mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
8452f48509
@ -0,0 +1,105 @@
|
||||
Fedora 中的容器技术:systemd-nspawn
|
||||
===
|
||||
|
||||
欢迎来到“Fedora 中的容器技术”系列!本文是该系列文章中的第一篇,它将说明你可以怎样使用 Fedora 中各种可用的容器技术。本文将学习 `systemd-nspawn` 的相关知识。
|
||||
|
||||
### 容器是什么?
|
||||
|
||||
一个容器就是一个用户空间实例,它能够在与托管容器的系统(叫做宿主系统)相隔离的环境中运行一个程序或者一个操作系统。这和 `chroot` 或 [虚拟机][1] 的思想非常类似。运行在容器中的进程是由与宿主操作系统相同的内核来管理的,但它们是与宿主文件系统以及其它进程隔离开的。
|
||||
|
||||
### 什么是 systemd-nspawn?
|
||||
|
||||
systemd 项目认为应当将容器技术变成桌面的基础部分,并且应当和用户的其余系统集成在一起。为此,systemd 提供了 `systemd-nspawn`,这款工具能够使用多种 Linux 技术创建容器。它也提供了一些容器管理工具。
|
||||
|
||||
`systemd-nspawn` 和 `chroot` 在许多方面都是类似的,但是前者更加强大。它虚拟化了文件系统、进程树以及客户系统中的进程间通信。它的吸引力在于它提供了很多用于管理容器的工具,例如用来管理容器的 `machinectl`。由 `systemd-nspawn` 运行的容器将会与 systemd 组件一同运行在宿主系统上。举例来说,一个容器的日志可以输出到宿主系统的日志中。
|
||||
|
||||
在 Fedora 24 上,`systemd-nspawn` 已经从 systemd 软件包分离出来了,所以你需要安装 `systemd-container` 软件包。一如往常,你可以使用 `dnf install systemd-container` 进行安装。
|
||||
|
||||
### 创建容器
|
||||
|
||||
使用 `systemd-nspawn` 创建一个容器是很容易的。假设你有一个专门为 Debian 创造的应用,并且无法在其它发行版中正常运行。那并不是一个问题,我们可以创造一个容器!为了设置容器使用最新版本的 Debian(现在是 Jessie),你需要挑选一个目录来放置你的系统。我暂时将使用目录 `~/DebianJessie`。
|
||||
|
||||
一旦你创建完目录,你需要运行 `debootstrap`,你可以从 Fedora 仓库中安装它。对于 Debian Jessie,你运行下面的命令来初始化一个 Debian 文件系统。
|
||||
|
||||
```
|
||||
$ debootstrap --arch=amd64 stable ~/DebianJessie
|
||||
```
|
||||
|
||||
以上默认你的架构是 x86_64。如果不是的话,你必须将架构的名称改为 `amd64`。你可以使用 `uname -m` 得知你的机器架构。
|
||||
|
||||
一旦设置好你的根目录,你就可以使用下面的命令来启动你的容器。
|
||||
|
||||
```
|
||||
$ systemd-nspawn -bD ~/DebianJessie
|
||||
```
|
||||
|
||||
容器将会在数秒后准备好并运行,当你试图登录时就会注意到:你无法使用你的系统上任何账户。这是因为 `systemd-nspawn` 虚拟化了用户。修复的方法很简单:将之前的命令中的 `-b` 移除即可。你将直接进入容器的 root 用户的 shell。此时,你只能使用 `passwd` 命令为 root 设置密码,或者使用 `adduser` 命令添加一个新用户。一旦设置好密码或添加好用户,你就可以把 `-b` 标志添加回去然后继续了。你会进入到熟悉的登录控制台,然后你使用设置好的认证信息登录进去。
|
||||
|
||||
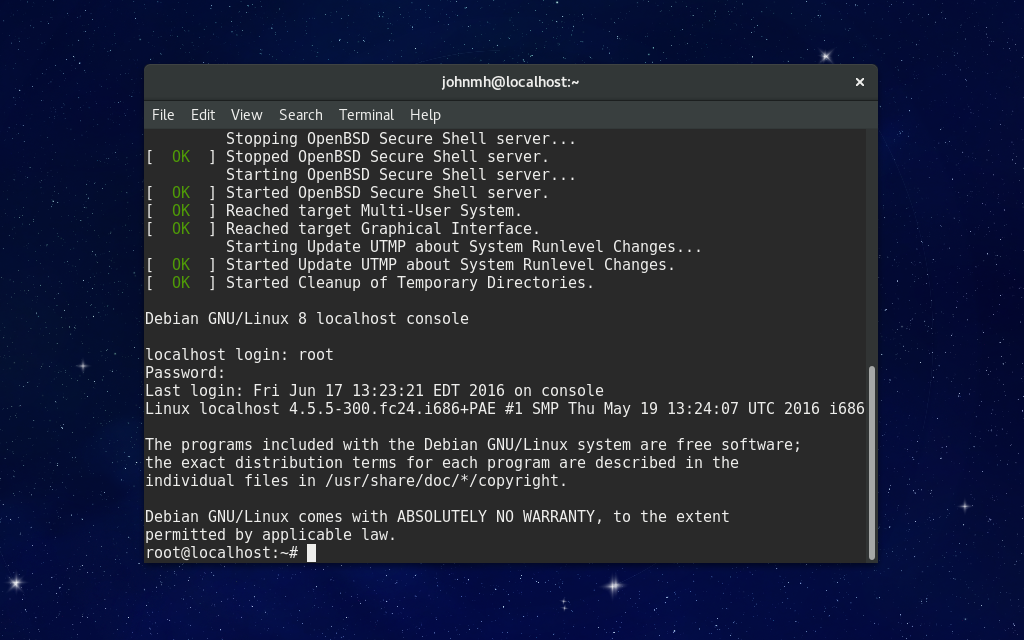
以上对于任意你想在容器中运行的发行版都适用,但前提是你需要使用正确的包管理器创建系统。对于 Fedora,你应使用 DNF 而非 `debootstrap`。想要设置一个最小化的 Fedora 系统,你可以运行下面的命令,要将“/absolute/path/”替换成任何你希望容器存放的位置。
|
||||
|
||||
```
|
||||
$ sudo dnf --releasever=24 --installroot=/absolute/path/ install systemd passwd dnf fedora-release
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 设置网络
|
||||
|
||||
如果你尝试启动一个服务,但它绑定了你宿主机正在使用的端口,你将会注意到这个问题:你的容器正在使用和宿主机相同的网络接口。幸运的是,`systemd-nspawn` 提供了几种可以将网络从宿主机分开的方法。
|
||||
|
||||
#### 本地网络
|
||||
|
||||
第一种方法是使用 `--private-network` 标志,它默认仅创建一个回环设备。这对于你不需要使用网络的环境是非常理想的,例如构建系统和其它持续集成系统。
|
||||
|
||||
#### 多个网络接口
|
||||
|
||||
如果你有多个网络接口设备,你可以使用 `--network-interface` 标志给容器分配一个接口。想要给我的容器分配 `eno1`,我会添加选项 `--network-interface=eno1`。当某个接口分配给一个容器后,宿主机就不能同时使用那个接口了。只有当容器彻底关闭后,宿主机才可以使用那个接口。
|
||||
|
||||
#### 共享网络接口
|
||||
|
||||
对于我们中那些并没有额外的网络设备的人来说,还有其它方法可以访问容器。一种就是使用 `--port` 选项。这会将容器中的一个端口定向到宿主机。使用格式是 `协议:宿主机端口:容器端口`,这里的协议可以是 `tcp` 或者 `udp`,`宿主机端口` 是宿主机的一个合法端口,`容器端口` 则是容器中的一个合法端口。你可以省略协议,只指定 `宿主机端口:容器端口`。我通常的用法类似 `--port=2222:22`。
|
||||
|
||||
你可以使用 `--network-veth` 启用完全的、仅宿主机模式的网络,这会在宿主机和容器之间创建一个虚拟的网络接口。你也可以使用 `--network-bridge` 桥接二者的连接。
|
||||
|
||||
### 使用 systemd 组件
|
||||
|
||||
如果你容器中的系统含有 D-Bus,你可以使用 systemd 提供的实用工具来控制并监视你的容器。基础安装的 Debian 并不包含 `dbus`。如果你想在 Debian Jessie 中使用 `dbus`,你需要运行命令 `apt install dbus`。
|
||||
|
||||
#### machinectl
|
||||
|
||||
为了能够轻松地管理容器,systemd 提供了 `machinectl` 实用工具。使用 `machinectl`,你可以使用 `machinectl login name` 登录到一个容器中、使用 `machinectl status name`检查状态、使用 `machinectl reboot name` 启动容器或者使用 `machinectl poweroff name` 关闭容器。
|
||||
|
||||
### 其它 systemd 命令
|
||||
|
||||
多数 systemd 命令,例如 `journalctl`, `systemd-analyze` 和 `systemctl`,都支持使用 `--machine` 选项来指定容器。例如,如果你想查看一个名为 “foobar” 的容器的日志,你可以使用 `journalctl --machine=foobar`。你也可以使用 `systemctl --machine=foobar status service` 来查看运行在这个容器中的服务状态。
|
||||
|
||||
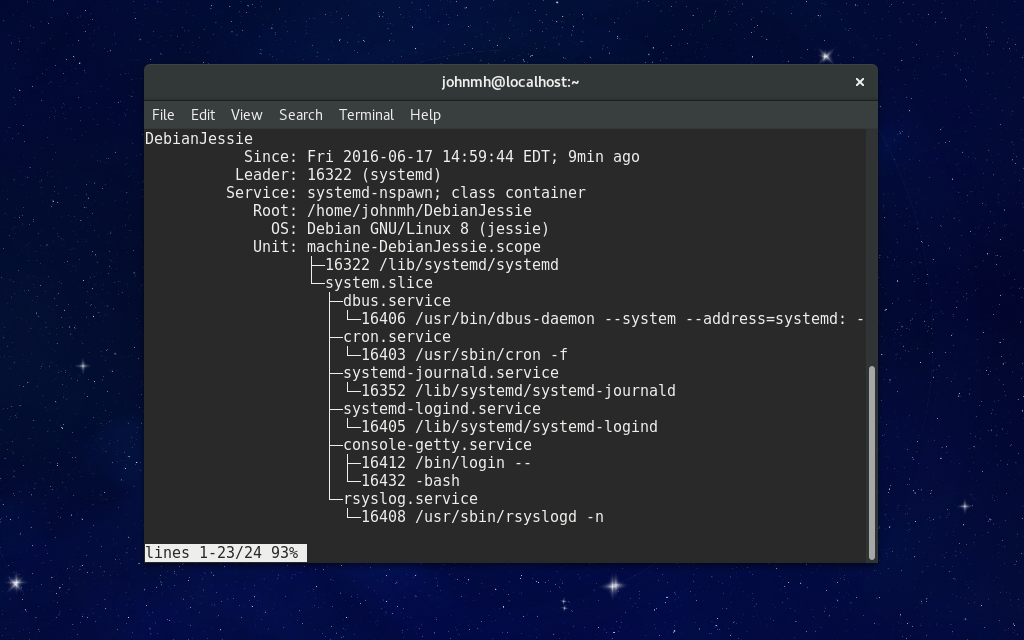
|
||||
|
||||
### 和 SELinux 一起工作
|
||||
|
||||
如果你要使用 SELinux 强制模式(Fedora 默认模式),你需要为你的容器设置 SELinux 环境。想要那样的话,你需要在宿主系统上运行下面两行命令。
|
||||
|
||||
```
|
||||
$ semanage fcontext -a -t svirt_sandbox_file_t "/path/to/container(/.*)?"
|
||||
$ restorecon -R /path/to/container/
|
||||
```
|
||||
|
||||
确保使用你的容器路径替换 “/path/to/container”。对于我的容器 "DebianJessie",我会运行下面的命令:
|
||||
|
||||
```
|
||||
$ semanage fcontext -a -t svirt_sandbox_file_t "/home/johnmh/DebianJessie(/.*)?"
|
||||
$ restorecon -R /home/johnmh/DebianJessie/
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/container-technologies-fedora-systemd-nspawn/
|
||||
|
||||
作者:[John M. Harris, Jr.][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/container-technologies-fedora-systemd-nspawn/
|
||||
[1]: https://en.wikipedia.org/wiki/Virtual_machine
|
||||
@ -0,0 +1,101 @@
|
||||
如何在 Ubuntu Linux 16.04上安装开源的 Discourse 论坛
|
||||
===============================================================================
|
||||
|
||||
Discourse 是一个开源的论坛,它可以以邮件列表、聊天室或者论坛等多种形式工作。它是一个广受欢迎的现代的论坛工具。在服务端,它使用 Ruby on Rails 和 Postgres 搭建, 并且使用 Redis 缓存来减少读取时间 , 在客户端,它使用支持 Java Script 的浏览器。它非常容易定制,结构良好,并且它提供了转换插件,可以对你现存的论坛、公告板进行转换,例如: vBulletin、phpBB、Drupal、SMF 等等。在这篇文章中,我们将学习在 Ubuntu 操作系统下安装 Discourse。
|
||||
|
||||
它以安全作为设计思想,所以发垃圾信息的人和黑客们不能轻易的实现其企图。它能很好的支持各种现代设备,并可以相应的调整以手机和平板的显示。
|
||||
|
||||
### 在 Ubuntu 16.04 上安装 Discourse
|
||||
|
||||
让我们开始吧 ! 最少需要 1G 的内存,并且官方支持的安装过程需要已经安装了 docker。 说到 docker,它还需要安装Git。要满足以上的两点要求我们只需要运行下面的命令:
|
||||
|
||||
```
|
||||
wget -qO- https://get.docker.com/ | sh
|
||||
```
|
||||
|
||||

|
||||
|
||||
用不了多久就安装好了 docker 和 Git,安装结束以后,在你的系统上的 /var 分区创建一个 Discourse 文件夹(当然你也可以选择其他的分区)。
|
||||
|
||||
```
|
||||
mkdir /var/discourse
|
||||
```
|
||||
|
||||
现在我们来克隆 Discourse 的 Github 仓库到这个新建的文件夹。
|
||||
|
||||
```
|
||||
git clone https://github.com/discourse/discourse_docker.git /var/discourse
|
||||
```
|
||||
|
||||
进入这个克隆的文件夹。
|
||||
|
||||
```
|
||||
cd /var/discourse
|
||||
```
|
||||
|
||||

|
||||
|
||||
你将看到“discourse-setup” 脚本文件,运行这个脚本文件进行 Discourse 的初始化。
|
||||
|
||||
```
|
||||
./discourse-setup
|
||||
```
|
||||
|
||||
**备注: 在安装 discourse 之前请确保你已经安装好了邮件服务器。**
|
||||
|
||||
安装向导将会问你以下六个问题:
|
||||
|
||||
```
|
||||
Hostname for your Discourse?
|
||||
Email address for admin account?
|
||||
SMTP server address?
|
||||
SMTP user name?
|
||||
SMTP port [587]:
|
||||
SMTP password? []:
|
||||
```
|
||||
|
||||

|
||||
|
||||
当你提交了以上信息以后, 它会让你提交确认, 如果一切都很正常,点击回车以后安装开始。
|
||||
|
||||

|
||||
|
||||
现在“坐等放宽”,需要花费一些时间来完成安装,倒杯咖啡,看看有什么错误信息没有。
|
||||
|
||||

|
||||
|
||||
安装成功以后看起来应该像这样。
|
||||
|
||||

|
||||
|
||||
现在打开浏览器,如果已经做了域名解析,你可以使用你的域名来连接 Discourse 页面 ,否则你只能使用IP地址了。你将看到如下信息:
|
||||
|
||||

|
||||
|
||||
就是这个,点击 “Sign Up” 选项创建一个新的账户,然后进行你的 Discourse 设置。
|
||||
|
||||

|
||||
|
||||
### 结论
|
||||
|
||||
它安装简便,运行完美。 它拥有现代论坛所有必备功能。它以 GPL 发布,是完全开源的产品。简单、易用、以及特性丰富是它的最大特点。希望你喜欢这篇文章,如果有问题,你可以给我们留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-discourse-on-ubuntu-linux-16-04/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxpitstop.com/author/aun/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
31
published/20160630 What makes up the Fedora kernel.md
Normal file
31
published/20160630 What makes up the Fedora kernel.md
Normal file
@ -0,0 +1,31 @@
|
||||
Fedora 内核是由什么构成的?
|
||||
====================================
|
||||
|
||||

|
||||
|
||||
每个 Fedora 系统都运行着一个内核。许多代码片段组合在一起使之成为现实。
|
||||
|
||||
每个 Fedora 内核都起始于一个来自于[上游社区][1]的基线版本——通常称之为 vanilla 内核。上游内核就是标准。(Fedora 的)目标是包含尽可能多的上游代码,这样使得 bug 修复和 API 更新更加容易,同时也会有更多的人审查代码。理想情况下,Fedora 能够直接获取 kernel.org 的内核,然后发送给所有用户。
|
||||
|
||||
现实情况是,使用 vanilla 内核并不能完全满足 Fedora。Vanilla 内核可能并不支持一些 Fedora 用户希望拥有的功能。用户接收的 [Fedora 内核] 是在 vanilla 内核之上打了很多补丁的内核。这些补丁被认为“不在树上(out of tree)”。许多这些位于补丁树之外的补丁都不会存在太久。如果某补丁能够修复一个问题,那么该补丁可能会被合并到 Fedora 树,以便用户能够更快地收到修复。当内核变基到一个新版本时,在新版本中的补丁都将被清除。
|
||||
|
||||
一些补丁会在 Fedora 内核树上存在很长时间。一个很好的例子是,安全启动补丁就是这类补丁。这些补丁提供了 Fedora 希望支持的功能,即使上游社区还没有接受它们。保持这些补丁更新是需要付出很多努力的,所以 Fedora 尝试减少不被上游内核维护者接受的补丁数量。
|
||||
|
||||
通常来说,想要在 Fedora 内核中获得一个补丁的最佳方法是先给 [Linux 内核邮件列表(LKML)][3] 发送补丁,然后请求将该补丁包含到 Fedora 中。如果某个维护者接受了补丁,就意味着 Fedora 内核树中将来很有可能会包含该补丁。一些来自于 GitHub 等地方的还没有提交给 LKML 的补丁是不可能进入内核树的。首先向 LKML 发送补丁是非常重要的,它能确保 Fedora 内核树中携带的补丁是功能正常的。如果没有社区审查,Fedora 最终携带的补丁将会充满 bug 并会导致问题。
|
||||
|
||||
Fedora 内核中包含的代码来自许多地方。一切都需要提供最佳的体验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
|
||||
作者:[Laura Abbott][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
[1]: http://www.kernel.org/
|
||||
[2]: http://pkgs.fedoraproject.org/cgit/rpms/kernel.git/
|
||||
[3]: http://www.labbott.name/blog/2015/10/02/the-art-of-communicating-with-lkml/
|
||||
@ -1,7 +1,7 @@
|
||||
使用 Python 创建你自己的 Shell:Part I
|
||||
使用 Python 创建你自己的 Shell (一)
|
||||
==========================================
|
||||
|
||||
我很想知道一个 shell (像 bash,csh 等)内部是如何工作的。为了满足自己的好奇心,我使用 Python 实现了一个名为 **yosh** (Your Own Shell)的 Shell。本文章所介绍的概念也可以应用于其他编程语言。
|
||||
我很想知道一个 shell (像 bash,csh 等)内部是如何工作的。于是为了满足自己的好奇心,我使用 Python 实现了一个名为 **yosh** (Your Own Shell)的 Shell。本文章所介绍的概念也可以应用于其他编程语言。
|
||||
|
||||
(提示:你可以在[这里](https://github.com/supasate/yosh)查找本博文使用的源代码,代码以 MIT 许可证发布。在 Mac OS X 10.11.5 上,我使用 Python 2.7.10 和 3.4.3 进行了测试。它应该可以运行在其他类 Unix 环境,比如 Linux 和 Windows 上的 Cygwin。)
|
||||
|
||||
@ -20,15 +20,15 @@ yosh_project
|
||||
|
||||
`yosh_project` 为项目根目录(你也可以把它简单命名为 `yosh`)。
|
||||
|
||||
`yosh` 为包目录,且 `__init__.py` 可以使它成为与包目录名字相同的包(如果你不写 Python,可以忽略它。)
|
||||
`yosh` 为包目录,且 `__init__.py` 可以使它成为与包的目录名字相同的包(如果你不用 Python 编写的话,可以忽略它。)
|
||||
|
||||
`shell.py` 是我们主要的脚本文件。
|
||||
|
||||
### 步骤 1:Shell 循环
|
||||
|
||||
当启动一个 shell,它会显示一个命令提示符并等待你的命令输入。在接收了输入的命令并执行它之后(稍后文章会进行详细解释),你的 shell 会重新回到循环,等待下一条指令。
|
||||
当启动一个 shell,它会显示一个命令提示符并等待你的命令输入。在接收了输入的命令并执行它之后(稍后文章会进行详细解释),你的 shell 会重新回到这里,并循环等待下一条指令。
|
||||
|
||||
在 `shell.py`,我们会以一个简单的 mian 函数开始,该函数调用了 shell_loop() 函数,如下:
|
||||
在 `shell.py` 中,我们会以一个简单的 main 函数开始,该函数调用了 shell_loop() 函数,如下:
|
||||
|
||||
```
|
||||
def shell_loop():
|
||||
@ -43,7 +43,7 @@ if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
接着,在 `shell_loop()`,为了指示循环是否继续或停止,我们使用了一个状态标志。在循环的开始,我们的 shell 将显示一个命令提示符,并等待读取命令输入。
|
||||
接着,在 `shell_loop()` 中,为了指示循环是否继续或停止,我们使用了一个状态标志。在循环的开始,我们的 shell 将显示一个命令提示符,并等待读取命令输入。
|
||||
|
||||
```
|
||||
import sys
|
||||
@ -56,15 +56,15 @@ def shell_loop():
|
||||
status = SHELL_STATUS_RUN
|
||||
|
||||
while status == SHELL_STATUS_RUN:
|
||||
# Display a command prompt
|
||||
### 显示命令提示符
|
||||
sys.stdout.write('> ')
|
||||
sys.stdout.flush()
|
||||
|
||||
# Read command input
|
||||
### 读取命令输入
|
||||
cmd = sys.stdin.readline()
|
||||
```
|
||||
|
||||
之后,我们切分命令输入并进行执行(我们即将实现`命令切分`和`执行`函数)。
|
||||
之后,我们切分命令(tokenize)输入并进行执行(execute)(我们即将实现 `tokenize` 和 `execute` 函数)。
|
||||
|
||||
因此,我们的 shell_loop() 会是如下这样:
|
||||
|
||||
@ -79,33 +79,33 @@ def shell_loop():
|
||||
status = SHELL_STATUS_RUN
|
||||
|
||||
while status == SHELL_STATUS_RUN:
|
||||
# Display a command prompt
|
||||
### 显示命令提示符
|
||||
sys.stdout.write('> ')
|
||||
sys.stdout.flush()
|
||||
|
||||
# Read command input
|
||||
### 读取命令输入
|
||||
cmd = sys.stdin.readline()
|
||||
|
||||
# Tokenize the command input
|
||||
### 切分命令输入
|
||||
cmd_tokens = tokenize(cmd)
|
||||
|
||||
# Execute the command and retrieve new status
|
||||
### 执行该命令并获取新的状态
|
||||
status = execute(cmd_tokens)
|
||||
```
|
||||
|
||||
这就是我们整个 shell 循环。如果我们使用 `python shell.py` 启动我们的 shell,它会显示命令提示符。然而如果我们输入命令并按回车,它会抛出错误,因为我们还没定义`命令切分`函数。
|
||||
这就是我们整个 shell 循环。如果我们使用 `python shell.py` 启动我们的 shell,它会显示命令提示符。然而如果我们输入命令并按回车,它会抛出错误,因为我们还没定义 `tokenize` 函数。
|
||||
|
||||
为了退出 shell,可以尝试输入 ctrl-c。稍后我将解释如何以优雅的形式退出 shell。
|
||||
|
||||
### 步骤 2:命令切分
|
||||
### 步骤 2:命令切分(tokenize)
|
||||
|
||||
当用户在我们的 shell 中输入命令并按下回车键,该命令将会是一个包含命令名称及其参数的很长的字符串。因此,我们必须切分该字符串(分割一个字符串为多个标记)。
|
||||
当用户在我们的 shell 中输入命令并按下回车键,该命令将会是一个包含命令名称及其参数的长字符串。因此,我们必须切分该字符串(分割一个字符串为多个元组)。
|
||||
|
||||
咋一看似乎很简单。我们或许可以使用 `cmd.split()`,以空格分割输入。它对类似 `ls -a my_folder` 的命令起作用,因为它能够将命令分割为一个列表 `['ls', '-a', 'my_folder']`,这样我们便能轻易处理它们了。
|
||||
|
||||
然而,也有一些类似 `echo "Hello World"` 或 `echo 'Hello World'` 以单引号或双引号引用参数的情况。如果我们使用 cmd.spilt,我们将会得到一个存有 3 个标记的列表 `['echo', '"Hello', 'World"']` 而不是 2 个标记的列表 `['echo', 'Hello World']`。
|
||||
|
||||
幸运的是,Python 提供了一个名为 `shlex` 的库,它能够帮助我们效验如神地分割命令。(提示:我们也可以使用正则表达式,但它不是本文的重点。)
|
||||
幸运的是,Python 提供了一个名为 `shlex` 的库,它能够帮助我们如魔法般地分割命令。(提示:我们也可以使用正则表达式,但它不是本文的重点。)
|
||||
|
||||
|
||||
```
|
||||
@ -120,23 +120,23 @@ def tokenize(string):
|
||||
...
|
||||
```
|
||||
|
||||
然后我们将这些标记发送到执行进程。
|
||||
然后我们将这些元组发送到执行进程。
|
||||
|
||||
### 步骤 3:执行
|
||||
|
||||
这是 shell 中核心和有趣的一部分。当 shell 执行 `mkdir test_dir` 时,到底发生了什么?(提示: `mkdir` 是一个带有 `test_dir` 参数的执行程序,用于创建一个名为 `test_dir` 的目录。)
|
||||
这是 shell 中核心而有趣的一部分。当 shell 执行 `mkdir test_dir` 时,到底发生了什么?(提示: `mkdir` 是一个带有 `test_dir` 参数的执行程序,用于创建一个名为 `test_dir` 的目录。)
|
||||
|
||||
`execvp` 是涉及这一步的首个函数。在我们解释 `execvp` 所做的事之前,让我们看看它的实际效果。
|
||||
`execvp` 是这一步的首先需要的函数。在我们解释 `execvp` 所做的事之前,让我们看看它的实际效果。
|
||||
|
||||
```
|
||||
import os
|
||||
...
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Execute command
|
||||
### 执行命令
|
||||
os.execvp(cmd_tokens[0], cmd_tokens)
|
||||
|
||||
# Return status indicating to wait for next command in shell_loop
|
||||
### 返回状态以告知在 shell_loop 中等待下一个命令
|
||||
return SHELL_STATUS_RUN
|
||||
|
||||
...
|
||||
@ -144,11 +144,11 @@ def execute(cmd_tokens):
|
||||
|
||||
再次尝试运行我们的 shell,并输入 `mkdir test_dir` 命令,接着按下回车键。
|
||||
|
||||
在我们敲下回车键之后,问题是我们的 shell 会直接退出而不是等待下一个命令。然而,目标正确地被创建。
|
||||
在我们敲下回车键之后,问题是我们的 shell 会直接退出而不是等待下一个命令。然而,目录正确地创建了。
|
||||
|
||||
因此,`execvp` 实际上做了什么?
|
||||
|
||||
`execvp` 是系统调用 `exec` 的一个变体。第一个参数是程序名字。`v` 表示第二个参数是一个程序参数列表(可变参数)。`p` 表示环境变量 `PATH` 会被用于搜索给定的程序名字。在我们上一次的尝试中,它将会基于我们的 `PATH` 环境变量查找`mkdir` 程序。
|
||||
`execvp` 是系统调用 `exec` 的一个变体。第一个参数是程序名字。`v` 表示第二个参数是一个程序参数列表(参数数量可变)。`p` 表示将会使用环境变量 `PATH` 搜索给定的程序名字。在我们上一次的尝试中,它将会基于我们的 `PATH` 环境变量查找`mkdir` 程序。
|
||||
|
||||
(还有其他 `exec` 变体,比如 execv、execvpe、execl、execlp、execlpe;你可以 google 它们获取更多的信息。)
|
||||
|
||||
@ -158,7 +158,7 @@ def execute(cmd_tokens):
|
||||
|
||||
因此,我们需要其他的系统调用来解决问题:`fork`。
|
||||
|
||||
`fork` 会开辟新的内存并拷贝当前进程到一个新的进程。我们称这个新的进程为**子进程**,调用者进程为**父进程**。然后,子进程内存会被替换为被执行的程序。因此,我们的 shell,也就是父进程,可以免受内存替换的危险。
|
||||
`fork` 会分配新的内存并拷贝当前进程到一个新的进程。我们称这个新的进程为**子进程**,调用者进程为**父进程**。然后,子进程内存会被替换为被执行的程序。因此,我们的 shell,也就是父进程,可以免受内存替换的危险。
|
||||
|
||||
让我们看看修改的代码。
|
||||
|
||||
@ -166,34 +166,34 @@ def execute(cmd_tokens):
|
||||
...
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Fork a child shell process
|
||||
# If the current process is a child process, its `pid` is set to `0`
|
||||
# else the current process is a parent process and the value of `pid`
|
||||
# is the process id of its child process.
|
||||
### 分叉一个子 shell 进程
|
||||
### 如果当前进程是子进程,其 `pid` 被设置为 `0`
|
||||
### 否则当前进程是父进程的话,`pid` 的值
|
||||
### 是其子进程的进程 ID。
|
||||
pid = os.fork()
|
||||
|
||||
if pid == 0:
|
||||
# Child process
|
||||
# Replace the child shell process with the program called with exec
|
||||
### 子进程
|
||||
### 用被 exec 调用的程序替换该子进程
|
||||
os.execvp(cmd_tokens[0], cmd_tokens)
|
||||
elif pid > 0:
|
||||
# Parent process
|
||||
### 父进程
|
||||
while True:
|
||||
# Wait response status from its child process (identified with pid)
|
||||
### 等待其子进程的响应状态(以进程 ID 来查找)
|
||||
wpid, status = os.waitpid(pid, 0)
|
||||
|
||||
# Finish waiting if its child process exits normally
|
||||
# or is terminated by a signal
|
||||
### 当其子进程正常退出时
|
||||
### 或者其被信号中断时,结束等待状态
|
||||
if os.WIFEXITED(status) or os.WIFSIGNALED(status):
|
||||
break
|
||||
|
||||
# Return status indicating to wait for next command in shell_loop
|
||||
### 返回状态以告知在 shell_loop 中等待下一个命令
|
||||
return SHELL_STATUS_RUN
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
当我们的父进程调用 `os.fork()`时,你可以想象所有的源代码被拷贝到了新的子进程。此时此刻,父进程和子进程看到的是相同的代码,且并行运行着。
|
||||
当我们的父进程调用 `os.fork()` 时,你可以想象所有的源代码被拷贝到了新的子进程。此时此刻,父进程和子进程看到的是相同的代码,且并行运行着。
|
||||
|
||||
如果运行的代码属于子进程,`pid` 将为 `0`。否则,如果运行的代码属于父进程,`pid` 将会是子进程的进程 id。
|
||||
|
||||
@ -205,13 +205,13 @@ def execute(cmd_tokens):
|
||||
|
||||
现在,你可以尝试运行我们的 shell 并输入 `mkdir test_dir2`。它应该可以正确执行。我们的主 shell 进程仍然存在并等待下一条命令。尝试执行 `ls`,你可以看到已创建的目录。
|
||||
|
||||
但是,这里仍有许多问题。
|
||||
但是,这里仍有一些问题。
|
||||
|
||||
第一,尝试执行 `cd test_dir2`,接着执行 `ls`。它应该会进入到一个空的 `test_dir2` 目录。然而,你将会看到目录并没有变为 `test_dir2`。
|
||||
|
||||
第二,我们仍然没有办法优雅地退出我们的 shell。
|
||||
|
||||
我们将会在 [Part 2][1] 解决诸如此类的问题。
|
||||
我们将会在 [第二部分][1] 解决诸如此类的问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -219,8 +219,8 @@ def execute(cmd_tokens):
|
||||
via: https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/
|
||||
|
||||
作者:[Supasate Choochaisri][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,17 +1,17 @@
|
||||
使用 Python 创建你自己的 Shell:Part II
|
||||
使用 Python 创建你自己的 Shell(下)
|
||||
===========================================
|
||||
|
||||
在[part 1][1] 中,我们已经创建了一个主要的 shell 循环、切分了的命令输入,以及通过 `fork` 和 `exec` 执行命令。在这部分,我们将会解决剩下的问题。首先,`cd test_dir2` 命令无法修改我们的当前目录。其次,我们仍无法优雅地从 shell 中退出。
|
||||
在[上篇][1]中,我们已经创建了一个 shell 主循环、切分了命令输入,以及通过 `fork` 和 `exec` 执行命令。在这部分,我们将会解决剩下的问题。首先,`cd test_dir2` 命令无法修改我们的当前目录。其次,我们仍无法优雅地从 shell 中退出。
|
||||
|
||||
### 步骤 4:内置命令
|
||||
|
||||
“cd test_dir2 无法修改我们的当前目录” 这句话是对的,但在某种意义上也是错的。在执行完该命令之后,我们仍然处在同一目录,从这个意义上讲,它是对的。然而,目录实际上已经被修改,只不过它是在子进程中被修改。
|
||||
“`cd test_dir2` 无法修改我们的当前目录” 这句话是对的,但在某种意义上也是错的。在执行完该命令之后,我们仍然处在同一目录,从这个意义上讲,它是对的。然而,目录实际上已经被修改,只不过它是在子进程中被修改。
|
||||
|
||||
还记得我们 fork 了一个子进程,然后执行命令,执行命令的过程没有发生在父进程上。结果是我们只是改变了子进程的当前目录,而不是父进程的目录。
|
||||
还记得我们分叉(fork)了一个子进程,然后执行命令,执行命令的过程没有发生在父进程上。结果是我们只是改变了子进程的当前目录,而不是父进程的目录。
|
||||
|
||||
然后子进程退出,而父进程在原封不动的目录下继续运行。
|
||||
|
||||
因此,这类与 shell 自己相关的命令必须是内置命令。它必须在 shell 进程中执行而没有分叉(forking)。
|
||||
因此,这类与 shell 自己相关的命令必须是内置命令。它必须在 shell 进程中执行而不是在分叉中(forking)。
|
||||
|
||||
#### cd
|
||||
|
||||
@ -35,7 +35,6 @@ yosh_project
|
||||
import os
|
||||
from yosh.constants import *
|
||||
|
||||
|
||||
def cd(args):
|
||||
os.chdir(args[0])
|
||||
|
||||
@ -66,23 +65,21 @@ SHELL_STATUS_RUN = 1
|
||||
|
||||
```python
|
||||
...
|
||||
# Import constants
|
||||
### 导入常量
|
||||
from yosh.constants import *
|
||||
|
||||
# Hash map to store built-in function name and reference as key and value
|
||||
### 使用哈希映射来存储内建的函数名及其引用
|
||||
built_in_cmds = {}
|
||||
|
||||
|
||||
def tokenize(string):
|
||||
return shlex.split(string)
|
||||
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Extract command name and arguments from tokens
|
||||
### 从元组中分拆命令名称与参数
|
||||
cmd_name = cmd_tokens[0]
|
||||
cmd_args = cmd_tokens[1:]
|
||||
|
||||
# If the command is a built-in command, invoke its function with arguments
|
||||
### 如果该命令是一个内建命令,使用参数调用该函数
|
||||
if cmd_name in built_in_cmds:
|
||||
return built_in_cmds[cmd_name](cmd_args)
|
||||
|
||||
@ -91,29 +88,29 @@ def execute(cmd_tokens):
|
||||
|
||||
我们使用一个 python 字典变量 `built_in_cmds` 作为哈希映射(hash map),以存储我们的内置函数。我们在 `execute` 函数中提取命令的名字和参数。如果该命令在我们的哈希映射中,则调用对应的内置函数。
|
||||
|
||||
(提示:`built_in_cmds[cmd_name]` 返回能直接使用参数调用的函数引用的。)
|
||||
(提示:`built_in_cmds[cmd_name]` 返回能直接使用参数调用的函数引用。)
|
||||
|
||||
我们差不多准备好使用内置的 `cd` 函数了。最后一步是将 `cd` 函数添加到 `built_in_cmds` 映射中。
|
||||
|
||||
```
|
||||
...
|
||||
# Import all built-in function references
|
||||
### 导入所有内建函数引用
|
||||
from yosh.builtins import *
|
||||
|
||||
...
|
||||
|
||||
# Register a built-in function to built-in command hash map
|
||||
### 注册内建函数到内建命令的哈希映射中
|
||||
def register_command(name, func):
|
||||
built_in_cmds[name] = func
|
||||
|
||||
|
||||
# Register all built-in commands here
|
||||
### 在此注册所有的内建命令
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
|
||||
|
||||
def main():
|
||||
# Init shell before starting the main loop
|
||||
###在开始主循环之前初始化 shell
|
||||
init()
|
||||
shell_loop()
|
||||
```
|
||||
@ -138,7 +135,7 @@ from yosh.builtins.cd import *
|
||||
|
||||
我们需要一个可以修改 shell 状态为 `SHELL_STATUS_STOP` 的函数。这样,shell 循环可以自然地结束,shell 将到达终点而退出。
|
||||
|
||||
和 `cd` 一样,如果我们在子进程中 fork 和执行 `exit` 函数,其对父进程是不起作用的。因此,`exit` 函数需要成为一个 shell 内置函数。
|
||||
和 `cd` 一样,如果我们在子进程中分叉并执行 `exit` 函数,其对父进程是不起作用的。因此,`exit` 函数需要成为一个 shell 内置函数。
|
||||
|
||||
让我们从这开始:在 `builtins` 目录下创建一个名为 `exit.py` 的新文件。
|
||||
|
||||
@ -159,7 +156,6 @@ yosh_project
|
||||
```
|
||||
from yosh.constants import *
|
||||
|
||||
|
||||
def exit(args):
|
||||
return SHELL_STATUS_STOP
|
||||
```
|
||||
@ -173,11 +169,10 @@ from yosh.builtins.exit import *
|
||||
|
||||
最后,我们在 `shell.py` 中的 `init()` 函数注册 `exit` 命令。
|
||||
|
||||
|
||||
```
|
||||
...
|
||||
|
||||
# Register all built-in commands here
|
||||
### 在此注册所有的内建命令
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
register_command("exit", exit)
|
||||
@ -193,7 +188,7 @@ def init():
|
||||
|
||||
我希望你能像我一样享受创建 `yosh` (**y**our **o**wn **sh**ell)的过程。但我的 `yosh` 版本仍处于早期阶段。我没有处理一些会使 shell 崩溃的极端状况。还有很多我没有覆盖的内置命令。为了提高性能,一些非内置命令也可以实现为内置命令(避免新进程创建时间)。同时,大量的功能还没有实现(请看 [公共特性](http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html) 和 [不同特性](http://www.tldp.org/LDP/intro-linux/html/x12249.html))
|
||||
|
||||
我已经在 github.com/supasate/yosh 中提供了源代码。请随意 fork 和尝试。
|
||||
我已经在 https://github.com/supasate/yosh 中提供了源代码。请随意 fork 和尝试。
|
||||
|
||||
现在该是创建你真正自己拥有的 Shell 的时候了。
|
||||
|
||||
@ -205,12 +200,12 @@ via: https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-pyt
|
||||
|
||||
作者:[Supasate Choochaisri][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://disqus.com/by/supasate_choochaisri/
|
||||
[1]: https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/
|
||||
[1]: https://linux.cn/article-7624-1.html
|
||||
[2]: http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html
|
||||
[3]: http://www.tldp.org/LDP/intro-linux/html/x12249.html
|
||||
[4]: https://github.com/supasate/yosh
|
||||
200
published/20160722 7 Best Markdown Editors for Linux.md
Normal file
200
published/20160722 7 Best Markdown Editors for Linux.md
Normal file
@ -0,0 +1,200 @@
|
||||
Linux 上 10 个最好的 Markdown 编辑器
|
||||
======================================
|
||||
|
||||
在这篇文章中,我们会点评一些可以在 Linux 上安装使用的最好的 Markdown 编辑器。 你可以找到非常多的 Linux 平台上的 Markdown 编辑器,但是在这里我们将尽可能地为您推荐那些最好的。
|
||||
|
||||
|
||||
|
||||
*Best Linux Markdown Editors*
|
||||
|
||||
对于不了解 Markdown 的人做个简单介绍,Markdown 是由著名的 Aaron Swartz 和 John Gruber 发明的标记语言,其最初的解析器是一个用 Perl 写的简单、轻量的[同名工具][1]。它可以将用户写的纯文本转为可用的 HTML(或 XHTML)。它实际上是一门易读,易写的纯文本语言,以及一个用于将文本转为 HTML 的转换工具。
|
||||
|
||||
希望你先对 Markdown 有一个稍微的了解,接下来让我们逐一列出这些编辑器。
|
||||
|
||||
### 1. Atom
|
||||
|
||||
Atom 是一个现代的、跨平台、开源且强大的文本编辑器,它可以运行在 Linux、Windows 和 MAC OS X 等操作系统上。用户可以在它的基础上进行定制,删减修改任何配置文件。
|
||||
|
||||
它包含了一些非常杰出的特性:
|
||||
|
||||
- 内置软件包管理器
|
||||
- 智能自动补全功能
|
||||
- 提供多窗口操作
|
||||
- 支持查找替换功能
|
||||
- 包含一个文件系统浏览器
|
||||
- 轻松自定义主题
|
||||
- 开源、高度扩展性的软件包等
|
||||
|
||||
|
||||
|
||||
*Atom Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://atom.io/>
|
||||
|
||||
### 2. GNU Emacs
|
||||
|
||||
Emacs 是 Linux 平台上一款的流行文本编辑器。它是一个非常棒的、具备高扩展性和定制性的 Markdown 语言编辑器。
|
||||
|
||||
它综合了以下这些神奇的特性:
|
||||
|
||||
- 带有丰富的内置文档,包括适合初学者的教程
|
||||
- 有完整的 Unicode 支持,可显示所有的人类符号
|
||||
- 支持内容识别的文本编辑模式
|
||||
- 包括多种文件类型的语法高亮
|
||||
- 可用 Emacs Lisp 或 GUI 对其进行高度定制
|
||||
- 提供了一个包系统可用来下载安装各种扩展等
|
||||
|
||||

|
||||
|
||||
*Emacs Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://www.gnu.org/software/emacs/>
|
||||
|
||||
### 3. Remarkable
|
||||
|
||||
Remarkable 可能是 Linux 上最好的 Markdown 编辑器了,它也适用于 Windows 操作系统。它的确是是一个卓越且功能齐全的 Markdown 编辑器,为用户提供了一些令人激动的特性。
|
||||
|
||||
一些卓越的特性:
|
||||
|
||||
- 支持实时预览
|
||||
- 支持导出 PDF 和 HTML
|
||||
- 支持 Github Markdown 语法
|
||||
- 支持定制 CSS
|
||||
- 支持语法高亮
|
||||
- 提供键盘快捷键
|
||||
- 高可定制性和其他
|
||||
|
||||
|
||||
|
||||
*Remarkable Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://remarkableapp.github.io>
|
||||
|
||||
### 4. Haroopad
|
||||
|
||||
Haroopad 是为 Linux,Windows 和 Mac OS X 构建的跨平台 Markdown 文档处理程序。用户可以用它来书写许多专家级格式的文档,包括电子邮件、报告、博客、演示文稿和博客文章等等。
|
||||
|
||||
功能齐全且具备以下的亮点:
|
||||
|
||||
- 轻松导入内容
|
||||
- 支持导出多种格式
|
||||
- 广泛支持博客和邮件
|
||||
- 支持许多数学表达式
|
||||
- 支持 Github Markdown 扩展
|
||||
- 为用户提供了一些令人兴奋的主题、皮肤和 UI 组件等等
|
||||
|
||||

|
||||
|
||||
*Haroopad Markdown Editor for Linux*
|
||||
|
||||
访问主页: <http://pad.haroopress.com/>
|
||||
|
||||
### 5. ReText
|
||||
|
||||
ReText 是为 Linux 和其它几个 POSIX 兼容操作系统提供的简单、轻量、强大的 Markdown 编辑器。它还可以作为一个 reStructuredText 编辑器,并且具有以下的特性:
|
||||
|
||||
- 简单直观的 GUI
|
||||
- 具备高定制性,用户可以自定义语法文件和配置选项
|
||||
- 支持多种配色方案
|
||||
- 支持使用多种数学公式
|
||||
- 启用导出扩展等等
|
||||
|
||||
|
||||
|
||||
*ReText Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://github.com/retext-project/retext>
|
||||
|
||||
### 6. UberWriter
|
||||
|
||||
UberWriter 是一个简单、易用的 Linux Markdown 编辑器。它的开发受 Mac OS X 上的 iA writer 影响很大,同样它也具备这些卓越的特性:
|
||||
|
||||
- 使用 pandoc 进行所有的文本到 HTML 的转换
|
||||
- 提供了一个简洁的 UI 界面
|
||||
- 提供了一种专心(distraction free)模式,高亮用户最后的句子
|
||||
- 支持拼写检查
|
||||
- 支持全屏模式
|
||||
- 支持用 pandoc 导出 PDF、HTML 和 RTF
|
||||
- 启用语法高亮和数学函数等等
|
||||
|
||||
|
||||
|
||||
*UberWriter Markdown Editor for Linux*
|
||||
|
||||
访问主页: <http://uberwriter.wolfvollprecht.de/>
|
||||
|
||||
### 7. Mark My Words
|
||||
|
||||
Mark My Words 同样也是一个轻量、强大的 Markdown 编辑器。它是一个相对比较新的编辑器,因此提供了包含语法高亮在内的大量的功能,简单和直观的 UI。
|
||||
|
||||
下面是一些棒极了,但还未捆绑到应用中的功能:
|
||||
|
||||
- 实时预览
|
||||
- Markdown 解析和文件 IO
|
||||
- 状态管理
|
||||
- 支持导出 PDF 和 HTML
|
||||
- 监测文件的修改
|
||||
- 支持首选项设置
|
||||
|
||||
|
||||
|
||||
*MarkMyWords Markdown Editor for-Linux*
|
||||
|
||||
访问主页: <https://github.com/voldyman/MarkMyWords>
|
||||
|
||||
### 8. Vim-Instant-Markdown 插件
|
||||
|
||||
Vim 是 Linux 上的一个久经考验的强大、流行而开源的文本编辑器。它用于编程极棒。它也高度支持插件功能,可以让用户为其增加一些其它功能,包括 Markdown 预览。
|
||||
|
||||
有好几种 Vim 的 Markdown 预览插件,但是 [Vim-Instant-Markdown][2] 的表现最佳。
|
||||
|
||||
###9. Bracket-MarkdownPreview 插件
|
||||
|
||||
Brackets 是一个现代、轻量、开源且跨平台的文本编辑器。它特别为 Web 设计和开发而构建。它的一些重要功能包括:支持内联编辑器、实时预览、预处理支持及更多。
|
||||
|
||||
它也是通过插件高度可扩展的,你可以使用 [Bracket-MarkdownPreview][3] 插件来编写和预览 Markdown 文档。
|
||||
|
||||

|
||||
|
||||
*Brackets Markdown Plugin Preview*
|
||||
|
||||
### 10. SublimeText-Markdown 插件
|
||||
|
||||
Sublime Text 是一个精心打造的、流行的、跨平台文本编辑器,用于代码、markdown 和普通文本。它的表现极佳,包括如下令人兴奋的功能:
|
||||
|
||||
- 简洁而美观的 GUI
|
||||
- 支持多重选择
|
||||
- 提供专心模式
|
||||
- 支持窗体分割编辑
|
||||
- 通过 Python 插件 API 支持高度插件化
|
||||
- 完全可定制化,提供命令查找模式
|
||||
|
||||
[SublimeText-Markdown][4] 插件是一个支持格式高亮的软件包,带有一些漂亮的颜色方案。
|
||||
|
||||
|
||||
|
||||
*SublimeText Markdown Plugin Preview*
|
||||
|
||||
### 结论
|
||||
|
||||
通过上面的列表,你大概已经知道要为你的 Linux 桌面下载、安装什么样的 Markdown 编辑器和文档处理程序了。
|
||||
|
||||
请注意,这里提到的最好的 Markdown 编辑器可能对你来说并不是最好的选择。因此你可以通过下面的反馈部分,为我们展示你认为列表中未提及的,并且具备足够的资格的,令人兴奋的 Markdown 编辑器。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/best-markdown-editors-for-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[Locez](https://github.com/locez)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: https://daringfireball.net/projects/markdown/
|
||||
[2]: https://github.com/suan/vim-instant-markdown
|
||||
[3]: https://github.com/gruehle/MarkdownPreview
|
||||
[4]: https://github.com/SublimeText-Markdown/MarkdownEditing
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
怎样在 Ubuntu 中修改默认程序
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
> 简介: 这个新手指南会向你展示如何在 Ubuntu Linux 中修改默认程序
|
||||
|
||||
对于我来说,安装 [VLC 多媒体播放器][1]是[安装完 Ubuntu 16.04 该做的事][2]中最先做的几件事之一。为了能够使我双击一个视频就用 VLC 打开,在我安装完 VLC 之后我会设置它为默认程序。
|
||||
|
||||
作为一个新手,你需要知道如何在 Ubuntu 中修改任何默认程序,这也是我今天在这篇指南中所要讲的。
|
||||
|
||||
### 在 UBUNTU 中修改默认程序
|
||||
|
||||
这里提及的方法适用于所有的 Ubuntu 12.04,Ubuntu 14.04 和Ubuntu 16.04。在 Ubuntu 中,这里有两种基本的方法可以修改默认程序:
|
||||
|
||||
- 通过系统设置
|
||||
- 通过右键菜单
|
||||
|
||||
#### 1.通过系统设置修改 Ubuntu 的默认程序
|
||||
|
||||
进入 Unity 面板并且搜索系统设置(System Settings):
|
||||
|
||||

|
||||
|
||||
在系统设置(System Settings)中,选择详细选项(Details):
|
||||
|
||||

|
||||
|
||||
在左边的面板中选择默认程序(Default Applications),你会发现在右边的面板中可以修改默认程序。
|
||||
|
||||

|
||||
|
||||
正如看到的那样,这里只有少数几类的默认程序可以被改变。你可以在这里改变浏览器、邮箱客户端、日历、音乐、视频和相册的默认程序。那其他类型的默认程序怎么修改?
|
||||
|
||||
不要担心,为了修改其他类型的默认程序,我们会用到右键菜单。
|
||||
|
||||
#### 2.通过右键菜单修改默认程序
|
||||
|
||||
如果你使用过 Windows 系统,你应该看见过右键菜单的“打开方式”,可以通过这个来修改默认程序。我们在 Ubuntu 中也有相似的方法。
|
||||
|
||||
右键一个还没有设置默认打开程序的文件,选择“属性(properties)”
|
||||
|
||||

|
||||
|
||||
*从右键菜单中选择属性*
|
||||
|
||||
在这里,你可以选择使用什么程序打开,并且设置为默认程序。
|
||||
|
||||

|
||||
|
||||
*在 Ubuntu 中设置打开 WebP 图片的默认程序为 gThumb*
|
||||
|
||||
小菜一碟不是么?一旦你做完这些,所有同样类型的文件都会用你选择的默认程序打开。
|
||||
|
||||
我很希望这个新手指南对你在修改 Ubuntu 的默认程序时有帮助。如果你有任何的疑问或者建议,可以随时在下面评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/change-default-applications-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[Locez](https://github.com/locez)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: http://www.videolan.org/vlc/index.html
|
||||
[2]: https://linux.cn/article-7453-1.html
|
||||
@ -0,0 +1,184 @@
|
||||
LFCS 系列第十二讲:如何使用 Linux 的帮助文档和工具
|
||||
==================================================================================
|
||||
|
||||
由于 2016 年 2 月 2 号开始启用了新的 LFCS 考试要求, 我们在 [LFCS 系列][1]系列添加了一些必要的内容。为了考试的需要,我们强烈建议你看一下[LFCE 系列][2]。
|
||||
|
||||

|
||||
|
||||
*LFCS: 了解 Linux 的帮助文档和工具*
|
||||
|
||||
当你习惯了在命令行下进行工作,你会发现 Linux 已经有了许多使用和配置 Linux 系统所需要的文档。
|
||||
|
||||
另一个你必须熟悉命令行帮助工具的理由是,在[LFCS][3] 和 [LFCE][4] 考试中,它们是你唯一能够使用的信息来源,没有互联网也没有百度。你只能依靠你自己和命令行。
|
||||
|
||||
基于上面的理由,在这一章里我们将给你一些建议来可以让你有效的使用这些安装的文档和工具,以帮助你通过**Linux 基金会认证**考试。
|
||||
|
||||
### Linux 帮助手册(man)
|
||||
|
||||
man 手册是 manual 手册的缩写,就是其名字所揭示的那样:一个给定工具的帮助手册。它包含了命令所支持的选项列表(以及解释),有些工具甚至还提供一些使用范例。
|
||||
|
||||
我们用 **man 命令** 跟上你想要了解的工具名称来打开一个帮助手册。例如:
|
||||
|
||||
```
|
||||
# man diff
|
||||
```
|
||||
|
||||
这将打开`diff`的手册页,这个工具将逐行对比文本文件(如你想退出只需要轻轻的点一下 q 键)。
|
||||
|
||||
下面我来比较两个文本文件 `file1` 和 `file2`。这两个文本文件包含了使用同一个 Linux 发行版相同版本安装的两台机器上的的安装包列表。
|
||||
|
||||
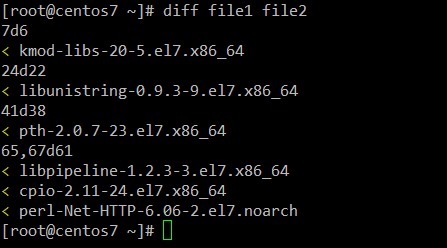
输入`diff` 命令它将告诉我们 `file1` 和`file2` 有什么不同:
|
||||
|
||||
```
|
||||
# diff file1 file2
|
||||
```
|
||||
|
||||
|
||||
|
||||
*在Linux中比较两个文本文件*
|
||||
|
||||
`<` 这个符号是说`file2`缺失的行。如果是 `file1`缺失,我们将用 `>` 符号来替代指示。
|
||||
|
||||
另外,**7d6** 意思是说`file1`的第**7**行要删除了才能和`file2`一致(**24d22** 和 **41d38** 也是同样的意思) **65,67d61** 告诉需要删除从第 **65** 行到 **67** 行。我们完成了以上步骤,那么这两个文件将完全一致。
|
||||
|
||||
此外,根据 man 手册说明,你还可以通过 `-y` 选项来以两路的方式显示文件。你可以发现这对于你找到两个文件间的不同根据方便容易。
|
||||
|
||||
```
|
||||
# diff -y file1 file2
|
||||
```
|
||||
|
||||

|
||||
|
||||
*比较并列出两个文件的不同*
|
||||
|
||||
此外,你也可以用`diff`来比较两个二进制文件。如果它们完全一样,`diff` 将什么也不会输出。否则,它将会返回如下信息:“**Binary files X and Y differ**”。
|
||||
|
||||
### –help 选项
|
||||
|
||||
`--help`选项,大多数命令都支持它(并不是所有), 它可以理解为一个命令的简短帮助手册。尽管它没有提供工具的详细介绍,但是确实是一个能够快速列出程序的所支持的选项的不错的方法。
|
||||
|
||||
例如,
|
||||
|
||||
```
|
||||
# sed --help
|
||||
```
|
||||
|
||||
将显示 sed (流编辑器)的每个支持的选项。
|
||||
|
||||
`sed`命令的一个典型用法是替换文件中的字符。用 `-i` 选项(意思是 “**原地编辑编辑文件**”),你可以编辑一个文件而且并不需要打开它。 如果你想要同时备份一个原始文件,用 `-i` 选项加后缀来创建一个原始文件的副本。
|
||||
|
||||
例如,替换 `lorem.txt` 中的`Lorem` 为 `Tecmint`(忽略大小写),并且创建一个原文件的备份副本,命令如下:
|
||||
|
||||
```
|
||||
# less lorem.txt | grep -i lorem
|
||||
# sed -i.orig 's/Lorem/Tecmint/gI' lorem.txt
|
||||
# less lorem.txt | grep -i lorem
|
||||
# less lorem.txt.orig | grep -i lorem
|
||||
```
|
||||
|
||||
请注意`lorem.txt`文件中`Lorem` 都已经替换为 `Tecmint`,并且原文件 `lorem.txt` 被保存为`lorem.txt.orig`。
|
||||
|
||||

|
||||
|
||||
*替换文件中的文本*
|
||||
|
||||
### /usr/share/doc 内的文档
|
||||
|
||||
这可能是我最喜欢的方法。如果你进入 `/usr/share/doc` 目录,并列出该目录,你可以看到许多以安装在你的 Linux 上的工具为名称的文件夹。
|
||||
|
||||
根据 [文件系统层级标准][5],这些文件夹包含了许多帮助手册没有的信息,还有一些可以使配置更方便的模板和配置文件。
|
||||
|
||||
例如,让我们来看一下 `squid-3.3.8` (不同发行版的版本可能会不同),这还是一个非常受欢迎的 HTTP 代理和 [squid 缓存服务器][6]。
|
||||
|
||||
让我们用`cd`命令进入目录:
|
||||
|
||||
```
|
||||
# cd /usr/share/doc/squid-3.3.8
|
||||
```
|
||||
|
||||
列出当前文件夹列表:
|
||||
|
||||
```
|
||||
# ls
|
||||
```
|
||||
|
||||

|
||||
|
||||
*使用 ls 列出目录*
|
||||
|
||||
你应该特别注意 `QUICKSTART` 和 `squid.conf.documented`。这些文件分别包含了 Squid 详细文档及其经过详细备注的配置文件。对于别的安装包来说,具体的名字可能不同(有可能是 **QuickRef** 或者**00QUICKSTART**),但意思是一样的。
|
||||
|
||||
对于另外一些安装包,比如 Apache web 服务器,在`/usr/share/doc`目录提供了配置模板,当你配置独立服务器或者虚拟主机的时候会非常有用。
|
||||
|
||||
### GNU 信息文档
|
||||
|
||||
你可以把它看做帮助手册的“开挂版”。它不仅仅提供工具的帮助信息,而且还是超级链接的形式(没错,在命令行中的超级链接),你可以通过箭头按钮从一个章节导航到另外章节,并按下回车按钮来确认。
|
||||
|
||||
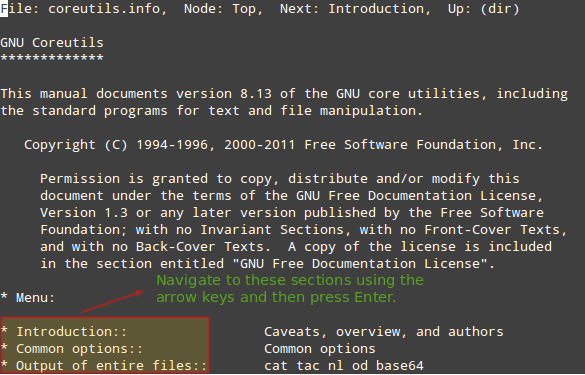
一个典型的例子是:
|
||||
|
||||
```
|
||||
# info coreutils
|
||||
```
|
||||
|
||||
因为 coreutils 包含了每个系统中都有的基本文件、shell 和文本处理工具,你自然可以从 coreutils 的 info 文档中得到它们的详细介绍。
|
||||
|
||||
|
||||
|
||||
*Info Coreutils*
|
||||
|
||||
和帮助手册一样,你可以按 q 键退出。
|
||||
|
||||
此外,GNU info 还可以显示标准的帮助手册。 例如:
|
||||
|
||||
```
|
||||
# info tune2fs
|
||||
```
|
||||
|
||||
它将显示 **tune2fs**的帮助手册, 这是一个 ext2/3/4 文件系统管理工具。
|
||||
|
||||
我们现在看到了,让我们来试试怎么用**tune2fs**:
|
||||
|
||||
显示 **/dev/mapper/vg00-vol_backups** 文件系统信息:
|
||||
|
||||
```
|
||||
# tune2fs -l /dev/mapper/vg00-vol_backups
|
||||
```
|
||||
|
||||
修改文件系统标签(修改为 Backups):
|
||||
|
||||
```
|
||||
# tune2fs -L Backups /dev/mapper/vg00-vol_backups
|
||||
```
|
||||
|
||||
设置文件系统的自检间隔及挂载计数(用`-c` 选项设置挂载计数间隔, 用 `-i` 选项设置自检时间间隔,这里 **d 表示天,w 表示周,m 表示月**)。
|
||||
|
||||
```
|
||||
# tune2fs -c 150 /dev/mapper/vg00-vol_backups # 每 150 次挂载检查一次
|
||||
# tune2fs -i 6w /dev/mapper/vg00-vol_backups # 每 6 周检查一次
|
||||
```
|
||||
|
||||
以上这些内容也可以通过 `--help` 选项找到,或者查看帮助手册。
|
||||
|
||||
### 摘要
|
||||
|
||||
不管你选择哪种方法,知道并且会使用它们在考试中对你是非常有用的。你知道其它的一些方法吗? 欢迎给我们留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/explore-linux-installed-help-documentation-and-tools/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]: https://linux.cn/article-7161-1.html
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: https://linux.cn/article-7161-1.html
|
||||
[4]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[5]: https://linux.cn/article-6132-1.html
|
||||
[6]: http://www.tecmint.com/configure-squid-server-in-linux/
|
||||
[7]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Part 1 - LXD 2.0: LXD 入门
|
||||
LXD 2.0 系列(一):LXD 入门
|
||||
======================================
|
||||
|
||||
这是 [LXD 2.0 系列介绍文章][1]的第一篇。
|
||||
@ -20,12 +20,11 @@ LXD 最主要的目标就是使用 Linux 容器而不是硬件虚拟化向用户
|
||||
|
||||
LXD 聚焦于系统容器,通常也被称为架构容器。这就是说 LXD 容器实际上如在裸机或虚拟机上运行一般运行了一个完整的 Linux 操作系统。
|
||||
|
||||
这些容器一般基于一个干净的发布镜像并会长时间运行。传统的配置管理工具和部署工具可以如在虚拟机、云和物理机器上一样与 LXD 一起使用。
|
||||
这些容器一般基于一个干净的发布镜像并会长时间运行。传统的配置管理工具和部署工具可以如在虚拟机、云实例和物理机器上一样与 LXD 一起使用。
|
||||
|
||||
相对的, Docker 关注于短期的、无状态的最小容器,这些容器通常并不会升级或者重新配置,而是作为一个整体被替换掉。这就使得 Docker 及类似项目更像是一种软件发布机制,而不是一个机器管理工具。
|
||||
|
||||
这两种模型并不是完全互斥的。你完全可以使用 LXD 为你的用户提供一个完整的 Linux 系统,而他们可以在 LXD 内安装 Docker 来运行他们想要的软件。
|
||||
相对的, Docker 关注于短期的、无状态的、最小化的容器,这些容器通常并不会升级或者重新配置,而是作为一个整体被替换掉。这就使得 Docker 及类似项目更像是一种软件发布机制,而不是一个机器管理工具。
|
||||
|
||||
这两种模型并不是完全互斥的。你完全可以使用 LXD 为你的用户提供一个完整的 Linux 系统,然后他们可以在 LXD 内安装 Docker 来运行他们想要的软件。
|
||||
|
||||
#### 为什么要用 LXD?
|
||||
|
||||
@ -35,56 +34,55 @@ LXD 聚焦于系统容器,通常也被称为架构容器。这就是说 LXD
|
||||
|
||||
我们把 LXD 作为解决这些缺陷的一个很好的机会。作为一个长时间运行的守护进程, LXD 可以绕开 LXC 的许多限制,比如动态资源限制、无法进行容器迁移和高效的在线迁移;同时,它也为创造新的默认体验提供了机会:默认开启安全特性,对用户更加友好。
|
||||
|
||||
|
||||
### LXD 的主要组件
|
||||
|
||||
LXD 是由几个主要组件构成的,这些组件都是 LXD 目录结构、命令行客户端和 API 结构体里下可见的。
|
||||
LXD 是由几个主要组件构成的,这些组件都出现在 LXD 目录结构、命令行客户端和 API 结构体里。
|
||||
|
||||
#### 容器
|
||||
|
||||
LXD 中的容器包括以下及部分:
|
||||
|
||||
- 根文件系统
|
||||
- 根文件系统(rootfs)
|
||||
- 配置选项列表,包括资源限制、环境、安全选项等等
|
||||
- 设备:包括磁盘、unix 字符/块设备、网络接口
|
||||
- 一组继承而来的容器配置文件
|
||||
- 属性(容器架构,暂时的或持久的,容器名)
|
||||
- 运行时状态(当时为了记录检查点、恢复时用到了 CRIU时)
|
||||
- 属性(容器架构、暂时的还是持久的、容器名)
|
||||
- 运行时状态(当用 CRIU 来中断/恢复时)
|
||||
|
||||
#### 快照
|
||||
|
||||
容器快照和容器是一回事,只不过快照是不可修改的,只能被重命名,销毁或者用来恢复系统,但是无论如何都不能被修改。
|
||||
|
||||
值得注意的是,因为我们允许用户保存容器的运行时状态,这就有效的为我们提供了“有状态”的快照的功能。这就是说我们可以使用快照回滚容器的 CPU 和内存。
|
||||
值得注意的是,因为我们允许用户保存容器的运行时状态,这就有效的为我们提供了“有状态”的快照的功能。这就是说我们可以使用快照回滚容器的状态,包括快照当时的 CPU 和内存状态。
|
||||
|
||||
#### 镜像
|
||||
|
||||
LXD 是基于镜像实现的,所有的 LXD 容器都是来自于镜像。容器镜像通常是一些纯净的 Linux 发行版的镜像,类似于你们在虚拟机和云实例上使用的镜像。
|
||||
|
||||
所以就可以「发布」容器:使用容器制作一个镜像并在本地或者远程 LXD 主机上使用。
|
||||
所以可以「发布」一个容器:使用容器制作一个镜像并在本地或者远程 LXD 主机上使用。
|
||||
|
||||
镜像通常使用全部或部分 sha256 哈希码来区分。因为输入长长的哈希码对用户来说不好,所以镜像可以使用几个自身的属性来区分,这就使得用户在镜像商店里方便搜索镜像。别名也可以用来 1 对 1 地把对用户友好的名字映射到某个镜像的哈希码。
|
||||
镜像通常使用全部或部分 sha256 哈希码来区分。因为输入长长的哈希码对用户来说不方便,所以镜像可以使用几个自身的属性来区分,这就使得用户在镜像商店里方便搜索镜像。也可以使用别名来一对一地将一个用户好记的名字映射到某个镜像的哈希码上。
|
||||
|
||||
LXD 安装时已经配置好了三个远程镜像服务器(参见下面的远程一节):
|
||||
|
||||
- “ubuntu:” 提供稳定版的 Ubuntu 镜像
|
||||
- “ubuntu-daily:” 提供每天构建出来的 Ubuntu
|
||||
- “images:” 社区维护的镜像服务器,提供一系列的 Linux 发布版,使用的是上游 LXC 的模板
|
||||
- “ubuntu”:提供稳定版的 Ubuntu 镜像
|
||||
- “ubuntu-daily”:提供 Ubuntu 的每日构建镜像
|
||||
- “images”: 社区维护的镜像服务器,提供一系列的其它 Linux 发布版,使用的是上游 LXC 的模板
|
||||
|
||||
LXD 守护进程会从镜像上次被使用开始自动缓存远程镜像一段时间(默认是 10 天),超过时限后这些镜像才会失效。
|
||||
|
||||
此外, LXD 还会自动更新远程镜像(除非指明不更新),所以本地的镜像会一直是最新版的。
|
||||
|
||||
|
||||
#### 配置
|
||||
|
||||
配置文件是一种在一处定义容器配置和容器设备,然后应用到一系列容器的方法。
|
||||
配置文件是一种在一个地方定义容器配置和容器设备,然后将其应用到一系列容器的方法。
|
||||
|
||||
一个容器可以被应用多个配置文件。当构建最终容器配置时(即通常的扩展配置),这些配置文件都会按照他们定义顺序被应用到容器上,当有重名的配置时,新的会覆盖掉旧的。然后本地容器设置会在这些基础上应用,覆盖所有来自配置文件的选项。
|
||||
一个容器可以被应用多个配置文件。当构建最终容器配置时(即通常的扩展配置),这些配置文件都会按照他们定义顺序被应用到容器上,当有重名的配置键或设备时,新的会覆盖掉旧的。然后本地容器设置会在这些基础上应用,覆盖所有来自配置文件的选项。
|
||||
|
||||
LXD 自带两种预配置的配置文件:
|
||||
|
||||
- 「 default 」配置是自动应用在所有容器之上,除非用户提供了一系列替代的配置文件。目前这个配置文件只做一件事,为容器定义 eth0 网络设备。
|
||||
- 「 docker” 」配置是一个允许你在容器里运行 Docker 容器的配置文件。它会要求 LXD 加载一些需要的内核模块以支持容器嵌套并创建一些设备入口。
|
||||
- “default”配置是自动应用在所有容器之上,除非用户提供了一系列替代的配置文件。目前这个配置文件只做一件事,为容器定义 eth0 网络设备。
|
||||
- “docker”配置是一个允许你在容器里运行 Docker 容器的配置文件。它会要求 LXD 加载一些需要的内核模块以支持容器嵌套并创建一些设备。
|
||||
|
||||
#### 远程
|
||||
|
||||
@ -92,14 +90,14 @@ LXD 自带两种预配置的配置文件:
|
||||
|
||||
默认情况下,我们的命令行客户端会与下面几个预定义的远程服务器通信:
|
||||
|
||||
- local:(默认的远程服务器,使用 UNIX socket 和本地的 LXD 守护进程通信)
|
||||
- ubuntu:( Ubuntu 镜像服务器,提供稳定版的 Ubuntu 镜像)
|
||||
- ubuntu-daily:( Ubuntu 镜像服务器,提供每天构建出来的 Ubuntu )
|
||||
- images:( images.linuxcontainers.org 镜像服务器)
|
||||
- local:默认的远程服务器,使用 UNIX socket 和本地的 LXD 守护进程通信
|
||||
- ubuntu:Ubuntu 镜像服务器,提供稳定版的 Ubuntu 镜像
|
||||
- ubuntu-daily:Ubuntu 镜像服务器,提供 Ubuntu 的每日构建版
|
||||
- images:images.linuxcontainers.org 的镜像服务器
|
||||
|
||||
所有这些远程服务器的组合都可以在命令行客户端里使用。
|
||||
|
||||
你也可以添加任意数量的远程 LXD 主机来监听网络。匿名的开放镜像服务器,或者通过认证可以管理远程容器的镜像服务器,都可以添加进来。
|
||||
你也可以添加任意数量的远程 LXD 主机,并配置它们监听网络。匿名的开放镜像服务器,或者通过认证可以管理远程容器的镜像服务器,都可以添加进来。
|
||||
|
||||
正是这种远程机制使得与远程镜像服务器交互及在主机间复制、移动容器成为可能。
|
||||
|
||||
@ -107,30 +105,29 @@ LXD 自带两种预配置的配置文件:
|
||||
|
||||
我们设计 LXD 时的一个核心要求,就是在不修改现代 Linux 发行版的前提下,使容器尽可能的安全。
|
||||
|
||||
LXD 使用的、通过使用 LXC 库实现的主要安全特性有:
|
||||
LXD 通过使用 LXC 库实现的主要安全特性有:
|
||||
|
||||
- 内核名字空间。尤其是用户名字空间,它让容器和系统剩余部分完全分离。LXD 默认使用用户名字空间(和 LXC 相反),并允许用户在需要的时候以容器为单位打开或关闭。
|
||||
- 内核名字空间。尤其是用户名字空间,它让容器和系统剩余部分完全分离。LXD 默认使用用户名字空间(和 LXC 相反),并允许用户在需要的时候以容器为单位关闭(将容器标为“特权的”)。
|
||||
- Seccomp 系统调用。用来隔离潜在危险的系统调用。
|
||||
- AppArmor:对 mount、socket、ptrace 和文件访问提供额外的限制。特别是限制跨容器通信。
|
||||
- AppArmor。对 mount、socket、ptrace 和文件访问提供额外的限制。特别是限制跨容器通信。
|
||||
- Capabilities。阻止容器加载内核模块,修改主机系统时间,等等。
|
||||
- CGroups。限制资源使用,防止对主机的 DoS 攻击。
|
||||
- CGroups。限制资源使用,防止针对主机的 DoS 攻击。
|
||||
|
||||
为了对用户友好,LXD 构建了一个新的配置语言把大部分的这些特性都抽象封装起来,而不是如 LXC 一般直接将这些特性暴露出来。举了例子,一个用户可以告诉 LXD 把主机设备放进容器而不需要手动检查他们的主/次设备号来手动更新 CGroup 策略。
|
||||
|
||||
为了对用户友好 , LXD 构建了一个新的配置语言把大部分的这些特性都抽象封装起来,而不是如 LXC 一般直接将这些特性暴露出来。举了例子,一个用户可以告诉 LXD 把主机设备放进容器而不需要手动检查他们的主/次设备号来更新 CGroup 策略。
|
||||
|
||||
和 LXD 本身通信是基于使用 TLS 1.2 保护的链路,这些链路只允许使用有限的几个被允许的密钥。当和那些经过系统证书认证之外的主机通信时, LXD 会提示用户验证主机的远程足迹(SSH 方式),然后把足迹缓存起来以供以后使用。
|
||||
和 LXD 本身通信是基于使用 TLS 1.2 保护的链路,只允许使用有限的几个被允许的密钥算法。当和那些经过系统证书认证之外的主机通信时, LXD 会提示用户验证主机的远程指纹(SSH 方式),然后把指纹缓存起来以供以后使用。
|
||||
|
||||
### REST 接口
|
||||
|
||||
LXD 的工作都是通过 REST 接口实现的。在客户端和守护进程之间并没有其他的通讯手段。
|
||||
LXD 的工作都是通过 REST 接口实现的。在客户端和守护进程之间并没有其他的通讯渠道。
|
||||
|
||||
REST 接口可以通过本地的 unix socket 访问,这只需要经过组认证,或者经过 HTTP 套接字使用客户端认证进行通信。
|
||||
REST 接口可以通过本地的 unix socket 访问,这只需要经过用户组认证,或者经过 HTTP 套接字使用客户端认证进行通信。
|
||||
|
||||
REST 接口的结构能够和上文所说的不同的组件匹配,是一种简单、直观的使用方法。
|
||||
|
||||
当需要一种复杂的通信机制时, LXD 将会进行 websocket 协商完成剩余的通信工作。这主要用于交互式终端会话、容器迁移和事件通知。
|
||||
|
||||
LXD 2.0 附带了 1.0 版的稳定 API。虽然我们在 1.0 版 API 添加了额外的特性,但是这不会在 1.0 版 API 的端点里破坏向后兼容性,因为我们会声明额外的 API 扩展使得客户端可以找到新的接口。
|
||||
LXD 2.0 附带了 1.0 版的稳定 API。虽然我们在 1.0 版 API 添加了额外的特性,但是这不会在 1.0 版 API 端点里破坏向后兼容性,因为我们会声明额外的 API 扩展使得客户端可以找到新的接口。
|
||||
|
||||
### 容器规模化
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
chenxinlong translating
|
||||
Who needs a GUI? How to live in a Linux terminal
|
||||
=================================================
|
||||
|
||||
@ -84,7 +85,7 @@ LibreOffice, Google Slides or, gasp, PowerPoint. I spend a lot of time in presen
|
||||
via: http://www.networkworld.com/article/3091139/linux/who-needs-a-gui-how-to-live-in-a-linux-terminal.html#slide1
|
||||
|
||||
作者:[Bryan Lunduke][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[译者ID](https://github.com/chenxinlong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,72 +0,0 @@
|
||||
Linux Practicality vs Activism
|
||||
==================================
|
||||
|
||||
>Is Linux actually more practical than other OSes, or is there some higher minded reason to use it?
|
||||
|
||||
One of the greatest things about running Linux is the freedom it provides. Where the division among the Linux community appears is in how we value this freedom.
|
||||
|
||||
For some, the freedom enjoyed by using Linux is the freedom from vendor lock-in or high software costs. Most would call this a practical consideration. Others users would tell you the freedom they enjoy is software freedom. This means embracing Linux distributions that support the [Free Software Movement][1], avoiding proprietary software completely and all things related.
|
||||
|
||||
In this article, I'll walk you through some of the differences between these two freedoms and how they affect Linux usage.
|
||||
|
||||
### The problem with proprietary
|
||||
|
||||
One thing most Linux users have in common is their preference for avoiding proprietary software. For practical enthusiasts like myself, it's a matter of how I spend my money, the ability to control my software and avoiding vendor lock-in. Granted, I'm not a coder...so my tweaks to my installed software are pretty mild. But there are instances where a minor tweak to an application can mean the difference between it working and it not working.
|
||||
|
||||
Then there are Linux enthusiasts who opt to avoid proprietary software because they feel it's unethical to use it. Usually the main concern here is that using proprietary software takes away or simply obstructs your personal freedom. Users in this corner prefer to use Linux distributions and software that support the [Free Software philosophy][2]. While it's similar to and often directly confused with Open Source concepts, [there are differences][3].
|
||||
|
||||
So here's the issue: Users such as myself tend to put convenience over the ideals of pure software freedom. Don't get me wrong, folks like me prefer to use software that meets the ideals behind Free Software, but we also are more likely to make concessions in order to accomplish specific tasks.
|
||||
|
||||
Both types of Linux enthusiasts prefer using non-proprietary solutions. But Free Software advocates won't use proprietary at all, where as the practical user will rely on the best tool with the best performance. This means there are instances where the practical user is willing to run a proprietary application or code on their non-proprietary operating system.
|
||||
|
||||
In the end, both user types enjoy using what Linux has to offer. But our reasons for doing so tend to vary. Some have argued that this is a matter of ignorance with those who don't support Free Software. I disagree and believe it's a matter of practical convenience. Users who prefer practical convenience simply aren't concerned about the politics of their software.
|
||||
|
||||
### Practical Convenience
|
||||
|
||||
When you ask most people why they use the operating system they use, it's usually tied in with practical convenience. Examples of this convenience might include "it's what I've always used" down to "it runs the software I need." Other folks might take this a step further and explain it's not so much the software that drives their OS preference, as the familiarity of the OS in question. And finally, there are specialty "niche tasks" or hardware compatibility issues that also provide good reasons for using one OS over another.
|
||||
|
||||
This might surprise many of you, but the single biggest reason I run desktop Linux today is due to familiarity. Even though I provide support for Windows and OS X for others, it's actually quite frustrating to use these operating systems as they're simply not what my muscle memory is used to. I like to believe this allows me to empathize with Linux newcomers, as I too know how off-putting it can be to step into the realm of the unfamiliar. My point here is this – familiarity has value. And familiarity also powers practical convenience as well.
|
||||
|
||||
Now if we compare this to the needs of a Free Software advocate, you'll find those folks are willing to learn something new and perhaps even more challenging if it translates into them avoiding using non-free software. It's actually something I've always admired about this type of user. Their willingness to take the path less followed to stick to their principles is, in my opinion, admirable.
|
||||
|
||||
### The price of freedom
|
||||
|
||||
One area I don't envy is the extra work involved in making sure a Free Software advocate is always using Linux distros and hardware that respect their digital freedom according to the standards set forth by the [Free Software Foundation][4]. This means the Linux kernel needs to be free from proprietary blobs for driver support and the hardware in question doesn't require any proprietary code whatsoever. Certainly not impossible, but it's pretty close.
|
||||
|
||||
The absolute best scenario a Free Software advocate can shoot for is hardware that is "freedom-compatible." There are vendors out there that can meet this need, however most of them are offering hardware that relies on Linux compatible proprietary firmware. Great for the practical user, a show-stopper for the Free Software advocate.
|
||||
|
||||
What all of this translates into is that the advocate must be far more vigilant than the practical Linux enthusiast. This isn't necessarily a negative thing per se, however it's a consideration if one is planning on jumping onto the Free Software approach to computing. Practical users, by contrast, can use any software or hardware that happens to be Linux compatible without a second thought. I don't know about you, but in my eyes this seems a bit easier to me.
|
||||
|
||||
### Defining software freedom
|
||||
|
||||
This part is going to get some folks upset as I personally don't subscribe to the belief that there's only one flavor of software freedom. From where I stand, I think true freedom is being able to soak in all the available data on a given issue and then come to terms with the approach that best suits that person's lifestyle.
|
||||
|
||||
So for me, I prefer using Linux distributions that provide me with the desktop that meets all of my needs. This includes the use of non-proprietary software and proprietary software. Even though it's fair to suggest that the proprietary software restricts my personal freedom, I must counter this by pointing out that I had the freedom to use it in the first place. One might even call this freedom of choice.
|
||||
|
||||
Perhaps this too, is why I find myself identifying more with the ideals of Open Source Software instead of sticking with the ideals behind the Free Software movement. I prefer to stand with the group that doesn't spend their time telling me how I'm wrong for using what works best for me. It's been my experience that the Open Source crowd is merely interested in sharing the merits of software freedom without the passion for Free Software idealism.
|
||||
|
||||
I think the concept of Free Software is great. And to those who need to be active in software politics and point out the flaws of using proprietary software to folks, then I think Linux ([GNU/Linux][5]) activism is a good fit. Where practical users such as myself tend to change course from Free Software Linux advocates is in our presentation.
|
||||
|
||||
When I present Linux on the desktop, I share my passion for its practical merits. And if I'm successful and they enjoy the experience, I allow the user to discover the Free Software perspective on their own. I've found most people use Linux on their computers not because they want to embrace software freedom, rather because they simply want the best user experience possible. Perhaps I'm alone in this, it's hard to say.
|
||||
|
||||
What say you? Are you a Free Software Advocate? Perhaps you're a fan of using proprietary software/code on your desktop Linux distribution? Hit the Comments and share your Linux desktop experiences.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/linux-practicality-vs-activism.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]: https://en.wikipedia.org/wiki/Free_software_movement
|
||||
[2]: https://www.gnu.org/philosophy/free-sw.en.html
|
||||
[3]: https://www.gnu.org/philosophy/free-software-for-freedom.en.html
|
||||
[4]: https://en.wikipedia.org/wiki/Free_Software_Foundation
|
||||
[5]: https://en.wikipedia.org/wiki/GNU/Linux_naming_controversy
|
||||
|
||||
|
||||
@ -1,320 +0,0 @@
|
||||
wyangsun translating
|
||||
How to build and deploy a Facebook Messenger bot with Python and Flask, a tutorial
|
||||
==========================================================================
|
||||
|
||||
This is my log of how I built a simple Facebook Messenger bot. The functionality is really simple, it’s an echo bot that will just print back to the user what they write.
|
||||
|
||||
This is something akin to the Hello World example for servers, the echo server.
|
||||
|
||||
The goal of the project is not to build the best Messenger bot, but rather to get a feel for what it takes to build a minimal bot and how everything comes together.
|
||||
|
||||
- [Tech Stack][1]
|
||||
- [Bot Architecture][2]
|
||||
- [The Bot Server][3]
|
||||
- [Deploying to Heroku][4]
|
||||
- [Creating the Facebook App][5]
|
||||
- [Conclusion][6]
|
||||
|
||||
### Tech Stack
|
||||
|
||||
The tech stack that was used is:
|
||||
|
||||
- [Heroku][7] for back end hosting. The free-tier is more than enough for a tutorial of this level. The echo bot does not require any sort of data persistence so a database was not used.
|
||||
- [Python][8] was the language of choice. The version that was used is 2.7 however it can easily be ported to Python 3 with minor alterations.
|
||||
- [Flask][9] as the web development framework. It’s a very lightweight framework that’s perfect for small scale projects/microservices.
|
||||
- Finally the [Git][10] version control system was used for code maintenance and to deploy to Heroku.
|
||||
- Worth mentioning: [Virtualenv][11]. This python tool is used to create “environments” clean of python libraries so you can only install the necessary requirements and minimize the app footprint.
|
||||
|
||||
### Bot Architecture
|
||||
|
||||
Messenger bots are constituted by a server that responds to two types of requests:
|
||||
|
||||
- GET requests are being used for authentication. They are sent by Messenger with an authentication code that you register on FB.
|
||||
- POST requests are being used for the actual communication. The typical workflow is that the bot will initiate the communication by sending the POST request with the data of the message sent by the user, we will handle it, send a POST request of our own back. If that one is completed successfully (a 200 OK status is returned) we also respond with a 200 OK code to the initial Messenger request.
|
||||
For this tutorial the app will be hosted on Heroku, which provides a nice and easy interface to deploy apps. As mentioned the free tier will suffice for this tutorial.
|
||||
|
||||
After the app has been deployed and is running, we’ll create a Facebook app and link it to our app so that messenger knows where to send the requests that are meant for our bot.
|
||||
|
||||
### The Bot Server
|
||||
The basic server code was taken from the following [Chatbot][12] project by Github user [hult (Magnus Hult)][13], with a few modifications to the code to only echo messages and a couple bugfixes I came across. This is the final version of the server code:
|
||||
|
||||
```
|
||||
from flask import Flask, request
|
||||
import json
|
||||
import requests
|
||||
|
||||
app = Flask(__name__)
|
||||
|
||||
# This needs to be filled with the Page Access Token that will be provided
|
||||
# by the Facebook App that will be created.
|
||||
PAT = ''
|
||||
|
||||
@app.route('/', methods=['GET'])
|
||||
def handle_verification():
|
||||
print "Handling Verification."
|
||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||
print "Verification successful!"
|
||||
return request.args.get('hub.challenge', '')
|
||||
else:
|
||||
print "Verification failed!"
|
||||
return 'Error, wrong validation token'
|
||||
|
||||
@app.route('/', methods=['POST'])
|
||||
def handle_messages():
|
||||
print "Handling Messages"
|
||||
payload = request.get_data()
|
||||
print payload
|
||||
for sender, message in messaging_events(payload):
|
||||
print "Incoming from %s: %s" % (sender, message)
|
||||
send_message(PAT, sender, message)
|
||||
return "ok"
|
||||
|
||||
def messaging_events(payload):
|
||||
"""Generate tuples of (sender_id, message_text) from the
|
||||
provided payload.
|
||||
"""
|
||||
data = json.loads(payload)
|
||||
messaging_events = data["entry"][0]["messaging"]
|
||||
for event in messaging_events:
|
||||
if "message" in event and "text" in event["message"]:
|
||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||
else:
|
||||
yield event["sender"]["id"], "I can't echo this"
|
||||
|
||||
|
||||
def send_message(token, recipient, text):
|
||||
"""Send the message text to recipient with id recipient.
|
||||
"""
|
||||
|
||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||
params={"access_token": token},
|
||||
data=json.dumps({
|
||||
"recipient": {"id": recipient},
|
||||
"message": {"text": text.decode('unicode_escape')}
|
||||
}),
|
||||
headers={'Content-type': 'application/json'})
|
||||
if r.status_code != requests.codes.ok:
|
||||
print r.text
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run()
|
||||
```
|
||||
|
||||
Let’s break down the code. The first part is the imports that will be needed:
|
||||
|
||||
```
|
||||
from flask import Flask, request
|
||||
import json
|
||||
import requests
|
||||
```
|
||||
|
||||
Next we define the two functions (using the Flask specific app.route decorators) that will handle the GET and POST requests to our bot.
|
||||
|
||||
```
|
||||
@app.route('/', methods=['GET'])
|
||||
def handle_verification():
|
||||
print "Handling Verification."
|
||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||
print "Verification successful!"
|
||||
return request.args.get('hub.challenge', '')
|
||||
else:
|
||||
print "Verification failed!"
|
||||
return 'Error, wrong validation token'
|
||||
```
|
||||
|
||||
The verify_token object that is being sent by Messenger will be declared by us when we create the Facebook app. We have to validate the one we are being have against itself. Finally we return the “hub.challenge” back to Messenger.
|
||||
|
||||
The function that handles the POST requests is a bit more interesting.
|
||||
|
||||
```
|
||||
@app.route('/', methods=['POST'])
|
||||
def handle_messages():
|
||||
print "Handling Messages"
|
||||
payload = request.get_data()
|
||||
print payload
|
||||
for sender, message in messaging_events(payload):
|
||||
print "Incoming from %s: %s" % (sender, message)
|
||||
send_message(PAT, sender, message)
|
||||
return "ok"
|
||||
```
|
||||
|
||||
When called we grab the massage payload, use function messaging_events to break it down and extract the sender user id and the actual message sent, generating a python iterator that we can loop over. Notice that in each request sent by Messenger it is possible to have more than one messages.
|
||||
|
||||
```
|
||||
def messaging_events(payload):
|
||||
"""Generate tuples of (sender_id, message_text) from the
|
||||
provided payload.
|
||||
"""
|
||||
data = json.loads(payload)
|
||||
messaging_events = data["entry"][0]["messaging"]
|
||||
for event in messaging_events:
|
||||
if "message" in event and "text" in event["message"]:
|
||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||
else:
|
||||
yield event["sender"]["id"], "I can't echo this"
|
||||
```
|
||||
|
||||
While iterating over each message we call the send_message function and we perform the POST request back to Messnger using the Facebook Graph messages API. During this time we still have not responded to the original Messenger request which we are blocking. This can lead to timeouts and 5XX errors.
|
||||
|
||||
The above was spotted during an outage due to a bug I came across, which was occurred when the user was sending emojis which are actual unicode ids, however Python was miss-encoding. We ended up sending back garbage.
|
||||
|
||||
This POST request back to Messenger would never finish, and that in turn would cause 5XX status codes to be returned to the original request, rendering the service unusable.
|
||||
|
||||
This was fixed by escaping the messages with `encode('unicode_escape')` and then just before we sent back the message decode it with `decode('unicode_escape')`.
|
||||
|
||||
```
|
||||
def send_message(token, recipient, text):
|
||||
"""Send the message text to recipient with id recipient.
|
||||
"""
|
||||
|
||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||
params={"access_token": token},
|
||||
data=json.dumps({
|
||||
"recipient": {"id": recipient},
|
||||
"message": {"text": text.decode('unicode_escape')}
|
||||
}),
|
||||
headers={'Content-type': 'application/json'})
|
||||
if r.status_code != requests.codes.ok:
|
||||
print r.text
|
||||
```
|
||||
|
||||
### Deploying to Heroku
|
||||
|
||||
Once the code was built to my liking it was time for the next step.
|
||||
Deploy the app.
|
||||
|
||||
Sure, but how?
|
||||
|
||||
I have deployed apps before to Heroku (mainly Rails) however I was always following a tutorial of some sort, so the configuration has already been created. In this case though I had to start from scratch.
|
||||
|
||||
Fortunately it was the official [Heroku documentation][14] to the rescue. The article explains nicely the bare minimum required for running an app.
|
||||
|
||||
Long story short, what we need besides our code are two files. The first file is the “requirements.txt” file which is a list of of the library dependencies required to run the application.
|
||||
|
||||
The second file required is the “Procfile”. This file is there to inform the Heroku how to run our service. Again the bare minimum needed for this file is the following:
|
||||
|
||||
>web: gunicorn echoserver:app
|
||||
|
||||
The way this will be interpreted by heroku is that our app is started by running the echoserver.py file and the app will be using gunicorn as the web server. The reason we are using an additional webserver is performance related and is explained in the above Heroku documentation:
|
||||
|
||||
>Web applications that process incoming HTTP requests concurrently make much more efficient use of dyno resources than web applications that only process one request at a time. Because of this, we recommend using web servers that support concurrent request processing whenever developing and running production services.
|
||||
|
||||
>The Django and Flask web frameworks feature convenient built-in web servers, but these blocking servers only process a single request at a time. If you deploy with one of these servers on Heroku, your dyno resources will be underutilized and your application will feel unresponsive.
|
||||
|
||||
>Gunicorn is a pure-Python HTTP server for WSGI applications. It allows you to run any Python application concurrently by running multiple Python processes within a single dyno. It provides a perfect balance of performance, flexibility, and configuration simplicity.
|
||||
|
||||
Going back to our “requirements.txt” file let’s see how it binds with the Virtualenv tool that was mentioned.
|
||||
|
||||
At anytime, your developement machine may have a number of python libraries installed. When deploying applications you don’t want to have these libraries loaded as it makes it hard to make out which ones you actually use.
|
||||
|
||||
What Virtualenv does is create a new blank virtual enviroment so that you can only install the libraries that your app requires.
|
||||
|
||||
You can check which libraries are currently installed by running the following command:
|
||||
|
||||
```
|
||||
kostis@KostisMBP ~ $ pip freeze
|
||||
cycler==0.10.0
|
||||
Flask==0.10.1
|
||||
gunicorn==19.6.0
|
||||
itsdangerous==0.24
|
||||
Jinja2==2.8
|
||||
MarkupSafe==0.23
|
||||
matplotlib==1.5.1
|
||||
numpy==1.10.4
|
||||
pyparsing==2.1.0
|
||||
python-dateutil==2.5.0
|
||||
pytz==2015.7
|
||||
requests==2.10.0
|
||||
scipy==0.17.0
|
||||
six==1.10.0
|
||||
virtualenv==15.0.1
|
||||
Werkzeug==0.11.10
|
||||
```
|
||||
|
||||
Note: The pip tool should already be installed on your machine along with Python.
|
||||
|
||||
If not check the [official site][15] for how to install it.
|
||||
|
||||
Now let’s use Virtualenv to create a new blank enviroment. First we create a new folder for our project, and change dir into it:
|
||||
|
||||
```
|
||||
kostis@KostisMBP projects $ mkdir echoserver
|
||||
kostis@KostisMBP projects $ cd echoserver/
|
||||
kostis@KostisMBP echoserver $
|
||||
```
|
||||
|
||||
Now let’s create a new enviroment called echobot. To activate it you run the following source command, and checking with pip freeze we can see that it’s now empty.
|
||||
|
||||
```
|
||||
kostis@KostisMBP echoserver $ virtualenv echobot
|
||||
kostis@KostisMBP echoserver $ source echobot/bin/activate
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||
(echobot) kostis@KostisMBP echoserver $
|
||||
```
|
||||
|
||||
We can start installing the libraries required. The ones we’ll need are flask, gunicorn, and requests and with them installed we create the requirements.txt file:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install flask
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install gunicorn
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install requests
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||
click==6.6
|
||||
Flask==0.11
|
||||
gunicorn==19.6.0
|
||||
itsdangerous==0.24
|
||||
Jinja2==2.8
|
||||
MarkupSafe==0.23
|
||||
requests==2.10.0
|
||||
Werkzeug==0.11.10
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze > requirements.txt
|
||||
```
|
||||
|
||||
After all the above have been run, we create the echoserver.py file with the python code and the Procfile with the command that was mentioned, and we should end up with the following files/folders:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ ls
|
||||
Procfile echobot echoserver.py requirements.txt
|
||||
```
|
||||
|
||||
We are now ready to upload to Heroku. We need to do two things. The first is to install the Heroku toolbet if it’s not already installed on your system (go to [Heroku][16] for details). The second is to create a new Heroku app through the [web interface][17].
|
||||
|
||||
Click on the big plus sign on the top right and select “Create new app”.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/
|
||||
|
||||
作者:[Konstantinos Tsaprailis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/kostistsaprailis
|
||||
[1]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#tech-stack
|
||||
[2]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#bot-architecture
|
||||
[3]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#the-bot-server
|
||||
[4]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#deploying-to-heroku
|
||||
[5]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#creating-the-facebook-app
|
||||
[6]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#conclusion
|
||||
[7]: https://www.heroku.com
|
||||
[8]: https://www.python.org
|
||||
[9]: http://flask.pocoo.org
|
||||
[10]: https://git-scm.com
|
||||
[11]: https://virtualenv.pypa.io/en/stable
|
||||
[12]: https://github.com/hult/facebook-chatbot-python
|
||||
[13]: https://github.com/hult
|
||||
[14]: https://devcenter.heroku.com/articles/python-gunicorn
|
||||
[15]: https://pip.pypa.io/en/stable/installing
|
||||
[16]: https://toolbelt.heroku.com
|
||||
[17]: https://dashboard.heroku.com/apps
|
||||
|
||||
|
||||
@ -1,106 +0,0 @@
|
||||
Container technologies in Fedora: systemd-nspawn
|
||||
===
|
||||
|
||||
Welcome to the “Container technologies in Fedora” series! This is the first article in a series of articles that will explain how you can use the various container technologies available in Fedora. This first article will deal with `systemd-nspawn`.
|
||||
|
||||
### What is a container?
|
||||
|
||||
A container is a user-space instance which can be used to run a program or an operating system in isolation from the system hosting the container (called the host system). The idea is very similar to a `chroot` or a [virtual machine][1]. The processes running in a container are managed by the same kernel as the host operating system, but they are isolated from the host file system, and from the other processes.
|
||||
|
||||
|
||||
### What is systemd-nspawn?
|
||||
|
||||
The systemd project considers container technologies as something that should fundamentally be part of the desktop and that should integrate with the rest of the user’s systems. To this end, systemd provides `systemd-nspawn`, a tool which is able to create containers using various Linux technologies. It also provides some container management tools.
|
||||
|
||||
In many ways, `systemd-nspawn` is similar to `chroot`, but is much more powerful. It virtualizes the file system, process tree, and inter-process communication of the guest system. Much of its appeal lies in the fact that it provides a number of tools, such as `machinectl`, for managing containers. Containers run by `systemd-nspawn` will integrate with the systemd components running on the host system. As an example, journal entries can be logged from a container in the host system’s journal.
|
||||
|
||||
In Fedora 24, `systemd-nspawn` has been split out from the systemd package, so you’ll need to install the `systemd-container` package. As usual, you can do that with a `dnf install systemd-container`.
|
||||
|
||||
### Creating the container
|
||||
|
||||
Creating a container with `systemd-nspawn` is easy. Let’s say you have an application made for Debian, and it doesn’t run well anywhere else. That’s not a problem, we can make a container! To set up a container with the latest version of Debian (at this point in time, Jessie), you need to pick a directory to set up your system in. I’ll be using `~/DebianJessie` for now.
|
||||
|
||||
Once the directory has been created, you need to run `debootstrap`, which you can install from the Fedora repositories. For Debian Jessie, you run the following command to initialize a Debian file system.
|
||||
|
||||
```
|
||||
$ debootstrap --arch=amd64 stable ~/DebianJessie
|
||||
```
|
||||
|
||||
This assumes your architecture is x86_64. If it isn’t, you must change `amd64` to the name of your architecture. You can find your machine’s architecture with `uname -m`.
|
||||
|
||||
Once your root directory is set up, you will start your container with the following command.
|
||||
|
||||
```
|
||||
$ systemd-nspawn -bD ~/DebianJessie
|
||||
```
|
||||
|
||||
You’ll be up and running within seconds. You’ll notice something as soon as you try to log in: you can’t use any accounts on your system. This is because systemd-nspawn virtualizes users. The fix is simple: remove -b from the previous command. You’ll boot directly to the root shell in the container. From there, you can just use passwd to set a password for root, or you can use adduser to add a new user. As soon as you’re done with that, go ahead and put the -b flag back. You’ll boot to the familiar login console and you log in with the credentials you set.
|
||||
|
||||
All of this applies for any distribution you would want to run in the container, but you need to create the system using the correct package manager. For Fedora, you would use DNF instead of debootstrap. To set up a minimal Fedora system, you can run the following command, replacing the absolute path with wherever you want the container to be.
|
||||
|
||||
```
|
||||
$ sudo dnf --releasever=24 --installroot=/absolute/path/ install systemd passwd dnf fedora-release
|
||||
```
|
||||
|
||||

|
||||
|
||||
### Setting up the network
|
||||
|
||||
You’ll notice an issue if you attempt to start a service that binds to a port currently in use on your host system. Your container is using the same network interface. Luckily, `systemd-nspawn` provides several ways to achieve separate networking from the host machine.
|
||||
|
||||
#### Local networking
|
||||
|
||||
The first method uses the `--private-network` flag, which only creates a loopback device by default. This is ideal for environments where you don’t need networking, such as build systems and other continuous integration systems.
|
||||
|
||||
#### Multiple networking interfaces
|
||||
|
||||
If you have multiple network devices, you can give one to the container with the `--network-interface` flag. To give `eno1` to my container, I would add the flag `--network-interface=eno1`. While an interface is assigned to a container, the host can’t use it at the same time. When the container is completely shut down, it will be available to the host again.
|
||||
|
||||
#### Sharing network interfaces
|
||||
|
||||
For those of us who don’t have spare network devices, there are other options for providing access to the container. One of those is the `--port` flag. This forwards a port on the container to the host. The format is `protocol:host:container`, where protocol is either `tcp` or `udp`, `host` is a valid port number on the host, and `container` is a valid port on the container. You can omit the protocol and specify only `host:container`. I often use something similar to `--port=2222:22`.
|
||||
|
||||
You can enable complete, host-only networking with the `--network-veth` flag, which creates a virtual Ethernet interface between the host and the container. You can also bridge two connections with `--network-bridge`.
|
||||
|
||||
### Using systemd components
|
||||
|
||||
If the system in your container has D-Bus, you can use systemd’s provided utilities to control and monitor your container. Debian doesn’t include dbus in the base install. If you want to use it with Debian Jessie, you’ll want to run `apt install dbus`.
|
||||
|
||||
#### machinectl
|
||||
|
||||
To easily manage containers, systemd provides the machinectl utility. Using machinectl, you can log in to a container with machinectl login name, check the status with machinectl status name, reboot with machinectl reboot name, or power it off with machinectl poweroff name.
|
||||
|
||||
### Other systemd commands
|
||||
|
||||
Most systemd commands, such as journalctl, systemd-analyze, and systemctl, support containers with the `--machine` option. For example, if you want to see the journals of a container named “foobar”, you can use journalctl `--machine=foobar`. You can also see the status of a service running in this container with `systemctl --machine=foobar` status service.
|
||||
|
||||

|
||||
|
||||
### Working with SELinux
|
||||
|
||||
If you’re running with SELinux enforcing (the default in Fedora), you’ll need to set the SELinux context for your container. To do that, you need to run the following two commands on the host system.
|
||||
|
||||
```
|
||||
$ semanage fcontext -a -t svirt_sandbox_file_t "/path/to/container(/.*)?"
|
||||
$ restorecon -R /path/to/container/
|
||||
```
|
||||
|
||||
Make sure you replace “/path/to/container” with the path to your container. For my container, “DebianJessie”, I would run the following:
|
||||
|
||||
```
|
||||
$ semanage fcontext -a -t svirt_sandbox_file_t "/home/johnmh/DebianJessie(/.*)?"
|
||||
$ restorecon -R /home/johnmh/DebianJessie/
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/set-nginx-reverse-proxy-centos-7-cpanel/
|
||||
|
||||
作者:[John M. Harris, Jr.][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linoxide.com/linux-how-to/set-nginx-reverse-proxy-centos-7-cpanel/
|
||||
[1]: https://en.wikipedia.org/wiki/Virtual_machine
|
||||
@ -1,3 +1,5 @@
|
||||
name1e5s translating
|
||||
|
||||
TOP 5 BEST VIDEO EDITING SOFTWARE FOR LINUX IN 2016
|
||||
=====================================================
|
||||
|
||||
|
||||
@ -1,101 +0,0 @@
|
||||
How To Setup Open Source Discussion Platform Discourse On Ubuntu Linux 16.04
|
||||
===============================================================================
|
||||
|
||||
Discourse is an open source discussion platform, that can work as a mailing list, a chat room and a forum as well. It is a popular tool and modern day implementation of a successful discussion platform. On server side, it is built using Ruby on Rails and uses Postgres on the backend, it also makes use of Redis caching to reduce the loading times, while on client’s side end, it runs in browser using Java Script. It is a pretty well optimized and well structured tool. It also offers converter plugins to migrate your existing discussion boards / forums like vBulletin, phpBB, Drupal, SMF etc to Discourse. In this article, we will be learning how to install Discourse on Ubuntu operating system.
|
||||
|
||||
It is developed by keeping security in mind, so spammers and hackers might not be lucky with this application. It works well with all modern devices, and adjusts its display setting accordingly for mobile devices and tablets.
|
||||
|
||||
### Installing Discourse on Ubuntu 16.04
|
||||
|
||||
Let’s get started ! the minimum system RAM to run Discourse is 1 GB and the officially supported installation process for Discourse requires dockers to be installed on our Linux system. Besides dockers, it also requires Git. We can fulfill these two requirements by simply running the following command on our system’s terminal.
|
||||
|
||||
```
|
||||
wget -qO- https://get.docker.com/ | sh
|
||||
```
|
||||
|
||||

|
||||
|
||||
It shouldn’t take longer to complete the installation for Docker and Git, as soon its installation process is complete, create a directory for Discourse inside /var partition of your system (You can choose any other partition here too).
|
||||
|
||||
```
|
||||
mkdir /var/discourse
|
||||
```
|
||||
|
||||
Now clone the Discourse’s Github repository to this newly created directory.
|
||||
|
||||
```
|
||||
git clone https://github.com/discourse/discourse_docker.git /var/discourse
|
||||
```
|
||||
|
||||
Go into the cloned directory.
|
||||
|
||||
```
|
||||
cd /var/discourse
|
||||
```
|
||||
|
||||

|
||||
|
||||
You should be able to locate “discourse-setup” script file here, simply run this script to initiate the installation wizard for Discourse.
|
||||
|
||||
```
|
||||
./discourse-setup
|
||||
```
|
||||
|
||||
**Side note: Please make sure you have a ready email server setup before attempting install for discourse.**
|
||||
|
||||
Installation wizard will ask you following six questions.
|
||||
|
||||
```
|
||||
Hostname for your Discourse?
|
||||
Email address for admin account?
|
||||
SMTP server address?
|
||||
SMTP user name?
|
||||
SMTP port [587]:
|
||||
SMTP password? []:
|
||||
```
|
||||
|
||||

|
||||
|
||||
Once you supply these information, it will ask for the confirmation, if everything is fine, hit “Enter” and installation process will take off.
|
||||
|
||||

|
||||
|
||||
Sit back and relax! it will take sweet amount of time to complete the installation, grab a cup of coffee, and keep an eye for any error messages.
|
||||
|
||||

|
||||
|
||||
Here is how the successful completion of the installation process should look alike.
|
||||
|
||||

|
||||
|
||||
Now launch your web browser, if the hostname for discourse installation resolves properly to IP, then you can use your hostname in browser , otherwise use your IP address to launch the Discourse page. Here is what you should see:
|
||||
|
||||

|
||||
|
||||
That’s it, create new account by using “Sign Up” option and you should be good to go with your Discourse setup.
|
||||
|
||||

|
||||
|
||||
### Conclusion
|
||||
|
||||
It is an easy to setup application and works flawlessly. It is equipped with all required features of modern day discussion board. It is available under General Public License and is 100% open source product. The simplicity, easy of use, powerful and long feature list are the most important feathers of this tool. Hope you enjoyed this article, Question? do let us know in comments please.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-discourse-on-ubuntu-linux-16-04/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxpitstop.com/author/aun/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,198 +0,0 @@
|
||||
Python 101: An Intro to urllib
|
||||
=================================
|
||||
|
||||
The urllib module in Python 3 is a collection of modules that you can use for working with URLs. If you are coming from a Python 2 background you will note that in Python 2 you had urllib and urllib2. These are now a part of the urllib package in Python 3. The current version of urllib is made up of the following modules:
|
||||
|
||||
- urllib.request
|
||||
- urllib.error
|
||||
- urllib.parse
|
||||
- urllib.rebotparser
|
||||
|
||||
We will be covering each part individually except for urllib.error. The official documentation actually recommends that you might want to check out the 3rd party library, requests, for a higher-level HTTP client interface. However, I believe that it can be useful to know how to open URLs and interact with them without using a 3rd party and it may also help you appreciate why the requests package is so popular.
|
||||
|
||||
---
|
||||
|
||||
### urllib.request
|
||||
|
||||
The urllib.request module is primarily used for opening and fetching URLs. Let’s take a look at some of the things you can do with the urlopen function:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = urllib.request.urlopen('https://www.google.com/')
|
||||
>>> url.geturl()
|
||||
'https://www.google.com/'
|
||||
>>> url.info()
|
||||
<http.client.HTTPMessage object at 0x7fddc2de04e0>
|
||||
>>> header = url.info()
|
||||
>>> header.as_string()
|
||||
('Date: Fri, 24 Jun 2016 18:21:19 GMT\n'
|
||||
'Expires: -1\n'
|
||||
'Cache-Control: private, max-age=0\n'
|
||||
'Content-Type: text/html; charset=ISO-8859-1\n'
|
||||
'P3P: CP="This is not a P3P policy! See '
|
||||
'https://www.google.com/support/accounts/answer/151657?hl=en for more info."\n'
|
||||
'Server: gws\n'
|
||||
'X-XSS-Protection: 1; mode=block\n'
|
||||
'X-Frame-Options: SAMEORIGIN\n'
|
||||
'Set-Cookie: '
|
||||
'NID=80=tYjmy0JY6flsSVj7DPSSZNOuqdvqKfKHDcHsPIGu3xFv41LvH_Jg6LrUsDgkPrtM2hmZ3j9V76pS4K_cBg7pdwueMQfr0DFzw33SwpGex5qzLkXUvUVPfe9g699Qz4cx9ipcbU3HKwrRYA; '
|
||||
'expires=Sat, 24-Dec-2016 18:21:19 GMT; path=/; domain=.google.com; HttpOnly\n'
|
||||
'Alternate-Protocol: 443:quic\n'
|
||||
'Alt-Svc: quic=":443"; ma=2592000; v="34,33,32,31,30,29,28,27,26,25"\n'
|
||||
'Accept-Ranges: none\n'
|
||||
'Vary: Accept-Encoding\n'
|
||||
'Connection: close\n'
|
||||
'\n')
|
||||
>>> url.getcode()
|
||||
200
|
||||
```
|
||||
|
||||
Here we import our module and ask it to open Google’s URL. Now we have an HTTPResponse object that we can interact with. The first thing we do is call the geturl method which will return the URL of the resource that was retrieved. This is useful for finding out if we followed a redirect.
|
||||
|
||||
Next we call info, which will return meta-data about the page, such as headers. Because of this, we assign that result to our headers variable and then call its as_string method. This prints out the header we received from Google. You can also get the HTTP response code by calling getcode, which in this case was 200, which means it worked successfully.
|
||||
|
||||
If you’d like to see the HTML of the page, you can call the read method on the url variable we created. I am not reproducing that here as the output will be quite long.
|
||||
|
||||
Please note that the request object defaults to a GET request unless you specify the data parameter. Should you pass in the data parameter, then the request object will issue a POST request instead.
|
||||
|
||||
---
|
||||
|
||||
### Downloading a file
|
||||
|
||||
A typical use case for the urllib package is for downloading a file. Let’s find out a couple of ways we can accomplish this task:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> response = urllib.request.urlopen(url)
|
||||
>>> data = response.read()
|
||||
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
|
||||
... fobj.write(data)
|
||||
...
|
||||
```
|
||||
|
||||
Here we just open a URL that leads us to a zip file stored on my blog. Then we read the data and write it out to disk. An alternate way to accomplish this is to use urlretrieve:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> tmp_file, header = urllib.request.urlretrieve(url)
|
||||
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
|
||||
... with open(tmp_file, 'rb') as tmp:
|
||||
... fobj.write(tmp.read())
|
||||
```
|
||||
|
||||
The urlretrieve method will copy a network object to a local file. The file it copies to is randomly named and goes into the temp directory unless you use the second parameter to urlretrieve where you can actually specify where you want the file saved. This will save you a step and make your code much simpler:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> urllib.request.urlretrieve(url, '/home/mike/Desktop/blog.zip')
|
||||
('/home/mike/Desktop/blog.zip',
|
||||
<http.client.HTTPMessage object at 0x7fddc21c2470>)
|
||||
```
|
||||
|
||||
As you can see, it returns the location of where it saved the file and the header information from the request.
|
||||
|
||||
### Specifying Your User Agent
|
||||
|
||||
When you visit a website with your browser, the browser tells the website who it is. This is called the user-agent string. Python’s urllib identifies itself as Python-urllib/x.y where the x and y are major and minor version numbers of Python. Some websites won’t recognize this user-agent string and will behave in strange ways or not work at all. Fortunately, it’s easy for you to set up your own custom user-agent string:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> user_agent = ' Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0'
|
||||
>>> url = 'http://www.whatsmyua.com/'
|
||||
>>> headers = {'User-Agent': user_agent}
|
||||
>>> request = urllib.request.Request(url, headers=headers)
|
||||
>>> with urllib.request.urlopen(request) as response:
|
||||
... with open('/home/mdriscoll/Desktop/user_agent.html', 'wb') as out:
|
||||
... out.write(response.read())
|
||||
```
|
||||
|
||||
Here we set up our user agent to Mozilla FireFox and we set out URL to <http://www.whatsmyua.com/> which will tell us what it thinks our user-agent string is. Then we create a Request instance using our url and headers and pass that to urlopen. Finally we save the result. If you open the result file, you will see that we successfully changed our user-agent string. Feel free to try out a few different strings with this code to see how it will change.
|
||||
|
||||
---
|
||||
|
||||
### urllib.parse
|
||||
|
||||
The urllib.parse library is your standard interface for breaking up URL strings and combining them back together. You can use it to convert a relative URL to an absolute URL, for example. Let’s try using it to parse a URL that includes a query:
|
||||
|
||||
```
|
||||
>>> from urllib.parse import urlparse
|
||||
>>> result = urlparse('https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa')
|
||||
>>> result
|
||||
ParseResult(scheme='https', netloc='duckduckgo.com', path='/', params='', query='q=python+stubbing&t=canonical&ia=qa', fragment='')
|
||||
>>> result.netloc
|
||||
'duckduckgo.com'
|
||||
>>> result.geturl()
|
||||
'https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa'
|
||||
>>> result.port
|
||||
None
|
||||
```
|
||||
|
||||
Here we import the urlparse function and pass it an URL that contains a search query to the duckduckgo website. My query was to look up articles on “python stubbing”. As you can see, it returned a ParseResult object that you can use to learn more about the URL. For example, you can get the port information (None in this case), the network location, path and much more.
|
||||
|
||||
### Submitting a Web Form
|
||||
|
||||
This module also holds the urlencode method, which is great for passing data to a URL. A typical use case for the urllib.parse library is submitting a web form. Let’s find out how you might do that by having the duckduckgo search engine look for Python:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> import urllib.parse
|
||||
>>> data = urllib.parse.urlencode({'q': 'Python'})
|
||||
>>> data
|
||||
'q=Python'
|
||||
>>> url = 'http://duckduckgo.com/html/'
|
||||
>>> full_url = url + '?' + data
|
||||
>>> response = urllib.request.urlopen(full_url)
|
||||
>>> with open('/home/mike/Desktop/results.html', 'wb') as f:
|
||||
... f.write(response.read())
|
||||
```
|
||||
|
||||
This is pretty straightforward. Basically we want to submit a query to duckduckgo ourselves using Python instead of a browser. To do that, we need to construct our query string using urlencode. Then we put that together to create a fully qualified URL and use urllib.request to submit the form. We then grab the result and save it to disk.
|
||||
|
||||
---
|
||||
|
||||
### urllib.robotparser
|
||||
|
||||
The robotparser module is made up of a single class, RobotFileParser. This class will answer questions about whether or not a specific user agent can fetch a URL that has a published robot.txt file. The robots.txt file will tell a web scraper or robot what parts of the server should not be accessed. Let’s take a look at a simple example using ArsTechnica’s website:
|
||||
|
||||
```
|
||||
>>> import urllib.robotparser
|
||||
>>> robot = urllib.robotparser.RobotFileParser()
|
||||
>>> robot.set_url('http://arstechnica.com/robots.txt')
|
||||
None
|
||||
>>> robot.read()
|
||||
None
|
||||
>>> robot.can_fetch('*', 'http://arstechnica.com/')
|
||||
True
|
||||
>>> robot.can_fetch('*', 'http://arstechnica.com/cgi-bin/')
|
||||
False
|
||||
```
|
||||
|
||||
Here we import the robot parser class and create an instance of it. Then we pass it a URL that specifies where the website’s robots.txt file resides. Next we tell our parser to read the file. Now that that’s done, we give it a couple of different URLs to find out which ones we can crawl and which ones we can’t. We quickly see that we can access the main site, but not the cgi-bin.
|
||||
|
||||
---
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
You have reached the point that you should be able to use Python’s urllib package competently. We learned how to download a file, submit a web form, change our user agent and access a robots.txt file in this chapter. The urllib has a lot of additional functionality that is not covered here, such as website authentication. However, you might want to consider switching to the requests library before trying to do authentication with urllib as the requests implementation is a lot easier to understand and debug. I also want to note that Python has support for Cookies via its http.cookies module although that is also wrapped quite well in the requests package. You should probably consider trying both to see which one makes the most sense to you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blog.pythonlibrary.org/2016/06/28/python-101-an-intro-to-urllib/
|
||||
|
||||
作者:[Mike][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.blog.pythonlibrary.org/author/mld/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,33 +0,0 @@
|
||||
What makes up the Fedora kernel?
|
||||
====================================
|
||||
|
||||

|
||||
|
||||
Every Fedora system runs a kernel. Many pieces of code come together to make this a reality.
|
||||
|
||||
Each release of the Fedora kernel starts with a baseline release from the [upstream community][1]. This is often called a ‘vanilla’ kernel. The upstream kernel is the standard. The goal is to have as much code upstream as possible. This makes it easier for bug fixes and API updates to happen as well as having more people review the code. In an ideal world, Fedora would be able to to take the kernel straight from kernel.org and send that out to all users.
|
||||
|
||||
Realistically, using the vanilla kernel isn’t complete enough for Fedora. Some features Fedora users want may not be available. The [Fedora kernel][2] that users actually receive contains a number of patches on top of the vanilla kernel. These patches are considered ‘out of tree’. Many of these patches will not exist out of tree patches very long. If patches are available to fix an issue, the patches may be pulled in to the Fedora tree so the fix can go out to users faster. When the kernel is rebased to a new version, the patches will be removed if they are in the new version.
|
||||
|
||||
Some patches remain in the Fedora kernel tree for an extended period of time. A good example of patches that fall into this category are the secure boot patches. These patches provide a feature Fedora wants to support even though the upstream community has not yet accepted them. It takes effort to keep these patches up to date so Fedora tries to minimize the number of patches that are carried without being accepted by an upstream kernel maintainer.
|
||||
|
||||
Generally, the best way to get a patch included in the Fedora kernel is to send it to the ]Linux Kernel Mailing List (LKML)][3] first and then ask for it to be included in Fedora. If a patch has been accepted by a maintainer it stands a very high chance of being included in the Fedora kernel tree. Patches that come from places like github which have not been submitted to LKML are unlikely to be taken into the tree. It’s important to send the patches to LKML first to ensure Fedora is carrying the correct patches in its tree. Without the community review, Fedora could end up carrying patches which are buggy and cause problems.
|
||||
|
||||
The Fedora kernel contains code from many places. All of it is necessary to give the best experience possible.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
|
||||
作者:[Laura Abbott][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
[1]: http://www.kernel.org/
|
||||
[2]: http://pkgs.fedoraproject.org/cgit/rpms/kernel.git/
|
||||
[3]: http://www.labbott.name/blog/2015/10/02/the-art-of-communicating-with-lkml/
|
||||
@ -1,100 +0,0 @@
|
||||
How to Encrypt a Flash Drive Using VeraCrypt
|
||||
============================================
|
||||
|
||||
Many security experts prefer open source software like VeraCrypt, which can be used to encrypt flash drives, because of its readily available source code.
|
||||
|
||||
Encryption is a smart idea for protecting data on a USB flash drive, as we covered in our piece that described ]how to encrypt a flash drive][1] using Microsoft BitLocker.
|
||||
|
||||
But what if you do not want to use BitLocker?
|
||||
|
||||
You may be concerned that because Microsoft's source code is not available for inspection, it could be susceptible to security "backdoors" used by the government or others. Because source code for open source software is widely shared, many security experts feel open source software is far less likely to have any backdoors.
|
||||
|
||||
Fortunately, there are several open source encryption alternatives to BitLocker.
|
||||
|
||||
If you need to be able to encrypt and access files on any Windows machine, as well as computers running Apple OS X or Linux, the open source [VeraCrypt][2] offers an excellent alternative.
|
||||
|
||||
VeraCrypt is derived from TrueCrypt, a well-regarded open source encryption software product that has now been discontinued. But the code for TrueCrypt was audited and no major security flaws were found. In addition, it has since been improved in VeraCrypt.
|
||||
|
||||
Versions exist for Windows, OS X and Linux.
|
||||
|
||||
Encrypting a USB flash drive with VeraCrypt is not as straightforward as it is with BitLocker, but it still only takes a few minutes.
|
||||
|
||||
### Encrypting Flash Drive with VeraCrypt in 8 Steps
|
||||
|
||||
After [downloading VeraCrypt][3] for your operating system:
|
||||
|
||||
Start VeraCrypt, and click on Create Volume to start the VeraCrypt Volume Creation Wizard.
|
||||
|
||||

|
||||
|
||||
The VeraCrypt Volume Creation Wizard allows you to create an encrypted file container on the flash drive which sits along with other unencrypted files, or you can choose to encrypt the entire flash drive. For the moment, we will choose to encrypt the entire flash drive.
|
||||
|
||||

|
||||
|
||||
On the next screen, choose Standard VeraCrypt Volume.
|
||||
|
||||

|
||||
|
||||
Select the drive letter of the flash drive you want to encrypt (in this case O:).
|
||||
|
||||

|
||||
|
||||
Choose the Volume Creation Mode. If your flash drive is empty or you want to delete everything it contains, choose the first option. If you want to keep any existing files, choose the second option.
|
||||
|
||||

|
||||
|
||||
This screen allows you to choose your encryption options. If you are unsure of which to choose, leave the default settings of AES and SHA-512.
|
||||
|
||||

|
||||
|
||||
After confirming the Volume Size screen, enter and re-enter the password you want to use to encrypt your data.
|
||||
|
||||

|
||||
|
||||
To work effectively, VeraCrypt must draw from a pool of entropy or "randomness." To generate this pool, you'll be asked to move your mouse around in a random fashion for about a minute. Once the bar has turned green, or preferably when it reaches the far right of the screen, click Format to finish creating your encrypted drive.
|
||||
|
||||

|
||||
|
||||
### Using a Flash Drive Encrypted with VeraCrypt
|
||||
|
||||
When you want to use an encrypted flash drive, first insert the drive in the computer and start VeraCrypt.
|
||||
|
||||
Then select an unused drive letter (such as z:) and click Auto-Mount Devices.
|
||||
|
||||

|
||||
|
||||
Enter your password and click OK.
|
||||
|
||||

|
||||
|
||||
The mounting process may take a few minutes, after which your unencrypted drive will become available with the drive letter you selected previously.
|
||||
|
||||
### VeraCrypt Traveler Disk Setup
|
||||
|
||||
If you set up a flash drive with an encrypted container rather than encrypting the whole drive, you also have the option to create what VeraCrypt calls a traveler disk. This installs a copy of VeraCrypt on the USB flash drive itself, so when you insert the drive in another Windows computer you can run VeraCrypt automatically from the flash drive; there is no need to install it on the computer.
|
||||
|
||||
You can set up a flash drive to be a Traveler Disk by choosing Traveler Disk SetUp from the Tools menu of VeraCrypt.
|
||||
|
||||

|
||||
|
||||
It is worth noting that in order to run VeraCrypt from a Traveler Disk on a computer, you must have administrator privileges on that computer. While that may seem to be a limitation, no confidential files can be opened safely on a computer that you do not control, such as one in a business center.
|
||||
|
||||
>Paul Rubens has been covering enterprise technology for over 20 years. In that time he has written for leading UK and international publications including The Economist, The Times, Financial Times, the BBC, Computing and ServerWatch.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.esecurityplanet.com/open-source-security/how-to-encrypt-flash-drive-using-veracrypt.html
|
||||
|
||||
作者:[Paul Rubens ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.esecurityplanet.com/author/3700/Paul-Rubens
|
||||
[1]: http://www.esecurityplanet.com/views/article.php/3880616/How-to-Encrypt-a-USB-Flash-Drive.htm
|
||||
[2]: http://www.esecurityplanet.com/open-source-security/veracrypt-a-worthy-truecrypt-alternative.html
|
||||
[3]: https://veracrypt.codeplex.com/releases/view/619351
|
||||
|
||||
|
||||
|
||||
@ -1,94 +0,0 @@
|
||||
Doing for User Space What We Did for Kernel Space
|
||||
=======================================================
|
||||
|
||||
I believe the best and worst thing about Linux is its hard distinction between kernel space and user space.
|
||||
|
||||
Without that distinction, Linux never would have become the most leveraged operating system in the world. Today, Linux has the largest range of uses for the largest number of users—most of whom have no idea they are using Linux when they search for something on Google or poke at their Android phones. Even Apple stuff wouldn't be what it is (for example, using BSD in its computers) were it not for Linux's success.
|
||||
|
||||
Not caring about user space is a feature of Linux kernel development, not a bug. As Linus put it on our 2003 Geek Cruise, "I only do kernel stuff...I don't know what happens outside the kernel, and I don't much care. What happens inside the kernel I care about." After Andrew Morton gave me additional schooling on the topic a couple years later on another Geek Cruise, I wrote:
|
||||
|
||||
>Kernel space is where the Linux species lives. User space is where Linux gets put to use, along with a lot of other natural building materials. The division between kernel space and user space is similar to the division between natural materials and stuff humans make out of those materials.
|
||||
|
||||
A natural outcome of this distinction, however, is for Linux folks to stay relatively small as a community while the world outside depends more on Linux every second. So, in hope that we can enlarge our number a bit, I want to point us toward two new things. One is already hot, and the other could be.
|
||||
|
||||
The first is [blockchain][1], made famous as the distributed ledger used by Bitcoin, but useful for countless other purposes as well. At the time of this writing, interest in blockchain is [trending toward the vertical][2].
|
||||
|
||||

|
||||
>Figure 1. Google Trends for Blockchain
|
||||
|
||||
The second is self-sovereign identity. To explain that, let me ask who and what you are.
|
||||
|
||||
If your answers come from your employer, your doctor, the Department of Motor Vehicles, Facebook, Twitter or Google, they are each administrative identifiers: entries in namespaces each of those organizations control, entirely for their own convenience. As Timothy Ruff of [Evernym][3] explains, "You don't exist for them. Only your identifier does." It's the dependent variable. The independent variable—the one controlling the identifier—is the organization.
|
||||
|
||||
If your answer comes from your self, we have a wide-open area for a new development category—one where, finally, we can be set fully free in the connected world.
|
||||
|
||||
The first person to explain this, as far as I know, was [Devon Loffreto][4] He wrote "What is 'Sovereign Source Authority'?" in February 2012, on his blog, [The Moxy Tongue][5]. In "[Self-Sovereign Identity][6]", published in February 2016, he writes:
|
||||
|
||||
>Self-Sovereign Identity must emit directly from an individual human life, and not from within an administrative mechanism...self-Sovereign Identity references every individual human identity as the origin of source authority. A self-Sovereign identity produces an administrative trail of data relations that begin and resolve to individual humans. Every individual human may possess a self-Sovereign identity, and no person or abstraction of any type created may alter this innate human Right. A self-Sovereign identity is the root of all participation as a valued social being within human societies of any type.
|
||||
|
||||
To put this in Linux terms, only the individual has root for his or her own source identity. In the physical world, this is a casual thing. For example, my own portfolio of identifiers includes:
|
||||
|
||||
- David Allen Searls, which my parents named me.
|
||||
- David Searls, the name I tend to use when I suspect official records are involved.
|
||||
- Dave, which is what most of my relatives and old friends call me.
|
||||
- Doc, which is what most people call me.
|
||||
|
||||
As the sovereign source authority over the use of those, I can jump from one to another in different contexts and get along pretty well. But, that's in the physical world. In the virtual one, it gets much more complicated. In addition to all the above, I am @dsearls (my Twitter handle) and dsearls (my handle in many other net-based services). I am also burdened by having my ability to relate contained within hundreds of different silos, each with their own logins and passwords.
|
||||
|
||||
You can get a sense of how bad this is by checking the list of logins and passwords on your browser. On Firefox alone, I have hundreds of them. Many are defunct (since my collection dates back to Netscape days), but I would guess that I still have working logins to hundreds of companies I need to deal with from time to time. For all of them, I'm the dependent variable. It's not the other way around. Even the term "user" testifies to the subordinate dependency that has become a primary fact of life in the connected world.
|
||||
|
||||
Today, the only easy way to bridge namespaces is via the compromised convenience of "Log in with Facebook" or "Log in with Twitter". In both of those cases, each of us is even less ourselves or in any kind of personal control over how we are known (if we wish to be knowable at all) to other entities in the connected world.
|
||||
|
||||
What we have needed from the start are personal systems for instantiating our sovereign selves and choosing how to reveal and protect ourselves when dealing with others in the connected world. For lack of that ability, we are deep in a metastasized mess that Shoshana Zuboff calls "surveillance capitalism", which she says is:
|
||||
|
||||
>...unimaginable outside the inscrutable high velocity circuits of Google's digital universe, whose signature feature is the Internet and its successors. While the world is riveted by the showdown between Apple and the FBI, the real truth is that the surveillance capabilities being developed by surveillance capitalists are the envy of every state security agency.
|
||||
|
||||
Then she asks, "How can we protect ourselves from its invasive power?"
|
||||
|
||||
I suggest self-sovereign identity. I believe it is only there that we have both safety from unwelcome surveillance and an Archimedean place to stand in the world. From that place, we can assert full agency in our dealings with others in society, politics and business.
|
||||
|
||||
I came to this provisional conclusion during [ID2020][7], a gathering at the UN on May. It was gratifying to see Devon Loffreto there, since he's the guy who got the sovereign ball rolling in 2013. Here's [what I wrote about][8] it at the time, with pointers to Devon's earlier posts (such as one sourced above).
|
||||
|
||||
Here are three for the field's canon:
|
||||
|
||||
- "[Self-Sovereign Identity][9]" by Devon Loffreto.
|
||||
- "[System or Human First][10]" by Devon Loffreto.
|
||||
- "[The Path to Self-Sovereign Identity][11]" by Christopher Allen.
|
||||
|
||||
A one-pager from Evernym, [digi.me][12], [iRespond][13] and [Respect Network][14] also was circulated there, contrasting administrative identity (which it calls the "current model") with the self-sovereign one. In it is the graphic shown in Figure 2.
|
||||
|
||||

|
||||
>Figure 2. Current Model of Identity vs. Self-Sovereign Identity
|
||||
|
||||
The [platform][15] for this is Sovrin, explained as a "Fully open-source, attribute-based, sovereign identity graph platform on an advanced, dedicated, permissioned, distributed ledger" There's a [white paper][16] too. The code is called [plenum][17], and it's at GitHub.
|
||||
|
||||
Here—and places like it—we can do for user space what we've done for the last quarter century for kernel space.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/doing-user-space-what-we-did-kernel-space
|
||||
|
||||
作者:[Doc Searls][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxjournal.com/users/doc-searls
|
||||
[1]: https://en.wikipedia.org/wiki/Block_chain_%28database%29
|
||||
[2]: https://www.google.com/trends/explore#q=blockchain
|
||||
[3]: http://evernym.com/
|
||||
[4]: https://twitter.com/nzn
|
||||
[5]: http://www.moxytongue.com/2012/02/what-is-sovereign-source-authority.html
|
||||
[6]: http://www.moxytongue.com/2016/02/self-sovereign-identity.html
|
||||
[7]: http://www.id2020.org/
|
||||
[8]: http://blogs.harvard.edu/doc/2013/10/14/iiw-challenge-1-sovereign-identity-in-the-great-silo-forest
|
||||
[9]: http://www.moxytongue.com/2016/02/self-sovereign-identity.html
|
||||
[10]: http://www.moxytongue.com/2016/05/system-or-human.html
|
||||
[11]: http://www.lifewithalacrity.com/2016/04/the-path-to-self-soverereign-identity.html
|
||||
[12]: https://get.digi.me/
|
||||
[13]: http://irespond.com/
|
||||
[14]: https://www.respectnetwork.com/
|
||||
[15]: http://evernym.com/technology
|
||||
[16]: http://evernym.com/assets/doc/Identity-System-Essentials.pdf?v=167284fd65
|
||||
[17]: https://github.com/evernym/plenum
|
||||
@ -1,141 +0,0 @@
|
||||
Being translated by ChrisLeeGit
|
||||
|
||||
Getting started with Git
|
||||
=========================
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
|
||||
In the introduction to this series we learned who should use Git, and what it is for. Today we will learn how to clone public Git repositories, and how to extract individual files without cloning the whole works.
|
||||
|
||||
Since Git is so popular, it makes life a lot easier if you're at least familiar with it at a basic level. If you can grasp the basics (and you can, I promise!), then you'll be able to download whatever you need, and maybe even contribute stuff back. And that, after all, is what open source is all about: having access to the code that makes up the software you run, the freedom to share it with others, and the right to change it as you please. Git makes this whole process easy, as long as you're comfortable with Git.
|
||||
|
||||
So let's get comfortable with Git.
|
||||
|
||||
### Read and write
|
||||
|
||||
Broadly speaking, there are two ways to interact with a Git repository: you can read from it, or you can write to it. It's just like a file: sometimes you open a document just to read it, and other times you open a document because you need to make changes.
|
||||
|
||||
In this article, we'll cover reading from a Git repository. We'll tackle the subject of writing back to a Git repository in a later article.
|
||||
|
||||
### Git or GitHub?
|
||||
|
||||
A word of clarification: Git is not the same as GitHub (or GitLab, or Bitbucket). Git is a command-line program, so it looks like this:
|
||||
|
||||
```
|
||||
$ git
|
||||
usage: Git [--version] [--help] [-C <path>]
|
||||
[-p | --paginate | --no-pager] [--bare]
|
||||
[--Git-dir=<path>] <command> [<args>]
|
||||
|
||||
```
|
||||
|
||||
As Git is open source, lots of smart people have built infrastructures around it which, in themselves, have become very popular.
|
||||
|
||||
My articles about Git teach pure Git first, because if you understand what Git is doing then you can maintain an indifference to what front end you are using. However, my articles also include common ways of accomplishing each task through popular Git services, since that's probably what you'll encounter first.
|
||||
|
||||
### Installing Git
|
||||
|
||||
To install Git on Linux, grab it from your distribution's software repository. BSD users should find Git in the Ports tree, in the devel section.
|
||||
|
||||
For non-open source operating systems, go to the [project site][1] and follow the instructions. Once installed, there should be no difference between Linux, BSD, and Mac OS X commands. Windows users will have to adapt Git commands to match the Windows file system, or install Cygwin to run Git natively, without getting tripped up by Windows file system conventions.
|
||||
|
||||
### Afternoon tea with Git
|
||||
|
||||
Not every one of us needs to adopt Git into our daily lives right away. Sometimes, the most interaction you have with Git is to visit a repository of code, download a file or two, and then leave. On the spectrum of getting to know Git, this is more like afternoon tea than a proper dinner party. You make some polite conversation, you get the information you need, and then you part ways without the intention of speaking again for at least another three months.
|
||||
|
||||
And that's OK.
|
||||
|
||||
Generally speaking, there are two ways to access Git: via command line, or by any one of the fancy Internet technologies providing quick and easy access through the web browser.
|
||||
|
||||
Say you want to install a trash bin for use in your terminal because you've been burned one too many times by the rm command. You've heard about Trashy, which calls itself "a sane intermediary to the rm command", and you want to look over its documentation before you install it. Lucky for you, [Trashy is hosted publicly on GitLab.com][2].
|
||||
|
||||
### Landgrab
|
||||
|
||||
The first way we'll work with this Git repository is a sort of landgrab method: we'll clone the entire thing, and then sort through the contents later. Since the repository is hosted with a public Git service, there are two ways to do this: on the command line, or through a web interface.
|
||||
|
||||
To grab an entire repository with Git, use the git clone command with the URL of the Git repository. If you're not clear on what the right URL is, the repository should tell you. GitLab gives you a copy-and-paste repository URL [for Trashy][3].
|
||||
|
||||
|
||||
|
||||
You might notice that on some services, both SSH and HTTPS links are provided. You can use SSH only if you have write permissions to the repository. Otherwise, you must use the HTTPS URL.
|
||||
|
||||
Once you have the right URL, cloning the repository is pretty simple. Just git clone the URL, and optionally name the directory to clone it into. The default behaviour is to clone the git directory to your current directory; for example, 'trashy.git' gets put in your current location as 'trashy'. I use the .clone extension as a shorthand for repositories that are read-only, and the .git extension as shorthand for repositories I can read and write, but that's not by any means an official mandate.
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/trashy/trashy.git trashy.clone
|
||||
Cloning into 'trashy.clone'...
|
||||
remote: Counting objects: 142, done.
|
||||
remote: Compressing objects: 100% (91/91), done.
|
||||
remote: Total 142 (delta 70), reused 103 (delta 47)
|
||||
Receiving objects: 100% (142/142), 25.99 KiB | 0 bytes/s, done.
|
||||
Resolving deltas: 100% (70/70), done.
|
||||
Checking connectivity... done.
|
||||
```
|
||||
|
||||
Once the repository has been cloned successfully, you can browse files in it just as you would any other directory on your computer.
|
||||
|
||||
The other way to get a copy of the repository is through the web interface. Both GitLab and GitHub provide a snapshot of any repository in a .zip file. GitHub has a big green download button, but on GitLab, look for an inconspicuous download button on the far right of your browser window:
|
||||
|
||||
|
||||
|
||||
### Pick and choose
|
||||
|
||||
An alternate method of obtaining a file from a Git repository is to find the file you're after and pluck it right out of the repository. This method is only supported via web interfaces, which is essentially you looking at someone else's clone of a repository; you can think of it as a sort of HTTP shared directory.
|
||||
|
||||
The problem with using this method is that you might find that certain files don't actually exist in a raw Git repository, as a file might only exist in its complete form after a make command builds the file, which won't happen until you download the repository, read the README or INSTALL file, and run the command. Assuming, however, that you are sure a file does exist and you just want to go into the repository, grab it, and walk away, you can do that.
|
||||
|
||||
In GitLab and GitHub, click the Files link for a file view, view the file in Raw mode, and use your web browser's save function, e.g. in Firefox, File > Save Page As. In a GitWeb repository (a web view of personal git repositories used some who prefer to host git themselves), the Raw view link is in the file listing view.
|
||||
|
||||
|
||||
|
||||
### Best practices
|
||||
|
||||
Generally, cloning an entire Git repository is considered the right way of interacting with Git. There are a few reasons for this. Firstly, a clone is easy to keep updated with the git pull command, so you won't have to keep going back to some web site for a new copy of a file each time an improvement has been made. Secondly, should you happen to make an improvement yourself, then it is easier to submit those changes to the original author if it is all nice and tidy in a Git repository.
|
||||
|
||||
For now, it's probably enough to just practice going out and finding interesting Git repositories and cloning them to your drive. As long as you know the basics of using a terminal, then it's not hard to do. Don't know the basics of terminal usage? Give me five more minutes of your time.
|
||||
|
||||
### Terminal basics
|
||||
|
||||
The first thing to understand is that all files have a path. That makes sense; if I told you to open a file for me on a regular non-terminal day, you'd have to get to where that file is on your drive, and you'd do that by navigating a bunch of computer windows until you reached that file. For example, maybe you'd click your home directory > Pictures > InktoberSketches > monkey.kra.
|
||||
|
||||
In that scenario, we could say that the file monkeysketch.kra has the path $HOME/Pictures/InktoberSketches/monkey.kra.
|
||||
|
||||
In the terminal, unless you're doing special sysadmin work, your file paths are generally going to start with $HOME (or, if you're lazy, just the ~ character) followed by a list of folders up to the filename itself. This is analogous to whatever icons you click in your GUI to reach the file or folder.
|
||||
|
||||
If you want to clone a Git repository into your Documents directory, then you could open a terminal and run this command:
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/foo/bar.git
|
||||
$HOME/Documents/bar.clone
|
||||
```
|
||||
|
||||
Once that is complete, you can open a file manager window, navigate to your Documents folder, and you'll find the bar.clone directory waiting for you.
|
||||
|
||||
If you want to get a little more advanced, you might revisit that repository at some later date, and try a git pull to see if there have been updates to the project:
|
||||
|
||||
```
|
||||
$ cd $HOME/Documents/bar.clone
|
||||
$ pwd
|
||||
bar.clone
|
||||
$ git pull
|
||||
```
|
||||
|
||||
For now, that's all the terminal commands you need to get started, so go out and explore. The more you do it, the better you get at it, and that is, at least give or take a vowel, the name of the game.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/stumbling-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://git-scm.com/download
|
||||
[2]: https://gitlab.com/trashy/trashy
|
||||
[3]: https://gitlab.com/trashy/trashy.git
|
||||
|
||||
131
sources/tech/20160715 bc - Command line calculator.md
Normal file
131
sources/tech/20160715 bc - Command line calculator.md
Normal file
@ -0,0 +1,131 @@
|
||||
bc: Command line calculator
|
||||
============================
|
||||
|
||||

|
||||
|
||||
If you run a graphical desktop environment, you probably point and click your way to a calculator when you need one. The Fedora Workstation, for example, includes the Calculator tool. It features several different operating modes that allow you to do, for example, complex math or financial calculations. But did you know the command line also offers a similar calculator called bc?
|
||||
|
||||
The bc utility gives you everything you expect from a scientific, financial, or even simple calculator. What’s more, it can be scripted from the command line if needed. This allows you to use it in shell scripts, in case you need to do more complex math.
|
||||
|
||||
Because bc is used by some other system software, like CUPS printing services, it’s probably installed on your Fedora system already. You can check with this command:
|
||||
|
||||
```
|
||||
dnf list installed bc
|
||||
```
|
||||
|
||||
If you don’t see it for some reason, you can install the package with this command:
|
||||
|
||||
```
|
||||
sudo dnf install bc
|
||||
```
|
||||
|
||||
### Doing simple math with bc
|
||||
|
||||
One way to use bc is to enter the calculator’s own shell. There you can run many calculations in a row. When you enter, the first thing that appears is a notice about the program:
|
||||
|
||||
```
|
||||
$ bc
|
||||
bc 1.06.95
|
||||
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
|
||||
This is free software with ABSOLUTELY NO WARRANTY.
|
||||
For details type `warranty'.
|
||||
```
|
||||
|
||||
Now you can type in calculations or commands, one per line:
|
||||
|
||||
```
|
||||
1+1
|
||||
```
|
||||
|
||||
The calculator helpfully answers:
|
||||
|
||||
```
|
||||
2
|
||||
```
|
||||
|
||||
You can perform other commands here. You can use addition (+), subtraction (-), multiplication (*), division (/), parentheses, exponents (^), and so forth. Note that the calculator respects all expected conventions such as order of operations. Try these examples:
|
||||
|
||||
```
|
||||
(4+7)*2
|
||||
4+7*2
|
||||
```
|
||||
|
||||
To exit, send the “end of input” signal with the key combination Ctrl+D.
|
||||
|
||||
Another way is to use the echo command to send calculations or commands. Here’s the calculator equivalent of “Hello, world,” using the shell’s pipe function (|) to send output from echo into bc:
|
||||
|
||||
```
|
||||
echo '1+1' | bc
|
||||
```
|
||||
|
||||
You can send more than one calculation using the shell pipe, with a semicolon to separate entries. The results are returned on separate lines.
|
||||
|
||||
```
|
||||
echo '1+1; 2+2' | bc
|
||||
```
|
||||
|
||||
### Scale
|
||||
|
||||
The bc calculator uses the concept of scale, or the number of digits after a decimal point, in some calculations. The default scale is 0. Division operations always use the scale setting. So if you don’t set scale, you may get unexpected answers:
|
||||
|
||||
```
|
||||
echo '3/2' | bc
|
||||
echo 'scale=3; 3/2' | bc
|
||||
```
|
||||
|
||||
Multiplication uses a more complex decision for scale:
|
||||
|
||||
```
|
||||
echo '3*2' | bc
|
||||
echo '3*2.0' | bc
|
||||
```
|
||||
|
||||
Meanwhile, addition and subtraction are more as expected:
|
||||
|
||||
```
|
||||
echo '7-4.15' | bc
|
||||
```
|
||||
|
||||
### Other base number systems
|
||||
|
||||
Another useful function is the ability to use number systems other than base-10 (decimal). For instance, you can easily do hexadecimal or binary math. Use the ibase and obase commands to set input and output base systems between base-2 and base-16. Remember that once you use ibase, any number you enter is expected to be in the new declared base.
|
||||
|
||||
To do hexadecimal to decimal conversions or math, you can use a command like this. Note the hexadecimal digits above 9 must be in uppercase (A-F):
|
||||
|
||||
```
|
||||
echo 'ibase=16; A42F' | bc
|
||||
echo 'ibase=16; 5F72+C39B' | bc
|
||||
```
|
||||
|
||||
To get results in hexadecimal, set the obase as well:
|
||||
|
||||
```
|
||||
echo 'obase=16; ibase=16; 5F72+C39B' | bc
|
||||
```
|
||||
|
||||
Here’s a trick, though. If you’re doing these calculations in the shell, how do you switch back to input in base-10? The answer is to use ibase, but you must set it to the equivalent of decimal number 10 in the current input base. For instance, if ibase was set to hexadecimal, enter:
|
||||
|
||||
```
|
||||
ibase=A
|
||||
```
|
||||
|
||||
Once you do this, all input numbers are now decimal again, so you can enter obase=10 to reset the output base system.
|
||||
|
||||
### Conclusion
|
||||
|
||||
This is only the beginning of what bc can do. It also allows you to define functions, variables, and loops for complex calculations and programs. You can save these programs as text files on your system to run whenever you need. You can find numerous resources on the web that offer examples and additional function libraries. Happy calculating!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[1]: http://phodd.net/gnu-bc/
|
||||
@ -1,181 +0,0 @@
|
||||
vim-kakali translating
|
||||
|
||||
|
||||
|
||||
Creating your first Git repository
|
||||
======================================
|
||||
|
||||

|
||||
|
||||
Now it is time to learn how to create your own Git repository, and how to add files and make commits.
|
||||
|
||||
In the previous installments in this series, you learned how to interact with Git as an end user; you were the aimless wanderer who stumbled upon an open source project's website, cloned a repository, and moved on with your life. You learned that interacting with Git wasn't as confusing as you may have thought it would be, and maybe you've been convinced that it's time to start leveraging Git for your own work.
|
||||
|
||||
While Git is definitely the tool of choice for major software projects, it doesn't only work with major software projects. It can manage your grocery lists (if they're that important to you, and they may be!), your configuration files, a journal or diary, a novel in progress, and even source code!
|
||||
|
||||
And it is well worth doing; after all, when have you ever been angry that you have a backup copy of something that you've just mangled beyond recognition?
|
||||
|
||||
Git can't work for you unless you use it, and there's no time like the present. Or, translated to Git, "There is no push like origin HEAD". You'll understand that later, I promise.
|
||||
|
||||
### The audio recording analogy
|
||||
|
||||
We tend to speak of computer imaging in terms of snapshots because most of us can identify with the idea of having a photo album filled with particular moments in time. It may be more useful, however, to think of Git more like an analogue audio recording.
|
||||
|
||||
A traditional studio tape deck, in case you're unfamiliar, has a few components: it contains the reels that turn either forward or in reverse, tape to preserve sound waves, and a playhead to record or detect sound waves on tape and present them to the listener.
|
||||
|
||||
In addition to playing a tape forward, you can rewind it to get back to a previous point in the tape, or fast-forward to skip ahead to a later point.
|
||||
|
||||
Imagine a band in the 1970s recording to tape. You can imagine practising a song over and over until all the parts are perfect, and then laying down a track. First, you record the drums, and then the bass, and then the guitar, and then the vocals. Each time you record, the studio engineer rewinds the tape and puts it into loop mode so that it plays the previous part as you play yours; that is, if you're on bass, you get to hear the drums in the background as you play, and then the guitarist hears the drums and bass (and cowbell) and so on. On each loop, you play over the part, and then on the following loop, the engineer hits the record button and lays the performance down on tape.
|
||||
|
||||
You can also copy and swap out a reel of tape entirely, should you decide to do a re-mix of something you're working on.
|
||||
|
||||
Now that I've hopefully painted a vivid Roger Dean-quality image of studio life in the 70s, let's translate that into Git.
|
||||
|
||||
### Create a Git repository
|
||||
|
||||
The first step is to go out and buy some tape for our virtual tape deck. In Git terms, that's the repository ; it's the medium or domain where all the work is going to live.
|
||||
|
||||
Any directory can become a Git repository, but to begin with let's start a fresh one. It takes three commands:
|
||||
|
||||
- Create the directory (you can do that in your GUI file manager, if you prefer).
|
||||
- Visit that directory in a terminal.
|
||||
- Initialise it as a directory managed by Git.
|
||||
|
||||
Specifically, run these commands:
|
||||
|
||||
```
|
||||
$ mkdir ~/jupiter # make directory
|
||||
$ cd ~/jupiter # change into the new directory
|
||||
$ git init . # initialise your new Git repo
|
||||
```
|
||||
|
||||
Is this example, the folder jupiter is now an empty but valid Git repository.
|
||||
|
||||
That's all it takes. You can clone the repository, you can go backward and forward in history (once it has a history), create alternate timelines, and everything else Git can normally do.
|
||||
|
||||
Working inside the Git repository is the same as working in any directory; create files, copy files into the directory, save files into it. You can do everything as normal; Git doesn't get involved until you involve it.
|
||||
|
||||
In a local Git repository, a file can have one of three states:
|
||||
|
||||
- Untracked: a file you create in a repository, but not yet added to Git.
|
||||
- Tracked: a file that has been added to Git.
|
||||
- Staged: a tracked file that has been changed and added to Git's commit queue.
|
||||
|
||||
Any file that you add to a Git repository starts life out as an untracked file. The file exists on your computer, but you have not told Git about it yet. In our tape deck analogy, the tape deck isn't even turned on yet; the band is just noodling around in the studio, nowhere near ready to record yet.
|
||||
|
||||
That is perfectly acceptable, and Git will let you know when it happens:
|
||||
|
||||
```
|
||||
$ echo "hello world" > foo
|
||||
$ git status
|
||||
On branch master
|
||||
Untracked files:
|
||||
(use "git add <file>..." to include in what will be committed)
|
||||
foo
|
||||
nothing added but untracked files present (use "git add" to track)
|
||||
```
|
||||
|
||||
As you can see, Git also tells you how to start tracking files.
|
||||
|
||||
### Git without Git
|
||||
|
||||
Creating a repository in GitHub or GitLab is a lot more clicky and pointy. It isn't difficult; you click the New Repository button and follow the prompts.
|
||||
|
||||
It is a good practice to include a README file so that people wandering by have some notion of what your repository is for, and it is a little more satisfying to clone a non-empty repository.
|
||||
|
||||
Cloning the repository is no different than usual, but obtaining permission to write back into that repository on GitHub is slightly more complex, because in order to authenticate to GitHub you must have an SSH key. If you're on Linux, create one with this command:
|
||||
|
||||
```
|
||||
$ ssh-keygen
|
||||
```
|
||||
|
||||
Then copy your new key, which is plain text. You can open it in a plain text editor, or use the cat command:
|
||||
|
||||
```
|
||||
$ cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
|
||||
Now paste your key into [GitHub's SSH configuration][1], or your [GitLab configuration][2].
|
||||
|
||||
As long as you clone your GitHub project via SSH, you'll be able to write back to your repository.
|
||||
|
||||
Alternately, you can use GitHub's file uploader interface to add files without even having Git on your system.
|
||||
|
||||
|
||||
|
||||
### Tracking files
|
||||
|
||||
As the output of git status tells you, if you want Git to start tracking a file, you must git add it. The git add action places a file in a special staging area, where files wait to be committed, or preserved for posterity in a snapshot. The point of a git add is to differentiate between files that you want to have included in a snapshot, and the new or temporary files you want Git to, at least for now, ignore.
|
||||
|
||||
In our tape deck analogy, this action turns the tape deck on and arms it for recording. You can picture the tape deck with the record and pause button pushed, or in a playback loop awaiting the next track to be laid down.
|
||||
|
||||
Once you add a file, Git will identify it as a tracked file:
|
||||
|
||||
```
|
||||
$ git add foo
|
||||
$ git status
|
||||
On branch master
|
||||
Changes to be committed:
|
||||
(use "git reset HEAD <file>..." to unstage)
|
||||
new file: foo
|
||||
```
|
||||
|
||||
Adding a file to Git's tracking system is not making a recording. It just puts a file on the stage in preparation for recording. You can still change a file after you've added it; it's being tracked and remains staged, so you can continue to refine it or change it before committing it to tape (but be warned; you're NOT recording yet, so if you break something in a file that was perfect, there's no going back in time yet, because you never got that perfect moment on tape).
|
||||
|
||||
If you decide that the file isn't really ready to be recorded in the annals of Git history, then you can unstage something, just as the Git message described:
|
||||
|
||||
```
|
||||
$ git reset HEAD foo
|
||||
```
|
||||
|
||||
This, in effect, disarms the tape deck from being ready to record, and you're back to just noodling around in the studio.
|
||||
|
||||
### The big commit
|
||||
|
||||
At some point, you're going to want to commit something; in our tape deck analogy, that means finally pressing record and laying a track down on tape.
|
||||
|
||||
At different stages of a project's life, how often you press that record button varies. For example, if you're hacking your way through a new Python toolkit and finally manage to get a window to appear, then you'll certainly want to commit so you have something to fall back on when you inevitably break it later as you try out new display options. But if you're working on a rough draft of some new graphics in Inkscape, you might wait until you have something you want to develop from before committing. Ultimately, though, it's up to you how often you commit; Git doesn't "cost" that much and hard drives these days are big, so in my view, the more the better.
|
||||
|
||||
A commit records all staged files in a repository. Git only records files that are tracked, that is, any file that you did a git add on at some point in the past. and that have been modified since the previous commit. If no previous commit exists, then all tracked files are included in the commit because they went from not existing to existing, which is a pretty major modification from Git's point-of-view.
|
||||
|
||||
To make a commit, run this command:
|
||||
|
||||
```
|
||||
$ git commit -m 'My great project, first commit.'
|
||||
```
|
||||
|
||||
This preserves all files committed for posterity (or, if you speak Gallifreyan, they become "fixed points in time"). You can see not only the commit event, but also the reference pointer back to that commit in your Git log:
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
55df4c2 My great project, first commit.
|
||||
```
|
||||
|
||||
For a more detailed report, just use git log without the --oneline option.
|
||||
|
||||
The reference number for the commit in this example is 55df4c2. It's called a commit hash and it represents all of the new material you just recorded, overlaid onto previous recordings. If you need to "rewind" back to that point in history, you can use that hash as a reference.
|
||||
|
||||
You can think of a commit hash as [SMPTE timecode][3] on an audio tape, or if we bend the analogy a little, one of those big gaps between songs on a vinyl record, or track numbers on a CD.
|
||||
|
||||
As you change files further and add them to the stage, and ultimately commit them, you accrue new commit hashes, each of which serve as pointers to different versions of your production.
|
||||
|
||||
And that's why they call Git a version control system, Charlie Brown.
|
||||
|
||||
In the next article, we'll explore everything you need to know about the Git HEAD, and we'll nonchalantly reveal the secret of time travel. No big deal, but you'll want to read it (or maybe you already have?).
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/creating-your-first-git-repository
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://github.com/settings/keys
|
||||
[2]: https://gitlab.com/profile/keys
|
||||
[3]: http://slackermedia.ml/handbook/doku.php?id=timecode
|
||||
64
sources/tech/20160722 Keeweb A Linux Password Manager.md
Normal file
64
sources/tech/20160722 Keeweb A Linux Password Manager.md
Normal file
@ -0,0 +1,64 @@
|
||||
Being translated by ChrisLeeGit
|
||||
|
||||
Keeweb A Linux Password Manager
|
||||
================================
|
||||
|
||||

|
||||
|
||||
Today we are depending on more and more online services. Each online service we sign up for, let us set a password and this way we have to remember hundreds of passwords. In this case, it is easy for anyone to forget passwords. In this article I am going to talk about Keeweb, a Linux password manager that can store all your passwords securely either online or offline.
|
||||
|
||||
When we talk about Linux password managers, there are so many. Password managers like, [Keepass][1] and [Encryptr, a Zero-knowledge system based password manager][2] have already been talked about on LinuxAndUbuntu. Keeweb is another password manager for Linux that we are going to see in this article.
|
||||
|
||||
### Keeweb can store passwords offline or online
|
||||
|
||||
Keeweb is a cross-platform password manager. It can store all your passwords offline and sync it with your own cloud storage services like OneDrive, Google Drive, Dropbox etc. Keeweb does not have online database of its own to sync your passwords.
|
||||
|
||||
To connect your online storage with Keeweb, just click more and click the service that you want to use.
|
||||
|
||||

|
||||
|
||||
Now Keeweb will prompt you to sign in to your drive. After sign in authenticate Keeweb to use your account.
|
||||
|
||||

|
||||
|
||||
### Store passwords with Keeweb
|
||||
|
||||
It is very easy to store your passwords with Keeweb. You can encrypt your password file with a complex password. Keeweb also allows you to lock file with a key file but I don't recommend it. If somebody gets your key file, it takes only a click to unlock your passwords file.
|
||||
|
||||
#### Create Passwords
|
||||
|
||||
To create a new password simply click the '+' sign and you will be presented all entries to fill up. You can create more entries if you want.
|
||||
|
||||
#### Search Passwords
|
||||
|
||||

|
||||
|
||||
Keeweb has a library of icons so that you can find any particular password entry easily. You can change the color of icons, download more icons and even import icons from your computer. When talking about finding passwords the search comes very handy.
|
||||
|
||||
Passwords of similar services can be grouped so that you can find them all at one place in one folder. You can also tag passwords to store them all in different categories.
|
||||
|
||||

|
||||
|
||||
### Themes
|
||||
|
||||

|
||||
|
||||
If you like light themes like white or high contrast then you can change theme from Settings > General > Themes. There are four themes available, two are dark and two are light.
|
||||
|
||||
### Dont' you Like Linux Passwords Manager? No problem!
|
||||
|
||||
I have already posted about two other Linux password managers, Keepass and Encryptr and there were arguments on Reddit, and other social media. There were people against using any password manager and vice-versa. In this article I want to clear out that it is our responsibility to save the file that passwords are stored in. I think Password managers like Keepass and Keeweb are good to use as they don't store your passwords in the cloud. These password managers create a file and you can store it on your hard drive or encrypt it with apps like VeraCrypt. I myself don't use or recommend to use services that store passwords in their own database.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
||||
|
||||
作者:[author][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxandubuntu.com/home/keeweb-a-linux-password-manager
|
||||
[1]: http://www.linuxandubuntu.com/home/keepass-password-management-tool-creates-strong-passwords-and-keeps-them-secure
|
||||
[2]: http://www.linuxandubuntu.com/home/encryptr-zero-knowledge-system-based-password-manager-for-linux
|
||||
@ -0,0 +1,85 @@
|
||||
Terminator A Linux Terminal Emulator With Multiple Terminals In One Window
|
||||
=============================================================================
|
||||
|
||||

|
||||
|
||||
Each Linux distribution has a default terminal emulator for interacting with system through commands. But the default terminal app might not be perfect for you. There are so many terminal apps that will provide you more functionalities to perform more tasks simultaneously to sky-rocket speed of your work. Such useful terminal emulators include Terminator, a multi-windows supported free terminal emulator for your Linux system.
|
||||
|
||||
### What Is Linux Terminal Emulator?
|
||||
|
||||
A Linux terminal emulator is a program that lets you interact with the shell. All Linux distributions come with a default Linux terminal app that let you pass commands to the shell.
|
||||
|
||||
### Terminator, A Free Linux Terminal App
|
||||
|
||||
Terminator is a Linux terminal emulator that provides several features that your default terminal app does not support. It provides the ability to create multiple terminals in one window and faster your work progress. Other than multiple windows, it allows you to change other properties such as, terminal fonts, fonts colour, background colour and so on. Let's see how we can install and use Terminator in different Linux distributions.
|
||||
|
||||
### How To Install Terminator In Linux?
|
||||
|
||||
#### Install Terminator In Ubuntu Based Distributions
|
||||
|
||||
Terminator is available in the default Ubuntu repository. So you don't require to add any additional PPA. Just use APT or Software App to install it in Ubuntu.
|
||||
|
||||
```
|
||||
sudo apt-get install terminator
|
||||
```
|
||||
|
||||
In case Terminator is not available in your default repository, just compile Terminator from source code.
|
||||
|
||||
[DOWNLOAD SOURCE CODE][1]
|
||||
|
||||
Download Terminator source code and extract it on your desktop. Now open your default terminal & cd into the extracted folder.
|
||||
|
||||
Now use the following command to install Terminator -
|
||||
|
||||
```
|
||||
sudo ./setup.py install
|
||||
```
|
||||
|
||||
#### Install Terminator In Fedora & Other Derivatives
|
||||
|
||||
```
|
||||
dnf install terminator
|
||||
```
|
||||
|
||||
#### Install Terminator In OpenSuse
|
||||
|
||||
[INSTALL IN OPENSUSE][2]
|
||||
|
||||
### How To Use Multiple Terminals In One Window?
|
||||
|
||||
After you have installed Terminator, simply open multiple terminals in one window. Simply right click and divide.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
You can create as many terminals as you want, if you can manage them.
|
||||
|
||||

|
||||
|
||||
### Customise Terminals
|
||||
|
||||
Right click the terminal and click Properties. Now you can customise fonts, fonts colour, title colour & background and terminal fonts colour & background.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Conclusion & What Is Your Favorite Terminal Emulator?
|
||||
|
||||
Terminator is an advanced terminal emulator and it also let you customize the interface. If you have not yet switched from your default terminal emulator then just try this one. I know you'll like it. If you're using any other free terminal emulator, then let us know your favorite terminal emulator. Also don't forget to share this article with your friends. Perhaps your friends are searching for something like this.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
||||
|
||||
作者:[author][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxandubuntu.com/home/terminator-a-linux-terminal-emulator-with-multiple-terminals-in-one-window
|
||||
[1]: https://launchpad.net/terminator/+download
|
||||
[2]: http://software.opensuse.org/download.html?project=home%3AKorbi123&package=terminator
|
||||
@ -1,3 +1,5 @@
|
||||
Being translated by ChrisLeeGit
|
||||
|
||||
Part 13 - LFCS: How to Configure and Troubleshoot Grand Unified Bootloader (GRUB)
|
||||
=====================================================================================
|
||||
|
||||
@ -167,7 +169,7 @@ Do you have questions or comments? Don’t hesitate to let us know using the com
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,275 @@
|
||||
translating by vim-kakali
|
||||
|
||||
|
||||
Learn How to Use Awk Variables, Numeric Expressions and Assignment Operators – part8
|
||||
|
||||
=======================================================================================
|
||||
|
||||
The [Awk command series][1] is getting exciting I believe, in the previous seven parts, we walked through some fundamentals of Awk that you need to master to enable you perform some basic text or string filtering in Linux.
|
||||
|
||||
Starting with this part, we shall dive into advance areas of Awk to handle more complex text or string filtering operations. Therefore, we are going to cover Awk features such as variables, numeric expressions and assignment operators.
|
||||
|
||||

|
||||
>Learn Awk Variables, Numeric Expressions and Assignment Operators
|
||||
|
||||
These concepts are not comprehensively distinct from the ones you may have probably encountered in many programming languages before such shell, C, Python plus many others, so there is no need to worry much about this topic, we are simply revising the common ideas of using these mentioned features.
|
||||
|
||||
This will probably be one of the easiest Awk command sections to understand, so sit back and lets get going.
|
||||
|
||||
### 1. Awk Variables
|
||||
|
||||
In any programming language, a variable is a place holder which stores a value, when you create a variable in a program file, as the file is executed, some space is created in memory that will store the value you specify for the variable.
|
||||
|
||||
You can define Awk variables in the same way you define shell variables as follows:
|
||||
|
||||
```
|
||||
variable_name=value
|
||||
```
|
||||
|
||||
In the syntax above:
|
||||
|
||||
- `variable_name`: is the name you give a variable
|
||||
- `value`: the value stored in the variable
|
||||
|
||||
Let’s look at some examples below:
|
||||
|
||||
```
|
||||
computer_name=”tecmint.com”
|
||||
port_no=”22”
|
||||
email=”admin@tecmint.com”
|
||||
server=”computer_name”
|
||||
```
|
||||
|
||||
Take a look at the simple examples above, in the first variable definition, the value `tecmint.com` is assigned to the variable `computer_name`.
|
||||
|
||||
Furthermore, the value 22 is assigned to the variable port_no, it is also possible to assign the value of one variable to another variable as in the last example where we assigned the value of computer_name to the variable server.
|
||||
|
||||
If you can recall, right from [part 2 of this Awk series][2] were we covered field editing, we talked about how Awk divides input lines into fields and uses standard field access operator, $ to read the different fields that have been parsed. We can also use variables to store the values of fields as follows.
|
||||
|
||||
```
|
||||
first_name=$2
|
||||
second_name=$3
|
||||
```
|
||||
|
||||
In the examples above, the value of first_name is set to second field and second_name is set to the third field.
|
||||
|
||||
As an illustration, consider a file named names.txt which contains a list of an application’s users indicating their first and last names plus gender. Using the [cat command][3], we can view the contents of the file as follows:
|
||||
|
||||
```
|
||||
$ cat names.txt
|
||||
```
|
||||
|
||||

|
||||
>List File Content Using cat Command
|
||||
|
||||
Then, we can also use the variables first_name and second_name to store the first and second names of the first user on the list as by running the Awk command below:
|
||||
|
||||
```
|
||||
$ awk '/Aaron/{ first_name=$2 ; second_name=$3 ; print first_name, second_name ; }' names.txt
|
||||
```
|
||||
|
||||

|
||||
>Store Variables Using Awk Command
|
||||
|
||||
Let us also take a look at another case, when you issue the command `uname -a` on your terminal, it prints out all your system information.
|
||||
|
||||
The second field contains your `hostname`, therefore we can store the hostname in a variable called hostname and print it using Awk as follows:
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
$ uname -a | awk '{hostname=$2 ; print hostname ; }'
|
||||
```
|
||||
|
||||

|
||||
>Store Command Output to Variable Using Awk
|
||||
|
||||
### 2. Numeric Expressions
|
||||
|
||||
In Awk, numeric expressions are built using the following numeric operators:
|
||||
|
||||
- `*` : multiplication operator
|
||||
- `+` : addition operator
|
||||
- `/` : division operator
|
||||
- `-` : subtraction operator
|
||||
- `%` : modulus operator
|
||||
- `^` : exponentiation operator
|
||||
|
||||
The syntax for a numeric expressions is:
|
||||
|
||||
```
|
||||
$ operand1 operator operand2
|
||||
```
|
||||
|
||||
In the form above, operand1 and operand2 can be numbers or variable names, and operator is any of the operators above.
|
||||
|
||||
Below are some examples to demonstrate how to build numeric expressions:
|
||||
|
||||
```
|
||||
counter=0
|
||||
num1=5
|
||||
num2=10
|
||||
num3=num2-num1
|
||||
counter=counter+1
|
||||
```
|
||||
|
||||
To understand the use of numeric expressions in Awk, we shall consider the following example below, with the file domains.txt which contains all domains owned by Tecmint.
|
||||
|
||||
```
|
||||
news.tecmint.com
|
||||
tecmint.com
|
||||
linuxsay.com
|
||||
windows.tecmint.com
|
||||
tecmint.com
|
||||
news.tecmint.com
|
||||
tecmint.com
|
||||
linuxsay.com
|
||||
tecmint.com
|
||||
news.tecmint.com
|
||||
tecmint.com
|
||||
linuxsay.com
|
||||
windows.tecmint.com
|
||||
tecmint.com
|
||||
```
|
||||
|
||||
To view the contents of the file, use the command below:
|
||||
|
||||
```
|
||||
$ cat domains.txt
|
||||
```
|
||||
|
||||

|
||||
>View Contents of File
|
||||
|
||||
If we want to count the number of times the domain tecmint.com appears in the file, we can write a simple script to do that as follows:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
for file in $@; do
|
||||
if [ -f $file ] ; then
|
||||
#print out filename
|
||||
echo "File is: $file"
|
||||
#print a number incrementally for every line containing tecmint.com
|
||||
awk '/^tecmint.com/ { counter=counter+1 ; printf "%s\n", counter ; }' $file
|
||||
else
|
||||
#print error info incase input is not a file
|
||||
echo "$file is not a file, please specify a file." >&2 && exit 1
|
||||
fi
|
||||
done
|
||||
#terminate script with exit code 0 in case of successful execution
|
||||
exit 0
|
||||
```
|
||||
|
||||
|
||||
>Shell Script to Count a String or Text in File
|
||||
|
||||
After creating the script, save it and make it executable, when we run it with the file, domains.txt as out input, we get the following output:
|
||||
|
||||
```
|
||||
$ ./script.sh ~/domains.txt
|
||||
```
|
||||
|
||||

|
||||
>Script to Count String or Text
|
||||
|
||||
From the output of the script, there are 6 lines in the file domains.txt which contain tecmint.com, to confirm that you can manually count them.
|
||||
|
||||
### 3. Assignment Operators
|
||||
|
||||
The last Awk feature we shall cover is assignment operators, there are several assignment operators in Awk and these include the following:
|
||||
|
||||
- `*=` : multiplication assignment operator
|
||||
- `+=` : addition assignment operator
|
||||
- `/=` : division assignment operator
|
||||
- `-=` : subtraction assignment operator
|
||||
- `%=` : modulus assignment operator
|
||||
- `^=` : exponentiation assignment operator
|
||||
|
||||
The simplest syntax of an assignment operation in Awk is as follows:
|
||||
|
||||
```
|
||||
$ variable_name=variable_name operator operand
|
||||
```
|
||||
|
||||
Examples:
|
||||
|
||||
```
|
||||
counter=0
|
||||
counter=counter+1
|
||||
num=20
|
||||
num=num-1
|
||||
```
|
||||
|
||||
You can use the assignment operators above to shorten assignment operations in Awk, consider the previous examples, we could perform the assignment in the following form:
|
||||
|
||||
```
|
||||
variable_name operator=operand
|
||||
counter=0
|
||||
counter+=1
|
||||
num=20
|
||||
num-=1
|
||||
```
|
||||
|
||||
Therefore, we can alter the Awk command in the shell script we just wrote above using += assignment operator as follows:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
for file in $@; do
|
||||
if [ -f $file ] ; then
|
||||
#print out filename
|
||||
echo "File is: $file"
|
||||
#print a number incrementally for every line containing tecmint.com
|
||||
awk '/^tecmint.com/ { counter+=1 ; printf "%s\n", counter ; }' $file
|
||||
else
|
||||
#print error info incase input is not a file
|
||||
echo "$file is not a file, please specify a file." >&2 && exit 1
|
||||
fi
|
||||
done
|
||||
#terminate script with exit code 0 in case of successful execution
|
||||
exit 0
|
||||
```
|
||||
|
||||
|
||||
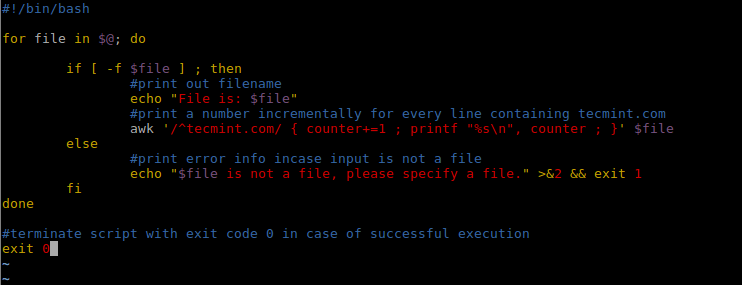
|
||||
>Alter Shell Script
|
||||
|
||||
In this segment of the [Awk series][4], we covered some powerful Awk features, that is variables, building numeric expressions and using assignment operators, plus some few illustrations of how we can actually use them.
|
||||
|
||||
These concepts are not any different from the one in other programming languages but there may be some significant distinctions under Awk programming.
|
||||
|
||||
In part 9, we shall look at more Awk features that is special patterns: BEGIN and END. Until then, stay connected to Tecmint.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/learn-awk-variables-numeric-expressions-and-assignment-operators/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对ID](https://github.com/校对ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[1]: http://www.tecmint.com/category/awk-command/
|
||||
[2]: http://www.tecmint.com/awk-print-fields-columns-with-space-separator/
|
||||
[3]: http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[4]: http://www.tecmint.com/category/awk-command/
|
||||
71
translated/talk/20160627 Linux Practicality vs Activism.md
Normal file
71
translated/talk/20160627 Linux Practicality vs Activism.md
Normal file
@ -0,0 +1,71 @@
|
||||
Linux 的实用性 VS 行动主义
|
||||
==================================
|
||||
|
||||
>我们使用 Linux 是因为它比其他操作系统更实用,还是其他更高级的理由呢?
|
||||
|
||||
其中一件关于运行 Linux 的最伟大的事情之一就是它所提供的自由。凡出现在 Linux 社区之间的划分在于我们如何珍惜这种自由。
|
||||
|
||||
一些人认为,通过使用 Linux 所享有的自由是从供应商锁定或高软件成本的自由。大多数人会称这个是一个实际的考虑。而其他用户会告诉你,他们享受的是自由软件的自由。那就意味着拥抱支持 [开源软件运动][1] 的 Linux 发行版,完全避免专有软件和所有相关的东西。
|
||||
|
||||
|
||||
在这篇文章中,我将带你比较这两种自由的区别,以及他们如何影响 Linux 的使用。
|
||||
|
||||
### 专有的问题
|
||||
|
||||
大多数的用户有一个共同的一点是他们的喜欢避免专有软件。对于像我这样的实际的爱好者来说,这是一个我怎么样花我的钱,来控制我的软件和避免供应商锁定的问题。当然,我不是一个程序员……所以我调整我的安装软件是十分温柔的。但也有一些个别情况,一个应用程序的小调整可以意味着它的工作和不工作的区别。
|
||||
|
||||
还有就是选择避开专有软件的Linux爱好者,因为他们觉得这是不道德的使用。通常这里主要的问题是使用专有软件会带走或者干脆阻碍你的个人自由。像这些用户更喜欢使用的Linux发行版和软件来支持 [自由软件理念][2] 。虽然它类似于开源的概念并经常直接与之混淆,[这里有些差异][3] 。
|
||||
|
||||
因此,这里有个问题:像我这样的用户往往以其便利掩盖了其纯软件自由的理想化。不要误会我的意思,像我这样的人更喜欢使用符合自由软件背后的理想软件,但我们也更有可能做出让步,以完成特定的任务。
|
||||
|
||||
这两种类型的 Linux 爱好者都喜欢使用非专有的解决方案。但是,自由软件倡导者根本不会去使用所有权,在那里作为实际的用户将依靠具有最佳性能的最佳工具。这意味着,在有些情况下的实际用户愿意来运行他们的非专有操作系统上的专有应用或代码实例。
|
||||
|
||||
最终,这两种类型的用户都喜欢使用 Linux 所提供的。但是,我们这样做的原因往往会有所不同。有人认为那些不支持自由软件的人是无知的。我不同意,我认为它是实用方便性的问题。那些喜欢实用方便性的用户根本不关心他们软件的政治问题。
|
||||
|
||||
### 实用方便性
|
||||
|
||||
当你问起绝大多数的人为什么使用他们现在的操作系统,回答通常都集中于实用方便性。这种关于方便性的例子可能包括“它是我一直使用的东西”、“它运行的软件是我需要的”。 其他人可能进一步解释说,并没有那么多软件影响他们对操作系统的偏好和熟悉程度,最后,有“利基任务”或硬件兼容性问题也提供了很好的理由让我们用这个操作系统而不是另一个。
|
||||
|
||||
这可能会让你们中许多人很惊讶,但我今天运行的桌面 Linux 最大的一个原因是由于熟悉。即使我为别人提供对 Windows 和 OS X 的支持,但实际上我是相当沮丧地使用这些操作系统,因为它们根本就不是我记忆中的那样习惯用法。我相信这可以让我对那些 Linux 新手表示同情,因为我太懂得踏入陌生的领域是怎样的让人倒胃口了。我的观点是这样的 —— 熟悉具有价值。而且熟悉同样使得实用方便性变得有力量。
|
||||
|
||||
现在,如果我们把它和一个自由软件倡导者的需求来比较,你会发现那些人都愿意学习新的东西,甚至更具挑战性,去学习那些若转化成为他们所避免使用的非自由软件。这就是我经常赞美的那种用户,我认为他们愿意采取最少路径来遵循坚持他们的原则是十分值得赞赏的。
|
||||
|
||||
### 自由的价值
|
||||
|
||||
我不羡慕那些自由软件倡导者的一个地方,就是根据 [自由软件基金会][4] 所规定的标准需要确保他们可以一直使用 Linux 发行版和硬件,以便于尊重他们的数字自由。这意味着 Linux 内核需要摆脱专有的斑点的驱动支持和不需要任何专有代码的硬件。当然不是不可能的,但它很接近。
|
||||
|
||||
一个自由软件倡导者可以达到的最好的情况是硬件是“自由兼容”的。有些供应商,可以满足这一需求,但他们大多是提供依赖于 Linux 兼容专有固件的硬件。伟大的实际用户对自由软件倡导者来说是个搅局者。
|
||||
|
||||
那么这一切意味着的是,倡导者必须比实际的 Linux 爱好者,更加警惕。这本身并不一定是消极的,但如果是打算用自由软件的方法来计算的话那就值得考虑了。通过对比,实用的用户可以专心地使用与 Linux 兼容的任何软件或硬件。我不知道你是怎么想的,但在我眼中是更轻松一点的。
|
||||
|
||||
### 定义自由软件
|
||||
|
||||
这一部分可能会让一部分人失望,因为我不相信自由软件只有一种。从我的立场,我认为真正的自由是能够在一个给定的情况里沉浸在所有可用的数据里,然后用最适合这个人的生活方式的途径来达成协议。
|
||||
|
||||
所以对我来说,我更喜欢使用的 Linux 桌面,满足了我所有的需求,这包括使用非专有软件和专有软件。尽管这是公平的建议,专有的软件限制了我的个人自由,但我必须反驳这一点,因为我有选择用不用它,即选择的自由。
|
||||
|
||||
或许,这也就是为什么我发现自己更确定开源软件的理想,而不是坚持自由软件运动背后的理念的原因。我更愿意和那些不会花时间告诉我,我是怎么用错了的那些人群在一起。我的经验是,那些开源的人群仅仅是感兴趣去分享自由软件的优点,而不是因为自由软件的理想主义的激情。
|
||||
|
||||
我觉的自由软件的概念实在是太棒了。对那些需要活跃在软件政治,并指出使用专有软件的人的缺陷的人来说,那么我认为 Linux ( [GNU/Linux][5] ) 行动是一个不错的选择。在我们的介绍里,像我一样的实际用户更倾向于从自由软件的支持者改变方向。
|
||||
|
||||
当我介绍 Linux 的桌面时,我富有激情地分享它的实际优点。而且我成功地让他们享受这一经历,我允许用户自己去发现自由软件的观点。但我发现大多数人使用的 Linux 不是因为他们想拥抱自由软件,而是因为他们只是想要最好的用户体验。也许只有我是这样的,很难说。
|
||||
|
||||
嘿!说你呢?你是一个自由软件倡导者吗?也许你是个使用桌面 Linux 发行专有软件/代码的粉丝?那么评论和分享您的 Linux 桌面体验吧!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/linux-practicality-vs-activism.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[joVoV](https://github.com/joVoV)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]: https://en.wikipedia.org/wiki/Free_software_movement
|
||||
[2]: https://www.gnu.org/philosophy/free-sw.en.html
|
||||
[3]: https://www.gnu.org/philosophy/free-software-for-freedom.en.html
|
||||
[4]: https://en.wikipedia.org/wiki/Free_Software_Foundation
|
||||
[5]: https://en.wikipedia.org/wiki/GNU/Linux_naming_controversy
|
||||
@ -0,0 +1,319 @@
|
||||
如何用Python和Flask建立部署一个Facebook信使机器人教程
|
||||
==========================================================================
|
||||
|
||||
这是我建立一个简单的Facebook信使机器人的记录。功能很简单,他是一个回显机器人,只是打印回用户写了什么。
|
||||
|
||||
回显服务器类似于服务器的“Hello World”例子。
|
||||
|
||||
这个项目的目的不是建立最好的信使机器人,而是获得建立一个小型机器人和每个事物是如何整合起来的感觉。
|
||||
|
||||
- [技术栈][1]
|
||||
- [机器人架构][2]
|
||||
- [机器人服务器][3]
|
||||
- [部署到 Heroku][4]
|
||||
- [创建 Facebook 应用][5]
|
||||
- [结论][6]
|
||||
|
||||
### 技术栈
|
||||
|
||||
使用到的技术栈:
|
||||
|
||||
- [Heroku][7] 做后端主机。免费层足够这个等级的教程。回显机器人不需要任何种类的数据持久,所以不需要数据库。
|
||||
- [Python][8] 是选择的一个语言。版本选择2.7,虽然它移植到 Pyhton 3 很容易,只需要很少的改动。
|
||||
- [Flask][9] 作为网站开发框架。它是非常轻量的框架,用在小型工程或微服务是完美的。
|
||||
- 最后 [Git][10] 版本控制系统用来维护代码和部署到 Heroku。
|
||||
- 值得一提:[Virtualenv][11]。这个 python 工具是用来创建清洁的 python 库“环境”的,你只用安装必要的需求和最小化的应用封装。
|
||||
|
||||
### 机器人架构
|
||||
|
||||
信使机器人是由一个服务器组成,响应两种请求:
|
||||
|
||||
- GET 请求被用来认证。他们与你注册的 FB 认证码一同被信使发出。
|
||||
- POST 请求被用来真实的通信。传统的工作流是,机器人将通过发送 POST 请求与用户发送的消息数据建立通信,我们将处理它,发送一个我们自己的 POST 请求回去。如果这一个完全成功(返回一个200 OK 状态)我们也响应一个200 OK 码给初始信使请求。
|
||||
这个教程应用将托管到Heroku,他提供了一个很好并且简单的接口来部署应用。如前所述,免费层可以满足这个教程。
|
||||
|
||||
在应用已经部署并且运行后,我们将创建一个 Facebook 应用然后连接它到我们的应用,以便信使知道发送请求到哪,这就是我们的机器人。
|
||||
|
||||
### 机器人服务器
|
||||
|
||||
基本的服务器代码可以在Github用户 [hult(Magnus Hult)][13] 的 [Chatbot][12] 工程上获取,经过一些代码修改只回显消息和一些我遇到的错误更正。最终版本的服务器代码:
|
||||
|
||||
```
|
||||
from flask import Flask, request
|
||||
import json
|
||||
import requests
|
||||
|
||||
app = Flask(__name__)
|
||||
|
||||
# 这需要填写被授予的页面通行令牌
|
||||
# 通过 Facebook 应用创建令牌。
|
||||
PAT = ''
|
||||
|
||||
@app.route('/', methods=['GET'])
|
||||
def handle_verification():
|
||||
print "Handling Verification."
|
||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||
print "Verification successful!"
|
||||
return request.args.get('hub.challenge', '')
|
||||
else:
|
||||
print "Verification failed!"
|
||||
return 'Error, wrong validation token'
|
||||
|
||||
@app.route('/', methods=['POST'])
|
||||
def handle_messages():
|
||||
print "Handling Messages"
|
||||
payload = request.get_data()
|
||||
print payload
|
||||
for sender, message in messaging_events(payload):
|
||||
print "Incoming from %s: %s" % (sender, message)
|
||||
send_message(PAT, sender, message)
|
||||
return "ok"
|
||||
|
||||
def messaging_events(payload):
|
||||
"""Generate tuples of (sender_id, message_text) from the
|
||||
provided payload.
|
||||
"""
|
||||
data = json.loads(payload)
|
||||
messaging_events = data["entry"][0]["messaging"]
|
||||
for event in messaging_events:
|
||||
if "message" in event and "text" in event["message"]:
|
||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||
else:
|
||||
yield event["sender"]["id"], "I can't echo this"
|
||||
|
||||
|
||||
def send_message(token, recipient, text):
|
||||
"""Send the message text to recipient with id recipient.
|
||||
"""
|
||||
|
||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||
params={"access_token": token},
|
||||
data=json.dumps({
|
||||
"recipient": {"id": recipient},
|
||||
"message": {"text": text.decode('unicode_escape')}
|
||||
}),
|
||||
headers={'Content-type': 'application/json'})
|
||||
if r.status_code != requests.codes.ok:
|
||||
print r.text
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run()
|
||||
```
|
||||
|
||||
让我们分解代码。第一部分是引入所需:
|
||||
|
||||
```
|
||||
from flask import Flask, request
|
||||
import json
|
||||
import requests
|
||||
```
|
||||
|
||||
接下来我们定义两个函数(使用 Flask 特定的 app.route 装饰器),用来处理到我们的机器人的 GET 和 POST 请求。
|
||||
|
||||
```
|
||||
@app.route('/', methods=['GET'])
|
||||
def handle_verification():
|
||||
print "Handling Verification."
|
||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||
print "Verification successful!"
|
||||
return request.args.get('hub.challenge', '')
|
||||
else:
|
||||
print "Verification failed!"
|
||||
return 'Error, wrong validation token'
|
||||
```
|
||||
|
||||
当我们创建 Facebook 应用时声明由信使发送的 verify_token 对象。我们必须对自己进行认证。最后我们返回“hub.challenge”给信使。
|
||||
|
||||
处理 POST 请求的函数更有趣
|
||||
|
||||
```
|
||||
@app.route('/', methods=['POST'])
|
||||
def handle_messages():
|
||||
print "Handling Messages"
|
||||
payload = request.get_data()
|
||||
print payload
|
||||
for sender, message in messaging_events(payload):
|
||||
print "Incoming from %s: %s" % (sender, message)
|
||||
send_message(PAT, sender, message)
|
||||
return "ok"
|
||||
```
|
||||
|
||||
当调用我们抓取的消息负载时,使用函数 messaging_events 来中断它并且提取发件人身份和真实发送消息,生成一个 python 迭代器循环遍历。请注意信使发送的每个请求有可能多于一个消息。
|
||||
|
||||
```
|
||||
def messaging_events(payload):
|
||||
"""Generate tuples of (sender_id, message_text) from the
|
||||
provided payload.
|
||||
"""
|
||||
data = json.loads(payload)
|
||||
messaging_events = data["entry"][0]["messaging"]
|
||||
for event in messaging_events:
|
||||
if "message" in event and "text" in event["message"]:
|
||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||
else:
|
||||
yield event["sender"]["id"], "I can't echo this"
|
||||
```
|
||||
|
||||
迭代完每个消息时我们调用send_message函数然后我们执行POST请求回给使用Facebook图形消息接口信使。在这期间我们一直没有回应我们阻塞的原始信使请求。这会导致超时和5XX错误。
|
||||
|
||||
上述的发现错误是中断期间我偶然发现的,当用户发送表情时其实的是当成了 unicode 标识,无论如何 Python 发生了误编码。我们以发送回垃圾结束。
|
||||
|
||||
这个 POST 请求回到信使将不会结束,这会导致发生5xx状态返回给原始的请求,显示服务不可用。
|
||||
|
||||
通过使用`encode('unicode_escape')`转义消息然后在我们发送回消息前用`decode('unicode_escape')`解码消息就可以解决。
|
||||
|
||||
```
|
||||
def send_message(token, recipient, text):
|
||||
"""Send the message text to recipient with id recipient.
|
||||
"""
|
||||
|
||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||
params={"access_token": token},
|
||||
data=json.dumps({
|
||||
"recipient": {"id": recipient},
|
||||
"message": {"text": text.decode('unicode_escape')}
|
||||
}),
|
||||
headers={'Content-type': 'application/json'})
|
||||
if r.status_code != requests.codes.ok:
|
||||
print r.text
|
||||
```
|
||||
|
||||
### 部署到 Heroku
|
||||
|
||||
一旦代码已经建立成我想要的样子时就可以进行下一步。部署应用。
|
||||
|
||||
当然,但是怎么做?
|
||||
|
||||
我之前已经部署了应用到 Heroku (主要是 Rails)然而我总是遵循某种教程,所以配置已经创建。在这种情况下,尽管我必须从头开始。
|
||||
|
||||
幸运的是有官方[Heroku文档][14]来帮忙。这篇文章很好地说明了运行应用程序所需的最低限度。
|
||||
|
||||
长话短说,我们需要的除了我们的代码还有两个文件。第一个文件是“requirements.txt”他列出了运行应用所依赖的库。
|
||||
|
||||
需要的第二个文件是“Procfile”。这个文件通知 Heroku 如何运行我们的服务。此外这个文件最低限度如下:
|
||||
|
||||
>web: gunicorn echoserver:app
|
||||
|
||||
heroku解读他的方式是我们的应用通过运行 echoserver.py 开始并且应用将使用 gunicorn 作为网站服务器。我们使用一个额外的网站服务器是因为与性能相关并在上面的Heroku文档里解释了:
|
||||
|
||||
>Web 应用程序并发处理传入的HTTP请求比一次只处理一个请求的Web应用程序,更有效利地用动态资源。由于这个原因,我们建议使用支持并发请求的 web 服务器处理开发和生产运行的服务。
|
||||
|
||||
>Django 和 Flask web 框架特性方便内建 web 服务器,但是这些阻塞式服务器一个时刻只处理一个请求。如果你部署这种服务到 Heroku上,你的动态资源不会充分使用并且你的应用会感觉迟钝。
|
||||
|
||||
>Gunicorn 是一个纯 Python HTTP 的 WSGI 引用服务器。允许你在单独一个动态资源内通过并发运行多 Python 进程的方式运行任一 Python 应用。它提供了一个完美性能,弹性,简单配置的平衡。
|
||||
|
||||
回到我们提到的“requirements.txt”文件,让我们看看它如何结合 Virtualenv 工具。
|
||||
|
||||
在任何时候,你的开发机器也许有若干已安装的 python 库。当部署应用时你不想这些库被加载因为很难辨认出你实际使用哪些库。
|
||||
|
||||
Virtualenv 创建一个新的空白虚拟环境,因此你可以只安装你应用需要的库。
|
||||
|
||||
你可以检查当前安装使用哪些库的命令如下:
|
||||
|
||||
```
|
||||
kostis@KostisMBP ~ $ pip freeze
|
||||
cycler==0.10.0
|
||||
Flask==0.10.1
|
||||
gunicorn==19.6.0
|
||||
itsdangerous==0.24
|
||||
Jinja2==2.8
|
||||
MarkupSafe==0.23
|
||||
matplotlib==1.5.1
|
||||
numpy==1.10.4
|
||||
pyparsing==2.1.0
|
||||
python-dateutil==2.5.0
|
||||
pytz==2015.7
|
||||
requests==2.10.0
|
||||
scipy==0.17.0
|
||||
six==1.10.0
|
||||
virtualenv==15.0.1
|
||||
Werkzeug==0.11.10
|
||||
```
|
||||
|
||||
注意:pip 工具应该已经与 Python 一起安装在你的机器上。
|
||||
|
||||
如果没有,查看[官方网站][15]如何安装他。
|
||||
|
||||
现在让我们使用 Virtualenv 来创建一个新的空白环境。首先我们给我们的工程创建一个新文件夹,然后进到目录下:
|
||||
|
||||
```
|
||||
kostis@KostisMBP projects $ mkdir echoserver
|
||||
kostis@KostisMBP projects $ cd echoserver/
|
||||
kostis@KostisMBP echoserver $
|
||||
```
|
||||
|
||||
现在来创建一个叫做 echobot 新的环境。运行下面的 source 命令激活它,然后使用 pip freeze 检查,我们能看到现在是空的。
|
||||
|
||||
```
|
||||
kostis@KostisMBP echoserver $ virtualenv echobot
|
||||
kostis@KostisMBP echoserver $ source echobot/bin/activate
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||
(echobot) kostis@KostisMBP echoserver $
|
||||
```
|
||||
|
||||
我们可以安装需要的库。我们需要是 flask,gunicorn,和 requests,他们被安装完我们就创建 requirements.txt 文件:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install flask
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install gunicorn
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install requests
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||
click==6.6
|
||||
Flask==0.11
|
||||
gunicorn==19.6.0
|
||||
itsdangerous==0.24
|
||||
Jinja2==2.8
|
||||
MarkupSafe==0.23
|
||||
requests==2.10.0
|
||||
Werkzeug==0.11.10
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze > requirements.txt
|
||||
```
|
||||
|
||||
毕竟上文已经被运行,我们用 python 代码创建 echoserver.py 文件然后用之前提到的命令创建 Procfile,我们应该以下面的文件/文件夹结束:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ ls
|
||||
Procfile echobot echoserver.py requirements.txt
|
||||
```
|
||||
|
||||
我们现在准备上传到 Heroku。我们需要做两件事。第一是安装 Heroku toolbet 如果你还没安装到你的系统中(详细看[Heroku][16])。第二通过[网页接口][17]创建一个新的 Heroku 应用。
|
||||
|
||||
点击右上的大加号然后选择“Create new app”。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/
|
||||
|
||||
作者:[Konstantinos Tsaprailis][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/kostistsaprailis
|
||||
[1]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#tech-stack
|
||||
[2]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#bot-architecture
|
||||
[3]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#the-bot-server
|
||||
[4]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#deploying-to-heroku
|
||||
[5]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#creating-the-facebook-app
|
||||
[6]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#conclusion
|
||||
[7]: https://www.heroku.com
|
||||
[8]: https://www.python.org
|
||||
[9]: http://flask.pocoo.org
|
||||
[10]: https://git-scm.com
|
||||
[11]: https://virtualenv.pypa.io/en/stable
|
||||
[12]: https://github.com/hult/facebook-chatbot-python
|
||||
[13]: https://github.com/hult
|
||||
[14]: https://devcenter.heroku.com/articles/python-gunicorn
|
||||
[15]: https://pip.pypa.io/en/stable/installing
|
||||
[16]: https://toolbelt.heroku.com
|
||||
[17]: https://dashboard.heroku.com/apps
|
||||
|
||||
|
||||
193
translated/tech/20160628 Python 101 An Intro to urllib.md
Normal file
193
translated/tech/20160628 Python 101 An Intro to urllib.md
Normal file
@ -0,0 +1,193 @@
|
||||
Python 101: urllib 简介
|
||||
=================================
|
||||
|
||||
Python 3 的 urllib 模块是一堆可以处理 URL 的组件集合。如果你有 Python 2 背景,那么你就会注意到 Python 2 中有 urllib 和 urllib2 两个版本的模块。这些现在都是 Python 3 的 urllib 包的一部分。当前版本的 urllib 包括下面几部分:
|
||||
|
||||
- urllib.request
|
||||
- urllib.error
|
||||
- urllib.parse
|
||||
- urllib.rebotparser
|
||||
|
||||
接下来我们会分开讨论除了 urllib.error 以外的几部分。官方文档实际推荐你尝试第三方库, requests,一个高级的 HTTP 客户端接口。然而我依然认为知道如何不依赖第三方库打开 URL 并与之进行交互是很有用的,而且这也可以帮助你理解为什么 requests 包是如此的流行。
|
||||
|
||||
---
|
||||
|
||||
### urllib.request
|
||||
|
||||
urllib.request 模块期初是用来打开和获取 URL 的。让我们看看你可以用函数 urlopen可以做的事:
|
||||
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = urllib.request.urlopen('https://www.google.com/')
|
||||
>>> url.geturl()
|
||||
'https://www.google.com/'
|
||||
>>> url.info()
|
||||
<http.client.HTTPMessage object at 0x7fddc2de04e0>
|
||||
>>> header = url.info()
|
||||
>>> header.as_string()
|
||||
('Date: Fri, 24 Jun 2016 18:21:19 GMT\n'
|
||||
'Expires: -1\n'
|
||||
'Cache-Control: private, max-age=0\n'
|
||||
'Content-Type: text/html; charset=ISO-8859-1\n'
|
||||
'P3P: CP="This is not a P3P policy! See '
|
||||
'https://www.google.com/support/accounts/answer/151657?hl=en for more info."\n'
|
||||
'Server: gws\n'
|
||||
'X-XSS-Protection: 1; mode=block\n'
|
||||
'X-Frame-Options: SAMEORIGIN\n'
|
||||
'Set-Cookie: '
|
||||
'NID=80=tYjmy0JY6flsSVj7DPSSZNOuqdvqKfKHDcHsPIGu3xFv41LvH_Jg6LrUsDgkPrtM2hmZ3j9V76pS4K_cBg7pdwueMQfr0DFzw33SwpGex5qzLkXUvUVPfe9g699Qz4cx9ipcbU3HKwrRYA; '
|
||||
'expires=Sat, 24-Dec-2016 18:21:19 GMT; path=/; domain=.google.com; HttpOnly\n'
|
||||
'Alternate-Protocol: 443:quic\n'
|
||||
'Alt-Svc: quic=":443"; ma=2592000; v="34,33,32,31,30,29,28,27,26,25"\n'
|
||||
'Accept-Ranges: none\n'
|
||||
'Vary: Accept-Encoding\n'
|
||||
'Connection: close\n'
|
||||
'\n')
|
||||
>>> url.getcode()
|
||||
200
|
||||
```
|
||||
|
||||
在这里我们包含了需要的模块,然后告诉它打开 Google 的 URL。现在我们就有了一个可以交互的 HTTPResponse 对象。我们要做的第一件事是调用方法 geturl ,它会返回根据 URL 获取的资源。这可以让我们发现 URL 是否进行了重定向。
|
||||
|
||||
接下来调用 info ,它会返回网页的元数据,比如头信息。因此,我们可以将结果赋给我们的 headers 变量,然后调用它的方法 as_string 。就可以打印出我们从 Google 收到的头信息。你也可以通过 getcode 得到网页的 HTTP 响应码,当前情况下就是 200,意思是正常工作。
|
||||
|
||||
如果你想看看网页的 HTML 代码,你可以调用变量 url 的方法 read。我不准备再现这个过程,因为输出结果太长了。
|
||||
|
||||
请注意 request 对象默认是 GET 请求,除非你指定它的 data 参数。你应该给它传递 data 参数,这样 request 对象才会变成 POST 请求。
|
||||
|
||||
---
|
||||
|
||||
### 下载文件
|
||||
|
||||
urllib 一个典型的应用场景是下载文件。让我们看看几种可以完成这个任务的方法:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> response = urllib.request.urlopen(url)
|
||||
>>> data = response.read()
|
||||
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
|
||||
... fobj.write(data)
|
||||
...
|
||||
```
|
||||
|
||||
这个例子中我们打开一个保存在我的博客上的 zip 压缩文件的 URL。然后我们读出数据并将数据写到磁盘。一个替代方法是使用 urlretrieve :
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> tmp_file, header = urllib.request.urlretrieve(url)
|
||||
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
|
||||
... with open(tmp_file, 'rb') as tmp:
|
||||
... fobj.write(tmp.read())
|
||||
```
|
||||
|
||||
方法 urlretrieve 会把网络对象拷贝到本地文件。除非你在使用 urlretrieve 的第二个参数指定你要保存文件的路径,否则这个文件在本地是随机命名的并且是保存在临时文件夹。这个可以为你节省一步操作,并且使代码开起来更简单:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> urllib.request.urlretrieve(url, '/home/mike/Desktop/blog.zip')
|
||||
('/home/mike/Desktop/blog.zip',
|
||||
<http.client.HTTPMessage object at 0x7fddc21c2470>)
|
||||
```
|
||||
|
||||
如你所见,它返回了文件保存的路径,以及从请求得来的头信息。
|
||||
|
||||
### 设置你的用户代理
|
||||
|
||||
当你使用浏览器访问网页时,浏览器会告诉网站它是谁。这就是所谓的 user-agent 字段。Python 的 urllib 会表示他自己为 Python-urllib/x.y , 其中 x 和 y 是你使用的 Python 的主、次版本号。有一些网站不认识这个用户代理字段,然后网站的可能会有奇怪的表现或者根本不能正常工作。辛运的是你可以很轻松的设置你自己的 user-agent 字段。
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> user_agent = ' Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0'
|
||||
>>> url = 'http://www.whatsmyua.com/'
|
||||
>>> headers = {'User-Agent': user_agent}
|
||||
>>> request = urllib.request.Request(url, headers=headers)
|
||||
>>> with urllib.request.urlopen(request) as response:
|
||||
... with open('/home/mdriscoll/Desktop/user_agent.html', 'wb') as out:
|
||||
... out.write(response.read())
|
||||
```
|
||||
|
||||
这里设置我们的用户代理为 Mozilla FireFox ,然后我们访问 <http://www.whatsmyua.com/> , 它会告诉我们它识别出的我们的 user-agent 字段。之后我们将 url 和我们的头信息传给 urlopen 创建一个 Request 实例。最后我们保存这个结果。如果你打开这个结果,你会看到我们成功的修改了自己的 user-agent 字段。使用这段代码尽情的尝试不同的值来看看它是如何改变的。
|
||||
|
||||
---
|
||||
|
||||
### urllib.parse
|
||||
|
||||
urllib.parse 库是用来拆分和组合 URL 字符串的标准接口。比如,你可以使用它来转换一个相对的 URL 为绝对的 URL。让我们试试用它来转换一个包含查询的 URL :
|
||||
|
||||
|
||||
```
|
||||
>>> from urllib.parse import urlparse
|
||||
>>> result = urlparse('https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa')
|
||||
>>> result
|
||||
ParseResult(scheme='https', netloc='duckduckgo.com', path='/', params='', query='q=python+stubbing&t=canonical&ia=qa', fragment='')
|
||||
>>> result.netloc
|
||||
'duckduckgo.com'
|
||||
>>> result.geturl()
|
||||
'https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa'
|
||||
>>> result.port
|
||||
None
|
||||
```
|
||||
|
||||
这里我们导入了函数 urlparse , 并且把一个包含搜索查询 duckduckgo 的 URL 作为参数传给它。我的查询的关于 “python stubbing” 的文章。如你所见,它返回了一个 ParseResult 对象,你可以用这个对象了解更多关于 URL 的信息。举个例子,你可以获取到短信息(此处的没有端口信息),网络位置,路径和很多其他东西。
|
||||
|
||||
### 提交一个 Web 表单
|
||||
|
||||
这个模块还有一个方法 urlencode 可以向 URL 传输数据。 urllib.parse 的一个典型使用场景是提交 Web 表单。让我们通过搜索引擎 duckduckgo 搜索 Python 来看看这个功能是怎么工作的。
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> import urllib.parse
|
||||
>>> data = urllib.parse.urlencode({'q': 'Python'})
|
||||
>>> data
|
||||
'q=Python'
|
||||
>>> url = 'http://duckduckgo.com/html/'
|
||||
>>> full_url = url + '?' + data
|
||||
>>> response = urllib.request.urlopen(full_url)
|
||||
>>> with open('/home/mike/Desktop/results.html', 'wb') as f:
|
||||
... f.write(response.read())
|
||||
```
|
||||
|
||||
这个例子很直接。基本上我们想使用 Python 而不是浏览器向 duckduckgo 提交一个查询。要完成这个我们需要使用 urlencode 构建我们的查询字符串。然后我们把这个字符串和网址拼接成一个完整的正确 URL ,然后使用 urllib.request 提交这个表单。最后我们就获取到了结果然后保存到磁盘上。
|
||||
|
||||
---
|
||||
|
||||
### urllib.robotparser
|
||||
|
||||
robotparser 模块是由一个单独的类 —— RobotFileParser —— 构成的。这个类会回答诸如一个特定的用户代理可以获取已经设置 robot.txt 的网站。 robot.txt 文件会告诉网络爬虫或者机器人当前网站的那些部分是不允许被访问的。让我们看一个简单的例子:
|
||||
|
||||
```
|
||||
>>> import urllib.robotparser
|
||||
>>> robot = urllib.robotparser.RobotFileParser()
|
||||
>>> robot.set_url('http://arstechnica.com/robots.txt')
|
||||
None
|
||||
>>> robot.read()
|
||||
None
|
||||
>>> robot.can_fetch('*', 'http://arstechnica.com/')
|
||||
True
|
||||
>>> robot.can_fetch('*', 'http://arstechnica.com/cgi-bin/')
|
||||
False
|
||||
```
|
||||
|
||||
这里我们导入了 robot 分析器类,然后创建一个实例。然后我们给它传递一个表明网站 robots.txt 位置的 URL 。接下来我们告诉分析器来读取这个文件。现在就完成了,我们给它了一组不同的 URL 让它找出那些我们可以爬取而那些不能爬取。我们很快就看到我们可以访问主站但是不包括 cgi-bin 路径。
|
||||
|
||||
---
|
||||
|
||||
### 总结一下
|
||||
|
||||
现在你就有能力使用 Python 的 urllib 包了。在这一节里,我们学习了如何下载文件,提交 Web 表单,修改自己的用户代理以及访问 robots.txt。 urllib 还有一大堆附加功能没有在这里提及,比如网站授权。然后你可能会考虑在使用 urllib 进行认证之前切换到 requests 库,因为 requests 已经以更易用和易调试的方式实现了这些功能。我同时也希望提醒你 Python 已经通过 http.cookies 模块支持 Cookies 了,虽然在 request 包里也很好的封装了这个功能。你应该可能考虑同时试试两个来决定那个最适合你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blog.pythonlibrary.org/2016/06/28/python-101-an-intro-to-urllib/
|
||||
|
||||
作者:[Mike][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.blog.pythonlibrary.org/author/mld/
|
||||
@ -0,0 +1,100 @@
|
||||
用 VeraCrypt 加密闪存盘
|
||||
============================================
|
||||
|
||||
很多安全专家偏好像 VeraCrypt 这类能够用来加密闪存盘的开源软件。因为获取它的源代码很简单。
|
||||
|
||||
保护 USB闪存盘里的数据,加密是一个聪明的方法,正如我们在使用 Microsoft 的 BitLocker [加密闪存盘][1] 一文中提到的。
|
||||
|
||||
但是如果你不想用 BitLocker 呢?
|
||||
|
||||
你可能有顾虑,因为你不能够查看 Microsoft 的程序源码,那么它容易被植入用于政府或其它用途的“后门”。由于开源软件的源码是公开的,很多安全专家认为开源软件很少藏有后门。
|
||||
|
||||
还好,有几个开源加密软件能作为 BitLocker 的替代。
|
||||
|
||||
要是你需要在 Windows 系统,苹果的 OS X 系统或者 Linux 系统上加密以及访问文件,开源软件 [VeraCrypt][2] 提供绝佳的选择。
|
||||
|
||||
VeraCrypt 源于 TrueCrypt。TrueCrypt是一个备受好评的开源加密软件,尽管它现在已经停止维护了。但是 TrueCrypt 的代码通过了审核,没有发现什么重要的安全漏洞。另外,它已经在 VeraCrypt 中进行了改善。
|
||||
|
||||
Windows,OS X 和 Linux 系统的版本都有。
|
||||
|
||||
用 VeraCrypt 加密 USB 闪存盘不像用 BitLocker 那么简单,但是它只要几分钟就好了。
|
||||
|
||||
### 用 VeraCrypt 加密闪存盘的 8 个步骤
|
||||
|
||||
对应操作系统 [下载 VeraCrypt][3] 之后:
|
||||
|
||||
打开 VeraCrypt,点击 Create Volume,进入 VeraCrypt 的创建卷的向导程序(VeraCrypt Volume Creation Wizard)。(注:VeraCrypt Volume Creation Wizard 首字母全大写,不清楚是否需要翻译,之后有很多首字母大写的词,都以括号标出)
|
||||
|
||||

|
||||
|
||||
VeraCrypt 创建卷向导(VeraCrypt Volume Creation Wizard)允许你在闪存盘里新建一个加密文件容器,这与其它未加密文件是独立的。或者你也可以选择加密整个闪存盘。这个时候你就选加密整个闪存盘就行。
|
||||
|
||||

|
||||
|
||||
然后选择标准模式(Standard VeraCrypt Volume)。
|
||||
|
||||

|
||||
|
||||
选择你想加密的闪存盘的驱动器卷标(这里是 O:)。
|
||||
|
||||

|
||||
|
||||
选择创建卷标模式(Volume Creation Mode)。如果你的闪存盘是空的,或者你想要删除它里面的所有东西,选第一个。要么你想保持所有现存的文件,选第二个就好了。
|
||||
|
||||

|
||||
|
||||
这一步允许你选择加密选项。要是你不确定选哪个,就用默认的 AES 和 SHA-512 设置。
|
||||
|
||||

|
||||
|
||||
确定了卷标容量后,输入并确认你想要用来加密数据密码。
|
||||
|
||||

|
||||
|
||||
要有效工作,VeraCrypt 要从一个熵或者“随机数”池中取出一个随机数。要初始化这个池,你将被要求随机地移动鼠标一分钟。一旦进度条变绿了,或者更方便的是等到进度条到了屏幕右边足够远的时候,点击 “Format” 来结束创建加密盘。
|
||||
|
||||

|
||||
|
||||
### 用 VeraCrypt 使用加密过的闪存盘
|
||||
|
||||
当你想要使用一个加密了的闪存盘,先插入闪存盘到电脑上,启动 VeraCrypt。
|
||||
|
||||
然后选择一个没有用过的卷标(比如 z:),点击自动挂载设备(Auto-Mount Devices)。
|
||||
|
||||

|
||||
|
||||
输入密码,点击确定。
|
||||
|
||||

|
||||
|
||||
挂载过程需要几分钟,这之后你的解密盘就能通过你先前选择的盘符进行访问了。
|
||||
|
||||
### VeraCrypt 移动硬盘安装步骤
|
||||
|
||||
如果你设置闪存盘的时候,选择的是加密过的容器而不是加密整个盘,你可以选择创建 VeraCrypt 称为移动盘(Traveler Disk)的设备。这会复制安装一个 VeraCrypt 在 USB 闪存盘。当你在别的 Windows 电脑上插入 U 盘时,就能从 U 盘自动运行 VeraCrypt;也就是说没必要在新电脑上安装 VeraCrypt。
|
||||
|
||||
你可以设置闪存盘作为一个移动硬盘(Traveler Disk),在 VeraCrypt 的工具栏(Tools)菜单里选择 Traveler Disk SetUp 就行了。
|
||||
|
||||

|
||||
|
||||
要从移动盘(Traveler Disk)上运行 VeraCrypt,你必须要有那台电脑的管理员权限,这不足为奇。尽管这看起来是个限制,机密文件无法在不受控制的电脑上安全打开,比如在一个商务中心的电脑上。
|
||||
|
||||
>Paul Rubens 从事技术行业已经超过 20 年。这期间他为英国和国际主要的出版社,包括 《The Economist》《The Times》《Financial Times》《The BBC》《Computing》和《ServerWatch》等出版社写过文章,
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.esecurityplanet.com/open-source-security/how-to-encrypt-flash-drive-using-veracrypt.html
|
||||
|
||||
作者:[Paul Rubens ][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.esecurityplanet.com/author/3700/Paul-Rubens
|
||||
[1]: http://www.esecurityplanet.com/views/article.php/3880616/How-to-Encrypt-a-USB-Flash-Drive.htm
|
||||
[2]: http://www.esecurityplanet.com/open-source-security/veracrypt-a-worthy-truecrypt-alternative.html
|
||||
[3]: https://veracrypt.codeplex.com/releases/view/619351
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,95 @@
|
||||
在用户空间做我们会在内核空间做的事情
|
||||
=======================================================
|
||||
|
||||
我相信,Linux 最好也是最坏的事情,就是内核空间和用户空间之间的巨大差别。
|
||||
|
||||
但是如果抛开这个区别,Linux 可能也不会成为世界上影响力最大的操作系统。如今,Linux 已经拥有世界上最大数量的用户,和最大范围的应用。尽管大多数用户并不知道,当他们进行谷歌搜索,或者触摸安卓手机的时候,他们其实正在使用 Linux。如果不是 Linux 的巨大成功,Apple 公司也可能并不会成为现在这样(苹果在他们的电脑产品中使用 BSD 发行版)。
|
||||
|
||||
不用担心,用户空间是 Linux 内核开发中的一个特性,并不是一个缺陷。正如 Linus 在 2003 的极客巡航中提到的那样,“”我只做内核相关技术……我并不知道内核之外发生的事情,而且我并不关心。我只关注内核部分发生的事情。” 在 Andrew Morton 在多年之后的另一个极客巡航上给我上了另外的一课,我写到:
|
||||
|
||||
> 内核空间是 Linux 核心存在的地方。用户空间是使用 Linux 时使用的空间,和其他的自然的建筑材料一样。内核空间和用户空间的区别,和自然材料和人类从中生产的人造材料的区别很类似。
|
||||
|
||||
这个区别的自然而然的结果,就是尽管外面的世界一刻也离不开 Linux, 但是 Linux 社区还是保持相对较小。所以,为了增加我们社区团体的数量,我希望指出两件事情。第一件已经非常火热,另外一件可能热门。
|
||||
|
||||
第一件事情就是 [blockchain][1],出自著名的分布式货币,比特币之手。当你正在阅读这篇文章的同时,对 blockchain 的[兴趣已经直线上升][2]。
|
||||
|
||||

|
||||
> 图1. 谷歌 Blockchain 的趋势
|
||||
|
||||
第二件事就是自主身份。为了解释这个,让我先来问你,你是谁或者你是什么。
|
||||
|
||||
如果你从你的雇员,你的医生,或者车管所,Facebook,Twitter 或者谷歌上得到答案,你就会发现他们每一个都有明显的社会性: 为了他们自己的便利,在进入这些机构的控制前,他们都会添加自己的命名空间。正如 Timothy Ruff 在 [Evernym][3] 中解释的,”你并不为了他们而存在,你只为了自己的身份而活。“。你的身份可能会变化,但是唯一不变的就是控制着身份的人,也就是这个组织。
|
||||
|
||||
如果你的答案出自你自己,我们就有一个广大空间来发展一个新的领域,在这个领域中,我们完全自由。
|
||||
|
||||
第一个解释这个的人,据我所知,是 [Devon Loffreto][4]。在 2012 年 2 月,在的他的博客中,他写道 ”什么是' Sovereign Source Authority'?“,[Moxy Tongue][5]。在他发表在 2016 年 2 月的 "[Self-Sovereign Identity][6]" 中,他写道:
|
||||
|
||||
> 自主身份必须是独立个人提出的,并且不包含社会因素。。。自主身份源于每个个体对其自身本源的认识。 一个自主身份可以为个体带来新的社会面貌。每个个体都可能为自己生成一个自主身份,并且这并不会改变固有的人权。使用自主身份机制是所有参与者参与的基石,并且 依旧可以同各种形式的人类社会保持联系。
|
||||
|
||||
为了将这个发布在 Linux 条款中,只有个人才能为他或她设定一个自己的开源社区身份。这在现实实践中,这只是一个非常偶然的事件。举个例子,我自己的身份包括:
|
||||
|
||||
- David Allen Searls,我父母会这样叫我。
|
||||
- David Searls,正式场合下我会这么称呼自己。
|
||||
- Dave,我的亲戚和好朋友会这么叫我。
|
||||
- Doc,大多数人会这么叫我。
|
||||
|
||||
在上述提到的身份认证中,我可以在不同的情景中轻易的转换。但是,这只是在现实世界中。在虚拟世界中,这就变得非常困难。除了上述的身份之外,我还可以是 @dsearls(我的 twitter 账号) 和 dsearls (其他的网络账号)。然而为了记住成百上千的不同账号的登录名和密码,我已经不堪重负。
|
||||
|
||||
你可以在你的浏览器上感受到这个糟糕的体验。在火狐上,我有成百上千个用户名密码。很多已经废弃(很多都是从 Netscape 时代遗留下来的),但是我依旧假设我有时会有大量的工作账号需要处理。对于这些,我只是被动接受者。没有其他的解决方法。甚至一些安全较低的用户认证,已经成为了现实世界中不可缺少的一环。
|
||||
|
||||
现在,最简单的方式来联系账号,就是通过 "Log in with Facebook" 或者 "Login in with Twitter" 来进行身份认证。在这些例子中,我们中的每一个甚至并不是真正意义上的自己,或者某种程度上是我们希望被大家认识的自己(如果我们希望被其他人认识的话)。
|
||||
|
||||
我们从一开始就需要的是一个可以实体化我们的自主身份和交流时选择如何保护和展示自身的个人系统。因为缺少这个能力,我们现在陷入混乱。Shoshana Zuboff 称之为 "监视资本主义",她如此说道:
|
||||
|
||||
>...难以想象,在见证了互联网和获得了的巨大成功的谷歌背后。世界因 Apple 和 FBI 的对决而紧密联系在一起。真相就是,被热衷于监视的资本家开发监视系统,是每一个国家安全机构真正的恶。
|
||||
|
||||
然后,她问道,”我们怎样才能保护自己远离他人的影响?“
|
||||
|
||||
我建议使用自主身份。我相信这是我们唯一的方式,来保证我们从一个被监视的世界中脱离出来。以此为基础,我们才可以完全无顾忌的和社会,政治,商业上的人交流。
|
||||
|
||||
我在五月联合国举行的 [ID2020][7] 会议中总结了这个临时的结论。很高兴,Devon Loffreto 也在那,自从他在2013年被选为作为轮值主席之后。这就是[我曾经写的一些文章][8],引用了 Devon 的早期博客(比如上面的原文)。
|
||||
|
||||
这有三篇这个领域的准则:
|
||||
|
||||
- "[Self-Sovereign Identity][9]" - Devon Loffreto.
|
||||
- "[System or Human First][10]" - Devon Loffreto.
|
||||
- "[The Path to Self-Sovereign Identity][11]" - Christopher Allen.
|
||||
|
||||
从Evernym 的简要说明中,[digi.me][12], [iRespond][13] 和 [Respect Network][14] 也被包括在内。自主身份和社会身份 (也被称为”current model“) 的对比结果,显示在图二中。
|
||||
|
||||

|
||||
> 图 2. Current Model 身份 vs. 自主身份
|
||||
|
||||
为此而生的[平台][15]就是 Sovrin,也被解释为“”依托于先进技术的,授权机制的,分布式货币上的一个完全开源,基于标识,声明身份的图平台“ 同时,这也有一本[白皮书][16]。代号为 [plenum][17],而且它在 Github 上。
|
||||
|
||||
在这-或者其他类似的地方-我们就可以在用户空间中重现我们在上一个的四分之一世纪中已经做过的事情。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/doing-user-space-what-we-did-kernel-space
|
||||
|
||||
作者:[Doc Searls][a]
|
||||
译者:[译者ID](https://github.com/MikeCoder)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxjournal.com/users/doc-searls
|
||||
[1]: https://en.wikipedia.org/wiki/Block_chain_%28database%29
|
||||
[2]: https://www.google.com/trends/explore#q=blockchain
|
||||
[3]: http://evernym.com/
|
||||
[4]: https://twitter.com/nzn
|
||||
[5]: http://www.moxytongue.com/2012/02/what-is-sovereign-source-authority.html
|
||||
[6]: http://www.moxytongue.com/2016/02/self-sovereign-identity.html
|
||||
[7]: http://www.id2020.org/
|
||||
[8]: http://blogs.harvard.edu/doc/2013/10/14/iiw-challenge-1-sovereign-identity-in-the-great-silo-forest
|
||||
[9]: http://www.moxytongue.com/2016/02/self-sovereign-identity.html
|
||||
[10]: http://www.moxytongue.com/2016/05/system-or-human.html
|
||||
[11]: http://www.lifewithalacrity.com/2016/04/the-path-to-self-soverereign-identity.html
|
||||
[12]: https://get.digi.me/
|
||||
[13]: http://irespond.com/
|
||||
[14]: https://www.respectnetwork.com/
|
||||
[15]: http://evernym.com/technology
|
||||
[16]: http://evernym.com/assets/doc/Identity-System-Essentials.pdf?v=167284fd65
|
||||
[17]: https://github.com/evernym/plenum
|
||||
130
translated/tech/20160711 Getting started with Git.md
Normal file
130
translated/tech/20160711 Getting started with Git.md
Normal file
@ -0,0 +1,130 @@
|
||||
初步了解 Git
|
||||
=========================
|
||||
|
||||

|
||||
> 图片来源:opensource.com
|
||||
|
||||
在这个系列的介绍中,我们学习到了谁应该使用 Git,以及 Git 是用来做什么的。今天,我们将学习如何克隆公共的 Git 仓库,以及如何提取出独立的文件而不用克隆整个仓库。
|
||||
|
||||
由于 Git 如此流行,因而如果你能够至少熟悉一些基础的 Git 知识也能为你的生活带来很多便捷。如果你可以掌握 Git 基础(你可以的,我发誓!),那么你将能够下载任何你需要的东西,甚至还可能做一些贡献作为回馈。毕竟,那就是开源的精髓所在:你拥有获取你使用的软件代码的权利,拥有和他人分享的自由,以及只要你愿意就可以修改它的权利。只要你熟悉了 Git,它就可以让这一切都变得很容易。
|
||||
|
||||
那么,让我们一起来熟悉 Git 吧。
|
||||
|
||||
### 读和写
|
||||
一般来说,有两种方法可以和 Git 仓库交互:你可以从仓库中读取,或者你也能够向仓库中写入。它就像一个文件:有时候你打开一个文档只是为了阅读它,而其它时候你打开文档是因为你需要做些改动。
|
||||
|
||||
本文仅讲解如何从 Git 仓库读取。我们将会在后面的一篇文章中讲解如何向 Git 仓库写回的主题。
|
||||
|
||||
### Git 还是 GitHub?
|
||||
一句话澄清:Git 不同于 GitHub(或 GitLab,或 Bitbucket)。Git 是一个命令行程序,所以它就像下面这样:
|
||||
|
||||
```
|
||||
$ git
|
||||
usage: Git [--version] [--help] [-C <path>]
|
||||
[-p | --paginate | --no-pager] [--bare]
|
||||
[--Git-dir=<path>] <command> [<args>]
|
||||
|
||||
```
|
||||
|
||||
由于 Git 是开源的,所以就有许多聪明人围绕它构建了基础软件;这些基础软件,包括在他们自己身边,都已经变得非常流行了。
|
||||
|
||||
我的文章系列将首先教你纯粹的 Git 知识,因为一旦你理解了 Git 在做什么,那么你就无需关心正在使用的前端工具是什么了。然而,我的文章系列也将涵盖通过流行的 Git 服务完成每项任务的常用方法,因为那些将可能是你首先会遇到的。
|
||||
|
||||
### 安装 Git
|
||||
在 Linux 系统上,你可以从所使用的发行版软件仓库中获取并安装 Git。BSD 用户应当在 Ports 树的 devel 部分查找 Git。
|
||||
|
||||
对于闭源的操作系统,请前往 [项目网站][1] 并根据说明安装。一旦安装后,在 Linux、BSD 和 Mac OS X 上的命令应当没有任何差别。Windows 用户需要调整 Git 命令,从而和 Windows 文件系统相匹配,或者安装 Cygwin 以原生的方式运行 Git,而不受 Windows 文件系统转换问题的羁绊。
|
||||
|
||||
### 下午茶和 Git
|
||||
并非每个人都需要立刻将 Git 加入到我们的日常生活中。有些时候,你和 Git 最多的交互就是访问一个代码库,下载一两个文件,然后就不用它了。以这样的方式看待 Git,它更像是下午茶而非一次正式的宴会。你进行一些礼节性的交谈,获得了需要的信息,然后你就会离开,至少接下来的三个月你不再想这样说话。
|
||||
|
||||
当然,那是可以的。
|
||||
|
||||
一般来说,有两种方法访问 Git:使用命令行,或者使用一种神奇的因特网技术通过 web 浏览器快速轻松地访问。
|
||||
|
||||
假设你想要在终端中安装并使用一个回收站,因为你已经被 rm 命令毁掉太多次了。你已经听说过 Trashy 了,它称自己为「理智的 rm 命令媒介」,并且你想在安装它之前阅读它的文档。幸运的是,[Trashy 公开地托管在 GitLab.com][2]。
|
||||
|
||||
### Landgrab
|
||||
我们工作的第一步是对这个 Git 仓库使用 landgrab 排序方法:我们会克隆这个完整的仓库,然后会根据内容排序。由于该仓库是托管在公共的 Git 服务平台上,所以有两种方式来完成工作:使用命令行,或者使用 web 界面。
|
||||
|
||||
要想使用 Git 获取整个仓库,就要使用 git clone 命令和 Git 仓库的 URL 作为参数。如果你不清楚正确的 URL 是什么,仓库应该会告诉你的。GitLab 为你提供了 [Trashy][3] 仓库的拷贝-粘贴 URL。
|
||||
|
||||

|
||||
|
||||
你也许注意到了,在某些服务平台上,会同时提供 SSH 和 HTTPS 链接。只有当你拥有仓库的写权限时,你才可以使用 SSH。否则的话,你必须使用 HTTPS URL。
|
||||
|
||||
一旦你获得了正确的 URL,克隆仓库是非常容易的。就是 git clone 这个 URL 即可,可选项是可以指定要克隆到的目录。默认情况下会将 git 目录克隆到你当前所在的位置;例如,'trashy.git' 表示将仓库克隆到你当前位置的 'trashy' 目录。我使用 .clone 扩展名标记那些只读的仓库,使用 .git 扩展名标记那些我可以读写的仓库,但那无论如何也不是官方要求的。
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/trashy/trashy.git trashy.clone
|
||||
Cloning into 'trashy.clone'...
|
||||
remote: Counting objects: 142, done.
|
||||
remote: Compressing objects: 100% (91/91), done.
|
||||
remote: Total 142 (delta 70), reused 103 (delta 47)
|
||||
Receiving objects: 100% (142/142), 25.99 KiB | 0 bytes/s, done.
|
||||
Resolving deltas: 100% (70/70), done.
|
||||
Checking connectivity... done.
|
||||
```
|
||||
|
||||
一旦成功地克隆了仓库,你就可以像对待你电脑上任何其它目录那样浏览仓库中的文件。
|
||||
|
||||
另外一种获得仓库拷贝的方式是使用 web 界面。GitLab 和 GitHub 都会提供一个 .zip 格式的仓库快照文件。GitHub 有一个大的绿色下载按钮,但是在 GitLab 中,可以浏览器的右侧找到并不显眼的下载按钮。
|
||||
|
||||

|
||||
|
||||
### 仔细挑选
|
||||
另外一种从 Git 仓库中获取文件的方法是找到你想要的文件,然后把它从仓库中拽出来。只有 web 界面才提供这种方法,本质上来说,你看到的是别人仓库的克隆;你可以把它想象成一个 HTTP 共享目录。
|
||||
|
||||
使用这种方法的问题是,你也许会发现某些文件并不存在于原始仓库中,因为完整形式的文件可能只有在执行 make 命令后才能构建,那只有你下载了完整的仓库,阅读了 README 或者 INSTALL 文件,然后运行相关命令之后才会产生。不过,假如你确信文件存在,而你只想进入仓库,获取那个文件,然后离开的话,你就可以那样做。
|
||||
|
||||
在 GitLab 和 GitHub 中,单击文件链接,并在 Raw 模式下查看,然后使用你的 web 浏览器的保存功能,例如:在 Firefox 中,文件 > 保存页面为。在一个 GitWeb 仓库中(一些更喜欢自己托管 git 的人使用的私有 git 仓库 web 查看器),Raw 查看链接在文件列表视图中。
|
||||
|
||||

|
||||
|
||||
### 最佳实践
|
||||
通常认为,和 Git 交互的正确方式是克隆完整的 Git 仓库。这样认为是有几个原因的。首先,可以使用 git pull 命令轻松地使克隆仓库保持更新,这样你就不必在每次文件改变时就重回 web 站点获得一份全新的拷贝。第二,你碰巧需要做些改进,只要保持仓库整洁,那么你可以非常轻松地向原来的作者提交所做的变更。
|
||||
|
||||
现在,可能是时候练习查找感兴趣的 Git 仓库,然后将它们克隆到你的硬盘中了。只要你了解使用终端的基础知识,那就不会太难做到。还不知道终端使用基础吗?那再给多我 5 分钟时间吧。
|
||||
|
||||
### 终端使用基础
|
||||
首先要知道的是,所有的文件都有一个路径。这是有道理的;如果我让你在常规的非终端环境下为我打开一个文件,你就要导航到文件在你硬盘的位置,并且直到你找到那个文件,你要浏览一大堆窗口。例如,你也许要点击你的家目录 > 图片 > InktoberSketches > monkey.kra。
|
||||
|
||||
在那样的场景下,我们可以说文件 monkeysketch.kra 的路径是:$HOME/图片/InktoberSketches/monkey.kra。
|
||||
|
||||
在终端中,除非你正在处理一些特殊的系统管理员任务,你的文件路径通常是以 $HOME 开头的(或者,如果你很懒,就使用 ~ 字符),后面紧跟着一些列的文件夹直到文件名自身。
|
||||
这就和你在 GUI 中点击各种图标直到找到相关的文件或文件夹类似。
|
||||
|
||||
如果你想把 Git 仓库克隆到你的文档目录,那么你可以打开一个终端然后运行下面的命令:
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/foo/bar.git
|
||||
$HOME/文档/bar.clone
|
||||
```
|
||||
一旦克隆完成,你可以打开一个文件管理器窗口,导航到你的文档文件夹,然后你就会发现 bar.clone 目录正在等待着你访问。
|
||||
|
||||
如果你想要更高级点,你或许会在以后再次访问那个仓库,可以尝试使用 git pull 命令来查看项目有没有更新:
|
||||
|
||||
```
|
||||
$ cd $HOME/文档/bar.clone
|
||||
$ pwd
|
||||
bar.clone
|
||||
$ git pull
|
||||
```
|
||||
|
||||
到目前为止,你需要初步了解的所有终端命令就是那些了,那就去探索吧。你实践得越多,Git 掌握得就越好(孰能生巧),那就是游戏的名称,至少给了或取了一个元音。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/stumbling-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://git-scm.com/download
|
||||
[2]: https://gitlab.com/trashy/trashy
|
||||
[3]: https://gitlab.com/trashy/trashy.git
|
||||
|
||||
199
translated/tech/20160718 Creating your first Git repository.md
Normal file
199
translated/tech/20160718 Creating your first Git repository.md
Normal file
@ -0,0 +1,199 @@
|
||||
|
||||
|
||||
建立你的第一个仓库
|
||||
======================================
|
||||
|
||||

|
||||
|
||||
|
||||
现在是时候学习怎样创建你自己的仓库了,还有怎样增加文件和完成提交。
|
||||
|
||||
在本系列前面文章的安装过程中,你已经学习了作为一个目标用户怎样与 Git 进行交互;你就像一个漫无目的的流浪者一样偶然发现了一个开源项目网站,然后克隆了仓库,Git 走进了你的生活。学习怎样和 Git 进行交互并不像你想的那样困难,或许你并不确信现在是否应该使用 Git 完成你的工作。
|
||||
|
||||
|
||||
Git 被认为是选择大多软件项目的工具,它不仅能够完成大多软件项目的工作;它也能管理你杂乱项目的列表(如果他们不重要,也可以这样说!),你的配置文件,一个日记,项目进展日志,甚至源代码!
|
||||
|
||||
使用 Git 是很有必要的,毕竟,你肯定有因为一个备份文件不能够辨认出版本信息而烦恼的时候。
|
||||
|
||||
你不使用 Git,它也就不会为你工作,或者也可以把 Git 理解为“没有任何推送就像源头指针一样”【译注: HEAD 可以理解为“头指针”,是当前工作区的“基础版本”,当执行提交时, HEAD 指向的提交将作为新提交的父提交。】。我保证,你很快就会对 Git 有所了解 。
|
||||
|
||||
|
||||
### 类比于录音
|
||||
|
||||
|
||||
我们更喜欢谈论快照上的图像,因为很多人都可以通过一个相册很快辨认出每个照片上特有的信息。这可能很有用,然而,我认为 Git 更像是在进行声音的记录。
|
||||
|
||||
传统的录音机,可能你对于它的部件不是很清楚:它包含转轴并且正转或反转,使用磁带保存声音波形,通过放音头记录声音并保存到磁带上然后播放给收听者。
|
||||
|
||||
|
||||
除了往前退磁带,你也可以把磁带多绕几圈到磁带前面的部分,或快进跳过前面的部分到最后。
|
||||
|
||||
想象一下 70 年代的磁带录制的声音。你可能想到那会正在反复练习一首歌直到非常完美,它们最终被记录下来了。起初,你记录了鼓声,低音,然后是吉他声,还有其他的声音。每次你录音,工作人员都会把磁带重绕并设置为环绕模式,这样在你演唱的时候录音磁带就会播放之前录制的声音。如果你是低音歌唱,你唱歌的时候就需要把有鼓声的部分作为背景音乐,然后就是吉他声、鼓声、低音(和牛铃声【译注:一种打击乐器,状如四棱锥。】)等等。在每一环,你完成了整个部分,到了下一环,工作人员就开始在磁带上制作你的演唱作品。
|
||||
|
||||
|
||||
你也可以拷贝或换出整个磁带,这是你需要继续录音并且进行多次混合的时候需要做的。
|
||||
|
||||
|
||||
现在我希望对于上述 70 年代的录音工作的描述足够生动,我们就可以把 Git 的工作想象成一个录音磁带了。
|
||||
|
||||
|
||||
### 新建一个 Git 仓库
|
||||
|
||||
|
||||
首先得为我们的虚拟的录音机买一些磁带。在 Git 术语中,这就是仓库;它是完成所有工作的基础,也就是说这里是存放 Git 文件的地方(即 Git 工作区)。
|
||||
|
||||
任何目录都可以是一个 Git 仓库,但是在开始的时候需要进行一次更新。需要下面三个命令:
|
||||
|
||||
|
||||
- 创建目录(如果你喜欢的话,你可以在你的 GUI 文件管理器里面完成。)
|
||||
- 在终端里查看目录。
|
||||
- 初始化这个目录使它可以被 Git管理。
|
||||
|
||||
|
||||
特别是运行如下代码:
|
||||
|
||||
```
|
||||
$ mkdir ~/jupiter # 创建目录
|
||||
$ cd ~/jupiter # 进入目录
|
||||
$ git init . # 初始化你的新 Git 工作区
|
||||
```
|
||||
|
||||
|
||||
在这个例子中,文件夹 jupiter 是空的但却成为了你的 Git 仓库。
|
||||
|
||||
有了仓库接下来的事件就按部就班了。你可以克隆项目仓库,你可以在一个历史点前后来回穿梭(前提是你有一个历史点),创建可交替时间线,然后剩下的工作 Git 就都能正常完成了。
|
||||
|
||||
|
||||
在 Git 仓库里面工作和在任何目录里面工作都是一样的;在仓库中新建文件,复制文件,保存文件。你可以像平常一样完成工作;Git 并不复杂,除非你把它想复杂了。
|
||||
|
||||
在本地的 Git 仓库中,一个文件可以有下面这三种状态:
|
||||
- 未跟踪文件:你在仓库里新建了一个文件,但是你没有把文件加入到 Git 的提交任务(提交暂存区,stage)中。
|
||||
- 已跟踪文件:已经加入到 Git 暂存区的文件。
|
||||
- 暂存区文件:存在于暂存区的文件已经加入到 Git 的提交队列中。
|
||||
|
||||
|
||||
任何你新加入到 Git 仓库中的文件都是未跟踪文件。文件还保存在你的电脑硬盘上,但是你没有告诉 Git 这是需要提交的文件,就像我们的录音机,如果你没有打开录音机;乐队开始演唱了,但是录音机并没有准备录音。
|
||||
|
||||
不用担心,Git 会告诉你存在的问题并提示你怎么解决:
|
||||
```
|
||||
$ echo "hello world" > foo
|
||||
$ git status
|
||||
位于您当前工作的分支 master 上
|
||||
未跟踪文件:
|
||||
(使用 "git add <file>" 更新要提交的内容)
|
||||
foo
|
||||
没有任何提交任务,但是存在未跟踪文件(用 "git add" 命令加入到提交任务)
|
||||
```
|
||||
|
||||
|
||||
你看到了,Git 会提醒你怎样把文件加入到提交任务中。
|
||||
|
||||
### 不使用 Git 命令进行 Git 操作
|
||||
|
||||
|
||||
在 GitHub 或 GitLab(译注:GitLab 是一个用于仓库管理系统的开源项目。使用Git作为代码管理工具,并在此基础上搭建起来的web服务。)上创建一个仓库大多是使用鼠标点击完成的。这不会很难,你单击 New Repository 这个按钮就会很快创建一个仓库。
|
||||
|
||||
在仓库中新建一个 README 文件是一个好习惯,这样人们在浏览你的仓库的时候就可以知道你的仓库基于什么项目,更有用的是通过 README 文件可以确定克隆的是否为一个非空仓库。
|
||||
|
||||
|
||||
克隆仓库通常很简单,但是在 GitHub 上获取仓库改动权限就不简单了,为了进行用户验证你必须有一个 SSH 秘钥。如果你使用 Linux 系统,通过下面的命令可以生成一个秘钥:
|
||||
```
|
||||
$ ssh-keygen
|
||||
```
|
||||
|
||||
|
||||
复制纯文本文件里的秘钥。你可以使用一个文本编辑器打开它,也可以使用 cat 命令:
|
||||
|
||||
```
|
||||
$ cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
|
||||
|
||||
现在把你的秘钥拷贝到 [GitHub SSH 配置文件][1] 中,或者 [GitLab 配置文件[2]。
|
||||
|
||||
如果你通过使用 SSH 模式克隆了你的项目,就可以在你的仓库开始工作了。
|
||||
|
||||
另外,如果你的系统上没有安装 Git 的话也可以使用 GitHub 的文件上传接口来克隆仓库。
|
||||
|
||||

|
||||
|
||||
|
||||
### 跟踪文件
|
||||
|
||||
命令 git status 的输出会告诉你如果你想让 git 跟踪一个文件,你必须使用命令 git add 把它加入到提交任务中。这个命令把文件存在了暂存区,暂存区存放的都是等待提交的文件,或者把仓库保存为一个快照。git add 命令的最主要目的是为了区分你已经保存在仓库快照里的文件,还有新建的或你想提交的临时文件,至少现在,你都不用为它们之间的不同之处而费神了。
|
||||
|
||||
类比大型录音机,这个动作就像打开录音机开始准备录音一样。你可以按已经录音的录音机上的 pause 按钮来完成推送,或者按下重置按钮等待开始跟踪下一个文件。
|
||||
|
||||
如果你把文件加入到提交任务中,Git 会自动标识为跟踪文件:
|
||||
|
||||
```
|
||||
$ git add foo
|
||||
$ git status
|
||||
位于您当前工作的分支 master 上
|
||||
下列修改将被提交:
|
||||
(使用 "git reset HEAD <file>..." 将下列改动撤出提交任务)
|
||||
新增文件:foo
|
||||
```
|
||||
|
||||
|
||||
加入文件到提交任务中并不会生成一个记录。这仅仅是为了之后方便记录而把文件存放到暂存区。在你把文件加入到提交任务后仍然可以修改文件;文件会被标记为跟踪文件并且存放到暂存区,所以你在最终提交之前都可以改动文件或撤出提交任务(但是请注意:你并没有记录文件,所以如果你完全改变了文件就没有办法撤销了,因为你没有记住最终修改的准确时间。)。
|
||||
|
||||
如果你决定不把文件记录到 Git 历史列表中,那么你可以撤出提交任务,在 Git 中是这样做的:
|
||||
```
|
||||
$ git reset HEAD foo
|
||||
```
|
||||
|
||||
|
||||
这实际上就是删除了录音机里面的录音,你只是在工作区转了一圈而已而已。
|
||||
|
||||
### 大型提交
|
||||
|
||||
有时候,你会需要完成很多提交;我们以录音机类比,这就好比按下录音键并最终按下保存键一样。
|
||||
|
||||
在一个项目从建立到完成,你会按记录键无数次。比如,如果你通过你的方式使用一个新的 Python 工具包并且最终实现了窗口展示,然后你就很肯定的提交了文件,但是不可避免的会发生一些错误,现在你却不能撤销你的提交操作了。
|
||||
|
||||
一次提交会记录仓库中所有的暂存区文件。Git 只记录加入到提交任务中的文件,也就是说在过去某个时刻你使用 git add 命令加入到暂存区的所有文件。还有从先前的提交开始被改动的文件。如果没有其他的提交,所有的跟踪文件都包含在这次提交中,因为在浏览 Git 历史点的时候,它们没有存在于仓库中。
|
||||
|
||||
完成一次提交需要运行下面的命令:
|
||||
```
|
||||
$ git commit -m 'My great project, first commit.'
|
||||
```
|
||||
|
||||
这就保存了所有需要在仓库中提交的文件(或者,如果你说到 Gallifreyan【译注:英国电视剧《神秘博士》里的时间领主使用的一种优雅的语言,】,它们可能就是“固定的时间点” )。你不仅能看到整个提交记录,还能通过 git log 命令查看修改日志找到提交时的版本号:
|
||||
```
|
||||
$ git log --oneline
|
||||
55df4c2 My great project, first commit.
|
||||
```
|
||||
|
||||
|
||||
如果想浏览更多信息,只需要使用不带 --oneline 选项的 git log 命令。
|
||||
|
||||
|
||||
在这个例子中提交时的版本号是 55df4c2。它被叫做 commit hash(译注:一个SHA-1生成的哈希码,用于表示一个git commit对象。),它表示着刚才你的提交包含的所有改动,覆盖了先前的记录。如果你想要“倒回”到你的提交历史点上就可以用这个 commit hash 作为依据。
|
||||
|
||||
你可以把 commit hash 想象成一个声音磁带上的 [SMPTE timecode][3],或者再夸张一点,这就是好比一个黑胶唱片上两首不同的歌之间的不同点,或是一个 CD 上的轨段编号。
|
||||
|
||||
|
||||
你在很久前改动了文件并且把它们加入到提交任务中,最终完成提交,这就会生成新的 commit hashes,每个 commit hashes 标示的历史点都代表着你的产品不同的版本。
|
||||
|
||||
|
||||
这就是 Charlie Brown 把 Git 称为版本控制系统的原因。
|
||||
|
||||
在接下来的文章中,我们将会讨论你需要知道的关于 Git HEAD 的一切,我们不准备讨论关于 Git 的提交历史问题。基本不会提及,但是你可能会需要了解它(或许你已经有所了解?)。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/creating-your-first-git-repository
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://github.com/settings/keys
|
||||
[2]: https://gitlab.com/profile/keys
|
||||
[3]: http://slackermedia.ml/handbook/doku.php?id=timecode
|
||||
71
translated/tech/20160718 OPEN SOURCE ACCOUNTING SOFTWARE.md
Normal file
71
translated/tech/20160718 OPEN SOURCE ACCOUNTING SOFTWARE.md
Normal file
@ -0,0 +1,71 @@
|
||||
GNU KHATA:开源的会计管理软件
|
||||
============================================
|
||||
|
||||
作为一个活跃的 Linux 爱好者,我经常向我的朋友们介绍 Linux,帮助他们选择最适合他们的发行版本,同时也会帮助他们安装一些适用于他们工作的开源软件。
|
||||
|
||||
但是,又一次,我就变得很无奈。我的叔叔,他是一个自由职业的会计师。他会有一系列的为了会计工作的付费软件。我就不那么确定,我能在在开软软件中找到这么一款可以替代的软件。直到昨天。
|
||||
|
||||
Abhishek 给我推荐了一些[很酷的软件][1],并且,GNU Khata 这个特殊的一款,脱颖而出。
|
||||
|
||||
[GNU Khata][2] 是一个会计工具。 或者,我可以说成是一系列的会计工具集合?这像经济管理方面的[Evernote][3]。他的应用是如此之广,以至于他可以处理个人的财务管理,到大型公司的管理,从店铺存货管理到税率计算,都可以有效处理。
|
||||
|
||||
对你来说一个有趣的点,'Khata' 在印度或者是其他的印度语国家中意味着账户,所以这个会计软件叫做 GNU Khata。
|
||||
|
||||
### 安装
|
||||
|
||||
互联网上有很多关于老旧版本的 Khata 安装的介绍。现在,GNU Khata 已经可以在 Debian/Ubuntu 和他们的衍生产中得到。我建议你按照如下 GNU Khata 官网的步骤来安装。我们来一次快速的入门。
|
||||
|
||||
- 从[这][4]下载安装器。
|
||||
- 在下载目录打开终端。
|
||||
- 粘贴复制以下的代码到终端,并且执行。
|
||||
|
||||
```
|
||||
sudo chmod 755 GNUKhatasetup.run
|
||||
sudo ./GNUKhatasetup.run
|
||||
```
|
||||
|
||||
- 这就结束了,从你的 Dash 或者是应用菜单中启动 GNU Khata 吧。
|
||||
### 第一次启动
|
||||
|
||||
GNU Khata 在浏览器中打开,并且展现以下的画面。
|
||||
|
||||

|
||||
|
||||
填写组织的名字和组织形式,经济年份并且点击 proceed 按钮进入管理设置页面。
|
||||
|
||||

|
||||
|
||||
仔细填写你的姓名,密码,安全问题和他的答案,并且点击“create and login”。
|
||||
|
||||

|
||||
|
||||
你已经全部设置完成了。使用菜单栏来开始使用 GNU Khata 来管理你的经济吧。这很容易。
|
||||
|
||||
### GNU KHATA 真的是市面上付费会计应用的竞争对手吗?
|
||||
|
||||
首先,GNU Khata 让所有的事情变得简单。顶部的菜单栏被方便的组织,可以帮助你有效的进行工作。 你可以选择管理不同的账户和项目,并且切换非常容易。[他们的官网][5]表明,GNU Khata 可以“方便的转变成印度语”。同时,你知道 GNU Khata 也可以在云端使用吗?
|
||||
|
||||
所有的主流的账户管理工具,将账簿分类,项目介绍,法规介绍等等用专业的方式整理,并且支持自定义整理和实时显示。这让会计和进存储管理看起来如此的简单。
|
||||
|
||||
这个项目正在积极的发展,从实际的操作中提交反馈来帮助这个软件更加进步。考虑到软件的成熟性,使用的便利性还有免费的 tag。GNU Khata 可能会成为最好的账簿助手。
|
||||
|
||||
请在评论框里留言吧,让我们知道你是如何看待 GNU Khata 的。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/using-gnu-khata/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/aquil/
|
||||
[1]: https://itsfoss.com/category/apps/
|
||||
[2]: http://www.gnukhata.in/
|
||||
[3]: https://evernote.com/
|
||||
[4]: https://cloud.openmailbox.org/index.php/s/L8ppsxtsFq1345E/download
|
||||
[5]: http://www.gnukhata.in/
|
||||
@ -0,0 +1,37 @@
|
||||
你能在浏览器中运行UBUNTU
|
||||
=====================================================
|
||||
|
||||
Canonical, Ubuntu的母公司, 为Linux推广做了很多努力. 无论你有多么不喜欢 Ubuntu, 你必须承认它对 “Linux 易用性”的影响. Ubuntu 以及其衍生是应用最多的Linux版本 .
|
||||
|
||||
为了进一步推广 Ubuntu Linux, Canonical 把它放到了浏览器里你可以再任何地方使用 [demo version of Ubuntu][1]. 它将帮你更好的体验 Ubuntu. 以便让新人更容易决定是否使用.
|
||||
|
||||
你可能争辩说USB版的linux更好. 我同意但是你要知道你要下载ISO, 创建USB驱动, 修改配置文件. 并不是每个人都乐意这么干的. 在线体验是一个更好的选择.
|
||||
|
||||
因此, 你能在Ubuntu在线看到什么. 实际上并不多.
|
||||
|
||||
你可以浏览文件, 你可以使用 Unity Dash, 浏览 Ubuntu Software Center, 甚至装几个 apps (当然它们不会真的安装), 看一看文件浏览器 和其它一些东西. 以上就是全部了. 但是在我看来, 它是非常漂亮的
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
如果你的朋友或者家人想试试Linux又不乐意安装, 你可以给他们以下链接:
|
||||
|
||||
[Ubuntu Online Tour][0]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-online-demo/?utm_source=newsletter&utm_medium=email&utm_campaign=linux_and_open_source_stories_this_week
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[校对ID](https://github.com/校对ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[0]: http://tour.ubuntu.com/en/
|
||||
[1]: http://tour.ubuntu.com/en/
|
||||
@ -0,0 +1,39 @@
|
||||
为你的Linux桌面设置一张真实的地球照片
|
||||
=================================================================
|
||||
|
||||
|
||||
|
||||
厌倦了看同样的桌面背景了么?这里有一个几乎这世界上最好的东西。
|
||||
|
||||
‘[Himawaripy][1]‘是一个Python 3脚本,它会接近实时抓取由[日本Himawari 8气象卫星][2]拍摄的地球照片,并将它设置成你的桌面背景。
|
||||
|
||||
安装完成后,你可以将它设置成每10分钟运行的任务(自然地它是在后台运行),这样它就可以实时地取回地球的照片并设置成背景了。
|
||||
|
||||
因为Himawari-8是一颗同步轨道卫星,你只能看到澳大利亚上空的地球的图片-但是它实时的天气形态、云团和光线仍使它很壮丽,即使对我而言在看到英国上方的更好!
|
||||
|
||||
高级设置允许你配置从卫星取回的图片质量,但是要记住增加图片质量会增加文件大小及更长的下载等待!
|
||||
|
||||
最后,虽然这个脚本与其他我们提到过的其他类似,它还仍保持更新及可用。
|
||||
|
||||
获取Himawaripy
|
||||
|
||||
Himawaripy已经在一系列的桌面环境中都测试过了,包括Unity、LXDE、i3、MATE和其他桌面环境。它是免费、开源软件但是并不能直接设置及配置。
|
||||
|
||||
在Github上查找获取安装的应用程序和设置的所有指令()提示:有没有一键安装)上。
|
||||
|
||||
[GitHub上的实时地球壁纸脚本][0]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
||||
|
||||
作者:[ JOEY-ELIJAH SNEDDON][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]: https://github.com/boramalper/himawaripy
|
||||
[2]: https://en.wikipedia.org/wiki/Himawari_8
|
||||
[0]: https://github.com/boramalper/himawaripy
|
||||
@ -0,0 +1,218 @@
|
||||
如何在Ubuntu Linux 16.04 LTS中使用多条连接加速apt-get/apt
|
||||
=========================================================================================
|
||||
|
||||
我该如何在Ubuntu Linux 16.04或者14.04 LTS中从多个仓库中下载包来加速apt-get或者apt命令?
|
||||
|
||||
你需要使用到apt-fast这个shell封装器。它会通过多个连接同时下载一个包来加速apt-get/apt和aptitude命令。所有的包都会同时下载。它使用aria2c作为默认的下载加速。
|
||||
|
||||
### 安装 apt-fast 工具
|
||||
|
||||
在Ubuntu Linux 14.04或者之后的版本尝试下面的命令:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:saiarcot895/myppa
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
|
||||
|
||||
更新你的仓库:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
|
||||
|
||||
安装 apt-fast:
|
||||
|
||||
```
|
||||
$ sudo apt-get -y install apt-fast
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
$ sudo apt -y install apt-fast
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
|
||||
```
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following additional packages will be installed:
|
||||
aria2 libc-ares2 libssh2-1
|
||||
Suggested packages:
|
||||
aptitude
|
||||
The following NEW packages will be installed:
|
||||
apt-fast aria2 libc-ares2 libssh2-1
|
||||
0 upgraded, 4 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 1,282 kB of archives.
|
||||
After this operation, 4,786 kB of additional disk space will be used.
|
||||
Do you want to continue? [Y/n] y
|
||||
Get:1 http://01.archive.ubuntu.com/ubuntu xenial/universe amd64 libssh2-1 amd64 1.5.0-2 [70.3 kB]
|
||||
Get:2 http://ppa.launchpad.net/saiarcot895/myppa/ubuntu xenial/main amd64 apt-fast all 1.8.3~137+git7b72bb7-0ubuntu1~ppa3~xenial1 [34.4 kB]
|
||||
Get:3 http://01.archive.ubuntu.com/ubuntu xenial/main amd64 libc-ares2 amd64 1.10.0-3 [33.9 kB]
|
||||
Get:4 http://01.archive.ubuntu.com/ubuntu xenial/universe amd64 aria2 amd64 1.19.0-1build1 [1,143 kB]
|
||||
54% [4 aria2 486 kB/1,143 kB 42%] 20.4 kB/s 32s
|
||||
```
|
||||
|
||||
### 配置 apt-fast
|
||||
|
||||
你将会得到下面的提示(必须输入一个5到16的数值):
|
||||
|
||||
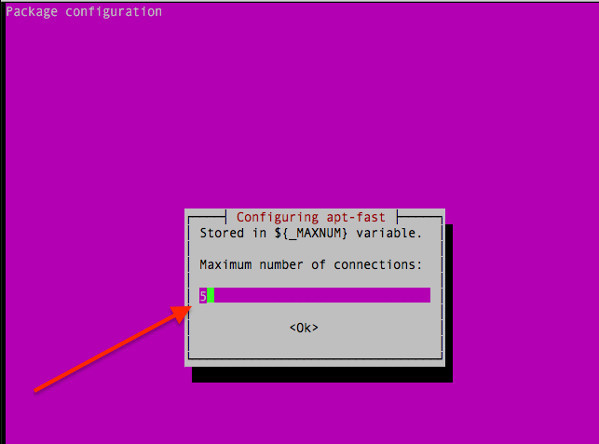
|
||||
|
||||
并且
|
||||
|
||||
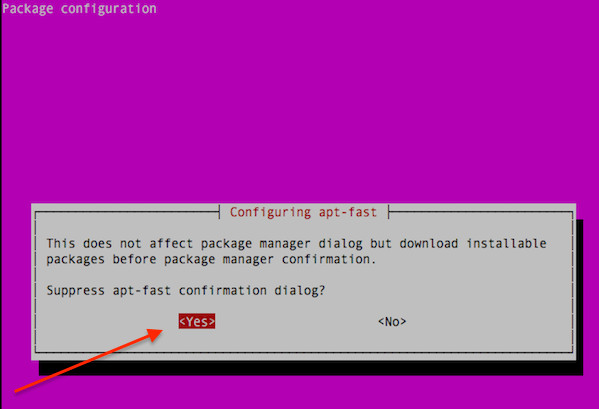
|
||||
|
||||
你可以直接编辑设置:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/apt-fast.conf
|
||||
```
|
||||
|
||||
>**请注意这个工具并不是给慢速网络连接的,它是给快速网络连接的。如果你的网速慢,那么你将无法从这个工具中得到好处。**
|
||||
|
||||
### 我该怎么使用 apt-fast 命令?
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
apt-fast command
|
||||
apt-fast [options] command
|
||||
```
|
||||
|
||||
#### 使用apt-fast取回新的包列表
|
||||
|
||||
```
|
||||
sudo apt-fast update
|
||||
```
|
||||
|
||||
#### 使用apt-fast执行升级
|
||||
|
||||
```
|
||||
sudo apt-fast upgrade
|
||||
```
|
||||
|
||||
|
||||
#### 执行发行版升级(发布或者强制内核升级),输入:
|
||||
|
||||
```
|
||||
$ sudo apt-fast dist-upgrade
|
||||
```
|
||||
|
||||
#### 安装新的包
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
sudo apt-fast install pkg
|
||||
```
|
||||
|
||||
比如要安装nginx,输入:
|
||||
|
||||
```
|
||||
$ sudo apt-fast install nginx
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
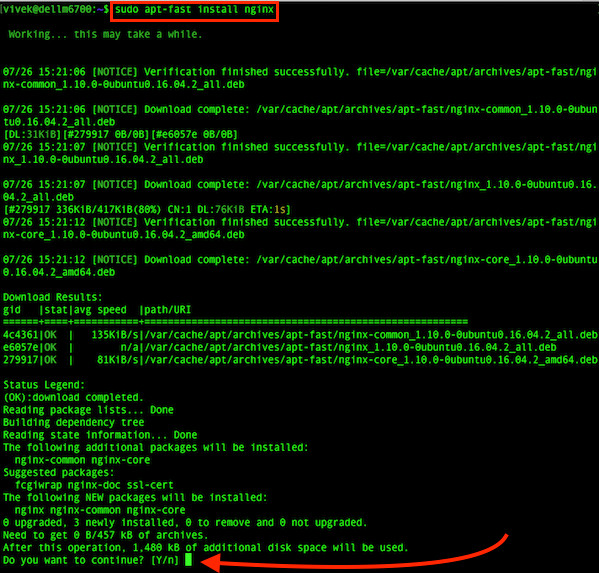
|
||||
|
||||
#### 删除包
|
||||
|
||||
```
|
||||
$ sudo apt-fast remove pkg
|
||||
$ sudo apt-fast remove nginx
|
||||
```
|
||||
|
||||
#### 删除包和它的配置文件
|
||||
|
||||
```
|
||||
$ sudo apt-fast purge pkg
|
||||
$ sudo apt-fast purge nginx
|
||||
```
|
||||
|
||||
#### 删除所有未使用的包
|
||||
|
||||
```
|
||||
$ sudo apt-fast autoremove
|
||||
```
|
||||
|
||||
#### 下载源码包
|
||||
|
||||
```
|
||||
$ sudo apt-fast source pkgNameHere
|
||||
```
|
||||
|
||||
#### 清理下载的文件
|
||||
|
||||
```
|
||||
$ sudo apt-fast clean
|
||||
```
|
||||
|
||||
#### 清理旧的下载文件
|
||||
|
||||
```
|
||||
$ sudo apt-fast autoclean
|
||||
```
|
||||
|
||||
#### 验证没有破坏的依赖
|
||||
|
||||
```
|
||||
$ sudo apt-fast check
|
||||
```
|
||||
|
||||
#### 下载二进制包到当前目录
|
||||
|
||||
```
|
||||
$ sudo apt-fast download pkgNameHere
|
||||
$ sudo apt-fast download nginx
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
[#7bee0c 0B/0B CN:1 DL:0B]
|
||||
07/26 15:35:42 [NOTICE] Verification finished successfully. file=/home/vivek/nginx_1.10.0-0ubuntu0.16.04.2_all.deb
|
||||
07/26 15:35:42 [NOTICE] Download complete: /home/vivek/nginx_1.10.0-0ubuntu0.16.04.2_all.deb
|
||||
Download Results:
|
||||
gid |stat|avg speed |path/URI
|
||||
======+====+===========+=======================================================
|
||||
7bee0c|OK | n/a|/home/vivek/nginx_1.10.0-0ubuntu0.16.04.2_all.deb
|
||||
Status Legend:
|
||||
(OK):download completed.
|
||||
```
|
||||
|
||||
#### 下载并显示指定包的changelog
|
||||
|
||||
```
|
||||
$ sudo apt-fast changelog pkgNameHere
|
||||
$ sudo apt-fast changelog nginx
|
||||
```
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/introducing-flatpak/
|
||||
|
||||
作者:[VIVEK GITE][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cyberciti.biz/tips/about-us
|
||||
@ -1,178 +0,0 @@
|
||||
LFCS第十二讲: 如何使用Linux的帮助文档和工具
|
||||
==================================================================================
|
||||
|
||||
由于 2016 年 2 月 2 号开始启用了新的 LFCS 考试要求, 我们在[LFCS series][1]系列添加了一些必要的内容 . 为了考试的需要, 我们强烈建议你看一下[LFCE series][2] .
|
||||
|
||||

|
||||
>LFCS: 了解Linux的帮助文档和工具
|
||||
|
||||
当你习惯了在命令行下进行工作, 你会发现Linux有许多文档需要你去使用和配置Linux系统.
|
||||
|
||||
另一个你必须熟悉命令行帮助工具的理由是,在[LFCS][3] 和 [LFCE][4] 考试中, 你只能靠你自己和命令行工具,没有互联网也没有百度。
|
||||
|
||||
基于上面的理由, 在这一章里我们将给你一些建议来帮助你通过**Linux Foundation Certification** 考试.
|
||||
|
||||
### Linux 帮助手册
|
||||
|
||||
man命令, 大体上来说就是一个工具手册. 它包含选项列表(和解释) , 甚至还提供一些例子.
|
||||
|
||||
我们用**man command** 加工具名称来打开一个帮助手册以便获取更多内容. 例如:
|
||||
|
||||
```
|
||||
# man diff
|
||||
```
|
||||
|
||||
我们将打开`diff`的手册页, 这个工具将一行一行的对比文本文档 (如你想退出只需要轻轻的点一下Q键).
|
||||
|
||||
下面我来比较两个文本文件 `file1` 和 `file2` . 这两个文本文件包含着相同版本Linux的安装包信息.
|
||||
|
||||
输入`diff` 命令它将告诉我们 `file1` 和`file2` 有什么不同:
|
||||
|
||||
```
|
||||
# diff file1 file2
|
||||
```
|
||||
|
||||

|
||||
>在Linux中比较两个文本文件
|
||||
|
||||
`<` 这个符号是说`file2`少一行. 如果是 `file1`少一行, 我们将用 `>` 符号来替代.
|
||||
|
||||
接下来说, **7d6** 意思是说 文件1的**#7**行在 `file2`中被删除了 ( **24d22** 和**41d38**是同样的意思), 65,67d61告诉我们移动 **65** 到 **67** . 我们把以上步骤都做了两个文件将完全匹配.
|
||||
|
||||
你还可以通过 `-y` 选项来对比两个文件:
|
||||
|
||||
```
|
||||
# diff -y file1 file2
|
||||
```
|
||||
|
||||

|
||||
>通过列表来列出两个文件的不同
|
||||
|
||||
当然你也可以用`diff`来比较两个二进制文件 . 如果它们完全一样, `diff` 将什么也不会输出. 否则, 他将会返回如下信息: “**Binary files X and Y differ**”.
|
||||
|
||||
### –help 选项
|
||||
|
||||
`--help`选项 , 大多数命令都可以用它(并不是所有) , 他可以理解为一个命令的简单介绍. 尽管它不提供工具的详细介绍, 但是确实是一个能够快速列出程序使用信息的不错的方法.
|
||||
|
||||
例如,
|
||||
|
||||
```
|
||||
# sed --help
|
||||
```
|
||||
|
||||
显示 sed 的每个选项的用法(sed文本流编辑器).
|
||||
|
||||
一个经典的`sed`例子,替换文件字符. 用 `-i` 选项 (描述为 “**编辑文件在指定位置**”), 你可以编辑一个文件而且并不需要打开他. 如果你想要备份一个原始文件, 用 `-i` 选项 加后缀来创建一个原始文件的副本.
|
||||
|
||||
例如, 替换 `lorem.txt`中的`Lorem` 为 `Tecmint` (忽略大小写) 并且创建一个新的原始文件副本, 命令如下:
|
||||
|
||||
```
|
||||
# less lorem.txt | grep -i lorem
|
||||
# sed -i.orig 's/Lorem/Tecmint/gI' lorem.txt
|
||||
# less lorem.txt | grep -i lorem
|
||||
# less lorem.txt.orig | grep -i lorem
|
||||
```
|
||||
|
||||
请注意`lorem.txt`文件中`Lorem` 都已经替换为 `Tecmint` , 并且原始的 `lorem.txt` 保存为`lorem.txt.orig`.
|
||||
|
||||

|
||||
>替换文件文本
|
||||
|
||||
### /usr/share/doc内的文档
|
||||
这可能是我最喜欢的方法. 如果你进入 `/usr/share/doc` 目录, 你可以看到好多Linux已经安装的工具的名称的文件夹.
|
||||
|
||||
根据[Filesystem Hierarchy Standard][5](文件目录标准),这些文件夹包含了许多帮助手册没有的信息, 还有一些模板和配置文件.
|
||||
|
||||
例如, 让我们来看一下 `squid-3.3.8` (版本可能会不同) 一个非常受欢迎的HTTP代理[squid cache server][6].
|
||||
|
||||
让我们用`cd`命令进入目录 :
|
||||
|
||||
```
|
||||
# cd /usr/share/doc/squid-3.3.8
|
||||
```
|
||||
|
||||
列出当前文件夹列表:
|
||||
|
||||
```
|
||||
# ls
|
||||
```
|
||||
|
||||

|
||||
>ls linux列表命令
|
||||
|
||||
你应该特别注意 `QUICKSTART` 和 `squid.conf.documented`. 这两个文件包含了Squid许多信息, . 对于别的安装包来说, 他们的名字可能不同 (有可能是 **QuickRef** 或者**00QUICKSTART**), 但原理是一样的.
|
||||
|
||||
对于另外一些安装包, 比如 the Apache web server, 在`/usr/share/doc`目录提供了配置模板, 当你配置独立服务器或者虚拟主机的时候会非常有用.
|
||||
|
||||
### GNU 信息文档
|
||||
|
||||
你可以把它想象为帮助手册的超级链接形式. 正如上面说的, 他不仅仅提供工具的帮助信息, 而且还是超级链接的形式(是的!在命令行中的超级链接) 你可以通过箭头按钮和回车按钮来浏览你需要的内容.
|
||||
|
||||
一个典型的例子是:
|
||||
|
||||
```
|
||||
# info coreutils
|
||||
```
|
||||
|
||||
通过coreutils 列出当前系统的 基本文件,shell脚本和文本处理工具[basic file, shell and text manipulation utilities][7] , 你可以得到他们的详细介绍.
|
||||
|
||||

|
||||
>Info Coreutils
|
||||
|
||||
和帮助手册一样你可以按Q键退出.
|
||||
|
||||
此外, GNU info 还可以像帮助手册一样使用. 例如:
|
||||
|
||||
```
|
||||
# info tune2fs
|
||||
```
|
||||
|
||||
它将显示 **tune2fs**的帮助手册, ext2/3/4 文件系统管理工具.
|
||||
|
||||
让我们来看看怎么用**tune2fs**:
|
||||
|
||||
显示 **/dev/mapper/vg00-vol_backups**文件系统信息:
|
||||
|
||||
```
|
||||
# tune2fs -l /dev/mapper/vg00-vol_backups
|
||||
```
|
||||
|
||||
修改文件系统标签 (修改为Backups):
|
||||
|
||||
```
|
||||
# tune2fs -L Backups /dev/mapper/vg00-vol_backups
|
||||
```
|
||||
|
||||
设置 `/` 自检的挂载次数 (用`-c` 选项设置 `/`的自检的挂载次数 或者用 `-i` 选项设置 自检时间 **d=days, w=weeks, and m=months**).
|
||||
|
||||
```
|
||||
# tune2fs -c 150 /dev/mapper/vg00-vol_backups # Check every 150 mounts
|
||||
# tune2fs -i 6w /dev/mapper/vg00-vol_backups # Check every 6 weeks
|
||||
```
|
||||
|
||||
以上这些内容也可以通过 `--help` 选项找到, 或者查看帮助手册.
|
||||
|
||||
### 摘要
|
||||
|
||||
不管你选择哪种方法,知道并且会使用它们在考试中对你是非常有用的. 你知道其它的一些方法吗? 欢迎给我们留言.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[4]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[5]: http://www.tecmint.com/linux-directory-structure-and-important-files-paths-explained/
|
||||
[6]: http://www.tecmint.com/configure-squid-server-in-linux/
|
||||
[7]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[8]:
|
||||
Loading…
Reference in New Issue
Block a user