mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
commit
855b8caa23
125
published/20180107 7 leadership rules for the DevOps age.md
Normal file
125
published/20180107 7 leadership rules for the DevOps age.md
Normal file
@ -0,0 +1,125 @@
|
||||
DevOps 时代的 7 个领导力准则
|
||||
======
|
||||
|
||||
> DevOps 是一种持续性的改变和提高:那么也准备改变你所珍视的领导力准则吧。
|
||||
|
||||

|
||||
|
||||
如果 [DevOps] 最终更多的是一种文化而非某种技术或者平台,那么请记住:它没有终点线。而是一种持续性的改变和提高——而且最高管理层并不及格。
|
||||
|
||||
然而,如果期望 DevOps 能够帮助获得更多的成果,领导者需要[修订他们的一些传统的方法][2]。让我们考虑 7 个在 DevOps 时代更有效的 IT 领导的想法。
|
||||
|
||||
### 1、 向失败说“是的”
|
||||
|
||||
“失败”这个词在 IT 领域中一直包含着非常具体的意义,而且通常是糟糕的意思:服务器失败、备份失败、硬盘驱动器失败——你的印象就是如此。
|
||||
|
||||
然而一个健康的 DevOps 文化取决于如何重新定义失败——IT 领导者应该在他们的字典里重新定义这个单词,使这个词的含义和“机会”对等起来。
|
||||
|
||||
“在 DevOps 之前,我们曾有一种惩罚失败者的文化,”[Datical][3] 的首席技术官兼联合创始人罗伯特·里夫斯说,“我们学到的仅仅是去避免错误。在 IT 领域避免错误的首要措施就是不要去改变任何东西:不要加速版本迭代的日程,不要迁移到云中,不要去做任何不同的事”
|
||||
|
||||
那是一个旧时代的剧本,里夫斯坦诚的说,它已经不起作用了,事实上,那种停滞实际上是失败。
|
||||
|
||||
“那些缓慢的发布周期并逃避云的公司被恐惧所麻痹——他们将会走向失败,”里夫斯说道。“IT 领导者必须拥抱失败,并把它当做成一个机遇。人们不仅仅从他们的过错中学习,也会从别人的错误中学习。开放和[安全心理][4]的文化促进学习和提高。”
|
||||
|
||||
**[相关文章:[为什么敏捷领导者谈论“失败”必须超越它本义][5]]**
|
||||
|
||||
### 2、 在管理层渗透开发运营的理念
|
||||
|
||||
尽管 DevOps 文化可以在各个方向有机的发展,那些正在从单体、孤立的 IT 实践中转变出来的公司,以及可能遭遇逆风的公司——需要高管层的全面支持。如果缺少了它,你就会传达模糊的信息,而且可能会鼓励那些宁愿被推着走的人,但这是我们一贯的做事方式。[改变文化是困难的][6];人们需要看到高管层完全投入进去并且知道改变已经实际发生了。
|
||||
|
||||
“高层管理必须全力支持 DevOps,才能成功的实现收益”,来自 [Rainforest QA][7] 的首席信息官德里克·蔡说道。
|
||||
|
||||
成为一个 DevOps 商店。德里克指出,涉及到公司的一切,从技术团队到工具到进程到规则和责任。
|
||||
|
||||
“没有高层管理的统一赞助支持,DevOps 的实施将很难成功,”德里克说道,“因此,在转变到 DevOps 之前在高层中保持一致是很重要的。”
|
||||
|
||||
### 3、 不要只是声明 “DevOps”——要明确它
|
||||
|
||||
即使 IT 公司也已经开始张开双臂拥抱 DevOps,也可能不是每个人都在同一个步调上。
|
||||
|
||||
**[参考我们的相关文章,[3 阐明了DevOps和首席技术官们必须在同一进程上][8]]**
|
||||
|
||||
造成这种脱节的一个根本原因是:人们对这个术语的有着不同的定义理解。
|
||||
|
||||
“DevOps 对不同的人可能意味着不同的含义,”德里克解释道,“对高管层和副总裁层来说,要执行明确的 DevOps 的目标,清楚地声明期望的成果,充分理解带来的成果将如何使公司的商业受益,并且能够衡量和报告成功的过程。”
|
||||
|
||||
事实上,在基线定义和远景之外,DevOps 要求正在进行频繁的交流,不是仅仅在小团队里,而是要贯穿到整个组织。IT 领导者必须将它设置为优先。
|
||||
|
||||
“不可避免的,将会有些阻碍,在商业中将会存在失败和破坏,”德里克说道,“领导者们需要清楚的将这个过程向公司的其他人阐述清楚,告诉他们他们作为这个过程的一份子能够期待的结果。”
|
||||
|
||||
### 4、 DevOps 对于商业和技术同样重要
|
||||
|
||||
IT 领导者们成功的将 DevOps 商店的这种文化和实践当做一项商业策略,以及构建和运营软件的方法。DevOps 是将 IT 从支持部门转向战略部门的推动力。
|
||||
|
||||
IT 领导者们必须转变他们的思想和方法,从成本和服务中心转变到驱动商业成果,而且 DevOps 的文化能够通过自动化和强大的协作加速这些成果,来自 [CYBRIC][9] 的首席技术官和联合创始人迈克·凯尔说道。
|
||||
|
||||
事实上,这是一个强烈的趋势,贯穿这些新“规则”,在 DevOps 时代走在前沿。
|
||||
|
||||
“促进创新并且鼓励团队成员去聪明的冒险是 DevOps 文化的一个关键部分,IT 领导者们需要在一个持续的基础上清楚的和他们交流”,凯尔说道。
|
||||
|
||||
“一个高效的 IT 领导者需要比以往任何时候都要积极的参与到业务中去,”来自 [West Monroe Partners][10] 的性能服务部门的主任埃文说道,“每年或季度回顾的日子一去不复返了——[你需要欢迎每两周一次的挤压整理][11],你需要有在年度水平上的思考战略能力,在冲刺阶段的互动能力,在商业期望满足时将会被给予一定的奖励。”
|
||||
|
||||
### 5、 改变妨碍 DevOps 目标的任何事情
|
||||
|
||||
虽然 DevOps 的老兵们普遍认为 DevOps 更多的是一种文化而不是技术,成功取决于通过正确的过程和工具激活文化。当你声称自己的部门是一个 DevOps 商店却拒绝对进程或技术做必要的改变,这就是你买了辆法拉利却使用了用了 20 年的引擎,每次转动钥匙都会冒烟。
|
||||
|
||||
展览 A: [自动化][12]。这是 DevOps 成功的重要并行策略。
|
||||
|
||||
“IT 领导者需要重点强调自动化,”卡伦德说,“这将是 DevOps 的前期投资,但是如果没有它,DevOps 将会很容易被低效吞噬,而且将会无法完整交付。”
|
||||
|
||||
自动化是基石,但改变不止于此。
|
||||
|
||||
“领导者们需要推动自动化、监控和持续交付过程。这意着对现有的实践、过程、团队架构以及规则的很多改变,” 德里克说。“领导者们需要改变一切会阻碍团队去实现完全自动化的因素。”
|
||||
|
||||
### 6、 重新思考团队架构和能力指标
|
||||
|
||||
当你想改变时……如果你桌面上的组织结构图和你过去大部分时候嵌入的名字都是一样的,那么你是时候该考虑改革了。
|
||||
|
||||
“在这个 DevOps 的新时代文化中,IT 执行者需要采取一个全新的方法来组织架构。”凯尔说,“消除组织的边界限制,它会阻碍团队间的合作,允许团队自我组织、敏捷管理。”
|
||||
|
||||
凯尔告诉我们在 DevOps 时代,这种反思也应该拓展应用到其他领域,包括你怎样衡量个人或者团队的成功,甚至是你和人们的互动。
|
||||
|
||||
“根据业务成果和总体的积极影响来衡量主动性,”凯尔建议。“最后,我认为管理中最重要的一个方面是:有同理心。”
|
||||
|
||||
注意很容易收集的到测量值不是 DevOps 真正的指标,[Red Hat] 的技术专家戈登·哈夫写到,“DevOps 应该把指标以某种形式和商业成果绑定在一起”,他指出,“你可能并不真正在乎开发者些了多少代码,是否有一台服务器在深夜硬件损坏,或者是你的测试是多么的全面。你甚至都不直接关注你的网站的响应情况或者是你更新的速度。但是你要注意的是这些指标可能和顾客放弃购物车去竞争对手那里有关,”参考他的文章,[DevOps 指标:你在测量什么?]
|
||||
|
||||
### 7、 丢弃传统的智慧
|
||||
|
||||
如果 DevOps 时代要求关于 IT 领导能力的新的思考方式,那么也就意味着一些旧的方法要被淘汰。但是是哪些呢?
|
||||
|
||||
“说实话,是全部”,凯尔说道,“要摆脱‘因为我们一直都是以这种方法做事的’的心态。过渡到 DevOps 文化是一种彻底的思维模式的转变,不是对瀑布式的过去和变革委员会的一些细微改变。”
|
||||
|
||||
事实上,IT 领导者们认识到真正的变革要求的不只是对旧方法的小小接触。它更多的是要求对之前的进程或者策略的一个重新启动。
|
||||
|
||||
West Monroe Partners 的卡伦德分享了一个阻碍 DevOps 的领导力的例子:未能拥抱 IT 混合模型和现代的基础架构比如说容器和微服务。
|
||||
|
||||
“我所看到的一个大的规则就是架构整合,或者认为在一个同质的环境下长期的维护会更便宜,”卡伦德说。
|
||||
|
||||
**领导者们,想要更多像这样的智慧吗?[注册我们的每周邮件新闻报道][15]。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/
|
||||
[5]:https://enterprisersproject.com/article/2017/10/why-agile-leaders-must-move-beyond-talking-about-failure?sc_cid=70160000000h0aXAAQ
|
||||
[6]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
|
||||
[7]:https://www.rainforestqa.com/
|
||||
[8]:https://enterprisersproject.com/article/2018/1/3-areas-where-devops-and-cios-must-get-same-page
|
||||
[9]:https://www.cybric.io/
|
||||
[10]:http://www.westmonroepartners.com/
|
||||
[11]:https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming
|
||||
[12]:https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA
|
||||
[13]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[14]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
[15]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -0,0 +1,146 @@
|
||||
如何使用命令行检查 Linux 上的磁盘空间
|
||||
========
|
||||
|
||||
> Linux 提供了所有必要的工具来帮助你确切地发现你的驱动器上剩余多少空间。Jack 在这里展示了如何做。
|
||||
|
||||

|
||||
|
||||
快速提问:你的驱动器剩余多少剩余空间?一点点还是很多?接下来的提问是:你知道如何找出这些剩余空间吗?如果你碰巧使用的是 GUI 桌面( 例如 GNOME、KDE、Mate、Pantheon 等 ),则任务可能非常简单。但是,当你要在一个没有 GUI 桌面的服务器上查询剩余空间,你该如何去做呢?你是否要为这个任务安装相应的软件工具?答案是绝对不是。在 Linux 中,具备查找驱动器上的剩余磁盘空间的所有工具。事实上,有两个非常容易使用的工具。
|
||||
|
||||
在本文中,我将演示这些工具。我将使用 [Elementary OS][1](LCTT译注:Elementary OS 是基于 Ubuntu 精心打磨美化的桌面 Linux 发行版 ),它还包括一个 GUI 方式,但我们将限制自己仅使用命令行。好消息是这些命令行工具随时可用于每个 Linux 发行版。在我的测试系统中,连接了许多的驱动器(内部的和外部的)。使用的命令与连接驱动器的位置无关,仅仅与驱动器是否已经挂载好并且对操作系统可见有关。
|
||||
|
||||
言归正传,让我们来试试这些工具。
|
||||
|
||||
### df
|
||||
|
||||
`df` 命令是我第一个用于在 Linux 上查询驱动器空间的工具,时间可以追溯到 20 世纪 90 年代。它的使用和报告结果非常简单。直到今天,`df` 还是我执行此任务的首选命令。此命令有几个选项开关,对于基本的报告,你实际上只需要一个选项。该命令是 `df -H` 。`-H` 选项开关用于将 `df` 的报告结果以人类可读的格式进行显示。`df -H` 的输出包括:已经使用了的空间量、可用空间、空间使用的百分比,以及每个磁盘连接到系统的挂载点(图 1)。
|
||||
|
||||
![df output][3]
|
||||
|
||||
*图 1:Elementary OS 系统上 `df -H` 命令的输出结果*
|
||||
|
||||
如果你的驱动器列表非常长并且你只想查看单个驱动器上使用的空间,该怎么办?对于 `df` 这没问题。我们来看一下位于 `/dev/sda1` 的主驱动器已经使用了多少空间。为此,执行如下命令:
|
||||
|
||||
```
|
||||
df -H /dev/sda1
|
||||
```
|
||||
输出将限于该驱动器(图 2)。
|
||||
|
||||
![disk usage][6]
|
||||
|
||||
*图 2:一个单独驱动器空间情况*
|
||||
|
||||
你还可以限制 `df` 命令结果报告中显示指定的字段。可用的字段包括:
|
||||
|
||||
- `source` — 文件系统的来源(LCTT译注:通常为一个设备,如 `/dev/sda1` )
|
||||
- `size` — 块总数
|
||||
- `used` — 驱动器已使用的空间
|
||||
- `avail` — 可以使用的剩余空间
|
||||
- `pcent` — 驱动器已经使用的空间占驱动器总空间的百分比
|
||||
- `target` —驱动器的挂载点
|
||||
|
||||
让我们显示所有驱动器的输出,仅显示 `size` ,`used` ,`avail` 字段。对此的命令是:
|
||||
|
||||
```
|
||||
df -H --output=size,used,avail
|
||||
```
|
||||
|
||||
该命令的输出非常简单( 图 3 )。
|
||||
|
||||
![output][8]
|
||||
|
||||
*图 3:显示我们驱动器的指定输出*
|
||||
|
||||
这里唯一需要注意的是我们不知道该输出的来源,因此,我们要把 `source` 加入命令中:
|
||||
|
||||
```
|
||||
df -H --output=source,size,used,avail
|
||||
```
|
||||
|
||||
现在输出的信息更加全面有意义(图 4)。
|
||||
|
||||
![source][10]
|
||||
|
||||
*图 4:我们现在知道了磁盘使用情况的来源*
|
||||
|
||||
### du
|
||||
|
||||
我们的下一个命令是 `du` 。 正如您所料,这代表<ruby>磁盘使用情况<rt>disk usage</rt></ruby>。 `du` 命令与 `df` 命令完全不同,因为它报告目录而不是驱动器的空间使用情况。 因此,您需要知道要检查的目录的名称。 假设我的计算机上有一个包含虚拟机文件的目录。 那个目录是 `/media/jack/HALEY/VIRTUALBOX` 。 如果我想知道该特定目录使用了多少空间,我将运行如下命令:
|
||||
|
||||
```
|
||||
du -h /media/jack/HALEY/VIRTUALBOX
|
||||
```
|
||||
|
||||
上面命令的输出将显示目录中每个文件占用的空间(图 5)。
|
||||
|
||||
![du command][12]
|
||||
|
||||
*图 5 在特定目录上运行 `du` 命令的输出*
|
||||
|
||||
到目前为止,这个命令并没有那么有用。如果我们想知道特定目录的总使用量怎么办?幸运的是,`du` 可以处理这项任务。对于同一目录,命令将是:
|
||||
|
||||
```
|
||||
du -sh /media/jack/HALEY/VIRTUALBOX/
|
||||
```
|
||||
|
||||
现在我们知道了上述目录使用存储空间的总和(图 6)。
|
||||
|
||||
![space used][14]
|
||||
|
||||
*图 6:我的虚拟机文件使用存储空间的总和是 559GB*
|
||||
|
||||
您还可以使用此命令查看父项的所有子目录使用了多少空间,如下所示:
|
||||
|
||||
```
|
||||
du -h /media/jack/HALEY
|
||||
```
|
||||
|
||||
此命令的输出见(图 7),是一个用于查看各子目录占用的驱动器空间的好方法。
|
||||
|
||||
![directories][16]
|
||||
|
||||
*图 7:子目录的存储空间使用情况*
|
||||
|
||||
`du` 命令也是一个很好的工具,用于查看使用系统磁盘空间最多的目录列表。执行此任务的方法是将 `du` 命令的输出通过管道传递给另外两个命令:`sort` 和 `head` 。下面的命令用于找出驱动器上占用存储空间最大的前 10 个目录:
|
||||
|
||||
```
|
||||
du -a /media/jack | sort -n -r |head -n 10
|
||||
```
|
||||
|
||||
输出将以从大到小的顺序列出这些目录(图 8)。
|
||||
|
||||
![top users][18]
|
||||
|
||||
*图 8:使用驱动器空间最多的 10 个目录*
|
||||
|
||||
### 没有你想像的那么难
|
||||
|
||||
查看 Linux 系统上挂载的驱动器的空间使用情况非常简单。只要你将你的驱动器挂载在 Linux 系统上,使用 `df` 命令或 `du` 命令在报告必要信息方面都会非常出色。使用 `df` 命令,您可以快速查看磁盘上总的空间使用量,使用 `du` 命令,可以查看特定目录的空间使用情况。对于每一个 Linux 系统的管理员来说,这两个命令的结合使用是必须掌握的。
|
||||
|
||||
而且,如果你没有注意到,我最近介绍了[查看 Linux 上内存使用情况的方法][19]。总之,这些技巧将大力帮助你成功管理 Linux 服务器。
|
||||
|
||||
通过 Linux Foundation 和 edX 免费提供的 “Linux 简介” 课程,了解更多有关 Linux 的信息。
|
||||
|
||||
--------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/6how-check-disk-space-linux-command-line
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[SunWave](https://github.com/SunWave)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://elementary.io/
|
||||
[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_1.jpg?itok=aJa8AZAM
|
||||
[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_2.jpg?itok=_PAq3kxC
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_3.jpg?itok=51m8I-Vu
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_4.jpg?itok=SuwgueN3
|
||||
[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_5.jpg?itok=XfS4s7Zq
|
||||
[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_6.jpg?itok=r71qICyG
|
||||
[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_7.jpg?itok=PtDe4q5y
|
||||
[18]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_8.jpg?itok=v9E1SFcC
|
||||
[19]:https://www.linux.com/learn/5-commands-checking-memory-usage-linux
|
||||
[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
55
published/20180627 CIP- Keeping the Lights On with Linux.md
Normal file
55
published/20180627 CIP- Keeping the Lights On with Linux.md
Normal file
@ -0,0 +1,55 @@
|
||||
CIP:延续 Linux 之光
|
||||
======
|
||||
|
||||
> CIP 的目标是创建一个基本的系统,使用开源软件来为我们现代社会的基础设施提供动力。
|
||||
|
||||

|
||||
|
||||
|
||||
现如今,现代民用基础设施遍及各处 —— 发电厂、雷达系统、交通信号灯、水坝和天气系统等。这些基础设施项目已然存在数十年,这些设施还将继续提供更长时间的服务,所以安全性和使用寿命是至关重要的。
|
||||
|
||||
并且,其中许多系统都是由 Linux 提供支持,它为技术提供商提供了对这些问题的更多控制。然而,如果每个提供商都在构建自己的解决方案,这可能会导致分散和重复工作。因此,<ruby>[民用基础设施平台][1]<rt>Civil Infrastructure Platform</rt></ruby>(CIP)最首要的目标是创造一个开源基础层,提供给工业设施,例如嵌入式控制器或是网关设备。
|
||||
|
||||
担任 CIP 的技术指导委员会主席的 Yoshitake Kobayashi 说过,“我们在这个领域有一种非常保守的文化,因为一旦我们建立了一个系统,它必须得到长达十多年的支持,在某些情况下超过 60 年。这就是为什么这个项目被创建的原因,因为这个行业的每个使用者都面临同样的问题,即能够长时间地使用 Linux。”
|
||||
|
||||
CIP 的架构是创建一个非常基础的系统,以在控制器上使用开源软件。其中,该基础层包括 Linux 内核和一系列常见的开源软件如 libc、busybox 等。由于软件的使用寿命是一个最主要的问题,CIP 选择使用 Linux 4.4 版本的内核,这是一个由 Greg Kroah-Hartman 维护的长期支持版本。
|
||||
|
||||
### 合作
|
||||
|
||||
由于 CIP 有上游优先政策,因此他们在项目中需要的代码必须位于上游内核中。为了与内核社区建立积极的反馈循环,CIP 聘请 Ben Hutchings 作为 CIP 的官方维护者。Hutchings 以他在 Debian LTS 版本上所做的工作而闻名,这也促成了 CIP 与 Debian 项目之间的官方合作。
|
||||
|
||||
在新的合作下,CIP 将使用 Debian LTS 版本作为构建平台。 CIP 还将支持 Debian 长期支持版本(LTS),延长所有 Debian 稳定版的生命周期。CIP 还将与 Freexian 进行密切合作,后者是一家围绕 Debian LTS 版本提供商业服务的公司。这两个组织将专注于嵌入式系统的开源软件的互操作性、安全性和维护。CIP 还会为一些 Debian LTS 版本提供资金支持。
|
||||
|
||||
Debian 项目负责人 Chris Lamb 表示,“我们对此次合作以及 CIP 对 Debian LTS 项目的支持感到非常兴奋,这样将使支持周期延长至五年以上。我们将一起致力于为用户提供长期支持,并为未来的城市奠定基础。”
|
||||
|
||||
### 安全性
|
||||
|
||||
Kobayashi 说过,其中最需要担心的是安全性。虽然出于明显的安全原因,大部分民用基础设施没有接入互联网(你肯定不想让一座核电站连接到互联网),但也存在其他风险。
|
||||
|
||||
仅仅是系统本身没有连接到互联网,这并不意味着能避开所有危险。其他系统,比如个人移动电脑也能够通过接入互联网而间接入侵到本地系统中。如若有人收到一封带有恶意文件作为电子邮件的附件,这将会“污染”系统内部的基础设备。
|
||||
|
||||
因此,至关重要的是保持运行在这些控制器上的所有软件是最新的并且完全修补的。为了确保安全性,CIP 还向后移植了<ruby>内核自我保护<rt>Kernel Self Protection</rt></ruby>(KSP)项目的许多组件。CIP 还遵循最严格的网络安全标准之一 —— IEC 62443,该标准定义了软件的流程和相应的测试,以确保系统更安全。
|
||||
|
||||
### 展望未来
|
||||
|
||||
随着 CIP 日趋成熟,官方正在加大与各个 Linux 提供商的合作力度。除了与 Debian 和 freexian 的合作外,CIP 最近还邀请了企业 Linux 操作系统供应商 Cybertrust Japan Co., Ltd. 作为新的银牌成员。
|
||||
|
||||
Cybertrust 与其他行业领军者合作,如西门子、东芝、Codethink、日立、Moxa、Plat'Home 和瑞萨,致力于为未来数十年打造一个可靠、安全的基于 Linux 的嵌入式软件平台。
|
||||
|
||||
这些公司在 CIP 的保护下所进行的工作,将确保管理我们现代社会中的民用基础设施的完整性。
|
||||
|
||||
想要了解更多信息,请访问 [民用基础设施官网][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/cip-keeping-lights-linux
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.cip-project.org/
|
||||
@ -0,0 +1,130 @@
|
||||
如何用 Scribus 和 Gedit 编辑 Adobe InDesign 文件
|
||||
======
|
||||
|
||||
> 学习一下这些用开源工具编辑 InDesign 文件的方案。
|
||||
|
||||
|
||||
|
||||
要想成为一名优秀的平面设计师,您必须善于使用各种各样专业的工具。现在,对大多数设计师来说,最常用的工具是 <ruby>Adobe 全家桶<rt>Adobe Creative Suite</rt></ruby>。
|
||||
|
||||
但是,有时候使用开源工具能够帮您摆脱困境。比如,您正在使用一台公共打印机打印一份用 Adobe InDesign 创建的文件。这时,您需要对文件做一些简单的改动(比如,改正一个错别字),但您无法立刻使用 Adobe 套件。虽然这种情况很少见,但电子杂志制作软件 [Scribus][1] 和文本编辑器 [Gedit][2] 等开源工具可以节约您的时间。
|
||||
|
||||
在本文中,我将向您展示如何使用 Scribus 和 Gedit 编辑 Adobe InDesign 文件。请注意,还有许多其他开源平面设计软件可以用来代替 Adobe InDesign 或者结合使用。详情请查看我的文章:[昂贵的工具(从来!)不是平面设计的唯一选择][3] 以及 [两个开源 Adobe InDesign 脚本][4].
|
||||
|
||||
在编写本文的时候,我阅读了一些关于如何使用开源软件编辑 InDesign 文件的博客,但没有找到有用的文章。我尝试了两个解决方案。一个是:在 InDesign 创建一个 EPS 并在文本编辑器 Scribus 中将其以可编辑文件打开,但这不起作用。另一个是:从 InDesign 中创建一个 IDML(一种旧的 InDesign 文件格式)文件,并在 Scribus 中打开它。第二种方法效果更好,也是我在下文中使用的解决方法。
|
||||
|
||||
### 编辑名片
|
||||
|
||||
我尝试在 Scribus 中打开和编辑 InDesign 名片文件的效果很好。唯一的问题是字母间的间距有些偏移,以及我用倒过来的 ‘J’ 来创建 “Jeff” 中的 ‘f’ 被翻转。其他部分,像样式和颜色等都完好无损。
|
||||
|
||||
![Business card in Adobe InDesign][6]
|
||||
|
||||
*图:在 Adobe InDesign 中编辑名片。*
|
||||
|
||||
![InDesign IDML file opened in Scribus][8]
|
||||
|
||||
*图:在 Scribus 中打开 InDesign IDML 文件。*
|
||||
|
||||
### 删除带页码的书籍中的副本
|
||||
|
||||
书籍的转换并不顺利。书籍的正文还 OK,但当我用 Scribus 打开 InDesign 文件,目录、页脚和一些首字下沉的段落都出现问题。不过至少,它是一个可编辑的文档。其中一个问题是一些块引用中的文字变成了默认的 Arial 字体,这是因为字体样式(似乎来自其原始的 Word 文档)的优先级比段落样式高。这个问题容易解决。
|
||||
|
||||
![Book layout in InDesign][10]
|
||||
|
||||
*图:InDesign 中的书籍布局。*
|
||||
|
||||
![InDesign IDML file of book layout opened in Scribus][12]
|
||||
|
||||
*图:用 Scribus 打开 InDesign IDML 文件的书籍布局。*
|
||||
|
||||
当我试图选择并删除一页文本的时候,发生了奇异事件。我把光标放在文本中,按下 `Command + A`(“全选”的快捷键)。表面看起来高亮显示了一页文本,但事实并非如此!
|
||||
|
||||
![Selecting text in Scribus][14]
|
||||
|
||||
*图:Scribus 中被选中的文本。*
|
||||
|
||||
当我按下“删除”键,整个文本(不只是高亮的部分)都消失了。
|
||||
|
||||
![Both pages of text deleted in Scribus][16]
|
||||
|
||||
*图:两页文本都被删除了。*
|
||||
|
||||
然后,更奇异的事情发生了……我按下 `Command + Z` 键来撤回删除操作,文本恢复,但文本格式全乱套了。
|
||||
|
||||
![Undo delete restored the text, but with bad formatting.][18]
|
||||
|
||||
*图:Command+Z (撤回删除操作) 恢复了文本,但格式乱套了。*
|
||||
|
||||
### 用文本编辑器打开 InDesign 文件
|
||||
|
||||
当您用普通的记事本(比如,Mac 中的 TextEdit)分别打开 Scribus 文件和 InDesign 文件,会发现 Scribus 文件是可读的,而 InDesign 文件全是乱码。
|
||||
|
||||
您可以用 TextEdit 对两者进行更改并成功保存,但得到的文件是损坏的。下图是当我用 InDesign 打开编辑后的文件时的报错。
|
||||
|
||||
![InDesign error message][20]
|
||||
|
||||
*图:InDesign 的报错。*
|
||||
|
||||
我在 Ubuntu 系统上用文本编辑器 Gedit 编辑 Scribus 时得到了更好的结果。我从命令行启动了 Gedit,然后打开并编辑 Scribus 文件,保存后,再次使用 Scribus 打开文件时,我在 Gedit 中所做的更改都成功显示在 Scribus 中。
|
||||
|
||||
![Editing Scribus file in Gedit][22]
|
||||
|
||||
*图:用 Gedit 编辑 Scribus 文件。*
|
||||
|
||||
![Result of the Gedit edit in Scribus][24]
|
||||
|
||||
*图:用 Scribus 打开 Gedit 编辑过的文件。*
|
||||
|
||||
当您正准备打印的时候,客户打来电话说有一个错别字需要更改,此时您不需要苦等客户爸爸发来新的文件,只需要用 Gedit 打开 Scribus 文件,改正错别字,继续打印。
|
||||
|
||||
### 把图像拖拽到 ID 文件中
|
||||
|
||||
我将 InDesign 文档另存为 IDML 文件,这样我就可以用 Scribus 往其中拖进一些 PDF 文档。似乎 Scribus 并不能像 InDesign 一样把 PDF 文档拖拽进去。于是,我把 PDF 文档转换成 JPG 格式的图片然后导入到 Scribus 中,成功了。但这么做的结果是,将 IDML 文档转换成 PDF 格式后,文件大小非常大。
|
||||
|
||||
![Huge PDF file][26]
|
||||
|
||||
*图:把 Scribus 转换成 PDF 时得到一个非常大的文件*。
|
||||
|
||||
我不确定为什么会这样——这个坑留着以后再填吧。
|
||||
|
||||
您是否有使用开源软件编辑平面图形文件的技巧?如果有,请在评论中分享哦。
|
||||
|
||||
------
|
||||
|
||||
via: https://opensource.com/article/18/7/adobe-indesign-open-source-tools
|
||||
|
||||
作者:[Jeff Macharyas][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[XiatianSummer](https://github.com/XiatianSummer)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rikki-endsley
|
||||
[1]: https://www.scribus.net/
|
||||
[2]: https://wiki.gnome.org/Apps/Gedit
|
||||
[3]: https://opensource.com/life/16/8/open-source-alternatives-graphic-design
|
||||
[4]: https://opensource.com/article/17/3/scripts-adobe-indesign
|
||||
[5]: /file/402516
|
||||
[6]: https://opensource.com/sites/default/files/uploads/1-business_card_designed_in_adobe_indesign_cc.png "Business card in Adobe InDesign"
|
||||
[7]: /file/402521
|
||||
[8]: https://opensource.com/sites/default/files/uploads/2-indesign_.idml_file_opened_in_scribus.png "InDesign IDML file opened in Scribus"
|
||||
[9]: /file/402531
|
||||
[10]: https://opensource.com/sites/default/files/uploads/3-book_layout_in_indesign.png "Book layout in InDesign"
|
||||
[11]: /file/402536
|
||||
[12]: https://opensource.com/sites/default/files/uploads/4-indesign_.idml_file_of_book_opened_in_scribus.png "InDesign IDML file of book layout opened in Scribus"
|
||||
[13]: /file/402541
|
||||
[14]: https://opensource.com/sites/default/files/uploads/5-command-a_in_the_scribus_file.png "Selecting text in Scribus"
|
||||
[15]: /file/402546
|
||||
[16]: https://opensource.com/sites/default/files/uploads/6-deleted_text_in_scribus.png "Both pages of text deleted in Scribus"
|
||||
[17]: /file/402551
|
||||
[18]: https://opensource.com/sites/default/files/uploads/7-command-z_in_scribus.png "Undo delete restored the text, but with bad formatting."
|
||||
[19]: /file/402556
|
||||
[20]: https://opensource.com/sites/default/files/uploads/8-indesign_error_message.png "InDesign error message"
|
||||
[21]: /file/402561
|
||||
[22]: https://opensource.com/sites/default/files/uploads/9-scribus_edited_in_gedit_on_linux.png "Editing Scribus file in Gedit"
|
||||
[23]: /file/402566
|
||||
[24]: https://opensource.com/sites/default/files/uploads/10-scribus_opens_after_gedit_changes.png "Result of the Gedit edit in Scribus"
|
||||
[25]: /file/402571
|
||||
[26]: https://opensource.com/sites/default/files/uploads/11-large_pdf_size.png "Huge PDF file"
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
为什么 Arch Linux 如此“难弄”又有何优劣?
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Arch Linux][1] 于 **2002** 年发布,由 **Aaron Grifin** 领头,是当下最热门的 Linux 发行版之一。从设计上说,Arch Linux 试图给用户提供简单、最小化且优雅的体验,但它的目标用户群可不是怕事儿多的用户。Arch 鼓励参与社区建设,并且从设计上期待用户自己有学习操作系统的能力。
|
||||
|
||||
很多 Linux 老鸟对于 **Arch Linux** 会更了解,但电脑前的你可能只是刚开始打算把 Arch 当作日常操作系统来使用。虽然我也不是权威人士,但下面几点优劣是我认为你总会在使用中慢慢发现的。
|
||||
|
||||
### 1、优点: 定制属于你自己的 Linux 操作系统
|
||||
|
||||
大多数热门的 Linux 发行版(比如 **Ubuntu** 和 **Fedora**)很像一般我们会看到的预装系统,和 **Windows** 或者 **MacOS** 一样。但 Arch 则会更鼓励你去把操作系统配置的符合你的品味。如果你能顺利做到这点的话,你会得到一个每一个细节都如你所想的操作系统。
|
||||
|
||||
#### 缺点: 安装过程让人头疼
|
||||
|
||||
[Arch Linux 的安装 ][2] 别辟蹊径——因为你要花些时间来微调你的操作系统。你会在过程中了解到不少终端命令和组成你系统的各种软件模块——毕竟你要自己挑选安装什么。当然,你也知道这个过程少不了阅读一些文档/教程。
|
||||
|
||||
### 2、优点: 没有预装垃圾
|
||||
|
||||
鉴于 **Arch** 允许你在安装时选择你想要的系统部件,你再也不用烦恼怎么处理你不想要的一堆预装软件。作为对比,**Ubuntu** 会预装大量的软件和桌面应用——很多你不需要、甚至卸载之前都不知道它们存在的东西。
|
||||
|
||||
总而言之,**Arch Linux* 能省去大量的系统安装后时间。**Pacman**,是 Arch Linux 默认使用的优秀包管理组件。或者你也可以选择 [Pamac][3] 作为替代。
|
||||
|
||||
### 3、优点: 无需繁琐系统升级
|
||||
|
||||
**Arch Linux** 采用滚动升级模型,简直妙极了。这意味着你不需要操心升级了。一旦你用上了 Arch,持续的更新体验会让你和一会儿一个版本的升级说再见。只要你记得‘滚’更新(Arch 用语),你就一直会使用最新的软件包们。
|
||||
|
||||
#### 缺点: 一些升级可能会滚坏你的系统
|
||||
|
||||
虽然升级过程是完全连续的,你有时得留意一下你在更新什么。没人能知道所有软件的细节配置,也没人能替你来测试你的情况。所以如果你盲目更新,有时候你会滚坏你的系统。(LCTT 译注:别担心,你可以‘滚’回来 ;D )
|
||||
|
||||
### 4、优点: Arch 有一个社区基因
|
||||
|
||||
所有 Linux 用户通常有一个共同点:对独立自由的追求。虽然大多数 Linux 发行版和公司企业等挂钩极少,但也并非没有。比如 基于 **Ubuntu** 的衍生版本们不得不受到 Canonical 公司决策的影响。
|
||||
|
||||
如果你想让你的电脑更独立,那么 Arch Linux 是你的伙伴。不像大多数操作系统,Arch 完全没有商业集团的影响,完全由社区驱动。
|
||||
|
||||
### 5、优点: Arch Wiki 无敌
|
||||
|
||||
[Arch Wiki][4] 是一个无敌文档库,几乎涵盖了所有关于安装和维护 Arch 以及关于操作系统本身的知识。Arch Wiki 最厉害的一点可能是,不管你在用什么发行版,你多多少少可能都在 Arch Wiki 的页面里找到有用信息。这是因为 Arch 用户也会用别的发行版用户会用的东西,所以一些技巧和知识得以泛化。
|
||||
|
||||
### 6、优点: 别忘了 Arch 用户软件库 (AUR)
|
||||
|
||||
<ruby>[Arch 用户软件库][5]<rt>Arch User Repository</rt></ruby> (AUR)是一个来自社区的超大软件仓库。如果你找了一个还没有 Arch 的官方仓库里出现的软件,那你肯定能在 AUR 里找到社区为你准备好的包。
|
||||
|
||||
AUR 是由用户自发编译和维护的。Arch 用户也可以给每个包投票,这样后来者就能找到最有用的那些软件包了。
|
||||
|
||||
#### 最后: Arch Linux 适合你吗?
|
||||
|
||||
**Arch Linux** 优点多于缺点,也有很多优缺点我无法在此一一叙述。安装过程很长,对非 Linux 用户来说也可能偏有些技术,但只要你投入一些时间和善用 Wiki,你肯定能迈过这道坎。
|
||||
|
||||
**Arch Linux** 是一个非常优秀的发行版——尽管它有一些复杂性。同时它也很受那些知道自己想要什么的用户的欢迎——只要你肯做点功课,有些耐心。
|
||||
|
||||
当你从零开始搭建完 Arch 的时候,你会掌握很多 GNU/Linux 的内部细节,也再也不会对你的电脑内部运作方式一无所知了。
|
||||
|
||||
欢迎读者们在评论区讨论你使用 Arch Linux 的优缺点?以及你曾经遇到过的一些挑战。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/why-is-arch-linux-so-challenging-what-are-pros-cons/
|
||||
|
||||
作者:[Martins D. Okoi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Moelf](https://github.com/Moelf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://www.tecmint.com/arch-linux-installation-and-configuration-guide/
|
||||
[3]:https://www.fossmint.com/pamac-arch-linux-gui-package-manager/
|
||||
[4]:https://wiki.archlinux.org/
|
||||
[5]:https://wiki.archlinux.org/index.php/Arch_User_Repository
|
||||
322
published/20180705 Testing Node.js in 2018.md
Normal file
322
published/20180705 Testing Node.js in 2018.md
Normal file
@ -0,0 +1,322 @@
|
||||
测试 Node.js,2018
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
超过 3 亿用户正在使用 [Stream][4]。这些用户全都依赖我们的框架,而我们十分擅长测试要放到生产环境中的任何东西。我们大部分的代码库是用 Go 语言编写的,剩下的部分则是用 Python 编写。
|
||||
|
||||
我们最新的展示应用,[Winds 2.0][5],是用 Node.js 构建的,很快我们就了解到测试 Go 和 Python 的常规方法并不适合它。而且,创造一个好的测试套件需要用 Node.js 做很多额外的工作,因为我们正在使用的框架没有提供任何内建的测试功能。
|
||||
|
||||
不论你用什么语言,要构建完好的测试框架可能都非常复杂。本文我们会展示 Node.js 测试过程中的困难部分,以及我们在 Winds 2.0 中用到的各种工具,并且在你要编写下一个测试集合时为你指明正确的方向。
|
||||
|
||||
### 为什么测试如此重要
|
||||
|
||||
我们都向生产环境中推送过糟糕的提交,并且遭受了其后果。碰到这样的情况不是好事。编写一个稳固的测试套件不仅仅是一个明智的检测,而且它还让你能够完全地重构代码,并自信重构之后的代码仍然可以正常运行。这在你刚刚开始编写代码的时候尤为重要。
|
||||
|
||||
如果你是与团队共事,达到测试覆盖率极其重要。没有它,团队中的其他开发者几乎不可能知道他们所做的工作是否导致重大变动(或破坏)。
|
||||
|
||||
编写测试同时会促进你和你的队友把代码分割成更小的片段。这让别人去理解你的代码和修改 bug 变得容易多了。产品收益变得更大,因为你能更早的发现 bug。
|
||||
|
||||
最后,没有测试,你的基本代码还不如一堆纸片。基本不能保证你的代码是稳定的。
|
||||
|
||||
### 困难的部分
|
||||
|
||||
在我看来,我们在 Winds 中遇到的大多数测试问题是 Node.js 中特有的。它的生态系统一直在变大。例如,如果你用的是 macOS,运行 `brew upgrade`(安装了 homebrew),你看到你一个新版本的 Node.js 的概率非常高。由于 Node.js 迭代频繁,相应的库也紧随其后,想要与最新的库保持同步非常困难。
|
||||
|
||||
以下是一些马上映入脑海的痛点:
|
||||
|
||||
1. 在 Node.js 中进行测试是非常主观而又不主观的。人们对于如何构建一个测试架构以及如何检验成功有不同的看法。沮丧的是还没有一个黄金准则规定你应该如何进行测试。
|
||||
2. 有一堆框架能够用在你的应用里。但是它们一般都很精简,没有完好的配置或者启动过程。这会导致非常常见的副作用,而且还很难检测到;所以你最终会想要从零开始编写自己的<ruby>测试执行平台<rt>test runner</rt></ruby>测试执行平台。
|
||||
3. 几乎可以保证你 _需要_ 编写自己的测试执行平台(马上就会讲到这一节)。
|
||||
|
||||
以上列出的情况不是理想的,而且这是 Node.js 社区应该尽管处理的事情。如果其他语言解决了这些问题,我认为也是作为广泛使用的语言, Node.js 解决这些问题的时候。
|
||||
|
||||
### 编写你自己的测试执行平台
|
||||
|
||||
所以……你可能会好奇<rt>test runner</rt></ruby>测试执行平台 _是_ 什么,说实话,它并不复杂。测试执行平台是测试套件中最高层的容器。它允许你指定全局配置和环境,还可以导入配置。可能有人觉得做这个很简单,对吧?别那么快下结论。
|
||||
|
||||
我们所了解到的是,尽管现在就有足够多的测试框架了,但没有一个测试框架为 Node.js 提供了构建你的测试执行平台的标准方式。不幸的是,这需要开发者来完成。这里有个关于测试执行平台的需求的简单总结:
|
||||
|
||||
* 能够加载不同的配置(比如,本地的、测试的、开发的),并确保你 _永远不会_ 加载一个生产环境的配置 —— 你能想象出那样会出什么问题。
|
||||
* 播种数据库——产生用于测试的数据。必须要支持多种数据库,不论是 MySQL、PostgreSQL、MongoDB 或者其它任何一个数据库。
|
||||
* 能够加载配置(带有用于开发环境测试的播种数据的文件)。
|
||||
|
||||
开发 Winds 的时候,我们选择 Mocha 作为测试执行平台。Mocha 提供了简单并且可编程的方式,通过命令行工具(整合了 Babel)来运行 ES6 代码的测试。
|
||||
|
||||
为了进行测试,我们注册了自己的 Babel 模块引导器。这为我们提供了更细的粒度,更强大的控制,在 Babel 覆盖掉 Node.js 模块加载过程前,对导入的模块进行控制,让我们有机会在所有测试运行前对模块进行模拟。
|
||||
|
||||
此外,我们还使用了 Mocha 的测试执行平台特性,预先把特定的请求赋给 HTTP 管理器。我们这么做是因为常规的初始化代码在测试中不会运行(服务器交互是用 Chai HTTP 插件模拟的),还要做一些安全性检查来确保我们不会连接到生产环境数据库。
|
||||
|
||||
尽管这不是测试执行平台的一部分,有一个<ruby>配置<rt>fixture</rt></ruby>加载器也是我们测试套件中的重要的一部分。我们试验过已有的解决方案;然而,我们最终决定编写自己的助手程序,这样它就能贴合我们的需求。根据我们的解决方案,在生成或手动编写配置时,通过遵循简单专有的协议,我们就能加载数据依赖很复杂的配置。
|
||||
|
||||
### Winds 中用到的工具
|
||||
|
||||
尽管过程很冗长,我们还是能够合理使用框架和工具,使得针对后台 API 进行的适当测试变成现实。这里是我们选择使用的工具:
|
||||
|
||||
#### Mocha
|
||||
|
||||
[Mocha][6],被称为 “运行在 Node.js 上的特性丰富的测试框架”,是我们用于该任务的首选工具。拥有超过 15K 的星标,很多支持者和贡献者,我们知道对于这种任务,这是正确的框架。
|
||||
|
||||
#### Chai
|
||||
|
||||
然后是我们的断言库。我们选择使用传统方法,也就是最适合配合 Mocha 使用的 —— [Chai][7]。Chai 是一个用于 Node.js,适合 BDD 和 TDD 模式的断言库。拥有简单的 API,Chai 很容易整合进我们的应用,让我们能够轻松地断言出我们 _期望_ 从 Winds API 中返回的应该是什么。最棒的地方在于,用 Chai 编写测试让人觉得很自然。这是一个简短的例子:
|
||||
|
||||
```
|
||||
describe('retrieve user', () => {
|
||||
let user;
|
||||
|
||||
before(async () => {
|
||||
await loadFixture('user');
|
||||
user = await User.findOne({email: authUser.email});
|
||||
expect(user).to.not.be.null;
|
||||
});
|
||||
|
||||
after(async () => {
|
||||
await User.remove().exec();
|
||||
});
|
||||
|
||||
describe('valid request', () => {
|
||||
it('should return 200 and the user resource, including the email field, when retrieving the authenticated user', async () => {
|
||||
const response = await withLogin(request(api).get(`/users/${user._id}`), authUser);
|
||||
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body._id).to.equal(user._id.toString());
|
||||
});
|
||||
|
||||
it('should return 200 and the user resource, excluding the email field, when retrieving another user', async () => {
|
||||
const anotherUser = await User.findOne({email: 'another_user@email.com'});
|
||||
|
||||
const response = await withLogin(request(api).get(`/users/${anotherUser.id}`), authUser);
|
||||
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body._id).to.equal(anotherUser._id.toString());
|
||||
expect(response.body).to.not.have.an('email');
|
||||
});
|
||||
|
||||
});
|
||||
|
||||
describe('invalid requests', () => {
|
||||
|
||||
it('should return 404 if requested user does not exist', async () => {
|
||||
const nonExistingId = '5b10e1c601e9b8702ccfb974';
|
||||
expect(await User.findOne({_id: nonExistingId})).to.be.null;
|
||||
|
||||
const response = await withLogin(request(api).get(`/users/${nonExistingId}`), authUser);
|
||||
expect(response).to.have.status(404);
|
||||
});
|
||||
});
|
||||
|
||||
});
|
||||
```
|
||||
|
||||
#### Sinon
|
||||
|
||||
拥有与任何单元测试框架相适应的能力,[Sinon][8] 是模拟库的首选。而且,精简安装带来的超级整洁的整合,让 Sinon 把模拟请求变成了简单而轻松的过程。它的网站有极其良好的用户体验,并且提供简单的步骤,供你将 Sinon 整合进自己的测试框架中。
|
||||
|
||||
#### Nock
|
||||
|
||||
对于所有外部的 HTTP 请求,我们使用健壮的 HTTP 模拟库 [nock][9],在你要和第三方 API 交互时非常易用(比如说 [Stream 的 REST API][10])。它做的事情非常酷炫,这就是我们喜欢它的原因,除此之外关于这个精妙的库没有什么要多说的了。这是我们的速成示例,调用我们在 Stream 引擎中提供的 [personalization][11]:
|
||||
|
||||
```
|
||||
nock(config.stream.baseUrl)
|
||||
.get(/winds_article_recommendations/)
|
||||
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
|
||||
```
|
||||
|
||||
#### Mock-require
|
||||
|
||||
[mock-require][12] 库允许依赖外部代码。用一行代码,你就可以替换一个模块,并且当代码尝试导入这个库时,将会产生模拟请求。这是一个小巧但稳定的库,我们是它的超级粉丝。
|
||||
|
||||
#### Istanbul
|
||||
|
||||
[Istanbul][13] 是 JavaScript 代码覆盖工具,在运行测试的时候,通过模块钩子自动添加覆盖率,可以计算语句,行数,函数和分支覆盖率。尽管我们有相似功能的 CodeCov(见下一节),进行本地测试时,这仍然是一个很棒的工具。
|
||||
|
||||
### 最终结果 — 运行测试
|
||||
|
||||
_有了这些库,还有之前提过的测试执行平台,现在让我们看看什么是完整的测试(你可以在 [_这里_][14] 看看我们完整的测试套件):_
|
||||
|
||||
```
|
||||
import nock from 'nock';
|
||||
import { expect, request } from 'chai';
|
||||
|
||||
import api from '../../src/server';
|
||||
import Article from '../../src/models/article';
|
||||
import config from '../../src/config';
|
||||
import { dropDBs, loadFixture, withLogin } from '../utils.js';
|
||||
|
||||
describe('Article controller', () => {
|
||||
let article;
|
||||
|
||||
before(async () => {
|
||||
await dropDBs();
|
||||
await loadFixture('initial-data', 'articles');
|
||||
article = await Article.findOne({});
|
||||
expect(article).to.not.be.null;
|
||||
expect(article.rss).to.not.be.null;
|
||||
});
|
||||
|
||||
describe('get', () => {
|
||||
it('should return the right article via /articles/:articleId', async () => {
|
||||
let response = await withLogin(request(api).get(`/articles/${article.id}`));
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('get parsed article', () => {
|
||||
it('should return the parsed version of the article', async () => {
|
||||
const response = await withLogin(
|
||||
request(api).get(`/articles/${article.id}`).query({ type: 'parsed' })
|
||||
);
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('list', () => {
|
||||
it('should return the list of articles', async () => {
|
||||
let response = await withLogin(request(api).get('/articles'));
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('list from personalization', () => {
|
||||
after(function () {
|
||||
nock.cleanAll();
|
||||
});
|
||||
|
||||
it('should return the list of articles', async () => {
|
||||
nock(config.stream.baseUrl)
|
||||
.get(/winds_article_recommendations/)
|
||||
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
|
||||
|
||||
const response = await withLogin(
|
||||
request(api).get('/articles').query({
|
||||
type: 'recommended',
|
||||
})
|
||||
);
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body.length).to.be.at.least(1);
|
||||
expect(response.body[0].url).to.eq(article.url);
|
||||
});
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
### 持续集成
|
||||
|
||||
有很多可用的持续集成服务,但我们钟爱 [Travis CI][15],因为他们和我们一样喜爱开源环境。考虑到 Winds 是开源的,它再合适不过了。
|
||||
|
||||
我们的集成非常简单 —— 我们用 [.travis.yml] 文件设置环境,通过简单的 [npm][17] 命令进行测试。测试覆盖率反馈给 GitHub,在 GitHub 上我们将清楚地看出我们最新的代码或者 PR 是不是通过了测试。GitHub 集成很棒,因为它可以自动查询 Travis CI 获取结果。以下是一个在 GitHub 上看到 (经过了测试的) PR 的简单截图:
|
||||
|
||||
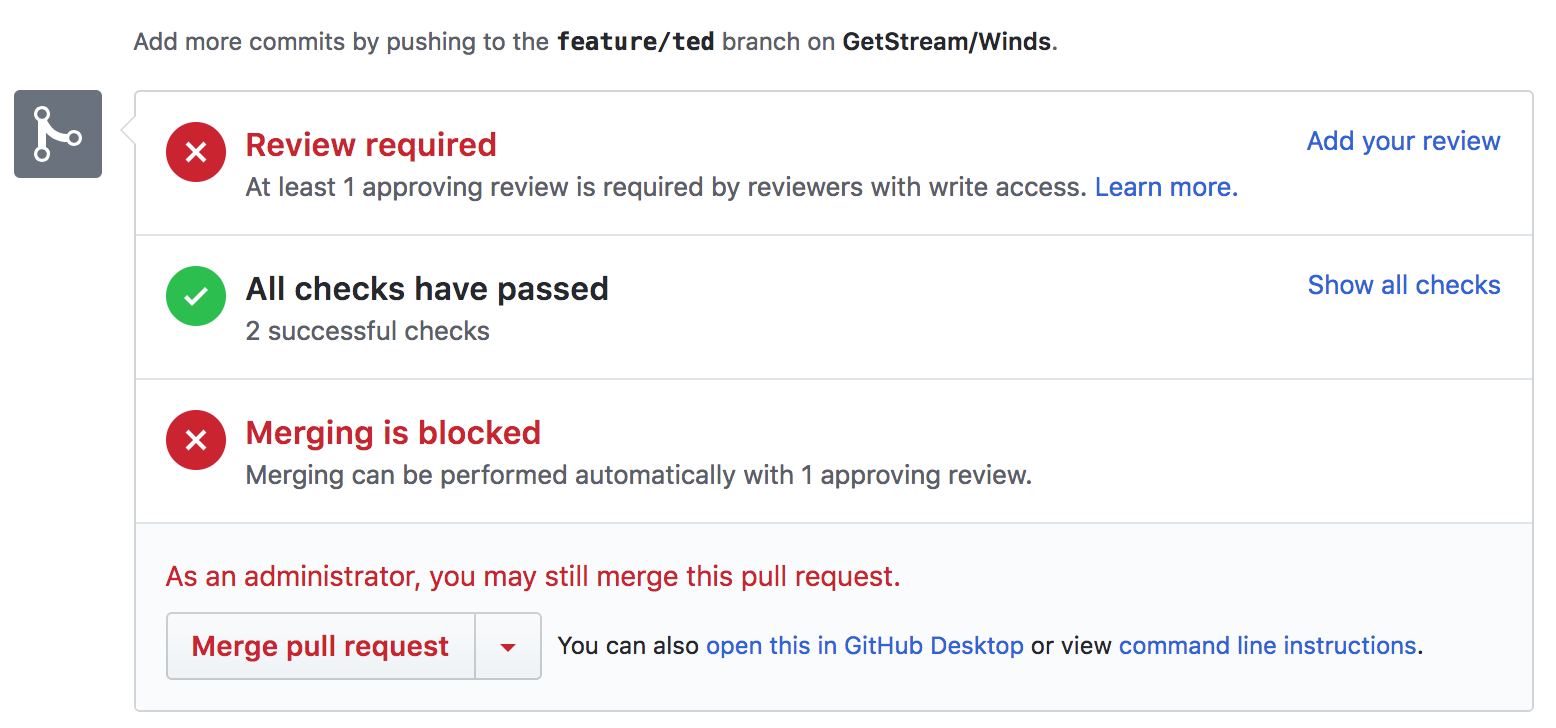
|
||||
|
||||
除了 Travis CI,我们还用到了叫做 [CodeCov][18] 的工具。CodeCov 和 [Istanbul] 很像,但它是个可视化的工具,方便我们查看代码覆盖率、文件变动、行数变化,还有其他各种小玩意儿。尽管不用 CodeCov 也可以可视化数据,但把所有东西囊括在一个地方也很不错。
|
||||
|
||||
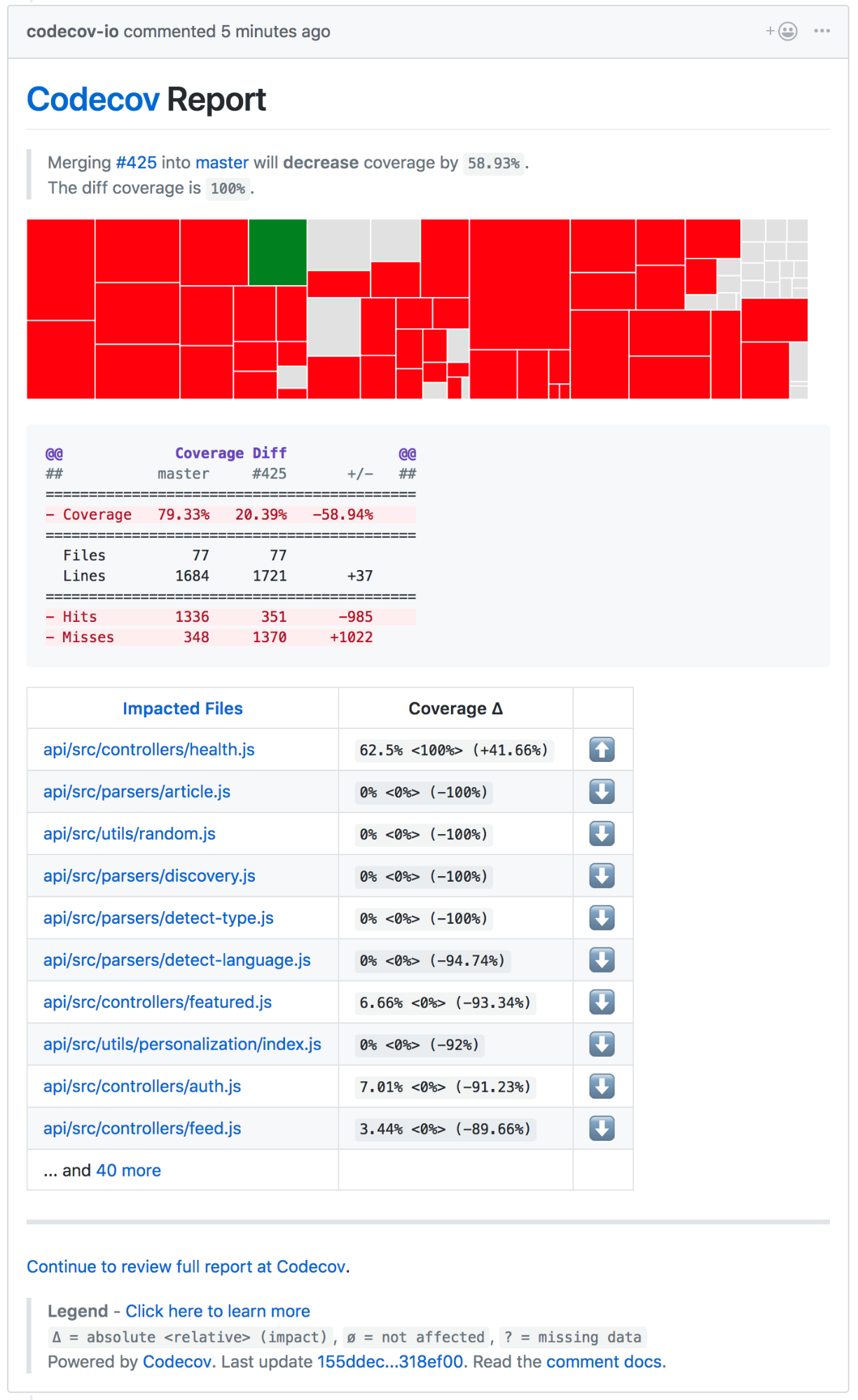
|
||||
|
||||
### 我们学到了什么
|
||||
|
||||
在开发我们的测试套件的整个过程中,我们学到了很多东西。开发时没有所谓“正确”的方法,我们决定开始创造自己的测试流程,通过理清楚可用的库,找到那些足够有用的东西添加到我们的工具箱中。
|
||||
|
||||
最终我们学到的是,在 Node.js 中进行测试不是听上去那么简单。还好,随着 Node.js 持续完善,社区将会聚集力量,构建一个坚固稳健的库,可以用“正确”的方式处理所有和测试相关的东西。
|
||||
|
||||
但在那时到来之前,我们还会接着用自己的测试套件,它开源在 [Winds 的 GitHub 仓库][20]。
|
||||
|
||||
### 局限
|
||||
|
||||
#### 创建配置没有简单的方法
|
||||
|
||||
有的框架和语言,就如 Python 中的 Django,有简单的方式来创建配置。比如,你可以使用下面这些 Django 命令,把数据导出到文件中来自动化配置的创建过程:
|
||||
|
||||
以下命令会把整个数据库导出到 `db.json` 文件中:
|
||||
|
||||
```
|
||||
./manage.py dumpdata > db.json
|
||||
```
|
||||
|
||||
以下命令仅导出 django 中 `admin.logentry` 表里的内容:
|
||||
|
||||
```
|
||||
./manage.py dumpdata admin.logentry > logentry.json
|
||||
```
|
||||
|
||||
以下命令会导出 `auth.user` 表中的内容:
|
||||
|
||||
```
|
||||
./manage.py dumpdata auth.user > user.json
|
||||
```
|
||||
|
||||
Node.js 里面没有创建配置的简单方式。我们最后做的事情是用 MongoDB Compass 工具导出数据到 JSON 中。这生成了不错的配置,如下图(但是,这是个乏味的过程,肯定会出错):
|
||||
|
||||
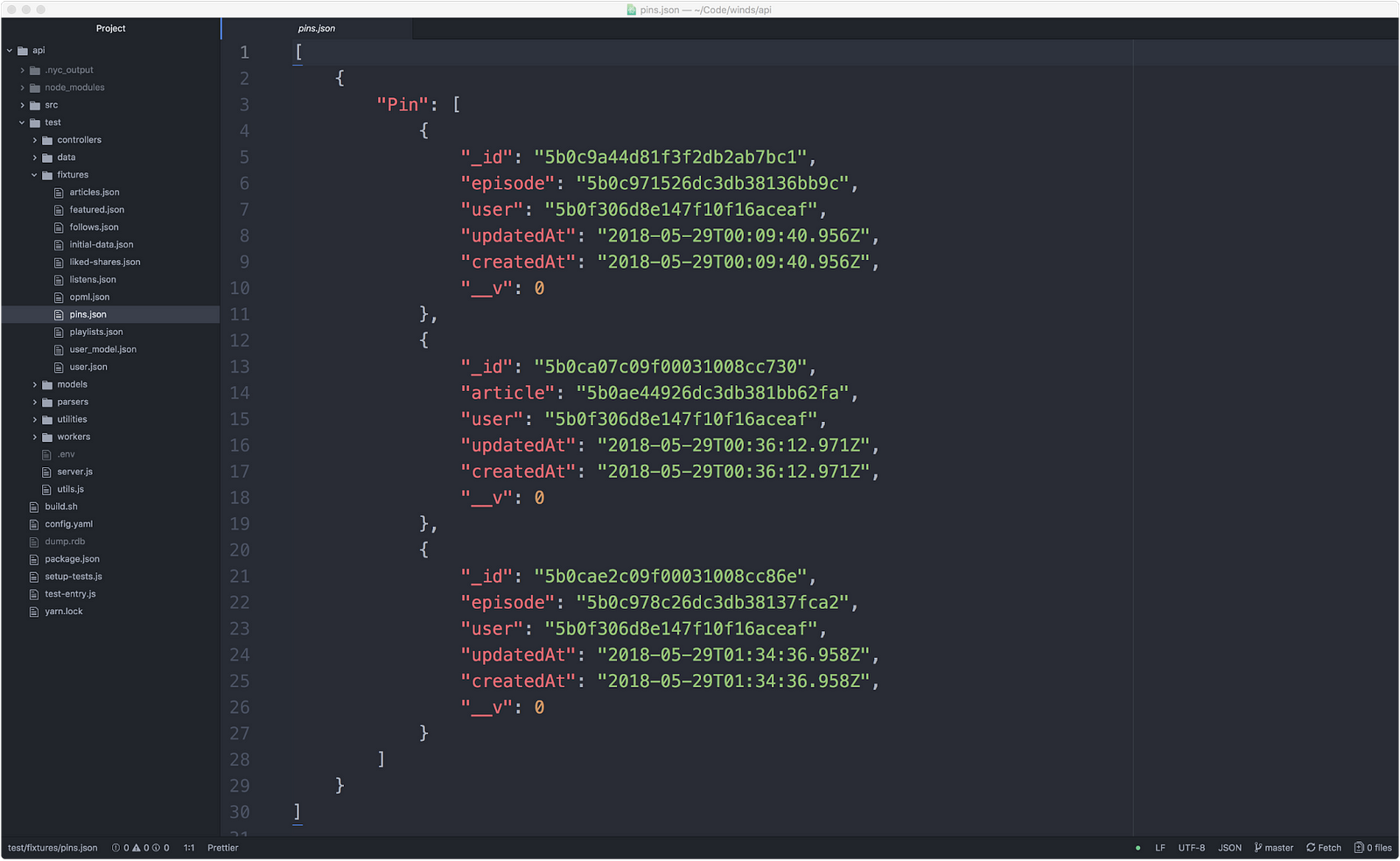
|
||||
|
||||
#### 使用 Babel,模拟模块和 Mocha 测试执行平台时,模块加载不直观
|
||||
|
||||
为了支持多种 node 版本,和获取 JavaScript 标准的最新附件,我们使用 Babel 把 ES6 代码转换成 ES5。Node.js 模块系统基于 CommonJS 标准,而 ES6 模块系统中有不同的语义。
|
||||
|
||||
Babel 在 Node.js 模块系统的顶层模拟 ES6 模块语义,但由于我们要使用 mock-require 来介入模块的加载,所以我们经历了罕见的怪异的模块加载过程,这看上去很不直观,而且能导致在整个代码中,导入的、初始化的和使用的模块有不同的版本。这使测试时的模拟过程和全局状态管理复杂化了。
|
||||
|
||||
#### 在使用 ES6 模块时声明的函数,模块内部的函数,都无法模拟
|
||||
|
||||
当一个模块导出多个函数,其中一个函数调用了其他的函数,就不可能模拟使用在模块内部的函数。原因在于当你引用一个 ES6 模块时,你得到的引用集合和模块内部的是不同的。任何重新绑定引用,将其指向新值的尝试都无法真正影响模块内部的函数,内部函数仍然使用的是原始的函数。
|
||||
|
||||
### 最后的思考
|
||||
|
||||
测试 Node.js 应用是复杂的过程,因为它的生态系统总在发展。掌握最新和最好的工具很重要,这样你就不会掉队了。
|
||||
|
||||
如今有很多方式获取 JavaScript 相关的新闻,导致与时俱进很难。关注邮件新闻刊物如 [JavaScript Weekly][21] 和 [Node Weekly][22] 是良好的开始。还有,关注一些 reddit 子模块如 [/r/node][23] 也不错。如果你喜欢了解最新的趋势,[State of JS][24] 在测试领域帮助开发者可视化趋势方面就做的很好。
|
||||
|
||||
最后,这里是一些我喜欢的博客,我经常在这上面发文章:
|
||||
|
||||
* [Hacker Noon][1]
|
||||
* [Free Code Camp][2]
|
||||
* [Bits and Pieces][3]
|
||||
|
||||
觉得我遗漏了某些重要的东西?在评论区或者 Twitter [@NickParsons][25] 让我知道。
|
||||
|
||||
还有,如果你想要了解 Stream,我们的网站上有很棒的 5 分钟教程。点 [这里][26] 进行查看。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Nick Parsons
|
||||
|
||||
Dreamer. Doer. Engineer. Developer Evangelist https://getstream.io.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/testing-node-js-in-2018-10a04dd77391
|
||||
|
||||
作者:[Nick Parsons][a]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@nparsons08?source=post_header_lockup
|
||||
[1]:https://hackernoon.com/
|
||||
[2]:https://medium.freecodecamp.org/
|
||||
[3]:https://blog.bitsrc.io/
|
||||
[4]:https://getstream.io/
|
||||
[5]:https://getstream.io/winds
|
||||
[6]:https://github.com/mochajs/mocha
|
||||
[7]:http://www.chaijs.com/
|
||||
[8]:http://sinonjs.org/
|
||||
[9]:https://github.com/node-nock/nock
|
||||
[10]:https://getstream.io/docs_rest/
|
||||
[11]:https://getstream.io/personalization
|
||||
[12]:https://github.com/boblauer/mock-require
|
||||
[13]:https://github.com/gotwarlost/istanbul
|
||||
[14]:https://github.com/GetStream/Winds/tree/master/api/test
|
||||
[15]:https://travis-ci.org/
|
||||
[16]:https://github.com/GetStream/Winds/blob/master/.travis.yml
|
||||
[17]:https://www.npmjs.com/
|
||||
[18]:https://codecov.io/#features
|
||||
[19]:https://github.com/gotwarlost/istanbul
|
||||
[20]:https://github.com/GetStream/Winds/tree/master/api/test
|
||||
[21]:https://javascriptweekly.com/
|
||||
[22]:https://nodeweekly.com/
|
||||
[23]:https://www.reddit.com/r/node/
|
||||
[24]:https://stateofjs.com/2017/testing/results/
|
||||
[25]:https://twitter.com/@nickparsons
|
||||
[26]:https://getstream.io/try-the-api
|
||||
@ -1,6 +1,8 @@
|
||||
系统管理员的一个网络管理指南
|
||||
面向系统管理员的网络管理指南
|
||||
======
|
||||
|
||||
> 一个使管理服务器和网络更轻松的 Linux 工具和命令的参考列表。
|
||||
|
||||

|
||||
|
||||
如果你是一位系统管理员,那么你的日常工作应该包括管理服务器和数据中心的网络。以下的 Linux 实用工具和命令 —— 从基础的到高级的 —— 将帮你更轻松地管理你的网络。
|
||||
@ -16,8 +18,6 @@
|
||||
* IPv4: `ping <ip address>/<fqdn>`
|
||||
* IPv6: `ping6 <ip address>/<fqdn>`
|
||||
|
||||
|
||||
|
||||
你也可以使用 `ping` 去解析出网站所对应的 IP 地址,如下图所示:
|
||||
|
||||
|
||||
@ -32,16 +32,12 @@
|
||||
|
||||
* `traceroute <ip address>/<fqdn>`
|
||||
|
||||
|
||||
|
||||
### Telnet
|
||||
|
||||
**语法:**
|
||||
|
||||
* `telnet <ip address>/<fqdn>` 是用于 [telnet][3] 进入任何支持该协议的服务器。
|
||||
|
||||
|
||||
|
||||
### Netstat
|
||||
|
||||
这个网络统计(`netstat`)实用工具是用于去分析解决网络连接问题和检查接口/端口统计数据、路由表、协议状态等等的。它是任何管理员都应该必须掌握的工具。
|
||||
@ -69,20 +65,14 @@
|
||||
**语法:**
|
||||
|
||||
* `nmcli device` 列出网络上的所有设备。
|
||||
|
||||
* `nmcli device show <interface>` 显示指定接口的网络相关的详细情况。
|
||||
|
||||
* `nmcli connection` 检查设备的连接情况。
|
||||
|
||||
* `nmcli connection down <interface>` 关闭指定接口。
|
||||
|
||||
* `nmcli connection up <interface>` 打开指定接口。
|
||||
|
||||
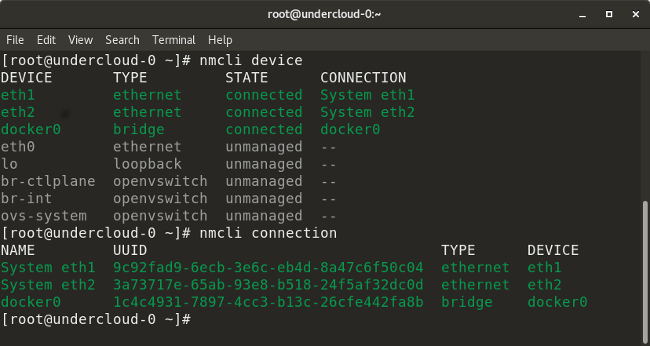
* `nmcli con add type vlan con-name <connection-name> dev <interface> id <vlan-number> ipv4 <ip/cidr> gw4 <gateway-ip>` 在特定的接口上使用指定的 VLAN 号添加一个虚拟局域网(VLAN)接口、IP 地址、和网关。
|
||||
|
||||
|
||||
|
||||
|
||||
### 路由
|
||||
|
||||
检查和配置路由的命令很多。下面是其中一些比较有用的:
|
||||
@ -101,13 +91,13 @@
|
||||
|
||||
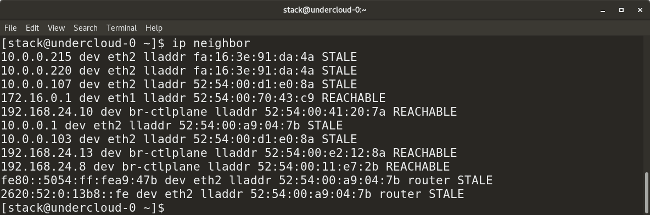
* `ip neighbor` 显示当前的邻接表和用于去添加、改变、或删除新的邻居。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
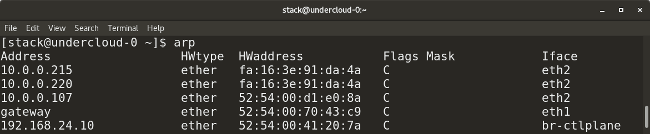
* `arp` (它的全称是 “地址解析协议”)类似于 `ip neighbor`。`arp` 映射一个系统的 IP 地址到它相应的 MAC(介质访问控制)地址。
|
||||
|
||||
|
||||

|
||||
|
||||
### Tcpdump 和 Wireshark
|
||||
|
||||
@ -117,7 +107,7 @@ Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark`
|
||||
|
||||
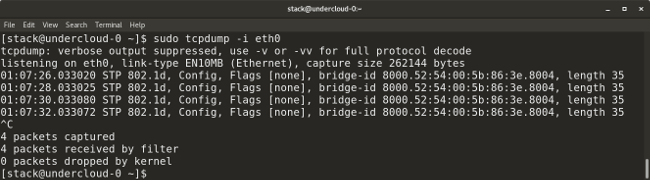
* `tcpdump -i <interface-name>` 显示指定接口上实时通过的数据包。通过在命令中添加一个 `-w` 标志和输出文件的名字,可以将数据包保存到一个文件中。例如:`tcpdump -w <output-file.> -i <interface-name>`。
|
||||
|
||||
|
||||

|
||||
|
||||
* `tcpdump -i <interface> src <source-ip>` 从指定的源 IP 地址上捕获数据包。
|
||||
* `tcpdump -i <interface> dst <destination-ip>` 从指定的目标 IP 地址上捕获数据包。
|
||||
@ -135,22 +125,16 @@ Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark`
|
||||
* `iptables -L` 列出所有已存在的 `iptables` 规则。
|
||||
* `iptables -F` 删除所有已存在的规则。
|
||||
|
||||
|
||||
|
||||
下列命令允许流量从指定端口到指定接口:
|
||||
|
||||
* `iptables -A INPUT -i <interface> -p tcp –dport <port-number> -m state –state NEW,ESTABLISHED -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o <interface> -p tcp -sport <port-number> -m state – state ESTABLISHED -j ACCEPT`
|
||||
|
||||
|
||||
|
||||
下列命令允许<ruby>环回<rt>loopback</rt></ruby>接口访问系统:
|
||||
|
||||
* `iptables -A INPUT -i lo -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o lo -j ACCEPT`
|
||||
|
||||
|
||||
|
||||
### Nslookup
|
||||
|
||||
`nslookup` 工具是用于去获得一个网站或域名所映射的 IP 地址。它也能用于去获得你的 DNS 服务器的信息,比如,一个网站的所有 DNS 记录(具体看下面的示例)。与 `nslookup` 类似的一个工具是 `dig`(Domain Information Groper)实用工具。
|
||||
@ -161,7 +145,6 @@ Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark`
|
||||
* `nslookup -type=any <website-name.com>` 显示指定网站/域中所有可用记录。
|
||||
|
||||
|
||||
|
||||
### 网络/接口调试
|
||||
|
||||
下面是用于接口连通性或相关网络问题调试所需的命令和文件的汇总。
|
||||
@ -182,7 +165,6 @@ Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark`
|
||||
* `/etc/ntp.conf` 指定 NTP 服务器域名。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-networking-commands
|
||||
@ -190,7 +172,7 @@ via: https://opensource.com/article/18/7/sysadmin-guide-networking-commands
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
Linux 下 cut 命令的 4 个本质且实用的示例
|
||||
Linux 下 cut 命令的 4 个基础实用的示例
|
||||
============================================================
|
||||
|
||||
`cut` 命令是用来从文本文件中移除“某些列”的经典工具。在本文中的“一列”可以被定义为按照一行中位置区分的一系列字符串或者字节, 或者是以某个分隔符为间隔的某些域。
|
||||
`cut` 命令是用来从文本文件中移除“某些列”的经典工具。在本文中的“一列”可以被定义为按照一行中位置区分的一系列字符串或者字节,或者是以某个分隔符为间隔的某些域。
|
||||
|
||||
先前我已经介绍了[如何使用 AWK 命令][13]。在本文中,我将解释 linux 下 `cut` 命令的 4 个本质且实用的例子,有时这些例子将帮你节省很多时间。
|
||||
|
||||
@ -11,26 +11,13 @@ Linux 下 cut 命令的 4 个本质且实用的示例
|
||||
|
||||
假如你想,你可以观看下面的视频,视频中解释了本文中我列举的 cut 命令的使用例子。
|
||||
|
||||
目录:
|
||||
- https://www.youtube.com/PhE_cFLzVFw
|
||||
|
||||
* [作用在一系列字符上][8]
|
||||
* [范围如何定义?][1]
|
||||
### 1、 作用在一系列字符上
|
||||
|
||||
* [作用在一系列字节上][9]
|
||||
* [作用在多字节编码的字符上][2]
|
||||
当启用 `-c` 命令行选项时,`cut` 命令将移除一系列字符。
|
||||
|
||||
* [作用在域上][10]
|
||||
* [处理不包含分隔符的行][3]
|
||||
|
||||
* [改变输出的分隔符][4]
|
||||
|
||||
* [非 POSIX GNU 扩展][11]
|
||||
|
||||
### 1\. 作用在一系列字符上
|
||||
|
||||
当启用 `-c` 命令行选项时,cut 命令将移除一系列字符。
|
||||
|
||||
和其他的过滤器类似, cut 命令不会就地改变输入的文件,它将复制已修改的数据到它的标准输出里去。你可以通过重定向命令的结果到一个文件中来保存修改后的结果,或者使用管道将结果送到另一个命令的输入中,这些都由你来负责。
|
||||
和其他的过滤器类似, `cut` 命令不会直接改变输入的文件,它将复制已修改的数据到它的标准输出里去。你可以通过重定向命令的结果到一个文件中来保存修改后的结果,或者使用管道将结果送到另一个命令的输入中,这些都由你来负责。
|
||||
|
||||
假如你已经下载了上面视频中的[示例测试文件][26],你将看到一个名为 `BALANCE.txt` 的数据文件,这些数据是直接从我妻子在她工作中使用的某款会计软件中导出的:
|
||||
|
||||
@ -50,7 +37,7 @@ ACCDOC ACCDOCDATE ACCOUNTNUM ACCOUNTLIB ACCDOCLIB
|
||||
|
||||
上述文件是一个固定宽度的文本文件,因为对于每一项数据,都使用了不定长的空格做填充,使得它看起来是一个对齐的列表。
|
||||
|
||||
这样一来,每一列数据开始和结束的位置都是一致的。从 cut 命令的字面意思去理解会给我们带来一个小陷阱:`cut` 命令实际上需要你指出你想_保留_的数据范围,而不是你想_移除_的范围。所以,假如我_只_需要上面文件中的 `ACCOUNTNUM` 和 `ACCOUNTLIB` 列,我需要这么做:
|
||||
这样一来,每一列数据开始和结束的位置都是一致的。从 `cut` 命令的字面意思去理解会给我们带来一个小陷阱:`cut` 命令实际上需要你指出你想_保留_的数据范围,而不是你想_移除_的范围。所以,假如我_只_需要上面文件中的 `ACCOUNTNUM` 和 `ACCOUNTLIB` 列,我需要这么做:
|
||||
|
||||
```
|
||||
sh$ cut -c 25-59 BALANCE.txt | head
|
||||
@ -68,17 +55,17 @@ ACCOUNTNUM ACCOUNTLIB
|
||||
|
||||
#### 范围如何定义?
|
||||
|
||||
正如我们上面看到的那样, cut 命令需要我们特别指定需要保留的数据的_范围_。所以,下面我将更正式地介绍如何定义范围:对于 `cut` 命令来说,范围是由连字符(`-`)分隔的起始和结束位置组成,范围是基于 1 计数的,即每行的第一项是从 1 开始计数的,而不是从 0 开始。范围是一个闭区间,开始和结束位置都将包含在结果之中,正如它们之间的所有字符那样。如果范围中的结束位置比起始位置小,则这种表达式是错误的。作为快捷方式,你可以省略起始_或_结束值,正如下面的表格所示:
|
||||
正如我们上面看到的那样, `cut` 命令需要我们特别指定需要保留的数据的_范围_。所以,下面我将更正式地介绍如何定义范围:对于 `cut` 命令来说,范围是由连字符(`-`)分隔的起始和结束位置组成,范围是基于 1 计数的,即每行的第一项是从 1 开始计数的,而不是从 0 开始。范围是一个闭区间,开始和结束位置都将包含在结果之中,正如它们之间的所有字符那样。如果范围中的结束位置比起始位置小,则这种表达式是错误的。作为快捷方式,你可以省略起始_或_结束值,正如下面的表格所示:
|
||||
|
||||
|
||||
|||
|
||||
|--|--|
|
||||
| 范围 | 含义 |
|
||||
|---|---|
|
||||
| `a-b` | a 和 b 之间的范围(闭区间) |
|
||||
|`a` | 与范围 `a-a` 等价 |
|
||||
| `-b` | 与范围 `1-a` 等价 |
|
||||
| `b-` | 与范围 `b-∞` 等价 |
|
||||
|
||||
cut 命令允许你通过逗号分隔多个范围,下面是一些示例:
|
||||
`cut` 命令允许你通过逗号分隔多个范围,下面是一些示例:
|
||||
|
||||
```
|
||||
# 保留 1 到 24 之间(闭区间)的字符
|
||||
@ -108,8 +95,7 @@ Files /dev/fd/63 and /dev/fd/62 are identical
|
||||
类似的,`cut` 命令 _不会重复数据_:
|
||||
|
||||
```
|
||||
# One might expect that could be a way to repeat
|
||||
# the first column three times, but no...
|
||||
# 某人或许期待这可以第一列三次,但并不会……
|
||||
cut -c -10,-10,-10 BALANCE.txt | head -5
|
||||
ACCDOC
|
||||
4
|
||||
@ -118,13 +104,13 @@ ACCDOC
|
||||
5
|
||||
```
|
||||
|
||||
值得提及的是,曾经有一个提议,建议使用 `-o` 选项来实现上面提到的两个限制,使得 `cut` 工具可以重排或者重复数据。但这个提议被 [POSIX 委员会拒绝了][14],_“因为这类增强不属于 IEEE P1003.2b 草案标准的范围”_。
|
||||
值得提及的是,曾经有一个提议,建议使用 `-o` 选项来去除上面提到的两个限制,使得 `cut` 工具可以重排或者重复数据。但这个提议被 [POSIX 委员会拒绝了][14],_“因为这类增强不属于 IEEE P1003.2b 草案标准的范围”_。
|
||||
|
||||
据我所知,我还没有见过哪个版本的 cut 程序实现了上面的提议,以此来作为扩展,假如你知道某些例外,请使用下面的评论框分享给大家!
|
||||
据我所知,我还没有见过哪个版本的 `cut` 程序实现了上面的提议,以此来作为扩展,假如你知道某些例外,请使用下面的评论框分享给大家!
|
||||
|
||||
### 2\. 作用在一系列字节上
|
||||
### 2、 作用在一系列字节上
|
||||
|
||||
当使用 `-b` 命令行选项时,cut 命令将移除字节范围。
|
||||
当使用 `-b` 命令行选项时,`cut` 命令将移除字节范围。
|
||||
|
||||
咋一看,使用_字符_范围和使用_字节_没有什么明显的不同:
|
||||
|
||||
@ -197,11 +183,11 @@ ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
|
||||
36 1012017 VAT BS/ENC 00000000013,83
|
||||
```
|
||||
|
||||
我已经_毫无删减地_复制了上面命令的输出。所以可以很明显地看出列对齐那里有些问题。
|
||||
我_毫无删减地_复制了上面命令的输出。所以可以很明显地看出列对齐那里有些问题。
|
||||
|
||||
对此我的解释是原来的数据文件只包含 US-ASCII 编码的字符(符号、标点符号、数字和没有发音符号的拉丁字母)。
|
||||
|
||||
但假如你仔细地查看经软件升级后产生的文件,你可以看到新导出的数据文件保留了带发音符号的字母。例如名为“ALNÉENRE”的公司现在被合理地记录了,而不是先前的 “ALNEENRE”(没有发音符号)。
|
||||
但假如你仔细地查看经软件升级后产生的文件,你可以看到新导出的数据文件保留了带发音符号的字母。例如现在合理地记录了名为 “ALNÉENRE” 的公司,而不是先前的 “ALNEENRE”(没有发音符号)。
|
||||
|
||||
`file -i` 正确地识别出了改变,因为它报告道现在这个文件是 [UTF-8 编码][15] 的。
|
||||
|
||||
@ -231,28 +217,26 @@ sh$ sed '2!d' BALANCE-V2.txt | hexdump -C
|
||||
在 `hexdump` 输出的 00000030 那行,在一系列的空格(字节 `20`)之后,你可以看到:
|
||||
|
||||
* 字母 `A` 被编码为 `41`,
|
||||
|
||||
* 字母 `L` 被编码为 `4c`,
|
||||
|
||||
* 字母 `N` 被编码为 `4e`。
|
||||
|
||||
但对于大写的[带有注音的拉丁大写字母 E][16] (这是它在 Unicode 标准中字母 _É_ 的官方名称),则是使用 _2_ 个字节 `c3 89` 来编码的。
|
||||
|
||||
这样便出现问题了:对于使用固定宽度编码的文件, 使用字节位置来表示范围的 `cut` 命令工作良好,但这并不适用于使用变长编码的 UTF-8 或者 [Shift JIS][17] 编码。这种情况在下面的 [POSIX标准的非规范性摘录][18] 中被明确地解释过:
|
||||
这样便出现问题了:对于使用固定宽度编码的文件, 使用字节位置来表示范围的 `cut` 命令工作良好,但这并不适用于使用变长编码的 UTF-8 或者 [Shift JIS][17] 编码。这种情况在下面的 [POSIX 标准的非规范性摘录][18] 中被明确地解释过:
|
||||
|
||||
> 先前版本的 cut 程序将字节和字符视作等同的环境下运作(正如在某些实现下对 退格键<backspace> 和制表键<tab> 的处理)。在针对多字节字符的情况下,特别增加了 `-b` 选项。
|
||||
> 先前版本的 `cut` 程序将字节和字符视作等同的环境下运作(正如在某些实现下对退格键 `<backspace>` 和制表键 `<tab>` 的处理)。在针对多字节字符的情况下,特别增加了 `-b` 选项。
|
||||
|
||||
嘿,等一下!我并没有在上面“有错误”的例子中使用 '-b' 选项,而是 `-c` 选项呀!所以,难道_不应该_能够成功处理了吗!?
|
||||
|
||||
是的,确实_应该_:但是很不幸,即便我们现在已身处 2018 年,GNU Coreutils 的版本为 8.30 了,cut 程序的 GNU 版本实现仍然不能很好地处理多字节字符。引用 [GNU 文档][19] 的话说,_`-c` 选项“现在和 `-b` 选项是相同的,但对于国际化的情形将有所不同[...]”_。需要提及的是,这个问题距今已有 10 年之久了!
|
||||
是的,确实_应该_:但是很不幸,即便我们现在已身处 2018 年,GNU Coreutils 的版本为 8.30 了,`cut` 程序的 GNU 版本实现仍然不能很好地处理多字节字符。引用 [GNU 文档][19] 的话说,_`-c` 选项“现在和 `-b` 选项是相同的,但对于国际化的情形将有所不同[...]”_。需要提及的是,这个问题距今已有 10 年之久了!
|
||||
|
||||
另一方面,[OpenBSD][20] 的实现版本和 POSIX 相吻合,这将归功于当前的本地化(locale) 设定来合理地处理多字节字符:
|
||||
另一方面,[OpenBSD][20] 的实现版本和 POSIX 相吻合,这将归功于当前的本地化(`locale`)设定来合理地处理多字节字符:
|
||||
|
||||
```
|
||||
# 确保随后的命令知晓我们现在处理的是 UTF-8 编码的文本文件
|
||||
openbsd-6.3$ export LC_CTYPE=en_US.UTF-8
|
||||
|
||||
# 使用 `-c` 选项, cut 能够合理地处理多字节字符
|
||||
# 使用 `-c` 选项, `cut` 能够合理地处理多字节字符
|
||||
openbsd-6.3$ cut -c -24,36-59,93- BALANCE-V2.txt
|
||||
ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
|
||||
4 1012017 TIDE SCHEDULE 00000001615,00
|
||||
@ -286,7 +270,7 @@ ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
|
||||
36 1012017 VAT BS/ENC 00000000013,83
|
||||
```
|
||||
|
||||
正如期望的那样,当使用 `-b` 选项而不是 `-c` 选项后, OpenBSD 版本的 cut 实现和传统的 `cut` 表现是类似的:
|
||||
正如期望的那样,当使用 `-b` 选项而不是 `-c` 选项后, OpenBSD 版本的 `cut` 实现和传统的 `cut` 表现是类似的:
|
||||
|
||||
```
|
||||
openbsd-6.3$ cut -b -24,36-59,93- BALANCE-V2.txt
|
||||
@ -322,7 +306,7 @@ ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
|
||||
36 1012017 VAT BS/ENC 00000000013,83
|
||||
```
|
||||
|
||||
### 3\. 作用在域上
|
||||
### 3、 作用在域上
|
||||
|
||||
从某种意义上说,使用 `cut` 来处理用特定分隔符隔开的文本文件要更加容易一些,因为只需要确定好每行中域之间的分隔符,然后复制域的内容到输出就可以了,而不需要烦恼任何与编码相关的问题。
|
||||
|
||||
@ -342,9 +326,9 @@ ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;ACCDOCLIB;DEBIT;CREDIT
|
||||
6;1012017;623795;TOURIST GUIDE BOOK;FACT FA00006253 - BIT QUIROBEN;00000001531,00;
|
||||
```
|
||||
|
||||
你可能知道上面文件是一个 [CSV][29] 格式的文件(它以逗号来分隔),即便有时候域分隔符不是逗号。例如分号(`;`)也常被用来作为分隔符,并且对于那些总使用逗号作为 [十进制分隔符][30]的国家(例如法国,所以上面我的示例文件中选用了他们国家的字符),当导出数据为 "CSV" 格式时,默认将使用分号来分隔数据。另一种常见的情况是使用 [tab 键][32] 来作为分隔符,从而生成叫做 [tab 分隔数值][32] 的文件。最后,在 Unix 和 Linux 领域,冒号 (`:`) 是另一种你能找到的常见分隔符号,例如在标准的 `/etc/passwd` 和 `/etc/group` 这两个文件里。
|
||||
你可能知道上面文件是一个 [CSV][29] 格式的文件(它以逗号来分隔),即便有时候域分隔符不是逗号。例如分号(`;`)也常被用来作为分隔符,并且对于那些总使用逗号作为 [十进制分隔符][30]的国家(例如法国,所以上面我的示例文件中选用了他们国家的字符),当导出数据为 “CSV” 格式时,默认将使用分号来分隔数据。另一种常见的情况是使用 [tab 键][32] 来作为分隔符,从而生成叫做 [tab 分隔的值][32] 的文件。最后,在 Unix 和 Linux 领域,冒号 (`:`) 是另一种你能找到的常见分隔符号,例如在标准的 `/etc/passwd` 和 `/etc/group` 这两个文件里。
|
||||
|
||||
当处理使用分隔符隔开的文本文件格式时,你可以向带有 `-f` 选项的 cut 命令提供需要保留的域的范围,并且你也可以使用 `-d` 选项来制定分隔符(当没有使用 `-d` 选项时,默认以 tab 字符来作为分隔符):
|
||||
当处理使用分隔符隔开的文本文件格式时,你可以向带有 `-f` 选项的 `cut` 命令提供需要保留的域的范围,并且你也可以使用 `-d` 选项来指定分隔符(当没有使用 `-d` 选项时,默认以 tab 字符来作为分隔符):
|
||||
|
||||
```
|
||||
sh$ cut -f 5- -d';' BALANCE.csv | head
|
||||
@ -362,9 +346,9 @@ FACT FA00006253 - BIT QUIROBEN;00000001531,00;
|
||||
|
||||
#### 处理不包含分隔符的行
|
||||
|
||||
但要是输入文件中的某些行没有分隔符又该怎么办呢?很容易地认为可以将这样的行视为只包含第一个域。但 cut 程序并 _不是_ 这样做的。
|
||||
但要是输入文件中的某些行没有分隔符又该怎么办呢?很容易地认为可以将这样的行视为只包含第一个域。但 `cut` 程序并 _不是_ 这样做的。
|
||||
|
||||
默认情况下,当使用 `-f` 选项时, cut 将总是原样输出不包含分隔符的那一行(可能假设它是非数据行,就像表头或注释等):
|
||||
默认情况下,当使用 `-f` 选项时,`cut` 将总是原样输出不包含分隔符的那一行(可能假设它是非数据行,就像表头或注释等):
|
||||
|
||||
```
|
||||
sh$ (echo "# 2018-03 BALANCE"; cat BALANCE.csv) > BALANCE-WITH-HEADER.csv
|
||||
@ -388,8 +372,7 @@ DEBIT;CREDIT
|
||||
00000001333,00;
|
||||
```
|
||||
|
||||
假如你好奇心强,你还可以探索这种特性,来作为一种相对
|
||||
隐晦的方式去保留那些只包含给定字符的行:
|
||||
假如你好奇心强,你还可以探索这种特性,来作为一种相对隐晦的方式去保留那些只包含给定字符的行:
|
||||
|
||||
```
|
||||
# 保留含有一个 `e` 的行
|
||||
@ -398,7 +381,7 @@ sh$ printf "%s\n" {mighty,bold,great}-{condor,monkey,bear} | cut -s -f 1- -d'e'
|
||||
|
||||
#### 改变输出的分隔符
|
||||
|
||||
作为一种扩展, GNU 版本实现的 cut 允许通过使用 `--output-delimiter` 选项来为结果指定一个不同的域分隔符:
|
||||
作为一种扩展, GNU 版本实现的 `cut` 允许通过使用 `--output-delimiter` 选项来为结果指定一个不同的域分隔符:
|
||||
|
||||
```
|
||||
sh$ cut -f 5,6- -d';' --output-delimiter="*" BALANCE.csv | head
|
||||
@ -416,10 +399,12 @@ FACT FA00006253 - BIT QUIROBEN*00000001531,00*
|
||||
|
||||
需要注意的是,在上面这个例子中,所有出现域分隔符的地方都被替换掉了,而不仅仅是那些在命令行中指定的作为域范围边界的分隔符。
|
||||
|
||||
### 4\. 非 POSIX GNU 扩展
|
||||
### 4、 非 POSIX GNU 扩展
|
||||
|
||||
说到非 POSIX GNU 扩展,它们中的某些特别有用。特别需要提及的是下面的扩展也同样对字节、字符或者域范围工作良好(相对于当前的 GNU 实现来说)。
|
||||
|
||||
`--complement`:
|
||||
|
||||
想想在 sed 地址中的感叹符号(`!`),使用它,`cut` 将只保存**没有**被匹配到的范围:
|
||||
|
||||
```
|
||||
@ -436,7 +421,9 @@ ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;DEBIT;CREDIT
|
||||
4;1012017;445452;VAT BS/ENC;00000000323,00;
|
||||
```
|
||||
|
||||
使用 [NUL 字符][6] 来作为行终止符,而不是 [新行(newline)字符][7]。当你的数据包含 新行 字符时, `-z` 选项就特别有用了,例如当处理文件名的时候(因为在文件名中 新行 字符是可以使用的,而 NUL 则不可以)。
|
||||
`--zero-terminated (-z)`:
|
||||
|
||||
使用 [NUL 字符][6] 来作为行终止符,而不是 [<ruby>新行<rt>newline</rt></ruby>字符][7]。当你的数据包含 新行字符时, `-z` 选项就特别有用了,例如当处理文件名的时候(因为在文件名中新行字符是可以使用的,而 NUL 则不可以)。
|
||||
|
||||
为了展示 `-z` 选项,让我们先做一点实验。首先,我们将创建一个文件名中包含换行符的文件:
|
||||
|
||||
@ -448,7 +435,7 @@ BALANCE-V2.txt
|
||||
EMPTY?FILE?WITH FUNKY?NAME.txt
|
||||
```
|
||||
|
||||
现在假设我想展示每个 `*.txt` 文件的前 5 个字符。一个想当然的解法将会失败:
|
||||
现在假设我想展示每个 `*.txt` 文件的前 5 个字符。一个想当然的解决方法将会失败:
|
||||
|
||||
```
|
||||
sh$ ls -1 *.txt | cut -c 1-5
|
||||
@ -460,7 +447,7 @@ WITH
|
||||
NAME.
|
||||
```
|
||||
|
||||
你可以已经知道 `[ls][21]` 是为了[方便人类使用][33]而特别设计的,并且在一个命令管道中使用它是一个反模式(确实是这样的)。所以让我们用 `[find][22]` 来替换它:
|
||||
你可以已经知道 [ls][21] 是为了[方便人类使用][33]而特别设计的,并且在一个命令管道中使用它是一个反模式(确实是这样的)。所以让我们用 [find][22] 来替换它:
|
||||
|
||||
```
|
||||
sh$ find . -name '*.txt' -printf "%f\n" | cut -c 1-5
|
||||
@ -484,11 +471,11 @@ EMPTY
|
||||
BALAN
|
||||
```
|
||||
|
||||
通过上面最后的例子,我们就达到了本文的最后部分了,所以我将让你自己试试 `-printf` 后面那个有趣的 `"%f\0"` 参数或者理解为什么我在管道的最后使用了 `[tr][23]` 命令。
|
||||
通过上面最后的例子,我们就达到了本文的最后部分了,所以我将让你自己试试 `-printf` 后面那个有趣的 `"%f\0"` 参数或者理解为什么我在管道的最后使用了 [tr][23] 命令。
|
||||
|
||||
### 使用 cut 命令可以实现更多功能
|
||||
|
||||
我只是列举了 cut 命令的最常见且在我眼中最实质的使用方式。你甚至可以将它以更加实用的方式加以运用,这取决于你的逻辑和想象。
|
||||
我只是列举了 `cut` 命令的最常见且在我眼中最基础的使用方式。你甚至可以将它以更加实用的方式加以运用,这取决于你的逻辑和想象。
|
||||
|
||||
不要再犹豫了,请使用下面的评论框贴出你的发现。最后一如既往的,假如你喜欢这篇文章,请不要忘记将它分享到你最喜爱网站和社交媒体中!
|
||||
|
||||
@ -496,9 +483,9 @@ BALAN
|
||||
|
||||
via: https://linuxhandbook.com/cut-command/
|
||||
|
||||
作者:[Sylvain Leroux ][a]
|
||||
作者:[Sylvain Leroux][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,23 +1,21 @@
|
||||
针对 Bash 的不完整路径展开(补全)
|
||||
针对 Bash 的不完整路径展开(补全)功能
|
||||
======
|
||||
|
||||
|
||||

|
||||
|
||||
[bash-complete-partial-path][1] 通过添加不完整的路径展开(类似于 Zsh)来增强 Bash(它在 Linux 上,macOS 使用 gnu-sed,Windows 使用 MSYS)中的路径补全。如果你想在 Bash 中使用这个省时特性,而不必切换到 Zsh,它将非常有用。
|
||||
|
||||
这是它如何工作的。当按下 `Tab` 键时,bash-complete-partial-path 假定每个部分都不完整并尝试展开它。假设你要进入 `/usr/share/applications` 。你可以输入 `cd /u/s/app`,按下 `Tab`,bash-complete-partial-path 应该把它展开成 `cd /usr/share/applications` 。如果存在冲突,那么按 `Tab` 仅补全没有冲突的路径。例如,Ubuntu 用户在 `/usr/share` 中应该有很多以 “app” 开头的文件夹,在这种情况下,输入 `cd /u/s/app` 只会展开 `/usr/share/` 部分。
|
||||
|
||||
这是更深层不完整文件路径展开的另一个例子。在Ubuntu系统上输入 `cd /u/s/f/t/u`,按下 `Tab`,它应该自动展开为 `cd /usr/share/fonts/truetype/ubuntu`。
|
||||
另一个更深层不完整文件路径展开的例子。在Ubuntu系统上输入 `cd /u/s/f/t/u`,按下 `Tab`,它应该自动展开为 `cd /usr/share/fonts/truetype/ubuntu`。
|
||||
|
||||
功能包括:
|
||||
|
||||
* 转义特殊字符
|
||||
|
||||
* 如果用户路径开头使用引号,则不转义字符转义,而是在展开路径后使用匹配字符结束引号
|
||||
|
||||
* 正确展开 ~ 表达式
|
||||
|
||||
* 如果 bash-completion 包正在使用,则此代码将安全地覆盖其 _filedir 函数。无需额外配置,只需确保在主 bash-completion 后 source 此项目。
|
||||
* 正确展开 `~` 表达式
|
||||
* 如果正在使用 bash-completion 包,则此代码将安全地覆盖其 `_filedir` 函数。无需额外配置,只需确保在主 bash-completion 后引入此项目。
|
||||
|
||||
查看[项目页面][2]以获取更多信息和演示截图。
|
||||
|
||||
@ -25,7 +23,7 @@
|
||||
|
||||
bash-complete-partial-path 安装说明指定直接下载 bash_completion 脚本。我更喜欢从 Git 仓库获取,这样我可以用一个简单的 `git pull` 来更新它,因此下面的说明将使用这种安装 bash-complete-partial-path。如果你喜欢,可以使用[官方][3]说明。
|
||||
|
||||
1. 安装 Git(需要克隆 bash-complete-partial-path 的 Git 仓库)。
|
||||
1、 安装 Git(需要克隆 bash-complete-partial-path 的 Git 仓库)。
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 等中,使用此命令安装 Git:
|
||||
|
||||
@ -33,13 +31,13 @@ bash-complete-partial-path 安装说明指定直接下载 bash_completion 脚本
|
||||
sudo apt install git
|
||||
```
|
||||
|
||||
2. 在 `~/.config/` 中克隆 bash-complete-partial-path 的 Git 仓库:
|
||||
2、 在 `~/.config/` 中克隆 bash-complete-partial-path 的 Git 仓库:
|
||||
|
||||
```
|
||||
cd ~/.config && git clone https://github.com/sio/bash-complete-partial-path
|
||||
```
|
||||
|
||||
3. 在 `~/.bashrc` 文件中 source `~/.config/bash-complete-partial-path/bash_completion`,
|
||||
3、 在 `~/.bashrc` 文件中 source `~/.config/bash-complete-partial-path/bash_completion`,
|
||||
|
||||
用文本编辑器打开 ~/.bashrc。例如你可以使用 Gedit:
|
||||
|
||||
@ -55,7 +53,7 @@ gedit ~/.bashrc
|
||||
|
||||
我提到在文件的末尾添加它,因为这需要包含在你的 `~/.bashrc` 文件的主 bash-completion 下面(之后)。因此,请确保不要将其添加到原始 bash-completion 之上,因为它会导致问题。
|
||||
|
||||
4\. Source `~/.bashrc`:
|
||||
4、 引入 `~/.bashrc`:
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
@ -63,8 +61,6 @@ source ~/.bashrc
|
||||
|
||||
这样就好了,现在应该安装完 bash-complete-partial-path 并可以使用了。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/incomplete-path-expansion-completion.html
|
||||
@ -72,7 +68,7 @@ via: https://www.linuxuprising.com/2018/07/incomplete-path-expansion-completion.
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,93 @@
|
||||
2018 年 7 月 COPR 中 4 个值得尝试很酷的新项目
|
||||
======
|
||||
|
||||

|
||||
|
||||
COPR 是个人软件仓库[集合][1],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不被 Fedora 基础设施不支持或没有被该项目所签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
|
||||
|
||||
这是 COPR 中一组新的有趣项目。
|
||||
|
||||
### Hledger
|
||||
|
||||
[Hledger][2] 是用于跟踪货币或其他商品的命令行程序。它使用简单的纯文本格式日志来存储数据和复式记帐。除了命令行界面,hledger 还提供终端界面和 Web 客户端,可以显示帐户余额图。
|
||||
|
||||
![][3]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 27、28 和 Rawhide 提供了 hledger。要安装 hledger,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable kefah/HLedger
|
||||
sudo dnf install hledger
|
||||
```
|
||||
|
||||
### Neofetch
|
||||
|
||||
[Neofetch][4] 是一个命令行工具,可显示有关操作系统、软件和硬件的信息。其主要目的是以紧凑的方式显示数据来截图。你可以使用命令行标志和配置文件将 Neofetch 配置为完全按照你希望的方式显示。
|
||||
|
||||
![][5]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 28 提供 Neofetch。要安装 Neofetch,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable sysek/neofetch
|
||||
sudo dnf install neofetch
|
||||
|
||||
```
|
||||
|
||||
### Remarkable
|
||||
|
||||
[Remarkable][6]是 Markdown 文本编辑器,它使用类似 GitHub 的 Markdown 风格。它提供了文档的预览,以及导出为 PDF 和 HTML 的选项。Markdown 有几种可用的样式,包括使用 CSS 创建自己的样式的选项。此外,Remarkable 支持用于编写方程的 LaTeX 语法和源代码的语法高亮。
|
||||
|
||||
![][7]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 28 和 Rawhide 提供 Remarkable。要安装 Remarkable,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable neteler/remarkable
|
||||
sudo dnf install remarkable
|
||||
```
|
||||
|
||||
### Aha
|
||||
|
||||
[Aha][8](即 ANSI HTML Adapter)是一个命令行工具,可将终端转义成 HTML 代码。这允许你将 git diff 或 htop 的输出共享为静态 HTML 页面。
|
||||
|
||||
![][9]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
[仓库][10] 目前为 Fedora 26、27、28 和 Rawhide、EPEL 6 和 7 以及其他发行版提供 aha。要安装 aha,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable scx/aha
|
||||
sudo dnf install aha
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-july-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:http://hledger.org/
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/hledger.png
|
||||
[4]:https://github.com/dylanaraps/neofetch
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/neofetch.png
|
||||
[6]:https://remarkableapp.github.io/linux.html
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/remarkable.png
|
||||
[8]:https://github.com/theZiz/aha
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/aha.png
|
||||
[10]:https://copr.fedorainfracloud.org/coprs/scx/aha/
|
||||
@ -0,0 +1,42 @@
|
||||
Textricator:让数据提取变得简单
|
||||
======
|
||||
|
||||
> 这个新的开源工具可以从 PDF 文档中提取复杂的数据,而无需编程技能。
|
||||
|
||||

|
||||
|
||||
你可能知道这种感觉:你请求得到数据并得到积极的响应,只打开电子邮件并发现一大堆附加的 PDF。数据——中断。
|
||||
|
||||
我们理解你的挫败感,并为此做了一些事情:让我们介绍下 [Textricator][1],这是我们的第一个开源产品。
|
||||
|
||||
我们是 “Measures for Justice”(MFJ),一个刑事司法研究和透明度组织。我们的使命是为整个司法系统从逮捕到定罪后提供数据透明度。我们通过制定一系列多达 32 项指标来实现这一目标,涵盖每个县的整个刑事司法系统。我们以多种方式获取数据 —— 当然,所有这些都是合法的 —— 虽然许多州和县机构都掌握数据,可以为我们提供 CSV 格式的高质量格式化数据,但这些数据通常捆绑在软件中,没有简单的方法可以提取。PDF 报告是他们能提供的最佳报告。
|
||||
|
||||
开发者 Joe Hale 和 Stephen Byrne 在过去两年中一直在开发 Textricator,它用来提取数万页数据供我们内部使用。Textricator 可以处理几乎任何基于文本的 PDF 格式 —— 不仅仅是表格,还包括复杂的报表,其中包含从 Crystal Reports 等工具生成的文本和细节部分。只需告诉 Textricator 你要收集的字段的属性,它就会整理文档,收集并写出你的记录。
|
||||
|
||||
不是软件工程师?Textricator 不需要编程技巧。相反,用户描述 PDF 的结构,Textricator 处理其余部分。大多数用户通过命令行运行它。但是,你可以使用基于浏览器的 GUI。
|
||||
|
||||
我们评估了其他很好的开源解决方案,如 [Tabula][2],但它们无法处理我们需要抓取的一些 PDF 的结构。技术总监 Andrew Branch 说:“Textricator 既灵活又强大,缩短了我们花费大量时间处理大型数据集的时间。”
|
||||
|
||||
在 MFJ,我们致力于透明度和知识共享,其中包括向任何人提供我们的软件,特别是那些试图公开自由共享数据的人。Textricator 可以在 [GitHub][3] 上找到,并在 [GNU Affero 通用公共许可证第 3 版][4]下发布。
|
||||
|
||||
你可以在我们的免费[在线数据门户][5]上查看我们的工作成果,包括通过 Textricator 处理的数据。Textricator 是我们流程的重要组成部分,我们希望民间技术机构和政府组织都可以使用这个新工具解锁更多数据。
|
||||
|
||||
如果你使用 Textricator,请告诉我们它如何帮助你解决数据问题。想要改进吗?提交一个拉取请求。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/textricator
|
||||
|
||||
作者:[Stephen Byrne][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/stephenbyrne-mfj
|
||||
[1]:https://textricator.mfj.io/
|
||||
[2]:https://tabula.technology/
|
||||
[3]:https://github.com/measuresforjustice/textricator
|
||||
[4]:https://www.gnu.org/licenses/agpl-3.0.en.html
|
||||
[5]:https://www.measuresforjustice.org/portal/
|
||||
121
published/20180726 4 cool apps for your terminal.md
Normal file
121
published/20180726 4 cool apps for your terminal.md
Normal file
@ -0,0 +1,121 @@
|
||||
4 款酷炫的终端应用
|
||||
======
|
||||
|
||||

|
||||
|
||||
许多 Linux 用户认为在终端中工作太复杂、无聊,并试图逃避它。但这里有个改善方法 —— 四款终端下很棒的开源程序。它们既有趣又易于使用,甚至可以在你需要在命令行中工作时照亮你的生活。
|
||||
|
||||
### No More Secrets
|
||||
|
||||
这是一个简单的命令行工具,可以重现 1992 年电影 [Sneakers][1] 中所见的著名数据解密效果。该项目让你编译个 `nms` 命令,该命令与管道数据一起使用并以混乱字符的形式打印输出。开始后,你可以按任意键,并能在输出中看到很酷的好莱坞效果的现场“解密”。
|
||||
|
||||
![][2]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
一个全新安装的 Fedora Workstation 系统已经包含了从源代码构建 No More Secrets 所需的一切。只需在终端中输入以下命令:
|
||||
|
||||
```
|
||||
git clone https://github.com/bartobri/no-more-secrets.git
|
||||
cd ./no-more-secrets
|
||||
make nms
|
||||
make sneakers ## Optional
|
||||
sudo make install
|
||||
```
|
||||
|
||||
对于那些记得原来的电影的人来说,`sneakers` 命令是一个小小的彩蛋,但主要的英雄是 `nms`。使用管道将任何 Linux 命令重定向到 `nms`,如下所示:
|
||||
|
||||
```
|
||||
systemctl list-units --type=target | nms
|
||||
```
|
||||
|
||||
当文本停止闪烁,按任意键“解密”它。上面的 `systemctl` 命令只是一个例子 —— 你几乎可以用任何东西替换它!
|
||||
|
||||
### lolcat
|
||||
|
||||
这是一个用彩虹为终端输出着色的命令。没什么用,但是它看起来很棒!
|
||||
|
||||
![][3]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
`lolcat` 是一个 Ruby 软件包,可从官方 Ruby Gems 托管中获得。所以,你首先需要 gem 客户端:
|
||||
|
||||
```
|
||||
sudo dnf install -y rubygems
|
||||
```
|
||||
|
||||
然后安装 `lolcat` 本身:
|
||||
|
||||
```
|
||||
gem install lolcat
|
||||
```
|
||||
|
||||
再说一次,使用 `lolcat` 命令管道任何其他命令,并在 Fedora 终端中享受彩虹(和独角兽!)。
|
||||
|
||||
### chafa
|
||||
|
||||
![][4]
|
||||
|
||||
`chafa` 是一个[命令行图像转换器和查看器][5]。它可以帮助你在不离开终端的情况下欣赏图像。语法非常简单:
|
||||
|
||||
```
|
||||
chafa /path/to/your/image
|
||||
```
|
||||
|
||||
你可以将几乎任何类型的图像投射到 `chafa`,包括 JPG、PNG、TIFF、BMP 或几乎任何 ImageMagick 支持的图像 - 这是 `chafa` 用于解析输入文件的引擎。最酷的部分是 `chafa` 还可以在你的终端内显示非常流畅的 GIF 动画!
|
||||
|
||||
#### 安装说明
|
||||
|
||||
`chafa` 还没有为 Fedora 打包,但从源代码构建它很容易。首先,获取必要的构建依赖项:
|
||||
|
||||
```
|
||||
sudo dnf install -y autoconf automake libtool gtk-doc glib2-devel ImageMagick-devel
|
||||
```
|
||||
|
||||
接下来,克隆代码或从项目的 GitHub 页面下载快照,然后 cd 到 `chafa` 目录,这样就行了:
|
||||
|
||||
```
|
||||
git clone https://github.com/hpjansson/chafa
|
||||
./autogen.sh
|
||||
make
|
||||
sudo make install
|
||||
```
|
||||
|
||||
大的图像在第一次运行时可能需要一段时间处理,但 `chafa` 会缓存你加载的所有内容。下一次运行几乎是瞬间完成的。
|
||||
|
||||
### Browsh
|
||||
|
||||
Browsh 是完善的终端网页浏览器。它比 Lynx 更强大,当然更引人注目。 Browsh 以无头模式启动 Firefox Web 浏览器(因此你无法看到它)并在特殊 Web 扩展的帮助下将其与你的终端连接。因此,Browsh 能像 Firefox 一样呈现所有富媒体内容,只是有点像素化的风格。
|
||||
|
||||
![][6]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该项目为各种 Linux 发行版提供了包,包括 Fedora。以这种方式安装:
|
||||
|
||||
```
|
||||
sudo dnf install -y https://github.com/browsh-org/browsh/releases/download/v1.4.6/browsh_1.4.6_linux_amd64.rpm
|
||||
```
|
||||
|
||||
之后,启动 `browsh` 命令并给它几秒钟加载。按 `Ctrl+L` 将焦点切换到地址栏并开始浏览 Web,就像以前一样使用!使用 `Ctrl+Q` 返回终端。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-apps-for-your-terminal/
|
||||
|
||||
作者:[atolstoy][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/atolstoy/
|
||||
[1]:https://www.imdb.com/title/tt0105435/
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/nms.gif
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/lolcat.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/sir.gif
|
||||
[5]:https://hpjansson.org/chafa/
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/browsh.png
|
||||
116
published/20180727 Three Graphical Clients for Git on Linux.md
Normal file
116
published/20180727 Three Graphical Clients for Git on Linux.md
Normal file
@ -0,0 +1,116 @@
|
||||
三款 Linux 下的 Git 图形客户端
|
||||
======
|
||||
|
||||
> 了解这三个 Git 图形客户端工具如何增强你的开发流程。
|
||||
|
||||

|
||||
|
||||
在 Linux 下工作的人们对 [Git][1] 非常熟悉。一个理所当然的原因是,Git 是我们这个星球上最广为人知也是使用最广泛的版本控制工具。不过大多数情况下,Git 需要学习繁杂的终端命令。毕竟,我们的大多数开发工作可能是基于命令行的,那么没理由不以同样的方式与 Git 交互。
|
||||
|
||||
但在某些情况下,使用带图形界面的工具可能使你的工作更高效一点(起码对那些更倾向于使用图形界面的人们来说)。那么,有哪些 Git 图形客户端可供选择呢?幸运的是,我们找到一些客户端值得你花费时间和金钱(一些情况下)去尝试一下。在此,我主要推荐三种可以运行在 Linux 操作系统上的 Git 客户端。在这几种中,你可以找到一款满足你所有要求的客户端。
|
||||
|
||||
在这里我假设你理解如何使用 Git 和具有 GitHub 类似功能的代码仓库,[使用方法我之前讲过了][2],因此我不再花费时间讲解如何使用这些工具。本篇文章主要是一篇介绍,介绍几种可以用在开发任务中的工具。
|
||||
|
||||
提前说明一下:这些工具并不都是免费的,它们中的一些可能需要商业授权。不过,它们都在 Linux 下运行良好并且可以轻而易举的和 GitHub 相结合。
|
||||
|
||||
就说这些了,快让我们看看这些出色的 Git 图形客户端吧。
|
||||
|
||||
### SmartGit
|
||||
|
||||
[SmartGit][3] 是一个商业工具,不过如果你在非商业环境下使用是免费的。如果你打算在商业环境下使用的话,一个许可证每人每年需要 99 美元,或者 5.99 美元一个月。还有一些其它升级功能(比如<ruby>分布式评审<rt>Distributed Reviews</rt></ruby>和<ruby>智能同步<rt>SmartSynchronize</rt></ruby>),这两个工具每个许可证需要另加 15 美元。你也能通过下载源码或者 deb 安装包进行安装。我在 Ubuntu 18.04 下测试,发现 SmartGit 运行良好,没有出现一点问题。
|
||||
|
||||
不过,我们为什么要用 SmartGit 呢?有许多原因,最重要的一点是,SmartGit 可以非常方便的和 GitHub 以及 Subversion 等版本控制工具整合。不需要你花费宝贵的时间去配置各种远程账号,SmartGit 的这些功能开箱即用。SmartGit 的界面(图 1)设计的也很好,整洁直观。
|
||||
|
||||
![SmartGit][5]
|
||||
|
||||
*图 1: SmartGit 帮助简化工作*
|
||||
|
||||
安装完 SmartGit 后,我马上就用它连接到了我的 GitHub 账户。默认的工具栏是和仓库操作相关联的,非常简洁。推送、拉取、检出、合并、添加分支、cherry pick、撤销、变基、重置 —— 这些 Git 的的流行功能都支持。除了支持标准 Git 和 GitHub 的大部分功能,SmartGit 运行也非常稳定。至少当你在 Ubuntu上使用时,你会觉得这一款软件是专门为 Linux 设计和开发的。
|
||||
|
||||
SmartGit 可能是使各个水平的 Git 用户都可以非常轻松的使用 Git,甚至 Git 高级功能的最好工具。为了了解更多 SmartGit 相关知识,你可以查看一下其[丰富的文档][7]。
|
||||
|
||||
### GitKraken
|
||||
|
||||
[GitKraken][8] 是另外一款商业 Git 图形客户端,它可以使你感受到一种绝不会后悔的使用 Git 或者 GitHub 的美妙体验。SmartGit 具有非常简洁的界面,而 GitKraken 拥有非常华丽的界面,它一开始就给你展现了很多特色。GitKraken 有一个免费版(你也可以使用完整版 15 天)。试用期过了,你也可以继续使用免费版,不过不能用于商业用途。
|
||||
|
||||
对那些想让其开发工作流发挥最大功效的人们来说,GitKraken 可能是一个比较好的选择。界面上具有的功能包括:可视化交互、可缩放的提交图、拖拽、与 Github、GitLab 和 BitBucked 的无缝整合、简单的应用内任务清单、应用内置的合并工具、模糊查找、支持 Gitflow、一键撤销与重做、快捷键、文件历史与追责、子模块、亮色和暗色主题、Git 钩子支持和 Git LFS 等许多功能。不过用户倍加赞赏的还是精美的界面(图 2)。
|
||||
|
||||
![GitKraken][10]
|
||||
|
||||
*图 2: GitKraken的界面非常出色*
|
||||
|
||||
除了令人惊艳的图形界面,另一个使 GitKraken 在 Git 图形客户端竞争中脱颖而出的功能是:GitKraken 使得使用多个远程仓库和多套配置变得非常简单。不过有一个告诫,使用 GitKraken 需要花钱(它是专有的)。如果你想商业使用,许可证的价钱如下:
|
||||
|
||||
* 一人一年 49 美元
|
||||
* 10 人以上团队,39 美元每人每年
|
||||
* 100 人以上团队, 29 美元每人每年
|
||||
|
||||
专业版账户不但可以在商业环境使用 Git 相关功能,还可以使用 Glo Boards(GitKraken 的项目管理工具)。Glo Boards 的一个吸引人的功能是可以将数据同步到 GitHub <ruby>工单<rt>Issues</rt></ruby>。Glo Boards 具有分享功能还具有搜索过滤、问题跟踪、Markdown 支持、附件、@ 功能、清单卡片等许多功能。所有的这些功能都可以在 GitKraken 界面里进行操作。
|
||||
|
||||
GitKraken 可以通过 deb 文件或者源码进行安装。
|
||||
|
||||
### Git Cola
|
||||
|
||||
[Git Cola][11] 是我们推荐列表中一款自由开源的 Git 图像客户端。不像 GitKraken 和 SmartGit,Git Cola是一款比较难啃的骨头,一款比较实用的 Git 客户端。Git Cola 是用 Python 写成的,使用的是 GTK 界面,因此无论你用的是什么 Linux 发行版和桌面,都可以无缝支持。并且因为它是开源的,你可以在你使用的发行版的包管理器中找到它。因此安装过程无非是打开应用商店,搜索 “Git Cola” 安装即可。你也可以通过下面的命令进行安装:
|
||||
|
||||
```
|
||||
sudo apt install git-cola
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
sudo dnf install git-cola
|
||||
```
|
||||
|
||||
Git Cola 看起来相对比较简单(图 3)。事实上,你无法找到更复杂的东西,因为 Git Cola 是非常基础的。
|
||||
|
||||
![Git Cola][13]
|
||||
|
||||
*图 3:Git Cola 界面是非常简单的*
|
||||
|
||||
因为 Git Cola 看起来回归自然,所以很多时间你必须同终端打交道。不过这并不是什么难事儿(因为大多数开发人员需要经常使用终端)。Git Cola 包含以下特性:
|
||||
|
||||
* 支持多个子命令
|
||||
* 自定义窗口设置
|
||||
* 可设置环境变量
|
||||
* 语言设置
|
||||
* 支持自定义 GUI 设置
|
||||
* 支持快捷键
|
||||
|
||||
尽管 Git Cola 支持连接到远程仓库,但和像 GitHub 这样的仓库整合看起来也没有 GitKraken 和 SmartGit 直观。不过如果你的大部分工作是在本地进行的,Git Cola 并不失为一个出色的工具。
|
||||
|
||||
Git Cola 也带有有一个高级的 DAG(有向无环图)可视化工具,叫做 Git DAG。这个工具可以使你获得分支的可视化展示。你可以独立使用 Git DAG,也可以在 Git Cola 内通过 “view->DAG” 菜单来打开。正是 Git DAG 这个威力巨大的工具使用 Git Cola 跻身于应用商店中 Git 图形客户端前列。
|
||||
|
||||
### 更多的客户端
|
||||
|
||||
还有更多的 Git 图形客户端。不过,从上面介绍的这几款中,你已经可以做很多事情了。无论你在寻找一款更有丰富功能的 Git 客户端(不管许可证的话)还是你本身是一名坚定的 GPL 支持者,都可以从上面找到适合自己的一款。
|
||||
|
||||
如果想学习更多关于 Linux 的知识,可以通过学习Linux基金会的[走进 Linux][14]课程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/7/three-graphical-clients-git-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[tarepanda1024](https://github.com/tarepanda1024)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://git-scm.com/
|
||||
[2]:https://www.linux.com/learn/intro-to-linux/2018/7/introduction-using-git
|
||||
[3]:https://www.syntevo.com/smartgit/
|
||||
[4]:/files/images/gitgui1jpg
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_1.jpg?itok=LEZ_PYIf (SmartGit)
|
||||
[6]:/licenses/category/used-permission
|
||||
[7]:http://www.syntevo.com/doc/display/SG/Manual
|
||||
[8]:https://www.gitkraken.com/
|
||||
[9]:/files/images/gitgui2jpg
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_2.jpg?itok=Y8crSLhf (GitKraken)
|
||||
[11]:https://git-cola.github.io/
|
||||
[12]:/files/images/gitgui3jpg
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_3.jpg?itok=bS9OYPQo (Git Cola)
|
||||
[14]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,5 @@
|
||||
translating by ynmlml
|
||||
|
||||
Write Dumb Code
|
||||
======
|
||||
The best way you can contribute to an open source project is to remove lines of code from it. We should endeavor to write code that a novice programmer can easily understand without explanation or that a maintainer can understand without significant time investment.
|
||||
|
||||
@ -1,97 +0,0 @@
|
||||
Translating by Valoniakim
|
||||
|
||||
What is open source programming?
|
||||
======
|
||||
|
||||

|
||||
|
||||
At the simplest level, open source programming is merely writing code that other people can freely use and modify. But you've heard the old chestnut about playing Go, right? "So simple it only takes a minute to learn the rules, but so complex it requires a lifetime to master." Writing open source code is a pretty similar experience. It's easy to chuck a few lines of code up on GitHub, Bitbucket, SourceForge, or your own blog or site. But doing it right requires some personal investment, effort, and forethought.
|
||||
|
||||

|
||||
|
||||
### What open source programming isn't
|
||||
|
||||
Let's be clear up front about something: Just being on GitHub in a public repo does not make your code open source. Copyright in nearly all countries attaches automatically when a work is fixed in a medium, without need for any action by the author. For any code that has not been licensed by the author, it is only the author who can exercise the rights associated with copyright ownership. Unlicensed code—no matter how publicly accessible—is a ticking time bomb for anyone who is unwise enough to use it.
|
||||
|
||||
A well-meaning author may think, "well, it's obvious this is free to use," and have no plans ever to sue anyone, but that doesn't mean the code is safe to use. No matter what you think someone will do, that author has the right to sue anyone who uses, modifies, or embeds that code anywhere else without an expressly granted license.
|
||||
|
||||
Clearly, you shouldn't put your own code out in public without a license and expect others to use or contribute to it. I would also recommend you avoid using (or even looking at) such code yourself. If you create a highly similar function or routine to a piece of unlicensed work you inspected at some point in the past, you could open yourself or your employer to infringement lawsuits.
|
||||
|
||||
Let's say that Jill Schmill writes AwesomeLib and puts it on GitHub without a license. Even if Jill never sues anybody, she might eventually sell all the rights to AwesomeLib to EvilCorp, who will. (Think of it as a lurking vulnerability, just waiting to be exploited.)
|
||||
|
||||
Unlicensed code is unsafe code, period.
|
||||
|
||||
### Choosing the right license
|
||||
|
||||
OK, you've decided you want to write a new program, and you want people to have open source rights to use it. The next step is figuring out which [license][1] best fits your needs. You can get started with the GitHub-curated [choosealicense.com][2], which is just what it says on the tin. The site is laid out a bit like a simple quiz, and most people should be one or two clicks at most from finding the right license for their project.
|
||||
|
||||
Unlicensed code is unsafe code, period.
|
||||
|
||||
A word of caution: Don't get overly fancy or self-important. If you choose a commonly used and well-known license like the
|
||||
|
||||
A word of caution: Don't get overly fancy or self-important. If you choose a commonly used and well-known license like the [Apache License][3] or the [GPLv3][4] , it's easy for people to understand what their rights are and what your rights are without needing a team of lawyers to look for pitfalls and problems. The further you stray from the beaten path, though, the more problems you open yourself and others up to.
|
||||
|
||||
Most importantly, do not write your own license! Making up your own license is an unnecessary source of confusion for everyone. Don't do it. If you absolutely must have your own special terms that you can't find in any existing license, write them as an addendum to an otherwise well-understood license... and keep the main license and your addendum clearly separated so everyone involved knows which parts they've got to be extra careful about.
|
||||
|
||||
I know some people stubborn up and say, "I don't care about licenses and don't want to think about them; it's public domain." The problem with that is that "public domain" isn't a universally understood term in a legal sense. It means different things from one country to the next, with different rights and terms attached. In some countries, you can't even place your own works in the public domain, because the government reserves control over that. Luckily, the [Unlicense][5] has you covered. The Unlicense uses as few words as possible to clearly describe what "just make it public domain!" means in a clear and universally enforceable way.
|
||||
|
||||
### How to apply the license
|
||||
|
||||
Once you've chosen a license, you need to clearly and unambiguously apply it. If you're publishing somewhere like GitHub or GitLab or BitBucket, you'll have what amounts to a folder structure for your project's files. In the root folder of your project, you should have a plaintext file called LICENSE.txt that contains the text of the license you selected.
|
||||
|
||||
Putting LICENSE.txt in the root folder of your project isn't quite the last step—you also need a comment block declaring the license at the header of each significant file in your project. This is one of those times where it comes in handy to be using a well-established license. A comment that says: `# this work (c)2018 myname, licensed GPLv3—see https://www.gnu.org/licenses/gpl-3.0.en.html` is much, much stronger and more useful than a comment block that merely makes a cryptic reference to a completely custom license.
|
||||
|
||||
If you're self-publishing your code on your own site, you'll want to follow basically the same process. Have a LICENSE.txt, put the full copy of your license in it, and link to your license in an abbreviated comment block at the head of each significant file.
|
||||
|
||||
### Open source code is different
|
||||
|
||||
A big difference between proprietary and open source code is that open source code is meant to be seen. As a 40-something sysadmin, I've written a lot of code. Most of it has been effectively proprietary—I started out writing code for myself to make my own jobs easier and scratch my own and/or my company's itches. The goal of such code is simple: All it has to do is work, in the exact way and under the exact circumstance its creator planned. As long as the thing you expected to happen when you invoked the program happens more frequently than not, it's a success.
|
||||
|
||||
A big difference between proprietary and open source code is that open source code is meant to be seen.
|
||||
|
||||
Open source code is very different. When you write open source code, you know that it not only has to work, it has to work in situations you never dreamed of and may not have planned for. Maybe you only had one very narrow use case for your code and invoked it in exactly the same way every time. The people you share it with, though... they'll expose use cases, mixtures of arguments, and just plain strange thought processes you never considered. Your code doesn't necessarily have to satisfy all of them—but it at least needs to handle their requests gracefully, and fail in predictable and logical ways when it can't service them. (For example: "Division by zero on line 583" is not an acceptable response to a failure to supply a command-line argument.)
|
||||
|
||||
Open source code is very different. When you write open source code, you know that it not only has to work, it has to work in situations you never dreamed of and may not have planned for. Maybe you only had one very narrow use case for your code and invoked it in exactly the same way every time. The people you share it with, though... they'll expose use cases, mixtures of arguments, and just plain strange thought processes you never considered. Your code doesn't necessarily have to satisfy all of them—but it at least needs to handle their requests gracefully, and fail in predictable and logical ways when it can't service them. (For example: "Division by zero on line 583" is not an acceptable response to a failure to supply a command-line argument.)
|
||||
|
||||
Your open source code also has to avoid unduly embarrassing you. That means that after you struggle and struggle to get a balky function or sub to finally produce the output you expected, you don't just sigh and move on to the next thing—you clean it up, because you don't want the rest of the world seeing your obvious house of cards. It means that you stop littering your code with variables like `$variable` and `$lol` and replace them with meaningful names like `$iterationcounter` or `$modelname`. And it means commenting things professionally (even if they're obvious to you in the heat of the moment) since you expect other people to be able to follow your code later.
|
||||
|
||||
This can be a little painful and frustrating at first—it's work you're not accustomed to doing. It makes you a better programmer, though, and it makes your code better as well. Just as important: Even if you're the only contributor your project ever has, it saves you work in the long run. Trust me, a year from now when you have to revisit your app, you're going to be very glad that `$modelname`, which gets parsed by several stunningly opaque regular expressions before getting socked into some other array somewhere, isn't named `$lol` anymore.
|
||||
|
||||
### You're not writing just for yourself
|
||||
|
||||
The true heart of open source isn't the code at all: it's the community. Projects with a strong community survive longer and are adopted much more heavily than those that don't. With that in mind, it's a good idea not only to embrace but actively plan for the community you hope to build around your project.
|
||||
|
||||
Batman might spend hundreds of hours in seclusion furiously building a project in secrecy, but you don't have to. Take to Twitter, Reddit, or mailing lists relevant to your project's scope, and announce that you're thinking of creating a new project. Talk about your design goals and how you plan to achieve them. Request input, listen to similar (but maybe not identical) use cases, and build that information into your process as you write code. You don't have to accept every suggestion or request—but if you know about them ahead of time, you can avoid pitfalls that require arduous major overhauls later.
|
||||
|
||||
This process doesn't end with the initial announcement. If you want your project to be adopted and used by other people, you need to develop it that way too. This isn't a barrier to entry; it's just a pattern to use. So don't just hunker down privately on your own machine with a text editor—start a real, publicly accessible project at one of the big foundries, and treat it as though the community was already there and watching.
|
||||
|
||||
### Ways to build a real public project
|
||||
|
||||
You can open accounts for open source projects at GitHub, GitLab, or BitBucket for free. Once you've opened your account and created a repository for your project, use it—create a README, assign a LICENSE, and push code incrementally as you develop it. This will build the habits you'll need to work with a real team later as you get accustomed to writing your code in measurable, documented commits with clear goals. The further you go, the more likely you'll start generating interest—usually in the form of end users first.
|
||||
|
||||
The users will start opening tickets, which will both delight and annoy you. You should take those tickets seriously and treat their owners courteously. Some of them will be based on tremendous misunderstandings of what your project is and what is or isn't within its scope—treat those courteously and professionally, also. In some cases, you'll guide those users into the fold of what you're doing. In others, however haltingly, they'll guide you into realizing the larger—or slightly differently centered—scope you probably should have planned for in the first place.
|
||||
|
||||
If you do a good job with the users, eventually fellow developers will show up and take an interest. This will also both delight and annoy you. At first, you'll probably just get trivial bugfixes. Eventually, you'll start to get pull requests that would either hardcode really, really niche special use-cases into your project (which would be a nightmare to maintain) or significantly alter the scope or even the focus of your project. You'll need to learn how to recognize which contributions are which and decide which ones you want to embrace and which you should politely reject.
|
||||
|
||||
### Why bother with all of this?
|
||||
|
||||
If all of this sounds like a lot of work, there's a good reason: it is. But it's rewarding work that you can cash in on in plenty of ways. Open source work sharpens your skills in ways you never realized were dull—from writing cleaner, more maintainable code to learning how to communicate well and work as a team. It's also the best possible resume builder for a working or aspiring professional developer; potential employers can hit your repository and see what you're capable of, and developers you've worked with on community projects may want to bring you in on paying gigs.
|
||||
|
||||
Ultimately, working on open source projects—yours or others'—means personal growth, because you're working on something larger than yourself.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/what-open-source-programming
|
||||
|
||||
作者:[Jim Salter][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-salter
|
||||
[1]:https://opensource.com/tags/licensing
|
||||
[2]:https://choosealicense.com/
|
||||
[3]:https://choosealicense.com/licenses/apache-2.0/
|
||||
[4]:https://choosealicense.com/licenses/gpl-3.0/
|
||||
[5]:https://choosealicense.com/licenses/unlicense/
|
||||
@ -1,251 +0,0 @@
|
||||
Translating by HardworkFish
|
||||
|
||||
Understanding Linux filesystems: ext4 and beyond
|
||||
======
|
||||
|
||||

|
||||
|
||||
The majority of modern Linux distributions default to the ext4 filesystem, just as previous Linux distributions defaulted to ext3, ext2, and—if you go back far enough—ext.
|
||||
|
||||
If you're new to Linux—or to filesystems—you might wonder what ext4 brings to the table that ext3 didn't. You might also wonder whether ext4 is still in active development at all, given the flurries of news coverage of alternate filesystems such as btrfs, xfs, and zfs.
|
||||
|
||||
We can't cover everything about filesystems in a single article, but we'll try to bring you up to speed on the history of Linux's default filesystem, where it stands, and what to look forward to.
|
||||
|
||||
I drew heavily on Wikipedia's various ext filesystem articles, kernel.org's wiki entries on ext4, and my own experiences while preparing this overview.
|
||||
|
||||
### A brief history of ext
|
||||
|
||||
#### MINIX filesystem
|
||||
|
||||
Before there was ext, there was the MINIX filesystem. If you're not up on your Linux history, MINIX was a very small Unix-like operating system for IBM PC/AT microcomputers. Andrew Tannenbaum developed it for teaching purposes and released its source code (in print form!) in 1987.
|
||||
|
||||

|
||||
|
||||
Although you could peruse MINIX's source, it was not actually free and open source software (FOSS). The publishers of Tannebaum's book required a $69 license fee to operate MINIX, which was included in the cost of the book. Still, this was incredibly inexpensive for the time, and MINIX adoption took off rapidly, soon exceeding Tannenbaum's original intent of using it simply to teach the coding of operating systems. By and throughout the 1990s, you could find MINIX installations thriving in universities worldwide—and a young Linus Torvalds used MINIX to develop the original Linux kernel, first announced in 1991, and released under the GPL in December 1992.
|
||||
|
||||
But wait, this is a filesystem article, right? Yes, and MINIX had its own filesystem, which early versions of Linux also relied on. Like MINIX, it could uncharitably be described as a "toy" example of its kind—the MINIX filesystem could handle filenames only up to 14 characters and address only 64MB of storage. In 1991, the typical hard drive was already 40-140MB in size. Linux clearly needed a better filesystem!
|
||||
|
||||
#### ext
|
||||
|
||||
While Linus hacked away on the fledgling Linux kernel, Rémy Card worked on the first ext filesystem. First implemented in 1992—only a year after the initial announcement of Linux itself!—ext solved the worst of the MINIX filesystem's problems.
|
||||
|
||||
1992's ext used the new virtual filesystem (VFS) abstraction layer in the Linux kernel. Unlike the MINIX filesystem before it, ext could address up to 2GB of storage and handle 255-character filenames.
|
||||
|
||||
But ext didn't have a long reign, largely due to its primitive timestamping (only one timestamp per file, rather than the three separate stamps for inode creation, file access, and file modification we're familiar with today). A mere year later, ext2 ate its lunch.
|
||||
|
||||
#### ext2
|
||||
|
||||
Rémy clearly realized ext's limitations pretty quickly, since he designed ext2 as its replacement a year later. While ext still had its roots in "toy" operating systems, ext2 was designed from the start as a commercial-grade filesystem, along the same principles as BSD's Berkeley Fast File System.
|
||||
|
||||
Ext2 offered maximum filesizes in the gigabytes and filesystem sizes in the terabytes, placing it firmly in the big leagues for the 1990s. It was quickly and widely adopted, both in the Linux kernel and eventually in MINIX, as well as by third-party modules making it available for MacOS and Windows.
|
||||
|
||||
There were still problems to solve, though: ext2 filesystems, like most filesystems of the 1990s, were prone to catastrophic corruption if the system crashed or lost power while data was being written to disk. They also suffered from significant performance losses due to fragmentation (the storage of a single file in multiple places, physically scattered around a rotating disk) as time went on.
|
||||
|
||||
Despite these problems, ext2 is still used in some isolated cases today—most commonly, as a format for portable USB thumb drives.
|
||||
|
||||
#### ext3
|
||||
|
||||
In 1998, six years after ext2's adoption, Stephen Tweedie announced he was working on significantly improving it. This became ext3, which was adopted into mainline Linux with kernel version 2.4.15, in November 2001.
|
||||
|
||||
|
||||
![Packard Bell computer][2]
|
||||
|
||||
Mid-1990s Packard Bell computer, [Spacekid][3], [CC0][4]
|
||||
|
||||
Ext2 had done very well by Linux distributions for the most part, but—like FAT, FAT32, HFS, and other filesystems of the time—it was prone to catastrophic corruption during power loss. If you lose power while writing data to the filesystem, it can be left in what's called an inconsistent state—one in which things have been left half-done and half-undone. This can result in loss or corruption of vast swaths of files unrelated to the one being saved or even unmountability of the entire filesystem.
|
||||
|
||||
Ext3, and other filesystems of the late 1990s, such as Microsoft's NTFS, uses journaling to solve this problem. The journal is a special allocation on disk where writes are stored in transactions; if the transaction finishes writing to disk, its data in the journal is committed to the filesystem itself. If the system crashes before that operation is committed, the newly rebooted system recognizes it as an incomplete transaction and rolls it back as though it had never taken place. This means that the file being worked on may still be lost, but the filesystem itself remains consistent, and all other data is safe. Three levels of journaling are available in the Linux kernel implementation of ext3: **journal** , **ordered** , and **writeback**.
|
||||
|
||||
* **Journal** is the lowest risk mode, writing both data and metadata to the journal before committing it to the filesystem. This ensures consistency of the file being written to, as well as the filesystem as a whole, but can significantly decrease performance.
|
||||
* **Ordered** is the default mode in most Linux distributions; ordered mode writes metadata to the journal but commits data directly to the filesystem. As the name implies, the order of operations here is rigid: First, metadata is committed to the journal; second, data is written to the filesystem, and only then is the associated metadata in the journal flushed to the filesystem itself. This ensures that, in the event of a crash, the metadata associated with incomplete writes is still in the journal, and the filesystem can sanitize those incomplete writes while rolling back the journal. In ordered mode, a crash may result in corruption of the file or files being actively written to during the crash, but the filesystem itself—and files not actively being written to—are guaranteed safe.
|
||||
* **Writeback** is the third—and least safe—journaling mode. In writeback mode, like ordered mode, metadata is journaled, but data is not. Unlike ordered mode, metadata and data alike may be written in whatever order makes sense for best performance. This can offer significant increases in performance, but it's much less safe. Although writeback mode still offers a guarantee of safety to the filesystem itself, files that were written to during or before the crash are vulnerable to loss or corruption.
|
||||
|
||||
|
||||
|
||||
Like ext2 before it, ext3 uses 16-bit internal addressing. This means that with a blocksize of 4K, the largest filesize it can handle is 2 TiB in a maximum filesystem size of 16 TiB.
|
||||
|
||||
#### ext4
|
||||
|
||||
Theodore Ts'o (who by then was ext3's principal developer) announced ext4 in 2006, and it was added to mainline Linux two years later, in kernel version 2.6.28. Ts'o describes ext4 as a stopgap technology which significantly extends ext3 but is still reliant on old technology. He expects it to be supplanted eventually by a true next-generation filesystem.
|
||||
|
||||

|
||||
|
||||
Ext4 is functionally very similar to ext3, but brings large filesystem support, improved resistance to fragmentation, higher performance, and improved timestamps.
|
||||
|
||||
### Ext4 vs ext3
|
||||
|
||||
Ext3 and ext4 have some very specific differences, which I'll focus on here.
|
||||
|
||||
#### Backwards compatibility
|
||||
|
||||
Ext4 was specifically designed to be as backward-compatible as possible with ext3. This not only allows ext3 filesystems to be upgraded in place to ext4; it also permits the ext4 driver to automatically mount ext3 filesystems in ext3 mode, making it unnecessary to maintain the two codebases separately.
|
||||
|
||||
#### Large filesystems
|
||||
|
||||
Ext3 filesystems used 32-bit addressing, limiting them to 2 TiB files and 16 TiB filesystems (assuming a 4 KiB blocksize; some ext3 filesystems use smaller blocksizes and are thus limited even further).
|
||||
|
||||
Ext4 uses 48-bit internal addressing, making it theoretically possible to allocate files up to 16 TiB on filesystems up to 1,000,000 TiB (1 EiB). Early implementations of ext4 were still limited to 16 TiB filesystems by some userland utilities, but as of 2011, e2fsprogs has directly supported the creation of >16TiB ext4 filesystems. As one example, Red Hat Enterprise Linux contractually supports ext4 filesystems only up to 50 TiB and recommends ext4 volumes no larger than 100 TiB.
|
||||
|
||||
#### Allocation improvements
|
||||
|
||||
Ext4 introduces a lot of improvements in the ways storage blocks are allocated before writing them to disk, which can significantly increase both read and write performance.
|
||||
|
||||
##### Extents
|
||||
|
||||
An extent is a range of contiguous physical blocks (up to 128 MiB, assuming a 4 KiB block size) that can be reserved and addressed at once. Utilizing extents decreases the number of inodes required by a given file and significantly decreases fragmentation and increases performance when writing large files.
|
||||
|
||||
##### Multiblock allocation
|
||||
|
||||
Ext3 called its block allocator once for each new block allocated. This could easily result in heavy fragmentation when multiple writers are open concurrently. However, ext4 uses delayed allocation, which allows it to coalesce writes and make better decisions about how to allocate blocks for the writes it has not yet committed.
|
||||
|
||||
##### Persistent pre-allocation
|
||||
|
||||
When pre-allocating disk space for a file, most file systems must write zeroes to the blocks for that file on creation. Ext4 allows the use of `fallocate()` instead, which guarantees the availability of the space (and attempts to find contiguous space for it) without first needing to write to it. This significantly increases performance in both writes and future reads of the written data for streaming and database applications.
|
||||
|
||||
##### Delayed allocation
|
||||
|
||||
This is a chewy—and contentious—feature. Delayed allocation allows ext4 to wait to allocate the actual blocks it will write data to until it's ready to commit that data to disk. (By contrast, ext3 would allocate blocks immediately, even while the data was still flowing into a write cache.)
|
||||
|
||||
Delaying allocation of blocks as data accumulates in cache allows the filesystem to make saner choices about how to allocate those blocks, reducing fragmentation (write and, later, read) and increasing performance significantly. Unfortunately, it increases the potential for data loss in programs that have not been specifically written to call `fsync()` when the programmer wants to ensure data has been flushed entirely to disk.
|
||||
|
||||
Let's say a program rewrites a file entirely:
|
||||
|
||||
`fd=open("file" ,O_TRUNC); write(fd, data); close(fd);`
|
||||
|
||||
With legacy filesystems, `close(fd);` is sufficient to guarantee that the contents of `file` will be flushed to disk. Even though the write is not, strictly speaking, transactional, there's very little risk of losing the data if a crash occurs after the file is closed.
|
||||
|
||||
If the write does not succeed (due to errors in the program, errors on the disk, power loss, etc.), both the original version and the newer version of the file may be lost or corrupted. If other processes access the file as it is being written, they will see a corrupted version. And if other processes have the file open and do not expect its contents to change—e.g., a shared library mapped into multiple running programs—they may crash.
|
||||
|
||||
To avoid these issues, some programmers avoid using `O_TRUNC` at all. Instead, they might write to a new file, close it, then rename it over the old one:
|
||||
|
||||
`fd=open("newfile"); write(fd, data); close(fd); rename("newfile", "file");`
|
||||
|
||||
Under filesystems without delayed allocation, this is sufficient to avoid the potential corruption and crash problems outlined above: Since `rename()` is an atomic operation, it won't be interrupted by a crash; and running programs will continue to reference the old, now unlinked version of `file` for as long as they have an open filehandle to it. But because ext4's delayed allocation can cause writes to be delayed and re-ordered, the `rename("newfile","file")` may be carried out before the contents of `newfile` are actually written to disk, which opens the problem of parallel processes getting bad versions of `file` all over again.
|
||||
|
||||
To mitigate this, the Linux kernel (since version 2.6.30) attempts to detect these common code cases and force the files in question to be allocated immediately. This reduces, but does not prevent, the potential for data loss—and it doesn't help at all with new files. If you're a developer, please take note: The only way to guarantee data is written to disk immediately is to call `fsync()` appropriately.
|
||||
|
||||
#### Unlimited subdirectories
|
||||
|
||||
Ext3 was limited to a total of 32,000 subdirectories; ext4 allows an unlimited number. Beginning with kernel 2.6.23, ext4 uses HTree indices to mitigate performance loss with huge numbers of subdirectories.
|
||||
|
||||
#### Journal checksumming
|
||||
|
||||
Ext3 did not checksum its journals, which presented problems for disk or controller devices with caches of their own, outside the kernel's direct control. If a controller or a disk with its own cache did writes out of order, it could break ext3's journaling transaction order, potentially corrupting files being written to during (or for some time preceding) a crash.
|
||||
|
||||
In theory, this problem is resolved by the use of write barriers—when mounting the filesystem, you set `barrier=1` in the mount options, and the device will then honor `fsync()` calls all the way down to the metal. In practice, it's been discovered that storage devices and controllers frequently do not honor write barriers—improving performance (and benchmarks, where they're compared to their competitors) but opening up the possibility of data corruption that should have been prevented.
|
||||
|
||||
Checksumming the journal allows the filesystem to realize that some of its entries are invalid or out-of-order on the first mount after a crash. This thereby avoids the mistake of rolling back partial or out-of-order journal entries and further damaging the filesystem—even if the storage devices lie and don't honor barriers.
|
||||
|
||||
#### Fast filesystem checks
|
||||
|
||||
Under ext3, the entire filesystem—including deleted and empty files—required checking when `fsck` is invoked. By contrast, ext4 marks unallocated blocks and sections of the inode table as such, allowing `fsck` to skip them entirely. This greatly reduces the time to run `fsck` on most filesystems and has been implemented since kernel 2.6.24.
|
||||
|
||||
#### Improved timestamps
|
||||
|
||||
Ext3 offered timestamps granular to one second. While sufficient for most uses, mission-critical applications are frequently looking for much, much tighter time control. Ext4 makes itself available to those enterprise, scientific, and mission-critical applications by offering timestamps in the nanoseconds.
|
||||
|
||||
Ext3 filesystems also did not provide sufficient bits to store dates beyond January 18, 2038. Ext4 adds an additional two bits here, extending [the Unix epoch][5] another 408 years. If you're reading this in 2446 AD, you have hopefully already moved onto a better filesystem—but it'll make me posthumously very, very happy if you're still measuring the time since UTC 00:00, January 1, 1970.
|
||||
|
||||
#### Online defragmentation
|
||||
|
||||
Neither ext2 nor ext3 directly supported online defragmentation—that is, defragging the filesystem while mounted. Ext2 had an included utility, **e2defrag** , that did what the name implies—but it needed to be run offline while the filesystem was not mounted. (This is, obviously, especially problematic for a root filesystem.) The situation was even worse in ext3—although ext3 was much less likely to suffer from severe fragmentation than ext2 was, running **e2defrag** against an ext3 filesystem could result in catastrophic corruption and data loss.
|
||||
|
||||
Although ext3 was originally deemed "unaffected by fragmentation," processes that employ massively parallel write processes to the same file (e.g., BitTorrent) made it clear that this wasn't entirely the case. Several userspace hacks and workarounds, such as [Shake][6], addressed this in one way or another—but they were slower and in various ways less satisfactory than a true, filesystem-aware, kernel-level defrag process.
|
||||
|
||||
Ext4 addresses this problem head on with **e4defrag** , an online, kernel-mode, filesystem-aware, block-and-extent-level defragmentation utility.
|
||||
|
||||
### Ongoing ext4 development
|
||||
|
||||
Ext4 is, as the Monty Python plague victim once said, "not quite dead yet!" Although [its principal developer regards it][7] as a mere stopgap along the way to a truly [next-generation filesystem][8], none of the likely candidates will be ready (due to either technical or licensing problems) for deployment as a root filesystem for some time yet.
|
||||
|
||||
There are still a few key features being developed into future versions of ext4, including metadata checksumming, first-class quota support, and large allocation blocks.
|
||||
|
||||
#### Metadata checksumming
|
||||
|
||||
Since ext4 has redundant superblocks, checksumming the metadata within them offers the filesystem a way to figure out for itself whether the primary superblock is corrupt and needs to use an alternate. It is possible to recover from a corrupt superblock without checksumming—but the user would first need to realize that it was corrupt, and then try manually mounting the filesystem using an alternate. Since mounting a filesystem read-write with a corrupt primary superblock can, in some cases, cause further damage, this isn't a sufficient solution, even with a sufficiently experienced user!
|
||||
|
||||
Compared to the extremely robust per-block checksumming offered by next-gen filesystems such as btrfs or zfs, ext4's metadata checksumming is a pretty weak feature. But it's much better than nothing.
|
||||
|
||||
Although it sounds like a no-brainer—yes, checksum ALL THE THINGS!—there are some significant challenges to bolting checksums into a filesystem after the fact; see [the design document][9] for the gritty details.
|
||||
|
||||
#### First-class quota support
|
||||
|
||||
Wait, quotas?! We've had those since the ext2 days! Yes, but they've always been an afterthought, and they've always kinda sucked. It's probably not worth going into the hairy details here, but the [design document][10] lays out the ways quotas will be moved from userspace into the kernel and more correctly and performantly enforced.
|
||||
|
||||
#### Large allocation blocks
|
||||
|
||||
As time goes by, those pesky storage systems keep getting bigger and bigger. With some solid-state drives already using 8K hardware blocksizes, ext4's current limitation to 4K blocks gets more and more limiting. Larger storage blocks can decrease fragmentation and increase performance significantly, at the cost of increased "slack" space (the space left over when you only need part of a block to store a file or the last piece of a file).
|
||||
|
||||
You can view the hairy details in the [design document][11].
|
||||
|
||||
### Practical limitations of ext4
|
||||
|
||||
Ext4 is a robust, stable filesystem, and it's what most people should probably be using as a root filesystem in 2018. But it can't handle everything. Let's talk briefly about some of the things you shouldn't expect from ext4—now or probably in the future.
|
||||
|
||||
Although ext4 can address up to 1 EiB—equivalent to 1,000,000 TiB—of data, you really, really shouldn't try to do so. There are problems of scale above and beyond merely being able to remember the addresses of a lot more blocks, and ext4 does not now (and likely will not ever) scale very well beyond 50-100 TiB of data.
|
||||
|
||||
Ext4 also doesn't do enough to guarantee the integrity of your data. As big an advancement as journaling was back in the ext3 days, it does not cover a lot of the common causes of data corruption. If data is [corrupted][12] while already on disk—by faulty hardware, impact of cosmic rays (yes, really), or simple degradation of data over time—ext4 has no way of either detecting or repairing such corruption.
|
||||
|
||||
Building on the last two items, ext4 is only a pure filesystem, and not a storage volume manager. This means that even if you've got multiple disks—and therefore parity or redundancy, which you could theoretically recover corrupt data from—ext4 has no way of knowing that or using it to your benefit. While it's theoretically possible to separate a filesystem and storage volume management system in discrete layers without losing automatic corruption detection and repair features, that isn't how current storage systems are designed, and it would present significant challenges to new designs.
|
||||
|
||||
### Alternate filesystems
|
||||
|
||||
Before we get started, a word of warning: Be very careful with any alternate filesystem which isn't built into and directly supported as a part of your distribution's mainline kernel!
|
||||
|
||||
Even if a filesystem is safe, using it as the root filesystem can be absolutely terrifying if something hiccups during a kernel upgrade. If you aren't extremely comfortable with the idea of booting from alternate media and poking manually and patiently at kernel modules, grub configs, and DKMS from a chroot... don't go off the reservation with the root filesystem on a system that matters to you.
|
||||
|
||||
There may well be good reasons to use a filesystem your distro doesn't directly support—but if you do, I strongly recommend you mount it after the system is up and usable. (For example, you might have an ext4 root filesystem, but store most of your data on a zfs or btrfs pool.)
|
||||
|
||||
#### XFS
|
||||
|
||||
XFS is about as mainline as a non-ext filesystem gets under Linux. It's a 64-bit, journaling filesystem that has been built into the Linux kernel since 2001 and offers high performance for large filesystems and high degrees of concurrency (i.e., a really large number of processes all writing to the filesystem at once).
|
||||
|
||||
XFS became the default filesystem for Red Hat Enterprise Linux, as of RHEL 7. It still has a few disadvantages for home or small business users—most notably, it's a real pain to resize an existing XFS filesystem, to the point it usually makes more sense to create another one and copy your data over.
|
||||
|
||||
While XFS is stable and performant, there's not enough of a concrete end-use difference between it and ext4 to recommend its use anywhere that it isn't the default (e.g., RHEL7) unless it addresses a specific problem you're having with ext4, such as >50 TiB capacity filesystems.
|
||||
|
||||
XFS is not in any way a "next-generation" filesystem in the ways that ZFS, btrfs, or even WAFL (a proprietary SAN filesystem) are. Like ext4, it should most likely be considered a stopgap along the way towards [something better][8].
|
||||
|
||||
#### ZFS
|
||||
|
||||
ZFS was developed by Sun Microsystems and named after the zettabyte—equivalent to 1 trillion gigabytes—as it could theoretically address storage systems that large.
|
||||
|
||||
A true next-generation filesystem, ZFS offers volume management (the ability to address multiple individual storage devices in a single filesystem), block-level cryptographic checksumming (allowing detection of data corruption with an extremely high accuracy rate), [automatic corruption repair][12] (where redundant or parity storage is available), rapid [asynchronous incremental replication][13], inline compression, and more. [A lot more][14].
|
||||
|
||||
The biggest problem with ZFS, from a Linux user's perspective, is the licensing. ZFS was licensed CDDL, which is a semi-permissive license that conflicts with the GPL. There is a lot of controversy over the implications of using ZFS with the Linux kernel, with opinions ranging from "it's a GPL violation" to "it's a CDDL violation" to "it's perfectly fine, it just hasn't been tested in court." Most notably, Canonical has included ZFS code inline in its default kernels since 2016 without legal challenge so far.
|
||||
|
||||
At this time, even as a very avid ZFS user myself, I would not recommend ZFS as a root Linux filesystem. If you want to leverage the benefits of ZFS on Linux, set up a small root filesystem on ext4, then put ZFS on your remaining storage, and put data, applications, whatever you like on it—but keep root on ext4, until your distribution explicitly supports a zfs root.
|
||||
|
||||
#### btrfs
|
||||
|
||||
Btrfs—short for B-Tree Filesystem, and usually pronounced "butter"—was announced by Chris Mason in 2007 during his tenure at Oracle. Btrfs aims at most of the same goals as ZFS, offering multiple device management, per-block checksumming, asynchronous replication, inline compression, and [more][8].
|
||||
|
||||
As of 2018, btrfs is reasonably stable and usable as a standard single-disk filesystem but should probably not be relied on as a volume manager. It suffers from significant performance problems compared to ext4, XFS, or ZFS in many common use cases, and its next-generation features—replication, multiple-disk topologies, and snapshot management—can be pretty buggy, with results ranging from catastrophically reduced performance to actual data loss.
|
||||
|
||||
The ongoing status of btrfs is controversial; SUSE Enterprise Linux adopted it as its default filesystem in 2015, whereas Red Hat announced it would no longer support btrfs beginning with RHEL 7.4 in 2017. It is probably worth noting that production, supported deployments of btrfs use it as a single-disk filesystem, not as a multiple-disk volume manager a la ZFS—even Synology, which uses btrfs on its storage appliances, but layers it atop conventional Linux kernel RAID (mdraid) to manage the disks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/ext4-filesystem
|
||||
|
||||
作者:[Jim Salter][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-salter
|
||||
[1]:https://opensource.com/file/391546
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/packard_bell_pc.jpg?itok=VI8dzcwp (Packard Bell computer)
|
||||
[3]:https://commons.wikimedia.org/wiki/File:Old_packard_bell_pc.jpg
|
||||
[4]:https://creativecommons.org/publicdomain/zero/1.0/deed.en
|
||||
[5]:https://en.wikipedia.org/wiki/Unix_time
|
||||
[6]:https://vleu.net/shake/
|
||||
[7]:http://www.linux-mag.com/id/7272/
|
||||
[8]:https://arstechnica.com/information-technology/2014/01/bitrot-and-atomic-cows-inside-next-gen-filesystems/
|
||||
[9]:https://ext4.wiki.kernel.org/index.php/Ext4_Metadata_Checksums
|
||||
[10]:https://ext4.wiki.kernel.org/index.php/Design_For_1st_Class_Quota_in_Ext4
|
||||
[11]:https://ext4.wiki.kernel.org/index.php/Design_for_Large_Allocation_Blocks
|
||||
[12]:https://en.wikipedia.org/wiki/Data_degradation#Visual_example_of_data_degradation
|
||||
[13]:https://arstechnica.com/information-technology/2015/12/rsync-net-zfs-replication-to-the-cloud-is-finally-here-and-its-fast/
|
||||
[14]:https://arstechnica.com/information-technology/2014/02/ars-walkthrough-using-the-zfs-next-gen-filesystem-on-linux/
|
||||
110
sources/talk/20180731 How to be the lazy sysadmin.md
Normal file
110
sources/talk/20180731 How to be the lazy sysadmin.md
Normal file
@ -0,0 +1,110 @@
|
||||
How to be the lazy sysadmin
|
||||
======
|
||||

|
||||
|
||||
The job of a Linux SysAdmin is always complex and often fraught with various pitfalls and obstacles. Ranging from never having enough time to do everything, to having the Pointy-Haired Boss (PHB) staring over your shoulder while you try to work on the task that she or he just gave you, to having the most critical server in your care crash at the most inopportune time, problems and challenges abound. I have found that becoming the Lazy Sysadmin can help.
|
||||
|
||||
I discuss how to be a lazy SysAdmin in detail in my forthcoming book, [The Linux Philosophy for SysAdmins][1], (Apress), which is scheduled to be available in September. Parts of this article are taken from that book, especially Chapter 9, "Be a Lazy SysAdmin." Let's take a brief look at what it means to be a Lazy SysAdmin before we discuss how to do it.
|
||||
|
||||
### Real vs. fake productivity
|
||||
|
||||
#### Fake productivity
|
||||
|
||||
At one place I worked, the PHB believed in the management style called "management by walking around," the supposition being that anyone who wasn't typing something on their keyboard, or at least examining something on their display, was not being productive. This was a horrible place to work. It had high administrative walls between departments that created many, tiny silos, a heavy overburden of useless paperwork, and excruciatingly long wait times to obtain permission to do anything. For these and other reasons, it was impossible to do anything efficiently—if at all—so we were incredibly non-productive. To look busy, we all had our Look Busy Kits (LBKs), which were just short Bash scripts that showed some activity, or programs like `top`, `htop`, `iotop`, or any monitoring tool that constantly displayed some activity. The ethos of this place made it impossible to be truly productive, and I hated both the place and the fact that it was nearly impossible to accomplish anything worthwhile.
|
||||
|
||||
That horrible place was a nightmare for real SysAdmins. None of us was happy. It took four or five months to accomplish what took only a single morning in other places. We had little real work to do but spent a huge amount of time working to look busy. We had an unspoken contest going to create the best LBK, and that is where we spent most of our time. I only managed to last a few months at that job, but it seemed like a lifetime. If you looked only at the surface of that dungeon, you could say we were lazy because we accomplished almost zero real work.
|
||||
|
||||
This is an extreme example, and it is totally the opposite of what I mean when I say I am a Lazy SysAdmin and being a Lazy SysAdmin is a good thing.
|
||||
|
||||
#### Real productivity
|
||||
|
||||
I am fortunate to have worked for some true managers—they were people who understood that the productivity of a SysAdmin is not measured by how many hours per day are spent banging on a keyboard. After all, even a monkey can bang on a keyboard, but that is no indication of the value of the results.
|
||||
|
||||
As I say in my book:
|
||||
|
||||
> "I am a lazy SysAdmin and yet I am also a very productive SysAdmin. Those two seemingly contradictory statements are not mutually exclusive, rather they are complementary in a very positive way. …
|
||||
>
|
||||
> "A SysAdmin is most productive when thinking—thinking about how to solve existing problems and about how to avoid future problems; thinking about how to monitor Linux computers in order to find clues that anticipate and foreshadow those future problems; thinking about how to make their work more efficient; thinking about how to automate all of those tasks that need to be performed whether every day or once a year.
|
||||
>
|
||||
> "This contemplative aspect of the SysAdmin job is not well known or understood by those who are not SysAdmins—including many of those who manage the SysAdmins, the Pointy Haired Bosses. SysAdmins all approach the contemplative parts of their job in different ways. Some of the SysAdmins I have known found their best ideas at the beach, cycling, participating in marathons, or climbing rock walls. Others think best when sitting quietly or listening to music. Still others think best while reading fiction, studying unrelated disciplines, or even while learning more about Linux. The point is that we all stimulate our creativity in different ways, and many of those creativity boosters do not involve typing a single keystroke on a keyboard. Our true productivity may be completely invisible to those around the SysAdmin."
|
||||
|
||||
There are some simple secrets to being the Lazy SysAdmin—the SysAdmin who accomplishes everything that needs to be done and more, all the while keeping calm and collected while others are running around in a state of panic. Part of this is working efficiently, and part is about preventing problems in the first place.
|
||||
|
||||
### Ways to be the Lazy SysAdmin
|
||||
|
||||
#### Thinking
|
||||
|
||||
I believe the most important secret about being the Lazy SysAdmin is thinking. As in the excerpt above, great SysAdmins spend a significant amount of time thinking about things we can do to work more efficiently, locate anomalies before they become problems, and work smarter, all while considering how to accomplish all of those things and more.
|
||||
|
||||
For example, right now—in addition to writing this article—I am thinking about a project I intend to start as soon as the new parts arrive from Amazon and the local computer store. The motherboard on one of my less critical computers is going bad, and it has been crashing more frequently recently. But my very old and minimal server—the one that handles my email and external websites, as well as providing DHCP and DNS services for the rest of my network—isn't failing but has to deal with intermittent overloads due to external attacks of various types.
|
||||
|
||||
I started by thinking I would just replace the motherboard and its direct components—memory, CPU, and possibly the power supply—in the failing unit. But after thinking about it for a while, I decided I should put the new components into the server and move the old (but still serviceable) ones from the server into the failing system. This would work and take only an hour, or perhaps two, to remove the old components from the server and install the new ones. Then I could take my time replacing the components in the failing computer. Great. So I started generating a mental list of tasks to do to accomplish this.
|
||||
|
||||
However, as I worked the list, I realized that about the only components of the server I wouldn't replace were the case and the hard drive, and the two computers' cases are almost identical. After having this little revelation, I started thinking about replacing the failing computer's components with the new ones and making it my server. Then, after some testing, I would just need to remove the hard drive from my current server and install it in the case with all the new components, change a couple of network configuration items, change the hostname on the KVM switch port, and change the hostname labels on the case, and it should be good to go. This will produce far less server downtime and significantly less stress for me. Also, if something fails, I can simply move the hard drive back to the original server until I can fix the problem with the new one.
|
||||
|
||||
So now I have created a mental list of the tasks I need to do to accomplish this. And—I hope you were watching closely—my fingers never once touched the keyboard while I was working all of this out in my head. My new mental action plan is low risk and involves a much smaller amount of server downtime compared to my original plan.
|
||||
|
||||
When I worked for IBM, I used to see signs all over that said "THINK" in many languages. Thinking can save time and stress and is the main hallmark of a Lazy SysAdmin.
|
||||
|
||||
#### Doing preventative maintenance
|
||||
|
||||
In the mid-1970s, I was hired as a customer engineer at IBM, and my territory consisted of a fairly large number of [unit record machines][2]. That just means that they were heavily mechanical devices that processed punched cards—a few dated from the 1930s. Because these machines were primarily mechanical, their parts often wore out or became maladjusted. Part of my job was to fix them when they broke. The main part of my job—the most important part—was to prevent them from breaking in the first place. The preventative maintenance was intended to replace worn parts before they broke and to lubricate and adjust the moving components to ensure that they were working properly.
|
||||
|
||||
As I say in The Linux Philosophy for SysAdmins:
|
||||
|
||||
> "My managers at IBM understood that was only the tip of the iceberg; they—and I—knew my job was customer satisfaction. Although that usually meant fixing broken hardware, it also meant reducing the number of times the hardware broke. That was good for the customer because they were more productive when their machines were working. It was good for me because I received far fewer calls from those happier customers. I also got to sleep more due to the resultant fewer emergency off-hours callouts. I was being the Lazy [Customer Engineer]. By doing the extra work upfront, I had to do far less work in the long run.
|
||||
>
|
||||
> "This same tenet has become one of the functional tenets of the Linux Philosophy for SysAdmins. As SysAdmins, our time is best spent doing those tasks that minimize future workloads."
|
||||
|
||||
Looking for problems to fix in a Linux computer is the equivalent of project management. I review the system logs looking for hints of problems that might become critical later. If something appears to be a little amiss, or I notice my workstation or a server is not responding as it should, or if the logs show something unusual—all of these can be indicative of an underlying problem that has not generated symptoms obvious to users or the PHB.
|
||||
|
||||
I do frequent checks of the files in `/var/log/`, especially messages and security. One of my more common problems is the many script kiddies who try various types of attacks on my firewall system. And, no, I do not rely on the alleged firewall in the modem/router provided by my ISP. These logs contain a lot of information about the source of the attempted attack and can be very valuable. But it takes a lot of work to scan the logs on various hosts and put solutions into place. So I turn to automation.
|
||||
|
||||
#### Automating
|
||||
|
||||
I have found that a very large percentage of my work can be performed by some form of automation. One of the tenets of the Linux Philosophy for SysAdmins is "automate everything," and this includes boring, drudge tasks like scanning logfiles every day.
|
||||
|
||||
Programs like [Logwatch][3] can monitor your logfiles for anomalous entries and notify you when they occur. Logwatch usually runs as a cron job once a day and sends an email to root on the localhost. You can run Logwatch from the command line and view the results immediately on your display. Now I just need to look at the Logwatch email notification every day.
|
||||
|
||||
But the reality is just getting a notification is not enough, because we can't sit and watch for problems all the time. Sometimes an immediate response is required. Another program I like, one that does all of the work for me—see, this is the real Lazy Admin—is [Fail2Ban][4]. Fail2Ban scans designated logfiles for various types of hacking and intrusion attempts, and if it sees enough sustained activity of a specific type from a particular IP address, it adds an entry to the firewall that blocks any further hacking attempts from that IP address for a specified time. The defaults tend to be around 10 minutes, but I like to specify 12 or 24 hours for most types of attacks. Each type of hacking attack is configured separately, such as those trying to log in via SSH and those attacking a web server.
|
||||
|
||||
#### Writing scripts
|
||||
|
||||
Automation is one of the key components of the Philosophy. Everything that can be automated should be, and the rest should be automated as much as possible. So, I also write a lot of scripts to solve problems, which also means I write scripts to do most of my work for me.
|
||||
|
||||
My scripts save me huge amounts of time because they contain the commands to perform specific tasks, which significantly reduces the amount of typing I need to do. For example, I frequently restart my email server and my spam-fighting software (which needs restarted when configuration changes are made to SpamAssassin's `local.cf` file). Those services must be stopped and restarted in a specific order. So, I wrote a short script with a few commands and stored it in `/usr/local/bin`, where it is accessible. Now, instead of typing several commands and waiting for each to finish before typing the next one—not to mention remembering the correct sequence of commands and the proper syntax of each—I type in a three-character command and leave the rest to my script.
|
||||
|
||||
#### Reducing typing
|
||||
|
||||
Another way to be the Lazy SysAdmin is to reduce the amount of typing we need to do. Besides, my typing skills are really horrible (that is to say I have none—a few clumsy fingers at best). One possible cause for errors is my poor typing, so I try to keep typing to a minimum.
|
||||
|
||||
The vast majority of GNU and Linux core utilities have very short names. They are, however, names that have some meaning. Tools like `cd` for change directory, `ls` for list (the contents of a directory), and `dd` for disk dump are pretty obvious. Short names mean less typing and fewer opportunities for errors to creep in. I think the short names are usually easier to remember.
|
||||
|
||||
When I write shell scripts, I like to keep the names short but meaningful (to me at least) like `rsbu` for Rsync BackUp. In some cases, I like the names a bit longer, such as `doUpdates` to perform system updates. In the latter case, the longer name makes the script's purpose obvious. This saves time because it's easy to remember the script's name.
|
||||
|
||||
Other methods to reduce typing are command line aliases and command line recall and editing. Aliases are simply substitutions that are made by the Bash shell when you type a command. Type the `alias` command and look at the list of aliases that are configured by default. For example, when you enter the command `ls`, the entry `alias ls='ls –color=auto'` substitutes the longer command, so you only need to type two characters instead of 14 to get a listing with colors. You can also use the `alias` command to add your own aliases.
|
||||
|
||||
Command line recall allows you to use the keyboard's Up and Down arrow keys to scroll through your command history. If you need to use the same command again, you can just press the Enter key when you find the one you need. If you need to change the command once you have found it, you can use standard command line editing features to make the changes.
|
||||
|
||||
### Parting thoughts
|
||||
|
||||
It is actually quite a lot of work being the Lazy SysAdmin. But we work smart, rather than working hard. We spend time exploring the hosts we are responsible for and dealing with any little problems long before they become large problems. We spend a lot of time thinking about the best ways to resolve problems, and we think a lot about discovering new ways to work smarter at being the Lazy SysAdmin.
|
||||
|
||||
There are many other ways to be the Lazy SysAdmin besides the few described here. I'm sure you have some of your own; please share them with the rest of us in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/how-be-lazy-sysadmin
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://www.apress.com/us/book/9781484237298
|
||||
[2]:https://en.wikipedia.org/wiki/Unit_record_equipment
|
||||
[3]:https://www.techrepublic.com/article/how-to-install-and-use-logwatch-on-linux/
|
||||
[4]:https://www.fail2ban.org/wiki/index.php/Main_Page
|
||||
95
sources/talk/20180802 Design thinking as a way of life.md
Normal file
95
sources/talk/20180802 Design thinking as a way of life.md
Normal file
@ -0,0 +1,95 @@
|
||||
Design thinking as a way of life
|
||||
======
|
||||
|
||||

|
||||
|
||||
Over the past few years, design has become more than a discipline. It has become a mindset, one gaining more and more traction in industrial practices, processes, and operations.
|
||||
|
||||
People have begun to recognize the value in making design the fundamental component of the process and methodologies aimed at both the "business side" and the "people side" of the organization. In other words, "thinking with design" is a great way to approach business problems and organizational culture problems.
|
||||
|
||||
Design thinkers have tried to visualize how design can be translated as the core of methodologies like Design Thinking, Lean, Agile, and others in a meaningful way, as industries begin seeing potential in a design-driven approach capable of helping organizations be more efficient and effective in delivering value to customers.
|
||||
|
||||
But still, many questions remain—especially questions about the operational aspect of translating core design values. For example:
|
||||
|
||||
* "When should we use Design Thinking?"
|
||||
* "What is the best way to run a design process?"
|
||||
* "How effectively we can fit design into Agile? Or Agile into the design process?"
|
||||
* "Which methodologies are best for my team and the design practices I am following?"
|
||||
|
||||
|
||||
|
||||
The list goes on. In general, though, the tighter integration of design principles into all phases of development processes is becoming more common—something we might call "[DesOps][1]." This mode of thinking, "Design Operations," is a mindset that some believe might be the successor of the DevOps movement. In this article, I want to explain how open principles intersect with the DesOps movement.
|
||||
|
||||
### Eureka
|
||||
|
||||
The quest for a design "Holy Grail," especially from a service design perspective, has led many on a journey through similar methodologies yet toward the same goal: that "eureka" moment that reveals the "best fit" service model for a design process that will work most effectively. But among those various methodologies and practices are so many overlaps, and as a result, everyone is looking for the common framework capable of assessing problems from diverse angles, like business and engineering. It's as if all the gospels of all major religions are preaching and striving for the same higher human values of love, peace, and conscience—but the question is "Which is the right and most effective way?"
|
||||
|
||||
I may have found an answer.
|
||||
|
||||
On my first day at Red Hat, I received a copy of Jim Whitehurst's The Open Organization. What immediately came to my mind was: "Oh, another book with rants about open source practices and benefits."
|
||||
|
||||
But over the weekend, as I scanned the book's pages, I realized it's about more than just "open source culture." It's a book about the quest to find an answer to a much more basic puzzle, one that every organization is currently trying to solve: "What is that common thread that can bind best practices and philosophies in a way that's meaningful for organizations?"
|
||||
|
||||
This was interesting! As I dove more deeply, I found something that made even more sense in context of all the design- and operations-related questions I've seen debated for years: Being "open" is the key to bringing together the best of different practices and philosophies, something that allows us to retain their authenticity and yet help in catering to real needs in operations and design.
|
||||
|
||||
It's also the key to thinking with DesOps.
|
||||
|
||||
### DesOps: Culture, process, technology
|
||||
|
||||
Like every organizational framework, DesOps touches upon culture, process, and technology—the entire ecosystem of the enterprise.
|
||||
|
||||
Like every organizational framework, DesOps touches upon culture, process, and technology—the entire ecosystem of the enterprise. Because it is inspired by the culture of DevOps, people tend to view it more from the angle of technological aspects (such as automation, continuous integration, and a delivery point of view). However the most difficult—and yet most important—piece of the DesOps puzzle to solve is the cultural one. This is critical because it involves human-to-human interactions (unlike the machine-to-machine or human-to-machine interactions that are a more common part of purely technological questions).
|
||||
|
||||
So DesOps is not only about bringing automation and continuous integration to systems-to-systems interactions. It's an approach to organically making the systems a part of all interaction touch points that actually enable in human-to-human communication and feedback models.
|
||||
|
||||
Humans are at the center of DesOps, which requires a culture that itself follows design philosophies and values, including "zero waste" in translation across interaction touch points (including lean methodologies across the activity chains). Stressing dynamic culture based on agile philosophies, DesOps is design thinking as a way of life.
|
||||
|
||||
But how can we build an organizational culture that aligns to basic DesOps philosophies? What kind of culture can organically compliment those meaningfully integrated system-to-system and system-to-human toolings and eco-systems as part of DesOps?
|
||||
|
||||
The answer can be found in The Open Organization.
|
||||
|
||||
A DesOps culture is essentially an open culture, and that solves a critical piece of the puzzle. What I realized during my [book-length exploration of DesOps][2] is that every DesOps-led organization is actually an open organization.
|
||||
|
||||
### DesOps, open by default
|
||||
|
||||
To ensure we can sustain our organizations in the future, we must rethink how to we work together and prepare ourselves—how we develop and sustain a culture of innovation.
|
||||
|
||||
Broadly, DesOps focuses on how to converge different work practices so that an organization's product management, design, engineering, and marketing teams can work together in an optimal way. Then the organization can nurture and sustain creativity and innovation, while at the same time delivering that "wow" experience to customers and end users through products and services.
|
||||
|
||||
At a fundamental level, DesOps is not about introducing new models or process in the enterprise; rather, it's about orchestrating best practices from Design Thinking, Lean Methodologies, User-Centered Design models, and other best practices with modern technologies to understand, create, and deliver value.
|
||||
|
||||
Let's take a closer look at core DesOps philosophies. Some are inherently aligned with and draw inspirations from the DevOps movement, and all are connected to the attributes of an open organization (both at organizational and individual levels).
|
||||
|
||||
Being "open" means:
|
||||
|
||||
* Every individual is transparent. So is the organization they're part of. The upshot is that each member of the organization enables greater transparency and more feedback-loops.
|
||||
* There's less manipulation in translation among touch points. This also means the process is lean and every touch point is easily accessible.
|
||||
* There's greater accessibility, which means the organizational structure tends towards zero hierarchy, as each ladder is accessible through openness. Every one is encouraged to interact, ask questions, and share thoughts and ideas, and provide feedback. When individuals ask and share ideas across roles, they feel more responsible, and a sense of ownership develops.
|
||||
* Greater accessibility, in turn, helps nurture ideas from bottom up, as it provides avenues for ideas to germinate and evolve upward.
|
||||
* Bottom-up momentum helps with inclusivity, as it opens doors for grassroots movements in the organization and eliminates structural boundaries within it.
|
||||
* Inclusivity reduces gaps among functional roles, again reducing hierarchy.
|
||||
* Feedback loops form across the organization (and also through development life cycles). This in return enables more meaningful data for informed decision making.
|
||||
* Empathy is nurtured, which helps people in the organization to understand the needs and pain-points of users and customers. Within the organization, it helps people identify and solve core issues, making it possible to implement design thinking as a way of life. With the enablement of empathy and humility, the culture becomes more receptive and will tend towards zero bias. The open, receptive, and empathetic team has greater agility, one that's more open to change.
|
||||
* Freedom arrives as a bonus when the organization has a open culture, and this creates a positive environment for the team to innovate, not feeling psychologically fearful and encourage fail-fast philosophies.
|
||||
|
||||
|
||||
|
||||
We're at an interesting historical moment, when competition in the market is increasing, technology has matured, and unstructured data is a fuel that can open up new possibilities. Our organizational management models have matured beyond corporate, autocratic ways of running people and systems. To ensure we can sustain our organizations in the future, we must rethink how to we work together and prepare ourselves—how we develop and sustain a culture of innovation.
|
||||
|
||||
Open organization principles are guideposts on that journey.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/8/introduction-to-desops
|
||||
|
||||
作者:[Samir Dash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sdash
|
||||
[1]:http://desops.io/
|
||||
[2]:http://desops.io/2018/06/07/paperback-the-desops-enterprise-re-invent-your-organization-volume-1-the-overview-culture/
|
||||
@ -0,0 +1,185 @@
|
||||
How blockchain will influence open source
|
||||
======
|
||||
|
||||

|
||||
|
||||
What [Satoshi Nakamoto][1] started as Bitcoin a decade ago has found a lot of followers and turned into a movement for decentralization. For some, blockchain technology is a religion that will have the same impact on humanity as the Internet has had. For others, it is hype and technology suitable only for Ponzi schemes. While blockchain is still evolving and trying to find its place, one thing is for sure: It is a disruptive technology that will fundamentally transform certain industries. And I'm betting open source will be one of them.
|
||||
|
||||
### The open source model
|
||||
|
||||
Open source is a collaborative software development and distribution model that allows people with common interests to gather and produce something that no individual can create on their own. It allows the creation of value that is bigger than the sum of its parts. Open source is enabled by distributed collaboration tools (IRC, email, git, wiki, issue trackers, etc.), distributed and protected by an open source licensing model and often governed by software foundations such as the [Apache Software Foundation][2] (ASF), [Cloud Native Computing Foundation][3] (CNCF), etc.
|
||||
|
||||
One interesting aspect of the open source model is the lack of financial incentives in its core. Some people believe open source work should remain detached from money and remain a free and voluntary activity driven only by intrinsic motivators (such as "common purpose" and "for the greater good”). Others believe open source work should be rewarded directly or indirectly through extrinsic motivators (such as financial incentive). While the idea of open source projects prospering only through voluntary contributions is romantic, in reality, the majority of open source contributions are done through paid development. Yes, we have a lot of voluntary contributions, but these are on a temporary basis from contributors who come and go, or for exceptionally popular projects while they are at their peak. Creating and sustaining open source projects that are useful for enterprises requires developing, documenting, testing, and bug-fixing for prolonged periods, even when the software is no longer shiny and exciting. It is a boring activity that is best motivated through financial incentives.
|
||||
|
||||
### Commercial open source
|
||||
|
||||
Software foundations such as ASF survive on donations and other income streams such as sponsorships, conference fees, etc. But those funds are primarily used to run the foundations, to provide legal protection for the projects, and to ensure there are enough servers to run builds, issue trackers, mailing lists, etc.
|
||||
|
||||
Similarly, CNCF has member fees and other income streams, which are used to run the foundation and provide resources for the projects. These days, most software is not built on laptops; it is run and tested on hundreds of machines on the cloud, and that requires money. Creating marketing campaigns, brand designs, distributing stickers, etc. takes money, and some foundations can assist with that as well. At its core, foundations implement the right processes to interact with users, developers, and control mechanisms and ensure distribution of available financial resources to open source projects for the common good.
|
||||
|
||||
If users of open source projects can donate money and the foundations can distribute it in a fair way, what is missing?
|
||||
|
||||
What is missing is a direct, transparent, trusted, decentralized, automated bidirectional link for transfer of value between the open source producers and the open source consumer. Currently, the link is either unidirectional or indirect:
|
||||
|
||||
* **Unidirectional** : A developer (think of a "developer" as any role that is involved in the production, maintenance, and distribution of software) can use their brain juice and devote time to do a contribution and share that value with all open source users. But there is no reverse link.
|
||||
|
||||
* **Indirect** : If there is a bug that affects a specific user/company, the options are:
|
||||
|
||||
* To have in-house developers to fix the bug and do a pull request. That is ideal, but it not always possible to hire in-house developers who are knowledgeable about hundreds of open source projects used daily.
|
||||
|
||||
* To hire a freelancer specializing in that specific open source project and pay for the services. Ideally, the freelancer is also a committer for the open source project and can directly change the project code quickly. Otherwise, the fix might not ever make it to the project.
|
||||
|
||||
* To approach a company providing services around the open source project. Such companies typically employ open source committers to influence and gain credibility in the community and offer products, expertise, and professional services.
|
||||
|
||||
|
||||
|
||||
|
||||
The third option has been a successful [model][4] for sustaining many open source projects. Whether they provide services (training, consulting, workshops), support, packaging, open core, or SaaS, there are companies that employ hundreds of staff members who work on open source full time. There is a long [list of companies][5] that have managed to build a successful open source business model over the years, and that list is growing steadily.
|
||||
|
||||
The companies that back open source projects play an important role in the ecosystem: They are the catalyst between the open source projects and the users. The ones that add real value do more than just package software nicely; they can identify user needs and technology trends, and they create a full stack and even an ecosystem of open source projects to address these needs. They can take a boring project and support it for years. If there is a missing piece in the stack, they can start an open source project from scratch and build a community around it. They can acquire a closed source software company and open source the projects (here I got a little carried away, but yes, I'm talking about my employer, [Red Hat][6]).
|
||||
|
||||
To summarize, with the commercial open source model, projects are officially or unofficially managed and controlled by a very few individuals or companies that monetize them and give back to the ecosystem by ensuring the project is successful. It is a win-win-win for open source developers, managing companies, and end users. The alternative is inactive projects and expensive closed source software.
|
||||
|
||||
### Self-sustaining, decentralized open source
|
||||
|
||||
For a project to become part of a reputable foundation, it must conform to certain criteria. For example, ASF and CNCF require incubation and graduation processes, respectively, where apart from all the technical and formal requirements, a project must have a healthy number of active committer and users. And that is the essence of forming a sustainable open source project. Having source code on GitHub is not the same thing as having an active open source project. The latter requires committers who write the code and users who use the code, with both groups enforcing each other continuously by exchanging value and forming an ecosystem where everybody benefits. Some project ecosystems might be tiny and short-lived, and some may consist of multiple projects and competing service providers, with very complex interactions lasting for many years. But as long as there is an exchange of value and everybody benefits from it, the project is developed, maintained, and sustained.
|
||||
|
||||
If you look at ASF [Attic][7], you will find projects that have reached their end of life. When a project is no longer technologically fit for its purpose, it is usually its natural end. Similarly, in the ASF [Incubator][8], you will find tons of projects that never graduated but were instead retired. Typically, these projects were not able to build a large enough community because they are too specialized or there are better alternatives available.
|
||||
|
||||
But there are also cases where projects with high potential and superior technology cannot sustain themselves because they cannot form or maintain a functioning ecosystem for the exchange of value. The open source model and the foundations do not provide a framework and mechanisms for developers to get paid for their work or for users to get their requests heard. There isn’t a common value commitment framework for either party. As a result, some projects can sustain themselves only in the context of commercial open source, where a company acts as an intermediary and value adder between developers and users. That adds another constraint and requires a service provider company to sustain some open source projects. Ideally, users should be able to express their interest in a project and developers should be able to show their commitment to the project in a transparent and measurable way, which forms a community with common interest and intent for the exchange of value.
|
||||
|
||||
Imagine there is a model with mechanisms and tools that enable direct interaction between open source users and developers. This includes not only code contributions through pull requests, questions over the mailing lists, GitHub stars, and stickers on laptops, but also other ways that allow users to influence projects' destinies in a richer, more self-controlled and transparent manner.
|
||||
|
||||
This model could include incentives for actions such as:
|
||||
|
||||
* Funding open source projects directly rather than through software foundations
|
||||
|
||||
* Influencing the direction of projects through voting (by token holders)
|
||||
|
||||
* Feature requests driven by user needs
|
||||
|
||||
* On-time pull request merges
|
||||
|
||||
* Bounties for bug hunts
|
||||
|
||||
* Better test coverage incentives
|
||||
|
||||
* Up-to-date documentation rewards
|
||||
|
||||
* Long-term support guarantees
|
||||
|
||||
* Timely security fixes
|
||||
|
||||
* Expert assistance, support, and services
|
||||
|
||||
* Budget for evangelism and promotion of the projects
|
||||
|
||||
* Budget for regular boring activities
|
||||
|
||||
* Fast email and chat assistance
|
||||
|
||||
* Full visibility of the overall project findings, etc.
|
||||
|
||||
|
||||
|
||||
|
||||
If you haven't guessed, I'm talking about using blockchain and [smart contracts][9] to allow such interactions between users and developers—smart contracts that will give power to the hand of token holders to influence projects.
|
||||
|
||||
![blockchain_in_open_source_ecosystem.png][11]
|
||||
|
||||
The usage of blockchain in the open source ecosystem
|
||||
|
||||
Existing channels in the open source ecosystem provide ways for users to influence projects through financial commitments to service providers or other limited means through the foundations. But the addition of blockchain-based technology to the open source ecosystem could open new channels for interaction between users and developers. I'm not saying this will replace the commercial open source model; most companies working with open source do many things that cannot be replaced by smart contracts. But smart contracts can spark a new way of bootstrapping new open source projects, giving a second life to commodity projects that are a burden to maintain. They can motivate developers to apply boring pull requests, write documentation, get tests to pass, etc., providing a direct value exchange channel between users and open source developers. Blockchain can add new channels to help open source projects grow and become self-sustaining in the long term, even when company backing is not feasible. It can create a new complementary model for self-sustaining open source projects—a win-win.
|
||||
|
||||
### Tokenizing open source
|
||||
|
||||
There are already a number of initiatives aiming to tokenize open source. Some focus only on an open source model, and some are more generic but apply to open source development as well:
|
||||
|
||||
* [Gitcoin][12] \- grow open source, one of the most promising ones in this area.
|
||||
|
||||
* [Oscoin][13] \- cryptocurrency for open source
|
||||
|
||||
* [Open collective][14] \- a platform for supporting open source projects.
|
||||
|
||||
* [FundYourselfNow][15] \- Kickstarter and ICOs for projects.
|
||||
|
||||
* [Kauri][16] \- support for open source project documentation.
|
||||
|
||||
* [Liberapay][17] \- a recurrent donations platform.
|
||||
|
||||
* [FundRequest][18] \- a decentralized marketplace for open source collaboration.
|
||||
|
||||
* [CanYa][19] \- recently acquired [Bountysource][20], now the world’s largest open source P2P bounty platform.
|
||||
|
||||
* [OpenGift][21] \- a new model for open source monetization.
|
||||
|
||||
* [Hacken][22] \- a white hat token for hackers.
|
||||
|
||||
* [Coinlancer][23] \- a decentralized job market.
|
||||
|
||||
* [CodeFund][24] \- an open source ad platform.
|
||||
|
||||
* [IssueHunt][25] \- a funding platform for open source maintainers and contributors.
|
||||
|
||||
* [District0x 1Hive][26] \- a crowdfunding and curation platform.
|
||||
|
||||
* [District0x Fixit][27] \- github bug bounties.
|
||||
|
||||
|
||||
|
||||
|
||||
This list is varied and growing rapidly. Some of these projects will disappear, others will pivot, but a few will emerge as the [SourceForge][28], the ASF, the GitHub of the future. That doesn't necessarily mean they'll replace these platforms, but they'll complement them with token models and create a richer open source ecosystem. Every project can pick its distribution model (license), governing model (foundation), and incentive model (token). In all cases, this will pump fresh blood to the open source world.
|
||||
|
||||
### The future is open and decentralized
|
||||
|
||||
* Software is eating the world.
|
||||
|
||||
* Every company is a software company.
|
||||
|
||||
* Open source is where innovation happens.
|
||||
|
||||
|
||||
|
||||
|
||||
Given that, it is clear that open source is too big to fail and too important to be controlled by a few or left to its own destiny. Open source is a shared-resource system that has value to all, and more importantly, it must be managed as such. It is only a matter of time until every company on earth will want to have a stake and a say in the open source world. Unfortunately, we don't have the tools and the habits to do it yet. Such tools would allow anybody to show their appreciation or ignorance of software projects. It would create a direct and faster feedback loop between producers and consumers, between developers and users. It will foster innovation—innovation driven by user needs and expressed through token metrics.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/open-source-tokenomics
|
||||
|
||||
作者:[Bilgin lbryam][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bibryam
|
||||
[1]:https://en.wikipedia.org/wiki/Satoshi_Nakamoto
|
||||
[2]:https://www.apache.org/
|
||||
[3]:https://www.cncf.io/
|
||||
[4]:https://medium.com/open-consensus/3-oss-business-model-progressions-dafd5837f2d
|
||||
[5]:https://docs.google.com/spreadsheets/d/17nKMpi_Dh5slCqzLSFBoWMxNvWiwt2R-t4e_l7LPLhU/edit#gid=0
|
||||
[6]:http://jobs.redhat.com/
|
||||
[7]:https://attic.apache.org/
|
||||
[8]:http://incubator.apache.org/
|
||||
[9]:https://en.wikipedia.org/wiki/Smart_contract
|
||||
[10]:/file/404421
|
||||
[11]:https://opensource.com/sites/default/files/uploads/blockchain_in_open_source_ecosystem.png (blockchain_in_open_source_ecosystem.png)
|
||||
[12]:https://gitcoin.co/
|
||||
[13]:http://oscoin.io/
|
||||
[14]:https://opencollective.com/opensource
|
||||
[15]:https://www.fundyourselfnow.com/page/about
|
||||
[16]:https://kauri.io/
|
||||
[17]:https://liberapay.com/
|
||||
[18]:https://fundrequest.io/
|
||||
[19]:https://canya.io/
|
||||
[20]:https://www.bountysource.com/
|
||||
[21]:https://opengift.io/pub/
|
||||
[22]:https://hacken.io/
|
||||
[23]:https://www.coinlancer.com/home
|
||||
[24]:https://codefund.io/
|
||||
[25]:https://issuehunt.io/
|
||||
[26]:https://blog.district0x.io/district-proposal-spotlight-1hive-283957f57967
|
||||
[27]:https://github.com/district0x/district-proposals/issues/177
|
||||
[28]:https://sourceforge.net/
|
||||
@ -1,3 +1,5 @@
|
||||
fuowang 翻译中
|
||||
|
||||
Arch Linux Applications Automatic Installation Script
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Linux command line tools for working with non-Linux users
|
||||
======
|
||||

|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
API Star: Python 3 API Framework – Polyglot.Ninja()
|
||||
======
|
||||
For building quick APIs in Python, I have mostly depended on [Flask][1]. Recently I came across a new API framework for Python 3 named “API Star” which seemed really interesting to me for several reasons. Firstly the framework embraces modern Python features like type hints and asyncio. And then it goes ahead and uses these features to provide awesome development experience for us, the developers. We will get into those features soon but before we begin, I would like to thank Tom Christie for all the work he has put into Django REST Framework and now API Star.
|
||||
|
||||
@ -1,175 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Splicing the Cloud Native Stack, One Floor at a Time
|
||||
======
|
||||
At Packet, our value (automated infrastructure) is super fundamental. As such, we spend an enormous amount of time looking up at the players and trends in all the ecosystems above us - as well as the very few below!
|
||||
|
||||
It’s easy to get confused, or simply lose track, when swimming deep in the oceans of any ecosystem. I know this for a fact because when I started at Packet last year, my English degree from Bryn Mawr didn’t quite come with a Kubernetes certification. :)
|
||||
|
||||
Due to its super fast evolution and massive impact, the cloud native ecosystem defies precedent. It seems that every time you blink, entirely new technologies (not to mention all of the associated logos) have become relevant...or at least interesting. Like many others, I’ve relied on the CNCF’s ubiquitous “[Cloud Native Landscape][1]” as a touchstone as I got to know the space. However, if there is one element that defines ecosystems, it is the people that contribute to and steer them.
|
||||
|
||||
That’s why, when we were walking back to the office one cold December afternoon, we hit upon a creative way to explain “cloud native” to an investor, whose eyes were obviously glazing over as we talked about the nuances that distinguished Cilium from Aporeto, and why everything from CoreDNS and Spiffe to Digital Rebar and Fission were interesting in their own right.
|
||||
|
||||
Looking up at our narrow 13 story office building in the shadow of the new World Trade Center, we hit on an idea that took us down an artistic rabbit hole: why not draw it?
|
||||
|
||||
![][2]
|
||||
|
||||
And thus began our journey to splice the Cloud Native Stack, one floor at a time. Let’s walk through it together and we can give you the “guaranteed to be outdated tomorrow” down low.
|
||||
|
||||
[[View a High Resolution JPG][3]] or email us to request a copy.
|
||||
|
||||
### Starting at the Very Bottom
|
||||
|
||||
As we started to put pen to paper, we knew we wanted to shine a light on parts of the stack that we interact with on a daily basis, but that is largely invisible to users further up: hardware. And like any good secret lab investing in the next great (usually proprietary) thing, we thought the basement was the perfect spot.
|
||||
|
||||
From the well established giants of the space like Intel, AMD and Huawei (rumor has it they employ nearly 80,000 engineers!), to more niche players like Mellanox, the hardware ecosystem is on fire. In fact, we may be entering a Golden Age of hardware, as billions of dollars are poured into upstarts hacking on new offloads, GPU’s, custom co-processors.
|
||||
|
||||
The famous software trailblazer Alan Kay said over 25 years ago: “People who are really serious about software should make their own hardware.” Good call Alan!
|
||||
|
||||
### The Cloud is About Capital
|
||||
|
||||
As our CEO Zac Smith has told me many times: it’s all about the money. And not just about making it, but spending it! In the cloud, it takes billions of dollars of capital to make computers show up in data centers so that developers can consume them with software. In other words:
|
||||
|
||||
|
||||
![][4]
|
||||
|
||||
We thought the best place for “The Bank” (e.g. the lenders and investors that make this cloud fly) was the ground floor. So we transformed our lobby into the Banker’s Cafe, complete with a wheel of fortune for all of us out there playing the startup game.
|
||||
|
||||
![][5]
|
||||
|
||||
### The Ping and Power
|
||||
|
||||
If the money is the grease, then the engine that consumes much of the fuel is the datacenter providers and the networks that connect them. We call them “power” and “ping”.
|
||||
|
||||
From top of mind names like Equinix and edge upstarts like Vapor.io, to the “pipes” that Verizon, Crown Castle and others literally put in the ground (or on the ocean floor), this is a part of the stack that we all rely upon but rarely see in person.
|
||||
|
||||
Since we spend a lot of time looking at datacenters and connectivity, one thing to note is that this space is changing quite rapidly, especially as 5G arrives in earnest and certain workloads start to depend on less centralized infrastructure.
|
||||
|
||||
The edge is coming y’all! :-)
|
||||
|
||||
![][6]
|
||||
|
||||
### Hey, It's Infrastructure!
|
||||
|
||||
Sitting on top of “ping” and “power” is the floor we lovingly call “processors”. This is where our magic happens - we turn the innovation and physical investments from down below into something at the end of an API.
|
||||
|
||||
Since this is a NYC building, we kept the cloud providers here fairly NYC centric. That’s why you see Sammy the Shark (of Digital Ocean lineage) and a nod to Google over in the “meet me” room.
|
||||
|
||||
As you’ll see, this scene is pretty physical. Racking and stacking, as it were. While we love our facilities manager in EWR1 (Michael Pedrazzini), we are working hard to remove as much of this manual labor as possible. PhD’s in cabling are hard to come by, after all.
|
||||
|
||||
![][7]
|
||||
|
||||
### Provisioning
|
||||
|
||||
One floor up, layered on top of infrastructure, is provisioning. This is one of our favorite spots, which years ago we might have called “config management.” But now it’s all about immutable infrastructure and automation from the start: Terraform, Ansible, Quay.io and the like. You can tell that software is working its way down the stack, eh?
|
||||
|
||||
Kelsey Hightower noted recently “it’s an exciting time to be in boring infrastructure.” I don’t think he meant the physical part (although we think it’s pretty dope), but as software continues to hack on all layers of the stack, you can guarantee a wild ride.
|
||||
|
||||
![][8]
|
||||
|
||||
### Operating Systems
|
||||
|
||||
With provisioning in place, we move to the operating system layer. This is where we get to start poking fun at some of our favorite folks as well: note Brian Redbeard’s above average yoga pose. :)
|
||||
|
||||
Packet offers eleven major operating systems for our clients to choose from, including some that you see in this illustration: Ubuntu, CoreOS, FreeBSD, Suse, and various Red Hat offerings. More and more, we see folks putting their opinion on this layer: from custom kernels and golden images of their favorite distros for immutable deploys, to projects like NixOS and LinuxKit.
|
||||
|
||||
![][9]
|
||||
|
||||
### Run Time
|
||||
|
||||
We had to have fun with this, so we placed the runtime in the gym, with a championship match between CoreOS-sponsored rkt and Docker’s containerd. Either way the CNCF wins!
|
||||
|
||||
We felt the fast-evolving storage ecosystem deserved some lockers. What’s fun about the storage aspect is the number of new players trying to conquer the challenging issue of persistence, as well as performance and flexibility. As they say: storage is just plain hard.
|
||||
|
||||
![][10]
|
||||
|
||||
### Orchestration
|
||||
|
||||
The orchestration layer has been all about Kubernetes this past year, so we took one of its most famous evangelists (Kelsey Hightower) and featured him in this rather odd meetup scene. We have some major Nomad fans on our team, and there is just no way to consider the cloud native space without the impact of Docker and its toolset.
|
||||
|
||||
While workload orchestration applications are fairly high up our stack, we see all kinds of evidence for these powerful tools are starting to look way down the stack to help users take advantage of GPU’s and other specialty hardware. Stay tuned - we’re in the early days of the container revolution!
|
||||
|
||||
![][11]
|
||||
|
||||
### Platforms
|
||||
|
||||
This is one of our favorite layers of the stack, because there is so much craft in how each platform helps users accomplish what they really want to do (which, by the way, isn’t run containers but run applications!). From Rancher and Kontena, to Tectonic and Redshift to totally different approaches like Cycle.io and Flynn.io - we’re always thrilled to see how each of these projects servers users differently.
|
||||
|
||||
The main takeaway: these platforms are helping to translate all of the various, fast-moving parts of the cloud native ecosystem to users. It’s great watching what they each come up with!
|
||||
|
||||
![][12]
|
||||
|
||||
### Security
|
||||
|
||||
When it comes to security, it’s been a busy year! We tried to represent some of the more famous attacks and illustrate how various tools are trying to help protect us as workloads become highly distributed and portable (while at the same time, attackers become ever more resourceful).
|
||||
|
||||
We see a strong movement towards trustless environments (see Aporeto) and low level security (Cilium), as well as tried and true approaches at the network level like Tigera. No matter your approach, it’s good to remember: This is definitely not fine. :0
|
||||
|
||||
![][13]
|
||||
|
||||
### Apps
|
||||
|
||||
How to represent the huge, vast, limitless ecosystem of applications? In this case, it was easy: stay close to NYC and pick our favorites. ;) From the Postgres “elephant in the room” and the Timescale clock, to the sneaky ScyllaDB trash and the chillin’ Travis dude - we had fun putting this slice together.
|
||||
|
||||
One thing that surprised us: how few people noticed the guy taking a photocopy of his rear end. I guess it’s just not that common to have a photocopy machine anymore?!?
|
||||
|
||||
![][14]
|
||||
|
||||
### Observability
|
||||
|
||||
As our workloads start moving all over the place, and the scale gets gigantic, there is nothing quite as comforting as a really good Grafana dashboard, or that handy Datadog agent. As complexity increases, the “SRE” generation are starting to rely ever more on alerting and other intelligence events to help us make sense of what’s going on, and work towards increasingly self-healing infrastructure and applications.
|
||||
|
||||
It will be interesting to see what kind of logos make their way into this floor over the coming months and years...maybe some AI, blockchain, ML powered dashboards? :-)
|
||||
|
||||
![][15]
|
||||
|
||||
### Traffic Management
|
||||
|
||||
People tend to think that the internet “just works” but in reality, we’re kind of surprised it works at all. I mean, a loose connection of disparate networks at massive scale - you have to be joking!?
|
||||
|
||||
One reason it all sticks together is traffic management, DNS and the like. More and more, these players are helping to make the interest both faster and safer, as well as more resilient. We’re especially excited to see upstarts like Fly.io and NS1 competing against well established players, and watching the entire ecosystem improve as a result. Keep rockin’ it y’all!
|
||||
|
||||
![][16]
|
||||
|
||||
### Users
|
||||
|
||||
What good is a technology stack if you don’t have fantastic users? Granted, they sit on top of a massive stack of innovation, but in the cloud native world they do more than just consume: they create and contribute. From massive contributions like Kubernetes to more incremental (but equally important) aspects, what we’re all a part of is really quite special.
|
||||
|
||||
Many of the users lounging on our rooftop deck, like Ticketmaster and the New York Times, are not mere upstarts: these are organizations that have embraced a new way of deploying and managing their applications, and their own users are reaping the rewards.
|
||||
|
||||
![][17]
|
||||
|
||||
### Last but not Least, the Adult Supervision!
|
||||
|
||||
In previous ecosystems, foundations have played a more passive “behind the scenes” role. Not the CNCF! Their goal of building a robust cloud native ecosystem has been supercharged by the incredible popularity of the movement - and they’ve not only caught up but led the way.
|
||||
|
||||
From rock solid governance and a thoughtful group of projects, to outreach like the CNCF Landscape, CNCF Cross Cloud CI, Kubernetes Certification, and Speakers Bureau - the CNCF is way more than “just” the ever popular KubeCon + CloudNativeCon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.packet.net/blog/splicing-the-cloud-native-stack/
|
||||
|
||||
作者:[Zoe Allen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.packet.net/about/zoe-allen/
|
||||
[1]:https://landscape.cncf.io/landscape=cloud
|
||||
[2]:https://assets.packet.net/media/images/PIFg-30.vesey.street.ny.jpg
|
||||
[3]:https://www.dropbox.com/s/ujxk3mw6qyhmway/Packet_Cloud_Native_Building_Stack.jpg?dl=0
|
||||
[4]:https://assets.packet.net/media/images/3vVx-there.is.no.cloud.jpg
|
||||
[5]:https://assets.packet.net/media/images/X0b9-the.bank.jpg
|
||||
[6]:https://assets.packet.net/media/images/2Etm-ping.and.power.jpg
|
||||
[7]:https://assets.packet.net/media/images/C800-infrastructure.jpg
|
||||
[8]:https://assets.packet.net/media/images/0V4O-provisioning.jpg
|
||||
[9]:https://assets.packet.net/media/images/eMYp-operating.system.jpg
|
||||
[10]:https://assets.packet.net/media/images/9BII-run.time.jpg
|
||||
[11]:https://assets.packet.net/media/images/njak-orchestration.jpg
|
||||
[12]:https://assets.packet.net/media/images/1QUS-platforms.jpg
|
||||
[13]:https://assets.packet.net/media/images/TeS9-security.jpg
|
||||
[14]:https://assets.packet.net/media/images/SFgF-apps.jpg
|
||||
[15]:https://assets.packet.net/media/images/SXoj-observability.jpg
|
||||
[16]:https://assets.packet.net/media/images/tKhf-traffic.management.jpg
|
||||
[17]:https://assets.packet.net/media/images/7cpe-users.jpg
|
||||
@ -1,76 +0,0 @@
|
||||
pinewall translating
|
||||
|
||||
How Graphics Cards Work
|
||||
======
|
||||
![AMD-Polaris][1]
|
||||
|
||||
Ever since 3dfx debuted the original Voodoo accelerator, no single piece of equipment in a PC has had as much of an impact on whether your machine could game as the humble graphics card. While other components absolutely matter, a top-end PC with 32GB of RAM, a $500 CPU, and PCIe-based storage will choke and die if asked to run modern AAA titles on a ten year-old card at modern resolutions and detail levels. Graphics cards (also commonly referred to as GPUs, or graphics processing units) are critical to game performance and we cover them extensively. But we don’t often dive into what makes a GPU tick and how the cards function.
|
||||
|
||||
By necessity, this will be a high-level overview of GPU functionality and cover information common to AMD, Nvidia, and Intel’s integrated GPUs, as well as any discrete cards Intel might build in the future. It should also be common to the mobile GPUs built by Apple, Imagination Technologies, Qualcomm, ARM, and other vendors.
|
||||
|
||||
### Why Don’t We Run Rendering With CPUs?
|
||||
|
||||
The first point I want to address is why we don’t use CPUs for rendering workloads in gaming in the first place. The honest answer to this question is that you can run rendering workloads directly on a CPU, at least in theory. Early 3D games that predate the widespread availability of graphics cards, like Ultima Underworld, ran entirely on the CPU. UU is a useful reference case for multiple reasons — it had a more advanced rendering engine than games like Doom, with full support for looking up and down, as well as then-advanced features like texture mapping. But this kind of support came at a heavy price — many people lacked a PC that could actually run the game.
|
||||
|
||||

|
||||
|
||||
In the early days of 3D gaming, many titles like Half Life and Quake II featured a software renderer to allow players without 3D accelerators to play the title. But the reason we dropped this option from modern titles is simple: CPUs are designed to be general-purpose microprocessors, which is another way of saying they lack the specialized hardware and capabilities that GPUs offer. A modern CPU could easily handle titles that tended to stutter when run in software 18 years ago, but no CPU on Earth could easily handle a modern AAA game from today if run in that mode. Not, at least, without some drastic changes to the scene, resolution, and various visual effects.
|
||||
|
||||
### What’s a GPU?
|
||||
|
||||
A GPU is a device with a set of specific hardware capabilities that are intended to map well to the way that various 3D engines execute their code, including geometry setup and execution, texture mapping, memory access, and shaders. There’s a relationship between the way 3D engines function and the way GPU designers build hardware. Some of you may remember that AMD’s HD 5000 family used a VLIW5 architecture, while certain high-end GPUs in the HD 6000 family used a VLIW4 architecture. With GCN, AMD changed its approach to parallelism, in the name of extracting more useful performance per clock cycle.
|
||||
|
||||

|
||||
|
||||
Nvidia first coined the term “GPU” with the launch of the original GeForce 256 and its support for performing hardware transform and lighting calculations on the GPU (this corresponded, roughly to the launch of Microsoft’s DirectX 7). Integrating specialized capabilities directly into hardware was a hallmark of early GPU technology. Many of those specialized technologies are still employed (in very different forms), because it’s more power efficient and faster to have dedicated resources on-chip for handling specific types of workloads than it is to attempt to handle all of the work in a single array of programmable cores.
|
||||
|
||||
There are a number of differences between GPU and CPU cores, but at a high level, you can think about them like this. CPUs are typically designed to execute single-threaded code as quickly and efficiently as possible. Features like SMT / Hyper-Threading improve on this, but we scale multi-threaded performance by stacking more high-efficiency single-threaded cores side-by-side. AMD’s 32-core / 64-thread Epyc CPUs are the largest you can buy today. To put that in perspective, the lowest-end Pascal GPU from Nvidia has 384 cores. A “core” in GPU parlance refers to a much smaller unit of processing capability than in a typical CPU.
|
||||
|
||||
**Note:** You cannot compare or estimate relative gaming performance between AMD and Nvidia simply by comparing the number of GPU cores. Within the same GPU family (for example, Nvidia’s GeForce GTX 10 series, or AMD’s RX 4xx or 5xx family), a higher GPU core count means that GPU is more powerful than a lower-end card.
|
||||
|
||||
The reason you can’t draw immediate conclusions on GPU performance between manufacturers or core families based solely on core counts is because different architectures are more and less efficient. Unlike CPUs, GPUs are designed to work in parallel. Both AMD and Nvidia structure their cards into blocks of computing resources. Nvidia calls these blocks an SM (Streaming Multiprocessor), while AMD refers to them as a Compute Unit.
|
||||
|
||||

|
||||
|
||||
Each block contains a group of cores, a scheduler, a register file, instruction cache, texture and L1 cache, and texture mapping units. The SM / CU can be thought of as the smallest functional block of the GPU. It doesn’t contain literally everything — video decode engines, render outputs required for actually drawing an image on-screen, and the memory interfaces used to communicate with onboard VRAM are all outside its purview — but when AMD refers to an APU as having 8 or 11 Vega Compute Units, this is the (equivalent) block of silicon they’re talking about. And if you look at a block diagram of a GPU, any GPU, you’ll notice that it’s the SM/CU that’s duplicated a dozen or more times in the image.
|
||||
|
||||

|
||||
|
||||
The higher the number of SM/CU units in a GPU, the more work it can perform in parallel per clock cycle. Rendering is a type of problem that’s sometimes referred to as “embarrassingly parallel,” meaning it has the potential to scale upwards extremely well as core counts increase.
|
||||
|
||||
When we discuss GPU designs, we often use a format that looks something like this: 4096:160:64. The GPU core count is the first number. The larger it is, the faster the GPU, provided we’re comparing within the same family (GTX 970 versus GTX 980 versus GTX 980 Ti, RX 560 versus RX 580, and so on).
|
||||
|
||||
### Texture Mapping and Render Outputs
|
||||
|
||||
There are two other major components of a GPU: texture mapping units and render outputs. The number of texture mapping units in a design dictates its maximum texel output and how quickly it can address and map textures on to objects. Early 3D games used very little texturing, because the job of drawing 3D polygonal shapes was difficult enough. Textures aren’t actually required for 3D gaming, though the list of games that don’t use them in the modern age is extremely small.
|
||||
|
||||
The number of texture mapping units in a GPU is signified by the second figure in the 4096:160:64 metric. AMD, Nvidia, and Intel typically shift these numbers equivalently as they scale a GPU family up and down. In other words, you won’t really find a scenario where one GPU has a 4096:160:64 configuration while a GPU above or below it in the stack is a 4096:320:64 configuration. Texture mapping can absolutely be a bottleneck in games, but the next-highest GPU in the product stack will typically offer at least more GPU cores and texture mapping units (whether higher-end cards have more ROPs depends on the GPU family and the card configuration).
|
||||
|
||||
Render outputs (also sometimes called raster operations pipelines) are where the GPU’s output is assembled into an image for display on a monitor or television. The number of render outputs multiplied by the clock speed of the GPU controls the pixel fill rate. A higher number of ROPs means that more pixels can be output simultaneously. ROPs also handle antialiasing, and enabling AA — especially supersampled AA — can result in a game that’s fill-rate limited.
|
||||
|
||||
### Memory Bandwidth, Memory Capacity
|
||||
|
||||
The last components we’ll discuss are memory bandwidth and memory capacity. Memory bandwidth refers to how much data can be copied to and from the GPU’s dedicated VRAM buffer per second. Many advanced visual effects (and higher resolutions more generally) require more memory bandwidth to run at reasonable frame rates because they increase the total amount of data being copied into and out of the GPU core.
|
||||
|
||||
In some cases, a lack of memory bandwidth can be a substantial bottleneck for a GPU. AMD’s APUs like the Ryzen 5 2400G are heavily bandwidth-limited, which means increasing your DDR4 clock rate can have a substantial impact on overall performance. The choice of game engine can also have a substantial impact on how much memory bandwidth a GPU needs to avoid this problem, as can a game’s target resolution.
|
||||
|
||||
The total amount of on-board memory is another critical factor in GPUs. If the amount of VRAM needed to run at a given detail level or resolution exceeds available resources, the game will often still run, but it’ll have to use the CPU’s main memory for storing additional texture data — and it takes the GPU vastly longer to pull data out of DRAM as opposed to its onboard pool of dedicated VRAM. This leads to massive stuttering as the game staggers between pulling data from a quick pool of local memory and general system RAM.
|
||||
|
||||
One thing to be aware of is that GPU manufacturers will sometimes equip a low-end or midrange card with more VRAM than is otherwise standard as a way to charge a bit more for the product. We can’t make an absolute prediction as to whether this makes the GPU more attractive because honestly, the results vary depending on the GPU in question. What we can tell you is that in many cases, it isn’t worth paying more for a card if the only difference is a larger RAM buffer. As a rule of thumb, lower-end GPUs tend to run into other bottlenecks before they’re choked by limited available memory. When in doubt, check reviews of the card and look for comparisons of whether a 2GB version is outperformed by the 4GB flavor or whatever the relevant amount of RAM would be. More often than not, assuming all else is equal between the two solutions, you’ll find the higher RAM loadout not worth paying for.
|
||||
|
||||
Check out our [ExtremeTech Explains][2] series for more in-depth coverage of today’s hottest tech topics.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.extremetech.com/gaming/269335-how-graphics-cards-work
|
||||
|
||||
作者:[Joel Hruska][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.extremetech.com/author/jhruska
|
||||
[1]:https://www.extremetech.com/wp-content/uploads/2016/07/AMD-Polaris-640x353.jpg
|
||||
[2]:http://www.extremetech.com/tag/extremetech-explains
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Auk7F7
|
||||
|
||||
How to Manage Fonts in Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,287 +0,0 @@
|
||||
A Set Of Useful Utilities For Debian And Ubuntu Users
|
||||
======
|
||||
|
||||

|
||||
|
||||
Are you using a Debian-based system? Great! I am here today with a good news for you. Say hello to **“Debian-goodies”** , a collection of useful utilities for Debian-based systems, like Ubuntu, Linux Mint. These set of utilities provides some additional useful commands which are not available by default in the Debian-based systems. Using these tools, the users can find which programs are consuming more disk space, which services need to be restarted after updating the system, search for a file matching a pattern in a package, list the installed packages based on the search string and a lot more. In this brief guide, we will be discussing some useful Debian goodies.
|
||||
|
||||
### Debian-goodies – Useful Utilities For Debian And Ubuntu Users
|
||||
|
||||
The debian-goodies package is available in the official repositories of Debian and its derivative Ubuntu and other Ubuntu variants such as Linux Mint. To install debian-goodies package, simply run:
|
||||
```
|
||||
$ sudo apt-get install debian-goodies
|
||||
|
||||
```
|
||||
|
||||
Debian-goodies has just been installed. Let us go ahead and see some useful utilities.
|
||||
|
||||
#### **1. Checkrestart**
|
||||
|
||||
Let me start from one of my favorite, the **“checkrestart”** utility. When installing security updates, some running applications might still use the old libraries. In order to apply the security updates completely, you need to find and restart all of them. This is where Checkrestart comes in handy. This utility will find which processes are still using the old versions of libs. You can then restart the services.
|
||||
|
||||
To check which daemons need to be restarted after library upgrades, run:
|
||||
```
|
||||
$ sudo checkrestart
|
||||
[sudo] password for sk:
|
||||
Found 0 processes using old versions of upgraded files
|
||||
|
||||
```
|
||||
|
||||
Since I didn’t perform any security updates lately, it shows nothing.
|
||||
|
||||
Please note that Checkrestart utility does work well. However, there is a new similar tool named “needrestart” available latest Debian systems. The needrestart is inspired by the checkrestart utility and it does exactly the same job. Needrestart is actively maintained and supports newer technologies such as containers (LXC, Docker).
|
||||
|
||||
Here are the features of Needrestart:
|
||||
|
||||
* supports (but does not require) systemd
|
||||
* binary blacklisting (i.e. display managers)
|
||||
* tries to detect pending kernel upgrades
|
||||
* tries to detect required restarts of interpreter based daemons (supports Perl, Python, Ruby)
|
||||
* fully integrated into apt/dpkg using hooks
|
||||
|
||||
|
||||
|
||||
It is available in the default repositories too. so, you can install it using command:
|
||||
```
|
||||
$ sudo apt-get install needrestart
|
||||
|
||||
```
|
||||
|
||||
Now you can check the list of daemons need to be restarted after updating your system using command:
|
||||
```
|
||||
$ sudo needrestart
|
||||
Scanning processes...
|
||||
Scanning linux images...
|
||||
|
||||
Running kernel seems to be up-to-date.
|
||||
|
||||
Failed to check for processor microcode upgrades.
|
||||
|
||||
No services need to be restarted.
|
||||
|
||||
No containers need to be restarted.
|
||||
|
||||
No user sessions are running outdated binaries.
|
||||
|
||||
```
|
||||
|
||||
The good thing is Needrestart works on other Linux distributions too. For example, you can install on Arch Linux and its variants from AUR using any AUR helper programs like below.
|
||||
```
|
||||
$ yaourt -S needrestart
|
||||
|
||||
```
|
||||
|
||||
On fedora:
|
||||
```
|
||||
$ sudo dnf install needrestart
|
||||
|
||||
```
|
||||
|
||||
#### 2. Check-enhancements
|
||||
|
||||
The check-enhancements utility is used to find packages which enhance the installed packages. This utility will list all packages that enhances other packages but are not strictly necessary to run it. You can find enhancements for a single package or all installed installed packages using “-ip” or “–installed-packages” flag.
|
||||
|
||||
For example, I am going to list the enhancements for gimp package.
|
||||
```
|
||||
$ check-enhancements gimp
|
||||
gimp => gimp-data: Installed: (none) Candidate: 2.8.22-1
|
||||
gimp => gimp-gmic: Installed: (none) Candidate: 1.7.9+zart-4build3
|
||||
gimp => gimp-gutenprint: Installed: (none) Candidate: 5.2.13-2
|
||||
gimp => gimp-help-ca: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-de: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-el: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-en: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-es: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-fr: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-it: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-ja: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-ko: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-nl: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-nn: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-pt: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-ru: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-sl: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-sv: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-plugin-registry: Installed: (none) Candidate: 7.20140602ubuntu3
|
||||
gimp => xcftools: Installed: (none) Candidate: 1.0.7-6
|
||||
|
||||
```
|
||||
|
||||
To list the enhancements for all installed packages, run:
|
||||
```
|
||||
$ check-enhancements -ip
|
||||
autoconf => autoconf-archive: Installed: (none) Candidate: 20170928-2
|
||||
btrfs-progs => snapper: Installed: (none) Candidate: 0.5.4-3
|
||||
ca-certificates => ca-cacert: Installed: (none) Candidate: 2011.0523-2
|
||||
cryptsetup => mandos-client: Installed: (none) Candidate: 1.7.19-1
|
||||
dpkg => debsig-verify: Installed: (none) Candidate: 0.18
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
#### 3. dgrep
|
||||
|
||||
As the name implies, dgrep is used to search all files in specified packages based on the given regex. For instance, I am going to search for files that contains the regex “text” in Vim package.
|
||||
```
|
||||
$ sudo dgrep "text" vim
|
||||
Binary file /usr/bin/vim.tiny matches
|
||||
/usr/share/doc/vim-tiny/copyright: that they must include this license text. You can also distribute
|
||||
/usr/share/doc/vim-tiny/copyright: include this license text. You are also allowed to include executables
|
||||
/usr/share/doc/vim-tiny/copyright: 1) This license text must be included unmodified.
|
||||
/usr/share/doc/vim-tiny/copyright: text under a) applies to those changes.
|
||||
/usr/share/doc/vim-tiny/copyright: context diff. You can choose what license to use for new code you
|
||||
/usr/share/doc/vim-tiny/copyright: context diff will do. The e-mail address to be used is
|
||||
/usr/share/doc/vim-tiny/copyright: On Debian systems, the complete text of the GPL version 2 license can be
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
The dgrep supports most of grep’s options. Refer the following guide to learn grep commands.
|
||||
|
||||
#### 4 dglob
|
||||
|
||||
The dglob utility generates a list of package names which match a pattern. For example, find the list of packages that matches the string “vim”.
|
||||
```
|
||||
$ sudo dglob vim
|
||||
vim-tiny:amd64
|
||||
vim:amd64
|
||||
vim-common:all
|
||||
vim-runtime:all
|
||||
|
||||
```
|
||||
|
||||
By default, dglob will display only the installed packages. If you want to list all packages (installed and not installed), use **-a** flag.
|
||||
```
|
||||
$ sudo dglob vim -a
|
||||
|
||||
```
|
||||
|
||||
#### 5. debget
|
||||
|
||||
The **debget** utility will download a .deb for a package in APT’s database. Please note that it will only download the given package, not the dependencies.
|
||||
```
|
||||
$ debget nano
|
||||
Get:1 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 nano amd64 2.9.3-2 [231 kB]
|
||||
Fetched 231 kB in 2s (113 kB/s)
|
||||
|
||||
```
|
||||
|
||||
#### 6. dpigs
|
||||
|
||||
This is another useful utility in this collection. The **dpigs** utility will find and show you which installed packages occupy the most disk space.
|
||||
```
|
||||
$ dpigs
|
||||
260644 linux-firmware
|
||||
167195 linux-modules-extra-4.15.0-20-generic
|
||||
75186 linux-headers-4.15.0-20
|
||||
64217 linux-modules-4.15.0-20-generic
|
||||
55620 snapd
|
||||
31376 git
|
||||
31070 libicu60
|
||||
28420 vim-runtime
|
||||
25971 gcc-7
|
||||
24349 g++-7
|
||||
|
||||
```
|
||||
|
||||
As you can see, the linux-firmware packages occupies the most disk space. By default, it will display the **top 10** packages that occupies the most disk space. If you want to display more packages, for example 20, run the following command:
|
||||
```
|
||||
$ dpigs -n 20
|
||||
|
||||
```
|
||||
|
||||
#### 7. debman
|
||||
|
||||
The **debman** utility allows you to easily view man pages from a binary **.deb** without extracting it. You don’t even need to install the .deb package. The following command displays the man page of nano package.
|
||||
```
|
||||
$ debman -f nano_2.9.3-2_amd64.deb nano
|
||||
|
||||
```
|
||||
|
||||
If you don’t have a local copy of the .deb package, use **-p** flag to download and view package’s man page.
|
||||
```
|
||||
$ debman -p nano nano
|
||||
|
||||
```
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
#### 8. debmany
|
||||
|
||||
An installed Debian package has not only a man page, but also includes other files such as acknowledgement, copy right, and read me etc. The **debmany** utility allows you to view and read those files.
|
||||
```
|
||||
$ debmany vim
|
||||
|
||||
```
|
||||
|
||||
![][1]
|
||||
|
||||
Choose the file you want to view using arrow keys and hit ENTER to view the selected file. Press **q** to go back to the main menu.
|
||||
|
||||
If the specified package is not installed, debmany will download it from the APT database and display the man pages. The **dialog** package should be installed to read the man pages.
|
||||
|
||||
#### 9. popbugs
|
||||
|
||||
If you’re a developer, the **popbugs** utility will be quite useful. It will display a customized release-critical bug list based on packages you use (using popularity-contest data). For those who don’t know, the popularity-contest package sets up a cron job that will periodically anonymously submit to the Debian developers statistics about the most used Debian packages on this system. This information helps Debian make decisions such as which packages should go on the first CD. It also lets Debian improve future versions of the distribution so that the most popular packages are the ones which are installed automatically for new users.
|
||||
|
||||
To generate a list of critical bugs and display the result in your default web browser, run:
|
||||
```
|
||||
$ popbugs
|
||||
|
||||
```
|
||||
|
||||
Also, you can save the result in a file as shown below.
|
||||
```
|
||||
$ popbugs --output=bugs.txt
|
||||
|
||||
```
|
||||
|
||||
#### 10. which-pkg-broke
|
||||
|
||||
This command will display all the dependencies of the given package and when each dependency was installed. By using this information, you can easily find which package might have broken another at what time after upgrading the system or a package.
|
||||
```
|
||||
$ which-pkg-broke vim
|
||||
Package <debconf-2.0> has no install time info
|
||||
debconf Wed Apr 25 08:08:40 2018
|
||||
gcc-8-base:amd64 Wed Apr 25 08:08:41 2018
|
||||
libacl1:amd64 Wed Apr 25 08:08:41 2018
|
||||
libattr1:amd64 Wed Apr 25 08:08:41 2018
|
||||
dpkg Wed Apr 25 08:08:41 2018
|
||||
libbz2-1.0:amd64 Wed Apr 25 08:08:41 2018
|
||||
libc6:amd64 Wed Apr 25 08:08:42 2018
|
||||
libgcc1:amd64 Wed Apr 25 08:08:42 2018
|
||||
liblzma5:amd64 Wed Apr 25 08:08:42 2018
|
||||
libdb5.3:amd64 Wed Apr 25 08:08:42 2018
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
#### 11. dhomepage
|
||||
|
||||
The dhomepage utility will display the official website of the given package in your default web browser. For example, the following command will open Vim editor’s home page.
|
||||
```
|
||||
$ dhomepage vim
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for now. Debian-goodies is a must-have tool in your arsenal. Even though, we don’t use all those utilities often, they are worth to learn and I am sure they will be really helpful at times.
|
||||
|
||||
I hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/debian-goodies-a-set-of-useful-utilities-for-debian-and-ubuntu-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://www.ostechnix.com/wp-content/uploads/2018/05/debmany.png
|
||||
@ -1,67 +0,0 @@
|
||||
How CERN Is Using Linux and Open Source
|
||||
============================================================
|
||||
|
||||

|
||||
>CERN relies on open source technology to handle huge amounts of data generated by the Large Hadron Collider. The ATLAS (shown here) is a general-purpose detector that probes for fundamental particles. (Image courtesy: CERN)[Used with permission][2]
|
||||
|
||||
[CERN][3]
|
||||
|
||||
[CERN][6] really needs no introduction. Among other things, the European Organization for Nuclear Research created the World Wide Web and the Large Hadron Collider (LHC), the world’s largest particle accelerator, which was used in discovery of the [Higgs boson][7]. Tim Bell, who is responsible for the organization’s IT Operating Systems and Infrastructure group, says the goal of his team is “to provide the compute facility for 13,000 physicists around the world to analyze those collisions, understand what the universe is made of and how it works.”
|
||||
|
||||
CERN is conducting hardcore science, especially with the LHC, which [generates massive amounts of data][8] when it’s operational. “CERN currently stores about 200 petabytes of data, with over 10 petabytes of data coming in each month when the accelerator is running. This certainly produces extreme challenges for the computing infrastructure, regarding storing this large amount of data, as well as the having the capability to process it in a reasonable timeframe. It puts pressure on the networking and storage technologies and the ability to deliver an efficient compute framework,” Bell said.
|
||||
|
||||
### [tim-bell-cern.png][4]
|
||||
|
||||

|
||||
Tim Bell, CERN[Used with permission][1]Swapnil Bhartiya
|
||||
|
||||
The scale at which LHC operates and the amount of data it generates pose some serious challenges. But CERN is not new to such problems. Founded in 1954, CERN has been around for about 60 years. “We've always been facing computing challenges that are difficult problems to solve, but we have been working with open source communities to solve them,” Bell said. “Even in the 90s, when we invented the World Wide Web, we were looking to share this with the rest of humanity in order to be able to benefit from the research done at CERN and open source was the right vehicle to do that.”
|
||||
|
||||
### Using OpenStack and CentOS
|
||||
|
||||
Today, CERN is a heavy user of OpenStack, and Bell is one of the Board Members of the OpenStack Foundation. But CERN predates OpenStack. For several years, they have been using various open source technologies to deliver services through Linux servers.
|
||||
|
||||
“Over the past 10 years, we've found that rather than taking our problems ourselves, we find upstream open source communities with which we can work, who are facing similar challenges and then we contribute to those projects rather than inventing everything ourselves and then having to maintain it as well,” said Bell.
|
||||
|
||||
A good example is Linux itself. CERN used to be a Red Hat Enterprise Linux customer. But, back in 2004, they worked with Fermilab to build their own Linux distribution called [Scientific Linux][9]. Eventually they realized that, because they were not modifying the kernel, there was no point in spending time spinning up their own distribution; so they migrated to CentOS. Because CentOS is a fully open source and community driven project, CERN could collaborate with the project and contribute to how CentOS is built and distributed.
|
||||
|
||||
CERN helps CentOS with infrastructure and they also organize CentOS DoJo at CERN where engineers can get together to improve the CentOS packaging.
|
||||
|
||||
In addition to OpenStack and CentOS, CERN is a heavy user of other open source projects, including Puppet for configuration management, Grafana and influxDB for monitoring, and is involved in many more.
|
||||
|
||||
“We collaborate with around 170 labs around the world. So every time that we find an improvement in an open source project, other labs can easily take that and use it,” said Bell, “At the same time, we also learn from others. When large scale installations like eBay and Rackspace make changes to improve scalability of solutions, it benefits us and allows us to scale.”
|
||||
|
||||
### Solving realistic problems
|
||||
|
||||
Around 2012, CERN was looking at ways to scale computing for the LHC, but the challenge was people rather than technology. The number of staff that CERN employs is fixed. “We had to find ways in which we can scale the compute without requiring a large number of additional people in order to administer that,” Bell said. “OpenStack provided us with an automated API-driven, software-defined infrastructure.” OpenStack also allowed CERN to look at problems related to the delivery of services and then automate those, without having to scale the staff.
|
||||
|
||||
“We're currently running about 280,000 cores and 7,000 servers across two data centers in Geneva and in Budapest. We are using software-defined infrastructure to automate everything, which allows us to continue to add additional servers while remaining within the same envelope of staff,” said Bell.
|
||||
|
||||
As time progresses, CERN will be dealing with even bigger challenges. Large Hadron Collider has a roadmap out to 2035, including a number of significant upgrades. “We run the accelerator for three to four years and then have a period of 18 months or two years when we upgrade the infrastructure. This maintenance period allows us to also do some computing planning,” said Bell. CERN is also planning High Luminosity Large Hadron Collider upgrade, which will allow for beams with higher luminosity. The upgrade would mean about 60 times more compute requirement compared to what CERN has today.
|
||||
|
||||
“With Moore's Law, we will maybe get one quarter of the way there, so we have to find ways under which we can be scaling the compute and the storage infrastructure correspondingly and finding automation and solutions such as OpenStack will help that,” said Bell.
|
||||
|
||||
“When we started off the large Hadron collider and looked at how we would deliver the computing, it was clear that we couldn't put everything into the data center at CERN, so we devised a distributed grid structure, with tier zero at CERN and then a cascading structure around that,” said Bell. “There are around 12 large tier one centers and then 150 small universities and labs around the world. They receive samples at the data from the LHC in order to assist the physicists to understand and analyze the data.”
|
||||
|
||||
That structure means CERN is collaborating internationally, with hundreds of countries contributing toward the analysis of that data. It boils down to the fundamental principle that open source is not just about sharing code, it’s about collaboration among people to share knowledge and achieve what no single individual, organization, or company can achieve alone. That’s the Higgs boson of the open source world.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/5/how-cern-using-linux-open-source
|
||||
|
||||
作者:[SWAPNIL BHARTIYA ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://home.cern/about/experiments/atlas
|
||||
[4]:https://www.linux.com/files/images/tim-bell-cernpng
|
||||
[5]:https://www.linux.com/files/images/atlas-cernjpg
|
||||
[6]:https://home.cern/
|
||||
[7]:https://home.cern/topics/higgs-boson
|
||||
[8]:https://home.cern/about/computing
|
||||
[9]:https://www.scientificlinux.org/
|
||||
@ -1,3 +1,4 @@
|
||||
translating by Flowsnow
|
||||
Getting started with the Python debugger
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by Flowsnow
|
||||
What is behavior-driven Python?
|
||||
======
|
||||

|
||||
|
||||
@ -0,0 +1,172 @@
|
||||
BootISO – A Simple Bash Script To Securely Create A Bootable USB Device From ISO File
|
||||
======
|
||||
Most of us (including me) very often create a bootable USB device from ISO file for OS installation.
|
||||
|
||||
There are many applications freely available in Linux for this purpose. Even we wrote few of the utility in the past.
|
||||
|
||||
Every one uses different application and each application has their own features and functionality.
|
||||
|
||||
In that few of applications are belongs to CLI and few of them associated with GUI.
|
||||
|
||||
Today we are going to discuss about similar kind of utility called BootISO. It’s a simple bash script, which allow users to create a USB device from ISO file.
|
||||
|
||||
Many of the Linux admin uses dd command to create bootable ISO, which is one of the native and famous method but the same time, it’s one of the very dangerous command. So, be careful, when you performing any action with dd command.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [Etcher – Easy way to Create a bootable USB drive & SD card from an ISO image][1]
|
||||
**(#)** [Create a bootable USB drive from an ISO image using dd command on Linux][2]
|
||||
|
||||
### What IS BootISO
|
||||
|
||||
[BootIOS][3] is a simple bash script, which allow users to securely create a bootable USB device from one ISO file. It’s written in bash.
|
||||
|
||||
It doesn’t offer any GUI but in the same time it has vast of options, which allow newbies to create a bootable USB device in Linux without any issues. Since it’s a intelligent tool that automatically choose if any USB device is connected on the system.
|
||||
|
||||
It will print the list when the system has more than one USB device connected. When you choose manually another hard disk manually instead of USB, this will safely exit without writing anything on it.
|
||||
|
||||
This script will also check for dependencies and prompt user for installation, it works with all package managers such as apt-get, yum, dnf, pacman and zypper.
|
||||
|
||||
### BootISO Features
|
||||
|
||||
* It checks whether the selected ISO has the correct mime-type or not. If no then it exit.
|
||||
* BootISO will exit automatically, if you selected any other disks (local hard drive) except USB drives.
|
||||
* BootISO allow users to select the desired USB drives when you have more than one.
|
||||
* BootISO prompts the user for confirmation before erasing and paritioning USB device.
|
||||
* BootISO will handle any failure from a command properly and exit.
|
||||
* BootISO will call a cleanup routine on exit with trap.
|
||||
|
||||
|
||||
|
||||
### How To Install BootISO In Linux
|
||||
|
||||
There are few ways are available to install BootISO in Linux but i would advise users to install using the following method.
|
||||
```
|
||||
$ curl -L https://git.io/bootiso -O
|
||||
$ chmod +x bootiso
|
||||
$ sudo mv bootiso /usr/local/bin/
|
||||
|
||||
```
|
||||
|
||||
Once BootISO installed, run the following command to list the available USB devices.
|
||||
```
|
||||
$ bootiso -l
|
||||
|
||||
Listing USB drives available in your system:
|
||||
NAME HOTPLUG SIZE STATE TYPE
|
||||
sdd 1 32G running disk
|
||||
|
||||
```
|
||||
|
||||
If you have only one USB device, then simple run the following command to create a bootable USB device from ISO file.
|
||||
```
|
||||
$ bootiso /path/to/iso file
|
||||
|
||||
$ bootiso /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
Granting root privileges for bootiso.
|
||||
Listing USB drives available in your system:
|
||||
NAME HOTPLUG SIZE STATE TYPE
|
||||
sdd 1 32G running disk
|
||||
Autoselecting `sdd' (only USB device candidate)
|
||||
The selected device `/dev/sdd' is connected through USB.
|
||||
Created ISO mount point at `/tmp/iso.vXo'
|
||||
`bootiso' is about to wipe out the content of device `/dev/sdd'.
|
||||
Are you sure you want to proceed? (y/n)>y
|
||||
Erasing contents of /dev/sdd...
|
||||
Creating FAT32 partition on `/dev/sdd1'...
|
||||
Created USB device mount point at `/tmp/usb.0j5'
|
||||
Copying files from ISO to USB device with `rsync'
|
||||
Synchronizing writes on device `/dev/sdd'
|
||||
`bootiso' took 250 seconds to write ISO to USB device with `rsync' method.
|
||||
ISO succesfully unmounted.
|
||||
USB device succesfully unmounted.
|
||||
USB device succesfully ejected.
|
||||
You can safely remove it !
|
||||
|
||||
```
|
||||
|
||||
Mention your device name, when you have more than one USB device using `--device` option.
|
||||
```
|
||||
$ bootiso -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
|
||||
```
|
||||
|
||||
By default bootios uses `rsync` command to perform all the action and if you want to use `dd` command instead of, use the following format.
|
||||
```
|
||||
$ bootiso --dd -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
|
||||
```
|
||||
|
||||
If you want to skip `mime-type` check, include the following option with bootios utility.
|
||||
```
|
||||
$ bootiso --no-mime-check -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
|
||||
```
|
||||
|
||||
Add the below option with bootios to skip user for confirmation before erasing and partitioning USB device.
|
||||
```
|
||||
$ bootiso -y -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
|
||||
```
|
||||
|
||||
Enable autoselecting USB devices in conjunction with -y option.
|
||||
```
|
||||
$ bootiso -y -a /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
|
||||
```
|
||||
|
||||
To know more all the available option for bootiso, run the following command.
|
||||
```
|
||||
$ bootiso -h
|
||||
Create a bootable USB from any ISO securely.
|
||||
Usage: bootiso [...]
|
||||
|
||||
Options
|
||||
|
||||
-h, --help, help Display this help message and exit.
|
||||
-v, --version Display version and exit.
|
||||
-d, --device Select block file as USB device.
|
||||
If is not connected through USB, `bootiso' will fail and exit.
|
||||
Device block files are usually situated in /dev/sXX or /dev/hXX.
|
||||
You will be prompted to select a device if you don't use this option.
|
||||
-b, --bootloader Install a bootloader with syslinux (safe mode) for non-hybrid ISOs. Does not work with `--dd' option.
|
||||
-y, --assume-yes `bootiso' won't prompt the user for confirmation before erasing and partitioning USB device.
|
||||
Use at your own risks.
|
||||
-a, --autoselect Enable autoselecting USB devices in conjunction with -y option.
|
||||
Autoselect will automatically select a USB drive device if there is exactly one connected to the system.
|
||||
Enabled by default when neither -d nor --no-usb-check options are given.
|
||||
-J, --no-eject Do not eject device after unmounting.
|
||||
-l, --list-usb-drives List available USB drives.
|
||||
-M, --no-mime-check `bootiso' won't assert that selected ISO file has the right mime-type.
|
||||
-s, --strict-mime-check Disallow loose application/octet-stream mime type in ISO file.
|
||||
-- POSIX end of options.
|
||||
--dd Use `dd' utility instead of mounting + `rsync'.
|
||||
Does not allow bootloader installation with syslinux.
|
||||
--no-usb-check `bootiso' won't assert that selected device is a USB (connected through USB bus).
|
||||
Use at your own risks.
|
||||
|
||||
Readme
|
||||
|
||||
Bootiso v2.5.2.
|
||||
Author: Jules Samuel Randolph
|
||||
Bugs and new features: https://github.com/jsamr/bootiso/issues
|
||||
If you like bootiso, please help the community by making it visible:
|
||||
* star the project at https://github.com/jsamr/bootiso
|
||||
* upvote those SE post: https://goo.gl/BNRmvm https://goo.gl/YDBvFe
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/bootiso-a-simple-bash-script-to-securely-create-a-bootable-usb-device-in-linux-from-iso-file/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/etcher-easy-way-to-create-a-bootable-usb-drive-sd-card-from-an-iso-image-on-linux/
|
||||
[2]:https://www.2daygeek.com/create-a-bootable-usb-drive-from-an-iso-image-using-dd-command-on-linux/
|
||||
[3]:https://github.com/jsamr/bootiso
|
||||
218
sources/tech/20180618 Twitter Sentiment Analysis using NodeJS.md
Normal file
218
sources/tech/20180618 Twitter Sentiment Analysis using NodeJS.md
Normal file
@ -0,0 +1,218 @@
|
||||
BriFuture is translating
|
||||
|
||||
Twitter Sentiment Analysis using NodeJS
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
If you want to know how people feel about something, there is no better place than Twitter. It is a continuous stream of opinion, with around 6,000 new tweets being created every second. The internet is quick to react to events and if you want to be updated with the latest and hottest, Twitter is the place to be.
|
||||
|
||||
Now, we live in an age where data is king and companies put Twitter's data to good use. From gauging the reception of their new products to trying to predict the next market trend, analysis of Twitter data has many uses. Businesses use it to market their product that to the right customers, to gather feedback on their brand and improve or to assess the reasons for the failure of a product or promotional campaign. Not only businesses, many political and economic decisions are made based on observation of people's opinion. Today, I will try and give you a taste of simple [sentiment analysis][1] of tweets to determine whether a tweet is positive, negative or neutral. It won't be as sophisticated as those used by professionals, but nonetheless, it will give you an idea about opinion mining.
|
||||
|
||||
We will be using NodeJs since JavaScript is ubiquitous nowadays and is one of the easiest languages to get started with.
|
||||
|
||||
### Prerequisite:
|
||||
|
||||
* NodeJs and NPM installed
|
||||
|
||||
* A little experience with NodeJs and NPM packages
|
||||
|
||||
* some familiarity with the command line.
|
||||
|
||||
Alright, that's it. Let's get started.
|
||||
|
||||
### Getting Started
|
||||
|
||||
Make a new directory for your project and go inside the directory. Open a terminal (or command line). Go inside the newly created directory and run the `npm init -y` command. This will create a `package.json` in your directory. Now we can install the npm packages we need. We just need to create a new file named `index.js` and then we are all set to start coding.
|
||||
|
||||
### Getting the tweets
|
||||
|
||||
Well, we want to analyze tweets and for that, we need programmatic access to Twitter. For this, we will use the [twit][2] package. So, let's install it with the `npm i twit` command. We also need to register an App through our account to gain access to the Twitter API. Head over to this [link][3], fill in all the details and copy ‘Consumer Key’, ‘Consumer Secret’, ‘Access token’ and ‘Access Token Secret’ from 'Keys and Access Token' tabs in a `.env` file like this:
|
||||
|
||||
```
|
||||
# .env
|
||||
# replace the stars with values you copied
|
||||
CONSUMER_KEY=************
|
||||
CONSUMER_SECRET=************
|
||||
ACCESS_TOKEN=************
|
||||
ACCESS_TOKEN_SECRET=************
|
||||
|
||||
```
|
||||
|
||||
Now, let's begin.
|
||||
|
||||
Open `index.js` in your favorite code editor. We need to install the `dotenv`package to read from `.env` file with the command `npm i dotenv`. Alright, let's create an API instance.
|
||||
|
||||
```
|
||||
const Twit = require('twit');
|
||||
const dotenv = require('dotenv');
|
||||
|
||||
dotenv.config();
|
||||
|
||||
const { CONSUMER_KEY
|
||||
, CONSUMER_SECRET
|
||||
, ACCESS_TOKEN
|
||||
, ACCESS_TOKEN_SECRET
|
||||
} = process.env;
|
||||
|
||||
const config_twitter = {
|
||||
consumer_key: CONSUMER_KEY,
|
||||
consumer_secret: CONSUMER_SECRET,
|
||||
access_token: ACCESS_TOKEN,
|
||||
access_token_secret: ACCESS_TOKEN_SECRET,
|
||||
timeout_ms: 60*1000
|
||||
};
|
||||
|
||||
let api = new Twit(config_twitter);
|
||||
|
||||
```
|
||||
|
||||
Here we have established a connection to the Twitter with the required configuration. But we are not doing anything with it. Let's define a function to get tweets.
|
||||
|
||||
```
|
||||
async function get_tweets(q, count) {
|
||||
let tweets = await api.get('search/tweets', {q, count, tweet_mode: 'extended'});
|
||||
return tweets.data.statuses.map(tweet => tweet.full_text);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This is an async function because of the `api.get` the function returns a promise and instead of chaining `then`s, I wanted an easy way to extract the text of the tweets. It accepts two arguments -q and count, `q` being the query or keyword we want to search for and `count` is the number of tweets we want the `api` to return.
|
||||
|
||||
So now we have an easy way to get the full texts from the tweets. But we still have a problem, the text that we will get now may contain some links or may be truncated if it's a retweet. So we will write another function that will extract and return the text of the tweets, even for retweets and remove the links if any.
|
||||
|
||||
```
|
||||
function get_text(tweet) {
|
||||
let txt = tweet.retweeted_status ? tweet.retweeted_status.full_text : tweet.full_text;
|
||||
return txt.split(/ |\n/).filter(v => !v.startsWith('http')).join(' ');
|
||||
}
|
||||
|
||||
async function get_tweets(q, count) {
|
||||
let tweets = await api.get('search/tweets', {q, count, 'tweet_mode': 'extended'});
|
||||
return tweets.data.statuses.map(get_text);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
So, now we have the text of tweets. Our next step is getting the sentiment from the text. For this, we will use another package from `npm` - [`sentiment`][4]package. Let's install it like the other packages and add to our script.
|
||||
|
||||
```
|
||||
const sentiment = require('sentiment')
|
||||
|
||||
```
|
||||
|
||||
Using `sentiment` is very easy. We will just have to call the `sentiment`function on the text that we want to analyze and it will return us the comparative score of the text. If the score is below 0, it expresses a negative sentiment, a score above 0 is positive and 0, as you may have guessed, is neutral. So based on this, we will print the tweets in different colors - green for positive, red for negative and blue for neutral. For this, we will use the [`colors`][5] package. Let's install it like the other packages and add to our script.
|
||||
|
||||
```
|
||||
const colors = require('colors/safe');
|
||||
|
||||
```
|
||||
|
||||
Alright, now let us bring it all together in a `main` function.
|
||||
|
||||
```
|
||||
async function main() {
|
||||
let keyword = \* define the keyword that you want to search for *\;
|
||||
let count = \* define the count of tweets you want *\;
|
||||
let tweets = await get_tweets(keyword, count);
|
||||
for (tweet of tweets) {
|
||||
let score = sentiment(tweet).comparative;
|
||||
tweet = `${tweet}\n`;
|
||||
if (score > 0) {
|
||||
tweet = colors.green(tweet);
|
||||
} else if (score < 0) {
|
||||
tweet = colors.red(tweet);
|
||||
} else {
|
||||
tweet = colors.blue(tweet);
|
||||
}
|
||||
console.log(tweet);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
And finally, execute the `main` function.
|
||||
|
||||
```
|
||||
main();
|
||||
|
||||
```
|
||||
|
||||
There you have it, a short script of analyzing the basic sentiments of a tweet.
|
||||
|
||||
```
|
||||
\\ full script
|
||||
const Twit = require('twit');
|
||||
const dotenv = require('dotenv');
|
||||
const sentiment = require('sentiment');
|
||||
const colors = require('colors/safe');
|
||||
|
||||
dotenv.config();
|
||||
|
||||
const { CONSUMER_KEY
|
||||
, CONSUMER_SECRET
|
||||
, ACCESS_TOKEN
|
||||
, ACCESS_TOKEN_SECRET
|
||||
} = process.env;
|
||||
|
||||
const config_twitter = {
|
||||
consumer_key: CONSUMER_KEY,
|
||||
consumer_secret: CONSUMER_SECRET,
|
||||
access_token: ACCESS_TOKEN,
|
||||
access_token_secret: ACCESS_TOKEN_SECRET,
|
||||
timeout_ms: 60*1000
|
||||
};
|
||||
|
||||
let api = new Twit(config_twitter);
|
||||
|
||||
function get_text(tweet) {
|
||||
let txt = tweet.retweeted_status ? tweet.retweeted_status.full_text : tweet.full_text;
|
||||
return txt.split(/ |\n/).filter(v => !v.startsWith('http')).join(' ');
|
||||
}
|
||||
|
||||
async function get_tweets(q, count) {
|
||||
let tweets = await api.get('search/tweets', {q, count, 'tweet_mode': 'extended'});
|
||||
return tweets.data.statuses.map(get_text);
|
||||
}
|
||||
|
||||
async function main() {
|
||||
let keyword = 'avengers';
|
||||
let count = 100;
|
||||
let tweets = await get_tweets(keyword, count);
|
||||
for (tweet of tweets) {
|
||||
let score = sentiment(tweet).comparative;
|
||||
tweet = `${tweet}\n`;
|
||||
if (score > 0) {
|
||||
tweet = colors.green(tweet);
|
||||
} else if (score < 0) {
|
||||
tweet = colors.red(tweet);
|
||||
} else {
|
||||
tweet = colors.blue(tweet)
|
||||
}
|
||||
console.log(tweet)
|
||||
}
|
||||
}
|
||||
|
||||
main();
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://boostlog.io/@anshulc95/twitter-sentiment-analysis-using-nodejs-5ad1331247018500491f3b6a
|
||||
|
||||
作者:[Anshul Chauhan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://boostlog.io/@anshulc95
|
||||
[1]:https://en.wikipedia.org/wiki/Sentiment_analysis
|
||||
[2]:https://github.com/ttezel/twit
|
||||
[3]:https://boostlog.io/@anshulc95/apps.twitter.com
|
||||
[4]:https://www.npmjs.com/package/sentiment
|
||||
[5]:https://www.npmjs.com/package/colors
|
||||
[6]:https://boostlog.io/tags/nodejs
|
||||
[7]:https://boostlog.io/tags/twitter
|
||||
[8]:https://boostlog.io/@anshulc95
|
||||
@ -1,254 +0,0 @@
|
||||
Translating by qhwdw
|
||||
How to reset, revert, and return to previous states in Git
|
||||
======
|
||||
|
||||

|
||||
|
||||
One of the lesser understood (and appreciated) aspects of working with Git is how easy it is to get back to where you were before—that is, how easy it is to undo even major changes in a repository. In this article, we'll take a quick look at how to reset, revert, and completely return to previous states, all with the simplicity and elegance of individual Git commands.
|
||||
|
||||
### Reset
|
||||
|
||||
Let's start with the Git command `reset`. Practically, you can think of it as a "rollback"—it points your local environment back to a previous commit. By "local environment," we mean your local repository, staging area, and working directory.
|
||||
|
||||
Take a look at Figure 1. Here we have a representation of a series of commits in Git. A branch in Git is simply a named, movable pointer to a specific commit. In this case, our branch master is a pointer to the latest commit in the chain.
|
||||
|
||||
![Local Git environment with repository, staging area, and working directory][2]
|
||||
|
||||
Fig. 1: Local Git environment with repository, staging area, and working directory
|
||||
|
||||
If we look at what's in our master branch now, we can see the chain of commits made so far.
|
||||
```
|
||||
$ git log --oneline
|
||||
b764644 File with three lines
|
||||
7c709f0 File with two lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
`reset` command to do this for us. For example, if we want to reset master to point to the commit two back from the current commit, we could use either of the following methods:
|
||||
|
||||
What happens if we want to roll back to a previous commit. Simple—we can just move the branch pointer. Git supplies thecommand to do this for us. For example, if we want to reset master to point to the commit two back from the current commit, we could use either of the following methods:
|
||||
|
||||
`$ git reset 9ef9173` (using an absolute commit SHA1 value 9ef9173)
|
||||
|
||||
or
|
||||
|
||||
`$ git reset current~2` (using a relative value -2 before the "current" tag)
|
||||
|
||||
Figure 2 shows the results of this operation. After this, if we execute a `git log` command on the current branch (master), we'll see just the one commit.
|
||||
```
|
||||
$ git log --oneline
|
||||
|
||||
9ef9173 File with one line
|
||||
|
||||
```
|
||||
|
||||
![After reset][4]
|
||||
|
||||
Fig. 2: After `reset`
|
||||
|
||||
The `git reset` command also includes options to update the other parts of your local environment with the contents of the commit where you end up. These options include: `hard` to reset the commit being pointed to in the repository, populate the working directory with the contents of the commit, and reset the staging area; `soft` to only reset the pointer in the repository; and `mixed` (the default) to reset the pointer and the staging area.
|
||||
|
||||
Using these options can be useful in targeted circumstances such as `git reset --hard <commit sha1 | reference>``.` This overwrites any local changes you haven't committed. In effect, it resets (clears out) the staging area and overwrites content in the working directory with the content from the commit you reset to. Before you use the `hard` option, be sure that's what you really want to do, since the command overwrites any uncommitted changes.
|
||||
|
||||
### Revert
|
||||
|
||||
The net effect of the `git revert` command is similar to reset, but its approach is different. Where the `reset` command moves the branch pointer back in the chain (typically) to "undo" changes, the `revert` command adds a new commit at the end of the chain to "cancel" changes. The effect is most easily seen by looking at Figure 1 again. If we add a line to a file in each commit in the chain, one way to get back to the version with only two lines is to reset to that commit, i.e., `git reset HEAD~1`.
|
||||
|
||||
Another way to end up with the two-line version is to add a new commit that has the third line removed—effectively canceling out that change. This can be done with a `git revert` command, such as:
|
||||
```
|
||||
$ git revert HEAD
|
||||
|
||||
```
|
||||
|
||||
Because this adds a new commit, Git will prompt for the commit message:
|
||||
```
|
||||
Revert "File with three lines"
|
||||
|
||||
This reverts commit b764644bad524b804577684bf74e7bca3117f554.
|
||||
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with '#' will be ignored, and an empty message aborts the commit.
|
||||
# On branch master
|
||||
# Changes to be committed:
|
||||
# modified: file1.txt
|
||||
#
|
||||
```
|
||||
|
||||
Figure 3 (below) shows the result after the `revert` operation is completed.
|
||||
|
||||
If we do a `git log` now, we'll see a new commit that reflects the contents before the previous commit.
|
||||
```
|
||||
$ git log --oneline
|
||||
11b7712 Revert "File with three lines"
|
||||
b764644 File with three lines
|
||||
7c709f0 File with two lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
Here are the current contents of the file in the working directory:
|
||||
```
|
||||
$ cat <filename>
|
||||
Line 1
|
||||
Line 2
|
||||
```
|
||||
|
||||
#### Revert or reset?
|
||||
|
||||
Why would you choose to do a `revert` over a `reset` operation? If you have already pushed your chain of commits to the remote repository (where others may have pulled your code and started working with it), a revert is a nicer way to cancel out changes for them. This is because the Git workflow works well for picking up additional commits at the end of a branch, but it can be challenging if a set of commits is no longer seen in the chain when someone resets the branch pointer back.
|
||||
|
||||
This brings us to one of the fundamental rules when working with Git in this manner: Making these kinds of changes in your local repository to code you haven't pushed yet is fine. But avoid making changes that rewrite history if the commits have already been pushed to the remote repository and others may be working with them.
|
||||
|
||||
In short, if you rollback, undo, or rewrite the history of a commit chain that others are working with, your colleagues may have a lot more work when they try to merge in changes based on the original chain they pulled. If you must make changes against code that has already been pushed and is being used by others, consider communicating before you make the changes and give people the chance to merge their changes first. Then they can pull a fresh copy after the infringing operation without needing to merge.
|
||||
|
||||
You may have noticed that the original chain of commits was still there after we did the reset. We moved the pointer and reset the code back to a previous commit, but it did not delete any commits. This means that, as long as we know the original commit we were pointing to, we can "restore" back to the previous point by simply resetting back to the original head of the branch:
|
||||
```
|
||||
git reset <sha1 of commit>
|
||||
|
||||
```
|
||||
|
||||
A similar thing happens in most other operations we do in Git when commits are replaced. New commits are created, and the appropriate pointer is moved to the new chain. But the old chain of commits still exists.
|
||||
|
||||
### Rebase
|
||||
|
||||
Now let's look at a branch rebase. Consider that we have two branches—master and feature—with the chain of commits shown in Figure 4 below. Master has the chain `C4->C2->C1->C0` and feature has the chain `C5->C3->C2->C1->C0`.
|
||||
|
||||
![Chain of commits for branches master and feature][6]
|
||||
|
||||
Fig. 4: Chain of commits for branches master and feature
|
||||
|
||||
If we look at the log of commits in the branches, they might look like the following. (The `C` designators for the commit messages are used to make this easier to understand.)
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
000f9ae C3
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
I tell people to think of a rebase as a "merge with history" in Git. Essentially what Git does is take each different commit in one branch and attempt to "replay" the differences onto the other branch.
|
||||
|
||||
So, we can rebase a feature onto master to pick up `C4` (e.g., insert it into feature's chain). Using the basic Git commands, it might look like this:
|
||||
```
|
||||
$ git checkout feature
|
||||
$ git rebase master
|
||||
|
||||
First, rewinding head to replay your work on top of it...
|
||||
Applying: C3
|
||||
Applying: C5
|
||||
```
|
||||
|
||||
Afterward, our chain of commits would look like Figure 5.
|
||||
|
||||
![Chain of commits after the rebase command][8]
|
||||
|
||||
Fig. 5: Chain of commits after the `rebase` command
|
||||
|
||||
Again, looking at the log of commits, we can see the changes.
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
|
||||
$ git log --oneline feature
|
||||
c4533a5 C5
|
||||
64f2047 C3
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
Notice that we have `C3'` and `C5'`—new commits created as a result of making the changes from the originals "on top of" the existing chain in master. But also notice that the "original" `C3` and `C5` are still there—they just don't have a branch pointing to them anymore.
|
||||
|
||||
If we did this rebase, then decided we didn't like the results and wanted to undo it, it would be as simple as:
|
||||
```
|
||||
$ git reset 79768b8
|
||||
|
||||
```
|
||||
|
||||
With this simple change, our branch would now point back to the same set of commits as before the `rebase` operation—effectively undoing it (Figure 6).
|
||||
|
||||
![After undoing rebase][10]
|
||||
|
||||
Fig. 6: After undoing the `rebase` operation
|
||||
|
||||
What happens if you can't recall what commit a branch pointed to before an operation? Fortunately, Git again helps us out. For most operations that modify pointers in this way, Git remembers the original commit for you. In fact, it stores it in a special reference named `ORIG_HEAD `within the `.git` repository directory. That path is a file containing the most recent reference before it was modified. If we `cat` the file, we can see its contents.
|
||||
```
|
||||
$ cat .git/ORIG_HEAD
|
||||
79768b891f47ce06f13456a7e222536ee47ad2fe
|
||||
```
|
||||
|
||||
We could use the `reset` command, as before, to point back to the original chain. Then the log would show this:
|
||||
```
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
000f9ae C3
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
Another place to get this information is in the reflog. The reflog is a play-by-play listing of switches or changes to references in your local repository. To see it, you can use the `git reflog` command:
|
||||
```
|
||||
$ git reflog
|
||||
79768b8 HEAD@{0}: reset: moving to 79768b
|
||||
c4533a5 HEAD@{1}: rebase finished: returning to refs/heads/feature
|
||||
c4533a5 HEAD@{2}: rebase: C5
|
||||
64f2047 HEAD@{3}: rebase: C3
|
||||
6a92e7a HEAD@{4}: rebase: checkout master
|
||||
79768b8 HEAD@{5}: checkout: moving from feature to feature
|
||||
79768b8 HEAD@{6}: commit: C5
|
||||
000f9ae HEAD@{7}: checkout: moving from master to feature
|
||||
6a92e7a HEAD@{8}: commit: C4
|
||||
259bf36 HEAD@{9}: checkout: moving from feature to master
|
||||
000f9ae HEAD@{10}: commit: C3
|
||||
259bf36 HEAD@{11}: checkout: moving from master to feature
|
||||
259bf36 HEAD@{12}: commit: C2
|
||||
f33ae68 HEAD@{13}: commit: C1
|
||||
5043e79 HEAD@{14}: commit (initial): C0
|
||||
```
|
||||
|
||||
You can then reset to any of the items in that list using the special relative naming format you see in the log:
|
||||
```
|
||||
$ git reset HEAD@{1}
|
||||
|
||||
```
|
||||
|
||||
Once you understand that Git keeps the original chain of commits around when operations "modify" the chain, making changes in Git becomes much less scary. This is one of Git's core strengths: being able to quickly and easily try things out and undo them if they don't work.
|
||||
|
||||
Brent Laster will present [Power Git: Rerere, Bisect, Subtrees, Filter Branch, Worktrees, Submodules, and More][11] at the 20th annual [OSCON][12] event, July 16-19 in Portland, Ore. For more tips and explanations about using Git at any level, checkout Brent's book "[Professional Git][13]," available on Amazon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/git-reset-revert-rebase-commands
|
||||
|
||||
作者:[Brent Laster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bclaster
|
||||
[1]:/file/401126
|
||||
[2]:https://opensource.com/sites/default/files/uploads/gitcommands1_local-environment.png (Local Git environment with repository, staging area, and working directory)
|
||||
[3]:/file/401131
|
||||
[4]:https://opensource.com/sites/default/files/uploads/gitcommands2_reset.png (After reset)
|
||||
[5]:/file/401141
|
||||
[6]:https://opensource.com/sites/default/files/uploads/gitcommands4_commits-branches.png (Chain of commits for branches master and feature)
|
||||
[7]:/file/401146
|
||||
[8]:https://opensource.com/sites/default/files/uploads/gitcommands5_commits-rebase.png (Chain of commits after the rebase command)
|
||||
[9]:/file/401151
|
||||
[10]:https://opensource.com/sites/default/files/uploads/gitcommands6_rebase-undo.png (After undoing rebase)
|
||||
[11]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67142
|
||||
[12]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
[13]:https://www.amazon.com/Professional-Git-Brent-Laster/dp/111928497X/ref=la_B01MTGIINQ_1_2?s=books&ie=UTF8&qid=1528826673&sr=1-2
|
||||
@ -1,103 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Bitcoin is a Cult — Adam Caudill
|
||||
======
|
||||
The Bitcoin community has changed greatly over the years; from technophiles that could explain a [Merkle tree][1] in their sleep, to speculators driven by the desire for a quick profit & blockchain startups seeking billion dollar valuations led by people who don’t even know what a Merkle tree is. As the years have gone on, a zealotry has been building around Bitcoin and other cryptocurrencies driven by people who see them as something far grander than they actually are; people who believe that normal (or fiat) currencies are becoming a thing of the past, and the cryptocurrencies will fundamentally change the world’s economy.
|
||||
|
||||
Every year, their ranks grow, and their perception of cryptocurrencies becomes more grandiose, even as [novel uses][2] of the technology brings it to its knees. While I’m a firm believer that a well designed cryptocurrency could ease the flow of money across borders, and provide a stable option in areas of mass inflation, the reality is that we aren’t there yet. In fact, it’s the substantial instability in value that allows speculators to make money. Those that preach that the US Dollar and Euro are on their deathbed have utterly abandoned an objective view of reality.
|
||||
|
||||
### A little background…
|
||||
|
||||
I read the Bitcoin white-paper the day it was released – an interesting use of [Merkle trees][1] to create a public ledger and a fairly reasonable consensus protocol – it got the attention of many in the cryptography sphere for its novel properties. In the years since that paper was released, Bitcoin has become rather valuable, attracted many that see it as an investment, and a loyal (and vocal) following of people who think it’ll change everything. This discussion is about the latter.
|
||||
|
||||
Yesterday, someone on Twitter posted the hash of a recent Bitcoin block, the thousands of Tweets and other conversations that followed have convinced me that Bitcoin has crossed the line into true cult territory.
|
||||
|
||||
It all started with this Tweet by Mark Wilcox:
|
||||
|
||||
> #00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a
|
||||
> — Mark Wilcox (@mwilcox) June 19, 2018
|
||||
|
||||
The value posted is the hash of [Bitcoin block #528249][3]. The leading zeros are a result of the mining process; to mine a block you combine the contents of the block with a nonce (and other data), hash it, and it has to have at least a certain number of leading zeros to be considered valid. If it doesn’t have the correct number, you change the nonce and try again. Repeat this until the number of leading zeros is the right number, and you now have a valid block. The part that people got excited about is what follows, 21e800.
|
||||
|
||||
Some are claiming this is an intentional reference, that whoever mined this block actually went well beyond the current difficulty to not just bruteforce the leading zeros, but also the next 24 bits – which would require some serious computing power. If someone had the ability to bruteforce this, it could indicate something rather serious, such as a substantial breakthrough in computing or cryptography.
|
||||
|
||||
You must be asking yourself, what’s so important about 21e800 – a question you would surely regret. Some are claiming it’s a reference to [E8 Theory][4] (a widely criticized paper that presents a standard field theory), or to the 21,000,000 total Bitcoins that will eventually exist (despite the fact that `21 x 10^8` would be 2,100,000,000). There are others, they are just too crazy to write about. Another important fact is that a block is mined on average on once a year that has 21e8 following the leading zeros – those were never seen as anything important.
|
||||
|
||||
This leads to where things get fun: the [theories][5] that are circulating about how this happened.
|
||||
|
||||
* A quantum computer, that is somehow able to hash at unbelievable speed. This is despite the fact that there’s no indication in theories around quantum computers that they’ll be able to do this; hashing is one thing that’s considered safe from quantum computers.
|
||||
* Time travel. Yes, people are actually saying that someone came back from the future to mine this block. I think this is crazy enough that I don’t need to get into why this is wrong.
|
||||
* Satoshi Nakamoto is back. Despite the fact that there has been no activity with his private keys, some theorize that he has returned, and is somehow able to do things that nobody can. These theories don’t explain how he could do it.
|
||||
|
||||
|
||||
|
||||
> So basically (as i understand) Satoshi, in order to have known and computed the things that he did, according to modern science he was either:
|
||||
>
|
||||
> A) Using a quantum computer
|
||||
> B) Fom the future
|
||||
> C) Both
|
||||
>
|
||||
> — Crypto Randy Marsh [REKT] (@nondualrandy) [June 21, 2018][6]
|
||||
|
||||
If all this sounds like [numerology][7] to you, you aren’t alone.
|
||||
|
||||
All this discussion around special meaning in block hashes also reignited the discussion around something that is, at least somewhat, interesting. The Bitcoin genesis block, the first bitcoin block, does have an unusual property: the early Bitcoin blocks required that the first 32 bits of the hash be zero; however the genesis block had 43 leading zero bits. As the code that produced the genesis block was never released, it’s not known how it was produced, nor is it known what type of hardware was used to produce it. Satoshi had an academic background, so may have had access to more substantial computing power than was common at the time via a university. At this point, the oddities of the genesis block are a historical curiosity, nothing more.
|
||||
|
||||
### A brief digression on hashing
|
||||
|
||||
This hullabaloo started with the hash of a Bitcoin block; so it’s important to understand just what a hash is, and understand one very important property they have. A hash is a one-way cryptographic function that creates a pseudo-random output based on the data that it’s given.
|
||||
|
||||
What this means, for the purposes of this discussion, is that for each input you get a random output. Random numbers have a way of sometimes looking interesting, simply as a result of being random and the human brain’s affinity to find order in everything. When you start looking for order in random data, you find interesting things – that are yet meaningless, as it’s simply random. When people ascribe significant meaning to random data, it tells you far more about the mindset of those involved rather than the data itself.
|
||||
|
||||
### Cult of the Coin
|
||||
|
||||
First, let us define a couple of terms:
|
||||
|
||||
* Cult: a system of religious veneration and devotion directed toward a particular figure or object.
|
||||
* Religion: a pursuit or interest to which someone ascribes supreme importance.
|
||||
|
||||
|
||||
|
||||
The Cult of the Coin has many saints, perhaps none greater than Satoshi Nakamoto, the pseudonym used by the person(s) that created Bitcoin. Vigorously defended, ascribed with ability and understanding far above that of a normal researcher, seen as a visionary beyond compare that is leading the world to a new economic order. When combined with Satoshi’s secretive nature and unknown true identify, adherents to the Cult view Satoshi as a truly venerated figure.
|
||||
|
||||
That is, of course, with the exception of adherents that follow a different saint, who is unquestionably correct, and any criticism is seen as not only an attack on their saint, but on themselves as well. Those that follow EOS for example, may see Satoshi has a hack that developed a failed project, yet will react fiercely to the slightest criticism of EOS, a reaction so strong that it’s reserved only for an attack on one’s deity. Those that follow IOTA react with equal fierceness; and there are many others.
|
||||
|
||||
These adherents have abandoned objectivity and reasonable discourse, and allowed their zealotry to cloud their vision. Any discussion of these projects and the people behind them that doesn’t include glowing praise inevitably ends with a level of vitriolic speech that is beyond reason for a discussion of technology.
|
||||
|
||||
This is dangerous, for many reasons:
|
||||
|
||||
* Developers & researchers are blinded to flaws. Due to the vast quantities of praise by adherents, those involved develop a grandiose view of their own abilities, and begin to view criticism as unjustified attacks – as they couldn’t possibly have been wrong.
|
||||
* Real problems are attacked. Instead of technical issues being seen as problems to be solved and opportunities to improve, they are seen as attacks from people who must be motivated to destroy the project.
|
||||
* One coin to rule them all. Adherents are often aligned to one, and only one, saint. Acknowledging the qualities of another project means acceptance of flaws or deficiencies in their own, which they will not do.
|
||||
* Preventing real progress. Evolution is brutal, it requires death, it requires projects to fail and that the reasons for those failures to be acknowledged. If lessons from failure are ignored, if things that should die aren’t allowed to, progress stalls.
|
||||
|
||||
|
||||
|
||||
Discussions around many of the cryptocurrencies and related blockchain projects are becoming more and more toxic, becoming impossible for well-intentioned people to have real technical discussions without being attacked. With discussions of real flaws, flaws that would doom a design in any other environment, being instantly treated as heretical without any analysis to determine the factual claims becoming routine, the cost for the well-intentioned to get involved has become extremely high. There are at least some that are aware of significant security flaws that have opted to remain silent due to the highly toxic environment.
|
||||
|
||||
What was once driven by curiosity, a desire to learn and improve, to determine the viability of ideas, is now driven by blind greed, religious zealotry, self-righteousness, and self-aggrandizement.
|
||||
|
||||
I have precious little hope for the future of projects that inspire this type of zealotry, and its continuous spread will likely harm real research in this area for many years to come. These are technical projects, some projects succeed, some fail – this is how technology evolves. Those designing these systems are human, just as flawed as the rest of us, and so too are the projects flawed. Some are well suited to certain use cases and not others, some aren’t suited to any use case, none yet are suited to all. The discussions about these projects should be focused on the technical aspects, and done so to evolve this field of research; adding a religious to these projects harms all.
|
||||
|
||||
[Note: There are many examples of this behavior that could be cited, however in the interest of protecting those that have been targeted for criticizing projects, I have opted to minimize such examples. I have seen too many people who I respect, too many that I consider friends, being viciously attacked – I have no desire to draw attention to those attacks, and risk restarting them.]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://adamcaudill.com/2018/06/21/bitcoin-is-a-cult/
|
||||
|
||||
作者:[Adam Caudill][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://adamcaudill.com/author/adam/
|
||||
[1]:https://en.wikipedia.org/wiki/Merkle_tree
|
||||
[2]:https://hackernoon.com/how-crypto-kitties-disrupted-the-ethereum-network-845c22aa1e6e
|
||||
[3]:https://blockchain.info/block-height/528249
|
||||
[4]:https://en.wikipedia.org/wiki/An_Exceptionally_Simple_Theory_of_Everything
|
||||
[5]:https://medium.com/@coop__soup/00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a-cd4b67d446be
|
||||
[6]:https://twitter.com/nondualrandy/status/1009609117768605696?ref_src=twsrc%5Etfw
|
||||
[7]:https://en.wikipedia.org/wiki/Numerology
|
||||
@ -1,3 +1,4 @@
|
||||
[Moelf](https://github.com/moelf/) Translating
|
||||
Don’t Install Yaourt! Use These Alternatives for AUR in Arch Linux
|
||||
======
|
||||
**Brief: Yaourt had been the most popular AUR helper, but it is not being developed anymore. In this article, we list out some of the best alternatives to Yaourt for Arch based Linux distributions. **
|
||||
|
||||
@ -1,130 +0,0 @@
|
||||
**Translating by XiatianSummer**
|
||||
|
||||
How to edit Adobe InDesign files with Scribus and Gedit
|
||||
======
|
||||
|
||||

|
||||
|
||||
To be a good graphic designer, you must be adept at using the profession's tools, which for most designers today are the ones in the proprietary Adobe Creative Suite.
|
||||
|
||||
However, there are times that open source tools will get you out of a jam. For example, imagine you're a commercial printer tasked with printing a file created in Adobe InDesign. You need to make a simple change (e.g., fixing a small typo) to the file, but you don't have immediate access to the Adobe suite. While these situations are admittedly rare, open source tools like desktop publishing software [Scribus][1] and text editor [Gedit][2] can save the day.
|
||||
|
||||
In this article, I'll show you how I edit Adobe InDesign files with Scribus and Gedit. Note that there are many open source graphic design solutions that can be used instead of or in conjunction with Adobe InDesign. For more on this subject, check out my articles: [Expensive tools aren't the only option for graphic design (and never were)][3] and [2 open][4][source][4][Adobe InDesign scripts][4].
|
||||
|
||||
When developing this solution, I read a few blogs on how to edit InDesign files with open source software but did not find what I was looking for. One suggestion I found was to create an EPS from InDesign and open it as an editable file in Scribus, but that did not work. Another suggestion was to create an IDML (an older InDesign file format) document from InDesign and open that in Scribus. That worked much better, so that's the workaround I used in the following examples.
|
||||
|
||||
### Editing a business card
|
||||
|
||||
Opening and editing my InDesign business card file in Scribus worked fairly well. The only issue I had was that the tracking (the space between letters) was a bit off and the upside-down "J" I used to create the lower-case "f" in "Jeff" was flipped. Otherwise, the styles and colors were all intact.
|
||||
|
||||
|
||||
![Business card in Adobe InDesign][6]
|
||||
|
||||
Business card designed in Adobe InDesign.
|
||||
|
||||
![InDesign IDML file opened in Scribus][8]
|
||||
|
||||
InDesign IDML file opened in Scribus.
|
||||
|
||||
### Deleting copy in a paginated book
|
||||
|
||||
The book conversion didn't go as well. The main body of the text was OK, but the table of contents and some of the drop caps and footers were messed up when I opened the InDesign file in Scribus. Still, it produced an editable document. One problem was some of my blockquotes defaulted to Arial font because a character style (apparently carried over from the original Word file) was on top of the paragraph style. This was simple to fix.
|
||||
|
||||
![Book layout in InDesign][10]
|
||||
|
||||
Book layout in InDesign.
|
||||
|
||||
![InDesign IDML file of book layout opened in Scribus][12]
|
||||
|
||||
InDesign IDML file of book layout opened in Scribus.
|
||||
|
||||
Trying to select and delete a page of text produced surprising results. I placed the cursor in the text and hit Command+A (the keyboard shortcut for "select all"). It looked like one page was highlighted. However, that wasn't really true.
|
||||
|
||||
![Selecting text in Scribus][14]
|
||||
|
||||
Selecting text in Scribus.
|
||||
|
||||
When I hit the Delete key, the entire text string (not just the highlighted page) disappeared.
|
||||
|
||||
![Both pages of text deleted in Scribus][16]
|
||||
|
||||
Both pages of text deleted in Scribus.
|
||||
|
||||
Then something even more interesting happened… I hit Command+Z to undo the deletion. When the text came back, the formatting was messed up.
|
||||
|
||||
![Undo delete restored the text, but with bad formatting.][18]
|
||||
|
||||
Command+Z (undo delete) restored the text, but the formatting was bad.
|
||||
|
||||
### Opening a design file in a text editor
|
||||
|
||||
If you open a Scribus file and an InDesign file in a standard text editor (e.g., TextEdit on a Mac), you will see that the Scribus file is very readable whereas the InDesign file is not.
|
||||
|
||||
You can use TextEdit to make changes to either type of file and save it, but the resulting file is useless. Here's the error I got when I tried re-opening the edited file in InDesign.
|
||||
|
||||
![InDesign error message][20]
|
||||
|
||||
InDesign error message.
|
||||
|
||||
I got much better results when I used Gedit on my Linux Ubuntu machine to edit the Scribus file. I launched Gedit from the command line and voilà, the Scribus file opened, and the changes I made in Gedit were retained.
|
||||
|
||||
![Editing Scribus file in Gedit][22]
|
||||
|
||||
Editing a Scribus file in Gedit.
|
||||
|
||||
![Result of the Gedit edit in Scribus][24]
|
||||
|
||||
Result of the Gedit edit opened in Scribus.
|
||||
|
||||
This could be very useful to a printer that receives a call from a client about a small typo in a project. Instead of waiting to get a new file, the printer could open the Scribus file in Gedit, make the change, and be good to go.
|
||||
|
||||
### Dropping images into a file
|
||||
|
||||
I converted an InDesign doc to an IDML file so I could try dropping in some PDFs using Scribus. It seems Scribus doesn't do this as well as InDesign, as it failed. Instead, I converted my PDFs to JPGs and imported them into Scribus. That worked great. However, when I exported my document as a PDF, I found that the files size was rather large.
|
||||
|
||||
![Huge PDF file][26]
|
||||
|
||||
Exporting Scribus to PDF produced a huge file.
|
||||
|
||||
I'm not sure why this happened—I'll have to investigate it later.
|
||||
|
||||
Do you have any tips for using open source software to edit graphics files? If so, please share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/adobe-indesign-open-source-tools
|
||||
|
||||
作者:[Jeff Macharyas][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rikki-endsley
|
||||
[1]:https://www.scribus.net/
|
||||
[2]:https://wiki.gnome.org/Apps/Gedit
|
||||
[3]:https://opensource.com/life/16/8/open-source-alternatives-graphic-design
|
||||
[4]:https://opensource.com/article/17/3/scripts-adobe-indesign
|
||||
[5]:/file/402516
|
||||
[6]:https://opensource.com/sites/default/files/uploads/1-business_card_designed_in_adobe_indesign_cc.png (Business card in Adobe InDesign)
|
||||
[7]:/file/402521
|
||||
[8]:https://opensource.com/sites/default/files/uploads/2-indesign_.idml_file_opened_in_scribus.png (InDesign IDML file opened in Scribus)
|
||||
[9]:/file/402531
|
||||
[10]:https://opensource.com/sites/default/files/uploads/3-book_layout_in_indesign.png (Book layout in InDesign)
|
||||
[11]:/file/402536
|
||||
[12]:https://opensource.com/sites/default/files/uploads/4-indesign_.idml_file_of_book_opened_in_scribus.png (InDesign IDML file of book layout opened in Scribus)
|
||||
[13]:/file/402541
|
||||
[14]:https://opensource.com/sites/default/files/uploads/5-command-a_in_the_scribus_file.png (Selecting text in Scribus)
|
||||
[15]:/file/402546
|
||||
[16]:https://opensource.com/sites/default/files/uploads/6-deleted_text_in_scribus.png (Both pages of text deleted in Scribus)
|
||||
[17]:/file/402551
|
||||
[18]:https://opensource.com/sites/default/files/uploads/7-command-z_in_scribus.png (Undo delete restored the text, but with bad formatting.)
|
||||
[19]:/file/402556
|
||||
[20]:https://opensource.com/sites/default/files/uploads/8-indesign_error_message.png (InDesign error message)
|
||||
[21]:/file/402561
|
||||
[22]:https://opensource.com/sites/default/files/uploads/9-scribus_edited_in_gedit_on_linux.png (Editing Scribus file in Gedit)
|
||||
[23]:/file/402566
|
||||
[24]:https://opensource.com/sites/default/files/uploads/10-scribus_opens_after_gedit_changes.png (Result of the Gedit edit in Scribus)
|
||||
[25]:/file/402571
|
||||
[26]:https://opensource.com/sites/default/files/uploads/11-large_pdf_size.png (Huge PDF file)
|
||||
@ -1,322 +0,0 @@
|
||||
BriFuture is translating
|
||||
|
||||
|
||||
Testing Node.js in 2018
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
[Stream][4] powers feeds for over 300+ million end users. With all of those users relying on our infrastructure, we’re very good about testing everything that gets pushed into production. Our primary codebase is written in Go, with some remaining bits of Python.
|
||||
|
||||
Our recent showcase application, [Winds 2.0][5], is built with Node.js and we quickly learned that our usual testing methods in Go and Python didn’t quite fit. Furthermore, creating a proper test suite requires a bit of upfront work in Node.js as the frameworks we are using don’t offer any type of built-in test functionality.
|
||||
|
||||
Setting up a good test framework can be tricky regardless of what language you’re using. In this post, we’ll uncover the hard parts of testing with Node.js, the various tooling we decided to utilize in Winds 2.0, and point you in the right direction for when it comes time for you to write your next set of tests.
|
||||
|
||||
### Why Testing is so Important
|
||||
|
||||
We’ve all pushed a bad commit to production and faced the consequences. It’s not a fun thing to have happen. Writing a solid test suite is not only a good sanity check, but it allows you to completely refactor code and feel confident that your codebase is still functional. This is especially important if you’ve just launched.
|
||||
|
||||
If you’re working with a team, it’s extremely important that you have test coverage. Without it, it’s nearly impossible for other developers on the team to know if their contributions will result in a breaking change (ouch).
|
||||
|
||||
Writing tests also encourage you and your teammates to split up code into smaller pieces. This makes it much easier to understand your code, and fix bugs along the way. The productivity gains are even bigger, due to the fact that you catch bugs early on.
|
||||
|
||||
Finally, without tests, your codebase might as well be a house of cards. There is simply zero certainty that your code is stable.
|
||||
|
||||
### The Hard Parts
|
||||
|
||||
In my opinion, most of the testing problems we ran into with Winds were specific to Node.js. The ecosystem is always growing. For example, if you are on macOS and run “brew upgrade” (with homebrew installed), your chances of seeing a new version of Node.js are quite high. With Node.js moving quickly and libraries following close behind, keeping up to date with the latest libraries is difficult.
|
||||
|
||||
Below are a few pain points that immediately come to mind:
|
||||
|
||||
1. Testing in Node.js is very opinionated and un-opinionated at the same time. Many people have different views on how a test infrastructure should be built and measured for success. The sad part is that there is no golden standard (yet) for how you should approach testing.
|
||||
|
||||
2. There are a large number of frameworks available to use in your application. However, they are generally minimal with no well-defined configuration or boot process. This leads to side effects that are very common, and yet hard to diagnose; so, you’ll likely end up writing your own test runner from scratch.
|
||||
|
||||
3. It’s almost guaranteed that you will be _required_ to write your own test runner (we’ll get to this in a minute).
|
||||
|
||||
The situations listed above are not ideal and it’s something that the Node.js community needs to address sooner rather than later. If other languages have figured it out, I think it’s time for Node.js, a widely adopted language, to figure it out as well.
|
||||
|
||||
### Writing Your Own Test Runner
|
||||
|
||||
So… you’re probably wondering what a test runner _is_ . To be honest, it’s not that complicated. A test runner is the highest component in the test suite. It allows for you to specify global configurations and environments, as well as import fixtures. One would assume this would be simple and easy to do… Right? Not so fast…
|
||||
|
||||
What we learned is that, although there is a solid number of test frameworks out there, not a single one for Node.js provides a unified way to construct your test runner. Sadly, it’s up to the developer to do so. Here’s a quick breakdown of the requirements for a test runner:
|
||||
|
||||
* Ability to load different configurations (e.g. local, test, development) and ensure that you _NEVER_ load a production configuration — you can guess what goes wrong when that happens.
|
||||
|
||||
* Lift and seed a database with dummy data for testing. This must work for various databases, whether it be MySQL, PostgreSQL, MongoDB, or any other, for that matter.
|
||||
|
||||
* Ability to load fixtures (files with seed data for testing in a development environment).
|
||||
|
||||
With Winds, we chose to use Mocha as our test runner. Mocha provides an easy and programmatic way to run tests on an ES6 codebase via command-line tools (integrated with Babel).
|
||||
|
||||
To kick off the tests, we register the Babel module loader ourselves. This provides us with finer grain greater control over which modules are imported before Babel overrides Node.js module loading process, giving us the opportunity to mock modules before any tests are run.
|
||||
|
||||
Additionally, we also use Mocha’s test runner feature to pre-assign HTTP handlers to specific requests. We do this because the normal initialization code is not run during tests (server interactions are mocked by the Chai HTTP plugin) and run some safety check to ensure we are not connecting to production databases.
|
||||
|
||||
While this isn’t part of the test runner, having a fixture loader is an important part of our test suite. We examined existing solutions; however, we settled on writing our own helper so that it was tailored to our requirements. With our solution, we can load fixtures with complex data-dependencies by following an easy ad-hoc convention when generating or writing fixtures by hand.
|
||||
|
||||
### Tooling for Winds
|
||||
|
||||
Although the process was cumbersome, we were able to find the right balance of tools and frameworks to make proper testing become a reality for our backend API. Here’s what we chose to go with:
|
||||
|
||||
### Mocha ☕
|
||||
|
||||
[Mocha][6], described as a “feature-rich JavaScript test framework running on Node.js”, was our immediate choice of tooling for the job. With well over 15k stars, many backers, sponsors, and contributors, we knew it was the right framework for the job.
|
||||
|
||||
### Chai 🥃
|
||||
|
||||
Next up was our assertion library. We chose to go with the traditional approach, which is what works best with Mocha — [Chai][7]. Chai is a BDD and TDD assertion library for Node.js. With a simple API, Chai was easy to integrate into our application and allowed for us to easily assert what we should _expect_ tobe returned from the Winds API. Best of all, writing tests feel natural with Chai. Here’s a short example:
|
||||
|
||||
```
|
||||
describe('retrieve user', () => {
|
||||
let user;
|
||||
|
||||
before(async () => {
|
||||
await loadFixture('user');
|
||||
user = await User.findOne({email: authUser.email});
|
||||
expect(user).to.not.be.null;
|
||||
});
|
||||
|
||||
after(async () => {
|
||||
await User.remove().exec();
|
||||
});
|
||||
|
||||
describe('valid request', () => {
|
||||
it('should return 200 and the user resource, including the email field, when retrieving the authenticated user', async () => {
|
||||
const response = await withLogin(request(api).get(`/users/${user._id}`), authUser);
|
||||
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body._id).to.equal(user._id.toString());
|
||||
});
|
||||
|
||||
it('should return 200 and the user resource, excluding the email field, when retrieving another user', async () => {
|
||||
const anotherUser = await User.findOne({email: 'another_user@email.com'});
|
||||
|
||||
const response = await withLogin(request(api).get(`/users/${anotherUser.id}`), authUser);
|
||||
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body._id).to.equal(anotherUser._id.toString());
|
||||
expect(response.body).to.not.have.an('email');
|
||||
});
|
||||
|
||||
});
|
||||
|
||||
describe('invalid requests', () => {
|
||||
|
||||
it('should return 404 if requested user does not exist', async () => {
|
||||
const nonExistingId = '5b10e1c601e9b8702ccfb974';
|
||||
expect(await User.findOne({_id: nonExistingId})).to.be.null;
|
||||
|
||||
const response = await withLogin(request(api).get(`/users/${nonExistingId}`), authUser);
|
||||
expect(response).to.have.status(404);
|
||||
});
|
||||
});
|
||||
|
||||
});
|
||||
```
|
||||
|
||||
### Sinon 🧙
|
||||
|
||||
With the ability to work with any unit testing framework, [Sinon][8] was our first choice for a mocking library. Again, a super clean integration with minimal setup, Sinon turns mocking requests into a simple and easy process. Their website has an extremely friendly user experience and offers up easy steps to integrate Sinon with your test suite.
|
||||
|
||||
### Nock 🔮
|
||||
|
||||
For all external HTTP requests, we use [nock][9], a robust HTTP mocking library that really comes in handy when you have to communicate with a third party API (such as [Stream’s REST API][10]). There’s not much to say about this little library aside from the fact that it is awesome at what it does, and that’s why we like it. Here’s a quick example of us calling our [personalization][11] engine for Stream:
|
||||
|
||||
```
|
||||
nock(config.stream.baseUrl)
|
||||
.get(/winds_article_recommendations/)
|
||||
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
|
||||
```
|
||||
|
||||
### Mock-require 🎩
|
||||
|
||||
The library [mock-require][12] allows dependencies on external code. In a single line of code, you can replace a module and mock-require will step in when some code attempts to import that module. It’s a small and minimalistic, but robust library, and we’re big fans.
|
||||
|
||||
### Istanbul 🔭
|
||||
|
||||
[Istanbul][13] is a JavaScript code coverage tool that computes statement, line, function and branch coverage with module loader hooks to transparently add coverage when running tests. Although we have similar functionality with CodeCov (see next section), this is a nice tool to have when running tests locally.
|
||||
|
||||
### The End Result — Working Tests
|
||||
|
||||
_With all of the libraries, including the test runner mentioned above, let’s have a look at what a full test looks like (you can have a look at our entire test suite _ [_here_][14] _):_
|
||||
|
||||
```
|
||||
import nock from 'nock';
|
||||
import { expect, request } from 'chai';
|
||||
|
||||
import api from '../../src/server';
|
||||
import Article from '../../src/models/article';
|
||||
import config from '../../src/config';
|
||||
import { dropDBs, loadFixture, withLogin } from '../utils.js';
|
||||
|
||||
describe('Article controller', () => {
|
||||
let article;
|
||||
|
||||
before(async () => {
|
||||
await dropDBs();
|
||||
await loadFixture('initial-data', 'articles');
|
||||
article = await Article.findOne({});
|
||||
expect(article).to.not.be.null;
|
||||
expect(article.rss).to.not.be.null;
|
||||
});
|
||||
|
||||
describe('get', () => {
|
||||
it('should return the right article via /articles/:articleId', async () => {
|
||||
let response = await withLogin(request(api).get(`/articles/${article.id}`));
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('get parsed article', () => {
|
||||
it('should return the parsed version of the article', async () => {
|
||||
const response = await withLogin(
|
||||
request(api).get(`/articles/${article.id}`).query({ type: 'parsed' })
|
||||
);
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('list', () => {
|
||||
it('should return the list of articles', async () => {
|
||||
let response = await withLogin(request(api).get('/articles'));
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('list from personalization', () => {
|
||||
after(function () {
|
||||
nock.cleanAll();
|
||||
});
|
||||
|
||||
it('should return the list of articles', async () => {
|
||||
nock(config.stream.baseUrl)
|
||||
.get(/winds_article_recommendations/)
|
||||
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
|
||||
|
||||
const response = await withLogin(
|
||||
request(api).get('/articles').query({
|
||||
type: 'recommended',
|
||||
})
|
||||
);
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body.length).to.be.at.least(1);
|
||||
expect(response.body[0].url).to.eq(article.url);
|
||||
});
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
### Continuous Integration
|
||||
|
||||
There are a lot of continuous integration services available, but we like to use [Travis CI][15] because they love the open-source environment just as much as we do. Given that Winds is open-source, it made for a perfect fit.
|
||||
|
||||
Our integration is rather simple — we have a [.travis.yml][16] file that sets up the environment and kicks off our tests via a simple [npm][17] command. The coverage reports back to GitHub, where we have a clear picture of whether or not our latest codebase or PR passes our tests. The GitHub integration is great, as it is visible without us having to go to Travis CI to look at the results. Below is a screenshot of GitHub when viewing the PR (after tests):
|
||||
|
||||

|
||||
|
||||
In addition to Travis CI, we use a tool called [CodeCov][18]. CodeCov is similar to [Istanbul][19], however, it’s a visualization tool that allows us to easily see code coverage, files changed, lines modified, and all sorts of other goodies. Though visualizing this data is possible without CodeCov, it’s nice to have everything in one spot.
|
||||
|
||||
### What We Learned
|
||||
|
||||

|
||||
|
||||
We learned a lot throughout the process of developing our test suite. With no “correct” way of doing things, we decided to set out and create our own test flow by sorting through the available libraries to find ones that were promising enough to add to our toolbox.
|
||||
|
||||
What we ultimately learned is that testing in Node.js is not as easy as it may sound. Hopefully, as Node.js continues to grow, the community will come together and build a rock solid library that handles everything test related in a “correct” manner.
|
||||
|
||||
Until then, we’ll continue to use our test suite, which is open-source on the [Winds GitHub repository][20].
|
||||
|
||||
### Limitations
|
||||
|
||||
#### No Easy Way to Create Fixtures
|
||||
|
||||
Frameworks and languages, such as Python’s Django, have easy ways to create fixtures. With Django, for example, you can use the following commands to automate the creation of fixtures by dumping data into a file:
|
||||
|
||||
The Following command will dump the whole database into a db.json file:
|
||||
./manage.py dumpdata > db.json
|
||||
|
||||
The Following command will dump only the content in django admin.logentry table:
|
||||
./manage.py dumpdata admin.logentry > logentry.json
|
||||
|
||||
The Following command will dump the content in django auth.user table: ./manage.py dumpdata auth.user > user.json
|
||||
|
||||
There’s no easy way to create a fixture in Node.js. What we ended up doing is using MongoDB Compass and exporting JSON from there. This resulted in a nice fixture, as shown below (however, it was a tedious process and prone to error):
|
||||
|
||||
|
||||

|
||||
|
||||
#### Unintuitive Module Loading When Using Babel, Mocked Modules, and Mocha Test-Runner
|
||||
|
||||
To support a broader variety of node versions and have access to latest additions to Javascript standard, we are using Babel to transpile our ES6 codebase to ES5\. Node.js module system is based on the CommonJS standard whereas the ES6 module system has different semantics.
|
||||
|
||||
Babel emulates ES6 module semantics on top of the Node.js module system, but because we are interfering with module loading by using mock-require, we are embarking on a journey through weird module loading corner cases, which seem unintuitive and can lead to multiple independent versions of the module imported and initialized and used throughout the codebase. This complicates mocking and global state management during testing.
|
||||
|
||||
#### Inability to Mock Functions Used Within the Module They Are Declared in When Using ES6 Modules
|
||||
|
||||
When a module exports multiple functions where one calls the other, it’s impossible to mock the function being used inside the module. The reason is that when you require an ES6 module you are presented with a separate set of references from the one used inside the module. Any attempt to rebind the references to point to new values does not really affect the code inside the module, which will continue to use the original function.
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
Testing Node.js applications is a complicated process because the ecosystem is always evolving. It’s important to stay on top of the latest and greatest tools so you don’t fall behind.
|
||||
|
||||
There are so many outlets for JavaScript related news these days that it’s hard to keep up to date with all of them. Following email newsletters such as [JavaScript Weekly][21] and [Node Weekly][22] is a good start. Beyond that, joining a subreddit such as [/r/node][23] is a great idea. If you like to stay on top of the latest trends, [State of JS][24] does a great job at helping developers visualize trends in the testing world.
|
||||
|
||||
Lastly, here are a couple of my favorite blogs where articles often popup:
|
||||
|
||||
* [Hacker Noon][1]
|
||||
|
||||
* [Free Code Camp][2]
|
||||
|
||||
* [Bits and Pieces][3]
|
||||
|
||||
Think I missed something important? Let me know in the comments, or on Twitter – [@NickParsons][25].
|
||||
|
||||
Also, if you’d like to check out Stream, we have a great 5 minute tutorial on our website. Give it a shot [here][26].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Nick Parsons
|
||||
|
||||
Dreamer. Doer. Engineer. Developer Evangelist https://getstream.io.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/testing-node-js-in-2018-10a04dd77391
|
||||
|
||||
作者:[Nick Parsons][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@nparsons08?source=post_header_lockup
|
||||
[1]:https://hackernoon.com/
|
||||
[2]:https://medium.freecodecamp.org/
|
||||
[3]:https://blog.bitsrc.io/
|
||||
[4]:https://getstream.io/
|
||||
[5]:https://getstream.io/winds
|
||||
[6]:https://github.com/mochajs/mocha
|
||||
[7]:http://www.chaijs.com/
|
||||
[8]:http://sinonjs.org/
|
||||
[9]:https://github.com/node-nock/nock
|
||||
[10]:https://getstream.io/docs_rest/
|
||||
[11]:https://getstream.io/personalization
|
||||
[12]:https://github.com/boblauer/mock-require
|
||||
[13]:https://github.com/gotwarlost/istanbul
|
||||
[14]:https://github.com/GetStream/Winds/tree/master/api/test
|
||||
[15]:https://travis-ci.org/
|
||||
[16]:https://github.com/GetStream/Winds/blob/master/.travis.yml
|
||||
[17]:https://www.npmjs.com/
|
||||
[18]:https://codecov.io/#features
|
||||
[19]:https://github.com/gotwarlost/istanbul
|
||||
[20]:https://github.com/GetStream/Winds/tree/master/api/test
|
||||
[21]:https://javascriptweekly.com/
|
||||
[22]:https://nodeweekly.com/
|
||||
[23]:https://www.reddit.com/r/node/
|
||||
[24]:https://stateofjs.com/2017/testing/results/
|
||||
[25]:https://twitter.com/@nickparsons
|
||||
[26]:https://getstream.io/try-the-api
|
||||
@ -1,72 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Revisiting wallabag, an open source alternative to Instapaper
|
||||
======
|
||||
|
||||

|
||||
|
||||
Back in 2014, I [wrote about wallabag][1], an open source alternative to read-it-later applications like Instapaper and Pocket. Go take a look at that article if you want to. Don't worry, I'll wait for you.
|
||||
|
||||
Done? Great!
|
||||
|
||||
In the four years since I wrote that article, a lot about [wallabag][2] has changed. It's time to take a peek to see how wallabag has matured.
|
||||
|
||||
### What's new
|
||||
|
||||
The biggest change took place behind the scenes. Wallabag's developer Nicolas Lœuillet and the project's contributors did a lot of tinkering with the code, which improved the application. You see and feel the changes wrought by wallabag's newer codebase every time you use it.
|
||||
|
||||
So what are some of those changes? There are [quite a few][3]. Here are the ones I found most interesting and useful.
|
||||
|
||||
Besides making wallabag a bit snappier and more stable, the application's ability to import and export content has improved. You can import articles from Pocket and Instapaper, as well as articles marked as "To read" in bookmarking service [Pinboard][4]. You can also import Firefox and Chrome bookmarks.
|
||||
|
||||
You can also export your articles in several formats including EPUB, MOBI, PDF, and plaintext. You can do that for individual articles, all your unread articles, or every article—read and unread. The version of wallabag that I used four years ago could export to EPUB and PDF, but that export was balky at times. Now, those exports are quick and smooth.
|
||||
|
||||
Annotations and highlighting in the web interface now work much better and more consistently. Admittedly, I don't use them often—but they don't randomly disappear like they sometimes did with version 1 of wallabag.
|
||||
|
||||

|
||||
|
||||
The look and feel of wallabag have improved, too. That's thanks to a new theme inspired by [Material Design][5]. That might not seem like a big deal, but that theme makes wallabag a bit more visually attractive and makes articles easier to scan and read. Yes, kids, good UX can make a difference.
|
||||
|
||||
|
||||
|
||||
One of the biggest changes was the introduction of [a hosted version][6] of wallabag. More than a few people (yours truly included) don't have a server to run web apps and aren't entirely comfortable doing that. When it comes to anything technical, I have 10 thumbs. I don't mind paying € 9 (just over US$ 10 at the time I wrote this) a year to get a fully working version of the application that I don't need to watch over.
|
||||
|
||||
### What hasn't changed
|
||||
|
||||
Overall, wallabag's core functions are the same. The updated codebase, as I mentioned above, makes those functions run quite a bit smoother and quicker.
|
||||
|
||||
Wallabag's [browser extensions][7] do the same job in the same way. I've found that the extensions work a bit better than they did when I first tried them and when the application was at version 1.
|
||||
|
||||
### What's disappointing
|
||||
|
||||
The mobile app is good, but it's not great. It does a good job of rendering articles and has a few configuration options. But you can't highlight or annotate articles. That said, you can use the app to dip into your stock of archived articles.
|
||||
|
||||
|
||||
|
||||
While wallabag does a great job collecting articles, there are sites whose content you can't save to it. I haven't run into many such sites, but there have been enough for the situation to be annoying. I'm not sure how much that has to do with wallabag. Rather, I suspect it has something to do with the way the sites are coded—I ran into the same problem while looking at a couple of proprietary read-it-later tools.
|
||||
|
||||
Wallabag might not be a feature-for-feature replacement for Pocket or Instapaper, but it does a great job. It has improved noticeably in the four years since I first wrote about it. There's still room for improvement, but does what it says on the tin.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
Since 2014, wallabag has evolved. It's gotten better, bit by bit and step by step. While it might not be a feature-for-feature replacement for the likes of Instapaper and Pocket, wallabag is a worthy open source alternative to proprietary read-it-later tools.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/wallabag
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/life/14/4/open-source-read-it-later-app-wallabag
|
||||
[2]:https://wallabag.org/en
|
||||
[3]:https://www.wallabag.org/en/news/wallabag-v2
|
||||
[4]:https://pinboard.in
|
||||
[5]:https://en.wikipedia.org/wiki/Material_Design
|
||||
[6]:https://www.wallabag.it
|
||||
[7]:https://github.com/wallabag/wallabagger
|
||||
@ -0,0 +1,143 @@
|
||||
bestony is translating
|
||||
|
||||
Becoming a senior developer: 9 experiences you'll encounter
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Plenty of career guides suggest appropriate steps to take if you want a management track. But what if you want to stay technical—and simply become the best possible programmer? These non-obvious markers let you know you’re on the right path.
|
||||
|
||||
Many programming career guidelines stress the skills a software developer is expected to acquire. Such general advice suggests that someone who wants to focus on a technical track—as opposed to, say, [taking a management path to CIO][5]—should go after the skills needed to mentor junior developers, design future application features, build out release engineering systems, and set company standards.
|
||||
|
||||
That isn’t this article.
|
||||
|
||||
Being a developer—a good one—isn't just about writing code. To be successful, you do a lot of planning, you deal with catastrophes, and you prevent catastrophes. Not to mention you spend plenty of time [working with other humans][6] about what your code should do.
|
||||
|
||||
Following are a number of markers you’ll likely encounter as your career progresses and you become a more accomplished developer. You’ll have highs that boost you up and remind you how awesome you are. You'll also encounter lows that keep you humble and give you wisdom—at least in retrospect, if you respond to them appropriately.
|
||||
|
||||
These experiences may feel good, they may be uncomfortable, or they may be downright scary. They're all learning experiences—at least for those developers who sincerely want to move forward, in both skills and professional ambition. These experiences often change the way developers look at their job or how they approach the next problem. It's why an experienced developer's value to a company is more than just a list of technology buzzwords.
|
||||
|
||||
Here, in no particular order, is a sampling of what you'll run into on your way to becoming a senior developer—not in terms of a specific job title but being confident about creating quality code that serves users.
|
||||
|
||||
### You write your first big bug into production
|
||||
|
||||
Probably your initial step into the big leagues is the first bug you write into production. It's a sickening feeling. You know that the software you're working on is now broken in some significant way because of something you did, code you wrote, or a test you didn't run.
|
||||
|
||||
No matter how good a programmer you are, you'll make mistakes. You're a human, and that's part of what we do.
|
||||
|
||||
Most developers learn from the “bug that went live” experience. You promise never to make the same bug again. You analyze what happened, and you think about how the bug could have been prevented. For me, one effect of discovering I let a bug into production code is that it reinforced my belief that compiler warnings and static analysis tools are a programmer's best friend.
|
||||
|
||||
You repeat the process when it happens again. It _will_ happen again, but as your programming skill improves, it happens less frequently.
|
||||
|
||||
### You delete production data for the first time
|
||||
|
||||
It might be a `DROP TABLE` in production or [a mistaken `rm -rf`][7]. Maybe you clicked on the wrong volume to format. You get an uneasy feeling that "this is taking longer to run than I would expect. It's not running on... oh, no!" followed by a mad scramble to fix it.
|
||||
|
||||
Data loss has long-term effects on a growing-wiser developer much like the production bug. Afterward, you re-examine how you work. It teaches you to take more safeguards than you did previously. Maybe you decide to create a more rigorous rotation schedule for backups, or even start having a backup schedule at all.
|
||||
|
||||
As with the bug in production, you learn that you can survive making a mistake, and it's not the end of the world.
|
||||
|
||||
### You automate away part of your job
|
||||
|
||||
There's an old saying that you can't get promoted if you can't be replaced. Anything that ties you to a specific job or task is an anchor on your ability to move up in the company or be assigned newer and more interesting tasks.
|
||||
|
||||
When good programmers find themselves doing drudgework as part of their job, they find a way to let a machine do it. If they are stuck [scanning server logs][8] every Monday looking for problems, they'll install a tool like Logwatch to summarize the results. When there are many servers to be monitored, a good programmer will turn to a more capable tool that analyzes logs on multiple servers.
|
||||
|
||||
Unsure how to get started with containers? Yes, we have a guide for that. Get Containers for Dummies.
|
||||
|
||||
[Download now][4]
|
||||
|
||||
In each case, wise programmers provide more value to their company, because an automated system is much cheaper than a senior programmer’s salary. They also grow personally by eliminating drudgery, leaving them more time to work on more challenging tasks.
|
||||
|
||||
### You use existing code instead of writing your own
|
||||
|
||||
A senior programmer knows that code that doesn't get written doesn't have bugs, and that many problems, both common and uncommon, have already been solved—in many cases, multiple times.
|
||||
|
||||
Senior programmers know that the chances are very low that they can write, test, and debug their own code for a task faster or cheaper than existing code that does what they want. It doesn't have to be perfect to make it worth their while.
|
||||
|
||||
It might take a little bit of turning down your ego to make it happen, but that's an excellent skill for senior programmers to have, too.
|
||||
|
||||
### You are publicly recognized for achievements
|
||||
|
||||
Many people aren't comfortable with public recognition. It's embarrassing. We have these amazing skills, and we like the feeling of helping others, but we can be embarrassed when it's called out.
|
||||
|
||||
Praise comes in many forms and many sizes. Maybe it's winning an "employee of the quarter" award for a project you drove and being presented a plaque onstage. It could be as low-key as your team leader saying, "Thanks to Cheryl for implementing that new microservice."
|
||||
|
||||
Whatever it is, accept it graciously and appreciatively, even if you're embarrassed by the attention. Don't diminish the praise you receive with, "Oh, it was nothing" or anything similar. Accept credit for the things that users and co-workers appreciate. Thank the speaker and say you were glad you could be of service.
|
||||
|
||||
First, this is the polite thing to do. When people praise you, they want it to be acknowledged. In addition, that warm recognition helps you in the future. Remembering it gets you through those crappy days, such as when you uncover bugs in your code.
|
||||
|
||||
### You turn down a user request
|
||||
|
||||
As much as we love being superheroes who can do amazing things with computers, sometimes turning down a request is best for the organization. Part of being a senior programmer is knowing when not to write code. A senior programmer knows that every bit of code in a codebase is a chance for things to go wrong and a potential future cost for maintenance.
|
||||
|
||||
You might be uncomfortable the first time you tell a user that you won’t be incorporating his maybe-even-useful suggestion. But this is a notable occasion. It means you understand the application and its role in a larger context. It also means you “own” the software, in a positive, confident way.
|
||||
|
||||
The organization need not be an employer, either. Open source project managers deal with this all the time, when they have to tell a user, "Sorry, it doesn't fit with where the project is going.”
|
||||
|
||||
### You know when to fight for what's right and when it really doesn't matter
|
||||
|
||||
Rookie programmers are full of knowledge straight from school, having learned all the right ways to do things. They're eager to apply their knowledge and make amazing things happen for their employers. However, they're often surprised to find that out in the business world, things sometimes don't get done the "right" way.
|
||||
|
||||
There's an old military saying: No plan survives contact with the enemy. It's the same with new programmers and project plans. Sometimes in the heat of the battle of business, the purist computer science techniques learned in school fall by the wayside.
|
||||
|
||||
Maybe the database schema gets slapped together in a way that isn't perfect [fifth normal form][9]. Sometimes code gets cut and pasted rather than refactored out into a new function or library. Plenty of production systems run on shell scripts and prayers. The wise programmer knows when to push for the right way to do things and when to take the cheap way out.
|
||||
|
||||
The first time you do it, it feels like you're selling out your principles. It’s not. The balance between academic purism and the realities of getting work done can be a delicate one, and that knowledge of when to do things less than perfectly is part of the wisdom you’ll acquire.
|
||||
|
||||
### You are asked what to do
|
||||
|
||||
After a while, you'll have earned a reputation in your organization for getting things done. It won’t be just for having expertise in a certain area—it’ll be wisdom. Someone will come to you and ask for guidance with a project or a problem.
|
||||
|
||||
That person isn't just asking you for help with a problem. You are being asked to lead.
|
||||
|
||||
A common situation is when you are asked to help a team of less-experienced developers that's navigating difficult new terrain or needs shepherding on a project. That's when you'll be called on to help not just do things but show people how to improve their own skills.
|
||||
|
||||
It might also be leadership from a technical point of view. Your boss might say, "We need a new indexing solution. Find out what you can about FooIndex and BarSearch, and let me know what you propose." That's the sort of responsibility given only to someone who has demonstrated wisdom and experience.
|
||||
|
||||
### You are seriously headhunted for the first time
|
||||
|
||||
Recruiting professionals are always looking for talent. Most recruiters seem to do random emailing and LinkedIn harvesting. But every so often, they find out about talented performers and hunt them down.
|
||||
|
||||
When that happens, it's a feather in your cap. Maybe a former colleague spoke to a recruiter friend trying to place a developer at a company that needs the skills you have. If you get a personal recommendation for a position—even if you don’t want the job—it means you've really arrived. You're recognized as an expert, or someone who brings value to an organization, enough to recommend you to others.
|
||||
|
||||
### Onward
|
||||
|
||||
I hope that my little list helps prompt some thought about [where you are in your career][10] or [where you might be headed][11]. Markers and milestones can help you understand what’s around you and what to expect.
|
||||
|
||||
This list is far from complete, of course. Everyone has their own story. In fact, one of the ways to know you’ve hit a milestone is when you find yourself telling a story about it to others. When you do find yourself looking back at a tough situation, make sure to reflect on what it means to you and why. Experience is a great teacher—if you listen to it.
|
||||
|
||||
What are your markers? How did you know you had finally become a senior programmer? Tweet at [@enterprisenxt][12] and let me know.
|
||||
|
||||
This article/content was written by the individual writer identified and does not necessarily reflect the view of Hewlett Packard Enterprise Company.
|
||||
|
||||
[][13]
|
||||
|
||||
### 作者简介
|
||||
|
||||
Andy Lester has been a programmer and developer since the 1980s, when COBOL walked the earth. He is the author of the job-hunting guide [Land the Tech Job You Love][2] (2009, Pragmatic Bookshelf). Andy has been an active contributor to the open source community for decades, most notably as the creator of the grep-like code search tool [ack][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.hpe.com/us/en/insights/articles/becoming-a-senior-developer-9-experiences-youll-encounter-1807.html
|
||||
|
||||
作者:[Andy Lester ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
|
||||
[1]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
|
||||
[2]:https://pragprog.com/book/algh/land-the-tech-job-you-love
|
||||
[3]:https://beyondgrep.com/
|
||||
[4]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_510384402_seniordev0718
|
||||
[5]:https://www.hpe.com/us/en/insights/articles/7-career-milestones-youll-meet-on-the-cio-and-it-management-track-1805.html
|
||||
[6]:https://www.hpe.com/us/en/insights/articles/how-to-succeed-in-it-without-social-skills-1705.html
|
||||
[7]:https://www.hpe.com/us/en/insights/articles/the-linux-commands-you-should-never-use-1712.html
|
||||
[8]:https://www.hpe.com/us/en/insights/articles/back-to-basics-what-sysadmins-must-know-about-logging-and-monitoring-1805.html
|
||||
[9]:http://www.bkent.net/Doc/simple5.htm
|
||||
[10]:https://www.hpe.com/us/en/insights/articles/career-interventions-when-your-it-career-needs-a-swift-kick-1806.html
|
||||
[11]:https://www.hpe.com/us/en/insights/articles/how-to-avoid-an-it-career-dead-end-1806.html
|
||||
[12]:https://twitter.com/enterprisenxt
|
||||
[13]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
|
||||
121
sources/tech/20180711 netdev-day-1--ipsec.md
Normal file
121
sources/tech/20180711 netdev-day-1--ipsec.md
Normal file
@ -0,0 +1,121 @@
|
||||
|
||||
FSSlc is translating
|
||||
|
||||
netdev day 1: IPsec!
|
||||
============================================================
|
||||
|
||||
Hello! This year, like last year, I’m at the [netdev conference][3]. (here are my [notes from last year][4]).
|
||||
|
||||
Today at the conference I learned a lot about IPsec, so we’re going to talk about IPsec! There was an IPsec workshop given by Sowmini Varadhan and [Paul Wouters][5]. All of the mistakes in this post are 100% my fault though :).
|
||||
|
||||
### what’s IPsec?
|
||||
|
||||
IPsec is a protocol used to encrypt IP packets. Some VPNs are implemented with IPsec. One big thing I hadn’t really realized until today is that there isn’t just one protocol used for VPNs – I think VPN is just a general term meaning “your IP packets get encrypted and sent through another server” and VPNs can be implemented using a bunch of different protocols (OpenVPN, PPTP, SSTP, IPsec, etc) in a bunch of different ways.
|
||||
|
||||
Why is IPsec different from other VPN protocols? (like, why was there a tutorial about it at netdev and not the other protocols?) My understanding is that there are 2 things that make it different:
|
||||
|
||||
* It’s an IETF standard, documented in eg [RFC 6071][1] (did you know the IETF is the group that makes RFCs? I didn’t until today!)
|
||||
|
||||
* it’s implemented in the Linux kernel (so it makes sense that there was a netdev tutorial on it, since netdev is a Linux kernel networking conference :))
|
||||
|
||||
### How does IPsec work?
|
||||
|
||||
So let’s say your laptop is using IPsec to encrypt its packets and send them through another device. How does that work? There are 2 parts to IPsec: a userspace part, and a kernel part.
|
||||
|
||||
The userspace part of IPsec is responsible for key exchange, using a protocol called [IKE][6] (“internet key exchange”). Basically when you open a new VPN connection, you need to talk to the VPN server and negotiate a key to do encryption.
|
||||
|
||||
The kernel part of IPsec is responsible for the actual encryption of packets – once a key is generated using IKE, the userspace part of IPsec will tell the kernel which encryption key to use. Then the kernel will use that key to encrypt packets!
|
||||
|
||||
### Security Policy & Security Associations
|
||||
|
||||
The kernel part of IPSec has two databases: the security policy database(SPD) and the security association database (SAD).
|
||||
|
||||
The security policy database has IP ranges and rules for what to do to packets for that IP range (“do IPsec to it”, “drop the packet”, “let it through”). I find this a little confusing because I’m used to rules about what to do to packets in various IP ranges being in the route table (`sudo ip route list`), but apparently you can have IPsec rules too and they’re in a different place!
|
||||
|
||||
The security association database I think has the encryption keys to use for various IPs.
|
||||
|
||||
The way you inspect these databases is, extremely unintuitively, using a command called `ip xfrm`. What does xfrm mean? I don’t know!
|
||||
|
||||
```
|
||||
# security policy database
|
||||
$ sudo ip xfrm policy
|
||||
$ sudo ip x p
|
||||
|
||||
# security association database
|
||||
$ sudo ip xfrm state
|
||||
$ sudo ip x s
|
||||
|
||||
```
|
||||
|
||||
### Why is IPsec implemented in the Linux kernel and TLS isn’t?
|
||||
|
||||
For both TLS and IPsec, you need to do a key exchange when opening the connection (using Diffie-Hellman or something). For some reason that might be obvious but that I don’t understand yet (??) people don’t want to do key exchange in the kernel.
|
||||
|
||||
The reason IPsec is easier to implement in the kernel is that with IPsec, you need to negotiate key exchanges much less frequently (once for every IP address you want to open a VPN connection with), and IPsec sessions are much longer lived. So it’s easy for userspace to do a key exchange, get the key, and hand it off to the kernel which will then use that key for every IP packet.
|
||||
|
||||
With TLS, there are a couple of problems:
|
||||
|
||||
a. you’re constantly doing new key exchanges every time you open a new TLS connection, and TLS connections are shorter-lived b. there isn’t a natural protocol boundary where you need to start doing encryption – with IPsec, you just encrypt every IP packet in a given IP range, but with TLS you need to look at your TCP stream, recognize whether the TCP packet is a data packet or not, and decide to encrypt it
|
||||
|
||||
There’s actually a patch [implementing TLS in the Linux kernel][7] which lets userspace do key exchange and then pass the kernel the keys, so this obviously isn’t impossible, but it’s a much newer thing and I think it’s more complicated with TLS than with IPsec.
|
||||
|
||||
### What software do you use to do IPsec?
|
||||
|
||||
The ones I know about are Libreswan and Strongswan. Today’s tutorial focused on Libreswan.
|
||||
|
||||
Somewhat confusingly, even though Libreswan and Strongswan are different software packages, they both install a binary called `ipsec` for managing IPsec connections, and the two `ipsec` binaries are not the same program (even though they do have the same role).
|
||||
|
||||
Strongswan and Libreswan do what’s described in the “how does IPsec work” section above – they do key exchange with IKE and tell the kernel about keys to configure it to do encryption.
|
||||
|
||||
### IPsec isn’t only for VPNs!
|
||||
|
||||
At the beginning of this post I said “IPsec is a VPN protocol”, which is true, but you don’t have to use IPsec to implement VPNs! There are actually two ways to use IPsec:
|
||||
|
||||
1. “transport mode”, where the IP header is unchanged and only the contents of the IP packet are encrypted. This mode is a little more like using TLS – you talk to the server you’re communicating with directly (not through a VPN server or something), it’s just that the contents of the IP packet get encrypted
|
||||
|
||||
2. “tunnel mode”, where the IP header and its contents are all encrypted and encapsulated into another UDP packet. This is the mode that’s used for VPNs – you take your packet that you’re sending to secret_site.com, encrypt it, send it to your VPN server, and the VPN server passes it on for you.
|
||||
|
||||
### opportunistic IPsec
|
||||
|
||||
An interesting application of “transport mode” IPsec I learned about today (where you open an IPsec connection directly with the host you’re communicating with instead of some other intermediary server) is this thing called “opportunistic IPsec”. There’s an opportunistic IPsec server here:[http://oe.libreswan.org/][8].
|
||||
|
||||
I think the idea is that if you set up Libreswan and unbound up on your computer, then when you connect to [http://oe.libreswan.org][9], what happens is:
|
||||
|
||||
1. `unbound` makes a DNS query for the IPSECKEY record of oe.libreswan.org (`dig ipseckey oe.libreswan.org`) to get a public key to use for that domain. (this requires DNSSEC to be secure which when I learn about it will be a whole other blog post, but you can just run that DNS query with dig and it will work if you want to see the results)
|
||||
|
||||
2. `unbound` gives the public key to libreswan, which uses it to do a key exchange with the IKE server running on oe.libreswan.org
|
||||
|
||||
3. `libreswan` finishes the key exchange, gives the encryption key to the kernel, and tells the kernel to use that encryption key when talking to `oe.libreswan.org`
|
||||
|
||||
4. Your connection is now encrypted! Even though it’s a HTTP connection! so interesting!
|
||||
|
||||
### IPsec and TLS learn from each other
|
||||
|
||||
One interesting tidbit from the tutorial today was that the IPsec and TLS protocols have actually learned from each other over time – like they said IPsec’s IKE protocol had perfect forward secrecy before TLS, and IPsec has also learned some things from TLS. It’s neat to hear about how different internet protocols are learning & changing over time!
|
||||
|
||||
### IPsec is interesting!
|
||||
|
||||
I’ve spent quite a lot of time learning about TLS, which is obviously a super important networking protocol (let’s encrypt the internet! :D). But IPsec is an important internet encryption protocol too, and it has a different role from TLS! Apparently some mobile phone protocols (like 5G/LTE) use IPsec to encrypt their network traffic!
|
||||
|
||||
I’m happy I know a little more about it now! As usual several things in this post are probably wrong, but hopefully not too wrong :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/07/11/netdev-day-1--ipsec/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://tools.ietf.org/html/rfc6071
|
||||
[2]:https://jvns.ca/categories/netdev
|
||||
[3]:https://www.netdevconf.org/0x12/
|
||||
[4]:https://jvns.ca/categories/netdev/
|
||||
[5]:https://nohats.ca/
|
||||
[6]:https://en.wikipedia.org/wiki/Internet_Key_Exchange
|
||||
[7]:https://blog.filippo.io/playing-with-kernel-tls-in-linux-4-13-and-go/
|
||||
[8]:http://oe.libreswan.org/
|
||||
[9]:http://oe.libreswan.org/
|
||||
@ -1,272 +0,0 @@
|
||||
Translating by qhwdw
|
||||
A sysadmin's guide to SELinux: 42 answers to the big questions
|
||||
======
|
||||
|
||||

|
||||
|
||||
> "It is an important and popular fact that things are not always what they seem…"
|
||||
> ―Douglas Adams, The Hitchhiker's Guide to the Galaxy
|
||||
|
||||
Security. Hardening. Compliance. Policy. The Four Horsemen of the SysAdmin Apocalypse. In addition to our daily tasks—monitoring, backup, implementation, tuning, updating, and so forth—we are also in charge of securing our systems. Even those systems where the third-party provider tells us to disable the enhanced security. It seems like a job for Mission Impossible's [Ethan Hunt][1].
|
||||
|
||||
Faced with this dilemma, some sysadmins decide to [take the blue pill][2] because they think they will never know the answer to the big question of life, the universe, and everything else. And, as we all know, that answer is **[42][3]**.
|
||||
|
||||
In the spirit of The Hitchhiker's Guide to the Galaxy, here are the 42 answers to the big questions about managing and using [SELinux][4] with your systems.
|
||||
|
||||
1. SELinux is a LABELING system, which means every process has a LABEL. Every file, directory, and system object has a LABEL. Policy rules control access between labeled processes and labeled objects. The kernel enforces these rules.
|
||||
|
||||
|
||||
2. The two most important concepts are: Labeling (files, process, ports, etc.) and Type enforcement (which isolates processes from each other based on types).
|
||||
|
||||
|
||||
3. The correct Label format is `user:role:type:level` (optional).
|
||||
|
||||
|
||||
4. The purpose of Multi-Level Security (MLS) enforcement is to control processes (domains) based on the security level of the data they will be using. For example, a secret process cannot read top-secret data.
|
||||
|
||||
|
||||
5. Multi-Category Security (MCS) enforcement protects similar processes from each other (like virtual machines, OpenShift gears, SELinux sandboxes, containers, etc.).
|
||||
|
||||
|
||||
6. Kernel parameters for changing SELinux modes at boot:
|
||||
* `autorelabel=1` → forces the system to relabel
|
||||
* `selinux=0` → kernel doesn't load any part of the SELinux infrastructure
|
||||
* `enforcing=0` → boot in permissive mode
|
||||
|
||||
|
||||
7. If you need to relabel the entire system:
|
||||
`# touch /.autorelabel #reboot`
|
||||
If the system labeling contains a large amount of errors, you might need to boot in permissive mode in order for the autorelabel to succeed.
|
||||
|
||||
|
||||
8. To check if SELinux is enabled: `# getenforce`
|
||||
|
||||
|
||||
9. To temporarily enable/disable SELinux: `# setenforce [1|0]`
|
||||
|
||||
|
||||
10. SELinux status tool: `# sestatus`
|
||||
|
||||
|
||||
11. Configuration file: `/etc/selinux/config`
|
||||
|
||||
|
||||
12. How does SELinux work? Here's an example of labeling for an Apache Web Server:
|
||||
* Binary: `/usr/sbin/httpd`→`httpd_exec_t`
|
||||
* Configuration directory: `/etc/httpd`→`httpd_config_t`
|
||||
* Logfile directory: `/var/log/httpd` → `httpd_log_t`
|
||||
* Content directory: `/var/www/html` → `httpd_sys_content_t`
|
||||
* Startup script: `/usr/lib/systemd/system/httpd.service` → `httpd_unit_file_d`
|
||||
* Process: `/usr/sbin/httpd -DFOREGROUND` → `httpd_t`
|
||||
* Ports: `80/tcp, 443/tcp` → `httpd_t, http_port_t`
|
||||
|
||||
|
||||
|
||||
A process running in the `httpd_t` context can interact with an object with the `httpd_something_t` label.
|
||||
|
||||
13. Many commands accept the argument `-Z` to view, create, and modify context:
|
||||
* `ls -Z`
|
||||
* `id -Z`
|
||||
* `ps -Z`
|
||||
* `netstat -Z`
|
||||
* `cp -Z`
|
||||
* `mkdir -Z`
|
||||
|
||||
|
||||
|
||||
Contexts are set when files are created based on their parent directory's context (with a few exceptions). RPMs can set contexts as part of installation.
|
||||
|
||||
14. There are four key causes of SELinux errors, which are further explained in items 15-21 below:
|
||||
* Labeling problems
|
||||
* Something SELinux needs to know
|
||||
* A bug in an SELinux policy/app
|
||||
* Your information may be compromised
|
||||
|
||||
|
||||
15. Labeling problem: If your files in `/srv/myweb` are not labeled correctly, access might be denied. Here are some ways to fix this:
|
||||
* If you know the label:
|
||||
`# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
|
||||
* If you know the file with the equivalent labeling:
|
||||
`# semanage fcontext -a -e /srv/myweb /var/www`
|
||||
* Restore the context (for both cases):
|
||||
`# restorecon -vR /srv/myweb`
|
||||
|
||||
|
||||
16. Labeling problem: If you move a file instead of copying it, the file keeps its original context. To fix these issues:
|
||||
* Change the context command with the label:
|
||||
`# chcon -t httpd_system_content_t /var/www/html/index.html`
|
||||
* Change the context command with the reference label:
|
||||
`# chcon --reference /var/www/html/ /var/www/html/index.html`
|
||||
* Restore the context (for both cases): `# restorecon -vR /var/www/html/`
|
||||
|
||||
|
||||
17. If SELinux needs to know HTTPD listens on port 8585, tell SELinux:
|
||||
`# semanage port -a -t http_port_t -p tcp 8585`
|
||||
|
||||
|
||||
18. SELinux needs to know booleans allow parts of SELinux policy to be changed at runtime without any knowledge of SELinux policy writing. For example, if you want httpd to send email, enter: `# setsebool -P httpd_can_sendmail 1`
|
||||
|
||||
|
||||
19. SELinux needs to know booleans are just off/on settings for SELinux:
|
||||
* To see all booleans: `# getsebool -a`
|
||||
* To see the description of each one: `# semanage boolean -l`
|
||||
* To set a boolean execute: `# setsebool [_boolean_] [1|0]`
|
||||
* To configure it permanently, add `-P`. For example:
|
||||
`# setsebool httpd_enable_ftp_server 1 -P`
|
||||
|
||||
|
||||
20. SELinux policies/apps can have bugs, including:
|
||||
* Unusual code paths
|
||||
* Configurations
|
||||
* Redirection of `stdout`
|
||||
* Leaked file descriptors
|
||||
* Executable memory
|
||||
* Badly built libraries Open a ticket (do not file a Bugzilla report; there are no SLAs with Bugzilla).
|
||||
|
||||
|
||||
21. Your information may be compromised if you have confined domains trying to:
|
||||
* Load kernel modules
|
||||
* Turn off the enforcing mode of SELinux
|
||||
* Write to `etc_t/shadow_t`
|
||||
* Modify iptables rules
|
||||
|
||||
|
||||
22. SELinux tools for the development of policy modules:
|
||||
`# yum -y install setroubleshoot setroubleshoot-server`
|
||||
Reboot or restart `auditd` after you install.
|
||||
|
||||
|
||||
23. Use `journalctl` for listing all logs related to `setroubleshoot`:
|
||||
`# journalctl -t setroubleshoot --since=14:20`
|
||||
|
||||
|
||||
24. Use `journalctl` for listing all logs related to a particular SELinux label. For example:
|
||||
`# journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
|
||||
|
||||
|
||||
25. Use `setroubleshoot` log when an SELinux error occurs and suggest some possible solutions. For example, from `journalctl`:
|
||||
[code] Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
|
||||
|
||||
|
||||
# sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
|
||||
SELinux is preventing httpd from getattr access on the file /var/www/html/index.html.
|
||||
|
||||
|
||||
|
||||
***** Plugin restorecon (99.5 confidence) suggests ************************
|
||||
|
||||
|
||||
|
||||
If you want to fix the label,
|
||||
|
||||
/var/www/html/index.html default label should be httpd_syscontent_t.
|
||||
|
||||
Then you can restorecon.
|
||||
|
||||
Do
|
||||
|
||||
# /sbin/restorecon -v /var/www/html/index.html
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
26. Logging: SELinux records information all over the place:
|
||||
* `/var/log/messages`
|
||||
* `/var/log/audit/audit.log`
|
||||
* `/var/lib/setroubleshoot/setroubleshoot_database.xml`
|
||||
|
||||
|
||||
27. Logging: Looking for SELinux errors in the audit log:
|
||||
`# ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
|
||||
|
||||
|
||||
28. To search for SELinux Access Vector Cache (AVC) messages for a particular service:
|
||||
`# ausearch -m avc -c httpd`
|
||||
|
||||
|
||||
29. The `audit2allow` utility gathers information from logs of denied operations and then generates SELinux policy-allow rules. For example:
|
||||
* To produce a human-readable description of why the access was denied: `# audit2allow -w -a`
|
||||
* To view the type enforcement rule that allows the denied access: `# audit2allow -a`
|
||||
* To create a custom module: `# audit2allow -a -M mypolicy`
|
||||
The `-M` option creates a type enforcement file (.te) with the name specified and compiles the rule into a policy package (.pp): `mypolicy.pp mypolicy.te`
|
||||
* To install the custom module: `# semodule -i mypolicy.pp`
|
||||
|
||||
|
||||
30. To configure a single process (domain) to run permissive: `# semanage permissive -a httpd_t`
|
||||
|
||||
|
||||
31. If you no longer want a domain to be permissive: `# semanage permissive -d httpd_t`
|
||||
|
||||
|
||||
32. To disable all permissive domains: `# semodule -d permissivedomains`
|
||||
|
||||
|
||||
33. Enabling SELinux MLS policy: `# yum install selinux-policy-mls`
|
||||
In `/etc/selinux/config:`
|
||||
`SELINUX=permissive`
|
||||
`SELINUXTYPE=mls`
|
||||
Make sure SELinux is running in permissive mode: `# setenforce 0`
|
||||
Use the `fixfiles` script to ensure that files are relabeled upon the next reboot:
|
||||
`# fixfiles -F onboot # reboot`
|
||||
|
||||
|
||||
34. Create a user with a specific MLS range: `# useradd -Z staff_u john`
|
||||
Using the `useradd` command, map the new user to an existing SELinux user (in this case, `staff_u`).
|
||||
|
||||
|
||||
35. To view the mapping between SELinux and Linux users: `# semanage login -l`
|
||||
|
||||
|
||||
36. Define a specific range for a user: `# semanage login --modify --range s2:c100 john`
|
||||
|
||||
|
||||
37. To correct the label on the user's home directory (if needed): `# chcon -R -l s2:c100 /home/john`
|
||||
|
||||
|
||||
38. To list the current categories: `# chcat -L`
|
||||
|
||||
|
||||
39. To modify the categories or to start creating your own, modify the file as follows:
|
||||
`/etc/selinux/_<selinuxtype>_/setrans.conf`
|
||||
|
||||
|
||||
40. To run a command or script in a specific file, role, and user context:
|
||||
`# runcon -t initrc_t -r system_r -u user_u yourcommandhere`
|
||||
* `-t` is the file context
|
||||
* `-r` is the role context
|
||||
* `-u` is the user context
|
||||
|
||||
|
||||
41. Containers running with SELinux disabled:
|
||||
* With Podman: `# podman run --security-opt label=disable` …
|
||||
* With Docker: `# docker run --security-opt label=disable` …
|
||||
|
||||
|
||||
42. If you need to give a container full access to the system:
|
||||
* With Podman: `# podman run --privileged` …
|
||||
* With Docker: `# docker run --privileged` …
|
||||
|
||||
|
||||
|
||||
And with this, you already know the answer. So please: **Don't panic, and turn on SELinux**.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-selinux
|
||||
|
||||
作者:[Alex Callejas][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/darkaxl
|
||||
[1]:https://en.wikipedia.org/wiki/Ethan_Hunt
|
||||
[2]:https://en.wikipedia.org/wiki/Red_pill_and_blue_pill
|
||||
[3]:https://en.wikipedia.org/wiki/Phrases_from_The_Hitchhiker%27s_Guide_to_the_Galaxy#Answer_to_the_Ultimate_Question_of_Life,_the_Universe,_and_Everything_%2842%29
|
||||
[4]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
@ -0,0 +1,283 @@
|
||||
FSSlc is translating
|
||||
|
||||
A sysadmin's guide to SELinux: 42 answers to the big questions
|
||||
============================================================
|
||||
|
||||
> Get answers to the big questions about life, the universe, and everything else about Security-Enhanced Linux.
|
||||
|
||||

|
||||
Image credits : [JanBaby][13], via Pixabay [CC0][14].
|
||||
|
||||
> "It is an important and popular fact that things are not always what they seem…"
|
||||
> ―Douglas Adams, _The Hitchhiker's Guide to the Galaxy_
|
||||
|
||||
Security. Hardening. Compliance. Policy. The Four Horsemen of the SysAdmin Apocalypse. In addition to our daily tasks—monitoring, backup, implementation, tuning, updating, and so forth—we are also in charge of securing our systems. Even those systems where the third-party provider tells us to disable the enhanced security. It seems like a job for _Mission Impossible_ 's [Ethan Hunt][15].
|
||||
|
||||
Faced with this dilemma, some sysadmins decide to [take the blue pill][16] because they think they will never know the answer to the big question of life, the universe, and everything else. And, as we all know, that answer is **[42][2]**.
|
||||
|
||||
In the spirit of _The Hitchhiker's Guide to the Galaxy_ , here are the 42 answers to the big questions about managing and using [SELinux][17] with your systems.
|
||||
|
||||
1. SELinux is a LABELING system, which means every process has a LABEL. Every file, directory, and system object has a LABEL. Policy rules control access between labeled processes and labeled objects. The kernel enforces these rules.
|
||||
|
||||
1. The two most important concepts are: _Labeling_ (files, process, ports, etc.) and _Type enforcement_ (which isolates processes from each other based on types).
|
||||
|
||||
1. The correct Label format is `user:role:type:level` ( _optional_ ).
|
||||
|
||||
1. The purpose of _Multi-Level Security (MLS) enforcement_ is to control processes ( _domains_ ) based on the security level of the data they will be using. For example, a secret process cannot read top-secret data.
|
||||
|
||||
1. _Multi-Category Security (MCS) enforcement_ protects similar processes from each other (like virtual machines, OpenShift gears, SELinux sandboxes, containers, etc.).
|
||||
|
||||
1. Kernel parameters for changing SELinux modes at boot:
|
||||
* `autorelabel=1` → forces the system to relabel
|
||||
|
||||
* `selinux=0` → kernel doesn't load any part of the SELinux infrastructure
|
||||
|
||||
* `enforcing=0` → boot in permissive mode
|
||||
|
||||
1. If you need to relabel the entire system:
|
||||
`# touch /.autorelabel
|
||||
#reboot`
|
||||
If the system labeling contains a large amount of errors, you might need to boot in permissive mode in order for the autorelabel to succeed.
|
||||
|
||||
1. To check if SELinux is enabled: `# getenforce`
|
||||
|
||||
1. To temporarily enable/disable SELinux: `# setenforce [1|0]`
|
||||
|
||||
1. SELinux status tool: `# sestatus`
|
||||
|
||||
1. Configuration file: `/etc/selinux/config`
|
||||
|
||||
1. How does SELinux work? Here's an example of labeling for an Apache Web Server:
|
||||
* Binary: `/usr/sbin/httpd`→`httpd_exec_t`
|
||||
|
||||
* Configuration directory: `/etc/httpd`→`httpd_config_t`
|
||||
|
||||
* Logfile directory: `/var/log/httpd` → `httpd_log_t`
|
||||
|
||||
* Content directory: `/var/www/html` → `httpd_sys_content_t`
|
||||
|
||||
* Startup script: `/usr/lib/systemd/system/httpd.service` → `httpd_unit_file_d`
|
||||
|
||||
* Process: `/usr/sbin/httpd -DFOREGROUND` → `httpd_t`
|
||||
|
||||
* Ports: `80/tcp, 443/tcp` → `httpd_t, http_port_t`
|
||||
|
||||
A process running in the `httpd_t` context can interact with an object with the `httpd_something_t` label.
|
||||
|
||||
1. Many commands accept the argument `-Z` to view, create, and modify context:
|
||||
* `ls -Z`
|
||||
|
||||
* `id -Z`
|
||||
|
||||
* `ps -Z`
|
||||
|
||||
* `netstat -Z`
|
||||
|
||||
* `cp -Z`
|
||||
|
||||
* `mkdir -Z`
|
||||
|
||||
Contexts are set when files are created based on their parent directory's context (with a few exceptions). RPMs can set contexts as part of installation.
|
||||
|
||||
1. There are four key causes of SELinux errors, which are further explained in items 15-21 below:
|
||||
* Labeling problems
|
||||
|
||||
* Something SELinux needs to know
|
||||
|
||||
* A bug in an SELinux policy/app
|
||||
|
||||
* Your information may be compromised
|
||||
|
||||
1. _Labeling problem:_ If your files in `/srv/myweb` are not labeled correctly, access might be denied. Here are some ways to fix this:
|
||||
* If you know the label:
|
||||
`# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
|
||||
|
||||
* If you know the file with the equivalent labeling:
|
||||
`# semanage fcontext -a -e /srv/myweb /var/www`
|
||||
|
||||
* Restore the context (for both cases):
|
||||
`# restorecon -vR /srv/myweb`
|
||||
|
||||
1. _Labeling problem:_ If you move a file instead of copying it, the file keeps its original context. To fix these issues:
|
||||
* Change the context command with the label:
|
||||
`# chcon -t httpd_system_content_t /var/www/html/index.html`
|
||||
|
||||
* Change the context command with the reference label:
|
||||
`# chcon --reference /var/www/html/ /var/www/html/index.html`
|
||||
|
||||
* Restore the context (for both cases): `# restorecon -vR /var/www/html/`
|
||||
|
||||
1. If _SELinux needs to know_ HTTPD listens on port 8585, tell SELinux:
|
||||
`# semanage port -a -t http_port_t -p tcp 8585`
|
||||
|
||||
1. _SELinux needs to know_ booleans allow parts of SELinux policy to be changed at runtime without any knowledge of SELinux policy writing. For example, if you want httpd to send email, enter: `# setsebool -P httpd_can_sendmail 1`
|
||||
|
||||
1. _SELinux needs to know_ booleans are just off/on settings for SELinux:
|
||||
* To see all booleans: `# getsebool -a`
|
||||
|
||||
* To see the description of each one: `# semanage boolean -l`
|
||||
|
||||
* To set a boolean execute: `# setsebool [_boolean_] [1|0]`
|
||||
|
||||
* To configure it permanently, add `-P`. For example:
|
||||
`# setsebool httpd_enable_ftp_server 1 -P`
|
||||
|
||||
1. SELinux policies/apps can have bugs, including:
|
||||
* Unusual code paths
|
||||
|
||||
* Configurations
|
||||
|
||||
* Redirection of `stdout`
|
||||
|
||||
* Leaked file descriptors
|
||||
|
||||
* Executable memory
|
||||
|
||||
* Badly built libraries
|
||||
Open a ticket (do not file a Bugzilla report; there are no SLAs with Bugzilla).
|
||||
|
||||
1. _Your information may be compromised_ if you have confined domains trying to:
|
||||
* Load kernel modules
|
||||
|
||||
* Turn off the enforcing mode of SELinux
|
||||
|
||||
* Write to `etc_t/shadow_t`
|
||||
|
||||
* Modify iptables rules
|
||||
|
||||
1. SELinux tools for the development of policy modules:
|
||||
`# yum -y install setroubleshoot setroubleshoot-server`
|
||||
Reboot or restart `auditd` after you install.
|
||||
|
||||
1. Use `journalctl` for listing all logs related to `setroubleshoot`:
|
||||
`# journalctl -t setroubleshoot --since=14:20`
|
||||
|
||||
1. Use `journalctl` for listing all logs related to a particular SELinux label. For example:
|
||||
`# journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
|
||||
|
||||
1. Use `setroubleshoot` log when an SELinux error occurs and suggest some possible solutions. For example, from `journalctl`:
|
||||
```
|
||||
Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
|
||||
# sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
SELinux is preventing httpd from getattr access on the file /var/www/html/index.html.
|
||||
|
||||
***** Plugin restorecon (99.5 confidence) suggests ************************
|
||||
|
||||
If you want to fix the label,
|
||||
/var/www/html/index.html default label should be httpd_syscontent_t.
|
||||
Then you can restorecon.
|
||||
Do
|
||||
# /sbin/restorecon -v /var/www/html/index.html
|
||||
```
|
||||
|
||||
1. Logging: SELinux records information all over the place:
|
||||
* `/var/log/messages`
|
||||
|
||||
* `/var/log/audit/audit.log`
|
||||
|
||||
* `/var/lib/setroubleshoot/setroubleshoot_database.xml`
|
||||
|
||||
1. Logging: Looking for SELinux errors in the audit log:
|
||||
`# ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
|
||||
|
||||
1. To search for SELinux Access Vector Cache (AVC) messages for a particular service:
|
||||
`# ausearch -m avc -c httpd`
|
||||
|
||||
1. The `audit2allow` utility gathers information from logs of denied operations and then generates SELinux policy-allow rules. For example:
|
||||
* To produce a human-readable description of why the access was denied: `# audit2allow -w -a`
|
||||
|
||||
* To view the type enforcement rule that allows the denied access: `# audit2allow -a`
|
||||
|
||||
* To create a custom module: `# audit2allow -a -M mypolicy`
|
||||
The `-M` option creates a type enforcement file (.te) with the name specified and compiles the rule into a policy package (.pp): `mypolicy.pp mypolicy.te`
|
||||
|
||||
* To install the custom module: `# semodule -i mypolicy.pp`
|
||||
|
||||
1. To configure a single process (domain) to run permissive: `# semanage permissive -a httpd_t`
|
||||
|
||||
1. If you no longer want a domain to be permissive: `# semanage permissive -d httpd_t`
|
||||
|
||||
1. To disable all permissive domains: `# semodule -d permissivedomains`
|
||||
|
||||
1. Enabling SELinux MLS policy: `# yum install selinux-policy-mls`
|
||||
In `/etc/selinux/config:`
|
||||
`SELINUX=permissive`
|
||||
`SELINUXTYPE=mls`
|
||||
Make sure SELinux is running in permissive mode: `# setenforce 0`
|
||||
Use the `fixfiles` script to ensure that files are relabeled upon the next reboot:
|
||||
`# fixfiles -F onboot # reboot`
|
||||
|
||||
1. Create a user with a specific MLS range: `# useradd -Z staff_u john`
|
||||
Using the `useradd` command, map the new user to an existing SELinux user (in this case, `staff_u`).
|
||||
|
||||
1. To view the mapping between SELinux and Linux users: `# semanage login -l`
|
||||
|
||||
1. Define a specific range for a user: `# semanage login --modify --range s2:c100 john`
|
||||
|
||||
1. To correct the label on the user's home directory (if needed): `# chcon -R -l s2:c100 /home/john`
|
||||
|
||||
1. To list the current categories: `# chcat -L`
|
||||
|
||||
1. To modify the categories or to start creating your own, modify the file as follows:
|
||||
`/etc/selinux/_<selinuxtype>_/setrans.conf`
|
||||
|
||||
1. To run a command or script in a specific file, role, and user context:
|
||||
`# runcon -t initrc_t -r system_r -u user_u yourcommandhere`
|
||||
* `-t` is the _file context_
|
||||
|
||||
* `-r` is the _role context_
|
||||
|
||||
* `-u` is the _user context_
|
||||
|
||||
1. Containers running with SELinux disabled:
|
||||
* With Podman: `# podman run --security-opt label=disable` …
|
||||
|
||||
* With Docker: `# docker run --security-opt label=disable` …
|
||||
|
||||
1. If you need to give a container full access to the system:
|
||||
* With Podman: `# podman run --privileged` …
|
||||
|
||||
* With Docker: `# docker run --privileged` …
|
||||
|
||||
And with this, you already know the answer. So please: **Don't panic, and turn on SELinux**.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
Alex Callejas - Alex Callejas is a Technical Account Manager of Red Hat in the LATAM region, based in Mexico City. With more than 10 years of experience as SysAdmin, he has strong expertise on Infrastructure Hardening. Enthusiast of the Open Source, supports the community sharing his knowledge in different events of public access and universities. Geek by nature, Linux by choice, Fedora of course.[More about me][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-selinux
|
||||
|
||||
作者:[ Alex Callejas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/darkaxl
|
||||
[1]:https://opensource.com/article/18/7/sysadmin-guide-selinux?rate=hR1QSlwcImXNksBPPrLOeP6ooSoOU7PZaR07aGFuYVo
|
||||
[2]:https://en.wikipedia.org/wiki/Phrases_from_The_Hitchhiker%27s_Guide_to_the_Galaxy#Answer_to_the_Ultimate_Question_of_Life,_the_Universe,_and_Everything_%2842%29
|
||||
[3]:https://fedorapeople.org/~dwalsh/SELinux/SELinux
|
||||
[4]:https://opensource.com/users/rhatdan
|
||||
[5]:https://opensource.com/business/13/11/selinux-policy-guide
|
||||
[6]:http://people.redhat.com/tcameron/Summit2018/selinux/SELinux_for_Mere_Mortals_Summit_2018.pdf
|
||||
[7]:http://twitter.com/thomasdcameron
|
||||
[8]:http://blog.linuxgrrl.com/2014/04/16/the-selinux-coloring-book/
|
||||
[9]:https://opensource.com/users/mairin
|
||||
[10]:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/selinux_users_and_administrators_guide/index
|
||||
[11]:https://opensource.com/users/darkaxl
|
||||
[12]:https://opensource.com/user/219886/feed
|
||||
[13]:https://pixabay.com/en/security-secure-technology-safety-2168234/
|
||||
[14]:https://creativecommons.org/publicdomain/zero/1.0/deed.en
|
||||
[15]:https://en.wikipedia.org/wiki/Ethan_Hunt
|
||||
[16]:https://en.wikipedia.org/wiki/Red_pill_and_blue_pill
|
||||
[17]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[18]:https://opensource.com/users/darkaxl
|
||||
[19]:https://opensource.com/users/darkaxl
|
||||
[20]:https://opensource.com/article/18/7/sysadmin-guide-selinux#comments
|
||||
[21]:https://opensource.com/tags/security
|
||||
[22]:https://opensource.com/tags/linux
|
||||
[23]:https://opensource.com/tags/sysadmin
|
||||
@ -0,0 +1,124 @@
|
||||
FSSlc is translating
|
||||
|
||||
|
||||
netdev day 2: moving away from "as fast as possible" in networking code
|
||||
============================================================
|
||||
|
||||
Hello! Today was day 2 of netdev. I only made it to the morning of the conference, but the morning was VERY EXCITING. The highlight of this morning was a keynote by [Van Jacobson][1] about the future of congestion control on the internet (!!!) called “Evolving from As Fast As Possible: Teaching NICs about time”
|
||||
|
||||
I’m going to try to summarize what I learned from this talk. I almost certainly have some things wrong, but let’s go!
|
||||
|
||||
This talk was about how the internet has changed since 1988, why we need new algorithms today, and how we can change Linux’s networking stack to implement those algorithms more easily.
|
||||
|
||||
### what’s congestion control?
|
||||
|
||||
Everyone on the internet is sending packets all at once, all the time. The links on the internet are of dramatically different speeds (some are WAY slower than others), and sometimes they get full! When a device on the internet receives packets at a rate faster than it can handle, it drops the packets.
|
||||
|
||||
The most naive you way you could imagine sending packets is:
|
||||
|
||||
1. Send all the packets you have to send all at once
|
||||
|
||||
2. If you discover any of those packets got dropped, resend the packet right away
|
||||
|
||||
It turns out that if you implemented TCP that way, the internet would collapse and grind to a halt. We know that it would collapse because it did kinda collapse, in 1986\. To fix this, folks invented congestion control algorithms – the original paper describing how they avoided collapsing the internet is [Congestion Avoidance and Control][2], by Van Jacobson from 1988\. (30 years ago!)
|
||||
|
||||
### How has the internet changed since 1988?
|
||||
|
||||
The main thing he said has changed about the internet is – it used to be that switches would always have faster network cards than servers on the internet. So the servers in the middle of the internet would be a lot faster than the clients, and it didn’t matter as much how fast clients sent packets.
|
||||
|
||||
Today apparently that’s not true! As we all know, computers today aren’t really faster than computers 5 years ago (we ran into some problems with the speed of light). So what happens (I think) is that the big switches in routers are not really that much faster than the NICs on servers in datacenters.
|
||||
|
||||
This is bad because it means that clients are much more easily able to saturate the links in the middle, which results in the internet getting slower. (and there’s [buffer bloat][3] which results in high latency)
|
||||
|
||||
So to improve performance on the internet and not saturate all the queues on every router, clients need to be a little better behaved and to send packets a bit more slowly.
|
||||
|
||||
### sending more packets more slowly results in better performance
|
||||
|
||||
Here’s an idea that was really surprising to me – sending packets more slowly often actually results in better performance (even if you are the only one doing it). Here’s why!
|
||||
|
||||
Suppose you’re trying to send 10MB of data, and there’s a link somewhere in the middle between you and the client you’re trying to talk to that is SLOW, like 1MB/s or something. Assuming that you can tell the speed of this slow link (more on that later), you have 2 choices:
|
||||
|
||||
1. Send the entire 10MB of data at once and see what happens
|
||||
|
||||
2. Slow it down so you send it at 1MB/s
|
||||
|
||||
Now – either way, you’re probably going to end up with some packet loss. So it seems like you might as well just send all the data at once if you’re going to end up with packet loss either way, right? No!! The key observation is that packet loss in the middle of your stream is much better than packet loss at the end of your stream. If a few packets in the middle are dropped, the client you’re sending to will realize, tell you, and you can just resend them. No big deal! But if packets at the END are dropped, the client has no way of knowing you sent those packets at all! So you basically need to time out at some point when you don’t get an ACK for those packets and resend it. And timeouts typically take a long time to happen!
|
||||
|
||||
So why is sending data more slowly better? Well, if you send data faster than the bottleneck for the link, what will happen is that all the packets will pile up in a queue somewhere, the queue will get full, and then the packets at the END of your stream will get dropped. And, like we just explained, the packets at the end of the stream are the worst packets to drop! So then you have all these timeouts, and sending your 10MB of data will take way longer than if you’d just sent your packets at the correct speed in the first place.
|
||||
|
||||
I thought this was really cool because it doesn’t require cooperation from anybody else on the internet – even if everybody else is sending all their packets really fast, it’s _still_ more advantageous for you to send your packets at the correct rate (the rate of the bottleneck in the middle)
|
||||
|
||||
### how to tell the right speed to send data at: BBR!
|
||||
|
||||
Earlier I said “assuming that you can tell the speed of the slow link between your client and server…“. How do you do that? Well, some folks from Google (where Jacobson works) came up with an algorithm for measuring the speed of bottlenecks! It’s called BBR. This post is already long enough, but for more about BBR, see [BBR: Congestion-based congestion control][4] and [the summary from the morning paper][5].
|
||||
|
||||
(as an aside, [https://blog.acolyer.org][6]’s daily “the morning paper” summaries are basically the only way I learn about / understand CS papers, it’s possibly the greatest blog on the internet)
|
||||
|
||||
### networking code is designed to run “as fast as possible”
|
||||
|
||||
So! Let’s say we believe we want to send data a little more slowly, at the speed of the bottleneck in our connection. This is all very well, but networking software isn’t really designed to send data at a controlled rate! This (as far as I understand it) is how most networking stuff is designed:
|
||||
|
||||
1. There’s a queue of packets coming in
|
||||
|
||||
2. It reads off the queue and sends the packets out as as fast as possible
|
||||
|
||||
3. That’s it
|
||||
|
||||
This is pretty inflexible! Like – suppose I have one really fast connection I’m sending packets on, and one really slow connection. If all I have is a queue to put packets on, I don’t get that much control over when the packets I’m sending actually get sent out. I can’t slow down the queue!
|
||||
|
||||
### a better way: give every packet an “earliest departure time”
|
||||
|
||||
His proposal was to modify the skb data structure in the Linux kernel (which is the data structure used to represent network packets) to have a TIMESTAMP on it representing the earliest time that packet should go out.
|
||||
|
||||
I don’t know a lot about the Linux network stack, but the interesting thing to me about this proposal is that it doesn’t sound like a huge change! It’s just an extra timestamp.
|
||||
|
||||
### replace queues with timing wheels!!!
|
||||
|
||||
Once we have all these packets with times on them, how do we get them sent out at the right time? TIMING WHEELS!
|
||||
|
||||
At Papers We Love a while back ([some good links in the meetup description][7]) there was a talk about timing wheels. Timing wheels are the algorithm the Linux process scheduler decides when to run processes.
|
||||
|
||||
He said that timing wheels actually perform better than queues for scheduling work – they both offer constant time operations, but the timing wheels constant is smaller because of some stuff to do with cache performance. I didn’t really follow the performance arguments.
|
||||
|
||||
One point he made about timing wheels is that you can easily implement a queue with a timing wheel (though not vice versa!) – if every time you add a new packet, you say that you want it to be sent RIGHT NOW at the earliest, then you effectively end up with a queue. So this timing wheel approach is backwards compatible, but it makes it much easier to implement more complex traffic shaping algorithms where you send out different packets at different rates.
|
||||
|
||||
### maybe we can fix the internet by improving Linux!
|
||||
|
||||
With any internet-scale problem, the tricky thing about making progress on it is that you need cooperation from SO MANY different parties to change how internet protocols are implemented. You have Linux machines, BSD machines, Windows machines, different kinds of phones, Juniper/Cisco routers, and lots of other devices!
|
||||
|
||||
But Linux is in kind of an interesting position in the networking landscape!
|
||||
|
||||
* Android phones run Linux
|
||||
|
||||
* Most consumer wifi routers run Linux
|
||||
|
||||
* Lots of servers run Linux
|
||||
|
||||
So in any given network connection, you’re actually relatively likely to have a Linux machine at both ends (a linux server, and either a Linux router or Android device).
|
||||
|
||||
So the point is that if you want to improve congestion on the internet in general, it would make a huge difference to just change the Linux networking stack. (and maybe the iOS networking stack too) Which is why there was a keynote at this Linux networking conference about it!
|
||||
|
||||
### the internet is still changing! Cool!
|
||||
|
||||
I usually think of TCP/IP as something that we figured out in the 80s, so it was really fascinating to hear that folks think that there are still serious issues with how we’re designing our networking protocols, and that there’s work to do to design them differently.
|
||||
|
||||
And of course it makes sense – the landscape of networking hardware and the relative speeds of everything and the kinds of things people are using the internet for (netflix!) is changing all the time, so it’s reasonable that at some point we need to start designing our algorithms differently for the internet of 2018 instead of the internet of 1998.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/07/12/netdev-day-2--moving-away-from--as-fast-as-possible/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://en.wikipedia.org/wiki/Van_Jacobson
|
||||
[2]:https://cs162.eecs.berkeley.edu/static/readings/jacobson-congestion.pdf
|
||||
[3]:https://apenwarr.ca/log/?m=201101#10
|
||||
[4]:https://queue.acm.org/detail.cfm?id=3022184
|
||||
[5]:https://blog.acolyer.org/2017/03/31/bbr-congestion-based-congestion-control/
|
||||
[6]:https://blog.acolyer.org/
|
||||
[7]:https://www.meetup.com/Papers-We-Love-Montreal/events/235100825/
|
||||
362
sources/tech/20180719 Building tiny container images.md
Normal file
362
sources/tech/20180719 Building tiny container images.md
Normal file
@ -0,0 +1,362 @@
|
||||
Building tiny container images
|
||||
======
|
||||
|
||||
|
||||
|
||||
When [Docker][1] exploded onto the scene a few years ago, it brought containers and container images to the masses. Although Linux containers existed before then, Docker made it easy to get started with a user-friendly command-line interface and an easy-to-understand way to build images using the Dockerfile format. But while it may be easy to jump in, there are still some nuances and tricks to building container images that are usable, even powerful, but still small in size.
|
||||
|
||||
### First pass: Clean up after yourself
|
||||
|
||||
Some of these examples involve the same kind of cleanup you would use with a traditional server, but more rigorously followed. Smaller image sizes are critical for quickly moving images around, and storing multiple copies of unnecessary data on disk is a waste of resources. Consequently, these techniques should be used more regularly than on a server with lots of dedicated storage.
|
||||
|
||||
An example of this kind of cleanup is removing cached files from an image to recover space. Consider the difference in size between a base image with [Nginx][2] installed by `dnf` with and without the metadata and yum cache cleaned up:
|
||||
```
|
||||
# Dockerfile with cache
|
||||
|
||||
FROM fedora:28
|
||||
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
|
||||
|
||||
RUN dnf install -y nginx
|
||||
|
||||
|
||||
|
||||
-----
|
||||
|
||||
|
||||
|
||||
# Dockerfile w/o cache
|
||||
|
||||
FROM fedora:28
|
||||
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
|
||||
|
||||
RUN dnf install -y nginx \
|
||||
|
||||
&& dnf clean all \
|
||||
|
||||
&& rm -rf /var/cache/yum
|
||||
|
||||
|
||||
|
||||
-----
|
||||
|
||||
|
||||
|
||||
[chris@krang] $ docker build -t cache -f Dockerfile .
|
||||
|
||||
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}"
|
||||
|
||||
| head -n 1
|
||||
|
||||
cache: 464 MB
|
||||
|
||||
|
||||
|
||||
[chris@krang] $ docker build -t no-cache -f Dockerfile-wo-cache .
|
||||
|
||||
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
|
||||
|
||||
no-cache: 271 MB
|
||||
|
||||
```
|
||||
|
||||
That is a significant difference in size. The version with the `dnf` cache is almost twice the size of the image without the metadata and cache. Package manager cache, Ruby gem temp files, `nodejs` cache, even downloaded source tarballs are all perfect candidates for cleaning up.
|
||||
|
||||
### Layers—a potential gotcha
|
||||
|
||||
Unfortunately (or fortunately, as you’ll see later), based on the way layers work with containers, you cannot simply add a `RUN rm -rf /var/cache/yum` line to your Dockerfile and call it a day. Each instruction of a Dockerfile is stored in a layer, with changes between layers applied on top. So even if you were to do this:
|
||||
```
|
||||
RUN dnf install -y nginx
|
||||
|
||||
RUN dnf clean all
|
||||
|
||||
RUN rm -rf /var/cache/yum
|
||||
|
||||
```
|
||||
|
||||
...you’d still end up with three layers, one of which contains all the cache, and two intermediate layers that "remove" the cache from the image. But the cache is actually still there, just as when you mount a filesystem over the top of another one, the files are there—you just can’t see or access them.
|
||||
|
||||
You’ll notice that the example in the previous section chains the cache cleanup in the same Dockerfile instruction where the cache is generated:
|
||||
```
|
||||
RUN dnf install -y nginx \
|
||||
|
||||
&& dnf clean all \
|
||||
|
||||
&& rm -rf /var/cache/yum
|
||||
|
||||
```
|
||||
|
||||
This is a single instruction and ends up being a single layer within the image. You’ll lose a bit of the Docker (*ahem*) cache this way, making a rebuild of the image slightly longer, but the cached data will not end up in your final image. As a nice compromise, just chaining related commands (e.g., `yum install` and `yum clean all`, or downloading, extracting and removing a source tarball, etc.) can save a lot on your final image size while still allowing you to take advantage of the Docker cache for quicker development.
|
||||
|
||||
This layer "gotcha" is more subtle than it first appears, though. Because the image layers document the _changes_ to each layer, one upon another, it’s not just the existence of files that add up, but any change to the file. For example, _even changing the mode_ of the file creates a copy of that file in the new layer.
|
||||
|
||||
For example, the output of `docker images` below shows information about two images. The first, `layer_test_1`, was created by adding a single 1GB file to a base CentOS image. The second image, `layer_test_2`, was created `FROM layer_test_1` and did nothing but change the mode of the 1GB file with `chmod u+x`.
|
||||
```
|
||||
layer_test_2 latest e11b5e58e2fc 7 seconds ago 2.35 GB
|
||||
|
||||
layer_test_1 latest 6eca792a4ebe 2 minutes ago 1.27 GB
|
||||
|
||||
```
|
||||
|
||||
As you can see, the new image is more than 1GB larger than the first. Despite the fact that `layer_test_1` is only the first two layers of `layer_test_2`, there’s still an extra 1GB file floating around hidden inside the second image. This is true anytime you remove, move, or change any file during the image build process.
|
||||
|
||||
### Purpose-built images vs. flexible images
|
||||
|
||||
An anecdote: As my office heavily invested in [Ruby on Rails][3] applications, we began to embrace the use of containers. One of the first things we did was to create an official Ruby base image for all of our teams to use. For simplicity’s sake (and suffering under “this is the way we did it on our servers”), we used [rbenv][4] to install the latest four versions of Ruby into the image, allowing our developers to migrate all of their applications into containers using a single image. This resulted in a very large but flexible (we thought) image that covered all the bases of the various teams we were working with.
|
||||
|
||||
This turned out to be wasted work. The effort required to maintain separate, slightly modified versions of a particular image was easy to automate, and selecting a specific image with a specific version actually helped to identify applications approaching end-of-life before a breaking change was introduced, wreaking havoc downstream. It also wasted resources: When we started to split out the different versions of Ruby, we ended up with multiple images that shared a single base and took up very little extra space if they coexisted on a server, but were considerably smaller to ship around than a giant image with multiple versions installed.
|
||||
|
||||
That is not to say building flexible images is not helpful, but in this case, creating purpose-build images from a common base ended up saving both storage space and maintenance time, and each team could modify their setup however they needed while maintaining the benefit of the common base image.
|
||||
|
||||
### Start without the cruft: Add what you need to a blank image
|
||||
|
||||
As friendly and easy-to-use as the _Dockerfile_ is, there are tools available that offer the flexibility to create very small Docker-compatible container images without the cruft of a full operating system—even those as small as the standard Docker base images.
|
||||
|
||||
[I’ve written about Buildah before][5], and I’ll mention it again because it is flexible enough to create an image from scratch using tools from your host to install packaged software and manipulate the image. Those tools then never need to be included in the image itself.
|
||||
|
||||
Buildah replaces the `docker build` command. With it, you can mount the filesystem of your container image to your host machine and interact with it using tools from the host.
|
||||
|
||||
Let’s try Buildah with the Nginx example from above (ignoring caches for now):
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
|
||||
set -o errexit
|
||||
|
||||
|
||||
|
||||
# Create a container
|
||||
|
||||
container=$(buildah from scratch)
|
||||
|
||||
|
||||
|
||||
# Mount the container filesystem
|
||||
|
||||
mountpoint=$(buildah mount $container)
|
||||
|
||||
|
||||
|
||||
# Install a basic filesystem and minimal set of packages, and nginx
|
||||
|
||||
dnf install --installroot $mountpoint --releasever 28 glibc-minimal-langpack nginx --setopt install_weak_deps=false -y
|
||||
|
||||
|
||||
|
||||
# Save the container to an image
|
||||
|
||||
buildah commit --format docker $container nginx
|
||||
|
||||
|
||||
|
||||
# Cleanup
|
||||
|
||||
buildah unmount $container
|
||||
|
||||
|
||||
|
||||
# Push the image to the Docker daemon’s storage
|
||||
|
||||
buildah push nginx:latest docker-daemon:nginx:latest
|
||||
|
||||
```
|
||||
|
||||
You’ll notice we’re no longer using a Dockerfile to build the image, but a simple Bash script, and we’re building it from a scratch (or blank) image. The Bash script mounts the container’s root filesystem to a mount point on the host, and then uses the hosts’ command to install the packages. This way the package manager doesn’t even have to exist inside the container.
|
||||
|
||||
Without extra cruft—all the extra stuff in the base image, like `dnf`, for example—the image weighs in at only 304 MB, more than 100 MB smaller than the Nginx image built with a Dockerfile above.
|
||||
```
|
||||
[chris@krang] $ docker images |grep nginx
|
||||
|
||||
docker.io/nginx buildah 2505d3597457 4 minutes ago 304 MB
|
||||
|
||||
```
|
||||
|
||||
_Note: The image name has`docker.io` appended to it due to the way the image is pushed into the Docker daemon’s namespace, but it is still the image built locally with the build script above._
|
||||
|
||||
That 100 MB is already a huge savings when you consider a base image is already around 300 MB on its own. Installing Nginx with a package manager brings in a ton of dependencies, too. For something compiled from source using tools from the host, the savings can be even greater because you can choose the exact dependencies and not pull in any extra files you don’t need.
|
||||
|
||||
If you’d like to try this route, [Tom Sweeney][6] wrote a much more in-depth article, [Creating small containers with Buildah][7], which you should check out.
|
||||
|
||||
Using Buildah to build images without a full operating system and included build tools can enable much smaller images than you would otherwise be able to create. For some types of images, we can take this approach even further and create images with _only_ the application itself included.
|
||||
|
||||
### Create images with only statically linked binaries
|
||||
|
||||
Following the same philosophy that leads us to ditch administrative and build tools inside images, we can go a step further. If we specialize enough and abandon the idea of troubleshooting inside of production containers, do we need Bash? Do we need the [GNU core utilities][8]? Do we _really_ need the basic Linux filesystem? You can do this with any compiled language that allows you to create binaries with [statically linked libraries][9]—where all the libraries and functions needed by the program are copied into and stored within the binary itself.
|
||||
|
||||
This is a relatively popular way of doing things within the [Golang][10] community, so we’ll use a Go application to demonstrate.
|
||||
|
||||
The Dockerfile below takes a small Go Hello-World application and compiles it in an image `FROM golang:1.8`:
|
||||
```
|
||||
FROM golang:1.8
|
||||
|
||||
|
||||
|
||||
ENV GOOS=linux
|
||||
|
||||
ENV appdir=/go/src/gohelloworld
|
||||
|
||||
|
||||
|
||||
COPY ./ /go/src/goHelloWorld
|
||||
|
||||
WORKDIR /go/src/goHelloWorld
|
||||
|
||||
|
||||
|
||||
RUN go get
|
||||
|
||||
RUN go build -o /goHelloWorld -a
|
||||
|
||||
|
||||
|
||||
CMD ["/goHelloWorld"]
|
||||
|
||||
```
|
||||
|
||||
The resulting image, containing the binary, the source code, and the base image layer comes in at 716 MB. The only thing we actually need for our application is the compiled binary, however. Everything else is unused cruft that gets shipped around with our image.
|
||||
|
||||
If we disable `cgo` with `CGO_ENABLED=0` when we compile, we can create a binary that doesn’t wrap C libraries for some of its functions:
|
||||
```
|
||||
GOOS=linux CGO_ENABLED=0 go build -a goHelloWorld.go
|
||||
|
||||
```
|
||||
|
||||
The resulting binary can be added to an empty, or "scratch" image:
|
||||
```
|
||||
FROM scratch
|
||||
|
||||
COPY goHelloWorld /
|
||||
|
||||
CMD ["/goHelloWorld"]
|
||||
|
||||
```
|
||||
|
||||
Let’s compare the difference in image size between the two:
|
||||
```
|
||||
[ chris@krang ] $ docker images
|
||||
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
|
||||
goHello scratch a5881650d6e9 13 seconds ago 1.55 MB
|
||||
|
||||
goHello builder 980290a100db 14 seconds ago 716 MB
|
||||
|
||||
```
|
||||
|
||||
That’s a huge difference. The image built from `golang:1.8` with the `goHelloWorld` binary in it (tagged "builder" above) is _460_ times larger than the scratch image with just the binary. The entirety of the scratch image with the binary is only 1.55 MB. That means we’d be shipping around 713 MB of unnecessary data if we used the builder image.
|
||||
|
||||
As mentioned above, this method of creating small images is used often in the Golang community, and there is no shortage of blog posts on the subject. [Kelsey Hightower][11] wrote [an article on the subject][12] that goes into more detail, including dealing with dependencies other than just C libraries.
|
||||
|
||||
### Consider squashing, if it works for you
|
||||
|
||||
There’s an alternative to chaining all the commands into layers in an attempt to save space: Squashing your image. When you squash an image, you’re really exporting it, removing all the intermediate layers, and saving a single layer with the current state of the image. This has the advantage of reducing that image to a much smaller size.
|
||||
|
||||
Squashing layers used to require some creative workarounds to flatten an image—exporting the contents of a container and re-importing it as a single layer image, or using tools like `docker-squash`. Starting in version 1.13, Docker introduced a handy flag, `--squash`, to accomplish the same thing during the build process:
|
||||
```
|
||||
FROM fedora:28
|
||||
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
|
||||
|
||||
RUN dnf install -y nginx
|
||||
|
||||
RUN dnf clean all
|
||||
|
||||
RUN rm -rf /var/cache/yum
|
||||
|
||||
|
||||
|
||||
[chris@krang] $ docker build -t squash -f Dockerfile-squash --squash .
|
||||
|
||||
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
|
||||
|
||||
squash: 271 MB
|
||||
|
||||
```
|
||||
|
||||
Using `docker squash` with this multi-layer Dockerfile, we end up with another 271MB image, as we did with the chained instruction example. This works great for this use case, but there’s a potential gotcha.
|
||||
|
||||
“What? ANOTHER gotcha?”
|
||||
|
||||
Well, sort of—it’s the same issue as before, causing problems in another way.
|
||||
|
||||
### Going too far: Too squashed, too small, too specialized
|
||||
|
||||
Images can share layers. The base may be _x_ megabytes in size, but it only needs to be pulled/stored once and each image can use it. The effective size of all the images sharing layers is the base layers plus the diff of each specific change on top of that. In this way, thousands of images may take up only a small amount more than a single image.
|
||||
|
||||
This is a drawback with squashing or specializing too much. When you squash an image into a single layer, you lose any opportunity to share layers with other images. Each image ends up being as large as the total size of its single layer. This might work well for you if you use only a few images and run many containers from them, but if you have many diverse images, it could end up costing you space in the long run.
|
||||
|
||||
Revisiting the Nginx squash example, we can see it’s not a big deal for this case. We end up with Fedora, Nginx installed, no cache, and squashing that is fine. Nginx by itself is not incredibly useful, though. You generally need customizations to do anything interesting—e.g., configuration files, other software packages, maybe some application code. Each of these would end up being more instructions in the Dockerfile.
|
||||
|
||||
With a traditional image build, you would have a single base image layer with Fedora, a second layer with Nginx installed (with or without cache), and then each customization would be another layer. Other images with Fedora and Nginx could share these layers.
|
||||
|
||||
Need an image:
|
||||
```
|
||||
[ App 1 Layer ( 5 MB) ] [ App 2 Layer (6 MB) ]
|
||||
|
||||
[ Nginx Layer ( 21 MB) ] ------------------^
|
||||
|
||||
[ Fedora Layer (249 MB) ]
|
||||
|
||||
```
|
||||
|
||||
But if you squash the image, then even the Fedora base layer is squashed. Any squashed image based on Fedora has to ship around its own Fedora content, adding another 249 MB for _each image!_
|
||||
```
|
||||
[ Fedora + Nginx + App 1 (275 MB)] [ Fedora + Nginx + App 2 (276 MB) ]
|
||||
|
||||
```
|
||||
|
||||
This also becomes a problem if you build lots of highly specialized, super-tiny images.
|
||||
|
||||
As with everything in life, moderation is key. Again, thanks to how layers work, you will find diminishing returns as your container images become smaller and more specialized and can no longer share base layers with other related images.
|
||||
|
||||
Images with small customizations can share base layers. As explained above, the base may be _x_ megabytes in size, but it only needs to be pulled/stored once and each image can use it. The effective size of all the images is the base layers plus the diff of each specific change on top of that. In this way, thousands of images may take up only a small amount more than a single image.
|
||||
```
|
||||
[ specific app ] [ specific app 2 ]
|
||||
|
||||
[ customizations ]--------------^
|
||||
|
||||
[ base layer ]
|
||||
|
||||
```
|
||||
|
||||
If you go too far with your image shrinking and you have too many variations or specializations, you can end up with many images, none of which share base layers and all of which take up their own space on disk.
|
||||
```
|
||||
[ specific app 1 ] [ specific app 2 ] [ specific app 3 ]
|
||||
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
There are a variety of different ways to reduce the amount of storage space and bandwidth you spend working with container images, but the most effective way is to reduce the size of the images themselves. Whether you simply clean up your caches (avoiding leaving them orphaned in intermediate layers), squash all your layers into one, or add only static binaries in an empty image, it’s worth spending some time looking at where bloat might exist in your container images and slimming them down to an efficient size.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/building-container-images
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clcollins
|
||||
[1]:https://www.docker.com/
|
||||
[2]:https://www.nginx.com/
|
||||
[3]:https://rubyonrails.org/
|
||||
[4]:https://github.com/rbenv/rbenv
|
||||
[5]:https://opensource.com/article/18/6/getting-started-buildah
|
||||
[6]:https://twitter.com/TSweeneyRedHat
|
||||
[7]:https://opensource.com/article/18/5/containers-buildah
|
||||
[8]:https://www.gnu.org/software/coreutils/coreutils.html
|
||||
[9]:https://en.wikipedia.org/wiki/Static_library
|
||||
[10]:https://golang.org/
|
||||
[11]:https://twitter.com/kelseyhightower
|
||||
[12]:https://medium.com/@kelseyhightower/optimizing-docker-images-for-static-binaries-b5696e26eb07
|
||||
@ -1,90 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
4 cool new projects to try in COPR for July 2018
|
||||
======
|
||||
|
||||

|
||||
|
||||
COPR is a [collection][1] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
Here’s a set of new and interesting projects in COPR.
|
||||
|
||||
### Hledger
|
||||
|
||||
[Hledger][2] is a command-line program for tracking money or other commodities. It uses a simple, plain-text formatted journal for storing data and double-entry accounting. In addition to the command-line interface, hledger offers a terminal interface and a web client that can show graphs of balance on the accounts.
|
||||
![][3]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides hledger for Fedora 27, 28, and Rawhide. To install hledger, use these commands:
|
||||
```
|
||||
sudo dnf copr enable kefah/HLedger
|
||||
sudo dnf install hledger
|
||||
|
||||
```
|
||||
|
||||
### Neofetch
|
||||
|
||||
[Neofetch][4] is a command-line tool that displays information about the operating system, software, and hardware. Its main purpose is to show the data in a compact way to take screenshots. You can configure Neofetch to display exactly the way you want, by using both command-line flags and a configuration file.
|
||||
![][5]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Neofetch for Fedora 28. To install Neofetch, use these commands:
|
||||
```
|
||||
sudo dnf copr enable sysek/neofetch
|
||||
sudo dnf install neofetch
|
||||
|
||||
```
|
||||
|
||||
### Remarkable
|
||||
|
||||
[Remarkable][6] is a Markdown text editor that uses the GitHub-like flavor of Markdown. It offers a preview of the document, as well as the option to export to PDF and HTML. There are several styles available for the Markdown, including an option to create your own styles using CSS. In addition, Remarkable supports LaTeX syntax for writing equations and syntax highlighting for source code.
|
||||
![][7]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Remarkable for Fedora 28 and Rawhide. To install Remarkable, use these commands:
|
||||
```
|
||||
sudo dnf copr enable neteler/remarkable
|
||||
sudo dnf install remarkable
|
||||
|
||||
```
|
||||
|
||||
### Aha
|
||||
|
||||
[Aha][8] (or ANSI HTML Adapter) is a command-line tool that converts terminal escape sequences to HTML code. This allows you to share, for example, output of git diff or htop as a static HTML page.
|
||||
![][9]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The [repo][10] currently provides aha for Fedora 26, 27, 28, and Rawhide, EPEL 6 and 7, and other distributions. To install aha, use these commands:
|
||||
```
|
||||
sudo dnf copr enable scx/aha
|
||||
sudo dnf install aha
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-july-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:http://hledger.org/
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/hledger.png
|
||||
[4]:https://github.com/dylanaraps/neofetch
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/neofetch.png
|
||||
[6]:https://remarkableapp.github.io/linux.html
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/remarkable.png
|
||||
[8]:https://github.com/theZiz/aha
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/aha.png
|
||||
[10]:https://copr.fedorainfracloud.org/coprs/scx/aha/
|
||||
@ -1,71 +0,0 @@
|
||||
4 open source media conversion tools for the Linux desktop
|
||||
======
|
||||
|
||||

|
||||
|
||||
Ah, so many file formats—especially audio and video ones—can make for fun times if you get a file with an extension you don't recognize, if your media player doesn't play a file in that format, or if you want to use an open format.
|
||||
|
||||
So, what can a Linux user do? Turn to one of the many open source media conversion tools for the Linux desktop, of course. Let's take a look at four of them.
|
||||
|
||||
### Gnac
|
||||
|
||||
|
||||
|
||||
[Gnac][1] is one of my favorite audio converters and has been for years. It's easy to use, it's powerful, and it does one thing well—as any top-notch utility should.
|
||||
|
||||
How easy? You click a toolbar button to add one or more files to convert, choose a format to convert to, and then click **Convert**. The conversions are quick, and they're clean.
|
||||
|
||||
How powerful? Gnac can handle all the audio formats that the [GStreamer][2] multimedia framework supports. Out of the box, you can convert between Ogg, FLAC, AAC, MP3, WAV, and SPX. You can also change the conversion options for each format or add new ones.
|
||||
|
||||
### SoundConverter
|
||||
|
||||
|
||||
|
||||
If simplicity with a few extra features is your thing, then give [SoundConverter][3] a look. As its name states, SoundConverter works its magic only on audio files. Like Gnac, it can read the formats that GStreamer supports, and it can spit out Ogg Vorbis, MP3, FLAC, WAV, AAC, and Opus files.
|
||||
|
||||
Load individual files or an entire folder by either clicking **Add File** or dragging and dropping it into the SoundConverter window. Click **Convert** , and the software powers through the conversion. It's fast, too—I've converted a folder containing a couple dozen files in about a minute.
|
||||
|
||||
SoundConverter has options for setting the quality of your converted files. You can change the way files are named (for example, include a track number or album name in the title) and create subfolders for the converted files.
|
||||
|
||||
### WinFF
|
||||
|
||||
|
||||
|
||||
[WinFF][4], on its own, isn't a converter. It's a graphical frontend to FFmpeg, which [Tim Nugent looked at][5] for Opensource.com. While WinFF doesn't have all the flexibility of FFmpeg, it makes FFmpeg easier to use and gets the job done quickly and fairly easily.
|
||||
|
||||
Although it's not the prettiest application out there, WinFF doesn't need to be. It's more than usable. You can choose what formats to convert to from a dropdown list and select several presets. On top of that, you can specify options like bitrates and frame rates, the number of audio channels to use, and even the size at which to crop videos.
|
||||
|
||||
The conversions, especially video, take a bit of time, but the results are generally quite good. Once in a while, the conversion gets a bit mangled—but not often enough to be a concern. And, as I said earlier, using WinFF can save me a bit of time.
|
||||
|
||||
### Miro Video Converter
|
||||
|
||||
|
||||
|
||||
Not all video files are created equally. Some are in proprietary formats. Others look great on a monitor or TV screen but aren't optimized for a mobile device. That's where [Miro Video Converter][6] comes to the rescue.
|
||||
|
||||
Miro Video Converter has a heavy emphasis on mobile. It can convert video that you can play on Android phones, Apple devices, the PlayStation Portable, and the Kindle Fire. It will convert most common video formats to MP4, [WebM][7] , and [Ogg Theora][8] . You can find a full list of supported devices and formats [on Miro's website][6]
|
||||
|
||||
To use it, either drag and drop a file into the window or select the file that you want to convert. Then, click the Format menu to choose the format for the conversion. You can also click the Apple, Android, or Other menus to choose a device for which you want to convert the file. Miro Video Converter resizes the video for the device's screen resolution.
|
||||
|
||||
Do you have a favorite Linux media conversion application? Feel free to share it by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/media-conversion-tools-linux
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:http://gnac.sourceforge.net
|
||||
[2]:http://www.gstreamer.net/
|
||||
[3]:http://soundconverter.org/
|
||||
[4]:https://www.biggmatt.com/winff/
|
||||
[5]:https://opensource.com/article/17/6/ffmpeg-convert-media-file-formats
|
||||
[6]:http://www.mirovideoconverter.com/
|
||||
[7]:https://en.wikipedia.org/wiki/WebM
|
||||
[8]:https://en.wikipedia.org/wiki/Ogg_theora
|
||||
@ -1,42 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Textricator: Data extraction made simple
|
||||
======
|
||||
|
||||

|
||||
|
||||
You probably know the feeling: You ask for data and get a positive response, only to open the email and find a whole bunch of PDFs attached. Data, interrupted.
|
||||
|
||||
We understand your frustration, and we’ve done something about it: Introducing [Textricator][1], our first open source product.
|
||||
|
||||
We’re Measures for Justice, a criminal justice research and transparency organization. Our mission is to provide data transparency for the entire justice system, from arrest to post-conviction. We do this by producing a series of up to 32 performance measures covering the entire criminal justice system, county by county. We get our data in many ways—all legal, of course—and while many state and county agencies are data-savvy, giving us quality, formatted data in CSVs, the data is often bundled inside software with no simple way to get it out. PDF reports are the best they can offer.
|
||||
|
||||
Developers Joe Hale and Stephen Byrne have spent the past two years developing Textricator to extract tens of thousands of pages of data for our internal use. Textricator can process just about any text-based PDF format—not just tables, but complex reports with wrapping text and detail sections generated from tools like Crystal Reports. Simply tell Textricator the attributes of the fields you want to collect, and it chomps through the document, collecting and writing out your records.
|
||||
|
||||
Not a software engineer? Textricator doesn’t require programming skills; rather, the user describes the structure of the PDF and Textricator handles the rest. Most users run it via the command line; however, a browser-based GUI is available.
|
||||
|
||||
We evaluated other great open source solutions like [Tabula][2], but they just couldn’t handle the structure of some of the PDFs we needed to scrape. “Textricator is both flexible and powerful and has cut the time we spend to process large datasets from days to hours,” says Andrew Branch, director of technology.
|
||||
|
||||
At MFJ, we’re committed to transparency and knowledge-sharing, which includes making our software available to anyone, especially those trying to free and share data publicly. Textricator is available on [GitHub][3] and released under [GNU Affero General Public License Version 3][4].
|
||||
|
||||
You can see the results of our work, including data processed via Textricator, on our free [online data portal][5]. Textricator is an essential part of our process and we hope civic tech and government organizations alike can unlock more data with this new tool.
|
||||
|
||||
If you use Textricator, let us know how it helped solve your data problem. Want to improve it? Submit a pull request.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/textricator
|
||||
|
||||
作者:[Stephen Byrne][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://textricator.mfj.io/
|
||||
[2]:https://tabula.technology/
|
||||
[3]:https://github.com/measuresforjustice/textricator
|
||||
[4]:https://www.gnu.org/licenses/agpl-3.0.en.html
|
||||
[5]:https://www.measuresforjustice.org/portal/
|
||||
@ -1,123 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
4 cool apps for your terminal
|
||||
======
|
||||
|
||||

|
||||
|
||||
Many Linux users think that working in a terminal is either too complex or boring, and try to escape it. Here is a fix, though — four great open source apps for your terminal. They’re fun and easy to use, and may even brighten up your life when you need to spend a time in the command line.
|
||||
|
||||
### No More Secrets
|
||||
|
||||
This is a simple command line tool that recreates the famous data decryption effect seen in the 1992 movie [Sneakers][1]. The project lets you compile the nms command, which works with piped data and prints the output in the form of messed characters. Once it does so, you can press any key, and see the live “deciphering” of the output with a cool Hollywood-style effect.
|
||||
|
||||
![][2]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
A fresh Fedora Workstation system already includes everything you need to build No More Secrets from source. Just enter the following command in your terminal:
|
||||
```
|
||||
git clone https://github.com/bartobri/no-more-secrets.git
|
||||
cd ./no-more-secrets
|
||||
make nms
|
||||
make sneakers ## Optional
|
||||
sudo make install
|
||||
|
||||
```
|
||||
|
||||
The sneakers command is a little bonus for those who remember the original movie, but the main hero is nms. Use a pipe to redirect any Linux command to nms, like this:
|
||||
```
|
||||
systemctl list-units --type=target | nms
|
||||
|
||||
```
|
||||
|
||||
Once the text stops flickering, hit any key to “decrypt” it. The systemctl command above is only an example — you can replace it with virtually anything!
|
||||
|
||||
### Lolcat
|
||||
|
||||
Here’s a command that colorizes the terminal output with rainbows. Nothing can be more useless, but boy, it looks awesome!
|
||||
|
||||
![][3]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
Lolcat is a Ruby package available from the official Ruby Gems hosting. So, you’ll need the gem client first:
|
||||
```
|
||||
sudo dnf install -y rubygems
|
||||
|
||||
```
|
||||
|
||||
And then install Lolcat itself:
|
||||
```
|
||||
gem install lolcat
|
||||
|
||||
```
|
||||
|
||||
Again, use the lolcat command in for piping any other command and enjoy rainbows (and unicorns!) right in your Fedora terminal.
|
||||
|
||||
### Chafa
|
||||
|
||||
![][4]
|
||||
|
||||
Chafa is a [command line image converter and viewer][5]. It helps you enjoy your images without leaving your lovely terminal. The syntax is very straightforward:
|
||||
```
|
||||
chafa /path/to/your/image
|
||||
|
||||
```
|
||||
|
||||
You can throw almost any sort of image to Chafa, including JPG, PNG, TIFF, BMP or virtually anything that ImageMagick supports — this is the engine that Chafa uses for parsing input files. The coolest part is that Chafa can also show very smooth and fluid GIF animations right inside your terminal!
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
Chafa isn’t packaged for Fedora yet, but it’s quite easy to build it from source. First, get the necessary build dependencies:
|
||||
```
|
||||
sudo dnf install -y autoconf automake libtool gtk-doc glib2-devel ImageMagick-devel
|
||||
|
||||
```
|
||||
|
||||
Next, clone the code or download a snapshot from the project’s Github page and cd to the Chafa directory. After that, you’re ready to go:
|
||||
```
|
||||
git clone https://github.com/hpjansson/chafa
|
||||
./autogen.sh
|
||||
make
|
||||
sudo make install
|
||||
|
||||
```
|
||||
|
||||
Large images can take a while to process at the first run, but Chafa caches everything you load with it. Next runs will be nearly instantaneous.
|
||||
|
||||
### Browsh
|
||||
|
||||
Browsh is a fully-fledged web browser for the terminal. It’s more powerful than Lynx and certainly more eye-catching. Browsh launches the Firefox web browser in a headless mode (so that you can’t see it) and connects it with your terminal with the help of special web extension. Therefore, Browsh renders all rich media content just like Firefox, only in a bit pixelated style.
|
||||
|
||||
![][6]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The project provides packages for various Linux distributions, including Fedora. Install it this way:
|
||||
```
|
||||
sudo dnf install -y https://github.com/browsh-org/browsh/releases/download/v1.4.6/browsh_1.4.6_linux_amd64.rpm
|
||||
|
||||
```
|
||||
|
||||
After that, launch the browsh command and give it a couple of seconds to load up. Press Ctrl+L to switch focus to the address bar and start browsing the Web like you never did before! Use Ctrl+Q to get back to your terminal.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-apps-for-your-terminal/
|
||||
|
||||
作者:[atolstoy][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/atolstoy/
|
||||
[1]:https://www.imdb.com/title/tt0105435/
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/nms.gif
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/lolcat.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/sir.gif
|
||||
[5]:https://hpjansson.org/chafa/
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/browsh.png
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by DavidChenLiang
|
||||
|
||||
The evolution of package managers
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,221 @@
|
||||
Download Subtitles Via Right Click From File Manager Or Command Line With OpenSubtitlesDownload.py
|
||||
======
|
||||
**If you're looking for a quick way to download subtitles from OpenSubtitles.org from your Linux desktop or server, give[OpenSubtitlesDownload.py][1] a try. This neat Python tool can be used as a Nautilus, Nemo or Caja script, or from the command line.**
|
||||
|
||||
|
||||
|
||||
The Python script **searches for subtitles on OpenSubtitles.org using the video hash sum to find exact matches** , and thus avoid out of sync subtitles. In case no match is found, it then tries to perform a search based on the video file name, although such subtitles may not always be in sync.
|
||||
|
||||
OpenSubtitlesDownload.py has quite a few cool features, including **support for more than 60 languages,** and it can query both multiple subtitle languages and videos in the same time (so it **supports mass subtitle search and download** ).
|
||||
|
||||
The **optional graphical user interface** (uses Zenity for Gnome and Kdialog for KDE) can display multiple subtitle matches and by digging into its settings you can enable the display of some extra information, like the subtitles download count, rating, language, and more.
|
||||
|
||||
Other OpenSubtitlesDownload.py features include:
|
||||
|
||||
* Option to download subtitles automatically if only one is available, choose the one you want otherwise.
|
||||
* Option to rename downloaded subtitles to match source video file. Possibility to append the language code to the file name (ex: movie_en.srt).
|
||||
|
||||
|
||||
|
||||
The Python tool does not yet support downloading subtitles for movies within a directory recursively, but this is a planned feature.
|
||||
|
||||
In case you encounter errors when downloading a large number of subtitles, you should be aware that OpenSubtitles has a daily subtitle download limit (it appears it was 200 subtitles downloads / day a while back, I'm not sure if it changed). For VIP users it's 1000 subtitles per day, but OpenSubtitlesDownload.py does not allow logging it to an OpenSubtitles account and thus, you can't take advantage of a VIP account while using this tool.
|
||||
|
||||
### Installing and using OpenSubtitlesDownload.py as a Nautilus, Nemo or Caja script
|
||||
|
||||
The instructions below explain how to install OpenSubtitlesDownload.py as a script for Caja, Nemo or Nautilus file managers. Thanks to this you'll be able to right click (context menu) one or multiple video files in your file manager, select `Scripts > OpenSubtitlesDownload.py` and the script will search for and download subtitles from OpenSubtitles.org for your video files.
|
||||
|
||||
This is OpenSubtitlesDownload.py used as a Nautilus script:
|
||||
|
||||
|
||||
|
||||
And as a Nemo script:
|
||||
|
||||
|
||||
|
||||
To install OpenSubtitlesDownload.py as a Nautilus, Nemo or Caja script, see the instructions below.
|
||||
|
||||
1\. Install the dependencies required by OpenSubtitlesDownload.py
|
||||
|
||||
You'll need to install `gzip` , `wget` and `zenity` before using OpenSubtitlesDownload.py. The instructions below assume you already have Python (both Python 2 and 3 will do it), as well as `ps` and `grep` available.
|
||||
|
||||
In Debian, Ubuntu, or Linux Mint, install `gzip` , `wget` and `zenity` using this command:
|
||||
```
|
||||
sudo apt install gzip wget zenity
|
||||
|
||||
```
|
||||
|
||||
2\. Now you can download the OpenSubtitlesDownload.py
|
||||
```
|
||||
wget https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py
|
||||
|
||||
```
|
||||
|
||||
3\. Use the commands below to move the downloaded OpenSubtitlesDownload.py script to the file manager scripts folder and make it executable (use the commands for your current file manager - Nautilus, Nemo or Caja):
|
||||
|
||||
* Nautilus (default Gnome, Unity and Solus OS file manager):
|
||||
|
||||
|
||||
```
|
||||
mkdir -p ~/.local/share/nautilus/scripts
|
||||
mv OpenSubtitlesDownload.py ~/.local/share/nautilus/scripts/
|
||||
chmod u+x ~/.local/share/nautilus/scripts/OpenSubtitlesDownload.py
|
||||
|
||||
```
|
||||
|
||||
* Nemo (default Cinnamon file manager):
|
||||
|
||||
|
||||
```
|
||||
mkdir -p ~/.local/share/nemo/scripts
|
||||
mv OpenSubtitlesDownload.py ~/.local/share/nemo/scripts/
|
||||
chmod u+x ~/.local/share/nemo/scripts/OpenSubtitlesDownload.py
|
||||
|
||||
```
|
||||
|
||||
* Caja (default MATE file manager):
|
||||
|
||||
|
||||
```
|
||||
mkdir -p ~/.config/caja/scripts
|
||||
mv OpenSubtitlesDownload.py ~/.config/caja/scripts/
|
||||
chmod u+x ~/.config/caja/scripts/OpenSubtitlesDownload.py
|
||||
|
||||
```
|
||||
|
||||
4\. Configure OpenSubtitlesDownload.py
|
||||
|
||||
Since it's running as a file manager script, without any arguments, you'll need to modify the script if you want to change some of its settings, like enabling the GUI, changing the subtitles language, and so on. These are optional of course, and you can use it directly to automatically download subtitles using its default settings.
|
||||
|
||||
To Configure OpenSubtitlesDownload.py, you'll need to open it with a text editor. The script path should now be:
|
||||
|
||||
* Nautilus:
|
||||
|
||||
`~/.local/share/nautilus/scripts`
|
||||
|
||||
* Nemo:
|
||||
|
||||
`~/.local/share/nemo/scripts`
|
||||
|
||||
* Caja:
|
||||
|
||||
`~/.config/caja/scripts`
|
||||
|
||||
|
||||
|
||||
|
||||
Navigate to that folder using your file manager and open the OpenSubtitlesDownload.py file with a text editor.
|
||||
|
||||
Here's what you may want to change in this file:
|
||||
|
||||
* To change the subtitle language, search for `opt_languages = ['eng']` and change the language from `['eng']` (English) to `['fre']` (French), or whatever language you want to use. The ISO codes for each language supported by OpenSubtitles.org are available on [this][2] page (use the code in the first column).
|
||||
|
||||
* If you want a GUI to present you with all subtitles options and let you choose which to download, find the `opt_selection_mode = 'default'` setting and change it to `'manual'` . You'll not want to change this to 'manual' (or better yet, change it to 'auto') if you want to download multiple subtitles in the same time and avoid having a window popup for each video!
|
||||
|
||||
* To force the Gnome GUI to be used, search for `opt_gui = 'auto'` and change `'auto'` to `'gnome'`
|
||||
|
||||
* You can also enable multiple info columns in the GUI:
|
||||
|
||||
* Search for `opt_selection_rating = 'off'` and change it to `'auto'` to display user ratings if available
|
||||
|
||||
* Search for `opt_selection_count = 'off'` and change it to `'auto'` to display the subtitle number of downloads if available
|
||||
|
||||
|
||||
**You can find a list of OpenSubtitlesDownload.py settings with explanations by visiting[this page][3].**
|
||||
|
||||
And you're done. OpenSubtitlesDownload.py should now appear in Nautilus, Nemo or Caja, when right clicking a file and selecting Scripts. Clicking OpenSubtitlesDownload.py should search and download subtitles for the selected video(s).
|
||||
|
||||
### Installing and using OpenSubtitlesDownload.py from the command line
|
||||
|
||||
1\. Install the dependencies required by OpenSubtitlesDownload.py (command line only)
|
||||
|
||||
You'll need to install `gzip` and `wget` . On Debian, Ubuntu or Linux Mint you can install these packages by using this command:
|
||||
```
|
||||
sudo apt install wget gzip
|
||||
|
||||
```
|
||||
|
||||
2\. Install the `/usr/local/bin/` and set it so it uses the command line interface by default:
|
||||
```
|
||||
wget https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py -O opensubtitlesdownload
|
||||
sed -i "s/opt_gui = 'auto'/opt_gui = 'cli'/" opensubtitlesdownload
|
||||
sudo install opensubtitlesdownload /usr/local/bin/
|
||||
|
||||
```
|
||||
|
||||
Now you can start using it. To use the script with automatic selection and download of the best available subtitle, type:
|
||||
```
|
||||
opensubtitlesdownload --auto /path/to/video.mkv
|
||||
|
||||
```
|
||||
|
||||
You can specify the language by appending `--lang LANG` , where `LANG` is the ISO code for a language supported by OpenSubtitles.org, available on
|
||||
```
|
||||
opensubtitlesdownload --lang SPA /home/logix/Videos/Sintel.2010.720p.mkv
|
||||
|
||||
```
|
||||
|
||||
Which provides this output (it allows you to choose the best subtitle since we didn't use `--auto` only, nor did we append `--select manual` to allow manual selection):
|
||||
```
|
||||
>> Title: Sintel
|
||||
>> Filename: Sintel.2010.720p.mkv
|
||||
>> Available subtitles:
|
||||
[1] "Sintel (2010).spa.srt" > "Language: Spanish"
|
||||
[2] "sintel_es.srt" > "Language: Spanish"
|
||||
[3] "Sintel.2010.720p.x264-VODO-spa.srt" > "Language: Spanish"
|
||||
[0] Cancel search
|
||||
>> Enter your choice (0-3): 1
|
||||
>> Downloading 'Spanish' subtitles for 'Sintel'
|
||||
2018-07-27 14:37:04 URL:http://dl.opensubtitles.org/en/download/src-api/vrf-19c10c57/sid-8rL5O0xhUw2BgKG6lvsVBM0p00f/filead/1955318590.gz [936/936] -> "-" [1]
|
||||
|
||||
```
|
||||
|
||||
These are all the available options:
|
||||
```
|
||||
$ opensubtitlesdownload --help
|
||||
usage: OpenSubtitlesDownload.py [-h] [-g GUI] [--cli] [-s SEARCH] [-t SELECT]
|
||||
[-a] [-v] [-l [LANG]]
|
||||
filePathListArg [filePathListArg ...]
|
||||
|
||||
This software is designed to help you find and download subtitles for your favorite videos!
|
||||
|
||||
|
||||
-h, --help show this help message and exit
|
||||
-g GUI, --gui GUI Select the GUI you want from: auto, kde, gnome, cli (default: auto)
|
||||
--cli Force CLI mode
|
||||
-s SEARCH, --search SEARCH
|
||||
Search mode: hash, filename, hash_then_filename, hash_and_filename (default: hash_then_filename)
|
||||
-t SELECT, --select SELECT
|
||||
Selection mode: manual, default, auto
|
||||
-a, --auto Force automatic selection and download of the best subtitles found
|
||||
-v, --verbose Force verbose output
|
||||
-l [LANG], --lang [LANG]
|
||||
Specify the language in which the subtitles should be downloaded (default: eng).
|
||||
Syntax:
|
||||
-l eng,fre: search in both language
|
||||
-l eng -l fre: download both language
|
||||
|
||||
```
|
||||
|
||||
**The theme used for the screenshots in this article is called[Canta][4].**
|
||||
|
||||
**You may also be interested in:[How To Replace Nautilus With Nemo File Manager On Ubuntu 18.04 Gnome Desktop (Complete Guide)][5]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/download-subtitles-via-right-click-from.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://emericg.github.io/OpenSubtitlesDownload/
|
||||
[2]:http://www.opensubtitles.org/addons/export_languages.php
|
||||
[3]:https://github.com/emericg/OpenSubtitlesDownload/wiki/Adjust-settings
|
||||
[4]:https://www.linuxuprising.com/2018/04/canta-is-amazing-material-design-gtk.html
|
||||
[5]:https://www.linuxuprising.com/2018/07/how-to-replace-nautilus-with-nemo-file.html
|
||||
[6]:https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py
|
||||
@ -1,134 +0,0 @@
|
||||
Three Graphical Clients for Git on Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Those that develop on Linux are likely familiar with [Git][1]. With good reason. Git is one of the most widely used and recognized version control systems on the planet. And for most, Git use tends to lean heavily on the terminal. After all, much of your development probably occurs at the command line, so why not interact with Git in the same manner?
|
||||
|
||||
In some instances, however, having a GUI tool to work with can make your workflow slightly more efficient (at least for those that tend to depend upon a GUI). To that end, what options do you have for Git GUI tools? Fortunately, we found some that are worthy of your time and (in some cases) money. I want to highlight three such Git clients that run on the Linux operating system. Out of these three, you should be able to find one that meets all of your needs.
|
||||
I am going to assume you understand how Git and repositories like GitHub function, [which I covered previously][2], so I won’t be taking the time for any how-tos with these tools. Instead, this will be an introduction, so you (the developer) know these tools are available for your development tasks.
|
||||
|
||||
A word of warning: Not all of these tools are free, and some are released under proprietary licenses. However, they all work quite well on the Linux platform and make interacting with GitHub a breeze.
|
||||
|
||||
With that said, let’s look at some outstanding Git GUIs.
|
||||
|
||||
### SmartGit
|
||||
|
||||
[SmartGit][3] is a proprietary tool that’s free for non-commercial usage. If you plan on employing SmartGit in a commercial environment, the license cost is $99 USD per year for one license or $5.99 per month. There are other upgrades (such as Distributed Reviews and SmartSynchronize), which are both $15 USD per licence. You can download either the source or a .deb package for installation. I tested SmartGit on Ubuntu 18.04 and it worked without issue.
|
||||
|
||||
But why would you want to use SmartGit? There are plenty of reasons. First and foremost, SmartGit makes it incredibly easy to integrate with the likes of GitHub and Subversion servers. Instead of spending your valuable time attempting to configure the GUI to work with your remote accounts, SmartGit takes the pain out of that task. The SmartGit GUI (Figure 1) is also very well designed to be uncluttered and intuitive.
|
||||
|
||||
|
||||
![SmartGit][5]
|
||||
|
||||
Figure 1: The SmartGit UI helps to simplify your workflow.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
After installing SmartGit, I had it connected with my personal GitHub account in seconds. The default toolbar makes working with a repository, incredibly simple. Push, pull, check out, merge, add branches, cherry pick, revert, rebase, reset — all of Git’s most popular features are there to use. Outside of supporting most of the standard Git and GitHub functions/features, SmartGit is very stable. At least when using the tool on the Ubuntu desktop, you feel like you’re working with an application that was specifically designed and built for Linux.
|
||||
|
||||
SmartGit is probably one of the best tools that makes working with even advanced Git features easy enough for any level of user. To learn more about SmartGit, take a look at the [extensive documentation][7].
|
||||
|
||||
### GitKraken
|
||||
|
||||
[GitKraken][8] is another proprietary GUI tool that makes working with both Git and GitHub an experience you won’t regret. Where SmartGit has a very simplified UI, GitKraken has a beautifully designed interface that offers a bit more feature-wise at the ready. There is a free version of GitKraken available (and you can test the full-blown paid version with a 15 day trial period). After the the trial period ends, you can continue using the free version, but for non-commercial use only.
|
||||
|
||||
For those who want to get the most out of their development workflow, GitKraken might be the tool to choose. This particular take on the Git GUI features the likes of visual interactions, resizable commit graphs, drag and drop, seamless integration (with GitHub, GitLab, and BitBucket), easy in-app tasks, in-app merge tools, fuzzy finder, gitflow support, 1-click undo & redo, keyboard shortcuts, file history & blame, submodules, light & dark themes, git hooks support, git LFS, and much more. But the one feature that many users will appreciate the most is the incredibly well-designed interface (Figure 2).
|
||||
|
||||
|
||||
![GitKraken][10]
|
||||
|
||||
Figure 2: The GitKraken interface is tops.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
Outside of the amazing interface, one of the things that sets GitKraken above the rest of the competition is how easy it makes working with multiple remote repositories and multiple profiles. The one caveat to using GitKraken (besides it being proprietary) is the cost. If you’re looking at using GitKraken for commercial use, the license costs are:
|
||||
|
||||
* $49 per user per year for individual
|
||||
|
||||
* $39 per user per year for 10+ users
|
||||
|
||||
* $29 per user per year for 100+ users
|
||||
|
||||
|
||||
|
||||
|
||||
The Pro accounts allow you to use both the Git Client and the Glo Boards (which is the GitKraken project management tool) commercially. The Glo Boards are an especially interesting feature as they allow you to sync your Glo Board to GitHub Issues. Glo Boards are sharable and include search & filters, issue tracking, markdown support, file attachments, @mentions, card checklists, and more. All of this can be accessed from within the GitKraken GUI.
|
||||
GitKraken is available for Linux as either an installable .deb file, or source.
|
||||
|
||||
### Git Cola
|
||||
|
||||
[Git Cola][11] is our free, open source entry in the list. Unlike both GitKraken and Smart Git, Git Cola is a pretty bare bones, no-nonsense Git client. Git Cola is written in Python with a GTK interface, so no matter what distribution and desktop combination you use, it should integrate seamlessly. And because it’s open source, you should find it in your distribution's package manager. So installation is nothing more than a matter of opening your distribution’s app store, searching for “Git Cola” and installing. You can also install from the command line like so:
|
||||
```
|
||||
sudo apt install git-cola
|
||||
|
||||
```
|
||||
|
||||
Or:
|
||||
```
|
||||
sudo dnf install git-cola
|
||||
|
||||
```
|
||||
|
||||
The Git Cola interface is pretty simple (Figure 3). In fact, you won’t find much in the way of too many bells and whistles, as Git Cola is all about the basics.
|
||||
|
||||
|
||||
![Git Cola][13]
|
||||
|
||||
Figure 3: The Git Cola interface is a much simpler affair.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
Because of Git Cola’s return to basics, there will be times when you must interface with the terminal. However, for many Linux users this won’t be a deal breaker (as most are developing within the terminal anyway). Git Cola does include features like:
|
||||
|
||||
* Multiple subcommands
|
||||
|
||||
* Custom window settings
|
||||
|
||||
* Configurable and environment variables
|
||||
|
||||
* Language settings
|
||||
|
||||
* Supports custom GUI settings
|
||||
|
||||
* Keyboard shortcuts
|
||||
|
||||
|
||||
|
||||
|
||||
Although Git Cola does support connecting to remote repositories, the integration to the likes of Github isn’t nearly as intuitive as it is on either GitKraken or SmartGit. But if you’re doing most of your work locally, Git Cola is an outstanding tool that won’t get in between you and Git.
|
||||
|
||||
Git Cola also comes with an advanced (Directed Acyclic Graph) DAG visualizer, called Git Dag. This tool allows you to get a visual representation of your branches. You start Git Dag either separately from Git Cola or within Git Cola from the View > DAG menu entry. Git DAG is a very powerful tool, which helps to make Git Cola one of the top open source Git GUIs on the market.
|
||||
|
||||
### There’s more where that came from
|
||||
|
||||
There are plenty more Git GUI tools available. However, from these three tools you can do some serious work. Whether you’re looking for a tool with all the bells and whistles (regardless of license) or if you’re a strict GPL user, one of these should fit the bill.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][14]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/7/three-graphical-clients-git-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://git-scm.com/
|
||||
[2]:https://www.linux.com/learn/intro-to-linux/2018/7/introduction-using-git
|
||||
[3]:https://www.syntevo.com/smartgit/
|
||||
[4]:/files/images/gitgui1jpg
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_1.jpg?itok=LEZ_PYIf (SmartGit)
|
||||
[6]:/licenses/category/used-permission
|
||||
[7]:http://www.syntevo.com/doc/display/SG/Manual
|
||||
[8]:https://www.gitkraken.com/
|
||||
[9]:/files/images/gitgui2jpg
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_2.jpg?itok=Y8crSLhf (GitKraken)
|
||||
[11]:https://git-cola.github.io/
|
||||
[12]:/files/images/gitgui3jpg
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_3.jpg?itok=bS9OYPQo (Git Cola)
|
||||
[14]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,121 @@
|
||||
7 Python libraries for more maintainable code
|
||||
======
|
||||
|
||||

|
||||
|
||||
> Readability counts.
|
||||
> — [The Zen of Python][1], Tim Peters
|
||||
|
||||
It's easy to let readability and coding standards fall by the wayside when a software project moves into "maintenance mode." (It's also easy to never establish those standards in the first place.) But maintaining consistent style and testing standards across a codebase is an important part of decreasing the maintenance burden, ensuring that future developers are able to quickly grok what's happening in a new-to-them project and safeguarding the health of the app over time.
|
||||
|
||||
### Check your code style
|
||||
|
||||
A great way to protect the future maintainability of a project is to use external libraries to check your code health for you. These are a few of our favorite libraries for [linting code][2] (checking for PEP 8 and other style errors), enforcing a consistent style, and ensuring acceptable test coverage as a project reaches maturity.
|
||||
|
||||
[PEP 8][3] is the Python code style guide, and it sets out rules for things like line length, indentation, multi-line expressions, and naming conventions. Your team might also have your own style rules that differ slightly from PEP 8. The goal of any code style guide is to enforce consistent standards across a codebase to make it more readable, and thus more maintainable. Here are three libraries to help prettify your code.
|
||||
|
||||
#### 1\. Pylint
|
||||
|
||||
[Pylint][4] is a library that checks for PEP 8 style violations and common errors. It integrates well with several popular [editors and IDEs][5] and can also be run from the command line.
|
||||
|
||||
To install, run `pip install pylint`.
|
||||
|
||||
To use Pylint from the command line, run `pylint [options] path/to/dir` or `pylint [options] path/to/module.py`. Pylint will output warnings about style violations and other errors to the console.
|
||||
|
||||
You can customize what errors Pylint checks for with a [configuration file][6] called `pylintrc`.
|
||||
|
||||
#### 2\. Flake8
|
||||
|
||||
[Flake8][7] is a "Python tool that glues together PEP8, Pyflakes (similar to Pylint), McCabe (code complexity checker), and third-party plugins to check the style and quality of some Python code."
|
||||
|
||||
To use Flake8, run `pip install flake8`. Then run `flake8 [options] path/to/dir` or `flake8 [options] path/to/module.py` to see its errors and warnings.
|
||||
|
||||
Like Pylint, Flake8 permits some customization for what it checks for with a [configuration file][8]. It has very clear docs, including some on useful [commit hooks][9] to automatically check your code as part of your development workflow.
|
||||
|
||||
Flake8 integrates with popular editors and IDEs, but those instructions generally aren't found in the docs. To integrate Flake8 with your favorite editor or IDE, search online for plugins (for example, [Flake8 plugin for Sublime Text][10]).
|
||||
|
||||
#### 3\. Isort
|
||||
|
||||
[Isort][11] is a library that sorts your imports alphabetically and breaks them up into [appropriate sections][12] (e.g., standard library imports, third-party library imports, imports from your own project, etc.). This increases readability and makes it easier to locate imports if you have a lot of them in your module.
|
||||
|
||||
Install isort with `pip install isort`, and run it with `isort path/to/module.py`. More configuration options are in the [documentation][13]. For example, you can [configure][14] how isort handles multi-line imports from one library in an `.isort.cfg` file.
|
||||
|
||||
Like Flake8 and Pylint, isort also provides plugins that integrate it with popular [editors and IDEs][15].
|
||||
|
||||
### Outsource your code style
|
||||
|
||||
Remembering to run linters manually from the command line for each file you change is a pain, and you might not like how a particular plugin behaves with your IDE. Also, your colleagues might prefer different linters or might not have plugins for their favorite editors, or you might be less meticulous about always running the linter and correcting the warnings. Over time, the codebase you all share will get messy and harder to read.
|
||||
|
||||
A great solution is to use a library that automatically reformats your code into something that passes PEP 8 for you. The three libraries we recommend all have different levels of customization and different defaults for how they format code. Some of these are more opinionated than others, so like with Pylint and Flake8, you'll want to test these out to see which offers the customizations you can't live without… and the unchangeable defaults you can live with.
|
||||
|
||||
#### 4\. Autopep8
|
||||
|
||||
[Autopep8][16] automatically formats the code in the module you specify. It will re-indent lines, fix indentation, remove extraneous whitespace, and refactor common comparison mistakes (like with booleans and `None`). See a full [list of corrections][17] in the docs.
|
||||
|
||||
To install, run `pip install --upgrade autopep8`. To reformat code in place, run `autopep8 --in-place --aggressive --aggressive <filename>`. The `aggressive` flags (and the number of them) indicate how much control you want to give autopep8 over your code style. Read more about [aggressive][18] options.
|
||||
|
||||
#### 5\. Yapf
|
||||
|
||||
[Yapf][19] is yet another option for reformatting code that comes with its own list of [configuration options][20]. It differs from autopep8 in that it doesn't just address PEP 8 violations. It also reformats code that doesn't violate PEP 8 specifically but isn't styled consistently or could be formatted better for readability.
|
||||
|
||||
To install, run `pip install yapf`. To reformat code, run, `yapf [options] path/to/dir` or `yapf [options] path/to/module.py`. There is also a full list of [customization options][20].
|
||||
|
||||
#### 6\. Black
|
||||
|
||||
[Black][21] is the new kid on the block for linters that reformat code in place. It's similar to autopep8 and Yapf, but way more opinionated. It has very few options for customization, which is kind of the point. The idea is that you shouldn't have to make decisions about code style; the only decision to make is to let Black decide for you. You can read about [limited customization options][22] and instructions on [storing them in a configuration file][23].
|
||||
|
||||
Black requires Python 3.6+ but can format Python 2 code. To use, run `pip install black`. To prettify your code, run: `black path/to/dir` or `black path/to/module.py`.
|
||||
|
||||
### Check your test coverage
|
||||
|
||||
You're writing tests, right? Then you will want to make sure new code committed to your codebase is tested and doesn't drop your overall amount of test coverage. While percentage of test coverage is not the only metric you should use to measure the effectiveness and sufficiency of your tests, it is one way to ensure basic testing standards are being followed in your project. For measuring test coverage, we have one recommendation: Coverage.
|
||||
|
||||
#### 7\. Coverage
|
||||
|
||||
[Coverage][24] has several options for the way it reports your test coverage to you, including outputting results to the console or to an HTML page and indicating which line numbers are missing test coverage. You can set up a [configuration file][25] to customize what Coverage checks for and make it easier to run.
|
||||
|
||||
To install, run `pip install coverage`. To run a program and see its output, run `coverage run [path/to/module.py] [args]`, and you will see your program's output. To see a report of which lines of code are missing coverage, run `coverage report -m`.
|
||||
|
||||
Continuous integration (CI) is a series of processes you can run to automatically check for linter errors and test coverage minimums before you merge and deploy code. There are lots of free or paid tools to automate this process, and a thorough walkthrough is beyond the scope of this article. But because setting up a CI process is an important step in removing blocks to more readable and maintainable code, you should investigate continuous integration tools in general; check out [Travis CI][26] and [Jenkins][27] in particular.
|
||||
|
||||
These are only a handful of the libraries available to check your Python code. If you have a favorite that's not on this list, please share it in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/7-python-libraries-more-maintainable-code
|
||||
|
||||
作者:[Jeff Triplett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/laceynwilliams
|
||||
[1]:https://www.python.org/dev/peps/pep-0020/
|
||||
[2]:https://en.wikipedia.org/wiki/Lint_(software)
|
||||
[3]:https://www.python.org/dev/peps/pep-0008/
|
||||
[4]:https://www.pylint.org/
|
||||
[5]:https://pylint.readthedocs.io/en/latest/user_guide/ide-integration.html
|
||||
[6]:https://pylint.readthedocs.io/en/latest/user_guide/run.html#command-line-options
|
||||
[7]:http://flake8.pycqa.org/en/latest/
|
||||
[8]:http://flake8.pycqa.org/en/latest/user/configuration.html#configuration-locations
|
||||
[9]:http://flake8.pycqa.org/en/latest/user/using-hooks.html
|
||||
[10]:https://github.com/SublimeLinter/SublimeLinter-flake8
|
||||
[11]:https://github.com/timothycrosley/isort
|
||||
[12]:https://github.com/timothycrosley/isort#how-does-isort-work
|
||||
[13]:https://github.com/timothycrosley/isort#using-isort
|
||||
[14]:https://github.com/timothycrosley/isort#configuring-isort
|
||||
[15]:https://github.com/timothycrosley/isort/wiki/isort-Plugins
|
||||
[16]:https://github.com/hhatto/autopep8
|
||||
[17]:https://github.com/hhatto/autopep8#id4
|
||||
[18]:https://github.com/hhatto/autopep8#id5
|
||||
[19]:https://github.com/google/yapf
|
||||
[20]:https://github.com/google/yapf#usage
|
||||
[21]:https://github.com/ambv/black
|
||||
[22]:https://github.com/ambv/black#command-line-options
|
||||
[23]:https://github.com/ambv/black#pyprojecttoml
|
||||
[24]:https://coverage.readthedocs.io/en/latest/
|
||||
[25]:https://coverage.readthedocs.io/en/latest/config.html
|
||||
[26]:https://travis-ci.org/
|
||||
[27]:https://jenkins.io/
|
||||
@ -0,0 +1,65 @@
|
||||
A single-user, lightweight OS for your next home project | Opensource.com
|
||||
======
|
||||

|
||||
|
||||
What on earth is RISC OS? Well, it's not a new kind of Linux. And it's not someone's take on Windows. In fact, released in 1987, it's older than either of these. But you wouldn't necessarily realize it by looking at it.
|
||||
|
||||
The point-and-click graphic user interface features a pinboard and an icon bar across the bottom for your active applications. So, it looks eerily like Windows 95, eight years before it happened.
|
||||
|
||||
This OS was originally written for the [Acorn Archimedes][1] . The Acorn RISC Machines CPU in this computer was completely new hardware that needed completely new software to run on it. This was the original operating system for the ARM chip, long before anyone had thought of Android or [Armbian][2]
|
||||
|
||||
And while the Acorn desktop eventually faded to obscurity, the ARM chip went on to conquer the world. And here, RISC OS has always had a niche—often in embedded devices, where you'd never actually know it was there. RISC OS was, for a long time, a completely proprietary operating system. But in recent years, the owners have started releasing the source code to a project called [RISC OS Open][3].
|
||||
|
||||
### 1\. You can install it on your Raspberry Pi
|
||||
|
||||
The Raspberry Pi's official operating system, [Raspbian][4], is actually pretty great (but if you aren't interested in tinkering with novel and different things in tech, you probably wouldn't be fiddling with a Raspberry Pi in the first place). Because RISC OS is written specifically for ARM, it can run on all kinds of small-board computers, including every model of Raspberry Pi.
|
||||
|
||||
### 2\. It's super lightweight
|
||||
|
||||
The RISC OS installation on my Raspberry Pi takes up a few hundred megabytes—and that's after I've loaded dozens of utilities and games. Most of these are well under a megabyte.
|
||||
|
||||
If you're really on a diet, the RISC OS Pico will fit on a 16MB SD card. This is perfect if you're hacking something to go in an embedded system or IoT project. Of course, 16MB is actually a fair bit more than the 512KB ROM chip squeezed into the old Archimedes. But I guess with 30 years of progress in memory technology, it's okay to stretch your legs just a little a bit.
|
||||
|
||||
### 3\. It's excellent for retro gaming
|
||||
|
||||
When the Archimedes was in its prime, the ARM CPU was several times faster than the Motorola 68000 in the Apple Macintosh and Commodore Amiga, and it totally smoked that new 386, too. This made it an attractive platform for game developers who wanted to strut their stuff with the most powerful desktop computer on the planet.
|
||||
|
||||
Many of the rights holders to these games have been generous enough to give permission for hobbyists to download their old work for free. And while RISC OS and the hardware has moved on, with a very small amount of fiddling you can get them to run.
|
||||
|
||||
If you're interested in exploring this, [here's a guide][5] to getting these games working on your Raspberry Pi.
|
||||
|
||||
### 4\. It's got BBC BASIC
|
||||
|
||||
Press F12 to go to the command line, type `*BASIC`, and you get a full BBC BASIC interpreter, just like the old days.
|
||||
|
||||
For those who weren't around for it in the 80s, let me explain: BBC BASIC was the first ever programming language for so many of us back in the day, for the excellent reason that it was specifically designed to teach children how to code. There were mountains of books and magazine articles that taught us to code our own simple but highly playable games.
|
||||
|
||||
Decades later, coding your own game in BBC BASIC is still a great project for a technically minded kid who wants something to do during school holidays. But few kids have a BBC micro at home anymore. So what should they run it on?
|
||||
|
||||
Well, there are interpreters you can run on just about every home computer, but that's not helpful when someone else needs to use it. So why not a Raspberry Pi with RISC OS installed?
|
||||
|
||||
### 5\. It's a simple, single-user operating system
|
||||
|
||||
RISC OS is not like Linux, with its user and superuser access. It has one user who has full access to the whole machine. So it's probably not the best daily driver to deploy across an enterprise, or even to give to granddad to do his banking. But if you're looking for something to hack and tinker with, it's absolutely fantastic. There isn't all that much between you and the bare metal, so you can just tuck right in.
|
||||
|
||||
### Further reading
|
||||
|
||||
If you want to learn more about this operating system, check out [RISC OS Open][3], or just flash an image to a card and start using it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/gentle-intro-risc-os
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dxmjames
|
||||
[1]:https://en.wikipedia.org/wiki/Acorn_Archimedes
|
||||
[2]:https://www.armbian.com/
|
||||
[3]:https://www.riscosopen.org/content/
|
||||
[4]:https://www.raspbian.org/
|
||||
[5]:https://www.riscosopen.org/wiki/documentation/show/Introduction%20to%20RISC%20OS
|
||||
@ -0,0 +1,160 @@
|
||||
How to use VS Code for your Python projects
|
||||
======
|
||||
|
||||

|
||||
Visual Studio Code, or VS Code, is an open source code editor that also includes tools for building and debugging an application. With the Python extension enabled, vscode becomes a great working environment for any Python developer. This article shows you which extensions are useful, and how to configure VS Code to get the most out of it.
|
||||
|
||||
If you don’t have it installed, check out our previous article, [Using Visual Studio Code on Fedora][1]:
|
||||
|
||||
[Using Visual Studio Code on Fedora ](https://fedoramagazine.org/using-visual-studio-code-fedora/)
|
||||
|
||||
### Install the VS Code Python extension
|
||||
|
||||
First, to make VS Code Python friendly, install the Python extension from the marketplace.
|
||||
|
||||
![][2]
|
||||
|
||||
Once the Python extension installed, you can now configure the Python extension.
|
||||
|
||||
VS Code manages its configuration inside JSON files. Two files are used:
|
||||
|
||||
* One for the global settings that applies to all projects
|
||||
* One for project specific settings
|
||||
|
||||
|
||||
|
||||
Press **Ctrl+,** (comma) to open the global settings.
|
||||
|
||||
#### Setup the Python Path
|
||||
|
||||
You can configure VS Code to automatically select the best Python interpreter for each of your projects. To do this, configure the python.pythonPath key in the global settings.
|
||||
```
|
||||
// Place your settings in this file to overwrite default and user settings.
|
||||
{
|
||||
"python.pythonPath":"${workspaceRoot}/.venv/bin/python",
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This sets VS Code to use the Python interpreter located in the project root directory under the .venv virtual environment directory.
|
||||
|
||||
#### Use environment variables
|
||||
|
||||
By default, VS Code uses environment variables defined in the project root directory in a .env file. This is useful to set environment variables like:
|
||||
```
|
||||
PYTHONWARNINGS="once"
|
||||
|
||||
```
|
||||
|
||||
That setting ensures that warnings are displayed when your program is running.
|
||||
|
||||
To change this default, set the python.envFile configuration key as follows:
|
||||
```
|
||||
"python.envFile": "${workspaceFolder}/.env",
|
||||
|
||||
```
|
||||
|
||||
### Code Linting
|
||||
|
||||
The Python extension also supports different code linters (pep8, flake8, pylint). To enable your favorite linter, or the one used by the project you’re working on, you need to set a few configuration items.
|
||||
|
||||
By default pylint is enabled. But for this example, configure flake8:
|
||||
```
|
||||
"python.linting.pylintEnabled": false,
|
||||
"python.linting.flake8Path": "${workspaceRoot}/.venv/bin/flake8",
|
||||
"python.linting.flake8Enabled": true,
|
||||
"python.linting.flake8Args": ["--max-line-length=90"],
|
||||
|
||||
```
|
||||
|
||||
After enabling the linter, your code is underlined to show where it doesn’t meet criteria enforced by the linter. Note that for this example to work, you need to install flake8 in the virtual environment of the project.
|
||||
|
||||
![][3]
|
||||
|
||||
### Code Formatting
|
||||
|
||||
VS Code also lets you configure automatic code formatting. The extension currently supports autopep8, black and yapf. Here’s how to configure black.
|
||||
```
|
||||
"python.formatting.provider": "black",
|
||||
"python.formatting.blackPath": "${workspaceRoot}/.venv/bin/black"
|
||||
"python.formatting.blackArgs": ["--line-length=90"],
|
||||
"editor.formatOnSave": true,
|
||||
|
||||
```
|
||||
|
||||
If you don’t want the editor to format your file on save, set the option to false and use **Ctrl+Shift+I** to format the current document. Note that for this example to work, you need to install black in the virtual environment of the project.
|
||||
|
||||
### Running Tasks
|
||||
|
||||
Another great feature of VS Code is that it can run tasks. These tasks are also defined in a JSON file saved in the project root directory.
|
||||
|
||||
#### Run a development flask server
|
||||
|
||||
In this example, you’ll create a task to run a Flask development server. Create a new Build using the basic template that can run an external command:
|
||||
|
||||
![][4]
|
||||
|
||||
Edit the tasks.json file as follows to create a new task that runs the Flask development server:
|
||||
```
|
||||
{
|
||||
// See https://go.microsoft.com/fwlink/?LinkId=733558
|
||||
// for the documentation about the tasks.json format
|
||||
"version": "2.0.0",
|
||||
"tasks": [
|
||||
{
|
||||
|
||||
"label": "Run Debug Server",
|
||||
"type": "shell",
|
||||
"command": "${workspaceRoot}/.venv/bin/flask run -h 0.0.0.0 -p 5000",
|
||||
"group": {
|
||||
"kind": "build",
|
||||
"isDefault": true
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The Flask development server uses an environment variable to get the entrypoint of the application. Use the .env file to declare these variables. For example:
|
||||
```
|
||||
FLASK_APP=wsgi.py
|
||||
FLASK_DEBUG=True
|
||||
|
||||
```
|
||||
|
||||
Now you can execute the task using **Ctrl+Shift+B**.
|
||||
|
||||
### Unit tests
|
||||
|
||||
VS Code also has the unit test runners pytest, unittest, and nosetest integrated out of the box. After you enable a test runner, VS Code discovers the unit tests and letsyou to run them individually, by test suite, or simply all the tests.
|
||||
|
||||
For example, to enable pytest:
|
||||
```
|
||||
"python.unitTest.pyTestEnabled": true,
|
||||
"python.unitTest.pyTestPath": "${workspaceRoot}/.venv/bin/pytest",
|
||||
|
||||
```
|
||||
|
||||
Note that for this example to work, you need to install pytest in the virtual environment of the project.
|
||||
|
||||
![][5]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/vscode-python-howto/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://fedoramagazine.org/using-visual-studio-code-fedora/
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-09-44.gif
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-12-05.gif
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-13-26.gif
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-15-33.gif
|
||||
198
sources/tech/20180731 A sysadmin-s guide to Bash.md
Normal file
198
sources/tech/20180731 A sysadmin-s guide to Bash.md
Normal file
@ -0,0 +1,198 @@
|
||||
translating by Flowsnow
|
||||
A sysadmin's guide to Bash
|
||||
======
|
||||
|
||||

|
||||
|
||||
Each trade has a tool that masters in that trade wield most often. For many sysadmins, that tool is their [shell][1]. On the majority of Linux and other Unix-like systems out there, the default shell is Bash.
|
||||
|
||||
Bash is a fairly old program—it originated in the late 1980s—but it builds on much, much older shells, like the C shell ([csh][2]), which is easily 10 years its senior. Because the concept of a shell is that old, there is an enormous amount of arcane knowledge out there waiting to be consumed to make any sysadmin guy's or gal's life a lot easier.
|
||||
|
||||
Let's take a look at some of the basics.
|
||||
|
||||
Who has, at some point, unintentionally ran a command as root and caused some kind of issue? raises hand
|
||||
|
||||
I'm pretty sure a lot of us have been that guy or gal at one point. Very painful. Here are some very simple tricks to prevent you from hitting that stone a second time.
|
||||
|
||||
### Use aliases
|
||||
|
||||
First, set up aliases for commands like **`mv`** and **`rm`** that point to `mv -I` and `rm -I`. This will make sure that running `rm -f /boot` at least asks you for confirmation. In Red Hat Enterprise Linux, these aliases are set up by default if you use the root account.
|
||||
|
||||
If you want to set those aliases for your normal user account as well, just drop these two lines into a file called .bashrc in your home directory (these will also work with sudo):
|
||||
```
|
||||
alias mv='mv -i'
|
||||
|
||||
alias rm='rm -i'
|
||||
|
||||
```
|
||||
|
||||
### Make your root prompt stand out
|
||||
|
||||
Another thing you can do to prevent mishaps is to make sure you are aware when you are using the root account. I usually do that by making the root prompt stand out really well from the prompt I use for my normal, everyday work.
|
||||
|
||||
If you drop the following into the .bashrc file in root's home directory, you will have a root prompt that is red on black, making it crystal clear that you (or anyone else) should tread carefully.
|
||||
```
|
||||
export PS1="\[$(tput bold)$(tput setab 0)$(tput setaf 1)\]\u@\h:\w # \[$(tput sgr0)\]"
|
||||
|
||||
```
|
||||
|
||||
In fact, you should refrain from logging in as root as much as possible and instead run the majority of your sysadmin commands through sudo, but that's a different story.
|
||||
|
||||
Having implemented a couple of minor tricks to help prevent "unintentional side-effects" of using the root account, let's look at a couple of nice things Bash can help you do in your daily work.
|
||||
|
||||
### Control your history
|
||||
|
||||
You probably know that when you press the Up arrow key in Bash, you can see and reuse all (well, many) of your previous commands. That is because those commands have been saved to a file called .bash_history in your home directory. That history file comes with a bunch of settings and commands that can be very useful.
|
||||
|
||||
First, you can view your entire recent command history by typing **`history`** , or you can limit it to your last 30 commands by typing **`history 30`**. But that's pretty vanilla. You have more control over what Bash saves and how it saves it.
|
||||
|
||||
For example, if you add the following to your .bashrc, any commands that start with a space will not be saved to the history list:
|
||||
```
|
||||
HISTCONTROL=ignorespace
|
||||
|
||||
```
|
||||
|
||||
This can be useful if you need to pass a password to a command in plaintext. (Yes, that is horrible, but it still happens.)
|
||||
|
||||
If you don't want a frequently executed command to show up in your history, use:
|
||||
```
|
||||
HISTCONTROL=ignorespace:erasedups
|
||||
|
||||
```
|
||||
|
||||
With this, every time you use a command, all its previous occurrences are removed from the history file, and only the last invocation is saved to your history list.
|
||||
|
||||
A history setting I particularly like is the **`HISTTIMEFORMAT`** setting. This will prepend all entries in your history file with a timestamp. For example, I use:
|
||||
```
|
||||
HISTTIMEFORMAT="%F %T "
|
||||
|
||||
```
|
||||
|
||||
When I type **`history 5`** , I get nice, complete information, like this:
|
||||
```
|
||||
1009 2018-06-11 22:34:38 cat /etc/hosts
|
||||
|
||||
1010 2018-06-11 22:34:40 echo $foo
|
||||
|
||||
1011 2018-06-11 22:34:42 echo $bar
|
||||
|
||||
1012 2018-06-11 22:34:44 ssh myhost
|
||||
|
||||
1013 2018-06-11 22:34:55 vim .bashrc
|
||||
|
||||
```
|
||||
|
||||
That makes it a lot easier to browse my command history and find the one I used two days ago to set up an SSH tunnel to my home lab (which I forget again, and again, and again…).
|
||||
|
||||
### Best Bash practices
|
||||
|
||||
I'll wrap this up with my top 11 list of the best (or good, at least; I don't claim omniscience) practices when writing Bash scripts.
|
||||
|
||||
11. Bash scripts can become complicated and comments are cheap. If you wonder whether to add a comment, add a comment. If you return after the weekend and have to spend time figuring out what you were trying to do last Friday, you forgot to add a comment.
|
||||
|
||||
|
||||
10. Wrap all your variable names in curly braces, like **`${myvariable}`**. Making this a habit makes things like `${variable}_suffix` possible and improves consistency throughout your scripts.
|
||||
|
||||
|
||||
9. Do not use backticks when evaluating an expression; use the **`$()`** syntax instead. So use:
|
||||
```
|
||||
for file in $(ls); do
|
||||
```
|
||||
|
||||
|
||||
not
|
||||
```
|
||||
for file in `ls`; do
|
||||
|
||||
```
|
||||
|
||||
The former option is nestable, more easily readable, and keeps the general sysadmin population happy. Do not use backticks.
|
||||
|
||||
|
||||
|
||||
8. Consistency is good. Pick one style of doing things and stick with it throughout your script. Obviously, I would prefer if people picked the **`$()`** syntax over backticks and wrapped their variables in curly braces. I would prefer it if people used two or four spaces—not tabs—to indent, but even if you choose to do it wrong, do it wrong consistently.
|
||||
|
||||
|
||||
7. Use the proper shebang for a Bash script. As I'm writing Bash scripts with the intention of only executing them with Bash, I most often use **`#!/usr/bin/bash`** as my shebang. Do not use **`#!/bin/sh`** or **`#!/usr/bin/sh`**. Your script will execute, but it'll run in compatibility mode—potentially with lots of unintended side effects. (Unless, of course, compatibility mode is what you want.)
|
||||
|
||||
|
||||
6. When comparing strings, it's a good idea to quote your variables in if-statements, because if your variable is empty, Bash will throw an error for lines like these:
|
||||
```
|
||||
if [ ${myvar} == "foo" ]; then
|
||||
|
||||
echo "bar"
|
||||
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
And will evaluate to false for a line like this:
|
||||
```
|
||||
if [ "${myvar}" == "foo" ]; then
|
||||
|
||||
echo "bar"
|
||||
|
||||
fi
|
||||
```
|
||||
|
||||
Also, if you are unsure about the contents of a variable (e.g., when you are parsing user input), quote your variables to prevent interpretation of some special characters and make sure the variable is considered a single word, even if it contains whitespace.
|
||||
|
||||
|
||||
|
||||
5. This is a matter of taste, I guess, but I prefer using the double equals sign ( **`==`** ) even when comparing strings in Bash. It's a matter of consistency, and even though—for string comparisons only—a single equals sign will work, my mind immediately goes "single equals is an assignment operator!"
|
||||
|
||||
|
||||
4. Use proper exit codes. Make sure that if your script fails to do something, you present the user with a written failure message (preferably with a way to fix the problem) and send a non-zero exit code:
|
||||
```
|
||||
# we have failed
|
||||
|
||||
echo "Process has failed to complete, you need to manually restart the whatchamacallit"
|
||||
|
||||
exit 1
|
||||
|
||||
```
|
||||
|
||||
This makes it easier to programmatically call your script from yet another script and verify its successful completion.
|
||||
|
||||
|
||||
|
||||
3. Use Bash's built-in mechanisms to provide sane defaults for your variables or throw errors if variables you expect to be defined are not defined:
|
||||
```
|
||||
# this sets the value of $myvar to redhat, and prints 'redhat'
|
||||
|
||||
echo ${myvar:=redhat}
|
||||
|
||||
# this throws an error reading 'The variable myvar is undefined, dear reader' if $myvar is undefined
|
||||
|
||||
${myvar:?The variable myvar is undefined, dear reader}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. Especially if you are writing a large script, and especially if you work on that large script with others, consider using the **`local`** keyword when defining variables inside functions. The **`local`** keyword will create a local variable, that is one that's visible only within that function. This limits the possibility of clashing variables.
|
||||
|
||||
|
||||
1. Every sysadmin must do it sometimes: debug something on a console, either a real one in a data center or a virtual one through a virtualization platform. If you have to debug a script that way, you will thank yourself for remembering this: Do not make the lines in your scripts too long!
|
||||
|
||||
On many systems, the default width of a console is still 80 characters. If you need to debug a script on a console and that script has very long lines, you'll be a sad panda. Besides, a script with shorter lines—the default is still 80 characters—is a lot easier to read and understand in a normal editor, too!
|
||||
|
||||
|
||||
|
||||
|
||||
I truly love Bash. I can spend hours writing about it or exchanging nice tricks with fellow enthusiasts. Make sure you drop your favorites in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/admin-guide-bash
|
||||
|
||||
作者:[Maxim Burgerhout][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/wzzrd
|
||||
[1]:http://www.catb.org/jargon/html/S/shell.html
|
||||
[2]:https://en.wikipedia.org/wiki/C_shell
|
||||
@ -0,0 +1,138 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Use Pbcopy And Pbpaste Commands On Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Since Linux and Mac OS X are *Nix based systems, many commands would work on both platforms. However, some commands may not available in on both platforms, for example **pbcopy** and **pbpaste**. These commands are exclusively available only on Mac OS X platform. The Pbcopy command will copy the standard input into clipboard. You can then paste the clipboard contents using Pbpaste command wherever you want. Of course, there could be some Linux alternatives to the above commands, for example **Xclip**. The Xclip will do exactly same as Pbcopy. But, the distro-hoppers who switched to Linux from Mac OS would miss this command-pair and still prefer to use them. No worries! This brief tutorial describes how to use Pbcopy and Pbpaste commands on Linux.
|
||||
|
||||
### Install Xclip / Xsel
|
||||
|
||||
Like I already said, Pbcopy and Pbpaste commands are not available in Linux. However, we can replicate the functionality of pbcopy and pbpaste commands using Xclip and/or Xsel commands via shell aliasing. Both Xclip and Xsel packages available in the default repositories of most Linux distributions. Please note that you need not to install both utilities. Just install any one of the above utilities.
|
||||
|
||||
To install them on Arch Linux and its derivatives, run:
|
||||
```
|
||||
$ sudo pacman xclip xsel
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
```
|
||||
$ sudo dnf xclip xsel
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
```
|
||||
$ sudo apt install xclip xsel
|
||||
|
||||
```
|
||||
|
||||
Once installed, you need create aliases for pbcopy and pbpaste commands. To do so, edit your **~/.bashrc** file:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
If you want to use Xclip, paste the following lines:
|
||||
```
|
||||
alias pbcopy='xclip -selection clipboard'
|
||||
alias pbpaste='xclip -selection clipboard -o'
|
||||
|
||||
```
|
||||
|
||||
If you want to use xsel, paste the following lines in your ~/.bashrc file.
|
||||
```
|
||||
alias pbcopy='xsel --clipboard --input'
|
||||
alias pbpaste='xsel --clipboard --output'
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Next, run the following command to update the changes in ~/.bashrc file.
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
The ZSH users paste the above lines in **~/.zshrc** file.
|
||||
|
||||
### Use Pbcopy And Pbpaste Commands On Linux
|
||||
|
||||
Let us see some examples.
|
||||
|
||||
The pbcopy command will copy the text from stdin into clipboard buffer. For example, have a look at the following example.
|
||||
```
|
||||
$ echo "Welcome To OSTechNix!" | pbcopy
|
||||
|
||||
```
|
||||
|
||||
The above command will copy the text “Welcome To OSTechNix” into clipboard. You can access this content later and paste them anywhere you want using Pbpaste command like below.
|
||||
```
|
||||
$ echo `pbpaste`
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
Here are some other use cases.
|
||||
|
||||
I have a file named **file.txt** with the following contents.
|
||||
```
|
||||
$ cat file.txt
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
You can directly copy the contents of a file into a clipboard as shown below.
|
||||
```
|
||||
$ pbcopy < file.txt
|
||||
|
||||
```
|
||||
|
||||
Now, the contents of the file is available in the clipboard as long as you updated with another file’s contents.
|
||||
|
||||
To retrieve the contents from clipboard, simply type:
|
||||
```
|
||||
$ pbpaste
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
You can also send the output of any Linux command to clip board using pipeline character. Have a look at the following example.
|
||||
```
|
||||
$ ps aux | pbcopy
|
||||
|
||||
```
|
||||
|
||||
Now, type “pbpaste” command at any time to display the output of “ps aux” command from the clipboard.
|
||||
```
|
||||
$ pbpaste
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
There is much more you can do with Pbcopy and Pbpaste commands. I hope you now got a basic idea about these commands.
|
||||
|
||||
And, that’s all for now. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-use-pbcopy-and-pbpaste-commands-on-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,64 @@
|
||||
What's in a container image: Meeting the legal challenges
|
||||
======
|
||||
|
||||
|
||||
[Container][1] technology has, for many years, been transforming how workloads in data centers are managed and speeding the cycle of application development and deployment.
|
||||
|
||||
In addition, container images are increasingly used as a distribution format, with container registries a mechanism for software distribution. Isn't this just like packages distributed using package management tools? Not quite. While container image distribution is similar to RPMs, DEBs, and other package management systems (for example, storing and distributing archives of files), the implications of container image distribution are more complicated. It is not the fault of container technology itself; rather, it's because container distribution is used differently than package management systems.
|
||||
|
||||
Talking about the challenges of license compliance for container images, [Dirk Hohndel][2], chief open source officer at VMware, pointed out that the content of a container image is more complex than most people expect, and many readily available images have been built in surprisingly cavalier ways. (See the [LWN.net article][3] by Jake Edge about a talk Dirk gave in April.)
|
||||
|
||||
Why is it hard to understand the licensing of container images? Shouldn't there just be a label for the image ("the license is X")? In the [Open Container Image Format Specification][4] , one of the pre-defined annotation keys is "org.opencontainers.image.licenses," which is described as "License(s) under which contained software is distributed as an SPDX License Expression." But that doesn't contemplate the complexity of a container image–while very simple images are built from tens of components, images are often built from hundreds of components. An [SPDX License Expression][5] is most frequently used to convey the licensing for a single source file. Such expressions can handle more than one license, such as "GPL-2.0 OR BSD-3-Clause" (see, for example, [Appendix IV][6] of version 2.1 of the SPDX specification). But the licensing for a typical container image is, typically, much more complicated.
|
||||
|
||||
In talking about container-related technology, the term "[container][7]" can lead to confusion. A container does not refer to the containment of files for storing or transferring. Rather, it refers to using features built into the kernel (such as cgroups and namespaces) to present a sort of "contained" experience to code running on the kernel. In other words, the containment to which "container" refers is an execution experience, not a distribution experience. The set of files to be laid out in a file system as the basis for an executing container is typically distributed in what is known as a "container image," sometimes confusingly referred to simply as a container, thereby awkwardly overloading the term "container."
|
||||
|
||||
In understanding software distribution via container images, I believe it is useful to consider two separate factors:
|
||||
|
||||
* **Diversity of content:** The basic unit of software distribution (a container image) includes a larger quantity and diversity of content than in the basic unit of distribution in typical software distribution mechanisms.
|
||||
* **Use model:** The nature of widely used tooling fosters the use of a registry, which is often publicly available, in the typical workflow.
|
||||
|
||||
|
||||
|
||||
### Diversity of content
|
||||
|
||||
When talking about a particular container image, the focus of attention is often on a particular software component (for example, a database or the code that implements one specific service). However, the container image includes a much larger collection of software. In fact, even the developer who created the image may have only a superficial understanding of and/or interest in most of the components in the image. With other distribution mechanisms, those other pieces of software would be identified as dependencies, and users of the software might be directed elsewhere for expertise on those components. In a container, the individual who acquires the container image isn't aware of those additional components that play supporting roles to the featured component.
|
||||
|
||||
#### The unit of distribution: user-driven vs. factory-driven
|
||||
|
||||
For container images, the distribution unit is user-driven, not factory-driven. Container images are a great tool for reducing the burden on software consumers. With a container image, the image's consumer can focus on the application of interest; the image's builder can take care of the dependencies and configuration. This simplification can be a huge benefit.
|
||||
|
||||
When the unit of software is driven by the "factory," the user bears a greater responsibility for building a platform on which to run the software of interest, assembling the correct versions of the dependencies, and getting all the configuration details right. The unit of distribution in a package management system is a modular unit, rather than a complete solution. This unit facilitates building and maintaining a flow of components that are flexible enough to be assembled into myriad solutions. Note that because of this unit, a package maintainer will typically be far more familiar with the content of the packages than someone who builds containers. A person building a container may have a detailed understanding of the container's featured components, but limited familiarity with the image's supporting components.
|
||||
|
||||
Packages, package management system tools, package maintenance processes, and package maintainers are incredibly underappreciated. They have been central to delivery of a large variety of software over the last two decades. While container images are playing a growing role, I don't expect the importance of package management systems to fade anytime soon. In fact, the bulk of the content in container images benefits from being built from such packages.
|
||||
|
||||
In understanding container images, it is important to appreciate how distribution via such images has different properties than distribution of packages. Much of the content in images is built from packages, but the image's consumer may not know what packages are included or other package-level information. In the future, a variety of techniques may be used to build containers, e.g., directly from source without involvement of a package maintainer.
|
||||
|
||||
### Use models
|
||||
|
||||
What about reports that so many container images are poorly built? In part, the volume of casually built images is because of container tools that facilitate a workflow to make images publicly available. When experimenting with container tools and moving to a workflow that extends beyond a laptop, the tools expect you to have a repository where multiple machines can pull container images (a container registry). You could spin up your own. Some widely used tools make it easy to use an existing registry that is available at no cost, provided the images are publicly available. This makes many casually built images visible, even those that were never intended to be maintained or updated.
|
||||
|
||||
By comparison, how often do you see developers publishing RPMs of their early explorations? RPMs resulting from experimentation by random developers are not ending up in the major package repositories.
|
||||
|
||||
Or consider someone experimenting with the latest machine learning frameworks. In the past, a researcher might have shared only analysis results. Now, they can share a full analytical software configuration by publishing a container image. This could be a great benefit to other researchers. However, those browsing a container registry could be confused by the ready-to-run nature of such images. It is important to distinguish between an image built for one individual's exploration and an image that was assembled and tested with broad use in mind.
|
||||
|
||||
Be aware that container images include supporting software, not just the featured software; a container image distributes a collection of software. If you are building upon or otherwise using images built by others, be aware of how that image was built and consider your level of confidence in the image's source.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/whats-container-image-meeting-legal-challenges
|
||||
|
||||
作者:[Scott Peterson][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/skpeterson
|
||||
[1]:https://opensource.com/resources/what-are-linux-containers
|
||||
[2]:https://www.linkedin.com/in/dirkhohndel
|
||||
[3]:https://lwn.net/Articles/752982/
|
||||
[4]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[5]:https://spdx.org/
|
||||
[6]:https://spdx.org/spdx-specification-21-web-version#h.jxpfx0ykyb60
|
||||
[7]:https://opensource.com/bus/16/8/introduction-linux-containers-and-image-signing
|
||||
@ -0,0 +1,83 @@
|
||||
5 of the Best Linux Games to Play in 2018
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux may not be establishing itself as the gamer’s platform of choice any time soon – the lack of success with Valve’s Steam Machines seems a poignant reminder of that – but that doesn’t mean that the platform isn’t steadily growing with its fair share of great games.
|
||||
|
||||
From indie hits to glorious RPGs, 2018 has already been a solid year for Linux games. Here we’ve listed our five favourites so far.
|
||||
|
||||
Looking for great Linux games but don’t want to splash the cash? Look to our list of the best [free Linux games][1] for guidance!
|
||||
|
||||
### 1. Pillars of Eternity II: Deadfire
|
||||
|
||||
![best-linux-games-2018-pillars-of-eternity-2-deadfire][2]
|
||||
|
||||
One of the titles that best represents the cRPG revival of recent years makes your typical Bethesda RPG look like a facile action-adventure. The latest entry in the majestic Pillars of Eternity series has a more buccaneering slant as you sail with a crew around islands filled with adventures and peril.
|
||||
|
||||
Adding naval combat to the mix, Deadfire continues with the rich storytelling and excellent writing of its predecessor while building on those beautiful graphics and hand-painted backgrounds of the original game.
|
||||
|
||||
This is a deep and unquestionably hardcore RPG that may cause some to bounce off it, but those who take to it will be absorbed in its world for months.
|
||||
|
||||
### 2. Slay the Spire
|
||||
|
||||
![best-linux-games-2018-slay-the-spire][3]
|
||||
|
||||
Still in early access, but already one of the best games of the year, Slay the Spire is a deck-building card game that’s embellished by a vibrant visual style and rogue-like mechanics that’ll leave you coming back for more after each infuriating (but probably deserved) death.
|
||||
|
||||
With endless card combinations and a different layout each time you play, Slay the Spire feels like the realisation of all the best systems that have been rocking the indie scene in recent years – card games and a permadeath adventure rolled into one.
|
||||
|
||||
And we repeat that it’s still in early access, so it’s only going to get better!
|
||||
|
||||
### 3. Battletech
|
||||
|
||||
![best-linux-games-2018-battletech][4]
|
||||
|
||||
As close as we get on this list to a “blockbuster” game, Battletech is an intergalactic wargame (based on a tabletop game) where you load up a team of Mechs and guide them through a campaign of rich, turn-based battles.
|
||||
|
||||
The action takes place across a range of terrain – from frigid wastelands to golden sun-soaked climes – as you load your squad of four with hulking hot weaponry, taking on rival squads. If this sounds a little “MechWarrior” to you, then you’re thinking along the right track, albeit this one’s more focused on the tactics than outright action.
|
||||
|
||||
Alongside a campaign that sees you navigate your way through a cosmic conflict, the multiplayer mode is also likely to consume untold hours of your life.
|
||||
|
||||
### 4. Dead Cells
|
||||
|
||||
![best-linux-games-2018-dead-cells][5]
|
||||
|
||||
This one deserves highlighting as the combat-platformer of the year. With its rogue-lite structure, Dead Cells throws you into a dark (yet gorgeously coloured) world where you slash and dodge your way through procedurally-generated levels. It’s a bit like a 2D Dark Souls, if Dark Souls were saturated in vibrant neon colours.
|
||||
|
||||
Dead Cells can be merciless, but its precise and responsive controls ensure that you only ever have yourself to blame for failure, and its upgrades system that carries over between runs ensures that you always have some sense of progress.
|
||||
|
||||
Dead Cells is a zenith of pixel-game graphics, animations and mechanics, a timely reminder of just how much can be achieved without the excesses of 3D graphics.
|
||||
|
||||
### 5. Iconoclasts
|
||||
|
||||
![best-linux-games-2018-iconoclasts][6]
|
||||
|
||||
A little less known than some of the above, this is still a lovely game that could be seen as a less foreboding, more cutesy alternative to Dead Cells. It casts you as Robin, a girl who’s cast out as a fugitive after finding herself at the wrong end of the twisted politics of an alien world.
|
||||
|
||||
It’s a good plot, even though your role in it is mainly blasting your way through the non-linear levels. Robin acquires all kinds of imaginative upgrades, the most crucial of which is her wrench, which you use to do everything from deflecting projectiles to solving the clever little environmental puzzles.
|
||||
|
||||
Iconoclasts is a joyful, vibrant platformer, borrowing from greats like Megaman for its combat and Metroid for its exploration. You can do a lot worse than take inspiration from those two classics.
|
||||
|
||||
### Conclusion
|
||||
|
||||
That’s it for our picks of the best Linux games to have come out in 2018. Have you dug up any gaming gems that we’ve missed? Let us know in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-linux-games/
|
||||
|
||||
作者:[Robert Zak][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/robzak/
|
||||
[1]:https://www.maketecheasier.com/open-source-linux-games/
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-pillars-of-eternity-2-deadfire.jpg (best-linux-games-2018-pillars-of-eternity-2-deadfire)
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-slay-the-spire.jpg (best-linux-games-2018-slay-the-spire)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-battletech.jpg (best-linux-games-2018-battletech)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-dead-cells.jpg (best-linux-games-2018-dead-cells)
|
||||
[6]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-iconoclasts.jpg (best-linux-games-2018-iconoclasts)
|
||||
55
sources/tech/20180801 Cross-Site Request Forgery.md
Normal file
55
sources/tech/20180801 Cross-Site Request Forgery.md
Normal file
@ -0,0 +1,55 @@
|
||||
translating---geekpi
|
||||
|
||||
Cross-Site Request Forgery
|
||||
======
|
||||

|
||||
Security is a major concern when designing web apps. And I am not talking about DDOS protection, using a strong password or 2 step verification. I am talking about the biggest threat to a web app. It is known as **CSRF** short for **Cross Site Resource Forgery**.
|
||||
|
||||
### What is CSRF?
|
||||
|
||||
[][1]
|
||||
|
||||
First thing first, **CSRF** is short for Cross Site Resource Forgery. It is commonly pronounced as sea-surf and often referred to as XSRF. CSRF is a type of attack where various actions are performed on the web app where the victim is logged in without the victim's knowledge. These actions could be anything ranging from simply liking or commenting on a social media post to sending abusive messages to people or even transferring money from the victim’s bank account.
|
||||
|
||||
### How CSRF works?
|
||||
|
||||
**CSRF** attacks try to bank upon a simple common vulnerability in all browsers. Every time, we authenticate or log in to a website, session cookies are stored in the browser. So whenever we make a request to the website these cookies are automatically sent to the server where the server identifies us by matching the cookie we sent with the server’s records. So that way it knows it’s us.
|
||||
|
||||
[][2]
|
||||
|
||||
This means that any request made by me, knowingly or unknowingly, will be fulfilled. Since the cookies are being sent and they will match the records on the server, the server thinks I am making that request.
|
||||
|
||||
|
||||
|
||||
CSRF attacks usually come in form of links. We may click them on other websites or receive them as email. On clicking these links, an unwanted request is made to the server. And as I previously said, the server thinks we made the request and authenticates it.
|
||||
|
||||
#### A Real World Example
|
||||
|
||||
To put things into perspective, imagine you are logged into your bank’s website. And you fill up a form on the page at **yourbank.com/transfer** . You fill in the account number of the receiver as 1234 and the amount of 5,000 and you click on the submit button. Now, a request will be made to **yourbank.com/transfer/send?to=1234&amount=5000** . So the server will act upon the request and make the transfer. Now just imagine you are on another website and you click on a link that opens up the above URL with the hacker’s account number. That money is now transferred to the hacker and the server thinks you made the transaction. Even though you didn’t.
|
||||
|
||||
[][3]
|
||||
|
||||
#### Protection against CSRF
|
||||
|
||||
CSRF protection is very easy to implement. It usually involves sending a token called the CSRF token to the webpage. This token is sent and verified on the server with every new request made. So malicious requests made by the server will pass cookie authentication but fail CSRF authentication. Most web frameworks provide out of the box support for preventing CSRF attacks and CSRF attacks are not as commonly seen today as they were some time back.
|
||||
|
||||
### Conclusion
|
||||
|
||||
CSRF attacks were a big thing 10 years back but today we don’t see too many of them. In the past, famous sites such as Youtube, The New York Times and Netflix have been vulnerable to CSRF. However, popularity and occurrence of CSRF attacks have decreased lately. Nevertheless, CSRF attacks are still a threat and it is important, you protect your website or app from it.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/understanding-csrf-cross-site-request-forgery
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-what-is-cross-site-forgery_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/cookies-set-by-website-chrome_orig.jpg
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-hacking-bank-account_orig.jpg
|
||||
@ -0,0 +1,299 @@
|
||||
Getting started with Standard Notes for encrypted note-taking
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Standard Notes][1] is a simple, encrypted notes app that aims to make dealing with your notes the easiest thing you'll do all day. When you sign up for a free sync account, your notes are automatically encrypted and seamlessly synced with all your devices.
|
||||
|
||||
There are two key factors that differentiate Standard Notes from other, commercial software solutions:
|
||||
|
||||
1. The server and client are both completely open source.
|
||||
2. The company is built on sustainable business practices and focuses on product development.
|
||||
|
||||
|
||||
|
||||
When you combine open source with ethical business practices, you get a software product that has the potential to serve you for decades. You start to feel ownership in the product rather than feeling like just another transaction for an IPO-bound company.
|
||||
|
||||
In this article, I’ll describe how to deploy your own Standard Notes open source syncing server on a Linux machine. You’ll then be able to use your server with our published applications for Linux, Windows, Android, Mac, iOS, and the web.
|
||||
|
||||
If you don’t want to host your own server and are ready to start using Standard Notes right away, you can use our public syncing server. Simply head on over to [Standard Notes][1] to get started.
|
||||
|
||||
### Hosting your own Standard Notes server
|
||||
|
||||
Get the [Standard File Rails app][2] running on your Linux box and expose it via [NGINX][3] or any other web server.
|
||||
|
||||
### Getting started
|
||||
|
||||
These instructions are based on setting up our syncing server on a fresh [CentOS][4]-like installation. You can use a hosting service like [AWS][5] or [DigitalOcean][6] to launch your server, or even run it locally on your own machine.
|
||||
|
||||
1. Update your system:
|
||||
|
||||
```
|
||||
sudo yum update
|
||||
|
||||
```
|
||||
|
||||
2. Install [RVM][7] (Ruby Version Manager):
|
||||
|
||||
```
|
||||
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3
|
||||
\curl -sSL https://get.rvm.io | bash -s stable
|
||||
|
||||
```
|
||||
|
||||
3. Begin using RVM in current session:
|
||||
```
|
||||
source /home/ec2-user/.rvm/scripts/rvm
|
||||
|
||||
```
|
||||
|
||||
4. Install [Ruby][8]:
|
||||
|
||||
```
|
||||
rvm install ruby
|
||||
|
||||
```
|
||||
|
||||
This should install the latest version of Ruby (2.3 at the time of this writing.)
|
||||
|
||||
Note that at least Ruby 2.2.2 is required for Rails 5.
|
||||
|
||||
5. Use Ruby:
|
||||
```
|
||||
rvm use ruby
|
||||
|
||||
```
|
||||
|
||||
6. Install [Bundler][9]:
|
||||
|
||||
```
|
||||
gem install bundler --no-ri --no-rdoc
|
||||
|
||||
```
|
||||
|
||||
7. Install [mysql-devel][10]:
|
||||
```
|
||||
sudo yum install mysql-devel
|
||||
|
||||
```
|
||||
|
||||
8. Install [MySQL][11] (optional; you can also use a hosted db through [Amazon RDS][12], which is recommended):
|
||||
```
|
||||
sudo yum install mysql56-server
|
||||
|
||||
sudo service mysqld start
|
||||
|
||||
sudo mysql_secure_installation
|
||||
|
||||
sudo chkconfig mysqld on
|
||||
|
||||
```
|
||||
|
||||
Create a database:
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
|
||||
> create database standard_file;
|
||||
|
||||
> quit;
|
||||
|
||||
```
|
||||
|
||||
9. Install [Passenger][13]:
|
||||
```
|
||||
sudo yum install rubygems
|
||||
|
||||
gem install rubygems-update --no-rdoc --no-ri
|
||||
|
||||
update_rubygems
|
||||
|
||||
gem install passenger --no-rdoc --no-ri
|
||||
|
||||
```
|
||||
|
||||
10. Remove system NGINX installation if installed (you’ll use Passenger’s instead):
|
||||
```
|
||||
sudo yum remove nginx
|
||||
sudo rm -rf /etc/nginx
|
||||
```
|
||||
|
||||
11. Configure Passenger:
|
||||
```
|
||||
sudo chmod o+x "/home/ec2-user"
|
||||
|
||||
sudo yum install libcurl-devel
|
||||
|
||||
rvmsudo passenger-install-nginx-module
|
||||
|
||||
rvmsudo passenger-config validate-install
|
||||
|
||||
```
|
||||
|
||||
12. Install Git:
|
||||
```
|
||||
sudo yum install git
|
||||
|
||||
```
|
||||
|
||||
13. Set up HTTPS/SSL for your server (free using [Let'sEncrypt][14]; required if using the secure client on [https://app.standardnotes.org][15]):
|
||||
```
|
||||
sudo chown ec2-user /opt
|
||||
|
||||
cd /opt
|
||||
|
||||
git clone https://github.com/letsencrypt/letsencrypt
|
||||
|
||||
cd letsencrypt
|
||||
|
||||
```
|
||||
|
||||
Run the setup wizard:
|
||||
```
|
||||
./letsencrypt-auto certonly --standalone --debug
|
||||
|
||||
```
|
||||
|
||||
Note the location of the certificates, typically `/etc/letsencrypt/live/domain.com/fullchain.pem`
|
||||
|
||||
14. Configure NGINX:
|
||||
```
|
||||
sudo vim /opt/nginx/conf/nginx.conf
|
||||
|
||||
```
|
||||
|
||||
Add this to the bottom of the file, inside the last curly brace:
|
||||
```
|
||||
server {
|
||||
|
||||
listen 443 ssl default_server;
|
||||
|
||||
ssl_certificate /etc/letsencrypt/live/domain.com/fullchain.pem;
|
||||
|
||||
ssl_certificate_key /etc/letsencrypt/live/domain.com/privkey.pem;
|
||||
|
||||
server_name domain.com;
|
||||
|
||||
passenger_enabled on;
|
||||
|
||||
passenger_app_env production;
|
||||
|
||||
root /home/ec2-user/ruby-server/public;
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
15. Make sure you are in your home directory and clone the Standard File [ruby-server][2] project:
|
||||
```
|
||||
cd ~
|
||||
|
||||
git clone https://github.com/standardfile/ruby-server.git
|
||||
|
||||
cd ruby-server
|
||||
|
||||
```
|
||||
|
||||
16. Set up project:
|
||||
```
|
||||
bundle install
|
||||
|
||||
bower install
|
||||
|
||||
rails assets:precompile
|
||||
|
||||
```
|
||||
|
||||
17. Create a .env file for your environment variables. The Rails app will automatically load these when it starts.
|
||||
|
||||
```
|
||||
vim .env
|
||||
|
||||
```
|
||||
|
||||
Insert:
|
||||
```
|
||||
RAILS_ENV=production
|
||||
|
||||
SECRET_KEY_BASE=use "bundle exec rake secret"
|
||||
|
||||
|
||||
|
||||
DB_HOST=localhost
|
||||
|
||||
DB_PORT=3306
|
||||
|
||||
DB_DATABASE=standard_file
|
||||
|
||||
DB_USERNAME=root
|
||||
|
||||
DB_PASSWORD=
|
||||
|
||||
```
|
||||
|
||||
18. Setup database:
|
||||
```
|
||||
rails db:migrate
|
||||
|
||||
```
|
||||
|
||||
19. Start NGINX:
|
||||
```
|
||||
sudo /opt/nginx/sbin/nginx
|
||||
|
||||
```
|
||||
|
||||
Tip: you will need to restart NGINX whenever you make changes to your environment variables or the NGINX configuration:
|
||||
```
|
||||
sudo /opt/nginx/sbin/nginx -s reload
|
||||
|
||||
```
|
||||
|
||||
20. You’re done!
|
||||
|
||||
|
||||
|
||||
|
||||
### Using your new server
|
||||
|
||||
Now that you have your server running, you can plug it into any of the Standard Notes applications and sign into it.
|
||||
|
||||
**On the Standard Notes web or desktop app:**
|
||||
|
||||
Click Account, then Register. Choose "Advanced Options" and you’ll see a field for Sync Server. Enter your server’s URL here.
|
||||
|
||||
**On the Standard Notes Android or iOS app:**
|
||||
|
||||
Open the Settings window, click "Advanced Options" when signing in or registering, and enter your server URL in the Sync Server field.
|
||||
|
||||
For help or questions with your Standard Notes server, join our [Slack group][16] in the #dev channel, or visit our [help page][17] for frequently asked questions and other topics.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/getting-started-standard-notes
|
||||
|
||||
作者:[Mo Bitar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mobitar
|
||||
[1]:https://standardnotes.org/
|
||||
[2]:https://github.com/standardfile/ruby-server
|
||||
[3]:https://www.nginx.com/
|
||||
[4]:https://www.centos.org/
|
||||
[5]:https://aws.amazon.com/
|
||||
[6]:https://www.digitalocean.com/
|
||||
[7]:https://rvm.io/
|
||||
[8]:https://www.ruby-lang.org/en/
|
||||
[9]:https://bundler.io/
|
||||
[10]:https://rpmfind.net/linux/rpm2html/search.php?query=mysql-devel
|
||||
[11]:https://www.mysql.com/
|
||||
[12]:https://aws.amazon.com/rds/
|
||||
[13]:https://www.phusionpassenger.com/
|
||||
[14]:https://letsencrypt.org/
|
||||
[15]:https://app.standardnotes.org/
|
||||
[16]:https://standardnotes.org/slack
|
||||
[17]:https://standardnotes.org/help
|
||||
@ -0,0 +1,114 @@
|
||||
Hiri is a Linux Email Client Exclusively Created for Microsoft Exchange
|
||||
======
|
||||
Previously, I have written about the email services [Protonmail][1] and [Tutanota][2] on It’s FOSS. And though I liked both of those email providers very much, some of us couldn’t possibly use these email services exclusively. If you are like me and you have an email address provided for you by your work, then you understand what I am talking about.
|
||||
|
||||
Some of us use [Thunderbird][3] for these types of use cases, while others of us use something like [Geary][4] or even [Mailspring][5]. But for those of us who have to deal with [Microsoft Exchange Servers][6], none of these offer seamless solutions on Linux for our work needs.
|
||||
|
||||
This is where [Hiri][7] comes in. We have already featured Hiri on our list of [best email clients for Linux][8], but we thought it was about time for an in-depth review.
|
||||
|
||||
FYI, Hiri is neither free nor open source software.
|
||||
|
||||
### Reviewing Hiri email client on Linux
|
||||
|
||||
![Hiri email client review][9]
|
||||
|
||||
According to their website, Hiri not only supports Microsoft Exchange and Office 365 accounts, it was exclusively “built for the Microsoft email ecosystem.”
|
||||
|
||||
Based in Dublin, Ireland, Hiri has raised $2 million in funding. They have been in the business for almost five years but started supporting Linux only last year. The support for Linux has brought Hiri a considerable amount of success.
|
||||
|
||||
I have been using Hiri for a week as of yesterday, and I have to say, I have been very pleased with my experience…for the most part.
|
||||
|
||||
#### Hiri features
|
||||
|
||||
Some of the main features of Hiri are:
|
||||
|
||||
* Cross-platform application available for Linux, macOS and Windows
|
||||
* **Supports only Office 365, Outlook and Microsoft Exchange for now**
|
||||
* Clean and intuitive UI
|
||||
* Action filters
|
||||
* Reminders
|
||||
* [Skills][10]: Plugins to make you more productive with your emails
|
||||
* Office 365 and Exchange and other Calendar Sync
|
||||
* Compatible with [Active Directory][11]
|
||||
* Offline email access
|
||||
* Secure (it doesn’t send data to any third party server, it’s just an email client)
|
||||
* Compatible with Microsoft’s archiving tool
|
||||
|
||||
|
||||
|
||||
#### Taking a look at Hiri Features
|
||||
|
||||
![][12]
|
||||
|
||||
Hiri can either be compiled manually or [installed easily as Snap][13] and comes jam-packed with useful features. But, if you knew me at all, you would know that usually, a robust feature list is not a huge selling point for me. As a self-proclaimed minimalist, I tend to believe the simpler option is often the better option, and the less “fluff” there is surrounding a product, the easier it is to get to the part that really matters. Admittedly, this is not always the case. For example, KDE’s [Plasma][14] desktop is known for its excessive amount of tweaks and features and I am still a huge Plasma fan. But in Hiri’s case, it has what feels like the perfect feature set and in no way feels convoluted or confusing.
|
||||
|
||||
That is partially due to the way that Hiri works. If I had to put it into my own words, I would say that Hiri feels almost modular. It does this by utilizing what Hiri calls the Skill Center. Here you can add or remove functionality in Hiri at the flip of a switch. This includes the ability to add tasks, delegate action items to other people, set reminders, and even enables the user to create better subject lines. None of which are required, but each of which adds something to Hiri that no other email client has done as well.
|
||||
|
||||
Using these features can help you organize your email like never before. The Dashboard feature allows you to monitor your time spent working on emails, the Task List enables you to stay on track, the Action/FYI feature allows you to tag your emails as needed to help you cipher through a messy inbox, and the Zero Inbox feature helps the user keep their inbox count at a minimum once they have sorted through the nonsense. And as someone who is an avid Inbox Zeroer (if that is even a thing), this to me was incredibly useful.
|
||||
|
||||
Hiri also syncs with your associated calendars as you would expect, and it even allows a global search for all of the other accounts associated with your office. Need to email Frank Smith in Human Resources but can’t remember his email address? No big deal! Hiri will auto-fill the email address once you start typing in his name just like in a native Outlook client.
|
||||
|
||||
Multiple account support is also available in Hiri. The support for IMAP will be added in a few months.
|
||||
|
||||
In short, Hiri’s feature-set allows for what feels like a truly native Microsoft offering on Linux. It is clean, simple enough, and allows someone with my productivity workflow to thrive. I really dig what Hiri has to offer, and it’s as simple as that.
|
||||
|
||||
#### Experiencing the Hiri UI
|
||||
|
||||
As far as design goes, Hiri gets a solid A from me. I never felt like I was using something outdated looking like [Evolution][15] (I know people like Evolution a lot, but to say it is clean and modern is a lie), it never felt overly complicated like [KMail][16], and it felt less cramped than Thunderbird. Though I love Thunderbird dearly, the inbox list is just a little too small to feel like I can really cipher through my emails in a decent amount of time. Hiri seemingly fixes this but adds another issue that may be even worse.
|
||||
|
||||
![][17]
|
||||
|
||||
Geary is an email client that I think does layouts just right. It is spacious, but not in a wasteful way, it is clean, simple, and allows me to get from point A to point B quickly. Hiri, on the other hand, falls just shy of layout heaven. Though the inbox list looks fantastic, when you click to read an email it takes up the whole screen. Whereas Geary or Thunderbird can be set up to have the user’s list of emails on the left and opened emails in the same window on the right, which is my preferred way to read email, Hiri does not allow this functionality. The layout either looks and functions like it belongs on a mobile device, or the email preview is below the email list instead of to the right. This isn’t a make or break issue for me, but I will be honest and say I really don’t like it.
|
||||
|
||||
In my opinion, Hiri could work even better with a couple of tweaks. But that opinion is just that, an opinion. Hiri is modern, clean, and intuitive enough, I am just obnoxiously picky. Other than that, the color palette is beautiful, the soft edges are pretty stunning, and Hiri’s overall design language is a breath of fresh air in the, at times, outdated feel that is oh so common in the Linux application world.
|
||||
|
||||
Also, this isn’t Hiri’s fault but since I installed the Hiri snap it still has the same cursor theme issue that many other snaps suffer from, which drives me UP A WALL when I move in and out of the application, so there’s that.
|
||||
|
||||
#### How much does Hiri cost?
|
||||
|
||||
![Hiri is compatible with Microsoft Active Directory][18]
|
||||
|
||||
Hiri is neither free nor open source software. [Hiri costs][19] either up to $39 a year or $119 for a lifetime license. However, it does provide a free seven day trial period.
|
||||
|
||||
Considering the features it provides, Hiri is a good product even if you don’t have to deal with Microsoft Exchange Servers. Don’t take my word for it. Give Hiri a try for free for the seven day trial and see for yourself if it is worth paying or not.
|
||||
|
||||
And if you decide to purchase it, I have further good news for you. Hiri team has agreed to provide an exclusive 60% discount to It’s FOSS readers. All you have to do is to use coupon code ITSFOSS60 at checkout.
|
||||
|
||||
[Get 60% Off with ITSFOSS60 Coupon Code][20]
|
||||
|
||||
#### Conclusion
|
||||
|
||||
In the end, Hiri is an amazingly beautiful piece of software that checks so many boxes for me. That being said, the three marks that it misses for me are collectively too big to overlook: the layout, the cost, and the freedom (or lack thereof). If you are someone who is really in need of a native client, the layout does not bother you, you can justify spending some money, and you don’t want or need it to be FOSS, then you may have just found your new email client!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/hiri-email-review/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://itsfoss.com/protonmail/
|
||||
[2]:https://itsfoss.com/tutanota-review/
|
||||
[3]:https://www.thunderbird.net/en-US/
|
||||
[4]:https://wiki.gnome.org/Apps/Geary
|
||||
[5]:http://getmailspring.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Microsoft_Exchange_Server
|
||||
[7]:https://www.hiri.com/
|
||||
[8]:https://itsfoss.com/best-email-clients-linux/
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/hiri-email-client-review.jpeg
|
||||
[10]:https://www.hiri.com/skills/
|
||||
[11]:https://en.wikipedia.org/wiki/Active_Directory
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri2-e1533106054811.png
|
||||
[13]:https://snapcraft.io/hiri
|
||||
[14]:https://www.kde.org/plasma-desktop
|
||||
[15]:https://wiki.gnome.org/Apps/Evolution
|
||||
[16]:https://www.kde.org/applications/internet/kmail/
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri3-e1533106099642.png
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri1-e1533106238745.png
|
||||
[19]:https://www.hiri.com/pricing/
|
||||
[20]:https://www.hiri.com/download/
|
||||
77
sources/tech/20180801 Migrating Perl 5 code to Perl 6.md
Normal file
77
sources/tech/20180801 Migrating Perl 5 code to Perl 6.md
Normal file
@ -0,0 +1,77 @@
|
||||
Migrating Perl 5 code to Perl 6
|
||||
======
|
||||
|
||||

|
||||
|
||||
Whether you are a programmer who is taking the first steps to convert your Perl 5 code to Perl 6 and encountering some issues or you're just interested in learning about what might happen if you try to port Perl 5 programs to Perl 6, this article should answer your questions.
|
||||
|
||||
The [Perl 6 documentation][1] already contains most (if not all) the [documentation you need][2] to deal with the issues you will confront in migrating Perl 5 code to Perl 6. But, as documentation goes, the focus is on the factual differences. I will try to go a little more in-depth about specific issues and provide a little more hands-on information based on my experience porting quite a lot of Perl 5 code to Perl 6.
|
||||
|
||||
### How is Perl 6 anyway?
|
||||
|
||||
Very well, thank you! Since its first official release in December 2015, Rakudo Perl 6 has seen an order of magnitude of improvement and quite a few bug fixes (more than 14,000 commits in total). Seven books about Perl 6 have been published so far. [Learning Perl 6][3] by Brian D. Foy will soon be published by O'Reilly, having been re-worked from the seminal [Learning Perl][4] (aka "The Llama Book") that many people have come to know and love.
|
||||
|
||||
The user distribution [Rakudo Star][5] is on a three-month release cycle, and more than 1,100 modules are available in the [Perl 6 ecosystem][6]. The Rakudo Compiler Release is on a monthly release cycle and typically contains contributions by more than 30 people. Perl 6 modules are uploaded to the Perl programming Authors Upload Server ([PAUSE][7]) and distributed all over the world using the Comprehensive Perl Archive Network ([CPAN][8]).
|
||||
|
||||
The online [Perl 6 Introduction][9] document has been translated into 12 languages, teaching over 3 billion people about Perl 6 in their native language. The most recent incarnation of [Perl 6 Weekly][10] has been reporting on all things Perl 6 every week since February 2014.
|
||||
|
||||
[Cro][11], a microservices framework, uses all of Perl 6's features from the ground up, providing HTTP 1.1 persistent connections, HTTP 2.0 with request multiplexing, and HTTPS with optional certificate authority out of the box. And a [Perl 6 IDE][12] is now in (paid) beta (think of it as a Kickstarter with immediate deliverables).
|
||||
|
||||
### Using Perl 5 features in Perl 6
|
||||
|
||||
Perl 5 code can be seamlessly integrated with Perl 6 using the [`Inline::Perl5`][13] module, making all of [CPAN][14] available to any Perl 6 program. This could be considered cheating, as it will embed a Perl 5 interpreter and therefore continues to have a dependency on the `perl` (5) runtime. But it does make it easy to get your Perl 6 code running (if you need access to modules that have not yet been ported) simply by adding `:from<Perl5>` to your `use` statement, like `use DBI:from<Perl5>;`.
|
||||
|
||||
In January 2018, I proposed a [CPAN Butterfly Plan][15] to convert Perl 5 functionality to Perl 6 as closely as possible to the original API. I stated this as a goal because Perl 5 (as a programming language) is so much more than syntax alone. Ask anyone what Perl's unique selling point is, and they will most likely tell you it is CPAN. Therefore, I think it's time to move from this view of the Perl universe:
|
||||
|
||||
|
||||
|
||||
to a more modern view:
|
||||
|
||||
|
||||
|
||||
In other words: put CPAN, as the most important element of Perl, in the center.
|
||||
|
||||
### Converting semantics
|
||||
|
||||
To run Perl 5 code natively in Perl 6, you also need a lot of Perl 5 semantics. Having (optional) support for Perl 5 semantics available in Perl 6 lowers the conceptual threshold that Perl 5 programmers perceive when trying to program in Perl 6. It's easier to feel at home!
|
||||
|
||||
Since the publication of the CPAN Butterfly Plan, more than 100 built-in Perl 5 functions are now supported in Perl 6 with the same API. Many functions already exist in Perl 6 but have slightly different semantics, e.g., `shift` in Perl 5 magically shifts from `@_` (or `@ARGV`) if no parameter is specified; in Perl 6 the parameter is obligatory.
|
||||
|
||||
More than 50 Perl 5 CPAN distributions have also been ported to Perl 6 while adhering to the original Perl 5 API. These include core modules such as [Scalar::Util][16] and [List::Util][17], but also non-core modules such as [Text::CSV][18] and [Memoize][19]. Distributions that are upstream on the [River of CPAN][20] are targeted to have as much effect on the ecosystem as possible.
|
||||
|
||||
### Summary
|
||||
|
||||
Rakudo Perl 6 has matured in such a way that using Perl 6 is now a viable approach to creating new, interactive projects. Being able to use reliable and proven Perl 5 language components aids in lowering the threshold for developers to use Perl 6, and it builds towards a situation where the sum of Perl 5 and Perl 6 becomes greater than its parts.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/migrating-perl-5-perl-6
|
||||
|
||||
作者:[Elizabeth Mattijsen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/lizmat
|
||||
[1]:https://docs.perl6.org/
|
||||
[2]:https://docs.perl6.org/language/5to6-overview
|
||||
[3]:https://www.learningperl6.com
|
||||
[4]:http://shop.oreilly.com/product/0636920049517.do
|
||||
[5]:https://rakudo.org/files
|
||||
[6]:https://modules.perl6.org
|
||||
[7]:https://pause.perl.org/pause/query?ACTION=pause_04about
|
||||
[8]:https://www.cpan.org
|
||||
[9]:https://perl6intro.com
|
||||
[10]:https://p6weekly.wordpress.com
|
||||
[11]:https://cro.services
|
||||
[12]:https://commaide.com
|
||||
[13]:http://modules.perl6.org/dist/Inline::Perl5:cpan:NINE
|
||||
[14]:https://metacpan.org
|
||||
[15]:https://www.perl.com/article/an-open-letter-to-the-perl-community/
|
||||
[16]:https://modules.perl6.org/dist/Scalar::Util
|
||||
[17]:https://modules.perl6.org/dist/List::Util
|
||||
[18]:https://modules.perl6.org/dist/Text::CSV
|
||||
[19]:https://modules.perl6.org/dist/Memoize
|
||||
[20]:http://neilb.org/2015/04/20/river-of-cpan.html
|
||||
@ -0,0 +1,370 @@
|
||||
6 Easy Ways to Check User Name And Other Information in Linux
|
||||
======
|
||||
This is very basic topic, everyone knows how to find a user information in Linux using **id** command. Some of the users are filtering a user information from **/etc/passwd** file.
|
||||
|
||||
We also using these commands to get a user information.
|
||||
|
||||
You may ask, Why are you discussing this basic topic? Even i thought the same, there is no other ways except this two but we are having some good alternatives too.
|
||||
|
||||
Those are giving more detailed information compared with those two, which is very helpful for newbies.
|
||||
|
||||
This is one of the basic command which helps admin to find out a user information in Linux. Everything is file in Linux, even user information were stored in a file.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [How To Check User Created Date On Linux][1]
|
||||
**(#)** [How To Check Which Groups A User Belongs To On Linux][2]
|
||||
**(#)** [How To Force User To Change Password On Next Login In Linux][3]
|
||||
|
||||
All the users are added in `/etc/passwd` file. This keep user name and other related details. Users details will be stored in /etc/passwd file when you created a user in Linux. The passwd file contain each/every user details as a single line with seven fields.
|
||||
|
||||
We can find a user information using the below six methods.
|
||||
|
||||
* `id :`Print user and group information for the specified username.
|
||||
* `getent :`Get entries from Name Service Switch libraries.
|
||||
* `/etc/passwd file :`The /etc/passwd file contain each/every user details as a single line with seven fields.
|
||||
* `finger :`User information lookup program
|
||||
* `lslogins :`lslogins display information about known users in the system
|
||||
* `compgen :`compgen is bash built-in command and it will show all available commands for the user.
|
||||
|
||||
|
||||
|
||||
### 1) Using id Command
|
||||
|
||||
id stands for identity. print real and effective user and group IDs. To print user and group information for the specified user, or for the current user.
|
||||
```
|
||||
# id daygeek
|
||||
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
|
||||
|
||||
```
|
||||
|
||||
Below are the detailed information for the above output.
|
||||
|
||||
* **`uid (1000/daygeek):`** It displays user ID & Name
|
||||
* **`gid (1000/daygeek):`** It displays user’s primary group ID & Name
|
||||
* **`groups:`** It displays user’s secondary groups ID & Name
|
||||
|
||||
|
||||
|
||||
### 2) Using getent Command
|
||||
|
||||
The getent command displays entries from databases supported by the Name Service Switch libraries, which are configured in /etc/nsswitch.conf.
|
||||
|
||||
getent command shows user details similar to /etc/passwd file, it shows every user details as a single line with seven fields.
|
||||
```
|
||||
# getent passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
bin:x:1:1:bin:/bin:/sbin/nologin
|
||||
daemon:x:2:2:daemon:/sbin:/sbin/nologin
|
||||
adm:x:3:4:adm:/var/adm:/sbin/nologin
|
||||
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
|
||||
sync:x:5:0:sync:/sbin:/bin/sync
|
||||
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
|
||||
halt:x:7:0:halt:/sbin:/sbin/halt
|
||||
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
|
||||
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
|
||||
operator:x:11:0:operator:/root:/sbin/nologin
|
||||
games:x:12:100:games:/usr/games:/sbin/nologin
|
||||
gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
|
||||
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
|
||||
nobody:x:99:99:Nobody:/:/sbin/nologin
|
||||
dbus:x:81:81:System message bus:/:/sbin/nologin
|
||||
vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
|
||||
abrt:x:173:173::/etc/abrt:/sbin/nologin
|
||||
haldaemon:x:68:68:HAL daemon:/:/sbin/nologin
|
||||
ntp:x:38:38::/etc/ntp:/sbin/nologin
|
||||
saslauth:x:499:76:Saslauthd user:/var/empty/saslauth:/sbin/nologin
|
||||
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
|
||||
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
|
||||
tcpdump:x:72:72::/:/sbin/nologin
|
||||
centos:x:500:500:Cloud User:/home/centos:/bin/bash
|
||||
prakash:x:501:501:2018/04/12:/home/prakash:/bin/bash
|
||||
apache:x:48:48:Apache:/var/www:/sbin/nologin
|
||||
nagios:x:498:498::/var/spool/nagios:/sbin/nologin
|
||||
rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
|
||||
nrpe:x:497:497:NRPE user for the NRPE service:/var/run/nrpe:/sbin/nologin
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
thanu:x:503:504:2g Editor - Thanisha M:/home/thanu:/bin/bash
|
||||
sudha:x:504:505:2g Editor - Sudha M:/home/sudha:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
Below are the detailed information about seven fields.
|
||||
```
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
* **`Username (magesh):`** Username of created user. Characters length should be between 1 to 32.
|
||||
* **`Password (x):`** It indicates that encrypted password is stored at /etc/shadow file.
|
||||
* **`User ID (UID-502):`** It indicates the user ID (UID) each user should be contain unique UID. UID (0-Zero) is reserved for root, UID (1-99) reserved for system users and UID (100-999) reserved for system accounts/groups
|
||||
* **`Group ID (GID-503):`** It indicates the group ID (GID) each group should be contain unique GID is stored at /etc/group file.
|
||||
* **`User ID Info (2g Admin - Magesh M):`** It indicates the command field. This field can be used to describe the user information.
|
||||
* **`Home Directory (/home/magesh):`** It indicates the user home directory.
|
||||
* **`shell (/bin/bash):`** It indicates the user’s bash shell.
|
||||
|
||||
|
||||
|
||||
If you would like to display only user names from the getent command output, use the below format.
|
||||
```
|
||||
# getent passwd | cut -d: -f1
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
lp
|
||||
sync
|
||||
shutdown
|
||||
halt
|
||||
mail
|
||||
uucp
|
||||
operator
|
||||
games
|
||||
gopher
|
||||
ftp
|
||||
nobody
|
||||
dbus
|
||||
vcsa
|
||||
abrt
|
||||
haldaemon
|
||||
ntp
|
||||
saslauth
|
||||
postfix
|
||||
sshd
|
||||
tcpdump
|
||||
centos
|
||||
prakash
|
||||
apache
|
||||
nagios
|
||||
rpc
|
||||
nrpe
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
To display only home directory users, use the below format.
|
||||
```
|
||||
# getent passwd | grep '/home' | cut -d: -f1
|
||||
centos
|
||||
prakash
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
### 3) Using /etc/passwd file
|
||||
|
||||
The `/etc/passwd` is a text file that contains each user information, which is necessary to login Linux system. It maintain useful information about users such as username, password, user ID, group ID, user ID info, home directory and shell. The /etc/passwd file contain every user details as a single line with seven fields as described below.
|
||||
```
|
||||
# cat /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
bin:x:1:1:bin:/bin:/sbin/nologin
|
||||
daemon:x:2:2:daemon:/sbin:/sbin/nologin
|
||||
adm:x:3:4:adm:/var/adm:/sbin/nologin
|
||||
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
|
||||
sync:x:5:0:sync:/sbin:/bin/sync
|
||||
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
|
||||
halt:x:7:0:halt:/sbin:/sbin/halt
|
||||
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
|
||||
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
|
||||
operator:x:11:0:operator:/root:/sbin/nologin
|
||||
games:x:12:100:games:/usr/games:/sbin/nologin
|
||||
gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
|
||||
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
|
||||
nobody:x:99:99:Nobody:/:/sbin/nologin
|
||||
dbus:x:81:81:System message bus:/:/sbin/nologin
|
||||
vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
|
||||
abrt:x:173:173::/etc/abrt:/sbin/nologin
|
||||
haldaemon:x:68:68:HAL daemon:/:/sbin/nologin
|
||||
ntp:x:38:38::/etc/ntp:/sbin/nologin
|
||||
saslauth:x:499:76:Saslauthd user:/var/empty/saslauth:/sbin/nologin
|
||||
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
|
||||
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
|
||||
tcpdump:x:72:72::/:/sbin/nologin
|
||||
centos:x:500:500:Cloud User:/home/centos:/bin/bash
|
||||
prakash:x:501:501:2018/04/12:/home/prakash:/bin/bash
|
||||
apache:x:48:48:Apache:/var/www:/sbin/nologin
|
||||
nagios:x:498:498::/var/spool/nagios:/sbin/nologin
|
||||
rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
|
||||
nrpe:x:497:497:NRPE user for the NRPE service:/var/run/nrpe:/sbin/nologin
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
thanu:x:503:504:2g Editor - Thanisha M:/home/thanu:/bin/bash
|
||||
sudha:x:504:505:2g Editor - Sudha M:/home/sudha:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
Below are the detailed information about seven fields.
|
||||
```
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
* **`Username (magesh):`** Username of created user. Characters length should be between 1 to 32.
|
||||
* **`Password (x):`** It indicates that encrypted password is stored at /etc/shadow file.
|
||||
* **`User ID (UID-502):`** It indicates the user ID (UID) each user should be contain unique UID. UID (0-Zero) is reserved for root, UID (1-99) reserved for system users and UID (100-999) reserved for system accounts/groups
|
||||
* **`Group ID (GID-503):`** It indicates the group ID (GID) each group should be contain unique GID is stored at /etc/group file.
|
||||
* **`User ID Info (2g Admin - Magesh M):`** It indicates the command field. This field can be used to describe the user information.
|
||||
* **`Home Directory (/home/magesh):`** It indicates the user home directory.
|
||||
* **`shell (/bin/bash):`** It indicates the user’s bash shell.
|
||||
|
||||
|
||||
|
||||
If you would like to display only user names from the /etc/passwd file, use the below format.
|
||||
```
|
||||
# cut -d: -f1 /etc/passwd
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
lp
|
||||
sync
|
||||
shutdown
|
||||
halt
|
||||
mail
|
||||
uucp
|
||||
operator
|
||||
games
|
||||
gopher
|
||||
ftp
|
||||
nobody
|
||||
dbus
|
||||
vcsa
|
||||
abrt
|
||||
haldaemon
|
||||
ntp
|
||||
saslauth
|
||||
postfix
|
||||
sshd
|
||||
tcpdump
|
||||
centos
|
||||
prakash
|
||||
apache
|
||||
nagios
|
||||
rpc
|
||||
nrpe
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
To display only home directory users, use the below format.
|
||||
```
|
||||
# cat /etc/passwd | grep '/home' | cut -d: -f1
|
||||
centos
|
||||
prakash
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
### 4) Using finger Command
|
||||
|
||||
The finger comamnd displays information about the system users. It displays the user’s real name, terminal name and write status (as a ‘‘*’’ after the terminal name if write permission is denied), idle time and login time.
|
||||
```
|
||||
# finger magesh
|
||||
Login: magesh Name: 2g Admin - Magesh M
|
||||
Directory: /home/magesh Shell: /bin/bash
|
||||
Last login Tue Jul 17 22:46 (EDT) on pts/2 from 103.5.134.167
|
||||
No mail.
|
||||
No Plan.
|
||||
|
||||
```
|
||||
|
||||
Below are the detailed information for the above output.
|
||||
|
||||
* **`Login:`** User’s login name
|
||||
* **`Name:`** Additional/Other information about the user
|
||||
* **`Directory:`** User home directory information
|
||||
* **`Shell:`** User’s shell information
|
||||
* **`LAST-LOGIN:`** Date of last login and other information
|
||||
|
||||
|
||||
|
||||
### 5) Using lslogins Command
|
||||
|
||||
It displays information about known users in the system. By default it will list information about all the users in the system.
|
||||
|
||||
The lslogins utility is inspired by the logins utility, which first appeared in FreeBSD 4.10.
|
||||
```
|
||||
# lslogins -u
|
||||
UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
|
||||
0 root 0 0 00:17:28 root
|
||||
500 centos 0 1 Cloud User
|
||||
501 prakash 0 0 Apr12/04:08 2018/04/12
|
||||
502 magesh 0 0 Jul17/22:46 2g Admin - Magesh M
|
||||
503 thanu 0 0 Jul18/00:40 2g Editor - Thanisha M
|
||||
504 sudha 0 0 Jul18/01:18 2g Editor - Sudha M
|
||||
|
||||
```
|
||||
|
||||
Below are the detailed information for the above output.
|
||||
|
||||
* **`UID:`** User id
|
||||
* **`USER:`** Name of the user
|
||||
* **`PWD-LOCK:`** password defined, but locked
|
||||
* **`PWD-DENY:`** login by password disabled
|
||||
* **`LAST-LOGIN:`** Date of last login
|
||||
* **`GECOS:`** Other information about the user
|
||||
|
||||
|
||||
|
||||
### 6) Using compgen Command
|
||||
|
||||
compgen is bash built-in command and it will show all available commands, aliases, and functions for you.
|
||||
```
|
||||
# compgen -u
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
lp
|
||||
sync
|
||||
shutdown
|
||||
halt
|
||||
mail
|
||||
uucp
|
||||
operator
|
||||
games
|
||||
gopher
|
||||
ftp
|
||||
nobody
|
||||
dbus
|
||||
vcsa
|
||||
abrt
|
||||
haldaemon
|
||||
ntp
|
||||
saslauth
|
||||
postfix
|
||||
sshd
|
||||
tcpdump
|
||||
centos
|
||||
prakash
|
||||
apache
|
||||
nagios
|
||||
rpc
|
||||
nrpe
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/6-easy-ways-to-check-user-name-and-other-information-in-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/how-to-check-user-created-date-on-linux/
|
||||
[2]:https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
|
||||
[3]:https://www.2daygeek.com/how-to-force-user-to-change-password-on-next-login-in-linux/
|
||||
@ -0,0 +1,71 @@
|
||||
translating----geekpi
|
||||
|
||||
Getting started with Mu, a Python editor for beginners
|
||||
======
|
||||
|
||||

|
||||
|
||||
Mu is a Python editor for beginning programmers, designed to make the learning experience more pleasant. It gives students the ability to experience success early on, which is important anytime you're learning something new.
|
||||
|
||||
If you have ever tried to teach young people how to program, you will immediately grasp the importance of [Mu][1]. Most programming tools are written by developers for developers and aren't well-suited for beginning programmers, regardless of their age. Mu, however, was written by a teacher for students.
|
||||
|
||||
### Mu's origins
|
||||
|
||||
Mu is the brainchild of [Nicholas Tollervey][2] (who I heard speak at PyCon2018 in May). Nicholas is a classically trained musician who became interested in Python and development early in his career while working as a music teacher. He also wrote [Python in Education][3], a free book you can download from O'Reilly.
|
||||
|
||||
Nicholas was looking for a simpler interface for Python programming. He wanted something without the complexity of other editors—even the IDLE3 editor that comes with Python—so he worked with [Carrie Ann Philbin][4] , director of education at the Raspberry Pi Foundation (which sponsored his work), to develop Mu.
|
||||
|
||||
Mu is an open source application (licensed under [GNU GPLv3][5]) written in Python. It was originally developed to work with the [Micro:bit][6] mini-computer, but feedback and requests from other teachers spurred him to rewrite Mu into a generic Python editor.
|
||||
|
||||
### Inspired by music
|
||||
|
||||
Nicholas' inspiration for Mu came from his approach to teaching music. He wondered what would happen if we taught programming the way we teach music and immediately saw the disconnect. Unlike with programming, we don't have music boot camps and we don't learn to play an instrument from a book on, say, how to play the flute.
|
||||
|
||||
Nicholas says, Mu "aims to be the real thing," because no one can learn Python in 30 minutes. As he developed Mu, he worked with teachers, observed coding clubs, and watched secondary school students as they worked with Python. He found that less is more and keeping things simple improves the finished product's functionality. Mu is only about 3,000 lines of code, Nicholas says.
|
||||
|
||||
### Using Mu
|
||||
|
||||
To try it out, [download][7] Mu and follow the easy installation instructions for [Linux, Windows, and Mac OS][8]. If, like me, you want to [install it on Raspberry Pi][9], enter the following in the terminal:
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install mu
|
||||
|
||||
```
|
||||
|
||||
Launch Mu from the Programming menu. Then you'll have a choice about how you will use Mu.
|
||||
|
||||
|
||||
|
||||
I chose Python 3, which launches an environment to write code; the Python shell is directly below, which allows you to see the code execution.
|
||||
|
||||
|
||||
|
||||
The menu is very simple to use and understand, which achieves Mu's purpose—making coding easy for beginning programmers.
|
||||
|
||||
[Tutorials][10] and other resources are available on the Mu users' website. On the site, you can also see names of some of the [volunteers][11] who helped develop Mu. If you would like to become one of them and [contribute to Mu's development][12], you are most welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://codewith.mu
|
||||
[2]:https://us.pycon.org/2018/speaker/profile/194/
|
||||
[3]:https://www.oreilly.com/programming/free/python-in-education.csp
|
||||
[4]:https://uk.linkedin.com/in/carrie-anne-philbin-a20649b7
|
||||
[5]:https://mu.readthedocs.io/en/latest/license.html
|
||||
[6]:http://microbit.org/
|
||||
[7]:https://codewith.mu/en/download
|
||||
[8]:https://codewith.mu/en/howto/install_with_python
|
||||
[9]:https://codewith.mu/en/howto/install_raspberry_pi
|
||||
[10]:https://codewith.mu/en/tutorials/
|
||||
[11]:https://codewith.mu/en/thanks
|
||||
[12]:https://mu.readthedocs.io/en/latest/contributing.html
|
||||
117
sources/tech/20180802 Walkthrough On How To Use GNOME Boxes.md
Normal file
117
sources/tech/20180802 Walkthrough On How To Use GNOME Boxes.md
Normal file
@ -0,0 +1,117 @@
|
||||
Walkthrough On How To Use GNOME Boxes
|
||||
======
|
||||
|
||||

|
||||
|
||||
Boxes or GNOME Boxes is a virtualization software for GNOME Desktop Environment. It is similar to Oracle VirtualBox but features a simple user interface. Boxes also pose some challenge for newbies and VirtualBox users, for instance, on VirtualBox, it is easy to install guest addition image through menu bar but the same is not true for Boxes. Rather, users are encouraged to install additional guest tools from the terminal program within the guest session.
|
||||
|
||||
This article will provide a walkthrough on how to use GNOME Boxes by installing the software and actually setting a guest session on the machine. It will also take you through the steps for installing the guest tools and provide some additional tips for Boxes configuration.
|
||||
|
||||
### Purpose of virtualization
|
||||
|
||||
If you are wondering what is the purpose of virtualization and why most computer experts and developers use them a lot. There is usually a common reason for this: **TESTING**.
|
||||
|
||||
Developers who use Linux and writes software for Windows has to test his program on an actual Windows environment before deploying it to the end users. Virtualization makes it possible for him to install and set up a Windows guest session on his Linux computer.
|
||||
|
||||
Virtualization is also used by ordinary users who wish to get hands-on with their favorite Linux distro that is still in beta release, without installing it on their physical computer. So in the event the virtual machine crashes, the host is not affected and the important files & documents stored on the physical disk remain intact.
|
||||
|
||||
Virtualization allows you to test a software built for another platform/architecture which may include ARM, MIPS, SPARC, etc on your computer equipped with another architecture such as Intel or AMD.
|
||||
|
||||
### Installing GNOME Boxes
|
||||
|
||||
Launch Ubuntu Software and key in " gnome boxes ". Click the application name to load its installer page and then select the Install button. [][1]
|
||||
|
||||
### Extra setup for Ubuntu 18.04
|
||||
|
||||
There's a bug in GNOME Boxes on Ubuntu 18.04; it fails to start the Virtual Machine (VM). To remedy that, perform the below two steps on a terminal program:
|
||||
|
||||
1. Add the line "group=kvm" to the qemu config file sudo gedit /etc/modprobe.d/qemu-system-x86.conf
|
||||
|
||||
2. Add your user account to kvm group sudo usermod -a -G kvm
|
||||
|
||||
[][2]
|
||||
|
||||
After that, logout and re-login again for the changes to take effect.
|
||||
|
||||
#### Downloading an image file
|
||||
|
||||
You can download an image file/Operating System (OS) from the Internet or within the GNOME Boxes setup itself. However, for this article we'll proceed with the realistic method ie., downloading an image file from the Internet. We'll be configuring Lubuntu on Boxes so head over to this website to download the Linux distro.
|
||||
|
||||
[Download][3]
|
||||
|
||||
#### To burn or not to burn
|
||||
|
||||
If you have no intention to distribute Lubuntu to your friends or install it on a physical machine then it's best not to burn the image file to a blank disc or portable USB drive. Instead just leave it as it is, we'll use it for creating a VM afterward.
|
||||
|
||||
#### Starting GNOME Boxes
|
||||
|
||||
Below is the interface of GNOME Boxes on Ubuntu - [][4]
|
||||
|
||||
The interface is simple and intuitive for newbies to get familiar right away without much effort. Boxes don't feature a menu bar or toolbar, unlike Oracle VirtualBox. On the top left is the New button to create a VM and on the right houses buttons for VM options; delete list or grid view, and configuration (they'll become available when a VM is created).
|
||||
|
||||
### Installing an Operating System
|
||||
|
||||
Click the New button and choose "Select a file". Select the downloaded Lubuntu image file on the Downloads library and then click Create button.
|
||||
|
||||
[][5]
|
||||
|
||||
In case this is your first time installing an OS on a VM, do not panic when the installer pops up a window asking you to erase the disk partition. It's safe, your physical computer hard drive won't be erased, only that the storage space would be allocated for your VM. So on a 1TB hard drive, if you allocate 30 GB for your VM, performing erase partition operation on Boxes would only erase that virtual 30 GB storage drive and not the physical storage.
|
||||
|
||||
_Usually, computer students find virtualization a useful tool for practicing advanced partitioning using UNIX based OS. You can too since there is no risk that would tamper the main OS files._
|
||||
|
||||
After installing Lubuntu, you'll be prompted to reboot the computer (VM) to finish the installation process and actually boot from the hard drive. Confirm the operation.
|
||||
|
||||
|
||||
|
||||
Sometimes, certain Linux distros hang in the reboot process after installation. The trick is to force shutdown the VM from the options button found on the top right side of the tile bar and then power it on again.
|
||||
|
||||
#### Set up Guest tools
|
||||
|
||||
By now you might have noticed Lubuntu's screen resolution is small with extra black spaces on the left and right side, and folder sharing is not enabled too. This brings up the need to install guest tools on Lubuntu.
|
||||
|
||||
|
||||
|
||||
Launch terminal program from the guest session (not your host terminal program) and install the guest tools using the below command:
|
||||
|
||||
sudo apt install spice-vdagent spice-webdavd
|
||||
|
||||
After that, reboot Lubuntu and the next boot will set the VM to its appropriate screen resolution; no more extra black spaces on the left and right side. You can resize Boxes window and the guest screen resolution will automatically resize itself.
|
||||
|
||||
[][6]
|
||||
|
||||
To share a folder between the host and guest, open Boxes options while the guest is still running and choose Properties. On the Devices & Shares category, click the + button and set up the name. By default, Public folder from the host will be shared with the guest OS. You can configure the directory of your choice. After that is done, launch Lubuntu's file manager program (it's called PCManFM) and click Go menu on the menu bar. Select Network and choose Spice Client Folder. The first time you try to open it a dialog box will pop up asking you which program should handle the network, select PCManFM under Accessories category and the network will be mounted on the desktop. Launch it and there you'll see your shared folder name.
|
||||
|
||||
Now you can share files and folders between host and guest computer. Subsequent launch of the network will directly open the shared folder so you don't have to open the folder manually the next time.
|
||||
|
||||
[][7]
|
||||
|
||||
#### Where's the OS installed?
|
||||
|
||||
Lubuntu is installed as a VM using **GNOME Boxes** but where does it store the disk image?
|
||||
|
||||
This question is of particular interest for those who wish to move the huge image file to another partition where there is sufficient storage. The trick is using symlinks which is efficient as it saves more space for Linux root partition and or home partition, depending on how the user set it up during installation. Boxes stores the disk image files to ~/.local/share/gnome-boxes/images folder
|
||||
|
||||
### Conclusion
|
||||
|
||||
We've successfully set up Lubuntu as a guest OS on our Ubuntu. You can try other variants of Ubuntu such as Kubuntu, Ubuntu MATE, Xubuntu, etc or some random Linux distros which in my opinion would be quite challenging due to varying package management. But there's no harm in wanting to :) You can also try installing other platforms like Microsoft Windows, OpenBSD, etc on your computer as a VM. And by the way, don't forget to leave your opinions in the comment section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/walkthrough-on-how-to-use-gnome-boxes
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-gnome-boxes_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-boxes-extras-for-ubuntu-18-04_orig.jpg
|
||||
[3]:https://lubuntu.net/
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/create-gnome-boxes_orig.jpg
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-os-on-ubuntu-guest-box_orig.jpg
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/lubuntu-on-gnome-boxes_orig.jpg
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-boxes-guest-addition_orig.jpg
|
||||
148
sources/tech/20180803 5 Essential Tools for Linux Development.md
Normal file
148
sources/tech/20180803 5 Essential Tools for Linux Development.md
Normal file
@ -0,0 +1,148 @@
|
||||
5 Essential Tools for Linux Development
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux has become a mainstay for many sectors of work, play, and personal life. We depend upon it. With Linux, technology is expanding and evolving faster than anyone could have imagined. That means Linux development is also happening at an exponential rate. Because of this, more and more developers will be hopping on board the open source and Linux dev train in the immediate, near, and far-off future. For that, people will need tools. Fortunately, there are a ton of dev tools available for Linux; so many, in fact, that it can be a bit intimidating to figure out precisely what you need (especially if you’re coming from another platform).
|
||||
|
||||
To make that easier, I thought I’d help narrow down the selection a bit for you. But instead of saying you should use Tool X and Tool Y, I’m going to narrow it down to five categories and then offer up an example for each. Just remember, for most categories, there are several available options. And, with that said, let’s get started.
|
||||
|
||||
### Containers
|
||||
|
||||
Let’s face it, in this day and age you need to be working with containers. Not only are they incredibly easy to deploy, they make for great development environments. If you regularly develop for a specific platform, why not do so by creating a container image that includes all of the tools you need to make the process quick and easy. With that image available, you can then develop and roll out numerous instances of whatever software or service you need.
|
||||
|
||||
Using containers for development couldn’t be easier than it is with [Docker][1]. The advantages of using containers (and Docker) are:
|
||||
|
||||
* Consistent development environment.
|
||||
|
||||
* You can trust it will “just work” upon deployment.
|
||||
|
||||
* Makes it easy to build across platforms.
|
||||
|
||||
* Docker images available for all types of development environments and languages.
|
||||
|
||||
* Deploying single containers or container clusters is simple.
|
||||
|
||||
|
||||
|
||||
|
||||
Thanks to [Docker Hub][2], you’ll find images for nearly any platform, development environment, server, service… just about anything you need. Using images from Docker Hub means you can skip over the creation of the development environment and go straight to work on developing your app, server, API, or service.
|
||||
|
||||
Docker is easily installable of most every Linux platform. For example: To install Docker on Ubuntu, you only have to open a terminal window and issue the command:
|
||||
```
|
||||
sudo apt-get install docker.io
|
||||
|
||||
```
|
||||
|
||||
With Docker installed, you’re ready to start pulling down specific images, developing, and deploying (Figure 1).
|
||||
|
||||
![Docker images][4]
|
||||
|
||||
Figure 1: Docker images ready to deploy.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
### Version control system
|
||||
|
||||
If you’re working on a large project or with a team on a project, you’re going to need a version control system. Why? Because you need to keep track of your code, where your code is, and have an easy means of making commits and merging code from others. Without such a tool, your projects would be nearly impossible to manage. For Linux users, you cannot beat the ease of use and widespread deployment of [Git][6] and [GitHub][7]. If you’re new to their worlds, Git is the version control system that you install on your local machine and GitHub is the remote repository you use to upload (and then manage) your projects. Git can be installed on most Linux distributions. For example, on a Debian-based system, the install is as simple as:
|
||||
```
|
||||
sudo apt-get install git
|
||||
|
||||
```
|
||||
|
||||
Once installed, you are ready to start your journey with version control (Figure 2).
|
||||
|
||||
![Git installed][9]
|
||||
|
||||
Figure 2: Git is installed and available for many important tasks.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Github requires you to create an account. You can use it for free for non-commercial projects, or you can pay for commercial project housing (for more information check out the price matrix [here][10]).
|
||||
|
||||
### Text editor
|
||||
|
||||
Let’s face it, developing on Linux would be a bit of a challenge without a text editor. Of course what a text editor is varies, depending upon who you ask. One person might say vim, emacs, or nano, whereas another might go full-on GUI with their editor. But since we’re talking development, we need a tool that can meet the needs of the modern day developer. And before I mention a couple of text editors, I will say this: Yes, I know that vim is a serious workhorse for serious developers and, if you know it well vim will meet and exceed all of your needs. However, getting up to speed enough that it won’t be in your way, can be a bit of a hurdle for some developers (especially those new to Linux). Considering my goal is to always help win over new users (and not just preach to an already devout choir), I’m taking the GUI route here.
|
||||
|
||||
As far as text editors are concerned, you cannot go wrong with the likes of [Bluefish][11]. Bluefish can be found in most standard repositories and features project support, multi-threaded support for remote files, search and replace, open files recursively, snippets sidebar, integrates with make, lint, weblint, xmllint, unlimited undo/redo, in-line spell checker, auto-recovery, full screen editing, syntax highlighting (Figure 3), support for numerous languages, and much more.
|
||||
|
||||
![Bluefish][13]
|
||||
|
||||
Figure 3: Bluefish running on Ubuntu Linux 18.04.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
### IDE
|
||||
|
||||
Integrated Development Environment (IDE) is a piece of software that includes a comprehensive set of tools that enable a one-stop-shop environment for developing. IDEs not only enable you to code your software, but document and build them as well. There are a number of IDEs for Linux, but one in particular is not only included in the standard repositories it is also very user-friendly and powerful. That tool in question is [Geany][14]. Geany features syntax highlighting, code folding, symbol name auto-completion, construct completion/snippets, auto-closing of XML and HTML tags, call tips, many supported filetypes, symbol lists, code navigation, build system to compile and execute your code, simple project management, and a built-in plugin system.
|
||||
|
||||
Geany can be easily installed on your system. For example, on a Debian-based distribution, issue the command:
|
||||
```
|
||||
sudo apt-get install geany
|
||||
|
||||
```
|
||||
|
||||
Once installed, you’re ready to start using this very powerful tool that includes a user-friendly interface (Figure 4) that has next to no learning curve.
|
||||
|
||||
![Geany][16]
|
||||
|
||||
Figure 4: Geany is ready to serve as your IDE.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
### diff tool
|
||||
|
||||
There will be times when you have to compare two files to find where they differ. This could be two different copies of what was the same file (only one compiles and the other doesn’t). When that happens, you don’t want to have to do that manually. Instead, you want to employ the power of tool like [Meld][17]. Meld is a visual diff and merge tool targeted at developers. With Meld you can make short shrift out of discovering the differences between two files. Although you can use a command line diff tool, when efficiency is the name of the game, you can’t beat Meld.
|
||||
|
||||
Meld allows you to open a comparison between to files and it will highlight the differences between each. Meld also allows you to merge comparisons either from the right or the left (as the files are opened side by side - Figure 5).
|
||||
|
||||
![Comparing two files][19]
|
||||
|
||||
Figure 5: Comparing two files with a simple difference.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Meld can be installed from most standard repositories. On a Debian-based system, the installation command is:
|
||||
```
|
||||
sudo apt-get install meld
|
||||
|
||||
```
|
||||
|
||||
### Working with efficiency
|
||||
|
||||
These five tools not only enable you to get your work done, they help to make it quite a bit more efficient. Although there are a ton of developer tools available for Linux, you’re going to want to make sure you have one for each of the above categories (maybe even starting with the suggestions I’ve made).
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][20]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/8/5-essential-tools-linux-development
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.docker.com/
|
||||
[2]:https://hub.docker.com/
|
||||
[3]:/files/images/5devtools1jpg
|
||||
[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_1.jpg?itok=V1Bsbkg9 (Docker images)
|
||||
[5]:/licenses/category/used-permission
|
||||
[6]:https://git-scm.com/
|
||||
[7]:https://github.com/
|
||||
[8]:/files/images/5devtools2jpg
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_2.jpg?itok=YJjhe4O6 (Git installed)
|
||||
[10]:https://github.com/pricing
|
||||
[11]:http://bluefish.openoffice.nl/index.html
|
||||
[12]:/files/images/5devtools3jpg
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_3.jpg?itok=66A7Svme (Bluefish)
|
||||
[14]:https://www.geany.org/
|
||||
[15]:/files/images/5devtools4jpg
|
||||
[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_4.jpg?itok=jRcA-0ue (Geany)
|
||||
[17]:http://meldmerge.org/
|
||||
[18]:/files/images/5devtools5jpg
|
||||
[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_5.jpg?itok=eLkfM9oZ (Comparing two files)
|
||||
[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,285 @@
|
||||
How to use Fedora Server to create a router / gateway
|
||||
======
|
||||
|
||||

|
||||
|
||||
Building a router (or gateway) using Fedora Server is an interesting project for users wanting to learn more about Linux system administration and networking. In this article, learn how to configure a Fedora Server minimal install to act as an internet router / gateway.
|
||||
|
||||
This guide is based on [Fedora 28][1] and assumes you have already installed Fedora Server (minimal install). Additionally, you require a suitable network card / modem for the incoming internet connection. In this example, the [DrayTek VigorNIC 132][2] NIC was used to create the router.
|
||||
|
||||
### Why build your own router
|
||||
|
||||
There are many benefits for building your own router over buying a standalone box (or using the one supplied by your internet provider):
|
||||
|
||||
* Easily update and run latest software versions
|
||||
* May be less prone to be part of larger hacking campaign as its not a common consumer device
|
||||
* Run your own VMs or containers on same host/router
|
||||
* Build OpenShift on top of router (future story in this series)
|
||||
* Include your own VPN, Tor, or other tunnel paths along with correct routing
|
||||
|
||||
|
||||
|
||||
The downside is related to time and knowledge.
|
||||
|
||||
* You have to manage your own security
|
||||
* You need to have the knowledge to troubleshoot if an issue happens or find it through the web (no support calls)
|
||||
* Costs more in most cases than hardware provided by an internet provider
|
||||
|
||||
|
||||
|
||||
Basic network topology
|
||||
|
||||
The diagram below describes the basic topology used in this setup. The machine running Fedora Server has a PCI Express modem for VDSL. Alternatively, if you use a [Raspberry Pi][3] with external modem the configuration is mostly similar.
|
||||
|
||||
![topology][4]
|
||||
|
||||
### Initial Setup
|
||||
|
||||
First of all, install the packages needed to make the router. Bash auto-complete is included to make things easier when later configuring. Additionally, install packages to allow you to host your own VMs on the same router/hosts via KVM-QEMU.
|
||||
```
|
||||
dnf install -y bash-completion NetworkManager-ppp qemu-kvm qemu-img virt-manager libvirt libvirt-python libvirt-client virt-install virt-viewer
|
||||
|
||||
```
|
||||
|
||||
Next, use **nmcli** to set the MTU on the WAN(PPPoE) interfaces to align with DSL/ATM MTU and create **pppoe** interface. This [link][5] has a great explanation on how this works. The username and password will be provided by your internet provider.
|
||||
```
|
||||
nmcli connection add type pppoe ifname enp2s0 username 00xxx5511yyy0001@t-online.de password XXXXXX 802-3-ethernet.mtu 1452
|
||||
|
||||
```
|
||||
|
||||
Now, set up the firewall with the default zone as external and remove incoming SSH access.
|
||||
```
|
||||
firewall-cmd --set-default-zone=external
|
||||
firewall-cmd --permanent --zone=external --remove-service=ssh
|
||||
|
||||
```
|
||||
|
||||
Add LAN interface(br0) along with preferred LAN IP address and then add your physical LAN interface to the bridge.
|
||||
```
|
||||
nmcli connection add ifname br0 type bridge con-name br0 bridge.stp no ipv4.addresses 10.0.0.1/24 ipv4.method manual
|
||||
nmcli connection add type bridge-slave ifname enp1s0 master br0
|
||||
|
||||
```
|
||||
|
||||
Remember to use a subnet that does not overlap with your works VPN subnet. For example my work provides a 10.32.0.0/16 subnet when I VPN into the office so I need to avoid using this in my home network. If you overlap addressing then the route provided by your VPN will likely have lower priority and you will not route through the VPN tunnel.
|
||||
|
||||
Now create a file called bridge.xml, containing a bridge definition that **virsh** will consume to create a bridge in **QEMU**.
|
||||
```
|
||||
cat > bridge.xml <<EOF
|
||||
<network>
|
||||
<name>host-bridge</name>
|
||||
<forward mode="bridge"/>
|
||||
<bridge name="br0"/>
|
||||
</network>
|
||||
EOF
|
||||
|
||||
```
|
||||
|
||||
Start and enable your libvirt-guests service so you can add the bridge in your virtual environment for the VMs to use.
|
||||
```
|
||||
systemctl start libvirt-guests.service
|
||||
systemctl enable libvirt-guests.service
|
||||
|
||||
```
|
||||
|
||||
Add your “host-bridge” to QEMU via virsh command and the XML file you created earlier.
|
||||
```
|
||||
virsh net-define bridge.xml
|
||||
|
||||
```
|
||||
|
||||
virsh net-start host-bridge virsh net-autostart host-bridge
|
||||
|
||||
Add br0 to internal zone and allow DNS and DHCP as we will be setting up our own services on this router.
|
||||
```
|
||||
firewall-cmd --permanent --zone=internal --add-interface=br0
|
||||
firewall-cmd --permanent --zone=internal --add-service=dhcp
|
||||
firewall-cmd --permanent --zone=internal --add-service=dns
|
||||
|
||||
```
|
||||
|
||||
Since many DHCP clients including Windows and Linux don’t take into account the MTU attribute in DHCP, we will need to allow TCP based protocols to set MSS based on PMTU size.
|
||||
```
|
||||
firewall-cmd --permanent --direct --add-passthrough ipv4 -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
|
||||
|
||||
```
|
||||
|
||||
Now we reload the firewall to take permanent changes into account.
|
||||
```
|
||||
nmcli connection reload
|
||||
|
||||
```
|
||||
|
||||
### Install and Configure DHCP
|
||||
|
||||
DHCP configuration depends on your home network setup. Use your own desired domain name and and the subnet was defined during the creation of **br0**. Be sure to note the MAC address in the config file below can either be capture from the command below once you have DHCP services up and running or you can pull it off the label externally on the device you want to set to static addressing.
|
||||
```
|
||||
cat /var/lib/dhcpd/dhcpd.leases
|
||||
|
||||
dnf -y install dhcp
|
||||
vi /etc/dhcp/dhcpd.conf
|
||||
|
||||
option domain-name "lajoie.org";
|
||||
option domain-name-servers 10.0.0.1;
|
||||
default-lease-time 600;
|
||||
max-lease-time 7200;
|
||||
authoritative;
|
||||
subnet 10.0.0.0 netmask 255.255.255.0 {
|
||||
range dynamic-bootp 10.0.0.100 10.0.0.254;
|
||||
option broadcast-address 10.0.0.255;
|
||||
option routers 10.0.0.1; option interface-mtu 1452;
|
||||
}
|
||||
host ubifi {
|
||||
option host-name "ubifi.lajoie.org";
|
||||
hardware ethernet f0:9f:c2:1f:c1:12;
|
||||
fixed-address 10.0.0.2;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Now enable and start your DHCP server
|
||||
```
|
||||
systemctl start dhcpd
|
||||
systemctl enable dhcpd
|
||||
|
||||
```
|
||||
|
||||
### DNS Install and Configure
|
||||
|
||||
Next, install **bind** and and **bind-utils** for tools like **nslookup** and **dig**.
|
||||
```
|
||||
dnf -y install bind bind-utils
|
||||
|
||||
```
|
||||
|
||||
Configure your bind server with listening address (LAN interface in this case) and the forward/reverse zones.
|
||||
```
|
||||
$ vi /etc/named.conf
|
||||
|
||||
options {
|
||||
listen-on port 53 { 10.0.0.1; };
|
||||
listen-on-v6 port 53 { none; };
|
||||
directory "/var/named";
|
||||
dump-file "/var/named/data/cache_dump.db";
|
||||
statistics-file "/var/named/data/named_stats.txt";
|
||||
memstatistics-file "/var/named/data/named_mem_stats.txt";
|
||||
secroots-file "/var/named/data/named.secroots";
|
||||
recursing-file "/var/named/data/named.recursing";
|
||||
allow-query { 10.0.0.0/24; };
|
||||
recursion yes;
|
||||
forwarders {8.8.8.8; 8.8.4.4; };
|
||||
dnssec-enable yes;
|
||||
dnssec-validation yes;
|
||||
managed-keys-directory "/var/named/dynamic";
|
||||
pid-file "/run/named/named.pid";
|
||||
session-keyfile "/run/named/session.key";
|
||||
include "/etc/crypto-policies/back-ends/bind.config";
|
||||
};
|
||||
controls { };
|
||||
logging {
|
||||
channel default_debug {
|
||||
file "data/named.run";
|
||||
severity dynamic;
|
||||
};
|
||||
};
|
||||
view "internal" {
|
||||
match-clients { localhost; 10.0.0.0/24; };
|
||||
zone "lajoie.org" IN {
|
||||
type master;
|
||||
file "lajoie.org.db";
|
||||
allow-update { none; };
|
||||
};
|
||||
zone "0.0.10.in-addr.arpa" IN {
|
||||
type master;
|
||||
file "0.0.10.db";
|
||||
allow-update { none; };
|
||||
};
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
Here is a zone file for example and make sure to update the serial number after each edit of the bind service will assume no changes took place.
|
||||
```
|
||||
$ vi /var/named/lajoie.org.db
|
||||
|
||||
$TTL 86400
|
||||
@ IN SOA gw.lajoie.org. root.lajoie.org. (
|
||||
2018040801 ;Serial
|
||||
3600 ;Refresh
|
||||
1800 ;Retry
|
||||
604800 ;Expire
|
||||
86400 ;Minimum TTL )
|
||||
IN NS gw.lajoie.org.
|
||||
IN A 10.0.0.1
|
||||
gw IN A 10.0.0.1
|
||||
ubifi IN A 10.0.0.2
|
||||
|
||||
```
|
||||
|
||||
Here is a reverse zone file for example and make sure to update the serial number after each edit of the bind service will assume no changes took place.
|
||||
```
|
||||
$ vi /var/named/0.0.10.db
|
||||
|
||||
$TTL 86400
|
||||
@ IN SOA gw.lajoie.org. root.lajoie.org. (
|
||||
2018040801 ;Serial
|
||||
3600 ;Refresh
|
||||
1800 ;Retry
|
||||
604800 ;Expire
|
||||
86400 ;Minimum TTL )
|
||||
IN NS gw.lajoie.org.
|
||||
IN PTR lajoie.org.
|
||||
IN A 255.255.255.0
|
||||
1 IN PTR gw.lajoie.org.
|
||||
2 IN PTR ubifi.lajoie.org.
|
||||
|
||||
```
|
||||
|
||||
Now enable and start your DNS server
|
||||
```
|
||||
systemctl start named
|
||||
systemctl enable named
|
||||
|
||||
```
|
||||
|
||||
# Secure SSH
|
||||
|
||||
Last simple step is to make SSH service listen only on your LAN segment. Run this command to see whats listening at this moment. Remember we did not allow SSH on the external firewall zone but this step is still best practice in my opinion.
|
||||
```
|
||||
ss -lnp4
|
||||
|
||||
```
|
||||
|
||||
Now edit the SSH service to only listen on your LAN segment.
|
||||
```
|
||||
vi /etc/ssh/sshd_config
|
||||
|
||||
AddressFamily inet
|
||||
ListenAddress 10.0.0.1
|
||||
|
||||
```
|
||||
|
||||
Restart your SSH service for changes to take effect.
|
||||
```
|
||||
systemctl restart sshd.service
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-fedora-server-create-router-gateway/
|
||||
|
||||
作者:[Eric Lajoie][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/elajoie/
|
||||
[1]:https://getfedora.org/en/server/
|
||||
[2]:https://www.draytek.com/en/products/products-a-z/router.all/vigornic-132-series/
|
||||
[3]:https://fedoraproject.org/wiki/Architectures/ARM/Raspberry_Pi
|
||||
[4]:https://ericlajoie.com/photo/FedoraRouter.png
|
||||
[5]:https://www.sonicwall.com/en-us/support/knowledge-base/170505851231244
|
||||
@ -0,0 +1,308 @@
|
||||
SDKMAN – A CLI Tool To Easily Manage Multiple Software Development Kits
|
||||
======
|
||||
|
||||

|
||||
|
||||
Are you a developer who often install and test applications on different SDKs? I’ve got a good news for you! Say hello to **SDKMAN** , a CLI tool that helps you to easily manage multiple software development kits. It provides a convenient way to install, switch, list and remove candidates. Using SDKMAN, you can now manage parallel versions of multiple SDKs easily on any Unix-like operating system. It allows the developers to install Software Development Kits for the JVM such as Java, Groovy, Scala, Kotlin and Ceylon. Ant, Gradle, Grails, Maven, SBT, Spark, Spring Boot, Vert.x and many others are also supported. SDKMAN is free, light weight, open source and written in **Bash**.
|
||||
|
||||
### Installing SDKMAN
|
||||
|
||||
Installing SDKMAN is trivial. First, make sure you have installed **zip** and **unzip** applications. It is available in the default repositories of most Linux distributions. For instance, to install unzip on Debian-based systems, simply run:
|
||||
```
|
||||
$ sudo apt-get install zip unzip
|
||||
|
||||
```
|
||||
|
||||
Then, install SDKMAN using command:
|
||||
```
|
||||
$ curl -s "https://get.sdkman.io" | bash
|
||||
|
||||
```
|
||||
|
||||
It’s that simple. Once the installation is completed, run the following command:
|
||||
```
|
||||
$ source "$HOME/.sdkman/bin/sdkman-init.sh"
|
||||
|
||||
```
|
||||
|
||||
If you want to install it in a custom location of your choice other than **$HOME/.sdkman** , for example **/usr/local/** , do:
|
||||
```
|
||||
$ export SDKMAN_DIR="/usr/local/sdkman" && curl -s "https://get.sdkman.io" | bash
|
||||
|
||||
```
|
||||
|
||||
Make sure your user has full access rights to this folder.
|
||||
|
||||
Finally, check if the installation is succeeded using command:
|
||||
```
|
||||
$ sdk version
|
||||
==== BROADCAST =================================================================
|
||||
* 01/08/18: Kotlin 1.2.60 released on SDKMAN! #kotlin
|
||||
* 31/07/18: Sbt 1.2.0 released on SDKMAN! #sbt
|
||||
* 31/07/18: Infrastructor 0.2.1 released on SDKMAN! #infrastructor
|
||||
================================================================================
|
||||
|
||||
SDKMAN 5.7.2+323
|
||||
|
||||
```
|
||||
|
||||
Congratulations! SDKMAN has been installed. Let us go ahead and see how to install and manage SDKs.
|
||||
|
||||
### Manage Multiple Software Development Kits
|
||||
|
||||
To view the list of available candidates(SDKs), run:
|
||||
```
|
||||
$ sdk list
|
||||
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
```
|
||||
================================================================================
|
||||
Available Candidates
|
||||
================================================================================
|
||||
q-quit /-search down
|
||||
j-down ?-search up
|
||||
k-up h-help
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
Ant (1.10.1) https://ant.apache.org/
|
||||
|
||||
Apache Ant is a Java library and command-line tool whose mission is to drive
|
||||
processes described in build files as targets and extension points dependent
|
||||
upon each other. The main known usage of Ant is the build of Java applications.
|
||||
Ant supplies a number of built-in tasks allowing to compile, assemble, test and
|
||||
run Java applications. Ant can also be used effectively to build non Java
|
||||
applications, for instance C or C++ applications. More generally, Ant can be
|
||||
used to pilot any type of process which can be described in terms of targets and
|
||||
tasks.
|
||||
|
||||
: $ sdk install ant
|
||||
|
||||
```
|
||||
|
||||
As you can see, SDKMAN list one candidate at a time along with the description of the candidate and it’s official website and the installation command. Press ENTER key to list the next candidates.
|
||||
|
||||
To install a SDK, for example Java JDK, run:
|
||||
```
|
||||
$ sdk install java
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
Downloading: java 8.0.172-zulu
|
||||
|
||||
In progress...
|
||||
|
||||
######################################################################################## 100.0%
|
||||
|
||||
Repackaging Java 8.0.172-zulu...
|
||||
|
||||
Done repackaging...
|
||||
|
||||
Installing: java 8.0.172-zulu
|
||||
Done installing!
|
||||
|
||||
Setting java 8.0.172-zulu as default.
|
||||
|
||||
```
|
||||
|
||||
If you have multiple SDKs, it will prompt if you want the currently installed version to be set as **default**. Answering **Yes** will set the currently installed version as default.
|
||||
|
||||
To install particular version of a SDK, do:
|
||||
```
|
||||
$ sdk install ant 1.10.1
|
||||
|
||||
```
|
||||
|
||||
If you already have local installation of a specific candidate, you can set it as local version like below.
|
||||
```
|
||||
$ sdk install groovy 3.0.0-SNAPSHOT /path/to/groovy-3.0.0-SNAPSHOT
|
||||
|
||||
```
|
||||
|
||||
To list a particular candidates versions:
|
||||
```
|
||||
$ sdk list ant
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
================================================================================
|
||||
Available Ant Versions
|
||||
================================================================================
|
||||
> * 1.10.1
|
||||
1.10.0
|
||||
1.9.9
|
||||
1.9.8
|
||||
1.9.7
|
||||
|
||||
================================================================================
|
||||
+ - local version
|
||||
* - installed
|
||||
> - currently in use
|
||||
================================================================================
|
||||
|
||||
```
|
||||
|
||||
Like I already said, If you have installed multiple versions, SDKMAN will prompt you if you want the currently installed version to be set as **default**. You can answer Yes to set it as default. Also, you can do that later by using the following command:
|
||||
```
|
||||
$ sdk default ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
The above command will set Apache Ant version 1.9.9 as default.
|
||||
|
||||
You can choose which version of an installed candidate to use by using the following command:
|
||||
```
|
||||
$ sdk use ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
To check what is currently in use for a Candidate, for example Java, run:
|
||||
```
|
||||
$ sdk current java
|
||||
|
||||
Using java version 8.0.172-zulu
|
||||
|
||||
```
|
||||
|
||||
To check what is currently in use for all Candidates, for example Java, run:
|
||||
```
|
||||
$ sdk current
|
||||
|
||||
Using:
|
||||
|
||||
ant: 1.10.1
|
||||
java: 8.0.172-zulu
|
||||
|
||||
```
|
||||
|
||||
To upgrade an outdated candidate, do:
|
||||
```
|
||||
$ sdk upgrade scala
|
||||
|
||||
```
|
||||
|
||||
You can also check what is outdated for all Candidates as well.
|
||||
```
|
||||
$ sdk upgrade
|
||||
|
||||
```
|
||||
|
||||
SDKMAN has offline mode feature that allows the SDKMAN to function when working offline. You can enable or disable the offline mode at any time by using the following commands:
|
||||
```
|
||||
$ sdk offline enable
|
||||
|
||||
$ sdk offline disable
|
||||
|
||||
```
|
||||
|
||||
To remove an installed SDK, run:
|
||||
```
|
||||
$ sdk uninstall ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
For more details, check the help section.
|
||||
```
|
||||
$ sdk help
|
||||
|
||||
Usage: sdk <command> [candidate] [version]
|
||||
sdk offline <enable|disable>
|
||||
|
||||
commands:
|
||||
install or i <candidate> [version]
|
||||
uninstall or rm <candidate> <version>
|
||||
list or ls [candidate]
|
||||
use or u <candidate> [version]
|
||||
default or d <candidate> [version]
|
||||
current or c [candidate]
|
||||
upgrade or ug [candidate]
|
||||
version or v
|
||||
broadcast or b
|
||||
help or h
|
||||
offline [enable|disable]
|
||||
selfupdate [force]
|
||||
update
|
||||
flush <broadcast|archives|temp>
|
||||
|
||||
candidate : the SDK to install: groovy, scala, grails, gradle, kotlin, etc.
|
||||
use list command for comprehensive list of candidates
|
||||
eg: $ sdk list
|
||||
|
||||
version : where optional, defaults to latest stable if not provided
|
||||
eg: $ sdk install groovy
|
||||
|
||||
```
|
||||
|
||||
### Update SDKMAN
|
||||
|
||||
The following command installs a new version of SDKMAN if it is available.
|
||||
```
|
||||
$ sdk selfupdate
|
||||
|
||||
```
|
||||
|
||||
SDKMAN will also periodically check for any updates and let you know with instruction on how to update.
|
||||
```
|
||||
WARNING: SDKMAN is out-of-date and requires an update.
|
||||
|
||||
$ sdk update
|
||||
Adding new candidates(s): scala
|
||||
|
||||
```
|
||||
|
||||
### Remove cache
|
||||
|
||||
It is recommended to clean the cache that contains the downloaded SDK binaries for time to time. To do so, simply run:
|
||||
```
|
||||
$ sdk flush archives
|
||||
|
||||
```
|
||||
|
||||
It is also good to clean temporary folder to save up some space:
|
||||
```
|
||||
$ sdk flush temp
|
||||
|
||||
```
|
||||
|
||||
### Uninstall SDKMAN
|
||||
|
||||
If you don’t need SDKMAN or don’t like it, remove as shown below.
|
||||
```
|
||||
$ tar zcvf ~/sdkman-backup_$(date +%F-%kh%M).tar.gz -C ~/ .sdkman
|
||||
$ rm -rf ~/.sdkman
|
||||
|
||||
```
|
||||
|
||||
Finally, open your **.bashrc** , **.bash_profile** and/or **.profile** files and find and remove the following lines.
|
||||
```
|
||||
#THIS MUST BE AT THE END OF THE FILE FOR SDKMAN TO WORK!!!
|
||||
export SDKMAN_DIR="/home/sk/.sdkman"
|
||||
[[ -s "/home/sk/.sdkman/bin/sdkman-init.sh" ]] && source "/home/sk/.sdkman/bin/sdkman-init.sh"
|
||||
|
||||
```
|
||||
|
||||
If you use ZSH, remove the above line from the **.zshrc** file.
|
||||
|
||||
And, that’s all for today. I hope you find SDKMAN useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/sdkman-a-cli-tool-to-easily-manage-multiple-software-development-kits/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
101
sources/tech/20180803 UNIX curiosities.md
Normal file
101
sources/tech/20180803 UNIX curiosities.md
Normal file
@ -0,0 +1,101 @@
|
||||
UNIX curiosities
|
||||
======
|
||||
Recently I've been doing more UNIXy things in various tools I'm writing, and I hit two interesting issues. Neither of these are "bugs", but behaviors that I wasn't expecting.
|
||||
|
||||
### Thread-safe printf
|
||||
|
||||
I have a C application that reads some images from disk, does some processing, and writes output about these images to STDOUT. Pseudocode:
|
||||
```
|
||||
for(imagefilename in images)
|
||||
{
|
||||
results = process(imagefilename);
|
||||
printf(results);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The processing is independent for each image, so naturally I want to distribute this processing between various CPUs to speed things up. I usually use `fork()`, so I wrote this:
|
||||
```
|
||||
for(child in children)
|
||||
{
|
||||
pipe = create_pipe();
|
||||
worker(pipe);
|
||||
}
|
||||
|
||||
// main parent process
|
||||
for(imagefilename in images)
|
||||
{
|
||||
write(pipe[i_image % N_children], imagefilename)
|
||||
}
|
||||
|
||||
worker()
|
||||
{
|
||||
while(1)
|
||||
{
|
||||
imagefilename = read(pipe);
|
||||
results = process(imagefilename);
|
||||
printf(results);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This is the normal thing: I make pipes for IPC, and send the child workers image filenames through these pipes. Each worker _could_ write its results back to the main process via another set of pipes, but that's a pain, so here each worker writes to the shared STDOUT directly. This works OK, but as one would expect, the writes to STDOUT clash, so the results for the various images end up interspersed. That's bad. I didn't feel like setting up my own locks, but fortunately GNU libc provides facilities for that: [`flockfile()`][1]. I put those in, and … it didn't work! Why? Because whatever `flockfile()` does internally ends up restricted to a single subprocess because of `fork()`'s copy-on-write behavior. I.e. the extra safety provided by `fork()` (compared to threads) actually ends up breaking the locks.
|
||||
|
||||
I haven't tried using other locking mechanisms (like pthread mutexes for instance), but I can imagine they'll have similar problems. And I want to keep things simple, so sending the output back to the parent for output is out of the question: this creates more work for both me the programmer, and for the computer running the program.
|
||||
|
||||
The solution: use threads instead of forks. This has a nice side effect of making the pipes redundant. Final pseudocode:
|
||||
```
|
||||
for(children)
|
||||
{
|
||||
pthread_create(worker, child_index);
|
||||
}
|
||||
for(children)
|
||||
{
|
||||
pthread_join(child);
|
||||
}
|
||||
|
||||
worker(child_index)
|
||||
{
|
||||
for(i_image = child_index; i_image < N_images; i_image += N_children)
|
||||
{
|
||||
results = process(images[i_image]);
|
||||
flockfile(stdout);
|
||||
printf(results);
|
||||
funlockfile(stdout);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Much simpler, and actually works as desired. I guess sometimes threads are better.
|
||||
|
||||
### Passing a partly-read file to a child process
|
||||
|
||||
For various [vnlog][2] tools I needed to implement this sequence:
|
||||
|
||||
1. process opens a file with O_CLOEXEC turned off
|
||||
2. process reads a part of this file (up-to the end of the legend in the case of vnlog)
|
||||
3. process calls exec to invoke another program to process the rest of the already-opened file
|
||||
|
||||
The second program may require a file name on the commandline instead of an already-opened file descriptor because this second program may be calling open() by itself. If I pass it the filename, this new program will re-open the file, and then start reading the file from the beginning, not from the location where the original program left off. It is important for my application that this does not happen, so passing the filename to the second program does not work.
|
||||
|
||||
So I really need to pass the already-open file descriptor somehow. I'm using Linux (other OSs maybe behave differently here), so I can in theory do this by passing /dev/fd/N instead of the filename. But it turns out this does not work either. On Linux (again, maybe this is Linux-specific somehow) for normal files /dev/fd/N is a symlink to the original file. So this ends up doing exactly the same thing that passing the filename does.
|
||||
|
||||
But there's a workaround! If we're reading a pipe instead of a file, then there's nothing to symlink to, and /dev/fd/N ends up passing the original pipe down to the second process, and things then work correctly. And I can fake this by changing the open("filename") above to something like popen("cat filename"). Yuck! Is this really the best we can do? What does this look like on one of the BSDs, say?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://notes.secretsauce.net/notes/2018/08/03_unix-curiosities.html
|
||||
|
||||
作者:[Dima Kogan][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://notes.secretsauce.net/
|
||||
[1]:https://www.gnu.org/software/libc/manual/html_node/Streams-and-Threads.html
|
||||
[2]:http://www.github.com/dkogan/vnlog
|
||||
@ -0,0 +1,75 @@
|
||||
Why I still love Alpine for email at the Linux terminal
|
||||
======
|
||||
|
||||

|
||||
|
||||
Maybe you can relate to this story: You try out a program and really love it. Over the years, new programs are developed that can do the same things and more, maybe even better. You try them out, and they are great too—but you keep coming back to the first program.
|
||||
|
||||
That is the story of my relationship with [Alpine Mail][1]. So I decided to write a little article praising my de facto favorite mail program.
|
||||
|
||||
![alpine_main_menu.png][3]
|
||||
|
||||
The main menu screen of the Alpine email client
|
||||
|
||||
In the mid-90's, I discovered the [GNU/Linux][4] operating system. Because I had never seen a Unix-like system before, I read a lot of documentation and books and tried a lot of programs to find my way through this fascinating OS.
|
||||
|
||||
After a while, [Pine][5] became my favorite mail client, followed by its successor, Alpine. I found it intuitive and easy to use—you can always see the possible commands or options at the bottom, so navigation is easy to learn quickly, and Alpine comes with very good help.
|
||||
|
||||
Getting started is easy.
|
||||
|
||||
Most distributions include Alpine. It can be installed via the package manager: Just press **S** (or navigate the bar to the setup line) and you will be directed to the categories you can configure. At the bottom, you can use the shortcut keys for commands you can do right away. For commands that don’t fit in there, press **O** (`Other Commands`).
|
||||
|
||||
Press **C** to enter the configuration dialog. When you scroll down the list, it becomes clear that you can make Alpine behave as you want. If you have only one mail account, simply navigate the bar to the line you want to change, press **C** (`Change Value`), and type in the values:
|
||||
|
||||
![alpine_setup_configuration.png][7]
|
||||
|
||||
The Alpine setup configuration screen
|
||||
|
||||
Note how the SNMP and IMAP servers are entered, as this is not the same as in mail clients with assistants and pre-filled fields. If you just enter the server/SSL/user like this:
|
||||
|
||||
`imap.myprovider.com:993/ssl/user=max@example.com`
|
||||
|
||||
Alpine will ask you if "Inbox" should be used (yes) and put curly brackets around the server part. When you're done, press **E** (`Exit Setup`) and commit your changes by pressing **Y** (yes). Back in the main menu, you can then move to the folder list and the Inbox to see if you have mail (you will be prompted for your password). You can now navigate using **`>`** and **`<`**.
|
||||
|
||||
![navigating_the_message_index.png][9]
|
||||
|
||||
Navigating the message index in Alpine
|
||||
|
||||
To compose an email, simply navigate to the corresponding menu entry and write. Note that the options at the bottom change depending on the line you are on. **`^T`** ( **Ctrl** \+ **T** ) can stand for `To Addressbook` or `To Files`. To attach files, just navigate to `Attchmt:` and press either **Ctrl** \+ **T** to go to a file browser, or **Ctrl** \+ **J** to enter a path.
|
||||
|
||||
Send the mail with `^X`.
|
||||
|
||||
![composing_an_email_in_alpine.png][11]
|
||||
|
||||
Composing an email in Alpine
|
||||
|
||||
### Why Alpine?
|
||||
|
||||
Of course, every user's personal preferences and needs are different. If you need a more "office-like" solution, an app like Evolution or Thunderbird might be a better choice.
|
||||
|
||||
But for me, Alpine (and Pine) are dinosaurs in the software world. You can manage your mail in a comfortable way—no more and no less. It is available for many operating systems (even [Termux for Android][12]). And because the configuration is stored in a plain text file (`.pinerc`), you can simply copy it to a device and it works.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/love-alpine
|
||||
|
||||
作者:[Heiko Ossowski][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/hossow
|
||||
[1]:https://en.wikipedia.org/wiki/Alpine_(email_client)
|
||||
[2]:/file/405641
|
||||
[3]:https://opensource.com/sites/default/files/uploads/alpine_main_menu.png (alpine_main_menu.png)
|
||||
[4]:https://www.gnu.org/gnu/linux-and-gnu.en.html
|
||||
[5]:https://en.wikipedia.org/wiki/Pine_(email_client)
|
||||
[6]:/file/405646
|
||||
[7]:https://opensource.com/sites/default/files/uploads/alpine_setup_configuration.png (alpine_setup_configuration.png)
|
||||
[8]:/file/405651
|
||||
[9]:https://opensource.com/sites/default/files/uploads/navigating_the_message_index.png (navigating_the_message_index.png)
|
||||
[10]:/file/405656
|
||||
[11]:https://opensource.com/sites/default/files/uploads/composing_an_email_in_alpine.png (composing_an_email_in_alpine.png)
|
||||
[12]:https://termux.com/
|
||||
159
sources/tech/20180804 Installing Android on VirtualBox.md
Normal file
159
sources/tech/20180804 Installing Android on VirtualBox.md
Normal file
@ -0,0 +1,159 @@
|
||||
Installing Android on VirtualBox
|
||||
======
|
||||
If you are developing mobile apps Android can be a bit of a hassle. While iOS comes with its niceties, provided you are using macOS, Android comes with just Android Studio which is designed to support more than a few Android version, including wearables.
|
||||
|
||||
Needless to say, all the binaries, SDKs, frameworks and debuggers are going to pollute your filesystem with lots and lots of files, logs and other miscellaneous objects. An efficient work around for this is installing Android on your VirtualBox which takes away one of the sluggiest aspect of Android development — The device emulator. You can use this VM to run your test application or just fiddle with Android’s internals. So without further ado let’s set on up!
|
||||
|
||||
### Getting Started
|
||||
|
||||
To get started we will need to have VirtualBox installed on our system, you can get a copy for Windows, macOS or any major distro of Linux [here][1]. Next you would need a copy of Android meant to run on x86 hardware, because that’s what VirtualBox is going to offer to a Virtual Machine an x86 or an x86_64 (a.k.a AMD64) platform to run.
|
||||
|
||||
While most Android devices run on ARM, we can take help of the project [Android on x86][2]. These fine folks have ported Android to run on x86 hardware (both real and virtual) and we can get a copy of the latest release candidate (Android 7.1) for our purposes. You may prefer using a more stable release but in that case Android 6.0 is about as latest as you can get, at the time of this writing.
|
||||
|
||||
#### Creating VM
|
||||
|
||||
Open VirtualBox and click on “New” (top-left corner) and in the Create Virtual Machine window select the type to be Linux and version Linux 2.6 / 3.x /4.x (64-bit) or (32-bit) depending upon whether the ISO you downloaded was x86_64 or x86 respectively.
|
||||
|
||||
RAM size could be anywhere from 2 GB to as much as your system resources can allow. Although if you want to emulate real world devices you should allocate upto 6GB for memory and 32GB for disk size which are typical in Android devices.
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
Upon creation, you might want to tweak a few additional settings, add in an additional processor core and improve display memory for starters. To do this, right-click on the VM and open up settings. In the Settings → System → Processor section you can allocate a few more cores if your desktop can pull it off.
|
||||
|
||||
![][5]
|
||||
|
||||
And in Settings → Display → Video Memory you can allocate a decent chunk of memory and enable 3D acceleration for a more responsive experience.
|
||||
|
||||
![][6]
|
||||
|
||||
Now we are ready to boot the VM.
|
||||
|
||||
#### Installing Android
|
||||
|
||||
Starting the VM for the first time, VirtualBox will insist you to supply it with a bootable media. Select the Android iso that you previously downloaded to boot the machine of with.
|
||||
|
||||
![][7]
|
||||
|
||||
Next, select the Installation option if you wish to install Android on the VM for a long term use, otherwise feel free to log into the live media and play around with the environment.
|
||||
|
||||
![][8]
|
||||
|
||||
Hit <Enter>.
|
||||
|
||||
##### Partitioning the Drive
|
||||
|
||||
Partitioning is done using a textual interface, which means we don’t get the niceties of a GUI and we will have to use the follow careful at what is being shown on the screen. For example, in the first screen when no partition has been created and just a raw (virtual) disk is detected you will see the following.
|
||||
|
||||
![][9]
|
||||
|
||||
The red lettered C and D indicates that if you hit the key C you can create or modify partitions and D will detect additional devices. You can press D and the live media will detect the disks attached, but that is optional since it did a check during the boot.
|
||||
|
||||
Let’s hit C and create partitions in the virtual disk. The offical page recommends against using GPT so we will not use that scheme. Select No using the arrow keys and hit <Enter>.
|
||||
|
||||
![][10]
|
||||
|
||||
And now you will be ushered into the fdisk utility.
|
||||
|
||||
![][11]
|
||||
|
||||
We will create just a single giant partition so as to keep things simple. Using arrow keys navigate to the New option and hit <Enter>. Select primary as the type of partition, and hit <Enter> to confirm
|
||||
|
||||
![][12]
|
||||
|
||||
The maximum size will already be selected for you, hit <Enter> to confirm that.
|
||||
|
||||
![][13]
|
||||
|
||||
This partition is where Android OS will reside, so of course we want it to be bootable. So select Bootable and hit enter (Boot will appear in the flags section in the table above) and then you can navigate to the Write section and hit <Enter> to write the changes to the partitioning table.
|
||||
|
||||
![][14]
|
||||
|
||||
Then you can Quit the partitioning utility and move on with the installation.
|
||||
|
||||
![][15]
|
||||
|
||||
##### Formatting with Ext4 and installing Android
|
||||
|
||||
A new partition will come in the Choose Partition menu where we were before we down the partitioning digression. Let’s select this partition and hit OK.
|
||||
|
||||
![][16]
|
||||
|
||||
Select ext4 as the de facto file system in the next menu. Confirm the changes in the next window by selecting **Yes** and the formatting will begin. When asked, say **Yes** to the GRUB boot loader installation. Similarly, say **Yes** to allowing read-write operations on the /system directory. Now the installation will begin.
|
||||
|
||||
Once it is installed, you can safely reboot the system when prompted to reboot. You may have to power down the machine before the next reboot happens, go to Settings → Storage and remove the android iso if it is still attached to the VM.
|
||||
|
||||
![][17]
|
||||
|
||||
Remove the media and save the changes, before starting up the VM.
|
||||
|
||||
##### Running Android
|
||||
|
||||
In the GRUB menu you will get options for running the OS in debug mode or the normal way. Let’s take a tour of Android in a VM using the default option, as shown below:
|
||||
|
||||
![][18]
|
||||
|
||||
And if everything works fine, you will see this:
|
||||
|
||||
![][19]
|
||||
|
||||
Now Android uses touch screen as an interface instead of a mouse, as far as its normal use is concerned. While the x86 port does come with a mouse point-and-click support you may have to use arrow keys a lot in the beginning.
|
||||
|
||||
![][20]
|
||||
|
||||
Navigate to let’s go, and hit enter, if you are using arrow keys and then select Setup as New.
|
||||
|
||||
![][21]
|
||||
|
||||
It will check for updates and device info, before asking you to sign in using a Google account. You can skip this if you want and move on to setting up Data and Time and give your username to the device after that.
|
||||
|
||||
A few other options would be presented, similar to the options you see when setting up a new Android device. Select appropriate options for privacy, updates, etc and of course Terms of Service, which we might have to Agree to.
|
||||
|
||||
![][22]
|
||||
|
||||
After this, it may ask you to add another email account or set up “On-body detection” since it is a VM, neither of the options are of much use to us and we can click on “All Set”
|
||||
|
||||
It would ask you to select Home App after that, which is upto you to decide, as it is a matter of Preference and you will finally be in a virtualized Android system.
|
||||
|
||||
![][23]
|
||||
|
||||
You may benefit greatly from a touch screen laptop if you desire to do some intensive testing on this VM, since that would emulate a real world use case much closely.
|
||||
|
||||
Hope you have found this tutorial useful in case, you have any other similar request for us to write about, please feel free to reach out to us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxhint.com/install_android_virtualbox/
|
||||
|
||||
作者:[Ranvir Singh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxhint.com/author/sranvir155/
|
||||
[1]:https://www.virtualbox.org/wiki/Downloads
|
||||
[2]:http://www.android-x86.org/
|
||||
[3]:https://linuxhint.com/wp-content/uploads/2018/08/a.png
|
||||
[4]:https://linuxhint.com/wp-content/uploads/2018/08/a1.png
|
||||
[5]:https://linuxhint.com/wp-content/uploads/2018/08/a2.png
|
||||
[6]:https://linuxhint.com/wp-content/uploads/2018/08/a3.png
|
||||
[7]:https://linuxhint.com/wp-content/uploads/2018/08/a4.png
|
||||
[8]:https://linuxhint.com/wp-content/uploads/2018/08/a5.png
|
||||
[9]:https://linuxhint.com/wp-content/uploads/2018/08/a6.png
|
||||
[10]:https://linuxhint.com/wp-content/uploads/2018/08/a7.png
|
||||
[11]:https://linuxhint.com/wp-content/uploads/2018/08/a8.png
|
||||
[12]:https://linuxhint.com/wp-content/uploads/2018/08/a9.png
|
||||
[13]:https://linuxhint.com/wp-content/uploads/2018/08/a10.png
|
||||
[14]:https://linuxhint.com/wp-content/uploads/2018/08/a11.png
|
||||
[15]:https://linuxhint.com/wp-content/uploads/2018/08/a12.png
|
||||
[16]:https://linuxhint.com/wp-content/uploads/2018/08/a13.png
|
||||
[17]:https://linuxhint.com/wp-content/uploads/2018/08/a14.png
|
||||
[18]:https://linuxhint.com/wp-content/uploads/2018/08/a16.png
|
||||
[19]:https://linuxhint.com/wp-content/uploads/2018/08/a17.png
|
||||
[20]:https://linuxhint.com/wp-content/uploads/2018/08/a18.png
|
||||
[21]:https://linuxhint.com/wp-content/uploads/2018/08/a19.png
|
||||
[22]:https://linuxhint.com/wp-content/uploads/2018/08/a20.png
|
||||
[23]:https://linuxhint.com/wp-content/uploads/2018/08/a21.png
|
||||
238
sources/tech/20180806 A gawk script to convert smart quotes.md
Normal file
238
sources/tech/20180806 A gawk script to convert smart quotes.md
Normal file
@ -0,0 +1,238 @@
|
||||
A gawk script to convert smart quotes
|
||||
======
|
||||
|
||||

|
||||
|
||||
I manage a personal website and edit the web pages by hand. Since I don't have many pages on my site, this works well for me, letting me "scratch the itch" of getting into the site's code.
|
||||
|
||||
When I updated my website's design recently, I decided to turn all the plain quotes into "smart quotes," or quotes that look like those used in print material: “” instead of "".
|
||||
|
||||
Editing all of the quotes by hand would take too long, so I decided to automate the process of converting the quotes in all of my HTML files. But doing so via a script or program requires some intelligence. The script needs to know when to convert a plain quote to a smart quote, and which quote to use.
|
||||
|
||||
You can use different methods to convert quotes. Greg Pittman wrote a [Python script][1] for fixing smart quotes in text. I wrote mine in GNU [awk][2] (gawk).
|
||||
|
||||
> Get our awk cheat sheet. [Free download][3].
|
||||
|
||||
To start, I wrote a simple gawk function to evaluate a single character. If that character is a quote, the function determines if it should output a plain quote or a smart quote. The function looks at the previous character; if the previous character is a space, the function outputs a left smart quote. Otherwise, the function outputs a right smart quote. The script does the same for single quotes.
|
||||
```
|
||||
function smartquote (char, prevchar) {
|
||||
|
||||
# print smart quotes depending on the previous character
|
||||
|
||||
# otherwise just print the character as-is
|
||||
|
||||
|
||||
|
||||
if (prevchar ~ /\s/) {
|
||||
|
||||
# prev char is a space
|
||||
|
||||
if (char == "'") {
|
||||
|
||||
printf("‘");
|
||||
|
||||
}
|
||||
|
||||
else if (char == "\"") {
|
||||
|
||||
printf("“");
|
||||
|
||||
}
|
||||
|
||||
else {
|
||||
|
||||
printf("%c", char);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
else {
|
||||
|
||||
# prev char is not a space
|
||||
|
||||
if (char == "'") {
|
||||
|
||||
printf("’");
|
||||
|
||||
}
|
||||
|
||||
else if (char == "\"") {
|
||||
|
||||
printf("”");
|
||||
|
||||
}
|
||||
|
||||
else {
|
||||
|
||||
printf("%c", char);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
With that function, the body of the gawk script processes the HTML input file character by character. The script prints all text verbatim when inside an HTML tag (for example, `<html lang="en">`. Outside any HTML tags, the script uses the `smartquote()` function to print text. The `smartquote()` function does the work of evaluating when to print plain quotes or smart quotes.
|
||||
```
|
||||
function smartquote (char, prevchar) {
|
||||
|
||||
...
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
BEGIN {htmltag = 0}
|
||||
|
||||
|
||||
|
||||
{
|
||||
|
||||
# for each line, scan one letter at a time:
|
||||
|
||||
|
||||
|
||||
linelen = length($0);
|
||||
|
||||
|
||||
|
||||
prev = "\n";
|
||||
|
||||
|
||||
|
||||
for (i = 1; i <= linelen; i++) {
|
||||
|
||||
char = substr($0, i, 1);
|
||||
|
||||
|
||||
|
||||
if (char == "<") {
|
||||
|
||||
htmltag = 1;
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
if (htmltag == 1) {
|
||||
|
||||
printf("%c", char);
|
||||
|
||||
}
|
||||
|
||||
else {
|
||||
|
||||
smartquote(char, prev);
|
||||
|
||||
prev = char;
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
if (char == ">") {
|
||||
|
||||
htmltag = 0;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
# add trailing newline at end of each line
|
||||
|
||||
printf ("\n");
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Here's an example:
|
||||
```
|
||||
gawk -f quotes.awk test.html > test2.html
|
||||
|
||||
```
|
||||
|
||||
Sample input:
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
|
||||
<html lang="en">
|
||||
|
||||
<head>
|
||||
|
||||
<title>Test page</title>
|
||||
|
||||
<link rel="stylesheet" type="text/css" href="/test.css" />
|
||||
|
||||
<meta charset="UTF-8">
|
||||
|
||||
<meta name="viewport" content="width=device-width" />
|
||||
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<h1><a href="/"><img src="logo.png" alt="Website logo" /></a></h1>
|
||||
|
||||
<p>"Hi there!"</p>
|
||||
|
||||
<p>It's and its.</p>
|
||||
|
||||
</body>
|
||||
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
|
||||
<html lang="en">
|
||||
|
||||
<head>
|
||||
|
||||
<title>Test page</title>
|
||||
|
||||
<link rel="stylesheet" type="text/css" href="/test.css" />
|
||||
|
||||
<meta charset="UTF-8">
|
||||
|
||||
<meta name="viewport" content="width=device-width" />
|
||||
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<h1><a href="/"><img src="logo.png" alt="Website logo" /></a></h1>
|
||||
|
||||
<p>“Hi there!”</p>
|
||||
|
||||
<p>It’s and its.</p>
|
||||
|
||||
</body>
|
||||
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/gawk-script-convert-smart-quotes
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://opensource.com/article/17/3/python-scribus-smart-quotes
|
||||
[2]:/downloads/cheat-sheet-awk-features
|
||||
[3]:https://opensource.com/downloads/cheat-sheet-awk-features
|
||||
@ -0,0 +1,96 @@
|
||||
GPaste Is A Great Clipboard Manager For Gnome Shell
|
||||
======
|
||||
**[GPaste][1] is a clipboard management system that consists of a library, daemon, and interfaces for the command line and Gnome (using a native Gnome Shell extension).**
|
||||
|
||||
A clipboard manager allows keeping track of what you're copying and pasting, providing access to previously copied items. GPaste, with its native Gnome Shell extension, makes the perfect addition for those looking for a Gnome clipboard manager.
|
||||
|
||||
[![GPaste Gnome Shell extension Ubuntu 18.04][2]][3]
|
||||
GPaste Gnome Shell extension
|
||||
**Using GPaste in Gnome, you get a configurable, searchable clipboard history, available with a click on the top panel. GPaste remembers not only the text you copy, but also file paths and images** (the latter needs to be enabled from its settings as it's disabled by default).
|
||||
|
||||
What's more, GPaste can detect growing lines, meaning it can detect when a new text copy is an extension of another and replaces it if it's true, useful for keeping your clipboard clean.
|
||||
|
||||
From the extension menu you can pause GPaste from tracking the clipboard, and remove items from the clipboard history or the whole history. You'll also find a button that launches the GPaste user interface window.
|
||||
|
||||
**If you prefer to use the keyboard, you can use a key shortcut to open the GPaste history from the top bar** (`Ctrl + Alt + H`), **or open the full GPaste GUI** (`Ctrl + Alt + G`).
|
||||
|
||||
The tool also incorporates keyboard shortcuts to (can be changed):
|
||||
|
||||
* delete the active item from history: `Ctrl + Alt + V`
|
||||
|
||||
* **mark the active item as being a password (which obfuscates the clipboard entry in GPaste):** `Ctrl + Alt + S`
|
||||
|
||||
* sync the clipboard to the primary selection: `Ctrl + Alt + O`
|
||||
|
||||
* sync the primary selection to the clipboard: `Ctrl + Alt + P`
|
||||
|
||||
* upload the active item to a pastebin service: `Ctrl + Alt + U`
|
||||
|
||||
[![][4]][5]
|
||||
GPaste GUI
|
||||
|
||||
The GPaste interface window provides access to the clipboard history (with options to clear, edit or upload items), which can be searched, an option to pause GPaste from tracking the clipboard, restart the GPaste daemon, backup current clipboard history, as well as to its settings.
|
||||
|
||||
[![][6]][7]
|
||||
GPaste GUI
|
||||
|
||||
From the GPaste UI you can change settings like:
|
||||
|
||||
* Enable or disable the Gnome Shell extension
|
||||
* Sync the daemon state with the extension's one
|
||||
* Primary selection affects history
|
||||
* Synchronize clipboard with primary selection
|
||||
* Image support
|
||||
* Trim items
|
||||
* Detect growing lines
|
||||
* Save history
|
||||
* History settings like max history size, memory usage, max text item length, and more
|
||||
* Keyboard shortcuts
|
||||
|
||||
|
||||
|
||||
### Download GPaste
|
||||
|
||||
[Download GPaste](https://github.com/Keruspe/GPaste)
|
||||
|
||||
The Gpaste project page does not link to any GPaste binaries, and only source installation instructions. Users running Linux distributions other than Debian or Ubuntu (for which you'll find GPaste installation instructions below) can search their distro repositories for GPaste.
|
||||
|
||||
Do not confuse GPaste with the GPaste Integration extension posted on the Gnome Shell extension website. That is a Gnome Shell extension that uses GPaste daemon, which is no longer maintained. The native Gnome Shell extension built into GPaste is still maintained.
|
||||
|
||||
#### Install GPaste in Ubuntu (18.04, 16.04) or Debian (Jessie and newer)
|
||||
|
||||
**For Debian, GPaste is available for Jessie and newer, while for Ubuntu, GPaste is in the repositories for 16.04 and newer (so it's available in the Ubuntu 18.04 Bionic Beaver).**
|
||||
|
||||
**You can install GPaste (the daemon and the Gnome Shell extension) in Debian or Ubuntu using this command:**
|
||||
```
|
||||
sudo apt install gnome-shell-extensions-gpaste gpaste
|
||||
|
||||
```
|
||||
|
||||
After the installation completes, restart Gnome Shell by pressing `Alt + F2` and typing `r` , then pressing the `Enter` key. The GPaste Gnome Shell extension should now be enabled and its icon should show up on the top Gnome Shell panel. If it's not, use Gnome Tweaks (Gnome Tweak Tool) to enable the extension.
|
||||
|
||||
**The GPaste 3.28.0 package from[Debian][8] and [Ubuntu][9] has a bug that makes it crash if the image support option is enabled, so do not enable this feature for now.** This was marked as
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/gpaste-is-great-clipboard-manager-for.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://github.com/Keruspe/GPaste
|
||||
[2]:https://2.bp.blogspot.com/-2ndArDBcrwY/W2gyhMc1kEI/AAAAAAAABS0/ZAe_onuGCacMblF733QGBX3XqyZd--WuACLcBGAs/s400/gpaste-gnome-shell-extension-ubuntu1804.png (Gpaste Gnome Shell)
|
||||
[3]:https://2.bp.blogspot.com/-2ndArDBcrwY/W2gyhMc1kEI/AAAAAAAABS0/ZAe_onuGCacMblF733QGBX3XqyZd--WuACLcBGAs/s1600/gpaste-gnome-shell-extension-ubuntu1804.png
|
||||
[4]:https://2.bp.blogspot.com/-7FBRsZJvYek/W2gyvzmeRxI/AAAAAAAABS4/LhokMFSn8_kZndrNB-BTP4W3e9IUuz9BgCLcBGAs/s640/gpaste-gui_1.png
|
||||
[5]:https://2.bp.blogspot.com/-7FBRsZJvYek/W2gyvzmeRxI/AAAAAAAABS4/LhokMFSn8_kZndrNB-BTP4W3e9IUuz9BgCLcBGAs/s1600/gpaste-gui_1.png
|
||||
[6]:https://4.bp.blogspot.com/-047ShYc6RrQ/W2gyz5FCf_I/AAAAAAAABTA/-o6jaWzwNpsSjG0QRwRJ5Xurq_A6dQ0sQCLcBGAs/s640/gpaste-gui_2.png
|
||||
[7]:https://4.bp.blogspot.com/-047ShYc6RrQ/W2gyz5FCf_I/AAAAAAAABTA/-o6jaWzwNpsSjG0QRwRJ5Xurq_A6dQ0sQCLcBGAs/s1600/gpaste-gui_2.png
|
||||
[8]:https://packages.debian.org/buster/gpaste
|
||||
[9]:https://launchpad.net/ubuntu/+source/gpaste
|
||||
[10]:https://www.imagination-land.org/posts/2018-04-13-gpaste-3.28.2-released.html
|
||||
@ -0,0 +1,126 @@
|
||||
How ProPublica Illinois uses GNU Make to load 1.4GB of data every day
|
||||
======
|
||||
|
||||

|
||||
|
||||
I avoided using GNU Make in my data journalism work for a long time, partly because the documentation was so obtuse that I couldn’t see how Make, one of many extract-transform-load (ETL) processes, could help my day-to-day data reporting. But this year, to build [The Money Game][1], I needed to load 1.4GB of Illinois political contribution and spending data every day, and the ETL process was taking hours, so I gave Make another chance.
|
||||
|
||||
Now the same process takes less than 30 minutes.
|
||||
|
||||
Here’s how it all works, but if you want to skip directly to the code, [we’ve open-sourced it here][2].
|
||||
|
||||
Fundamentally, Make lets you say:
|
||||
|
||||
* File X depends on a transformation applied to file Y
|
||||
* If file X doesn’t exist, apply that transformation to file Y and make file X
|
||||
|
||||
|
||||
|
||||
This “start with file Y to get file X” pattern is a daily reality of data journalism, and using Make to load political contribution and spending data was a great use case. The data is fairly large, accessed via a slow FTP server, has a quirky format, has just enough integrity issues to keep things interesting, and needs to be compatible with a legacy codebase. To tackle it, I needed to start from the beginning.
|
||||
|
||||
### Overview
|
||||
|
||||
The financial disclosure data we’re using is from the Illinois State Board of Elections, but the [Illinois Sunshine project][3] had released open source code (no longer available) to handle the ETL process and fundraising calculations. Using their code, the ETL process took about two hours to run on robust hardware and over five hours on our servers, where it would sometimes fail for reasons I never quite understood. I needed it to work better and work faster.
|
||||
|
||||
The process looks like this:
|
||||
|
||||
* **Download** data files via FTP from Illinois State Board Of Elections.
|
||||
* **Clean** the data using Python to resolve integrity issues and create clean versions of the data files.
|
||||
* **Load** the clean data into PostgreSQL using its highly efficient but finicky “\copy” command.
|
||||
* **Transform** the data in the database to clean up column names and provide more immediately useful forms of the data using “raw” and “public” PostgreSQL schemas and materialized views (essentially persistently cached versions of standard SQL views).
|
||||
|
||||
|
||||
|
||||
The cleaning step must happen before any data is loaded into the database, so we can take advantage of PostgreSQL’s efficient import tools. If a single row has a string in a column where it’s expecting an integer, the whole operation fails.
|
||||
|
||||
GNU Make is well-suited to this task. Make’s model is built around describing the output files your ETL process should produce and the operations required to go from a set of original source files to a set of output files.
|
||||
|
||||
As with any ETL process, the goal is to preserve your original data, keep operations atomic and provide a simple and repeatable process that can be run over and over.
|
||||
|
||||
Let’s examine a few of the steps:
|
||||
|
||||
### Download and pre-import cleaning
|
||||
|
||||
Take a look at this snippet, which could be a standalone Makefile:
|
||||
```
|
||||
data/download/%.txt : aria2c -x5 -q -d data/download --ftp-user="$(ILCAMPAIGNCASH_FTP_USER)" --ftp-passwd="$(ILCAMPAIGNCASH_FTP_PASSWD)" ftp://ftp.elections.il.gov/CampDisclDataFiles/$*.txt data/processed/%.csv : data/download/%.txt python processors/clean_isboe_tsv.py $< $* > $@
|
||||
|
||||
```
|
||||
|
||||
This snippet first downloads a file via FTP and then uses Python to process it. For example, if “Expenditures.txt” is one of my source data files, I can run `make data/processed/Expenditures.csv` to download and process the expenditure data.
|
||||
|
||||
There are two things to note here.
|
||||
|
||||
The first is that we use [Aria2][4] to handle FTP duties. Earlier versions of the script used other FTP clients that were either slow as molasses or painful to use. After some trial and error, I found Aria2 did the job better than lftp (which is fast but fussy) or good old ftp (which is both slow and fussy). I also found some incantations that took download times from roughly an hour to less than 20 minutes.
|
||||
|
||||
Second, the cleaning step is crucial for this dataset. It uses a simple class-based Python validation scheme you can [see here][5]. The important thing to note is that while Python is pretty slow generally, Python 3 is fast enough for this. And as long as you are [only processing row-by-row][6] without any objects accumulating in memory or doing any extra disk writes, performance is fine, even on low-resource machines like the servers in ProPublica’s cluster, and there aren’t any unexpected quirks.
|
||||
|
||||
### Loading
|
||||
|
||||
Make is built around file inputs and outputs. But what happens if our data is both in files and database tables? Here are a few valuable tricks I learned for integrating database tables into Makefiles:
|
||||
|
||||
**One SQL file per table / transform** : Make loves both files and simple mappings, so I created individual files with the schema definitions for each table or any other atomic table-level operation. The table names match the SQL filenames, the SQL filenames match the source data filenames. You can see them [here][7].
|
||||
|
||||
**Use exit code magic to make tables look like files to Make** : Hannah Cushman and Forrest Gregg from DataMade [introduced me to this trick on Twitter][8]. Make can be fooled into treating tables like files if you prefix table level commands with commands that emit appropriate exit codes. If a table exists, emit a successful code. If it doesn’t, emit an error.
|
||||
|
||||
Beyond that, loading consists solely of the highly efficient PostgreSQL `\copy` command. While the `COPY` command is even more efficient, it doesn’t play nicely with Amazon RDS. Even if ProPublica moved to a different database provider, I’d continue to use `\copy` for portability unless eking out a little more performance was mission-critical.
|
||||
|
||||
There’s one last curveball: The loading step imports data to a PostgreSQL schema called `raw` so that we can cleanly transform the data further. Postgres schemas provide a useful way of segmenting data within a single database — instead of a single namespace with tables like `raw_contributions` and `clean_contributions`, you can keep things simple and clear with an almost folder-like structure of `raw.contributions` and `public.contributions`.
|
||||
|
||||
### Post-import transformations
|
||||
|
||||
The Illinois Sunshine code also renames columns and slightly reshapes the data for usability and performance reasons. Column aliasing is useful for end users and the intermediate tables are required for compatibility with the legacy code.
|
||||
|
||||
In this case, the loader imports into a schema called `raw` that is as close to the source data as humanly possible.
|
||||
|
||||
The data is then transformed by creating materialized views of the raw tables that rename columns and handle some light post-processing. This is enough for our purposes, but more elaborate transformations could be applied without sacrificing clarity or obscuring the source data. Here’s a snippet of one of these view definitions:
|
||||
```
|
||||
CREATE MATERIALIZED VIEW d2_reports AS SELECT id as id, committeeid as committee_id, fileddocid as filed_doc_id, begfundsavail as beginning_funds_avail, indivcontribi as individual_itemized_contrib, indivcontribni as individual_non_itemized_contrib, xferini as transfer_in_itemized, xferinni as transfer_in_non_itemized, # …. FROM raw.d2totals WITH DATA;
|
||||
```
|
||||
|
||||
These transformations are very simple, but simply using more readable column names is a big improvement for end-users.
|
||||
|
||||
As with table schema definitions, there is a file for each table that describes the transformed view. We use materialized views, which, again, are essentially persistently cached versions of standard SQL views, because storage is cheap and they are faster than traditional SQL views.
|
||||
|
||||
### A note about security
|
||||
|
||||
You’ll notice we use environment variables that are expanded inline when the commands are run. That’s useful for debugging and helps with portability. But it’s not a good idea if you think log files or terminal output could be compromised or people who shouldn’t know these secrets have access to logs or shared systems. For more security, you could use a system like the PostgreSQL `pgconf` file and remove the environment variable references.
|
||||
|
||||
### Makefiles for the win
|
||||
|
||||
My only prior experience with Make was in a computational math course 15 years ago, where it was a frustrating and poorly explained footnote. The combination of obtuse documentation, my bad experience in school and an already reliable framework kept me away. Plus, my shell scripts and Python Fabric/Invoke code were doing a fine job building reliable data processing pipelines based on the same principles for the smaller, quick turnaround projects I was doing.
|
||||
|
||||
But after trying Make for this project, I was more than impressed with the results. It’s concise and expressive. It enforces atomic operations, but rewards them with dead simple ways to handle partial builds, which is a big deal during development when you really don’t want to be repeating expensive operations to test individual components. Combined with PostgreSQL’s speedy import tools, schemas, and materialized views, I was able to load the data in a fraction of the time. And just as important, the performance of the new process is less sensitive to varying system resources.
|
||||
|
||||
If you’re itching to get started with Make, here are a few additional resources:
|
||||
|
||||
+ [Making Data, The Datamade Way][9], by Hannah Cushman. My original inspiration.
|
||||
+ [“Why Use Make”][10] by Mike Bostock.
|
||||
+ [“Practical Makefiles, by example”][11] by John Tsiombikas is a nice resource if you want to dig deeper, but Make’s documentation is intimidating.
|
||||
|
||||
|
||||
In the end, the best build/processing system is any system that never alters source data, clearly shows transformations, uses version control and can be easily run over and over. Grunt, Gulp, Rake, Make, Invoke … you have options. As long as you like what you use and use it religiously, your work will benefit.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/how-propublica-illinois-uses-gnu-make
|
||||
|
||||
作者:[David Eads][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eads
|
||||
[1]:https://www.propublica.org/article/illinois-governors-race-campaign-widget-update
|
||||
[2]:https://github.com/propublica/ilcampaigncash/
|
||||
[3]:https://illinoissunshine.org/
|
||||
[4]:https://aria2.github.io/
|
||||
[5]:https://github.com/propublica/ilcampaigncash/blob/master/processors/lib/models.py
|
||||
[6]:https://github.com/propublica/ilcampaigncash/blob/master/processors/clean_isboe_tsv.py#L13
|
||||
[7]:https://github.com/propublica/ilcampaigncash/tree/master/sql/tables
|
||||
[8]:https://twitter.com/eads/status/968970130427404293
|
||||
[9]: https://github.com/datamade/data-making-guidelines
|
||||
[10]: https://bost.ocks.org/mike/make/
|
||||
[11]: http://nuclear.mutantstargoat.com/articles/make/
|
||||
@ -0,0 +1,160 @@
|
||||
Installing and using Git and GitHub on Ubuntu Linux: A beginner's guide
|
||||
======
|
||||
|
||||
GitHub is a treasure trove of some of the world's best projects, built by the contributions of developers all across the globe. This simple, yet extremely powerful platform helps every individual interested in building or developing something big to contribute and get recognized in the open source community.
|
||||
|
||||
This tutorial is a quick setup guide for installing and using GitHub and how to perform its various functions of creating a repository locally, connecting this repo to the remote host that contains your project (where everyone can see), committing the changes and finally pushing all the content in the local system to GitHub.
|
||||
|
||||
Please note that this tutorial assumes that you have a basic knowledge of the terms used in Git such as push, pull requests, commit, repository, etc. It also requires you to register to GitHub [here][1] and make a note of your GitHub username. So let's begin:
|
||||
|
||||
### 1 Installing Git for Linux
|
||||
|
||||
Download and install Git for Linux:
|
||||
|
||||
```
|
||||
sudo apt-get install git
|
||||
```
|
||||
|
||||
The above command is for Ubuntu and works on all Recent Ubuntu versions, tested from Ubuntu 16.04 to Ubuntu 18.04 LTS (Bionic Beaver) and it's likely to work the same way on future versions.
|
||||
|
||||
### 2 Configuring GitHub
|
||||
|
||||
Once the installation has successfully completed, the next thing to do is to set up the configuration details of the GitHub user. To do this use the following two commands by replacing "user_name" with your GitHub username and replacing "email_id" with your email-id you used to create your GitHub account.
|
||||
|
||||
```
|
||||
git config --global user.name "user_name"
|
||||
|
||||
git config --global user.email "email_id"
|
||||
```
|
||||
|
||||
The following image shows an example of my configuration with my "user_name" being "akshaypai" and my "email_id" being "[[email protected]][2]"
|
||||
|
||||
[![Git config][3]][4]
|
||||
|
||||
### 3 Creating a local repository
|
||||
|
||||
Create a folder on your system. This will serve as a local repository which will later be pushed onto the GitHub website. Use the following command:
|
||||
|
||||
```
|
||||
git init Mytest
|
||||
```
|
||||
|
||||
If the repository is created successfully, then you will get the following line:
|
||||
|
||||
Initialized empty Git repository in /home/akshay/Mytest/.git/
|
||||
|
||||
This line may vary depending on your system.
|
||||
|
||||
So here, Mytest is the folder that is created and "init" makes the folder a GitHub repository. Change the directory to this newly created folder:
|
||||
|
||||
```
|
||||
cd Mytest
|
||||
```
|
||||
|
||||
### 4 Creating a README file to describe the repository
|
||||
|
||||
Now create a README file and enter some text like "this is a git setup on Linux". The README file is generally used to describe what the repository contains or what the project is all about. Example:
|
||||
|
||||
```
|
||||
gedit README
|
||||
```
|
||||
|
||||
You can use any other text editors. I use gedit. The content of the README file will be:
|
||||
|
||||
This is a git repo
|
||||
|
||||
### 5 Adding repository files to an index
|
||||
|
||||
This is an important step. Here we add all the things that need to be pushed onto the website into an index. These things might be the text files or programs that you might add for the first time into the repository or it could be adding a file that already exists but with some changes (a newer version/updated version).
|
||||
|
||||
Here we already have the README file. So, let's create another file which contains a simple C program and call it sample.c. The contents of it will be:
|
||||
```
|
||||
|
||||
#include<stdio.h>
|
||||
int main()
|
||||
{
|
||||
printf("hello world");
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
So, now that we have 2 files
|
||||
|
||||
README and sample.c
|
||||
|
||||
add it to the index by using the following 2 commands:
|
||||
|
||||
```
|
||||
git add README
|
||||
|
||||
git add smaple.c
|
||||
```
|
||||
|
||||
Note that the "git add" command can be used to add any number of files and folders to the index. Here, when I say index, what I am referring to is a buffer like space that stores the files/folders that have to be added into the Git repository.
|
||||
|
||||
### 6 Committing changes made to the index
|
||||
|
||||
Once all the files are added, we can commit it. This means that we have finalized what additions and/or changes have to be made and they are now ready to be uploaded to our repository. Use the command :
|
||||
|
||||
```
|
||||
git commit -m "some_message"
|
||||
```
|
||||
|
||||
"some_message" in the above command can be any simple message like "my first commit" or "edit in readme", etc.
|
||||
|
||||
### 7 Creating a repository on GitHub
|
||||
|
||||
Create a repository on GitHub. Notice that the name of the repository should be the same as the repository's on the local system. In this case, it will be "Mytest". To do this login to your account on <https://github.com>. Then click on the "plus(+)" symbol at the top right corner of the page and select "create new repository". Fill the details as shown in the image below and click on "create repository" button.
|
||||
|
||||
[![Creating a repository on GitHub][5]][6]
|
||||
|
||||
Once this is created, we can push the contents of the local repository onto the GitHub repository in your profile. Connect to the repository on GitHub using the command:
|
||||
|
||||
Important Note: Make sure you replace 'user_name' and 'Mytest' in the path with your Github username and folder before running the command!
|
||||
|
||||
```
|
||||
git remote add origin <https://github.com/user\_name/Mytest.git>
|
||||
```
|
||||
|
||||
### 8 Pushing files in local repository to GitHub repository
|
||||
|
||||
The final step is to push the local repository contents into the remote host repository (GitHub), by using the command:
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
Enter the login credentials [user_name and password].
|
||||
|
||||
The following image shows the procedure from step 5 to step 8
|
||||
|
||||
[![Pushing files in local repository to GitHub repository][7]][8]
|
||||
|
||||
So this adds all the contents of the 'Mytest' folder (my local repository) to GitHub. For subsequent projects or for creating repositories, you can start off with step 3 directly. Finally, if you log in to your GitHub account and click on your Mytest repository, you can see that the 2 files README and sample.c have been uploaded and are visible to all as shown in the following image.
|
||||
|
||||
[![Content uploaded to Github][9]][10]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-git-and-github-on-ubuntu/
|
||||
|
||||
作者:[Akshay Pai][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
|
||||
[1]:https://github.com/
|
||||
[2]:https://www.howtoforge.com/cdn-cgi/l/email-protection
|
||||
[3]:https://www.howtoforge.com/images/ubuntu_github_getting_started/config.png
|
||||
[4]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/config.png
|
||||
[5]:https://www.howtoforge.com/images/ubuntu_github_getting_started/details.png
|
||||
[6]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/details.png
|
||||
[7]:https://www.howtoforge.com/images/ubuntu_github_getting_started/steps.png
|
||||
[8]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/steps.png
|
||||
[9]:https://www.howtoforge.com/images/ubuntu_github_getting_started/final.png
|
||||
[10]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/final.png
|
||||
@ -0,0 +1,75 @@
|
||||
Learn Python programming the easy way with EduBlocks
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you are you looking for a way to move your students (or yourself) from programming in [Scratch][1] to learning [Python][2], I recommend you look into [EduBlocks][3]. It brings a familiar drag-and-drop graphical user interface (GUI) to Python 3 programming.
|
||||
|
||||
One of the barriers when transitioning from Scratch to Python is the absence of the drag-and-drop GUI that has made Scratch the go-to application in K-12 schools. EduBlocks' drag-and-drop version of Python 3 changes that paradigm. It aims to "help teachers to introduce text-based programming languages, like Python, to children at an earlier age."
|
||||
|
||||
The hardware requirements for EduBlocks are quite modest—a Raspberry Pi and an internet connection—and should be available in many classrooms.
|
||||
|
||||
EduBlocks was developed by Joshua Lowe, a 14-year-old Python developer from the United Kingdom. I saw Joshua demonstrate his project at [PyCon 2018][4] in May 2018.
|
||||
|
||||
### Getting started
|
||||
|
||||
It's easy to install EduBlocks. The website provides clear installation instructions, and you can find detailed screenshots in the project's [GitHub][5] repository.
|
||||
|
||||
Install EduBlocks from the Raspberry Pi command line by issuing the following command:
|
||||
```
|
||||
curl -sSL get.edublocks.org | bash
|
||||
|
||||
```
|
||||
|
||||
### Programming EduBlocks
|
||||
|
||||
Once the installation is complete, launch EduBlocks from either the desktop shortcut or the Programming menu on the Raspberry Pi.
|
||||
|
||||

|
||||
|
||||
Once you launch the application, you can start creating Python 3 code with EduBlocks' drag-and-drop interface. Its menus are clearly labeled. You can start with sample code by clicking the **Samples** menu button. You can also choose a different color scheme for your programming palette by clicking **Theme**. With the **Save** menu, you can save your code as you work, then **Download** your Python code. Click **Run** to execute and test your code.
|
||||
|
||||
You can see your code by clicking the **Blockly** button at the far right. It allows you to toggle between the "Blockly" interface and the normal Python code view (as you would see in any other Python editor).
|
||||
|
||||
|
||||
|
||||
EduBlocks comes with a range of code libraries, including [EduPython][6], [Minecraft][7], [Sonic Pi][8], [GPIO Zero][9], and [Sense Hat][10].
|
||||
|
||||
### Learning and support
|
||||
|
||||
The project maintains a [learning portal][11] with tutorials and other resources for easily [hacking][12] the version of Minecraft that comes with Raspberry Pi, programming the GPIOZero and Sonic Pi, and controlling LEDs with the Micro:bit code editor. Support for EduBlocks is available on Twitter [@edu_blocks][13] and [@all_about_code][14] and through [email][15].
|
||||
|
||||
For a deeper dive, you can access EduBlocks' source code on [GitHub][16]; the application is [licensed][17] under GNU Affero General Public License v3.0. EduBlocks' creators (project lead [Joshua Lowe][18] and fellow developers [Chris Dell][19] and [Les Pounder][20]) want it to be a community project and invite people to open issues, provide feedback, and submit pull requests to add features or fixes to the project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/edublocks
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://scratch.mit.edu/
|
||||
[2]:https://www.python.org/
|
||||
[3]:https://edublocks.org/
|
||||
[4]:https://us.pycon.org/2018/about/
|
||||
[5]:https://github.com/AllAboutCode/EduBlocks
|
||||
[6]:https://edupython.tuxfamily.org/
|
||||
[7]:https://minecraft.net/en-us/edition/pi/
|
||||
[8]:https://sonic-pi.net/
|
||||
[9]:https://gpiozero.readthedocs.io/en/stable/
|
||||
[10]:https://www.raspberrypi.org/products/sense-hat/
|
||||
[11]:https://edublocks.org/learn.html
|
||||
[12]:https://edublocks.org/resources/1.pdf
|
||||
[13]:https://twitter.com/edu_blocks?lang=en
|
||||
[14]:https://twitter.com/all_about_code
|
||||
[15]:mailto:support@edublocks.org
|
||||
[16]:https://github.com/allaboutcode/edublocks
|
||||
[17]:https://github.com/AllAboutCode/EduBlocks/blob/tarball-install/LICENSE
|
||||
[18]:https://github.com/JoshuaLowe1002
|
||||
[19]:https://twitter.com/cjdell?lang=en
|
||||
[20]:https://twitter.com/biglesp?lang=en
|
||||
220
sources/tech/20180806 Systemd Timers- Three Use Cases.md
Normal file
220
sources/tech/20180806 Systemd Timers- Three Use Cases.md
Normal file
@ -0,0 +1,220 @@
|
||||
Systemd Timers: Three Use Cases
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this systemd tutorial series, we have[ already talked about systemd timer units to some degree][1], but, before moving on to the sockets, let's look at three examples that illustrate how you can best leverage these units.
|
||||
|
||||
### Simple _cron_ -like behavior
|
||||
|
||||
This is something I have to do: collect [popcon data from Debian][2] every week, preferably at the same time so I can see how the downloads for certain applications evolve. This is the typical thing you can have a _cron_ job do, but a systemd timer can do it too:
|
||||
```
|
||||
# cron-like popcon.timer
|
||||
|
||||
[Unit]
|
||||
Description= Says when to download and process popcons
|
||||
|
||||
[Timer]
|
||||
OnCalendar= Thu *-*-* 05:32:07
|
||||
Unit= popcon.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The actual _popcon.service_ runs a regular _wget_ job, so nothing special. What is new in here is the `OnCalendar=` directive. This is what lets you set a service to run on a certain date at a certain time. In this case, `Thu` means " _run on Thursdays_ " and the `*-*-*` means " _the exact date, month and year don't matter_ ", which translates to " _run on Thursday, regardless of the date, month or year_ ".
|
||||
|
||||
Then you have the time you want to run the service. I chose at about 5:30 am CEST, which is when the server is not very busy.
|
||||
|
||||
If the server is down and misses the weekly deadline, you can also work an _anacron_ -like functionality into the same timer:
|
||||
```
|
||||
# popcon.timer with anacron-like functionality
|
||||
|
||||
[Unit]
|
||||
Description=Says when to download and process popcons
|
||||
|
||||
[Timer]
|
||||
Unit=popcon.service
|
||||
OnCalendar=Thu *-*-* 05:32:07
|
||||
Persistent=true
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
|
||||
```
|
||||
|
||||
When you set the `Persistent=` directive to true, it tells systemd to run the service immediately after booting if the server was down when it was supposed to run. This means that if the machine was down, say for maintenance, in the early hours of Thursday, as soon as it is booted again, _popcon.service_ will be run immediately and then it will go back to the routine of running the service every Thursday at 5:32 am.
|
||||
|
||||
So far, so straightforward.
|
||||
|
||||
### Delayed execution
|
||||
|
||||
But let's kick thing up a notch and "improve" the [systemd-based surveillance system][3]. Remember that the system started taking pictures the moment you plugged in a camera. Suppose you don't want pictures of your face while you install the camera. You will want to delay the start up of the picture-taking service by a minute or two so you can plug in the camera and move out of frame.
|
||||
|
||||
To do this; first change the Udev rule so it points to a timer:
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
|
||||
ATTRS{idProduct}=="e207", TAG+="systemd", ENV{SYSTEMD_WANTS}="picchanged.timer",
|
||||
SYMLINK+="mywebcam", MODE="0666"
|
||||
|
||||
```
|
||||
|
||||
The timer looks like this:
|
||||
```
|
||||
# picchanged.timer
|
||||
|
||||
[Unit]
|
||||
Description= Runs picchanged 1 minute after the camera is plugged in
|
||||
|
||||
[Timer]
|
||||
OnActiveSec= 1 m
|
||||
Unit= picchanged.path
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The Udev rule gets triggered when you plug the camera in and it calls the timer. The timer waits for one minute after it starts (`OnActiveSec= 1 m`) and then runs _picchanged.path_ , which [monitors to see if the master image changes][4]. The _picchanged.path_ is also in charge of pulling in the _webcam.service_ , the service that actually takes the picture.
|
||||
|
||||
### Start and stop Minetest server at a certain time every day
|
||||
|
||||
In the final example, let's say you have decided to delegate parenting to systemd. I mean, systemd seems to be already taking over most of your life anyway. Why not embrace the inevitable?
|
||||
|
||||
So you have your Minetest service set up for your kids. You also want to give some semblance of caring about their education and upbringing and have them do homework and chores. What you want to do is make sure Minetest is only available for a limited time (say from 5 pm to 7 pm) every evening.
|
||||
|
||||
This is different from " _starting a service at certain time_ " in that, writing a timer to start the service at 5 pm is easy...:
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= Runs the minetest.service at 5pm everyday
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 17:00:00
|
||||
Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
... But writing a counterpart timer that shuts down a service at a certain time needs a bigger dose of lateral thinking.
|
||||
|
||||
Let's start with the obvious -- the timer:
|
||||
```
|
||||
# stopminetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= Stops the minetest.service at 7 pm everyday
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 19:05:00
|
||||
Unit= stopminetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The tricky part is how to tell _stopminetest.service_ to actually, you know, stop the Minetest. There is no way to pass the PID of the Minetest server from _minetest.service_. and there are no obvious commands in systemd's unit vocabulary to stop or disable a running service.
|
||||
|
||||
The trick is to use systemd's `Conflicts=` directive. The `Conflicts=` directive is similar to systemd's `Wants=` directive, in that it does _exactly the opposite_. If you have `Wants=a.service` in a unit called _b.service_ , when it starts, _b.service_ will run _a.service_ if it is not running already. Likewise, if you have a line that reads `Conflicts= a.service` in your _b.service_ unit, as soon as _b.service_ starts, systemd will stop _a.service_.
|
||||
|
||||
This was created for when two services could clash when trying to take control of the same resource simultaneously, say when two services needed to access your printer at the same time. By putting a `Conflicts=` in your preferred service, you could make sure it would override the least important one.
|
||||
|
||||
You are going to use `Conflicts=` a bit differently, however. You will use `Conflicts=` to close down cleanly the _minetest.service_ :
|
||||
```
|
||||
# stopminetest.service
|
||||
|
||||
[Unit]
|
||||
Description= Closes down the Minetest service
|
||||
Conflicts= minetest.service
|
||||
|
||||
[Service]
|
||||
Type= oneshot
|
||||
ExecStart= /bin/echo "Closing down minetest.service"
|
||||
|
||||
```
|
||||
|
||||
The _stopminetest.service_ doesn't do much at all. Indeed, it could do nothing at all, but just because it contins that `Conflicts=` line in there, when it is started, systemd will close down _minetest.service_.
|
||||
|
||||
There is one last wrinkle in your perfect Minetest set up: What happens if you are late home from work, it is past the time when the server should be up but playtime is not over? The `Persistent=` directive (see above) that runs a service if it has missed its start time is no good here, because if you switch the server on, say at 11 am, it would start Minetest and that is not what you want. What you really want is a way to make sure that systemd will only start Minetest between the hours of 5 and 7 in the evening:
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= Runs the minetest.service every minute between the hours of 5pm and 7pm
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 17..19:*:00
|
||||
Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The line `OnCalendar= *-*-* 17..19:*:00` is interesting for two reasons: (1) `17..19` is not a point in time, but a period of time, in this case the period of time between the times of 17 and 19; and (2) the `*` in the minute field indicates that the service must be run every minute. Hence, you would read this as " _run the minetest.service every minute between 5 and 7 pm_ ".
|
||||
|
||||
There is still one catch, though: once the _minetest.service_ is up and running, you want _minetest.timer_ to stop trying to run it again and again. You can do that by including a `Conflicts=` directive into _minetest.service_ :
|
||||
```
|
||||
# minetest.service
|
||||
|
||||
[Unit]
|
||||
Description= Runs Minetest server
|
||||
Conflicts= minetest.timer
|
||||
|
||||
[Service]
|
||||
Type= simple
|
||||
User= <your user name>
|
||||
|
||||
ExecStart= /usr/bin/minetest --server
|
||||
ExecStop= /bin/kill -2 $MAINPID
|
||||
|
||||
[Install]
|
||||
WantedBy= multi-user.targe
|
||||
|
||||
```
|
||||
|
||||
The `Conflicts=` directive shown above makes sure _minetest.timer_ is stopped as soon as the _minetest.service_ is successfully started.
|
||||
|
||||
Now enable and start _minetest.timer_ :
|
||||
```
|
||||
systemctl enable minetest.timer
|
||||
systemctl start minetest.timer
|
||||
|
||||
```
|
||||
|
||||
And, if you boot the server at, say, 6 o'clock, _minetest.timer_ will start up and, as the time falls between 5 and 7, _minetest.timer_ will try and start _minetest.service_ every minute. But, as soon as _minetest.service_ is running, systemd will stop _minetest.timer_ because it "conflicts" with _minetest.service_ , thus avoiding the timer from trying to start the service over and over when it is already running.
|
||||
|
||||
It is a bit counterintuitive that you use the service to kill the timer that started it up in the first place, but it works.
|
||||
|
||||
### Conclusion
|
||||
|
||||
You probably think that there are better ways of doing all of the above. I have heard the term "overengineered" in regard to these articles, especially when using systemd timers instead of cron.
|
||||
|
||||
But, the purpose of this series of articles is not to provide the best solution to any particular problem. The aim is to show solutions that use systemd units as much as possible, even to a ridiculous length. The aim is to showcase plenty of examples of how the different types of units and the directives they contain can be leveraged. It is up to you, the reader, to find the real practical applications for all of this.
|
||||
|
||||
Be that as it may, there is still one more thing to go: next time, we'll be looking at _sockets_ and _targets_ , and then we'll be done with systemd units.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][5]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2018/8/systemd-timers-two-use-cases-0
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
|
||||
[2]:https://popcon.debian.org/
|
||||
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
312
sources/tech/20180806 Use Gstreamer and Python to rip CDs.md
Normal file
312
sources/tech/20180806 Use Gstreamer and Python to rip CDs.md
Normal file
@ -0,0 +1,312 @@
|
||||
Use Gstreamer and Python to rip CDs
|
||||
======
|
||||
|
||||

|
||||
|
||||
In a previous article, you learned how to use the MusicBrainz service to provide tag information for your audio files, using a simple Python script. This article shows you how to also script an all-in-one solution to copy your CDs down to a music library folder in your choice of formats.
|
||||
|
||||
Unfortunately, the powers that be make it impossible for Fedora to carry the necessary bits to encode MP3 in official repos. So that part is left as an exercise for the reader. But if you use a cloud service such as Google Play to host your music, this script makes audio files you can upload easily.
|
||||
|
||||
The script will record your CD down to one of the following file formats:
|
||||
|
||||
* Uncompressed WAV, which you can further encode or play with.
|
||||
* Compressed but lossless FLAC. Lossless files preserve all the fidelity of the original audio.
|
||||
* Compressed, lossy Ogg Vorbis. Like MP3 and Apple’s AAC, Ogg Vorbis uses special algorithms and psychoacoustic properties to sound close to the original audio. However, Ogg Vorbis usually produces superior results to those other compressed formats at the same file sizes. You can[read more about it here][1] if you like technical details.
|
||||
|
||||
|
||||
|
||||
### The components
|
||||
|
||||
The first element of the script is a [GStreamer][2] pipeline. GStreamer is a full featured multimedia framework included in Fedora. It comes [installed by default in Workstation][3], too. GStreamer is used behind the scene by many multimedia apps in Fedora. It lets apps manipulate all kinds of video and audio files.
|
||||
|
||||
The second major component in this script is choosing, and using, a multimedia tagging library. In this case [the mutagen library][4] makes it easy to tag many kinds of multimedia files. The script in this article uses mutagen to tag Ogg Vorbis or FLAC files.
|
||||
|
||||
Finally, the script uses [Python’s argparse, part of the standard library][5], for some easy to use options and help text. The argparse library is useful for most Python scripts where you expect the user to provide parameters. This article won’t cover this part of the script in great detail.
|
||||
|
||||
### The script
|
||||
|
||||
You may recall [the previous article][6] that used MusicBrainz to fetch tag information. This script includes that code, with some tweaks to make it integrate better with the new functions. (You may find it easier to read this script if you copy and paste it into your favorite editor.)
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
|
||||
import os, sys
|
||||
import subprocess
|
||||
from argparse import ArgumentParser
|
||||
import libdiscid
|
||||
import musicbrainzngs as mb
|
||||
import requests
|
||||
import json
|
||||
from getpass import getpass
|
||||
|
||||
parser = ArgumentParser()
|
||||
parser.add_argument('-f', '--flac', action='store_true', dest='flac',
|
||||
default=False, help='Rip to FLAC format')
|
||||
parser.add_argument('-w', '--wav', action='store_true', dest='wav',
|
||||
default=False, help='Rip to WAV format')
|
||||
parser.add_argument('-o', '--ogg', action='store_true', dest='ogg',
|
||||
default=False, help='Rip to Ogg Vorbis format')
|
||||
options = parser.parse_args()
|
||||
|
||||
# Set up output varieties
|
||||
if options.wav + options.ogg + options.flac > 1:
|
||||
raise parser.error("Only one of -f, -o, -w please")
|
||||
if options.wav:
|
||||
fmt = 'wav'
|
||||
encoding = 'wavenc'
|
||||
elif options.flac:
|
||||
fmt = 'flac'
|
||||
encoding = 'flacenc'
|
||||
from mutagen.flac import FLAC as audiofile
|
||||
elif options.ogg:
|
||||
fmt = 'oga'
|
||||
quality = 'quality=0.3'
|
||||
encoding = 'vorbisenc {} ! oggmux'.format(quality)
|
||||
from mutagen.oggvorbis import OggVorbis as audiofile
|
||||
|
||||
# Get MusicBrainz info
|
||||
this_disc = libdiscid.read(libdiscid.default_device())
|
||||
mb.set_useragent(app='get-contents', version='0.1')
|
||||
mb.auth(u=input('Musicbrainz username: '), p=getpass())
|
||||
|
||||
release = mb.get_releases_by_discid(this_disc.id, includes=['artists',
|
||||
'recordings'])
|
||||
if release.get('disc'):
|
||||
this_release=release['disc']['release-list'][0]
|
||||
|
||||
album = this_release['title']
|
||||
artist = this_release['artist-credit'][0]['artist']['name']
|
||||
year = this_release['date'].split('-')[0]
|
||||
|
||||
for medium in this_release['medium-list']:
|
||||
for disc in medium['disc-list']:
|
||||
if disc['id'] == this_disc.id:
|
||||
tracks = medium['track-list']
|
||||
break
|
||||
|
||||
# We assume here the disc was found. If you see this:
|
||||
# NameError: name 'tracks' is not defined
|
||||
# ...then the CD doesn't appear in MusicBrainz and can't be
|
||||
# tagged. Use your MusicBrainz account to create a release for
|
||||
# the CD and then try again.
|
||||
|
||||
# Get cover art to cover.jpg
|
||||
if this_release['cover-art-archive']['artwork'] == 'true':
|
||||
url = 'http://coverartarchive.org/release/' + this_release['id']
|
||||
art = json.loads(requests.get(url, allow_redirects=True).content)
|
||||
for image in art['images']:
|
||||
if image['front'] == True:
|
||||
cover = requests.get(image['image'], allow_redirects=True)
|
||||
fname = '{0} - {1}.jpg'.format(artist, album)
|
||||
print('Saved cover art as {}'.format(fname))
|
||||
f = open(fname, 'wb')
|
||||
f.write(cover.content)
|
||||
f.close()
|
||||
break
|
||||
|
||||
for trackn in range(len(tracks)):
|
||||
track = tracks[trackn]['recording']['title']
|
||||
|
||||
# Output file name based on MusicBrainz values
|
||||
outfname = '{:02} - {}.{}'.format(trackn+1, track, fmt).replace('/', '-')
|
||||
|
||||
print('Ripping track {}...'.format(outfname))
|
||||
cmd = 'gst-launch-1.0 cdiocddasrc track={} ! '.format(trackn+1) + \
|
||||
'audioconvert ! {} ! '.format(encoding) + \
|
||||
'filesink location="{}"'.format(outfname)
|
||||
msgs = subprocess.getoutput(cmd)
|
||||
|
||||
if not options.wav:
|
||||
audio = audiofile(outfname)
|
||||
print('Tagging track {}...'.format(outfname))
|
||||
audio['TITLE'] = track
|
||||
audio['TRACKNUMBER'] = str(trackn+1)
|
||||
audio['ARTIST'] = artist
|
||||
audio['ALBUM'] = album
|
||||
audio['DATE'] = year
|
||||
audio.save()
|
||||
|
||||
```
|
||||
|
||||
#### Determining output format
|
||||
|
||||
This part of the script lets the user decide how to format the output files:
|
||||
```
|
||||
parser = ArgumentParser()
|
||||
parser.add_argument('-f', '--flac', action='store_true', dest='flac',
|
||||
default=False, help='Rip to FLAC format')
|
||||
parser.add_argument('-w', '--wav', action='store_true', dest='wav',
|
||||
default=False, help='Rip to WAV format')
|
||||
parser.add_argument('-o', '--ogg', action='store_true', dest='ogg',
|
||||
default=False, help='Rip to Ogg Vorbis format')
|
||||
options = parser.parse_args()
|
||||
|
||||
# Set up output varieties
|
||||
if options.wav + options.ogg + options.flac > 1:
|
||||
raise parser.error("Only one of -f, -o, -w please")
|
||||
if options.wav:
|
||||
fmt = 'wav'
|
||||
encoding = 'wavenc'
|
||||
elif options.flac:
|
||||
fmt = 'flac'
|
||||
encoding = 'flacenc'
|
||||
from mutagen.flac import FLAC as audiofile
|
||||
elif options.ogg:
|
||||
fmt = 'oga'
|
||||
quality = 'quality=0.3'
|
||||
encoding = 'vorbisenc {} ! oggmux'.format(quality)
|
||||
from mutagen.oggvorbis import OggVorbis as audiofile
|
||||
|
||||
```
|
||||
|
||||
The parser, built from the argparse library, gives you a built in –help function:
|
||||
```
|
||||
$ ipod-cd --help
|
||||
usage: ipod-cd [-h] [-b BITRATE] [-w] [-o]
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
-b BITRATE, --bitrate BITRATE
|
||||
Set a target bitrate
|
||||
-w, --wav Rip to WAV format
|
||||
-o, --ogg Rip to Ogg Vorbis format
|
||||
|
||||
```
|
||||
|
||||
The script allows the user to use -f, -w, or -o on the command line to choose a format. Since these are stored as True (a Python boolean value), they can also be treated as the integer value 1. If more than one is selected, the parser generates an error.
|
||||
|
||||
Otherwise, the script sets an appropriate encoding string to be used with GStreamer later in the script. Notice the Ogg Vorbis selection also includes a quality setting, which is then included in the encoding. Care to try your hand at an easy change? Try making a parser argument and additional formatting code so the user can select a quality value between -0.1 and 1.0.
|
||||
|
||||
Notice also that for each of the file formats that allows tagging (WAV does not), the script imports a different tagging class. This way the script can have simpler, less confusing tagging code later in the script. In this script, both Ogg Vorbis and FLAC are using classes from the mutagen library.
|
||||
|
||||
#### Getting CD info
|
||||
|
||||
The next section of the script attempts to load MusicBrainz info for the disc. You’ll find that audio files ripped with this script have data not included in the Python code here. This is because GStreamer is also capable of detecting CD-Text that’s included on some discs during the mastering and manufacturing process. Often, though, this data is in all capitals (like “TRACK TITLE”). MusicBrainz info is more compatible with modern apps and other platforms.
|
||||
|
||||
For more information on this section, [refer to the previous article here on the Magazine][6]. A few trivial changes appear here to make the script work better as a single process.
|
||||
|
||||
One item to note is this warning:
|
||||
```
|
||||
# We assume here the disc was found. If you see this:
|
||||
# NameError: name 'tracks' is not defined
|
||||
# ...then the CD doesn't appear in MusicBrainz and can't be
|
||||
# tagged. Use your MusicBrainz account to create a release for
|
||||
# the CD and then try again.
|
||||
|
||||
```
|
||||
|
||||
The script as shown doesn’t include a way to handle cases where CD information isn’t found. This is on purpose. If it happens, take a moment to help the community by [entering CD information on MusicBrainz][7], using your login account.
|
||||
|
||||
#### Ripping and labeling tracks
|
||||
|
||||
The next section of the script actually does the work. It’s a simple loop that iterates through the track list found via MusicBrainz.
|
||||
|
||||
First, the script sets the output filename for the individual track based on the format the user selected:
|
||||
```
|
||||
for trackn in range(len(tracks)):
|
||||
track = tracks[trackn]['recording']['title']
|
||||
|
||||
# Output file name based on MusicBrainz values
|
||||
outfname = '{:02} - {}.{}'.format(trackn+1, track, fmt)
|
||||
|
||||
```
|
||||
|
||||
Then, the script calls a CLI GStreamer utility to perform the ripping and encoding process. That process turns each CD track into an audio file in your current directory:
|
||||
```
|
||||
print('Ripping track {}...'.format(outfname))
|
||||
cmd = 'gst-launch-1.0 cdiocddasrc track={} ! '.format(trackn+1) + \
|
||||
'audioconvert ! {} ! '.format(encoding) + \
|
||||
'filesink location="{}"'.format(outfname)
|
||||
msgs = subprocess.getoutput(cmd)
|
||||
|
||||
```
|
||||
|
||||
The complete GStreamer pipeline would look like this at a command line:
|
||||
```
|
||||
gst-launch-1.0 cdiocddasrc track=1 ! audioconvert ! vorbisenc quality=0.3 ! oggmux ! filesink location="01 - Track Name.oga"
|
||||
|
||||
```
|
||||
|
||||
GStreamer has Python libraries to let you use the framework in interesting ways directly without using subprocess. To keep this article less complex, the script calls the command line utility from Python to do the multimedia work.
|
||||
|
||||
Finally, the script labels the output file if it’s not a WAV file. Both Ogg Vorbis and FLAC use similar methods in their mutagen classes. That means this code can remain very simple:
|
||||
```
|
||||
if not options.wav:
|
||||
audio = audiofile(outfname)
|
||||
print('Tagging track {}...'.format(outfname))
|
||||
audio['TITLE'] = track
|
||||
audio['TRACKNUMBER'] = str(trackn+1)
|
||||
audio['ARTIST'] = artist
|
||||
audio['ALBUM'] = album
|
||||
audio['DATE'] = year
|
||||
audio.save()
|
||||
|
||||
```
|
||||
|
||||
If you decide to write code for another file format, you need to import the correct class earlier, and then perform the tagging correctly. You don’t have to use the mutagen class. For instance, you might choose to use eyed3 for tagging MP3 files. In that case, the tagging code might look like this:
|
||||
```
|
||||
...
|
||||
# In the parser handling for MP3 format
|
||||
from eyed3 import load as audiofile
|
||||
...
|
||||
# In the handling for MP3 tags
|
||||
audio.tag.version = (2, 3, 0)
|
||||
audio.tag.artist = artist
|
||||
audio.tag.title = track
|
||||
audio.tag.album = album
|
||||
audio.tag.track_num = (trackn+1, len(tracks))
|
||||
audio.tag.save()
|
||||
|
||||
```
|
||||
|
||||
(Note the encoding function is up to you to provide.)
|
||||
|
||||
### Running the script
|
||||
|
||||
Here’s an example output of the script:
|
||||
```
|
||||
$ ipod-cd -o
|
||||
Ripping track 01 - Shout, Pt. 1.oga...
|
||||
Tagging track 01 - Shout, Pt. 1.oga...
|
||||
Ripping track 02 - Stars of New York.oga...
|
||||
Tagging track 02 - Stars of New York.oga...
|
||||
Ripping track 03 - Breezy.oga...
|
||||
Tagging track 03 - Breezy.oga...
|
||||
Ripping track 04 - Aeroplane.oga...
|
||||
Tagging track 04 - Aeroplane.oga...
|
||||
Ripping track 05 - Minor Is the Lonely Key.oga...
|
||||
Tagging track 05 - Minor Is the Lonely Key.oga...
|
||||
Ripping track 06 - You Can Come Round If You Want To.oga...
|
||||
Tagging track 06 - You Can Come Round If You Want To.oga...
|
||||
Ripping track 07 - I'm Gonna Haunt This Place.oga...
|
||||
Tagging track 07 - I'm Gonna Haunt This Place.oga...
|
||||
Ripping track 08 - Crash That Piano.oga...
|
||||
Tagging track 08 - Crash That Piano.oga...
|
||||
Ripping track 09 - Save Yourself.oga...
|
||||
Tagging track 09 - Save Yourself.oga...
|
||||
Ripping track 10 - Get on Home.oga...
|
||||
Tagging track 10 - Get on Home.oga...
|
||||
|
||||
```
|
||||
|
||||
Enjoy burning your old CDs into easily portable audio files!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-gstreamer-python-rip-cds/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://xiph.org/vorbis/
|
||||
[2]:https://gstreamer.freedesktop.org/
|
||||
[3]:https://getfedora.org/workstation
|
||||
[4]:https://mutagen.readthedocs.io/en/latest/
|
||||
[5]:https://docs.python.org/3/library/argparse.html
|
||||
[6]:https://fedoramagazine.org/use-musicbrainz-get-cd-information/
|
||||
[7]:https://musicbrainz.org/
|
||||
223
sources/tech/20180806 What is CI-CD.md
Normal file
223
sources/tech/20180806 What is CI-CD.md
Normal file
@ -0,0 +1,223 @@
|
||||
What is CI/CD?
|
||||
======
|
||||
|
||||

|
||||
|
||||
Continuous integration (CI) and continuous delivery (CD) are extremely common terms used when talking about producing software. But what do they really mean? In this article, I'll explain the meaning and significance behind these and related terms, such as continuous testing and continuous deployment.
|
||||
|
||||
### Quick summary
|
||||
|
||||
An assembly line in a factory produces consumer goods from raw materials in a fast, automated, reproducible manner. Similarly, a software delivery pipeline produces releases from source code in a fast, automated, and reproducible manner. The overall design for how this is done is called "continuous delivery." The process that kicks off the assembly line is referred to as "continuous integration." The process that ensures quality is called "continuous testing" and the process that makes the end product available to users is called "continuous deployment." And the overall efficiency experts that make everything run smoothly and simply for everyone are known as "DevOps" practitioners.
|
||||
|
||||
### What does "continuous" mean?
|
||||
|
||||
Continuous is used to describe many different processes that follow the practices I describe here. It doesn't mean "always running." It does mean "always ready to run." In the context of creating software, it also includes several core concepts/best practices. These are:
|
||||
|
||||
* **Frequent releases:** The goal behind continuous practices is to enable delivery of quality software at frequent intervals. Frequency here is variable and can be defined by the team or company. For some products, once a quarter, month, week, or day may be frequent enough. For others, multiple times a day may be desired and doable. Continuous can also take on an "occasional, as-needed" aspect. The end goal is the same: Deliver software updates of high quality to end users in a repeatable, reliable process. Often this may be done with little to no interaction or even knowledge of the users (think device updates).
|
||||
|
||||
* **Automated processes:** A key part of enabling this frequency is having automated processes to handle nearly all aspects of software production. This includes building, testing, analysis, versioning, and, in some cases, deployment.
|
||||
|
||||
* **Repeatable:** If we are using automated processes that always have the same behavior given the same inputs, then processing should be repeatable. That is, if we go back and enter the same version of code as an input, we should get the same set of deliverables. This also assumes we have the same versions of external dependencies (i.e., other deliverables we don't create that our code uses). Ideally, this also means that the processes in our pipelines can be versioned and re-created (see the DevOps discussion later on).
|
||||
|
||||
* **Fast processing:** "Fast" is a relative term here, but regardless of the frequency of software updates/releases, continuous processes are expected to process changes from source code to deliverables in an efficient manner. Automation takes care of much of this, but automated processes may still be slow. For example, integrated testing across all aspects of a product that takes most of the day may be too slow for product updates that have a new candidate release multiple times per day.
|
||||
|
||||
|
||||
|
||||
|
||||
### What is a "continuous delivery pipeline"?
|
||||
|
||||
The different tasks and jobs that handle transforming source code into a releasable product are usually strung together into a software "pipeline" where successful completion of one automatic process kicks off the next process in the sequence. Such pipelines go by many different names, such as continuous delivery pipeline, deployment pipeline, and software development pipeline. An overall supervisor application manages the definition, running, monitoring, and reporting around the different pieces of the pipeline as they are executed.
|
||||
|
||||
### How does a continuous delivery pipeline work?
|
||||
|
||||
The actual implementation of a software delivery pipeline can vary widely. There are a large number and variety of applications that may be used in a pipeline for the various aspects of source tracking, building, testing, gathering metrics, managing versions, etc. But the overall workflow is generally the same. A single orchestration/workflow application manages the overall pipeline, and each of the processes runs as a separate job or is stage-managed by that application. Typically, the individual "jobs" are defined in a syntax and structure that the orchestration application understands and can manage as a workflow.
|
||||
|
||||
Jobs are created to do one or more functions (building, testing, deploying, etc.). Each job may use a different technology or multiple technologies. The key is that the jobs are automated, efficient, and repeatable. If a job is successful, the workflow manager application triggers the next job in the pipeline. If a job fails, the workflow manager alerts developers, testers, and others so they can correct the problem as quickly as possible. Because of the automation, errors can be found much more quickly than by running a set of manual processes. This quick identification of errors is called "fail fast" and can be just as valuable in getting to the pipeline's endpoint.
|
||||
|
||||
### What is meant by "fail fast"?
|
||||
|
||||
One of a pipeline's jobs is to quickly process changes. Another is to monitor the different tasks/jobs that create the release. Since code that doesn't compile or fails a test can hold up the pipeline, it's important for the users to be notified quickly of such situations. Fail fast refers to the idea that the pipeline processing finds problems as soon as possible and quickly notifies users so the problems can be corrected and code resubmitted for another run through the pipeline. Often, the pipeline process can look at the history to determine who made that change and notify the person and their team.
|
||||
|
||||
### Do all parts of a continuous delivery pipeline have to be automated?
|
||||
|
||||
Nearly all parts of the pipeline should be automated. For some parts, it may make sense to have a spot for human intervention/interaction. An example might be for user-acceptance testing (having end users try out the software and make sure it does what they want/expect). Another case might be deployment to production environments where groups want to have more human control. And, of course, human intervention is required if the code isn't correct and breaks.
|
||||
|
||||
With that background on the meaning of continuous, let's look at the different types of continuous processing and what each means in the context of a software pipeline.
|
||||
|
||||
### What is continuous integration?
|
||||
|
||||
Continuous integration (CI) is the process of automatically detecting, pulling, building, and (in most cases) doing unit testing as source code is changed for a product. CI is the activity that starts the pipeline (although certain pre-validations—often called "pre-flight checks"—are sometimes incorporated ahead of CI).
|
||||
|
||||
The goal of CI is to quickly make sure a new change from a developer is "good" and suitable for further use in the code base.
|
||||
|
||||
### How does continuous integration work?
|
||||
|
||||
The basic idea is having an automated process "watching" one or more source code repositories for changes. When a change is pushed to the repositories, the watching process detects the change, pulls down a copy, builds it, and runs any associated unit tests.
|
||||
|
||||
### How does continuous integration detect changes?
|
||||
|
||||
These days, the watching process is usually an application like [Jenkins][1] that also orchestrates all (or most) of the processes running in the pipeline and monitors for changes as one of its functions. The watching application can monitor for changes in several different ways. These include:
|
||||
|
||||
* **Polling:** The monitoring program repeatedly asks the source management system, "Do you have anything new in the repositories I'm interested in?" When the source management system has new changes, the monitoring program "wakes up" and does its work to pull the new code and build/test it.
|
||||
|
||||
* **Periodic:** The monitoring program is configured to periodically kick off a build regardless of whether there are changes or not. Ideally, if there are no changes, then nothing new is built, so this doesn't add much additional cost.
|
||||
|
||||
* **Push:** This is the inverse of the monitoring application checking with the source management system. In this case, the source management system is configured to "push out" a notification to the monitoring application when a change is committed into a repository. Most commonly, this can be done in the form of a "webhook"—a program that is "hooked" to run when new code is pushed and sends a notification over the internet to the monitoring program. For this to work, the monitoring program must have an open port that can receive the webhook information over the internet.
|
||||
|
||||
|
||||
|
||||
|
||||
### What are "pre-checks" (aka pre-flight checks)?
|
||||
|
||||
Additional validations may be done before code is introduced into the source repository and triggers continuous integration. These follow best practices such as test builds and code reviews. They are usually built into the development process before the code is introduced in the pipeline. But some pipelines may also include them as part of their monitored processes or workflows.
|
||||
|
||||
As an example, a tool called [Gerrit][2] allows for formal code reviews, validations, and test builds after a developer has pushed code but before it is allowed into the ([Git][3] remote) repository. Gerrit sits between the developer's workspace and the Git remote repository. It "catches" pushes from the developer and can do pass/fail validations to ensure they pass before being allowed to make it into the repository. This can include detecting the proposed change and kicking off a test build (a form of CI). It also allows for groups to do formal code reviews at that point. In this way, there is an extra measure of confidence that the change will not break anything when it is merged into the codebase.
|
||||
|
||||
### What are "unit tests"?
|
||||
|
||||
Unit tests (also known as "commit tests") are small, focused tests written by developers to ensure new code works in isolation. "In isolation" here means not depending on or making calls to other code that isn't directly accessible nor depending on external data sources or other modules. If such a dependency is required for the code to run, those resources can be represented by mocks. Mocks refer to using a code stub that looks like the resource and can return values but doesn't implement any functionality.
|
||||
|
||||
In most organizations, developers are responsible for creating unit tests to prove their code works. In fact, one model (known as test-driven development [TDD]) requires unit tests to be designed first as a basis for clearly identifying what the code should do. Because such code changes can be fast and numerous, they must also be fast to execute.
|
||||
|
||||
As they relate to the continuous integration workflow, a developer creates or updates the source in their local working environment and uses the unit tests to ensure the newly developed function or method works. Typically, these tests take the form of asserting that a given set of inputs to a function or method produces a given set of outputs. They generally test to ensure that error conditions are properly flagged and handled. Various unit-testing frameworks, such as [JUnit][4] for Java development, are available to assist.
|
||||
|
||||
### What is continuous testing?
|
||||
|
||||
Continuous testing refers to the practice of running automated tests of broadening scope as code goes through the CD pipeline. Unit testing is typically integrated with the build processes as part of the CI stage and focused on testing code in isolation from other code interacting with it.
|
||||
|
||||
Beyond that, there are various forms of testing that can/should occur. These can include:
|
||||
|
||||
* **Integration testing** validates that groups of components and services all work together.
|
||||
|
||||
* **Functional testing** validates the result of executing functions in the product are as expected.
|
||||
|
||||
* **Acceptance testing** measures some characteristic of the system against acceptable criteria. Examples include performance, scalability, stress, and capacity.
|
||||
|
||||
|
||||
|
||||
|
||||
All of these may not be present in the automated pipeline, and the lines between some of the different types can be blurred. But the goal of continuous testing in a delivery pipeline is always the same: to prove by successive levels of testing that the code is of a quality that it can be used in the release that's in progress. Building on the continuous principle of being fast, a secondary goal is to find problems quickly and alert the development team. This is usually referred to as fail fast.
|
||||
|
||||
### Besides testing, what other kinds of validations can be done against code in the pipeline?
|
||||
|
||||
In addition to the pass/fail aspects of tests, applications exist that can also tell us the number of source code lines that are exercised (covered) by our test cases. This is an example of a metric that can be computed across the source code. This metric is called code-coverage and can be measured by tools (such as [JaCoCo][5] for Java source).
|
||||
|
||||
Many other types of metrics exist, such as counting lines of code, measuring complexity, and comparing coding structures against known patterns. Tools such as [SonarQube][6] can examine source code and compute these metrics. Beyond that, users can set thresholds for what kind of ranges they are willing to accept as "passing" for these metrics. Then, processing in the pipeline can be set to check the computed values against the thresholds, and if the values aren't in the acceptable range, processing can be stopped. Applications such as SonarQube are highly configurable and can be tuned to check only for the things that a team is interested in.
|
||||
|
||||
### What is continuous delivery?
|
||||
|
||||
Continuous delivery (CD) generally refers to the overall chain of processes (pipeline) that automatically gets source code changes and runs them through build, test, packaging, and related operations to produce a deployable release, largely without any human intervention.
|
||||
|
||||
The goals of CD in producing software releases are automation, efficiency, reliability, reproducibility, and verification of quality (through continuous testing).
|
||||
|
||||
CD incorporates CI (automatically detecting source code changes, executing build processes for the changes, and running unit tests to validate), continuous testing (running various kinds of tests on the code to gain successive levels of confidence in the quality of the code), and (optionally) continuous deployment (making releases from the pipeline automatically available to users).
|
||||
|
||||
### How are multiple versions identified/tracked in pipelines?
|
||||
|
||||
Versioning is a key concept in working with CD and pipelines. Continuous implies the ability to frequently integrate new code and make updated releases available. But that doesn't imply that everyone always wants the "latest and greatest." This may be especially true for internal teams that want to develop or test against a known, stable release. So, it is important that the pipeline versions objects that it creates and can easily store and access those versioned objects.
|
||||
|
||||
The objects created in the pipeline processing from the source code can generally be called artifacts. Artifacts should have versions applied to them when they are built. The recommended strategy for assigning version numbers to artifacts is called semantic versioning. (This also applies to versions of dependent artifacts that are brought in from external sources.)
|
||||
|
||||
Semantic version numbers have three parts: major, minor, and patch. (For example, 1.4.3 reflects major version 1, minor version 4, and patch version 3.) The idea is that a change in one of these parts represents a level of update in the artifact. The major version is incremented only for incompatible API changes. The minor version is incremented when functionality is added in a backward-compatible manner. And the patch version is incremented when backward-compatible bug fixes are made. These are recommended guidelines, but teams are free to vary from this approach, as long as they do so in a consistent and well-understood manner across the organization. For example, a number that increases each time a build is done for a release may be put in the patch field.
|
||||
|
||||
### How are artifacts "promoted"?
|
||||
|
||||
Teams can assign a promotion "level" to artifacts to indicate suitability for testing, production, etc. There are various approaches. Applications such as Jenkins or [Artifactory][7] can be enabled to do promotion. Or a simple scheme can be to add a label to the end of the version string. For example, -snapshot can indicate the latest version (snapshot) of the code was used to build the artifact. Various promotion strategies or tools can be used to "promote" the artifact to other levels such as -milestone or -production as an indication of the artifact's stability and readiness for release.
|
||||
|
||||
### How are multiple versions of artifacts stored and accessed?
|
||||
|
||||
Versioned artifacts built from source can be stored via applications that manage "artifact repositories." Artifact repositories are like source management for built artifacts. The application (such as Artifactory or [Nexus][8]) can accept versioned artifacts, store and track them, and provide ways for them to be retrieved.
|
||||
|
||||
Pipeline users can specify the versions they want to use and have the pipeline pull in those versions.
|
||||
|
||||
### What is continuous deployment?
|
||||
|
||||
Continuous deployment (CD) refers to the idea of being able to automatically take a release of code that has come out of the CD pipeline and make it available for end users. Depending on the way the code is "installed" by users, that may mean automatically deploying something in a cloud, making an update available (such as for an app on a phone), updating a website, or simply updating the list of available releases.
|
||||
|
||||
An important point here is that just because continuous deployment can be done doesn't mean that every set of deliverables coming out of a pipeline is always deployed. It does mean that, via the pipeline, every set of deliverables is proven to be "deployable." This is accomplished in large part by the successive levels of continuous testing (see the section on Continuous Testing in this article).
|
||||
|
||||
Whether or not a release from a pipeline run is deployed may be gated by human decisions and various methods employed to "try out" a release before fully deploying it.
|
||||
|
||||
### What are some ways to test out deployments before fully deploying to all users?
|
||||
|
||||
Since having to rollback/undo a deployment to all users can be a costly situation (both technically and in the users' perception), numerous techniques have been developed to allow "trying out" deployments of new functionality and easily "undoing" them if issues are found. These include:
|
||||
|
||||
#### Blue/green testing/deployments
|
||||
|
||||
In this approach to deploying software, two identical hosting environments are maintained — a _blue_ one and a _green_ one. (The colors are not significant and only serves as identifers.) At any given point, one of these is the _production_ deployment and the other is the _candidate_ deployment.
|
||||
|
||||
In front of these instances is a router or other system that serves as the customer “gateway” to the product or application. By pointing the router to the desired blue or green instance, customer traffic can be directed to the desired deployment. In this way, swapping out which deployment instance is pointed to (blue or green) is quick, easy, and transparent to the user.
|
||||
|
||||
When a new release is ready for testing, it can be deployed to the non-production environment. After it’s been tested and approved, the router can be changed to point the incoming production traffic to it (so it becomes the new production site). Now the hosting environment that was production is available for the next candidate.
|
||||
|
||||
Likewise, if a problem is found with the latest deployment and the previous production instance is still deployed in the other environment, a simple change can point the customer traffic back to the previous production instance — effectively taking the instance with the problem “offline” and rolling back to the previous version. The new deployment with the problem can then be fixed in the other area.
|
||||
|
||||
#### Canary testing/deployment
|
||||
|
||||
In some cases, swapping out the entire deployment via a blue/green environment may not be workable or desired. Another approach is known as _canary_ testing/deployment. In this model, a portion of customer traffic is rerouted to new pieces of the product. For example, a new version of a search service in a product may be deployed alongside the current production version of the service. Then, 10% of search queries may be routed to the new version to test it out in a production environment.
|
||||
|
||||
If the new service handles the limited traffic with no problems, then more traffic may be routed to it over time. If no problems arise, then over time, the amount of traffic routed to the new service can be increased until 100% of the traffic is going to it. This effectively “retires” the previous version of the service and puts the new version into effect for all customers.
|
||||
|
||||
#### Feature toggles
|
||||
|
||||
For new functionality that may need to be easily backed out (in case a problem is found), developers can add a feature toggle. This is a software if-then switch in the code that only activates the code if a data value is set. This data value can be a globally accessible place that the deployed application checks to see whether it should execute the new code. If the data value is set, it executes the code; if not, it doesn't.
|
||||
|
||||
This gives developers a remote "kill switch" to turn off the new functionality if a problem is found after deployment to production.
|
||||
|
||||
#### Dark launch
|
||||
|
||||
In this practice, code is incrementally tested/deployed into production, but changes are not made visible to users (thus the "dark" name). For example, in the production release, some portion of web queries might be redirected to a service that queries a new data source. This information can be collected by development for analysis—without exposing any information about the interface, transaction, or results back to users.
|
||||
|
||||
The idea here is to get real information on how a candidate change would perform under a production load without impacting users or changing their experience. Over time, more load can be redirected until either a problem is found or the new functionality is deemed ready for all to use. Feature flags can be used actually to handle the mechanics of dark launches.
|
||||
|
||||
### What is DevOps?
|
||||
|
||||
[DevOps][9] is a set of ideas and recommended practices around how to make it easier for development and operational teams to work together on developing and releasing software. Historically, development teams created products but did not install/deploy them in a regular, repeatable way, as customers would do. That set of install/deploy tasks (as well as other support tasks) were left to the operations teams to sort out late in the cycle. This often resulted in a lot of confusion and problems, since the operations team was brought into the loop late in the cycle and had to make what they were given work in a short timeframe. As well, development teams were often left in a bad position—because they had not sufficiently tested the product's install/deploy functionality, they could be surprised by problems that emerged during that process.
|
||||
|
||||
This often led to a serious disconnect and lack of cooperation between development and operations teams. The DevOps ideals advocate ways of doing things that involve both development and operations staff from the start of the cycle through the end, such as CD.
|
||||
|
||||
### How does CD intersect with DevOps?
|
||||
|
||||
The CD pipeline is an implementation of several DevOps ideals. The later stages of a product, such as packaging and deployment, can always be done on each run of the pipeline rather than waiting for a specific point in the product development cycle. As well, both development and operations staff can clearly see when things work and when they don't, from development to deployment. For a cycle of a CD pipeline to be successful, it must pass through not only the processes associated with development but also the ones associated with operations.
|
||||
|
||||
Carried to the next level, DevOps suggests that even the infrastructure that implements the pipeline be treated like code. That is, it should be automatically provisioned, trackable, easy to change, and spawn a new run of the pipeline if it changes. This can be done by implementing the pipeline as code.
|
||||
|
||||
### What is "pipeline-as-code"?
|
||||
|
||||
Pipeline-as-code is a general term for creating pipeline jobs/tasks via programming code, just as developers work with source code for products. The goal is to have the pipeline implementation expressed as code so it can be stored with the code, reviewed, tracked over time, and easily spun up again if there is a problem and the pipeline must be stopped. Several tools allow this, including [Jenkins 2][1].
|
||||
|
||||
### How does DevOps impact infrastructure for producing software?
|
||||
|
||||
Traditionally, individual hardware systems used in pipelines were configured with software (operating systems, applications, development tools, etc.) one at a time. At the extreme, each system was a custom, hand-crafted setup. This meant that when a system had problems or needed to be updated, that was frequently a custom task as well. This kind of approach goes against the fundamental CD ideal of having an easily reproducible and trackable environment.
|
||||
|
||||
Over the years, applications have been developed to standardize provisioning (installing and configuring) systems. As well, virtual machines were developed as programs that emulate computers running on top of other computers. These VMs require a supervisory program to run them on the underlying host system. And they require their own operating system copy to run.
|
||||
|
||||
Next came containers. Containers, while similar in concept to VMs, work differently. Instead of requiring a separate program and a copy of an OS to run, they simply use some existing OS constructs to carve out isolated space in the operating system. Thus, they behave similarly to a VM to provide the isolation but don't require the overhead.
|
||||
|
||||
Because VMs and containers are created from stored definitions, they can be destroyed and re-created easily with no impact to the host systems where they are running. This allows a re-creatable system to run pipelines on. Also, for containers, we can track changes to the definition file they are built from—just as we would for source code.
|
||||
|
||||
Thus, if we run into a problem in a VM or container, it may be easier and quicker to just destroy and re-create it instead of trying to debug and make a fix to the existing one.
|
||||
|
||||
This also implies that any change to the code for the pipeline can trigger a new run of the pipeline (via CI) just as a change to code would. This is one of the core ideals of DevOps regarding infrastructure.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/what-cicd
|
||||
|
||||
作者:[Brent Laster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bclaster
|
||||
[1]:https://jenkins.io
|
||||
[2]:https://www.gerritcodereview.com
|
||||
[3]:https://opensource.com/resources/what-is-git
|
||||
[4]:https://junit.org/junit5/
|
||||
[5]:https://www.eclemma.org/jacoco/
|
||||
[6]:https://www.sonarqube.org/
|
||||
[7]:https://jfrog.com/artifactory/
|
||||
[8]:https://www.sonatype.com/nexus-repository-sonatype
|
||||
[9]:https://opensource.com/resources/devops
|
||||
@ -1,119 +0,0 @@
|
||||
DevOps时代的7个领导准则
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果[DevOps]最终更多的是关于文化而不是任何其他的技术或者平台,那么请记住:没有终点线。而是继续改变和提高--而且最高管理层并没有通过。
|
||||
|
||||
然而,如果期望DevOps能够帮助获得更多的成果,领导者需要[修订他们的一些传统的方法][2]让我们考虑7个在DevOps时代更有效的IT领导的想法。
|
||||
|
||||
### 1. 向失败说“是的”
|
||||
|
||||
“失败”这个词在IT领域中一直包含着特殊的内涵,而且通常是糟糕的意思:服务器失败,备份失败,硬盘驱动器失败-你得了解这些情况。
|
||||
|
||||
然而一种健康的DevOps文化取决于重新定义失败-IT领导者在他们的字典里应该重新定义这个单词将它的含义和“机会”对等起来。
|
||||
|
||||
“在DevOps之前,我们曾有一种惩罚失败者的文化,”罗伯特·里夫斯说,[Datical][3]的首席技术官兼联合创始人。“我们学到的仅仅是去避免错误。在IT领域避免错误的首要措施就是不要去改变任何东西:不要加速版本迭代的日程,不要迁移到云中,不要去做任何不同的事”
|
||||
|
||||
那是过去的一个时代的剧本,里夫斯坦诚的说,它已经不起作用了,事实上,那种停滞是失败的。
|
||||
|
||||
“那些缓慢的释放并逃避云的公司被恐惧所麻痹-他们将会走向失败,”里夫斯说道。“IT领导者必须拥抱失败并把它当做成一个机遇。人们不仅仅从他们的过错中学习,也会从其他的错误中学习。一种开放和[安全心里][4]的文化促进学习和提高”
|
||||
**[相关文章:[为什么敏捷领导者谈论“失败”必须超越它本义]]
|
||||
### 2. 在管理层渗透开发运营的理念
|
||||
|
||||
尽管DevOps文化可以在各个方向有机的发展,那些正在从整体中转变,孤立的IT实践,而且可能遭遇逆风的公司-需要执行领导层的全面支持。你正在传达模糊的信息
|
||||
而且可能会鼓励那些愿意推一把的人,这是我们一贯的做事方式。[改变文化是困难的][6];人们需要看到领导层完全投入进去并且知道改变已经实际发生了。
|
||||
|
||||
“为了成功的实现利益的兑现高层管理必须全力支持DevOps,”来自[Rainforest QA][7]的首席技术官说道。
|
||||
|
||||
成为一个DevOps商店。德里克指出,涉及到公司的一切,从技术团队到工具到进程到规则和责任。
|
||||
|
||||
"没有高层管理的统一赞助支持,DevOps的实施将很难成功,"德里克说道。"因此,在转变到DevOps之前在高层中有支持的领导同盟是很重要的。"
|
||||
|
||||
### 3. 不要只是声明“DevOps”-要明确它
|
||||
即使IT公司也已经开始拥抱欢迎DevOps,每个人可能不是在同一个进程上。
|
||||
**[参考我们的相关文章,**][**3 阐明了DevOps和首席技术官们必须在同一进程上**][8] **.]**
|
||||
|
||||
造成这种脱节的一个根本原因是:人们对这个术语的有着不同的定义理解。
|
||||
|
||||
“DevOps 对不同的人可能意味着不同的含义,”德里克解释道。“对高管层和副总裁层来说,执行明确的DevOps的目标,清楚的声明期望的成果,充分理解带来的成果将如何使公司的商业受益并且能够衡量和报告成功的过程。”
|
||||
|
||||
事实上,在基线和视野之上,DevOps要求正在进行频繁的交流,不是仅仅在小团队里,而是要贯穿到整个组织。IT领导者必须为它设置优先级。
|
||||
|
||||
“不可避免的,将会有些阻碍,在商业中将会存在失败和破坏,”德里克说道。“领导者名需要清楚的将这个过程向公司的其他人阐述清楚告诉他们他们作为这个过程的一份子能够期待的结果。”
|
||||
|
||||
### 4. DevOps和技术同样重要
|
||||
|
||||
IT领导者们成功的将DevOps商店的这种文化和实践当做一项商业策略,与构建和运营软件的方法相结合。DevOps是将IT从支持部门转向战略部门的推动力。
|
||||
|
||||
IT领导者们必须转变他们的思想和方法,从成本和服务中心转变到驱动商业成果,而且DevOps的文化能够通过自动化和强大的协作加速收益。来自[CYBRIC][9]的首席技术官和联合创始人迈克说道。
|
||||
|
||||
事实上,这是一个强烈的趋势通过更多的这些规则在DevOps时代走在前沿。
|
||||
|
||||
“促进创新并且鼓励团队成员去聪明的冒险是DevOps文化的一个关键部分,IT领导者们需要在一个持续的基础上清楚的和他们交流,”凯尔说道。
|
||||
|
||||
“一个高效的IT领导者需要比以往任何时候都要积极的参与到商业中去,”来自[West Monroe Partners][10]的性能服务部门的主任埃文说道。“每年或季度回顾的日子一去不复返了-你需要欢迎每两周一次的待办事项。[11]你需要有在年度水平上的思考战略能力,在冲刺阶段的互动能力,在商业期望满足时将会被给予一定的奖励。”
|
||||
|
||||
### 5. 改变妨碍DevOps目标的任何事情
|
||||
|
||||
虽然DevOps的老兵们普遍认为DevOps更多的是一种文化而不是技术,成功取决于通过正确的过程和工具激活文化。当你声称自己的部门是一个DevOps商店却拒绝对进程或技术做必要的改变,这就是你买了辆法拉利却使用了用过20年的引擎,每次转动钥匙都会冒烟。
|
||||
|
||||
展览 A: [自动化][12].这是DevOps成功的重要并行策略。
|
||||
|
||||
“IT领导者需要重点强调自动化,”卡伦德说。“这将是DevOps的前期投资,但是如果没有它,DevOps将会很容易被低效吞噬自己而且将会无法完整交付。”
|
||||
|
||||
自动化是基石,但改变不止于此。
|
||||
|
||||
“领导者们需要推动自动化,监控和持续的交付过程。这意着对现有的实践,过程,团队架构以及规则的很多改变,”Choy说。“领导者们需要改变一切会阻碍隐藏团队去全利实现自动化的因素。”
|
||||
|
||||
### 6. 重新思考团队架构和能力指标
|
||||
|
||||
当你想改变时...如果你桌面上的组织结构图和你过去大部分时候嵌入的名字都是一样的,那么你是时候该考虑改革了。
|
||||
|
||||
“在这个DevOps的新时代文化中,IT执行者需要采取一个全新的方法来组织架构。”Kail说。“消除组织的边界限制,它会阻碍团队间的合作,允许团队自我组织,敏捷管理。”
|
||||
|
||||
Kail告诉我们在DevOps时代,这种反思也应该拓展应用到其他领域,包括你怎样衡量个人或者团队的成功,甚至是你和人们的互动。
|
||||
|
||||
“根据业务成果和总体的积极影响来衡量主动性,”Kail建议。“最后,我认为管理中最重要的一个方面是:有同理心。”
|
||||
|
||||
注意很容易收集的到测量值不是DevOps真正的指标,[Red Hat]的技术专员Gardon Half写到,“DevOps应该把指标以某种形式和商业成果绑定在一起,”他指出。“你可能真的不在乎开发者些了多少代码,是否有一台服务器在深夜硬件损坏,或者是你的测试是多么的全面。你甚至都不直接关注你的网站的响应情况或者是你更新的速度。但是你要注意的是这些指标可能和顾客放弃购物车去竞争对手那里有关,”参考他的文章,[DevOps 指标:你在测量什么?]
|
||||
|
||||
### 7. 丢弃传统的智慧
|
||||
|
||||
如果DevOps时代要求关于IT领导能力的新的思考方式,那么也就意味着一些旧的方法要被淘汰。但是是哪些呢?
|
||||
|
||||
“是实话,是全部,”Kail说道。“要摆脱‘因为我们一直都是以这种方法做事的’的心态。过渡到DevOps文化是一种彻底的思维模式的转变,不是对瀑布式的过去和变革委员会的一些细微改变。”
|
||||
|
||||
事实上,IT领导者们认识到真正的变革要求的不只是对旧方法的小小接触。它更多的是要求对之前的进程或者策略的一个重新启动。
|
||||
|
||||
West Monroe Partners的卡伦德分享了一个阻碍DevOps的领导力的例子:未能拥抱IT混合模型和现代的基础架构比如说容器和微服务
|
||||
|
||||
“我所看到的一个大的规则就是架构整合,或者认为在一个同质的环境下长期的维护会更便宜,”卡伦德说。
|
||||
|
||||
**想要更多像这样的智慧吗?[注册我们的每周邮件新闻报道][15].**
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[译者FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/
|
||||
[5]:https://enterprisersproject.com/article/2017/10/why-agile-leaders-must-move-beyond-talking-about-failure?sc_cid=70160000000h0aXAAQ
|
||||
[6]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
|
||||
[7]:https://www.rainforestqa.com/
|
||||
[8]:https://enterprisersproject.com/article/2018/1/3-areas-where-devops-and-cios-must-get-same-page
|
||||
[9]:https://www.cybric.io/
|
||||
[10]:http://www.westmonroepartners.com/
|
||||
[11]:https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming
|
||||
[12]:https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA
|
||||
[13]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[14]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
[15]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
89
translated/talk/20180308 What is open source programming.md
Normal file
89
translated/talk/20180308 What is open source programming.md
Normal file
@ -0,0 +1,89 @@
|
||||
何为开源?
|
||||
======
|
||||
|
||||

|
||||
|
||||
简单来说,开源项目就是书写一些大家可以随意取用、修改的代码。但你肯定听过关于Go语言的那个笑话,说 Go 语言简单到看一眼就可以明白规则,但需要一辈子去学会运用它。其实写开源代码也是这样的。往 GitHub, Bitbucket, SourceForge 等网站或者是你自己的博客,网站上丢几行代码不是难事,但想要有效地操作,还需要个人的努力付出,和高瞻远瞩。
|
||||
|
||||

|
||||
|
||||
### 我们对开源项目的误解
|
||||
|
||||
首先我要说清楚一点:把你的代码写在 GitHub 的公开资源库中并不意味着把你的代码开源化了。在几乎全世界,根本不用创作者做什么,只要作品形成,版权就随之而生了。在创作者进行授权之前,只有作者可以行使版权相关的权力。未经创作者授权的代码,不论有多少人在使用,都是一颗定时炸弹,只有愚蠢的人才会去用它。
|
||||
|
||||
有些创作者很善良,认为“很明显我的代码是免费提供给大家使用的。”,他也并不想起诉那些用了他的代码的人,但这并不意味着这些代码可以放心使用。不论在你眼中创作者们多么善良,他们都是有权力起诉任何使用、修改代码,或未经明确授权就将代码嵌入的人。
|
||||
|
||||
很明显,你不应该在没有指定开源许可证的情况下将你的源代码发布到网上然后期望别人使用它并为其做出贡献,我建议你也尽量避免使用这种代码,甚至疑似未授权的也不要使用。如果你开发了一个函数和实现,它和之前一个疑似未授权代码很像,源代码作者就可以对你就侵权提起诉讼。
|
||||
|
||||
举个例子, Jill Schmill 写了 AwesomeLib 然后未明确授权就把它放到了 GitHub 上,就算 Jill Schmill 不起诉任何人,只要她把 AwesomeLib 的完整版权都卖给 EvilCorp,EvilCorp 就会起诉之前违规使用这段代码的人。这种行为就好像是埋下了计算机安全隐患,总有一天会为人所用。
|
||||
|
||||
没有许可证的代码的危险的,以上。
|
||||
|
||||
### 选择恰当的开源许可证
|
||||
|
||||
假设你证要写一个新程序,而且打算把它放在开源平台上,你需要选择最贴合你需求的[许可证][1]。和宣传中说的一样,你可以从 [GitHub-curated][2] 上得到你想要的信息。这个网站设置得像个小问卷,特别方便快捷,点几下就能找到合适的许可证。
|
||||
|
||||
没有许可证的代码的危险的,切记。
|
||||
|
||||
在选择许可证时不要过于自负,如果你选的是 [Apache License][3] 或者 [GPLv3][4] 这种广为使用的许可证,人们很容易理解其对于权利的规划,你也不需要请律师来排查其中的漏洞。你选择的许可证使用的人越少,带来的麻烦越多。
|
||||
|
||||
最重要的一点是:千万不要试图自己编造许可证!自己编造许可证会给大家带来更多的困惑和困扰,不要这样做。如果在现有的许可证中确实找不到你需要的程式,你可以在现有的许可证中附加上你的要求,并且重点标注出来,提醒使用者们注意。
|
||||
|
||||
我知道有些人会说:“我才懒得管什么许可证,我已经把代码发到公共域了。”但问题是,公共域的法律效力并不是受全世界认可的。在不同的国家,公共域的效力和表现形式不同。有些国家的政府管控下,你甚至不可以把自己的源代码发到公共域中。万幸,[Unlicense][5] 可以弥补这些漏洞,它语言简洁,但其效力为全世界认可。
|
||||
|
||||
### 怎样引入许可证
|
||||
|
||||
确定使用哪个许可证之后,你需要明文指定它。如果你是在 GitHub 、 GitLab 或 BitBucket 这几个网站发布,你需要构建很多个文件夹,在根文件夹中,你应把许可证创建为一个以 LICENSE 命名的 txt 格式明文文件。
|
||||
|
||||
创建 LICENSE.txt 这个文件之后还有其他事要做。你需要在每个有效文件的页眉中添加注释块来申明许可证。如果你使用的是一现有的许可证,这一步对你来说十分简便。一个 `# 项目名 (c)2018作者名, GPLv3 许可证,详情见 https://www.gnu.org/licenses/gpl-3.0.en.html` 这样的注释块比隐约指代的许可证的效力要强得多。
|
||||
|
||||
如果你是要发布在自己的网站上,步骤也差不多。先创建 LICENSE.txt 文件,放入许可证,再表明许可证出处。
|
||||
|
||||
### 开源代码的不同之处
|
||||
|
||||
开源代码和专有代码的一个区别的开源代码写出来就是为了给别人看的。我是个40多岁的系统管理员,已经写过许许多多的代码。最开始我写代码是为了工作,为了解决公司的问题,所以其中大部分代码都是专有代码。这种代码的目的很简单,只要能在特定场合通过特定方式发挥作用就行。
|
||||
|
||||
开源代码则大不相同。在写开源代码时,你知道它可能会被用于各种各样的环境中。也许你的使用案例的环境条件很局限,但你仍旧希望它能在各种环境下发挥理想的效果。不同的人使用这些代码时,你会看到各类冲突,还有你没有考虑过的思路。虽然代码不一定要满足所有人,但最少它们可以顺利解决使用者遇到的问题,就算解决不了,也可以转换回常见的逻辑,不会给使用者添麻烦。(例如“第583行的内容除以零”就不能作为命令行参数正确的结果)
|
||||
|
||||
你的源代码也可能逼疯你,尤其是在你一遍又一遍地修改错误的函数或是子过程后,终于出现了你希望的结果,这时你不会叹口气就继续下一个任务,你会把过程清理干净,因为你不会愿意别人看出你一遍遍尝试的痕迹。比如你会把 `$variable` `$lol`全都换成有意义的 `$iterationcounter` 和 `$modelname`。这意味着你要认真专业地进行注释(尽管对于头脑风暴中的你来说它并不难懂),但为了之后有更多的人可以使用你的代码,你会尽力去注释,但注意适可而止。
|
||||
|
||||
这个过程难免有些痛苦沮丧,毕竟这不是你常做的事,会有些不习惯。但它会使你成为一位更好的程序员,也会让你的代码升华。即使你的项目只有你在贡献,清理代码也会节约你后期的很多工作,相信我一年后你更新 app 时,你会庆幸自己现在写下的是 `$modelname`,还有清晰的注释,而不是什么不知名的数列,甚至连 `$lol`也不是。
|
||||
|
||||
### 你并不是为你一人而写
|
||||
|
||||
开源的真正核心并不是那些代码,是社区。更大的社区的项目维持的时间更长,也更容易为人们接受。因此不仅要加入社区,还要多多为社区发展贡献思路,让自己的项目能够为社区所用。
|
||||
|
||||
蝙蝠侠为了完成目标暗中独自花了很大功夫,你用不着这样,你可以登录 Twitter , Reddit, 或者给你项目的相关人士发邮件,发布你正在筹备新项目的消息,仔细聊聊项目的设计初衷和你的计划,让大家一起帮忙,向大家征集数据输入,类似的使用案例,把这些信息整合起来,用在你的代码里。你不用看所有的回复,但你要对它有个大概把握,这样在你之后完善时可以躲过一些陷阱。
|
||||
|
||||
不发首次通告这个过程还不算完整。如果你希望大家能够接受你的作品,并且使用它,你就要以此为初衷来设计。公众说不定可以帮到你,你不必对公开这件事如临大敌。所以不要闭门造车,既然你是为大家而写,那就开设一个真实、公开的项目,想象你在社区的监督下,认真地一步步完成它。
|
||||
|
||||
### 建立项目的方式
|
||||
|
||||
你可以在 GitHub, GitLab, or BitBucket 上免费注册账号来管理你的项目。注册之后,创建知识库,建立 README 文件,分配一个许可证,一步步写入代码。这样可以帮你建立好习惯,让你之后和现实中的团队一起工作时,也能目的清晰地朝着目标稳妥地进行工作。这样你做得越久,就越有兴趣。
|
||||
|
||||
用户们会开始对你产生兴趣,这会让你开心也会让你不爽,但你应该亲切礼貌地对待他们,就算他们很多人根本不知道你的项目做的是什么,你可以把文件给他们看,让他们了解你在干什么。有些还在犹豫的用户可以给你提个醒,告诉你最开始设计的用户范围中落下了哪些人。
|
||||
|
||||
如果你的项目很受用户青睐,总会有开发者出现,并表示出兴趣。这也许是好事,也可能激怒你。最开始你可能只会做简单的错误修正,但总有一天你会收到拉请求,有可能是特殊利基案例,它可能改变你项目的作用域,甚至改变你项目的初衷。你需要学会分辨哪个有贡献,根据这个决定合并哪个,婉拒哪个。
|
||||
|
||||
### 我们为什么要开源?
|
||||
|
||||
开源听起来任务繁重,它也确实是这样。但它对你也有很多好处。它可以在无形之中磨练你,让你写出纯净持久的代码,也教会你与人沟通,团队协作。对于一位志向远大的专业开发者来说,它是最好的简历书写者。你的未来雇主很有可能点开你的知识库,了解你的能力范围;而你的开发者也有可能想带你进全球信息网络工作。
|
||||
|
||||
最后,为开源工作,意味着个人的提升,因为你在做的事不是为了你一个人,这比养活自己重要得多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/what-open-source-programming
|
||||
|
||||
作者:[Jim Salter][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-salter
|
||||
[1]:https://opensource.com/tags/licensing
|
||||
[2]:https://choosealicense.com/
|
||||
[3]:https://choosealicense.com/licenses/apache-2.0/
|
||||
[4]:https://choosealicense.com/licenses/gpl-3.0/
|
||||
[5]:https://choosealicense.com/licenses/unlicense/
|
||||
@ -0,0 +1,272 @@
|
||||
|
||||
理解 Linux 文件系统:ext4 以及更多文件系统
|
||||
==========================================
|
||||
|
||||

|
||||
|
||||
目前的大部分 Linux 文件系统都默认采用 ext4 文件系统, 正如以前的 Linux 发行版默认使用 ext3、ext2 以及更久前的 ext。对于不熟悉 Linux 或文件系统的朋友而言,你可能不清楚 ext4 相对于上一版本 ext3 带来了什么变化。你可能还想知道在一连串关于可替代文件系统例如 btrfs、xfs 和 zfs 不断被发布的情况下,ext4 是否仍然能得到进一步的发展 。
|
||||
|
||||
在一篇文章中,我们不可能讲述文件系统的所有方面,但我们尝试让您尽快了解 Linux 默认文件系统的发展历史,包括它的产生以及未来发展。我仔细研究了维基百科里的各种关于 ext 文件系统文章、kernel.org‘s wiki 中关于 ext4 的条目以及结合自己的经验写下这篇文章。
|
||||
|
||||
### ext 简史
|
||||
|
||||
#### MINIX 文件系统
|
||||
|
||||
在有 ext 之前, 使用的是 MINIX 文件系统。如果你不熟悉 Linux 历史, 那么可以理解为 MINIX 相对于 IBM PC/AT 微型计算机来说是一个非常小的类 Unix 系统。Andrew Tannenbaum 为了教学的目的而开发了它并于 1987 年发布了源代码(印刷版!)。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
虽然你可以读阅 MINIX 的源代码,但实际上它并不是免费的开源软件(FOSS)。出版 Tannebaum 著作的出版商要求你花 69 美元的许可费来获得 MINIX 的操作权,而这笔费用包含在书籍的费用中。尽管如此,在那时来说非常便宜,并且 MINIX 的使用得到迅速发展,很快超过了 Tannebaum 当初使用它来教授操作系统编码的意图。在整个 20 世纪 90 年代,你可以发现 MINIX 的安装在世界各个大学里面非常流行。
|
||||
而此时,年轻的 Lius Torvalds 使用 MINIX 来开发原始 Linux 内核,并于 1991 年首次公布。而后在 1992 年 12 月在 GPL 开源协议下发布。
|
||||
|
||||
但是等等,这是一篇以*文件系统*为主题的文章不是吗?是的,MINIX 有自己的文件系统,早期的 Linux 版本依赖于它。跟 MINIX 一样,Linux 的文件系统也如同玩具那般小 —— MINX 文件系统最多能处理 14 个字符的文件名,并且只能处理 64MB 的存储空间。到了 1991 年,一般的硬盘尺寸已经达到了 40-140MB。很显然,Linux 需要一个更好的文件系统。
|
||||
|
||||
#### ext
|
||||
|
||||
当 Linus 开发出刚起步的 Linux 内核时,Rémy Card 从事第一代的 ext 文件系统的开发工作。 ext 文件系统在 1992 首次实现并发布 —— 仅在 Linux 首次发布后的一年! —— ext 解决了 MINIX 文件系统中最糟糕的问题。
|
||||
|
||||
1992年的 ext 使用在 Linux 内核中的新虚拟文件系统(VFS)抽象层。与之前的 MINIX 文件系统不同的是,ext 可以处理高达 2GB 存储空间并处理 255 个字符的文件名。
|
||||
|
||||
但 ext 并没有长时间占统治地位,主要是由于它的原始时间戳(每个文件仅有一个时间戳,而不是今天我们所熟悉的有 inode 、最近文件访问时间和最新文件修改时间的时间戳。)仅仅一年后,ext2 就替代了它。
|
||||
|
||||
#### ext2
|
||||
|
||||
Rémy 很快就意识到 ext 的局限性,所以一年后他设计出 ext2 替代它。当 ext 仍然根植于 "玩具” 操作系统时,ext2 从一开始就被设计为一个商业级文件系统,沿用 BSD 的 Berkeley 文件系统的设计原理。
|
||||
|
||||
Ext2 提供了 GB 级别的最大文件大小和 TB 级别的文件系统大小,使其在 20 世纪 90 年代的地位牢牢巩固在文件系统大联盟中。很快它被广泛地使用,无论是在 Linux 内核中还是最终在 MINIX 中,且利用第三方模块可以使其应用于 MacOs 和 Windows。
|
||||
|
||||
但这里仍然有一些问题需要解决:ext2 文件系统与 20 世纪 90 年代的大多数文件系统一样,如果在将数据写入到磁盘的时候,系统发生奔溃或断电,则容易发生灾难性的数据损坏。随着时间的推移,由于碎片(单个文件存储在多个位置,物理上其分散在旋转的磁盘上),它们也遭受了严重的性能损失。
|
||||
|
||||
尽管存在这些问题,但今天 ext2 还是用在某些特殊的情况下 —— 最常见的是,作为便携式 USB 拇指驱动器的文件系统格式。
|
||||
|
||||
#### ext3
|
||||
|
||||
1998 年, 在 ext2 被采用后的 6 年后,Stephen Tweedie 宣布他正在致力于改进 ext2。这成了 ext3,并于 2001 年 11 月在 2.4.15 内核版本中被采用到 Linux 内核主线中。
|
||||
|
||||
|
||||
![Packard Bell 计算机][2]
|
||||
|
||||
20世纪90年代中期的 Packard Bell 计算机, [Spacekid][3], [CC0][4]
|
||||
|
||||
在大部分情况下,Ext2 在 Linux 发行版中做得很好,但像 FAT、FAT32、HFS 和当时的其他文件系统一样 —— 在断电时容易发生灾难性的破坏。如果在将数据写入文件系统时候发生断电,则可能会将其留在所谓 *不一致* 的状态 —— 事情只完成一半而另一半未完成。这可能导致大量文件丢失或损坏,这些文件与正在保存的文件无关甚至导致整个文件系统无法卸载。
|
||||
|
||||
Ext3 和 20 世纪 90 年代后期的其他文件系统,如微软的 NTFS ,使用*日志*来解决这个问题。 日志是磁盘上的一种特殊分配,其写入存储在事务中;如果事务完成写入磁盘,则日志中的数据将提交给文件系统它本身。如果文件在它提交操作前崩溃,则重新启动的系统识别其为未完成的事务而将其进行回滚,就像从未发生过一样。这意味着正在处理的文件可能依然会丢失,但文件系统本身保持一致,且其他所有数据都是安全的。
|
||||
|
||||
在使用 ext3 文件系统的 Linux 内核中实现了三个级别的日志记录方式:**日记(journal)** , **顺序(ordered)** , 和 **回写(writeback)**。
|
||||
|
||||
* **日记(Journal)** 是最低风险模式,在将数据和元数据提交给文件系统之前将其写入日志。这可以保证正在写入的文件与整个文件系统的一致性,但其显著降低了性能。
|
||||
* **顺序(Ordered)** 是大多数 Linux 发行版默认模式;ordered 模式将元数据写入日志且直接将数据提交到文件系统。顾名思义,这里的操作顺序是固定的:首先,元数据提交到日志;其次,数据写入文件系统,然后才将日志中关联的元数据更新到文件系统。这确保了在发生奔溃时,与未完整写入相关联的元数据仍在日志中,且文件系统可以在回滚日志时清理那些不完整的写入事务。在 ordered 模式下,系统崩溃可能导致在崩溃期间文件被主动写入或损坏,但文件系统它本身 —— 以及未被主动写入的文件 —— 确保是安全的。
|
||||
* **回写(Writeback)** 是第三种模式 —— 也是最不安全的日志模式。在 writeback 模式下,像 ordered 模式一样,元数据会被记录,但数据不会。与 ordered 模式不同,元数据和数据都可以以任何有利于获得最佳性能的顺序写入。这可以显著提高性能,但安全性低很多。尽管 wireteback 模式仍然保证文件系统本身的安全性,但在奔溃或之前写入的文件很容易丢失或损坏。
|
||||
|
||||
|
||||
跟之前的 ext2 类似,ext3 使用 16 位内部寻址。这意味着对于有着 4K 块大小的 ext3 在最大规格为 16TiB 的文件系统中可以处理的最大文件大小为 2TiB。
|
||||
|
||||
#### ext4
|
||||
|
||||
Theodore Ts'o (是当时 ext3 主要开发人员) 在 2006 年发表的 ext4 ,于两年后在 2.6.28 内核版本中被加入到了 Linux 主线。
|
||||
|
||||
Ts’o 将 ext4 描述为一个显著扩展 ext3 的临时技术,但它仍然依赖于旧技术。他预计 ext4 终将会被真正的下一代文件系统所取代。
|
||||
|
||||

|
||||
|
||||
Ext4 在功能上与 Ext3 在功能上非常相似,但大大支持文件系统、提高了对碎片的抵抗力,有更高的性能以及更好的时间戳。
|
||||
|
||||
### Ext4 vs ext3
|
||||
|
||||
Ext3 和 Ext4 有一些非常明确的差别,在这里集中讨论下。
|
||||
|
||||
#### 向后兼容性
|
||||
|
||||
Ext4 特地设计为尽可能地向后兼容 ext3。这不仅允许 ext3 文件系统升级到 ext4;也允许 ext4 驱动程序在 ext3 模式下自动挂载 ext3 文件系统,因此使它无需单独维护两个代码库。
|
||||
|
||||
#### 大文件系统
|
||||
|
||||
Ext3 文进系统使用 32 为寻址,这限制它仅支持 2TiB 文件大小和 16TiB 文件系统系统大小(这是假设在块大小为 4KiB 的情况下,一些 ext3 文件系统使用更小的块大小,因此对其进一步做了限制)。
|
||||
|
||||
Ext4 使用 48 位的内部寻址,理论上可以在文件系统上分配高达 16TiB 大小的文件,其中文件系统大小最高可达 1000 000 TiB(1EiB)。在早期 ext4 的实现中 有些用户空间的程序仍然将其限制为最大大小为 16TiB 的文件系统,但截至 2011 年,e2fsprogs 已经直接支持大于 16TiB 大小的 ext4 文件系统。例如,红帽企业 Linux 合同上仅支持最高 50TiB 的 ext4 文件系统,并建议 ext4 卷不超过 100TiB。
|
||||
|
||||
#### 分配改进
|
||||
|
||||
Ext4 在将存储块写入磁盘之前对存储块的分配方式进行了大量改进,这可以显著提高读写性能。
|
||||
|
||||
##### 区段(extent)
|
||||
|
||||
extent 是一系列连续的物理块大小 (最多达 128 MiB,假设块大小为 4KiB),可以一次性保留和寻址。使用区段可以减少给定未见所需的 inode 数量,并显著减少碎片并提高写入大文件时的性能。
|
||||
|
||||
##### 多块分配
|
||||
|
||||
Ext3 为每一个新分配的块调用一次块分配器。当多个块调用同时打开分配器时,很容易导致严重的碎片。然而,ext4 使用延迟分配,这允许它合并写入并更好地决定如何为尚未提交的写入分配块。
|
||||
|
||||
##### 持续的预分配
|
||||
|
||||
在为文件预分配磁盘空间时,大部分文件系统必须在创建时将零写入该文件的块中。Ext4 允许使用 `fallocate()`,它保证了空间的可用性(并试图为它找到连续的空间),而不需要县写入它。
|
||||
这显著提高了写入和将来读取流和数据库应用程序的写入数据的性能。
|
||||
|
||||
##### 延迟分配
|
||||
|
||||
这是一个耐人嚼味而有争议性的功能。延迟分配允许 ext4 等待分配将写入数据的实际块,直到它准备好将数据提交到磁盘。(相比之下,即使数据仍然在写入缓存,ext3 也会立即分配块。)
|
||||
|
||||
当缓存中的数据累积时,延迟分配块允许文件系统做出更好的选择。然而不幸的是,当程序员想确保数据完全刷新到磁盘时,它增加了在还没有专门编写调用 ‘fsync()’方法的程序中的数据丢失的可能性。
|
||||
|
||||
假设一个程序完全重写了一个文件:
|
||||
|
||||
`fd=open("file" ,O_TRUNC); write(fd, data); close(fd);`
|
||||
|
||||
使用旧的文件系统, `close(fd);` 足以保证 `file` 中的内存刷新到磁盘。即使严格来说,写不是事务性的,但如果文件关闭后发生崩溃,则丢失数据的风险很小。如果写入不成功(由于程序上的错误、磁盘上的错误、断电等),文件的原始版本和较新版本都可能丢失数据或损坏。如果其他进程在写入文件时访问文件,则会看到损坏的版本。
|
||||
如果其他进程打开文件并且不希望其内容发生更改 —— 例如,映射到多个正在运行的程序的共享库。这些进程可能会崩溃。
|
||||
|
||||
为了避免这些问题,一些程序员完全避免使用 `O_TRUNC`。相反,他们可能会写入一个新文件,关闭它,然后将其重命名为旧文件名:
|
||||
|
||||
`fd=open("newfile"); write(fd, data); close(fd); rename("newfile", "file");`
|
||||
|
||||
在没有延迟分配的文件系统下,这足以避免上面列出的潜在的损坏和崩溃问题:因为`rename()` 是原子操作,所以它不会被崩溃中断;并且运行的程序将引用旧的。现在 `file` 的未链接版本主要有一个打开的文件文件句柄即可。
|
||||
但是因为 ext4 的延迟分配会导致写入被延迟和重新排序,`rename("newfile","file")` 可以在 `newfile` 的内容实际写入磁盘内容之前执行,这打开了并行进行再次获得 `file` 坏版本的问题。
|
||||
|
||||
|
||||
为了缓解这种情况,Linux 内核(自版本 2.6.30 )尝试检测这些常见代码情况并强制立即分配。这减少但不能防止数据丢失的可能性 —— 并且它对新文件没有任何帮助。如果你是一位开发人员,请注意:
|
||||
|
||||
保证数据立即写入磁盘的方法是正确调用 `fsync()` 。
|
||||
|
||||
#### 无限制的子目录
|
||||
|
||||
Ext3 仅限于 32000 个子目录;ext4 允许无限数量的子目录。从 2.6.23 内核版本开始,ext4 使用 HTree 索引来减少大量子目录的性能损失。
|
||||
|
||||
#### 日志校验
|
||||
|
||||
Ext3 没有对日志进行校验,这给内核直接控制之外的磁盘或控制器设备带来了自己的缓存问题。如果控制器或具有子集对缓存的磁盘确实无序写入,则可能会破坏 ext3 的日记事务顺序,
|
||||
从而可能破坏在崩溃期间(或之前一段时间)写入的文件。
|
||||
|
||||
理论上,这个问题可以使用 write barriers —— 在安装文件系统时,你在挂载选项设置 `barrier=1` ,然后将设备 `fsync` 一直向下调用直到 metal。通过实践,可以发现存储设备和控制器经常不遵守 write barriers —— 提高性能(和 benchmarks,跟竞争对手比较),但增加了本应该防止数据损坏的可能性。
|
||||
|
||||
对日志进行校验和允许文件系统奔溃后意识到其某些条目在第一次安装时无效或无序。因此,这避免了即使部分存储设备不存在 barriers ,也会回滚部分或无序日志条目和进一步损坏的文件系统的错误。
|
||||
|
||||
#### 快速文件系统检查
|
||||
|
||||
在 ext3 下,整个文件系统 —— 包括已删除或空文件 —— 在 `fsck` 被调用时需要检查。相比之下,ext4 标记了未分配块和 inode 表的小部分,从而允许 `fsck` 完全跳过它们。
|
||||
这大大减少了在大多数文件系统上运行 `fsck` 的时间,并从内核 2.6.24 开始实现。
|
||||
|
||||
#### 改进的时间戳
|
||||
|
||||
Ext3 提供粒度为一秒的时间戳。虽然足以满足大多数用途,但任务关键型应用程序经常需要更严格的时间控制。Ext4 通过提供纳秒级的时间戳,使其可用于那些企业,科学以及任务关键型的应用程序。
|
||||
|
||||
Ext3文件系统也没有提供足够的位来存储 2038 年 1 月 18 日以后的日期。Ext4 在这里增加了两位,将 [the Unix epoch][5] 扩展了 408 年。如果你在公元 2446 年读到这篇文章,
|
||||
你很有可能已经转移到一个更好的文件系统 —— 如果你还在测量 UTC 00:00,1970 年 1 月 1 日以来的时间,这会让我非常非常高兴。
|
||||
|
||||
#### 在线碎片整理
|
||||
|
||||
ext2 和 ext3 都不直接支持在线碎片整理 —— 即在挂载时会对文件系统进行碎片整理。Ext2 有一个包含的实用程序,**e2defrag**,它的名字暗示 —— 它需要在文件系统未挂载时脱机运行。(显然,这对于根文件系统来说非常有问题。)在 ext3 中的情况甚至更糟糕 —— 虽然 ext3 比 ext2 更不容易受到严重碎片的影响,但 ext3 文件系统运行 **e2defrag** 可能会导致灾难性损坏和数据丢失。
|
||||
|
||||
尽管 ext3 最初被认为“不受碎片影响”,但对同一文件(例如 BitTorrent)采用大规模并行写入过程的过程清楚地表明情况并非完全如此。一些用户空间攻击和解决方法,例如 [Shake][6],
|
||||
以这种或那种方式解决了这个问题 —— 但它们比真正的、文件系统感知的、内核级碎片整理过程更慢并且在各方面都不太令人满意。
|
||||
|
||||
Ext4通过 **e4defrag** 解决了这个问题,且是一个在线、内核模式、文件系统感知、块和范围级别的碎片整理实用程序。
|
||||
|
||||
### 正在进行的ext4开发
|
||||
|
||||
Ext4,正如 Monty Python 中瘟疫感染者曾经说过的那样,“我还没死呢!” 虽然它的[主要开发人员][7]认为它只是一个真正的[下一代文件系统][8]的权宜之计,但是在一段时间内,没有任何可能的候选人准备好(由于技术或许可问题)部署为根文件系统。
|
||||
|
||||
在未来的 ext4 版本中仍然有一些关键功能,包括元数据校验和、一流的配额支持和大型分配块。
|
||||
|
||||
#### 元数据校验和
|
||||
|
||||
由于 ext4 具有冗余超级块,因此为文件系统校验其中的元数据提供了一种方法,可以自行确定主超级块是否已损坏并需要使用备用块。可以在没有校验和的情况下,从损坏的超级块恢复 —— 但是用户首先需要意识到它已损坏,然后尝试使用备用方法手动挂载文件系统。由于在某些情况下,使用损坏的主超级块安装文件系统读写可能会造成进一步的损坏,即使是经验丰富的用户也无法避免,这也不是一个完美的解决方案!
|
||||
|
||||
与 btrfs 或 zfs 等下一代文件系统提供的极其强大的每块校验和相比,ext4 的元数据校验和功能非常弱。但它总比没有好。虽然校验和所有的事情都听起来很简单!—— 事实上,将校验和连接到文件系统有一些重大的挑战; 请参阅[设计文档][9]了解详细信息。
|
||||
|
||||
#### 一流的配额支持
|
||||
|
||||
等等,配额?!从 ext2 出现的那条开始我们就有了这些!是的,但他们一直都是事后的想法,而且他们总是有点傻逼。这里可能不值得详细介绍,
|
||||
但[设计文档][10]列出了配额将从用户空间移动到内核中的方式,并且能够更加正确和高效地执行。
|
||||
|
||||
#### 大分配块
|
||||
随着时间的推移,那些讨厌的存储系统不断变得越来越大。由于一些固态硬盘已经使用 8K 硬件模块,因此 ext4 对 4K 模块的当前限制越来越受到限制。
|
||||
较大的存储块可以显着减少碎片并提高性能,代价是增加“松弛”空间(当您只需要块的一部分来存储文件或文件的最后一块时留下的空间)。
|
||||
|
||||
您可以在[设计文档][11]中查看详细说明。
|
||||
|
||||
### ext4的实际限制
|
||||
|
||||
Ext4 是一个健壮,稳定的文件系统。它是大多数人应该都在 2018 年用它作为根文件系统,但它无法处理所有需求。让我们简单地谈谈你不应该期待的一些事情 —— 现在或可能在未来。
|
||||
|
||||
虽然 ext4 可以处理高达 1 EiB 大小相当于 1,000,000 TiB 大小的数据,但你真的、真的不应该尝试这样做。除了仅仅能够记住更多块的地址之外,还存在规模上的问题
|
||||
并且现在 ext4 不会处理(并且可能永远不会)超过 50 —— 100TiB 的数据。
|
||||
|
||||
Ext4 也不足以保证数据的完整性。随着日志记录的重大进展又回到了前 3 天,它并未涵盖数据损坏的许多常见原因。如果数据已经在磁盘上被[破坏][12]——由于故障硬件,
|
||||
宇宙射线的影响(是的,真的),或者数据随时间的简单降级 —— ext4无法检测或修复这种损坏。
|
||||
|
||||
最后两点是,ext4 只是一个纯文件系统,而不是存储卷管理器。这意味着,即使你有多个磁盘 ——也就是奇偶校验或冗余,理论上你可以从 ext4 中恢复损坏的数据,但无法知道使用它是否对你有利。虽然理论上可以在离散层中分离文件系统和存储卷管理系统而不会丢失自动损坏检测和修复功能,但这不是当前存储系统的设计方式,并且它将给新设计带来重大挑战。
|
||||
|
||||
### 备用文件系统
|
||||
在我们开始之前,提醒一句:要非常小心这是没有内置任何备用的文件系统,并直接支持为您分配的主线内核的一部分!
|
||||
|
||||
即使文件系统是安全的,如果在内核升级期间出现问题,使用它作为根文件系统也是非常可怕的。如果你没有充分的想法通过一个 chroot 去使用介质引导,耐心地操作内核模块和 grub 配置,
|
||||
和 DKMS...不要在一个很重要的系统中去掉对根文件的备份。
|
||||
|
||||
可能有充分的理由使用您的发行版不直接支持的文件系统 —— 但如果您这样做,我强烈建议您在系统启动并可用后再安装它。
|
||||
(例如,您可能有一个 ext4 根文件系统,但是将大部分数据存储在 zfs 或 btrfs 池中。)
|
||||
|
||||
#### XFS
|
||||
|
||||
XFS 与 非 ext 文件系统在Linux下的主线一样。它是一个 64 位的日志文件系统,自 2001 年以来内置于 Linux 内核中,为大型文件系统和高度并发性提供了高性能
|
||||
(即,大量的进程都会立即写入文件系统)。
|
||||
|
||||
从 RHEL 7开始,XFS 成为 Red Hat Enterprise Linux 的默认文件系统。对于家庭或小型企业用户来说,它仍然有一些缺点 —— 最值得注意的是,重新调整现有 XFS 文件系统
|
||||
是一件非常痛苦的事情,不如创建另一个并复制数据更有意义。
|
||||
|
||||
虽然 XFS 是稳定且是高性能的,但它和 ext4 之间没有足够的具体的最终用途差异来推荐它在非默认值的任何地方使用(例如,RHEL7),除非它解决了对 ext4 的特定问题,例如> 50 TiB容量的文件系统。
|
||||
|
||||
XFS 在任何方面都不是 ZFS,btrfs 甚至 WAFL(专有 SAN 文件系统)的“下一代”文件系统。就像 ext4 一样,它应该被视为一种更好的方式的权宜之计。
|
||||
|
||||
#### ZFS
|
||||
|
||||
ZFS 由 Sun Microsystems 开发,以 zettabyte 命名 —— 相当于 1 万亿 GB —— 因为它理论上可以解决大型存储系统。
|
||||
|
||||
作为真正的下一代文件系统,ZFS 提供卷管理(能够在单个文件系统中处理多个单独的存储设备),块级加密校验和(允许以极高的准确率检测数据损坏),
|
||||
[自动损坏修复][12](其中冗余或奇偶校验存储可用),[快速异步增量复制][13],内联压缩等,[还有更多][14]。
|
||||
|
||||
从 Linux 用户的角度来看,ZFS 的最大问题是许可证问题。ZFS 许可证是 CDDL 许可证,这是一种与 GPL 冲突的半许可许可证。关于在 Linux 内核中使用 ZFS 的意义存在很多争议,
|
||||
其争议范围从“它是 GPL 违规”到“它是 CDDL 违规”到“它完全没问题,它还没有在法庭上进行过测试。 “ 最值得注意的是,自2016 年以来,Canonical 已将 ZFS 代码内联
|
||||
在其默认内核中,而且目前尚无法律挑战。
|
||||
|
||||
此时,即使我作为一个非常狂热于 ZFS 的用户,我也不建议将 ZFS 作为 Linux的 root 文件系统。如果你想在 Linux 上利用 ZFS 的优势,在 ext4 上设置一个小的根文件系统,
|
||||
然后将 ZFS 放在你剩余的存储上,把数据,应用程序以及你喜欢的东西放在它上面 —— 但在 ext4 上保持 root,直到你的发行版明显支持 zfs 根目录。
|
||||
|
||||
#### BTRFS
|
||||
|
||||
Btrfs 是 B-Tree Filesystem 的简称,通常发音为 “butter” —— 由 Chris Mason 于 2007 年在 Oracle 任职期间宣布。BTRFS 旨在跟 ZFS 有大部分相同的目标,
|
||||
提供多种设备管理,每块校验、异步复制、直列压缩等,[还有更多][8]。
|
||||
|
||||
截至 2018 年,btrfs 相当稳定,可用作标准的单磁盘文件系统,但可能不应该依赖于卷管理器。与许多常见用例中的 ext4,XFS 或 ZFS 相比,它存在严重的性能问题,
|
||||
其下一代功能 —— 复制(replication),多磁盘拓扑和快照管理 —— 可能非常多,其结果可能是从灾难性地性能降低到实际数据的丢失。
|
||||
|
||||
btrfs 的持续状态是有争议的; SUSE Enterprise Linux 在 2015 年采用它作为默认文件系统,而 Red Hat 宣布它将不再支持从 2017 年开始使用 RHEL 7.4 的 btrfs。
|
||||
可能值得注意的是,生产,支持的 btrfs 部署将其用作单磁盘文件系统,而不是作为一个多磁盘卷管理器 —— a la ZFS —— 甚至 Synology 在它的存储设备使用 BTRFS,
|
||||
但是它在传统 Linux 内核 RAID(mdraid)之上分层来管理磁盘。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/ext4-filesystem
|
||||
|
||||
作者:[Jim Salter][a]
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-salter
|
||||
[1]:https://opensource.com/file/391546
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/packard_bell_pc.jpg?itok=VI8dzcwp (Packard Bell computer)
|
||||
[3]:https://commons.wikimedia.org/wiki/File:Old_packard_bell_pc.jpg
|
||||
[4]:https://creativecommons.org/publicdomain/zero/1.0/deed.en
|
||||
[5]:https://en.wikipedia.org/wiki/Unix_time
|
||||
[6]:https://vleu.net/shake/
|
||||
[7]:http://www.linux-mag.com/id/7272/
|
||||
[8]:https://arstechnica.com/information-technology/2014/01/bitrot-and-atomic-cows-inside-next-gen-filesystems/
|
||||
[9]:https://ext4.wiki.kernel.org/index.php/Ext4_Metadata_Checksums
|
||||
[10]:https://ext4.wiki.kernel.org/index.php/Design_For_1st_Class_Quota_in_Ext4
|
||||
[11]:https://ext4.wiki.kernel.org/index.php/Design_for_Large_Allocation_Blocks
|
||||
[12]:https://en.wikipedia.org/wiki/Data_degradation#Visual_example_of_data_degradation
|
||||
[13]:https://arstechnica.com/information-technology/2015/12/rsync-net-zfs-replication-to-the-cloud-is-finally-here-and-its-fast/
|
||||
[14]:https://arstechnica.com/information-technology/2014/02/ars-walkthrough-using-the-zfs-next-gen-filesystem-on-linux/
|
||||
@ -1,57 +0,0 @@
|
||||
CIP:延续 Linux 之光
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
现如今,现代民用基础设施遍及各处 —— 发电厂、雷达系统、交通信号灯、水坝和天气系统等。这些基础设施项目已然存在数十年,这些设施还将继续提供更长时间的服务,所以安全性和使用寿命是至关重要的。
|
||||
|
||||
|
||||
并且,其中许多系统都是由 Linux 提供支持,它为技术提供商提供了对这些问题的更多控制。然而,如果每个提供商都在构建自己的解决方案,这可能会导致分散和重复工作。因此,[民用基础设施平台(CIP)][1]最首要的目标是创造一个开源基础层,提供给工业设施,例如嵌入式控制器或是网关设备。
|
||||
|
||||
Yoshitake Kobayashi,担任 CIP 的技术指导委员会主席说过,“我们在这个领域有一种非常保守的文化,因为一旦我们建立了一个系统,它必须得到长达十多年的支持,在某些情况下超过 60 年。这就是为什么这个项目被创建的原因,因为这个行业的每个使用者都有同样的问题,即能够长时间使用 Linux。”
|
||||
|
||||
CIP 的架构是创建一个基础系统,能够在控制器上使用开源软件。其中,该基础层包括 Linux 内核和一系列常见的开源软件如 libc、busybox 等。由于软件的使用寿命是一个最主要的问题,CIP 选择使用 Linux 4.4 版本的内核,这是一个由 Greg Kroah-Hartman 维护的长期支持版本。
|
||||
|
||||
### 合作
|
||||
|
||||
由于 CIP 有上游优先政策,因此他们在项目中需要的代码必须位于上游内核中。为了与内核社区建立积极的反馈循环,CIP聘请 Ben Hutchings 作为 CIP 的官方维护者。Hutchings以他在Debian LTS 版本上所做的工作而闻名,这也促成了 CIP 与 Debian 项目之间的官方合作。
|
||||
|
||||
在新的合作下,CIP 将使用 Debian LTS 版本构建平台。 CIP 还将支持 Debian 长期支持版本(LTS),延长所有 Debian 稳定版的生命周期。CIP 还将与 Freexian 进行密切合作,后者是一家围绕 Debian LTS 版本提供商业服务的公司。这两个组织将专注于嵌入式系统的开源软件的操作性、安全性和维护。CIP 还会为一些 Debian LTS 版本提供资金支持。
|
||||
|
||||
Chris Lamb,Debian 项目负责人表示,“我们对此次合作以及 CIP 对 Debian LTS 项目的支持感到非常兴奋,这样将使支持生命周期延长至五年以上。我们将一起致力于为用户提供长期支持,并为未来的城市奠定基础。”
|
||||
|
||||
### 安全性
|
||||
|
||||
|
||||
Kobayashi 说过,其中最需要担心的是安全性。虽然出于明显的安全原因,大部分民用基础设施没有接入互联网(你肯定不想让一座核电站连接到互联网),况且也存在其他风险。
|
||||
|
||||
仅仅因为系统本身没有连接到互联网,这并不意味着能避开所有危险。其他系统,比如个人移动电脑也能够通过接入互联网而间接入侵到本地系统中。如若有人收到一封带有恶意文件作为电子邮件的附件,这将会“污染”系统内部的基础设备。
|
||||
|
||||
因此,保持所有软件在这些控制器上运行是最新的并且完全修补是至关重要的。为了确保安全性,CIP 还向后移植了内核自我保护项目的许多组件。CIP还遵循最严格的网络安全标准之一 —— IEC 62443,该标准定义了软件的流程和相应的测试,以确保系统更安全。
|
||||
|
||||
|
||||
### 展望未来
|
||||
|
||||
|
||||
随着 CIP 日趋成熟,官方正在加大与各个 Linux 提供商的合作力度。除了与 Debian 和 freexian 的合作外,CIP最近还邀请了企业 Linux 操作系统供应商 Cybertrust Japan Co., Ltd. 作为新的银牌成员。
|
||||
|
||||
Cybertrust 与其他行业领军者合作,如西门子,东芝,Codethink,日立,Moxa,Plat'Home 和瑞萨,致力于打造在未来数十年里,一个可靠、安全的基于 Linux 的嵌入式软件平台。
|
||||
|
||||
这些公司在 CIP 的保护下所进行的工作,将确保管理我们现代社会中的民用基础设施的完整性。
|
||||
|
||||
想要了解更多信息,请访问 [民用基础设施官网][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/cip-keeping-lights-linux
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.cip-project.org/
|
||||
@ -0,0 +1,51 @@
|
||||
那些数据对于云来说风险太大?
|
||||
======
|
||||
|
||||

|
||||
|
||||
在这个由四部分组成的系列文章中,我们一直在关注每个组织在将操作转换到云时应避免的陷阱 - 特别是混合多云环境。
|
||||
在第一部分中,我们介绍了基本定义以及我们对混合云和多云的看法,确保显示两者之间的分界线。 在第二部分中,我们讨论了三个陷阱中的第一个:为什么成本并不总是成为迁移到云的明显动力。 而且,在第三部分中,我们研究了将所有工作负载迁移到云的可行性。
|
||||
最后,在第四部分中,我们将研究如何处理云中的数据。 您应该将数据移动到云中吗? 多少? 什么数据在云中起作用,是什么造成移动风险太大?
|
||||
|
||||
### 数据... 数据... 数据...
|
||||
影响您对云中数据的所有决策的关键因素是确定您的带宽和存储需求。 Gartner预计“数据存储将在2018年成为[1730亿美元] [4]业务”,其中大部分资金浪费在不必要的容量上:“全球公司只需优化工作量就可以节省620亿美元的IT成本。” 根据Gartner的研究,令人惊讶的是,公司“为云服务平均支付的费用比他们实际需要的多36%”。
|
||||
如果您已经阅读了本系列的前三篇文章,那么您不应该对此感到惊讶。 然而,令人惊讶的是,Gartner的结论是,“如果他们将服务器数据直接转移到云上,只有25%的公司会省钱。”
|
||||
等一下......工作负载可以针对云进行优化,但只有一小部分公司会通过将数据迁移到云来节省资金吗? 这是什么意思?
|
||||
如果您认为云提供商通常会根据带宽收取费率,那么将所有内部部署数据移至云中很快就会成为成本负担。 有三种情况,公司决定将数据放入云中是值得的:
|
||||
|
||||
具有存储和应用程序的单个云
|
||||
|
||||
云中的应用程序,内部存储
|
||||
|
||||
云中的应用程序和缓存在云中的数据,以及内部存储
|
||||
|
||||
|
||||
在第一种情况下,通过将所有内容保留在单个云供应商中来降低带宽成本。 但是,这会产生锁定,这通常与CIO的云战略或风险防范计划相悖。
|
||||
第二种方案仅保留应用程序在云中收集的数据,并将最小值传输到本地存储。 这需要仔细考虑的策略,其中只有使用最少数据的应用程序部署在云中。
|
||||
在第三种情况下,数据缓存在云中,应用程序和存储的数据,或存储在内部的“一个事实”。 这意味着分析,人工智能和机器学习可以在内部运行,而无需将数据上传到云提供商,然后在处理后再返回。 缓存数据仅基于应用程序需求,甚至可以跨多云部署进行缓存。
|
||||
|
||||
要获得更多信息,请下载红帽[案例研究] [5],其中描述了跨混合多云环境的阿姆斯特丹史基浦机场数据,云和部署策略。
|
||||
### 数据危险
|
||||
大多数公司都认识到他们的数据是他们在市场上的专有优势,智能能力。 因此,他们非常仔细地考虑了它的储存地点。
|
||||
想象一下这种情况:你是一个零售商,全球十大零售商之一。 您已经计划了一段时间的云战略,并决定使用亚马逊的云服务。 突然,[亚马逊购买了Whole Foods] [6]并且正在进入你的市场。
|
||||
一夜之间,亚马逊已经增长到零售规模的50%。 您是否信任其零售数据的云? 如果您的数据已经在亚马逊云中,您会怎么做? 您是否使用退出策略创建了云计划? 虽然亚马逊可能永远不会利用您的数据的潜在见解 - 该公司甚至有针对此的协议 - 你能相信今天世界上任何人的话吗?
|
||||
### 陷阱分享,避免陷阱
|
||||
分享我们在经验中看到的一些陷阱应该有助于您的公司规划更安全,更安全,更持久的云战略。 了解[成本不是明显的激励因素] [2],[并非一切都应该在云中] [3],并且您必须在云中有效地管理数据才是您成功的关键。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/data-risky-cloud
|
||||
|
||||
作者:[Eric D.Schabell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekmar](https://github.com/geekmar)
|
||||
校对:[geekmar](https://github.com/geekmar)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eschabell
|
||||
[1]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
|
||||
[2]:https://opensource.com/article/18/6/reasons-move-to-cloud
|
||||
[3]:https://opensource.com/article/18/7/why-you-cant-move-everything-cloud
|
||||
[4]:http://www.businessinsider.com/companies-waste-62-billion-on-the-cloud-by-paying-for-storage-they-dont-need-according-to-a-report-2017-11
|
||||
[5]:https://www.redhat.com/en/resources/amsterdam-airport-schiphol-case-study
|
||||
[6]:https://www.forbes.com/sites/ciocentral/2017/06/23/amazon-buys-whole-foods-now-what-the-story-behind-the-story/#33e9cc6be898
|
||||
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,174 @@
|
||||
逐层拼接云原生栈
|
||||
======
|
||||
在 Packet,我们的价值(自动化的基础设施)是非常基础的。因此,我们花费大量的时间来研究我们之上所有生态系统中的参与者和趋势 —— 以及之下的极少数!
|
||||
|
||||
当你在任何生态系统的汪洋大海中徜徉时,很容易困惑或迷失方向。我知道这是事实,因为当我去年进入 Packet 工作时,从 Bryn Mawr 获得的英语学位,并没有让我完全得到一个 Kubernetes 的认证。 :)
|
||||
|
||||
由于它超快的演进和巨大的影响,云原生生态系统打破了先例。似乎每眨一次眼睛,之前全新的技术(更不用说所有相关的理念了)就变得有意义 ... 或至少有趣了。和其他许多人一样,我依据无处不在的 CNCF 的 “[云原生蓝图][1]” 作为我去了解这个空间的参考标准。尽管如此,如果有一个定义这个生态系统的元素,那它一定是贡献和控制他们的人。
|
||||
|
||||
所以,在 12 月份一个很冷的下午,当我们走回办公室时,我们偶然发现了一个给投资人解释“云原生”的创新方式,当我们谈到从 Aporeto 中区分 Cilium 的细微差别时,他的眼睛中充满了兴趣,以及为什么从 CoreDNS 和 Spiffe 到 Digital Rebar 和 Fission 的所有这些都这么有趣。
|
||||
|
||||
在新世贸中心的阴影下,看到我们位于 13 层的狭窄办公室,我突然想到一个好主意,把我们带到《兔子洞》的艺术世界中:为什么不把它画出来呢?
|
||||
|
||||
![][2]
|
||||
|
||||
于是,我们开始了把云原生栈逐层拼接起来的旅程。让我们一起探索它,并且我们可以给你一个“仅限今日”的低价。
|
||||
|
||||
[[查看高清大图][3]] 或给我们发邮件索取副本。
|
||||
|
||||
### 从最底层开始
|
||||
|
||||
当我们开始下笔的时候,我们知道,我们希望首先亮出的是每天都与之交互的栈的那一部分,但它对用户却是不可见的:硬件。就像任何投资于下一个伟大的(通常是私有的)东西的秘密实验室一样,我们认为地下室是最好的地点。
|
||||
|
||||
从大家公认的像 Intel、AMD 和华为(传言他们雇佣的工程师接近 80000 名)这样的巨头,到像 Mellanox 这样的细分市场参与者,硬件生态系统现在非常火。事实上,随着数十亿美元投入去攻克新的 offloads、GPU、定制协处理器,我们可能正在进入硬件的黄金时代。
|
||||
|
||||
著名的软件先驱 Alan Kay 在 25 年前说过:“对软件非常认真的人都应该去制造他自己的硬件” ,为 Alan 打 call!
|
||||
|
||||
### 云即资本
|
||||
|
||||
就像我们的 CEO Zac Smith 多次告诉我:所有都是钱的问题。不仅要制造它,还要消费它!在云中,数十亿美元的投入才能让数据中心出现计算机,这样才能让开发者使用软件去消费它。换句话说:
|
||||
|
||||
|
||||
![][4]
|
||||
|
||||
我们认为,对于“银行”(即能让云运转起来的借款人或投资人)来说最好的位置就是一楼。因此我们将大堂改造成银行家的咖啡馆,以便为所有的创业者提供幸运之轮。
|
||||
|
||||
![][5]
|
||||
|
||||
### 连通和动力
|
||||
|
||||
如果金钱是燃料,那么消耗大量燃料的引擎就是数据中心供应商和连接它们的网络。我们称他们为“动力”和“连通”。
|
||||
|
||||
从像 Equinix 这样处于核心的和像 Vapor.io 这样的接入新贵,到 Verizon、Crown Castle 和其它的处于地下(或海底)的“管道”,这是我们所有的栈都依赖但很少有人能看到的一部分。
|
||||
|
||||
因为我们花费大量的时间去研究数据中心和连通性,需要注意的一件事情是,这一部分的变化非常快,尤其是在 5G 正式商用时,某些负载开始不再那么依赖中心化的基础设施了。
|
||||
|
||||
接入即将到来! :-)
|
||||
|
||||
![][6]
|
||||
|
||||
### 嗨,它就是基础设施!
|
||||
|
||||
居于“连接”和“动力”之上的这一层,我们爱称为“处理器们”。这是奇迹发生的地方 —— 我们将来自下层的创新和实物投资转变成一个 API 尽头的某些东西。
|
||||
|
||||
由于这是纽约的一个大楼,我们让在这里的云供应商处于纽约的中心。这就是为什么你会看到(Digital Ocean 系的)鲨鱼 Sammy 和在 Google 之上的 “meet me” 的房间中和我打招呼的原因了。
|
||||
|
||||
正如你所见,这个场景是非常写实的。它就是一垛一垛堆起来的。尽管我们爱 EWR1 的设备经理(Michael Pedrazzini),我们努力去尽可能减少这种体力劳动。毕竟布线专业的博士学位是很难拿到的。
|
||||
|
||||
![][7]
|
||||
|
||||
### 供给
|
||||
|
||||
再上一层,在基础设施层之上是供给层。这是我们最喜欢的地方之一,它以前被我们称为“配置管理”。但是现在到处都是一开始就是不可改变的基础设施和自动化:Terraform、Ansible、Quay.io 等等类似的东西。你可以看出软件是按它的方式来工作的,对吗?
|
||||
|
||||
Kelsey Hightower 最近写道“呆在无聊的基础设施中是一个让人兴奋的时刻”,我不认为它说的是物理部分(虽然我们认为它非常让人兴奋),但是由于软件持续侵入到栈的所有层,可以保证你有一个疯狂的旅程。
|
||||
|
||||
![][8]
|
||||
|
||||
### 操作系统
|
||||
|
||||
供应就绪后,我们来到操作系统层。这就是我们开始取笑我们最喜欢的一个人的地方:注意上面 Brian Redbeard 的瑜珈姿势。:)
|
||||
|
||||
Packet 为我们的客户提供了 11 种主要的操作系统去选择,包括一些你在图中看到的:Ubuntu、CoreOS、FreeBSD、Suse、和各种 Red Hat 的作品。我们看到越来越多的人们在这一层上有了他们自己的看法:从定制的内核和为了不可改变的部署而使用的他们最喜欢的发行版,到像 NixOS 和 LinuxKit 这样的项目。
|
||||
|
||||
![][9]
|
||||
|
||||
### 运行时
|
||||
|
||||
我们玩的很开心,因此我们将运行时放在了体育馆内,并在 CoreOS 赞助的 rkt 和 Docker 的容器化之间进行了一场锦标赛。无论哪种方式赢家都是 CNCF!
|
||||
|
||||
我们认为快速演进的存储生态系统应该得到一些可上锁的储物柜。关于存储部分有趣的地方在于许多的新玩家尝试去解决持久性的挑战问题,以及性能和灵活性问题。就像他们说的:存储很简单。
|
||||
|
||||
![][10]
|
||||
|
||||
### 编排
|
||||
|
||||
在过去的这些年里,编排层所有都是关于 Kubernetes 的,因此我们选取了其中一位著名的布道者(Kelsey Hightower),并在这个古怪的会议场景中给他一个特写。在我们的团队中有一些主要的 Nomad 粉丝,并且如果没有 Docker 和它的工具集的影响,根本就没有办法去考虑云原生空间。
|
||||
|
||||
虽然负载编排应用程序在我们栈中的地位非常高,我们看到的各种各样的证据表明,这些强大的工具开始去深入到栈中,以帮助用户利用 GPU 和其它特定硬件的优势。请继续关注 —— 我们正处于容器化革命的早期阶段!
|
||||
|
||||
![][11]
|
||||
|
||||
### 平台
|
||||
|
||||
这是栈中我们喜欢的层之一,因为每个平台都有很多技能帮助用户去完成他们想要做的事情(顺便说一下,不是去运行容器,而是运行应用程序)。从 Rancher 和 Kontena,到 Tectonic 和 Redshift 都是像 Cycle.io 和 Flynn.io 一样是完全不同的方法 —— 我们看到这些项目如何以不同的方式为用户提供服务,总是激动不已。
|
||||
|
||||
关键点:这些平台是帮助去转化各种各样的云原生生态系统的快速变化部分给用户。很高兴能看到他们每个人带来的东西!
|
||||
|
||||
![][12]
|
||||
|
||||
### 安全
|
||||
|
||||
当说到安全时,今年是很忙的一年!我们尝试去展示一些很著名的攻击,并说明随着工作负载变得更加分散和更加便携(当然,同时攻击也变得更加智能),这些各式各样的工具是如何去帮助保护我们的。
|
||||
|
||||
我们看到一个用于不可信环境(Aporeto)和低级安全(Cilium)的强大动作,以及尝试在网络级别上的像 Tigera 这样的可信方法。不管你的方法如何,记住这一点:关于安全这肯定不够。:0
|
||||
|
||||
![][13]
|
||||
|
||||
### 应用程序
|
||||
|
||||
如何去表示海量的、无限的应用程序生态系统?在这个案例中,很容易:我们在纽约,选我们最喜欢的。;) 从 Postgres “房间里的大象” 和 Timescale 时钟,到鬼鬼崇崇的 ScyllaDB 垃圾桶和 chillin 的《特拉维斯兄弟》—— 我们把这个片子拼到一起很有趣。
|
||||
|
||||
让我们感到很惊奇的一件事情是:很少有人注意到那个复印他的屁股的家伙。我想现在复印机已经不常见了吧?
|
||||
|
||||
![][14]
|
||||
|
||||
### 可观测性
|
||||
|
||||
由于我们的工作负载开始到处移动,规模也越来越大,这里没有一件事情能够像一个非常好用的 Grafana 仪表盘、或方便的 Datadog 代理让人更加欣慰了。由于复杂度的提升,“SRE” 的产生开始越来越多地依赖警报和其它情报事件去帮我们感知发生的事件,以及获得越来越多的自我修复的基础设施和应用程序。
|
||||
|
||||
在未来的几个月或几年中,我们将看到什么样的公司进入这一领域 … 或许是一些人工智能、区块链、机器学习支撑的仪表盘?:-)
|
||||
|
||||
![][15]
|
||||
|
||||
### 流量管理
|
||||
|
||||
人们倾向于认为互联网“只是工作而已”,但事实上,我们很惊讶于它的工作方式。我的意思是,大规模的独立的网络的一个松散连接 —— 你不是在开玩笑吧?
|
||||
|
||||
能够把所有的这些独立的网络拼接到一起的一个原因是流量管理、DNS 和类似的东西。随着规模越来越大,这些参与者帮助让互联网变得更快、更安全、同时更具弹性。我们尤其高兴的是看到像 Fly.io 和 NS1 这样的新贵与优秀的老牌参与者进行竞争,最后的结果是整个生态系统都得以提升。让竞争来的更激烈吧!
|
||||
|
||||
![][16]
|
||||
|
||||
### 用户
|
||||
|
||||
如果没有非常棒的用户,技术栈还有什么用呢?确实,它们位于大量的创新之上,但在云原生的世界里,他们所做的远不止消费这么简单:他们设计和贡献。从像 Kubernetes 这样的大量的贡献者到越来越多的(但同样重要)更多方面,我们都是其中的非常棒的一份子。
|
||||
|
||||
在我们屋顶的客厅上的许多用户,比如 Ticketmaster 和《纽约时报》,而不仅仅是新贵:这些组织采用了一种新的方式去部署和管理他们的应用程序,并且他们自己的用户正在收获回报。
|
||||
|
||||
![][17]
|
||||
|
||||
### 最后的但并非是不重要的,成熟的监管!
|
||||
|
||||
在以前的生态系统中,基金会扮演了一个“在场景背后”的非常被动的角色。而 CNCF 不是!他们的目标(构建一个健壮的云原生生态系统),被美妙的流行动向所推动 —— 他们不仅已迎头赶上还一路领先。
|
||||
|
||||
从坚实的管理和一个经过深思熟虑的项目组,到提出像 CNCF 这样的蓝图,CNCF 横跨云 CI、Kubernetes 认证、和演讲者委员会 —— CNCF 已不再是 “仅仅” 受欢迎的 KubeCon + CloudNativeCon 了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.packet.net/blog/splicing-the-cloud-native-stack/
|
||||
|
||||
作者:[Zoe Allen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.packet.net/about/zoe-allen/
|
||||
[1]:https://landscape.cncf.io/landscape=cloud
|
||||
[2]:https://assets.packet.net/media/images/PIFg-30.vesey.street.ny.jpg
|
||||
[3]:https://www.dropbox.com/s/ujxk3mw6qyhmway/Packet_Cloud_Native_Building_Stack.jpg?dl=0
|
||||
[4]:https://assets.packet.net/media/images/3vVx-there.is.no.cloud.jpg
|
||||
[5]:https://assets.packet.net/media/images/X0b9-the.bank.jpg
|
||||
[6]:https://assets.packet.net/media/images/2Etm-ping.and.power.jpg
|
||||
[7]:https://assets.packet.net/media/images/C800-infrastructure.jpg
|
||||
[8]:https://assets.packet.net/media/images/0V4O-provisioning.jpg
|
||||
[9]:https://assets.packet.net/media/images/eMYp-operating.system.jpg
|
||||
[10]:https://assets.packet.net/media/images/9BII-run.time.jpg
|
||||
[11]:https://assets.packet.net/media/images/njak-orchestration.jpg
|
||||
[12]:https://assets.packet.net/media/images/1QUS-platforms.jpg
|
||||
[13]:https://assets.packet.net/media/images/TeS9-security.jpg
|
||||
[14]:https://assets.packet.net/media/images/SFgF-apps.jpg
|
||||
[15]:https://assets.packet.net/media/images/SXoj-observability.jpg
|
||||
[16]:https://assets.packet.net/media/images/tKhf-traffic.management.jpg
|
||||
[17]:https://assets.packet.net/media/images/7cpe-users.jpg
|
||||
74
translated/tech/20180516 How Graphics Cards Work.md
Normal file
74
translated/tech/20180516 How Graphics Cards Work.md
Normal file
@ -0,0 +1,74 @@
|
||||
显卡工作原理简介
|
||||
======
|
||||
![AMD-Polaris][1]
|
||||
|
||||
自从 sdfx 推出最初的 Voodoo 加速器以来,不起眼的显卡对你的 PC 是否可以玩游戏起到决定性作用,PC 上任何其它设备都无法与其相比。其它组件当然也很重要,但对于一个拥有 32GB 内存、价值 500 美金的 CPU 和 基于 PCIe 的存储设备的高端 PC,如果使用 10 年前的显卡,都无法以最高分辨率和细节质量运行当前<ruby>最高品质的游戏<rt>AAA titles</rt></ruby>,会发生卡顿甚至无响应。显卡(也常被称为 GPU, 或<ruby>图形处理单元<rt>Graphic Processing Unit</rt></ruby>)对游戏性能影响极大,我们反复强调这一点;但我们通常并不会深入了解显卡的工作原理。
|
||||
|
||||
出于实际考虑,本文将概述 GPU 的上层功能特性,内容包括 AMD 显卡、Nvidia 显卡、Intel 集成显卡以及 Intel 后续可能发布的独立显卡之间共同的部分。也应该适用于 Apple, Imagination Technologies, Qualcomm, ARM 和 其它显卡生产商发布的移动平台 GPU。
|
||||
|
||||
### 我们为何不使用 CPU 进行渲染?
|
||||
|
||||
我要说明的第一点是我们为何不直接使用 CPU 完成游戏中的渲染工作。坦率的说,在理论上你确实可以直接使用 CPU 完成<ruby>渲染<rt>rendering</rt></ruby>工作。在显卡没有广泛普及之前,早期的 3D 游戏就是完全基于 CPU 运行的,例如 Ultima Underworld(LCTT 译注:中文名为 _地下创世纪_ ,下文中简称 UU)。UU 是一个很特别的例子,原因如下:与 Doom (LCTT 译注:中文名 _毁灭战士_)相比,UU 具有一个更高级的渲染引擎,全面支持<ruby>向上或向下查找<rt>looking up and down</rt></ruby>以及一些在当时比较高级的特性,例如<ruby>纹理映射<rt>texture mapping</rt></ruby>。但为支持这些高级特性,需要付出高昂的代价,很少有人可以拥有真正能运行起 UU 的 PC。
|
||||
|
||||

|
||||
|
||||
对于早期的 3D 游戏,包括 Half Life 和 Quake II 在内的很多游戏,内部包含一个软件渲染器,让没有 3D 加速器的玩家也可以玩游戏。但现代游戏都弃用了这种方式,原因很简单:CPU 是设计用于通用任务的微处理器,意味着缺少 GPU 提供的<ruby>专用硬件<rt>specialized hardware</rt></ruby>和<ruby>功能<rt>capabilities</rt></ruby>。对于 18 年前使用软件渲染的那些游戏,当代 CPU 可以轻松胜任;但对于当代最高品质的游戏,除非明显降低<ruby>景象质量<rt>scene</rt></ruby>、分辨率和各种虚拟特效,否则现有的 CPU 都无法胜任。
|
||||
|
||||
### 什么是 GPU ?
|
||||
|
||||
GPU 是一种包含一系列专用硬件特性的设备,其中这些特性可以让各种 3D 引擎更好地执行代码,包括<ruby>形状构建<rt>geometry setup</rt></ruby>,纹理映射,<ruby>访存<rt>memory access</rt></ruby>和<ruby>着色器<rt>shaders</rt></ruby>等。3D 引擎的功能特性影响着设计者如何设计 GPU。可能有人还记得,AMD HD5000 系列使用 VLIW5 <ruby>架构<rt>archtecture</rt></ruby>;但在更高端的 HD 6000 系列中使用了 VLIW4 架构。通过 GCN (LCTT 译注:GCN 是 Graphics Core Next 的缩写,字面意思是下一代图形核心,既是若干代微体系结构的代号,也是指令集的名称),AMD 改变了并行化的实现方法,提高了每个时钟周期的有效性能。
|
||||
|
||||

|
||||
|
||||
Nvidia 在发布首款 GeForce 256 时(大致对应 Microsoft 推出 DirectX7 的时间点)提出了 GPU 这个术语,这款 GPU 支持在硬件上执行转换和<ruby>光照计算<rt>lighting calculation</rt></ruby>。将专用功能直接集成到硬件中是早期 GPU 的显著技术特点。很多专用功能还在(以一种极为不同的方式)使用,毕竟对于特定类型的工作任务,使用<ruby>片上<rt>on-chip</rt></ruby>专用计算资源明显比使用一组<ruby>可编程单元<rt>programmable cores</rt></ruby>要更加高效和快速。
|
||||
|
||||
GPU 和 CPU 的核心有很多差异,但我们可以按如下方式比较其上层特性。CPU 一般被设计成尽可能快速和高效的执行单线程代码。虽然 <ruby>同时多线程<rt>SMT, Simultaneous multithreading</rt></ruby> 或 <ruby>超线程<rt>Hyper-Threading</rt></ruby>在这方面有所改进,但我们实际上通过堆叠众多高效率的单线程核心来扩展多线程性能。AMD 的 32 核心/64 线程 Epyc CPU 已经是我们能买到的核心数最多的 CPU;相比而言,Nvidia 最低端的 Pascal GPU 都拥有 384 个核心。但相比 CPU 的核心,GPU 所谓的核心是处理能力低得多的的处理单元。
|
||||
|
||||
**注意:** 简单比较 GPU 核心数,无法比较或评估 AMD 与 Nvidia 的相对游戏性能。在同样 GPU 系列(例如 Nvidia 的 GeForce GTX 10 系列,或 AMD 的 RX 4xx 或 5xx 系列)的情况下,更高的 GPU 核心数往往意味着更高的性能。
|
||||
|
||||
你无法只根据核心数比较不同供应商或核心系列的 GPU 之间的性能,这是因为不同的架构对应的效率各不相同。与 CPU 不同,GPU 被设计用于并行计算。AMD 和 Nvidia 在结构上都划分为计算资源<ruby>块<rt>block</rt></ruby>。Nvidia 将这些块称之为<ruby>流处理器<rt>SM, Streaming Multiprocessor</rt></ruby>,而 AMD 则称之为<ruby>计算单元<rt>Compute Unit</rt></ruby>。
|
||||
|
||||

|
||||
|
||||
每个块都包含如下组件:一组核心,一个<ruby>调度器<rt>scheduler</rt></ruby>,一个<ruby>寄存器文件<rt>register file</rt></ruby>,指令缓存,纹理和 L1 缓存以及纹理<ruby>映射单元<rt>mapping units</rt></ruby>。SM/CU 可以被认为是 GPU 中最小的可工作块。SM/CU 没有涵盖全部的功能单元,例如视频解码引擎,实际在屏幕绘图所需的渲染输出,以及与<ruby>板载<rt>onboard</rt></ruby><ruby>显存<rt>VRAM, Video Memory</rt></ruby>通信相关的<ruby>内存接口<rt>memory interfaces</rt></ruby>都不在 SM/CU 的范围内;但当 AMD 提到一个 APU 拥有 8 或 11 个 Vega 计算单元时,所指的是(等价的)<ruby>硅晶块<rt>block of silicon</rt></ruby>数目。如果你查看任意一款 GPU 的模块设计图,你会发现图中 SM/CU 是反复出现很多次的部分。
|
||||
|
||||

|
||||
|
||||
GPU 中的 SM/CU 数目越多,每个时钟周期内可以并行完成的工作也越多。渲染是一种通常被认为是“高度并行”的计算问题,意味着随着核心数增加带来的可扩展性很高。
|
||||
|
||||
当我们讨论 GPU 设计时,我们通常会使用一种形如 4096:160:64 的格式,其中第一个数字代表核心数。在核心系列(如 GTX970/GTX 980/GTX 980 Ti, 如 RX 560/RX 580 等等)一致的情况下,核心数越高,GPU 也就相对更快。
|
||||
|
||||
### 纹理映射和渲染输出
|
||||
|
||||
GPU 的另外两个主要组件是纹理映射单元和渲染输出。设计中的纹理映射单元数目决定了最大的<ruby>纹素<rt>texel</rt></ruby>输出以及可以多快的处理并将纹理映射到对象上。早期的 3D 游戏很少用到纹理,这是因为绘制 3D 多边形形状的工作有较大的难度。纹理其实并不是 3D 游戏必须的,但不使用纹理的现代游戏屈指可数。
|
||||
|
||||
GPU 中的纹理映射单元数目用 4096:160:64 指标中的第二个数字表示。AMD,Nvidia 和 Intel 一般都等比例变更指标中的数字。换句话说,如果你找到一个指标为 4096:160:64 的 GPU,同系列中不会出现指标为 4096:320:64 的 GPU。纹理映射绝对有可能成为游戏的瓶颈,但产品系列中次高级别的 GPU 往往提供更多的核心和纹理映射单元(是否拥有更高的渲染输出单元取决于 GPU 系列和显卡的指标)。
|
||||
|
||||
<ruby>渲染输出单元<rt>Render outputs, ROPs</rt></ruby>(有时也叫做<ruby>光栅操作管道<rt>raster operations pipelines</rt></ruby>是 GPU 输出汇集成图像的场所,图像最终会在显示器或电视上呈现。渲染输出单元的数目乘以 GPU 的时钟频率决定了<ruby>像素填充速率<rt>pixel fill rate</rt></ruby>。渲染输出单元数目越多意味着可以同时输出的像素越多。渲染输出单元还处理<ruby>抗锯齿<rt>antialiasing</rt></ruby>,启用抗锯齿(尤其是<ruby>超级采样<rt>supersampled</rt></ruby>抗锯齿)会导致游戏填充速率受限。
|
||||
|
||||
### 显存带宽与显存容量
|
||||
|
||||
我们最后要讨论的是<ruby>显存带宽<rt>memory bandwidth</rt></ruby>和<ruby>显存容量<rt>memory capacity</rt></ruby>。显存带宽是指一秒时间内可以从 GPU 专用的显存缓冲区内拷贝进或拷贝出多少数据。很多高级视觉特效(以及更常见的高分辨率)需要更高的显存带宽,以便保证足够的<ruby>帧率<rt>frame rates</rt></ruby>,因为需要拷贝进和拷贝出 GPU 核心的数据总量增大了。
|
||||
|
||||
在某些情况下,显存带宽不足会成为 GPU 的显著瓶颈。以 Ryzen 5 2400G 为例的 AMD APU 就是严重带宽受限的,以至于提高 DDR4 的时钟频率可以显著提高整体性能。导致瓶颈的显存带宽阈值,也与游戏引擎和游戏使用的分辨率相关。
|
||||
|
||||
板载内存大小也是 GPU 的重要指标。如果按指定细节级别或分辨率运行所需的显存量超过了可用的资源量,游戏通常仍可以运行,但会使用 CPU 的主存存储额外的纹理数据;而从 DRAM 中提取数据比从板载显存中提取数据要慢得多。这会导致游戏在板载的快速访问内存池和系统内存中共同提取数据时出现明显的卡顿。
|
||||
|
||||
有一点我们需要留意,GPU 生产厂家通常为一款低端或中端 GPU 配置比通常更大的显存,这是他们为产品提价的一种常用手段。很难说大显存是否更具有吸引力,毕竟需要具体问题具体分析。大多数情况下,用更高的价格购买一款仅显存更高的显卡是不划算的。经验规律告诉我们,低端显卡遇到显存瓶颈之前就会碰到其它瓶颈。如果存在疑问,可以查看相关评论,例如 4G 版本或其它数目的版本是否性能超过 2G 版本。更多情况下,如果其它指标都相同,购买大显存版本并不值得。
|
||||
|
||||
查看我们的[极致技术讲解][2]系列,深入了解更多当前最热的技术话题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.extremetech.com/gaming/269335-how-graphics-cards-work
|
||||
|
||||
作者:[Joel Hruska][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.extremetech.com/author/jhruska
|
||||
[1]:https://www.extremetech.com/wp-content/uploads/2016/07/AMD-Polaris-640x353.jpg
|
||||
[2]:http://www.extremetech.com/tag/extremetech-explains
|
||||
@ -0,0 +1,290 @@
|
||||
献给 Debian 和 Ubuntu 用户的一组实用程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
你使用的是基于 Debian 的系统吗?如果是,太好了!我今天在这里给你带来了一个好消息。先向 **“Debian-goodies”** 打个招呼,这是一组基于 Debian 系统(比如:Ubuntu, Linux Mint)的有用工具。这些实用工具提供了一些额外的有用的命令,这些命令在基于 Debian 的系统中默认不可用。通过使用这些工具,用户可以找到哪些程序占用更多磁盘空间,更新系统后需要重新启动哪些服务,在一个包中搜索与模式匹配的文件,根据搜索字符串列出已安装的包等等。在这个简短的指南中,我们将讨论一些有用的 Debian 的好东西。
|
||||
|
||||
### Debian-goodies – 给 Debian 和 Ubuntu 用户的实用程序
|
||||
|
||||
debian-goodies 包可以在 Debian 和其衍生的 Ubuntu 以及其它 Ubuntu 变体(如 Linux Mint)的官方仓库中找到。要安装 debian-goodies,只需简单运行:
|
||||
```
|
||||
$ sudo apt-get install debian-goodies
|
||||
|
||||
```
|
||||
|
||||
debian-goodies 安装完成后,让我们继续看一看一些有用的实用程序。
|
||||
|
||||
#### **1. Checkrestart**
|
||||
|
||||
让我从我最喜欢的 **“checkrestart”** 实用程序开始。安装某些安全更新时,某些正在运行的应用程序可能仍然会使用旧库。要彻底应用安全更新,你需要查找并重新启动所有这些更新。这就是 Checkrestart 派上用场的地方。该实用程序将查找哪些进程仍在使用旧版本的库,然后,你可以重新启动服务。
|
||||
|
||||
在进行库更新后,要检查哪些守护进程应该被重新启动,运行:
|
||||
```
|
||||
$ sudo checkrestart
|
||||
[sudo] password for sk:
|
||||
Found 0 processes using old versions of upgraded files
|
||||
|
||||
```
|
||||
|
||||
由于我最近没有执行任何安全更新,因此没有显示任何内容。
|
||||
|
||||
请注意,Checkrestart 实用程序确实运行良好。但是,有一个名为 “needrestart” 的类似工具可用于最新的 Debian 系统。Needrestart 的灵感来自 checkrestart 实用程序,它完成了同样的工作。 Needrestart 得到了积极维护,并支持容器(LXC, Docker)等新技术。
|
||||
|
||||
以下是 Needrestart 的特点:
|
||||
|
||||
* 支持(当不要求)systemd
|
||||
* 二进制黑名单(即显示管理员)
|
||||
* 试图检测挂起的内核升级
|
||||
* 尝试检测基于解释器的守护进程所需的重启(支持 Perl, Python, Ruby)
|
||||
* 使用钩子完全集成到 apt/dpkg 中
|
||||
|
||||
它在默认仓库中也可以使用。所以,你可以使用如下命令安装它:
|
||||
```
|
||||
$ sudo apt-get install needrestart
|
||||
|
||||
```
|
||||
|
||||
现在,你可以使用以下命令检查更新系统后需要重新启动的守护程序列表:
|
||||
```
|
||||
$ sudo needrestart
|
||||
Scanning processes...
|
||||
Scanning linux images...
|
||||
|
||||
Running kernel seems to be up-to-date.
|
||||
|
||||
Failed to check for processor microcode upgrades.
|
||||
|
||||
No services need to be restarted.
|
||||
|
||||
No containers need to be restarted.
|
||||
|
||||
No user sessions are running outdated binaries.
|
||||
|
||||
```
|
||||
|
||||
好消息是 Needrestart 同样也适用于其它 Linux 发行版。例如,你可以从 Arch Linux 及其衍生版的 AUR 或者其它任何 AUR 帮助程序来安装,就像下面这样:
|
||||
```
|
||||
$ yaourt -S needrestart
|
||||
|
||||
```
|
||||
|
||||
在 fedora:
|
||||
```
|
||||
$ sudo dnf install needrestart
|
||||
|
||||
```
|
||||
|
||||
#### 2. Check-enhancements
|
||||
|
||||
Check-enhancements 实用程序用于查找那些用于增强已安装的包的软件包。此实用程序将列出增强其它包但不是必须运行它的包。你可以通过 “-ip” 或 “–installed-packages” 选项来查找增强单个包或所有已安装包的软件包。
|
||||
|
||||
例如,我将列出增强 gimp 包功能的包:
|
||||
```
|
||||
$ check-enhancements gimp
|
||||
gimp => gimp-data: Installed: (none) Candidate: 2.8.22-1
|
||||
gimp => gimp-gmic: Installed: (none) Candidate: 1.7.9+zart-4build3
|
||||
gimp => gimp-gutenprint: Installed: (none) Candidate: 5.2.13-2
|
||||
gimp => gimp-help-ca: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-de: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-el: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-en: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-es: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-fr: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-it: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-ja: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-ko: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-nl: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-nn: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-pt: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-ru: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-sl: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-sv: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-plugin-registry: Installed: (none) Candidate: 7.20140602ubuntu3
|
||||
gimp => xcftools: Installed: (none) Candidate: 1.0.7-6
|
||||
|
||||
```
|
||||
|
||||
要列出增强所有已安装包的,请运行:
|
||||
```
|
||||
$ check-enhancements -ip
|
||||
autoconf => autoconf-archive: Installed: (none) Candidate: 20170928-2
|
||||
btrfs-progs => snapper: Installed: (none) Candidate: 0.5.4-3
|
||||
ca-certificates => ca-cacert: Installed: (none) Candidate: 2011.0523-2
|
||||
cryptsetup => mandos-client: Installed: (none) Candidate: 1.7.19-1
|
||||
dpkg => debsig-verify: Installed: (none) Candidate: 0.18
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
#### 3. dgrep
|
||||
|
||||
顾名思义,dgrep 用于根据给定的正则表达式搜索制指定包的所有文件。例如,我将在 Vim 包中搜索包含正则表达式 “text” 的文件。
|
||||
```
|
||||
$ sudo dgrep "text" vim
|
||||
Binary file /usr/bin/vim.tiny matches
|
||||
/usr/share/doc/vim-tiny/copyright: that they must include this license text. You can also distribute
|
||||
/usr/share/doc/vim-tiny/copyright: include this license text. You are also allowed to include executables
|
||||
/usr/share/doc/vim-tiny/copyright: 1) This license text must be included unmodified.
|
||||
/usr/share/doc/vim-tiny/copyright: text under a) applies to those changes.
|
||||
/usr/share/doc/vim-tiny/copyright: context diff. You can choose what license to use for new code you
|
||||
/usr/share/doc/vim-tiny/copyright: context diff will do. The e-mail address to be used is
|
||||
/usr/share/doc/vim-tiny/copyright: On Debian systems, the complete text of the GPL version 2 license can be
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
dgrep 支持大多数 grep 的选项。参阅以下指南以了解 grep 命令。
|
||||
|
||||
* [献给初学者的 Grep 命令教程][2]
|
||||
|
||||
#### 4 dglob
|
||||
|
||||
dglob 实用程序生成与给定模式匹配的包名称列表。例如,找到与字符串 “vim” 匹配的包列表。
|
||||
```
|
||||
$ sudo dglob vim
|
||||
vim-tiny:amd64
|
||||
vim:amd64
|
||||
vim-common:all
|
||||
vim-runtime:all
|
||||
|
||||
```
|
||||
|
||||
默认情况下,dglob 将仅显示已安装的软件包。如果要列出所有包(包括已安装的和未安装的),使用 **-a** 标志。
|
||||
```
|
||||
$ sudo dglob vim -a
|
||||
|
||||
```
|
||||
|
||||
#### 5. debget
|
||||
|
||||
**debget** 实用程序将在 APT 的数据库中下载一个包的 .deb 文件。请注意,它只会下载给定的包,不包括依赖项。
|
||||
```
|
||||
$ debget nano
|
||||
Get:1 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 nano amd64 2.9.3-2 [231 kB]
|
||||
Fetched 231 kB in 2s (113 kB/s)
|
||||
|
||||
```
|
||||
|
||||
#### 6. dpigs
|
||||
|
||||
这是此次集合中另一个有用的实用程序。**dpigs** 实用程序将查找并显示那些占用磁盘空间最多的已安装包。
|
||||
```
|
||||
$ dpigs
|
||||
260644 linux-firmware
|
||||
167195 linux-modules-extra-4.15.0-20-generic
|
||||
75186 linux-headers-4.15.0-20
|
||||
64217 linux-modules-4.15.0-20-generic
|
||||
55620 snapd
|
||||
31376 git
|
||||
31070 libicu60
|
||||
28420 vim-runtime
|
||||
25971 gcc-7
|
||||
24349 g++-7
|
||||
|
||||
```
|
||||
|
||||
如你所见,linux-firmware 包占用的磁盘空间最多。默认情况下,它将显示占用磁盘空间的 **前 10 个**包。如果要显示更多包,例如 20 个,运行以下命令:
|
||||
```
|
||||
$ dpigs -n 20
|
||||
|
||||
```
|
||||
|
||||
#### 7. debman
|
||||
|
||||
**debman** 实用程序允许你轻松查看二进制文件 **.deb** 中的手册页而不提取它。你甚至不需要安装 .deb 包。以下命令显示 nano 包的手册页。
|
||||
```
|
||||
$ debman -f nano_2.9.3-2_amd64.deb nano
|
||||
|
||||
```
|
||||
如果你没有 .deb 软件包的本地副本,使用 **-p** 标志下载并查看包的手册页。
|
||||
```
|
||||
$ debman -p nano nano
|
||||
|
||||
```
|
||||
|
||||
**建议阅读:**
|
||||
[每个 Linux 用户都应该知道的 3 个 man 的替代品][3]
|
||||
|
||||
#### 8. debmany
|
||||
|
||||
安装的 Debian 包不仅包含手册页,还包括其它文件,如确认,版权和 read me (自述文件)等。**debmany** 实用程序允许你查看和读取那些文件。
|
||||
```
|
||||
$ debmany vim
|
||||
|
||||
```
|
||||
|
||||
![][1]
|
||||
|
||||
使用方向键选择要查看的文件,然后按 ENTER 键查看所选文件。按 **q** 返回主菜单。
|
||||
|
||||
如果未安装指定的软件包,debmany 将从 APT 数据库下载并显示手册页。应安装 **dialog** 包来阅读手册页。
|
||||
|
||||
#### 9. popbugs
|
||||
|
||||
如果你是开发人员,**popbugs** 实用程序将非常有用。它将根据你使用的包显示一个定制的发布关键 bug 列表(使用热门竞赛数据)。对于那些不关心的人,Popular-contest 包设置了一个 cron (定时)任务,它将定期匿名向 Debian 开发人员提交有关该系统上最常用的 Debian 软件包的统计信息。这些信息有助于 Debian 做出决定,例如哪些软件包应该放在第一张 CD 上。它还允许 Debian 改进未来的发行版本,以便为新用户自动安装最流行的软件包。
|
||||
|
||||
要生成严重 bug 列表并在默认 Web 浏览器中显示结果,运行:
|
||||
```
|
||||
$ popbugs
|
||||
|
||||
```
|
||||
|
||||
此外,你可以将结果保存在文件中,如下所示。
|
||||
```
|
||||
$ popbugs --output=bugs.txt
|
||||
|
||||
```
|
||||
|
||||
#### 10. which-pkg-broke
|
||||
|
||||
此命令将显示给定包的所有依赖项以及安装每个依赖项的时间。通过使用此信息,你可以在升级系统或软件包之后轻松找到哪个包可能会在什么时间损坏另一个包。
|
||||
```
|
||||
$ which-pkg-broke vim
|
||||
Package <debconf-2.0> has no install time info
|
||||
debconf Wed Apr 25 08:08:40 2018
|
||||
gcc-8-base:amd64 Wed Apr 25 08:08:41 2018
|
||||
libacl1:amd64 Wed Apr 25 08:08:41 2018
|
||||
libattr1:amd64 Wed Apr 25 08:08:41 2018
|
||||
dpkg Wed Apr 25 08:08:41 2018
|
||||
libbz2-1.0:amd64 Wed Apr 25 08:08:41 2018
|
||||
libc6:amd64 Wed Apr 25 08:08:42 2018
|
||||
libgcc1:amd64 Wed Apr 25 08:08:42 2018
|
||||
liblzma5:amd64 Wed Apr 25 08:08:42 2018
|
||||
libdb5.3:amd64 Wed Apr 25 08:08:42 2018
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
#### 11. dhomepage
|
||||
|
||||
dhomepage 实用程序将在默认 Web 浏览器中显示给定包的官方网站。例如,以下命令将打开 Vim 编辑器的主页。
|
||||
```
|
||||
$ dhomepage vim
|
||||
|
||||
```
|
||||
|
||||
这就是全部了。Debian-goodies 是你武器库中必备的工具。即使我们不经常使用所有这些实用程序,但它们值得学习,我相信它们有时会非常有用。
|
||||
|
||||
我希望这很有用。更多好东西要来了。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/debian-goodies-a-set-of-useful-utilities-for-debian-and-ubuntu-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://www.ostechnix.com/wp-content/uploads/2018/05/debmany.png
|
||||
[2]:
|
||||
https://www.ostechnix.com/the-grep-command-tutorial-with-examples-for-beginners/
|
||||
[3]:
|
||||
https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
@ -0,0 +1,67 @@
|
||||
欧洲核子研究组织(CERN)是如何使用 Linux 和开源的
|
||||
============================================================
|
||||
|
||||

|
||||
>欧洲核子研究组织(简称 CERN)依靠开源技术处理大型强子对撞机生成的大量数据。ATLAS(超环面仪器,如图所示)是一种探测基本粒子的通用探测器。(图片来源:CERN)[经许可使用][2]
|
||||
|
||||
[CERN][3]
|
||||
|
||||
[CERN][6] 无需过多介绍了吧。CERN 创建了万维网和大型强子对撞机(LHC),这是世界上最大的粒子加速器,就是通过它发现了 [希格斯玻色子][7]。负责该组织 IT 操作系统和基础架构的 Tim Bell 表示,他的团队的目标是“为全球 13000 名物理学家提供计算设施,以分析这些碰撞、了解宇宙的构成以及是如何运转的。”
|
||||
|
||||
CERN 正在进行硬核科学研究,尤其是大型强子对撞机,它在运行时 [生成大量数据][8]。“CERN 目前存储大约 200 PB 的数据,当加速器运行时,每月有超过 10 PB 的数据产生。这必然会给计算基础架构带来极大的挑战,包括存储大量数据,以及能够在合理的时间范围内处理数据,对于网络、存储技术和高效计算架构都是很大的压力。“Bell 说到。
|
||||
|
||||
### [tim-bell-cern.png][4]
|
||||
|
||||

|
||||
Tim Bell, CERN [经许可使用][1] Swapnil Bhartiya
|
||||
|
||||
大型强子对撞机的运作规模和它产生的数据量带来了严峻的挑战,但 CERN 对这些问题并不陌生。CERN 成立于 1954 年,已经 60 余年了。“我们一直面临着难以解决的计算能力挑战,但我们一直在与开源社区合作解决这些问题。”Bell 说,“即使在 90 年代,当我们发明万维网时,我们也希望与人们共享,使其能够从 CERN 的研究中受益,开源是做这件事的再合适不过的工具了。”
|
||||
|
||||
### 使用 OpenStack 和 CentOS
|
||||
|
||||
时至今日,CERN 是 OpenStack 的深度用户,而 Bell 则是 OpenStack 基金会的董事会成员之一。不过 CERN 比 OpenStack 出现的要早,多年来,他们一直在使用各种开源技术通过 Linux 服务器提供服务。
|
||||
|
||||
“在过去的十年中,我们发现,与其自己解决问题,不如找到面临类似挑战的上游开源社区进行合作,然后我们一同为这些项目做出贡献,而不是一切都由自己来创造和维护。“Bell 说。
|
||||
|
||||
一个很好的例子是 Linux 本身。CERN 曾经是 Red Hat Enterprise Linux 的客户。其实,早在 2004 年,他们就与 Fermilab 合作一起建立了自己的 Linux 发行版,名为 [Scientific Linux][9]。最终他们意识到,因为没有修改内核,耗费时间建立自己的发行版是没有意义的,所以他们迁移到了 CentOS 上。由于 CentOS 是一个完全开源和社区驱使的项目,CERN 可以与该项目合作,并为 CentOS 的构建和分发做出贡献。
|
||||
|
||||
CERN 帮助 CentOS 提供基础架构,他们还组织了 CentOS DoJo 活动(LCTT 译者注:CentOS Dojo 是为期一日的活动,汇聚来自 CentOS 社群的人分享系统管理、最佳实践及新兴科技。),工程师可以汇聚在此共同改进 CentOS 的封装。
|
||||
|
||||
除了 OpenStack 和 CentOS 之外,CERN 还是其他开源项目的深度用户,包括用于配置管理的 Puppet、用于监控的 Grafana 和 InfluxDB,等等。
|
||||
|
||||
“我们与全球约 170 个实验室合作。因此,每当我们发现一个开源项目的可完善之处,其他实验室便可以很容易地采纳使用。“Bell 说,”与此同时,我们也向其他项目学习。当像 eBay 和 Rackspace 这样大规模的安装提高了解决方案的可扩展性时,我们也从中受益,也可以扩大规模。“
|
||||
|
||||
### 解决现实问题
|
||||
|
||||
2012 年左右,CERN 正在研究如何为大型强子对撞机扩展计算能力,但难点是人员而不是技术。CERN 雇用的员工人数是固定的。“我们必须找到一种方法来扩展计算能力,而不需要大量额外的人来管理。”Bell 说,“OpenStack 为我们提供了一个自动的 API 驱动和软件定义的基础架构。”OpenStack 还帮助 CERN 检查与服务交付相关的问题,然后使其自动化,而无需增加员工。
|
||||
|
||||
“我们目前在日内瓦和布达佩斯的两个数据中心运行大约 280000 个核心(cores)和 7000 台服务器。我们正在使用软件定义的基础架构使一切自动化,这使我们能够在保持员工数量不变的同时继续添加更多的服务器。“Bell 说。
|
||||
|
||||
随着时间的推移,CERN 将面临更大的挑战。大型强子对撞机有一个到 2035 年的蓝图,包括一些重要的升级。“我们的加速器运转三到四年,然后会用 18 个月或两年的时间来升级基础架构。在这维护期间我们会做一些计算能力的规划。“Bell 说。CERN 还计划升级高亮度大型强子对撞机,会允许更高光度的光束。与目前的 CERN 的规模相比,升级意味着计算需求需增加约 60 倍。
|
||||
|
||||
“根据摩尔定律,我们可能只能满足需求的四分之一,因此我们必须找到相应的扩展计算能力和存储基础架构的方法,并找到自动化和解决方案,例如 OpenStack,将有助于此。”Bell 说。
|
||||
|
||||
“当我们开始使用大型强子对撞机并观察我们如何提供计算能力时,很明显我们无法将所有内容都放入 CERN 的数据中心,因此我们设计了一个分布式网格结构:位于中心的 CERN 和围绕着它的级联结构。“Bell 说,“全世界约有 12 个大型一级数据中心,然后是 150 所小型大学和实验室。他们从大型强子对撞机的数据中收集样本,以帮助物理学家理解和分析数据。“
|
||||
|
||||
这种结构意味着 CERN 正在进行国际合作,数百个国家正致力于分析这些数据。归结为一个基本原则,即开源不仅仅是共享代码,还包括人们之间的协作、知识共享,以实现个人、组织或公司无法单独实现的目标。这就是开源世界的希格斯玻色子。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/5/how-cern-using-linux-open-source
|
||||
|
||||
作者:[SWAPNIL BHARTIYA ][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://home.cern/about/experiments/atlas
|
||||
[4]:https://www.linux.com/files/images/tim-bell-cernpng
|
||||
[5]:https://www.linux.com/files/images/atlas-cernjpg
|
||||
[6]:https://home.cern/
|
||||
[7]:https://home.cern/topics/higgs-boson
|
||||
[8]:https://home.cern/about/computing
|
||||
[9]:https://www.scientificlinux.org/
|
||||
@ -0,0 +1,253 @@
|
||||
如何在 Git 中重置、恢复、和返回到以前的状态
|
||||
======
|
||||
|
||||

|
||||
|
||||
使用 Git 工作时其中一个鲜为人知(和没有意识到)的方面就是,如何很容易地返回到你以前的位置 —— 也就是说,在仓库中如何很容易地去撤销那怕是重大的变更。在本文中,我们将带你了解如何去重置、恢复、和完全回到以前的状态,做到这些只需要几个简单而优雅的 Git 命令。
|
||||
|
||||
### reset
|
||||
|
||||
我们从 Git 的 `reset` 命令开始。确实,你应该能够想到它就是一个 "回滚" — 它将你本地环境返回到前面的提交。这里的 "本地环境" 一词,我们指的是你的本地仓库、暂存区、以及工作目录。
|
||||
|
||||
先看一下图 1。在这里我们有一个在 Git 中表示一系列状态的提交。在 Git 中一个分支就是简单的一个命名的、可移动指针到一个特定的提交。在这种情况下,我们的 master 分支是链中指向最新提交的一个指针。
|
||||
|
||||
![Local Git environment with repository, staging area, and working directory][2]
|
||||
|
||||
图 1:有仓库、暂存区、和工作目录的本地环境
|
||||
|
||||
如果看一下我们的 master 分支是什么,可以看一下到目前为止我们产生的提交链。
|
||||
```
|
||||
$ git log --oneline
|
||||
b764644 File with three lines
|
||||
7c709f0 File with two lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
如果我们想回滚到前一个提交会发生什么呢?很简单 —— 我们只需要移动分支指针即可。Git 提供了为我们做这个动作的命令。例如,如果我们重置 master 为当前提交回退两个提交的位置,我们可以使用如下之一的方法:
|
||||
|
||||
`$ git reset 9ef9173`(使用一个绝对的提交 SHA1 值 9ef9173)
|
||||
|
||||
或
|
||||
|
||||
`$ git reset current~2`(在 “current” 标签之前,使用一个相对值 -2)
|
||||
|
||||
图 2 展示了操作的结果。在这之后,如果我们在当前分支(master)上运行一个 `git log` 命令,我们将看到只有一个提交。
|
||||
```
|
||||
$ git log --oneline
|
||||
|
||||
9ef9173 File with one line
|
||||
|
||||
```
|
||||
|
||||
![After reset][4]
|
||||
|
||||
图 2:在 `reset` 之后
|
||||
|
||||
`git reset` 命令也包含使用一个你最终满意的提交内容去更新本地环境的其它部分的选项。这些选项包括:`hard` 在仓库中去重置指向的提交,用提交的内容去填充工作目录,并重置暂存区;`soft` 仅重置仓库中的指针;而 `mixed`(默认值)将重置指针和暂存区。
|
||||
|
||||
这些选项在特定情况下非常有用,比如,`git reset --hard <commit sha1 | reference>` 这个命令将覆盖本地任何未提交的更改。实际上,它重置了(清除掉)暂存区,并用你重置的提交内容去覆盖了工作区中的内容。在你使用 `hard` 选项之前,一定要确保这是你真正地想要做的操作,因为这个命令会覆盖掉任何未提交的更改。
|
||||
|
||||
### revert
|
||||
|
||||
`git revert` 命令的实际结果类似于 `reset`,但它的方法不同。`reset` 命令是在(默认)链中向后移动分支的指针去“撤销”更改,`revert` 命令是在链中添加一个新的提交去“取消”更改。再次查看图 1 可以非常轻松地看到这种影响。如果我们在链中的每个提交中向文件添加一行,一种方法是使用 `reset` 使那个提交返回到仅有两行的那个版本,如:`git reset HEAD~1`。
|
||||
|
||||
另一个方法是添加一个新的提交去删除第三行,以使最终结束变成两行的版本 — 实际效果也是取消了那个更改。使用一个 `git revert` 命令可以实现上述目的,比如:
|
||||
```
|
||||
$ git revert HEAD
|
||||
|
||||
```
|
||||
|
||||
因为它添加了一个新的提交,Git 将提示如下的提交信息:
|
||||
```
|
||||
Revert "File with three lines"
|
||||
|
||||
This reverts commit b764644bad524b804577684bf74e7bca3117f554.
|
||||
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with '#' will be ignored, and an empty message aborts the commit.
|
||||
# On branch master
|
||||
# Changes to be committed:
|
||||
# modified: file1.txt
|
||||
#
|
||||
```
|
||||
|
||||
图 3(在下面)展示了 `revert` 操作完成后的结果。
|
||||
|
||||
如果我们现在运行一个 `git log` 命令,我们将看到前面的提交之前的一个新提交。
|
||||
```
|
||||
$ git log --oneline
|
||||
11b7712 Revert "File with three lines"
|
||||
b764644 File with three lines
|
||||
7c709f0 File with two lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
这里是工作目录中这个文件当前的内容:
|
||||
```
|
||||
$ cat <filename>
|
||||
Line 1
|
||||
Line 2
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### Revert 或 reset 如何选择?
|
||||
|
||||
为什么要优先选择 `revert` 而不是 `reset` 操作?如果你已经将你的提交链推送到远程仓库(其它人可以已经拉取了你的代码并开始工作),一个 `revert` 操作是让他们去获得更改的非常友好的方式。这是因为 Git 工作流可以非常好地在分支的末端添加提交,但是当有人 `reset` 分支指针之后,一组提交将再也看不见了,这可能会是一个挑战。
|
||||
|
||||
当我们以这种方式使用 Git 工作时,我们的基本规则之一是:在你的本地仓库中使用这种方式去更改还没有推送的代码是可以的。如果提交已经推送到了远程仓库,并且可能其它人已经使用它来工作了,那么应该避免这些重写提交历史的更改。
|
||||
|
||||
总之,如果你想回滚、撤销、或者重写其它人已经在使用的一个提交链的历史,当你的同事试图将他们的更改合并到他们拉取的原始链上时,他们可能需要做更多的工作。如果你必须对已经推送并被其他人正在使用的代码做更改,在你做更改之前必须要与他们沟通,让他们先合并他们的更改。然后在没有需要去合并的侵入操作之后,他们再拉取最新的副本。
|
||||
|
||||
你可能注意到了,在我们做了 `reset` 操作之后,原始的链仍然在那个位置。我们移动了指针,然后 `reset` 代码回到前一个提交,但它并没有删除任何提交。换句话说就是,只要我们知道我们所指向的原始提交,我们能够通过简单的返回到分支的原始头部来“恢复”指针到前面的位置:
|
||||
```
|
||||
git reset <sha1 of commit>
|
||||
|
||||
```
|
||||
|
||||
当提交被替换之后,我们在 Git 中做的大量其它操作也会发生类似的事情。新提交被创建,有关的指针被移动到一个新的链,但是老的提交链仍然存在。
|
||||
|
||||
### Rebase
|
||||
|
||||
现在我们来看一个分支变基。假设我们有两个分支 — master 和 feature — 提交链如下图 4 所示。Master 的提交链是 `C4->C2->C1->C0` 和 feature 的提交链是 `C5->C3->C2->C1->C0`.
|
||||
|
||||
![Chain of commits for branches master and feature][6]
|
||||
|
||||
图 4:master 和 feature 分支的提交链
|
||||
|
||||
如果我们在分支中看它的提交记录,它们看起来应该像下面的这样。(为了易于理解,`C` 表示提交信息)
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
000f9ae C3
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
我给人讲,在 Git 中,可以将 `rebase` 认为是 “将历史合并”。从本质上来说,Git 将一个分支中的每个不同提交尝试“重放”到另一个分支中。
|
||||
|
||||
因此,我们使用基本的 Git 命令,可以 rebase 一个 feature 分支进入到 master 中,并将它拼入到 `C4` 中(比如,将它插入到 feature 的链中)。操作命令如下:
|
||||
```
|
||||
$ git checkout feature
|
||||
$ git rebase master
|
||||
|
||||
First, rewinding head to replay your work on top of it...
|
||||
Applying: C3
|
||||
Applying: C5
|
||||
```
|
||||
|
||||
完成以后,我们的提交链将变成如下图 5 的样子。
|
||||
|
||||
![Chain of commits after the rebase command][8]
|
||||
|
||||
图 5:`rebase` 命令完成后的提交链
|
||||
|
||||
接着,我们看一下提交历史,它应该变成如下的样子。
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
|
||||
$ git log --oneline feature
|
||||
c4533a5 C5
|
||||
64f2047 C3
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
注意那个 `C3'` 和 `C5'`— 在 master 分支上已处于提交链的“顶部”,由于产生了更改而创建了新提交。但是也要注意的是,rebase 后“原始的” `C3` 和 `C5` 仍然在那里 — 只是再没有一个分支指向它们而已。
|
||||
|
||||
如果我们做了这个 rebase,然后确定这不是我们想要的结果,希望去撤销它,我们可以做下面示例所做的操作:
|
||||
```
|
||||
$ git reset 79768b8
|
||||
|
||||
```
|
||||
|
||||
由于这个简单的变更,现在我们的分支将重新指向到做 `rebase` 操作之前一模一样的位置 —— 完全等效于撤销操作(图 6)。
|
||||
|
||||
![After undoing rebase][10]
|
||||
|
||||
图 6:撤销 `rebase` 操作之后
|
||||
|
||||
如果你想不起来之前一个操作指向的一个分支上提交了什么内容怎么办?幸运的是,Git 命令依然可以帮助你。用这种方式可以修改大多数操作的指针,Git 会记住你的原始提交。事实上,它是在 `.git` 仓库目录下,将它保存为一个特定的名为 `ORIG_HEAD ` 的文件中。在它被修改之前,那个路径是一个包含了大多数最新引用的文件。如果我们 `cat` 这个文件,我们可以看到它的内容。
|
||||
```
|
||||
$ cat .git/ORIG_HEAD
|
||||
79768b891f47ce06f13456a7e222536ee47ad2fe
|
||||
```
|
||||
|
||||
我们可以使用 `reset` 命令,正如前面所述,它返回指向到原始的链。然后它的历史将是如下的这样:
|
||||
```
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
000f9ae C3
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
在 reflog 中是获取这些信息的另外一个地方。这个 reflog 是你本地仓库中相关切换或更改的详细描述清单。你可以使用 `git reflog` 命令去查看它的内容:
|
||||
```
|
||||
$ git reflog
|
||||
79768b8 HEAD@{0}: reset: moving to 79768b
|
||||
c4533a5 HEAD@{1}: rebase finished: returning to refs/heads/feature
|
||||
c4533a5 HEAD@{2}: rebase: C5
|
||||
64f2047 HEAD@{3}: rebase: C3
|
||||
6a92e7a HEAD@{4}: rebase: checkout master
|
||||
79768b8 HEAD@{5}: checkout: moving from feature to feature
|
||||
79768b8 HEAD@{6}: commit: C5
|
||||
000f9ae HEAD@{7}: checkout: moving from master to feature
|
||||
6a92e7a HEAD@{8}: commit: C4
|
||||
259bf36 HEAD@{9}: checkout: moving from feature to master
|
||||
000f9ae HEAD@{10}: commit: C3
|
||||
259bf36 HEAD@{11}: checkout: moving from master to feature
|
||||
259bf36 HEAD@{12}: commit: C2
|
||||
f33ae68 HEAD@{13}: commit: C1
|
||||
5043e79 HEAD@{14}: commit (initial): C0
|
||||
```
|
||||
|
||||
你可以使用日志中列出的、你看到的相关命名格式,去 reset 任何一个东西:
|
||||
```
|
||||
$ git reset HEAD@{1}
|
||||
|
||||
```
|
||||
|
||||
一旦你理解了当“修改”链的操作发生后,Git 是如何跟踪原始提交链的基本原理,那么在 Git 中做一些更改将不再是那么可怕的事。这就是强大的 Git 的核心能力之一:能够很快速、很容易地尝试任何事情,并且如果不成功就撤销它们。
|
||||
|
||||
Brent Laster 将在 7 月 16 日至 19 日在俄勒冈州波特兰举行的第 20 届 OSCON 年度活动上,展示 [强大的 Git:Rerere, Bisect, Subtrees, Filter Branch, Worktrees, Submodules, 等等][11]。想了解在任何水平上使用 Git 的一些技巧和缘由,请查阅 Brent 的书 ——"[Professional Git][13]",它在 Amazon 上有售。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/git-reset-revert-rebase-commands
|
||||
|
||||
作者:[Brent Laster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bclaster
|
||||
[1]:/file/401126
|
||||
[2]:https://opensource.com/sites/default/files/uploads/gitcommands1_local-environment.png "Local Git environment with repository, staging area, and working directory"
|
||||
[3]:/file/401131
|
||||
[4]:https://opensource.com/sites/default/files/uploads/gitcommands2_reset.png "After reset"
|
||||
[5]:/file/401141
|
||||
[6]:https://opensource.com/sites/default/files/uploads/gitcommands4_commits-branches.png "Chain of commits for branches master and feature"
|
||||
[7]:/file/401146
|
||||
[8]:https://opensource.com/sites/default/files/uploads/gitcommands5_commits-rebase.png "Chain of commits after the rebase command"
|
||||
[9]:/file/401151
|
||||
[10]:https://opensource.com/sites/default/files/uploads/gitcommands6_rebase-undo.png "After undoing rebase"
|
||||
[11]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67142
|
||||
[12]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
[13]:https://www.amazon.com/Professional-Git-Brent-Laster/dp/111928497X/ref=la_B01MTGIINQ_1_2?s=books&ie=UTF8&qid=1528826673&sr=1-2
|
||||
102
translated/tech/20180621 Bitcoin is a Cult - Adam Caudill.md
Normal file
102
translated/tech/20180621 Bitcoin is a Cult - Adam Caudill.md
Normal file
@ -0,0 +1,102 @@
|
||||
比特币是一个邪教 — Adam Caudill
|
||||
======
|
||||
经过这些年,比特币社区已经发生了非常大的变化;社区成员从闭着眼睛都能讲解 [Merkle 树][1] 的技术迷们,变成了被一夜爆富欲望驱使的投机者和由一些连什么是 Merkle 树都不懂的人所领导的企图寻求 10 亿美元估值的区块链初创公司。随着时间的流逝,围绕比特币和其它加密货币形成了一个狂热,他们认为比特币和其它加密货币远比实际的更重要;他们相信常见的货币(法定货币)正在成为过去,而加密货币将从根本上改变世界经济。
|
||||
|
||||
每一年他们的队伍都在壮大,而他们对加密货币的看法也在变得更加宏伟,那怕是因为[使用新技术][2]而使它陷入困境的情况下。虽然我坚信设计优良的加密货币可以使金钱的跨境流动更容易,并且在大规模通胀的领域提供一个更稳定的选择,但现实情况是,我们并没有做到这些。实际上,正是价值的巨大不稳定性才使得投机者赚钱。那些宣扬美元和欧元即将死去的人,已经完全抛弃了对现实世界客观公正的看法。
|
||||
|
||||
### 一点点背景 …
|
||||
|
||||
比特币发行那天,我读了它的白皮书 —— 它使用有趣的 [Merkle 树][1] 去创建一个公共账簿和一个非常合理的共识协议 —— 由于它新颖的特性引起了密码学领域中许多人的注意。在白皮书发布后的几年里,比特币变得非常有价值,并由此吸引了许多人将它视为是一种投资,和那些认为它将改变一切的忠实追随者(和发声者)。这篇文章将讨论的正是后者。
|
||||
|
||||
昨天,有人在推特上发布了一个最近的比特币区块的哈希,下面成千上万的推文和其它讨论让我相信,比特币已经跨越界线进入了真正的邪教领域。
|
||||
|
||||
一切都源于 Mark Wilcox 的这个推文:
|
||||
|
||||
> #00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a
|
||||
> — Mark Wilcox (@mwilcox) June 19, 2018
|
||||
|
||||
张贴的这个值是 [比特币 #528249 号区块][3] 的哈希值。前导零是挖矿过程的结果;挖掘一个区块就是把区块内容与一个 nonce(和其它数据)组合起来,然后做哈希运算,并且它至少有一定数量的前导零才能被验证为有效区块。如果它不是正确的数字,你可以更换 nonce 再试。重复这个过程直到哈希值的前导零数量是正确的数字之后,你就有了一个有效的区块。让人们感到很兴奋的部分是接下来的 21e800。
|
||||
|
||||
一些人说这是一个有意义的编号,挖掘出这个区块的人实际上的难度远远超出当前所看到的,不仅要调整前导零的数量,还要匹配接下来的 24 位 —— 它要求非常强大的计算能力。如果有人能够以蛮力去实现它,这将表明有些事情很严重,比如,在计算或密码学方面的重大突破。
|
||||
|
||||
你一定会有疑问,为什么 21e800 如此重要 —— 一个你问了肯定会后悔的问题。有人说它是参考了 [E8 理论][4](一个广受批评的提出标准场理论的论文),或是表示总共存在 2100000000 枚比特币(`21 x 10^8` 就是 2,100,000,000)。还有其它说法,因为太疯狂了而没有办法写出来。另一个重要的事实是,在前导零后面有 21e8 的区块平均每年被挖掘出一次 —— 这些从来没有人认为是很重要的。
|
||||
|
||||
这就引出了有趣的地方:关于这是如何发生的[理论][5]。
|
||||
|
||||
* 一台量子计算机,它能以某种方式用不可思议的速度做哈希运算。尽管在量子计算机的理论中还没有迹象表明它能够做这件事。哈希是量子计算机认为很安全的东西之一。
|
||||
* 时间旅行。是的,真的有人这么说,有人从未来穿梭回到现在去挖掘这个区块。我认为这种说法太荒谬了,都懒得去解释它为什么是错误的。
|
||||
* 中本聪回来了。尽管事实上他的私钥没有任何活动,一些人从理论上认为他回来了,他能做一些没人能做的事情。这些理论是无法解释他如何做到的。
|
||||
|
||||
|
||||
|
||||
> 因此,总的来说(按我的理解)中本聪,为了知道和计算他做的事情,根据现代科学,他可能是以下之一:
|
||||
>
|
||||
> A) 使用了一台量子计算机
|
||||
> B) 来自未来
|
||||
> C) 两者都是
|
||||
>
|
||||
> — Crypto Randy Marsh [REKT] (@nondualrandy) [June 21, 2018][6]
|
||||
|
||||
如果你觉得所有的这一切听起来像 [命理学][7],不止你一个人是这样想的。
|
||||
|
||||
所有围绕有特殊意义的区块哈希的讨论,也引发了对在某种程度上比较有趣的东西的讨论。比特币的创世区块,它是第一个比特币区块,有一个不寻常的属性:早期的比特币要求哈希值的前 32 位是零;而创始区块的前导零有 43 位。因为由代码产生的创世区块从不会发布,它不知道它是如何产生的,也不知道是用什么类型的硬件产生的。中本聪有学术背景,因此可能他有比那个时候大学中常见设备更强大的计算能力。从这一点上说,只是对古怪的创世区块的历史有点好奇,仅此而已。
|
||||
|
||||
### 关于哈希运算的简单题外话
|
||||
|
||||
这种喧嚣始于比特币区块的哈希运算;因此理解哈希是什么很重要,并且要理解一个非常重要的属性,一个哈希是单向加密函数,它能够基于给定的数据创建一个伪随机输出。
|
||||
|
||||
这意味着什么呢?基于本文讨论的目的,对于每个给定的输入你将得到一个随机的输出。随机数有时看起来很有趣,很简单,因为它是随机的结果,并且人类大脑可以很容易从任何东西中找到顺序。当你从随机数据中开始查看顺序时,你就会发现有趣的事情 —— 这些东西毫无意义,因为它们只是简单地随机数。当人们把重要的意义归属到随机数据上时,它将告诉你很多这些参与者观念相关的东西,而不是数据本身。
|
||||
|
||||
### 币的邪教
|
||||
|
||||
首先,我们来定义一组术语:
|
||||
|
||||
* 邪教:一个宗教崇拜和直接向一个特定的人或物虔诚的体系。
|
||||
* 宗教:有人认为是至高无上的追求或兴趣。
|
||||
|
||||
|
||||
|
||||
币的狂热追捧者中的许多圣人,或许没有人比中本聪更伟大,他是比特币创始人的假名。强力的护卫、赋予能力和理解力远超过一般的研究人员,认为他的远见卓视无人能比,他影响了世界新经济的秩序。当将中本聪的神秘本质和未知的真实身份结合起来时,狂热的追随着们将中本聪视为一个真正的值的尊敬的人物。
|
||||
|
||||
当然,除了追随其他圣人的追捧者之外,毫无疑问这些追捧者认为自己是正确的。任何对他们的圣人的批评都被认为也是对他们的批评。例如,那些追捧 EOS 的人,可能会认为中本聪是开发了一个失败项目的黑客,而对 EOS 那怕是最轻微的批评,他们也会作出激烈的反应,之所以反应如此强烈,仅仅是因为攻击了他们心目中的神。那些追捧 IOTA 的人的反应也一样;还有更多这样的例子。
|
||||
|
||||
这些追随着在讨论问题时已经失去了理性和客观,他们的狂热遮盖了他们的视野。任何对这些项目和项目背后的人的讨论,如果不是溢美之词,必然以某种程序的刻薄言辞结束,对于一个技术的讨论那种做法是毫无道理的。
|
||||
|
||||
这很危险,原因很多:
|
||||
|
||||
* 开发者 & 研究者对缺陷视而不见。由于追捧者的大量赞美,这些参与开发的人对自己的能力开始膨胀,并将一些批评看作是无端的攻击 —— 因为他们认为自己是不可能错的。
|
||||
* 真正的问题是被攻击。技术问题不再被看作是需要去解决的问题和改进的机会,他们认为是来自那些想去破坏项目的人的攻击。
|
||||
* 用一枚币来控制他们。追随者们通常会结盟,而圣人仅有一个。承认其它项目的优越,意味着认同自己项目的缺陷或不足,而这是他们不愿意做的事情。
|
||||
* 阻止真实的进步。进化是很残酷的,它要求死亡,项目失败,以及承认这些失败的原因。如果忽视失败的教训,如果不允许那些应该去死亡的事情发生,进步就会停止。
|
||||
|
||||
|
||||
|
||||
许多围绕加密货币和相关区块链项目的讨论已经开始变得越来越”有毒“,善意的人想在不受攻击的情况下进行技术性讨论越来越不可能。随着对真正缺陷的讨论,那些在其它环境中注定要失败的缺陷,在没有做任何的事实分析的情况下即刻被判定为异端已经成为了惯例,善意的人参与其中的代价变得极其昂贵。至少有些人已经意识到极其严重的安全漏洞,由于高“毒性”的环境,他们选择保持沉默。
|
||||
|
||||
曾经被好奇、学习和改进的期望、创意可行性所驱动的东西,现在被盲目的贪婪、宗教般的狂热、自以为是和自我膨胀所驱动。
|
||||
|
||||
我对受这种狂热激励的项目的未来不抱太多的希望,而它持续地传播,可能会损害多年来在这个领域中真正的研究者。这些技术项目中,一些项目成功了,一些项目失败了 —— 这就是技术演进的方式。设计这些系统的人,就和你我一样都有缺点,同样这些项目也有缺陷。有些项目非常适合某些使用场景而不适合其它场景,有些项目不适合任何使用场景,没有一个项目适合所有使用场景。关于这些项目的讨论应该关注于技术方面,这样做是为了让这一研究领域得以发展;在这些项目中掺杂宗教般狂热必将损害所有人。
|
||||
|
||||
[注意:这种行为有许多例子可以引用,但是为了保护那些因批评项目而成为被攻击目标的人,我选择尽可能少的列出这种例子。我看到许多我很尊敬的人、许多我认为是朋友的人成为这种恶毒攻击的受害者 —— 我不想引起人们对这些攻击的注意和重新引起对他们的攻击。]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://adamcaudill.com/2018/06/21/bitcoin-is-a-cult/
|
||||
|
||||
作者:[Adam Caudill][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://adamcaudill.com/author/adam/
|
||||
[1]:https://en.wikipedia.org/wiki/Merkle_tree
|
||||
[2]:https://hackernoon.com/how-crypto-kitties-disrupted-the-ethereum-network-845c22aa1e6e
|
||||
[3]:https://blockchain.info/block-height/528249
|
||||
[4]:https://en.wikipedia.org/wiki/An_Exceptionally_Simple_Theory_of_Everything
|
||||
[5]:https://medium.com/@coop__soup/00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a-cd4b67d446be
|
||||
[6]:https://twitter.com/nondualrandy/status/1009609117768605696?ref_src=twsrc%5Etfw
|
||||
[7]:https://en.wikipedia.org/wiki/Numerology
|
||||
@ -1,138 +0,0 @@
|
||||
如何使用命令行检查 Linux 上的磁盘空间
|
||||
========
|
||||
|
||||
>通过使用 `df` 命令和 `du` 命令查看 Linux 系统上挂载的驱动器的空间使用情况
|
||||
|
||||

|
||||
|
||||
-----------------------------
|
||||
|
||||
*** 快速提问: ***你的驱动器剩余多少剩余空间?一点点还是很多?接下来的提问是:你知道如何找出这些剩余空间吗?如果你使用的是 GUI 桌面( 例如 GNOME,KDE,Mate,Pantheon 等 ),则任务可能非常简单。但是,当你要在一个没有 GUI 桌面的服务器上查询剩余空间,你该如何去做呢?你是否要为这个任务安装相应的软件工具?答案是绝对不是。在 Linux 中,具备查找驱动器上的剩余磁盘空间的所有工具。事实上,有两个非常容易使用的工具。
|
||||
|
||||
在本文中,我将演示这些工具。我将使用 Elementary OS( LCTT译注:Elementary OS 是基于 Ubuntu 精心打磨美化的桌面 Linux 发行版 ),它还包括一个 GUI 选项,但我们将限制自己仅使用命令行。好消息是这些命令行工具随时可用于每个 Linux 发行版。在我的测试系统中,连接了许多的驱动器( 内部的和外部的 )。使用的命令与连接驱动器的位置无关,仅仅与驱动器是否已经挂载好并且对操作系统可见。
|
||||
|
||||
话虽如此,让我们来试试这些工具。
|
||||
|
||||
### df
|
||||
|
||||
`df` 命令是我第一次用于在 Linux 上查询驱动器空间的工具,时间可以追溯到20世纪90年代。它的使用和报告结果非常简单。直到今天,`df` 还是我执行此任务的首选命令。此命令有几个选项开关,对于基本的报告,你实际上只需要一个选项。该命令是 `df -H` 。`-H` 选项开关用于将df的报告结果以人类可读的格式进行显示。`df -H` 的输出包括:已经使用了的空间量,可用空间,空间使用的百分比,以及每个磁盘连接到系统的挂载点( 图 1 )。
|
||||
|
||||

|
||||
|
||||
图 1:Elementary OS 系统上 `df -H` 命令的输出结果
|
||||
|
||||
如果你的驱动器列表非常长并且你只想查看单个驱动器上使用的空间,该怎么办?有了 `df`,就可以做到。我们来看一下位于 `/dev/sda1` 的主驱动器已经使用了多少空间。为此,执行如下命令:
|
||||
```
|
||||
df -H /dev/sda1
|
||||
```
|
||||
输出将限于该驱动器( 图 2 )。
|
||||

|
||||
|
||||
图 2:一个单独驱动器空间情况
|
||||
|
||||
你还可以限制 `df` 命令结果报告中显示指定的字段。可用的字段包括:
|
||||
|
||||
- source — 文件系统的来源( LCTT译注:通常为一个设备,如 `/dev/sda1` )
|
||||
- size — 块总数
|
||||
- used — 驱动器已使用的空间
|
||||
- avail — 可以使用的剩余空间
|
||||
- pcent — 驱动器已经使用的空间占驱动器总空间的百分比
|
||||
- target —驱动器的挂载点
|
||||
|
||||
让我们显示所有驱动器的输出,仅显示 `size` ,`used` ,`avail` 字段。对此的命令是:
|
||||
```
|
||||
df -H --output=size,used,avail
|
||||
```
|
||||
该命令的输出非常简单( 图 3 )。
|
||||

|
||||
|
||||
图 3:显示我们驱动器的指定输出
|
||||
|
||||
这里唯一需要注意的是我们不知道输出的来源,因此,我们要把来源加入命令中:
|
||||
```
|
||||
df -H --output=source,size,used,avail
|
||||
```
|
||||
现在输出的信息更加全面有意义( 图 4 )。
|
||||

|
||||
|
||||
图 4:我们现在知道了磁盘使用情况的来源
|
||||
|
||||
|
||||
### du
|
||||
|
||||
我们的下一个命令是 `du` 。 正如您所料,这代表磁盘使用情况( disk usage )。 `du` 命令与 `df` 命令完全不同,因为它报告目录而不是驱动器的空间使用情况。 因此,您需要知道要检查的目录的名称。 假设我的计算机上有一个包含虚拟机文件的目录。 那个目录是 `/media/jack/HALEY/VIRTUALBOX` 。 如果我想知道该特定目录使用了多少空间,我将运行如下命令:
|
||||
```
|
||||
du -h /media/jack/HALEY/VIRTUALBOX
|
||||
```
|
||||
上面命令的输出将显示目录中每个文件占用的空间( 图 5 )。
|
||||

|
||||
|
||||
图 5 在特定目录上运行 `du` 命令的输出
|
||||
|
||||
到目前为止,这个命令并没有那么有用。如果我们想知道特定目录的总使用量怎么办?幸运的是,`du` 可以处理这项任务。对于同一目录,命令将是:
|
||||
```
|
||||
du -sh /media/jack/HALEY/VIRTUALBOX/
|
||||
```
|
||||
现在我们知道了上述目录使用存储空间的总和( 图 6 )。
|
||||

|
||||
|
||||
图 6:我的虚拟机文件使用存储空间的总和是 559GB
|
||||
|
||||
您还可以使用此命令查看父项的所有子目录使用了多少空间,如下所示:
|
||||
```
|
||||
du -h /media/jack/HALEY
|
||||
```
|
||||
此命令的输出见( 图 7 ),是一个用于查看各子目录占用的驱动器空间的好方法。
|
||||

|
||||
|
||||
图 7:子目录的存储空间使用情况
|
||||
|
||||
`du` 命令也是一个很好的工具,用于查看使用系统磁盘空间最多的目录列表。执行此任务的方法是将 `du` 命令的输出通过管道传递给另外两个命令:`sort` 和 `head` 。下面的命令用于找出驱动器上占用存储空间最大的前10各目录:
|
||||
```
|
||||
du -a /media/jack | sort -n -r |head -n 10
|
||||
```
|
||||
输出将以从大到小的顺序列出这些目录( 图 8 )。
|
||||

|
||||
|
||||
图 8:使用驱动器空间最多的 10 个目录
|
||||
|
||||
### 没有你想像的那么难
|
||||
|
||||
查看 Linux 系统上挂载的驱动器的空间使用情况非常简单。只要你将你的驱动器挂载在 Linux 系统上,使用 `df` 命令或 `du` 命令在报告必要信息方面都会非常出色。使用 `df` 命令,您可以快速查看磁盘上总的空间使用量,使用 `du` 命令,可以查看特定目录的空间使用情况。对于每一个 Linux 系统的管理员来说,这两个命令的结合使用是必须掌握的。
|
||||
|
||||
而且,如果你不需要使用 `du` 或 `df` 命令查看驱动器空间的使用情况,我最近介绍了查看 Linux 上内存使用情况的方法。总之,这些技巧将大力帮助你成功管理 Linux 服务器。
|
||||
|
||||
通过 Linux Foundation 和 edX 免费提供的 “ Linux 简介 ” 课程,了解更多有关 Linux 的信息。
|
||||
|
||||
--------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/6how-check-disk-space-linux-command-line
|
||||
|
||||
作者:Jack Wallen 选题:lujun9972 译者:SunWave 校对:校对者ID
|
||||
|
||||
本文由 LCTT 原创编译,Linux中国 荣誉推出
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,73 +0,0 @@
|
||||
为什么 Arch Linux 如此'难弄'又有何优劣?
|
||||
======
|
||||
|
||||

|
||||
[Arch Linux][1] 于**2002**年发布,由** Aaron Grifin** 领头,是当下最热门的 Linux 发行版之一。从设计上说,Arch Linux 试图给用户提供简单,最小化且优雅的体验,但他的目标用户群可不是怕事儿多的用户。Arch 鼓励参与社区建设,并且从设计上期待用户自己有学习操作系统的能力。
|
||||
|
||||
很多 Linux 老鸟对于 **Arch Linux** 会更了解,但电脑前的你可能只是刚开始打算把 Arch 当作日常操作系统来使用。虽然我也不是权威人士,但下面几点优劣是我认为你总会在使用中慢慢发现的。
|
||||
|
||||
### 1\. Pro: 定制属于你自己的 Linux 操作系统
|
||||
|
||||
大多数热门的 Linux 发行版(比如**Ubuntu** 和 **Fedora**) 很像一般我们会看到的预装系统,和**Windows** 或者 **MacOS** 一样。但 Arch 则会更鼓励你去把操作系统配置到符合你的胃口。如果你能顺利做到这点的话,你会得到一个每一个细节都如你所想的操作系统。
|
||||
|
||||
#### Con: 安装过程让人头疼
|
||||
|
||||
[安装 Arch Linux][2] 是主流发行版里的一支独苗——因为你要花些时间来微调你的操作系统。你会在过程中学到不少终端命令,和组成你系统的各种软件模块——毕竟你要自己挑选安装什么。当然,你也知道这个过程少不了阅读一些文档/教程。
|
||||
|
||||
### 2\. Pro: 没有预装垃圾
|
||||
|
||||
介于 **Arch** 允许你在安装时选择你想要的系统部件,你再也不用烦恼怎么处理你不想要的一堆预装软件。作为对比,**Ubuntu** 会预装大量的软件和桌面应用——很多你不需要甚至卸载之前都不知道他们存在的东西。
|
||||
|
||||
长话短说,**Arch Linux* 能省去大量的系统安装后时间。**Pacman**,是 Arch Linux 默认使用的优秀包管理组件。或者你也可以选择 [Pamac][3] 作为替代。
|
||||
|
||||
### 3\. Pro: 无需繁琐系统升级
|
||||
|
||||
**Arch Linux** 采用滚动升级模型,妙极了。这意味着你不需要担心老是被升级打断。一旦你用上了 Arch,连续地更新体验会让你和一会儿一个版本的升级说再见。只要你记得‘滚’更新(Arch 用语),你就一直会使用最新的软件包们。
|
||||
|
||||
#### Con: 一些升级可能会滚坏你的系统
|
||||
|
||||
虽然升级过程是完全连续的,你有时得留意一下你在更新什么。没人能知道所有软件的细节配置,也没人能替你来测试你的情况。所以如果你盲目更新,有时候你会滚坏你的系统。(译者:别担心,你可以回滚)
|
||||
|
||||
### 4\. Pro: Arch 有一个社区基因
|
||||
|
||||
所有 Linux 用户通常有一个共同点:对独立自由的追求。虽然大多数 Linux 发行版和公司企业等挂钩极少,但有时候也不是不存在的。比如 基于 **Ubuntu** 的变化版本们不得不受到 Canonical 公司决策的影响。
|
||||
|
||||
如果你想让你的电脑更独立,那么 Arch Linux 是你的伙伴。不像大多数操作系统,Arch 完全没有商业集团的影响,完全由社区驱动。
|
||||
|
||||
### 5\. Pro: Arch Wiki 无敌
|
||||
|
||||
[Arch Wiki][4] 是一个无敌文档库,几乎涵盖了所有关于安装和维护 Arch 以及关于操作系统本身的知识。Arch Wiki 最厉害的一点可能是,不管你在用什么发行版,你多多少少可能都在 Arch Wiki 的页面里找到过有用信息。这是因为 Arch 用户也会用别的发行版用户会用的东西,所以一些技巧和知识得以泛化。
|
||||
|
||||
### 6\. Pro: 别忘了 Arch 用户软件库 (AUR)
|
||||
|
||||
[Arch User Repository (AUR)][5] 是一个来自社区的超大软件仓库。如果你找一个还没有 Arch 的官方仓库里出现的软件,你肯定能在 AUR 里找到社区为你准备好的包。
|
||||
|
||||
AUR 是由用户自发编译和维护的。Arch 用户也可以给每个包投票,这样后来者就能找到最有用的那些软件包了。
|
||||
|
||||
#### 最后: Arch Linux 适合你吗?
|
||||
|
||||
**Arch Linux** 优点多于缺点,也有很多优缺点我无法在此一一叙述。安装过程很长,对非 Linux 用户来说也可能偏有些技术,但只要你投入一些时间和善用 Wiki,你肯定能迈过这道坎。
|
||||
|
||||
**Arch Linux** 是一个非常优秀的发行版——尽管它有一些复杂性。同时它也很受那些知道自己想要什么的用户的欢迎——只要你肯做点功课,有些耐心。
|
||||
|
||||
当你从0搭安装完 Arch 的时候,你会掌握很多 GNU/Linux 的内部细节,也再也不会对你的电脑内部运作方式一无所知了。
|
||||
|
||||
欢迎读者们在评论区讨论你使用 Arch Linux 的优缺点?以及你曾经遇到过的一些挑战。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/why-is-arch-linux-so-challenging-what-are-pros-cons/
|
||||
|
||||
作者:[Martins D. Okoi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Moelf](https://github.com/Moelf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://www.tecmint.com/arch-linux-installation-and-configuration-guide/
|
||||
[3]:https://www.fossmint.com/pamac-arch-linux-gui-package-manager/
|
||||
[4]:https://wiki.archlinux.org/
|
||||
[5]:https://wiki.archlinux.org/index.php/Arch_User_Repository
|
||||
@ -0,0 +1,70 @@
|
||||
重温 wallabag,Instapaper 的开源替代品
|
||||
======
|
||||
|
||||

|
||||
|
||||
早在 2014 年,我[写了篇关于 wallabag 的文章][1],它是稍后阅读应用如 Instapaper 和 Pocket 的开源替代品。如果你愿意,去看看那篇文章吧。别担心,我会等你的。
|
||||
|
||||
好了么?很好
|
||||
|
||||
自从我写这篇文章的四年来,[wallabag][2]的很多东西都发生了变化。现在是时候看看 wallabag 是如何成熟的。
|
||||
|
||||
### 有什么新的
|
||||
|
||||
最大的变化发生在幕后。Wallabag 的开发人员 Nicolas Lœuillet 和该项目的贡献者对代码进行了大量修改,从而改进了程序。每次使用时,你都会看到并感受到 wallabag 新代码库所带来的变化。
|
||||
|
||||
那么这些变化有哪些呢?有[很多][3]。以下是我发现最有趣和最有用的内容。
|
||||
|
||||
除了使 wallabag 更加快速和稳定之外,程序的导入和导出内容的能力也得到了提高。你可以从 Pocket 和 Instapaper 导入文章,也可导入书签服务 [Pinboard][4] 中标记为 “To read” 的文章。你还可以导入 Firefox 和 Chrome 书签。
|
||||
|
||||
你还可以以多种格式导出文章,包括 EPUB、MOBI、PDF 和纯文本。你可以为单篇文章、所有未读文章或所有已读和未读执行此操作。我四年前使用的 wallabag 版本可以导出到 EPUB 和 PDF,但有时导出很糟糕。现在,这些导出快速而顺利。
|
||||
|
||||
Web 界面中的注释和高亮显示现在可以更好,更一致地工作。不可否认,我并不经常使用它们 - 但它们不会像 wallabag v1 那样随机消失。
|
||||
|
||||

|
||||
|
||||
wallabag 的外观和感觉也有所改善。这要归功于受 [Material Design][5] 启发的新主题。这似乎不是什么大不了的事,但这个主题使得 wallabag 在视觉上更具吸引力,使文章更容易扫描和阅读。是的,孩子们,良好的用户体验可以有所不同。
|
||||
|
||||

|
||||
|
||||
其中一个最大的变化是引入了 wallabag 的[托管版本][6]。不止一些人(包括你在内)没有服务器来运行网络程序,并且不太愿意这样做。当遇到任何技术问题时,我很窘迫。我不介意每年花 9 欧元(我写这篇文章的时候只要 10 美元),以获得一个我不需要关注的程序的完整工作版本。
|
||||
|
||||
### 没有改变什么
|
||||
|
||||
总的来说,wallabag 的核心功能是相同的。如上所述,更新的代码库使这些函数运行得更顺畅,更快速。
|
||||
|
||||
Wallabag 的[浏览器扩展][7]以同样的方式完成同样的工作。我发现这些扩展比我第一次尝试时和程序的 v1 版本时要好一些。
|
||||
|
||||
### 有什么令人失望的
|
||||
|
||||
移动应用良好,但没有很棒。它在渲染文章方面做得很好,并且有一些配置选项。但是你不能高亮或注释文章。也就是说,你可以使用该程序浏览你的存档文章。
|
||||
|
||||

|
||||
|
||||
虽然 wallabag 在收藏文章方面做得很好,但有些网站的内容却无法保存。我没有碰到很多这样的网站,但已经遇到让人烦恼的情况。我不确定与 wallabag 有多大关系。相反,我怀疑它与网站的编码方式有关 - 我在使用几个专有的稍后阅读工具时遇到了同样的问题。
|
||||
|
||||
Wallabag 可能不是 Pocket 或 Instapaper 的等功能的替代品,但它做得很好。自从我第一次写这篇文章以来的四年里,它已经有了明显的改善。它仍然有改进的余地,但要做好它宣传的。
|
||||
|
||||
### 最后的想法
|
||||
|
||||
自 2014 年以来,wallabag 在一直在演化。它一点一滴,一步一步地变得更好。虽然它可能不是 Instapaper 和 Pocket 等功能的替代品,但 wallabag 有价值的专有稍后阅读工具的开源替代品。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/wallabag
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/life/14/4/open-source-read-it-later-app-wallabag
|
||||
[2]:https://wallabag.org/en
|
||||
[3]:https://www.wallabag.org/en/news/wallabag-v2
|
||||
[4]:https://pinboard.in
|
||||
[5]:https://en.wikipedia.org/wiki/Material_Design
|
||||
[6]:https://www.wallabag.it
|
||||
[7]:https://github.com/wallabag/wallabagger
|
||||
@ -0,0 +1,273 @@
|
||||
系统管理员的 SELinux 指南:这个大问题的 42 个答案
|
||||
======
|
||||
|
||||

|
||||
|
||||
> "一个重要而普遍的事实是,事情并不总是你看上去的那样 …"
|
||||
> ―Douglas Adams,银河系漫游指南
|
||||
|
||||
安全、坚固、遵从性、策略 —— 系统管理员启示录的四骑士。除了我们的日常任务之外 —— 监视、备份、实施、调优、更新等等 —— 我们还负责我们的系统安全。甚至是那些第三方提供给我们的禁用了安全增强的系统。这看起来像《碟中碟》中 [Ethan Hunt][1] 的工作一样。
|
||||
|
||||
面对这种窘境,一些系统管理员决定去[服用蓝色小药丸][2],因为他们认为他们永远也不会知道如生命、宇宙、以及其它一些大问题的答案。而我们都知道,它的答案就是这 **[42][3]** 个。
|
||||
|
||||
按《银河系漫游指南》的精神,这里是关于在你的系统上管理和使用 [SELinux][4] 这个大问题的 42 个答案。
|
||||
|
||||
1. SELinux 是一个标签系统,这意味着每个进程都有一个标签。每个文件、目录、以及系统对象都有一个标签。策略规则负责控制标签化进程和标签化对象之间的访问。由内核强制执行这些规则。
|
||||
|
||||
|
||||
2. 两个最重要的概念是:标签化(文件、进程、端口等等)和强制类型(它将基于类型对每个进程进行隔离)。
|
||||
|
||||
|
||||
3. 正确的标签格式是 `user:role:type:level`(可选)。
|
||||
|
||||
|
||||
4. 多级别安全(MLS)的目的是基于它们所使用数据的安全级别,对进程(域)强制实施控制。比如,一个秘密级别的进程是不能读取极机密级别的数据。
|
||||
|
||||
|
||||
5. 多类别安全(MCS)从每个其它类(如虚拟机、OpenShift gears、SELinux 沙盒、容器等等)中强制保护类似的进程。
|
||||
|
||||
|
||||
6. 在引导时内核参数可以改变 SELinux 模式:
|
||||
* `autorelabel=1` → 强制给系统标签化
|
||||
* `selinux=0` → 内核不加载 SELinux 基础设施的任何部分
|
||||
* `enforcing=0` → 引导为 permissive 模式
|
||||
|
||||
|
||||
7. 如果给整个系统标签化:
|
||||
`# touch /.autorelabel #reboot`
|
||||
如果系统标签中有大量的错误,为了能够让 autorelabel 成功,你可以用 permissive 模式引导系统。
|
||||
|
||||
|
||||
8. 检查 SELinux 是否启用:`# getenforce`
|
||||
|
||||
|
||||
9. 临时启用/禁用 SELinux:`# setenforce [1|0]`
|
||||
|
||||
|
||||
10. SELinux 状态工具:`# sestatus`
|
||||
|
||||
|
||||
11. 配置文件:`/etc/selinux/config`
|
||||
|
||||
|
||||
12. SELinux 是如何工作的?这是一个为 Apache Web Server 标签化的示例:
|
||||
* 二进制文件:`/usr/sbin/httpd`→`httpd_exec_t`
|
||||
* 配置文件目录:`/etc/httpd`→`httpd_config_t`
|
||||
* 日志文件目录:`/var/log/httpd` → `httpd_log_t`
|
||||
* 内容目录:`/var/www/html` → `httpd_sys_content_t`
|
||||
* 启动脚本:`/usr/lib/systemd/system/httpd.service` → `httpd_unit_file_d`
|
||||
* 进程:`/usr/sbin/httpd -DFOREGROUND` → `httpd_t`
|
||||
* 端口:`80/tcp, 443/tcp` → `httpd_t, http_port_t`
|
||||
|
||||
|
||||
|
||||
在 `httpd_t` 环境中运行的一个进程可以与具有 `httpd_something_t` 标签的对象交互。
|
||||
|
||||
13. 许多命令都可以接收一个 `-Z` 参数去查看、创建、和修改环境:
|
||||
* `ls -Z`
|
||||
* `id -Z`
|
||||
* `ps -Z`
|
||||
* `netstat -Z`
|
||||
* `cp -Z`
|
||||
* `mkdir -Z`
|
||||
|
||||
|
||||
|
||||
当文件基于它们的父级目录的环境(有一些例外)创建后,它的环境就已经被设置。RPM 包可以在安装时设置环境。
|
||||
|
||||
14. 这里有导致 SELinux 出错的四个关键原因,它们将在下面的 15 - 21 号问题中展开描述:
|
||||
* 标签化问题
|
||||
* SELinux 需要知道一些东西
|
||||
* 在一个 SELinux 策略/app 中有 bug
|
||||
* 你的信息可能被损坏
|
||||
|
||||
|
||||
15. 标签化问题:如果在 `/srv/myweb` 中你的文件没有正确的标签,访问可能会被拒绝。这里有一些修复这类问题的方法:
|
||||
* 如果你知道标签:
|
||||
`# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
|
||||
* 如果你知道使用等价标签的文件:
|
||||
`# semanage fcontext -a -e /srv/myweb /var/www`
|
||||
* 恢复环境(对于以上两种情况):
|
||||
`# restorecon -vR /srv/myweb`
|
||||
|
||||
|
||||
16. 标签化问题:如果你是移动了一个文件,而不是去复制它,那么这个文件将保持原始的环境。修复这类问题:
|
||||
* 用标签改变环境的命令:
|
||||
`# chcon -t httpd_system_content_t /var/www/html/index.html`
|
||||
|
||||
* 用引用标签改变环境的命令:
|
||||
`# chcon --reference /var/www/html/ /var/www/html/index.html`
|
||||
|
||||
* 恢复环境(对于以上两种情况):
|
||||
|
||||
`# restorecon -vR /var/www/html/`
|
||||
|
||||
|
||||
17. 如果 SELinux 需要知道 HTTPD 是在 8585 端口上监听,告诉 SELinux:
|
||||
`# semanage port -a -t http_port_t -p tcp 8585`
|
||||
|
||||
|
||||
18. SELinux 需要知道是否允许在运行时无需重写 SELinux 策略而改变 SELinux 策略部分的布尔值。例如,如果希望 httpd 去发送邮件,输入:`# setsebool -P httpd_can_sendmail 1`
|
||||
|
||||
|
||||
19. SELinux 需要知道 SELinux 设置的 off/on 的布尔值:
|
||||
* 查看所有的布尔值:`# getsebool -a`
|
||||
* 查看每个布尔值的描述:`# semanage boolean -l`
|
||||
* 设置布尔值:`# setsebool [_boolean_] [1|0]`
|
||||
* 将它配置为永久值,添加 `-P` 标志。例如:
|
||||
`# setsebool httpd_enable_ftp_server 1 -P`
|
||||
|
||||
|
||||
20. SELinux 策略/apps 可能有 bug,包括:
|
||||
* 与众不同的代码路径
|
||||
* 配置
|
||||
* 重定向 `stdout`
|
||||
* 文件描述符漏洞
|
||||
* 可运行内存
|
||||
* 错误构建的库打开了一个 ticket(不要提交 Bugzilla 报告;这里没有使用 Bugzilla 的 SLAs)
|
||||
|
||||
|
||||
21. 如果你定义了域,你的信息可能被损坏:
|
||||
* 加载内核模块
|
||||
* 关闭 SELinux 的强制模式
|
||||
* 写入 `etc_t/shadow_t`
|
||||
* 修改 iptables 规则
|
||||
|
||||
|
||||
22. 开发策略模块的 SELinux 工具:
|
||||
`# yum -y install setroubleshoot setroubleshoot-server`
|
||||
安装完成之后重引导机器或重启 `auditd` 服务。
|
||||
|
||||
|
||||
23. 使用 `journalctl` 去列出所有与 `setroubleshoot` 相关的日志:
|
||||
`# journalctl -t setroubleshoot --since=14:20`
|
||||
|
||||
|
||||
24. 使用 `journalctl` 去列出所有与特定 SELinux 标签相关的日志。例如:
|
||||
`# journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
|
||||
|
||||
|
||||
25. 当 SELinux 发生错误以及建议一些可能的解决方案时,使用 `setroubleshoot` 日志。例如:从 `journalctl` 中:
|
||||
[code] Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
|
||||
|
||||
|
||||
# sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
|
||||
SELinux is preventing httpd from getattr access on the file /var/www/html/index.html.
|
||||
|
||||
|
||||
|
||||
***** Plugin restorecon (99.5 confidence) suggests ************************
|
||||
|
||||
|
||||
|
||||
If you want to fix the label,
|
||||
|
||||
/var/www/html/index.html default label should be httpd_syscontent_t.
|
||||
|
||||
Then you can restorecon.
|
||||
|
||||
Do
|
||||
|
||||
# /sbin/restorecon -v /var/www/html/index.html
|
||||
|
||||
|
||||
|
||||
|
||||
26. 日志:SELinux 记录的信息全部在这些地方:
|
||||
* `/var/log/messages`
|
||||
* `/var/log/audit/audit.log`
|
||||
* `/var/lib/setroubleshoot/setroubleshoot_database.xml`
|
||||
|
||||
|
||||
27. 日志:在审计日志中查找 SELinux 错误:
|
||||
`# ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
|
||||
|
||||
|
||||
28. 为特定的服务去搜索 SELinux 的访问向量缓存(AVC)信息:
|
||||
`# ausearch -m avc -c httpd`
|
||||
|
||||
|
||||
29. `audit2allow` 实用工具从拒绝的操作的日志中采集信息,然后生成 SELinux policy-allow 规则。例如:
|
||||
* 产生一个人类可读的关于为什么拒绝访问的描述:`# audit2allow -w -a`
|
||||
* 查看已允许的拒绝访问的强制类型规则:`# audit2allow -a`
|
||||
* 创建一个自定义模块:`# audit2allow -a -M mypolicy`
|
||||
`-M` 选项使用一个指定的名字去创建一个类型强制文件(.te)并编译这个规则到一个策略包(.pp)中:`mypolicy.pp mypolicy.te`
|
||||
* 安装自定义模块:`# semodule -i mypolicy.pp`
|
||||
|
||||
|
||||
30. 配置单个进程(域)运行在 permissive 模式:`# semanage permissive -a httpd_t`
|
||||
|
||||
|
||||
31. 如果不再希望一个域在 permissive 模式中:`# semanage permissive -d httpd_t`
|
||||
|
||||
|
||||
32. 禁用所有的 permissive 域:`# semodule -d permissivedomains`
|
||||
|
||||
|
||||
33. 启用 SELinux MLS 策略:`# yum install selinux-policy-mls`
|
||||
在 `/etc/selinux/config` 中:
|
||||
`SELINUX=permissive`
|
||||
`SELINUXTYPE=mls`
|
||||
确保 SELinux 运行在 permissive 模式:`# setenforce 0`
|
||||
使用 `fixfiles` 脚本去确保那个文件在下次重引导后重打标签:
|
||||
`# fixfiles -F onboot # reboot`
|
||||
|
||||
|
||||
34. 使用一个特定的 MLS 范围创建用户:`# useradd -Z staff_u john`
|
||||
使用 `useradd` 命令,映射新用户到一个已存在的 SELinux 用户(上面例子中是 `staff_u`)。
|
||||
|
||||
|
||||
35. 查看 SELinux 和 Linux 用户之间的映射:`# semanage login -l`
|
||||
|
||||
|
||||
36. 为用户定义一个指定的范围:`# semanage login --modify --range s2:c100 john`
|
||||
|
||||
|
||||
37. 调整用户 home 目录上的标签(如果需要的话):`# chcon -R -l s2:c100 /home/john`
|
||||
|
||||
|
||||
38. 列出当前分类:`# chcat -L`
|
||||
|
||||
|
||||
39. 修改分类或者开始去创建你自己的分类、修改文件:
|
||||
`/etc/selinux/_<selinuxtype>_/setrans.conf`
|
||||
|
||||
|
||||
40. 在指定的文件、角色、和用户环境中运行一个命令或脚本:
|
||||
`# runcon -t initrc_t -r system_r -u user_u yourcommandhere`
|
||||
* `-t` 是文件环境
|
||||
* `-r` 是角色环境
|
||||
* `-u` 是用户环境
|
||||
|
||||
|
||||
41. 在容器中禁用 SELinux:
|
||||
* 使用 Podman:`# podman run --security-opt label=disable` …
|
||||
* 使用 Docker:`# docker run --security-opt label=disable` …
|
||||
|
||||
|
||||
42. 如果需要给容器提供完全访问系统的权限:
|
||||
* 使用 Podman:`# podman run --privileged` …
|
||||
* 使用 Docker:`# docker run --privileged` …
|
||||
|
||||
|
||||
|
||||
就这些了,你已经知道了答案。因此请相信我:**不用恐慌,去打开 SELinux 吧**。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-selinux
|
||||
|
||||
作者:[Alex Callejas][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/darkaxl
|
||||
[1]:https://en.wikipedia.org/wiki/Ethan_Hunt
|
||||
[2]:https://en.wikipedia.org/wiki/Red_pill_and_blue_pill
|
||||
[3]:https://en.wikipedia.org/wiki/Phrases_from_The_Hitchhiker%27s_Guide_to_the_Galaxy#Answer_to_the_Ultimate_Question_of_Life,_the_Universe,_and_Everything_%2842%29
|
||||
[4]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
@ -0,0 +1,71 @@
|
||||
Linux 桌面中 4 个开源媒体转换工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
啊,有这么多的文件格式,特别是音频和视频格式,如果你不认识这个文件扩展名或者你的播放器无法播放那个格式,或者你想使用一种开放格式,那会有点有趣。
|
||||
|
||||
那么,Linux 用户可以做些什么呢?当然是去使用 Linux 桌面的众多开源媒体转换工具之一。我们来看看其中的四个。
|
||||
|
||||
### Gnac
|
||||
|
||||

|
||||
|
||||
[Gnac][1] 是我最喜欢的音频转换器之一,已经存在很多年了。它易于使用,功能强大,并且它做得很好 - 任何一流的程序都应该如此。
|
||||
|
||||
有多简单?单击工具栏按钮添加一个或多个要转换的文件,选择要转换的格式,然后单击**转换**。转换很快,而且很干净。
|
||||
|
||||
有多强大?Gnac 可以处理 [GStreamer][2] 多媒体框架支持的所有音频格式。开箱即用,你可以在 Ogg、FLAC、AAC、MP3、WAV 和 SPX 之间进行转换。你还可以更改每种格式的转换选项或添加新格式。
|
||||
|
||||
### SoundConverter
|
||||
|
||||

|
||||
|
||||
如果在简单的同时你还要一些额外的功能,那么请看一下 [SoundConverter][3]。正如其名称所述,SoundConverter 仅对音频文件起作用。与 Gnac 一样,它可以读取 GStreamer 支持的格式,它可以输出 Ogg Vorbis、MP3、FLAC、WAV、AAC 和 Opus 文件。
|
||||
|
||||
通过单击**添加文件**或将其拖放到 SoundConverter 窗口中来加载单个文件或整个文件夹。单击**转换**,软件将完成转换。它也很快 - 我已经在大约一分钟内转换了一个包含几十个文件的文件夹。
|
||||
|
||||
SoundConverter 有设置转换文件质量的选项。你可以更改文件的命名方式(例如,在标题中包含曲目编号或专辑名称),并为转换后的文件创建子文件夹。
|
||||
|
||||
### WinFF
|
||||
|
||||

|
||||
|
||||
[WinFF][4] 本身并不是转换器。它是 FFmpeg 的图形化前端,[Tim Nugent][5] 在 Opensource.com 写了篇文章。虽然 WinFF 没有 FFmpeg 的所有灵活性,但它使 FFmpeg 更易于使用,并且可以快速,轻松地完成工作。
|
||||
|
||||
虽然它不是这里最漂亮的程序,WinFF 也并不需要。它不仅仅是可用的。你可以从下拉列表中选择要转换的格式,并选择多个预设。最重要的是,你可以指定比特率和帧速率,要使用的音频通道数量,甚至裁剪视频的大小等选项。
|
||||
|
||||
转换,特别是视频,需要一些时间,但结果通常非常好。有时,转换会有点受损 - 但往往不足以引起关注。而且,正如我之前所说,使用 WinFF 可以节省一些时间。
|
||||
|
||||
### Miro Video Converter
|
||||
|
||||

|
||||
|
||||
并非所有视频文件都是平等创建的。有些是专有格式。有的在显示器或电视屏幕上看起来很棒但是没有针对移动设备进行优化。这就是 [Miro Video Converter][6] 可以用的地方。
|
||||
|
||||
Miro Video Converter 非常重视移动设备。它可以转换在 Android 手机、Apple 设备、PlayStation Portable 和 Kindle Fire 上播放的视频。它会将最常见的视频格式转换为 MP4、[WebM][7] 和 [Ogg Theora][8]。你可以[在 Miro 的网站][6]上找到支持的设备和格式的完整列表
|
||||
|
||||
要使用它,可以将文件拖放到窗口中,也可以选择要转换的文件。然后,单击“格式”菜单以选择转换的格式。你还可以单击 Apple、Android 或其他菜单以选择要转换文件的设备。Miro Video Converter 会为设备屏幕分辨率调整视频大小。
|
||||
|
||||
你有最喜欢的 Linux 媒体转换程序吗?请留下评论,随意分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/media-conversion-tools-linux
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:http://gnac.sourceforge.net
|
||||
[2]:http://www.gstreamer.net/
|
||||
[3]:http://soundconverter.org/
|
||||
[4]:https://www.biggmatt.com/winff/
|
||||
[5]:https://opensource.com/article/17/6/ffmpeg-convert-media-file-formats
|
||||
[6]:http://www.mirovideoconverter.com/
|
||||
[7]:https://en.wikipedia.org/wiki/WebM
|
||||
[8]:https://en.wikipedia.org/wiki/Ogg_theora
|
||||
Loading…
Reference in New Issue
Block a user