻塞 I/O (“从网络连接读取并给出数据”),也提供了非阻塞 I/O (“告知我何时这些网络连接具有新数据”)的方法。使用的是哪种机制对调用进程的阻塞时长有截然不同的影响。
|
||||||
|
|
||||||
|
#### 调度
|
||||||
|
|
||||||
|
关键的第三件事是当你有很多线程或进程开始阻塞时会发生什么。
|
||||||
|
|
||||||
|
根据我们的理解,线程和进程之间没有很大的区别。在现实生活中,最显著的性能相关的差异在于,由于线程共享相同的内存,而进程每个都有自己的内存空间,使得单独的进程往往占用更多的内存。但是当我们谈论<ruby>调度<rt>Scheduling</rt></ruby>时,它真正归结为一类事情(线程和进程类同),每个都需要在可用的 CPU 内核上获得一段执行时间。如果你有 300 个线程运行在 8 个内核上,则必须将时间分成几份,以便每个线程和进程都能分享它,每个运行一段时间,然后交给下一个。这是通过 “<ruby>上下文切换<rt>context switch</rt></ruby>” 完成的,可以使 CPU 从运行到一个线程/进程到切换下一个。
|
||||||
|
|
||||||
|
这些上下文切换也有相关的成本 - 它们需要一些时间。在某些快速的情况下,它可能小于 100 纳秒,但根据实际情况、处理器速度/体系结构、CPU 缓存等,偶见花费 1000 纳秒或更长时间。
|
||||||
|
|
||||||
|
而线程(或进程)越多,上下文切换就越多。当我们涉及数以千计的线程时,每个线程花费数百纳秒,就会变得很慢。
|
||||||
|
|
||||||
|
然而,非阻塞调用实质上是告诉内核“仅在这些连接之一有新的数据或事件时再叫我”。这些非阻塞调用旨在有效地处理大量 I/O 负载并减少上下文交换。
|
||||||
|
|
||||||
|
这些你明白了么?现在来到了真正有趣的部分:我们来看看一些流行的语言对那些工具的使用,并得出关于易用性和性能之间权衡的结论,以及一些其他有趣小东西。
|
||||||
|
|
||||||
|
声明,本文中显示的示例是零碎的(片面的,只能体现相关的信息); 数据库访问、外部缓存系统( memcache 等等)以及任何需要 I/O 的东西都将执行某种类型的 I/O 调用,其实质与上面所示的简单示例效果相同。此外,对于将 I/O 描述为“阻塞”( PHP、Java )的情况,HTTP 请求和响应读取和写入本身就是阻塞调用:系统中隐藏着更多 I/O 及其伴生的性能问题需要考虑。
|
||||||
|
|
||||||
|
为一个项目选择编程语言要考虑很多因素。甚至当你只考虑效率时,也有很多因素。但是,如果你担心你的程序将主要受到 I/O 的限制,如果 I/O 性能影响到项目的成败,那么这些是你需要了解的。
|
||||||
|
|
||||||
|
### “保持简单”方法:PHP
|
||||||
|
|
||||||
|
早在 90 年代,很多人都穿着 [Converse][1] 鞋,用 Perl 写着 CGI 脚本。然后 PHP 来了,就像一些人喜欢咒骂的一样,它使得动态网页更容易。
|
||||||
|
|
||||||
|
PHP 使用的模型相当简单。虽有一些出入,但你的 PHP 服务器基本上是这样:
|
||||||
|
|
||||||
|
HTTP 请求来自用户的浏览器,并访问你的 Apache Web 服务器。Apache 为每个请求创建一个单独的进程,有一些优化方式可以重新使用它们,以最大限度地减少创建次数( 相对而言,创建进程较慢 )。Apache 调用 PHP 并告诉它运行磁盘上合适的 `.php` 文件。PHP 代码执行并阻塞 I/O 调用。你在 PHP 中调用 `file_get_contents()` ,其底层会调用 `read()` 系统调用并等待结果。
|
||||||
|
|
||||||
|
当然,实际的代码是直接嵌入到你的页面,并且该操作被阻塞:
|
||||||
|
|
||||||
|
```
|
||||||
|
<?php
|
||||||
|
|
||||||
|
// blocking file I/O
|
||||||
|
$file_data = file_get_contents(‘/path/to/file.dat’);
|
||||||
|
|
||||||
|
// blocking network I/O
|
||||||
|
$curl = curl_init('http://example.com/example-microservice');
|
||||||
|
$result = curl_exec($curl);
|
||||||
|
|
||||||
|
// some more blocking network I/O
|
||||||
|
$result = $db->query('SELECT id, data FROM examples ORDER BY id DESC limit 100');
|
||||||
|
|
||||||
|
?>
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
关于如何与系统集成,就像这样:
|
||||||
|
|
||||||
|
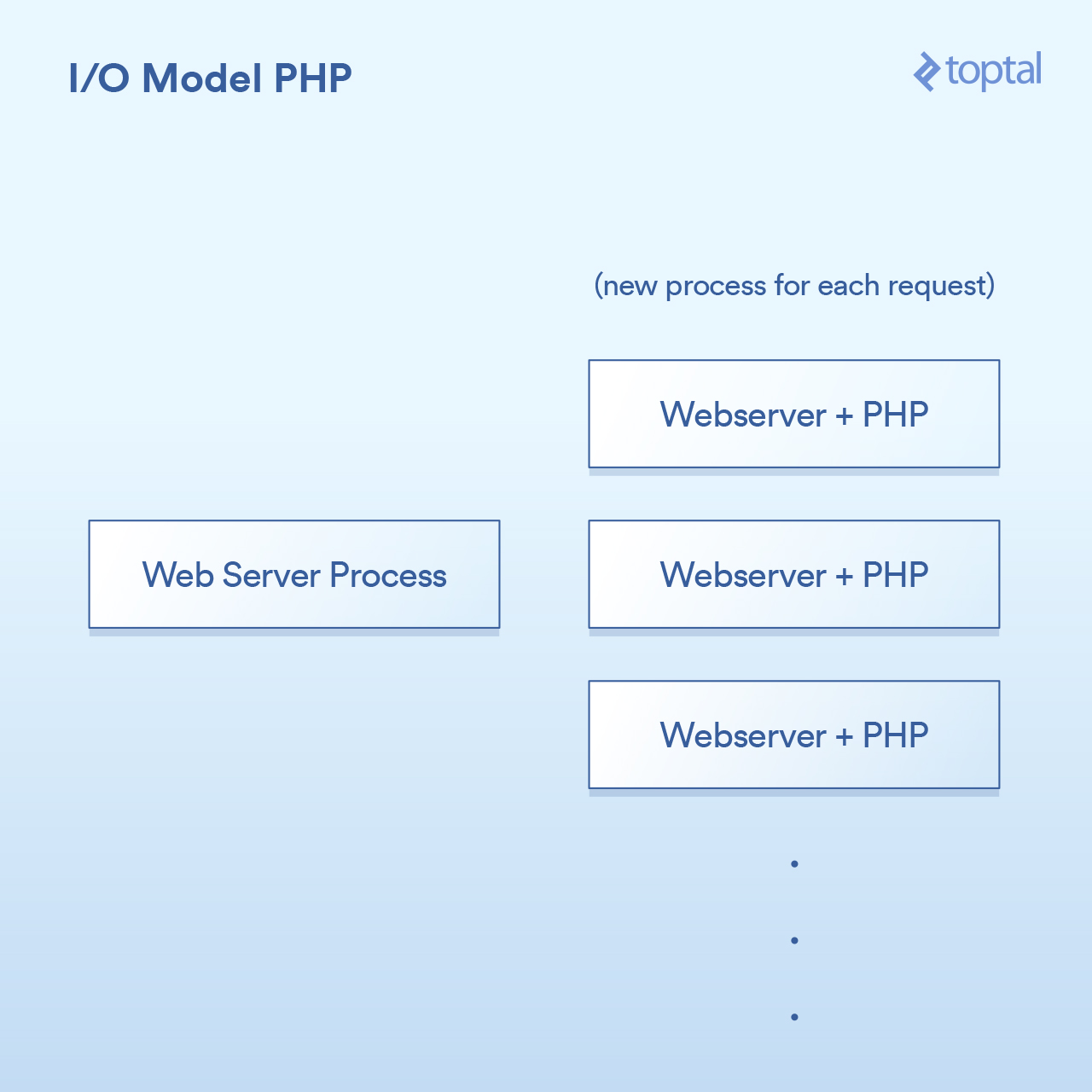
|
||||||
|
|
||||||
|
很简单:每个请求一个进程。 I/O 调用就阻塞。优点是简单可工作,缺点是,同时与 20,000 个客户端连接,你的服务器将会崩溃。这种方法不能很好地扩展,因为内核提供的用于处理大容量 I/O (epoll 等) 的工具没有被使用。 雪上加霜的是,为每个请求运行一个单独的进程往往会使用大量的系统资源,特别是内存,这通常是你在这样的场景中遇到的第一个问题。
|
||||||
|
|
||||||
|
_注意:Ruby 使用的方法与 PHP 非常相似,在大致的方面上,它们可以被认为是相同的。_
|
||||||
|
|
||||||
|
### 多线程方法: Java
|
||||||
|
|
||||||
|
就在你购买你的第一个域名,在某个句子后很酷地随机说出 “dot com” 的那个时候,Java 来了。而 Java 具有内置于该语言中的多线程功能,它非常棒(特别是在创建时)。
|
||||||
|
|
||||||
|
大多数 Java Web 服务器通过为每个请求启动一个新的执行线程,然后在该线程中最终调用你(作为应用程序开发人员)编写的函数。
|
||||||
|
|
||||||
|
在 Java Servlet 中执行 I/O 往往看起来像:
|
||||||
|
|
||||||
|
```
|
||||||
|
public void doGet(HttpServletRequest request,
|
||||||
|
HttpServletResponse response) throws ServletException, IOException
|
||||||
|
{
|
||||||
|
|
||||||
|
// blocking file I/O
|
||||||
|
InputStream fileIs = new FileInputStream("/path/to/file");
|
||||||
|
|
||||||
|
// blocking network I/O
|
||||||
|
URLConnection urlConnection = (new URL("http://example.com/example-microservice")).openConnection();
|
||||||
|
InputStream netIs = urlConnection.getInputStream();
|
||||||
|
|
||||||
|
// some more blocking network I/O
|
||||||
|
out.println("...");
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
由于我们上面的 `doGet` 方法对应于一个请求,并且在其自己的线程中运行,而不是每个请求一个单独的进程,申请自己的内存。这样有一些好处,比如在线程之间共享状态、缓存数据等,因为它们可以访问彼此的内存,但是它与调度的交互影响与之前的 PHP 的例子几乎相同。每个请求获得一个新线程,该线程内的各种 I/O 操作阻塞在线程内,直到请求被完全处理为止。线程被池化以最小化创建和销毁它们的成本,但是数千个连接仍然意味着数千个线程,这对调度程序是不利的。
|
||||||
|
|
||||||
|
重要的里程碑出现在 Java 1.4 版本(以及 1.7 的重要升级)中,它获得了执行非阻塞 I/O 调用的能力。大多数应用程序、web 应用和其它用途不会使用它,但至少它是可用的。一些 Java Web 服务器尝试以各种方式利用这一点;然而,绝大多数部署的 Java 应用程序仍然如上所述工作。
|
||||||
|
|
||||||
|
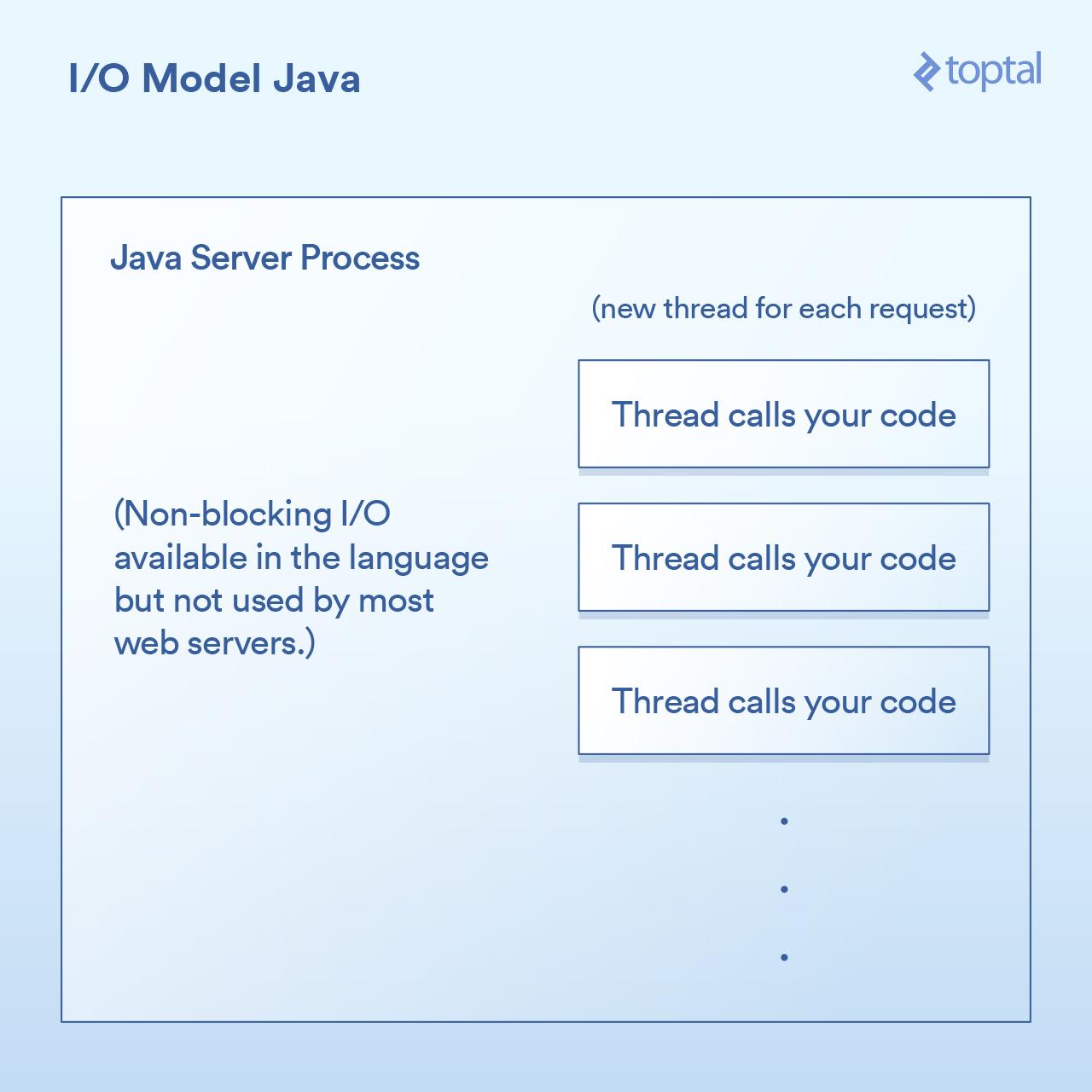
|
||||||
|
|
||||||
|
肯定有一些很好的开箱即用的 I/O 功能,Java 让我们更接近,但它仍然没有真正解决当你有一个大量的 I/O 绑定的应用程序被数千个阻塞线程所压垮的问题。
|
||||||
|
|
||||||
|
### 无阻塞 I/O 作为一等公民: Node
|
||||||
|
|
||||||
|
当更好的 I/O 模式来到 Node.js,阻塞才真正被解决。任何一个曾听过 Node 简单介绍的人都被告知这是“非阻塞”,可以有效地处理 I/O。这在一般意义上是正确的。但在细节中则不尽然,而且当在进行性能工程时,这种巫术遇到了问题。
|
||||||
|
|
||||||
|
Node 实现的范例基本上不是说 “在这里写代码来处理请求”,而是说 “在这里写代码来**开始**处理请求”。每次你需要做一些涉及到 I/O 的操作,你会创建一个请求并给出一个回调函数,Node 将在完成之后调用该函数。
|
||||||
|
|
||||||
|
在请求中执行 I/O 操作的典型 Node 代码如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
http.createServer(function(request, response) {
|
||||||
|
fs.readFile('/path/to/file', 'utf8', function(err, data) {
|
||||||
|
response.end(data);
|
||||||
|
});
|
||||||
|
});
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以看到,这里有两个回调函数。当请求开始时,第一个被调用,当文件数据可用时,第二个被调用。
|
||||||
|
|
||||||
|
这样做的基本原理是让 Node 有机会有效地处理这些回调之间的 I/O 。一个更加密切相关的场景是在 Node 中进行数据库调用,但是我不会在这个例子中啰嗦,因为它遵循完全相同的原则:启动数据库调用,并给 Node 一个回调函数,它使用非阻塞调用单独执行 I/O 操作,然后在你要求的数据可用时调用回调函数。排队 I/O 调用和让 Node 处理它然后获取回调的机制称为“事件循环”。它工作的很好。
|
||||||
|
|
||||||
|
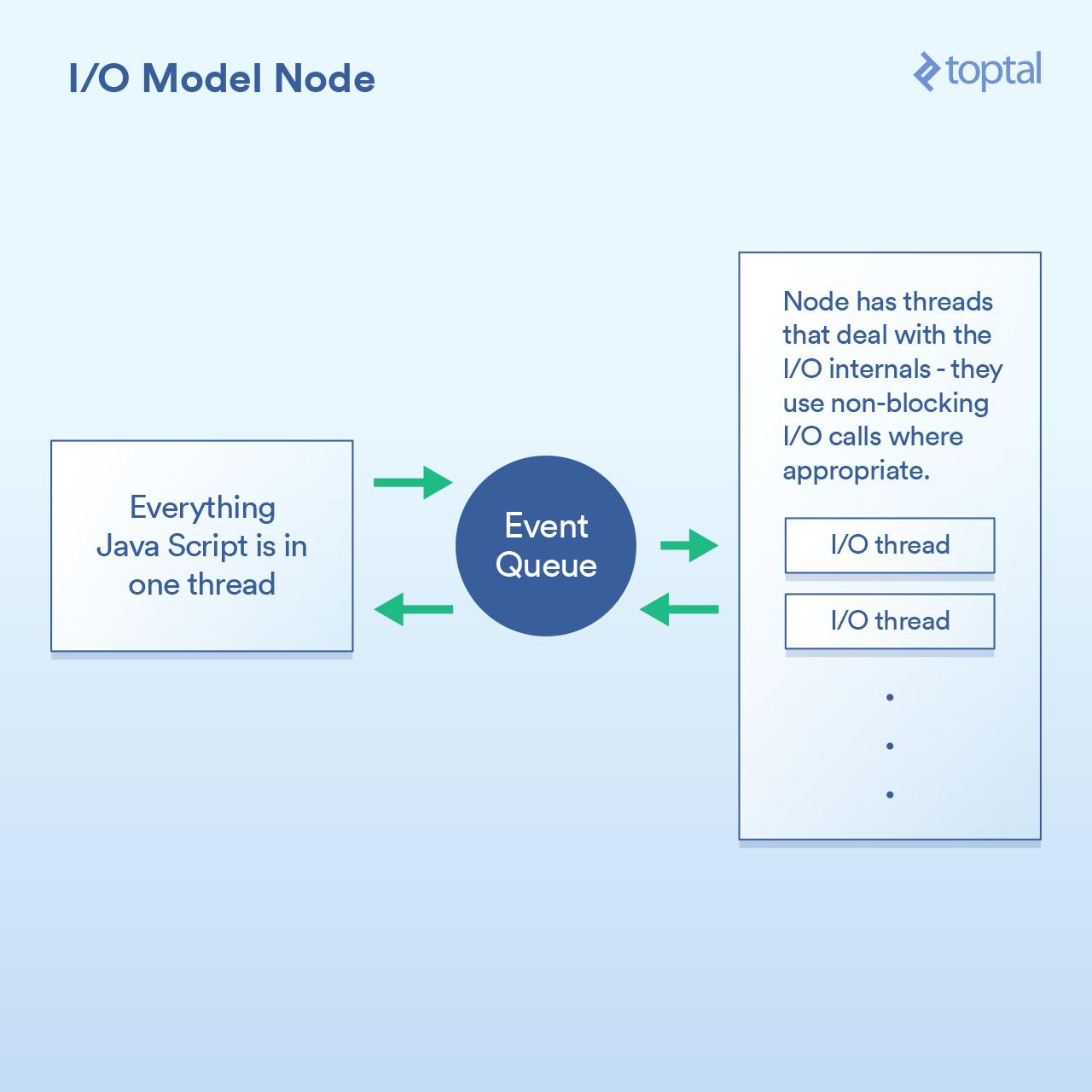
|
||||||
|
|
||||||
|
然而,这个模型有一个陷阱,究其原因,很多是与 V8 JavaScript 引擎(Node 用的是 Chrome 浏览器的 JS 引擎)如何实现的有关^注1 。你编写的所有 JS 代码都运行在单个线程中。你可以想想,这意味着当使用高效的非阻塞技术执行 I/O 时,你的 JS 可以在单个线程中运行计算密集型的操作,每个代码块都会阻塞下一个。可能出现这种情况的一个常见例子是以某种方式遍历数据库记录,然后再将其输出到客户端。这是一个示例,展示了其是如何工作:
|
||||||
|
|
||||||
|
```
|
||||||
|
var handler = function(request, response) {
|
||||||
|
|
||||||
|
connection.query('SELECT ...', function (err, rows) {
|
||||||
|
|
||||||
|
if (err) { throw err };
|
||||||
|
|
||||||
|
for (var i = 0; i < rows.length; i++) {
|
||||||
|
// do processing on each row
|
||||||
|
}
|
||||||
|
|
||||||
|
response.end(...); // write out the results
|
||||||
|
|
||||||
|
})
|
||||||
|
|
||||||
|
};
|
||||||
|
```
|
||||||
|
|
||||||
|
虽然 Node 确实有效地处理了 I/O ,但是上面的例子中 `for` 循环是在你的唯一的一个主线程中占用 CPU 周期。这意味着如果你有 10,000 个连接,则该循环可能会使你的整个应用程序像爬行般缓慢,具体取决于其会持续多久。每个请求必须在主线程中分享一段时间,一次一段。
|
||||||
|
|
||||||
|
这整个概念的前提是 I/O 操作是最慢的部分,因此最重要的是要有效地处理这些操作,即使这意味着要连续进行其他处理。这在某些情况下是正确的,但不是全部。
|
||||||
|
|
||||||
|
另一点是,虽然这只是一个观点,但是写一堆嵌套的回调可能是相当令人讨厌的,有些则认为它使代码更难以追踪。在 Node 代码中看到回调嵌套 4 层、5 层甚至更多层并不罕见。
|
||||||
|
|
||||||
|
我们再次来权衡一下。如果你的主要性能问题是 I/O,则 Node 模型工作正常。然而,它的关键是,你可以在一个处理 HTTP 请求的函数里面放置 CPU 密集型的代码,而且不小心的话会导致每个连接都很慢。
|
||||||
|
|
||||||
|
### 最自然的非阻塞:Go
|
||||||
|
|
||||||
|
在我进入 Go 部分之前,我应该披露我是一个 Go 的粉丝。我已经在许多项目中使用过它,我是一个其生产力优势的公开支持者,我在我的工作中使用它。
|
||||||
|
|
||||||
|
那么,让我们来看看它是如何处理 I/O 的。Go 语言的一个关键特征是它包含自己的调度程序。在 Go 中,不是每个执行线程对应于一个单一的 OS 线程,其通过一种叫做 “<ruby>协程<rt>goroutine</rt></ruby>” 的概念来工作。而 Go 的运行时可以将一个协程分配给一个 OS 线程,使其执行或暂停它,并且它不与一个 OS 线程相关联——这要基于那个协程正在做什么。来自 Go 的 HTTP 服务器的每个请求都在单独的协程中处理。
|
||||||
|
|
||||||
|
调度程序的工作原理如图所示:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在底层,这是通过 Go 运行时中的各个部分实现的,它通过对请求的写入/读取/连接等操作来实现 I/O 调用,将当前协程休眠,并当采取进一步动作时唤醒该协程。
|
||||||
|
|
||||||
|
从效果上看,Go 运行时做的一些事情与 Node 做的没有太大不同,除了回调机制是内置到 I/O 调用的实现中,并自动与调度程序交互。它也不会受到必须让所有处理程序代码在同一个线程中运行的限制,Go 将根据其调度程序中的逻辑自动将协程映射到其认为适当的 OS 线程。结果是这样的代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
|
||||||
|
|
||||||
|
// the underlying network call here is non-blocking
|
||||||
|
rows, err := db.Query("SELECT ...")
|
||||||
|
|
||||||
|
for _, row := range rows {
|
||||||
|
// do something with the rows,
|
||||||
|
// each request in its own goroutine
|
||||||
|
}
|
||||||
|
|
||||||
|
w.Write(...) // write the response, also non-blocking
|
||||||
|
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
如上所述,我们重构基本的代码结构为更简化的方式,并在底层仍然实现了非阻塞 I/O。
|
||||||
|
|
||||||
|
在大多数情况下,最终是“两全其美”的。非阻塞 I/O 用于所有重要的事情,但是你的代码看起来像是阻塞,因此更容易理解和维护。Go 调度程序和 OS 调度程序之间的交互处理其余部分。这不是完整的魔法,如果你建立一个大型系统,那么值得我们来看看有关它的工作原理的更多细节;但与此同时,你获得的“开箱即用”的环境可以很好地工作和扩展。
|
||||||
|
|
||||||
|
Go 可能有其缺点,但一般来说,它处理 I/O 的方式不在其中。
|
||||||
|
|
||||||
|
### 谎言,可恶的谎言和基准
|
||||||
|
|
||||||
|
对这些各种模式的上下文切换进行准确的定时是很困难的。我也可以认为这对你来说不太有用。相反,我会给出一些比较这些服务器环境的整个 HTTP 服务器性能的基本基准。请记住,影响整个端到端 HTTP 请求/响应路径的性能有很多因素,这里提供的数字只是我将一些样本放在一起进行基本比较的结果。
|
||||||
|
|
||||||
|
对于这些环境中的每一个,我写了适当的代码在一个 64k 文件中读取随机字节,在其上运行了一个 SHA-256 哈希 N 次( N 在 URL 的查询字符串中指定,例如 .../test.php?n=100),并打印出结果十六进制散列。我选择这样做,是因为使用一些一致的 I/O 和受控的方式来运行相同的基准测试是一个增加 CPU 使用率的非常简单的方法。
|
||||||
|
|
||||||
|
有关使用的环境的更多细节,请参阅 [基准说明][3] 。
|
||||||
|
|
||||||
|
首先,我们来看一些低并发的例子。运行 2000 次迭代,300 个并发请求,每个请求只有一个散列(N = 1),结果如下:
|
||||||
|
|
||||||
|
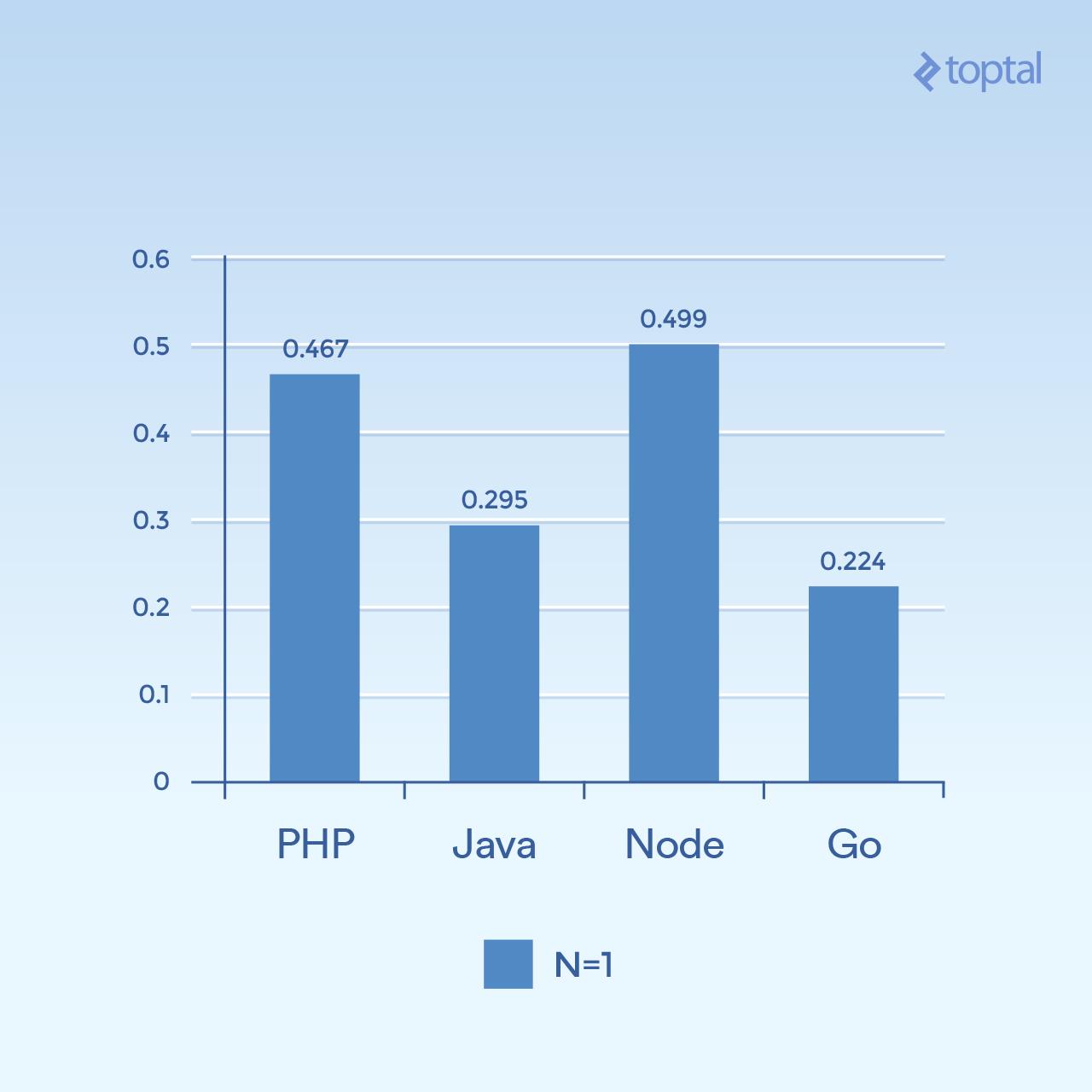
|
||||||
|
|
||||||
|
*时间是在所有并发请求中完成请求的平均毫秒数。越低越好。*
|
||||||
|
|
||||||
|
仅从一张图很难得出结论,但是对我来说,似乎在大量的连接和计算量上,我们看到时间更多地与语言本身的一般执行有关,对于 I/O 更是如此。请注意,那些被视为“脚本语言”的语言(松散类型,动态解释)执行速度最慢。
|
||||||
|
|
||||||
|
但是,如果我们将 N 增加到 1000,仍然有 300 个并发请求,相同的任务,但是哈希迭代是 1000 倍(显着增加了 CPU 负载):
|
||||||
|
|
||||||
|
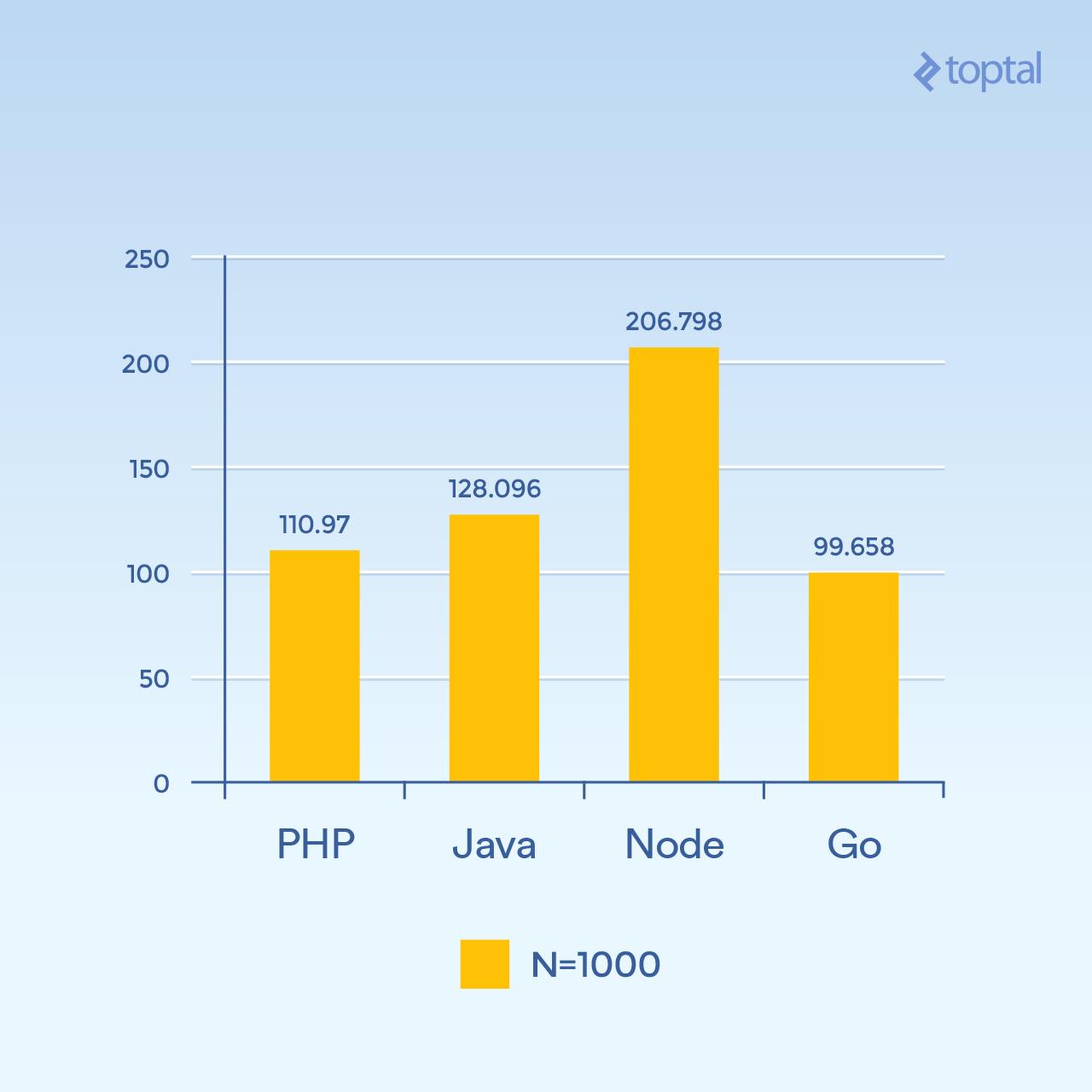
|
||||||
|
|
||||||
|
*时间是在所有并发请求中完成请求的平均毫秒数。越低越好。*
|
||||||
|
|
||||||
|
突然间, Node 性能显著下降,因为每个请求中的 CPU 密集型操作都相互阻塞。有趣的是,在这个测试中,PHP 的性能要好得多(相对于其他的),并且打败了 Java。(值得注意的是,在 PHP 中,SHA-256 实现是用 C 编写的,在那个循环中执行路径花费了更多的时间,因为现在我们正在进行 1000 个哈希迭代)。
|
||||||
|
|
||||||
|
现在让我们尝试 5000 个并发连接(N = 1) - 或者是我可以发起的最大连接。不幸的是,对于大多数这些环境,故障率并不显着。对于这个图表,我们来看每秒的请求总数。 _越高越好_ :
|
||||||
|
|
||||||
|
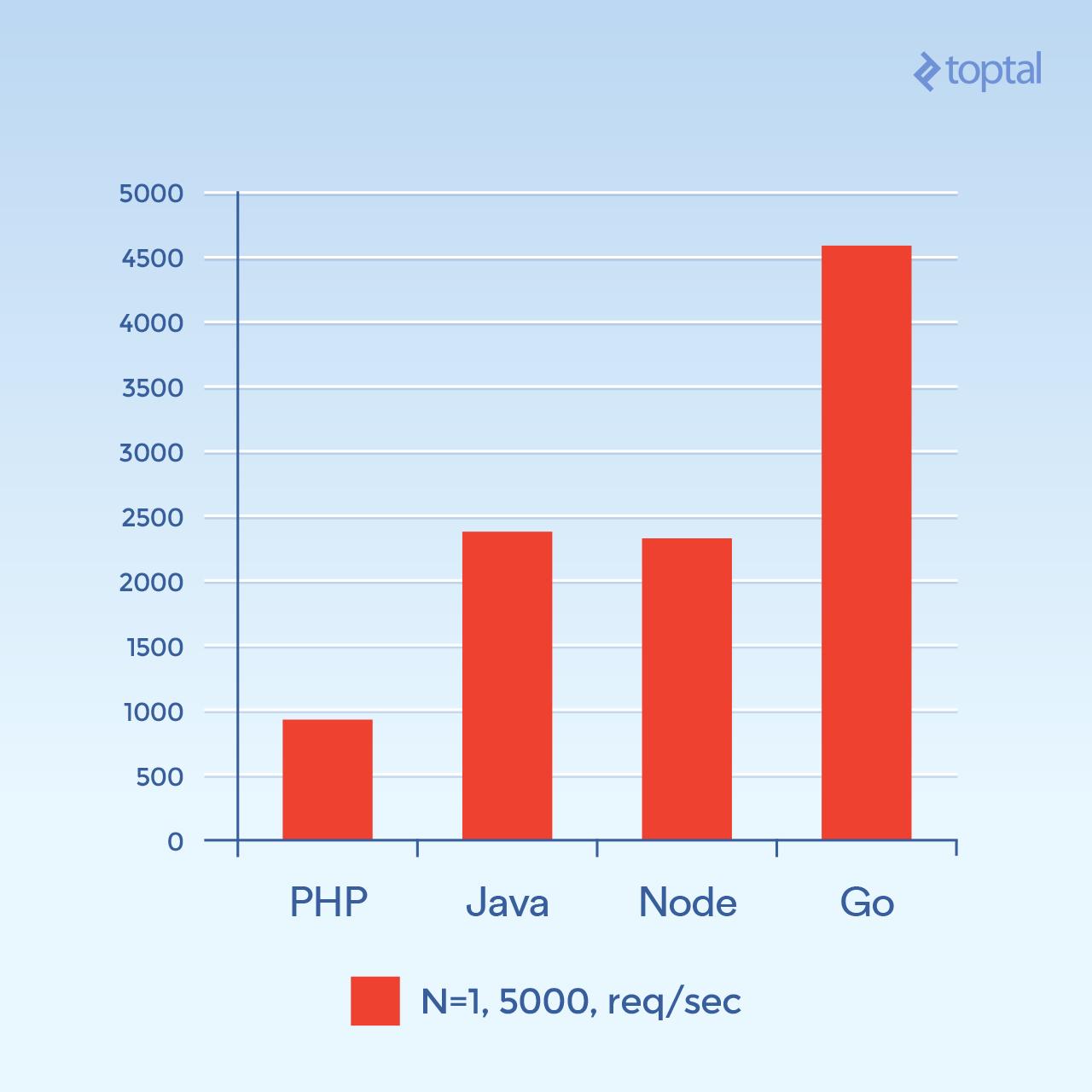
|
||||||
|
|
||||||
|
*每秒请求数。越高越好。*
|
||||||
|
|
||||||
|
这个图看起来有很大的不同。我猜测,但是看起来像在高连接量时,产生新进程所涉及的每连接开销以及与 PHP + Apache 相关联的附加内存似乎成为主要因素,并阻止了 PHP 的性能。显然,Go 是这里的赢家,其次是 Java,Node,最后是 PHP。
|
||||||
|
|
||||||
|
虽然与你的整体吞吐量相关的因素很多,并且在应用程序之间也有很大的差异,但是你对底层发生什么的事情以及所涉及的权衡了解更多,你将会得到更好的结果。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
以上所有这一切,很显然,随着语言的发展,处理大量 I/O 的大型应用程序的解决方案也随之发展。
|
||||||
|
|
||||||
|
为了公平起见,PHP 和 Java,尽管这篇文章中的描述,确实 [实现了][4] 在 [ web 应用程序][7] 中 [可使用的][6] [ 非阻塞 I/O][5] 。但是这些方法并不像上述方法那么常见,并且需要考虑使用这种方法来维护服务器的随之而来的操作开销。更不用说你的代码必须以与这些环境相适应的方式进行结构化;你的 “正常” PHP 或 Java Web 应用程序通常不会在这样的环境中进行重大修改。
|
||||||
|
|
||||||
|
作为比较,如果我们考虑影响性能和易用性的几个重要因素,我们得出以下结论:
|
||||||
|
|
||||||
|
| 语言 | 线程与进程 | 非阻塞 I/O | 使用便捷性 |
|
||||||
|
| --- | --- | --- | --- |
|
||||||
|
| PHP | 进程 | 否 | |
|
||||||
|
| Java | 线程 | 可用 | 需要回调 |
|
||||||
|
| Node.js | 线程 | 是 | 需要回调 |
|
||||||
|
| Go | 线程 (协程) | 是 | 不需要回调 |
|
||||||
|
|
||||||
|
线程通常要比进程有更高的内存效率,因为它们共享相同的内存空间,而进程则没有。结合与非阻塞 I/O 相关的因素,我们可以看到,至少考虑到上述因素,当我们从列表往下看时,与 I/O 相关的一般设置得到改善。所以如果我不得不在上面的比赛中选择一个赢家,那肯定会是 Go。
|
||||||
|
|
||||||
|
即使如此,在实践中,选择构建应用程序的环境与你的团队对所述环境的熟悉程度以及你可以实现的总体生产力密切相关。因此,每个团队都深入并开始在 Node 或 Go 中开发 Web 应用程序和服务可能就没有意义。事实上,寻找开发人员或你内部团队的熟悉度通常被认为是不使用不同语言和/或环境的主要原因。也就是说,过去十五年来,时代已经发生了变化。
|
||||||
|
|
||||||
|
希望以上内容可以帮助你更清楚地了解底层发生的情况,并为你提供如何处理应用程序的现实可扩展性的一些想法。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.toptal.com/back-end/server-side-io-performance-node-php-java-go
|
||||||
|
|
||||||
|
作者:[BRAD PEABODY][a]
|
||||||
|
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.toptal.com/resume/brad-peabody
|
||||||
|
[1]:https://www.pinterest.com/pin/414401603185852181/
|
||||||
|
[2]:http://www.journaldev.com/7462/node-js-architecture-single-threaded-event-loop
|
||||||
|
[3]:https://peabody.io/post/server-env-benchmarks/
|
||||||
|
[4]:http://reactphp.org/
|
||||||
|
[5]:http://amphp.org/
|
||||||
|
[6]:http://undertow.io/
|
||||||
|
[7]:https://netty.io/
|
||||||
@ -0,0 +1,86 @@
|
|||||||
|
促使项目团队作出改变的五步计划
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
目的是任何团队组建的首要之事。如果一个人足以实现那个目的,那么就没有必要组成团队。而且如果没有重要目标,你根本不需要一个团队。但只要任务需要的专业知识比一个人所拥有的更多,我们就会遇到集体参与的问题——如果处理不当,会使你脱离正轨。
|
||||||
|
|
||||||
|
想象一群人困在洞穴中。没有一个人具备如何出去的全部知识,所以每个人要协作,心路常开,在想要做的事情上尽力配合。当(且仅当)组建了适当的工作团队之后,才能为实现团队的共同目标创造出合适的环境。
|
||||||
|
|
||||||
|
但确实有人觉得待在洞穴中很舒适而且只想待在那里。在组织里,领导者们如何掌控那些实际上抵触改善、待在洞穴中觉得舒适的人?同时该如何找到拥有共同目标但是不在自己组织的人?
|
||||||
|
|
||||||
|
我从事指导国际销售培训,刚开始甚至很少有人认为我的工作有价值。所以,我想出一套使他们信服的战术。那个战术非常成功以至于我决定深入研究它并与各位[分享][2]。
|
||||||
|
|
||||||
|
### 获得支持
|
||||||
|
|
||||||
|
为了建立公司强大的企业文化,有人会反对改变,并且从幕后打压任何改变的提议。他们希望每个人都待在那个舒适的洞穴里。例如,当我第一次接触到海外销售培训,我受到了一些关键人物的严厉阻挠。他们迫使其他人相信某个东京人做不了销售培训——只要基本的产品培训就行了。
|
||||||
|
|
||||||
|
尽管我最终解决了这个问题,但我那时候真的不知道该怎么办。所以,我开始研究顾问们在改变公司里抗拒改变的人的想法这个问题上该如何给出建议。从学者 [Laurence Haughton][3] 的研究中,我发现一般对于改变的提议,组织中 83% 的人最开始不会支持你。大约 17% _会_从一开始就支持你,但是只要看到一个实验案例成功之后,他们觉得这个主意安全可行了,60% 的人会支持你。最后,有部分人会反对任何改变,无论它有多棒。
|
||||||
|
|
||||||
|
我研究的步骤:
|
||||||
|
|
||||||
|
* 从试验项目开始
|
||||||
|
* 开导洞穴人
|
||||||
|
* 快速跟进
|
||||||
|
* 开导洞穴首领
|
||||||
|
* 全局展开
|
||||||
|
|
||||||
|
### 1、 从试验项目开始
|
||||||
|
|
||||||
|
找到高价值且成功率较高的项目——而不是大的、成本高的、周期长的、全局的行动。然后,找到能看到项目价值、理解它的价值并能为之奋斗的关键人物。这些人不应该只是“老好人”或者“朋友”;他们必须相信项目的目标而且拥有推进项目的能力或经验。不要急于求成。只要足够支持你研究并保持进度即可。
|
||||||
|
|
||||||
|
个人而言,我在新加坡的一个小型车辆代理商那里举办了自己的第一场销售研讨会。虽然并不是特别成功,但足以让人们开始讨论销售训练会达到怎样的效果。那时候的我困在洞穴里(那是一份我不想做的工作)。这个试验销售训练是我走出困境的蓝图。
|
||||||
|
|
||||||
|
### 2、 开导洞穴人
|
||||||
|
|
||||||
|
洞穴(CAVE)实际上是我从 Laurence Haughton 那里听来的缩略词。它代表着 Citizens Against Virtually Everything。(LCTT 译注,此处一语双关前文提及的洞穴。)
|
||||||
|
|
||||||
|
你得辨别这些人,因为他们会暗地里阻挠项目的进展,特别是早期脆弱的时候。他们容易黑化:总是消极。他们频繁使用“但是”、“如果”和“为什么”,只是想推脱你。他们询问轻易不可得的细节信息。他们花费过多的时间在问题上,而不是寻找解决方案。他们认为每个失败都是一个趋势。他们总是对人而不是对事。他们作出反对建议的陈述却又不能简单确认。
|
||||||
|
|
||||||
|
避开洞穴人;不要让他们太早加入项目的讨论。他们固守成见,因为他们看不到改变所具有的价值。他们安居于洞穴,所以试着让他们去做些其他事。你应该找出我上面提到那 17% 的人群中的关键人物,那些想要改变的人,并且跟他们开一个非常隐秘的准备会。
|
||||||
|
|
||||||
|
我在五十铃汽车(股东之一是通用汽车公司)的时候,销售训练项目开始于一个销往世界上其他小国家的合资分销商,主要是非洲、南亚、拉丁美洲和中东。我的个人团队由通用汽车公司雪佛兰的人、五十铃产品经理和分公司的销售计划员工组成。隔绝其他任何人于这个圈子之外。
|
||||||
|
|
||||||
|
### 3、 快速跟进
|
||||||
|
|
||||||
|
洞穴人总是慢吞吞的,那么你就迅速行动起来。如果你在他们参与之前就有了小成就的经历,他们对你团队产生消极影响的能力将大大减弱——你要在他们提出之前就解决他们必然反对的问题。再一次,选择一个成功率高的试验项目,很快能出结果的。然后宣传成功,就像广告上的加粗标题。
|
||||||
|
|
||||||
|
当我在新加坡研讨会上所言开始流传时,其他地区开始意识到销售训练的好处。仅在新加坡研讨会之后,我就被派到马来西亚开展了四次以上。
|
||||||
|
|
||||||
|
### 4、 开导洞穴首领
|
||||||
|
|
||||||
|
只要你取得了第一个小项目的成功,就针对能影响洞穴首领的关键人物推荐项目。让团队继续该项目以告诉关键人物成功的经历。一线人员甚至顾客也能提供有力的证明。 洞穴管理者往往只着眼于销量和收益,那么就宣扬项目在降低开支、减少浪费和增加销量方面的价值。
|
||||||
|
|
||||||
|
自新加坡的第一次研讨会及之后,我向直接掌握了五十铃销售渠道的前线销售部门员工和通用汽车真正想看到进展的人极力宣传他们的成功。当他们接受了之后,他们会向上级提出培训请求并让其看到分公司销量的提升。
|
||||||
|
|
||||||
|
### 5、 全局展开
|
||||||
|
|
||||||
|
一旦一把手站在了自己这边,立马向整个组织宣告成功的试验项目。讨论项目的扩展。
|
||||||
|
|
||||||
|
用上面的方法,在 21 年的职业生涯中,我在世界各地超过 60 个国家举办了研讨会。我确实走出了洞穴——并且真的看到了广阔的世界。
|
||||||
|
|
||||||
|
(题图:opensource.com)
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Ron McFarland - Ron McFarland 已在日本工作 40 年,从事国际销售、销售管理和在世界范围内扩展销售业务 30 载有余。他曾去过或就职于 80 多个国家。在过去的 14 年里, Ron 为总部位于东京的日本硬件切割厂在美国和欧洲各地建立分销商。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/open-organization/17/1/escape-the-cave
|
||||||
|
|
||||||
|
作者:[Ron McFarland][a]
|
||||||
|
译者:[XYenChi](https://github.com/XYenChi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/ron-mcfarland
|
||||||
|
[1]:https://opensource.com/open-organization/17/1/escape-the-cave?rate=dBJIKVJy720uFj0PCfa1JXDZKkMwozxV8TB2qJnoghM
|
||||||
|
[2]:http://www.slideshare.net/RonMcFarland1/creating-change-58994683
|
||||||
|
[3]:http://www.laurencehaughton.com/
|
||||||
|
[4]:https://opensource.com/user/68021/feed
|
||||||
|
[5]:https://opensource.com/open-organization/17/1/escape-the-cave#comments
|
||||||
|
[6]:https://opensource.com/users/ron-mcfarland
|
||||||
@ -0,0 +1,66 @@
|
|||||||
|
为什么 DevOps 如我们所知道的那样,是安全的终结
|
||||||
|
==========
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
安全难以推行。在企业管理者迫使开发团队尽快发布程序的大环境下,很难说服他们花费有限的时间来修补安全漏洞。但是鉴于所有网络攻击中有 84% 发生在应用层,作为一个组织是无法承担其开发团队不包括安全性带来的后果。
|
||||||
|
|
||||||
|
DevOps 的崛起为许多安全负责人带来了困境。Sonatype 的前 CTO [Josh Corman][2] 说:“这是对安全的威胁,但这也是让安全变得更好的机会。” Corman 是一个坚定的[将安全和 DevOps 实践整合起来创建 “坚固的 DevOps”][3]的倡导者。_Business Insights_ 与 Corman 谈论了安全和 DevOps 共同的价值,以及这些共同价值如何帮助组织更少地受到中断和攻击的影响。
|
||||||
|
|
||||||
|
### 安全和 DevOps 实践如何互惠互利?
|
||||||
|
|
||||||
|
**Josh Corman:** 一个主要的例子是 DevOps 团队对所有可测量的东西进行检测的倾向。安全性一直在寻找更多的情报和遥测。你可以获取许多 DevOps 团队正在测量的信息,并将这些信息输入到你的日志管理或 SIEM (安全信息和事件管理系统)。
|
||||||
|
|
||||||
|
一个 OODA 循环(<ruby>观察<rt>observe</rt></ruby>、<ruby>定向<rt>orient</rt></ruby>、<ruby>决定<rt>decide</rt></ruby>、<ruby>行为<rt>act</rt></ruby>)的前提是有足够普遍的眼睛和耳朵,以注意到窃窃私语和回声。DevOps 为你提供无处不在的仪器。
|
||||||
|
|
||||||
|
### 他们有分享其他文化观点吗?
|
||||||
|
|
||||||
|
**JC:** “严肃对待你的代码”是一个共同的价值观。例如,由 Netflix 编写的软件工具 Chaos Monkey 是 DevOps 团队的分水岭。它是为了测试亚马逊网络服务的弹性和可恢复性而创建的,Chaos Monkey 使得 Netflix 团队更加强大,更容易为中断做好准备。
|
||||||
|
|
||||||
|
所以现在有个想法是我们的系统需要测试,因此,James Wickett 和我及其他人决定做一个邪恶的、带有攻击性的 Chaos Monkey,这就是 GAUNTLT 项目的来由。它基本上是一堆安全测试, 可以在 DevOps 周期和 DevOps 工具链中使用。它也有非常适合 DevOps 的API。
|
||||||
|
|
||||||
|
### 企业安全和 DevOps 价值在哪里相交?
|
||||||
|
|
||||||
|
**JC:** 这两个团队都认为复杂性是一切事情的敌人。例如,[安全人员和 Rugged DevOps 人员][4]实际上可以说:“看,我们在我们的项目中使用了 11 个日志框架 - 也许我们不需要那么多,也许攻击面和复杂性可能会让我们受到伤害或者损害产品的质量或可用性。”
|
||||||
|
|
||||||
|
复杂性往往是许多事情的敌人。通常情况下,你不会很难说服 DevOps 团队在架构层面使用更好的建筑材料:使用最新的、最不易受攻击的版本,并使用较少的组件。
|
||||||
|
|
||||||
|
### “更好的建筑材料”是什么意思?
|
||||||
|
|
||||||
|
**JC:** 我是世界上最大的开源仓库的保管人,所以我能看到他们在使用哪些版本,里面有哪些漏洞,何时他们没有修复漏洞,以及等了多久。例如,某些日志记录框架从不会修复任何错误。其中一些会在 90 天内修复了大部分的安全漏洞。人们越来越多地遭到攻击,因为他们使用了一个毫无安全的框架。
|
||||||
|
|
||||||
|
除此之外,即使你不知道日志框架的质量,拥有 11 个不同的框架会变得非常笨重、出现 bug,还有额外的工作和复杂性。你暴露在漏洞中的风险是非常大的。你想把时间花在修复大量的缺陷上,还是在制造下一个大的破坏性的事情上?
|
||||||
|
|
||||||
|
[Rugged DevOps 的关键是软件供应链管理][5],其中包含三个原则:使用更少和更好的供应商、使用这些供应商的最高质量的部分、并跟踪这些部分,以便在发生错误时,你可以有一个及时和敏捷的响应。
|
||||||
|
|
||||||
|
### 所以变更管理也很重要。
|
||||||
|
|
||||||
|
**JC:** 是的,这是另一个共同的价值。我发现,当一家公司想要执行诸如异常检测或净流量分析等安全测试时,他们需要知道“正常”的样子。让人们失误的许多基本事情与仓库和补丁管理有关。
|
||||||
|
|
||||||
|
我在 _Verizon 数据泄露调查报告_中看到,追踪去年被成功利用的漏洞后,其中 97% 归结为 10 个 CVE(常见漏洞和风险),而这 10 个已经被修复了十多年。所以,我们羞于谈论高级间谍活动。我们没有做基本的补丁工作。现在,我不是说如果你修复这 10 个CVE,那么你就没有被利用,而是这占据了人们实际失误的最大份额。
|
||||||
|
|
||||||
|
[DevOps 自动化工具][6]的好处是它们已经成为一个意外的变更管理数据库。其真实反应了谁在哪里什么时候做了变更。这是一个巨大的胜利,因为我们经常对安全性有最大影响的因素无法控制。你承受了 CIO 和 CTO 做出的选择的后果。随着 IT 通过自动化变得更加严格和可重复,你可以减少人为错误的机会,并且哪里发生了变化更加可追溯。
|
||||||
|
|
||||||
|
### 你认为什么是最重要的共同价值?
|
||||||
|
|
||||||
|
**JC:** DevOps 涉及到过程和工具链,但我认为定义这种属性的是文化,特别是同感。 DevOps 有用是因为开发人员和运维团队能够更好地了解彼此,并做出更明智的决策。不是在解决孤岛中的问题,而是为了活动流程和目标解决。如果你向 DevOps 的团队展示安全如何能使他们变得更好,那么作为回馈他们往往会问:“那么,我们是否有任何选择让你的生活更轻松?”因为他们通常不知道他们做的 X、Y 或 Z 的选择使它无法包含安全性。
|
||||||
|
|
||||||
|
对于安全团队,驱动价值的方法之一是在寻求帮助之前变得更有所帮助,在我们告诉 DevOps 团队要做什么之前提供定性和定量的价值。你必须获得 DevOps 团队的信任,并获得发挥的权利,然后才能得到回报。它通常比你想象的快很多。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://techbeacon.com/why-devops-end-security-we-know-it
|
||||||
|
|
||||||
|
作者:[Mike Barton][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://twitter.com/intent/follow?original_referer=https%3A%2F%2Ftechbeacon.com%2Fwhy-devops-end-security-we-know-it%3Fimm_mid%3D0ee8c5%26cmp%3Dem-webops-na-na-newsltr_20170310&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=mikebarton&tw_p=followbutton
|
||||||
|
[1]:https://techbeacon.com/resources/application-security-devops-true-state?utm_source=tb&utm_medium=article&utm_campaign=inline-cta
|
||||||
|
[2]:https://twitter.com/joshcorman
|
||||||
|
[3]:https://techbeacon.com/want-rugged-devops-team-your-release-security-engineers
|
||||||
|
[4]:https://techbeacon.com/rugged-devops-rsa-6-takeaways-security-ops-pros
|
||||||
|
[5]:https://techbeacon.com/josh-corman-security-devops-how-shared-team-values-can-reduce-threats
|
||||||
|
[6]:https://techbeacon.com/devops-automation-best-practices-how-much-too-much
|
||||||
@ -1,21 +1,23 @@
|
|||||||
OpenGL 与 Go 教程第三节:实现游戏
|
OpenGL 与 Go 教程(三)实现游戏
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
[第一节: Hello, OpenGL][8] | [第二节: 绘制游戏面板][9] | [第三节:实现游戏功能][10]
|
- [第一节: Hello, OpenGL][8]
|
||||||
|
- [第二节: 绘制游戏面板][9]
|
||||||
|
- [第三节:实现游戏功能][10]
|
||||||
|
|
||||||
该教程的完整源代码可以从 [GitHub][11] 上获得。
|
该教程的完整源代码可以从 [GitHub][11] 上找到。
|
||||||
|
|
||||||
欢迎回到《OpenGL 与 Go 教程》!如果你还没有看过 [第一节][12] 和 [第二节][13],那就要回过头去看一看。
|
欢迎回到《OpenGL 与 Go 教程》!如果你还没有看过 [第一节][12] 和 [第二节][13],那就要回过头去看一看。
|
||||||
|
|
||||||
到目前为止,你应该懂得如何创建网格系统以及创建代表方格中每一个单元的格子阵列。现在可以开始把网格当作游戏面板实现《Conway's Game of Life》。
|
到目前为止,你应该懂得如何创建网格系统以及创建代表方格中每一个单元的格子阵列。现在可以开始把网格当作游戏面板实现<ruby>康威生命游戏<rt>Conway's Game of Life</rt></ruby>。
|
||||||
|
|
||||||
开始吧!
|
开始吧!
|
||||||
|
|
||||||
### 实现 《Conway’s Game》
|
### 实现康威生命游戏
|
||||||
|
|
||||||
《Conway's Game》的其中一个要点是所有 cell 必须同时基于当前 cell 在面板中的状态确定下一个 cell 的状态。也就是说如果 Cell (X=3,Y=4)在计算过程中状态发生了改变,那么邻近的 cell (X=4,Y=4)必须基于(X=3,T=4)的状态决定自己的状态变化,而不是基于自己现在的状态。简单的讲,这意味着我们必须遍历 cell ,确定下一个 cell 的状态,在绘制之前,不改变他们的当前状态,然后在下一次循环中我们将新状态应用到游戏里,依此循环往复。
|
康威生命游戏的其中一个要点是所有<ruby>细胞<rt>cell</rt></ruby>必须同时基于当前细胞在面板中的状态确定下一个细胞的状态。也就是说如果细胞 `(X=3,Y=4)` 在计算过程中状态发生了改变,那么邻近的细胞 `(X=4,Y=4)` 必须基于 `(X=3,Y=4)` 的状态决定自己的状态变化,而不是基于自己现在的状态。简单的讲,这意味着我们必须遍历细胞,确定下一个细胞的状态,而在绘制之前不改变他们的当前状态,然后在下一次循环中我们将新状态应用到游戏里,依此循环往复。
|
||||||
|
|
||||||
为了完成这个功能,我们需要在 cell 结构体中添加两个布尔型变量:
|
为了完成这个功能,我们需要在 `cell` 结构体中添加两个布尔型变量:
|
||||||
|
|
||||||
```
|
```
|
||||||
type cell struct {
|
type cell struct {
|
||||||
@ -29,6 +31,8 @@ type cell struct {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
这里我们添加了 `alive` 和 `aliveNext`,前一个是细胞当前的专题,后一个是经过计算后下一回合的状态。
|
||||||
|
|
||||||
现在添加两个函数,我们会用它们来确定 cell 的状态:
|
现在添加两个函数,我们会用它们来确定 cell 的状态:
|
||||||
|
|
||||||
```
|
```
|
||||||
@ -39,22 +43,22 @@ func (c *cell) checkState(cells [][]*cell) {
|
|||||||
|
|
||||||
liveCount := c.liveNeighbors(cells)
|
liveCount := c.liveNeighbors(cells)
|
||||||
if c.alive {
|
if c.alive {
|
||||||
// 1\. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
|
// 1. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
|
||||||
if liveCount < 2 {
|
if liveCount < 2 {
|
||||||
c.aliveNext = false
|
c.aliveNext = false
|
||||||
}
|
}
|
||||||
|
|
||||||
// 2\. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
|
// 2. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
|
||||||
if liveCount == 2 || liveCount == 3 {
|
if liveCount == 2 || liveCount == 3 {
|
||||||
c.aliveNext = true
|
c.aliveNext = true
|
||||||
}
|
}
|
||||||
|
|
||||||
// 3\. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
|
// 3. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
|
||||||
if liveCount > 3 {
|
if liveCount > 3 {
|
||||||
c.aliveNext = false
|
c.aliveNext = false
|
||||||
}
|
}
|
||||||
} else {
|
} else {
|
||||||
// 4\. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
|
// 4. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
|
||||||
if liveCount == 3 {
|
if liveCount == 3 {
|
||||||
c.aliveNext = true
|
c.aliveNext = true
|
||||||
}
|
}
|
||||||
@ -95,9 +99,11 @@ func (c *cell) liveNeighbors(cells [][]*cell) int {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
更加值得注意的是 liveNeighbors 函数里在返回地方,我们返回的是当前处于存活状态的 cell 的邻居个数。我们定义了一个叫做 add 的内嵌函数,它会对 X 和 Y 坐标做一些重复性的验证。它所做的事情是检查我们传递的数字是否超出了范围——比如说,如果 cell(X=0,Y=5)想要验证它左边的 cell,它就得验证面板另一边的 cell(X=9,Y=5),Y 轴与之类似。
|
在 `checkState` 中我们设置当前状态(`alive`) 等于我们最近迭代结果(`aliveNext`)。接下来我们计数邻居数量,并根据游戏的规则来决定 `aliveNext` 状态。该规则是比较清晰的,而且我们在上面的代码当中也有说明,所以这里不再赘述。
|
||||||
|
|
||||||
在 add 内嵌函数后面,我们给当前 cell 附近的八个 cell 分别调用 add 函数,示意如下:
|
更加值得注意的是 `liveNeighbors` 函数里,我们返回的是当前处于存活(`alive`)状态的细胞的邻居个数。我们定义了一个叫做 `add` 的内嵌函数,它会对 `X` 和 `Y` 坐标做一些重复性的验证。它所做的事情是检查我们传递的数字是否超出了范围——比如说,如果细胞 `(X=0,Y=5)` 想要验证它左边的细胞,它就得验证面板另一边的细胞 `(X=9,Y=5)`,Y 轴与之类似。
|
||||||
|
|
||||||
|
在 `add` 内嵌函数后面,我们给当前细胞附近的八个细胞分别调用 `add` 函数,示意如下:
|
||||||
|
|
||||||
```
|
```
|
||||||
[
|
[
|
||||||
@ -109,9 +115,9 @@ func (c *cell) liveNeighbors(cells [][]*cell) int {
|
|||||||
]
|
]
|
||||||
```
|
```
|
||||||
|
|
||||||
在该示意中,每一个叫做 N 的 cell 是与 C 相邻的 cell。
|
在该示意中,每一个叫做 N 的细胞是 C 的邻居。
|
||||||
|
|
||||||
现在是我们的主函数,在我们执行循环核心游戏的地方,调用每个 cell 的 checkState 函数进行绘制:
|
现在是我们的 `main` 函数,这里我们执行核心游戏循环,调用每个细胞的 `checkState` 函数进行绘制:
|
||||||
|
|
||||||
```
|
```
|
||||||
func main() {
|
func main() {
|
||||||
@ -129,6 +135,8 @@ func main() {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
现在我们的游戏逻辑全都设置好了,我们需要修改细胞绘制函数来跳过绘制不存活的细胞:
|
||||||
|
|
||||||
```
|
```
|
||||||
func (c *cell) draw() {
|
func (c *cell) draw() {
|
||||||
if !c.alive {
|
if !c.alive {
|
||||||
@ -140,7 +148,10 @@ func (c *cell) draw() {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
现在完善这个函数。回到 makeCells 函数,我们用 0.0 到 1.0 之间的一个随机数来设置游戏的初始状态。我们会定义一个大小为 0.15 的常量阈值,也就是说每个 cell 都有 15% 的几率处于存活状态。
|
如果我们现在运行这个游戏,你将看到一个纯黑的屏幕,而不是我们辛苦工作后应该看到生命模拟。为什么呢?其实这正是模拟在工作。因为我们没有活着的细胞,所以就一个都不会绘制出来。
|
||||||
|
|
||||||
|
|
||||||
|
现在完善这个函数。回到 `makeCells` 函数,我们用 `0.0` 到 `1.0` 之间的一个随机数来设置游戏的初始状态。我们会定义一个大小为 `0.15` 的常量阈值,也就是说每个细胞都有 15% 的几率处于存活状态。
|
||||||
|
|
||||||
```
|
```
|
||||||
import (
|
import (
|
||||||
@ -174,11 +185,13 @@ func makeCells() [][]*cell {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
接下来在循环中,在用 newCell 函数创造一个新的 cell 时,我们根据随机数的大小设置它的存活状态,随机数在 0.0 到 1.0 之间,如果比阈值(0.15)小,就是存活状态。再次强调,这意味着每个 cell 在开始时都有 15% 的几率是存活的。你可以修改数值大小,增加或者减少当前游戏中存活的 cell。我们还把 aliveNext 设成 alive 状态,否则在第一次迭代之后我们会发现一大片 cell 消亡了,这是因为 aliveNext 将永远是 false。
|
我们首先增加两个引入:随机(`math/rand`)和时间(`time`),并定义我们的常量阈值。然后在 `makeCells` 中我们使用当前时间作为随机种子,给每个游戏一个独特的起始状态。你也可也指定一个特定的种子值,来始终得到一个相同的游戏,这在你想重放某个有趣的模拟时很有用。
|
||||||
|
|
||||||
现在接着往下看,运行它,你很有可能看到 cell 们一闪而过,但你却无法理解这是为什么。原因可能在于你的电脑太快了,在你能够看清楚之前就运行了(甚至完成了)模拟过程。
|
接下来在循环中,在用 `newCell` 函数创造一个新的细胞时,我们根据随机浮点数的大小设置它的存活状态,随机数在 `0.0` 到 `1.0` 之间,如果比阈值(`0.15`)小,就是存活状态。再次强调,这意味着每个细胞在开始时都有 15% 的几率是存活的。你可以修改数值大小,增加或者减少当前游戏中存活的细胞。我们还把 `aliveNext` 设成 `alive` 状态,否则在第一次迭代之后我们会发现一大片细胞消亡了,这是因为 `aliveNext` 将永远是 `false`。
|
||||||
|
|
||||||
降低游戏速度,在主循环中引入一个 frames-per-second 限制:
|
现在继续运行它,你很有可能看到细胞们一闪而过,但你却无法理解这是为什么。原因可能在于你的电脑太快了,在你能够看清楚之前就运行了(甚至完成了)模拟过程。
|
||||||
|
|
||||||
|
让我们降低游戏速度,在主循环中引入一个帧率(FPS)限制:
|
||||||
|
|
||||||
```
|
```
|
||||||
const (
|
const (
|
||||||
@ -223,7 +236,7 @@ const (
|
|||||||
)
|
)
|
||||||
```
|
```
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
试着修改常量,看看它们是怎么影响模拟过程的 —— 这是你用 Go 语言写的第一个 OpenGL 程序,很酷吧?
|
试着修改常量,看看它们是怎么影响模拟过程的 —— 这是你用 Go 语言写的第一个 OpenGL 程序,很酷吧?
|
||||||
|
|
||||||
@ -231,20 +244,18 @@ const (
|
|||||||
|
|
||||||
这是《OpenGL 与 Go 教程》的最后一节,但是这不意味着到此而止。这里有些新的挑战,能够增进你对 OpenGL (以及 Go)的理解。
|
这是《OpenGL 与 Go 教程》的最后一节,但是这不意味着到此而止。这里有些新的挑战,能够增进你对 OpenGL (以及 Go)的理解。
|
||||||
|
|
||||||
1. 给每个 cell 一种不同的颜色。
|
1. 给每个细胞一种不同的颜色。
|
||||||
2. 让用户能够通过命令行参数指定格子尺寸,帧率,种子和阈值。在 GitHub 上的 [github.com/KyleBanks/conways-gol][4] 里你可以看到一个已经实现的程序。
|
2. 让用户能够通过命令行参数指定格子尺寸、帧率、种子和阈值。在 GitHub 上的 [github.com/KyleBanks/conways-gol][4] 里你可以看到一个已经实现的程序。
|
||||||
3. 把格子的形状变成其它更有意思的,比如六边形。
|
3. 把格子的形状变成其它更有意思的,比如六边形。
|
||||||
4. 用颜色表示 cell 的状态 —— 比如,在第一帧把存活状态的格子设成绿色,如果它们存活了超过三帧的时间,就变成黄色。
|
4. 用颜色表示细胞的状态 —— 比如,在第一帧把存活状态的格子设成绿色,如果它们存活了超过三帧的时间,就变成黄色。
|
||||||
5. 如果模拟过程结束了,就自动关闭窗口,也就是说所有 cell 都消亡了,或者是最后两帧里没有格子的状态有改变。
|
5. 如果模拟过程结束了,就自动关闭窗口,也就是说所有细胞都消亡了,或者是最后两帧里没有格子的状态有改变。
|
||||||
6. 将着色器源代码放到单独的文件中,而不是把它们用字符串的形式放在 Go 的源代码中。
|
6. 将着色器源代码放到单独的文件中,而不是把它们用字符串的形式放在 Go 的源代码中。
|
||||||
|
|
||||||
### 总结
|
### 总结
|
||||||
|
|
||||||
希望这篇教程对想要入门 OpenGL (或者是 Go)的人有所帮助!这很有趣,因此我也希望理解学习它也很有趣。
|
希望这篇教程对想要入门 OpenGL (或者是 Go)的人有所帮助!这很有趣,因此我也希望理解学习它也很有趣。
|
||||||
|
|
||||||
正如我所说的,OpenGL 可能是非常恐怖的,但只要你开始着手了就不会太差。你只用制定一个个可达成的小目标,然后享受每一次成功,因为尽管 OpenGL 不会总像它看上去的那么难,但也肯定有些难懂的东西。我发现,当遇到一个难于用 go-gl 方式理解的 OpenGL 问题时,你总是可以参考一下在网上更流行的当作教程的 C 语言代码,这很有用。通常 C 语言和 Go 语言的唯一区别是在 Go 中,gl 的前缀是 gl. 而不是 GL_。这极大地增加了你的绘制知识!
|
正如我所说的,OpenGL 可能是非常恐怖的,但只要你开始着手了就不会太差。你只用制定一个个可达成的小目标,然后享受每一次成功,因为尽管 OpenGL 不会总像它看上去的那么难,但也肯定有些难懂的东西。我发现,当遇到一个难于理解用 go-gl 生成的代码的 OpenGL 问题时,你总是可以参考一下在网上更流行的当作教程的 C 语言代码,这很有用。通常 C 语言和 Go 语言的唯一区别是在 Go 中,gl 函数的前缀是 `gl.` 而不是 `gl`,常量的前缀是 `gl` 而不是 `GL_`。这可以极大地增加了你的绘制知识!
|
||||||
|
|
||||||
[第一节: Hello, OpenGL][14] | [第二节: 绘制游戏面板][15] | [第三节:实现游戏功能][16]
|
|
||||||
|
|
||||||
该教程的完整源代码可从 [GitHub][17] 上获得。
|
该教程的完整源代码可从 [GitHub][17] 上获得。
|
||||||
|
|
||||||
@ -419,22 +430,22 @@ func (c *cell) checkState(cells [][]*cell) {
|
|||||||
|
|
||||||
liveCount := c.liveNeighbors(cells)
|
liveCount := c.liveNeighbors(cells)
|
||||||
if c.alive {
|
if c.alive {
|
||||||
// 1\. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
|
// 1. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
|
||||||
if liveCount < 2 {
|
if liveCount < 2 {
|
||||||
c.aliveNext = false
|
c.aliveNext = false
|
||||||
}
|
}
|
||||||
|
|
||||||
// 2\. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
|
// 2. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
|
||||||
if liveCount == 2 || liveCount == 3 {
|
if liveCount == 2 || liveCount == 3 {
|
||||||
c.aliveNext = true
|
c.aliveNext = true
|
||||||
}
|
}
|
||||||
|
|
||||||
// 3\. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
|
// 3. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
|
||||||
if liveCount > 3 {
|
if liveCount > 3 {
|
||||||
c.aliveNext = false
|
c.aliveNext = false
|
||||||
}
|
}
|
||||||
} else {
|
} else {
|
||||||
// 4\. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
|
// 4. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
|
||||||
if liveCount == 3 {
|
if liveCount == 3 {
|
||||||
c.aliveNext = true
|
c.aliveNext = true
|
||||||
}
|
}
|
||||||
@ -570,9 +581,9 @@ func compileShader(source string, shaderType uint32) (uint32, error) {
|
|||||||
|
|
||||||
via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||||
|
|
||||||
作者:[kylewbanks ][a]
|
作者:[kylewbanks][a]
|
||||||
译者:[GitFuture](https://github.com/GitFuture)
|
译者:[GitFuture](https://github.com/GitFuture)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -584,14 +595,14 @@ via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing
|
|||||||
[5]:https://kylewbanks.com/category/golang
|
[5]:https://kylewbanks.com/category/golang
|
||||||
[6]:https://kylewbanks.com/category/opengl
|
[6]:https://kylewbanks.com/category/opengl
|
||||||
[7]:https://twitter.com/kylewbanks
|
[7]:https://twitter.com/kylewbanks
|
||||||
[8]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
[8]:https://linux.cn/article-8933-1.html
|
||||||
[9]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
[9]:https://linux.cn/article-8937-1.html
|
||||||
[10]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
[10]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||||
[11]:https://github.com/KyleBanks/conways-gol
|
[11]:https://github.com/KyleBanks/conways-gol
|
||||||
[12]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
[12]:https://linux.cn/article-8933-1.html
|
||||||
[13]:https://kylewbanks.com/blog/[Part%202:%20Drawing%20the%20Game%20Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)
|
[13]:https://kylewbanks.com/blog/[Part%202:%20Drawing%20the%20Game%20Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)
|
||||||
[14]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
[14]:https://linux.cn/article-8933-1.html
|
||||||
[15]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
[15]:https://linux.cn/article-8937-1.html
|
||||||
[16]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
[16]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||||
[17]:https://github.com/KyleBanks/conways-gol
|
[17]:https://github.com/KyleBanks/conways-gol
|
||||||
[18]:https://twitter.com/kylewbanks
|
[18]:https://twitter.com/kylewbanks
|
||||||
@ -0,0 +1,211 @@
|
|||||||
|
介绍 Flashback,一个互联网模拟工具
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> Flashback 用于测试目的来模拟 HTTP 和 HTTPS 资源,如 Web 服务和 REST API。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在 LinkedIn,我们经常开发需要与第三方网站交互的 Web 应用程序。我们还采用自动测试,以确保我们的软件在发布到生产环境之前的质量。然而,测试只是在它可靠时才有用。
|
||||||
|
|
||||||
|
考虑到这一点,有外部依赖关系的测试是有很大的问题的,例如在第三方网站上。这些外部网站可能会没有通知地发生改变、遭受停机,或者由于互联网的不可靠性暂时无法访问。
|
||||||
|
|
||||||
|
如果我们的一个测试依赖于能够与第三方网站通信,那么任何故障的原因都很难确定。失败可能是因为 LinkedIn 的内部变更、第三方网站的维护人员进行的外部变更,或网络基础设施的问题。你可以想像,与第三方网站的交互可能会有很多失败的原因,因此你可能想要知道,我将如何处理这个问题?
|
||||||
|
|
||||||
|
好消息是有许多互联网模拟工具可以帮助。其中一个是 [Betamax][4]。它通过拦截 Web 应用程序发起的 HTTP 连接,之后进行重放的方式来工作。对于测试,Betamax 可以用以前记录的响应替换 HTTP 上的任何交互,它可以非常可靠地提供这个服务。
|
||||||
|
|
||||||
|
最初,我们选择在 LinkedIn 的自动化测试中使用 Betamax。它工作得很好,但我们遇到了一些问题:
|
||||||
|
|
||||||
|
* 出于安全考虑,我们的测试环境没有接入互联网。然而,与大多数代理一样,Betamax 需要 Internet 连接才能正常运行。
|
||||||
|
* 我们有许多需要使用身份验证协议的情况,例如 OAuth 和 OpenId。其中一些协议需要通过 HTTP 进行复杂的交互。为了模拟它们,我们需要一个复杂的模型来捕获和重放请求。
|
||||||
|
|
||||||
|
为了应对这些挑战,我们决定基于 Betamax 的思路,构建我们自己的互联网模拟工具,名为 Flashback。我们也很自豪地宣布 Flashback 现在是开源的。
|
||||||
|
|
||||||
|
### 什么是 Flashback?
|
||||||
|
|
||||||
|
Flashback 用于测试目的来模拟 HTTP 和 HTTPS 资源,如 Web 服务和 [REST][5] API。它记录 HTTP/HTTPS 请求并重放以前记录的 HTTP 事务 - 我们称之为“<ruby>场景<rt>scene</rt></ruby>”,这样就不需要连接到 Internet 才能完成测试。
|
||||||
|
|
||||||
|
Flashback 也可以根据请求的部分匹配重放场景。它使用的是“匹配规则”。匹配规则将传入请求与先前记录的请求相关联,然后将其用于生成响应。例如,以下代码片段实现了一个基本匹配规则,其中测试方法“匹配”[此 URL][6]的传入请求。
|
||||||
|
|
||||||
|
HTTP 请求通常包含 URL、方法、标头和正文。Flashback 允许为这些组件的任意组合定义匹配规则。Flashback 还允许用户向 URL 查询参数,标头和正文添加白名单或黑名单标签。
|
||||||
|
|
||||||
|
例如,在 OAuth 授权流程中,请求查询参数可能如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
oauth_consumer_key="jskdjfljsdklfjlsjdfs",
|
||||||
|
oauth_nonce="ajskldfjalksjdflkajsdlfjasldfja;lsdkj",
|
||||||
|
oauth_signature="asdfjaklsdjflasjdflkajsdklf",
|
||||||
|
oauth_signature_method="HMAC-SHA1",
|
||||||
|
oauth_timestamp="1318622958",
|
||||||
|
oauth_token="asdjfkasjdlfajsdklfjalsdjfalksdjflajsdlfa",
|
||||||
|
oauth_version="1.0"
|
||||||
|
```
|
||||||
|
|
||||||
|
这些值许多将随着每个请求而改变,因为 OAuth 要求客户端每次为 `oauth_nonce` 生成一个新值。在我们的测试中,我们需要验证 `oauth_consumer_key`、`oauth_signature_method` 和 `oauth_version` 的值,同时确保 `oauth_nonce`、`oauth_signature`、`oauth_timestamp` 和 `oauth_token` 存在于请求中。Flashback 使我们有能力创建我们自己的匹配规则来实现这一目标。此功能允许我们测试随时间变化的数据、签名、令牌等的请求,而客户端没有任何更改。
|
||||||
|
|
||||||
|
这种灵活的匹配和在不连接互联网的情况下运行的功能是 Flashback 与其他模拟解决方案不同的特性。其他一些显著特点包括:
|
||||||
|
|
||||||
|
* Flashback 是一种跨平台和跨语言解决方案,能够测试 JVM(Java虚拟机)和非 JVM(C++、Python 等)应用程序。
|
||||||
|
* Flashback 可以随时生成 SSL/TLS 证书,以模拟 HTTPS 请求的安全通道。
|
||||||
|
|
||||||
|
### 如何记录 HTTP 事务
|
||||||
|
|
||||||
|
使用 Flashback 记录 HTTP 事务以便稍后重放是一个比较简单的过程。在我们深入了解流程之前,我们首先列出一些术语:
|
||||||
|
|
||||||
|
* `Scene` :场景存储以前记录的 HTTP 事务 (以 JSON 格式),它可以在以后重放。例如,这里是一个[Flashback 场景][1]示例。
|
||||||
|
* `Root Path` :根路径是包含 Flashback 场景数据的目录的文件路径。
|
||||||
|
* `Scene Name` :场景名称是给定场景的名称。
|
||||||
|
* `Scene Mode` :场景模式是使用场景的模式, 即“录制”或“重放”。
|
||||||
|
* `Match Rule` :匹配规则确定传入的客户端请求是否与给定场景的内容匹配的规则。
|
||||||
|
* `Flashback Proxy` :Flashback 代理是一个 HTTP 代理,共有录制和重放两种操作模式。
|
||||||
|
* `Host` 和 `Port` :代理主机和端口。
|
||||||
|
|
||||||
|
为了录制场景,你必须向目的地址发出真实的外部请求,然后 HTTPS 请求和响应将使用你指定的匹配规则存储在场景中。在录制时,Flashback 的行为与典型的 MITM(中间人)代理完全相同 - 只有在重放模式下,连接流和数据流仅限于客户端和代理之间。
|
||||||
|
|
||||||
|
要实际看下 Flashback,让我们创建一个场景,通过执行以下操作捕获与 example.org 的交互:
|
||||||
|
|
||||||
|
1、 取回 Flashback 的源码:
|
||||||
|
|
||||||
|
```
|
||||||
|
git clone https://github.com/linkedin/flashback.git
|
||||||
|
```
|
||||||
|
|
||||||
|
2、 启动 Flashback 管理服务器:
|
||||||
|
|
||||||
|
```
|
||||||
|
./startAdminServer.sh -port 1234
|
||||||
|
```
|
||||||
|
|
||||||
|
3、 注意上面的 Flashback 将在本地端口 5555 上启动录制模式。匹配规则需要完全匹配(匹配 HTTP 正文、标题和 URL)。场景将存储在 `/tmp/test1` 下。
|
||||||
|
|
||||||
|
4、 Flashback 现在可以记录了,所以用它来代理对 example.org 的请求:
|
||||||
|
|
||||||
|
```
|
||||||
|
curl http://www.example.org -x localhost:5555 -X GET
|
||||||
|
```
|
||||||
|
|
||||||
|
5、 Flashback 可以(可选)在一个记录中记录多个请求。要完成录制,[关闭 Flashback][8]。
|
||||||
|
|
||||||
|
6、 要验证已记录的内容,我们可以在输出目录(`/tmp/test1`)中查看场景的内容。它应该[包含以下内容][9]。
|
||||||
|
|
||||||
|
[在 Java 代码中使用 Flashback][10]也很容易。
|
||||||
|
|
||||||
|
### 如何重放 HTTP 事务
|
||||||
|
|
||||||
|
要重放先前存储的场景,请使用与录制时使用的相同的基本设置。唯一的区别是[将“场景模式”设置为上述步骤 3 中的“播放”][11]。
|
||||||
|
|
||||||
|
验证响应来自场景而不是外部源的一种方法,是在你执行步骤 1 到 6 时临时禁用 Internet 连接。另一种方法是修改场景文件,看看响应是否与文件中的相同。
|
||||||
|
|
||||||
|
这是 [Java 中的一个例子][12]。
|
||||||
|
|
||||||
|
### 如何记录并重播 HTTPS 事务
|
||||||
|
|
||||||
|
使用 Flashback 记录并重放 HTTPS 事务的过程非常类似于 HTTP 事务的过程。但是,需要特别注意用于 HTTPS SSL 组件的安全证书。为了使 Flashback 作为 MITM 代理,必须创建证书颁发机构(CA)证书。在客户端和 Flashback 之间创建安全通道时将使用此证书,并允许 Flashback 检查其代理的 HTTPS 请求中的数据。然后将此证书存储为受信任的源,以便客户端在进行调用时能够对 Flashback 进行身份验证。有关如何创建证书的说明,有很多[类似这样][13]的资源是非常有帮助的。大多数公司都有自己的管理和获取证书的内部策略 - 请务必用你们自己的方法。
|
||||||
|
|
||||||
|
这里值得一提的是,Flashback 仅用于测试目的。你可以随时随地将 Flashback 与你的服务集成在一起,但需要注意的是,Flashback 的记录功能将需要存储所有的数据,然后在重放模式下使用它。我们建议你特别注意确保不会无意中记录或存储敏感成员数据。任何可能违反贵公司数据保护或隐私政策的行为都是你的责任。
|
||||||
|
|
||||||
|
一旦涉及安全证书,HTTP 和 HTTPS 之间在记录设置方面的唯一区别是添加了一些其他参数。
|
||||||
|
|
||||||
|
* `RootCertificateInputStream`: 表示 CA 证书文件路径或流。
|
||||||
|
* `RootCertificatePassphrase`: 为 CA 证书创建的密码。
|
||||||
|
* `CertificateAuthority`: CA 证书的属性
|
||||||
|
|
||||||
|
[查看 Flashback 中用于记录 HTTPS 事务的代码][14],它包括上述条目。
|
||||||
|
|
||||||
|
用 Flashback 重放 HTTPS 事务的过程与录制相同。唯一的区别是场景模式设置为“播放”。这在[此代码][15]中演示。
|
||||||
|
|
||||||
|
### 支持动态修改
|
||||||
|
|
||||||
|
为了测试灵活性,Flashback 允许你动态地更改场景和匹配规则。动态更改场景允许使用不同的响应(如 `success`、`time_out`、`rate_limit` 等)测试相同的请求。[场景更改][16]仅适用于我们已经 POST 更新外部资源的场景。以下图为例。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
能够动态[更改匹配规则][17]可以使我们测试复杂的场景。例如,我们有一个使用情况,要求我们测试 Twitter 的公共和私有资源的 HTTP 调用。对于公共资源,HTTP 请求是不变的,所以我们可以使用 “MatchAll” 规则。然而,对于私人资源,我们需要使用 OAuth 消费者密码和 OAuth 访问令牌来签名请求。这些请求包含大量具有不可预测值的参数,因此静态 MatchAll 规则将无法正常工作。
|
||||||
|
|
||||||
|
### 使用案例
|
||||||
|
|
||||||
|
在 LinkedIn,Flashback 主要用于在集成测试中模拟不同的互联网提供商,如下图所示。第一张图展示了 LinkedIn 生产数据中心内的一个内部服务,通过代理层,与互联网提供商(如 Google)进行交互。我们想在测试环境中测试这个内部服务。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
第二和第三张图表展示了我们如何在不同的环境中录制和重放场景。记录发生在我们的开发环境中,用户在代理启动的同一端口上启动 Flashback。从内部服务到提供商的所有外部请求将通过 Flashback 而不是我们的代理层。在必要场景得到记录后,我们可以将其部署到我们的测试环境中。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在测试环境(隔离并且没有 Internet 访问)中,Flashback 在与开发环境相同的端口上启动。所有 HTTP 请求仍然来自内部服务,但响应将来自 Flashback 而不是 Internet 提供商。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 未来方向
|
||||||
|
|
||||||
|
我们希望将来可以支持非 HTTP 协议(如 FTP 或 JDBC),甚至可以让用户使用 MITM 代理框架来自行注入自己的定制协议。我们将继续改进 Flashback 设置 API,使其更容易支持非 Java 语言。
|
||||||
|
|
||||||
|
### 现在为一个开源项目
|
||||||
|
|
||||||
|
我们很幸运能够在 GTAC 2015 上发布 Flashback。在展会上,有几名观众询问是否将 Flashback 作为开源项目发布,以便他们可以将其用于自己的测试工作。
|
||||||
|
|
||||||
|
### Google TechTalks:GATC 2015 - 模拟互联网
|
||||||
|
|
||||||
|
<iframe allowfullscreen="" frameborder="0" height="315" src="https://www.youtube.com/embed/6gPNrujpmn0?origin=https://opensource.com&enablejsapi=1" width="560" id="6gPNrujpmn0" data-sdi="true"></iframe>
|
||||||
|
|
||||||
|
我们很高兴地宣布,Flashback 现在以 BSD 两句版许可证开源。要开始使用,请访问 [Flashback GitHub 仓库][18]。
|
||||||
|
|
||||||
|
_该文原始发表在[LinkedIn 工程博客上][2]。获得转载许可_
|
||||||
|
|
||||||
|
### 致谢
|
||||||
|
|
||||||
|
Flashback 由 [Shangshang Feng][19]、[Yabin Kang][20] 和 [Dan Vinegrad][21] 创建,并受到 [Betamax][22] 启发。特别感谢 [Hwansoo Lee][23]、[Eran Leshem][24]、[Kunal Kandekar][25]、[Keith Dsouza][26] 和 [Kang Wang][27] 帮助审阅代码。同样感谢我们的管理层 - [Byron Ma][28]、[Yaz Shimizu][29]、[Yuliya Averbukh][30]、[Christopher Hazlett][31] 和 [Brandon Duncan][32] - 感谢他们在开发和开源 Flashback 中的支持。
|
||||||
|
|
||||||
|
|
||||||
|
(题图:Opensource.com)
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Shangshang Feng - Shangshang 是 LinkedIn 纽约市办公室的高级软件工程师。在 LinkedIn 他从事了三年半的网关平台工作。在加入 LinkedIn 之前,他曾在 Thomson Reuters 和 ViewTrade 证券的基础设施团队工作。
|
||||||
|
|
||||||
|
---------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/4/flashback-internet-mocking-tool
|
||||||
|
|
||||||
|
作者:[Shangshang Feng][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/shangshangfeng
|
||||||
|
[1]:https://gist.github.com/anonymous/17d226050d8a9b79746a78eda9292382
|
||||||
|
[2]:https://engineering.linkedin.com/blog/2017/03/flashback-mocking-tool
|
||||||
|
[3]:https://opensource.com/article/17/4/flashback-internet-mocking-tool?rate=Jwt7-vq6jP9kS7gOT6f6vgwVlZupbyzWsVXX41ikmGk
|
||||||
|
[4]:https://github.com/betamaxteam/betamax
|
||||||
|
[5]:https://en.wikipedia.org/wiki/Representational_state_transfer
|
||||||
|
[6]:https://gist.github.com/anonymous/91637854364287b38897c0970aad7451
|
||||||
|
[7]:https://gist.github.com/anonymous/2f5271191edca93cd2e03ce34d1c2b62
|
||||||
|
[8]:https://gist.github.com/anonymous/f899ebe7c4246904bc764b4e1b93c783
|
||||||
|
[9]:https://gist.github.com/sf1152/c91d6d62518fe62cc87157c9ce0e60cf
|
||||||
|
[10]:https://gist.github.com/anonymous/fdd972f1dfc7363f4f683a825879ce19
|
||||||
|
[11]:https://gist.github.com/anonymous/ae1c519a974c3bc7de2a925254b6550e
|
||||||
|
[12]:https://gist.github.com/anonymous/edcc1d60847d51b159c8fd8a8d0a5f8b
|
||||||
|
[13]:https://jamielinux.com/docs/openssl-certificate-authority/introduction.html
|
||||||
|
[14]:https://gist.github.com/anonymous/091d13179377c765f63d7bf4275acc11
|
||||||
|
[15]:https://gist.github.com/anonymous/ec6a0fd07aab63b7369bf8fde69c1f16
|
||||||
|
[16]:https://gist.github.com/anonymous/1f1660280acb41277fbe2c257bab2217
|
||||||
|
[17]:https://gist.github.com/anonymous/0683c43f31bd916b76aff348ff87f51b
|
||||||
|
[18]:https://github.com/linkedin/flashback
|
||||||
|
[19]:https://www.linkedin.com/in/shangshangfeng
|
||||||
|
[20]:https://www.linkedin.com/in/benykang
|
||||||
|
[21]:https://www.linkedin.com/in/danvinegrad/
|
||||||
|
[22]:https://github.com/betamaxteam/betamax
|
||||||
|
[23]:https://www.linkedin.com/in/hwansoo/
|
||||||
|
[24]:https://www.linkedin.com/in/eranl/
|
||||||
|
[25]:https://www.linkedin.com/in/kunalkandekar/
|
||||||
|
[26]:https://www.linkedin.com/in/dsouzakeith/
|
||||||
|
[27]:https://www.linkedin.com/in/kang-wang-44960b4/
|
||||||
|
[28]:https://www.linkedin.com/in/byronma/
|
||||||
|
[29]:https://www.linkedin.com/in/yazshimizu/
|
||||||
|
[30]:https://www.linkedin.com/in/yuliya-averbukh-818a41/
|
||||||
|
[31]:https://www.linkedin.com/in/chazlett/
|
||||||
|
[32]:https://www.linkedin.com/in/dudcat/
|
||||||
|
[33]:https://opensource.com/user/125361/feed
|
||||||
|
[34]:https://opensource.com/users/shangshangfeng
|
||||||
98
published/201710/20170421 A Window Into the Linux Desktop.md
Normal file
98
published/201710/20170421 A Window Into the Linux Desktop.md
Normal file
@ -0,0 +1,98 @@
|
|||||||
|
进入 Linux 桌面之窗
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> “它能做什么 Windows 不能做的吗?”
|
||||||
|
|
||||||
|
这是许多人在考虑使用 Linux 桌面时的第一个问题。虽然支撑 Linux 的开源哲学对于某些人来说就是一个很好的理由,但是有些人想知道它在外观、感受和功能上有多么不同。在某种程度上,这取决于你是否选择桌面环境或窗口管理器。
|
||||||
|
|
||||||
|
如果你想要的是闪电般快速的桌面体验且向高效妥协, 那么上述的经典桌面中的窗口管理器可能适合你。
|
||||||
|
|
||||||
|
### 事实之真相
|
||||||
|
|
||||||
|
“<ruby>桌面环境<rt>Desktop Environment</rt></ruby>(DE)”是一个技术术语,指典型的、全功能桌面,即你的操作系统的完整图形化布局。除了显示你的程序,桌面环境还包括应用程序启动器,菜单面板和小部件等组成部分。
|
||||||
|
|
||||||
|
在 Microsoft Windows 中,桌面环境包括开始菜单、显示打开的程序的任务栏和通知中心,还有与操作系统捆绑在一起的所有 Windows 程序,以及围绕这打开的程序的框架(包括右上角的最小按钮、最大按钮和关闭按钮)。
|
||||||
|
|
||||||
|
Linux 中有很多相似之处。
|
||||||
|
|
||||||
|
例如,Linux [Gnome][3] 桌面环境的设计略有不同,但它共享了所有的 Microsoft Windows 的基本元素 - 从应用程序菜单到显示打开的应用程序的面板、通知栏、窗框式程序。
|
||||||
|
|
||||||
|
窗口程序框架依赖于一个组件来绘制它们,并允许你移动并调整大小:它被称为“<ruby>窗口管理器<rt>Window Manager</rt></ruby>(WM)”。因为它们都有窗口,所以每个桌面环境都包含一个窗口管理器。
|
||||||
|
|
||||||
|
然而,并不是每个窗口管理器都是桌面环境的一部分。你可以只运行窗口管理器,并且完全有这么做的需要。
|
||||||
|
|
||||||
|
### 离开你的环境
|
||||||
|
|
||||||
|
对本专栏而言,所谓的“窗口管理器”指的是可以那种独立进行的。如果在现有的 Linux 系统上安装了一个窗口管理器,你可以在不关闭系统的情况下注销,在登录屏幕上选择新的窗口管理器,然后重新登录。
|
||||||
|
|
||||||
|
不过, 在研究你的窗口管理器之前,你可能不想这么做,因为你将会看到一个空白屏幕和稀疏的状态栏,而且它或许能、或许不能点击。
|
||||||
|
|
||||||
|
通常情况下,可以直接在窗口管理器中直接启动终端,因为这是你编辑其配置文件的方式。在那里你会发现用来启动程序的按键和鼠标组合,你实际上也可以使用你的新设置。
|
||||||
|
|
||||||
|
例如,在流行的 i3 窗口管理器中,你可以通过按下 `Super` 键(即 `Windows` 键)加 `Enter` 键来启动终端,或者按 `Super + D` 启动<ruby>应用程序启动器<rt>app launcher</rt></ruby>。你可以在其中输入应用程序名称,然后按 `Enter` 键将其打开。所有已有的应用程序都可以通过这种方式找到,一旦选择后,它们将会全屏打开。
|
||||||
|
|
||||||
|
[][4]
|
||||||
|
|
||||||
|
i3 还是一个平铺式窗口管理器,这意味着它可以确保所有的窗口均匀地扩展到屏幕,既不重叠也不浪费空间。当弹出新窗口时,它会减少现有的窗口,将它们推到一边腾出空间。用户可以以垂直或水平相邻的方式打开下一个窗口。
|
||||||
|
|
||||||
|
### 功能亦敌亦友
|
||||||
|
|
||||||
|
当然,桌面环境有其优点。首先,它们提供功能丰富、可识别的界面。每个都有其特征鲜明的风格,但总体而言,它们提供了普适的默认设置,这使得桌面环境从一开始就可以使用。
|
||||||
|
|
||||||
|
另一个优点是桌面环境带有一组程序和媒体编解码器,允许用户立即完成简单的任务。此外,它们还包括一些方便的功能,如电池监视器、无线小部件和系统通知。
|
||||||
|
|
||||||
|
与桌面环境的完善相应的,是这种大型软件库和用户体验理念独一无二,这就意味着它们所能做的都是有限度的。这也意味着它们并不总是非常可配置。桌面环境强调的是漂亮的外表,很多时候是金玉其外的。
|
||||||
|
|
||||||
|
许多桌面环境对系统资源的渴求是众所周知的,所以它们不太喜欢低端硬件。因为在其上运行的视觉效果,还有更多的东西可能会出错。我曾经尝试调整与我正在运行的桌面环境无关的网络设置,然后整个崩溃了。而当我打开一个窗口管理器,我就可以改变设置。
|
||||||
|
|
||||||
|
那些优先考虑安全性的人可能希望不要桌面环境,因为更多的程序意味着更大的攻击面 —— 也就是坏人可以突破的入口点。
|
||||||
|
|
||||||
|
然而,如果你想尝试一下桌面环境,XFCE 是一个很好的起点,因为它的较小的软件库消除了一些臃肿,如果你不往里面塞东西,垃圾就会更少。
|
||||||
|
|
||||||
|
乍一看,它不是最漂亮的,但在下载了一些 GTK 主题包(每个桌面环境都可以提供这些主题或 Qt 主题,而 XFCE 在 GTK 阵营之中),并且在“外观”部分的设置中,你可以轻松地修改。你甚至可以在这个[集中式画廊][5]中找到你最喜欢的主题。
|
||||||
|
|
||||||
|
### 时间就是生命
|
||||||
|
|
||||||
|
如果你想了解桌面环境之外可以做什么,你会发现窗口管理器给了你足够的回旋余地。
|
||||||
|
|
||||||
|
无论如何,窗口管理器都是与定制有关的。事实上,它们的可定制性已经催生了无数的画廊,承载着一个充满活力的社区用户,他们手中的调色板就是窗口管理器。
|
||||||
|
|
||||||
|
窗口管理器的少量资源需求使它们成为较低规格硬件的理想选择,并且由于大多数窗口管理器不附带任何程序,因此允许喜欢模块化的用户只添加所需的程序。
|
||||||
|
|
||||||
|
可能与桌面环境最为显著的区别是,窗口管理器通常通过鼠标移动和键盘热键来打开程序或启动器来聚焦效率。
|
||||||
|
|
||||||
|
键盘驱动的窗口管理器特别流畅,你可以启动新的窗口、输入文本或更多的键盘命令、移动它们,并再次关闭它们,这一切无需将手从<ruby>键盘中间<rt>home row</rt></ruby>移开。一旦你适应了其设计逻辑,你会惊讶于你能够如此快速地完成任务。
|
||||||
|
|
||||||
|
尽管它们提供了自由,窗口管理器也有其缺点。最显著的是,它们是赤裸裸的开箱即用。在你可以使用其中一个之前,你必须花时间阅读窗口管理器的文档以获取配置语法,可能还需要更多的时间来找到该语法的窍门。
|
||||||
|
|
||||||
|
如果你从桌面环境(这是最可能的情况)切换过来,尽管你会有一些用户程序,你也会缺少一些熟悉的东西,如电池指示器和网络小部件,并且需要一些时间来设置新的。
|
||||||
|
|
||||||
|
如果你想深入窗口管理器,i3 有[完整的文档][6]和简明直白的配置语法。配置文件不使用任何编程语言 - 它只是每行定义一个变量值对。创建热键只要输入 `bindsym`、键盘绑定以及该组合启动的动作即可。
|
||||||
|
|
||||||
|
虽然窗口管理器不适合每个人,但它们提供了独特的计算体验,而 Linux 是少数允许使用它们的操作系统之一。无论你最终采用哪种模式,我希望这个概观能够给你足够的信息,以便对你所做的选择感到自信 —— 或者有足够的信心跨出您熟悉的区域来看看还有什么可用的。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Jonathan Terrasi - 自 2017 年以来一直是 ECT 新闻网专栏作家。他的主要兴趣是计算机安全(特别是 Linux 桌面)、加密和分析政治和时事。他是全职自由作家和音乐家。他的背景包括在芝加哥委员会发表的关于维护人权法案的文章中提供技术评论和分析。
|
||||||
|
|
||||||
|
-----------
|
||||||
|
|
||||||
|
via: http://www.linuxinsider.com/story/84473.html
|
||||||
|
|
||||||
|
作者:[Jonathan Terrasi][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:
|
||||||
|
[1]:http://www.linuxinsider.com/story/84473.html?rss=1#
|
||||||
|
[2]:http://www.linuxinsider.com/perl/mailit/?id=84473
|
||||||
|
[3]:http://en.wikipedia.org/wiki/GNOME
|
||||||
|
[4]:http://www.linuxinsider.com/article_images/2017/84473_1200x750.jpg
|
||||||
|
[5]:http://www.xfce-look.org/
|
||||||
|
[6]:https://i3wm.org/docs/
|
||||||
@ -1,21 +1,13 @@
|
|||||||
当你只想将事情搞定时,为什么开放式工作这么难?
|
当你只想将事情搞定时,为什么开放式工作这么难?
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
### 学习使用开放式决策框架来写一本书
|
> 学习使用开放式决策框架来写一本书
|
||||||
|
|
||||||

|

|
||||||
>图片来源 : opensource.com
|
|
||||||
|
|
||||||
GSD(get stuff done 的缩写,即搞定)指导着我的工作方式。数年来,我将各种方法论融入我日常工作的习惯中,包括精益方法的反馈循环,和敏捷开发的迭代优化,以此来更好地 GSD(如果把 GSD 当作动词的话)。这意味着我必须非常有效地利用我的时间:列出清晰,各自独立的目标;标记已完成的项目;用迭代的方式地持续推进项目进度。但是当我们默认使用开放的时仍然能够 GSD 吗?又或者 GSD 的方法完全行不通呢?大多数人都认为这会导致糟糕的状况,但我发现事实并不一定这样。
|
GSD(get stuff done 的缩写,即搞定)指导着我的工作方式。数年来,我将各种方法论融入我日常工作的习惯中,包括精益方法的反馈循环,和敏捷开发的迭代优化,以此来更好地 GSD(如果把 GSD 当作动词的话)。这意味着我必须非常有效地利用我的时间:列出清晰、各自独立的目标;标记已完成的项目;用迭代的方式地持续推进项目进度。但是当我们以开放为基础时仍然能够 GSD 吗?又或者 GSD 的方法完全行不通呢?大多数人都认为这会导致糟糕的状况,但我发现事实并不一定这样。
|
||||||
|
|
||||||
在开放的环境中工作,遵循[开放式决策框架][6]中的指导,会让项目起步变慢。但是在最近的一个项目中,我们作出了一个决定,一个从开始就正确的决定:以开放的方式工作,并与我们的社群一起合作。
|
在开放的环境中工作,遵循<ruby>[开放式决策框架][6]<rt>Open Decision Framework</rt></ruby>中的指导,会让项目起步变慢。但是在最近的一个项目中,我们作出了一个决定,一个从开始就正确的决定:以开放的方式工作,并与我们的社群一起合作。
|
||||||
|
|
||||||
关于开放式组织的资料
|
|
||||||
|
|
||||||
* [下载《开放式组织 IT 文化变革指南》][1]
|
|
||||||
* [下载《开放式组织领袖手册》][2]
|
|
||||||
* [什么是开放式组织][3]
|
|
||||||
* [什么是开放决策][4]
|
|
||||||
|
|
||||||
这是我们能做的最好的决定。
|
这是我们能做的最好的决定。
|
||||||
|
|
||||||
@ -23,13 +15,13 @@ GSD(get stuff done 的缩写,即搞定)指导着我的工作方式。数
|
|||||||
|
|
||||||
### 建立社区
|
### 建立社区
|
||||||
|
|
||||||
2014 年 10 月,我接手了一个新的项目:当时红帽的 CEO Jim Whitehurst 即将推出一本新书《开放式组织》,我要根据书中提出的概念,建立一个社区。“太棒了,这听起来是一个挑战,我加入了!”我这样想。但不久,[冒牌者综合征][7]便出现了,我又开始想:“我们究竟要做什么呢?怎样才算成功呢?”
|
2014 年 10 月,我接手了一个新的项目:当时红帽的 CEO Jim Whitehurst 即将推出一本新书<ruby>《开放式组织》<rt>The Open Organization</rt></ruby>,我要根据书中提出的概念,建立一个社区。“太棒了,这听起来是一个挑战,我加入了!”我这样想。但不久,[冒牌者综合征][7]便出现了,我又开始想:“我们究竟要做什么呢?怎样才算成功呢?”
|
||||||
|
|
||||||
让我剧透一下,在这本书的结尾处,Jim 鼓励读者访问 Opensource.com,继续探讨 21 世纪的开放和管理。所以,在 2015 年 5 月,我们的团队在网站上建立了一个新的板块来讨论这些想法。我们计划讲一些故事,就像我们在 Opensource.com 上常做的那样,只不过这次围绕着书中的观点与概念。之后,我们每周都发布新的文章,在 Twitter 上举办了一个在线的读书俱乐部,还将《开放式组织》打造成了系列书籍。
|
让我剧透一下,在这本书的结尾处,Jim 鼓励读者访问 Opensource.com,继续探讨 21 世纪的开放和管理。所以,在 2015 年 5 月,我们的团队在网站上建立了一个新的板块来讨论这些想法。我们计划讲一些故事,就像我们在 Opensource.com 上常做的那样,只不过这次围绕着书中的观点与概念。之后,我们每周都发布新的文章,在 Twitter 上举办了一个在线的读书俱乐部,还将《开放式组织》打造成了系列书籍。
|
||||||
|
|
||||||
我们内部独自完成了该系列书籍的前三期,每隔六个月发布一期。每完成一期,我们就向社区发布。然后我们继续完成下一期的工作,如此循环下去。
|
我们内部独自完成了该系列书籍的前三期,每隔六个月发布一期。每完成一期,我们就向社区发布。然后我们继续完成下一期的工作,如此循环下去。
|
||||||
|
|
||||||
这种工作方式,让我们看到了很大的成功。近 3000 人订阅了[该系列的新书][9],《开放式组织领袖手册》。我们用 6 个月的周期来完成这个项目,这样新书的发行日正好是前书的两周年纪念日。
|
这种工作方式,让我们看到了很大的成功。近 3000 人订阅了[该系列的新书][9]:《开放式组织领袖手册》。我们用 6 个月的周期来完成这个项目,这样新书的发行日正好是前书的两周年纪念日。
|
||||||
|
|
||||||
在这样的背景下,我们完成这本书的方式是简单直接的:针对开放工作这个主题,我们收集了最好的故事,并将它们组织起来形成文章,招募作者填补一些内容上的空白,使用开源工具调整字体样式,与设计师一起完成封面,最终发布这本书。这样的工作方式使得我们能按照自己的时间线(GSD)全速前进。到[第三本书][10]时,我们的工作流已经基本完善了。
|
在这样的背景下,我们完成这本书的方式是简单直接的:针对开放工作这个主题,我们收集了最好的故事,并将它们组织起来形成文章,招募作者填补一些内容上的空白,使用开源工具调整字体样式,与设计师一起完成封面,最终发布这本书。这样的工作方式使得我们能按照自己的时间线(GSD)全速前进。到[第三本书][10]时,我们的工作流已经基本完善了。
|
||||||
|
|
||||||
@ -39,59 +31,55 @@ GSD(get stuff done 的缩写,即搞定)指导着我的工作方式。数
|
|||||||
|
|
||||||
开放式决策框架列出了组成开放决策制定过程的 4 个阶段。下面是我们在每个阶段中的工作情况(以及开放是如何帮助完成工作的)。
|
开放式决策框架列出了组成开放决策制定过程的 4 个阶段。下面是我们在每个阶段中的工作情况(以及开放是如何帮助完成工作的)。
|
||||||
|
|
||||||
### 1\. 构思
|
#### 1、 构思
|
||||||
|
|
||||||
我们首先写了一份草稿,罗列了对项目设想的愿景。我们需要拿出东西来和潜在的“顾客”分享(在这个例子中,“顾客”指潜在的利益相关者和作者)。然后我们约了一些领域专家面谈,这些专家能够给我们直接的诚实的意见。这些专家表现出的热情与他们提供的指导验证了我们的想法,同时提出了反馈意见使我们能继续向前。如果我们没有得到这些验证,我们会退回到我们最初的想法,再决定从哪里重新开始。
|
我们首先写了一份草稿,罗列了对项目设想的愿景。我们需要拿出东西来和潜在的“顾客”分享(在这个例子中,“顾客”指潜在的利益相关者和作者)。然后我们约了一些领域专家面谈,这些专家能够给我们直接的诚实的意见。这些专家表现出的热情与他们提供的指导验证了我们的想法,同时提出了反馈意见使我们能继续向前。如果我们没有得到这些验证,我们会退回到我们最初的想法,再决定从哪里重新开始。
|
||||||
|
|
||||||
### 2\. 计划与研究
|
#### 2、 计划与研究
|
||||||
|
|
||||||
经过几次面谈,我们准备在 [Opensource.com 上公布这个项目][11]。同时,我们在 [Github 上也公布了这个项目][12], 提供了项目描述,预计的时间线,并阐明了我们所受的约束。这次公布得到了很好的效果,我们最初计划的目录中欠缺了一些内容,在项目公布之后的 72 小时内就被补充完整了。另外(也是更重要的),读者针对一些章节,提出了本不在我们计划中的想法,但是读者觉得这些想法能够补充我们最初设想的版本。
|
经过几次面谈,我们准备在 [Opensource.com 上公布这个项目][11]。同时,我们在 [Github 上也启动了这个项目][12],提供了项目描述、预计的时间线,并阐明了我们所受的约束。这次公布得到了很好的效果,我们最初计划的目录中欠缺了一些内容,在项目公布之后的 72 小时内就被补充完整了。另外(也是更重要的),读者针对一些章节,提出了本不在我们计划中的想法,但是读者觉得这些想法能够补充我们最初设想的版本。
|
||||||
|
|
||||||
我们体会到了 [Linus 法则][16]: "With more eyes, all _typos_ are shallow."
|
回顾过去,我觉得在项目的第一和第二个阶段,开放项目并不会影响我们搞定项目的能力。事实上,这样工作有一个很大的好处:发现并填补内容的空缺。我们不只是填补了空缺,我们是迅速地填补了空缺,并且还是用我们自己从未考虑过的点子。这并不一定要求我们做更多的工作,只是改变了我们的工作方式。我们动用有限的人脉,邀请别人来写作,再组织收到的内容,设置上下文,将人们导向正确的方向。
|
||||||
|
|
||||||
回顾过去,我觉得在项目的第一和第二个阶段,开放项目并不会影响我们搞定项目的能力。事实上,这样工作有一个很大的好处:发现并填补内容的空缺。我们不只是填补了空缺,我们是迅速地就填补了空缺,并且还是用我们自己从未考虑过的点子。这并不一定要求我们做更多的工作,只是改变了我们的工作方式。我们动用有限的人脉,邀请别人来写作,再组织收到的内容,设置上下文,将人们导向正确的方向。
|
#### 3、 设计,开发和测试
|
||||||
|
|
||||||
### 3\. 设计,开发和测试
|
|
||||||
|
|
||||||
项目的这个阶段完全围绕项目管理,管理一些像猫一样特立独行的人,并处理项目的预期。我们有明确的截止时间,我们提前沟通,频繁沟通。我们还使用了一个战略:列出了贡献者和利益相关者,在项目的整个过程中向他们告知项目的进度,尤其是我们在 Github 上标出的里程碑。
|
项目的这个阶段完全围绕项目管理,管理一些像猫一样特立独行的人,并处理项目的预期。我们有明确的截止时间,我们提前沟通,频繁沟通。我们还使用了一个战略:列出了贡献者和利益相关者,在项目的整个过程中向他们告知项目的进度,尤其是我们在 Github 上标出的里程碑。
|
||||||
|
|
||||||
最后,我们的书需要一个名字。我们收集了许多反馈,指出书名应该是什么,更重要的反馈指出了书名不应该是什么。我们通过 [Github 上的 issue][13] 收集反馈意见,并公开表示我们的团队将作最后的决定。当我们准备宣布最后的书名时,我的同事 Bryan Behrenshausen 做了很好的工作,[分享了我们作出决定的过程][14]。人们似乎对此感到高兴——即使他们不同意我们最后的书名。
|
最后,我们的书需要一个名字。我们收集了许多反馈,指出书名应该是什么,更重要的是反馈指出了书名不应该是什么。我们通过 [Github 上的工单][13]收集反馈意见,并公开表示我们的团队将作最后的决定。当我们准备宣布最后的书名时,我的同事 Bryan Behrenshausen 做了很好的工作,[分享了我们作出决定的过程][14]。人们似乎对此感到高兴——即使他们不同意我们最后的书名。
|
||||||
|
|
||||||
书的“测试”阶段需要大量的[校对][15]。社区成员真的参与到回答这个“求助”贴中来。我们在 GitHub issue 上收到了大约 80 条意见,汇报校对工作的进度(更不用说通过电子邮件和其他反馈渠道获得的许多额外的反馈)。
|
书的“测试”阶段需要大量的[校对][15]。社区成员真的参与到回答这个“求助”贴中来。我们在 GitHub 工单上收到了大约 80 条意见,汇报校对工作的进度(更不用说通过电子邮件和其他反馈渠道获得的许多额外的反馈)。
|
||||||
|
|
||||||
关于搞定任务:在这个阶段,我们亲身体会了 [Linus 法则][16]:"With more eyes, all _typos_ are shallow." 如果我们像前三本书一样自己独立完成,那么整个校对的负担就会落在我们的肩上(就像这些书一样)!相反,社区成员慷慨地帮我们承担了校对的重担,我们的工作从自己校对(尽管我们仍然做了很多工作)转向管理所有的 change requests。对我们团队来说,这是一个受大家欢迎的改变;对社区来说,这是一个参与的机会。如果我们自己做的话,我们肯定能更快地完成校对,但是在开放的情况下,我们在截止日期之前发现了更多的错误,这一点毋庸置疑。
|
关于搞定任务:在这个阶段,我们亲身体会了 [Linus 法则][16]:“<ruby>众目之下,_笔误_无所遁形。<rt>With more eyes, all _typos_ are shallow.</rt></ruby>” 如果我们像前三本书一样自己独立完成,那么整个校对的负担就会落在我们的肩上(就像这些书一样)!相反,社区成员慷慨地帮我们承担了校对的重担,我们的工作从自己校对(尽管我们仍然做了很多工作)转向管理所有的 change requests。对我们团队来说,这是一个受大家欢迎的改变;对社区来说,这是一个参与的机会。如果我们自己做的话,我们肯定能更快地完成校对,但是在开放的情况下,我们在截止日期之前发现了更多的错误,这一点毋庸置疑。
|
||||||
|
|
||||||
### 4\. Launch
|
#### 4、 发布
|
||||||
|
|
||||||
### 4\. 发布
|
|
||||||
|
|
||||||
好了,我们现在推出了这本书的最终版本。(或者只是第一版?)
|
好了,我们现在推出了这本书的最终版本。(或者只是第一版?)
|
||||||
|
|
||||||
遵循开放决策框架是《IT 文化变革指南》成功的关键。
|
|
||||||
|
|
||||||
我们把发布分为两个阶段。首先,根据我们的公开的项目时间表,在最终日期之前的几天,我们安静地推出了这本书,以便让我们的社区贡献者帮助我们测试[下载表格][17]。第二阶段也就是现在,这本书的[通用版][18]的正式公布。当然,我们在发布后的仍然接受反馈,开源方式也正是如此。
|
我们把发布分为两个阶段。首先,根据我们的公开的项目时间表,在最终日期之前的几天,我们安静地推出了这本书,以便让我们的社区贡献者帮助我们测试[下载表格][17]。第二阶段也就是现在,这本书的[通用版][18]的正式公布。当然,我们在发布后的仍然接受反馈,开源方式也正是如此。
|
||||||
|
|
||||||
### 成就解锁
|
### 成就解锁
|
||||||
|
|
||||||
遵循开放式决策框架是《IT 文化变革指南》成功的关键。通过与客户和利益相关者的合作,分享我们的制约因素,工作透明化,我们甚至超出了自己对图书项目的期望。
|
遵循开放式决策框架是<ruby>《IT 文化变革指南》<rt>Guide to IT Culture Change</rt></ruby>成功的关键。通过与客户和利益相关者的合作,分享我们的制约因素,工作透明化,我们甚至超出了自己对图书项目的期望。
|
||||||
|
|
||||||
我对整个项目中的合作,反馈和活动感到非常满意。虽然有一段时间内没有像我想要的那样快速完成任务,这让我有一种焦虑感,但我很快就意识到,开放这个过程实际上让我们能完成更多的事情。基于上面我的概述这一点显而易见。
|
我对整个项目中的合作,反馈和活动感到非常满意。虽然有一段时间内没有像我想要的那样快速完成任务,这让我有一种焦虑感,但我很快就意识到,开放这个过程实际上让我们能完成更多的事情。基于上面我的概述这一点显而易见。
|
||||||
|
|
||||||
所以也许我应该重新考虑我的 GSD 心态,并将其扩展到 GMD:Get **more** done,搞定**更多**工作,并且就这个例子说,取得更好的结果。
|
所以也许我应该重新考虑我的 GSD 心态,并将其扩展到 GMD:Get **More** Done,搞定**更多**工作,并且就这个例子说,取得更好的结果。
|
||||||
|
|
||||||
|
(题图:opensource.com)
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
作者简介:
|
作者简介:
|
||||||
|
|
||||||
Jason Hibbets - Jason Hibbets 是 Red Hat 企业营销中的高级社区传播者,也是 Opensource.com 的社区经理。 他自2003年以来一直在 Red Hat,并且是开源城市基金会的创立者。之前的职位包括高级营销专员,项目经理,Red Hat 知识库维护人员和支持工程师。
|
Jason Hibbets - Jason Hibbets 是 Red Hat 企业营销中的高级社区传播者,也是 Opensource.com 的社区经理。 他自2003 年以来一直在 Red Hat,并且是开源城市基金会的创立者。之前的职位包括高级营销专员、项目经理、Red Hat 知识库维护人员和支持工程师。
|
||||||
|
|
||||||
-----------
|
-----------
|
||||||
|
|
||||||
via: https://opensource.com/open-organization/17/6/working-open-and-gsd
|
via: https://opensource.com/open-organization/17/6/working-open-and-gsd
|
||||||
|
|
||||||
作者:[Jason Hibbets ][a]
|
作者:[Jason Hibbets][a]
|
||||||
译者:[explosic4](https://github.com/explosic4)
|
译者:[explosic4](https://github.com/explosic4)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,311 @@
|
|||||||
|
关于 HTML5 你需要了解的基础知识
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> HTML5 是第五个且是当前的 HTML 版本,它是用于在万维网上构建和呈现内容的标记语言。本文将帮助读者了解它。
|
||||||
|
|
||||||
|
HTML5 通过 W3C 和<ruby>Web 超文本应用技术工作组<rt>Web Hypertext Application Technology Working Group</rt></ruby>之间的合作发展起来。它是一个更高版本的 HTML,它的许多新元素可以使你的页面更加语义化和动态。它是为所有人提供更好的 Web 体验而开发的。HTML5 提供了很多的功能,使 Web 更加动态和交互。
|
||||||
|
|
||||||
|
HTML5 的新功能是:
|
||||||
|
|
||||||
|
* 新标签,如 `<header>` 和 `<section>`
|
||||||
|
* 用于 2D 绘图的 `<canvas>` 元素
|
||||||
|
* 本地存储
|
||||||
|
* 新的表单控件,如日历、日期和时间
|
||||||
|
* 新媒体功能
|
||||||
|
* 地理位置
|
||||||
|
|
||||||
|
HTML5 还不是正式标准(LCTT 译注:HTML5 已于 2014 年成为“推荐标准”),因此,并不是所有的浏览器都支持它或其中一些功能。开发 HTML5 背后最重要的原因之一是防止用户下载并安装像 Silverlight 和 Flash 这样的多个插件。
|
||||||
|
|
||||||
|
**新标签和元素**
|
||||||
|
|
||||||
|
- **语义化元素:** 图 1 展示了一些有用的语义化元素。
|
||||||
|
- **表单元素:** HTML5 中的表单元素如图 2 所示。
|
||||||
|
- **图形元素:** HTML5 中的图形元素如图 3 所示。
|
||||||
|
- **媒体元素:** HTML5 中的新媒体元素如图 4 所示。
|
||||||
|
|
||||||
|
|
||||||
|
[][3]
|
||||||
|
|
||||||
|
*图 1:语义化元素*
|
||||||
|
|
||||||
|
[][4]
|
||||||
|
|
||||||
|
*图 2:表单元素*
|
||||||
|
|
||||||
|
[][5]
|
||||||
|
|
||||||
|
*图 3:图形元素*
|
||||||
|
|
||||||
|
[][6]
|
||||||
|
|
||||||
|
*图 4:媒体元素*
|
||||||
|
|
||||||
|
### HTML5 的高级功能
|
||||||
|
|
||||||
|
#### 地理位置
|
||||||
|
|
||||||
|
这是一个 HTML5 API,用于获取网站用户的地理位置,用户必须首先允许网站获取他或她的位置。这通常通过按钮和/或浏览器弹出窗口来实现。所有最新版本的 Chrome、Firefox、IE、Safari 和 Opera 都可以使用 HTML5 的地理位置功能。
|
||||||
|
|
||||||
|
地理位置的一些用途是:
|
||||||
|
|
||||||
|
* 公共交通网站
|
||||||
|
* 出租车及其他运输网站
|
||||||
|
* 电子商务网站计算运费
|
||||||
|
* 旅行社网站
|
||||||
|
* 房地产网站
|
||||||
|
* 在附近播放的电影的电影院网站
|
||||||
|
* 在线游戏
|
||||||
|
* 网站首页提供本地标题和天气
|
||||||
|
* 工作职位可以自动计算通勤时间
|
||||||
|
|
||||||
|
**工作原理:** 地理位置通过扫描位置信息的常见源进行工作,其中包括以下:
|
||||||
|
|
||||||
|
* 全球定位系统(GPS)是最准确的
|
||||||
|
* 网络信号 - IP地址、RFID、Wi-Fi 和蓝牙 MAC地址
|
||||||
|
* GSM/CDMA 蜂窝 ID
|
||||||
|
* 用户输入
|
||||||
|
|
||||||
|
该 API 提供了非常方便的函数来检测浏览器中的地理位置支持:
|
||||||
|
|
||||||
|
```
|
||||||
|
if (navigator.geolocation) {
|
||||||
|
// do stuff
|
||||||
|
}
|
||||||
|
```
|
||||||
|
`getCurrentPosition` API 是使用地理位置的主要方法。它检索用户设备的当前地理位置。该位置被描述为一组地理坐标以及航向和速度。位置信息作为位置对象返回。
|
||||||
|
|
||||||
|
语法是:
|
||||||
|
|
||||||
|
```
|
||||||
|
getCurrentPosition(showLocation, ErrorHandler, options);
|
||||||
|
```
|
||||||
|
|
||||||
|
* `showLocation`:定义了检索位置信息的回调方法。
|
||||||
|
* `ErrorHandler`(可选):定义了在处理异步调用时发生错误时调用的回调方法。
|
||||||
|
* `options` (可选): 定义了一组用于检索位置信息的选项。
|
||||||
|
|
||||||
|
我们可以通过两种方式向用户提供位置信息:测地和民用。
|
||||||
|
|
||||||
|
1. 描述位置的测地方式直接指向纬度和经度。
|
||||||
|
2. 位置信息的民用表示法是人类可读的且容易理解。
|
||||||
|
|
||||||
|
如下表 1 所示,每个属性/参数都具有测地和民用表示。
|
||||||
|
|
||||||
|
[][7]
|
||||||
|
|
||||||
|
图 5 包含了一个位置对象返回的属性集。
|
||||||
|
|
||||||
|
[][8]
|
||||||
|
|
||||||
|
*图5:位置对象属性*
|
||||||
|
|
||||||
|
#### 网络存储
|
||||||
|
|
||||||
|
在 HTML 中,为了在本机存储用户数据,我们需要使用 JavaScript cookie。为了避免这种情况,HTML5 已经引入了 Web 存储,网站利用它在本机上存储用户数据。
|
||||||
|
|
||||||
|
与 Cookie 相比,Web 存储的优点是:
|
||||||
|
|
||||||
|
* 更安全
|
||||||
|
* 更快
|
||||||
|
* 存储更多的数据
|
||||||
|
* 存储的数据不会随每个服务器请求一起发送。只有在被要求时才包括在内。这是 HTML5 Web 存储超过 Cookie 的一大优势。
|
||||||
|
|
||||||
|
有两种类型的 Web 存储对象:
|
||||||
|
|
||||||
|
1. 本地 - 存储没有到期日期的数据。
|
||||||
|
2. 会话 - 仅存储一个会话的数据。
|
||||||
|
|
||||||
|
**如何工作:** `localStorage` 和 `sessionStorage` 对象创建一个 `key=value` 对。比如: `key="Name"`,` value="Palak"`。
|
||||||
|
|
||||||
|
这些存储为字符串,但如果需要,可以使用 JavaScript 函数(如 `parseInt()` 和 `parseFloat()`)进行转换。
|
||||||
|
|
||||||
|
下面给出了使用 Web 存储对象的语法:
|
||||||
|
|
||||||
|
- 存储一个值:
|
||||||
|
- `localStorage.setItem("key1", "value1");`
|
||||||
|
- `localStorage["key1"] = "value1";`
|
||||||
|
- 得到一个值:
|
||||||
|
- `alert(localStorage.getItem("key1"));`
|
||||||
|
- `alert(localStorage["key1"]);`
|
||||||
|
- 删除一个值:
|
||||||
|
-`removeItem("key1");`
|
||||||
|
- 删除所有值:
|
||||||
|
- `localStorage.clear();`
|
||||||
|
|
||||||
|
#### 应用缓存(AppCache)
|
||||||
|
|
||||||
|
使用 HTML5 AppCache,我们可以使 Web 应用程序在没有 Internet 连接的情况下脱机工作。除 IE 之外,所有浏览器都可以使用 AppCache(截止至此时)。
|
||||||
|
|
||||||
|
应用缓存的优点是:
|
||||||
|
|
||||||
|
* 网页浏览可以脱机
|
||||||
|
* 页面加载速度更快
|
||||||
|
* 服务器负载更小
|
||||||
|
|
||||||
|
`cache manifest` 是一个简单的文本文件,其中列出了浏览器应缓存的资源以进行脱机访问。 `manifest` 属性可以包含在文档的 HTML 标签中,如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
<html manifest="test.appcache">
|
||||||
|
...
|
||||||
|
</html>
|
||||||
|
```
|
||||||
|
|
||||||
|
它应该在你要缓存的所有页面上。
|
||||||
|
|
||||||
|
缓存的应用程序页面将一直保留,除非:
|
||||||
|
|
||||||
|
1. 用户清除它们
|
||||||
|
2. `manifest` 被修改
|
||||||
|
3. 缓存更新
|
||||||
|
|
||||||
|
#### 视频
|
||||||
|
|
||||||
|
在 HTML5 发布之前,没有统一的标准来显示网页上的视频。大多数视频都是通过 Flash 等不同的插件显示的。但 HTML5 规定了使用 video 元素在网页上显示视频的标准方式。
|
||||||
|
|
||||||
|
目前,video 元素支持三种视频格式,如表 2 所示。
|
||||||
|
|
||||||
|
[][9]
|
||||||
|
|
||||||
|
下面的例子展示了 video 元素的使用:
|
||||||
|
|
||||||
|
```
|
||||||
|
<! DOCTYPE HTML>
|
||||||
|
<html>
|
||||||
|
<body>
|
||||||
|
|
||||||
|
<video src=" vdeo.ogg" width="320" height="240" controls="controls">
|
||||||
|
|
||||||
|
This browser does not support the video element.
|
||||||
|
|
||||||
|
</video>
|
||||||
|
|
||||||
|
</body>
|
||||||
|
</html>
|
||||||
|
```
|
||||||
|
|
||||||
|
例子使用了 Ogg 文件,并且可以在 Firefox、Opera 和 Chrome 中使用。要使视频在 Safari 和未来版本的 Chrome 中工作,我们必须添加一个 MPEG4 和 WebM 文件。
|
||||||
|
|
||||||
|
`video` 元素允许多个 `source` 元素。`source` 元素可以链接到不同的视频文件。浏览器将使用第一个识别的格式,如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
<video width="320" height="240" controls="controls">
|
||||||
|
<source src="vdeo.ogg" type="video/ogg" />
|
||||||
|
<source src=" vdeo.mp4" type="video/mp4" />
|
||||||
|
<source src=" vdeo.webm" type="video/webm" />
|
||||||
|
This browser does not support the video element.
|
||||||
|
</video>
|
||||||
|
```
|
||||||
|
|
||||||
|
[][10]
|
||||||
|
|
||||||
|
*图6:Canvas 的输出*
|
||||||
|
|
||||||
|
#### 音频
|
||||||
|
|
||||||
|
对于音频,情况类似于视频。在 HTML5 发布之前,在网页上播放音频没有统一的标准。大多数音频也通过 Flash 等不同的插件播放。但 HTML5 规定了通过使用音频元素在网页上播放音频的标准方式。音频元素用于播放声音文件和音频流。
|
||||||
|
|
||||||
|
目前,HTML5 `audio` 元素支持三种音频格式,如表 3 所示。
|
||||||
|
|
||||||
|
[][11]
|
||||||
|
|
||||||
|
`audio` 元素的使用如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
<! DOCTYPE HTML>
|
||||||
|
<html>
|
||||||
|
<body>
|
||||||
|
|
||||||
|
<audio src=" song.ogg" controls="controls">
|
||||||
|
|
||||||
|
This browser does not support the audio element.
|
||||||
|
|
||||||
|
</video>
|
||||||
|
|
||||||
|
</body>
|
||||||
|
</html>
|
||||||
|
```
|
||||||
|
|
||||||
|
此例使用 Ogg 文件,并且可以在 Firefox、Opera 和 Chrome 中使用。要在 Safari 和 Chrome 的未来版本中使 audio 工作,我们必须添加一个 MP3 和 Wav 文件。
|
||||||
|
|
||||||
|
`audio` 元素允许多个 `source` 元素,它可以链接到不同的音频文件。浏览器将使用第一个识别的格式,如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
<audio controls="controls">
|
||||||
|
<source src="song.ogg" type="audio/ogg" />
|
||||||
|
<source src="song.mp3" type="audio/mpeg" />
|
||||||
|
|
||||||
|
This browser does not support the audio element.
|
||||||
|
|
||||||
|
</audio>
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 画布(Canvas)
|
||||||
|
|
||||||
|
要在网页上创建图形,HTML5 使用 画布 API。我们可以用它绘制任何东西,并且它使用 JavaScript。它通过避免从网络下载图像而提高网站性能。使用画布,我们可以绘制形状和线条、弧线和文本、渐变和图案。此外,画布可以让我们操作图像中甚至视频中的像素。你可以将 `canvas` 元素添加到 HTML 页面,如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
<canvas id="myCanvas" width="200" height="100"></canvas>
|
||||||
|
```
|
||||||
|
|
||||||
|
画布元素不具有绘制元素的功能。我们可以通过使用 JavaScript 来实现绘制。所有绘画应在 JavaScript 中。
|
||||||
|
|
||||||
|
```
|
||||||
|
<script type="text/javascript">
|
||||||
|
var c=document.getElementById("myCanvas");
|
||||||
|
var cxt=c.getContext("2d");
|
||||||
|
cxt.fillStyle="blue";
|
||||||
|
cxt.storkeStyle = "red";
|
||||||
|
cxt.fillRect(10,10,100,100);
|
||||||
|
cxt.storkeRect(10,10,100,100);
|
||||||
|
</script>
|
||||||
|
```
|
||||||
|
|
||||||
|
以上脚本的输出如图 6 所示。
|
||||||
|
|
||||||
|
你可以绘制许多对象,如弧、圆、线/垂直梯度等。
|
||||||
|
|
||||||
|
### HTML5 工具
|
||||||
|
|
||||||
|
为了有效操作,所有熟练的或业余的 Web 开发人员/设计人员都应该使用 HTML5 工具,当需要设置工作流/网站或执行重复任务时,这些工具非常有帮助。它们提高了网页设计的可用性。
|
||||||
|
|
||||||
|
以下是一些帮助创建很棒的网站的必要工具。
|
||||||
|
|
||||||
|
- **HTML5 Maker:** 用来在 HTML、JavaScript 和 CSS 的帮助下与网站内容交互。非常容易使用。它还允许我们开发幻灯片、滑块、HTML5 动画等。
|
||||||
|
- **Liveweave:** 用来测试代码。它减少了保存代码并将其加载到屏幕上所花费的时间。在编辑器中粘贴代码即可得到结果。它非常易于使用,并为一些代码提供自动完成功能,这使得开发和测试更快更容易。
|
||||||
|
- **Font dragr:** 在浏览器中预览定制的 Web 字体。它会直接载入该字体,以便你可以知道看起来是否正确。也提供了拖放界面,允许你拖动字形、Web 开放字体和矢量图形来马上测试。
|
||||||
|
- **HTML5 Please:** 可以让我们找到与 HTML5 相关的任何内容。如果你想知道如何使用任何一个功能,你可以在 HTML Please 中搜索。它提供了支持的浏览器和设备的有用资源的列表,语法,以及如何使用元素的一般建议等。
|
||||||
|
- **Modernizr:** 这是一个开源工具,用于给访问者浏览器提供最佳体验。使用此工具,你可以检测访问者的浏览器是否支持 HTML5 功能,并加载相应的脚本。
|
||||||
|
- **Adobe Edge Animate:** 这是必须处理交互式 HTML 动画的 HTML5 开发人员的有用工具。它用于数字出版、网络和广告领域。此工具允许用户创建无瑕疵的动画,可以跨多个设备运行。
|
||||||
|
- **Video.js:** 这是一款基于 JavaScript 的 HTML5 视频播放器。如果要将视频添加到你的网站,你应该使用此工具。它使视频看起来不错,并且是网站的一部分。
|
||||||
|
- **The W3 Validator:** W3 验证工具测试 HTML、XHTML、SMIL、MathML 等中的网站标记的有效性。要测试任何网站的标记有效性,你必须选择文档类型为 HTML5 并输入你网页的 URL。这样做之后,你的代码将被检查,并将提供所有错误和警告。
|
||||||
|
- **HTML5 Reset:** 此工具允许开发人员在 HTML5 中重写旧网站的代码。你可以使用这些工具为你网站的访问者提供一个良好的网络体验。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
Palak Shah
|
||||||
|
|
||||||
|
作者是高级软件工程师。她喜欢探索新技术,学习创新概念。她也喜欢哲学。你可以通过 palak311@gmail.com 联系她。
|
||||||
|
|
||||||
|
--------------------
|
||||||
|
via: http://opensourceforu.com/2017/06/introduction-to-html5/
|
||||||
|
|
||||||
|
作者:[Palak Shah][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://opensourceforu.com/author/palak-shah/
|
||||||
|
[1]:http://opensourceforu.com/2017/06/introduction-to-html5/#disqus_thread
|
||||||
|
[2]:http://opensourceforu.com/author/palak-shah/
|
||||||
|
[3]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-1-7.jpg
|
||||||
|
[4]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-2-5.jpg
|
||||||
|
[5]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-3-2.jpg
|
||||||
|
[6]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure-4-2.jpg
|
||||||
|
[7]:http://opensourceforu.com/wp-content/uploads/2017/05/table-1.jpg
|
||||||
|
[8]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure5-1.jpg
|
||||||
|
[9]:http://opensourceforu.com/wp-content/uploads/2017/05/table-2.jpg
|
||||||
|
[10]:http://opensourceforu.com/wp-content/uploads/2017/05/Figure6-1.jpg
|
||||||
|
[11]:http://opensourceforu.com/wp-content/uploads/2017/05/table-3.jpg
|
||||||
@ -0,0 +1,716 @@
|
|||||||
|
JavaScript 函数式编程介绍
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 探索函数式编程,通过它让你的程序更具有可读性和易于调试
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
>Image credits : Steve Jurvetson via [Flickr][80] (CC-BY-2.0)
|
||||||
|
|
||||||
|
当 Brendan Eich 在 1995 年创造 JavaScript 时,他原本打算[将 Scheme 移植到浏览器里][81] 。Scheme 作为 Lisp 的方言,是一种函数式编程语言。而当 Eich 被告知新的语言应该是一种可以与 Java 相比的脚本语言后,他最终确立了一种拥有 C 风格语法的语言(也和 Java 一样),但将函数视作一等公民。而 Java 直到版本 8 才从技术上将函数视为一等公民,虽然你可以用匿名类来模拟它。这个特性允许 JavaScript 通过函数式范式编程。
|
||||||
|
|
||||||
|
JavaScript 是一个多范式语言,允许你自由地混合和使用面向对象式、过程式和函数式的编程范式。最近,函数式编程越来越火热。在诸如 [Angular][82] 和 [React][83] 这样的框架中,通过使用不可变数据结构可以切实提高性能。不可变是函数式编程的核心原则,它以及纯函数使得编写和调试程序变得更加容易。使用函数来代替程序的循环可以提高程序的可读性并使它更加优雅。总之,函数式编程拥有很多优点。
|
||||||
|
|
||||||
|
### 什么不是函数式编程
|
||||||
|
|
||||||
|
在讨论什么是函数式编程前,让我们先排除那些不属于函数式编程的东西。实际上它们是你需要丢弃的语言组件(再见,老朋友):
|
||||||
|
|
||||||
|
* 循环:
|
||||||
|
* `while`
|
||||||
|
* `do...while`
|
||||||
|
* `for`
|
||||||
|
* `for...of`
|
||||||
|
* `for...in`
|
||||||
|
* 用 `var` 或者 `let` 来声明变量
|
||||||
|
* 没有返回值的函数
|
||||||
|
* 改变对象的属性 (比如: `o.x = 5;`)
|
||||||
|
* 改变数组本身的方法:
|
||||||
|
* `copyWithin`
|
||||||
|
* `fill`
|
||||||
|
* `pop`
|
||||||
|
* `push`
|
||||||
|
* `reverse`
|
||||||
|
* `shift`
|
||||||
|
* `sort`
|
||||||
|
* `splice`
|
||||||
|
* `unshift`
|
||||||
|
* 改变映射本身的方法:
|
||||||
|
* `clear`
|
||||||
|
* `delete`
|
||||||
|
* `set`
|
||||||
|
* 改变集合本身的方法:
|
||||||
|
* `add`
|
||||||
|
* `clear`
|
||||||
|
* `delete`
|
||||||
|
|
||||||
|
脱离这些特性应该如何编写程序呢?这是我们将在后面探索的问题。
|
||||||
|
|
||||||
|
### 纯函数
|
||||||
|
|
||||||
|
你的程序中包含函数不一定意味着你正在进行函数式编程。函数式范式将<ruby>纯函数<rt>pure function</rt></ruby>和<ruby>非纯函数<rt>impure function</rt></ruby>区分开。鼓励你编写纯函数。纯函数必须满足下面的两个属性:
|
||||||
|
|
||||||
|
* 引用透明:函数在传入相同的参数后永远返回相同的返回值。这意味着该函数不依赖于任何可变状态。
|
||||||
|
* 无副作用:函数不能导致任何副作用。副作用可能包括 I/O(比如向终端或者日志文件写入),改变一个不可变的对象,对变量重新赋值等等。
|
||||||
|
|
||||||
|
我们来看一些例子。首先,`multiply` 就是一个纯函数的例子,它在传入相同的参数后永远返回相同的返回值,并且不会导致副作用。
|
||||||
|
|
||||||
|
```
|
||||||
|
function multiply(a, b) {
|
||||||
|
return a * b;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
下面是非纯函数的例子。`canRide` 函数依赖捕获的 `heightRequirement` 变量。被捕获的变量不一定导致一个函数是非纯函数,除非它是一个可变的变量(或者可以被重新赋值)。这种情况下使用 `let` 来声明这个变量,意味着可以对它重新赋值。`multiply` 函数是非纯函数,因为它会导致在 console 上输出。
|
||||||
|
|
||||||
|
```
|
||||||
|
let heightRequirement = 46;
|
||||||
|
|
||||||
|
// Impure because it relies on a mutable (reassignable) variable.
|
||||||
|
function canRide(height) {
|
||||||
|
return height >= heightRequirement;
|
||||||
|
}
|
||||||
|
|
||||||
|
// Impure because it causes a side-effect by logging to the console.
|
||||||
|
function multiply(a, b) {
|
||||||
|
console.log('Arguments: ', a, b);
|
||||||
|
return a * b;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
下面的列表包含着 JavaScript 内置的非纯函数。你可以指出它们不满足两个属性中的哪个吗?
|
||||||
|
|
||||||
|
* `console.log`
|
||||||
|
* `element.addEventListener`
|
||||||
|
* `Math.random`
|
||||||
|
* `Date.now`
|
||||||
|
* `$.ajax` (这里 `$` 代表你使用的 Ajax 库)
|
||||||
|
|
||||||
|
理想的程序中所有的函数都是纯函数,但是从上面的函数列表可以看出,任何有意义的程序都将包含非纯函数。大多时候我们需要进行 AJAX 调用,检查当前日期或者获取一个随机数。一个好的经验法则是遵循 80/20 规则:函数中有 80% 应该是纯函数,剩下的 20% 的必要性将不可避免地是非纯函数。
|
||||||
|
|
||||||
|
使用纯函数有几个优点:
|
||||||
|
|
||||||
|
* 它们很容易导出和调试,因为它们不依赖于可变的状态。
|
||||||
|
* 返回值可以被缓存或者“记忆”来避免以后重复计算。
|
||||||
|
* 它们很容易测试,因为没有需要模拟(mock)的依赖(比如日志,AJAX,数据库等等)。
|
||||||
|
|
||||||
|
你编写或者使用的函数返回空(换句话说它没有返回值),那代表它是非纯函数。
|
||||||
|
|
||||||
|
### 不变性
|
||||||
|
|
||||||
|
让我们回到捕获变量的概念上。来看看 `canRide` 函数。我们认为它是一个非纯函数,因为 `heightRequirement` 变量可以被重新赋值。下面是一个构造出来的例子来说明如何用不可预测的值来对它重新赋值。
|
||||||
|
|
||||||
|
```
|
||||||
|
let heightRequirement = 46;
|
||||||
|
|
||||||
|
function canRide(height) {
|
||||||
|
return height >= heightRequirement;
|
||||||
|
}
|
||||||
|
|
||||||
|
// Every half second, set heightRequirement to a random number between 0 and 200.
|
||||||
|
setInterval(() => heightRequirement = Math.floor(Math.random() * 201), 500);
|
||||||
|
|
||||||
|
const mySonsHeight = 47;
|
||||||
|
|
||||||
|
// Every half second, check if my son can ride.
|
||||||
|
// Sometimes it will be true and sometimes it will be false.
|
||||||
|
setInterval(() => console.log(canRide(mySonsHeight)), 500);
|
||||||
|
```
|
||||||
|
|
||||||
|
我要再次强调被捕获的变量不一定会使函数成为非纯函数。我们可以通过只是简单地改变 `heightRequirement` 的声明方式来使 `canRide` 函数成为纯函数。
|
||||||
|
|
||||||
|
```
|
||||||
|
const heightRequirement = 46;
|
||||||
|
|
||||||
|
function canRide(height) {
|
||||||
|
return height >= heightRequirement;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
通过用 `const` 来声明变量意味着它不能被再次赋值。如果尝试对它重新赋值,运行时引擎将抛出错误;那么,如果用对象来代替数字来存储所有的“常量”怎么样?
|
||||||
|
|
||||||
|
```
|
||||||
|
const constants = {
|
||||||
|
heightRequirement: 46,
|
||||||
|
// ... other constants go here
|
||||||
|
};
|
||||||
|
|
||||||
|
function canRide(height) {
|
||||||
|
return height >= constants.heightRequirement;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
我们用了 `const` ,所以这个变量不能被重新赋值,但是还有一个问题:这个对象可以被改变。下面的代码展示了,为了真正使其不可变,你不仅需要防止它被重新赋值,你也需要不可变的数据结构。JavaScript 语言提供了 `Object.freeze` 方法来阻止对象被改变。
|
||||||
|
|
||||||
|
```
|
||||||
|
'use strict';
|
||||||
|
|
||||||
|
// CASE 1: 对象的属性是可变的,并且变量可以被再次赋值。
|
||||||
|
let o1 = { foo: 'bar' };
|
||||||
|
|
||||||
|
// 改变对象的属性
|
||||||
|
o1.foo = 'something different';
|
||||||
|
|
||||||
|
// 对变量再次赋值
|
||||||
|
o1 = { message: "I'm a completely new object" };
|
||||||
|
|
||||||
|
|
||||||
|
// CASE 2: 对象的属性还是可变的,但是变量不能被再次赋值。
|
||||||
|
const o2 = { foo: 'baz' };
|
||||||
|
|
||||||
|
// 仍然能改变对象
|
||||||
|
o2.foo = 'Something different, yet again';
|
||||||
|
|
||||||
|
// 不能对变量再次赋值
|
||||||
|
// o2 = { message: 'I will cause an error if you uncomment me' }; // Error!
|
||||||
|
|
||||||
|
|
||||||
|
// CASE 3: 对象的属性是不可变的,但是变量可以被再次赋值。
|
||||||
|
let o3 = Object.freeze({ foo: "Can't mutate me" });
|
||||||
|
|
||||||
|
// 不能改变对象的属性
|
||||||
|
// o3.foo = 'Come on, uncomment me. I dare ya!'; // Error!
|
||||||
|
|
||||||
|
// 还是可以对变量再次赋值
|
||||||
|
o3 = { message: "I'm some other object, and I'm even mutable -- so take that!" };
|
||||||
|
|
||||||
|
|
||||||
|
// CASE 4: 对象的属性是不可变的,并且变量不能被再次赋值。这是我们想要的!!!!!!!!
|
||||||
|
const o4 = Object.freeze({ foo: 'never going to change me' });
|
||||||
|
|
||||||
|
// 不能改变对象的属性
|
||||||
|
// o4.foo = 'talk to the hand' // Error!
|
||||||
|
|
||||||
|
// 不能对变量再次赋值
|
||||||
|
// o4 = { message: "ain't gonna happen, sorry" }; // Error
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
不变性适用于所有的数据结构,包括数组、映射和集合。它意味着不能调用例如 `Array.prototype.push` 等会导致本身改变的方法,因为它会改变已经存在的数组。可以通过创建一个含有原来元素和新加元素的新数组,而不是将新元素加入一个已经存在的数组。其实所有会导致数组本身被修改的方法都可以通过一个返回修改好的新数组的函数代替。
|
||||||
|
|
||||||
|
```
|
||||||
|
'use strict';
|
||||||
|
|
||||||
|
const a = Object.freeze([4, 5, 6]);
|
||||||
|
|
||||||
|
// Instead of: a.push(7, 8, 9);
|
||||||
|
const b = a.concat(7, 8, 9);
|
||||||
|
|
||||||
|
// Instead of: a.pop();
|
||||||
|
const c = a.slice(0, -1);
|
||||||
|
|
||||||
|
// Instead of: a.unshift(1, 2, 3);
|
||||||
|
const d = [1, 2, 3].concat(a);
|
||||||
|
|
||||||
|
// Instead of: a.shift();
|
||||||
|
const e = a.slice(1);
|
||||||
|
|
||||||
|
// Instead of: a.sort(myCompareFunction);
|
||||||
|
const f = R.sort(myCompareFunction, a); // R = Ramda
|
||||||
|
|
||||||
|
// Instead of: a.reverse();
|
||||||
|
const g = R.reverse(a); // R = Ramda
|
||||||
|
|
||||||
|
// 留给读者的练习:
|
||||||
|
// copyWithin
|
||||||
|
// fill
|
||||||
|
// splice
|
||||||
|
```
|
||||||
|
|
||||||
|
[映射][84] 和 [集合][85] 也很相似。可以通过返回一个新的修改好的映射或者集合来代替使用会修改其本身的函数。
|
||||||
|
|
||||||
|
```
|
||||||
|
const map = new Map([
|
||||||
|
[1, 'one'],
|
||||||
|
[2, 'two'],
|
||||||
|
[3, 'three']
|
||||||
|
]);
|
||||||
|
|
||||||
|
// Instead of: map.set(4, 'four');
|
||||||
|
const map2 = new Map([...map, [4, 'four']]);
|
||||||
|
|
||||||
|
// Instead of: map.delete(1);
|
||||||
|
const map3 = new Map([...map].filter(([key]) => key !== 1));
|
||||||
|
|
||||||
|
// Instead of: map.clear();
|
||||||
|
const map4 = new Map();
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
const set = new Set(['A', 'B', 'C']);
|
||||||
|
|
||||||
|
// Instead of: set.add('D');
|
||||||
|
const set2 = new Set([...set, 'D']);
|
||||||
|
|
||||||
|
// Instead of: set.delete('B');
|
||||||
|
const set3 = new Set([...set].filter(key => key !== 'B'));
|
||||||
|
|
||||||
|
// Instead of: set.clear();
|
||||||
|
const set4 = new Set();
|
||||||
|
```
|
||||||
|
|
||||||
|
我想提一句如果你在使用 TypeScript(我非常喜欢 TypeScript),你可以用 `Readonly<T>`、`ReadonlyArray<T>`、`ReadonlyMap<K, V>` 和 `ReadonlySet<T>` 接口来在编译期检查你是否尝试更改这些对象,有则抛出编译错误。如果在对一个对象字面量或者数组调用 `Object.freeze`,编译器会自动推断它是只读的。由于映射和集合在其内部表达,所以在这些数据结构上调用 `Object.freeze` 不起作用。但是你可以轻松地告诉编译器它们是只读的变量。
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
*TypeScript 只读接口*
|
||||||
|
|
||||||
|
好,所以我们可以通过创建新的对象来代替修改原来的对象,但是这样不会导致性能损失吗?当然会。确保在你自己的应用中做了性能测试。如果你需要提高性能,可以考虑使用 [Immutable.js][86]。Immutable.js 用[持久的数据结构][91] 实现了[链表][87]、[堆栈][88]、[映射][89]、[集合][90]和其他数据结构。使用了如同 Clojure 和 Scala 这样的函数式语言中相同的技术。
|
||||||
|
|
||||||
|
```
|
||||||
|
// Use in place of `[]`.
|
||||||
|
const list1 = Immutable.List(['A', 'B', 'C']);
|
||||||
|
const list2 = list1.push('D', 'E');
|
||||||
|
|
||||||
|
console.log([...list1]); // ['A', 'B', 'C']
|
||||||
|
console.log([...list2]); // ['A', 'B', 'C', 'D', 'E']
|
||||||
|
|
||||||
|
|
||||||
|
// Use in place of `new Map()`
|
||||||
|
const map1 = Immutable.Map([
|
||||||
|
['one', 1],
|
||||||
|
['two', 2],
|
||||||
|
['three', 3]
|
||||||
|
]);
|
||||||
|
const map2 = map1.set('four', 4);
|
||||||
|
|
||||||
|
console.log([...map1]); // [['one', 1], ['two', 2], ['three', 3]]
|
||||||
|
console.log([...map2]); // [['one', 1], ['two', 2], ['three', 3], ['four', 4]]
|
||||||
|
|
||||||
|
|
||||||
|
// Use in place of `new Set()`
|
||||||
|
const set1 = Immutable.Set([1, 2, 3, 3, 3, 3, 3, 4]);
|
||||||
|
const set2 = set1.add(5);
|
||||||
|
|
||||||
|
console.log([...set1]); // [1, 2, 3, 4]
|
||||||
|
console.log([...set2]); // [1, 2, 3, 4, 5]
|
||||||
|
```
|
||||||
|
|
||||||
|
### 函数组合
|
||||||
|
|
||||||
|
记不记得在中学时我们学过一些像 `(f ∘ g)(x)` 的东西?你那时可能想,“我什么时候会用到这些?”,好了,现在就用到了。你准备好了吗?`f ∘ g`读作 “函数 f 和函数 g 组合”。对它的理解有两种等价的方式,如等式所示: `(f ∘ g)(x) = f(g(x))`。你可以认为 `f ∘ g` 是一个单独的函数,或者视作将调用函数 `g` 的结果作为参数传给函数 `f`。注意这些函数是从右向左依次调用的,先执行 `g`,接下来执行 `f`。
|
||||||
|
|
||||||
|
关于函数组合的几个要点:
|
||||||
|
|
||||||
|
1. 我们可以组合任意数量的函数(不仅限于 2 个)。
|
||||||
|
2. 组合函数的一个方式是简单地把一个函数的输出作为下一个函数的输入(比如 `f(g(x))`)。
|
||||||
|
|
||||||
|
```
|
||||||
|
// h(x) = x + 1
|
||||||
|
// number -> number
|
||||||
|
function h(x) {
|
||||||
|
return x + 1;
|
||||||
|
}
|
||||||
|
|
||||||
|
// g(x) = x^2
|
||||||
|
// number -> number
|
||||||
|
function g(x) {
|
||||||
|
return x * x;
|
||||||
|
}
|
||||||
|
|
||||||
|
// f(x) = convert x to string
|
||||||
|
// number -> string
|
||||||
|
function f(x) {
|
||||||
|
return x.toString();
|
||||||
|
}
|
||||||
|
|
||||||
|
// y = (f ∘ g ∘ h)(1)
|
||||||
|
const y = f(g(h(1)));
|
||||||
|
console.log(y); // '4'
|
||||||
|
```
|
||||||
|
|
||||||
|
[Ramda][92] 和 [lodash][93] 之类的库提供了更优雅的方式来组合函数。我们可以在更多的在数学意义上处理函数组合,而不是简单地将一个函数的返回值传递给下一个函数。我们可以创建一个由这些函数组成的单一复合函数(就是 `(f ∘ g)(x)`)。
|
||||||
|
|
||||||
|
```
|
||||||
|
// h(x) = x + 1
|
||||||
|
// number -> number
|
||||||
|
function h(x) {
|
||||||
|
return x + 1;
|
||||||
|
}
|
||||||
|
|
||||||
|
// g(x) = x^2
|
||||||
|
// number -> number
|
||||||
|
function g(x) {
|
||||||
|
return x * x;
|
||||||
|
}
|
||||||
|
|
||||||
|
// f(x) = convert x to string
|
||||||
|
// number -> string
|
||||||
|
function f(x) {
|
||||||
|
return x.toString();
|
||||||
|
}
|
||||||
|
|
||||||
|
// R = Ramda
|
||||||
|
// composite = (f ∘ g ∘ h)
|
||||||
|
const composite = R.compose(f, g, h);
|
||||||
|
|
||||||
|
// Execute single function to get the result.
|
||||||
|
const y = composite(1);
|
||||||
|
console.log(y); // '4'
|
||||||
|
```
|
||||||
|
|
||||||
|
好了,我们可以在 JavaScript 中组合函数了。接下来呢?好,如果你已经入门了函数式编程,理想中你的程序将只有函数的组合。代码里没有循环(`for`, `for...of`, `for...in`, `while`, `do`),基本没有。你可能觉得那是不可能的。并不是这样。我们下面的两个话题是:递归和高阶函数。
|
||||||
|
|
||||||
|
### 递归
|
||||||
|
|
||||||
|
假设你想实现一个计算数字的阶乘的函数。 让我们回顾一下数学中阶乘的定义:
|
||||||
|
|
||||||
|
`n! = n * (n-1) * (n-2) * ... * 1`.
|
||||||
|
|
||||||
|
`n!` 是从 `n` 到 `1` 的所有整数的乘积。我们可以编写一个循环轻松地计算出结果。
|
||||||
|
|
||||||
|
```
|
||||||
|
function iterativeFactorial(n) {
|
||||||
|
let product = 1;
|
||||||
|
for (let i = 1; i <= n; i++) {
|
||||||
|
product *= i;
|
||||||
|
}
|
||||||
|
return product;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
注意 `product` 和 `i` 都在循环中被反复重新赋值。这是解决这个问题的标准过程式方法。如何用函数式的方法解决这个问题呢?我们需要消除循环,确保没有变量被重新赋值。递归是函数式程序员的最有力的工具之一。递归需要我们将整体问题分解为类似整体问题的子问题。
|
||||||
|
|
||||||
|
计算阶乘是一个很好的例子,为了计算 `n!` 我们需要将 n 乘以所有比它小的正整数。它的意思就相当于:
|
||||||
|
|
||||||
|
`n! = n * (n-1)!`
|
||||||
|
|
||||||
|
啊哈!我们发现了一个解决 `(n-1)!` 的子问题,它类似于整个问题 `n!`。还有一个需要注意的地方就是基础条件。基础条件告诉我们何时停止递归。 如果我们没有基础条件,那么递归将永远持续。 实际上,如果有太多的递归调用,程序会抛出一个堆栈溢出错误。啊哈!
|
||||||
|
|
||||||
|
```
|
||||||
|
function recursiveFactorial(n) {
|
||||||
|
// Base case -- stop the recursion
|
||||||
|
if (n === 0) {
|
||||||
|
return 1; // 0! is defined to be 1.
|
||||||
|
}
|
||||||
|
return n * recursiveFactorial(n - 1);
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
然后我们来计算 `recursiveFactorial(20000)` 因为……,为什么不呢?当我们这样做的时候,我们得到了这个结果:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*堆栈溢出错误*
|
||||||
|
|
||||||
|
这里发生了什么?我们得到一个堆栈溢出错误!这不是无穷的递归导致的。我们已经处理了基础条件(`n === 0` 的情况)。那是因为浏览器的堆栈大小是有限的,而我们的代码使用了越过了这个大小的堆栈。每次对 `recursiveFactorial` 的调用导致了新的帧被压入堆栈中,就像一个盒子压在另一个盒子上。每当 `recursiveFactorial` 被调用,一个新的盒子被放在最上面。下图展示了在计算 `recursiveFactorial(3)` 时堆栈的样子。注意在真实的堆栈中,堆栈顶部的帧将存储在执行完成后应该返回的内存地址,但是我选择用变量 `r` 来表示返回值,因为 JavaScript 开发者一般不需要考虑内存地址。
|
||||||
|
|
||||||
|
")
|
||||||
|
|
||||||
|
*递归计算 3! 的堆栈(三次乘法)*
|
||||||
|
|
||||||
|
你可能会想象当计算 `n = 20000` 时堆栈会更高。我们可以做些什么优化它吗?当然可以。作为 ES2015 (又名 ES6) 标准的一部分,有一个优化用来解决这个问题。它被称作<ruby>尾调用优化<rt>proper tail calls optimization</rt></ruby>(PTC)。当递归函数做的最后一件事是调用自己并返回结果的时候,它使得浏览器删除或者忽略堆栈帧。实际上,这个优化对于相互递归函数也是有效的,但是为了简单起见,我们还是来看单一递归函数。
|
||||||
|
|
||||||
|
你可能会注意到,在递归函数调用之后,还要进行一次额外的计算(`n * r`)。那意味着浏览器不能通过 PTC 来优化递归;然而,我们可以通过重写函数使最后一步变成递归调用以便优化。一个窍门是将中间结果(在这里是 `product`)作为参数传递给函数。
|
||||||
|
|
||||||
|
```
|
||||||
|
'use strict';
|
||||||
|
|
||||||
|
// Optimized for tail call optimization.
|
||||||
|
function factorial(n, product = 1) {
|
||||||
|
if (n === 0) {
|
||||||
|
return product;
|
||||||
|
}
|
||||||
|
return factorial(n - 1, product * n)
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
让我们来看看优化后的计算 `factorial(3)` 时的堆栈。如下图所示,堆栈不会增长到超过两层。原因是我们把必要的信息都传到了递归函数中(比如 `product`)。所以,在 `product` 被更新后,浏览器可以丢弃掉堆栈中原先的帧。你可以在图中看到每次最上面的帧下沉变成了底部的帧,原先底部的帧被丢弃,因为不再需要它了。
|
||||||
|
|
||||||
|
 using PTC")
|
||||||
|
|
||||||
|
*递归计算 3! 的堆栈(三次乘法)使用 PTC*
|
||||||
|
|
||||||
|
现在选一个浏览器运行吧,假设你在使用 Safari,你会得到 `Infinity`(它是比在 JavaScript 中能表达的最大值更大的数)。但是我们没有得到堆栈溢出错误,那很不错!现在在其他的浏览器中呢怎么样呢?Safari 可能现在乃至将来是实现 PTC 的唯一一个浏览器。看看下面的兼容性表格:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*PTC 兼容性*
|
||||||
|
|
||||||
|
其他浏览器提出了一种被称作<ruby>[语法级尾调用][95]<rt>syntactic tail calls</rt></ruby>(STC)的竞争标准。“语法级”意味着你需要用新的语法来标识你想要执行尾递归优化的函数。即使浏览器还没有广泛支持,但是把你的递归函数写成支持尾递归优化的样子还是一个好主意。
|
||||||
|
|
||||||
|
### 高阶函数
|
||||||
|
|
||||||
|
我们已经知道 JavaScript 将函数视作一等公民,可以把函数像其他值一样传递。所以,把一个函数传给另一个函数也很常见。我们也可以让函数返回一个函数。就是它!我们有高阶函数。你可能已经很熟悉几个在 `Array.prototype` 中的高阶函数。比如 `filter`、`map` 和 `reduce` 就在其中。对高阶函数的一种理解是:它是接受(一般会调用)一个回调函数参数的函数。让我们来看看一些内置的高阶函数的例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
const vehicles = [
|
||||||
|
{ make: 'Honda', model: 'CR-V', type: 'suv', price: 24045 },
|
||||||
|
{ make: 'Honda', model: 'Accord', type: 'sedan', price: 22455 },
|
||||||
|
{ make: 'Mazda', model: 'Mazda 6', type: 'sedan', price: 24195 },
|
||||||
|
{ make: 'Mazda', model: 'CX-9', type: 'suv', price: 31520 },
|
||||||
|
{ make: 'Toyota', model: '4Runner', type: 'suv', price: 34210 },
|
||||||
|
{ make: 'Toyota', model: 'Sequoia', type: 'suv', price: 45560 },
|
||||||
|
{ make: 'Toyota', model: 'Tacoma', type: 'truck', price: 24320 },
|
||||||
|
{ make: 'Ford', model: 'F-150', type: 'truck', price: 27110 },
|
||||||
|
{ make: 'Ford', model: 'Fusion', type: 'sedan', price: 22120 },
|
||||||
|
{ make: 'Ford', model: 'Explorer', type: 'suv', price: 31660 }
|
||||||
|
];
|
||||||
|
|
||||||
|
const averageSUVPrice = vehicles
|
||||||
|
.filter(v => v.type === 'suv')
|
||||||
|
.map(v => v.price)
|
||||||
|
.reduce((sum, price, i, array) => sum + price / array.length, 0);
|
||||||
|
|
||||||
|
console.log(averageSUVPrice); // 33399
|
||||||
|
```
|
||||||
|
|
||||||
|
注意我们在一个数组对象上调用其方法,这是面向对象编程的特性。如果我们想要更函数式一些,我们可以用 Rmmda 或者 lodash/fp 提供的函数。注意如果我们使用 `R.compose` 的话,需要倒转函数的顺序,因为它从右向左依次调用函数(从底向上);然而,如果我们想从左向右调用函数就像上面的例子,我们可以用 `R.pipe`。下面两个例子用了 Rmmda。注意 Rmmda 有一个 `mean` 函数用来代替 `reduce` 。
|
||||||
|
|
||||||
|
```
|
||||||
|
const vehicles = [
|
||||||
|
{ make: 'Honda', model: 'CR-V', type: 'suv', price: 24045 },
|
||||||
|
{ make: 'Honda', model: 'Accord', type: 'sedan', price: 22455 },
|
||||||
|
{ make: 'Mazda', model: 'Mazda 6', type: 'sedan', price: 24195 },
|
||||||
|
{ make: 'Mazda', model: 'CX-9', type: 'suv', price: 31520 },
|
||||||
|
{ make: 'Toyota', model: '4Runner', type: 'suv', price: 34210 },
|
||||||
|
{ make: 'Toyota', model: 'Sequoia', type: 'suv', price: 45560 },
|
||||||
|
{ make: 'Toyota', model: 'Tacoma', type: 'truck', price: 24320 },
|
||||||
|
{ make: 'Ford', model: 'F-150', type: 'truck', price: 27110 },
|
||||||
|
{ make: 'Ford', model: 'Fusion', type: 'sedan', price: 22120 },
|
||||||
|
{ make: 'Ford', model: 'Explorer', type: 'suv', price: 31660 }
|
||||||
|
];
|
||||||
|
|
||||||
|
// Using `pipe` executes the functions from top-to-bottom.
|
||||||
|
const averageSUVPrice1 = R.pipe(
|
||||||
|
R.filter(v => v.type === 'suv'),
|
||||||
|
R.map(v => v.price),
|
||||||
|
R.mean
|
||||||
|
)(vehicles);
|
||||||
|
|
||||||
|
console.log(averageSUVPrice1); // 33399
|
||||||
|
|
||||||
|
// Using `compose` executes the functions from bottom-to-top.
|
||||||
|
const averageSUVPrice2 = R.compose(
|
||||||
|
R.mean,
|
||||||
|
R.map(v => v.price),
|
||||||
|
R.filter(v => v.type === 'suv')
|
||||||
|
)(vehicles);
|
||||||
|
|
||||||
|
console.log(averageSUVPrice2); // 33399
|
||||||
|
```
|
||||||
|
|
||||||
|
使用函数式方法的优点是清楚地分开了数据(`vehicles`)和逻辑(函数 `filter`,`map` 和 `reduce`)。面向对象的代码相比之下把数据和函数用以方法的对象的形式混合在了一起。
|
||||||
|
|
||||||
|
### 柯里化
|
||||||
|
|
||||||
|
不规范地说,<ruby>柯里化<rt>currying</rt></ruby>是把一个接受 `n` 个参数的函数变成 `n` 个每个接受单个参数的函数的过程。函数的 `arity` 是它接受参数的个数。接受一个参数的函数是 `unary`,两个的是 `binary`,三个的是 `ternary`,`n` 个的是 `n-ary`。那么,我们可以把柯里化定义成将一个 `n-ary` 函数转换成 `n` 个 `unary` 函数的过程。让我们通过简单的例子开始,一个计算两个向量点积的函数。回忆一下线性代数,两个向量 `[a, b, c]` 和 `[x, y, z]` 的点积是 `ax + by + cz`。
|
||||||
|
|
||||||
|
```
|
||||||
|
function dot(vector1, vector2) {
|
||||||
|
return vector1.reduce((sum, element, index) => sum += element * vector2[index], 0);
|
||||||
|
}
|
||||||
|
|
||||||
|
const v1 = [1, 3, -5];
|
||||||
|
const v2 = [4, -2, -1];
|
||||||
|
|
||||||
|
console.log(dot(v1, v2)); // 1(4) + 3(-2) + (-5)(-1) = 4 - 6 + 5 = 3
|
||||||
|
```
|
||||||
|
|
||||||
|
`dot` 函数是 binary,因为它接受两个参数;然而我们可以将它手动转换成两个 unary 函数,就像下面的例子。注意 `curriedDot` 是一个 unary 函数,它接受一个向量并返回另一个接受第二个向量的 unary 函数。
|
||||||
|
|
||||||
|
```
|
||||||
|
function curriedDot(vector1) {
|
||||||
|
return function(vector2) {
|
||||||
|
return vector1.reduce((sum, element, index) => sum += element * vector2[index], 0);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// Taking the dot product of any vector with [1, 1, 1]
|
||||||
|
// is equivalent to summing up the elements of the other vector.
|
||||||
|
const sumElements = curriedDot([1, 1, 1]);
|
||||||
|
|
||||||
|
console.log(sumElements([1, 3, -5])); // -1
|
||||||
|
console.log(sumElements([4, -2, -1])); // 1
|
||||||
|
```
|
||||||
|
|
||||||
|
很幸运,我们不需要把每一个函数都手动转换成柯里化以后的形式。[Ramda][96] 和 [lodash][97] 等库可以为我们做这些工作。实际上,它们是柯里化的混合形式。你既可以每次传递一个参数,也可以像原来一样一次传递所有参数。
|
||||||
|
|
||||||
|
```
|
||||||
|
function dot(vector1, vector2) {
|
||||||
|
return vector1.reduce((sum, element, index) => sum += element * vector2[index], 0);
|
||||||
|
}
|
||||||
|
|
||||||
|
const v1 = [1, 3, -5];
|
||||||
|
const v2 = [4, -2, -1];
|
||||||
|
|
||||||
|
// Use Ramda to do the currying for us!
|
||||||
|
const curriedDot = R.curry(dot);
|
||||||
|
|
||||||
|
const sumElements = curriedDot([1, 1, 1]);
|
||||||
|
|
||||||
|
console.log(sumElements(v1)); // -1
|
||||||
|
console.log(sumElements(v2)); // 1
|
||||||
|
|
||||||
|
// This works! You can still call the curried function with two arguments.
|
||||||
|
console.log(curriedDot(v1, v2)); // 3
|
||||||
|
```
|
||||||
|
|
||||||
|
Ramda 和 lodash 都允许你“跳过”一些变量之后再指定它们。它们使用置位符来做这些工作。因为点积的计算可以交换两项。传入向量的顺序不影响结果。让我们换一个例子来阐述如何使用一个置位符。Ramda 使用双下划线作为其置位符。
|
||||||
|
|
||||||
|
```
|
||||||
|
const giveMe3 = R.curry(function(item1, item2, item3) {
|
||||||
|
return `
|
||||||
|
1: ${item1}
|
||||||
|
2: ${item2}
|
||||||
|
3: ${item3}
|
||||||
|
`;
|
||||||
|
});
|
||||||
|
|
||||||
|
const giveMe2 = giveMe3(R.__, R.__, 'French Hens'); // Specify the third argument.
|
||||||
|
const giveMe1 = giveMe2('Partridge in a Pear Tree'); // This will go in the first slot.
|
||||||
|
const result = giveMe1('Turtle Doves'); // Finally fill in the second argument.
|
||||||
|
|
||||||
|
console.log(result);
|
||||||
|
// 1: Partridge in a Pear Tree
|
||||||
|
// 2: Turtle Doves
|
||||||
|
// 3: French Hens
|
||||||
|
```
|
||||||
|
|
||||||
|
在我们结束探讨柯里化之前最后的议题是<ruby>偏函数应用<rt>partial application</rt></ruby>。偏函数应用和柯里化经常同时出场,尽管它们实际上是不同的概念。一个柯里化的函数还是柯里化的函数,即使没有给它任何参数。偏函数应用,另一方面是仅仅给一个函数传递部分参数而不是所有参数。柯里化是偏函数应用常用的方法之一,但是不是唯一的。
|
||||||
|
|
||||||
|
JavaScript 拥有一个内置机制可以不依靠柯里化来做偏函数应用。那就是 [function.prototype.bind][98] 方法。这个方法的一个特殊之处在于,它要求你将 `this` 作为第一个参数传入。 如果你不进行面向对象编程,那么你可以通过传入 `null` 来忽略 `this`。
|
||||||
|
|
||||||
|
```
|
||||||
|
1function giveMe3(item1, item2, item3) {
|
||||||
|
return `
|
||||||
|
1: ${item1}
|
||||||
|
2: ${item2}
|
||||||
|
3: ${item3}
|
||||||
|
`;
|
||||||
|
}
|
||||||
|
|
||||||
|
const giveMe2 = giveMe3.bind(null, 'rock');
|
||||||
|
const giveMe1 = giveMe2.bind(null, 'paper');
|
||||||
|
const result = giveMe1('scissors');
|
||||||
|
|
||||||
|
console.log(result);
|
||||||
|
// 1: rock
|
||||||
|
// 2: paper
|
||||||
|
// 3: scissors
|
||||||
|
```
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
我希望你享受探索 JavaScript 中函数式编程的过程。对一些人来说,它可能是一个全新的编程范式,但我希望你能尝试它。你会发现你的程序更易于阅读和调试。不变性还将允许你优化 Angular 和 React 的性能。
|
||||||
|
|
||||||
|
_这篇文章基于 Matt 在 OpenWest 的演讲 [JavaScript the Good-er Parts][77]. [OpenWest][78] ~~将~~在 6/12-15 ,2017 在 Salt Lake City, Utah 举行。_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Matt Banz - Matt 于 2008 年五月在犹他大学获得了数学学位毕业。一个月后他得到了一份 web 开发者的工作,他从那时起就爱上了它!在 2013 年,他在北卡罗莱纳州立大学获得了计算机科学硕士学位。他在 LDS 商学院和戴维斯学区社区教育计划教授 Web 课程。他现在是就职于 Motorola Solutions 公司的高级前端开发者。
|
||||||
|
|
||||||
|
--------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/6/functional-javascript
|
||||||
|
|
||||||
|
作者:[Matt Banz][a]
|
||||||
|
译者:[trnhoe](https://github.com/trnhoe)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/battmanz
|
||||||
|
[1]:https://opensource.com/tags/python?src=programming_resource_menu1
|
||||||
|
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu2
|
||||||
|
[3]:https://opensource.com/tags/perl?src=programming_resource_menu3
|
||||||
|
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;src=programming_resource_menu4
|
||||||
|
[5]:https://gist.github.com/battmanz/62fa0a78841aa0fe29d99e80ba8db2b1/raw/fd586c5da7c936235a6d99b11cb80c9c67e4deaf/pure-function-example.js
|
||||||
|
[6]:https://gist.github.com/battmanz/62fa0a78841aa0fe29d99e80ba8db2b1#file-pure-function-example-js
|
||||||
|
[7]:https://github.com/
|
||||||
|
[8]:https://gist.github.com/battmanz/459c13138ea8e333fc6603ae688b7992/raw/ceda8a5c36c5bde69d4000b6ecb8fee98c9edcd3/impure-functions.js
|
||||||
|
[9]:https://gist.github.com/battmanz/459c13138ea8e333fc6603ae688b7992#file-impure-functions-js
|
||||||
|
[10]:https://github.com/
|
||||||
|
[11]:https://gist.github.com/battmanz/bc13c4cf24b380cbd7b3f7b0c12ab8e4/raw/e2b6365e79def9b80bd7652cf15078d613ed686f/mutable-state.js
|
||||||
|
[12]:https://gist.github.com/battmanz/bc13c4cf24b380cbd7b3f7b0c12ab8e4#file-mutable-state-js
|
||||||
|
[13]:https://github.com/
|
||||||
|
[14]:https://gist.github.com/battmanz/b65416550d62da94a69eea51c2678983/raw/6792dd568e0fc3e6b372d078735d5b74857dbae4/immutable-state.js
|
||||||
|
[15]:https://gist.github.com/battmanz/b65416550d62da94a69eea51c2678983#file-immutable-state-js
|
||||||
|
[16]:https://github.com/
|
||||||
|
[17]:https://gist.github.com/battmanz/d32f2be485f4224121019ba4d070c25b/raw/f7318904effbef28e3a47989d4899ab019127c05/captured-mutable-object.js
|
||||||
|
[18]:https://gist.github.com/battmanz/d32f2be485f4224121019ba4d070c25b#file-captured-mutable-object-js
|
||||||
|
[19]:https://github.com/
|
||||||
|
[20]:https://gist.github.com/battmanz/c5046c2d0af45938190e1178ab9cb007/raw/6cfd1b9644486f257357e611b2eeb148b3956baf/immutability-vs-reassignment.js
|
||||||
|
[21]:https://gist.github.com/battmanz/c5046c2d0af45938190e1178ab9cb007#file-immutability-vs-reassignment-js
|
||||||
|
[22]:https://github.com/
|
||||||
|
[23]:https://gist.github.com/battmanz/a400ad93d9922fdc3a2ff87c0bf7da68/raw/6771481278c95942b4627a709c377f62856a0a3a/array-mutator-method-replacement.js
|
||||||
|
[24]:https://gist.github.com/battmanz/a400ad93d9922fdc3a2ff87c0bf7da68#file-array-mutator-method-replacement-js
|
||||||
|
[25]:https://github.com/
|
||||||
|
[26]:https://gist.github.com/battmanz/9ffbac3c18c6cf33d97a4ad511129e94/raw/433f65ebe3d2a7fda7ac1f434c2d56ad98a04ce0/map-mutator-method-replacement.js
|
||||||
|
[27]:https://gist.github.com/battmanz/9ffbac3c18c6cf33d97a4ad511129e94#file-map-mutator-method-replacement-js
|
||||||
|
[28]:https://github.com/
|
||||||
|
[29]:https://gist.github.com/battmanz/d42d3224c99d76d780f68daaa6a87338/raw/111578801a4120726a369a43f87d33a64b39dc83/set-mutator-method-replacement.js
|
||||||
|
[30]:https://gist.github.com/battmanz/d42d3224c99d76d780f68daaa6a87338#file-set-mutator-method-replacement-js
|
||||||
|
[31]:https://github.com/
|
||||||
|
[32]:https://opensource.com/file/357111
|
||||||
|
[33]:https://gist.github.com/battmanz/7cec8c2f22ee55f60dd0c478236892de/raw/2cad9d5441ebef816e3d1cbc03af883451e68dc3/immutable-js-demo.js
|
||||||
|
[34]:https://gist.github.com/battmanz/7cec8c2f22ee55f60dd0c478236892de#file-immutable-js-demo-js
|
||||||
|
[35]:https://github.com/
|
||||||
|
[36]:https://gist.github.com/battmanz/99325b35a147c37b20f5652785430381/raw/28a6dc814aaf7d023cebefb6d7f694d76f99f9da/function-composition-basic.js
|
||||||
|
[37]:https://gist.github.com/battmanz/99325b35a147c37b20f5652785430381#file-function-composition-basic-js
|
||||||
|
[38]:https://github.com/
|
||||||
|
[39]:https://gist.github.com/battmanz/e250ae6c628550f6f0ac718d046ea74e/raw/a0c22d4a1afaf68c6297df3de4736c62e58cb028/function-composition-elegant.js
|
||||||
|
[40]:https://gist.github.com/battmanz/e250ae6c628550f6f0ac718d046ea74e#file-function-composition-elegant-js
|
||||||
|
[41]:https://github.com/
|
||||||
|
[42]:https://gist.github.com/battmanz/bc225959e1328e73b08c1fe4ab59b630/raw/648090bc2d40f4fc6e137f7426b803337c5fa3bb/iterative-factorial.js
|
||||||
|
[43]:https://gist.github.com/battmanz/bc225959e1328e73b08c1fe4ab59b630#file-iterative-factorial-js
|
||||||
|
[44]:https://github.com/
|
||||||
|
[45]:https://gist.github.com/battmanz/63961ad6fa380463785b69a1b34e7997/raw/550f6922ecc5adc21ab38f281a788e286abc107a/recursive-factorial.js
|
||||||
|
[46]:https://gist.github.com/battmanz/63961ad6fa380463785b69a1b34e7997#file-recursive-factorial-js
|
||||||
|
[47]:https://github.com/
|
||||||
|
[48]:https://opensource.com/file/357126
|
||||||
|
[49]:https://opensource.com/file/357131
|
||||||
|
[50]:https://gist.github.com/battmanz/26ecb25247a01030ca4ab0cd1ebfc5b3/raw/e3aaa078b9d262dcd35e534145cba0f52b5d5d67/factorial-tail-recursion.js
|
||||||
|
[51]:https://gist.github.com/battmanz/26ecb25247a01030ca4ab0cd1ebfc5b3#file-factorial-tail-recursion-js
|
||||||
|
[52]:https://github.com/
|
||||||
|
[53]:https://opensource.com/file/357116
|
||||||
|
[54]:https://opensource.com/file/357121
|
||||||
|
[55]:https://gist.github.com/battmanz/9eda50362457362f2d8a28384bf1adfc/raw/bb7252ef116d5a2ae430e68c6b5650d1dd6f44a4/built-in-higher-order-functions.js
|
||||||
|
[56]:https://gist.github.com/battmanz/9eda50362457362f2d8a28384bf1adfc#file-built-in-higher-order-functions-js
|
||||||
|
[57]:https://github.com/
|
||||||
|
[58]:https://gist.github.com/battmanz/bee10f02a076f064f72e20cd4aea6b85/raw/bd3de649887d515f4166290802d4a3d89f80210c/composing-higher-order-functions.js
|
||||||
|
[59]:https://gist.github.com/battmanz/bee10f02a076f064f72e20cd4aea6b85#file-composing-higher-order-functions-js
|
||||||
|
[60]:https://github.com/
|
||||||
|
[61]:https://gist.github.com/battmanz/e28311f765a18fc6a841201912422d60/raw/e3e5489652e1f4815bf810f98b4aba6f5ec934e6/dot-product.js
|
||||||
|
[62]:https://gist.github.com/battmanz/e28311f765a18fc6a841201912422d60#file-dot-product-js
|
||||||
|
[63]:https://github.com/
|
||||||
|
[64]:https://gist.github.com/battmanz/3a3694f87b9c48ac0752e8fe3e3a0b8d/raw/c886e5ea1fd7b6e4a130925634c1d1d6f8ffc689/manual-currying.js
|
||||||
|
[65]:https://gist.github.com/battmanz/3a3694f87b9c48ac0752e8fe3e3a0b8d#file-manual-currying-js
|
||||||
|
[66]:https://github.com/
|
||||||
|
[67]:https://gist.github.com/battmanz/3335a949ea88b8d969c359774b76ee35/raw/99a2997e4609e9ca294d7b58e330f2cf6dbaefcb/fancy-currying.js
|
||||||
|
[68]:https://gist.github.com/battmanz/3335a949ea88b8d969c359774b76ee35#file-fancy-currying-js
|
||||||
|
[69]:https://github.com/
|
||||||
|
[70]:https://gist.github.com/battmanz/ea5e1f34cf468214039557c78e43a9b5/raw/9b6556bd9111efd03dd69bee5596c29002e2279a/currying-placeholder.js
|
||||||
|
[71]:https://gist.github.com/battmanz/ea5e1f34cf468214039557c78e43a9b5#file-currying-placeholder-js
|
||||||
|
[72]:https://github.com/
|
||||||
|
[73]:https://gist.github.com/battmanz/dadae797f9d3cfcce85af0aecfd6f6e3/raw/3d248b9810cab7d02ecd050ec549247499de6f31/partial-application-using-bind.js
|
||||||
|
[74]:https://gist.github.com/battmanz/dadae797f9d3cfcce85af0aecfd6f6e3#file-partial-application-using-bind-js
|
||||||
|
[75]:https://github.com/
|
||||||
|
[76]:https://opensource.com/article/17/6/functional-javascript?rate=rGE6lsdTzq9H9vSv4jiF7pTN9hYG5Ehm_GsfSJbJsDM
|
||||||
|
[77]:https://www.openwest.org/schedule/#talk-5
|
||||||
|
[78]:https://www.openwest.org/
|
||||||
|
[79]:https://opensource.com/user/146401/feed
|
||||||
|
[80]:https://www.flickr.com/photos/jurvetson/882193732/
|
||||||
|
[81]:https://brendaneich.com/2008/04/popularity/
|
||||||
|
[82]:https://angular-2-training-book.rangle.io/handout/change-detection/change_detection_strategy_onpush.html
|
||||||
|
[83]:https://facebook.github.io/react/docs/optimizing-performance.html#the-power-of-not-mutating-data
|
||||||
|
[84]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map
|
||||||
|
[85]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Set
|
||||||
|
[86]:https://facebook.github.io/immutable-js/
|
||||||
|
[87]:https://facebook.github.io/immutable-js/docs/#/List
|
||||||
|
[88]:https://facebook.github.io/immutable-js/docs/#/Stack
|
||||||
|
[89]:https://facebook.github.io/immutable-js/docs/#/Map
|
||||||
|
[90]:https://facebook.github.io/immutable-js/docs/#/Set
|
||||||
|
[91]:https://en.wikipedia.org/wiki/Persistent_data_structure
|
||||||
|
[92]:http://ramdajs.com/
|
||||||
|
[93]:https://github.com/lodash/lodash/wiki/FP-Guide
|
||||||
|
[94]:https://math.stackexchange.com/questions/20969/prove-0-1-from-first-principles
|
||||||
|
[95]:https://github.com/tc39/proposal-ptc-syntax#syntactic-tail-calls-stc
|
||||||
|
[96]:http://ramdajs.com/docs/#curry
|
||||||
|
[97]:https://lodash.com/docs/4.17.4#curry
|
||||||
|
[98]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/bind
|
||||||
|
[99]:https://opensource.com/users/battmanz
|
||||||
@ -0,0 +1,159 @@
|
|||||||
|
用 Linux、Python 和树莓派酿制啤酒
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 怎样在家用 Python 和树莓派搭建一个家用便携的自制酿啤酒装置
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
大约十年前我开始酿制自制啤酒,和许多自己酿酒的人一样,我开始在厨房制造提纯啤酒。这需要一些设备并且做出来后确实是好的啤酒,最终,我用一个放入了所有大麦的大贮藏罐作为我的麦芽浆桶。几年之后我一次酿制过 5 加仑啤酒,但是酿制 10 加仑时也会花费同样的时间和效用(只是容器比之前大些),之前我就是这么做的。容量提升到 10 加仑之后,我偶然看到了 [StrangeBrew Elsinore][38] ,我意识到我真正需要的是将整个酿酒过程转换成全电子化的,用树莓派来运行它。
|
||||||
|
|
||||||
|
建造自己的家用电动化酿酒系统需要大量这方面的技术信息,许多学习酿酒的人是在 [TheElectricBrewery.com][28] 这个网站起步的,只不过将那些控制版搭建在一起是十分复杂的,尽管最简单的办法在这个网站上总结的很好。当然你也能用[一个小成本的方法][26]并且依旧可以得到相同的结果 —— 用一个热水壶和热酒容器通过一个 PID 控制器来加热你的酿酒原料。但是我认为这有点太无聊(这也意味着你不能体验到完整的酿酒过程)。
|
||||||
|
|
||||||
|
### 需要用到的硬件
|
||||||
|
|
||||||
|
在我开始我的这个项目之前, 我决定开始买零件,我最基础的设计是一个可以将液体加热到 5500 瓦的热酒容器(HLT)和开水壶,加一个活底的麦芽浆桶,我通过一个 50 英尺的不锈钢线圈在热酒容器里让泵来再循环麦芽浆(["热量交换再循环麦芽浆系统, 也叫 HERMS][27])。同时我需要另一个泵来在热酒容器里循环水,并且把水传输到麦芽浆桶里,整个电子部件全部是用树莓派来控制的。
|
||||||
|
|
||||||
|
建立我的电子酿酒系统并且尽可能的自动化意味着我需要以下的组件:
|
||||||
|
|
||||||
|
* 一个 5500 瓦的电子加热酒精容器(HLT)
|
||||||
|
* 能够放入加热酒精容器里的 50 英尺(0.5 英寸)的不锈钢线圈(热量交换再循环麦芽浆系统)
|
||||||
|
* 一个 5500 瓦的电子加热水壶
|
||||||
|
* 多个固态继电器加热开关
|
||||||
|
* 2 个高温食品级泵
|
||||||
|
* 泵的开关用继电器
|
||||||
|
* 可拆除装置和一个硅管
|
||||||
|
* 不锈钢球阀
|
||||||
|
* 一个测量温度的探针
|
||||||
|
* 很多线
|
||||||
|
* 一个来容纳这些配件的电路盒子
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*酿酒系统 (photo by Christopher Aedo. [CC BY-SA 4.0)][5]*
|
||||||
|
|
||||||
|
建立酿酒系统的电气化方面的细节 [The Electric Brewery][28] 这个网站概括的很好,这里我不再重复,当你计划用树莓派代替这个 PID 控制器的话,你可以读以下的建议。
|
||||||
|
|
||||||
|
一个重要的事情需要注意,固态继电器(SSR)信号电压,许多教程建议使用一个 12 伏的固态继电器来关闭电路,树莓派的 GPIO 针插口只支持 3 伏输出电压,然而,必须购买继电器将电压变为 3 伏。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Inkbird SSR (photo by Christopher Aedo. [CC BY-SA 4.0)][6]*
|
||||||
|
|
||||||
|
要运行酿酒系统,你的树莓派必须做两个关键事情:测量来自几个不同位置的温度,用继电器开关来控制加热元件,树莓派很容易来处理这些任务。
|
||||||
|
|
||||||
|
这里有一些不同的方法来将温度传感器连到树莓派上,但是我找到了最方便的方法用[单总线][29]。这就可以让多个传感器分享相同的线路(实际上是三根线),这三根线可以使酿酒系统的多个设备更方便的工作,如果你要从网上找一个防水的 DS18B20 温度传感器,你可以会找到很多选择。我用的是[日立 DS18B20 防水温度传感器][30]。
|
||||||
|
|
||||||
|
要控制加热元件,树莓派包括了几个用来软件寻址的总线扩展器(GPIO),它会通过在某个文件写入 0 或者 1 让你发送3.3v 的电压到一个继电器,在我第一次了解树莓派是怎样工作的时候,这个[用 GPIO 驱动继电器的树莓派教程][46]对我来说是最有帮助的,总线扩展器控制着多个固态继电器,通过酿酒软件来直接控制加热元件的开关。
|
||||||
|
|
||||||
|
我首先将所有部件放到这个电路盒子,因为这将成为一个滚动的小车,我要让它便于移动,而不是固定不动的,如果我有一个店(比如说在车库、工具房、或者地下室),我需要要用一个装在墙上的更大的电路盒,而现在我找到一个大小正好的[防水工程盒子][31],能放进每件东西,最后它成为小巧紧凑工具盒,并且能够工作。在左下角是和树莓派连接的为总线扩展器到单总线温度探针和[固态继电器][32]的扩展板。
|
||||||
|
|
||||||
|
要保持 240v 的固态继电器温度不高,我在盒子上切了个洞,在盒子的外面用 CPU 降温凝胶把[铜片散热片][33]安装到盒子外面的热槽之间。它工作的很好,盒子里没有温度上的问题了,在盒子盖上我放了两个开关为 120v 的插座,加两个240v 的 led 来显示加热元件是否通电。我用干燥器的插座和插头,所以可以很容易的断开电热水壶的连接。首次尝试每件事情都工作正常。(第一次绘制电路图必有回报)
|
||||||
|
|
||||||
|
这个照片来自“概念”版,最终生产系统应该有两个以上的固态继电器,以便 240v 的电路两个针脚能够切换,另外我将通过软件来切换泵的开关。现在通过盒子前面的物理开关控制它们,但是也很容易用继电器控制它们。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*控制盒子 (photo by Christopher Aedo. [CC BY-SA 4.0)][7]*
|
||||||
|
|
||||||
|
唯一剩下有点棘手的事情是温度探针的压合接头,这个探针安装在加热酒精容器和麦芽浆桶球形的最底部阀门前的 T 字型接头上。当液体流过温度传感器,温度可以准确显示。我考虑加一个套管到热水壶里,但是对于我的酿造工艺没有什么用。最后,我买到了[四分之一英寸的压合接头][34],它们工作完美。
|
||||||
|
|
||||||
|
### 软件
|
||||||
|
|
||||||
|
一旦硬件整理好,我就有时间来处理软件了,我在树莓派上跑了最新的 [Raspbian 发行版][35],操作系统方面没有什么特别的。
|
||||||
|
|
||||||
|
我开始使用 [Strangebrew Elsinore][36] 酿酒软件,当我的朋友问我是否我听说过 [Hosehead][37](一个基于树莓派的酿酒控制器),我找到了 [Strangebrew Elsinore][36] 。我认为 [Hosehead][37] 很棒,但我并不是要买一个酿酒控制器,而是要挑战自己,搭建一个自己的。
|
||||||
|
|
||||||
|
设置 [Strangebrew Elsinore][36] 很简单,其[文档][38]直白,没有遇到任何的问题。尽管 Strangebrew Elsinore 工作的很好,但在我的一代树莓派上运行 java 有时是费力的,不止崩溃一次。我看到这个软件开发停顿也很伤心,似乎他们也没有更多贡献者的大型社区(尽管有很多人还在用它)。
|
||||||
|
|
||||||
|
#### CraftBeerPi
|
||||||
|
|
||||||
|
之后我偶然遇到了一个用 Python 写的 [CraftbeerPI][39],它有活跃的贡献者支持的开发社区。原作者(也是当前维护者) Manuel Fritsch 在贡献和反馈问题处理方面做的很好。克隆[这个仓库][40]然后开始只用了我一点时间。其 README 文档也是一个连接 DS1820 温度传感器的好例子,同时也有关于硬件接口到树莓派或者[芯片电脑][41] 的注意事项。
|
||||||
|
|
||||||
|
在启动的时候,CraftbeerPI 引导用户通过一个设置过程来发现温度探针是否可用,并且让你指定哪个 GPIO 总线扩展器指针来管理树莓派上哪个配件。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*CraftBeerPi (photo by Christopher Aedo. [CC BY-SA 4.0)][8]*
|
||||||
|
|
||||||
|
用这个系统进行自制酿酒是容易的,我能够依靠它掌握可靠的温度,我能输入多个温度段来控制麦芽浆温度,用CraftbeerPi 酿酒的日子有一点点累,但是我很高兴用传统的手工管理丙烷燃烧器的“兴奋”来换取这个系统的有效性和持续性。
|
||||||
|
|
||||||
|
CraftBeerPI 的用户友好性鼓舞我设置了另一个控制器来运行“发酵室”。就我来说,那是一个二手冰箱,我用了 50 美元加上放在里面的 25 美元的加热器。CraftBeerPI 很容易控制电器元件的冷热,你也能够设置多个温度阶段。举个例子,这个图表显示我最近做的 IPA 进程的发酵温度。发酵室发酵麦芽汁在 67F° 的温度下需要 4 天,然后每 12 小时上升一度直到温度到达 72F°。剩下两天温度保持不变是为了双乙酰生成。之后 5 天温度降到 65F°,这段时间是让啤酒变“干”,最后啤酒发酵温度直接降到 38F°。CraftBeerPI 可以加入各个阶段,让软件管理发酵更加容易。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*SIPA 发酵设置 (photo by Christopher Aedo. [CC BY-SA 4.0)][9]*
|
||||||
|
|
||||||
|
我也试验过用[液体比重计][42]来对酵啤酒的比重进行监测,通过蓝牙连接的浮动传感器可以达到。有一个整合的计划能让 CraftbeerPi 很好工作,现在它记录这些比重数据到谷歌的电子表格里。一旦这个液体比重计能连接到发酵控制器,设置的自动发酵设置会基于酵母的活动性直接运行且更加容易,而不是在 4 天内完成主要发酵,可以在比重稳定 24 小时后设定温度。
|
||||||
|
|
||||||
|
像这样的一些项目,构想并计划改进和增加组件是很容易,不过,我很高兴今天经历过的事情。我用这种装置酿造了很多啤酒,每次都能达到预期的麦芽汁比率,而且啤酒一直都很美味。我的最重要的消费者 —— 就是我!很高兴我可以随时饮用。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*随时饮用 (photo by Christopher Aedo. [CC BY-SA 4.0)][10]*
|
||||||
|
|
||||||
|
这篇文章基于 Christopher 的开放的西部的讲话《用Linux、Python 和树莓派酿制啤酒》。
|
||||||
|
|
||||||
|
(题图:[Quinn Dombrowski][21]. Modified by Opensource.com. [CC BY-SA 4.0][22])
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Christopher Aedo 从他的学生时代就从事并且贡献于开源软件事业。最近他在 IBM 领导一个极棒的上游开发者团队,同时他也是开发者拥护者。当他不再工作或者实在会议室演讲的时候,他可能在波特兰市俄勒冈州用树莓派酿制和发酵一杯美味的啤酒。
|
||||||
|
|
||||||
|
----
|
||||||
|
via: https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi
|
||||||
|
|
||||||
|
作者:[Christopher Aedo][a]
|
||||||
|
译者:[hwlife](https://github.com/hwlife)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/docaedo
|
||||||
|
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu1
|
||||||
|
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu2
|
||||||
|
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu3
|
||||||
|
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu4
|
||||||
|
[5]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[6]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[7]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[8]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[9]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[10]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[11]:https://opensource.com/file/358661
|
||||||
|
[12]:https://opensource.com/file/358666
|
||||||
|
[13]:https://opensource.com/file/358676
|
||||||
|
[14]:https://opensource.com/file/359061
|
||||||
|
[15]:https://opensource.com/file/358681
|
||||||
|
[16]:https://opensource.com/file/359071
|
||||||
|
[17]:https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi?rate=fbKzT1V9gqGsmNCTuQIashC1xaHT5P_2LUaeTn6Kz1Y
|
||||||
|
[18]:https://www.openwest.org/custom/description.php?id=139
|
||||||
|
[19]:https://www.openwest.org/
|
||||||
|
[20]:https://opensource.com/user/145976/feed
|
||||||
|
[21]:https://www.flickr.com/photos/quinndombrowski/
|
||||||
|
[22]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[23]:https://github.com/DougEdey/SB_Elsinore_Server
|
||||||
|
[24]:https://opensource.com/tags/raspberry-pi
|
||||||
|
[25]:http://www.theelectricbrewery.com/
|
||||||
|
[26]:http://www.instructables.com/id/Electric-Brewery-Control-Panel-on-the-Cheap/
|
||||||
|
[27]:https://byo.com/hops/item/1325-rims-and-herms-brewing-advanced-homebrewing
|
||||||
|
[28]:http://theelectricbrewery.com/
|
||||||
|
[29]:https://en.wikipedia.org/wiki/1-Wire
|
||||||
|
[30]:https://smile.amazon.com/gp/product/B018KFX5X0/
|
||||||
|
[31]:http://amzn.to/2hupFCr
|
||||||
|
[32]:http://amzn.to/2hL8JDS
|
||||||
|
[33]:http://amzn.to/2i4DYwy
|
||||||
|
[34]:https://www.brewershardware.com/CF1412.html
|
||||||
|
[35]:https://www.raspberrypi.org/downloads/raspbian/
|
||||||
|
[36]:https://github.com/DougEdey/SB_Elsinore_Server
|
||||||
|
[37]:https://brewtronix.com/
|
||||||
|
[38]:http://dougedey.github.io/SB_Elsinore_Server/
|
||||||
|
[39]:http://www.craftbeerpi.com/
|
||||||
|
[40]:https://github.com/manuel83/craftbeerpi
|
||||||
|
[41]:https://www.nextthing.co/pages/chip
|
||||||
|
[42]:https://tilthydrometer.com/
|
||||||
|
[43]:https://opensource.com/users/docaedo
|
||||||
|
[44]:https://opensource.com/users/docaedo
|
||||||
|
[45]:https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi#comments
|
||||||
|
[46]:http://www.susa.net/wordpress/2012/06/raspberry-pi-relay-using-gpio/
|
||||||
@ -0,0 +1,80 @@
|
|||||||
|
混合云的变化
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 围绕云计算的概念和术语仍然很新,但是也在不断的改进。
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
不管怎么看,云计算也只有十多年的发展时间。一些我们习以为常的云计算的概念和术语仍然很新。美国国家标准与技术研究所(NIST)文档显示,一些已经被熟悉的术语定义在 2011 年才被发布,例如基础设施即服务(IaaS),而在此之前它就以草案的形式广泛流传。
|
||||||
|
|
||||||
|
在该文档中其它定义中,有一个叫做<ruby>混合云<rt>hybrid cloud</rt></ruby>。让我们回溯一下该术语在这段期间的变化是很有启发性的。云基础设施已经超越了相对简单的分类。此外,它还强调了开源软件的使用者所熟悉的优先级,例如灵活性、可移植性、选择性,已经被运用到了混合云上。
|
||||||
|
|
||||||
|
NIST 对混合云最初的定义主要集中于<ruby>云爆发<rt>cloud bursting</rt></ruby>,你能使用内部的基础设施去处理一个基本的计算负荷,但是如果你的负荷量暴涨,可以将多出来的转为使用公有云。与之密切联系的是加强私有云与公有云之间 API 的兼容性,甚至是创造一个现货市场来提供最便宜的容量。
|
||||||
|
|
||||||
|
Nick Carr 在 [The Big Switch][10] 一书中提出一个概念,云是一种计算单元,其与输电网类似。这个故事不错,但是即使在早期,[这种类比的局限性也变得很明显][11]。计算不是以电流方式呈现的一种物品。需要关注的是,公有云提供商以及 OpenStack 一类的开源云软件激增的新功能,可见许多用户并不仅仅是寻找最便宜的通用计算能力。
|
||||||
|
|
||||||
|
云爆发的概念基本上忽略了计算是与数据相联系的现实,你不可能只移动洪水般突如其来的数据而不承担巨大的带宽费用,以及不用为转移需要花费的时间而操作。Dave McCrory 发明了 “<ruby>数据引力<rt>data gravity</rt></ruby>”一词去描述这个限制。
|
||||||
|
|
||||||
|
那么既然混合云有如此负面的情况,为什么我们现在还要再讨论混合云?
|
||||||
|
|
||||||
|
正如我说的,混合云的最初的构想是在云爆发的背景下诞生的。云爆发强调的是快速甚至是即时的将工作环境从一个云转移到另一个云上;然而,混合云也意味着应用和数据的移植性。确实,如之前 [2011 年我在 CNET 的文章][12]中写到:“我认为过度关注于全自动的工作转换给我们自己造成了困扰,我们真正应该关心的是,如果供应商不能满意我们的需求或者尝试将我们锁定在其平台上时,我们是否有将数据从一个地方到另一个地方的迁移能力。”
|
||||||
|
|
||||||
|
从那以后,探索云之间的移植性有了进一步的进展。
|
||||||
|
|
||||||
|
Linux 是云移植性的关键,因为它能运行在各种地方,无论是从裸机到内部虚拟基础设施,还是从私有云到公有云。Linux 提供了一个完整、可靠的平台,其具有稳定的 API 接口,且可以依靠这些接口编写程序。
|
||||||
|
|
||||||
|
被广泛采纳的容器进一步加强了 Linux 提供应用在云之间移植的能力。通过提供一个包含了应用的基础配置环境的镜像,应用在开发、测试和最终运行环境之间移动时容器提供了可移植性和兼容性。
|
||||||
|
|
||||||
|
Linux 容器被应用到要求可移植性、可配置性以及独立性的许多方面上。不管是预置的云,还是公有云,以及混合云都是如此。
|
||||||
|
|
||||||
|
容器使用的是基于镜像的部署模式,这让在不同环境中分享一个应用或者具有全部基础环境的服务集变得容易了。
|
||||||
|
|
||||||
|
在 OCI 支持下开发的规范定义了容器镜像的内容及其所依赖、环境、参数和一些镜像正确运行所必须的要求。在标准化的作用下,OCI 为许多其它工具提供了一个机会,它们现在可以依靠稳定的运行环境和镜像规范了。
|
||||||
|
|
||||||
|
同时,通过 Gluster 和 Ceph 这类的开源技术,分布式存储能提供数据在云上的可移植性。 物理约束限制了如何快速简单地把数据从一个地方移动到另一个地方;然而,随着组织部署和使用不同类型的基础架构,他们越来越渴望一个不受物理、虚拟和云资源限制的开放的软件定义储存平台。
|
||||||
|
|
||||||
|
尤其是在数据存储需求飞速增长的情况下,由于预测分析,物联网和实时监控的趋势。[2016 年的一项研究表明][13],98% 的 IT 决策者认为一个更敏捷的存储解决方案对他们的组织是有利的。在同一个研究中,他们列举出不恰当的存储基础设施是最令他们组织受挫的事情之一。
|
||||||
|
|
||||||
|
混合云表现出的是提供在不同计算能力和资源之间合适的移植性和兼容性。其不仅仅是将私有云和公有云同时运用在一个应用中。它是一套多种类型的服务,其中的一部分可能是你们 IT 部门建立和操作的,而另一部分可能来源于外部。
|
||||||
|
|
||||||
|
它们可能是软件即服务(SaaS)应用的混合,例如邮件和客户关系管理(CRM)。被 Kubernetes 这类开源软件协调在一起的容器平台越来越受新开发应用的欢迎。你的组织可能正在运用某一家大型云服务提供商来做一些事情。同时你也能在私有云或更加传统的内部基础设施上操作一些你自己的基础设施。
|
||||||
|
|
||||||
|
这就是现在混合云的现状,它能被归纳为两个选择,选择最合适的基础设施和服务,以及选择把应用和数据从一个地方移动到另一个你想的地方。
|
||||||
|
|
||||||
|
**相关阅读: [多重云和混合云有什么不同?][6]**
|
||||||
|
|
||||||
|
(题图 : [Flickr 使用者: theaucitron][9] (CC BY-SA 2.0))
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Gordon Haff 是红帽云的布道者,常受到业内和客户的高度赞赏,帮助红帽云组合方案的发展。他是《Computing Next: How the Cloud Opens the Future》的作者,除此之外他还有许多出版物。在红帽之前,Gordon 写了大量的研究简报,经常被纽约时报等出版物在 IT 类话题上引用,在产品和市场策略上给予客户建议。他职业生涯的早期,在 Data General 他负责将各种不同的计算机系统,从微型计算机到大型的 UNIX 服务器,引入市场。他有麻省理工学院和达特茅斯学院的工程学位,还是康奈尔大学约翰逊商学院的工商管理学硕士。
|
||||||
|
|
||||||
|
-----
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/7/hybrid-cloud
|
||||||
|
|
||||||
|
作者:[Gordon Haff (Red Hat)][a]
|
||||||
|
译者:[ZH1122](https://github.com/ZH1122)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/ghaff
|
||||||
|
[1]:https://opensource.com/resources/cloud?src=cloud_resource_menu1
|
||||||
|
[2]:https://opensource.com/resources/what-is-openstack?src=cloud_resource_menu2
|
||||||
|
[3]:https://opensource.com/resources/what-is-kubernetes?src=cloud_resource_menu3
|
||||||
|
[4]:https://opensource.com/16/12/yearbook-why-operating-system-matters?src=cloud_resource_menu4
|
||||||
|
[5]:https://opensource.com/business/16/10/interview-andy-cathrow-anchore?src=cloud_resource_menu5
|
||||||
|
[6]:https://enterprisersproject.com/article/2017/7/multi-cloud-vs-hybrid-cloud-whats-difference
|
||||||
|
[7]:https://opensource.com/article/17/7/hybrid-cloud?rate=ztmV2D_utD03cID1u41Al08w0XFm6rXXwCJdTwqI4iw
|
||||||
|
[8]:https://opensource.com/user/21220/feed
|
||||||
|
[9]:https://www.flickr.com/photos/theaucitron/5810163712/in/photolist-5p9nh3-6EkSKG-6EgGEF-9hYBcr-abCSpq-9zbjDz-4PVqwm-9RqBfq-abA2T4-4nXfwv-9RQkdN-dmjSdA-84o2ER-abA2Wp-ehyhPC-7oFYrc-4nvqBz-csMQXb-nRegFf-ntS23C-nXRyaB-6Xw3Mq-cRMaCq-b6wkkP-7u8sVQ-yqcg-6fTmk7-bzm3vU-6Xw3vL-6EkzCQ-d3W8PG-5MoveP-oMWsyY-jtMME6-XEMwS-2SeRXT-d2hjzJ-p2ZZVZ-7oFYoX-84r6Mo-cCizvm-gnnsg5-77YfPx-iDjqK-8gszbW-6MUZEZ-dhtwtk-gmpTob-6TBJ8p-mWQaAC/
|
||||||
|
[10]:http://www.nicholascarr.com/?page_id=21
|
||||||
|
[11]:https://www.cnet.com/news/there-is-no-big-switch-for-cloud-computing/
|
||||||
|
[12]:https://www.cnet.com/news/cloudbursting-or-just-portable-clouds/
|
||||||
|
[13]:https://www.redhat.com/en/technologies/storage/vansonbourne
|
||||||
|
[14]:https://opensource.com/users/ghaff
|
||||||
|
[15]:https://opensource.com/users/ghaff
|
||||||
@ -1,22 +1,17 @@
|
|||||||
translating by sugarfillet
|
用 C 语言对 Gtk+ 应用进行功能测试
|
||||||
Functional testing Gtk+ applications in C
|
========
|
||||||
============================================================
|
|
||||||
|
|
||||||
### Learn how to test your application's function with this simple tutorial.
|
> 这个简单教程教你如何测试你应用的功能
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||

|
自动化测试用来保证你程序的质量以及让它以预想的运行。单元测试只是检测你算法的某一部分,而并不注重各组件间的适应性。这就是为什么会有功能测试,它有时也称为集成测试。
|
||||||
Image by :
|
|
||||||
|
|
||||||
opensource.com
|
功能测试简单地与你的用户界面进行交互,无论它是网站还是桌面应用。为了展示功能测试如何工作,我们以测试一个 Gtk+ 应用为例。为了简单起见,这个教程里,我们使用 Gtk+ 2.0 教程的示例。
|
||||||
|
|
||||||
Automated tests are required to ensure your program's quality and that it works as expected. Unit tests examine only certain parts of your algorithm, but don't look at how each component fits together. That's where functional testing, sometimes referred as integration testing, comes in.
|
### 基础设置
|
||||||
|
|
||||||
A functional test basically interacts with your user interface, whether through a website or a desktop application. To show you how that works, let's look at how to test a Gtk+ application. For simplicity, in this tutorial let's use the [Tictactoe][6] example from the Gtk+ 2.0 tutorial.
|
对于每一个功能测试,你通常需要定义一些全局变量,比如 “用户交互时延” 或者 “失败的超时时间”(也就是说,如果在指定的时间内一个事件没有发生,程序就要中断)。
|
||||||
|
|
||||||
### Basic setup
|
|
||||||
|
|
||||||
For every functional test, you usually define some global variables, such as "user interaction delay" or "timeout until a failure is indicated" (i.e., when an event doesn't occur until the specified time and the application is doomed).
|
|
||||||
|
|
||||||
```
|
```
|
||||||
#define TTT_FUNCTIONAL_TEST_UTIL_IDLE_CONDITION(f) ((TttFunctionalTestUtilIdleCondition)(f))
|
#define TTT_FUNCTIONAL_TEST_UTIL_IDLE_CONDITION(f) ((TttFunctionalTestUtilIdleCondition)(f))
|
||||||
@ -29,7 +24,7 @@ struct timespec ttt_functional_test_util_default_timeout = {
|
|||||||
};
|
};
|
||||||
```
|
```
|
||||||
|
|
||||||
Now we can implement our dead-time functions. Here, we'll use the **usleep** function in order to get the desired delay.
|
现在我们可以实现我们自己的超时函数。这里,为了能够得到期望的延迟,我们采用 `usleep` 函数。
|
||||||
|
|
||||||
```
|
```
|
||||||
void
|
void
|
||||||
@ -45,7 +40,7 @@ ttt_functional_test_util_reaction_time_long()
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
The timeout function delays execution until a state of a control is applied. It is useful for actions that are applied asynchronously, and that is why it delays for a longer period of time.
|
直到获得控制状态,超时函数才会推迟执行。这对于一个异步执行的动作很有帮助,这也是为什么采用这么长的时延。
|
||||||
|
|
||||||
```
|
```
|
||||||
void
|
void
|
||||||
@ -74,17 +69,16 @@ ttt_functional_test_util_idle_condition_and_timeout(
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### Interacting with the graphical user interface
|
### 与图形化用户界面交互
|
||||||
|
|
||||||
In order to simulate user interaction, the [**Gdk library**][7] provides the functions we need. To do our work here, we need only these three functions:
|
为了模拟用户交互的操作, [Gdk 库][7] 为我们提供了一些需要的函数。要完成我们的工作,我们只需要如下 3 个函数:
|
||||||
|
|
||||||
* gdk_display_warp_pointer()
|
* `gdk_display_warp_pointer()`
|
||||||
|
* `gdk_test_simulate_button()`
|
||||||
|
* `gdk_test_simulate_key()`
|
||||||
|
|
||||||
* gdk_test_simulate_button()
|
|
||||||
|
|
||||||
* gdk_test_simulate_key()
|
举个例子,为了测试按钮点击,我们可以这么做:
|
||||||
|
|
||||||
For instance, to test a button click, we do the following:
|
|
||||||
|
|
||||||
```
|
```
|
||||||
gboolean
|
gboolean
|
||||||
@ -151,7 +145,8 @@ ttt_functional_test_util_button_click(GtkButton *button)
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We want to ensure the button has an active state, so we provide an idle-condition function:
|
|
||||||
|
我们想要保证按钮处于激活状态,因此我们提供一个空闲条件函数:
|
||||||
|
|
||||||
```
|
```
|
||||||
gboolean
|
gboolean
|
||||||
@ -176,11 +171,12 @@ ttt_functional_test_util_idle_test_toggle_active(
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### The test scenario
|
|
||||||
|
|
||||||
Since the Tictactoe program is very simple, we just need to ensure that a [**GtkToggleButton**][8] was clicked. The functional test can proceed once it asserts the button entered the active state. To click the buttons, we use the handy **util** function provided above.
|
### 测试场景
|
||||||
|
|
||||||
For illustration, let's assume player A wins immediately by filling the very first row, because player B is not paying attention and just filled the second row:
|
因为这个 Tictactoe 程序非常简单,我们只需要确保点击了一个 [**GtkToggleButton**][8] 按钮即可。一旦该按钮肯定进入了激活状态,功能测试就可以执行。为了点击按钮,我们使用上面提到的很方便的 `util` 函数。
|
||||||
|
|
||||||
|
如图所示,我们假设,填满第一行,玩家 A 就赢,因为玩家 B 没有注意,只填充了第二行。
|
||||||
|
|
||||||
```
|
```
|
||||||
GtkWindow *window;
|
GtkWindow *window;
|
||||||
@ -265,18 +261,21 @@ main(int argc, char **argv)
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
(题图:opensource.com)
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
作者简介:
|
作者简介:
|
||||||
|
|
||||||
Joël Krähemann - Free software enthusiast with a strong knowledge about the C programming language. I don't fear any code complexity as long it is written in a simple manner. As developer of Advanced Gtk+ Sequencer I know how challenging multi-threaded applications can be and with it we have a great basis for future demands.my personal website
|
|
||||||
|
|
||||||
|
Joël Krähemann - 精通 C 语言编程的自由软件爱好者。不管代码多复杂,它也是一点点写成的。作为高级的 Gtk+ 程序开发者,我知道多线程编程有多大的挑战性,有了多线程编程,我们就有了未来需求的良好基础。
|
||||||
|
|
||||||
|
----
|
||||||
via: https://opensource.com/article/17/7/functional-testing
|
via: https://opensource.com/article/17/7/functional-testing
|
||||||
|
|
||||||
作者:[Joël Krähemann][a]
|
作者:[Joël Krähemann][a]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[sugarfillet](https://github.com/sugarfillet)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,347 @@
|
|||||||
|
通过 SSH 实现 TCP / IP 隧道(端口转发):使用 OpenSSH 可能的 8 种场景
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
对于 [Secure Shell (SSH)][21] 这样的网络协议来说,其主要职责就是在终端模式下访问一个远程系统。因为 SSH 协议对传输数据进行了加密,所以通过它在远端系统执行命令是安全的。此外,我们还可以在这种加密后的连接上通过创建隧道(端口转发)的方式,来实现两个不同终端间的互联。凭借这种方式,只要我们能通过 SSH 创建连接,就可以绕开防火墙或者端口禁用的限制。
|
||||||
|
|
||||||
|
这个话题在网络领域有大量的应用和讨论:
|
||||||
|
|
||||||
|
* [Wikipedia: SSH Tunneling][12]
|
||||||
|
* [O’Reilly: Using SSH Tunneling][13]
|
||||||
|
* [Ssh.com: Tunneling Explained][14]
|
||||||
|
* [Ssh.com: Port Forwarding][15]
|
||||||
|
* [SecurityFocus: SSH Port Forwarding][16]
|
||||||
|
* [Red Hat Magazine: SSH Port Forwarding][17]
|
||||||
|
|
||||||
|
我们在接下来的内容中并不讨论端口转发的细节,而是准备介绍一个如何使用 [OpenSSH][22] 来完成 TCP 端口转发的速查表,其中包含了八种常见的场景。有些 SSH 客户端,比如 [PuTTY][23],也允许通过界面配置的方式来实现端口转发。而我们着重关注的是通过 OpenSSH 来实现的的方式。
|
||||||
|
|
||||||
|
在下面的例子当中,我们假设环境中的网络划分为外部网络(network1)和内部网络(network2)两部分,并且这两个网络之间,只能在 externo1 与 interno1 之间通过 SSH 连接的方式来互相访问。外部网络的节点之间和内部网络的节点之间是完全联通的。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 场景 1
|
||||||
|
|
||||||
|
> 在 externo1 节点访问由 interno1 节点提供的 TCP 服务(本地端口转发 / 绑定地址 = localhost / 主机 = localhost )
|
||||||
|
|
||||||
|
externo1 节点可以通过 OpenSSH 连接到 interno1 节点,之后我们想通过其访问运行在 5900 端口上的 VNC 服务。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我们可以通过下面的命令来实现:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -L 7900:localhost:5900 user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,我们可以在 externo1 节点上确认下 7900 端口是否处于监听状态中:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ netstat -ltn
|
||||||
|
Active Internet connections (only servers)
|
||||||
|
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||||
|
...
|
||||||
|
Tcp 0 0 127.0.0.1:7900 0.0.0.0:* LISTEN
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
我们只需要在 externo1 节点上执行如下命令即可访问 internal 节点的 VNC 服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ vncviewer localhost::7900
|
||||||
|
```
|
||||||
|
|
||||||
|
注意:在 [vncviewer 的 man 手册](http://www.realvnc.com/products/free/4.1/man/vncviewer.html)中并未提及这种修改端口号的方式。在 [About VNCViewer configuration of the output TCP port][18] 中可以看到。这也是 [the TightVNC vncviewer][19] 所介绍的的。
|
||||||
|
|
||||||
|
### 场景 2
|
||||||
|
|
||||||
|
> 在 externo2 节点上访问由 interno1 节点提供的 TCP 服务(本地端口转发 / 绑定地址 = 0.0.0.0 / 主机 = localhost)
|
||||||
|
|
||||||
|
这次的场景跟方案 1 的场景的类似,但是我们这次想从 externo2 节点来连接到 interno1 上的 VNC 服务:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
正确的命令如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -L 0.0.0.0:7900:localhost:5900 user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
看起来跟方案 1 中的命令类似,但是让我们看看 `netstat` 命令的输出上的区别。7900 端口被绑定到了本地(`127.0.0.1`),所以只有本地进程可以访问。这次我们将端口关联到了 `0.0.0.0`,所以系统允许任何 IP 地址的机器访问 7900 这个端口。
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ netstat -ltn
|
||||||
|
Active Internet connections (only servers)
|
||||||
|
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||||
|
...
|
||||||
|
Tcp 0 0 0.0.0.0:7900 0.0.0.0:* LISTEN
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
所以现在在 externo2 节点上,我们可以执行:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo2 $ vncviewer externo1::7900
|
||||||
|
```
|
||||||
|
|
||||||
|
来连接到 interno1 节点上的 VNC 服务。
|
||||||
|
|
||||||
|
除了将 IP 指定为 `0.0.0.0` 之外,我们还可以使用参数 `-g`(允许远程机器使用本地端口转发),完整命令如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -g -L 7900:localhost:5900 user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
这条命令与前面的命令能实现相同效果:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -L 0.0.0.0:7900:localhost:5900 user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
换句话说,如果我们想限制只能连接到系统上的某个 IP,可以像下面这样定义:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -L 192.168.24.80:7900:localhost:5900 user@interno1
|
||||||
|
|
||||||
|
externo1 $ netstat -ltn
|
||||||
|
Active Internet connections (only servers)
|
||||||
|
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||||
|
...
|
||||||
|
Tcp 0 0 192.168.24.80:7900 0.0.0.0:* LISTEN
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
### 场景 3
|
||||||
|
|
||||||
|
> 在 interno1 上访问由 externo1 提供的 TCP 服务(远程端口转发 / 绑定地址 = localhost / 主机 = localhost)
|
||||||
|
|
||||||
|
在场景 1 中 SSH 服务器与 TCP 服务(VNC)提供者在同一个节点上。现在我们想在 SSH 客户端所在的节点上,提供一个 TCP 服务(VNC)供 SSH 服务端来访问:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
将方案 1 中的命令参数由 `-L` 替换为 `-R`。
|
||||||
|
|
||||||
|
完整命令如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -R 7900:localhost:5900 user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
然后我们就能看到 interno1 节点上对 7900 端口正在监听:
|
||||||
|
|
||||||
|
```
|
||||||
|
interno1 $ netstat -lnt
|
||||||
|
Active Internet connections (only servers)
|
||||||
|
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||||
|
...
|
||||||
|
Tcp 0 0 127.0.0.1:7900 0.0.0.0:* LISTEN
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
现在在 interno1 节点上,我们可以使用如下命令来访问 externo1 上的 VNC 服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
interno1 $ vncviewer localhost::7900
|
||||||
|
```
|
||||||
|
|
||||||
|
### 场景 4
|
||||||
|
|
||||||
|
> interno2 使用 externo1 上提供的 TCP 服务(远端端口转发 / 绑定地址 = 0.0.0.0 / 主机 = localhost)
|
||||||
|
|
||||||
|
与场景 3 类似,但是现在我们尝试指定允许访问转发端口的 IP(就像场景 2 中做的一样)为 `0.0.0.0`,这样其他节点也可以访问 VNC 服务:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
正确的命令是:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -R 0.0.0.0:7900:localhost:5900 user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
但是这里有个重点需要了解,出于安全的原因,如果我们直接执行该命令的话可能不会生效,因为我们需要修改 SSH 服务端的一个参数值 `GatewayPorts`,它的默认值是:`no`。
|
||||||
|
|
||||||
|
> GatewayPorts
|
||||||
|
>
|
||||||
|
> 该参数指定了远程主机是否允许客户端访问转发端口。默认情况下,sshd(8) 只允许本机进程访问转发端口。这是为了阻止其他主机连接到该转发端口。GatewayPorts 参数可用于让 sshd 允许远程转发端口绑定到非回环地址上,从而可以让远程主机访问。当参数值设置为 “no” 的时候只有本机可以访问转发端口;“yes” 则表示允许远程转发端口绑定到通配地址上;或者设置为 “clientspecified” 则表示由客户端来选择哪些主机地址允许访问转发端口。默认值是 “no”。
|
||||||
|
|
||||||
|
如果我们没有修改服务器配置的权限,我们将不能使用该方案来进行端口转发。这是因为如果没有其他的限制,用户可以开启一个端口(> 1024)来监听来自外部的请求并转发到 `localhost:7900`。
|
||||||
|
|
||||||
|
参照这个案例:[netcat][24] ( [Debian # 310431: sshd_config should warn about the GatewayPorts workaround.][25] )
|
||||||
|
|
||||||
|
所以我们修改 `/etc/ssh/sshd_config`,添加如下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
GatewayPorts clientspecified
|
||||||
|
```
|
||||||
|
|
||||||
|
然后,我们使用如下命令来重载修改后的配置文件(在 Debian 和 Ubuntu 上)。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo /etc/init.d/ssh reload
|
||||||
|
```
|
||||||
|
|
||||||
|
我们确认一下现在 interno1 节点上存在 7900 端口的监听程序,监听来自不同 IP 的请求:
|
||||||
|
|
||||||
|
```
|
||||||
|
interno1 $ netstat -ltn
|
||||||
|
Active Internet connections (only servers)
|
||||||
|
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||||
|
...
|
||||||
|
Tcp 0 0 0.0.0.0:7900 0.0.0.0:* LISTEN
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
然后我们就可以在 interno2 节点上使用 VNC 服务了:
|
||||||
|
|
||||||
|
```
|
||||||
|
interno2 $ internal vncviewer1::7900
|
||||||
|
```
|
||||||
|
|
||||||
|
### 场景 5
|
||||||
|
|
||||||
|
> 在 externo1 上使用由 interno2 提供的 TCP 服务(本地端口转发 / 绑定地址 localhost / 主机 = interno2 )
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在这种场景下我们使用如下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -L 7900:interno2:5900 user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
然后我们就能在 externo1 节点上,通过执行如下命令来使用 VNC 服务了:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ vncviewer localhost::7900
|
||||||
|
```
|
||||||
|
|
||||||
|
### 场景 6
|
||||||
|
|
||||||
|
> 在 interno1 上使用由 externo2 提供的 TCP 服务(远程端口转发 / 绑定地址 = localhost / host = externo2)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在这种场景下,我们使用如下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -R 7900:externo2:5900 user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
然后我们可以在 interno1 上通过执行如下命令来访问 VNC 服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
interno1 $ vncviewer localhost::7900
|
||||||
|
```
|
||||||
|
|
||||||
|
### 场景7
|
||||||
|
|
||||||
|
> 在 externo2 上使用由 interno2 提供的 TCP 服务(本地端口转发 / 绑定地址 = 0.0.0.0 / 主机 = interno2)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
本场景下,我们使用如下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -L 0.0.0.0:7900:interno2:5900 user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
或者:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -g -L 7900:interno2:5900 user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
然后我们就可以在 externo2 上执行如下命令来访问 vnc 服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo2 $ vncviewer externo1::7900
|
||||||
|
```
|
||||||
|
|
||||||
|
### 场景 8
|
||||||
|
|
||||||
|
> 在 interno2 上使用由 externo2 提供的 TCP 服务(远程端口转发 / 绑定地址 = 0.0.0.0 / 主机 = externo2)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
本场景下我们使用如下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -R 0.0.0.0:7900:externo2:5900 user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
SSH 服务器需要配置为:
|
||||||
|
|
||||||
|
```
|
||||||
|
GatewayPorts clientspecified
|
||||||
|
```
|
||||||
|
|
||||||
|
就像我们在场景 4 中讲过的那样。
|
||||||
|
|
||||||
|
然后我们可以在 interno2 节点上执行如下命令来访问 VNC 服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
interno2 $ internal vncviewer1::7900
|
||||||
|
```
|
||||||
|
|
||||||
|
如果我们需要一次性的创建多个隧道,使用配置文件的方式替代一个可能很长的命令是一个更好的选择。假设我们只能通过 SSH 的方式访问某个特定网络,同时又需要创建多个隧道来访问该网络内不同服务器上的服务,比如 VNC 或者 [远程桌面][26]。此时只需要创建一个如下的配置文件 `$HOME/redirects` 即可(在 SOCKS 服务器 上)。
|
||||||
|
|
||||||
|
```
|
||||||
|
# SOCKS server
|
||||||
|
DynamicForward 1080
|
||||||
|
|
||||||
|
# SSH redirects
|
||||||
|
LocalForward 2221 serverlinux1: 22
|
||||||
|
LocalForward 2222 serverlinux2: 22
|
||||||
|
LocalForward 2223 172.16.23.45:22
|
||||||
|
LocalForward 2224 172.16.23.48:22
|
||||||
|
|
||||||
|
# RDP redirects for Windows systems
|
||||||
|
LocalForward 3391 serverwindows1: 3389
|
||||||
|
LocalForward 3392 serverwindows2: 3389
|
||||||
|
|
||||||
|
# VNC redirects for systems with "vncserver"
|
||||||
|
LocalForward 5902 serverlinux1: 5901
|
||||||
|
LocalForward 5903 172.16.23.45:5901
|
||||||
|
```
|
||||||
|
|
||||||
|
然后我们只需要执行如下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
externo1 $ ssh -F $HOME/redirects user@interno1
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/
|
||||||
|
|
||||||
|
作者:[Ahmad][a]
|
||||||
|
译者:[toutoudnf](https://github.com/toutoudnf)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://wesharethis.com/author/ahmad/
|
||||||
|
[1]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#
|
||||||
|
[2]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_1_Use_onexterno1a_TCP_service_offered_byinterno1Local_port_forwarding_bind_address_localhost_host_localhost
|
||||||
|
[3]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_2_Use_onexterno2a_TCP_service_offered_byinterno1Local_port_forwarding_bind_address_0000_host_localhost
|
||||||
|
[4]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_3_Use_ininterno1a_TCP_service_offered_byexterno1Remote_port_forwarding_bind_address_localhost_host_localhost
|
||||||
|
[5]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_4_Use_ininterno2a_TCP_service_offered_byexterno1Remote_port_forwarding_bind_address_0000_host_localhost
|
||||||
|
[6]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_5_Use_inexterno1a_TCP_service_offered_byinterno2Local_port_forwarding_bind_address_localhost_host_interno2
|
||||||
|
[7]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_6_Use_ininterno1a_TCP_service_offered_byexterno2Remote_port_forwarding_bind_address_localhost_host_externo2
|
||||||
|
[8]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_7_Use_inexterno2a_TCP_service_offered_byinterno2Local_port_forwarding_bind_address_0000_host_interno2
|
||||||
|
[9]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_8_Use_ininterno2a_TCP_service_offered_byexterno2Remote_port_forwarding_bind_address_0000_host_externo2
|
||||||
|
[10]:https://wesharethis.com/author/ahmad/
|
||||||
|
[11]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#comments
|
||||||
|
[12]:http://en.wikipedia.org/wiki/Tunneling_protocol#SSH_tunneling
|
||||||
|
[13]:http://www.oreillynet.com/pub/a/wireless/2001/02/23/wep.html
|
||||||
|
[14]:http://www.ssh.com/support/documentation/online/ssh/winhelp/32/Tunneling_Explained.html
|
||||||
|
[15]:http://www.ssh.com/support/documentation/online/ssh/adminguide/32/Port_Forwarding.html
|
||||||
|
[16]:http://www.securityfocus.com/infocus/1816
|
||||||
|
[17]:http://magazine.redhat.com/2007/11/06/ssh-port-forwarding/
|
||||||
|
[18]:http://www.realvnc.com/pipermail/vnc-list/2006-April/054551.html
|
||||||
|
[19]:http://www.tightvnc.com/vncviewer.1.html
|
||||||
|
[20]:https://bufferapp.com/add?url=https%3A%2F%2Fwesharethis.com%2F2017%2F07%2Fcreating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh%2F&text=Creating%20TCP%20/%20IP%20(port%20forwarding)%20tunnels%20with%20SSH:%20The%208%20possible%20scenarios%20using%20OpenSSH
|
||||||
|
[21]:http://en.wikipedia.org/wiki/Secure_Shell
|
||||||
|
[22]:http://www.openssh.com/
|
||||||
|
[23]:http://www.chiark.greenend.org.uk/~sgtatham/putty/
|
||||||
|
[24]:http://en.wikipedia.org/wiki/Netcat
|
||||||
|
[25]:http://bugs.debian.org/cgi-bin/bugreport.cgi?bug=310431
|
||||||
|
[26]:http://en.wikipedia.org/wiki/Remote_Desktop_Services
|
||||||
@ -0,0 +1,160 @@
|
|||||||
|
动态端口转发:安装带有 SSH 的 SOCKS 服务器
|
||||||
|
=================
|
||||||
|
|
||||||
|
在上一篇文章([通过 SSH 实现 TCP / IP 隧道(端口转发):使用 OpenSSH 可能的 8 种场景][17])中,我们看到了处理端口转发的所有可能情况,不过那只是静态端口转发。也就是说,我们只介绍了通过 SSH 连接来访问另一个系统的端口的情况。
|
||||||
|
|
||||||
|
在那篇文章中,我们未涉及动态端口转发,此外一些读者没看过该文章,本篇文章中将尝试补充完整。
|
||||||
|
|
||||||
|
当我们谈论使用 SSH 进行动态端口转发时,我们说的是将 SSH 服务器转换为 [SOCKS][2] 服务器。那么什么是 SOCKS 服务器?
|
||||||
|
|
||||||
|
你知道 [Web 代理][3]是用来做什么的吗?答案可能是肯定的,因为很多公司都在使用它。它是一个直接连接到互联网的系统,允许没有互联网访问的[内部网][4]客户端让其浏览器通过代理来(尽管也有[透明代理][5])浏览网页。Web 代理除了允许输出到 Internet 之外,还可以缓存页面、图像等。已经由某客户端下载的资源,另一个客户端不必再下载它们。此外,它还可以过滤内容并监视用户的活动。当然了,它的基本功能是转发 HTTP 和 HTTPS 流量。
|
||||||
|
|
||||||
|
一个 SOCKS 服务器提供的服务类似于公司内部网络提供的代理服务器服务,但不限于 HTTP/HTTPS,它还允许转发任何 TCP/IP 流量(SOCKS 5 也支持 UDP)。
|
||||||
|
|
||||||
|
例如,假设我们希望在一个没有直接连接到互联网的内部网上通过 Thunderbird 使用 POP3 、 ICMP 和 SMTP 的邮件服务。如果我们只有一个 web 代理可以用,我们可以使用的唯一的简单方式是使用某个 webmail(也可以使用 [Thunderbird 的 Webmail 扩展][6])。我们还可以通过 [HTTP 隧道][7]来起到代理的用途。但最简单的方式是在网络中设置一个 SOCKS 服务器,它可以让我们使用 POP3、ICMP 和 SMTP,而不会造成任何的不便。
|
||||||
|
|
||||||
|
虽然有很多软件可以配置非常专业的 SOCKS 服务器,但用 OpenSSH 设置一个只需要简单的一条命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
Clientessh $ ssh -D 1080 user@servidorssh
|
||||||
|
```
|
||||||
|
|
||||||
|
或者我们可以改进一下:
|
||||||
|
|
||||||
|
```
|
||||||
|
Clientessh $ ssh -fN -D 0.0.0.0:1080 user@servidorssh
|
||||||
|
```
|
||||||
|
|
||||||
|
其中:
|
||||||
|
|
||||||
|
* 选项 `-D` 类似于选项为 `-L` 和 `-R` 的静态端口转发。像那些一样,我们可以让客户端只监听本地请求或从其他节点到达的请求,具体取决于我们将请求关联到哪个地址:
|
||||||
|
```
|
||||||
|
-D [bind_address:] port
|
||||||
|
```
|
||||||
|
|
||||||
|
在静态端口转发中可以看到,我们使用选项 `-R` 进行反向端口转发,而动态转发是不可能的。我们只能在 SSH 客户端创建 SOCKS 服务器,而不能在 SSH 服务器端创建。
|
||||||
|
* 1080 是 SOCKS 服务器的典型端口,正如 8080 是 Web 代理服务器的典型端口一样。
|
||||||
|
* 选项 `-N` 防止实际启动远程 shell 交互式会话。当我们只用 `ssh` 来建立隧道时很有用。
|
||||||
|
* 选项 `-f` 会使 `ssh` 停留在后台并将其与当前 shell 分离,以便使该进程成为守护进程。如果没有选项 `-N`(或不指定命令),则不起作用,否则交互式 shell 将与后台进程不兼容。
|
||||||
|
|
||||||
|
使用 [PuTTY][8] 也可以非常简单地进行端口重定向。与 `ssh -D 0.0.0.0:1080` 相当的配置如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
对于通过 SOCKS 服务器访问另一个网络的应用程序,如果应用程序提供了对 SOCKS 服务器的特别支持,就会非常方便(虽然不是必需的),就像浏览器支持使用代理服务器一样。作为一个例子,如 Firefox 或 Internet Explorer 这样的浏览器使用 SOCKS 服务器访问另一个网络的应用程序:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
注意:上述截图来自 [IE for Linux][1] :如果您需要在 Linux 上使用 Internet Explorer,强烈推荐!
|
||||||
|
|
||||||
|
然而,最常见的浏览器并不要求 SOCKS 服务器,因为它们通常与代理服务器配合得更好。
|
||||||
|
|
||||||
|
不过,Thunderbird 也支持 SOCKS,而且很有用:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
另一个例子:[Spotify][9] 客户端同样支持 SOCKS:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
需要关注一下名称解析。有时我们会发现,在目前的网络中,我们无法解析 SOCKS 服务器另一端所要访问的系统的名称。SOCKS 5 还允许我们通过隧道传播 DNS 请求( 因为 SOCKS 5 允许我们使用 UDP)并将它们发送到另一端:可以指定是本地还是远程解析(或者也可以两者都试试)。支持此功能的应用程序也必须考虑到这一点。例如,Firefox 具有参数 `network.proxy.socks_remote_dns`(在 `about:config` 中),允许我们指定远程解析。而默认情况下,它在本地解析。
|
||||||
|
|
||||||
|
Thunderbird 也支持参数 `network.proxy.socks_remote_dns`,但由于没有地址栏来放置 `about:config`,我们需要改变它,就像在 [MozillaZine:about:config][10] 中读到的,依次点击 工具 → 选项 → 高级 → 常规 → 配置编辑器(按钮)。
|
||||||
|
|
||||||
|
没有对 SOCKS 特别支持的应用程序可以被 <ruby>sock 化<rt>socksified</rt></ruby>。这对于使用 TCP/IP 的许多应用程序都没有问题,但并不是全部。“sock 化” 需要加载一个额外的库,它可以检测对 TCP/IP 堆栈的请求,并修改请求,以通过 SOCKS 服务器重定向,从而不需要特别编程来支持 SOCKS 便可以正常通信。
|
||||||
|
|
||||||
|
在 Windows 和 [Linux][18] 上都有 “Sock 化工具”。
|
||||||
|
|
||||||
|
对于 Windows,我们举个例子,SocksCap 是一种闭源,但对非商业使用免费的产品,我使用了很长时间都十分满意。SocksCap 由一家名为 Permeo 的公司开发,该公司是创建 SOCKS 参考技术的公司。Permeo 被 [Blue Coat][11] 买下后,它[停止了 SocksCap 项目][12]。现在你仍然可以在互联网上找到 `sc32r240.exe` 文件。[FreeCap][13] 也是面向 Windows 的免费代码项目,外观和使用都非常类似于 SocksCap。然而,它工作起来更加糟糕,多年来一直没有缺失维护。看起来,它的作者倾向于推出需要付款的新产品 [WideCap][14]。
|
||||||
|
|
||||||
|
这是 SocksCap 的一个界面,可以看到我们 “sock 化” 了的几个应用程序。当我们从这里启动它们时,这些应用程序将通过 SOCKS 服务器访问网络:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在配置对话框中可以看到,如果选择了协议 SOCKS 5,我们可以选择在本地或远程解析名称:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在 Linux 上,如同往常一样,对某个远程命令我们都有许多替代方案。在 Debian/Ubuntu 中,命令行:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ Apt-cache search socks
|
||||||
|
```
|
||||||
|
|
||||||
|
的输出会告诉我们很多。
|
||||||
|
|
||||||
|
最著名的是 [tsocks][15] 和 [proxychains][16]。它们的工作方式大致相同:只需用它们启动我们想要 “sock 化” 的应用程序就行。使用 `proxychains` 的 `wget` 的例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ Proxychains wget http://www.google.com
|
||||||
|
ProxyChains-3.1 (http://proxychains.sf.net)
|
||||||
|
--19: 13: 20-- http://www.google.com/
|
||||||
|
Resolving www.google.com ...
|
||||||
|
DNS-request | Www.google.com
|
||||||
|
| S-chain | - <- - 10.23.37.3:1080-<><>-4.2.2.2:53-<><>-OK
|
||||||
|
| DNS-response | Www.google.com is 72.14.221.147
|
||||||
|
72.14.221.147
|
||||||
|
Connecting to www.google.com | 72.14.221.147 |: 80 ...
|
||||||
|
| S-chain | - <- - 10.23.37.3:1080-<><>-72.14.221.147:80-<><>-OK
|
||||||
|
Connected.
|
||||||
|
HTTP request sent, awaiting response ... 200 OK
|
||||||
|
Length: unspecified [text / html]
|
||||||
|
Saving to: `index.html '
|
||||||
|
|
||||||
|
[<=>] 6,016 24.0K / s in 0.2s
|
||||||
|
|
||||||
|
19:13:21 (24.0 KB / s) - `index.html 'saved [6016]
|
||||||
|
```
|
||||||
|
|
||||||
|
要让它可以工作,我们必须在 `/etc/proxychains.conf` 中指定要使用的代理服务器:
|
||||||
|
|
||||||
|
```
|
||||||
|
[ProxyList]
|
||||||
|
Socks5 clientessh 1080
|
||||||
|
```
|
||||||
|
|
||||||
|
我们也设置远程进行 DNS 请求:
|
||||||
|
|
||||||
|
```
|
||||||
|
# Proxy DNS requests - no leak for DNS data
|
||||||
|
Proxy_dns
|
||||||
|
```
|
||||||
|
|
||||||
|
另外,在前面的输出中,我们已经看到了同一个 `proxychains` 的几条信息性的消息, 非 `wget` 的行是标有字符串 `|DNS-request|`、`|S-chain|` 或 `|DNS-response|` 的。如果我们不想看到它们,也可以在配置中进行调整:
|
||||||
|
|
||||||
|
```
|
||||||
|
# Quiet mode (no output from library)
|
||||||
|
Quiet_mode
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://wesharethis.com/2017/07/15/dynamic-port-forwarding-mount-socks-server-ssh/
|
||||||
|
|
||||||
|
作者:[Ahmad][a]
|
||||||
|
译者:[firmianay](https://github.com/firmianay)
|
||||||
|
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://wesharethis.com/author/ahmad/
|
||||||
|
[1]:https://wesharethis.com/goto/http://www.tatanka.com.br/ies4linux/page/Main_Page
|
||||||
|
[2]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/SOCKS
|
||||||
|
[3]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Proxy_server
|
||||||
|
[4]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Intranet
|
||||||
|
[5]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Proxy_server#Transparent_and_non-transparent_proxy_server
|
||||||
|
[6]:https://wesharethis.com/goto/http://webmail.mozdev.org/
|
||||||
|
[7]:https://wesharethis.com/goto/http://en.wikipedia.org/wiki/HTTP_tunnel_(software)
|
||||||
|
[8]:https://wesharethis.com/goto/http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html
|
||||||
|
[9]:https://wesharethis.com/goto/https://www.spotify.com/int/download/linux/
|
||||||
|
[10]:https://wesharethis.com/goto/http://kb.mozillazine.org/About:config
|
||||||
|
[11]:https://wesharethis.com/goto/http://www.bluecoat.com/
|
||||||
|
[12]:https://wesharethis.com/goto/http://www.bluecoat.com/products/sockscap
|
||||||
|
[13]:https://wesharethis.com/goto/http://www.freecap.ru/eng/
|
||||||
|
[14]:https://wesharethis.com/goto/http://widecap.ru/en/support/
|
||||||
|
[15]:https://wesharethis.com/goto/http://tsocks.sourceforge.net/
|
||||||
|
[16]:https://wesharethis.com/goto/http://proxychains.sourceforge.net/
|
||||||
|
[17]:https://linux.cn/article-8945-1.html
|
||||||
|
[18]:https://wesharethis.com/2017/07/10/linux-swap-partition/
|
||||||
@ -1,95 +1,68 @@
|
|||||||
开发一个 Linux 调试器(十):高级主题
|
开发一个 Linux 调试器(十):高级主题
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
我们终于来到这个系列的最后一篇文章!这一次,我将对调试中的一些更高级的概念进行高层的概述:远程调试、共享库支持、表达式计算和多线程支持。这些想法实现起来比较复杂,所以我不会详细说明如何做,但是如果有的话,我很乐意回答有关这些概念的问题。
|
我们终于来到这个系列的最后一篇文章!这一次,我将对调试中的一些更高级的概念进行高层的概述:远程调试、共享库支持、表达式计算和多线程支持。这些想法实现起来比较复杂,所以我不会详细说明如何做,但是如果你有问题的话,我很乐意回答有关这些概念的问题。
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### 系列索引
|
### 系列索引
|
||||||
|
|
||||||
1. [准备环境][1]
|
1. [准备环境][1]
|
||||||
|
|
||||||
2. [断点][2]
|
2. [断点][2]
|
||||||
|
|
||||||
3. [寄存器和内存][3]
|
3. [寄存器和内存][3]
|
||||||
|
|
||||||
4. [Elves 和 dwarves][4]
|
4. [Elves 和 dwarves][4]
|
||||||
|
|
||||||
5. [源码和信号][5]
|
5. [源码和信号][5]
|
||||||
|
|
||||||
6. [源码层逐步执行][6]
|
6. [源码层逐步执行][6]
|
||||||
|
|
||||||
7. [源码层断点][7]
|
7. [源码层断点][7]
|
||||||
|
|
||||||
8. [调用栈][8]
|
8. [调用栈][8]
|
||||||
|
|
||||||
9. [处理变量][9]
|
9. [处理变量][9]
|
||||||
|
|
||||||
10. [高级主题][10]
|
10. [高级主题][10]
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### 远程调试
|
### 远程调试
|
||||||
|
|
||||||
远程调试对于嵌入式系统或不同环境的调试非常有用。它还在高级调试器操作和与操作系统和硬件的交互之间设置了一个很好的分界线。事实上,像 GDB 和 LLDB 这样的调试器即使在调试本地程序时也可以作为远程调试器运行。一般架构是这样的:
|
远程调试对于嵌入式系统或对不同环境进行调试非常有用。它还在高级调试器操作和与操作系统和硬件的交互之间设置了一个很好的分界线。事实上,像 GDB 和 LLDB 这样的调试器即使在调试本地程序时也可以作为远程调试器运行。一般架构是这样的:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
调试器是我们通过命令行交互的组件。也许如果你使用的是 IDE,那么顶层中另一个层可以通过_机器接口_与调试器进行通信。在目标机器上(可能与本机一样)有一个 _debug stub_ ,它理论上是一个非常小的操作系统调试库的包装程序,它执行所有的低级调试任务,如在地址上设置断点。我说“在理论上”,因为如今 stub 变得越来越大。例如,我机器上的 LLDB debug stub 大小是 7.6MB。debug stub 通过一些使用特定于操作系统的功能(在我们的例子中是 “ptrace”)和被调试进程以及通过远程协议的调试器通信。
|
调试器是我们通过命令行交互的组件。也许如果你使用的是 IDE,那么在其上有另一个层可以通过_机器接口_与调试器进行通信。在目标机器上(可能与本机一样)有一个<ruby>调试存根<rt>debug stub</rt></ruby> ,理论上它是一个非常小的操作系统调试库的包装程序,它执行所有的低级调试任务,如在地址上设置断点。我说“在理论上”,因为如今调试存根变得越来越大。例如,我机器上的 LLDB 调试存根大小是 7.6MB。调试存根通过使用一些特定于操作系统的功能(在我们的例子中是 `ptrace`)和被调试进程以及通过远程协议的调试器通信。
|
||||||
|
|
||||||
最常见的远程调试协议是 GDB 远程协议。这是一种基于文本的数据包格式,用于在调试器和 debug
|
最常见的远程调试协议是 GDB 远程协议。这是一种基于文本的数据包格式,用于在调试器和调试存根之间传递命令和信息。我不会详细介绍它,但你可以在[这里][11]进一步阅读。如果你启动 LLDB 并执行命令 `log enable gdb-remote packets`,那么你将获得通过远程协议发送的所有数据包的跟踪信息。在 GDB 上,你可以用 `set remotelogfile <file>` 做同样的事情。
|
||||||
stub 之间传递命令和信息。我不会详细介绍它,但你可以在[这里][11]阅读你想知道的。如果你启动 LLDB 并执行命令 `log enable gdb-remote packets`,那么你将获得通过远程协议发送的所有数据包的跟踪。在 GDB 上,你可以用 `set remotelogfile <file>` 做同样的事情。
|
|
||||||
|
|
||||||
作为一个简单的例子,这是数据包设置断点:
|
作为一个简单的例子,这是设置断点的数据包:
|
||||||
|
|
||||||
```
|
```
|
||||||
$Z0,400570,1#43
|
$Z0,400570,1#43
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
`$` 标记数据包的开始。`Z0` 是插入内存断点的命令。`400570` 和 `1` 是参数,其中前者是设置断点的地址,后者是特定目标的断点类型说明符。最后,`#43` 是校验值,以确保数据没有损坏。
|
`$` 标记数据包的开始。`Z0` 是插入内存断点的命令。`400570` 和 `1` 是参数,其中前者是设置断点的地址,后者是特定目标的断点类型说明符。最后,`#43` 是校验值,以确保数据没有损坏。
|
||||||
|
|
||||||
GDB 远程协议非常易于扩展自定义数据包,这对于实现平台或语言特定的功能非常有用。
|
GDB 远程协议非常易于扩展自定义数据包,这对于实现平台或语言特定的功能非常有用。
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### 共享库和动态加载支持
|
### 共享库和动态加载支持
|
||||||
|
|
||||||
调试器需要知道调试程序加载了哪些共享库,以便它可以设置断点,获取源代码级别的信息和符号等。除查找被动态链接的库之外,调试器还必须跟踪在运行时通过 `dlopen` 加载的库。为了打到这个目的,动态链接器维护一个 _交会结构体_。该结构体维护共享描述符的链表以及指向每当更新链表时调用的函数的指针。这个结构存储在 ELF 文件的 `.dynamic` 段中,在程序执行之前被初始化。
|
调试器需要知道被调试程序加载了哪些共享库,以便它可以设置断点、获取源代码级别的信息和符号等。除查找被动态链接的库之外,调试器还必须跟踪在运行时通过 `dlopen` 加载的库。为了达到这个目的,动态链接器维护一个 _交汇结构体_。该结构体维护共享库描述符的链表,以及一个指向每当更新链表时调用的函数的指针。这个结构存储在 ELF 文件的 `.dynamic` 段中,在程序执行之前被初始化。
|
||||||
|
|
||||||
一个简单的跟踪算法:
|
一个简单的跟踪算法:
|
||||||
|
|
||||||
* 追踪程序在 ELF 头中查找程序的入口(或者可以使用存储在 `/proc/<pid>/aux` 中的辅助向量)
|
* 追踪程序在 ELF 头中查找程序的入口(或者可以使用存储在 `/proc/<pid>/aux` 中的辅助向量)。
|
||||||
|
|
||||||
* 追踪程序在程序的入口处设置一个断点,并开始执行。
|
* 追踪程序在程序的入口处设置一个断点,并开始执行。
|
||||||
|
|
||||||
* 当到达断点时,通过在 ELF 文件中查找 `.dynamic` 的加载地址找到交汇结构体的地址。
|
* 当到达断点时,通过在 ELF 文件中查找 `.dynamic` 的加载地址找到交汇结构体的地址。
|
||||||
|
|
||||||
* 检查交汇结构体以获取当前加载的库的列表。
|
* 检查交汇结构体以获取当前加载的库的列表。
|
||||||
|
* 链接器更新函数上设置断点。
|
||||||
* 链接器更新函数上设置断点
|
* 每当到达断点时,列表都会更新。
|
||||||
|
|
||||||
* 每当到达断点时,列表都会更新
|
|
||||||
|
|
||||||
* 追踪程序无限循环,继续执行程序并等待信号,直到追踪程序信号退出。
|
* 追踪程序无限循环,继续执行程序并等待信号,直到追踪程序信号退出。
|
||||||
|
|
||||||
我给这些概念写了一个小例子,你可以在[这里][12]找到。如果有人有兴趣,我可以将来写得更详细一点。
|
我给这些概念写了一个小例子,你可以在[这里][12]找到。如果有人有兴趣,我可以将来写得更详细一点。
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### 表达式计算
|
### 表达式计算
|
||||||
|
|
||||||
表达式计算是程序的一项功能,允许用户在调试程序时对原始源语言中的表达式进行计算。例如,在 LLDB 或 GDB 中,可以执行 `print foo()` 来调用 `foo` 函数并打印结果。
|
表达式计算是程序的一项功能,允许用户在调试程序时对原始源语言中的表达式进行计算。例如,在 LLDB 或 GDB 中,可以执行 `print foo()` 来调用 `foo` 函数并打印结果。
|
||||||
|
|
||||||
根据表达的复杂程度,有几种不同的计算方法。如果表达式只是一个简单的标识符,那么调试器可以查看调试信息,找到变量并打印出该值,就像我们在本系列最后一部分中所做的那样。如果表达式有点复杂,则可能将代码编译成中间表达式 (IR) 并解释来获得结果。例如,对于某些表达式,LLDB 将使用 Clang 将表达式编译为 LLVM IR 并将其解释。如果表达式更复杂,或者需要调用某些函数,那么代码可能需要 JIT 到目标并在被调试者的地址空间中执行。这涉及到调用 `mmap` 来分配一些可执行内存,然后将编译的代码复制到该块并执行。LLDB 通过使用 LLVM 的 JIT 功能来实现。
|
根据表达式的复杂程度,有几种不同的计算方法。如果表达式只是一个简单的标识符,那么调试器可以查看调试信息,找到该变量并打印出该值,就像我们在本系列最后一部分中所做的那样。如果表达式有点复杂,则可能将代码编译成中间表达式 (IR) 并解释来获得结果。例如,对于某些表达式,LLDB 将使用 Clang 将表达式编译为 LLVM IR 并将其解释。如果表达式更复杂,或者需要调用某些函数,那么代码可能需要 JIT 到目标并在被调试者的地址空间中执行。这涉及到调用 `mmap` 来分配一些可执行内存,然后将编译的代码复制到该块并执行。LLDB 通过使用 LLVM 的 JIT 功能来实现。
|
||||||
|
|
||||||
如果你想更多地了解 JIT 编译,我强烈推荐[ Eli Bendersky 关于这个主题的文章][13]。
|
如果你想更多地了解 JIT 编译,我强烈推荐 [Eli Bendersky 关于这个主题的文章][13]。
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### 多线程调试支持
|
### 多线程调试支持
|
||||||
|
|
||||||
本系列展示的调试器仅支持单线程应用程序,但是为了调试大多数真实程序,多线程支持是非常需要的。支持这一点的最简单的方法是跟踪线程创建并解析 procfs 以获取所需的信息。
|
本系列展示的调试器仅支持单线程应用程序,但是为了调试大多数真实程序,多线程支持是非常需要的。支持这一点的最简单的方法是跟踪线程的创建,并解析 procfs 以获取所需的信息。
|
||||||
|
|
||||||
Linux 线程库称为 `pthreads`。当调用 `pthread_create` 时,库会使用 `clone` 系统调用来创建一个新的线程,我们可以用 `ptrace` 跟踪这个系统调用(假设你的内核早于 2.5.46)。为此,你需要在连接到调试器之后设置一些 `ptrace` 选项:
|
Linux 线程库称为 `pthreads`。当调用 `pthread_create` 时,库会使用 `clone` 系统调用来创建一个新的线程,我们可以用 `ptrace` 跟踪这个系统调用(假设你的内核早于 2.5.46)。为此,你需要在连接到调试器之后设置一些 `ptrace` 选项:
|
||||||
|
|
||||||
@ -97,7 +70,7 @@ Linux 线程库称为 `pthreads`。当调用 `pthread_create` 时,库会使用
|
|||||||
ptrace(PTRACE_SETOPTIONS, m_pid, nullptr, PTRACE_O_TRACECLONE);
|
ptrace(PTRACE_SETOPTIONS, m_pid, nullptr, PTRACE_O_TRACECLONE);
|
||||||
```
|
```
|
||||||
|
|
||||||
现在当 `clone` 被调用时,该进程将收到我们的老朋友 `SIGTRAP` 发出信号。对于本系列中的调试器,你可以将一个例子添加到 `handle_sigtrap` 来处理新线程的创建:
|
现在当 `clone` 被调用时,该进程将收到我们的老朋友 `SIGTRAP` 信号。对于本系列中的调试器,你可以将一个例子添加到 `handle_sigtrap` 来处理新线程的创建:
|
||||||
|
|
||||||
```
|
```
|
||||||
case (SIGTRAP | (PTRACE_EVENT_CLONE << 8)):
|
case (SIGTRAP | (PTRACE_EVENT_CLONE << 8)):
|
||||||
@ -115,32 +88,30 @@ GDB 使用 `libthread_db`,它提供了一堆帮助函数,这样你就不需
|
|||||||
|
|
||||||
多线程支持中最复杂的部分是调试器中线程状态的建模,特别是如果你希望支持[不间断模式][15]或当你计算中涉及不止一个 CPU 的某种异构调试。
|
多线程支持中最复杂的部分是调试器中线程状态的建模,特别是如果你希望支持[不间断模式][15]或当你计算中涉及不止一个 CPU 的某种异构调试。
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### 最后!
|
### 最后!
|
||||||
|
|
||||||
呼!这个系列花了很长时间才写完,但是我在这个过程中学到了很多东西,我希望它是有帮助的。如果你聊有关调试或本系列中的任何问题,请在 Twitter [@TartanLlama][16]或评论区联系我。如果你有想看到的其他任何调试主题,让我知道我或许会再发其他的文章。
|
呼!这个系列花了很长时间才写完,但是我在这个过程中学到了很多东西,我希望它是有帮助的。如果你有关于调试或本系列中的任何问题,请在 Twitter [@TartanLlama][16]或评论区联系我。如果你有想看到的其他任何调试主题,让我知道我或许会再发其他的文章。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
via: https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/
|
via: https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/
|
||||||
|
|
||||||
作者:[Simon Brand ][a]
|
作者:[Simon Brand][a]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
[a]:https://www.twitter.com/TartanLlama
|
[a]:https://www.twitter.com/TartanLlama
|
||||||
[1]:https://blog.tartanllama.xyz/writing-a-linux-debugger-setup/
|
[1]:https://linux.cn/article-8626-1.html
|
||||||
[2]:https://blog.tartanllama.xyz/writing-a-linux-debugger-breakpoints/
|
[2]:https://linux.cn/article-8645-1.html
|
||||||
[3]:https://blog.tartanllama.xyz/writing-a-linux-debugger-registers/
|
[3]:https://linux.cn/article-8663-1.html
|
||||||
[4]:https://blog.tartanllama.xyz/writing-a-linux-debugger-elf-dwarf/
|
[4]:https://linux.cn/article-8719-1.html
|
||||||
[5]:https://blog.tartanllama.xyz/writing-a-linux-debugger-source-signal/
|
[5]:https://linux.cn/article-8812-1.html
|
||||||
[6]:https://blog.tartanllama.xyz/writing-a-linux-debugger-dwarf-step/
|
[6]:https://linux.cn/article-8813-1.html
|
||||||
[7]:https://blog.tartanllama.xyz/writing-a-linux-debugger-source-break/
|
[7]:https://linux.cn/article-8890-1.html
|
||||||
[8]:https://blog.tartanllama.xyz/writing-a-linux-debugger-unwinding/
|
[8]:https://linux.cn/article-8930-1.html
|
||||||
[9]:https://blog.tartanllama.xyz/writing-a-linux-debugger-variables/
|
[9]:https://linux.cn/article-8936-1.html
|
||||||
[10]:https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/
|
[10]:https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/
|
||||||
[11]:https://sourceware.org/gdb/onlinedocs/gdb/Remote-Protocol.html
|
[11]:https://sourceware.org/gdb/onlinedocs/gdb/Remote-Protocol.html
|
||||||
[12]:https://github.com/TartanLlama/dltrace
|
[12]:https://github.com/TartanLlama/dltrace
|
||||||
@ -0,0 +1,497 @@
|
|||||||
|
Up:在几秒钟内部署无服务器应用程序
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
去年,我[为 Up 规划了一份蓝图][1],其中描述了如何以最小的成本在 AWS 上为大多数构建块创建一个很棒的无服务器环境。这篇文章则是讨论了 [Up][2] 的初始 alpha 版本。
|
||||||
|
|
||||||
|
为什么关注<ruby>无服务器<rt>serverless</rt></ruby>?对于初学者来说,它可以节省成本,因为你可以按需付费,且只为你使用的付费。无服务器方式是自愈的,因为每个请求被隔离并被视作“无状态的”。最后,它可以无限轻松地扩展 —— 没有机器或集群要管理。部署你的代码就行了。
|
||||||
|
|
||||||
|
大约一个月前,我决定开始在 [apex/up][3] 上开发它,并为动态 SVG 版本的 GitHub 用户投票功能写了第一个小型无服务器示例程序 [tj/gh-polls][4]。它运行良好,成本低于每月 1 美元即可为数百万次投票服务,因此我会继续这个项目,看看我是否可以提供开源版本及商业的变体版本。
|
||||||
|
|
||||||
|
其长期的目标是提供“你自己的 Heroku” 的版本,支持许多平台。虽然平台即服务(PaaS)并不新鲜,但无服务器生态系统正在使这种方案日益萎缩。据说,AWS 和其他的供应商经常由于他们提供的灵活性而被人诟病用户体验。Up 将复杂性抽象出来,同时为你提供一个几乎无需运维的解决方案。
|
||||||
|
|
||||||
|
### 安装
|
||||||
|
|
||||||
|
你可以使用以下命令安装 Up,查看这篇[临时文档][5]开始使用。或者如果你使用安装脚本,请下载[二进制版本][6]。(请记住,这个项目还在早期。)
|
||||||
|
|
||||||
|
```
|
||||||
|
curl -sfL https://raw.githubusercontent.com/apex/up/master/install.sh | sh
|
||||||
|
```
|
||||||
|
|
||||||
|
只需运行以下命令随时升级到最新版本:
|
||||||
|
|
||||||
|
```
|
||||||
|
up upgrade
|
||||||
|
```
|
||||||
|
|
||||||
|
你也可以通过 NPM 进行安装:
|
||||||
|
|
||||||
|
```
|
||||||
|
npm install -g up
|
||||||
|
```
|
||||||
|
|
||||||
|
### 功能
|
||||||
|
|
||||||
|
这个早期 alpha 版本提供什么功能?让我们来看看!请记住,Up 不是托管服务,因此你需要一个 AWS 帐户和 [AWS 凭证][8]。如果你对 AWS 不熟悉,你可能需要先停下来,直到熟悉流程。
|
||||||
|
|
||||||
|
我遇到的第一个问题是:up(1) 与 [apex(1)][9] 有何不同?Apex 专注于部署功能,用于管道和事件处理,而 Up 则侧重于应用程序、API 和静态站点,也就是单个可部署单元。Apex 不为你提供 API 网关、SSL 证书或 DNS,也不提供 URL 重写,脚本注入等。
|
||||||
|
|
||||||
|
#### 单命令无服务器应用程序
|
||||||
|
|
||||||
|
Up 可以让你使用单条命令部署应用程序、API 和静态站点。要创建一个应用程序,你只需要一个文件,在 Node.js 的情况下,`./app.js` 监听由 Up 提供的 `PORT'。请注意,如果你使用的是 `package.json` ,则会检测并使用 `start`和 `build` 脚本。
|
||||||
|
|
||||||
|
```
|
||||||
|
const http = require('http')
|
||||||
|
const { PORT = 3000 } = process.env
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
http.createServer((req, res) => {
|
||||||
|
res.end('Hello World\n')
|
||||||
|
}).listen(PORT)
|
||||||
|
```
|
||||||
|
|
||||||
|
额外的[运行时环境][10]也支持开箱可用,例如用于 Golang 的 “main.go”,所以你可以在几秒钟内部署 Golang、Python、Crystal 或 Node.js 应用程序。
|
||||||
|
|
||||||
|
```
|
||||||
|
package main
|
||||||
|
|
||||||
|
import (
|
||||||
|
"fmt"
|
||||||
|
"log"
|
||||||
|
"net/http"
|
||||||
|
"os"
|
||||||
|
)
|
||||||
|
|
||||||
|
func main() {
|
||||||
|
addr := ":" + os.Getenv("PORT")
|
||||||
|
http.HandleFunc("/", hello)
|
||||||
|
log.Fatal(http.ListenAndServe(addr, nil))
|
||||||
|
}
|
||||||
|
|
||||||
|
func hello(w http.ResponseWriter, r *http.Request) {
|
||||||
|
fmt.Fprintln(w, "Hello World from Go")
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
要部署应用程序输入 `up` 来创建所需的资源并部署应用程序本身。这里没有模糊不清的地方,一旦它说“完成”了那就完成了,该应用程序立即可用 —— 没有远程构建过程。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
后续的部署将会更快,因为栈已被配置:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
使用 `up url --open` 测试你的程序,以在浏览器中浏览它,`up url --copy` 可以将 URL 保存到剪贴板,或者可以尝试使用 curl:
|
||||||
|
|
||||||
|
```
|
||||||
|
curl `up url`
|
||||||
|
Hello World
|
||||||
|
```
|
||||||
|
|
||||||
|
要删除应用程序及其资源,只需输入 `up stack delete`:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
例如,使用 `up staging` 或 `up production` 和 `up url --open production` 部署到预发布或生产环境。请注意,自定义域名尚不可用,[它们将很快可用][11]。之后,你还可以将版本“推广”到其他环境。
|
||||||
|
|
||||||
|
#### 反向代理
|
||||||
|
|
||||||
|
Up 的一个独特的功能是,它不仅仅是简单地部署代码,它将一个 Golang 反向代理放在应用程序的前面。这提供了许多功能,如 URL 重写、重定向、脚本注入等等,我们将在后面进一步介绍。
|
||||||
|
|
||||||
|
#### 基础设施即代码
|
||||||
|
|
||||||
|
在配置方面,Up 遵循现代最佳实践,因此对基础设施的更改都可以在部署之前预览,并且 IAM 策略的使用还可以限制开发人员访问以防止事故发生。一个附带的好处是它有助于自动记录你的基础设施。
|
||||||
|
|
||||||
|
以下是使用 Let's Encrypt 通过 AWS ACM 配置一些(虚拟)DNS 记录和免费 SSL 证书的示例。
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"name": "app",
|
||||||
|
"dns": {
|
||||||
|
"myapp.com": [
|
||||||
|
{
|
||||||
|
"name": "myapp.com",
|
||||||
|
"type": "A",
|
||||||
|
"ttl": 300,
|
||||||
|
"value": ["35.161.83.243"]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "blog.myapp.com",
|
||||||
|
"type": "CNAME",
|
||||||
|
"ttl": 300,
|
||||||
|
"value": ["34.209.172.67"]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "api.myapp.com",
|
||||||
|
"type": "A",
|
||||||
|
"ttl": 300,
|
||||||
|
"value": ["54.187.185.18"]
|
||||||
|
}
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"certs": [
|
||||||
|
{
|
||||||
|
"domains": ["myapp.com", "*.myapp.com"]
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
当你首次通过 `up` 部署应用程序时,需要所有的权限,它为你创建 API 网关、Lambda 函数、ACM 证书、Route53 DNS 记录等。
|
||||||
|
|
||||||
|
[ChangeSets][12] 尚未实现,但你能使用 `up stack plan` 预览进一步的更改,并使用 `up stack apply` 提交,这与 Terraform 非常相似。
|
||||||
|
|
||||||
|
详细信息请参阅[配置文档][13]。
|
||||||
|
|
||||||
|
#### 全球部署
|
||||||
|
|
||||||
|
`regions` 数组可以指定应用程序的目标区域。例如,如果你只对单个地区感兴趣,请使用:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"regions": ["us-west-2"]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你的客户集中在北美,你可能需要使用美国和加拿大所有地区:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"regions": ["us-*", "ca-*"]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
最后,你可以使用 AWS 目前支持的所有 14 个地区:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"regions": ["*"]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
多区域支持仍然是一个正在进行的工作,因为需要一些新的 AWS 功能来将它们结合在一起。
|
||||||
|
|
||||||
|
#### 静态文件服务
|
||||||
|
|
||||||
|
Up 默认支持静态文件服务,并带有 HTTP 缓存支持,因此你可以在应用程序前使用 CloudFront 或任何其他 CDN 来大大减少延迟。
|
||||||
|
|
||||||
|
当 `type` 为 `static` 时,默认情况下的工作目录是 `.`,但是你也可以提供一个 `static.dir`:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"name": "app",
|
||||||
|
"type": "static",
|
||||||
|
"static": {
|
||||||
|
"dir": "public"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 构建钩子
|
||||||
|
|
||||||
|
构建钩子允许你在部署或执行其他操作时定义自定义操作。一个常见的例子是使用 Webpack 或 Browserify 捆绑 Node.js 应用程序,这大大减少了文件大小,因为 node 模块是_很大_的。
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"name": "app",
|
||||||
|
"hooks": {
|
||||||
|
"build": "browserify --node server.js > app.js",
|
||||||
|
"clean": "rm app.js"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 脚本和样式表插入
|
||||||
|
|
||||||
|
Up 允许你插入脚本和样式,无论是内联方式或声明路径。它甚至支持一些“罐头”脚本,用于 Google Analytics(分析)和 [Segment][14],只需复制并粘贴你的写入密钥即可。
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"name": "site",
|
||||||
|
"type": "static",
|
||||||
|
"inject": {
|
||||||
|
"head": [
|
||||||
|
{
|
||||||
|
"type": "segment",
|
||||||
|
"value": "API_KEY"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"type": "inline style",
|
||||||
|
"file": "/css/primer.css"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"body": [
|
||||||
|
{
|
||||||
|
"type": "script",
|
||||||
|
"value": "/app.js"
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 重写和重定向
|
||||||
|
|
||||||
|
Up 通过 `redirects` 对象支持重定向和 URL 重写,该对象将路径模式映射到新位置。如果省略 `status` 参数(或值为 200),那么它是重写,否则是重定向。
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"name": "app",
|
||||||
|
"type": "static",
|
||||||
|
"redirects": {
|
||||||
|
"/blog": {
|
||||||
|
"location": "https://blog.apex.sh/",
|
||||||
|
"status": 301
|
||||||
|
},
|
||||||
|
"/docs/:section/guides/:guide": {
|
||||||
|
"location": "/help/:section/:guide",
|
||||||
|
"status": 302
|
||||||
|
},
|
||||||
|
"/store/*": {
|
||||||
|
"location": "/shop/:splat"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
用于重写的常见情况是 SPA(单页面应用程序),你希望不管路径如何都提供 `index.html`,当然除非文件存在。
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"name": "app",
|
||||||
|
"type": "static",
|
||||||
|
"redirects": {
|
||||||
|
"/*": {
|
||||||
|
"location": "/",
|
||||||
|
"status": 200
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
如果要强制实施该规则,无论文件是否存在,只需添加 `"force": true` 。
|
||||||
|
|
||||||
|
#### 环境变量
|
||||||
|
|
||||||
|
密码将在下一个版本中有,但是现在支持纯文本环境变量:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"name": "api",
|
||||||
|
"environment": {
|
||||||
|
"API_FEATURE_FOO": "1",
|
||||||
|
"API_FEATURE_BAR": "0"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
#### CORS 支持
|
||||||
|
|
||||||
|
[CORS][16] 支持允许你指定哪些(如果有的话)域可以从浏览器访问你的 API。如果你希望允许任何网站访问你的 API,只需启用它:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"cors": {
|
||||||
|
"enable": true
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
你还可以自定义访问,例如仅将 API 访问限制为你的前端或 SPA。
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"cors": {
|
||||||
|
"allowed_origins": ["https://myapp.com"],
|
||||||
|
"allowed_methods": ["HEAD", "GET", "POST", "PUT", "DELETE"],
|
||||||
|
"allowed_headers": ["Content-Type", "Authorization"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 日志
|
||||||
|
|
||||||
|
对于 $0.5/GB 的低价格,你可以使用 CloudWatch 日志进行结构化日志查询和跟踪。Up 实现了一种用于改进 CloudWatch 提供的自定义[查询语言][18],专门用于查询结构化 JSON 日志。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
你可以查询现有日志:
|
||||||
|
|
||||||
|
```
|
||||||
|
up logs
|
||||||
|
```
|
||||||
|
|
||||||
|
跟踪在线日志:
|
||||||
|
|
||||||
|
```
|
||||||
|
up logs -f
|
||||||
|
```
|
||||||
|
|
||||||
|
或者对其中任一个进行过滤,例如只显示耗时超过 5 毫秒的 200 个 GET/HEAD 请求:
|
||||||
|
|
||||||
|
```
|
||||||
|
up logs 'method in ("GET", "HEAD") status = 200 duration >= 5'
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
查询语言是非常灵活的,这里有更多来自于 `up help logs` 的例子
|
||||||
|
|
||||||
|
```
|
||||||
|
### 显示过去 5 分钟的日志
|
||||||
|
$ up logs
|
||||||
|
|
||||||
|
### 显示过去 30 分钟的日志
|
||||||
|
$ up logs -s 30m
|
||||||
|
|
||||||
|
### 显示过去 5 小时的日志
|
||||||
|
$ up logs -s 5h
|
||||||
|
|
||||||
|
### 实时显示日志
|
||||||
|
$ up logs -f
|
||||||
|
|
||||||
|
### 显示错误日志
|
||||||
|
$ up logs error
|
||||||
|
|
||||||
|
### 显示错误和致命错误日志
|
||||||
|
$ up logs 'error or fatal'
|
||||||
|
|
||||||
|
### 显示非 info 日志
|
||||||
|
$ up logs 'not info'
|
||||||
|
|
||||||
|
### 显示特定消息的日志
|
||||||
|
$ up logs 'message = "user login"'
|
||||||
|
|
||||||
|
### 显示超时 150ms 的 200 响应
|
||||||
|
$ up logs 'status = 200 duration > 150'
|
||||||
|
|
||||||
|
### 显示 4xx 和 5xx 响应
|
||||||
|
$ up logs 'status >= 400'
|
||||||
|
|
||||||
|
### 显示用户邮件包含 @apex.sh 的日志
|
||||||
|
$ up logs 'user.email contains "@apex.sh"'
|
||||||
|
|
||||||
|
### 显示用户邮件以 @apex.sh 结尾的日志
|
||||||
|
$ up logs 'user.email = "*@apex.sh"'
|
||||||
|
|
||||||
|
### 显示用户邮件以 tj@ 开始的日志
|
||||||
|
$ up logs 'user.email = "tj@*"'
|
||||||
|
|
||||||
|
### 显示路径 /tobi 和 /loki 下的错误日志
|
||||||
|
$ up logs 'error and (path = "/tobi" or path = "/loki")'
|
||||||
|
|
||||||
|
### 和上面一样,用 in 显示
|
||||||
|
$ up logs 'error and path in ("/tobi", "/loki")'
|
||||||
|
|
||||||
|
### 更复杂的查询方式
|
||||||
|
$ up logs 'method in ("POST", "PUT") ip = "207.*" status = 200 duration >= 50'
|
||||||
|
|
||||||
|
### 将 JSON 格式的错误日志发送给 jq 工具
|
||||||
|
$ up logs error | jq
|
||||||
|
```
|
||||||
|
|
||||||
|
请注意,`and` 关键字是暗含的,虽然你也可以使用它。
|
||||||
|
|
||||||
|
#### 冷启动时间
|
||||||
|
|
||||||
|
这是 AWS Lambda 平台的特性,但冷启动时间通常远远低于 1 秒,在未来,我计划提供一个选项来保持它们在线。
|
||||||
|
|
||||||
|
#### 配置验证
|
||||||
|
|
||||||
|
`up config` 命令输出解析后的配置,有默认值和推断的运行时设置 - 它也起到验证配置的双重目的,因为任何错误都会导致退出状态 > 0。
|
||||||
|
|
||||||
|
#### 崩溃恢复
|
||||||
|
|
||||||
|
使用 Up 作为反向代理的另一个好处是执行崩溃恢复 —— 在崩溃后重新启动服务器,并在将错误的响应发送给客户端之前重新尝试该请求。
|
||||||
|
|
||||||
|
例如,假设你的 Node.js 程序由于间歇性数据库问题而导致未捕获的异常崩溃,Up 可以在响应客户端之前重试该请求。之后这个行为会更加可定制。
|
||||||
|
|
||||||
|
#### 适合持续集成
|
||||||
|
|
||||||
|
很难说这是一个功能,但是感谢 Golang 相对较小和独立的二进制文件,你可以在一两秒中在 CI 中安装 Up。
|
||||||
|
|
||||||
|
#### HTTP/2
|
||||||
|
|
||||||
|
Up 通过 API 网关支持 HTTP/2,对于服务很多资源的应用和站点可以减少延迟。我将来会对许多平台进行更全面的测试,但是 Up 的延迟已经很好了:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### 错误页面
|
||||||
|
|
||||||
|
Up 提供了一个默认错误页面,如果你要提供支持电子邮件或调整颜色,你可以使用 `error_pages` 自定义。
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"name": "site",
|
||||||
|
"type": "static",
|
||||||
|
"error_pages": {
|
||||||
|
"variables": {
|
||||||
|
"support_email": "support@apex.sh",
|
||||||
|
"color": "#228ae6"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
默认情况下,它看上去像这样:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
如果你想提供自定义模板,你可以创建以下一个或多个文件。特定文件优先。
|
||||||
|
|
||||||
|
* `error.html` – 匹配任何 4xx 或 5xx
|
||||||
|
* `5xx.html` – 匹配任何 5xx 错误
|
||||||
|
* `4xx.html` – 匹配任何 4xx 错误
|
||||||
|
* `CODE.html` – 匹配一个特定的代码,如 404.html
|
||||||
|
|
||||||
|
查看[文档][22]阅读更多有关模板的信息。
|
||||||
|
|
||||||
|
### 伸缩和成本
|
||||||
|
|
||||||
|
你已经做了这么多,但是 Up 怎么伸缩?目前,API 网关和 AWS 是目标平台,因此你无需进行任何更改即可扩展,只需部署代码即可完成。你只需按需支付实际使用的数量并且无需人工干预。
|
||||||
|
|
||||||
|
AWS 每月免费提供 1,000,000 个请求,但你可以使用 [http://serverlesscalc.com][23] 来插入预期流量。在未来 Up 将提供更多的平台,所以如果一个成本过高,你可以迁移到另一个!
|
||||||
|
|
||||||
|
### 未来
|
||||||
|
|
||||||
|
目前为止就这样了!它可能看起来不是很多,但它已经超过 10,000 行代码,并且我刚刚开始开发。看看这个问题队列,假设项目可持续发展,看看未来会有什么期待。
|
||||||
|
|
||||||
|
如果你发现这个免费版本有用,请考虑在 [OpenCollective][24] 上捐赠我,因为我没有任何工作。我将在短期内开发早期专业版,对早期用户有年费优惠。专业或企业版也将提供源码,因此可以进行内部修复和自定义。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://medium.freecodecamp.org/up-b3db1ca930ee
|
||||||
|
|
||||||
|
作者:[TJ Holowaychuk][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://medium.freecodecamp.org/@tjholowaychuk?source=post_header_lockup
|
||||||
|
[1]:https://medium.com/@tjholowaychuk/blueprints-for-up-1-5f8197179275
|
||||||
|
[2]:https://github.com/apex/up
|
||||||
|
[3]:https://github.com/apex/up
|
||||||
|
[4]:https://github.com/tj/gh-polls
|
||||||
|
[5]:https://github.com/apex/up/tree/master/docs
|
||||||
|
[6]:https://github.com/apex/up/releases
|
||||||
|
[7]:https://raw.githubusercontent.com/apex/up/master/install.sh
|
||||||
|
[8]:https://github.com/apex/up/blob/master/docs/aws-credentials.md
|
||||||
|
[9]:https://github.com/apex/apex
|
||||||
|
[10]:https://github.com/apex/up/blob/master/docs/runtimes.md
|
||||||
|
[11]:https://github.com/apex/up/issues/166
|
||||||
|
[12]:https://github.com/apex/up/issues/115
|
||||||
|
[13]:https://github.com/apex/up/blob/master/docs/configuration.md
|
||||||
|
[14]:https://segment.com/
|
||||||
|
[15]:https://blog.apex.sh/
|
||||||
|
[16]:https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS
|
||||||
|
[17]:https://myapp.com/
|
||||||
|
[18]:https://github.com/apex/up/blob/master/internal/logs/parser/grammar.peg
|
||||||
|
[19]:http://twitter.com/apex
|
||||||
|
[20]:http://twitter.com/apex
|
||||||
|
[21]:http://twitter.com/apex
|
||||||
|
[22]:https://github.com/apex/up/blob/master/docs/configuration.md#error-pages
|
||||||
|
[23]:http://serverlesscalc.com/
|
||||||
|
[24]:https://opencollective.com/apex-up
|
||||||
@ -0,0 +1,394 @@
|
|||||||
|
使用 Docker 构建你的 Serverless 树莓派集群
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
这篇博文将向你展示如何使用 Docker 和 [OpenFaaS][33] 框架构建你自己的 Serverless 树莓派集群。大家常常问我能用他们的集群来做些什么?而这个应用完美匹配卡片尺寸的设备——只需添加更多的树莓派就能获取更强的计算能力。
|
||||||
|
|
||||||
|
> “Serverless” (无服务器)是事件驱动架构的一种设计模式,与“桥接模式”、“外观模式”、“工厂模式”和“云”这些名词一样,都是一种抽象概念。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
_图片:3 个 Raspberry Pi Zero_
|
||||||
|
|
||||||
|
这是我在本文中描述的集群,用黄铜支架分隔每个设备。
|
||||||
|
|
||||||
|
### Serverless 是什么?它为何重要?
|
||||||
|
|
||||||
|
行业对于 “serverless” 这个术语的含义有几种解释。在这篇博文中,我们就把它理解为一种事件驱动的架构模式,它能让你用自己喜欢的任何语言编写轻量可复用的功能。[更多关于 Serverless 的资料][22]。
|
||||||
|
|
||||||
|
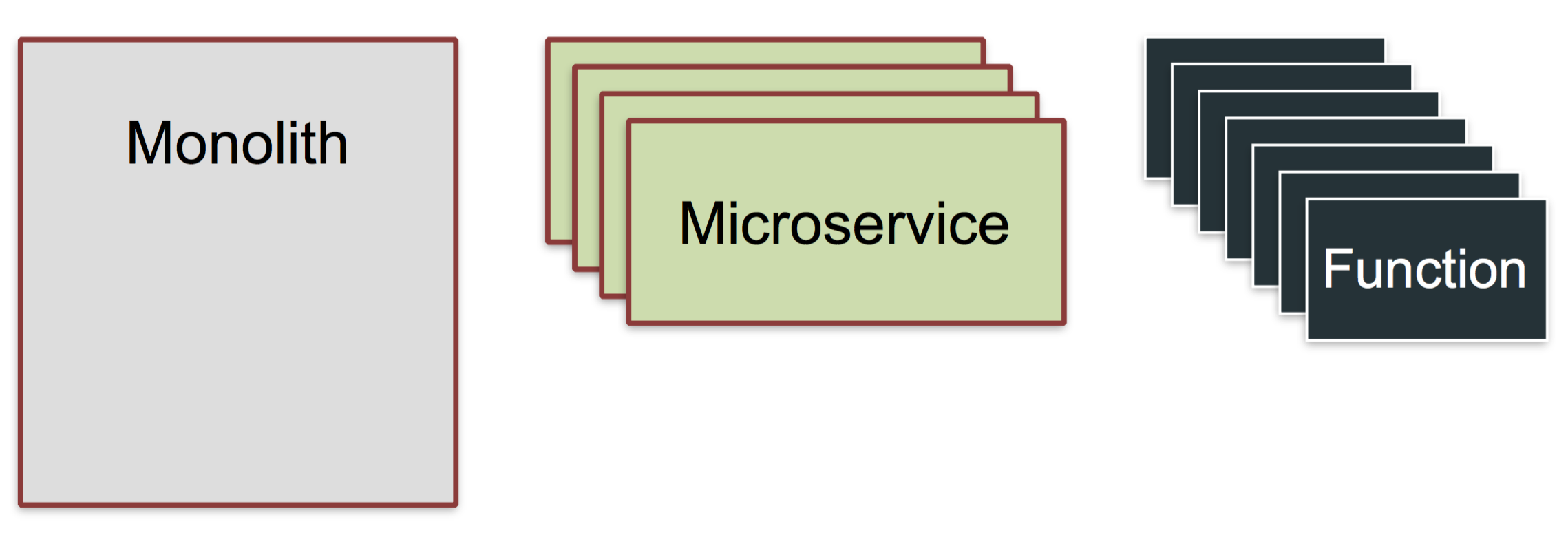
|
||||||
|
|
||||||
|
_Serverless 架构也引出了“功能即服务服务”模式,简称 FaaS_
|
||||||
|
|
||||||
|
Serverless 的“功能”可以做任何事,但通常用于处理给定的输入——例如来自 GitHub、Twitter、PayPal、Slack、Jenkins CI pipeline 的事件;或者以树莓派为例,处理像红外运动传感器、激光绊网、温度计等真实世界的传感器的输入。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Serverless 功能能够更好地结合第三方的后端服务,使系统整体的能力大于各部分之和。
|
||||||
|
|
||||||
|
了解更多背景信息,可以阅读我最近一偏博文:[功能即服务(FaaS)简介][34]。
|
||||||
|
|
||||||
|
### 概述
|
||||||
|
|
||||||
|
我们将使用 [OpenFaaS][35],它能够让主机或者集群作为支撑 Serverless 功能运行的后端。任何能够使用 Docker 部署的可执行二进制文件、脚本或者编程语言都能在 [OpenFaaS][36] 上运作,你可以根据速度和伸缩性选择部署的规模。另一个优点是,它还内建了用户界面和监控系统。
|
||||||
|
|
||||||
|
这是我们要执行的步骤:
|
||||||
|
|
||||||
|
* 在一个或多个主机上配置 Docker (树莓派 2 或者 3);
|
||||||
|
* 利用 Docker Swarm 将它们连接;
|
||||||
|
* 部署 [OpenFaaS][23];
|
||||||
|
* 使用 Python 编写我们的第一个功能。
|
||||||
|
|
||||||
|
### Docker Swarm
|
||||||
|
|
||||||
|
Docker 是一项打包和部署应用的技术,支持集群上运行,有着安全的默认设置,而且在搭建集群时只需要一条命令。OpenFaaS 使用 Docker 和 Swarm 在你的可用树莓派上传递你的 Serverless 功能。
|
||||||
|
|
||||||
|
我推荐你在这个项目中使用带树莓派 2 或者 3,以太网交换机和[强大的 USB 多端口电源适配器][37]。
|
||||||
|
|
||||||
|
### 准备 Raspbian
|
||||||
|
|
||||||
|
把 [Raspbian Jessie Lite][38] 写入 SD 卡(8GB 容量就正常工作了,但还是推荐使用 16GB 的 SD 卡)。
|
||||||
|
|
||||||
|
_注意:不要下载成 Raspbian Stretch 了_
|
||||||
|
|
||||||
|
> 社区在努力让 Docker 支持 Raspbian Stretch,但是还未能做到完美运行。请从[树莓派基金会网站][24]下载 Jessie Lite 镜像。
|
||||||
|
|
||||||
|
我推荐使用 [Etcher.io][39] 烧写镜像。
|
||||||
|
|
||||||
|
> 在引导树莓派之前,你需要在引导分区创建名为 `ssh` 的空白文件。这样才能允许远程登录。
|
||||||
|
|
||||||
|
#### 接通电源,然后修改主机名
|
||||||
|
|
||||||
|
现在启动树莓派的电源并且使用 `ssh` 连接:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ssh pi@raspberrypi.local
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
> 默认密码是 `raspberry`
|
||||||
|
|
||||||
|
使用 `raspi-config` 工具把主机名改为 `swarm-1` 或者类似的名字,然后重启。
|
||||||
|
|
||||||
|
当你到了这一步,你还可以把划分给 GPU (显卡)的内存设置为 16MB。
|
||||||
|
|
||||||
|
#### 现在安装 Docker
|
||||||
|
|
||||||
|
我们可以使用通用脚本来安装:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ curl -sSL https://get.docker.com | sh
|
||||||
|
```
|
||||||
|
|
||||||
|
> 这个安装方式在将来可能会发生变化。如上文所说,你的系统需要是 Jessie,这样才能得到一个确定的配置。
|
||||||
|
|
||||||
|
你可能会看到类似下面的警告,不过你可以安全地忽略它并且成功安装上 Docker CE 17.05:
|
||||||
|
|
||||||
|
```
|
||||||
|
WARNING: raspbian is no longer updated @ https://get.docker.com/
|
||||||
|
Installing the legacy docker-engine package...
|
||||||
|
```
|
||||||
|
|
||||||
|
之后,用下面这个命令确保你的用户帐号可以访问 Docker 客户端:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ usermod pi -aG docker
|
||||||
|
```
|
||||||
|
|
||||||
|
> 如果你的用户名不是 `pi`,那就把它替换成你的用户名。
|
||||||
|
|
||||||
|
#### 修改默认密码
|
||||||
|
|
||||||
|
输入 `$sudo passwd pi`,然后设置一个新密码,请不要跳过这一步!
|
||||||
|
|
||||||
|
#### 重复以上步骤
|
||||||
|
|
||||||
|
现在为其它的树莓派重复上述步骤。
|
||||||
|
|
||||||
|
### 创建你的 Swarm 集群
|
||||||
|
|
||||||
|
登录你的第一个树莓派,然后输入下面的命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ docker swarm init
|
||||||
|
Swarm initialized: current node (3ra7i5ldijsffjnmubmsfh767) is now a manager.
|
||||||
|
|
||||||
|
To add a worker to this swarm, run the following command:
|
||||||
|
|
||||||
|
docker swarm join \
|
||||||
|
--token SWMTKN-1-496mv9itb7584pzcddzj4zvzzfltgud8k75rvujopw15n3ehzu-af445b08359golnzhncbdj9o3 \
|
||||||
|
192.168.0.79:2377
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
你会看到它显示了一个口令,以及其它节点加入集群的命令。接下来使用 `ssh` 登录每个树莓派,运行这个加入集群的命令。
|
||||||
|
|
||||||
|
等待连接完成后,在第一个树莓派上查看集群的节点:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ docker node ls
|
||||||
|
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
|
||||||
|
3ra7i5ldijsffjnmubmsfh767 * swarm1 Ready Active Leader
|
||||||
|
k9mom28s2kqxocfq1fo6ywu63 swarm3 Ready Active
|
||||||
|
y2p089bs174vmrlx30gc77h4o swarm4 Ready Active
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
恭喜你!你现在拥有一个树莓派集群了!
|
||||||
|
|
||||||
|
#### 更多关于集群的内容
|
||||||
|
|
||||||
|
你可以看到三个节点启动运行。这时只有一个节点是集群管理者。如果我们的管理节点_死机_了,集群就进入了不可修复的状态。我们可以通过添加冗余的管理节点解决这个问题。而且它们依然会运行工作负载,除非你明确设置了让你的服务只运作在工作节点上。
|
||||||
|
|
||||||
|
要把一个工作节点升级为管理节点,只需要在其中一个管理节点上运行 `docker node promote <node_name>` 命令。
|
||||||
|
|
||||||
|
> 注意: Swarm 命令,例如 `docker service ls` 或者 `docker node ls` 只能在管理节点上运行。
|
||||||
|
|
||||||
|
想深入了解管理节点与工作节点如何保持一致性,可以查阅 [Docker Swarm 管理指南][40]。
|
||||||
|
|
||||||
|
### OpenFaaS
|
||||||
|
|
||||||
|
现在我们继续部署程序,让我们的集群能够运行 Serverless 功能。[OpenFaaS][41] 是一个利用 Docker 在任何硬件或者云上让任何进程或者容器成为一个 Serverless 功能的框架。因为 Docker 和 Golang 的可移植性,它也能很好地运行在树莓派上。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 如果你支持 [OpenFaaS][41],希望你能 **星标** [OpenFaaS][25] 的 GitHub 仓库。
|
||||||
|
|
||||||
|
登录你的第一个树莓派(你运行 `docker swarm init` 的节点),然后部署这个项目:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git clone https://github.com/alexellis/faas/
|
||||||
|
$ cd faas
|
||||||
|
$ ./deploy_stack.armhf.sh
|
||||||
|
Creating network func_functions
|
||||||
|
Creating service func_gateway
|
||||||
|
Creating service func_prometheus
|
||||||
|
Creating service func_alertmanager
|
||||||
|
Creating service func_nodeinfo
|
||||||
|
Creating service func_markdown
|
||||||
|
Creating service func_wordcount
|
||||||
|
Creating service func_echoit
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
你的其它树莓派会收到 Docer Swarm 的指令,开始从网上拉取这个 Docker 镜像,并且解压到 SD 卡上。这些工作会分布到各个节点上,所以没有哪个节点产生过高的负载。
|
||||||
|
|
||||||
|
这个过程会持续几分钟,你可以用下面指令查看它的完成状况:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ watch 'docker service ls'
|
||||||
|
ID NAME MODE REPLICAS IMAGE PORTS
|
||||||
|
57ine9c10xhp func_wordcount replicated 1/1 functions/alpine:latest-armhf
|
||||||
|
d979zipx1gld func_prometheus replicated 1/1 alexellis2/prometheus-armhf:1.5.2 *:9090->9090/tcp
|
||||||
|
f9yvm0dddn47 func_echoit replicated 1/1 functions/alpine:latest-armhf
|
||||||
|
lhbk1fc2lobq func_markdown replicated 1/1 functions/markdownrender:latest-armhf
|
||||||
|
pj814yluzyyo func_alertmanager replicated 1/1 alexellis2/alertmanager-armhf:0.5.1 *:9093->9093/tcp
|
||||||
|
q4bet4xs10pk func_gateway replicated 1/1 functions/gateway-armhf:0.6.0 *:8080->8080/tcp
|
||||||
|
v9vsvx73pszz func_nodeinfo replicated 1/1 functions/nodeinfo:latest-armhf
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
我们希望看到每个服务都显示 “1/1”。
|
||||||
|
|
||||||
|
你可以根据服务名查看该服务被调度到哪个树莓派上:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ docker service ps func_markdown
|
||||||
|
ID IMAGE NODE STATE
|
||||||
|
func_markdown.1 functions/markdownrender:latest-armhf swarm4 Running
|
||||||
|
```
|
||||||
|
|
||||||
|
状态一项应该显示 `Running`,如果它是 `Pending`,那么镜像可能还在下载中。
|
||||||
|
|
||||||
|
在这时,查看树莓派的 IP 地址,然后在浏览器中访问它的 8080 端口:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ifconfig
|
||||||
|
```
|
||||||
|
|
||||||
|
例如,如果你的 IP 地址是 192.168.0.100,那就访问 http://192.168.0.100:8080 。
|
||||||
|
|
||||||
|
这是你会看到 FaaS UI(也叫 API 网关)。这是你定义、测试、调用功能的地方。
|
||||||
|
|
||||||
|
点击名称为 “func_markdown” 的 Markdown 转换功能,输入一些 Markdown(这是 Wikipedia 用来组织内容的语言)文本。
|
||||||
|
|
||||||
|
然后点击 “invoke”。你会看到调用计数增加,屏幕下方显示功能调用的结果。
|
||||||
|
|
||||||
|
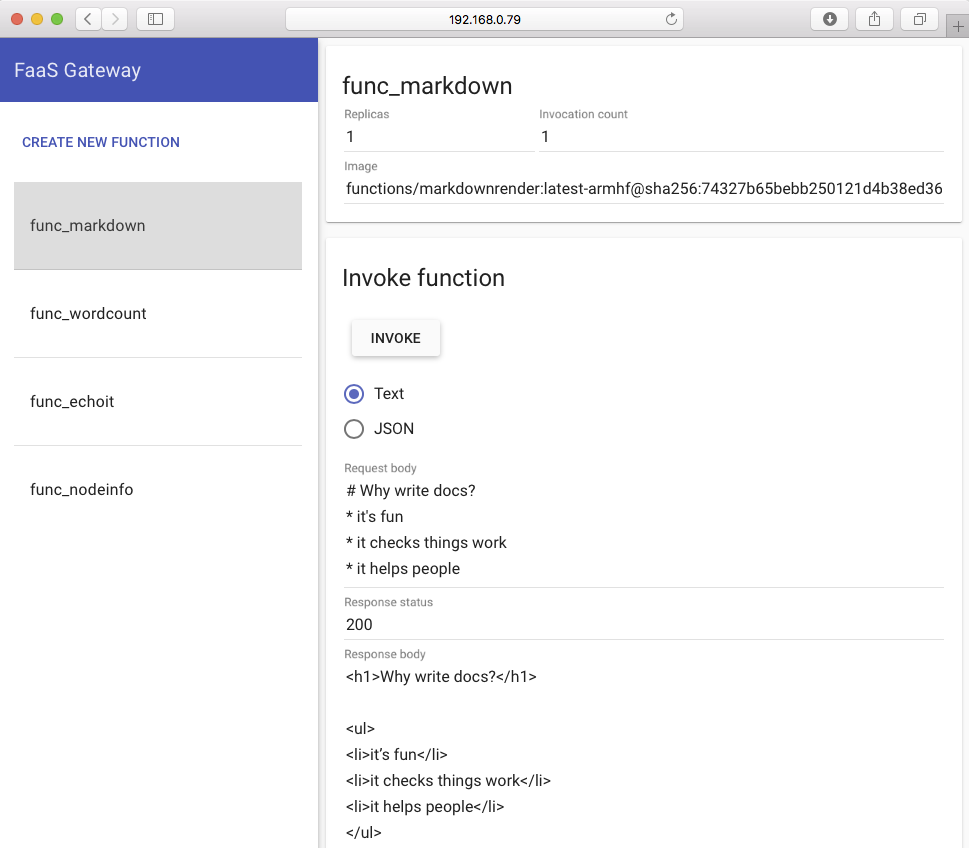
|
||||||
|
|
||||||
|
### 部署你的第一个 Serverless 功能:
|
||||||
|
|
||||||
|
这一节的内容已经有相关的教程,但是我们需要几个步骤来配置树莓派。
|
||||||
|
|
||||||
|
#### 获取 FaaS-CLI
|
||||||
|
|
||||||
|
```
|
||||||
|
$ curl -sSL cli.openfaas.com | sudo sh
|
||||||
|
armv7l
|
||||||
|
Getting package https://github.com/alexellis/faas-cli/releases/download/0.4.5-b/faas-cli-armhf
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 下载样例
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git clone https://github.com/alexellis/faas-cli
|
||||||
|
$ cd faas-cli
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 为树莓派修补样例模版
|
||||||
|
|
||||||
|
我们临时修改我们的模版,让它们能在树莓派上工作:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cp template/node-armhf/Dockerfile template/node/
|
||||||
|
$ cp template/python-armhf/Dockerfile template/python/
|
||||||
|
```
|
||||||
|
|
||||||
|
这么做是因为树莓派和我们平时关注的大多数计算机使用不一样的处理器架构。
|
||||||
|
|
||||||
|
> 了解 Docker 在树莓派上的最新状况,请查阅: [你需要了解的五件事][26]。
|
||||||
|
|
||||||
|
现在你可以跟着下面为 PC、笔记本和云端所写的教程操作,但我们在树莓派上要先运行一些命令。
|
||||||
|
|
||||||
|
* [使用 OpenFaaS 运行你的第一个 Serverless Python 功能][27]
|
||||||
|
|
||||||
|
注意第 3 步:
|
||||||
|
|
||||||
|
* 把你的功能放到先前从 GitHub 下载的 `faas-cli` 文件夹中,而不是 `~/functinos/hello-python` 里。
|
||||||
|
* 同时,在 `stack.yml` 文件中把 `localhost` 替换成第一个树莓派的 IP 地址。
|
||||||
|
|
||||||
|
集群可能会花费几分钟把 Serverless 功能下载到相关的树莓派上。你可以用下面的命令查看你的服务,确保副本一项显示 “1/1”:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ watch 'docker service ls'
|
||||||
|
pv27thj5lftz hello-python replicated 1/1 alexellis2/faas-hello-python-armhf:latest
|
||||||
|
```
|
||||||
|
|
||||||
|
**继续阅读教程:** [使用 OpenFaaS 运行你的第一个 Serverless Python 功能][43]
|
||||||
|
|
||||||
|
关于 Node.js 或者其它语言的更多信息,可以进一步访问 [FaaS 仓库][44]。
|
||||||
|
|
||||||
|
### 检查功能的指标
|
||||||
|
|
||||||
|
既然使用 Serverless,你也不想花时间监控你的功能。幸运的是,OpenFaaS 内建了 [Prometheus][45] 指标检测,这意味着你可以追踪每个功能的运行时长和调用频率。
|
||||||
|
|
||||||
|
#### 指标驱动自动伸缩
|
||||||
|
|
||||||
|
如果你给一个功能生成足够的负载,OpenFaaS 将自动扩展你的功能;当需求消失时,你又会回到单一副本的状态。
|
||||||
|
|
||||||
|
这个请求样例你可以复制到浏览器中:
|
||||||
|
|
||||||
|
只要把 IP 地址改成你的即可。
|
||||||
|
|
||||||
|
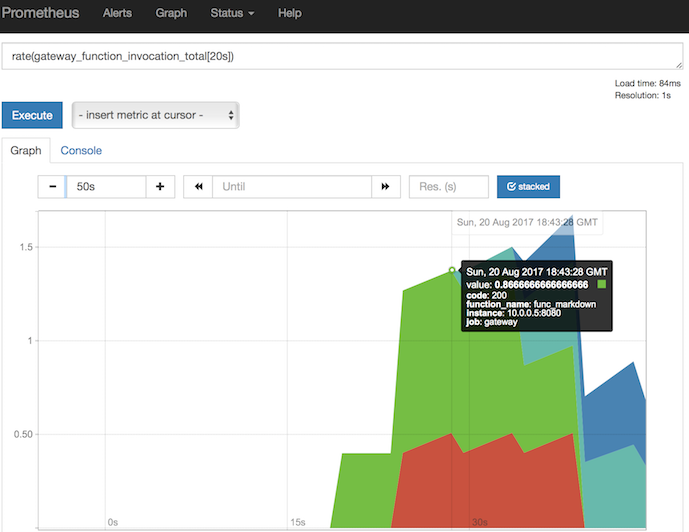
|
||||||
|
|
||||||
|
```
|
||||||
|
http://192.168.0.25:9090/graph?g0.range_input=15m&g0.stacked=1&g0.expr=rate(gateway_function_invocation_total%5B20s%5D)&g0.tab=0&g1.range_input=1h&g1.expr=gateway_service_count&g1.tab=0
|
||||||
|
```
|
||||||
|
|
||||||
|
这些请求使用 PromQL(Prometheus 请求语言)编写。第一个请求返回功能调用的频率:
|
||||||
|
|
||||||
|
```
|
||||||
|
rate(gateway_function_invocation_total[20s])
|
||||||
|
```
|
||||||
|
|
||||||
|
第二个请求显示每个功能的副本数量,最开始应该是每个功能只有一个副本。
|
||||||
|
|
||||||
|
```
|
||||||
|
gateway_service_count
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你想触发自动扩展,你可以在树莓派上尝试下面指令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ while [ true ]; do curl -4 localhost:8080/function/func_echoit --data "hello world" ; done
|
||||||
|
```
|
||||||
|
|
||||||
|
查看 Prometheus 的 “alerts” 页面,可以知道你是否产生足够的负载来触发自动扩展。如果没有,你可以尝试在多个终端同时运行上面的指令。
|
||||||
|
|
||||||
|
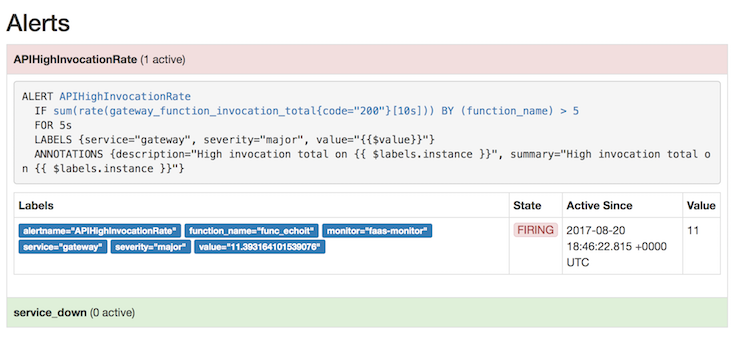
|
||||||
|
|
||||||
|
当你降低负载,副本数量显示在你的第二个图表中,并且 `gateway_service_count` 指标再次降回 1。
|
||||||
|
|
||||||
|
### 结束演讲
|
||||||
|
|
||||||
|
我们现在配置好了 Docker、Swarm, 并且让 OpenFaaS 运行代码,把树莓派像大型计算机一样使用。
|
||||||
|
|
||||||
|
> 希望大家支持这个项目,**星标** [FaaS 的 GitHub 仓库][28]。
|
||||||
|
|
||||||
|
你是如何搭建好了自己的 Docker Swarm 集群并且运行 OpenFaaS 的呢?在 Twitter [@alexellisuk][46] 上分享你的照片或推文吧。
|
||||||
|
|
||||||
|
**观看我在 Dockercon 上关于 OpenFaaS 的视频**
|
||||||
|
|
||||||
|
我在 [Austin 的 Dockercon][47] 上展示了 OpenFaaS。——观看介绍和互动例子的视频: https://www.youtube.com/embed/-h2VTE9WnZs
|
||||||
|
|
||||||
|
有问题?在下面的评论中提出,或者给我发邮件,邀请我进入你和志同道合者讨论树莓派、Docker、Serverless 的 Slack channel。
|
||||||
|
|
||||||
|
**想要学习更多关于树莓派上运行 Docker 的内容?**
|
||||||
|
|
||||||
|
我建议从 [你需要了解的五件事][48] 开始,它包含了安全性、树莓派和普通 PC 间微妙差别等话题。
|
||||||
|
|
||||||
|
* [Dockercon tips: Docker & Raspberry Pi][18]
|
||||||
|
* [Control GPIO with Docker Swarm][19]
|
||||||
|
* [Is that a Docker Engine in your pocket??][20]
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://blog.alexellis.io/your-serverless-raspberry-pi-cluster/
|
||||||
|
|
||||||
|
作者:[Alex Ellis][a]
|
||||||
|
译者:[haoqixu](https://github.com/haoqixu)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://twitter.com/alexellisuk
|
||||||
|
[1]:https://twitter.com/alexellisuk
|
||||||
|
[2]:https://twitter.com/intent/tweet?in_reply_to=898978596773138436
|
||||||
|
[3]:https://twitter.com/intent/retweet?tweet_id=898978596773138436
|
||||||
|
[4]:https://twitter.com/intent/like?tweet_id=898978596773138436
|
||||||
|
[5]:https://twitter.com/alexellisuk
|
||||||
|
[6]:https://twitter.com/alexellisuk
|
||||||
|
[7]:https://twitter.com/Docker
|
||||||
|
[8]:https://twitter.com/Raspberry_Pi
|
||||||
|
[9]:https://twitter.com/alexellisuk/status/898978596773138436
|
||||||
|
[10]:https://twitter.com/alexellisuk/status/899545370916728832/photo/1
|
||||||
|
[11]:https://twitter.com/alexellisuk
|
||||||
|
[12]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||||
|
[13]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||||
|
[14]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||||
|
[15]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||||
|
[16]:https://twitter.com/alexellisuk/status/899545370916728832/photo/1
|
||||||
|
[17]:https://support.twitter.com/articles/20175256
|
||||||
|
[18]:https://blog.alexellis.io/dockercon-tips-docker-raspberry-pi/
|
||||||
|
[19]:https://blog.alexellis.io/gpio-on-swarm/
|
||||||
|
[20]:https://blog.alexellis.io/docker-engine-in-your-pocket/
|
||||||
|
[21]:https://news.ycombinator.com/item?id=15052192
|
||||||
|
[22]:https://blog.alexellis.io/introducing-functions-as-a-service/
|
||||||
|
[23]:https://github.com/alexellis/faas
|
||||||
|
[24]:http://downloads.raspberrypi.org/raspbian_lite/images/raspbian_lite-2017-07-05/
|
||||||
|
[25]:https://github.com/alexellis/faas
|
||||||
|
[26]:https://blog.alexellis.io/5-things-docker-rpi/
|
||||||
|
[27]:https://blog.alexellis.io/first-faas-python-function
|
||||||
|
[28]:https://github.com/alexellis/faas
|
||||||
|
[29]:https://blog.alexellis.io/tag/docker/
|
||||||
|
[30]:https://blog.alexellis.io/tag/raspberry-pi/
|
||||||
|
[31]:https://blog.alexellis.io/tag/openfaas/
|
||||||
|
[32]:https://blog.alexellis.io/tag/faas/
|
||||||
|
[33]:https://github.com/alexellis/faas
|
||||||
|
[34]:https://blog.alexellis.io/introducing-functions-as-a-service/
|
||||||
|
[35]:https://github.com/alexellis/faas
|
||||||
|
[36]:https://github.com/alexellis/faas
|
||||||
|
[37]:https://www.amazon.co.uk/Anker-PowerPort-Family-Sized-Technology-Smartphones/dp/B00PK1IIJY
|
||||||
|
[38]:http://downloads.raspberrypi.org/raspbian/images/raspbian-2017-07-05/
|
||||||
|
[39]:https://etcher.io/
|
||||||
|
[40]:https://docs.docker.com/engine/swarm/admin_guide/
|
||||||
|
[41]:https://github.com/alexellis/faas
|
||||||
|
[42]:http://192.168.0.100:8080/
|
||||||
|
[43]:https://blog.alexellis.io/first-faas-python-function
|
||||||
|
[44]:https://github.com/alexellis/faas
|
||||||
|
[45]:https://prometheus.io/
|
||||||
|
[46]:https://twitter.com/alexellisuk
|
||||||
|
[47]:https://blog.alexellis.io/dockercon-2017-captains-log/
|
||||||
|
[48]:https://blog.alexellis.io/5-things-docker-rpi/
|
||||||
124
published/201710/20170903 Genymotion vs Android Emulator.md
Normal file
124
published/201710/20170903 Genymotion vs Android Emulator.md
Normal file
@ -0,0 +1,124 @@
|
|||||||
|
Genymotion vs Android 模拟器
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> Android 模拟器是否改善到足以取代 Genymotion
|
||||||
|
|
||||||
|
一直以来有关于选择 android 模拟器或者 Genymotion 的争论,我看到很多讨论最后以赞成 Genymotion 而告终。我根据我周围最常见的情况收集了一些数据,基于此,我将连同 Genymotion 全面评估 android 模拟器。
|
||||||
|
|
||||||
|
结论剧透:配置正确时,Android 模拟器比 Genymotion 快。
|
||||||
|
|
||||||
|
使用带 Google API 的 x86(32位)镜像、3GB RAM、四核CPU。
|
||||||
|
|
||||||
|
> - 哈,很高兴我们知道了最终结果
|
||||||
|
> - 现在,让我们深入
|
||||||
|
|
||||||
|
免责声明:我已经测试了我看到的一般情况,即运行测试。所有的基准测试都是在 2015 年中期的 MacBook Pro 上完成的。无论何时我提及 Genymotion 指的都是 Genymotion Desktop。他们还有其他产品,如 Genymotion on Cloud&Genymotion on Demand,但这里没有考虑。我不是说 Genymotion 是不合适的,但运行测试比某些 Android 模拟器慢。
|
||||||
|
|
||||||
|
关于这个问题的一点背景,然后我们将转到具体内容上去。
|
||||||
|
|
||||||
|
_过去:我有一些基准测试,继续下去。_
|
||||||
|
|
||||||
|
很久以前,Android 模拟器是唯一的选择。但是它们太慢了,这是架构改变的原因。对于在 x86 机器上运行的 ARM 模拟器,你能期待什么?每个指令都必须从 ARM 转换为 x86 架构,这使得它的速度非常慢。
|
||||||
|
|
||||||
|
随之而来的是 Android 的 x86 镜像,随着它们摆脱了 ARM 到 x86 平台转化,速度更快了。现在,你可以在 x86 机器上运行 x86 Android 模拟器。
|
||||||
|
|
||||||
|
> - _问题解决了!!!_
|
||||||
|
> - 没有!
|
||||||
|
|
||||||
|
Android 模拟器仍然比人们想要的慢。随后出现了 Genymotion,这是一个在 virtual box 中运行的 Android 虚拟机。与在 qemu 上运行的普通老式 android 模拟器相比,它相当稳定和快速。
|
||||||
|
|
||||||
|
我们来看看今天的情况。
|
||||||
|
|
||||||
|
我在持续集成的基础设施上和我的开发机器上使用 Genymotion。我手头的任务是摆脱持续集成基础设施和开发机器上使用 Genymotion。
|
||||||
|
|
||||||
|
> - 你问为什么?
|
||||||
|
> - 授权费钱。
|
||||||
|
|
||||||
|
在快速看了一下以后,这似乎是一个愚蠢的举动,因为 Android 模拟器的速度很慢而且有 bug,它们看起来适得其反,但是当你深入的时候,你会发现 Android 模拟器是优越的。
|
||||||
|
|
||||||
|
我们的情况是对它们进行集成测试(主要是 espresso)。我们的应用程序中只有 1100 多个测试,Genymotion 需要大约 23 分钟才能运行所有测试。
|
||||||
|
|
||||||
|
在 Genymotion 中我们面临的另一些问题是:
|
||||||
|
|
||||||
|
* 有限的命令行工具([GMTool][1])。
|
||||||
|
* 由于内存问题,它们需要定期重新启动。这是一个手动任务,想象在配有许多机器的持续集成基础设施上进行这些会怎样。
|
||||||
|
|
||||||
|
**进入 Android 模拟器**
|
||||||
|
|
||||||
|
首先是尝试在它给你这么多的选择中设置一个,这会让你会觉得你在赛百味餐厅一样。最大的问题是 x86 或 x86_64 以及是否有 Google API。
|
||||||
|
|
||||||
|
我用这些组合做了一些研究和基准测试,这是我们所想到的。
|
||||||
|
|
||||||
|
鼓声……
|
||||||
|
|
||||||
|
> - 比赛的获胜者是带 Google API 的 x86
|
||||||
|
> - 但是如何胜利的?为什么?
|
||||||
|
|
||||||
|
嗯,我会告诉你每一个问题。
|
||||||
|
|
||||||
|
x86_64 比 x86 慢
|
||||||
|
|
||||||
|
> - 你问慢多少。
|
||||||
|
> - 28.2% 多!!!
|
||||||
|
|
||||||
|
使用 Google API 的模拟器更加稳定,没有它们容易崩溃。
|
||||||
|
|
||||||
|
这使我们得出结论:最好的是带 Google API 的x86。
|
||||||
|
|
||||||
|
在我们抛弃 Genymotion 开始使用模拟器之前。有下面几点重要的细节。
|
||||||
|
|
||||||
|
* 我使用的是带 Google API 的 Nexus 5 镜像。
|
||||||
|
* 我注意到,给模拟器较少的内存会造成了很多 Google API 崩溃。所以为模拟器设定了 3GB 的 RAM。
|
||||||
|
* 模拟器有四核。
|
||||||
|
* HAXM 安装在主机上。
|
||||||
|
|
||||||
|
**基准测试的时候到了**
|
||||||
|
|
||||||
|
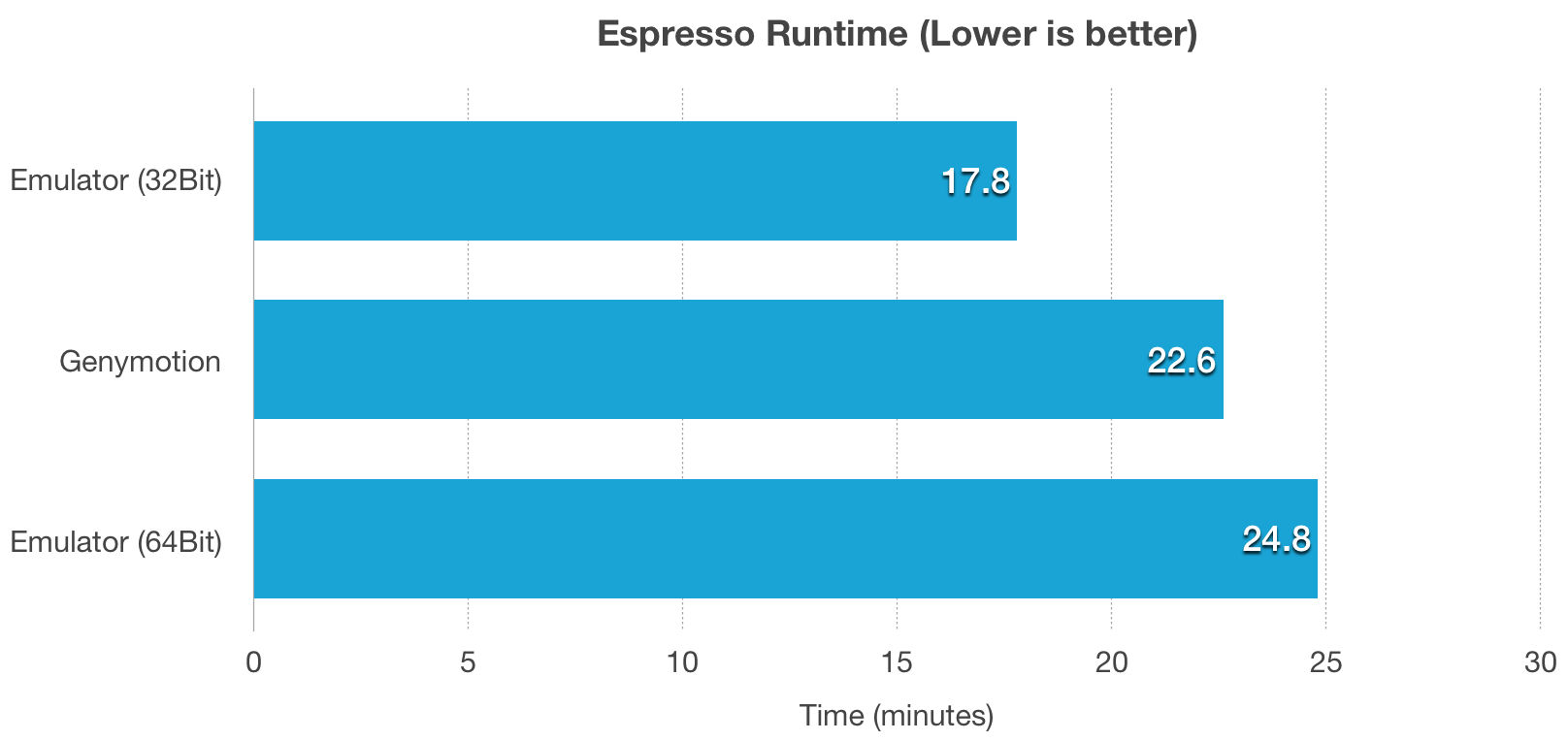
|
||||||
|
|
||||||
|
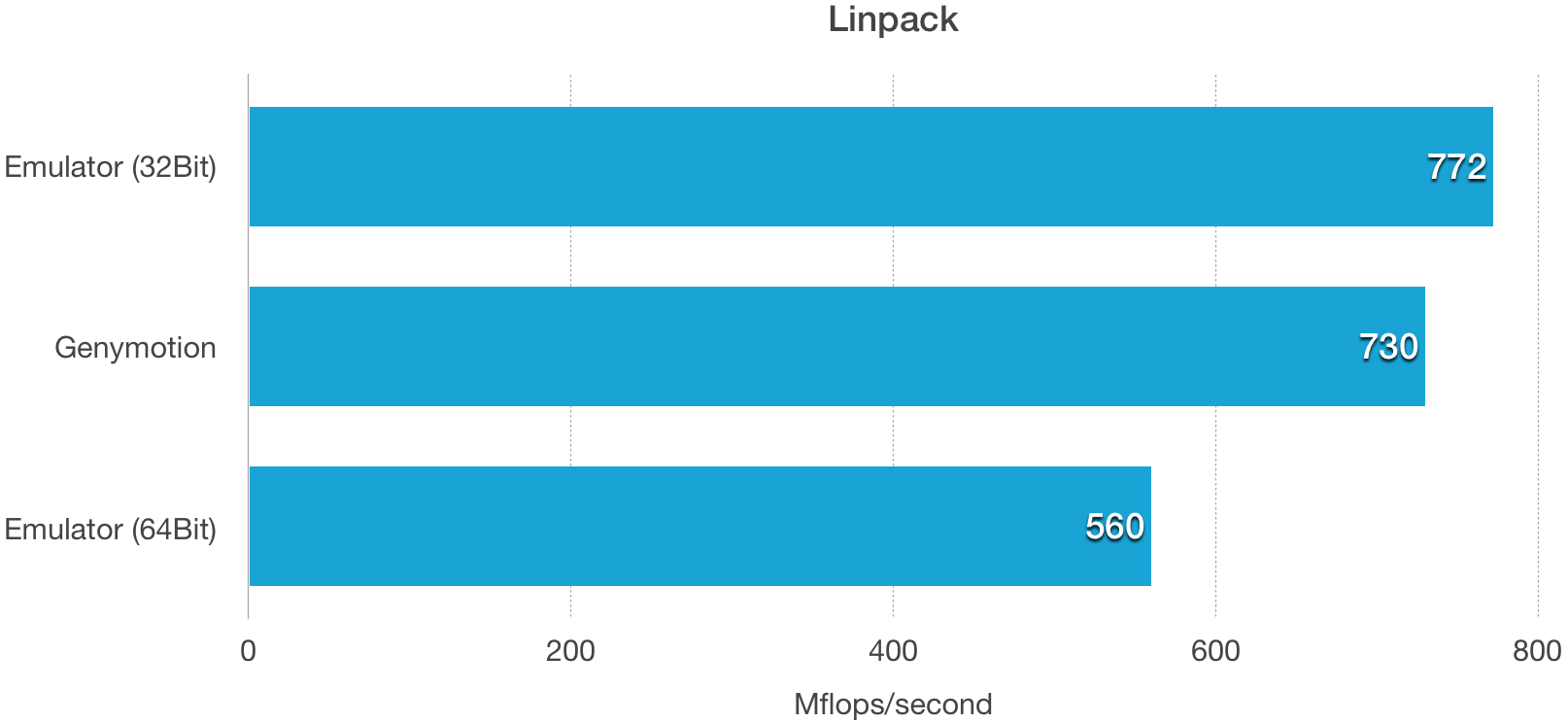
|
||||||
|
|
||||||
|
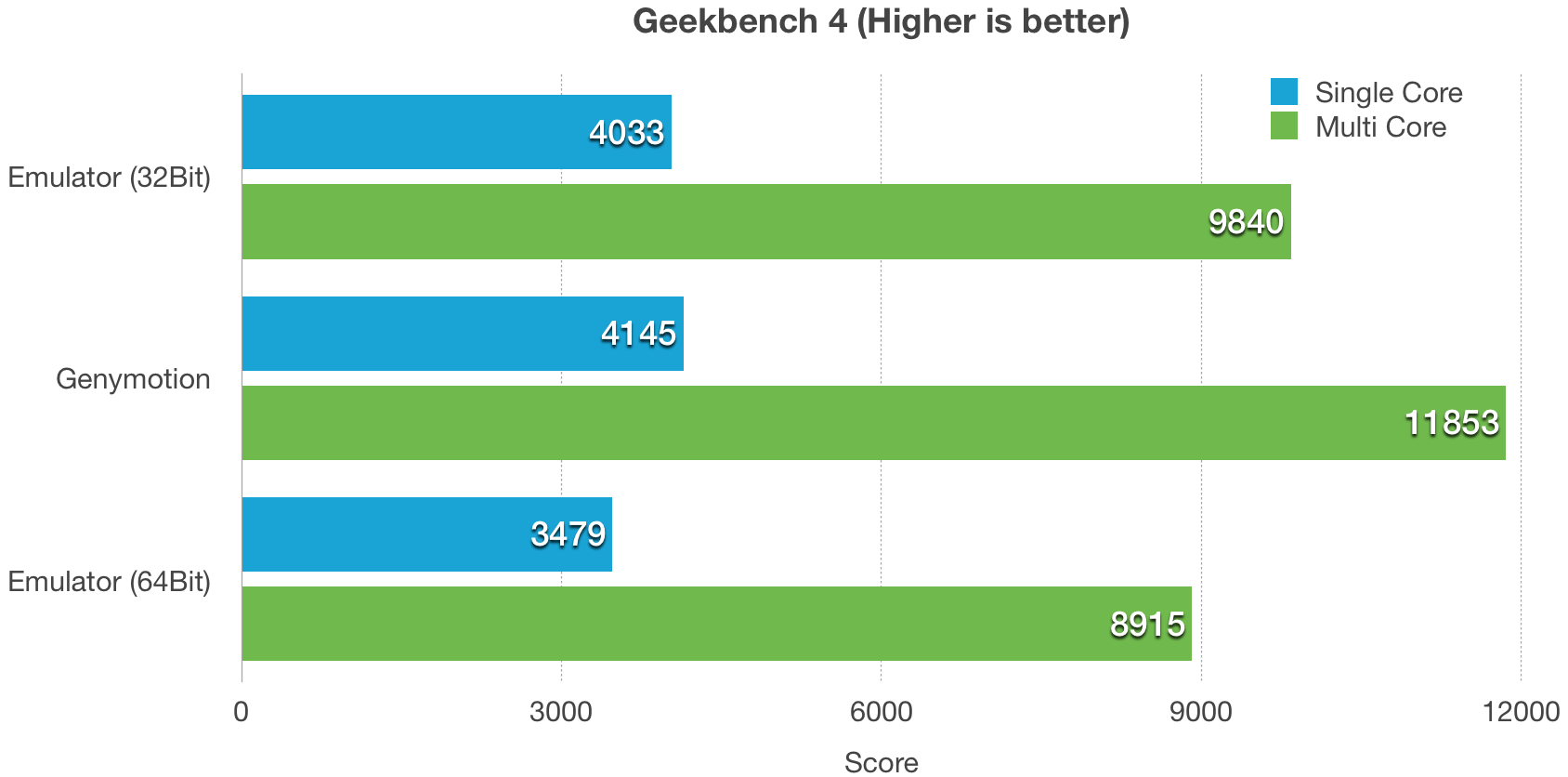
|
||||||
|
|
||||||
|
从基准测试上你可以看到除了 Geekbench4,Android 模拟器都击败了 Genymotion,我感觉更像是virtual box 击败了 qemu。
|
||||||
|
|
||||||
|
> 欢呼模拟器之王
|
||||||
|
|
||||||
|
我们现在有更快的测试执行时间、更好的命令行工具。最新的 [Android 模拟器][2]创下的新的记录。更快的启动时间之类。
|
||||||
|
|
||||||
|
Goolgle 一直努力让
|
||||||
|
|
||||||
|
> Android 模拟器变得更好
|
||||||
|
|
||||||
|
如果你没有在使用 Android 模拟器。我建议你重新试下,可以节省一些钱。
|
||||||
|
|
||||||
|
我尝试的另一个但是没有成功的方案是在 AWS 上运行 [Android-x86][3] 镜像。我能够在 vSphere ESXi Hypervisor 中运行它,但不能在 AWS 或任何其他云平台上运行它。如果有人知道原因,请在下面评论。
|
||||||
|
|
||||||
|
PS:[VMWare 现在可以在 AWS 上使用][4],在 AWS 上使用 [Android-x86][5] 毕竟是有可能的。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
嗨,我的名字是 Sumit Gupta。我是来自印度古尔冈的软件/应用/网页开发人员。我做这个是因为我喜欢技术,并且一直迷恋它。我已经工作了 3 年以上,但我还是有很多要学习。他们不是说如果你有知识,让别人点亮他们的蜡烛。
|
||||||
|
|
||||||
|
当在编译时,我阅读很多文章,或者听音乐。
|
||||||
|
|
||||||
|
如果你想联系,下面是我的社交信息和 [email][6]。
|
||||||
|
|
||||||
|
----
|
||||||
|
via: https://www.plightofbyte.com/android/2017/09/03/genymotion-vs-android-emulator/
|
||||||
|
|
||||||
|
作者:[Sumit Gupta][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.plightofbyte.com/about-me
|
||||||
|
[1]:https://docs.genymotion.com/Content/04_Tools/GMTool/GMTool.htm
|
||||||
|
[2]:https://developer.android.com/studio/releases/emulator.html
|
||||||
|
[3]:http://www.android-x86.org/
|
||||||
|
[4]:https://aws.amazon.com/vmware/
|
||||||
|
[5]:http://www.android-x86.org/
|
||||||
|
[6]:thesumitgupta@outlook.com
|
||||||
@ -0,0 +1,325 @@
|
|||||||
|
12 件可以用 GitHub 完成的很酷的事情
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
我不能为我的人生想出一个引子来,所以……
|
||||||
|
|
||||||
|
### #1 在 GitHub.com 上编辑代码
|
||||||
|
|
||||||
|
我想我要开始介绍的第一件事是多数人都已经知道的(尽管我一周之前还不知道)。
|
||||||
|
|
||||||
|
当你登录到 GitHub ,查看一个文件时(任何文本文件,任何版本库),右上方会有一只小铅笔。点击它,你就可以编辑文件了。 当你编辑完成后,GitHub 会给出文件变更的建议,然后为你<ruby>复刻<rt>fork</rt></ruby>该仓库并创建一个<ruby>拉取请求<rt>pull request</rt></ruby>(PR)。
|
||||||
|
|
||||||
|
是不是很疯狂?它为你创建了一个复刻!
|
||||||
|
|
||||||
|
你不需要自己去复刻、拉取,然后本地修改,再推送,然后创建一个 PR。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
*不是一个真正的 PR*
|
||||||
|
|
||||||
|
这对于修改错误拼写以及编辑代码时的一些糟糕的想法是很有用的。
|
||||||
|
|
||||||
|
### #2 粘贴图像
|
||||||
|
|
||||||
|
在评论和<ruby>工单<rt>issue</rt></ruby>的描述中并不仅限于使用文字。你知道你可以直接从剪切板粘贴图像吗? 在你粘贴的时候,你会看到图片被上传 (到云端,这毫无疑问),并转换成 markdown 显示的图片格式。
|
||||||
|
|
||||||
|
棒极了。
|
||||||
|
|
||||||
|
### #3 格式化代码
|
||||||
|
|
||||||
|
如果你想写一个代码块的话,你可以用三个反引号(```)作为开始 —— 就像你在浏览 [精通 Markdown][3] 时所学到的一样 —— 而且 GitHub 会尝试去推测你所写下的编程语言。
|
||||||
|
|
||||||
|
但如果你粘贴的像是 Vue、Typescript 或 JSX 这样的代码,你就需要明确指出才能获得高亮显示。
|
||||||
|
|
||||||
|
在首行注明 ````jsx`:
|
||||||
|
|
||||||
|
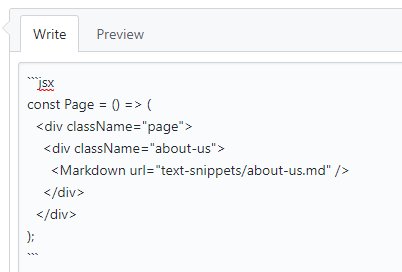
|
||||||
|
|
||||||
|
…这意味着代码段已经正确的呈现:
|
||||||
|
|
||||||
|
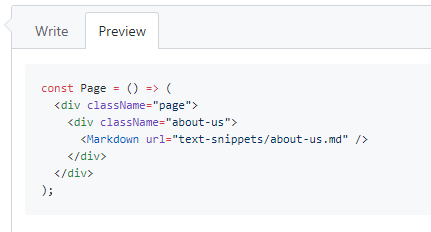
|
||||||
|
|
||||||
|
(顺便说一下,这些用法也可以用到 gist。 如果你给一个 gist 用上 `.jsx` 扩展名,你的 JSX 语法就会高亮显示。)
|
||||||
|
|
||||||
|
这里是[所有被支持的语法][4]的清单。
|
||||||
|
|
||||||
|
### #4 用 PR 中的魔法词来关闭工单
|
||||||
|
|
||||||
|
比方说你已经创建了一个用来修复 `#234` 工单的拉取请求。那么你就可以把 `fixes #234` 这段文字放在你的 PR 的描述中(或者是在 PR 的评论的任何位置)。
|
||||||
|
|
||||||
|
接下来,在合并 PR 时会自动关闭与之对应的工单。这是不是很酷?
|
||||||
|
|
||||||
|
这里是[更详细的学习帮助][5]。
|
||||||
|
|
||||||
|
### #5 链接到评论
|
||||||
|
|
||||||
|
是否你曾经想要链接到一个特定的评论但却无从着手?这是因为你不知道如何去做到这些。不过那都过去了,我的朋友,我告诉你啊,点击紧挨着名字的日期或时间,这就是如何链接到一个评论的方法。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
*嘿,这里有 gaearon 的照片!*
|
||||||
|
|
||||||
|
### #6 链接到代码
|
||||||
|
|
||||||
|
那么你想要链接到代码的特定行么。我了解了。
|
||||||
|
|
||||||
|
试试这个:在查看文件的时候,点击挨着代码的行号。
|
||||||
|
|
||||||
|
哇哦,你看到了么?URL 更新了,加上了行号!如果你按下 `Shift` 键并点击其他的行号,格里格里巴巴变!URL 再一次更新并且现在出现了行范围的高亮。
|
||||||
|
|
||||||
|
分享这个 URL 将会链接到这个文件的那些行。但等一下,链接所指向的是当前分支。如果文件发生变更了怎么办?也许一个文件当前状态的<ruby>永久链接<rt>permalink</rt></ruby>就是你以后需要的。
|
||||||
|
|
||||||
|
我比较懒,所以我已经在一张截图中做完了上面所有的步骤:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
*说起 URL…*
|
||||||
|
|
||||||
|
### #7 像命令行一样使用 GitHub URL
|
||||||
|
|
||||||
|
使用 UI 来浏览 GitHub 有着很好的体验。但有些时候最快到达你想去的地方的方法就是在地址栏输入。举个例子,如果我想要跳转到一个我正在工作的分支,然后查看与 master 分支的差异,我就可以在我的仓库名称的后边输入 `/compare/branch-name` 。
|
||||||
|
|
||||||
|
这样就会访问到指定分支的 diff 页面。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
然而这就是与 master 分支的 diff,如果我要与 develoment 分支比较,我可以输入 `/compare/development...my-branch`。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
对于你这种键盘快枪手来说,`ctrl`+`L` 或 `cmd`+`L` 将会向上跳转光标进入 URL 那里(至少在 Chrome 中是这样)。这(再加上你的浏览器会自动补全)能够成为一种在分支间跳转的便捷方式。
|
||||||
|
|
||||||
|
专家技巧:使用方向键在 Chrome 的自动完成建议中移动同时按 `shift`+`delete` 来删除历史条目(例如,一旦分支被合并后)。
|
||||||
|
|
||||||
|
(我真的好奇如果我把快捷键写成 `shift + delete` 这样的话,是不是读起来会更加容易。但严格来说 ‘+’ 并不是快捷键的一部分,所以我并不觉得这很舒服。这一点纠结让 _我_ 整晚难以入睡,Rhonda。)
|
||||||
|
|
||||||
|
### #8 在工单中创建列表
|
||||||
|
|
||||||
|
你想要在你的<ruby>工单<rt>issue</rt></ruby>中看到一个复选框列表吗?
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
你想要在工单列表中显示为一个漂亮的 “2 of 5” 进度条吗?
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
很好!你可以使用这些的语法创建交互式的复选框:
|
||||||
|
|
||||||
|
```
|
||||||
|
- [ ] Screen width (integer)
|
||||||
|
- [x] Service worker support
|
||||||
|
- [x] Fetch support
|
||||||
|
- [ ] CSS flexbox support
|
||||||
|
- [ ] Custom elements
|
||||||
|
```
|
||||||
|
|
||||||
|
它的表示方法是空格、破折号、再空格、左括号、填入空格(或者一个 `x` ),然后封闭括号,接着空格,最后是一些话。
|
||||||
|
|
||||||
|
然后你可以实际选中或取消选中这些框!出于一些原因这些对我来说看上去就像是技术魔法。你可以_选中_这些框! 同时底层的文本会进行更新。
|
||||||
|
|
||||||
|
他们接下来会想到什么魔法?
|
||||||
|
|
||||||
|
噢,如果你在一个<ruby>项目面板<rt>project board</rt></ruby>上有这些工单的话,它也会在这里显示进度:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
如果在我提到“在一个项目面板上”时你不知道我在说些什么,那么你会在本页下面进一步了解。
|
||||||
|
|
||||||
|
比如,在本页面下 2 厘米的地方。
|
||||||
|
|
||||||
|
### #9 GitHub 上的项目面板
|
||||||
|
|
||||||
|
我常常在大项目中使用 Jira 。而对于个人项目我总是会使用 Trello 。我很喜欢它们两个。
|
||||||
|
|
||||||
|
当我学会 GitHub 的几周后,它也有了自己的项目产品,就在我的仓库上的 Project 标签,我想我会照搬一套我已经在 Trello 上进行的任务。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
*没有一个是有趣的任务*
|
||||||
|
|
||||||
|
这里是在 GitHub 项目上相同的内容:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
*你的眼睛最终会适应这种没有对比的显示*
|
||||||
|
|
||||||
|
出于速度的缘故,我把上面所有的都添加为 “<ruby>备注<rt>note</rt></ruby>” —— 意思是它们不是真正的 GitHub 工单。
|
||||||
|
|
||||||
|
但在 GitHub 上,管理任务的能力被集成在版本库的其他地方 —— 所以你可能想要从仓库添加已有的工单到面板上。
|
||||||
|
|
||||||
|
你可以点击右上角的<ruby>添加卡片<rt>Add Cards</rt></ruby>,然后找你想要添加的东西。在这里,特殊的[搜索语法][6]就派上用场了,举个例子,输入 `is:pr is:open` 然后现在你可以拖动任何开启的 PR 到项目面板上,或者要是你想清理一些 bug 的话就输入 `label:bug`。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
亦或者你可以将现有的备注转换为工单。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
再或者,从一个现有工单的屏幕上,把它添加到右边面板的项目上。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
它们将会进入那个项目面板的分类列表,这样你就能决定放到哪一类。
|
||||||
|
|
||||||
|
在实现那些任务的同一个仓库下放置任务的内容有一个巨大(超大)的好处。这意味着今后的几年你能够在一行代码上做一个 `git blame`,可以让你找出最初在这个任务背后写下那些代码的根据,而不需要在 Jira、Trello 或其它地方寻找蛛丝马迹。
|
||||||
|
|
||||||
|
#### 缺点
|
||||||
|
|
||||||
|
在过去的三周我已经对所有的任务使用 GitHub 取代 Jira 进行了测试(在有点看板风格的较小规模的项目上) ,到目前为止我都很喜欢。
|
||||||
|
|
||||||
|
但是我无法想象在 scrum(LCTT 译注:迭代式增量软件开发过程)项目上使用它,我想要在那里完成正确的工期估算、开发速度的测算以及所有的好东西怕是不行。
|
||||||
|
|
||||||
|
好消息是,GitHub 项目只有很少一些“功能”,并不会让你花很长时间去评估它是否值得让你去切换。因此要不要试试,你自己看着办。
|
||||||
|
|
||||||
|
无论如何,我_听说过_ [ZenHub][7] 并且在 10 分钟前第一次打开了它。它是对 GitHub 高效的延伸,可以让你估计你的工单并创建 epic 和 dependency。它也有 velocity 和<ruby>燃尽图<rt>burndown chart</rt></ruby>功能;这看起来_可能是_世界上最棒的东西了。
|
||||||
|
|
||||||
|
延伸阅读: [GitHub help on Projects][8]。
|
||||||
|
|
||||||
|
### #10 GitHub 维基
|
||||||
|
|
||||||
|
对于一堆非结构化页面(就像维基百科一样), GitHub <ruby>维基<rt>wiki</rt></ruby>提供的(下文我会称之为 Gwiki)就很优秀。
|
||||||
|
|
||||||
|
结构化的页面集合并没那么多,比如说你的文档。这里没办法说“这个页面是那个页面的子页”,或者有像‘下一节’和‘上一节’这样的按钮。Hansel 和 Gretel 将会完蛋,因为这里没有面包屑导航(LCTT 译注:引自童话故事《糖果屋》)。
|
||||||
|
|
||||||
|
(边注,你有_读过_那个故事吗? 这是个残酷的故事。两个混蛋小子将饥肠辘辘的老巫婆烧死在_她自己的火炉_里。毫无疑问她是留下来收拾残局的。我想这就是为什么如今的年轻人是如此的敏感 —— 今天的睡前故事太不暴力了。)
|
||||||
|
|
||||||
|
继续 —— 把 Gwiki 拿出来接着讲,我输入一些 NodeJS 文档中的内容作为维基页面,然后创建一个侧边栏以模拟一些真实结构。这个侧边栏会一直存在,尽管它无法高亮显示你当前所在的页面。
|
||||||
|
|
||||||
|
其中的链接必须手动维护,但总的来说,我认为这已经很好了。如果你觉得有需要的话可以[看一下][9]。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
它将不会与像 GitBook(它使用了 [Redux 文档][10])或定制的网站这样的东西相比较。但它八成够用了,而且它就在你的仓库里。
|
||||||
|
|
||||||
|
我是它的一个粉丝。
|
||||||
|
|
||||||
|
我的建议:如果你已经拥有不止一个 `README.md` 文件,并且想要一些不同的页面作为用户指南或是更详细的文档,那么下一步你就需要停止使用 Gwiki 了。
|
||||||
|
|
||||||
|
如果你开始觉得缺少的结构或导航非常有必要的话,去切换到其他的产品吧。
|
||||||
|
|
||||||
|
### #11 GitHub 页面(带有 Jekyll)
|
||||||
|
|
||||||
|
你可能已经知道了可以使用 GitHub <ruby>页面<rt>Pages</rt></ruby> 来托管静态站点。如果你不知道的话现在就可以去试试。不过这一节确切的说是关于使用 Jekyll 来构建一个站点。
|
||||||
|
|
||||||
|
最简单的来说, GitHub 页面 + Jekyll 会将你的 `README.md` 呈现在一个漂亮的主题中。举个例子,看看我的 [关于 github][11] 中的 readme 页面:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
点击 GitHub 上我的站点的<ruby>设置<rt>settings</rt></ruby>标签,开启 GitHub 页面功能,然后挑选一个 Jekyll 主题……
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
我就会得到一个 [Jekyll 主题的页面][12]:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
由此我可以构建一个主要基于易于编辑的 markdown 文件的静态站点,其本质上是把 GitHub 变成一个 CMS(LCTT 译注:内容管理系统)。
|
||||||
|
|
||||||
|
我还没有真正的使用过它,但这就是 React 和 Bootstrap 网站构建的过程,所以并不可怕。
|
||||||
|
|
||||||
|
注意,在本地运行它需要 Ruby (Windows 用户会彼此交换一下眼神,然后转头看向其它的方向。macOS 用户会发出这样这样的声音 “出什么问题了,你要去哪里?Ruby 可是一个通用平台!GEMS 万岁!”)。
|
||||||
|
|
||||||
|
(这里也有必要加上,“暴力或威胁的内容或活动” 在 GitHub 页面上是不允许的,因此你不能去部署你的 Hansel 和 Gretel 重启之旅了。)
|
||||||
|
|
||||||
|
#### 我的意见
|
||||||
|
|
||||||
|
为了这篇文章,我对 GitHub 页面 + Jekyll 研究越多,就越觉得这件事情有点奇怪。
|
||||||
|
|
||||||
|
“拥有你自己的网站,让所有的复杂性远离”这样的想法是很棒的。但是你仍然需要在本地生成配置。而且可怕的是需要为这样“简单”的东西使用很多 CLI(LCTT 译注:命令行界面)命令。
|
||||||
|
|
||||||
|
我只是略读了[入门部分][13]的七页,给我的感觉像是_我才是_那个小白。此前我甚至从来没有学习过所谓简单的 “Front Matter” 的语法或者所谓简单的 “Liquid 模板引擎” 的来龙去脉。
|
||||||
|
|
||||||
|
我宁愿去手工编写一个网站。
|
||||||
|
|
||||||
|
老实说我有点惊讶 Facebook 使用它来写 React 文档,因为他们能够用 React 来构建他们的帮助文档,并且在一天之内[预渲染到静态的 HTML 文件][14]。
|
||||||
|
|
||||||
|
他们所需要做的就是利用已有的 Markdown 文件,就像跟使用 CMS 一样。
|
||||||
|
|
||||||
|
我想是这样……
|
||||||
|
|
||||||
|
### #12 使用 GitHub 作为 CMS
|
||||||
|
|
||||||
|
比如说你有一个带有一些文本的网站,但是你并不想在 HTML 的标记中储存那些文本。
|
||||||
|
|
||||||
|
取而代之,你想要把这堆文本存放到某个地方,以便非开发者也可以很容易地编辑。也许要使用某种形式的版本控制。甚至还可能需要一个审查过程。
|
||||||
|
|
||||||
|
这里是我的建议:在你的版本库中使用 markdown 文件存储文本。然后在你的前端使用插件来获取这些文本块并在页面呈现。
|
||||||
|
|
||||||
|
我是 React 的支持者,因此这里有一个 `<Markdown>` 插件的示例,给出一些 markdown 的路径,它就会被获取、解析,并以 HTML 的形式呈现。
|
||||||
|
|
||||||
|
(我正在使用 [marked][1] npm 包来将 markdown 解析为 HTML。)
|
||||||
|
|
||||||
|
这里是我的示例仓库 [/text-snippets][2],里边有一些 markdown 文件 。
|
||||||
|
|
||||||
|
(你也可以使用 GitHub API 来[获取内容][15] —— 但我不确定你是否能搞定。)
|
||||||
|
|
||||||
|
你可以像这样使用插件:
|
||||||
|
|
||||||
|
如此,GitHub 就是你的 CMS 了,可以说,不管有多少文本块都可以放进去。
|
||||||
|
|
||||||
|
上边的示例只是在浏览器上安装好插件后获取 markdown 。如果你想要一个静态站点那么你需要服务器端渲染。
|
||||||
|
|
||||||
|
有个好消息!没有什么能阻止你从服务器中获取所有的 markdown 文件 (并配上各种为你服务的缓存策略)。如果你沿着这条路继续走下去的话,你可能会想要去试试使用 GitHub API 去获取目录中的所有 markdown 文件的列表。
|
||||||
|
|
||||||
|
### 奖励环节 —— GitHub 工具!
|
||||||
|
|
||||||
|
我曾经使用过一段时间的 [Chrome 的扩展 Octotree][16],而且现在我推荐它。虽然不是吐血推荐,但不管怎样我还是推荐它。
|
||||||
|
|
||||||
|
它会在左侧提供一个带有树状视图的面板以显示当前你所查看的仓库。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
从[这个视频][17]中我了解到了 [octobox][18] ,到目前为止看起来还不错。它是一个 GitHub 工单的收件箱。这一句介绍就够了。
|
||||||
|
|
||||||
|
说到颜色,在上面所有的截图中我都使用了亮色主题,所以希望不要闪瞎你的双眼。不过说真的,我看到的其他东西都是黑色的主题,为什么我非要忍受 GitHub 这个苍白的主题呐?
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
这是由 Chrome 扩展 [Stylish][19](它可以在任何网站使用主题)和 [GitHub Dark][20] 风格的一个组合。要完全黑化,那黑色主题的 Chrome 开发者工具(这是内建的,在设置中打开) 以及 [Atom One Dark for Chrome 主题][21]你肯定也需要。
|
||||||
|
|
||||||
|
### Bitbucket
|
||||||
|
|
||||||
|
这些内容不适合放在这篇文章的任何地方,但是如果我不称赞 Bitbucket 的话,那就不对了。
|
||||||
|
|
||||||
|
两年前我开始了一个项目并花了大半天时间评估哪一个 git 托管服务更适合,最终 Bitbucket 赢得了相当不错的成绩。他们的代码审查流程遥遥领先(这甚至比 GitHub 拥有的指派审阅者的概念要早很长时间)。
|
||||||
|
|
||||||
|
GitHub 后来在这次审查竞赛中追了上来,干的不错。不幸的是在过去的一年里我没有机会再使用 Bitbucket —— 也许他们依然在某些方面领先。所以,我会力劝每一个选择 git 托管服务的人考虑一下 Bitbucket 。
|
||||||
|
|
||||||
|
### 结尾
|
||||||
|
|
||||||
|
就是这样!我希望这里至少有三件事是你此前并不知道的,祝好。
|
||||||
|
|
||||||
|
修订:在评论中有更多的技巧;请尽管留下你自己喜欢的技巧。真的,真心祝好。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://hackernoon.com/12-cool-things-you-can-do-with-github-f3e0424cf2f0
|
||||||
|
|
||||||
|
作者:[David Gilbertson][a]
|
||||||
|
译者:[softpaopao](https://github.com/softpaopao)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://hackernoon.com/@david.gilbertson
|
||||||
|
[1]:https://www.npmjs.com/package/marked
|
||||||
|
[2]:https://github.com/davidgilbertson/about-github/tree/master/text-snippets
|
||||||
|
[3]:https://guides.github.com/features/mastering-markdown/
|
||||||
|
[4]:https://github.com/github/linguist/blob/fc1404985abb95d5bc33a0eba518724f1c3c252e/vendor/README.md
|
||||||
|
[5]:https://help.github.com/articles/closing-issues-using-keywords/
|
||||||
|
[6]:https://help.github.com/articles/searching-issues-and-pull-requests/
|
||||||
|
[7]:https://www.zenhub.com/
|
||||||
|
[8]:https://help.github.com/articles/tracking-the-progress-of-your-work-with-project-boards/
|
||||||
|
[9]:https://github.com/davidgilbertson/about-github/wiki
|
||||||
|
[10]:http://redux.js.org/
|
||||||
|
[11]:https://github.com/davidgilbertson/about-github
|
||||||
|
[12]:https://davidgilbertson.github.io/about-github/
|
||||||
|
[13]:https://jekyllrb.com/docs/home/
|
||||||
|
[14]:https://github.com/facebookincubator/create-react-app/blob/master/packages/react-scripts/template/README.md#pre-rendering-into-static-html-files
|
||||||
|
[15]:https://developer.github.com/v3/repos/contents/#get-contents
|
||||||
|
[16]:https://chrome.google.com/webstore/detail/octotree/bkhaagjahfmjljalopjnoealnfndnagc?hl=en-US
|
||||||
|
[17]:https://www.youtube.com/watch?v=NhlzMcSyQek&index=2&list=PLNYkxOF6rcIB3ci6nwNyLYNU6RDOU3YyL
|
||||||
|
[18]:https://octobox.io/
|
||||||
|
[19]:https://chrome.google.com/webstore/detail/stylish-custom-themes-for/fjnbnpbmkenffdnngjfgmeleoegfcffe/related?hl=en
|
||||||
|
[20]:https://userstyles.org/styles/37035/github-dark
|
||||||
|
[21]:https://chrome.google.com/webstore/detail/atom-one-dark-theme/obfjhhknlilnfgfakanjeimidgocmkim?hl=en
|
||||||
@ -0,0 +1,57 @@
|
|||||||
|
如何让网站不下线而从 Redis 2 迁移到 Redis 3
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
我们在 Sky Betting&Gaming 中使用 [Redis][2] 作为共享内存缓存,用于那些需要跨 API 服务器或者 Web 服务器鉴别令牌之类的操作。在 Core Tribe 内,它用来帮助处理日益庞大的登录数量,特别是在繁忙的时候,我们在一分钟内登录数量会超过 20,000 人。这在很大程度上适用于数据存放在大量服务器的情况下(在 SSO 令牌用于 70 台 Apache HTTPD 服务器的情况下)。我们最近着手升级 Redis 服务器,此升级旨在使用 Redis 3.2 提供的原生集群功能。这篇博客希望解释为什么我们要使用集群、我们遇到的问题以及我们的解决方案。
|
||||||
|
|
||||||
|
### 在开始阶段(或至少在升级之前)
|
||||||
|
|
||||||
|
我们的传统缓存中每个缓存都包括一对 Redis 服务器,使用 keepalive 确保始终有一个主节点监听<ruby>浮动 IP <rt>floating IP</rt></ruby>地址。当出现问题时,这些服务器对需要很大的精力来进行管理,而故障模式有时是非常各种各样的。有时,只允许读取它所持有的数据,而不允许写入的从属节点却会得到浮动 IP 地址,这种问题是相对容易诊断的,但会让无论哪个程序试图使用该缓存时都很麻烦。
|
||||||
|
|
||||||
|
### 新的应用程序
|
||||||
|
|
||||||
|
因此,这种情况下,我们需要构建一个新的应用程序,一个使用<ruby>共享内存缓存<rt>shared in-memory cache</rt></ruby>的应用程序,但是我们不希望对该缓存进行迂回的故障切换过程。因此,我们的要求是共享的内存缓存,没有单点故障,可以使用尽可能少的人为干预来应对多种不同的故障模式,并且在事件恢复之后也能够在很少的人为干预下恢复,一个额外的要求是提高缓存的安全性,以减少数据泄露的范围(稍后再说)。当时 Redis Sentinel 看起来很有希望,并且有许多程序支持代理 Redis 连接,比如 [twemproxy][3]。这会导致还要安装其它很多组件,它应该有效,并且人际交互最少,但它复杂而需要运行大量的服务器和服务,并且相互通信。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
将会有大量的应用服务器与 twemproxy 进行通信,这会将它们的调用路由到合适的 Redis 主节点,twemproxy 将从 sentinal 集群获取主节点的信息,它将控制哪台 Redis 实例是主,哪台是从。这个设置是复杂的,而且仍有单点故障,它依赖于 twemproxy 来处理分片,来连接到正确的 Redis 实例。它具有对应用程序透明的优点,所以我们可以在理论上做到将现有的应用程序转移到这个 Redis 配置,而不用改变应用程序。但是我们要从头开始构建一个应用程序,所以迁移应用程序不是一个必需条件。
|
||||||
|
|
||||||
|
幸运的是,这个时候,Redis 3.2 出来了,而且内置了原生集群,消除了对单一 sentinel 集群需要。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
它有一个更简单的设置,但 twemproxy 不支持 Redis 集群分片,它能为你分片数据,但是如果尝试在与分片不一致的集群中这样做会导致问题。有参考的指南可以使其匹配,但是集群可以自动改变形式,并改变分片的设置方式。它仍然有单点故障。正是在这一点上,我将永远感谢我的一位同事发现了一个 Node.js 的 Redis 的集群发现驱动程序,让我们完全放弃了 twemproxy。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
因此,我们能够自动分片数据,故障转移和故障恢复基本上是自动的。应用程序知道哪些节点存在,并且在写入数据时,如果写入错误的节点,集群将自动重定向该写入。这是被选的配置,这让我们共享的内存缓存相当健壮,可以没有干预地应付基本的故障模式。在测试期间,我们的确发现了一些缺陷。复制是在一个接一个节点的基础上进行的,因此如果我们丢失了一个主节点,那么它的从节点会成为一个单点故障,直到死去的节点恢复服务,也只有主节点对集群健康投票,所以如果我们一下失去太多主节点,那么集群无法自我恢复。但这比我们过去的好。
|
||||||
|
|
||||||
|
### 向前进
|
||||||
|
|
||||||
|
随着使用集群 Redis 配置的新程序,我们对于老式 Redis 实例的状态变得越来越不适应,但是新程序与现有程序的规模并不相同(超过 30GB 的内存专用于我们最大的老式 Redis 实例数据库)。因此,随着 Redis 集群在底层得到了证实,我们决定迁移老式的 Redis 实例到新的 Redis 集群中。
|
||||||
|
|
||||||
|
由于我们有一个原生支持 Redis 集群的 Node.js Redis 驱动程序,因此我们开始将 Node.js 程序迁移到 Redis 集群。但是,如何将数十亿字节的数据从一个地方移动到另一个地方,而不会造成重大问题?特别是考虑到这些数据是认证令牌,所以如果它们错了,我们的终端用户将会被登出。一个选择是要求网站完全下线,将所有内容都指向新的 Redis 群集,并将数据迁移到其中,以希望获得最佳效果。另一个选择是切换到新集群,并强制所有用户再次登录。由于显而易见的原因,这些都不是非常合适的。我们决定采取的替代方法是将数据同时写入老式 Redis 实例和正在替换它的集群,同时随着时间的推移,我们将逐渐更多地向该集群读取。由于数据的有效期有限(令牌在几个小时后到期),这种方法可以导致零停机,并且不会有数据丢失的风险。所以我们这么做了。迁移是成功的。
|
||||||
|
|
||||||
|
剩下的就是服务于我们的 PHP 代码(其中还有一个项目是有用的,其它的最终是没必要的)的 Redis 的实例了,我们在这过程中遇到了一个困难,实际上是两个。首先,也是最紧迫的是找到在 PHP 中使用的 Redis 集群发现驱动程序,还要是我们正在使用的 PHP 版本。这被证明是可行的,因为我们升级到了最新版本的 PHP。我们选择的驱动程序不喜欢使用 Redis 的授权方式,因此我们决定使用 Redis 集群作为一个额外的安全步骤 (我告诉你,这将有更多的安全性)。当我们用 Redis 集群替换每个老式 Redis 实例时,修复似乎很直接,将 Redis 授权关闭,这样它将会响应所有的请求。然而,这并不是真的,由于某些原因,Redis 集群不会接受来自 Web 服务器的连接。 Redis 在版本 3 中引入的称为“保护模式”的新安全功能将在 Redis 绑定到任何接口时将停止监听来自外部 IP 地址的连接,并无需配置 Redis 授权密码。这被证明相当容易修复,但让我们保持警惕。
|
||||||
|
|
||||||
|
### 现在?
|
||||||
|
|
||||||
|
这就是我们现在的情况。我们已经迁移了我们的一些老式 Redis 实例,并且正在迁移其余的。我们通过这样做解决了我们的一些技术债务,并提高了我们的平台的稳定性。使用 Redis 集群,我们还可以扩展内存数据库并扩展它们。 Redis 是单线程的,所以只要在单个实例中留出更多的内存就会可以得到这么多的增长,而且我们已经紧跟在这个限制后面。我们期待着从新的集群中获得改进的性能,同时也为我们提供了扩展和负载均衡的更多选择。
|
||||||
|
|
||||||
|
### 未来怎么样?
|
||||||
|
|
||||||
|
我们解决了一些技术性债务,这使我们的服务更容易支持,更加稳定。但这并不意味着这项工作完成了,Redis 4 似乎有一些我们可能想要研究的功能。而且 Redis 并不是我们使用的唯一软件。我们将继续努力改进平台,缩短处理技术债务的时间,但随着客户群体的扩大,我们力求提供更丰富的服务,我们总是会遇到需要改进的事情。下一个挑战可能与每分钟超过 20,000次 登录到超过 40,000 次甚至更高的扩展有关。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://engineering.skybettingandgaming.com/2017/09/25/redis-2-to-redis-3/
|
||||||
|
|
||||||
|
作者:[Craig Stewart][a]
|
||||||
|
译者:[ ](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://engineering.skybettingandgaming.com/authors#craig_stewart
|
||||||
|
[1]:http://engineering.skybettingandgaming.com/category/devops/
|
||||||
|
[2]:https://redis.io/
|
||||||
|
[3]:https://github.com/twitter/twemproxy
|
||||||
@ -0,0 +1,204 @@
|
|||||||
|
每个安卓开发初学者应该了解的 12 个技巧
|
||||||
|
====
|
||||||
|
|
||||||
|
> 一次掌握一个技巧,更好地学习安卓
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
距离安迪·鲁宾和他的团队着手开发一个希望颠覆传统手机操作模式的操作系统已经过去 12 年了,这套系统有可能让手机或者智能机给消费者以及软件开发人员带来全新的体验。之前的智能机仅限于收发短信和查看电子邮件(当然还可以打电话),给用户和开发者带来很大的限制。
|
||||||
|
|
||||||
|
安卓,作为打破这个枷锁的系统,拥有非常优秀的框架设计,给大家提供的不仅仅是一组有限的功能,更多的是自由的探索。有人会说 iPhone 才是手机产业的颠覆产品,不过我们说的不是 iPhone 有多么酷(或者多么贵,是吧?),它还是有限制的,而这是我们从来都不希望有的。
|
||||||
|
|
||||||
|
不过,就像本大叔说的,能力越大责任越大,我们也需要更加认真对待安卓应用的设计方式。我看到很多教程都忽略了向初学者传递这个理念,在动手之前请先充分理解系统架构。他们只是把一堆的概念和代码丢给读者,却没有解释清楚相关的优缺点,它们对系统的影响,以及该用什么不该用什么等等。
|
||||||
|
|
||||||
|
在这篇文章里,我们将介绍一些初学者以及中级开发人员都应该掌握的技巧,以帮助更好地理解安卓框架。后续我们还会在这个系列里写更多这样的关于实用技巧的文章。我们开始吧。
|
||||||
|
|
||||||
|
### 1、 `@+id` 和 `@id` 的区别
|
||||||
|
|
||||||
|
要在 Java 代码里访问一个图形控件(或组件),或者是要让它成为其他控件的依赖,我们需要一个唯一的值来引用它。这个唯一值用 `android:id` 属性来定义,本质上就是把用户提供的 id 附加到 `@+id/` 后面,写入到 _id 资源文件_,供其他控件使用。一个 Toolbar 的 id 可以这样定义,
|
||||||
|
|
||||||
|
```
|
||||||
|
android:id="@+id/toolbar"
|
||||||
|
```
|
||||||
|
|
||||||
|
然后这个 id 值就能被 `findViewById(…)` 识别,这个函数会在资源文件里查找 id,或者直接从 R.id 路径引用,然后返回所查找的 View 的类型。
|
||||||
|
|
||||||
|
而另一种,`@id`,和 `findViewById(…)` 行为一样 - 也会根据提供的 id 查找组件,不过仅限于布局时使用。一般用来布置相关控件。
|
||||||
|
|
||||||
|
```
|
||||||
|
android:layout_below="@id/toolbar"
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2、 使用 `@string` 资源为 XML 提供字符串
|
||||||
|
|
||||||
|
简单来说,就是不要在 XML 里直接用字符串。原因很简单。当我们在 XML 里直接使用了字符串,我们一般会在其它地方再次用到同样的字符串。想像一下当我们需要在不同的地方调整同一个字符串的噩梦,而如果使用字符串资源就只改一个地方就够了。另一个好处是,使用资源文件可以提供多国语言支持,因为可以为不同的语言创建相应的字符串资源文件。
|
||||||
|
|
||||||
|
```
|
||||||
|
android:text="My Awesome Application"
|
||||||
|
```
|
||||||
|
|
||||||
|
当你直接使用字符串时,你会在 Android Studio 里收到警告,提示说应该把写死的字符串改成字符串资源。可以点击这个提示,然后按下 `ALT + ENTER` 打开字符串编辑。你也可以直接打开 `res` 目录下的 `values` 目录里的 `strings.xml` 文件,然后像下面这样声明一个字符串资源。
|
||||||
|
|
||||||
|
```
|
||||||
|
<string name="app_name">My Awesome Application</string>
|
||||||
|
```
|
||||||
|
|
||||||
|
然后用它来替换写死的字符串,
|
||||||
|
|
||||||
|
```
|
||||||
|
android:text="@string/app_name"
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3、 使用 `@android` 和 `?attr` 常量
|
||||||
|
|
||||||
|
尽量使用系统预先定义的常量而不是重新声明。举个例子,在布局中有几个地方要用白色或者 #ffffff 颜色值。不要每次都直接用 #ffffff 数值,也不要自己为白色重新声明资源,我们可以直接用这个,
|
||||||
|
|
||||||
|
```
|
||||||
|
@android:color/white
|
||||||
|
```
|
||||||
|
|
||||||
|
安卓预先定义了很多常用的颜色常量,比如白色,黑色或粉色。最经典的应用场景是透明色:
|
||||||
|
|
||||||
|
```
|
||||||
|
@android:color/transparent
|
||||||
|
```
|
||||||
|
|
||||||
|
另一个引用常量的方式是 `?attr`,用来将预先定义的属性值赋值给不同的属性。举个自定义 Toolbar 的例子。这个 Toolbar 需要定义宽度和高度。宽度通常可以设置为 `MATCH_PARENT`,但高度呢?我们大多数人都没有注意设计指导,只是简单地随便设置一个看上去差不多的值。这样做不对。不应该随便自定义高度,而应该这样做,
|
||||||
|
|
||||||
|
```
|
||||||
|
android:layout_height="?attr/actionBarSize"
|
||||||
|
```
|
||||||
|
|
||||||
|
`?attr` 的另一个应用是点击视图时画水波纹效果。`SelectableItemBackground` 是一个预定义的 drawable,任何视图需要增加波纹效果时可以将它设为背景:
|
||||||
|
|
||||||
|
```
|
||||||
|
android:background="?attr/selectableItemBackground"
|
||||||
|
```
|
||||||
|
|
||||||
|
也可以用这个:
|
||||||
|
|
||||||
|
```
|
||||||
|
android:background="?attr/selectableItemBackgroundBorderless"
|
||||||
|
```
|
||||||
|
|
||||||
|
来显示无边框波纹。
|
||||||
|
|
||||||
|
### 4、 SP 和 DP 的区别
|
||||||
|
|
||||||
|
虽然这两个没有本质上的区别,但知道它们是什么以及在什么地方适合用哪个很重要。
|
||||||
|
|
||||||
|
SP 的意思是缩放无关像素,一般建议用于 TextView,首先文字不会因为显示密度不同而显示效果不一样,另外 TextView 的内容还需要根据用户设定做拉伸,或者只调整字体大小。
|
||||||
|
|
||||||
|
其他需要定义尺寸和位置的地方,可以使用 DP,也就是密度无关像素。之前说过,DP 和 SP 的性质是一样的,只是 DP 会根据显示密度自动拉伸,因为安卓系统会动态计算实际显示的像素,这样就可以让使用 DP 的组件在不同显示密度的设备上都可以拥有相同的显示效果。
|
||||||
|
|
||||||
|
### 5、 Drawable 和 Mipmap 的应用
|
||||||
|
|
||||||
|
这两个最让人困惑的是 - drawable 和 mipmap 有多少差异?
|
||||||
|
|
||||||
|
虽然这两个好像有同样的用途,但它们设计目的不一样。mipmap 是用来储存图标的,而 drawable 用于任何其他格式。我们可以看一下系统内部是如何使用它们的,就知道为什么不能混用了。
|
||||||
|
|
||||||
|
你可以看到你的应用里有几个 mipmap 和 drawable 目录,每一个分别代表不同的显示分辨率。当系统从 drawable 目录读取资源时,只会根据当前设备的显示密度选择确定的目录。然而,在读取 mipmap 时,系统会根据需要选择合适的目录,而不仅限于当前显示密度,主要是因为有些启动器会故意显示较大的图标,所以系统会使用较大分辨率的资源。
|
||||||
|
|
||||||
|
总之,用 mipmap 来存放图标或标记图片,可以在不同显示密度的设备上看到分辨率变化,而其它根据需要显示的图片资源都用 drawable。
|
||||||
|
|
||||||
|
比如说,Nexus 5 的显示分辨率是 xxhdpi。当我们把图标放到 `mipmap` 目录里时,所有 `mipmap` 目录都将读入内存。而如果放到 drawable 里,只有 `drawable-xxhdpi` 目录会被读取,其他目录都会被忽略。
|
||||||
|
|
||||||
|
### 6、 使用矢量图形
|
||||||
|
|
||||||
|
为了支持不同显示密度的屏幕,将同一个资源的多个版本(大小)添加到项目里是一个很常见的技巧。这种方式确实有用,不过它也会带来一定的性能开支,比如更大的 apk 文件以及额外的开发工作。为了消除这种影响,谷歌的安卓团队发布了新增的矢量图形。
|
||||||
|
|
||||||
|
矢量图形是用 XML 描述的 SVG(可拉伸矢量图形),是用点、直线和曲线组合以及填充颜色绘制出的图形。正因为矢量图形是由点和线动态画出来的,在不同显示密度下拉伸也不会损失分辨率。而矢量图形带来的另一个好处是更容易做动画。往一个 AnimatedVectorDrawable 文件里添加多个矢量图形就可以做出动画,而不用添加多张图片然后再分别处理。
|
||||||
|
|
||||||
|
```
|
||||||
|
<vector xmlns:android="http://schemas.android.com/apk/res/android"
|
||||||
|
android:width="24dp"
|
||||||
|
android:height="24dp"
|
||||||
|
android:viewportWidth="24.0"
|
||||||
|
android:viewportHeight="24.0">
|
||||||
|
|
||||||
|
<path android:fillColor="#69cdff" android:pathData="M3,18h18v-2L3,16v2zM3,13h18v-2L3,11v2zM3,6v2h18L21,6L3,6z"/>
|
||||||
|
|
||||||
|
</vector>
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的向量定义可以画出下面的图形,
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
要在你的安卓项目里添加矢量图形,可以右键点击你项目里的应用模块,然后选择 New >> Vector Assets。然后会打开 Assets Studio,你可以有两种方式添加矢量图形。第一种是从 Material 图标里选择,另一种是选择本地的 SVG 或 PSD 文件。
|
||||||
|
|
||||||
|
谷歌建议与应用相关都使用 Material 图标,来保持安卓的连贯性和统一体验。[这里][1]有全部图标,记得看一下。
|
||||||
|
|
||||||
|
### 7、 设定边界的开始和结束
|
||||||
|
|
||||||
|
这是人们最容易忽略的地方之一。边界!增加边界当然很简单,但是如果要考虑支持很旧的平台呢?
|
||||||
|
|
||||||
|
边界的“开始”和“结束”分别是“左”和“右”的超集,所以如果应用的 `minSdkVersion` 是 17 或更低,边界和填充的“开始”和“结束”定义是旧的“左”/“右”所需要的。在那些没有定义“开始”和“结束”的系统上,这两个定义可以被安全地忽略。可以像下面这样声明:
|
||||||
|
|
||||||
|
```
|
||||||
|
android:layout_marginEnd="20dp"
|
||||||
|
android:paddingStart="20dp"
|
||||||
|
```
|
||||||
|
|
||||||
|
### 8、 使用 Getter/Setter 生成工具
|
||||||
|
|
||||||
|
在创建一个容器类(只是用来简单的存放一些变量数据)时很烦的一件事情是写多个 getter 和 setter,复制/粘贴该方法的主体再为每个变量重命名。
|
||||||
|
|
||||||
|
幸运的是,Android Studio 有一个解决方法。可以这样做,在类里声明你需要的所有变量,然后打开 Toolbar >> Code。快捷方式是 `ALT + Insert`。点击 Code 会显示 Generate,点击它会出来很多选项,里面有 Getter 和 Setter 选项。在保持焦点在你的类页面然后点击,就会为当前类添加所有的 getter 和 setter(有需要的话可以再去之前的窗口操作)。很爽吧。
|
||||||
|
|
||||||
|
### 9、 使用 Override/Implement 生成工具
|
||||||
|
|
||||||
|
这是另一个很好用的生成工具。自定义一个类然后再扩展很容易,但是如果要扩展你不熟悉的类呢。比如说 PagerAdapter,你希望用 ViewPager 来展示一些页面,那就需要定制一个 PagerAdapter 并实现它的重载方法。但是具体有哪些方法呢?Android Studio 非常贴心地为自定义类强行添加了一个构造函数,或者可以用快捷键(`ALT + Enter`),但是父类 PagerAdapter 里的其他(虚拟)方法需要自己手动添加,我估计大多数人都觉得烦。
|
||||||
|
|
||||||
|
要列出所有可以重载的方法,可以点击 Code >> Generate and Override methods 或者 Implement methods,根据你的需要。你还可以为你的类选择多个方法,只要按住 Ctrl 再选择方法,然后点击 OK。
|
||||||
|
|
||||||
|
### 10、 正确理解 Context
|
||||||
|
|
||||||
|
Context 有点恐怖,我估计许多初学者从没有认真理解过 Context 类的结构 - 它是什么,为什么到处都要用到它。
|
||||||
|
|
||||||
|
简单地说,它将你能从屏幕上看到的所有内容都整合在一起。所有的视图(或者它们的扩展)都通过 Context 绑定到当前的环境。Context 用来管理应用层次的资源,比如说显示密度,或者当前的关联活动。活动、服务和应用都实现了 Context 类的接口来为其他关联组件提供内部资源。举个添加到 MainActivity 的 TextView 的例子。你应该注意到了,在创建一个对象的时候,TextView 的构造函数需要 Context 参数。这是为了获取 TextView 里定义到的资源。比如说,TextView 需要在内部用到 Roboto 字体。这样的话,TextView 需要 Context。而且在我们将 Context(或者 `this`)传递给 TextView 的时候,也就是告诉它绑定当前活动的生命周期。
|
||||||
|
|
||||||
|
另一个 Context 的关键应用是初始化应用层次的操作,比如初始化一个库。库的生命周期和应用是不相关的,所以它需要用 `getApplicationContext()` 来初始化,而不是用 `getContext` 或 `this` 或 `getActivity()`。掌握正确使用不同 Context 类型非常重要,可以避免内存泄漏。另外,要用到 Context 来启动一个活动或服务。还记得 `startActivity(…)` 吗?当你需要在一个非活动类里切换活动时,你需要一个 Context 对象来调用 `startActivity` 方法,因为它是 Context 类的方法,而不是 Activity 类。
|
||||||
|
|
||||||
|
```
|
||||||
|
getContext().startActivity(getContext(), SecondActivity.class);
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你想了解更多 Context 的行为,可以看看[这里][2]或[这里][3]。第一个是一篇关于 Context 的很好的文章,介绍了在哪些地方要用到它。而另一个是安卓关于 Context 的文档,全面介绍了所有的功能 - 方法,静态标识以及更多。
|
||||||
|
|
||||||
|
### 奖励 #1: 格式化代码
|
||||||
|
|
||||||
|
有人会不喜欢整齐,统一格式的代码吗?好吧,几乎我们每一个人,在写一个超过 1000 行的类的时候,都希望我们的代码能有合适的结构。而且,并不仅仅大的类才需要格式化,每一个小模块类也需要让代码保持可读性。
|
||||||
|
|
||||||
|
使用 Android Studio,或者任何 JetBrains IDE,你都不需要自己手动整理你的代码,像增加缩进或者 = 之前的空格。就按自己希望的方式写代码,在想要格式化的时候,如果是 Windows 系统可以按下 `ALT + CTRL + L`,Linux 系统按下 `ALT + CTRL + SHIFT + L`。*代码就自动格式化好了*
|
||||||
|
|
||||||
|
### 奖励 #2: 使用库
|
||||||
|
|
||||||
|
面向对象编程的一个重要原则是增加代码的可重用性,或者说减少重新发明轮子的习惯。很多初学者错误地遵循了这个原则。这条路有两个方向,
|
||||||
|
|
||||||
|
- 不用任何库,自己写所有的代码。
|
||||||
|
- 用库来处理所有事情。
|
||||||
|
|
||||||
|
不管哪个方向走到底都是不对的。如果你彻底选择第一个方向,你将消耗大量的资源,仅仅是为了满足自己拥有一切的骄傲。很可能你的代码没有做过替代库那么多的测试,从而增加模块出问题的可能。如果资源有限,不要重复发明轮子。直接用经过测试的库,在有了明确目标以及充分的资源后,可以用自己的可靠代码来替换这个库。
|
||||||
|
|
||||||
|
而彻底走向另一个方向,问题更严重 - 别人代码的可靠性。不要习惯于所有事情都依赖于别人的代码。在不用太多资源或者自己能掌控的情况下尽量自己写代码。你不需要用库来自定义一个 TypeFaces(字体),你可以自己写一个。
|
||||||
|
|
||||||
|
所以要记住,在这两个极端中间平衡一下 - 不要重新创造所有事情,也不要过分依赖外部代码。保持中立,根据自己的能力写代码。
|
||||||
|
|
||||||
|
这篇文章最早发布在 [What’s That Lambda][4] 上。请访问网站阅读更多关于 Android、Node.js、Angular.js 等等类似文章。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://android.jlelse.eu/12-practices-every-android-beginner-should-know-cd43c3710027
|
||||||
|
|
||||||
|
作者:[Nilesh Singh][a]
|
||||||
|
译者:[zpl1025](https://github.com/zpl1025)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://android.jlelse.eu/@nileshsingh?source=post_header_lockup
|
||||||
|
[1]:https://material.io/icons/
|
||||||
|
[2]:https://blog.mindorks.com/understanding-context-in-android-application-330913e32514
|
||||||
|
[3]:https://developer.android.com/reference/android/content/Context.html
|
||||||
|
[4]:https://www.whatsthatlambda.com/android/android-dev-101-things-every-beginner-must-know
|
||||||
@ -0,0 +1,206 @@
|
|||||||
|
并发服务器(一):简介
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
这是关于并发网络服务器编程的第一篇教程。我计划测试几个主流的、可以同时处理多个客户端请求的服务器并发模型,基于可扩展性和易实现性对这些模型进行评判。所有的服务器都会监听套接字连接,并且实现一些简单的协议用于与客户端进行通讯。
|
||||||
|
|
||||||
|
该系列的所有文章:
|
||||||
|
|
||||||
|
* [第一节 - 简介][7]
|
||||||
|
* [第二节 - 线程][8]
|
||||||
|
* [第三节 - 事件驱动][9]
|
||||||
|
|
||||||
|
### 协议
|
||||||
|
|
||||||
|
该系列教程所用的协议都非常简单,但足以展示并发服务器设计的许多有趣层面。而且这个协议是 _有状态的_ —— 服务器根据客户端发送的数据改变内部状态,然后根据内部状态产生相应的行为。并非所有的协议都是有状态的 —— 实际上,基于 HTTP 的许多协议是无状态的,但是有状态的协议也是很常见,值得认真讨论。
|
||||||
|
|
||||||
|
在服务器端看来,这个协议的视图是这样的:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
总之:服务器等待新客户端的连接;当一个客户端连接的时候,服务器会向该客户端发送一个 `*` 字符,进入“等待消息”的状态。在该状态下,服务器会忽略客户端发送的所有字符,除非它看到了一个 `^` 字符,这表示一个新消息的开始。这个时候服务器就会转变为“正在通信”的状态,这时它会向客户端回送数据,把收到的所有字符的每个字节加 1 回送给客户端^注1 。当客户端发送了 `$` 字符,服务器就会退回到等待新消息的状态。`^` 和 `$` 字符仅仅用于分隔消息 —— 它们不会被服务器回送。
|
||||||
|
|
||||||
|
每个状态之后都有个隐藏的箭头指向 “等待客户端” 状态,用来客户端断开连接。因此,客户端要表示“我已经结束”的方法很简单,关掉它那一端的连接就好。
|
||||||
|
|
||||||
|
显然,这个协议是真实协议的简化版,真实使用的协议一般包含复杂的报文头、转义字符序列(例如让消息体中可以出现 `$` 符号),额外的状态变化。但是我们这个协议足以完成期望。
|
||||||
|
|
||||||
|
另一点:这个系列是介绍性的,并假设客户端都工作的很好(虽然可能运行很慢);因此没有设置超时,也没有设置特殊的规则来确保服务器不会因为客户端的恶意行为(或是故障)而出现阻塞,导致不能正常结束。
|
||||||
|
|
||||||
|
### 顺序服务器
|
||||||
|
|
||||||
|
这个系列中我们的第一个服务端程序是一个简单的“顺序”服务器,用 C 进行编写,除了标准的 POSIX 中用于套接字的内容以外没有使用其它库。服务器程序是顺序,因为它一次只能处理一个客户端的请求;当有客户端连接时,像之前所说的那样,服务器会进入到状态机中,并且不再监听套接字接受新的客户端连接,直到当前的客户端结束连接。显然这不是并发的,而且即便在很少的负载下也不能服务多个客户端,但它对于我们的讨论很有用,因为我们需要的是一个易于理解的基础。
|
||||||
|
|
||||||
|
这个服务器的完整代码在[这里][11];接下来,我会着重于一些重点的部分。`main` 函数里面的外层循环用于监听套接字,以便接受新客户端的连接。一旦有客户端进行连接,就会调用 `serve_connection`,这个函数中的代码会一直运行,直到客户端断开连接。
|
||||||
|
|
||||||
|
顺序服务器在循环里调用 `accept` 用来监听套接字,并接受新连接:
|
||||||
|
|
||||||
|
```
|
||||||
|
while (1) {
|
||||||
|
struct sockaddr_in peer_addr;
|
||||||
|
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||||
|
|
||||||
|
int newsockfd =
|
||||||
|
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||||
|
|
||||||
|
if (newsockfd < 0) {
|
||||||
|
perror_die("ERROR on accept");
|
||||||
|
}
|
||||||
|
|
||||||
|
report_peer_connected(&peer_addr, peer_addr_len);
|
||||||
|
serve_connection(newsockfd);
|
||||||
|
printf("peer done\n");
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
`accept` 函数每次都会返回一个新的已连接的套接字,然后服务器调用 `serve_connection`;注意这是一个 _阻塞式_ 的调用 —— 在 `serve_connection` 返回前,`accept` 函数都不会再被调用了;服务器会被阻塞,直到客户端结束连接才能接受新的连接。换句话说,客户端按 _顺序_ 得到响应。
|
||||||
|
|
||||||
|
这是 `serve_connection` 函数:
|
||||||
|
|
||||||
|
```
|
||||||
|
typedef enum { WAIT_FOR_MSG, IN_MSG } ProcessingState;
|
||||||
|
|
||||||
|
void serve_connection(int sockfd) {
|
||||||
|
if (send(sockfd, "*", 1, 0) < 1) {
|
||||||
|
perror_die("send");
|
||||||
|
}
|
||||||
|
|
||||||
|
ProcessingState state = WAIT_FOR_MSG;
|
||||||
|
|
||||||
|
while (1) {
|
||||||
|
uint8_t buf[1024];
|
||||||
|
int len = recv(sockfd, buf, sizeof buf, 0);
|
||||||
|
if (len < 0) {
|
||||||
|
perror_die("recv");
|
||||||
|
} else if (len == 0) {
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
|
||||||
|
for (int i = 0; i < len; ++i) {
|
||||||
|
switch (state) {
|
||||||
|
case WAIT_FOR_MSG:
|
||||||
|
if (buf[i] == '^') {
|
||||||
|
state = IN_MSG;
|
||||||
|
}
|
||||||
|
break;
|
||||||
|
case IN_MSG:
|
||||||
|
if (buf[i] == '$') {
|
||||||
|
state = WAIT_FOR_MSG;
|
||||||
|
} else {
|
||||||
|
buf[i] += 1;
|
||||||
|
if (send(sockfd, &buf[i], 1, 0) < 1) {
|
||||||
|
perror("send error");
|
||||||
|
close(sockfd);
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
close(sockfd);
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
它完全是按照状态机协议进行编写的。每次循环的时候,服务器尝试接收客户端的数据。收到 0 字节意味着客户端断开连接,然后循环就会退出。否则,会逐字节检查接收缓存,每一个字节都可能会触发一个状态。
|
||||||
|
|
||||||
|
`recv` 函数返回接收到的字节数与客户端发送消息的数量完全无关(`^...$` 闭合序列的字节)。因此,在保持状态的循环中遍历整个缓冲区很重要。而且,每一个接收到的缓冲中可能包含多条信息,但也有可能开始了一个新消息,却没有显式的结束字符;而这个结束字符可能在下一个缓冲中才能收到,这就是处理状态在循环迭代中进行维护的原因。
|
||||||
|
|
||||||
|
例如,试想主循环中的 `recv` 函数在某次连接中返回了三个非空的缓冲:
|
||||||
|
|
||||||
|
1. `^abc$de^abte$f`
|
||||||
|
2. `xyz^123`
|
||||||
|
3. `25$^ab$abab`
|
||||||
|
|
||||||
|
服务端返回的是哪些数据?追踪代码对于理解状态转变很有用。(答案见^注[2] )
|
||||||
|
|
||||||
|
### 多个并发客户端
|
||||||
|
|
||||||
|
如果多个客户端在同一时刻向顺序服务器发起连接会发生什么事情?
|
||||||
|
|
||||||
|
服务器端的代码(以及它的名字 “顺序服务器”)已经说的很清楚了,一次只能处理 _一个_ 客户端的请求。只要服务器在 `serve_connection` 函数中忙于处理客户端的请求,就不会接受别的客户端的连接。只有当前的客户端断开了连接,`serve_connection` 才会返回,然后最外层的循环才能继续执行接受其他客户端的连接。
|
||||||
|
|
||||||
|
为了演示这个行为,[该系列教程的示例代码][13] 包含了一个 Python 脚本,用于模拟几个想要同时连接服务器的客户端。每一个客户端发送类似之前那样的三个数据缓冲 ^注3 ,不过每次发送数据之间会有一定延迟。
|
||||||
|
|
||||||
|
客户端脚本在不同的线程中并发地模拟客户端行为。这是我们的序列化服务器与客户端交互的信息记录:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||||
|
INFO:2017-09-16 14:14:17,763:conn1 connected...
|
||||||
|
INFO:2017-09-16 14:14:17,763:conn1 sending b'^abc$de^abte$f'
|
||||||
|
INFO:2017-09-16 14:14:17,763:conn1 received b'b'
|
||||||
|
INFO:2017-09-16 14:14:17,802:conn1 received b'cdbcuf'
|
||||||
|
INFO:2017-09-16 14:14:18,764:conn1 sending b'xyz^123'
|
||||||
|
INFO:2017-09-16 14:14:18,764:conn1 received b'234'
|
||||||
|
INFO:2017-09-16 14:14:19,764:conn1 sending b'25$^ab0000$abab'
|
||||||
|
INFO:2017-09-16 14:14:19,765:conn1 received b'36bc1111'
|
||||||
|
INFO:2017-09-16 14:14:19,965:conn1 disconnecting
|
||||||
|
INFO:2017-09-16 14:14:19,966:conn2 connected...
|
||||||
|
INFO:2017-09-16 14:14:19,967:conn2 sending b'^abc$de^abte$f'
|
||||||
|
INFO:2017-09-16 14:14:19,967:conn2 received b'b'
|
||||||
|
INFO:2017-09-16 14:14:20,006:conn2 received b'cdbcuf'
|
||||||
|
INFO:2017-09-16 14:14:20,968:conn2 sending b'xyz^123'
|
||||||
|
INFO:2017-09-16 14:14:20,969:conn2 received b'234'
|
||||||
|
INFO:2017-09-16 14:14:21,970:conn2 sending b'25$^ab0000$abab'
|
||||||
|
INFO:2017-09-16 14:14:21,970:conn2 received b'36bc1111'
|
||||||
|
INFO:2017-09-16 14:14:22,171:conn2 disconnecting
|
||||||
|
INFO:2017-09-16 14:14:22,171:conn0 connected...
|
||||||
|
INFO:2017-09-16 14:14:22,172:conn0 sending b'^abc$de^abte$f'
|
||||||
|
INFO:2017-09-16 14:14:22,172:conn0 received b'b'
|
||||||
|
INFO:2017-09-16 14:14:22,210:conn0 received b'cdbcuf'
|
||||||
|
INFO:2017-09-16 14:14:23,173:conn0 sending b'xyz^123'
|
||||||
|
INFO:2017-09-16 14:14:23,174:conn0 received b'234'
|
||||||
|
INFO:2017-09-16 14:14:24,175:conn0 sending b'25$^ab0000$abab'
|
||||||
|
INFO:2017-09-16 14:14:24,176:conn0 received b'36bc1111'
|
||||||
|
INFO:2017-09-16 14:14:24,376:conn0 disconnecting
|
||||||
|
```
|
||||||
|
|
||||||
|
这里要注意连接名:`conn1` 是第一个连接到服务器的,先跟服务器交互了一段时间。接下来的连接 `conn2` —— 在第一个断开连接后,连接到了服务器,然后第三个连接也是一样。就像日志显示的那样,每一个连接让服务器变得繁忙,持续了大约 2.2 秒的时间(这实际上是人为地在客户端代码中加入的延迟),在这段时间里别的客户端都不能连接。
|
||||||
|
|
||||||
|
显然,这不是一个可扩展的策略。这个例子中,客户端中加入了延迟,让服务器不能处理别的交互动作。一个智能服务器应该能处理一堆客户端的请求,而这个原始的服务器在结束连接之前一直繁忙(我们将会在之后的章节中看到如何实现智能的服务器)。尽管服务端有延迟,但这不会过度占用 CPU;例如,从数据库中查找信息(时间基本上是花在连接到数据库服务器上,或者是花在硬盘中的本地数据库)。
|
||||||
|
|
||||||
|
### 总结及期望
|
||||||
|
|
||||||
|
这个示例服务器达成了两个预期目标:
|
||||||
|
|
||||||
|
1. 首先是介绍了问题范畴和贯彻该系列文章的套接字编程基础。
|
||||||
|
2. 对于并发服务器编程的抛砖引玉 —— 就像之前的部分所说,顺序服务器还不能在非常轻微的负载下进行扩展,而且没有高效的利用资源。
|
||||||
|
|
||||||
|
在看下一篇文章前,确保你已经理解了这里所讲的服务器/客户端协议,还有顺序服务器的代码。我之前介绍过了这个简单的协议;例如 [串行通信分帧][15] 和 [用协程来替代状态机][16]。要学习套接字网络编程的基础,[Beej 的教程][17] 用来入门很不错,但是要深入理解我推荐你还是看本书。
|
||||||
|
|
||||||
|
如果有什么不清楚的,请在评论区下进行评论或者向我发送邮件。深入理解并发服务器!
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
- 注1:状态转变中的 In/Out 记号是指 [Mealy machine][2]。
|
||||||
|
- 注2:回应的是 `bcdbcuf23436bc`。
|
||||||
|
- 注3:这里在结尾处有一点小区别,加了字符串 `0000` —— 服务器回应这个序列,告诉客户端让其断开连接;这是一个简单的握手协议,确保客户端有足够的时间接收到服务器发送的所有回复。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||||
|
|
||||||
|
作者:[Eli Bendersky][a]
|
||||||
|
译者:[GitFuture](https://github.com/GitFuture)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://eli.thegreenplace.net/pages/about
|
||||||
|
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id1
|
||||||
|
[2]:https://en.wikipedia.org/wiki/Mealy_machine
|
||||||
|
[3]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id2
|
||||||
|
[4]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id3
|
||||||
|
[5]:https://eli.thegreenplace.net/tag/concurrency
|
||||||
|
[6]:https://eli.thegreenplace.net/tag/c-c
|
||||||
|
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||||
|
[8]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||||
|
[9]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||||
|
[10]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id4
|
||||||
|
[11]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/sequential-server.c
|
||||||
|
[12]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id5
|
||||||
|
[13]:https://github.com/eliben/code-for-blog/tree/master/2017/async-socket-server
|
||||||
|
[14]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/#id6
|
||||||
|
[15]:http://eli.thegreenplace.net/2009/08/12/framing-in-serial-communications/
|
||||||
|
[16]:http://eli.thegreenplace.net/2009/08/29/co-routines-as-an-alternative-to-state-machines
|
||||||
|
[17]:http://beej.us/guide/bgnet/
|
||||||
|
[18]:https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||||
294
published/201710/20171004 Concurrent Servers Part 2 - Threads.md
Normal file
294
published/201710/20171004 Concurrent Servers Part 2 - Threads.md
Normal file
@ -0,0 +1,294 @@
|
|||||||
|
并发服务器(二):线程
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
这是并发网络服务器系列的第二节。[第一节][20] 提出了服务端实现的协议,还有简单的顺序服务器的代码,是这整个系列的基础。
|
||||||
|
|
||||||
|
这一节里,我们来看看怎么用多线程来实现并发,用 C 实现一个最简单的多线程服务器,和用 Python 实现的线程池。
|
||||||
|
|
||||||
|
该系列的所有文章:
|
||||||
|
|
||||||
|
* [第一节 - 简介][8]
|
||||||
|
* [第二节 - 线程][9]
|
||||||
|
* [第三节 - 事件驱动][10]
|
||||||
|
|
||||||
|
### 多线程的方法设计并发服务器
|
||||||
|
|
||||||
|
说起第一节里的顺序服务器的性能,最显而易见的,是在服务器处理客户端连接时,计算机的很多资源都被浪费掉了。尽管假定客户端快速发送完消息,不做任何等待,仍然需要考虑网络通信的开销;网络要比现在的 CPU 慢上百万倍还不止,因此 CPU 运行服务器时会等待接收套接字的流量,而大量的时间都花在完全不必要的等待中。
|
||||||
|
|
||||||
|
这里是一份示意图,表明顺序时客户端的运行过程:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
这个图片上有 3 个客户端程序。棱形表示客户端的“到达时间”(即客户端尝试连接服务器的时间)。黑色线条表示“等待时间”(客户端等待服务器真正接受连接所用的时间),有色矩形表示“处理时间”(服务器和客户端使用协议进行交互所用的时间)。有色矩形的末端表示客户端断开连接。
|
||||||
|
|
||||||
|
上图中,绿色和橘色的客户端尽管紧跟在蓝色客户端之后到达服务器,也要等到服务器处理完蓝色客户端的请求。这时绿色客户端得到响应,橘色的还要等待一段时间。
|
||||||
|
|
||||||
|
多线程服务器会开启多个控制线程,让操作系统管理 CPU 的并发(使用多个 CPU 核心)。当客户端连接的时候,创建一个线程与之交互,而在主线程中,服务器能够接受其他的客户端连接。下图是该模式的时间轴:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 每个客户端一个线程,在 C 语言里要用 pthread
|
||||||
|
|
||||||
|
这篇文章的 [第一个示例代码][11] 是一个简单的 “每个客户端一个线程” 的服务器,用 C 语言编写,使用了 [phtreads API][12] 用于实现多线程。这里是主循环代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
while (1) {
|
||||||
|
struct sockaddr_in peer_addr;
|
||||||
|
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||||
|
|
||||||
|
int newsockfd =
|
||||||
|
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||||
|
|
||||||
|
if (newsockfd < 0) {
|
||||||
|
perror_die("ERROR on accept");
|
||||||
|
}
|
||||||
|
|
||||||
|
report_peer_connected(&peer_addr, peer_addr_len);
|
||||||
|
pthread_t the_thread;
|
||||||
|
|
||||||
|
thread_config_t* config = (thread_config_t*)malloc(sizeof(*config));
|
||||||
|
if (!config) {
|
||||||
|
die("OOM");
|
||||||
|
}
|
||||||
|
config->sockfd = newsockfd;
|
||||||
|
pthread_create(&the_thread, NULL, server_thread, config);
|
||||||
|
|
||||||
|
// 回收线程 —— 在线程结束的时候,它占用的资源会被回收
|
||||||
|
// 因为主线程在一直运行,所以它比服务线程存活更久。
|
||||||
|
pthread_detach(the_thread);
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
这是 `server_thread` 函数:
|
||||||
|
|
||||||
|
```
|
||||||
|
void* server_thread(void* arg) {
|
||||||
|
thread_config_t* config = (thread_config_t*)arg;
|
||||||
|
int sockfd = config->sockfd;
|
||||||
|
free(config);
|
||||||
|
|
||||||
|
// This cast will work for Linux, but in general casting pthread_id to an 这个类型转换在 Linux 中可以正常运行,但是一般来说将 pthread_id 类型转换成整形不便于移植代码
|
||||||
|
// integral type isn't portable.
|
||||||
|
unsigned long id = (unsigned long)pthread_self();
|
||||||
|
printf("Thread %lu created to handle connection with socket %d\n", id,
|
||||||
|
sockfd);
|
||||||
|
serve_connection(sockfd);
|
||||||
|
printf("Thread %lu done\n", id);
|
||||||
|
return 0;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
线程 “configuration” 是作为 `thread_config_t` 结构体进行传递的:
|
||||||
|
|
||||||
|
```
|
||||||
|
typedef struct { int sockfd; } thread_config_t;
|
||||||
|
```
|
||||||
|
|
||||||
|
主循环中调用的 `pthread_create` 产生一个新线程,然后运行 `server_thread` 函数。这个线程会在 `server_thread` 返回的时候结束。而在 `serve_connection` 返回的时候 `server_thread` 才会返回。`serve_connection` 和第一节完全一样。
|
||||||
|
|
||||||
|
第一节中我们用脚本生成了多个并发访问的客户端,观察服务器是怎么处理的。现在来看看多线程服务器的处理结果:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||||
|
INFO:2017-09-20 06:31:56,632:conn1 connected...
|
||||||
|
INFO:2017-09-20 06:31:56,632:conn2 connected...
|
||||||
|
INFO:2017-09-20 06:31:56,632:conn0 connected...
|
||||||
|
INFO:2017-09-20 06:31:56,632:conn1 sending b'^abc$de^abte$f'
|
||||||
|
INFO:2017-09-20 06:31:56,632:conn2 sending b'^abc$de^abte$f'
|
||||||
|
INFO:2017-09-20 06:31:56,632:conn0 sending b'^abc$de^abte$f'
|
||||||
|
INFO:2017-09-20 06:31:56,633:conn1 received b'b'
|
||||||
|
INFO:2017-09-20 06:31:56,633:conn2 received b'b'
|
||||||
|
INFO:2017-09-20 06:31:56,633:conn0 received b'b'
|
||||||
|
INFO:2017-09-20 06:31:56,670:conn1 received b'cdbcuf'
|
||||||
|
INFO:2017-09-20 06:31:56,671:conn0 received b'cdbcuf'
|
||||||
|
INFO:2017-09-20 06:31:56,671:conn2 received b'cdbcuf'
|
||||||
|
INFO:2017-09-20 06:31:57,634:conn1 sending b'xyz^123'
|
||||||
|
INFO:2017-09-20 06:31:57,634:conn2 sending b'xyz^123'
|
||||||
|
INFO:2017-09-20 06:31:57,634:conn1 received b'234'
|
||||||
|
INFO:2017-09-20 06:31:57,634:conn0 sending b'xyz^123'
|
||||||
|
INFO:2017-09-20 06:31:57,634:conn2 received b'234'
|
||||||
|
INFO:2017-09-20 06:31:57,634:conn0 received b'234'
|
||||||
|
INFO:2017-09-20 06:31:58,635:conn1 sending b'25$^ab0000$abab'
|
||||||
|
INFO:2017-09-20 06:31:58,635:conn2 sending b'25$^ab0000$abab'
|
||||||
|
INFO:2017-09-20 06:31:58,636:conn1 received b'36bc1111'
|
||||||
|
INFO:2017-09-20 06:31:58,636:conn2 received b'36bc1111'
|
||||||
|
INFO:2017-09-20 06:31:58,637:conn0 sending b'25$^ab0000$abab'
|
||||||
|
INFO:2017-09-20 06:31:58,637:conn0 received b'36bc1111'
|
||||||
|
INFO:2017-09-20 06:31:58,836:conn2 disconnecting
|
||||||
|
INFO:2017-09-20 06:31:58,836:conn1 disconnecting
|
||||||
|
INFO:2017-09-20 06:31:58,837:conn0 disconnecting
|
||||||
|
```
|
||||||
|
|
||||||
|
实际上,所有客户端同时连接,它们与服务器的通信是同时发生的。
|
||||||
|
|
||||||
|
### 每个客户端一个线程的难点
|
||||||
|
|
||||||
|
尽管在现代操作系统中就资源利用率方面来看,线程相当的高效,但前一节中讲到的方法在高负载时却会出现纰漏。
|
||||||
|
|
||||||
|
想象一下这样的情景:很多客户端同时进行连接,某些会话持续的时间长。这意味着某个时刻服务器上有很多活跃的线程。太多的线程会消耗掉大量的内存和 CPU 资源,而仅仅是用于上下文切换^注1 。另外其也可视为安全问题:因为这样的设计容易让服务器成为 [DoS 攻击][14] 的目标 —— 上百万个客户端同时连接,并且客户端都处于闲置状态,这样耗尽了所有资源就可能让服务器宕机。
|
||||||
|
|
||||||
|
当服务器要与每个客户端通信,CPU 进行大量计算时,就会出现更严重的问题。这种情况下,容易想到的方法是减少服务器的响应能力 —— 只有其中一些客户端能得到服务器的响应。
|
||||||
|
|
||||||
|
因此,对多线程服务器所能够处理的并发客户端数做一些 _速率限制_ 就是个明智的选择。有很多方法可以实现。最容易想到的是计数当前已经连接上的客户端,把连接数限制在某个范围内(需要通过仔细的测试后决定)。另一种流行的多线程应用设计是使用 _线程池_。
|
||||||
|
|
||||||
|
### 线程池
|
||||||
|
|
||||||
|
[线程池][15] 很简单,也很有用。服务器创建几个任务线程,这些线程从某些队列中获取任务。这就是“池”。然后每一个客户端的连接被当成任务分发到池中。只要池中有空闲的线程,它就会去处理任务。如果当前池中所有线程都是繁忙状态,那么服务器就会阻塞,直到线程池可以接受任务(某个繁忙状态的线程处理完当前任务后,变回空闲的状态)。
|
||||||
|
|
||||||
|
这里有个 4 线程的线程池处理任务的图。任务(这里就是客户端的连接)要等到线程池中的某个线程可以接受新任务。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
非常明显,线程池的定义就是一种按比例限制的机制。我们可以提前设定服务器所能拥有的线程数。那么这就是并发连接的最多的客户端数 —— 其它的客户端就要等到线程空闲。如果我们的池中有 8 个线程,那么 8 就是服务器可以处理的最多的客户端并发连接数,哪怕上千个客户端想要同时连接。
|
||||||
|
|
||||||
|
那么怎么确定池中需要有多少个线程呢?通过对问题范畴进行细致的分析、评估、实验以及根据我们拥有的硬件配置。如果是单核的云服务器,答案只有一个;如果是 100 核心的多套接字的服务器,那么答案就有很多种。也可以在运行时根据负载动态选择池的大小 —— 我会在这个系列之后的文章中谈到这个东西。
|
||||||
|
|
||||||
|
使用线程池的服务器在高负载情况下表现出 _性能退化_ —— 客户端能够以稳定的速率进行连接,可能会比其它时刻得到响应的用时稍微久一点;也就是说,无论多少个客户端同时进行连接,服务器总能保持响应,尽最大能力响应等待的客户端。与之相反,每个客户端一个线程的服务器,会接收多个客户端的连接直到过载,这时它更容易崩溃或者因为要处理_所有_客户端而变得缓慢,因为资源都被耗尽了(比如虚拟内存的占用)。
|
||||||
|
|
||||||
|
### 在服务器上使用线程池
|
||||||
|
|
||||||
|
为了[改变服务器的实现][16],我用了 Python,在 Python 的标准库中带有一个已经实现好的稳定的线程池。(`concurrent.futures` 模块里的 `ThreadPoolExecutor`) ^注2 。
|
||||||
|
|
||||||
|
服务器创建一个线程池,然后进入循环,监听套接字接收客户端的连接。用 `submit` 把每一个连接的客户端分配到池中:
|
||||||
|
|
||||||
|
```
|
||||||
|
pool = ThreadPoolExecutor(args.n)
|
||||||
|
sockobj = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||||
|
sockobj.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||||
|
sockobj.bind(('localhost', args.port))
|
||||||
|
sockobj.listen(15)
|
||||||
|
|
||||||
|
try:
|
||||||
|
while True:
|
||||||
|
client_socket, client_address = sockobj.accept()
|
||||||
|
pool.submit(serve_connection, client_socket, client_address)
|
||||||
|
except KeyboardInterrupt as e:
|
||||||
|
print(e)
|
||||||
|
sockobj.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
`serve_connection` 函数和 C 的那部分很像,与一个客户端交互,直到其断开连接,并且遵循我们的协议:
|
||||||
|
|
||||||
|
```
|
||||||
|
ProcessingState = Enum('ProcessingState', 'WAIT_FOR_MSG IN_MSG')
|
||||||
|
|
||||||
|
def serve_connection(sockobj, client_address):
|
||||||
|
print('{0} connected'.format(client_address))
|
||||||
|
sockobj.sendall(b'*')
|
||||||
|
state = ProcessingState.WAIT_FOR_MSG
|
||||||
|
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
buf = sockobj.recv(1024)
|
||||||
|
if not buf:
|
||||||
|
break
|
||||||
|
except IOError as e:
|
||||||
|
break
|
||||||
|
for b in buf:
|
||||||
|
if state == ProcessingState.WAIT_FOR_MSG:
|
||||||
|
if b == ord(b'^'):
|
||||||
|
state = ProcessingState.IN_MSG
|
||||||
|
elif state == ProcessingState.IN_MSG:
|
||||||
|
if b == ord(b'$'):
|
||||||
|
state = ProcessingState.WAIT_FOR_MSG
|
||||||
|
else:
|
||||||
|
sockobj.send(bytes([b + 1]))
|
||||||
|
else:
|
||||||
|
assert False
|
||||||
|
|
||||||
|
print('{0} done'.format(client_address))
|
||||||
|
sys.stdout.flush()
|
||||||
|
sockobj.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
来看看线程池的大小对并行访问的客户端的阻塞行为有什么样的影响。为了演示,我会运行一个池大小为 2 的线程池服务器(只生成两个线程用于响应客户端)。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python3.6 threadpool-server.py -n 2
|
||||||
|
```
|
||||||
|
|
||||||
|
在另外一个终端里,运行客户端模拟器,产生 3 个并发访问的客户端:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||||
|
INFO:2017-09-22 05:58:52,815:conn1 connected...
|
||||||
|
INFO:2017-09-22 05:58:52,827:conn0 connected...
|
||||||
|
INFO:2017-09-22 05:58:52,828:conn1 sending b'^abc$de^abte$f'
|
||||||
|
INFO:2017-09-22 05:58:52,828:conn0 sending b'^abc$de^abte$f'
|
||||||
|
INFO:2017-09-22 05:58:52,828:conn1 received b'b'
|
||||||
|
INFO:2017-09-22 05:58:52,828:conn0 received b'b'
|
||||||
|
INFO:2017-09-22 05:58:52,867:conn1 received b'cdbcuf'
|
||||||
|
INFO:2017-09-22 05:58:52,867:conn0 received b'cdbcuf'
|
||||||
|
INFO:2017-09-22 05:58:53,829:conn1 sending b'xyz^123'
|
||||||
|
INFO:2017-09-22 05:58:53,829:conn0 sending b'xyz^123'
|
||||||
|
INFO:2017-09-22 05:58:53,830:conn1 received b'234'
|
||||||
|
INFO:2017-09-22 05:58:53,831:conn0 received b'2'
|
||||||
|
INFO:2017-09-22 05:58:53,831:conn0 received b'34'
|
||||||
|
INFO:2017-09-22 05:58:54,831:conn1 sending b'25$^ab0000$abab'
|
||||||
|
INFO:2017-09-22 05:58:54,832:conn1 received b'36bc1111'
|
||||||
|
INFO:2017-09-22 05:58:54,832:conn0 sending b'25$^ab0000$abab'
|
||||||
|
INFO:2017-09-22 05:58:54,833:conn0 received b'36bc1111'
|
||||||
|
INFO:2017-09-22 05:58:55,032:conn1 disconnecting
|
||||||
|
INFO:2017-09-22 05:58:55,032:conn2 connected...
|
||||||
|
INFO:2017-09-22 05:58:55,033:conn2 sending b'^abc$de^abte$f'
|
||||||
|
INFO:2017-09-22 05:58:55,033:conn0 disconnecting
|
||||||
|
INFO:2017-09-22 05:58:55,034:conn2 received b'b'
|
||||||
|
INFO:2017-09-22 05:58:55,071:conn2 received b'cdbcuf'
|
||||||
|
INFO:2017-09-22 05:58:56,036:conn2 sending b'xyz^123'
|
||||||
|
INFO:2017-09-22 05:58:56,036:conn2 received b'234'
|
||||||
|
INFO:2017-09-22 05:58:57,037:conn2 sending b'25$^ab0000$abab'
|
||||||
|
INFO:2017-09-22 05:58:57,038:conn2 received b'36bc1111'
|
||||||
|
INFO:2017-09-22 05:58:57,238:conn2 disconnecting
|
||||||
|
```
|
||||||
|
|
||||||
|
回顾之前讨论的服务器行为:
|
||||||
|
|
||||||
|
1. 在顺序服务器中,所有的连接都是串行的。一个连接结束后,下一个连接才能开始。
|
||||||
|
2. 前面讲到的每个客户端一个线程的服务器中,所有连接都被同时接受并得到服务。
|
||||||
|
|
||||||
|
这里可以看到一种可能的情况:两个连接同时得到服务,只有其中一个结束连接后第三个才能连接上。这就是把线程池大小设置成 2 的结果。真实用例中我们会把线程池设置的更大些,取决于机器和实际的协议。线程池的缓冲机制就能很好理解了 —— 我 [几个月前][18] 更详细的介绍过这种机制,关于 Clojure 的 `core.async` 模块。
|
||||||
|
|
||||||
|
### 总结与展望
|
||||||
|
|
||||||
|
这篇文章讨论了在服务器中,用多线程作并发的方法。每个客户端一个线程的方法最早提出来,但是实际上却不常用,因为它并不安全。
|
||||||
|
|
||||||
|
线程池就常见多了,最受欢迎的几个编程语言有良好的实现(某些编程语言,像 Python,就是在标准库中实现)。这里说的使用线程池的服务器,不会受到每个客户端一个线程的弊端。
|
||||||
|
|
||||||
|
然而,线程不是处理多个客户端并行访问的唯一方法。下一节中我们会看看其它的解决方案,可以使用_异步处理_,或者_事件驱动_的编程。
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
- 注1:老实说,现代 Linux 内核可以承受足够多的并发线程 —— 只要这些线程主要在 I/O 上被阻塞。[这里有个示例程序][2],它产生可配置数量的线程,线程在循环体中是休眠的,每 50 ms 唤醒一次。我在 4 核的 Linux 机器上可以轻松的产生 10000 个线程;哪怕这些线程大多数时间都在睡眠,它们仍然消耗一到两个核心,以便实现上下文切换。而且,它们占用了 80 GB 的虚拟内存(Linux 上每个线程的栈大小默认是 8MB)。实际使用中,线程会使用内存并且不会在循环体中休眠,因此它可以非常快的占用完一个机器的内存。
|
||||||
|
- 注2:自己动手实现一个线程池是个有意思的练习,但我现在还不想做。我曾写过用来练手的 [针对特殊任务的线程池][4]。是用 Python 写的;用 C 重写的话有些难度,但对于经验丰富的程序员,几个小时就够了。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||||
|
|
||||||
|
作者:[Eli Bendersky][a]
|
||||||
|
译者:[GitFuture](https://github.com/GitFuture)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://eli.thegreenplace.net/pages/about
|
||||||
|
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id1
|
||||||
|
[2]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threadspammer.c
|
||||||
|
[3]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id2
|
||||||
|
[4]:http://eli.thegreenplace.net/2011/12/27/python-threads-communication-and-stopping
|
||||||
|
[5]:https://eli.thegreenplace.net/tag/concurrency
|
||||||
|
[6]:https://eli.thegreenplace.net/tag/c-c
|
||||||
|
[7]:https://eli.thegreenplace.net/tag/python
|
||||||
|
[8]:https://linux.cn/article-8993-1.html
|
||||||
|
[9]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||||
|
[10]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||||
|
[11]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threaded-server.c
|
||||||
|
[12]:http://eli.thegreenplace.net/2010/04/05/pthreads-as-a-case-study-of-good-api-design
|
||||||
|
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id3
|
||||||
|
[14]:https://en.wikipedia.org/wiki/Denial-of-service_attack
|
||||||
|
[15]:https://en.wikipedia.org/wiki/Thread_pool
|
||||||
|
[16]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threadpool-server.py
|
||||||
|
[17]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id4
|
||||||
|
[18]:http://eli.thegreenplace.net/2017/clojure-concurrency-and-blocking-with-coreasync/
|
||||||
|
[19]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||||
|
[20]:https://linux.cn/article-8993-1.html
|
||||||
@ -0,0 +1,92 @@
|
|||||||
|
如何在一个 U 盘上安装多个 Linux 发行版
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 概要:本教程介绍如何在一个 U 盘上安装多个 Linux 发行版。这样,你可以在单个 U 盘上享受多个<ruby>现场版<rt>live</rt></ruby> Linux 发行版了。
|
||||||
|
|
||||||
|
我喜欢通过 U 盘尝试不同的 Linux 发行版。它让我可以在真实的硬件上测试操作系统,而不是虚拟化的环境中。此外,我可以将 USB 插入任何系统(比如 Windows 系统),做任何我想要的事情,以及享受相同的 Linux 体验。而且,如果我的系统出现问题,我可以使用 U 盘恢复!
|
||||||
|
|
||||||
|
创建单个[可启动的现场版 Linux USB][8] 很简单,你只需下载一个 ISO 文件并将其刻录到 U 盘。但是,如果你想尝试多个 Linux 发行版呢?你可以使用多个 U 盘,也可以覆盖同一个 U 盘以尝试其他 Linux 发行版。但这两种方法都不是很方便。
|
||||||
|
|
||||||
|
那么,有没有在单个 U 盘上安装多个 Linux 发行版的方式呢?我们将在本教程中看到如何做到这一点。
|
||||||
|
|
||||||
|
### 如何创建有多个 Linux 发行版的可启动 USB
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我们有一个工具正好可以做到_在单个 U 盘上保留多个 Linux 发行版_。你所需要做的只是选择要安装的发行版。在本教程中,我们将介绍_如何在 U 盘中安装多个 Linux 发行版_用于<ruby>现场会话<rt>live session</rt></ruby>。
|
||||||
|
|
||||||
|
要确保你有一个足够大的 U 盘,以便在它上面安装多个 Linux 发行版,一个 8 GB 的 U 盘应该足够用于三四个 Linux 发行版。
|
||||||
|
|
||||||
|
#### 步骤 1
|
||||||
|
|
||||||
|
[MultiBootUSB][9] 是一个自由、开源的跨平台应用程序,允许你创建具有多个 Linux 发行版的 U 盘。它还支持在任何时候卸载任何发行版,以便你回收驱动器上的空间用于另一个发行版。
|
||||||
|
|
||||||
|
下载 .deb 包并双击安装。
|
||||||
|
|
||||||
|
[下载 MultiBootUSB][10]
|
||||||
|
|
||||||
|
#### 步骤 2
|
||||||
|
|
||||||
|
推荐的文件系统是 FAT32,因此在创建多引导 U 盘之前,请确保格式化 U 盘。
|
||||||
|
|
||||||
|
#### 步骤 3
|
||||||
|
|
||||||
|
下载要安装的 Linux 发行版的 ISO 镜像。
|
||||||
|
|
||||||
|
#### 步骤 4
|
||||||
|
|
||||||
|
完成这些后,启动 MultiBootUSB。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
主屏幕要求你选择 U 盘和你打算放到 U 盘上的 Linux 发行版镜像文件。
|
||||||
|
|
||||||
|
MultiBootUSB 支持 Ubuntu、Fedora 和 Debian 发行版的持久化,这意味着对 Linux 发行版的现场版本所做的更改将保存到 USB 上。
|
||||||
|
|
||||||
|
你可以通过拖动 MultiBootUSB 选项卡下的滑块来选择持久化大小。持久化为你提供了在运行时将更改保存到 U 盘的选项。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 步骤 5
|
||||||
|
|
||||||
|
单击“安装发行版”选项并继续安装。在显示成功的安装消息之前,需要一些时间才能完成。
|
||||||
|
|
||||||
|
你现在可以在已安装部分中看到发行版了。对于另外的操作系统,重复该过程。这是我安装 Ubuntu 16.10 和 Fedora 24 后的样子。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 步骤 6
|
||||||
|
|
||||||
|
下次通过 USB 启动时,我可以选择任何一个发行版。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
只要你的 U 盘允许,你可以添加任意数量的发行版。要删除发行版,请从列表中选择它,然后单击卸载发行版。
|
||||||
|
|
||||||
|
### 最后的话
|
||||||
|
|
||||||
|
MultiBootUSB 真的很便于在 U 盘上安装多个 Linux 发行版。只需点击几下,我就有两个我最喜欢的操作系统的工作盘了,我可以在任何系统上启动它们。
|
||||||
|
|
||||||
|
如果你在安装或使用 MultiBootUSB 时遇到任何问题,请在评论中告诉我们。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/multiple-linux-one-usb/
|
||||||
|
|
||||||
|
作者:[Ambarish Kumar][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://itsfoss.com/author/ambarish/
|
||||||
|
[1]:https://itsfoss.com/author/ambarish/
|
||||||
|
[2]:https://itsfoss.com/multiple-linux-one-usb/#comments
|
||||||
|
[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fmultiple-linux-one-usb%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||||
|
[4]:https://twitter.com/share?original_referer=/&text=How+to+Install+Multiple+Linux+Distributions+on+One+USB&url=https://itsfoss.com/multiple-linux-one-usb/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=itsfoss2
|
||||||
|
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fmultiple-linux-one-usb%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||||
|
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fmultiple-linux-one-usb%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||||
|
[7]:https://www.reddit.com/submit?url=https://itsfoss.com/multiple-linux-one-usb/&title=How+to+Install+Multiple+Linux+Distributions+on+One+USB
|
||||||
|
[8]:https://itsfoss.com/create-live-usb-of-ubuntu-in-windows/
|
||||||
|
[9]:http://multibootusb.org/
|
||||||
|
[10]:https://github.com/mbusb/multibootusb/releases/download/v8.8.0/python3-multibootusb_8.8.0-1_all.deb
|
||||||
@ -0,0 +1,58 @@
|
|||||||
|
OpenMessaging:构建一个分布式消息分发开放标准
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|
通过在云计算、大数据和标准 API 上的企业及社区的协作,我很高兴 OpenMessaging 项目进入 Linux 基金会。OpenMessaging 社区的目标是为分布式消息分发创建全球采用的、供应商中立的和开放标准,可以部署在云端、内部和混合云情景中。
|
||||||
|
|
||||||
|
阿里巴巴、雅虎、滴滴和 Streamlio 是该项目的创始贡献者。Linux 基金会已与这个初始项目社区合作来建立一个治理模式和结构,以实现运作在消息 API 标准上的生态系统的长期受益。
|
||||||
|
|
||||||
|
由于越来越多的公司和开发者迈向<ruby>云原生应用<rt>cloud native application</rt></ruby>,消息式应用和流式应用的扩展面临的挑战也在不断发展。这包括平台之间的互操作性问题,<ruby>[线路级协议](https://en.wikipedia.org/wiki/Wire_protocol)<rt>wire-level protocol</rt></ruby>之间缺乏兼容性以及系统间缺乏标准的基准测试。
|
||||||
|
|
||||||
|
特别是当数据跨不同的消息平台和流平台进行传输时会出现兼容性问题,这意味着额外的工作和维护成本。现有解决方案缺乏负载平衡、容错、管理、安全性和流功能的标准化指南。目前的系统不能满足现代面向云的消息应用和流应用的需求。这可能导致开发人员额外的工作,并且难以或不可能满足物联网、边缘计算、智能城市等方面的尖端业务需求。
|
||||||
|
|
||||||
|
OpenMessaging 的贡献者正在寻求通过以下方式改进分布式消息分发:
|
||||||
|
|
||||||
|
* 为分布式消息分发创建一个面向全球、面向云、供应商中立的行业标准
|
||||||
|
* 促进用于测试应用程序的标准基准发展
|
||||||
|
* 支持平台独立
|
||||||
|
* 以可伸缩性、灵活性、隔离和安全性为目标的云数据的流和消息分发要求
|
||||||
|
* 培育不断发展的开发贡献者社区
|
||||||
|
|
||||||
|
你可以在这了解有关新项目的更多信息以及如何参与: [http://openmessaging.cloud][1]。
|
||||||
|
|
||||||
|
这些是支持 OpenMessaging 的一些组织:
|
||||||
|
|
||||||
|
“我们多年来一直专注于消息分发和流领域,在此期间,我们探索了 Corba 通知、JMS 和其它标准,来试图解决我们最严格的业务需求。阿里巴巴在评估了可用的替代品后,选择创建一个新的面向云的消息分发标准 OpenMessaging,这是一个供应商中立,且语言无关的标准,并为金融、电子商务、物联网和大数据等领域提供了行业指南。此外,它目地在于跨异构系统和平台间开发消息分发和流应用。我们希望它可以是开放、简单、可扩展和可互操作的。另外,我们要根据这个标准建立一个生态系统,如基准测试、计算和各种连接器。我们希望有新的贡献,并希望大家能够共同努力,推动 OpenMessaging 标准的发展。”
|
||||||
|
|
||||||
|
——阿里巴巴高级架构师 Von Gosling,Apache RocketMQ 的联合创始人,以及 OpenMessaging 的原始发起人
|
||||||
|
|
||||||
|
“随着应用程序消息的复杂性和规模的不断扩大,缺乏标准的接口为开发人员和组织带来了复杂性和灵活性的障碍。Streamlio 很高兴与其他领导者合作推出 OpenMessaging 标准倡议来给客户一个轻松使用高性能、低延迟的消息传递解决方案,如 Apache Pulsar,它提供了企业所需的耐用性、一致性和可用性。“
|
||||||
|
|
||||||
|
—— Streamlio 的软件工程师、Apache Pulsar 的联合创始人以及 Apache BookKeeper PMC 的成员 Matteo Merli
|
||||||
|
|
||||||
|
“Oath(Verizon 旗下领先的媒体和技术品牌,包括雅虎和 AOL)支持开放,协作的举措,并且很乐意加入 OpenMessaging 项目。”
|
||||||
|
|
||||||
|
—— Joe Francis,核心平台总监
|
||||||
|
|
||||||
|
“在滴滴中,我们定义了一组私有的生产者 API 和消费者 API 来隐藏开源的 MQ(如 Apache Kafka、Apache RocketMQ 等)之间的差异,并提供额外的自定义功能。我们计划将这些发布到开源社区。到目前为止,我们已经积累了很多关于 MQ 和 API 统一的经验,并愿意在 OpenMessaging 中与其它 API 一起构建 API 的共同标准。我们真诚地认为,统一和广泛接受的 API 标准可以使 MQ 技术和依赖于它的应用程序受益。”
|
||||||
|
|
||||||
|
—— 滴滴的架构师 Neil Qi_
|
||||||
|
|
||||||
|
“有许多不同的开源消息分发解决方案,包括 Apache ActiveMQ、Apache RocketMQ、Apache Pulsar 和 Apache Kafka。缺乏行业级的可扩展消息分发标准使得评估合适的解决方案变得困难。我们很高兴能够与多个开源项目共同努力,共同确定可扩展的开放消息规范。 Apache BookKeeper 已成功在雅虎(通过 Apache Pulsar)和 Twitter(通过 Apache DistributedLog)的生产环境中部署,它作为其企业级消息系统的持久化、高性能、低延迟存储基础。我们很高兴加入 OpenMessaging 帮助其它项目解决诸如低延迟持久化、一致性和可用性等在消息分发方案中的常见问题。”
|
||||||
|
|
||||||
|
—— Streamlio 的联合创始人、Apache BookKeeper 的 PMC 主席、Apache DistributedLog 的联合创造者,Sijie Guo
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linuxfoundation.org/blog/building-open-standard-distributed-messaging-introducing-openmessaging/
|
||||||
|
|
||||||
|
作者:[Mike Dolan][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linuxfoundation.org/author/mdolan/
|
||||||
|
[1]:http://openmessaging.cloud/
|
||||||
|
[2]:https://www.linuxfoundation.org/author/mdolan/
|
||||||
|
[3]:https://www.linuxfoundation.org/category/blog/
|
||||||
@ -0,0 +1,32 @@
|
|||||||
|
密码修改最佳实践
|
||||||
|
=============
|
||||||
|
|
||||||
|
NIST 最近发表了四卷 [SP800-63b 数字身份指南][3]。除此之外,它还对密码提供三个重要的建议:
|
||||||
|
|
||||||
|
1. 不要再纠结于复杂的密码规则。它们使密码难以记住。因为人为的复杂密码很难输入,因此增加了错误。它们[也没有很大帮助][1]。最好让人们使用密码短语。
|
||||||
|
2. 停止密码到期。这是[我们以前使用计算机的一个老的想法][2]。如今不要让人改变密码,除非有泄密的迹象。
|
||||||
|
3. 让人们使用密码管理器。这就是处理我们所有密码的方式。
|
||||||
|
|
||||||
|
这些密码规则不能[让用户安全][4]。让系统安全才是最重要的。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
自从 2004 年以来,我一直在博客上写关于安全的文章,以及从 1998 年以来我的每月订阅中也有。我写书、文章和学术论文。目前我是 IBM Resilient 的首席技术官,哈佛伯克曼中心的研究员,EFF 的董事会成员。
|
||||||
|
|
||||||
|
-----------------
|
||||||
|
|
||||||
|
via: https://www.schneier.com/blog/archives/2017/10/changes_in_pass.html
|
||||||
|
|
||||||
|
作者:[Bruce Schneier][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.schneier.com/blog/about/
|
||||||
|
[1]:https://www.wsj.com/articles/the-man-who-wrote-those-password-rules-has-a-new-tip-n3v-r-m1-d-1502124118
|
||||||
|
[2]:https://securingthehuman.sans.org/blog/2017/03/23/time-for-password-expiration-to-die
|
||||||
|
[3]:http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-63b.pdf
|
||||||
|
[4]:http://ieeexplore.ieee.org/document/7676198/?reload=true
|
||||||
@ -0,0 +1,51 @@
|
|||||||
|
见多识广的 Pornhub 人工智能比你认识更多的 XXX 明星
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
你有没有想过,之所以能够根据自己不同兴趣的组合搜索到需要的视频,是因为有那些每日浏览无数视频内容且对它们进行分类和标记的可怜人存在,然而这些看不见的英雄们却在人工智能面前变得英雄无用武之地。
|
||||||
|
|
||||||
|
世界上最大的 XXX 电影分享网站 Pornhub 宣布,它将推出新的 AI 模型,利用计算机视觉技术自动检测和识别 XXX 明星的名字。
|
||||||
|
|
||||||
|
根据 X-rated 网站的消息,目前该算法经过训练后已经通过简单的扫描和对镜头的理解,可以识别超过 1 万名 XXX 明星。Pornhub 说,通过向此 AI 模型输入数千个视频和 XXX 明星的正式照片,以让它学习如何返回准确的名字。
|
||||||
|
|
||||||
|
为了减小错误,这个成人网站将向用户求证由 AI 提供的标签和分类是否合适。用户可以根据结果的准确度,提出支持或是反对。这将会让算法变得更加智能。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
“现在,用户可以根据自身喜好寻找指定的 XXX 明星,我们也能够返回给用户尽可能精确的搜索结果,” PornHub 副总裁 Corey Price 说。“毫无疑问,我们的模型也将在未来的发展中扮演关键角色,尤其是考虑到每天有超过 1 万个的视频添加到网站上。”
|
||||||
|
|
||||||
|
“事实上,在过去的一个月里,我们测试了这个模型的测试版本,它(每天)可以扫描 5 万段视频,并且向视频添加或者移除标签。”
|
||||||
|
|
||||||
|
除了识别表演者,该算法还能区分不同类别的内容:比如在 “Public” 类别下的是户外拍摄的视频,以及 “Blonde” 类别下的视频应该至少有名金发女郎。
|
||||||
|
|
||||||
|
XXX 公司计划明年在 AI 模型的帮助下,对全部 500 万个视频编目,希望能让用户更容易找到与他们的期望最接近的视频片段。
|
||||||
|
|
||||||
|
早先就有研究人员借助计算机视觉算法对 XXX 电影进行描述。之前就有一名开发者使用微软的人工智能技术来构建这个机器人,它可以整天[观察和解读][2]各种内容。
|
||||||
|
|
||||||
|
Pornhub 似乎让这一想法更进一步,这些那些遍布全球的视频审看员的噩梦。
|
||||||
|
|
||||||
|
虽然人工智能被发展到这个方面可能会让你感觉有些不可思议,但 XXX 业因其对搜索引擎优化技术的狂热追求而[闻名][3]。
|
||||||
|
|
||||||
|
事实上,[成人内容服务][4]一直以来都[有广泛市场][5],且[受众不分年龄][6],这也是这些公司盈利的重要组成部分。
|
||||||
|
|
||||||
|
但是,这些每日阅片无数、兢兢业业为其分类的人们可能很快就会成为自动化威胁的牺牲品。但从好的一面看,他们终于有机会坐下来[让自动化为他们工作][7]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://thenextweb.com/artificial-intelligence/2017/10/11/pornhub-ai-watch-tag/
|
||||||
|
|
||||||
|
作者:[MIX][a]
|
||||||
|
译者:[东风唯笑](https://github.com/dongfengweixiao)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://thenextweb.com/author/dimitarmihov/
|
||||||
|
[1]:https://thenextweb.com/author/dimitarmihov/
|
||||||
|
[2]:https://thenextweb.com/shareables/2017/03/03/porn-bot-microsoft-ai-pornhub/?amp=1
|
||||||
|
[3]:https://moz.com/ugc/yes-dear-there-is-porn-seo-and-we-can-learn-a-lot-from-it
|
||||||
|
[4]:https://www.upwork.com/job/Native-English-Speaker-Required-For-Video-Titles-Descriptions_~0170f127db07b9232b/
|
||||||
|
[5]:https://www.quora.com/How-do-adult-sites-practice-SEO
|
||||||
|
[6]:https://www.blackhatworld.com/seo/adult-looking-for-content-writer-for-porn-site.502731/
|
||||||
|
[7]:https://thenextweb.com/gear/2017/07/07/fleshlight-launch-review-masturbation/?amp=1
|
||||||
@ -0,0 +1,148 @@
|
|||||||
|
NixOS Linux: 先配置后安装的 Linux
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
配置是成功安装 NixOS 的关键。
|
||||||
|
|
||||||
|
我用 Linux 有些年头了。在这些年里我很有幸见证了开源的发展。各色各样的发行版在安装方面的努力,也是其中的一个比较独特的部分。以前,安装 Linux 是个最好让有技术的人来干的任务。现在,只要你会装软件,你就会安装 Linux。简单,并且,不是我吹,在吸引新用户方面效果拔群。事实上安装整个 Linux 操作系统都要比 Windows 用户安装个更新看起来要快一点。
|
||||||
|
|
||||||
|
但每一次,我都喜欢看到一些不同的东西——那些可以让我体验新鲜的东西。[NixOS][9] 在这方面就做的别具一格。讲真,我原来也就把它当作另一个提供标准特性和 KDE Plasma 5 界面的 Linux 发行版。
|
||||||
|
|
||||||
|
好像也没什么不对。
|
||||||
|
|
||||||
|
[下载 ISO 映像][10]后,我启动了 [VirtualBox][11] 并用下载的镜像创建了个新的虚拟机。VM 启动后,出来的是 Bash 的登录界面,界面上指导我用空密码去登录 root 账号,以及我该如何启动 GUI 显示管理器(图 1)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 1: 与 NixOS 的初次接触可能不是太和谐。*
|
||||||
|
|
||||||
|
“好吧”我这样想着,“打开看看吧!”
|
||||||
|
|
||||||
|
GUI 启动和运行时(KDE Plasma 5),我没找到喜闻乐见的“安装”按钮。原来,NixOS 是一个在安装前需要你配置的发行版,真有趣。那就让我们瞧瞧它是如何做到的吧!
|
||||||
|
|
||||||
|
### 安装前配置
|
||||||
|
|
||||||
|
你需要做的第一件事是建分区。由于 NixOS 安装程序不包含分区工具,你得用自带的 GParted (图 2)来创建一个 EXT4 分区。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 2: 安装前对磁盘分区。*
|
||||||
|
|
||||||
|
创建好分区,然后用命令 `mount /dev/sdX /mnt` 挂载。(请自行替换 `sdX` 为你新创建的分区)。
|
||||||
|
|
||||||
|
你现在需要创建一个配置文件。命令如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
nixos-generate-config --root /mnt
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的命令会创建两个文件(存放在目录 `/mnt/etc/nixos` 中):
|
||||||
|
|
||||||
|
* `configuration.nix` — 默认配置文件。
|
||||||
|
* `hardware-configuration.nix` — 硬件配置(无法编辑)
|
||||||
|
|
||||||
|
通过命令 `nano /mnt/etc/nixos/configuration.nix` 打开文件。其中有一些需要编辑的地方得注意。第一个改动便是设置启动选项。找到行:
|
||||||
|
|
||||||
|
```
|
||||||
|
# boot.loader.grub.device = "/dev/sda"; # 或 efi 时用 "nodev"
|
||||||
|
```
|
||||||
|
|
||||||
|
删除行首的 `#` 使该选项生效(确保 `/dev/sda` 与你新建的分区)。
|
||||||
|
|
||||||
|
通过配置文件,你可以设置时区和追加要安装的软件包。来看一个被注释掉的安装包的示例:
|
||||||
|
|
||||||
|
```
|
||||||
|
# List packages installed in system profile. To search by name, run:
|
||||||
|
# nix-env -aqP | grep wget
|
||||||
|
# environment.systemPackages = with pkgs; [
|
||||||
|
# wget vim
|
||||||
|
# ];
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你想要添加软件包,并在安装时安装它们,那就取消掉这段注释,并添加你需要的软件包。举个例子,比方说你要把 LibreOffice 加进去。示例详见下方:
|
||||||
|
|
||||||
|
```
|
||||||
|
# List packages installed in system profile. To search by name, run:
|
||||||
|
nix-env -aqP | grep wget
|
||||||
|
environment.systemPackages = with pkgs; [
|
||||||
|
libreoffice wget vim
|
||||||
|
];
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以通过输入命令 `nix-env -aqP | grep PACKAGENAME` 来寻找确切的包名(`PACKAGENAME` 为你想要找的软件包)。如果你不想输命令,你也可以检索 [NixOS 的软件包数据库][12]。
|
||||||
|
|
||||||
|
在你把所有的软件包都添加完后,你还有件事儿需要做(如果你想要登录到桌面的话,我觉得你还得折腾下 KDE Plasma 5 桌面)。翻到配置文件的末尾并在最后的 `}` 符号前,追加如下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
services.xserver = {
|
||||||
|
enable = true;
|
||||||
|
displayManager.sddm.enable = true;
|
||||||
|
desktopManager.plasma5.enable = true;
|
||||||
|
};
|
||||||
|
```
|
||||||
|
|
||||||
|
在 [NixOS 官方文件][13] 中,你能找到配置文件中更多的选项。保存并关掉配置文件。
|
||||||
|
|
||||||
|
### 安装
|
||||||
|
|
||||||
|
在你按照自己的需求完善好配置之后,使用命令(需要 root 权限) `nixos-install`。完成安装所需要的时间,会随着你加入的软件包多少有所区别。安装结束后,你可以使用命令重启系统,(重启之后)迎接你的就是 KDE Plasma 5 的登录管理界面了(图 3)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 3: KDE Plasma 5 登录管理界面*
|
||||||
|
|
||||||
|
### 安装后
|
||||||
|
|
||||||
|
你要首先要做的两件事之一便是给 root 用户设个密码(通过输入命令 `passwd` 来修改默认的密码),以及添加一个标准用户。做法和其它的 Linux 发行版无二。用 root 用户登录,然后在终端输入命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
useradd -m USER
|
||||||
|
```
|
||||||
|
|
||||||
|
将 `USER` 替换成你想要添加的用户名。然后通过下面的命令给用户设上密码:
|
||||||
|
|
||||||
|
```
|
||||||
|
passwd USER
|
||||||
|
```
|
||||||
|
|
||||||
|
同样的将 `USER` 替换成你添加的用户。
|
||||||
|
|
||||||
|
然后会有提示引导你填写并验证新密码。然后,你就能用标准用户登录 NixOS 啦。
|
||||||
|
|
||||||
|
NixOS 在你安装并运行后,你可以为系统添加新的软件包,但并非通过寻常的方式。如果你发现你需要安装些新东西,你得回到配置文件(位置就是 `/etc/nixos/` ),找到之前安装时添加软件包的位置,运行以下命令(需要 root 权限):
|
||||||
|
|
||||||
|
```
|
||||||
|
nixos-rebuild switch
|
||||||
|
```
|
||||||
|
|
||||||
|
命令执行结束后,你就能使用新安装的软件包了。
|
||||||
|
|
||||||
|
### Enjoy NixOS
|
||||||
|
|
||||||
|
现在,NixOS 已经带着所有你想安装的软件和 KDE Plasma 5 桌面运行起来了。要知道,你所做的不仅仅只是安装了个 Linux 发行版,关键是你自定义出来的发行版非常符合你的需求。所以好好享受你的 NixOS 吧!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linux.com/learn/intro-to-linux/2017/10/nixos-linux-lets-you-configure-your-os-installing
|
||||||
|
|
||||||
|
作者:[JACK WALLEN][a]
|
||||||
|
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linux.com/users/jlwallen
|
||||||
|
[1]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[2]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[3]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[4]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||||
|
[5]:https://www.linux.com/files/images/nixos1jpg
|
||||||
|
[6]:https://www.linux.com/files/images/nixos2jpg
|
||||||
|
[7]:https://www.linux.com/files/images/nixos3jpg
|
||||||
|
[8]:https://www.linux.com/files/images/configurationjpg
|
||||||
|
[9]:https://nixos.org/
|
||||||
|
[10]:https://nixos.org/nixos/download.html
|
||||||
|
[11]:https://www.virtualbox.org/wiki/Downloads
|
||||||
|
[12]:https://nixos.org/nixos/packages.html
|
||||||
|
[13]:https://nixos.org/nixos/manual/index.html#ch-configuration
|
||||||
@ -0,0 +1,57 @@
|
|||||||
|
Grafeas:旨在更好地审计容器
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> Google 的 Grafeas 为容器的元数据提供了一个从镜像、构建细节到安全漏洞的通用 API。
|
||||||
|
|
||||||
|

|
||||||
|
Thinkstock
|
||||||
|
|
||||||
|
我们运行的软件从来没有比今天更难获得。它分散在本地部署和云服务之间,由不知到有多少的开源组件构建而成,以快速的时间表交付,因此保证安全和质量变成了一个挑战。
|
||||||
|
|
||||||
|
最终的结果是软件难以审计、推断、安全化和管理。困难的不只是知道 VM 或容器是用什么构建的, 而是由谁来添加、删除或更改的。[Grafeas][5] 最初由 Google 设计,旨在使这些问题更容易解决。
|
||||||
|
|
||||||
|
### 什么是 Grafeas?
|
||||||
|
|
||||||
|
Grafeas 是一个定义软件组件的元数据 API 的开源项目。旨在提供一个统一的元数据模式,允许 VM、容器、JAR 文件和其他软件<ruby>工件<rt>artifact</rt></ruby>描述自己的运行环境以及管理它们的用户。目标是允许像在给定环境中使用的软件一样的审计,以及对该软件所做的更改的审计,并以一致和可靠的方式进行。
|
||||||
|
|
||||||
|
Grafeas提供两种格式的元数据 API —— 备注和事件:
|
||||||
|
|
||||||
|
* <ruby>备注<rt>note</rt></ruby>是有关软件工件的某些方面的细节。可以是已知软件漏洞的描述,有关如何构建软件的详细信息(构建器版本、校验和等),部署历史等。
|
||||||
|
* <ruby>事件<rt>occurrence</rt></ruby>是备注的实例,包含了它们创建的地方和方式的细节。例如,已知软件漏洞的详细信息可能会有描述哪个漏洞扫描程序检测到它的情况、何时被检测到的事件信息,以及该漏洞是否被解决。
|
||||||
|
|
||||||
|
备注和事件都存储在仓库中。每个备注和事件都使用标识符进行跟踪,该标识符区分它并使其唯一。
|
||||||
|
|
||||||
|
Grafeas 规范包括备注类型的几个基本模式。例如,软件包漏洞模式描述了如何存储 CVE 或漏洞描述的备注信息。现在没有接受新模式类型的正式流程,但是[这已经在计划][6]创建这样一个流程。
|
||||||
|
|
||||||
|
### Grafeas 客户端和第三方支持
|
||||||
|
|
||||||
|
现在,Grafeas 主要作为规范和参考形式存在,它在 [GitHub 上提供][7]。 [Go][8]、[Python][9] 和 [Java][10] 的客户端都可以[用 Swagger 生成][11],所以其他语言的客户端也应该不难写出来。
|
||||||
|
|
||||||
|
Google 计划让 Grafeas 广泛使用的主要方式是通过 Kubernetes。 Kubernetes 的一个名为 Kritis 的策略引擎,可以根据 Grafeas 元数据对容器采取措施。
|
||||||
|
|
||||||
|
除 Google 之外的几家公司已经宣布计划将 Grafeas 的支持添加到现有产品中。例如,CoreOS 正在考察 Grafeas 如何与 Tectonic 集成,[Red Hat][12] 和 [IBM][13] 都计划在其容器产品和服务中添加 Grafeas 集成。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.infoworld.com/article/3230462/security/what-is-grafeas-better-auditing-for-containers.html
|
||||||
|
|
||||||
|
作者:[Serdar Yegulalp][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.infoworld.com/author/Serdar-Yegulalp/
|
||||||
|
[1]:https://www.infoworld.com/author/Serdar-Yegulalp/
|
||||||
|
[2]:https://www.infoworld.com/author/Serdar-Yegulalp/
|
||||||
|
[3]:https://www.infoworld.com/article/3207686/cloud-computing/how-to-get-started-with-kubernetes.html#tk.ifw-infsb
|
||||||
|
[4]:https://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||||
|
[5]:http://grafeas.io/
|
||||||
|
[6]:https://github.com/Grafeas/Grafeas/issues/38
|
||||||
|
[7]:https://github.com/grafeas/grafeas
|
||||||
|
[8]:https://github.com/Grafeas/client-go
|
||||||
|
[9]:https://github.com/Grafeas/client-python
|
||||||
|
[10]:https://github.com/Grafeas/client-java
|
||||||
|
[11]:https://www.infoworld.com/article/2902750/application-development/manage-apis-with-swagger.html
|
||||||
|
[12]:https://www.redhat.com/en/blog/red-hat-google-cloud-and-other-industry-leaders-join-together-standardize-kubernetes-service-component-auditing-and-policy-enforcement
|
||||||
|
[13]:https://developer.ibm.com/dwblog/2017/grafeas/
|
||||||
@ -0,0 +1,53 @@
|
|||||||
|
如何成规模地部署多云的无服务器程序和 Cloud Foundry API
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> IBM 的 Ken Parmelee 说:“微服务和 API 是产品,我们需要以这种方式思考。”
|
||||||
|
|
||||||
|
领导 IBM 的 API 网关和 Big Blue 开源项目的的 Ken Parmelee 对以开源方式 “进攻” API 以及如何创建微服务和使其伸缩有一些思考。
|
||||||
|
|
||||||
|
Parmelee 说:“微服务和 API 是产品,我们需要以这种方式思考这些问题。当你开始这么做,人们依赖它作为它们业务的一部分。这是你在这个领域所做的关键方面。”
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
他在最近的[北欧 APIs 2017 平台峰会][3]登上讲台,并挑战了一些流行的观念。
|
||||||
|
|
||||||
|
“快速失败不是一个很好的概念。你想在第一场比赛中获得一些非常棒的东西。这并不意味着你需要花费大量的时间,而是应该让它变得非常棒,然后不断的发展和改进。如果一开始真的很糟糕,人们就不会想要用你。”
|
||||||
|
|
||||||
|
他谈及包括 [OpenWhisk][4] 在内的 IBM 现代无服务器架构,这是一个 IBM 和 Apache 之间的开源伙伴关系。 云优先的基于分布式事件的编程服务是这两年多来重点关注这个领域的成果;IBM 是该领域领先的贡献者,它是 IBM 云服务的基础。它提供基础设施即服务(IaaS)、自动缩放、为多种语言提供支持、用户只需支付实际使用费用即可。这次旅程充满了挑战,因为他们发现服务器操作需要安全、并且需要轻松 —— 匿名访问、缺少使用路径、固定的 URL 格式等。
|
||||||
|
|
||||||
|
任何人都可以在 30 秒内在 [https://console.bluemix.net/openwhisk/][5] 上尝试这些无服务器 API。“这听起来很有噱头,但这是很容易做到的。我们正在结合 [Cloud Foundry 中完成的工作][6],并在 OpenWhisk 下的 Bluemix 中发布了它们,以提供安全性和可扩展性。”
|
||||||
|
|
||||||
|
他说:“灵活性对于微服务也是非常重要的。 当你使用 API 在现实世界中工作时,你开始需要跨云进行扩展。”这意味着从你的内部云走向公共云,并且“对你要怎么做有一个实在的概念很重要”。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在思考“任何云概念”的时候,他警告说,不是“将其放入一个 Docker 容器,并到处运行。这很棒,但需要在这些环境中有效运行。Docker 和 Kubernetes 有提供了很多帮助,但是你想要你的操作方式付诸实施。” 提前考虑 API 的使用,无论是在内部运行还是扩展到公有云并可以公开调用 - 你需要有这样的“架构观”,他补充道。
|
||||||
|
|
||||||
|
Parmelee 说:“我们都希望我们所创造的有价值,并被广泛使用。” API 越成功,将其提升到更高水平的挑战就越大。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*API 是微服务或“服务间”的组成部分。*
|
||||||
|
|
||||||
|
他说,API 的未来是原生云的 - 无论你从哪里开始。关键因素是可扩展性,简化后端管理,降低成本,避免厂商锁定。
|
||||||
|
|
||||||
|
你可以在下面或在 [YouTube][7] 观看他整整 23 分钟的演讲。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://superuser.openstack.org/articles/deploy-multi-cloud-serverless-cloud-foundry-apis-scale/
|
||||||
|
|
||||||
|
作者:[Superuser][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://superuser.openstack.org/articles/author/superuser/
|
||||||
|
[1]:http://superuser.openstack.org/articles/author/superuser/
|
||||||
|
[2]:http://superuser.openstack.org/articles/deploy-multi-cloud-serverless-cloud-foundry-apis-scale/
|
||||||
|
[3]:https://nordicapis.com/events/the-2017-api-platform-summit/
|
||||||
|
[4]:https://developer.ibm.com/openwhisk/
|
||||||
|
[5]:https://console.bluemix.net/openwhisk/
|
||||||
|
[6]:https://cloudfoundry.org/the-foundry/ibm-cloud/
|
||||||
|
[7]:https://www.youtube.com/jA25Kmxr6fU
|
||||||
@ -0,0 +1,41 @@
|
|||||||
|
Linus Torvalds 说针对性的模糊测试正提升 Linux 安全性
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
Linux 4.14 发布候选第五版已经出来。Linus Torvalds 说:“可以去测试了。”
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
随着宣布推出 Linux 内核 4.14 的第五个候选版本,Linus Torvalds 表示<ruby>模糊测试<rt>fuzzing</rt></ruby>正产生一系列稳定的安全更新。
|
||||||
|
|
||||||
|
模糊测试通过产生随机代码来引发错误来对系统进行压力测试,从而有助于识别潜在的安全漏洞。模糊测试可以帮助软件开发人员在向用户发布软件之前捕获错误。
|
||||||
|
|
||||||
|
Google 使用各种模糊测试工具来查找它及其它供应商软件中的错误。微软推出了 [Project Springfield][1] 模糊测试服务,它能让企业客户测试自己的软件。
|
||||||
|
|
||||||
|
正如 Torvalds 指出的那样,Linux 内核开发人员从一开始就一直在使用模糊测试流程,例如 1991 年发布的工具 “crashme”,它在近 20 年后被 [Google 安全研究员 Tavis Ormandy ][2] 用来测试在虚拟机中处理不受信任的数据时,宿主机是否受到良好保护。
|
||||||
|
|
||||||
|
Torvalds [说][3]:“另外值得一提的是人们做了多少随机化模糊测试,而且这正在发现东西。”
|
||||||
|
|
||||||
|
“我们一直在做模糊测试(谁还记得只是生成随机代码,并跳转过去的老 “crashme” 程序?我们过去很早就这样做),人们在驱动子系统等方面做了一些很好的针对性模糊测试,而且已经有了各种各样的修复(不仅仅是上周的这些)。很高兴可以看到。”
|
||||||
|
|
||||||
|
Torvalds 提到,到目前为止,4.14 的发展“比预想的要麻烦一些”,但现在已经好了,并且在这个版本已经跑通了一些针对 x86 系统以及 AMD 芯片系统的修复。还有几个驱动程序、核心内核组件和工具的更新。
|
||||||
|
|
||||||
|
如前[所述][4],Linux 4.14 是 2017 年的长期稳定版本,迄今为止,它引入了核心内存管理功能、设备驱动程序更新以及文档、架构、文件系统、网络和工具的修改。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.zdnet.com/article/linus-torvalds-says-targeted-fuzzing-is-improving-linux-security/
|
||||||
|
|
||||||
|
作者:[Liam Tung][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.zdnet.com/meet-the-team/eu/liam-tung/
|
||||||
|
[1]:http://www.zdnet.com/article/microsoft-seeks-testers-for-project-springfield-bug-detection-service/
|
||||||
|
[2]:http://taviso.decsystem.org/virtsec.pdf
|
||||||
|
[3]:http://lkml.iu.edu/hypermail/linux/kernel/1710.1/06454.html
|
||||||
|
[4]:http://www.zdnet.com/article/first-linux-4-14-release-adds-very-core-features-arrives-in-time-for-kernels-26th-birthday/
|
||||||
|
[5]:http://www.zdnet.com/meet-the-team/eu/liam-tung/
|
||||||
|
[6]:http://www.zdnet.com/meet-the-team/eu/liam-tung/
|
||||||
|
[7]:http://www.zdnet.com/topic/security/
|
||||||
73
published/201710/20171017 PingCAP Launches TiDB 1.0.md
Normal file
73
published/201710/20171017 PingCAP Launches TiDB 1.0.md
Normal file
@ -0,0 +1,73 @@
|
|||||||
|
PingCAP 推出 TiDB 1.0
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> PingCAP 推出了 TiDB 1.0,一个可扩展的混合数据库解决方案
|
||||||
|
|
||||||
|
2017 年 10 月 16 日, 一家尖端的分布式数据库技术公司 PingCAP Inc. 正式宣布发布 [TiDB][4] 1.0。TiDB 是一个开源的分布式混合事务/分析处理 (HTAP) 数据库,它使企业能够使用单个数据库来满足这两个负载。
|
||||||
|
|
||||||
|
在当前的数据库环境中,基础架构工程师通常要使用一个数据库进行在线事务处理(OLTP),另一个用于在线分析处理(OLAP)。TiDB 旨在通过构建一个基于实时事务数据的实时业务分析的 HTAP 数据库来打破这种分离。有了 TiDB,工程师现在可以花更少的时间来管理多个数据库解决方案,并有更多的时间为他们的公司提供业务价值。TiDB 的一个金融证券公司的用户正在利用这项技术为财富管理和用户角色的应用提供支持。借助 TiDB,该公司可以轻松处理 web 量级的计费记录,并进行关键任务时间敏感的数据分析。
|
||||||
|
|
||||||
|
PingCAP 联合创始人兼 CEO 刘奇(Max Liu)说:
|
||||||
|
|
||||||
|
> “两年半前,Edward、Dylan 和我开始这个旅程,为长期困扰基础设施软件业的老问题建立一个新的数据库。今天,我们很自豪地宣布,这个数据库 TiDB 可以面向生产环境了。亚伯拉罕·林肯曾经说过,‘预测未来的最好办法就是创造’,我们在 771 天前预测的未来,现在我们已经创造了,这不仅是我们团队的每一个成员,也是我们的开源社区的每个贡献者、用户和合作伙伴的努力工作和奉献。今天,我们庆祝和感谢开源精神的力量。明天,我们将继续创造我们相信的未来。”
|
||||||
|
|
||||||
|
TiDB 已经在亚太地区 30 多家公司投入生产环境,其中包括 [摩拜][5]、[Gaea][6] 和 [YOUZU][7] 等快速增长的互联网公司。使用案例涵盖从在线市场和游戏到金融科技、媒体和旅游的多个行业。
|
||||||
|
|
||||||
|
### TiDB 功能
|
||||||
|
|
||||||
|
**水平可扩展性**
|
||||||
|
|
||||||
|
TiDB 随着你的业务发展而增长。你可以通过添加更多机器来增加存储和计算能力。
|
||||||
|
|
||||||
|
**兼容 MySQL 协议**
|
||||||
|
|
||||||
|
像用 MySQL 一样使用 TiDB。你可以用 TiDB 替换 MySQL 来增强你的应用,且在大多数情况下不用更改一行代码,也几乎没有迁移成本。
|
||||||
|
|
||||||
|
**自动故障切换和高可用性**
|
||||||
|
|
||||||
|
你的数据和程序始终处于在线状态。TiDB 自动处理故障并保护你的应用免受整个数据中心的机器故障甚至停机。
|
||||||
|
|
||||||
|
**一致的分布式事务**
|
||||||
|
|
||||||
|
TiDB 类似于单机关系型数据库系统(RDBMS)。你可以启动跨多台机器的事务,而不用担心一致性。TiDB 使你的应用程序代码简单而强大。
|
||||||
|
|
||||||
|
**在线 DDL**
|
||||||
|
|
||||||
|
根据你的要求更改 TiDB 模式。你可以添加新的列和索引,而不会停止或影响你正在进行的操作。
|
||||||
|
|
||||||
|
[现在尝试TiDB!][8]
|
||||||
|
|
||||||
|
### 使用案例
|
||||||
|
|
||||||
|
- [yuanfudao.com 中 TiDB 如何处理快速的数据增长和复杂查询] [9]
|
||||||
|
- [从 MySQL 迁移到 TiDB 以每天处理数千万行数据] [10]
|
||||||
|
|
||||||
|
### 更多信息:
|
||||||
|
|
||||||
|
TiDB 内部:
|
||||||
|
|
||||||
|
* [数据存储][1]
|
||||||
|
* [计算][2]
|
||||||
|
* [调度][3]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://pingcap.github.io/blog/2017/10/17/announcement/
|
||||||
|
|
||||||
|
作者:[PingCAP][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://pingcap.github.io/blog/
|
||||||
|
[1]:https://pingcap.github.io/blog/2017/07/11/tidbinternal1/
|
||||||
|
[2]:https://pingcap.github.io/blog/2017/07/11/tidbinternal2/
|
||||||
|
[3]:https://pingcap.github.io/blog/2017/07/20/tidbinternal3/
|
||||||
|
[4]:https://github.com/pingcap/tidb
|
||||||
|
[5]:https://en.wikipedia.org/wiki/Mobike
|
||||||
|
[6]:http://www.gaea.com/en/
|
||||||
|
[7]:http://www.yoozoo.com/aboutEn
|
||||||
|
[8]:https://pingcap.com/doc-QUICKSTART
|
||||||
|
[9]:https://pingcap.github.io/blog/2017/08/08/tidbforyuanfudao/
|
||||||
|
[10]:https://pingcap.github.io/blog/2017/05/22/Comparison-between-MySQL-and-TiDB-with-tens-of-millions-of-data-per-day/
|
||||||
@ -0,0 +1,43 @@
|
|||||||
|
IoT 网络安全:后备计划是什么?
|
||||||
|
=======
|
||||||
|
|
||||||
|
八月份,四名美国参议员提出了一项旨在改善物联网(IoT)安全性的法案。2017 年的 “物联网网络安全改进法” 是一项小幅的立法。它没有规范物联网市场。它没有任何特别关注的行业,或强制任何公司做任何事情。甚至没有修改嵌入式软件的法律责任。无论安全多么糟糕,公司可以继续销售物联网设备。
|
||||||
|
|
||||||
|
法案的做法是利用政府的购买力推动市场:政府购买的任何物联网产品都必须符合最低安全标准。它要求供应商确保设备不仅可以打补丁,而且是以认证和及时的方式进行修补,没有不可更改的默认密码,并且没有已知的漏洞。这是一个你可以达到的低安全值,并且将大大提高安全性,可以说明关于物联网安全性的当前状态。(全面披露:我帮助起草了一些法案的安全性要求。)
|
||||||
|
|
||||||
|
该法案还将修改“计算机欺诈和滥用”和“数字千年版权”法案,以便安全研究人员研究政府购买的物联网设备的安全性。这比我们的行业需求要窄得多。但这是一个很好的第一步,这可能是对这个立法最好的事。
|
||||||
|
|
||||||
|
不过,这一步甚至不可能施行。我在八月份写这个专栏,毫无疑问,这个法案你在十月份或以后读的时候会没有了。如果听证会举行,它们无关紧要。该法案不会被任何委员会投票,不会在任何立法日程上。这个法案成为法律的可能性是零。这不仅仅是因为目前的政治 - 我在奥巴马政府下同样悲观。
|
||||||
|
|
||||||
|
但情况很严重。互联网是危险的 - 物联网不仅给了眼睛和耳朵,而且还给手脚。一旦有影响到位和字节的安全漏洞、利用和攻击现在将会影响到其血肉。
|
||||||
|
|
||||||
|
正如我们在过去一个世纪一再学到的那样,市场是改善产品和服务安全的可怕机制。汽车、食品、餐厅、飞机、火灾和金融仪器安全都是如此。原因很复杂,但基本上卖家不会在安全方面进行竞争,因为买方无法根据安全考虑有效区分产品。市场使用的竞相降低门槛的机制价格降到最低的同时也将质量降至最低。没有政府干预,物联网仍然会很不安全。
|
||||||
|
|
||||||
|
美国政府对干预没有兴趣,所以我们不会看到严肃的安全和保障法规、新的联邦机构或更好的责任法。我们可能在欧盟有更好的机会。根据“通用数据保护条例”在数据隐私的规定,欧盟可能会在 5 年内通过类似的安全法。没有其他国家有足够的市场份额来做改变。
|
||||||
|
|
||||||
|
有时我们可以选择不使用物联网,但是这个选择变得越来越少见了。去年,我试着不连接网络来购买新车但是失败了。再过几年, 就几乎不可能不连接到物联网。我们最大的安全风险将不会来自我们与之有市场关系的设备,而是来自其他人的汽车、照相机、路由器、无人机等等。
|
||||||
|
|
||||||
|
我们可以尝试为理想买单,并要求更多的安全性,但企业不会在物联网安全方面进行竞争 - 而且我们的安全专家不是一个可以产生影响的足够大的市场力量。
|
||||||
|
|
||||||
|
我们需要一个后备计划,虽然我不知道是什么。如果你有任何想法请评论。
|
||||||
|
|
||||||
|
这篇文章以前出现在 9/10 月的 《IEEE 安全与隐私》上。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
自从 2004 年以来,我一直在博客上写关于安全的文章,以及从 1998 年以来我的每月订阅中也有。我写书、文章和学术论文。目前我是 IBM Resilient 的首席技术官,哈佛伯克曼中心的研究员,EFF 的董事会成员。
|
||||||
|
|
||||||
|
------------------
|
||||||
|
|
||||||
|
|
||||||
|
via: https://www.schneier.com/blog/archives/2017/10/iot_cybersecuri.html
|
||||||
|
|
||||||
|
作者:[Bruce Schneier][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.schneier.com/blog/about/
|
||||||
157
published/201710/20171019 How to run DOS programs in Linux.md
Normal file
157
published/201710/20171019 How to run DOS programs in Linux.md
Normal file
@ -0,0 +1,157 @@
|
|||||||
|
怎么在 Linux 中运行 DOS 程序
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> QEMU 和 FreeDOS 使得很容易在 Linux 中运行老的 DOS 程序
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Image by : opensource.com
|
||||||
|
|
||||||
|
传统的 DOS 操作系统支持的许多非常优秀的应用程序: 文字处理,电子表格,游戏和其它的程序。但是一个应用程序太老了,并不意味着它没用了。
|
||||||
|
|
||||||
|
如今有很多理由去运行一个旧的 DOS 应用程序。或许是从一个遗留的业务应用程序中提取一个报告,或者是想玩一个经典的 DOS 游戏,或者只是因为你对“传统计算机”很好奇。你不需要去双引导你的系统去运行 DOS 程序。取而代之的是,你可以在 Linux 中在一个 PC 仿真程序和 [FreeDOS][18] 的帮助下去正确地运行它们。
|
||||||
|
|
||||||
|
FreeDOS 是一个完整的、免费的、DOS 兼容的操作系统,你可以用它来玩经典的游戏、运行旧式业务软件,或者开发嵌入式系统。任何工作在 MS-DOS 中的程序也可以运行在 FreeDOS 中。
|
||||||
|
|
||||||
|
在那些“过去的时光”里,你安装的 DOS 是作为一台计算机上的独占操作系统。 而现今,它可以很容易地安装到 Linux 上运行的一台虚拟机中。 [QEMU][19] (<ruby>快速仿真程序<rt>Quick EMUlator</rt></ruby>的缩写) 是一个开源的虚拟机软件,它可以在 Linux 中以一个“<ruby>访客<rt>guest</rt></ruby>”操作系统来运行 DOS。许多流行的 Linux 系统都默认包含了 QEMU 。
|
||||||
|
|
||||||
|
通过以下四步,很容易地在 Linux 下通过使用 QEMU 和 FreeDOS 去运行一个老的 DOS 程序。
|
||||||
|
|
||||||
|
### 第 1 步:设置一个虚拟磁盘
|
||||||
|
|
||||||
|
你需要一个地方来在 QEMU 中安装 FreeDOS,为此你需要一个虚拟的 C: 驱动器。在 DOS 中,字母`A:` 和 `B:` 是分配给第一和第二个软盘驱动器的,而 `C:` 是第一个硬盘驱动器。其它介质,包括其它硬盘驱动器和 CD-ROM 驱动器,依次分配 `D:`、`E:` 等等。
|
||||||
|
|
||||||
|
在 QEMU 中,虚拟磁盘是一个镜像文件。要初始化一个用做虚拟 `C: ` 驱动器的文件,使用 `qemu-img` 命令。要创建一个大约 200 MB 的镜像文件,可以这样输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
qemu-img create dos.img 200M
|
||||||
|
```
|
||||||
|
|
||||||
|
与现代计算机相比, 200MB 看起来非常小,但是早在 1990 年代, 200MB 是非常大的。它足够安装和运行 DOS。
|
||||||
|
|
||||||
|
### 第 2 步: QEMU 选项
|
||||||
|
|
||||||
|
与 PC 仿真系统 VMware 或 VirtualBox 不同,你需要通过 QEMU 命令去增加每个虚拟机的组件来 “构建” 你的虚拟系统 。虽然,这可能看起来很费力,但它实际并不困难。这些是我们在 QEMU 中用于去引导 FreeDOS 的参数:
|
||||||
|
|
||||||
|
| | |
|
||||||
|
|:-- |:--|
|
||||||
|
| `qemu-system-i386` | QEMU 可以仿真几种不同的系统,但是要引导到 DOS,我们需要有一个 Intel 兼容的 CPU。 为此,使用 i386 命令启动 QEMU。 |
|
||||||
|
| `-m 16` | 我喜欢定义一个使用 16MB 内存的虚拟机。它看起来很小,但是 DOS 工作不需要很多的内存。在 DOS 时代,计算机使用 16MB 或者 8MB 内存是非常普遍的。 |
|
||||||
|
| `-k en-us` | 从技术上说,这个 `-k` 选项是不需要的,因为 QEMU 会设置虚拟键盘去匹配你的真实键盘(在我的例子中, 它是标准的 US 布局的英语键盘)。但是我还是喜欢去指定它。 |
|
||||||
|
| `-rtc base=localtime` | 每个传统的 PC 设备有一个实时时钟 (RTC) 以便于系统可以保持跟踪时间。我发现它是设置虚拟 RTC 匹配你的本地时间的最简单的方法。 |
|
||||||
|
| `-soundhw sb16,adlib,pcspk` | 如果你需要声音,尤其是为了玩游戏时,我更喜欢定义 QEMU 支持 SoundBlaster 16 声音硬件和 AdLib 音乐。SoundBlaster 16 和 AdLib 是在 DOS 时代非常常见的声音硬件。一些老的程序也许使用 PC 喇叭发声; QEMU 也可以仿真这个。 |
|
||||||
|
| `-device cirrus-vga` | 要使用图像,我喜欢去仿真一个简单的 VGA 视频卡。Cirrus VGA 卡是那时比较常见的图形卡, QEMU 可以仿真它。 |
|
||||||
|
| `-display gtk` | 对于虚拟显示,我设置 QEMU 去使用 GTK toolkit,它可以将虚拟系统放到它自己的窗口内,并且提供一个简单的菜单去控制虚拟机。 |
|
||||||
|
| `-boot order=` | 你可以告诉 QEMU 从多个引导源来引导虚拟机。从软盘驱动器引导(在 DOS 机器中一般情况下是 `A:` )指定 `order=a`。 从第一个硬盘驱动器引导(一般称为 `C:`) 使用 `order=c`。 或者去从一个 CD-ROM 驱动器(在 DOS 中经常分配为 `D:` ) 使用 `order=d`。 你可以使用组合字母去指定一个特定的引导顺序, 比如 `order=dc` 去第一个使用 CD-ROM 驱动器,如果 CD-ROM 驱动器中没有引导介质,然后使用硬盘驱动器。 |
|
||||||
|
|
||||||
|
### 第 3 步: 引导和安装 FreeDOS
|
||||||
|
|
||||||
|
现在 QEMU 已经设置好运行虚拟机,我们需要一个 DOS 系统来在那台虚拟机中安装和引导。 FreeDOS 做这个很容易。它的最新版本是 FreeDOS 1.2, 发行于 2016 年 12 月。
|
||||||
|
|
||||||
|
从 [FreeDOS 网站][20]上下载 FreeDOS 1.2 的发行版。 FreeDOS 1.2 CD-ROM “standard” 安装器 (`FD12CD.iso`) 可以很好地在 QEMU 上运行,因此,我推荐使用这个版本。
|
||||||
|
|
||||||
|
安装 FreeDOS 很简单。首先,告诉 QEMU 使用 CD-ROM 镜像并从其引导。 记住,第一个硬盘驱动器是 `C:` 驱动器,因此, CD-ROM 将以 `D:` 驱动器出现。
|
||||||
|
|
||||||
|
```
|
||||||
|
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -display gtk -hda dos.img -cdrom FD12CD.iso -boot order=d
|
||||||
|
```
|
||||||
|
|
||||||
|
正如下面的提示,你将在几分钟内安装完成 FreeDOS 。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在你安装完成之后,关闭窗口退出 QEMU。
|
||||||
|
|
||||||
|
### 第 4 步:安装并运行你的 DOS 应用程序
|
||||||
|
|
||||||
|
一旦安装完 FreeDOS,你可以在 QEMU 中运行各种 DOS 应用程序。你可以在线上通过各种档案文件或其它[网站][21]找到老的 DOS 程序。
|
||||||
|
|
||||||
|
QEMU 提供了一个在 Linux 上访问本地文件的简单方法。比如说,想去用 QEMU 共享 `dosfiles/` 文件夹。 通过使用 `-drive` 选项,简单地告诉 QEMU 去使用这个文件夹作为虚拟的 FAT 驱动器。 QEMU 将像一个硬盘驱动器一样访问这个文件夹。
|
||||||
|
|
||||||
|
```
|
||||||
|
-drive file=fat:rw:dosfiles/
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,你可以使用合适的选项去启动 QEMU,加上一个外部的虚拟 FAT 驱动器:
|
||||||
|
|
||||||
|
```
|
||||||
|
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -display gtk -hda dos.img -drive file=fat:rw:dosfiles/ -boot order=c
|
||||||
|
```
|
||||||
|
|
||||||
|
一旦你引导进入 FreeDOS,你保存在 `D:` 驱动器中的任何文件将被保存到 Linux 上的 `dosfiles/` 文件夹中。可以从 Linux 上很容易地直接去读取该文件;然而,必须注意的是,启动 QEMU 后,不能从 Linux 中去改变 `dosfiles/` 这个文件夹。 当你启动 QEMU 时,QEMU 一次性构建一个虚拟的 FAT 表,如果你在启动 QEMU 之后,在 `dosfiles/` 文件夹中增加或删除文件,仿真程序可能会很困惑。
|
||||||
|
|
||||||
|
我使用 QEMU 像这样运行一些我收藏的 DOS 程序, 比如 As-Easy-As 电子表格程序。这是一个在上世纪八九十年代非常流行的电子表格程序,它和现在的 Microsoft Excel 和 LibreOffice Calc 或和以前更昂贵的 Lotus 1-2-3 电子表格程序完成的工作是一样的。 As-Easy-As 和 Lotus 1-2-3 都保存数据为 WKS 文件,最新版本的 Microsoft Excel 不能读取它,但是,根据兼容性, LibreOffice Calc 可以支持它。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*As-Easy-As 电子表格程序*
|
||||||
|
|
||||||
|
我也喜欢在 QEMU中引导 FreeDOS 去玩一些收藏的 DOS 游戏,比如原版的 Doom。这些老的 DOS 游戏玩起来仍然非常有趣, 并且它们现在在 QEMU 上运行的非常好。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Doom*
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Heretic*
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Jill of the Jungle*
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Commander Keen*
|
||||||
|
|
||||||
|
QEMU 和 FreeDOS 使得在 Linux 上运行老的 DOS 程序变得很容易。你一旦设置好了 QEMU 作为虚拟机仿真程序并安装了 FreeDOS,你将可以在 Linux 上运行你收藏的经典的 DOS 程序。
|
||||||
|
|
||||||
|
_所有图片要致谢 [FreeDOS.org][16]。_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Jim Hall 是一位开源软件的开发者和支持者,可能最广为人知的是他是 FreeDOS 的创始人和项目协调者。 Jim 也非常活跃于开源软件适用性领域,作为 GNOME Outreachy 适用性测试的导师,同时也作为一名兼职教授,教授一些开源软件适用性的课程,从 2016 到 2017, Jim 在 GNOME 基金会的董事会担任董事,在工作中, Jim 是本地政府部门的 CIO。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/10/run-dos-applications-linux
|
||||||
|
|
||||||
|
作者:[Jim Hall][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/jim-hall
|
||||||
|
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[6]:https://opensource.com/file/374821
|
||||||
|
[7]:https://opensource.com/file/374771
|
||||||
|
[8]:https://opensource.com/file/374776
|
||||||
|
[9]:https://opensource.com/file/374781
|
||||||
|
[10]:https://opensource.com/file/374761
|
||||||
|
[11]:https://opensource.com/file/374786
|
||||||
|
[12]:https://opensource.com/file/374791
|
||||||
|
[13]:https://opensource.com/file/374796
|
||||||
|
[14]:https://opensource.com/file/374801
|
||||||
|
[15]:https://opensource.com/article/17/10/run-dos-applications-linux?rate=STdDX4LLLyyllTxAOD-CdfSwrZQ9D3FNqJTpMGE7v_8
|
||||||
|
[16]:http://www.freedos.org/
|
||||||
|
[17]:https://opensource.com/user/126046/feed
|
||||||
|
[18]:http://www.freedos.org/
|
||||||
|
[19]:https://www.qemu.org/
|
||||||
|
[20]:http://www.freedos.org/
|
||||||
|
[21]:http://www.freedos.org/links/
|
||||||
|
[22]:https://opensource.com/users/jim-hall
|
||||||
|
[23]:https://opensource.com/users/jim-hall
|
||||||
|
[24]:https://opensource.com/article/17/10/run-dos-applications-linux#comments
|
||||||
@ -0,0 +1,75 @@
|
|||||||
|
为什么要切换到 Linux 系统?我该怎么做?
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 是时候做出改变了。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*让 Ubuntu,一个简单易用的 Linux 版本,来掌管你的电脑。*
|
||||||
|
|
||||||
|
当你在选购电脑的时候,你可能会在 [Windows][1] 和 [macOS][2] 之间犹豫,但是可能基本不会想到 Linux。尽管如此,这个名气没那么大的操作系统仍然拥有庞大而忠诚的粉丝。因为它相对于它的竞争者,有很大的优势。
|
||||||
|
|
||||||
|
不管你是完全不了解 Linux,或是已经尝试过一两次,我们希望你考虑一下在你的下一台笔记本或台式机上运行 Linux,或者可以和现存系统做个双启动。请继续阅读下去,看是不是时候该切换了。
|
||||||
|
|
||||||
|
### 什么是 Linux?
|
||||||
|
|
||||||
|
如果你已经非常熟悉 Linux,可以跳过这个部分。对于不熟悉的其他人,Linux 是一个免费的开源操作系统,所有人都可以去探索它的代码。技术上来说,术语“Linux”说的只是内核,或者核心代码。不过,人们一般用这个名字统称整个操作系统,包括界面和集成的应用。
|
||||||
|
|
||||||
|
因为所有人都可以修改它,Linux 有非常自由的可定制性,这鼓舞了很多程序员制作并发布了自己的系统——常称为<ruby>发行版<rt>distro</rt></ruby>。这些不同口味的系统,每一个都有自己特色的软件和界面。一些比较有名的发行版,模仿了熟悉的 Windows 或 macOS 操作系统,比如 [Ubuntu][3]、 [Linux Mint][4] 和 [Zorin OS][5]。当你准备选择一个发行版时,可以去它们官网看一下,试试看是不是适合自己。
|
||||||
|
|
||||||
|
为了制作和维护这些 Linux 发行版,大量的开发者无偿地贡献了自己的时间。有时候,利润主导的公司为了拓展自己的软件销售领域,也会主导开发带有独特特性的 Linux 版本。比如 Android(它虽然不能当作一个完整的 Linux 操作系统)就是以基于 Linux 内核的,这也是为什么它有很多[不同变种][6]的原因。另外,很多服务器和数据中心也运行了 Linux,所以很有可能这个操作系统托管着你正在看的网页。
|
||||||
|
|
||||||
|
### 有什么好处?
|
||||||
|
|
||||||
|
首先,Linux 是免费而且开源的,意味着你可以将它安装到你现有的电脑或笔记本上,或者你自己组装的机器,而不用支付任何费用。系统会自带一些常用软件,包括网页浏览器、媒体播放器、[图像编辑器][7]和[办公软件][8],所以你也不用为了查看图片或处理文档再支付其他额外费用。而且,以后还可以免费升级。
|
||||||
|
|
||||||
|
Linux 比其他系统能更好的防御恶意软件,强大到你都不需要运行杀毒软件。开发者们在最早构建时就考虑了安全性,比如说,操作系统只运行可信的软件。而且,很少有恶意软件针对这个系统,对于黑客来说,这样做没有价值。Linux 也并不是完全没有任何漏洞,只不过对于一般只运行已验证软件的家庭用户来说,并不用太担心安全性。
|
||||||
|
|
||||||
|
这个操作系统对硬件资源的要求比起数据臃肿的 Windows 或 macOS 来说也更少。一些发行版不像它们名气更大的表兄弟,默认集成了更少的组件,开发者特别开发了一些,比如 [Puppy Linux][9] 和 [Linux Lite][10],让系统尽可能地轻量。这让 Linux 非常适合那些家里有很老的电脑的人。如果你的远古笔记本正在原装操作系统的重压下喘息,试试装一个 Linux,应该会快很多。如果不愿意的话,你也不用抛弃旧系统,我们会在后面的部分里解释怎么做。
|
||||||
|
|
||||||
|
尽管你可能会需要一点时间来适应新系统,不过不用太久,你就会发现 Linux 界面很容易使用。任何年龄和任何技术水平的人都可以掌握这个软件。而且在线的 Linux 社区提供了大量的帮助和支持。说到社区,下载 Linux 也是对开源软件运动的支持:这些开发者一起工作,并不收取任何费用,为全球用户开发更优秀的软件。
|
||||||
|
|
||||||
|
### 我该从哪儿开始?
|
||||||
|
|
||||||
|
Linux 据说只有专家才能安装。不过比起前几年,现在安装并运行操作系统已经非常简单了。
|
||||||
|
|
||||||
|
首先,打开你喜欢的发行版的网站,按照上面的安装指南操作。一般会需要烧录一张 DVD 或者制作一个带有必要程序的 U 盘,然后重启你的电脑,执行这段程序。实际上,这个操作系统的一个好处是,你可以将它直接安装在可插拔的 U 盘上,我们有一个[如何把电脑装在 U 盘里][11]的完整指南。
|
||||||
|
|
||||||
|
如果你想在不影响原来旧系统的情况下运行 Linux,你可以选择从 DVD 或 U 盘或者电脑硬盘的某个分区(分成不同的区来独立运行不同的操作系统)单独启动。有些 Linux 发行版在安装过程中会帮你自动处理磁盘分区。或者你可以用[磁盘管理器][12] (Windows)或者[磁盘工具][13] (macOS)自己调整分区。
|
||||||
|
|
||||||
|
这些安装说明可能看上去很模糊,但是不要担心:每个发行版都会提供详细的安装指引,虽然大多数情况下过程都差不多。比如,如果你想安装 Ubuntu(最流行的家用 Linux 发行版中的一个),可以[参考这里的指引][14]。(在安装之前,你也可以[尝试运行一下][15])你需要下载最新的版本,烧录到 DVD 或是 U 盘里,然后再用光盘或 U 盘引导开机,然后跟随安装向导里的指引操作。安装完成时提示安装额外软件时,Ubuntu 会引导你打开合适的工具。
|
||||||
|
|
||||||
|
如果你要在一台全新的电脑上安装 Linux,那没什么需要特别留意的。不过如果你要保留旧系统的情况下安装新系统,我们建议你首先[备份自己的数据][16]。在安装过程中,也要注意选择双启动选项,避免擦除现有的系统和文件。你选好的发行版的介绍里会有更详细的说明:你可以在[这里][17]查看 Zorin OS 的完整介绍,[这里][18]有 Linux Mint的,其他发行版的介绍在他们各自的网站上也都会有。
|
||||||
|
|
||||||
|
就这些了!那么,你准备好试试 Linux 了吗?
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.popsci.com/switch-to-linux-operating-system
|
||||||
|
|
||||||
|
作者:[David Nield][a]
|
||||||
|
译者:[zpl1025](https://github.com/zpl1025)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.popsci.com/authors/david-nield
|
||||||
|
[1]:https://www.popsci.com/windows-tweaks-improve-performance
|
||||||
|
[2]:https://www.popsci.com/macos-tweaks-improve-performance
|
||||||
|
[3]:https://www.ubuntu.com/
|
||||||
|
[4]:https://linuxmint.com/
|
||||||
|
[5]:https://zorinos.com/
|
||||||
|
[6]:https://lineageos.org/
|
||||||
|
[7]:https://www.gimp.org/
|
||||||
|
[8]:https://www.libreoffice.org/
|
||||||
|
[9]:http://puppylinux.org/main/Overview%20and%20Getting%20Started.htm
|
||||||
|
[10]:https://www.linuxliteos.com/
|
||||||
|
[11]:https://www.popsci.com/portable-computer-usb-stick
|
||||||
|
[12]:https://www.disk-partition.com/windows-10/windows-10-disk-management-0528.html
|
||||||
|
[13]:https://support.apple.com/kb/PH22240?locale=en_US
|
||||||
|
[14]:https://tutorials.ubuntu.com/tutorial/tutorial-install-ubuntu-desktop?backURL=%2F#0
|
||||||
|
[15]:https://tutorials.ubuntu.com/tutorial/try-ubuntu-before-you-install?backURL=%2F#0
|
||||||
|
[16]:https://www.popsci.com/back-up-and-protect-your-data
|
||||||
|
[17]:https://zorinos.com/help/install-zorin-os/
|
||||||
|
[18]:https://linuxmint.com/documentation.php
|
||||||
|
[19]:https://www.popsci.com/authors/david-nield
|
||||||
250
published/20171002 Scaling the GitLab database.md
Normal file
250
published/20171002 Scaling the GitLab database.md
Normal file
@ -0,0 +1,250 @@
|
|||||||
|
在 GitLab 我们是如何扩展数据库的
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 在扩展 GitLab 数据库和我们应用的解决方案,去帮助解决我们的数据库设置中的问题时,我们深入分析了所面临的挑战。
|
||||||
|
|
||||||
|
很长时间以来 GitLab.com 使用了一个单个的 PostgreSQL 数据库服务器和一个用于灾难恢复的单个复制。在 GitLab.com 最初的几年,它工作的还是很好的,但是,随着时间的推移,我们看到这种设置的很多问题,在这篇文章中,我们将带你了解我们在帮助解决 GitLab.com 和 GitLab 实例所在的主机时都做了些什么。
|
||||||
|
|
||||||
|
例如,数据库长久处于重压之下, CPU 使用率几乎所有时间都处于 70% 左右。并不是因为我们以最好的方式使用了全部的可用资源,而是因为我们使用了太多的(未经优化的)查询去“冲击”服务器。我们意识到需要去优化设置,这样我们就可以平衡负载,使 GitLab.com 能够更灵活地应对可能出现在主数据库服务器上的任何问题。
|
||||||
|
|
||||||
|
在我们使用 PostgreSQL 去跟踪这些问题时,使用了以下的四种技术:
|
||||||
|
|
||||||
|
1. 优化你的应用程序代码,以使查询更加高效(并且理论上使用了很少的资源)。
|
||||||
|
2. 使用一个连接池去减少必需的数据库连接数量(及相关的资源)。
|
||||||
|
3. 跨多个数据库服务器去平衡负载。
|
||||||
|
4. 分片你的数据库
|
||||||
|
|
||||||
|
在过去的两年里,我们一直在积极地优化应用程序代码,但它不是一个完美的解决方案,甚至,如果你改善了性能,当流量也增加时,你还需要去应用其它的几种技术。出于本文的目的,我们将跳过优化应用代码这个特定主题,而专注于其它技术。
|
||||||
|
|
||||||
|
### 连接池
|
||||||
|
|
||||||
|
在 PostgreSQL 中,一个连接是通过启动一个操作系统进程来处理的,这反过来又需要大量的资源,更多的连接(及这些进程)将使用你的数据库上的更多的资源。 PostgreSQL 也在 [max_connections][5] 设置中定义了一个强制的最大连接数量。一旦达到这个限制,PostgreSQL 将拒绝新的连接, 比如,下面的图表示的设置:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
这里我们的客户端直接连接到 PostgreSQL,这样每个客户端请求一个连接。
|
||||||
|
|
||||||
|
通过连接池,我们可以有多个客户端侧的连接重复使用一个 PostgreSQL 连接。例如,没有连接池时,我们需要 100 个 PostgreSQL 连接去处理 100 个客户端连接;使用连接池后,我们仅需要 10 个,或者依据我们配置的 PostgreSQL 连接。这意味着我们的连接图表将变成下面看到的那样:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
这里我们展示了一个示例,四个客户端连接到 pgbouncer,但不是使用了四个 PostgreSQL 连接,而是仅需要两个。
|
||||||
|
|
||||||
|
对于 PostgreSQL 有两个最常用的连接池:
|
||||||
|
|
||||||
|
* [pgbouncer][1]
|
||||||
|
* [pgpool-II][2]
|
||||||
|
|
||||||
|
pgpool 有一点特殊,因为它不仅仅是连接池:它有一个内置的查询缓存机制,可以跨多个数据库负载均衡、管理复制等等。
|
||||||
|
|
||||||
|
另一个 pgbouncer 是很简单的:它就是一个连接池。
|
||||||
|
|
||||||
|
### 数据库负载均衡
|
||||||
|
|
||||||
|
数据库级的负载均衡一般是使用 PostgreSQL 的 “<ruby>[热备机][6]<rt>hot-standby</rt></ruby>” 特性来实现的。 热备机是允许你去运行只读 SQL 查询的 PostgreSQL 副本,与不允许运行任何 SQL 查询的普通<ruby>备用机<rt>standby</rt></ruby>相反。要使用负载均衡,你需要设置一个或多个热备服务器,并且以某些方式去平衡这些跨主机的只读查询,同时将其它操作发送到主服务器上。扩展这样的一个设置是很容易的:(如果需要的话)简单地增加多个热备机以增加只读流量。
|
||||||
|
|
||||||
|
这种方法的另一个好处是拥有一个更具弹性的数据库集群。即使主服务器出现问题,仅使用次级服务器也可以继续处理 Web 请求;当然,如果这些请求最终使用主服务器,你可能仍然会遇到错误。
|
||||||
|
|
||||||
|
然而,这种方法很难实现。例如,一旦它们包含写操作,事务显然需要在主服务器上运行。此外,在写操作完成之后,我们希望继续使用主服务器一会儿,因为在使用异步复制的时候,热备机服务器上可能还没有这些更改。
|
||||||
|
|
||||||
|
### 分片
|
||||||
|
|
||||||
|
分片是水平分割你的数据的行为。这意味着数据保存在特定的服务器上并且使用一个分片键检索。例如,你可以按项目分片数据并且使用项目 ID 做为分片键。当你的写负载很高时,分片数据库是很有用的(除了一个多主设置外,均衡写操作没有其它的简单方法),或者当你有_大量_的数据并且你不再使用传统方式保存它也是有用的(比如,你不能把它简单地全部放进一个单个磁盘中)。
|
||||||
|
|
||||||
|
不幸的是,设置分片数据库是一个任务量很大的过程,甚至,在我们使用诸如 [Citus][7] 的软件时也是这样。你不仅需要设置基础设施 (不同的复杂程序取决于是你运行在你自己的数据中心还是托管主机的解决方案),你还得需要调整你的应用程序中很大的一部分去支持分片。
|
||||||
|
|
||||||
|
#### 反对分片的案例
|
||||||
|
|
||||||
|
在 GitLab.com 上一般情况下写负载是非常低的,同时大多数的查询都是只读查询。在极端情况下,尖峰值达到每秒 1500 元组写入,但是,在大多数情况下不超过每秒 200 元组写入。另一方面,我们可以在任何给定的次级服务器上轻松达到每秒 1000 万元组读取。
|
||||||
|
|
||||||
|
存储方面,我们也不使用太多的数据:大约 800 GB。这些数据中的很大一部分是在后台迁移的,这些数据一经迁移后,我们的数据库收缩的相当多。
|
||||||
|
|
||||||
|
接下来的工作量就是调整应用程序,以便于所有查询都可以正确地使用分片键。 我们的一些查询包含了一个项目 ID,它是我们使用的分片键,也有许多查询没有包含这个分片键。分片也会影响提交到 GitLab 的改变内容的过程,每个提交者现在必须确保在他们的查询中包含分片键。
|
||||||
|
|
||||||
|
最后,是完成这些工作所需要的基础设施。服务器已经完成设置,监视也添加了、工程师们必须培训,以便于他们熟悉上面列出的这些新的设置。虽然托管解决方案可能不需要你自己管理服务器,但它不能解决所有问题。工程师们仍然需要去培训(很可能非常昂贵)并需要为此支付账单。在 GitLab 上,我们也非常乐意提供我们用过的这些工具,这样社区就可以使用它们。这意味着如果我们去分片数据库, 我们将在我们的 Omnibus 包中提供它(或至少是其中的一部分)。确保你提供的服务的唯一方法就是你自己去管理它,这意味着我们不能使用主机托管的解决方案。
|
||||||
|
|
||||||
|
最终,我们决定不使用数据库分片,因为它是昂贵的、费时的、复杂的解决方案。
|
||||||
|
|
||||||
|
### GitLab 的连接池
|
||||||
|
|
||||||
|
对于连接池我们有两个主要的诉求:
|
||||||
|
|
||||||
|
1. 它必须工作的很好(很显然这是必需的)。
|
||||||
|
2. 它必须易于在我们的 Omnibus 包中运用,以便于我们的用户也可以从连接池中得到好处。
|
||||||
|
|
||||||
|
用下面两步去评估这两个解决方案(pgpool 和 pgbouncer):
|
||||||
|
|
||||||
|
1. 执行各种技术测试(是否有效,配置是否容易,等等)。
|
||||||
|
2. 找出使用这个解决方案的其它用户的经验,他们遇到了什么问题?怎么去解决的?等等。
|
||||||
|
|
||||||
|
pgpool 是我们考察的第一个解决方案,主要是因为它提供的很多特性看起来很有吸引力。我们其中的一些测试数据可以在 [这里][8] 找到。
|
||||||
|
|
||||||
|
最终,基于多个因素,我们决定不使用 pgpool 。例如, pgpool 不支持<ruby>粘连接<rt>sticky connection</rt></ruby>。 当执行一个写入并(尝试)立即显示结果时,它会出现问题。想像一下,创建一个<ruby>工单<rt>issue</rt></ruby>并立即重定向到这个页面, 没有想到会出现 HTTP 404,这是因为任何用于只读查询的服务器还没有收到数据。针对这种情况的一种解决办法是使用同步复制,但这会给表带来更多的其它问题,而我们希望避免这些问题。
|
||||||
|
|
||||||
|
另一个问题是, pgpool 的负载均衡逻辑与你的应用程序是不相干的,是通过解析 SQL 查询并将它们发送到正确的服务器。因为这发生在你的应用程序之外,你几乎无法控制查询运行在哪里。这实际上对某些人也可能是有好处的, 因为你不需要额外的应用程序逻辑。但是,它也妨碍了你在需要的情况下调整路由逻辑。
|
||||||
|
|
||||||
|
由于配置选项非常多,配置 pgpool 也是很困难的。或许促使我们最终决定不使用它的原因是我们从过去使用过它的那些人中得到的反馈。即使是在大多数的案例都不是很详细的情况下,我们收到的反馈对 pgpool 通常都持有负面的观点。虽然出现的报怨大多数都与早期版本的 pgpool 有关,但仍然让我们怀疑使用它是否是个正确的选择。
|
||||||
|
|
||||||
|
结合上面描述的问题和反馈,最终我们决定不使用 pgpool 而是使用 pgbouncer 。我们用 pgbouncer 执行了一套类似的测试,并且对它的结果是非常满意的。它非常容易配置(而且一开始不需要很多的配置),运用相对容易,仅专注于连接池(而且它真的很好),而且没有明显的负载开销(如果有的话)。也许我唯一的报怨是,pgbouncer 的网站有点难以导航。
|
||||||
|
|
||||||
|
使用 pgbouncer 后,通过使用<ruby>事务池<rt>transaction pooling</rt></ruby>我们可以将活动的 PostgreSQL 连接数从几百个降到仅 10 - 20 个。我们选择事务池是因为 Rails 数据库连接是持久的。这个设置中,使用<ruby>会话池<rt>session pooling</rt></ruby>不能让我们降低 PostgreSQL 连接数,从而受益(如果有的话)。通过使用事务池,我们可以调低 PostgreSQL 的 `max_connections` 的设置值,从 3000 (这个特定值的原因我们也不清楚) 到 300 。这样配置的 pgbouncer ,即使在尖峰时,我们也仅需要 200 个连接,这为我们提供了一些额外连接的空间,如 `psql` 控制台和维护任务。
|
||||||
|
|
||||||
|
对于使用事务池的负面影响方面,你不能使用预处理语句,因为 `PREPARE` 和 `EXECUTE` 命令也许最终在不同的连接中运行,从而产生错误的结果。 幸运的是,当我们禁用了预处理语句时,并没有测量到任何响应时间的增加,但是我们 _确定_ 测量到在我们的数据库服务器上内存使用减少了大约 20 GB。
|
||||||
|
|
||||||
|
为确保我们的 web 请求和后台作业都有可用连接,我们设置了两个独立的池: 一个有 150 个连接的后台进程连接池,和一个有 50 个连接的 web 请求连接池。对于 web 连接需要的请求,我们很少超过 20 个,但是,对于后台进程,由于在 GitLab.com 上后台运行着大量的进程,我们的尖峰值可以很容易达到 100 个连接。
|
||||||
|
|
||||||
|
今天,我们提供 pgbouncer 作为 GitLab EE 高可用包的一部分。对于更多的信息,你可以参考 “[Omnibus GitLab PostgreSQL High Availability][9]”。
|
||||||
|
|
||||||
|
### GitLab 上的数据库负载均衡
|
||||||
|
|
||||||
|
使用 pgpool 和它的负载均衡特性,我们需要一些其它的东西去分发负载到多个热备服务器上。
|
||||||
|
|
||||||
|
对于(但不限于) Rails 应用程序,它有一个叫 [Makara][10] 的库,它实现了负载均衡的逻辑并包含了一个 ActiveRecord 的缺省实现。然而,Makara 也有一些我们认为是有些遗憾的问题。例如,它支持的粘连接是非常有限的:当你使用一个 cookie 和一个固定的 TTL 去执行一个写操作时,连接将粘到主服务器。这意味着,如果复制极大地滞后于 TTL,最终你可能会发现,你的查询运行在一个没有你需要的数据的主机上。
|
||||||
|
|
||||||
|
Makara 也需要你做很多配置,如所有的数据库主机和它们的角色,没有服务发现机制(我们当前的解决方案也不支持它们,即使它是将来计划的)。 Makara 也 [似乎不是线程安全的][11],这是有问题的,因为 Sidekiq (我们使用的后台进程)是多线程的。 最终,我们希望尽可能地去控制负载均衡的逻辑。
|
||||||
|
|
||||||
|
除了 Makara 之外 ,还有一个 [Octopus][12] ,它也是内置的负载均衡机制。但是 Octopus 是面向分片数据库的,而不仅是均衡只读查询的。因此,最终我们不考虑使用 Octopus。
|
||||||
|
|
||||||
|
最终,我们直接在 GitLab EE构建了自己的解决方案。 添加初始实现的<ruby>合并请求<rt>merge request</rt></ruby>可以在 [这里][13]找到,尽管一些更改、提升和修复是以后增加的。
|
||||||
|
|
||||||
|
我们的解决方案本质上是通过用一个处理查询的路由的代理对象替换 `ActiveRecord::Base.connection` 。这可以让我们均衡负载尽可能多的查询,甚至,包括不是直接来自我们的代码中的查询。这个代理对象基于调用方式去决定将查询转发到哪个主机, 消除了解析 SQL 查询的需要。
|
||||||
|
|
||||||
|
#### 粘连接
|
||||||
|
|
||||||
|
粘连接是通过在执行写入时,将当前 PostgreSQL WAL 位置存储到一个指针中实现支持的。在请求即将结束时,指针短期保存在 Redis 中。每个用户提供他自己的 key,因此,一个用户的动作不会导致其他的用户受到影响。下次请求时,我们取得指针,并且与所有的次级服务器进行比较。如果所有的次级服务器都有一个超过我们的指针的 WAL 指针,那么我们知道它们是同步的,我们可以为我们的只读查询安全地使用次级服务器。如果一个或多个次级服务器没有同步,我们将继续使用主服务器直到它们同步。如果 30 秒内没有写入操作,并且所有的次级服务器还没有同步,我们将恢复使用次级服务器,这是为了防止有些人的查询永远运行在主服务器上。
|
||||||
|
|
||||||
|
检查一个次级服务器是否就绪十分简单,它在如下的 `Gitlab::Database::LoadBalancing::Host#caught_up?` 中实现:
|
||||||
|
|
||||||
|
```
|
||||||
|
def caught_up?(location)
|
||||||
|
string = connection.quote(location)
|
||||||
|
|
||||||
|
query = "SELECT NOT pg_is_in_recovery() OR " \
|
||||||
|
"pg_xlog_location_diff(pg_last_xlog_replay_location(), #{string}) >= 0 AS result"
|
||||||
|
|
||||||
|
row = connection.select_all(query).first
|
||||||
|
|
||||||
|
row && row['result'] == 't'
|
||||||
|
ensure
|
||||||
|
release_connection
|
||||||
|
end
|
||||||
|
|
||||||
|
```
|
||||||
|
这里的大部分代码是运行原生查询(raw queries)和获取结果的标准的 Rails 代码,查询的最有趣的部分如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT NOT pg_is_in_recovery()
|
||||||
|
OR pg_xlog_location_diff(pg_last_xlog_replay_location(), WAL-POINTER) >= 0 AS result"
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
这里 `WAL-POINTER` 是 WAL 指针,通过 PostgreSQL 函数 `pg_current_xlog_insert_location()` 返回的,它是在主服务器上执行的。在上面的代码片断中,该指针作为一个参数传递,然后它被引用或转义,并传递给查询。
|
||||||
|
|
||||||
|
使用函数 `pg_last_xlog_replay_location()` 我们可以取得次级服务器的 WAL 指针,然后,我们可以通过函数 `pg_xlog_location_diff()` 与我们的主服务器上的指针进行比较。如果结果大于 0 ,我们就可以知道次级服务器是同步的。
|
||||||
|
|
||||||
|
当一个次级服务器被提升为主服务器,并且我们的 GitLab 进程还不知道这一点的时候,添加检查 `NOT pg_is_in_recovery()` 以确保查询不会失败。在这个案例中,主服务器总是与它自己是同步的,所以它简单返回一个 `true`。
|
||||||
|
|
||||||
|
#### 后台进程
|
||||||
|
|
||||||
|
我们的后台进程代码 _总是_ 使用主服务器,因为在后台执行的大部分工作都是写入。此外,我们不能可靠地使用一个热备机,因为我们无法知道作业是否在主服务器执行,也因为许多作业并没有直接绑定到用户上。
|
||||||
|
|
||||||
|
#### 连接错误
|
||||||
|
|
||||||
|
要处理连接错误,比如负载均衡器不会使用一个视作离线的次级服务器,会增加主机上(包括主服务器)的连接错误,将会导致负载均衡器多次重试。这是确保,在遇到偶发的小问题或数据库失败事件时,不会立即显示一个错误页面。当我们在负载均衡器级别上处理 [热备机冲突][14] 的问题时,我们最终在次级服务器上启用了 `hot_standby_feedback` ,这样就解决了热备机冲突的所有问题,而不会对表膨胀造成任何负面影响。
|
||||||
|
|
||||||
|
我们使用的过程很简单:对于次级服务器,我们在它们之间用无延迟试了几次。对于主服务器,我们通过使用越来越快的回退尝试几次。
|
||||||
|
|
||||||
|
更多信息你可以查看 GitLab EE 上的源代码:
|
||||||
|
|
||||||
|
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb][3]
|
||||||
|
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing][4]
|
||||||
|
|
||||||
|
数据库负载均衡首次引入是在 GitLab 9.0 中,并且 _仅_ 支持 PostgreSQL。更多信息可以在 [9.0 release post][15] 和 [documentation][16] 中找到。
|
||||||
|
|
||||||
|
### Crunchy Data
|
||||||
|
|
||||||
|
我们与 [Crunchy Data][17] 一起协同工作来部署连接池和负载均衡。不久之前我还是唯一的 [数据库专家][18],它意味着我有很多工作要做。此外,我对 PostgreSQL 的内部细节的和它大量的设置所知有限 (或者至少现在是),这意味着我能做的也有限。因为这些原因,我们雇用了 Crunchy 去帮我们找出问题、研究慢查询、建议模式优化、优化 PostgreSQL 设置等等。
|
||||||
|
|
||||||
|
在合作期间,大部分工作都是在相互信任的基础上完成的,因此,我们共享私人数据,比如日志。在合作结束时,我们从一些资料和公开的内容中删除了敏感数据,主要的资料在 [gitlab-com/infrastructure#1448][19],这又反过来导致产生和解决了许多分立的问题。
|
||||||
|
|
||||||
|
这次合作的好处是巨大的,它帮助我们发现并解决了许多的问题,如果必须我们自己来做的话,我们可能需要花上几个月的时间来识别和解决它。
|
||||||
|
|
||||||
|
幸运的是,最近我们成功地雇佣了我们的 [第二个数据库专家][20] 并且我们希望以后我们的团队能够发展壮大。
|
||||||
|
|
||||||
|
### 整合连接池和数据库负载均衡
|
||||||
|
|
||||||
|
整合连接池和数据库负载均衡可以让我们去大幅减少运行数据库集群所需要的资源和在分发到热备机上的负载。例如,以前我们的主服务器 CPU 使用率一直徘徊在 70%,现在它一般在 10% 到 20% 之间,而我们的两台热备机服务器则大部分时间在 20% 左右:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在这里, `db3.cluster.gitlab.com` 是我们的主服务器,而其它的两台是我们的次级服务器。
|
||||||
|
|
||||||
|
其它的负载相关的因素,如平均负载、磁盘使用、内存使用也大为改善。例如,主服务器现在的平均负载几乎不会超过 10,而不像以前它一直徘徊在 20 左右:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在业务繁忙期间,我们的次级服务器每秒事务数在 12000 左右(大约为每分钟 740000),而主服务器每秒事务数在 6000 左右(大约每分钟 340000):
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
可惜的是,在部署 pgbouncer 和我们的数据库负载均衡器之前,我们没有关于事务速率的任何数据。
|
||||||
|
|
||||||
|
我们的 PostgreSQL 的最新统计数据的摘要可以在我们的 [public Grafana dashboard][21] 上找到。
|
||||||
|
|
||||||
|
我们的其中一些 pgbouncer 的设置如下:
|
||||||
|
|
||||||
|
| 设置 | 值 |
|
||||||
|
| --- | --- |
|
||||||
|
| `default_pool_size` | 100 |
|
||||||
|
| `reserve_pool_size` | 5 |
|
||||||
|
| `reserve_pool_timeout` | 3 |
|
||||||
|
| `max_client_conn` | 2048 |
|
||||||
|
| `pool_mode` | transaction |
|
||||||
|
| `server_idle_timeout` | 30 |
|
||||||
|
|
||||||
|
除了前面所说的这些外,还有一些工作要作,比如: 部署服务发现([#2042][22]), 持续改善如何检查次级服务器是否可用([#2866][23]),和忽略落后于主服务器太多的次级服务器 ([#2197][24])。
|
||||||
|
|
||||||
|
值得一提的是,到目前为止,我们还没有任何计划将我们的负载均衡解决方案,独立打包成一个你可以在 GitLab 之外使用的库,相反,我们的重点是为 GitLab EE 提供一个可靠的负载均衡解决方案。
|
||||||
|
|
||||||
|
如果你对它感兴趣,并喜欢使用数据库、改善应用程序性能、给 GitLab上增加数据库相关的特性(比如: [服务发现][25]),你一定要去查看一下我们的 [招聘职位][26] 和 [数据库专家手册][27] 去获取更多信息。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://about.gitlab.com/2017/10/02/scaling-the-gitlab-database/
|
||||||
|
|
||||||
|
作者:[Yorick Peterse][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://about.gitlab.com/team/#yorickpeterse
|
||||||
|
[1]:https://pgbouncer.github.io/
|
||||||
|
[2]:http://pgpool.net/mediawiki/index.php/Main_Page
|
||||||
|
[3]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb
|
||||||
|
[4]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing
|
||||||
|
[5]:https://www.postgresql.org/docs/9.6/static/runtime-config-connection.html#GUC-MAX-CONNECTIONS
|
||||||
|
[6]:https://www.postgresql.org/docs/9.6/static/hot-standby.html
|
||||||
|
[7]:https://www.citusdata.com/
|
||||||
|
[8]:https://gitlab.com/gitlab-com/infrastructure/issues/259#note_23464570
|
||||||
|
[9]:https://docs.gitlab.com/ee/administration/high_availability/alpha_database.html
|
||||||
|
[10]:https://github.com/taskrabbit/makara
|
||||||
|
[11]:https://github.com/taskrabbit/makara/issues/151
|
||||||
|
[12]:https://github.com/thiagopradi/octopus
|
||||||
|
[13]:https://gitlab.com/gitlab-org/gitlab-ee/merge_requests/1283
|
||||||
|
[14]:https://www.postgresql.org/docs/current/static/hot-standby.html#HOT-STANDBY-CONFLICT
|
||||||
|
[15]:https://about.gitlab.com/2017/03/22/gitlab-9-0-released/
|
||||||
|
[16]:https://docs.gitlab.com/ee/administration/database_load_balancing.html
|
||||||
|
[17]:https://www.crunchydata.com/
|
||||||
|
[18]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||||
|
[19]:https://gitlab.com/gitlab-com/infrastructure/issues/1448
|
||||||
|
[20]:https://gitlab.com/_stark
|
||||||
|
[21]:http://monitor.gitlab.net/dashboard/db/postgres-stats?refresh=5m&orgId=1
|
||||||
|
[22]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||||
|
[23]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2866
|
||||||
|
[24]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2197
|
||||||
|
[25]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||||
|
[26]:https://about.gitlab.com/jobs/specialist/database/
|
||||||
|
[27]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||||
57
published/20171003 PostgreSQL Hash Indexes Are Now Cool.md
Normal file
57
published/20171003 PostgreSQL Hash Indexes Are Now Cool.md
Normal file
@ -0,0 +1,57 @@
|
|||||||
|
PostgreSQL 的哈希索引现在很酷
|
||||||
|
======
|
||||||
|
|
||||||
|
由于我刚刚提交了最后一个改进 PostgreSQL 11 哈希索引的补丁,并且大部分哈希索引的改进都致力于预计下周发布的 PostgreSQL 10(LCTT 译注:已发布),因此现在似乎是对过去 18 个月左右所做的工作进行简要回顾的好时机。在版本 10 之前,哈希索引在并发性能方面表现不佳,缺少预写日志记录,因此在宕机或复制时都是不安全的,并且还有其他二等公民。在 PostgreSQL 10 中,这在很大程度上被修复了。
|
||||||
|
|
||||||
|
虽然我参与了一些设计,但改进哈希索引的首要功劳来自我的同事 Amit Kapila,[他在这个话题下的博客值得一读][1]。哈希索引的问题不仅在于没有人打算写预写日志记录的代码,还在于代码没有以某种方式进行结构化,使其可以添加实际上正常工作的预写日志记录。要拆分一个桶,系统将锁定已有的桶(使用一种十分低效的锁定机制),将半个元组移动到新的桶中,压缩已有的桶,然后松开锁。即使记录了个别更改,在错误的时刻发生崩溃也会使索引处于损坏状态。因此,Aimt 首先做的是重新设计锁定机制。[新的机制][2]在某种程度上允许扫描和拆分并行进行,并且允许稍后完成那些因报错或崩溃而被中断的拆分。完成了一系列漏洞的修复和一些重构工作,Aimt 就打了另一个补丁,[添加了支持哈希索引的预写日志记录][3]。
|
||||||
|
|
||||||
|
与此同时,我们发现哈希索引已经错过了许多已应用于 B 树索引多年的相当明显的性能改进。因为哈希索引不支持预写日志记录,以及旧的锁定机制十分笨重,所以没有太多的动机去提升其他的性能。而这意味着如果哈希索引会成为一个非常有用的技术,那么需要做的事只是添加预写日志记录而已。PostgreSQL 索引存取方法的抽象层允许索引保留有关其信息的后端专用缓存,避免了重复查询索引本身来获取相关的元数据。B 树和 SQLite 的索引正在使用这种机制,但哈希索引没有,所以我的同事 Mithun Cy 写了一个补丁来[使用此机制缓存哈希索引的元页][4]。同样,B 树索引有一个称为“单页回收”的优化,它巧妙地从索引页移除没用的索引指针,从而防止了大量索引膨胀。我的同事 Ashutosh Sharma 打了一个补丁将[这个逻辑移植到哈希索引上][5],也大大减少了索引的膨胀。最后,B 树索引[自 2006 年以来][6]就有了一个功能,可以避免重复锁定和解锁同一个索引页——所有元组都在页中一次性删除,然后一次返回一个。Ashutosh Sharma 也[将此逻辑移植到了哈希索引中][7],但是由于缺少时间,这个优化没有在版本 10 中完成。在这个博客提到的所有内容中,这是唯一一个直到版本 11 才会出现的改进。
|
||||||
|
|
||||||
|
关于哈希索引的工作有一个更有趣的地方是,很难确定行为是否真的正确。锁定行为的更改只可能在繁重的并发状态下失败,而预写日志记录中的错误可能仅在崩溃恢复的情况下显示出来。除此之外,在每种情况下,问题可能是微妙的。没有东西崩溃还不够;它们还必须在所有情况下产生正确的答案,并且这似乎很难去验证。为了协助这项工作,我的同事 Kuntal Ghosh 先后跟进了最初由 Heikki Linnakangas 和 Michael Paquier 开始的工作,并且制作了一个 WAL 一致性检查器,它不仅可以作为开发人员测试的专用补丁,还能真正[提交到 PostgreSQL][8]。在提交之前,我们对哈希索引的预写日志代码使用此工具进行了广泛的测试,并十分成功地查找到了一些漏洞。这个工具并不仅限于哈希索引,相反:它也可用于其他模块的预写日志记录代码,包括堆,当今的所有 AM 索引,以及一些以后开发的其他东西。事实上,它已经成功地[在 BRIN 中找到了一个漏洞][9]。
|
||||||
|
|
||||||
|
虽然 WAL 一致性检查是主要的开发者工具——尽管它也适合用户使用,如果怀疑有错误——也可以升级到专为数据库管理人员提供的几种工具。Jesper Pedersen 写了一个补丁来[升级 pageinspect contrib 模块来支持哈希索引][10],Ashutosh Sharma 做了进一步的工作,Peter Eisentraut 提供了测试用例(这是一个很好的办法,因为这些测试用例迅速失败,引发了几轮漏洞修复)。多亏了 Ashutosh Sharma 的工作,pgstattuple contrib 模块[也支持哈希索引了][11]。
|
||||||
|
|
||||||
|
一路走来,也有一些其他性能的改进。我一开始没有意识到的是,当一个哈希索引开始新一轮的桶拆分时,磁盘上的大小会突然加倍,这对于 1MB 的索引来说并不是一个问题,但是如果你碰巧有一个 64GB 的索引,那就有些不幸了。Mithun Cy 通过编写一个补丁,把加倍过程[分为四个阶段][12]在某个程度上解决了这一问题,这意味着我们将从 64GB 到 80GB 到 96GB 到 112GB 到 128GB,而不是一次性从 64GB 到 128GB。这个问题可以进一步改进,但需要对磁盘格式进行更深入的重构,并且需要仔细考虑对查找性能的影响。
|
||||||
|
|
||||||
|
七月时,一份[来自于“AP”测试人员][13]的报告使我们感到需要做进一步的调整。AP 发现,若试图将 20 亿行数据插入到新创建的哈希索引中会导致错误。为了解决这个问题,Amit 修改了拆分桶的代码,[使得在每次拆分之后清理旧的桶][14],大大减少了溢出页的累积。为了得以确保,Aimt 和我也[增加了四倍的位图页的最大数量][15],用于跟踪溢出页分配。
|
||||||
|
|
||||||
|
虽然还是有更多的事情要做,但我觉得,我和我的同事们——以及在 PostgreSQL 团队中的其他人的帮助下——已经完成了我们的目标,使哈希索引成为一个一流的功能,而不是被严重忽视的半成品。不过,你或许会问,这个功能可能有哪些应用场景。我在文章开头提到的(以及链接中的)Amit 的博客内容表明,即使是 pgbench 的工作负载,哈希索引页也可能在低级和高级并发方面优于 B 树。然而,从某种意义上说,这确实是最坏的情况。哈希索引的卖点之一是,索引存储的是字段的哈希值,而不是原始值——所以,我希望像 UUID 或者长字符串的宽键将有更大的改进。它们可能会在读取繁重的工作负载时做得更好。我们没有像优化读取那种程度来优化写入,但我鼓励任何对此技术感兴趣的人去尝试并将结果发到邮件列表(或发私人电子邮件),因为对于开发一个功能而言,真正关键的并不是一些开发人员去思考在实验室中会发生什么,而是在实际中发生了什么。
|
||||||
|
|
||||||
|
最后,我要感谢 Jeff Janes 和 Jesper Pedersen 为这个项目及其相关所做的宝贵的测试工作。这样一个规模适当的项目并不易得,以及有一群坚持不懈的测试人员,他们勇于打破任何废旧的东西的决心起了莫大的帮助。除了以上提到的人之外,其他人同样在测试,审查以及各种各样的日常帮助方面值得赞扬,其中包括 Andreas Seltenreich,Dilip Kumar,Tushar Ahuja,Alvaro Herrera,Micheal Paquier,Mark Kirkwood,Tom Lane,Kyotaro Horiguchi。谢谢你们,也同样感谢那些本该被提及却被我无意中忽略的所有朋友。
|
||||||
|
|
||||||
|
---
|
||||||
|
via:https://rhaas.blogspot.jp/2017/09/postgresqls-hash-indexes-are-now-cool.html
|
||||||
|
|
||||||
|
作者:[Robert Haas][a]
|
||||||
|
译者:[polebug](https://github.com/polebug)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由[LCTT](https://github.com/LCTT/TranslateProject)原创编译,[Linux中国](https://linux.cn/)荣誉推出
|
||||||
|
|
||||||
|
[a]:http://rhaas.blogspot.jp
|
||||||
|
[1]:http://amitkapila16.blogspot.jp/2017/03/hash-indexes-are-faster-than-btree.html
|
||||||
|
[2]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=6d46f4783efe457f74816a75173eb23ed8930020
|
||||||
|
[3]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=c11453ce0aeaa377cbbcc9a3fc418acb94629330
|
||||||
|
[4]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=293e24e507838733aba4748b514536af2d39d7f2
|
||||||
|
[5]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=6977b8b7f4dfb40896ff5e2175cad7fdbda862eb
|
||||||
|
[6]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=7c75ef571579a3ad7a1d3ee909f11dba5e0b9440
|
||||||
|
[7]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=a507b86900f695aacc8d52b7d2cfcb65f58862a2
|
||||||
|
[8]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=7403561c0f6a8c62b79b6ddf0364ae6c01719068
|
||||||
|
[9]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=08bf6e529587e1e9075d013d859af2649c32a511
|
||||||
|
[10]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=e759854a09d49725a9519c48a0d71a32bab05a01
|
||||||
|
[11]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=ea69a0dead5128c421140dc53fac165ba4af8520
|
||||||
|
[12]:https://www.postgresql.org/message-id/20170704105728.mwb72jebfmok2nm2@zip.com.au
|
||||||
|
[13]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=ff98a5e1e49de061600feb6b4de5ce0a22d386af
|
||||||
|
[14]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=ff98a5e1e49de061600feb6b4de5ce0a22d386af
|
||||||
|
[15]:https://www.postgresql.org/message-id/CA%2BTgmoax6DhnKsuE_gzY5qkvmPEok77JAP1h8wOTbf%2Bdg2Ycrw%40mail.gmail.com
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@ -0,0 +1,66 @@
|
|||||||
|
不,Linux 桌面版并没有突然流行起来
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 最近流传着这样一个传闻,Linux 桌面版已经突然流行起来了,并且使用者超过了 macOS。其实,并不是的。
|
||||||
|
|
||||||
|
有一些传闻说,Linux 桌面版的市场占有率从通常的 1.5% - 3% 翻了一番,达到 5%。那些报道是基于 [NetMarketShare][4] 的桌面操作系统分析报告而来的,据其显示,在七月份,Linux 桌面版的市场占有率从 2.5% 飙升,在九月份几乎达到 5%。但对 Linux 爱好者来说,很不幸,它并不是真的。
|
||||||
|
|
||||||
|
它也不是因为加入了谷歌推出的 Chrome OS,它在 [NetMarketShare][4] 和 [StatCounter][5] 的桌面操作系统的数据中被低估,它被认为是 Linux。但请注意,那是公正的,因为 [Chrome OS 是基于 Linux 的][6]。
|
||||||
|
|
||||||
|
真正的解释要简单的多。这似乎只是一个错误。NetMarketShare 的市场营销高管 Vince Vizzaccaro 告诉我,“Linux 份额是不正确的。我们意识到这个问题,目前正在调查此事”。
|
||||||
|
|
||||||
|
如果这听起来很奇怪,那是因为你可能认为,NetMarketShare 和 StatCounter 只是计算用户数量。但他们不是这样的。相反,他们都使用自己的秘密的方法去统计这些操作系统的数据。
|
||||||
|
|
||||||
|
NetMarketShare 的方法是对 “[从网站访问者的浏览器中收集数据][7]到我们专用的请求式 HitsLink 分析网络中和 SharePost 客户端。该网络包括超过 4 万个网站,遍布全球。我们‘计数’访问我们的网络站点的唯一访客,并且一个唯一访客每天每个网络站点只计数一次。”
|
||||||
|
|
||||||
|
然后,公司按国家对数据进行加权。“我们将我们的流量与 CIA 互联网流量按国家进行比较,并相应地对我们的数据进行加权。例如,如果我们的全球数据显示巴西占我们网络流量的 2%,而 CIA 的数据显示巴西占全球互联网流量的 4%,那么我们将统计每一个来自巴西的唯一访客两次。”
|
||||||
|
|
||||||
|
他们究竟如何 “权衡” 每天访问一个站点的数据?我们不知道。
|
||||||
|
|
||||||
|
StatCounter 也有自己的方法。它使用 “[在全球超过 200 万个站点上安装的跟踪代码][8]。这些网站涵盖了各种类型和不同的地理位置。每个月,我们都会记录在这些站点上的数十亿页的页面访问。对于每个页面访问,我们分析其使用的浏览器/操作系统/屏幕分辨率(如果页面访问来自移动设备)。 ... 我们统计了所有这些数据以获取我们的全球统计信息。
|
||||||
|
|
||||||
|
我们为互联网使用趋势提供独立的、公正的统计数据。我们不与任何其他信息源核对我们的统计数据,也 [没有使用人为加权][9]。”
|
||||||
|
|
||||||
|
他们如何汇总他们的数据?你猜猜看?其它我们也不知道。
|
||||||
|
|
||||||
|
因此,无论何时,你看到的他们这些经常被引用的操作系统或浏览器的数字,使用它们要有很大的保留余地。
|
||||||
|
|
||||||
|
对于更精确的,以美国为对象的操作系统和浏览器数量,我更喜欢使用联邦政府的 [数字分析计划(DAP)][10]。
|
||||||
|
|
||||||
|
与其它的不同, DAP 的数字来自在过去的 90 天访问过 [400 个美国政府行政机构域名][11] 的数十亿访问者。那里有 [大概 5000 个网站][12],并且包含每个内阁部门。 DAP 从一个谷歌分析帐户中得到原始数据。 DAP [开源了它在这个网站上显示其数据的代码][13] 以及它的 [数据收集代码][14]。最重要的是,与其它的不同,你可以以 [JSON][15] 格式下载它的数据,这样你就可以自己分析原始数据了。
|
||||||
|
|
||||||
|
在 [美国分析][16] 网站上,它汇总了 DAP 的数据,你可以找到 Linux 桌面版,和往常一样,它仍以 1.5% 列在 “其它” 中。Windows 仍然是高达 45.9%,接下来是 Apple iOS,占 25.5%,Android 占 18.6%,而 macOS 占 8.5%。
|
||||||
|
|
||||||
|
对不起,伙计们,我也希望它更高,但是,这就是事实。没有人,即使是 DAP,似乎都无法很好地将基于 Linux 的 Chrome OS 数据单列出来。尽管如此,Linux 桌面版仍然是 Linux 高手、软件开发者、系统管理员和工程师的专利。Linux 爱好者们还只能对其它所有的计算机设备 —— 服务器、云、超级计算机等等的(Linux)操作系统表示自豪。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.zdnet.com/article/no-the-linux-desktop-hasnt-jumped-in-popularity/
|
||||||
|
|
||||||
|
作者:[Steven J. Vaughan-Nichols][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||||
|
[1]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||||
|
[2]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||||
|
[3]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||||
|
[4]:https://www.netmarketshare.com/
|
||||||
|
[5]:https://statcounter.com/
|
||||||
|
[6]:http://www.zdnet.com/article/the-secret-origins-of-googles-chrome-os/
|
||||||
|
[7]:http://www.netmarketshare.com/faq.aspx#Methodology
|
||||||
|
[8]:http://gs.statcounter.com/faq#methodology
|
||||||
|
[9]:http://gs.statcounter.com/faq#no-weighting
|
||||||
|
[10]:https://www.digitalgov.gov/services/dap/
|
||||||
|
[11]:https://analytics.usa.gov/data/live/second-level-domains.csv
|
||||||
|
[12]:https://analytics.usa.gov/data/live/sites.csv
|
||||||
|
[13]:https://github.com/GSA/analytics.usa.gov
|
||||||
|
[14]:https://github.com/18F/analytics-reporter
|
||||||
|
[15]:http://json.org/
|
||||||
|
[16]:https://analytics.usa.gov/
|
||||||
|
[17]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||||
|
[18]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||||
|
[19]:http://www.zdnet.com/blog/open-source/
|
||||||
|
[20]:http://www.zdnet.com/topic/enterprise-software/
|
||||||
@ -0,0 +1,163 @@
|
|||||||
|
瞬间提升命令行的生产力 100%
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
关于生产力的话题总是让人充满兴趣的。
|
||||||
|
|
||||||
|
这里有许多方式提升你的生产力。今天,我共享一些命令行的小技巧,以及让你的人生更轻松的小秘诀。
|
||||||
|
|
||||||
|
### TL;DR
|
||||||
|
|
||||||
|
在本文中讨论的内容的全部设置及更多的信息,可以查看: [https://github.com/sobolevn/dotfiles][9] 。
|
||||||
|
|
||||||
|
### Shell
|
||||||
|
|
||||||
|
使用一个好用的,并且稳定的 shell 对你的命令行生产力是非常关键的。这儿有很多选择,我喜欢 `zsh` 和 `oh-my-zsh`。它是非常神奇的,理由如下:
|
||||||
|
|
||||||
|
* 自动补完几乎所有的东西
|
||||||
|
* 大量的插件
|
||||||
|
* 确实有用且能定制化的“提示符”
|
||||||
|
|
||||||
|
你可以通过下列的步骤去安装它:
|
||||||
|
|
||||||
|
1. 安装 `zsh`: [https://github.com/robbyrussell/oh-my-zsh/wiki/Installing-ZSH][1]
|
||||||
|
2. 安装 `oh-my-zsh`: [http://ohmyz.sh/][2]
|
||||||
|
3. 选择对你有用的插件: [https://github.com/robbyrussell/oh-my-zsh/wiki/Plugins][3]
|
||||||
|
|
||||||
|
你也可以调整你的设置以 [关闭自动补完的大小写敏感][10] ,或改变你的 [命令行历史的工作方式][11]。
|
||||||
|
|
||||||
|
就是这样。你将立马获得 +50% 的生产力提升。现在你可以打开足够多的选项卡(tab)了!(LCTT 译注:指多选项卡的命令行窗口)
|
||||||
|
|
||||||
|
### 主题
|
||||||
|
|
||||||
|
选择主题也很重要,因为你从头到尾都在看它。它必须是有用且漂亮的。我也喜欢简约的主题,因为它不包含一些视觉噪音和没用的信息。
|
||||||
|
|
||||||
|
你的主题将为你展示:
|
||||||
|
|
||||||
|
* 当前文件夹
|
||||||
|
* 当前的版本分支
|
||||||
|
* 当前版本库状态:干净或脏的(LCTT 译注:指是否有未提交版本库的内容)
|
||||||
|
* 任何的错误返回码(如果有)(LCTT 译注:Linux 命令如果执行错误,会返回错误码)
|
||||||
|
|
||||||
|
我也喜欢我的主题可以在新起的一行输入新命令,这样就有足够的空间去阅读和书写命令了。
|
||||||
|
|
||||||
|
我个人使用 [`sobole`][12] 主题。它看起来非常棒,它有两种模式。
|
||||||
|
|
||||||
|
亮色的:
|
||||||
|
|
||||||
|
[][13]
|
||||||
|
|
||||||
|
以及暗色的:
|
||||||
|
|
||||||
|
[][14]
|
||||||
|
|
||||||
|
你得到了另外 +15% 的提升,以及一个看起来很漂亮的主题。
|
||||||
|
|
||||||
|
### 语法高亮
|
||||||
|
|
||||||
|
对我来说,从我的 shell 中得到足够的可视信息对做出正确的判断是非常重要的。比如 “这个命令有没有拼写错误?” 或者 “这个命令有相应的作用域吗?” 这样的提示。我经常会有拼写错误。
|
||||||
|
|
||||||
|
因此, [`zsh-syntax-highlighting`][15] 对我是非常有用的。 它有合适的默认值,当然你可以 [改变任何你想要的设置][16]。
|
||||||
|
|
||||||
|
这个步骤可以带给我们额外的 +5% 的提升。
|
||||||
|
|
||||||
|
### 文件处理
|
||||||
|
|
||||||
|
我在我的目录中经常遍历许多文件,至少看起来很多。我经常做这些事情:
|
||||||
|
|
||||||
|
* 来回导航
|
||||||
|
* 列出文件和目录
|
||||||
|
* 显示文件内容
|
||||||
|
|
||||||
|
我喜欢去使用 [`z`][17] 导航到我已经去过的文件夹。这个工具是非常棒的。 它使用“<ruby>近常<rt>frecency</rt></ruby>” 方法来把你输入的 `.dot TAB` 转换成 `~/dev/shell/config/.dotfiles`。真的很不错!
|
||||||
|
|
||||||
|
当你显示文件时,你通常要了解如下几个内容:
|
||||||
|
|
||||||
|
* 文件名
|
||||||
|
* 权限
|
||||||
|
* 所有者
|
||||||
|
* 这个文件的 git 版本状态
|
||||||
|
* 修改日期
|
||||||
|
* 人类可读形式的文件大小
|
||||||
|
|
||||||
|
你也或许希望缺省展示隐藏文件。因此,我使用 [`exa`][18] 来替代标准的 `ls`。为什么呢?因为它缺省启用了很多的东西:
|
||||||
|
|
||||||
|
[][19]
|
||||||
|
|
||||||
|
要显示文件内容,我使用标准的 `cat`,或者,如果我希望看到语法高亮,我使用一个定制的别名:
|
||||||
|
|
||||||
|
```
|
||||||
|
# exa:
|
||||||
|
alias la="exa -abghl --git --color=automatic"
|
||||||
|
|
||||||
|
# `cat` with beautiful colors. requires: pip install -U Pygments
|
||||||
|
alias c='pygmentize -O style=borland -f console256 -g'
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,你已经掌握了导航。它使你的生产力提升 +15% 。
|
||||||
|
|
||||||
|
### 搜索
|
||||||
|
|
||||||
|
当你在应用程序的源代码中搜索时,你不会想在你的搜索结果中缺省包含像 `node_modules` 或 `bower_components` 这样的文件夹。或者,当你想搜索执行的更快更流畅时。
|
||||||
|
|
||||||
|
这里有一个比内置的搜索方式更好的替代: [`the_silver_searcher`][20]。
|
||||||
|
|
||||||
|
它是用纯 `C` 写成的,并且使用了很多智能化的逻辑让它工作的更快。
|
||||||
|
|
||||||
|
在命令行 `history` 中,使用 `ctrl` + `R` 进行 [反向搜索][21] 是非常有用的。但是,你有没有发现你自己甚至不能完全记住一个命令呢?如果有一个工具可以模糊搜索而且用户界面更好呢?
|
||||||
|
|
||||||
|
这里确实有这样一个工具。它叫做 `fzf`:
|
||||||
|
|
||||||
|
[][22]
|
||||||
|
|
||||||
|
它可以被用于任何模糊查询,而不仅是在命令行历史中,但它需要 [一些配置][23]。
|
||||||
|
|
||||||
|
你现在有了一个搜索工具,可以额外提升 +15% 的生产力。
|
||||||
|
|
||||||
|
### 延伸阅读
|
||||||
|
|
||||||
|
更好地使用命令行: [https://dev.to/sobolevn/using-better-clis-6o8][24]。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
通过这些简单的步骤,你可以显著提升你的命令行的生产力 +100% 以上(数字是估计的)。
|
||||||
|
|
||||||
|
这里还有其它的工具和技巧,我将在下一篇文章中介绍。
|
||||||
|
|
||||||
|
你喜欢阅读软件开发方面的最新趋势吗?在这里订阅我们的愽客吧 [https://medium.com/wemake-services][25]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://dev.to/sobolevn/instant-100-command-line-productivity-boost
|
||||||
|
|
||||||
|
作者:[Nikita Sobolev][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://dev.to/sobolevn
|
||||||
|
[1]:https://github.com/robbyrussell/oh-my-zsh/wiki/Installing-ZSH
|
||||||
|
[2]:http://ohmyz.sh/
|
||||||
|
[3]:https://github.com/robbyrussell/oh-my-zsh/wiki/Plugins
|
||||||
|
[4]:https://dev.to/sobolevn
|
||||||
|
[5]:http://github.com/sobolevn
|
||||||
|
[6]:https://dev.to/t/commandline
|
||||||
|
[7]:https://dev.to/t/dotfiles
|
||||||
|
[8]:https://dev.to/t/productivity
|
||||||
|
[9]:https://github.com/sobolevn/dotfiles
|
||||||
|
[10]:https://github.com/sobolevn/dotfiles/blob/master/zshrc#L12
|
||||||
|
[11]:https://github.com/sobolevn/dotfiles/blob/master/zshrc#L24
|
||||||
|
[12]:https://github.com/sobolevn/sobole-zsh-theme
|
||||||
|
[13]:https://res.cloudinary.com/practicaldev/image/fetch/s--Lz_uthoR--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/sobolevn/sobole-zsh-theme/master/showcases/env-and-user.png
|
||||||
|
[14]:https://res.cloudinary.com/practicaldev/image/fetch/s--4o6hZwL9--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/sobolevn/sobole-zsh-theme/master/showcases/dark-mode.png
|
||||||
|
[15]:https://github.com/zsh-users/zsh-syntax-highlighting
|
||||||
|
[16]:https://github.com/zsh-users/zsh-syntax-highlighting/blob/master/docs/highlighters.md
|
||||||
|
[17]:https://github.com/rupa/z
|
||||||
|
[18]:https://github.com/ogham/exa
|
||||||
|
[19]:https://res.cloudinary.com/practicaldev/image/fetch/s--n_YCO9Hj--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/ogham/exa/master/screenshots.png
|
||||||
|
[20]:https://github.com/ggreer/the_silver_searcher
|
||||||
|
[21]:https://unix.stackexchange.com/questions/73498/how-to-cycle-through-reverse-i-search-in-bash
|
||||||
|
[22]:https://res.cloudinary.com/practicaldev/image/fetch/s--hykHvwjq--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://thepracticaldev.s3.amazonaws.com/i/erts5tffgo5i0rpi8q3r.png
|
||||||
|
[23]:https://github.com/sobolevn/dotfiles/blob/master/shell/.external#L19
|
||||||
|
[24]:https://dev.to/sobolevn/using-better-clis-6o8
|
||||||
|
[25]:https://medium.com/wemake-services
|
||||||
308
published/20171008 8 best languages to blog about.md
Normal file
308
published/20171008 8 best languages to blog about.md
Normal file
@ -0,0 +1,308 @@
|
|||||||
|
如何分析博客中最流行的编程语言
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
摘要:这篇文章我们将对一些各种各样的博客的流行度相对于他们在谷歌上的排名进行一个分析。所有代码可以在 [github][38] 上找到.
|
||||||
|
|
||||||
|
### 想法来源
|
||||||
|
|
||||||
|
我一直在想,各种各样的博客每天到底都有多少页面浏览量,以及在博客阅读受众中最受欢迎的是什么编程语言。我也很感兴趣的是,它们在谷歌的网站排名是否与它们的受欢迎程度直接相关。
|
||||||
|
|
||||||
|
为了回答这些问题,我决定做一个 Scrapy 项目,它将收集一些数据,然后对所获得的信息执行特定的数据分析和数据可视化。
|
||||||
|
|
||||||
|
### 第一部分:Scrapy
|
||||||
|
|
||||||
|
我们将使用 [Scrapy][39] 为我们的工作,因为它为抓取和对该请求处理后的反馈进行管理提供了干净和健壮的框架。我们还将使用 [Splash][40] 来解析需要处理的 Javascript 页面。Splash 使用自己的 Web 服务器充当代理,并处理 Javascript 响应,然后再将其重定向到我们的爬虫进程。
|
||||||
|
|
||||||
|
> 我这里没有描述 Scrapy 的设置,也没有描述 Splash 的集成。你可以在[这里][34]找到 Scrapy 的示例,而[这里][35]还有 Scrapy+Splash 指南。
|
||||||
|
|
||||||
|
#### 获得相关的博客
|
||||||
|
|
||||||
|
第一步显然是获取数据。我们需要关于编程博客的谷歌搜索结果。你看,如果我们开始仅仅用谷歌自己来搜索,比如说查询 “Python”,除了博客,我们还会得到很多其它的东西。我们需要的是做一些过滤,只留下特定的博客。幸运的是,有一种叫做 [Google 自定义搜索引擎(CSE)][41]的东西,它能做到这一点。还有一个网站 [www.blogsearchengine.org][42],它正好可以满足我们需要,它会将用户请求委托给 CSE,这样我们就可以查看它的查询并重复利用它们。
|
||||||
|
|
||||||
|
所以,我们要做的是到 [www.blogsearchengine.org][43] 网站,搜索 “python”,并在一侧打开 Chrome 开发者工具中的网络标签页。这截图是我们将要看到的:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
突出显示的是 blogsearchengine 向谷歌委派的一个搜索请求,所以我们将复制它,并在我们的 scraper 中使用。
|
||||||
|
|
||||||
|
这个博客抓取爬行器类会是如下这样的:
|
||||||
|
|
||||||
|
```
|
||||||
|
class BlogsSpider(scrapy.Spider):
|
||||||
|
name = 'blogs'
|
||||||
|
allowed_domains = ['cse.google.com']
|
||||||
|
|
||||||
|
def __init__(self, queries):
|
||||||
|
super(BlogsSpider, self).__init__()
|
||||||
|
self.queries = queries
|
||||||
|
```
|
||||||
|
|
||||||
|
与典型的 Scrapy 爬虫不同,我们的方法覆盖了 `__init__` 方法,它接受额外的参数 `queries`,它指定了我们想要执行的查询列表。
|
||||||
|
|
||||||
|
现在,最重要的部分是构建和执行这个实际的查询。这个过程放在 `start_requests` 爬虫的方法里面执行,我们愉快地覆盖它:
|
||||||
|
|
||||||
|
```
|
||||||
|
def start_requests(self):
|
||||||
|
params_dict = {
|
||||||
|
'cx': ['partner-pub-9634067433254658:5laonibews6'],
|
||||||
|
'cof': ['FORID:10'],
|
||||||
|
'ie': ['ISO-8859-1'],
|
||||||
|
'q': ['query'],
|
||||||
|
'sa.x': ['0'],
|
||||||
|
'sa.y': ['0'],
|
||||||
|
'sa': ['Search'],
|
||||||
|
'ad': ['n9'],
|
||||||
|
'num': ['10'],
|
||||||
|
'rurl': [
|
||||||
|
'http://www.blogsearchengine.org/search.html?cx=partner-pub'
|
||||||
|
'-9634067433254658%3A5laonibews6&cof=FORID%3A10&ie=ISO-8859-1&'
|
||||||
|
'q=query&sa.x=0&sa.y=0&sa=Search'
|
||||||
|
],
|
||||||
|
'siteurl': ['http://www.blogsearchengine.org/']
|
||||||
|
}
|
||||||
|
|
||||||
|
params = urllib.parse.urlencode(params_dict, doseq=True)
|
||||||
|
url_template = urllib.parse.urlunparse(
|
||||||
|
['https', self.allowed_domains[0], '/cse',
|
||||||
|
'', params, 'gsc.tab=0&gsc.q=query&gsc.page=page_num'])
|
||||||
|
for query in self.queries:
|
||||||
|
for page_num in range(1, 11):
|
||||||
|
url = url_template.replace('query', urllib.parse.quote(query))
|
||||||
|
url = url.replace('page_num', str(page_num))
|
||||||
|
yield SplashRequest(url, self.parse, endpoint='render.html',
|
||||||
|
args={'wait': 0.5})
|
||||||
|
```
|
||||||
|
|
||||||
|
在这里你可以看到相当复杂的 `params_dict` 字典,它控制所有我们之前找到的 Google CSE URL 的参数。然后我们准备好 `url_template` 里的一切,除了已经填好的查询和页码。我们对每种编程语言请求 10 页,每一页包含 10 个链接,所以是每种语言有 100 个不同的博客用来分析。
|
||||||
|
|
||||||
|
在 `42-43` 行,我使用一个特殊的类 `SplashRequest` 来代替 Scrapy 自带的 Request 类。它封装了 Splash 库内部的重定向逻辑,所以我们无需为此担心。十分整洁。
|
||||||
|
|
||||||
|
最后,这是解析程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
def parse(self, response):
|
||||||
|
urls = response.css('div.gs-title.gsc-table-cell-thumbnail') \
|
||||||
|
.xpath('./a/@href').extract()
|
||||||
|
gsc_fragment = urllib.parse.urlparse(response.url).fragment
|
||||||
|
fragment_dict = urllib.parse.parse_qs(gsc_fragment)
|
||||||
|
page_num = int(fragment_dict['gsc.page'][0])
|
||||||
|
query = fragment_dict['gsc.q'][0]
|
||||||
|
page_size = len(urls)
|
||||||
|
for i, url in enumerate(urls):
|
||||||
|
parsed_url = urllib.parse.urlparse(url)
|
||||||
|
rank = (page_num - 1) * page_size + i
|
||||||
|
yield {
|
||||||
|
'rank': rank,
|
||||||
|
'url': parsed_url.netloc,
|
||||||
|
'query': query
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
所有 Scraper 的核心和灵魂就是解析器逻辑。可以有多种方法来理解响应页面的结构并构建 XPath 查询字符串。您可以使用 [Scrapy shell][44] 尝试并随时调整你的 XPath 查询,而不用运行爬虫。不过我更喜欢可视化的方法。它需要再次用到谷歌 Chrome 开发人员控制台。只需右键单击你想要用在你的爬虫里的元素,然后按下 Inspect。它将打开控制台,并定位到你指定位置的 HTML 源代码。在本例中,我们想要得到实际的搜索结果链接。他们的源代码定位是这样的:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在查看这个元素的描述后我们看到所找的 `<div>` 有一个 `.gsc-table-cell-thumbnail` CSS 类,它是 `.gs-title` `<div>` 的子元素,所以我们把它放到响应对象的 `css` 方法(`46` 行)。然后,我们只需要得到博客文章的 URL。它很容易通过`'./a/@href'` XPath 字符串来获得,它能从我们的 `<div>` 直接子元素的 `href` 属性找到。(LCTT 译注:此处图文对不上)
|
||||||
|
|
||||||
|
#### 寻找流量数据
|
||||||
|
|
||||||
|
下一个任务是估测每个博客每天得到的页面浏览量。得到这样的数据有[各种方式][45],有免费的,也有付费的。在快速搜索之后,我决定基于简单且免费的原因使用网站 [www.statshow.com][46] 来做。爬虫将抓取这个网站,我们在前一步获得的博客的 URL 将作为这个网站的输入参数,获得它们的流量信息。爬虫的初始化是这样的:
|
||||||
|
|
||||||
|
```
|
||||||
|
class TrafficSpider(scrapy.Spider):
|
||||||
|
name = 'traffic'
|
||||||
|
allowed_domains = ['www.statshow.com']
|
||||||
|
|
||||||
|
def __init__(self, blogs_data):
|
||||||
|
super(TrafficSpider, self).__init__()
|
||||||
|
self.blogs_data = blogs_data
|
||||||
|
```
|
||||||
|
|
||||||
|
`blogs_data` 应该是以下格式的词典列表:`{"rank": 70, "url": "www.stat.washington.edu", "query": "Python"}`。
|
||||||
|
|
||||||
|
请求构建函数如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
def start_requests(self):
|
||||||
|
url_template = urllib.parse.urlunparse(
|
||||||
|
['http', self.allowed_domains[0], '/www/{path}', '', '', ''])
|
||||||
|
for blog in self.blogs_data:
|
||||||
|
url = url_template.format(path=blog['url'])
|
||||||
|
request = SplashRequest(url, endpoint='render.html',
|
||||||
|
args={'wait': 0.5}, meta={'blog': blog})
|
||||||
|
yield request
|
||||||
|
```
|
||||||
|
|
||||||
|
它相当的简单,我们只是把字符串 `/www/web-site-url/` 添加到 `'www.statshow.com'` URL 中。
|
||||||
|
|
||||||
|
现在让我们看一下语法解析器是什么样子的:
|
||||||
|
|
||||||
|
```
|
||||||
|
def parse(self, response):
|
||||||
|
site_data = response.xpath('//div[@id="box_1"]/span/text()').extract()
|
||||||
|
views_data = list(filter(lambda r: '$' not in r, site_data))
|
||||||
|
if views_data:
|
||||||
|
blog_data = response.meta.get('blog')
|
||||||
|
traffic_data = {
|
||||||
|
'daily_page_views': int(views_data[0].translate({ord(','): None})),
|
||||||
|
'daily_visitors': int(views_data[1].translate({ord(','): None}))
|
||||||
|
}
|
||||||
|
blog_data.update(traffic_data)
|
||||||
|
yield blog_data
|
||||||
|
```
|
||||||
|
|
||||||
|
与博客解析程序类似,我们只是通过 StatShow 示例的返回页面,然后找到包含每日页面浏览量和每日访问者的元素。这两个参数都确定了网站的受欢迎程度,对于我们的分析只需要使用页面浏览量即可 。
|
||||||
|
|
||||||
|
### 第二部分:分析
|
||||||
|
|
||||||
|
这部分是分析我们搜集到的所有数据。然后,我们用名为 [Bokeh][47] 的库来可视化准备好的数据集。我在这里没有给出运行器和可视化的代码,但是它可以在 [GitHub repo][48] 中找到,包括你在这篇文章中看到的和其他一切东西。
|
||||||
|
|
||||||
|
> 最初的结果集含有少许偏离过大的数据,(如 google.com、linkedin.com、Oracle.com 等)。它们显然不应该被考虑。即使其中有些有博客,它们也不是针对特定语言的。这就是为什么我们基于这个 [StackOverflow 回答][36] 中所建议的方法来过滤异常值。
|
||||||
|
|
||||||
|
#### 语言流行度比较
|
||||||
|
|
||||||
|
首先,让我们对所有的语言进行直接的比较,看看哪一种语言在前 100 个博客中有最多的浏览量。
|
||||||
|
|
||||||
|
这是能进行这个任务的函数:
|
||||||
|
|
||||||
|
```
|
||||||
|
def get_languages_popularity(data):
|
||||||
|
query_sorted_data = sorted(data, key=itemgetter('query'))
|
||||||
|
result = {'languages': [], 'views': []}
|
||||||
|
popularity = []
|
||||||
|
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
|
||||||
|
group = list(group)
|
||||||
|
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
|
||||||
|
total_page_views = sum(daily_page_views)
|
||||||
|
popularity.append((group[0]['query'], total_page_views))
|
||||||
|
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
|
||||||
|
languages, views = zip(*sorted_popularity)
|
||||||
|
result['languages'] = languages
|
||||||
|
result['views'] = views
|
||||||
|
return result
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
在这里,我们首先按语言(词典中的关键字“query”)来分组我们的数据,然后使用 python 的 `groupby` 函数,这是一个从 SQL 中借来的奇妙函数,从我们的数据列表中生成一组条目,每个条目都表示一些编程语言。然后,在第 `14` 行我们计算每一种语言的总页面浏览量,然后添加 `('Language', rank)` 形式的元组到 `popularity` 列表中。在循环之后,我们根据总浏览量对流行度数据进行排序,并将这些元组展开到两个单独的列表中,然后在 `result` 变量中返回它们。
|
||||||
|
|
||||||
|
> 最初的数据集有很大的偏差。我检查了到底发生了什么,并意识到如果我在 [blogsearchengine.org][37] 上查询“C”,我就会得到很多无关的链接,其中包含了 “C” 的字母。因此,我必须将 C 排除在分析之外。这种情况几乎不会在 “R” 和其他类似 C 的名称中出现:“C++”、“C”。
|
||||||
|
|
||||||
|
因此,如果我们将 C 从考虑中移除并查看其他语言,我们可以看到如下图:
|
||||||
|
|
||||||
|
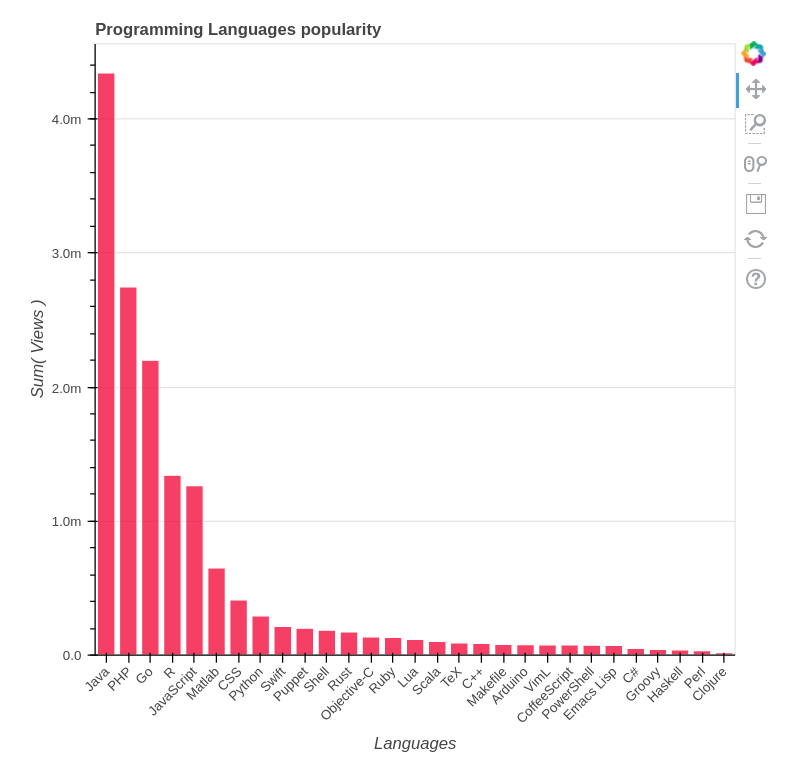
|
||||||
|
|
||||||
|
评估结论:Java 每天有超过 400 万的浏览量,PHP 和 Go 有超过 200 万,R 和 JavaScript 也突破了百万大关。
|
||||||
|
|
||||||
|
#### 每日网页浏览量与谷歌排名
|
||||||
|
|
||||||
|
现在让我们来看看每日访问量和谷歌的博客排名之间的联系。从逻辑上来说,不那么受欢迎的博客应该排名靠后,但这并没那么简单,因为其他因素也会影响排名,例如,如果在人气较低的博客上的文章更新一些,那么它很可能会首先出现。
|
||||||
|
|
||||||
|
数据准备工作以下列方式进行:
|
||||||
|
|
||||||
|
```
|
||||||
|
def get_languages_popularity(data):
|
||||||
|
query_sorted_data = sorted(data, key=itemgetter('query'))
|
||||||
|
result = {'languages': [], 'views': []}
|
||||||
|
popularity = []
|
||||||
|
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
|
||||||
|
group = list(group)
|
||||||
|
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
|
||||||
|
total_page_views = sum(daily_page_views)
|
||||||
|
popularity.append((group[0]['query'], total_page_views))
|
||||||
|
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
|
||||||
|
languages, views = zip(*sorted_popularity)
|
||||||
|
result['languages'] = languages
|
||||||
|
result['views'] = views
|
||||||
|
return result
|
||||||
|
```
|
||||||
|
|
||||||
|
该函数接受爬取到的数据和需要考虑的语言列表。我们对这些数据以语言的流行程度进行排序。后来,在类似的语言分组循环中,我们构建了 `(rank, views_number)` 元组(从 1 开始的排名)被转换为 2 个单独的列表。然后将这一对列表写入到生成的字典中。
|
||||||
|
|
||||||
|
前 8 位 GitHub 语言(除了 C)是如下这些:
|
||||||
|
|
||||||
|
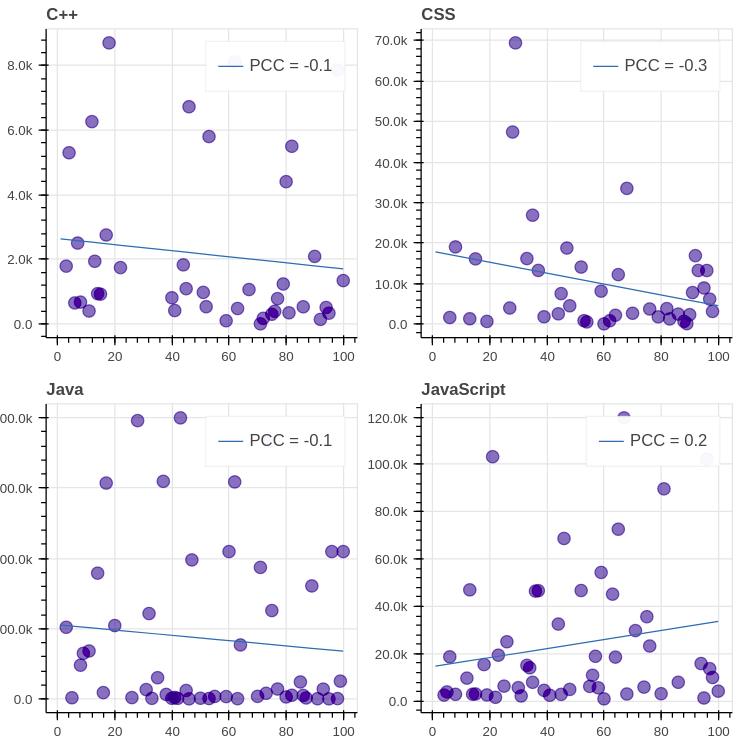
|
||||||
|
|
||||||
|
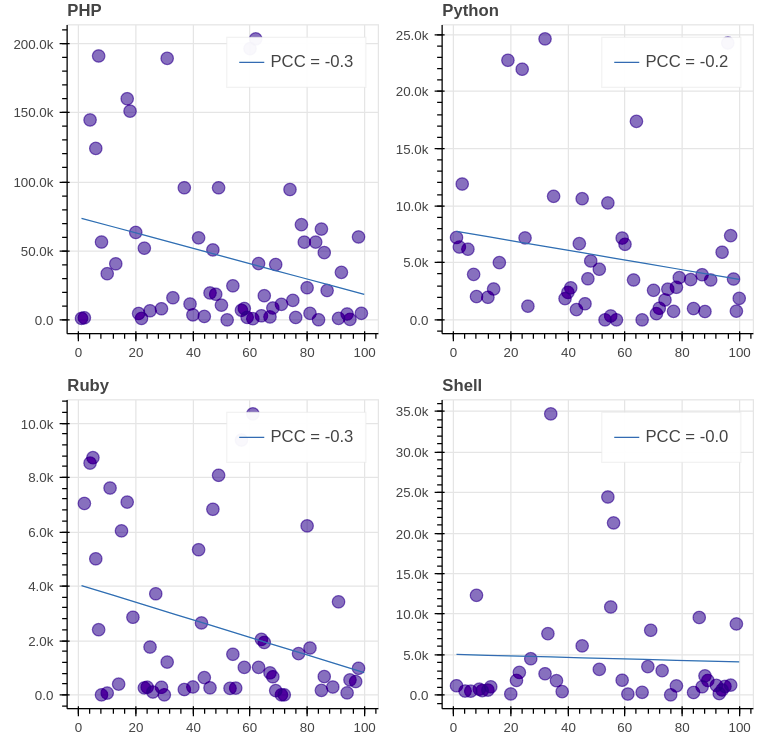
|
||||||
|
|
||||||
|
评估结论:我们看到,所有图的 [PCC (皮尔逊相关系数)][49]都远离 1/-1,这表示每日浏览量与排名之间缺乏相关性。值得注意的是,在大多数图表(8 个中的 7 个)中,相关性是负的,这意味着排名的降低会导致浏览量的减少。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
因此,根据我们的分析,Java 是目前最流行的编程语言,其次是 PHP、Go、R 和 JavaScript。在日常浏览量和谷歌排名上,排名前 8 的语言都没有很强的相关性,所以即使你刚刚开始写博客,你也可以在搜索结果中获得很高的评价。不过,成为热门博客究竟需要什么,可以留待下次讨论。
|
||||||
|
|
||||||
|
> 这些结果是相当有偏差的,如果没有更多的分析,就不能过分的考虑这些结果。首先,在较长的一段时间内收集更多的流量信息,然后分析每日浏览量和排名的平均值(中值)值是一个好主意。也许我以后还会再回来讨论这个。
|
||||||
|
|
||||||
|
### 引用
|
||||||
|
|
||||||
|
1. 抓取:
|
||||||
|
2. [blog.scrapinghub.com: Handling Javascript In Scrapy With Splash][27]
|
||||||
|
3. [BlogSearchEngine.org][28]
|
||||||
|
4. [twingly.com: Twingly Real-Time Blog Search][29]
|
||||||
|
5. [searchblogspot.com: finding blogs on blogspot platform][30]
|
||||||
|
6. 流量评估:
|
||||||
|
7. [labnol.org: Find Out How Much Traffic a Website Gets][31]
|
||||||
|
8. [quora.com: What are the best free tools that estimate visitor traffic…][32]
|
||||||
|
9. [StatShow.com: The Stats Maker][33]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.databrawl.com/2017/10/08/blog-analysis/
|
||||||
|
|
||||||
|
作者:[Serge Mosin][a]
|
||||||
|
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.databrawl.com/author/svmosingmail-com/
|
||||||
|
[1]:https://bokeh.pydata.org/
|
||||||
|
[2]:https://bokeh.pydata.org/
|
||||||
|
[3]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||||
|
[4]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||||
|
[5]:https://github.com/
|
||||||
|
[6]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||||
|
[7]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||||
|
[8]:https://github.com/
|
||||||
|
[9]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/blogs.py
|
||||||
|
[10]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-blogs-py
|
||||||
|
[11]:https://github.com/
|
||||||
|
[12]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||||
|
[13]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||||
|
[14]:https://github.com/
|
||||||
|
[15]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||||
|
[16]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||||
|
[17]:https://github.com/
|
||||||
|
[18]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/traffic.py
|
||||||
|
[19]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-traffic-py
|
||||||
|
[20]:https://github.com/
|
||||||
|
[21]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/analysis.py
|
||||||
|
[22]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-analysis-py
|
||||||
|
[23]:https://github.com/
|
||||||
|
[24]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee/raw/4ebb94aa41e9ab25fc79af26b49272b2eff47e00/analysis.py
|
||||||
|
[25]:https://gist.github.com/Greyvend/f730ccd5dc1e7eacc4f27b0c9da86eee#file-analysis-py
|
||||||
|
[26]:https://github.com/
|
||||||
|
[27]:https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/
|
||||||
|
[28]:http://www.blogsearchengine.org/
|
||||||
|
[29]:https://www.twingly.com/
|
||||||
|
[30]:http://www.searchblogspot.com/
|
||||||
|
[31]:https://www.labnol.org/internet/find-website-traffic-hits/8008/
|
||||||
|
[32]:https://www.quora.com/What-are-the-best-free-tools-that-estimate-visitor-traffic-for-a-given-page-on-a-particular-website-that-you-do-not-own-or-operate-3rd-party-sites
|
||||||
|
[33]:http://www.statshow.com/
|
||||||
|
[34]:https://docs.scrapy.org/en/latest/intro/tutorial.html
|
||||||
|
[35]:https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/
|
||||||
|
[36]:https://stackoverflow.com/a/16562028/1573766
|
||||||
|
[37]:http://blogsearchengine.org/
|
||||||
|
[38]:https://github.com/Databrawl/blog_analysis
|
||||||
|
[39]:https://scrapy.org/
|
||||||
|
[40]:https://github.com/scrapinghub/splash
|
||||||
|
[41]:https://en.wikipedia.org/wiki/Google_Custom_Search
|
||||||
|
[42]:http://www.blogsearchengine.org/
|
||||||
|
[43]:http://www.blogsearchengine.org/
|
||||||
|
[44]:https://doc.scrapy.org/en/latest/topics/shell.html
|
||||||
|
[45]:https://www.labnol.org/internet/find-website-traffic-hits/8008/
|
||||||
|
[46]:http://www.statshow.com/
|
||||||
|
[47]:https://bokeh.pydata.org/en/latest/
|
||||||
|
[48]:https://github.com/Databrawl/blog_analysis
|
||||||
|
[49]:https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
|
||||||
|
[50]:https://www.databrawl.com/author/svmosingmail-com/
|
||||||
|
[51]:https://www.databrawl.com/2017/10/08/
|
||||||
@ -0,0 +1,71 @@
|
|||||||
|
CyberShaolin:培养下一代网络安全专家
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> CyberShaolin 联合创始人 Reuben Paul 将在布拉格的开源峰会上发表演讲,强调网络安全意识对于孩子们的重要性。
|
||||||
|
|
||||||
|
Reuben Paul 并不是唯一一个玩电子游戏的孩子,但是他对游戏和电脑的痴迷使他走上了一段独特的好奇之旅,引起了他对网络安全教育和宣传的早期兴趣,并创立了 CyberShaolin,一个帮助孩子理解网络攻击的威胁。现年 11 岁的 Paul 将在[布拉格开源峰会](LCTT 译注:已于 10 月 28 举办)上发表主题演讲,分享他的经验,并强调玩具、设备和日常使用的其他技术的不安全性。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*CyberShaolin 联合创始人 Reuben Paul*
|
||||||
|
|
||||||
|
我们采访了 Paul 听取了他的故事,并讨论 CyberShaolin 及其教育、赋予孩子(及其父母)的网络安全危险和防御知识。
|
||||||
|
|
||||||
|
Linux.com:你对电脑的迷恋是什么时候开始的?
|
||||||
|
|
||||||
|
Reuben Paul:我对电脑的迷恋始于电子游戏。我喜欢手机游戏以及视频游戏。(我记得是)当我大约 5 岁时,我通过 Gameloft 在手机上玩 “Asphalt” 赛车游戏。这是一个简单而有趣的游戏。我得触摸手机右侧加快速度,触摸手机左侧减慢速度。我问我爸,“游戏怎么知道我触摸了哪里?”
|
||||||
|
|
||||||
|
他研究发现,手机屏幕是一个 xy 坐标系统,所以他告诉我,如果 x 值大于手机屏幕宽度的一半,那么它是右侧的触摸。否则,这是左侧接触。为了帮助我更好地理解这是如何工作的,他给了我一个线性的方程,它是 y = mx + b,并问:“你能找每个 x 值 对应的 y 值吗?”大约 30 分钟后,我计算出了所有他给我的 x 对应的 y 值。
|
||||||
|
|
||||||
|
当我父亲意识到我能够学习编程的一些基本逻辑时,他给我介绍了 Scratch,并且使用鼠标指针的 x 和 y 值编写了我的第一个游戏 - 名为 “大鱼吃小鱼”。然后,我爱上了电脑。
|
||||||
|
|
||||||
|
Linux.com:你对网络安全感兴趣吗?
|
||||||
|
|
||||||
|
Paul:我的父亲 Mano Paul 曾经在网络安全方面培训他的商业客户。每当他在家里工作,我都会听到他的电话交谈。到了我 6 岁的时候,我就知道互联网、防火墙和云计算等东西。当我的父亲意识到我有兴趣和学习的潜力,他开始教我安全方面,如社会工程技术、克隆网站、中间人攻击技术、hack 移动应用等等。当我第一次从目标测试机器上获得一个 meterpreter shell 时,我的感觉就像 Peter Parker 刚刚发现他的蜘蛛侠的能力一样。
|
||||||
|
|
||||||
|
Linux.com:你是如何以及为什么创建 CyberShaolin 的?
|
||||||
|
|
||||||
|
Paul:当我 8 岁的时候,我首先在 DerbyCon 上做了主题为“来自(8 岁大)孩子之口的安全信息”的演讲。那是在 2014 年 9 月。那次会议之后,我收到了几个邀请函,2014 年底之前,我还在其他三个会议上做了主题演讲。
|
||||||
|
|
||||||
|
所以,当孩子们开始听到我在这些不同的会议上发言时,他们开始写信给我,要我教他们。我告诉我的父母,我想教别的孩子,他们问我怎么想。我说:“也许我可以制作一些视频,并在像 YouTube 这样的频道上发布。”他们问我是否要收费,而我说“不”。我希望我的视频可以免费供在世界上任何地方的任何孩子使用。CyberShaolin 就是这样创建的。
|
||||||
|
|
||||||
|
Linux.com:CyberShaolin 的目标是什么?
|
||||||
|
|
||||||
|
Paul:CyberShaolin 是我父母帮助我创立的非营利组织。它的任务是教育、赋予孩子(和他们的父母)掌握网络安全的危险和防范知识,我在学校的空闲时间开发了这些视频和其他训练材料,连同功夫、体操、游泳、曲棍球、钢琴和鼓等。迄今为止,我已经在 www.CyberShaolin.org 网站上发布了大量的视频,并计划开发更多的视频。我也想制作游戏和漫画来支持安全学习。
|
||||||
|
|
||||||
|
CyberShaolin 来自两个词:网络和少林。网络这个词当然是来自技术。少林来自功夫武术,我和我的父亲都是黑带 2 段。在功夫方面,我们有显示知识进步的缎带,你可以想像 CyberShaolin 像数码技术方面的功夫,在我们的网站上学习和考试后,孩子们可以成为网络黑带。
|
||||||
|
|
||||||
|
Linux.com:你认为孩子对网络安全的理解有多重要?
|
||||||
|
|
||||||
|
Paul:我们生活在一个技术和设备不仅存在我们家里,还在我们学校和几乎任何你去的地方的时代。世界也正在与物联网联系起来,这些物联网很容易成为威胁网(Internet of Threats)。儿童是这些技术和设备的主要用户之一。不幸的是,这些设备和设备上的应用程序不是很安全,可能会给儿童和家庭带来严重的问题。例如,最近(2017 年 5 月),我演示了如何攻入智能玩具泰迪熊,并将其变成远程侦察设备。孩子也是下一代。如果他们对网络安全没有意识和训练,那么未来(我们的未来)将不会很好。
|
||||||
|
|
||||||
|
Linux.com:该项目如何帮助孩子?
|
||||||
|
|
||||||
|
Paul:正如我之前提到的,CyberShaolin 的使命是教育、赋予孩子(和他们的父母)网络安全的危险和防御知识。
|
||||||
|
|
||||||
|
当孩子们受到网络欺凌、中间人、钓鱼、隐私、在线威胁、移动威胁等网络安全危害的教育时,他们将具备知识和技能,从而使他们能够在网络空间做出明智的决定并保持安全。而且,正如我永远不会用我的功夫技能去伤害某个人一样,我希望所有的 CyberShaolin 毕业生都能利用他们的网络功夫技能为人类的利益创造一个安全的未来。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Swapnil Bhartiya 是一名记者和作家,专注在 Linux 和 Open Source 上 10 多年。
|
||||||
|
|
||||||
|
-------------------------
|
||||||
|
|
||||||
|
via: https://www.linuxfoundation.org/blog/cybershaolin-teaching-next-generation-cybersecurity-experts/
|
||||||
|
|
||||||
|
作者:[Swapnil Bhartiya][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linuxfoundation.org/author/sbhartiya/
|
||||||
|
[1]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||||
|
[2]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||||
|
[3]:https://www.linuxfoundation.org/author/sbhartiya/
|
||||||
|
[4]:https://www.linuxfoundation.org/category/blog/
|
||||||
|
[5]:https://www.linuxfoundation.org/category/campaigns/events-campaigns/
|
||||||
|
[6]:https://www.linuxfoundation.org/category/blog/qa/
|
||||||
@ -0,0 +1,364 @@
|
|||||||
|
如何在 Apache Kafka 中通过 KSQL 分析 Twitter 数据
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
[KSQL][8] 是 Apache Kafka 中的开源的流式 SQL 引擎。它可以让你在 Kafka <ruby>主题<rt>topic</rt></ruby>上,使用一个简单的并且是交互式的 SQL 接口,很容易地做一些复杂的流处理。在这个短文中,我们将看到如何轻松地配置并运行在一个沙箱中去探索它,并使用大家都喜欢的演示数据库源: Twitter。我们将从推文的原始流中获取,通过使用 KSQL 中的条件去过滤它,来构建一个聚合,如统计每个用户每小时的推文数量。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
首先, [获取一个 Confluent 平台的副本][9]。我使用的是 RPM 包,但是,如果你需要的话,你也可以使用 [tar、 zip 等等][10] 。启动 Confluent 系统:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ confluent start
|
||||||
|
```
|
||||||
|
|
||||||
|
(如果你感兴趣,这里有一个 [Confluent 命令行的快速教程][11])
|
||||||
|
|
||||||
|
我们将使用 Kafka Connect 从 Twitter 上拉取数据。 这个 Twitter 连接器可以在 [GitHub][12] 上找到。要安装它,像下面这样操作:
|
||||||
|
|
||||||
|
```
|
||||||
|
# Clone the git repo
|
||||||
|
cd /home/rmoff
|
||||||
|
git clone https://github.com/jcustenborder/kafka-connect-twitter.git
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
# Compile the code
|
||||||
|
cd kafka-connect-twitter
|
||||||
|
mvn clean package
|
||||||
|
```
|
||||||
|
|
||||||
|
要让 Kafka Connect 去使用我们构建的[连接器][13], 你要去修改配置文件。因为我们使用 Confluent 命令行,真实的配置文件是在 `etc/schema-registry/connect-avro-distributed.properties`,因此去修改它并增加如下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
plugin.path=/home/rmoff/kafka-connect-twitter/target/kafka-connect-twitter-0.2-SNAPSHOT.tar.gz
|
||||||
|
```
|
||||||
|
|
||||||
|
重启动 Kafka Connect:
|
||||||
|
|
||||||
|
```
|
||||||
|
confluent stop connect
|
||||||
|
confluent start connect
|
||||||
|
```
|
||||||
|
|
||||||
|
一旦你安装好插件,你可以很容易地去配置它。你可以直接使用 Kafka Connect 的 REST API ,或者创建你的配置文件,这就是我要在这里做的。如果你需要全部的方法,请首先访问 Twitter 来获取你的 [API 密钥][14]。
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"name": "twitter_source_json_01",
|
||||||
|
"config": {
|
||||||
|
"connector.class": "com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector",
|
||||||
|
"twitter.oauth.accessToken": "xxxx",
|
||||||
|
"twitter.oauth.consumerSecret": "xxxxx",
|
||||||
|
"twitter.oauth.consumerKey": "xxxx",
|
||||||
|
"twitter.oauth.accessTokenSecret": "xxxxx",
|
||||||
|
"kafka.delete.topic": "twitter_deletes_json_01",
|
||||||
|
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
|
||||||
|
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
|
||||||
|
"value.converter.schemas.enable": false,
|
||||||
|
"key.converter.schemas.enable": false,
|
||||||
|
"kafka.status.topic": "twitter_json_01",
|
||||||
|
"process.deletes": true,
|
||||||
|
"filter.keywords": "rickastley,kafka,ksql,rmoff"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
假设你写这些到 `/home/rmoff/twitter-source.json`,你可以现在运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ confluent load twitter_source -d /home/rmoff/twitter-source.json
|
||||||
|
```
|
||||||
|
|
||||||
|
然后推文就从大家都喜欢的网络明星 [rick] 滚滚而来……
|
||||||
|
|
||||||
|
```
|
||||||
|
$ kafka-console-consumer --bootstrap-server localhost:9092 --from-beginning --topic twitter_json_01|jq '.Text'
|
||||||
|
{
|
||||||
|
"string": "RT @rickastley: 30 years ago today I said I was Never Gonna Give You Up. I am a man of my word - Rick x https://t.co/VmbMQA6tQB"
|
||||||
|
}
|
||||||
|
{
|
||||||
|
"string": "RT @mariteg10: @rickastley @Carfestevent Wonderful Rick!!\nDo not forget Chile!!\nWe hope you get back someday!!\nHappy weekend for you!!\n❤…"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
现在我们从 KSQL 开始 ! 马上去下载并构建它:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd /home/rmoff
|
||||||
|
git clone https://github.com/confluentinc/ksql.git
|
||||||
|
cd /home/rmoff/ksql
|
||||||
|
mvn clean compile install -DskipTests
|
||||||
|
```
|
||||||
|
|
||||||
|
构建完成后,让我们来运行它:
|
||||||
|
|
||||||
|
```
|
||||||
|
./bin/ksql-cli local --bootstrap-server localhost:9092
|
||||||
|
```
|
||||||
|
```
|
||||||
|
======================================
|
||||||
|
= _ __ _____ ____ _ =
|
||||||
|
= | |/ // ____|/ __ \| | =
|
||||||
|
= | ' /| (___ | | | | | =
|
||||||
|
= | < \___ \| | | | | =
|
||||||
|
= | . \ ____) | |__| | |____ =
|
||||||
|
= |_|\_\_____/ \___\_\______| =
|
||||||
|
= =
|
||||||
|
= Streaming SQL Engine for Kafka =
|
||||||
|
Copyright 2017 Confluent Inc.
|
||||||
|
|
||||||
|
CLI v0.1, Server v0.1 located at http://localhost:9098
|
||||||
|
|
||||||
|
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
|
||||||
|
|
||||||
|
ksql>
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 KSQL, 我们可以让我们的数据保留在 Kafka 主题上并可以查询它。首先,我们需要去告诉 KSQL 主题上的<ruby>数据模式<rt>schema</rt></ruby>是什么,一个 twitter 消息实际上是一个非常巨大的 JSON 对象, 但是,为了简洁,我们只选出其中几行:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> CREATE STREAM twitter_raw (CreatedAt BIGINT, Id BIGINT, Text VARCHAR) WITH (KAFKA_TOPIC='twitter_json_01', VALUE_FORMAT='JSON');
|
||||||
|
|
||||||
|
Message
|
||||||
|
----------------
|
||||||
|
Stream created
|
||||||
|
```
|
||||||
|
|
||||||
|
在定义的模式中,我们可以查询这些流。要让 KSQL 从该主题的开始展示数据(而不是默认的当前时间点),运行如下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> SET 'auto.offset.reset' = 'earliest';
|
||||||
|
Successfully changed local property 'auto.offset.reset' from 'null' to 'earliest'
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,让我们看看这些数据,我们将使用 LIMIT 从句仅检索一行:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> SELECT text FROM twitter_raw LIMIT 1;
|
||||||
|
RT @rickastley: 30 years ago today I said I was Never Gonna Give You Up. I am a man of my word - Rick x https://t.co/VmbMQA6tQB
|
||||||
|
LIMIT reached for the partition.
|
||||||
|
Query terminated
|
||||||
|
ksql>
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,让我们使用刚刚定义和可用的推文内容的全部数据重新定义该流:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> DROP stream twitter_raw;
|
||||||
|
Message
|
||||||
|
--------------------------------
|
||||||
|
Source TWITTER_RAW was dropped
|
||||||
|
|
||||||
|
ksql> CREATE STREAM twitter_raw (CreatedAt bigint,Id bigint, Text VARCHAR, SOURCE VARCHAR, Truncated VARCHAR, InReplyToStatusId VARCHAR, InReplyToUserId VARCHAR, InReplyToScreenName VARCHAR, GeoLocation VARCHAR, Place VARCHAR, Favorited VARCHAR, Retweeted VARCHAR, FavoriteCount VARCHAR, User VARCHAR, Retweet VARCHAR, Contributors VARCHAR, RetweetCount VARCHAR, RetweetedByMe VARCHAR, CurrentUserRetweetId VARCHAR, PossiblySensitive VARCHAR, Lang VARCHAR, WithheldInCountries VARCHAR, HashtagEntities VARCHAR, UserMentionEntities VARCHAR, MediaEntities VARCHAR, SymbolEntities VARCHAR, URLEntities VARCHAR) WITH (KAFKA_TOPIC='twitter_json_01',VALUE_FORMAT='JSON');
|
||||||
|
Message
|
||||||
|
----------------
|
||||||
|
Stream created
|
||||||
|
|
||||||
|
ksql>
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,我们可以操作和检查更多的最近的数据,使用一般的 SQL 查询:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> SELECT TIMESTAMPTOSTRING(CreatedAt, 'yyyy-MM-dd HH:mm:ss.SSS') AS CreatedAt,\
|
||||||
|
EXTRACTJSONFIELD(user,'$.ScreenName') as ScreenName,Text \
|
||||||
|
FROM twitter_raw \
|
||||||
|
WHERE LCASE(hashtagentities) LIKE '%oow%' OR \
|
||||||
|
LCASE(hashtagentities) LIKE '%ksql%';
|
||||||
|
|
||||||
|
2017-09-29 13:59:58.000 | rmoff | Looking forward to talking all about @apachekafka & @confluentinc’s #KSQL at #OOW17 on Sunday 13:45 https://t.co/XbM4eIuzeG
|
||||||
|
```
|
||||||
|
|
||||||
|
注意这里没有 LIMIT 从句,因此,你将在屏幕上看到 “continuous query” 的结果。不像关系型数据表中返回一个确定数量结果的查询,一个持续查询会运行在无限的流式数据上, 因此,它总是可能返回更多的记录。点击 Ctrl-C 去中断然后返回到 KSQL 提示符。在以上的查询中我们做了一些事情:
|
||||||
|
|
||||||
|
* **TIMESTAMPTOSTRING** 将时间戳从 epoch 格式转换到人类可读格式。(LCTT 译注: epoch 指的是一个特定的时间 1970-01-01 00:00:00 UTC)
|
||||||
|
* **EXTRACTJSONFIELD** 来展示数据源中嵌套的用户域中的一个字段,它看起来像:
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"CreatedAt": 1506570308000,
|
||||||
|
"Text": "RT @gwenshap: This is the best thing since partitioned bread :) https://t.co/1wbv3KwRM6",
|
||||||
|
[...]
|
||||||
|
"User": {
|
||||||
|
"Id": 82564066,
|
||||||
|
"Name": "Robin Moffatt \uD83C\uDF7B\uD83C\uDFC3\uD83E\uDD53",
|
||||||
|
"ScreenName": "rmoff",
|
||||||
|
[...]
|
||||||
|
```
|
||||||
|
|
||||||
|
* 应用断言去展示内容,对 #(hashtag)使用模式匹配, 使用 LCASE 去强制小写字母。(LCTT 译注:hashtag 是twitter 中用来标注线索主题的标签)
|
||||||
|
|
||||||
|
关于支持的函数列表,请查看 [KSQL 文档][15]。
|
||||||
|
|
||||||
|
我们可以创建一个从这个数据中得到的流:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> CREATE STREAM twitter AS \
|
||||||
|
SELECT TIMESTAMPTOSTRING(CreatedAt, 'yyyy-MM-dd HH:mm:ss.SSS') AS CreatedAt,\
|
||||||
|
EXTRACTJSONFIELD(user,'$.Name') AS user_Name,\
|
||||||
|
EXTRACTJSONFIELD(user,'$.ScreenName') AS user_ScreenName,\
|
||||||
|
EXTRACTJSONFIELD(user,'$.Location') AS user_Location,\
|
||||||
|
EXTRACTJSONFIELD(user,'$.Description') AS user_Description,\
|
||||||
|
Text,hashtagentities,lang \
|
||||||
|
FROM twitter_raw ;
|
||||||
|
|
||||||
|
Message
|
||||||
|
----------------------------
|
||||||
|
Stream created and running
|
||||||
|
|
||||||
|
ksql> DESCRIBE twitter;
|
||||||
|
Field | Type
|
||||||
|
------------------------------------
|
||||||
|
ROWTIME | BIGINT
|
||||||
|
ROWKEY | VARCHAR(STRING)
|
||||||
|
CREATEDAT | VARCHAR(STRING)
|
||||||
|
USER_NAME | VARCHAR(STRING)
|
||||||
|
USER_SCREENNAME | VARCHAR(STRING)
|
||||||
|
USER_LOCATION | VARCHAR(STRING)
|
||||||
|
USER_DESCRIPTION | VARCHAR(STRING)
|
||||||
|
TEXT | VARCHAR(STRING)
|
||||||
|
HASHTAGENTITIES | VARCHAR(STRING)
|
||||||
|
LANG | VARCHAR(STRING)
|
||||||
|
ksql>
|
||||||
|
```
|
||||||
|
|
||||||
|
并且查询这个得到的流:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> SELECT CREATEDAT, USER_NAME, TEXT \
|
||||||
|
FROM TWITTER \
|
||||||
|
WHERE TEXT LIKE '%KSQL%';
|
||||||
|
|
||||||
|
2017-10-03 23:39:37.000 | Nicola Ferraro | RT @flashdba: Again, I'm really taken with the possibilities opened up by @confluentinc's KSQL engine #Kafka https://t.co/aljnScgvvs
|
||||||
|
```
|
||||||
|
|
||||||
|
在我们结束之前,让我们去看一下怎么去做一些聚合。
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> SELECT user_screenname, COUNT(*) \
|
||||||
|
FROM twitter WINDOW TUMBLING (SIZE 1 HOUR) \
|
||||||
|
GROUP BY user_screenname HAVING COUNT(*) > 1;
|
||||||
|
|
||||||
|
oracleace | 2
|
||||||
|
rojulman | 2
|
||||||
|
smokeinpublic | 2
|
||||||
|
ArtFlowMe | 2
|
||||||
|
[...]
|
||||||
|
```
|
||||||
|
|
||||||
|
你将可能得到满屏幕的结果;这是因为 KSQL 在每次给定的时间窗口更新时实际发出聚合值。因为我们设置 KSQL 去读取在主题上的全部消息(`SET 'auto.offset.reset' = 'earliest';`),它是一次性读取这些所有的消息并计算聚合更新。这里有一个微妙之处值得去深入研究。我们的入站推文流正好就是一个流。但是,现有它不能创建聚合,我们实际上是创建了一个表。一个表是在给定时间点的给定键的值的一个快照。 KSQL 聚合数据基于消息的事件时间,并且如果它更新了,通过简单的相关窗口重申去操作后面到达的数据。困惑了吗? 我希望没有,但是,让我们看一下,如果我们可以用这个例子去说明。 我们将申明我们的聚合作为一个真实的表:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> CREATE TABLE user_tweet_count AS \
|
||||||
|
SELECT user_screenname, count(*) AS tweet_count \
|
||||||
|
FROM twitter WINDOW TUMBLING (SIZE 1 HOUR) \
|
||||||
|
GROUP BY user_screenname ;
|
||||||
|
|
||||||
|
Message
|
||||||
|
---------------------------
|
||||||
|
Table created and running
|
||||||
|
```
|
||||||
|
|
||||||
|
看表中的列,这里除了我们要求的外,还有两个隐含列:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> DESCRIBE user_tweet_count;
|
||||||
|
|
||||||
|
Field | Type
|
||||||
|
-----------------------------------
|
||||||
|
ROWTIME | BIGINT
|
||||||
|
ROWKEY | VARCHAR(STRING)
|
||||||
|
USER_SCREENNAME | VARCHAR(STRING)
|
||||||
|
TWEET_COUNT | BIGINT
|
||||||
|
ksql>
|
||||||
|
```
|
||||||
|
|
||||||
|
我们看一下这些是什么:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> SELECT TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS') , \
|
||||||
|
ROWKEY, USER_SCREENNAME, TWEET_COUNT \
|
||||||
|
FROM user_tweet_count \
|
||||||
|
WHERE USER_SCREENNAME= 'rmoff';
|
||||||
|
|
||||||
|
2017-09-29 11:00:00.000 | rmoff : Window{start=1506708000000 end=-} | rmoff | 2
|
||||||
|
2017-09-29 12:00:00.000 | rmoff : Window{start=1506711600000 end=-} | rmoff | 4
|
||||||
|
2017-09-28 22:00:00.000 | rmoff : Window{start=1506661200000 end=-} | rmoff | 2
|
||||||
|
2017-09-29 09:00:00.000 | rmoff : Window{start=1506700800000 end=-} | rmoff | 4
|
||||||
|
2017-09-29 15:00:00.000 | rmoff : Window{start=1506722400000 end=-} | rmoff | 2
|
||||||
|
2017-09-29 13:00:00.000 | rmoff : Window{start=1506715200000 end=-} | rmoff | 6
|
||||||
|
```
|
||||||
|
|
||||||
|
`ROWTIME` 是窗口开始时间, `ROWKEY` 是 `GROUP BY`(`USER_SCREENNAME`)加上窗口的组合。因此,我们可以通过创建另外一个衍生的表来整理一下:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> CREATE TABLE USER_TWEET_COUNT_DISPLAY AS \
|
||||||
|
SELECT TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS') AS WINDOW_START ,\
|
||||||
|
USER_SCREENNAME, TWEET_COUNT \
|
||||||
|
FROM user_tweet_count;
|
||||||
|
|
||||||
|
Message
|
||||||
|
---------------------------
|
||||||
|
Table created and running
|
||||||
|
```
|
||||||
|
|
||||||
|
现在它更易于查询和查看我们感兴趣的数据:
|
||||||
|
|
||||||
|
```
|
||||||
|
ksql> SELECT WINDOW_START , USER_SCREENNAME, TWEET_COUNT \
|
||||||
|
FROM USER_TWEET_COUNT_DISPLAY WHERE TWEET_COUNT> 20;
|
||||||
|
|
||||||
|
2017-09-29 12:00:00.000 | VikasAatOracle | 22
|
||||||
|
2017-09-28 14:00:00.000 | Throne_ie | 50
|
||||||
|
2017-09-28 14:00:00.000 | pikipiki_net | 22
|
||||||
|
2017-09-29 09:00:00.000 | johanlouwers | 22
|
||||||
|
2017-09-28 09:00:00.000 | yvrk1973 | 24
|
||||||
|
2017-09-28 13:00:00.000 | cmosoares | 22
|
||||||
|
2017-09-29 11:00:00.000 | ypoirier | 24
|
||||||
|
2017-09-28 14:00:00.000 | pikisec | 22
|
||||||
|
2017-09-29 07:00:00.000 | Throne_ie | 22
|
||||||
|
2017-09-29 09:00:00.000 | ChrisVoyance | 24
|
||||||
|
2017-09-28 11:00:00.000 | ChrisVoyance | 28
|
||||||
|
```
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
所以我们有了它! 我们可以从 Kafka 中取得数据, 并且很容易使用 KSQL 去探索它。 而不仅是去浏览和转换数据,我们可以很容易地使用 KSQL 从流和表中建立流处理。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果你对 KSQL 能够做什么感兴趣,去查看:
|
||||||
|
|
||||||
|
* [KSQL 公告][1]
|
||||||
|
* [我们最近的 KSQL 在线研讨会][2] 和 [Kafka 峰会讲演][3]
|
||||||
|
* [clickstream 演示][4],它是 [KSQL 的 GitHub 仓库][5] 的一部分
|
||||||
|
* [我最近做的演讲][6] 展示了 KSQL 如何去支持基于流的 ETL 平台
|
||||||
|
|
||||||
|
记住,KSQL 现在正处于开发者预览阶段。 欢迎在 KSQL 的 GitHub 仓库上提出任何问题, 或者去我们的 [community Slack group][16] 的 #KSQL 频道。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.confluent.io/blog/using-ksql-to-analyse-query-and-transform-data-in-kafka
|
||||||
|
|
||||||
|
作者:[Robin Moffatt][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.confluent.io/blog/author/robin/
|
||||||
|
[1]:https://www.confluent.io/blog/ksql-open-source-streaming-sql-for-apache-kafka/
|
||||||
|
[2]:https://www.confluent.io/online-talk/ksql-streaming-sql-for-apache-kafka/
|
||||||
|
[3]:https://www.confluent.io/kafka-summit-sf17/Databases-and-Stream-Processing-1
|
||||||
|
[4]:https://www.youtube.com/watch?v=A45uRzJiv7I
|
||||||
|
[5]:https://github.com/confluentinc/ksql
|
||||||
|
[6]:https://speakerdeck.com/rmoff/look-ma-no-code-building-streaming-data-pipelines-with-apache-kafka
|
||||||
|
[7]:https://www.confluent.io/blog/author/robin/
|
||||||
|
[8]:https://github.com/confluentinc/ksql/
|
||||||
|
[9]:https://www.confluent.io/download/
|
||||||
|
[10]:https://docs.confluent.io/current/installation.html?
|
||||||
|
[11]:https://www.youtube.com/watch?v=ZKqBptBHZTg
|
||||||
|
[12]:https://github.com/jcustenborder/kafka-connect-twitter
|
||||||
|
[13]:https://docs.confluent.io/current/connect/userguide.html#connect-installing-plugins
|
||||||
|
[14]:https://apps.twitter.com/
|
||||||
|
[15]:https://github.com/confluentinc/ksql/blob/0.1.x/docs/syntax-reference.md
|
||||||
|
[16]:https://slackpass.io/confluentcommunity
|
||||||
@ -0,0 +1,260 @@
|
|||||||
|
怎么在一台树莓派上安装 Postgres 数据库
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 在你的下一个树莓派项目上安装和配置流行的开源数据库 Postgres 并去使用它。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Image credits : Raspberry Pi Foundation. [CC BY-SA 4.0][12].
|
||||||
|
|
||||||
|
保存你的项目或应用程序持续增加的数据,数据库是一种很好的方式。你可以在一个会话中将数据写入到数据库,并且在下次你需要查找的时候找到它。一个设计良好的数据库可以做到在巨大的数据集中高效地找到数据,只要告诉它你想去找什么,而不用去考虑它是如何查找的。为一个基本的 [CRUD][13] (创建、记录、更新、删除)应用程序安装一个数据库是非常简单的, 它是一个很通用的模式,并且也适用于很多项目。
|
||||||
|
|
||||||
|
为什么 [PostgreSQL][14],一般被为 Postgres? 它被认为是功能和性能最好的开源数据库。如果你使用过 MySQL,它们是很相似的。但是,如果你希望使用它更高级的功能,你会发现优化 Postgres 是比较容易的。它便于安装、容易使用、方便安全, 而且在树莓派 3 上运行的非常好。
|
||||||
|
|
||||||
|
本教程介绍了怎么在一个树莓派上去安装 Postgres;创建一个表;写简单查询;在树莓派、PC,或者 Mac 上使用 pgAdmin 图形用户界面;从 Python 中与数据库交互。
|
||||||
|
|
||||||
|
你掌握了这些基础知识后,你可以让你的应用程序使用复合查询连接多个表,那个时候你需要考虑的是,怎么去使用主键或外键优化及最佳实践等等。
|
||||||
|
|
||||||
|
### 安装
|
||||||
|
|
||||||
|
一开始,你将需要去安装 Postgres 和一些其它的包。打开一个终端窗口并连接到因特网,然后运行以下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt install postgresql libpq-dev postgresql-client
|
||||||
|
postgresql-client-common -y
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
当安装完成后,切换到 Postgres 用户去配置数据库:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo su postgres
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,你可以创建一个数据库用户。如果你创建了一个与你的 Unix 用户帐户相同名字的用户,那个用户将被自动授权访问该数据库。因此在本教程中,为简单起见,我们将假设你使用了默认用户 `pi` 。运行 `createuser` 命令以继续:
|
||||||
|
|
||||||
|
```
|
||||||
|
createuser pi -P --interactive
|
||||||
|
```
|
||||||
|
|
||||||
|
当得到提示时,输入一个密码 (并记住它), 选择 `n` 使它成为一个非超级用户(LCTT 译注:此处原文有误),接下来两个问题选择 `y`(LCTT 译注:分别允许创建数据库和其它用户)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
现在,使用 Postgres shell 连接到 Postgres 去创建一个测试数据库:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ psql
|
||||||
|
> create database test;
|
||||||
|
```
|
||||||
|
|
||||||
|
按下 `Ctrl+D` **两次**从 psql shell 和 postgres 用户中退出,再次以 `pi` 用户登入。你创建了一个名为 `pi` 的 Postgres 用户后,你可以从这里无需登录凭据即可访问 Postgres shell:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ psql test
|
||||||
|
```
|
||||||
|
|
||||||
|
你现在已经连接到 "test" 数据库。这个数据库当前是空的,不包含任何表。你可以在 psql shell 里创建一个简单的表:
|
||||||
|
|
||||||
|
```
|
||||||
|
test=> create table people (name text, company text);
|
||||||
|
```
|
||||||
|
|
||||||
|
现在你可插入数据到表中:
|
||||||
|
|
||||||
|
```
|
||||||
|
test=> insert into people values ('Ben Nuttall', 'Raspberry Pi Foundation');
|
||||||
|
|
||||||
|
test=> insert into people values ('Rikki Endsley', 'Red Hat');
|
||||||
|
```
|
||||||
|
|
||||||
|
然后尝试进行查询:
|
||||||
|
|
||||||
|
```
|
||||||
|
test=> select * from people;
|
||||||
|
|
||||||
|
name | company
|
||||||
|
---------------+-------------------------
|
||||||
|
Ben Nuttall | Raspberry Pi Foundation
|
||||||
|
Rikki Endsley | Red Hat
|
||||||
|
(2 rows)
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
```
|
||||||
|
test=> select name from people where company = 'Red Hat';
|
||||||
|
|
||||||
|
name | company
|
||||||
|
---------------+---------
|
||||||
|
Rikki Endsley | Red Hat
|
||||||
|
(1 row)
|
||||||
|
```
|
||||||
|
|
||||||
|
### pgAdmin
|
||||||
|
|
||||||
|
如果希望使用一个图形工具去访问数据库,你可以使用它。 PgAdmin 是一个全功能的 PostgreSQL GUI,它允许你去创建和管理数据库和用户、创建和修改表、执行查询,和如同在电子表格一样熟悉的视图中浏览结果。psql 命令行工具可以很好地进行简单查询,并且你会发现很多高级用户一直在使用它,因为它的执行速度很快 (并且因为他们不需要借助 GUI),但是,一般用户学习和操作数据库,使用 pgAdmin 是一个更适合的方式。
|
||||||
|
|
||||||
|
关于 pgAdmin 可以做的其它事情:你可以用它在树莓派上直接连接数据库,或者用它在其它的电脑上远程连接到树莓派上的数据库。
|
||||||
|
|
||||||
|
如果你想去访问树莓派,你可以用 `apt` 去安装它:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt install pgadmin3
|
||||||
|
```
|
||||||
|
|
||||||
|
它是和基于 Debian 的系统如 Ubuntu 是完全相同的;如果你在其它发行版上安装,尝试与你的系统相关的等价的命令。 或者,如果你在 Windows 或 macOS 上,尝试从 [pgAdmin.org][15] 上下载 pgAdmin。注意,在 `apt` 上的可用版本是 pgAdmin3,而最新的版本 pgAdmin4,在其网站上可以找到。
|
||||||
|
|
||||||
|
在同一台树莓派上使用 pgAdmin 连接到你的数据库,从主菜单上简单地打开 pgAdmin3 ,点击 **new connection** 图标,然后完成注册,这时,你将需要一个名字(连接名,比如 test),改变用户为 “pi”,然后剩下的输入框留空 (或者如它们原本不动)。点击 OK,然后你在左侧的侧面版中将发现一个新的连接。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
要从另外一台电脑上使用 pgAdmin 连接到你的树莓派数据库上,你首先需要编辑 PostgreSQL 配置允许远程连接:
|
||||||
|
|
||||||
|
1、 编辑 PostgreSQL 配置文件 `/etc/postgresql/9.6/main/postgresql.conf` ,取消 `listen_addresses` 行的注释,并把它的值从 `localhost` 改变成 `*`。然后保存并退出。
|
||||||
|
|
||||||
|
2、 编辑 pg_hba 配置文件 `/etc/postgresql/9.6/main/postgresql.conf`,将 `127.0.0.1/32` 改变成 `0.0.0.0/0` (对于IPv4)和将 `::1/128` 改变成 `::/0` (对于 IPv6)。然后保存并退出。
|
||||||
|
|
||||||
|
3、 重启 PostgreSQL 服务: `sudo service postgresql restart`。
|
||||||
|
|
||||||
|
注意,如果你使用一个旧的 Raspbian 镜像或其它发行版,版本号可能不一样。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
做完这些之后,在其它的电脑上打开 pgAdmin 并创建一个新的连接。这时,需要提供一个连接名,输入树莓派的 IP 地址作为主机(这可以在任务栏的 WiFi 图标上悬停鼠标找到,或者在一个终端中输入 `hostname -I` 找到)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
不论你连接的是本地的还是远程的数据库,点击打开 **Server Groups > Servers > test > Schemas > public > Tables**,右键单击 **people** 表,然后选择 **View Data > View top 100 Rows**。你现在将看到你前面输入的数据。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
你现在可以创建和修改数据库和表、管理用户,和使用 GUI 去写你自己的查询了。你可能会发现这种可视化方法比命令行更易于管理。
|
||||||
|
|
||||||
|
### Python
|
||||||
|
|
||||||
|
要从一个 Python 脚本连接到你的数据库,你将需要 [Psycopg2][16] 这个 Python 包。你可以用 [pip][17] 来安装它:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo pip3 install psycopg2
|
||||||
|
```
|
||||||
|
|
||||||
|
现在打开一个 Python 编辑器写一些代码连接到你的数据库:
|
||||||
|
|
||||||
|
```
|
||||||
|
import psycopg2
|
||||||
|
|
||||||
|
conn = psycopg2.connect('dbname=test')
|
||||||
|
cur = conn.cursor()
|
||||||
|
|
||||||
|
cur.execute('select * from people')
|
||||||
|
|
||||||
|
results = cur.fetchall()
|
||||||
|
|
||||||
|
for result in results:
|
||||||
|
print(result)
|
||||||
|
```
|
||||||
|
|
||||||
|
运行这个代码去看查询结果。注意,如果你连接的是远程数据库,在连接字符串中你将需要提供更多的凭据,比如,增加主机 IP、用户名,和数据库密码:
|
||||||
|
|
||||||
|
```
|
||||||
|
conn = psycopg2.connect('host=192.168.86.31 user=pi
|
||||||
|
password=raspberry dbname=test')
|
||||||
|
```
|
||||||
|
|
||||||
|
你甚至可以创建一个函数去运行特定的查询:
|
||||||
|
|
||||||
|
```
|
||||||
|
def get_all_people():
|
||||||
|
query = """
|
||||||
|
SELECT
|
||||||
|
*
|
||||||
|
FROM
|
||||||
|
people
|
||||||
|
"""
|
||||||
|
cur.execute(query)
|
||||||
|
return cur.fetchall()
|
||||||
|
```
|
||||||
|
|
||||||
|
和一个包含参数的查询:
|
||||||
|
|
||||||
|
```
|
||||||
|
def get_people_by_company(company):
|
||||||
|
query = """
|
||||||
|
SELECT
|
||||||
|
*
|
||||||
|
FROM
|
||||||
|
people
|
||||||
|
WHERE
|
||||||
|
company = %s
|
||||||
|
"""
|
||||||
|
values = (company, )
|
||||||
|
cur.execute(query, values)
|
||||||
|
return cur.fetchall()
|
||||||
|
```
|
||||||
|
|
||||||
|
或者甚至是一个增加记录的函数:
|
||||||
|
|
||||||
|
```
|
||||||
|
def add_person(name, company):
|
||||||
|
query = """
|
||||||
|
INSERT INTO
|
||||||
|
people
|
||||||
|
VALUES
|
||||||
|
(%s, %s)
|
||||||
|
"""
|
||||||
|
values = (name, company)
|
||||||
|
cur.execute(query, values)
|
||||||
|
```
|
||||||
|
|
||||||
|
注意,这里使用了一个注入字符串到查询中的安全的方法, 你不希望被 [小鲍勃的桌子][18] 害死!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
现在你知道了这些基础知识,如果你想去进一步掌握 Postgres ,查看在 [Full Stack Python][19] 上的文章。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Ben Nuttall - 树莓派社区的管理者。除了它为树莓派基金会所做的工作之外 ,他也投入开源软件、数学、皮艇运动、GitHub、探险活动和 Futurama。在 Twitter [@ben_nuttall][10] 上关注他。
|
||||||
|
|
||||||
|
-------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi
|
||||||
|
|
||||||
|
作者:[Ben Nuttall][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/bennuttall
|
||||||
|
[1]:https://opensource.com/file/374246
|
||||||
|
[2]:https://opensource.com/file/374241
|
||||||
|
[3]:https://opensource.com/file/374251
|
||||||
|
[4]:https://opensource.com/file/374221
|
||||||
|
[5]:https://opensource.com/file/374236
|
||||||
|
[6]:https://opensource.com/file/374226
|
||||||
|
[7]:https://opensource.com/file/374231
|
||||||
|
[8]:https://opensource.com/file/374256
|
||||||
|
[9]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021&rate=t-XUFUPa6mURgML4cfL1mjxsmFBG-VQTG4R39QvFVQA
|
||||||
|
[10]:http://www.twitter.com/ben_nuttall
|
||||||
|
[11]:https://opensource.com/user/26767/feed
|
||||||
|
[12]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[13]:https://en.wikipedia.org/wiki/Create,_read,_update_and_delete
|
||||||
|
[14]:https://www.postgresql.org/
|
||||||
|
[15]:https://www.pgadmin.org/download/
|
||||||
|
[16]:http://initd.org/psycopg/
|
||||||
|
[17]:https://pypi.python.org/pypi/pip
|
||||||
|
[18]:https://xkcd.com/327/
|
||||||
|
[19]:https://www.fullstackpython.com/postgresql.html
|
||||||
|
[20]:https://opensource.com/users/bennuttall
|
||||||
|
[21]:https://opensource.com/users/bennuttall
|
||||||
|
[22]:https://opensource.com/users/bennuttall
|
||||||
|
[23]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021#comments
|
||||||
|
[24]:https://opensource.com/tags/raspberry-pi
|
||||||
|
[25]:https://opensource.com/tags/raspberry-pi-column
|
||||||
|
[26]:https://opensource.com/tags/how-tos-and-tutorials
|
||||||
|
[27]:https://opensource.com/tags/programming
|
||||||
93
published/20171011 Why Linux Works.md
Normal file
93
published/20171011 Why Linux Works.md
Normal file
@ -0,0 +1,93 @@
|
|||||||
|
Linux 是如何成功运作的
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
_在大量金钱与围绕 Linux 激烈争夺的公司之间,真正给操作系统带来活力的正是那些开发者。_
|
||||||
|
|
||||||
|
事实证明上,Linux 社区是可行的,因为它本身无需太过担心社区的正常运作。尽管 Linux 已经在超级计算机、移动设备和云计算等多个领域占据了主导的地位,但 Linux 内核开发人员更多的是关注于代码本身,而不是其所在公司的利益。
|
||||||
|
|
||||||
|
这是一个出现在 [Dawn Foster 博士][8]研究 Linux 内核协作开发的博士论文中的重要结论。Foster 是在英特尔公司和<ruby>木偶实验室<rt>Puppet Labs</rt></ruby>的前任社区领导人,他写到,“很多人首先把自己看作是 Linux 内核开发者,其次才是作为一名雇员。”
|
||||||
|
|
||||||
|
随着大量的“<ruby>基金洗劫型<rt>foundation washing</rt></ruby>”公司开始侵蚀各种开源项目,意图在虚构的社区面具之下隐藏企业特权,但 Linux 依然设法保持了自身的纯粹。问题是这是怎么做到的?
|
||||||
|
|
||||||
|
### 跟随金钱的脚步
|
||||||
|
|
||||||
|
毕竟,如果有任何开源项目会进入到企业贪婪的视线中,那它一定是 Linux。早在 2008 年,[Linux 生态系统的估值已经达到了最高 250 亿美元][9]。最近 10 年,伴随着数量众多的云服务、移动端,以及大数据基础设施对于 Linux 的依赖,这一数据一定倍增了。甚至在像 Oracle 这样单独一个公司里,Linux 也能提供数十亿美元的价值。
|
||||||
|
|
||||||
|
那么就难怪有这样一个通过代码来影响 Linux 发展方向的必争之地。
|
||||||
|
|
||||||
|
在 [Linux 基金会的最新报道][10]中,让我们看看在过去一年中那些最活跃的 Linux 贡献者,以及他们所在的企业[像](https://linux.cn/article-8220-1.html)[“海龟”一样](https://en.wikipedia.org/wiki/Turtles_all_the_way_down)高高叠起。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
这些企业花费大量的资金来雇佣开发者去为自由软件做贡献,并且每个企业都从这些投资中得到了回报。由于存在企业对 Linux 过度影响的潜在可能,导致一些人对引领 Linux 开发的 Linux 基金会[表示不满][11]。在像微软这样曾经的开源界宿敌的企业挥舞着钞票进入 Linux 基金会之后,这些批评言论正变得越来越响亮。
|
||||||
|
|
||||||
|
但这只是一位虚假的敌人,坦率地说,这是一个以前的敌人。
|
||||||
|
|
||||||
|
虽然企业为了利益而给 Linux 基金会投入资金已经是事实,不过这些赞助并不能收买基金会而影响到代码。在这个最伟大的开源社区中,金钱可以帮助招募到开发者,但这些开发者相比关注企业而更专注于代码。就像 Linux 基金会执行董事 [Jim Zemlin 所强调的][12]:
|
||||||
|
|
||||||
|
> “我们的项目中技术角色都是独立于企业的。没有人会在其提交的内容上标记他们的企业身份: 在 Linux 基金会的项目当中有关代码的讨论是最大声的。在我们的项目中,开发者可以从一个公司跳槽到另一个公司而不会改变他们在项目中所扮演的角色。之后企业或政府采用了这些代码而创造的价值,反过来又投资到项目上。这样的良性循环有益于所有人,并且也是我们的项目目标。”
|
||||||
|
|
||||||
|
任何读过 [Linus Torvalds 的][13] 的邮件列表评论的人都不可能认为他是个代表着这个或那个公司的人。这对于其他的杰出贡献者来说也是一样的。虽然他们几乎都是被大公司所雇佣,但是一般情况下,这些公司为这些开发者支付薪水让他们去做想做的开发,而且事实上,他们正在做他们想做的。
|
||||||
|
|
||||||
|
毕竟,很少有公司会有足够的耐心或承受风险来为资助一群新手 Linux 内核开发者,并等上几年,等他们中出现几个人可以贡献出质量足以打动内核团队的代码。所以他们选择雇佣已有的、值得信赖的开发者。正如 [2016 Linux 基金会报告][14]所写的,“无薪开发者的数量正在持续地缓慢下降,同时 Linux 内核开发被证明是一种雇主们所需要的日益有价值的技能,这确保了有经验的内核开发者不会长期停留在无薪阶段。”
|
||||||
|
|
||||||
|
然而,这样的信任是代码所带来的,并不是通过企业的金钱。因此没有一个 Linux 内核开发者会为眼前的金钱而丢掉他们已经积攒的信任,当出现新的利益冲突时妥协代码质量就很快失去信任。因此不存在这种问题。
|
||||||
|
|
||||||
|
### 不是康巴亚,就是权利的游戏,非此即彼
|
||||||
|
|
||||||
|
最终,Linux 内核开发就是一种身份认同, Foster 的研究是这样认为的。
|
||||||
|
|
||||||
|
为 Google 工作也许很棒,而且也许带有一个体面的头衔以及免费的干洗。然而,作为一个关键的 Linux 内核子系统的维护人员,很难得到任意数量的公司承诺高薪酬的雇佣机会。
|
||||||
|
|
||||||
|
Foster 这样写到,“他们甚至享受当前的工作并且觉得他们的雇主不错,许多(Linux 内核开发者)倾向于寻找一些临时的工作关系,那样他们作为内核开发者的身份更被视作固定工作,而且更加重要。”
|
||||||
|
|
||||||
|
由于作为一名 Linux 开发者的身份优先,企业职员的身份次之,Linux 内核开发者甚至可以轻松地与其雇主的竞争对手合作。之所以这样,是因为雇主们最终只能有限制地控制开发者的工作,原因如上所述。Foster 深入研究了这一问题:
|
||||||
|
|
||||||
|
> “尽管企业对其雇员所贡献的领域产生了一些影响,在他们如何去完成工作这点上,雇员还是很自由的。许多人在日常工作中几乎没有接受任何指令,来自雇主的高度信任对工作是非常有帮助的。然而,他们偶尔会被要求做一些特定的零碎工作或者是在一个对公司重要的特定领域投入兴趣。
|
||||||
|
|
||||||
|
> 许多内核开发者也与他们的竞争者展开日常的基础协作,在这里他们仅作为个人相互交流,而不需要关心雇主之间的竞争。这是我在 Intel 工作时经常见到的一幕,因为我们内核开发者几乎都是与我们主要的竞争对手一同工作的。”
|
||||||
|
|
||||||
|
那些公司可能会在运行 Linux 的芯片上、或 Linux 发行版,亦或者是被其他健壮的操作系统支持的软件上产生竞争,但开发者们主要专注于一件事情:使 Linux 越来越好。同样,这是因为他们的身份与 Linux 维系在一起,而不是编码时所在防火墙(指公司)。
|
||||||
|
|
||||||
|
Foster 通过 USB 子系统的邮件列表(在 2013 年到 2015 年之间)说明了这种相互作用,用深色线条描绘了公司之间更多的电子邮件交互:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在价格讨论中一些公司明显的来往可能会引起反垄断机构的注意,但在 Linux 大陆中,这只是简单的商业行为。结果导致为所有各方在自由市场相互竞争中得到一个更好的操作系统。
|
||||||
|
|
||||||
|
### 寻找合适的平衡
|
||||||
|
|
||||||
|
这样的“合作”,如 Novell 公司的创始人 Ray Noorda 所说的那样,存在于最佳的开源社区里,但只有在真正的社区里才存在。这很难做到,举个例子,对一个由单一供应商所主导的项目来说,实现正确的合作关系很困难。由 Google 发起的 [Kubernetes][15] 表明这是可能的,但其它像是 Docker 这样的项目却在为同样的目标而挣扎,很大一部分原因是他们一直不愿放弃对自己项目的技术领导。
|
||||||
|
|
||||||
|
也许 Kubernetes 能够工作的很好是因为 Google 并不觉得必须占据重要地位,而且事实上,它_希望_其他公司担负起开发领导的职责。凭借出色的代码解决了一个重要的行业需求,像 Kubernetes 这样的项目就能获得成功,只要 Google 既能帮助它,又为它开辟出一条道路,这就鼓励了 Red Hat 及其它公司做出杰出的贡献。
|
||||||
|
|
||||||
|
不过,Kubernetes 是个例外,就像 Linux 曾经那样。成功是因为企业的贪婪,有许多要考虑的,并且要在之间获取平衡。如果一个项目仅仅被公司自己的利益所控制,常常会在公司的技术管理上体现出来,而且再怎么开源许可也无法对企业产生影响。
|
||||||
|
|
||||||
|
简而言之,Linux 的成功运作是因为众多企业都想要控制它但却难以做到,由于其在工业中的重要性,使得开发者和构建人员更愿意作为一名 _Linux 开发者_ 而不是 Red Hat (或 Intel 亦或 Oracle … )工程师。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.datamation.com/open-source/why-linux-works.html
|
||||||
|
|
||||||
|
作者:[Matt Asay][a]
|
||||||
|
译者:[softpaopao](https://github.com/softpaopao)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||||
|
[1]:https://www.datamation.com/feedback/https://www.datamation.com/open-source/why-linux-works.html
|
||||||
|
[2]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||||
|
[3]:https://www.datamation.com/e-mail/https://www.datamation.com/open-source/why-linux-works.html
|
||||||
|
[4]:https://www.datamation.com/print/https://www.datamation.com/open-source/why-linux-works.html
|
||||||
|
[5]:https://www.datamation.com/open-source/why-linux-works.html#comment_form
|
||||||
|
[6]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||||
|
[7]:https://www.datamation.com/open-source/
|
||||||
|
[8]:https://opensource.com/article/17/10/collaboration-linux-kernel
|
||||||
|
[9]:http://www.osnews.com/story/20416/Linux_Ecosystem_Worth_25_Billion
|
||||||
|
[10]:https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5
|
||||||
|
[11]:https://www.datamation.com/open-source/the-linux-foundation-and-the-uneasy-alliance.html
|
||||||
|
[12]:https://thenewstack.io/linux-foundation-critics/
|
||||||
|
[13]:https://github.com/torvalds
|
||||||
|
[14]:https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5
|
||||||
|
[15]:https://kubernetes.io/
|
||||||
@ -0,0 +1,82 @@
|
|||||||
|
开源软件对于商业机构的六个好处
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 这就是为什么商业机构应该选择开源模式的原因
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
图片来源 : opensource.com
|
||||||
|
|
||||||
|
在相同的基础上,开源软件要优于专有软件。想知道为什么?这里有六个商业机构及政府部门可以从开源技术中获得好处的原因。
|
||||||
|
|
||||||
|
### 1、 让供应商审核更简单
|
||||||
|
|
||||||
|
在你投入工程和金融资源将一个产品整合到你的基础设施之前,你需要知道你选择了正确的产品。你想要一个处于积极开发的产品,它有定期的安全更新和漏洞修复,同时在你有需求时,产品能有相应的更新。这最后一点也许比你想的还要重要:没错,解决方案一定是满足你的需求的。但是产品的需求随着市场的成熟以及你商业的发展在变化。如果该产品随之改变,在未来你需要花费很大的代价来进行迁移。
|
||||||
|
|
||||||
|
你怎么才能知道你没有正在把你的时间和资金投入到一个正在消亡的产品?在开源的世界里,你可以不选择一个只有卖家有话语权的供应商。你可以通过考虑[发展速度以及社区健康程度][3]来比较供应商。一到两年之后,一个更活跃、多样性和健康的社区将开发出一个更好的产品,这是一个重要的考虑因素。当然,就像这篇 [关于企业开源软件的博文][4] 指出的,供应商必须有能力处理由于项目发展创新带来的不稳定性。寻找一个有长支持周期的供应商来避免混乱的更新。
|
||||||
|
|
||||||
|
### 2、 来自独立性的长寿
|
||||||
|
|
||||||
|
福布斯杂志指出 [90%的初创公司是失败的][5] ,而他们中不到一半的中小型公司能存活超过五年。当你不得不迁移到一个新的供应商时,你花费的代价是昂贵的。所以最好避免一些只有一个供应商支持的产品。
|
||||||
|
|
||||||
|
开源使得社区成员能够协同编写软件。例如 OpenStack [是由许多公司以及个人志愿者一起编写的][6],这给客户提供了一个保证,不管任何一个独立供应商发生问题,也总会有一个供应商能提供支持。随着软件的开源,企业会长期投入开发团队,以实现产品开发。能够使用开源代码可以确保你总是能从贡献者中雇佣到人来保持你的开发活跃。当然,如果没有一个大的、活跃的社区,也就只有少量的贡献者能被雇佣,所以活跃贡献者的数量是重要的。
|
||||||
|
|
||||||
|
### 3、 安全性
|
||||||
|
|
||||||
|
安全是一件复杂的事情。这就是为什么开源开发是构建安全解决方案的关键因素和先决条件。同时每一天安全都在变得更重要。当开发以开源方式进行,你能直接的校验供应商是否积极的在追求安全,以及看到供应商是如何对待安全问题的。研究代码和执行独立代码审计的能力可以让供应商尽可能早的发现和修复漏洞。一些供应商给社区提供上千的美金的[漏洞奖金][7]作为额外的奖励来鼓励开发者发现他们产品的安全漏洞,这同时也展示了供应商对于自己产品的信任。
|
||||||
|
|
||||||
|
除了代码,开源开发同样意味着开源过程,所以你能检查和看到供应商是否遵循 ISO27001、 [云安全准则][8] 及其他标准所推荐的工业级的开发过程。当然,一个可信组织外部检查提供了额外的保障,就像我们在 Nextcloud 与 [NCC小组][9]合作的一样。
|
||||||
|
|
||||||
|
### 4、 更多的顾客导向
|
||||||
|
|
||||||
|
由于用户和顾客能直接看到和参与到产品的开发中,开源项目比那些只关注于营销团队回应的闭源软件更加的贴合用户的需求。你可以注意到开源软件项目趋向于以“宽松”方式发展。一个商业供应商也许关注在某个特定的事情方面,而一个社区则有许多要做的事情并致力于开发更多的功能,而这些全都是公司或个人贡献者中的某人或某些人所感兴趣的。这导致更少的为了销售而发布的版本,因为各种改进混搭在一起根本就不是一回事。但是它创造了许多对用户更有价值的产品。
|
||||||
|
|
||||||
|
### 5、 更好的支持
|
||||||
|
|
||||||
|
专有供应商通常是你遇到问题时唯一能给你提供帮助的一方。但如果他们不提供你所需要的服务,或者对调整你的商务需求收取额外昂贵的费用,那真是不好运。对专有软件提供的支持是一个典型的 “[柠檬市场][10]”。 随着软件的开源,供应商要么提供更大的支持,要么就有其它人来填补空白——这是自由市场的最佳选择,这可以确保你总是能得到最好的服务支持。
|
||||||
|
|
||||||
|
### 6、 更佳的许可
|
||||||
|
|
||||||
|
典型的软件许可证[充斥着令人不愉快的条款][11],通常都是强制套利,你甚至不会有机会起诉供应商的不当行为。其中一个问题是你仅仅被授予了软件的使用权,这通常完全由供应商自行决定。如果软件不运行或者停止运行或者如果供应商要求支付更多的费用,你得不到软件的所有权或其他的权利。像 GPL 一类的开源许可证是为保护客户专门设计的,而不是保护供应商,它确保你可以如你所需的使用软件,而没有专制限制,只要你喜欢就行。
|
||||||
|
|
||||||
|
由于它们的广泛使用,GPL 的含义及其衍生出来的其他许可证得到了广泛的理解。例如,你能确保该许可允许你现存的基础设施(开源或闭源)通过设定好的 API 去进行连接,其没有时间或者是用户人数上的限制,同时也不会强迫你公开软件架构或者是知识产权(例如公司商标)。
|
||||||
|
|
||||||
|
这也让合规变得更加的容易;使用专有软件意味着你面临着苛刻的法规遵从性条款和高额的罚款。更糟糕的是一些<ruby>开源内核<rt>open core</rt></ruby>的产品在混合了 GPL 软件和专有软件。这[违反了许可证规定][12]并将顾客置于风险中。同时 Gartner 指出,开源内核模式意味着你[不能从开源中获利][13]。纯净的开源许可的产品避免了所有这些问题。取而代之,你只需要遵从一个规则:如果你对代码做出了修改(不包括配置、商标或其他类似的东西),你必须将这些与你的软件分发随同分享,如果他们要求的话。
|
||||||
|
|
||||||
|
显然开源软件是更好的选择。它易于选择正确的供应商(不会被供应商锁定),加之你也可以受益于更安全、对客户更加关注和更好的支持。而最后,你将处于法律上的安全地位。
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
一个善于与人打交道的技术爱好者和开源传播者。Nextcloud 的销售主管,曾是 ownCloud 和 SUSE 的社区经理,同时还是一个有多年经验的 KDE 销售人员。喜欢骑自行车穿越柏林和为家人朋友做饭。[点击这里找到我的博客][16]。
|
||||||
|
|
||||||
|
-----------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/10/6-reasons-choose-open-source-software
|
||||||
|
|
||||||
|
作者:[Jos Poortvliet Feed][a]
|
||||||
|
译者:[ZH1122](https://github.com/ZH1122)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/jospoortvliet
|
||||||
|
[1]:https://opensource.com/article/17/10/6-reasons-choose-open-source-software?rate=um7KfpRlV5lROQDtqJVlU4y8lBa9rsZ0-yr2aUd8fXY
|
||||||
|
[2]:https://opensource.com/user/27446/feed
|
||||||
|
[3]:https://nextcloud.com/blog/nextcloud-the-most-active-open-source-file-sync-and-share-project/
|
||||||
|
[4]:http://www.redhat-cloudstrategy.com/open-source-for-business-people/
|
||||||
|
[5]:http://www.forbes.com/sites/neilpatel/2015/01/16/90-of-startups-will-fail-heres-what-you-need-to-know-about-the-10/
|
||||||
|
[6]:http://stackalytics.com/
|
||||||
|
[7]:https://hackerone.com/nextcloud
|
||||||
|
[8]:https://www.ncsc.gov.uk/guidance/implementing-cloud-security-principles
|
||||||
|
[9]:https://nextcloud.com/secure
|
||||||
|
[10]:https://en.wikipedia.org/wiki/The_Market_for_Lemons
|
||||||
|
[11]:http://boingboing.net/2016/11/01/why-are-license-agreements.html
|
||||||
|
[12]:https://www.gnu.org/licenses/gpl-faq.en.html#GPLPluginsInNF
|
||||||
|
[13]:http://blogs.gartner.com/brian_prentice/2010/03/31/open-core-the-emperors-new-clothes/
|
||||||
|
[14]:https://opensource.com/users/jospoortvliet
|
||||||
|
[15]:https://opensource.com/users/jospoortvliet
|
||||||
|
[16]:http://blog.jospoortvliet.com/
|
||||||
|
|
||||||
83
published/20171013 Best of PostgreSQL 10 for the DBA.md
Normal file
83
published/20171013 Best of PostgreSQL 10 for the DBA.md
Normal file
@ -0,0 +1,83 @@
|
|||||||
|
对 DBA 最重要的 PostgreSQL 10 新亮点
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
前段时间新的重大版本的 PostgreSQL 10 发布了! 强烈建议阅读[公告][3]、[发布说明][4]和“[新功能][5]”概述可以在[这里][3]、[这里][4]和[这里][5]。像往常一样,已经有相当多的博客覆盖了所有新的东西,但我猜每个人都有自己认为重要的角度,所以与 9.6 版一样我再次在这里列出我印象中最有趣/相关的功能。
|
||||||
|
|
||||||
|
与往常一样,升级或初始化一个新集群的用户将获得更好的性能(例如,更好的并行索引扫描、合并 join 和不相关的子查询,更快的聚合、远程服务器上更加智能的 join 和聚合),这些都开箱即用,但本文中我想讲一些不能开箱即用,实际上你需要采取一些步骤才能从中获益的内容。下面重点展示的功能是从 DBA 的角度来汇编的,很快也有一篇文章从开发者的角度讲述更改。
|
||||||
|
|
||||||
|
### 升级注意事项
|
||||||
|
|
||||||
|
首先有些从现有设置升级的提示 - 有一些小的事情会导致从 9.6 或更旧的版本迁移时引起问题,所以在真正的升级之前,一定要在单独的副本上测试升级,并遍历发行说明中所有可能的问题。最值得注意的缺陷是:
|
||||||
|
|
||||||
|
* 所有包含 “xlog” 的函数都被重命名为使用 “wal” 而不是 “xlog”。
|
||||||
|
|
||||||
|
后一个命名可能与正常的服务器日志混淆,因此这是一个“以防万一”的更改。如果使用任何第三方备份/复制/HA 工具,请检查它们是否为最新版本。
|
||||||
|
* 存放服务器日志(错误消息/警告等)的 pg_log 文件夹已重命名为 “log”。
|
||||||
|
|
||||||
|
确保验证你的日志解析或 grep 脚本(如果有)可以工作。
|
||||||
|
* 默认情况下,查询将最多使用 2 个后台进程。
|
||||||
|
|
||||||
|
如果在 CPU 数量较少的机器上在 `postgresql.conf` 设置中使用默认值 `10`,则可能会看到资源使用率峰值,因为默认情况下并行处理已启用 - 这是一件好事,因为它应该意味着更快的查询。如果需要旧的行为,请将 `max_parallel_workers_per_gather` 设置为 `0`。
|
||||||
|
* 默认情况下,本地主机的复制连接已启用。
|
||||||
|
|
||||||
|
为了简化测试等工作,本地主机和本地 Unix 套接字复制连接现在在 `pg_hba.conf` 中以“<ruby>信任<rt>trust</rt></ruby>”模式启用(无密码)!因此,如果其他非 DBA 用户也可以访问真实的生产计算机,请确保更改配置。
|
||||||
|
|
||||||
|
### 从 DBA 的角度来看我的最爱
|
||||||
|
|
||||||
|
* 逻辑复制
|
||||||
|
|
||||||
|
这个期待已久的功能在你只想要复制一张单独的表、部分表或者所有表时只需要简单的设置而性能损失最小,这也意味着之后主要版本可以零停机升级!历史上(需要 Postgres 9.4+),这可以通过使用第三方扩展或缓慢的基于触发器的解决方案来实现。对我而言这是 10 最好的功能。
|
||||||
|
* 声明分区
|
||||||
|
|
||||||
|
以前管理分区的方法通过继承并创建触发器来把插入操作重新路由到正确的表中,这一点很烦人,更不用说性能的影响了。目前支持的是 “range” 和 “list” 分区方案。如果有人在某些数据库引擎中缺少 “哈希” 分区,则可以使用带表达式的 “list” 分区来实现相同的功能。
|
||||||
|
* 可用的哈希索引
|
||||||
|
|
||||||
|
哈希索引现在是 WAL 记录的,因此是崩溃安全的,并获得了一些性能改进,对于简单的搜索,它们比在更大的数据上的标准 B 树索引快。也支持更大的索引大小。
|
||||||
|
|
||||||
|
* 跨列优化器统计
|
||||||
|
|
||||||
|
这样的统计数据需要在一组表的列上手动创建,以指出这些值实际上是以某种方式相互依赖的。这将能够应对计划器认为返回的数据很少(概率的乘积通常会产生非常小的数字)从而导致在大量数据下性能不好的的慢查询问题(例如选择“嵌套循环” join)。
|
||||||
|
* 副本上的并行快照
|
||||||
|
|
||||||
|
现在可以在 pg_dump 中使用多个进程(`-jobs` 标志)来极大地加快备用服务器上的备份。
|
||||||
|
* 更好地调整并行处理 worker 的行为
|
||||||
|
|
||||||
|
参考 `max_parallel_workers` 和 `min_parallel_table_scan_size`/`min_parallel_index_scan_size` 参数。我建议增加一点后两者的默认值(8MB、512KB)。
|
||||||
|
* 新的内置监控角色,便于工具使用
|
||||||
|
|
||||||
|
新的角色 `pg_monitor`、`pg_read_all_settings`、`pg_read_all_stats` 和 `pg_stat_scan_tables` 能更容易进行各种监控任务 - 以前必须使用超级用户帐户或一些 SECURITY DEFINER 包装函数。
|
||||||
|
* 用于更安全的副本生成的临时 (每个会话) 复制槽
|
||||||
|
* 用于检查 B 树索引的有效性的一个新的 Contrib 扩展
|
||||||
|
|
||||||
|
这两个智能检查发现结构不一致和页面级校验未覆盖的内容。希望不久的将来能更加深入。
|
||||||
|
* Psql 查询工具现在支持基本分支(`if`/`elif`/`else`)
|
||||||
|
|
||||||
|
例如下面的将启用具有特定版本分支(对 pg_stat* 视图等有不同列名)的单个维护/监视脚本,而不是许多版本特定的脚本。
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT :VERSION_NAME = '10.0' AS is_v10 \gset
|
||||||
|
\if :is_v10
|
||||||
|
SELECT 'yippee' AS msg;
|
||||||
|
\else
|
||||||
|
SELECT 'time to upgrade!' AS msg;
|
||||||
|
\endif
|
||||||
|
```
|
||||||
|
|
||||||
|
这次就这样了!当然有很多其他的东西没有列出,所以对于专职 DBA,我一定会建议你更全面地看发布记录。非常感谢那 300 多为这个版本做出贡献的人!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.cybertec.at/best-of-postgresql-10-for-the-dba/
|
||||||
|
|
||||||
|
作者:[Kaarel Moppel][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.cybertec.at/author/kaarel-moppel/
|
||||||
|
[1]:http://www.cybertec.at/author/kaarel-moppel/
|
||||||
|
[2]:http://www.cybertec.at/best-of-postgresql-10-for-the-dba/
|
||||||
|
[3]:https://www.postgresql.org/about/news/1786/
|
||||||
|
[4]:https://www.postgresql.org/docs/current/static/release-10.html
|
||||||
|
[5]:https://wiki.postgresql.org/wiki/New_in_postgres_10
|
||||||
@ -0,0 +1,121 @@
|
|||||||
|
原生云计算:你所不知道的 Kubernetes 特性和工具
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 开放容器计划(OCI)和原生云计算基金会(CNCF)的代表说,Kubernetes 和容器可以在降低程序员和系统管理成本的同时加速部署进程,从被忽视的 Kubernetes 特性(比如命令空间)开始,去利用 Kubernetes 和它的相关工具运行一个原生云架构。
|
||||||
|
|
||||||
|
[Kubernetes][2] 不止是一个云容器管理器。正如 Steve Pousty,他是 [Red Hat][3] 支持的 [OpenShift][4] 的首席开发者,在 [Linux 基金会][5]的[开源峰会][6]上的讲演中解释的那样,Kubernetes 提供了一个 “使用容器进行原生云计算的通用操作平台”。
|
||||||
|
|
||||||
|
Pousty 的意思是什么?先让我们复习一下基础知识。
|
||||||
|
|
||||||
|
[开源容器计划][7](OCI)和 [原生云计算基金会][8] (CNCF)的执行董事 Chris Aniszczyk 的解释是,“原生云计算使用开源软件栈将应用程序部署为微服务,打包每一个部分到其容器中,并且动态地编排这些容器以优化资源使用”。[Kubernetes 一直在关注着原生云计算的最新要素][9]。这将最终将导致 IT 中很大的一部分发生转变,如从服务器到虚拟机,从<ruby>构建包<rt>buildpack</rt></ruby>到现在的 [容器][10]。
|
||||||
|
|
||||||
|
会议主持人表示,数据中心的演变将节省相当可观的成本,部分原因是它需要更少的专职员工。例如,据 Aniszczyk 说,通过使用 Kubernetes,谷歌每 10000 台机器仅需要一个网站可靠性工程师(LCTT 译注:即 SRE)。
|
||||||
|
|
||||||
|
实际上,系统管理员可以利用新的 Kubernetes 相关的工具的优势,并了解那些被低估的功能。
|
||||||
|
|
||||||
|
### 构建一个原生云平台
|
||||||
|
|
||||||
|
Pousty 解释说,“对于 Red Hat 来说,Kubernetes 是云 Linux 的内核。它是每个人都可以构建于其上的基础设施”。
|
||||||
|
|
||||||
|
例如,假如你在一个容器镜像中有一个应用程序。你怎么知道它是安全的呢? Red Hat 和其它的公司使用 [OpenSCAP][11],它是基于 <ruby>[安全内容自动化协议][12]<rt>Security Content Automation Protocol</rt></ruby>(SCAP)的,是使用标准化的方式表达和操作安全数据的一个规范。OpenSCAP 项目提供了一个开源的强化指南和配置基准。选择一个合适的安全策略,然后,使用 OpenSCAP 认可的安全工具去使某些由 Kubernetes 控制的容器中的程序遵守这些定制的安全标准。
|
||||||
|
|
||||||
|
Red Hat 将使用<ruby>[原子扫描][13]<rt>Atomic Scan</rt></ruby>来自动处理这个过程;它借助 OpenSCAP <ruby>提供者<rt>provider</rt></ruby>来扫描容器镜像中已知的安全漏洞和策略配置问题。原子扫描会以只读方式加载文件系统。这些通过扫描的容器,会在一个可写入的目录存放扫描器的输出。
|
||||||
|
|
||||||
|
Pousty 指出,这种方法有几个好处,主要是,“你可以扫描一个容器镜像而不用实际运行它”。因此,如果在容器中有糟糕的代码或有缺陷的安全策略,它不会影响到你的系统。
|
||||||
|
|
||||||
|
原子扫描比手动运行 OpenSCAP 快很多。 因为容器从启用到消毁可能就在几分钟或几小时内,原子扫描允许 Kubernetes 用户在(很快的)容器生命期间保持容器安全,而不是在更缓慢的系统管理时间跨度里进行。
|
||||||
|
|
||||||
|
### 关于工具
|
||||||
|
|
||||||
|
帮助系统管理员和 DevOps 管理大部分 Kubernetes 操作的另一个工具是 [CRI-O][14]。这是一个基于 OCI 实现的 [Kubernetes 容器运行时接口][15]。CRI-O 是一个守护进程, Kubernetes 可以用于运行存储在 Docker 仓库中的容器镜像,Dan Walsh 解释说,他是 Red Hat 的顾问工程师和 [SELinux][16] 项目领导者。它允许你直接从 Kubernetes 中启动容器镜像,而不用花费时间和 CPU 处理时间在 [Docker 引擎][17] 上启动。并且它的镜像格式是与容器无关的。
|
||||||
|
|
||||||
|
在 Kubernetes 中, [kubelet][18] 管理 pod(容器集群)。使用 CRI-O,Kubernetes 及其 kubelet 可以管理容器的整个生命周期。这个工具也不是和 Docker 镜像捆绑在一起的。你也可以使用新的 [OCI 镜像格式][19] 和 [CoreOS 的 rkt][20] 容器镜像。
|
||||||
|
|
||||||
|
同时,这些工具正在成为一个 Kubernetes 栈:编排系统、[容器运行时接口][21] (CRI)和 CRI-O。Kubernetes 首席工程师 Kelsey Hightower 说,“我们实际上不需要这么多的容器运行时——无论它是 Docker 还是 [rkt][22]。只需要给我们一个到内核的 API 就行”,这个结果是这些技术人员的承诺,是推动容器比以往更快发展的强大动力。
|
||||||
|
|
||||||
|
Kubernetes 也可以加速构建容器镜像。目前为止,有[三种方法来构建容器][23]。第一种方法是通过一个 Docker 或者 CoreOS 去构建容器。第二种方法是注入定制代码到一个预构建镜像中。最后一种方法是,<ruby>资产生成管道<rt>Asset Generation Pipeline</rt></ruby>使用容器去编译那些<ruby>资产<rt>asset</rt></ruby>,然后其被包含到使用 Docker 的<ruby>[多阶段构建][24]<rt>Multi-Stage Build</rt></ruby>所构建的随后镜像中。
|
||||||
|
|
||||||
|
现在,还有一个 Kubernetes 原生的方法:Red Hat 的 [Buildah][25], 这是[一个脚本化的 shell 工具][26] 用于快速、高效地构建 OCI 兼容的镜像和容器。Buildah 降低了容器环境的学习曲线,简化了创建、构建和更新镜像的难度。Pousty 说。你可以使用它和 Kubernetes 一起基于应用程序的调用来自动创建和使用容器。Buildah 也更节省系统资源,因为它不需要容器运行时守护进程。
|
||||||
|
|
||||||
|
因此,比起真实地引导一个容器和在容器内按步骤操作,Pousty 说,“挂载该文件系统,就如同它是一个常规的文件系统一样做一些正常操作,并且在最后提交”。
|
||||||
|
|
||||||
|
这意味着你可以从一个仓库中拉取一个镜像,创建它所匹配的容器,并且优化它。然后,你可以使用 Kubernetes 中的 Buildah 在你需要时去创建一个新的运行镜像。最终结果是,他说,运行 Kubernetes 管理的容器化应用程序比以往速度更快,需要的资源更少。
|
||||||
|
|
||||||
|
### 你所不知道的 Kubernetes 拥有的特性
|
||||||
|
|
||||||
|
你不需要在其它地方寻找工具。Kubernetes 有几个被低估的特性。
|
||||||
|
|
||||||
|
根据谷歌云全球产品经理 Allan Naim 的说法,其中一个是 [Kubernetes 命名空间][27]。Naim 在开源峰会上谈及 “Kubernetes 最佳实践”,他说,“很少有人使用命名空间,这是一个失误。”
|
||||||
|
|
||||||
|
“命名空间是将一个单个的 Kubernetes 集群分成多个虚拟集群的方法”,Naim 说。例如,“你可以认为命名空间就是<ruby>姓氏<rt>family name</rt></ruby>”,因此,假如说 “Simth” 用来标识一个家族,如果有个成员 Steve Smith,他的名字就是 “Steve”,但是,家族范围之外的,它就是 “Steve Smith” 或称 “来自 Chicago 的 Steve Smith”。
|
||||||
|
|
||||||
|
严格来说,“命名空间是一个逻辑分区技术,它允许一个 Kubernetes 集群被多个用户、用户团队或者一个用户的多个不能混淆的应用程序所使用。Naim 解释说,“每个用户、用户团队、或者应用程序都可以存在于它的命名空间中,与集群中的其他用户是隔离的,并且可以像你是这个集群的唯一用户一样操作它。”
|
||||||
|
|
||||||
|
Practically 说,你可以使用命名空间去构建一个企业的多个业务/技术的实体进入 Kubernetes。例如,云架构可以通过映射产品、地点、团队和成本中心为命名空间,从而定义公司的命名空间策略。
|
||||||
|
|
||||||
|
Naim 建议的另外的方法是,去使用命名空间将软件开发<ruby>流程<rt>pipeline</rt></ruby>划分到分离的命名空间中,如测试、质量保证、<ruby>预演<rt>staging</rt></ruby>和成品等常见阶段。或者命名空间也可以用于管理单独的客户。例如,你可以为每个客户、客户项目、或者客户业务单元去创建一个单独的命名空间。它可以更容易地区分项目,避免重用相同名字的资源。
|
||||||
|
|
||||||
|
然而,Kubernetes 现在还没有提供一个跨命名空间访问的控制机制。因此,Naim 建议你不要使用这种方法去对外公开程序。还要注意的是,命名空间也不是一个管理的“万能药”。例如,你不能将命名空间嵌套在另一个命名空间中。另外,也没有跨命名空间的强制安全机制。
|
||||||
|
|
||||||
|
尽管如此,小心地使用命名空间,还是很有用的。
|
||||||
|
|
||||||
|
### 以人为中心的建议
|
||||||
|
|
||||||
|
从谈论较深奥的技术换到项目管理。Pousty 建议,在转移到原生云和微服务架构时,在你的团队中要有一个微服务操作人员。“如果你去做微服务,你的团队最终做的就是 Ops-y。并且,不去使用已经知道这种操作的人是愚蠢的行为”,他说。“你需要一个正确的团队核心能力。我不想开发人员重新打造运维的轮子”。
|
||||||
|
|
||||||
|
而是,将你的工作流彻底地改造成一个能够使用容器和云的过程,对此,Kubernetes 是很适用的。
|
||||||
|
|
||||||
|
### 使用 Kubernetes 的原生云计算:领导者的课程
|
||||||
|
|
||||||
|
* 迅速扩大的原生云生态系统。寻找可以扩展你使用容器的方法的工具。
|
||||||
|
* 探索鲜为人知的 Kubernetes 特性,如命名空间。它们可以改善你的组织和自动化程度。
|
||||||
|
* 确保部署到容器的开发团队有一个 Ops 人员参与。否则,冲突将不可避免。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Steven J. Vaughan-Nichols, Vaughan-Nichols & Associates 的 CEO
|
||||||
|
|
||||||
|
Steven J. Vaughan-Nichols,即 sjvn,是一个技术方面的作家,从 CP/M-80 还是前沿技术、PC 操作系统、300bps 是非常快的因特网连接、WordStar 是最先进的文字处理程序的那个时候开始,一直从事于商业技术的写作,而且喜欢它。他的作品已经发布在了从高科技出版物(IEEE Computer、ACM Network、 Byte)到商业出版物(eWEEK、 InformationWeek、ZDNet),从大众科技(Computer Shopper、PC Magazine、PC World)再到主流出版商(Washington Post、San Francisco Chronicle、BusinessWeek) 等媒体之上。
|
||||||
|
|
||||||
|
---------------------
|
||||||
|
|
||||||
|
via: https://insights.hpe.com/articles/how-to-implement-cloud-native-computing-with-kubernetes-1710.html
|
||||||
|
|
||||||
|
作者:[Steven J. Vaughan-Nichols][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://insights.hpe.com/contributors/steven-j-vaughan-nichols.html
|
||||||
|
[1]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_insights~510287587~Containers_Dummies~sjvn_Kubernetes
|
||||||
|
[2]:https://kubernetes.io/
|
||||||
|
[3]:https://www.redhat.com/en
|
||||||
|
[4]:https://www.openshift.com/
|
||||||
|
[5]:https://www.linuxfoundation.org/
|
||||||
|
[6]:http://events.linuxfoundation.org/events/open-source-summit-north-america
|
||||||
|
[7]:https://www.opencontainers.org/
|
||||||
|
[8]:https://www.cncf.io/
|
||||||
|
[9]:https://insights.hpe.com/articles/the-basics-explaining-kubernetes-mesosphere-and-docker-swarm-1702.html
|
||||||
|
[10]:https://insights.hpe.com/articles/when-to-use-containers-and-when-not-to-1705.html
|
||||||
|
[11]:https://www.open-scap.org/
|
||||||
|
[12]:https://scap.nist.gov/
|
||||||
|
[13]:https://developers.redhat.com/blog/2016/05/02/introducing-atomic-scan-container-vulnerability-detection/
|
||||||
|
[14]:http://cri-o.io/
|
||||||
|
[15]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||||
|
[16]:https://wiki.centos.org/HowTos/SELinux
|
||||||
|
[17]:https://docs.docker.com/engine/
|
||||||
|
[18]:https://kubernetes.io/docs/admin/kubelet/
|
||||||
|
[19]:http://www.zdnet.com/article/containers-consolidation-open-container-initiative-1-0-released/
|
||||||
|
[20]:https://coreos.com/rkt/docs/latest/
|
||||||
|
[21]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||||
|
[22]:https://coreos.com/rkt/
|
||||||
|
[23]:http://chris.collins.is/2017/02/24/three-docker-build-strategies/
|
||||||
|
[24]:https://docs.docker.com/engine/userguide/eng-image/multistage-build/#use-multi-stage-builds
|
||||||
|
[25]:https://github.com/projectatomic/buildah
|
||||||
|
[26]:https://www.projectatomic.io/blog/2017/06/introducing-buildah/
|
||||||
|
[27]:https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
|
||||||
242
published/20171015 Monitoring Slow SQL Queries via Slack.md
Normal file
242
published/20171015 Monitoring Slow SQL Queries via Slack.md
Normal file
@ -0,0 +1,242 @@
|
|||||||
|
通过 Slack 监视慢 SQL 查询
|
||||||
|
==============
|
||||||
|
|
||||||
|
> 一个获得关于慢查询、意外错误和其它重要日志通知的简单 Go 秘诀。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我的 Slack bot 提示我一个运行了很长时间 SQL 查询。我应该尽快解决它。
|
||||||
|
|
||||||
|
**我们不能管理我们无法去测量的东西。**每个后台应用程序都需要我们去监视它在数据库上的性能。如果一个特定的查询随着数据量增长变慢,你必须在它变得太慢之前去优化它。
|
||||||
|
|
||||||
|
由于 Slack 已经成为我们工作的中心,它也在改变我们监视系统的方式。 虽然我们已经有非常不错的监视工具,如果在系统中任何东西有正在恶化的趋势,让 Slack 机器人告诉我们,也是非常棒的主意。比如,一个太长时间才完成的 SQL 查询,或者,在一个特定的 Go 包中发生一个致命的错误。
|
||||||
|
|
||||||
|
在这篇博客文章中,我们将告诉你,通过使用已经支持这些特性的[一个简单的日志系统][8] 和 [一个已存在的数据库库(database library)][9] 怎么去设置来达到这个目的。
|
||||||
|
|
||||||
|
### 使用记录器
|
||||||
|
|
||||||
|
[logger][10] 是一个为 Go 库和应用程序使用设计的小型库。在这个例子中我们使用了它的三个重要的特性:
|
||||||
|
|
||||||
|
* 它为测量性能提供了一个简单的定时器。
|
||||||
|
* 支持复杂的输出过滤器,因此,你可以从指定的包中选择日志。例如,你可以告诉记录器仅从数据库包中输出,并且仅输出超过 500 ms 的定时器日志。
|
||||||
|
* 它有一个 Slack 钩子,因此,你可以过滤并将日志输入到 Slack。
|
||||||
|
|
||||||
|
让我们看一下在这个例子中,怎么去使用定时器,稍后我们也将去使用过滤器:
|
||||||
|
|
||||||
|
```
|
||||||
|
package main
|
||||||
|
|
||||||
|
import (
|
||||||
|
"github.com/azer/logger"
|
||||||
|
"time"
|
||||||
|
)
|
||||||
|
|
||||||
|
var (
|
||||||
|
users = logger.New("users")
|
||||||
|
database = logger.New("database")
|
||||||
|
)
|
||||||
|
|
||||||
|
func main () {
|
||||||
|
users.Info("Hi!")
|
||||||
|
|
||||||
|
timer := database.Timer()
|
||||||
|
time.Sleep(time.Millisecond * 250) // sleep 250ms
|
||||||
|
timer.End("Connected to database")
|
||||||
|
|
||||||
|
users.Error("Failed to create a new user.", logger.Attrs{
|
||||||
|
"e-mail": "foo@bar.com",
|
||||||
|
})
|
||||||
|
|
||||||
|
database.Info("Just a random log.")
|
||||||
|
|
||||||
|
fmt.Println("Bye.")
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
运行这个程序没有输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ go run example-01.go
|
||||||
|
Bye
|
||||||
|
```
|
||||||
|
|
||||||
|
记录器是[缺省静默的][11],因此,它可以在库的内部使用。我们简单地通过一个环境变量去查看日志:
|
||||||
|
|
||||||
|
例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ LOG=database@timer go run example-01.go
|
||||||
|
01:08:54.997 database(250.095587ms): Connected to database.
|
||||||
|
Bye
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的示例我们使用了 `database@timer` 过滤器去查看 `database` 包中输出的定时器日志。你也可以试一下其它的过滤器,比如:
|
||||||
|
|
||||||
|
* `LOG=*`: 所有日志
|
||||||
|
* `LOG=users@error,database`: 所有来自 `users` 的错误日志,所有来自 `database` 的所有日志
|
||||||
|
* `LOG=*@timer,database@info`: 来自所有包的定时器日志和错误日志,以及来自 `database` 的所有日志
|
||||||
|
* `LOG=*,users@mute`: 除了 `users` 之外的所有日志
|
||||||
|
|
||||||
|
### 发送日志到 Slack
|
||||||
|
|
||||||
|
控制台日志是用于开发环境的,但是我们需要产品提供一个友好的界面。感谢 [slack-hook][12], 我们可以很容易地在上面的示例中,使用 Slack 去整合它:
|
||||||
|
|
||||||
|
```
|
||||||
|
import (
|
||||||
|
"github.com/azer/logger"
|
||||||
|
"github.com/azer/logger-slack-hook"
|
||||||
|
)
|
||||||
|
|
||||||
|
func init () {
|
||||||
|
logger.Hook(&slackhook.Writer{
|
||||||
|
WebHookURL: "https://hooks.slack.com/services/...",
|
||||||
|
Channel: "slow-queries",
|
||||||
|
Username: "Query Person",
|
||||||
|
Filter: func (log *logger.Log) bool {
|
||||||
|
return log.Package == "database" && log.Level == "TIMER" && log.Elapsed >= 200
|
||||||
|
}
|
||||||
|
})
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
我们来解释一下,在上面的示例中我们做了什么:
|
||||||
|
|
||||||
|
* 行 #5: 设置入站 webhook url。这个 URL [链接在这里][1]。
|
||||||
|
* 行 #6: 选择流日志的入口通道。
|
||||||
|
* 行 #7: 显示的发送者的用户名。
|
||||||
|
* 行 #11: 使用流过滤器,仅输出时间超过 200 ms 的定时器日志。
|
||||||
|
|
||||||
|
希望这个示例能给你提供一个大概的思路。如果你有更多的问题,去看这个 [记录器][13]的文档。
|
||||||
|
|
||||||
|
### 一个真实的示例: CRUD
|
||||||
|
|
||||||
|
[crud][14] 是一个用于 Go 的数据库的 ORM 式的类库,它有一个隐藏特性是内部日志系统使用 [logger][15] 。这可以让我们很容易地去监视正在运行的 SQL 查询。
|
||||||
|
|
||||||
|
#### 查询
|
||||||
|
|
||||||
|
这有一个通过给定的 e-mail 去返回用户名的简单查询:
|
||||||
|
|
||||||
|
```
|
||||||
|
func GetUserNameByEmail (email string) (string, error) {
|
||||||
|
var name string
|
||||||
|
if err := DB.Read(&name, "SELECT name FROM user WHERE email=?", email); err != nil {
|
||||||
|
return "", err
|
||||||
|
}
|
||||||
|
|
||||||
|
return name, nil
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
好吧,这个太短了, 感觉好像缺少了什么,让我们增加全部的上下文:
|
||||||
|
|
||||||
|
```
|
||||||
|
import (
|
||||||
|
"github.com/azer/crud"
|
||||||
|
_ "github.com/go-sql-driver/mysql"
|
||||||
|
"os"
|
||||||
|
)
|
||||||
|
|
||||||
|
var db *crud.DB
|
||||||
|
|
||||||
|
func main () {
|
||||||
|
var err error
|
||||||
|
|
||||||
|
DB, err = crud.Connect("mysql", os.Getenv("DATABASE_URL"))
|
||||||
|
if err != nil {
|
||||||
|
panic(err)
|
||||||
|
}
|
||||||
|
|
||||||
|
username, err := GetUserNameByEmail("foo@bar.com")
|
||||||
|
if err != nil {
|
||||||
|
panic(err)
|
||||||
|
}
|
||||||
|
|
||||||
|
fmt.Println("Your username is: ", username)
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
因此,我们有一个通过环境变量 `DATABASE_URL` 连接到 MySQL 数据库的 [crud][16] 实例。如果我们运行这个程序,将看到有一行输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ DATABASE_URL=root:123456@/testdb go run example.go
|
||||||
|
Your username is: azer
|
||||||
|
```
|
||||||
|
|
||||||
|
正如我前面提到的,日志是 [缺省静默的][17]。让我们看一下 crud 的内部日志:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ LOG=crud go run example.go
|
||||||
|
22:56:29.691 crud(0): SQL Query Executed: SELECT username FROM user WHERE email='foo@bar.com'
|
||||||
|
Your username is: azer
|
||||||
|
```
|
||||||
|
|
||||||
|
这很简单,并且足够我们去查看在我们的开发环境中查询是怎么执行的。
|
||||||
|
|
||||||
|
#### CRUD 和 Slack 整合
|
||||||
|
|
||||||
|
记录器是为配置管理应用程序级的“内部日志系统”而设计的。这意味着,你可以通过在你的应用程序级配置记录器,让 crud 的日志流入 Slack :
|
||||||
|
|
||||||
|
```
|
||||||
|
import (
|
||||||
|
"github.com/azer/logger"
|
||||||
|
"github.com/azer/logger-slack-hook"
|
||||||
|
)
|
||||||
|
|
||||||
|
func init () {
|
||||||
|
logger.Hook(&slackhook.Writer{
|
||||||
|
WebHookURL: "https://hooks.slack.com/services/...",
|
||||||
|
Channel: "slow-queries",
|
||||||
|
Username: "Query Person",
|
||||||
|
Filter: func (log *logger.Log) bool {
|
||||||
|
return log.Package == "mysql" && log.Level == "TIMER" && log.Elapsed >= 250
|
||||||
|
}
|
||||||
|
})
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
在上面的代码中:
|
||||||
|
|
||||||
|
* 我们导入了 [logger][2] 和 [logger-slack-hook][3] 库。
|
||||||
|
* 我们配置记录器日志流入 Slack。这个配置覆盖了代码库中 [记录器][4] 所有的用法, 包括第三方依赖。
|
||||||
|
* 我们使用了流过滤器,仅输出 MySQL 包中超过 250 ms 的定时器日志。
|
||||||
|
|
||||||
|
这种使用方法可以被扩展,而不仅是慢查询报告。我个人使用它去跟踪指定包中的重要错误, 也用于统计一些类似新用户登入或生成支付的日志。
|
||||||
|
|
||||||
|
### 在这篇文章中提到的包
|
||||||
|
|
||||||
|
* [crud][5]
|
||||||
|
* [logger][6]
|
||||||
|
* [logger-slack-hook][7]
|
||||||
|
|
||||||
|
[告诉我们][18] 如果你有任何的问题或建议。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/
|
||||||
|
|
||||||
|
作者:[Azer Koçulu][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://azer.bike/
|
||||||
|
[1]:https://my.slack.com/services/new/incoming-webhook/
|
||||||
|
[2]:https://github.com/azer/logger
|
||||||
|
[3]:https://github.com/azer/logger-slack-hook
|
||||||
|
[4]:https://github.com/azer/logger
|
||||||
|
[5]:https://github.com/azer/crud
|
||||||
|
[6]:https://github.com/azer/logger
|
||||||
|
[7]:https://github.com/azer/logger
|
||||||
|
[8]:http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/?utm_source=dbweekly&utm_medium=email#logger
|
||||||
|
[9]:http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/?utm_source=dbweekly&utm_medium=email#crud
|
||||||
|
[10]:https://github.com/azer/logger
|
||||||
|
[11]:http://www.linfo.org/rule_of_silence.html
|
||||||
|
[12]:https://github.com/azer/logger-slack-hook
|
||||||
|
[13]:https://github.com/azer/logger
|
||||||
|
[14]:https://github.com/azer/crud
|
||||||
|
[15]:https://github.com/azer/logger
|
||||||
|
[16]:https://github.com/azer/crud
|
||||||
|
[17]:http://www.linfo.org/rule_of_silence.html
|
||||||
|
[18]:https://twitter.com/afrikaradyo
|
||||||
106
published/20171015 Why Use Docker with R A DevOps Perspective.md
Normal file
106
published/20171015 Why Use Docker with R A DevOps Perspective.md
Normal file
@ -0,0 +1,106 @@
|
|||||||
|
为什么要在 Docker 中使用 R? 一位 DevOps 的看法
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
[][11]
|
||||||
|
|
||||||
|
> R 语言,一种自由软件编程语言与操作环境,主要用于统计分析、绘图、数据挖掘。R 内置多种统计学及数字分析功能。R 的另一强项是绘图功能,制图具有印刷的素质,也可加入数学符号。——引自维基百科。
|
||||||
|
|
||||||
|
已经有几篇关于为什么要在 Docker 中使用 R 的文章。在这篇文章中,我将尝试加入一个 DevOps 的观点,并解释在 OpenCPU 系统的环境中如何使用容器化 R 来构建和部署 R 服务器。
|
||||||
|
|
||||||
|
> 有在 [#rstats][2] 世界的人真正地写过*为什么*他们使用 Docker,而不是*如何*么?
|
||||||
|
>
|
||||||
|
> — Jenny Bryan (@JennyBryan) [September 29, 2017][3]
|
||||||
|
|
||||||
|
### 1:轻松开发
|
||||||
|
|
||||||
|
OpenCPU 系统的旗舰是 [OpenCPU 服务器][12]:它是一个成熟且强大的 Linux 栈,用于在系统和应用程序中嵌入 R。因为 OpenCPU 是完全开源的,我们可以在 DockerHub 上构建和发布。可以使用以下命令启动一个可以立即使用的 OpenCPU 和 RStudio 的 Linux 服务器(使用端口 8004 或 80):
|
||||||
|
|
||||||
|
```
|
||||||
|
docker run -t -p 8004:8004 opencpu/rstudio
|
||||||
|
```
|
||||||
|
|
||||||
|
现在只需在你的浏览器打开 http://localhost:8004/ocpu/ 和 http://localhost:8004/rstudio/ 即可!在 rstudio 中用用户 `opencpu`(密码:`opencpu`)登录来构建或安装应用程序。有关详细信息,请参阅[自述文件][15]。
|
||||||
|
|
||||||
|
Docker 让开始使用 OpenCPU 变得简单。容器给你一个充分灵活的 Linux 机器,而无需在系统上安装任何东西。你可以通过 rstudio 服务器安装软件包或应用程序,也可以使用 `docker exec` 进入到正在运行的服务器的 root shell 中:
|
||||||
|
|
||||||
|
```
|
||||||
|
# Lookup the container ID
|
||||||
|
docker ps
|
||||||
|
|
||||||
|
# Drop a shell
|
||||||
|
docker exec -i -t eec1cdae3228 /bin/bash
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以在服务器的 shell 中安装其他软件,自定义 apache2 的 httpd 配置(auth,代理等),调整 R 选项,通过预加载数据或包等来优化性能。
|
||||||
|
|
||||||
|
### 2: 通过 DockerHub 发布和部署
|
||||||
|
|
||||||
|
最强大的是,Docker 可以通过 DockerHub 发布和部署。要创建一个完全独立的应用程序容器,只需使用标准的 [opencpu 镜像][16]并添加你的程序。
|
||||||
|
|
||||||
|
出于本文的目的,我通过在每个仓库中添加一个非常简单的 “Dockerfile”,将一些[示例程序][17]打包为 docker 容器。例如:[nabel][18] 的 [Dockerfile][19] 包含以下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
FROM opencpu/base
|
||||||
|
|
||||||
|
RUN R -e 'devtools::install_github("rwebapps/nabel")'
|
||||||
|
```
|
||||||
|
|
||||||
|
它采用标准的 [opencpu/base][20] 镜像,并从 Github [仓库][21]安装 nabel。最终得到一个完全隔离、独立的程序。任何人可以使用下面这样的命令启动程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
docker run -d 8004:8004 rwebapps/nabel
|
||||||
|
```
|
||||||
|
|
||||||
|
`-d` 代表守护进程监听 8004 端口。很显然,你可以调整 `Dockerfile` 来安装任何其它的软件或设置你需要的程序。
|
||||||
|
|
||||||
|
容器化部署展示了 Docker 的真正能力:它可以发布可以开箱即用的独立软件,而无需安装任何软件或依赖付费托管的服务。如果你更喜欢专业的托管,那会有许多公司乐意在可扩展的基础设施上为你托管 docker 程序。
|
||||||
|
|
||||||
|
### 3: 跨平台构建
|
||||||
|
|
||||||
|
还有 Docker 用于 OpenCPU 的第三种方式。每次发布,我们都构建 6 个操作系统的 `opencpu-server` 安装包,它们在 [https://archive.opencpu.org][22] 上公布。这个过程已经使用 DockerHub 完全自动化了。以下镜像从源代码自动构建所有栈:
|
||||||
|
|
||||||
|
* [opencpu/ubuntu-16.04][4]
|
||||||
|
* [opencpu/debian-9][5]
|
||||||
|
* [opencpu/fedora-25][6]
|
||||||
|
* [opencpu/fedora-26][7]
|
||||||
|
* [opencpu/centos-6][8]
|
||||||
|
* [opencpu/centos-7][9]
|
||||||
|
|
||||||
|
当 GitHub 上发布新版本时,DockerHub 会自动重建此镜像。要做的就是运行一个[脚本][23],它会取回镜像并将 `opencpu-server` 二进制复制到[归档服务器上][24]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.r-bloggers.com/why-use-docker-with-r-a-devops-perspective/
|
||||||
|
|
||||||
|
作者:[Jeroen Ooms][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.r-bloggers.com/author/jeroen-ooms/
|
||||||
|
[1]:https://www.opencpu.org/posts/opencpu-with-docker/
|
||||||
|
[2]:https://twitter.com/hashtag/rstats?src=hash&ref_src=twsrc%5Etfw
|
||||||
|
[3]:https://twitter.com/JennyBryan/status/913785731998289920?ref_src=twsrc%5Etfw
|
||||||
|
[4]:https://hub.docker.com/r/opencpu/ubuntu-16.04/
|
||||||
|
[5]:https://hub.docker.com/r/opencpu/debian-9/
|
||||||
|
[6]:https://hub.docker.com/r/opencpu/fedora-25/
|
||||||
|
[7]:https://hub.docker.com/r/opencpu/fedora-26/
|
||||||
|
[8]:https://hub.docker.com/r/opencpu/centos-6/
|
||||||
|
[9]:https://hub.docker.com/r/opencpu/centos-7/
|
||||||
|
[10]:https://www.r-bloggers.com/
|
||||||
|
[11]:https://www.opencpu.org/posts/opencpu-with-docker
|
||||||
|
[12]:https://www.opencpu.org/download.html
|
||||||
|
[13]:http://localhost:8004/ocpu/
|
||||||
|
[14]:http://localhost:8004/rstudio/
|
||||||
|
[15]:https://hub.docker.com/r/opencpu/rstudio/
|
||||||
|
[16]:https://hub.docker.com/u/opencpu/
|
||||||
|
[17]:https://www.opencpu.org/apps.html
|
||||||
|
[18]:https://rwebapps.ocpu.io/nabel/www/
|
||||||
|
[19]:https://github.com/rwebapps/nabel/blob/master/Dockerfile
|
||||||
|
[20]:https://hub.docker.com/r/opencpu/base/
|
||||||
|
[21]:https://github.com/rwebapps
|
||||||
|
[22]:https://archive.opencpu.org/
|
||||||
|
[23]:https://github.com/opencpu/archive/blob/gh-pages/update.sh
|
||||||
|
[24]:https://archive.opencpu.org/
|
||||||
|
[25]:https://www.r-bloggers.com/author/jeroen-ooms/
|
||||||
71
published/20171016 Introducing CRI-O 1.0.md
Normal file
71
published/20171016 Introducing CRI-O 1.0.md
Normal file
@ -0,0 +1,71 @@
|
|||||||
|
CRI-O 1.0 简介
|
||||||
|
=====
|
||||||
|
|
||||||
|
去年,Kubernetes 项目推出了<ruby>[容器运行时接口][11]<rt>Container Runtime Interface</rt></ruby>(CRI):这是一个插件接口,它让 kubelet(用于创建 pod 和启动容器的集群节点代理)有使用不同的兼容 OCI 的容器运行时的能力,而不需要重新编译 Kubernetes。在这项工作的基础上,[CRI-O][12] 项目([原名 OCID] [13])准备为 Kubernetes 提供轻量级的运行时。
|
||||||
|
|
||||||
|
那么这个**真正的**是什么意思?
|
||||||
|
|
||||||
|
CRI-O 允许你直接从 Kubernetes 运行容器,而不需要任何不必要的代码或工具。只要容器符合 OCI 标准,CRI-O 就可以运行它,去除外来的工具,并让容器做其擅长的事情:加速你的新一代原生云程序。
|
||||||
|
|
||||||
|
在引入 CRI 之前,Kubernetes 通过“[一个内部的][14][易失性][15][接口][16]”与特定的容器运行时相关联。这导致了上游 Kubernetes 社区以及在编排平台之上构建解决方案的供应商的大量维护开销。
|
||||||
|
|
||||||
|
使用 CRI,Kubernetes 可以与容器运行时无关。容器运行时的提供者不需要实现 Kubernetes 已经提供的功能。这是社区的胜利,因为它让项目独立进行,同时仍然可以共同工作。
|
||||||
|
|
||||||
|
在大多数情况下,我们不认为 Kubernetes 的用户(或 Kubernetes 的发行版,如 OpenShift)真的关心容器运行时。他们希望它工作,但他们不希望考虑太多。就像你(通常)不关心机器上是否有 GNU Bash、Korn、Zsh 或其它符合 POSIX 标准 shell。你只是要一个标准的方式来运行你的脚本或程序而已。
|
||||||
|
|
||||||
|
### CRI-O:Kubernetes 的轻量级容器运行时
|
||||||
|
|
||||||
|
这就是 CRI-O 提供的。该名称来自 CRI 和开放容器计划(OCI),因为 CRI-O 严格关注兼容 OCI 的运行时和容器镜像。
|
||||||
|
|
||||||
|
现在,CRI-O 支持 runc 和 Clear Container 运行时,尽管它应该支持任何遵循 OCI 的运行时。它可以从任何容器仓库中拉取镜像,并使用<ruby>[容器网络接口][17]<rt>Container Network Interface</rt></ruby>(CNI)处理网络,以便任何兼容 CNI 的网络插件可与该项目一起使用。
|
||||||
|
|
||||||
|
当 Kubernetes 需要运行容器时,它会与 CRI-O 进行通信,CRI-O 守护程序与 runc(或另一个符合 OCI 标准的运行时)一起启动容器。当 Kubernetes 需要停止容器时,CRI-O 会来处理。这没什么令人兴奋的,它只是在幕后管理 Linux 容器,以便用户不需要担心这个关键的容器编排。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### CRI-O 不是什么
|
||||||
|
|
||||||
|
值得花一点时间了解下 CRI-O _不是_什么。CRI-O 的范围是与 Kubernetes 一起工作来管理和运行 OCI 容器。这不是一个面向开发人员的工具,尽管该项目确实有一些面向用户的工具进行故障排除。
|
||||||
|
|
||||||
|
例如,构建镜像超出了 CRI-O 的范围,这些留给像 Docker 的构建命令、 [Buildah][18] 或 [OpenShift 的 Source-to-Image][19](S2I)这样的工具。一旦构建完镜像,CRI-O 将乐意运行它,但构建镜像留给其他工具。
|
||||||
|
|
||||||
|
虽然 CRI-O 包含命令行界面 (CLI),但它主要用于测试 CRI-O,而不是真正用于在生产环境中管理容器的方法。
|
||||||
|
|
||||||
|
### 下一步
|
||||||
|
|
||||||
|
现在 CRI-O 1.0 发布了,我们希望看到它作为一个稳定功能在下一个 Kubernetes 版本中发布。1.0 版本将与 Kubernetes 1.7.x 系列一起使用,即将发布的 CRI-O 1.8-rc1 适合 Kubernetes 1.8.x。
|
||||||
|
|
||||||
|
我们邀请您加入我们,以促进开源 CRI-O 项目的开发,并感谢我们目前的贡献者为达成这一里程碑而提供的帮助。如果你想贡献或者关注开发,就去 [CRI-O 项目的 GitHub 仓库][20],然后关注 [CRI-O 博客][21]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.redhat.com/en/blog/introducing-cri-o-10
|
||||||
|
|
||||||
|
作者:[Joe Brockmeier][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.redhat.com/en/blog/authors/joe-brockmeier
|
||||||
|
[1]:https://www.redhat.com/en/blog/authors/joe-brockmeier
|
||||||
|
[2]:https://www.redhat.com/en/blog/authors/senior-evangelist
|
||||||
|
[3]:https://www.redhat.com/en/blog/authors/linux-containers
|
||||||
|
[4]:https://www.redhat.com/en/blog/authors/red-hat-0
|
||||||
|
[5]:https://www.redhat.com/en/blog
|
||||||
|
[6]:https://www.redhat.com/en/blog/tag/community
|
||||||
|
[7]:https://www.redhat.com/en/blog/tag/containers
|
||||||
|
[8]:https://www.redhat.com/en/blog/tag/hybrid-cloud
|
||||||
|
[9]:https://www.redhat.com/en/blog/tag/platform
|
||||||
|
[10]:mailto:?subject=Check%20out%20this%20redhat.com%20page:%20Introducing%20CRI-O%201.0&body=I%20saw%20this%20on%20redhat.com%20and%20thought%20you%20might%20be%20interested.%20%20Click%20the%20following%20link%20to%20read:%20https://www.redhat.com/en/blog/introducing-cri-o-10https://www.redhat.com/en/blog/introducing-cri-o-10
|
||||||
|
[11]:https://github.com/kubernetes/kubernetes/blob/242a97307b34076d5d8f5bbeb154fa4d97c9ef1d/docs/devel/container-runtime-interface.md
|
||||||
|
[12]:http://cri-o.io/
|
||||||
|
[13]:https://www.redhat.com/en/blog/running-production-applications-containers-introducing-ocid
|
||||||
|
[14]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||||
|
[15]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||||
|
[16]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||||
|
[17]:https://github.com/containernetworking/cni
|
||||||
|
[18]:https://github.com/projectatomic/buildah
|
||||||
|
[19]:https://github.com/openshift/source-to-image
|
||||||
|
[20]:https://github.com/kubernetes-incubator/cri-o
|
||||||
|
[21]:https://medium.com/cri-o
|
||||||
115
published/20171017 A tour of Postgres Index Types.md
Normal file
115
published/20171017 A tour of Postgres Index Types.md
Normal file
@ -0,0 +1,115 @@
|
|||||||
|
Postgres 索引类型探索之旅
|
||||||
|
=============
|
||||||
|
|
||||||
|
在 Citus 公司,为让事情做的更好,我们与客户一起在数据建模、优化查询、和增加 [索引][3]上花费了许多时间。我的目标是为客户的需求提供更好的服务,从而创造成功。我们所做的其中一部分工作是[持续][5]为你的 Citus 集群保持良好的优化和 [高性能][4];另外一部分是帮你了解关于 Postgres 和 Citus 你所需要知道的一切。毕竟,一个健康和高性能的数据库意味着 app 执行的更快,并且谁不愿意这样呢? 今天,我们简化一些内容,与客户分享一些关于 Postgres 索引的信息。
|
||||||
|
|
||||||
|
Postgres 有几种索引类型, 并且每个新版本都似乎增加一些新的索引类型。每个索引类型都是有用的,但是具体使用哪种类型取决于(1)数据类型,有时是(2)表中的底层数据和(3)执行的查找类型。接下来的内容我们将介绍在 Postgres 中你可以使用的索引类型,以及你何时该使用何种索引类型。在开始之前,这里有一个我们将带你亲历的索引类型列表:
|
||||||
|
|
||||||
|
* B-Tree
|
||||||
|
* <ruby>倒排索引<rt>Generalized Inverted Index</rt></ruby> (GIN)
|
||||||
|
* <ruby>倒排搜索树<rt>Generalized Inverted Seach Tree</rt></ruby> (GiST)
|
||||||
|
* <ruby>空间分区的<rt>Space partitioned</rt></ruby> GiST (SP-GiST)
|
||||||
|
* <ruby>块范围索引<rt>Block Range Index</rt></ruby> (BRIN)
|
||||||
|
* Hash
|
||||||
|
|
||||||
|
现在开始介绍索引。
|
||||||
|
|
||||||
|
### 在 Postgres 中,B-Tree 索引是你使用的最普遍的索引
|
||||||
|
|
||||||
|
如果你有一个计算机科学的学位,那么 B-Tree 索引可能是你学会的第一个索引。[B-tree 索引][6] 会创建一个始终保持自身平衡的一棵树。当它根据索引去查找某个东西时,它会遍历这棵树去找到键,然后返回你要查找的数据。使用索引是大大快于顺序扫描的,因为相对于顺序扫描成千上万的记录,它可以仅需要读几个 [页][7] (当你仅返回几个记录时)。
|
||||||
|
|
||||||
|
如果你运行一个标准的 `CREATE INDEX` 语句,它将为你创建一个 B-tree 索引。 B-tree 索引在大多数的数据类型上是很有价值的,比如文本、数字和时间戳。如果你刚开始在你的数据库中使用索引,并且不在你的数据库上使用太多的 Postgres 的高级特性,使用标准的 B-Tree 索引可能是你最好的选择。
|
||||||
|
|
||||||
|
### GIN 索引,用于多值列
|
||||||
|
|
||||||
|
<ruby>倒排索引<rt>Generalized Inverted Index</rt></ruby>,一般称为 [GIN][8],大多适用于当单个列中包含多个值的数据类型。
|
||||||
|
|
||||||
|
据 Postgres 文档:
|
||||||
|
|
||||||
|
> “GIN 设计用于处理被索引的条目是复合值的情况,并且由索引处理的查询需要搜索在复合条目中出现的值。例如,这个条目可能是文档,查询可以搜索文档中包含的指定字符。”
|
||||||
|
|
||||||
|
包含在这个范围内的最常见的数据类型有:
|
||||||
|
|
||||||
|
* [hStore][1]
|
||||||
|
* Array
|
||||||
|
* Range
|
||||||
|
* [JSONB][2]
|
||||||
|
|
||||||
|
关于 GIN 索引中最让人满意的一件事是,它们能够理解存储在复合值中的数据。但是,因为一个 GIN 索引需要有每个被添加的单独类型的数据结构的特定知识,因此,GIN 索引并不是支持所有的数据类型。
|
||||||
|
|
||||||
|
### GiST 索引, 用于有重叠值的行
|
||||||
|
|
||||||
|
<ruby>倒排搜索树<rt>Generalized Inverted Seach Tree</rt></ruby>(GiST)索引多适用于当你的数据与同一列的其它行数据重叠时。GiST 索引最好的用处是:如果你声明一个几何数据类型,并且你希望知道两个多边型是否包含一些点时。在一种情况中一个特定的点可能被包含在一个盒子中,而与此同时,其它的点仅存在于一个多边形中。使用 GiST 索引的常见数据类型有:
|
||||||
|
|
||||||
|
* 几何类型
|
||||||
|
* 需要进行全文搜索的文本类型
|
||||||
|
|
||||||
|
GiST 索引在大小上有很多的固定限制,否则,GiST 索引可能会变的特别大。作为其代价,GiST 索引是有损的(不精确的)。
|
||||||
|
|
||||||
|
据官方文档:
|
||||||
|
|
||||||
|
> “GiST 索引是有损的,这意味着索引可能产生虚假匹配,所以需要去检查真实的表行去消除虚假匹配。 (当需要时 PostgreSQL 会自动执行这个动作)”
|
||||||
|
|
||||||
|
这并不意味着你会得到一个错误结果,它只是说明了在 Postgres 给你返回数据之前,会做了一个很小的额外工作来过滤这些虚假结果。
|
||||||
|
|
||||||
|
特别提示:同一个数据类型上 GIN 和 GiST 索引往往都可以使用。通常一个有很好的性能表现,但会占用很大的磁盘空间,反之亦然。说到 GIN 与 GiST 的比较,并没有某个完美的方案可以适用所有情况,但是,以上规则应用于大部分常见情况。
|
||||||
|
|
||||||
|
### SP-GiST 索引,用于更大的数据
|
||||||
|
|
||||||
|
空间分区 GiST (SP-GiST)索引采用来自 [Purdue][9] 研究的空间分区树。 SP-GiST 索引经常用于当你的数据有一个天然的聚集因素,并且不是一个平衡树的时候。 电话号码是一个非常好的例子 (至少 US 的电话号码是)。 它们有如下的格式:
|
||||||
|
|
||||||
|
* 3 位数字的区域号
|
||||||
|
* 3 位数字的前缀号 (与以前的电话交换机有关)
|
||||||
|
* 4 位的线路号
|
||||||
|
|
||||||
|
这意味着第一组前三位处有一个天然的聚集因素,接着是第二组三位,然后的数字才是一个均匀的分布。但是,在电话号码的一些区域号中,存在一个比其它区域号更高的饱合状态。结果可能导致树非常的不平衡。因为前面有一个天然的聚集因素,并且数据不对等分布,像电话号码一样的数据可能会是 SP-GiST 的一个很好的案例。
|
||||||
|
|
||||||
|
### BRIN 索引, 用于更大的数据
|
||||||
|
|
||||||
|
块范围索引(BRIN)专注于一些类似 SP-GiST 的情形,它们最好用在当数据有一些自然排序,并且往往数据量很大时。如果有一个以时间为序的 10 亿条的记录,BRIN 也许就能派上用场。如果你正在查询一组很大的有自然分组的数据,如有几个邮编的数据,BRIN 能帮你确保相近的邮编存储在磁盘上相近的地方。
|
||||||
|
|
||||||
|
当你有一个非常大的比如以日期或邮编排序的数据库, BRIN 索引可以让你非常快的跳过或排除一些不需要的数据。此外,与整体数据量大小相比,BRIN 索引相对较小,因此,当你有一个大的数据集时,BRIN 索引就可以表现出较好的性能。
|
||||||
|
|
||||||
|
### Hash 索引, 总算不怕崩溃了
|
||||||
|
|
||||||
|
Hash 索引在 Postgres 中已经存在多年了,但是,在 Postgres 10 发布之前,对它们的使用一直有个巨大的警告,它不是 WAL-logged 的。这意味着如果你的服务器崩溃,并且你无法使用如 [wal-g][10] 故障转移到备机或从存档中恢复,那么你将丢失那个索引,直到你重建它。 随着 Postgres 10 发布,它们现在是 WAL-logged 的,因此,你可以再次考虑使用它们 ,但是,真正的问题是,你应该这样做吗?
|
||||||
|
|
||||||
|
Hash 索引有时会提供比 B-Tree 索引更快的查找,并且创建也很快。最大的问题是它们被限制仅用于“相等”的比较操作,因此你只能用于精确匹配的查找。这使得 hash 索引的灵活性远不及通常使用的 B-Tree 索引,并且,你不能把它看成是一种替代品,而是一种用于特殊情况的索引。
|
||||||
|
|
||||||
|
### 你该使用哪个?
|
||||||
|
|
||||||
|
我们刚才介绍了很多,如果你有点被吓到,也很正常。 如果在你知道这些之前, `CREATE INDEX` 将始终为你创建使用 B-Tree 的索引,并且有一个好消息是,对于大多数的数据库, Postgres 的性能都很好或非常好。 :) 如果你考虑使用更多的 Postgres 特性,下面是一个当你使用其它 Postgres 索引类型的备忘清单:
|
||||||
|
|
||||||
|
* B-Tree - 适用于大多数的数据类型和查询
|
||||||
|
* GIN - 适用于 JSONB/hstore/arrays
|
||||||
|
* GiST - 适用于全文搜索和几何数据类型
|
||||||
|
* SP-GiST - 适用于有天然的聚集因素但是分布不均匀的大数据集
|
||||||
|
* BRIN - 适用于有顺序排列的真正的大数据集
|
||||||
|
* Hash - 适用于相等操作,而且,通常情况下 B-Tree 索引仍然是你所需要的。
|
||||||
|
|
||||||
|
如果你有关于这篇文章的任何问题或反馈,欢迎加入我们的 [slack channel][11]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||||
|
|
||||||
|
作者:[Craig Kerstiens][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||||
|
[1]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||||
|
[2]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||||
|
[3]:https://www.citusdata.com/blog/2017/10/11/index-all-the-things-in-postgres/
|
||||||
|
[4]:https://www.citusdata.com/blog/2017/09/29/what-performance-can-you-expect-from-postgres/
|
||||||
|
[5]:https://www.citusdata.com/product/cloud
|
||||||
|
[6]:https://en.wikipedia.org/wiki/B-tree
|
||||||
|
[7]:https://www.8kdata.com/blog/postgresql-page-layout/
|
||||||
|
[8]:https://www.postgresql.org/docs/10/static/gin.html
|
||||||
|
[9]:https://www.cs.purdue.edu/spgist/papers/W87R36P214137510.pdf
|
||||||
|
[10]:https://www.citusdata.com/blog/2017/08/18/introducing-wal-g-faster-restores-for-postgres/
|
||||||
|
[11]:https://slack.citusdata.com/
|
||||||
|
[12]:https://twitter.com/share?url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/&text=A%20tour%20of%20Postgres%20Index%20Types&via=citusdata
|
||||||
|
[13]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||||
@ -0,0 +1,66 @@
|
|||||||
|
容器和微服务是如何改变了安全性
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 云原生程序和基础架构需要完全不同的安全方式。牢记这些最佳实践
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
>thinkstock
|
||||||
|
|
||||||
|
如今,大大小小的组织正在探索云原生技术的采用。“<ruby>云原生<rt>Cloud-native</rt></ruby>”是指将软件打包到被称为容器的标准化单元中的方法,这些单元组织成微服务,它们必须对接以形成程序,并确保正在运行的应用程序完全自动化以实现更高的速度、灵活性和可伸缩性。
|
||||||
|
|
||||||
|
由于这种方法从根本上改变了软件的构建、部署和运行方式,它也从根本上改变了软件需要保护的方式。云原生程序和基础架构为安全专业人员带来了若干新的挑战,他们需要建立新的安全计划来支持其组织对云原生技术的使用。
|
||||||
|
|
||||||
|
让我们来看看这些挑战,然后我们将讨论安全团队应该采取的哪些最佳实践来解决这些挑战。首先挑战是:
|
||||||
|
|
||||||
|
* **传统的安全基础设施缺乏容器可视性。** 大多数现有的基于主机和网络的安全工具不具备监视或捕获容器活动的能力。这些工具是为了保护单个操作系统或主机之间的流量,而不是其上运行的应用程序,从而导致容器事件、系统交互和容器间流量的可视性缺乏。
|
||||||
|
* **攻击面可以快速更改。**云原生应用程序由许多较小的组件组成,这些组件称为微服务,它们是高度分布式的,每个都应该分别进行审计和保护。因为这些应用程序的设计是通过编排系统进行配置和调整的,所以其攻击面也在不断变化,而且比传统的独石应用程序要快得多。
|
||||||
|
* **分布式数据流需要持续监控。**容器和微服务被设计为轻量级的,并且以可编程方式与对方或外部云服务进行互连。这会在整个环境中产生大量的快速移动数据,需要进行持续监控,以便应对攻击和危害指标以及未经授权的数据访问或渗透。
|
||||||
|
* **检测、预防和响应必须自动化。** 容器生成的事件的速度和容量压倒了当前的安全操作流程。容器的短暂寿命也成为难以捕获、分析和确定事故的根本原因。有效的威胁保护意味着自动化数据收集、过滤、关联和分析,以便能够对新事件作出足够快速的反应。
|
||||||
|
|
||||||
|
面对这些新的挑战,安全专业人员将需要建立新的安全计划以支持其组织对云原生技术的使用。自然地,你的安全计划应该解决云原生程序的整个生命周期的问题,这些应用程序可以分为两个不同的阶段:构建和部署阶段以及运行时阶段。每个阶段都有不同的安全考虑因素,必须全部加以解决才能形成一个全面的安全计划。
|
||||||
|
|
||||||
|
### 确保容器的构建和部署
|
||||||
|
|
||||||
|
构建和部署阶段的安全性侧重于将控制应用于开发人员工作流程和持续集成和部署管道,以降低容器启动后可能出现的安全问题的风险。这些控制可以包含以下准则和最佳实践:
|
||||||
|
|
||||||
|
* **保持镜像尽可能小。**容器镜像是一个轻量级的可执行文件,用于打包应用程序代码及其依赖项。将每个镜像限制为软件运行所必需的内容, 从而最小化从镜像启动的每个容器的攻击面。从最小的操作系统基础镜像(如 Alpine Linux)开始,可以减少镜像大小,并使镜像更易于管理。
|
||||||
|
* **扫描镜像的已知问题。**当镜像构建后,应该检查已知的漏洞披露。可以扫描构成镜像的每个文件系统层,并将结果与定期更新的常见漏洞披露数据库(CVE)进行比较。然后开发和安全团队可以在镜像被用来启动容器之前解决发现的漏洞。
|
||||||
|
* **数字签名的镜像。**一旦建立镜像,应在部署之前验证它们的完整性。某些镜像格式使用被称为摘要的唯一标识符,可用于检测镜像内容何时发生变化。使用私钥签名镜像提供了加密的保证,以确保每个用于启动容器的镜像都是由可信方创建的。
|
||||||
|
* **强化并限制对主机操作系统的访问。**由于在主机上运行的容器共享相同的操作系统,因此必须确保它们以适当限制的功能集启动。这可以通过使用内核安全功能和 Seccomp、AppArmor 和 SELinux 等模块来实现。
|
||||||
|
* **指定应用程序级别的分割策略。**微服务之间的网络流量可以被分割,以限制它们彼此之间的连接。但是,这需要根据应用级属性(如标签和选择器)进行配置,从而消除了处理传统网络详细信息(如 IP 地址)的复杂性。分割带来的挑战是,必须事先定义策略来限制通信,而不会影响容器在环境内部和环境之间进行通信的能力,这是正常活动的一部分。
|
||||||
|
* **保护容器所使用的秘密信息。**微服务彼此相互之间频繁交换敏感数据,如密码、令牌和密钥,这称之为<ruby>秘密信息<rt>secret</rt></ruby>。如果将这些秘密信息存储在镜像或环境变量中,则可能会意外暴露这些。因此,像 Docker 和 Kubernetes 这样的多个编排平台都集成了秘密信息管理,确保只有在需要的时候才将秘密信息分发给使用它们的容器。
|
||||||
|
|
||||||
|
来自诸如 Docker、Red Hat 和 CoreOS 等公司的几个领先的容器平台和工具提供了部分或全部这些功能。开始使用这些方法之一是在构建和部署阶段确保强大安全性的最简单方法。
|
||||||
|
|
||||||
|
但是,构建和部署阶段控制仍然不足以确保全面的安全计划。提前解决容器开始运行之前的所有安全事件是不可能的,原因如下:首先,漏洞永远不会被完全消除,新的漏洞会一直出现。其次,声明式的容器元数据和网络分段策略不能完全预见高度分布式环境中的所有合法应用程序活动。第三,运行时控制使用起来很复杂,而且往往配置错误,就会使应用程序容易受到威胁。
|
||||||
|
|
||||||
|
### 在运行时保护容器
|
||||||
|
|
||||||
|
运行时阶段的安全性包括所有功能(可见性、检测、响应和预防),这些功能是发现和阻止容器运行后发生的攻击和策略违规所必需的。安全团队需要对安全事件的根源进行分类、调查和确定,以便对其进行全面补救。以下是成功的运行时阶段安全性的关键方面:
|
||||||
|
|
||||||
|
* **检测整个环境以得到持续可见性。**能够检测攻击和违规行为始于能够实时捕获正在运行的容器中的所有活动,以提供可操作的“真相源”。捕获不同类型的容器相关数据有各种检测框架。选择一个能够处理容器的容量和速度的方案至关重要。
|
||||||
|
* **关联分布式威胁指标。** 容器设计为基于资源可用性以跨计算基础架构而分布。由于应用程序可能由数百或数千个容器组成,因此危害指标可能分布在大量主机上,使得难以确定那些与主动威胁相关的相关指标。需要大规模,快速的相关性来确定哪些指标构成特定攻击的基础。
|
||||||
|
* **分析容器和微服务行为。**微服务和容器使得应用程序可以分解为执行特定功能的最小组件,并被设计为不可变的。这使得比传统的应用环境更容易理解预期行为的正常模式。偏离这些行为基准可能反映恶意行为,可用于更准确地检测威胁。
|
||||||
|
* **通过机器学习增强威胁检测。**容器环境中生成的数据量和速度超过了传统的检测技术。自动化和机器学习可以实现更有效的行为建模、模式识别和分类,从而以更高的保真度和更少的误报来检测威胁。注意使用机器学习的解决方案只是为了生成静态白名单,用于警报异常,这可能会导致严重的警报噪音和疲劳。
|
||||||
|
* **拦截并阻止未经授权的容器引擎命令。**发送到容器引擎(例如 Docker)的命令用于创建、启动和终止容器以及在正在运行的容器中运行命令。这些命令可以反映危害容器的意图,这意味着可以禁止任何未经授权的命令。
|
||||||
|
* **自动响应和取证。**容器的短暂寿命意味着它们往往只能提供很少的事件信息,以用于事件响应和取证。此外,云原生架构通常将基础设施视为不可变的,自动将受影响的系统替换为新系统,这意味着在调查时的容器可能会消失。自动化可以确保足够快地捕获、分析和升级信息,以减轻攻击和违规的影响。
|
||||||
|
|
||||||
|
基于容器技术和微服务架构的云原生软件正在迅速实现应用程序和基础架构的现代化。这种模式转变迫使安全专业人员重新考虑有效保护其组织所需的计划。随着容器的构建、部署和运行,云原生软件的全面安全计划将解决整个应用程序生命周期问题。通过使用上述指导方针实施计划,组织可以为容器基础设施以及运行在上面的应用程序和服务构建安全的基础。
|
||||||
|
|
||||||
|
_WeLien Dang 是 StackRox 的产品副总裁,StackRox 是一家为容器提供自适应威胁保护的安全公司。此前,他曾担任 CoreOS 产品负责人,并在亚马逊、Splunk 和 Bracket Computing 担任安全和云基础架构的高级产品管理职位。_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.infoworld.com/article/3233139/cloud-computing/how-cloud-native-applications-change-security.html
|
||||||
|
|
||||||
|
作者:[Wei Lien Dang][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.infoworld.com/blog/new-tech-forum/
|
||||||
|
[1]:https://www.stackrox.com/
|
||||||
|
[2]:https://www.infoworld.com/article/3204171/what-is-docker-linux-containers-explained.html#tk.ifw-infsb
|
||||||
|
[3]:https://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker.html#tk.ifw-infsb
|
||||||
@ -0,0 +1,362 @@
|
|||||||
|
通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 不论是经验丰富的老程序员,还是没有经验的新手,Python 都是一个非常好的编程语言。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Image by : opensource.com
|
||||||
|
|
||||||
|
[Python][9] 是一个非常流行的编程语言,它可以用于创建桌面应用程序、3D 图形、视频游戏、甚至是网站。它是非常好的首选编程语言,因为它易于学习,不像一些复杂的语言,比如,C、 C++、 或 Java。 即使如此, Python 依然也是强大且健壮的,足以创建高级的应用程序,并且几乎适用于所有使用电脑的行业。不论是经验丰富的老程序员,还是没有经验的新手,Python 都是一个非常好的编程语言。
|
||||||
|
|
||||||
|
### 安装 Python
|
||||||
|
|
||||||
|
在学习 Python 之前,你需要先去安装它:
|
||||||
|
|
||||||
|
**Linux: **如果你使用的是 Linux 系统, Python 是已经包含在里面了。但是,你如果确定要使用 Python 3 。应该去检查一下你安装的 Python 版本,打开一个终端窗口并输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
python3 -V
|
||||||
|
```
|
||||||
|
|
||||||
|
如果提示该命令没有找到,你需要从你的包管理器中去安装 Python 3。
|
||||||
|
|
||||||
|
**MacOS:** 如果你使用的是一台 Mac,可以看上面 Linux 的介绍来确认是否安装了 Python 3。MacOS 没有内置的包管理器,因此,如果发现没有安装 Python 3,可以从 [python.org/downloads/mac-osx][10] 安装它。即使 macOS 已经安装了 Python 2,你还是应该学习 Python 3。
|
||||||
|
|
||||||
|
**Windows:** 微软 Windows 当前是没有安装 Python 的。从 [python.org/downloads/windows][11] 安装它。在安装向导中一定要选择 **Add Python to PATH** 来将 Python 执行程序放到搜索路径。
|
||||||
|
|
||||||
|
### 在 IDE 中运行
|
||||||
|
|
||||||
|
在 Python 中写程序,你需要准备一个文本编辑器,使用一个集成开发环境(IDE)是非常实用的。IDE 在一个文本编辑器中集成了一些方便而有用的 Python 功能。IDLE 3 和 NINJA-IDE 是你可以考虑的两种选择:
|
||||||
|
|
||||||
|
#### IDLE 3
|
||||||
|
|
||||||
|
Python 自带的一个基本的 IDE 叫做 IDLE。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
它有关键字高亮功能,可以帮助你检测拼写错误,并且有一个“运行”按钮可以很容易地快速测试代码。
|
||||||
|
|
||||||
|
要使用它:
|
||||||
|
|
||||||
|
* 在 Linux 或 macOS 上,启动一个终端窗口并输入 `idle3`。
|
||||||
|
* 在 Windows,从开始菜单中启动 Python 3。
|
||||||
|
* 如果你在开始菜单中没有看到 Python,在开始菜单中通过输入 `cmd` 启动 Windows 命令提示符,然后输入 `C:\Windows\py.exe`。
|
||||||
|
* 如果它没有运行,试着重新安装 Python。并且确认在安装向导中选择了 “Add Python to PATH”。参考 [docs.python.org/3/using/windows.html][1] 中的详细介绍。
|
||||||
|
* 如果仍然不能运行,那就使用 Linux 吧!它是免费的,只要将你的 Python 文件保存到一个 U 盘中,你甚至不需要安装它就可以使用。
|
||||||
|
|
||||||
|
#### Ninja-IDE
|
||||||
|
|
||||||
|
[Ninja-IDE][12] 是一个优秀的 Python IDE。它有关键字高亮功能可以帮助你检测拼写错误、引号和括号补全以避免语法错误,行号(在调试时很有帮助)、缩进标记,以及运行按钮可以很容易地进行快速代码测试。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
要使用它:
|
||||||
|
|
||||||
|
1. 安装 Ninja-IDE。如果你使用的是 Linux,使用包管理器安装是非常简单的;否则, 从 NINJA-IDE 的网站上 [下载][7] 合适的安装版本。
|
||||||
|
2. 启动 Ninja-IDE。
|
||||||
|
3. 转到 Edit 菜单,并选择 Preferences 设置。
|
||||||
|
4. 在 Preferences 窗口中,点击 Execution 选项卡。
|
||||||
|
5. 在 Execution 选项卡上,更改 `python` 为 `python3`。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Ninja-IDE 中的 Python3*
|
||||||
|
|
||||||
|
### 告诉 Python 想做什么
|
||||||
|
|
||||||
|
关键字可以告诉 Python 你想要做什么。不论是在 IDLE 还是在 Ninja 中,转到 File 菜单并创建一个新文件。对于 Ninja 用户:不要创建一个新项目,仅创建一个新文件。
|
||||||
|
|
||||||
|
在你的新的空文件中,在 IDLE 或 Ninja 中输入以下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
print("Hello world.")
|
||||||
|
```
|
||||||
|
|
||||||
|
* 如果你使用的是 IDLE,转到 Run 菜单并选择 Run module 选项。
|
||||||
|
* 如果你使用的是 Ninja,在左侧按钮条中点击 Run File 按钮。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*在 Ninja 中运行文件*
|
||||||
|
|
||||||
|
关键字 `print` 告诉 Python 去打印输出在圆括号中引用的文本内容。
|
||||||
|
|
||||||
|
虽然,这并不是特别刺激。在其内部, Python 只能访问基本的关键字,像 `print`、 `help`,最基本的数学函数,等等。
|
||||||
|
|
||||||
|
可以使用 `import` 关键字加载更多的关键字。在 IDLE 或 Ninja 中开始一个新文件,命名为 `pen.py`。
|
||||||
|
|
||||||
|
**警告:**不要命名你的文件名为 `turtle.py`,因为名为 `turtle.py` 的文件是包含在你正在控制的 turtle (海龟)程序中的。命名你的文件名为 `turtle.py` ,将会把 Python 搞糊涂,因为它会认为你将导入你自己的文件。
|
||||||
|
|
||||||
|
在你的文件中输入下列的代码,然后运行它:
|
||||||
|
|
||||||
|
```
|
||||||
|
import turtle
|
||||||
|
```
|
||||||
|
|
||||||
|
Turtle 是一个非常有趣的模块,试着这样做:
|
||||||
|
|
||||||
|
```
|
||||||
|
turtle.begin_fill()
|
||||||
|
turtle.forward(100)
|
||||||
|
turtle.left(90)
|
||||||
|
turtle.forward(100)
|
||||||
|
turtle.left(90)
|
||||||
|
turtle.forward(100)
|
||||||
|
turtle.left(90)
|
||||||
|
turtle.forward(100)
|
||||||
|
turtle.end_fill()
|
||||||
|
```
|
||||||
|
|
||||||
|
看一看你现在用 turtle 模块画出了一个什么形状。
|
||||||
|
|
||||||
|
要擦除你的海龟画图区,使用 `turtle.clear()` 关键字。想想看,使用 `turtle.color("blue")` 关键字会出现什么情况?
|
||||||
|
|
||||||
|
尝试更复杂的代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
import turtle as t
|
||||||
|
import time
|
||||||
|
|
||||||
|
t.color("blue")
|
||||||
|
t.begin_fill()
|
||||||
|
|
||||||
|
counter=0
|
||||||
|
|
||||||
|
while counter < 4:
|
||||||
|
t.forward(100)
|
||||||
|
t.left(90)
|
||||||
|
counter = counter+1
|
||||||
|
|
||||||
|
t.end_fill()
|
||||||
|
time.sleep(5)
|
||||||
|
```
|
||||||
|
|
||||||
|
运行完你的脚本后,是时候探索更有趣的模块了。
|
||||||
|
|
||||||
|
### 通过创建一个游戏来学习 Python
|
||||||
|
|
||||||
|
想学习更多的 Python 关键字,和用图形编程的高级特性,让我们来关注于一个游戏逻辑。在这个教程中,我们还将学习一些关于计算机程序是如何构建基于文本的游戏的相关知识,在游戏里面计算机和玩家掷一个虚拟骰子,其中掷的最高的是赢家。
|
||||||
|
|
||||||
|
#### 规划你的游戏
|
||||||
|
|
||||||
|
在写代码之前,最重要的事情是考虑怎么去写。在他们写代码 _之前_,许多程序员是先 [写简单的文档][13],这样,他们就有一个编程的目标。如果你想给这个程序写个文档的话,这个游戏看起来应该是这样的:
|
||||||
|
|
||||||
|
1. 启动掷骰子游戏并按下 Return 或 Enter 去掷骰子
|
||||||
|
2. 结果打印在你的屏幕上
|
||||||
|
3. 提示你再次掷骰子或者退出
|
||||||
|
|
||||||
|
这是一个简单的游戏,但是,文档会告诉你需要做的事很多。例如,它告诉你写这个游戏需要下列的组件:
|
||||||
|
|
||||||
|
* 玩家:你需要一个人去玩这个游戏。
|
||||||
|
* AI:计算机也必须去掷,否则,就没有什么输或赢了
|
||||||
|
* 随机数:一个常见的六面骰子表示从 1-6 之间的一个随机数
|
||||||
|
* 运算:一个简单的数学运算去比较一个数字与另一个数字的大小
|
||||||
|
* 一个赢或者输的信息
|
||||||
|
* 一个再次玩或退出的提示
|
||||||
|
|
||||||
|
#### 制作掷骰子游戏的 alpha 版
|
||||||
|
|
||||||
|
很少有程序,一开始就包含其所有的功能,因此,它们的初始版本仅实现最基本的功能。首先是几个定义:
|
||||||
|
|
||||||
|
**变量**是一个经常要改变的值,它在 Python 中使用的非常多。每当你需要你的程序去“记住”一些事情的时候,你就要使用一个变量。事实上,运行于代码中的信息都保存在变量中。例如,在数学方程式 `x + 5 = 20` 中,变量是 `x` ,因为字母 `x` 是一个变量占位符。
|
||||||
|
|
||||||
|
**整数**是一个数字, 它可以是正数也可以是负数。例如,`1` 和 `-1` 都是整数,因此,`14`、`21`,甚至 `10947` 都是。
|
||||||
|
|
||||||
|
在 Python 中变量创建和使用是非常容易的。这个掷骰子游戏的初始版使用了两个变量: `player` 和 `ai`。
|
||||||
|
|
||||||
|
在命名为 `dice_alpha.py` 的新文件中输入下列代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
import random
|
||||||
|
|
||||||
|
player = random.randint(1,6)
|
||||||
|
ai = random.randint(1,6)
|
||||||
|
|
||||||
|
if player > ai :
|
||||||
|
print("You win") # notice indentation
|
||||||
|
else:
|
||||||
|
print("You lose")
|
||||||
|
```
|
||||||
|
|
||||||
|
启动你的游戏,确保它能工作。
|
||||||
|
|
||||||
|
这个游戏的基本版本已经工作的非常好了。它实现了游戏的基本目标,但是,它看起来不像是一个游戏。玩家不知道他们摇了什么,电脑也不知道摇了什么,并且,即使玩家还想玩但是游戏已经结束了。
|
||||||
|
|
||||||
|
这是软件的初始版本(通常称为 alpha 版)。现在你已经确信实现了游戏的主要部分(掷一个骰子),是时候该加入到程序中了。
|
||||||
|
|
||||||
|
#### 改善这个游戏
|
||||||
|
|
||||||
|
在你的游戏的第二个版本中(称为 beta 版),将做一些改进,让它看起来像一个游戏。
|
||||||
|
|
||||||
|
##### 1、 描述结果
|
||||||
|
|
||||||
|
不要只告诉玩家他们是赢是输,他们更感兴趣的是他们掷的结果。在你的代码中尝试做如下的改变:
|
||||||
|
|
||||||
|
```
|
||||||
|
player = random.randint(1,6)
|
||||||
|
print("You rolled " + player)
|
||||||
|
|
||||||
|
ai = random.randint(1,6)
|
||||||
|
print("The computer rolled " + ai)
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,如果你运行这个游戏,它将崩溃,因为 Python 认为你在尝试做数学运算。它认为你试图在 `player` 变量上加字母 `You rolled` ,而保存在其中的是数字。
|
||||||
|
|
||||||
|
你必须告诉 Python 处理在 `player` 和 `ai` 变量中的数字,就像它们是一个句子中的单词(一个字符串)而不是一个数学方程式中的一个数字(一个整数)。
|
||||||
|
|
||||||
|
在你的代码中做如下的改变:
|
||||||
|
|
||||||
|
```
|
||||||
|
player = random.randint(1,6)
|
||||||
|
print("You rolled " + str(player) )
|
||||||
|
|
||||||
|
ai = random.randint(1,6)
|
||||||
|
print("The computer rolled " + str(ai) )
|
||||||
|
```
|
||||||
|
|
||||||
|
现在运行你的游戏将看到该结果。
|
||||||
|
|
||||||
|
##### 2、 让它慢下来
|
||||||
|
|
||||||
|
计算机运行的非常快。人有时可以很快,但是在游戏中,产生悬念往往更好。你可以使用 Python 的 `time` 函数,在这个紧张时刻让你的游戏慢下来。
|
||||||
|
|
||||||
|
```
|
||||||
|
import random
|
||||||
|
import time
|
||||||
|
|
||||||
|
player = random.randint(1,6)
|
||||||
|
print("You rolled " + str(player) )
|
||||||
|
|
||||||
|
ai = random.randint(1,6)
|
||||||
|
print("The computer rolls...." )
|
||||||
|
time.sleep(2)
|
||||||
|
print("The computer has rolled a " + str(player) )
|
||||||
|
|
||||||
|
if player > ai :
|
||||||
|
print("You win") # notice indentation
|
||||||
|
else:
|
||||||
|
print("You lose")
|
||||||
|
```
|
||||||
|
|
||||||
|
启动你的游戏去测试变化。
|
||||||
|
|
||||||
|
##### 3、 检测关系
|
||||||
|
|
||||||
|
如果你多玩几次你的游戏,你就会发现,即使你的游戏看起来运行很正确,它实际上是有一个 bug 在里面:当玩家和电脑摇出相同的数字的时候,它就不知道该怎么办了。
|
||||||
|
|
||||||
|
去检查一个值是否与另一个值相等,Python 使用 `==`。那是个“双”等号标记,不是一个。如果你仅使用一个,Python 认为你尝试去创建一个新变量,但是,实际上你是去尝试做数学运算。
|
||||||
|
|
||||||
|
当你想有比两个选项(即,赢或输)更多的选择时,你可以使用 Python 的 `elif` 关键字,它的意思是“否则,如果”。这允许你的代码去检查,是否在“许多”结果中有一个是 `true`, 而不是只检查“一个”是 `true`。
|
||||||
|
|
||||||
|
像这样修改你的代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
if player > ai :
|
||||||
|
print("You win") # notice indentation
|
||||||
|
elif player == ai:
|
||||||
|
print("Tie game.")
|
||||||
|
else:
|
||||||
|
print("You lose")
|
||||||
|
```
|
||||||
|
|
||||||
|
多运行你的游戏几次,去看一下你能否和电脑摇出一个平局。
|
||||||
|
|
||||||
|
#### 编写最终版
|
||||||
|
|
||||||
|
你的掷骰子游戏的 beta 版的功能和感觉比起 alpha 版更像游戏了,对于最终版,让我们来创建你的第一个 Python **函数**。
|
||||||
|
|
||||||
|
函数是可以作为一个独立的单元来调用的一组代码的集合。函数是非常重要的,因为,大多数应用程序里面都有许多代码,但不是所有的代码都只运行一次。函数可以启用应用程序并控制什么时候可以发生什么事情。
|
||||||
|
|
||||||
|
将你的代码变成这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
import random
|
||||||
|
import time
|
||||||
|
|
||||||
|
def dice():
|
||||||
|
player = random.randint(1,6)
|
||||||
|
print("You rolled " + str(player) )
|
||||||
|
|
||||||
|
ai = random.randint(1,6)
|
||||||
|
print("The computer rolls...." )
|
||||||
|
time.sleep(2)
|
||||||
|
print("The computer has rolled a " + str(player) )
|
||||||
|
|
||||||
|
if player > ai :
|
||||||
|
print("You win") # notice indentation
|
||||||
|
else:
|
||||||
|
print("You lose")
|
||||||
|
|
||||||
|
print("Quit? Y/N")
|
||||||
|
cont = input()
|
||||||
|
|
||||||
|
if cont == "Y" or cont == "y":
|
||||||
|
exit()
|
||||||
|
elif cont == "N" or cont == "n":
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
print("I did not understand that. Playing again.")
|
||||||
|
```
|
||||||
|
|
||||||
|
游戏的这个版本,在他们玩游戏之后会询问玩家是否退出。如果他们用一个 `Y` 或 `y` 去响应, Python 就会调用它的 `exit` 函数去退出游戏。
|
||||||
|
|
||||||
|
更重要的是,你将创建一个称为 `dice` 的你自己的函数。这个 `dice` 函数并不会立即运行,事实上,如果在这个阶段你尝试去运行你的游戏,它不会崩溃,但它也不会正式运行。要让 `dice` 函数真正运行起来做一些事情,你必须在你的代码中去**调用它**。
|
||||||
|
|
||||||
|
在你的现有代码下面增加这个循环,前两行就是上文中的前两行,不需要再次输入,并且要注意哪些需要缩进哪些不需要。**要注意缩进格式**。
|
||||||
|
|
||||||
|
```
|
||||||
|
else:
|
||||||
|
print("I did not understand that. Playing again.")
|
||||||
|
|
||||||
|
# main loop
|
||||||
|
while True:
|
||||||
|
print("Press return to roll your die.")
|
||||||
|
roll = input()
|
||||||
|
dice()
|
||||||
|
```
|
||||||
|
|
||||||
|
`while True` 代码块首先运行。因为 `True` 被定义为总是真,这个代码块将一直运行,直到 Python 告诉它退出为止。
|
||||||
|
|
||||||
|
`while True` 代码块是一个循环。它首先提示用户去启动这个游戏,然后它调用你的 `dice` 函数。这就是游戏的开始。当 `dice` 函数运行结束,根据玩家的回答,你的循环再次运行或退出它。
|
||||||
|
|
||||||
|
使用循环来运行程序是编写应用程序最常用的方法。循环确保应用程序保持长时间的可用,以便计算机用户使用应用程序中的函数。
|
||||||
|
|
||||||
|
### 下一步
|
||||||
|
|
||||||
|
现在,你已经知道了 Python 编程的基础知识。这个系列的下一篇文章将描述怎么使用 [PyGame][14] 去编写一个视频游戏,一个比 turtle 模块有更多功能的模块,但它也更复杂一些。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Seth Kenlon - 一个独立的多媒体大师,自由文化的倡导者,和 UNIX 极客。他同时从事电影和计算机行业。他是基于 slackwarers 的多媒体制作项目的维护者之一, http://slackermedia.info
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/10/python-101
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/seth
|
||||||
|
[1]:https://docs.python.org/3/using/windows.html
|
||||||
|
[2]:https://opensource.com/file/374606
|
||||||
|
[3]:https://opensource.com/file/374611
|
||||||
|
[4]:https://opensource.com/file/374621
|
||||||
|
[5]:https://opensource.com/file/374616
|
||||||
|
[6]:https://opensource.com/article/17/10/python-101?rate=XlcW6PAHGbAEBboJ3z6P_4Sx-hyMDMlga9NfoauUA0w
|
||||||
|
[7]:http://ninja-ide.org/downloads/
|
||||||
|
[8]:https://opensource.com/user/15261/feed
|
||||||
|
[9]:https://www.python.org/
|
||||||
|
[10]:https://www.python.org/downloads/mac-osx/
|
||||||
|
[11]:https://www.python.org/downloads/windows
|
||||||
|
[12]:http://ninja-ide.org/
|
||||||
|
[13]:https://opensource.com/article/17/8/doc-driven-development
|
||||||
|
[14]:https://www.pygame.org/news
|
||||||
|
[15]:https://opensource.com/users/seth
|
||||||
|
[16]:https://opensource.com/users/seth
|
||||||
|
[17]:https://opensource.com/article/17/10/python-101#comments
|
||||||
@ -0,0 +1,100 @@
|
|||||||
|
由 KRACK 攻击想到的确保网络安全的小贴士
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 最近的 KRACK (密钥重装攻击,这是一个安全漏洞名称或该漏洞利用攻击行为的名称)漏洞攻击的目标是位于你的设备和 Wi-Fi 访问点之间的链路,这个访问点或许是在你家里、办公室中、或你喜欢的咖啡吧中的任何一台路由器。这些提示能帮你提升你的连接的安全性。
|
||||||
|
|
||||||
|
[KRACK 漏洞攻击][4] 出现已经一段时间了,并且已经在 [相关技术网站][5] 上有很多详细的讨论,因此,我将不在这里重复攻击的技术细节。攻击方式的总结如下:
|
||||||
|
|
||||||
|
* 在 WPA2 无线握手协议中的一个缺陷允许攻击者在你的设备和 wi-fi 访问点之间嗅探或操纵通讯。
|
||||||
|
* 这个问题在 Linux 和 Android 设备上尤其严重,由于在 WPA2 标准中的措辞含糊不清,也或许是在实现它时的错误理解,事实上,在底层的操作系统打完补丁以前,该漏洞一直可以强制无线流量以无加密方式通讯。
|
||||||
|
* 还好这个漏洞可以在客户端上修补,因此,天并没有塌下来,而且,WPA2 加密标准并没有像 WEP 标准那样被淘汰(不要通过切换到 WEP 加密的方式去“修复”这个问题)。
|
||||||
|
* 大多数流行的 Linux 发行版都已经通过升级修复了这个客户端上的漏洞,因此,老老实实地去更新它吧。
|
||||||
|
* Android 也很快修复了这个漏洞。如果你的设备在接收 Android 安全补丁,你会很快修复这个漏洞。如果你的设备不再接收这些更新,那么,这个特别的漏洞将是你停止使用你的旧设备的一个理由。
|
||||||
|
|
||||||
|
即使如此,从我的观点来看, Wi-Fi 是不可信任的基础设施链中的另一个环节,并且,我们应该完全避免将其视为可信任的通信通道。
|
||||||
|
|
||||||
|
### Wi-Fi 是不受信任的基础设备
|
||||||
|
|
||||||
|
如果从你的笔记本电脑或移动设备中读到这篇文章,那么,你的通信链路看起来应该是这样:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
KRACK 攻击目标是在你的设备和 Wi-Fi 访问点之间的链接,访问点或许是在你家里、办公室中、或你喜欢的咖啡吧中的任何一台路由器。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
实际上,这个图示应该看起来像这样:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Wi-Fi 仅仅是在我们所不应该信任的信道上的长长的通信链的第一个链路。让我来猜猜,你使用的 Wi-Fi 路由器或许从开始使用的第一天气就没有得到过一个安全更新,并且,更糟糕的是,它或许使用了一个从未被更改过的、缺省的、易猜出的管理凭据(用户名和密码)。除非你自己安装并配置你的路由器,并且你能记得你上次更新的它的固件的时间,否则,你应该假设现在它已经被一些人控制并不能信任的。
|
||||||
|
|
||||||
|
在 Wi-Fi 路由器之后,我们的通讯进入一般意义上的常见不信任区域 —— 这要根据你的猜疑水平。这里有上游的 ISP 和接入提供商,其中的很多已经被指认监视、更改、分析和销售我们的流量数据,试图从我们的浏览习惯中挣更多的钱。通常他们的安全补丁计划辜负了我们的期望,最终让我们的流量暴露在一些恶意者眼中。
|
||||||
|
|
||||||
|
一般来说,在互联网上,我们还必须担心强大的国家级的参与者能够操纵核心网络协议,以执行大规模的网络监视和状态级的流量过滤。
|
||||||
|
|
||||||
|
### HTTPS 协议
|
||||||
|
|
||||||
|
值的庆幸的是,我们有一个基于不信任的介质进行安全通讯的解决方案,并且,我们可以每天都能使用它 —— 这就是 HTTPS 协议,它加密你的点对点的互联网通讯,并且确保我们可以信任站点与我们之间的通讯。
|
||||||
|
|
||||||
|
Linux 基金会的一些措施,比如像 [Let’s Encrypt][7] 使世界各地的网站所有者都可以很容易地提供端到端的加密,这有助于确保我们的个人设备与我们试图访问的网站之间的任何有安全隐患的设备不再是个问题。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
是的... 基本没关系。
|
||||||
|
|
||||||
|
### DNS —— 剩下的一个问题
|
||||||
|
|
||||||
|
虽然,我们可以尽量使用 HTTPS 去创建一个可信的通信信道,但是,这里仍然有一个攻击者可以访问我们的路由器或修改我们的 Wi-Fi 流量的机会 —— 在使用 KRACK 的这个案例中 —— 可以欺骗我们的通讯进入一个错误的网站。他们可以利用我们仍然非常依赖 DNS 的这一事实 —— 这是一个未加密的、易受欺骗的 [诞生自上世纪 80 年代的协议][8]。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
DNS 是一个将像 “linux.com” 这样人类友好的域名,转换成计算机可以用于和其它计算机通讯的 IP 地址的一个系统。要转换一个域名到一个 IP 地址,计算机将会查询解析器软件 —— 它通常运行在 Wi-Fi 路由器或一个系统上。解析器软件将查询一个分布式的“根”域名服务器网络,去找到在互联网上哪个系统有 “linux.com” 域名所对应的 IP 地址的“权威”信息。
|
||||||
|
|
||||||
|
麻烦就在于,所有发生的这些通讯都是未经认证的、[易于欺骗的][9]、明文协议、并且响应可以很容易地被攻击者修改,去返回一个不正确的数据。如果有人去欺骗一个 DNS 查询并且返回错误的 IP 地址,他们可以操纵我们的系统最终发送 HTTP 请求到那里。
|
||||||
|
|
||||||
|
幸运的是,HTTPS 有一些内置的保护措施去确保它不会很容易地被其它人诱导至其它假冒站点。恶意服务器上的 TLS 凭据必须与你请求的 DNS 名字匹配 —— 并且它必须由一个你的浏览器认可的信誉良好的 [认证机构(CA)][10] 所签发。如果不是这种情况,你的浏览器将在你试图去与他们告诉你的地址进行通讯时出现一个很大的警告。如果你看到这样的警告,在选择不理会警告之前,请你格外小心,因为,它有可能会把你的秘密泄露给那些可能会对付你的人。
|
||||||
|
|
||||||
|
如果攻击者完全控制了路由器,他们可以在一开始时,通过拦截来自服务器指示你建立一个安全连接的响应,以阻止你使用 HTTPS 连接(这被称为 “[SSL 脱衣攻击][11]”)。 为了帮助你防护这种类型的攻击,网站可以增加一个 [特殊响应头(HSTS)][12] 去告诉你的浏览器以后与它通讯时总是使用 HTTPS 协议,但是,这仅仅是在你首次访问之后的事。对于一些非常流行的站点,浏览器现在包含一个 [硬编码的域名列表][13],即使是首次连接,它也将总是使用 HTTPS 协议访问。
|
||||||
|
|
||||||
|
现在已经有了 DNS 欺骗的解决方案,它被称为 [DNSSEC][14],由于有重大的障碍 —— 真实和可感知的(LCTT 译注,指的是要求实名认证),它看起来接受程度很慢。在 DNSSEC 被普遍使用之前,我们必须假设,我们接收到的 DNS 信息是不能完全信任的。
|
||||||
|
|
||||||
|
### 使用 VPN 去解决“最后一公里”的安全问题
|
||||||
|
|
||||||
|
因此,如果你不能信任固件太旧的 Wi-Fi 和/或无线路由器,我们能做些什么来确保发生在你的设备与常说的互联网之间的“最后一公里”通讯的完整性呢?
|
||||||
|
|
||||||
|
一个可接受的解决方案是去使用信誉好的 VPN 供应商的服务,它将在你的系统和他们的基础设施之间建立一条安全的通讯链路。这里有一个期望,就是它比你的路由器提供者和你的当前互联网供应商更注重安全,因为,他们处于一个更好的位置去确保你的流量不会受到恶意的攻击或欺骗。在你的工作站和移动设备之间使用 VPN,可以确保免受像 KRACK 这样的漏洞攻击,不安全的路由器不会影响你与外界通讯的完整性。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
这有一个很重要的警告是,当你选择一个 VPN 供应商时,你必须确信他们的信用;否则,你将被一拨恶意的人出卖给其它人。远离任何人提供的所谓“免费 VPN”,因为,它们可以通过监视你和向市场营销公司销售你的流量来赚钱。 [这个网站][2] 是一个很好的资源,你可以去比较他们提供的各种 VPN,去看他们是怎么互相竞争的。
|
||||||
|
|
||||||
|
注意,你所有的设备都应该在它上面安装 VPN,那些你每天使用的网站,你的私人信息,尤其是任何与你的钱和你的身份(政府、银行网站、社交网络、等等)有关的东西都必须得到保护。VPN 并不是对付所有网络级漏洞的万能药,但是,当你在机场使用无法保证的 Wi-Fi 时,或者下次发现类似 KRACK 的漏洞时,它肯定会保护你。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linux.com/blog/2017/10/tips-secure-your-network-wake-krack
|
||||||
|
|
||||||
|
作者:[KONSTANTIN RYABITSEV][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linux.com/users/mricon
|
||||||
|
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||||
|
[2]:https://www.vpnmentor.com/bestvpns/overall/
|
||||||
|
[3]:https://www.linux.com/files/images/krack-securityjpg
|
||||||
|
[4]:https://www.krackattacks.com/
|
||||||
|
[5]:https://blog.cryptographyengineering.com/2017/10/16/falling-through-the-kracks/
|
||||||
|
[6]:https://en.wikipedia.org/wiki/BGP_hijacking
|
||||||
|
[7]:https://letsencrypt.org/
|
||||||
|
[8]:https://en.wikipedia.org/wiki/Domain_Name_System#History
|
||||||
|
[9]:https://en.wikipedia.org/wiki/DNS_spoofing
|
||||||
|
[10]:https://en.wikipedia.org/wiki/Certificate_authority
|
||||||
|
[11]:https://en.wikipedia.org/wiki/Moxie_Marlinspike#Notable_research
|
||||||
|
[12]:https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security
|
||||||
|
[13]:https://hstspreload.org/
|
||||||
|
[14]:https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions
|
||||||
177
published/20171019 3 Simple Excellent Linux Network Monitors.md
Normal file
177
published/20171019 3 Simple Excellent Linux Network Monitors.md
Normal file
@ -0,0 +1,177 @@
|
|||||||
|
3 个简单、优秀的 Linux 网络监视器
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*用 iftop、Nethogs 和 vnstat 了解更多关于你的网络连接。*
|
||||||
|
|
||||||
|
你可以通过这三个 Linux 网络命令,了解有关你网络连接的大量信息。iftop 通过进程号跟踪网络连接,Nethogs 可以快速显示哪个在占用你的带宽,而 vnstat 作为一个很好的轻量级守护进程运行,可以随时随地记录你的使用情况。
|
||||||
|
|
||||||
|
### iftop
|
||||||
|
|
||||||
|
[iftop][7] 监听你指定的网络接口,并以 `top` 的形式展示连接。
|
||||||
|
|
||||||
|
这是一个很好的小工具,用于快速识别占用、测量速度,并保持网络流量的总体运行。看到我们使用了多少带宽是非常令人惊讶的,特别是对于我们这些还记得使用电话线、调制解调器、让人尖叫的 Kbit 速度和真实的实时波特率的老年人来说。我们很久以前就放弃了波特率,转而使用比特率。波特率测量信号变化,有时与比特率相同,但大多数情况下不是。
|
||||||
|
|
||||||
|
如果你只有一个网络接口,可以不带选项运行 `iftop`。`iftop` 需要 root 权限:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo iftop
|
||||||
|
```
|
||||||
|
|
||||||
|
当你有多个接口时,指定要监控的接口:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo iftop -i wlan0
|
||||||
|
```
|
||||||
|
|
||||||
|
就像 top 一样,你可以在运行时更改显示选项。
|
||||||
|
|
||||||
|
* `h` 切换帮助屏幕。
|
||||||
|
* `n` 切换名称解析。
|
||||||
|
* `s` 切换源主机显示,`d` 切换目标主机。
|
||||||
|
* `s` 切换端口号。
|
||||||
|
* `N` 切换端口解析。要全看到端口号,请关闭解析。
|
||||||
|
* `t` 切换文本界面。默认显示需要 ncurses。我认为文本显示更易于阅读和更好的组织(图1)。
|
||||||
|
* `p` 暂停显示。
|
||||||
|
* `q` 退出程序。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 1:文本显示是可读的和可组织的。*
|
||||||
|
|
||||||
|
当你切换显示选项时,`iftop` 会继续测量所有流量。你还可以选择要监控的单个主机。你需要主机的 IP 地址和网络掩码。我很好奇 Pandora 在我那可怜的带宽中占用了多少,所以我先用 `dig` 找到它们的 IP 地址:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ dig A pandora.com
|
||||||
|
[...]
|
||||||
|
;; ANSWER SECTION:
|
||||||
|
pandora.com. 267 IN A 208.85.40.20
|
||||||
|
pandora.com. 267 IN A 208.85.40.50
|
||||||
|
```
|
||||||
|
|
||||||
|
网络掩码是什么? [ipcalc][8] 告诉我们:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ipcalc -b 208.85.40.20
|
||||||
|
Address: 208.85.40.20
|
||||||
|
Netmask: 255.255.255.0 = 24
|
||||||
|
Wildcard: 0.0.0.255
|
||||||
|
=>
|
||||||
|
Network: 208.85.40.0/24
|
||||||
|
```
|
||||||
|
|
||||||
|
现在将地址和网络掩码提供给 iftop:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo iftop -F 208.85.40.20/24 -i wlan0
|
||||||
|
```
|
||||||
|
|
||||||
|
这不是真的吗?我很惊讶地发现,我珍贵的带宽对于 Pandora 很宽裕,每小时使用大约使用 500Kb。而且,像大多数流媒体服务一样,Pandora 的流量也有峰值,其依赖于缓存来缓解阻塞。
|
||||||
|
|
||||||
|
你可以使用 `-G` 选项对 IPv6 地址执行相同操作。请参阅手册页了解 `iftop` 的其他功能,包括使用自定义配置文件定制默认选项,并应用自定义过滤器(请参阅 [PCAP-FILTER][9] 作为过滤器参考)。
|
||||||
|
|
||||||
|
### Nethogs
|
||||||
|
|
||||||
|
当你想要快速了解谁占用了你的带宽时,Nethogs 是快速和容易的。以 root 身份运行,并指定要监听的接口。它显示了空闲的应用程序和进程号,以便如果你愿意的话,你可以杀死它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo nethogs wlan0
|
||||||
|
|
||||||
|
NetHogs version 0.8.1
|
||||||
|
|
||||||
|
PID USER PROGRAM DEV SENT RECEIVED
|
||||||
|
7690 carla /usr/lib/firefox wlan0 12.494 556.580 KB/sec
|
||||||
|
5648 carla .../chromium-browser wlan0 0.052 0.038 KB/sec
|
||||||
|
TOTAL 12.546 556.618 KB/sec
|
||||||
|
```
|
||||||
|
|
||||||
|
Nethogs 选项很少:在 kb/s、kb、b 和 mb 之间循环;通过接收或发送的数据包进行排序;并调整刷新之间的延迟。请参阅 `man nethogs`,或者运行 `nethogs -h`。
|
||||||
|
|
||||||
|
### vnstat
|
||||||
|
|
||||||
|
[vnstat][10] 是最容易使用的网络数据收集器。它是轻量级的,不需要 root 权限。它作为守护进程运行,并记录你网络统计信息。`vnstat` 命令显示累计的数据:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vnstat -i wlan0
|
||||||
|
Database updated: Tue Oct 17 08:36:38 2017
|
||||||
|
|
||||||
|
wlan0 since 10/17/2017
|
||||||
|
|
||||||
|
rx: 45.27 MiB tx: 3.77 MiB total: 49.04 MiB
|
||||||
|
|
||||||
|
monthly
|
||||||
|
rx | tx | total | avg. rate
|
||||||
|
------------------------+-------------+-------------+---------------
|
||||||
|
Oct '17 45.27 MiB | 3.77 MiB | 49.04 MiB | 0.28 kbit/s
|
||||||
|
------------------------+-------------+-------------+---------------
|
||||||
|
estimated 85 MiB | 5 MiB | 90 MiB |
|
||||||
|
|
||||||
|
daily
|
||||||
|
rx | tx | total | avg. rate
|
||||||
|
------------------------+-------------+-------------+---------------
|
||||||
|
today 45.27 MiB | 3.77 MiB | 49.04 MiB | 12.96 kbit/s
|
||||||
|
------------------------+-------------+-------------+---------------
|
||||||
|
estimated 125 MiB | 8 MiB | 133 MiB |
|
||||||
|
```
|
||||||
|
|
||||||
|
它默认显示所有的网络接口。使用 `-i` 选项选择单个接口。以这种方式合并多个接口的数据:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vnstat -i wlan0+eth0+eth1
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以通过以下几种方式过滤显示:
|
||||||
|
|
||||||
|
* `-h` 以小时显示统计数据。
|
||||||
|
* `-d` 以天数显示统计数据。
|
||||||
|
* `-w` 和 `-m` 按周和月显示统计数据。
|
||||||
|
* 使用 `-l` 选项查看实时更新。
|
||||||
|
|
||||||
|
此命令删除 wlan1 的数据库,并停止监控它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vnstat -i wlan1 --delete
|
||||||
|
```
|
||||||
|
|
||||||
|
此命令为网络接口创建别名。此例使用 Ubuntu 16.04 中的一个奇怪的接口名称:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vnstat -u -i enp0s25 --nick eth0
|
||||||
|
```
|
||||||
|
|
||||||
|
默认情况下,vnstat 监视 eth0。你可以在 `/etc/vnstat.conf` 中更改此内容,或在主目录中创建自己的个人配置文件。请参见 `man vnstat` 以获得完整的参考。
|
||||||
|
|
||||||
|
你还可以安装 `vnstati` 创建简单的彩色图(图2):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vnstati -s -i wlx7cdd90a0a1c2 -o vnstat.png
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 2:你可以使用 vnstati 创建简单的彩色图表。*
|
||||||
|
|
||||||
|
有关完整选项,请参见 `man vnstati`。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linux.com/learn/intro-to-linux/2017/10/3-simple-excellent-linux-network-monitors
|
||||||
|
|
||||||
|
作者:[CARLA SCHRODER][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linux.com/users/cschroder
|
||||||
|
[1]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[2]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[3]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[4]:https://www.linux.com/files/images/fig-1png-8
|
||||||
|
[5]:https://www.linux.com/files/images/fig-2png-5
|
||||||
|
[6]:https://www.linux.com/files/images/bannerpng-3
|
||||||
|
[7]:http://www.ex-parrot.com/pdw/iftop/
|
||||||
|
[8]:https://www.linux.com/learn/intro-to-linux/2017/8/how-calculate-network-addresses-ipcalc
|
||||||
|
[9]:http://www.tcpdump.org/manpages/pcap-filter.7.html
|
||||||
|
[10]:http://humdi.net/vnstat/
|
||||||
@ -0,0 +1,317 @@
|
|||||||
|
用 Kubernetes 和 Docker 部署 Java 应用
|
||||||
|
==========================
|
||||||
|
|
||||||
|
> 大规模容器应用编排起步
|
||||||
|
|
||||||
|
通过《[面向 Java 开发者的 Kubernetes][3]》,学习基本的 Kubernetes 概念和自动部署、维护和扩展你的 Java 应用程序的机制。[下载该电子书的免费副本][3]
|
||||||
|
|
||||||
|
在 《[Java 的容器化持续交付][23]》 中,我们探索了在 Docker 容器内打包和部署 Java 应用程序的基本原理。这只是创建基于容器的生产级系统的第一步。在真实的环境中运行容器还需要一个容器编排和计划的平台,并且,现在已经存在了很多个这样的平台(如,Docker Swarm、Apach Mesos、AWS ECS),而最受欢迎的是 [Kubernetes][24]。Kubernetes 被用于很多组织的产品中,并且,它现在由[原生云计算基金会(CNCF)][25]所管理。在这篇文章中,我们将使用以前的一个简单的基于 Java 的电子商务商店,我们将它打包进 Docker 容器内,并且在 Kubernetes 上运行它。
|
||||||
|
|
||||||
|
### “Docker Java Shopfront” 应用程序
|
||||||
|
|
||||||
|
我们将打包进容器,并且部署在 Kubernetes 上的 “Docker Java Shopfront” 应用程序的架构,如下面的图所示:
|
||||||
|
|
||||||
|
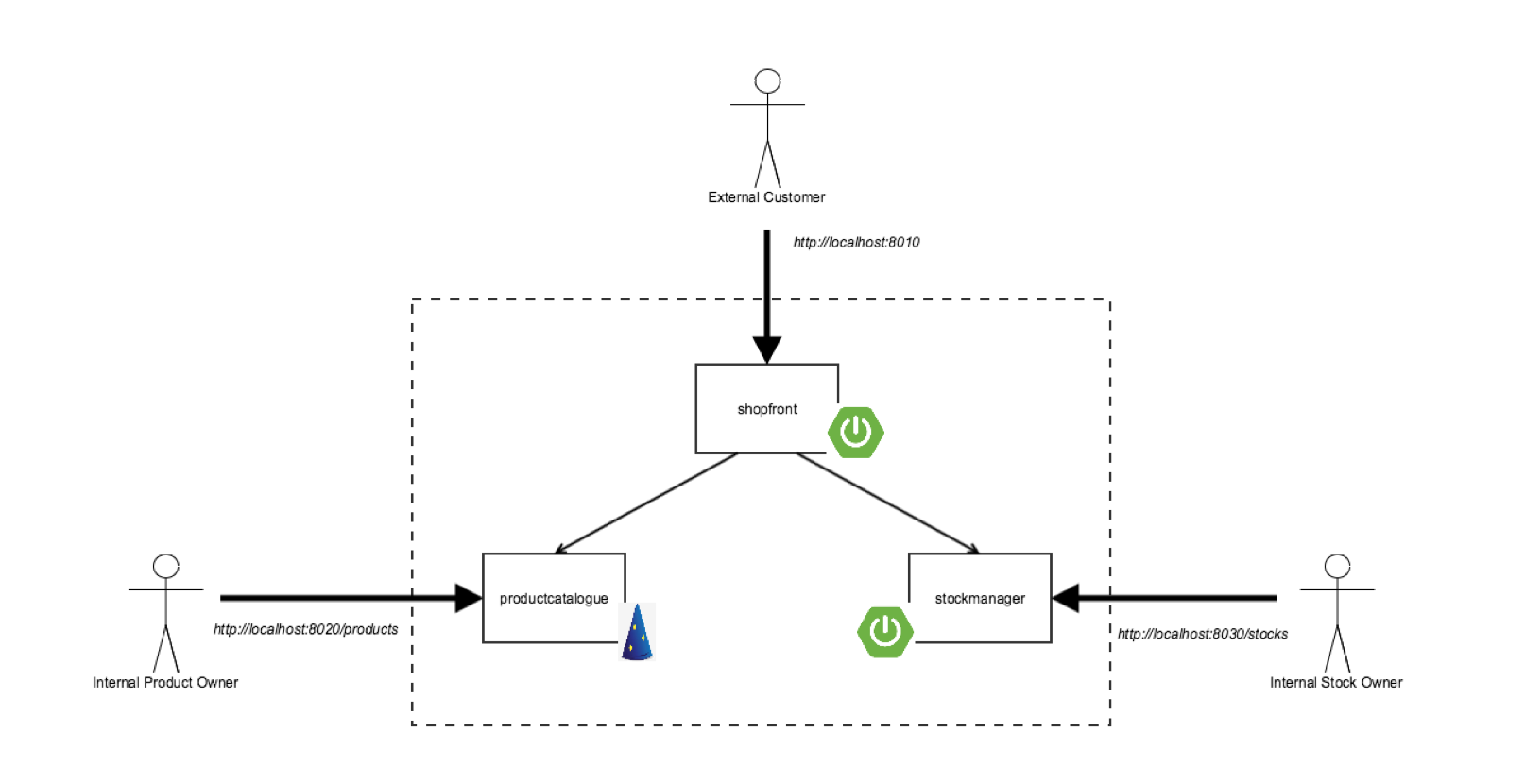
|
||||||
|
|
||||||
|
在我们开始去创建一个所需的 Kubernetes 部署配置文件之前,让我们先学习一下关于容器编排平台中的一些核心概念。
|
||||||
|
|
||||||
|
### Kubernetes 101
|
||||||
|
|
||||||
|
Kubernetes 是一个最初由谷歌开发的开源的部署容器化应用程序的<ruby>编排器<rt>orchestrator</rt></ruby>。谷歌已经运行容器化应用程序很多年了,并且,由此产生了 [Borg 容器编排器][26],它是应用于谷歌内部的,是 Kubernetes 创意的来源。如果你对这个技术不熟悉,一些出现的许多核心概念刚开始你会不理解,但是,实际上它们都很强大。首先, Kubernetes 采用了不可变的基础设施的原则。部署到容器中的内容(比如应用程序)是不可变的,不能通过登录到容器中做成改变。而是要以部署新的版本替代。第二,Kubernetes 内的任何东西都是<ruby>声明式<rt>declaratively</rt></ruby>配置。开发者或运维指定系统状态是通过部署描述符和配置文件进行的,并且,Kubernetes 是可以响应这些变化的——你不需要去提供命令,一步一步去进行。
|
||||||
|
|
||||||
|
不可变基础设施和声明式配置的这些原则有许多好处:它容易防止配置<ruby>偏移<rt>drift</rt></ruby>,或者 “<ruby>雪花<rt>snowflake</rt></ruby>” 应用程序实例;声明部署配置可以保存在版本控制中,与代码在一起;并且, Kubernetes 大部分都可以自我修复,比如,如果系统经历失败,假如是一个底层的计算节点失败,系统可以重新构建,并且根据在声明配置中指定的状态去重新均衡应用程序。
|
||||||
|
|
||||||
|
Kubernetes 提供几个抽象概念和 API,使之可以更容易地去构建这些分布式的应用程序,比如,如下的这些基于微服务架构的:
|
||||||
|
|
||||||
|
* [<ruby>豆荚<rt>Pod</rt></ruby>][5] —— 这是 Kubernetes 中的最小部署单元,并且,它本质上是一组容器。 <ruby>豆荚<rt>Pod</rt></ruby>可以让一个微服务应用程序容器与其它“挎斗” 容器,像日志、监视或通讯管理这样的系统服务一起被分组。在一个豆荚中的容器共享同一个文件系统和网络命名空间。注意,一个单个的容器也是可以被部署的,但是,通常的做法是部署在一个豆荚中。
|
||||||
|
* [服务][6] —— Kubernetes 服务提供负载均衡、命名和发现,以将一个微服务与其它隔离。服务是通过[复制控制器][7]支持的,它反过来又负责维护在系统内运行期望数量的豆荚实例的相关细节。服务、复制控制器和豆荚在 Kubernetes 中通过使用“[标签][8]”连接到一起,并通过它进行命名和选择。
|
||||||
|
|
||||||
|
现在让我们来为我们的基于 Java 的微服务应用程序创建一个服务。
|
||||||
|
|
||||||
|
### 构建 Java 应用程序和容器镜像
|
||||||
|
|
||||||
|
在我们开始创建一个容器和相关的 Kubernetes 部署配置之前,我们必须首先确认,我们已经安装了下列必需的组件:
|
||||||
|
|
||||||
|
* 适用于 [Mac][11] / [Windows][12] / [Linux][13] 的 Docker - 这允许你在本地机器上,在 Kubernetes 之外去构建、运行和测试 Docker 容器。
|
||||||
|
* [Minikube][14] - 这是一个工具,它可以通过虚拟机,在你本地部署的机器上很容易地去运行一个单节点的 Kubernetes 测试集群。
|
||||||
|
* 一个 [GitHub][15] 帐户和本地安装的 [Git][16] - 示例代码保存在 GitHub 上,并且通过使用本地的 Git,你可以复刻该仓库,并且去提交改变到该应用程序的你自己的副本中。
|
||||||
|
* [Docker Hub][17] 帐户 - 如果你想跟着这篇教程进行,你将需要一个 Docker Hub 帐户,以便推送和保存你将在后面创建的容器镜像的拷贝。
|
||||||
|
* [Java 8][18] (或 9) SDK 和 [Maven][19] - 我们将使用 Maven 和附属的工具使用 Java 8 特性去构建代码。
|
||||||
|
|
||||||
|
从 GitHub 克隆项目库代码(可选,你可以<ruby>复刻<rt>fork</rt></ruby>这个库,并且克隆一个你个人的拷贝),找到 “shopfront” 微服务应用: [https://github.com/danielbryantuk/oreilly-docker-java-shopping/][27]。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git clone git@github.com:danielbryantuk/oreilly-docker-java-shopping.git
|
||||||
|
$ cd oreilly-docker-java-shopping/shopfront
|
||||||
|
```
|
||||||
|
|
||||||
|
请加载 shopfront 代码到你选择的编辑器中,比如,IntelliJ IDE 或 Eclipse,并去研究它。让我们使用 Maven 来构建应用程序。最终生成包含该应用的可运行的 JAR 文件位于 `./target` 的目录中。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ mvn clean install
|
||||||
|
…
|
||||||
|
[INFO] ------------------------------------------------------------------------
|
||||||
|
[INFO] BUILD SUCCESS
|
||||||
|
[INFO] ------------------------------------------------------------------------
|
||||||
|
[INFO] Total time: 17.210 s
|
||||||
|
[INFO] Finished at: 2017-09-30T11:28:37+01:00
|
||||||
|
[INFO] Final Memory: 41M/328M
|
||||||
|
[INFO] ------------------------------------------------------------------------
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,我们将构建 Docker 容器镜像。一个容器镜像的操作系统选择、配置和构建步骤,一般情况下是通过一个 Dockerfile 指定的。我们看一下,我们的示例中位于 shopfront 目录中的 Dockerfile:
|
||||||
|
|
||||||
|
```
|
||||||
|
FROM openjdk:8-jre
|
||||||
|
ADD target/shopfront-0.0.1-SNAPSHOT.jar app.jar
|
||||||
|
EXPOSE 8010
|
||||||
|
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
|
||||||
|
```
|
||||||
|
|
||||||
|
第一行指定了,我们的容器镜像将被 “<ruby>从<rt>from</rt></ruby>” 这个 openjdk:8-jre 基础镜像中创建。[openjdk:8-jre][28] 镜像是由 OpenJDK 团队维护的,并且包含了我们在 Docker 容器(就像一个安装和配置了 OpenJDK 8 JDK的操作系统)中运行 Java 8 应用程序所需要的一切东西。第二行是,将我们上面构建的可运行的 JAR “<ruby>添加<rt>add</rt></ruby>” 到这个镜像。第三行指定了端口号是 8010,我们的应用程序将在这个端口号上监听,如果外部需要可以访问,必须要 “<ruby>暴露<rt>exposed</rt></ruby>” 它,第四行指定 “<ruby>入口<rt>entrypoint</rt></ruby>” ,即当容器初始化后去运行的命令。现在,我们来构建我们的容器:
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
$ docker build -t danielbryantuk/djshopfront:1.0 .
|
||||||
|
Successfully built 87b8c5aa5260
|
||||||
|
Successfully tagged danielbryantuk/djshopfront:1.0
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,我们推送它到 Docker Hub。如果你没有通过命令行登入到 Docker Hub,现在去登入,输入你的用户名和密码:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ docker login
|
||||||
|
Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.
|
||||||
|
Username:
|
||||||
|
Password:
|
||||||
|
Login Succeeded
|
||||||
|
$
|
||||||
|
$ docker push danielbryantuk/djshopfront:1.0
|
||||||
|
The push refers to a repository [docker.io/danielbryantuk/djshopfront]
|
||||||
|
9b19f75e8748: Pushed
|
||||||
|
...
|
||||||
|
cf4ecb492384: Pushed
|
||||||
|
1.0: digest: sha256:8a6b459b0210409e67bee29d25bb512344045bd84a262ede80777edfcff3d9a0 size: 2210
|
||||||
|
```
|
||||||
|
|
||||||
|
### 部署到 Kubernetes 上
|
||||||
|
|
||||||
|
现在,让我们在 Kubernetes 中运行这个容器。首先,切换到项目根目录的 `kubernetes` 目录:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd ../kubernetes
|
||||||
|
```
|
||||||
|
|
||||||
|
打开 Kubernetes 部署文件 `shopfront-service.yaml`,并查看内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: Service
|
||||||
|
metadata:
|
||||||
|
name: shopfront
|
||||||
|
labels:
|
||||||
|
app: shopfront
|
||||||
|
spec:
|
||||||
|
type: NodePort
|
||||||
|
selector:
|
||||||
|
app: shopfront
|
||||||
|
ports:
|
||||||
|
- protocol: TCP
|
||||||
|
port: 8010
|
||||||
|
name: http
|
||||||
|
|
||||||
|
---
|
||||||
|
apiVersion: v1
|
||||||
|
kind: ReplicationController
|
||||||
|
metadata:
|
||||||
|
name: shopfront
|
||||||
|
spec:
|
||||||
|
replicas: 1
|
||||||
|
template:
|
||||||
|
metadata:
|
||||||
|
labels:
|
||||||
|
app: shopfront
|
||||||
|
spec:
|
||||||
|
containers:
|
||||||
|
- name: shopfront
|
||||||
|
image: danielbryantuk/djshopfront:latest
|
||||||
|
ports:
|
||||||
|
- containerPort: 8010
|
||||||
|
livenessProbe:
|
||||||
|
httpGet:
|
||||||
|
path: /health
|
||||||
|
port: 8010
|
||||||
|
initialDelaySeconds: 30
|
||||||
|
timeoutSeconds: 1
|
||||||
|
```
|
||||||
|
|
||||||
|
这个 yaml 文件的第一节创建了一个名为 “shopfront” 的服务,它将到该服务(8010 端口)的 TCP 流量路由到标签为 “app: shopfront” 的豆荚中 。配置文件的第二节创建了一个 `ReplicationController` ,其通知 Kubernetes 去运行我们的 shopfront 容器的一个复制品(实例),它是我们标为 “app: shopfront” 的声明(spec)的一部分。我们也指定了暴露在我们的容器上的 8010 应用程序端口,并且声明了 “livenessProbe” (即健康检查),Kubernetes 可以用于去决定我们的容器应用程序是否正确运行并准备好接受流量。让我们来启动 `minikube` 并部署这个服务(注意,根据你部署的机器上的可用资源,你可能需要去修 `minikube` 中的指定使用的 CPU 和<ruby>内存<rt>memory</rt></ruby>):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ minikube start --cpus 2 --memory 4096
|
||||||
|
Starting local Kubernetes v1.7.5 cluster...
|
||||||
|
Starting VM...
|
||||||
|
Getting VM IP address...
|
||||||
|
Moving files into cluster...
|
||||||
|
Setting up certs...
|
||||||
|
Connecting to cluster...
|
||||||
|
Setting up kubeconfig...
|
||||||
|
Starting cluster components...
|
||||||
|
Kubectl is now configured to use the cluster.
|
||||||
|
$ kubectl apply -f shopfront-service.yaml
|
||||||
|
service "shopfront" created
|
||||||
|
replicationcontroller "shopfront" created
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以通过使用 `kubectl get svc` 命令查看 Kubernetes 中所有的服务。你也可以使用 `kubectl get pods` 命令去查看所有相关的豆荚(注意,你第一次执行 get pods 命令时,容器可能还没有创建完成,并被标记为未准备好):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ kubectl get svc
|
||||||
|
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||||
|
kubernetes 10.0.0.1 <none> 443/TCP 18h
|
||||||
|
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 12s
|
||||||
|
$ kubectl get pods
|
||||||
|
NAME READY STATUS RESTARTS AGE
|
||||||
|
shopfront-0w1js 0/1 ContainerCreating 0 18s
|
||||||
|
$ kubectl get pods
|
||||||
|
NAME READY STATUS RESTARTS AGE
|
||||||
|
shopfront-0w1js 1/1 Running 0 2m
|
||||||
|
```
|
||||||
|
|
||||||
|
我们现在已经成功地在 Kubernetes 中部署完成了我们的第一个服务。
|
||||||
|
|
||||||
|
### 是时候进行烟雾测试了
|
||||||
|
|
||||||
|
现在,让我们使用 curl 去看一下,我们是否可以从 shopfront 应用程序的健康检查端点中取得数据:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ curl $(minikube service shopfront --url)/health
|
||||||
|
{"status":"UP"}
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以从 curl 的结果中看到,应用的 health 端点是启用的,并且是运行中的,但是,在应用程序按我们预期那样运行之前,我们需要去部署剩下的微服务应用程序容器。
|
||||||
|
|
||||||
|
### 构建剩下的应用程序
|
||||||
|
|
||||||
|
现在,我们有一个容器已经运行,让我们来构建剩下的两个微服务应用程序和容器:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd ..
|
||||||
|
$ cd productcatalogue/
|
||||||
|
$ mvn clean install
|
||||||
|
…
|
||||||
|
$ docker build -t danielbryantuk/djproductcatalogue:1.0 .
|
||||||
|
...
|
||||||
|
$ docker push danielbryantuk/djproductcatalogue:1.0
|
||||||
|
...
|
||||||
|
$ cd ..
|
||||||
|
$ cd stockmanager/
|
||||||
|
$ mvn clean install
|
||||||
|
...
|
||||||
|
$ docker build -t danielbryantuk/djstockmanager:1.0 .
|
||||||
|
...
|
||||||
|
$ docker push danielbryantuk/djstockmanager:1.0
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
这个时候, 我们已经构建了所有我们的微服务和相关的 Docker 镜像,也推送镜像到 Docker Hub 上。现在,我们去在 Kubernetes 中部署 `productcatalogue` 和 `stockmanager` 服务。
|
||||||
|
|
||||||
|
### 在 Kubernetes 中部署整个 Java 应用程序
|
||||||
|
|
||||||
|
与我们上面部署 shopfront 服务时类似的方式去处理它,我们现在可以在 Kubernetes 中部署剩下的两个微服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd ..
|
||||||
|
$ cd kubernetes/
|
||||||
|
$ kubectl apply -f productcatalogue-service.yaml
|
||||||
|
service "productcatalogue" created
|
||||||
|
replicationcontroller "productcatalogue" created
|
||||||
|
$ kubectl apply -f stockmanager-service.yaml
|
||||||
|
service "stockmanager" created
|
||||||
|
replicationcontroller "stockmanager" created
|
||||||
|
$ kubectl get svc
|
||||||
|
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||||
|
|
||||||
|
kubernetes 10.0.0.1 <none> 443/TCP 19h
|
||||||
|
productcatalogue 10.0.0.37 <nodes> 8020:31803/TCP 42s
|
||||||
|
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 13m
|
||||||
|
stockmanager 10.0.0.149 <nodes> 8030:30723/TCP 16s
|
||||||
|
$ kubectl get pods
|
||||||
|
NAME READY STATUS RESTARTS AGE
|
||||||
|
productcatalogue-79qn4 1/1 Running 0 55s
|
||||||
|
shopfront-0w1js 1/1 Running 0 13m
|
||||||
|
stockmanager-lmgj9 1/1 Running 0 29s
|
||||||
|
```
|
||||||
|
|
||||||
|
取决于你执行 “kubectl get pods” 命令的速度,你或许会看到所有都处于不再运行状态的豆荚。在转到这篇文章的下一节之前,我们要等着这个命令展示出所有豆荚都运行起来(或许,这个时候应该来杯咖啡!)
|
||||||
|
|
||||||
|
### 查看完整的应用程序
|
||||||
|
|
||||||
|
在所有的微服务部署完成并且所有相关的豆荚都正常运行后,我们现在将去通过 shopfront 服务的 GUI 去访问我们完整的应用程序。我们可以通过执行 `minikube` 命令在默认浏览器中打开这个服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ minikube service shopfront
|
||||||
|
```
|
||||||
|
|
||||||
|
如果一切正常,你将在浏览器中看到如下的页面:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
在这篇文章中,我们已经完成了由三个 Java Spring Boot 和 Dropwizard 微服务组成的应用程序,并且将它部署到 Kubernetes 上。未来,我们需要考虑的事还很多,比如,调试服务(或许是通过工具,像 [Telepresence][29] 和 [Sysdig][30]),通过一个像 [Jenkins][31] 或 [Spinnaker][32] 这样的可持续交付的过程去测试和部署,并且观察我们的系统运行。
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_本文是与 NGINX 协作创建的。 [查看我们的编辑独立性声明][22]._
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Daniel Bryant 是一名独立技术顾问,他是 SpectoLabs 的 CTO。他目前关注于通过识别价值流、创建构建过程、和实施有效的测试策略,从而在组织内部实现持续交付。Daniel 擅长并关注于“DevOps”工具、云/容器平台和微服务实现。他也贡献了几个开源项目,并定期为 InfoQ、 O’Reilly、和 Voxxed 撰稿...
|
||||||
|
|
||||||
|
------------------
|
||||||
|
|
||||||
|
via: https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java
|
||||||
|
|
||||||
|
作者:[Daniel Bryant][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.oreilly.com/people/d3f4d647-482d-4dce-a0e5-a09773b77150
|
||||||
|
[1]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||||
|
[2]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||||
|
[3]:https://www.nginx.com/resources/library/kubernetes-for-java-developers/
|
||||||
|
[4]:https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021
|
||||||
|
[5]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||||
|
[6]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||||
|
[7]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||||
|
[8]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||||
|
[9]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||||
|
[10]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||||
|
[11]:https://docs.docker.com/docker-for-mac/install/
|
||||||
|
[12]:https://docs.docker.com/docker-for-windows/install/
|
||||||
|
[13]:https://docs.docker.com/engine/installation/linux/ubuntu/
|
||||||
|
[14]:https://kubernetes.io/docs/tasks/tools/install-minikube/
|
||||||
|
[15]:https://github.com/
|
||||||
|
[16]:https://git-scm.com/
|
||||||
|
[17]:https://hub.docker.com/
|
||||||
|
[18]:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
|
||||||
|
[19]:https://maven.apache.org/
|
||||||
|
[20]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||||
|
[21]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||||
|
[22]:http://www.oreilly.com/about/editorial_independence.html
|
||||||
|
[23]:https://www.nginx.com/resources/library/containerizing-continuous-delivery-java/
|
||||||
|
[24]:https://kubernetes.io/
|
||||||
|
[25]:https://www.cncf.io/
|
||||||
|
[26]:https://research.google.com/pubs/pub44843.html
|
||||||
|
[27]:https://github.com/danielbryantuk/oreilly-docker-java-shopping/
|
||||||
|
[28]:https://hub.docker.com/_/openjdk/
|
||||||
|
[29]:https://telepresence.io/
|
||||||
|
[30]:https://www.sysdig.org/
|
||||||
|
[31]:https://wiki.jenkins.io/display/JENKINS/Kubernetes+Plugin
|
||||||
|
[32]:https://www.spinnaker.io/
|
||||||
@ -0,0 +1,136 @@
|
|||||||
|
记不住 Linux 命令?这三个工具可以帮你
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*apropos 工具几乎默认安装在每个 Linux 发行版上,它可以帮你找到你所需的命令。*
|
||||||
|
|
||||||
|
Linux 桌面从开始的简陋到现在走了很长的路。在我早期使用 Linux 的那段日子里,掌握命令行是最基本的 —— 即使是在桌面版。不过现在变了,很多人可能从没用过命令行。但对于 Linux 系统管理员来说,可不能这样。实际上,对于任何 Linux 管理员(不管是服务器还是桌面),命令行仍是必须的。从管理网络到系统安全,再到应用和系统设定 —— 没有什么工具比命令行更强大。
|
||||||
|
|
||||||
|
但是,实际上……你可以在 Linux 系统里找到_非常多_命令。比如只看 `/usr/bin` 目录,你就可以找到很多命令执行文件(你可以运行 `ls/usr/bin/ | wc -l` 看一下你的系统里这个目录下到底有多少命令)。当然,它们并不全是针对用户的执行文件,但是可以让你感受下 Linux 命令数量。在我的 Elementary OS 系统里,目录 `/usr/bin` 下有 2029 个可执行文件。尽管我只会用到其中的一小部分,我要怎么才能记住这一部分呢?
|
||||||
|
|
||||||
|
幸运的是,你可以使用一些工具和技巧,这样你就不用每天挣扎着去记忆这些命令了。我想和大家分享几个这样的小技巧,希望能让你们能稍微有效地使用命令行(顺便节省点脑力)。
|
||||||
|
|
||||||
|
我们从一个系统内置的工具开始介绍,然后再介绍两个可以安装的非常实用的程序。
|
||||||
|
|
||||||
|
### Bash 命令历史
|
||||||
|
|
||||||
|
不管你知不知道,Bash(最流行的 Linux shell)会保留你执行过的命令的历史。想实际操作下看看吗?有两种方式。打开终端窗口然后按向上方向键。你应该可以看到会有命令出现,一个接一个。一旦你找到了想用的命令,不用修改的话,可以直接按 Enter 键执行,或者修改后再按 Enter 键。
|
||||||
|
|
||||||
|
要重新执行(或修改一下再执行)之前运行过的命令,这是一个很好的方式。我经常用这个功能。它不仅仅让我不用去记忆一个命令的所有细节,而且可以不用一遍遍重复地输入同样的命令。
|
||||||
|
|
||||||
|
说到 Bash 的命令历史,如果你执行命令 `history`,你可以列出你过去执行过的命令列表(图 1)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 1: 你能找到我敲的命令里的错误吗?*
|
||||||
|
|
||||||
|
你的 Bash 命令历史保存的历史命令的数量可以在 `~/.bashrc` 文件里设置。在这个文件里,你可以找到下面两行:
|
||||||
|
|
||||||
|
```
|
||||||
|
HISTSIZE=1000
|
||||||
|
|
||||||
|
HISTFILESIZE=2000
|
||||||
|
```
|
||||||
|
|
||||||
|
`HISTSIZE` 是命令历史列表里记录的命令的最大数量,而 `HISTFILESIZE` 是命令历史文件的最大行数。
|
||||||
|
|
||||||
|
显然,默认情况下,Bash 会记录你的 1000 条历史命令。这已经很多了。有时候,这也被认为是一个安全漏洞。如果你在意的话,你可以随意减小这个数值,在安全性和实用性之间平衡。如果你不希望 Bash 记录你的命令历史,可以将 `HISTSIZE` 设置为 `0`。
|
||||||
|
|
||||||
|
如果你修改了 `~/.bashrc` 文件,记得要登出后再重新登录(否则改动不会生效)。
|
||||||
|
|
||||||
|
### apropos
|
||||||
|
|
||||||
|
这是第一个我要介绍的工具,可以帮助你记忆 Linux 命令。apropos (意即“关于”)能够搜索 Linux 帮助文档来帮你找到你想要的命令。比如说,你不记得你用的发行版用的什么防火墙工具了。你可以输入 `apropos “firewall” `,然后这个工具会返回相关的命令(图 2)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 2: 你用的什么防火墙?*
|
||||||
|
|
||||||
|
再假如你需要一个操作目录的命令,但是完全不知道要用哪个呢?输入 `apropos “directory”` 就可以列出在帮助文档里包含了字符 “directory” 的所有命令(图 3)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 3: 可以操作目录的工具有哪些呢?*
|
||||||
|
|
||||||
|
apropos 工具在几乎所有 Linux 发行版里都会默认安装。
|
||||||
|
|
||||||
|
### Fish
|
||||||
|
|
||||||
|
还有另一个能帮助你记忆命令的很好的工具。Fish 是 Linux/Unix/Mac OS 的一个命令行 shell,有一些很好用的功能。
|
||||||
|
|
||||||
|
* 自动推荐
|
||||||
|
* VGA 颜色
|
||||||
|
* 完美的脚本支持
|
||||||
|
* 基于网页的配置
|
||||||
|
* 帮助文档自动补全
|
||||||
|
* 语法高亮
|
||||||
|
* 以及更多
|
||||||
|
|
||||||
|
自动推荐功能让 fish 非常方便(特别是你想不起来一些命令的时候)。
|
||||||
|
|
||||||
|
你可能觉得挺好,但是 fish 没有被默认安装。对于 Ubuntu(以及它的衍生版),你可以用下面的命令安装:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt-add-repository ppa:fish-shell/release-2
|
||||||
|
sudo apt update
|
||||||
|
sudo apt install fish
|
||||||
|
```
|
||||||
|
|
||||||
|
对于类 CentOS 系统,可以这样安装 fish。用下面的命令增加仓库:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo -s
|
||||||
|
cd /etc/yum.repos.d/
|
||||||
|
wget http://download.opensuse.org/repositories/shells:fish:release:2/CentOS_7/shells:fish:release:2.repo
|
||||||
|
```
|
||||||
|
|
||||||
|
用下面的命令更新仓库:
|
||||||
|
|
||||||
|
```
|
||||||
|
yum repolist
|
||||||
|
yum update
|
||||||
|
```
|
||||||
|
|
||||||
|
然后用下面的命令安装 fish:
|
||||||
|
|
||||||
|
```
|
||||||
|
yum install fish
|
||||||
|
```
|
||||||
|
|
||||||
|
fish 用起来可能没你想象的那么直观。记住,fish 是一个 shell,所以在使用命令之前你得先登录进去。在你的终端里,运行命令 fish 然后你就会看到自己已经打开了一个新的 shell(图 4)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图 4: fish 的交互式 shell。*
|
||||||
|
|
||||||
|
在开始输入命令的时候,fish 会自动补齐命令。如果推荐的命令不是你想要的,按下键盘的 Tab 键可以浏览更多选择。如果正好是你想要的,按下键盘的向右键补齐命令,然后按下 Enter 执行。在用完 fish 后,输入 exit 来退出 shell。
|
||||||
|
|
||||||
|
Fish 还可以做更多事情,但是这里只介绍用来帮助你记住命令,自动推荐功能足够了。
|
||||||
|
|
||||||
|
### 保持学习
|
||||||
|
|
||||||
|
Linux 上有太多的命令了。但你也不用记住所有命令。多亏有 Bash 命令历史以及像 apropos 和 fish 这样的工具,你不用消耗太多记忆来回忆那些帮你完成任务的命令。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linux.com/learn/intro-to-linux/2017/10/3-tools-help-you-remember-linux-commands
|
||||||
|
|
||||||
|
作者:[JACK WALLEN][a]
|
||||||
|
译者:[zpl1025](https://github.com/zpl1025)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linux.com/users/jlwallen
|
||||||
|
[1]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[2]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[3]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[4]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[5]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[6]:https://www.linux.com/files/images/commands1jpg
|
||||||
|
[7]:https://www.linux.com/files/images/commands2jpg
|
||||||
|
[8]:https://www.linux.com/files/images/commands3jpg
|
||||||
|
[9]:https://www.linux.com/files/images/commands4jpg
|
||||||
|
[10]:https://www.linux.com/files/images/commands-mainjpg
|
||||||
|
[11]:http://download.opensuse.org/repositories/shells:fish:release:2/CentOS_7/shells:fish:release:2.repo
|
||||||
@ -0,0 +1,71 @@
|
|||||||
|
在 Linux 图形栈上运行 Android
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 根据 Collabora 的 Linux 图形栈贡献者和软件工程师 Robert Foss 的说法,你现在可以在常规的 Linux 图形处理平台上运行 Android,这是非常强大的功能。了解更多关于他在欧洲嵌入式 Linux 会议上的演讲。[Creative Commons Zero][2] Pixabay
|
||||||
|
|
||||||
|
你现在可以在常规的 Linux 图形栈之上运行 Android。以前并不能这样,根据 Collabora 的 Linux 图形栈贡献者和软件工程师 Robert Foss 的说法,这是非常强大的功能。在即将举行的[欧洲 Linux 嵌入式会议][5]的讲话中,Foss 将会介绍这一领域的最新进展,并讨论这些变化如何让你可以利用内核中的新功能和改进。
|
||||||
|
|
||||||
|
在本文中,Foss 解释了更多内容,并提供了他的演讲的预览。
|
||||||
|
|
||||||
|
**Linux.com:你能告诉我们一些你谈论的图形栈吗?**
|
||||||
|
|
||||||
|
**Foss:** 传统的 Linux 图形系统(如 X11)大都没有使用<ruby>平面图形<rt>plane</rt></ruby>。但像 Android 和 Wayland 这样的现代图形系统可以充分利用它。
|
||||||
|
|
||||||
|
Android 在 HWComposer 中最成功实现了平面支持,其图形栈与通常的 Linux 桌面图形栈有所不同。在桌面上,典型的合成器只是使用 GPU 进行所有的合成,因为这是桌面上唯一有的东西。
|
||||||
|
|
||||||
|
大多数嵌入式和移动芯片都有为 Android 设计的专门的 2D 合成硬件。这是通过将显示的内容分成不同的图层,然后智能地将图层送到经过优化处理图层的硬件。这就可以释放 GPU 来处理你真正关心的事情,同时它让硬件更有效率地做最好一件事。
|
||||||
|
|
||||||
|
**Linux.com:当你说到 Android 时,你的意思是 Android 开源项目 (AOSP) 么?**
|
||||||
|
|
||||||
|
**Foss:** Android 开源项目(AOSP)是许多 Android 产品建立的基础,AOSP 和 Android 之间没有什么区别。
|
||||||
|
|
||||||
|
具体来说,我的工作已经在 AOSP 上完成,但没有什么可以阻止将此项工作加入到已经发货的 Android 产品中。
|
||||||
|
|
||||||
|
区别更多在于授权和满足 Google 对 Android 产品的要求,而不是代码。
|
||||||
|
|
||||||
|
**Linux.com: 谁想要运行它,为什么?有什么好处?**
|
||||||
|
|
||||||
|
**Foss:** AOSP 为你提供了大量免费的东西,例如针对可用性、低功耗和多样化硬件进行优化的软件栈。它比任何一家公司自行开发的更精致、更灵活, 而不需要投入大量资源。
|
||||||
|
|
||||||
|
作为制造商,它还为你提供了一个能够立即为你的平台开发的大量开发人员。
|
||||||
|
|
||||||
|
**Linux.com:有什么实际使用情况?**
|
||||||
|
|
||||||
|
** Foss:** 新的部分是在常规 Linux 图形栈上运行 Android 的能力。可以在主线/上游内核和驱动来做到这一点,让你可以利用内核中的新功能和改进,而不仅仅依赖于来自于你的供应商的大量分支的 BSP。
|
||||||
|
|
||||||
|
对于任何有合理标准的 Linux 支持的 GPU,你现在可以在上面运行 Android。以前并不能这样。而且这样做是非常强大的。
|
||||||
|
|
||||||
|
同样重要的是,它鼓励 GPU 设计者与上游的驱动一起工作。现在他们有一个简单的方法来提供适用于 Android 和 Linux 的驱动程序,而无需额外的努力。他们的成本将会降低,维护上游 GPU 驱动变得更有吸引力。
|
||||||
|
|
||||||
|
例如,我们希望看到主线内核支持高通 SOC,我们希望成为实现这一目标的一部分。
|
||||||
|
|
||||||
|
总而言之,这将有助于硬件生态系统获得更好的软件支持,软件生态系统有更多的硬件配合。
|
||||||
|
|
||||||
|
* 它改善了 SBC/开发板制造商的经济性:它们可以提供一个经过良好测试的栈,既可以在两者之间工作,而不必提供 “Linux 栈” 和 Android 栈。
|
||||||
|
* 它简化了驱动程序开发人员的工作,因为只有一个优化和支持目标。
|
||||||
|
* 它支持 Android 社区,因为在主线内核上运行的 Android 可以让他们分享上游的改进。
|
||||||
|
* 这有助于上游,因为我们获得了一个产品级质量的栈,这些栈已经在硬件设计师的帮助下进行了测试和开发。
|
||||||
|
|
||||||
|
以前,Mesa 被视为二等栈,但现在它是最新的(完全符合 Vulkan 1.0、OpenGL 4.6、OpenGL ES 3.2)另外还有性能和产品质量。
|
||||||
|
|
||||||
|
这意味着驱动开发人员可以参与 Mesa,相信他们正在分享他人的辛勤工作,并且还有一个很好的基础。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linux.com/blog/event/elce/2017/10/running-android-top-linux-graphics-stack
|
||||||
|
|
||||||
|
作者:[SWAPNIL BHARTIYA][a]
|
||||||
|
译者:[ ](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linux.com/users/arnieswap
|
||||||
|
[1]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||||
|
[3]:https://www.linux.com/files/images/robert-fosspng
|
||||||
|
[4]:https://www.linux.com/files/images/linux-graphics-stackjpg
|
||||||
|
[5]:http://events.linuxfoundation.org/events/embedded-linux-conference-europe
|
||||||
66
published/20171024 Top 5 Linux pain points in 2017.md
Normal file
66
published/20171024 Top 5 Linux pain points in 2017.md
Normal file
@ -0,0 +1,66 @@
|
|||||||
|
2017 年 Linux 的五大痛点
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 目前为止糟糕的文档是 Linux 用户最头痛的问题。这里还有一些其他常见的问题。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
图片提供: [Internet Archive Book Images][8]. Opensource.com 修改 [CC BY-SA 4.0][9]
|
||||||
|
|
||||||
|
正如我在 [2016 年开源年鉴][10]的“[故障排除提示:5 个最常见的 Linux 问题][11]”中所讨论的,对大多数用户而言 Linux 能安装并按照预期运行,但有些不可避免地会遇到问题。过去一年在这方面有什么变化?又一次,我将问题提交给 LinuxQuestions.org 和社交媒体,并分析了 LQ 回复情况。以下是更新后的结果。
|
||||||
|
|
||||||
|
### 1、 文档
|
||||||
|
|
||||||
|
文档及其不足是今年最大的痛点之一。尽管开源的方式产生了优秀的代码,但是制作高质量文档的重要性在最近才走到了前列。随着越来越多的非技术用户采用 Linux 和开源软件,文档的质量和数量将变得至关重要。如果你想为开源项目做出贡献,但不觉得你有足够的技术来提供代码,那么改进文档是参与的好方法。许多项目甚至将文档保存在其仓库中,因此你可以使用你的贡献来适应版本控制的工作流。
|
||||||
|
|
||||||
|
### 2、 软件/库版本不兼容
|
||||||
|
|
||||||
|
我对此感到惊讶,但软件/库版本不兼容性屡被提及。如果你没有运行某个主流发行版,这个问题似乎更加严重。我个人_许多_年来没有遇到这个问题,但是越来越多的诸如 [AppImage][15]、[Flatpak][16] 和 Snaps 等解决方案的采用让我相信可能确实存在这些情况。我有兴趣听到更多关于这个问题的信息。如果你最近遇到过,请在评论中告诉我。
|
||||||
|
|
||||||
|
### 3、 UEFI 和安全启动
|
||||||
|
|
||||||
|
尽管随着更多支持的硬件部署,这个问题在继续得到改善,但许多用户表示仍然存在 UEFI 和/或<ruby>安全启动<rt>secure boot</rt></ruby>问题。使用开箱即用完全支持 UEFI/安全启动的发行版是最好的解决方案。
|
||||||
|
|
||||||
|
### 4、 弃用 32 位
|
||||||
|
|
||||||
|
许多用户对他们最喜欢的发行版和软件项目中的 32 位支持感到失望。尽管如果 32 位支持是必须的,你仍然有很多选择,但可能会继续支持市场份额和心理份额不断下降的平台的项目越来越少。幸运的是,我们谈论的是开源,所以只要_有人_关心这个平台,你可能至少有几个选择。
|
||||||
|
|
||||||
|
### 5、 X 转发的支持和测试恶化
|
||||||
|
|
||||||
|
尽管 Linux 的许多长期和资深的用户经常使用 <ruby>X 转发<rt>X-forwarding</rt></ruby>,并将其视为关键功能,但随着 Linux 变得越来越主流,它看起来很少得到测试和支持,特别是对较新的应用程序。随着 Wayland 网络透明转发的不断发展,情况可能会进一步恶化。
|
||||||
|
|
||||||
|
### 对比去年的遗留和改进
|
||||||
|
|
||||||
|
视频(特别是视频加速器、最新的显卡、专有驱动程序、高效的电源管理)、蓝牙支持、特定 WiFi 芯片和打印机以及电源管理以及挂起/恢复,对许多用户来说仍然是麻烦的。更积极的一点的是,安装、HiDPI 和音频问题比一年前显著降低。
|
||||||
|
|
||||||
|
Linux 继续取得巨大的进步,而持续的、几乎必然的改进周期将会确保持续数年。然而,与任何复杂的软件一样,总会有问题。
|
||||||
|
|
||||||
|
那么说,你在 2017 年发现 Linux 最常见的技术问题是什么?让我在评论中知道它们。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/10/top-5-linux-painpoints
|
||||||
|
|
||||||
|
作者:[Jeremy Garcia][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/jeremy-garcia
|
||||||
|
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[6]:https://opensource.com/article/17/10/top-5-linux-painpoints?rate=p-SFnMtS8f6qYAt2xW-CYdGHottubCz2XoPptwCzSiU
|
||||||
|
[7]:https://opensource.com/user/86816/feed
|
||||||
|
[8]:https://www.flickr.com/photos/internetarchivebookimages/20570945848/in/photolist-xkMtw9-xA5zGL-tEQLWZ-wFwzFM-aNwxgn-aFdWBj-uyFKYv-7ZCCBU-obY1yX-UAPafA-otBzDF-ovdDo6-7doxUH-obYkeH-9XbHKV-8Zk4qi-apz7Ky-apz8Qu-8ZoaWG-orziEy-aNwxC6-od8NTv-apwpMr-8Zk4vn-UAP9Sb-otVa3R-apz6Cb-9EMPj6-eKfyEL-cv5mwu-otTtHk-7YjK1J-ovhxf6-otCg2K-8ZoaJf-UAPakL-8Zo8j7-8Zk74v-otp4Ls-8Zo8h7-i7xvpR-otSosT-9EMPja-8Zk6Zi-XHpSDB-hLkuF3-of24Gf-ouN1Gv-fJzkJS-icfbY9
|
||||||
|
[9]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[10]:https://opensource.com/yearbook/2016
|
||||||
|
[11]:https://linux.cn/article-8185-1.html
|
||||||
|
[12]:https://opensource.com/users/jeremy-garcia
|
||||||
|
[13]:https://opensource.com/users/jeremy-garcia
|
||||||
|
[14]:https://opensource.com/article/17/10/top-5-linux-painpoints#comments
|
||||||
|
[15]:https://appimage.org/
|
||||||
|
[16]:http://flatpak.org/
|
||||||
@ -0,0 +1,211 @@
|
|||||||
|
2017 年哪个公司对开源贡献最多?让我们用 GitHub 的数据分析下
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
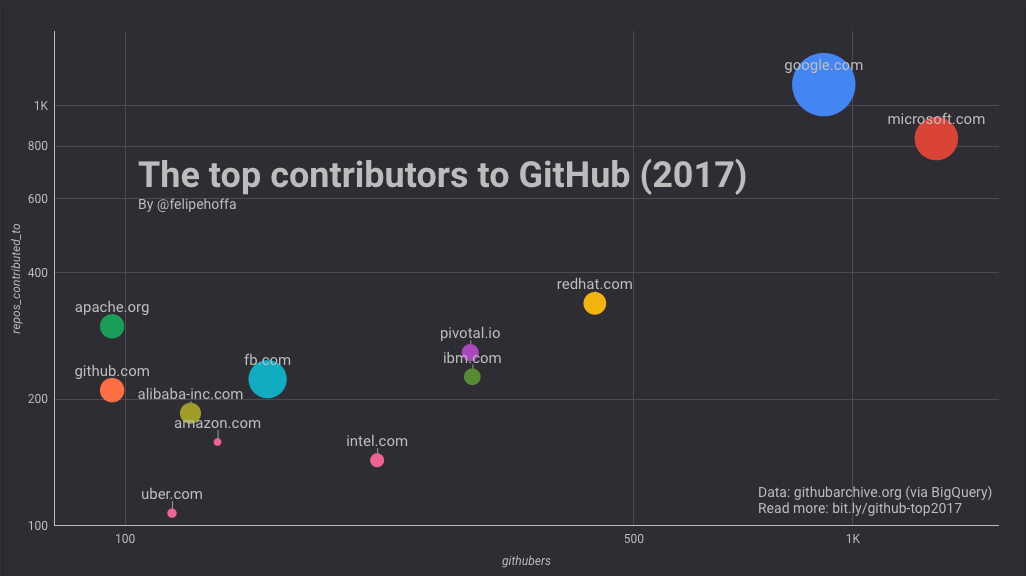
|
||||||
|
|
||||||
|
在这篇分析报告中,我们将使用 2017 年度截止至当前时间(2017 年 10 月)为止,GitHub 上所有公开的推送事件的数据。对于每个 GitHub 用户,我们将尽可能地猜测其所属的公司。此外,我们仅查看那些今年得到了至少 20 个星标的仓库。
|
||||||
|
|
||||||
|
以下是我的报告结果,你也可以[在我的交互式 Data Studio 报告上进一步加工][1]。
|
||||||
|
|
||||||
|
### 顶级云服务商的比较
|
||||||
|
|
||||||
|
2017 年它们在 GitHub 上的表现:
|
||||||
|
|
||||||
|
* 微软看起来约有 1300 名员工积极地推送代码到 GitHub 上的 825 个顶级仓库。
|
||||||
|
* 谷歌显示出约有 900 名员工在 GitHub 上活跃,他们推送代码到大约 1100 个顶级仓库。
|
||||||
|
* 亚马逊似乎只有 134 名员工活跃在 GitHub 上,他们推送代码到仅仅 158 个顶级项目上。
|
||||||
|
* 不是所有的项目都一样:在超过 25% 的仓库上谷歌员工要比微软员工贡献的多,而那些仓库得到了更多的星标(53 万对比 26 万)。亚马逊的仓库 2017 年合计才得到了 2.7 万个星标。
|
||||||
|
|
||||||
|
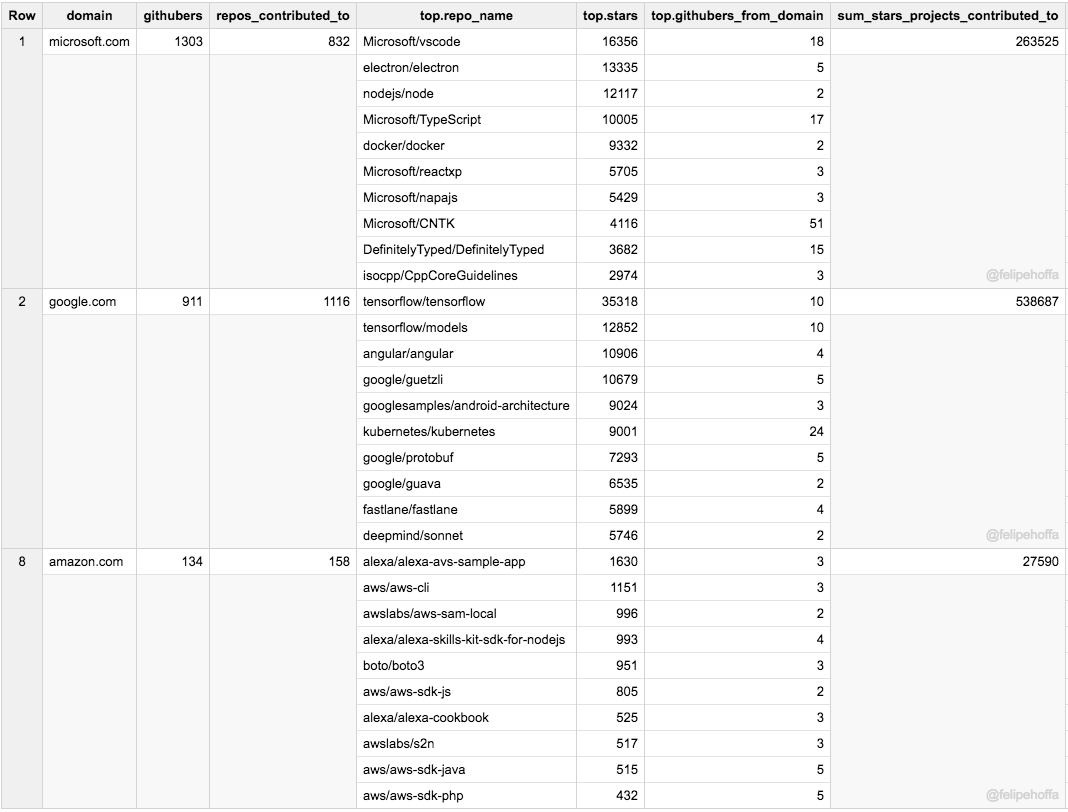
|
||||||
|
|
||||||
|
### 红帽、IBM、Pivotal、英特尔和 Facebook
|
||||||
|
|
||||||
|
如果说亚马逊看起来被微软和谷歌远远抛在了身后,那么这之间还有哪些公司呢?根据这个排名来看,红帽、Pivotal 和英特尔在 GitHub 上做出了巨大贡献:
|
||||||
|
|
||||||
|
注意,下表中合并了所有的 IBM 地区域名(各个地区会展示在其后的表格中)。
|
||||||
|
|
||||||
|
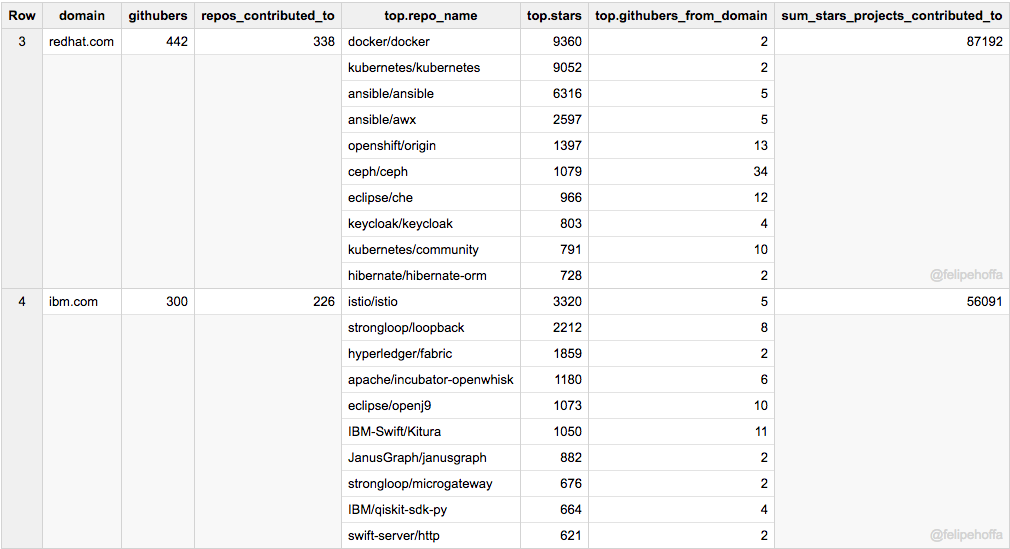
|
||||||
|
|
||||||
|
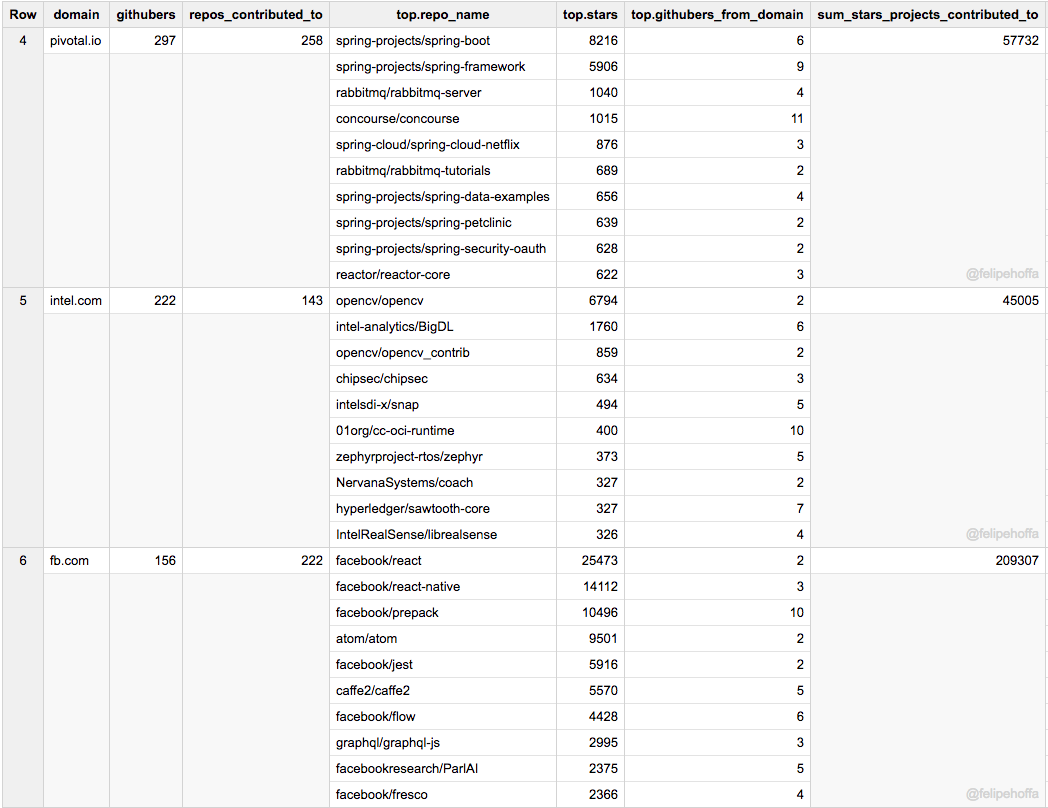
|
||||||
|
|
||||||
|
Facebook 和 IBM(美)在 GitHub 上的活跃用户数同亚马逊差不多,但是它们所贡献的项目得到了更多的星标(特别是 Facebook):
|
||||||
|
|
||||||
|
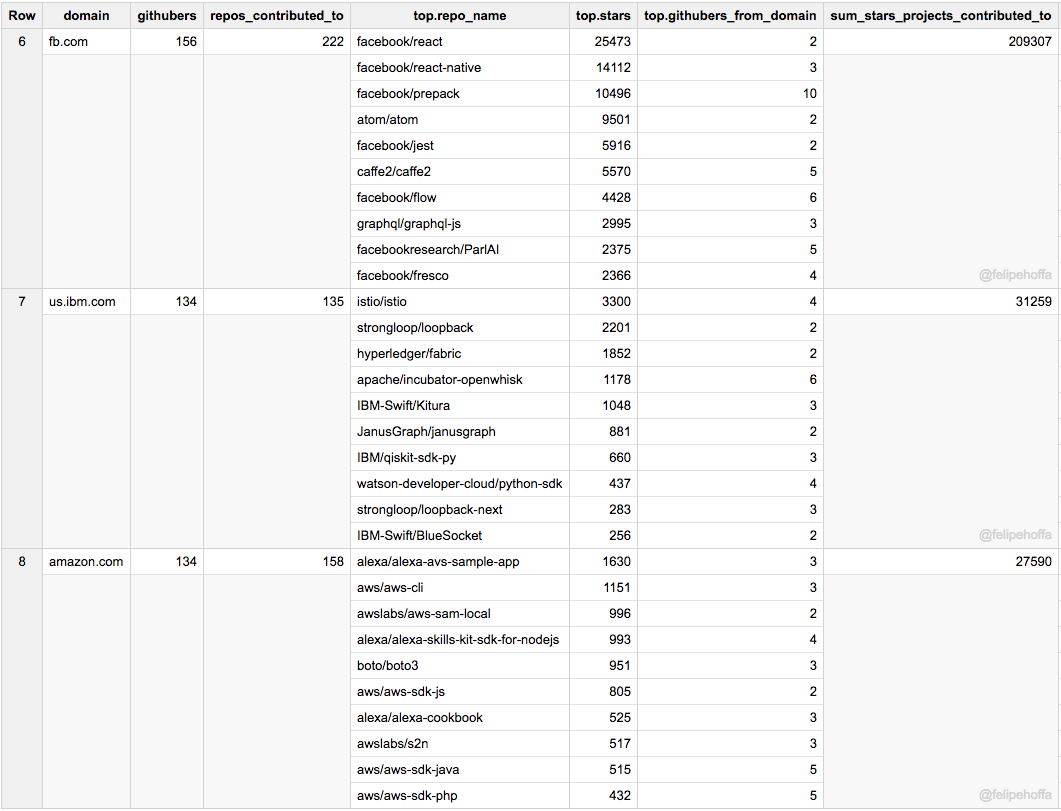
|
||||||
|
|
||||||
|
接下来是阿里巴巴、Uber 和 Wix:
|
||||||
|
|
||||||
|
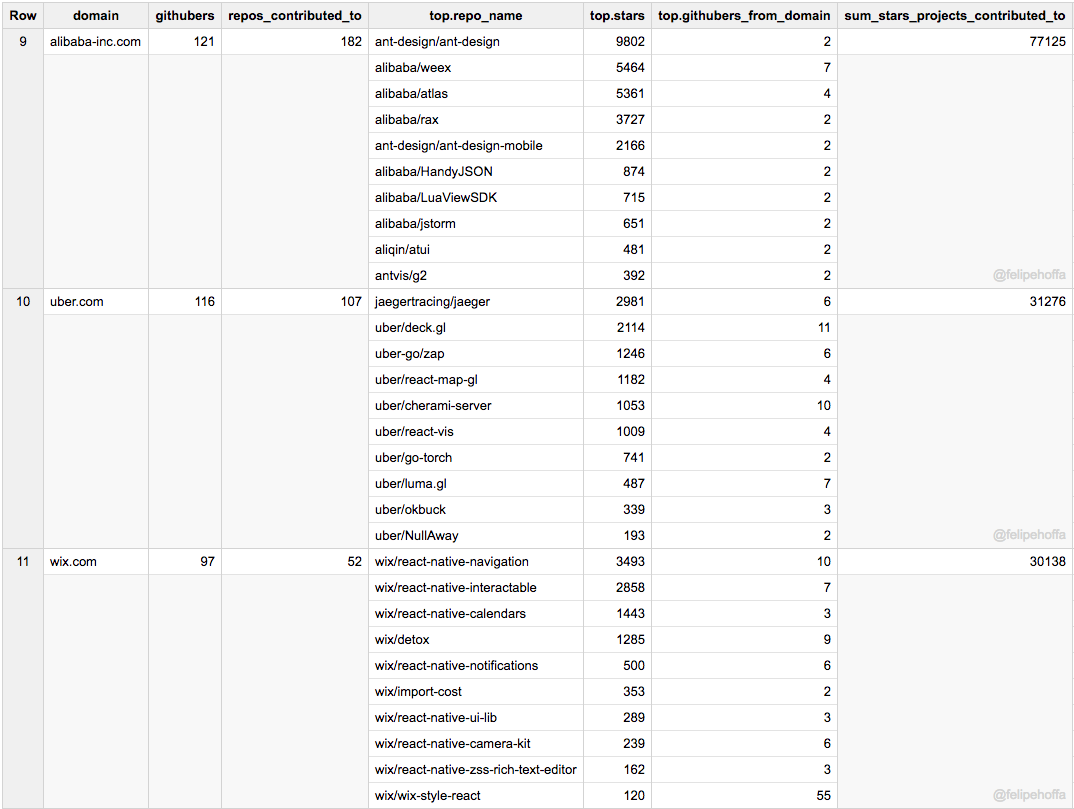
|
||||||
|
|
||||||
|
以及 GitHub 自己、Apache 和腾讯:
|
||||||
|
|
||||||
|
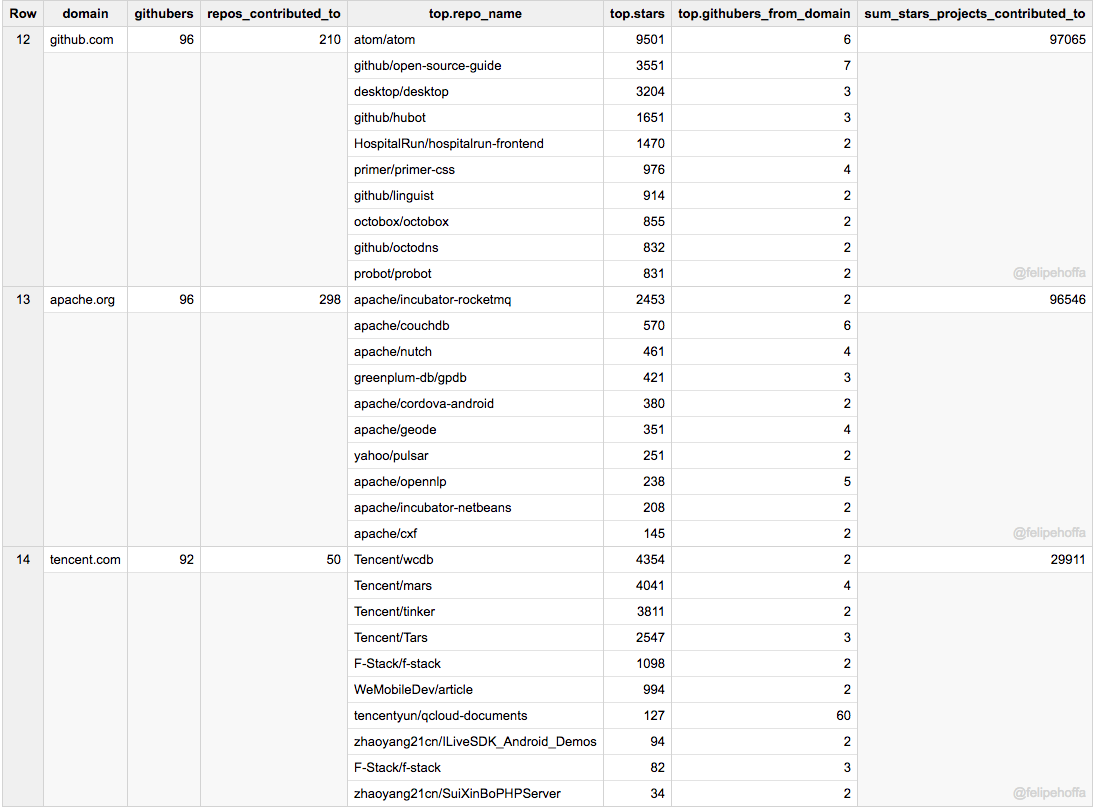
|
||||||
|
|
||||||
|
百度、苹果和 Mozilla:
|
||||||
|
|
||||||
|
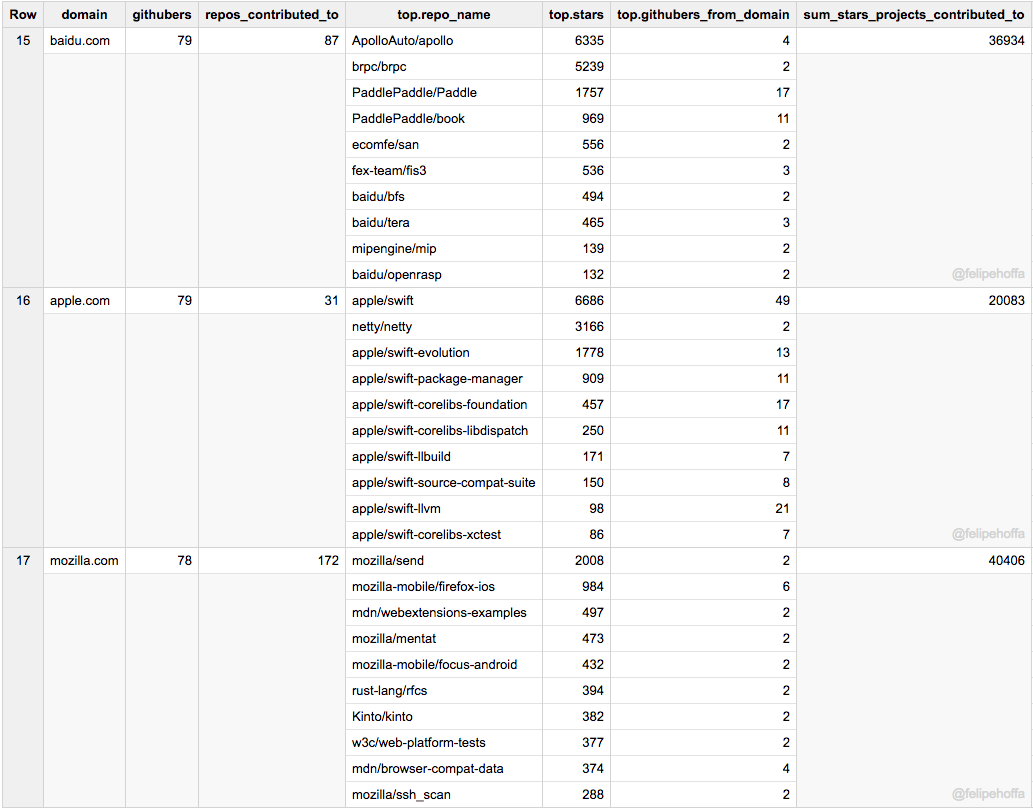
|
||||||
|
|
||||||
|
(LCTT 译注:很高兴看到国内的顶级互联网公司阿里巴巴、腾讯和百度在这里排名前列!)
|
||||||
|
|
||||||
|
甲骨文、斯坦福大学、麻省理工、Shopify、MongoDb、伯克利大学、VmWare、Netflix、Salesforce 和 Gsa.gov:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
LinkedIn、Broad Institute、Palantir、雅虎、MapBox、Unity3d、Automattic(WordPress 的开发商)、Sandia、Travis-ci 和 Spotify:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Chromium、UMich、Zalando、Esri、IBM (英)、SAP、EPAM、Telerik、UK Cabinet Office 和 Stripe:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Cern、Odoo、Kitware、Suse、Yandex、IBM (加)、Adobe、AirBnB、Chef 和 The Guardian:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Arm、Macports、Docker、Nuxeo、NVidia、Yelp、Elastic、NYU、WSO2、Mesosphere 和 Inria:
|
||||||
|
|
||||||
|
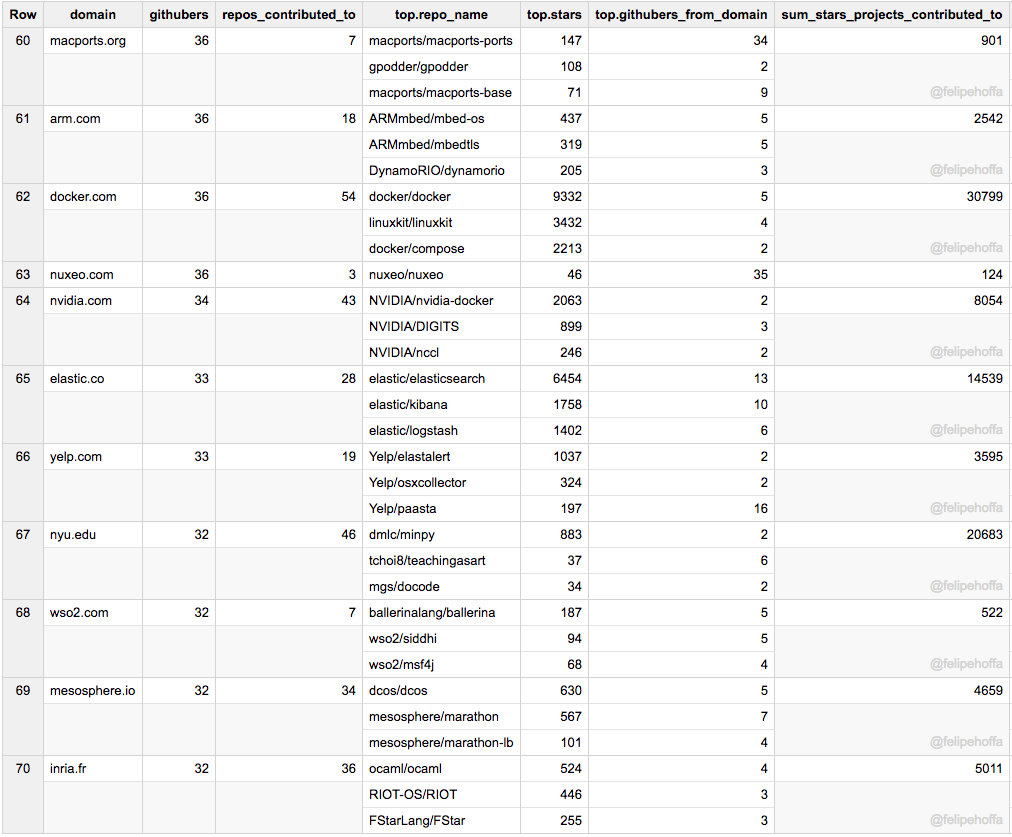
|
||||||
|
|
||||||
|
Puppet、斯坦福(计算机科学)、DatadogHQ、Epfl、NTT Data 和 Lawrence Livermore Lab:
|
||||||
|
|
||||||
|
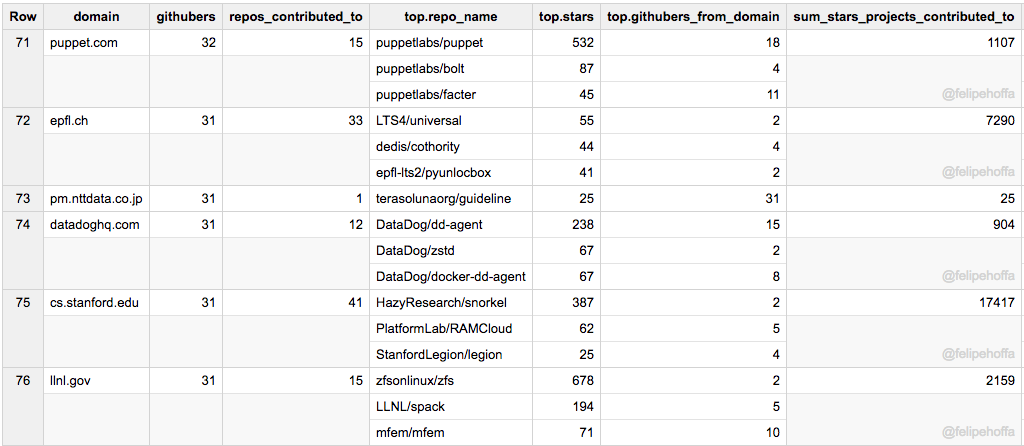
|
||||||
|
|
||||||
|
### 我的分析方法
|
||||||
|
|
||||||
|
#### 我是怎样将 GitHub 用户关联到其公司的
|
||||||
|
|
||||||
|
在 GitHub 上判定每个用户所述的公司并不容易,但是我们可以使用其推送事件的提交消息中展示的邮件地址域名来判断。
|
||||||
|
|
||||||
|
* 同样的邮件地址可以出现在几个用户身上,所以我仅考虑那些对此期间获得了超过 20 个星标的项目进行推送的用户。
|
||||||
|
* 我仅统计了在此期间推送超过 3 次的 GitHub 用户。
|
||||||
|
* 用户推送代码到 GitHub 上可以在其推送中显示许多不同的邮件地址,这部分是由 GIt 工作机制决定的。为了判定每个用户的组织,我会查找那些在推送中出现更频繁的邮件地址。
|
||||||
|
* 不是每个用户都在 GitHub 上使用其组织的邮件。有许多人使用 gmail.com、users.noreply.github.com 和其它邮件托管商的邮件地址。有时候这是为了保持匿名和保护其公司邮箱,但是如果我不能定位其公司域名,这些用户我就不会统计。抱歉。
|
||||||
|
* 有时候员工会更换所任职的公司。我会将他们分配给其推送最多的公司。
|
||||||
|
|
||||||
|
#### 我的查询语句
|
||||||
|
|
||||||
|
```
|
||||||
|
#standardSQL
|
||||||
|
WITH
|
||||||
|
period AS (
|
||||||
|
SELECT *
|
||||||
|
FROM `githubarchive.month.2017*` a
|
||||||
|
),
|
||||||
|
repo_stars AS (
|
||||||
|
SELECT repo.id, COUNT(DISTINCT actor.login) stars, APPROX_TOP_COUNT(repo.name, 1)[OFFSET(0)].value repo_name
|
||||||
|
FROM period
|
||||||
|
WHERE type='WatchEvent'
|
||||||
|
GROUP BY 1
|
||||||
|
HAVING stars>20
|
||||||
|
),
|
||||||
|
pushers_guess_emails_and_top_projects AS (
|
||||||
|
SELECT *
|
||||||
|
# , REGEXP_EXTRACT(email, r'@(.*)') domain
|
||||||
|
, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
|
||||||
|
FROM (
|
||||||
|
SELECT actor.id
|
||||||
|
, APPROX_TOP_COUNT(actor.login,1)[OFFSET(0)].value login
|
||||||
|
, APPROX_TOP_COUNT(JSON_EXTRACT_SCALAR(payload, '$.commits[0].author.email'),1)[OFFSET(0)].value email
|
||||||
|
, COUNT(*) c
|
||||||
|
, ARRAY_AGG(DISTINCT TO_JSON_STRING(STRUCT(b.repo_name,stars))) repos
|
||||||
|
FROM period a
|
||||||
|
JOIN repo_stars b
|
||||||
|
ON a.repo.id=b.id
|
||||||
|
WHERE type='PushEvent'
|
||||||
|
GROUP BY 1
|
||||||
|
HAVING c>3
|
||||||
|
)
|
||||||
|
)
|
||||||
|
SELECT * FROM (
|
||||||
|
SELECT domain
|
||||||
|
, githubers
|
||||||
|
, (SELECT COUNT(DISTINCT repo) FROM UNNEST(repos) repo) repos_contributed_to
|
||||||
|
, ARRAY(
|
||||||
|
SELECT AS STRUCT JSON_EXTRACT_SCALAR(repo, '$.repo_name') repo_name
|
||||||
|
, CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64) stars
|
||||||
|
, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo
|
||||||
|
GROUP BY 1, 2
|
||||||
|
HAVING githubers_from_domain>1
|
||||||
|
ORDER BY stars DESC LIMIT 3
|
||||||
|
) top
|
||||||
|
, (SELECT SUM(CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64)) FROM (SELECT DISTINCT repo FROM UNNEST(repos) repo)) sum_stars_projects_contributed_to
|
||||||
|
FROM (
|
||||||
|
SELECT domain, COUNT(*) githubers, ARRAY_CONCAT_AGG(ARRAY(SELECT * FROM UNNEST(repos) repo)) repos
|
||||||
|
FROM pushers_guess_emails_and_top_projects
|
||||||
|
#WHERE domain IN UNNEST(SPLIT('google.com|microsoft.com|amazon.com', '|'))
|
||||||
|
WHERE domain NOT IN UNNEST(SPLIT('gmail.com|users.noreply.github.com|qq.com|hotmail.com|163.com|me.com|googlemail.com|outlook.com|yahoo.com|web.de|iki.fi|foxmail.com|yandex.ru', '|')) # email hosters
|
||||||
|
GROUP BY 1
|
||||||
|
HAVING githubers > 30
|
||||||
|
)
|
||||||
|
WHERE (SELECT MAX(githubers_from_domain) FROM (SELECT repo, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo GROUP BY repo))>4 # second filter email hosters
|
||||||
|
)
|
||||||
|
ORDER BY githubers DESC
|
||||||
|
```
|
||||||
|
|
||||||
|
### FAQ
|
||||||
|
|
||||||
|
#### 有的公司有 1500 个仓库,为什么只统计了 200 个?有的仓库有 7000 个星标,为什么只显示 1500 个?
|
||||||
|
|
||||||
|
我进行了过滤。我只统计了 2017 年的星标。举个例子说,Apache 在 GitHub 上有超过 1500 个仓库,但是今年只有 205 个项目得到了超过 20 个星标。
|
||||||
|
|
||||||
|
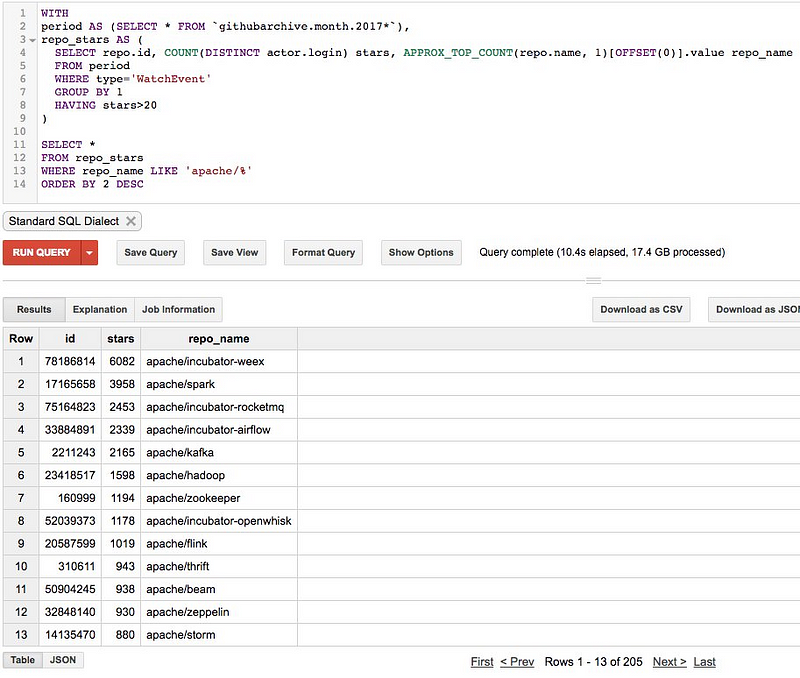
|
||||||
|
|
||||||
|
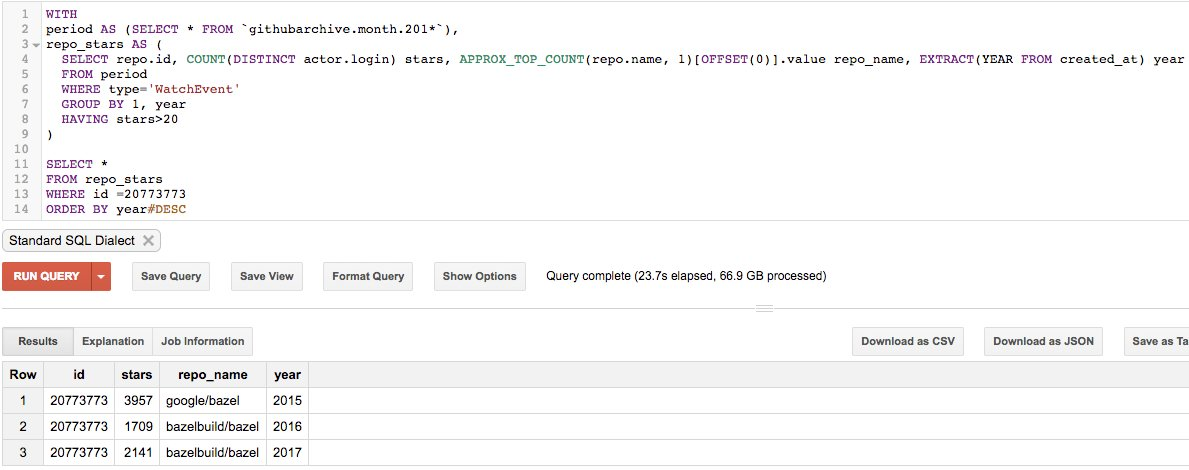
|
||||||
|
|
||||||
|
#### 这表明了开源的发展形势么?
|
||||||
|
|
||||||
|
注意,这个对 GitHub 的分析没有包括像 Android、Chromium、GNU、Mozilla 等顶级社区,也没有包括 Apache 基金会或 Eclipse 基金会,还有一些[其它][2]项目选择在 GitHub 之外开展起活动。
|
||||||
|
|
||||||
|
#### 这对于我的组织不公平
|
||||||
|
|
||||||
|
我只能统计我所看到的数据。欢迎对我的统计的前提提出意见,以及对我的统计方法给出改进方法。如果有能用的查询语句就更好了。
|
||||||
|
|
||||||
|
举个例子,要看看当我合并了 IBM 的各个地区域名到其顶级域时排名发生了什么变化,可以用一条 SQL 语句解决:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT *, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
|
||||||
|
```
|
||||||
|
|
||||||
|
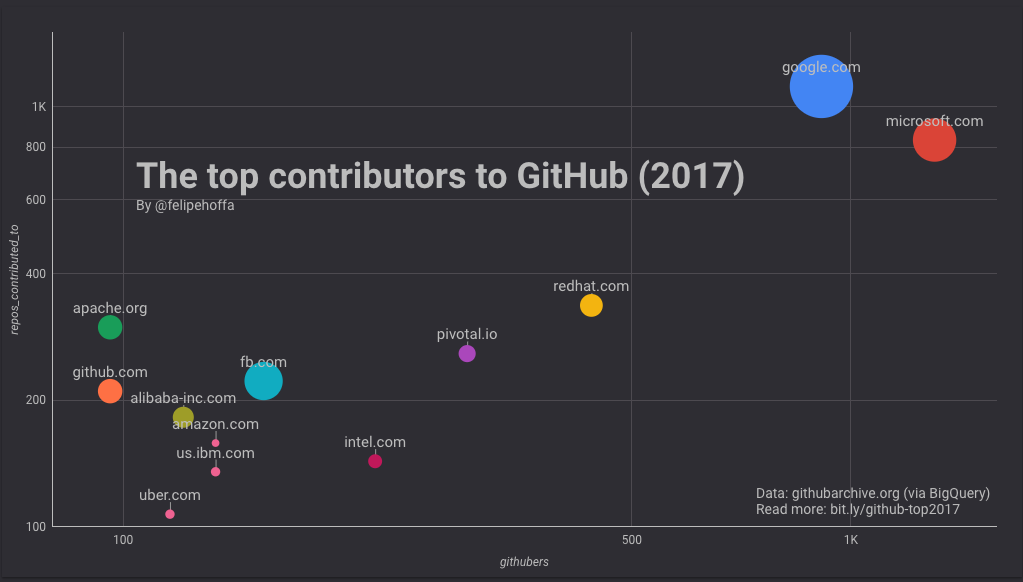
|
||||||
|
|
||||||
|
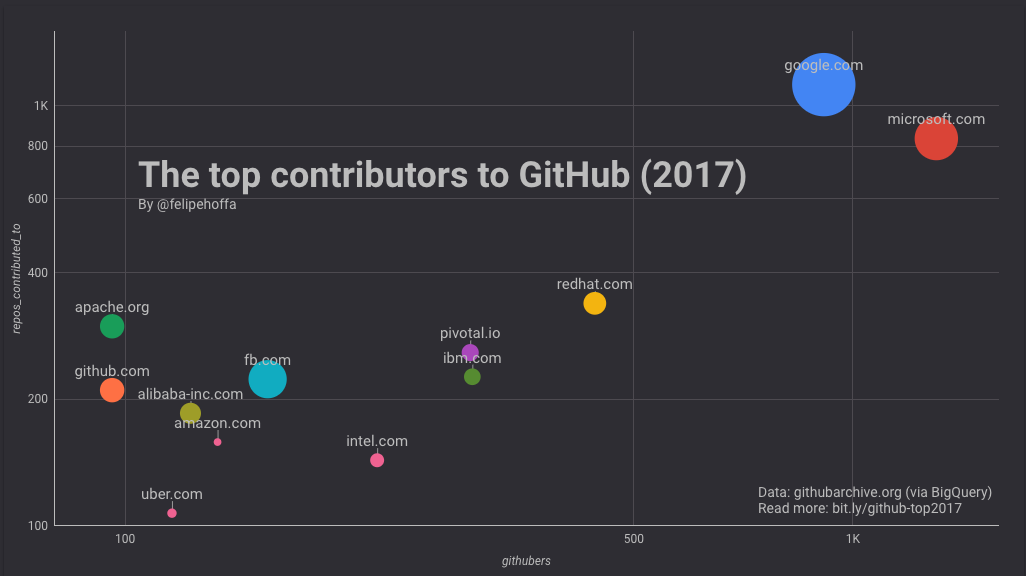
|
||||||
|
|
||||||
|
当合并了其地区域名后, IBM 的相对位置明显上升了。
|
||||||
|
|
||||||
|
#### 回音
|
||||||
|
|
||||||
|
- [关于“ GitHub 2017 年顶级贡献者”的一些思考][3]
|
||||||
|
|
||||||
|
### 接下来
|
||||||
|
|
||||||
|
我以前犯过错误,而且以后也可能再次出错。请查看所有的原始数据,并质疑我的前提假设——看看你能得到什么结论是很有趣的。
|
||||||
|
|
||||||
|
- [用一下交互式 Data Studio 报告][5]
|
||||||
|
|
||||||
|
感谢 [Ilya Grigorik][6] 保留的 [GitHub Archive][7] 提供了这么多年的 GitHub 数据!
|
||||||
|
|
||||||
|
想要看更多的文章?看看我的 [Medium][8]、[在 twitter 上关注我][9] 并订阅 [reddit.com/r/bigquery][10]。[试试 BigQuery][11],每个月可以[免费][12]分析 1 TB 的数据。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://medium.freecodecamp.org/the-top-contributors-to-github-2017-be98ab854e87
|
||||||
|
|
||||||
|
作者:[Felipe Hoffa][a]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://medium.freecodecamp.org/@hoffa?source=post_header_lockup
|
||||||
|
[1]:https://datastudio.google.com/open/0ByGAKP3QmCjLU1JzUGtJdTlNOG8
|
||||||
|
[2]:https://developers.google.com/open-source/organizations
|
||||||
|
[3]:https://redmonk.com/jgovernor/2017/10/25/some-thoughts-on-the-top-contributors-to-github-2017/
|
||||||
|
[4]:https://redmonk.com/jgovernor/2017/10/25/some-thoughts-on-the-top-contributors-to-github-2017/
|
||||||
|
[5]:https://datastudio.google.com/open/0ByGAKP3QmCjLU1JzUGtJdTlNOG8
|
||||||
|
[6]:https://medium.com/@igrigorik
|
||||||
|
[7]:http://githubarchive.org/
|
||||||
|
[8]:http://medium.com/@hoffa/
|
||||||
|
[9]:http://twitter.com/felipehoffa
|
||||||
|
[10]:https://reddit.com/r/bigquery
|
||||||
|
[11]:https://www.reddit.com/r/bigquery/comments/3dg9le/analyzing_50_billion_wikipedia_pageviews_in_5/
|
||||||
|
[12]:https://cloud.google.com/blog/big-data/2017/01/how-to-run-a-terabyte-of-google-bigquery-queries-each-month-without-a-credit-card
|
||||||
@ -0,0 +1,127 @@
|
|||||||
|
为什么 Ubuntu 放弃 Unity?创始人如是说
|
||||||
|
===========
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Mark Shuttleworth 是 Ubuntu 的创始人
|
||||||
|
|
||||||
|
Ubuntu 之前[在 4 月份][4]宣布决定放弃 Unity 让包括我在内的所有人都大感意外。
|
||||||
|
|
||||||
|
现在,Ubuntu 的创始人 [Mark Shuttleworth][7] 分享了关于 Ubuntu 为什么会选择放弃 Unity 的更多细节。
|
||||||
|
|
||||||
|
答案可能会出乎意料……
|
||||||
|
|
||||||
|
或许不会,因为答案也在情理之中。
|
||||||
|
|
||||||
|
### 为什么 Ubuntu 放弃 Unity?
|
||||||
|
|
||||||
|
上周(10 月 20 日)[Ubuntu 17.10][8] 已经发布,这是自 [2011 年引入][9] Unity 以来,Ubuntu 第一次没有带 Unity 桌面发布。
|
||||||
|
|
||||||
|
当然,主流媒体对 Unity 的未来感到好奇,因此 Mark Shuttleworth [向 eWeek][10] 详细介绍了他决定在 Ubuntu 路线图中抛弃 Unity 的原因。
|
||||||
|
|
||||||
|
简而言之就是他把驱逐 Unity 作为节约成本的一部分,旨在使 Canonical 走上 IPO 的道路。
|
||||||
|
|
||||||
|
是的,投资者来了。
|
||||||
|
|
||||||
|
但是完整采访提供了更多关于这个决定的更多内容,并且披露了放弃曾经悉心培养的桌面对他而言是多么艰难。
|
||||||
|
|
||||||
|
### “Ubuntu 已经进入主流”
|
||||||
|
|
||||||
|
Mark Shuttleworth 和 [Sean Michael Kerner][12] 的谈话,首先提醒了我们 Ubuntu 有多么伟大:
|
||||||
|
|
||||||
|
> “Ubuntu 的美妙之处在于,我们创造了一个对终端用户免费,并围绕其提供商业服务的平台,在这个梦想中,我们可以用各种不同的方式定义未来。
|
||||||
|
|
||||||
|
> 我们确实已经看到,Ubuntu 在很多领域已经进入了主流。”
|
||||||
|
|
||||||
|
但是受欢迎并不意味着盈利,Mark 指出:
|
||||||
|
|
||||||
|
> “我们现在所做的一些事情很明显在商业上是不可能永远持续的,而另外一些事情无疑商业上是可持续发展的,或者已经在商业上可持续。
|
||||||
|
|
||||||
|
> 只要我们还是一个纯粹的私人公司,我们就有完全的自由裁量权来决定是否支持那些商业上不可持续的事情。”
|
||||||
|
|
||||||
|
Shuttleworth 说,他和 Canonical 的其他“领导”通过协商一致认为,他们应该让公司走上成为上市公司的道路。
|
||||||
|
|
||||||
|
为了吸引潜在的投资者,公司必须把重点放在盈利领域 —— 而 Unity、Ubuntu 电话、Unity 8 以及<ruby>融合<rt>convergence</rt></ruby>不属于这个部分:
|
||||||
|
|
||||||
|
> “[这个决定]意味着我们不能让我们的名册中拥有那些根本没有商业前景实际上却非常重大的项目。
|
||||||
|
|
||||||
|
> 这并不意味着我们会考虑改变 Ubuntu 的条款,因为它是我们所做的一切的基础。而且实际上,我们也没有必要。”
|
||||||
|
|
||||||
|
### “Ubuntu 本身现在完全可持续发展”
|
||||||
|
|
||||||
|
钱可能意味着 Unity 的消亡,但会让更广泛的 Ubuntu 项目健康发展。正如 Shuttleworth 解释说的:
|
||||||
|
|
||||||
|
> “我最为自豪的事情之一就是在过去的 7 年中,Ubuntu 本身变得完全可持续发展。即使明天我被车撞倒,而 Ubuntu 也可以继续发展下去。
|
||||||
|
|
||||||
|
> 这很神奇吧?对吧?这是一个世界级的企业平台,它不仅完全免费,而且是可持续的。
|
||||||
|
|
||||||
|
> 这主要要感谢 Jane Silber。” (LCTT 译注:Canonical 公司的 CEO)
|
||||||
|
|
||||||
|
虽然桌面用户都会关注桌面,但比起我们期待的每 6 个月发布的版本,对 Canonical 公司的关注显然要多得多。
|
||||||
|
|
||||||
|
失去 Unity 对桌面用户可能是一个沉重打击,但它有助于平衡公司的其他部分:
|
||||||
|
|
||||||
|
> “除此之外,我们在企业中还有巨大的可能性,比如在真正定义云基础设施是如何构建的方面,云应用程序是如何操作的等等。而且,在物联网中,看看下一波的可能性,那些创新者们正在基于物联网创造的东西。
|
||||||
|
|
||||||
|
> 所有这些都足以让我们在这方面进行 IPO。”
|
||||||
|
|
||||||
|
然而,对于 Mark 来说,放弃 Unity 并不容易,
|
||||||
|
|
||||||
|
> “我们在 Unity 上做了很多工作,我真的很喜欢它。
|
||||||
|
|
||||||
|
> 我认为 Unity 8 工程非常棒,而且如何将这些不同形式的要素结合在一起的深层理念是非常迷人的。”
|
||||||
|
|
||||||
|
> “但是,如果我们要走上 IPO 的道路,我不能再为将它留在 Canonical 来争论了。
|
||||||
|
|
||||||
|
> 在某个阶段你们应该会看到,我想我们很快就会宣布,没有 Unity, 我们实际上已经几乎打破了我们在商业上所做的所有事情。”
|
||||||
|
|
||||||
|
在这之后不久,他说公司可能会进行第一轮用于增长的投资,以此作为转变为正式上市公司前的过渡。
|
||||||
|
|
||||||
|
但 Mark 并不想让任何人认为投资者会 “毁了派对”:
|
||||||
|
|
||||||
|
> “我们还没沦落到需要根据风投的指示来行动的地步。我们清楚地看到了我们的客户喜欢什么,我们已经找到了适用于云和物联网的很好的市场着力点和产品。”
|
||||||
|
|
||||||
|
Mark 补充到,Canonical 公司的团队对这个决定 “无疑很兴奋”。
|
||||||
|
|
||||||
|
> “在情感上,我不想再经历这样的过程。我对 Unity 做了一些误判。我曾天真的认为业界会支持一个独立自由平台的想法。
|
||||||
|
|
||||||
|
> 但我也不后悔做过这件事。很多人会抱怨他们的选择,而不去创造其他选择。
|
||||||
|
|
||||||
|
> 事实证明,这需要一点勇气以及相当多的钱去尝试和创造这些选择。”
|
||||||
|
|
||||||
|
### OMG! IPO? NO!
|
||||||
|
|
||||||
|
在对 Canonical(可能)成为一家上市公司的观念进行争辩之前,我们要记住,**RedHat 已经是一家 20 年之久的上市公司了**。GNOME 桌面和 Fedora 在没有任何 “赚钱” 措施的干预下也都活得很不错。
|
||||||
|
|
||||||
|
Canonical 的 IPO 不太可能对 Ubuntu 产生突然的引人注目的的改变,因为就像 Shuttleworth 自己所说的那样,这是其它所有东西得以成立的基础。
|
||||||
|
|
||||||
|
Ubuntu 是已被认可的。这是云上的头号操作系统。它是世界上最受欢迎的 Linux 发行版(除了 [Distrowatch 排名][13])。并且它似乎在物联网上也有巨大的应用前景。
|
||||||
|
|
||||||
|
Mark 说 Ubuntu 现在是完全可持续发展的。
|
||||||
|
|
||||||
|
随着一个[迎接 Ubuntu 17.10 到来的热烈招待会][14],以及一个新的 LTS 将要发布,事情看起来相当不错……
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.omgubuntu.co.uk/2017/10/why-did-ubuntu-drop-unity-mark-shuttleworth-explains
|
||||||
|
|
||||||
|
作者:[JOEY SNEDDON][a]
|
||||||
|
译者:[Snapcrafter](https://github.com/Snapcrafter),[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||||
|
[1]:https://trw.431.night8.win/yy.php/H5aIh_2F/ywcKfGz_/2BKS471c/l3mPrAOp/L1WrIpnn/GpPc4TFY/yHh6t5Cu/gk7ZPrW2/omFcT6ao/A9I_3D/b0/
|
||||||
|
[2]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU38e9i0/RMyYqikJ/lzgv8Nfz/0gk_3D/b0/
|
||||||
|
[3]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU38e9i0/RMyYqikO/nDs5/b0/
|
||||||
|
[4]:https://linux.cn/article-8428-1.html
|
||||||
|
[5]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3m/DJLa_2FH/EIgGEu68/W3whyDb7/Om4zhPVa/LtGc511Z/WysilILZ/4JLodYKV/r1TGTQPz/vy99PlQJ/jKI1w_3D/b0/
|
||||||
|
[7]:https://en.wikipedia.org/wiki/Mark_Shuttleworth
|
||||||
|
[8]:https://linux.cn/article-8980-1.html
|
||||||
|
[9]:http://www.omgubuntu.co.uk/2010/10/ubuntu-11-04-unity-default-desktop
|
||||||
|
[10]:http://www.eweek.com/enterprise-apps/canonical-on-path-to-ipo-as-ubuntu-unity-linux-desktop-gets-ditched
|
||||||
|
[11]:https://en.wikipedia.org/wiki/Initial_public_offering
|
||||||
|
[12]:https://twitter.com/TechJournalist
|
||||||
|
[13]:http://distrowatch.com/table.php?distribution=ubuntu
|
||||||
|
[14]:http://www.omgubuntu.co.uk/2017/10/ubuntu-17-10-review-roundup
|
||||||
@ -0,0 +1,223 @@
|
|||||||
|
如何使用 BorgBackup、Rclone 和 Wasabi 云存储推出自己的备份解决方案
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 使用基于开源软件和廉价云存储的自动备份解决方案来保护你的数据。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
图片提供: opensource.com
|
||||||
|
|
||||||
|
几年来,我用 CrashPlan 来备份我家的电脑,包括属于我妻子和兄弟姐妹的电脑。CrashPlan 本质上是“永远在线”,不需要为它操心就可以做的规律性的备份,这真是太棒了。此外,能使用时间点恢复的能力多次派上用场。因为我通常是家庭的 IT 人员,所以我对其用户界面非常容易使用感到高兴,家人可以在没有我帮助的情况下恢复他们的数据。
|
||||||
|
|
||||||
|
最近 [CrashPlan 宣布][5],它正在放弃其消费者订阅,专注于其企业客户。我想,这是有道理的,因为它不能从像我这样的人赚到很多钱,而我们的家庭计划在其系统上使用了大量的存储空间。
|
||||||
|
|
||||||
|
我决定,我需要一个合适的替代功能,包括:
|
||||||
|
|
||||||
|
* 跨平台支持 Linux 和 Mac
|
||||||
|
* 自动化(所以没有必要记得点击“备份”)
|
||||||
|
* 时间点恢复(可以关闭),所以如果你不小心删除了一个文件,但直到后来才注意到,它仍然可以恢复
|
||||||
|
* 低成本
|
||||||
|
* 备份有多份存储,这样数据存在于多个地方(即,不仅仅是备份到本地 USB 驱动器上)
|
||||||
|
* 加密以防备份文件落入坏人手中
|
||||||
|
|
||||||
|
我四处搜寻,问我的朋友有关类似于 CrashPlan 的服务。我对其中一个 [Arq][6] 非常满意,但没有 Linux 支持意味着对我没用。[Carbonite][7] 与 CrashPlan 类似,但会很昂贵,因为我有多台机器需要备份。[Backblaze][8] 以优惠的价格(每月 5 美金)提供无限备份,但其备份客户端不支持 Linux。[BackupPC][9] 是一个强有力的竞争者,但在我想起它之前,我已经开始测试我的解决方案了。我看到的其它选项都不符合我要的一切。这意味着我必须找出一种方法来复制 CrashPlan 为我和我的家人提供的服务。
|
||||||
|
|
||||||
|
我知道在 Linux 系统上备份文件有很多好的选择。事实上,我一直在使用 [rdiff-backup][10] 至少 10 年了,通常用于本地保存远程文件系统的快照。我希望能够找到可以去除备份数据中重复部分的工具,因为我知道有些(如音乐库和照片)会存储在多台计算机上。
|
||||||
|
|
||||||
|
我认为我所做的工作非常接近实现我的目标。
|
||||||
|
|
||||||
|
### 我的备份解决方案
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
最终,我的目标落在 [BorgBackup][11]、[Rclone][12] 和 [Wasabi 云存储][13]的组合上,我的决定让我感到无比快乐。Borg 符合我所有的标准,并有一个非常健康的[用户和贡献者社区][14]。它提供重复数据删除和压缩功能,并且在 PC、Mac 和 Linux 上运行良好。我使用 Rclone 将来自 Borg 主机的备份仓库同步到 Wasabi 上的 S3 兼容存储。任何与 S3 兼容的存储都可以工作,但是我选择了 Wasabi,因为它的价格好,而且它的性能超过了亚马逊的 S3。使用此设置,我可以从本地 Borg 主机或从 Wasabi 恢复文件。
|
||||||
|
|
||||||
|
在我的机器上安装 Borg 只要 `sudo apt install borgbackup`。我的备份主机是一台连接有 1.5TB USB 驱动器的 Linux 机器。如果你没有可用的机器,那么备份主机可以像 Raspberry Pi 一样轻巧。只要确保所有的客户端机器都可以通过 SSH 访问这个服务器,那么你就能用了。
|
||||||
|
|
||||||
|
在备份主机上,使用以下命令初始化新的备份仓库:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ borg init /mnt/backup/repo1
|
||||||
|
```
|
||||||
|
|
||||||
|
根据你要备份的内容,你可能会选择在每台计算机上创建多个仓库,或者为所有计算机创建一个大型仓库。由于 Borg 有重复数据删除功能,如果在多台计算机上有相同的数据,那么从所有这些计算机向同一个仓库发送备份可能是有意义的。
|
||||||
|
|
||||||
|
在 Linux 上安装 Borg 非常简单。在 Mac OS X 上,我需要首先安装 XCode 和 Homebrew。我遵循 [how-to][15] 来安装命令行工具,然后使用 `pip3 install borgbackup`。
|
||||||
|
|
||||||
|
### 备份
|
||||||
|
|
||||||
|
每台机器都有一个 `backup.sh` 脚本(见下文),由 cron 任务定期启动。它每天只做一个备份集,但在同一天尝试几次也没有什么不好的。笔记本电脑每隔两个小时就会尝试备份一次,因为不能保证它们在某个特定的时间开启,但很可能在其中一个时间开启。这可以通过编写一个始终运行的守护进程来改进,并在笔记本电脑唤醒时触发备份尝试。但现在,我对它的运作方式感到满意。
|
||||||
|
|
||||||
|
我可以跳过 cron 任务,并为每个用户提供一个相对简单的方法来使用 [BorgWeb][16] 来触发备份,但是我真的不希望任何人必须记得备份。我倾向于忘记点击那个备份按钮,直到我急需修复(这时太迟了!)。
|
||||||
|
|
||||||
|
我使用的备份脚本来自 Borg 的[快速入门][17]文档,另外我在顶部添加了一些检查,看 Borg 是否已经在运行,如果之前的备份运行仍在进行这个脚本就会退出。这个脚本会创建一个新的备份集,并用主机名和当前日期来标记它。然后用简单的保留计划来整理旧的备份集。
|
||||||
|
|
||||||
|
这是我的 `backup.sh` 脚本:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/sh
|
||||||
|
|
||||||
|
REPOSITORY=borg@borgserver:/mnt/backup/repo1
|
||||||
|
|
||||||
|
#Bail if borg is already running, maybe previous run didn't finish
|
||||||
|
if pidof -x borg >/dev/null; then
|
||||||
|
echo "Backup already running"
|
||||||
|
exit
|
||||||
|
fi
|
||||||
|
|
||||||
|
# Setting this, so you won't be asked for your repository passphrase:
|
||||||
|
export BORG_PASSPHRASE='thisisnotreallymypassphrase'
|
||||||
|
# or this to ask an external program to supply the passphrase:
|
||||||
|
export BORG_PASSCOMMAND='pass show backup'
|
||||||
|
|
||||||
|
# Backup all of /home and /var/www except a few
|
||||||
|
# excluded directories
|
||||||
|
borg create -v --stats \
|
||||||
|
$REPOSITORY::'{hostname}-{now:%Y-%m-%d}' \
|
||||||
|
/home/doc \
|
||||||
|
--exclude '/home/doc/.cache' \
|
||||||
|
--exclude '/home/doc/.minikube' \
|
||||||
|
--exclude '/home/doc/Downloads' \
|
||||||
|
--exclude '/home/doc/Videos' \
|
||||||
|
--exclude '/home/doc/Music' \
|
||||||
|
|
||||||
|
# Use the `prune` subcommand to maintain 7 daily, 4 weekly and 6 monthly
|
||||||
|
# archives of THIS machine. The '{hostname}-' prefix is very important to
|
||||||
|
# limit prune's operation to this machine's archives and not apply to
|
||||||
|
# other machine's archives also.
|
||||||
|
borg prune -v --list $REPOSITORY --prefix '{hostname}-' \
|
||||||
|
--keep-daily=7 --keep-weekly=4 --keep-monthly=6
|
||||||
|
```
|
||||||
|
|
||||||
|
备份的输出如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
------------------------------------------------------------------------------
|
||||||
|
Archive name: x250-2017-10-05
|
||||||
|
Archive fingerprint: xxxxxxxxxxxxxxxxxxx
|
||||||
|
Time (start): Thu, 2017-10-05 03:09:03
|
||||||
|
Time (end): Thu, 2017-10-05 03:12:11
|
||||||
|
Duration: 3 minutes 8.12 seconds
|
||||||
|
Number of files: 171150
|
||||||
|
------------------------------------------------------------------------------
|
||||||
|
Original size Compressed size Deduplicated size
|
||||||
|
This archive: 27.75 GB 27.76 GB 323.76 MB
|
||||||
|
All archives: 3.08 TB 3.08 TB 262.76 GB
|
||||||
|
|
||||||
|
Unique chunks Total chunks
|
||||||
|
Chunk index: 1682989 24007828
|
||||||
|
------------------------------------------------------------------------------
|
||||||
|
[...]
|
||||||
|
Keeping archive: x250-2017-09-17 Sun, 2017-09-17 03:09:02
|
||||||
|
Pruning archive: x250-2017-09-28 Thu, 2017-09-28 03:09:02
|
||||||
|
```
|
||||||
|
|
||||||
|
我在将所有的机器备份到主机上后,我遵循[安装预编译的 Rclone 二进制文件指导][18],并将其设置为访问我的 Wasabi 帐户。
|
||||||
|
|
||||||
|
此脚本每天晚上运行以将任何更改同步到备份集:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/bash
|
||||||
|
set -e
|
||||||
|
|
||||||
|
repos=( repo1 repo2 repo3 )
|
||||||
|
|
||||||
|
#Bail if rclone is already running, maybe previous run didn't finish
|
||||||
|
if pidof -x rclone >/dev/null; then
|
||||||
|
echo "Process already running"
|
||||||
|
exit
|
||||||
|
fi
|
||||||
|
|
||||||
|
for i in "${repos[@]}"
|
||||||
|
do
|
||||||
|
#Lets see how much space is used by directory to back up
|
||||||
|
#if directory is gone, or has gotten small, we will exit
|
||||||
|
space=`du -s /mnt/backup/$i|awk '{print $1}'`
|
||||||
|
|
||||||
|
if (( $space < 34500000 )); then
|
||||||
|
echo "EXITING - not enough space used in $i"
|
||||||
|
exit
|
||||||
|
fi
|
||||||
|
|
||||||
|
/usr/bin/rclone -v sync /mnt/backup/$i wasabi:$i >> /home/borg/wasabi-sync.log 2>&1
|
||||||
|
done
|
||||||
|
```
|
||||||
|
|
||||||
|
第一次用 Rclone 同步备份集到 Wasabi 花了好几天,但是我大约有 400GB 的新数据,而且我的出站连接速度不是很快。但是每日的增量是非常小的,能在几分钟内完成。
|
||||||
|
|
||||||
|
### 恢复文件
|
||||||
|
|
||||||
|
恢复文件并不像 CrashPlan 那样容易,但是相对简单。最快的方法是从存储在 Borg 备份服务器上的备份中恢复。以下是一些用于恢复的示例命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
#List which backup sets are in the repo
|
||||||
|
$ borg list borg@borgserver:/mnt/backup/repo1
|
||||||
|
Remote: Authenticated with partial success.
|
||||||
|
Enter passphrase for key ssh://borg@borgserver/mnt/backup/repo1:
|
||||||
|
x250-2017-09-17 Sun, 2017-09-17 03:09:02
|
||||||
|
#List contents of a backup set
|
||||||
|
$ borg list borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 | less
|
||||||
|
#Restore one file from the repo
|
||||||
|
$ borg extract borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 home/doc/somefile.jpg
|
||||||
|
#Restore a whole directory
|
||||||
|
$ borg extract borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 home/doc
|
||||||
|
```
|
||||||
|
|
||||||
|
如果本地的 Borg 服务器或拥有所有备份仓库的 USB 驱动器发生问题,我也可以直接从 Wasabi 直接恢复。如果机器安装了 Rclone,使用 [rclone mount][3],我可以将远程存储仓库挂载到本地文件系统:
|
||||||
|
|
||||||
|
```
|
||||||
|
#Mount the S3 store and run in the background
|
||||||
|
$ rclone mount wasabi:repo1 /mnt/repo1 &
|
||||||
|
#List archive contents
|
||||||
|
$ borg list /mnt/repo1
|
||||||
|
#Extract a file
|
||||||
|
$ borg extract /mnt/repo1::x250-2017-09-17 home/doc/somefile.jpg
|
||||||
|
```
|
||||||
|
|
||||||
|
### 它工作得怎样
|
||||||
|
|
||||||
|
现在我已经使用了这个备份方法几个星期了,我可以说我真的很高兴。设置所有这些并使其运行当然比安装 CrashPlan 要复杂得多,但这就是使用你自己的解决方案和使用服务之间的区别。我将不得不密切关注以确保备份继续运行,数据与 Wasabi 正确同步。
|
||||||
|
|
||||||
|
但是,总的来说,以一个非常合理的价格替换 CrashPlan 以提供相似的备份覆盖率,结果比我预期的要容易一些。如果你看到有待改进的空间,请告诉我。
|
||||||
|
|
||||||
|
_这最初发表在 [Local Conspiracy][19],并被许可转载。_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Christopher Aedo - Christopher Aedo 自从大学时开始就一直在用开源软件工作并为之作出贡献。最近他在领导一支非常棒的 IBM 上游开发团队,他们也是开发支持者。当他不在工作或在会议上发言时,他可能在俄勒冈州波特兰市使用 RaspberryPi 酿造和发酵美味的自制啤酒。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/10/backing-your-machines-borg
|
||||||
|
|
||||||
|
作者:[Christopher Aedo][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/docaedo
|
||||||
|
[1]:https://opensource.com/file/375066
|
||||||
|
[2]:https://opensource.com/article/17/10/backing-your-machines-borg?rate=Aa1IjkXuXy95tnvPGLWcPQJCKBih4Wo9hNPxhDs-mbQ
|
||||||
|
[3]:https://rclone.org/commands/rclone_mount/
|
||||||
|
[4]:https://opensource.com/user/145976/feed
|
||||||
|
[5]:https://www.crashplan.com/en-us/consumer/nextsteps/
|
||||||
|
[6]:https://www.arqbackup.com/
|
||||||
|
[7]:https://www.carbonite.com/
|
||||||
|
[8]:https://www.backblaze.com/
|
||||||
|
[9]:http://backuppc.sourceforge.net/BackupPCServerStatus.html
|
||||||
|
[10]:http://www.nongnu.org/rdiff-backup/
|
||||||
|
[11]:https://www.borgbackup.org/
|
||||||
|
[12]:https://rclone.org/
|
||||||
|
[13]:https://wasabi.com/
|
||||||
|
[14]:https://github.com/borgbackup/borg/
|
||||||
|
[15]:http://osxdaily.com/2014/02/12/install-command-line-tools-mac-os-x/
|
||||||
|
[16]:https://github.com/borgbackup/borgweb
|
||||||
|
[17]:https://borgbackup.readthedocs.io/en/stable/quickstart.html
|
||||||
|
[18]:https://rclone.org/install/
|
||||||
|
[19]:http://localconspiracy.com/2017/10/backup-everything.html
|
||||||
|
[20]:https://opensource.com/users/docaedo
|
||||||
|
[21]:https://opensource.com/users/docaedo
|
||||||
|
[22]:https://opensource.com/article/17/10/backing-your-machines-borg#comments
|
||||||
97
published/20171026 But I dont know what a container is .md
Normal file
97
published/20171026 But I dont know what a container is .md
Normal file
@ -0,0 +1,97 @@
|
|||||||
|
很遗憾,我也不知道什么是容器!
|
||||||
|
========================
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 题图抽象的形容了容器和虚拟机是那么的相似,又是那么的不同!
|
||||||
|
|
||||||
|
在近期的一些会议和学术交流会上,我一直在讲述有关 DevOps 的安全问题(亦称为 DevSecOps)^注1 。通常,我首先都会问一个问题:“在座的各位有谁知道什么是容器吗?” 通常并没有很多人举手^注2 ,所以我都会先简单介绍一下什么是容器^注3 ,然后再进行深层次的讨论交流。
|
||||||
|
|
||||||
|
更准确的说,在运用 DevOps 或者 DevSecOps 的时候,容器并不是必须的。但容器能很好的融于 DevOps 和 DevSecOps 方案中,结果就是,虽然不用容器便可以运用 DevOps ,但我还是假设大部分人依然会使用容器。
|
||||||
|
|
||||||
|
### 什么是容器
|
||||||
|
|
||||||
|
几个月前的一个会议上,一个同事正在容器上操作演示,因为大家都不是这个方面的专家,所以该同事就很简单的开始了他的演示。他说了诸如“在 Linux 内核源码中没有一处提及到<ruby>容器<rt>container</rt></ruby>。“之类的话。事实上,在这样的特殊群体中,这种描述表达是很危险的。就在几秒钟内,我和我的老板(坐在我旁边)下载了最新版本的内核源代码并且查找统计了其中 “container” 单词出现的次数。很显然,这位同事的说法并不准确。更准确来说,我在旧版本内核(4.9.2)代码中发现有 15273 行代码包含 “container” 一词^注4 。我和我老板会心一笑,确认同事的说法有误,并在休息时纠正了他这个有误的描述。
|
||||||
|
|
||||||
|
后来我们搞清楚同事想表达的意思是 Linux 内核中并没有明确提及容器这个概念。换句话说,容器使用了 Linux 内核中的一些概念、组件、工具以及机制,并没有什么特殊的东西;这些东西也可以用于其他目的^注 5 。所以才有会说“从 Linux 内核角度来看,并没有容器这样的东西。”
|
||||||
|
|
||||||
|
然后,什么是容器呢?我有着虚拟化(<ruby>管理器<rt>hypervisor</rt></ruby>和虚拟机)技术的背景,在我看来, 容器既像虚拟机(VM)又不像虚拟机。我知道这种解释好像没什么用,不过请听我细细道来。
|
||||||
|
|
||||||
|
### 容器和虚拟机相似之处有哪些?
|
||||||
|
|
||||||
|
容器和虚拟机相似的一个主要方面就是它是一个可执行单元。将文件打包生成镜像文件,然后它就可以运行在合适的主机平台上。和虚拟机一样,它运行于主机上,同样,它的运行也受制于该主机。主机平台为容器的运行提供软件环境和硬件资源(诸如 CPU 资源、网络环境、存储资源等等),除此之外,主机还需要负责以下的任务:
|
||||||
|
|
||||||
|
1. 为每一个工作单元(这里指虚拟机和容器)提供保护机制,这样可以保证即使某一个工作单元出现恶意的、有害的以及不能写入的情况时不会影响其他的工作单元。
|
||||||
|
2. 主机保护自己不会受一些恶意运行或出现故障的工作单元影响。
|
||||||
|
|
||||||
|
虚拟机和容器实现这种隔离的原理并不一样,虚拟机的隔离是由管理器对硬件资源划分,而容器的隔离则是通过 Linux 内核提供的软件功能实现的^注6 。这种软件控制机制通过不同的“命名空间”保证了每一个容器的文件、用户以及网络连接等互不可见,当然容器和主机之间也互不可见。这种功能也能由 SELinux 之类软件提供,它们提供了进一步隔离容器的功能。
|
||||||
|
|
||||||
|
### 容器和虚拟机不同之处又有哪些?
|
||||||
|
|
||||||
|
以上描述有个问题,如果你对<ruby>管理器<rt>hypervisor</rt></ruby>机制概念比较模糊,也许你会认为容器就是虚拟机,但它确实不是。
|
||||||
|
|
||||||
|
首先,最为重要的一点^注7 ,容器是一种包格式。也许你会惊讶的反问我“什么,你不是说过容器是某种可执行文件么?” 对,容器确实是可执行文件,但容器如此迷人的一个主要原因就是它能很容易的生成比虚拟机小很多的实体化镜像文件。由于这些原因,容器消耗很少的内存,并且能非常快的启动与关闭。你可以在几分钟或者几秒钟(甚至毫秒级别)之内就启动一个容器,而虚拟机则不具备这些特点。
|
||||||
|
|
||||||
|
正因为容器是如此轻量级且易于替换,人们使用它们来创建微服务——应用程序拆分而成的最小组件,它们可以和一个或多个其它微服务构成任何你想要的应用。假使你只在一个容器内运行某个特定功能或者任务,你也可以让容器变得很小,这样丢弃旧容器创建新容器将变得很容易。我将在后续的文章中继续跟进这个问题以及它们对安全性的可能影响,当然,也包括 DevSecOps 。
|
||||||
|
|
||||||
|
希望这是一次对容器的有用的介绍,并且能带动你有动力去学习 DevSecOps 的知识(如果你不是,假装一下也好)。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
- 注 1:我觉得 DevSecOps 读起来很奇怪,而 DevOpsSec 往往有多元化的理解,然后所讨论的主题就不一样了。
|
||||||
|
- 注 2:我应该注意到这不仅仅会被比较保守、不太喜欢被人注意的英国听众所了解,也会被加拿大人和美国人所了解,他们的性格则和英国人不一样。
|
||||||
|
- 注 3:当然,我只是想讨论 Linux 容器。我知道关于这个问题,是有历史根源的,所以它也值得注意,而不是我故弄玄虚。
|
||||||
|
- 注 4:如果你感兴趣的话,我使用的是命令 `grep -ir container linux-4.9.2 | wc -l`
|
||||||
|
- 注 5:公平的说,我们快速浏览一下,一些用途与我们讨论容器的方式无关,我们讨论的是 Linux 容器,它是抽象的,可以用来包含其他元素,因此在逻辑上被称为容器。
|
||||||
|
- 注 6:也有一些巧妙的方法可以将容器和虚拟机结合起来以发挥它们各自的优势,那个不在我今天的主题范围内。
|
||||||
|
- 注 7:很明显,除了我们刚才介绍的执行位。
|
||||||
|
|
||||||
|
*原文来自 [Alice, Eve, and Bob—a security blog][7] ,转载请注明*
|
||||||
|
|
||||||
|
(题图: opensource.com )
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**作者简介**:
|
||||||
|
|
||||||
|
原文作者 Mike Bursell 是一名居住在英国、喜欢威士忌的开源爱好者, Red Hat 首席安全架构师。其自从 1997 年接触开源世界以来,生活和工作中一直使用 Linux (尽管不是一直都很容易)。更多信息请参考作者的博客 https://aliceevebob.com ,作者会不定期的更新一些有关安全方面的文章。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/10/what-are-containers
|
||||||
|
|
||||||
|
作者:[Mike Bursell][a]
|
||||||
|
译者:[jrglinux](https://github.com/jrglinux)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/mikecamel
|
||||||
|
[1]: https://opensource.com/resources/what-are-linux-containers?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||||
|
[2]: https://opensource.com/resources/what-docker?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||||
|
[3]: https://opensource.com/resources/what-is-kubernetes?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||||
|
[4]: https://developers.redhat.com/blog/2016/01/13/a-practical-introduction-to-docker-container-terminology/?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||||
|
[5]: https://opensource.com/article/17/10/what-are-containers?rate=sPHuhiD4Z3D3vJ6ZqDT-wGp8wQjcQDv-iHf2OBG_oGQ
|
||||||
|
[6]: https://opensource.com/article/17/10/what-are-containers#*******
|
||||||
|
[7]: https://aliceevebob.wordpress.com/2017/07/04/but-i-dont-know-what-a-container-is/
|
||||||
|
[8]: https://opensource.com/user/105961/feed
|
||||||
|
[9]: https://opensource.com/article/17/10/what-are-containers#*
|
||||||
|
[10]: https://opensource.com/article/17/10/what-are-containers#**
|
||||||
|
[11]: https://opensource.com/article/17/10/what-are-containers#***
|
||||||
|
[12]: https://opensource.com/article/17/10/what-are-containers#******
|
||||||
|
[13]: https://opensource.com/article/17/10/what-are-containers#*****
|
||||||
|
[14]: https://opensource.com/users/mikecamel
|
||||||
|
[15]: https://opensource.com/users/mikecamel
|
||||||
|
[16]: https://opensource.com/article/17/10/what-are-containers#****
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
71
published/20171026 Why is Kubernetes so popular.md
Normal file
71
published/20171026 Why is Kubernetes so popular.md
Normal file
@ -0,0 +1,71 @@
|
|||||||
|
为何 Kubernetes 如此受欢迎?
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> Google 开发的这个容器管理系统很快成为开源历史上最成功的案例之一。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
图片来源: RIkki Endsley. [CC BY-SA 4.0][7]
|
||||||
|
|
||||||
|
[Kubernetes][8] 是一个在过去几年中快速蹿升起来的开源的容器管理系统。它被众多行业中最大的企业用于关键任务,已成为开源方面最成功的案例之一。这是怎么发生的?该如何解释 Kubernetes 的广泛应用呢?
|
||||||
|
|
||||||
|
### Kubernetes 的背景:起源于 Google 的 Borg 系统
|
||||||
|
|
||||||
|
随着计算世界变得更加分布式、更加基于网络、以及更多的云计算,我们看到了大型的<ruby>独石<rt>monolithic</rt></ruby>应用慢慢地转化为多个敏捷微服务。这些微服务能让用户单独缩放应用程序的关键功能,以处理数百万客户。除此之外,我们还看到像 Docker 这样的容器等技术出现在企业中,为用户快速构建这些微服务创造了一致的、可移植的、便捷的方式。
|
||||||
|
|
||||||
|
随着 Docker 继续蓬勃发展,管理这些微服务器和容器成为最重要的要求。这时已经运行基于容器的基础设施已经多年的 Google 大胆地决定开源一个名为 [Borg][15] 的项目。Borg 系统是运行诸如 Google 搜索和 Gmail 这样的 Google 服务的关键。谷歌决定开源其基础设施为世界上任何一家公司创造了一种像顶尖公司一样运行其基础架构的方式。
|
||||||
|
|
||||||
|
### 最大的开源社区之一
|
||||||
|
|
||||||
|
在开源之后,Kubernetes 发现自己在与其他容器管理系统竞争,即 Docker Swarm 和 Apache Mesos。Kubernetes 近几个月来超过这些其他系统的原因之一得益于社区和系统背后的支持:它是最大的开源社区之一(GitHub 上超过 27,000 多个星标),有来自上千个组织(1,409 个贡献者)的贡献,并且被集中在一个大型、中立的开源基金会里,即[原生云计算基金会][9](CNCF)。
|
||||||
|
|
||||||
|
CNCF 也是更大的 Linux 基金会的一部分,拥有一些顶级企业成员,其中包括微软、谷歌和亚马逊。此外,CNCF 的企业成员队伍持续增长,SAP 和 Oracle 在过去几个月内加入白金会员。这些加入 CNCF 的公司,其中 Kubernetes 项目是前沿和中心的,这证明了有多少企业投注于社区来实现云计算战略的一部分。
|
||||||
|
|
||||||
|
Kubernetes 外围的企业社区也在激增,供应商提供了带有更多的安全性、可管理性和支持的企业版。Red Hat、CoreOS 和 Platform 9 是少数几个使企业级 Kubernetes 成为战略前进的关键因素,并投入巨资以确保开源项目继续得到维护的公司。
|
||||||
|
|
||||||
|
### 混合云带来的好处
|
||||||
|
|
||||||
|
企业以这样一个飞速的方式采用 Kubernetes 的另一个原因是 Kubernetes 可以在任何云端工作。大多数企业在现有的内部数据中心和公共云之间共享资产,对混合云技术的需求至关重要。
|
||||||
|
|
||||||
|
Kubernetes 可以部署在公司先前存在的数据中心内、任意一个公共云环境、甚至可以作为服务运行。由于 Kubernetes 抽象了底层基础架构层,开发人员可以专注于构建应用程序,然后将它们部署到任何这些环境中。这有助于加速公司的 Kubernetes 采用,因为它可以在内部运行 Kubernetes,同时继续构建云战略。
|
||||||
|
|
||||||
|
### 现实世界的案例
|
||||||
|
|
||||||
|
Kubernetes 继续增长的另一个原因是,大型公司正在利用这项技术来解决业界最大的挑战。Capital One、Pearson Education 和 Ancestry.com 只是少数几家公布了 Kubernetes [使用案例][10]的公司。
|
||||||
|
|
||||||
|
[Pokemon Go][11] 是最流行的宣传 Kubernetes 能力的使用案例。在它发布之前,人们都觉得在线多人游戏会相当的得到追捧。但当它一旦发布,就像火箭一样起飞,达到了预期流量的 50 倍。通过使用 Kubernetes 作为 Google Cloud 之上的基础设施层,Pokemon Go 可以大规模扩展以满足意想不到的需求。
|
||||||
|
|
||||||
|
最初作为来自 Google 的开源项目,背后有 Google 15 年的服务经验和来自 Borg 的继承- Kubernetes 现在是有许多企业成员的大型基金会(CNCF)的一部分。它继续受到欢迎,并被广泛应用于金融、大型多人在线游戏(如 Pokemon Go)以及教育公司和传统企业 IT 的关键任务中。考虑到所有,所有的迹象表明,Kubernetes 将继续更加流行,并仍然是开源中最大的成功案例之一。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Anurag Gupta - Anurag Gupta 是推动统一日志层 Fluentd Enterprise 发展的 Treasure Data 的产品经理。 Anurag 致力于大型数据技术,包括 Azure Log Analytics 和如 Microsoft System Center 的企业 IT 服务。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/10/why-kubernetes-so-popular
|
||||||
|
|
||||||
|
作者:[Anurag Gupta][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/anuraggupta
|
||||||
|
[1]:https://opensource.com/resources/what-are-linux-containers?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||||
|
[2]:https://opensource.com/resources/what-docker?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||||
|
[3]:https://opensource.com/resources/what-is-kubernetes?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||||
|
[4]:https://developers.redhat.com/blog/2016/01/13/a-practical-introduction-to-docker-container-terminology/?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||||
|
[5]:https://opensource.com/article/17/10/why-kubernetes-so-popular?rate=LM949RNFmORuG0I79_mgyXiVXrdDqSxIQjOReJ9_SbE
|
||||||
|
[6]:https://opensource.com/user/171186/feed
|
||||||
|
[7]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[8]:https://kubernetes.io/
|
||||||
|
[9]:https://www.cncf.io/
|
||||||
|
[10]:https://kubernetes.io/case-studies/
|
||||||
|
[11]:https://cloudplatform.googleblog.com/2016/09/bringing-Pokemon-GO-to-life-on-Google-Cloud.html
|
||||||
|
[12]:https://opensource.com/users/anuraggupta
|
||||||
|
[13]:https://opensource.com/users/anuraggupta
|
||||||
|
[14]:https://opensource.com/article/17/10/why-kubernetes-so-popular#comments
|
||||||
|
[15]:http://queue.acm.org/detail.cfm?id=2898444
|
||||||
270
published/20171101 How to use cron in Linux.md
Normal file
270
published/20171101 How to use cron in Linux.md
Normal file
@ -0,0 +1,270 @@
|
|||||||
|
在 Linux 中怎么使用 cron 计划任务
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 没有时间运行命令?使用 cron 的计划任务意味着你不用熬夜程序也可以运行。
|
||||||
|
|
||||||
|

|
||||||
|
Image by : [Internet Archive Book Images][11]. Modified by Opensource.com. [CC BY-SA 4.0][12]
|
||||||
|
|
||||||
|
系统管理员(在许多好处中)的挑战之一是在你该睡觉的时候去运行一些任务。例如,一些任务(包括定期循环运行的任务)需要在没有人使用计算机资源的时候去运行,如午夜或周末。在下班后,我没有时间去运行命令或脚本。而且,我也不想在晚上去启动备份或重大更新。
|
||||||
|
|
||||||
|
取而代之的是,我使用两个服务功能在我预定的时间去运行命令、程序和任务。[cron][13] 和 at 服务允许系统管理员去安排任务运行在未来的某个特定时间。at 服务指定在某个时间去运行一次任务。cron 服务可以安排任务在一个周期上重复,比如天、周、或月。
|
||||||
|
|
||||||
|
在这篇文章中,我将介绍 cron 服务和怎么去使用它。
|
||||||
|
|
||||||
|
### 常见(和非常见)的 cron 用途
|
||||||
|
|
||||||
|
我使用 cron 服务去安排一些常见的事情,比如,每天凌晨 2:00 发生的定期备份,我也使用它去做一些不常见的事情。
|
||||||
|
|
||||||
|
* 许多电脑上的系统时钟(比如,操作系统时间)都设置为使用网络时间协议(NTP)。 NTP 设置系统时间后,它不会去设置硬件时钟,它可能会“漂移”。我使用 cron 基于系统时间去设置硬件时钟。
|
||||||
|
* 我还有一个 Bash 程序,我在每天早晨运行它,去在每台电脑上创建一个新的 “每日信息” (MOTD)。它包含的信息有当前的磁盘使用情况等有用的信息。
|
||||||
|
* 许多系统进程和服务,像 [Logwatch][7]、[logrotate][8]、和 [Rootkit Hunter][9],使用 cron 服务去安排任务和每天运行程序。
|
||||||
|
|
||||||
|
crond 守护进程是一个完成 cron 功能的后台服务。
|
||||||
|
|
||||||
|
cron 服务检查在 `/var/spool/cron` 和 `/etc/cron.d` 目录中的文件,以及 `/etc/anacrontab` 文件。这些文件的内容定义了以不同的时间间隔运行的 cron 作业。个体用户的 cron 文件是位于 `/var/spool/cron`,而系统服务和应用生成的 cron 作业文件放在 `/etc/cron.d` 目录中。`/etc/anacrontab` 是一个特殊的情况,它将在本文中稍后部分介绍。
|
||||||
|
|
||||||
|
### 使用 crontab
|
||||||
|
|
||||||
|
cron 实用程序运行基于一个 cron 表(`crontab`)中指定的命令。每个用户,包括 root,都有一个 cron 文件。这些文件缺省是不存在的。但可以使用 `crontab -e` 命令创建在 `/var/spool/cron` 目录中,也可以使用该命令去编辑一个 cron 文件(看下面的脚本)。我强烈建议你,_不要_使用标准的编辑器(比如,Vi、Vim、Emacs、Nano、或者任何其它可用的编辑器)。使用 `crontab` 命令不仅允许你去编辑命令,也可以在你保存并退出编辑器时,重启动 crond 守护进程。`crontab` 命令使用 Vi 作为它的底层编辑器,因为 Vi 是预装的(至少在大多数的基本安装中是预装的)。
|
||||||
|
|
||||||
|
现在,cron 文件是空的,所以必须从头添加命令。 我增加下面示例中定义的作业到我的 cron 文件中,这是一个快速指南,以便我知道命令中的各个部分的意思是什么,你可以自由拷贝它,供你自己使用。
|
||||||
|
|
||||||
|
```
|
||||||
|
# crontab -e
|
||||||
|
SHELL=/bin/bash
|
||||||
|
MAILTO=root@example.com
|
||||||
|
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
|
||||||
|
|
||||||
|
# For details see man 4 crontabs
|
||||||
|
|
||||||
|
# Example of job definition:
|
||||||
|
# .---------------- minute (0 - 59)
|
||||||
|
# | .------------- hour (0 - 23)
|
||||||
|
# | | .---------- day of month (1 - 31)
|
||||||
|
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
|
||||||
|
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
|
||||||
|
# | | | | |
|
||||||
|
# * * * * * user-name command to be executed
|
||||||
|
|
||||||
|
# backup using the rsbu program to the internal 4TB HDD and then 4TB external
|
||||||
|
01 01 * * * /usr/local/bin/rsbu -vbd1 ; /usr/local/bin/rsbu -vbd2
|
||||||
|
|
||||||
|
# Set the hardware clock to keep it in sync with the more accurate system clock
|
||||||
|
03 05 * * * /sbin/hwclock --systohc
|
||||||
|
|
||||||
|
# Perform monthly updates on the first of the month
|
||||||
|
# 25 04 1 * * /usr/bin/dnf -y update
|
||||||
|
```
|
||||||
|
|
||||||
|
*`crontab` 命令用于查看或编辑 cron 文件。*
|
||||||
|
|
||||||
|
上面代码中的前三行设置了一个缺省环境。对于给定用户,环境变量必须是设置的,因为,cron 不提供任何方式的环境。`SHELL` 变量指定命令运行使用的 shell。这个示例中,指定为 Bash shell。`MAILTO` 变量设置发送 cron 作业结果的电子邮件地址。这些电子邮件提供了 cron 作业(备份、更新、等等)的状态,和你从命令行中手动运行程序时看到的结果是一样的。第三行为环境设置了 `PATH` 变量。但即使在这里设置了路径,我总是使用每个程序的完全限定路径。
|
||||||
|
|
||||||
|
在上面的示例中有几个注释行,它详细说明了定义一个 cron 作业所要求的语法。我将在下面分别讲解这些命令,然后,增加更多的 crontab 文件的高级特性。
|
||||||
|
|
||||||
|
```
|
||||||
|
01 01 * * * /usr/local/bin/rsbu -vbd1 ; /usr/local/bin/rsbu -vbd2
|
||||||
|
```
|
||||||
|
|
||||||
|
*在我的 `/etc/crontab` 中的这一行运行一个脚本,用于为我的系统执行备份。*
|
||||||
|
|
||||||
|
这一行运行我自己编写的 Bash shell 脚本 `rsbu`,它对我的系统做完全备份。这个作业每天的凌晨 1:01 (`01 01`) 运行。在这三、四、五位置上的星号(*),像文件通配符一样代表一个特定的时间,它们代表 “一个月中的每天”、“每个月” 和 “一周中的每天”,这一行会运行我的备份两次,一次备份内部专用的硬盘驱动器,另外一次运行是备份外部的 USB 驱动器,使用它这样我可以很保险。
|
||||||
|
|
||||||
|
接下来的行我设置了一个硬件时钟,它使用当前系统时钟作为源去设置硬件时钟。这一行设置为每天凌晨 5:03 分运行。
|
||||||
|
|
||||||
|
```
|
||||||
|
03 05 * * * /sbin/hwclock --systohc
|
||||||
|
```
|
||||||
|
|
||||||
|
*这一行使用系统时间作为源来设置硬件时钟。*
|
||||||
|
|
||||||
|
我使用的第三个也是最后一个的 cron 作业是去执行一个 `dnf` 或 `yum` 更新,它在每个月的第一天的凌晨 04:25 运行,但是,我注释掉了它,以后不再运行。
|
||||||
|
|
||||||
|
```
|
||||||
|
# 25 04 1 * * /usr/bin/dnf -y update
|
||||||
|
```
|
||||||
|
|
||||||
|
*这一行用于执行一个每月更新,但是,我也把它注释掉了。*
|
||||||
|
|
||||||
|
#### 其它的定时任务技巧
|
||||||
|
|
||||||
|
现在,让我们去做一些比基本知识更有趣的事情。假设你希望在每周四下午 3:00 去运行一个特别的作业:
|
||||||
|
|
||||||
|
```
|
||||||
|
00 15 * * Thu /usr/local/bin/mycronjob.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
这一行会在每周四下午 3:00 运行 `mycronjob.sh` 这个脚本。
|
||||||
|
|
||||||
|
或者,或许你需要在每个季度末去运行一个季度报告。cron 服务没有为 “每个月的最后一天” 设置选项,因此,替代方式是使用下一个月的第一天,像如下所示(这里假设当作业准备运行时,报告所需要的数据已经准备好了)。
|
||||||
|
|
||||||
|
```
|
||||||
|
02 03 1 1,4,7,10 * /usr/local/bin/reports.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
*在季度末的下一个月的第一天运行这个 cron 作业。*
|
||||||
|
|
||||||
|
下面展示的这个作业,在每天的上午 9:01 到下午 5:01 之间,每小时运行一次。
|
||||||
|
|
||||||
|
```
|
||||||
|
01 09-17 * * * /usr/local/bin/hourlyreminder.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
*有时,你希望作业在业务期间定时运行。*
|
||||||
|
|
||||||
|
我遇到一个情况,需要作业在每二、三或四小时去运行。它需要用期望的间隔去划分小时,比如, `*/3` 为每三个小时,或者 `6-18/3` 为上午 6 点到下午 6 点每三个小时运行一次。其它的时间间隔的划分也是类似的。例如,在分钟位置的表达式 `*/15` 意思是 “每 15 分钟运行一次作业”。
|
||||||
|
|
||||||
|
```
|
||||||
|
*/5 08-18/2 * * * /usr/local/bin/mycronjob.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
*这个 cron 作业在上午 8:00 到下午 18:59 之间,每五分钟运行一次作业。*
|
||||||
|
|
||||||
|
需要注意的一件事情是:除法表达式的结果必须是余数为 0(即整除)。换句话说,在这个例子中,这个作业被设置为在上午 8 点到下午 6 点之间的偶数小时每 5 分钟运行一次(08:00、08:05、 08:10、 08:15……18:55 等等),而不运行在奇数小时。另外,这个作业不能运行在下午 7:00 到上午 7:59 之间。(LCTT 译注:此处本文表述有误,根据正确情况修改)
|
||||||
|
|
||||||
|
我相信,你可以根据这些例子想到许多其它的可能性。
|
||||||
|
|
||||||
|
#### 限制访问 cron
|
||||||
|
|
||||||
|
普通用户使用 cron 访问可能会犯错误,例如,可能导致系统资源(比如内存和 CPU 时间)被耗尽。为避免这种可能的问题, 系统管理员可以通过创建一个 `/etc/cron.allow` 文件去限制用户访问,它包含了一个允许去创建 cron 作业的用户列表。(不管是否列在这个列表中,)不能阻止 root 用户使用 cron。
|
||||||
|
|
||||||
|
通过阻止非 root 用户创建他们自己的 cron 作业,那也许需要将非 root 用户的 cron 作业添加到 root 的 crontab 中, “但是,等等!” 你说,“不是以 root 去运行这些作业?” 不一定。在这篇文章中的第一个示例中,出现在注释中的用户名字段可以用于去指定一个运行作业的用户 ID。这可以防止特定的非 root 用户的作业以 root 身份去运行。下面的示例展示了一个作业定义,它以 “student” 用户去运行这个作业:
|
||||||
|
|
||||||
|
```
|
||||||
|
04 07 * * * student /usr/local/bin/mycronjob.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
如果没有指定用户,这个作业将以 contab 文件的所有者用户去运行,在这个情况中是 root。
|
||||||
|
|
||||||
|
#### cron.d
|
||||||
|
|
||||||
|
目录 `/etc/cron.d` 中是一些应用程序,比如 [SpamAssassin][14] 和 [sysstat][15] 安装的 cron 文件。因为,这里没有 spamassassin 或者 sysstat 用户,这些程序需要一个位置去放置 cron 文件,因此,它们被放在 `/etc/cron.d` 中。
|
||||||
|
|
||||||
|
下面的 `/etc/cron.d/sysstat` 文件包含系统活动报告(SAR)相关的 cron 作业。这些 cron 文件和用户 cron 文件格式相同。
|
||||||
|
|
||||||
|
```
|
||||||
|
# Run system activity accounting tool every 10 minutes
|
||||||
|
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||||
|
# Generate a daily summary of process accounting at 23:53
|
||||||
|
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||||
|
```
|
||||||
|
|
||||||
|
*sysstat 包安装了 `/etc/cron.d/sysstat` cron 文件来运行程序生成 SAR。*
|
||||||
|
|
||||||
|
该 sysstat cron 文件有两行执行任务。第一行每十分钟去运行 `sa1` 程序去收集数据,存储在 `/var/log/sa` 目录中的一个指定的二进制文件中。然后,在每天晚上的 23:53, `sa2` 程序运行来创建一个每日汇总。
|
||||||
|
|
||||||
|
#### 计划小贴士
|
||||||
|
|
||||||
|
我在 crontab 文件中设置的有些时间看上起似乎是随机的,在某种程度上说,确实是这样的。尝试去安排 cron 作业可能是件很具有挑战性的事, 尤其是作业的数量越来越多时。我通常在我的每个电脑上仅有一些任务,它比起我工作用的那些生产和实验环境中的电脑简单多了。
|
||||||
|
|
||||||
|
我管理的一个系统有 12 个每天晚上都运行 cron 作业,另外 3、4 个在周末或月初运行。那真是个挑战,因为,如果有太多作业在同一时间运行,尤其是备份和编译系统,会耗尽内存并且几乎填满交换文件空间,这会导致系统性能下降甚至是超负荷,最终什么事情都完不成。我增加了一些内存并改进了如何计划任务。我还删除了一些写的很糟糕、使用大量内存的任务。
|
||||||
|
|
||||||
|
crond 服务假设主机计算机 24 小时运行。那意味着如果在一个计划运行的期间关闭计算机,这些计划的任务将不再运行,直到它们计划的下一次运行时间。如果这里有关键的 cron 作业,这可能导致出现问题。 幸运的是,在定期运行的作业上,还有一个其它的选择: `anacron`。
|
||||||
|
|
||||||
|
### anacron
|
||||||
|
|
||||||
|
[anacron][16] 程序执行和 cron 一样的功能,但是它增加了运行被跳过的作业的能力,比如,如果计算机已经关闭或者其它的原因导致无法在一个或多个周期中运行作业。它对笔记本电脑或其它被关闭或进行睡眠模式的电脑来说是非常有用的。
|
||||||
|
|
||||||
|
只要电脑一打开并引导成功,anacron 会检查过去是否有计划的作业被错过。如果有,这些作业将立即运行,但是,仅运行一次(而不管它错过了多少次循环运行)。例如,如果一个每周运行的作业在最近三周因为休假而系统关闭都没有运行,它将在你的电脑一启动就立即运行,但是,它仅运行一次,而不是三次。
|
||||||
|
|
||||||
|
anacron 程序提供了一些对周期性计划任务很好用的选项。它是安装在你的 `/etc/cron.[hourly|daily|weekly|monthly]` 目录下的脚本。 根据它们需要的频率去运行。
|
||||||
|
|
||||||
|
它是怎么工作的呢?接下来的这些要比前面的简单一些。
|
||||||
|
|
||||||
|
1、 crond 服务运行在 `/etc/cron.d/0hourly` 中指定的 cron 作业。
|
||||||
|
|
||||||
|
```
|
||||||
|
# Run the hourly jobs
|
||||||
|
SHELL=/bin/bash
|
||||||
|
PATH=/sbin:/bin:/usr/sbin:/usr/bin
|
||||||
|
MAILTO=root
|
||||||
|
01 * * * * root run-parts /etc/cron.hourly
|
||||||
|
```
|
||||||
|
|
||||||
|
*`/etc/cron.d/0hourly` 中的内容使位于 `/etc/cron.hourly` 中的 shell 脚本运行。*
|
||||||
|
|
||||||
|
2、 在 `/etc/cron.d/0hourly` 中指定的 cron 作业每小时运行一次 `run-parts` 程序。
|
||||||
|
|
||||||
|
3、 `run-parts` 程序运行所有的在 `/etc/cron.hourly` 目录中的脚本。
|
||||||
|
|
||||||
|
4、 `/etc/cron.hourly` 目录包含的 `0anacron` 脚本,它使用如下的 `/etdc/anacrontab` 配置文件去运行 anacron 程序。
|
||||||
|
|
||||||
|
```
|
||||||
|
# /etc/anacrontab: configuration file for anacron
|
||||||
|
|
||||||
|
# See anacron(8) and anacrontab(5) for details.
|
||||||
|
|
||||||
|
SHELL=/bin/sh
|
||||||
|
PATH=/sbin:/bin:/usr/sbin:/usr/bin
|
||||||
|
MAILTO=root
|
||||||
|
# the maximal random delay added to the base delay of the jobs
|
||||||
|
RANDOM_DELAY=45
|
||||||
|
# the jobs will be started during the following hours only
|
||||||
|
START_HOURS_RANGE=3-22
|
||||||
|
|
||||||
|
#period in days delay in minutes job-identifier command
|
||||||
|
1 5 cron.daily nice run-parts /etc/cron.daily
|
||||||
|
7 25 cron.weekly nice run-parts /etc/cron.weekly
|
||||||
|
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
|
||||||
|
```
|
||||||
|
|
||||||
|
*`/etc/anacrontab` 文件中的内容在合适的时间运行在 `cron.[daily|weekly|monthly]` 目录中的可执行文件。*
|
||||||
|
|
||||||
|
5、 anacron 程序每日运行一次位于 `/etc/cron.daily` 中的作业。它每周运行一次位于 `/etc/cron.weekly` 中的作业。以及每月运行一次 `cron.monthly` 中的作业。注意,在每一行指定的延迟时间,它可以帮助避免这些作业与其它 cron 作业重叠。
|
||||||
|
|
||||||
|
我在 `/usr/local/bin` 目录中放置它们,而不是在 `cron.X` 目录中放置完整的 Bash 程序,这会使我从命令行中运行它们更容易。然后,我在 cron 目录中增加一个符号连接,比如,`/etc/cron.daily`。
|
||||||
|
|
||||||
|
anacron 程序不是设计用于在指定时间运行程序的。而是,用于在一个指定的时间开始,以一定的时间间隔去运行程序,比如,从每天的凌晨 3:00(看上面脚本中的 `START_HOURS_RANGE` 行)、从周日(每周第一天)和这个月的第一天。如果任何一个或多个循环错过,anacron 将立即运行这个错过的作业。
|
||||||
|
|
||||||
|
### 更多的关于设置限制
|
||||||
|
|
||||||
|
我在我的计算机上使用了很多运行计划任务的方法。所有的这些任务都需要一个 root 权限去运行。在我的经验中,很少有普通用户去需要运行 cron 任务,一种情况是开发人员需要一个 cron 作业去启动一个开发实验室的每日编译。
|
||||||
|
|
||||||
|
限制非 root 用户去访问 cron 功能是非常重要的。然而,在一些特殊情况下,用户需要去设置一个任务在预先指定时间运行,而 cron 可以允许他们去那样做。许多用户不理解如何正确地配置 cron 去完成任务,并且他们会出错。这些错误可能是无害的,但是,往往不是这样的,它们可能导致问题。通过设置功能策略,使用户与管理员互相配合,可以使个别的 cron 作业尽可能地不干扰其它的用户和系统功能。
|
||||||
|
|
||||||
|
可以给为单个用户或组分配的资源设置限制,但是,这是下一篇文章中的内容。
|
||||||
|
|
||||||
|
更多信息,在 [cron][17]、[crontab][18]、[anacron][19]、[anacrontab][20]、和 [run-parts][21] 的 man 页面上,所有的这些信息都描述了 cron 系统是如何工作的。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
David Both - 是一位 Linux 和开源软件的倡导者,居住在 Raleigh,North Carolina。他从事 IT 行业超过四十年,并且在 IBM 教授 OS/2 超过 20 年时间,他在 1981 年 IBM 期间,为最初的 IBM PC 写了第一部培训教程。他为 Red Hat 教授 RHCE 系列课程,并且他也为 MCI Worldcom、 Cisco、和 North Carolina 州工作。他使用 Linux 和开源软件工作差不多 20 年了。
|
||||||
|
|
||||||
|
---------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/11/how-use-cron-linux
|
||||||
|
|
||||||
|
作者:[David Both][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/dboth
|
||||||
|
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||||
|
[6]:https://opensource.com/article/17/11/how-use-cron-linux?rate=9R7lrdQXsne44wxIh0Wu91ytYaxxi86zT1-uHo1a1IU
|
||||||
|
[7]:https://sourceforge.net/projects/logwatch/files/
|
||||||
|
[8]:https://github.com/logrotate/logrotate
|
||||||
|
[9]:http://rkhunter.sourceforge.net/
|
||||||
|
[10]:https://opensource.com/user/14106/feed
|
||||||
|
[11]:https://www.flickr.com/photos/internetarchivebookimages/20570945848/in/photolist-xkMtw9-xA5zGL-tEQLWZ-wFwzFM-aNwxgn-aFdWBj-uyFKYv-7ZCCBU-obY1yX-UAPafA-otBzDF-ovdDo6-7doxUH-obYkeH-9XbHKV-8Zk4qi-apz7Ky-apz8Qu-8ZoaWG-orziEy-aNwxC6-od8NTv-apwpMr-8Zk4vn-UAP9Sb-otVa3R-apz6Cb-9EMPj6-eKfyEL-cv5mwu-otTtHk-7YjK1J-ovhxf6-otCg2K-8ZoaJf-UAPakL-8Zo8j7-8Zk74v-otp4Ls-8Zo8h7-i7xvpR-otSosT-9EMPja-8Zk6Zi-XHpSDB-hLkuF3-of24Gf-ouN1Gv-fJzkJS-icfbY9
|
||||||
|
[12]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[13]:https://en.wikipedia.org/wiki/Cron
|
||||||
|
[14]:http://spamassassin.apache.org/
|
||||||
|
[15]:https://github.com/sysstat/sysstat
|
||||||
|
[16]:https://en.wikipedia.org/wiki/Anacron
|
||||||
|
[17]:http://man7.org/linux/man-pages/man8/cron.8.html
|
||||||
|
[18]:http://man7.org/linux/man-pages/man5/crontab.5.html
|
||||||
|
[19]:http://man7.org/linux/man-pages/man8/anacron.8.html
|
||||||
|
[20]:http://man7.org/linux/man-pages/man5/anacrontab.5.html
|
||||||
|
[21]:http://manpages.ubuntu.com/manpages/zesty/man8/run-parts.8.html
|
||||||
|
[22]:https://opensource.com/users/dboth
|
||||||
|
[23]:https://opensource.com/users/dboth
|
||||||
|
[24]:https://opensource.com/article/17/11/how-use-cron-linux#comments
|
||||||
@ -0,0 +1,43 @@
|
|||||||
|
GitLab:我们正将源码贡献许可证切换到 DCO
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 我们希望通过取消“<ruby>贡献者许可协议<rt>Contributor License Agreement</rt></ruby>”(CLA)来支持“<ruby>[开发者原创证书][3]<rt>Developer's Certificate of Origin</rt></ruby>”(DCO),让每个人都能更轻松地做出贡献。
|
||||||
|
|
||||||
|
我们致力于成为[开源的好管家][1],而这一承诺的一部分意味着我们永远不会停止重新评估我们如何做到这一点。承诺“每个人都可以贡献”就是消除贡献的障碍。对于我们的一些社区,“<ruby>贡献者许可协议<rt>Contributor License Agreement</rt></ruby>”(CLA)是对 GitLab 贡献的阻碍,所以我们改为“<ruby>[开发者原创证书][3]<rt>Developer's Certificate of Origin</rt></ruby>”(DCO)。
|
||||||
|
|
||||||
|
许多大型的开源项目都想成为自己命运的主人。拥有基于开源软件运行自己的基础架构的自由,以及修改和审计源代码的能力,而不依赖于供应商,这使开源具有吸引力。我们希望 GitLab 成为每个人的选择。
|
||||||
|
|
||||||
|
### 为什么改变?
|
||||||
|
|
||||||
|
贡献者许可协议(CLA)是对其它项目进行开源贡献的行业标准,但对于不愿意考虑法律条款的开发人员来说,这是不受欢迎的,并且由于需要审查冗长的合同而潜在地放弃他们的一些权利。贡献者发现协议不必要的限制,并且阻止开源项目的开发者使用 GitLab。我们接触过 Debian 开发人员,他们考虑放弃 CLA,而这就是我们正在做的。
|
||||||
|
|
||||||
|
### 改变了什么?
|
||||||
|
|
||||||
|
到今天为止,我们正在推出更改,以便 GitLab 源码的贡献者只需要一个项目许可证(所有仓库都是 MIT,除了 Omnibus 是 Apache 许可证)和一个[开发者原创证书][2] (DCO)即可。DCO 为开发人员提供了更大的灵活性和可移植性,这也是 Debian 和 GNOME 计划将其社区和项目迁移到 GitLab 的原因之一。我们希望这一改变能够鼓励更多的开发者为 GitLab 做出贡献。谢谢 Debian,提醒我们做出这个改变。
|
||||||
|
|
||||||
|
> “我们赞扬 GitLab 放弃他们的 CLA,转而使用对 OSS 更加友好的方式,开源社区诞生于一个汇集在一起并转化为项目的贡献海洋,这一举动肯定了 GitLab 愿意保护个人及其创作过程,最重要的是,把知识产权掌握在创造者手中。”
|
||||||
|
|
||||||
|
> —— GNOME 董事会主席 Carlos Soriano
|
||||||
|
|
||||||
|
|
||||||
|
> “我们很高兴看到 GitLab 通过从 CLA 转换到 DCO 来简化和鼓励社区贡献。我们认识到,做这种本质性的改变并不容易,我们赞扬 GitLab 在这里所展示的时间、耐心和深思熟虑的考虑。”
|
||||||
|
|
||||||
|
> —— Debian 项目负责人 Chris Lamb
|
||||||
|
|
||||||
|
你可以[阅读这篇关于我们做出这个决定的分析][3]。阅读所有关于我们 [GitLab 社区版的管理][4]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://about.gitlab.com/2017/11/01/gitlab-switches-to-dco-license/
|
||||||
|
|
||||||
|
作者:[Jamie Hurewitz][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://about.gitlab.com/team/#hurewitzjamie
|
||||||
|
[1]:https://about.gitlab.com/2016/01/11/being-a-good-open-source-steward/
|
||||||
|
[2]:https://developercertificate.org/
|
||||||
|
[3]:https://docs.google.com/a/gitlab.com/document/d/1zpjDzL7yhGBZz3_7jCjWLfRQ1Jryg1mlIVmG8y6B1_Q/edit?usp=sharing
|
||||||
|
[4]:https://about.gitlab.com/stewardship/
|
||||||
@ -0,0 +1,340 @@
|
|||||||
|
Linux 中管理 EXT2、 EXT3 和 EXT4 健康状况的 4 个工具
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
文件系统是一个在计算机上帮你去管理数据怎么去存储和检索的数据结构。文件系统也可以被视作是磁盘上的物理(或扩展)分区。如果它没有很好地被维护或定期监视,它可能在长期运行中出现各种各样的错误或损坏。
|
||||||
|
|
||||||
|
这里有几个可能导致文件系统出问题的因素:系统崩溃、硬件或软件故障、 有问题的驱动和程序、不正确的优化、大量的数据过载加上一些小故障。
|
||||||
|
|
||||||
|
这其中的任何一个问题都可以导致 Linux 不能顺利地挂载(或卸载)一个文件系统,从而导致系统故障。
|
||||||
|
|
||||||
|
扩展阅读:[Linux 中判断文件系统类型(Ext2, Ext3 或 Ext4)的 7 种方法][7]
|
||||||
|
|
||||||
|
另外,受损的文件系统运行在你的系统上可能导致操作系统中的组件或用户应用程序的运行时错误,它可能会进一步扩大到服务器数据的丢失。为避免文件系统错误或损坏,你需要去持续关注它的健康状况。
|
||||||
|
|
||||||
|
在这篇文章中,我们将介绍监视或维护一个 ext2、ext3 和 ext4 文件系统健康状况的工具。在这里描述的所有工具都需要 root 用户权限,因此,需要使用 [sudo 命令][8]去运行它们。
|
||||||
|
|
||||||
|
### 怎么去查看 EXT2/EXT3/EXT4 文件系统信息
|
||||||
|
|
||||||
|
`dumpe2fs` 是一个命令行工具,用于去转储 ext2/ext3/ext4 文件系统信息,这意味着它可以显示设备上文件系统的超级块和块组信息。
|
||||||
|
|
||||||
|
在运行 `dumpe2fs` 之前,先去运行 [df -hT][9] 命令,确保知道文件系统的设备名。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dumpe2fs /dev/sda10
|
||||||
|
```
|
||||||
|
|
||||||
|
**示例输出:**
|
||||||
|
|
||||||
|
```
|
||||||
|
dumpe2fs 1.42.13 (17-May-2015)
|
||||||
|
Filesystem volume name:
|
||||||
|
Last mounted on: /
|
||||||
|
Filesystem UUID: bb29dda3-bdaa-4b39-86cf-4a6dc9634a1b
|
||||||
|
Filesystem magic number: 0xEF53
|
||||||
|
Filesystem revision #: 1 (dynamic)
|
||||||
|
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
|
||||||
|
Filesystem flags: signed_directory_hash
|
||||||
|
Default mount options: user_xattr acl
|
||||||
|
Filesystem state: clean
|
||||||
|
Errors behavior: Continue
|
||||||
|
Filesystem OS type: Linux
|
||||||
|
Inode count: 21544960
|
||||||
|
Block count: 86154752
|
||||||
|
Reserved block count: 4307737
|
||||||
|
Free blocks: 22387732
|
||||||
|
Free inodes: 21026406
|
||||||
|
First block: 0
|
||||||
|
Block size: 4096
|
||||||
|
Fragment size: 4096
|
||||||
|
Reserved GDT blocks: 1003
|
||||||
|
Blocks per group: 32768
|
||||||
|
Fragments per group: 32768
|
||||||
|
Inodes per group: 8192
|
||||||
|
Inode blocks per group: 512
|
||||||
|
Flex block group size: 16
|
||||||
|
Filesystem created: Sun Jul 31 16:19:36 2016
|
||||||
|
Last mount time: Mon Nov 6 10:25:28 2017
|
||||||
|
Last write time: Mon Nov 6 10:25:19 2017
|
||||||
|
Mount count: 432
|
||||||
|
Maximum mount count: -1
|
||||||
|
Last checked: Sun Jul 31 16:19:36 2016
|
||||||
|
Check interval: 0 ()
|
||||||
|
Lifetime writes: 2834 GB
|
||||||
|
Reserved blocks uid: 0 (user root)
|
||||||
|
Reserved blocks gid: 0 (group root)
|
||||||
|
First inode: 11
|
||||||
|
Inode size: 256
|
||||||
|
Required extra isize: 28
|
||||||
|
Desired extra isize: 28
|
||||||
|
Journal inode: 8
|
||||||
|
First orphan inode: 6947324
|
||||||
|
Default directory hash: half_md4
|
||||||
|
Directory Hash Seed: 9da5dafb-bded-494d-ba7f-5c0ff3d9b805
|
||||||
|
Journal backup: inode blocks
|
||||||
|
Journal features: journal_incompat_revoke
|
||||||
|
Journal size: 128M
|
||||||
|
Journal length: 32768
|
||||||
|
Journal sequence: 0x00580f0c
|
||||||
|
Journal start: 12055
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以通过 `-b` 选项来显示文件系统中的任何保留块,比如坏块(无输出说明没有坏块):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dumpe2fs -b
|
||||||
|
```
|
||||||
|
|
||||||
|
### 检查 EXT2/EXT3/EXT4 文件系统的错误
|
||||||
|
|
||||||
|
`e2fsck` 用于去检查 ext2/ext3/ext4 文件系统的错误。`fsck` 可以检查并且可选地 [修复 Linux 文件系统][10];它实际上是底层 Linux 提供的一系列文件系统检查器 (fsck.fstype,例如 fsck.ext3、fsck.sfx 等等) 的前端程序。
|
||||||
|
|
||||||
|
记住,在系统引导时,Linux 会为 `/etc/fstab` 配置文件中被标为“检查”的分区自动运行 `e2fsck`/`fsck`。而在一个文件系统没有被干净地卸载时,一般也会运行它。
|
||||||
|
|
||||||
|
注意:不要在已挂载的文件系统上运行 e2fsck 或 fsck,在你运行这些工具之前,首先要去卸载分区,如下所示。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo unmount /dev/sda10
|
||||||
|
$ sudo fsck /dev/sda10
|
||||||
|
```
|
||||||
|
|
||||||
|
此外,可以使用 `-V` 开关去启用详细输出,使用 `-t` 去指定文件系统类型,像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo fsck -Vt ext4 /dev/sda10
|
||||||
|
```
|
||||||
|
|
||||||
|
### 调优 EXT2/EXT3/EXT4 文件系统
|
||||||
|
|
||||||
|
我们前面提到过,导致文件系统损坏的其中一个因素就是不正确的调优。你可以使用 `tune2fs` 实用程序去改变 ext2/ext3/ext4 文件系统的可调优参数,像下面讲的那样。
|
||||||
|
|
||||||
|
去查看文件系统的超级块,包括参数的当前值,使用 `-l` 选项,如下所示。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo tune2fs -l /dev/sda10
|
||||||
|
```
|
||||||
|
|
||||||
|
**示例输出:**
|
||||||
|
|
||||||
|
```
|
||||||
|
tune2fs 1.42.13 (17-May-2015)
|
||||||
|
Filesystem volume name:
|
||||||
|
Last mounted on: /
|
||||||
|
Filesystem UUID: bb29dda3-bdaa-4b39-86cf-4a6dc9634a1b
|
||||||
|
Filesystem magic number: 0xEF53
|
||||||
|
Filesystem revision #: 1 (dynamic)
|
||||||
|
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
|
||||||
|
Filesystem flags: signed_directory_hash
|
||||||
|
Default mount options: user_xattr acl
|
||||||
|
Filesystem state: clean
|
||||||
|
Errors behavior: Continue
|
||||||
|
Filesystem OS type: Linux
|
||||||
|
Inode count: 21544960
|
||||||
|
Block count: 86154752
|
||||||
|
Reserved block count: 4307737
|
||||||
|
Free blocks: 22387732
|
||||||
|
Free inodes: 21026406
|
||||||
|
First block: 0
|
||||||
|
Block size: 4096
|
||||||
|
Fragment size: 4096
|
||||||
|
Reserved GDT blocks: 1003
|
||||||
|
Blocks per group: 32768
|
||||||
|
Fragments per group: 32768
|
||||||
|
Inodes per group: 8192
|
||||||
|
Inode blocks per group: 512
|
||||||
|
Flex block group size: 16
|
||||||
|
Filesystem created: Sun Jul 31 16:19:36 2016
|
||||||
|
Last mount time: Mon Nov 6 10:25:28 2017
|
||||||
|
Last write time: Mon Nov 6 10:25:19 2017
|
||||||
|
Mount count: 432
|
||||||
|
Maximum mount count: -1
|
||||||
|
Last checked: Sun Jul 31 16:19:36 2016
|
||||||
|
Check interval: 0 ()
|
||||||
|
Lifetime writes: 2834 GB
|
||||||
|
Reserved blocks uid: 0 (user root)
|
||||||
|
Reserved blocks gid: 0 (group root)
|
||||||
|
First inode: 11
|
||||||
|
Inode size: 256
|
||||||
|
Required extra isize: 28
|
||||||
|
Desired extra isize: 28
|
||||||
|
Journal inode: 8
|
||||||
|
First orphan inode: 6947324
|
||||||
|
Default directory hash: half_md4
|
||||||
|
Directory Hash Seed: 9da5dafb-bded-494d-ba7f-5c0ff3d9b805
|
||||||
|
Journal backup: inode blocks
|
||||||
|
```
|
||||||
|
|
||||||
|
接下来,使用 `-c` 标识,你可以设置文件系统在挂载多少次后将进行 `e2fsck` 检查。下面这个命令指示系统每挂载 4 次之后,去对 `/dev/sda10` 运行 `e2fsck`。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo tune2fs -c 4 /dev/sda10
|
||||||
|
tune2fs 1.42.13 (17-May-2015)
|
||||||
|
Setting maximal mount count to 4
|
||||||
|
```
|
||||||
|
|
||||||
|
你也可以使用 `-i` 选项定义两次文件系统检查的时间间隔。下列的命令在两次文件系统检查之间设置了一个 2 天的时间间隔。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo tune2fs -i 2d /dev/sda10
|
||||||
|
tune2fs 1.42.13 (17-May-2015)
|
||||||
|
Setting interval between checks to 172800 seconds
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,如果你运行下面的命令,你可以看到对 `/dev/sda10` 已经设置了文件系统检查的时间间隔。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo tune2fs -l /dev/sda10
|
||||||
|
```
|
||||||
|
|
||||||
|
**示例输出:**
|
||||||
|
|
||||||
|
```
|
||||||
|
Filesystem created: Sun Jul 31 16:19:36 2016
|
||||||
|
Last mount time: Mon Nov 6 10:25:28 2017
|
||||||
|
Last write time: Mon Nov 6 13:49:50 2017
|
||||||
|
Mount count: 432
|
||||||
|
Maximum mount count: 4
|
||||||
|
Last checked: Sun Jul 31 16:19:36 2016
|
||||||
|
Check interval: 172800 (2 days)
|
||||||
|
Next check after: Tue Aug 2 16:19:36 2016
|
||||||
|
Lifetime writes: 2834 GB
|
||||||
|
Reserved blocks uid: 0 (user root)
|
||||||
|
Reserved blocks gid: 0 (group root)
|
||||||
|
First inode: 11
|
||||||
|
Inode size: 256
|
||||||
|
Required extra isize: 28
|
||||||
|
Desired extra isize: 28
|
||||||
|
Journal inode: 8
|
||||||
|
First orphan inode: 6947324
|
||||||
|
Default directory hash: half_md4
|
||||||
|
Directory Hash Seed: 9da5dafb-bded-494d-ba7f-5c0ff3d9b805
|
||||||
|
Journal backup: inode blocks
|
||||||
|
```
|
||||||
|
|
||||||
|
要改变缺省的日志参数,可以使用 `-J` 选项。这个选项也有子选项: `size=journal-size` (设置日志的大小)、`device=external-journal` (指定日志存储的设备)和 `location=journal-location` (定义日志的位置)。
|
||||||
|
|
||||||
|
注意,这里一次仅可以为文件系统设置一个日志大小或设备选项:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo tune2fs -J size=4MB /dev/sda10
|
||||||
|
```
|
||||||
|
|
||||||
|
最后,同样重要的是,可以去使用 `-L` 选项设置文件系统的卷标,如下所示。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo tune2fs -L "ROOT" /dev/sda10
|
||||||
|
```
|
||||||
|
|
||||||
|
### 调试 EXT2/EXT3/EXT4 文件系统
|
||||||
|
|
||||||
|
`debugfs` 是一个简单的、交互式的、基于 ext2/ext3/ext4 文件系统的命令行调试器。它允许你去交互式地修改文件系统参数。输入 `?` 查看子命令或请求。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo debugfs /dev/sda10
|
||||||
|
```
|
||||||
|
|
||||||
|
缺省情况下,文件系统将以只读模式打开,使用 `-w` 标识去以读写模式打开它。使用 `-c` 选项以灾难(catastrophic)模式打开它。
|
||||||
|
|
||||||
|
**示例输出:**
|
||||||
|
|
||||||
|
```
|
||||||
|
debugfs 1.42.13 (17-May-2015)
|
||||||
|
debugfs: ?
|
||||||
|
Available debugfs requests:
|
||||||
|
show_debugfs_params, params
|
||||||
|
Show debugfs parameters
|
||||||
|
open_filesys, open Open a filesystem
|
||||||
|
close_filesys, close Close the filesystem
|
||||||
|
freefrag, e2freefrag Report free space fragmentation
|
||||||
|
feature, features Set/print superblock features
|
||||||
|
dirty_filesys, dirty Mark the filesystem as dirty
|
||||||
|
init_filesys Initialize a filesystem (DESTROYS DATA)
|
||||||
|
show_super_stats, stats Show superblock statistics
|
||||||
|
ncheck Do inode->name translation
|
||||||
|
icheck Do block->inode translation
|
||||||
|
change_root_directory, chroot
|
||||||
|
....
|
||||||
|
```
|
||||||
|
|
||||||
|
要展示未使用空间的碎片,使用 `freefrag` 请求,像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
debugfs: freefrag
|
||||||
|
```
|
||||||
|
|
||||||
|
**示例输出:**
|
||||||
|
|
||||||
|
```
|
||||||
|
Device: /dev/sda10
|
||||||
|
Blocksize: 4096 bytes
|
||||||
|
Total blocks: 86154752
|
||||||
|
Free blocks: 22387732 (26.0%)
|
||||||
|
Min. free extent: 4 KB
|
||||||
|
Max. free extent: 2064256 KB
|
||||||
|
Avg. free extent: 2664 KB
|
||||||
|
Num. free extent: 33625
|
||||||
|
HISTOGRAM OF FREE EXTENT SIZES:
|
||||||
|
Extent Size Range : Free extents Free Blocks Percent
|
||||||
|
4K... 8K- : 4883 4883 0.02%
|
||||||
|
8K... 16K- : 4029 9357 0.04%
|
||||||
|
16K... 32K- : 3172 15824 0.07%
|
||||||
|
32K... 64K- : 2523 27916 0.12%
|
||||||
|
64K... 128K- : 2041 45142 0.20%
|
||||||
|
128K... 256K- : 2088 95442 0.43%
|
||||||
|
256K... 512K- : 2462 218526 0.98%
|
||||||
|
512K... 1024K- : 3175 571055 2.55%
|
||||||
|
1M... 2M- : 4551 1609188 7.19%
|
||||||
|
2M... 4M- : 2870 1942177 8.68%
|
||||||
|
4M... 8M- : 1065 1448374 6.47%
|
||||||
|
8M... 16M- : 364 891633 3.98%
|
||||||
|
16M... 32M- : 194 984448 4.40%
|
||||||
|
32M... 64M- : 86 873181 3.90%
|
||||||
|
64M... 128M- : 77 1733629 7.74%
|
||||||
|
128M... 256M- : 11 490445 2.19%
|
||||||
|
256M... 512M- : 10 889448 3.97%
|
||||||
|
512M... 1024M- : 2 343904 1.54%
|
||||||
|
1G... 2G- : 22 10217801 45.64%
|
||||||
|
debugfs:
|
||||||
|
```
|
||||||
|
|
||||||
|
通过去简单浏览它所提供的简要描述,你可以试试更多的请求,比如,创建或删除文件或目录,改变当前工作目录等等。要退出 `debugfs`,使用 `q`。
|
||||||
|
|
||||||
|
现在就这些!我们收集了不同分类下的相关文章,你可以在里面找到对你有用的内容。
|
||||||
|
|
||||||
|
**文件系统使用信息:**
|
||||||
|
|
||||||
|
1. [12 Useful “df” Commands to Check Disk Space in Linux][1]
|
||||||
|
2. [Pydf an Alternative “df” Command to Check Disk Usage in Different Colours][2]
|
||||||
|
3. [10 Useful du (Disk Usage) Commands to Find Disk Usage of Files and Directories][3]
|
||||||
|
|
||||||
|
**检查磁盘或分区健康状况:**
|
||||||
|
|
||||||
|
1. [3 Useful GUI and Terminal Based Linux Disk Scanning Tools][4]
|
||||||
|
2. [How to Check Bad Sectors or Bad Blocks on Hard Disk in Linux][5]
|
||||||
|
3. [How to Repair and Defragment Linux System Partitions and Directories][6]
|
||||||
|
|
||||||
|
维护一个健康的文件系统可以提升你的 Linux 系统的整体性能。如果你有任何问题或更多的想法,可以使用下面的评论去分享。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.tecmint.com/manage-ext2-ext3-and-ext4-health-in-linux/
|
||||||
|
|
||||||
|
作者:[Aaron Kili][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:https://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||||
|
[2]:https://www.tecmint.com/pyd-command-to-check-disk-usage/
|
||||||
|
[3]:https://www.tecmint.com/check-linux-disk-usage-of-files-and-directories/
|
||||||
|
[4]:https://www.tecmint.com/linux-disk-scanning-tools/
|
||||||
|
[5]:https://www.tecmint.com/check-linux-hard-disk-bad-sectors-bad-blocks/
|
||||||
|
[6]:https://www.tecmint.com/defragment-linux-system-partitions-and-directories/
|
||||||
|
[7]:https://linux.cn/article-8289-1.html
|
||||||
|
[8]:https://linux.cn/article-8278-1.html
|
||||||
|
[9]:https://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||||
|
[10]:https://www.tecmint.com/defragment-linux-system-partitions-and-directories/
|
||||||
|
[11]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[12]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[13]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
162
published/20171106 Finding Files with mlocate.md
Normal file
162
published/20171106 Finding Files with mlocate.md
Normal file
@ -0,0 +1,162 @@
|
|||||||
|
使用 mlocate 查找文件
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在这一系列的文章中,我们将来看下 `mlocate`,来看看如何快速、轻松地满足你的需求。
|
||||||
|
|
||||||
|
[Creative Commons Zero][1]Pixabay
|
||||||
|
|
||||||
|
对于一个系统管理员来说,草中寻针一样的查找文件的事情并不少见。在一台拥挤的机器上,文件系统中可能存在数十万个文件。当你需要确定一个特定的配置文件是最新的,但是你不记得它在哪里时怎么办?
|
||||||
|
|
||||||
|
如果你使用过一些类 Unix 机器,那么你肯定用过 `find` 命令。毫无疑问,它是非常复杂和功能强大的。以下是一个只搜索目录中的符号链接,而忽略文件的例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
# find . -lname "*"
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以用 `find` 命令做几乎无尽的事情,这是不容否认的。`find` 命令好用的时候是很好且简洁的,但是它也可以很复杂。这不一定是因为 `find` 命令本身的原因,而是它与 `xargs` 结合,你可以传递各种选项来调整你的输出,并删除你找到的那些文件。
|
||||||
|
|
||||||
|
### 位置、位置,让人沮丧
|
||||||
|
|
||||||
|
然而,通常情况下简单是最好的选择,特别是当一个脾气暴躁的老板搭着你的肩膀,闲聊着时间的重要性时。你还在模糊地猜测这个你从来没有见过的文件的路径,而你的老板却肯定它在拥挤的 /var 分区的某处。
|
||||||
|
|
||||||
|
进一步看下 `mlocate`。你也许注意过它的一个近亲:`slocate`,它安全地(注意前缀字母 s 代表安全)记录了相关的文件权限,以防止非特权用户看到特权文件。此外,还有它们所起源的一个更老的,原始 `locate` 命令。
|
||||||
|
|
||||||
|
`mlocate` 与其家族的其他成员(至少包括 `slocate`)的不同之处在于,在扫描文件系统时,`mlocate` 不需要持续重新扫描所有的文件系统。相反,它将其发现的文件(注意前面的 m 代表合并)与现有的文件列表合并在一起,使其可以借助系统缓存从而性能更高、更轻量级。
|
||||||
|
|
||||||
|
在本系列文章中,我们将更仔细地了解 `mlocate` (由于其流行,所以也简称其为 `locate`),并研究如何快速轻松地将其调整到你心中所想的方式。
|
||||||
|
|
||||||
|
### 小巧和 紧凑
|
||||||
|
|
||||||
|
除非你经常重复使用复杂的命令,否则就会像我一样,最终会忘记它们而需要在用的时候寻找它们。`locate` 命令的优点是可以快速查询整个文件系统,而不用担心你处于顶层目录、根目录和所在路径,只需要简单地使用 `locate` 命令。
|
||||||
|
|
||||||
|
以前你可能已经发现 `find` 命令非常不听话,让你经常抓耳挠腮。你知道,丢失了一个分号或一个没有正确转义的特殊的字符就会这样。现在让我们离开这个复杂的 `find` 命令,放松一下,看一下这个聪明的小命令。
|
||||||
|
|
||||||
|
你可能需要首先通过运行以下命令来检查它是否在你的系统上:
|
||||||
|
|
||||||
|
对于 Red Hat 家族:
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum install mlocate
|
||||||
|
```
|
||||||
|
|
||||||
|
对于 Debian 家族:
|
||||||
|
|
||||||
|
```
|
||||||
|
# apt-get install mlocate
|
||||||
|
```
|
||||||
|
|
||||||
|
发行版之间不应该有任何区别,但版本之间几乎肯定有细微差别。小心。
|
||||||
|
|
||||||
|
接下来,我们将介绍 `locate` 命令的一个关键组件,名为 `updatedb`。正如你可能猜到的那样,这是**更新** `locate` 命令的**数据库**的命令。这名字非常符合直觉。
|
||||||
|
|
||||||
|
这个数据库是我之前提到的 `locate` 命令的文件列表。该列表被保存在一个相对简单而高效的数据库中。`updatedb` 通过 cron 任务定期运行,通常在一天中的安静时间运行。在下面的清单 1 中,我们可以看到文件 `/etc/cron.daily/mlocate.cron` 的内部(该文件的路径及其内容可能因发行版不同)。
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/sh
|
||||||
|
|
||||||
|
nodevs=$(< /proc/filesystems awk '$1 == "nodev" { print $2 }')
|
||||||
|
|
||||||
|
renice +19 -p $$ >/dev/null 2>&1
|
||||||
|
|
||||||
|
ionice -c2 -n7 -p $$ >/dev/null 2>&1
|
||||||
|
|
||||||
|
/usr/bin/updatedb -f "$nodevs"
|
||||||
|
```
|
||||||
|
|
||||||
|
**清单 1:** 每天如何触发 “updatedb” 命令。
|
||||||
|
|
||||||
|
如你所见,`mlocate.cron` 脚本使用了优秀的 `nice` 命令来尽可能少地影响系统性能。我还没有明确指出这个命令每天都在设定的时间运行(但如果我没有记错的话,原始的 `locate` 命令与你在午夜时的计算机减速有关)。这是因为,在一些 “cron” 版本上,延迟现在被引入到隔夜开始时间。
|
||||||
|
|
||||||
|
这可能是因为所谓的 “<ruby>河马之惊群<rt>Thundering Herd of Hippos</rt></ruby>”问题。想象许多计算机(或饥饿的动物)同时醒来从单一或有限的来源要求资源(或食物)。当所有的“河马”都使用 NTP 设置它们的手表时,这可能会发生(好吧,这个寓言扯多了,但请忍受一下)。想象一下,正好每五分钟(就像一个 “cron 任务”),它们都要求获得食物或其他东西。
|
||||||
|
|
||||||
|
如果你不相信我,请看下配置文件 - 清单 2 中名为 `anacron` 的 cron 版本,这是文件 `/etc/anacrontab` 的内容。
|
||||||
|
|
||||||
|
```
|
||||||
|
# /etc/anacrontab: configuration file for anacron
|
||||||
|
|
||||||
|
# See anacron(8) and anacrontab(5) for details.
|
||||||
|
|
||||||
|
SHELL=/bin/sh
|
||||||
|
|
||||||
|
PATH=/sbin:/bin:/usr/sbin:/usr/bin
|
||||||
|
|
||||||
|
MAILTO=root
|
||||||
|
|
||||||
|
# the maximal random delay added to the base delay of the jobs
|
||||||
|
|
||||||
|
RANDOM_DELAY=45
|
||||||
|
|
||||||
|
# the jobs will be started during the following hours only
|
||||||
|
|
||||||
|
START_HOURS_RANGE=3-22
|
||||||
|
|
||||||
|
#period in days delay in minutes job-identifier command
|
||||||
|
|
||||||
|
1 5 cron.daily nice run-parts /etc/cron.daily
|
||||||
|
|
||||||
|
7 25 cron.weekly nice run-parts /etc/cron.weekly
|
||||||
|
|
||||||
|
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
|
||||||
|
```
|
||||||
|
|
||||||
|
**清单 2:** 运行 “cron” 任务时延迟是怎样被带入的。
|
||||||
|
|
||||||
|
从清单 2 可以看到 `RANDOM_DELAY` 和 “delay in minutes” 列。如果你不熟悉 cron 这个方面,那么你可以在这找到更多的东西:
|
||||||
|
|
||||||
|
```
|
||||||
|
# man anacrontab
|
||||||
|
```
|
||||||
|
|
||||||
|
否则,如果你愿意,你可以自己延迟一下。有个[很棒的网页][3](现在已有十多年的历史)以非常合理的方式讨论了这个问题。本网站讨论如何使用 `sleep` 来引入一个随机性,如清单 3 所示。
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/sh
|
||||||
|
|
||||||
|
# Grab a random value between 0-240.
|
||||||
|
value=$RANDOM
|
||||||
|
while [ $value -gt 240 ] ; do
|
||||||
|
value=$RANDOM
|
||||||
|
done
|
||||||
|
|
||||||
|
# Sleep for that time.
|
||||||
|
sleep $value
|
||||||
|
|
||||||
|
# Syncronize.
|
||||||
|
/usr/bin/rsync -aqzC --delete --delete-after masterhost::master /some/dir/
|
||||||
|
```
|
||||||
|
|
||||||
|
**清单 3:**在触发事件之前引入随机延迟的 shell 脚本,以避免[河马之惊群][4]。
|
||||||
|
|
||||||
|
在提到这些(可能令人惊讶的)延迟时,是指 `/etc/crontab` 或 root 用户自己的 crontab 文件。如果你想改变 `locate` 命令运行的时间,特别是由于磁盘访问速度减慢时,那么它不是太棘手。实现它可能会有更优雅的方式,但是你也可以把文件 `/etc/cron.daily/mlocate.cron` 移到别的地方(我使用 `/usr/local/etc` 目录),使用 root 用户添加一条记录到 root 用户的 crontab,粘贴以下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
# crontab -e
|
||||||
|
|
||||||
|
33 3 * * * /usr/local/etc/mlocate.cron
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 anacron,而不是通过 `/var/log/cron` 以及它的旧的、轮转的版本,你可以快速地告诉它上次 cron.daily 任务被触发的时间:
|
||||||
|
|
||||||
|
```
|
||||||
|
# ls -hal /var/spool/anacron
|
||||||
|
```
|
||||||
|
|
||||||
|
下一次,我们会看更多的使用 `locate`、`updatedb` 和其他工具来查找文件的方法。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linux.com/blog/learn/intro-to-linux/2017/11/finding-files-mlocate
|
||||||
|
|
||||||
|
作者:[CHRIS BINNIE][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linux.com/users/chrisbinnie
|
||||||
|
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||||
|
[2]:https://www.linux.com/files/images/question-markjpg
|
||||||
|
[3]:http://www.moundalexis.com/archives/000076.php
|
||||||
|
[4]:http://www.moundalexis.com/archives/000076.php
|
||||||
@ -0,0 +1,53 @@
|
|||||||
|
Linux 基金会发布了新的企业开源指南
|
||||||
|
===============
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Linux 基金会在其企业开源指南文集中为开发和使用开源软件增加了三篇新的指南。
|
||||||
|
|
||||||
|
这个有着 17 年历史的非营利组织的主要任务是支持开源社区,并且,作为该任务的一部分,它在 9 月份发布了六篇 [企业开源指南][2],涉及从招募开发人员到使用开源代码的各个主题。
|
||||||
|
|
||||||
|
最近一段时间以来,Linux 基金会与开源专家组 [TODO Group][3](Talk Openly, Develop Openly)合作发布了三篇指南。
|
||||||
|
|
||||||
|
这一系列的指南用于在多个层次上帮助企业员工 —— 执行官、开源计划经理、开发者、律师和其他决策者 —— 学习怎么在开源活动中取得更好的收益。
|
||||||
|
|
||||||
|
该组织是这样描述这三篇指南的:
|
||||||
|
|
||||||
|
* **提升你的开源开发的影响力**, —— 来自 Ibrahim Haddad,三星美国研究院。该指南涵盖了企业可以采用的一些做法,以帮助企业扩大他们在大型开源项目中的影响。
|
||||||
|
* **启动一个开源项目**,—— 来自 Christine Abernathy,Facebook;Ibrahim Haddad;Guy Martin,Autodesk;John Mertic,Linux 基金会;Jared Smith,第一资本(Capital One)。这个指南帮助已经熟悉开源的企业学习怎么去开始自己的开源项目。
|
||||||
|
* **开源阅读列表**。一个开源程序管理者必读书清单,由 TODO Group 成员编制完成的。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*企业开源指南的 ‘阅读列表’ 中的一部分产品 (来源:Linux 基金会)*
|
||||||
|
|
||||||
|
在九月份发布的六篇指南包括:
|
||||||
|
|
||||||
|
* **创建一个开源计划:** 学习怎么去建立一个计划去管理内部开源使用和外部贡献。
|
||||||
|
* **开源管理工具:** 一系列可用于跟踪和管理开源项目的工具。
|
||||||
|
* **衡量你的开源计划是否成功:** 了解更多关于顶级组织评估其开源计划和贡献的 ROI 的方法。
|
||||||
|
* **招聘开发人员:** 学习如何通过创建开源文化和贡献开源项目来招募开发人员或从内部挖掘人才。
|
||||||
|
* **参与开源社区:** 了解奉献内部开发者资源去参与开源社区的重要性,和怎么去操作的最佳方法。
|
||||||
|
* **使用开源代码:** 在你的商业产品中集成开源代码时,确保你的组织符合它的法律责任。
|
||||||
|
|
||||||
|
更多的指南正在编制中,它们将和这些指南一样发布在 Linux 基金会和 [GitHub][5] 的网站上。
|
||||||
|
|
||||||
|
TODO Group 也发布了四个 [案例研究][6] 的补充材料,详细描述了 Autodesk、Comcast、Facebook 和 Salesforce 在构建他们的开源计划中的经验。以后,还有更多的计划。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://adtmag.com/articles/2017/11/06/open-source-guides.aspx
|
||||||
|
|
||||||
|
作者:[David Ramel][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://adtmag.com/forms/emailtoauthor.aspx?AuthorItem={53762E17-6187-46B4-8C04-9DFA282EBB67}&ArticleItem={855B2913-5DCF-4871-8563-6D88DA5A7C3C}
|
||||||
|
[1]:https://adtmag.com/forms/emailtoauthor.aspx?AuthorItem={53762E17-6187-46B4-8C04-9DFA282EBB67}&ArticleItem={855B2913-5DCF-4871-8563-6D88DA5A7C3C}
|
||||||
|
[2]:https://www.linuxfoundation.org/resources/open-source-guides/
|
||||||
|
[3]:http://todogroup.org/
|
||||||
|
[4]:https://adtmag.com/articles/2017/11/06/~/media/ECG/adtmag/Images/2017/11/open_source_list.asxh
|
||||||
|
[5]:https://github.com/todogroup/guides
|
||||||
|
[6]:https://github.com/todogroup/guides/tree/master/casestudies
|
||||||
@ -0,0 +1,62 @@
|
|||||||
|
大多数公司对开源社区不得要领,正确的打开方式是什么?
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> Red Hat 已经学会了跟随开源社区,并将其商业化。你也可以。
|
||||||
|
|
||||||
|
开源中最强大但最困难的事情之一就是社区。红帽首席执行官 Jim Whitehurst 在与 Slashdot 的[最近一次采访][7]中宣称:“有强大社区的存在,开源总是赢得胜利”。但是建设这个社区很难。真的,真的很难。尽管[预测开源社区蓬勃发展的必要组成部分][8]很简单,但是预测这些部分在何时何地将会组成像 Linux 或 Kubernetes 这样的社区则极其困难。
|
||||||
|
|
||||||
|
这就是为什么聪明的资金似乎在随社区而动,而不是试图创建它们。
|
||||||
|
|
||||||
|
### 可爱的开源寄生虫
|
||||||
|
|
||||||
|
在阅读 Whitehurst 的 Slashdot 采访时,这个想法让我感到震惊。虽然他谈及了从 Linux 桌面到 systemd 的很多内容,但 Whitehurst 关于社区的评论对我来说是最有说服力的:
|
||||||
|
|
||||||
|
> 建立一个新社区是困难的。我们在红帽开始做一点,但大部分时间我们都在寻找已经拥有强大社区的现有项目。在强大的社区存在的情况下,开源始终是胜利的。
|
||||||
|
|
||||||
|
虽然这种方法 —— 加强现有的、不断发展的社区,似乎是一种逃避,它实际上是最明智的做法。早期,开源几乎总是支离破碎的,因为每个项目都试图获得足够的成员。在某些时候,人们开始聚集两到三名获胜者身边(例如 KDE vs. Gnome,或者 Kubernetes vs. Docker Swarm 与 Apache Mesos)。但最终,很难维持不同的社区“标准”,每个人都最终围拢到一个赢家身边(例如 Kubernetes)。
|
||||||
|
|
||||||
|
**参见:[混合云和开源:红帽数字化转型的秘诀][5](Tech Pro Research)**
|
||||||
|
|
||||||
|
这不是投降 —— 这是培养资源和推动标准化的更好方式。例如,Linux 已经成为如此强大的力量的一个原因是,它鼓励在一个地方进行操作系统创新,即使存在不同的分支社区(以及贡献代码的大量的各个公司和个人)不断为它做贡献。红帽的发展很快,部分原因是它在早期就做出了聪明的社区选择,选择了一个赢家(比如 Kubernetes),并帮助它取得更大的成功。
|
||||||
|
|
||||||
|
而这反过来又为其商业模式提供动力。
|
||||||
|
|
||||||
|
### 从社区混乱中赚钱
|
||||||
|
|
||||||
|
对红帽而言一件很好的事是社区越多,项目就越成功。但是,开源的“成功”并不一定意味着企业会接受该项目,这仅仅意味着他们_愿意_这样做。红帽公司早期的直觉和不断地支付分红,就是理解那些枯燥、平庸的企业想要开源的活力,而不要,好吧,还是活力。他们需要把它驯服,变得枯燥而又平庸。Whitehurst 在采访中完美地表达了这一点:
|
||||||
|
|
||||||
|
> 红帽是成功的,因为我们沉迷于寻找方法来增加我们每个产品的代码价值。我们认为自己是帮助企业客户轻松消费开源创新的。
|
||||||
|
>
|
||||||
|
> 仅举一例:对于我们所有的产品,我们关注生命周期。开源是一个伟大的开发模式,但其“尽早发布、频繁发布”的风格使其在生产中难以实施。我们在 Linux 中发挥的一个重要价值是,我们在受支持的内核中支持 bug 修复和安全更新十多年,同时从不破坏 API 兼容性。这对于运行长期应用程序的企业具有巨大的价值。我们通过这种类型的流程来应对我们选择进行产品化的所有项目,以确定我们如何增加源代码之外的价值。
|
||||||
|
|
||||||
|
对于大多数想要开源的公司来说,挑战在于他们可能认识到社区的价值,但是不知道怎么不去销售代码。毕竟,销售软件几十年来一直是一个非常有利可图的商业模式,并产生了一些地球上最有价值的公司。
|
||||||
|
|
||||||
|
**参看[红帽如何使 Kubernetes 乏味并且成功][6]**
|
||||||
|
|
||||||
|
然而, 正如 Whitehurst 指出的那样,开源需要一种不同的方法。他在采访中断言:“**你不能出售功能**, 因为它是免费的”。相反, 你必须找到其他的价值,比如在很长一段周期内让开源得到支持。这是枯燥的工作,但对红帽而言每年值数十亿美元。
|
||||||
|
|
||||||
|
所有这一切都从社区开始。社区更有活力,更好的是它能使开源产品市场化,并能赚钱。为什么?嗯,因为更多的发展的部分等价于更大的价值,随之让自由发展的项目对企业消费而言更加稳定。这是一个成功的公式,并可以发挥所有开源的好处,而不会将它受制于二十世纪的商业模式。
|
||||||
|
|
||||||
|
 Image: iStockphoto/ipopba
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.techrepublic.com/article/most-companies-cant-buy-an-open-source-community-clue-heres-how-to-do-it-right/
|
||||||
|
|
||||||
|
作者:[Matt Asay][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.techrepublic.com/meet-the-team/us/matt-asay/
|
||||||
|
[1]:https://www.techrepublic.com/article/git-everything-the-pros-need-to-know/
|
||||||
|
[2]:https://www.techrepublic.com/article/ditching-windows-for-linux-led-to-major-difficulties-says-open-source-champion-munich/
|
||||||
|
[3]:http://www.techproresearch.com/downloads/securing-linux-policy/
|
||||||
|
[4]:https://www.techrepublic.com/newsletters/
|
||||||
|
[5]:http://www.techproresearch.com/article/hybrid-cloud-and-open-source-red-hats-recipe-for-digital-transformation/
|
||||||
|
[6]:https://www.techrepublic.com/article/how-red-hat-aims-to-make-kubernetes-boring-and-successful/
|
||||||
|
[7]:https://linux.slashdot.org/story/17/10/30/0237219/interviews-red-hat-ceo-jim-whitehurst-answers-your-questions
|
||||||
|
[8]:http://asay.blogspot.com/2005/09/so-you-want-to-build-open-source.html
|
||||||
|
[9]:https://www.techrepublic.com/meet-the-team/us/matt-asay/
|
||||||
|
[10]:https://twitter.com/intent/user?screen_name=mjasay
|
||||||
@ -0,0 +1,75 @@
|
|||||||
|
AWS 采用自制的 KVM 作为新的管理程序
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 摆脱了 Xen,新的 C5 实例和未来的虚拟机将采用“核心 KVM 技术”
|
||||||
|
|
||||||
|
AWS 透露说它已经创建了一个基于 KVM 的新的<ruby>管理程序<rt>hypervisor</rt></ruby>,而不是多年来依赖的 Xen 管理程序。
|
||||||
|
|
||||||
|
新的虚拟机管理程序披露在 EC2 新实例类型的[新闻][3]脚注里,新实例类型被称为 “C5”,由英特尔的 Skylake Xeon 提供支持。AWS 关于新实例的 [FAQ][4] 提及“C5 实例使用新的基于核心 KVM 技术的 EC2 虚拟机管理程序”。
|
||||||
|
|
||||||
|
这是爆炸性的新闻,因为 AWS 长期以来一直支持 Xen 管理程序。Xen 项目从最强大的公共云使用其开源软件的这个事实中吸取了力量。Citrix 将其大部分 Xen 服务器运行了 AWS 的管理程序的闭源版本。
|
||||||
|
|
||||||
|
更有趣的是,AWS 新闻中说:“未来,我们将使用这个虚拟机管理程序为其他实例类型提供动力。” 这个互联网巨头的文章中计划在“一系列 AWS re:Invent 会议中分享更多的技术细节”。
|
||||||
|
|
||||||
|
这听上去和很像 AWS 要放弃 Xen。
|
||||||
|
|
||||||
|
新的管理程序还有很长的路要走,这解释了为什么 AWS 是[最后一个运行 Intel 新的 Skylake Xeon CPU 的大型云服务商][5],因为 AWS 还透露了新的 C5 实例运行在它所描述的“定制处理器上,针对 EC2 进行了优化。”
|
||||||
|
|
||||||
|
Intel 和 AWS 都表示这是一款定制的 3.0 GHz Xeon Platinum 8000 系列处理器。Chipzilla 提供了一些该 CPU 的[新闻发布级别的细节][6],称它与 AWS 合作开发了“使用最新版本的 Intel 数学核心库优化的 AI/深度学习引擎”,以及“ MXNet 和其他深度学习框架为在 Amazon EC2 C5 实例上运行进行了高度优化。”
|
||||||
|
|
||||||
|
Intel 之前定制了 Xeons,将其提供给 [Oracle][7] 等等。AWS 大量购买 CPU,所以英特尔再次这样做并不意外。
|
||||||
|
|
||||||
|
迁移到 KVM 更令人惊讶,但是 AWS 可以根据需要来调整云服务以获得最佳性能。如果这意味着构建一个虚拟机管理程序,并确保它使用自定义的 Xeon,那就这样吧。
|
||||||
|
|
||||||
|
不管它在三周内发布了什么,AWS 现在都在说 C5 实例和它们的新虚拟机管理程序有更高的吞吐量,新的虚拟机在连接到弹性块存储 (EBS) 的网络和带宽都超过了之前的最佳记录。
|
||||||
|
|
||||||
|
以下是 AWS 在 FAQ 中的说明:
|
||||||
|
|
||||||
|
> 随着 C5 实例的推出,Amazon EC2 的新管理程序是一个主要为 C5 实例提供 CPU 和内存隔离的组件。VPC 网络和 EBS 存储资源是由所有当前 EC2 实例家族的一部分的专用硬件组件实现的。
|
||||||
|
|
||||||
|
> 它基于核心的 Linux 内核虚拟机(KVM)技术,但不包括通用的操作系统组件。
|
||||||
|
|
||||||
|
换句话说,网络和存储在其他地方完成,而不是集中在隔离 CPU 和内存资源的管理程序上:
|
||||||
|
|
||||||
|
> 新的 EC2 虚拟机管理程序通过删除主机系统软件组件,为 EC2 虚拟化实例提供一致的性能和增长的计算和内存资源。该硬件使新的虚拟机管理程序非常小,并且对用于网络和存储的数据处理任务没有影响。
|
||||||
|
|
||||||
|
> 最终,所有新实例都将使用新的 EC2 虚拟机管理程序,但是在近期内,根据平台的需求,一些新的实例类型将使用 Xen。
|
||||||
|
|
||||||
|
> 运行在新 EC2 虚拟机管理程序上的实例最多支持 27 个用于 EBS 卷和 VPC ENI 的附加 PCI 设备。每个 EBS 卷或 VPC ENI 使用一个 PCI 设备。例如,如果将 3 个附加网络接口连接到使用新 EC2 虚拟机管理程序的实例,则最多可以为该实例连接 24 个 EBS 卷。
|
||||||
|
|
||||||
|
> 所有面向公众的与运行新的 EC2 管理程序的 EC2 交互 API 都保持不变。例如,DescribeInstances 响应的 “hypervisor” 字段将继续为所有 EC2 实例报告 “xen”,即使是在新的管理程序下运行的实例也是如此。这个字段可能会在未来版本的 EC2 API 中删除。
|
||||||
|
|
||||||
|
你应该查看 FAQ 以了解 AWS 转移到其新虚拟机管理程序的全部影响。以下是新的基于 KVM 的 C5 实例的统计数据:
|
||||||
|
|
||||||
|
|
||||||
|
| 实例名 | vCPU | RAM(GiB) | EBS*带宽 | 网络带宽 |
|
||||||
|
|:--|:--|:--|:--|:--|
|
||||||
|
| c5.large | 2 | 4 | 最高 2.25 Gbps | 最高 10 Gbps |
|
||||||
|
| c5.xlarge | 4 | 8 | 最高 2.25 Gbps | 最高 10 Gbps |
|
||||||
|
| c5.2xlarge | 8 | 16 | 最高 2.25 Gbps | 最高 10 Gbps |
|
||||||
|
| c5.4xlarge | 16 | 32 | 2.25 Gbps | 最高 10 Gbps |
|
||||||
|
| c5.9xlarge | 36 | 72 | 4.5 Gbps | 10 Gbps |
|
||||||
|
| c5.18xlarge | 72 | 144 | 9 Gbps | 25 Gbps |
|
||||||
|
|
||||||
|
每个 vCPU 都是 Amazon 购买的物理 CPU 上的一个线程。
|
||||||
|
|
||||||
|
现在,在 AWS 的美国东部、美国西部(俄勒冈州)和欧盟地区,可以使用 C5 实例作为按需或点播服务器。该公司承诺其他地区将尽快提供。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.theregister.co.uk/2017/11/07/aws_writes_new_kvm_based_hypervisor_to_make_its_cloud_go_faster/
|
||||||
|
|
||||||
|
作者:[Simon Sharwood][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.theregister.co.uk/Author/Simon-Sharwood
|
||||||
|
[1]:https://www.theregister.co.uk/Author/Simon-Sharwood
|
||||||
|
[2]:https://forums.theregister.co.uk/forum/1/2017/11/07/aws_writes_new_kvm_based_hypervisor_to_make_its_cloud_go_faster/
|
||||||
|
[3]:https://aws.amazon.com/blogs/aws/now-available-compute-intensive-c5-instances-for-amazon-ec2/
|
||||||
|
[4]:https://aws.amazon.com/ec2/faqs/#compute-optimized
|
||||||
|
[5]:https://www.theregister.co.uk/2017/10/24/azure_adds_skylakes_in_fv2_instances/
|
||||||
|
[6]:https://newsroom.intel.com/news/intel-xeon-scalable-processors-supercharge-amazon-web-services/
|
||||||
|
[7]:https://www.theregister.co.uk/2015/06/04/oracle_intel_team_on_server_with_a_dimmer_switch/
|
||||||
@ -0,0 +1,221 @@
|
|||||||
|
怎么在 Fedora 中创建我的第一个 RPM 包?
|
||||||
|
==============
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
过了这个夏天,我把我的桌面环境迁移到了 i3,这是一个瓦片式窗口管理器。当初,切换到 i3 是一个挑战,因为我必须去处理许多以前 GNOME 帮我处理的事情。其中一件事情就是改变屏幕亮度。 xbacklight 这个在笔记本电脑上改变背光亮度的标准方法,它在我的硬件上不工作了。
|
||||||
|
|
||||||
|
最近,我发现一个改变背光亮度的工具 [brightlight][1]。我决定去试一下它,它工作在 root 权限下。但是,我发现 brightligh 在 Fedora 下没有 RPM 包。我决定,是在 Fedora 下尝试创建一个包的时候了,并且可以学习怎么去创建一个 RPM 包。
|
||||||
|
|
||||||
|
在这篇文章中,我将分享以下的内容:
|
||||||
|
|
||||||
|
* 创建 RPM SPEC 文件
|
||||||
|
* 在 Koji 和 Copr 中构建包
|
||||||
|
* 使用调试包处理一个问题
|
||||||
|
* 提交这个包到 Fedora 包集合中
|
||||||
|
|
||||||
|
### 前提条件
|
||||||
|
|
||||||
|
在 Fedora 上,我安装了包构建过程中所有步骤涉及到的包。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo dnf install fedora-packager fedpkg fedrepo_req copr-cli
|
||||||
|
```
|
||||||
|
|
||||||
|
### 创建 RPM SPEC 文件
|
||||||
|
|
||||||
|
创建 RPM 包的第一步是去创建 SPEC 文件。这些规范,或者是指令,它告诉 RPM 怎么去构建包。这是告诉 RPM 从包的源代码中创建一个二进制文件。创建 SPEC 文件看上去是整个包处理过程中最难的一部分,并且它的难度取决于项目。
|
||||||
|
|
||||||
|
对我而言,幸运的是,brightlight 是一个用 C 写的简单应用程序。维护人员用一个 Makefile 使创建二进制应用程序变得很容易。构建它只是在仓库中简单运行 `make` 的问题。因此,我现在可以用一个简单的项目去学习 RPM 打包。
|
||||||
|
|
||||||
|
#### 查找文档
|
||||||
|
|
||||||
|
谷歌搜索 “how to create an RPM package” 有很多结果。我开始使用的是 [IBM 的文档][2]。然而,我发现它理解起来非常困难,不知所云(虽然十分详细,它可能适用于复杂的 app)。我也在 Fedora 维基上找到了 [创建包][3] 的介绍。这个文档在构建和处理上解释的非常好,但是,我一直困惑于 “怎么去开始呢?”
|
||||||
|
|
||||||
|
最终,我找到了 [RPM 打包指南][4],它是大神 [Adam Miller][5] 写的。这些介绍非常有帮助,并且包含了三个优秀的示例,它们分别是用 Bash、C 和 Python 编写的程序。这个指南帮我很容易地理解了怎么去构建一个 RPM SPEC,并且,更重要的是,解释了怎么把这些片断拼到一起。
|
||||||
|
|
||||||
|
有了这些之后,我可以去写 brightlight 程序的我的 [第一个 SPEC 文件][6] 了。因为它是很简单的,SPEC 很短也很容易理解。我有了 SPEC 文件之后,我发现其中有一些错误。处理掉一些错误之后,我创建了源 RPM (SRPM) 和二进制 RPM,然后,我解决了出现的每个问题。
|
||||||
|
|
||||||
|
```
|
||||||
|
rpmlint SPECS/brightlight.spec
|
||||||
|
rpmbuild -bs SPECS/brightlight.spec
|
||||||
|
rpmlint SRPMS/brightlight-5-1.fc26.src.rpm
|
||||||
|
rpmbuild -bb SPECS/brightlight-5-1.fc26.x86_64.rpm
|
||||||
|
rpmlint RPMS/x86_64/brightlight-5-1.fc26.x86_64.rpm
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,我有了一个可用的 RPM,可以发送到 Fedora 仓库了。
|
||||||
|
|
||||||
|
### 在 Copr 和 Koji 中构建
|
||||||
|
|
||||||
|
接下来,我读了该 [指南][7] 中关于怎么成为一个 Fedora 打包者。在提交之前,他们鼓励打包者通过在在 [Koji][9] 中托管、并在 [Copr][8] 中构建项目来测试要提交的包。
|
||||||
|
|
||||||
|
#### 使用 Copr
|
||||||
|
|
||||||
|
首先,我为 brightlight 创建了一个 [Copr 仓库][10],[Copr][11] 是在 Fedora 的基础设施中的一个服务,它构建你的包,并且为你任意选择的 Fedora 或 EPEL 版本创建一个定制仓库。它对于快速托管你的 RPM 包,并与其它人去分享是非常方便的。你不需要特别操心如何去托管一个 Copr 仓库。
|
||||||
|
|
||||||
|
我从 Web 界面创建了我的 Copr 项目,但是,你也可以使用 `copr-cli` 工具。在 Fedora 开发者网站上有一个 [非常优秀的指南][12]。在该网站上创建了我的仓库之后,我使用这个命令构建了我的包。
|
||||||
|
|
||||||
|
```
|
||||||
|
copr-cli build brightlight SRPMS/brightlight.5-1.fc26.src.rpm
|
||||||
|
```
|
||||||
|
|
||||||
|
我的包在 Corp 上成功构建,并且,我可以很容易地在我的 Fedora 系统上成功安装它。
|
||||||
|
|
||||||
|
#### 使用 Koji
|
||||||
|
|
||||||
|
任何人都可以使用 [Koji][13] 在多种架构和 Fedora 或 CentOS/RHEL 版本上测试他们的包。在 Koji 中测试,你必须有一个源 RPM。我希望 brightlight 包在 Fedora 所有的版本中都支持,因此,我运行如下的命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
koji build --scratch f25 SRPMS/brightlight-5-1.fc26.src.rpm
|
||||||
|
koji build --scratch f26 SRPMS/brightlight-5-1.fc26.src.rpm
|
||||||
|
koji build --scratch f27 SRPMS/brightlight-5-1.fc26.src.rpm
|
||||||
|
```
|
||||||
|
|
||||||
|
它花费了一些时间,但是,Koji 构建了所有的包。我的包可以很完美地运行在 Fedora 25 和 26 中,但是 Fedora 27 失败了。 Koji 模拟构建可以使我走在正确的路线上,并且确保我的包构建成功。
|
||||||
|
|
||||||
|
### 问题:Fedora 27 构建失败!
|
||||||
|
|
||||||
|
现在,我已经知道我的 Fedora 27 上的包在 Koji 上构建失败了。但是,为什么呢?我发现在 Fedora 27 上有两个相关的变化。
|
||||||
|
|
||||||
|
* [Subpackage and Source Debuginfo][14]
|
||||||
|
* [RPM 4.14][15] (特别是,debuginfo 包重写了)
|
||||||
|
|
||||||
|
这些变化意味着 RPM 包必须使用一个 debuginfo 包去构建。这有助于排错或调试一个应用程序。在我的案例中,这并不是关键的或者很必要的,但是,我需要去构建一个。
|
||||||
|
|
||||||
|
感谢 Igor Gnatenko,他帮我理解了为什么我在 Fedora 27 上构建包时需要去将这些增加到我的包的 SPEC 中。在 `%make_build` 宏指令之前,我增加了这些行。
|
||||||
|
|
||||||
|
```
|
||||||
|
export CFLAGS="%{optflags}"
|
||||||
|
export LDFLAGS="%{__global_ldflags}"
|
||||||
|
```
|
||||||
|
|
||||||
|
我构建了一个新的 SRPM 并且提交它到 Koji 去在 Fedora 27 上构建。成功了,它构建成功了!
|
||||||
|
|
||||||
|
### 提交这个包
|
||||||
|
|
||||||
|
现在,我在 Fedora 25 到 27 上成功校验了我的包,是时候为 Fedora 打包了。第一步是提交这个包,为了请求一个包评估,要在 Red Hat Bugzilla 创建一个新 bug。我为 brightlight [创建了一个工单][16]。因为这是我的第一个包,我明确标注它 “这是我的第一个包”,并且我寻找一个发起人。在工单中,我链接 SPEC 和 SRPM 文件到我的 Git 仓库中。
|
||||||
|
|
||||||
|
#### 进入 dist-git
|
||||||
|
|
||||||
|
[Igor Gnatenko][17] 发起我进入 Fedora 打包者群组,并且在我的包上留下反馈。我学习了一些其它的关于 C 应用程序打包的特定的知识。在他响应我之后,我可以在 [dist-git][18] 上申请一个仓库,Fedora 的 RPM 包集合仓库为所有的 Fedora 版本保存了 SPEC 文件。
|
||||||
|
|
||||||
|
一个很方便的 Python 工具使得这一部分很容易。`fedrepo-req` 是一个用于创建一个新的 dist-git 仓库的请求的工具。我用这个命令提交我的请求。
|
||||||
|
|
||||||
|
```
|
||||||
|
fedrepo-req brightlight \
|
||||||
|
--ticket 1505026 \
|
||||||
|
--description "CLI tool to change screen back light brightness" \
|
||||||
|
--upstreamurl https://github.com/multiplexd/brightlight
|
||||||
|
```
|
||||||
|
|
||||||
|
它为我在 fedora-scm-requests 仓库创建了一个新的工单。这是一个我是管理员的 [创建的仓库][19]。现在,我可以开始干了!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*My first RPM in Fedora dist-git – woohoo!*
|
||||||
|
|
||||||
|
#### 与 dist-git 一起工作
|
||||||
|
|
||||||
|
接下来,`fedpkg` 是用于和 dist-git 仓库进行交互的工具。我改变当前目录到我的 git 工作目录,然后运行这个命令。
|
||||||
|
|
||||||
|
```
|
||||||
|
fedpkg clone brightlight
|
||||||
|
```
|
||||||
|
|
||||||
|
`fedpkg` 从 dist-git 克隆了我的包的仓库。对于这个仅有的第一个分支,你需要去导入 SRPM。
|
||||||
|
|
||||||
|
```
|
||||||
|
fedpkg import SRPMS/brightlight-5-1.fc26.src.rpm
|
||||||
|
```
|
||||||
|
|
||||||
|
`fedpkg` 导入你的包的 SRPM 到这个仓库中,然后设置源为你的 Git 仓库。这一步对于使用 `fedpkg` 是很重要的,因为它用一个 Fedora 友好的方去帮助规范这个仓库(与手动添加文件相比)。一旦你导入了 SRPM,推送这个改变到 dist-git 仓库。
|
||||||
|
|
||||||
|
```
|
||||||
|
git commit -m "Initial import (#1505026)."
|
||||||
|
git push
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 构建包
|
||||||
|
|
||||||
|
自从你推送第一个包导入到你的 dist-git 仓库中,你已经准备好了为你的项目做一次真实的 Koji 构建。要构建你的项目,运行这个命令。
|
||||||
|
|
||||||
|
```
|
||||||
|
fedpkg build
|
||||||
|
```
|
||||||
|
|
||||||
|
它会在 Koji 中为 Rawhide 构建你的包,这是 Fedora 中的非版本控制的分支。在你为其它分支构建之前,你必须在 Rawhide 分支上构建成功。如果一切构建成功,你现在可以为你的项目的其它分支发送请求了。
|
||||||
|
|
||||||
|
```
|
||||||
|
fedrepo-req brightlight f27 -t 1505026
|
||||||
|
fedrepo-req brightlight f26 -t 1505026
|
||||||
|
fedrepo-req brightlight f25 -t 1505026
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 关于构建其它分支的注意事项
|
||||||
|
|
||||||
|
一旦你最初导入了 SRPM,如果你选择去创建其它分支,记得合并你的主分支到它们。例如,如果你后面为 Fedora 27 请求一个分支,你将需要去使用这些命令。
|
||||||
|
|
||||||
|
```
|
||||||
|
fedpkg switch-branch f27
|
||||||
|
git merge master
|
||||||
|
git push
|
||||||
|
fedpkg build
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 提交更新到 Bodhi
|
||||||
|
|
||||||
|
这个过程的最后一步是,把你的新包作为一个更新包提交到 Bodhi 中。当你初次提交你的更新包时,它将去测试这个仓库。任何人都可以测试你的包并且增加 karma 到该更新中。如果你的更新接收了 3 个以上的投票(或者像 Bodhi 称它为 karma),你的包将自动被推送到稳定仓库。否则,一周之后,推送到测试仓库中。
|
||||||
|
|
||||||
|
要提交你的更新到 Bodhi,你仅需要一个命令。
|
||||||
|
|
||||||
|
```
|
||||||
|
fedpkg update
|
||||||
|
```
|
||||||
|
|
||||||
|
它为你的包用一个不同的配置选项打开一个 Vim 窗口。一般情况下,你仅需要去指定一个 类型(比如,`newpackage`)和一个你的包评估的票据 ID。对于更深入的讲解,在 Fedora 维基上有一篇[更新的指南][23]。
|
||||||
|
|
||||||
|
在保存和退出这个文件后,`fedpkg` 会把你的包以一个更新包提交到 Bodhi,最后,同步到 Fedora 测试仓库。我也可以用这个命令去安装我的包。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo dnf install brightlight -y --enablerepo=updates-testing --refresh
|
||||||
|
```
|
||||||
|
|
||||||
|
### 稳定仓库
|
||||||
|
|
||||||
|
最近提交了我的包到 [Fedora 26 稳定仓库][20],并且不久将进入 [Fedora 25][21] 和 [Fedora 27][22] 稳定仓库。感谢帮助我完成我的第一个包的每个人。我期待有更多的机会为发行版添加包。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://blog.justinwflory.com/2017/11/first-rpm-package-fedora/
|
||||||
|
|
||||||
|
作者:[JUSTIN W. FLORY][a]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://blog.justinwflory.com/author/jflory7/
|
||||||
|
[1]:https://github.com/multiplexd/brightlight
|
||||||
|
[2]:https://www.ibm.com/developerworks/library/l-rpm1/index.html
|
||||||
|
[3]:https://fedoraproject.org/wiki/How_to_create_an_RPM_package
|
||||||
|
[4]:https://fedoraproject.org/wiki/How_to_create_an_RPM_package
|
||||||
|
[5]:https://github.com/maxamillion
|
||||||
|
[6]:https://src.fedoraproject.org/rpms/brightlight/blob/master/f/brightlight.spec
|
||||||
|
[7]:https://fedoraproject.org/wiki/Join_the_package_collection_maintainers
|
||||||
|
[8]:https://copr.fedoraproject.org/
|
||||||
|
[9]:https://koji.fedoraproject.org/koji/
|
||||||
|
[10]:https://copr.fedorainfracloud.org/coprs/jflory7/brightlight/
|
||||||
|
[11]:https://developer.fedoraproject.org/deployment/copr/about.html
|
||||||
|
[12]:https://developer.fedoraproject.org/deployment/copr/copr-cli.html
|
||||||
|
[13]:https://koji.fedoraproject.org/koji/
|
||||||
|
[14]:https://fedoraproject.org/wiki/Changes/SubpackageAndSourceDebuginfo
|
||||||
|
[15]:https://fedoraproject.org/wiki/Changes/RPM-4.14
|
||||||
|
[16]:https://bugzilla.redhat.com/show_bug.cgi?id=1505026
|
||||||
|
[17]:https://fedoraproject.org/wiki/User:Ignatenkobrain
|
||||||
|
[18]:https://src.fedoraproject.org/
|
||||||
|
[19]:https://src.fedoraproject.org/rpms/brightlight
|
||||||
|
[20]:https://bodhi.fedoraproject.org/updates/brightlight-5-1.fc26
|
||||||
|
[21]:https://bodhi.fedoraproject.org/updates/FEDORA-2017-8071ee299f
|
||||||
|
[22]:https://bodhi.fedoraproject.org/updates/FEDORA-2017-f3f085b86e
|
||||||
|
[23]: https://fedoraproject.org/wiki/Package_update_HOWTO
|
||||||
@ -0,0 +1,232 @@
|
|||||||
|
使用 Ansible Container 构建和测试应用程序
|
||||||
|
=======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
容器是一个日益流行的开发环境。作为一名开发人员,你可以选择多种工具来管理你的容器。本文将向你介绍 Ansible Container,并展示如何在类似生产环境中运行和测试你的应用程序。
|
||||||
|
|
||||||
|
### 入门
|
||||||
|
|
||||||
|
这个例子使用了一个简单的 Flask Hello World 程序。这个程序就像在生产环境中一样由 Apache HTTP 服务器提供服务。首先,安装必要的 `docker` 包:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo dnf install docker
|
||||||
|
```
|
||||||
|
|
||||||
|
Ansible Container 需要通过本地套接字与 Docker 服务进行通信。以下命令将更改套接字所有者,并将你添加到可访问此套接字的 `docker` 用户组:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo groupadd docker && sudo gpasswd -a $USER docker
|
||||||
|
MYGRP=$(id -g) ; newgrp docker ; newgrp $MYGRP
|
||||||
|
```
|
||||||
|
|
||||||
|
运行 `id` 命令以确保 `docker` 组在你的组成员中列出。最后,[使用 sudo ][2]启用并启动 docker 服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl enable docker.service
|
||||||
|
sudo systemctl start docker.service
|
||||||
|
```
|
||||||
|
|
||||||
|
### 设置 Ansible Container
|
||||||
|
|
||||||
|
Ansible Container 使你能够构建容器镜像并使用 Ansible playbook 进行编排。该程序在一个 YAML 文件中描述,而不是使用 Dockerfile,列出组成容器镜像的 Ansible 角色。
|
||||||
|
|
||||||
|
不幸的是,Ansible Container 在 Fedora 中没有 RPM 包可用。要安装它,请使用 python3 虚拟环境模块。
|
||||||
|
|
||||||
|
```
|
||||||
|
mkdir ansible-container-flask-example
|
||||||
|
cd ansible-container-flask-example
|
||||||
|
python3 -m venv .venv
|
||||||
|
source .venv/bin/activate
|
||||||
|
pip install ansible-container[docker]
|
||||||
|
```
|
||||||
|
|
||||||
|
这些命令将安装 Ansible Container 及 Docker 引擎。 Ansible Container 提供三种引擎:Docker、Kubernetes 和 Openshift。
|
||||||
|
|
||||||
|
### 设置项目
|
||||||
|
|
||||||
|
现在已经安装了 Ansible Container,接着设置这个项目。Ansible Container 提供了一个简单的命令来创建启动所需的所有文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
ansible-container init
|
||||||
|
```
|
||||||
|
|
||||||
|
来看看这个命令在当前目录中创建的文件:
|
||||||
|
|
||||||
|
* `ansible.cfg`
|
||||||
|
* `ansible-requirements.txt`
|
||||||
|
* `container.yml`
|
||||||
|
* `meta.yml`
|
||||||
|
* `requirements.yml`
|
||||||
|
|
||||||
|
该项目仅使用 `container.yml` 来描述程序服务。有关其他文件的更多信息,请查看 Ansible Container 的[入门][3]文档。
|
||||||
|
|
||||||
|
### 定义容器
|
||||||
|
|
||||||
|
如下更新 `container.yml`:
|
||||||
|
|
||||||
|
```
|
||||||
|
version: "2"
|
||||||
|
settings:
|
||||||
|
conductor:
|
||||||
|
# The Conductor container does the heavy lifting, and provides a portable
|
||||||
|
# Python runtime for building your target containers. It should be derived
|
||||||
|
# from the same distribution as you're building your target containers with.
|
||||||
|
base: fedora:26
|
||||||
|
# roles_path: # Specify a local path containing Ansible roles
|
||||||
|
# volumes: # Provide a list of volumes to mount
|
||||||
|
# environment: # List or mapping of environment variables
|
||||||
|
|
||||||
|
# Set the name of the project. Defaults to basename of the project directory.
|
||||||
|
# For built services, concatenated with service name to form the built image name.
|
||||||
|
project_name: flask-helloworld
|
||||||
|
|
||||||
|
services:
|
||||||
|
# Add your containers here, specifying the base image you want to build from.
|
||||||
|
# To use this example, uncomment it and delete the curly braces after services key.
|
||||||
|
# You may need to run `docker pull ubuntu:trusty` for this to work.
|
||||||
|
web:
|
||||||
|
from: "fedora:26"
|
||||||
|
roles:
|
||||||
|
- base
|
||||||
|
ports:
|
||||||
|
- "5000:80"
|
||||||
|
command: ["/usr/bin/dumb-init", "httpd", "-DFOREGROUND"]
|
||||||
|
volumes:
|
||||||
|
- $PWD/flask-helloworld:/flaskapp:Z
|
||||||
|
```
|
||||||
|
|
||||||
|
`conductor` 部分更新了基本设置以使用 Fedora 26 容器基础镜像。
|
||||||
|
|
||||||
|
`services` 部分添加了 `web` 服务。这个服务使用 Fedora 26,后面有一个名为 `base` 的角色。它还设置容器和主机之间的端口映射。Apache HTTP 服务器为容器的端口 80 上的 Flask 程序提供服务,该容器重定向到主机的端口 5000。然后这个文件定义了一个卷,它将 Flask 程序源代码挂载到容器中的 `/flaskapp` 中。
|
||||||
|
|
||||||
|
最后,容器启动时运行 `command` 配置。这个例子中使用 [dumb-init][4],一个简单的进程管理器并初始化系统启动 Apache HTTP 服务器。
|
||||||
|
|
||||||
|
### Ansible 角色
|
||||||
|
|
||||||
|
现在已经设置完了容器,创建一个 Ansible 角色来安装并配置 Flask 程序所需的依赖关系。首先,创建 `base` 角色。
|
||||||
|
|
||||||
|
```
|
||||||
|
mkdir -p roles/base/tasks
|
||||||
|
touch roles/base/tasks/main.yml
|
||||||
|
```
|
||||||
|
|
||||||
|
现在编辑 `main.yml` ,它看起来像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
---
|
||||||
|
- name: Install dependencies
|
||||||
|
dnf: pkg={{item}} state=present
|
||||||
|
with_items:
|
||||||
|
- python3-flask
|
||||||
|
- dumb-init
|
||||||
|
- httpd
|
||||||
|
- python3-mod_wsgi
|
||||||
|
|
||||||
|
- name: copy the apache configuration
|
||||||
|
copy:
|
||||||
|
src: flask-helloworld.conf
|
||||||
|
dest: /etc/httpd/conf.d/flask-helloworld.conf
|
||||||
|
owner: apache
|
||||||
|
group: root
|
||||||
|
mode: 655
|
||||||
|
```
|
||||||
|
|
||||||
|
这个 Ansible 角色是简单的。首先它安装依赖关系。然后,复制 Apache HTTP 服务器配置。如果你对 Ansible 角色不熟悉,请查看[角色文档][5]。
|
||||||
|
|
||||||
|
### Apache HTTP 配置
|
||||||
|
|
||||||
|
接下来,通过创建 `flask-helloworld.conf` 来配置 Apache HTTP 服务器:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ mkdir -p roles/base/files
|
||||||
|
$ touch roles/base/files/flask-helloworld.conf
|
||||||
|
```
|
||||||
|
|
||||||
|
最后将以下内容添加到文件中:
|
||||||
|
|
||||||
|
```
|
||||||
|
<VirtualHost *>
|
||||||
|
ServerName example.com
|
||||||
|
|
||||||
|
WSGIDaemonProcess hello_world user=apache group=root
|
||||||
|
WSGIScriptAlias / /flaskapp/flask-helloworld.wsgi
|
||||||
|
|
||||||
|
<Directory /flaskapp>
|
||||||
|
WSGIProcessGroup hello_world
|
||||||
|
WSGIApplicationGroup %{GLOBAL}
|
||||||
|
Require all granted
|
||||||
|
</Directory>
|
||||||
|
</VirtualHost>
|
||||||
|
```
|
||||||
|
|
||||||
|
这个文件的重要部分是 `WSGIScriptAlias`。该指令将脚本 `flask-helloworld.wsgi` 映射到 `/`。有关 Apache HTTP 服务器和 mod_wsgi 的更多详细信息,请阅读 [Flask 文档][6]。
|
||||||
|
|
||||||
|
### Flask “hello world”
|
||||||
|
|
||||||
|
最后,创建一个简单的 Flask 程序和 ` flask-helloworld.wsgi` 脚本。
|
||||||
|
|
||||||
|
```
|
||||||
|
mkdir flask-helloworld
|
||||||
|
touch flask-helloworld/app.py
|
||||||
|
touch flask-helloworld/flask-helloworld.wsgi
|
||||||
|
```
|
||||||
|
|
||||||
|
将以下内容添加到 `app.py`:
|
||||||
|
|
||||||
|
```
|
||||||
|
from flask import Flask
|
||||||
|
app = Flask(__name__)
|
||||||
|
|
||||||
|
@app.route("/")
|
||||||
|
def hello():
|
||||||
|
return "Hello World!"
|
||||||
|
```
|
||||||
|
|
||||||
|
然后编辑 `flask-helloworld.wsgi` ,添加这个:
|
||||||
|
|
||||||
|
```
|
||||||
|
import sys
|
||||||
|
sys.path.insert(0, '/flaskapp/')
|
||||||
|
|
||||||
|
from app import app as application
|
||||||
|
```
|
||||||
|
|
||||||
|
### 构建并运行
|
||||||
|
|
||||||
|
现在是时候使用 `ansible-container build` 和 `ansible-container run` 命令来构建和运行容器。
|
||||||
|
|
||||||
|
```
|
||||||
|
ansible-container build
|
||||||
|
```
|
||||||
|
|
||||||
|
这个命令需要一些时间来完成,所以要耐心等待。
|
||||||
|
|
||||||
|
```
|
||||||
|
ansible-container run
|
||||||
|
```
|
||||||
|
|
||||||
|
你现在可以通过以下 URL 访问你的 flask 程序: http://localhost:5000/
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
你现在已经看到如何使用 Ansible Container 来管理、构建和配置在容器中运行的程序。本例的所有配置文件和源代码在 [Pagure.io][7] 上。你可以使用此例作为基础来开始在项目中使用 Ansible Container。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/build-test-applications-ansible-container/
|
||||||
|
|
||||||
|
作者:[Clement Verna][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://fedoramagazine.org/author/cverna/
|
||||||
|
[1]:https://fedoramagazine.org/build-test-applications-ansible-container/
|
||||||
|
[2]:https://fedoramagazine.org/howto-use-sudo/
|
||||||
|
[3]:https://docs.ansible.com/ansible-container/getting_started.html
|
||||||
|
[4]:https://github.com/Yelp/dumb-init
|
||||||
|
[5]:http://docs.ansible.com/ansible/latest/playbooks_reuse_roles.html
|
||||||
|
[6]:http://flask.pocoo.org/docs/0.12/deploying/mod_wsgi/
|
||||||
|
[7]:https://pagure.io/ansible-container-flask-example
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user