mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
84c7fde18d
@ -1,13 +1,13 @@
|
||||
translating by StdioA
|
||||
|
||||
搭个 Web 服务器(三)
|
||||
=====================================
|
||||
|
||||
>“当我们必须创造时,才能够学到更多。” ——伯爵
|
||||
>“当我们必须创造时,才能够学到更多。” ——皮亚杰
|
||||
|
||||
在本系列的第二部分中,你创造了一个可以处理基本 HTTP GET 请求的、朴素的 WSGI 服务器。当时我问了一个问题:“你该如何让你的服务器在同一时间处理多个请求呢?”在这篇文章中,你会找到答案。系好安全带,我们要认真起来,全速前进了!你将会体验到一段非常快速的旅程。准备好你的 Linux,Mac OS X(或者其他 *nix 系统),还有你的 Python. 本文中所有源代码均可在 [GitHub][1] 上找到。
|
||||
在本系列的[第二部分](https://linux.cn/article-7685-1.html)中,你创造了一个可以处理基本 HTTP GET 请求的、朴素的 WSGI 服务器。当时我问了一个问题:“你该如何让你的服务器在同一时间处理多个请求呢?”在这篇文章中,你会找到答案。系好安全带,我们要认真起来,全速前进了!你将会体验到一段非常快速的旅程。准备好你的 Linux、Mac OS X(或者其他 *nix 系统),还有你的 Python。本文中所有源代码均可在 [GitHub][1] 上找到。
|
||||
|
||||
首先,我们来回顾一下 Web 服务器的基本结构,以及服务器处理来自客户端的请求时,所需的必要步骤。你在第一及第二部分中创建的轮询服务器只能够在同一时间内处理一个请求。在处理完当前请求之前,它不能够打开一个新的客户端连接。所有请求为了等待服务都需要排队,在服务繁忙时,这个队伍可能会排的很长,一些客户端可能会感到不开心。
|
||||
### 服务器的基本结构及如何处理请求
|
||||
|
||||
首先,我们来回顾一下 Web 服务器的基本结构,以及服务器处理来自客户端的请求时,所需的必要步骤。你在[第一部分](https://linux.cn/article-7662-1.html)及[第二部分](https://linux.cn/article-7685-1.html)中创建的轮询服务器只能够一次处理一个请求。在处理完当前请求之前,它不能够接受新的客户端连接。所有请求为了等待服务都需要排队,在服务繁忙时,这个队伍可能会排的很长,一些客户端可能会感到不开心。
|
||||
|
||||
|
||||
|
||||
@ -53,7 +53,7 @@ if __name__ == '__main__':
|
||||
serve_forever()
|
||||
```
|
||||
|
||||
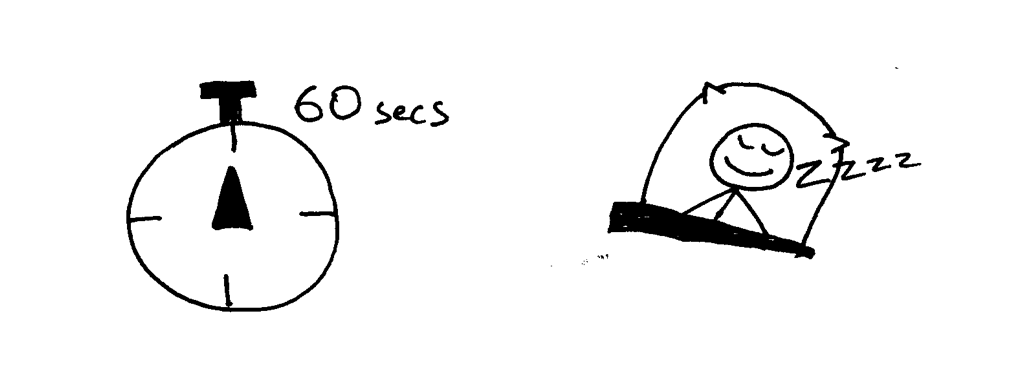
为了观察到你的服务器在同一时间只能处理一个请求,我们对服务器的代码做一点点修改:在将响应发送至客户端之后,将程序阻塞 60 秒。这个修改只需要一行代码,来告诉服务器进程暂停 60 秒钟。
|
||||
为了观察到你的服务器在同一时间只能处理一个请求的行为,我们对服务器的代码做一点点修改:在将响应发送至客户端之后,将程序阻塞 60 秒。这个修改只需要一行代码,来告诉服务器进程暂停 60 秒钟。
|
||||
|
||||
|
||||
|
||||
@ -84,7 +84,7 @@ HTTP/1.1 200 OK
|
||||
Hello, World!
|
||||
"""
|
||||
client_connection.sendall(http_response)
|
||||
time.sleep(60) # 睡眠语句,阻塞该进程 60 秒
|
||||
time.sleep(60) ### 睡眠语句,阻塞该进程 60 秒
|
||||
|
||||
|
||||
def serve_forever():
|
||||
@ -126,88 +126,85 @@ $ curl http://localhost:8888/hello
|
||||
|
||||
|
||||
|
||||
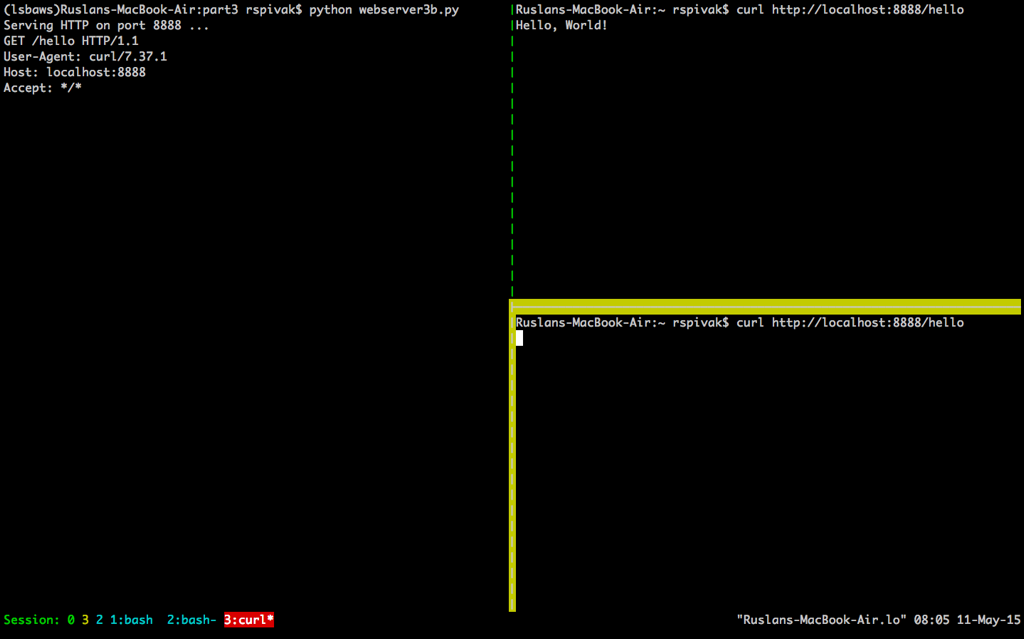
当你等待足够长的时间(60 秒以上)后,你会看到第一个 `curl` 程序完成,而第二个 `curl` 在屏幕上输出了“Hello, World!”,然后休眠 60 秒,进而停止运行。
|
||||
当你等待足够长的时间(60 秒以上)后,你会看到第一个 `curl` 程序完成,而第二个 `curl` 在屏幕上输出了“Hello, World!”,然后休眠 60 秒,进而终止。
|
||||
|
||||
|
||||
|
||||
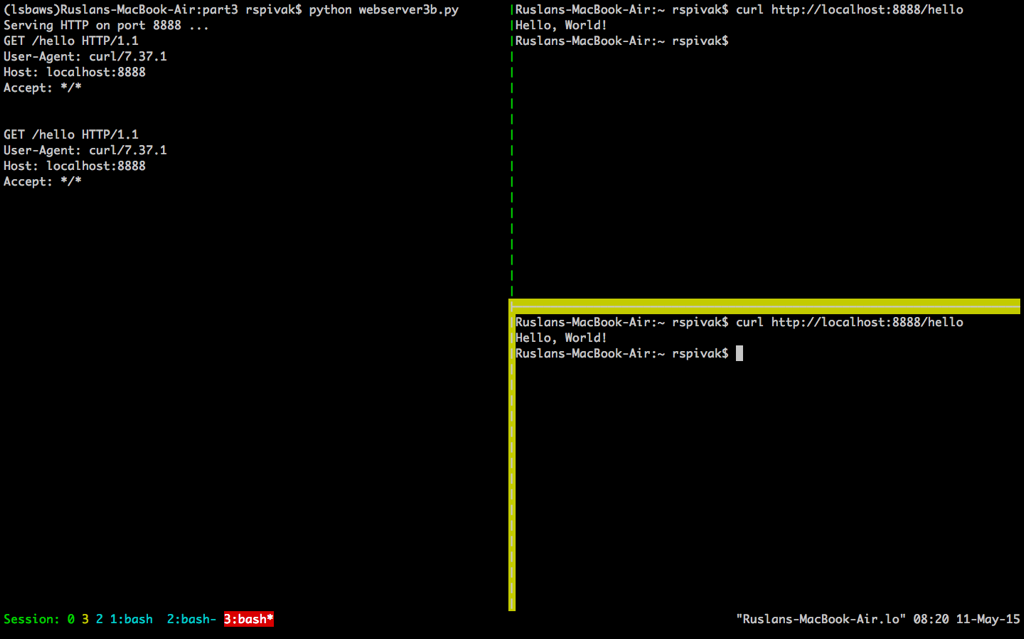
这两个程序这样运行,是因为在服务器在处理完第一个来自 `curl` 的请求之后,只有等待 60 秒才能开始处理第二个请求。这个处理请求的过程按顺序进行(也可以说,迭代进行),一步一步进行,在我们刚刚给出的例子中,在同一时间内只能处理一个请求。
|
||||
这样运行的原因是因为在服务器在处理完第一个来自 `curl` 的请求之后,只有等待 60 秒才能开始处理第二个请求。这个处理请求的过程按顺序进行(也可以说,迭代进行),一步一步进行,在我们刚刚给出的例子中,在同一时间内只能处理一个请求。
|
||||
|
||||
现在,我们来简单讨论一下客户端与服务器的交流过程。为了让两个程序在网络中互相交流,它们必须使用套接字。你应当在本系列的前两部分中见过它几次了。但是,套接字是什么?
|
||||
|
||||
|
||||
|
||||
套接字是一个交互通道的端点的抽象形式,它可以让你的程序通过文件描述符来与其它程序进行交流。在这篇文章中,我只会单独讨论 Linux 或 Mac OS X 中的 TCP/IP 套接字。这里有一个重点概念需要你去理解:TCP 套接字对。
|
||||
套接字(socket)是一个通讯通道端点(endpoint)的抽象描述,它可以让你的程序通过文件描述符来与其它程序进行交流。在这篇文章中,我只会单独讨论 Linux 或 Mac OS X 中的 TCP/IP 套接字。这里有一个重点概念需要你去理解:TCP 套接字对(socket pair)。
|
||||
|
||||
> TCP 连接使用的套接字对是一个由 4 个元素组成的元组,它确定了 TCP 连接的两端:本地 IP 地址、本地端口、远端 IP 地址及远端端口。一个套接字对独一无二地确定了网络中的每一个 TCP 连接。在连接一端的两个值:一个 IP 地址和一个端口,通常被称作一个套接字。[1][4]
|
||||
> TCP 连接使用的套接字对是一个由 4 个元素组成的元组,它确定了 TCP 连接的两端:本地 IP 地址、本地端口、远端 IP 地址及远端端口。一个套接字对唯一地确定了网络中的每一个 TCP 连接。在连接一端的两个值:一个 IP 地址和一个端口,通常被称作一个套接字。(引自[《UNIX 网络编程 卷1:套接字联网 API (第3版)》][4])
|
||||
|
||||
|
||||
|
||||
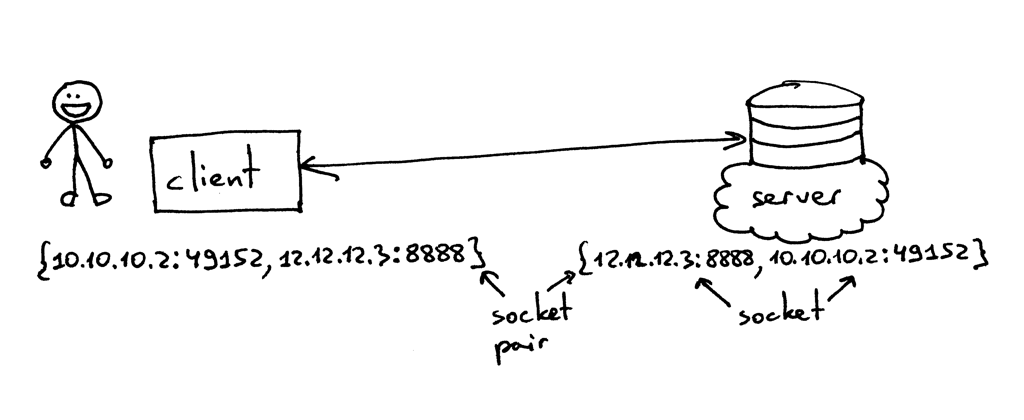
所以,元组 {10.10.10.2:49152, 12.12.12.3:8888} 就是一个能够在客户端确定 TCP 连接两端的套接字对,而元组 {12.12.12.3:8888, 10.10.10.2:49152} 则是在服务端确定 TCP 连接两端的套接字对。在这个例子中,确定 TCP 服务端的两个值(IP 地址 `12.12.12.3` 及端口 `8888`),代表一个套接字;另外两个值则代表客户端的套接字。
|
||||
所以,元组 `{10.10.10.2:49152, 12.12.12.3:8888}` 就是一个能够在客户端确定 TCP 连接两端的套接字对,而元组 `{12.12.12.3:8888, 10.10.10.2:49152}` 则是在服务端确定 TCP 连接两端的套接字对。在这个例子中,确定 TCP 服务端的两个值(IP 地址 `12.12.12.3` 及端口 `8888`),代表一个套接字;另外两个值则代表客户端的套接字。
|
||||
|
||||
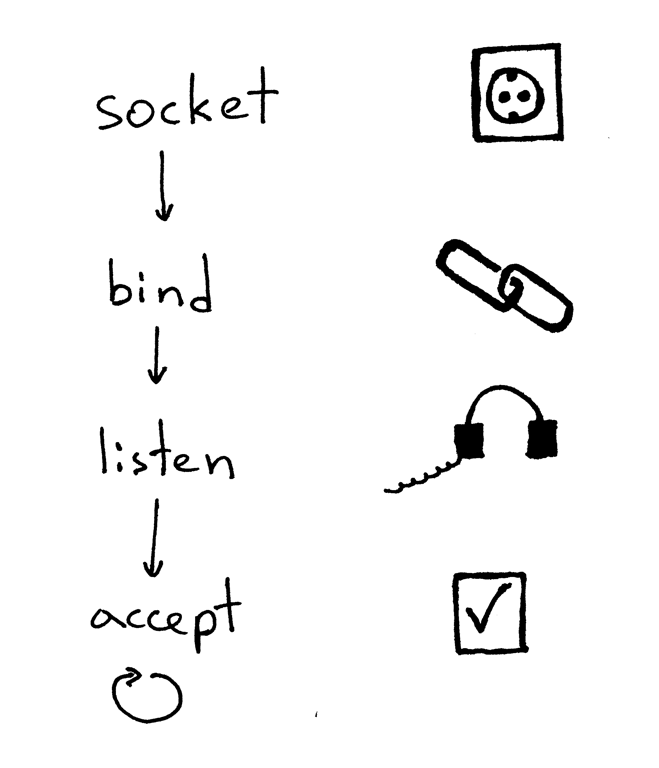
一个服务器创建一个套接字并开始建立连接的基本工作流程如下:
|
||||
|
||||
|
||||
|
||||
1. 服务器创建一个 TCP/IP 套接字。我们可以用下面那条 Python 语句来创建:
|
||||
1. 服务器创建一个 TCP/IP 套接字。我们可以用这条 Python 语句来创建:
|
||||
|
||||
```
|
||||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
```
|
||||
```
|
||||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
```
|
||||
2. 服务器可能会设定一些套接字选项(这个步骤是可选的,但是你可以看到上面的服务器代码做了设定,这样才能够在重启服务器时多次复用同一地址):
|
||||
|
||||
2. 服务器可能会设定一些套接字选项(这个步骤是可选的,但是你可以看到上面的服务器代码做了设定,这样才能够在重启服务器时多次复用同一地址)。
|
||||
|
||||
```
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
```
|
||||
|
||||
3. 然后,服务器绑定一个地址。绑定函数可以将一个本地协议地址赋给套接字。若使用 TCP 协议,调用绑定函数时,需要指定一个端口号,一个 IP 地址,或两者兼有,或两者兼无。[1][4]
|
||||
|
||||
```
|
||||
listen_socket.bind(SERVER_ADDRESS)
|
||||
```
|
||||
```
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
```
|
||||
3. 然后,服务器绑定一个地址。绑定函数 `bind` 可以将一个本地协议地址赋给套接字。若使用 TCP 协议,调用绑定函数 `bind` 时,需要指定一个端口号,一个 IP 地址,或两者兼有,或两者全无。(引自[《UNIX网络编程 卷1:套接字联网 API (第3版)》][4])
|
||||
|
||||
```
|
||||
listen_socket.bind(SERVER_ADDRESS)
|
||||
```
|
||||
4. 然后,服务器开启套接字的监听模式。
|
||||
|
||||
```
|
||||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||||
```
|
||||
```
|
||||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||||
```
|
||||
|
||||
监听函数只应在服务端调用。它会通知操作系统内核,标明它会接受所有向该套接字发送请求的链接。
|
||||
监听函数 `listen` 只应在服务端调用。它会通知操作系统内核,表明它会接受所有向该套接字发送的入站连接请求。
|
||||
|
||||
以上四步完成后,服务器将循环接收来自客户端的连接,一次循环处理一条。当有连接可用时,`accept` 函数将会返回一个已连接的客户端套接字。然后,服务器从客户端套接字中读取请求数据,将它在标准输出流中打印出来,并向客户端回送一条消息。然后,服务器会关闭这个客户端连接,并准备接收一个新的客户端连接。
|
||||
以上四步完成后,服务器将循环接收来自客户端的连接,一次循环处理一条。当有连接可用时,接受请求函数 `accept` 将会返回一个已连接的客户端套接字。然后,服务器从这个已连接的客户端套接字中读取请求数据,将数据在其标准输出流中输出出来,并向客户端回送一条消息。然后,服务器会关闭这个客户端连接,并准备接收一个新的客户端连接。
|
||||
|
||||
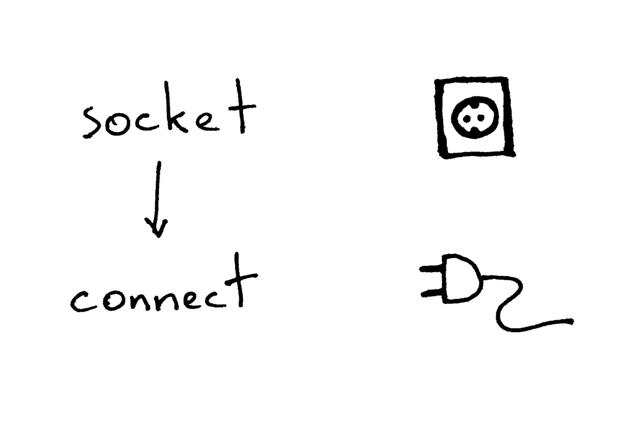
这是客户端使用 TCP/IP 协议与服务器通信的必要步骤:
|
||||
|
||||
|
||||
|
||||
下面是一段示例代码,使用这段代码,客户端可以连接你的服务器,发送一个请求,并打印响应内容:
|
||||
下面是一段示例代码,使用这段代码,客户端可以连接你的服务器,发送一个请求,并输出响应内容:
|
||||
|
||||
```
|
||||
import socket
|
||||
|
||||
# 创建一个套接字,并连接值服务器
|
||||
### 创建一个套接字,并连接值服务器
|
||||
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
sock.connect(('localhost', 8888))
|
||||
|
||||
# 发送一段数据,并接收响应数据
|
||||
### 发送一段数据,并接收响应数据
|
||||
sock.sendall(b'test')
|
||||
data = sock.recv(1024)
|
||||
print(data.decode())
|
||||
```
|
||||
|
||||
在创建套接字后,客户端需要连接至服务器。我们可以调用 `connect` 函数来完成这个操作:
|
||||
在创建套接字后,客户端需要连接至服务器。我们可以调用连接函数 `connect` 来完成这个操作:
|
||||
|
||||
```
|
||||
sock.connect(('localhost', 8888))
|
||||
```
|
||||
|
||||
客户端只需提供待连接服务器的 IP 地址(或主机名),及端口号,即可连接至远端服务器。
|
||||
客户端只需提供待连接的远程服务器的 IP 地址(或主机名),及端口号,即可连接至远端服务器。
|
||||
|
||||
你可能已经注意到了,客户端不需要调用 `bind` 及 `accept` 函数,就可以与服务器建立连接。客户端不需要调用 `bind` 函数是因为客户端不需要关注本地 IP 地址及端口号。操作系统内核中的 TCP/IP 协议栈会在客户端调用 `connect` 函数时,自动为套接字分配本地 IP 地址及本地端口号。这个本地端口被称为临时端口,也就是一个短暂开放的端口。
|
||||
你可能已经注意到了,客户端不需要调用 `bind` 及 `accept` 函数,就可以与服务器建立连接。客户端不需要调用 `bind` 函数是因为客户端不需要关注本地 IP 地址及端口号。操作系统内核中的 TCP/IP 协议栈会在客户端调用 `connect` 函数时,自动为套接字分配本地 IP 地址及本地端口号。这个本地端口被称为临时端口(ephemeral port),即一个短暂开放的端口。
|
||||
|
||||

|
||||
|
||||
服务器中有一些端口被用于承载一些众所周知的服务,它们被称作通用端口:如 80 端口用于 HTTP 服务,22 端口用于 SSH 服务。打开你的 Python shell,与你在本地运行的服务器建立一个连接,来看看内核给你的客户端套接字分配了哪个临时端口(在尝试这个例子之前,你需要运行服务器程序 `webserver3a.py` 或 `webserver3b.py`):
|
||||
服务器中有一些端口被用于承载一些众所周知的服务,它们被称作通用(well-known)端口:如 80 端口用于 HTTP 服务,22 端口用于 SSH 服务。打开你的 Python shell,与你在本地运行的服务器建立一个连接,来看看内核给你的客户端套接字分配了哪个临时端口(在尝试这个例子之前,你需要运行服务器程序 `webserver3a.py` 或 `webserver3b.py`):
|
||||
|
||||
```
|
||||
>>> import socket
|
||||
@ -222,12 +219,11 @@ sock.connect(('localhost', 8888))
|
||||
|
||||
在我开始回答我在第二部分中提出的问题之前,我还需要快速讲解一些概念。你很快就会明白这些概念为什么非常重要。这两个概念,一个是进程,另外一个是文件描述符。
|
||||
|
||||
什么是进程?进程就是一个程序执行的实体。举个例子:当你的服务器代码被执行时,它会被载入内存,而内存中表现此次程序运行的实体就叫做进程。内核记录了进程的一系列有关信息——比如进程 ID——来追踪它的运行情况。当你在执行轮询服务器 `webserver3a.py` 或 `webserver3b.py` 时,你只启动了一个进程。
|
||||
什么是进程?进程就是一个程序执行的实体。举个例子:当你的服务器代码被执行时,它会被载入内存,而内存中表现此次程序运行的实体就叫做进程。内核记录了进程的一系列有关信息——比如进程 ID——来追踪它的运行情况。当你在执行轮询服务器 `webserver3a.py` 或 `webserver3b.py` 时,你其实只是启动了一个进程。
|
||||
|
||||
|
||||
|
||||
我们在终端窗口中运行 `webserver3b.py`:
|
||||
Start the server webserver3b.py in a terminal window:
|
||||
|
||||
```
|
||||
$ python webserver3b.py
|
||||
@ -240,7 +236,7 @@ $ ps | grep webserver3b | grep -v grep
|
||||
7182 ttys003 0:00.04 python webserver3b.py
|
||||
```
|
||||
|
||||
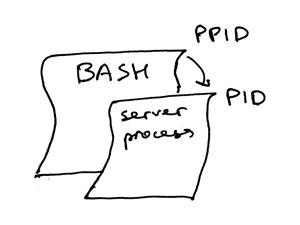
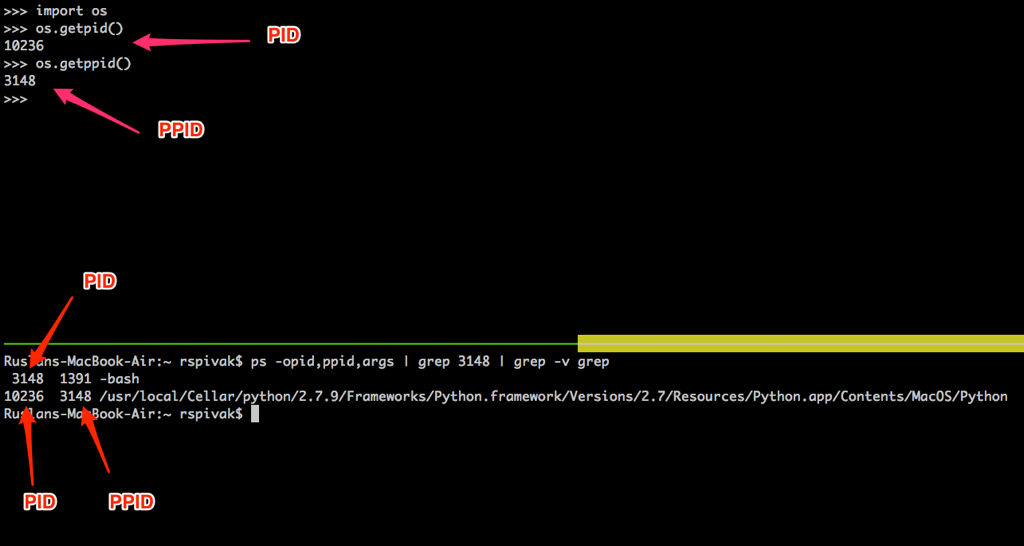
`ps` 命令显示,我们刚刚只运行了一个 Python 进程 `webserver3b`。当一个进程被创建时,内核会为其分配一个进程 ID,也就是 PID。在 UNIX 中,所有用户进程都有一个父进程;当然,这个父进程也有进程 ID,叫做父进程 ID,缩写为 PPID。假设你默认使用 BASH shell,那当你启动服务器时,一个新的进程会被启动,同时被赋予一个 PID,而它的父进程 PID 会被设为 BASH shell 的 PID。
|
||||
`ps` 命令显示,我们刚刚只运行了一个 Python 进程 `webserver3b.py`。当一个进程被创建时,内核会为其分配一个进程 ID,也就是 PID。在 UNIX 中,所有用户进程都有一个父进程;当然,这个父进程也有进程 ID,叫做父进程 ID,缩写为 PPID。假设你默认使用 BASH shell,那当你启动服务器时,就会启动一个新的进程,同时被赋予一个 PID,而它的父进程 PID 会被设为 BASH shell 的 PID。
|
||||
|
||||
|
||||
|
||||
@ -248,11 +244,11 @@ $ ps | grep webserver3b | grep -v grep
|
||||
|
||||
|
||||
|
||||
另外一个需要了解的概念,就是文件描述符。什么是文件描述符?文件描述符是一个非负整数,当进程打开一个现有文件、创建新文件或创建一个新的套接字时,内核会将这个数返回给进程。你以前可能听说过,在 UNIX 中,一切皆是文件。内核会根据一个文件描述符来为一个进程打开一个文件。当你需要读取文件或向文件写入时,我们同样通过文件描述符来定位这个文件。Python 提供了高层次的文件(或套接字)对象,所以你不需要直接通过文件描述符来定位文件。但是,在高层对象之下,我们就是用它来在 UNIX 中定位文件及套接字:整形的文件描述符。
|
||||
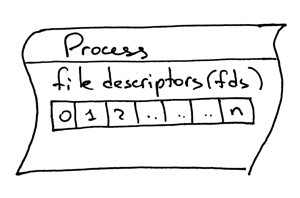
另外一个需要了解的概念,就是文件描述符。什么是文件描述符?文件描述符是一个非负整数,当进程打开一个现有文件、创建新文件或创建一个新的套接字时,内核会将这个数返回给进程。你以前可能听说过,在 UNIX 中,一切皆是文件。内核会按文件描述符来找到一个进程所打开的文件。当你需要读取文件或向文件写入时,我们同样通过文件描述符来定位这个文件。Python 提供了高层次的操作文件(或套接字)的对象,所以你不需要直接通过文件描述符来定位文件。但是,在高层对象之下,我们就是用它来在 UNIX 中定位文件及套接字,通过这个整数的文件描述符。
|
||||
|
||||
|
||||
|
||||
一般情况下,UNIX shell 会将一个进程的标准输入流的文件描述符设为 0,标准输出流设为 1,而标准错误打印的文件描述符会被设为 2。
|
||||
一般情况下,UNIX shell 会将一个进程的标准输入流(STDIN)的文件描述符设为 0,标准输出流(STDOUT)设为 1,而标准错误打印(STDERR)的文件描述符会被设为 2。
|
||||
|
||||
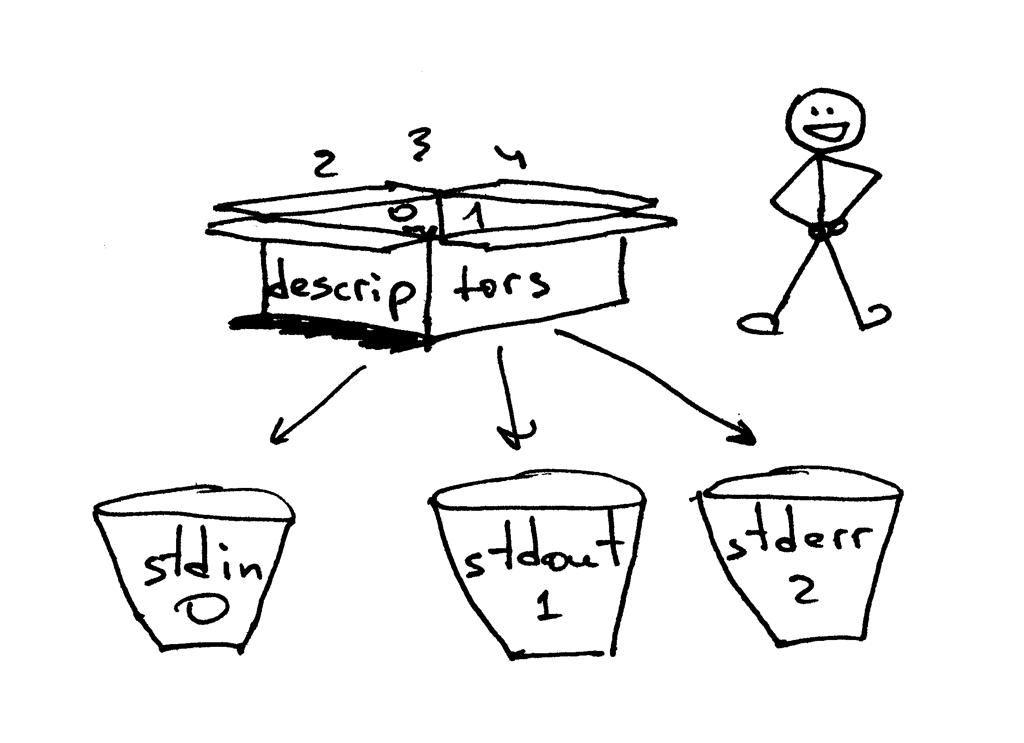
|
||||
|
||||
@ -289,7 +285,7 @@ hello
|
||||
3
|
||||
```
|
||||
|
||||
我还想再提一件事:不知道你有没有注意到,在我们的第二个轮询服务器 `webserver3b.py` 中,当你的服务器休眠 60 秒的过程中,你仍然可以通过第二个 `curl` 命令连接至服务器。当然 `curl` 命令并没有立刻输出任何内容而是挂在哪里,但是既然服务器没有接受连接,那它为什么不立即拒绝掉连接,而让它还能够继续与服务器建立连接呢?这个问题的答案是:当我在调用套接字对象的 `listen` 方法时,我为该方法提供了一个 `BACKLOG` 参数,在代码中用 `REQUEST_QUEUE_SIZE` 变量来表示。`BACKLOG` 参数决定了在内核中为存放即将到来的连接请求所创建的队列的大小。当服务器 `webserver3b.py` 被挂起的时候,你运行的第二个 `curl` 命令依然能够连接至服务器,因为内核中用来存放即将接收的连接请求的队列依然拥有足够大的可用空间。
|
||||
我还想再提一件事:不知道你有没有注意到,在我们的第二个轮询服务器 `webserver3b.py` 中,当你的服务器休眠 60 秒的过程中,你仍然可以通过第二个 `curl` 命令连接至服务器。当然 `curl` 命令并没有立刻输出任何内容而是挂在哪里,但是既然服务器没有接受连接,那它为什么不立即拒绝掉连接,而让它还能够继续与服务器建立连接呢?这个问题的答案是:当我在调用套接字对象的 `listen` 方法时,我为该方法提供了一个 `BACKLOG` 参数,在代码中用 `REQUEST_QUEUE_SIZE` 常量来表示。`BACKLOG` 参数决定了在内核中为存放即将到来的连接请求所创建的队列的大小。当服务器 `webserver3b.py` 在睡眠的时候,你运行的第二个 `curl` 命令依然能够连接至服务器,因为内核中用来存放即将接收的连接请求的队列依然拥有足够大的可用空间。
|
||||
|
||||
尽管增大 `BACKLOG` 参数并不能神奇地使你的服务器同时处理多个请求,但当你的服务器很繁忙时,将它设置为一个较大的值还是相当重要的。这样,在你的服务器调用 `accept` 方法时,不需要再等待一个新的连接建立,而可以立刻直接抓取队列中的第一个客户端连接,并不加停顿地立刻处理它。
|
||||
|
||||
@ -297,7 +293,7 @@ hello
|
||||
|
||||

|
||||
|
||||
- 迭代服务器
|
||||
- 轮询服务器
|
||||
- 服务端套接字创建流程(创建套接字,绑定,监听及接受)
|
||||
- 客户端连接创建流程(创建套接字,连接)
|
||||
- 套接字对
|
||||
@ -308,6 +304,8 @@ hello
|
||||
- 文件描述符
|
||||
- 套接字的 `listen` 方法中,`BACKLOG` 参数的含义
|
||||
|
||||
### 如何并发处理多个请求
|
||||
|
||||
现在,我可以开始回答第二部分中的那个问题了:“你该如何让你的服务器在同一时间处理多个请求呢?”或者换一种说法:“如何编写一个并发服务器?”
|
||||
|
||||
|
||||
@ -368,13 +366,13 @@ def serve_forever():
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中复制的套接字对象
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中复制的套接字对象
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0) # 子进程在这里退出
|
||||
else: # 父进程
|
||||
client_connection.close() # 关闭父进程中的客户端连接对象,并循环执行
|
||||
os._exit(0) ### 子进程在这里退出
|
||||
else: ### 父进程
|
||||
client_connection.close() ### 关闭父进程中的客户端连接对象,并循环执行
|
||||
|
||||
if __name__ == '__main__':
|
||||
serve_forever()
|
||||
@ -386,13 +384,13 @@ if __name__ == '__main__':
|
||||
$ python webserver3c.py
|
||||
```
|
||||
|
||||
然后,像我们之前测试轮询服务器那样,运行两个 `curl` 命令,来看看这次的效果。现在你可以看到,即使子进程在处理客户端请求后会休眠 60 秒,但它并不会影响其它客户端连接,因为他们都是由完全独立的进程来处理的。你应该看到你的 `curl` 命令立即输出了“Hello, World!”然后挂起 60 秒。你可以按照你的想法运行尽可能多的 `curl` 命令(好吧,并不能运行特别特别多 ^_^),所有的命令都会立刻输出来自服务器的响应“Hello, World!”,并不会出现任何可被察觉到的延迟行为。试试看吧。
|
||||
然后,像我们之前测试轮询服务器那样,运行两个 `curl` 命令,来看看这次的效果。现在你可以看到,即使子进程在处理客户端请求后会休眠 60 秒,但它并不会影响其它客户端连接,因为他们都是由完全独立的进程来处理的。你应该看到你的 `curl` 命令立即输出了“Hello, World!”然后挂起 60 秒。你可以按照你的想法运行尽可能多的 `curl` 命令(好吧,并不能运行特别特别多 `^_^`),所有的命令都会立刻输出来自服务器的响应 “Hello, World!”,并不会出现任何可被察觉到的延迟行为。试试看吧。
|
||||
|
||||
如果你要理解 `fork()`,那最重要的一点是:你调用了它一次,但是它会返回两次:一次在父进程中,另一次是在子进程中。当你创建了一个新进程,那么 `fork()` 在子进程中的返回值是 0。如果是在父进程中,那 `fork()` 函数会返回子进程的 PID。
|
||||
如果你要理解 `fork()`,那最重要的一点是:**你调用了它一次,但是它会返回两次** —— 一次在父进程中,另一次是在子进程中。当你创建了一个新进程,那么 `fork()` 在子进程中的返回值是 0。如果是在父进程中,那 `fork()` 函数会返回子进程的 PID。
|
||||
|
||||
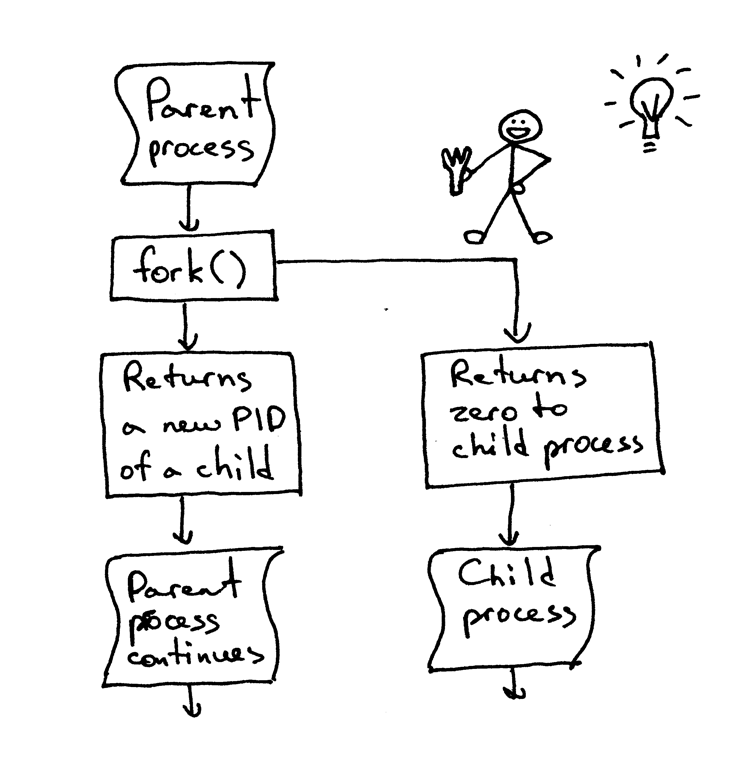
|
||||
|
||||
我依然记得在第一次看到它并尝试使用 `fork()` 的时候,我是多么的入迷。它在我眼里就像是魔法一样。这就好像我在读一段顺序执行的代码,然后“砰”地一声,代码变成了两份,然后出现了两个实体,同时并行地运行相同的代码。讲真,那个时候我觉得它真的跟魔法一样神奇。
|
||||
我依然记得在第一次看到它并尝试使用 `fork()` 的时候,我是多么的入迷。它在我眼里就像是魔法一样。这就好像我在读一段顺序执行的代码,然后“砰!”地一声,代码变成了两份,然后出现了两个实体,同时并行地运行相同的代码。讲真,那个时候我觉得它真的跟魔法一样神奇。
|
||||
|
||||
当父进程创建出一个新的子进程时,子进程会复制从父进程中复制一份文件描述符:
|
||||
|
||||
@ -401,38 +399,39 @@ $ python webserver3c.py
|
||||
你可能注意到,在上面的代码中,父进程关闭了客户端连接:
|
||||
|
||||
```
|
||||
else: # parent
|
||||
else: ### parent
|
||||
client_connection.close() # close parent copy and loop over
|
||||
```
|
||||
|
||||
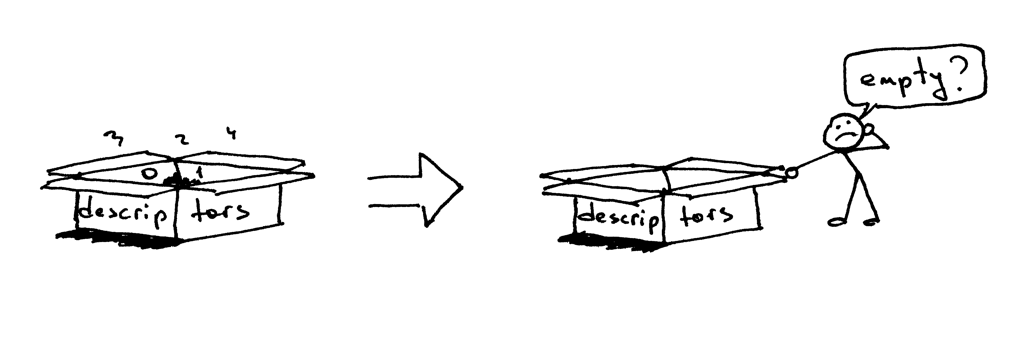
不过,既然父进程关闭了这个套接字,那为什么子进程仍然能够从来自客户端的套接字中读取数据呢?答案就在上面的图片中。内核会使用描述符引用计数器来决定是否要关闭一个套接字。当你的服务器创建一个子进程时,子进程会复制父进程的所有文件描述符,内核中改描述符的引用计数也会增加。如果只有一个父进程及一个子进程,那客户端套接字的文件描述符引用数应为 2;当父进程关闭客户端连接的套接字时,内核只会减少它的引用计数,将其变为 1,但这仍然不会使内核关闭该套接字。子进程也关闭了父进程中 `listen_socket` 的复制实体,因为子进程不需要关注新的客户端连接,而只需要处理已建立的客户端连接中的请求。
|
||||
不过,既然父进程关闭了这个套接字,那为什么子进程仍然能够从来自客户端的套接字中读取数据呢?答案就在上面的图片中。内核会使用描述符引用计数器来决定是否要关闭一个套接字。当你的服务器创建一个子进程时,子进程会复制父进程的所有文件描述符,内核中该描述符的引用计数也会增加。如果只有一个父进程及一个子进程,那客户端套接字的文件描述符引用数应为 2;当父进程关闭客户端连接的套接字时,内核只会减少它的引用计数,将其变为 1,但这仍然不会使内核关闭该套接字。子进程也关闭了父进程中 `listen_socket` 的复制实体,因为子进程不需要关注新的客户端连接,而只需要处理已建立的客户端连接中的请求。
|
||||
|
||||
```
|
||||
listen_socket.close() # 关闭子进程中的复制实体
|
||||
listen_socket.close() ### 关闭子进程中的复制实体
|
||||
```
|
||||
|
||||
我们将会在后文中讨论,如果你不关闭那些重复的描述符,会发生什么。
|
||||
|
||||
你可以从你的并发服务器源码看到,父进程的主要职责为:接受一个新的客户端连接,复制出一个子进程来处理这个连接,然后继续循环来接受另外的客户端连接,仅此而已。服务器父进程并不会处理客户端连接——子进程才会做这件事。
|
||||
你可以从你的并发服务器源码中看到,父进程的主要职责为:接受一个新的客户端连接,复制出一个子进程来处理这个连接,然后继续循环来接受另外的客户端连接,仅此而已。服务器父进程并不会处理客户端连接——子进程才会做这件事。
|
||||
|
||||
打个岔:当我们说两个事件并发执行时,我们在说什么?
|
||||
A little aside. What does it mean when we say that two events are concurrent?
|
||||
打个岔:当我们说两个事件并发执行时,我们所要表达的意思是什么?
|
||||
|
||||
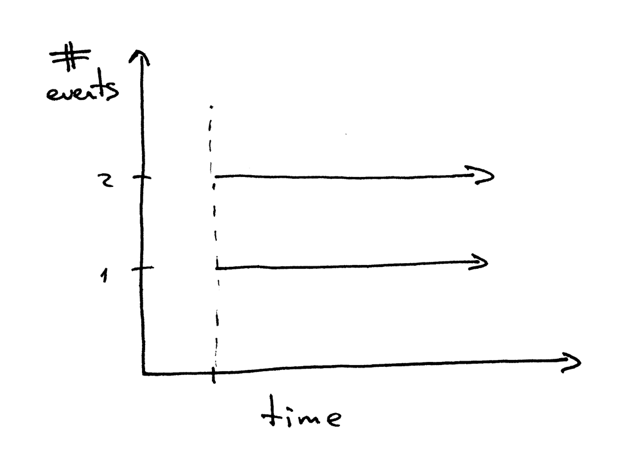
|
||||
|
||||
当我们说“两个事件并发执行”时,它通常意味着这两个事件同时发生。简单来讲,这个定义没问题,但你应该记住它的严格定义:
|
||||
|
||||
> 如果你阅读代码时,无法判断两个事件的发生顺序,那这两个事件就是并发执行的。[2][5]
|
||||
> 如果你不能在代码中判断两个事件的发生顺序,那这两个事件就是并发执行的。(引自[《信号系统简明手册 (第二版): 并发控制深入浅出及常见错误》][5])
|
||||
|
||||
好的,现在你又该回顾一下你刚刚学过的知识点了。
|
||||
|
||||

|
||||
|
||||
- 在 Unix 中,编写一个并发服务器的最简单的方式——使用 `fork()` 系统调用;
|
||||
- 当一个进程复制出另一个进程时,它会变成刚刚复制出的进程的父进程;
|
||||
- 当一个进程分叉(`fork`)出另一个进程时,它会变成刚刚分叉出的进程的父进程;
|
||||
- 在进行 `fork` 调用后,父进程和子进程共享相同的文件描述符;
|
||||
- 系统内核通过描述符引用计数来决定是否要关闭该描述符对应的文件或套接字;
|
||||
- 服务器父进程的主要职责:现在它做的只是从客户端接受一个新的连接,复制出子进程来处理这个客户端连接,然后开始下一轮循环,去接收新的客户端连接。
|
||||
- 系统内核通过描述符的引用计数来决定是否要关闭该描述符对应的文件或套接字;
|
||||
- 服务器父进程的主要职责:现在它做的只是从客户端接受一个新的连接,分叉出子进程来处理这个客户端连接,然后开始下一轮循环,去接收新的客户端连接。
|
||||
|
||||
### 进程分叉后不关闭重复的套接字会发生什么?
|
||||
|
||||
我们来看看,如果我们不在父进程与子进程中关闭重复的套接字描述符会发生什么。下面是刚才的并发服务器代码的修改版本,这段代码(`webserver3d.py` 中,服务器不会关闭重复的描述符):
|
||||
|
||||
@ -470,15 +469,15 @@ def serve_forever():
|
||||
clients = []
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
# 将引用存储起来,否则在下一轮循环时,他们会被垃圾回收机制销毁
|
||||
### 将引用存储起来,否则在下一轮循环时,他们会被垃圾回收机制销毁
|
||||
clients.append(client_connection)
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的套接字
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的套接字
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0) # 子进程在这里结束
|
||||
else: # 父进程
|
||||
os._exit(0) ### 子进程在这里结束
|
||||
else: ### 父进程
|
||||
# client_connection.close()
|
||||
print(len(clients))
|
||||
|
||||
@ -503,7 +502,7 @@ Hello, World!
|
||||
|
||||
|
||||
|
||||
所以,为什么 `curl` 不终止呢?原因就在于多余的文件描述符。当子进程关闭客户端连接时,系统内核会减少客户端套接字的引用计数,将其变为 1。服务器子进程退出了,但客户端套接字并没有被内核关闭,因为该套接字的描述符引用计数并没有变为 0,所以,这就导致了连接终止包(在 TCP/IP 协议中称作 `FIN`)不会被发送到客户端,所以客户端会一直保持连接。这里就会出现另一个问题:如果你的服务器在长时间运行,并且不关闭重复的文件描述符,那么可用的文件描述符会被消耗殆尽:
|
||||
所以,为什么 `curl` 不终止呢?原因就在于文件描述符的副本。当子进程关闭客户端连接时,系统内核会减少客户端套接字的引用计数,将其变为 1。服务器子进程退出了,但客户端套接字并没有被内核关闭,因为该套接字的描述符引用计数并没有变为 0,所以,这就导致了连接终止包(在 TCP/IP 协议中称作 `FIN`)不会被发送到客户端,所以客户端会一直保持连接。这里也会出现另一个问题:如果你的服务器长时间运行,并且不关闭文件描述符的副本,那么可用的文件描述符会被消耗殆尽:
|
||||
|
||||
|
||||
|
||||
@ -529,7 +528,7 @@ virtual memory (kbytes, -v) unlimited
|
||||
file locks (-x) unlimited
|
||||
```
|
||||
|
||||
你可以从上面的结果看到,在我的 Ubuntu box 中,系统为我的服务器进程分配的最大可用文件描述符(文件打开)数为 1024。
|
||||
你可以从上面的结果看到,在我的 Ubuntu 机器中,系统为我的服务器进程分配的最大可用文件描述符(文件打开)数为 1024。
|
||||
|
||||
现在我们来看一看,如果你的服务器不关闭重复的描述符,它会如何消耗可用的文件描述符。在一个已有的或新建的终端窗口中,将你的服务器进程的最大可用文件描述符设为 256:
|
||||
|
||||
@ -607,15 +606,18 @@ if __name__ == '__main__':
|
||||
$ python client3.py --max-clients=300
|
||||
```
|
||||
|
||||
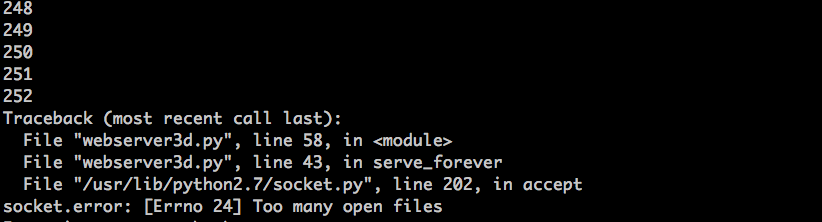
过一会,你的服务器就该爆炸了。这是我的环境中出现的异常截图:
|
||||
过一会,你的服务器进程就该爆了。这是我的环境中出现的异常截图:
|
||||
|
||||
|
||||
|
||||
这个例子很明显——你的服务器应该关闭重复的描述符。但是,即使你关闭了多余的描述符,你依然没有摆脱险境,因为你的服务器还有一个问题,这个问题在于“僵尸”!
|
||||
这个例子很明显——你的服务器应该关闭描述符副本。
|
||||
|
||||
#### 僵尸进程
|
||||
|
||||
但是,即使你关闭了描述符副本,你依然没有摆脱险境,因为你的服务器还有一个问题,这个问题在于“僵尸(zombies)”!
|
||||
|
||||
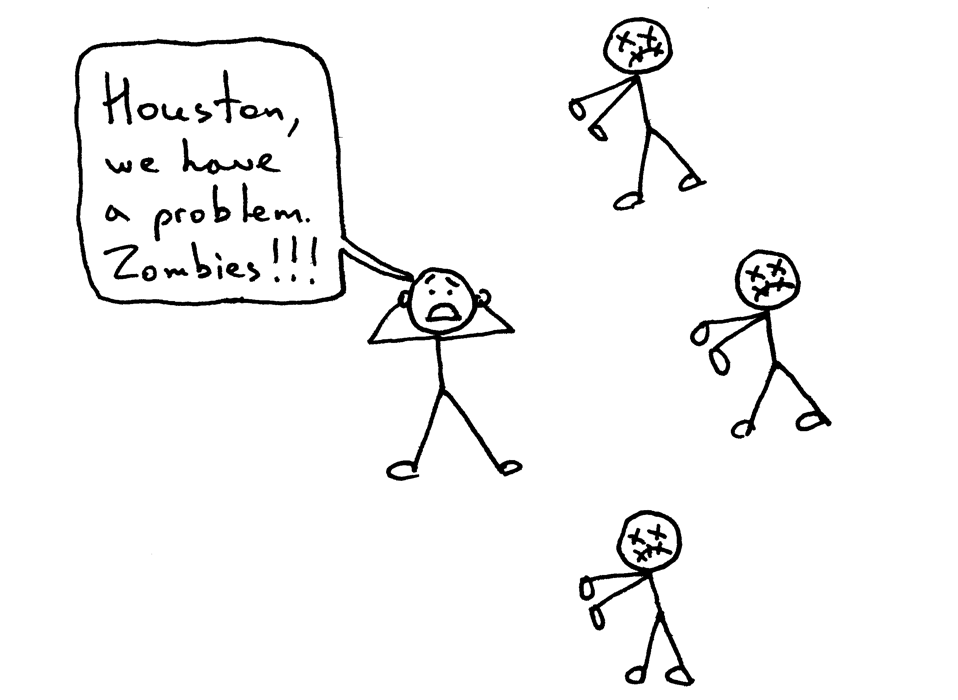
|
||||
|
||||
|
||||
没错,这个服务器代码确实在制造僵尸进程。我们来看看怎么回事。重新运行你的服务器:
|
||||
|
||||
```
|
||||
@ -636,13 +638,13 @@ vagrant 9099 0.0 1.2 31804 6256 pts/0 S+ 16:33 0:00 python webserve
|
||||
vagrant 9102 0.0 0.0 0 0 pts/0 Z+ 16:33 0:00 [python] <defunct>
|
||||
```
|
||||
|
||||
你看到第二行中,pid 为 9102,状态为 Z+,名字里面有个 `<defunct>` 的进程了吗?那就是我们的僵尸进程。这个僵尸进程的问题在于:你无法将它杀掉。
|
||||
你看到第二行中,pid 为 9102,状态为 `Z+`,名字里面有个 `<defunct>` 的进程了吗?那就是我们的僵尸进程。这个僵尸进程的问题在于:你无法将它杀掉!
|
||||
|
||||
|
||||
|
||||
就算你尝试使用 `kill -9` 来杀死僵尸进程,它们仍旧会存活。自己试试看,看看结果。
|
||||
|
||||
这个僵尸到底是什么,为什么我们的服务器会造出它们呢?一个僵尸进程是一个已经结束的进程,但它的父进程并没有等待它结束,并且也没有收到它的终结状态。如果一个进程在父进程退出之前退出,系统内核会把它变为一个僵尸进程,存储它的部分信息,以便父进程读取。内核保存的进程信息通常包括进程 ID,进程终止状态,以及进程的资源占用情况。OK,所以僵尸进程确实有存在的意义,但如果服务器不管这些僵尸进程,你的系统调用将会被阻塞。我们来看看这个要如何发生。首先,关闭你的服务器;然后,在一个新的终端窗口中,使用 `ulimit` 命令将最大用户进程数设为 400(同时,要确保你的最大可用描述符数大于这个数字,我们在这里设为 500):
|
||||
这个僵尸到底是什么,为什么我们的服务器会造出它们呢?一个僵尸进程(zombie)是一个已经结束的进程,但它的父进程并没有等待(`waited`)它结束,并且也没有收到它的终结状态。如果一个进程在父进程退出之前退出,系统内核会把它变为一个僵尸进程,存储它的部分信息,以便父进程读取。内核保存的进程信息通常包括进程 ID、进程终止状态,以及进程的资源占用情况。OK,所以僵尸进程确实有存在的意义,但如果服务器不管这些僵尸进程,你的系统将会被壅塞。我们来看看这个会如何发生。首先,关闭你运行的服务器;然后,在一个新的终端窗口中,使用 `ulimit` 命令将最大用户进程数设为 400(同时,要确保你的最大可用描述符数大于这个数字,我们在这里设为 500):
|
||||
|
||||
```
|
||||
$ ulimit -u 400
|
||||
@ -661,33 +663,35 @@ $ python webserver3d.py
|
||||
$ python client3.py --max-clients=500
|
||||
```
|
||||
|
||||
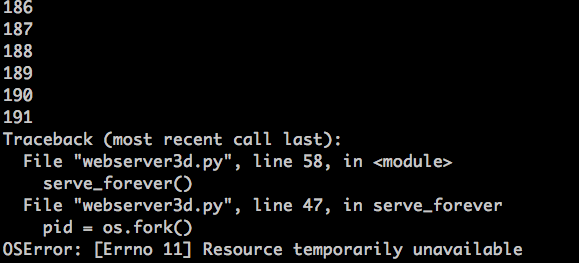
然后,过一会,你的服务器应该会再次爆炸,它会在创建新进程时抛出一个 `OSError: 资源暂时不可用` 异常。但它并没有达到系统允许的最大进程数。这是我的环境中输出的异常信息截图:
|
||||
然后,过一会,你的服务器进程应该会再次爆了,它会在创建新进程时抛出一个 `OSError: 资源暂时不可用` 的异常。但它并没有达到系统允许的最大进程数。这是我的环境中输出的异常信息截图:
|
||||
|
||||
|
||||
|
||||
你可以看到,如果服务器不管僵尸进程,它们会引发问题。我会简单探讨一下僵尸进程问题的解决方案。
|
||||
你可以看到,如果服务器不管僵尸进程,它们会引发问题。接下来我会简单探讨一下僵尸进程问题的解决方案。
|
||||
|
||||
我们来回顾一下你刚刚掌握的知识点:
|
||||
|
||||

|
||||
|
||||
- 如果你不关闭重复的描述符,客户端就不会在请求处理完成后终止,因为客户端连接没有被关闭;
|
||||
- 如果你不关闭重复的描述符,长久运行的服务器最终会把可用的文件描述符(最大文件打开数)消耗殆尽;
|
||||
- 当你创建一个新进程,而父进程不等待子进程,也不在子进程结束后收集它的终止状态,它会变为一个僵尸进程;
|
||||
- 僵尸通常都会吃东西,在我们的例子中,僵尸进程会占用资源。如果你的服务器不管僵尸进程,它最终会消耗掉所有的可用进程(最大用户进程数);
|
||||
- 你不能杀死僵尸进程,你需要等待它。
|
||||
- 如果你不关闭文件描述符副本,客户端就不会在请求处理完成后终止,因为客户端连接没有被关闭;
|
||||
- 如果你不关闭文件描述符副本,长久运行的服务器最终会把可用的文件描述符(最大文件打开数)消耗殆尽;
|
||||
- 当你创建一个新进程,而父进程不等待(`wait`)子进程,也不在子进程结束后收集它的终止状态,它会变为一个僵尸进程;
|
||||
- 僵尸通常都会吃东西,在我们的例子中,僵尸进程会吃掉资源。如果你的服务器不管僵尸进程,它最终会消耗掉所有的可用进程(最大用户进程数);
|
||||
- 你不能杀死(`kill`)僵尸进程,你需要等待(`wait`)它。
|
||||
|
||||
所以,你需要做什么来处理僵尸进程呢?你需要修改你的服务器代码,来等待僵尸进程,并收集它们的终止信息。你可以在代码中使用系统调用 `wait` 来完成这个任务。不幸的是,这个方法里理想目标还很远,因为在没有终止的子进程存在的情况下调用 `wait` 会导致程序阻塞,这会阻碍你的服务器处理新的客户端连接请求。那么,我们有其他选择吗?嗯,有的,其中一个解决方案需要结合信号处理以及 `wait` 系统调用。
|
||||
### 如何处理僵尸进程?
|
||||
|
||||
所以,你需要做什么来处理僵尸进程呢?你需要修改你的服务器代码,来等待(`wait`)僵尸进程,并收集它们的终止信息。你可以在代码中使用系统调用 `wait` 来完成这个任务。不幸的是,这个方法离理想目标还很远,因为在没有终止的子进程存在的情况下调用 `wait` 会导致服务器进程阻塞,这会阻碍你的服务器处理新的客户端连接请求。那么,我们有其他选择吗?嗯,有的,其中一个解决方案需要结合信号处理以及 `wait` 系统调用。
|
||||
|
||||

|
||||
|
||||
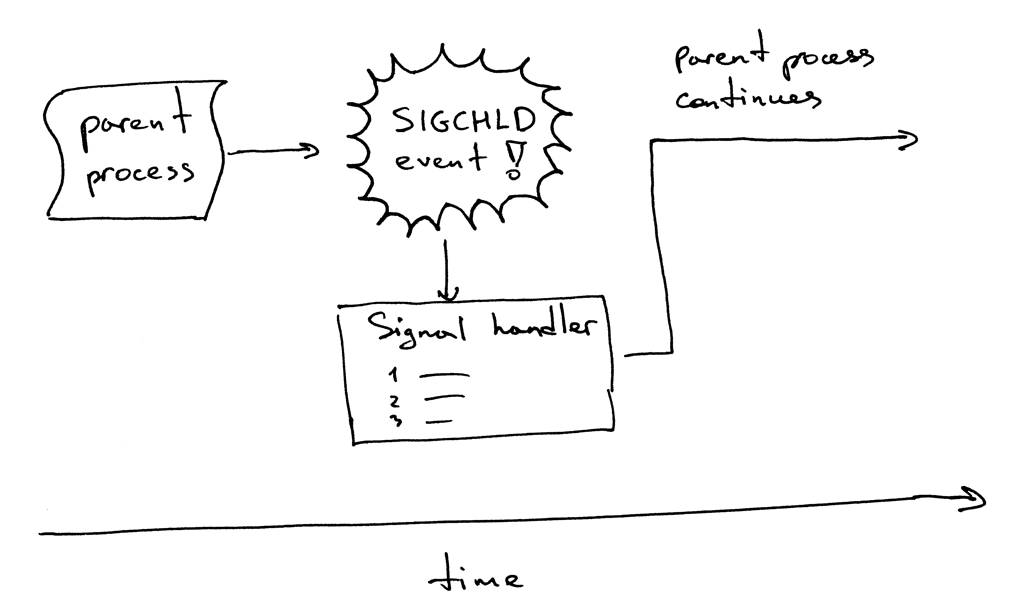
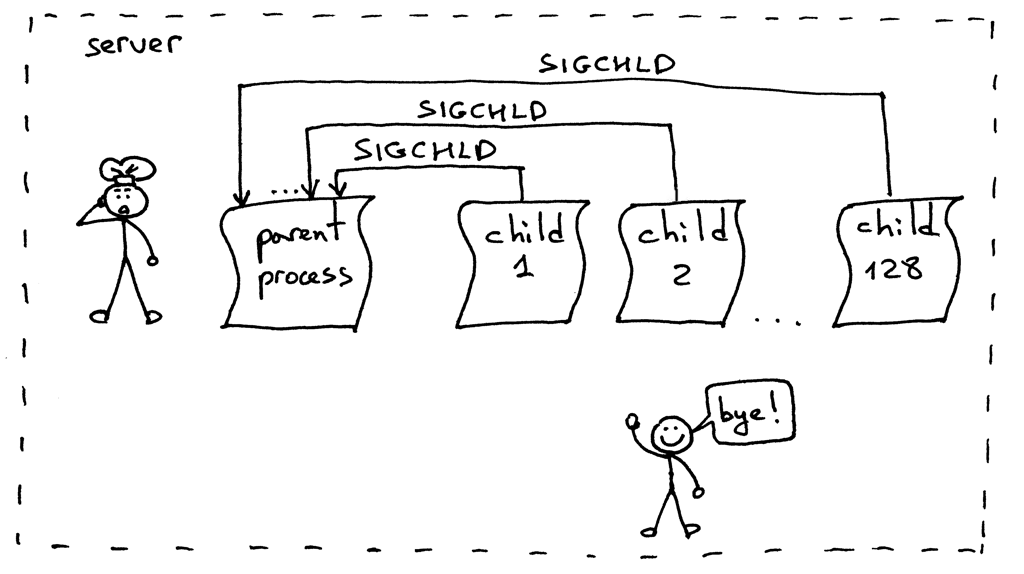
这是它的工作流程。当一个子进程退出时,内核会发送 `SIGCHLD` 信号。父进程可以设置一个信号处理器,它可以异步响应 `SIGCHLD` 信号,并在信号响应函数中等待子进程收集终止信息,从而阻止了僵尸进程的存在。
|
||||
这是它的工作流程。当一个子进程退出时,内核会发送 `SIGCHLD` 信号。父进程可以设置一个信号处理器,它可以异步响应 `SIGCHLD` 信号,并在信号响应函数中等待(`wait`)子进程收集终止信息,从而阻止了僵尸进程的存在。
|
||||
|
||||
|
||||
|
||||
顺便,异步事件意味着父进程无法提前知道事件的发生时间。
|
||||
顺便说一下,异步事件意味着父进程无法提前知道事件的发生时间。
|
||||
|
||||
修改你的服务器代码,设置一个 `SIGCHLD` 信号处理器,在信号处理器中等待终止的子进程。修改后的代码如下(webserver3e.py):
|
||||
修改你的服务器代码,设置一个 `SIGCHLD` 信号处理器,在信号处理器中等待(`wait`)终止的子进程。修改后的代码如下(webserver3e.py):
|
||||
|
||||
```
|
||||
#######################################################
|
||||
@ -722,7 +726,7 @@ HTTP/1.1 200 OK
|
||||
Hello, World!
|
||||
"""
|
||||
client_connection.sendall(http_response)
|
||||
# 挂起进程,来允许父进程完成循环,并在 "accept" 处阻塞
|
||||
### 挂起进程,来允许父进程完成循环,并在 "accept" 处阻塞
|
||||
time.sleep(3)
|
||||
|
||||
|
||||
@ -738,12 +742,12 @@ def serve_forever():
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的套接字
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的套接字
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0)
|
||||
else: # 父进程
|
||||
else: ### 父进程
|
||||
client_connection.close()
|
||||
|
||||
if __name__ == '__main__':
|
||||
@ -766,7 +770,7 @@ $ curl http://localhost:8888/hello
|
||||
|
||||
|
||||
|
||||
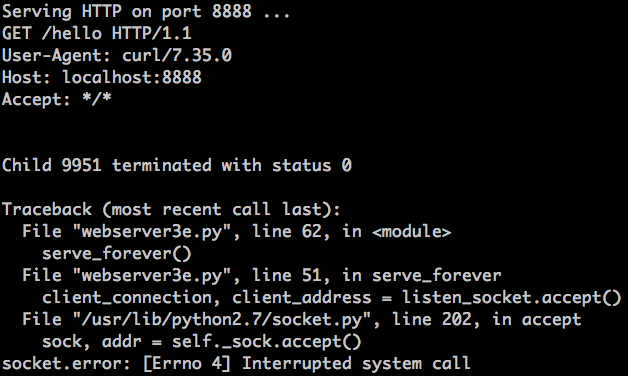
刚刚发生了什么?`accept` 调用失败了,错误信息为 `EINTR`
|
||||
刚刚发生了什么?`accept` 调用失败了,错误信息为 `EINTR`。
|
||||
|
||||

|
||||
|
||||
@ -822,20 +826,20 @@ def serve_forever():
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
except IOError as e:
|
||||
code, msg = e.args
|
||||
# 若 'accept' 被打断,那么重启它
|
||||
### 若 'accept' 被打断,那么重启它
|
||||
if code == errno.EINTR:
|
||||
continue
|
||||
else:
|
||||
raise
|
||||
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的描述符
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的描述符
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0)
|
||||
else: # 父进程
|
||||
client_connection.close() # 关闭父进程中多余的描述符,继续下一轮循环
|
||||
else: ### 父进程
|
||||
client_connection.close() ### 关闭父进程中多余的描述符,继续下一轮循环
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
@ -854,7 +858,7 @@ $ python webserver3f.py
|
||||
$ curl http://localhost:8888/hello
|
||||
```
|
||||
|
||||
看到了吗?没有 EINTR 异常出现了。现在检查一下,确保没有僵尸进程存活,调用 `wait` 函数的 `SIGCHLD` 信号处理器能够正常处理被终止的子进程。我们只需使用 `ps` 命令,然后看看现在没有处于 Z+ 状态(或名字包含 `<defunct>` )的 Python 进程就好了。很棒!僵尸进程没有了,我们很安心。
|
||||
看到了吗?没有 EINTR 异常出现了。现在检查一下,确保没有僵尸进程存活,调用 `wait` 函数的 `SIGCHLD` 信号处理器能够正常处理被终止的子进程。我们只需使用 `ps` 命令,然后看看现在没有处于 `Z+` 状态(或名字包含 `<defunct>` )的 Python 进程就好了。很棒!僵尸进程没有了,我们很安心。
|
||||
|
||||

|
||||
|
||||
@ -862,6 +866,8 @@ $ curl http://localhost:8888/hello
|
||||
- 使用 `SIGCHLD` 信号处理器可以异步地等待子进程终止,并收集其终止状态;
|
||||
- 当使用事件处理器时,你需要牢记,系统调用可能会被打断,所以你需要处理这种情况发生时带来的异常。
|
||||
|
||||
#### 正确处理 SIGCHLD 信号
|
||||
|
||||
好的,一切顺利。是不是没问题了?额,几乎是。重新尝试运行 `webserver3f.py` 但我们这次不会只发送一个请求,而是同步创建 128 个连接:
|
||||
|
||||
```
|
||||
@ -882,7 +888,7 @@ $ ps auxw | grep -i python | grep -v grep
|
||||
|
||||
|
||||
|
||||
这个问题的解决方案依然是设置 `SIGCHLD` 事件处理器。但我们这次将会用 `WNOHANG` 参数循环调用 `waitpid`,来保证所有处于终止状态的子进程都会被处理。下面是修改后的代码,`webserver3g.py`:
|
||||
这个问题的解决方案依然是设置 `SIGCHLD` 事件处理器。但我们这次将会用 `WNOHANG` 参数循环调用 `waitpid` 来替代 `wait`,以保证所有处于终止状态的子进程都会被处理。下面是修改后的代码,`webserver3g.py`:
|
||||
|
||||
```
|
||||
#######################################################
|
||||
@ -904,13 +910,13 @@ def grim_reaper(signum, frame):
|
||||
while True:
|
||||
try:
|
||||
pid, status = os.waitpid(
|
||||
-1, # 等待所有子进程
|
||||
os.WNOHANG # 无终止进程时,不阻塞进程,并抛出 EWOULDBLOCK 错误
|
||||
-1, ### 等待所有子进程
|
||||
os.WNOHANG ### 无终止进程时,不阻塞进程,并抛出 EWOULDBLOCK 错误
|
||||
)
|
||||
except OSError:
|
||||
return
|
||||
|
||||
if pid == 0: # 没有僵尸进程存在了
|
||||
if pid == 0: ### 没有僵尸进程存在了
|
||||
return
|
||||
|
||||
|
||||
@ -939,20 +945,20 @@ def serve_forever():
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
except IOError as e:
|
||||
code, msg = e.args
|
||||
# 若 'accept' 被打断,那么重启它
|
||||
### 若 'accept' 被打断,那么重启它
|
||||
if code == errno.EINTR:
|
||||
continue
|
||||
else:
|
||||
raise
|
||||
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的描述符
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的描述符
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0)
|
||||
else: # 父进程
|
||||
client_connection.close() # 关闭父进程中多余的描述符,继续下一轮循环
|
||||
else: ### 父进程
|
||||
client_connection.close() ### 关闭父进程中多余的描述符,继续下一轮循环
|
||||
|
||||
if __name__ == '__main__':
|
||||
serve_forever()
|
||||
@ -974,13 +980,15 @@ $ python client3.py --max-clients 128
|
||||
|
||||

|
||||
|
||||
恭喜!你刚刚经历了一段很长的旅程,我希望你能够喜欢它。现在你拥有了自己的建议并发服务器,并且这段代码能够为你在继续研究生产级 Web 服务器的路上奠定基础。
|
||||
### 大功告成
|
||||
|
||||
恭喜!你刚刚经历了一段很长的旅程,我希望你能够喜欢它。现在你拥有了自己的简易并发服务器,并且这段代码能够为你在继续研究生产级 Web 服务器的路上奠定基础。
|
||||
|
||||
我将会留一个作业:你需要将第二部分中的 WSGI 服务器升级,将它改造为一个并发服务器。你可以在[这里][12]找到更改后的代码。但是,当你实现了自己的版本之后,你才应该来看我的代码。你已经拥有了实现这个服务器所需的所有信息。所以,快去实现它吧 ^_^
|
||||
|
||||
然后要做什么呢?乔希·比林斯说过:
|
||||
|
||||
> “我们应该做一枚邮票——专注于一件事,不达目的不罢休。”
|
||||
> “就像一枚邮票一样——专注于一件事,不达目的不罢休。”
|
||||
|
||||
开始学习基本知识。回顾你已经学过的知识。然后一步一步深入。
|
||||
|
||||
@ -990,13 +998,13 @@ $ python client3.py --max-clients 128
|
||||
|
||||
下面是一份书单,我从这些书中提炼出了这篇文章所需的素材。他们能助你在我刚刚所述的几个方面中发掘出兼具深度和广度的知识。我极力推荐你们去搞到这几本书看看:从你的朋友那里借,在当地的图书馆中阅读,或者直接在亚马逊上把它买回来。下面是我的典藏秘籍:
|
||||
|
||||
1. [UNIX网络编程 (卷1):套接字联网API (第3版)][6]
|
||||
2. [UNIX环境高级编程 (第3版)][7]
|
||||
3. [Linux/UNIX系统编程手册][8]
|
||||
4. [TCP/IP详解 (卷1):协议 (第2版) (爱迪生-韦斯莱专业编程系列)][9]
|
||||
5. [信号系统简明手册 (第二版): 并发控制深入浅出及常见错误][10]. 这本书也可以从[作者的个人网站][11]中买到。
|
||||
1. [《UNIX 网络编程 卷1:套接字联网 API (第3版)》][6]
|
||||
2. [《UNIX 环境高级编程(第3版)》][7]
|
||||
3. [《Linux/UNIX 系统编程手册》][8]
|
||||
4. [《TCP/IP 详解 卷1:协议(第2版)][9]
|
||||
5. [《信号系统简明手册 (第二版): 并发控制深入浅出及常见错误》][10],这本书也可以从[作者的个人网站][11]中免费下载到。
|
||||
|
||||
顺便,我在撰写一本名为《搭个 Web 服务器:从头开始》的书。这本书讲解了如何从头开始编写一个基本的 Web 服务器,里面包含本文中没有的更多细节。订阅邮件列表,你就可以获取到这本书的最新进展,以及发布日期。
|
||||
顺便,我在撰写一本名为《搭个 Web 服务器:从头开始》的书。这本书讲解了如何从头开始编写一个基本的 Web 服务器,里面包含本文中没有的更多细节。订阅[原文下方的邮件列表][13],你就可以获取到这本书的最新进展,以及发布日期。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1004,7 +1012,7 @@ via: https://ruslanspivak.com/lsbaws-part3/
|
||||
|
||||
作者:[Ruslan][a]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1013,12 +1021,13 @@ via: https://ruslanspivak.com/lsbaws-part3/
|
||||
[1]: https://github.com/rspivak/lsbaws/blob/master/part3/
|
||||
[2]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3a.py
|
||||
[3]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3b.py
|
||||
[4]: https://ruslanspivak.com/lsbaws-part3/#fn:1
|
||||
[5]: https://ruslanspivak.com/lsbaws-part3/#fn:2
|
||||
[6]: http://www.amazon.com/gp/product/0131411551/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0131411551&linkCode=as2&tag=russblo0b-20&linkId=2F4NYRBND566JJQL
|
||||
[7]: http://www.amazon.com/gp/product/0321637739/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0321637739&linkCode=as2&tag=russblo0b-20&linkId=3ZYAKB537G6TM22J
|
||||
[8]: http://www.amazon.com/gp/product/1593272200/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1593272200&linkCode=as2&tag=russblo0b-20&linkId=CHFOMNYXN35I2MON
|
||||
[9]: http://www.amazon.com/gp/product/0321336313/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0321336313&linkCode=as2&tag=russblo0b-20&linkId=K467DRFYMXJ5RWAY
|
||||
[4]: http://www.epubit.com.cn/book/details/1692
|
||||
[5]: http://www.amazon.com/gp/product/1441418687/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1441418687&linkCode=as2&tag=russblo0b-20&linkId=QFOAWARN62OWTWUG
|
||||
[6]: http://www.epubit.com.cn/book/details/1692
|
||||
[7]: http://www.epubit.com.cn/book/details/1625
|
||||
[8]: http://www.epubit.com.cn/book/details/1432
|
||||
[9]: http://www.epubit.com.cn/book/details/4232
|
||||
[10]: http://www.amazon.com/gp/product/1441418687/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1441418687&linkCode=as2&tag=russblo0b-20&linkId=QFOAWARN62OWTWUG
|
||||
[11]: http://greenteapress.com/semaphores/
|
||||
[12]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3h.py
|
||||
[13]: https://ruslanspivak.com/lsbaws-part1/
|
||||
@ -0,0 +1,66 @@
|
||||
Ryver:你应该使用它替代 Slack
|
||||
===============
|
||||
|
||||

|
||||
|
||||
貌似每个人都听说过 [Slack][1],它是一款跨平台的,可以使你时刻保持与他人同步的团队沟通应用。它革新了用户讨论和规划项目的方式,显而易见,它升级了 email 的沟通功能。
|
||||
|
||||
我在一个非常小的写作团队工作,不管是通过手机还是电脑,我从未在使用 Slack 过程中遇到过沟通问题。若想与任何规模的团队保持同步,继续使用 Slack 仍然不失为不错的方式。
|
||||
|
||||
既然如此,为什么我们还要讨论今天的话题?Ryver 被人们认为是下一个热点,相比 Slack,Ryver 提供了升级版的服务。Ryver 完全免费,它的团队正在奋力争取更大的市场份额。
|
||||
|
||||
是否 Ryver 已经强大到可以扮演 Slack 杀手的角色?这两种旗鼓相当的消息应用究竟有何不同?
|
||||
|
||||
欲知详情,请阅读下文。
|
||||
|
||||
### 为什么用 Ryver ?
|
||||
|
||||

|
||||
|
||||
既然 Slack 能用为什么还要折腾呢?Ryver 的开发者对 Slack 的功能滚瓜烂熟,他们希望 Ryver 改进的服务足以让你移情别恋。他们承诺 Ryver 提供完全免费的团队沟通服务,并且不会在任何一个环节隐形收费。
|
||||
|
||||
谢天谢地,他们用高质量产品兑现了自己的承诺。
|
||||
|
||||
额外的内容是关键所在,他们承诺去掉一些你在 Slack 免费账号上面遇到的限制。无限的存储空间是一个加分点,除此之外,在许多其他方面 Ryver 也更加开放。如果存储空间限制对你来说是个痛点,不防试试 Ryver。
|
||||
|
||||
这是一个简单易用的系统,所有的功能都可以一键搞定。这种设计哲学使 Apple 大获成功。当你开始使用它之后,也不会遭遇成长的烦恼。
|
||||
|
||||

|
||||
|
||||
会话分为私聊和公示,这意味着团队平台和私人用途有明确的界限。它应该有助于避免将任何尴尬的广而告之给你的同事,这些问题我在使用 Slack 期间都遇到过。
|
||||
|
||||
Ryver 支持与大量现成的 App 的集成,并在大多数平台上有原生应用程序。
|
||||
|
||||
在需要时,你可以添加访客而无需增加费用,如果你经常和外部客户打交道,这将是一个非常有用的功能。访客可以增加更多的访客,这种流动性的元素是无法从其他更流行的消息应用中看到的。
|
||||
|
||||
考虑到 Ryver 是一个为迎合不同需求而产生的完全不同的服务。如果你需要一个账户来处理几个客户,Ryver 值得一试。
|
||||
|
||||
问题是它是如何做到免费的呢? 简单的答案是高级用户将为你的使用付了费。 就像 Spotify 和其他应用一样,有一小部分人为我们其他人支付了费用。 这里有一个[直接链接][2]到他们的下载页面的地址,如果有兴趣就去试一试吧。
|
||||
|
||||
### 你应该切换到 Ryver 吗?
|
||||
|
||||

|
||||
|
||||
像我一样在小团队使用 Slack 的体验还是非常棒,但是 Ryver 可以给予的更多。一个完全免费的团队沟通应用的想法不可谓不宏伟,更何况它工作的十分完美。
|
||||
|
||||
同时使用这两种消息应用也无可厚非,但是如果你不愿意为一个白金 Slack 账户付费,一定要尝试一下竞争对手的服务。你可能会发现,两者各擅胜场,这取决于你需要什么。
|
||||
|
||||
最重要的是,Ryver 是一个极棒的免费替代品,它不仅仅是一个 Slack 克隆。他们清楚地知道他们想要实现什么,他们有一个可以在拥挤不堪的市场提供不同的东西的不错的产品。
|
||||
|
||||
但是,如果将来持续缺乏资金,Ryver 有可能消失。 它可能会让你的团队和讨论陷入混乱。 目前一切还好,但是如果你计划把更大的业务委托给这个新贵还是需要三思而行。
|
||||
|
||||
如果你厌倦了 Slack 对免费帐户的限制,你会对 Ryver 印象深刻。 要了解更多,请访问其网站以获取有关服务的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/why-use-ryver-instead-of-slack/
|
||||
|
||||
作者:[James Milin-Ashmore][a]
|
||||
译者:[firstadream](https://github.com/firstadream)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/james-ashmore/
|
||||
[1]: https://www.maketecheasier.com/new-slack-features/
|
||||
[2]: http://www.ryver.com/downloads/
|
||||
@ -1,3 +1,5 @@
|
||||
Editing by FrankXinqi
|
||||
|
||||
Linux vs. Windows device driver model : architecture, APIs and build environment comparison
|
||||
============================================================================================
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
[Translating by itsang]
|
||||
[Translating by bestony]
|
||||
4 Container Networking Tools to Know
|
||||
=======================================
|
||||
|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
|
||||
###################Translating by messon007###################
|
||||
|
||||
Going Serverless with AWS Lambda and API Gateway
|
||||
============================
|
||||
|
||||
|
||||
@ -1,265 +0,0 @@
|
||||
Being translated by Bestony
|
||||
How to Monitor Docker Containers using Grafana on Ubuntu
|
||||
================================================================================
|
||||
|
||||
Grafana is an open source feature rich metrics dashboard. It is very useful for visualizing large-scale measurement data. It provides a powerful and elegant way to create, share, and explore data and dashboards from your disparate metric databases.
|
||||
|
||||
It supports a wide variety of graphing options for ultimate flexibility. Furthermore, it supports many different storage backends for your Data Source. Each Data Source has a specific Query Editor that is customized for the features and capabilities that the particular Data Source exposes. The following datasources are officially supported by Grafana: Graphite, InfluxDB, OpenTSDB, Prometheus, Elasticsearch and Cloudwatch
|
||||
|
||||
The query language and capabilities of each Data Source are obviously very different. You can combine data from multiple Data Sources onto a single Dashboard, but each Panel is tied to a specific Data Source that belongs to a particular Organization. It supports authenticated login and a basic role based access control implementation. It is deployed as a single software installation which is written in Go and Javascript.
|
||||
|
||||
In this article, I'll explain on how to install Grafana on a docker container in Ubuntu 16.04 and configure docker monitoring using this software.
|
||||
|
||||
### Pre-requisites ###
|
||||
|
||||
- Docker installed server
|
||||
|
||||
### Installing Grafana ###
|
||||
|
||||
We can build our Grafana in a docker container. There is an official docker image available for building Grafana. Please run this command to build a Grafana container.
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -i -p 3000:3000 grafana/grafana
|
||||
|
||||
Unable to find image 'grafana/grafana:latest' locally
|
||||
latest: Pulling from grafana/grafana
|
||||
5c90d4a2d1a8: Pull complete
|
||||
b1a9a0b6158e: Pull complete
|
||||
acb23b0d58de: Pull complete
|
||||
Digest: sha256:34ca2f9c7986cb2d115eea373083f7150a2b9b753210546d14477e2276074ae1
|
||||
Status: Downloaded newer image for grafana/grafana:latest
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Starting Grafana" logger=main version=3.1.0 commit=v3.1.0 compiled=2016-07-12T06:42:28+0000
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config loaded from" logger=settings file=/usr/share/grafana/conf/defaults.ini
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config loaded from" logger=settings file=/etc/grafana/grafana.ini
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.data=/var/lib/grafana"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.logs=/var/log/grafana"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.plugins=/var/lib/grafana/plugins"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Home" logger=settings path=/usr/share/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Data" logger=settings path=/var/lib/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Logs" logger=settings path=/var/log/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Plugins" logger=settings path=/var/lib/grafana/plugins
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Initializing DB" logger=sqlstore dbtype=sqlite3
|
||||
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create playlist table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create playlist item table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="drop preferences table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="drop preferences table v3"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create preferences table v3"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Created default admin user: [admin]"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Starting plugin search" logger=plugins
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Server Listening" logger=server address=0.0.0.0:3000 protocol=http subUrl=
|
||||
```
|
||||
|
||||
We can confirm the working of the Grafana container by running this command `docker ps -a` or by accessing it by URL `http://Docker IP:3000`
|
||||
|
||||
All Grafana configuration settings are defined using environment variables, this is much useful when using container technology. The Grafana configuration file is located at /etc/grafana/grafana.ini.
|
||||
|
||||
### Understanding the Configuration ###
|
||||
|
||||
The Grafana has number of configuration options that can be specified in its configuration file as .ini file or can be specified using environment variables as mentioned before.
|
||||
|
||||
#### Config file locations ####
|
||||
|
||||
Normal config file locations.
|
||||
|
||||
- Default configuration from : $WORKING_DIR/conf/defaults.ini
|
||||
- Custom configuration from : $WORKING_DIR/conf/custom.ini
|
||||
|
||||
PS : When you install Grafana using the deb or rpm packages or docker images, then your configuration file is located at /etc/grafana/grafana.ini
|
||||
|
||||
#### Understanding the config variables ####
|
||||
|
||||
Let's see some of the variables in the configuration file below:
|
||||
|
||||
`instance_name` : It's the name of the grafana server instance. It default value is fetched from ${HOSTNAME}, which will be replaced with environment variable HOSTNAME, if that is empty or does not exist Grafana will try to use system calls to get the machine name.
|
||||
|
||||
`[paths]`
|
||||
|
||||
`data` : It's the path where Grafana stores the sqlite3 database (when used), file based sessions (when used), and other data.
|
||||
|
||||
`logs` : It's where Grafana stores the logs.
|
||||
|
||||
Both these paths are usually specified via command line in the init.d scripts or the systemd service file.
|
||||
|
||||
`[server]`
|
||||
|
||||
`http_addr` : The IP address to bind the application. If it's left empty it will bind to all interfaces.
|
||||
|
||||
`http_port` : The port to which the application is bind to, defaults is 3000. You can redirect your 80 port to 3000 using the below command.
|
||||
|
||||
```
|
||||
$iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 3000
|
||||
```
|
||||
|
||||
`root_url` : This is the URL used to access Grafana from a web browser.
|
||||
|
||||
`cert_file` : Path to the certificate file (if protocol is set to https).
|
||||
|
||||
`cert_key` : Path to the certificate key file (if protocol is set to https).
|
||||
|
||||
`[database]`
|
||||
|
||||
Grafana uses a database to store its users and dashboards and other informations. By default it is configured to use sqlite3 which is an embedded database included in the main Grafana binary.
|
||||
|
||||
`type`
|
||||
You can choose mysql, postgres or sqlite3 as per our requirement.
|
||||
|
||||
`path`
|
||||
It's applicable only for sqlite3 database. The file path where the database will be stored.
|
||||
|
||||
`host`
|
||||
It's applicable only to MySQL or Postgres. it includes IP or hostname and port. For example, for MySQL running on the same host as Grafana: host = 127.0.0.1:3306
|
||||
|
||||
`name`
|
||||
The name of the Grafana database. Leave it set to grafana or some other name.
|
||||
|
||||
`user`
|
||||
The database user (not applicable for sqlite3).
|
||||
|
||||
`password`
|
||||
The database user's password (not applicable for sqlite3).
|
||||
|
||||
`ssl_mode`
|
||||
For Postgres, use either disable, require or verify-full. For MySQL, use either true, false, or skip-verify.
|
||||
|
||||
`ca_cert_path`
|
||||
(MySQL only) The path to the CA certificate to use. On many linux systems, certs can be found in /etc/ssl/certs.
|
||||
|
||||
`client_key_path`
|
||||
(MySQL only) The path to the client key. Only if server requires client authentication.
|
||||
|
||||
`client_cert_path`
|
||||
(MySQL only) The path to the client cert. Only if server requires client authentication.
|
||||
|
||||
`server_cert_name`
|
||||
(MySQL only) The common name field of the certificate used by the mysql server. Not necessary if ssl_mode is set to skip-verify.
|
||||
|
||||
`[security]`
|
||||
|
||||
`admin_user` : It is the name of the default Grafana admin user. The default name set is admin.
|
||||
|
||||
`admin_password` : It is the password of the default Grafana admin. It is set on first-run. The default password is admin.
|
||||
|
||||
`login_remember_days` : The number of days the keep me logged in / remember me cookie lasts.
|
||||
|
||||
`secret_key` : It is used for signing keep me logged in / remember me cookies.
|
||||
|
||||
### Essentials components for setting up Monitoring ###
|
||||
|
||||
We use the below components to create our Docker Monitoring system.
|
||||
|
||||
`cAdvisor` : It is otherwise called Container Advisor. It provides its users an understanding of the resource usage and performance characteristics. It collects, aggregates, processes and exports information about the running containers. You can go through this documentation for more information about this.
|
||||
|
||||
`InfluxDB` : It is a time series, metrics, and analytic database. We use this datasource for setting up our monitoring. cAdvisor displays only real time information and doesn’t store the metrics. Influx Db helps to store the monitoring information which cAdvisor provides in order to display a time range other than real time.
|
||||
|
||||
`Grafana Dashboard` : It allows us to combine all the pieces of information together visually. This powerful Dashboard allows us to run queries against the data store InfluxDB and chart them accordingly in beautiful layout.
|
||||
|
||||
### Installation of Docker Monitoring ###
|
||||
|
||||
We need to install each of these components one by one in our docker system.
|
||||
|
||||
#### Installing InfluxDB ####
|
||||
|
||||
We can use this command to pull InfluxDB image and setuup a influxDB container.
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -d -p 8083:8083 -p 8086:8086 --expose 8090 --expose 8099 -e PRE_CREATE_DB=cadvisor --name influxsrv tutum/influxdb:0.8.8
|
||||
Unable to find image 'tutum/influxdb:0.8.8' locally
|
||||
0.8.8: Pulling from tutum/influxdb
|
||||
a3ed95caeb02: Already exists
|
||||
23efb549476f: Already exists
|
||||
aa2f8df21433: Already exists
|
||||
ef072d3c9b41: Already exists
|
||||
c9f371853f28: Already exists
|
||||
a248b0871c3c: Already exists
|
||||
749db6d368d0: Already exists
|
||||
7d7c7d923e63: Pull complete
|
||||
e47cc7808961: Pull complete
|
||||
1743b6eeb23f: Pull complete
|
||||
Digest: sha256:8494b31289b4dbc1d5b444e344ab1dda3e18b07f80517c3f9aae7d18133c0c42
|
||||
Status: Downloaded newer image for tutum/influxdb:0.8.8
|
||||
d3b6f7789e0d1d01fa4e0aacdb636c221421107d1df96808ecbe8e241ceb1823
|
||||
|
||||
-p 8083:8083 : user interface, log in with username-admin, pass-admin
|
||||
-p 8086:8086 : interaction with other application
|
||||
--name influxsrv : container have name influxsrv, use to cAdvisor link it.
|
||||
```
|
||||
|
||||
You can test your InfluxDB installation by calling this URL >>http://45.79.148.234:8083 and login with user/password as "root".
|
||||
|
||||

|
||||
|
||||
We can create our required databases from this tab.
|
||||
|
||||

|
||||
|
||||
#### Installing cAdvisor ####
|
||||
|
||||
Our next step is to install cAdvisor container and link it to the InfluxDB container. You can use this command to create it.
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8080:8080 --detach=true --link influxsrv:influxsrv --name=cadvisor google/cadvisor:latest -storage_driver_db=cadvisor -storage_driver_host=influxsrv:8086
|
||||
Unable to find image 'google/cadvisor:latest' locally
|
||||
latest: Pulling from google/cadvisor
|
||||
09d0220f4043: Pull complete
|
||||
151807d34af9: Pull complete
|
||||
14cd28dce332: Pull complete
|
||||
Digest: sha256:8364c7ab7f56a087b757a304f9376c3527c8c60c848f82b66dd728980222bd2f
|
||||
Status: Downloaded newer image for google/cadvisor:latest
|
||||
3bfdf7fdc83872485acb06666a686719983a1172ac49895cd2a260deb1cdde29
|
||||
root@ubuntu:~#
|
||||
|
||||
--publish=8080:8080 : user interface
|
||||
--link=influxsrv:influxsrv: link to container influxsrv
|
||||
-storage_driver=influxdb: set the storage driver as InfluxDB
|
||||
Specify what InfluxDB instance to push data to:
|
||||
-storage_driver_host=influxsrv:8086: The ip:port of the database. Default is ‘localhost:8086’
|
||||
-storage_driver_db=cadvisor: database name. Uses db ‘cadvisor’ by default
|
||||
```
|
||||
|
||||
You can test our cAdvisor installation by calling this URL >>http://45.79.148.234:8080. This will provide you the statistics of your Docker host and containers.
|
||||
|
||||

|
||||
|
||||
#### Installing the Grafana Dashboard ####
|
||||
|
||||
Finally, we need to install the Grafana Dashboard and link to the InfluxDB. You can run this command to setup that.
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -d -p 3000:3000 -e INFLUXDB_HOST=localhost -e INFLUXDB_PORT=8086 -e INFLUXDB_NAME=cadvisor -e INFLUXDB_USER=root -e INFLUXDB_PASS=root --link influxsrv:influxsrv --name grafana grafana/grafana
|
||||
f3b7598529202b110e4e6b998dca6b6e60e8608d75dcfe0d2b09ae408f43684a
|
||||
```
|
||||
|
||||
Now we can login to Grafana and configure the Data Sources. Navigate to http://45.79.148.234:3000 or just http://45.79.148.234:
|
||||
|
||||
Username - admin
|
||||
Password - admin
|
||||
|
||||
Once we've installed Grafana, we can connect the InfluxDB. Login on the Dashboard and click on the Grafana icon(Fireball) in the upper left hand corner of the panel. Click on Data Sources to configure.
|
||||
|
||||

|
||||
|
||||
Now you can add our new Graph to our default Datasource InfluxDB.
|
||||
|
||||

|
||||
|
||||
We can edit and modify our query by adjusting our graph at Metric tab.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
You can get [more information][1] on docker monitoring here. Thank you for reading this. I would suggest your valuable comments and suggestions on this. Hope you'd a wonderful day!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/monitor-docker-containers-grafana-ubuntu/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/saheethas/
|
||||
[1]:https://github.com/vegasbrianc/docker-monitoring
|
||||
@ -1,64 +0,0 @@
|
||||
firstadream is translating
|
||||
|
||||
Ryver: Why You Should Be Using It instead of Slack
|
||||
=====
|
||||
|
||||
It seems like everyone has heard of Slack, a team communication tool that can be used across multiple platforms to stay in the loop. It has revolutionised the way users discuss and plan projects, and it’s a clear upgrade to emails.
|
||||
|
||||
I work in small writing teams, and I’ve never had a problem with communicating with others on my phone or computer while using it. If you want to keep up to date with team of any size, it’s a great way to stay in the loop.
|
||||
|
||||
So, why are we here? Ryver is supposed to be the next big thing, offering an upgraded service in comparison to Slack. It’s completely free, and they’re pushing for a larger share of the market.
|
||||
|
||||
Is it good enough to be a Slack-Killer? What are the differences between two similar sounding services?
|
||||
|
||||
Read on to find out more.
|
||||
|
||||
### Why Ryver?
|
||||
|
||||

|
||||
|
||||
Why mess with something that works? The developers at Ryver are well aware of Slack, and they’re hoping their improved service will be enough to make you switch over. They promise a completely free team-communication service with no hidden charges along the way.
|
||||
|
||||
Thankfully, they deliver on their main aim with a high quality product.
|
||||
|
||||
Extra content is the name of the game, and they promise to remove some of the limits you’ll find on a free account with Slack. Unlimited data storage is a major plus point, and it’s also more open in a number of ways. If storage limits are an issue for you, you have to check out Ryver.
|
||||
|
||||
It’s a simple system to use, as it was built so that all functions are always one click away. It’s a mantra used to great success by Apple, and there aren’t many growing pains when you first get started.
|
||||
|
||||

|
||||
|
||||
Conversations are split between personal chats and public posts, and it means there’s a clear line between team platforms and personal use. It should help to avoid broadcasting any embarrassing announcements to your colleagues, and I’ve seen a few during my time as a Slack user.
|
||||
|
||||
Integration with a number of existing apps is supported, and there are native applications for most platforms.
|
||||
|
||||
You can add guests when needed at no additional cost, and it’s useful if you deal with external clients regularly. Guests can add more guests, so there’s an element of fluidity that isn’t seen with the more popular option.
|
||||
|
||||
Think of Ryver as a completely different service that will cater to different needs. If you need to deal with numerous clients on the same account, it’s worth trying out.
|
||||
|
||||
The question is how is it free? The quick answer is premium users will be paying your way. Like Spotify and other services, there’s a minority paying for the rest of us. Here’s a direct link to their download page if you’re interested in giving it a go.
|
||||
|
||||
### Should You Switch to Ryver?
|
||||
|
||||

|
||||
|
||||
Slack is great as long as you stick to smaller teams like I do, but Ryver has a lot to offer. The idea of a completely free team messaging program is noble, and it works perfectly.
|
||||
|
||||
There’s nothing wrong with using both, so make sure to try out the competition if you’re not willing to pay for a premium Slack account. You might find that both are better in different situations, depending on what you need.
|
||||
|
||||
Above all, Ryver is a great free alternative, and it’s more than just a Slack clone. They have a clear idea of what they’re trying to achieve, and they have a decent product that offers something different in a crowded marketplace.
|
||||
|
||||
However, there’s a chance that it will disappear if there’s a sustained lack of funding in the future. It could leave your teams and discussions in disarray. Everything is fine for now, but be careful if you plan to export a larger business over to the new upstart.
|
||||
|
||||
If you’re tired of Slack’s limitations on a free account, you’ll be impressed by what Ryver has to offer. To learn more, check out their website for information about the service.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/why-use-ryver-instead-of-slack/?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+maketecheasier
|
||||
|
||||
作者:[James Milin-Ashmore][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/james-ashmore/
|
||||
@ -0,0 +1,265 @@
|
||||
# 如何在 Ubuntu 上使用 Grafana 监控 Docker
|
||||
|
||||
Grafana 是一个有着丰富指标的开源控制面板。在进行大型的测量数据的可视化时是非常有用的。根据不同的丰富指标,它提供了一个强大、优雅的方式来创建、浏览数据的方式。
|
||||
|
||||
它提供了丰富多样、灵活的图形选项。此外,针对数据源,它支持许多不同的存储后端。每个数据源都有针对特定数据源公开的特性和功能定制的查询编辑器。下述数据源 Grafana 提供了正式的支持:Graphite, InfluxDB, OpenTSDB, Prometheus, Elasticsearch 和 Cloudwatch。
|
||||
|
||||
查询语言和每个数据源的能力显然是不同的,你可以将来自多个数据源的数据混合到一个单一的仪表盘上,但每个小组被绑定到属于一个特定组织的特点数据源。它支持验证登陆和基于角色的访问控制的实现。它是作为一个独立软件部署的,使用 Go 和 JavaScript 编写的。
|
||||
|
||||
在这篇文章,我将讲解如何在 Ubuntu 16.04 上安装 Grafana 并使用这个软件配置 Docker 监控
|
||||
|
||||
### 先决条件
|
||||
|
||||
- 安装好 Docker 的服务器
|
||||
|
||||
### 安装 Grafana
|
||||
|
||||
我们可以在 Docker 中构建我们的 Grafana。 这里有一个官方的 Grafana Docker 镜像.请运行下述命令来构建Grafana 容器。
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -i -p 3000:3000 grafana/grafana
|
||||
|
||||
Unable to find image 'grafana/grafana:latest' locally
|
||||
latest: Pulling from grafana/grafana
|
||||
5c90d4a2d1a8: Pull complete
|
||||
b1a9a0b6158e: Pull complete
|
||||
acb23b0d58de: Pull complete
|
||||
Digest: sha256:34ca2f9c7986cb2d115eea373083f7150a2b9b753210546d14477e2276074ae1
|
||||
Status: Downloaded newer image for grafana/grafana:latest
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Starting Grafana" logger=main version=3.1.0 commit=v3.1.0 compiled=2016-07-12T06:42:28+0000
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config loaded from" logger=settings file=/usr/share/grafana/conf/defaults.ini
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config loaded from" logger=settings file=/etc/grafana/grafana.ini
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.data=/var/lib/grafana"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.logs=/var/log/grafana"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.plugins=/var/lib/grafana/plugins"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Home" logger=settings path=/usr/share/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Data" logger=settings path=/var/lib/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Logs" logger=settings path=/var/log/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Plugins" logger=settings path=/var/lib/grafana/plugins
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Initializing DB" logger=sqlstore dbtype=sqlite3
|
||||
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create playlist table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create playlist item table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="drop preferences table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="drop preferences table v3"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create preferences table v3"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Created default admin user: [admin]"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Starting plugin search" logger=plugins
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Server Listening" logger=server address=0.0.0.0:3000 protocol=http subUrl=
|
||||
```
|
||||
|
||||
我们可以通过运行此命令确认 Grafana 容器的工作状态 `docker ps -a` 或通过这个URL访问 `http://Docker IP:3000`
|
||||
|
||||
所有的 Grafana 配置设置都使用环境变量定义,在使用容器技术时这个是非常有用的。Grafana 配置文件路径为 /etc/grafana/grafana.ini.
|
||||
|
||||
### 理解配置项
|
||||
|
||||
Grafana 有多个 ini 文件作为被指定的配置文件,或可以指定使用前面提到的环境变量。
|
||||
|
||||
#### 配置文件位置
|
||||
|
||||
通常配置文件路径:
|
||||
|
||||
- 默认配置文件路径 : $WORKING_DIR/conf/defaults.ini
|
||||
- 自定义配置文件路径 : $WORKING_DIR/conf/custom.ini
|
||||
|
||||
PS:当你使用 deb、rpm 或 docker 镜像安装 Grafana ,你的配置文件在 /etc/grafana/grafana.ini
|
||||
|
||||
#### 理解配置变量
|
||||
|
||||
现在我们看一些配置文件中的变量:
|
||||
|
||||
`instance_name` : 这是 Grafana 服务器实例的名字。默认值从 ${HOSTNAME} 获取,将会被环境变量 HOSTNAME替换,如果为空或不存在,Grafana 将会尝试使用系统调用来获取机器名。
|
||||
|
||||
`[paths]`
|
||||
|
||||
`data` : 这个是 Grafana 存储 sqlite3 数据库(如果使用),基于文件的 Sessions(如果使用),和其他数据的路径
|
||||
|
||||
`logs` : 这个是 Grafana 存储日志的路径
|
||||
|
||||
这些路径通常都是在 init.d 脚本或 systemd service文件通过命令行指定。
|
||||
|
||||
`[server]`
|
||||
|
||||
`http_addr` : 应用监听的 IP 地址,如果为空,则监听所有的IP。
|
||||
|
||||
`http_port` : 应用监听的端口,默认是 3000,你可以使用下面的命令在 80 端口重定向到 3000 端口。
|
||||
|
||||
```
|
||||
$iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 3000
|
||||
```
|
||||
|
||||
`root_url` : 这个 URL 用于从浏览器访问 Grafana 。
|
||||
|
||||
`cert_file` : 证书文件的路径(如果协议是 HTTPS)
|
||||
|
||||
`cert_key` : 证书密钥文件的路径(如果协议是 HTTPS)
|
||||
|
||||
`[database]`
|
||||
|
||||
Grafana 使用数据库来存储用户和仪表盘以及其他信息,默认配置为使用嵌入在 Grafana 主要的二进制文件中传的 SQLite3
|
||||
|
||||
`type`
|
||||
你可以根据你的需求选择 MySQL、Postgres、SQLite3。
|
||||
|
||||
`path`
|
||||
|
||||
它只在选择 SQLite3 数据库时被应用,这个是数据库将要被存储的路径。
|
||||
|
||||
`host`
|
||||
仅适用 MySQL 或者 Postgres。它包括 IP 地址或主机名以及端口。例如,Grafana 和 MySQL 运行在同一台主机上设置如: host = 127.0.0.1:3306
|
||||
|
||||
`name`
|
||||
Grafana 数据库的名称,把它设置为 Grafana 或其它名称。
|
||||
|
||||
`user`
|
||||
数据库用户(不适用于 SQLite3)
|
||||
|
||||
`password`
|
||||
数据库用户密码(不适用于 SQLite3)
|
||||
|
||||
`ssl_mode`
|
||||
对于Postgres,使用 disable,require,或 verify-full.对于 MySQL,使用 true,false,或 skip-verify
|
||||
|
||||
`ca_cert_path`
|
||||
|
||||
(只适用于MySQL)CA 证书文件路径,在多数 Linux 系统中,证书可以在 /etc/ssl/certs 找到
|
||||
|
||||
`client_key_path`
|
||||
(只适用于MySQL)客户端密钥的路径,只在服务端需要用户端验证时使用。
|
||||
|
||||
`client_cert_path`
|
||||
(只适用于MySQL)客户端证书的路径,只在服务端需要用户端验证时使用。
|
||||
|
||||
`server_cert_name`
|
||||
(只适用于MySQL) MySQL 服务端使用的证书的通用名称字段。如果 ssl_mode 设置为 skip-verify 时可以不设置
|
||||
|
||||
`[security]`
|
||||
|
||||
`admin_user` : 这个是 Grafana 默认的管理员用户的用户名,默认设置为 admin.
|
||||
|
||||
`admin_password` : 这个是 Grafana 默认的管理员用户的密码,在第一次运行时设置,默认为 admin
|
||||
|
||||
`login_remember_days` : 保持登陆/记住我 的持续天数
|
||||
|
||||
`secret_key` : 用于保持登陆/记住我的 cookies 的签名
|
||||
|
||||
### 设置监控的重要组件
|
||||
|
||||
我们可以使用下面的组件来创建我们的 Docker 监控系统
|
||||
|
||||
`cAdvisor` : 他被称为 Container Advisor。它提供了对用户的资源利用和性能特征的解读。它收集、合并、处理、导出运行中的容器的信息。你可以通过文档了解更多关于这个。
|
||||
|
||||
`InfluxDB` : 这是一个时间排序、度量和分析数据库。我们使用这个数据源来设置我们的监控。cAdvisor 只展示时间信息,不保存度量信息。Influx Db帮助保存 cAdvisor 提供的监控数据,以展示非实时数据。
|
||||
|
||||
`Grafana Dashboard` : 它可以帮助我们在视觉上整合所有的信息。这个强大的仪表盘使我们能够针对数据存储 InfluxDB 进行查询并将他们放在一个布局合理好看的图表中。
|
||||
|
||||
### Docker监控的安装
|
||||
|
||||
我们需要一步一步的安装每一个下面的组件在我们的 Docker 系统中。
|
||||
|
||||
#### 安装 InfluxDB
|
||||
|
||||
我们可以使用这个命令来拉取 InfluxDB 镜像,并部署了 influxDB 容器。
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -d -p 8083:8083 -p 8086:8086 --expose 8090 --expose 8099 -e PRE_CREATE_DB=cadvisor --name influxsrv tutum/influxdb:0.8.8
|
||||
Unable to find image 'tutum/influxdb:0.8.8' locally
|
||||
0.8.8: Pulling from tutum/influxdb
|
||||
a3ed95caeb02: Already exists
|
||||
23efb549476f: Already exists
|
||||
aa2f8df21433: Already exists
|
||||
ef072d3c9b41: Already exists
|
||||
c9f371853f28: Already exists
|
||||
a248b0871c3c: Already exists
|
||||
749db6d368d0: Already exists
|
||||
7d7c7d923e63: Pull complete
|
||||
e47cc7808961: Pull complete
|
||||
1743b6eeb23f: Pull complete
|
||||
Digest: sha256:8494b31289b4dbc1d5b444e344ab1dda3e18b07f80517c3f9aae7d18133c0c42
|
||||
Status: Downloaded newer image for tutum/influxdb:0.8.8
|
||||
d3b6f7789e0d1d01fa4e0aacdb636c221421107d1df96808ecbe8e241ceb1823
|
||||
|
||||
-p 8083:8083 : user interface, log in with username-admin, pass-admin
|
||||
-p 8086:8086 : interaction with other application
|
||||
--name influxsrv : container have name influxsrv, use to cAdvisor link it.
|
||||
```
|
||||
|
||||
你可以测试 InfluxDB 是否安装好,通过访问这个 URL>>http://45.79.148.234:8083 (译者注,应当访问你自己的服务器的IP:8083),并且使用 root 用户的帐号和密码登陆
|
||||
|
||||

|
||||
|
||||
我们可以在这个界面上创建我们需要的数据库.
|
||||
|
||||

|
||||
|
||||
#### 安装 cAdvisor
|
||||
|
||||
我们的下一个步骤是安装 cAdvisor 容器,并将其链接到 InfluxDB 容器。你可以使用此命令来创建它。
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8080:8080 --detach=true --link influxsrv:influxsrv --name=cadvisor google/cadvisor:latest -storage_driver_db=cadvisor -storage_driver_host=influxsrv:8086
|
||||
Unable to find image 'google/cadvisor:latest' locally
|
||||
latest: Pulling from google/cadvisor
|
||||
09d0220f4043: Pull complete
|
||||
151807d34af9: Pull complete
|
||||
14cd28dce332: Pull complete
|
||||
Digest: sha256:8364c7ab7f56a087b757a304f9376c3527c8c60c848f82b66dd728980222bd2f
|
||||
Status: Downloaded newer image for google/cadvisor:latest
|
||||
3bfdf7fdc83872485acb06666a686719983a1172ac49895cd2a260deb1cdde29
|
||||
root@ubuntu:~#
|
||||
|
||||
--publish=8080:8080 : user interface
|
||||
--link=influxsrv:influxsrv: link to container influxsrv
|
||||
-storage_driver=influxdb: set the storage driver as InfluxDB
|
||||
Specify what InfluxDB instance to push data to:
|
||||
-storage_driver_host=influxsrv:8086: The ip:port of the database. Default is ‘localhost:8086’
|
||||
-storage_driver_db=cadvisor: database name. Uses db ‘cadvisor’ by default
|
||||
```
|
||||
|
||||
你可以通过访问这个地址来测试安装 cAdvisor 是否正常 >>http://45.79.148.234:8080. 这将为你的 Docker 主机和容器提供统计信息。
|
||||
|
||||

|
||||
|
||||
#### 安装 Grafana 控制面板
|
||||
|
||||
首先我们需要安装 Grafana 仪表板并链接到 InfluxDB,你可以执行下面的命令来设置他
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -d -p 3000:3000 -e INFLUXDB_HOST=localhost -e INFLUXDB_PORT=8086 -e INFLUXDB_NAME=cadvisor -e INFLUXDB_USER=root -e INFLUXDB_PASS=root --link influxsrv:influxsrv --name grafana grafana/grafana
|
||||
f3b7598529202b110e4e6b998dca6b6e60e8608d75dcfe0d2b09ae408f43684a
|
||||
```
|
||||
|
||||
现在我们可以登陆 Grafana 来配置数据源. 访问 http://45.79.148.234:3000 或 http://45.79.148.234:
|
||||
|
||||
用户名- admin
|
||||
密码- admin
|
||||
|
||||
一旦我们安装好了 Grafana,我们可以链接 InfluxDB。登陆到控制台并且点击面板左上方角落的 Grafana 图标(火球)。点击数据源(Data Sources)来配置。
|
||||
|
||||

|
||||
|
||||
现在你可以添加我们新的图像到我们默认的数据源 InfluxDB.
|
||||
|
||||

|
||||
|
||||
我们可以通过在测量页面调整我们的图像可以编辑和调整我们的查询
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
你可以在 [更多信息][1]看到更多关于Docker监控的小心。 感谢你的阅读。我希望你可以留下有价值的建议和评论。希望你有个美好的一天
|
||||
|
||||
------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/monitor-docker-containers-grafana-ubuntu/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linoxide.com/author/saheethas/
|
||||
[1]: https://github.com/vegasbrianc/docker-monitoring
|
||||
Loading…
Reference in New Issue
Block a user