-}
-```
-
-It’s that simple. We just passed `props` as an argument to a plain JavaScript function and returned, _umm, well, what was that? That _ `_
{props.name}
_` _thing!_ It’s JSX (JavaScript Extended). We will learn more about it in a later section.
-
-This above function will render the following HTML in the browser.
-
-```
-
-
- rajat
-
-```
-
-
-> Read the section below about JSX, where I have explained how did we get this HTML from our JSX code.
-
-How can you use this functional component in your React app? Glad you asked! It’s as simple as the following.
-
-```
-
-```
-
-The attribute `name` in the above code becomes `props.name` inside our `Hello`component. The attribute `age` becomes `props.age` and so on.
-
-> Remember! You can nest one React component inside other React components.
-
-Let’s use this `Hello` component in our codepen playground. Replace the `div`inside `ReactDOM.render()` with our `Hello` component, as follows, and see the changes in the bottom window.
-
-```
-function Hello(props) {
- return
{props.name}
-}
-
-ReactDOM.render(, document.getElementById('root'));
-```
-
-
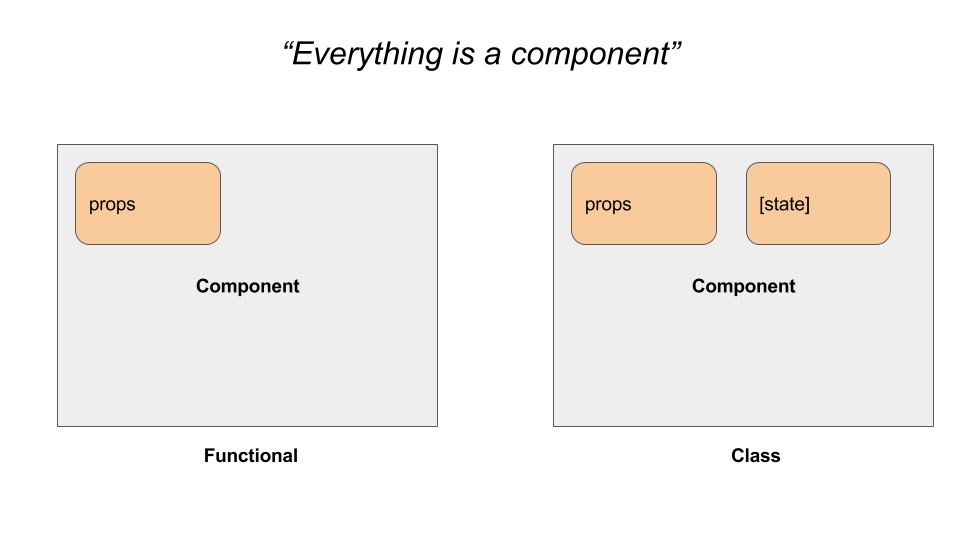
-> But what if your component has some internal state. For instance, like the following counter component, which has an internal count variable, which changes on + and — key presses.
-
-A React component with an internal state
-
-#### b) Class-based component
-
-The class-based component has an additional property `state` , which you can use to hold a component’s private data. We can rewrite our `Hello` component using class notation as follows. Since these components have a state, these are also known as Stateful components.
-
-```
-class Counter extends React.Component {
- // this method should be present in your component
- render() {
- return (
-
- {this.props.name}
-
- );
- }
-}
-```
-
-We extend `React.Component` class of React library to make class-based components in React. Learn more about JavaScript classes [here][5].
-
-The `render()` method must be present in your class as React looks for this method in order to know what UI it should render on screen.
-
-To use this sort of internal state, we first have to initialize the `state` object in the constructor of the component class, in the following way.
-
-```
-class Counter extends React.Component {
- constructor() {
- super();
-
- // define the internal state of the component
- this.state = {name: 'rajat'}
- }
-
- render() {
- return (
-
- {this.state.name}
-
- );
- }
-}
-
-// Usage:
-// In your react app:
-```
-
-Similarly, the `props` can be accessed inside our class-based component using `this.props` object.
-
-To set the state, you use `React.Component`'s `setState()`. We will see an example of this, in the last part of this tutorial.
-
-> Tip: Never call `setState()` inside `render()` function, as `setState()` causes component to re-render and this will result in endless loop.
-
-
-
-A class-based component has an optional property “state”.
-
- _Apart from _ `_state_` _, a class-based component has some life-cycle methods like _ `_componentWillMount()._` _ These you can use to do stuff, like initializing the _ `_state_` _and all but that is out of the scope of this post._
-
-### JSX
-
-JSX is a short form of _JavaScript Extended_ and it is a way to write `React`components. Using JSX, you get the full power of JavaScript inside XML like tags.
-
-You put JavaScript expressions inside `{}`. The following are some valid JSX examples.
-
- ```
-
-
- ;
-
-
-
- ```
-
-The way it works is you write JSX to describe what your UI should look like. A [transpiler][6] like `Babel` converts that code into a bunch of `React.createElement()` calls. The React library then uses those `React.createElement()` calls to construct a tree-like structure of DOM elements. In case of React for Web or Native views in case of React Native. It keeps it in the memory.
-
-React then calculates how it can effectively mimic this tree in the memory of the UI displayed to the user. This process is known as [reconciliation][7]. After that calculation is done, React makes the changes to the actual UI on the screen.
-
- ** 此处有Canvas,请手动处理 **
-
-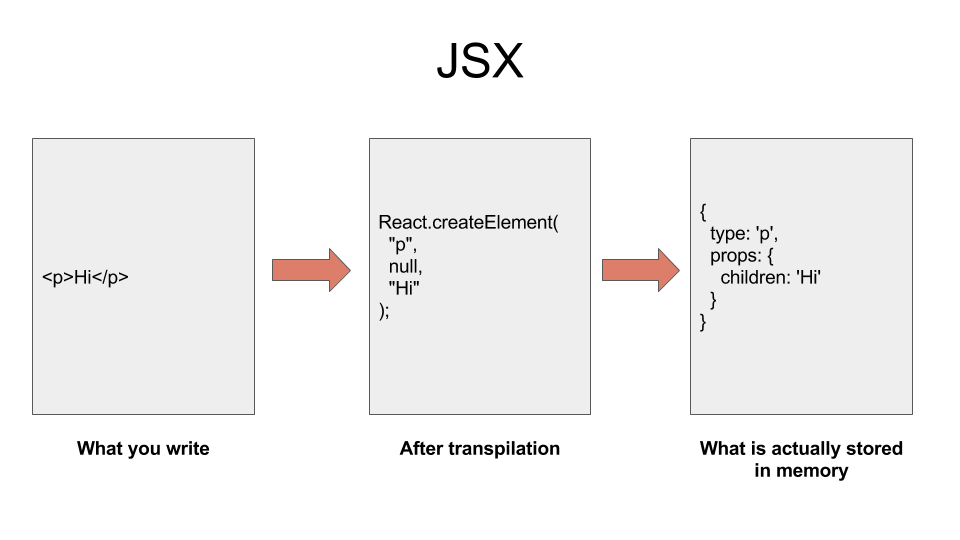
-How React converts your JSX into a tree which describes your app’s UI
-
-You can use [Babel’s online REPL][8] to see what React actually outputs when you write some JSX.
-
-
-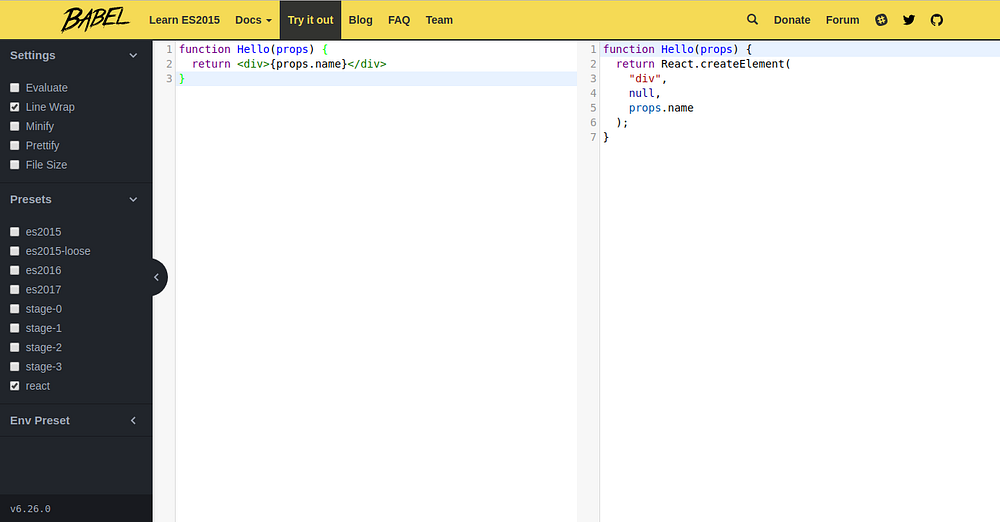
-Use Babel REPL to transform JSX into plain JavaScript
-
-> Since JSX is just a syntactic sugar over plain `React.createElement()` calls, React can be used without JSX.
-
-Now we have every concept in place, so we are well positioned to write a `counter` component that we saw earlier as a GIF.
-
-The code is as follows and I hope that you already know how to render that in our playground.
-
-```
-class Counter extends React.Component {
- constructor(props) {
- super(props);
-
- this.state = {count: this.props.start || 0}
-
- // the following bindings are necessary to make `this` work in the callback
- this.inc = this.inc.bind(this);
- this.dec = this.dec.bind(this);
- }
-
- inc() {
- this.setState({
- count: this.state.count + 1
- });
- }
-
- dec() {
- this.setState({
- count: this.state.count - 1
- });
- }
-
- render() {
- return (
-
-
-
-
{this.state.count}
-
- );
- }
-}
-```
-
-The following are some salient points about the above code.
-
-1. JSX uses `camelCasing` hence `button`'s attribute is `onClick`, not `onclick`, as we use in HTML.
-
-2. Binding is necessary for `this` to work on callbacks. See line #8 and 9 in the code above.
-
-The final interactive code is located [here][9].
-
-With that, we’ve reached the conclusion of our React crash course. I hope I have shed some light on how React works and how you can use React to build bigger apps, using smaller and reusable components.
-
-* * *
-
-If you have any queries or doubts, hit me up on Twitter [@rajat1saxena][10] or write to me at [rajat@raynstudios.com][11].
-
-* * *
-
-#### Please recommend this post, if you liked it and share it with your network. Follow me for more tech related posts and consider subscribing to my channel [Rayn Studios][12] on YouTube. Thanks a lot.
-
---------------------------------------------------------------------------------
-
-via: https://medium.freecodecamp.org/rock-solid-react-js-foundations-a-beginners-guide-c45c93f5a923
-
-作者:[Rajat Saxena ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://medium.freecodecamp.org/@rajat1saxena
-[1]:https://kivenaa.com/
-[2]:https://play.google.com/store/apps/details?id=com.pollenchat.android
-[3]:https://facebook.github.io/react-native/
-[4]:https://codepen.io/raynesax/pen/MrNmBM
-[5]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes
-[6]:https://en.wikipedia.org/wiki/Source-to-source_compiler
-[7]:https://reactjs.org/docs/reconciliation.html
-[8]:https://babeljs.io/repl
-[9]:https://codepen.io/raynesax/pen/QaROqK
-[10]:https://twitter.com/rajat1saxena
-[11]:mailto:rajat@raynstudios.com
-[12]:https://www.youtube.com/channel/UCUmQhjjF9bsIaVDJUHSIIKw
\ No newline at end of file
diff --git a/sources/tech/20180205 Writing eBPF tracing tools in Rust.md b/sources/tech/20180205 Writing eBPF tracing tools in Rust.md
index 093d3de215..18b8eb5742 100644
--- a/sources/tech/20180205 Writing eBPF tracing tools in Rust.md
+++ b/sources/tech/20180205 Writing eBPF tracing tools in Rust.md
@@ -1,4 +1,3 @@
-Zafiry translating...
Writing eBPF tracing tools in Rust
============================================================
diff --git a/sources/tech/20180215 Build a bikesharing app with Redis and Python.md b/sources/tech/20180215 Build a bikesharing app with Redis and Python.md
index 06e4c6949a..d3232a0b4c 100644
--- a/sources/tech/20180215 Build a bikesharing app with Redis and Python.md
+++ b/sources/tech/20180215 Build a bikesharing app with Redis and Python.md
@@ -1,3 +1,5 @@
+translating by Flowsnow
+
Build a bikesharing app with Redis and Python
======
diff --git a/sources/tech/29180329 Python ChatOps libraries- Opsdroid and Errbot.md b/sources/tech/20180329 Python ChatOps libraries- Opsdroid and Errbot.md
similarity index 99%
rename from sources/tech/29180329 Python ChatOps libraries- Opsdroid and Errbot.md
rename to sources/tech/20180329 Python ChatOps libraries- Opsdroid and Errbot.md
index d7ef058106..5f409956f7 100644
--- a/sources/tech/29180329 Python ChatOps libraries- Opsdroid and Errbot.md
+++ b/sources/tech/20180329 Python ChatOps libraries- Opsdroid and Errbot.md
@@ -1,5 +1,3 @@
-Translating by shipsw
-
Python ChatOps libraries: Opsdroid and Errbot
======
diff --git a/sources/tech/20180412 A Desktop GUI Application For NPM.md b/sources/tech/20180412 A Desktop GUI Application For NPM.md
deleted file mode 100644
index 4eabc40672..0000000000
--- a/sources/tech/20180412 A Desktop GUI Application For NPM.md
+++ /dev/null
@@ -1,147 +0,0 @@
-A Desktop GUI Application For NPM
-======
-
-
-
-NPM, short for **N** ode **P** ackage **M** anager, is a command line package manager for installing NodeJS packages, or modules. We already have have published a guide that described how to [**manage NodeJS packages using NPM**][1]. As you may noticed, managing NodeJS packages or modules using Npm is not a big deal. However, if you’re not compatible with CLI-way, there is a desktop GUI application named **NDM** which can be used for managing NodeJS applications/modules. NDM, stands for **N** PM **D** esktop **M** anager, is a free, open source graphical front-end for NPM that allows us to install, update, remove NodeJS packages via a simple graphical window.
-
-In this brief tutorial, we are going to learn about Ndm in Linux.
-
-### Install NDM
-
-NDM is available in AUR, so you can install it using any AUR helpers on Arch Linux and its derivatives like Antergos and Manjaro Linux.
-
-Using [**Pacaur**][2]:
-```
-$ pacaur -S ndm
-
-```
-
-Using [**Packer**][3]:
-```
-$ packer -S ndm
-
-```
-
-Using [**Trizen**][4]:
-```
-$ trizen -S ndm
-
-```
-
-Using [**Yay**][5]:
-```
-$ yay -S ndm
-
-```
-
-Using [**Yaourt**][6]:
-```
-$ yaourt -S ndm
-
-```
-
-On RHEL based systems like CentOS, run the following command to install NDM.
-```
-$ echo "[fury] name=ndm repository baseurl=https://repo.fury.io/720kb/ enabled=1 gpgcheck=0" | sudo tee /etc/yum.repos.d/ndm.repo && sudo yum update &&
-
-```
-
-On Debian, Ubuntu, Linux Mint:
-```
-$ echo "deb [trusted=yes] https://apt.fury.io/720kb/ /" | sudo tee /etc/apt/sources.list.d/ndm.list && sudo apt-get update && sudo apt-get install ndm
-
-```
-
-NDM can also be installed using **Linuxbrew**. First, install Linuxbrew as described in the following link.
-
-After installing Linuxbrew, you can install NDM using the following commands:
-```
-$ brew update
-
-$ brew install ndm
-
-```
-
-On other Linux distributions, go to the [**NDM releases page**][7], download the latest version, compile and install it yourself.
-
-### NDM Usage
-
-Launch NDM wither from the Menu or using application launcher. This is how NDM’s default interface looks like.
-
-![][9]
-
-From here, you can install NodeJS packages/modules either locally or globally.
-
-**Install NodeJS packages locally**
-
-To install a package locally, first choose project directory by clicking on the **“Add projects”** button from the Home screen and select the directory where you want to keep your project files. For example, I have chosen a directory named **“demo”** as my project directory.
-
-Click on the project directory (i.e **demo** ) and then, click **Add packages** button.
-
-![][10]
-
-Type the package name you want to install and hit the **Install** button.
-
-![][11]
-
-Once installed, the packages will be listed under the project’s directory. Simply click on the directory to view the list of installed packages locally.
-
-![][12]
-
-Similarly, you can create separate project directories and install NodeJS modules in them. To view the list of installed modules on a project, click on the project directory, and you will the packages on the right side.
-
-**Install NodeJS packages globally**
-
-To install NodeJS packages globally, click on the **Globals** button on the left from the main interface. Then, click “Add packages” button, type the name of the package and hit “Install” button.
-
-**Manage packages**
-
-Click on any installed packages and you will see various options on the top, such as
-
- 1. Version (to view the installed version),
- 2. Latest (to install latest available version),
- 3. Update (to update the currently selected package),
- 4. Uninstall (to remove the selected package) etc.
-
-
-
-![][13]
-
-NDM has two more options namely **“Update npm”** which is used to update the node package manager to latest available version, and **Doctor** that runs a set of checks to ensure that your npm installation has what it needs to manage your packages/modules.
-
-### Conclusion
-
-NDM makes the process of installing, updating, removing NodeJS packages easier! You don’t need to memorize the commands to perform those tasks. NDM lets us to do them all with a few mouse clicks via simple graphical window. For those who are lazy to type commands, NDM is perfect companion to manage NodeJS packages.
-
-Cheers!
-
-**Resource:**
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/ndm-a-desktop-gui-application-for-npm/
-
-作者:[SK][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/manage-nodejs-packages-using-npm/
-[2]:https://www.ostechnix.com/install-pacaur-arch-linux/
-[3]:https://www.ostechnix.com/install-packer-arch-linux-2/
-[4]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
-[5]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
-[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
-[7]:https://github.com/720kb/ndm/releases
-[8]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[9]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-1.png
-[10]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-5-1.png
-[11]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-6.png
-[12]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-7.png
-[13]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-8.png
diff --git a/sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md b/sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md
index 761138908d..50d68ad445 100644
--- a/sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md
+++ b/sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md
@@ -1,5 +1,3 @@
-translated by cyleft
-
How to Enable Click to Minimize On Ubuntu
============================================================
diff --git a/sources/tech/20180615 Complete Sed Command Guide [Explained with Practical Examples].md b/sources/tech/20180615 Complete Sed Command Guide [Explained with Practical Examples].md
index e548213483..d2c50b6029 100644
--- a/sources/tech/20180615 Complete Sed Command Guide [Explained with Practical Examples].md
+++ b/sources/tech/20180615 Complete Sed Command Guide [Explained with Practical Examples].md
@@ -1,3 +1,4 @@
+Translating by qhwdw
Complete Sed Command Guide [Explained with Practical Examples]
======
In a previous article, I showed the [basic usage of Sed][1], the stream editor, on a practical use case. Today, be prepared to gain more insight about Sed as we will take an in-depth tour of the sed execution model. This will be also an opportunity to make an exhaustive review of all Sed commands and to dive into their details and subtleties. So, if you are ready, launch a terminal, [download the test files][2] and sit comfortably before your keyboard: we will start our exploration right now!
diff --git a/sources/tech/20180615 How To Rename Multiple Files At Once In Linux.md b/sources/tech/20180615 How To Rename Multiple Files At Once In Linux.md
index d03dd4527b..f5c36573be 100644
--- a/sources/tech/20180615 How To Rename Multiple Files At Once In Linux.md
+++ b/sources/tech/20180615 How To Rename Multiple Files At Once In Linux.md
@@ -1,3 +1,5 @@
+translating by Flowsnow
+
How To Rename Multiple Files At Once In Linux
======
diff --git a/sources/tech/20180703 Install Oracle VirtualBox On Ubuntu 18.04 LTS Headless Server.md b/sources/tech/20180703 Install Oracle VirtualBox On Ubuntu 18.04 LTS Headless Server.md
deleted file mode 100644
index dd8c3cdb13..0000000000
--- a/sources/tech/20180703 Install Oracle VirtualBox On Ubuntu 18.04 LTS Headless Server.md
+++ /dev/null
@@ -1,320 +0,0 @@
-Install Oracle VirtualBox On Ubuntu 18.04 LTS Headless Server
-======
-
-
-
-This step by step tutorial walk you through how to install **Oracle VirtualBox** on Ubuntu 18.04 LTS headless server. And, this guide also describes how to manage the VirtualBox headless instances using **phpVirtualBox** , a web-based front-end tool for VirtualBox. The steps described below might also work on Debian, and other Ubuntu derivatives such as Linux Mint. Let us get started.
-
-### Prerequisites
-
-Before installing Oracle VirtualBox, we need to do the following prerequisites in our Ubuntu 18.04 LTS server.
-
-First of all, update the Ubuntu server by running the following commands one by one.
-```
-$ sudo apt update
-
-$ sudo apt upgrade
-
-$ sudo apt dist-upgrade
-
-```
-
-Next, install the following necessary packages:
-```
-$ sudo apt install build-essential dkms unzip wget
-
-```
-
-After installing all updates and necessary prerequisites, restart the Ubuntu server.
-```
-$ sudo reboot
-
-```
-
-### Install Oracle VirtualBox on Ubuntu 18.04 LTS server
-
-Add Oracle VirtualBox official repository. To do so, edit **/etc/apt/sources.list** file:
-```
-$ sudo nano /etc/apt/sources.list
-
-```
-
-Add the following lines.
-
-Here, I will be using Ubuntu 18.04 LTS, so I have added the following repository.
-```
-deb http://download.virtualbox.org/virtualbox/debian bionic contrib
-
-```
-
-![][2]
-
-Replace the word **‘bionic’** with your Ubuntu distribution’s code name, such as ‘xenial’, ‘vivid’, ‘utopic’, ‘trusty’, ‘raring’, ‘quantal’, ‘precise’, ‘lucid’, ‘jessie’, ‘wheezy’, or ‘squeeze**‘.**
-
-Then, run the following command to add the Oracle public key:
-```
-$ wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
-
-```
-
-For VirtualBox older versions, add the following key:
-```
-$ wget -q https://www.virtualbox.org/download/oracle_vbox.asc -O- | sudo apt-key add -
-
-```
-
-Next, update the software sources using command:
-```
-$ sudo apt update
-
-```
-
-Finally, install latest Oracle VirtualBox latest version using command:
-```
-$ sudo apt install virtualbox-5.2
-
-```
-
-### Adding users to VirtualBox group
-
-We need to create and add our system user to the **vboxusers** group. You can either create a separate user and assign it to vboxusers group or use the existing user. I don’t want to create a new user, so I added my existing user to this group. Please note that if you use a separate user for virtualbox, you must log out and log in to that particular user and do the rest of the steps.
-
-I am going to use my username named **sk** , so, I ran the following command to add it to the vboxusers group.
-```
-$ sudo usermod -aG vboxusers sk
-
-```
-
-Now, run the following command to check if virtualbox kernel modules are loaded or not.
-```
-$ sudo systemctl status vboxdrv
-
-```
-
-![][3]
-
-As you can see in the above screenshot, the vboxdrv module is loaded and running!
-
-For older Ubuntu versions, run:
-```
-$ sudo /etc/init.d/vboxdrv status
-
-```
-
-If the virtualbox module doesn’t start, run the following command to start it.
-```
-$ sudo /etc/init.d/vboxdrv setup
-
-```
-
-Great! We have successfully installed VirtualBox and started virtualbox module. Now, let us go ahead and install Oracle VirtualBox extension pack.
-
-### Install VirtualBox Extension pack
-
-The VirtualBox Extension pack provides the following functionalities to the VirtualBox guests.
-
- * The virtual USB 2.0 (EHCI) device
- * VirtualBox Remote Desktop Protocol (VRDP) support
- * Host webcam passthrough
- * Intel PXE boot ROM
- * Experimental support for PCI passthrough on Linux hosts
-
-
-
-Download the latest Extension pack for VirtualBox 5.2.x from [**here**][4].
-```
-$ wget https://download.virtualbox.org/virtualbox/5.2.14/Oracle_VM_VirtualBox_Extension_Pack-5.2.14.vbox-extpack
-
-```
-
-Install Extension pack using command:
-```
-$ sudo VBoxManage extpack install Oracle_VM_VirtualBox_Extension_Pack-5.2.14.vbox-extpack
-
-```
-
-Congratulations! We have successfully installed Oracle VirtualBox with extension pack in Ubuntu 16.04 LTS server. It is time to deploy virtual machines. Refer the [**virtualbox official guide**][5] to start creating and managing virtual machines in command line.
-
-Not everyone is command line expert. Some of you might want to create and use virtual machines graphically. No worries! Here is where **phpVirtualBox** comes in handy!!
-
-### About phpVirtualBox
-
-**phpVirtualBox** is a free, web-based front-end to Oracle VirtualBox. It is written using PHP language. Using phpVirtualBox, we can easily create, delete, manage and administer virtual machines via a web browser from any remote system on the network.
-
-### Install phpVirtualBox in Ubuntu 18.04 LTS
-
-Since it is a web-based tool, we need to install Apache web server, PHP and some php modules.
-
-To do so, run:
-```
-$ sudo apt install apache2 php php-mysql libapache2-mod-php php-soap php-xml
-
-```
-
-Then, Download the phpVirtualBox 5.2.x version from the [**releases page**][6]. Please note that we have installed VirtualBox 5.2, so we must install phpVirtualBox version 5.2 as well.
-
-To download it, run:
-```
-$ wget https://github.com/phpvirtualbox/phpvirtualbox/archive/5.2-0.zip
-
-```
-
-Extract the downloaded archive with command:
-```
-$ unzip 5.2-0.zip
-
-```
-
-This command will extract the contents of 5.2.0.zip file into a folder named “phpvirtualbox-5.2-0”. Now, copy or move the contents of this folder to your apache web server root folder.
-```
-$ sudo mv phpvirtualbox-5.2-0/ /var/www/html/phpvirtualbox
-
-```
-
-Assign the proper permissions to the phpvirtualbox folder.
-```
-$ sudo chmod 777 /var/www/html/phpvirtualbox/
-
-```
-
-Next, let us configure phpVirtualBox.
-
-Copy the sample config file as shown below.
-```
-$ sudo cp /var/www/html/phpvirtualbox/config.php-example /var/www/html/phpvirtualbox/config.php
-
-```
-
-Edit phpVirtualBox **config.php** file:
-```
-$ sudo nano /var/www/html/phpvirtualbox/config.php
-
-```
-
-Find the following lines and replace the username and password with your system user (The same username that we used in “Adding users to VirtualBox group” section).
-
-In my case, my Ubuntu system username is **sk** , and its password is **ubuntu**.
-```
-var $username = 'sk';
-var $password = 'ubuntu';
-
-```
-
-![][7]
-
-Save and close the file.
-
-Next, create a new file called **/etc/default/virtualbox** :
-```
-$ sudo nano /etc/default/virtualbox
-
-```
-
-Add the following line. Replace ‘sk’ with your own username.
-```
-VBOXWEB_USER=sk
-
-```
-
-Finally, Reboot your system or simply restart the following services to complete the configuration.
-```
-$ sudo systemctl restart vboxweb-service
-
-$ sudo systemctl restart vboxdrv
-
-$ sudo systemctl restart apache2
-
-```
-
-### Adjust firewall to allow Apache web server
-
-By default, the apache web browser can’t be accessed from remote systems if you have enabled the UFW firewall in Ubuntu 18.04 LTS. You must allow the http and https traffic via UFW by following the below steps.
-
-First, let us view which applications have installed a profile using command:
-```
-$ sudo ufw app list
-Available applications:
-Apache
-Apache Full
-Apache Secure
-OpenSSH
-
-```
-
-As you can see, Apache and OpenSSH applications have installed UFW profiles.
-
-If you look into the **“Apache Full”** profile, you will see that it enables traffic to the ports **80** and **443** :
-```
-$ sudo ufw app info "Apache Full"
-Profile: Apache Full
-Title: Web Server (HTTP,HTTPS)
-Description: Apache v2 is the next generation of the omnipresent Apache web
-server.
-
-Ports:
-80,443/tcp
-
-```
-
-Now, run the following command to allow incoming HTTP and HTTPS traffic for this profile:
-```
-$ sudo ufw allow in "Apache Full"
-Rules updated
-Rules updated (v6)
-
-```
-
-If you want to allow https traffic, but only http (80) traffic, run:
-```
-$ sudo ufw app info "Apache"
-
-```
-
-### Access phpVirtualBox Web console
-
-Now, go to any remote system that has graphical web browser.
-
-In the address bar, type: ****.
-
-In my case, I navigated to this link – ****
-
-You should see the following screen. Enter the phpVirtualBox administrative user credentials.
-
-The default username and phpVirtualBox is **admin** / **admin**.
-
-![][8]
-
-Congratulations! You will now be greeted with phpVirtualBox dashboard.
-
-![][9]
-
-Now, start creating your VMs and manage them from phpvirtualbox dashboard. As I mentioned earlier, You can access the phpVirtualBox from any system in the same network. All you need is a web browser and the username and password of phpVirtualBox.
-
-If you haven’t enabled virtualization support in the BISO of host system (not the guest), phpVirtualBox allows you to create 32-bit guests only. To install 64-bit guest systems, you must enable virtualization in your host system’s BIOS. Look for an option that is something like “virtualization” or “hypervisor” in your bios and make sure it is enabled.
-
-That’s it. Hope this helps. If you find this guide useful, please share it on your social networks and support us.
-
-More good stuffs to come. Stay tuned!
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/install-oracle-virtualbox-ubuntu-16-04-headless-server/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[2]:http://www.ostechnix.com/wp-content/uploads/2016/07/Add-VirtualBox-repository.png
-[3]:http://www.ostechnix.com/wp-content/uploads/2016/07/vboxdrv-service.png
-[4]:https://www.virtualbox.org/wiki/Downloads
-[5]:http://www.virtualbox.org/manual/ch08.html
-[6]:https://github.com/phpvirtualbox/phpvirtualbox/releases
-[7]:http://www.ostechnix.com/wp-content/uploads/2016/07/phpvirtualbox-config.png
-[8]:http://www.ostechnix.com/wp-content/uploads/2016/07/phpvirtualbox-1.png
-[9]:http://www.ostechnix.com/wp-content/uploads/2016/07/phpvirtualbox-2.png
diff --git a/sources/tech/20180704 Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS.md b/sources/tech/20180704 Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS.md
deleted file mode 100644
index a85a637830..0000000000
--- a/sources/tech/20180704 Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS.md
+++ /dev/null
@@ -1,332 +0,0 @@
-Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS
-======
-
-
-
-We already have covered [**setting up Oracle VirtualBox on Ubuntu 18.04**][1] headless server. In this tutorial, we will be discussing how to setup headless virtualization server using **KVM** and how to manage the guest machines from a remote client. As you may know already, KVM ( **K** ernel-based **v** irtual **m** achine) is an open source, full virtualization for Linux. Using KVM, we can easily turn any Linux server in to a complete virtualization environment in minutes and deploy different kind of VMs such as GNU/Linux, *BSD, Windows etc.
-
-### Setup Headless Virtualization Server Using KVM
-
-I tested this guide on Ubuntu 18.04 LTS server, however this tutorial will work on other Linux distributions such as Debian, CentOS, RHEL and Scientific Linux. This method will be perfectly suitable for those who wants to setup a simple virtualization environment in a Linux server that doesn’t have any graphical environment.
-
-For the purpose of this guide, I will be using two systems.
-
-**KVM virtualization server:**
-
- * **Host OS** – Ubuntu 18.04 LTS minimal server (No GUI)
- * **IP Address of Host OS** : 192.168.225.22/24
- * **Guest OS** (Which we are going to host on Ubuntu 18.04) : Ubuntu 16.04 LTS server
-
-
-
-**Remote desktop client :**
-
- * **OS** – Arch Linux
-
-
-
-### Install KVM
-
-First, let us check if our system supports hardware virtualization. To do so, run the following command from the Terminal:
-```
-$ egrep -c '(vmx|svm)' /proc/cpuinfo
-
-```
-
-If the result is **zero (0)** , the system doesn’t support hardware virtualization or the virtualization is disabled in the Bios. Go to your bios and check for the virtualization option and enable it.
-
-if the result is **1** or **more** , the system will support hardware virtualization. However, you still need to enable the virtualization option in Bios before running the above commands.
-
-Alternatively, you can use the following command to verify it. You need to install kvm first as described below, in order to use this command.
-```
-$ kvm-ok
-
-```
-
-**Sample output:**
-```
-INFO: /dev/kvm exists
-KVM acceleration can be used
-
-```
-
-If you got the following error instead, you still can run guest machines in KVM, but the performance will be very poor.
-```
-INFO: Your CPU does not support KVM extensions
-INFO: For more detailed results, you should run this as root
-HINT: sudo /usr/sbin/kvm-ok
-
-```
-
-Also, there are other ways to find out if your CPU supports Virtualization or not. Refer the following guide for more details.
-
-Next, Install KVM and other required packages to setup a virtualization environment in Linux.
-
-On Ubuntu and other DEB based systems, run:
-```
-$ sudo apt-get install qemu-kvm libvirt-bin virtinst bridge-utils cpu-checker
-
-```
-
-Once KVM installed, start libvertd service (If it is not started already):
-```
-$ sudo systemctl enable libvirtd
-
-$ sudo systemctl start libvirtd
-
-```
-
-### Create Virtual machines
-
-All virtual machine files and other related files will be stored under **/var/lib/libvirt/**. The default path of ISO images is **/var/lib/libvirt/boot/**.
-
-First, let us see if there is any virtual machines. To view the list of available virtual machines, run:
-```
-$ sudo virsh list --all
-
-```
-
-**Sample output:**
-```
-Id Name State
-----------------------------------------------------
-
-```
-
-![][3]
-
-As you see above, there is no virtual machine available right now.
-
-Now, let us crate one.
-
-For example, let us create Ubuntu 16.04 Virtual machine with 512 MB RAM, 1 CPU core, 8 GB Hdd.
-```
-$ sudo virt-install --name Ubuntu-16.04 --ram=512 --vcpus=1 --cpu host --hvm --disk path=/var/lib/libvirt/images/ubuntu-16.04-vm1,size=8 --cdrom /var/lib/libvirt/boot/ubuntu-16.04-server-amd64.iso --graphics vnc
-
-```
-
-Please make sure you have Ubuntu 16.04 ISO image in path **/var/lib/libvirt/boot/** or any other path you have given in the above command.
-
-**Sample output:**
-```
-WARNING Graphics requested but DISPLAY is not set. Not running virt-viewer.
-WARNING No console to launch for the guest, defaulting to --wait -1
-
-Starting install...
-Creating domain... | 0 B 00:00:01
-Domain installation still in progress. Waiting for installation to complete.
-Domain has shutdown. Continuing.
-Domain creation completed.
-Restarting guest.
-
-```
-
-![][4]
-
-Let us break down the above command and see what each option do.
-
- * **–name** : This option defines the name of the virtual name. In our case, the name of VM is **Ubuntu-16.04**.
- * **–ram=512** : Allocates 512MB RAM to the VM.
- * **–vcpus=1** : Indicates the number of CPU cores in the VM.
- * **–cpu host** : Optimizes the CPU properties for the VM by exposing the host’s CPU’s configuration to the guest.
- * **–hvm** : Request the full hardware virtualization.
- * **–disk path** : The location to save VM’s hdd and it’s size. In our example, I have allocated 8GB hdd size.
- * **–cdrom** : The location of installer ISO image. Please note that you must have the actual ISO image in this location.
- * **–graphics vnc** : Allows VNC access to the VM from a remote client.
-
-
-
-### Access Virtual machines using VNC client
-
-Now, go to the remote Desktop system. SSH to the Ubuntu server(Virtualization server) as shown below.
-
-Here, **sk** is my Ubuntu server’s user name and **192.168.225.22** is its IP address.
-
-Run the following command to find out the VNC port number. We need this to access the Vm from a remote system.
-```
-$ sudo virsh dumpxml Ubuntu-16.04 | grep vnc
-
-```
-
-**Sample output:**
-```
-
-
-```
-
-![][5]
-
-Note down the port number **5900**. Install any VNC client application. For this guide, I will be using TigerVnc. TigerVNC is available in the Arch Linux default repositories. To install it on Arch based systems, run:
-```
-$ sudo pacman -S tigervnc
-
-```
-
-Type the following SSH port forwarding command from your remote client system that has VNC client application installed.
-
-Again, **192.168.225.22** is my Ubuntu server’s (virtualization server) IP address.
-
-Then, open the VNC client from your Arch Linux (client).
-
-Type **localhost:5900** in the VNC server field and click **Connect** button.
-
-![][6]
-
-Then start installing the Ubuntu VM as the way you do in the physical system.
-
-![][7]
-
-![][8]
-
-Similarly, you can setup as many as virtual machines depending upon server hardware specifications.
-
-Alternatively, you can use **virt-viewer** utility in order to install operating system in the guest machines. virt-viewer is available in the most Linux distribution’s default repositories. After installing virt-viewer, run the following command to establish VNC access to the VM.
-```
-$ sudo virt-viewer --connect=qemu+ssh://192.168.225.22/system --name Ubuntu-16.04
-
-```
-
-### Manage virtual machines
-
-Managing VMs from the command-line using virsh management user interface is very interesting and fun. The commands are very easy to remember. Let us see some examples.
-
-To view the list of running VMs, run:
-```
-$ sudo virsh list
-
-```
-
-Or,
-```
-$ sudo virsh list --all
-
-```
-
-**Sample output:**
-```
- Id Name State
-----------------------------------------------------
- 2 Ubuntu-16.04 running
-
-```
-
-![][9]
-
-To start a VM, run:
-```
-$ sudo virsh start Ubuntu-16.04
-
-```
-
-Alternatively, you can use the VM id to start it.
-
-![][10]
-
-As you see in the above output, Ubuntu 16.04 virtual machine’s Id is 2. So, in order to start it, just specify its Id like below.
-```
-$ sudo virsh start 2
-
-```
-
-To restart a VM, run:
-```
-$ sudo virsh reboot Ubuntu-16.04
-
-```
-
-**Sample output:**
-```
-Domain Ubuntu-16.04 is being rebooted
-
-```
-
-![][11]
-
-To pause a running VM, run:
-```
-$ sudo virsh suspend Ubuntu-16.04
-
-```
-
-**Sample output:**
-```
-Domain Ubuntu-16.04 suspended
-
-```
-
-To resume the suspended VM, run:
-```
-$ sudo virsh resume Ubuntu-16.04
-
-```
-
-**Sample output:**
-```
-Domain Ubuntu-16.04 resumed
-
-```
-
-To shutdown a VM, run:
-```
-$ sudo virsh shutdown Ubuntu-16.04
-
-```
-
-**Sample output:**
-```
-Domain Ubuntu-16.04 is being shutdown
-
-```
-
-To completely remove a VM, run:
-```
-$ sudo virsh undefine Ubuntu-16.04
-
-$ sudo virsh destroy Ubuntu-16.04
-
-```
-
-**Sample output:**
-```
-Domain Ubuntu-16.04 destroyed
-
-```
-
-![][12]
-
-For more options, I recommend you to look into the man pages.
-```
-$ man virsh
-
-```
-
-That’s all for now folks. Start playing with your new virtualization environment. KVM virtualization will be opt for research & development and testing purposes, but not limited to. If you have sufficient hardware, you can use it for large production environments. Have fun and don’t forget to leave your valuable comments in the comment section below.
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/setup-headless-virtualization-server-using-kvm-ubuntu/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/install-oracle-virtualbox-ubuntu-16-04-headless-server/
-[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[3]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_001.png
-[4]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_008-1.png
-[5]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_002.png
-[6]:http://www.ostechnix.com/wp-content/uploads/2016/11/VNC-Viewer-Connection-Details_005.png
-[7]:http://www.ostechnix.com/wp-content/uploads/2016/11/QEMU-Ubuntu-16.04-TigerVNC_006.png
-[8]:http://www.ostechnix.com/wp-content/uploads/2016/11/QEMU-Ubuntu-16.04-TigerVNC_007.png
-[9]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_010-1.png
-[10]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_010-2.png
-[11]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_011-1.png
-[12]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_012.png
diff --git a/sources/tech/20180715 Why is Python so slow.md b/sources/tech/20180715 Why is Python so slow.md
new file mode 100644
index 0000000000..5c39a528a1
--- /dev/null
+++ b/sources/tech/20180715 Why is Python so slow.md
@@ -0,0 +1,207 @@
+HankChow translating
+
+Why is Python so slow?
+============================================================
+
+Python is booming in popularity. It is used in DevOps, Data Science, Web Development and Security.
+
+It does not, however, win any medals for speed.
+
+
+
+
+> How does Java compare in terms of speed to C or C++ or C# or Python? The answer depends greatly on the type of application you’re running. No benchmark is perfect, but The Computer Language Benchmarks Game is [a good starting point][5].
+
+I’ve been referring to the Computer Language Benchmarks Game for over a decade; compared with other languages like Java, C#, Go, JavaScript, C++, Python is [one of the slowest][6]. This includes [JIT][7] (C#, Java) and [AOT][8] (C, C++) compilers, as well as interpreted languages like JavaScript.
+
+ _NB: When I say “Python”, I’m talking about the reference implementation of the language, CPython. I will refer to other runtimes in this article._
+
+> I want to answer this question: When Python completes a comparable application 2–10x slower than another language, _why is it slow_ and can’t we _make it faster_ ?
+
+Here are the top theories:
+
+* “ _It’s the GIL (Global Interpreter Lock)_ ”
+
+* “ _It’s because its interpreted and not compiled_ ”
+
+* “ _It’s because its a dynamically typed language_ ”
+
+Which one of these reasons has the biggest impact on performance?
+
+### “It’s the GIL”
+
+Modern computers come with CPU’s that have multiple cores, and sometimes multiple processors. In order to utilise all this extra processing power, the Operating System defines a low-level structure called a thread, where a process (e.g. Chrome Browser) can spawn multiple threads and have instructions for the system inside. That way if one process is particularly CPU-intensive, that load can be shared across the cores and this effectively makes most applications complete tasks faster.
+
+My Chrome Browser, as I’m writing this article, has 44 threads open. Keep in mind that the structure and API of threading are different between POSIX-based (e.g. Mac OS and Linux) and Windows OS. The operating system also handles the scheduling of threads.
+
+IF you haven’t done multi-threaded programming before, a concept you’ll need to quickly become familiar with locks. Unlike a single-threaded process, you need to ensure that when changing variables in memory, multiple threads don’t try and access/change the same memory address at the same time.
+
+When CPython creates variables, it allocates the memory and then counts how many references to that variable exist, this is a concept known as reference counting. If the number of references is 0, then it frees that piece of memory from the system. This is why creating a “temporary” variable within say, the scope of a for loop, doesn’t blow up the memory consumption of your application.
+
+The challenge then becomes when variables are shared within multiple threads, how CPython locks the reference count. There is a “global interpreter lock” that carefully controls thread execution. The interpreter can only execute one operation at a time, regardless of how many threads it has.
+
+#### What does this mean to the performance of Python application?
+
+If you have a single-threaded, single interpreter application. It will make no difference to the speed. Removing the GIL would have no impact on the performance of your code.
+
+If you wanted to implement concurrency within a single interpreter (Python process) by using threading, and your threads were IO intensive (e.g. Network IO or Disk IO), you would see the consequences of GIL-contention.
+
+
+From David Beazley’s GIL visualised post [http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html][1]
+
+If you have a web-application (e.g. Django) and you’re using WSGI, then each request to your web-app is a separate Python interpreter, so there is only 1 lock _per_ request. Because the Python interpreter is slow to start, some WSGI implementations have a “Daemon Mode” [which keep Python process(es) on the go for you.][9]
+
+#### What about other Python runtimes?
+
+[PyPy has a GIL][10] and it is typically >3x faster than CPython.
+
+[Jython does not have a GIL][11] because a Python thread in Jython is represented by a Java thread and benefits from the JVM memory-management system.
+
+#### How does JavaScript do this?
+
+Well, firstly all Javascript engines [use mark-and-sweep Garbage Collection][12]. As stated, the primary need for the GIL is CPython’s memory-management algorithm.
+
+JavaScript does not have a GIL, but it’s also single-threaded so it doesn’t require one. JavaScript’s event-loop and Promise/Callback pattern are how asynchronous-programming is achieved in place of concurrency. Python has a similar thing with the asyncio event-loop.
+
+### “It’s because its an interpreted language”
+
+I hear this a lot and I find it a gross-simplification of the way CPython actually works. If at a terminal you wrote `python myscript.py` then CPython would start a long sequence of reading, lexing, parsing, compiling, interpreting and executing that code.
+
+If you’re interested in how that process works, I’ve written about it before:
+
+[Modifying the Python language in 6 minutes
+This week I raised my first pull-request to the CPython core project, which was declined :-( but as to not completely…hackernoon.com][13][][14]
+
+An important point in that process is the creation of a `.pyc` file, at the compiler stage, the bytecode sequence is written to a file inside `__pycache__/`on Python 3 or in the same directory in Python 2\. This doesn’t just apply to your script, but all of the code you imported, including 3rd party modules.
+
+So most of the time (unless you write code which you only ever run once?), Python is interpreting bytecode and executing it locally. Compare that with Java and C#.NET:
+
+> Java compiles to an “Intermediate Language” and the Java Virtual Machine reads the bytecode and just-in-time compiles it to machine code. The .NET CIL is the same, the .NET Common-Language-Runtime, CLR, uses just-in-time compilation to machine code.
+
+So, why is Python so much slower than both Java and C# in the benchmarks if they all use a virtual machine and some sort of Bytecode? Firstly, .NET and Java are JIT-Compiled.
+
+JIT or Just-in-time compilation requires an intermediate language to allow the code to be split into chunks (or frames). Ahead of time (AOT) compilers are designed to ensure that the CPU can understand every line in the code before any interaction takes place.
+
+The JIT itself does not make the execution any faster, because it is still executing the same bytecode sequences. However, JIT enables optimizations to be made at runtime. A good JIT optimizer will see which parts of the application are being executed a lot, call these “hot spots”. It will then make optimizations to those bits of code, by replacing them with more efficient versions.
+
+This means that when your application does the same thing again and again, it can be significantly faster. Also, keep in mind that Java and C# are strongly-typed languages so the optimiser can make many more assumptions about the code.
+
+PyPy has a JIT and as mentioned in the previous section, is significantly faster than CPython. This performance benchmark article goes into more detail —
+
+[Which is the fastest version of Python?
+Of course, “it depends”, but what does it depend on and how can you assess which is the fastest version of Python for…hackernoon.com][15][][16]
+
+#### So why doesn’t CPython use a JIT?
+
+There are downsides to JITs: one of those is startup time. CPython startup time is already comparatively slow, PyPy is 2–3x slower to start than CPython. The Java Virtual Machine is notoriously slow to boot. The .NET CLR gets around this by starting at system-startup, but the developers of the CLR also develop the Operating System on which the CLR runs.
+
+If you have a single Python process running for a long time, with code that can be optimized because it contains “hot spots”, then a JIT makes a lot of sense.
+
+However, CPython is a general-purpose implementation. So if you were developing command-line applications using Python, having to wait for a JIT to start every time the CLI was called would be horribly slow.
+
+CPython has to try and serve as many use cases as possible. There was the possibility of [plugging a JIT into CPython][17] but this project has largely stalled.
+
+> If you want the benefits of a JIT and you have a workload that suits it, use PyPy.
+
+### “It’s because its a dynamically typed language”
+
+In a “Statically-Typed” language, you have to specify the type of a variable when it is declared. Those would include C, C++, Java, C#, Go.
+
+In a dynamically-typed language, there are still the concept of types, but the type of a variable is dynamic.
+
+```
+a = 1
+a = "foo"
+```
+
+In this toy-example, Python creates a second variable with the same name and a type of `str` and deallocates the memory created for the first instance of `a`
+
+Statically-typed languages aren’t designed as such to make your life hard, they are designed that way because of the way the CPU operates. If everything eventually needs to equate to a simple binary operation, you have to convert objects and types down to a low-level data structure.
+
+Python does this for you, you just never see it, nor do you need to care.
+
+Not having to declare the type isn’t what makes Python slow, the design of the Python language enables you to make almost anything dynamic. You can replace the methods on objects at runtime, you can monkey-patch low-level system calls to a value declared at runtime. Almost anything is possible.
+
+It’s this design that makes it incredibly hard to optimise Python.
+
+To illustrate my point, I’m going to use a syscall tracing tool that works in Mac OS called Dtrace. CPython distributions do not come with DTrace builtin, so you have to recompile CPython. I’m using 3.6.6 for my demo
+
+```
+wget https://github.com/python/cpython/archive/v3.6.6.zip
+unzip v3.6.6.zip
+cd v3.6.6
+./configure --with-dtrace
+make
+```
+
+Now `python.exe` will have Dtrace tracers throughout the code. [Paul Ross wrote an awesome Lightning Talk on Dtrace][19]. You can [download DTrace starter files][20] for Python to measure function calls, execution time, CPU time, syscalls, all sorts of fun. e.g.
+
+`sudo dtrace -s toolkit/.d -c ‘../cpython/python.exe script.py’`
+
+The `py_callflow` tracer shows all the function calls in your application
+
+
+
+
+So, does Python’s dynamic typing make it slow?
+
+* Comparing and converting types is costly, every time a variable is read, written to or referenced the type is checked
+
+* It is hard to optimise a language that is so dynamic. The reason many alternatives to Python are so much faster is that they make compromises to flexibility in the name of performance
+
+* Looking at [Cython][2], which combines C-Static Types and Python to optimise code where the types are known[ can provide ][3]an 84x performanceimprovement.
+
+### Conclusion
+
+> Python is primarily slow because of its dynamic nature and versatility. It can be used as a tool for all sorts of problems, where more optimised and faster alternatives are probably available.
+
+There are, however, ways of optimising your Python applications by leveraging async, understanding the profiling tools, and consider using multiple-interpreters.
+
+For applications where startup time is unimportant and the code would benefit a JIT, consider PyPy.
+
+For parts of your code where performance is critical and you have more statically-typed variables, consider using [Cython][4].
+
+#### Further reading
+
+Jake VDP’s excellent article (although slightly dated) [https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/][21]
+
+Dave Beazley’s talk on the GIL [http://www.dabeaz.com/python/GIL.pdf][22]
+
+All about JIT compilers [https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/][23]
+
+--------------------------------------------------------------------------------
+
+via: https://hackernoon.com/why-is-python-so-slow-e5074b6fe55b
+
+作者:[Anthony Shaw][a]
+选题:[oska874][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://hackernoon.com/@anthonypjshaw?source=post_header_lockup
+[b]:https://github.com/oska874
+[1]:http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html
+[2]:http://cython.org/
+[3]:http://notes-on-cython.readthedocs.io/en/latest/std_dev.html
+[4]:http://cython.org/
+[5]:http://algs4.cs.princeton.edu/faq/
+[6]:https://benchmarksgame-team.pages.debian.net/benchmarksgame/faster/python.html
+[7]:https://en.wikipedia.org/wiki/Just-in-time_compilation
+[8]:https://en.wikipedia.org/wiki/Ahead-of-time_compilation
+[9]:https://www.slideshare.net/GrahamDumpleton/secrets-of-a-wsgi-master
+[10]:http://doc.pypy.org/en/latest/faq.html#does-pypy-have-a-gil-why
+[11]:http://www.jython.org/jythonbook/en/1.0/Concurrency.html#no-global-interpreter-lock
+[12]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Memory_Management
+[13]:https://hackernoon.com/modifying-the-python-language-in-7-minutes-b94b0a99ce14
+[14]:https://hackernoon.com/modifying-the-python-language-in-7-minutes-b94b0a99ce14
+[15]:https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b
+[16]:https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b
+[17]:https://www.slideshare.net/AnthonyShaw5/pyjion-a-jit-extension-system-for-cpython
+[18]:https://github.com/python/cpython/archive/v3.6.6.zip
+[19]:https://github.com/paulross/dtrace-py#the-lightning-talk
+[20]:https://github.com/paulross/dtrace-py/tree/master/toolkit
+[21]:https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/
+[22]:http://www.dabeaz.com/python/GIL.pdf
+[23]:https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/
diff --git a/sources/tech/20180724 75 Most Used Essential Linux Applications of 2018.md b/sources/tech/20180724 75 Most Used Essential Linux Applications of 2018.md
deleted file mode 100644
index 919182ba1f..0000000000
--- a/sources/tech/20180724 75 Most Used Essential Linux Applications of 2018.md
+++ /dev/null
@@ -1,988 +0,0 @@
-75 Most Used Essential Linux Applications of 2018
-======
-
-**2018** has been an awesome year for a lot of applications, especially those that are both free and open source. And while various Linux distributions come with a number of default apps, users are free to take them out and use any of the free or paid alternatives of their choice.
-
-Today, we bring you a [list of Linux applications][3] that have been able to make it to users’ Linux installations almost all the time despite the butt-load of other alternatives.
-
-To simply put, any app on this list is among the most used in its category, and if you haven’t already tried it out you are probably missing out. Enjoy!
-
-### Backup Tools
-
-#### Rsync
-
-[Rsync][4] is an open source bandwidth-friendly utility tool for performing swift incremental file transfers and it is available for free.
-```
-$ rsync [OPTION...] SRC... [DEST]
-
-```
-
-To know more examples and usage, read our article “[10 Practical Examples of Rsync Command][5]” to learn more about it.
-
-#### Timeshift
-
-[Timeshift][6] provides users with the ability to protect their system by taking incremental snapshots which can be reverted to at a different date – similar to the function of Time Machine in Mac OS and System restore in Windows.
-
-
-
-### BitTorrent Client
-
-
-
-#### Deluge
-
-[Deluge][7] is a beautiful cross-platform BitTorrent client that aims to perfect the **μTorrent** experience and make it available to users for free.
-
-Install **Deluge** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:deluge-team/ppa
-$ sudo apt-get update
-$ sudo apt-get install deluge
-
-```
-
-#### qBittorent
-
-[qBittorent][8] is an open source BitTorrent protocol client that aims to provide a free alternative to torrent apps like μTorrent.
-
-Install **qBittorent** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:qbittorrent-team/qbittorrent-stable
-$ sudo apt-get update
-$ sudo apt-get install qbittorrent
-
-```
-
-#### Transmission
-
-[Transmission][9] is also a BitTorrent client with awesome functionalities and a major focus on speed and ease of use. It comes preinstalled with many Linux distros.
-
-Install **Transmission** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:transmissionbt/ppa
-$ sudo apt-get update
-$ sudo apt-get install transmission-gtk transmission-cli transmission-common transmission-daemon
-
-```
-
-### Cloud Storage
-
-
-
-#### Dropbox
-
-The [Dropbox][10] team rebranded their cloud service earlier this year to provide an even better performance and app integration for their clients. It starts with 2GB of storage for free.
-
-Install **Dropbox** on **Ubuntu** and **Debian** , using following commands.
-```
-$ cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86" | tar xzf - [On 32-Bit]
-$ cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86_64" | tar xzf - [On 64-Bit]
-$ ~/.dropbox-dist/dropboxd
-
-```
-
-#### Google Drive
-
-[Google Drive][11] is Google’s cloud service solution and my guess is that it needs no introduction. Just like with **Dropbox** , you can sync files across all your connected devices. It starts with 15GB of storage for free and this includes Gmail, Google photos, Maps, etc.
-
-Check out: [5 Google Drive Clients for Linux][12]
-
-#### Mega
-
-[Mega][13] stands out from the rest because apart from being extremely security-conscious, it gives free users 50GB to do as they wish! Its end-to-end encryption ensures that they can’t access your data, and if you forget your recovery key, you too wouldn’t be able to.
-
-[**Download MEGA Cloud Storage for Ubuntu][14]
-
-### Commandline Editors
-
-
-
-#### Vim
-
-[Vim][15] is an open source clone of vi text editor developed to be customizable and able to work with any type of text.
-
-Install **Vim** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:jonathonf/vim
-$ sudo apt update
-$ sudo apt install vim
-
-```
-
-#### Emacs
-
-[Emacs][16] refers to a set of highly configurable text editors. The most popular variant, GNU Emacs, is written in Lisp and C to be self-documenting, extensible, and customizable.
-
-Install **Emacs** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:kelleyk/emacs
-$ sudo apt update
-$ sudo apt install emacs25
-
-```
-
-#### Nano
-
-[Nano][17] is a feature-rich CLI text editor for power users and it has the ability to work with different terminals, among other functionalities.
-
-Install **Nano** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:n-muench/programs-ppa
-$ sudo apt-get update
-$ sudo apt-get install nano
-
-```
-
-### Download Manager
-
-
-
-#### Aria2
-
-[Aria2][18] is an open source lightweight multi-source and multi-protocol command line-based downloader with support for Metalinks, torrents, HTTP/HTTPS, SFTP, etc.
-
-Install **Aria2** on **Ubuntu** and **Debian** , using following command.
-```
-$ sudo apt-get install aria2
-
-```
-
-#### uGet
-
-[uGet][19] has earned its title as the **#1** open source download manager for Linux distros and it features the ability to handle any downloading task you can throw at it including using multiple connections, using queues, categories, etc.
-
-Install **uGet** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:plushuang-tw/uget-stable
-$ sudo apt update
-$ sudo apt install uget
-
-```
-
-#### XDM
-
-[XDM][20], **Xtreme Download Manager** is an open source downloader written in Java. Like any good download manager, it can work with queues, torrents, browsers, and it also includes a video grabber and a smart scheduler.
-
-Install **XDM** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:noobslab/apps
-$ sudo apt-get update
-$ sudo apt-get install xdman
-
-```
-
-### Email Clients
-
-
-
-#### Thunderbird
-
-[Thunderbird][21] is among the most popular email applications. It is free, open source, customizable, feature-rich, and above all, easy to install.
-
-Install **Thunderbird** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:ubuntu-mozilla-security/ppa
-$ sudo apt-get update
-$ sudo apt-get install thunderbird
-
-```
-
-#### Geary
-
-[Geary][22] is an open source email client based on WebKitGTK+. It is free, open-source, feature-rich, and adopted by the GNOME project.
-
-Install **Geary** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:geary-team/releases
-$ sudo apt-get update
-$ sudo apt-get install geary
-
-```
-
-#### Evolution
-
-[Evolution][23] is a free and open source email client for managing emails, meeting schedules, reminders, and contacts.
-
-Install **Evolution** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:gnome3-team/gnome3-staging
-$ sudo apt-get update
-$ sudo apt-get install evolution
-
-```
-
-### Finance Software
-
-
-
-#### GnuCash
-
-[GnuCash][24] is a free, cross-platform, and open source software for financial accounting tasks for personal and small to mid-size businesses.
-
-Install **GnuCash** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo sh -c 'echo "deb http://archive.getdeb.net/ubuntu $(lsb_release -sc)-getdeb apps" >> /etc/apt/sources.list.d/getdeb.list'
-$ sudo apt-get update
-$ sudo apt-get install gnucash
-
-```
-
-#### KMyMoney
-
-[KMyMoney][25] is a finance manager software that provides all important features found in the commercially-available, personal finance managers.
-
-Install **KMyMoney** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:claydoh/kmymoney2-kde4
-$ sudo apt-get update
-$ sudo apt-get install kmymoney
-
-```
-
-### IDE Editors
-
-
-
-#### Eclipse IDE
-
-[Eclipse][26] is the most widely used Java IDE containing a base workspace and an impossible-to-overemphasize configurable plug-in system for personalizing its coding environment.
-
-For installation, read our article “[How to Install Eclipse Oxygen IDE in Debian and Ubuntu][27]”
-
-#### Netbeans IDE
-
-A fan-favourite, [Netbeans][28] enables users to easily build applications for mobile, desktop, and web platforms using Java, PHP, HTML5, JavaScript, and C/C++, among other languages.
-
-For installation, read our article “[How to Install Netbeans Oxygen IDE in Debian and Ubuntu][29]”
-
-#### Brackets
-
-[Brackets][30] is an advanced text editor developed by Adobe to feature visual tools, preprocessor support, and a design-focused user flow for web development. In the hands of an expert, it can serve as an IDE in its own right.
-
-Install **Brackets** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:webupd8team/brackets
-$ sudo apt-get update
-$ sudo apt-get install brackets
-
-```
-
-#### Atom IDE
-
-[Atom IDE][31] is a more robust version of Atom text editor achieved by adding a number of extensions and libraries to boost its performance and functionalities. It is, in a sense, Atom on steroids.
-
-Install **Atom** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install snapd
-$ sudo snap install atom --classic
-
-```
-
-#### Light Table
-
-[Light Table][32] is a self-proclaimed next-generation IDE developed to offer awesome features like data value flow stats and coding collaboration.
-
-Install **Light Table** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:dr-akulavich/lighttable
-$ sudo apt-get update
-$ sudo apt-get install lighttable-installer
-
-```
-
-#### Visual Studio Code
-
-[Visual Studio Code][33] is a source code editor created by Microsoft to offer users the best-advanced features in a text editor including syntax highlighting, code completion, debugging, performance statistics and graphs, etc.
-
-[**Download Visual Studio Code for Ubuntu][34]
-
-### Instant Messaging
-
-
-
-#### Pidgin
-
-[Pidgin][35] is an open source instant messaging app that supports virtually all chatting platforms and can have its abilities extended using extensions.
-
-Install **Pidgin** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:jonathonf/backports
-$ sudo apt-get update
-$ sudo apt-get install pidgin
-
-```
-
-#### Skype
-
-[Skype][36] needs no introduction and its awesomeness is available for any interested Linux user.
-
-Install **Skype** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt install snapd
-$ sudo snap install skype --classic
-
-```
-
-#### Empathy
-
-[Empathy][37] is a messaging app with support for voice, video chat, text, and file transfers over multiple several protocols. It also allows you to add other service accounts to it and interface with all of them through it.
-
-Install **Empathy** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install empathy
-
-```
-
-### Linux Antivirus
-
-#### ClamAV/ClamTk
-
-[ClamAV][38] is an open source and cross-platform command line antivirus app for detecting Trojans, viruses, and other malicious codes. [ClamTk][39] is its GUI front-end.
-
-Install **ClamAV/ClamTk** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install clamav
-$ sudo apt-get install clamtk
-
-```
-
-### Linux Desktop Environments
-
-#### Cinnamon
-
-[Cinnamon][40] is a free and open-source derivative of **GNOME3** and it follows the traditional desktop metaphor conventions.
-
-Install **Cinnamon** desktop on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:embrosyn/cinnamon
-$ sudo apt update
-$ sudo apt install cinnamon-desktop-environment lightdm
-
-```
-
-#### Mate
-
-The [Mate][41] Desktop Environment is a derivative and continuation of **GNOME2** developed to offer an attractive UI on Linux using traditional metaphors.
-
-Install **Mate** desktop on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt install tasksel
-$ sudo apt update
-$ sudo tasksel install ubuntu-mate-desktop
-
-```
-
-#### GNOME
-
-[GNOME][42] is a Desktop Environment comprised of several free and open-source applications and can run on any Linux distro and on most BSD derivatives.
-
-Install **Gnome** desktop on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt install tasksel
-$ sudo apt update
-$ sudo tasksel install ubuntu-desktop
-
-```
-
-#### KDE
-
-[KDE][43] is developed by the KDE community to provide users with a graphical solution to interfacing with their system and performing several computing tasks.
-
-Install **KDE** desktop on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt install tasksel
-$ sudo apt update
-$ sudo tasksel install kubuntu-desktop
-
-```
-
-### Linux Maintenance Tools
-
-#### GNOME Tweak Tool
-
-The [GNOME Tweak Tool][44] is the most popular tool for customizing and tweaking GNOME3 and GNOME Shell settings.
-
-Install **GNOME Tweak Tool** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt install gnome-tweak-tool
-
-```
-
-#### Stacer
-
-[Stacer][45] is a free, open-source app for monitoring and optimizing Linux systems.
-
-Install **Stacer** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:oguzhaninan/stacer
-$ sudo apt-get update
-$ sudo apt-get install stacer
-
-```
-
-#### BleachBit
-
-[BleachBit][46] is a free disk space cleaner that also works as a privacy manager and system optimizer.
-
-[**Download BleachBit for Ubuntu][47]
-
-### Linux Terminals
-
-#### GNOME Terminal
-
-[GNOME Terminal][48] is GNOME’s default terminal emulator.
-
-Install **Gnome Terminal** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install gnome-terminal
-
-```
-
-#### Konsole
-
-[Konsole][49] is a terminal emulator for KDE.
-
-Install **Konsole** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install konsole
-
-```
-
-#### Terminator
-
-[Terminator][50] is a feature-rich GNOME Terminal-based terminal app built with a focus on arranging terminals, among other functions.
-
-Install **Terminator** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install terminator
-
-```
-
-#### Guake
-
-[Guake][51] is a lightweight drop-down terminal for the GNOME Desktop Environment.
-
-Install **Guake** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install guake
-
-```
-
-### Multimedia Editors
-
-#### Ardour
-
-[Ardour][52] is a beautiful Digital Audio Workstation (DAW) for recording, editing, and mixing audio professionally.
-
-Install **Ardour** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:dobey/audiotools
-$ sudo apt-get update
-$ sudo apt-get install ardour
-
-```
-
-#### Audacity
-
-[Audacity][53] is an easy-to-use cross-platform and open source multi-track audio editor and recorder; arguably the most famous of them all.
-
-Install **Audacity** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:ubuntuhandbook1/audacity
-$ sudo apt-get update
-$ sudo apt-get install audacity
-
-```
-
-#### GIMP
-
-[GIMP][54] is the most popular open source Photoshop alternative and it is for a reason. It features various customization options, 3rd-party plugins, and a helpful user community.
-
-Install **Gimp** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:otto-kesselgulasch/gimp
-$ sudo apt update
-$ sudo apt install gimp
-
-```
-
-#### Krita
-
-[Krita][55] is an open source painting app that can also serve as an image manipulating tool and it features a beautiful UI with a reliable performance.
-
-Install **Krita** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:kritalime/ppa
-$ sudo apt update
-$ sudo apt install krita
-
-```
-
-#### Lightworks
-
-[Lightworks][56] is a powerful, flexible, and beautiful tool for editing videos professionally. It comes feature-packed with hundreds of amazing effects and presets that allow it to handle any editing task that you throw at it and it has 25 years of experience to back up its claims.
-
-[**Download Lightworks for Ubuntu][57]
-
-#### OpenShot
-
-[OpenShot][58] is an award-winning free and open source video editor known for its excellent performance and powerful capabilities.
-
-Install **Openshot** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:openshot.developers/ppa
-$ sudo apt update
-$ sudo apt install openshot-qt
-
-```
-
-#### PiTiV
-
-[Pitivi][59] is a beautiful video editor that features a beautiful code base, awesome community, is easy to use, and allows for hassle-free collaboration.
-
-Install **PiTiV** on **Ubuntu** and **Debian** , using following commands.
-```
-$ flatpak install --user https://flathub.org/repo/appstream/org.pitivi.Pitivi.flatpakref
-$ flatpak install --user http://flatpak.pitivi.org/pitivi.flatpakref
-$ flatpak run org.pitivi.Pitivi//stable
-
-```
-
-### Music Players
-
-#### Rhythmbox
-
-[Rhythmbox][60] posses the ability to perform all music tasks you throw at it and has so far proved to be a reliable music player that it ships with Ubuntu.
-
-Install **Rhythmbox** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:fossfreedom/rhythmbox
-$ sudo apt-get update
-$ sudo apt-get install rhythmbox
-
-```
-
-#### Lollypop
-
-[Lollypop][61] is a beautiful, relatively new, open source music player featuring a number of advanced options like online radio, scrubbing support and party mode. Yet, it manages to keep everything simple and easy to manage.
-
-Install **Lollypop** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:gnumdk/lollypop
-$ sudo apt-get update
-$ sudo apt-get install lollypop
-
-```
-
-#### Amarok
-
-[Amarok][62] is a robust music player with an intuitive UI and tons of advanced features bundled into a single unit. It also allows users to discover new music based on their genre preferences.
-
-Install **Amarok** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install amarok
-
-```
-
-#### Clementine
-
-[Clementine][63] is an Amarok-inspired music player that also features a straight-forward UI, advanced control features, and the ability to let users search for and discover new music.
-
-Install **Clementine** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:me-davidsansome/clementine
-$ sudo apt-get update
-$ sudo apt-get install clementine
-
-```
-
-#### Cmus
-
-[Cmus][64] is arguably the most efficient CLI music player, Cmus is fast and reliable, and its functionality can be increased using extensions.
-
-Install **Cmus** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:jmuc/cmus
-$ sudo apt-get update
-$ sudo apt-get install cmus
-
-```
-
-### Office Suites
-
-#### Calligra Suite
-
-The [Calligra Suite][65] provides users with a set of 8 applications which cover working with office, management, and graphics tasks.
-
-Install **Calligra Suite** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install calligra
-
-```
-
-#### LibreOffice
-
-[LibreOffice][66] the most actively developed office suite in the open source community, LibreOffice is known for its reliability and its functions can be increased using extensions.
-
-Install **LibreOffice** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:libreoffice/ppa
-$ sudo apt update
-$ sudo apt install libreoffice
-
-```
-
-#### WPS Office
-
-[WPS Office][67] is a beautiful office suite alternative with a more modern UI.
-
-[**Download WPS Office for Ubuntu][68]
-
-### Screenshot Tools
-
-#### Shutter
-
-[Shutter][69] allows users to take screenshots of their desktop and then edit them using filters and other effects coupled with the option to upload and share them online.
-
-Install **Shutter** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository -y ppa:shutter/ppa
-$ sudo apt update
-$ sudo apt install shutter
-
-```
-
-#### Kazam
-
-[Kazam][70] screencaster captures screen content to output a video and audio file supported by any video player with VP8/WebM and PulseAudio support.
-
-Install **Kazam** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:kazam-team/unstable-series
-$ sudo apt update
-$ sudo apt install kazam python3-cairo python3-xlib
-
-```
-
-#### Gnome Screenshot
-
-[Gnome Screenshot][71] was once bundled with Gnome utilities but is now a standalone app. It can be used to take screencasts in a format that is easily shareable.
-
-Install **Gnome Screenshot** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install gnome-screenshot
-
-```
-
-### Screen Recorders
-
-#### SimpleScreenRecorder
-
-[SimpleScreenRecorder][72] was created to be better than the screen-recording apps available at the time of its creation and has now turned into one of the most efficient and easy-to-use screen recorders for Linux distros.
-
-Install **SimpleScreenRecorder** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:maarten-baert/simplescreenrecorder
-$ sudo apt-get update
-$ sudo apt-get install simplescreenrecorder
-
-```
-
-#### recordMyDesktop
-
-[recordMyDesktop][73] is an open source session recorder that is also capable of recording desktop session audio.
-
-Install **recordMyDesktop** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install gtk-recordmydesktop
-
-```
-
-### Text Editors
-
-#### Atom
-
-[Atom][74] is a modern and customizable text editor created and maintained by GitHub. It is ready for use right out of the box and can have its functionality enhanced and its UI customized using extensions and themes.
-
-Install **Atom** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install snapd
-$ sudo snap install atom --classic
-
-```
-
-#### Sublime Text
-
-[Sublime Text][75] is easily among the most awesome text editors to date. It is customizable, lightweight (even when bulldozed with a lot of data files and extensions), flexible, and remains free to use forever.
-
-Install **Sublime Text** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install snapd
-$ sudo snap install sublime-text
-
-```
-
-#### Geany
-
-[Geany][76] is a memory-friendly text editor with basic IDE features designed to exhibit shot load times and extensible functions using libraries.
-
-Install **Geany** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install geany
-
-```
-
-#### Gedit
-
-[Gedit][77] is famous for its simplicity and it comes preinstalled with many Linux distros because of its function as an excellent general purpose text editor.
-
-Install **Gedit** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install gedit
-
-```
-
-### To-Do List Apps
-
-#### Evernote
-
-[Evernote][78] is a cloud-based note-taking productivity app designed to work perfectly with different types of notes including to-do lists and reminders.
-
-There is no any official evernote app for Linux, so check out other third party [6 Evernote Alternative Clients for Linux][79].
-
-#### Everdo
-
-[Everdo][78] is a beautiful, security-conscious, low-friction Getting-Things-Done app productivity app for handling to-dos and other note types. If Evernote comes off to you in an unpleasant way, Everdo is a perfect alternative.
-
-[**Download Everdo for Ubuntu][80]
-
-#### Taskwarrior
-
-[Taskwarrior][81] is an open source and cross-platform command line app for managing tasks. It is famous for its speed and distraction-free environment.
-
-Install **Taskwarrior** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get update
-$ sudo apt-get install taskwarrior
-
-```
-
-### Video Players
-
-#### Banshee
-
-[Banshee][82] is an open source multi-format-supporting media player that was first developed in 2005 and has only been getting better since.
-
-Install **Banshee** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:banshee-team/ppa
-$ sudo apt-get update
-$ sudo apt-get install banshee
-
-```
-
-#### VLC
-
-[VLC][83] is my favourite video player and it’s so awesome that it can play almost any audio and video format you throw at it. You can also use it to play internet radio, record desktop sessions, and stream movies online.
-
-Install **VLC** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:videolan/stable-daily
-$ sudo apt-get update
-$ sudo apt-get install vlc
-
-```
-
-#### Kodi
-
-[Kodi][84] is among the world’s most famous media players and it comes as a full-fledged media centre app for playing all things media whether locally or remotely.
-
-Install **Kodi** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo apt-get install software-properties-common
-$ sudo add-apt-repository ppa:team-xbmc/ppa
-$ sudo apt-get update
-$ sudo apt-get install kodi
-
-```
-
-#### SMPlayer
-
-[SMPlayer][85] is a GUI for the award-winning **MPlayer** and it is capable of handling all popular media formats; coupled with the ability to stream from YouTube, Chromcast, and download subtitles.
-
-Install **SMPlayer** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:rvm/smplayer
-$ sudo apt-get update
-$ sudo apt-get install smplayer
-
-```
-
-### Virtualization Tools
-
-#### VirtualBox
-
-[VirtualBox][86] is an open source app created for general-purpose OS virtualization and it can be run on servers, desktops, and embedded systems.
-
-Install **VirtualBox** on **Ubuntu** and **Debian** , using following commands.
-```
-$ wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
-$ wget -q https://www.virtualbox.org/download/oracle_vbox.asc -O- | sudo apt-key add -
-$ sudo apt-get update
-$ sudo apt-get install virtualbox-5.2
-$ virtualbox
-
-```
-
-#### VMWare
-
-[VMware][87] is a digital workspace that provides platform virtualization and cloud computing services to customers and is reportedly the first to successfully virtualize x86 architecture systems. One of its products, VMware workstations allows users to run multiple OSes in a virtual memory.
-
-For installation, read our article “[How to Install VMware Workstation Pro on Ubuntu][88]“.
-
-### Web Browsers
-
-#### Chrome
-
-[Google Chrome][89] is undoubtedly the most popular browser. Known for its speed, simplicity, security, and beauty following Google’s Material Design trend, Chrome is a browser that web developers cannot do without. It is also free to use and open source.
-
-Install **Google Chrome** on **Ubuntu** and **Debian** , using following commands.
-```
-$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
-$ sudo sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
-$ sudo apt-get update
-$ sudo apt-get install google-chrome-stable
-
-```
-
-#### Firefox
-
-[Firefox Quantum][90] is a beautiful, speed, task-ready, and customizable browser capable of any browsing task that you throw at it. It is also free, open source, and packed with developer-friendly tools that are easy for even beginners to get up and running with.
-
-Install **Firefox Quantum** on **Ubuntu** and **Debian** , using following commands.
-```
-$ sudo add-apt-repository ppa:mozillateam/firefox-next
-$ sudo apt update && sudo apt upgrade
-$ sudo apt install firefox
-
-```
-
-#### Vivaldi
-
-[Vivaldi][91] is a free and open source Chrome-based project that aims to perfect Chrome’s features with a couple of more feature additions. It is known for its colourful panels, memory-friendly performance, and flexibility.
-
-[**Download Vivaldi for Ubuntu][91]
-
-That concludes our list for today. Did I skip a famous title? Tell me about it in the comments section below.
-
-Don’t forget to share this post and to subscribe to our newsletter to get the latest publications from FossMint.
-
-
---------------------------------------------------------------------------------
-
-via: https://www.fossmint.com/most-used-linux-applications/
-
-作者:[Martins D. Okoi][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.fossmint.com/author/dillivine/
-[1]:https://plus.google.com/share?url=https://www.fossmint.com/most-used-linux-applications/ (Share on Google+)
-[2]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.fossmint.com/most-used-linux-applications/ (Share on LinkedIn)
-[3]:https://www.fossmint.com/awesome-linux-software/
-[4]:https://rsync.samba.org/
-[5]:https://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
-[6]:https://github.com/teejee2008/timeshift
-[7]:https://deluge-torrent.org/
-[8]:https://www.qbittorrent.org/
-[9]:https://transmissionbt.com/
-[10]:https://www.dropbox.com/
-[11]:https://www.google.com/drive/
-[12]:https://www.fossmint.com/best-google-drive-clients-for-linux/
-[13]:https://mega.nz/
-[14]:https://mega.nz/sync!linux
-[15]:https://www.vim.org/
-[16]:https://www.gnu.org/s/emacs/
-[17]:https://www.nano-editor.org/
-[18]:https://aria2.github.io/
-[19]:http://ugetdm.com/
-[20]:http://xdman.sourceforge.net/
-[21]:https://www.thunderbird.net/
-[22]:https://github.com/GNOME/geary
-[23]:https://github.com/GNOME/evolution
-[24]:https://www.gnucash.org/
-[25]:https://kmymoney.org/
-[26]:https://www.eclipse.org/ide/
-[27]:https://www.tecmint.com/install-eclipse-oxygen-ide-in-ubuntu-debian/
-[28]:https://netbeans.org/
-[29]:https://www.tecmint.com/install-netbeans-ide-in-ubuntu-debian-linux-mint/
-[30]:http://brackets.io/
-[31]:https://ide.atom.io/
-[32]:http://lighttable.com/
-[33]:https://code.visualstudio.com/
-[34]:https://code.visualstudio.com/download
-[35]:https://www.pidgin.im/
-[36]:https://www.skype.com/
-[37]:https://wiki.gnome.org/Apps/Empathy
-[38]:https://www.clamav.net/
-[39]:https://dave-theunsub.github.io/clamtk/
-[40]:https://github.com/linuxmint/cinnamon-desktop
-[41]:https://mate-desktop.org/
-[42]:https://www.gnome.org/
-[43]:https://www.kde.org/plasma-desktop
-[44]:https://github.com/nzjrs/gnome-tweak-tool
-[45]:https://github.com/oguzhaninan/Stacer
-[46]:https://www.bleachbit.org/
-[47]:https://www.bleachbit.org/download
-[48]:https://github.com/GNOME/gnome-terminal
-[49]:https://konsole.kde.org/
-[50]:https://gnometerminator.blogspot.com/p/introduction.html
-[51]:http://guake-project.org/
-[52]:https://ardour.org/
-[53]:https://www.audacityteam.org/
-[54]:https://www.gimp.org/
-[55]:https://krita.org/en/
-[56]:https://www.lwks.com/
-[57]:https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206
-[58]:https://www.openshot.org/
-[59]:http://www.pitivi.org/
-[60]:https://wiki.gnome.org/Apps/Rhythmbox
-[61]:https://gnumdk.github.io/lollypop-web/
-[62]:https://amarok.kde.org/en
-[63]:https://www.clementine-player.org/
-[64]:https://cmus.github.io/
-[65]:https://www.calligra.org/tour/calligra-suite/
-[66]:https://www.libreoffice.org/
-[67]:https://www.wps.com/
-[68]:http://wps-community.org/downloads
-[69]:http://shutter-project.org/
-[70]:https://launchpad.net/kazam
-[71]:https://gitlab.gnome.org/GNOME/gnome-screenshot
-[72]:http://www.maartenbaert.be/simplescreenrecorder/
-[73]:http://recordmydesktop.sourceforge.net/about.php
-[74]:https://atom.io/
-[75]:https://www.sublimetext.com/
-[76]:https://www.geany.org/
-[77]:https://wiki.gnome.org/Apps/Gedit
-[78]:https://everdo.net/
-[79]:https://www.fossmint.com/evernote-alternatives-for-linux/
-[80]:https://everdo.net/linux/
-[81]:https://taskwarrior.org/
-[82]:http://banshee.fm/
-[83]:https://www.videolan.org/
-[84]:https://kodi.tv/
-[85]:https://www.smplayer.info/
-[86]:https://www.virtualbox.org/wiki/VirtualBox
-[87]:https://www.vmware.com/
-[88]:https://www.tecmint.com/install-vmware-workstation-in-linux/
-[89]:https://www.google.com/chrome/
-[90]:https://www.mozilla.org/en-US/firefox/
-[91]:https://vivaldi.com/
diff --git a/sources/tech/20180724 Building a network attached storage device with a Raspberry Pi.md b/sources/tech/20180724 Building a network attached storage device with a Raspberry Pi.md
deleted file mode 100644
index 3144efd4ee..0000000000
--- a/sources/tech/20180724 Building a network attached storage device with a Raspberry Pi.md
+++ /dev/null
@@ -1,284 +0,0 @@
-Building a network attached storage device with a Raspberry Pi
-======
-
-
-
-In this three-part series, I'll explain how to set up a simple, useful NAS (network attached storage) system. I use this kind of setup to store my files on a central system, creating incremental backups automatically every night. To mount the disk on devices that are located in the same network, NFS is installed. To access files offline and share them with friends, I use [Nextcloud][1].
-
-This article will cover the basic setup of software and hardware to mount the data disk on a remote device. In the second article, I will discuss a backup strategy and set up a cron job to create daily backups. In the third and last article, we will install Nextcloud, a tool for easy file access to devices synced offline as well as online using a web interface. It supports multiple users and public file-sharing so you can share pictures with friends, for example, by sending a password-protected link.
-
-The target architecture of our system looks like this:
-
-
-### Hardware
-
-Let's get started with the hardware you need. You might come up with a different shopping list, so consider this one an example.
-
-The computing power is delivered by a [Raspberry Pi 3][2], which comes with a quad-core CPU, a gigabyte of RAM, and (somewhat) fast ethernet. Data will be stored on two USB hard drives (I use 1-TB disks); one is used for the everyday traffic, the other is used to store backups. Be sure to use either active USB hard drives or a USB hub with an additional power supply, as the Raspberry Pi will not be able to power two USB drives.
-
-### Software
-
-The operating system with the highest visibility in the community is [Raspbian][3] , which is excellent for custom projects. There are plenty of [guides][4] that explain how to install Raspbian on a Raspberry Pi, so I won't go into details here. The latest official supported version at the time of this writing is [Raspbian Stretch][5] , which worked fine for me.
-
-At this point, I will assume you have configured your basic Raspbian and are able to connect to the Raspberry Pi by `ssh`.
-
-### Prepare the USB drives
-
-To achieve good performance reading from and writing to the USB hard drives, I recommend formatting them with ext4. To do so, you must first find out which disks are attached to the Raspberry Pi. You can find the disk devices in `/dev/sd/`. Using the command `fdisk -l`, you can find out which two USB drives you just attached. Please note that all data on the USB drives will be lost as soon as you follow these steps.
-```
-pi@raspberrypi:~ $ sudo fdisk -l
-
-
-
-<...>
-
-
-
-Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
-
-Units: sectors of 1 * 512 = 512 bytes
-
-Sector size (logical/physical): 512 bytes / 512 bytes
-
-I/O size (minimum/optimal): 512 bytes / 512 bytes
-
-Disklabel type: dos
-
-Disk identifier: 0xe8900690
-
-
-
-Device Boot Start End Sectors Size Id Type
-
-/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
-
-
-
-
-
-Disk /dev/sdb: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
-
-Units: sectors of 1 * 512 = 512 bytes
-
-Sector size (logical/physical): 512 bytes / 512 bytes
-
-I/O size (minimum/optimal): 512 bytes / 512 bytes
-
-Disklabel type: dos
-
-Disk identifier: 0x6aa4f598
-
-
-
-Device Boot Start End Sectors Size Id Type
-
-/dev/sdb1 * 2048 1953521663 1953519616 931.5G 83 Linux
-
-```
-
-As those devices are the only 1TB disks attached to the Raspberry Pi, we can easily see that `/dev/sda` and `/dev/sdb` are the two USB drives. The partition table at the end of each disk shows how it should look after the following steps, which create the partition table and format the disks. To do this, repeat the following steps for each of the two devices by replacing `sda` with `sdb` the second time (assuming your devices are also listed as `/dev/sda` and `/dev/sdb` in `fdisk`).
-
-First, delete the partition table of the disk and create a new one containing only one partition. In `fdisk`, you can use interactive one-letter commands to tell the program what to do. Simply insert them after the prompt `Command (m for help):` as follows (you can also use the `m` command anytime to get more information):
-```
-pi@raspberrypi:~ $ sudo fdisk /dev/sda
-
-
-
-Welcome to fdisk (util-linux 2.29.2).
-
-Changes will remain in memory only, until you decide to write them.
-
-Be careful before using the write command.
-
-
-
-
-
-Command (m for help): o
-
-Created a new DOS disklabel with disk identifier 0x9c310964.
-
-
-
-Command (m for help): n
-
-Partition type
-
- p primary (0 primary, 0 extended, 4 free)
-
- e extended (container for logical partitions)
-
-Select (default p): p
-
-Partition number (1-4, default 1):
-
-First sector (2048-1953525167, default 2048):
-
-Last sector, +sectors or +size{K,M,G,T,P} (2048-1953525167, default 1953525167):
-
-
-
-Created a new partition 1 of type 'Linux' and of size 931.5 GiB.
-
-
-
-Command (m for help): p
-
-
-
-Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
-
-Units: sectors of 1 * 512 = 512 bytes
-
-Sector size (logical/physical): 512 bytes / 512 bytes
-
-I/O size (minimum/optimal): 512 bytes / 512 bytes
-
-Disklabel type: dos
-
-Disk identifier: 0x9c310964
-
-
-
-Device Boot Start End Sectors Size Id Type
-
-/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
-
-
-
-Command (m for help): w
-
-The partition table has been altered.
-
-Syncing disks.
-
-```
-
-Now we will format the newly created partition `/dev/sda1` using the ext4 filesystem:
-```
-pi@raspberrypi:~ $ sudo mkfs.ext4 /dev/sda1
-
-mke2fs 1.43.4 (31-Jan-2017)
-
-Discarding device blocks: done
-
-
-
-<...>
-
-
-
-Allocating group tables: done
-
-Writing inode tables: done
-
-Creating journal (1024 blocks): done
-
-Writing superblocks and filesystem accounting information: done
-
-```
-
-After repeating the above steps, let's label the new partitions according to their usage in your system:
-```
-pi@raspberrypi:~ $ sudo e2label /dev/sda1 data
-
-pi@raspberrypi:~ $ sudo e2label /dev/sdb1 backup
-
-```
-
-Now let's get those disks mounted to store some data. My experience, based on running this setup for over a year now, is that USB drives are not always available to get mounted when the Raspberry Pi boots up (for example, after a power outage), so I recommend using autofs to mount them when needed.
-
-First install autofs and create the mount point for the storage:
-```
-pi@raspberrypi:~ $ sudo apt install autofs
-
-pi@raspberrypi:~ $ sudo mkdir /nas
-
-```
-
-Then mount the devices by adding the following line to `/etc/auto.master`:
-```
-/nas /etc/auto.usb
-
-```
-
-Create the file `/etc/auto.usb` if not existing with the following content, and restart the autofs service:
-```
-data -fstype=ext4,rw :/dev/disk/by-label/data
-
-backup -fstype=ext4,rw :/dev/disk/by-label/backup
-
-pi@raspberrypi3:~ $ sudo service autofs restart
-
-```
-
-Now you should be able to access the disks at `/nas/data` and `/nas/backup`, respectively. Clearly, the content will not be too thrilling, as you just erased all the data from the disks. Nevertheless, you should be able to verify the devices are mounted by executing the following commands:
-```
-pi@raspberrypi3:~ $ cd /nas/data
-
-pi@raspberrypi3:/nas/data $ cd /nas/backup
-
-pi@raspberrypi3:/nas/backup $ mount
-
-<...>
-
-/etc/auto.usb on /nas type autofs (rw,relatime,fd=6,pgrp=463,timeout=300,minproto=5,maxproto=5,indirect)
-
-<...>
-
-/dev/sda1 on /nas/data type ext4 (rw,relatime,data=ordered)
-
-/dev/sdb1 on /nas/backup type ext4 (rw,relatime,data=ordered)
-
-```
-
-First move into the directories to make sure autofs mounts the devices. Autofs tracks access to the filesystems and mounts the needed devices on the go. Then the `mount` command shows that the two devices are actually mounted where we wanted them.
-
-Setting up autofs is a bit fault-prone, so do not get frustrated if mounting doesn't work on the first try. Give it another chance, search for more detailed resources (there is plenty of documentation online), or leave a comment.
-
-### Mount network storage
-
-Now that you have set up the basic network storage, we want it to be mounted on a remote Linux machine. We will use the network file system (NFS) for this. First, install the NFS server on the Raspberry Pi:
-```
-pi@raspberrypi:~ $ sudo apt install nfs-kernel-server
-
-```
-
-Next we need to tell the NFS server to expose the `/nas/data` directory, which will be the only device accessible from outside the Raspberry Pi (the other one will be used for backups only). To export the directory, edit the file `/etc/exports` and add the following line to allow all devices with access to the NAS to mount your storage:
-```
-/nas/data *(rw,sync,no_subtree_check)
-
-```
-
-For more information about restricting the mount to single devices and so on, refer to `man exports`. In the configuration above, anyone will be able to mount your data as long as they have access to the ports needed by NFS: `111` and `2049`. I use the configuration above and allow access to my home network only for ports 22 and 443 using the routers firewall. That way, only devices in the home network can reach the NFS server.
-
-To mount the storage on a Linux computer, run the commands:
-```
-you@desktop:~ $ sudo mkdir /nas/data
-
-you@desktop:~ $ sudo mount -t nfs :/nas/data /nas/data
-
-```
-
-Again, I recommend using autofs to mount this network device. For extra help, check out [How to use autofs to mount NFS shares][6].
-
-Now you are able to access files stored on your own RaspberryPi-powered NAS from remote devices using the NFS mount. In the next part of this series, I will cover how to automatically back up your data to the second hard drive using `rsync`. To save space on the device while still doing daily backups, you will learn how to create incremental backups with `rsync`.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
-
-作者:[Manuel Dewald][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/ntlx
-[1]:https://nextcloud.com/
-[2]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
-[3]:https://www.raspbian.org/
-[4]:https://www.raspberrypi.org/documentation/installation/installing-images/
-[5]:https://www.raspberrypi.org/blog/raspbian-stretch/
-[6]:https://opensource.com/article/18/6/using-autofs-mount-nfs-shares
diff --git a/sources/tech/20180727 How to analyze your system with perf and Python.md b/sources/tech/20180727 How to analyze your system with perf and Python.md
index ccc66b04a7..c1be98cc0e 100644
--- a/sources/tech/20180727 How to analyze your system with perf and Python.md
+++ b/sources/tech/20180727 How to analyze your system with perf and Python.md
@@ -1,5 +1,3 @@
-pinewall translating
-
How to analyze your system with perf and Python
======
diff --git a/sources/tech/20180803 5 Essential Tools for Linux Development.md b/sources/tech/20180803 5 Essential Tools for Linux Development.md
deleted file mode 100644
index 006372ca82..0000000000
--- a/sources/tech/20180803 5 Essential Tools for Linux Development.md
+++ /dev/null
@@ -1,148 +0,0 @@
-5 Essential Tools for Linux Development
-======
-
-
-
-Linux has become a mainstay for many sectors of work, play, and personal life. We depend upon it. With Linux, technology is expanding and evolving faster than anyone could have imagined. That means Linux development is also happening at an exponential rate. Because of this, more and more developers will be hopping on board the open source and Linux dev train in the immediate, near, and far-off future. For that, people will need tools. Fortunately, there are a ton of dev tools available for Linux; so many, in fact, that it can be a bit intimidating to figure out precisely what you need (especially if you’re coming from another platform).
-
-To make that easier, I thought I’d help narrow down the selection a bit for you. But instead of saying you should use Tool X and Tool Y, I’m going to narrow it down to five categories and then offer up an example for each. Just remember, for most categories, there are several available options. And, with that said, let’s get started.
-
-### Containers
-
-Let’s face it, in this day and age you need to be working with containers. Not only are they incredibly easy to deploy, they make for great development environments. If you regularly develop for a specific platform, why not do so by creating a container image that includes all of the tools you need to make the process quick and easy. With that image available, you can then develop and roll out numerous instances of whatever software or service you need.
-
-Using containers for development couldn’t be easier than it is with [Docker][1]. The advantages of using containers (and Docker) are:
-
- * Consistent development environment.
-
- * You can trust it will “just work” upon deployment.
-
- * Makes it easy to build across platforms.
-
- * Docker images available for all types of development environments and languages.
-
- * Deploying single containers or container clusters is simple.
-
-
-
-
-Thanks to [Docker Hub][2], you’ll find images for nearly any platform, development environment, server, service… just about anything you need. Using images from Docker Hub means you can skip over the creation of the development environment and go straight to work on developing your app, server, API, or service.
-
-Docker is easily installable of most every Linux platform. For example: To install Docker on Ubuntu, you only have to open a terminal window and issue the command:
-```
-sudo apt-get install docker.io
-
-```
-
-With Docker installed, you’re ready to start pulling down specific images, developing, and deploying (Figure 1).
-
-![Docker images][4]
-
-Figure 1: Docker images ready to deploy.
-
-[Used with permission][5]
-
-### Version control system
-
-If you’re working on a large project or with a team on a project, you’re going to need a version control system. Why? Because you need to keep track of your code, where your code is, and have an easy means of making commits and merging code from others. Without such a tool, your projects would be nearly impossible to manage. For Linux users, you cannot beat the ease of use and widespread deployment of [Git][6] and [GitHub][7]. If you’re new to their worlds, Git is the version control system that you install on your local machine and GitHub is the remote repository you use to upload (and then manage) your projects. Git can be installed on most Linux distributions. For example, on a Debian-based system, the install is as simple as:
-```
-sudo apt-get install git
-
-```
-
-Once installed, you are ready to start your journey with version control (Figure 2).
-
-![Git installed][9]
-
-Figure 2: Git is installed and available for many important tasks.
-
-[Used with permission][5]
-
-Github requires you to create an account. You can use it for free for non-commercial projects, or you can pay for commercial project housing (for more information check out the price matrix [here][10]).
-
-### Text editor
-
-Let’s face it, developing on Linux would be a bit of a challenge without a text editor. Of course what a text editor is varies, depending upon who you ask. One person might say vim, emacs, or nano, whereas another might go full-on GUI with their editor. But since we’re talking development, we need a tool that can meet the needs of the modern day developer. And before I mention a couple of text editors, I will say this: Yes, I know that vim is a serious workhorse for serious developers and, if you know it well vim will meet and exceed all of your needs. However, getting up to speed enough that it won’t be in your way, can be a bit of a hurdle for some developers (especially those new to Linux). Considering my goal is to always help win over new users (and not just preach to an already devout choir), I’m taking the GUI route here.
-
-As far as text editors are concerned, you cannot go wrong with the likes of [Bluefish][11]. Bluefish can be found in most standard repositories and features project support, multi-threaded support for remote files, search and replace, open files recursively, snippets sidebar, integrates with make, lint, weblint, xmllint, unlimited undo/redo, in-line spell checker, auto-recovery, full screen editing, syntax highlighting (Figure 3), support for numerous languages, and much more.
-
-![Bluefish][13]
-
-Figure 3: Bluefish running on Ubuntu Linux 18.04.
-
-[Used with permission][5]
-
-### IDE
-
-Integrated Development Environment (IDE) is a piece of software that includes a comprehensive set of tools that enable a one-stop-shop environment for developing. IDEs not only enable you to code your software, but document and build them as well. There are a number of IDEs for Linux, but one in particular is not only included in the standard repositories it is also very user-friendly and powerful. That tool in question is [Geany][14]. Geany features syntax highlighting, code folding, symbol name auto-completion, construct completion/snippets, auto-closing of XML and HTML tags, call tips, many supported filetypes, symbol lists, code navigation, build system to compile and execute your code, simple project management, and a built-in plugin system.
-
-Geany can be easily installed on your system. For example, on a Debian-based distribution, issue the command:
-```
-sudo apt-get install geany
-
-```
-
-Once installed, you’re ready to start using this very powerful tool that includes a user-friendly interface (Figure 4) that has next to no learning curve.
-
-![Geany][16]
-
-Figure 4: Geany is ready to serve as your IDE.
-
-[Used with permission][5]
-
-### diff tool
-
-There will be times when you have to compare two files to find where they differ. This could be two different copies of what was the same file (only one compiles and the other doesn’t). When that happens, you don’t want to have to do that manually. Instead, you want to employ the power of tool like [Meld][17]. Meld is a visual diff and merge tool targeted at developers. With Meld you can make short shrift out of discovering the differences between two files. Although you can use a command line diff tool, when efficiency is the name of the game, you can’t beat Meld.
-
-Meld allows you to open a comparison between to files and it will highlight the differences between each. Meld also allows you to merge comparisons either from the right or the left (as the files are opened side by side - Figure 5).
-
-![Comparing two files][19]
-
-Figure 5: Comparing two files with a simple difference.
-
-[Used with permission][5]
-
-Meld can be installed from most standard repositories. On a Debian-based system, the installation command is:
-```
-sudo apt-get install meld
-
-```
-
-### Working with efficiency
-
-These five tools not only enable you to get your work done, they help to make it quite a bit more efficient. Although there are a ton of developer tools available for Linux, you’re going to want to make sure you have one for each of the above categories (maybe even starting with the suggestions I’ve made).
-
-Learn more about Linux through the free ["Introduction to Linux" ][20]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/8/5-essential-tools-linux-development
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://www.docker.com/
-[2]:https://hub.docker.com/
-[3]:/files/images/5devtools1jpg
-[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_1.jpg?itok=V1Bsbkg9 (Docker images)
-[5]:/licenses/category/used-permission
-[6]:https://git-scm.com/
-[7]:https://github.com/
-[8]:/files/images/5devtools2jpg
-[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_2.jpg?itok=YJjhe4O6 (Git installed)
-[10]:https://github.com/pricing
-[11]:http://bluefish.openoffice.nl/index.html
-[12]:/files/images/5devtools3jpg
-[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_3.jpg?itok=66A7Svme (Bluefish)
-[14]:https://www.geany.org/
-[15]:/files/images/5devtools4jpg
-[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_4.jpg?itok=jRcA-0ue (Geany)
-[17]:http://meldmerge.org/
-[18]:/files/images/5devtools5jpg
-[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/5devtools_5.jpg?itok=eLkfM9oZ (Comparing two files)
-[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180815 How to Create M3U Playlists in Linux [Quick Tip].md b/sources/tech/20180815 How to Create M3U Playlists in Linux [Quick Tip].md
deleted file mode 100644
index 3c0b63d63b..0000000000
--- a/sources/tech/20180815 How to Create M3U Playlists in Linux [Quick Tip].md
+++ /dev/null
@@ -1,84 +0,0 @@
-translating by lujun9972
-How to Create M3U Playlists in Linux [Quick Tip]
-======
-**Brief: A quick tip on how to create M3U playlists in Linux terminal from unordered files to play them in a sequence.**
-
-![Create M3U playlists in Linux Terminal][1]
-
-I am a fan of foreign tv series and it’s not always easy to get them on DVD or on streaming services like [Netflix][2]. Thankfully, you can find some of them on YouTube and [download them from YouTube][3].
-
-Now there comes a problem. Your files might not be sorted in a particular order. In GNU/Linux files are not naturally sort ordered by number sequencing so I had to make a .m3u playlist so [MPV video player][4] would play the videos in sequence and not out of sequence.
-
-Also sometimes the numbers are in the middle or the end like ‘My Web Series S01E01.mkv’ as an example. The episode information here is in the middle of the filename, the ‘S01E01’ which tells us, humans, which is the first episode and which needs to come in next.
-
-So what I did was to generate an m3u playlist in the video directory and tell MPV to play the .m3u playlist and it would take care of playing them in the sequence.
-
-### What is an M3U file?
-
-[M3U][5] is basically a text file that contains filenames in a specific order. When a player like MPV or VLC opens an M3U file, it tries to play the specified files in the given sequence.
-
-### Creating M3U to play audio/video files in a sequence
-
-In my case, I used the following command:
-```
-$/home/shirish/Videos/web-series-video/$ ls -1v |grep .mkv > /tmp/1.m3u && mv /tmp/1.m3u .
-
-```
-
-Let’s break it down a bit and see each bit as to what it means –
-
-**ls -1v** = This is using the plain ls or listing entries in the directory. The -1 means list one file per line. while -v natural sort of (version) numbers within text
-
-**| grep .mkv** = It’s basically telling `ls` to look for files which are ending in .mkv . It could be .mp4 or any other media file format that you want.
-
-It’s usually a good idea to do a dry run by running the command on the console:
-```
-ls -1v |grep .mkv
-My Web Series S01E01 [Episode 1 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E02 [Episode 2 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E03 [Episode 3 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E04 [Episode 4 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E05 [Episode 5 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E06 [Episode 6 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E07 [Episode 7 Name] Multi 480p WEBRip x264 - xRG.mkv
-My Web Series S01E08 [Episode 8 Name] Multi 480p WEBRip x264 - xRG.mkv
-
-```
-
-This tells me that what I’m trying to do is correct. Now just have to make that the output is in the form of a .m3u playlist which is the next part.
-```
-ls -1v |grep .mkv > /tmp/web_playlist.m3u && mv /tmp/web_playlist.m3u .
-
-```
-
-This makes the .m3u generate in the current directory. The .m3u playlist is nothing but a .txt file with the same contents as above with the .m3u extension. You can edit it manually as well and add the exact filenames in an order you desire.
-
-After that you just have to do something like this:
-```
-mpv web_playlist.m3u
-
-```
-
-The great thing about MPV and the playlists, in general, is that you don’t have to binge-watch. You can see however much you want to do in one sitting and see the rest in the next session or the session after that.
-
-I hope to do articles featuring MPV as well as how to make mkv files embedding subtitles in a media file but that’s in the future.
-
-Note: It’s FOSS doesn’t encourage piracy.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/create-m3u-playlist-linux/
-
-作者:[Shirsh][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/shirish/
-[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/Create-M3U-Playlists.jpeg
-[2]:https://itsfoss.com/netflix-open-source-ai/
-[3]:https://itsfoss.com/download-youtube-linux/
-[4]:https://itsfoss.com/mpv-video-player/
-[5]:https://en.wikipedia.org/wiki/M3U
diff --git a/sources/tech/20180817 How To Lock The Keyboard And Mouse, But Not The Screen In Linux.md b/sources/tech/20180817 How To Lock The Keyboard And Mouse, But Not The Screen In Linux.md
index d3c729f1d0..d671a35457 100644
--- a/sources/tech/20180817 How To Lock The Keyboard And Mouse, But Not The Screen In Linux.md
+++ b/sources/tech/20180817 How To Lock The Keyboard And Mouse, But Not The Screen In Linux.md
@@ -1,3 +1,4 @@
+FSSlc Translating
How To Lock The Keyboard And Mouse, But Not The Screen In Linux
======
diff --git a/sources/tech/20180821 A checklist for submitting your first Linux kernel patch.md b/sources/tech/20180821 A checklist for submitting your first Linux kernel patch.md
deleted file mode 100644
index 1fc4677491..0000000000
--- a/sources/tech/20180821 A checklist for submitting your first Linux kernel patch.md
+++ /dev/null
@@ -1,170 +0,0 @@
-A checklist for submitting your first Linux kernel patch
-======
-
-
-
-One of the biggest—and the fastest moving—open source projects, the Linux kernel, is composed of about 53,600 files and nearly 20-million lines of code. With more than 15,600 programmers contributing to the project worldwide, the Linux kernel follows a maintainer model for collaboration.
-
-
-
-In this article, I'll provide a quick checklist of steps involved with making your first kernel contribution, and look at what you should know before submitting a patch. For a more in-depth look at the submission process for contributing your first patch, read the [KernelNewbies First Kernel Patch tutorial][1].
-
-### Contributing to the kernel
-
-#### Step 1: Prepare your system.
-
-Steps in this article assume you have the following tools on your system:
-
-+ Text editor
-+ Email client
-+ Version control system (e.g., git)
-
-#### Step 2: Download the Linux kernel code repository`:`
-```
-git clone -b staging-testing
-
-git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/staging.git
-
-```
-
-### Copy your current config: ````
-```
-cp /boot/config-`uname -r`* .config
-
-```
-
-### Step 3: Build/install your kernel.
-```
-make -jX
-
-sudo make modules_install install
-
-```
-
-### Step 4: Make a branch and switch to it.
-```
-git checkout -b first-patch
-
-```
-
-### Step 5: Update your kernel to point to the latest code base.
-```
-git fetch origin
-
-git rebase origin/staging-testing
-
-```
-
-### Step 6: Make a change to the code base.
-
-Recompile using `make` command to ensure that your change does not produce errors.
-
-### Step 7: Commit your changes and create a patch.
-```
-git add
-
-git commit -s -v
-
-git format-patch -o /tmp/ HEAD^
-
-```
-
-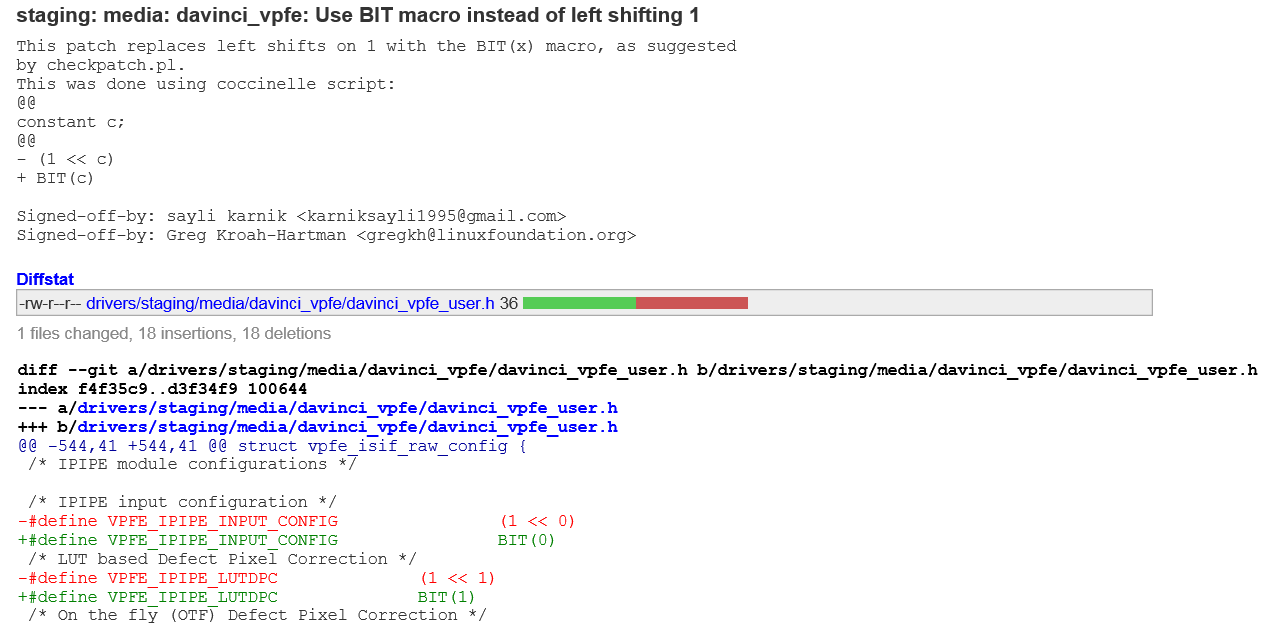
-
-The subject consists of the path to the file name separated by colons, followed by what the patch does in the imperative tense. After a blank line comes the description of the patch and the mandatory signed off tag and, lastly, a diff of your patch.
-
-Here is another example of a simple patch:
-
-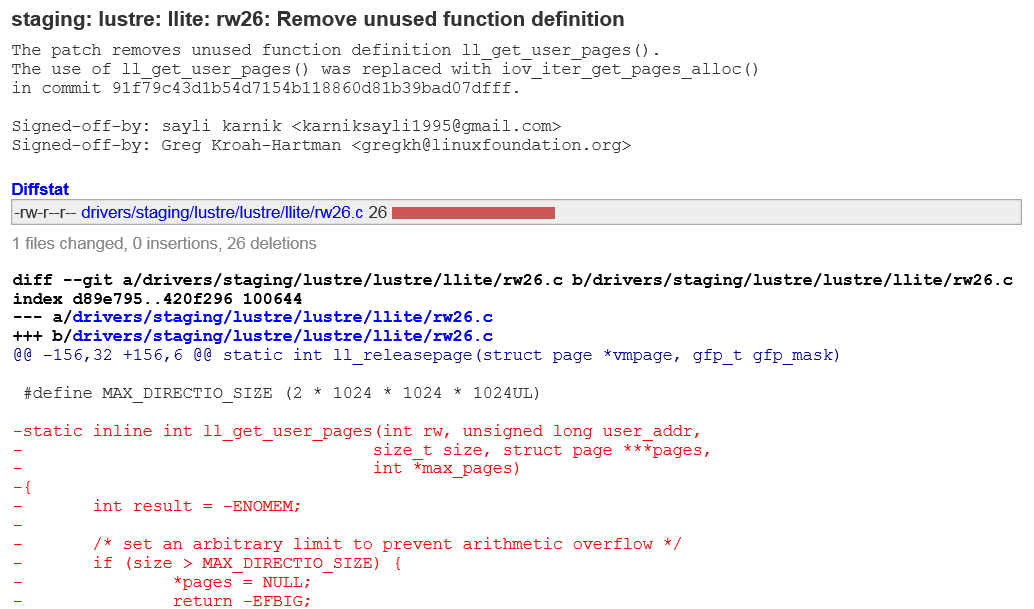
-
-Next, send the patch [using email from the command line][2] (in this case, Mutt): ``
-```
-mutt -H /tmp/0001-
-
-```
-
-To know the list of maintainers to whom to send the patch, use the [get_maintainer.pl script][11].
-
-
-### What to know before submitting your first patch
-
- * [Greg Kroah-Hartman][3]'s [staging tree][4] is a good place to submit your [first patch][1] as he accepts easy patches from new contributors. When you get familiar with the patch-sending process, you could send subsystem-specific patches with increased complexity.
-
- * You also could start with correcting coding style issues in the code. To learn more, read the [Linux kernel coding style documentation][5].
-
- * The script [checkpatch.pl][6] detects coding style errors for you. For example, run:
- ```
- perl scripts/checkpatch.pl -f drivers/staging/android/* | less
-
- ```
-
- * You could complete TODOs left incomplete by developers:
- ```
- find drivers/staging -name TODO
- ```
-
- * [Coccinelle][7] is a helpful tool for pattern matching.
-
- * Read the [kernel mailing archives][8].
-
- * Go through the [linux.git log][9] to see commits by previous authors for inspiration.
-
- * Note: Do not top-post to communicate with the reviewer of your patch! Here's an example:
-
-**Wrong way:**
-
-Chris,
-_Yes let’s schedule the meeting tomorrow, on the second floor._
-> On Fri, Apr 26, 2013 at 9:25 AM, Chris wrote:
-> Hey John, I had some questions:
-> 1\. Do you want to schedule the meeting tomorrow?
-> 2\. On which floor in the office?
-> 3\. What time is suitable to you?
-
-(Notice that the last question was unintentionally left unanswered in the reply.)
-
-**Correct way:**
-
-Chris,
-See my answers below...
-> On Fri, Apr 26, 2013 at 9:25 AM, Chris wrote:
-> Hey John, I had some questions:
-> 1\. Do you want to schedule the meeting tomorrow?
-_Yes tomorrow is fine._
-> 2\. On which floor in the office?
-_Let's keep it on the second floor._
-> 3\. What time is suitable to you?
-_09:00 am would be alright._
-
-(All questions were answered, and this way saves reading time.)
-
- * The [Eudyptula challenge][10] is a great way to learn kernel basics.
-
-
-To learn more, read the [KernelNewbies First Kernel Patch tutorial][1]. After that, if you still have any questions, ask on the [kernelnewbies mailing list][12] or in the [#kernelnewbies IRC channel][13].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/first-linux-kernel-patch
-
-作者:[Sayli Karnik][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/sayli
-[1]:https://kernelnewbies.org/FirstKernelPatch
-[2]:https://opensource.com/life/15/8/top-4-open-source-command-line-email-clients
-[3]:https://twitter.com/gregkh
-[4]:https://www.kernel.org/doc/html/v4.15/process/2.Process.html
-[5]:https://www.kernel.org/doc/html/v4.10/process/coding-style.html
-[6]:https://github.com/torvalds/linux/blob/master/scripts/checkpatch.pl
-[7]:http://coccinelle.lip6.fr/
-[8]:linux-kernel@vger.kernel.org
-[9]:https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/log/
-[10]:http://eudyptula-challenge.org/
-[11]:https://github.com/torvalds/linux/blob/master/scripts/get_maintainer.pl
-[12]:https://kernelnewbies.org/MailingList
-[13]:https://kernelnewbies.org/IRC
diff --git a/sources/tech/20180823 CLI- improved.md b/sources/tech/20180823 CLI- improved.md
index d06bb1b2aa..52edaa28c8 100644
--- a/sources/tech/20180823 CLI- improved.md
+++ b/sources/tech/20180823 CLI- improved.md
@@ -1,3 +1,5 @@
+Translating by DavidChenLiang
+
CLI: improved
======
I'm not sure many web developers can get away without visiting the command line. As for me, I've been using the command line since 1997, first at university when I felt both super cool l33t-hacker and simultaneously utterly out of my depth.
diff --git a/sources/tech/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md b/sources/tech/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md
deleted file mode 100644
index aa4ec0a655..0000000000
--- a/sources/tech/20180823 How To Easily And Safely Manage Cron Jobs In Linux.md
+++ /dev/null
@@ -1,131 +0,0 @@
-How To Easily And Safely Manage Cron Jobs In Linux
-======
-
-
-
-When it comes to schedule tasks in Linux, which utility comes to your mind first? Yeah, you guessed it right. **Cron!** The cron utility helps you to schedule commands/tasks at specific time in Unix-like operating systems. We already published a [**beginners guides to Cron jobs**][1]. I have a few years experience in Linux, so setting up cron jobs is no big deal for me. But, it is not piece of cake for newbies. The noobs may unknowingly do small mistakes while editing plain text crontab and bring down all cron jobs. Just in case, if you think you might mess up with your cron jobs, there is a good alternative way. Say hello to **Crontab UI** , a web-based tool to easily and safely manage cron jobs in Unix-like operating systems.
-
-You don’t need to manually edit the crontab file to create, delete and manage cron jobs. Everything can be done via a web browser with a couple mouse clicks. Crontab UI allows you to easily create, edit, pause, delete, backup cron jobs, and even import, export and deploy jobs on other machines without much hassle. Error log, mailing and hooks support also possible. It is free, open source and written using NodeJS.
-
-### Installing Crontab UI
-
-Installing Crontab UI is just a one-liner command. Make sure you have installed NPM. If you haven’t install npm yet, refer the following link.
-
-Next, run the following command to install Crontab UI.
-```
-$ npm install -g crontab-ui
-
-```
-
-It’s that simple. Let us go ahead and see how to manage cron jobs using Crontab UI.
-
-### Easily And Safely Manage Cron Jobs In Linux
-
-To launch Crontab UI, simply run:
-```
-$ crontab-ui
-
-```
-
-You will see the following output:
-```
-Node version: 10.8.0
-Crontab UI is running at http://127.0.0.1:8000
-
-```
-
-Now, open your web browser and navigate to ****. Make sure the port no 8000 is allowed in your firewall/router.
-
-Please note that you can only access Crontab UI web dashboard within the local system itself.
-
-If you want to run Crontab UI with your system’s IP and custom port (so you can access it from any remote system in the network), use the following command instead:
-```
-$ HOST=0.0.0.0 PORT=9000 crontab-ui
-Node version: 10.8.0
-Crontab UI is running at http://0.0.0.0:9000
-
-```
-
-Now, Crontab UI can be accessed from the any system in the nework using URL – **http:// :9000**.
-
-This is how Crontab UI dashboard looks like.
-
-
-
-As you can see in the above screenshot, Crontab UI dashbaord is very simply. All options are self-explanatory.
-
-To exit Crontab UI, press **CTRL+C**.
-
-**Create, edit, run, stop, delete a cron job**
-
-To create a new cron job, click on “New” button. Enter your cron job details and click Save.
-
- 1. Name the cron job. It is optional.
- 2. The full command you want to run.
- 3. Choose schedule time. You can either choose the quick schedule time, (such as Startup, Hourly, Daily, Weekly, Monthly, Yearly) or set the exact time to run the command. After you choosing the schedule time, the syntax of the cron job will be shown in **Jobs** field.
- 4. Choose whether you want to enable error logging for the particular job.
-
-
-
-Here is my sample cron job.
-
-
-
-As you can see, I have setup a cron job to clear pacman cache at every month.
-
-Similarly, you can create any number of jobs as you want. You will see all cron jobs in the dashboard.
-
-
-
-If you wanted to change any parameter in a cron job, just click on the **Edit** button below the job and modify the parameters as you wish. To run a job immediately, click on the button that says **Run**. To stop a job, click **Stop** button. You can view the log details of any job by clicking on the **Log** button. If the job is no longer required, simply press **Delete** button.
-
-**Backup cron jobs**
-
-To backup all cron jobs, press the Backup from main dashboard and choose OK to confirm the backup.
-
-
-
-You can use this backup in case you messed with the contents of the crontab file.
-
-**Import/Export cron jobs to other systems**
-
-Another notable feature of Crontab UI is you can import, export and deploy cron jobs to other systems. If you have multiple systems on your network that requires the same cron jobs, just press **Export** button and choose the location to save the file. All contents of crontab file will be saved in a file named **crontab.db**.
-
-Here is the contents of the crontab.db file.
-```
-$ cat Downloads/crontab.db
-{"name":"Remove Pacman Cache","command":"rm -rf /var/cache/pacman","schedule":"@monthly","stopped":false,"timestamp":"Thu Aug 23 2018 10:34:19 GMT+0000 (Coordinated Universal Time)","logging":"true","mailing":{},"created":1535020459093,"_id":"lcVc1nSdaceqS1ut"}
-
-```
-
-Then you can transfer the entire crontab.db file to some other system and import its to the new system. You don’t need to manually create cron jobs in all systems. Just create them in one system and export and import all of them to every system on the network.
-
-**Get the contents from or save to existing crontab file**
-
-There are chances that you might have already created some cron jobs using **crontab** command. If so, you can retrieve contents of the existing crontab file by click on the **“Get from crontab”** button in main dashboard.
-
-
-
-Similarly, you can save the newly created jobs using Crontab UI utility to existing crontab file in your system. To do so, just click **Save to crontab** option in the dashboard.
-
-See? Managing cron jobs is not that complicated. Any newbie user can easily maintain any number of jobs without much hassle using Crontab UI. Give it a try and let us know what do you think about this tool. I am all ears!
-
-And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-easily-and-safely-manage-cron-jobs-in-linux/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
diff --git a/sources/tech/20180824 What Stable Kernel Should I Use.md b/sources/tech/20180824 What Stable Kernel Should I Use.md
deleted file mode 100644
index bfd64a2ec2..0000000000
--- a/sources/tech/20180824 What Stable Kernel Should I Use.md
+++ /dev/null
@@ -1,139 +0,0 @@
-What Stable Kernel Should I Use?
-======
-I get a lot of questions about people asking me about what stable kernel should they be using for their product/device/laptop/server/etc. all the time. Especially given the now-extended length of time that some kernels are being supported by me and others, this isn’t always a very obvious thing to determine. So this post is an attempt to write down my opinions on the matter. Of course, you are free to use what ever kernel version you want, but here’s what I recommend.
-
-As always, the opinions written here are my own, I speak for no one but myself.
-
-### What kernel to pick
-
-Here’s the my short list of what kernel you should use, raked from best to worst options. I’ll go into the details of all of these below, but if you just want the summary of all of this, here it is:
-
-Hierarchy of what kernel to use, from best solution to worst:
-
- * Supported kernel from your favorite Linux distribution
- * Latest stable release
- * Latest LTS release
- * Older LTS release that is still being maintained
-
-
-
-What kernel to never use:
-
- * Unmaintained kernel release
-
-
-
-To give numbers to the above, today, as of August 24, 2018, the front page of kernel.org looks like this:
-
-![][1]
-
-So, based on the above list that would mean that:
-
- * 4.18.5 is the latest stable release
- * 4.14.67 is the latest LTS release
- * 4.9.124, 4.4.152, and 3.16.57 are the older LTS releases that are still being maintained
- * 4.17.19 and 3.18.119 are “End of Life” kernels that have had a release in the past 60 days, and as such stick around on the kernel.org site for those who still might want to use them.
-
-
-
-Quite easy, right?
-
-Ok, now for some justification for all of this:
-
-### Distribution kernels
-
-The best solution for almost all Linux users is to just use the kernel from your favorite Linux distribution. Personally, I prefer the community based Linux distributions that constantly roll along with the latest updated kernel and it is supported by that developer community. Distributions in this category are Fedora, openSUSE, Arch, Gentoo, CoreOS, and others.
-
-All of these distributions use the latest stable upstream kernel release and make sure that any needed bugfixes are applied on a regular basis. That is the one of the most solid and best kernel that you can use when it comes to having the latest fixes ([remember all fixes are security fixes][2]) in it.
-
-There are some community distributions that take a bit longer to move to a new kernel release, but eventually get there and support the kernel they currently have quite well. Those are also great to use, and examples of these are Debian and Ubuntu.
-
-Just because I did not list your favorite distro here does not mean its kernel is not good. Look on the web site for the distro and make sure that the kernel package is constantly updated with the latest security patches, and all should be well.
-
-Lots of people seem to like the old, “traditional” model of a distribution and use RHEL, SLES, CentOS or the “LTS” Ubuntu release. Those distros pick a specific kernel version and then camp out on it for years, if not decades. They do loads of work backporting the latest bugfixes and sometimes new features to these kernels, all in a Quixote quest to keep the version number from never being changed, despite having many thousands of changes on top of that older kernel version. This work is a truly thankless job, and the developers assigned to these tasks do some wonderful work in order to achieve these goals. If you like never seeing your kernel version number change, then use these distributions. They usually cost some money to use, but the support you get from these companies is worth it when something goes wrong.
-
-So again, the best kernel you can use is one that someone else supports, and you can turn to for help. Use that support, usually you are already paying for it (for the enterprise distributions), and those companies know what they are doing.
-
-But, if you do not want to trust someone else to manage your kernel for you, or you have hardware that a distribution does not support, then you want to run the Latest stable release:
-
-### Latest stable release
-
-This kernel is the latest one from the Linux kernel developer community that they declare as “stable”. About every three months, the community releases a new stable kernel that contains all of the newest hardware support, the latest performance improvements, as well as the latest bugfixes for all parts of the kernel. Over the next 3 months, bugfixes that go into the next kernel release to be made are backported into this stable release, so that any users of this kernel are sure to get them as soon as possible.
-
-This is usually the kernel that most community distributions use as well, so you can be sure it is tested and has a large audience of users. Also, the kernel community (all 4000+ developers) are willing to help support users of this release, as it is the latest one that they made.
-
-After 3 months, a new kernel is released and you should move to it to ensure that you stay up to date, as support for this kernel is usually dropped a few weeks after the newer release happens.
-
-If you have new hardware that is purchased after the last LTS release came out, you almost are guaranteed to have to run this kernel in order to have it supported. So for desktops or new servers, this is usually the recommended kernel to be running.
-
-### Latest LTS release
-
-If your hardware relies on a vendors out-of-tree patch in order to make it work properly (like almost all embedded devices these days), then the next best kernel to be using is the latest LTS release. That release gets all of the latest kernel fixes that goes into the stable releases where applicable, and lots of users test and use it.
-
-Note, no new features and almost no new hardware support is ever added to these kernels, so if you need to use a new device, it is better to use the latest stable release, not this release.
-
-Also this release is common for users that do not like to worry about “major” upgrades happening on them every 3 months. So they stick to this release and upgrade every year instead, which is a fine practice to follow.
-
-The downsides of using this release is that you do not get the performance improvements that happen in newer kernels, except when you update to the next LTS kernel, potentially a year in the future. That could be significant for some workloads, so be very aware of this.
-
-Also, if you have problems with this kernel release, the first thing that any developer whom you report the issue to is going to ask you to do is, “does the latest stable release have this problem?” So you will need to be aware that support might not be as easy to get as with the latest stable releases.
-
-Now if you are stuck with a large patchset and can not update to a new LTS kernel once a year, perhaps you want the older LTS releases:
-
-### Older LTS release
-
-These releases have traditionally been supported by the community for 2 years, sometimes longer for when a major distribution relies on this (like Debian or SLES). However in the past year, thanks to a lot of suport and investment in testing and infrastructure from Google, Linaro, Linaro member companies, [kernelci.org][3], and others, these kernels are starting to be supported for much longer.
-
-Here’s the latest LTS releases and how long they will be supported for, as shown at [kernel.org/category/releases.html][4] on August 24, 2018:
-
-![][5]
-
-The reason that Google and other companies want to have these kernels live longer is due to the crazy (some will say broken) development model of almost all SoC chips these days. Those devices start their development lifecycle a few years before the chip is released, however that code is never merged upstream, resulting in a brand new chip being released based on a 2 year old kernel. These SoC trees usually have over 2 million lines added to them, making them something that I have started calling “Linux-like” kernels.
-
-If the LTS releases stop happening after 2 years, then support from the community instantly stops, and no one ends up doing bugfixes for them. This results in millions of very insecure devices floating around in the world, not something that is good for any ecosystem.
-
-Because of this dependency, these companies now require new devices to constantly update to the latest LTS releases as they happen for their specific release version (i.e. every 4.9.y release that happens). An example of this is the Android kernel requirements for new devices shipping for the “O” and now “P” releases specified the minimum kernel version allowed, and Android security releases might start to require those “.y” releases to happen more frequently on devices.
-
-I will note that some manufacturers are already doing this today. Sony is one great example of this, updating to the latest 4.4.y release on many of their new phones for their quarterly security release. Another good example is the small company Essential which has been tracking the 4.4.y releases faster than anyone that I know of.
-
-There is one huge caveat when using a kernel like this. The number of security fixes that get backported are not as great as with the latest LTS release, because the traditional model of the devices that use these older LTS kernels is a much more reduced user model. These kernels are not to be used in any type of “general computing” model where you have untrusted users or virtual machines, as the ability to do some of the recent Spectre-type fixes for older releases is greatly reduced, if present at all in some branches.
-
-So again, only use older LTS releases in a device that you fully control, or lock down with a very strong security model (like Android enforces using SELinux and application isolation). Never use these releases on a server with untrusted users, programs, or virtual machines.
-
-Also, support from the community for these older LTS releases is greatly reduced even from the normal LTS releases, if available at all. If you use these kernels, you really are on your own, and need to be able to support the kernel yourself, or rely on you SoC vendor to provide that support for you (note that almost none of them do provide that support, so beware…)
-
-### Unmaintained kernel release
-
-Surprisingly, many companies do just grab a random kernel release, slap it into their product and proceed to ship it in hundreds of thousands of units without a second thought. One crazy example of this would be the Lego Mindstorm systems that shipped a random -rc release of a kernel in their device for some unknown reason. A -rc release is a development release that not even the Linux kernel developers feel is ready for everyone to use just yet, let alone millions of users.
-
-You are of course free to do this if you want, but note that you really are on your own here. The community can not support you as no one is watching all kernel versions for specific issues, so you will have to rely on in-house support for everything that could go wrong. Which for some companies and systems, could be just fine, but be aware of the “hidden” cost this might cause if you do not plan for this up front.
-
-### Summary
-
-So, here’s a short list of different types of devices, and what I would recommend for their kernels:
-
- * Laptop / Desktop: Latest stable release
- * Server: Latest stable release or latest LTS release
- * Embedded device: Latest LTS release or older LTS release if the security model used is very strong and tight.
-
-
-
-And as for me, what do I run on my machines? My laptops run the latest development kernel (i.e. Linus’s development tree) plus whatever kernel changes I am currently working on and my servers run the latest stable release. So despite being in charge of the LTS releases, I don’t run them myself, except in testing systems. I rely on the development and latest stable releases to ensure that my machines are running the fastest and most secure releases that we know how to create at this point in time.
-
---------------------------------------------------------------------------------
-
-via: http://kroah.com/log/blog/2018/08/24/what-stable-kernel-should-i-use/
-
-作者:[Greg Kroah-Hartman][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://kroah.com
-[1]:https://s3.amazonaws.com/kroah.com/images/kernel.org_2018_08_24.png
-[2]:http://kroah.com/log/blog/2018/02/05/linux-kernel-release-model/
-[3]:https://kernelci.org/
-[4]:https://www.kernel.org/category/releases.html
-[5]:https://s3.amazonaws.com/kroah.com/images/kernel.org_releases_2018_08_24.png
diff --git a/sources/tech/20180827 4 tips for better tmux sessions.md b/sources/tech/20180827 4 tips for better tmux sessions.md
deleted file mode 100644
index b6d6a3e4fe..0000000000
--- a/sources/tech/20180827 4 tips for better tmux sessions.md
+++ /dev/null
@@ -1,89 +0,0 @@
-translating by lujun9972
-4 tips for better tmux sessions
-======
-
-
-
-The tmux utility, a terminal multiplexer, lets you treat your terminal as a multi-paned window into your system. You can arrange the configuration, run different processes in each, and generally make better use of your screen. We introduced some readers to this powerful tool [in this earlier article][1]. Here are some tips that will help you get more out of tmux if you’re getting started.
-
-This article assumes your current prefix key is Ctrl+b. If you’ve remapped that prefix, simply substitute your prefix in its place.
-
-### Set your terminal to automatically use tmux
-
-One of the biggest benefits of tmux is being able to disconnect and reconnect to sesions at wilI. This makes remote login sessions more powerful. Have you ever lost a connection and wished you could get back the work you were doing on the remote system? With tmux this problem is solved.
-
-However, you may sometimes find yourself doing work on a remote system, and realize you didn’t start a session. One way to avoid this is to have tmux start or attach every time you login to a system with in interactive shell.
-
-Add this to your remote system’s ~/.bash_profile file:
-
-```
-if [ -z "$TMUX" ]; then
- tmux attach -t default || tmux new -s default
-fi
-```
-
-Then logout of the remote system, and log back in with SSH. You’ll find you’re in a tmux session named default. This session will be regenerated at next login if you exit it. But more importantly, if you detach from it as normal, your work is waiting for you next time you login — especially useful if your connection is interrupted.
-
-Of course you can add this to your local system as well. Note that terminals inside most GUIs won’t use the default session automatically, because they aren’t login shells. While you can change that behavior, it may result in nesting that makes the session less usable, so proceed with caution.
-
-### Use zoom to focus on a single process
-
-While the point of tmux is to offer multiple windows, panes, and processes in a single session, sometimes you need to focus. If you’re in a process and need more space, or to focus on a single task, the zoom command works well. It expands the current pane to take up the entire current window space.
-
-Zoom can be useful in other situations too. For instance, imagine you’re using a terminal window in a graphical desktop. Panes can make it harder to copy and paste multiple lines from inside your tmux session. If you zoom the pane, you can do a clean copy/paste of multiple lines of data with ease.
-
-To zoom into the current pane, hit Ctrl+b, z. When you’re finished with the zoom function, hit the same key combo to unzoom the pane.
-
-### Bind some useful commands
-
-By default tmux has numerous commands available. But it’s helpful to have some of the more common operations bound to keys you can easily remember. Here are some examples you can add to your ~/.tmux.conf file to make sessions more enjoyable:
-
-```
-bind r source-file ~/.tmux.conf \; display "Reloaded config"
-```
-
-This command rereads the commands and bindings in your config file. Once you add this binding, exit any tmux sessions and then restart one. Now after you make any other future changes, simply run Ctrl+b, r and the changes will be part of your existing session.
-
-```
-bind V split-window -h
-bind H split-window
-```
-
-These commands make it easier to split the current window across a vertical axis (note that’s Shift+V) or across a horizontal axis (Shift+H).
-
-If you want to see how all keys are bound, use Ctrl+B, ? to see a list. You may see keys bound in copy-mode first, for when you’re working with copy and paste inside tmux. The prefix mode bindings are where you’ll see ones you’ve added above. Feel free to experiment with your own!
-
-### Use powerline for great justice
-
-[As reported in a previous Fedora Magazine article][2], the powerline utility is a fantastic addition to your shell. But it also has capabilities when used with tmux. Because tmux takes over the entire terminal space, the powerline window can provide more than just a better shell prompt.
-
- [][3]
-
-If you haven’t already, follow the instructions in the [Magazine’s powerline article][4] to install that utility. Then, install the addon [using sudo][5]:
-
-```
-sudo dnf install tmux-powerline
-```
-
-Now restart your session, and you’ll see a spiffy new status line at the bottom. Depending on the terminal width, the default status line now shows your current session ID, open windows, system information, date and time, and hostname. If you change directory into a git-controlled project, you’ll see the branch and color-coded status as well.
-
-Of course, this status bar is highly configurable as well. Enjoy your new supercharged tmux session, and have fun experimenting with it.
-
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/4-tips-better-tmux-sessions/
-
-作者:[Paul W. Frields][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://fedoramagazine.org/author/pfrields/
-[1]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
-[2]:https://fedoramagazine.org/add-power-terminal-powerline/
-[3]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot-from-2018-08-25-19-36-53.png
-[4]:https://fedoramagazine.org/add-power-terminal-powerline/
-[5]:https://fedoramagazine.org/howto-use-sudo/
diff --git a/sources/tech/20180827 Solve -error- failed to commit transaction (conflicting files)- In Arch Linux.md b/sources/tech/20180827 Solve -error- failed to commit transaction (conflicting files)- In Arch Linux.md
deleted file mode 100644
index bb0479e7fe..0000000000
--- a/sources/tech/20180827 Solve -error- failed to commit transaction (conflicting files)- In Arch Linux.md
+++ /dev/null
@@ -1,50 +0,0 @@
-translating by lujun9972
-Solve "error: failed to commit transaction (conflicting files)" In Arch Linux
-======
-
-
-
-It’s been a month since I upgraded my Arch Linux desktop. Today, I tried to update my Arch Linux system, and ran into an error that said **“error: failed to commit transaction (conflicting files) stfl: /usr/lib/libstfl.so.0 exists in filesystem”**. It looks like one library (/usr/lib/libstfl.so.0) that exists on my filesystem and pacman can’t upgrade it. If you’re encountered with the same error, here is a quick fix to resolve it.
-
-### Solve “error: failed to commit transaction (conflicting files)” In Arch Linux
-
-You have three options.
-
-1. Simply ignore the problematic **stfl** library from being upgraded and try to update the system again. Refer this guide to know [**how to ignore package from being upgraded**][1].
-
-2. Overwrite the package using command:
-```
-$ sudo pacman -Syu --overwrite /usr/lib/libstfl.so.0
-```
-
-3. Remove stfl library file manually and try to upgrade the system again. Please make sure the intended package is not a dependency to any important package. and check the archlinux.org whether are mentions of this conflict.
-```
-$ sudo rm /usr/lib/libstfl.so.0
-```
-
-Now, try to update the system:
-```
-$ sudo pacman -Syu
-```
-
-I chose the third option and just deleted the file and upgraded my Arch Linux system. It works now!
-
-Hope this helps. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-solve-error-failed-to-commit-transaction-conflicting-files-in-arch-linux/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/safely-ignore-package-upgraded-arch-linux/
diff --git a/sources/tech/20180831 Publishing Markdown to HTML with MDwiki.md b/sources/tech/20180831 Publishing Markdown to HTML with MDwiki.md
index c25239b7ba..769f9ba420 100644
--- a/sources/tech/20180831 Publishing Markdown to HTML with MDwiki.md
+++ b/sources/tech/20180831 Publishing Markdown to HTML with MDwiki.md
@@ -1,3 +1,4 @@
+Translating by z52527
Publishing Markdown to HTML with MDwiki
======
diff --git a/sources/tech/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md b/sources/tech/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md
deleted file mode 100644
index 11d266e163..0000000000
--- a/sources/tech/20180906 How To Limit Network Bandwidth In Linux Using Wondershaper.md
+++ /dev/null
@@ -1,196 +0,0 @@
-How To Limit Network Bandwidth In Linux Using Wondershaper
-======
-
-
-
-This tutorial will help you to easily limit network bandwidth and shape your network traffic in Unix-like operating systems. By limiting the network bandwidth usage, you can save unnecessary bandwidth consumption’s by applications, such as package managers (pacman, yum, apt), web browsers, torrent clients, download managers etc., and prevent the bandwidth abuse by a single or multiple users in the network. For the purpose of this tutorial, we will be using a command line utility named **Wondershaper**. Trust me, it is not that hard as you may think. It is one of the easiest and quickest way ever I have come across to limit the Internet or local network bandwidth usage in your own Linux system. Read on.
-
-Please be mindful that the aforementioned utility can only limit the incoming and outgoing traffic of your local network interfaces, not the interfaces of your router or modem. In other words, Wondershaper will only limit the network bandwidth in your local system itself, not any other systems in the network. These utility is mainly designed for limiting the bandwidth of one or more network adapters in your local system. Hope you got my point.
-
-Let us see how to use Wondershaper to shape the network traffic.
-
-### Limit Network Bandwidth In Linux Using Wondershaper
-
-**Wondershaper** is simple script used to limit the bandwidth of your system’s network adapter(s). It limits the bandwidth iproute’s tc command, but greatly simplifies its operation.
-
-**Installing Wondershaper**
-
-To install the latest version, git clone wondershaoer repository:
-
-```
-$ git clone https://github.com/magnific0/wondershaper.git
-
-```
-
-Go to the wondershaper directory and install it as show below
-
-```
-$ cd wondershaper
-
-$ sudo make install
-
-```
-
-And, run the following command to start wondershaper service automatically on every reboot.
-
-```
-$ sudo systemctl enable wondershaper.service
-
-$ sudo systemctl start wondershaper.service
-
-```
-
-You can also install using your distribution’s package manager (official or non-official) if you don’t mind the latest version.
-
-Wondershaper is available in [**AUR**][1], so you can install it in Arch-based systems using AUR helper programs such as [**Yay**][2].
-
-```
-$ yay -S wondershaper-git
-
-```
-
-On Debian, Ubuntu, Linux Mint:
-
-```
-$ sudo apt-get install wondershaper
-
-```
-
-On Fedora:
-
-```
-$ sudo dnf install wondershaper
-
-```
-
-On RHEL, CentOS, enable EPEL repository and install wondershaper as shown below.
-
-```
-$ sudo yum install epel-release
-
-$ sudo yum install wondershaper
-
-```
-
-Finally, start wondershaper service automatically on every reboot.
-
-```
-$ sudo systemctl enable wondershaper.service
-
-$ sudo systemctl start wondershaper.service
-
-```
-
-**Usage**
-
-First, find the name of your network interface. Here are some common ways to find the details of a network card.
-
-```
-$ ip addr
-
-$ route
-
-$ ifconfig
-
-```
-
-Once you find the network card name, you can limit the bandwidth rate as shown below.
-
-```
-$ sudo wondershaper -a -d -u
-
-```
-
-For instance, if your network card name is **enp0s8** and you wanted to limit the bandwidth to **1024 Kbps** for **downloads** and **512 kbps** for **uploads** , the command would be:
-
-```
-$ sudo wondershaper -a enp0s8 -d 1024 -u 512
-
-```
-
-Where,
-
- * **-a** : network card name
- * **-d** : download rate
- * **-u** : upload rate
-
-
-
-To clear the limits from a network adapter, simply run:
-
-```
-$ sudo wondershaper -c -a enp0s8
-
-```
-
-Or
-
-```
-$ sudo wondershaper -c enp0s8
-
-```
-
-Just in case, there are more than one network card available in your system, you need to manually set the download/upload rates for each network interface card as described above.
-
-If you have installed Wondershaper by cloning its GitHub repository, there is a configuration named **wondershaper.conf** exists in **/etc/conf.d/** location. Make sure you have set the download or upload rates by modifying the appropriate values(network card name, download/upload rate) in this file.
-
-```
-$ sudo nano /etc/conf.d/wondershaper.conf
-
-[wondershaper]
-# Adapter
-#
-IFACE="eth0"
-
-# Download rate in Kbps
-#
-DSPEED="2048"
-
-# Upload rate in Kbps
-#
-USPEED="512"
-
-```
-
-Here is the sample before Wondershaper:
-
-After enabling Wondershaper:
-
-As you can see, the download rate has been tremendously reduced after limiting the bandwidth using WOndershaper in my Ubuntu 18.o4 LTS server.
-
-For more details, view the help section by running the following command:
-
-```
-$ wondershaper -h
-
-```
-
-Or, refer man pages.
-
-```
-$ man wondershaper
-
-```
-
-As far as tested, Wondershaper worked just fine as described above. Give it a try and let us know what do you think about this utility.
-
-And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned.
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-limit-network-bandwidth-in-linux-using-wondershaper/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[1]: https://aur.archlinux.org/packages/wondershaper-git/
-[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
diff --git a/sources/tech/20180907 6.828 lab tools guide.md b/sources/tech/20180907 6.828 lab tools guide.md
new file mode 100644
index 0000000000..e9061a3097
--- /dev/null
+++ b/sources/tech/20180907 6.828 lab tools guide.md
@@ -0,0 +1,201 @@
+6.828 lab tools guide
+======
+### 6.828 lab tools guide
+
+Familiarity with your environment is crucial for productive development and debugging. This page gives a brief overview of the JOS environment and useful GDB and QEMU commands. Don't take our word for it, though. Read the GDB and QEMU manuals. These are powerful tools that are worth knowing how to use.
+
+#### Debugging tips
+
+##### Kernel
+
+GDB is your friend. Use the qemu-gdb target (or its `qemu-gdb-nox` variant) to make QEMU wait for GDB to attach. See the GDB reference below for some commands that are useful when debugging kernels.
+
+If you're getting unexpected interrupts, exceptions, or triple faults, you can ask QEMU to generate a detailed log of interrupts using the -d argument.
+
+To debug virtual memory issues, try the QEMU monitor commands info mem (for a high-level overview) or info pg (for lots of detail). Note that these commands only display the _current_ page table.
+
+(Lab 4+) To debug multiple CPUs, use GDB's thread-related commands like thread and info threads.
+
+##### User environments (lab 3+)
+
+GDB also lets you debug user environments, but there are a few things you need to watch out for, since GDB doesn't know that there's a distinction between multiple user environments, or between user and kernel.
+
+You can start JOS with a specific user environment using make run- _name_ (or you can edit `kern/init.c` directly). To make QEMU wait for GDB to attach, use the run- _name_ -gdb variant.
+
+You can symbolically debug user code, just like you can kernel code, but you have to tell GDB which symbol table to use with the symbol-file command, since it can only use one symbol table at a time. The provided `.gdbinit` loads the kernel symbol table, `obj/kern/kernel`. The symbol table for a user environment is in its ELF binary, so you can load it using symbol-file obj/user/ _name_. _Don't_ load symbols from any `.o` files, as those haven't been relocated by the linker (libraries are statically linked into JOS user binaries, so those symbols are already included in each user binary). Make sure you get the _right_ user binary; library functions will be linked at different EIPs in different binaries and GDB won't know any better!
+
+(Lab 4+) Since GDB is attached to the virtual machine as a whole, it sees clock interrupts as just another control transfer. This makes it basically impossible to step through user code because a clock interrupt is virtually guaranteed the moment you let the VM run again. The stepi command works because it suppresses interrupts, but it only steps one assembly instruction. Breakpoints generally work, but watch out because you can hit the same EIP in a different environment (indeed, a different binary altogether!).
+
+#### Reference
+
+##### JOS makefile
+
+The JOS GNUmakefile includes a number of phony targets for running JOS in various ways. All of these targets configure QEMU to listen for GDB connections (the `*-gdb` targets also wait for this connection). To start once QEMU is running, simply run gdb from your lab directory. We provide a `.gdbinit` file that automatically points GDB at QEMU, loads the kernel symbol file, and switches between 16-bit and 32-bit mode. Exiting GDB will shut down QEMU.
+
+ * make qemu
+Build everything and start QEMU with the VGA console in a new window and the serial console in your terminal. To exit, either close the VGA window or press `Ctrl-c` or `Ctrl-a x` in your terminal.
+ * make qemu-nox
+Like `make qemu`, but run with only the serial console. To exit, press `Ctrl-a x`. This is particularly useful over SSH connections to Athena dialups because the VGA window consumes a lot of bandwidth.
+ * make qemu-gdb
+Like `make qemu`, but rather than passively accepting GDB connections at any time, this pauses at the first machine instruction and waits for a GDB connection.
+ * make qemu-nox-gdb
+A combination of the `qemu-nox` and `qemu-gdb` targets.
+ * make run- _name_
+(Lab 3+) Run user program _name_. For example, `make run-hello` runs `user/hello.c`.
+ * make run- _name_ -nox, run- _name_ -gdb, run- _name_ -gdb-nox,
+(Lab 3+) Variants of `run-name` that correspond to the variants of the `qemu` target.
+
+
+
+The makefile also accepts a few useful variables:
+
+ * make V=1 ...
+Verbose mode. Print out every command being executed, including arguments.
+ * make V=1 grade
+Stop after any failed grade test and leave the QEMU output in `jos.out` for inspection.
+ * make QEMUEXTRA=' _args_ ' ...
+Specify additional arguments to pass to QEMU.
+
+
+
+##### JOS obj/
+
+The JOS GNUmakefile includes a number of phony targets for running JOS in various ways. All of these targets configure QEMU to listen for GDB connections (thetargets also wait for this connection). To start once QEMU is running, simply runfrom your lab directory. We provide afile that automatically points GDB at QEMU, loads the kernel symbol file, and switches between 16-bit and 32-bit mode. Exiting GDB will shut down QEMU.The makefile also accepts a few useful variables:
+
+When building JOS, the makefile also produces some additional output files that may prove useful while debugging:
+
+ * `obj/boot/boot.asm`, `obj/kern/kernel.asm`, `obj/user/hello.asm`, etc.
+Assembly code listings for the bootloader, kernel, and user programs.
+ * `obj/kern/kernel.sym`, `obj/user/hello.sym`, etc.
+Symbol tables for the kernel and user programs.
+ * `obj/boot/boot.out`, `obj/kern/kernel`, `obj/user/hello`, etc
+Linked ELF images of the kernel and user programs. These contain symbol information that can be used by GDB.
+
+
+
+##### GDB
+
+See the [GDB manual][1] for a full guide to GDB commands. Here are some particularly useful commands for 6.828, some of which don't typically come up outside of OS development.
+
+ * Ctrl-c
+Halt the machine and break in to GDB at the current instruction. If QEMU has multiple virtual CPUs, this halts all of them.
+ * c (or continue)
+Continue execution until the next breakpoint or `Ctrl-c`.
+ * si (or stepi)
+Execute one machine instruction.
+ * b function or b file:line (or breakpoint)
+Set a breakpoint at the given function or line.
+ * b * _addr_ (or breakpoint)
+Set a breakpoint at the EIP _addr_.
+ * set print pretty
+Enable pretty-printing of arrays and structs.
+ * info registers
+Print the general purpose registers, `eip`, `eflags`, and the segment selectors. For a much more thorough dump of the machine register state, see QEMU's own `info registers` command.
+ * x/ _N_ x _addr_
+Display a hex dump of _N_ words starting at virtual address _addr_. If _N_ is omitted, it defaults to 1. _addr_ can be any expression.
+ * x/ _N_ i _addr_
+Display the _N_ assembly instructions starting at _addr_. Using `$eip` as _addr_ will display the instructions at the current instruction pointer.
+ * symbol-file _file_
+(Lab 3+) Switch to symbol file _file_. When GDB attaches to QEMU, it has no notion of the process boundaries within the virtual machine, so we have to tell it which symbols to use. By default, we configure GDB to use the kernel symbol file, `obj/kern/kernel`. If the machine is running user code, say `hello.c`, you can switch to the hello symbol file using `symbol-file obj/user/hello`.
+
+
+
+QEMU represents each virtual CPU as a thread in GDB, so you can use all of GDB's thread-related commands to view or manipulate QEMU's virtual CPUs.
+
+ * thread _n_
+GDB focuses on one thread (i.e., CPU) at a time. This command switches that focus to thread _n_ , numbered from zero.
+ * info threads
+List all threads (i.e., CPUs), including their state (active or halted) and what function they're in.
+
+
+
+##### QEMU
+
+QEMU includes a built-in monitor that can inspect and modify the machine state in useful ways. To enter the monitor, press Ctrl-a c in the terminal running QEMU. Press Ctrl-a c again to switch back to the serial console.
+
+For a complete reference to the monitor commands, see the [QEMU manual][2]. Here are some particularly useful commands:
+
+ * xp/ _N_ x _paddr_
+Display a hex dump of _N_ words starting at _physical_ address _paddr_. If _N_ is omitted, it defaults to 1. This is the physical memory analogue of GDB's `x` command.
+
+ * info registers
+Display a full dump of the machine's internal register state. In particular, this includes the machine's _hidden_ segment state for the segment selectors and the local, global, and interrupt descriptor tables, plus the task register. This hidden state is the information the virtual CPU read from the GDT/LDT when the segment selector was loaded. Here's the CS when running in the JOS kernel in lab 1 and the meaning of each field:
+```
+ CS =0008 10000000 ffffffff 10cf9a00 DPL=0 CS32 [-R-]
+```
+
+ * `CS =0008`
+The visible part of the code selector. We're using segment 0x8. This also tells us we're referring to the global descriptor table (0x8 &4=0), and our CPL (current privilege level) is 0x8&3=0.
+ * `10000000`
+The base of this segment. Linear address = logical address + 0x10000000.
+ * `ffffffff`
+The limit of this segment. Linear addresses above 0xffffffff will result in segment violation exceptions.
+ * `10cf9a00`
+The raw flags of this segment, which QEMU helpfully decodes for us in the next few fields.
+ * `DPL=0`
+The privilege level of this segment. Only code running with privilege level 0 can load this segment.
+ * `CS32`
+This is a 32-bit code segment. Other values include `DS` for data segments (not to be confused with the DS register), and `LDT` for local descriptor tables.
+ * `[-R-]`
+This segment is read-only.
+ * info mem
+(Lab 2+) Display mapped virtual memory and permissions. For example,
+```
+ ef7c0000-ef800000 00040000 urw
+ efbf8000-efc00000 00008000 -rw
+
+```
+
+tells us that the 0x00040000 bytes of memory from 0xef7c0000 to 0xef800000 are mapped read/write and user-accessible, while the memory from 0xefbf8000 to 0xefc00000 is mapped read/write, but only kernel-accessible.
+
+ * info pg
+(Lab 2+) Display the current page table structure. The output is similar to `info mem`, but distinguishes page directory entries and page table entries and gives the permissions for each separately. Repeated PTE's and entire page tables are folded up into a single line. For example,
+```
+ VPN range Entry Flags Physical page
+ [00000-003ff] PDE[000] -------UWP
+ [00200-00233] PTE[200-233] -------U-P 00380 0037e 0037d 0037c 0037b 0037a ..
+ [00800-00bff] PDE[002] ----A--UWP
+ [00800-00801] PTE[000-001] ----A--U-P 0034b 00349
+ [00802-00802] PTE[002] -------U-P 00348
+
+```
+
+This shows two page directory entries, spanning virtual addresses 0x00000000 to 0x003fffff and 0x00800000 to 0x00bfffff, respectively. Both PDE's are present, writable, and user and the second PDE is also accessed. The second of these page tables maps three pages, spanning virtual addresses 0x00800000 through 0x00802fff, of which the first two are present, user, and accessed and the third is only present and user. The first of these PTE's maps physical page 0x34b.
+
+
+
+
+QEMU also takes some useful command line arguments, which can be passed into the JOS makefile using the
+
+ * make QEMUEXTRA='-d int' ...
+Log all interrupts, along with a full register dump, to `qemu.log`. You can ignore the first two log entries, "SMM: enter" and "SMM: after RMS", as these are generated before entering the boot loader. After this, log entries look like
+```
+ 4: v=30 e=0000 i=1 cpl=3 IP=001b:00800e2e pc=00800e2e SP=0023:eebfdf28 EAX=00000005
+ EAX=00000005 EBX=00001002 ECX=00200000 EDX=00000000
+ ESI=00000805 EDI=00200000 EBP=eebfdf60 ESP=eebfdf28
+ ...
+
+```
+
+The first line describes the interrupt. The `4:` is just a log record counter. `v` gives the vector number in hex. `e` gives the error code. `i=1` indicates that this was produced by an `int` instruction (versus a hardware interrupt). The rest of the line should be self-explanatory. See info registers for a description of the register dump that follows.
+
+Note: If you're running a pre-0.15 version of QEMU, the log will be written to `/tmp` instead of the current directory.
+
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://pdos.csail.mit.edu/6.828/2018/labguide.html
+
+作者:[csail.mit][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://pdos.csail.mit.edu
+[b]: https://github.com/lujun9972
+[1]: http://sourceware.org/gdb/current/onlinedocs/gdb/
+[2]: http://wiki.qemu.org/download/qemu-doc.html#pcsys_005fmonitor
diff --git a/sources/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md b/sources/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md
deleted file mode 100644
index a9d3eb0895..0000000000
--- a/sources/tech/20180907 How to Use the Netplan Network Configuration Tool on Linux.md
+++ /dev/null
@@ -1,230 +0,0 @@
-LuuMing translating
-How to Use the Netplan Network Configuration Tool on Linux
-======
-
-
-
-For years Linux admins and users have configured their network interfaces in the same way. For instance, if you’re a Ubuntu user, you could either configure the network connection via the desktop GUI or from within the /etc/network/interfaces file. The configuration was incredibly easy and never failed to work. The configuration within that file looked something like this:
-
-```
-auto enp10s0
-
-iface enp10s0 inet static
-
-address 192.168.1.162
-
-netmask 255.255.255.0
-
-gateway 192.168.1.100
-
-dns-nameservers 1.0.0.1,1.1.1.1
-
-```
-
-Save and close that file. Restart networking with the command:
-
-```
-sudo systemctl restart networking
-
-```
-
-Or, if you’re not using a non-systemd distribution, you could restart networking the old fashioned way like so:
-
-```
-sudo /etc/init.d/networking restart
-
-```
-
-Your network will restart and the newly configured interface is good to go.
-
-That’s how it’s been done for years. Until now. With certain distributions (such as Ubuntu Linux 18.04), the configuration and control of networking has changed considerably. Instead of that interfaces file and using the /etc/init.d/networking script, we now turn to [Netplan][1]. Netplan is a command line utility for the configuration of networking on certain Linux distributions. Netplan uses YAML description files to configure network interfaces and, from those descriptions, will generate the necessary configuration options for any given renderer tool.
-
-I want to show you how to use Netplan on Linux, to configure a static IP address and a DHCP address. I’ll be demonstrating on Ubuntu Server 18.04. I will give you one word of warning, the .yaml files you create for Netplan must be consistent in spacing, otherwise they’ll fail to work. You don’t have to use a specific spacing for each line, it just has to remain consistent.
-
-### The new configuration files
-
-Open a terminal window (or log into your Ubuntu Server via SSH). You will find the new configuration files for Netplan in the /etc/netplan directory. Change into that directory with the command cd /etc/netplan. Once in that directory, you will probably only see a single file:
-
-```
-01-netcfg.yaml
-
-```
-
-You can create a new file or edit the default. If you opt to edit the default, I suggest making a copy with the command:
-
-```
-sudo cp /etc/netplan/01-netcfg.yaml /etc/netplan/01-netcfg.yaml.bak
-
-```
-
-With your backup in place, you’re ready to configure.
-
-### Network Device Name
-
-Before you configure your static IP address, you’ll need to know the name of device to be configured. To do that, you can issue the command ip a and find out which device is to be used (Figure 1).
-
-![netplan][3]
-
-Figure 1: Finding our device name with the ip a command.
-
-[Used with permission][4]
-
-I’ll be configuring ens5 for a static IP address.
-
-### Configuring a Static IP Address
-
-Open the original .yaml file for editing with the command:
-
-```
-sudo nano /etc/netplan/01-netcfg.yaml
-
-```
-
-The layout of the file looks like this:
-
-network:
-
-Version: 2
-
-Renderer: networkd
-
-ethernets:
-
-DEVICE_NAME:
-
-Dhcp4: yes/no
-
-Addresses: [IP/NETMASK]
-
-Gateway: GATEWAY
-
-Nameservers:
-
-Addresses: [NAMESERVER, NAMESERVER]
-
-Where:
-
- * DEVICE_NAME is the actual device name to be configured.
-
- * yes/no is an option to enable or disable dhcp4.
-
- * IP is the IP address for the device.
-
- * NETMASK is the netmask for the IP address.
-
- * GATEWAY is the address for your gateway.
-
- * NAMESERVER is the comma-separated list of DNS nameservers.
-
-
-
-
-Here’s a sample .yaml file:
-
-```
-network:
-
- version: 2
-
- renderer: networkd
-
- ethernets:
-
- ens5:
-
- dhcp4: no
-
- addresses: [192.168.1.230/24]
-
- gateway4: 192.168.1.254
-
- nameservers:
-
- addresses: [8.8.4.4,8.8.8.8]
-
-```
-
-Edit the above to fit your networking needs. Save and close that file.
-
-Notice the netmask is no longer configured in the form 255.255.255.0. Instead, the netmask is added to the IP address.
-
-### Testing the Configuration
-
-Before we apply the change, let’s test the configuration. To do that, issue the command:
-
-```
-sudo netplan try
-
-```
-
-The above command will validate the configuration before applying it. If it succeeds, you will see Configuration accepted. In other words, Netplan will attempt to apply the new settings to a running system. Should the new configuration file fail, Netplan will automatically revert to the previous working configuration. Should the new configuration work, it will be applied.
-
-### Applying the New Configuration
-
-If you are certain of your configuration file, you can skip the try option and go directly to applying the new options. The command for this is:
-
-```
-sudo netplan apply
-
-```
-
-At this point, you can issue the command ip a to see that your new address configurations are in place.
-
-### Configuring DHCP
-
-Although you probably won’t be configuring your server for DHCP, it’s always good to know how to do this. For example, you might not know what static IP addresses are currently available on your network. You could configure the device for DHCP, get an IP address, and then reconfigure that address as static.
-
-To use DHCP with Netplan, the configuration file would look something like this:
-
-```
-network:
-
- version: 2
-
- renderer: networkd
-
- ethernets:
-
- ens5:
-
- Addresses: []
-
- dhcp4: true
-
- optional: true
-
-```
-
-Save and close that file. Test the file with:
-
-```
-sudo netplan try
-
-```
-
-Netplan should succeed and apply the DHCP configuration. You could then issue the ip a command, get the dynamically assigned address, and then reconfigure a static address. Or, you could leave it set to use DHCP (but seeing as how this is a server, you probably won’t want to do that).
-
-Should you have more than one interface, you could name the second .yaml configuration file 02-netcfg.yaml. Netplan will apply the configuration files in numerical order, so 01 will be applied before 02. Create as many configuration files as needed for your server.
-
-### That’s All There Is
-
-Believe it or not, that’s all there is to using Netplan. Although it is a significant change to how we’re accustomed to configuring network addresses, it’s not all that hard to get used to. But this style of configuration is here to stay… so you will need to get used to it.
-
-Learn more about Linux through the free ["Introduction to Linux" ][5]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/9/how-use-netplan-network-configuration-tool-linux
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linux.com/users/jlwallen
-[1]: https://netplan.io/
-[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/netplan_1.jpg?itok=XuIsXWbV (netplan)
-[4]: /licenses/category/used-permission
-[5]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180911 Tools Used in 6.828.md b/sources/tech/20180911 Tools Used in 6.828.md
new file mode 100644
index 0000000000..c9afeae4ea
--- /dev/null
+++ b/sources/tech/20180911 Tools Used in 6.828.md
@@ -0,0 +1,247 @@
+Tools Used in 6.828
+======
+### Tools Used in 6.828
+
+You'll use two sets of tools in this class: an x86 emulator, QEMU, for running your kernel; and a compiler toolchain, including assembler, linker, C compiler, and debugger, for compiling and testing your kernel. This page has the information you'll need to download and install your own copies. This class assumes familiarity with Unix commands throughout.
+
+We highly recommend using a Debathena machine, such as athena.dialup.mit.edu, to work on the labs. If you use the MIT Athena machines that run Linux, then all the software tools you will need for this course are located in the 6.828 locker: just type 'add -f 6.828' to get access to them.
+
+If you don't have access to a Debathena machine, we recommend you use a virtual machine with Linux. If you really want to, you can build and install the tools on your own machine. We have instructions below for Linux and MacOS computers.
+
+It should be possible to get this development environment running under windows with the help of [Cygwin][1]. Install cygwin, and be sure to install the flex and bison packages (they are under the development header).
+
+For an overview of useful commands in the tools used in 6.828, see the [lab tools guide][2].
+
+#### Compiler Toolchain
+
+A "compiler toolchain" is the set of programs, including a C compiler, assemblers, and linkers, that turn code into executable binaries. You'll need a compiler toolchain that generates code for 32-bit Intel architectures ("x86" architectures) in the ELF binary format.
+
+##### Test Your Compiler Toolchain
+
+Modern Linux and BSD UNIX distributions already provide a toolchain suitable for 6.828. To test your distribution, try the following commands:
+
+```
+% objdump -i
+
+```
+
+The second line should say `elf32-i386`.
+
+```
+% gcc -m32 -print-libgcc-file-name
+
+```
+
+The command should print something like `/usr/lib/gcc/i486-linux-gnu/version/libgcc.a` or `/usr/lib/gcc/x86_64-linux-gnu/version/32/libgcc.a`
+
+If both these commands succeed, you're all set, and don't need to compile your own toolchain.
+
+If the gcc command fails, you may need to install a development environment. On Ubuntu Linux, try this:
+
+```
+% sudo apt-get install -y build-essential gdb
+
+```
+
+On 64-bit machines, you may need to install a 32-bit support library. The symptom is that linking fails with error messages like "`__udivdi3` not found" and "`__muldi3` not found". On Ubuntu Linux, try this to fix the problem:
+
+```
+% sudo apt-get install gcc-multilib
+
+```
+
+##### Using a Virtual Machine
+
+Otherwise, the easiest way to get a compatible toolchain is to install a modern Linux distribution on your computer. With platform virtualization, Linux can cohabitate with your normal computing environment. Installing a Linux virtual machine is a two step process. First, you download the virtualization platform.
+
+ * [**VirtualBox**][3] (free for Mac, Linux, Windows) — [Download page][3]
+ * [VMware Player][4] (free for Linux and Windows, registration required)
+ * [VMware Fusion][5] (Downloadable from IS&T for free).
+
+
+
+VirtualBox is a little slower and less flexible, but free!
+
+Once the virtualization platform is installed, download a boot disk image for the Linux distribution of your choice.
+
+ * [Ubuntu Desktop][6] is what we use.
+
+
+
+This will download a file named something like `ubuntu-10.04.1-desktop-i386.iso`. Start up your virtualization platform and create a new (32-bit) virtual machine. Use the downloaded Ubuntu image as a boot disk; the procedure differs among VMs but is pretty simple. Type `objdump -i`, as above, to verify that your toolchain is now set up. You will do your work inside the VM.
+
+##### Building Your Own Compiler Toolchain
+
+This will take longer to set up, but give slightly better performance than a virtual machine, and lets you work in your own familiar environment (Unix/MacOS). Fast-forward to the end for MacOS instructions.
+
+###### Linux
+
+You can use your own tool chain by adding the following line to `conf/env.mk`:
+
+```
+GCCPREFIX=
+
+```
+
+We assume that you are installing the toolchain into `/usr/local`. You will need a fair amount of disk space to compile the tools (around 1GiB). If you don't have that much space, delete each directory after its `make install` step.
+
+Download the following packages:
+
++ ftp://ftp.gmplib.org/pub/gmp-5.0.2/gmp-5.0.2.tar.bz2
++ https://www.mpfr.org/mpfr-3.1.2/mpfr-3.1.2.tar.bz2
++ http://www.multiprecision.org/downloads/mpc-0.9.tar.gz
++ http://ftpmirror.gnu.org/binutils/binutils-2.21.1.tar.bz2
++ http://ftpmirror.gnu.org/gcc/gcc-4.6.4/gcc-core-4.6.4.tar.bz2
++ http://ftpmirror.gnu.org/gdb/gdb-7.3.1.tar.bz2
+
+(You may also use newer versions of these packages.) Unpack and build the packages. The `green bold` text shows you how to install into `/usr/local`, which is what we recommend. To install into a different directory, $PFX, note the differences in lighter type ([hide][7]). If you have problems, see below.
+
+```
+export PATH=$PFX/bin:$PATH
+export LD_LIBRARY_PATH=$PFX/lib:$LD_LIBRARY_PATH
+
+tar xjf gmp-5.0.2.tar.bz2
+cd gmp-5.0.2
+./configure --prefix=$PFX
+make
+make install # This step may require privilege (sudo make install)
+cd ..
+
+tar xjf mpfr-3.1.2.tar.bz2
+cd mpfr-3.1.2
+./configure --prefix=$PFX --with-gmp=$PFX
+make
+make install # This step may require privilege (sudo make install)
+cd ..
+
+tar xzf mpc-0.9.tar.gz
+cd mpc-0.9
+./configure --prefix=$PFX --with-gmp=$PFX --with-mpfr=$PFX
+make
+make install # This step may require privilege (sudo make install)
+cd ..
+
+
+tar xjf binutils-2.21.1.tar.bz2
+cd binutils-2.21.1
+./configure --prefix=$PFX --target=i386-jos-elf --disable-werror
+make
+make install # This step may require privilege (sudo make install)
+cd ..
+
+i386-jos-elf-objdump -i
+# Should produce output like:
+# BFD header file version (GNU Binutils) 2.21.1
+# elf32-i386
+# (header little endian, data little endian)
+# i386...
+
+
+tar xjf gcc-core-4.6.4.tar.bz2
+cd gcc-4.6.4
+mkdir build # GCC will not compile correctly unless you build in a separate directory
+cd build
+../configure --prefix=$PFX --with-gmp=$PFX --with-mpfr=$PFX --with-mpc=$PFX \
+ --target=i386-jos-elf --disable-werror \
+ --disable-libssp --disable-libmudflap --with-newlib \
+ --without-headers --enable-languages=c MAKEINFO=missing
+make all-gcc
+make install-gcc # This step may require privilege (sudo make install-gcc)
+make all-target-libgcc
+make install-target-libgcc # This step may require privilege (sudo make install-target-libgcc)
+cd ../..
+
+i386-jos-elf-gcc -v
+# Should produce output like:
+# Using built-in specs.
+# COLLECT_GCC=i386-jos-elf-gcc
+# COLLECT_LTO_WRAPPER=/usr/local/libexec/gcc/i386-jos-elf/4.6.4/lto-wrapper
+# Target: i386-jos-elf
+
+
+tar xjf gdb-7.3.1.tar.bz2
+cd gdb-7.3.1
+./configure --prefix=$PFX --target=i386-jos-elf --program-prefix=i386-jos-elf- \
+ --disable-werror
+make all
+make install # This step may require privilege (sudo make install)
+cd ..
+
+```
+
+###### Linux troubleshooting
+
+ * Q. I can't run `make install` because I don't have root permission on this machine.
+A. Our instructions assume you are installing into the `/usr/local` directory. However, this may not be allowed in your environment. If you can only install code into your home directory, that's OK. In the instructions above, replace `--prefix=/usr/local` with `--prefix=$HOME` (and [click here][7] to update the instructions further). You will also need to change your `PATH` and `LD_LIBRARY_PATH` environment variables, to inform your shell where to find the tools. For example:
+```
+ export PATH=$HOME/bin:$PATH
+ export LD_LIBRARY_PATH=$HOME/lib:$LD_LIBRARY_PATH
+```
+
+Enter these lines in your `~/.bashrc` file so you don't need to type them every time you log in.
+
+
+
+ * Q. My build fails with an inscrutable message about "library not found".
+A. You need to set your `LD_LIBRARY_PATH`. The environment variable must include the `PREFIX/lib` directory (for instance, `/usr/local/lib`).
+
+
+
+#### MacOS
+
+First begin by installing developer tools on Mac OSX:
+`xcode-select --install`
+
+First begin by installing developer tools on Mac OSX:
+
+You can install the qemu dependencies from homebrew, however do not install qemu itself as you will need the 6.828 patched version.
+
+`brew install $(brew deps qemu)`
+
+The gettext utility does not add installed binaries to the path, so you will need to run
+
+`PATH=${PATH}:/usr/local/opt/gettext/bin make install`
+
+when installing qemu below.
+
+### QEMU Emulator
+
+[QEMU][8] is a modern and fast PC emulator. QEMU version 2.3.0 is set up on Athena for x86 machines in the 6.828 locker (`add -f 6.828`)
+
+Unfortunately, QEMU's debugging facilities, while powerful, are somewhat immature, so we highly recommend you use our patched version of QEMU instead of the stock version that may come with your distribution. The version installed on Athena is already patched. To build your own patched version of QEMU:
+
+ 1. Clone the IAP 6.828 QEMU git repository `git clone https://github.com/mit-pdos/6.828-qemu.git qemu`
+ 2. On Linux, you may need to install several libraries. We have successfully built 6.828 QEMU on Debian/Ubuntu 16.04 after installing the following packages: libsdl1.2-dev, libtool-bin, libglib2.0-dev, libz-dev, and libpixman-1-dev.
+ 3. Configure the source code (optional arguments are shown in square brackets; replace PFX with a path of your choice)
+ 1. Linux: `./configure --disable-kvm --disable-werror [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]`
+ 2. OS X: `./configure --disable-kvm --disable-werror --disable-sdl [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]` The `prefix` argument specifies where to install QEMU; without it QEMU will install to `/usr/local` by default. The `target-list` argument simply slims down the architectures QEMU will build support for.
+ 4. Run `make && make install`
+
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://pdos.csail.mit.edu/6.828/2018/tools.html
+
+作者:[csail.mit][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://pdos.csail.mit.edu
+[b]: https://github.com/lujun9972
+[1]: http://www.cygwin.com
+[2]: labguide.html
+[3]: http://www.oracle.com/us/technologies/virtualization/oraclevm/
+[4]: http://www.vmware.com/products/player/
+[5]: http://www.vmware.com/products/fusion/
+[6]: http://www.ubuntu.com/download/desktop
+[7]:
+[8]: http://www.nongnu.org/qemu/
+[9]: mailto:6828-staff@lists.csail.mit.edu
+[10]: https://i.creativecommons.org/l/by/3.0/us/88x31.png
+[11]: https://creativecommons.org/licenses/by/3.0/us/
+[12]: https://pdos.csail.mit.edu/6.828/2018/index.html
diff --git a/sources/tech/20180913 Lab 1- PC Bootstrap and GCC Calling Conventions.md b/sources/tech/20180913 Lab 1- PC Bootstrap and GCC Calling Conventions.md
new file mode 100644
index 0000000000..365b5eb5f8
--- /dev/null
+++ b/sources/tech/20180913 Lab 1- PC Bootstrap and GCC Calling Conventions.md
@@ -0,0 +1,616 @@
+Lab 1: PC Bootstrap and GCC Calling Conventions
+======
+### Lab 1: Booting a PC
+
+#### Introduction
+
+This lab is split into three parts. The first part concentrates on getting familiarized with x86 assembly language, the QEMU x86 emulator, and the PC's power-on bootstrap procedure. The second part examines the boot loader for our 6.828 kernel, which resides in the `boot` directory of the `lab` tree. Finally, the third part delves into the initial template for our 6.828 kernel itself, named JOS, which resides in the `kernel` directory.
+
+##### Software Setup
+
+The files you will need for this and subsequent lab assignments in this course are distributed using the [Git][1] version control system. To learn more about Git, take a look at the [Git user's manual][2], or, if you are already familiar with other version control systems, you may find this [CS-oriented overview of Git][3] useful.
+
+The URL for the course Git repository is . To install the files in your Athena account, you need to _clone_ the course repository, by running the commands below. You must use an x86 Athena machine; that is, `uname -a` should mention `i386 GNU/Linux` or `i686 GNU/Linux` or `x86_64 GNU/Linux`. You can log into a public Athena host with `ssh -X athena.dialup.mit.edu`.
+
+```
+athena% mkdir ~/6.828
+athena% cd ~/6.828
+athena% add git
+athena% git clone https://pdos.csail.mit.edu/6.828/2018/jos.git lab
+Cloning into lab...
+athena% cd lab
+athena%
+
+```
+
+Git allows you to keep track of the changes you make to the code. For example, if you are finished with one of the exercises, and want to checkpoint your progress, you can _commit_ your changes by running:
+
+```
+athena% git commit -am 'my solution for lab1 exercise 9'
+Created commit 60d2135: my solution for lab1 exercise 9
+ 1 files changed, 1 insertions(+), 0 deletions(-)
+athena%
+
+```
+
+You can keep track of your changes by using the git diff command. Running git diff will display the changes to your code since your last commit, and git diff origin/lab1 will display the changes relative to the initial code supplied for this lab. Here, `origin/lab1` is the name of the git branch with the initial code you downloaded from our server for this assignment.
+
+We have set up the appropriate compilers and simulators for you on Athena. To use them, run add -f 6.828. You must run this command every time you log in (or add it to your `~/.environment` file). If you get obscure errors while compiling or running `qemu`, double check that you added the course locker.
+
+If you are working on a non-Athena machine, you'll need to install `qemu` and possibly `gcc` following the directions on the [tools page][4]. We've made several useful debugging changes to `qemu` and some of the later labs depend on these patches, so you must build your own. If your machine uses a native ELF toolchain (such as Linux and most BSD's, but notably _not_ OS X), you can simply install `gcc` from your package manager. Otherwise, follow the directions on the tools page.
+
+##### Hand-In Procedure
+
+You will turn in your assignments using the [submission website][5]. You need to request an API key from the submission website before you can turn in any assignments or labs.
+
+The lab code comes with GNU Make rules to make submission easier. After committing your final changes to the lab, type make handin to submit your lab.
+
+```
+athena% git commit -am "ready to submit my lab"
+[lab1 c2e3c8b] ready to submit my lab
+ 2 files changed, 18 insertions(+), 2 deletions(-)
+
+athena% make handin
+git archive --prefix=lab1/ --format=tar HEAD | gzip > lab1-handin.tar.gz
+Get an API key for yourself by visiting https://6828.scripts.mit.edu/2018/handin.py/
+Please enter your API key: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
+ % Total % Received % Xferd Average Speed Time Time Time Current
+ Dload Upload Total Spent Left Speed
+100 50199 100 241 100 49958 414 85824 --:--:-- --:--:-- --:--:-- 85986
+athena%
+
+```
+
+make handin will store your API key in _myapi.key_. If you need to change your API key, just remove this file and let make handin generate it again ( _myapi.key_ must not include newline characters).
+
+If use make handin and you have either uncomitted changes or untracked files, you will see output similar to the following:
+
+```
+ M hello.c
+?? bar.c
+?? foo.pyc
+Untracked files will not be handed in. Continue? [y/N]
+
+```
+
+Inspect the above lines and make sure all files that your lab solution needs are tracked i.e. not listed in a line that begins with ??.
+
+In the case that make handin does not work properly, try fixing the problem with the curl or Git commands. Or you can run make tarball. This will make a tar file for you, which you can then upload via our [web interface][5].
+
+You can run make grade to test your solutions with the grading program. The [web interface][5] uses the same grading program to assign your lab submission a grade. You should check the output of the grader (it may take a few minutes since the grader runs periodically) and ensure that you received the grade which you expected. If the grades don't match, your lab submission probably has a bug -- check the output of the grader (resp-lab*.txt) to see which particular test failed.
+
+For Lab 1, you do not need to turn in answers to any of the questions below. (Do answer them for yourself though! They will help with the rest of the lab.)
+
+#### Part 1: PC Bootstrap
+
+The purpose of the first exercise is to introduce you to x86 assembly language and the PC bootstrap process, and to get you started with QEMU and QEMU/GDB debugging. You will not have to write any code for this part of the lab, but you should go through it anyway for your own understanding and be prepared to answer the questions posed below.
+
+##### Getting Started with x86 assembly
+
+If you are not already familiar with x86 assembly language, you will quickly become familiar with it during this course! The [PC Assembly Language Book][6] is an excellent place to start. Hopefully, the book contains mixture of new and old material for you.
+
+_Warning:_ Unfortunately the examples in the book are written for the NASM assembler, whereas we will be using the GNU assembler. NASM uses the so-called _Intel_ syntax while GNU uses the _AT &T_ syntax. While semantically equivalent, an assembly file will differ quite a lot, at least superficially, depending on which syntax is used. Luckily the conversion between the two is pretty simple, and is covered in [Brennan's Guide to Inline Assembly][7].
+
+Exercise 1. Familiarize yourself with the assembly language materials available on [the 6.828 reference page][8]. You don't have to read them now, but you'll almost certainly want to refer to some of this material when reading and writing x86 assembly.
+
+We do recommend reading the section "The Syntax" in [Brennan's Guide to Inline Assembly][7]. It gives a good (and quite brief) description of the AT&T assembly syntax we'll be using with the GNU assembler in JOS.
+
+Certainly the definitive reference for x86 assembly language programming is Intel's instruction set architecture reference, which you can find on [the 6.828 reference page][8] in two flavors: an HTML edition of the old [80386 Programmer's Reference Manual][9], which is much shorter and easier to navigate than more recent manuals but describes all of the x86 processor features that we will make use of in 6.828; and the full, latest and greatest [IA-32 Intel Architecture Software Developer's Manuals][10] from Intel, covering all the features of the most recent processors that we won't need in class but you may be interested in learning about. An equivalent (and often friendlier) set of manuals is [available from AMD][11]. Save the Intel/AMD architecture manuals for later or use them for reference when you want to look up the definitive explanation of a particular processor feature or instruction.
+
+##### Simulating the x86
+
+Instead of developing the operating system on a real, physical personal computer (PC), we use a program that faithfully emulates a complete PC: the code you write for the emulator will boot on a real PC too. Using an emulator simplifies debugging; you can, for example, set break points inside of the emulated x86, which is difficult to do with the silicon version of an x86.
+
+In 6.828 we will use the [QEMU Emulator][12], a modern and relatively fast emulator. While QEMU's built-in monitor provides only limited debugging support, QEMU can act as a remote debugging target for the [GNU debugger][13] (GDB), which we'll use in this lab to step through the early boot process.
+
+To get started, extract the Lab 1 files into your own directory on Athena as described above in "Software Setup", then type make (or gmake on BSD systems) in the `lab` directory to build the minimal 6.828 boot loader and kernel you will start with. (It's a little generous to call the code we're running here a "kernel," but we'll flesh it out throughout the semester.)
+
+```
+athena% cd lab
+athena% make
++ as kern/entry.S
++ cc kern/entrypgdir.c
++ cc kern/init.c
++ cc kern/console.c
++ cc kern/monitor.c
++ cc kern/printf.c
++ cc kern/kdebug.c
++ cc lib/printfmt.c
++ cc lib/readline.c
++ cc lib/string.c
++ ld obj/kern/kernel
++ as boot/boot.S
++ cc -Os boot/main.c
++ ld boot/boot
+boot block is 380 bytes (max 510)
++ mk obj/kern/kernel.img
+
+```
+
+(If you get errors like "undefined reference to `__udivdi3'", you probably don't have the 32-bit gcc multilib. If you're running Debian or Ubuntu, try installing the gcc-multilib package.)
+
+Now you're ready to run QEMU, supplying the file `obj/kern/kernel.img`, created above, as the contents of the emulated PC's "virtual hard disk." This hard disk image contains both our boot loader (`obj/boot/boot`) and our kernel (`obj/kernel`).
+
+```
+athena% make qemu
+
+```
+
+or
+
+```
+athena% make qemu-nox
+
+```
+
+This executes QEMU with the options required to set the hard disk and direct serial port output to the terminal. Some text should appear in the QEMU window:
+
+```
+Booting from Hard Disk...
+6828 decimal is XXX octal!
+entering test_backtrace 5
+entering test_backtrace 4
+entering test_backtrace 3
+entering test_backtrace 2
+entering test_backtrace 1
+entering test_backtrace 0
+leaving test_backtrace 0
+leaving test_backtrace 1
+leaving test_backtrace 2
+leaving test_backtrace 3
+leaving test_backtrace 4
+leaving test_backtrace 5
+Welcome to the JOS kernel monitor!
+Type 'help' for a list of commands.
+K>
+
+```
+
+Everything after '`Booting from Hard Disk...`' was printed by our skeletal JOS kernel; the `K>` is the prompt printed by the small _monitor_ , or interactive control program, that we've included in the kernel. If you used make qemu, these lines printed by the kernel will appear in both the regular shell window from which you ran QEMU and the QEMU display window. This is because for testing and lab grading purposes we have set up the JOS kernel to write its console output not only to the virtual VGA display (as seen in the QEMU window), but also to the simulated PC's virtual serial port, which QEMU in turn outputs to its own standard output. Likewise, the JOS kernel will take input from both the keyboard and the serial port, so you can give it commands in either the VGA display window or the terminal running QEMU. Alternatively, you can use the serial console without the virtual VGA by running make qemu-nox. This may be convenient if you are SSH'd into an Athena dialup. To quit qemu, type Ctrl+a x.
+
+There are only two commands you can give to the kernel monitor, `help` and `kerninfo`.
+
+```
+K> help
+help - display this list of commands
+kerninfo - display information about the kernel
+K> kerninfo
+Special kernel symbols:
+ entry f010000c (virt) 0010000c (phys)
+ etext f0101a75 (virt) 00101a75 (phys)
+ edata f0112300 (virt) 00112300 (phys)
+ end f0112960 (virt) 00112960 (phys)
+Kernel executable memory footprint: 75KB
+K>
+
+```
+
+The `help` command is obvious, and we will shortly discuss the meaning of what the `kerninfo` command prints. Although simple, it's important to note that this kernel monitor is running "directly" on the "raw (virtual) hardware" of the simulated PC. This means that you should be able to copy the contents of `obj/kern/kernel.img` onto the first few sectors of a _real_ hard disk, insert that hard disk into a real PC, turn it on, and see exactly the same thing on the PC's real screen as you did above in the QEMU window. (We don't recommend you do this on a real machine with useful information on its hard disk, though, because copying `kernel.img` onto the beginning of its hard disk will trash the master boot record and the beginning of the first partition, effectively causing everything previously on the hard disk to be lost!)
+
+##### The PC's Physical Address Space
+
+We will now dive into a bit more detail about how a PC starts up. A PC's physical address space is hard-wired to have the following general layout:
+
+```
++------------------+ <- 0xFFFFFFFF (4GB)
+| 32-bit |
+| memory mapped |
+| devices |
+| |
+/\/\/\/\/\/\/\/\/\/\
+
+/\/\/\/\/\/\/\/\/\/\
+| |
+| Unused |
+| |
++------------------+ <- depends on amount of RAM
+| |
+| |
+| Extended Memory |
+| |
+| |
++------------------+ <- 0x00100000 (1MB)
+| BIOS ROM |
++------------------+ <- 0x000F0000 (960KB)
+| 16-bit devices, |
+| expansion ROMs |
++------------------+ <- 0x000C0000 (768KB)
+| VGA Display |
++------------------+ <- 0x000A0000 (640KB)
+| |
+| Low Memory |
+| |
++------------------+ <- 0x00000000
+
+```
+
+The first PCs, which were based on the 16-bit Intel 8088 processor, were only capable of addressing 1MB of physical memory. The physical address space of an early PC would therefore start at 0x00000000 but end at 0x000FFFFF instead of 0xFFFFFFFF. The 640KB area marked "Low Memory" was the _only_ random-access memory (RAM) that an early PC could use; in fact the very earliest PCs only could be configured with 16KB, 32KB, or 64KB of RAM!
+
+The 384KB area from 0x000A0000 through 0x000FFFFF was reserved by the hardware for special uses such as video display buffers and firmware held in non-volatile memory. The most important part of this reserved area is the Basic Input/Output System (BIOS), which occupies the 64KB region from 0x000F0000 through 0x000FFFFF. In early PCs the BIOS was held in true read-only memory (ROM), but current PCs store the BIOS in updateable flash memory. The BIOS is responsible for performing basic system initialization such as activating the video card and checking the amount of memory installed. After performing this initialization, the BIOS loads the operating system from some appropriate location such as floppy disk, hard disk, CD-ROM, or the network, and passes control of the machine to the operating system.
+
+When Intel finally "broke the one megabyte barrier" with the 80286 and 80386 processors, which supported 16MB and 4GB physical address spaces respectively, the PC architects nevertheless preserved the original layout for the low 1MB of physical address space in order to ensure backward compatibility with existing software. Modern PCs therefore have a "hole" in physical memory from 0x000A0000 to 0x00100000, dividing RAM into "low" or "conventional memory" (the first 640KB) and "extended memory" (everything else). In addition, some space at the very top of the PC's 32-bit physical address space, above all physical RAM, is now commonly reserved by the BIOS for use by 32-bit PCI devices.
+
+Recent x86 processors can support _more_ than 4GB of physical RAM, so RAM can extend further above 0xFFFFFFFF. In this case the BIOS must arrange to leave a _second_ hole in the system's RAM at the top of the 32-bit addressable region, to leave room for these 32-bit devices to be mapped. Because of design limitations JOS will use only the first 256MB of a PC's physical memory anyway, so for now we will pretend that all PCs have "only" a 32-bit physical address space. But dealing with complicated physical address spaces and other aspects of hardware organization that evolved over many years is one of the important practical challenges of OS development.
+
+##### The ROM BIOS
+
+In this portion of the lab, you'll use QEMU's debugging facilities to investigate how an IA-32 compatible computer boots.
+
+Open two terminal windows and cd both shells into your lab directory. In one, enter make qemu-gdb (or make qemu-nox-gdb). This starts up QEMU, but QEMU stops just before the processor executes the first instruction and waits for a debugging connection from GDB. In the second terminal, from the same directory you ran `make`, run make gdb. You should see something like this,
+
+```
+athena% make gdb
+GNU gdb (GDB) 6.8-debian
+Copyright (C) 2008 Free Software Foundation, Inc.
+License GPLv3+: GNU GPL version 3 or later
+This is free software: you are free to change and redistribute it.
+There is NO WARRANTY, to the extent permitted by law. Type "show copying"
+and "show warranty" for details.
+This GDB was configured as "i486-linux-gnu".
++ target remote localhost:26000
+The target architecture is assumed to be i8086
+[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
+0x0000fff0 in ?? ()
++ symbol-file obj/kern/kernel
+(gdb)
+
+```
+
+We provided a `.gdbinit` file that set up GDB to debug the 16-bit code used during early boot and directed it to attach to the listening QEMU. (If it doesn't work, you may have to add an `add-auto-load-safe-path` in your `.gdbinit` in your home directory to convince `gdb` to process the `.gdbinit` we provided. `gdb` will tell you if you have to do this.)
+
+The following line:
+
+```
+[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
+
+```
+
+is GDB's disassembly of the first instruction to be executed. From this output you can conclude a few things:
+
+ * The IBM PC starts executing at physical address 0x000ffff0, which is at the very top of the 64KB area reserved for the ROM BIOS.
+ * The PC starts executing with `CS = 0xf000` and `IP = 0xfff0`.
+ * The first instruction to be executed is a `jmp` instruction, which jumps to the segmented address `CS = 0xf000` and `IP = 0xe05b`.
+
+
+
+Why does QEMU start like this? This is how Intel designed the 8088 processor, which IBM used in their original PC. Because the BIOS in a PC is "hard-wired" to the physical address range 0x000f0000-0x000fffff, this design ensures that the BIOS always gets control of the machine first after power-up or any system restart - which is crucial because on power-up there _is_ no other software anywhere in the machine's RAM that the processor could execute. The QEMU emulator comes with its own BIOS, which it places at this location in the processor's simulated physical address space. On processor reset, the (simulated) processor enters real mode and sets CS to 0xf000 and the IP to 0xfff0, so that execution begins at that (CS:IP) segment address. How does the segmented address 0xf000:fff0 turn into a physical address?
+
+To answer that we need to know a bit about real mode addressing. In real mode (the mode that PC starts off in), address translation works according to the formula: _physical address_ = 16 选题模板.txt 中文排版指北.md comic core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated _segment_ \+ _offset_. So, when the PC sets CS to 0xf000 and IP to 0xfff0, the physical address referenced is:
+
+```
+ 16 * 0xf000 + 0xfff0 # in hex multiplication by 16 is
+ = 0xf0000 + 0xfff0 # easy--just append a 0.
+ = 0xffff0
+
+```
+
+`0xffff0` is 16 bytes before the end of the BIOS (`0x100000`). Therefore we shouldn't be surprised that the first thing that the BIOS does is `jmp` backwards to an earlier location in the BIOS; after all how much could it accomplish in just 16 bytes?
+
+Exercise 2. Use GDB's si (Step Instruction) command to trace into the ROM BIOS for a few more instructions, and try to guess what it might be doing. You might want to look at [Phil Storrs I/O Ports Description][14], as well as other materials on the [6.828 reference materials page][8]. No need to figure out all the details - just the general idea of what the BIOS is doing first.
+
+When the BIOS runs, it sets up an interrupt descriptor table and initializes various devices such as the VGA display. This is where the "`Starting SeaBIOS`" message you see in the QEMU window comes from.
+
+After initializing the PCI bus and all the important devices the BIOS knows about, it searches for a bootable device such as a floppy, hard drive, or CD-ROM. Eventually, when it finds a bootable disk, the BIOS reads the _boot loader_ from the disk and transfers control to it.
+
+#### Part 2: The Boot Loader
+
+Floppy and hard disks for PCs are divided into 512 byte regions called _sectors_. A sector is the disk's minimum transfer granularity: each read or write operation must be one or more sectors in size and aligned on a sector boundary. If the disk is bootable, the first sector is called the _boot sector_ , since this is where the boot loader code resides. When the BIOS finds a bootable floppy or hard disk, it loads the 512-byte boot sector into memory at physical addresses 0x7c00 through 0x7dff, and then uses a `jmp` instruction to set the CS:IP to `0000:7c00`, passing control to the boot loader. Like the BIOS load address, these addresses are fairly arbitrary - but they are fixed and standardized for PCs.
+
+The ability to boot from a CD-ROM came much later during the evolution of the PC, and as a result the PC architects took the opportunity to rethink the boot process slightly. As a result, the way a modern BIOS boots from a CD-ROM is a bit more complicated (and more powerful). CD-ROMs use a sector size of 2048 bytes instead of 512, and the BIOS can load a much larger boot image from the disk into memory (not just one sector) before transferring control to it. For more information, see the ["El Torito" Bootable CD-ROM Format Specification][15].
+
+For 6.828, however, we will use the conventional hard drive boot mechanism, which means that our boot loader must fit into a measly 512 bytes. The boot loader consists of one assembly language source file, `boot/boot.S`, and one C source file, `boot/main.c` Look through these source files carefully and make sure you understand what's going on. The boot loader must perform two main functions:
+
+ 1. First, the boot loader switches the processor from real mode to _32-bit protected mode_ , because it is only in this mode that software can access all the memory above 1MB in the processor's physical address space. Protected mode is described briefly in sections 1.2.7 and 1.2.8 of [PC Assembly Language][6], and in great detail in the Intel architecture manuals. At this point you only have to understand that translation of segmented addresses (segment:offset pairs) into physical addresses happens differently in protected mode, and that after the transition offsets are 32 bits instead of 16.
+ 2. Second, the boot loader reads the kernel from the hard disk by directly accessing the IDE disk device registers via the x86's special I/O instructions. If you would like to understand better what the particular I/O instructions here mean, check out the "IDE hard drive controller" section on [the 6.828 reference page][8]. You will not need to learn much about programming specific devices in this class: writing device drivers is in practice a very important part of OS development, but from a conceptual or architectural viewpoint it is also one of the least interesting.
+
+
+
+After you understand the boot loader source code, look at the file `obj/boot/boot.asm`. This file is a disassembly of the boot loader that our GNUmakefile creates _after_ compiling the boot loader. This disassembly file makes it easy to see exactly where in physical memory all of the boot loader's code resides, and makes it easier to track what's happening while stepping through the boot loader in GDB. Likewise, `obj/kern/kernel.asm` contains a disassembly of the JOS kernel, which can often be useful for debugging.
+
+You can set address breakpoints in GDB with the `b` command. For example, b *0x7c00 sets a breakpoint at address 0x7C00. Once at a breakpoint, you can continue execution using the c and si commands: c causes QEMU to continue execution until the next breakpoint (or until you press Ctrl-C in GDB), and si _N_ steps through the instructions _`N`_ at a time.
+
+To examine instructions in memory (besides the immediate next one to be executed, which GDB prints automatically), you use the x/i command. This command has the syntax x/ _N_ i _ADDR_ , where _N_ is the number of consecutive instructions to disassemble and _ADDR_ is the memory address at which to start disassembling.
+
+Exercise 3. Take a look at the [lab tools guide][16], especially the section on GDB commands. Even if you're familiar with GDB, this includes some esoteric GDB commands that are useful for OS work.
+
+Set a breakpoint at address 0x7c00, which is where the boot sector will be loaded. Continue execution until that breakpoint. Trace through the code in `boot/boot.S`, using the source code and the disassembly file `obj/boot/boot.asm` to keep track of where you are. Also use the `x/i` command in GDB to disassemble sequences of instructions in the boot loader, and compare the original boot loader source code with both the disassembly in `obj/boot/boot.asm` and GDB.
+
+Trace into `bootmain()` in `boot/main.c`, and then into `readsect()`. Identify the exact assembly instructions that correspond to each of the statements in `readsect()`. Trace through the rest of `readsect()` and back out into `bootmain()`, and identify the begin and end of the `for` loop that reads the remaining sectors of the kernel from the disk. Find out what code will run when the loop is finished, set a breakpoint there, and continue to that breakpoint. Then step through the remainder of the boot loader.
+
+Be able to answer the following questions:
+
+ * At what point does the processor start executing 32-bit code? What exactly causes the switch from 16- to 32-bit mode?
+ * What is the _last_ instruction of the boot loader executed, and what is the _first_ instruction of the kernel it just loaded?
+ * _Where_ is the first instruction of the kernel?
+ * How does the boot loader decide how many sectors it must read in order to fetch the entire kernel from disk? Where does it find this information?
+
+
+
+##### Loading the Kernel
+
+We will now look in further detail at the C language portion of the boot loader, in `boot/main.c`. But before doing so, this is a good time to stop and review some of the basics of C programming.
+
+Exercise 4. Read about programming with pointers in C. The best reference for the C language is _The C Programming Language_ by Brian Kernighan and Dennis Ritchie (known as 'K &R'). We recommend that students purchase this book (here is an [Amazon Link][17]) or find one of [MIT's 7 copies][18].
+
+Read 5.1 (Pointers and Addresses) through 5.5 (Character Pointers and Functions) in K&R. Then download the code for [pointers.c][19], run it, and make sure you understand where all of the printed values come from. In particular, make sure you understand where the pointer addresses in printed lines 1 and 6 come from, how all the values in printed lines 2 through 4 get there, and why the values printed in line 5 are seemingly corrupted.
+
+There are other references on pointers in C (e.g., [A tutorial by Ted Jensen][20] that cites K&R heavily), though not as strongly recommended.
+
+_Warning:_ Unless you are already thoroughly versed in C, do not skip or even skim this reading exercise. If you do not really understand pointers in C, you will suffer untold pain and misery in subsequent labs, and then eventually come to understand them the hard way. Trust us; you don't want to find out what "the hard way" is.
+
+To make sense out of `boot/main.c` you'll need to know what an ELF binary is. When you compile and link a C program such as the JOS kernel, the compiler transforms each C source ('`.c`') file into an _object_ ('`.o`') file containing assembly language instructions encoded in the binary format expected by the hardware. The linker then combines all of the compiled object files into a single _binary image_ such as `obj/kern/kernel`, which in this case is a binary in the ELF format, which stands for "Executable and Linkable Format".
+
+Full information about this format is available in [the ELF specification][21] on [our reference page][8], but you will not need to delve very deeply into the details of this format in this class. Although as a whole the format is quite powerful and complex, most of the complex parts are for supporting dynamic loading of shared libraries, which we will not do in this class. The [Wikipedia page][22] has a short description.
+
+For purposes of 6.828, you can consider an ELF executable to be a header with loading information, followed by several _program sections_ , each of which is a contiguous chunk of code or data intended to be loaded into memory at a specified address. The boot loader does not modify the code or data; it loads it into memory and starts executing it.
+
+An ELF binary starts with a fixed-length _ELF header_ , followed by a variable-length _program header_ listing each of the program sections to be loaded. The C definitions for these ELF headers are in `inc/elf.h`. The program sections we're interested in are:
+
+ * `.text`: The program's executable instructions.
+ * `.rodata`: Read-only data, such as ASCII string constants produced by the C compiler. (We will not bother setting up the hardware to prohibit writing, however.)
+ * `.data`: The data section holds the program's initialized data, such as global variables declared with initializers like `int x = 5;`.
+
+
+
+When the linker computes the memory layout of a program, it reserves space for _uninitialized_ global variables, such as `int x;`, in a section called `.bss` that immediately follows `.data` in memory. C requires that "uninitialized" global variables start with a value of zero. Thus there is no need to store contents for `.bss` in the ELF binary; instead, the linker records just the address and size of the `.bss` section. The loader or the program itself must arrange to zero the `.bss` section.
+
+Examine the full list of the names, sizes, and link addresses of all the sections in the kernel executable by typing:
+
+```
+athena% objdump -h obj/kern/kernel
+
+(If you compiled your own toolchain, you may need to use i386-jos-elf-objdump)
+
+```
+
+You will see many more sections than the ones we listed above, but the others are not important for our purposes. Most of the others are to hold debugging information, which is typically included in the program's executable file but not loaded into memory by the program loader.
+
+Take particular note of the "VMA" (or _link address_ ) and the "LMA" (or _load address_ ) of the `.text` section. The load address of a section is the memory address at which that section should be loaded into memory.
+
+The link address of a section is the memory address from which the section expects to execute. The linker encodes the link address in the binary in various ways, such as when the code needs the address of a global variable, with the result that a binary usually won't work if it is executing from an address that it is not linked for. (It is possible to generate _position-independent_ code that does not contain any such absolute addresses. This is used extensively by modern shared libraries, but it has performance and complexity costs, so we won't be using it in 6.828.)
+
+Typically, the link and load addresses are the same. For example, look at the `.text` section of the boot loader:
+
+```
+athena% objdump -h obj/boot/boot.out
+
+```
+
+The boot loader uses the ELF _program headers_ to decide how to load the sections. The program headers specify which parts of the ELF object to load into memory and the destination address each should occupy. You can inspect the program headers by typing:
+
+```
+athena% objdump -x obj/kern/kernel
+
+```
+
+The program headers are then listed under "Program Headers" in the output of objdump. The areas of the ELF object that need to be loaded into memory are those that are marked as "LOAD". Other information for each program header is given, such as the virtual address ("vaddr"), the physical address ("paddr"), and the size of the loaded area ("memsz" and "filesz").
+
+Back in boot/main.c, the `ph->p_pa` field of each program header contains the segment's destination physical address (in this case, it really is a physical address, though the ELF specification is vague on the actual meaning of this field).
+
+The BIOS loads the boot sector into memory starting at address 0x7c00, so this is the boot sector's load address. This is also where the boot sector executes from, so this is also its link address. We set the link address by passing `-Ttext 0x7C00` to the linker in `boot/Makefrag`, so the linker will produce the correct memory addresses in the generated code.
+
+Exercise 5. Trace through the first few instructions of the boot loader again and identify the first instruction that would "break" or otherwise do the wrong thing if you were to get the boot loader's link address wrong. Then change the link address in `boot/Makefrag` to something wrong, run make clean, recompile the lab with make, and trace into the boot loader again to see what happens. Don't forget to change the link address back and make clean again afterward!
+
+Look back at the load and link addresses for the kernel. Unlike the boot loader, these two addresses aren't the same: the kernel is telling the boot loader to load it into memory at a low address (1 megabyte), but it expects to execute from a high address. We'll dig in to how we make this work in the next section.
+
+Besides the section information, there is one more field in the ELF header that is important to us, named `e_entry`. This field holds the link address of the _entry point_ in the program: the memory address in the program's text section at which the program should begin executing. You can see the entry point:
+
+```
+athena% objdump -f obj/kern/kernel
+
+```
+
+You should now be able to understand the minimal ELF loader in `boot/main.c`. It reads each section of the kernel from disk into memory at the section's load address and then jumps to the kernel's entry point.
+
+Exercise 6. We can examine memory using GDB's x command. The [GDB manual][23] has full details, but for now, it is enough to know that the command x/ _N_ x _ADDR_ prints _`N`_ words of memory at _`ADDR`_. (Note that both '`x`'s in the command are lowercase.) _Warning_ : The size of a word is not a universal standard. In GNU assembly, a word is two bytes (the 'w' in xorw, which stands for word, means 2 bytes).
+
+Reset the machine (exit QEMU/GDB and start them again). Examine the 8 words of memory at 0x00100000 at the point the BIOS enters the boot loader, and then again at the point the boot loader enters the kernel. Why are they different? What is there at the second breakpoint? (You do not really need to use QEMU to answer this question. Just think.)
+
+#### Part 3: The Kernel
+
+We will now start to examine the minimal JOS kernel in a bit more detail. (And you will finally get to write some code!). Like the boot loader, the kernel begins with some assembly language code that sets things up so that C language code can execute properly.
+
+##### Using virtual memory to work around position dependence
+
+When you inspected the boot loader's link and load addresses above, they matched perfectly, but there was a (rather large) disparity between the _kernel's_ link address (as printed by objdump) and its load address. Go back and check both and make sure you can see what we're talking about. (Linking the kernel is more complicated than the boot loader, so the link and load addresses are at the top of `kern/kernel.ld`.)
+
+Operating system kernels often like to be linked and run at very high _virtual address_ , such as 0xf0100000, in order to leave the lower part of the processor's virtual address space for user programs to use. The reason for this arrangement will become clearer in the next lab.
+
+Many machines don't have any physical memory at address 0xf0100000, so we can't count on being able to store the kernel there. Instead, we will use the processor's memory management hardware to map virtual address 0xf0100000 (the link address at which the kernel code _expects_ to run) to physical address 0x00100000 (where the boot loader loaded the kernel into physical memory). This way, although the kernel's virtual address is high enough to leave plenty of address space for user processes, it will be loaded in physical memory at the 1MB point in the PC's RAM, just above the BIOS ROM. This approach requires that the PC have at least a few megabytes of physical memory (so that physical address 0x00100000 works), but this is likely to be true of any PC built after about 1990.
+
+In fact, in the next lab, we will map the _entire_ bottom 256MB of the PC's physical address space, from physical addresses 0x00000000 through 0x0fffffff, to virtual addresses 0xf0000000 through 0xffffffff respectively. You should now see why JOS can only use the first 256MB of physical memory.
+
+For now, we'll just map the first 4MB of physical memory, which will be enough to get us up and running. We do this using the hand-written, statically-initialized page directory and page table in `kern/entrypgdir.c`. For now, you don't have to understand the details of how this works, just the effect that it accomplishes. Up until `kern/entry.S` sets the `CR0_PG` flag, memory references are treated as physical addresses (strictly speaking, they're linear addresses, but boot/boot.S set up an identity mapping from linear addresses to physical addresses and we're never going to change that). Once `CR0_PG` is set, memory references are virtual addresses that get translated by the virtual memory hardware to physical addresses. `entry_pgdir` translates virtual addresses in the range 0xf0000000 through 0xf0400000 to physical addresses 0x00000000 through 0x00400000, as well as virtual addresses 0x00000000 through 0x00400000 to physical addresses 0x00000000 through 0x00400000. Any virtual address that is not in one of these two ranges will cause a hardware exception which, since we haven't set up interrupt handling yet, will cause QEMU to dump the machine state and exit (or endlessly reboot if you aren't using the 6.828-patched version of QEMU).
+
+Exercise 7. Use QEMU and GDB to trace into the JOS kernel and stop at the `movl %eax, %cr0`. Examine memory at 0x00100000 and at 0xf0100000. Now, single step over that instruction using the stepi GDB command. Again, examine memory at 0x00100000 and at 0xf0100000. Make sure you understand what just happened.
+
+What is the first instruction _after_ the new mapping is established that would fail to work properly if the mapping weren't in place? Comment out the `movl %eax, %cr0` in `kern/entry.S`, trace into it, and see if you were right.
+
+##### Formatted Printing to the Console
+
+Most people take functions like `printf()` for granted, sometimes even thinking of them as "primitives" of the C language. But in an OS kernel, we have to implement all I/O ourselves.
+
+Read through `kern/printf.c`, `lib/printfmt.c`, and `kern/console.c`, and make sure you understand their relationship. It will become clear in later labs why `printfmt.c` is located in the separate `lib` directory.
+
+Exercise 8. We have omitted a small fragment of code - the code necessary to print octal numbers using patterns of the form "%o". Find and fill in this code fragment.
+
+Be able to answer the following questions:
+
+ 1. Explain the interface between `printf.c` and `console.c`. Specifically, what function does `console.c` export? How is this function used by `printf.c`?
+
+ 2. Explain the following from `console.c`:
+```
+ 1 if (crt_pos >= CRT_SIZE) {
+ 2 int i;
+ 3 memmove(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) 选题模板.txt 中文排版指北.md comic core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated sizeof(uint16_t));
+ 4 for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++)
+ 5 crt_buf[i] = 0x0700 | ' ';
+ 6 crt_pos -= CRT_COLS;
+ 7 }
+
+```
+
+ 3. For the following questions you might wish to consult the notes for Lecture 2. These notes cover GCC's calling convention on the x86.
+
+Trace the execution of the following code step-by-step:
+```
+ int x = 1, y = 3, z = 4;
+ cprintf("x %d, y %x, z %d\n", x, y, z);
+
+```
+
+ * In the call to `cprintf()`, to what does `fmt` point? To what does `ap` point?
+ * List (in order of execution) each call to `cons_putc`, `va_arg`, and `vcprintf`. For `cons_putc`, list its argument as well. For `va_arg`, list what `ap` points to before and after the call. For `vcprintf` list the values of its two arguments.
+ 4. Run the following code.
+```
+ unsigned int i = 0x00646c72;
+ cprintf("H%x Wo%s", 57616, &i);
+
+```
+
+What is the output? Explain how this output is arrived at in the step-by-step manner of the previous exercise. [Here's an ASCII table][24] that maps bytes to characters.
+
+The output depends on that fact that the x86 is little-endian. If the x86 were instead big-endian what would you set `i` to in order to yield the same output? Would you need to change `57616` to a different value?
+
+[Here's a description of little- and big-endian][25] and [a more whimsical description][26].
+
+ 5. In the following code, what is going to be printed after `'y='`? (note: the answer is not a specific value.) Why does this happen?
+```
+ cprintf("x=%d y=%d", 3);
+
+```
+
+ 6. Let's say that GCC changed its calling convention so that it pushed arguments on the stack in declaration order, so that the last argument is pushed last. How would you have to change `cprintf` or its interface so that it would still be possible to pass it a variable number of arguments?
+
+
+
+
+Challenge Enhance the console to allow text to be printed in different colors. The traditional way to do this is to make it interpret [ANSI escape sequences][27] embedded in the text strings printed to the console, but you may use any mechanism you like. There is plenty of information on [the 6.828 reference page][8] and elsewhere on the web on programming the VGA display hardware. If you're feeling really adventurous, you could try switching the VGA hardware into a graphics mode and making the console draw text onto the graphical frame buffer.
+
+##### The Stack
+
+In the final exercise of this lab, we will explore in more detail the way the C language uses the stack on the x86, and in the process write a useful new kernel monitor function that prints a _backtrace_ of the stack: a list of the saved Instruction Pointer (IP) values from the nested `call` instructions that led to the current point of execution.
+
+Exercise 9. Determine where the kernel initializes its stack, and exactly where in memory its stack is located. How does the kernel reserve space for its stack? And at which "end" of this reserved area is the stack pointer initialized to point to?
+
+The x86 stack pointer (`esp` register) points to the lowest location on the stack that is currently in use. Everything _below_ that location in the region reserved for the stack is free. Pushing a value onto the stack involves decreasing the stack pointer and then writing the value to the place the stack pointer points to. Popping a value from the stack involves reading the value the stack pointer points to and then increasing the stack pointer. In 32-bit mode, the stack can only hold 32-bit values, and esp is always divisible by four. Various x86 instructions, such as `call`, are "hard-wired" to use the stack pointer register.
+
+The `ebp` (base pointer) register, in contrast, is associated with the stack primarily by software convention. On entry to a C function, the function's _prologue_ code normally saves the previous function's base pointer by pushing it onto the stack, and then copies the current `esp` value into `ebp` for the duration of the function. If all the functions in a program obey this convention, then at any given point during the program's execution, it is possible to trace back through the stack by following the chain of saved `ebp` pointers and determining exactly what nested sequence of function calls caused this particular point in the program to be reached. This capability can be particularly useful, for example, when a particular function causes an `assert` failure or `panic` because bad arguments were passed to it, but you aren't sure _who_ passed the bad arguments. A stack backtrace lets you find the offending function.
+
+Exercise 10. To become familiar with the C calling conventions on the x86, find the address of the `test_backtrace` function in `obj/kern/kernel.asm`, set a breakpoint there, and examine what happens each time it gets called after the kernel starts. How many 32-bit words does each recursive nesting level of `test_backtrace` push on the stack, and what are those words?
+
+Note that, for this exercise to work properly, you should be using the patched version of QEMU available on the [tools][4] page or on Athena. Otherwise, you'll have to manually translate all breakpoint and memory addresses to linear addresses.
+
+The above exercise should give you the information you need to implement a stack backtrace function, which you should call `mon_backtrace()`. A prototype for this function is already waiting for you in `kern/monitor.c`. You can do it entirely in C, but you may find the `read_ebp()` function in `inc/x86.h` useful. You'll also have to hook this new function into the kernel monitor's command list so that it can be invoked interactively by the user.
+
+The backtrace function should display a listing of function call frames in the following format:
+
+```
+Stack backtrace:
+ ebp f0109e58 eip f0100a62 args 00000001 f0109e80 f0109e98 f0100ed2 00000031
+ ebp f0109ed8 eip f01000d6 args 00000000 00000000 f0100058 f0109f28 00000061
+ ...
+
+```
+
+Each line contains an `ebp`, `eip`, and `args`. The `ebp` value indicates the base pointer into the stack used by that function: i.e., the position of the stack pointer just after the function was entered and the function prologue code set up the base pointer. The listed `eip` value is the function's _return instruction pointer_ : the instruction address to which control will return when the function returns. The return instruction pointer typically points to the instruction after the `call` instruction (why?). Finally, the five hex values listed after `args` are the first five arguments to the function in question, which would have been pushed on the stack just before the function was called. If the function was called with fewer than five arguments, of course, then not all five of these values will be useful. (Why can't the backtrace code detect how many arguments there actually are? How could this limitation be fixed?)
+
+The first line printed reflects the _currently executing_ function, namely `mon_backtrace` itself, the second line reflects the function that called `mon_backtrace`, the third line reflects the function that called that one, and so on. You should print _all_ the outstanding stack frames. By studying `kern/entry.S` you'll find that there is an easy way to tell when to stop.
+
+Here are a few specific points you read about in K&R Chapter 5 that are worth remembering for the following exercise and for future labs.
+
+ * If `int *p = (int*)100`, then `(int)p + 1` and `(int)(p + 1)` are different numbers: the first is `101` but the second is `104`. When adding an integer to a pointer, as in the second case, the integer is implicitly multiplied by the size of the object the pointer points to.
+ * `p[i]` is defined to be the same as `*(p+i)`, referring to the i'th object in the memory pointed to by p. The above rule for addition helps this definition work when the objects are larger than one byte.
+ * `&p[i]` is the same as `(p+i)`, yielding the address of the i'th object in the memory pointed to by p.
+
+
+
+Although most C programs never need to cast between pointers and integers, operating systems frequently do. Whenever you see an addition involving a memory address, ask yourself whether it is an integer addition or pointer addition and make sure the value being added is appropriately multiplied or not.
+
+Exercise 11. Implement the backtrace function as specified above. Use the same format as in the example, since otherwise the grading script will be confused. When you think you have it working right, run make grade to see if its output conforms to what our grading script expects, and fix it if it doesn't. _After_ you have handed in your Lab 1 code, you are welcome to change the output format of the backtrace function any way you like.
+
+If you use `read_ebp()`, note that GCC may generate "optimized" code that calls `read_ebp()` _before_ `mon_backtrace()`'s function prologue, which results in an incomplete stack trace (the stack frame of the most recent function call is missing). While we have tried to disable optimizations that cause this reordering, you may want to examine the assembly of `mon_backtrace()` and make sure the call to `read_ebp()` is happening after the function prologue.
+
+At this point, your backtrace function should give you the addresses of the function callers on the stack that lead to `mon_backtrace()` being executed. However, in practice you often want to know the function names corresponding to those addresses. For instance, you may want to know which functions could contain a bug that's causing your kernel to crash.
+
+To help you implement this functionality, we have provided the function `debuginfo_eip()`, which looks up `eip` in the symbol table and returns the debugging information for that address. This function is defined in `kern/kdebug.c`.
+
+Exercise 12. Modify your stack backtrace function to display, for each `eip`, the function name, source file name, and line number corresponding to that `eip`.
+
+In `debuginfo_eip`, where do `__STAB_*` come from? This question has a long answer; to help you to discover the answer, here are some things you might want to do:
+
+ * look in the file `kern/kernel.ld` for `__STAB_*`
+ * run objdump -h obj/kern/kernel
+ * run objdump -G obj/kern/kernel
+ * run gcc -pipe -nostdinc -O2 -fno-builtin -I. -MD -Wall -Wno-format -DJOS_KERNEL -gstabs -c -S kern/init.c, and look at init.s.
+ * see if the bootloader loads the symbol table in memory as part of loading the kernel binary
+
+
+
+Complete the implementation of `debuginfo_eip` by inserting the call to `stab_binsearch` to find the line number for an address.
+
+Add a `backtrace` command to the kernel monitor, and extend your implementation of `mon_backtrace` to call `debuginfo_eip` and print a line for each stack frame of the form:
+
+```
+K> backtrace
+Stack backtrace:
+ ebp f010ff78 eip f01008ae args 00000001 f010ff8c 00000000 f0110580 00000000
+ kern/monitor.c:143: monitor+106
+ ebp f010ffd8 eip f0100193 args 00000000 00001aac 00000660 00000000 00000000
+ kern/init.c:49: i386_init+59
+ ebp f010fff8 eip f010003d args 00000000 00000000 0000ffff 10cf9a00 0000ffff
+ kern/entry.S:70: +0
+K>
+
+```
+
+Each line gives the file name and line within that file of the stack frame's `eip`, followed by the name of the function and the offset of the `eip` from the first instruction of the function (e.g., `monitor+106` means the return `eip` is 106 bytes past the beginning of `monitor`).
+
+Be sure to print the file and function names on a separate line, to avoid confusing the grading script.
+
+Tip: printf format strings provide an easy, albeit obscure, way to print non-null-terminated strings like those in STABS tables. `printf("%.*s", length, string)` prints at most `length` characters of `string`. Take a look at the printf man page to find out why this works.
+
+You may find that some functions are missing from the backtrace. For example, you will probably see a call to `monitor()` but not to `runcmd()`. This is because the compiler in-lines some function calls. Other optimizations may cause you to see unexpected line numbers. If you get rid of the `-O2` from `GNUMakefile`, the backtraces may make more sense (but your kernel will run more slowly).
+
+**This completes the lab.** In the `lab` directory, commit your changes with git commit and type make handin to submit your code.
+
+--------------------------------------------------------------------------------
+
+via: https://pdos.csail.mit.edu/6.828/2018/labs/lab1/
+
+作者:[csail.mit][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:
+[b]: https://github.com/lujun9972
+[1]: http://www.git-scm.com/
+[2]: http://www.kernel.org/pub/software/scm/git/docs/user-manual.html
+[3]: http://eagain.net/articles/git-for-computer-scientists/
+[4]: https://pdos.csail.mit.edu/6.828/2018/tools.html
+[5]: https://6828.scripts.mit.edu/2018/handin.py/
+[6]: https://pdos.csail.mit.edu/6.828/2018/readings/pcasm-book.pdf
+[7]: http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html
+[8]: https://pdos.csail.mit.edu/6.828/2018/reference.html
+[9]: https://pdos.csail.mit.edu/6.828/2018/readings/i386/toc.htm
+[10]: http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
+[11]: http://developer.amd.com/resources/developer-guides-manuals/
+[12]: http://www.qemu.org/
+[13]: http://www.gnu.org/software/gdb/
+[14]: http://web.archive.org/web/20040404164813/members.iweb.net.au/~pstorr/pcbook/book2/book2.htm
+[15]: https://pdos.csail.mit.edu/6.828/2018/readings/boot-cdrom.pdf
+[16]: https://pdos.csail.mit.edu/6.828/2018/labguide.html
+[17]: http://www.amazon.com/C-Programming-Language-2nd/dp/0131103628/sr=8-1/qid=1157812738/ref=pd_bbs_1/104-1502762-1803102?ie=UTF8&s=books
+[18]: http://library.mit.edu/F/AI9Y4SJ2L5ELEE2TAQUAAR44XV5RTTQHE47P9MKP5GQDLR9A8X-10422?func=item-global&doc_library=MIT01&doc_number=000355242&year=&volume=&sub_library=
+[19]: https://pdos.csail.mit.edu/6.828/2018/labs/lab1/pointers.c
+[20]: https://pdos.csail.mit.edu/6.828/2018/readings/pointers.pdf
+[21]: https://pdos.csail.mit.edu/6.828/2018/readings/elf.pdf
+[22]: http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
+[23]: https://sourceware.org/gdb/current/onlinedocs/gdb/Memory.html
+[24]: http://web.cs.mun.ca/~michael/c/ascii-table.html
+[25]: http://www.webopedia.com/TERM/b/big_endian.html
+[26]: http://www.networksorcery.com/enp/ien/ien137.txt
+[27]: http://rrbrandt.dee.ufcg.edu.br/en/docs/ansi/
diff --git a/sources/tech/20180921 Clinews - Read News And Latest Headlines From Commandline.md b/sources/tech/20180921 Clinews - Read News And Latest Headlines From Commandline.md
deleted file mode 100644
index b7082ea141..0000000000
--- a/sources/tech/20180921 Clinews - Read News And Latest Headlines From Commandline.md
+++ /dev/null
@@ -1,138 +0,0 @@
-translating----geekpi
-
-Clinews – Read News And Latest Headlines From Commandline
-======
-
-
-
-A while ago, we have written about a CLI news client named [**InstantNews**][1] that helps you to read news and latest headlines from commandline instantly. Today, I stumbled upon a similar utility named **Clinews** which serves the same purpose – reading news and latest headlines from popular websites, blogs from Terminal. You don’t need to install GUI applications or mobile apps. You can read what’s happening in the world right from your Terminal. It is free, open source utility written using **NodeJS**.
-
-### Installing Clinews
-
-Since Clinews is written using NodeJS, you can install it using NPM package manager. If you haven’t install NodeJS, install it as described in the following link.
-
-Once node installed, run the following command to install Clinews:
-
-```
-$ npm i -g clinews
-```
-
-You can also install Clinews using **Yarn** :
-
-```
-$ yarn global add clinews
-```
-
-Yarn itself can installed using npm
-
-```
-$ npm -i yarn
-```
-
-### Configure News API
-
-Clinews retrieves all news headlines from [**News API**][2]. News API is a simple and easy-to-use API that returns JSON metadata for the headlines currently published on a range of news sources and blogs. It currently provides live headlines from 70 popular sources, including Ars Technica, BBC, Blooberg, CNN, Daily Mail, Engadget, ESPN, Financial Times, Google News, hacker News, IGN, Mashable, National Geographic, Reddit r/all, Reuters, Speigel Online, Techcrunch, The Guardian, The Hindu, The Huffington Post, The Newyork Times, The Next Web, The Wall street Journal, USA today and [**more**][3].
-
-First, you need an API key from News API. Go to [**https://newsapi.org/register**][4] URL and register a free account to get the API key.
-
-Once you got the API key from News API site, edit your **.bashrc** file:
-
-```
-$ vi ~/.bashrc
-
-```
-
-Add newsapi API key at the end like below:
-
-```
-export IN_API_KEY="Paste-API-key-here"
-
-```
-
-Please note that you need to paste the key inside the double quotes. Save and close the file.
-
-Run the following command to update the changes.
-
-```
-$ source ~/.bashrc
-
-```
-
-Done. Now let us go ahead and fetch the latest headlines from new sources.
-
-### Read News And Latest Headlines From Commandline
-
-To read news and latest headlines from specific new source, for example **The Hindu** , run:
-
-```
-$ news fetch the-hindu
-
-```
-
-Here, **“the-hindu”** is the new source id (fetch id).
-
-The above command will fetch latest 10 headlines from The Hindu news portel and display them in the Terminal. Also, it displays a brief description of the news, the published date and time, and the actual link to the source.
-
-**Sample output:**
-
-
-
-To read a news in your browser, hold Ctrl key and click on the URL. It will open in your default web browser.
-
-To view all the sources you can get news from, run:
-
-```
-$ news sources
-
-```
-
-**Sample output:**
-
-
-
-As you see in the above screenshot, Clinews lists all news sources including the name of the news source, fetch id, description of the site, website URL and the country where it is located. As of writing this guide, Clinews currently supports 70+ news sources.
-
-Clinews can also able to search for news stories across all sources matching search criteria/term. Say for example, to list all news stories with titles containing the words **“Tamilnadu”** , use the following command:
-
-```
-$ news search "Tamilnadu"
-```
-
-This command will scrap all news sources for stories that match term **Tamilnadu**.
-
-Clinews has some extra flags that helps you to
-
- * limit the amount of news stories you want to see,
- * sort news stories (top, latest, popular),
- * display news stories category wise (E.g. business, entertainment, gaming, general, music, politics, science-and-nature, sport, technology)
-
-
-
-For more details, see the help section:
-
-```
-$ clinews -h
-```
-
-And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/clinews-read-news-and-latest-headlines-from-commandline/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[1]: https://www.ostechnix.com/get-news-instantly-commandline-linux/
-[2]: https://newsapi.org/
-[3]: https://newsapi.org/sources
-[4]: https://newsapi.org/register
diff --git a/sources/tech/20180921 Control your data with Syncthing- An open source synchronization tool.md b/sources/tech/20180921 Control your data with Syncthing- An open source synchronization tool.md
index 32be152b4c..97aa36801b 100644
--- a/sources/tech/20180921 Control your data with Syncthing- An open source synchronization tool.md
+++ b/sources/tech/20180921 Control your data with Syncthing- An open source synchronization tool.md
@@ -1,3 +1,5 @@
+translating by ypingcn
+
Control your data with Syncthing: An open source synchronization tool
======
Decide how to store and share your personal information.
diff --git a/sources/tech/20180924 A Simple, Beautiful And Cross-platform Podcast App.md b/sources/tech/20180924 A Simple, Beautiful And Cross-platform Podcast App.md
deleted file mode 100644
index 628a805144..0000000000
--- a/sources/tech/20180924 A Simple, Beautiful And Cross-platform Podcast App.md
+++ /dev/null
@@ -1,114 +0,0 @@
-translating by Flowsnow
-
-A Simple, Beautiful And Cross-platform Podcast App
-======
-
-
-
-Podcasts have become very popular in the last few years. Podcasts are what’s called “infotainment”, they are generally light-hearted, but they generally give you valuable information. Podcasts have blown up in the last few years, and if you like something, chances are there is a podcast about it. There are a lot of podcast players out there for the Linux desktop, but if you want something that is visually beautiful, has slick animations, and works on every platform, there aren’t a lot of alternatives to **CPod**. CPod (formerly known as **Cumulonimbus** ) is an open source and slickest podcast app that works on Linux, MacOS and Windows.
-
-CPod runs on something called **Electron** – a tool that allows developers to build cross-platform (E.g Windows, MacOs and Linux) desktop GUI applications. In this brief guide, we will be discussing – how to install and use CPod podcast app in Linux.
-
-### Installing CPod
-
-Go to the [**releases page**][1] of CPod. Download and Install the binary for your platform of choice. If you use Ubuntu/Debian, you can just download and install the .deb file from the releases page as shown below.
-
-```
-$ wget https://github.com/z-------------/CPod/releases/download/v1.25.7/CPod_1.25.7_amd64.deb
-
-$ sudo apt update
-
-$ sudo apt install gdebi
-
-$ sudo gdebi CPod_1.25.7_amd64.deb
-```
-
-If you use any other distribution, you probably should use the **AppImage** in the releases page.
-
-Download the AppImage file from the releases page.
-
-Open your terminal, and go to the directory where the AppImage file has been stored. Change the permissions to allow execution:
-
-```
-$ chmod +x CPod-1.25.7-x86_64.AppImage
-```
-
-Execute the AppImage File:
-
-```
-$ ./CPod-1.25.7-x86_64.AppImage
-```
-
-You’ll be presented a dialog asking whether to integrate the app with the system. Click **Yes** if you want to do so.
-
-### Features
-
-**Explore Tab**
-
-
-
-CPod uses the Apple iTunes database to find podcasts. This is good, because the iTunes database is the biggest one out there. If there is a podcast out there, chances are it’s on iTunes. To find podcasts, just use the top search bar in the Explore section. The Explore Section also shows a few popular podcasts.
-
-**Home Tab**
-
-
-
-The Home Tab is the tab that opens by default when you open the app. The Home Tab shows a chronological list of all the episodes of all the podcasts that you have subscribed to.
-
-From the home tab, you can:
-
- 1. Mark episodes read.
- 2. Download them for offline playing
- 3. Add them to the queue.
-
-
-
-**Subscriptions Tab**
-
-
-
-You can of course, subscribe to podcasts that you like. A few other things you can do in the Subscriptions Tab is:
-
- 1. Refresh Podcast Artwork
- 2. Export and Import Subscriptions to/from an .OPML file.
-
-
-
-**The Player**
-
-
-
-The player is perhaps the most beautiful part of CPod. The app changes the overall look and feel according to the banner of the podcast. There’s a sound visualiser at the bottom. To the right, you can see and search for other episodes of this podcast.
-
-**Cons/Missing Features**
-
-While I love this app, there are a few features and disadvantages that CPod does have:
-
- 1. Poor MPRIS Integration – You can play/pause the podcast from the media player dialog of your desktop environment, but not much more. The name of the podcast is not shown, and you can go to the next/previous episode.
- 2. No support for chapters.
- 3. No auto-downloading – you have to manually download episodes.
- 4. CPU usage during use is pretty high (even for an Electron app).
-
-
-
-### Verdict
-
-While it does have its cons, CPod is clearly the most aesthetically pleasing podcast player app out there, and it has most basic features down. If you love using visually beautiful apps, and don’t need the advanced features, this is the perfect app for you. I know for a fact that I’m going to use it.
-
-Do you like CPod? Please put your opinions on the comments below!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/cpod-a-simple-beautiful-and-cross-platform-podcast-app/
-
-作者:[EDITOR][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/editor/
-[1]: https://github.com/z-------------/CPod/releases
diff --git a/sources/tech/20180925 Hegemon - A Modular System Monitor Application Written In Rust.md b/sources/tech/20180925 Hegemon - A Modular System Monitor Application Written In Rust.md
deleted file mode 100644
index a75c1f3e9a..0000000000
--- a/sources/tech/20180925 Hegemon - A Modular System Monitor Application Written In Rust.md
+++ /dev/null
@@ -1,80 +0,0 @@
-translating---geekpi
-
-Hegemon – A Modular System Monitor Application Written In Rust
-======
-
-
-
-When it comes to monitor running processes in Unix-like systems, the most commonly used applications are **top** and **htop** , which is an enhanced version of top. My personal favorite is htop. However, the developers are releasing few alternatives to these applications every now and then. One such alternative to top and htop utilities is **Hegemon**. It is a modular system monitor application written using **Rust** programming language.
-
-Concerning about the features of Hegemon, we can list the following:
-
- * Hegemon will monitor the usage of CPU, memory and Swap.
- * It monitors the system’s temperature and fan speed.
- * The update interval time can be adjustable. The default value is 3 seconds.
- * We can reveal more detailed graph and additional information by expanding the data streams.
- * Unit tests
- * Clean interface
- * Free and open source.
-
-
-
-### Installing Hegemon
-
-Make sure you have installed **Rust 1.26** or later version. To install Rust in your Linux distribution, refer the following guide:
-
-[Install Rust Programming Language In Linux][2]
-
-Also, install [libsensors][1] library. It is available in the default repositories of most Linux distributions. For example, you can install it in RPM based systems such as Fedora using the following command:
-
-```
-$ sudo dnf install lm_sensors-devel
-```
-
-On Debian-based systems like Ubuntu, Linux Mint, it can be installed using command:
-
-```
-$ sudo apt-get install libsensors4-dev
-```
-
-Once you installed Rust and libsensors, install Hegemon using command:
-
-```
-$ cargo install hegemon
-```
-
-Once hegemon installed, start monitoring the running processes in your Linux system using command:
-
-```
-$ hegemon
-```
-
-Here is the sample output from my Arch Linux desktop.
-
-
-
-To exit, press **Q**.
-
-
-Please be mindful that hegemon is still in its early development stage and it is not complete replacement for **top** command. There might be bugs and missing features. If you came across any bugs, report them in the project’s github page. The developer is planning to bring more features in the upcoming versions. So, keep an eye on this project.
-
-And, that’s all for now. Hope this helps. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/hegemon-a-modular-system-monitor-application-written-in-rust/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[1]: https://github.com/lm-sensors/lm-sensors
-[2]: https://www.ostechnix.com/install-rust-programming-language-in-linux/
diff --git a/sources/tech/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md b/sources/tech/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md
deleted file mode 100644
index ff33e7c175..0000000000
--- a/sources/tech/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md
+++ /dev/null
@@ -1,88 +0,0 @@
-How to Boot Ubuntu 18.04 / Debian 9 Server in Rescue (Single User mode) / Emergency Mode
-======
-Booting a Linux Server into a single user mode or **rescue mode** is one of the important troubleshooting that a Linux admin usually follow while recovering the server from critical conditions. In Ubuntu 18.04 and Debian 9, single user mode is known as a rescue mode.
-
-Apart from the rescue mode, Linux servers can be booted in **emergency mode** , the main difference between them is that, emergency mode loads a minimal environment with read only root file system file system, also it does not enable any network or other services. But rescue mode try to mount all the local file systems & try to start some important services including network.
-
-In this article we will discuss how we can boot our Ubuntu 18.04 LTS / Debian 9 Server in rescue mode and emergency mode.
-
-#### Booting Ubuntu 18.04 LTS Server in Single User / Rescue Mode:
-
-Reboot your server and go to boot loader (Grub) screen and Select “ **Ubuntu** “, bootloader screen would look like below,
-
-
-
-Press “ **e** ” and then go the end of line which starts with word “ **linux** ” and append “ **systemd.unit=rescue.target** “. Remove the word “ **$vt_handoff** ” if it exists.
-
-
-
-Now Press Ctrl-x or F10 to boot,
-
-
-
-Now press enter and then you will get the shell where all file systems will be mounted in read-write mode and do the troubleshooting. Once you are done with troubleshooting, you can reboot your server using “ **reboot** ” command.
-
-#### Booting Ubuntu 18.04 LTS Server in emergency mode
-
-Reboot the server and go the boot loader screen and select “ **Ubuntu** ” and then press “ **e** ” and go to the end of line which starts with word linux, and append “ **systemd.unit=emergency.target** ”
-
-
-
-Now Press Ctlr-x or F10 to boot in emergency mode, you will get a shell and do the troubleshooting from there. As we had already discussed that in emergency mode, file systems will be mounted in read-only mode and also there will be no networking in this mode,
-
-
-
-Use below command to mount the root file system in read-write mode,
-
-```
-# mount -o remount,rw /
-
-```
-
-Similarly, you can remount rest of file systems in read-write mode .
-
-#### Booting Debian 9 into Rescue & Emergency Mode
-
-Reboot your Debian 9.x server and go to grub screen and select “ **Debian GNU/Linux** ”
-
-
-
-Press “ **e** ” and go to end of line which starts with word linux and append “ **systemd.unit=rescue.target** ” to boot the system in rescue mode and to boot in emergency mode then append “ **systemd.unit=emergency.target** ”
-
-#### Rescue mode :
-
-
-
-Now press Ctrl-x or F10 to boot in rescue mode
-
-
-
-Press Enter to get the shell and from there you can start troubleshooting.
-
-#### Emergency Mode:
-
-
-
-Now press ctrl-x or F10 to boot your system in emergency mode
-
-
-
-Press enter to get the shell and use “ **mount -o remount,rw /** ” command to mount the root file system in read-write mode.
-
-**Note:** In case root password is already set in Ubuntu 18.04 and Debian 9 Server then you must enter root password to get shell in rescue and emergency mode
-
-That’s all from this article, please do share your feedback and comments in case you like this article.
-
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxtechi.com/boot-ubuntu-18-04-debian-9-rescue-emergency-mode/
-
-作者:[Pradeep Kumar][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: http://www.linuxtechi.com/author/pradeep/
diff --git a/sources/tech/20180925 How to Replace one Linux Distro With Another in Dual Boot -Guide.md b/sources/tech/20180925 How to Replace one Linux Distro With Another in Dual Boot -Guide.md
deleted file mode 100644
index ab9fa8acc3..0000000000
--- a/sources/tech/20180925 How to Replace one Linux Distro With Another in Dual Boot -Guide.md
+++ /dev/null
@@ -1,160 +0,0 @@
-How to Replace one Linux Distro With Another in Dual Boot [Guide]
-======
-**If you have a Linux distribution installed, you can replace it with another distribution in the dual boot. You can also keep your personal documents while switching the distribution.**
-
-![How to Replace One Linux Distribution With Another From Dual Boot][1]
-
-Suppose you managed to [successfully dual boot Ubuntu and Windows][2]. But after reading the [Linux Mint versus Ubuntu discussion][3], you realized that [Linux Mint][4] is more suited for your needs. What would you do now? How would you [remove Ubuntu][5] and [install Mint in dual boot][6]?
-
-You might think that you need to uninstall [Ubuntu][7] from dual boot first and then repeat the dual booting steps with Linux Mint. Let me tell you something. You don’t need to do all of that.
-
-If you already have a Linux distribution installed in dual boot, you can easily replace it with another. You don’t have to uninstall the existing Linux distribution. You simply delete its partition and install the new distribution on the disk space vacated by the previous distribution.
-
-Another good news is that you may be able to keep your Home directory with all your documents and pictures while switching the Linux distributions.
-
-Let me show you how to switch Linux distributions.
-
-### Replace one Linux with another from dual boot
-
-
-
-Let me describe the scenario I am going to use here. I have Linux Mint 19 installed on my system in dual boot mode with Windows 10. I am going to replace it with elementary OS 5. I’ll also keep my personal files (music, pictures, videos, documents from my home directory) while switching distributions.
-
-Let’s first take a look at the requirements:
-
- * A system with Linux and Windows dual boot
- * Live USB of Linux you want to install
- * Backup of your important files in Windows and in Linux on an external disk (optional yet recommended)
-
-
-
-#### Things to keep in mind for keeping your home directory while changing Linux distribution
-
-If you want to keep your files from existing Linux install as it is, you must have a separate root and home directory. You might have noticed that in my [dual boot tutorials][8], I always go for ‘Something Else’ option and then manually create root and home partitions instead of choosing ‘Install alongside Windows’ option. This is where all the troubles in manually creating separate home partition pay off.
-
-Keeping Home on a separate partition is helpful in situations when you want to replace your existing Linux install with another without losing your files.
-
-Note: You must remember the exact username and password of your existing Linux install in order to use the same home directory as it is in the new distribution.
-
-If you don’t have a separate Home partition, you may create it later as well BUT I won’t recommend that. That process is slightly complicated and I don’t want you to mess up your system.
-
-With that much background information, it’s time to see how to replace a Linux distribution with another.
-
-#### Step 1: Create a live USB of the new Linux distribution
-
-Alright! I already mentioned it in the requirements but I still included it in the main steps to avoid confusion.
-
-You can create a live USB using a start up disk creator like [Etcher][9] in Windows or Linux. The process is simple so I am not going to list the steps here.
-
-#### Step 2: Boot into live USB and proceed to installing Linux
-
-Since you have already dual booted before, you probably know the drill. Plugin the live USB, restart your system and at the boot time, press F10 or F12 repeatedly to enter BIOS settings.
-
-In here, choose to boot from the USB. And then you’ll see the option to try the live environment or installing it immediately.
-
-You should start the installation procedure. When you reach the ‘Installation type’ screen, choose the ‘Something else’ option.
-
-![Replacing one Linux with another from dual boot][10]
-Select ‘Something else’ here
-
-#### Step 3: Prepare the partition
-
-You’ll see the partitioning screen now. Look closely and you’ll see your Linux installation with Ext4 file system type.
-
-![Identifying Linux partition in dual boot][11]
-Identify where your Linux is installed
-
-In the above picture, the Ext4 partition labeled as Linux Mint 19 is the root partition. The second Ext4 partition of 82691 MB is the Home partition. I [haven’t used any swap space][12] here.
-
-Now, if you have just one Ext4 partition, that means that your home directory is on the same partition as root. In this case, you won’t be able to keep your Home directory. I suggest that you copy the important files to an external disk else you’ll lose them forever.
-
-It’s time to delete the root partition. Select the root partition and click the – sign. This will create some free space.
-
-![Delete root partition of your existing Linux install][13]
-Delete root partition
-
-When you have the free space, click on + sign.
-
-![Create root partition for the new Linux][14]
-Create a new root partition
-
-Now you should create a new partition out of this free space. If you had just one root partition in your previous Linux install, you should create root and home partitions here. You can also create the swap partition if you want to.
-
-If you had root and home partition separately, just create a root partition from the deleted root partition.
-
-![Create root partition for the new Linux][15]
-Creating root partition
-
-You may ask why did I use delete and add instead of using the ‘change’ option. It’s because a few years ago, using change didn’t work for me. So I prefer to do a – and +. Is it superstition? Maybe.
-
-One important thing to do here is to mark the newly created partition for format. f you don’t change the size of the partition, it won’t be formatted unless you explicitly ask it to format. And if the partition is not formatted, you’ll have issues.
-
-![][16]
-It’s important to format the root partition
-
-Now if you already had a separate Home partition on your existing Linux install, you should select it and click on change.
-
-![Recreate home partition][17]
-Retouch the already existing home partition (if any)
-
-You just have to specify that you are mounting it as home partition.
-
-![Specify the home mount point][18]
-Specify the home mount point
-
-If you had a swap partition, you can repeat the same steps as the home partition. This time specify that you want to use the space as swap.
-
-At this stage, you should have a root partition (with format option selected) and a home partition (and a swap if you want to). Hit the install now button to start the installation.
-
-![Verify partitions while replacing one Linux with another][19]
-Verify the partitions
-
-The next few screens would be familiar to you. What matters is the screen where you are asked to create user and password.
-
-If you had a separate home partition previously and you want to use the same home directory, you MUST use the same username and password that you had before. Computer name doesn’t matter.
-
-![To keep the home partition intact, use the previous user and password][20]
-To keep the home partition intact, use the previous user and password
-
-Your struggle is almost over. You don’t have to do anything else other than waiting for the installation to finish.
-
-![Wait for installation to finish][21]
-Wait for installation to finish
-
-Once the installation is over, restart your system. You’ll have a new Linux distribution or version.
-
-In my case, I had the entire home directory of Linux Mint 19 as it is in the elementary OS. All the videos, pictures I had remained as it is. Isn’t that nice?
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/replace-linux-from-dual-boot/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/Replace-Linux-Distro-from-dual-boot.png
-[2]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
-[3]: https://itsfoss.com/linux-mint-vs-ubuntu/
-[4]: https://www.linuxmint.com/
-[5]: https://itsfoss.com/uninstall-ubuntu-linux-windows-dual-boot/
-[6]: https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
-[7]: https://www.ubuntu.com/
-[8]: https://itsfoss.com/guide-install-elementary-os-luna/
-[9]: https://etcher.io/
-[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-1.jpg
-[11]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-2.jpg
-[12]: https://itsfoss.com/swap-size/
-[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-3.jpg
-[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-4.jpg
-[15]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-5.jpg
-[16]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-6.jpg
-[17]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-7.jpg
-[18]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-8.jpg
-[19]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-9.jpg
-[20]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-10.jpg
-[21]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-11.jpg
diff --git a/sources/tech/20180926 3 open source distributed tracing tools.md b/sources/tech/20180926 3 open source distributed tracing tools.md
deleted file mode 100644
index 9879302d38..0000000000
--- a/sources/tech/20180926 3 open source distributed tracing tools.md
+++ /dev/null
@@ -1,90 +0,0 @@
-translating by belitex
-
-3 open source distributed tracing tools
-======
-
-Find performance issues quickly with these tools, which provide a graphical view of what's happening across complex software systems.
-
-
-
-Distributed tracing systems enable users to track a request through a software system that is distributed across multiple applications, services, and databases as well as intermediaries like proxies. This allows for a deeper understanding of what is happening within the software system. These systems produce graphical representations that show how much time the request took on each step and list each known step.
-
-A user reviewing this content can determine where the system is experiencing latencies or blockages. Instead of testing the system like a binary search tree when requests start failing, operators and developers can see exactly where the issues begin. This can also reveal where performance changes might be occurring from deployment to deployment. It’s always better to catch regressions automatically by alerting to the anomalous behavior than to have your customers tell you.
-
-How does this tracing thing work? Well, each request gets a special ID that’s usually injected into the headers. This ID uniquely identifies that transaction. This transaction is normally called a trace. The trace is the overall abstract idea of the entire transaction. Each trace is made up of spans. These spans are the actual work being performed, like a service call or a database request. Each span also has a unique ID. Spans can create subsequent spans called child spans, and child spans can have multiple parents.
-
-Once a transaction (or trace) has run its course, it can be searched in a presentation layer. There are several tools in this space that we’ll discuss later, but the picture below shows [Jaeger][1] from my [Istio walkthrough][2]. It shows multiple spans of a single trace. The power of this is immediately clear as you can better understand the transaction’s story at a glance.
-
-
-
-This demo uses Istio’s built-in OpenTracing implementation, so I can get tracing without even modifying my application. It also uses Jaeger, which is OpenTracing-compatible.
-
-So what is OpenTracing? Let’s find out.
-
-### OpenTracing API
-
-[OpenTracing][3] is a spec that grew out of [Zipkin][4] to provide cross-platform compatibility. It offers a vendor-neutral API for adding tracing to applications and delivering that data into distributed tracing systems. A library written for the OpenTracing spec can be used with any system that is OpenTracing-compliant. Zipkin, Jaeger, and Appdash are examples of open source tools that have adopted the open standard, but even proprietary tools like [Datadog][5] and [Instana][6] are adopting it. This is expected to continue as OpenTracing reaches ubiquitous status.
-
-### OpenCensus
-
-Okay, we have OpenTracing, but what is this [OpenCensus][7] thing that keeps popping up in my searches? Is it a competing standard, something completely different, or something complementary?
-
-The answer depends on who you ask. I will do my best to explain the difference (as I understand it): OpenCensus takes a more holistic or all-inclusive approach. OpenTracing is focused on establishing an open API and spec and not on open implementations for each language and tracing system. OpenCensus provides not only the specification but also the language implementations and wire protocol. It also goes beyond tracing by including additional metrics that are normally outside the scope of distributed tracing systems.
-
-OpenCensus allows viewing data on the host where the application is running, but it also has a pluggable exporter system for exporting data to central aggregators. The current exporters produced by the OpenCensus team include Zipkin, Prometheus, Jaeger, Stackdriver, Datadog, and SignalFx, but anyone can create an exporter.
-
-From my perspective, there’s a lot of overlap. One isn’t necessarily better than the other, but it’s important to know what each does and doesn’t do. OpenTracing is primarily a spec, with others doing the implementation and opinionation. OpenCensus provides a holistic approach for the local component with more opinionation but still requires other systems for remote aggregation.
-
-### Tool options
-
-#### Zipkin
-
-Zipkin was one of the first systems of this kind. It was developed by Twitter based on the [Google Dapper paper][8] about the internal system Google uses. Zipkin was written using Java, and it can use Cassandra or ElasticSearch as a scalable backend. Most companies should be satisfied with one of those options. The lowest supported Java version is Java 6. It also uses the [Thrift][9] binary communication protocol, which is popular in the Twitter stack and is hosted as an Apache project.
-
-The system consists of reporters (clients), collectors, a query service, and a web UI. Zipkin is meant to be safe in production by transmitting only a trace ID within the context of a transaction to inform receivers that a trace is in process. The data collected in each reporter is then transmitted asynchronously to the collectors. The collectors store these spans in the database, and the web UI presents this data to the end user in a consumable format. The delivery of data to the collectors can occur in three different methods: HTTP, Kafka, and Scribe.
-
-The [Zipkin community][10] has also created [Brave][11], a Java client implementation compatible with Zipkin. It has no dependencies, so it won’t drag your projects down or clutter them with libraries that are incompatible with your corporate standards. There are many other implementations, and Zipkin is compatible with the OpenTracing standard, so these implementations should also work with other distributed tracing systems. The popular Spring framework has a component called [Spring Cloud Sleuth][12] that is compatible with Zipkin.
-
-#### Jaeger
-
-[Jaeger][1] is a newer project from Uber Technologies that the [CNCF][13] has since adopted as an Incubating project. It is written in Golang, so you don’t have to worry about having dependencies installed on the host or any overhead of interpreters or language virtual machines. Similar to Zipkin, Jaeger also supports Cassandra and ElasticSearch as scalable storage backends. Jaeger is also fully compatible with the OpenTracing standard.
-
-Jaeger’s architecture is similar to Zipkin, with clients (reporters), collectors, a query service, and a web UI, but it also has an agent on each host that locally aggregates the data. The agent receives data over a UDP connection, which it batches and sends to a collector. The collector receives that data in the form of the [Thrift][14] protocol and stores that data in Cassandra or ElasticSearch. The query service can access the data store directly and provide that information to the web UI.
-
-By default, a user won’t get all the traces from the Jaeger clients. The system samples 0.1% (1 in 1,000) of traces that pass through each client. Keeping and transmitting all traces would be a bit overwhelming to most systems. However, this can be increased or decreased by configuring the agents, which the client consults with for its configuration. This sampling isn’t completely random, though, and it’s getting better. Jaeger uses probabilistic sampling, which tries to make an educated guess at whether a new trace should be sampled or not. [Adaptive sampling is on its roadmap][15], which will improve the sampling algorithm by adding additional context for making decisions.
-
-#### Appdash
-
-[Appdash][16] is a distributed tracing system written in Golang, like Jaeger. It was created by [Sourcegraph][17] based on Google’s Dapper and Twitter’s Zipkin. Similar to Jaeger and Zipkin, Appdash supports the OpenTracing standard; this was a later addition and requires a component that is different from the default component. This adds risk and complexity.
-
-At a high level, Appdash’s architecture consists mostly of three components: a client, a local collector, and a remote collector. There’s not a lot of documentation, so this description comes from testing the system and reviewing the code. The client in Appdash gets added to your code. Appdash provides Python, Golang, and Ruby implementations, but OpenTracing libraries can be used with Appdash’s OpenTracing implementation. The client collects the spans and sends them to the local collector. The local collector then sends the data to a centralized Appdash server running its own local collector, which is the remote collector for all other nodes in the system.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/distributed-tracing-tools
-
-作者:[Dan Barker][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/barkerd427
-[1]: https://www.jaegertracing.io/
-[2]: https://www.youtube.com/watch?v=T8BbeqZ0Rls
-[3]: http://opentracing.io/
-[4]: https://zipkin.io/
-[5]: https://www.datadoghq.com/
-[6]: https://www.instana.com/
-[7]: https://opencensus.io/
-[8]: https://research.google.com/archive/papers/dapper-2010-1.pdf
-[9]: https://thrift.apache.org/
-[10]: https://zipkin.io/pages/community.html
-[11]: https://github.com/openzipkin/brave
-[12]: https://cloud.spring.io/spring-cloud-sleuth/
-[13]: https://www.cncf.io/
-[14]: https://en.wikipedia.org/wiki/Apache_Thrift
-[15]: https://www.jaegertracing.io/docs/roadmap/#adaptive-sampling
-[16]: https://github.com/sourcegraph/appdash
-[17]: https://about.sourcegraph.com/
diff --git a/sources/tech/20180926 An introduction to swap space on Linux systems.md b/sources/tech/20180926 An introduction to swap space on Linux systems.md
deleted file mode 100644
index da50208533..0000000000
--- a/sources/tech/20180926 An introduction to swap space on Linux systems.md
+++ /dev/null
@@ -1,302 +0,0 @@
-heguangzhi Translating
-
-An introduction to swap space on Linux systems
-======
-
-
-
-Swap space is a common aspect of computing today, regardless of operating system. Linux uses swap space to increase the amount of virtual memory available to a host. It can use one or more dedicated swap partitions or a swap file on a regular filesystem or logical volume.
-
-There are two basic types of memory in a typical computer. The first type, random access memory (RAM), is used to store data and programs while they are being actively used by the computer. Programs and data cannot be used by the computer unless they are stored in RAM. RAM is volatile memory; that is, the data stored in RAM is lost if the computer is turned off.
-
-Hard drives are magnetic media used for long-term storage of data and programs. Magnetic media is nonvolatile; the data stored on a disk remains even when power is removed from the computer. The CPU (central processing unit) cannot directly access the programs and data on the hard drive; it must be copied into RAM first, and that is where the CPU can access its programming instructions and the data to be operated on by those instructions. During the boot process, a computer copies specific operating system programs, such as the kernel and init or systemd, and data from the hard drive into RAM, where it is accessed directly by the computer’s processor, the CPU.
-
-### Swap space
-
-Swap space is the second type of memory in modern Linux systems. The primary function of swap space is to substitute disk space for RAM memory when real RAM fills up and more space is needed.
-
-For example, assume you have a computer system with 8GB of RAM. If you start up programs that don’t fill that RAM, everything is fine and no swapping is required. But suppose the spreadsheet you are working on grows when you add more rows, and that, plus everything else that's running, now fills all of RAM. Without swap space available, you would have to stop working on the spreadsheet until you could free up some of your limited RAM by closing down some other programs.
-
-The kernel uses a memory management program that detects blocks, aka pages, of memory in which the contents have not been used recently. The memory management program swaps enough of these relatively infrequently used pages of memory out to a special partition on the hard drive specifically designated for “paging,” or swapping. This frees up RAM and makes room for more data to be entered into your spreadsheet. Those pages of memory swapped out to the hard drive are tracked by the kernel’s memory management code and can be paged back into RAM if they are needed.
-
-The total amount of memory in a Linux computer is the RAM plus swap space and is referred to as virtual memory.
-
-### Types of Linux swap
-
-Linux provides for two types of swap space. By default, most Linux installations create a swap partition, but it is also possible to use a specially configured file as a swap file. A swap partition is just what its name implies—a standard disk partition that is designated as swap space by the `mkswap` command.
-
-A swap file can be used if there is no free disk space in which to create a new swap partition or space in a volume group where a logical volume can be created for swap space. This is just a regular file that is created and preallocated to a specified size. Then the `mkswap` command is run to configure it as swap space. I don’t recommend using a file for swap space unless absolutely necessary.
-
-### Thrashing
-
-Thrashing can occur when total virtual memory, both RAM and swap space, become nearly full. The system spends so much time paging blocks of memory between swap space and RAM and back that little time is left for real work. The typical symptoms of this are obvious: The system becomes slow or completely unresponsive, and the hard drive activity light is on almost constantly.
-
-If you can manage to issue a command like `free` that shows CPU load and memory usage, you will see that the CPU load is very high, perhaps as much as 30 to 40 times the number of CPU cores in the system. Another symptom is that both RAM and swap space are almost completely allocated.
-
-After the fact, looking at SAR (system activity report) data can also show these symptoms. I install SAR on every system I work on and use it for post-repair forensic analysis.
-
-### What is the right amount of swap space?
-
-Many years ago, the rule of thumb for the amount of swap space that should be allocated on the hard drive was 2X the amount of RAM installed in the computer (of course, that was when most computers' RAM was measured in KB or MB). So if a computer had 64KB of RAM, a swap partition of 128KB would be an optimum size. This rule took into account the facts that RAM sizes were typically quite small at that time and that allocating more than 2X RAM for swap space did not improve performance. With more than twice RAM for swap, most systems spent more time thrashing than actually performing useful work.
-
-RAM has become an inexpensive commodity and most computers these days have amounts of RAM that extend into tens of gigabytes. Most of my newer computers have at least 8GB of RAM, one has 32GB, and my main workstation has 64GB. My older computers have from 4 to 8 GB of RAM.
-
-When dealing with computers having huge amounts of RAM, the limiting performance factor for swap space is far lower than the 2X multiplier. The Fedora 28 online Installation Guide, which can be found online at [Fedora Installation Guide][1], defines current thinking about swap space allocation. I have included below some discussion and the table of recommendations from that document.
-
-The following table provides the recommended size of a swap partition depending on the amount of RAM in your system and whether you want sufficient memory for your system to hibernate. The recommended swap partition size is established automatically during installation. To allow for hibernation, however, you will need to edit the swap space in the custom partitioning stage.
-
-_Table 1: Recommended system swap space in Fedora 28 documentation_
-
-| **Amount of system RAM** | **Recommended swap space** | **Recommended swap with hibernation** |
-|--------------------------|-----------------------------|---------------------------------------|
-| less than 2 GB | 2 times the amount of RAM | 3 times the amount of RAM |
-| 2 GB - 8 GB | Equal to the amount of RAM | 2 times the amount of RAM |
-| 8 GB - 64 GB | 0.5 times the amount of RAM | 1.5 times the amount of RAM |
-| more than 64 GB | workload dependent | hibernation not recommended |
-
-At the border between each range listed above (for example, a system with 2 GB, 8 GB, or 64 GB of system RAM), use discretion with regard to chosen swap space and hibernation support. If your system resources allow for it, increasing the swap space may lead to better performance.
-
-Of course, most Linux administrators have their own ideas about the appropriate amount of swap space—as well as pretty much everything else. Table 2, below, contains my recommendations based on my personal experiences in multiple environments. These may not work for you, but as with Table 1, they may help you get started.
-
-_Table 2: Recommended system swap space per the author_
-
-| Amount of RAM | Recommended swap space |
-|---------------|------------------------|
-| ≤ 2GB | 2X RAM |
-| 2GB – 8GB | = RAM |
-| >8GB | 8GB |
-
-One consideration in both tables is that as the amount of RAM increases, beyond a certain point adding more swap space simply leads to thrashing well before the swap space even comes close to being filled. If you have too little virtual memory while following these recommendations, you should add more RAM, if possible, rather than more swap space. As with all recommendations that affect system performance, use what works best for your specific environment. This will take time and effort to experiment and make changes based on the conditions in your Linux environment.
-
-#### Adding more swap space to a non-LVM disk environment
-
-Due to changing requirements for swap space on hosts with Linux already installed, it may become necessary to modify the amount of swap space defined for the system. This procedure can be used for any general case where the amount of swap space needs to be increased. It assumes sufficient available disk space is available. This procedure also assumes that the disks are partitioned in “raw” EXT4 and swap partitions and do not use logical volume management (LVM).
-
-The basic steps to take are simple:
-
- 1. Turn off the existing swap space.
-
- 2. Create a new swap partition of the desired size.
-
- 3. Reread the partition table.
-
- 4. Configure the partition as swap space.
-
- 5. Add the new partition/etc/fstab.
-
- 6. Turn on swap.
-
-
-
-
-A reboot should not be necessary.
-
-For safety's sake, before turning off swap, at the very least you should ensure that no applications are running and that no swap space is in use. The `free` or `top` commands can tell you whether swap space is in use. To be even safer, you could revert to run level 1 or single-user mode.
-
-Turn off the swap partition with the command which turns off all swap space:
-
-```
-swapoff -a
-
-```
-
-Now display the existing partitions on the hard drive.
-
-```
-fdisk -l
-
-```
-
-This displays the current partition tables on each drive. Identify the current swap partition by number.
-
-Start `fdisk` in interactive mode with the command:
-
-```
-fdisk /dev/
-
-```
-
-For example:
-
-```
-fdisk /dev/sda
-
-```
-
-At this point, `fdisk` is now interactive and will operate only on the specified disk drive.
-
-Use the fdisk `p` sub-command to verify that there is enough free space on the disk to create the new swap partition. The space on the hard drive is shown in terms of 512-byte blocks and starting and ending cylinder numbers, so you may have to do some math to determine the available space between and at the end of allocated partitions.
-
-Use the `n` sub-command to create a new swap partition. fdisk will ask you the starting cylinder. By default, it chooses the lowest-numbered available cylinder. If you wish to change that, type in the number of the starting cylinder.
-
-The `fdisk` command now allows you to enter the size of the partitions in a number of formats, including the last cylinder number or the size in bytes, KB or MB. Type in 4000M, which will give about 4GB of space on the new partition (for example), and press Enter.
-
-Use the `p` sub-command to verify that the partition was created as you specified it. Note that the partition will probably not be exactly what you specified unless you used the ending cylinder number. The `fdisk` command can only allocate disk space in increments on whole cylinders, so your partition may be a little smaller or larger than you specified. If the partition is not what you want, you can delete it and create it again.
-
-Now it is necessary to specify that the new partition is to be a swap partition. The sub-command `t` allows you to specify the type of partition. So enter `t`, specify the partition number, and when it asks for the hex code partition type, type 82, which is the Linux swap partition type, and press Enter.
-
-When you are satisfied with the partition you have created, use the `w` sub-command to write the new partition table to the disk. The `fdisk` program will exit and return you to the command prompt after it completes writing the revised partition table. You will probably receive the following message as `fdisk` completes writing the new partition table:
-
-```
-The partition table has been altered!
-Calling ioctl() to re-read partition table.
-WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
-The kernel still uses the old table.
-The new table will be used at the next reboot.
-Syncing disks.
-```
-
-At this point, you use the `partprobe` command to force the kernel to re-read the partition table so that it is not necessary to perform a reboot.
-
-```
-partprobe
-```
-
-Now use the command `fdisk -l` to list the partitions and the new swap partition should be among those listed. Be sure that the new partition type is “Linux swap”.
-
-It will be necessary to modify the /etc/fstab file to point to the new swap partition. The existing line may look like this:
-
-```
-LABEL=SWAP-sdaX swap swap defaults 0 0
-
-```
-
-where `X` is the partition number. Add a new line that looks similar this, depending upon the location of your new swap partition:
-
-```
-/dev/sdaY swap swap defaults 0 0
-
-```
-
-Be sure to use the correct partition number. Now you can perform the final step in creating the swap partition. Use the `mkswap` command to define the partition as a swap partition.
-
-```
-mkswap /dev/sdaY
-
-```
-
-The final step is to turn swap on using the command:
-
-```
-swapon -a
-
-```
-
-Your new swap partition is now online along with the previously existing swap partition. You can use the `free` or `top` commands to verify this.
-
-#### Adding swap to an LVM disk environment
-
-If your disk setup uses LVM, changing swap space will be fairly easy. Again, this assumes that space is available in the volume group in which the current swap volume is located. By default, the installation procedures for Fedora Linux in an LVM environment create the swap partition as a logical volume. This makes it easy because you can simply increase the size of the swap volume.
-
-Here are the steps required to increase the amount of swap space in an LVM environment:
-
- 1. Turn off all swap.
-
- 2. Increase the size of the logical volume designated for swap.
-
- 3. Configure the resized volume as swap space.
-
- 4. Turn on swap.
-
-
-
-
-First, let’s verify that swap exists and is a logical volume using the `lvs` command (list logical volume).
-
-```
-[root@studentvm1 ~]# lvs
- LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
- home fedora_studentvm1 -wi-ao---- 2.00g
- pool00 fedora_studentvm1 twi-aotz-- 2.00g 8.17 2.93
- root fedora_studentvm1 Vwi-aotz-- 2.00g pool00 8.17
- swap fedora_studentvm1 -wi-ao---- 8.00g
- tmp fedora_studentvm1 -wi-ao---- 5.00g
- usr fedora_studentvm1 -wi-ao---- 15.00g
- var fedora_studentvm1 -wi-ao---- 10.00g
-[root@studentvm1 ~]#
-```
-
-You can see that the current swap size is 8GB. In this case, we want to add 2GB to this swap volume. First, stop existing swap. You may have to terminate running programs if swap space is in use.
-
-```
-swapoff -a
-
-```
-
-Now increase the size of the logical volume.
-
-```
-[root@studentvm1 ~]# lvextend -L +2G /dev/mapper/fedora_studentvm1-swap
- Size of logical volume fedora_studentvm1/swap changed from 8.00 GiB (2048 extents) to 10.00 GiB (2560 extents).
- Logical volume fedora_studentvm1/swap successfully resized.
-[root@studentvm1 ~]#
-```
-
-Run the `mkswap` command to make this entire 10GB partition into swap space.
-
-```
-[root@studentvm1 ~]# mkswap /dev/mapper/fedora_studentvm1-swap
-mkswap: /dev/mapper/fedora_studentvm1-swap: warning: wiping old swap signature.
-Setting up swapspace version 1, size = 10 GiB (10737414144 bytes)
-no label, UUID=3cc2bee0-e746-4b66-aa2d-1ea15ef1574a
-[root@studentvm1 ~]#
-```
-
-Turn swap back on.
-
-```
-[root@studentvm1 ~]# swapon -a
-[root@studentvm1 ~]#
-```
-
-Now verify the new swap space is present with the list block devices command. Again, a reboot is not required.
-
-```
-[root@studentvm1 ~]# lsblk
-NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
-sda 8:0 0 60G 0 disk
-|-sda1 8:1 0 1G 0 part /boot
-`-sda2 8:2 0 59G 0 part
- |-fedora_studentvm1-pool00_tmeta 253:0 0 4M 0 lvm
- | `-fedora_studentvm1-pool00-tpool 253:2 0 2G 0 lvm
- | |-fedora_studentvm1-root 253:3 0 2G 0 lvm /
- | `-fedora_studentvm1-pool00 253:6 0 2G 0 lvm
- |-fedora_studentvm1-pool00_tdata 253:1 0 2G 0 lvm
- | `-fedora_studentvm1-pool00-tpool 253:2 0 2G 0 lvm
- | |-fedora_studentvm1-root 253:3 0 2G 0 lvm /
- | `-fedora_studentvm1-pool00 253:6 0 2G 0 lvm
- |-fedora_studentvm1-swap 253:4 0 10G 0 lvm [SWAP]
- |-fedora_studentvm1-usr 253:5 0 15G 0 lvm /usr
- |-fedora_studentvm1-home 253:7 0 2G 0 lvm /home
- |-fedora_studentvm1-var 253:8 0 10G 0 lvm /var
- `-fedora_studentvm1-tmp 253:9 0 5G 0 lvm /tmp
-sr0 11:0 1 1024M 0 rom
-[root@studentvm1 ~]#
-```
-
-You can also use the `swapon -s` command, or `top`, `free`, or any of several other commands to verify this.
-
-```
-[root@studentvm1 ~]# free
- total used free shared buff/cache available
-Mem: 4038808 382404 2754072 4152 902332 3404184
-Swap: 10485756 0 10485756
-[root@studentvm1 ~]#
-```
-
-Note that the different commands display or require as input the device special file in different forms. There are a number of ways in which specific devices are accessed in the /dev directory. My article, [Managing Devices in Linux][2], includes more information about the /dev directory and its contents.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/swap-space-linux-systems
-
-作者:[David Both][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/dboth
-[1]: https://docs.fedoraproject.org/en-US/fedora/f28/install-guide/
-[2]: https://opensource.com/article/16/11/managing-devices-linux
diff --git a/sources/tech/20180926 How to use the Scikit-learn Python library for data science projects.md b/sources/tech/20180926 How to use the Scikit-learn Python library for data science projects.md
deleted file mode 100644
index e8b108720e..0000000000
--- a/sources/tech/20180926 How to use the Scikit-learn Python library for data science projects.md
+++ /dev/null
@@ -1,260 +0,0 @@
-translating by Flowsnow
-
-How to use the Scikit-learn Python library for data science projects
-======
-
-
-
-The Scikit-learn Python library, initially released in 2007, is commonly used in solving machine learning and data science problems—from the beginning to the end. The versatile library offers an uncluttered, consistent, and efficient API and thorough online documentation.
-
-### What is Scikit-learn?
-
-[Scikit-learn][1] is an open source Python library that has powerful tools for data analysis and data mining. It's available under the BSD license and is built on the following machine learning libraries:
-
- * **NumPy** , a library for manipulating multi-dimensional arrays and matrices. It also has an extensive compilation of mathematical functions for performing various calculations.
- * **SciPy** , an ecosystem consisting of various libraries for completing technical computing tasks.
- * **Matplotlib** , a library for plotting various charts and graphs.
-
-
-
-Scikit-learn offers an extensive range of built-in algorithms that make the most of data science projects.
-
-Here are the main ways the Scikit-learn library is used.
-
-#### 1. Classification
-
-The [classification][2] tools identify the category associated with provided data. For example, they can be used to categorize email messages as either spam or not.
-
- * Support vector machines (SVMs)
- * Nearest neighbors
- * Random forest
-
-
-
-#### 2. Regression
-
-Classification algorithms in Scikit-learn include:
-
-Regression involves creating a model that tries to comprehend the relationship between input and output data. For example, regression tools can be used to understand the behavior of stock prices.
-
-Regression algorithms include:
-
- * SVMs
- * Ridge regression
- * Lasso
-
-
-
-#### 3. Clustering
-
-The Scikit-learn clustering tools are used to automatically group data with the same characteristics into sets. For example, customer data can be segmented based on their localities.
-
-Clustering algorithms include:
-
- * K-means
- * Spectral clustering
- * Mean-shift
-
-
-
-#### 4. Dimensionality reduction
-
-Dimensionality reduction lowers the number of random variables for analysis. For example, to increase the efficiency of visualizations, outlying data may not be considered.
-
-Dimensionality reduction algorithms include:
-
- * Principal component analysis (PCA)
- * Feature selection
- * Non-negative matrix factorization
-
-
-
-#### 5. Model selection
-
-Model selection algorithms offer tools to compare, validate, and select the best parameters and models to use in your data science projects.
-
-Model selection modules that can deliver enhanced accuracy through parameter tuning include:
-
- * Grid search
- * Cross-validation
- * Metrics
-
-
-
-#### 6. Preprocessing
-
-The Scikit-learn preprocessing tools are important in feature extraction and normalization during data analysis. For example, you can use these tools to transform input data—such as text—and apply their features in your analysis.
-
-Preprocessing modules include:
-
- * Preprocessing
- * Feature extraction
-
-
-
-### A Scikit-learn library example
-
-Let's use a simple example to illustrate how you can use the Scikit-learn library in your data science projects.
-
-We'll use the [Iris flower dataset][3], which is incorporated in the Scikit-learn library. The Iris flower dataset contains 150 details about three flower species:
-
- * Setosa—labeled 0
- * Versicolor—labeled 1
- * Virginica—labeled 2
-
-
-
-The dataset includes the following characteristics of each flower species (in centimeters):
-
- * Sepal length
- * Sepal width
- * Petal length
- * Petal width
-
-
-
-#### Step 1: Importing the library
-
-Since the Iris dataset is included in the Scikit-learn data science library, we can load it into our workspace as follows:
-
-```
-from sklearn import datasets
-iris = datasets.load_iris()
-```
-
-These commands import the **datasets** module from **sklearn** , then use the **load_digits()** method from **datasets** to include the data in the workspace.
-
-#### Step 2: Getting dataset characteristics
-
-The **datasets** module contains several methods that make it easier to get acquainted with handling data.
-
-In Scikit-learn, a dataset refers to a dictionary-like object that has all the details about the data. The data is stored using the **.data** key, which is an array list.
-
-For instance, we can utilize **iris.data** to output information about the Iris flower dataset.
-
-```
-print(iris.data)
-```
-
-Here is the output (the results have been truncated):
-
-```
-[[5.1 3.5 1.4 0.2]
- [4.9 3. 1.4 0.2]
- [4.7 3.2 1.3 0.2]
- [4.6 3.1 1.5 0.2]
- [5. 3.6 1.4 0.2]
- [5.4 3.9 1.7 0.4]
- [4.6 3.4 1.4 0.3]
- [5. 3.4 1.5 0.2]
- [4.4 2.9 1.4 0.2]
- [4.9 3.1 1.5 0.1]
- [5.4 3.7 1.5 0.2]
- [4.8 3.4 1.6 0.2]
- [4.8 3. 1.4 0.1]
- [4.3 3. 1.1 0.1]
- [5.8 4. 1.2 0.2]
- [5.7 4.4 1.5 0.4]
- [5.4 3.9 1.3 0.4]
- [5.1 3.5 1.4 0.3]
-```
-
-Let's also use **iris.target** to give us information about the different labels of the flowers.
-
-```
-print(iris.target)
-```
-
-Here is the output:
-
-```
-[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2]
-
-```
-
-If we use **iris.target_names** , we'll output an array of the names of the labels found in the dataset.
-
-```
-print(iris.target_names)
-```
-
-Here is the result after running the Python code:
-
-```
-['setosa' 'versicolor' 'virginica']
-```
-
-#### Step 3: Visualizing the dataset
-
-We can use the [box plot][4] to produce a visual depiction of the Iris flower dataset. The box plot illustrates how the data is distributed over the plane through their quartiles.
-
-Here's how to achieve this:
-
-```
-import seaborn as sns
-box_data = iris.data #variable representing the data array
-box_target = iris.target #variable representing the labels array
-sns.boxplot(data = box_data,width=0.5,fliersize=5)
-sns.set(rc={'figure.figsize':(2,15)})
-```
-
-Let's see the result:
-
-
-
-On the horizontal axis:
-
- * 0 is sepal length
- * 1 is sepal width
- * 2 is petal length
- * 3 is petal width
-
-
-
-The vertical axis is dimensions in centimeters.
-
-### Wrapping up
-
-Here is the entire code for this simple Scikit-learn data science tutorial.
-
-```
-from sklearn import datasets
-iris = datasets.load_iris()
-print(iris.data)
-print(iris.target)
-print(iris.target_names)
-import seaborn as sns
-box_data = iris.data #variable representing the data array
-box_target = iris.target #variable representing the labels array
-sns.boxplot(data = box_data,width=0.5,fliersize=5)
-sns.set(rc={'figure.figsize':(2,15)})
-```
-
-Scikit-learn is a versatile Python library you can use to efficiently complete data science projects.
-
-If you want to learn more, check out the tutorials on [LiveEdu][5], such as Andrey Bulezyuk's video on using the Scikit-learn library to create a [machine learning application][6].
-
-Do you have any questions or comments? Feel free to share them below.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/how-use-scikit-learn-data-science-projects
-
-作者:[Dr.Michael J.Garbade][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/drmjg
-[1]: http://scikit-learn.org/stable/index.html
-[2]: https://blog.liveedu.tv/regression-versus-classification-machine-learning-whats-the-difference/
-[3]: https://en.wikipedia.org/wiki/Iris_flower_data_set
-[4]: https://en.wikipedia.org/wiki/Box_plot
-[5]: https://www.liveedu.tv/guides/data-science/
-[6]: https://www.liveedu.tv/andreybu/REaxr-machine-learning-model-python-sklearn-kera/oPGdP-machine-learning-model-python-sklearn-kera/
diff --git a/sources/tech/20180927 5 cool tiling window managers.md b/sources/tech/20180927 5 cool tiling window managers.md
new file mode 100644
index 0000000000..f687918c65
--- /dev/null
+++ b/sources/tech/20180927 5 cool tiling window managers.md
@@ -0,0 +1,87 @@
+5 cool tiling window managers
+======
+
+
+The Linux desktop ecosystem offers multiple window managers (WMs). Some are developed as part of a desktop environment. Others are meant to be used as standalone application. This is the case of tiling WMs, which offer a more lightweight, customized environment. This article presents five such tiling WMs for you to try out.
+
+### i3
+
+[i3][1] is one of the most popular tiling window managers. Like most other such WMs, i3 focuses on low resource consumption and customizability by the user.
+
+You can refer to [this previous article in the Magazine][2] to get started with i3 installation details and how to configure it.
+
+### sway
+
+[sway][3] is a tiling Wayland compositor. It has the advantage of compatibility with an existing i3 configuration, so you can use it to replace i3 and use Wayland as the display protocol.
+
+You can use dnf to install sway from Fedora repository:
+
+```
+$ sudo dnf install sway
+```
+
+If you want to migrate from i3 to sway, there’s a small [migration guide][4] available.
+
+### Qtile
+
+[Qtile][5] is another tiling manager that also happens to be written in Python. By default, you configure Qtile in a Python script located under ~/.config/qtile/config.py. When this script is not available, Qtile uses a default [configuration][6].
+
+One of the benefits of Qtile being in Python is you can write scripts to control the WM. For example, the following script prints the screen details:
+
+```
+> from libqtile.command import Client
+> c = Client()
+> print(c.screen.info)
+{'index': 0, 'width': 1920, 'height': 1006, 'x': 0, 'y': 0}
+```
+
+To install Qlite on Fedora, use the following command:
+
+```
+$ sudo dnf install qtile
+```
+
+### dwm
+
+The [dwm][7] window manager focuses more on being lightweight. One goal of the project is to keep dwm minimal and small. For example, the entire code base never exceeded 2000 lines of code. On the other hand, dwm isn’t as easy to customize and configure. Indeed, the only way to change dwm default configuration is to [edit the source code and recompile the application][8].
+
+If you want to try the default configuration, you can install dwm in Fedora using dnf:
+
+```
+$ sudo dnf install dwm
+```
+
+For those who wand to change their dwm configuration, the dwm-user package is available in Fedora. This package automatically recompiles dwm using the configuration stored in the user home directory at ~/.dwm/config.h.
+
+### awesome
+
+[awesome][9] originally started as a fork of dwm, to provide configuration of the WM using an external configuration file. The configuration is done via Lua scripts, which allow you to write scripts to automate tasks or create widgets.
+
+You can check out awesome on Fedora by installing it like this:
+
+```
+$ sudo dnf install awesome
+```
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/5-cool-tiling-window-managers/
+
+作者:[Clément Verna][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org
+[1]: https://i3wm.org/
+[2]: https://fedoramagazine.org/getting-started-i3-window-manager/
+[3]: https://swaywm.org/
+[4]: https://github.com/swaywm/sway/wiki/i3-Migration-Guide
+[5]: http://www.qtile.org/
+[6]: https://github.com/qtile/qtile/blob/develop/libqtile/resources/default_config.py
+[7]: https://dwm.suckless.org/
+[8]: https://dwm.suckless.org/customisation/
+[9]: https://awesomewm.org/
diff --git a/sources/tech/20180927 How To Find And Delete Duplicate Files In Linux.md b/sources/tech/20180927 How To Find And Delete Duplicate Files In Linux.md
deleted file mode 100644
index e3a0a9d561..0000000000
--- a/sources/tech/20180927 How To Find And Delete Duplicate Files In Linux.md
+++ /dev/null
@@ -1,441 +0,0 @@
-How To Find And Delete Duplicate Files In Linux
-======
-
-
-
-I always backup the configuration files or any old files to somewhere in my hard disk before edit or modify them, so I can restore them from the backup if I accidentally did something wrong. But the problem is I forgot to clean up those files and my hard disk is filled with a lot of duplicate files after a certain period of time. I feel either too lazy to clean the old files or afraid that I may delete an important files. If you’re anything like me and overwhelming with multiple copies of same files in different backup directories, you can find and delete duplicate files using the tools given below in Unix-like operating systems.
-
-**A word of caution:**
-
-Please be careful while deleting duplicate files. If you’re not careful, it will lead you to [**accidental data loss**][1]. I advice you to pay extra attention while using these tools.
-
-### Find And Delete Duplicate Files In Linux
-
-For the purpose of this guide, I am going to discuss about three utilities namely,
-
- 1. Rdfind,
- 2. Fdupes,
- 3. FSlint.
-
-
-
-These three utilities are free, open source and works on most Unix-like operating systems.
-
-##### 1. Rdfind
-
-**Rdfind** , stands for **r** edundant **d** ata **find** , is a free and open source utility to find duplicate files across and/or within directories and sub-directories. It compares files based on their content, not on their file names. Rdfind uses **ranking** algorithm to classify original and duplicate files. If you have two or more equal files, Rdfind is smart enough to find which is original file, and consider the rest of the files as duplicates. Once it found the duplicates, it will report them to you. You can decide to either delete them or replace them with [**hard links** or **symbolic (soft) links**][2].
-
-**Installing Rdfind**
-
-Rdfind is available in [**AUR**][3]. So, you can install it in Arch-based systems using any AUR helper program like [**Yay**][4] as shown below.
-
-```
-$ yay -S rdfind
-
-```
-
-On Debian, Ubuntu, Linux Mint:
-
-```
-$ sudo apt-get install rdfind
-
-```
-
-On Fedora:
-
-```
-$ sudo dnf install rdfind
-
-```
-
-On RHEL, CentOS:
-
-```
-$ sudo yum install epel-release
-
-$ sudo yum install rdfind
-
-```
-
-**Usage**
-
-Once installed, simply run Rdfind command along with the directory path to scan for the duplicate files.
-
-```
-$ rdfind ~/Downloads
-
-```
-
-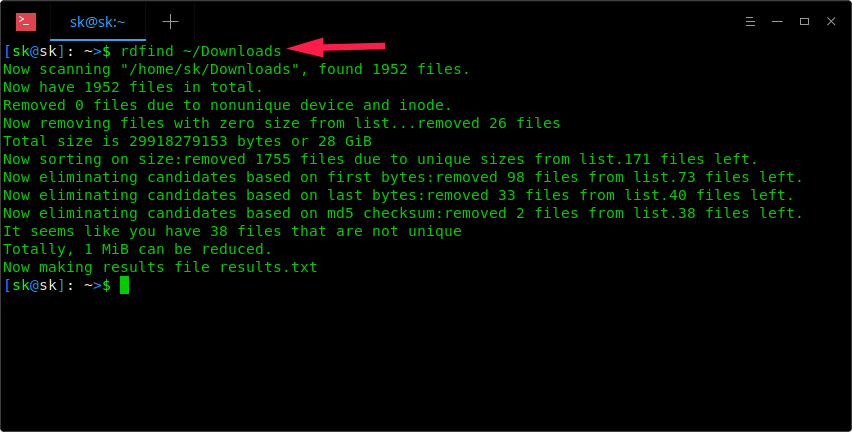
-
-As you see in the above screenshot, Rdfind command will scan ~/Downloads directory and save the results in a file named **results.txt** in the current working directory. You can view the name of the possible duplicate files in results.txt file.
-
-```
-$ cat results.txt
-# Automatically generated
-# duptype id depth size device inode priority name
-DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex
-DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex
-[...]
-DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf
-DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf
-# end of file
-
-```
-
-By reviewing the results.txt file, you can easily find the duplicates. You can remove the duplicates manually if you want to.
-
-Also, you can **-dryrun** option to find all duplicates in a given directory without changing anything and output the summary in your Terminal:
-
-```
-$ rdfind -dryrun true ~/Downloads
-
-```
-
-Once you found the duplicates, you can replace them with either hardlinks or symlinks.
-
-To replace all duplicates with hardlinks, run:
-
-```
-$ rdfind -makehardlinks true ~/Downloads
-
-```
-
-To replace all duplicates with symlinks/soft links, run:
-
-```
-$ rdfind -makesymlinks true ~/Downloads
-
-```
-
-You may have some empty files in a directory and want to ignore them. If so, use **-ignoreempty** option like below.
-
-```
-$ rdfind -ignoreempty true ~/Downloads
-
-```
-
-If you don’t want the old files anymore, just delete duplicate files instead of replacing them with hard or soft links.
-
-To delete all duplicates, simply run:
-
-```
-$ rdfind -deleteduplicates true ~/Downloads
-
-```
-
-If you do not want to ignore empty files and delete them along with all duplicates, run:
-
-```
-$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
-
-```
-
-For more details, refer the help section:
-
-```
-$ rdfind --help
-
-```
-
-And, the manual pages:
-
-```
-$ man rdfind
-
-```
-
-##### 2. Fdupes
-
-**Fdupes** is yet another command line utility to identify and remove the duplicate files within specified directories and the sub-directories. It is free, open source utility written in **C** programming language. Fdupes identifies the duplicates by comparing file sizes, partial MD5 signatures, full MD5 signatures, and finally performing a byte-by-byte comparison for verification.
-
-Similar to Rdfind utility, Fdupes comes with quite handful of options to perform operations, such as:
-
- * Recursively search duplicate files in directories and sub-directories
- * Exclude empty files and hidden files from consideration
- * Show the size of the duplicates
- * Delete duplicates immediately as they encountered
- * Exclude files with different owner/group or permission bits as duplicates
- * And a lot more.
-
-
-
-**Installing Fdupes**
-
-Fdupes is available in the default repositories of most Linux distributions.
-
-On Arch Linux and its variants like Antergos, Manjaro Linux, install it using Pacman like below.
-
-```
-$ sudo pacman -S fdupes
-
-```
-
-On Debian, Ubuntu, Linux Mint:
-
-```
-$ sudo apt-get install fdupes
-
-```
-
-On Fedora:
-
-```
-$ sudo dnf install fdupes
-
-```
-
-On RHEL, CentOS:
-
-```
-$ sudo yum install epel-release
-
-$ sudo yum install fdupes
-
-```
-
-**Usage**
-
-Fdupes usage is pretty simple. Just run the following command to find out the duplicate files in a directory, for example **~/Downloads**.
-
-```
-$ fdupes ~/Downloads
-
-```
-
-Sample output from my system:
-
-```
-/home/sk/Downloads/Hyperledger.pdf
-/home/sk/Downloads/Hyperledger(1).pdf
-
-```
-
-As you can see, I have a duplicate file in **/home/sk/Downloads/** directory. It shows the duplicates from the parent directory only. How to view the duplicates from sub-directories? Just use **-r** option like below.
-
-```
-$ fdupes -r ~/Downloads
-
-```
-
-Now you will see the duplicates from **/home/sk/Downloads/** directory and its sub-directories as well.
-
-Fdupes can also be able to find duplicates from multiple directories at once.
-
-```
-$ fdupes ~/Downloads ~/Documents/ostechnix
-
-```
-
-You can even search multiple directories, one recursively like below:
-
-```
-$ fdupes ~/Downloads -r ~/Documents/ostechnix
-
-```
-
-The above commands searches for duplicates in “~/Downloads” directory and “~/Documents/ostechnix” directory and its sub-directories.
-
-Sometimes, you might want to know the size of the duplicates in a directory. If so, use **-S** option like below.
-
-```
-$ fdupes -S ~/Downloads
-403635 bytes each:
-/home/sk/Downloads/Hyperledger.pdf
-/home/sk/Downloads/Hyperledger(1).pdf
-
-```
-
-Similarly, to view the size of the duplicates in parent and child directories, use **-Sr** option.
-
-We can exclude empty and hidden files from consideration using **-n** and **-A** respectively.
-
-```
-$ fdupes -n ~/Downloads
-
-$ fdupes -A ~/Downloads
-
-```
-
-The first command will exclude zero-length files from consideration and the latter will exclude hidden files from consideration while searching for duplicates in the specified directory.
-
-To summarize duplicate files information, use **-m** option.
-
-```
-$ fdupes -m ~/Downloads
-1 duplicate files (in 1 sets), occupying 403.6 kilobytes
-
-```
-
-To delete all duplicates, use **-d** option.
-
-```
-$ fdupes -d ~/Downloads
-
-```
-
-Sample output:
-
-```
-[1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf
-[2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf
-
-Set 1 of 1, preserve files [1 - 2, all]:
-
-```
-
-This command will prompt you for files to preserve and delete all other duplicates. Just enter any number to preserve the corresponding file and delete the remaining files. Pay more attention while using this option. You might delete original files if you’re not be careful.
-
-If you want to preserve the first file in each set of duplicates and delete the others without prompting each time, use **-dN** option (not recommended).
-
-```
-$ fdupes -dN ~/Downloads
-
-```
-
-To delete duplicates as they are encountered, use **-I** flag.
-
-```
-$ fdupes -I ~/Downloads
-
-```
-
-For more details about Fdupes, view the help section and man pages.
-
-```
-$ fdupes --help
-
-$ man fdupes
-
-```
-
-##### 3. FSlint
-
-**FSlint** is yet another duplicate file finder utility that I use from time to time to get rid of the unnecessary duplicate files and free up the disk space in my Linux system. Unlike the other two utilities, FSlint has both GUI and CLI modes. So, it is more user-friendly tool for newbies. FSlint not just finds the duplicates, but also bad symlinks, bad names, temp files, bad IDS, empty directories, and non stripped binaries etc.
-
-**Installing FSlint**
-
-FSlint is available in [**AUR**][5], so you can install it using any AUR helpers.
-
-```
-$ yay -S fslint
-
-```
-
-On Debian, Ubuntu, Linux Mint:
-
-```
-$ sudo apt-get install fslint
-
-```
-
-On Fedora:
-
-```
-$ sudo dnf install fslint
-
-```
-
-On RHEL, CentOS:
-
-```
-$ sudo yum install epel-release
-
-```
-
-$ sudo yum install fslint
-
-Once it is installed, launch it from menu or application launcher.
-
-This is how FSlint GUI looks like.
-
-
-
-As you can see, the interface of FSlint is user-friendly and self-explanatory. In the **Search path** tab, add the path of the directory you want to scan and click **Find** button on the lower left corner to find the duplicates. Check the recurse option to recursively search for duplicates in directories and sub-directories. The FSlint will quickly scan the given directory and list out them.
-
-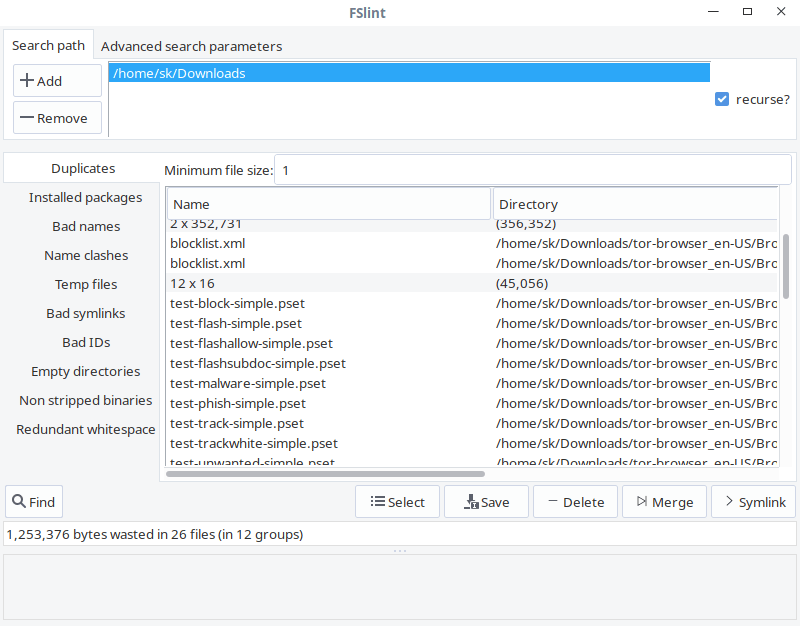
-
-From the list, choose the duplicates you want to clean and select any one of them given actions like Save, Delete, Merge and Symlink.
-
-In the **Advanced search parameters** tab, you can specify the paths to exclude while searching for duplicates.
-
-
-
-**FSlint command line options**
-
-FSlint provides a collection of the following CLI utilities to find duplicates in your filesystem:
-
- * **findup** — find DUPlicate files
- * **findnl** — find Name Lint (problems with filenames)
- * **findu8** — find filenames with invalid utf8 encoding
- * **findbl** — find Bad Links (various problems with symlinks)
- * **findsn** — find Same Name (problems with clashing names)
- * **finded** — find Empty Directories
- * **findid** — find files with dead user IDs
- * **findns** — find Non Stripped executables
- * **findrs** — find Redundant Whitespace in files
- * **findtf** — find Temporary Files
- * **findul** — find possibly Unused Libraries
- * **zipdir** — Reclaim wasted space in ext2 directory entries
-
-
-
-All of these utilities are available under **/usr/share/fslint/fslint/fslint** location.
-
-For example, to find duplicates in a given directory, do:
-
-```
-$ /usr/share/fslint/fslint/findup ~/Downloads/
-
-```
-
-Similarly, to find empty directories, the command would be:
-
-```
-$ /usr/share/fslint/fslint/finded ~/Downloads/
-
-```
-
-To get more details on each utility, for example **findup** , run:
-
-```
-$ /usr/share/fslint/fslint/findup --help
-
-```
-
-For more details about FSlint, refer the help section and man pages.
-
-```
-$ /usr/share/fslint/fslint/fslint --help
-
-$ man fslint
-
-```
-
-##### Conclusion
-
-You know now about three tools to find and delete unwanted duplicate files in Linux. Among these three tools, I often use Rdfind. It doesn’t mean that the other two utilities are not efficient, but I am just happy with Rdfind so far. Well, it’s your turn. Which is your favorite tool and why? Let us know them in the comment section below.
-
-And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-find-and-delete-duplicate-files-in-linux/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[1]: https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/
-[2]: https://www.ostechnix.com/explaining-soft-link-and-hard-link-in-linux-with-examples/
-[3]: https://aur.archlinux.org/packages/rdfind/
-[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
-[5]: https://aur.archlinux.org/packages/fslint/
diff --git a/sources/tech/20180927 Lab 2- Memory Management.md b/sources/tech/20180927 Lab 2- Memory Management.md
new file mode 100644
index 0000000000..386bf6ceaf
--- /dev/null
+++ b/sources/tech/20180927 Lab 2- Memory Management.md
@@ -0,0 +1,272 @@
+Lab 2: Memory Management
+======
+### Lab 2: Memory Management
+
+#### Introduction
+
+In this lab, you will write the memory management code for your operating system. Memory management has two components.
+
+The first component is a physical memory allocator for the kernel, so that the kernel can allocate memory and later free it. Your allocator will operate in units of 4096 bytes, called _pages_. Your task will be to maintain data structures that record which physical pages are free and which are allocated, and how many processes are sharing each allocated page. You will also write the routines to allocate and free pages of memory.
+
+The second component of memory management is _virtual memory_ , which maps the virtual addresses used by kernel and user software to addresses in physical memory. The x86 hardware's memory management unit (MMU) performs the mapping when instructions use memory, consulting a set of page tables. You will modify JOS to set up the MMU's page tables according to a specification we provide.
+
+##### Getting started
+
+In this and future labs you will progressively build up your kernel. We will also provide you with some additional source. To fetch that source, use Git to commit changes you've made since handing in lab 1 (if any), fetch the latest version of the course repository, and then create a local branch called `lab2` based on our lab2 branch, `origin/lab2`:
+
+```
+ athena% cd ~/6.828/lab
+ athena% add git
+ athena% git pull
+ Already up-to-date.
+ athena% git checkout -b lab2 origin/lab2
+ Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
+ Switched to a new branch "lab2"
+ athena%
+```
+
+The git checkout -b command shown above actually does two things: it first creates a local branch `lab2` that is based on the `origin/lab2` branch provided by the course staff, and second, it changes the contents of your `lab` directory to reflect the files stored on the `lab2` branch. Git allows switching between existing branches using git checkout _branch-name_ , though you should commit any outstanding changes on one branch before switching to a different one.
+
+You will now need to merge the changes you made in your `lab1` branch into the `lab2` branch, as follows:
+
+```
+ athena% git merge lab1
+ Merge made by recursive.
+ kern/kdebug.c | 11 +++++++++--
+ kern/monitor.c | 19 +++++++++++++++++++
+ lib/printfmt.c | 7 +++----
+ 3 files changed, 31 insertions(+), 6 deletions(-)
+ athena%
+```
+
+In some cases, Git may not be able to figure out how to merge your changes with the new lab assignment (e.g. if you modified some of the code that is changed in the second lab assignment). In that case, the git merge command will tell you which files are _conflicted_ , and you should first resolve the conflict (by editing the relevant files) and then commit the resulting files with git commit -a.
+
+Lab 2 contains the following new source files, which you should browse through:
+
+ * `inc/memlayout.h`
+ * `kern/pmap.c`
+ * `kern/pmap.h`
+ * `kern/kclock.h`
+ * `kern/kclock.c`
+
+
+
+`memlayout.h` describes the layout of the virtual address space that you must implement by modifying `pmap.c`. `memlayout.h` and `pmap.h` define the `PageInfo` structure that you'll use to keep track of which pages of physical memory are free. `kclock.c` and `kclock.h` manipulate the PC's battery-backed clock and CMOS RAM hardware, in which the BIOS records the amount of physical memory the PC contains, among other things. The code in `pmap.c` needs to read this device hardware in order to figure out how much physical memory there is, but that part of the code is done for you: you do not need to know the details of how the CMOS hardware works.
+
+Pay particular attention to `memlayout.h` and `pmap.h`, since this lab requires you to use and understand many of the definitions they contain. You may want to review `inc/mmu.h`, too, as it also contains a number of definitions that will be useful for this lab.
+
+Before beginning the lab, don't forget to add -f 6.828 to get the 6.828 version of QEMU.
+
+##### Lab Requirements
+
+In this lab and subsequent labs, do all of the regular exercises described in the lab and _at least one_ challenge problem. (Some challenge problems are more challenging than others, of course!) Additionally, write up brief answers to the questions posed in the lab and a short (e.g., one or two paragraph) description of what you did to solve your chosen challenge problem. If you implement more than one challenge problem, you only need to describe one of them in the write-up, though of course you are welcome to do more. Place the write-up in a file called `answers-lab2.txt` in the top level of your `lab` directory before handing in your work.
+
+##### Hand-In Procedure
+
+When you are ready to hand in your lab code and write-up, add your `answers-lab2.txt` to the Git repository, commit your changes, and then run make handin.
+
+```
+ athena% git add answers-lab2.txt
+ athena% git commit -am "my answer to lab2"
+ [lab2 a823de9] my answer to lab2
+ 4 files changed, 87 insertions(+), 10 deletions(-)
+ athena% make handin
+```
+
+As before, we will be grading your solutions with a grading program. You can run make grade in the `lab` directory to test your kernel with the grading program. You may change any of the kernel source and header files you need to in order to complete the lab, but needless to say you must not change or otherwise subvert the grading code.
+
+#### Part 1: Physical Page Management
+
+The operating system must keep track of which parts of physical RAM are free and which are currently in use. JOS manages the PC's physical memory with _page granularity_ so that it can use the MMU to map and protect each piece of allocated memory.
+
+You'll now write the physical page allocator. It keeps track of which pages are free with a linked list of `struct PageInfo` objects (which, unlike xv6, are not embedded in the free pages themselves), each corresponding to a physical page. You need to write the physical page allocator before you can write the rest of the virtual memory implementation, because your page table management code will need to allocate physical memory in which to store page tables.
+
+Exercise 1. In the file `kern/pmap.c`, you must implement code for the following functions (probably in the order given).
+
+`boot_alloc()`
+`mem_init()` (only up to the call to `check_page_free_list(1)`)
+`page_init()`
+`page_alloc()`
+`page_free()`
+
+`check_page_free_list()` and `check_page_alloc()` test your physical page allocator. You should boot JOS and see whether `check_page_alloc()` reports success. Fix your code so that it passes. You may find it helpful to add your own `assert()`s to verify that your assumptions are correct.
+
+This lab, and all the 6.828 labs, will require you to do a bit of detective work to figure out exactly what you need to do. This assignment does not describe all the details of the code you'll have to add to JOS. Look for comments in the parts of the JOS source that you have to modify; those comments often contain specifications and hints. You will also need to look at related parts of JOS, at the Intel manuals, and perhaps at your 6.004 or 6.033 notes.
+
+#### Part 2: Virtual Memory
+
+Before doing anything else, familiarize yourself with the x86's protected-mode memory management architecture: namely _segmentation_ and _page translation_.
+
+Exercise 2. Look at chapters 5 and 6 of the [Intel 80386 Reference Manual][1], if you haven't done so already. Read the sections about page translation and page-based protection closely (5.2 and 6.4). We recommend that you also skim the sections about segmentation; while JOS uses the paging hardware for virtual memory and protection, segment translation and segment-based protection cannot be disabled on the x86, so you will need a basic understanding of it.
+
+##### Virtual, Linear, and Physical Addresses
+
+In x86 terminology, a _virtual address_ consists of a segment selector and an offset within the segment. A _linear address_ is what you get after segment translation but before page translation. A _physical address_ is what you finally get after both segment and page translation and what ultimately goes out on the hardware bus to your RAM.
+
+```
+ Selector +--------------+ +-----------+
+ ---------->| | | |
+ | Segmentation | | Paging |
+Software | |-------->| |----------> RAM
+ Offset | Mechanism | | Mechanism |
+ ---------->| | | |
+ +--------------+ +-----------+
+ Virtual Linear Physical
+
+```
+
+A C pointer is the "offset" component of the virtual address. In `boot/boot.S`, we installed a Global Descriptor Table (GDT) that effectively disabled segment translation by setting all segment base addresses to 0 and limits to `0xffffffff`. Hence the "selector" has no effect and the linear address always equals the offset of the virtual address. In lab 3, we'll have to interact a little more with segmentation to set up privilege levels, but as for memory translation, we can ignore segmentation throughout the JOS labs and focus solely on page translation.
+
+Recall that in part 3 of lab 1, we installed a simple page table so that the kernel could run at its link address of 0xf0100000, even though it is actually loaded in physical memory just above the ROM BIOS at 0x00100000. This page table mapped only 4MB of memory. In the virtual address space layout you are going to set up for JOS in this lab, we'll expand this to map the first 256MB of physical memory starting at virtual address 0xf0000000 and to map a number of other regions of the virtual address space.
+
+Exercise 3. While GDB can only access QEMU's memory by virtual address, it's often useful to be able to inspect physical memory while setting up virtual memory. Review the QEMU [monitor commands][2] from the lab tools guide, especially the `xp` command, which lets you inspect physical memory. To access the QEMU monitor, press Ctrl-a c in the terminal (the same binding returns to the serial console).
+
+Use the xp command in the QEMU monitor and the x command in GDB to inspect memory at corresponding physical and virtual addresses and make sure you see the same data.
+
+Our patched version of QEMU provides an info pg command that may also prove useful: it shows a compact but detailed representation of the current page tables, including all mapped memory ranges, permissions, and flags. Stock QEMU also provides an info mem command that shows an overview of which ranges of virtual addresses are mapped and with what permissions.
+
+From code executing on the CPU, once we're in protected mode (which we entered first thing in `boot/boot.S`), there's no way to directly use a linear or physical address. _All_ memory references are interpreted as virtual addresses and translated by the MMU, which means all pointers in C are virtual addresses.
+
+The JOS kernel often needs to manipulate addresses as opaque values or as integers, without dereferencing them, for example in the physical memory allocator. Sometimes these are virtual addresses, and sometimes they are physical addresses. To help document the code, the JOS source distinguishes the two cases: the type `uintptr_t` represents opaque virtual addresses, and `physaddr_t` represents physical addresses. Both these types are really just synonyms for 32-bit integers (`uint32_t`), so the compiler won't stop you from assigning one type to another! Since they are integer types (not pointers), the compiler _will_ complain if you try to dereference them.
+
+The JOS kernel can dereference a `uintptr_t` by first casting it to a pointer type. In contrast, the kernel can't sensibly dereference a physical address, since the MMU translates all memory references. If you cast a `physaddr_t` to a pointer and dereference it, you may be able to load and store to the resulting address (the hardware will interpret it as a virtual address), but you probably won't get the memory location you intended.
+
+To summarize:
+
+C typeAddress type `T*` Virtual `uintptr_t` Virtual `physaddr_t` Physical
+
+Question
+
+ 1. Assuming that the following JOS kernel code is correct, what type should variable `x` have, `uintptr_t` or `physaddr_t`?
+
+```
+ mystery_t x;
+ char* value = return_a_pointer();
+ *value = 10;
+ x = (mystery_t) value;
+
+```
+
+
+
+
+The JOS kernel sometimes needs to read or modify memory for which it knows only the physical address. For example, adding a mapping to a page table may require allocating physical memory to store a page directory and then initializing that memory. However, the kernel cannot bypass virtual address translation and thus cannot directly load and store to physical addresses. One reason JOS remaps all of physical memory starting from physical address 0 at virtual address 0xf0000000 is to help the kernel read and write memory for which it knows just the physical address. In order to translate a physical address into a virtual address that the kernel can actually read and write, the kernel must add 0xf0000000 to the physical address to find its corresponding virtual address in the remapped region. You should use `KADDR(pa)` to do that addition.
+
+The JOS kernel also sometimes needs to be able to find a physical address given the virtual address of the memory in which a kernel data structure is stored. Kernel global variables and memory allocated by `boot_alloc()` are in the region where the kernel was loaded, starting at 0xf0000000, the very region where we mapped all of physical memory. Thus, to turn a virtual address in this region into a physical address, the kernel can simply subtract 0xf0000000. You should use `PADDR(va)` to do that subtraction.
+
+##### Reference counting
+
+In future labs you will often have the same physical page mapped at multiple virtual addresses simultaneously (or in the address spaces of multiple environments). You will keep a count of the number of references to each physical page in the `pp_ref` field of the `struct PageInfo` corresponding to the physical page. When this count goes to zero for a physical page, that page can be freed because it is no longer used. In general, this count should be equal to the number of times the physical page appears below `UTOP` in all page tables (the mappings above `UTOP` are mostly set up at boot time by the kernel and should never be freed, so there's no need to reference count them). We'll also use it to keep track of the number of pointers we keep to the page directory pages and, in turn, of the number of references the page directories have to page table pages.
+
+Be careful when using `page_alloc`. The page it returns will always have a reference count of 0, so `pp_ref` should be incremented as soon as you've done something with the returned page (like inserting it into a page table). Sometimes this is handled by other functions (for example, `page_insert`) and sometimes the function calling `page_alloc` must do it directly.
+
+##### Page Table Management
+
+Now you'll write a set of routines to manage page tables: to insert and remove linear-to-physical mappings, and to create page table pages when needed.
+
+Exercise 4. In the file `kern/pmap.c`, you must implement code for the following functions.
+
+```
+
+ pgdir_walk()
+ boot_map_region()
+ page_lookup()
+ page_remove()
+ page_insert()
+
+
+```
+
+`check_page()`, called from `mem_init()`, tests your page table management routines. You should make sure it reports success before proceeding.
+
+#### Part 3: Kernel Address Space
+
+JOS divides the processor's 32-bit linear address space into two parts. User environments (processes), which we will begin loading and running in lab 3, will have control over the layout and contents of the lower part, while the kernel always maintains complete control over the upper part. The dividing line is defined somewhat arbitrarily by the symbol `ULIM` in `inc/memlayout.h`, reserving approximately 256MB of virtual address space for the kernel. This explains why we needed to give the kernel such a high link address in lab 1: otherwise there would not be enough room in the kernel's virtual address space to map in a user environment below it at the same time.
+
+You'll find it helpful to refer to the JOS memory layout diagram in `inc/memlayout.h` both for this part and for later labs.
+
+##### Permissions and Fault Isolation
+
+Since kernel and user memory are both present in each environment's address space, we will have to use permission bits in our x86 page tables to allow user code access only to the user part of the address space. Otherwise bugs in user code might overwrite kernel data, causing a crash or more subtle malfunction; user code might also be able to steal other environments' private data. Note that the writable permission bit (`PTE_W`) affects both user and kernel code!
+
+The user environment will have no permission to any of the memory above `ULIM`, while the kernel will be able to read and write this memory. For the address range `[UTOP,ULIM)`, both the kernel and the user environment have the same permission: they can read but not write this address range. This range of address is used to expose certain kernel data structures read-only to the user environment. Lastly, the address space below `UTOP` is for the user environment to use; the user environment will set permissions for accessing this memory.
+
+##### Initializing the Kernel Address Space
+
+Now you'll set up the address space above `UTOP`: the kernel part of the address space. `inc/memlayout.h` shows the layout you should use. You'll use the functions you just wrote to set up the appropriate linear to physical mappings.
+
+Exercise 5. Fill in the missing code in `mem_init()` after the call to `check_page()`.
+
+Your code should now pass the `check_kern_pgdir()` and `check_page_installed_pgdir()` checks.
+
+Question
+
+ 2. What entries (rows) in the page directory have been filled in at this point? What addresses do they map and where do they point? In other words, fill out this table as much as possible:
+ | Entry | Base Virtual Address | Points to (logically): |
+ |-------|----------------------|---------------------------------------|
+ | 1023 | ? | Page table for top 4MB of phys memory |
+ | 1022 | ? | ? |
+ | . | ? | ? |
+ | . | ? | ? |
+ | . | ? | ? |
+ | 2 | 0x00800000 | ? |
+ | 1 | 0x00400000 | ? |
+ | 0 | 0x00000000 | [see next question] |
+ 3. We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel's memory? What specific mechanisms protect the kernel memory?
+ 4. What is the maximum amount of physical memory that this operating system can support? Why?
+ 5. How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
+ 6. Revisit the page table setup in `kern/entry.S` and `kern/entrypgdir.c`. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
+
+
+```
+Challenge! We consumed many physical pages to hold the page tables for the KERNBASE mapping. Do a more space-efficient job using the PTE_PS ("Page Size") bit in the page directory entries. This bit was _not_ supported in the original 80386, but is supported on more recent x86 processors. You will therefore have to refer to [Volume 3 of the current Intel manuals][3]. Make sure you design the kernel to use this optimization only on processors that support it!
+```
+
+```
+Challenge! Extend the JOS kernel monitor with commands to:
+
+ * Display in a useful and easy-to-read format all of the physical page mappings (or lack thereof) that apply to a particular range of virtual/linear addresses in the currently active address space. For example, you might enter `'showmappings 0x3000 0x5000'` to display the physical page mappings and corresponding permission bits that apply to the pages at virtual addresses 0x3000, 0x4000, and 0x5000.
+ * Explicitly set, clear, or change the permissions of any mapping in the current address space.
+ * Dump the contents of a range of memory given either a virtual or physical address range. Be sure the dump code behaves correctly when the range extends across page boundaries!
+ * Do anything else that you think might be useful later for debugging the kernel. (There's a good chance it will be!)
+```
+
+
+##### Address Space Layout Alternatives
+
+The address space layout we use in JOS is not the only one possible. An operating system might map the kernel at low linear addresses while leaving the _upper_ part of the linear address space for user processes. x86 kernels generally do not take this approach, however, because one of the x86's backward-compatibility modes, known as _virtual 8086 mode_ , is "hard-wired" in the processor to use the bottom part of the linear address space, and thus cannot be used at all if the kernel is mapped there.
+
+It is even possible, though much more difficult, to design the kernel so as not to have to reserve _any_ fixed portion of the processor's linear or virtual address space for itself, but instead effectively to allow user-level processes unrestricted use of the _entire_ 4GB of virtual address space - while still fully protecting the kernel from these processes and protecting different processes from each other!
+
+```
+Challenge! Each user-level environment maps the kernel. Change JOS so that the kernel has its own page table and so that a user-level environment runs with a minimal number of kernel pages mapped. That is, each user-level environment maps just enough pages mapped so that the user-level environment can enter and leave the kernel correctly. You also have to come up with a plan for the kernel to read/write arguments to system calls.
+```
+
+```
+Challenge! Write up an outline of how a kernel could be designed to allow user environments unrestricted use of the full 4GB virtual and linear address space. Hint: do the previous challenge exercise first, which reduces the kernel to a few mappings in a user environment. Hint: the technique is sometimes known as " _follow the bouncing kernel_. " In your design, be sure to address exactly what has to happen when the processor transitions between kernel and user modes, and how the kernel would accomplish such transitions. Also describe how the kernel would access physical memory and I/O devices in this scheme, and how the kernel would access a user environment's virtual address space during system calls and the like. Finally, think about and describe the advantages and disadvantages of such a scheme in terms of flexibility, performance, kernel complexity, and other factors you can think of.
+```
+
+```
+Challenge! Since our JOS kernel's memory management system only allocates and frees memory on page granularity, we do not have anything comparable to a general-purpose `malloc`/`free` facility that we can use within the kernel. This could be a problem if we want to support certain types of I/O devices that require _physically contiguous_ buffers larger than 4KB in size, or if we want user-level environments, and not just the kernel, to be able to allocate and map 4MB _superpages_ for maximum processor efficiency. (See the earlier challenge problem about PTE_PS.)
+
+Generalize the kernel's memory allocation system to support pages of a variety of power-of-two allocation unit sizes from 4KB up to some reasonable maximum of your choice. Be sure you have some way to divide larger allocation units into smaller ones on demand, and to coalesce multiple small allocation units back into larger units when possible. Think about the issues that might arise in such a system.
+```
+
+**This completes the lab.** Make sure you pass all of the make grade tests and don't forget to write up your answers to the questions and a description of your challenge exercise solution in `answers-lab2.txt`. Commit your changes (including adding `answers-lab2.txt`) and type make handin in the `lab` directory to hand in your lab.
+
+--------------------------------------------------------------------------------
+
+via: https://pdos.csail.mit.edu/6.828/2018/labs/lab2/
+
+作者:[csail.mit][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://pdos.csail.mit.edu
+[b]: https://github.com/lujun9972
+[1]: https://pdos.csail.mit.edu/6.828/2018/readings/i386/toc.htm
+[2]: https://pdos.csail.mit.edu/6.828/2018/labguide.html#qemu
+[3]: https://pdos.csail.mit.edu/6.828/2018/readings/ia32/IA32-3A.pdf
diff --git a/sources/tech/20180928 10 handy Bash aliases for Linux.md b/sources/tech/20180928 10 handy Bash aliases for Linux.md
deleted file mode 100644
index 7ae1070997..0000000000
--- a/sources/tech/20180928 10 handy Bash aliases for Linux.md
+++ /dev/null
@@ -1,118 +0,0 @@
-translating---geekpi
-
-10 handy Bash aliases for Linux
-======
-Get more efficient by using condensed versions of long Bash commands.
-
-
-
-How many times have you repeatedly typed out a long command on the command line and wished there was a way to save it for later? This is where Bash aliases come in handy. They allow you to condense long, cryptic commands down to something easy to remember and use. Need some examples to get you started? No problem!
-
-To use a Bash alias you've created, you need to add it to your .bash_profile file, which is located in your home folder. Note that this file is hidden and accessible only from the command line. The easiest way to work with this file is to use something like Vi or Nano.
-
-### 10 handy Bash aliases
-
- 1. How many times have you needed to unpack a .tar file and couldn't remember the exact arguments needed? Aliases to the rescue! Just add the following to your .bash_profile file and then use **untar FileName** to unpack any .tar file.
-
-
-
-```
-alias untar='tar -zxvf '
-
-```
-
- 2. Want to download something but be able to resume if something goes wrong?
-
-
-
-```
-alias wget='wget -c '
-
-```
-
- 3. Need to generate a random, 20-character password for a new online account? No problem.
-
-
-
-```
-alias getpass="openssl rand -base64 20"
-
-```
-
- 4. Downloaded a file and need to test the checksum? We've got that covered too.
-
-
-
-```
-alias sha='shasum -a 256 '
-
-```
-
- 5. A normal ping will go on forever. We don't want that. Instead, let's limit that to just five pings.
-
-
-
-```
-alias ping='ping -c 5'
-
-```
-
- 6. Start a web server in any folder you'd like.
-
-
-
-```
-alias www='python -m SimpleHTTPServer 8000'
-
-```
-
- 7. Want to know how fast your network is? Just download Speedtest-cli and use this alias. You can choose a server closer to your location by using the **speedtest-cli --list** command.
-
-
-
-```
-alias speed='speedtest-cli --server 2406 --simple'
-
-```
-
- 8. How many times have you needed to know your external IP address and had no idea how to get that info? Yeah, me too.
-
-
-
-```
-alias ipe='curl ipinfo.io/ip'
-
-```
-
- 9. Need to know your local IP address?
-
-
-
-```
-alias ipi='ipconfig getifaddr en0'
-
-```
-
- 10. Finally, let's clear the screen.
-
-
-
-```
-alias c='clear'
-
-```
-
-As you can see, Bash aliases are a super-easy way to simplify your life on the command line. Want more info? I recommend a quick Google search for "Bash aliases" or a trip to GitHub.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/handy-bash-aliases
-
-作者:[Patrick H.Mullins][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/pmullins
diff --git a/sources/tech/20180928 A Free And Secure Online PDF Conversion Suite.md b/sources/tech/20180928 A Free And Secure Online PDF Conversion Suite.md
deleted file mode 100644
index afb66e43ee..0000000000
--- a/sources/tech/20180928 A Free And Secure Online PDF Conversion Suite.md
+++ /dev/null
@@ -1,111 +0,0 @@
-A Free And Secure Online PDF Conversion Suite
-======
-
-
-
-We are always in search for a better and more efficient solution that can make our lives more convenient. That is why when you are working with PDF documents you need a fast and reliable tool that you can use in every situation. Therefore, we wanted to introduce you to **EasyPDF** Online PDF Suite for every occasion. The promise behind this tool is that it can make your PDF management easier and we tested it to check that claim.
-
-But first, here are the most important things you need to know about EasyPDF:
-
- * EasyPDF is free and anonymous online PDF Conversion Suite.
- * Convert PDF to Word, Excel, PowerPoint, AutoCAD, JPG, GIF and Text.
- * Create PDF from Word, PowerPoint, JPG, Excel files and many other formats.
- * Manipulate PDFs with PDF Merge, Split and Compress.
- * OCR conversion of scanned PDFs and images.
- * Upload files from your device or the Cloud (Google Drive and DropBox).
- * Available on Windows, Linux, Mac, and smartphones via any browser.
- * Multiple languages supported.
-
-
-
-### EasyPDF User Interface
-
-
-
-One of the first things that catches your eye is the sleek user interface which gives the tool clean and functional environment in where you can work comfortably. The whole experience is even better because there are no ads on a website at all.
-
-All different types of conversions have their dedicated menu with a simple box to add files, so you don’t have to wonder about what you need to do.
-
-Most websites aren’t optimized to work well and run smoothly on mobile phones, but EasyPDF is an exception from that rule. It opens almost instantly on smartphone and is easy to navigate. You can also add it as the shortcut on your home screen from the **three dots menu** on the Chrome app.
-
-
-
-### Functionality
-
-Apart from looking nice, EasyPDF is pretty straightforward to use. You **don’t need to register** or leave an **email** to use the tool. It is completely anonymous. Additionally, it doesn’t put any limitations to the number or size of files for conversion. No installation required either! Cool, yeah?
-
-You choose a desired conversion format, for example, PDF to Word. Select the PDF file you want to convert. You can upload a file from the device by either drag & drop or selecting the file from the folder. There is also an option to upload a document from [**Google Drive**][1] or [**Dropbox**][2].
-
-After you choose the file, press the Convert button to start the conversion process. You won’t wait for a long time to get your file because conversion will finish in a minute. If you have some more files to convert, remember to download the file before you proceed further. If you don’t download the document first, you will lose it.
-
-
-
-For a different type of conversion, return to the homepage.
-
-The currently available types of conversions are:
-
- * **PDF to Word** – Convert PDF documents to Word documents
-
- * **PDF to PowerPoint** – Convert PDF documents to PowerPoint Presentations
-
- * **PDF to Excel** – Convert PDF documents to Excel documents
-
- * **PDF Creation** – Create PDF documents from any type of file (E.g text, doc, odt)
-
- * **Word to PDF** – Convert Word documents to PDF documents
-
- * **JPG to PDF** – Convert JPG images to PDF documents
-
- * **PDF to AutoCAD** – Convert PDF documents to .dwg format (DWG is native format for CAD packages)
-
- * **PDF to Text** – Convert PDF documents to Text documents
-
- * **PDF Split** – Split PDF files into multiple parts
-
- * **PDF Merge** – Merge multiple PDF files into one
-
- * **PDF Compress** – Compress PDF documents
-
- * **PDF to JPG** – Convert PDF documents to JPG images
-
- * **PDF to PNG** – Convert PDF documents to PNG images
-
- * **PDF to GIF** – Convert PDF documents to GIF files
-
- * **OCR Online** –
-
-Convert scanned paper documents
-
-to editable files (E.g Word, Excel, Text)
-
-
-
-
-Want to give it a try? Great! Click the following link and start converting!
-
-[][https://easypdf.com/]
-
-### Conclusion
-
-EasyPDF lives up to its name and enables easier PDF management. As far as I tested EasyPDF service, It offers out of the box conversion feature completely **FREE!** It is fast, secure and reliable. You will find the quality of services most satisfying without having to pay anything or leaving your personal data like email address. Give it a try and who knows maybe you will find your new favorite PDF tool.
-
-And, that’s all for now. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/easypdf-a-free-and-secure-online-pdf-conversion-suite/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[1]: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
-[2]: https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/
diff --git a/sources/tech/20180928 How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions.md b/sources/tech/20180928 How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions.md
deleted file mode 100644
index 578624aba4..0000000000
--- a/sources/tech/20180928 How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions.md
+++ /dev/null
@@ -1,233 +0,0 @@
-Translating by dianbanjiu How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions
-======
-**Brief: This tutorial shows you how to install Popcorn Time on Ubuntu and other Linux distributions. Some handy Popcorn Time tips have also been discussed.**
-
-[Popcorn Time][1] is an open source [Netflix][2] inspired [torrent][3] streaming application for Linux, Mac and Windows.
-
-With the regular torrents, you have to wait for the download to finish before you could watch the videos.
-
-[Popcorn Time][4] is different. It uses torrent underneath but allows you to start watching the videos (almost) immediately. It’s like you are watching videos on streaming websites like YouTube or Netflix. You don’t have to wait for the download to finish here.
-
-![Popcorn Time in Ubuntu Linux][5]
-Popcorn Time
-
-If you want to watch movies online without those creepy ads, Popcorn Time is a good alternative. Keep in mind that the streaming quality depends on the number of available seeds.
-
-Popcorn Time also provides a nice user interface where you can browse through available movies, tv-series and other contents. If you ever used [Netflix on Linux][6], you will find it’s somewhat a similar experience.
-
-Using torrent to download movies is illegal in several countries where there are strict laws against piracy. In countries like the USA, UK and West European you may even get legal notices. That said, it’s up to you to decide if you want to use it or not. You have been warned.
-(If you still want to take the risk and use Popcorn Time, you should use a VPN service like [Ivacy][7] that has been specifically designed for using Torrents and protecting your identity. Even then it’s not always easy to avoid the snooping authorities.)
-
-Some of the main features of Popcorn Time are:
-
- * Watch movies and TV Series online using Torrent
- * A sleek user interface lets you browse the available movies and TV series
- * Change streaming quality
- * Bookmark content for watching later
- * Download content for offline viewing
- * Ability to enable subtitles by default, change the subtitles size etc
- * Keyboard shortcuts to navigate through Popcorn Time
-
-
-
-### How to install Popcorn Time on Ubuntu and other Linux Distributions
-
-I am using Ubuntu 18.04 in this tutorial but you can use the same instructions for other Linux distributions such as Linux Mint, Debian, Manjaro, Deepin etc.
-
-Let’s see how to install Popcorn time on Linux. It’s really easy actually. Simply follow the instructions and copy paste the commands I have mentioned.
-
-#### Step 1: Download Popcorn Time
-
-You can download Popcorn Time from its official website. The download link is present on the homepage itself.
-
-[Get Popcorn Time](https://popcorntime.sh/)
-
-#### Step 2: Install Popcorn Time
-
-Once you have downloaded Popcorn Time, it’s time to use it. The downloaded file is a tar file that consists of an executable among other files. While you can extract this tar file anywhere, the [Linux convention is to install additional software in][8] /[opt directory.][8]
-
-Create a new directory in /opt:
-
-```
-sudo mkdir /opt/popcorntime
-```
-
-Now go to the Downloads directory.
-
-```
-cd ~/Downloads
-```
-
-Extract the downloaded Popcorn Time files into the newly created /opt/popcorntime directory.
-
-```
-sudo tar Jxf Popcorn-Time-* -C /opt/popcorntime
-```
-
-#### Step 3: Make Popcorn Time accessible for everyone
-
-You would want every user on your system to be able to run Popcorn Time without sudo access, right? To do that, you need to create a [symbolic link][9] to the executable in /usr/bin directory.
-
-```
-ln -sf /opt/popcorntime/Popcorn-Time /usr/bin/Popcorn-Time
-```
-
-#### Step 4: Create desktop launcher for Popcorn Time
-
-So far so good. But you would also like to see Popcorn Time in the application menu, add it to your favorite application list etc.
-
-For that, you need to create a desktop entry.
-
-Open a terminal and create a new file named popcorntime.desktop in /usr/share/applications.
-
-You can use any [command line based text editor][10]. Ubuntu has [Nano][11] installed by default so you can use that.
-
-```
-sudo nano /usr/share/applications/popcorntime.desktop
-```
-
-Insert the following lines here:
-
-```
-[Desktop Entry]
-Version = 1.0
-Type = Application
-Terminal = false
-Name = Popcorn Time
-Exec = /usr/bin/Popcorn-Time
-Icon = /opt/popcorntime/popcorn.png
-Categories = Application;
-```
-
-If you used Nano editor, save it using shortcut Ctrl+X. When asked for saving, enter Y and then press enter again to save and exit.
-
-We are almost there. One last thing to do here is to have the correct icon for Popcorn Time. For that, you can download a Popcorn Time icon and save it as popcorn.png in /opt/popcorntime directory.
-
-You can do that using the command below:
-
-```
-sudo wget -O /opt/popcorntime/popcorn.png https://upload.wikimedia.org/wikipedia/commons/d/df/Pctlogo.png
-
-```
-
-That’s it. Now you can search for Popcorn Time and click on it to launch it.
-
-![Popcorn Time installed on Ubuntu][12]
-Search for Popcorn Time in Menu
-
-On the first launch, you’ll have to accept the terms and conditions.
-
-![Popcorn Time in Ubuntu Linux][13]
-Accept the Terms of Service
-
-Once you do that, you can enjoy the movies and TV shows.
-
-![Watch movies on Popcorn Time][14]
-
-Well, that’s all you needed to install Popcorn Time on Ubuntu or any other Linux distribution. You can start watching your favorite movies straightaway.
-
-However, if you are interested, I would suggest reading these Popcorn Time tips to get more out of it.
-
-[![][15]][16]
-![][17]
-
-### 7 Tips for using Popcorn Time effectively
-
-Now that you have installed Popcorn Time, I am going to tell you some nifty Popcorn Time tricks. I assure you that it will enhance your experience with Popcorn Time multiple folds.
-
-#### 1\. Use advanced settings
-
-Always have the advanced settings enabled. It gives you more options to tweak Popcorn Time. Go to the top right corner and click on the gear symbol. Click on it and check advanced settings on the next screen.
-
-
-
-#### 2\. Watch the movies in VLC or other players
-
-Did you know that you can choose to watch a file in your preferred media player instead of the default Popcorn Time player? Of course, that media player should have been installed in the system.
-
-Now you may ask why would one want to use another player. And my answer is because other players like VLC has hidden features which you might not find in the Popcorn Time player.
-
-For example, if a file has very low volume, you can use VLC to enhance the audio by 400 percent. You can also [synchronize incoherent subtitles with VLC][18]. You can switch between media players before you start to play a file:
-
-
-
-#### 3\. Bookmark movies and watch it later
-
-Just browsing through movies and TV series but don’t have time or mood to watch those? No issues. You can add the movies to the bookmark and can access these bookmarked videos from the Favorites tab. This enables you to create a list of movies you would watch later.
-
-
-
-#### 4\. Check torrent health and seed information
-
-As I had mentioned earlier, your viewing experience in Popcorn Times depends on torrent speed. Good thing is that Popcorn time shows the health of the torrent file so that you can be aware of the streaming speed.
-
-You will see a green/yellow/red dot on the file. Green means there are plenty of seeds and the file will stream easily. Yellow means a medium number of seeds, streaming should be okay. Red means there are very few seeds available and the streaming will be poor or won’t work at all.
-
-
-
-#### 5\. Add custom subtitles
-
-If you need subtitles and it is not available in your preferred language, you can add custom subtitles downloaded from external websites. Get the .srt files and use it inside Popcorn Time:
-
-
-
-This is where VLC comes handy as you can [download subtitles automatically with VLC][19].
-
-
-#### 6\. Save the files for offline viewing
-
-When Popcorn Times stream a content, it downloads it and store temporarily. When you close the app, it’s cleaned out. You can change this behavior so that the downloaded file remains there for your future use.
-
-In the advanced settings, scroll down a bit. Look for Cache directory. You can change this to some other directory like Downloads. This way, even if you close Popcorn Time, the file will be available for viewing.
-
-
-
-#### 7\. Drag and drop external torrent files to play immediately
-
-I bet you did not know about this one. If you don’t find a certain movie on Popcorn Time, download the torrent file from your favorite torrent website. Open Popcorn Time and just drag and drop the torrent file in Popcorn Time. It will start playing the file, depending upon seeds. This way, you don’t need to download the entire file before watching it.
-
-When you drag and drop the torrent file in Popcorn Time, it will give you the option to choose which video file should it play. If there are subtitles in it, it will play automatically or else, you can add external subtitles.
-
-
-
-There are plenty of other features in Popcorn Time. But I’ll stop with my list here and let you explore Popcorn Time on Ubuntu Linux. I hope you find these Popcorn Time tips and tricks useful.
-
-I am repeating again. Using Torrents is illegal in many countries. If you do that, take precaution and use a VPN service. If you are looking for my recommendation, you can go for [Swiss-based privacy company ProtonVPN][20] (of [ProtonMail][21] fame). Singapore based [Ivacy][7] is another good option. If you think these are expensive, you can look for [cheap VPN deals on It’s FOSS Shop][22].
-
-Note: This article contains affiliate links. Please read our [affiliate policy][23].
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/popcorn-time-ubuntu-linux/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[1]: https://popcorntime.sh/
-[2]: https://netflix.com/
-[3]: https://en.wikipedia.org/wiki/Torrent_file
-[4]: https://en.wikipedia.org/wiki/Popcorn_Time
-[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-linux.jpeg
-[6]: https://itsfoss.com/netflix-firefox-linux/
-[7]: https://billing.ivacy.com/page/23628
-[8]: http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/opt.html
-[9]: https://en.wikipedia.org/wiki/Symbolic_link
-[10]: https://itsfoss.com/command-line-text-editors-linux/
-[11]: https://itsfoss.com/nano-3-release/
-[12]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-ubuntu-menu.jpg
-[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-ubuntu-license.jpeg
-[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-watch-movies.jpeg
-[15]: https://ivacy.postaffiliatepro.com/accounts/default1/vdegzkxbw/7f82d531.png
-[16]: https://billing.ivacy.com/page/23628/7f82d531
-[17]: http://ivacy.postaffiliatepro.com/scripts/vdegzkxiw?aff=23628&a_bid=7f82d531
-[18]: https://itsfoss.com/how-to-synchronize-subtitles-with-movie-quick-tip/
-[19]: https://itsfoss.com/download-subtitles-automatically-vlc-media-player-ubuntu/
-[20]: https://protonvpn.net/?aid=chmod777
-[21]: https://itsfoss.com/protonmail/
-[22]: https://shop.itsfoss.com/search?utf8=%E2%9C%93&query=vpn
-[23]: https://itsfoss.com/affiliate-policy/
diff --git a/sources/tech/20180928 What containers can teach us about DevOps.md b/sources/tech/20180928 What containers can teach us about DevOps.md
deleted file mode 100644
index 33f83fb0f7..0000000000
--- a/sources/tech/20180928 What containers can teach us about DevOps.md
+++ /dev/null
@@ -1,100 +0,0 @@
-认领:by sd886393
-What containers can teach us about DevOps
-======
-
-The use of containers supports the three pillars of DevOps practices: flow, feedback, and continual experimentation and learning.
-
-
-
-One can argue that containers and DevOps were made for one another. Certainly, the container ecosystem benefits from the skyrocketing popularity of DevOps practices, both in design choices and in DevOps’ use by teams developing container technologies. Because of this parallel evolution, the use of containers in production can teach teams the fundamentals of DevOps and its three pillars: [The Three Ways][1].
-
-### Principles of flow
-
-**Container flow**
-
-A container can be seen as a silo, and from inside, it is easy to forget the rest of the system: the host node, the cluster, the underlying infrastructure. Inside the container, it might appear that everything is functioning in an acceptable manner. From the outside perspective, though, the application inside the container is a part of a larger ecosystem of applications that make up a service: the web API, the web app user interface, the database, the workers, and caching services and garbage collectors. Teams put constraints on the container to limit performance impact on infrastructure, and much has been done to provide metrics for measuring container performance because overloaded or slow container workloads have downstream impact on other services or customers.
-
-**Real-world flow**
-
-This lesson can be applied to teams functioning in a silo as well. Every process (be it code release, infrastructure creation or even, say, manufacturing of [Spacely’s Sprockets][2]), follows a linear path from conception to realization. In technology, this progress flows from development to testing to operations and release. If a team working alone becomes a bottleneck or introduces a problem, the impact is felt all along the entire pipeline. A defect passed down the line destroys productivity downstream. While the broken process within the scope of the team itself may seem perfectly correct, it has a negative impact on the environment as a whole.
-
-**DevOps and flow**
-
-The first way of DevOps, principles of flow, is about approaching the process as a whole, striving to comprehend how the system works together and understanding the impact of issues on the entire process. To increase the efficiency of the process, pain points and waste are identified and removed. This is an ongoing process; teams must continually strive to increase visibility into the process and find and fix trouble spots and waste.
-
-> “The outcomes of putting the First Way into practice include never passing a known defect to downstream work centers, never allowing local optimization to create global degradation, always seeking to increase flow, and always seeking to achieve a profound understanding of the system (as per Deming).”
-
-–Gene Kim, [The Three Ways: The Principles Underpinning DevOps][3], IT Revolution, 25 Apr. 2017
-
-### Principles of feedback
-
-**Container feedback**
-
-In addition to limiting containers to prevent impact elsewhere, many products have been created to monitor and trend container metrics in an effort to understand what they are doing and notify when they are misbehaving. [Prometheus][4], for example, is [all the rage][5] for collecting metrics from containers and clusters. Containers are excellent at separating applications and providing a way to ship an environment together with the code, sometimes at the cost of opacity, so much is done to try to provide rapid feedback so issues can be addressed promptly within the silo.
-
-**Real-world feedback**
-
-The same is necessary for the flow of the system. From inception to realization, an efficient process quickly provides relevant feedback to identify when there is an issue. The key words here are “quick” and “relevant.” Burying teams in thousands of irrelevant notifications make it difficult or even impossible to notice important events that need immediate action, and receiving even relevant information too late may allow small, easily solved issues to move downstream and become bigger problems. Imagine [if Lucy and Ethel][6] had provided immediate feedback that the conveyor belt was too fast—there would have been no problem with the chocolate production (though that would not have been nearly as funny).
-
-**DevOps and feedback**
-
-The Second Way of DevOps, principles of feedback, is all about getting relevant information quickly. With immediate, useful feedback, problems can be identified as they happen and addressed before impact is felt elsewhere in the development process. DevOps teams strive to “optimize for downstream” and immediately move to fix problems that might impact other teams that come after them. As with flow, feedback is a continual process to identify ways to quickly get important data and act on problems as they occur.
-
-> “Creating fast feedback is critical to achieving quality, reliability, and safety in the technology value stream.”
-
-–Gene Kim, et al., The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations, IT Revolution Press, 2016
-
-### Principles of continual experimentation and learning
-
-**Container continual experimentation and learning**
-
-It is a bit more challenging applying operational learning to the Third Way of DevOps:continual experimentation and learning. Trying to salvage what we can grasp of the very edges of the metaphor, containers make development easy, allowing developers and operations teams to test new code or configurations locally and safely outside of production and incorporate discovered benefits into production in a way that was difficult in the past. Changes can be radical and still version-controlled, documented, and shared quickly and easily.
-
-**Real-world continual experimentation and learning**
-
-For example, consider this anecdote from my own experience: Years ago, as a young, inexperienced sysadmin (just three weeks into the job), I was asked to make changes to an Apache virtual host running the website of the central IT department for a university. Without an easy-to-use test environment, I made a configuration change to the production site that I thought would accomplish the task and pushed it out. Within a few minutes, I overheard coworkers in the next cube:
-
-“Wait, is the website down?”
-
-“Hrm, yeah, it looks like it. What the heck?”
-
-There was much eye-rolling involved.
-
-Mortified (the shame is real, folks), I sunk down as far as I could into my seat and furiously tried to back out the changes I’d introduced. Later that same afternoon, the director of the department—the boss of my boss’s boss—appeared in my cube to talk about what had happened. “Don’t worry,” she told me. “We’re not mad at you. It was a mistake and now you have learned.”
-
-In the world of containers, this could have been easily changed and tested on my own laptop and the broken configuration identified by more skilled team members long before it ever made it into production.
-
-**DevOps continual experimentation and learning**
-
-A real culture of experimentation promotes the individual’s ability to find where a change in the process may be beneficial, and to test that assumption without the fear of retaliation if they fail. For DevOps teams, failure becomes an educational tool that adds to the knowledge of the individual and organization, rather than something to be feared or punished. Individuals in the DevOps team dedicate themselves to continuous learning, which in turn benefits the team and wider organization as that knowledge is shared.
-
-As the metaphor completely falls apart, focus needs to be given to a specific point: The other two principles may appear at first glance to focus entirely on process, but continual learning is a human task—important for the future of the project, the person, the team, and the organization. It has an impact on the process, but it also has an impact on the individual and other people.
-
-> “Experimentation and risk-taking are what enable us to relentlessly improve our system of work, which often requires us to do things very differently than how we’ve done it for decades.”
-
-–Gene Kim, et al., [The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win][7], IT Revolution Press, 2013
-
-### Containers can teach us DevOps
-
-Learning to work effectively with containers can help teach DevOps and the Three Ways: principles of flow, principles of feedback, and principles of continuous experimentation and learning. Looking holistically at the application and infrastructure rather than putting on blinders to everything outside the container teaches us to take all parts of the system and understand their upstream and downstream impacts, break out of silos, and work as a team to increase global performance and deep understanding of the entire system. Working to provide timely and accurate feedback teaches us to create effective feedback patterns within our organizations to identify problems before their impact grows. Finally, providing a safe environment to try new ideas and learn from them teaches us to create a culture where failure represents a positive addition to our knowledge and the ability to take big chances with educated guesses can result in new, elegant solutions to complex problems.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/containers-can-teach-us-devops
-
-作者:[Chris Hermansen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/clhermansen
-[1]: https://itrevolution.com/the-three-ways-principles-underpinning-devops/
-[2]: https://en.wikipedia.org/wiki/The_Jetsons
-[3]: http://itrevolution.com/the-three-ways-principles-underpinning-devops
-[4]: https://prometheus.io/
-[5]: https://opensource.com/article/18/9/prometheus-operational-advantage
-[6]: https://www.youtube.com/watch?v=8NPzLBSBzPI
-[7]: https://itrevolution.com/book/the-phoenix-project/
diff --git a/sources/tech/20181001 16 iptables tips and tricks for sysadmins.md b/sources/tech/20181001 16 iptables tips and tricks for sysadmins.md
new file mode 100644
index 0000000000..9e07971c81
--- /dev/null
+++ b/sources/tech/20181001 16 iptables tips and tricks for sysadmins.md
@@ -0,0 +1,261 @@
+16 iptables tips and tricks for sysadmins
+======
+Iptables provides powerful capabilities to control traffic coming in and out of your system.
+
+
+
+Modern Linux kernels come with a packet-filtering framework named [Netfilter][1]. Netfilter enables you to allow, drop, and modify traffic coming in and going out of a system. The **iptables** userspace command-line tool builds upon this functionality to provide a powerful firewall, which you can configure by adding rules to form a firewall policy. [iptables][2] can be very daunting with its rich set of capabilities and baroque command syntax. Let's explore some of them and develop a set of iptables tips and tricks for many situations a system administrator might encounter.
+
+### Avoid locking yourself out
+
+Scenario: You are going to make changes to the iptables policy rules on your company's primary server. You want to avoid locking yourself—and potentially everybody else—out. (This costs time and money and causes your phone to ring off the wall.)
+
+#### Tip #1: Take a backup of your iptables configuration before you start working on it.
+
+Back up your configuration with the command:
+
+```
+/sbin/iptables-save > /root/iptables-works
+
+```
+#### Tip #2: Even better, include a timestamp in the filename.
+
+Add the timestamp with the command:
+
+```
+/sbin/iptables-save > /root/iptables-works-`date +%F`
+
+```
+
+You get a file with a name like:
+
+```
+/root/iptables-works-2018-09-11
+
+```
+
+If you do something that prevents your system from working, you can quickly restore it:
+
+```
+/sbin/iptables-restore < /root/iptables-works-2018-09-11
+
+```
+
+#### Tip #3: Every time you create a backup copy of the iptables policy, create a link to the file with 'latest' in the name.
+
+```
+ln –s /root/iptables-works-`date +%F` /root/iptables-works-latest
+
+```
+
+#### Tip #4: Put specific rules at the top of the policy and generic rules at the bottom.
+
+Avoid generic rules like this at the top of the policy rules:
+
+```
+iptables -A INPUT -p tcp --dport 22 -j DROP
+
+```
+
+The more criteria you specify in the rule, the less chance you will have of locking yourself out. Instead of the very generic rule above, use something like this:
+
+```
+iptables -A INPUT -p tcp --dport 22 –s 10.0.0.0/8 –d 192.168.100.101 -j DROP
+
+```
+
+This rule appends ( **-A** ) to the **INPUT** chain a rule that will **DROP** any packets originating from the CIDR block **10.0.0.0/8** on TCP ( **-p tcp** ) port 22 ( **\--dport 22** ) destined for IP address 192.168.100.101 ( **-d 192.168.100.101** ).
+
+There are plenty of ways you can be more specific. For example, using **-i eth0** will limit the processing to a single NIC in your server. This way, the filtering actions will not apply the rule to **eth1**.
+
+#### Tip #5: Whitelist your IP address at the top of your policy rules.
+
+This is a very effective method of not locking yourself out. Everybody else, not so much.
+
+```
+iptables -I INPUT -s -j ACCEPT
+
+```
+
+You need to put this as the first rule for it to work properly. Remember, **-I** inserts it as the first rule; **-A** appends it to the end of the list.
+
+#### Tip #6: Know and understand all the rules in your current policy.
+
+Not making a mistake in the first place is half the battle. If you understand the inner workings behind your iptables policy, it will make your life easier. Draw a flowchart if you must. Also remember: What the policy does and what it is supposed to do can be two different things.
+
+### Set up a workstation firewall policy
+
+Scenario: You want to set up a workstation with a restrictive firewall policy.
+
+#### Tip #1: Set the default policy as DROP.
+
+```
+# Set a default policy of DROP
+*filter
+:INPUT DROP [0:0]
+:FORWARD DROP [0:0]
+:OUTPUT DROP [0:0]
+```
+
+#### Tip #2: Allow users the minimum amount of services needed to get their work done.
+
+The iptables rules need to allow the workstation to get an IP address, netmask, and other important information via DHCP ( **-p udp --dport 67:68 --sport 67:68** ). For remote management, the rules need to allow inbound SSH ( **\--dport 22** ), outbound mail ( **\--dport 25** ), DNS ( **\--dport 53** ), outbound ping ( **-p icmp** ), Network Time Protocol ( **\--dport 123 --sport 123** ), and outbound HTTP ( **\--dport 80** ) and HTTPS ( **\--dport 443** ).
+
+```
+# Set a default policy of DROP
+*filter
+:INPUT DROP [0:0]
+:FORWARD DROP [0:0]
+:OUTPUT DROP [0:0]
+
+# Accept any related or established connections
+-I INPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
+-I OUTPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
+
+# Allow all traffic on the loopback interface
+-A INPUT -i lo -j ACCEPT
+-A OUTPUT -o lo -j ACCEPT
+
+# Allow outbound DHCP request
+-A OUTPUT –o eth0 -p udp --dport 67:68 --sport 67:68 -j ACCEPT
+
+# Allow inbound SSH
+-A INPUT -i eth0 -p tcp -m tcp --dport 22 -m state --state NEW -j ACCEPT
+
+# Allow outbound email
+-A OUTPUT -i eth0 -p tcp -m tcp --dport 25 -m state --state NEW -j ACCEPT
+
+# Outbound DNS lookups
+-A OUTPUT -o eth0 -p udp -m udp --dport 53 -j ACCEPT
+
+# Outbound PING requests
+-A OUTPUT –o eth0 -p icmp -j ACCEPT
+
+# Outbound Network Time Protocol (NTP) requests
+-A OUTPUT –o eth0 -p udp --dport 123 --sport 123 -j ACCEPT
+
+# Outbound HTTP
+-A OUTPUT -o eth0 -p tcp -m tcp --dport 80 -m state --state NEW -j ACCEPT
+-A OUTPUT -o eth0 -p tcp -m tcp --dport 443 -m state --state NEW -j ACCEPT
+
+COMMIT
+```
+
+### Restrict an IP address range
+
+Scenario: The CEO of your company thinks the employees are spending too much time on Facebook and not getting any work done. The CEO tells the CIO to do something about the employees wasting time on Facebook. The CIO tells the CISO to do something about employees wasting time on Facebook. Eventually, you are told the employees are wasting too much time on Facebook, and you have to do something about it. You decide to block all access to Facebook. First, find out Facebook's IP address by using the **host** and **whois** commands.
+
+```
+host -t a www.facebook.com
+www.facebook.com is an alias for star.c10r.facebook.com.
+star.c10r.facebook.com has address 31.13.65.17
+whois 31.13.65.17 | grep inetnum
+inetnum: 31.13.64.0 - 31.13.127.255
+```
+
+Then convert that range to CIDR notation by using the [CIDR to IPv4 Conversion][3] page. You get **31.13.64.0/18**. To prevent outgoing access to [www.facebook.com][4], enter:
+
+```
+iptables -A OUTPUT -p tcp -i eth0 –o eth1 –d 31.13.64.0/18 -j DROP
+```
+
+### Regulate by time
+
+Scenario: The backlash from the company's employees over denying access to Facebook access causes the CEO to relent a little (that and his administrative assistant's reminding him that she keeps HIS Facebook page up-to-date). The CEO decides to allow access to Facebook.com only at lunchtime (12PM to 1PM). Assuming the default policy is DROP, use iptables' time features to open up access.
+
+```
+iptables –A OUTPUT -p tcp -m multiport --dport http,https -i eth0 -o eth1 -m time --timestart 12:00 --timestart 12:00 –timestop 13:00 –d
+31.13.64.0/18 -j ACCEPT
+```
+
+This command sets the policy to allow ( **-j ACCEPT** ) http and https ( **-m multiport --dport http,https** ) between noon ( **\--timestart 12:00** ) and 13PM ( **\--timestop 13:00** ) to Facebook.com ( **–d[31.13.64.0/18][5]** ).
+
+### Regulate by time—Take 2
+
+Scenario: During planned downtime for system maintenance, you need to deny all TCP and UDP traffic between the hours of 2AM and 3AM so maintenance tasks won't be disrupted by incoming traffic. This will take two iptables rules:
+
+```
+iptables -A INPUT -p tcp -m time --timestart 02:00 --timestop 03:00 -j DROP
+iptables -A INPUT -p udp -m time --timestart 02:00 --timestop 03:00 -j DROP
+```
+
+With these rules, TCP and UDP traffic ( **-p tcp and -p udp** ) are denied ( **-j DROP** ) between the hours of 2AM ( **\--timestart 02:00** ) and 3AM ( **\--timestop 03:00** ) on input ( **-A INPUT** ).
+
+### Limit connections with iptables
+
+Scenario: Your internet-connected web servers are under attack by bad actors from around the world attempting to DoS (Denial of Service) them. To mitigate these attacks, you restrict the number of connections a single IP address can have to your web server:
+
+```
+iptables –A INPUT –p tcp –syn -m multiport -–dport http,https –m connlimit -–connlimit-above 20 –j REJECT -–reject-with-tcp-reset
+```
+
+Let's look at what this rule does. If a host makes more than 20 ( **-–connlimit-above 20** ) new connections ( **–p tcp –syn** ) in a minute to the web servers ( **-–dport http,https** ), reject the new connection ( **–j REJECT** ) and tell the connecting host you are rejecting the connection ( **-–reject-with-tcp-reset** ).
+
+### Monitor iptables rules
+
+Scenario: Since iptables operates on a "first match wins" basis as packets traverse the rules in a chain, frequently matched rules should be near the top of the policy and less frequently matched rules should be near the bottom. How do you know which rules are traversed the most or the least so they can be ordered nearer the top or the bottom?
+
+#### Tip #1: See how many times each rule has been hit.
+
+Use this command:
+
+```
+iptables -L -v -n –line-numbers
+```
+
+The command will list all the rules in the chain ( **-L** ). Since no chain was specified, all the chains will be listed with verbose output ( **-v** ) showing packet and byte counters in numeric format ( **-n** ) with line numbers at the beginning of each rule corresponding to that rule's position in the chain.
+
+Using the packet and bytes counts, you can order the most frequently traversed rules to the top and the least frequently traversed rules towards the bottom.
+
+#### Tip #2: Remove unnecessary rules.
+
+Which rules aren't getting any matches at all? These would be good candidates for removal from the policy. You can find that out with this command:
+
+```
+iptables -nvL | grep -v "0 0"
+```
+
+Note: that's not a tab between the zeros; there are five spaces between the zeros.
+
+#### Tip #3: Monitor what's going on.
+
+You would like to monitor what's going on with iptables in real time, like with **top**. Use this command to monitor the activity of iptables activity dynamically and show only the rules that are actively being traversed:
+
+```
+watch --interval=5 'iptables -nvL | grep -v "0 0"'
+```
+
+**watch** runs **'iptables -nvL | grep -v "0 0"'** every five seconds and displays the first screen of its output. This allows you to watch the packet and byte counts change over time.
+
+### Report on iptables
+
+Scenario: Your manager thinks this iptables firewall stuff is just great, but a daily activity report would be even better. Sometimes it's more important to write a report than to do the work.
+
+Use the packet filter/firewall/IDS log analyzer [FWLogwatch][6] to create reports based on the iptables firewall logs. FWLogwatch supports many log formats and offers many analysis options. It generates daily and monthly summaries of the log files, allowing the security administrator to free up substantial time, maintain better control over network security, and reduce unnoticed attacks.
+
+Here is sample output from FWLogwatch:
+
+
+
+### More than just ACCEPT and DROP
+
+We've covered many facets of iptables, all the way from making sure you don't lock yourself out when working with iptables to monitoring iptables to visualizing the activity of an iptables firewall. These will get you started down the path to realizing even more iptables tips and tricks.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/10/iptables-tips-and-tricks
+
+作者:[Gary Smith][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/greptile
+[1]: https://en.wikipedia.org/wiki/Netfilter
+[2]: https://en.wikipedia.org/wiki/Iptables
+[3]: http://www.ipaddressguide.com/cidr
+[4]: http://www.facebook.com
+[5]: http://31.13.64.0/18
+[6]: http://fwlogwatch.inside-security.de/
diff --git a/sources/tech/20181001 Turn your book into a website and an ePub using Pandoc.md b/sources/tech/20181001 Turn your book into a website and an ePub using Pandoc.md
new file mode 100644
index 0000000000..bd79cb3c04
--- /dev/null
+++ b/sources/tech/20181001 Turn your book into a website and an ePub using Pandoc.md
@@ -0,0 +1,263 @@
+Turn your book into a website and an ePub using Pandoc
+======
+Write once, publish twice using Markdown and Pandoc.
+
+
+
+Pandoc is a command-line tool for converting files from one markup language to another. In my [introduction to Pandoc][1], I explained how to convert text written in Markdown into a website, a slideshow, and a PDF.
+
+In this follow-up article, I'll dive deeper into [Pandoc][2], showing how to produce a website and an ePub book from the same Markdown source file. I'll use my upcoming e-book, [GRASP Principles for the Object-Oriented Mind][3], which I created using this process, as an example.
+
+First I will explain the file structure used for the book, then how to use Pandoc to generate a website and deploy it in GitHub. Finally, I demonstrate how to generate its companion ePub book.
+
+You can find the code in my [Programming Fight Club][4] GitHub repository.
+
+### Setting up the writing structure
+
+I do all of my writing in Markdown syntax. You can also use HTML, but the more HTML you introduce the highest risk that problems arise when Pandoc converts Markdown to an ePub document. My books follow the one-chapter-per-file pattern. Declare chapters using the Markdown heading H1 ( **#** ). You can put more than one chapter in each file, but putting them in separate files makes it easier to find content and do updates later.
+
+The meta-information follows a similar pattern: each output format has its own meta-information file. Meta-information files define information about your documents, such as text to add to your HTML or the license of your ePub. I store all of my Markdown documents in a folder named parts (this is important for the Makefile that generates the website and ePub). As an example, let's take the table of contents, the preface, and the about chapters (divided into the files toc.md, preface.md, and about.md) and, for clarity, we will leave out the remaining chapters.
+
+My about file might begin like:
+
+```
+# About this book {-}
+
+## Who should read this book {-}
+
+Before creating a complex software system one needs to create a solid foundation.
+General Responsibility Assignment Software Principles (GRASP) are guidelines to assign
+responsibilities to software classes in object-oriented programming.
+```
+
+Once the chapters are finished, the next step is to add meta-information to setup the format for the website and the ePub.
+
+### Generating the website
+
+#### Create the HTML meta-information file
+
+The meta-information file (web-metadata.yaml) for my website is a simple YAML file that contains information about the author, title, rights, content for the **< head>** tag, and content for the beginning and end of the HTML file.
+
+I recommend (at minimum) including the following fields in the web-metadata.yaml file:
+
+```
+---
+title: GRASP principles for the Object-oriented mind
+author: Kiko Fernandez-Reyes
+rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
+header-includes:
+- |
+ \```{=html}
+
+
+ \```
+include-before:
+- |
+ \```{=html}
+
+ \```
+---
+```
+
+Some variables to note:
+
+ * The **header-includes** variable contains HTML that will be embedded inside the **< head>** tag.
+ * The line after calling a variable must be **\- |**. The next line must begin with triple backquotes that are aligned with the **|** or Pandoc will reject it. **{=html}** tells Pandoc that this is raw text and should not be processed as Markdown. (For this to work, you need to check that the **raw_attribute** extension in Pandoc is enabled. To check, type **pandoc --list-extensions | grep raw** and make sure the returned list contains an item named **+raw_html** ; the plus sign indicates it is enabled.)
+ * The variable **include-before** adds some HTML at the beginning of your website, and I ask readers to consider spreading the word or buying me a coffee.
+ * The **include-after** variable appends raw HTML at the end of the website and shows my book's license.
+
+
+
+These are only some of the fields available; take a look at the template variables in HTML (my article [introduction to Pandoc][1] covered this for LaTeX but the process is the same for HTML) to learn about others.
+
+#### Split the website into chapters
+
+The website can be generated as a whole, resulting in a long page with all the content, or split into chapters, which I think is easier to read. I'll explain how to divide the website into chapters so the reader doesn't get intimidated by a long website.
+
+To make the website easy to deploy on GitHub Pages, we need to create a root folder called docs (which is the root folder that GitHub Pages uses by default to render a website). Then we need to create folders for each chapter under docs, place the HTML chapters in their own folders, and the file content in a file named index.html.
+
+For example, the about.md file is converted to a file named index.html that is placed in a folder named about (about/index.html). This way, when users type **http:// /about/**, the index.html file from the folder about will be displayed in their browser.
+
+The following Makefile does all of this:
+
+```
+# Your book files
+DEPENDENCIES= toc preface about
+
+# Placement of your HTML files
+DOCS=docs
+
+all: web
+
+web: setup $(DEPENDENCIES)
+ @cp $(DOCS)/toc/index.html $(DOCS)
+
+
+# Creation and copy of stylesheet and images into
+# the assets folder. This is important to deploy the
+# website to Github Pages.
+setup:
+ @mkdir -p $(DOCS)
+ @cp -r assets $(DOCS)
+
+
+# Creation of folder and index.html file on a
+# per-chapter basis
+
+$(DEPENDENCIES):
+ @mkdir -p $(DOCS)/$@
+ @pandoc -s --toc web-metadata.yaml parts/$@.md \
+ -c /assets/pandoc.css -o $(DOCS)/$@/index.html
+
+clean:
+ @rm -rf $(DOCS)
+
+.PHONY: all clean web setup
+```
+
+The option **-c /assets/pandoc.css** declares which CSS stylesheet to use; it will be fetched from **/assets/pandoc.css**. In other words, inside the **< head>** HTML tag, Pandoc adds the following line:
+
+```
+
+```
+
+To generate the website, type:
+
+```
+make
+```
+
+The root folder should contain now the following structure and files:
+
+```
+.---parts
+| |--- toc.md
+| |--- preface.md
+| |--- about.md
+|
+|---docs
+ |--- assets/
+ |--- index.html
+ |--- toc
+ | |--- index.html
+ |
+ |--- preface
+ | |--- index.html
+ |
+ |--- about
+ |--- index.html
+
+```
+
+#### Deploy the website
+
+To deploy the website on GitHub, follow these steps:
+
+ 1. Create a new repository
+ 2. Push your content to the repository
+ 3. Go to the GitHub Pages section in the repository's Settings and select the option for GitHub to use the content from the Master branch
+
+
+
+You can get more details on the [GitHub Pages][5] site.
+
+Check out [my book's website][6], generated using this process, to see the result.
+
+### Generating the ePub book
+
+#### Create the ePub meta-information file
+
+The ePub meta-information file, epub-meta.yaml, is similar to the HTML meta-information file. The main difference is that ePub offers other template variables, such as **publisher** and **cover-image**. Your ePub book's stylesheet will probably differ from your website's; mine uses one named epub.css.
+
+```
+---
+title: 'GRASP principles for the Object-oriented Mind'
+publisher: 'Programming Language Fight Club'
+author: Kiko Fernandez-Reyes
+rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
+cover-image: assets/cover.png
+stylesheet: assets/epub.css
+...
+```
+
+Add the following content to the previous Makefile:
+
+```
+epub:
+ @pandoc -s --toc epub-meta.yaml \
+ $(addprefix parts/, $(DEPENDENCIES:=.md)) -o $(DOCS)/assets/book.epub
+```
+
+The command for the ePub target takes all the dependencies from the HTML version (your chapter names), appends to them the Markdown extension, and prepends them with the path to the folder chapters' so Pandoc knows how to process them. For example, if **$(DEPENDENCIES)** was only **preface about** , then the Makefile would call:
+
+```
+@pandoc -s --toc epub-meta.yaml \
+parts/preface.md parts/about.md -o $(DOCS)/assets/book.epub
+```
+
+Pandoc would take these two chapters, combine them, generate an ePub, and place the book under the Assets folder.
+
+Here's an [example][7] of an ePub created using this process.
+
+### Summarizing the process
+
+The process to create a website and an ePub from a Markdown file isn't difficult, but there are a lot of details. The following outline may make it easier for you to follow.
+
+ * HTML book:
+ * Write chapters in Markdown
+ * Add metadata
+ * Create a Makefile to glue pieces together
+ * Set up GitHub Pages
+ * Deploy
+ * ePub book:
+ * Reuse chapters from previous work
+ * Add new metadata file
+ * Create a Makefile to glue pieces together
+ * Set up GitHub Pages
+ * Deploy
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/10/book-to-website-epub-using-pandoc
+
+作者:[Kiko Fernandez-Reyes][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/kikofernandez
+[1]: https://opensource.com/article/18/9/intro-pandoc
+[2]: https://pandoc.org/
+[3]: https://www.programmingfightclub.com/
+[4]: https://github.com/kikofernandez/programmingfightclub
+[5]: https://pages.github.com/
+[6]: https://www.programmingfightclub.com/grasp-principles/
+[7]: https://github.com/kikofernandez/programmingfightclub/raw/master/docs/web_assets/demo.epub
diff --git a/sources/tech/20181002 4 open source invoicing tools for small businesses.md b/sources/tech/20181002 4 open source invoicing tools for small businesses.md
new file mode 100644
index 0000000000..29589a6ad1
--- /dev/null
+++ b/sources/tech/20181002 4 open source invoicing tools for small businesses.md
@@ -0,0 +1,76 @@
+4 open source invoicing tools for small businesses
+======
+Manage your billing and get paid with easy-to-use, web-based invoicing software.
+
+
+
+No matter what your reasons for starting a small business, the key to keeping that business going is getting paid. Getting paid usually means sending a client an invoice.
+
+It's easy enough to whip up an invoice using LibreOffice Writer or LibreOffice Calc, but sometimes you need a bit more. A more professional look. A way of keeping track of your invoices. Reminders about when to follow up on the invoices you've sent.
+
+There's a wide range of commercial and closed-source invoicing tools out there. But the offerings on the open source side of the fence are just as good, and maybe even more flexible, than their closed source counterparts.
+
+Let's take a look at four web-based open source invoicing tools that are great choices for freelancers and small businesses on a tight budget. I reviewed two of them in 2014, in an [earlier version][1] of this article. These four picks are easy to use and you can use them on just about any device.
+
+### Invoice Ninja
+
+I've never been a fan of the term ninja. Despite that, I like [Invoice Ninja][2]. A lot. It melds a simple interface with a set of features that let you create, manage, and send invoices to clients and customers.
+
+You can easily configure multiple clients, track payments and outstanding invoices, generate quotes, and email invoices. What sets Invoice Ninja apart from its competitors is its [integration with][3] over 40 online popular payment gateways, including PayPal, Stripe, WePay, and Apple Pay.
+
+[Download][4] a version that you can install on your own server or get an account with the [hosted version][5] of Invoice Ninja. There's a free version and a paid tier that will set you back US$ 8 a month.
+
+### InvoicePlane
+
+Once upon a time, there was a nifty open source invoicing tool called FusionInvoice. One day, its creators took the latest version of the code proprietary. That didn't end happily, as FusionInvoice's doors were shut for good in 2018. But that wasn't the end of the application. An old version of the code stayed open source and morphed into [InvoicePlane][6], which packs all of FusionInvoice's goodness.
+
+Creating an invoice takes just a couple of clicks. You can make them as minimal or detailed as you need. When you're ready, you can email your invoices or output them as PDFs. You can also create recurring invoices for clients or customers you regularly bill.
+
+InvoicePlane does more than generate and track invoices. You can also create quotes for jobs or goods, track products you sell, view and enter payments, and run reports on your invoices.
+
+[Grab the code][7] and install it on your web server. Or, if you're not quite ready to do that, [take the demo][8] for a spin.
+
+### OpenSourceBilling
+
+Described by its developer as "beautifully simple billing software," [OpenSourceBilling][9] lives up to the description. It has one of the cleanest interfaces I've seen, which makes configuring and using the tool a breeze.
+
+OpenSourceBilling stands out because of its dashboard, which tracks your current and past invoices, as well as any outstanding amounts. Your information is broken up into graphs and tables, which makes it easy to follow.
+
+You do much of the configuration on the invoice itself. You can add items, tax rates, clients, and even payment terms with a click and a few keystrokes. OpenSourceBilling saves that information across all of your invoices, both new and old.
+
+As with some of the other tools we've looked at, OpenSourceBilling has a [demo][10] you can try.
+
+### BambooInvoice
+
+When I was a full-time freelance writer and consultant, I used [BambooInvoice][11] to bill my clients. When its original developer stopped working on the software, I was a bit disappointed. But BambooInvoice is back, and it's as good as ever.
+
+What attracted me to BambooInvoice is its simplicity. It does one thing and does it well. You can create and edit invoices, and BambooInvoice keeps track of them by client and by the invoice numbers you assign to them. It also lets you know which invoices are open or overdue. You can email the invoices from within the application or generate PDFs. You can also run reports to keep tabs on your income.
+
+To [install][12] and use BambooInvoice, you'll need a web server running PHP 5 or newer as well as a MySQL database. Chances are you already have access to one, so you're good to go.
+
+Do you have a favorite open source invoicing tool? Feel free to share it by leaving a comment.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/10/open-source-invoicing-tools
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[1]: https://opensource.com/business/14/9/4-open-source-invoice-tools
+[2]: https://www.invoiceninja.org/
+[3]: https://www.invoiceninja.com/integrations/
+[4]: https://github.com/invoiceninja/invoiceninja
+[5]: https://www.invoiceninja.com/invoicing-pricing-plans/
+[6]: https://invoiceplane.com/
+[7]: https://wiki.invoiceplane.com/en/1.5/getting-started/installation
+[8]: https://demo.invoiceplane.com/
+[9]: http://www.opensourcebilling.org/
+[10]: http://demo.opensourcebilling.org/
+[11]: https://www.bambooinvoice.net/
+[12]: https://sourceforge.net/projects/bambooinvoice/
diff --git a/sources/tech/20181003 Introducing Swift on Fedora.md b/sources/tech/20181003 Introducing Swift on Fedora.md
new file mode 100644
index 0000000000..186117cd7c
--- /dev/null
+++ b/sources/tech/20181003 Introducing Swift on Fedora.md
@@ -0,0 +1,72 @@
+translating---geekpi
+
+Introducing Swift on Fedora
+======
+
+
+
+Swift is a general-purpose programming language built using a modern approach to safety, performance, and software design patterns. It aims to be the best language for a variety of programming projects, ranging from systems programming to desktop applications and scaling up to cloud services. Read more about it and how to try it out in Fedora.
+
+### Safe, Fast, Expressive
+
+Like many modern programming languages, Swift was designed to be safer than C-based languages. For example, variables are always initialized before they can be used. Arrays and integers are checked for overflow. Memory is automatically managed.
+
+Swift puts intent right in the syntax. To declare a variable, use the var keyword. To declare a constant, use let.
+
+Swift also guarantees that objects can never be nil; in fact, trying to use an object known to be nil will cause a compile-time error. When using a nil value is appropriate, it supports a mechanism called **optionals**. An optional may contain nil, but is safely unwrapped using the **?** operator.
+
+Some additional features include:
+
+ * Closures unified with function pointers
+ * Tuples and multiple return values
+ * Generics
+ * Fast and concise iteration over a range or collection
+ * Structs that support methods, extensions, and protocols
+ * Functional programming patterns, e.g., map and filter
+ * Powerful error handling built-in
+ * Advanced control flow with do, guard, defer, and repeat keywords
+
+
+
+### Try Swift out
+
+Swift is available in Fedora 28 under then package name **swift-lang**. Once installed, run swift and the REPL console starts up.
+
+```
+$ swift
+Welcome to Swift version 4.2 (swift-4.2-RELEASE). Type :help for assistance.
+ 1> let greeting="Hello world!"
+greeting: String = "Hello world!"
+ 2> print(greeting)
+Hello world!
+ 3> greeting = "Hello universe!"
+error: repl.swift:3:10: error: cannot assign to value: 'greeting' is a 'let' constant
+greeting = "Hello universe!"
+~~~~~~~~ ^
+
+
+ 3>
+
+```
+
+Swift has a growing community, and in particular, a [work group][1] dedicated to making it an efficient and effective server-side programming language. Be sure to visit [its home page][2] for more ways to get involved.
+
+Photo by [Uillian Vargas][3] on [Unsplash][4].
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/introducing-swift-fedora/
+
+作者:[Link Dupont][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/linkdupont/
+[1]: https://swift.org/server/
+[2]: http://swift.org
+[3]: https://unsplash.com/photos/7oJpVR1inGk?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[4]: https://unsplash.com/search/photos/fast?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
diff --git a/sources/tech/20181003 Oomox - Customize And Create Your Own GTK2, GTK3 Themes.md b/sources/tech/20181003 Oomox - Customize And Create Your Own GTK2, GTK3 Themes.md
new file mode 100644
index 0000000000..e45d96470f
--- /dev/null
+++ b/sources/tech/20181003 Oomox - Customize And Create Your Own GTK2, GTK3 Themes.md
@@ -0,0 +1,128 @@
+Oomox – Customize And Create Your Own GTK2, GTK3 Themes
+======
+
+
+
+Theming and Visual customization is one of the main advantages of Linux. Since all the code is open, you can change how your Linux system looks and behaves to a greater degree than you ever could with Windows/Mac OS. GTK theming is perhaps the most popular way in which people customize their Linux desktops. The GTK toolkit is used by a wide variety of desktop environments like Gnome, Cinnamon, Unity, XFCE, and budgie. This means that a single theme made for GTK can be applied to any of these Desktop Environments with little changes.
+
+There are a lot of very high quality popular GTK themes out there, such as **Arc** , **Numix** , and **Adapta**. But if you want to customize these themes and create your own visual design, you can use **Oomox**.
+
+The Oomox is a graphical app for customizing and creating your own GTK theme complete with your own color, icon and terminal style. It comes with several presets, which you can apply on a Numix, Arc, or Materia style theme to create your own GTK theme.
+
+### Installing Oomox
+
+On Arch Linux and its variants:
+
+Oomox is available on [**AUR**][1], so you can install it using any AUR helper programs like [**Yay**][2].
+
+```
+$ yay -S oomox
+
+```
+
+On Debian/Ubuntu/Linux Mint, download `oomox.deb`package from [**here**][3] and install it as shown below. As of writing this guide, the latest version was **oomox_1.7.0.5.deb**.
+
+```
+$ sudo dpkg -i oomox_1.7.0.5.deb
+$ sudo apt install -f
+
+```
+
+On Fedora, Oomox is available in third-party **COPR** repository.
+
+```
+$ sudo dnf copr enable tcg/themes
+$ sudo dnf install oomox
+
+```
+
+Oomox is also available as a [**Flatpak app**][4]. Make sure you have installed Flatpak as described in [**this guide**][5]. And then, install and run Oomox using the following commands:
+
+```
+$ flatpak install flathub com.github.themix_project.Oomox
+
+$ flatpak run com.github.themix_project.Oomox
+
+```
+
+For other Linux distributions, go to the Oomox project page (Link is given at the end of this guide) on Github and compile and install it manually from source.
+
+### Customize And Create Your Own GTK2, GTK3 Themes
+
+**Theme Customization**
+
+
+
+You can change the colour of practically every UI element, like:
+
+ 1. Headers
+ 2. Buttons
+ 3. Buttons inside Headers
+ 4. Menus
+ 5. Selected Text
+
+
+
+To the left, there are a number of presets, like the Cars theme, modern themes like Materia, and Numix, and retro themes. Then, at the top of the main window, there’s an option called **Theme Style** , that lets you set the overall visual style of the theme. You can choose from between Numix, Arc, and Materia.
+
+With certain styles like Numix, you can even change things like the Header Gradient, Outline Width and Panel Opacity. You can also add a Dark Mode for your theme that will be automatically created from the default theme.
+
+
+
+**Iconset Customization**
+
+You can customize the iconset that will be used for the theme icons. There are 2 options – Gnome Colors and Archdroid. You an change the base, and stroke colours of the iconset.
+
+**Terminal Customization**
+
+You can also customize the terminal colours. The app has several presets for this, but you can customize the exact colour code for each colour value like red, green,black, and so on. You can also auto swap the foreground and background colours.
+
+**Spotify Theme**
+
+A unique feature this app has is that you can theme the spotify app to your liking. You can change the foreground, background, and accent color of the spotify app to match the overall GTK theme.
+
+Then, just press the **Apply Spotify Theme** button, and you’ll get this window:
+
+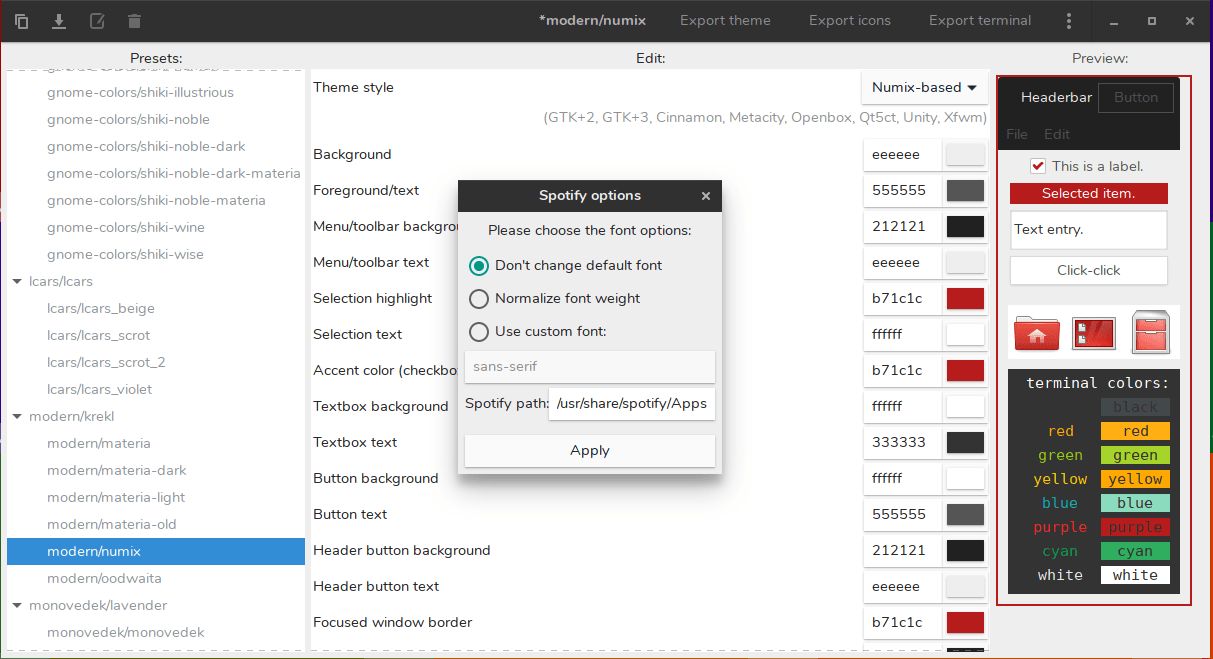
+
+Just hit apply, and you’re done.
+
+**Exporting your Theme**
+
+Once you’re done customizing the theme to your liking, you can rename it by clicking the rename button at the top left:
+
+
+
+And then, just hit **Export Theme** to export the theme to your system.
+
+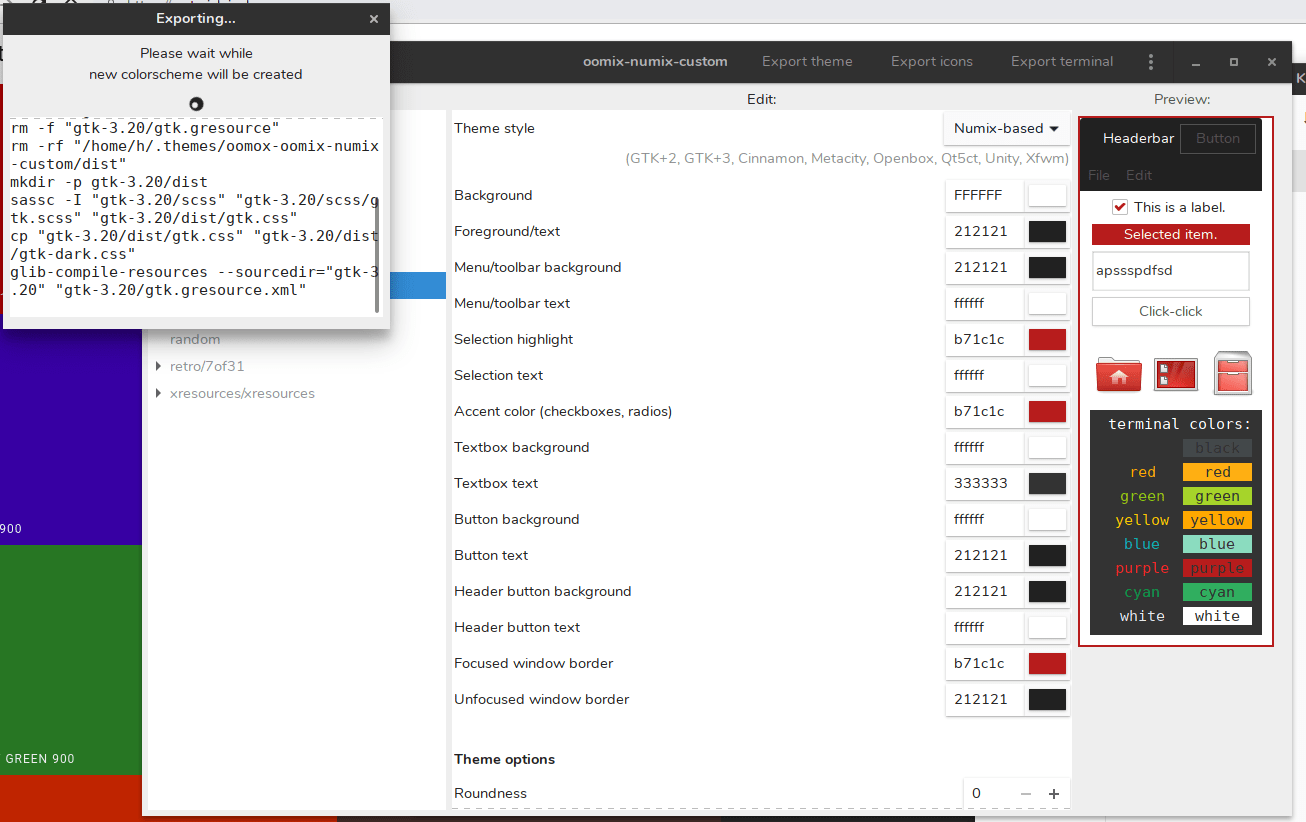
+
+You can also just export just the Iconset or the terminal theme.
+
+After this, you can open any Visual Customization app for your Desktop Environment, like Tweaks for Gnome based DEs, or the **XFCE Appearance Settings** , and select your exported GTK and Shell theme.
+
+### Verdict
+
+If you are a Linux theme junkie, and you know exactly how each button, how each header in your system should look like, Oomox is worth a look. For extreme customizers, it lets you change virtually everything about how your system looks. For people who just want to tweak an existing theme a little bit, it has many, many presets so you can get what you want without a lot of effort.
+
+Have you tried it? What are your thoughts on Oomox? Put them in the comments below!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/
+
+作者:[EDITOR][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/editor/
+[1]: https://aur.archlinux.org/packages/oomox/
+[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
+[3]: https://github.com/themix-project/oomox/releases
+[4]: https://flathub.org/apps/details/com.github.themix_project.Oomox
+[5]: https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
diff --git a/sources/tech/20181003 Tips for listing files with ls at the Linux command line.md b/sources/tech/20181003 Tips for listing files with ls at the Linux command line.md
new file mode 100644
index 0000000000..fda48f1622
--- /dev/null
+++ b/sources/tech/20181003 Tips for listing files with ls at the Linux command line.md
@@ -0,0 +1,75 @@
+translating---geekpi
+
+Tips for listing files with ls at the Linux command line
+======
+Learn some of the Linux 'ls' command's most useful variations.
+
+
+One of the first commands I learned in Linux was `ls`. Knowing what’s in a directory where a file on your system resides is important. Being able to see and modify not just some but all of the files is also important.
+
+My first LInux cheat sheet was the [One Page Linux Manual][1] , which was released in1999 and became my go-to reference. I taped it over my desk and referred to it often as I began to explore Linux. Listing files with `ls -l` is introduced on the first page, at the bottom of the first column.
+
+Later, I would learn other iterations of this most basic command. Through the `ls` command, I began to learn about the complexity of the Linux file permissions and what was mine and what required root or sudo permission to change. I became very comfortable on the command line over time, and while I still use `ls -l` to find files in the directory, I frequently use `ls -al` so I can see hidden files that might need to be changed, like configuration files.
+
+According to an article by Eric Fischer about the `ls` command in the [Linux Documentation Project][2], the command's roots go back to the `listf` command on MIT’s Compatible Time Sharing System in 1961. When CTSS was replaced by [Multics][3], the command became `list`, with switches like `list -all`. According to [Wikipedia][4], `ls` appeared in the original version of AT&T Unix. The `ls` command we use today on Linux systems comes from the [GNU Core Utilities][5].
+
+Most of the time, I use only a couple of iterations of the command. Looking inside a directory with `ls` or `ls -al` is how I generally use the command, but there are many other options that you should be familiar with.
+
+`$ ls -l` provides a simple list of the directory:
+
+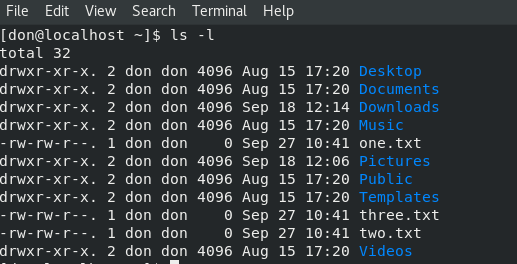
+
+Using the man pages of my Fedora 28 system, I find that there are many other options to `ls`, all of which provide interesting and useful information about the Linux file system. By entering `man ls` at the command prompt, we can begin to explore some of the other options:
+
+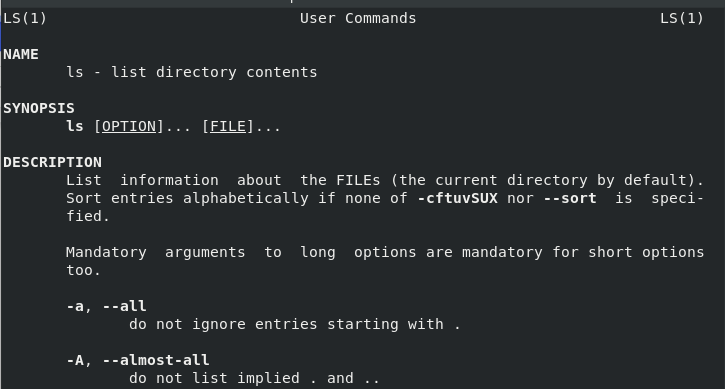
+
+To sort the directory by file sizes, use `ls -lS`:
+
+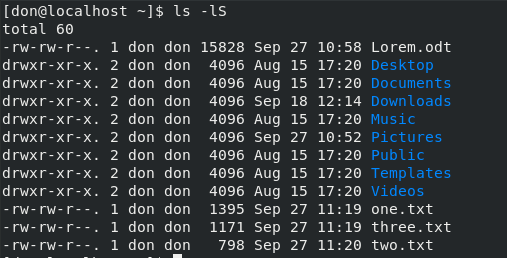
+
+To list the contents in reverse order, use `ls -lr`:
+
+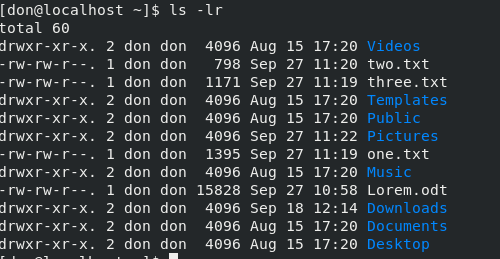
+
+To list contents by columns, use `ls -c`:
+
+
+
+`ls -al` provides a list of all the files in the same directory:
+
+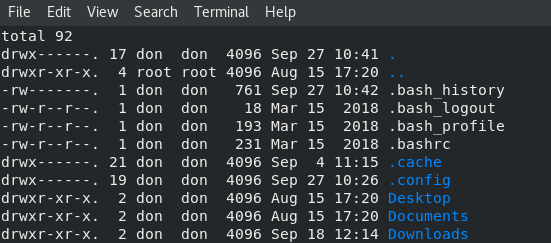
+
+Here are some additional options that I find useful and interesting:
+
+ * List only the .txt files in the directory: `ls *.txt`
+ * List by file size: `ls -s`
+ * Sort by time and date: `ls -d`
+ * Sort by extension: `ls -X`
+ * Sort by file size: `ls -S`
+ * Long format with file size: `ls -ls`
+ * List only the .txt files in a directory: `ls *.txt`
+
+
+
+To generate a directory list in the specified format and send it to a file for later viewing, enter `ls -al > mydirectorylist`. Finally, one of the more exotic commands I found is `ls -R`, which provides a recursive list of all the directories on your computer and their contents.
+
+For a complete list of the all the iterations of the `ls` command, refer to the [GNU Core Utilities][6].
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/10/ls-command
+
+作者:[Don Watkins][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[1]: http://hackerspace.cs.rutgers.edu/library/General/One_Page_Linux_Manual.pdf
+[2]: http://www.tldp.org/LDP/LG/issue48/fischer.html
+[3]: https://en.wikipedia.org/wiki/Multics
+[4]: https://en.wikipedia.org/wiki/Ls
+[5]: http://www.gnu.org/s/coreutils/
+[6]: https://www.gnu.org/software/coreutils/manual/html_node/ls-invocation.html#ls-invocation
diff --git a/sources/tech/20181004 Archiving web sites.md b/sources/tech/20181004 Archiving web sites.md
new file mode 100644
index 0000000000..558c057913
--- /dev/null
+++ b/sources/tech/20181004 Archiving web sites.md
@@ -0,0 +1,119 @@
+Archiving web sites
+======
+
+I recently took a deep dive into web site archival for friends who were worried about losing control over the hosting of their work online in the face of poor system administration or hostile removal. This makes web site archival an essential instrument in the toolbox of any system administrator. As it turns out, some sites are much harder to archive than others. This article goes through the process of archiving traditional web sites and shows how it falls short when confronted with the latest fashions in the single-page applications that are bloating the modern web.
+
+### Converting simple sites
+
+The days of handcrafted HTML web sites are long gone. Now web sites are dynamic and built on the fly using the latest JavaScript, PHP, or Python framework. As a result, the sites are more fragile: a database crash, spurious upgrade, or unpatched vulnerability might lose data. In my previous life as web developer, I had to come to terms with the idea that customers expect web sites to basically work forever. This expectation matches poorly with "move fast and break things" attitude of web development. Working with the [Drupal][2] content-management system (CMS) was particularly challenging in that regard as major upgrades deliberately break compatibility with third-party modules, which implies a costly upgrade process that clients could seldom afford. The solution was to archive those sites: take a living, dynamic web site and turn it into plain HTML files that any web server can serve forever. This process is useful for your own dynamic sites but also for third-party sites that are outside of your control and you might want to safeguard.
+
+For simple or static sites, the venerable [Wget][3] program works well. The incantation to mirror a full web site, however, is byzantine:
+
+```
+ $ nice wget --mirror --execute robots=off --no-verbose --convert-links \
+ --backup-converted --page-requisites --adjust-extension \
+ --base=./ --directory-prefix=./ --span-hosts \
+ --domains=www.example.com,example.com http://www.example.com/
+
+```
+
+The above downloads the content of the web page, but also crawls everything within the specified domains. Before you run this against your favorite site, consider the impact such a crawl might have on the site. The above command line deliberately ignores [`robots.txt`][] rules, as is now [common practice for archivists][4], and hammer the website as fast as it can. Most crawlers have options to pause between hits and limit bandwidth usage to avoid overwhelming the target site.
+
+The above command will also fetch "page requisites" like style sheets (CSS), images, and scripts. The downloaded page contents are modified so that links point to the local copy as well. Any web server can host the resulting file set, which results in a static copy of the original web site.
+
+That is, when things go well. Anyone who has ever worked with a computer knows that things seldom go according to plan; all sorts of things can make the procedure derail in interesting ways. For example, it was trendy for a while to have calendar blocks in web sites. A CMS would generate those on the fly and make crawlers go into an infinite loop trying to retrieve all of the pages. Crafty archivers can resort to regular expressions (e.g. Wget has a `--reject-regex` option) to ignore problematic resources. Another option, if the administration interface for the web site is accessible, is to disable calendars, login forms, comment forms, and other dynamic areas. Once the site becomes static, those will stop working anyway, so it makes sense to remove such clutter from the original site as well.
+
+### JavaScript doom
+
+Unfortunately, some web sites are built with much more than pure HTML. In single-page sites, for example, the web browser builds the content itself by executing a small JavaScript program. A simple user agent like Wget will struggle to reconstruct a meaningful static copy of those sites as it does not support JavaScript at all. In theory, web sites should be using [progressive enhancement][5] to have content and functionality available without JavaScript but those directives are rarely followed, as anyone using plugins like [NoScript][6] or [uMatrix][7] will confirm.
+
+Traditional archival methods sometimes fail in the dumbest way. When trying to build an offsite backup of a local newspaper ([pamplemousse.ca][8]), I found that WordPress adds query strings (e.g. `?ver=1.12.4`) at the end of JavaScript includes. This confuses content-type detection in the web servers that serve the archive, which rely on the file extension to send the right `Content-Type` header. When such an archive is loaded in a web browser, it fails to load scripts, which breaks dynamic websites.
+
+As the web moves toward using the browser as a virtual machine to run arbitrary code, archival methods relying on pure HTML parsing need to adapt. The solution for such problems is to record (and replay) the HTTP headers delivered by the server during the crawl and indeed professional archivists use just such an approach.
+
+### Creating and displaying WARC files
+
+At the [Internet Archive][9], Brewster Kahle and Mike Burner designed the [ARC][10] (for "ARChive") file format in 1996 to provide a way to aggregate the millions of small files produced by their archival efforts. The format was eventually standardized as the WARC ("Web ARChive") [specification][11] that was released as an ISO standard in 2009 and revised in 2017. The standardization effort was led by the [International Internet Preservation Consortium][12] (IIPC), which is an "international organization of libraries and other organizations established to coordinate efforts to preserve internet content for the future", according to Wikipedia; it includes members such as the US Library of Congress and the Internet Archive. The latter uses the WARC format internally in its Java-based [Heritrix crawler][13].
+
+A WARC file aggregates multiple resources like HTTP headers, file contents, and other metadata in a single compressed archive. Conveniently, Wget actually supports the file format with the `--warc` parameter. Unfortunately, web browsers cannot render WARC files directly, so a viewer or some conversion is necessary to access the archive. The simplest such viewer I have found is [pywb][14], a Python package that runs a simple webserver to offer a Wayback-Machine-like interface to browse the contents of WARC files. The following set of commands will render a WARC file on `http://localhost:8080/`:
+
+```
+ $ pip install pywb
+ $ wb-manager init example
+ $ wb-manager add example crawl.warc.gz
+ $ wayback
+
+```
+
+This tool was, incidentally, built by the folks behind the [Webrecorder][15] service, which can use a web browser to save dynamic page contents.
+
+Unfortunately, pywb has trouble loading WARC files generated by Wget because it [followed][16] an [inconsistency in the 1.0 specification][17], which was [fixed in the 1.1 specification][18]. Until Wget or pywb fix those problems, WARC files produced by Wget are not reliable enough for my uses, so I have looked at other alternatives. A crawler that got my attention is simply called [crawl][19]. Here is how it is invoked:
+
+```
+ $ crawl https://example.com/
+
+```
+
+(It does say "very simple" in the README.) The program does support some command-line options, but most of its defaults are sane: it will fetch page requirements from other domains (unless the `-exclude-related` flag is used), but does not recurse out of the domain. By default, it fires up ten parallel connections to the remote site, a setting that can be changed with the `-c` flag. But, best of all, the resulting WARC files load perfectly in pywb.
+
+### Future work and alternatives
+
+There are plenty more [resources][20] for using WARC files. In particular, there's a Wget drop-in replacement called [Wpull][21] that is specifically designed for archiving web sites. It has experimental support for [PhantomJS][22] and [youtube-dl][23] integration that should allow downloading more complex JavaScript sites and streaming multimedia, respectively. The software is the basis for an elaborate archival tool called [ArchiveBot][24], which is used by the "loose collective of rogue archivists, programmers, writers and loudmouths" at [ArchiveTeam][25] in its struggle to "save the history before it's lost forever". It seems that PhantomJS integration does not work as well as the team wants, so ArchiveTeam also uses a rag-tag bunch of other tools to mirror more complex sites. For example, [snscrape][26] will crawl a social media profile to generate a list of pages to send into ArchiveBot. Another tool the team employs is [crocoite][27], which uses the Chrome browser in headless mode to archive JavaScript-heavy sites.
+
+This article would also not be complete without a nod to the [HTTrack][28] project, the "website copier". Working similarly to Wget, HTTrack creates local copies of remote web sites but unfortunately does not support WARC output. Its interactive aspects might be of more interest to novice users unfamiliar with the command line.
+
+In the same vein, during my research I found a full rewrite of Wget called [Wget2][29] that has support for multi-threaded operation, which might make it faster than its predecessor. It is [missing some features][30] from Wget, however, most notably reject patterns, WARC output, and FTP support but adds RSS, DNS caching, and improved TLS support.
+
+Finally, my personal dream for these kinds of tools would be to have them integrated with my existing bookmark system. I currently keep interesting links in [Wallabag][31], a self-hosted "read it later" service designed as a free-software alternative to [Pocket][32] (now owned by Mozilla). But Wallabag, by design, creates only a "readable" version of the article instead of a full copy. In some cases, the "readable version" is actually [unreadable][33] and Wallabag sometimes [fails to parse the article][34]. Instead, other tools like [bookmark-archiver][35] or [reminiscence][36] save a screenshot of the page along with full HTML but, unfortunately, no WARC file that would allow an even more faithful replay.
+
+The sad truth of my experiences with mirrors and archival is that data dies. Fortunately, amateur archivists have tools at their disposal to keep interesting content alive online. For those who do not want to go through that trouble, the Internet Archive seems to be here to stay and Archive Team is obviously [working on a backup of the Internet Archive itself][37].
+
+--------------------------------------------------------------------------------
+
+via: https://anarc.at/blog/2018-10-04-archiving-web-sites/
+
+作者:[Anarcat][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://anarc.at
+[1]: https://anarc.at/blog
+[2]: https://drupal.org
+[3]: https://www.gnu.org/software/wget/
+[4]: https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/
+[5]: https://en.wikipedia.org/wiki/Progressive_enhancement
+[6]: https://noscript.net/
+[7]: https://github.com/gorhill/uMatrix
+[8]: https://pamplemousse.ca/
+[9]: https://archive.org
+[10]: http://www.archive.org/web/researcher/ArcFileFormat.php
+[11]: https://iipc.github.io/warc-specifications/
+[12]: https://en.wikipedia.org/wiki/International_Internet_Preservation_Consortium
+[13]: https://github.com/internetarchive/heritrix3/wiki
+[14]: https://github.com/webrecorder/pywb
+[15]: https://webrecorder.io/
+[16]: https://github.com/webrecorder/pywb/issues/294
+[17]: https://github.com/iipc/warc-specifications/issues/23
+[18]: https://github.com/iipc/warc-specifications/pull/24
+[19]: https://git.autistici.org/ale/crawl/
+[20]: https://archiveteam.org/index.php?title=The_WARC_Ecosystem
+[21]: https://github.com/chfoo/wpull
+[22]: http://phantomjs.org/
+[23]: http://rg3.github.io/youtube-dl/
+[24]: https://www.archiveteam.org/index.php?title=ArchiveBot
+[25]: https://archiveteam.org/
+[26]: https://github.com/JustAnotherArchivist/snscrape
+[27]: https://github.com/PromyLOPh/crocoite
+[28]: http://www.httrack.com/
+[29]: https://gitlab.com/gnuwget/wget2
+[30]: https://gitlab.com/gnuwget/wget2/wikis/home
+[31]: https://wallabag.org/
+[32]: https://getpocket.com/
+[33]: https://github.com/wallabag/wallabag/issues/2825
+[34]: https://github.com/wallabag/wallabag/issues/2914
+[35]: https://pirate.github.io/bookmark-archiver/
+[36]: https://github.com/kanishka-linux/reminiscence
+[37]: http://iabak.archiveteam.org
diff --git a/sources/tech/20181004 Functional programming in Python- Immutable data structures.md b/sources/tech/20181004 Functional programming in Python- Immutable data structures.md
new file mode 100644
index 0000000000..e6050d52f9
--- /dev/null
+++ b/sources/tech/20181004 Functional programming in Python- Immutable data structures.md
@@ -0,0 +1,191 @@
+Translating by Ryze-Borgia
+Functional programming in Python: Immutable data structures
+======
+Immutability can help us better understand our code. Here's how to achieve it without sacrificing performance.
+
+
+
+In this two-part series, I will discuss how to import ideas from the functional programming methodology into Python in order to have the best of both worlds.
+
+This first post will explore how immutable data structures can help. The second part will explore higher-level functional programming concepts in Python using the **toolz** library.
+
+Why functional programming? Because mutation is hard to reason about. If you are already convinced that mutation is problematic, great. If you're not convinced, you will be by the end of this post.
+
+Let's begin by considering squares and rectangles. If we think in terms of interfaces, neglecting implementation details, are squares a subtype of rectangles?
+
+The definition of a subtype rests on the [Liskov substitution principle][1]. In order to be a subtype, it must be able to do everything the supertype does.
+
+How would we define an interface for a rectangle?
+
+```
+from zope.interface import Interface
+
+class IRectangle(Interface):
+ def get_length(self):
+ """Squares can do that"""
+ def get_width(self):
+ """Squares can do that"""
+ def set_dimensions(self, length, width):
+ """Uh oh"""
+```
+
+If this is the definition, then squares cannot be a subtype of rectangles; they cannot respond to a `set_dimensions` method if the length and width are different.
+
+A different approach is to choose to make rectangles immutable.
+
+```
+class IRectangle(Interface):
+ def get_length(self):
+ """Squares can do that"""
+ def get_width(self):
+ """Squares can do that"""
+ def with_dimensions(self, length, width):
+ """Returns a new rectangle"""
+```
+
+Now, a square can be a rectangle. It can return a new rectangle (which would not usually be a square) when `with_dimensions` is called, but it would not stop being a square.
+
+This might seem like an academic problem—until we consider that squares and rectangles are, in a sense, a container for their sides. After we understand this example, the more realistic case this comes into play with is more traditional containers. For example, consider random-access arrays.
+
+We have `ISquare` and `IRectangle`, and `ISquare` is a subtype of `IRectangle`.
+
+We want to put rectangles in a random-access array:
+
+```
+class IArrayOfRectangles(Interface):
+ def get_element(self, i):
+ """Returns Rectangle"""
+ def set_element(self, i, rectangle):
+ """'rectangle' can be any IRectangle"""
+```
+
+We want to put squares in a random-access array too:
+
+```
+class IArrayOfSquare(Interface):
+ def get_element(self, i):
+ """Returns Square"""
+ def set_element(self, i, square):
+ """'square' can be any ISquare"""
+```
+
+Even though `ISquare` is a subtype of `IRectangle`, no array can implement both `IArrayOfSquare` and `IArrayOfRectangle`.
+
+Why not? Assume `bucket` implements both.
+
+```
+>>> rectangle = make_rectangle(3, 4)
+>>> bucket.set_element(0, rectangle) # This is allowed by IArrayOfRectangle
+>>> thing = bucket.get_element(0) # That has to be a square by IArrayOfSquare
+>>> assert thing.height == thing.width
+Traceback (most recent call last):
+ File "", line 1, in
+AssertionError
+```
+
+Being unable to implement both means that neither is a subtype of the other, even though `ISquare` is a subtype of `IRectangle`. The problem is the `set_element` method: If we had a read-only array, `IArrayOfSquare` would be a subtype of `IArrayOfRectangle`.
+
+Mutability, in both the mutable `IRectangle` interface and the mutable `IArrayOf*` interfaces, has made thinking about types and subtypes much more difficult—and giving up on the ability to mutate meant that the intuitive relationships we expected to have between the types actually hold.
+
+Mutation can also have non-local effects. This happens when a shared object between two places is mutated by one. The classic example is one thread mutating a shared object with another thread, but even in a single-threaded program, sharing between places that are far apart is easy. Consider that in Python, most objects are reachable from many places: as a module global, or in a stack trace, or as a class attribute.
+
+If we cannot constrain the sharing, we might think about constraining the mutability.
+
+Here is an immutable rectangle, taking advantage of the [attrs][2] library:
+
+```
+@attr.s(frozen=True)
+class Rectange(object):
+ length = attr.ib()
+ width = attr.ib()
+ @classmethod
+ def with_dimensions(cls, length, width):
+ return cls(length, width)
+```
+
+Here is a square:
+
+```
+@attr.s(frozen=True)
+class Square(object):
+ side = attr.ib()
+ @classmethod
+ def with_dimensions(cls, length, width):
+ return Rectangle(length, width)
+```
+
+Using the `frozen` argument, we can easily have `attrs`-created classes be immutable. All the hard work of writing `__setitem__` correctly has been done by others and is completely invisible to us.
+
+It is still easy to modify objects; it's just nigh impossible to mutate them.
+
+```
+too_long = Rectangle(100, 4)
+reasonable = attr.evolve(too_long, length=10)
+```
+
+The [Pyrsistent][3] package allows us to have immutable containers.
+
+```
+# Vector of integers
+a = pyrsistent.v(1, 2, 3)
+# Not a vector of integers
+b = a.set(1, "hello")
+```
+
+While `b` is not a vector of integers, nothing will ever stop `a` from being one.
+
+What if `a` was a million elements long? Is `b` going to copy 999,999 of them? Pyrsistent comes with "big O" performance guarantees: All operations take `O(log n)` time. It also comes with an optional C extension to improve performance beyond the big O.
+
+For modifying nested objects, it comes with a concept of "transformers:"
+
+```
+blog = pyrsistent.m(
+ title="My blog",
+ links=pyrsistent.v("github", "twitter"),
+ posts=pyrsistent.v(
+ pyrsistent.m(title="no updates",
+ content="I'm busy"),
+ pyrsistent.m(title="still no updates",
+ content="still busy")))
+new_blog = blog.transform(["posts", 1, "content"],
+ "pretty busy")
+```
+
+`new_blog` will now be the immutable equivalent of
+
+```
+{'links': ['github', 'twitter'],
+ 'posts': [{'content': "I'm busy",
+ 'title': 'no updates'},
+ {'content': 'pretty busy',
+ 'title': 'still no updates'}],
+ 'title': 'My blog'}
+```
+
+But `blog` is still the same. This means anyone who had a reference to the old object has not been affected: The transformation had only local effects.
+
+This is useful when sharing is rampant. For example, consider default arguments:
+
+```
+def silly_sum(a, b, extra=v(1, 2)):
+ extra = extra.extend([a, b])
+ return sum(extra)
+```
+
+In this post, we have learned why immutability can be useful for thinking about our code, and how to achieve it without an extravagant performance price. Next time, we will learn how immutable objects allow us to use powerful programming constructs.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshez
+[1]: https://en.wikipedia.org/wiki/Liskov_substitution_principle
+[2]: https://www.attrs.org/en/stable/
+[3]: https://pyrsistent.readthedocs.io/en/latest/
diff --git a/sources/tech/20181004 Lab 3- User Environments.md b/sources/tech/20181004 Lab 3- User Environments.md
new file mode 100644
index 0000000000..2dc1522b69
--- /dev/null
+++ b/sources/tech/20181004 Lab 3- User Environments.md
@@ -0,0 +1,524 @@
+Lab 3: User Environments
+======
+### Lab 3: User Environments
+
+#### Introduction
+
+In this lab you will implement the basic kernel facilities required to get a protected user-mode environment (i.e., "process") running. You will enhance the JOS kernel to set up the data structures to keep track of user environments, create a single user environment, load a program image into it, and start it running. You will also make the JOS kernel capable of handling any system calls the user environment makes and handling any other exceptions it causes.
+
+**Note:** In this lab, the terms _environment_ and _process_ are interchangeable - both refer to an abstraction that allows you to run a program. We introduce the term "environment" instead of the traditional term "process" in order to stress the point that JOS environments and UNIX processes provide different interfaces, and do not provide the same semantics.
+
+##### Getting Started
+
+Use Git to commit your changes after your Lab 2 submission (if any), fetch the latest version of the course repository, and then create a local branch called `lab3` based on our lab3 branch, `origin/lab3`:
+
+```
+ athena% cd ~/6.828/lab
+ athena% add git
+ athena% git commit -am 'changes to lab2 after handin'
+ Created commit 734fab7: changes to lab2 after handin
+ 4 files changed, 42 insertions(+), 9 deletions(-)
+ athena% git pull
+ Already up-to-date.
+ athena% git checkout -b lab3 origin/lab3
+ Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
+ Switched to a new branch "lab3"
+ athena% git merge lab2
+ Merge made by recursive.
+ kern/pmap.c | 42 +++++++++++++++++++
+ 1 files changed, 42 insertions(+), 0 deletions(-)
+ athena%
+```
+
+Lab 3 contains a number of new source files, which you should browse:
+
+```
+inc/ env.h Public definitions for user-mode environments
+ trap.h Public definitions for trap handling
+ syscall.h Public definitions for system calls from user environments to the kernel
+ lib.h Public definitions for the user-mode support library
+kern/ env.h Kernel-private definitions for user-mode environments
+ env.c Kernel code implementing user-mode environments
+ trap.h Kernel-private trap handling definitions
+ trap.c Trap handling code
+ trapentry.S Assembly-language trap handler entry-points
+ syscall.h Kernel-private definitions for system call handling
+ syscall.c System call implementation code
+lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
+ entry.S Assembly-language entry-point for user environments
+ libmain.c User-mode library setup code called from entry.S
+ syscall.c User-mode system call stub functions
+ console.c User-mode implementations of putchar and getchar, providing console I/O
+ exit.c User-mode implementation of exit
+ panic.c User-mode implementation of panic
+user/ * Various test programs to check kernel lab 3 code
+```
+
+In addition, a number of the source files we handed out for lab2 are modified in lab3. To see the differences, you can type:
+
+```
+ $ git diff lab2
+
+```
+
+You may also want to take another look at the [lab tools guide][1], as it includes information on debugging user code that becomes relevant in this lab.
+
+##### Lab Requirements
+
+This lab is divided into two parts, A and B. Part A is due a week after this lab was assigned; you should commit your changes and make handin your lab before the Part A deadline, making sure your code passes all of the Part A tests (it is okay if your code does not pass the Part B tests yet). You only need to have the Part B tests passing by the Part B deadline at the end of the second week.
+
+As in lab 2, you will need to do all of the regular exercises described in the lab and _at least one_ challenge problem (for the entire lab, not for each part). Write up brief answers to the questions posed in the lab and a one or two paragraph description of what you did to solve your chosen challenge problem in a file called `answers-lab3.txt` in the top level of your `lab` directory. (If you implement more than one challenge problem, you only need to describe one of them in the write-up.) Do not forget to include the answer file in your submission with git add answers-lab3.txt.
+
+##### Inline Assembly
+
+In this lab you may find GCC's inline assembly language feature useful, although it is also possible to complete the lab without using it. At the very least, you will need to be able to understand the fragments of inline assembly language ("`asm`" statements) that already exist in the source code we gave you. You can find several sources of information on GCC inline assembly language on the class [reference materials][2] page.
+
+#### Part A: User Environments and Exception Handling
+
+The new include file `inc/env.h` contains basic definitions for user environments in JOS. Read it now. The kernel uses the `Env` data structure to keep track of each user environment. In this lab you will initially create just one environment, but you will need to design the JOS kernel to support multiple environments; lab 4 will take advantage of this feature by allowing a user environment to `fork` other environments.
+
+As you can see in `kern/env.c`, the kernel maintains three main global variables pertaining to environments:
+
+```
+ struct Env *envs = NULL; // All environments
+ struct Env *curenv = NULL; // The current env
+ static struct Env *env_free_list; // Free environment list
+
+```
+
+Once JOS gets up and running, the `envs` pointer points to an array of `Env` structures representing all the environments in the system. In our design, the JOS kernel will support a maximum of `NENV` simultaneously active environments, although there will typically be far fewer running environments at any given time. (`NENV` is a constant `#define`'d in `inc/env.h`.) Once it is allocated, the `envs` array will contain a single instance of the `Env` data structure for each of the `NENV` possible environments.
+
+The JOS kernel keeps all of the inactive `Env` structures on the `env_free_list`. This design allows easy allocation and deallocation of environments, as they merely have to be added to or removed from the free list.
+
+The kernel uses the `curenv` symbol to keep track of the _currently executing_ environment at any given time. During boot up, before the first environment is run, `curenv` is initially set to `NULL`.
+
+##### Environment State
+
+The `Env` structure is defined in `inc/env.h` as follows (although more fields will be added in future labs):
+
+```
+ struct Env {
+ struct Trapframe env_tf; // Saved registers
+ struct Env *env_link; // Next free Env
+ envid_t env_id; // Unique environment identifier
+ envid_t env_parent_id; // env_id of this env's parent
+ enum EnvType env_type; // Indicates special system environments
+ unsigned env_status; // Status of the environment
+ uint32_t env_runs; // Number of times environment has run
+
+ // Address space
+ pde_t *env_pgdir; // Kernel virtual address of page dir
+ };
+```
+
+Here's what the `Env` fields are for:
+
+ * **env_tf** :
+This structure, defined in `inc/trap.h`, holds the saved register values for the environment while that environment is _not_ running: i.e., when the kernel or a different environment is running. The kernel saves these when switching from user to kernel mode, so that the environment can later be resumed where it left off.
+ * **env_link** :
+This is a link to the next `Env` on the `env_free_list`. `env_free_list` points to the first free environment on the list.
+ * **env_id** :
+The kernel stores here a value that uniquely identifiers the environment currently using this `Env` structure (i.e., using this particular slot in the `envs` array). After a user environment terminates, the kernel may re-allocate the same `Env` structure to a different environment - but the new environment will have a different `env_id` from the old one even though the new environment is re-using the same slot in the `envs` array.
+ * **env_parent_id** :
+The kernel stores here the `env_id` of the environment that created this environment. In this way the environments can form a “family tree,” which will be useful for making security decisions about which environments are allowed to do what to whom.
+ * **env_type** :
+This is used to distinguish special environments. For most environments, it will be `ENV_TYPE_USER`. We'll introduce a few more types for special system service environments in later labs.
+ * **env_status** :
+This variable holds one of the following values:
+ * `ENV_FREE`:
+Indicates that the `Env` structure is inactive, and therefore on the `env_free_list`.
+ * `ENV_RUNNABLE`:
+Indicates that the `Env` structure represents an environment that is waiting to run on the processor.
+ * `ENV_RUNNING`:
+Indicates that the `Env` structure represents the currently running environment.
+ * `ENV_NOT_RUNNABLE`:
+Indicates that the `Env` structure represents a currently active environment, but it is not currently ready to run: for example, because it is waiting for an interprocess communication (IPC) from another environment.
+ * `ENV_DYING`:
+Indicates that the `Env` structure represents a zombie environment. A zombie environment will be freed the next time it traps to the kernel. We will not use this flag until Lab 4.
+ * **env_pgdir** :
+This variable holds the kernel _virtual address_ of this environment's page directory.
+
+
+
+Like a Unix process, a JOS environment couples the concepts of "thread" and "address space". The thread is defined primarily by the saved registers (the `env_tf` field), and the address space is defined by the page directory and page tables pointed to by `env_pgdir`. To run an environment, the kernel must set up the CPU with _both_ the saved registers and the appropriate address space.
+
+Our `struct Env` is analogous to `struct proc` in xv6. Both structures hold the environment's (i.e., process's) user-mode register state in a `Trapframe` structure. In JOS, individual environments do not have their own kernel stacks as processes do in xv6. There can be only one JOS environment active in the kernel at a time, so JOS needs only a _single_ kernel stack.
+
+##### Allocating the Environments Array
+
+In lab 2, you allocated memory in `mem_init()` for the `pages[]` array, which is a table the kernel uses to keep track of which pages are free and which are not. You will now need to modify `mem_init()` further to allocate a similar array of `Env` structures, called `envs`.
+
+```
+Exercise 1. Modify `mem_init()` in `kern/pmap.c` to allocate and map the `envs` array. This array consists of exactly `NENV` instances of the `Env` structure allocated much like how you allocated the `pages` array. Also like the `pages` array, the memory backing `envs` should also be mapped user read-only at `UENVS` (defined in `inc/memlayout.h`) so user processes can read from this array.
+```
+
+You should run your code and make sure `check_kern_pgdir()` succeeds.
+
+##### Creating and Running Environments
+
+You will now write the code in `kern/env.c` necessary to run a user environment. Because we do not yet have a filesystem, we will set up the kernel to load a static binary image that is _embedded within the kernel itself_. JOS embeds this binary in the kernel as a ELF executable image.
+
+The Lab 3 `GNUmakefile` generates a number of binary images in the `obj/user/` directory. If you look at `kern/Makefrag`, you will notice some magic that "links" these binaries directly into the kernel executable as if they were `.o` files. The `-b binary` option on the linker command line causes these files to be linked in as "raw" uninterpreted binary files rather than as regular `.o` files produced by the compiler. (As far as the linker is concerned, these files do not have to be ELF images at all - they could be anything, such as text files or pictures!) If you look at `obj/kern/kernel.sym` after building the kernel, you will notice that the linker has "magically" produced a number of funny symbols with obscure names like `_binary_obj_user_hello_start`, `_binary_obj_user_hello_end`, and `_binary_obj_user_hello_size`. The linker generates these symbol names by mangling the file names of the binary files; the symbols provide the regular kernel code with a way to reference the embedded binary files.
+
+In `i386_init()` in `kern/init.c` you'll see code to run one of these binary images in an environment. However, the critical functions to set up user environments are not complete; you will need to fill them in.
+
+```
+Exercise 2. In the file `env.c`, finish coding the following functions:
+
+ * `env_init()`
+Initialize all of the `Env` structures in the `envs` array and add them to the `env_free_list`. Also calls `env_init_percpu`, which configures the segmentation hardware with separate segments for privilege level 0 (kernel) and privilege level 3 (user).
+ * `env_setup_vm()`
+Allocate a page directory for a new environment and initialize the kernel portion of the new environment's address space.
+ * `region_alloc()`
+Allocates and maps physical memory for an environment
+ * `load_icode()`
+You will need to parse an ELF binary image, much like the boot loader already does, and load its contents into the user address space of a new environment.
+ * `env_create()`
+Allocate an environment with `env_alloc` and call `load_icode` to load an ELF binary into it.
+ * `env_run()`
+Start a given environment running in user mode.
+
+
+
+As you write these functions, you might find the new cprintf verb `%e` useful -- it prints a description corresponding to an error code. For example,
+
+ r = -E_NO_MEM;
+ panic("env_alloc: %e", r);
+
+will panic with the message "env_alloc: out of memory".
+```
+
+Below is a call graph of the code up to the point where the user code is invoked. Make sure you understand the purpose of each step.
+
+ * `start` (`kern/entry.S`)
+ * `i386_init` (`kern/init.c`)
+ * `cons_init`
+ * `mem_init`
+ * `env_init`
+ * `trap_init` (still incomplete at this point)
+ * `env_create`
+ * `env_run`
+ * `env_pop_tf`
+
+
+
+Once you are done you should compile your kernel and run it under QEMU. If all goes well, your system should enter user space and execute the `hello` binary until it makes a system call with the `int` instruction. At that point there will be trouble, since JOS has not set up the hardware to allow any kind of transition from user space into the kernel. When the CPU discovers that it is not set up to handle this system call interrupt, it will generate a general protection exception, find that it can't handle that, generate a double fault exception, find that it can't handle that either, and finally give up with what's known as a "triple fault". Usually, you would then see the CPU reset and the system reboot. While this is important for legacy applications (see [this blog post][3] for an explanation of why), it's a pain for kernel development, so with the 6.828 patched QEMU you'll instead see a register dump and a "Triple fault." message.
+
+We'll address this problem shortly, but for now we can use the debugger to check that we're entering user mode. Use make qemu-gdb and set a GDB breakpoint at `env_pop_tf`, which should be the last function you hit before actually entering user mode. Single step through this function using si; the processor should enter user mode after the `iret` instruction. You should then see the first instruction in the user environment's executable, which is the `cmpl` instruction at the label `start` in `lib/entry.S`. Now use b *0x... to set a breakpoint at the `int $0x30` in `sys_cputs()` in `hello` (see `obj/user/hello.asm` for the user-space address). This `int` is the system call to display a character to the console. If you cannot execute as far as the `int`, then something is wrong with your address space setup or program loading code; go back and fix it before continuing.
+
+##### Handling Interrupts and Exceptions
+
+At this point, the first `int $0x30` system call instruction in user space is a dead end: once the processor gets into user mode, there is no way to get back out. You will now need to implement basic exception and system call handling, so that it is possible for the kernel to recover control of the processor from user-mode code. The first thing you should do is thoroughly familiarize yourself with the x86 interrupt and exception mechanism.
+
+```
+Exercise 3. Read Chapter 9, Exceptions and Interrupts in the 80386 Programmer's Manual (or Chapter 5 of the IA-32 Developer's Manual), if you haven't already.
+```
+
+In this lab we generally follow Intel's terminology for interrupts, exceptions, and the like. However, terms such as exception, trap, interrupt, fault and abort have no standard meaning across architectures or operating systems, and are often used without regard to the subtle distinctions between them on a particular architecture such as the x86. When you see these terms outside of this lab, the meanings might be slightly different.
+
+##### Basics of Protected Control Transfer
+
+Exceptions and interrupts are both "protected control transfers," which cause the processor to switch from user to kernel mode (CPL=0) without giving the user-mode code any opportunity to interfere with the functioning of the kernel or other environments. In Intel's terminology, an _interrupt_ is a protected control transfer that is caused by an asynchronous event usually external to the processor, such as notification of external device I/O activity. An _exception_ , in contrast, is a protected control transfer caused synchronously by the currently running code, for example due to a divide by zero or an invalid memory access.
+
+In order to ensure that these protected control transfers are actually _protected_ , the processor's interrupt/exception mechanism is designed so that the code currently running when the interrupt or exception occurs _does not get to choose arbitrarily where the kernel is entered or how_. Instead, the processor ensures that the kernel can be entered only under carefully controlled conditions. On the x86, two mechanisms work together to provide this protection:
+
+ 1. **The Interrupt Descriptor Table.** The processor ensures that interrupts and exceptions can only cause the kernel to be entered at a few specific, well-defined entry-points _determined by the kernel itself_ , and not by the code running when the interrupt or exception is taken.
+
+The x86 allows up to 256 different interrupt or exception entry points into the kernel, each with a different _interrupt vector_. A vector is a number between 0 and 255. An interrupt's vector is determined by the source of the interrupt: different devices, error conditions, and application requests to the kernel generate interrupts with different vectors. The CPU uses the vector as an index into the processor's _interrupt descriptor table_ (IDT), which the kernel sets up in kernel-private memory, much like the GDT. From the appropriate entry in this table the processor loads:
+
+ * the value to load into the instruction pointer (`EIP`) register, pointing to the kernel code designated to handle that type of exception.
+ * the value to load into the code segment (`CS`) register, which includes in bits 0-1 the privilege level at which the exception handler is to run. (In JOS, all exceptions are handled in kernel mode, privilege level 0.)
+ 2. **The Task State Segment.** The processor needs a place to save the _old_ processor state before the interrupt or exception occurred, such as the original values of `EIP` and `CS` before the processor invoked the exception handler, so that the exception handler can later restore that old state and resume the interrupted code from where it left off. But this save area for the old processor state must in turn be protected from unprivileged user-mode code; otherwise buggy or malicious user code could compromise the kernel.
+
+For this reason, when an x86 processor takes an interrupt or trap that causes a privilege level change from user to kernel mode, it also switches to a stack in the kernel's memory. A structure called the _task state segment_ (TSS) specifies the segment selector and address where this stack lives. The processor pushes (on this new stack) `SS`, `ESP`, `EFLAGS`, `CS`, `EIP`, and an optional error code. Then it loads the `CS` and `EIP` from the interrupt descriptor, and sets the `ESP` and `SS` to refer to the new stack.
+
+Although the TSS is large and can potentially serve a variety of purposes, JOS only uses it to define the kernel stack that the processor should switch to when it transfers from user to kernel mode. Since "kernel mode" in JOS is privilege level 0 on the x86, the processor uses the `ESP0` and `SS0` fields of the TSS to define the kernel stack when entering kernel mode. JOS doesn't use any other TSS fields.
+
+
+
+
+##### Types of Exceptions and Interrupts
+
+All of the synchronous exceptions that the x86 processor can generate internally use interrupt vectors between 0 and 31, and therefore map to IDT entries 0-31. For example, a page fault always causes an exception through vector 14. Interrupt vectors greater than 31 are only used by _software interrupts_ , which can be generated by the `int` instruction, or asynchronous _hardware interrupts_ , caused by external devices when they need attention.
+
+In this section we will extend JOS to handle the internally generated x86 exceptions in vectors 0-31. In the next section we will make JOS handle software interrupt vector 48 (0x30), which JOS (fairly arbitrarily) uses as its system call interrupt vector. In Lab 4 we will extend JOS to handle externally generated hardware interrupts such as the clock interrupt.
+
+##### An Example
+
+Let's put these pieces together and trace through an example. Let's say the processor is executing code in a user environment and encounters a divide instruction that attempts to divide by zero.
+
+ 1. The processor switches to the stack defined by the `SS0` and `ESP0` fields of the TSS, which in JOS will hold the values `GD_KD` and `KSTACKTOP`, respectively.
+
+ 2. The processor pushes the exception parameters on the kernel stack, starting at address `KSTACKTOP`:
+
+```
+ +--------------------+ KSTACKTOP
+ | 0x00000 | old SS | " - 4
+ | old ESP | " - 8
+ | old EFLAGS | " - 12
+ | 0x00000 | old CS | " - 16
+ | old EIP | " - 20 <---- ESP
+ +--------------------+
+
+```
+
+ 3. Because we're handling a divide error, which is interrupt vector 0 on the x86, the processor reads IDT entry 0 and sets `CS:EIP` to point to the handler function described by the entry.
+
+ 4. The handler function takes control and handles the exception, for example by terminating the user environment.
+
+
+
+
+For certain types of x86 exceptions, in addition to the "standard" five words above, the processor pushes onto the stack another word containing an _error code_. The page fault exception, number 14, is an important example. See the 80386 manual to determine for which exception numbers the processor pushes an error code, and what the error code means in that case. When the processor pushes an error code, the stack would look as follows at the beginning of the exception handler when coming in from user mode:
+
+```
+ +--------------------+ KSTACKTOP
+ | 0x00000 | old SS | " - 4
+ | old ESP | " - 8
+ | old EFLAGS | " - 12
+ | 0x00000 | old CS | " - 16
+ | old EIP | " - 20
+ | error code | " - 24 <---- ESP
+ +--------------------+
+```
+
+##### Nested Exceptions and Interrupts
+
+The processor can take exceptions and interrupts both from kernel and user mode. It is only when entering the kernel from user mode, however, that the x86 processor automatically switches stacks before pushing its old register state onto the stack and invoking the appropriate exception handler through the IDT. If the processor is _already_ in kernel mode when the interrupt or exception occurs (the low 2 bits of the `CS` register are already zero), then the CPU just pushes more values on the same kernel stack. In this way, the kernel can gracefully handle _nested exceptions_ caused by code within the kernel itself. This capability is an important tool in implementing protection, as we will see later in the section on system calls.
+
+If the processor is already in kernel mode and takes a nested exception, since it does not need to switch stacks, it does not save the old `SS` or `ESP` registers. For exception types that do not push an error code, the kernel stack therefore looks like the following on entry to the exception handler:
+
+```
+ +--------------------+ <---- old ESP
+ | old EFLAGS | " - 4
+ | 0x00000 | old CS | " - 8
+ | old EIP | " - 12
+ +--------------------+
+```
+
+For exception types that push an error code, the processor pushes the error code immediately after the old `EIP`, as before.
+
+There is one important caveat to the processor's nested exception capability. If the processor takes an exception while already in kernel mode, and _cannot push its old state onto the kernel stack_ for any reason such as lack of stack space, then there is nothing the processor can do to recover, so it simply resets itself. Needless to say, the kernel should be designed so that this can't happen.
+
+##### Setting Up the IDT
+
+You should now have the basic information you need in order to set up the IDT and handle exceptions in JOS. For now, you will set up the IDT to handle interrupt vectors 0-31 (the processor exceptions). We'll handle system call interrupts later in this lab and add interrupts 32-47 (the device IRQs) in a later lab.
+
+The header files `inc/trap.h` and `kern/trap.h` contain important definitions related to interrupts and exceptions that you will need to become familiar with. The file `kern/trap.h` contains definitions that are strictly private to the kernel, while `inc/trap.h` contains definitions that may also be useful to user-level programs and libraries.
+
+Note: Some of the exceptions in the range 0-31 are defined by Intel to be reserved. Since they will never be generated by the processor, it doesn't really matter how you handle them. Do whatever you think is cleanest.
+
+The overall flow of control that you should achieve is depicted below:
+
+```
+ IDT trapentry.S trap.c
+
++----------------+
+| &handler1 |---------> handler1: trap (struct Trapframe *tf)
+| | // do stuff {
+| | call trap // handle the exception/interrupt
+| | // ... }
++----------------+
+| &handler2 |--------> handler2:
+| | // do stuff
+| | call trap
+| | // ...
++----------------+
+ .
+ .
+ .
++----------------+
+| &handlerX |--------> handlerX:
+| | // do stuff
+| | call trap
+| | // ...
++----------------+
+```
+
+Each exception or interrupt should have its own handler in `trapentry.S` and `trap_init()` should initialize the IDT with the addresses of these handlers. Each of the handlers should build a `struct Trapframe` (see `inc/trap.h`) on the stack and call `trap()` (in `trap.c`) with a pointer to the Trapframe. `trap()` then handles the exception/interrupt or dispatches to a specific handler function.
+
+```
+Exercise 4. Edit `trapentry.S` and `trap.c` and implement the features described above. The macros `TRAPHANDLER` and `TRAPHANDLER_NOEC` in `trapentry.S` should help you, as well as the T_* defines in `inc/trap.h`. You will need to add an entry point in `trapentry.S` (using those macros) for each trap defined in `inc/trap.h`, and you'll have to provide `_alltraps` which the `TRAPHANDLER` macros refer to. You will also need to modify `trap_init()` to initialize the `idt` to point to each of these entry points defined in `trapentry.S`; the `SETGATE` macro will be helpful here.
+
+Your `_alltraps` should:
+
+ 1. push values to make the stack look like a struct Trapframe
+ 2. load `GD_KD` into `%ds` and `%es`
+ 3. `pushl %esp` to pass a pointer to the Trapframe as an argument to trap()
+ 4. `call trap` (can `trap` ever return?)
+
+
+
+Consider using the `pushal` instruction; it fits nicely with the layout of the `struct Trapframe`.
+
+Test your trap handling code using some of the test programs in the `user` directory that cause exceptions before making any system calls, such as `user/divzero`. You should be able to get make grade to succeed on the `divzero`, `softint`, and `badsegment` tests at this point.
+```
+
+```
+Challenge! You probably have a lot of very similar code right now, between the lists of `TRAPHANDLER` in `trapentry.S` and their installations in `trap.c`. Clean this up. Change the macros in `trapentry.S` to automatically generate a table for `trap.c` to use. Note that you can switch between laying down code and data in the assembler by using the directives `.text` and `.data`.
+```
+
+```
+Questions
+
+Answer the following questions in your `answers-lab3.txt`:
+
+ 1. What is the purpose of having an individual handler function for each exception/interrupt? (i.e., if all exceptions/interrupts were delivered to the same handler, what feature that exists in the current implementation could not be provided?)
+ 2. Did you have to do anything to make the `user/softint` program behave correctly? The grade script expects it to produce a general protection fault (trap 13), but `softint`'s code says `int $14`. _Why_ should this produce interrupt vector 13? What happens if the kernel actually allows `softint`'s `int $14` instruction to invoke the kernel's page fault handler (which is interrupt vector 14)?
+```
+
+
+This concludes part A of the lab. Don't forget to add `answers-lab3.txt`, commit your changes, and run make handin before the part A deadline.
+
+#### Part B: Page Faults, Breakpoints Exceptions, and System Calls
+
+Now that your kernel has basic exception handling capabilities, you will refine it to provide important operating system primitives that depend on exception handling.
+
+##### Handling Page Faults
+
+The page fault exception, interrupt vector 14 (`T_PGFLT`), is a particularly important one that we will exercise heavily throughout this lab and the next. When the processor takes a page fault, it stores the linear (i.e., virtual) address that caused the fault in a special processor control register, `CR2`. In `trap.c` we have provided the beginnings of a special function, `page_fault_handler()`, to handle page fault exceptions.
+
+```
+Exercise 5. Modify `trap_dispatch()` to dispatch page fault exceptions to `page_fault_handler()`. You should now be able to get make grade to succeed on the `faultread`, `faultreadkernel`, `faultwrite`, and `faultwritekernel` tests. If any of them don't work, figure out why and fix them. Remember that you can boot JOS into a particular user program using make run- _x_ or make run- _x_ -nox. For instance, make run-hello-nox runs the _hello_ user program.
+```
+
+You will further refine the kernel's page fault handling below, as you implement system calls.
+
+##### The Breakpoint Exception
+
+The breakpoint exception, interrupt vector 3 (`T_BRKPT`), is normally used to allow debuggers to insert breakpoints in a program's code by temporarily replacing the relevant program instruction with the special 1-byte `int3` software interrupt instruction. In JOS we will abuse this exception slightly by turning it into a primitive pseudo-system call that any user environment can use to invoke the JOS kernel monitor. This usage is actually somewhat appropriate if we think of the JOS kernel monitor as a primitive debugger. The user-mode implementation of `panic()` in `lib/panic.c`, for example, performs an `int3` after displaying its panic message.
+
+```
+Exercise 6. Modify `trap_dispatch()` to make breakpoint exceptions invoke the kernel monitor. You should now be able to get make grade to succeed on the `breakpoint` test.
+```
+
+```
+Challenge! Modify the JOS kernel monitor so that you can 'continue' execution from the current location (e.g., after the `int3`, if the kernel monitor was invoked via the breakpoint exception), and so that you can single-step one instruction at a time. You will need to understand certain bits of the `EFLAGS` register in order to implement single-stepping.
+
+Optional: If you're feeling really adventurous, find some x86 disassembler source code - e.g., by ripping it out of QEMU, or out of GNU binutils, or just write it yourself - and extend the JOS kernel monitor to be able to disassemble and display instructions as you are stepping through them. Combined with the symbol table loading from lab 1, this is the stuff of which real kernel debuggers are made.
+```
+
+```
+Questions
+
+ 3. The break point test case will either generate a break point exception or a general protection fault depending on how you initialized the break point entry in the IDT (i.e., your call to `SETGATE` from `trap_init`). Why? How do you need to set it up in order to get the breakpoint exception to work as specified above and what incorrect setup would cause it to trigger a general protection fault?
+ 4. What do you think is the point of these mechanisms, particularly in light of what the `user/softint` test program does?
+```
+
+
+##### System calls
+
+User processes ask the kernel to do things for them by invoking system calls. When the user process invokes a system call, the processor enters kernel mode, the processor and the kernel cooperate to save the user process's state, the kernel executes appropriate code in order to carry out the system call, and then resumes the user process. The exact details of how the user process gets the kernel's attention and how it specifies which call it wants to execute vary from system to system.
+
+In the JOS kernel, we will use the `int` instruction, which causes a processor interrupt. In particular, we will use `int $0x30` as the system call interrupt. We have defined the constant `T_SYSCALL` to 48 (0x30) for you. You will have to set up the interrupt descriptor to allow user processes to cause that interrupt. Note that interrupt 0x30 cannot be generated by hardware, so there is no ambiguity caused by allowing user code to generate it.
+
+The application will pass the system call number and the system call arguments in registers. This way, the kernel won't need to grub around in the user environment's stack or instruction stream. The system call number will go in `%eax`, and the arguments (up to five of them) will go in `%edx`, `%ecx`, `%ebx`, `%edi`, and `%esi`, respectively. The kernel passes the return value back in `%eax`. The assembly code to invoke a system call has been written for you, in `syscall()` in `lib/syscall.c`. You should read through it and make sure you understand what is going on.
+
+```
+Exercise 7. Add a handler in the kernel for interrupt vector `T_SYSCALL`. You will have to edit `kern/trapentry.S` and `kern/trap.c`'s `trap_init()`. You also need to change `trap_dispatch()` to handle the system call interrupt by calling `syscall()` (defined in `kern/syscall.c`) with the appropriate arguments, and then arranging for the return value to be passed back to the user process in `%eax`. Finally, you need to implement `syscall()` in `kern/syscall.c`. Make sure `syscall()` returns `-E_INVAL` if the system call number is invalid. You should read and understand `lib/syscall.c` (especially the inline assembly routine) in order to confirm your understanding of the system call interface. Handle all the system calls listed in `inc/syscall.h` by invoking the corresponding kernel function for each call.
+
+Run the `user/hello` program under your kernel (make run-hello). It should print "`hello, world`" on the console and then cause a page fault in user mode. If this does not happen, it probably means your system call handler isn't quite right. You should also now be able to get make grade to succeed on the `testbss` test.
+```
+
+```
+Challenge! Implement system calls using the `sysenter` and `sysexit` instructions instead of using `int 0x30` and `iret`.
+
+The `sysenter/sysexit` instructions were designed by Intel to be faster than `int/iret`. They do this by using registers instead of the stack and by making assumptions about how the segmentation registers are used. The exact details of these instructions can be found in Volume 2B of the Intel reference manuals.
+
+The easiest way to add support for these instructions in JOS is to add a `sysenter_handler` in `kern/trapentry.S` that saves enough information about the user environment to return to it, sets up the kernel environment, pushes the arguments to `syscall()` and calls `syscall()` directly. Once `syscall()` returns, set everything up for and execute the `sysexit` instruction. You will also need to add code to `kern/init.c` to set up the necessary model specific registers (MSRs). Section 6.1.2 in Volume 2 of the AMD Architecture Programmer's Manual and the reference on SYSENTER in Volume 2B of the Intel reference manuals give good descriptions of the relevant MSRs. You can find an implementation of `wrmsr` to add to `inc/x86.h` for writing to these MSRs [here][4].
+
+Finally, `lib/syscall.c` must be changed to support making a system call with `sysenter`. Here is a possible register layout for the `sysenter` instruction:
+
+ eax - syscall number
+ edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
+ esi - return pc
+ ebp - return esp
+ esp - trashed by sysenter
+
+GCC's inline assembler will automatically save registers that you tell it to load values directly into. Don't forget to either save (push) and restore (pop) other registers that you clobber, or tell the inline assembler that you're clobbering them. The inline assembler doesn't support saving `%ebp`, so you will need to add code to save and restore it yourself. The return address can be put into `%esi` by using an instruction like `leal after_sysenter_label, %%esi`.
+
+Note that this only supports 4 arguments, so you will need to leave the old method of doing system calls around to support 5 argument system calls. Furthermore, because this fast path doesn't update the current environment's trap frame, it won't be suitable for some of the system calls we add in later labs.
+
+You may have to revisit your code once we enable asynchronous interrupts in the next lab. Specifically, you'll need to enable interrupts when returning to the user process, which `sysexit` doesn't do for you.
+```
+
+##### User-mode startup
+
+A user program starts running at the top of `lib/entry.S`. After some setup, this code calls `libmain()`, in `lib/libmain.c`. You should modify `libmain()` to initialize the global pointer `thisenv` to point at this environment's `struct Env` in the `envs[]` array. (Note that `lib/entry.S` has already defined `envs` to point at the `UENVS` mapping you set up in Part A.) Hint: look in `inc/env.h` and use `sys_getenvid`.
+
+`libmain()` then calls `umain`, which, in the case of the hello program, is in `user/hello.c`. Note that after printing "`hello, world`", it tries to access `thisenv->env_id`. This is why it faulted earlier. Now that you've initialized `thisenv` properly, it should not fault. If it still faults, you probably haven't mapped the `UENVS` area user-readable (back in Part A in `pmap.c`; this is the first time we've actually used the `UENVS` area).
+
+```
+Exercise 8. Add the required code to the user library, then boot your kernel. You should see `user/hello` print "`hello, world`" and then print "`i am environment 00001000`". `user/hello` then attempts to "exit" by calling `sys_env_destroy()` (see `lib/libmain.c` and `lib/exit.c`). Since the kernel currently only supports one user environment, it should report that it has destroyed the only environment and then drop into the kernel monitor. You should be able to get make grade to succeed on the `hello` test.
+```
+
+##### Page faults and memory protection
+
+Memory protection is a crucial feature of an operating system, ensuring that bugs in one program cannot corrupt other programs or corrupt the operating system itself.
+
+Operating systems usually rely on hardware support to implement memory protection. The OS keeps the hardware informed about which virtual addresses are valid and which are not. When a program tries to access an invalid address or one for which it has no permissions, the processor stops the program at the instruction causing the fault and then traps into the kernel with information about the attempted operation. If the fault is fixable, the kernel can fix it and let the program continue running. If the fault is not fixable, then the program cannot continue, since it will never get past the instruction causing the fault.
+
+As an example of a fixable fault, consider an automatically extended stack. In many systems the kernel initially allocates a single stack page, and then if a program faults accessing pages further down the stack, the kernel will allocate those pages automatically and let the program continue. By doing this, the kernel only allocates as much stack memory as the program needs, but the program can work under the illusion that it has an arbitrarily large stack.
+
+System calls present an interesting problem for memory protection. Most system call interfaces let user programs pass pointers to the kernel. These pointers point at user buffers to be read or written. The kernel then dereferences these pointers while carrying out the system call. There are two problems with this:
+
+ 1. A page fault in the kernel is potentially a lot more serious than a page fault in a user program. If the kernel page-faults while manipulating its own data structures, that's a kernel bug, and the fault handler should panic the kernel (and hence the whole system). But when the kernel is dereferencing pointers given to it by the user program, it needs a way to remember that any page faults these dereferences cause are actually on behalf of the user program.
+ 2. The kernel typically has more memory permissions than the user program. The user program might pass a pointer to a system call that points to memory that the kernel can read or write but that the program cannot. The kernel must be careful not to be tricked into dereferencing such a pointer, since that might reveal private information or destroy the integrity of the kernel.
+
+
+
+For both of these reasons the kernel must be extremely careful when handling pointers presented by user programs.
+
+You will now solve these two problems with a single mechanism that scrutinizes all pointers passed from userspace into the kernel. When a program passes the kernel a pointer, the kernel will check that the address is in the user part of the address space, and that the page table would allow the memory operation.
+
+Thus, the kernel will never suffer a page fault due to dereferencing a user-supplied pointer. If the kernel does page fault, it should panic and terminate.
+
+```
+Exercise 9. Change `kern/trap.c` to panic if a page fault happens in kernel mode.
+
+Hint: to determine whether a fault happened in user mode or in kernel mode, check the low bits of the `tf_cs`.
+
+Read `user_mem_assert` in `kern/pmap.c` and implement `user_mem_check` in that same file.
+
+Change `kern/syscall.c` to sanity check arguments to system calls.
+
+Boot your kernel, running `user/buggyhello`. The environment should be destroyed, and the kernel should _not_ panic. You should see:
+
+ [00001000] user_mem_check assertion failure for va 00000001
+ [00001000] free env 00001000
+ Destroyed the only environment - nothing more to do!
+Finally, change `debuginfo_eip` in `kern/kdebug.c` to call `user_mem_check` on `usd`, `stabs`, and `stabstr`. If you now run `user/breakpoint`, you should be able to run backtrace from the kernel monitor and see the backtrace traverse into `lib/libmain.c` before the kernel panics with a page fault. What causes this page fault? You don't need to fix it, but you should understand why it happens.
+```
+
+Note that the same mechanism you just implemented also works for malicious user applications (such as `user/evilhello`).
+
+```
+Exercise 10. Boot your kernel, running `user/evilhello`. The environment should be destroyed, and the kernel should not panic. You should see:
+
+ [00000000] new env 00001000
+ ...
+ [00001000] user_mem_check assertion failure for va f010000c
+ [00001000] free env 00001000
+```
+
+**This completes the lab.** Make sure you pass all of the make grade tests and don't forget to write up your answers to the questions and a description of your challenge exercise solution in `answers-lab3.txt`. Commit your changes and type make handin in the `lab` directory to submit your work.
+
+Before handing in, use git status and git diff to examine your changes and don't forget to git add answers-lab3.txt. When you're ready, commit your changes with git commit -am 'my solutions to lab 3', then make handin and follow the directions.
+
+--------------------------------------------------------------------------------
+
+via: https://pdos.csail.mit.edu/6.828/2018/labs/lab3/
+
+作者:[csail.mit][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://pdos.csail.mit.edu
+[b]: https://github.com/lujun9972
+[1]: https://pdos.csail.mit.edu/6.828/2018/labs/labguide.html
+[2]: https://pdos.csail.mit.edu/6.828/2018/labs/reference.html
+[3]: http://blogs.msdn.com/larryosterman/archive/2005/02/08/369243.aspx
+[4]: http://ftp.kh.edu.tw/Linux/SuSE/people/garloff/linux/k6mod.c
diff --git a/sources/tech/20181004 PyTorch 1.0 Preview Release- Facebook-s newest Open Source AI.md b/sources/tech/20181004 PyTorch 1.0 Preview Release- Facebook-s newest Open Source AI.md
new file mode 100644
index 0000000000..6418db9444
--- /dev/null
+++ b/sources/tech/20181004 PyTorch 1.0 Preview Release- Facebook-s newest Open Source AI.md
@@ -0,0 +1,181 @@
+PyTorch 1.0 Preview Release: Facebook’s newest Open Source AI
+======
+Facebook already uses its own Open Source AI, PyTorch quite extensively in its own artificial intelligence projects. Recently, they have gone a league ahead by releasing a pre-release preview version 1.0.
+
+For those who are not familiar, [PyTorch][1] is a Python-based library for Scientific Computing.
+
+PyTorch harnesses the [superior computational power of Graphical Processing Units (GPUs)][2] for carrying out complex [Tensor][3] computations and implementing [deep neural networks][4]. So, it is used widely across the world by numerous researchers and developers.
+
+This new ready-to-use [Preview Release][5] was announced at the [PyTorch Developer Conference][6] at [The Midway][7], San Francisco, CA on Tuesday, October 2, 2018.
+
+### Highlights of PyTorch 1.0 Release Candidate
+
+![PyTorhc is Python based open source AI framework from Facebook][8]
+
+Some of the main new features in the release candidate are:
+
+#### 1\. JIT
+
+JIT is a set of compiler tools to bring research close to production. It includes a Python-based language called Torch Script and also ways to make existing code compatible with itself.
+
+#### 2\. New torch.distributed library: “C10D”
+
+“C10D” enables asynchronous operation on different backends with performance improvements on slower networks and more.
+
+#### 3\. C++ frontend (experimental)
+
+Though it has been specifically mentioned as an unstable API (expected in a pre-release), this is a pure C++ interface to the PyTorch backend that follows the API and architecture of the established Python frontend to enable research in high performance, low latency and C++ applications installed directly on hardware.
+
+To know more, you can take a look at the complete [update notes][9] on GitHub.
+
+The first stable version PyTorch 1.0 will be released in summer.
+
+### Installing PyTorch on Linux
+
+To install PyTorch v1.0rc0, the developers recommend using [conda][10] while there also other ways to do that as shown on their [local installation page][11] where they have documented everything necessary in detail.
+
+#### Prerequisites
+
+ * Linux
+ * Pip
+ * Python
+ * [CUDA][12] (For Nvidia GPU owners)
+
+
+
+As we recently showed you [how to install and use Pip][13], let’s get to know how we can install PyTorch with it.
+
+Note that PyTorch has GPU and CPU-only variants. You should install the one that suits your hardware.
+
+#### Installing old and stable version of PyTorch
+
+If you want the stable release (version 0.4) for your GPU, use:
+
+```
+pip install torch torchvision
+
+```
+
+Use these two commands in succession for a CPU-only stable release:
+
+```
+pip install http://download.pytorch.org/whl/cpu/torch-0.4.1-cp27-cp27mu-linux_x86_64.whl
+pip install torchvision
+
+```
+
+#### Installing PyTorch 1.0 Release Candidate
+
+You install PyTorch 1.0 RC GPU version with this command:
+
+```
+pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cu92/torch_nightly.html
+
+```
+
+If you do not have a GPU and would prefer a CPU-only version, use:
+
+```
+pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
+
+```
+
+#### Verifying your PyTorch installation
+
+Startup the python console on a terminal with the following simple command:
+
+```
+python
+
+```
+
+Now enter the following sample code line by line to verify your installation:
+
+```
+from __future__ import print_function
+import torch
+x = torch.rand(5, 3)
+print(x)
+
+```
+
+You should get an output like:
+
+```
+tensor([[0.3380, 0.3845, 0.3217],
+ [0.8337, 0.9050, 0.2650],
+ [0.2979, 0.7141, 0.9069],
+ [0.1449, 0.1132, 0.1375],
+ [0.4675, 0.3947, 0.1426]])
+
+```
+
+To check whether you can use PyTorch’s GPU capabilities, use the following sample code:
+
+```
+import torch
+torch.cuda.is_available()
+
+```
+
+The resulting output should be:
+
+```
+True
+
+```
+
+Support for AMD GPUs for PyTorch is still under development, so complete test coverage is not yet provided as reported [here][14], suggesting this [resource][15] in case you have an AMD GPU.
+
+Lets now look into some research projects that extensively use PyTorch:
+
+### Ongoing Research Projects based on PyTorch
+
+ * [Detectron][16]: Facebook AI Research’s software system to intelligently detect and classify objects. It is based on Caffe2. Earlier this year, Caffe2 and PyTorch [joined forces][17] to create a Research + Production enabled PyTorch 1.0 we talk about.
+ * [Unsupervised Sentiment Discovery][18]: Such methods are extensively used with social media algorithms.
+ * [vid2vid][19]: Photorealistic video-to-video translation
+ * [DeepRecommender][20] (We covered how such systems work on our past [Netflix AI article][21])
+
+
+
+Nvidia, leading GPU manufacturer covered more on this with their own [update][22] on this recent development where you can also read about ongoing collaborative research endeavours.
+
+### How should we react to such PyTorch capabilities?
+
+To think Facebook applies such amazingly innovative projects and more in its social media algorithms, should we appreciate all this or get alarmed? This is almost [Skynet][23]! This newly improved production-ready pre-release of PyTorch will certainly push things further ahead! Feel free to share your thoughts with us in the comments below!
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/pytorch-open-source-ai-framework/
+
+作者:[Avimanyu Bandyopadhyay][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/avimanyu/
+[1]: https://pytorch.org/
+[2]: https://en.wikipedia.org/wiki/General-purpose_computing_on_graphics_processing_units
+[3]: https://en.wikipedia.org/wiki/Tensor
+[4]: https://www.techopedia.com/definition/32902/deep-neural-network
+[5]: https://code.fb.com/ai-research/facebook-accelerates-ai-development-with-new-partners-and-production-capabilities-for-pytorch-1-0
+[6]: https://pytorch.fbreg.com/
+[7]: https://www.themidwaysf.com/
+[8]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/pytorch.jpeg
+[9]: https://github.com/pytorch/pytorch/releases/tag/v1.0rc0
+[10]: https://conda.io/
+[11]: https://pytorch.org/get-started/locally/
+[12]: https://www.pugetsystems.com/labs/hpc/How-to-install-CUDA-9-2-on-Ubuntu-18-04-1184/
+[13]: https://itsfoss.com/install-pip-ubuntu/
+[14]: https://github.com/pytorch/pytorch/issues/10657#issuecomment-415067478
+[15]: https://rocm.github.io/install.html#installing-from-amd-rocm-repositories
+[16]: https://github.com/facebookresearch/Detectron
+[17]: https://caffe2.ai/blog/2018/05/02/Caffe2_PyTorch_1_0.html
+[18]: https://github.com/NVIDIA/sentiment-discovery
+[19]: https://github.com/NVIDIA/vid2vid
+[20]: https://github.com/NVIDIA/DeepRecommender/
+[21]: https://itsfoss.com/netflix-open-source-ai/
+[22]: https://news.developer.nvidia.com/pytorch-1-0-accelerated-on-nvidia-gpus/
+[23]: https://en.wikipedia.org/wiki/Skynet_(Terminator)
diff --git a/sources/tech/20181005 Dbxfs - Mount Dropbox Folder Locally As Virtual File System In Linux.md b/sources/tech/20181005 Dbxfs - Mount Dropbox Folder Locally As Virtual File System In Linux.md
new file mode 100644
index 0000000000..691600a4cc
--- /dev/null
+++ b/sources/tech/20181005 Dbxfs - Mount Dropbox Folder Locally As Virtual File System In Linux.md
@@ -0,0 +1,133 @@
+Dbxfs – Mount Dropbox Folder Locally As Virtual File System In Linux
+======
+
+
+
+A while ago, we summarized all the possible ways to **[mount Google drive locally][1]** as a virtual file system and access the files stored in the google drive from your Linux operating system. Today, we are going to learn to mount Dropbox folder in your local file system using **dbxfs** utility. The dbxfs is used to mount your Dropbox folder locally as a virtual filesystem in Unix-like operating systems. While it is easy to [**install Dropbox client**][2] in Linux, this approach slightly differs from the official method. It is a command line dropbox client and requires no disk space for access. The dbxfs application is free, open source and written for Python 3.5+.
+
+### Installing dbxfs
+
+The dbxfs officially supports Linux and Mac OS. However, it should work on any POSIX system that provides a **FUSE-compatible library** or has the ability to mount **SMB** shares. Since it is written for Python 3.5, it can installed using **pip3** package manager. Refer the following guide if you haven’t installed PIP yet.
+
+And, install FUSE library as well.
+
+On Debian-based systems, run the following command to install FUSE:
+
+```
+$ sudo apt install libfuse2
+
+```
+
+On Fedora:
+
+```
+$ sudo dnf install fuse
+
+```
+
+Once you installed all required dependencies, run the following command to install dbxfs utility:
+
+```
+$ pip3 install dbxfs
+
+```
+
+### Mount Dropbox folder locally
+
+Create a mount point to mount your dropbox folder in your local file system.
+
+```
+$ mkdir ~/mydropbox
+
+```
+
+Then, mount the dropbox folder locally using dbxfs utility as shown below:
+
+```
+$ dbxfs ~/mydropbox
+
+```
+
+You will be asked to generate an access token:
+
+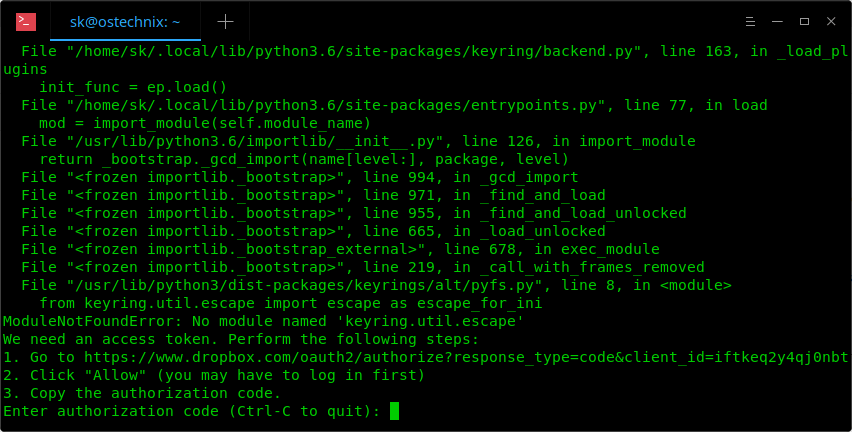
+
+To generate an access token, just navigate to the URL given in the above output from your web browser and click **Allow** to authenticate Dropbox access. You need to log in to your dropbox account to complete authorization process.
+
+A new authorization code will be generated in the next screen. Copy the code and head back to your Terminal and paste it into cli-dbxfs prompt to finish the process.
+
+You will be then asked to save the credentials for future access. Type **Y** or **N** whether you want to save or decline. And then, you need to enter a passphrase twice for the new access token.
+
+Finally, click **Y** to accept **“/home/username/mydropbox”** as the default mount point. If you want to set different path, type **N** and enter the location of your choice.
+
+[![Generate access token 2][3]][4]
+
+All done! From now on, you can see your Dropbox folder is locally mounted in your filesystem.
+
+
+
+### Change Access Token Storage Path
+
+By default, the dbxfs application will store your Dropbox access token in the system keyring or an encrypted file. However, you might want to store it in a **gpg** encrypted file or something else. If so, get an access token by creating a personal app on the [Dropbox developers app console][5].
+
+
+
+Once the app is created, click **Generate** button in the next button. This access token can be used to access your Dropbox account via the API. Don’t share your access token with anyone.
+
+
+
+Once you created an access token, encrypt it using any encryption tools of your choice, such as [**Cryptomater**][6], [**Cryptkeeper**][7], [**CryptGo**][8], [**Cryptr**][9], [**Tomb**][10], [**Toplip**][11] and [**GnuPG**][12] etc., and store it in your preferred location.
+
+Next edit the dbxfs configuration file and add the following line in it:
+
+```
+"access_token_command": ["gpg", "--decrypt", "/path/to/access/token/file.gpg"]
+
+```
+
+You can find the dbxfs configuration file by running the following command:
+
+```
+$ dbxfs --print-default-config-file
+
+```
+
+For more details, refer dbxfs help section:
+
+```
+$ dbxfs -h
+
+```
+
+As you can see, mounting Dropfox folder locally in your file system using Dbxfs utility is no big deal. As far tested, dbxfs just works fine as expected. Give it a try if you’re interested to see how it works and let us know about your experience in the comment section below.
+
+And, that’s all for now. Hope this was useful. More good stuff to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/dbxfs-mount-dropbox-folder-locally-as-virtual-file-system-in-linux/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[1]: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
+[2]: https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/
+[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[4]: http://www.ostechnix.com/wp-content/uploads/2018/10/Generate-access-token-2.png
+[5]: https://dropbox.com/developers/apps
+[6]: https://www.ostechnix.com/cryptomator-open-source-client-side-encryption-tool-cloud/
+[7]: https://www.ostechnix.com/how-to-encrypt-your-personal-foldersdirectories-in-linux-mint-ubuntu-distros/
+[8]: https://www.ostechnix.com/cryptogo-easy-way-encrypt-password-protect-files/
+[9]: https://www.ostechnix.com/cryptr-simple-cli-utility-encrypt-decrypt-files/
+[10]: https://www.ostechnix.com/tomb-file-encryption-tool-protect-secret-files-linux/
+[11]: https://www.ostechnix.com/toplip-strong-file-encryption-decryption-cli-utility/
+[12]: https://www.ostechnix.com/an-easy-way-to-encrypt-and-decrypt-files-from-commandline-in-linux/
diff --git a/sources/tech/20181005 How to use Kolibri to access educational material offline.md b/sources/tech/20181005 How to use Kolibri to access educational material offline.md
new file mode 100644
index 0000000000..f856a497cd
--- /dev/null
+++ b/sources/tech/20181005 How to use Kolibri to access educational material offline.md
@@ -0,0 +1,107 @@
+How to use Kolibri to access educational material offline
+======
+Kolibri makes digital educational materials available to students without internet access.
+
+
+
+While the internet has thoroughly transformed the availability of educational content for much of the world, many people still live in places where online access is poor or even nonexistent. [Kolibri][1] is a great solution for these communities. It's an app that creates an offline server to deliver high-quality educational resources to learners. You can set up Kolibri on a wide range of [hardware][2], including low-cost Windows, MacOS, and Linux (including Raspberry Pi) computers. A version for Android tablets is in the works.
+
+Because it's open source, free to use, works without broadband access (after initial setup), and includes a wide range of educational content, it gives students in rural schools, refugee camps, orphanages, informal schools, prisons, and other places without reliable internet service access to many of the same resources used by students all over the world.
+
+In addition to being simple to install, it's easy to customize Kolibri for various educational missions and needs, including literacy building, general reference materials, and life skills training. Kolibri includes content from sources including [OpenStax,][3] [CK-12][4], [Khan Academy][5], and [EngageNY][6]; once these packages are "seeded" by connecting the Kolibri serving device to a robust internet connection, they are immediately available for offline access on client devices through a compatible browser.
+
+### Installation and setup
+
+I installed Kolibri on an Intel i3-based laptop running Fedora 28. I chose the **pip install** method, which is very easy. Here's how to do it.
+
+Open a terminal and enter:
+
+```
+$ sudo pip install kolibri
+
+```
+
+Start Kolibri by entering **$** **kolibri** **start** in the terminal.
+
+Find your Kolibri installation's URL in the terminal.
+
+
+
+Open your browser and point it to that URL, being sure to append port **8080**.
+
+Select the default language—options include English, Spanish, French, Arabic, Portuguese, Hindi, Farsi, Burmese, and Bengali. (I chose English.)
+
+Name your facility, i.e., your classroom, library, or home. (I named mine Test.)
+
+
+
+Tell Kolibri what type of facility you're setting up—self-managed, admin-managed, or informal. (I chose self-managed.)
+
+
+
+Create an admin account.
+
+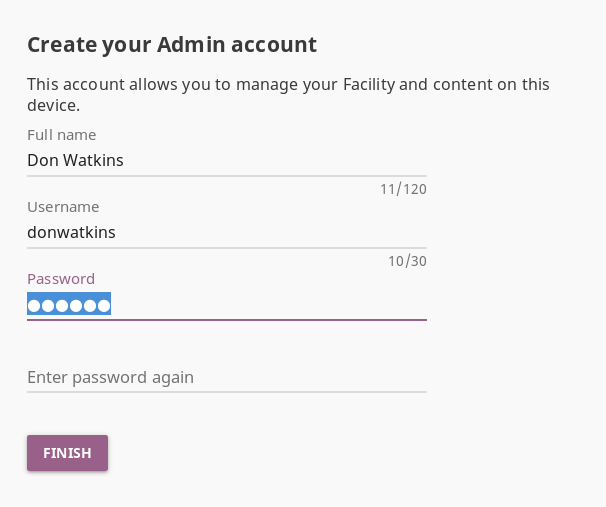
+
+### Add content
+
+You can add Kolibri-curated content channels while you are connected to broadband service. Explore and add content from the menu at the top-left of the browser.
+
+
+
+Choose Device and Import.
+
+
+
+Selecting English as the default language provides access to 29 content channels including Touchable Earth, Global Digital Library, Khan Academy, OpenStax, CK-12, EngageNY, Blockly games, and more.
+
+Select a channel you're interested in. You have the option to download the entire channel (which might take a long time) or to select the specific content you want to download.
+
+
+
+To access your content, return to the top-left menu and select Learn.
+
+
+
+### Add users
+
+User accounts can be set up as learners, coaches, or admins. Users can access the Kolibri server from most web browsers on any Linux, MacOS, Windows, Android, or iOS device on the same network, even if the network isn't connected to the internet. Admins can set up classes on the device, assign coaches and learners to classes, and see every user's interaction and how much time they spend with the content.
+
+If your Kolibri server is set up as self-managed, users can create their own accounts by entering the Kolibri URL in their browser and following the prompts. For information on setting up users on an admin-managed server, check out Kolibri's [documentation][7].
+
+
+
+After logging in, the user can access content right away to begin learning.
+
+### Learn more
+
+Kolibri is a very powerful learning resource, especially for people who don't have a robust connection to the internet. Its [documentation][8] is very complete, and a [demo][9] site maintained by the project allows you to try it out.
+
+Kolibri is open source under the [MIT License][10]. The project, which is managed by the nonprofit organization Learning Equality, is looking for developers—if you would like to get involved, be sure to check out them on [GitHub][11]. To learn more, follow Learning Equality and Kolibri on its [blog][12], [Twitter][13], and [Facebook][14] pages.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/10/getting-started-kolibri
+
+作者:[Don Watkins][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[1]: https://learningequality.org/kolibri/
+[2]: https://drive.google.com/file/d/0B9ZzDms8cSNgVWRKdUlPc2lkTkk/view
+[3]: https://openstax.org/
+[4]: https://www.ck12.org/
+[5]: https://www.khanacademy.org/
+[6]: https://www.engageny.org/
+[7]: https://kolibri.readthedocs.io/en/latest/manage.html#create-a-new-user-account
+[8]: https://learningequality.org/documentation/
+[9]: http://kolibridemo.learningequality.org/learn/#/topics
+[10]: https://github.com/learningequality/kolibri/blob/develop/LICENSE
+[11]: https://github.com/learningequality/
+[12]: https://blog.learningequality.org/
+[13]: https://twitter.com/LearnEQ/
+[14]: https://www.facebook.com/learningequality
diff --git a/sources/tech/20181005 Open Source Logging Tools for Linux.md b/sources/tech/20181005 Open Source Logging Tools for Linux.md
new file mode 100644
index 0000000000..723488008a
--- /dev/null
+++ b/sources/tech/20181005 Open Source Logging Tools for Linux.md
@@ -0,0 +1,188 @@
+Open Source Logging Tools for Linux
+======
+
+
+
+If you’re a Linux systems administrator, one of the first tools you will turn to for troubleshooting are log files. These files hold crucial information that can go a long way to help you solve problems affecting your desktops and servers. For many sysadmins (especially those of an old-school sort), nothing beats the command line for checking log files. But for those who’d rather have a more efficient (and possibly modern) approach to troubleshooting, there are plenty of options.
+
+In this article, I’ll highlight a few such tools available for the Linux platform. I won’t be getting into logging tools that might be specific to a certain service (such as Kubernetes or Apache), and instead will focus on tools that work to mine the depths of all that magical information written into /var/log.
+
+Speaking of which…
+
+### What is /var/log?
+
+If you’re new to Linux, you might not know what the /var/log directory contains. However, the name is very telling. Within this directory is housed all of the log files from the system and any major service (such as Apache, MySQL, MariaDB, etc.) installed on the operating system. Open a terminal window and issue the command cd /var/log. Follow that with the command ls and you’ll see all of the various systems that have log files you can view (Figure 1).
+
+![/var/log/][2]
+
+Figure 1: Our ls command reveals the logs available in /var/log/.
+
+[Used with permission][3]
+
+Say, for instance, you want to view the syslog log file. Issue the command less syslog and you can scroll through all of the gory details of that particular log. But what if the standard terminal isn’t for you? What options do you have? Plenty. Let’s take a look at few such options.
+
+### Logs
+
+If you use the GNOME desktop (or other, as Logs can be installed on more than just GNOME), you have at your fingertips a log viewer that mainly just adds the slightest bit of GUI goodness over the log files to create something as simple as it is effective. Once installed (from the standard repositories), open Logs from the desktop menu, and you’ll be treated to an interface (Figure 2) that allows you to select from various types of logs (Important, All, System, Security, and Hardware), as well as select a boot period (from the top center drop-down), and even search through all of the available logs.
+
+![Logs tool][5]
+
+Figure 2: The GNOME Logs tool is one of the easiest GUI log viewers you’ll find for Linux.
+
+[Used with permission][3]
+
+Logs is a great tool, especially if you’re not looking for too many bells and whistles getting in the way of you viewing crucial log entries, so you can troubleshoot your systems.
+
+### KSystemLog
+
+KSystemLog is to KDE what Logs is to GNOME, but with a few more features to add into the mix. Although both make it incredibly simple to view your system log files, only KSystemLog includes colorized log lines, tabbed viewing, copy log lines to the desktop clipboard, built-in capability for sending log messages directly to the system, read detailed information for each log line, and more. KSystemLog views all the same logs found in GNOME Logs, only with a different layout.
+
+From the main window (Figure 3), you can view any of the different log (from System Log, Authentication Log, X.org Log, Journald Log), search the logs, filter by Date, Host, Process, Message, and select log priorities.
+
+![KSystemLog][7]
+
+Figure 3: The KSystemLog main window.
+
+[Used with permission][3]
+
+If you click on the Window menu, you can open a new tab, where you can select a different log/filter combination to view. From that same menu, you can even duplicate the current tab. If you want to manually add a log to a file, do the following:
+
+ 1. Open KSystemLog.
+
+ 2. Click File > Add Log Entry.
+
+ 3. Create your log entry (Figure 4).
+
+ 4. Click OK
+
+
+![log entry][9]
+
+Figure 4: Creating a manual log entry with KSystemLog.
+
+[Used with permission][3]
+
+KSystemLog makes viewing logs in KDE an incredibly easy task.
+
+### Logwatch
+
+Logwatch isn’t a fancy GUI tool. Instead, logwatch allows you to set up a logging system that will email you important alerts. You can have those alerts emailed via an SMTP server or you can simply view them on the local machine. Logwatch can be found in the standard repositories for almost every distribution, so installation can be done with a single command, like so:
+
+```
+sudo apt-get install logwatch
+```
+
+Or:
+
+```
+sudo dnf install logwatch
+```
+
+During the installation, you will be required to select the delivery method for alerts (Figure 5). If you opt to go the local mail delivery only, you’ll need to install the mailutils app (so you can view mail locally, via the mail command).
+
+![ Logwatch][11]
+
+Figure 5: Configuring Logwatch alert sending method.
+
+[Used with permission][3]
+
+All Logwatch configurations are handled in a single file. To edit that file, issue the command sudo nano /usr/share/logwatch/default.conf/logwatch.conf. You’ll want to edit the MailTo = option. If you’re viewing this locally, set that to the Linux username you want the logs sent to (such as MailTo = jack). If you are sending these logs to an external email address, you’ll also need to change the MailFrom = option to a legitimate email address. From within that same configuration file, you can also set the detail level and the range of logs to send. Save and close that file.
+Once configured, you can send your first mail with a command like:
+
+```
+logwatch --detail Med --mailto ADDRESS --service all --range today
+Where ADDRESS is either the local user or an email address.
+
+```
+
+For more information on using Logwatch, issue the command man logwatch. Read through the manual page to see the different options that can be used with the tool.
+
+### Rsyslog
+
+Rsyslog is a convenient way to send remote client logs to a centralized server. Say you have one Linux server you want to use to collect the logs from other Linux servers in your data center. With Rsyslog, this is easily done. Rsyslog has to be installed on all clients and the centralized server (by issuing a command like sudo apt-get install rsyslog). Once installed, create the /etc/rsyslog.d/server.conf file on the centralized server, with the contents:
+
+```
+# Provide UDP syslog reception
+$ModLoad imudp
+$UDPServerRun 514
+
+# Provide TCP syslog reception
+$ModLoad imtcp
+$InputTCPServerRun 514
+
+# Use custom filenaming scheme
+$template FILENAME,"/var/log/remote/%HOSTNAME%.log"
+*.* ?FILENAME
+
+$PreserveFQDN on
+
+```
+
+Save and close that file. Now, on every client machine, create the file /etc/rsyslog.d/client.conf with the contents:
+
+```
+$PreserveFQDN on
+$ActionQueueType LinkedList
+$ActionQueueFileName srvrfwd
+$ActionResumeRetryCount -1
+$ActionQueueSaveOnShutdown on
+*.* @@SERVER_IP:514
+
+```
+
+Where SERVER_IP is the IP address of your centralized server. Save and close that file. Restart rsyslog on all machines with the command:
+
+```
+sudo systemctl restart rsyslog
+
+```
+
+You can now view the centralized log files with the command (run on the centralized server):
+
+```
+tail -f /var/log/remote/*.log
+
+```
+
+The tail command allows you to view those files as they are written to, in real time. You should see log entries appear that include the client hostname (Figure 6).
+
+![Rsyslog][13]
+
+Figure 6: Rsyslog showing entries for a connected client.
+
+[Used with permission][3]
+
+Rsyslog is a great tool for creating a single point of entry for viewing the logs of all of your Linux servers.
+
+### More where that came from
+
+This article only scratched the surface of the logging tools to be found on the Linux platform. And each of the above tools is capable of more than what is outlined here. However, this overview should give you a place to start your long day's journey into the Linux log file.
+
+Learn more about Linux through the free ["Introduction to Linux" ][14]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/10/open-source-logging-tools-linux
+
+作者:[JACK WALLEN][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[1]: /files/images/logs1jpg
+[2]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_1.jpg?itok=8yO2q1rW (/var/log/)
+[3]: /licenses/category/used-permission
+[4]: /files/images/logs2jpg
+[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_2.jpg?itok=kF6V46ZB (Logs tool)
+[6]: /files/images/logs3jpg
+[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_3.jpg?itok=PhrIzI1N (KSystemLog)
+[8]: /files/images/logs4jpg
+[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_4.jpg?itok=OxsGJ-TJ (log entry)
+[10]: /files/images/logs5jpg
+[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_5.jpg?itok=GeAR551e (Logwatch)
+[12]: /files/images/logs6jpg
+[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_6.jpg?itok=ira8UZOr (Rsyslog)
+[14]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20181005 Terminalizer - A Tool To Record Your Terminal And Generate Animated Gif Images.md b/sources/tech/20181005 Terminalizer - A Tool To Record Your Terminal And Generate Animated Gif Images.md
new file mode 100644
index 0000000000..26d1941cc1
--- /dev/null
+++ b/sources/tech/20181005 Terminalizer - A Tool To Record Your Terminal And Generate Animated Gif Images.md
@@ -0,0 +1,171 @@
+Terminalizer – A Tool To Record Your Terminal And Generate Animated Gif Images
+======
+This is know topic for most of us and i don’t want to give you the detailed information about this flow. Also, we had written many article under this topics.
+
+Script command is the one of the standard command to record Linux terminal sessions. Today we are going to discuss about same kind of tool called Terminalizer.
+
+This tool will help us to record the users terminal activity, also will help us to identify other useful information from the output.
+
+### What Is Terminalizer
+
+Terminalizer allow users to record their terminal activity and allow them to generate animated gif images. It’s highly customizable CLI tool that user can share a link for an online player, web player for a recording file.
+
+**Suggested Read :**
+**(#)** [Script – A Simple Command To Record Your Terminal Session Activity][1]
+**(#)** [Automatically Record/Capture All Users Terminal Sessions Activity In Linux][2]
+**(#)** [Teleconsole – A Tool To Share Your Terminal Session Instantly To Anyone In Seconds][3]
+**(#)** [tmate – Instantly Share Your Terminal Session To Anyone In Seconds][4]
+**(#)** [Peek – Create a Animated GIF Recorder in Linux][5]
+**(#)** [Kgif – A Simple Shell Script to Create a Gif File from Active Window][6]
+**(#)** [Gifine – Quickly Create An Animated GIF Video In Ubuntu/Debian][7]
+
+There is no distribution official package to install this utility and we can easily install it by using Node.js.
+
+### How To Install Noje.js in Linux
+
+Node.js can be installed in multiple ways. Here, we are going to teach you the standard method.
+
+For Ubuntu/LinuxMint use [APT-GET Command][8] or [APT Command][9] to install Node.js
+
+```
+$ curl -sL https://deb.nodesource.com/setup_8.x | sudo -E bash -
+$ sudo apt-get install -y nodejs
+
+```
+
+For Debian use [APT-GET Command][8] or [APT Command][9] to install Node.js
+
+```
+# curl -sL https://deb.nodesource.com/setup_8.x | bash -
+# apt-get install -y nodejs
+
+```
+
+For **`RHEL/CentOS`** , use [YUM Command][10] to install tmux.
+
+```
+$ sudo curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash -
+$ sudo yum install epel-release
+$ sudo yum -y install nodejs
+
+```
+
+For **`Fedora`** , use [DNF Command][11] to install tmux.
+
+```
+$ sudo dnf install nodejs
+
+```
+
+For **`Arch Linux`** , use [Pacman Command][12] to install tmux.
+
+```
+$ sudo pacman -S nodejs npm
+
+```
+
+For **`openSUSE`** , use [Zypper Command][13] to install tmux.
+
+```
+$ sudo zypper in nodejs6
+
+```
+
+### How to Install Terminalizer
+
+As you have already installed prerequisite package called Node.js, now it’s time to install Terminalizer on your system. Simple run the below npm command to install Terminalizer.
+
+```
+$ sudo npm install -g terminalizer
+
+```
+
+### How to Use Terminalizer
+
+To record your session activity using Terminalizer, just run the following Terminalizer command. Once you started the recording then play around it and finally hit `CTRL+D` to exit and save the recording.
+
+```
+# terminalizer record 2g-session
+
+defaultConfigPath
+The recording session is started
+Press CTRL+D to exit and save the recording
+
+```
+
+This will save your recording session as a YAML file, in this case my filename would be 2g-session-activity.yml.
+![][15]
+
+Just type few commands to verify this and finally hit `CTRL+D` to exit the current capture. When you hit `CTRL+D` on the terminal and you will be getting the below output.
+
+```
+# logout
+Successfully Recorded
+The recording data is saved into the file:
+/home/daygeek/2g-session.yml
+You can edit the file and even change the configurations.
+
+```
+
+![][16]
+
+### How to Play the Recorded File
+
+Use the below command format to paly your recorded YAML file. Make sure, you have to input your recorded file instead of us.
+
+```
+# terminalizer play 2g-session
+
+```
+
+Render a recording file as an animated gif image.
+
+```
+# terminalizer render 2g-session
+
+```
+
+`Note:` Below two commands are not implemented yet in the current version and will be available in the next version.
+
+If you would like to share your recording to others then upload a recording file and get a link for an online player and share it.
+
+```
+terminalizer share 2g-session
+
+```
+
+Generate a web player for a recording file
+
+```
+# terminalizer generate 2g-session
+
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/terminalizer-a-tool-to-record-your-terminal-and-generate-animated-gif-images/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/prakash/
+[1]: https://www.2daygeek.com/script-command-record-save-your-terminal-session-activity-linux/
+[2]: https://www.2daygeek.com/automatically-record-all-users-terminal-sessions-activity-linux-script-command/
+[3]: https://www.2daygeek.com/teleconsole-share-terminal-session-instantly-to-anyone-in-seconds/
+[4]: https://www.2daygeek.com/tmate-instantly-share-your-terminal-session-to-anyone-in-seconds/
+[5]: https://www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/
+[6]: https://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/
+[7]: https://www.2daygeek.com/gifine-create-animated-gif-vedio-recorder-linux-mint-debian-ubuntu/
+[8]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
+[9]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
+[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
+[11]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
+[12]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
+[13]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
+[14]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[15]: https://www.2daygeek.com/wp-content/uploads/2018/10/terminalizer-record-2g-session-1.gif
+[16]: https://www.2daygeek.com/wp-content/uploads/2018/10/terminalizer-play-2g-session.gif
diff --git a/sources/tech/20181008 KeeWeb - An Open Source, Cross Platform Password Manager.md b/sources/tech/20181008 KeeWeb - An Open Source, Cross Platform Password Manager.md
new file mode 100644
index 0000000000..a9b20ac54d
--- /dev/null
+++ b/sources/tech/20181008 KeeWeb - An Open Source, Cross Platform Password Manager.md
@@ -0,0 +1,110 @@
+KeeWeb – An Open Source, Cross Platform Password Manager
+======
+
+
+
+If you’ve been using the internet for any amount of time, chances are, you have a lot of accounts on a lot of websites. All of those accounts must have passwords, and you have to remember all those passwords. Either that, or write them down somewhere. Writing down passwords on paper may not be secure, and remembering them won’t be practically possible if you have more than a few passwords. This is why Password Managers have exploded in popularity in the last few years. A password Manager is like a central repository where you store all your passwords for all your accounts, and you lock it with a master password. With this approach, the only thing you need to remember is the Master password.
+
+**KeePass** is one such open source password manager. KeePass has an official client, but it’s pretty barebones. But there are a lot of other apps, both for your computer and for your phone, that are compatible with the KeePass file format for storing encrypted passwords. One such app is **KeeWeb**.
+
+KeeWeb is an open source, cross platform password manager with features like cloud sync, keyboard shortcuts and plugin support. KeeWeb uses Electron, which means it runs on Windows, Linux, and Mac OS.
+
+### Using KeeWeb Password Manager
+
+When it comes to using KeeWeb, you actually have 2 options. You can either use KeeWeb webapp without having to install it on your system and use it on the fly or simply install KeeWeb client in your local system.
+
+**Using the KeeWeb webapp**
+
+If you don’t want to bother installing a desktop app, you can just go to [**https://app.keeweb.info/**][1] and use it as a password manager.
+
+
+
+It has all the features of the desktop app. Obviously, this requires you to be online when using the app.
+
+**Installing KeeWeb on your Desktop**
+
+If you like the comfort and offline availability of using a desktop app, you can also install it on your desktop.
+
+If you use Ubuntu/Debian, you can just go to [**releases pages**][2] and download KeeWeb latest **.deb** file, which you can install via this command:
+
+```
+$ sudo dpkg -i KeeWeb-1.6.3.linux.x64.deb
+
+```
+
+If you’re on Arch, it is available in the [**AUR**][3], so you can install using any helper programs like [**Yay**][4]:
+
+```
+$ yay -S keeweb
+
+```
+
+Once installed, launch it from Menu or application launcher. This is how KeeWeb default interface looks like:
+
+
+
+### General Layout
+
+KeeWeb basically shows a list of all your passwords, along with all your tags to the left. Clicking on a tag will filter the list to only passwords of that tag. To the right, all the fields for the selected account are shown. You can set username, password, website, or just add a custom note. You can even create your own fields and mark them as secure fields, which is great when storing things like credit card information. You can copy passwords by just clicking on them. KeeWeb also shows the date when an account was created and modified. Deleted passwords are kept in the trash, where they can be restored or permanently deleted.
+
+
+
+### KeeWeb Features
+
+**Cloud Sync**
+
+One of the main features of KeeWeb is the support for a wide variety of remote locations and cloud services.
+Other than loading local files, you can open files from:
+
+ 1. WebDAV Servers
+ 2. Google Drive
+ 3. Dropbox
+ 4. OneDrive
+
+
+
+This means that if you use multiple computers, you can synchronize the password files between them, so you don’t have to worry about not having all the passwords available on all devices.
+
+**Password Generator**
+
+
+
+Along with encrypting your passwords, it’s also important to create new, strong passwords for every single account. This means that if one of your account gets hacked, the attacker won’t be able to get in to your other accounts using the same password.
+
+To achieve this, KeeWeb has a built-in password generator, that lets you generate a custom password of a specific length, including specific type of characters.
+
+**Plugins**
+
+
+
+You can extend KeeWeb functionality with plugins. Some of these plugins are translations for other languages, while others add new functionality, like checking **** for exposed passwords.
+
+**Local Backups**
+
+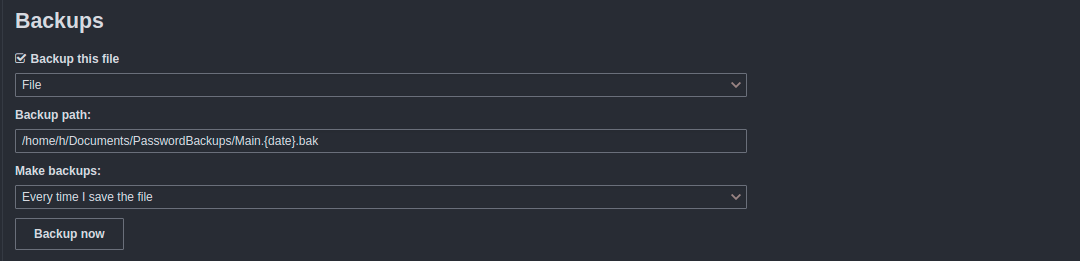
+
+Regardless of where your password file is stored, you should probably keep local backups of the file on your computer. Luckily, KeeWeb has this feature built-in. You can backup to a specific path, and set it to backup periodically, or just whenever the file is changed.
+
+
+### Verdict
+
+I have actually been using KeeWeb for several years now. It completely changed the way I store my passwords. The cloud sync is basically the feature that makes it a done deal for me. I don’t have to worry about keeping multiple unsynchronized files on multiple devices. If you want a great looking password manager that has cloud sync, KeeWeb is something you should look at.
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-manager/
+
+作者:[EDITOR][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/editor/
+[1]: https://app.keeweb.info/
+[2]: https://github.com/keeweb/keeweb/releases/latest
+[3]: https://aur.archlinux.org/packages/keeweb/
+[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
diff --git a/sources/tech/20181008 Play Windows games on Fedora with Steam Play and Proton.md b/sources/tech/20181008 Play Windows games on Fedora with Steam Play and Proton.md
new file mode 100644
index 0000000000..16930083fd
--- /dev/null
+++ b/sources/tech/20181008 Play Windows games on Fedora with Steam Play and Proton.md
@@ -0,0 +1,105 @@
+translating by hopefully2333
+
+Play Windows games on Fedora with Steam Play and Proton
+======
+
+
+
+Some weeks ago, Steam [announced][1] a new addition to Steam Play with Linux support for Windows games using Proton, a fork from WINE. This capability is still in beta, and not all games work. Here are some more details about Steam and Proton.
+
+According to the Steam website, there are new features in the beta release:
+
+ * Windows games with no Linux version currently available can now be installed and run directly from the Linux Steam client, complete with native Steamworks and OpenVR support.
+ * DirectX 11 and 12 implementations are now based on Vulkan, which improves game compatibility and reduces performance impact.
+ * Fullscreen support has been improved. Fullscreen games seamlessly stretch to the desired display without interfering with the native monitor resolution or requiring the use of a virtual desktop.
+ * Improved game controller support. Games automatically recognize all controllers supported by Steam. Expect more out-of-the-box controller compatibility than even the original version of the game.
+ * Performance for multi-threaded games has been greatly improved compared to vanilla WINE.
+
+
+
+### Installation
+
+If you’re interested in trying Steam with Proton out, just follow these easy steps. (Note that you can ignore the first steps to enable the Steam Beta if you have the [latest updated version of Steam installed][2]. In that case you no longer need Steam Beta to use Proton.)
+
+Open up Steam and log in to your account. This example screenshot shows support for only 22 games before enabling Proton.
+
+![][3]
+
+Now click on Steam option on top of the client. This displays a drop down menu. Then select Settings.
+
+![][4]
+
+Now the settings window pops up. Select the Account option and next to Beta participation, click on change.
+
+![][5]
+
+Now change None to Steam Beta Update.
+
+![][6]
+
+Click on OK and a prompt asks you to restart.
+
+![][7]
+
+Let Steam download the update. This can take a while depending on your internet speed and computer resources.
+
+![][8]
+
+After restarting, go back to the Settings window. This time you’ll see a new option. Make sure the check boxes for Enable Steam Play for supported titles, Enable Steam Play for all titles and Use this tool instead of game-specific selections from Steam are enabled. The compatibility tool should be Proton.
+
+![][9]
+
+The Steam client asks you to restart. Do so, and once you log back into your Steam account, your game library for Linux should be extended.
+
+![][10]
+
+### Installing a Windows game using Steam Play
+
+Now that you have Proton enabled, install a game. Select the title you want and you’ll find the process is similar to installing a normal game on Steam, as shown in these screenshots.
+
+![][11]
+
+![][12]
+
+![][13]
+
+![][14]
+
+After the game is done downloading and installing, you can play it.
+
+![][15]
+
+![][16]
+
+Some games may be affected by the beta nature of Proton. The game in this example, Chantelise, had no audio and a low frame rate. Keep in mind this capability is still in beta and Fedora is not responsible for results. If you’d like to read further, the community has created a [Google doc][17] with a list of games that have been tested.
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/play-windows-games-steam-play-proton/
+
+作者:[Francisco J. Vergara Torres][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/patxi/
+[1]: https://steamcommunity.com/games/221410/announcements/detail/1696055855739350561
+[2]: https://fedoramagazine.org/third-party-repositories-fedora/
+[3]: https://fedoramagazine.org/wp-content/uploads/2018/09/listOfGamesLinux-300x197.png
+[4]: https://fedoramagazine.org/wp-content/uploads/2018/09/1-300x169.png
+[5]: https://fedoramagazine.org/wp-content/uploads/2018/09/2-300x196.png
+[6]: https://fedoramagazine.org/wp-content/uploads/2018/09/4-300x272.png
+[7]: https://fedoramagazine.org/wp-content/uploads/2018/09/6-300x237.png
+[8]: https://fedoramagazine.org/wp-content/uploads/2018/09/7-300x126.png
+[9]: https://fedoramagazine.org/wp-content/uploads/2018/09/10-300x237.png
+[10]: https://fedoramagazine.org/wp-content/uploads/2018/09/12-300x196.png
+[11]: https://fedoramagazine.org/wp-content/uploads/2018/09/13-300x196.png
+[12]: https://fedoramagazine.org/wp-content/uploads/2018/09/14-300x195.png
+[13]: https://fedoramagazine.org/wp-content/uploads/2018/09/15-300x196.png
+[14]: https://fedoramagazine.org/wp-content/uploads/2018/09/16-300x195.png
+[15]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-14-59-300x169.png
+[16]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-19-34-300x169.png
+[17]: https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/edit#gid=1003113831
diff --git a/sources/tech/20181008 Taking notes with Laverna, a web-based information organizer.md b/sources/tech/20181008 Taking notes with Laverna, a web-based information organizer.md
new file mode 100644
index 0000000000..27616a9f6e
--- /dev/null
+++ b/sources/tech/20181008 Taking notes with Laverna, a web-based information organizer.md
@@ -0,0 +1,128 @@
+Taking notes with Laverna, a web-based information organizer
+======
+
+
+
+I don’t know anyone who doesn’t take notes. Most of the people I know use an online note-taking application like Evernote, Simplenote, or Google Keep.
+
+All of those are good tools, but they’re proprietary. And you have to wonder about the privacy of your information—especially in light of [Evernote’s great privacy flip-flop of 2016][1]. If you want more control over your notes and your data, you need to turn to an open source tool—preferably one that you can host yourself.
+
+And there are a number of good [open source alternatives to Evernote][2]. One of these is Laverna. Let’s take a look at it.
+
+### Getting Laverna
+
+You can [host Laverna yourself][3] or use the [web version][4]
+
+Since I have nowhere to host the application, I’ll focus here on using the web version of Laverna. Aside from the installation and setting up storage (more on that below), I’m told that the experience with a self-hosted version of Laverna is the same.
+
+### Setting up Laverna
+
+To start using Laverna right away, click the **Start using now** button on the front page of [Laverna.cc][5].
+
+On the welcome screen, click **Next**. You’ll be asked to enter an encryption password to secure your notes and get to them when you need to. You’ll also be asked to choose a way to synchronize your notes. I’ll discuss synchronization in a moment, so just enter a password and click **Next**.
+
+
+
+When you log in, you'll see a blank canvas:
+
+
+
+### Storing your notes
+
+Before diving into how to use Laverna, let’s walk through how to store your notes.
+
+Out of the box, Laverna stores your notes in your browser’s cache. The problem with that is when you clear the cache, you lose your notes. You can also store your notes using:
+
+ * Dropbox, a popular and proprietary web-based file syncing and storing service
+ * [remoteStorage][6], which offers a way for web applications to store information in the cloud.
+
+
+
+Using Dropbox is convenient, but it’s proprietary. There are also concerns about [privacy and surveillance][7]. Laverna encrypts your notes before saving them, but not all encryption is foolproof. Even if you don’t have anything illegal or sensitive in your notes, they’re no one’s business but your own.
+
+remoteStorage, on the other hand, is kind of techie to set up. There are few hosted storage services out there. I use [5apps][8].
+
+To change how Laverna stores your notes, click the hamburger menu in the top-left corner. Click **Settings** and then **Sync**.
+
+
+
+Select the service you want to use, then click **Save**. After that, click the left arrow in the top-left corner. You’ll be asked to authorize Laverna with the service you chose.
+
+### Using Laverna
+
+With that out of the way, let’s get down to using Laverna. Create a new note by clicking the **New Note** icon, which opens the note editor:
+
+
+
+Type a title for your note, then start typing the note in the left pane of the editor. The right pane displays a preview of your note:
+
+
+
+You can format your notes using Markdown; add formatting using your keyboard or the toolbar at the top of the window.
+
+You can also embed an image or file from your computer into a note, or link to one on the web. When you embed an image, it’s stored with your note.
+
+When you’re done, click **Save**.
+
+### Organizing your notes
+
+Like some other note-taking tools, Laverna lists the last note that you created or edited at the top. If you have a lot of notes, it can take a bit of work to find the one you're looking for.
+
+To better organize your notes, you can group them into notebooks, where you can quickly filter them based on a topic or a grouping.
+
+When you’re creating or editing a note, you can select a notebook from the **Select notebook** list in the top-left corner of the window. If you don’t have any notebooks, select **Add a new notebook** from the list and type the notebook’s name.
+
+You can also make that notebook a child of another notebook. Let’s say, for example, you maintain three blogs. You can create a notebook called **Blog Post Notes** and name children for each blog.
+
+To filter your notes by notebook, click the hamburger menu, followed by the name of a notebook. Only the notes in the notebook you choose will appear in the list.
+
+
+
+### Using Laverna across devices
+
+I use Laverna on my laptop and on an eight-inch tablet running [LineageOS][9]. Getting the two devices to use the same storage and display the same notes takes a little work.
+
+First, you’ll need to export your settings. Log into wherever you’re using Laverna and click the hamburger menu. Click **Settings** , then **Import & Export**. Under **Settings** , click **Export settings**. Laverna saves a file named laverna-settings.json to your device.
+
+Copy that file to the other device or devices on which you want to use Laverna. You can do that by emailing it to yourself or by syncing the file across devices using an application like [ownCloud][10] or [Nextcloud][11].
+
+On the other device, click **Import** on the splash screen. Otherwise, click the hamburger menu and then **Settings > Import & Export**. Click **Import settings**. Find the JSON file with your settings, click **Open** and then **Save**.
+
+Laverna will ask you to:
+
+ * Log back in using your password.
+ * Register with the storage service you’re using.
+
+
+
+Repeat this process for each device that you want to use. It’s cumbersome, I know. I’ve done it. You should need to do it only once per device, though.
+
+### Final thoughts
+
+Once you set up Laverna, it’s easy to use and has just the right features for what I need to do. I’m hoping that the developers can expand the storage and syncing options to include open source applications like Nextcloud and ownCloud.
+
+While Laverna doesn’t have all the bells and whistles of a note-taking application like Evernote, it does a great job of letting you take and organize your notes. The fact that Laverna is open source and supports Markdown are two additional great reasons to use it.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/10/taking-notes-laverna
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[1]: https://blog.evernote.com/blog/2016/12/15/evernote-revisits-privacy-policy/
+[2]: https://opensource.com/life/16/8/open-source-alternatives-evernote
+[3]: https://github.com/Laverna/laverna
+[4]: https://laverna.cc/
+[5]: http://laverna.cc/
+[6]: https://remotestorage.io/
+[7]: https://www.zdnet.com/article/dropbox-faces-questions-over-claims-of-improper-data-sharing/
+[8]: https://5apps.com/storage/beta
+[9]: https://lineageos.org/
+[10]: https://owncloud.com/
+[11]: https://nextcloud.com/
diff --git a/sources/tech/20181009 6 Commands To Shutdown And Reboot The Linux System From Terminal.md b/sources/tech/20181009 6 Commands To Shutdown And Reboot The Linux System From Terminal.md
new file mode 100644
index 0000000000..c119f69ebf
--- /dev/null
+++ b/sources/tech/20181009 6 Commands To Shutdown And Reboot The Linux System From Terminal.md
@@ -0,0 +1,331 @@
+translating---cyleft
+====
+
+6 Commands To Shutdown And Reboot The Linux System From Terminal
+======
+Linux administrator performing many tasks in their routine work. The system Shutdown and Reboot task also included in it.
+
+It’s one of the risky task for them because some times it wont come back due to some reasons and they need to spend more time on it to troubleshoot.
+
+These task can be performed through CLI in Linux. Most of the time Linux administrator prefer to perform these kind of tasks via CLI because they are familiar on this.
+
+There are few commands are available in Linux to perform these tasks and user needs to choose appropriate command to perform the task based on the requirement.
+
+All these commands has their own feature and allow Linux admin to use it.
+
+**Suggested Read :**
+**(#)** [11 Methods To Find System/Server Uptime In Linux][1]
+**(#)** [Tuptime – A Tool To Report The Historical And Statistical Running Time Of Linux System][2]
+
+When the system is initiated for Shutdown or Reboot. It will be notified to all logged-in users and processes. Also, it wont allow any new logins if the time argument is used.
+
+I would suggest you to double check before you perform this action because you need to follow few prerequisites to make sure everything is fine.
+
+Those steps are listed below.
+
+ * Make sure you should have a console access to troubleshoot further in case any issues arise. VMWare access for VMs and IPMI/iLO/iDRAC access for physical servers.
+ * You have to create a ticket as per your company procedure either Incident or Change ticket and get approval
+ * Take the important configuration files backup and move to other servers for safety
+ * Verify the log files (Perform the pre-check)
+ * Communicate about your activity with other dependencies teams like DBA, Application, etc
+ * Ask them to bring down their Database service or Application service and get a confirmation from them.
+ * Validate the same from your end using the appropriate command to double confirm this.
+ * Finally reboot the system
+ * Verify the log files (Perform the post-check), If everything is good then move to next step. If you found something is wrong then troubleshoot accordingly.
+ * If it’s back to up and running, ask the dependencies team to bring up their applications.
+ * Monitor for some time, and communicate back to them saying everything is working fine as expected.
+
+
+
+This task can be performed using following commands.
+
+ * **`shutdown Command:`** shutdown command used to halt, power-off or reboot the machine.
+ * **`halt Command:`** halt command used to halt, power-off or reboot the machine.
+ * **`poweroff Command:`** poweroff command used to halt, power-off or reboot the machine.
+ * **`reboot Command:`** reboot command used to halt, power-off or reboot the machine.
+ * **`init Command:`** init (short for initialization) is the first process started during booting of the computer system.
+ * **`systemctl Command:`** systemd is a system and service manager for Linux operating systems.
+
+
+
+### Method-1: How To Shutdown And Reboot The Linux System Using Shutdown Command
+
+shutdown command used to power-off or reboot a Linux remote machine or local host. It’s offering
+multiple options to perform this task effectively. If the time argument is used, 5 minutes before the system goes down the /run/nologin file is created to ensure that further logins shall not be allowed.
+
+The general syntax is
+
+```
+# shutdown [OPTION] [TIME] [MESSAGE]
+
+```
+
+Run the below command to shutdown a Linux machine immediately. It will kill all the processes immediately and will shutdown the system.
+
+```
+# shutdown -h now
+
+```
+
+ * **`-h:`** Equivalent to –poweroff, unless –halt is specified.
+
+
+
+Alternatively we can use the shutdown command with `halt` option to bring down the machine immediately.
+
+```
+# shutdown --halt now
+or
+# shutdown -H now
+
+```
+
+ * **`-H, --halt:`** Halt the machine.
+
+
+
+Alternatively we can use the shutdown command with `poweroff` option to bring down the machine immediately.
+
+```
+# shutdown --poweroff now
+or
+# shutdown -P now
+
+```
+
+ * **`-P, --poweroff:`** Power-off the machine (the default).
+
+
+
+Run the below command to shutdown a Linux machine immediately. It will kill all the processes immediately and will shutdown the system.
+
+```
+# shutdown -h now
+
+```
+
+ * **`-h:`** Equivalent to –poweroff, unless –halt is specified.
+
+
+
+If you run the below commands without time parameter, it will wait for a minute then execute the given command.
+
+```
+# shutdown -h
+Shutdown scheduled for Mon 2018-10-08 06:42:31 EDT, use 'shutdown -c' to cancel.
+
+[email protected]#
+Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
+
+The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
+
+```
+
+All other logged in users can see a broadcast message in their terminal like below.
+
+```
+[[email protected] ~]$
+Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
+
+The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
+
+```
+
+for Halt option.
+
+```
+# shutdown -H
+Shutdown scheduled for Mon 2018-10-08 06:37:53 EDT, use 'shutdown -c' to cancel.
+
+[email protected]#
+Broadcast message from [email protected] (Mon 2018-10-08 06:36:53 EDT):
+
+The system is going down for system halt at Mon 2018-10-08 06:37:53 EDT!
+
+```
+
+for Poweroff option.
+
+```
+# shutdown -P
+Shutdown scheduled for Mon 2018-10-08 06:40:07 EDT, use 'shutdown -c' to cancel.
+
+[email protected]#
+Broadcast message from [email protected] (Mon 2018-10-08 06:39:07 EDT):
+
+The system is going down for power-off at Mon 2018-10-08 06:40:07 EDT!
+
+```
+
+This can be cancelled by hitting `shutdown -c` option on your terminal.
+
+```
+# shutdown -c
+
+Broadcast message from [email protected] (Mon 2018-10-08 06:39:09 EDT):
+
+The system shutdown has been cancelled at Mon 2018-10-08 06:40:09 EDT!
+
+```
+
+All other logged in users can see a broadcast message in their terminal like below.
+
+```
+[[email protected] ~]$
+Broadcast message from [email protected] (Mon 2018-10-08 06:41:35 EDT):
+
+The system shutdown has been cancelled at Mon 2018-10-08 06:42:35 EDT!
+
+```
+
+Add a time parameter, if you want to perform shutdown or reboot in `N` seconds. Here you can add broadcast a custom message to logged-in users. In this example, we are rebooting the machine in another 5 minutes.
+
+```
+# shutdown -r +5 "To activate the latest Kernel"
+Shutdown scheduled for Mon 2018-10-08 07:13:16 EDT, use 'shutdown -c' to cancel.
+
+[[email protected] ~]#
+Broadcast message from [email protected] (Mon 2018-10-08 07:08:16 EDT):
+
+To activate the latest Kernel
+The system is going down for reboot at Mon 2018-10-08 07:13:16 EDT!
+
+```
+
+Run the below command to reboot a Linux machine immediately. It will kill all the processes immediately and will reboot the system.
+
+```
+# shutdown -r now
+
+```
+
+ * **`-r, --reboot:`** Reboot the machine.
+
+
+
+### Method-2: How To Shutdown And Reboot The Linux System Using reboot Command
+
+reboot command used to power-off or reboot a Linux remote machine or local host. Reboot command comes with two useful options.
+
+It will perform a graceful shutdown and restart of the machine (This is similar to your restart option which is available in your system menu).
+
+Run “reboot’ command without any option to reboot Linux machine.
+
+```
+# reboot
+
+```
+
+Run the “reboot” command with `-p` option to power-off or shutdown the Linux machine.
+
+```
+# reboot -p
+
+```
+
+ * **`-p, --poweroff:`** Power-off the machine, either halt or poweroff commands is invoked.
+
+
+
+Run the “reboot” command with `-f` option to forcefully reboot the Linux machine (This is similar to pressing the power button on the CPU).
+
+```
+# reboot -f
+
+```
+
+ * **`-f, --force:`** Force immediate halt, power-off, or reboot.
+
+
+
+### Method-3: How To Shutdown And Reboot The Linux System Using init Command
+
+init (short for initialization) is the first process started during booting of the computer system.
+
+It will check the /etc/inittab file to decide the Linux run level. Also, allow users to perform shutdown and reboot the Linux machine. There are seven runlevels exist, from zero to six.
+
+**Suggested Read :**
+**(#)** [How To Check All Running Services In Linux][3]
+
+Run the below init command to shutdown the system .
+
+```
+# init 0
+
+```
+
+ * **`0:`** Halt – to shutdown the system.
+
+
+
+Run the below init command to reboot the system .
+
+```
+# init 6
+
+```
+
+ * **`6:`** Reboot – to reboot the system.
+
+
+
+### Method-4: How To Shutdown The Linux System Using halt Command
+
+halt command used to power-off or shutdown a Linux remote machine or local host.
+halt terminates all processes and shuts down the cpu.
+
+```
+# halt
+
+```
+
+### Method-5: How To Shutdown The Linux System Using poweroff Command
+
+poweroff command used to power-off or shutdown a Linux remote machine or local host. Poweroff is exactly like halt, but it also turns off the unit itself (lights and everything on a PC). It sends an ACPI command to the board, then to the PSU, to cut the power.
+
+```
+# poweroff
+
+```
+
+### Method-6: How To Shutdown And Reboot The Linux System Using systemctl Command
+
+Systemd is a new init system and system manager which was implemented/adapted into all the major Linux distributions over the traditional SysV init systems.
+
+systemd is compatible with SysV and LSB init scripts. It can work as a drop-in replacement for sysvinit system. systemd is the first process get started by kernel and holding PID 1.
+
+**Suggested Read :**
+**(#)** [chkservice – A Tool For Managing Systemd Units From Linux Terminal][4]
+
+It’s a parent process for everything and Fedora 15 is the first distribution which was adapted systemd instead of upstart.
+
+systemctl is command line utility and primary tool to manage the systemd daemons/services such as (start, restart, stop, enable, disable, reload & status).
+
+systemd uses .service files Instead of bash scripts (SysVinit uses). systemd sorts all daemons into their own Linux cgroups and you can see the system hierarchy by exploring /cgroup/systemd file.
+
+```
+# systemctl halt
+# systemctl poweroff
+# systemctl reboot
+# systemctl suspend
+# systemctl hibernate
+
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/6-commands-to-shutdown-halt-poweroff-reboot-the-linux-system/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/prakash/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/
+[2]: https://www.2daygeek.com/tuptime-a-tool-to-report-the-historical-and-statistical-running-time-of-linux-system/
+[3]: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
+[4]: https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/
diff --git a/sources/tech/20181009 Convert Screenshots of Equations into LaTeX Instantly With This Nifty Tool.md b/sources/tech/20181009 Convert Screenshots of Equations into LaTeX Instantly With This Nifty Tool.md
new file mode 100644
index 0000000000..8e9abf4b52
--- /dev/null
+++ b/sources/tech/20181009 Convert Screenshots of Equations into LaTeX Instantly With This Nifty Tool.md
@@ -0,0 +1,72 @@
+translating---geekpi
+
+Convert Screenshots of Equations into LaTeX Instantly With This Nifty Tool
+======
+**Mathpix is a nifty little tool that allows you to take screenshots of complex mathematical equations and instantly converts it into LaTeX editable text.**
+
+![Mathpix converts math equations images into LaTeX][1]
+
+[LaTeX editors][2] are excellent when it comes to writing academic and scientific documentation.
+
+There is a steep learning curved involved of course. And this learning curve becomes steeper if you have to write complex mathematical equations.
+
+[Mathpix][3] is a nifty little tool that helps you in this regard.
+
+Suppose you are reading a document that has mathematical equations. If you want to use those equations in your [LaTeX document][4], you need to use your ninja LaTeX skills and plenty of time.
+
+But Mathpix solves this problem for you. With Mathpix, you take the screenshot of the mathematical equations, and it will instantly give you the LaTeX code. You can then use this code in your [favorite LaTeX editor][2].
+
+See Mathpix in action in the video below:
+
+
+
+[Video credit][5]: Reddit User [kaitlinmcunningham][6]
+
+Isn’t it super-cool? I guess the hardest part of writing LaTeX documents are those complicated equations. For lazy bums like me, Mathpix is a godsend.
+
+### Getting Mathpix
+
+Mathpix is available for Linux, macOS, Windows and iOS. There is no Android app for the moment.
+
+Note: Mathpix is a free to use tool but it’s not open source.
+
+On Linux, [Mathpix is available as a Snap package][7]. Which means [if you have Snap support enabled on your Linux distribution][8], you can install Mathpix with this simple command:
+
+```
+sudo snap install mathpix-snipping-tool
+
+```
+
+Using Mathpix is simple. Once installed, open the tool. You’ll find it in the top panel. You can start taking the screenshot with Mathpix using the keyboard shortcut Ctrl+Alt+M.
+
+It will instantly translate the image of equation into a LaTeX code. The code will be copied into clipboard and you can then paste it in a LaTeX editor.
+
+Mathpix’s optical character recognition technology is [being used][9] by a number of companies like [WolframAlpha][10], Microsoft, Google, etc. to improve their tools’ image recognition capability while dealing with math symbols.
+
+Altogether, it’s an awesome tool for students and academics. It’s free to use and I so wish that it was an open source tool. We cannot get everything in life, can we?
+
+Do you use Mathpix or some other similar tool while dealing with mathematical symbols in LaTeX? What do you think of Mathpix? Share your views with us in the comment section.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/mathpix/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/mathpix-converts-equations-into-latex.jpeg
+[2]: https://itsfoss.com/latex-editors-linux/
+[3]: https://mathpix.com/
+[4]: https://www.latex-project.org/
+[5]: https://g.redditmedia.com/b-GL1rQwNezQjGvdlov9U_6vDwb1A7kEwGHYcQ1Ogtg.gif?fm=mp4&mp4-fragmented=false&s=39fd1816b43e2b544986d629f75a7a8e
+[6]: https://www.reddit.com/user/kaitlinmcunningham
+[7]: https://snapcraft.io/mathpix-snipping-tool
+[8]: https://itsfoss.com/install-snap-linux/
+[9]: https://mathpix.com/api.html
+[10]: https://www.wolframalpha.com/
diff --git a/sources/tech/20181009 How To Create And Maintain Your Own Man Pages.md b/sources/tech/20181009 How To Create And Maintain Your Own Man Pages.md
new file mode 100644
index 0000000000..cb93af4b92
--- /dev/null
+++ b/sources/tech/20181009 How To Create And Maintain Your Own Man Pages.md
@@ -0,0 +1,199 @@
+Translating by way-ww
+How To Create And Maintain Your Own Man Pages
+======
+
+
+
+We already have discussed about a few [**good alternatives to Man pages**][1]. Those alternatives are mainly used for learning concise Linux command examples without having to go through the comprehensive man pages. If you’re looking for a quick and dirty way to easily and quickly learn a Linux command, those alternatives are worth trying. Now, you might be thinking – how can I create my own man-like help pages for a Linux command? This is where **“Um”** comes in handy. Um is a command line utility, used to easily create and maintain your own Man pages that contains only what you’ve learned about a command so far.
+
+By creating your own alternative to man pages, you can avoid lots of unnecessary, comprehensive details in a man page and include only what is necessary to keep in mind. If you ever wanted to created your own set of man-like pages, Um will definitely help. In this brief tutorial, we will see how to install “Um” command line utility and how to create our own man pages.
+
+### Installing Um
+
+Um is available for Linux and Mac OS. At present, it can only be installed using **Linuxbrew** package manager in Linux systems. Refer the following link if you haven’t installed Linuxbrew yet.
+
+Once Linuxbrew installed, run the following command to install Um utility.
+
+```
+$ brew install sinclairtarget/wst/um
+
+```
+
+If you will see an output something like below, congratulations! Um has been installed and ready to use.
+
+```
+[...]
+==> Installing sinclairtarget/wst/um
+==> Downloading https://github.com/sinclairtarget/um/archive/4.0.0.tar.gz
+==> Downloading from https://codeload.github.com/sinclairtarget/um/tar.gz/4.0.0
+-=#=# # #
+==> Downloading https://rubygems.org/gems/kramdown-1.17.0.gem
+######################################################################## 100.0%
+==> gem install /home/sk/.cache/Homebrew/downloads/d0a5d978120a791d9c5965fc103866815189a4e3939
+==> Caveats
+Bash completion has been installed to:
+/home/linuxbrew/.linuxbrew/etc/bash_completion.d
+==> Summary
+🍺 /home/linuxbrew/.linuxbrew/Cellar/um/4.0.0: 714 files, 1.3MB, built in 35 seconds
+==> Caveats
+==> openssl
+A CA file has been bootstrapped using certificates from the SystemRoots
+keychain. To add additional certificates (e.g. the certificates added in
+the System keychain), place .pem files in
+/home/linuxbrew/.linuxbrew/etc/openssl/certs
+
+and run
+/home/linuxbrew/.linuxbrew/opt/openssl/bin/c_rehash
+==> ruby
+Emacs Lisp files have been installed to:
+/home/linuxbrew/.linuxbrew/share/emacs/site-lisp/ruby
+==> um
+Bash completion has been installed to:
+/home/linuxbrew/.linuxbrew/etc/bash_completion.d
+
+```
+
+Before going to use to make your man pages, you need to enable bash completion for Um.
+
+To do so, open your **~/.bash_profile** file:
+
+```
+$ nano ~/.bash_profile
+
+```
+
+And, add the following lines in it:
+
+```
+if [ -f $(brew --prefix)/etc/bash_completion.d/um-completion.sh ]; then
+ . $(brew --prefix)/etc/bash_completion.d/um-completion.sh
+fi
+
+```
+
+Save and close the file. Run the following commands to update the changes.
+
+```
+$ source ~/.bash_profile
+
+```
+
+All done. let us go ahead and create our first man page.
+
+### Create And Maintain Your Own Man Pages
+
+Let us say, you want to create your own man page for “dpkg” command. To do so, run:
+
+```
+$ um edit dpkg
+
+```
+
+The above command will open a markdown template in your default editor:
+
+
+
+My default editor is Vi, so the above commands open it in the Vi editor. Now, start adding everything you want to remember about “dpkg” command in this template.
+
+Here is a sample:
+
+
+
+As you see in the above output, I have added Synopsis, description and two options for dpkg command. You can add as many as sections you want in the man pages. Make sure you have given proper and easily-understandable titles for each section. Once done, save and quit the file (If you use Vi editor, Press **ESC** key and type **:wq** ).
+
+Finally, view your newly created man page using command:
+
+```
+$ um dpkg
+
+```
+
+
+
+As you can see, the the dpkg man page looks exactly like the official man pages. If you want to edit and/or add more details in a man page, again run the same command and add the details.
+
+```
+$ um edit dpkg
+
+```
+
+To view the list of newly created man pages using Um, run:
+
+```
+$ um list
+
+```
+
+All man pages will be saved under a directory named**`.um`**in your home directory
+
+Just in case, if you don’t want a particular page, simply delete it as shown below.
+
+```
+$ um rm dpkg
+
+```
+
+To view the help section and all available general options, run:
+
+```
+$ um --help
+usage: um
+ um [ARGS...]
+
+The first form is equivalent to `um read `.
+
+Subcommands:
+ um (l)ist List the available pages for the current topic.
+ um (r)ead Read the given page under the current topic.
+ um (e)dit Create or edit the given page under the current topic.
+ um rm Remove the given page.
+ um (t)opic [topic] Get or set the current topic.
+ um topics List all topics.
+ um (c)onfig [config key] Display configuration environment.
+ um (h)elp [sub-command] Display this help message, or the help message for a sub-command.
+
+```
+
+### Configure Um
+
+To view the current configuration, run:
+
+```
+$ um config
+Options prefixed by '*' are set in /home/sk/.um/umconfig.
+editor = vi
+pager = less
+pages_directory = /home/sk/.um/pages
+default_topic = shell
+pages_ext = .md
+
+```
+
+In this file, you can edit and change the values for **pager** , **editor** , **default_topic** , **pages_directory** , and **pages_ext** options as you wish. Say for example, if you want to save the newly created Um pages in your **[Dropbox][2]** folder, simply change the value of **pages_directory** directive and point it to the Dropbox folder in **~/.um/umconfig** file.
+
+```
+pages_directory = /Users/myusername/Dropbox/um
+
+```
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-create-and-maintain-your-own-man-pages/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
+[2]: https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/
diff --git a/sources/tech/20181010 5 alerting and visualization tools for sysadmins.md b/sources/tech/20181010 5 alerting and visualization tools for sysadmins.md
new file mode 100644
index 0000000000..f933449461
--- /dev/null
+++ b/sources/tech/20181010 5 alerting and visualization tools for sysadmins.md
@@ -0,0 +1,163 @@
+5 alerting and visualization tools for sysadmins
+======
+These open source tools help users understand system behavior and output, and provide alerts for potential problems.
+
+
+
+You probably know (or can guess) what alerting and visualization tools are used for. Why would we discuss them as observability tools, especially since some systems include visualization as a feature?
+
+Observability comes from control theory and describes our ability to understand a system based on its inputs and outputs. This article focuses on the output component of observability.
+
+Alerting and visualization tools analyze the outputs of other systems and provide structured representations of these outputs. Alerts are basically a synthesized understanding of negative system outputs, and visualizations are disambiguated structured representations that facilitate user comprehension.
+
+### Common types of alerts and visualizations
+
+#### Alerts
+
+Let’s first cover what alerts are _not_. Alerts should not be sent if the human responder can’t do anything about the problem. This includes alerts that are sent to multiple individuals with only a few who can respond, or situations where every anomaly in the system triggers an alert. This leads to alert fatigue and receivers ignoring all alerts within a specific medium until the system escalates to a medium that isn’t already saturated.
+
+For example, if an operator receives hundreds of emails a day from the alerting system, that operator will soon ignore all emails from the alerting system. The operator will respond to a real incident only when he or she is experiencing the problem, emailed by a customer, or called by the boss. In this case, alerts have lost their meaning and usefulness.
+
+Alerts are not a constant stream of information or a status update. They are meant to convey a problem from which the system can’t automatically recover, and they are sent only to the individual most likely to be able to recover the system. Everything that falls outside this definition isn’t an alert and will only damage your employees and company culture.
+
+Everyone has a different set of alert types, so I won't discuss things like priority levels (P1-P5) or models that use words like "Informational," "Warning," and "Critical." Instead, I’ll describe the generic categories emergent in complex systems’ incident response.
+
+You might have noticed I mentioned an “Informational” alert type right after I wrote that alerts shouldn’t be informational. Well, not everyone agrees, but I don’t consider something an alert if it isn’t sent to anyone. It is a data point that many systems refer to as an alert. It represents some event that should be known but not responded to. It is generally part of the visualization system of the alerting tool and not an event that triggers actual notifications. Mike Julian covers this and other aspects of alerting in his book [Practical Monitoring][1]. It's a must read for work in this area.
+
+Non-informational alerts consist of types that can be responded to or require action. I group these into two categories: internal outage and external outage. (Most companies have more than two levels for prioritizing their response efforts.) Degraded system performance is considered an outage in this model, as the impact to each user is usually unknown.
+
+Internal outages are a lower priority than external outages, but they still need to be responded to quickly. They often include internal systems that company employees use or components of applications that are visible only to company employees.
+
+External outages consist of any system outage that would immediately impact a customer. These don’t include a system outage that prevents releasing updates to the system. They do include customer-facing application failures, database outages, and networking partitions that hurt availability or consistency if either can impact a user. They also include outages of tools that may not have a direct impact on users, as the application continues to run but this transparent dependency impacts performance. This is common when the system uses some external service or data source that isn’t necessary for full functionality but may cause delays as the application performs retries or handles errors from this external dependency.
+
+### Visualizations
+
+There are many visualization types, and I won’t cover them all here. It’s a fascinating area of research. On the data analytics side of my career, learning and applying that knowledge is a constant challenge. We need to provide simple representations of complex system outputs for the widest dissemination of information. [Google Charts][2] and [Tableau][3] have a wide selection of visualization types. We’ll cover the most common visualizations and some innovative solutions for quickly understanding systems.
+
+#### Line chart
+
+The line chart is probably the most common visualization. It does a pretty good job of producing an understanding of a system over time. A line chart in a metrics system would have a line for each unique metric or some aggregation of metrics. This can get confusing when there are a lot of metrics in the same dashboard (as shown below), but most systems can select specific metrics to view rather than having all of them visible. Also, anomalous behavior is easy to spot if it’s significant enough to escape the noise of normal operations. Below we can see purple, yellow, and light blue lines that might indicate anomalous behavior.
+
+
+
+Another feature of a line chart is that you can often stack them to show relationships. For example, you might want to look at requests on each server individually, but also in aggregate. This allows you to understand the overall system as well as each instance in the same graph.
+
+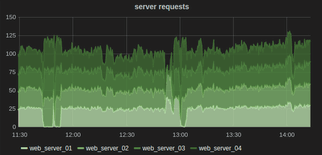
+
+#### Heatmaps
+
+Another common visualization is the heatmap. It is useful when looking at histograms. This type of visualization is similar to a bar chart but can show gradients within the bars representing the different percentiles of the overall metric. For example, suppose you’re looking at request latencies and you want to quickly understand the overall trend as well as the distribution of all requests. A heatmap is great for this, and it can use color to disambiguate the quantity of each section with a quick glance.
+
+The heatmap below shows the higher concentration around the centerline of the graph with an easy-to-understand visualization of the distribution vertically for each time bucket. We might want to review a couple of points in time where the distribution gets wide while the others are fairly tight like at 14:00. This distribution might be a negative performance indicator.
+
+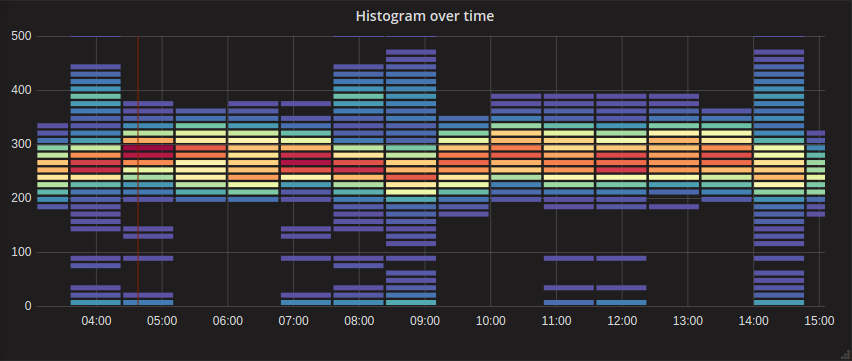
+
+#### Gauges
+
+The last common visualization I’ll cover here is the gauge, which helps users understand a single metric quickly. Gauges can represent a single metric, like your speedometer represents your driving speed or your gas gauge represents the amount of gas in your car. Similar to the gas gauge, most monitoring gauges clearly indicate what is good and what isn’t. Often (as is shown below), good is represented by green, getting worse by orange, and “everything is breaking” by red. The middle row below shows traditional gauges.
+
+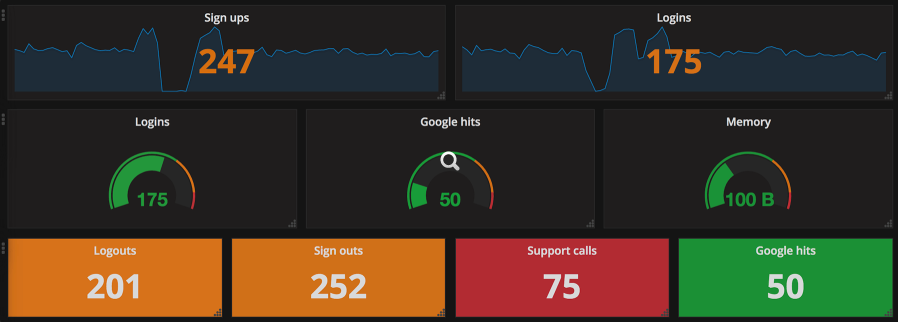
+
+This image shows more than just traditional gauges. The other gauges are single stat representations that are similar to the function of the classic gauge. They all use the same color scheme to quickly indicate system health with just a glance. Arguably, the bottom row is probably the best example of a gauge that allows you to glance at a dashboard and know that everything is healthy (or not). This type of visualization is usually what I put on a top-level dashboard. It offers a full, high-level understanding of system health in seconds.
+
+#### Flame graphs
+
+A less common visualization is the flame graph, introduced by [Netflix’s Brendan Gregg][4] in 2011. It’s not ideal for dashboarding or quickly observing high-level system concerns; it’s normally seen when trying to understand a specific application problem. This visualization focuses on CPU and memory and the associated frames. The X-axis lists the frames alphabetically, and the Y-axis shows stack depth. Each rectangle is a stack frame and includes the function being called. The wider the rectangle, the more it appears in the stack. This method is invaluable when trying to diagnose system performance at the application level and I urge everyone to give it a try.
+
+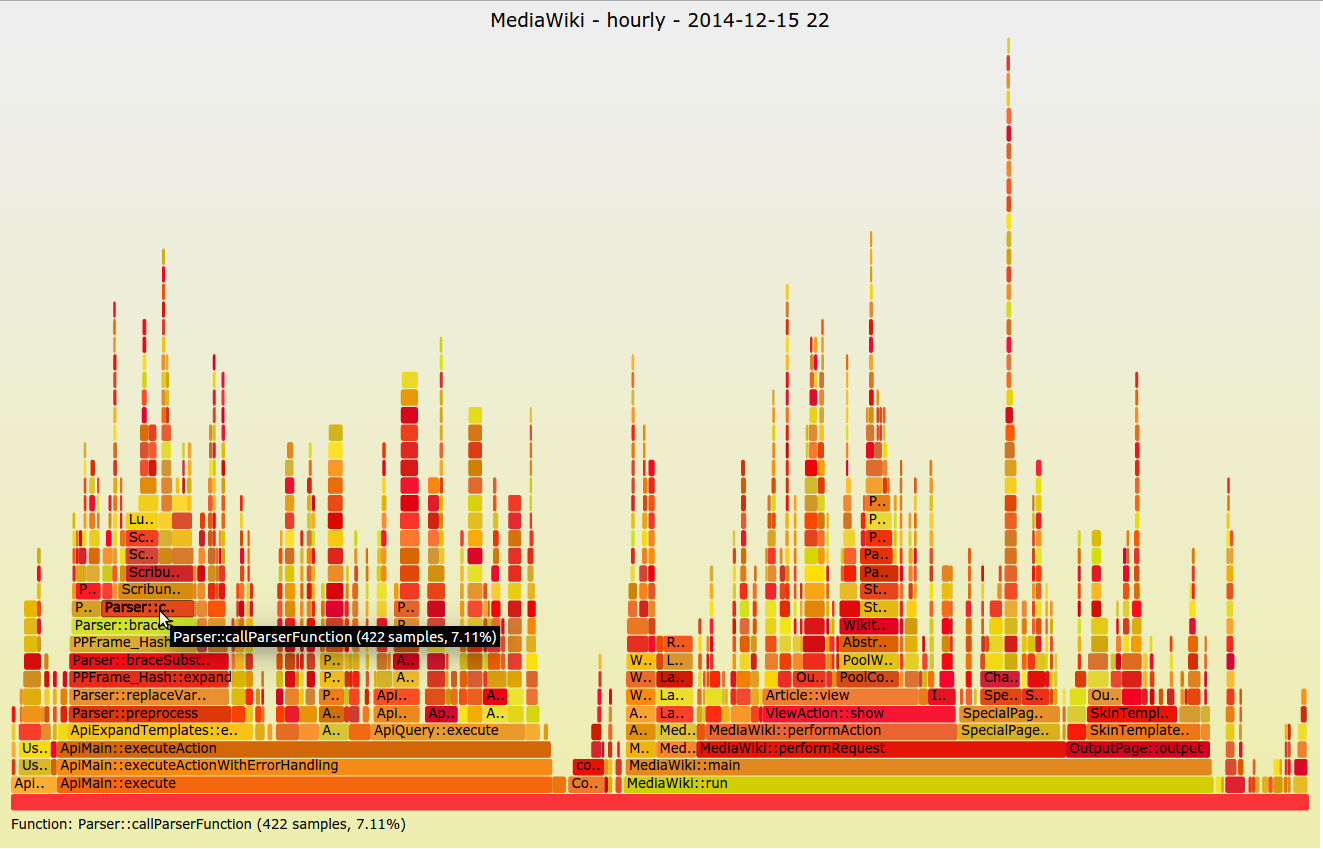
+
+### Tool options
+
+There are several commercial options for alerting, but since this is Opensource.com, I’ll cover only systems that are being used at scale by real companies that you can use at no cost. Hopefully, you’ll be able to contribute new and innovative features to make these systems even better.
+
+### Alerting tools
+
+#### Bosun
+
+If you’ve ever done anything with computers and gotten stuck, the help you received was probably thanks to a Stack Exchange system. Stack Exchange runs many different websites around a crowdsourced question-and-answer model. [Stack Overflow][5] is very popular with developers, and [Super User][6] is popular with operations. However, there are now hundreds of sites ranging from parenting to sci-fi and philosophy to bicycles.
+
+Stack Exchange open-sourced its alert management system, [Bosun][7], around the same time Prometheus and its [AlertManager][8] system were released. There were many similarities in the two systems, and that’s a really good thing. Like Prometheus, Bosun is written in Golang. Bosun’s scope is more extensive than Prometheus’ as it can interact with systems beyond metrics aggregation. It can also ingest data from log and event aggregation systems. It supports Graphite, InfluxDB, OpenTSDB, and Elasticsearch.
+
+Bosun’s architecture consists of a single server binary, a backend like OpenTSDB, Redis, and [scollector agents][9]. The scollector agents automatically detect services on a host and report metrics for those processes and other system resources. This data is sent to a metrics backend. The Bosun server binary then queries the backends to determine if any alerts need to be fired. Bosun can also be used by tools like [Grafana][10] to query the underlying backends through one common interface. Redis is used to store state and metadata for Bosun.
+
+A really neat feature of Bosun is that it lets you test your alerts against historical data. This was something I missed in Prometheus several years ago, when I had data for an issue I wanted alerts on but no easy way to test it. To make sure my alerts were working, I had to create and insert dummy data. This system alleviates that very time-consuming process.
+
+Bosun also has the usual features like showing simple graphs and creating alerts. It has a powerful expression language for writing alerting rules. However, it only has email and HTTP notification configurations, which means connecting to Slack and other tools requires a bit more customization ([which its documentation covers][11]). Similar to Prometheus, Bosun can use templates for these notifications, which means they can look as awesome as you want them to. You can use all your HTML and CSS skills to create the baddest email alert anyone has ever seen.
+
+#### Cabot
+
+[Cabot][12] was created by a company called [Arachnys][13]. You may not know who Arachnys is or what it does, but you have probably felt its impact: It built the leading cloud-based solution for fighting financial crimes. That sounds pretty cool, right? At a previous company, I was involved in similar functions around [“know your customer"][14] laws. Most companies would consider it a very bad thing to be linked to a terrorist group, for example, funneling money through their systems. These solutions also help defend against less-atrocious offenders like fraudsters who could also pose a risk to the institution.
+
+So why did Arachnys create Cabot? Well, it is kind of a Christmas present to everyone, as it was a Christmas project built because its developers couldn’t wrap their heads around [Nagios][15]. And really, who can blame them? Cabot was written with Django and Bootstrap, so it should be easy for most to contribute to the project. (Another interesting factoid: The name comes from the creator’s dog.)
+
+The Cabot architecture is similar to Bosun in that it doesn’t collect any data. Instead, it accesses data through the APIs of the tools it is alerting for. Therefore, Cabot uses a pull (rather than a push) model for alerting. It reaches out into each system’s API and retrieves the information it needs to make a decision based on a specific check. Cabot stores the alerting data in a Postgres database and also has a cache using Redis.
+
+Cabot natively supports [Graphite][16], but it also supports [Jenkins][17], which is rare in this area. [Arachnys][13] uses Jenkins like a centralized cron, but I like this idea of treating build failures like outages. Obviously, a build failure isn’t as critical as a production outage, but it could still alert the team and escalate if the failure isn’t resolved. Who actually checks Jenkins every time an email comes in about a build failure? Yeah, me too!
+
+Another interesting feature is that Cabot can integrate with Google Calendar for on-call rotations. Cabot calls this feature Rota, which is a British term for a roster or rotation. This makes a lot of sense, and I wish other systems would take this idea further. Cabot doesn’t support anything more complex than primary and backup personnel, but there is certainly room for additional features. The docs say if you want something more advanced, you should look at a commercial option.
+
+#### StatsAgg
+
+[StatsAgg][18]? How did that make the list? Well, it’s not every day you come across a publishing company that has created an alerting platform. I think that deserves recognition. Of course, [Pearson][19] isn’t just a publishing company anymore; it has several web presences and a joint venture with [O’Reilly Media][20]. However, I still think of it as the company that published my schoolbooks and tests.
+
+StatsAgg isn’t just an alerting platform; it’s also a metrics aggregation platform. And it’s kind of like a proxy for other systems. It supports Graphite, StatsD, InfluxDB, and OpenTSDB as inputs, but it can also forward those metrics to their respective platforms. This is an interesting concept, but potentially risky as loads increase on a central service. However, if the StatsAgg infrastructure is robust enough, it can still produce alerts even when a backend storage platform has an outage.
+
+StatsAgg is written in Java and consists only of the main server and UI, which keeps complexity to a minimum. It can send alerts based on regular expression matching and is focused on alerting by service rather than host or instance. Its goal is to fill a void in the open source observability stack, and I think it does that quite well.
+
+### Visualization tools
+
+#### Grafana
+
+Almost everyone knows about [Grafana][10], and many have used it. I have used it for years whenever I need a simple dashboard. The tool I used before was deprecated, and I was fairly distraught about that until Grafana made it okay. Grafana was gifted to us by Torkel Ödegaard. Like Cabot, Grafana was also created around Christmastime, and released in January 2014. It has come a long way in just a few years. It started life as a Kibana dashboarding system, and Torkel forked it into what became Grafana.
+
+Grafana’s sole focus is presenting monitoring data in a more usable and pleasing way. It can natively gather data from Graphite, Elasticsearch, OpenTSDB, Prometheus, and InfluxDB. There’s an Enterprise version that uses plugins for more data sources, but there’s no reason those other data source plugins couldn’t be created as open source, as the Grafana plugin ecosystem already offers many other data sources.
+
+What does Grafana do for me? It provides a central location for understanding my system. It is web-based, so anyone can access the information, although it can be restricted using different authentication methods. Grafana can provide knowledge at a glance using many different types of visualizations. However, it has started integrating alerting and other features that aren’t traditionally combined with visualizations.
+
+Now you can set alerts visually. That means you can look at a graph, maybe even one showing where an alert should have triggered due to some degradation of the system, click on the graph where you want the alert to trigger, and then tell Grafana where to send the alert. That’s a pretty powerful addition that won’t necessarily replace an alerting platform, but it can certainly help augment it by providing a different perspective on alerting criteria.
+
+Grafana has also introduced more collaboration features. Users have been able to share dashboards for a long time, meaning you don’t have to create your own dashboard for your [Kubernetes][21] cluster because there are several already available—with some maintained by Kubernetes developers and others by Grafana developers.
+
+The most significant addition around collaboration is annotations. Annotations allow a user to add context to part of a graph. Other users can then use this context to understand the system better. This is an invaluable tool when a team is in the middle of an incident and communication and common understanding are critical. Having all the information right where you’re already looking makes it much more likely that knowledge will be shared across the team quickly. It’s also a nice feature to use during blameless postmortems when the team is trying to understand how the failure occurred and learn more about their system.
+
+#### Vizceral
+
+Netflix created [Vizceral][22] to understand its traffic patterns better when performing a traffic failover. Unlike Grafana, which is a more general tool, Vizceral serves a very specific use case. Netflix no longer uses this tool internally and says it is no longer actively maintained, but it still updates the tool periodically. I highlight it here primarily to point out an interesting visualization mechanism and how it can help solve a problem. It’s worth running it in a demo environment just to better grasp the concepts and witness what’s possible with these systems.
+
+### What to read next
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/10/alerting-and-visualization-tools-sysadmins
+
+作者:[Dan Barker][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/barkerd427
+[b]: https://github.com/lujun9972
+[1]: https://www.practicalmonitoring.com/
+[2]: https://developers.google.com/chart/interactive/docs/gallery
+[3]: https://libguides.libraries.claremont.edu/c.php?g=474417&p=3286401
+[4]: http://www.brendangregg.com/flamegraphs.html
+[5]: https://stackoverflow.com/
+[6]: https://superuser.com/
+[7]: http://bosun.org/
+[8]: https://prometheus.io/docs/alerting/alertmanager/
+[9]: https://bosun.org/scollector/
+[10]: https://grafana.com/
+[11]: https://bosun.org/notifications
+[12]: https://cabotapp.com/
+[13]: https://www.arachnys.com/
+[14]: https://en.wikipedia.org/wiki/Know_your_customer
+[15]: https://www.nagios.org/
+[16]: https://graphiteapp.org/
+[17]: https://jenkins.io/
+[18]: https://github.com/PearsonEducation/StatsAgg
+[19]: https://www.pearson.com/us/
+[20]: https://www.oreilly.com/
+[21]: https://opensource.com/resources/what-is-kubernetes
+[22]: https://github.com/Netflix/vizceral
diff --git a/sources/tech/20181010 An introduction to using tcpdump at the Linux command line.md b/sources/tech/20181010 An introduction to using tcpdump at the Linux command line.md
new file mode 100644
index 0000000000..6998661f23
--- /dev/null
+++ b/sources/tech/20181010 An introduction to using tcpdump at the Linux command line.md
@@ -0,0 +1,457 @@
+An introduction to using tcpdump at the Linux command line
+======
+
+This flexible, powerful command-line tool helps ease the pain of troubleshooting network issues.
+
+
+
+In my experience as a sysadmin, I have often found network connectivity issues challenging to troubleshoot. For those situations, tcpdump is a great ally.
+
+Tcpdump is a command line utility that allows you to capture and analyze network traffic going through your system. It is often used to help troubleshoot network issues, as well as a security tool.
+
+A powerful and versatile tool that includes many options and filters, tcpdump can be used in a variety of cases. Since it's a command line tool, it is ideal to run in remote servers or devices for which a GUI is not available, to collect data that can be analyzed later. It can also be launched in the background or as a scheduled job using tools like cron.
+
+In this article, we'll look at some of tcpdump's most common features.
+
+### 1\. Installation on Linux
+
+Tcpdump is included with several Linux distributions, so chances are, you already have it installed. Check if tcpdump is installed on your system with the following command:
+
+```
+$ which tcpdump
+/usr/sbin/tcpdump
+```
+
+If tcpdump is not installed, you can install it but using your distribution's package manager. For example, on CentOS or Red Hat Enterprise Linux, like this:
+
+```
+$ sudo yum install -y tcpdump
+```
+
+Tcpdump requires `libpcap`, which is a library for network packet capture. If it's not installed, it will be automatically added as a dependency.
+
+You're ready to start capturing some packets.
+
+### 2\. Capturing packets with tcpdump
+
+To capture packets for troubleshooting or analysis, tcpdump requires elevated permissions, so in the following examples most commands are prefixed with `sudo`.
+
+To begin, use the command `tcpdump -D` to see which interfaces are available for capture:
+
+```
+$ sudo tcpdump -D
+1.eth0
+2.virbr0
+3.eth1
+4.any (Pseudo-device that captures on all interfaces)
+5.lo [Loopback]
+```
+
+In the example above, you can see all the interfaces available in my machine. The special interface `any` allows capturing in any active interface.
+
+Let's use it to start capturing some packets. Capture all packets in any interface by running this command:
+
+```
+$ sudo tcpdump -i any
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+09:56:18.293641 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 3770820720:3770820916, ack 3503648727, win 309, options [nop,nop,TS val 76577898 ecr 510770929], length 196
+09:56:18.293794 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 196, win 391, options [nop,nop,TS val 510771017 ecr 76577898], length 0
+09:56:18.295058 IP rhel75.59883 > gateway.domain: 2486+ PTR? 1.64.168.192.in-addr.arpa. (43)
+09:56:18.310225 IP gateway.domain > rhel75.59883: 2486 NXDomain* 0/1/0 (102)
+09:56:18.312482 IP rhel75.49685 > gateway.domain: 34242+ PTR? 28.64.168.192.in-addr.arpa. (44)
+09:56:18.322425 IP gateway.domain > rhel75.49685: 34242 NXDomain* 0/1/0 (103)
+09:56:18.323164 IP rhel75.56631 > gateway.domain: 29904+ PTR? 1.122.168.192.in-addr.arpa. (44)
+09:56:18.323342 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 196:584, ack 1, win 309, options [nop,nop,TS val 76577928 ecr 510771017], length 388
+09:56:18.323563 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 584, win 411, options [nop,nop,TS val 510771047 ecr 76577928], length 0
+09:56:18.335569 IP gateway.domain > rhel75.56631: 29904 NXDomain* 0/1/0 (103)
+09:56:18.336429 IP rhel75.44007 > gateway.domain: 61677+ PTR? 98.122.168.192.in-addr.arpa. (45)
+09:56:18.336655 IP gateway.domain > rhel75.44007: 61677* 1/0/0 PTR rhel75. (65)
+09:56:18.337177 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 584:1644, ack 1, win 309, options [nop,nop,TS val 76577942 ecr 510771047], length 1060
+
+---- SKIPPING LONG OUTPUT -----
+
+09:56:19.342939 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 1752016, win 1444, options [nop,nop,TS val 510772067 ecr 76578948], length 0
+^C
+9003 packets captured
+9010 packets received by filter
+7 packets dropped by kernel
+$
+```
+
+Tcpdump continues to capture packets until it receives an interrupt signal. You can interrupt capturing by pressing `Ctrl+C`. As you can see in this example, `tcpdump` captured more than 9,000 packets. In this case, since I am connected to this server using `ssh`, tcpdump captured all these packages. To limit the number of packets captured and stop `tcpdump`, use the `-c` option:
+
+```
+$ sudo tcpdump -i any -c 5
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+11:21:30.242740 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 3772575680:3772575876, ack 3503651743, win 309, options [nop,nop,TS val 81689848 ecr 515883153], length 196
+11:21:30.242906 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 196, win 1443, options [nop,nop,TS val 515883235 ecr 81689848], length 0
+11:21:30.244442 IP rhel75.43634 > gateway.domain: 57680+ PTR? 1.64.168.192.in-addr.arpa. (43)
+11:21:30.244829 IP gateway.domain > rhel75.43634: 57680 NXDomain 0/0/0 (43)
+11:21:30.247048 IP rhel75.33696 > gateway.domain: 37429+ PTR? 28.64.168.192.in-addr.arpa. (44)
+5 packets captured
+12 packets received by filter
+0 packets dropped by kernel
+$
+```
+
+In this case, `tcpdump` stopped capturing automatically after capturing five packets. This is useful in different scenarios—for instance, if you're troubleshooting connectivity and capturing a few initial packages is enough. This is even more useful when we apply filters to capture specific packets (shown below).
+
+By default, tcpdump resolves IP addresses and ports into names, as shown in the previous example. When troubleshooting network issues, it is often easier to use the IP addresses and port numbers; disable name resolution by using the option `-n` and port resolution with `-nn`:
+
+```
+$ sudo tcpdump -i any -c5 -nn
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+23:56:24.292206 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 166198580:166198776, ack 2414541257, win 309, options [nop,nop,TS val 615664 ecr 540031155], length 196
+23:56:24.292357 IP 192.168.64.1.35110 > 192.168.64.28.22: Flags [.], ack 196, win 1377, options [nop,nop,TS val 540031229 ecr 615664], length 0
+23:56:24.292570 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 615664 ecr 540031229], length 372
+23:56:24.292655 IP 192.168.64.1.35110 > 192.168.64.28.22: Flags [.], ack 568, win 1400, options [nop,nop,TS val 540031229 ecr 615664], length 0
+23:56:24.292752 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 568:908, ack 1, win 309, options [nop,nop,TS val 615664 ecr 540031229], length 340
+5 packets captured
+6 packets received by filter
+0 packets dropped by kernel
+```
+
+As shown above, the capture output now displays the IP addresses and port numbers. This also prevents tcpdump from issuing DNS lookups, which helps to lower network traffic while troubleshooting network issues.
+
+Now that you're able to capture network packets, let's explore what this output means.
+
+### 3\. Understanding the output format
+
+Tcpdump is capable of capturing and decoding many different protocols, such as TCP, UDP, ICMP, and many more. While we can't cover all of them here, to help you get started, let's explore the TCP packet. You can find more details about the different protocol formats in tcpdump's [manual pages][1]. A typical TCP packet captured by tcpdump looks like this:
+
+```
+08:41:13.729687 IP 192.168.64.28.22 > 192.168.64.1.41916: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 117964079 ecr 816509256], length 372
+```
+
+The fields may vary depending on the type of packet being sent, but this is the general format.
+
+The first field, `08:41:13.729687,` represents the timestamp of the received packet as per the local clock.
+
+Next, `IP` represents the network layer protocol—in this case, `IPv4`. For `IPv6` packets, the value is `IP6`.
+
+The next field, `192.168.64.28.22`, is the source IP address and port. This is followed by the destination IP address and port, represented by `192.168.64.1.41916`.
+
+After the source and destination, you can find the TCP Flags `Flags [P.]`. Typical values for this field include:
+
+| Value | Flag Type | Description |
+|-------| --------- | ----------------- |
+| S | SYN | Connection Start |
+| F | FIN | Connection Finish |
+| P | PUSH | Data push |
+| R | RST | Connection reset |
+| . | ACK | Acknowledgment |
+
+This field can also be a combination of these values, such as `[S.]` for a `SYN-ACK` packet.
+
+Next is the sequence number of the data contained in the packet. For the first packet captured, this is an absolute number. Subsequent packets use a relative number to make it easier to follow. In this example, the sequence is `seq 196:568,` which means this packet contains bytes 196 to 568 of this flow.
+
+This is followed by the Ack Number: `ack 1`. In this case, it is 1 since this is the side sending data. For the side receiving data, this field represents the next expected byte (data) on this flow. For example, the Ack number for the next packet in this flow would be 568.
+
+The next field is the window size `win 309`, which represents the number of bytes available in the receiving buffer, followed by TCP options such as the MSS (Maximum Segment Size) or Window Scale. For details about TCP protocol options, consult [Transmission Control Protocol (TCP) Parameters][2].
+
+Finally, we have the packet length, `length 372`, which represents the length, in bytes, of the payload data. The length is the difference between the last and first bytes in the sequence number.
+
+Now let's learn how to filter packages to narrow down results and make it easier to troubleshoot specific issues.
+
+### 4\. Filtering packets
+
+As mentioned above, tcpdump can capture too many packages, some of which are not even related to the issue you're troubleshooting. For example, if you're troubleshooting a connectivity issue with a web server you're not interested in the SSH traffic, so removing the SSH packets from the output makes it easier to work on the real issue.
+
+One of tcpdump's most powerful features is its ability to filter the captured packets using a variety of parameters, such as source and destination IP addresses, ports, protocols, etc. Let's look at some of the most common ones.
+
+#### Protocol
+
+To filter packets based on protocol, specifying the protocol in the command line. For example, capture ICMP packets only by using this command:
+
+```
+$ sudo tcpdump -i any -c5 icmp
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+```
+
+In a different terminal, try to ping another machine:
+
+```
+$ ping opensource.com
+PING opensource.com (54.204.39.132) 56(84) bytes of data.
+64 bytes from ec2-54-204-39-132.compute-1.amazonaws.com (54.204.39.132): icmp_seq=1 ttl=47 time=39.6 ms
+```
+
+Back in the tcpdump capture, notice that tcpdump captures and displays only the ICMP-related packets. In this case, tcpdump is not displaying name resolution packets that were generated when resolving the name `opensource.com`:
+
+```
+09:34:20.136766 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 1, length 64
+09:34:20.176402 IP ec2-54-204-39-132.compute-1.amazonaws.com > rhel75: ICMP echo reply, id 20361, seq 1, length 64
+09:34:21.140230 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 2, length 64
+09:34:21.180020 IP ec2-54-204-39-132.compute-1.amazonaws.com > rhel75: ICMP echo reply, id 20361, seq 2, length 64
+09:34:22.141777 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 3, length 64
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+#### Host
+
+Limit capture to only packets related to a specific host by using the `host` filter:
+
+```
+$ sudo tcpdump -i any -c5 -nn host 54.204.39.132
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+09:54:20.042023 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [S], seq 1375157070, win 29200, options [mss 1460,sackOK,TS val 122350391 ecr 0,nop,wscale 7], length 0
+09:54:20.088127 IP 54.204.39.132.80 > 192.168.122.98.39326: Flags [S.], seq 1935542841, ack 1375157071, win 28960, options [mss 1460,sackOK,TS val 522713542 ecr 122350391,nop,wscale 9], length 0
+09:54:20.088204 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 122350437 ecr 522713542], length 0
+09:54:20.088734 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 122350438 ecr 522713542], length 112: HTTP: GET / HTTP/1.1
+09:54:20.129733 IP 54.204.39.132.80 > 192.168.122.98.39326: Flags [.], ack 113, win 57, options [nop,nop,TS val 522713552 ecr 122350438], length 0
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+In this example, tcpdump captures and displays only packets to and from host `54.204.39.132`.
+
+#### Port
+
+To filter packets based on the desired service or port, use the `port` filter. For example, capture packets related to a web (HTTP) service by using this command:
+
+```
+$ sudo tcpdump -i any -c5 -nn port 80
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+09:58:28.790548 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [S], seq 1745665159, win 29200, options [mss 1460,sackOK,TS val 122599140 ecr 0,nop,wscale 7], length 0
+09:58:28.834026 IP 54.204.39.132.80 > 192.168.122.98.39330: Flags [S.], seq 4063583040, ack 1745665160, win 28960, options [mss 1460,sackOK,TS val 522775728 ecr 122599140,nop,wscale 9], length 0
+09:58:28.834093 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 122599183 ecr 522775728], length 0
+09:58:28.834588 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 122599184 ecr 522775728], length 112: HTTP: GET / HTTP/1.1
+09:58:28.878445 IP 54.204.39.132.80 > 192.168.122.98.39330: Flags [.], ack 113, win 57, options [nop,nop,TS val 522775739 ecr 122599184], length 0
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+#### Source IP/hostname
+
+You can also filter packets based on the source or destination IP Address or hostname. For example, to capture packets from host `192.168.122.98`:
+
+```
+$ sudo tcpdump -i any -c5 -nn src 192.168.122.98
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+10:02:15.220824 IP 192.168.122.98.39436 > 192.168.122.1.53: 59332+ A? opensource.com. (32)
+10:02:15.220862 IP 192.168.122.98.39436 > 192.168.122.1.53: 20749+ AAAA? opensource.com. (32)
+10:02:15.364062 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [S], seq 1108640533, win 29200, options [mss 1460,sackOK,TS val 122825713 ecr 0,nop,wscale 7], length 0
+10:02:15.409229 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [.], ack 669337581, win 229, options [nop,nop,TS val 122825758 ecr 522832372], length 0
+10:02:15.409667 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [P.], seq 0:112, ack 1, win 229, options [nop,nop,TS val 122825759 ecr 522832372], length 112: HTTP: GET / HTTP/1.1
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+Notice that tcpdumps captured packets with source IP address `192.168.122.98` for multiple services such as name resolution (port 53) and HTTP (port 80). The response packets are not displayed since their source IP is different.
+
+Conversely, you can use the `dst` filter to filter by destination IP/hostname:
+
+```
+$ sudo tcpdump -i any -c5 -nn dst 192.168.122.98
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+10:05:03.572931 IP 192.168.122.1.53 > 192.168.122.98.47049: 2248 1/0/0 A 54.204.39.132 (48)
+10:05:03.572944 IP 192.168.122.1.53 > 192.168.122.98.47049: 33770 0/0/0 (32)
+10:05:03.621833 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [S.], seq 3474204576, ack 3256851264, win 28960, options [mss 1460,sackOK,TS val 522874425 ecr 122993922,nop,wscale 9], length 0
+10:05:03.667767 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [.], ack 113, win 57, options [nop,nop,TS val 522874436 ecr 122993972], length 0
+10:05:03.672221 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 522874437 ecr 122993972], length 642: HTTP: HTTP/1.1 302 Found
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+#### Complex expressions
+
+You can also combine filters by using the logical operators `and` and `or` to create more complex expressions. For example, to filter packets from source IP address `192.168.122.98` and service HTTP only, use this command:
+
+```
+$ sudo tcpdump -i any -c5 -nn src 192.168.122.98 and port 80
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+10:08:00.472696 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [S], seq 2712685325, win 29200, options [mss 1460,sackOK,TS val 123170822 ecr 0,nop,wscale 7], length 0
+10:08:00.516118 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [.], ack 268723504, win 229, options [nop,nop,TS val 123170865 ecr 522918648], length 0
+10:08:00.516583 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [P.], seq 0:112, ack 1, win 229, options [nop,nop,TS val 123170866 ecr 522918648], length 112: HTTP: GET / HTTP/1.1
+10:08:00.567044 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 123170916 ecr 522918661], length 0
+10:08:00.788153 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [F.], seq 112, ack 643, win 239, options [nop,nop,TS val 123171137 ecr 522918661], length 0
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+You can create more complex expressions by grouping filter with parentheses. In this case, enclose the entire filter expression with quotation marks to prevent the shell from confusing them with shell expressions:
+
+```
+$ sudo tcpdump -i any -c5 -nn "port 80 and (src 192.168.122.98 or src 54.204.39.132)"
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+10:10:37.602214 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [S], seq 871108679, win 29200, options [mss 1460,sackOK,TS val 123327951 ecr 0,nop,wscale 7], length 0
+10:10:37.650651 IP 54.204.39.132.80 > 192.168.122.98.39346: Flags [S.], seq 854753193, ack 871108680, win 28960, options [mss 1460,sackOK,TS val 522957932 ecr 123327951,nop,wscale 9], length 0
+10:10:37.650708 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 123328000 ecr 522957932], length 0
+10:10:37.651097 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 123328000 ecr 522957932], length 112: HTTP: GET / HTTP/1.1
+10:10:37.692900 IP 54.204.39.132.80 > 192.168.122.98.39346: Flags [.], ack 113, win 57, options [nop,nop,TS val 522957942 ecr 123328000], length 0
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+In this example, we're filtering packets for HTTP service only (port 80) and source IP addresses `192.168.122.98` or `54.204.39.132`. This is a quick way of examining both sides of the same flow.
+
+### 5\. Checking packet content
+
+In the previous examples, we're checking only the packets' headers for information such as source, destinations, ports, etc. Sometimes this is all we need to troubleshoot network connectivity issues. Sometimes, however, we need to inspect the content of the packet to ensure that the message we're sending contains what we need or that we received the expected response. To see the packet content, tcpdump provides two additional flags: `-X` to print content in hex, and ASCII or `-A` to print the content in ASCII.
+
+For example, inspect the HTTP content of a web request like this:
+
+```
+$ sudo tcpdump -i any -c10 -nn -A port 80
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+13:02:14.871803 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [S], seq 2546602048, win 29200, options [mss 1460,sackOK,TS val 133625221 ecr 0,nop,wscale 7], length 0
+E..<..@.@.....zb6.'....P...@......r............
+............................
+13:02:14.910734 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [S.], seq 1877348646, ack 2546602049, win 28960, options [mss 1460,sackOK,TS val 525532247 ecr 133625221,nop,wscale 9], length 0
+E..<..@./..a6.'...zb.P..o..&...A..q a..........
+.R.W....... ................
+13:02:14.910832 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 133625260 ecr 525532247], length 0
+E..4..@.@.....zb6.'....P...Ao..'...........
+.....R.W................
+13:02:14.911808 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 133625261 ecr 525532247], length 112: HTTP: GET / HTTP/1.1
+E.....@.@..1..zb6.'....P...Ao..'...........
+.....R.WGET / HTTP/1.1
+User-Agent: Wget/1.14 (linux-gnu)
+Accept: */*
+Host: opensource.com
+Connection: Keep-Alive
+
+................
+13:02:14.951199 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [.], ack 113, win 57, options [nop,nop,TS val 525532257 ecr 133625261], length 0
+E..4.F@./.."6.'...zb.P..o..'.......9.2.....
+.R.a....................
+13:02:14.955030 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 525532258 ecr 133625261], length 642: HTTP: HTTP/1.1 302 Found
+E....G@./...6.'...zb.P..o..'.......9.......
+.R.b....HTTP/1.1 302 Found
+Server: nginx
+Date: Sun, 23 Sep 2018 17:02:14 GMT
+Content-Type: text/html; charset=iso-8859-1
+Content-Length: 207
+X-Content-Type-Options: nosniff
+Location: https://opensource.com/
+Cache-Control: max-age=1209600
+Expires: Sun, 07 Oct 2018 17:02:14 GMT
+X-Request-ID: v-6baa3acc-bf52-11e8-9195-22000ab8cf2d
+X-Varnish: 632951979
+Age: 0
+Via: 1.1 varnish (Varnish/5.2)
+X-Cache: MISS
+Connection: keep-alive
+
+
+
+302 Found
+
+
+
+................
+13:02:14.955083 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 133625304 ecr 525532258], length 0
+E..4..@.@.....zb6.'....P....o..............
+.....R.b................
+13:02:15.195524 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [F.], seq 113, ack 643, win 239, options [nop,nop,TS val 133625545 ecr 525532258], length 0
+E..4..@.@.....zb6.'....P....o..............
+.....R.b................
+13:02:15.236592 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 525532329 ecr 133625545], length 0
+E..4.H@./.. 6.'...zb.P..o..........9.I.....
+.R......................
+13:02:15.236656 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 644, win 239, options [nop,nop,TS val 133625586 ecr 525532329], length 0
+E..4..@.@.....zb6.'....P....o..............
+.....R..................
+10 packets captured
+10 packets received by filter
+0 packets dropped by kernel
+```
+
+This is helpful for troubleshooting issues with API calls, assuming the calls are using plain HTTP. For encrypted connections, this output is less useful.
+
+### 6\. Saving captures to a file
+
+Another useful feature provided by tcpdump is the ability to save the capture to a file so you can analyze the results later. This allows you to capture packets in batch mode overnight, for example, and verify the results in the morning. It also helps when there are too many packets to analyze since real-time capture can occur too fast.
+
+To save packets to a file instead of displaying them on screen, use the option `-w`:
+
+```
+$ sudo tcpdump -i any -c10 -nn -w webserver.pcap port 80
+[sudo] password for ricardo:
+tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+10 packets captured
+10 packets received by filter
+0 packets dropped by kernel
+```
+
+This command saves the output in a file named `webserver.pcap`. The `.pcap` extension stands for "packet capture" and is the convention for this file format.
+
+As shown in this example, nothing gets displayed on-screen, and the capture finishes after capturing 10 packets, as per the option `-c10`. If you want some feedback to ensure packets are being captured, use the option `-v`.
+
+Tcpdump creates a file in binary format so you cannot simply open it with a text editor. To read the contents of the file, execute tcpdump with the `-r` option:
+
+```
+$ tcpdump -nn -r webserver.pcap
+reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
+13:36:57.679494 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [S], seq 3709732619, win 29200, options [mss 1460,sackOK,TS val 135708029 ecr 0,nop,wscale 7], length 0
+13:36:57.718932 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [S.], seq 1999298316, ack 3709732620, win 28960, options [mss 1460,sackOK,TS val 526052949 ecr 135708029,nop,wscale 9], length 0
+13:36:57.719005 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 135708068 ecr 526052949], length 0
+13:36:57.719186 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 135708068 ecr 526052949], length 112: HTTP: GET / HTTP/1.1
+13:36:57.756979 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [.], ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 0
+13:36:57.760122 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 642: HTTP: HTTP/1.1 302 Found
+13:36:57.760182 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 135708109 ecr 526052959], length 0
+13:36:57.977602 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [F.], seq 113, ack 643, win 239, options [nop,nop,TS val 135708327 ecr 526052959], length 0
+13:36:58.022089 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 526053025 ecr 135708327], length 0
+13:36:58.022132 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 644, win 239, options [nop,nop,TS val 135708371 ecr 526053025], length 0
+$
+```
+
+Since you're no longer capturing the packets directly from the network interface, `sudo` is not required to read the file.
+
+You can also use any of the filters we've discussed to filter the content from the file, just as you would with real-time data. For example, inspect the packets in the capture file from source IP address `54.204.39.132` by executing this command:
+
+```
+$ tcpdump -nn -r webserver.pcap src 54.204.39.132
+reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
+13:36:57.718932 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [S.], seq 1999298316, ack 3709732620, win 28960, options [mss 1460,sackOK,TS val 526052949 ecr 135708029,nop,wscale 9], length 0
+13:36:57.756979 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [.], ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 0
+13:36:57.760122 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 642: HTTP: HTTP/1.1 302 Found
+13:36:58.022089 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 526053025 ecr 135708327], length 0
+```
+
+### What's next?
+
+These basic features of tcpdump will help you get started with this powerful and versatile tool. To learn more, consult the [tcpdump website][3] and [man pages][4].
+
+The tcpdump command line interface provides great flexibility for capturing and analyzing network traffic. If you need a graphical tool to understand more complex flows, look at [Wireshark][5].
+
+One benefit of Wireshark is that it can read `.pcap` files captured by tcpdump. You can use tcpdump to capture packets in a remote machine that does not have a GUI and analyze the result file with Wireshark, but that is a topic for another day.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/10/introduction-tcpdump
+
+作者:[Ricardo Gerardi][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/rgerardi
+[b]: https://github.com/lujun9972
+[1]: http://www.tcpdump.org/manpages/tcpdump.1.html#lbAG
+[2]: https://www.iana.org/assignments/tcp-parameters/tcp-parameters.xhtml
+[3]: http://www.tcpdump.org/#
+[4]: http://www.tcpdump.org/manpages/tcpdump.1.html
+[5]: https://www.wireshark.org/
diff --git a/sources/tech/20181010 How To List The Enabled-Active Repositories In Linux.md b/sources/tech/20181010 How To List The Enabled-Active Repositories In Linux.md
new file mode 100644
index 0000000000..b4ff872202
--- /dev/null
+++ b/sources/tech/20181010 How To List The Enabled-Active Repositories In Linux.md
@@ -0,0 +1,289 @@
+How To List The Enabled/Active Repositories In Linux
+======
+There are many ways to list enabled repositories in Linux.
+
+Here we are going to show you the easy methods to list active repositories.
+
+It will helps you to know what are the repositories enabled on your system.
+
+Once you have this information in handy then you can add any repositories that you want if it’s not already enabled.
+
+Say for example, if you would like to enable `epel repository` then you need to check whether the epel repository is enabled or not. In this case this tutorial would help you.
+
+### What Is Repository?
+
+A software repository is a central place which stores the software packages for the particular application.
+
+All the Linux distributions are maintaining their own repositories and they allow users to retrieve and install packages on their machine.
+
+Each vendor offered a unique package management tool to manage their repositories such as search, install, update, upgrade, remove, etc.
+
+Most of the Linux distributions comes as freeware except RHEL and SUSE. To access their repositories you need to buy a subscriptions.
+
+**Suggested Read :**
+**(#)** [How To Add, Enable And Disable A Repository By Using The DNF/YUM Config Manager Command On Linux][1]
+**(#)** [How To List Installed Packages By Size (Largest) On Linux][2]
+**(#)** [How To View/List The Available Packages Updates In Linux][3]
+**(#)** [How To View A Particular Package Installed/Updated/Upgraded/Removed/Erased Date On Linux][4]
+**(#)** [How To View Detailed Information About A Package In Linux][5]
+**(#)** [How To Search If A Package Is Available On Your Linux Distribution Or Not][6]
+**(#)** [How To List An Available Package Groups In Linux][7]
+**(#)** [Newbies corner – A Graphical frontend tool for Linux Package Manager][8]
+**(#)** [Linux Expert should knows, list of Command line Package Manager & Usage][9]
+
+### How To List The Enabled Repositories on RHEL/CentOS
+
+RHEL & CentOS systems are using RPM packages hence we can use the `Yum Package Manager` to get this information.
+
+YUM stands for Yellowdog Updater, Modified is an open-source command-line front-end package-management utility for RPM based systems such as Red Hat Enterprise Linux (RHEL) and CentOS.
+
+Yum is the primary tool for getting, installing, deleting, querying, and managing RPM packages from distribution repositories, as well as other third-party repositories.
+
+**Suggested Read :** [YUM Command To Manage Packages on RHEL/CentOS Systems][10]
+
+RHEL based systems are mainly offering the below three major repositories. These repository will be enabled by default.
+
+ * **`base:`** It’s containing all the core packages and base packages.
+ * **`extras:`** It provides additional functionality to CentOS without breaking upstream compatibility or updating base components. It is an upstream repository, as well as additional CentOS packages.
+ * **`updates:`** It’s offering bug fixed packages, Security packages and Enhancement packages.
+
+
+
+```
+# yum repolist
+or
+# yum repolist enabled
+
+Loaded plugins: fastestmirror
+Determining fastest mirrors
+ 选题模板.txt 中文排版指北.md comic core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated epel: ewr.edge.kernel.org
+repo id repo name status
+!base/7/x86_64 CentOS-7 - Base 9,911
+!epel/x86_64 Extra Packages for Enterprise Linux 7 - x86_64 12,687
+!extras/7/x86_64 CentOS-7 - Extras 403
+!updates/7/x86_64 CentOS-7 - Updates 1,348
+repolist: 24,349
+
+```
+
+### How To List The Enabled Repositories on Fedora
+
+DNF stands for Dandified yum. We can tell DNF, the next generation of yum package manager (Fork of Yum) using hawkey/libsolv library for backend. Aleš Kozumplík started working on DNF since Fedora 18 and its implemented/launched in Fedora 22 finally.
+
+Dnf command is used to install, update, search & remove packages on Fedora 22 and later system. It automatically resolve dependencies and make it smooth package installation without any trouble.
+
+Yum replaced by DNF due to several long-term problems in Yum which was not solved. Asked why ? he did not patches the Yum issues. Aleš Kozumplík explains that patching was technically hard and YUM team wont accept the changes immediately and other major critical, YUM is 56K lines but DNF is 29K lies. So, there is no option for further development, except to fork.
+
+**Suggested Read :** [DNF (Fork of YUM) Command To Manage Packages on Fedora System][11]
+
+Fedora system is mainly offering the below two major repositories. These repository will be enabled by default.
+
+ * **`fedora:`** It’s containing all the core packages and base packages.
+ * **`updates:`** It’s offering bug fixed packages, Security packages and Enhancement packages from the stable release branch.
+
+
+
+```
+# dnf repolist
+or
+# dnf repolist enabled
+
+Last metadata expiration check: 0:02:56 ago on Wed 10 Oct 2018 06:12:22 PM IST.
+repo id repo name status
+docker-ce-stable Docker CE Stable - x86_64 6
+*fedora Fedora 26 - x86_64 53,912
+home_mhogomchungu mhogomchungu's Home Project (Fedora_25) 19
+home_moritzmolch_gencfsm Gnome Encfs Manager (Fedora_25) 5
+mystro256-gnome-redshift Copr repo for gnome-redshift owned by mystro256 6
+nodesource Node.js Packages for Fedora Linux 26 - x86_64 83
+rabiny-albert Copr repo for albert owned by rabiny 3
+*rpmfusion-free RPM Fusion for Fedora 26 - Free 536
+*rpmfusion-free-updates RPM Fusion for Fedora 26 - Free - Updates 278
+*rpmfusion-nonfree RPM Fusion for Fedora 26 - Nonfree 202
+*rpmfusion-nonfree-updates RPM Fusion for Fedora 26 - Nonfree - Updates 95
+*updates Fedora 26 - x86_64 - Updates 14,595
+
+```
+
+### How To List The Enabled Repositories on Debian/Ubuntu
+
+Debian based systems are using APT/APT-GET package manager hence we can use the `APT/APT-GET Package Manager` to get this information.
+
+APT stands for Advanced Packaging Tool (APT) which is replacement for apt-get, like how DNF came to picture instead of YUM. It’s feature rich command-line tools with included all the futures in one command (APT) such as apt-cache, apt-search, dpkg, apt-cdrom, apt-config, apt-key, etc..,. and several other unique features. For example we can easily install .dpkg packages through APT but we can’t do through Apt-Get similar more features are included into APT command. APT-GET replaced by APT Due to lock of futures missing in apt-get which was not solved.
+
+Apt-Get stands for Advanced Packaging Tool (APT). apg-get is a powerful command-line tool which is used to automatically download and install new software packages, upgrade existing software packages, update the package list index, and to upgrade the entire Debian based systems.
+
+```
+# apt-cache policy
+Package files:
+ 100 /var/lib/dpkg/status
+ release a=now
+ 500 http://ppa.launchpad.net/peek-developers/stable/ubuntu artful/main amd64 Packages
+ release v=17.10,o=LP-PPA-peek-developers-stable,a=artful,n=artful,l=Peek stable releases,c=main,b=amd64
+ origin ppa.launchpad.net
+ 500 http://ppa.launchpad.net/notepadqq-team/notepadqq/ubuntu artful/main amd64 Packages
+ release v=17.10,o=LP-PPA-notepadqq-team-notepadqq,a=artful,n=artful,l=Notepadqq,c=main,b=amd64
+ origin ppa.launchpad.net
+ 500 http://dl.google.com/linux/chrome/deb stable/main amd64 Packages
+ release v=1.0,o=Google, Inc.,a=stable,n=stable,l=Google,c=main,b=amd64
+ origin dl.google.com
+ 500 https://download.docker.com/linux/ubuntu artful/stable amd64 Packages
+ release o=Docker,a=artful,l=Docker CE,c=stable,b=amd64
+ origin download.docker.com
+ 500 http://security.ubuntu.com/ubuntu artful-security/multiverse amd64 Packages
+ release v=17.10,o=Ubuntu,a=artful-security,n=artful,l=Ubuntu,c=multiverse,b=amd64
+ origin security.ubuntu.com
+ 500 http://security.ubuntu.com/ubuntu artful-security/universe amd64 Packages
+ release v=17.10,o=Ubuntu,a=artful-security,n=artful,l=Ubuntu,c=universe,b=amd64
+ origin security.ubuntu.com
+ 500 http://security.ubuntu.com/ubuntu artful-security/restricted i386 Packages
+ release v=17.10,o=Ubuntu,a=artful-security,n=artful,l=Ubuntu,c=restricted,b=i386
+ origin security.ubuntu.com
+.
+.
+ origin in.archive.ubuntu.com
+ 500 http://in.archive.ubuntu.com/ubuntu artful/restricted amd64 Packages
+ release v=17.10,o=Ubuntu,a=artful,n=artful,l=Ubuntu,c=restricted,b=amd64
+ origin in.archive.ubuntu.com
+ 500 http://in.archive.ubuntu.com/ubuntu artful/main i386 Packages
+ release v=17.10,o=Ubuntu,a=artful,n=artful,l=Ubuntu,c=main,b=i386
+ origin in.archive.ubuntu.com
+ 500 http://in.archive.ubuntu.com/ubuntu artful/main amd64 Packages
+ release v=17.10,o=Ubuntu,a=artful,n=artful,l=Ubuntu,c=main,b=amd64
+ origin in.archive.ubuntu.com
+Pinned packages:
+
+```
+
+### How To List The Enabled Repositories on openSUSE
+
+openSUSE system uses zypper package manager hence we can use the zypper Package Manager to get this information.
+
+Zypper is a command line package manager for suse & openSUSE distributions. It’s used to install, update, search & remove packages & manage repositories, perform various queries, and more. Zypper command-line interface to ZYpp system management library (libzypp).
+
+**Suggested Read :** [Zypper Command To Manage Packages On openSUSE & suse Systems][12]
+
+```
+# zypper repos
+
+# | Alias | Name | Enabled | GPG Check | Refresh
+--+-----------------------+-----------------------------------------------------+---------+-----------+--------
+1 | packman-repository | packman-repository | Yes | (r ) Yes | Yes
+2 | google-chrome | google-chrome | Yes | (r ) Yes | Yes
+3 | home_lazka0_ql-stable | Stable Quod Libet / Ex Falso Builds (openSUSE_42.1) | Yes | (r ) Yes | No
+4 | repo-non-oss | openSUSE-leap/42.1-Non-Oss | Yes | (r ) Yes | Yes
+5 | repo-oss | openSUSE-leap/42.1-Oss | Yes | (r ) Yes | Yes
+6 | repo-update | openSUSE-42.1-Update | Yes | (r ) Yes | Yes
+7 | repo-update-non-oss | openSUSE-42.1-Update-Non-Oss | Yes | (r ) Yes | Yes
+
+```
+
+List Repositories with URI.
+
+```
+# zypper lr -u
+
+# | Alias | Name | Enabled | GPG Check | Refresh | URI
+--+-----------------------+-----------------------------------------------------+---------+-----------+---------+---------------------------------------------------------------------------------
+1 | packman-repository | packman-repository | Yes | (r ) Yes | Yes | http://ftp.gwdg.de/pub/linux/packman/suse/openSUSE_Leap_42.1/
+2 | google-chrome | google-chrome | Yes | (r ) Yes | Yes | http://dl.google.com/linux/chrome/rpm/stable/x86_64
+3 | home_lazka0_ql-stable | Stable Quod Libet / Ex Falso Builds (openSUSE_42.1) | Yes | (r ) Yes | No | http://download.opensuse.org/repositories/home:/lazka0:/ql-stable/openSUSE_42.1/
+4 | repo-non-oss | openSUSE-leap/42.1-Non-Oss | Yes | (r ) Yes | Yes | http://download.opensuse.org/distribution/leap/42.1/repo/non-oss/
+5 | repo-oss | openSUSE-leap/42.1-Oss | Yes | (r ) Yes | Yes | http://download.opensuse.org/distribution/leap/42.1/repo/oss/
+6 | repo-update | openSUSE-42.1-Update | Yes | (r ) Yes | Yes | http://download.opensuse.org/update/leap/42.1/oss/
+7 | repo-update-non-oss | openSUSE-42.1-Update-Non-Oss | Yes | (r ) Yes | Yes | http://download.opensuse.org/update/leap/42.1/non-oss/
+
+```
+
+List Repositories by priority.
+
+```
+# zypper lr -p
+
+# | Alias | Name | Enabled | GPG Check | Refresh | Priority
+--+-----------------------+-----------------------------------------------------+---------+-----------+---------+---------
+1 | packman-repository | packman-repository | Yes | (r ) Yes | Yes | 99
+2 | google-chrome | google-chrome | Yes | (r ) Yes | Yes | 99
+3 | home_lazka0_ql-stable | Stable Quod Libet / Ex Falso Builds (openSUSE_42.1) | Yes | (r ) Yes | No | 99
+4 | repo-non-oss | openSUSE-leap/42.1-Non-Oss | Yes | (r ) Yes | Yes | 99
+5 | repo-oss | openSUSE-leap/42.1-Oss | Yes | (r ) Yes | Yes | 99
+6 | repo-update | openSUSE-42.1-Update | Yes | (r ) Yes | Yes | 99
+7 | repo-update-non-oss | openSUSE-42.1-Update-Non-Oss | Yes | (r ) Yes | Yes | 99
+
+```
+
+### How To List The Enabled Repositories on ArchLinux
+
+Arch Linux based systems are using pacman package manager hence we can use the pacman Package Manager to get this information.
+
+pacman stands for package manager utility (pacman). pacman is a command-line utility to install, build, remove and manage Arch Linux packages. pacman uses libalpm (Arch Linux Package Management (ALPM) library) as a back-end to perform all the actions.
+
+**Suggested Read :** [Pacman Command To Manage Packages On Arch Linux Based Systems][13]
+
+```
+# pacman -Syy
+:: Synchronizing package databases...
+ core 132.6 KiB 1524K/s 00:00 [############################################] 100%
+ extra 1859.0 KiB 750K/s 00:02 [############################################] 100%
+ community 3.5 MiB 149K/s 00:24 [############################################] 100%
+ multilib 182.7 KiB 1363K/s 00:00 [############################################] 100%
+
+```
+
+### How To List The Enabled Repositories on Linux using INXI Utility
+
+inxi is a nifty tool to check hardware information on Linux and offers wide range of option to get all the hardware information on Linux system that i never found in any other utility which are available in Linux. It was forked from the ancient and mindbendingly perverse yet ingenius infobash, by locsmif.
+
+inxi is a script that quickly shows system hardware, CPU, drivers, Xorg, Desktop, Kernel, GCC version(s), Processes, RAM usage, and a wide variety of other useful information, also used for forum technical support & debugging tool.
+
+Additionally this utility will display all the distribution repository data information such as RHEL, CentOS, Fedora, Debain, Ubuntu, LinuxMint, ArchLinux, openSUSE, Manjaro, etc.,
+
+**Suggested Read :** [inxi – A Great Tool to Check Hardware Information on Linux][14]
+
+```
+# inxi -r
+Repos: Active apt sources in file: /etc/apt/sources.list
+ deb http://in.archive.ubuntu.com/ubuntu/ yakkety main restricted
+ deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates main restricted
+ deb http://in.archive.ubuntu.com/ubuntu/ yakkety universe
+ deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates universe
+ deb http://in.archive.ubuntu.com/ubuntu/ yakkety multiverse
+ deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates multiverse
+ deb http://in.archive.ubuntu.com/ubuntu/ yakkety-backports main restricted universe multiverse
+ deb http://security.ubuntu.com/ubuntu yakkety-security main restricted
+ deb http://security.ubuntu.com/ubuntu yakkety-security universe
+ deb http://security.ubuntu.com/ubuntu yakkety-security multiverse
+ Active apt sources in file: /etc/apt/sources.list.d/arc-theme.list
+ deb http://download.opensuse.org/repositories/home:/Horst3180/xUbuntu_16.04/ /
+ Active apt sources in file: /etc/apt/sources.list.d/snwh-ubuntu-pulp-yakkety.list
+ deb http://ppa.launchpad.net/snwh/pulp/ubuntu yakkety main
+
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/how-to-list-the-enabled-active-repositories-in-linux/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/prakash/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-config-manager-on-linux/
+[2]: https://www.2daygeek.com/how-to-list-installed-packages-by-size-largest-on-linux/
+[3]: https://www.2daygeek.com/how-to-view-list-the-available-packages-updates-in-linux/
+[4]: https://www.2daygeek.com/how-to-view-a-particular-package-installed-updated-upgraded-removed-erased-date-on-linux/
+[5]: https://www.2daygeek.com/how-to-view-detailed-information-about-a-package-in-linux/
+[6]: https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/
+[7]: https://www.2daygeek.com/how-to-list-an-available-package-groups-in-linux/
+[8]: https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
+[9]: https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
+[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
+[11]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
+[12]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
+[13]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
+[14]: https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
diff --git a/sources/tech/20181011 The First Beta of Haiku is Released After 16 Years of Development.md b/sources/tech/20181011 The First Beta of Haiku is Released After 16 Years of Development.md
new file mode 100644
index 0000000000..b6daaef053
--- /dev/null
+++ b/sources/tech/20181011 The First Beta of Haiku is Released After 16 Years of Development.md
@@ -0,0 +1,87 @@
+The First Beta of Haiku is Released After 16 Years of Development
+======
+There are a number of small operating systems out there that are designed to replicate the past. Haiku is one of those. We will look to see where Haiku came from and what the new release has to offer.
+
+![Haiku OS desktop screenshot][1]Haiku desktop
+
+### What is Haiku?
+
+Haiku’s history begins with the now defunct [Be Inc][2]. Be Inc was founded by former Apple executive [Jean-Louis Gassée][3] after he was ousted by CEO [John Sculley][4]. Gassée wanted to create a new operating system from the ground up. BeOS was created with digital media work in mind and was designed to take advantage of the most modern hardware of the time. Originally, Be Inc attempted to create their own platform encompassing both hardware and software. The result was called the [BeBox][5]. After BeBox failed to sell well, Be turned their attention to BeOS.
+
+In the 1990s, Apple was looking for a new operating system to replace the aging Classic Mac OS. The two contenders were Gassée’s BeOS and Steve Jobs’ NeXTSTEP. In the end, Apple went with NeXTSTEP. Be tried to license BeOS to hardware makers, but [in at least one case][6] Microsoft threatened to revoke a manufacturer’s Windows license if they sold BeOS machines. Eventually, Be Inc was sold to Palm in 2001 for $11 million. BeOS was subsequently discontinued.
+
+Following the news of Palm’s purchase, a number of loyal fans decided they wanted to keep the operating system alive. The original name of the project was OpenBeOS, but was changed to Haiku to avoid infringing on Palm’s trademarks. The name is a reference to reference to the [haikus][7] used as error messages by many of the applications. Haiku is completely written from scratch and is compatible with BeOS.
+
+### Why Haiku?
+
+According to the project’s website, [Haiku][8] “is a fast, efficient, simple to use, easy to learn, and yet very powerful system for computer users of all levels”. Haiku comes with a kernel that have been customized for performance. Like FreeBSD, there is a “single team writing everything from the kernel, drivers, userland services, toolkit, and graphics stack to the included desktop applications and preflets”.
+
+### New Features in Haiku Beta Release
+
+A number of new features have been introduced since the release of Alpha 4.1. (Please note that Haiku is a passion project and all the devs are part-time, so some they can’t spend as much time working on Haiku as they would like.)
+
+![Haiku OS software][9]
+HaikuDepot, Haiku’s package manager
+
+One of the biggest features is the inclusion of a complete package management system. HaikuDepot allows you to sort through many applications. Many are built specifically for Haiku, but a number have been ported to the platform, such as [LibreOffice][10], [Otter Browser][11], and [Calligra][12]. Interestingly, each Haiku package is [“a special type of compressed filesystem image, which is ‘mounted’ upon installation”][13]. There is also a command line interface for package management named `pkgman`.
+
+Another big feature is an upgraded browser. Haiku was able to hire a developer to work full-time for a year to improve the performance of WebPositive, the built-in browser. This included an update to a newer version of WebKit. WebPositive will now play Youtube videos properly.
+
+![Haiku OS WebPositive browser][14]
+WebPositive, Haiku’s built-in browser
+
+Other features include:
+
+ * A completely rewritten network preflet
+ * User interface cleanup
+ * Media subsystem improvements, including better streaming support, HDA driver improvements, and FFmpeg decoder plugin improvements
+ * Native RemoteDesktop improved
+ * Add EFI bootloader and GPT support
+ * Updated Ethernet & WiFi drivers
+ * Updated filesystem drivers
+ * General system stabilization
+ * Experimental Bluetooth stack
+
+
+
+### Thoughts on Haiku OS
+
+I have been following Haiku for many years. I’ve installed and played with the nightly builds a dozen times over the last couple of years. I even took some time to start learning one of its programming languages, so that I could write apps. But I got busy with other things.
+
+I’m very conflicted about it. I like Haiku because it is a neat non-Linux project, but it is only just getting features that everyone else takes for granted, like a package manager.
+
+If you’ve got a couple of minutes, download the [ISO][15] and install it on the virtual machine of your choice. You just might like it.
+
+Have you ever used Haiku or BeOS? If so, what are your favorite features? Let us know in the comments below.
+
+If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][16].
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/haiku-os-release/
+
+作者:[John Paul][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[b]: https://github.com/lujun9972
+[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/haiku.jpg
+[2]: https://en.wikipedia.org/wiki/Be_Inc.
+[3]: https://en.wikipedia.org/wiki/Jean-Louis_Gass%C3%A9e
+[4]: https://en.wikipedia.org/wiki/John_Sculley
+[5]: https://en.wikipedia.org/wiki/BeBox
+[6]: https://birdhouse.org/beos/byte/30-bootloader/
+[7]: https://en.wikipedia.org/wiki/Haiku
+[8]: https://www.haiku-os.org/about/
+[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/haiku-depot.png
+[10]: https://www.libreoffice.org/
+[11]: https://itsfoss.com/otter-browser-review/
+[12]: https://www.calligra.org/
+[13]: https://www.haiku-os.org/get-haiku/release-notes/
+[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/webpositive.jpg
+[15]: https://www.haiku-os.org/get-haiku
+[16]: http://reddit.com/r/linuxusersgroup
diff --git a/translated/talk/20180117 How to get into DevOps.md b/translated/talk/20180117 How to get into DevOps.md
deleted file mode 100644
index ec169be76f..0000000000
--- a/translated/talk/20180117 How to get into DevOps.md
+++ /dev/null
@@ -1,145 +0,0 @@
-
-DevOps 实践指南
-======
-
-
-
-在去年大概一年的时间里,我注意到对“Devops 实践”感兴趣的开发人员和系统管理员突然有了明显的增加。这样的变化也合理:现在开发者只要花很少的钱,调用一些 API, 就能单枪匹马地在一整套分布式基础设施上运行自己的应用, 在这个时代,开发和运维的紧密程度前所未有。我看过许多博客和文章介绍很酷的 DevOps 工具和相关思想,但是给那些希望践行 DevOps 的人以指导和建议的内容,我却很少看到。
-
-这篇文章的目的就是描述一下如何去实践。我的想法基于 Reddit 上 [devops][1] 的一些访谈、聊天和深夜讨论,还有一些随机谈话,一般都发生在享受啤酒和美食的时候。如果你已经开始这样实践,我对你的反馈很感兴趣,请通过 [我的博客][2] 或者 [Twitter][3] 联系我,也可以直接在下面评论。我很乐意听到你们的想法和故事。
-
-### 古代的 IT
-
-了解历史是搞清楚未来的关键,DevOps 也不例外。想搞清楚 DevOps 运动的普及和流行,去了解一下上世纪 90 年代后期和 21 世纪前十年 IT 的情况会有帮助。这是我的经验。
-
-我的第一份工作是在一家大型跨国金融服务公司做 Windows 系统管理员。当时给计算资源扩容需要给 Dell 打电话 (或者像我们公司那样打给 CDW ),并下一个价值数十万美元的订单,包含服务器、网络设备、电缆和软件,所有这些都要运到在线或离线的数据中心去。虽然 VMware 仍在尝试说服企业使用虚拟机运行他们的“性能敏感”型程序是更划算的,但是包括我们在内的很多公司都还忠于使用他们的物理机运行应用。
-
-在我们技术部门,有一个专门做数据中心工程和操作的完整团队,他们的工作包括价格谈判,让荒唐的租赁月费能够下降一点点,还包括保证我们的系统能够正常冷却(如果设备太多,这个事情的难度会呈指数增长)。如果这个团队足够幸运足够有钱,境外数据中心的工作人员对我们所有的服务器型号又都有足够的了解,就能避免在盘后交易中不小心扯错东西。那时候亚马逊 AWS 和 Rackspace 逐渐开始加速扩张,但还远远没到临界规模。
-
-当时我们还有专门的团队来保证硬件上运行着的操作系统和软件能够按照预期工作。这些工程师负责设计可靠的架构以方便给系统打补丁,监控和报警,还要定义基础镜像 (gold image) 的内容。这些大都是通过很多手工实验完成的,很多手工实验是为了编写一个运行说明书 (runbook) 来描述要做的事情,并确保按照它执行后的结果确实在预期内。在我们这么大的组织里,这样做很重要,因为一线和二线的技术支持都是境外的,而他们的培训内容只覆盖到了这些运行说明而已。
-
-(这是我职业生涯前三年的世界。我那时候的梦想是成为制定金本位制的人!)
-
-软件发布则完全是另外一头怪兽。无可否认,我在这方面并没有积累太多经验。但是,从我收集的故事(和最近的经历)来看,当时大部分软件开发的日常大概是这样:
-
- * 开发人员按照技术和功能需求来编写代码,这些需求来自于业务分析人员的会议,但是会议并没有邀请开发人员参加。
- * 开发人员可以选择为他们的代码编写单元测试,以确保在代码里没有任何明显的疯狂行为,比如除以 0 但不抛出异常。
- * 然后开发者会把他们的代码标记为 "Ready for QA."(准备好了接受测试),质量保障的成员会把这个版本的代码发布到他们自己的环境中,这个环境和生产环境可能相似,也可能不相似,甚至和开发环境相比也不一定相似。
- * 故障会在几天或者几个星期内反馈到开发人员那里,这个时长取决于其他业务活动和优先事项。
-
-
-
-虽然系统管理员和开发人员经常有不一致的意见,但是对“变更管理”的痛恨却是一致的。变更管理由高度规范的(就我当时的雇主而言)和非常有必要的规则和程序组成,用来管理一家公司应该什么时候做技术变更,以及如何做。很多公司都按照 [ITIL][4] 来操作, 简单的说,ITIL 问了很多和事情发生的原因、时间、地点和方式相关的问题,而且提供了一个过程,对产生最终答案的决定做审计跟踪。
-
-你可能从我的简短历史课上了解到,当时 IT 的很多很多事情都是手工完成的。这导致了很多错误。错误又导致了很多财产损失。变更管理的工作就是尽量减少这些损失,它常常以这样的形式出现:不管变更的影响和规模大小,每两周才能发布部署一次。周五下午 4 点到周一早上 5 点 59 分这段时间,需要排队等候发布窗口。(讽刺的是,这种流程导致了更多错误,通常还是更严重的那种错误)
-
-### DevOps 不是专家团
-
-你可能在想 "Carlos 你在讲啥啊,什么时候才能说到 Ansible playbooks? ",我热爱 Ansible, 但是请再等一会;下面这些很重要。
-
-你有没有过被分配到过需要跟"DevOps"小组打交道的项目?你有没有依赖过“配置管理”或者“持续集成/持续交付”小组来保证业务流水线设置正确?你有没有在代码开发完的数周之后才参加发布部署的会议?
-
-如果有过,那么你就是在重温历史,这个历史是由上面所有这些导致的。
-
-出于本能,我们喜欢和像自己的人一起工作,这会导致[筒仓][5]的行成。很自然,这种人类特质也会在工作场所表现出来是不足为奇的。我甚至在一个 250 人的创业公司里见到过这样的现象,当时我在那里工作。刚开始的时候,开发人员都在聚在一起工作,彼此深度协作。随着代码变得复杂,开发相同功能的人自然就坐到了一起,解决他们自己的复杂问题。然后按功能划分的小组很快就正式形成了。
-
-在我工作过的很多公司里,系统管理员和开发人员不仅像这样形成了天然的筒仓,而且彼此还有激烈的对抗。开发人员的环境出问题了或者他们的权限太小了,就会对系统管理员很恼火。系统管理员怪开发者无时不刻的不在用各种方式破坏他们的环境,怪开发人员申请的计算资源严重超过他们的需要。双方都不理解对方,更糟糕的是,双方都不愿意去理解对方。
-
-大部分开发人员对操作系统,内核或计算机硬件都不感兴趣。同样的,大部分系统管理员,即使是 Linux 的系统管理员,也都不愿意学习编写代码,他们在大学期间学过一些 C 语言,然后就痛恨它,并且永远都不想再碰 IDE. 所以,开发人员把运行环境的问题甩给围墙外的系统管理员,系统管理员把这些问题和甩过来的其他上百个问题放在一起,做一个优先级安排。每个人都很忙,心怀怨恨的等待着。DevOps 的目的就是解决这种矛盾。
-
-DevOps 不是一个团队,CI/CD 也不是 Jira 系统的一个用户组。DevOps 是一种思考方式。根据这个运动来看,在理想的世界里,开发人员、系统管理员和业务相关人将作为一个团队工作。虽然他们可能不完全了解彼此的世界,可能没有足够的知识去了解彼此的积压任务,但他们在大多数情况下能有一致的看法。
-
-把所有基础设施和业务逻辑都代码化,再串到一个发布部署流水线里,就像是运行在这之上的应用一样。这个理念的基础就是 DevOps. 因为大家都理解彼此,所以人人都是赢家。聊天机器人和易用的监控工具、可视化工具的兴起,背后的基础也是 DevOps.
-
-[Adam Jacob][6] 说的最好:"DevOps 就是企业往软件导向型过渡时我们用来描述操作的词"
-
-### 要实践 DevOps 我需要知道些什么
-
-我经常被问到这个问题,它的答案,和同属于开放式的其他大部分问题一样:视情况而定。
-
-现在“DevOps 工程师”在不同的公司有不同的含义。在软件开发人员比较多但是很少有人懂基础设施的小公司,他们很可能是在找有更多系统管理经验的人。而其他公司,通常是大公司或老公司或又大又老的公司,已经有一个稳固的系统管理团队了,他们在向类似于谷歌 [SRE][7] 的方向做优化,也就是“设计操作功能的软件工程师”。但是,这并不是金科玉律,就像其他技术类工作一样,这个决定很大程度上取决于他的招聘经理。
-
-也就是说,我们一般是在找对深入学习以下内容感兴趣的工程师:
-
- * 如何管理和设计安全、可扩展的云上的平台(通常是在 AWS 上,不过微软的 Azure, 谷歌的 Cloud Platform,还有 DigitalOcean 和 Heroku 这样的 PaaS 提供商,也都很流行)
- * 如何用流行的 [CI/CD][8] 工具,比如 Jenkins,Gocd,还有基于云的 Travis CI 或者 CircleCI,来构造一条优化的发布部署流水线,和发布部署策略。
- * 如何在你的系统中使用基于时间序列的工具,比如 Kibana,Grafana,Splunk,Loggly 或者 Logstash,来监控,记录,并在变化的时候报警,还有
- * 如何使用配置管理工具,例如 Chef,Puppet 或者 Ansible 做到“基础设施即代码”,以及如何使用像 Terraform 或 CloudFormation 的工具发布这些基础设施。
-
-
-
-容器也变得越来越受欢迎。尽管有人对大规模使用 Docker 的现状[表示不满][9],但容器正迅速地成为一种很好的方式来实现在更少的操作系统上运行超高密度的服务和应用,同时提高它们的可靠性。(像 Kubernetes 或者 Mesos 这样的容器编排工具,能在宿主机故障的时候,几秒钟之内重新启动新的容器。)考虑到这些,掌握 Docker 或者 rkt 以及容器编排平台的知识会对你大有帮助。
-
-如果你是希望做 DevOps 实践的系统管理员,你还需要知道如何写代码。Python 和 Ruby 是 DevOps 领域的流行语言,因为他们是可移植的(也就是说可以在任何操作系统上运行),快速的,而且易读易学。它们还支撑着这个行业最流行的配置管理工具(Ansible 是使用 Python 写的,Chef 和 Puppet 是使用 Ruby 写的)以及云平台的 API 客户端(亚马逊 AWS, 微软 Azure, 谷歌 Cloud Platform 的客户端通常会提供 Python 和 Ruby 语言的版本)。
-
-如果你是开发人员,也希望做 DevOps 的实践,我强烈建议你去学习 Unix,Windows 操作系统以及网络基础知识。虽然云计算把很多系统管理的难题抽象化了,但是对慢应用的性能做 debug 的时候,你知道操作系统如何工作的就会有很大的帮助。下文包含了一些这个主题的图书。
-
-如果你觉得这些东西听起来内容太多,大家都是这么想的。幸运的是,有很多小项目可以让你开始探索。其中一个启动项目是 Gary Stafford 的[选举服务](https://github.com/garystafford/voter-service), 一个基于 Java 的简单投票平台。我们要求面试候选人通过一个流水线将该服务从 GitHub 部署到生产环境基础设施上。你可以把这个服务与 Rob Mile 写的了不起的 DevOps [入门教程](https://github.com/maxamg/cd-office-hours)结合起来,学习如何编写流水线。
-
-还有一个熟悉这些工具的好方法,找一个流行的服务,然后只使用 AWS 和配置管理工具来搭建这个服务所需要的基础设施。第一次先手动搭建,了解清楚要做的事情,然后只用 CloudFormation (或者 Terraform) 和 Ansible 重写刚才的手动操作。令人惊讶的是,这就是我们基础设施开发人员为客户所做的大部分日常工作,我们的客户认为这样的工作非常有意义!
-
-### 需要读的书
-
-如果你在找 DevOps 的其他资源,下面这些理论和技术书籍值得一读。
-
-#### 理论书籍
-
- * Gene Kim 写的 [The Phoenix Project (凤凰项目)][10]。这是一本很不错的书,内容涵盖了我上文解释过的历史(写的更生动形象),描述了一个运行在敏捷和 DevOps 之上的公司向精益前进的过程。
- * Terrance Ryan 写的 [Driving Technical Change (布道之道)][11]。非常好的一小本书,讲了大多数技术型组织内的常见性格特点以及如何和他们打交道。这本书对我的帮助比我想象的更多。
- * Tom DeMarco 和 Tim Lister 合著的 [Peopleware (人件)][12]。管理工程师团队的经典图书,有一点过时,但仍然很有价值。
- * Tom Limoncelli 写的 [Time Management for System Administrators (时间管理: 给系统管理员)][13]。这本书主要面向系统管理员,它对很多大型组织内的系统管理员生活做了深入的展示。如果你想了解更多系统管理员和开发人员之间的冲突,这本书可能解释了更多。
- * Eric Ries 写的 [The Lean Startup (精益创业)][14]。描述了 Eric 自己的 3D 虚拟形象公司,IMVU, 发现了如何精益工作,快速失败和更快盈利。
- * Jez Humble 和他的朋友写的[Lean Enterprise (精益企业)][15]。这本书是对精益创业做的改编,以更适应企业,两本书都很棒,都很好的解释了 DevOps 背后的商业动机。
- * Kief Morris 写的 [Infrastructure As Code (基础设施即代码)][16]。关于 "基础设施即代码" 的非常好的入门读物!很好的解释了为什么所有公司都有必要采纳这种做法。
- * Betsy Beyer, Chris Jones, Jennifer Petoff 和 Niall Richard Murphy 合著的 [Site Reliability Engineering (站点可靠性工程师)][17]。一本解释谷歌 SRE 实践的书,也因为是 "DevOps 诞生之前的 DevOps" 被人熟知。在如何处理运行时间、时延和保持工程师快乐方面提供了有趣的看法。
-
-
-
-#### 技术书籍
-
-如果你想找的是让你直接跟代码打交道的书,看这里就对了。
-
- * W. Richard Stevens 的 [TCP/IP Illustrated (TCP/IP 详解)][18]。这是一套经典的(也可以说是最全面的)讲解基本网络协议的巨著,重点介绍了 TCP/IP 协议族。如果你听说过 1,2, 3,4 层网络,而且对深入学习他们感兴趣,那么你需要这本书。
- * Evi Nemeth, Trent Hein 和 Ben Whaley 合著的 [UNIX and Linux System Administration Handbook (UNIX/Linux 系统管理员手册)][19]。一本很好的入门书,介绍 Linux/Unix 如何工作以及如何使用。
- * Don Jones 和 Jeffrey Hicks 合著的 [Learn Windows Powershell In A Month of Lunches (Windows PowerShell实战指南)][20]. 如果你在 Windows 系统下做自动化任务,你需要学习怎么使用 Powershell。这本书能够帮助你。Don Jones 是这方面著名的 MVP。
- * 几乎所有 [James Turnbull][21] 写的东西,针对流行的 DevOps 工具,他发表了很好的技术入门读物。
-
-
-
-不管是在那些把所有应用都直接部署在物理机上的公司,(现在很多公司仍然有充分的理由这样做)还是在那些把所有应用都做成 serverless 的先驱公司,DevOps 都很可能会持续下去。这部分工作很有趣,产出也很有影响力,而且最重要的是,它搭起桥梁衔接了技术和业务之间的缺口。DevOps 是一个值得期待的美好事物。
-
-首次发表在 [Neurons Firing on a Keyboard][22]。使用 CC-BY-SA 协议。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/1/getting-devops
-
-作者:[Carlos Nunez][a]
-译者:[belitex](https://github.com/belitex)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/carlosonunez
-[1]:https://www.reddit.com/r/devops/
-[2]:https://carlosonunez.wordpress.com/
-[3]:https://twitter.com/easiestnameever
-[4]:https://en.wikipedia.org/wiki/ITIL
-[5]:https://www.psychologytoday.com/blog/time-out/201401/getting-out-your-silo
-[6]:https://twitter.com/adamhjk/status/572832185461428224
-[7]:https://landing.google.com/sre/interview/ben-treynor.html
-[8]:https://en.wikipedia.org/wiki/CI/CD
-[9]:https://thehftguy.com/2016/11/01/docker-in-production-an-history-of-failure/
-[10]:https://itrevolution.com/book/the-phoenix-project/
-[11]:https://pragprog.com/book/trevan/driving-technical-change
-[12]:https://en.wikipedia.org/wiki/Peopleware:_Productive_Projects_and_Teams
-[13]:http://shop.oreilly.com/product/9780596007836.do
-[14]:http://theleanstartup.com/
-[15]:https://info.thoughtworks.com/lean-enterprise-book.html
-[16]:http://infrastructure-as-code.com/book/
-[17]:https://landing.google.com/sre/book.html
-[18]:https://en.wikipedia.org/wiki/TCP/IP_Illustrated
-[19]:http://www.admin.com/
-[20]:https://www.manning.com/books/learn-windows-powershell-in-a-month-of-lunches-third-edition
-[21]:https://jamesturnbull.net/
-[22]:https://carlosonunez.wordpress.com/2017/03/02/getting-into-devops/
diff --git a/translated/talk/20180915 Linux vs Mac- 7 Reasons Why Linux is a Better Choice than Mac.md b/translated/talk/20180915 Linux vs Mac- 7 Reasons Why Linux is a Better Choice than Mac.md
new file mode 100644
index 0000000000..a9ece78ef7
--- /dev/null
+++ b/translated/talk/20180915 Linux vs Mac- 7 Reasons Why Linux is a Better Choice than Mac.md
@@ -0,0 +1,131 @@
+Linux vs Mac: Linux 比 Mac 好的七个原因
+======
+最近我们谈论了一些[为什么 Linux 比 Windows 好][1]的原因。毫无疑问, Linux 是个非常优秀的平台。但是它和其他的操作系统一样也会有缺点。对于某些专门的领域,像是游戏, Windows 当然更好。 而对于视频编辑等任务, Mac 系统可能更为方便。这一切都取决于你的爱好,以及你想用你的系统做些什么。在这篇文章中,我们将会介绍一些 Linux 相对于 Mac 更好的一些地方。
+
+如果你已经在用 Mac 或者打算买一台 Mac 电脑,我们建议你仔细考虑一下,看看是改为使用 Linux 还是继续使用 Mac 。
+
+### Linux 比 Mac 好的 7 个原因
+
+![Linux vs Mac: 为什么 Linux 更好][2]
+
+Linux 和 macOS 都是类 Unix 操作系统,并且都支持 Unix 命令行、 bash 和其他一些命令行工具,相比于 Windows ,他们所支持的应用和游戏比较少。但缺点也仅仅如此。
+
+平面设计师和视频剪辑师更加倾向于使用 Mac 系统,而 Linux 更加适合做开发、系统管理、运维的工程师。
+
+那要不要使用 Linux 呢,为什么要选择 Linux 呢?下面是根据实际经验和理性分析给出的一些建议。
+
+#### 1\. 价格
+
+![Linux vs Mac: 为什么 Linux 更好][3]
+
+假设你只是需要浏览文件、看电影、下载图片、写文档、制作报表或者做一些类似的工作,并且你想要一个更加安全的系统。
+
+那在这种情况下,你觉得花费几百块买个系统完成这项工作,或者花费更多直接买个 Macbook 划算吗?当然,最终的决定权还是在你。
+
+买个装好 Mac 系统的电脑还是买个便宜的电脑,然后自己装上免费的 Linux 系统,这个要看你自己的偏好。就我个人而言,除了音视频剪辑创作之外,Linux 都非常好地用,而对于音视频方面,我更倾向于使用 Final Cut Pro (专业的视频编辑软件) 和 Logic Pro X (专业的音乐制作软件)(这两款软件都是苹果公司推出的)。
+
+#### 2\. 硬件支持
+
+![Linux vs Mac: 为什么 Linux 更好][4]
+
+Linux 支持多种平台. 无论你的电脑配置如何,你都可以在上面安装 Linux,无论性能好或者差,Linux 都可以运行。[即使你的电脑已经使用很久了, 你仍然可以通过选择安装合适的发行版让 Linux 在你的电脑上流畅的运行][5].
+
+而 Mac 不同,它是苹果机专用系统。如果你希望买个便宜的电脑,然后自己装上 Mac 系统,这几乎是不可能的。一般来说 Mac 都是和苹果设备连在一起的。
+
+这是[在非苹果系统上安装 Mac OS 的教程][6]. 这里面需要用到的专业技术以及可能遇到的一些问题将会花费你许多时间,你需要想好这样做是否值得。
+
+总之,Linux 所支持的硬件平台很广泛,而 MacOS 相对而言则非常少。
+
+#### 3\. 安全性
+
+![Linux vs Mac: 为什么 Linux 更好][7]
+
+很多人都说 ios 和 Mac 是非常安全的平台。的确,相比于 Windows ,它确实比较安全,可并不一定有 Linux 安全。
+
+我不是在危言耸听。 Mac 系统上也有不少恶意软件和广告,并且[数量与日俱增][8]。我认识一些不太懂技术的用户 使用着非常缓慢的 Mac 电脑并且为此苦苦挣扎。一项快速调查显示[浏览器恶意劫持软件][9]是罪魁祸首.
+
+从来没有绝对安全的操作系统,Linux 也不例外。 Linux 也有漏洞,但是 Linux 发行版提供的及时更新弥补了这些漏洞。另外,到目前为止在 Linux 上还没有自动运行的病毒或浏览器劫持恶意软件的案例发生。
+
+这可能也是一个你应该选择 Linux 而不是 Mac 的原因。
+
+#### 4\. 可定制性与灵活性
+
+![Linux vs Mac: 为什么 Linux 更好][10]
+
+如果你有不喜欢的东西,自己定制或者修改它都行。
+
+举个例子,如果你不喜欢 Ubuntu 18.04.1 的 [Gnome 桌面环境][11],你可以换成 [KDE Plasma][11]。 你也可以尝试一些 [Gnome 扩展][12]丰富你的桌面选择。这种灵活性和可定制性在 Mac OS 是不可能有的。
+
+除此之外你还可以根据需要修改一些操作系统的代码(但是可能需要一些专业知识)以创造出适合你的系统。这个在 Mac OS 上可以做吗?
+
+另外你可以根据需要从一系列的 Linux 发行版进行选择。比如说,如果你想喜欢 Mac OS上的工作流, [Elementary OS][13] 可能是个不错的选择。你想在你的旧电脑上装上一个轻量级的 Linux 发行版系统吗?这里是一个[轻量级 Linux 发行版列表][5]。相比较而言, Mac OS 缺乏这种灵活性。
+
+#### 5\. 使用 Linux 有助于你的职业生涯 [针对 IT 行业和科学领域的学生]
+
+![Linux vs Mac: 为什么 Linux 更好][14]
+
+对于 IT 领域的学生和求职者而言,这是有争议的但是也是有一定的帮助的。使用 Linux 并不会让你成为一个优秀的人,也不一定能让你得到任何与 IT 相关的工作。
+
+但是当你开始使用 Linux 并且开始探索如何使用的时候,你将会获得非常多的经验。作为一名技术人员,你迟早会接触终端,学习通过命令行实现文件系统管理以及应用程序安装。你可能不会知道这些都是一些 IT 公司的新职员需要培训的内容。
+
+除此之外,Linux 在就业市场上还有很大的发展空间。 Linux 相关的技术有很多( Cloud 、 Kubernetes 、Sysadmin 等),您可以学习,获得证书并获得一份相关的高薪的工作。要学习这些,你必须使用 Linux 。
+
+#### 6\. 可靠
+
+![Linux vs Mac: 为什么 Linux 更好][15]
+
+想想为什么服务器上用的都是 Linux 系统,当然是因为它可靠。
+
+但是它为什么可靠呢,相比于 Mac OS ,它的可靠体现在什么方面呢?
+
+答案很简单——给用户更多的控制权,同时提供更好的安全性。在 Mac OS 上,你并不能完全控制它,这样做是为了让操作变得更容易,同时提高你的用户体验。使用 Linux ,你可以做任何你想做的事情——这可能会导致(对某些人来说)糟糕的用户体验——但它确实使其更可靠。
+
+#### 7\. 开源
+
+![Linux vs Mac: 为什么 Linux 更好][16]
+
+开源并不是每个人都关心的。但对我来说,Linux 最重要的优势在于它的开源特性。下面讨论的大多数观点都是开源软件的直接优势。
+
+简单解释一下,如果是开源软件,你可以自己查看或者修改它。但对 Mac 来说,苹果拥有独家控制权。即使你有足够的技术知识,也无法查看 Mac OS 的源代码。
+
+形象点说,Mac 驱动的系统可以让你得到一辆车,但缺点是你不能打开引擎盖看里面是什么。那可能非常糟糕!
+
+如果你想深入了解开源软件的优势,可以在 OpenSource.com 上浏览一下 [Ben Balter 的文章][17]。
+
+### 总结
+
+现在你应该知道为什么 Linux 比 Mac 好了吧,你觉得呢?上面的这些原因可以说服你选择 Linux 吗?如果不行的话那又是为什么呢?
+
+在下方评论让我们知道你的想法。
+
+Note: 这里的图片是以企鹅俱乐部为原型的。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/linux-vs-mac/
+
+作者:[Ankush Das][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[Ryze-Borgia](https://github.com/Ryze-Borgia)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[1]: https://itsfoss.com/linux-better-than-windows/
+[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/Linux-vs-mac-featured.png
+[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-1.jpeg
+[4]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-4.jpeg
+[5]: https://itsfoss.com/lightweight-linux-beginners/
+[6]: https://hackintosh.com/
+[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-2.jpeg
+[8]: https://www.computerworld.com/article/3262225/apple-mac/warning-as-mac-malware-exploits-climb-270.html
+[9]: https://www.imore.com/how-to-remove-browser-hijack
+[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-3.jpeg
+[11]: https://www.gnome.org/
+[12]: https://itsfoss.com/best-gnome-extensions/
+[13]: https://elementary.io/
+[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-5.jpeg
+[15]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-6.jpeg
+[16]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-7.jpeg
+[17]: https://opensource.com/life/15/12/why-open-source
diff --git a/translated/tech/20180105 The Best Linux Distributions for 2018.md b/translated/tech/20180105 The Best Linux Distributions for 2018.md
new file mode 100644
index 0000000000..ed373a6f6e
--- /dev/null
+++ b/translated/tech/20180105 The Best Linux Distributions for 2018.md
@@ -0,0 +1,134 @@
+# 2018 年最好的 Linux 发行版
+
+
+Jack Wallen 分享他挑选的 2018 年最好的 Linux 发行版。
+
+这是新的一年,Linux仍有无限可能。而且许多 Linux 在 2017 年都带来了许多重大的改变,我相信在 2018 年它在服务器和桌面上将会带来更加稳定的系统和市场份额的增长。
+
+对于那些期待迁移到开源平台(或是那些想要切换到)的人对于即将到来的一年,什么是最好的选择?如果你去 [Distrowatch][14] 找一下,你可能会因为众多的发行版而感到头晕,其中一些的排名在上升,而还有一些则恰恰相反。
+
+因此,哪个 Linux 发行版将在 2018 年得到偏爱?我有我的看法。事实上,我现在就要和你们分享它。
+
+跟我做的 [去年清单][15] 相似,我将会打破那张清单,使任务更加轻松。普通的 Linux 用户,至少包含以下几个类别:系统管理员,轻量级发行版,桌面,为物联网和服务器发行的版本。
+
+根据这些,让我们开始 2018 年最好的 Linux 发行版清单吧。
+
+### 对系统管理员最好的发行版
+
+[Debian][16] 不常出现在“最好的”列表中。但他应该出现,为什么呢?如果了解到 Ubuntu 是基于 Debian 构建的(其实有很多的发行版都基于 Debian),你就很容易理解为什么这个发行版应该在许多“最好”清单中。但为什么是对管理员最好的呢?我想这是由于两个非常重要的原因:
+
+* 容易使用
+* 非常稳定
+
+因为 Debain 使用 dpkg 和 apt 包管理,它使得使用环境非常简单。而且因为 Debian 提供了最稳定的 Linux 平台之一,它为许多事物提供了理想的环境:桌面,服务器,测试,开发。虽然 Debian 可能不包括去年获奖者发现的大量应用程序,但添加完成任务所需的任何/所有必要应用程序都非常容易。而且因为 Debian 可以根据你的选择安装桌面(Cinnamon, GNOME, KDE, LXDE, Mate, 或者 Xfce),你可以确定满足你需要的桌面。
+
+
+图1:在 Debian 9.3 上运行的 GNOME 桌面。[使用][1]
+
+同时,Debain 在 Distrowatch 上名列第二。下载,安装,然后让它为你的工作而服务吧。Debain 尽管不那么华丽,但是对于管理员的工作来说十分有用。
+
+### 最轻量级的发行版
+
+轻量级的发行版对于一些老旧或是性能底下的机器有很好的支持。但是这不意味着这些发行版仅仅只为了老旧的硬件机器而生。如果你想要的是运行速度,你可能会想知道在你的现代机器上,这类发行版的运行速度。
+
+在 2018 年上榜的最轻量级的发行版是 [Lubuntu][18]。尽管在这个类别里还有很多选择,而且尽管 Lubuntu 的大小与 Puppy Linux 相接近,但得益于它是 Ubuntu 家庭的一员,这弥补了它在易用性上的一些不足。但是不要担心,Lubuntu 对于硬件的要求并不高:
+
++ CPU:奔腾 4 或者 奔腾 M 或者 AMD K8 以上
++ 对于本地应用,512 MB 的内存就可以了,对于网络使用(Youtube,Google+,Google Drive, Facebook),建议 1 GB 以上。
+
+Lubuntu 使用的是 LXDE 桌面,这意味着用户在初次使用这个 Linux 发行版时不会有任何问题。这份短清单中包含的应用(例如:Abiword, Gnumeric, 和 Firefox)都是非常轻量,且对用户友好的。
+
+### [lubuntu,jpg][8]
+
+图2:LXDE桌面。[使用][2]
+
+Lubuntu 能让十年以上的电脑如获新生。
+
+### 最好的桌面发行版
+
+[Elementary OS][19] 连续两年都是我清单中最好的桌面发行版。对于许多人,[Linux Mint][20] 都是桌面发行版的领导。但是,与我来说,它在易用性和稳定性上很难打败 Elementary OS。例如,我确信 [Ubuntu][21] 17.10 的发布会让我迁移回 Canonical 的发行版。不久之后我会迁移到 新的使用 GNOME 桌面的 Ubuntu,但是我发现我少了 Elementary OS 外观,可用性和感觉。在使用 Ubuntu 两周以后,我又换回了 Elementary OS。
+
+### [elementaros.jpg][9]
+
+
+图3:Pantheon 桌面是一件像艺术品一样的桌面。[使用][3]
+
+任何使用 Elementary OS 的感觉很好。Pantheon 桌面是缺省和用户友好做的最完美的桌面。每次更新,它都会变得更好。
+
+尽管 Elementary OS 在 Distrowatch 中排名第六,但我预计到 2018 年第,它将至少上升至第三名。Elementary 开发人员非常关注用户的需求。他们倾听并且改进,他们目前的状态是如此之好,似乎所有他们都可以做的更好。 如果您需要一个具有出色可靠性和易用性的桌面,Elementary OS 就是你的发行版。
+
+### 能够证明自己的最好的发行版
+
+很长一段时间内,[Gentoo][22]都稳坐“展现你技能”的发行版的首座。但是,我认为现在 Gentoo 是时候让出“证明自己”的宝座给 [Linux From Svratch][23]。你可能认为这不公平,因为 LFS 实际上不是一个发行版,而是一个帮助用户创建自己的 Linux 发行版的项目。但是,有什么能比你自己创建一个自己的发行版更能证明自己所学的 Linux 知识的呢?在 LFS 项目中,你可以从头开始构建自定义的 Linux 系统。 所以,如果你真的有需要证明的东西,请下载 [Linux From Scratch Book][24] 并开始构建。
+
+### 对于物联网最好的发行版
+
+[Ubuntu Core][25] 已经是第二年赢得了该项的冠军。Ubuntu Core 是 Ubuntu 的一个小型版本,专为嵌入式和物联网设备而构建。使Ubuntu Core 如此完美的物联网的原因在于它将重点放在快照包 - 通用包上,可以安装到平台上,而不会干扰基本系统。这些快照包包含它们运行所需的所有内容(包括依赖项),因此不必担心安装会破坏操作系统(或任何其他已安装的软件)。 此外,快照非常容易升级并在隔离的沙箱中运行,这使它们成为物联网的理想解决方案。
+
+Ubuntu Core 内置的另一个安全领域是登录机制。Ubuntu Core使用Ubuntu One ssh密钥,这样登录系统的唯一方法是通过上传的ssh密钥到[Ubuntu One帐户][26]。这为你的物联网设备提供了更高的安全性。
+
+### [ubuntucore.jpg][10]
+
+图4:Ubuntu Core屏幕指示通过Ubuntu One用户启用远程访问。[使用][3]
+
+### 最好的服务器发行版
+
+这让事情变得有些混乱。 主要原因是支持。 如果你需要商业支持,乍一看,你最好的选择可能是 [Red Hat Enterprise Linux][27]。红帽年复一年地证明了自己不仅是全球最强大的企业服务器平台之一,而且是单一最赚钱的开源业务(年收入超过20亿美元)。
+
+但是,Red Hat 并不是唯一的服务器发行版。 实际上,Red Hat 甚至不支持企业服务器计算的各个方面。如果你关注亚马逊 Elastic Compute Cloud 上的云统计数据,Ubuntu 就会打败红帽企业Linux。根据[云市场][28],EC2 统计数据显示 RHEL 的部署率低于 10 万,而 Ubuntu 的部署量超过 20 万。
+
+最终的结果是,Ubuntu 几乎已经成为云计算的领导者。如果你将它与 Ubuntu 易于使用和管理容器结合起来,就会发现 Ubuntu Server 是服务器类别的明显赢家。而且,如果你需要商业支持,Canonical 将为你提供 [Ubuntu Advantage][29]。
+
+对使用 Ubuntu Server 的一个警告是它默认为纯文本界面。如果需要,你可以安装 GUI,但使用Ubuntu Server 命令行非常简单(每个Linux管理员都应该知道)。
+
+### [ubuntuserver.jpg][11]
+
+
+图5:Ubuntu 服务器登录,通知更新。[使用][3]
+
+### 你最好的选择
+
+正如我之前所说,这些选择都非常主观,但如果你正在寻找一个好的开始,那就试试这些发行版。每一个都可以用于非常特定的目的,并且比大多数做得更好。虽然你可能不同意我的特定选择,但你可能会同意 Linux 在每个方面都提供了惊人的可能性。并且,请继续关注下周更多“最佳发行版”选秀。
+
+通过 Linux 基金会和 edX 的免费[“Linux 简介”][13]课程了解有关Linux的更多信息。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/best-linux-distributions-2018
+
+作者:[JACK WALLEN ][a]
+译者:[dianbanjiu](https://github.com/dianbanjiu)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/jlwallen
+[1]:https://www.linux.com/licenses/category/used-permission
+[2]:https://www.linux.com/licenses/category/used-permission
+[3]:https://www.linux.com/licenses/category/used-permission
+[4]:https://www.linux.com/licenses/category/used-permission
+[5]:https://www.linux.com/licenses/category/used-permission
+[6]:https://www.linux.com/licenses/category/creative-commons-zero
+[7]:https://www.linux.com/files/images/debianjpg
+[8]:https://www.linux.com/files/images/lubuntujpg-2
+[9]:https://www.linux.com/files/images/elementarosjpg
+[10]:https://www.linux.com/files/images/ubuntucorejpg
+[11]:https://www.linux.com/files/images/ubuntuserverjpg-1
+[12]:https://www.linux.com/files/images/linux-distros-2018jpg
+[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
+[14]:https://distrowatch.com/
+[15]:https://www.linux.com/news/learn/sysadmin/best-linux-distributions-2017
+[16]:https://www.debian.org/
+[17]:https://www.parrotsec.org/
+[18]:http://lubuntu.me/
+[19]:https://elementary.io/
+[20]:https://linuxmint.com/
+[21]:https://www.ubuntu.com/
+[22]:https://www.gentoo.org/
+[23]:http://www.linuxfromscratch.org/
+[24]:http://www.linuxfromscratch.org/lfs/download.html
+[25]:https://www.ubuntu.com/core
+[26]:https://login.ubuntu.com/
+[27]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
+[28]:http://thecloudmarket.com/stats#/by_platform_definition
+[29]:https://buy.ubuntu.com/?_ga=2.177313893.113132429.1514825043-1939188204.1510782993
diff --git a/translated/tech/20180201 Rock Solid React.js Foundations A Beginners Guide.md b/translated/tech/20180201 Rock Solid React.js Foundations A Beginners Guide.md
new file mode 100644
index 0000000000..bdb2abca36
--- /dev/null
+++ b/translated/tech/20180201 Rock Solid React.js Foundations A Beginners Guide.md
@@ -0,0 +1,281 @@
+坚实的 React 基础:初学者指南
+============================================================
+
+React.js crash course
+
+在过去的几个月里,我一直在使用 React 和 React-Native。我已经发布了两个作为产品的应用, [Kiven Aa][1](React)和 [Pollen Chat][2](React Native)。当我开始学习 React 时,我找了一些不仅仅是教我如何用 React 写应用的东西(一个博客,一个视频,一个课程,等等),我也想让它帮我做好面试准备。
+
+我发现的大部分资料都集中在某一单一方面上。所以,这篇文章针对的是那些希望理论与实践完美结合的观众。我会告诉你一些理论,以便你了解幕后发生的事情,然后我会向你展示如何编写一些 React.js 代码。
+
+如果你更喜欢视频形式,我在YouTube上传了整个课程,请去看看。
+
+
+让我们开始......
+
+> React.js 是一个用于构建用户界面的 JavaScript 库
+
+你可以构建各种单页应用程序。例如,你希望在用户界面上实时显示更改的聊天软件和电子商务门户。
+
+### 一切都是组件
+
+React 应用由组件组成,数量多且互相嵌套。你或许会问:”可什么是组件呢?“
+
+组件是可重用的代码段,它定义了某些功能在 UI 上的外观和行为。 比如,按钮就是一个组件。
+
+让我们看看下面的计算器,当你尝试计算2 + 2 = 4 -1 = 3(简单的数学题)时,你会在Google上看到这个计算器。
+
+
+红色标记表示组件
+
+
+
+如上图所示,这个计算器有很多区域,比如展示窗口和数字键盘。所有这些都可以是许多单独的组件或一个巨大的组件。这取决于在 React 中分解和抽象出事物的程度。你为所有这些组件分别编写代码,然后合并这些组件到一个容器中,而这个容器又是一个 React 组件。这样你就可以创建可重用的组件,最终的应用将是一组协同工作的单独组件。
+
+
+
+以下是一个你践行了以上原则并可以用 React 编写计算器的方法。
+
+```
+
+
+
+
+
+ .
+ .
+ .
+
+
+
+
+```
+
+没错!它看起来像HTML代码,然而并不是。我们将在后面的部分中详细探讨它。
+
+### 设置我们的 Playground
+
+这篇教程专注于 React 的基础部分。它没有偏向 Web 或 React Native(开发移动应用)。所以,我们会用一个在线编辑器,这样可以在学习 React 能做什么之前避免 web 或 native 的具体配置。
+
+我已经为读者在 [codepen.io][4] 设置好了开发环境。只需点开这个链接并且阅读所有 HTML 和 JavaScript 注释。
+
+### 控制组件
+
+我们已经了解到 React 应用是各种组件的集合,结构为嵌套树。因此,我们需要某种机制来将数据从一个组件传递到另一个组件。
+
+#### 进入 “props”
+
+我们可以使用 `props` 对象将任意数据传递给我们的组件。 React 中的每个组件都会获取 `props` 对象。在学习如何使用 `props` 之前,让我们学习函数式组件。
+
+#### a) 函数式组件
+
+在 React 中,一个函数式组件通过 `props` 对象使用你传递给它的任意数据。它返回一个对象,该对象描述了 React 应渲染的 UI。函数式组件也称为无状态组件。
+
+
+
+让我们编写第一个函数式组件。
+
+```
+function Hello(props) {
+ return