mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
commit
84cc11db6f
.gitignorelctt2018.md
published
20140607 Five things that make Go fast.md
201509
201703
20170810 How we built our first full-stack JavaScript web app in three weeks.md20170926 Managing users on Linux systems.md20171022 Review- Algorithms to Live By by Brian Christian - Tom Griffiths.md20171129 How to Install and Use Wireshark on Debian and Ubuntu 16.04_17.10.md20180117 How to get into DevOps.md20180123 Moving to Linux from dated Windows machines.md20180201 Conditional Rendering in React using Ternaries and.md20180412 A Desktop GUI Application For NPM.md20180413 The df Command Tutorial With Examples For Beginners.md201805
20140107 Caffeinated 6.828- Exercise- Shell.md20140403 Easily Install Android Studio in Ubuntu And Linux Mint.md20140410 Recursion- dream within a dream.md20140510 Journey to the Stack Part I.md20141106 System Calls Make the World Go Round.md20170119 Be a force for good in your community.md20170213 Getting Started with Taskwarrior.md20170320 Education of a Programmer.md20170628 Notes on BPF and eBPF.md20170925 Advanced image viewing tricks with ImageMagick.md20171009 What-s next in DevOps- 5 trends to watch.md20171101 -dev-urandom- entropy explained.md20171109 Testing IPv6 Networking in KVM- Part 2.md20171116 10 easy steps from proprietary to open source.md20171121 How To Kill The Largest Process In An Unresponsive Linux System.md20171122 How DevOps eliminated bottlenecks for Ranger community.md20171129 5 best practices for getting started with DevOps.md20171213 Will DevOps steal my job-.md20171220 Containers without Docker at Red Hat.md20171221 A Commandline Food Recipes Manager.md20171221 How to create mobile-friendly documentation.md20180101 How Exit Traps Can Make Your Bash Scripts Way More Robust And Reliable.md20180104 4 Tools for Network Snooping on Linux.md20180115 2 scientific calculators for the Linux desktop.md20180116 How to Install and Optimize Apache on Ubuntu - ThisHosting.Rocks.md20180116 Why building a community is worth the extra effort.md20180122 A Simple Command-line Snippet Manager.md20180126 How To Manage NodeJS Packages Using Npm.md20180129 How To Resume Partially Transferred Files Over SSH Using Rsync.md20180131 Microservices vs. monolith How to choose.md20180205 How to Create, Revert and Delete KVM Virtual machine snapshot with virsh command.md20180208 Python Global, Local and Nonlocal variables (With Examples).md20180220 How slowing down made me a better leader.md20180220 How to format academic papers on Linux with groff -me.md20180222 Linux LAN Routing for Beginners- Part 1.md20180227 How to block local spoofed addresses using the Linux firewall.md20180228 Protecting Code Integrity with PGP - Part 3- Generating PGP Subkeys.md20180301 Linux LAN Routing for Beginners- Part 2.md20180307 Host your own email with projectx-os and a Raspberry Pi.md20180308 How to set up a print server on a Raspberry Pi.md20180312 How To Quickly Monitor Multiple Hosts In Linux.md20180314 How to measure particulate matter with a Raspberry Pi.md20180317 How To Edit Multiple Files Using Vim Editor.md20180319 A Command Line Productivity Tool For Tracking Work Hours.md20180320 Dry - An Interactive CLI Manager For Docker Containers.md20180321 How to use Ansible to patch systems and install applications.md20180325 Could we run Python 2 and Python 3 code in the same VM with no code changes.md20180326 4 command line note-taking applications for Linux.md20180327 Loop better- A deeper look at iteration in Python.md20180327 Reliable IoT event logging with syslog-ng.md20180328 Build a baby monitor with a Raspberry Pi.md20180328 Getting started with Jupyter Notebooks.md20180328 How To Use Instagram In Terminal.md20180401 9 Useful touch command examples in Linux.md20180403 10 fundamental commands for new Linux users.md20180403 Why I love ARM and PowerPC.md20180405 Getting started with Vagrant.md20180407 The Shuf Command Tutorial With Examples For Beginners.md20180409 A Kernel Module That Forcibly Shutdown Your System.md20180409 Yet Another TUI Graphical Activity Monitor, Written In Go.md20180410 Bootiso Lets You Safely Create Bootable USB Drive.md20180412 BUILDING GO PROJECTS WITH DOCKER ON GITLAB CI.md20180412 Easily Run And Integrate AppImage Files With AppImageLauncher.md20180412 How To Check User Created Date On Linux.md20180413 Finding what you-re looking for on Linux.md20180413 Useful Resources for Those Who Want to Know More About Linux.md20180414 The Vrms Program Helps You To Find Non-free Software In Debian.md20180416 4 cool new projects to try in COPR for April.md20180417 How to do math on the Linux command line.md20180419 6 Python datetime libraries - Opensource.com.md20180420 A Perl module for better debugging.md20180420 How to start developing on Java in Fedora.md20180424 Things You Should Know About Ubuntu 18.04.md20180425 Enhance your Python with an interactive shell.md20180427 How to Compile a Linux Kernel.md20180427 How to use FIND in Linux.md20180430 Easily Search And Install Google Web Fonts In Linux.md20180430 Reset a lost root password in under 5 minutes.md20180501 How To Use Vim Editor To Input Text Anywhere.md20180502 zzupdate - Single Command To Upgrade Ubuntu.md20180503 How to build container images with Buildah.md20180504 A Beginners Guide To Cron Jobs.md20180507 4 Firefox extensions to install now.md20180507 How To Improve Application Startup Time In Linux.md20180509 3 Methods To Install Latest Python3 Package On CentOS 6 System.md20180510 How To Display Images In The Terminal.md
2
.gitignore
vendored
2
.gitignore
vendored
@ -3,3 +3,5 @@ members.md
|
||||
*.html
|
||||
*.bak
|
||||
.DS_Store
|
||||
sources/*/.*
|
||||
translated/*/.*
|
||||
75
lctt2018.md
Normal file
75
lctt2018.md
Normal file
@ -0,0 +1,75 @@
|
||||
LCTT 2018:五周年纪念日
|
||||
======
|
||||
|
||||
我是老王,可能大家有不少人知道我,由于历史原因,我有好几个生日(;o),但是这些年来,我又多了一个生日,或者说纪念日——每过两年,我就要严肃认真地写一篇 [LCTT](https://linux.cn/lctt) 生日纪念文章。
|
||||
|
||||
喏,这一篇,就是今年的了,LCTT 如今已经五岁了!
|
||||
|
||||
或许如同小孩子过生日总是比较快乐,而随着年岁渐长,过生日往往有不少负担——比如说,每次写这篇纪念文章时,我就需要回忆、反思这两年的做了些什么,往往颇为汗颜。
|
||||
|
||||
不过不管怎么说,总要总结一下这两年我们做了什么,有什么不足,也发一些展望吧。
|
||||
|
||||
### 江山代有英豪出
|
||||
|
||||
LCTT,如同一般的开源贡献组织,总是有不断的新老传承。我们的翻译组,也有不少成员,由于工作学习的原因,慢慢淡出,但同时,也不断有新的成员加入并接过前辈手中的旗帜(就是没人接我的)。
|
||||
|
||||
> **加入方式**
|
||||
|
||||
> 请首先加入翻译组的 QQ 群,群号是:**198889102**,加群时请说明是“**志愿者**”。加入后记得修改您的群名片为您的 GitHub 的 ID。
|
||||
|
||||
> 加入的成员,请先阅读 [WIKI 如何开始](https://github.com/LCTT/TranslateProject/wiki/01-%E5%A6%82%E4%BD%95%E5%BC%80%E5%A7%8B)。
|
||||
|
||||
比如说,我们这两年来,oska874 承担了主要的选题工作,然后 lujun9972 适时的出现接过了不少选题工作;再比如说,qhwdw 出现后承担了大量繁难文章的翻译,pityonline 则专注于校对,甚至其校对的严谨程度让我都甘拜下风。还有 MjSeven 也同 qhwdw 一样,以极高的翻译频率从一星译者迅速登顶五星译者。当然,还有 Bestony、Locez、VizV 等人为 LCTT 提供了不少技术支持和开发工作。
|
||||
|
||||
### 硕果累累
|
||||
|
||||
我们并没有特别的招新渠道,但是总是时不时会有新的成员慕名而来,到目前为止,我们已经有 [331](https://linux.cn/lctt-list) 位做过贡献的成员,已经翻译发布了 3885 篇译文,合计字节达 33MB 之多!
|
||||
|
||||
这两年,我们不但翻译了很多技术、新闻和评论类文章,也新增了新的翻译类型:[漫画](https://linux.cn/talk/comic/),其中一些漫画得到了很多好评。
|
||||
|
||||
我们发布的文章有一些达到了 100000+ 的访问量,这对于我们这种技术垂直内容可不容易。
|
||||
|
||||
而同时,[Linux 中国](https://linux.cn/)也发布了近万篇文章,而这一篇,应该就是第 [9999](https://linux.cn/article-9999-1.html) 篇文章,我们将在明天,进入新的篇章。
|
||||
|
||||
### 贡献者主页和贡献者证书
|
||||
|
||||
为了彰显诸位贡献者的贡献,我们为每位贡献者创立的自己的专页,并据此建立了[排行榜](https://linux.cn/lctt-list)。
|
||||
|
||||
同时,我们还特意请 Bestony 和“一一”设计开发和”贡献者证书”,大家可以在 [LCTT 贡献平台](https://lctt.linux.cn/)中领取。
|
||||
|
||||
### 规则进化
|
||||
|
||||
LCTT 最初创立时,甚至都没有采用 PR 模式。但是随着贡献者的增多,我们也逐渐在改善我们的流程、方法。
|
||||
|
||||
之前采用了很粗糙的 PR 模式,对 PR 中的文件、提交乃至于信息都没有进行硬性约束。后来在 VizV 的帮助下,建立了对 PR 的合规性检查;又在 pityonline 的督促下,采用了更为严格的 PR 审查机制。
|
||||
|
||||
LCTT 创立几年来,我们的一些流程和规范,已经成为其它一些翻译组的参考范本,我们也希望我们的这些经验,可以进一步帮助到其它的开源社区。
|
||||
|
||||
### 仓库重建和版权问题
|
||||
|
||||
今年还发生一次严重的事故,由于对选题来源把控不严和对版权问题没有引起足够的重视,我们引用的一篇文章违背了原文的版权规定,结果被原文作者投诉到 GitHub。而我并没有及时看到 GitHub 给我发的 DMCA 处理邮件,因此错过了处理窗口期,从而被 GitHub 将整个库予以删除。
|
||||
|
||||
出现这样的重大失误之后,经过大家的帮助,我们历经周折才将仓库基本恢复。这要特别感谢 VizV 的辛苦工作。
|
||||
|
||||
在此之后,我们对译文选文的规则进行了梳理,并全面清查了文章版权。这个教训对我们来说弥足沉重。
|
||||
|
||||
### 通证时代
|
||||
|
||||
在 Linux 中国及 LCTT 发展过程中,我一直小心翼翼注意商业化的问题。严格来说,没有经济支持的开源组织如同无根之木,无源之水,是长久不了的。而商业化的技术社区又难免为了三斗米而折腰。所以往往很多技术社区要么渐渐凋零,要么就变成了商业机构。
|
||||
|
||||
从中国电信辞职后,我专职运营 Linux 中国这个开源社区已经近三年了,其间也有一些商业性收入,但是仅能勉强承担基本的运营费用。
|
||||
|
||||
这种尴尬的局面,使我,以及其它的开源社区同仁们纷纷寻求更好的发展之路。
|
||||
|
||||
去年参加中国开源年会时,在闭门会上,大家的讨论启发了我和诸位同仁,我们认为,开源社区结合通证经济,似乎是一条可行的开源社区发展之路。
|
||||
|
||||
今年 8 月 1 日,我们经过了半年的论证和实验,[发布了社区通证 LCCN](https://linux.cn/article-9886-1.html),并已经初步发放到了各位译者手中。我们还在继续建设通证生态各种工具,如合约、交易商城等。
|
||||
|
||||
我们希望能够通过通证为开源社区转入新的活力,也愿意将在探索道路上遇到的问题和解决的思路、工具链分享给更多的社区。
|
||||
|
||||
### 总结
|
||||
|
||||
从上一次总结以来,这又是七百多天,时光荏苒,而 LCTT 的创立也近两千天了。我希望,我们的翻译组以及更多的贡献者可以在通证经济的推动下,找到自洽、自治的发展道路;也希望能有更多的贡献者涌现出来接过我们的大旗,将开源发扬光大。
|
||||
|
||||
wxy
|
||||
2018/9/9 夜
|
||||
489
published/20140607 Five things that make Go fast.md
Normal file
489
published/20140607 Five things that make Go fast.md
Normal file
@ -0,0 +1,489 @@
|
||||
五种加速 Go 的特性
|
||||
========
|
||||
|
||||
_Anthony Starks 使用他出色的 Deck 演示工具重构了我原来的基于 Google Slides 的幻灯片。你可以在他的博客上查看他重构后的幻灯片,
|
||||
[mindchunk.blogspot.com.au/2014/06/remixing-with-deck][5]。_
|
||||
|
||||
我最近被邀请在 Gocon 发表演讲,这是一个每半年在日本东京举行的 Go 的精彩大会。[Gocon 2014][6] 是一个完全由社区驱动的为期一天的活动,由培训和一整个下午的围绕着生产环境中的 Go</q> 这个主题的演讲组成.(LCTT 译注:本文发表于 2014 年)
|
||||
|
||||
以下是我的讲义。原文的结构能让我缓慢而清晰的演讲,因此我已经编辑了它使其更可读。
|
||||
|
||||
我要感谢 [Bill Kennedy][7] 和 Minux Ma,特别是 [Josh Bleecher Snyder][8],感谢他们在我准备这次演讲中的帮助。
|
||||
|
||||
* * *
|
||||
|
||||
大家下午好。
|
||||
|
||||
我叫 David.
|
||||
|
||||
我很高兴今天能来到 Gocon。我想参加这个会议已经两年了,我很感谢主办方能提供给我向你们演讲的机会。
|
||||
|
||||
[][9]
|
||||
|
||||
我想以一个问题开始我的演讲。
|
||||
|
||||
为什么选择 Go?
|
||||
|
||||
当大家讨论学习或在生产环境中使用 Go 的原因时,答案不一而足,但因为以下三个原因的最多。
|
||||
|
||||
[][10]
|
||||
|
||||
这就是 TOP3 的原因。
|
||||
|
||||
第一,并发。
|
||||
|
||||
Go 的 <ruby>并发原语<rt>Concurrency Primitives</rt></ruby> 对于来自 Nodejs,Ruby 或 Python 等单线程脚本语言的程序员,或者来自 C++ 或 Java 等重量级线程模型的语言都很有吸引力。
|
||||
|
||||
易于部署。
|
||||
|
||||
我们今天从经验丰富的 Gophers 那里听说过,他们非常欣赏部署 Go 应用的简单性。
|
||||
|
||||
[][11]
|
||||
|
||||
然后是性能。
|
||||
|
||||
我相信人们选择 Go 的一个重要原因是它 _快_。
|
||||
|
||||
[][12]
|
||||
|
||||
在今天的演讲中,我想讨论五个有助于提高 Go 性能的特性。
|
||||
|
||||
我还将与大家分享 Go 如何实现这些特性的细节。
|
||||
|
||||
[][13]
|
||||
|
||||
我要谈的第一个特性是 Go 对于值的高效处理和存储。
|
||||
|
||||
[][14]
|
||||
|
||||
这是 Go 中一个值的例子。编译时,`gocon` 正好消耗四个字节的内存。
|
||||
|
||||
让我们将 Go 与其他一些语言进行比较
|
||||
|
||||
[][15]
|
||||
|
||||
由于 Python 表示变量的方式的开销,使用 Python 存储相同的值会消耗六倍的内存。
|
||||
|
||||
Python 使用额外的内存来跟踪类型信息,进行 <ruby>引用计数<rt>Reference Counting</rt></ruby> 等。
|
||||
|
||||
让我们看另一个例子:
|
||||
|
||||
[][16]
|
||||
|
||||
与 Go 类似,Java 消耗 4 个字节的内存来存储 `int` 型。
|
||||
|
||||
但是,要在像 `List` 或 `Map` 这样的集合中使用此值,编译器必须将其转换为 `Integer` 对象。
|
||||
|
||||
[][17]
|
||||
|
||||
因此,Java 中的整数通常消耗 16 到 24 个字节的内存。
|
||||
|
||||
为什么这很重要? 内存便宜且充足,为什么这个开销很重要?
|
||||
|
||||
[][18]
|
||||
|
||||
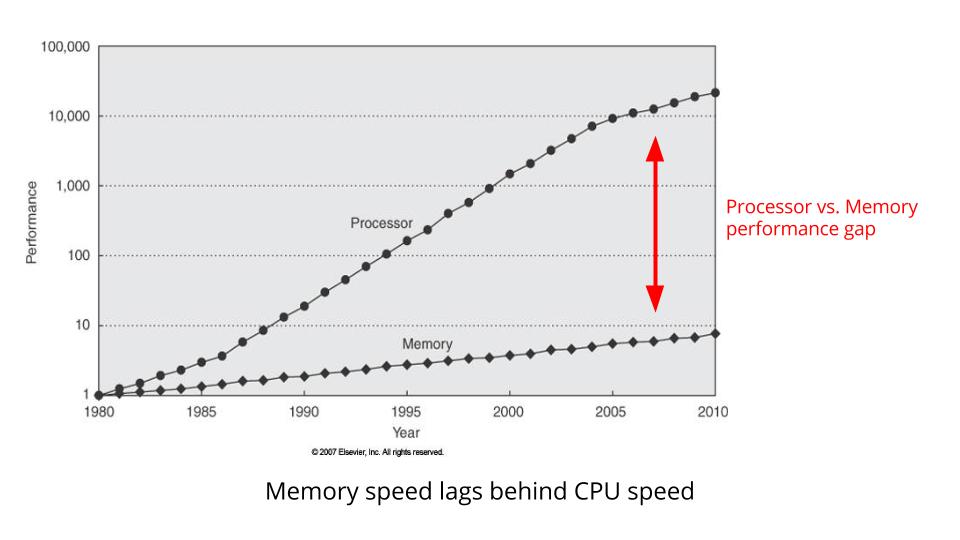
这是一张显示 CPU 时钟速度与内存总线速度的图表。
|
||||
|
||||
请注意 CPU 时钟速度和内存总线速度之间的差距如何继续扩大。
|
||||
|
||||
两者之间的差异实际上是 CPU 花费多少时间等待内存。
|
||||
|
||||
[][19]
|
||||
|
||||
自 1960 年代后期以来,CPU 设计师已经意识到了这个问题。
|
||||
|
||||
他们的解决方案是一个缓存,一个更小、更快的内存区域,介入 CPU 和主存之间。
|
||||
|
||||
[][20]
|
||||
|
||||
这是一个 `Location` 类型,它保存物体在三维空间中的位置。它是用 Go 编写的,因此每个 `Location` 只消耗 24 个字节的存储空间。
|
||||
|
||||
我们可以使用这种类型来构造一个容纳 1000 个 `Location` 的数组类型,它只消耗 24000 字节的内存。
|
||||
|
||||
在数组内部,`Location` 结构体是顺序存储的,而不是随机存储的 1000 个 `Location` 结构体的指针。
|
||||
|
||||
这很重要,因为现在所有 1000 个 `Location` 结构体都按顺序放在缓存中,紧密排列在一起。
|
||||
|
||||
[][21]
|
||||
|
||||
Go 允许您创建紧凑的数据结构,避免不必要的填充字节。
|
||||
|
||||
紧凑的数据结构能更好地利用缓存。
|
||||
|
||||
更好的缓存利用率可带来更好的性能。
|
||||
|
||||
[][22]
|
||||
|
||||
函数调用不是无开销的。
|
||||
|
||||
[][23]
|
||||
|
||||
调用函数时会发生三件事。
|
||||
|
||||
创建一个新的 <ruby>栈帧<rt>Stack Frame</rt></ruby>,并记录调用者的详细信息。
|
||||
|
||||
在函数调用期间可能被覆盖的任何寄存器都将保存到栈中。
|
||||
|
||||
处理器计算函数的地址并执行到该新地址的分支。
|
||||
|
||||
[][24]
|
||||
|
||||
由于函数调用是非常常见的操作,因此 CPU 设计师一直在努力优化此过程,但他们无法消除开销。
|
||||
|
||||
函调固有开销,或重于泰山,或轻于鸿毛,这取决于函数做了什么。
|
||||
|
||||
减少函数调用开销的解决方案是 <ruby>内联<rt>Inlining</rt></ruby>。
|
||||
|
||||
[][25]
|
||||
|
||||
Go 编译器通过将函数体视为调用者的一部分来内联函数。
|
||||
|
||||
内联也有成本,它增加了二进制文件大小。
|
||||
|
||||
只有当调用开销与函数所做工作关联度的很大时内联才有意义,因此只有简单的函数才能用于内联。
|
||||
|
||||
复杂的函数通常不受调用它们的开销所支配,因此不会内联。
|
||||
|
||||
[][26]
|
||||
|
||||
这个例子显示函数 `Double` 调用 `util.Max`。
|
||||
|
||||
为了减少调用 `util.Max` 的开销,编译器可以将 `util.Max` 内联到 `Double` 中,就象这样
|
||||
|
||||
[][27]
|
||||
|
||||
内联后不再调用 `util.Max`,但是 `Double` 的行为没有改变。
|
||||
|
||||
内联并不是 Go 独有的。几乎每种编译或及时编译的语言都执行此优化。但是 Go 的内联是如何实现的?
|
||||
|
||||
Go 实现非常简单。编译包时,会标记任何适合内联的小函数,然后照常编译。
|
||||
|
||||
然后函数的源代码和编译后版本都会被存储。
|
||||
|
||||
[][28]
|
||||
|
||||
此幻灯片显示了 `util.a` 的内容。源代码已经过一些转换,以便编译器更容易快速处理。
|
||||
|
||||
当编译器编译 `Double` 时,它看到 `util.Max` 可内联的,并且 `util.Max` 的源代码是可用的。
|
||||
|
||||
就会替换原函数中的代码,而不是插入对 `util.Max` 的编译版本的调用。
|
||||
|
||||
拥有该函数的源代码可以实现其他优化。
|
||||
|
||||
[][29]
|
||||
|
||||
在这个例子中,尽管函数 `Test` 总是返回 `false`,但 `Expensive` 在不执行它的情况下无法知道结果。
|
||||
|
||||
当 `Test` 被内联时,我们得到这样的东西。
|
||||
|
||||
[][30]
|
||||
|
||||
编译器现在知道 `Expensive` 的代码无法访问。
|
||||
|
||||
这不仅节省了调用 `Test` 的成本,还节省了编译或运行任何现在无法访问的 `Expensive` 代码。
|
||||
|
||||
Go 编译器可以跨文件甚至跨包自动内联函数。还包括从标准库调用的可内联函数的代码。
|
||||
|
||||
[][31]
|
||||
|
||||
<ruby>强制垃圾回收<rt>Mandatory Garbage Collection</rt></ruby> 使 Go 成为一种更简单,更安全的语言。
|
||||
|
||||
这并不意味着垃圾回收会使 Go 变慢,或者垃圾回收是程序速度的瓶颈。
|
||||
|
||||
这意味着在堆上分配的内存是有代价的。每次 GC 运行时都会花费 CPU 时间,直到释放内存为止。
|
||||
|
||||
[][32]
|
||||
|
||||
然而,有另一个地方分配内存,那就是栈。
|
||||
|
||||
与 C 不同,它强制您选择是否将值通过 `malloc` 将其存储在堆上,还是通过在函数范围内声明将其储存在栈上;Go 实现了一个名为 <ruby>逃逸分析<rt>Escape Analysis</rt></ruby> 的优化。
|
||||
|
||||
[][33]
|
||||
|
||||
逃逸分析决定了对一个值的任何引用是否会从被声明的函数中逃逸。
|
||||
|
||||
如果没有引用逃逸,则该值可以安全地存储在栈中。
|
||||
|
||||
存储在栈中的值不需要分配或释放。
|
||||
|
||||
让我们看一些例子
|
||||
|
||||
[][34]
|
||||
|
||||
`Sum` 返回 1 到 100 的整数的和。这是一种相当不寻常的做法,但它说明了逃逸分析的工作原理。
|
||||
|
||||
因为切片 `numbers` 仅在 `Sum` 内引用,所以编译器将安排到栈上来存储的 100 个整数,而不是安排到堆上。
|
||||
|
||||
没有必要回收 `numbers`,它会在 `Sum` 返回时自动释放。
|
||||
|
||||
[][35]
|
||||
|
||||
第二个例子也有点尬。在 `CenterCursor` 中,我们创建一个新的 `Cursor` 对象并在 `c` 中存储指向它的指针。
|
||||
|
||||
然后我们将 `c` 传递给 `Center()` 函数,它将 `Cursor` 移动到屏幕的中心。
|
||||
|
||||
最后我们打印出那个 'Cursor` 的 X 和 Y 坐标。
|
||||
|
||||
即使 `c` 被 `new` 函数分配了空间,它也不会存储在堆上,因为没有引用 `c` 的变量逃逸 `CenterCursor` 函数。
|
||||
|
||||
[][36]
|
||||
|
||||
默认情况下,Go 的优化始终处于启用状态。可以使用 `-gcflags = -m` 开关查看编译器的逃逸分析和内联决策。
|
||||
|
||||
因为逃逸分析是在编译时执行的,而不是运行时,所以无论垃圾回收的效率如何,栈分配总是比堆分配快。
|
||||
|
||||
我将在本演讲的其余部分详细讨论栈。
|
||||
|
||||
[][37]
|
||||
|
||||
Go 有 goroutine。 这是 Go 并发的基石。
|
||||
|
||||
我想退一步,探索 goroutine 的历史。
|
||||
|
||||
最初,计算机一次运行一个进程。在 60 年代,多进程或 <ruby>分时<rt>Time Sharing</rt></ruby> 的想法变得流行起来。
|
||||
|
||||
在分时系统中,操作系统必须通过保护当前进程的现场,然后恢复另一个进程的现场,不断地在这些进程之间切换 CPU 的注意力。
|
||||
|
||||
这称为 _进程切换_。
|
||||
|
||||
[][38]
|
||||
|
||||
进程切换有三个主要开销。
|
||||
|
||||
首先,内核需要保护该进程的所有 CPU 寄存器的现场,然后恢复另一个进程的现场。
|
||||
|
||||
内核还需要将 CPU 的映射从虚拟内存刷新到物理内存,因为这些映射仅对当前进程有效。
|
||||
|
||||
最后是操作系统 <ruby>上下文切换<rt>Context Switch</rt></ruby> 的成本,以及 <ruby>调度函数<rt>Scheduler Function</rt></ruby> 选择占用 CPU 的下一个进程的开销。
|
||||
|
||||
[][39]
|
||||
|
||||
现代处理器中有数量惊人的寄存器。我很难在一张幻灯片上排开它们,这可以让你知道保护和恢复它们需要多少时间。
|
||||
|
||||
由于进程切换可以在进程执行的任何时刻发生,因此操作系统需要存储所有寄存器的内容,因为它不知道当前正在使用哪些寄存器。
|
||||
|
||||
[][40]
|
||||
|
||||
这导致了线程的出生,这些线程在概念上与进程相同,但共享相同的内存空间。
|
||||
|
||||
由于线程共享地址空间,因此它们比进程更轻,因此创建速度更快,切换速度更快。
|
||||
|
||||
[][41]
|
||||
|
||||
Goroutine 升华了线程的思想。
|
||||
|
||||
Goroutine 是 <ruby>协作式调度<rt>Cooperative Scheduled
|
||||
</rt></ruby>的,而不是依靠内核来调度。
|
||||
|
||||
当对 Go <ruby>运行时调度器<rt>Runtime Scheduler</rt></ruby> 进行显式调用时,goroutine 之间的切换仅发生在明确定义的点上。
|
||||
|
||||
编译器知道正在使用的寄存器并自动保存它们。
|
||||
|
||||
[][42]
|
||||
|
||||
虽然 goroutine 是协作式调度的,但运行时会为你处理。
|
||||
|
||||
Goroutine 可能会给禅让给其他协程时刻是:
|
||||
|
||||
* 阻塞式通道发送和接收。
|
||||
* Go 声明,虽然不能保证会立即调度新的 goroutine。
|
||||
* 文件和网络操作式的阻塞式系统调用。
|
||||
* 在被垃圾回收循环停止后。
|
||||
|
||||
[][43]
|
||||
|
||||
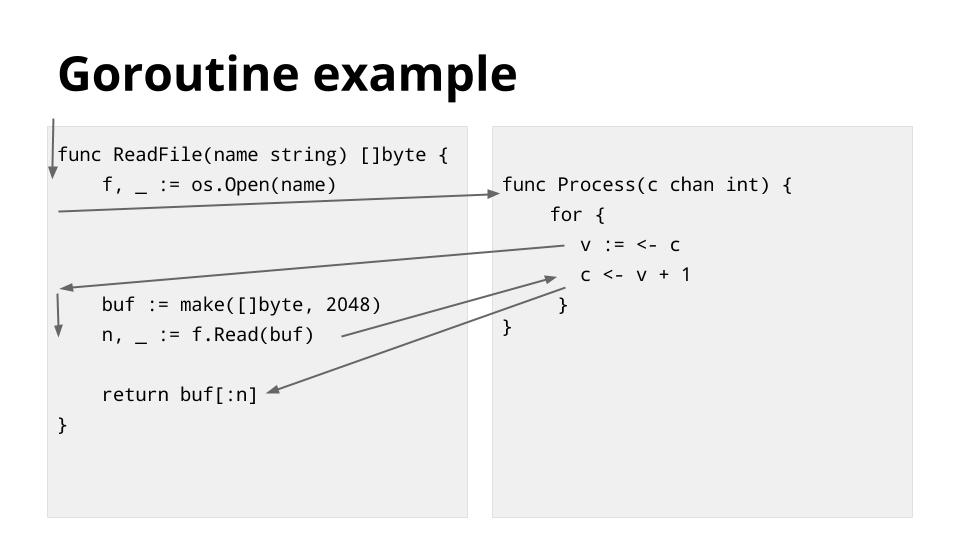
这个例子说明了上一张幻灯片中描述的一些调度点。
|
||||
|
||||
箭头所示的线程从左侧的 `ReadFile` 函数开始。遇到 `os.Open`,它在等待文件操作完成时阻塞线程,因此调度器将线程切换到右侧的 goroutine。
|
||||
|
||||
继续执行直到从通道 `c` 中读,并且此时 `os.Open` 调用已完成,因此调度器将线程切换回左侧并继续执行 `file.Read` 函数,然后又被文件 IO 阻塞。
|
||||
|
||||
调度器将线程切换回右侧以进行另一个通道操作,该操作在左侧运行期间已解锁,但在通道发送时再次阻塞。
|
||||
|
||||
最后,当 `Read` 操作完成并且数据可用时,线程切换回左侧。
|
||||
|
||||
[][44]
|
||||
|
||||
这张幻灯片显示了低级语言描述的 `runtime.Syscall` 函数,它是 `os` 包中所有函数的基础。
|
||||
|
||||
只要你的代码调用操作系统,就会通过此函数。
|
||||
|
||||
对 `entersyscall` 的调用通知运行时该线程即将阻塞。
|
||||
|
||||
这允许运行时启动一个新线程,该线程将在当前线程被阻塞时为其他 goroutine 提供服务。
|
||||
|
||||
这导致每 Go 进程的操作系统线程相对较少,Go 运行时负责将可运行的 Goroutine 分配给空闲的操作系统线程。
|
||||
|
||||
[][45]
|
||||
|
||||
在上一节中,我讨论了 goroutine 如何减少管理许多(有时是数十万个并发执行线程)的开销。
|
||||
|
||||
Goroutine故事还有另一面,那就是栈管理,它引导我进入我的最后一个话题。
|
||||
|
||||
[][46]
|
||||
|
||||
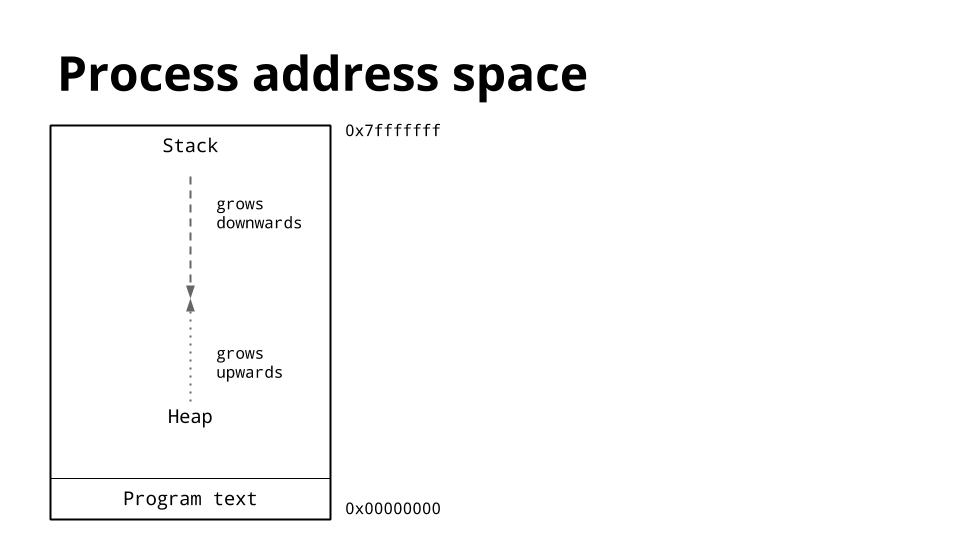
这是一个进程的内存布局图。我们感兴趣的关键是堆和栈的位置。
|
||||
|
||||
传统上,在进程的地址空间内,堆位于内存的底部,位于程序(代码)的上方并向上增长。
|
||||
|
||||
栈位于虚拟地址空间的顶部,并向下增长。
|
||||
|
||||
[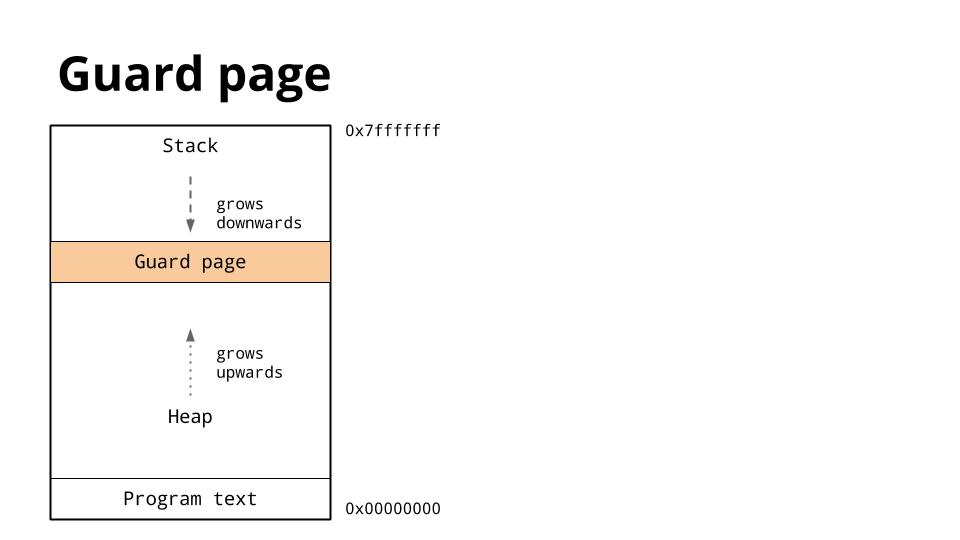][47]
|
||||
|
||||
因为堆和栈相互覆盖的结果会是灾难性的,操作系统通常会安排在栈和堆之间放置一个不可写内存区域,以确保如果它们发生碰撞,程序将中止。
|
||||
|
||||
这称为保护页,有效地限制了进程的栈大小,通常大约为几兆字节。
|
||||
|
||||
[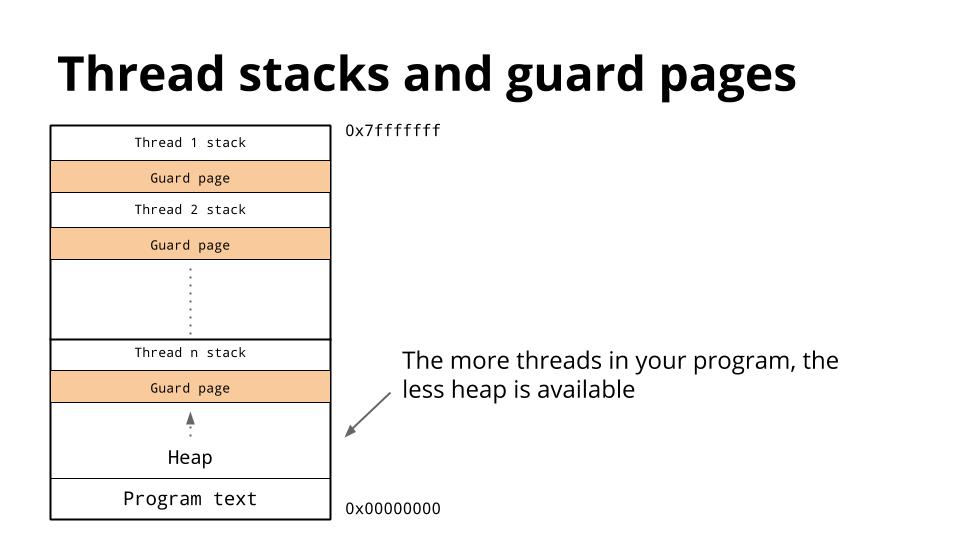][48]
|
||||
|
||||
我们已经讨论过线程共享相同的地址空间,因此对于每个线程,它必须有自己的栈。
|
||||
|
||||
由于很难预测特定线程的栈需求,因此为每个线程的栈和保护页面保留了大量内存。
|
||||
|
||||
希望是这些区域永远不被使用,而且防护页永远不会被击中。
|
||||
|
||||
缺点是随着程序中线程数的增加,可用地址空间的数量会减少。
|
||||
|
||||
[][49]
|
||||
|
||||
我们已经看到 Go 运行时将大量的 goroutine 调度到少量线程上,但那些 goroutines 的栈需求呢?
|
||||
|
||||
Go 编译器不使用保护页,而是在每个函数调用时插入一个检查,以检查是否有足够的栈来运行该函数。如果没有,运行时可以分配更多的栈空间。
|
||||
|
||||
由于这种检查,goroutines 初始栈可以做得更小,这反过来允许 Go 程序员将 goroutines 视为廉价资源。
|
||||
|
||||
[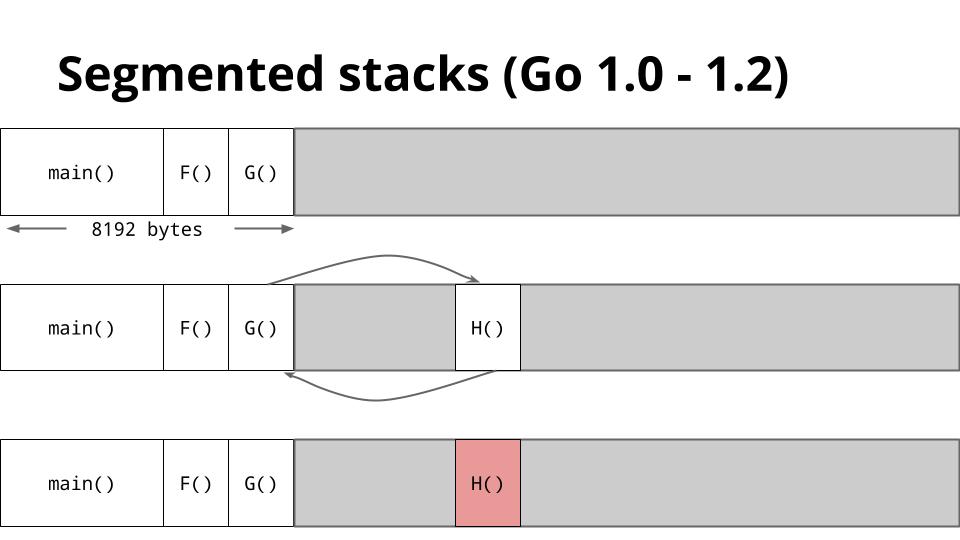][50]
|
||||
|
||||
这是一张显示了 Go 1.2 如何管理栈的幻灯片。
|
||||
|
||||
当 `G` 调用 `H` 时,没有足够的空间让 `H` 运行,所以运行时从堆中分配一个新的栈帧,然后在新的栈段上运行 `H`。当 `H` 返回时,栈区域返回到堆,然后返回到 `G`。
|
||||
|
||||
[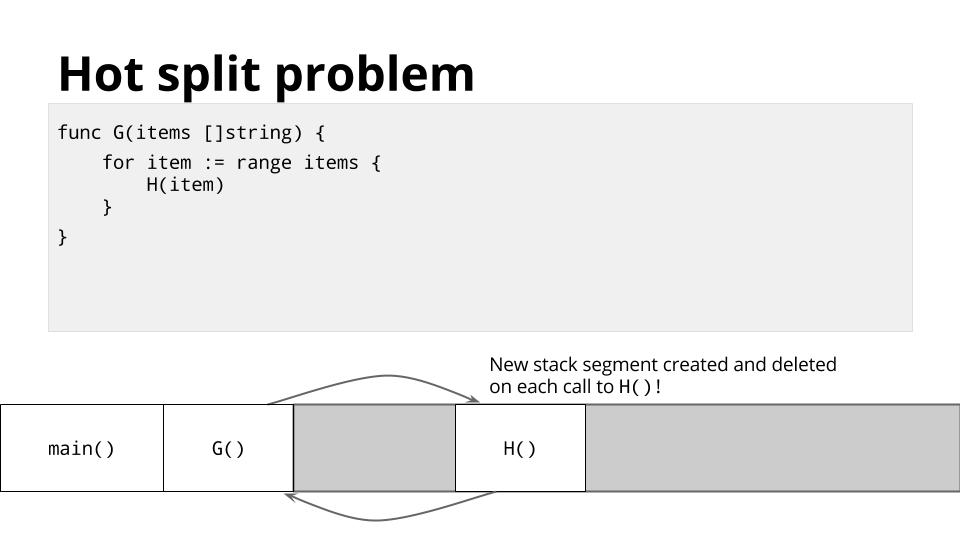][51]
|
||||
|
||||
这种管理栈的方法通常很好用,但对于某些类型的代码,通常是递归代码,它可能导致程序的内部循环跨越这些栈边界之一。
|
||||
|
||||
例如,在程序的内部循环中,函数 `G` 可以在循环中多次调用 `H`,
|
||||
|
||||
每次都会导致栈拆分。 这被称为 <ruby>热分裂<rt>Hot Split</rt></ruby> 问题。
|
||||
|
||||
[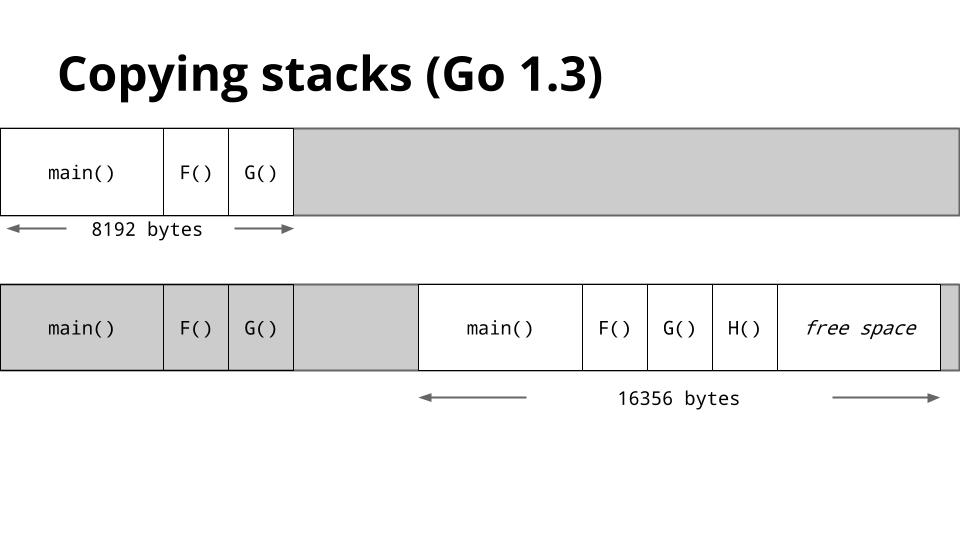][52]
|
||||
|
||||
为了解决热分裂问题,Go 1.3 采用了一种新的栈管理方法。
|
||||
|
||||
如果 goroutine 的栈太小,则不会添加和删除其他栈段,而是分配新的更大的栈。
|
||||
|
||||
旧栈的内容被复制到新栈,然后 goroutine 使用新的更大的栈继续运行。
|
||||
|
||||
在第一次调用 `H` 之后,栈将足够大,对可用栈空间的检查将始终成功。
|
||||
|
||||
这解决了热分裂问题。
|
||||
|
||||
[][53]
|
||||
|
||||
值,内联,逃逸分析,Goroutines 和分段/复制栈。
|
||||
|
||||
这些是我今天选择谈论的五个特性,但它们绝不是使 Go 成为快速的语言的唯一因素,就像人们引用他们学习 Go 的理由的三个原因一样。
|
||||
|
||||
这五个特性一样强大,它们不是孤立存在的。
|
||||
|
||||
例如,运行时将 goroutine 复用到线程上的方式在没有可扩展栈的情况下几乎没有效率。
|
||||
|
||||
内联通过将较小的函数组合成较大的函数来降低栈大小检查的成本。
|
||||
|
||||
逃逸分析通过自动将从实例从堆移动到栈来减少垃圾回收器的压力。
|
||||
|
||||
逃逸分析还提供了更好的 <ruby>缓存局部性<rt>Cache Locality</rt></ruby>。
|
||||
|
||||
如果没有可增长的栈,逃逸分析可能会对栈施加太大的压力。
|
||||
|
||||
[][54]
|
||||
|
||||
* 感谢 Gocon 主办方允许我今天发言
|
||||
* twitter / web / email details
|
||||
* 感谢 @offbymany,@billkennedy_go 和 Minux 在准备这个演讲的过程中所提供的帮助。
|
||||
|
||||
### 相关文章:
|
||||
|
||||
1. [听我在 OSCON 上关于 Go 性能的演讲][1]
|
||||
2. [为什么 Goroutine 的栈是无限大的?][2]
|
||||
3. [Go 的运行时环境变量的旋风之旅][3]
|
||||
4. [没有事件循环的性能][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David 是来自澳大利亚悉尼的程序员和作者。
|
||||
|
||||
自 2011 年 2 月起成为 Go 的 contributor,自 2012 年 4 月起成为 committer。
|
||||
|
||||
联系信息
|
||||
|
||||
* dave@cheney.net
|
||||
* twitter: @davecheney
|
||||
|
||||
----------------------
|
||||
|
||||
via: https://dave.cheney.net/2014/06/07/five-things-that-make-go-fast
|
||||
|
||||
作者:[Dave Cheney][a]
|
||||
译者:[houbaron](https://github.com/houbaron)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dave.cheney.net/
|
||||
[1]:https://dave.cheney.net/2015/05/31/hear-me-speak-about-go-performance-at-oscon
|
||||
[2]:https://dave.cheney.net/2013/06/02/why-is-a-goroutines-stack-infinite
|
||||
[3]:https://dave.cheney.net/2015/11/29/a-whirlwind-tour-of-gos-runtime-environment-variables
|
||||
[4]:https://dave.cheney.net/2015/08/08/performance-without-the-event-loop
|
||||
[5]:http://mindchunk.blogspot.com.au/2014/06/remixing-with-deck.html
|
||||
[6]:http://ymotongpoo.hatenablog.com/entry/2014/06/01/124350
|
||||
[7]:http://www.goinggo.net/
|
||||
[8]:https://twitter.com/offbymany
|
||||
[9]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-1.jpg
|
||||
[10]:https://dave.cheney.net/2014/06/07/five-things-that-make-go-fast/gocon-2014-2
|
||||
[11]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-3.jpg
|
||||
[12]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-4.jpg
|
||||
[13]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-5.jpg
|
||||
[14]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-6.jpg
|
||||
[15]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-7.jpg
|
||||
[16]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-8.jpg
|
||||
[17]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-9.jpg
|
||||
[18]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-10.jpg
|
||||
[19]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-11.jpg
|
||||
[20]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-12.jpg
|
||||
[21]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-13.jpg
|
||||
[22]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-14.jpg
|
||||
[23]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-15.jpg
|
||||
[24]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-16.jpg
|
||||
[25]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-17.jpg
|
||||
[26]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-18.jpg
|
||||
[27]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-19.jpg
|
||||
[28]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-20.jpg
|
||||
[29]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-21.jpg
|
||||
[30]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-22.jpg
|
||||
[31]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-23.jpg
|
||||
[32]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-24.jpg
|
||||
[33]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-25.jpg
|
||||
[34]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-26.jpg
|
||||
[35]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-27.jpg
|
||||
[36]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-28.jpg
|
||||
[37]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-30.jpg
|
||||
[38]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-29.jpg
|
||||
[39]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-31.jpg
|
||||
[40]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-32.jpg
|
||||
[41]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-33.jpg
|
||||
[42]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-34.jpg
|
||||
[43]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-35.jpg
|
||||
[44]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-36.jpg
|
||||
[45]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-37.jpg
|
||||
[46]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-39.jpg
|
||||
[47]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-40.jpg
|
||||
[48]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-41.jpg
|
||||
[49]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-42.jpg
|
||||
[50]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-43.jpg
|
||||
[51]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-44.jpg
|
||||
[52]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-45.jpg
|
||||
[53]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-46.jpg
|
||||
[54]:https://dave.cheney.net/wp-content/uploads/2014/06/Gocon-2014-47.jpg
|
||||
@ -23,7 +23,7 @@ Ubuntu 麒麟的外观和感觉很像 Ubuntu 的现代版本。它拥有的 [Uni
|
||||
via: http://thevarguy.com/open-source-application-software-companies/091515/ubuntu-linux-based-open-source-os-runs-42-percent-dell-pc
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[geekpi](https://github.com/geeekpi)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -104,10 +104,10 @@ Arch Linux 也因其丰富的 Wiki 帮助文档而大受推崇。该系统基于
|
||||
][23]
|
||||
|
||||
输入下面的命令来检查网络连接。
|
||||
|
||||
|
||||
```
|
||||
ping google.com
|
||||
```
|
||||
```
|
||||
|
||||
这个单词 ping 表示网路封包搜寻。你将会看到下面的返回信息,表明 Arch Linux 已经连接到外网了。这是执行安装过程中的很关键的一点。(LCTT 译注:或许你 ping 不到那个不存在的网站,你选个存在的吧。)
|
||||
|
||||
@ -117,8 +117,8 @@ ping google.com
|
||||
|
||||
输入如下命令清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
在开始安装之前,你得先为硬盘分区。输入 `fdisk -l` ,你将会看到当前系统的磁盘分区情况。注意一开始你给 Arch Linux 系统分配的 20 GB 存储空间。
|
||||
@ -137,8 +137,8 @@ clear
|
||||
|
||||
输入下面的命令:
|
||||
|
||||
```
|
||||
cfdisk
|
||||
```
|
||||
cfdisk
|
||||
```
|
||||
|
||||
你将看到 `gpt`、`dos`、`sgi` 和 `sun` 类型,选择 `dos` 选项,然后按回车。
|
||||
@ -185,8 +185,8 @@ cfdisk
|
||||
|
||||
以同样的方式创建逻辑分区。在“退出(quit)”选项按回车键,然后输入下面的命令来清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
[
|
||||
@ -195,21 +195,21 @@ clear
|
||||
|
||||
输入下面的命令来格式化新建的分区:
|
||||
|
||||
```
|
||||
```
|
||||
mkfs.ext4 /dev/sda1
|
||||
```
|
||||
```
|
||||
|
||||
这里的 `sda1` 是分区名。使用同样的命令来格式化第二个分区 `sda3` :
|
||||
|
||||
```
|
||||
```
|
||||
mkfs.ext4 /dev/sda3
|
||||
```
|
||||
```
|
||||
|
||||
格式化 swap 分区:
|
||||
|
||||
```
|
||||
```
|
||||
mkswap /dev/sda2
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -217,14 +217,14 @@ mkswap /dev/sda2
|
||||
|
||||
使用下面的命令来激活 swap 分区:
|
||||
|
||||
```
|
||||
swapon /dev/sda2
|
||||
```
|
||||
swapon /dev/sda2
|
||||
```
|
||||
|
||||
输入 clear 命令清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
[
|
||||
@ -233,9 +233,9 @@ clear
|
||||
|
||||
输入下面的命令来挂载主分区以开始系统安装:
|
||||
|
||||
```
|
||||
mount /dev/sda1 / mnt
|
||||
```
|
||||
```
|
||||
mount /dev/sda1 /mnt
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -245,9 +245,9 @@ mount /dev/sda1 / mnt
|
||||
|
||||
输入下面的命令来引导系统启动:
|
||||
|
||||
```
|
||||
```
|
||||
pacstrap /mnt base base-devel
|
||||
```
|
||||
```
|
||||
|
||||
可以看到系统正在同步数据包。
|
||||
|
||||
@ -263,9 +263,9 @@ pacstrap /mnt base base-devel
|
||||
|
||||
系统基本软件安装完成后,输入下面的命令来创建 fstab 文件:
|
||||
|
||||
```
|
||||
```
|
||||
genfstab /mnt>> /mnt/etc/fstab
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -275,14 +275,14 @@ genfstab /mnt>> /mnt/etc/fstab
|
||||
|
||||
输入下面的命令来更改系统的根目录为 Arch Linux 的安装目录:
|
||||
|
||||
```
|
||||
```
|
||||
arch-chroot /mnt /bin/bash
|
||||
```
|
||||
```
|
||||
|
||||
现在来更改语言配置:
|
||||
|
||||
```
|
||||
nano /etc/local.gen
|
||||
```
|
||||
nano /etc/locale.gen
|
||||
```
|
||||
|
||||
[
|
||||
@ -297,9 +297,9 @@ nano /etc/local.gen
|
||||
|
||||
输入下面的命令来激活它:
|
||||
|
||||
```
|
||||
```
|
||||
locale-gen
|
||||
```
|
||||
```
|
||||
|
||||
按回车。
|
||||
|
||||
@ -309,8 +309,8 @@ locale-gen
|
||||
|
||||
使用下面的命令来创建 `/etc/locale.conf` 配置文件:
|
||||
|
||||
```
|
||||
nano /etc/locale.conf
|
||||
```
|
||||
nano /etc/locale.conf
|
||||
```
|
||||
|
||||
然后按回车。现在你就可以在配置文件中输入下面一行内容来为系统添加语言:
|
||||
@ -326,9 +326,9 @@ LANG=en_US.UTF-8
|
||||
][44]
|
||||
|
||||
输入下面的命令来同步时区:
|
||||
|
||||
|
||||
```
|
||||
ls user/share/zoneinfo
|
||||
ls /usr/share/zoneinfo
|
||||
```
|
||||
|
||||
下面你将看到整个世界的时区列表。
|
||||
@ -339,9 +339,9 @@ ls user/share/zoneinfo
|
||||
|
||||
输入下面的命令来选择你所在的时区:
|
||||
|
||||
```
|
||||
```
|
||||
ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
|
||||
```
|
||||
```
|
||||
|
||||
或者你可以从下面的列表中选择其它名称。
|
||||
|
||||
@ -351,8 +351,8 @@ ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
|
||||
|
||||
使用下面的命令来设置标准时间:
|
||||
|
||||
```
|
||||
hwclock --systohc –utc
|
||||
```
|
||||
hwclock --systohc --utc
|
||||
```
|
||||
|
||||
硬件时钟已同步。
|
||||
@ -363,8 +363,8 @@ hwclock --systohc –utc
|
||||
|
||||
设置 root 帐号密码:
|
||||
|
||||
```
|
||||
passwd
|
||||
```
|
||||
passwd
|
||||
```
|
||||
|
||||
按回车。 然而输入你想设置的密码,按回车确认。
|
||||
@ -377,9 +377,9 @@ passwd
|
||||
|
||||
使用下面的命令来设置主机名:
|
||||
|
||||
```
|
||||
```
|
||||
nano /etc/hostname
|
||||
```
|
||||
```
|
||||
|
||||
然后按回车。输入你想设置的主机名称,按 `control + x` ,按 `y` ,再按回车 。
|
||||
|
||||
@ -389,9 +389,9 @@ nano /etc/hostname
|
||||
|
||||
启用 dhcpcd :
|
||||
|
||||
```
|
||||
```
|
||||
systemctl enable dhcpcd
|
||||
```
|
||||
```
|
||||
|
||||
这样在下一次系统启动时, dhcpcd 将会自动启动,并自动获取一个 IP 地址:
|
||||
|
||||
@ -403,9 +403,9 @@ systemctl enable dhcpcd
|
||||
|
||||
最后一步,输入以下命令来初始化 grub 安装。输入以下命令:
|
||||
|
||||
```
|
||||
```
|
||||
pacman –S grub os-rober
|
||||
```
|
||||
```
|
||||
|
||||
然后按 `y` ,将会下载相关程序。
|
||||
|
||||
@ -415,14 +415,14 @@ pacman –S grub os-rober
|
||||
|
||||
使用下面的命令来将启动加载程序安装到硬盘上:
|
||||
|
||||
```
|
||||
```
|
||||
grub-install /dev/sda
|
||||
```
|
||||
```
|
||||
|
||||
然后进行配置:
|
||||
|
||||
```
|
||||
grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
|
||||
[
|
||||
@ -431,9 +431,9 @@ grub-mkconfig -o /boot/grub/grub.cfg
|
||||
|
||||
最后重启系统:
|
||||
|
||||
```
|
||||
```
|
||||
reboot
|
||||
```
|
||||
```
|
||||
|
||||
然后按回车 。
|
||||
|
||||
@ -459,7 +459,7 @@ reboot
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-arch-linux-on-virtualbox/
|
||||
|
||||
译者简介:
|
||||
译者简介:
|
||||
|
||||
rusking:春城初春/春水初生/春林初盛/春風十裏不如妳
|
||||
|
||||
|
||||
@ -0,0 +1,181 @@
|
||||
三周内构建 JavaScript 全栈 web 应用
|
||||
===========
|
||||
|
||||
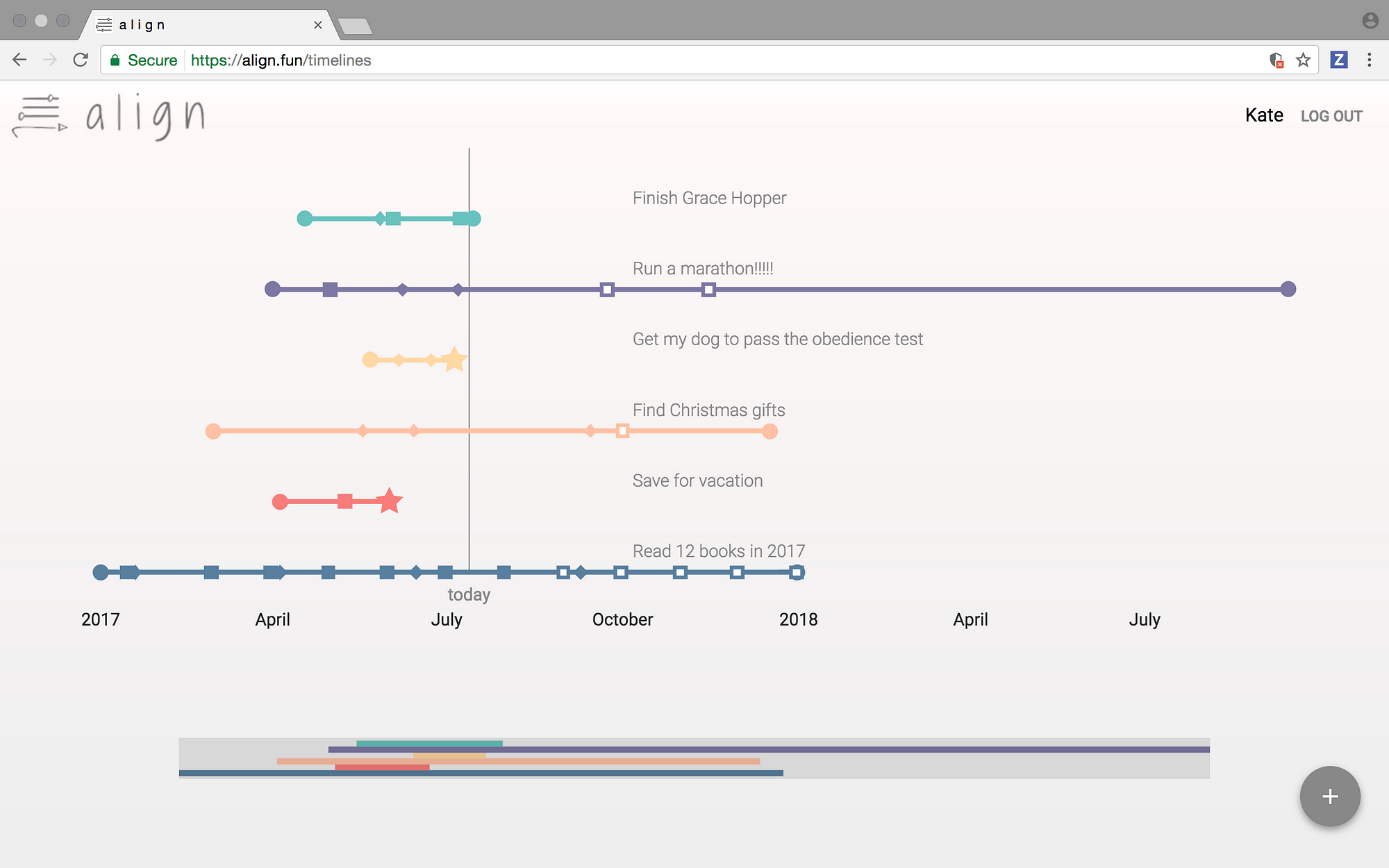
|
||||
|
||||
*应用 Align 中,用户主页的控制面板*
|
||||
|
||||
### 从构思到部署应用程序的简单分步指南
|
||||
|
||||
我在 Grace Hopper Program 为期三个月的编码训练营即将结束,实际上这篇文章的标题有些纰漏 —— 现在我已经构建了 _三个_ 全栈应用:[从零开始的电子商店][3]、我个人的 [私人黑客马拉松项目][4],还有这个“三周的结业项目”。这个项目是迄今为止强度最大的 —— 我和另外两名队友共同花费三周的时光 —— 而它也是我在训练营中最引以为豪的成就。这是我目前所构建和涉及的第一款稳定且复杂的应用。
|
||||
|
||||
如大多数开发者所知,即使你“知道怎么编写代码”,但真正要制作第一款全栈的应用却是非常困难的。JavaScript 生态系统出奇的大:有包管理器、模块、构建工具、转译器、数据库、库文件,还要对上述所有东西进行选择,难怪如此多的编程新手除了 Codecademy 的教程外,做不了任何东西。这就是为什么我想让你体验这个决策的分布教程,跟着我们队伍的脚印,构建可用的应用。
|
||||
|
||||
* * *
|
||||
|
||||
首先,简单的说两句。Align 是一个 web 应用,它使用直观的时间线界面帮助用户管理时间、设定长期目标。我们的技术栈有:用于后端服务的 Firebase 和用于前端的 React。我和我的队友在这个短视频中解释的更详细:
|
||||
|
||||
[video](https://youtu.be/YacM6uYP2Jo)
|
||||
|
||||
展示 Align @ Demo Day Live // 2017 年 7 月 10 日
|
||||
|
||||
从第 1 天(我们组建团队的那天)开始,直到最终应用的完成,我们是如何做的?这里是我们采取的步骤纲要:
|
||||
|
||||
* * *
|
||||
|
||||
### 第 1 步:构思
|
||||
|
||||
第一步是弄清楚我们到底要构建什么东西。过去我在 IBM 中当咨询师的时候,我和合作组长一同带领着构思工作组。从那之后,我一直建议小组使用经典的头脑风暴策略,在会议中我们能够提出尽可能多的想法 —— 即使是 “愚蠢的想法” —— 这样每个人的大脑都在思考,没有人因顾虑而不敢发表意见。
|
||||
|
||||

|
||||
|
||||
在产生了好几个关于应用的想法时,我们把这些想法分类记录下来,以便更好的理解我们大家都感兴趣的主题。在我们这个小组中,我们看到实现想法的清晰趋势,需要自我改进、设定目标、情怀,还有个人发展。我们最后从中决定了具体的想法:做一个用于设置和管理长期目标的控制面板,有保存记忆的元素,可以根据时间将数据可视化。
|
||||
|
||||
从此,我们创作出了一系列用户故事(从一个终端用户的视角,对我们想要拥有的功能进行描述),阐明我们到底想要应用实现什么功能。
|
||||
|
||||
### 第 2 步:UX/UI 示意图
|
||||
|
||||
接下来,在一块白板上,我们画出了想象中应用的基本视图。结合了用户故事,以便理解在应用基本框架中这些视图将会如何工作。
|
||||
|
||||
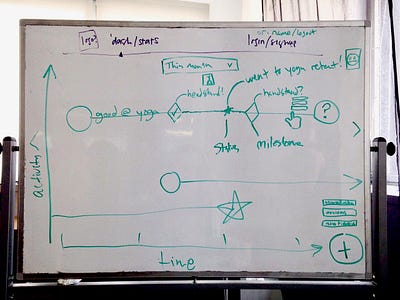
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
这些骨架确保我们意见统一,提供了可预见的蓝图,让我们向着计划的方向努力。
|
||||
|
||||
### 第 3 步:选好数据结构和数据库类型
|
||||
|
||||
到了设计数据结构的时候。基于我们的示意图和用户故事,我们在 Google doc 中制作了一个清单,它包含我们将会需要的模型和每个模型应该包含的属性。我们知道需要 “目标(goal)” 模型、“用户(user)”模型、“里程碑(milestone)”模型、“记录(checkin)”模型还有最后的“资源(resource)”模型和“上传(upload)”模型,
|
||||
|
||||

|
||||
|
||||
*最初的数据模型结构*
|
||||
|
||||
在正式确定好这些模型后,我们需要选择某种 _类型_ 的数据库:“关系型的”还是“非关系型的”(也就是“SQL”还是“NoSQL”)。由于基于表的 SQL 数据库需要预定义的格式,而基于文档的 NoSQL 数据库却可以用动态格式描述非结构化数据。
|
||||
|
||||
对于我们这个情况,用 SQL 型还是 No-SQL 型的数据库没多大影响,由于下列原因,我们最终选择了 Google 的 NoSQL 云数据库 Firebase:
|
||||
|
||||
1. 它能够把用户上传的图片保存在云端并存储起来
|
||||
2. 它包含 WebSocket 功能,能够实时更新
|
||||
3. 它能够处理用户验证,并且提供简单的 OAuth 功能。
|
||||
|
||||
我们确定了数据库后,就要理解数据模型之间的关系了。由于 Firebase 是 NoSQL 类型,我们无法创建联合表或者设置像 _“记录 (Checkins)属于目标(Goals)”_ 的从属关系。因此我们需要弄清楚 JSON 树是什么样的,对象是怎样嵌套的(或者不是嵌套的关系)。最终,我们构建了像这样的模型:
|
||||
|
||||

|
||||
|
||||
*我们最终为目标(Goal)对象确定的 Firebase 数据格式。注意里程碑(Milestones)和记录(Checkins)对象嵌套在 Goals 中。*
|
||||
|
||||
_(注意: 出于性能考虑,Firebase 更倾向于简单、常规的数据结构, 但对于我们这种情况,需要在数据中进行嵌套,因为我们不会从数据库中获取目标(Goal)却不获取相应的子对象里程碑(Milestones)和记录(Checkins)。)_
|
||||
|
||||
### 第 4 步:设置好 Github 和敏捷开发工作流
|
||||
|
||||
我们知道,从一开始就保持井然有序、执行敏捷开发对我们有极大好处。我们设置好 Github 上的仓库,我们无法直接将代码合并到主(master)分支,这迫使我们互相审阅代码。
|
||||
|
||||
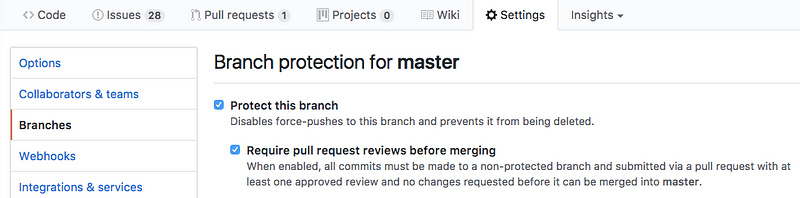
|
||||
|
||||
我们还在 [Waffle.io][5] 网站上创建了敏捷开发的面板,它是免费的,很容易集成到 Github。我们在 Waffle 面板上罗列出所有用户故事以及需要我们去修复的 bug。之后当我们开始编码时,我们每个人会为自己正在研究的每一个用户故事创建一个 git 分支,在完成工作后合并这一条条的分支。
|
||||
|
||||
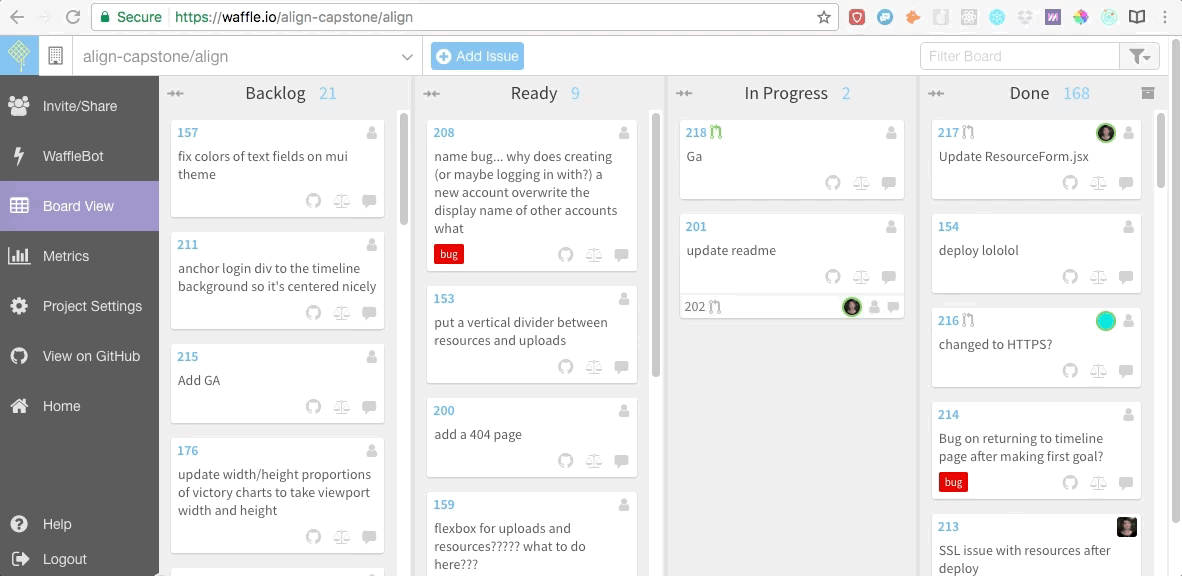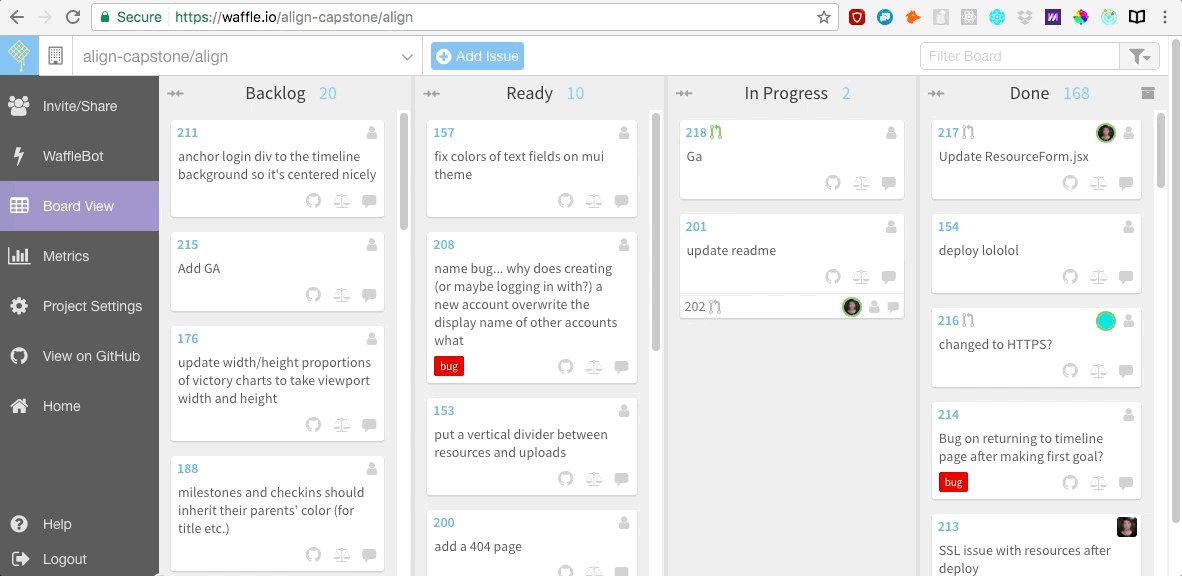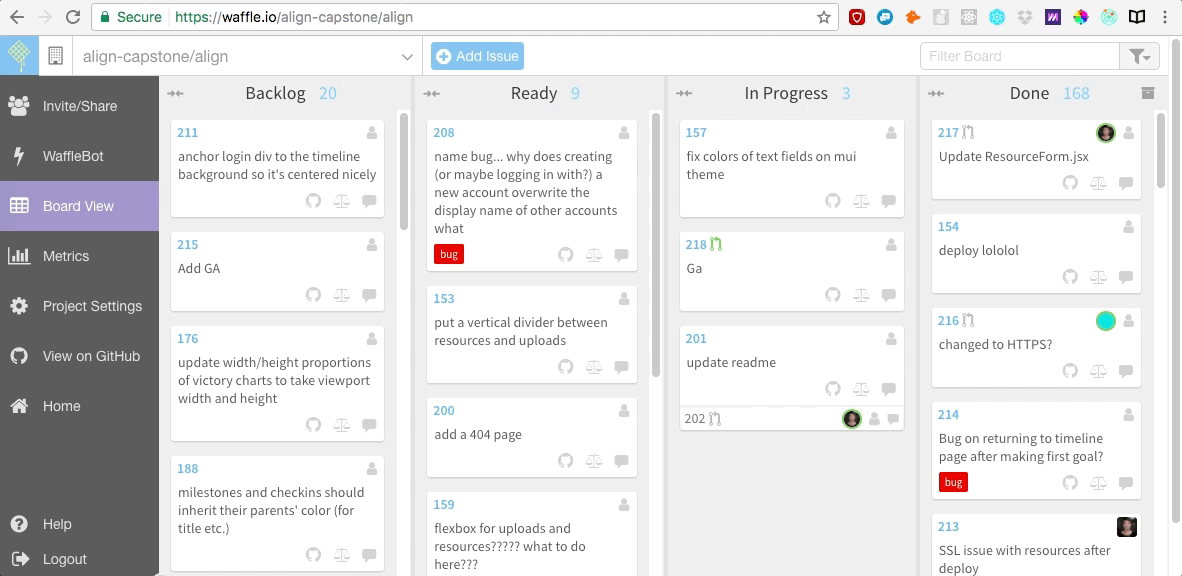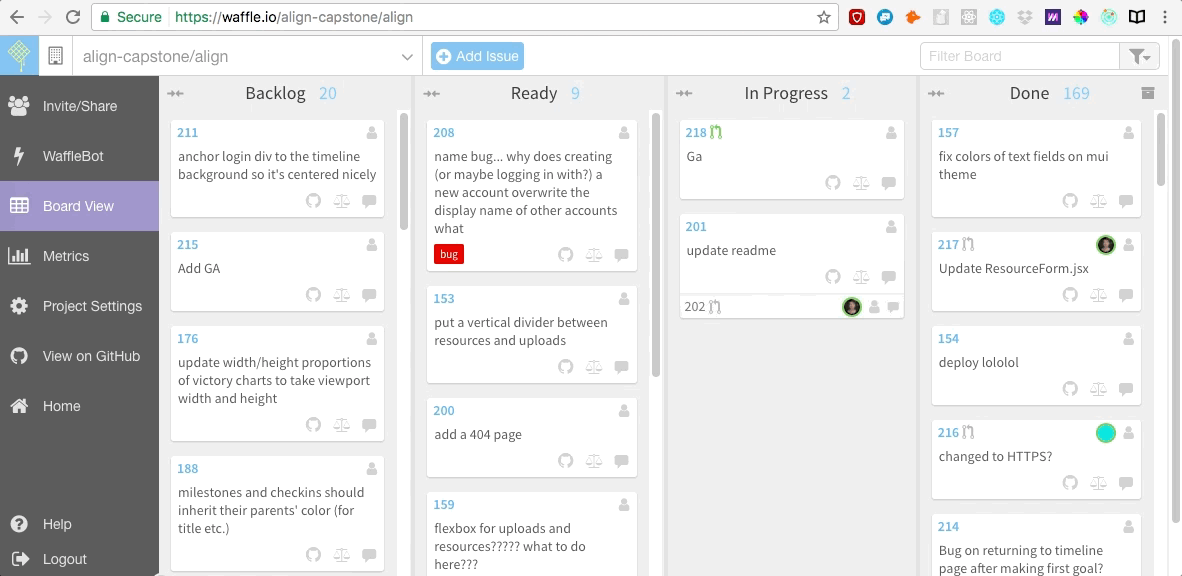
|
||||
|
||||
我们还开始保持晨会的习惯,讨论前一天的工作和每一个人遇到的阻碍。会议常常决定了当天的流程 —— 哪些人要结对编程,哪些人要独自处理问题。
|
||||
|
||||
我认为这种类型的工作流程非常好,因为它让我们能够清楚地找到自己的定位,不用顾虑人际矛盾地高效执行工作。
|
||||
|
||||
### 第 5 步: 选择、下载样板文件
|
||||
|
||||
由于 JavaScript 的生态系统过于复杂,我们不打算从最底层开始构建应用。把宝贵的时间花在连通 Webpack 构建脚本和加载器,把符号链接指向项目工程这些事情上感觉很没必要。我的团队选择了 [Firebones][6] 框架,因为它恰好适用于我们这个情况,当然还有很多可供选择的开源框架。
|
||||
|
||||
### 第 6 步:编写后端 API 路由(或者 Firebase 监听器)
|
||||
|
||||
如果我们没有用基于云的数据库,这时就应该开始编写执行数据库查询的后端高速路由了。但是由于我们用的是 Firebase,它本身就是云端的,可以用不同的方式进行代码交互,因此我们只需要设置好一个可用的数据库监听器。
|
||||
|
||||
为了确保监听器在工作,我们用代码做出了用于创建目标(Goal)的基本用户表格,实际上当我们完成表格时,就看到数据库执行可更新。数据库就成功连接了!
|
||||
|
||||
### 第 7 步:构建 “概念证明”
|
||||
|
||||
接下来是为应用创建 “概念证明”,也可以说是实现起来最复杂的基本功能的原型,证明我们的应用 _可以_ 实现。对我们而言,这意味着要找个前端库来实现时间线的渲染,成功连接到 Firebase,显示数据库中的一些种子数据。
|
||||
|
||||

|
||||
|
||||
*Victory.JS 绘制的简单时间线*
|
||||
|
||||
我们找到了基于 D3 构建的响应式库 Victory.JS,花了一天时间阅读文档,用 _VictoryLine_ 和 _VictoryScatter_ 组件实现了非常基础的示例,能够可视化地显示数据库中的数据。实际上,这很有用!我们可以开始构建了。
|
||||
|
||||
### 第 8 步:用代码实现功能
|
||||
|
||||
最后,是时候构建出应用中那些令人期待的功能了。取决于你要构建的应用,这一重要步骤会有些明显差异。我们根据所用的框架,编码出不同的用户故事并保存在 Waffle 上。常常需要同时接触前端和后端代码(比如,创建一个前端表格同时要连接到数据库)。我们实现了包含以下这些大大小小的功能:
|
||||
|
||||
* 能够创建新目标、里程碑和记录
|
||||
* 能够删除目标,里程碑和记录
|
||||
* 能够更改时间线的名称,颜色和详细内容
|
||||
* 能够缩放时间线
|
||||
* 能够为资源添加链接
|
||||
* 能够上传视频
|
||||
* 在达到相关目标的里程碑和记录时弹出资源和视频
|
||||
* 集成富文本编辑器
|
||||
* 用户注册、验证、OAuth 验证
|
||||
* 弹出查看时间线选项
|
||||
* 加载画面
|
||||
|
||||
有各种原因,这一步花了我们很多时间 —— 这一阶段是产生最多优质代码的阶段,每当我们实现了一个功能,就会有更多的事情要完善。
|
||||
|
||||
### 第 9 步: 选择并实现设计方案
|
||||
|
||||
当我们使用 MVP 架构实现了想要的功能,就可以开始清理,对它进行美化了。像表单,菜单和登陆栏等组件,我的团队用的是 Material-UI,不需要很多深层次的设计知识,它也能确保每个组件看上去都很圆润光滑。
|
||||
|
||||
|
||||
|
||||
*这是我制作的最喜爱功能之一了。它美得令人心旷神怡。*
|
||||
|
||||
我们花了一点时间来选择颜色方案和编写 CSS ,这让我们在编程中休息了一段美妙的时间。期间我们还设计了 logo 图标,还上传了网站图标。
|
||||
|
||||
### 第 10 步: 找出并减少 bug
|
||||
|
||||
我们一开始就应该使用测试驱动开发的模式,但时间有限,我们那点时间只够用来实现功能。这意味着最后的两天时间我们花在了模拟我们能够想到的每一种用户流,并从应用中找出 bug。
|
||||
|
||||

|
||||
|
||||
这一步是最不具系统性的,但是我们发现了一堆够我们忙乎的 bug,其中一个是在某些情况下加载动画不会结束的 bug,还有一个是资源组件会完全停止运行的 bug。修复 bug 是件令人恼火的事情,但当软件可以运行时,又特别令人满足。
|
||||
|
||||
### 第 11 步:应用上线
|
||||
|
||||
最后一步是上线应用,这样才可以让用户使用它!由于我们使用 Firebase 存储数据,因此我们使用了 Firebase Hosting,它很直观也很简单。如果你要选择其它的数据库,你可以使用 Heroku 或者 DigitalOcean。一般来讲,可以在主机网站中查看使用说明。
|
||||
|
||||
我们还在 Namecheap.com 上购买了一个便宜的域名,这让我们的应用更加完善,很容易被找到。
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
好了,这就是全部的过程 —— 我们都是这款实用的全栈应用的合作开发者。如果要继续讲,那么第 12 步将会是对用户进行 A/B 测试,这样我们才能更好地理解:实际用户与这款应用交互的方式和他们想在 V2 版本中看到的新功能。
|
||||
|
||||
但是,现在我们感到非常开心,不仅是因为成品,还因为我们从这个过程中获得了难以估量的知识和理解。点击 [这里][7] 查看 Align 应用!
|
||||
|
||||

|
||||
|
||||
*Align 团队:Sara Kladky(左),Melanie Mohn(中),还有我自己。*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/ladies-storm-hackathons/how-we-built-our-first-full-stack-javascript-web-app-in-three-weeks-8a4668dbd67c?imm_mid=0f581a&cmp=em-web-na-na-newsltr_20170816
|
||||
|
||||
作者:[Sophia Ciocca][a]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@sophiaciocca?source=post_header_lockup
|
||||
[1]:https://medium.com/@sophiaciocca?source=post_header_lockup
|
||||
[2]:https://medium.com/@sophiaciocca?source=post_header_lockup
|
||||
[3]:https://github.com/limitless-leggings/limitless-leggings
|
||||
[4]:https://www.youtube.com/watch?v=qyLoInHNjoc
|
||||
[5]:http://www.waffle.io/
|
||||
[6]:https://github.com/FullstackAcademy/firebones
|
||||
[7]:https://align.fun/
|
||||
[8]:https://github.com/align-capstone/align
|
||||
[9]:https://github.com/sophiaciocca
|
||||
[10]:https://github.com/Kladky
|
||||
[11]:https://github.com/melaniemohn
|
||||
224
published/20170926 Managing users on Linux systems.md
Normal file
224
published/20170926 Managing users on Linux systems.md
Normal file
@ -0,0 +1,224 @@
|
||||
管理 Linux 系统中的用户
|
||||
======
|
||||
|
||||

|
||||
|
||||
也许你的 Linux 用户并不是愤怒的公牛,但是当涉及管理他们的账户的时候,能让他们一直满意也是一种挑战。你需要监控他们的访问权限,跟进他们遇到问题时的解决方案,并且把他们在使用系统时出现的重要变动记录下来。这里有一些方法和工具可以让这个工作轻松一点。
|
||||
|
||||
### 配置账户
|
||||
|
||||
添加和删除账户是管理用户中比较简单的一项,但是这里面仍然有很多需要考虑的方面。无论你是用桌面工具或是命令行选项,这都是一个非常自动化的过程。你可以使用 `adduser jdoe` 命令添加一个新用户,同时会触发一系列的反应。在创建 John 这个账户时会自动使用下一个可用的 UID,并有很多自动生成的文件来完成这个工作。当你运行 `adduser` 后跟一个参数时(要创建的用户名),它会提示一些额外的信息,同时解释这是在干什么。
|
||||
|
||||
```
|
||||
$ sudo adduser jdoe
|
||||
Adding user 'jdoe' ...
|
||||
Adding new group `jdoe' (1001) ...
|
||||
Adding new user `jdoe' (1001) with group `jdoe' ...
|
||||
Creating home directory `/home/jdoe' ...
|
||||
Copying files from `/etc/skel' …
|
||||
Enter new UNIX password:
|
||||
Retype new UNIX password:
|
||||
passwd: password updated successfully
|
||||
Changing the user information for jdoe
|
||||
Enter the new value, or press ENTER for the default
|
||||
Full Name []: John Doe
|
||||
Room Number []:
|
||||
Work Phone []:
|
||||
Home Phone []:
|
||||
Other []:
|
||||
Is the information correct? [Y/n] Y
|
||||
```
|
||||
|
||||
如你所见,`adduser` 会添加用户的信息(到 `/etc/passwd` 和 `/etc/shadow` 文件中),创建新的<ruby>家目录<rt>home directory</rt></ruby>,并用 `/etc/skel` 里设置的文件填充家目录,提示你分配初始密码和认证信息,然后确认这些信息都是正确的,如果你在最后的提示 “Is the information correct?” 处的回答是 “n”,它会回溯你之前所有的回答,允许修改任何你想要修改的地方。
|
||||
|
||||
创建好一个用户后,你可能会想要确认一下它是否是你期望的样子,更好的方法是确保在添加第一个帐户**之前**,“自动”选择与你想要查看的内容是否匹配。默认有默认的好处,它对于你想知道他们定义在哪里很有用,以便你想做出一些变动 —— 例如,你不想让用户的家目录在 `/home` 里,你不想让用户 UID 从 1000 开始,或是你不想让家目录下的文件被系统中的**每个人**都可读。
|
||||
|
||||
`adduser` 的一些配置细节设置在 `/etc/adduser.conf` 文件里。这个文件包含的一些配置项决定了一个新的账户如何配置,以及它之后的样子。注意,注释和空白行将会在输出中被忽略,因此我们更关注配置项。
|
||||
|
||||
```
|
||||
$ cat /etc/adduser.conf | grep -v "^#" | grep -v "^$"
|
||||
DSHELL=/bin/bash
|
||||
DHOME=/home
|
||||
GROUPHOMES=no
|
||||
LETTERHOMES=no
|
||||
SKEL=/etc/skel
|
||||
FIRST_SYSTEM_UID=100
|
||||
LAST_SYSTEM_UID=999
|
||||
FIRST_SYSTEM_GID=100
|
||||
LAST_SYSTEM_GID=999
|
||||
FIRST_UID=1000
|
||||
LAST_UID=29999
|
||||
FIRST_GID=1000
|
||||
LAST_GID=29999
|
||||
USERGROUPS=yes
|
||||
USERS_GID=100
|
||||
DIR_MODE=0755
|
||||
SETGID_HOME=no
|
||||
QUOTAUSER=""
|
||||
SKEL_IGNORE_REGEX="dpkg-(old|new|dist|save)"
|
||||
```
|
||||
|
||||
可以看到,我们有了一个默认的 shell(`DSHELL`),UID(`FIRST_UID`)的起始值,家目录(`DHOME`)的位置,以及启动文件(`SKEL`)的来源位置。这个文件也会指定分配给家目录(`DIR_HOME`)的权限。
|
||||
|
||||
其中 `DIR_HOME` 是最重要的设置,它决定了每个家目录被使用的权限。这个设置分配给用户创建的目录权限是 755,家目录的权限将会设置为 `rwxr-xr-x`。用户可以读其他用户的文件,但是不能修改和移除它们。如果你想要更多的限制,你可以更改这个设置为 750(用户组外的任何人都不可访问)甚至是 700(除用户自己外的人都不可访问)。
|
||||
|
||||
任何用户账号在创建之前都可以进行手动修改。例如,你可以编辑 `/etc/passwd` 或者修改家目录的权限,开始在新服务器上添加用户之前配置 `/etc/adduser.conf` 可以确保一定的一致性,从长远来看可以节省时间和避免一些麻烦。
|
||||
|
||||
`/etc/adduser.conf` 的修改将会在之后创建的用户上生效。如果你想以不同的方式设置某个特定账户,除了用户名之外,你还可以选择使用 `adduser` 命令提供账户配置选项。或许你想为某些账户分配不同的 shell,分配特殊的 UID,或完全禁用该账户登录。`adduser` 的帮助页将会为你显示一些配置个人账户的选择。
|
||||
|
||||
```
|
||||
adduser [options] [--home DIR] [--shell SHELL] [--no-create-home]
|
||||
[--uid ID] [--firstuid ID] [--lastuid ID] [--ingroup GROUP | --gid ID]
|
||||
[--disabled-password] [--disabled-login] [--gecos GECOS]
|
||||
[--add_extra_groups] [--encrypt-home] user
|
||||
```
|
||||
|
||||
每个 Linux 系统现在都会默认把每个用户放入对应的组中。作为一个管理员,你可能会选择以不同的方式。你也许会发现把用户放在一个共享组中更适合你的站点,你就可以选择使用 `adduser` 的 `--gid` 选项指定一个特定的组。当然,用户总是许多组的成员,因此也有一些选项来管理主要和次要的组。
|
||||
|
||||
### 处理用户密码
|
||||
|
||||
一直以来,知道其他人的密码都不是一件好事,在设置账户时,管理员通常使用一个临时密码,然后在用户第一次登录时运行一条命令强制他修改密码。这里是一个例子:
|
||||
|
||||
```
|
||||
$ sudo chage -d 0 jdoe
|
||||
```
|
||||
|
||||
当用户第一次登录时,会看到类似下面的提示:
|
||||
|
||||
```
|
||||
WARNING: Your password has expired.
|
||||
You must change your password now and login again!
|
||||
Changing password for jdoe.
|
||||
(current) UNIX password:
|
||||
```
|
||||
|
||||
### 添加用户到副组
|
||||
|
||||
添加用户到副组中,你可能会用如下所示的 `usermod` 命令添加用户到组中并确认已经做出变动。
|
||||
|
||||
```
|
||||
$ sudo usermod -a -G sudo jdoe
|
||||
$ sudo grep sudo /etc/group
|
||||
sudo:x:27:shs,jdoe
|
||||
```
|
||||
|
||||
记住在一些组意味着特别的权限,如 sudo 或者 wheel 组,一定要特别注意这一点。
|
||||
|
||||
### 移除用户,添加组等
|
||||
|
||||
Linux 系统也提供了移除账户,添加新的组,移除组等一些命令。例如,`deluser` 命令,将会从 `/etc/passwd` 和 `/etc/shadow` 中移除用户记录,但是会完整保留其家目录,除非你添加了 `--remove-home` 或者 `--remove-all-files` 选项。`addgroup` 命令会添加一个组,默认按目前组的次序分配下一个 id(在用户组范围内),除非你使用 `--gid` 选项指定 id。
|
||||
|
||||
```
|
||||
$ sudo addgroup testgroup --gid=131
|
||||
Adding group `testgroup' (GID 131) ...
|
||||
Done.
|
||||
```
|
||||
|
||||
### 管理特权账户
|
||||
|
||||
一些 Linux 系统中有一个 wheel 组,它给组中成员赋予了像 root 一样运行命令的权限。在这种情况下,`/etc/sudoers` 将会引用该组。在 Debian 系统中,这个组被叫做 sudo,但是原理是相同的,你在 `/etc/sudoers` 中可以看到像这样的信息:
|
||||
|
||||
```
|
||||
%sudo ALL=(ALL:ALL) ALL
|
||||
```
|
||||
|
||||
这行基本的配置意味着任何在 wheel 或者 sudo 组中的成员只要在他们运行的命令之前添加 `sudo`,就可以以 root 的权限去运行命令。
|
||||
|
||||
你可以向 sudoers 文件中添加更多有限的权限 —— 也许给特定用户几个能以 root 运行的命令。如果你是这样做的,你应该定期查看 `/etc/sudoers` 文件以评估用户拥有的权限,以及仍然需要提供的权限。
|
||||
|
||||
在下面显示的命令中,我们过滤了 `/etc/sudoers` 中有效的配置行。其中最有意思的是,它包含了能使用 `sudo` 运行命令的路径设置,以及两个允许通过 `sudo` 运行命令的组。像刚才提到的那样,单个用户可以通过包含在 sudoers 文件中来获得权限,但是更有实际意义的方法是通过组成员来定义各自的权限。
|
||||
|
||||
```
|
||||
# cat /etc/sudoers | grep -v "^#" | grep -v "^$"
|
||||
Defaults env_reset
|
||||
Defaults mail_badpass
|
||||
Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
|
||||
root ALL=(ALL:ALL) ALL
|
||||
%admin ALL=(ALL) ALL <== admin group
|
||||
%sudo ALL=(ALL:ALL) ALL <== sudo group
|
||||
```
|
||||
|
||||
### 登录检查
|
||||
|
||||
你可以通过以下命令查看用户的上一次登录:
|
||||
|
||||
```
|
||||
# last jdoe
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 08:44 - 11:48 (00:04)
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 13:43 - 18:44 (00:00)
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:00)
|
||||
```
|
||||
|
||||
如果你想查看每一个用户上一次的登录情况,你可以通过一个像这样的循环来运行 `last` 命令:
|
||||
|
||||
```
|
||||
$ for user in `ls /home`; do last $user | head -1; done
|
||||
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43 (00:03)
|
||||
|
||||
rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02 (00:00)
|
||||
shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged in
|
||||
```
|
||||
|
||||
此命令仅显示自当前 wtmp 文件登录过的用户。空白行表示用户自那以后从未登录过,但没有将他们显示出来。一个更好的命令可以明确地显示这期间从未登录过的用户:
|
||||
|
||||
```
|
||||
$ for user in `ls /home`; do echo -n "$user"; last $user | head -1 | awk '{print substr($0,40)}'; done
|
||||
dhayes
|
||||
jdoe pts/18 192.168.0.11 Thu Sep 14 19:42 - 19:43
|
||||
peanut pts/19 192.168.0.29 Mon Sep 11 09:15 - 17:11
|
||||
rocket pts/18 192.168.0.11 Thu Sep 14 13:02 - 13:02
|
||||
shs pts/17 192.168.0.11 Thu Sep 14 12:45 still logged
|
||||
tsmith
|
||||
```
|
||||
|
||||
这个命令要打很多字,但是可以通过一个脚本使它更加清晰易用。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
for user in `ls /home`
|
||||
do
|
||||
echo -n "$user ";last $user | head -1 | awk '{print substr($0,40)}'
|
||||
done
|
||||
```
|
||||
|
||||
有时这些信息可以提醒你用户角色的变动,表明他们可能不再需要相关帐户了。
|
||||
|
||||
### 与用户沟通
|
||||
|
||||
Linux 提供了许多和用户沟通的方法。你可以向 `/etc/motd` 文件中添加信息,当用户从终端登录到服务器时,将会显示这些信息。你也可以通过例如 `write`(通知单个用户)或者 `wall`(write 给所有已登录的用户)命令发送通知。
|
||||
|
||||
```
|
||||
$ wall System will go down in one hour
|
||||
|
||||
Broadcast message from shs@stinkbug (pts/17) (Thu Sep 14 14:04:16 2017):
|
||||
|
||||
System will go down in one hour
|
||||
```
|
||||
|
||||
重要的通知应该通过多个渠道传达,因为很难预测用户实际会注意到什么。mesage-of-the-day(motd),`wall` 和 email 通知可以吸引用户大部分的注意力。
|
||||
|
||||
### 注意日志文件
|
||||
|
||||
多注意日志文件也可以帮你理解用户的活动情况。尤其 `/var/log/auth.log` 文件将会显示用户的登录和注销活动,组的创建记录等。`/var/log/message` 或者 `/var/log/syslog` 文件将会告诉你更多有关系统活动的日志。
|
||||
|
||||
### 追踪问题和需求
|
||||
|
||||
无论你是否在 Linux 系统上安装了事件跟踪系统,跟踪用户遇到的问题以及他们提出的需求都非常重要。如果需求的一部分久久不见回应,用户必然不会高兴。即使是记录在纸上也是有用的,或者最好有个电子表格,这可以让你注意到哪些问题仍然悬而未决,以及问题的根本原因是什么。确认问题和需求非常重要,记录还可以帮助你记住你必须采取的措施来解决几个月甚至几年后重新出现的问题。
|
||||
|
||||
### 总结
|
||||
|
||||
在繁忙的服务器上管理用户帐号,部分取决于配置良好的默认值,部分取决于监控用户活动和遇到的问题。如果用户觉得你对他们的顾虑有所回应并且知道在需要系统升级时会发生什么,他们可能会很高兴。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3225109/linux/managing-users-on-linux-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[wxy](https://github.com/wxy)、[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
@ -0,0 +1,45 @@
|
||||
书评:《算法之美( Algorithms to Live By )》
|
||||
======
|
||||
|
||||

|
||||
|
||||
又一次为了工作图书俱乐部而读书。除了其它我亲自推荐的书,这是我至今最喜爱的书。
|
||||
|
||||
作为计算机科学基础之一的研究领域是算法:我们如何高效地用计算机程序解决问题?这基本上属于数学领域,但是这很少关于理想的或理论上的解决方案,而是更在于最高效地利用有限的资源获得一个充分(如果不能完美)的答案。其中许多问题要么是日常的生活问题,要么与人们密切相关。毕竟,计算机科学的目的是为了用计算机解决实际问题。《<ruby>算法之美<rt>Algorithms to Live By</rt></ruby>》提出的问题是:“我们可以反过来吗”——我们可以通过学习计算机科学解决问题的方式来帮助我们做出日常决定吗?
|
||||
|
||||
本书的十一个章节有很多有趣的内容,但也有一个有趣的主题:人类早已擅长这一点。很多章节以一个算法研究和对问题的数学分析作为开始,接着深入到探讨如何利用这些结果做出更好的决策,然后讨论关于人类真正会做出的决定的研究,之后,考虑到典型生活情境的限制,会发现人类早就在应用我们提出的最佳算法的特殊版本了。这往往会破坏本书的既定目标,值得庆幸的是,它决不会破坏对一般问题的有趣讨论,即计算机科学如何解决它们,以及我们对这些问题的数学和技术形态的了解。我认为这本书的自助效用比作者打算的少一些,但有很多可供思考的东西。
|
||||
|
||||
(也就是说,值得考虑这种一致性是否太少了,因为人类已经擅长这方面了,更因为我们的算法是根据人类直觉设计的。可能我们的最佳算法只是反映了人类的思想。在某些情况下,我们发现我们的方案和数学上的典范不一样,但是在另一些情况下,它们仍然是我们当下最好的猜想。)
|
||||
|
||||
这是那种章节列表是书评里重要部分的书。这里讨论的算法领域有最优停止、探索和利用决策(什么时候带着你发现的最好东西走,以及什么时候寻觅更好的东西),以及排序、缓存、调度、贝叶斯定理(一般还有预测)、创建模型时的过拟合、放松(解决容易的问题而不是你的实际问题)、随机算法、一系列网络算法,最后还有游戏理论。其中每一项都有有用的见解和发人深省的讨论——这些有时显得十分理论化的概念令人吃惊地很好地映射到了日常生活。这本书以一段关于“可计算的善意”的讨论结束:鼓励减少你自己和你交往的人所需的计算和复杂性惩罚。
|
||||
|
||||
如果你有计算机科学背景(就像我一样),其中许多都是熟悉的概念,而且你因为被普及了很多新东西或许会有疑惑。然而,请给这本书一个机会,类比法没你担忧的那么令人紧张。作者既小心又聪明地应用了这些原则。这本书令人惊喜地通过了一个重要的合理性检查:涉及到我知道或反复思考过的主题的章节很少有或没有明显的错误,而且能讲出有用和重要的事情。比如,调度的那一章节毫不令人吃惊地和时间管理有关,通过直接跳到时间管理问题的核心而胜过了半数的时间管理类书籍:如果你要做一个清单上的所有事情,你做这些事情的顺序很少要紧,所以最难的调度问题是决定不做哪些事情而不是做这些事情的顺序。
|
||||
|
||||
作者在贝叶斯定理这一章节中的观点完全赢得了我的心。本章的许多内容都是关于贝叶斯先验的,以及一个人对过去事件的了解为什么对分析未来的概率很重要。作者接着讨论了著名的棉花糖实验。即给了儿童一个棉花糖以后,儿童被研究者告知如果他们能够克制自己不吃这个棉花糖,等到研究者回来时,会给他们两个棉花糖。克制自己不吃棉花糖(在心理学文献中叫作“延迟满足”)被发现与未来几年更好的生活有关。这个实验多年来一直被引用和滥用于各种各样的宣传,关于选择未来的收益放弃即时的快乐从而拥有成功的生活,以及生活中的失败是因为无法延迟满足。更多的邪恶分析(当然)将这种能力与种族联系在一起,带有可想而知的种族主义结论。
|
||||
|
||||
我对棉花糖实验有点兴趣。这是一个百分百让我愤怒咆哮的话题。
|
||||
|
||||
《算法之美》是我读过的唯一提到了棉花糖实验并应用了我认为更有说服力的分析的书。这不是一个关于儿童天赋的实验,这是一个关于他们的贝叶斯先验的实验。什么时候立即吃棉花糖而不是等待奖励是完全合理的?当他们过去的经历告诉他们成年人不可靠,不可信任,会在不可预测的时间内消失并且撒谎的时候。而且,更好的是,作者用我之前没有听说过的后续研究和观察支持了这一分析,观察到的内容是,一些孩子会等待一段时间然后“放弃”。如果他们下意识地使用具有较差先验的贝叶斯模型,这就完全合情合理。
|
||||
|
||||
这是一本很好的书。它可能在某些地方的尝试有点太勉强(数学上最优停止对于日常生活的适用性比我认为作者想要表现的更加偶然和牵强附会),如果你学过算法,其中一些内容会感到熟悉,但是它的行文思路清晰,简洁,而且编辑得非常好。这本书没有哪一部分对不起它所受到的欢迎,书中的讨论贯穿始终。如果你发现自己“已经知道了这一切”,你可能还会在接下来几页中遇到一个新的概念或一个简洁的解释。有时作者会做一些我从没想到但是回想起来正确的联系,比如将网络协议中的指数退避和司法系统中的选择惩罚联系起来。还有意识到我们的现代通信世界并不是一直联系的,它是不断缓冲的,我们中的许多人正深受缓冲膨胀这一独特现象的苦恼。
|
||||
|
||||
我认为你并不必须是计算机科学专业或者精通数学才能读这本书。如果你想深入,每章的结尾都有许多数学上的细节,但是正文总是易读而清晰,至少就我所知是这样(作为一个以计算机科学为专业并学到了很多数学知识的人,你至少可以有保留地相信我)。即使你已经钻研了多年的算法,这本书仍然可以提供很多东西。
|
||||
|
||||
这本书我读得越多越喜欢。如果你喜欢阅读这种对生活的分析,我当然是赞成的。
|
||||
|
||||
Rating: 9 out of 10
|
||||
|
||||
Reviewed: 2017-10-22
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.eyrie.org/~eagle/reviews/books/1-62779-037-3.html
|
||||
|
||||
作者:[Brian Christian;Tom Griffiths][a]
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.eyrie.org
|
||||
[1]:https://www.eyrie.org1-59184-679-X.html
|
||||
@ -0,0 +1,176 @@
|
||||
如何安装并使用 Wireshark
|
||||
======
|
||||
|
||||
[][2]
|
||||
|
||||
Wireshark 是自由开源的、跨平台的基于 GUI 的网络数据包分析器,可用于 Linux、Windows、MacOS、Solaris 等。它可以实时捕获网络数据包,并以人性化的格式呈现。Wireshark 允许我们监控网络数据包直到其微观层面。Wireshark 还有一个名为 `tshark` 的命令行实用程序,它与 Wireshark 执行相同的功能,但它是通过终端而不是 GUI。
|
||||
|
||||
Wireshark 可用于网络故障排除、分析、软件和通信协议开发以及用于教育目的。Wireshark 使用 `pcap` 库来捕获网络数据包。
|
||||
|
||||
Wireshark 具有许多功能:
|
||||
|
||||
* 支持数百项协议检查
|
||||
* 能够实时捕获数据包并保存,以便以后进行离线分析
|
||||
* 许多用于分析数据的过滤器
|
||||
* 捕获的数据可以即时压缩和解压缩
|
||||
* 支持各种文件格式的数据分析,输出也可以保存为 XML、CSV 和纯文本格式
|
||||
* 数据可以从以太网、wifi、蓝牙、USB、帧中继、令牌环等多个接口中捕获
|
||||
|
||||
在本文中,我们将讨论如何在 Ubuntu/Debian 上安装 Wireshark,并将学习如何使用 Wireshark 捕获网络数据包。
|
||||
|
||||
#### 在 Ubuntu 16.04 / 17.10 上安装 Wireshark
|
||||
|
||||
Wireshark 在 Ubuntu 默认仓库中可用,只需使用以下命令即可安装。但有可能得不到最新版本的 wireshark。
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo apt-get update
|
||||
linuxtechi@nixworld:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
因此,要安装最新版本的 wireshark,我们必须启用或配置官方 wireshark 仓库。
|
||||
|
||||
使用下面的命令来配置仓库并安装最新版本的 wireshark 实用程序。
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo add-apt-repository ppa:wireshark-dev/stable
|
||||
linuxtechi@nixworld:~$ sudo apt-get update
|
||||
linuxtechi@nixworld:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
一旦安装了 wireshark,执行以下命令,以便非 root 用户也可以捕获接口的实时数据包。
|
||||
|
||||
```
|
||||
linuxtechi@nixworld:~$ sudo setcap 'CAP_NET_RAW+eip CAP_NET_ADMIN+eip' /usr/bin/dumpcap
|
||||
```
|
||||
|
||||
#### 在 Debian 9 上安装 Wireshark
|
||||
|
||||
Wireshark 包及其依赖项已存在于 debian 9 的默认仓库中,因此要在 Debian 9 上安装最新且稳定版本的 Wireshark,请使用以下命令:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo apt-get update
|
||||
linuxtechi@nixhome:~$ sudo apt-get install wireshark -y
|
||||
```
|
||||
|
||||
在安装过程中,它会提示我们为非超级用户配置 dumpcap,
|
||||
|
||||
选择 `yes` 并回车。
|
||||
|
||||
[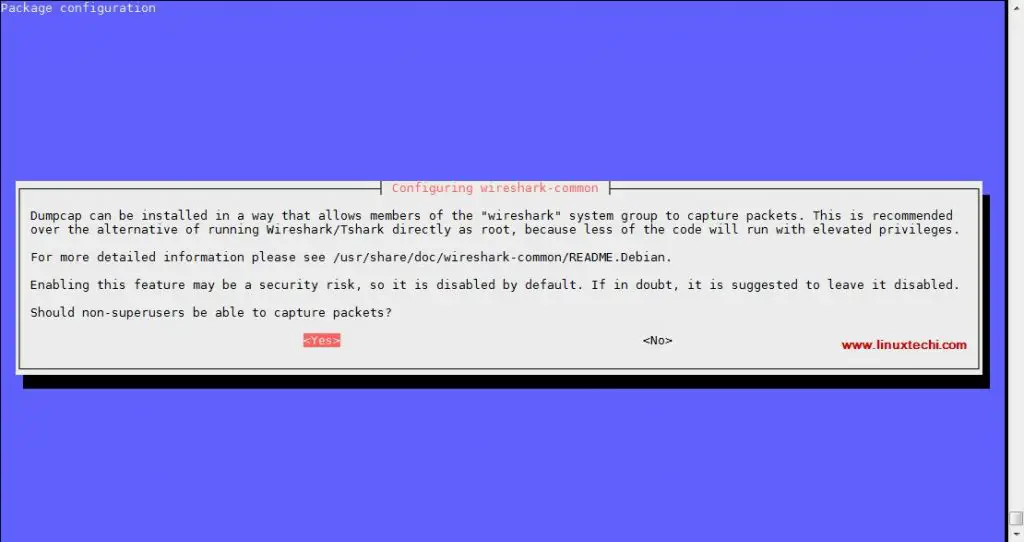][3]
|
||||
|
||||
安装完成后,执行以下命令,以便非 root 用户也可以捕获接口的实时数据包。
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo chmod +x /usr/bin/dumpcap
|
||||
```
|
||||
|
||||
我们还可以使用最新的源代码包在 Ubuntu/Debian 和其它 Linux 发行版上安装 wireshark。
|
||||
|
||||
#### 在 Debian / Ubuntu 系统上使用源代码安装 Wireshark
|
||||
|
||||
首先下载最新的源代码包(写这篇文章时它的最新版本是 2.4.2),使用以下命令:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ wget https://1.as.dl.wireshark.org/src/wireshark-2.4.2.tar.xz
|
||||
```
|
||||
|
||||
然后解压缩包,进入解压缩的目录:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ tar -xf wireshark-2.4.2.tar.xz -C /tmp
|
||||
linuxtechi@nixhome:~$ cd /tmp/wireshark-2.4.2
|
||||
```
|
||||
|
||||
现在我们使用以下命令编译代码:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ ./configure --enable-setcap-install
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ make
|
||||
```
|
||||
|
||||
最后安装已编译的软件包以便在系统上安装 Wireshark:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ sudo make install
|
||||
linuxtechi@nixhome:/tmp/wireshark-2.4.2$ sudo ldconfig
|
||||
```
|
||||
|
||||
在安装后,它将创建一个单独的 Wireshark 组,我们现在将我们的用户添加到组中,以便它可以与 Wireshark 一起使用,否则在启动 wireshark 时可能会出现 “permission denied(权限被拒绝)”错误。
|
||||
|
||||
要将用户添加到 wireshark 组,执行以下命令:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ sudo usermod -a -G wireshark linuxtechi
|
||||
```
|
||||
|
||||
现在我们可以使用以下命令从 GUI 菜单或终端启动 wireshark:
|
||||
|
||||
```
|
||||
linuxtechi@nixhome:~$ wireshark
|
||||
```
|
||||
|
||||
#### 在 Debian 9 系统上使用 Wireshark
|
||||
|
||||
[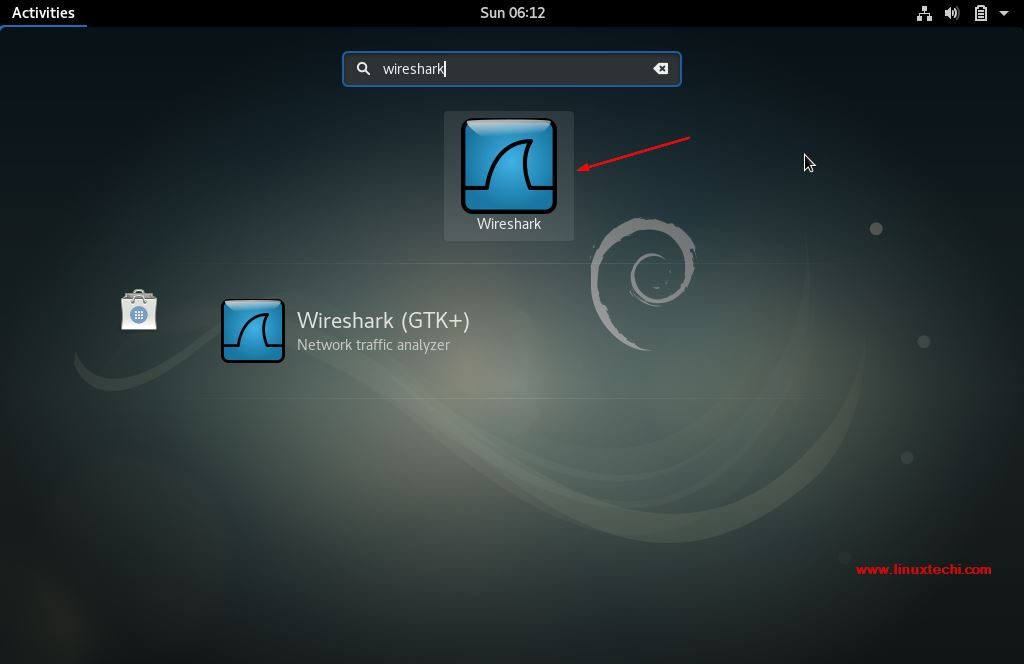][4]
|
||||
|
||||
点击 Wireshark 图标。
|
||||
|
||||
[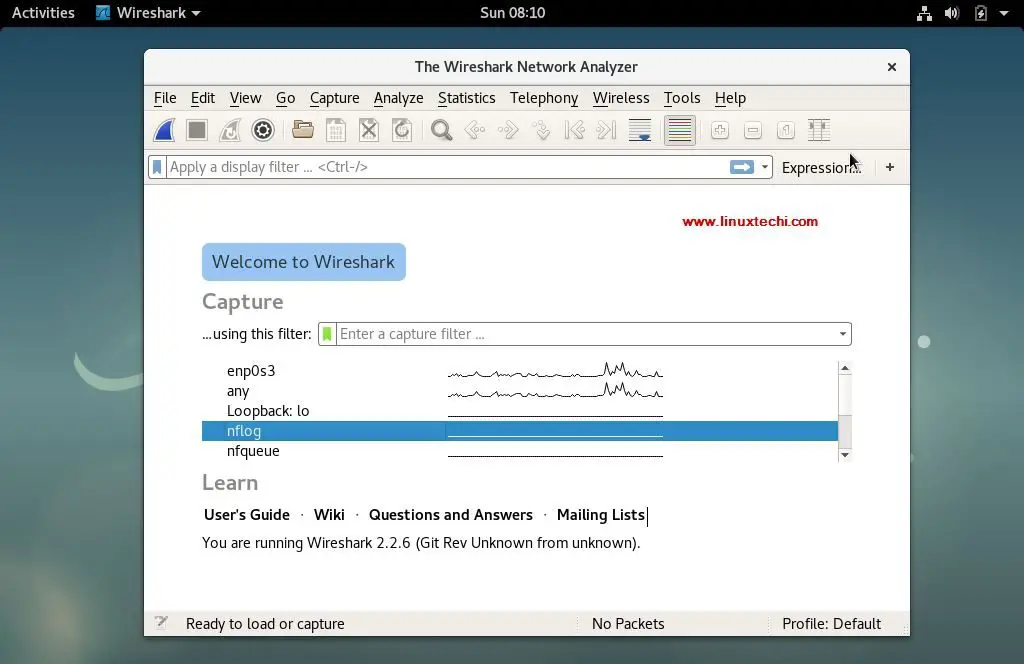][5]
|
||||
|
||||
#### 在 Ubuntu 16.04 / 17.10 上使用 Wireshark
|
||||
|
||||
[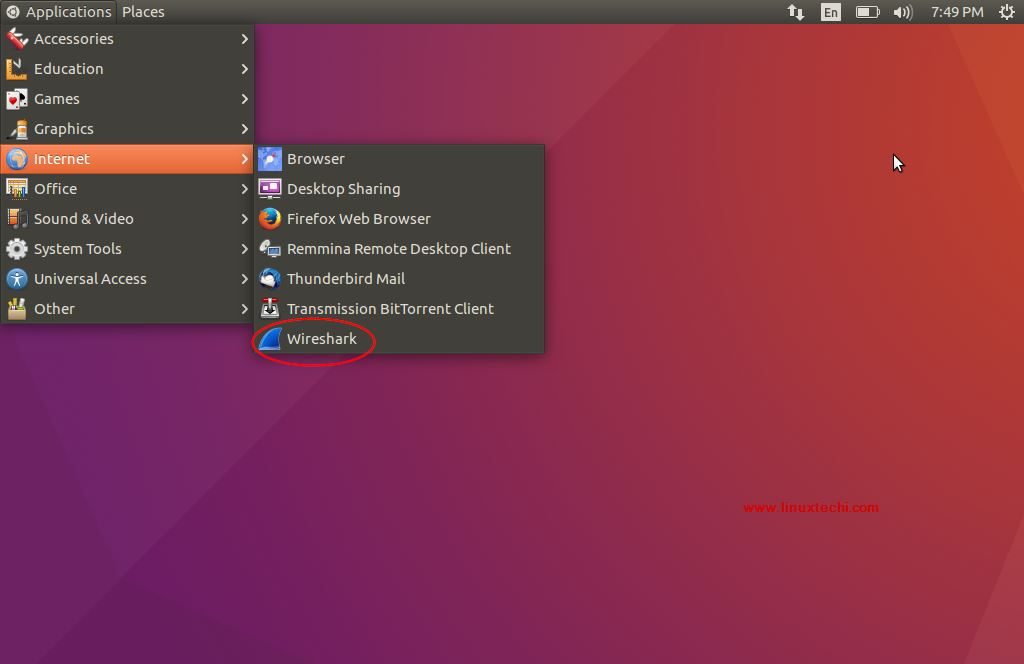][6]
|
||||
|
||||
点击 Wireshark 图标。
|
||||
|
||||
[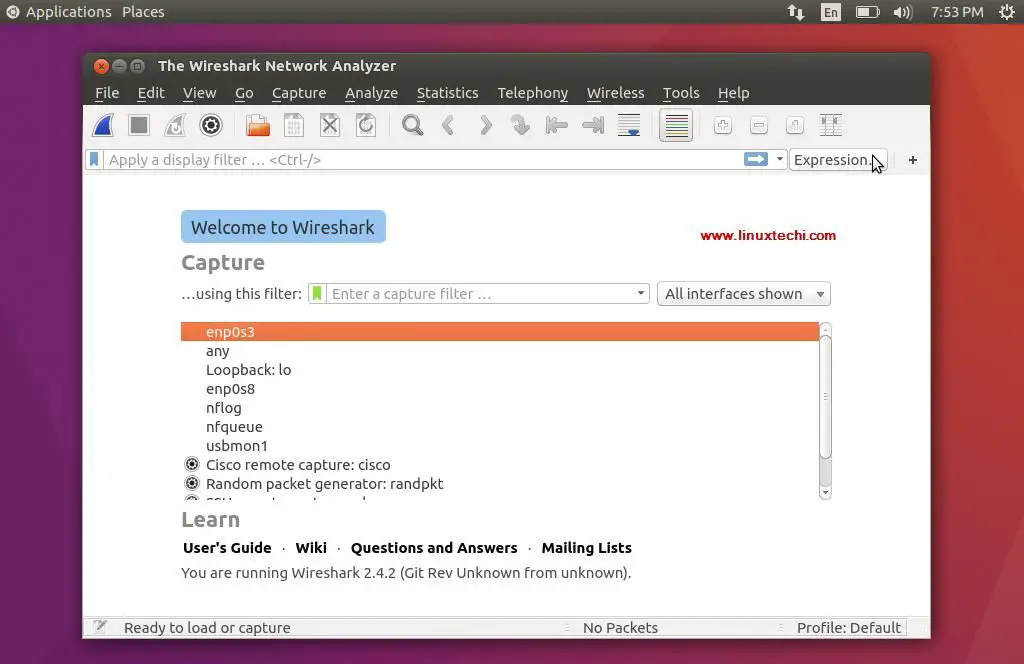][7]
|
||||
|
||||
#### 捕获并分析数据包
|
||||
|
||||
一旦 wireshark 启动,我们就会看到 wireshark 窗口,上面有 Ubuntu 和 Debian 系统的示例。
|
||||
|
||||
[][8]
|
||||
|
||||
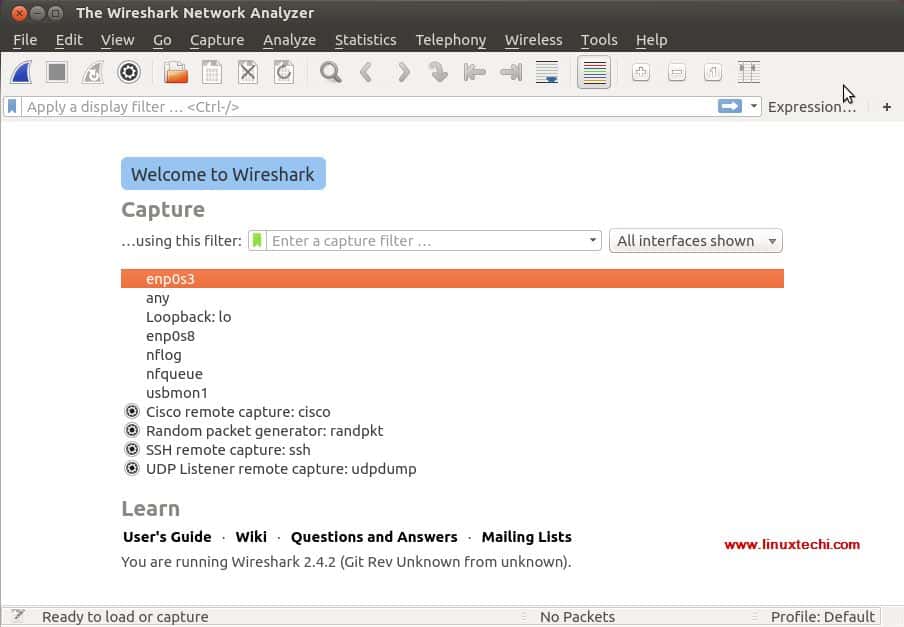
所有这些都是我们可以捕获网络数据包的接口。根据你系统上的接口,此屏幕可能与你的不同。
|
||||
|
||||
我们选择 `enp0s3` 来捕获该接口的网络流量。选择接口后,在我们网络上所有设备的网络数据包开始填充(参考下面的屏幕截图):
|
||||
|
||||
[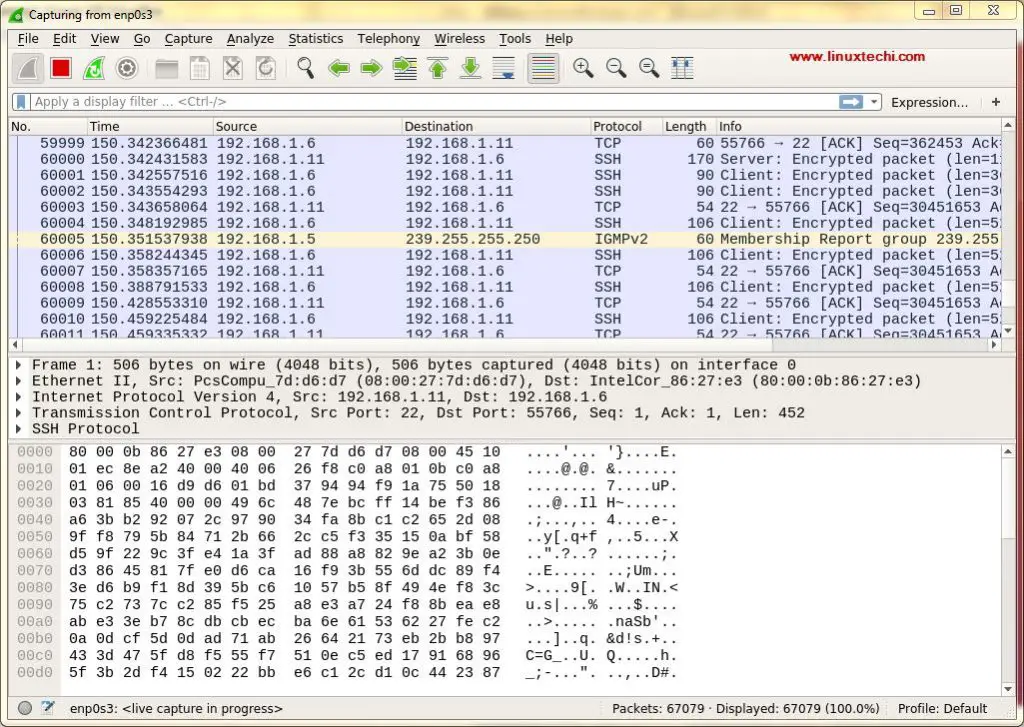][9]
|
||||
|
||||
第一次看到这个屏幕,我们可能会被这个屏幕上显示的数据所淹没,并且可能已经想过如何整理这些数据,但不用担心,Wireshark 的最佳功能之一就是它的过滤器。
|
||||
|
||||
我们可以根据 IP 地址、端口号,也可以使用来源和目标过滤器、数据包大小等对数据进行排序和过滤,也可以将两个或多个过滤器组合在一起以创建更全面的搜索。我们也可以在 “Apply a Display Filter(应用显示过滤器)”选项卡中编写过滤规则,也可以选择已创建的规则。要选择之前构建的过滤器,请单击 “Apply a Display Filter(应用显示过滤器)”选项卡旁边的旗帜图标。
|
||||
|
||||
[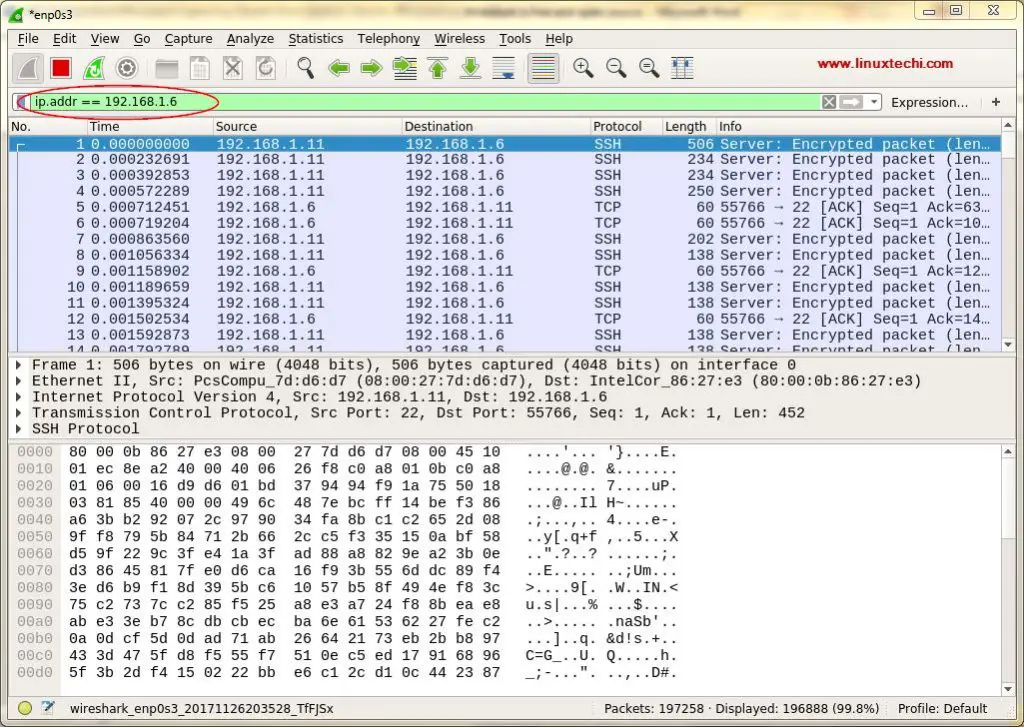][10]
|
||||
|
||||
我们还可以根据颜色编码过滤数据,默认情况下,浅紫色是 TCP 流量,浅蓝色是 UDP 流量,黑色标识有错误的数据包,看看这些编码是什么意思,点击 “View -> Coloring Rules”,我们也可以改变这些编码。
|
||||
|
||||
[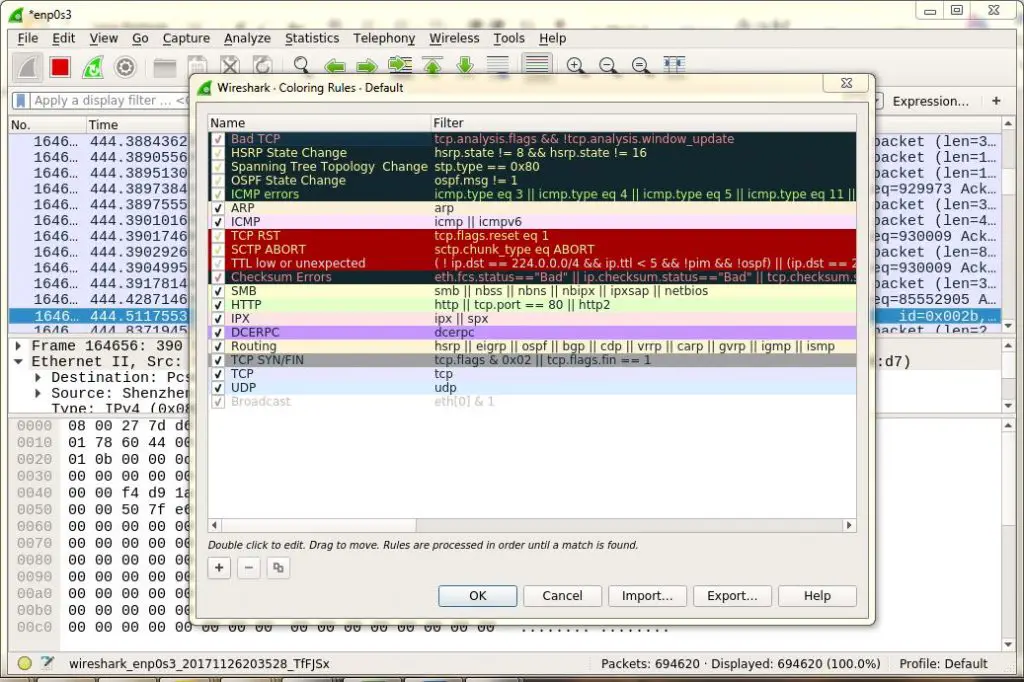][11]
|
||||
|
||||
在我们得到我们需要的结果之后,我们可以点击任何捕获的数据包以获得有关该数据包的更多详细信息,这将显示该网络数据包的所有数据。
|
||||
|
||||
Wireshark 是一个非常强大的工具,需要一些时间来习惯并对其进行命令操作,本教程将帮助你入门。请随时在下面的评论框中提出你的疑问或建议。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/install-use-wireshark-debian-9-ubuntu/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/author/pradeep/
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2017/11/wireshark-Debian-9-Ubuntu-16.04-17.10.jpg
|
||||
[3]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Configure-Wireshark-Debian9.jpg
|
||||
[4]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Access-wireshark-debian9.jpg
|
||||
[5]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Wireshark-window-debian9.jpg
|
||||
[6]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Access-wireshark-Ubuntu.jpg
|
||||
[7]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Wireshark-window-Ubuntu.jpg
|
||||
[8]:https://www.linuxtechi.com/wp-content/uploads/2017/11/wireshark-Linux-system.jpg
|
||||
[9]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Capturing-Packet-from-enp0s3-Ubuntu-Wireshark.jpg
|
||||
[10]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Filter-in-wireshark-Ubuntu.jpg
|
||||
[11]:https://www.linuxtechi.com/wp-content/uploads/2017/11/Packet-Colouring-Wireshark.jpg
|
||||
137
published/20180117 How to get into DevOps.md
Normal file
137
published/20180117 How to get into DevOps.md
Normal file
@ -0,0 +1,137 @@
|
||||
DevOps 实践指南
|
||||
======
|
||||
> 这些技巧或许对那些想要践行 DevOps 的系统运维和开发者能有所帮助。
|
||||
|
||||

|
||||
|
||||
在去年大概一年的时间里,我注意到对“Devops 实践”感兴趣的开发人员和系统管理员突然有了明显的增加。这样的变化也合理:现在开发者只要花很少的钱,调用一些 API,就能单枪匹马地在一整套分布式基础设施上运行自己的应用,在这个时代,开发和运维的紧密程度前所未有。我看过许多博客和文章介绍很酷的 DevOps 工具和相关思想,但是给那些希望践行 DevOps 的人以指导和建议的内容,我却很少看到。
|
||||
|
||||
这篇文章的目的就是描述一下如何去实践。我的想法基于 Reddit 上 [devops][1] 的一些访谈、聊天和深夜讨论,还有一些随机谈话,一般都发生在享受啤酒和美食的时候。如果你已经开始这样实践,我对你的反馈很感兴趣,请通过[我的博客][2]或者 [Twitter][3] 联系我,也可以直接在下面评论。我很乐意听到你们的想法和故事。
|
||||
|
||||
### 古代的 IT
|
||||
|
||||
了解历史是搞清楚未来的关键,DevOps 也不例外。想搞清楚 DevOps 运动的普及和流行,去了解一下上世纪 90 年代后期和 21 世纪前十年 IT 的情况会有帮助。这是我的经验。
|
||||
|
||||
我的第一份工作是在一家大型跨国金融服务公司做 Windows 系统管理员。当时给计算资源扩容需要给 Dell 打电话(或者像我们公司那样打给 CDW),并下一个价值数十万美元的订单,包含服务器、网络设备、电缆和软件,所有这些都要运到生产或线下的数据中心去。虽然 VMware 仍在尝试说服企业使用虚拟机运行他们的“性能敏感”型程序是更划算的,但是包括我们在内的很多公司都还是愿意使用他们的物理机运行应用。
|
||||
|
||||
在我们技术部门,有一个专门做数据中心工程和运营的团队,他们的工作包括价格谈判,让荒唐的月租能够降一点点,还包括保证我们的系统能够正常冷却(如果设备太多,这个事情的难度会呈指数增长)。如果这个团队足够幸运足够有钱,境外数据中心的工作人员对我们所有的服务器型号又都有足够的了解,就能避免在盘后交易中不小心搞错东西。那时候亚马逊 AWS 和 Rackspace 逐渐开始加速扩张,但还远远没到临界规模。
|
||||
|
||||
当时我们还有专门的团队来保证硬件上运行着的操作系统和软件能够按照预期工作。这些工程师负责设计可靠的架构以方便给系统打补丁、监控和报警,还要定义<ruby>基础镜像<rt>gold image</rt></ruby>的内容。这些大都是通过很多手工实验完成的,很多手工实验是为了编写一个<ruby>运行说明书<rt>runbook</rt></ruby>来描述要做的事情,并确保按照它执行后的结果确实在预期内。在我们这么大的组织里,这样做很重要,因为一线和二线的技术支持都是境外的,而他们的培训内容只覆盖到了这些运行说明而已。
|
||||
|
||||
(这是我职业生涯前三年的世界。我那时候的梦想是成为制定最高标准的人!)
|
||||
|
||||
软件发布则完全是另外一头怪兽。无可否认,我在这方面并没有积累太多经验。但是,从我收集的故事(和最近的经历)来看,当时大部分软件开发的日常大概是这样:
|
||||
|
||||
* 开发人员按照技术和功能需求来编写代码,这些需求来自于业务分析人员的会议,但是会议并没有邀请开发人员参加。
|
||||
* 开发人员可以选择为他们的代码编写单元测试,以确保在代码里没有任何明显的疯狂行为,比如除以 0 但不抛出异常。
|
||||
* 然后开发者会把他们的代码标记为 “Ready for QA”(准备好了接受测试),质量保障的成员会把这个版本的代码发布到他们自己的环境中,这个环境和生产环境可能相似,也可能不,甚至和开发环境相比也不一定相似。
|
||||
* 故障会在几天或者几个星期内反馈到开发人员那里,这个时长取决于其它业务活动和优先事项。
|
||||
|
||||
虽然系统管理员和开发人员经常有不一致的意见,但是对“变更管理”却一致痛恨。变更管理由高度规范的(就我当时的雇主而言)和非常必要的规则和程序组成,用来管理一家公司应该什么时候做技术变更,以及如何做。很多公司都按照 [ITIL][4] 来操作,简单的说,ITIL 问了很多和事情发生的原因、时间、地点和方式相关的问题,而且提供了一个过程,对产生最终答案的决定做审计跟踪。
|
||||
|
||||
你可能从我的简短历史课上了解到,当时 IT 的很多很多事情都是手工完成的。这导致了很多错误。错误又导致了很多财产损失。变更管理的工作就是尽量减少这些损失,它常常以这样的形式出现:不管变更的影响和规模大小,每两周才能发布部署一次。周五下午 4 点到周一早上 5 点 59 分这段时间,需要排队等候发布窗口。(讽刺的是,这种流程导致了更多错误,通常还是更严重的那种错误)
|
||||
|
||||
### DevOps 不是专家团
|
||||
|
||||
你可能在想 “Carlos 你在讲啥啊,什么时候才能说到 Ansible playbooks?”,我喜欢 Ansible,但是请稍等 —— 下面这些很重要。
|
||||
|
||||
你有没有过被分配到需要跟 DevOps 小组打交道的项目?你有没有依赖过“配置管理”或者“持续集成/持续交付”小组来保证业务流水线设置正确?你有没有在代码开发完的数周之后才参加发布部署的会议?
|
||||
|
||||
如果有过,那么你就是在重温历史,这个历史是由上面所有这些导致的。
|
||||
|
||||
出于本能,我们喜欢和像自己的人一起工作,这会导致[壁垒][5]的形成。很自然,这种人类特质也会在工作场所表现出来是不足为奇的。我甚至在曾经工作过的一个 250 人的创业公司里见到过这样的现象。刚开始的时候,开发人员都在聚在一起工作,彼此深度协作。随着代码变得复杂,开发相同功能的人自然就坐到了一起,解决他们自己的复杂问题。然后按功能划分的小组很快就正式形成了。
|
||||
|
||||
在我工作过的很多公司里,系统管理员和开发人员不仅像这样形成了天然的壁垒,而且彼此还有激烈的对抗。开发人员的环境出问题了或者他们的权限太小了,就会对系统管理员很恼火。系统管理员怪开发人员无时无刻地在用各种方式破坏他们的环境,怪开发人员申请的计算资源严重超过他们的需要。双方都不理解对方,更糟糕的是,双方都不愿意去理解对方。
|
||||
|
||||
大部分开发人员对操作系统,内核或计算机硬件都不感兴趣。同样,大部分系统管理员,即使是 Linux 的系统管理员,也都不愿意学习编写代码,他们在大学期间学过一些 C 语言,然后就痛恨它,并且永远都不想再碰 IDE。所以,开发人员把运行环境的问题甩给围墙外的系统管理员,系统管理员把这些问题和甩过来的其它上百个问题放在一起安排优先级。每个人都忙于怨恨对方。DevOps 的目的就是解决这种矛盾。
|
||||
|
||||
DevOps 不是一个团队,CI/CD 也不是 JIRA 系统的一个用户组。DevOps 是一种思考方式。根据这个运动来看,在理想的世界里,开发人员、系统管理员和业务相关人将作为一个团队工作。虽然他们可能不完全了解彼此的世界,可能没有足够的知识去了解彼此的积压任务,但他们在大多数情况下能有一致的看法。
|
||||
|
||||
把所有基础设施和业务逻辑都代码化,再串到一个发布部署流水线里,就像是运行在这之上的应用一样。这个理念的基础就是 DevOps。因为大家都理解彼此,所以人人都是赢家。聊天机器人和易用的监控工具、可视化工具的兴起,背后的基础也是 DevOps。
|
||||
|
||||
[Adam Jacob][6] 说的最好:“DevOps 就是企业往软件导向型过渡时我们用来描述操作的词。”
|
||||
|
||||
### 要实践 DevOps 我需要知道些什么
|
||||
|
||||
我经常被问到这个问题,它的答案和同属于开放式的其它大部分问题一样:视情况而定。
|
||||
|
||||
现在“DevOps 工程师”在不同的公司有不同的含义。在软件开发人员比较多但是很少有人懂基础设施的小公司,他们很可能是在找有更多系统管理经验的人。而其他公司,通常是大公司或老公司,已经有一个稳固的系统管理团队了,他们在向类似于谷歌 [SRE][7] 的方向做优化,也就是“设计运维功能的软件工程师”。但是,这并不是金科玉律,就像其它技术类工作一样,这个决定很大程度上取决于他的招聘经理。
|
||||
|
||||
也就是说,我们一般是在找对深入学习以下内容感兴趣的工程师:
|
||||
|
||||
* 如何管理和设计安全、可扩展的云平台(通常是在 AWS 上,不过微软的 Azure、Google Cloud Platform,还有 DigitalOcean 和 Heroku 这样的 PaaS 提供商,也都很流行)。
|
||||
* 如何用流行的 [CI/CD][8] 工具,比如 Jenkins、GoCD,还有基于云的 Travis CI 或者 CircleCI,来构造一条优化的发布部署流水线和发布部署策略。
|
||||
* 如何在你的系统中使用基于时间序列的工具,比如 Kibana、Grafana、Splunk、Loggly 或者 Logstash 来监控、记录,并在变化的时候报警。
|
||||
* 如何使用配置管理工具,例如 Chef、Puppet 或者 Ansible 做到“基础设施即代码”,以及如何使用像 Terraform 或 CloudFormation 的工具发布这些基础设施。
|
||||
|
||||
容器也变得越来越受欢迎。尽管有人对大规模使用 Docker 的现状[表示不满][9],但容器正迅速地成为一种很好的方式来实现在更少的操作系统上运行超高密度的服务和应用,同时提高它们的可靠性。(像 Kubernetes 或者 Mesos 这样的容器编排工具,能在宿主机故障的时候,几秒钟之内重新启动新的容器。)考虑到这些,掌握 Docker 或者 rkt 以及容器编排平台的知识会对你大有帮助。
|
||||
|
||||
如果你是希望做 DevOps 实践的系统管理员,你还需要知道如何写代码。Python 和 Ruby 是 DevOps 领域的流行语言,因为它们是可移植的(也就是说可以在任何操作系统上运行)、快速的,而且易读易学。它们还支撑着这个行业最流行的配置管理工具(Ansible 是使用 Python 写的,Chef 和 Puppet 是使用 Ruby 写的)以及云平台的 API 客户端(亚马逊 AWS、微软 Azure、Google Cloud Platform 的客户端通常会提供 Python 和 Ruby 语言的版本)。
|
||||
|
||||
如果你是开发人员,也希望做 DevOps 的实践,我强烈建议你去学习 Unix、Windows 操作系统以及网络基础知识。虽然云计算把很多系统管理的难题抽象化了,但是对应用的性能做调试的时候,如果你知道操作系统如何工作的就会有很大的帮助。下文包含了一些这个主题的图书。
|
||||
|
||||
如果你觉得这些东西听起来内容太多,没关系,大家都是这么想的。幸运的是,有很多小项目可以让你开始探索。其中一个项目是 Gary Stafford 的[选举服务](https://github.com/garystafford/voter-service),一个基于 Java 的简单投票平台。我们要求面试候选人通过一个流水线将该服务从 GitHub 部署到生产环境基础设施上。你可以把这个服务与 Rob Mile 写的了不起的 DevOps [入门教程](https://github.com/maxamg/cd-office-hours)结合起来学习。
|
||||
|
||||
还有一个熟悉这些工具的好方法,找一个流行的服务,然后只使用 AWS 和配置管理工具来搭建这个服务所需要的基础设施。第一次先手动搭建,了解清楚要做的事情,然后只用 CloudFormation(或者 Terraform)和 Ansible 重写刚才的手动操作。令人惊讶的是,这就是我们基础设施开发人员为客户所做的大部分日常工作,我们的客户认为这样的工作非常有意义!
|
||||
|
||||
### 需要读的书
|
||||
|
||||
如果你在找 DevOps 的其它资源,下面这些理论和技术书籍值得一读。
|
||||
|
||||
#### 理论书籍
|
||||
|
||||
* Gene Kim 写的 《<ruby>[凤凰项目][10]<rt>The Phoenix Project</rt></ruby>》。这是一本很不错的书,内容涵盖了我上文解释过的历史(写的更生动形象),描述了一个运行在敏捷和 DevOps 之上的公司向精益前进的过程。
|
||||
* Terrance Ryan 写的 《<ruby>[布道之道][11]<rt>Driving Technical Change</rt></ruby>》。非常好的一小本书,讲了大多数技术型组织内的常见性格特点以及如何和他们打交道。这本书对我的帮助比我想象的更多。
|
||||
* Tom DeMarco 和 Tim Lister 合著的 《<ruby>[人件][12]<rt>Peopleware</rt></ruby>》。管理工程师团队的经典图书,有一点过时,但仍然很有价值。
|
||||
* Tom Limoncelli 写的 《<ruby>[时间管理:给系统管理员][13]<rt>Time Management for System Administrators</rt></ruby>》。这本书主要面向系统管理员,它对很多大型组织内的系统管理员生活做了深入的展示。如果你想了解更多系统管理员和开发人员之间的冲突,这本书可能解释了更多。
|
||||
* Eric Ries 写的 《<ruby>[精益创业][14]<rt>The Lean Startup</rt></ruby>》。描述了 Eric 自己的 3D 虚拟形象公司,IMVU,发现了如何精益工作,快速失败和更快盈利。
|
||||
* Jez Humble 和他的朋友写的 《<ruby>[精益企业][15]<rt>Lean Enterprise</rt></ruby>》。这本书是对精益创业做的改编,以更适应企业,两本书都很棒,都很好地解释了 DevOps 背后的商业动机。
|
||||
* Kief Morris 写的 《<ruby>[基础设施即代码][16]<rt>Infrastructure As Code</rt></ruby>》。关于“基础设施即代码”的非常好的入门读物!很好的解释了为什么所有公司都有必要采纳这种做法。
|
||||
* Betsy Beyer、Chris Jones、Jennifer Petoff 和 Niall Richard Murphy 合著的 《<ruby>[站点可靠性工程师][17]<rt>Site Reliability Engineering</rt></ruby>》。一本解释谷歌 SRE 实践的书,也因为是“DevOps 诞生之前的 DevOps”被人熟知。在如何处理运行时间、时延和保持工程师快乐方面提供了有意思的看法。
|
||||
|
||||
#### 技术书籍
|
||||
|
||||
如果你想找的是让你直接跟代码打交道的书,看这里就对了。
|
||||
|
||||
* W. Richard Stevens 的 《<ruby>[TCP/IP 详解][18]<rt>TCP/IP Illustrated</rt></ruby>》。这是一套经典的(也可以说是最全面的)讲解网络协议基础的巨著,重点介绍了 TCP/IP 协议族。如果你听说过 1、2、3、4 层网络,而且对深入学习它们感兴趣,那么你需要这本书。
|
||||
* Evi Nemeth、Trent Hein 和 Ben Whaley 合著的 《<ruby>[UNIX/Linux 系统管理员手册][19]<rt>UNIX and Linux System Administration Handbook</rt></ruby>》。一本很好的入门书,介绍 Linux/Unix 如何工作以及如何使用。
|
||||
* Don Jones 和 Jeffrey Hicks 合著的 《<ruby>[Windows PowerShell 实战指南][20]<rt>Learn Windows Powershell In A Month of Lunches</rt></ruby>》。如果你在 Windows 系统下做自动化任务,你需要学习怎么使用 Powershell。这本书能够帮助你。Don Jones 是这方面著名的 MVP。
|
||||
* 几乎所有 [James Turnbull][21] 写的东西,针对流行的 DevOps 工具,他发表了很好的技术入门读物。
|
||||
|
||||
不管是在那些把所有应用都直接部署在物理机上的公司,(现在很多公司仍然有充分的理由这样做)还是在那些把所有应用都做成 serverless 的先驱公司,DevOps 都很可能会持续下去。这部分工作很有趣,产出也很有影响力,而且最重要的是,它搭起桥梁衔接了技术和业务之间的缺口。DevOps 是一个值得期待的美好事物。
|
||||
|
||||
首次发表在 [Neurons Firing on a Keyboard][22]。使用 CC-BY-SA 协议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/getting-devops
|
||||
|
||||
作者:[Carlos Nunez][a]
|
||||
译者:[belitex](https://github.com/belitex)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/carlosonunez
|
||||
[1]: https://www.reddit.com/r/devops/
|
||||
[2]: https://carlosonunez.wordpress.com/
|
||||
[3]: https://twitter.com/easiestnameever
|
||||
[4]: https://en.wikipedia.org/wiki/ITIL
|
||||
[5]: https://www.psychologytoday.com/blog/time-out/201401/getting-out-your-silo
|
||||
[6]: https://twitter.com/adamhjk/status/572832185461428224
|
||||
[7]: https://landing.google.com/sre/interview/ben-treynor.html
|
||||
[8]: https://en.wikipedia.org/wiki/CI/CD
|
||||
[9]: https://thehftguy.com/2016/11/01/docker-in-production-an-history-of-failure/
|
||||
[10]: https://itrevolution.com/book/the-phoenix-project/
|
||||
[11]: https://pragprog.com/book/trevan/driving-technical-change
|
||||
[12]: https://en.wikipedia.org/wiki/Peopleware:_Productive_Projects_and_Teams
|
||||
[13]: http://shop.oreilly.com/product/9780596007836.do
|
||||
[14]: http://theleanstartup.com/
|
||||
[15]: https://info.thoughtworks.com/lean-enterprise-book.html
|
||||
[16]: http://infrastructure-as-code.com/book/
|
||||
[17]: https://landing.google.com/sre/book.html
|
||||
[18]: https://en.wikipedia.org/wiki/TCP/IP_Illustrated
|
||||
[19]: http://www.admin.com/
|
||||
[20]: https://www.manning.com/books/learn-windows-powershell-in-a-month-of-lunches-third-edition
|
||||
[21]: https://jamesturnbull.net/
|
||||
[22]: https://carlosonunez.wordpress.com/2017/03/02/getting-into-devops/
|
||||
@ -0,0 +1,49 @@
|
||||
从过时的 Windows 机器迁移到 Linux
|
||||
======
|
||||
> 这是一个当老旧的 Windows 机器退役时,决定迁移到 Linux 的故事。
|
||||
|
||||

|
||||
|
||||
我在 ONLYOFFICE 的市场部门工作的每一天,我都能看到 Linux 用户在网上讨论我们的办公软件。我们的产品在 Linux 用户中很受欢迎,这使得我对使用 Linux 作为日常工具的体验非常好奇。我的老旧的 Windows XP 机器在性能上非常差,因此我决定了解 Linux 系统(特别是 Ubuntu)并且决定去尝试使用它。我的两个同事也加入了我的计划。
|
||||
|
||||
### 为何选择 Linux ?
|
||||
|
||||
我们必须做出改变,首先,我们的老系统在性能方面不够用:我们经历过频繁的崩溃,每当运行超过两个应用时,机器就会负载过度,关闭机器时有一半的几率冻结等等。这很容易让我们从工作中分心,意味着我们没有我们应有的工作效率了。
|
||||
|
||||
升级到 Windows 的新版本也是一种选择,但这样可能会带来额外的开销,而且我们的软件本身也是要与 Microsoft 的办公软件竞争。因此我们在这方面也存在意识形态的问题。
|
||||
|
||||
其次,就像我之前提过的, ONLYOFFICE 产品在 Linux 社区内非常受欢迎。通过阅读 Linux 用户在使用我们的软件时的体验,我们也对加入他们很感兴趣。
|
||||
|
||||
在我们要求转换到 Linux 系统一周后,我们拿到了崭新的装好了 [Kubuntu][1] 的机器。我们选择了 16.04 版本,因为这个版本支持 KDE Plasma 5.5 和包括 Dolphin 在内的很多 KDE 应用,同时也包括 LibreOffice 5.1 和 Firefox 45 。
|
||||
|
||||
### Linux 让人喜欢的地方
|
||||
|
||||
我相信 Linux 最大的优势是它的运行速度,比如,从按下机器的电源按钮到开始工作只需要几秒钟时间。从一开始,一切看起来都超乎寻常地快:总体的响应速度,图形界面,甚至包括系统更新的速度。
|
||||
|
||||
另一个使我惊奇的事情是跟 Windows 相比, Linux 几乎能让你配置任何东西,包括整个桌面的外观。在设置里面,我发现了如何修改各种栏目、按钮和字体的颜色和形状,也可以重新布置任意桌面组件的位置,组合桌面小工具(甚至包括漫画和颜色选择器)。我相信我还仅仅只是了解了基本的选项,之后还需要探索这个系统更多著名的定制化选项。
|
||||
|
||||
Linux 发行版通常是一个非常安全的环境。人们很少在 Linux 系统中使用防病毒的软件,因为很少有人会写病毒程序来攻击 Linux 系统。因此你可以拥有很好的系统速度,并且节省了时间和金钱。
|
||||
|
||||
总之, Linux 已经改变了我们的日常生活,用一系列的新选项和功能大大震惊了我们。仅仅通过短时间的使用,我们已经可以给它总结出以下特性:
|
||||
|
||||
* 操作很快很顺畅
|
||||
* 高度可定制
|
||||
* 对新手很友好
|
||||
* 了解基本组件很有挑战性,但回报丰厚
|
||||
* 安全可靠
|
||||
* 对所有想改变工作场所的人来说都是一次绝佳的体验
|
||||
|
||||
你已经从 Windows 或 MacOS 系统换到 Kubuntu 或其他 Linux 变种了么?或者你是否正在考虑做出改变?请分享你想要采用 Linux 系统的原因,连同你对开源的印象一起写在评论中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/move-to-linux-old-windows
|
||||
|
||||
作者:[Michael Korotaev][a]
|
||||
译者:[bookug](https://github.com/bookug)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/michaelk
|
||||
[1]:https://kubuntu.org/
|
||||
@ -0,0 +1,203 @@
|
||||
在 React 条件渲染中使用三元表达式和 “&&”
|
||||
=======
|
||||
|
||||

|
||||
|
||||
React 组件可以通过多种方式决定渲染内容。你可以使用传统的 `if` 语句或 `switch` 语句。在本文中,我们将探讨一些替代方案。但要注意,如果你不小心,有些方案会带来自己的陷阱。
|
||||
|
||||
### 三元表达式 vs if/else
|
||||
|
||||
假设我们有一个组件被传进来一个 `name` 属性。 如果这个字符串非空,我们会显示一个问候语。否则,我们会告诉用户他们需要登录。
|
||||
|
||||
这是一个只实现了如上功能的无状态函数式组件(SFC)。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => {
|
||||
if (name) {
|
||||
return (
|
||||
<div className="hello">
|
||||
Hello {name}
|
||||
</div>
|
||||
);
|
||||
}
|
||||
return (
|
||||
<div className="hello">
|
||||
Please sign in
|
||||
</div>
|
||||
);
|
||||
};
|
||||
```
|
||||
|
||||
这个很简单但是我们可以做得更好。这是使用<ruby>三元运算符<rt>conditional ternary operator</rt></ruby>编写的相同组件。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => (
|
||||
<div className="hello">
|
||||
{name ? `Hello ${name}` : 'Please sign in'}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
请注意这段代码与上面的例子相比是多么简洁。
|
||||
|
||||
有几点需要注意。因为我们使用了箭头函数的单语句形式,所以隐含了`return` 语句。另外,使用三元运算符允许我们省略掉重复的 `<div className="hello">` 标记。
|
||||
|
||||
### 三元表达式 vs &&
|
||||
|
||||
正如您所看到的,三元表达式用于表达 `if`/`else` 条件式非常好。但是对于简单的 `if` 条件式怎么样呢?
|
||||
|
||||
让我们看另一个例子。如果 `isPro`(一个布尔值)为真,我们将显示一个奖杯表情符号。我们也要渲染星星的数量(如果不是 0)。我们可以这样写。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro ? '♨' : null}
|
||||
</div>
|
||||
{stars ? (
|
||||
<div>
|
||||
Stars:{'☆'.repeat(stars)}
|
||||
</div>
|
||||
) : null}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
请注意 `else` 条件返回 `null` 。 这是因为三元表达式要有“否则”条件。
|
||||
|
||||
对于简单的 `if` 条件式,我们可以使用更合适的东西:`&&` 运算符。这是使用 `&&` 编写的相同代码。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro && '♨'}
|
||||
</div>
|
||||
{stars && (
|
||||
<div>
|
||||
Stars:{'☆'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
没有太多区别,但是注意我们消除了每个三元表达式最后面的 `: null` (`else` 条件式)。一切都应该像以前一样渲染。
|
||||
|
||||
嘿!约翰得到了什么?当什么都不应该渲染时,只有一个 `0`。这就是我上面提到的陷阱。这里有解释为什么:
|
||||
|
||||
[根据 MDN][3],一个逻辑运算符“和”(也就是 `&&`):
|
||||
|
||||
> `expr1 && expr2`
|
||||
|
||||
> 如果 `expr1` 可以被转换成 `false` ,返回 `expr1`;否则返回 `expr2`。 如此,当与布尔值一起使用时,如果两个操作数都是 `true`,`&&` 返回 `true` ;否则,返回 `false`。
|
||||
|
||||
好的,在你开始拔头发之前,让我为你解释它。
|
||||
|
||||
在我们这个例子里, `expr1` 是变量 `stars`,它的值是 `0`,因为 0 是假值,`0` 会被返回和渲染。看,这还不算太坏。
|
||||
|
||||
我会简单地这么写。
|
||||
|
||||
> 如果 `expr1` 是假值,返回 `expr1` ,否则返回 `expr2`。
|
||||
|
||||
所以,当对非布尔值使用 `&&` 时,我们必须让这个假值返回 React 无法渲染的东西,比如说,`false` 这个值。
|
||||
|
||||
我们可以通过几种方式实现这一目标。让我们试试吧。
|
||||
|
||||
```
|
||||
{!!stars && (
|
||||
<div>
|
||||
{'☆'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
```
|
||||
|
||||
注意 `stars` 前的双感叹操作符(`!!`)(呃,其实没有双感叹操作符。我们只是用了感叹操作符两次)。
|
||||
|
||||
第一个感叹操作符会强迫 `stars` 的值变成布尔值并且进行一次“非”操作。如果 `stars` 是 `0` ,那么 `!stars` 会是 `true`。
|
||||
|
||||
然后我们执行第二个`非`操作,所以如果 `stars` 是 `0`,`!!stars` 会是 `false`。正好是我们想要的。
|
||||
|
||||
如果你不喜欢 `!!`,那么你也可以强制转换出一个布尔数比如这样(这种方式我觉得有点冗长)。
|
||||
|
||||
```
|
||||
{Boolean(stars) && (
|
||||
```
|
||||
|
||||
或者只是用比较符产生一个布尔值(有些人会说这样甚至更加语义化)。
|
||||
|
||||
```
|
||||
{stars > 0 && (
|
||||
```
|
||||
|
||||
#### 关于字符串
|
||||
|
||||
空字符串与数字有一样的毛病。但是因为渲染后的空字符串是不可见的,所以这不是那种你很可能会去处理的难题,甚至可能不会注意到它。然而,如果你是完美主义者并且不希望 DOM 上有空字符串,你应采取我们上面对数字采取的预防措施。
|
||||
|
||||
### 其它解决方案
|
||||
|
||||
一种可能的将来可扩展到其他变量的解决方案,是创建一个单独的 `shouldRenderStars` 变量。然后你用 `&&` 处理布尔值。
|
||||
|
||||
```
|
||||
const shouldRenderStars = stars > 0;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'☆'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
之后,在将来,如果业务规则要求你还需要已登录,拥有一条狗以及喝淡啤酒,你可以改变 `shouldRenderStars` 的得出方式,而返回的内容保持不变。你还可以把这个逻辑放在其它可测试的地方,并且保持渲染明晰。
|
||||
|
||||
```
|
||||
const shouldRenderStars =
|
||||
stars > 0 && loggedIn && pet === 'dog' && beerPref === 'light`;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'☆'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
我认为你应该充分利用这种语言。对于 JavaScript,这意味着为 `if/else` 条件式使用三元表达式,以及为 `if` 条件式使用 `&&` 操作符。
|
||||
|
||||
我们可以回到每处都使用三元运算符的舒适区,但你现在消化了这些知识和力量,可以继续前进 `&&` 取得成功了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
美国运通工程博客的执行编辑 http://aexp.io 以及 @AmericanExpress 的工程总监。MyViews !== ThoseOfMyEmployer.
|
||||
|
||||
----------------
|
||||
|
||||
via: https://medium.freecodecamp.org/conditional-rendering-in-react-using-ternaries-and-logical-and-7807f53b6935
|
||||
|
||||
作者:[Donavon West][a]
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@donavon
|
||||
[1]:https://unsplash.com/photos/pKeF6Tt3c08?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[2]:https://unsplash.com/search/photos/road-sign?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Logical_Operators
|
||||
140
published/20180412 A Desktop GUI Application For NPM.md
Normal file
140
published/20180412 A Desktop GUI Application For NPM.md
Normal file
@ -0,0 +1,140 @@
|
||||
ndm:NPM 的桌面 GUI 程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
NPM 是 **N**ode **P**ackage **M**anager (node 包管理器)的缩写,它是用于安装 NodeJS 软件包或模块的命令行软件包管理器。我们发布过一个指南描述了如何[使用 NPM 管理 NodeJS 包][1]。你可能已经注意到,使用 Npm 管理 NodeJS 包或模块并不是什么大问题。但是,如果你不习惯用 CLI 的方式,这有一个名为 **NDM** 的桌面 GUI 程序,它可用于管理 NodeJS 程序/模块。 NDM,代表 **N**PM **D**esktop **M**anager (npm 桌面管理器),是 NPM 的自由开源图形前端,它允许我们通过简单图形桌面安装、更新、删除 NodeJS 包。
|
||||
|
||||
在这个简短的教程中,我们将了解 Linux 中的 Ndm。
|
||||
|
||||
### 安装 NDM
|
||||
|
||||
NDM 在 AUR 中可用,因此你可以在 Arch Linux 及其衍生版(如 Antergos 和 Manjaro Linux)上使用任何 AUR 助手程序安装。
|
||||
|
||||
使用 [Pacaur][2]:
|
||||
|
||||
```
|
||||
$ pacaur -S ndm
|
||||
```
|
||||
|
||||
使用 [Packer][3]:
|
||||
|
||||
```
|
||||
$ packer -S ndm
|
||||
```
|
||||
|
||||
使用 [Trizen][4]:
|
||||
|
||||
```
|
||||
$ trizen -S ndm
|
||||
```
|
||||
|
||||
使用 [Yay][5]:
|
||||
|
||||
```
|
||||
$ yay -S ndm
|
||||
```
|
||||
|
||||
使用 [Yaourt][6]:
|
||||
|
||||
```
|
||||
$ yaourt -S ndm
|
||||
```
|
||||
|
||||
在基于 RHEL 的系统(如 CentOS)上,运行以下命令以安装 NDM。
|
||||
|
||||
```
|
||||
$ echo "[fury] name=ndm repository baseurl=https://repo.fury.io/720kb/ enabled=1 gpgcheck=0" | sudo tee /etc/yum.repos.d/ndm.repo && sudo yum update &&
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint:
|
||||
|
||||
```
|
||||
$ echo "deb [trusted=yes] https://apt.fury.io/720kb/ /" | sudo tee /etc/apt/sources.list.d/ndm.list && sudo apt-get update && sudo apt-get install ndm
|
||||
```
|
||||
|
||||
也可以使用 **Linuxbrew** 安装 NDM。首先,按照以下链接中的说明安装 Linuxbrew。
|
||||
|
||||
安装 Linuxbrew 后,可以使用以下命令安装 NDM:
|
||||
|
||||
```
|
||||
$ brew update
|
||||
$ brew install ndm
|
||||
```
|
||||
|
||||
在其他 Linux 发行版上,进入 [NDM 发布页面][7],下载最新版本,自行编译和安装。
|
||||
|
||||
### NDM 使用
|
||||
|
||||
从菜单或使用应用启动器启动 NDM。这就是 NDM 的默认界面。
|
||||
|
||||
![][9]
|
||||
|
||||
在这里你可以本地或全局安装 NodeJS 包/模块。
|
||||
|
||||
#### 本地安装 NodeJS 包
|
||||
|
||||
要在本地安装软件包,首先通过单击主屏幕上的 “Add projects” 按钮选择项目目录,然后选择要保留项目文件的目录。例如,我选择了一个名为 “demo” 的目录作为我的项目目录。
|
||||
|
||||
单击项目目录(即 demo),然后单击 “Add packages” 按钮。
|
||||
|
||||
![][10]
|
||||
|
||||
输入要安装的软件包名称,然后单击 “Install” 按钮。
|
||||
|
||||
![][11]
|
||||
|
||||
安装后,软件包将列在项目目录下。只需单击该目录即可在本地查看已安装软件包的列表。
|
||||
|
||||
![][12]
|
||||
|
||||
同样,你可以创建单独的项目目录并在其中安装 NodeJS 模块。要查看项目中已安装模块的列表,请单击项目目录,右侧将显示软件包。
|
||||
|
||||
#### 全局安装 NodeJS 包
|
||||
|
||||
要全局安装 NodeJS 包,请单击主界面左侧的 “Globals” 按钮。然后,单击 “Add packages” 按钮,输入包的名称并单击 “Install” 按钮。
|
||||
|
||||
#### 管理包
|
||||
|
||||
单击任何已安装的包,不将在顶部看到各种选项,例如:
|
||||
|
||||
1. 版本(查看已安装的版本),
|
||||
2. 最新(安装最新版本),
|
||||
3. 更新(更新当前选定的包),
|
||||
4. 卸载(删除所选包)等。
|
||||
|
||||
![][13]
|
||||
|
||||
NDM 还有两个选项,即 “Update npm” 用于将 node 包管理器更新成最新可用版本, 而 “Doctor” 会运行一组检查以确保你的 npm 安装有所需的功能管理你的包/模块。
|
||||
|
||||
### 总结
|
||||
|
||||
NDM 使安装、更新、删除 NodeJS 包的过程更加容易!你无需记住执行这些任务的命令。NDM 让我们在简单的图形界面中点击几下鼠标即可完成所有操作。对于那些懒得输入命令的人来说,NDM 是管理 NodeJS 包的完美伴侣。
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/ndm-a-desktop-gui-application-for-npm/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/manage-nodejs-packages-using-npm/
|
||||
[2]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[3]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[4]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
|
||||
[5]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[7]:https://github.com/720kb/ndm/releases
|
||||
[8]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-1.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-5-1.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-6.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-7.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-8.png
|
||||
@ -1,21 +1,22 @@
|
||||
The df Command Tutorial With Examples For Beginners
|
||||
df 命令新手教程
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this guide, we are going to learn to use **df** command. The df command, stands for **D** isk **F** ree, reports file system disk space usage. It displays the amount of disk space available on the file system in a Linux system. The df command is not to be confused with **du** command. Both serves different purposes. The df command reports **how much disk space we have** (i.e free space) whereas the du command reports **how much disk space is being consumed** by the files and folders. Hope I made myself clear. Let us go ahead and see some practical examples of df command, so you can understand it better.
|
||||
在本指南中,我们将学习如何使用 `df` 命令。df 命令是 “Disk Free” 的首字母组合,它报告文件系统磁盘空间的使用情况。它显示一个 Linux 系统中文件系统上可用磁盘空间的数量。`df` 命令很容易与 `du` 命令混淆。它们的用途不同。`df` 命令报告我们拥有多少磁盘空间(空闲磁盘空间),而 `du` 命令报告被文件和目录占用了多少磁盘空间。希望我这样的解释你能更清楚。在继续之前,我们来看一些 `df` 命令的实例,以便于你更好地理解它。
|
||||
|
||||
### The df Command Tutorial With Examples
|
||||
### df 命令使用举例
|
||||
|
||||
**1\. View entire file system disk space usage**
|
||||
#### 1、查看整个文件系统磁盘空间使用情况
|
||||
|
||||
无需任何参数来运行 `df` 命令,以显示整个文件系统磁盘空间使用情况。
|
||||
|
||||
Run df command without any arguments to display the entire file system disk space.
|
||||
```
|
||||
$ df
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
dev 4033216 0 4033216 0% /dev
|
||||
@ -27,25 +28,23 @@ tmpfs 4038880 11636 4027244 1% /tmp
|
||||
/dev/loop0 84096 84096 0 100% /var/lib/snapd/snap/core/4327
|
||||
/dev/sda1 95054 55724 32162 64% /boot
|
||||
tmpfs 807776 28 807748 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
As you can see, the result is divided into six columns. Let us see what each column means.
|
||||
正如你所见,输出结果分为六列。我们来看一下每一列的含义。
|
||||
|
||||
* **Filesystem** – the filesystem on the system.
|
||||
* **1K-blocks** – the size of the filesystem, measured in 1K blocks.
|
||||
* **Used** – the amount of space used in 1K blocks.
|
||||
* **Available** – the amount of available space in 1K blocks.
|
||||
* **Use%** – the percentage that the filesystem is in use.
|
||||
* **Mounted on** – the mount point where the filesystem is mounted.
|
||||
* `Filesystem` – Linux 系统中的文件系统
|
||||
* `1K-blocks` – 文件系统的大小,用 1K 大小的块来表示。
|
||||
* `Used` – 以 1K 大小的块所表示的已使用数量。
|
||||
* `Available` – 以 1K 大小的块所表示的可用空间的数量。
|
||||
* `Use%` – 文件系统中已使用的百分比。
|
||||
* `Mounted on` – 已挂载的文件系统的挂载点。
|
||||
|
||||
#### 2、以人类友好格式显示文件系统硬盘空间使用情况
|
||||
|
||||
在上面的示例中你可能已经注意到了,它使用 1K 大小的块为单位来表示使用情况,如果你以人类友好格式来显示它们,可以使用 `-h` 标志。
|
||||
|
||||
**2\. Display file system disk usage in human readable format**
|
||||
|
||||
As you may noticed in the above examples, the usage is showed in 1k blocks. If you want to display them in human readable format, use **-h** flag.
|
||||
```
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
@ -61,11 +60,12 @@ tmpfs 789M 28K 789M 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
Now look at the **Size** and **Avail** columns, the usage is shown in GB and MB.
|
||||
现在,在 `Size` 列和 `Avail` 列,使用情况是以 GB 和 MB 为单位来显示的。
|
||||
|
||||
**3\. Display disk space usage only in MB**
|
||||
#### 3、仅以 MB 为单位来显示文件系统磁盘空间使用情况
|
||||
|
||||
如果仅以 MB 为单位来显示文件系统磁盘空间使用情况,使用 `-m` 标志。
|
||||
|
||||
To view file system disk space usage only in Megabytes, use **-m** flag.
|
||||
```
|
||||
$ df -m
|
||||
Filesystem 1M-blocks Used Available Use% Mounted on
|
||||
@ -78,12 +78,12 @@ tmpfs 3945 12 3933 1% /tmp
|
||||
/dev/loop0 83 83 0 100% /var/lib/snapd/snap/core/4327
|
||||
/dev/sda1 93 55 32 64% /boot
|
||||
tmpfs 789 1 789 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
**4\. List inode information instead of block usage**
|
||||
#### 4、列出节点而不是块的使用情况
|
||||
|
||||
如下所示,我们可以通过使用 `-i` 标记来列出节点而不是块的使用情况。
|
||||
|
||||
We can list inode information instead of block usage by using **-i** flag as shown below.
|
||||
```
|
||||
$ df -i
|
||||
Filesystem Inodes IUsed IFree IUse% Mounted on
|
||||
@ -96,12 +96,12 @@ tmpfs 1009720 3008 1006712 1% /tmp
|
||||
/dev/loop0 12829 12829 0 100% /var/lib/snapd/snap/core/4327
|
||||
/dev/sda1 25688 390 25298 2% /boot
|
||||
tmpfs 1009720 29 1009691 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
**5\. Display the file system type**
|
||||
#### 5、显示文件系统类型
|
||||
|
||||
使用 `-T` 标志显示文件系统类型。
|
||||
|
||||
To display the file system type, use **-T** flag.
|
||||
```
|
||||
$ df -T
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
@ -114,27 +114,27 @@ tmpfs tmpfs 4038880 11984 4026896 1% /tmp
|
||||
/dev/loop0 squashfs 84096 84096 0 100% /var/lib/snapd/snap/core/4327
|
||||
/dev/sda1 ext4 95054 55724 32162 64% /boot
|
||||
tmpfs tmpfs 807776 28 807748 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
As you see, there is an extra column (second from left) that shows the file system type.
|
||||
正如你所见,现在出现了显示文件系统类型的额外的列(从左数的第二列)。
|
||||
|
||||
**6\. Display only the specific file system type**
|
||||
#### 6、仅显示指定类型的文件系统
|
||||
|
||||
我们可以限制仅列出某些文件系统。比如,只列出 ext4 文件系统。我们使用 `-t` 标志。
|
||||
|
||||
We can limit the listing to a certain file systems. for example **ext4**. To do so, we use **-t** flag.
|
||||
```
|
||||
$ df -t ext4
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/sda2 478425016 428790896 25308436 95% /
|
||||
/dev/sda1 95054 55724 32162 64% /boot
|
||||
|
||||
```
|
||||
|
||||
See? This command shows only the ext4 file system disk space usage.
|
||||
看到了吗?这个命令仅显示了 ext4 文件系统的磁盘空间使用情况。
|
||||
|
||||
**7\. Exclude specific file system type**
|
||||
#### 7、不列出指定类型的文件系统
|
||||
|
||||
有时,我们可能需要从结果中去排除指定类型的文件系统。我们可以使用 `-x` 标记达到我们的目的。
|
||||
|
||||
Some times, you may want to exclude a specific file system from the result. This can be achieved by using **-x** flag.
|
||||
```
|
||||
$ df -x ext4
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
@ -145,34 +145,32 @@ tmpfs 4038880 0 4038880 0% /sys/fs/cgroup
|
||||
tmpfs 4038880 11984 4026896 1% /tmp
|
||||
/dev/loop0 84096 84096 0 100% /var/lib/snapd/snap/core/4327
|
||||
tmpfs 807776 28 807748 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
The above command will display all file systems usage, except **ext4**.
|
||||
上面的命令列出了除 ext4 类型以外的全部文件系统。
|
||||
|
||||
**8\. Display usage for a folder**
|
||||
#### 8、显示一个目录的磁盘使用情况
|
||||
|
||||
去显示某个目录的硬盘空间使用情况以及它的挂载点,例如 `/home/sk/` 目录,可以使用如下的命令:
|
||||
|
||||
To display the disk space available and where it is mounted for a folder, for example **/home/sk/** , use this command:
|
||||
```
|
||||
$ df -hT /home/sk/
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/sda2 ext4 457G 409G 25G 95% /
|
||||
|
||||
```
|
||||
|
||||
This command shows the file system type, used and available space in human readable form and where it is mounted. If you don’t to display the file system type, just ignore the **-t** flag.
|
||||
这个命令显示文件系统类型、以人类友好格式显示已使用和可用磁盘空间、以及它的挂载点。如果你不想去显示文件系统类型,只需要忽略 `-t` 标志即可。
|
||||
|
||||
更详细的使用情况,请参阅 man 手册页。
|
||||
|
||||
For more details, refer the man pages.
|
||||
```
|
||||
$ man df
|
||||
|
||||
```
|
||||
|
||||
**Recommended read:**
|
||||
|
||||
And, that’s all for today! I hope this was useful. More good stuffs to come. Stay tuned!
|
||||
今天就到此这止!我希望对你有用。还有更多更好玩的东西即将奉上。请继续关注!
|
||||
|
||||
Cheers!
|
||||
再见!
|
||||
|
||||
|
||||
|
||||
@ -181,12 +179,13 @@ Cheers!
|
||||
via: https://www.ostechnix.com/the-df-command-tutorial-with-examples-for-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/04/df-command.png
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user