mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-28 23:20:10 +08:00
Merge pull request #15 from LCTT/master
Merge pull request #13 from LCTT/master
This commit is contained in:
commit
83176973d3
@ -2,13 +2,13 @@ Ubuntu中跟踪多个时区的简捷方法
|
||||
================================================================================
|
||||

|
||||
|
||||
**我是否要确保在我醒来时或者安排与*山姆陈*,Ohso的半个开发商,进行Skype通话时,澳大利亚一个关于Chromebook销售的推特已经售罄,我大脑同时在多个时区下工作。**
|
||||
**无论我是要在醒来时发个关于澳大利亚的 Chromebook 销售已经售罄的推特,还是要记着和Ohso的半个开发商山姆陈进行Skype通话,我大脑都需要同时工作在多个时区下。**
|
||||
|
||||
那里头有个问题,如果你认识我,你会知道我的脑容量也就那么丁点,跟金鱼差不多,里头却塞着像Windows Vista这样一个臃肿货(也就是,不是很好)。我几乎记不得昨天之前的事情,更记不得我的门和金门大桥脚之间的时间差!
|
||||
|
||||
作为臂助,我使用一些小部件和菜单项来让我保持同步。在我常规工作日的空间里,我在多个操作系统间游弋,涵盖移动系统和桌面系统,但只有一个让我最快速便捷地设置“世界时钟”。
|
||||
作为臂助,我使用一些小部件和菜单项来让我保持同步。在我常规工作日的空间里,我在多个操作系统间游弋,涵盖移动系统和桌面系统,但只有一个可以让我最快速便捷地设置“世界时钟”。
|
||||
|
||||
**而它刚好是那个名字放在门上方的东西。**
|
||||
**它的名字就是我们标题上提到的那个。**
|
||||
|
||||

|
||||
|
||||
@ -16,10 +16,10 @@ Ubuntu中跟踪多个时区的简捷方法
|
||||
|
||||
Unity中默认的日期-时间指示器提供了添加并查看多个时区的支持,不需要附加组件,不需要额外的包。
|
||||
|
||||
1. 点击时钟小应用,然后uxuanze‘**时间和日期设置**’条目
|
||||
1. 点击时钟小应用,然后选择‘**时间和日期设置**’条目
|
||||
1. 在‘**时钟**’标签中,选中‘**其它位置的时间**’选框
|
||||
1. 点击‘**选择位置**’按钮
|
||||
1. 点击‘**+**’,然后输入位置名称那个
|
||||
1. 点击‘**+**’,然后输入位置名称
|
||||
|
||||
#### 其它桌面环境 ####
|
||||
|
||||
@ -34,13 +34,13 @@ Unity中默认的日期-时间指示器提供了添加并查看多个时区的
|
||||
|
||||

|
||||
|
||||
Cinnamon 2.4中的世界时钟日历
|
||||
*Cinnamon 2.4中的世界时钟日历*
|
||||
|
||||
**XFCE**和**LXDE**就不那么慷慨了,除了自带的“工作区”作为**多个时钟**添加到面板外,每个都需要手动配置以指定位置。两个都支持‘指示器小部件’,所以,如果你没有依赖于Unity,你可以安装/添加单独的日期/时间指示器。
|
||||
**XFCE**和**LXDE**就不那么慷慨了,除了自带的“工作区”作为**多个时钟**添加到面板外,每个都需要手动配置以指定位置。两个都支持‘指示器小部件’,所以,如果你不用Unity的话,你可以安装/添加单独的日期/时间指示器。
|
||||
|
||||
**Budgie**还刚初出茅庐,不足以胜任角落里的需求,因为Pantheon我还没试过——希望你们通过评论来让我知道得更多。
|
||||
**Budgie**还刚初出茅庐,不足以胜任这种角落里的需求,因为Pantheon我还没试过——希望你们通过评论来让我知道得更多。
|
||||
|
||||
#### Desktop Apps, Widgets & Conky Themes桌面应用、不见和Conky主题 ####
|
||||
#### 桌面应用、部件和Conky主题 ####
|
||||
|
||||
当然,面板小部件只是收纳其它国家多个时区的一种方式。如果你不满意通过面板去访问,那里还有各种各样的**桌面应用**可供使用,其中许多都可以跨版本,甚至跨平台使用。
|
||||
|
||||
@ -54,7 +54,7 @@ via: http://www.omgubuntu.co.uk/2014/12/add-time-zones-world-clock-ubuntu
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,143 @@
|
||||
20条Linux命令面试问答
|
||||
================================================================================
|
||||
**问:1 如何查看当前的Linux服务器的运行级别?**
|
||||
|
||||
答: ‘who -r’ 和 ‘runlevel’ 命令可以用来查看当前的Linux服务器的运行级别。
|
||||
|
||||
**问:2 如何查看Linux的默认网关?**
|
||||
|
||||
答: 用 “route -n” 和 “netstat -nr” 命令,我们可以查看默认网关。除了默认的网关信息,这两个命令还可以显示当前的路由表。
|
||||
|
||||
**问:3 如何在Linux上重建初始化内存盘镜像文件?**
|
||||
|
||||
答: 在CentOS 5.X / RHEL 5.X中,可以用mkinitrd命令来创建初始化内存盘文件,举例如下:
|
||||
|
||||
# mkinitrd -f -v /boot/initrd-$(uname -r).img $(uname -r)
|
||||
|
||||
如果你想要给特定的内核版本创建初始化内存盘,你就用所需的内核名替换掉 ‘uname -r’ 。
|
||||
|
||||
在CentOS 6.X / RHEL 6.X中,则用dracut命令来创建初始化内存盘文件,举例如下:
|
||||
|
||||
# dracut -f
|
||||
|
||||
以上命令能给当前的系统版本创建初始化内存盘,给特定的内核版本重建初始化内存盘文件则使用以下命令:
|
||||
|
||||
# dracut -f initramfs-2.x.xx-xx.el6.x86_64.img 2.x.xx-xx.el6.x86_64
|
||||
|
||||
**问:4 cpio命令是什么?**
|
||||
|
||||
答: cpio就是复制入和复制出的意思。cpio可以向一个归档文件(或单个文件)复制文件、列表,还可以从中提取文件。
|
||||
|
||||
**问:5 patch命令是什么?如何使用?**
|
||||
|
||||
答: 顾名思义,patch命令就是用来将修改(或补丁)写进文本文件里。patch命令通常是接收diff的输出并把文件的旧版本转换为新版本。举个例子,Linux内核源代码由百万行代码文件构成,所以无论何时,任何代码贡献者贡献出代码,只需发送改动的部分而不是整个源代码,然后接收者用patch命令将改动写进原始的源代码里。
|
||||
|
||||
创建一个diff文件给patch使用,
|
||||
|
||||
# diff -Naur old_file new_file > diff_file
|
||||
|
||||
旧文件和新文件要么都是单个的文件要么都是包含文件的目录,-r参数支持目录树递归。
|
||||
|
||||
一旦diff文件创建好,我们就能在旧的文件上打上补丁,把它变成新文件:
|
||||
|
||||
# patch < diff_file
|
||||
|
||||
**问:6 aspell有什么用 ?**
|
||||
|
||||
答: 顾名思义,aspell就是Linux操作系统上的一款交互式拼写检查器。aspell命令继任了更早的一个名为ispell的程序,并且作为一款免费替代品 ,最重要的是它非常好用。当aspell程序主要被其它一些需要拼写检查能力的程序所使用的时候,在命令行中作为一个独立运行的工具的它也能十分有效。
|
||||
|
||||
**问:7 如何从命令行查看域SPF记录?**
|
||||
|
||||
答: 我们可以用dig命令来查看域SPF记录。举例如下:
|
||||
|
||||
linuxtechi@localhost:~$ dig -t TXT google.com
|
||||
|
||||
**问:8 如何识别Linux系统中指定文件(/etc/fstab)的关联包?**
|
||||
|
||||
答: # rpm -qf /etc/fstab
|
||||
|
||||
以上命令能列出提供“/etc/fstab”这个文件的包。
|
||||
|
||||
**问:9 哪条命令用来查看bond0的状态?**
|
||||
|
||||
答: cat /proc/net/bonding/bond0
|
||||
|
||||
**问:10 Linux系统中的/proc文件系统有什么用?**
|
||||
|
||||
答: /proc文件系统是一个基于内存的文件系统,其维护着关于当前正在运行的内核状态信息,其中包括CPU、内存、分区划分、I/O地址、直接内存访问通道和正在运行的进程。这个文件系统所代表的并不是各种实际存储信息的文件,它们指向的是内存里的信息。/proc文件系统是由系统自动维护的。
|
||||
|
||||
**问:11 如何在/usr目录下找出大小超过10MB的文件?**
|
||||
|
||||
答: # find /usr -size +10M
|
||||
|
||||
**问:12 如何在/home目录下找出120天之前被修改过的文件?**
|
||||
|
||||
答: # find /home -mtime +120
|
||||
|
||||
**问:13 如何在/var目录下找出90天之内未被访问过的文件?**
|
||||
|
||||
答: # find /var \\! -atime -90
|
||||
|
||||
**问:14 在整个目录树下查找文件“core”,如发现则无需提示直接删除它们。**
|
||||
|
||||
答: # find / -name core -exec rm {} \;
|
||||
|
||||
**问:15 strings命令有什么作用?**
|
||||
|
||||
答: strings命令用来提取和显示非文本文件中的文本字符串。(LCTT 译注:当用来分析你系统上莫名其妙出现的二进制程序时,可以从中找到可疑的文件访问,对于追查入侵有用处)
|
||||
|
||||
**问:16 tee 过滤器有什么作用 ?**
|
||||
|
||||
答: tee 过滤器用来向多个目标发送输出内容。如果用于管道的话,它可以将输出复制一份到一个文件,并复制另外一份到屏幕上(或一些其它程序)。
|
||||
|
||||
linuxtechi@localhost:~$ ll /etc | nl | tee /tmp/ll.out
|
||||
|
||||
在以上例子中,从ll输出可以捕获到 /tmp/ll.out 文件中,并且同样在屏幕上显示了出来。
|
||||
|
||||
**问:17 export PS1 = ”$LOGNAME@`hostname`:\$PWD: 这条命令是在做什么?**
|
||||
|
||||
答: 这条export命令会更改登录提示符来显示用户名、本机名和当前工作目录。
|
||||
|
||||
**问:18 ll | awk ‘{print $3,”owns”,$9}’ 这条命令是在做什么?**
|
||||
|
||||
答: 这条ll命令会显示这些文件的文件名和它们的拥有者。
|
||||
|
||||
**问:19 :Linux中的at命令有什么用?**
|
||||
|
||||
答: at命令用来安排一个程序在未来的做一次一次性执行。所有提交的任务都被放在 /var/spool/at 目录下并且到了执行时间的时候通过atd守护进程来执行。
|
||||
|
||||
**问:20 linux中lspci命令的作用是什么?**
|
||||
|
||||
答: lspci命令用来显示你的系统上PCI总线和附加设备的信息。指定-v,-vv或-vvv来获取越来越详细的输出,加上-r参数的话,命令的输出则会更具有易读性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/20-linux-commands-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
[1]:
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,13 +1,11 @@
|
||||
Linux有问必答 - linux如何安装WPS
|
||||
Linux有问必答 - 如何在linux上安装WPS
|
||||
================================================================================
|
||||
> **问题**: 我听说一个好东西Kingsoft Office(译注:就是WPS),所以我想在我的Linux上试试。我怎样才能安装Kingsoft Office呢?
|
||||
|
||||
Kingsoft Office 一套办公套件,支持多个平台,包括Windows, Linux, iOS 和 Android。它包含三个组件:Writer(WPS文字)用来文字处理,Presentation(WPS演示)支持幻灯片,Spereadsheets(WPS表格)为电子表格。使用免费增值模式,其中基础版本是免费使用。比较其他的linux办公套件,如LibreOffice、 OpenOffice,最大优势在于,Kingsoft Office能最好的兼容微软的Office(译注:版权问题?了解下wps和Office的历史问题,可以得到一些结论)。因此如果你需要在windowns和linux平台间交互,Kingsoft office是一个很好的选择。
|
||||
|
||||
Kingsoft Office 是一套办公套件,支持多个平台,包括Windows, Linux, iOS 和 Android。它包含三个组件:Writer(WPS文字)用来文字处理,Presentation(WPS演示)支持幻灯片,Spereadsheets(WPS表格)是电子表格。其使用免费增值模式,其中基础版本是免费使用。比较其他的linux办公套件,如LibreOffice、 OpenOffice,其最大优势在于,Kingsoft Office能最好的兼容微软的Office(译注:版权问题?了解下wps和Office的历史问题,可以得到一些结论)。因此如果你需要在windows和linux平台间交互,Kingsoft office是一个很好的选择。
|
||||
|
||||
### CentOS, Fedora 或 RHEL中安装Kingsoft Office ###
|
||||
|
||||
|
||||
在[官方页面][1]下载RPM文件.官方RPM包只支持32位版本linux,但是你可以在64位中安装。
|
||||
|
||||
需要使用yum命令并用"localinstall"选项来本地安装这个RPM包
|
||||
@ -39,7 +37,7 @@ DEB包同样遇到一堆依赖。因此使用[gdebi][3]命令来代替dpkg来自
|
||||
|
||||
### 启动 Kingsoft Office ###
|
||||
|
||||
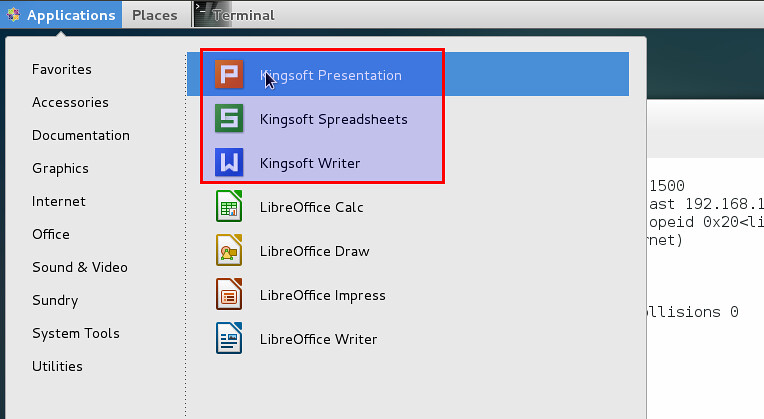
安装完成后,你就可以在桌面管理器轻松启动Witer(WPS文字), Presentation(WPS演示), and Spreadsheets(WPS表格),如下图
|
||||
安装完成后,你就可以在桌面管理器轻松启动Witer(WPS文字), Presentation(WPS演示), and Spreadsheets(WPS表格),如下图。
|
||||
|
||||
Ubuntu Unity中:
|
||||
|
||||
@ -49,7 +47,7 @@ GNOME桌面中:
|
||||
|
||||
|
||||
|
||||
不但如此,你也可以在命令行中启动Kingsoft Office
|
||||
不但如此,你也可以在命令行中启动Kingsoft Office。
|
||||
|
||||
启动Wirter(WPS文字),使用这个命令:
|
||||
|
||||
@ -74,7 +72,7 @@ GNOME桌面中:
|
||||
via: http://ask.xmodulo.com/install-kingsoft-office-linux.html
|
||||
|
||||
译者:[Vic020/VicYu](http://www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,9 +2,9 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
当你想重装Ubuntu或者仅仅是想安装它的一个新版本的时候,寻到一个便捷的方法去重新安装之前的应用并且重置其设置是很有用的。此时 *Aptik* 粉墨登场,它可以帮助你轻松实现。
|
||||
当你想重装Ubuntu或者仅仅是想安装它的一个新版本的时候,如果有个便捷的方法来重新安装之前的应用并且重置其设置会很方便的。此时 *Aptik* 粉墨登场,它可以帮助你轻松实现。
|
||||
|
||||
Aptik(自动包备份和回复)是一个可以用在Ubuntu,Linux Mint, 和其他基于Debian以及Ubuntu的Linux发行版上的应用,它允许你将已经安装过的包括软件库、下载包、安装的应用及其主题和设置在内的PPAs(个人软件包存档)备份到外部的U盘、网络存储或者类似于Dropbox的云服务上。
|
||||
Aptik(自动包备份和恢复)是一个可以用在Ubuntu,Linux Mint 和其他基于Debian以及Ubuntu的Linux发行版上的应用,它允许你将已经安装过的包括软件库、下载包、安装的应用和主题、用户设置在内的PPAs(个人软件包存档)备份到外部的U盘、网络存储或者类似于Dropbox的云服务上。
|
||||
|
||||
注意:当我们在此文章中说到输入某些东西的时候,如果被输入的内容被引号包裹,请不要将引号一起输入进去,除非我们有特殊说明。
|
||||
|
||||
@ -16,7 +16,7 @@ Aptik(自动包备份和回复)是一个可以用在Ubuntu,Linux Mint, 和
|
||||
|
||||

|
||||
|
||||
输入下边的命令到提示符旁边,来确保资源库已经是最新版本。
|
||||
在命令行提示符输入下边的命令,来确保资源库已经是最新版本。
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
@ -86,11 +86,11 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||
接下来,“Downloaded Packages (APT Cache)”的项目只对重装同样版本的Ubuntu有用处。它会备份下你系统缓存(/var/cache/apt/archives)中的包。如果你是升级系统的话,可以跳过这个条目,因为针对新系统的包会比现有系统缓存中的包更加新一些。
|
||||
|
||||
备份和回复下载过的包,这可以在重装Ubuntu,并且重装包的时候节省时间和网络带宽。因为一旦你把这些包恢复到系统缓存中之后,他们可以重新被利用起来,这样下载过程就免了,包的安装会更加快捷。
|
||||
备份和恢复下载过的包,这可以在重装Ubuntu,并且重装包的时候节省时间和网络带宽。因为一旦你把这些包恢复到系统缓存中之后,他们可以重新被利用起来,这样下载过程就免了,包的安装会更加快捷。
|
||||
|
||||
如果你是重装相同版本的Ubuntu系统的话,点击 “Downloaded Packages (APT Cache)” 右侧的 “Backup” 按钮来备份系统缓存中的包。
|
||||
|
||||
注意:当你备份下载过的包的时候是没有二级对话框出现。你系统缓存 (/var/cache/apt/archives) 中的包会被拷贝到备份目录下一个名叫 “archives” 的文件夹中,当整个过程完成后会出现一个对话框来告诉你备份已经完成。
|
||||
注意:当你备份下载过的包的时候是没有二级对话框出现的。你系统缓存 (/var/cache/apt/archives) 中的包会被拷贝到备份目录下一个名叫 “archives” 的文件夹中,当整个过程完成后会出现一个对话框来告诉你备份已经完成。
|
||||
|
||||

|
||||
|
||||
@ -104,7 +104,7 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||

|
||||
|
||||
名为 “packages.list” and “packages-installed.list” 的两个文件出现在了备份目录中,并且一个用来通知你备份完成的对话框出现。点击 ”OK“关闭它。
|
||||
备份目录中出现了两个名为 “packages.list” 和“packages-installed.list” 的文件,并且会弹出一个通知你备份完成的对话框。点击 ”OK“关闭它。
|
||||
|
||||
注意:“packages-installed.list”文件包含了所有的包,而 “packages.list” 在包含了所有包的前提下还指出了那些包被选择上了。
|
||||
|
||||
@ -120,27 +120,27 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||

|
||||
|
||||
当打包完成后,打包后的文件被拷贝到备份目录下,另外一个备份成功的对话框出现。点击”OK“,关掉。
|
||||
当打包完成后,打包后的文件被拷贝到备份目录下,另外一个备份成功的对话框出现。点击“OK”关掉。
|
||||
|
||||

|
||||
|
||||
来自 “/usr/share/themes” 目录的主题和来自 “/usr/share/icons” 目录的图标也可以备份。点击 “Themes and Icons” 右侧的 “Backup” 来进行此操作。“Backup Themes” 对话框默认选择了所有的主题和图标。你可以安装需要取消到一些然后点击 “Backup” 进行备份。
|
||||
放在 “/usr/share/themes” 目录的主题和放在 “/usr/share/icons” 目录的图标也可以备份。点击 “Themes and Icons” 右侧的 “Backup” 来进行此操作。“Backup Themes” 对话框默认选择了所有的主题和图标。你可以安装需要的、取消一些不要的,然后点击 “Backup” 进行备份。
|
||||
|
||||

|
||||
|
||||
主题被打包拷贝到备份目录下的 “themes” 文件夹中,图标被打包拷贝到备份目录下的 “icons” 文件夹中。然后成功提示对话框出现,点击”OK“关闭它。
|
||||
主题被打包拷贝到备份目录下的 “themes” 文件夹中,图标被打包拷贝到备份目录下的 “icons” 文件夹中。然后成功提示对话框出现,点击“OK”关闭它。
|
||||
|
||||

|
||||
|
||||
一旦你完成了需要的备份,点击主界面左上角的”X“关闭 Aptik 。
|
||||
一旦你完成了需要的备份,点击主界面左上角的“X”关闭 Aptik 。
|
||||
|
||||

|
||||
|
||||
备份过的文件已存在于你选择的备份目录中,可以随时取阅。
|
||||
备份过的文件已存在于你选择的备份目录中,可以随时查看。
|
||||
|
||||

|
||||
|
||||
当你重装Ubuntu或者安装新版本的Ubuntu后,在新的系统中安装 Aptik 并且将备份好的文件置于新系统中让其可被使用。运行 Aptik,并使用每个条目的 “Restore” 按钮来恢复你的软件源、应用、包、设置、主题以及图标。
|
||||
当你重装Ubuntu或者安装新版本的Ubuntu后,在新的系统中安装 Aptik 并且将备份好的文件置于新系统中使用。运行 Aptik,并使用每个条目的 “Restore” 按钮来恢复你的软件源、应用、包、设置、主题以及图标。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -148,7 +148,7 @@ via: http://www.howtogeek.com/206454/how-to-backup-and-restore-your-apps-and-ppa
|
||||
|
||||
作者:Lori Kaufman
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,18 +1,17 @@
|
||||
如何在 Linux 上使用 HAProxy 配置 HTTP 负载均衡器
|
||||
使用 HAProxy 配置 HTTP 负载均衡器
|
||||
================================================================================
|
||||
随着基于 Web 的应用和服务的增多,IT 系统管理员肩上的责任也越来越重。当遇到不可预期的事件如流量达到高峰,流量增大或者内部的挑战比如硬件的损坏或紧急维修,无论如何,你的 Web 应用都必须要保持可用性。甚至现在流行的 devops 和持续交付也可能威胁到你的 Web 服务的可靠性和性能的一致性。
|
||||
随着基于 Web 的应用和服务的增多,IT 系统管理员肩上的责任也越来越重。当遇到不可预期的事件如流量达到高峰,流量增大或者内部的挑战比如硬件的损坏或紧急维修,无论如何,你的 Web 应用都必须要保持可用性。甚至现在流行的 devops 和持续交付(CD)也可能威胁到你的 Web 服务的可靠性和性能的一致性。
|
||||
|
||||
不可预测,不一直的性能表现是你无法接受的。但是我们怎样消除这些缺点呢?大多数情况下一个合适的负载均衡解决方案可以解决这个问题。今天我会给你们介绍如何使用 [HAProxy][1] 配置 HTTP 负载均衡器。
|
||||
不可预测,不一致的性能表现是你无法接受的。但是我们怎样消除这些缺点呢?大多数情况下一个合适的负载均衡解决方案可以解决这个问题。今天我会给你们介绍如何使用 [HAProxy][1] 配置 HTTP 负载均衡器。
|
||||
|
||||
###什么是 HTTP 负载均衡? ###
|
||||
|
||||
HTTP 负载均衡是一个网络解决方案,它将发入的 HTTP 或 HTTPs 请求分配至一组提供相同的 Web 应用内容的服务器用于响应。通过将请求在这样的多个服务器间进行均衡,负载均衡器可以防止服务器出现单点故障,可以提升整体的可用性和响应速度。它还可以让你能够简单的通过添加或者移除服务器来进行横向扩展或收缩,对工作负载进行调整。
|
||||
HTTP 负载均衡是一个网络解决方案,它将进入的 HTTP 或 HTTPs 请求分配至一组提供相同的 Web 应用内容的服务器用于响应。通过将请求在这样的多个服务器间进行均衡,负载均衡器可以防止服务器出现单点故障,可以提升整体的可用性和响应速度。它还可以让你能够简单的通过添加或者移除服务器来进行横向扩展或收缩,对工作负载进行调整。
|
||||
|
||||
### 什么时候,什么情况下需要使用负载均衡? ###
|
||||
|
||||
负载均衡可以提升服务器的使用性能和最大可用性,当你的服务器开始出现高负载时就可以使用负载均衡。或者你在为一个大型项目设计架构时,在前端使用负载均衡是一个很好的习惯。当你的环境需要扩展的时候它会很有用。
|
||||
|
||||
|
||||
### 什么是 HAProxy? ###
|
||||
|
||||
HAProxy 是一个流行的开源的 GNU/Linux 平台下的 TCP/HTTP 服务器的负载均衡和代理软件。HAProxy 是单线程,事件驱动架构,可以轻松的处理 [10 Gbps 速率][2] 的流量,在生产环境中被广泛的使用。它的功能包括自动健康状态检查,自定义负载均衡算法,HTTPS/SSL 支持,会话速率限制等等。
|
||||
@ -24,13 +23,13 @@ HAProxy 是一个流行的开源的 GNU/Linux 平台下的 TCP/HTTP 服务器的
|
||||
### 准备条件 ###
|
||||
|
||||
你至少要有一台,或者最好是两台 Web 服务器来验证你的负载均衡的功能。我们假设后端的 HTTP Web 服务器已经配置好并[可以运行][3]。
|
||||
You will need at least one, or preferably two web servers to verify functionality of your load balancer. We assume that backend HTTP web servers are already [up and running][3].
|
||||
|
||||
|
||||
### 在 Linux 中安装 HAProxy ###
|
||||
## 在 Linux 中安装 HAProxy ##
|
||||
|
||||
对于大多数的发行版,我们可以使用发行版的包管理器来安装 HAProxy。
|
||||
|
||||
#### 在 Debian 中安装 HAProxy ####
|
||||
### 在 Debian 中安装 HAProxy ###
|
||||
|
||||
在 Debian Wheezy 中我们需要添加源,在 /etc/apt/sources.list.d 下创建一个文件 "backports.list" ,写入下面的内容
|
||||
|
||||
@ -41,25 +40,25 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
# apt get update
|
||||
# apt get install haproxy
|
||||
|
||||
#### 在 Ubuntu 中安装 HAProxy ####
|
||||
### 在 Ubuntu 中安装 HAProxy ###
|
||||
|
||||
# apt get install haproxy
|
||||
|
||||
#### 在 CentOS 和 RHEL 中安装 HAProxy ####
|
||||
### 在 CentOS 和 RHEL 中安装 HAProxy ###
|
||||
|
||||
# yum install haproxy
|
||||
|
||||
### 配置 HAProxy ###
|
||||
## 配置 HAProxy ##
|
||||
|
||||
本教程假设有两台运行的 HTTP Web 服务器,它们的 IP 地址是 192.168.100.2 和 192.168.100.3。我们将负载均衡配置在 192.168.100.4 的这台服务器上。
|
||||
|
||||
为了让 HAProxy 工作正常,你需要修改 /etc/haproxy/haproxy.cfg 中的一些选项。我们会在这一节中解释这些修改。一些配置可能因 GNU/Linux 发行版的不同而变化,这些会被标注出来。
|
||||
|
||||
#### 1. 配置日志功能 ####
|
||||
### 1. 配置日志功能 ###
|
||||
|
||||
你要做的第一件事是为 HAProxy 配置日志功能,在排错时日志将很有用。日志配置可以在 /etc/haproxy/haproxy.cfg 的 global 段中找到他们。下面是针对不同的 Linux 发型版的 HAProxy 日志配置。
|
||||
|
||||
**CentOS 或 RHEL:**
|
||||
#### CentOS 或 RHEL:####
|
||||
|
||||
在 CentOS/RHEL中启用日志,将下面的:
|
||||
|
||||
@ -82,7 +81,7 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
**Debian 或 Ubuntu:**
|
||||
####Debian 或 Ubuntu:####
|
||||
|
||||
在 Debian 或 Ubuntu 中启用日志,将下面的内容
|
||||
|
||||
@ -106,7 +105,7 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
#### 2. 设置默认选项 ####
|
||||
### 2. 设置默认选项 ###
|
||||
|
||||
下一步是设置 HAProxy 的默认选项。在 /etc/haproxy/haproxy.cfg 的 default 段中,替换为下面的配置:
|
||||
|
||||
@ -124,7 +123,7 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
|
||||
上面的配置是当 HAProxy 为 HTTP 负载均衡时建议使用的,但是并不一定是你的环境的最优方案。你可以自己研究 HAProxy 的手册并配置它。
|
||||
|
||||
#### 3. Web 集群配置 ####
|
||||
### 3. Web 集群配置 ###
|
||||
|
||||
Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡中的大多数设置都在这里。现在我们会创建一些基本配置,定义我们的节点。将配置文件中从 frontend 段开始的内容全部替换为下面的:
|
||||
|
||||
@ -141,14 +140,14 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
"listen webfarm *:80" 定义了负载均衡器监听的地址和端口。为了教程的需要,我设置为 "\*" 表示监听在所有接口上。在真实的场景汇总,这样设置可能不太合适,应该替换为可以从 internet 访问的那个网卡接口。
|
||||
"listen webfarm \*:80" 定义了负载均衡器监听的地址和端口。为了教程的需要,我设置为 "*" 表示监听在所有接口上。在真实的场景汇总,这样设置可能不太合适,应该替换为可以从 internet 访问的那个网卡接口。
|
||||
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
|
||||
上面的设置定义了,负载均衡器的状态统计信息可以通过 http://<load-balancer-IP>/haproxy?stats 访问。访问需要简单的 HTTP 认证,用户名为 "haproxy" 密码为 "stats"。这些设置可以替换为你自己的认证方式。如果你不需要状态统计信息,可以完全禁用掉。
|
||||
上面的设置定义了,负载均衡器的状态统计信息可以通过 http://\<load-balancer-IP>/haproxy?stats 访问。访问需要简单的 HTTP 认证,用户名为 "haproxy" 密码为 "stats"。这些设置可以替换为你自己的认证方式。如果你不需要状态统计信息,可以完全禁用掉。
|
||||
|
||||
下面是一个 HAProxy 统计信息的例子
|
||||
|
||||
@ -160,7 +159,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
- **source**:对请求的客户端 IP 地址进行哈希计算,根据哈希值和服务器的权重将请求调度至后端服务器。
|
||||
- **uri**:对 URI 的左半部分(问号之前的部分)进行哈希,根据哈希结果和服务器的权重对请求进行调度
|
||||
- **url_param**:根据每个 HTTP GET 请求的 URL 查询参数进行调度,使用固定的请求参数将会被调度至指定的服务器上
|
||||
- **hdr(name**):根据 HTTP 首部中的 <name> 字段来进行调度
|
||||
- **hdr(name**):根据 HTTP 首部中的 \<name> 字段来进行调度
|
||||
|
||||
"cookie LBN insert indirect nocache" 这一行表示我们的负载均衡器会存储 cookie 信息,可以将后端服务器池中的节点与某个特定会话绑定。节点的 cookie 存储为一个自定义的名字。这里,我们使用的是 "LBN",你可以指定其他的名称。后端节点会保存这个 cookie 的会话。
|
||||
|
||||
@ -169,25 +168,25 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
上面是我们的 Web 服务器节点的定义。服务器有由内部名称(如web01,web02),IP 地址和唯一的 cookie 字符串表示。cookie 字符串可以自定义,我这里使用的是简单的 node1,node2 ... node(n)
|
||||
|
||||
### 启动 HAProxy ###
|
||||
## 启动 HAProxy ##
|
||||
|
||||
如果你完成了配置,现在启动 HAProxy 并验证是否运行正常。
|
||||
|
||||
#### 在 Centos/RHEL 中启动 HAProxy ####
|
||||
### 在 Centos/RHEL 中启动 HAProxy ###
|
||||
|
||||
让 HAProxy 开机自启,使用下面的命令
|
||||
|
||||
# chkconfig haproxy on
|
||||
# service haproxy start
|
||||
|
||||
当然,防火墙需要开放 80 端口,想下面这样
|
||||
当然,防火墙需要开放 80 端口,像下面这样
|
||||
|
||||
**CentOS/RHEL 7 的防火墙**
|
||||
####CentOS/RHEL 7 的防火墙####
|
||||
|
||||
# firewallcmd permanent zone=public addport=80/tcp
|
||||
# firewallcmd reload
|
||||
|
||||
**CentOS/RHEL 6 的防火墙**
|
||||
####CentOS/RHEL 6 的防火墙####
|
||||
|
||||
把下面内容加至 /etc/sysconfig/iptables 中的 ":OUTPUT ACCEPT" 段中
|
||||
|
||||
@ -197,9 +196,9 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
# service iptables restart
|
||||
|
||||
#### 在 Debian 中启动 HAProxy ####
|
||||
### 在 Debian 中启动 HAProxy ###
|
||||
|
||||
#### 启动 HAProxy ####
|
||||
启动 HAProxy
|
||||
|
||||
# service haproxy start
|
||||
|
||||
@ -207,7 +206,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
A INPUT p tcp dport 80 j ACCEPT
|
||||
|
||||
#### 在 Ubuntu 中启动HAProxy ####
|
||||
### 在 Ubuntu 中启动HAProxy ###
|
||||
|
||||
让 HAProxy 开机自动启动在 /etc/default/haproxy 中配置
|
||||
|
||||
@ -221,7 +220,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
# ufw allow 80
|
||||
|
||||
### 测试 HAProxy ###
|
||||
## 测试 HAProxy ##
|
||||
|
||||
检查 HAProxy 是否工作正常,我们可以这样做
|
||||
|
||||
@ -239,7 +238,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
$ curl http://192.168.100.4/test.php
|
||||
|
||||
我们多次使用这个命令此时,会发现交替的输出下面的内容(因为使用了轮询算法):
|
||||
我们多次运行这个命令此时,会发现交替的输出下面的内容(因为使用了轮询算法):
|
||||
|
||||
Server IP: 192.168.100.2
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
@ -251,13 +250,13 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
如果我们停掉一台后端 Web 服务,curl 命令仍然正常工作,请求被分发至另一台可用的 Web 服务器。
|
||||
|
||||
### 总结 ###
|
||||
## 总结 ##
|
||||
|
||||
现在你有了一个完全可用的负载均衡器,以轮询的模式对你的 Web 节点进行负载均衡。还可以去实验其他的配置选项以适应你的环境。希望这个教程可以帮会组你们的 Web 项目有更好的可用性。
|
||||
现在你有了一个完全可用的负载均衡器,以轮询的模式对你的 Web 节点进行负载均衡。还可以去实验其他的配置选项以适应你的环境。希望这个教程可以帮助你们的 Web 项目有更好的可用性。
|
||||
|
||||
你可能已经发现了,这个教程只包含单台负载均衡的设置。这意味着我们仍然有单点故障的问题。在真实场景中,你应该至少部署 2 台或者 3 台负载均衡以防止意外发生,但这不是本教程的范围。
|
||||
|
||||
如果 你有任何问题或建议,请在评论中提出,我会尽我的努力回答。
|
||||
如果你有任何问题或建议,请在评论中提出,我会尽我的努力回答。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -265,11 +264,11 @@ via: http://xmodulo.com/haproxy-http-load-balancer-linux.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[Liao](https://github.com/liaoishere)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://www.haproxy.org/
|
||||
[2]:http://www.haproxy.org/10g.html
|
||||
[3]:http://xmodulo.com/how-to-install-lamp-server-on-ubuntu.html
|
||||
[3]:http://linux.cn/article-1567-1.html
|
||||
158
published/201501/20141203 Docker--Present and Future.md
Normal file
158
published/201501/20141203 Docker--Present and Future.md
Normal file
@ -0,0 +1,158 @@
|
||||
Docker 的现状与未来
|
||||
================================================================================
|
||||
|
||||
### Docker - 迄今为止发生的那些事情 ###
|
||||
|
||||
Docker 是一个专为 Linux 容器而设计的工具集,用于‘构建、交付和运行’分布式应用。它最初是 DotCloud 的一个开源项目,于2013年3月发布。这个项目越来越受欢迎,以至于 DotCloud 公司都更名为 Docker 公司(并最终[出售了原有的 PaaS 业务][1])。[Docker 1.0][2]是在2014年6月发布的,而且延续了之前每月更新一个版本的传统。
|
||||
|
||||
Docker 1.0版本的发布标志着 Docker 公司认为该平台已经充分成熟,足以用于生产环境中(由该公司与合作伙伴提供付费支持选择)。每个月发布的更新表明该项目正在迅速发展,比如增添一些新特性、解决一些他们发现的问题。该项目已经成功地分离了‘运行’和‘交付’两件事,所以来自任何版本的 Docker 镜像源都可以与其它版本共同使用(具备向前和向后兼容的特性),这为 Docker 应对快速变化提供了稳定的保障。
|
||||
|
||||
Docker 之所以能够成为最受欢迎的开源项目之一可能会被很多人看做是炒作,但是也是由其坚实的基础所决定的。Docker 的影响力已经得到整个行业许多大企业的支持,包括亚马逊, Canonical 公司, CenturyLink, 谷歌, IBM, 微软, New Relic, Pivotal, 红帽和 VMware。这使得只要有 Linux 的地方,Docker 就可以无处不在。除了这些鼎鼎有名的大公司以外,许多初创公司也在围绕着 Docker 发展,或者改变他们的发展方向来与 Docker 更好地结合起来。这些合作伙伴们(无论大或小)都将帮助推动 Docker 核心项目及其周边生态环境的快速发展。
|
||||
|
||||
### Docker 技术简要综述 ###
|
||||
|
||||
Docker 利用 Linux 的一些内核机制例如 [cGroups][3]、命名空间和 [SElinux][4] 来实现容器之间的隔离。起初 Docker 只是 [LXC][5] 容器管理器子系统的前端,但是在 0.9 版本中引入了 [libcontainer][6],这是一个原生的 go 语言库,提供了用户空间和内核之间的接口。
|
||||
|
||||
容器是基于 [AUFS][7] 这样的联合文件系统的,它允许跨多个容器共享组件,如操作系统镜像和已安装的相关库。这种文件系统的分层方法也被 [Dockerfile][8] 的 DevOps 工具所利用,这些工具能够缓存成功完成的操作。这就省下了安装操作系统和相关应用程序依赖包的时间,极大地加速测试周期。另外,在容器之间的共享库也能够减少内存的占用。
|
||||
|
||||
一个容器是从一个镜像开始运行的,它可以来自本地创建,本地缓存,或者从一个注册库(registry)下载。Docker 公司运营的 [Docker Hub 公有注册库][9],为各种操作系统、中间件和数据库提供了官方仓库存储。各个组织和个人都可以在 docker Hub 上发布的镜像的公有库,也可以注册成私有仓库。由于上传的镜像可以包含几乎任何内容,所以 Docker 提供了一种自动构建工具(以往称为“可信构建”),镜像可以从一种称之为 Dockerfile 的镜像内容清单构建而成。
|
||||
|
||||
### 容器 vs. 虚拟机 ###
|
||||
|
||||
容器会比虚拟机更高效,因为它们能够分享一个内核和分享应用程序库。相比虚拟机系统,这也将使得 Docker 使用的内存更小,即便虚拟机利用了内存超量使用的技术。部署容器时共享底层的镜像层也可以减少存储占用。IBM 的 Boden Russel 已经做了一些[基准测试][10]来说明两者之间的不同。
|
||||
|
||||
相比虚拟机系统,容器具有较低系统开销的优势,所以在容器中,应用程序的运行效率将会等效于在同样的应用程序在虚拟机中运行,甚至效果更佳。IBM 的一个研究团队已经发表了一本名为[虚拟机与 Linux 容器的性能比较]的文章[11]。
|
||||
|
||||
容器只是在隔离特性上要比虚拟机逊色。虚拟机可以利用如 Intel 的 VT-d 和 VT-x 技术的 ring-1 [硬件隔离][12]技术。这种隔离可以防止虚拟机突破和彼此交互。而容器至今还没有任何形式的硬件隔离,这使它容易受到攻击。一个称为 [Shocker][13] 的概念攻击验证表明,在 Docker 1.0 之前的版本是存在这种脆弱性的。尽管 Docker 1.0 修复了许多由 Shocker 漏洞带来的较为严重的问题,Docker 的 CTO Solomon Hykes 仍然[说][14],“当我们可以放心宣称 Docker 的开箱即用是安全的,即便是不可信的 uid0 程序(超级用户权限程序),我们将会很明确地告诉大家。”Hykes 的声明承认,其漏洞及相关的风险依旧存在,所以在容器成为受信任的工具之前将有更多的工作要做。
|
||||
|
||||
对于许多用户案例而言,在容器和虚拟机之间二者选择其一是种错误的二分法。Docker 同样可以在虚拟机中工作的很好,这让它可以用在现有的虚拟基础措施、私有云或者公有云中。同样也可以在容器里跑虚拟机,这也类似于谷歌在其云平台的使用方式。像 IaaS 服务这样普遍可用的基础设施,能够即时提供所需的虚拟机,可以预期容器与虚拟机一起使用的情景将会在数年后出现。容器管理和虚拟机技术也有可能被集成到一起提供一个两全其美的方案;这样,一个硬件信任锚微虚拟化所支撑的 libcontainer 容器,可与前端 Docker 工具链和生态系统整合,而使用提供更好隔离性的不同后端。微虚拟化(例如 Bromium 的 [vSentry][15] 和 VMware 的 [Project Fargo][16])已经用于在桌面环境中以提供基于硬件的应用程序隔离,所以类似的方法也可以用于 libcontainer,作为 Linux内核中的容器机制的替代技术。
|
||||
|
||||
### ‘容器化’ 的应用程序 ###
|
||||
|
||||
几乎所有 Linux 应用程序都可以在 Docker 容器中运行,并没有编程语言或框架的限制。唯一的实际限制是以操作系统的角度来允许容器做什么。即使如此,也可以在特权模式下运行容器,从而大大减少了限制(与之对应的是容器中的应用程序的风险增加,可能导致损坏主机操作系统)。
|
||||
|
||||
容器都是从镜像开始运行的,而镜像也可以从运行中的容器获取。本质上说,有两种方法可以将应用程序放到容器中,分别是手动构建和 Dockerfile。
|
||||
|
||||
#### 手动构建 ####
|
||||
|
||||
手动构建从启动一个基础的操作系统镜像开始,然后在交互式终端中用你所选的 Linux 提供的包管理器安装应用程序及其依赖项。Zef Hemel 在‘[使用 Linux 容器来支持便携式应用程序部署][17]’的文章中讲述了他部署的过程。一旦应用程序被安装之后,容器就可以被推送至注册库(例如Docker Hub)或者导出为一个tar文件。
|
||||
|
||||
#### Dockerfile ####
|
||||
|
||||
Dockerfile 是一个用于构建 Docker 容器的脚本化系统。每一个 Dockerfile 定义了开始的基础镜像,以及一系列在容器中运行的命令或者一些被添加到容器中的文件。Dockerfile 也可以指定对外的端口和当前工作目录,以及容器启动时默认执行的命令。用 Dockerfile 构建的容器可以像手工构建的镜像一样推送或导出。Dockerfile 也可以用于 Docker Hub 的自动构建系统,即在 Docker 公司的控制下从头构建,并且该镜像的源代码是任何需要使用它的人可见的。
|
||||
|
||||
#### 单进程? ####
|
||||
|
||||
无论镜像是手动构建还是通过 Dockerfile 构建,有一个要考虑的关键因素是当容器启动时仅启动一个进程。对于一个单一用途的容器,例如运行一个应用服务器,运行一个单一的进程不是一个问题(有些关于容器应该只有一个单独的进程的争议)。对于一些容器需要启动多个进程的情况,必须先启动 [supervisor][18] 进程,才能生成其它内部所需的进程。由于容器内没有初始化系统,所以任何依赖于 systemd、upstart 或类似初始化系统的东西不修改是无法工作的。
|
||||
|
||||
### 容器和微服务 ###
|
||||
|
||||
全面介绍使用微服务结构体系的原理和好处已经超出了这篇文章的范畴(在 [InfoQ eMag: Microservices][19] 有全面阐述)。然而容器是绑定和部署微服务实例的捷径。
|
||||
|
||||
大规模微服务部署的多数案例都是部署在虚拟机上,容器只是用于较小规模的部署上。容器具有共享操作系统和公用库的的内存和硬盘存储的能力,这也意味着它可以非常有效的并行部署多个版本的服务。
|
||||
|
||||
### 连接容器 ###
|
||||
|
||||
一些小的应用程序适合放在单独的容器中,但在许多案例中应用程序需要分布在多个容器中。Docker 的成功包括催生了一连串新的应用程序组合工具、编制工具及平台作为服务(PaaS)的实现。在这些努力的背后,是希望简化从一组相互连接的容器来创建应用的过程。很多工具也在扩展、容错、性能管理以及对已部署资产进行版本控制方面提供了帮助。
|
||||
|
||||
#### 连通性 ####
|
||||
|
||||
Docker 的网络功能是相当原始的。在同一主机,容器内的服务可以互相访问,而且 Docker 也可以通过端口映射到主机操作系统,使服务可以通过网络访问。官方支持的提供连接能力的库叫做 [libchan][20],这是一个提供给 Go 语言的网络服务库,类似于[channels][21]。在 libchan 找到进入应用的方法之前,第三方应用仍然有很大空间可提供配套的网络服务。例如,[Flocker][22] 已经采取了基于代理的方法使服务实现跨主机(以及底层存储)的移植。
|
||||
|
||||
#### 合成 ####
|
||||
|
||||
Docker 本身拥有把容器连接在一起的机制,与元数据相关的依赖项可以被传递到相依赖的容器中,并用于环境变量和主机入口。如 [Fig][23] 和 [geard][24] 这样的应用合成工具可以在单一文件中展示出这种依赖关系图,这样多个容器就可以汇聚成一个连贯的系统。CenturyLink 公司的 [Panamax][25] 合成工具类似 Fig 和 geard 的底层实现方法,但新增了一些基于 web 的用户接口,并直接与 GitHub 相结合,以便于应用程序分享。
|
||||
|
||||
#### 编制 ####
|
||||
|
||||
像 [Decking][26]、New Relic 公司的 [Centurion][27] 和谷歌公司的 [Kubernetes][28] 这样的编制系统都是旨在协助容器的部署和管理其生命周期系统。也有许多 [Apache Mesos][30] (特别是 [Marathon(马拉松式)持续运行很久的框架])的案例(例如[Mesosphere][29])已经被用于配合 Docker 一起使用。通过为应用程序与底层基础架构之间(例如传递 CPU 核数和内存的需求)提供一个抽象的模型,编制工具提供了两者的解耦,简化了应用程序开发和数据中心操作。有很多各种各样的编制系统,因为许多来自内部系统的以前开发的用于大规模容器部署的工具浮现出来了;如 Kubernetes 是基于谷歌的 [Omega][32] 系统的,[Omega][32] 是用于管理遍布谷歌云环境中容器的系统。
|
||||
|
||||
虽然从某种程度上来说合成工具和编制工具的功能存在重叠,但这也是它们之间互补的一种方式。例如 Fig 可以被用于描述容器间如何实现功能交互,而 Kubernetes pods(容器组)可用于提供监控和扩展。
|
||||
|
||||
#### 平台(即服务)####
|
||||
|
||||
有一些 Docker 原生的 PaaS 服务实现,例如 [Deis][33] 和 [Flynn][34] 已经显现出 Linux 容器在开发上的的灵活性(而不是那些“自以为是”的给出一套语言和框架)。其它平台,例如 CloudFoundry、OpenShift 和 Apcera Continuum 都已经采取将 Docker 基础功能融入其现有的系统的技术路线,这样基于 Docker 镜像(或者基于 Dockerfile)的应用程序也可以与之前用支持的语言和框架的开发的应用一同部署和管理。
|
||||
|
||||
### 所有的云 ###
|
||||
|
||||
由于 Docker 能够运行在任何正常更新内核的 Linux 虚拟机中,它几乎可以用在所有提供 IaaS 服务的云上。大多数的主流云厂商已经宣布提供对 Docker 及其生态系统的支持。
|
||||
|
||||
亚马逊已经把 Docker 引入它们的 Elastic Beanstalk 系统(这是在底层 IaaS 上的一个编制系统)。谷歌使 Docker 成为了“可管理的 VM”,它提供了GAE PaaS 和GCE IaaS 之间的中转站。微软和 IBM 也都已经宣布了基于 Kubernetes 的服务,这样可以在它们的云上部署和管理多容器应用程序。
|
||||
|
||||
为了给现有种类繁多的后端提供可用的一致接口,Docker 团队已经引进 [libswarm][35], 它可以集成于众多的云和资源管理系统。Libswarm 所阐明的目标之一是“通过切换服务来源避免被特定供应商套牢”。这是通过呈现一组一致的服务(与API相关联的)来完成的,该服务会通过特定的后端服务所实现。例如 Docker 服务器将支持本地 Docker 命令行工具的 Docker 远程 API 调用,这样就可以管理一组服务供应商的容器了。
|
||||
|
||||
基于 Docker 的新服务类型仍在起步阶段。总部位于伦敦的 Orchard 实验室提供了 Docker 的托管服务,但是 Docker 公司表示,收购 Orchard 后,其相关服务不会置于优先位置。Docker 公司也出售了之前 DotCloud 的PaaS 业务给 cloudControl。基于更早的容器管理系统的服务例如 [OpenVZ][36] 已经司空见惯了,所以在一定程度上 Docker 需要向主机托管商们证明其价值。
|
||||
|
||||
### Docker 及其发行版 ###
|
||||
|
||||
Docker 已经成为大多数 Linux 发行版例如 Ubuntu、Red Hat 企业版(RHEL)和 CentOS 的一个标准功能。遗憾的是这些发行版的步调和 Docker 项目并不一致,所以在发布版中找到的版本总是远远落后于最新版本。例如 Ubuntu 14.04 版本中的版本是 Docker 0.9.1,而当 Ubuntu 升级至 14.04.1 时 Docker 版本并没有随之升级(此时 Docker 已经升至 1.1.2 版本)。在发行版的软件仓库中还有一个名字空间的冲突,因为 “Docker” 也是 KDE 系统托盘的名字;所以在 Ubuntu 14.04 版本中相关安装包的名字和命令行工具都是使用“Docker.io”的名字。
|
||||
|
||||
在企业级 Linux 的世界中,情况也并没有因此而不同。CentOS 7 中的 Docker 版本是 0.11.1,这是 Docker 公司宣布准备发行 Docker 1.0 产品版本之前的开发版。Linux 发行版用户如果希望使用最新版本以保障其稳定、性能和安全,那么最好地按照 Docker 的[安装说明][37]进行,使用 Docker 公司的所提供的软件库而不是采用发行版的。
|
||||
|
||||
Docker 的到来也催生了新的 Linux 发行版,如 [CoreOS][38] 和红帽的 [Project Atomic][39],它们被设计为能运行容器的最小环境。这些发布版相比传统的发行版,带着更新的内核及 Docker 版本,对内存的使用和硬盘占用率也更低。新发行版也配备了用于大型部署的新工具,例如 [fleet][40](一个分布式初始化系统)和[etcd][41](用于元数据管理)。这些发行版也有新的自我更新机制,以便可以使用最新的内核和 Docker。这也意味着使用 Docker 的影响之一是它抛开了对发行版和相关的包管理解决方案的关注,而对 Linux 内核(及使用它的 Docker 子系统)更加关注。
|
||||
|
||||
这些新发行版也许是运行 Docker 的最好方式,但是传统的发行版和它们的包管理器对容器来说仍然是非常重要的。Docker Hub 托管的官方镜像有 Debian、Ubuntu 和 CentOS,以及一个‘半官方’的 Fedora 镜像库。RHEL 镜像在Docker Hub 中不可用,因为它是 Red Hat 直接发布的。这意味着在 Docker Hub 的自动构建机制仅仅用于那些纯开源发行版下(并愿意信任那些源于 Docker 公司团队提供的基础镜像)。
|
||||
|
||||
Docker Hub 集成了如 Git Hub 和 Bitbucket 这样源代码控制系统来自动构建包管理器,用于管理构建过程中创建的构建规范(在Dockerfile中)和生成的镜像之间的复杂关系。构建过程的不确定结果并非是 Docker 的特定问题——而与软件包管理器如何工作有关。今天构建完成的是一个版本,明天构建的可能就是更新的版本,这就是为什么软件包管理器需要升级的原因。容器抽象(较少关注容器中的内容)以及容器扩展(因为轻量级资源利用率)有可能让这种不确定性成为 Docker 的痛点。
|
||||
|
||||
### Docker 的未来 ###
|
||||
|
||||
Docker 公司对核心功能(libcontainer),跨服务管理(libswarm) 和容器间的信息传递(libchan)的发展上提出了明确的路线。与此同时,该公司已经表明愿意收购 Orchard 实验室,将其纳入自身生态系统。然而 Docker 不仅仅是 Docker 公司的,这个项目的贡献者也来自许多大牌贡献者,其中不乏像谷歌、IBM 和 Red Hat 这样的大公司。在仁慈独裁者、CTO Solomon Hykes 掌舵的形势下,为公司和项目明确了技术领导关系。在前18个月的项目中通过成果输出展现了其快速行动的能力,而且这种趋势并没有减弱的迹象。
|
||||
|
||||
许多投资者正在寻找10年前 VMware 公司的 ESX/vSphere 平台的特征矩阵,并试图找出虚拟机的普及而带动的企业预期和当前 Docker 生态系统两者的距离(和机会)。目前 Docker 生态系统正缺乏类似网络、存储和(对于容器的内容的)细粒度版本管理,这些都为初创企业和创业者提供了机会。
|
||||
|
||||
随着时间的推移,在虚拟机和容器(Docker 的“运行”部分)之间的区别将变得没那么重要了,而关注点将会转移到“构建”和“交付”方面。这些变化将会使“Docker发生什么?”变得不如“Docker将会给IT产业带来什么?”那么重要了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoq.com/articles/docker-future
|
||||
|
||||
作者:[Chris Swan][a]
|
||||
译者:[disylee](https://github.com/disylee)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoq.com/author/Chris-Swan
|
||||
[1]:http://blog.dotcloud.com/dotcloud-paas-joins-cloudcontrol
|
||||
[2]:http://www.infoq.com/news/2014/06/docker_1.0
|
||||
[3]:https://www.kernel.org/doc/Documentation/cgroups/cgroups.txt
|
||||
[4]:http://selinuxproject.org/page/Main_Page
|
||||
[5]:https://linuxcontainers.org/
|
||||
[6]:http://blog.docker.com/2014/03/docker-0-9-introducing-execution-drivers-and-libcontainer/
|
||||
[7]:http://aufs.sourceforge.net/aufs.html
|
||||
[8]:https://docs.docker.com/reference/builder/
|
||||
[9]:https://registry.hub.docker.com/
|
||||
[10]:http://bodenr.blogspot.co.uk/2014/05/kvm-and-docker-lxc-benchmarking-with.html?m=1
|
||||
[11]:http://domino.research.ibm.com/library/cyberdig.nsf/papers/0929052195DD819C85257D2300681E7B/$File/rc25482.pdf
|
||||
[12]:https://en.wikipedia.org/wiki/X86_virtualization#Hardware-assisted_virtualization
|
||||
[13]:http://stealth.openwall.net/xSports/shocker.c
|
||||
[14]:https://news.ycombinator.com/item?id=7910117
|
||||
[15]:http://www.bromium.com/products/vsentry.html
|
||||
[16]:http://cto.vmware.com/vmware-docker-better-together/
|
||||
[17]:http://www.infoq.com/articles/docker-containers
|
||||
[18]:http://docs.docker.com/articles/using_supervisord/
|
||||
[19]:http://www.infoq.com/minibooks/emag-microservices
|
||||
[20]:https://github.com/docker/libchan
|
||||
[21]:https://gobyexample.com/channels
|
||||
[22]:http://www.infoq.com/news/2014/08/clusterhq-launch-flocker
|
||||
[23]:http://www.fig.sh/
|
||||
[24]:http://openshift.github.io/geard/
|
||||
[25]:http://panamax.io/
|
||||
[26]:http://decking.io/
|
||||
[27]:https://github.com/newrelic/centurion
|
||||
[28]:https://github.com/GoogleCloudPlatform/kubernetes
|
||||
[29]:https://mesosphere.io/2013/09/26/docker-on-mesos/
|
||||
[30]:http://mesos.apache.org/
|
||||
[31]:https://github.com/mesosphere/marathon
|
||||
[32]:http://static.googleusercontent.com/media/research.google.com/en/us/pubs/archive/41684.pdf
|
||||
[33]:http://deis.io/
|
||||
[34]:https://flynn.io/
|
||||
[35]:https://github.com/docker/libswarm
|
||||
[36]:http://openvz.org/Main_Page
|
||||
[37]:https://docs.docker.com/installation/#installation
|
||||
[38]:https://coreos.com/
|
||||
[39]:http://www.projectatomic.io/
|
||||
[40]:https://github.com/coreos/fleet
|
||||
[41]:https://github.com/coreos/etcd
|
||||
@ -1,6 +1,6 @@
|
||||
CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
================================================================================
|
||||
**Chrony**是一个开源而自由的应用,它能帮助你保持系统时钟与时钟服务器同步,因此让你的时间保持精确。它由两个程序组成,分别是chronyd和chronyc。chronyd是一个后台运行的守护进程,用于调整内核中运行的系统时钟和时钟服务器同步。它确定计算机获取或丢失时间的比率,并对此进行补偿。chronyc提供了一个用户界面,用于监控性能并进行多样化的配置。它可以在chronyd实例控制的计算机上干这些事,也可以在一台不同的远程计算机上干这些事。
|
||||
**Chrony**是一个开源的自由软件,它能帮助你保持系统时钟与时钟服务器(NTP)同步,因此让你的时间保持精确。它由两个程序组成,分别是chronyd和chronyc。chronyd是一个后台运行的守护进程,用于调整内核中运行的系统时钟和时钟服务器同步。它确定计算机增减时间的比率,并对此进行补偿。chronyc提供了一个用户界面,用于监控性能并进行多样化的配置。它可以在chronyd实例控制的计算机上工作,也可以在一台不同的远程计算机上工作。
|
||||
|
||||
在像CentOS 7之类基于RHEL的操作系统上,已经默认安装有Chrony。
|
||||
|
||||
@ -10,19 +10,17 @@ CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
|
||||
**server** - 该参数可以多次用于添加时钟服务器,必须以"server "格式使用。一般而言,你想添加多少服务器,就可以添加多少服务器。
|
||||
|
||||
Example:
|
||||
server 0.centos.pool.ntp.org
|
||||
server 3.europe.pool.ntp.org
|
||||
|
||||
**stratumweight** - stratumweight指令设置当chronyd从可用源中选择同步源时,每个层应该添加多少距离到同步距离。默认情况下,CentOS中设置为0,让chronyd在选择源时忽略层。
|
||||
**stratumweight** - stratumweight指令设置当chronyd从可用源中选择同步源时,每个层应该添加多少距离到同步距离。默认情况下,CentOS中设置为0,让chronyd在选择源时忽略源的层级。
|
||||
|
||||
**driftfile** - chronyd程序的主要行为之一,就是根据实际时间计算出计算机获取或丢失时间的比率,将它记录到一个文件中是最合理的,它会在重启后为系统时钟作出补偿,甚至它可能有机会从时钟服务器获得好的估值。
|
||||
**driftfile** - chronyd程序的主要行为之一,就是根据实际时间计算出计算机增减时间的比率,将它记录到一个文件中是最合理的,它会在重启后为系统时钟作出补偿,甚至可能的话,会从时钟服务器获得较好的估值。
|
||||
|
||||
**rtcsync** - rtcsync指令将启用一个内核模式,在该模式中,系统时间每11分钟会拷贝到实时时钟(RTC)。
|
||||
|
||||
**allow / deny** - 这里你可以指定一台主机、子网,或者网络以允许或拒绝NTP连接到扮演时钟服务器的机器。
|
||||
|
||||
Examples:
|
||||
allow 192.168.4.5
|
||||
deny 192.168/16
|
||||
|
||||
@ -30,11 +28,10 @@ CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
|
||||
**bindcmdaddress** - 该指令允许你限制chronyd监听哪个网络接口的命令包(由chronyc执行)。该指令通过cmddeny机制提供了一个除上述限制以外可用的额外的访问控制等级。
|
||||
|
||||
Example:
|
||||
bindcmdaddress 127.0.0.1
|
||||
bindcmdaddress ::1
|
||||
|
||||
**makestep** - 通常,chronyd将根据需求通过减慢或加速时钟,使得系统逐步纠正所有时间偏差。在某些特定情况下,系统时钟可能会漂移过快,导致该回转过程消耗很长的时间来纠正系统时钟。该指令强制chronyd在调整期大于某个阀值时调停系统时钟,但只有在因为chronyd启动时间超过指定限制(可使用负值来禁用限制),没有更多时钟更新时才生效。
|
||||
**makestep** - 通常,chronyd将根据需求通过减慢或加速时钟,使得系统逐步纠正所有时间偏差。在某些特定情况下,系统时钟可能会漂移过快,导致该调整过程消耗很长的时间来纠正系统时钟。该指令强制chronyd在调整期大于某个阀值时步进调整系统时钟,但只有在因为chronyd启动时间超过指定限制(可使用负值来禁用限制),没有更多时钟更新时才生效。
|
||||
|
||||
### 使用chronyc ###
|
||||
|
||||
@ -66,7 +63,7 @@ via: http://linoxide.com/linux-command/chrony-time-sync/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,30 +1,30 @@
|
||||
Linux 有问必答:如何在Ubuntu或者Debian中启动进入命令行
|
||||
Linux 有问必答:如何在Ubuntu或者Debian中启动后进入命令行
|
||||
================================================================================
|
||||
> **提问**:我运行的是Ubuntu桌面,但是我希望启动后临时进入命令行。有什么简便的方法可以启动进入终端?
|
||||
|
||||
Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),它们可以让计算机启动自动进入一个基于GUI的登录环境。然而,如果你要直接启动进入终端怎么办? 比如,你在排查桌面相关的问题或者想要运行一个不需要GUI的发行程序。
|
||||
Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),它们可以让计算机启动自动进入一个基于GUI的登录环境。然而,如果你要直接启动进入终端怎么办? 比如,你在排查桌面相关的问题或者想要运行一个不需要GUI的应用程序。
|
||||
|
||||
注意你可以通过按下Ctrl+Alt+F1到F6临时从桌面GUI切换到虚拟终端。然而,在本例中你的桌面GUI仍在后台运行,这不同于纯文本模式启动。
|
||||
注意虽然你可以通过按下Ctrl+Alt+F1到F6临时从桌面GUI切换到虚拟终端。然而,在这种情况下你的桌面GUI仍在后台运行,这不同于纯文本模式启动。
|
||||
|
||||
在Ubuntu或者Debian桌面中,你可以通过传递合适的内核参数在启动时启动文本模式。
|
||||
|
||||
### 启动临时进入命令行 ###
|
||||
|
||||
如果你想要禁止桌面GUI并只有一次进入文本模式,你可以使用GRUB菜单。
|
||||
如果你想要禁止桌面GUI并临时进入一次文本模式,你可以使用GRUB菜单。
|
||||
|
||||
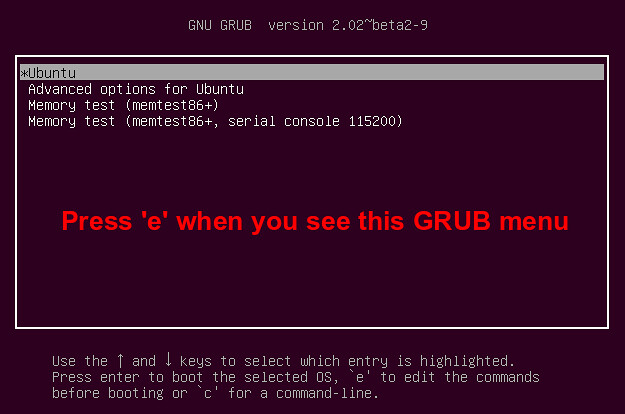
首先,打开你的电脑。当你看到初始的GRUB菜单时,按下‘e’。
|
||||
|
||||
|
||||
|
||||
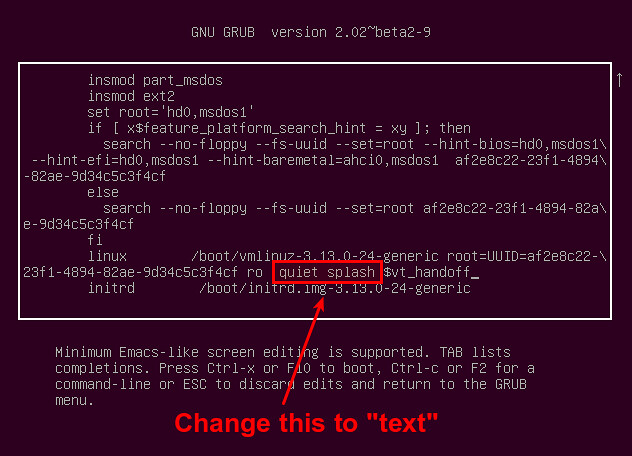
接着会进入下一屏,这里你可以修改内核启动选项。向下滚动到以“linux”开始的行,这里就是内核参数的列表。删除列表中的“quiet”和“splash”。在列表中添加“text”。
|
||||
接着会进入下一屏,这里你可以修改内核启动选项。向下滚动到以“linux”开始的行,这里就是内核参数的列表。删除参数列表中的“quiet”和“splash”。在参数列表中添加“text”。
|
||||
|
||||
|
||||
|
||||
升级的内核选项列表看上去像这样。按下Ctrl+x继续启动。这会一次性以详细模式启动控制台。
|
||||
升级的内核选项列表看上去像这样。按下Ctrl+x继续启动。这会以详细模式启动控制台一次(LCTT译注:由于没有保存修改,所以下次重启还会进入 GUI)。
|
||||
|
||||

|
||||
|
||||
永久启动进入命令行。
|
||||
### 永久启动进入命令行 ###
|
||||
|
||||
如果你想要永久启动进入命令行,你需要[更新定义了内核启动参数GRUB设置][1]。
|
||||
|
||||
@ -32,7 +32,7 @@ Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),
|
||||
|
||||
$ sudo vi /etc/default/grub
|
||||
|
||||
查找以GRUB_CMDLINE_LINUX_DEFAULT开头的行,并用“#”注释这行。这会禁止初始屏幕,而启动详细模式(也就是说显示详细的的启动过程)。
|
||||
查找以GRUB\_CMDLINE\_LINUX\_DEFAULT开头的行,并用“#”注释这行。这会禁止初始屏幕,而启动详细模式(也就是说显示详细的的启动过程)。
|
||||
|
||||
更改GRUB_CMDLINE_LINUX="" 成:
|
||||
|
||||
@ -48,7 +48,7 @@ Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),
|
||||
|
||||
$ sudo update-grub
|
||||
|
||||
这时,你的桌面应该从GUI启动切换到控制台启动了。可以通过重启验证。
|
||||
这时,你的桌面应该可以从GUI启动切换到控制台启动了。可以通过重启验证。
|
||||
|
||||

|
||||
|
||||
@ -57,7 +57,7 @@ Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),
|
||||
via: http://ask.xmodulo.com/boot-into-command-line-ubuntu-debian.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,50 @@
|
||||
交友网站的2000万用户数据遭泄露
|
||||
----------
|
||||
*泄露数据包括Gmail、Hotmail以及Yahoo邮箱*
|
||||
|
||||

|
||||
|
||||
#一名黑客非法窃取了在线交友网站Topface一个包含2000万用户资料的数据库。
|
||||
|
||||
目前并不清楚这些数据是否已经公开,但是根据某些未公开页面的消息说,某个网名为“Mastermind”的人声称掌握着这些数据。
|
||||
|
||||
#泄露数据列表涵盖了全世界数百个域名
|
||||
|
||||
此人号称泄露数据的内容100%真实有效,而Easy Solutions的CTO,Daniel Ingevaldson 周日在一篇博客中说道,泄露数据包括Hotmail、Yahoo和Gmail等邮箱地址。
|
||||
|
||||
Easy Solutions是一家位于美国的公司,提供多个不同平台的网络检测与安全防护产品。
|
||||
|
||||
据Ingevaldson所说,泄露的数据中,700万来自于Hotmail,250万来自于Yahoo,220万来自于Gmail.com。
|
||||
|
||||
我们并不清楚这些数据是可以直接登录邮箱账户的用户名和密码,还是登录交友网站的账户。另外,也不清楚这些数据在数据库中是加密状态还是明文存在的。
|
||||
|
||||
邮箱地址常常被用于在线网站的登录用户名,用户可以凭借唯一密码进行登录。然而重复使用同一个密码是许多用户的常用作法,同一个密码可以登录许多在线账户。
|
||||
|
||||
[Ingevaldson 还说](1):“看起来,这些数据事实上涵盖了全世界数百个域名。除了原始被黑的网页,黑客和不法分子很可能利用窃取的帐密进行暴库、自动扫描、危害包括银行业、旅游业以及email提供商在内的多个网站。”
|
||||
|
||||
#预计将披露更多信息
|
||||
|
||||
据我们的多个消息源爆料,数据的泄露源就是Topface,一个包含9000万用户的在线交友网站。其总部位于俄罗斯圣彼得堡,超过50%的用户来自于俄罗斯以外的国家。
|
||||
|
||||
我们联系了Topface,向他们求证最近是否遭受了可能导致如此大量数据泄露的网络攻击;但目前我们仍未收到该公司的回复。
|
||||
|
||||
攻击者可能无需获得非法访问权限就窃取了这些数据,Easy Solutions 推测攻击者很可能针对网站客户端使用钓鱼邮件直接获取到了用户数据。
|
||||
|
||||
我们无法通过Easy Solutions的在线网站联系到他们,但我们已经尝试了其他交互通讯方式,目前正在等待更多信息的披露。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Data-of-20-Million-Users-Stolen-from-Dating-Website-471179.shtml
|
||||
|
||||
本文发布时间:26 Jan 2015, 10:20 GMT
|
||||
|
||||
作者:[Ionut Ilascu][a]
|
||||
|
||||
译者:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/ionut-ilascu
|
||||
[1]:http://newblog.easysol.net/dating-site-breached/
|
||||
@ -1,7 +1,7 @@
|
||||
Linux下如何过滤、分割以及合并 pcap 文件
|
||||
=============
|
||||
|
||||
如果你是个网络管理员,并且你的工作包括测试一个[入侵侦测系统][1]或一些网络访问控制策略,那么你通常需要抓取数据包并且在离线状态下分析这些文件。当需要保存捕获的数据包时,我们会想到 libpcap 的数据包格式被广泛使用于许多开源的嗅探工具以及捕包程序。如果 pcap 文件被用于入侵测试或离线分析的话,那么在将他们[注入][2]网络之前通常要先对 pcap 文件进行一些操作。
|
||||
如果你是一个测试[入侵侦测系统][1]或一些网络访问控制策略的网络管理员,那么你经常需要抓取数据包并在离线状态下分析这些文件。当需要保存捕获的数据包时,我们一般会存储为 libpcap 的数据包格式 pcap,这是一种被许多开源的嗅探工具以及捕包程序广泛使用的格式。如果 pcap 文件被用于入侵测试或离线分析的话,那么在将他们[注入][2]网络之前通常要先对 pcap 文件进行一些操作。
|
||||
|
||||
|
||||
|
||||
@ -9,9 +9,9 @@ Linux下如何过滤、分割以及合并 pcap 文件
|
||||
|
||||
### Editcap 与 Mergecap###
|
||||
|
||||
Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非常有用的命令行工具集。其中包括 editcap 与 mergecap。editcap 是一个万能的 pcap 编辑器,它可以过滤并且能以多种方式来分割 pcap 文件。mergecap 可以将多个 pcap 文件合并为一个。 这篇文章就是基于这些 Wireshark 命令行工具。
|
||||
Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它带了一套非常有用的命令行工具集。其中包括 editcap 与 mergecap。editcap 是一个万能的 pcap 编辑器,它可以过滤并且能以多种方式来分割 pcap 文件。mergecap 可以将多个 pcap 文件合并为一个。 这篇文章就是基于这些 Wireshark 命令行工具的。
|
||||
|
||||
如果你已经安装过Wireshark了,那么这些工具已经在你的系统中了。如果还没装的话,那么我们接下来就安装 Wireshark 命令行工具。 需要注意的是,在基于 Debian 的发行版上我们可以不用安装 Wireshark GUI 而仅安装 命令行工具,但是在 Red Hat 及 基于它的发行版中则需要安装整个 Wireshark 包。
|
||||
如果你已经安装过 Wireshark 了,那么这些工具已经在你的系统中了。如果还没装的话,那么我们接下来就安装 Wireshark 命令行工具。 需要注意的是,在基于 Debian 的发行版上我们可以不用安装 Wireshark GUI 而仅安装命令行工具,但是在 Red Hat 及 基于它的发行版中则需要安装整个 Wireshark 包。
|
||||
|
||||
**Debian, Ubuntu 或 Linux Mint**
|
||||
|
||||
@ -27,15 +27,15 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
|
||||
通过 editcap, 我们能以很多不同的规则来过滤 pcap 文件中的内容,并且将过滤结果保存到新文件中。
|
||||
|
||||
首先,以“起止时间”来过滤 pcap 文件。 " - A < start-time > and " - B < end-time > 选项可以过滤出处在这个时间段到达的数据包(如,从 2:30 ~ 2:35)。时间的格式为 “ YYYY-MM-DD HH:MM:SS"。
|
||||
首先,以“起止时间”来过滤 pcap 文件。 " - A < start-time > 和 " - B < end-time > 选项可以过滤出在这个时间段到达的数据包(如,从 2:30 ~ 2:35)。时间的格式为 “ YYYY-MM-DD HH:MM:SS"。
|
||||
|
||||
$ editcap -A '2014-12-10 10:11:01' -B '2014-12-10 10:21:01' input.pcap output.pcap
|
||||
$ editcap -A '2014-12-10 10:11:01' -B '2014-12-10 10:21:01' input.pcap output.pcap
|
||||
|
||||
也可以从某个文件中提取指定的 N 个包。下面的命令行从 input.pcap 文件中提取100个包(从 401 到 500)并将它们保存到 output.pcap 中:
|
||||
|
||||
$ editcap input.pcap output.pcap 401-500
|
||||
|
||||
使用 "-D< dup-window >" (dup-window可以看成是对比的窗口大小,仅与此范围内的包进行对比)选项可以提取出重复包。每个包都依次与它之前的 < dup-window > -1 个包对比长度与MD5值,如果有匹配的则丢弃。
|
||||
使用 "-D < dup-window >" (dup-window可以看成是对比的窗口大小,仅与此范围内的包进行对比)选项可以提取出重复包。每个包都依次与它之前的 < dup-window > -1 个包对比长度与MD5值,如果有匹配的则丢弃。
|
||||
|
||||
$ editcap -D 10 input.pcap output.pcap
|
||||
|
||||
@ -71,13 +71,13 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
|
||||
如果要忽略时间戳,仅仅想以命令行中的顺序来合并文件,那么使用 -a 选项即可。
|
||||
|
||||
例如,下列命令会将 input.pcap文件的内容写入到 output.pcap, 并且将 input2.pcap 的内容追加在后面。
|
||||
例如,下列命令会将 input.pcap 文件的内容写入到 output.pcap, 并且将 input2.pcap 的内容追加在后面。
|
||||
|
||||
$ mergecap -a -w output.pcap input.pcap input2.pcap
|
||||
|
||||
###总结###
|
||||
|
||||
在这篇指导中,我演示了多个 editcap、 mergecap 操作 pcap 文件的案例。除此之外,还有其它的相关工具,如 [reordercap][3]用于将数据包重新排序,[text2pcap][4] 用于将pcap 文件转换为 文本格式, [pcap-diff][5]用于比较 pcap 文件的异同,等等。当进行网络入侵测试及解决网络问题时,这些工具与[包注入工具][6]非常实用,所以最好了解他们。
|
||||
在这篇指导中,我演示了多个 editcap、 mergecap 操作 pcap 文件的例子。除此之外,还有其它的相关工具,如 [reordercap][3]用于将数据包重新排序,[text2pcap][4] 用于将 pcap 文件转换为文本格式, [pcap-diff][5]用于比较 pcap 文件的异同,等等。当进行网络入侵测试及解决网络问题时,这些工具与[包注入工具][6]非常实用,所以最好了解他们。
|
||||
|
||||
你是否使用过 pcap 工具? 如果用过的话,你用它来做过什么呢?
|
||||
|
||||
@ -86,8 +86,8 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
via: http://xmodulo.com/filter-split-merge-pcap-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[SPccman](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[SPccman](https://github.com/SPccman)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
如何在Linux/类Unix系统中解压tar文件到不同的目录中
|
||||
如何解压 tar 文件到不同的目录中
|
||||
================================================================================
|
||||
我想要解压一个tar文件到一个指定的目录叫/tmp/data。我该如何在Linux或者类Unix的系统中使用tar命令解压一个tar文件到不同的目录中?
|
||||
|
||||
你不必使用cd名切换到其他的目录并解压。可以使用下面的语法解压一个文件:
|
||||
我想要解压一个tar文件到一个叫/tmp/data的指定目录。我该如何在Linux或者类Unix的系统中使用tar命令解压一个tar文件到不同的目录中?
|
||||
|
||||
你不必使用cd命令切换到其他的目录并解压。可以使用下面的语法解压一个文件:
|
||||
|
||||
### 语法 ###
|
||||
|
||||
@ -16,9 +17,9 @@ GNU/tar 语法:
|
||||
|
||||
tar xf file.tar --directory /path/to/directory
|
||||
|
||||
### 示例:解压文件到另一个文件夹中 ###
|
||||
### 示例:解压文件到另一个目录中 ###
|
||||
|
||||
在本例中。我解压$HOME/etc.backup.tar到文件夹/tmp/data中。首先,你需要手动创建这个目录,输入:
|
||||
在本例中。我解压$HOME/etc.backup.tar到/tmp/data目录中。首先,需要手动创建这个目录,输入:
|
||||
|
||||
mkdir /tmp/data
|
||||
|
||||
@ -34,7 +35,7 @@ GNU/tar 语法:
|
||||
|
||||

|
||||
|
||||
Gif 01: tar命令解压文件到不同的目录
|
||||
*Gif 01: tar命令解压文件到不同的目录*
|
||||
|
||||
你也可以指定解压的文件:
|
||||
|
||||
@ -56,8 +57,8 @@ via: http://www.cyberciti.biz/faq/howto-extract-tar-file-to-specific-directory-o
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cyberciti.biz/tips/about-us
|
||||
[a]:http://www.cyberciti.biz/tips/about-us
|
||||
@ -0,0 +1,58 @@
|
||||
在 Ubuntu 14.04 中Apache从2.2迁移到2.4的问题
|
||||
================================================================================
|
||||
如果你将**Ubuntu**从12.04升级跨越到了14.04的,那么这其中包括了一个重大的升级--**Apache**从2.2版本升级到2.4版本。**Apache**的这次升级带来了许多性能提升,**但是如果继续使用2.2的配置文件会导致很多错误**。
|
||||
|
||||
### 访问控制的改变 ###
|
||||
|
||||
从**Apache 2.4**起所启用授权机制比起2.2的只是针对单一数据存储的单一检查更加灵活。过去很难确定哪个 order 授权怎样被使用的,但是授权容器指令的引入解决了这些问题,现在,配置可以控制什么时候授权方法被调用,什么条件决定何时授权访问。
|
||||
|
||||
这就是为什么大多数的升级失败是由于配置错误的原因。2.2的访问控制是基于IP地址、主机名和其他角色,通过使用指令Order,来设置Allow, Deny或 Satisfy;但是2.4,这些一切都通过新的授权方式进行检查。
|
||||
|
||||
为了弄清楚这些,可以来看一些虚拟主机的例子,这些可以在/etc/apache2/sites-enabled/default 或者 /etc/apache2/sites-enabled/*你的网站名称* 中找到:
|
||||
|
||||
旧的2.2虚拟主机配置:
|
||||
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
|
||||
新的2.4虚拟主机配置:
|
||||
|
||||
Require all granted
|
||||
|
||||

|
||||
|
||||
(LCTT 译注:Order、Allow和deny 这些将在之后的版本废弃,请尽量避免使用,Require 指令已可以提供比其更强大和灵活的功能。)
|
||||
|
||||
### .htaccess 问题 ###
|
||||
|
||||
升级后如果一些设置不工作,或者你得到重定向错误,请检查是否这些设置是放在.htaccess文件中。如果Apache 2.4没有使用 .htaccess 文件中的设置,那是因为在2.4中AllowOverride指令的默认是 none,因此忽略了.htaccess文件。你只需要做的就是修改或者添加AllowOverride All命令到你的网站配置文件中。
|
||||
|
||||
上面截图中,可以看见AllowOverride All指令。
|
||||
|
||||
### 丢失配置文件或者模块 ###
|
||||
|
||||
根据我的经验,这次升级带来的另一个问题就是在2.4中,一些旧模块和配置文件不再需要或者不被支持了。你将会收到一条“Apache不能包含相应的文件”的明确警告,你需要做的是在配置文件中移除这些导致问题的配置行。之后你可以搜索和安装相似的模块来替代。
|
||||
|
||||
### 其他需要了解的小改变 ###
|
||||
|
||||
这里还有一些其他的改变需要考虑,虽然这些通常只会发生警告,而不是错误。
|
||||
|
||||
- MaxClients重命名为MaxRequestWorkers,使之有更准确的描述。而异步MPM,如event,客户端最大连接数不等于工作线程数。旧的配置名依然支持。
|
||||
- DefaultType命令无效,使用它已经没有任何效果了。如果使用除了 none 之外的其它配置值,你会得到一个警告。需要使用其他配置设定来替代它。
|
||||
- EnableSendfile默认关闭
|
||||
- FileETag 现在默认为"MTime Size"(没有INode)
|
||||
- KeepAlive 只接受“On”或“Off”值。之前的任何不是“Off”或者“0”的值都被认为是“On”
|
||||
- 单一的 Mutex 已经替代了 Directives AcceptMutex, LockFile, RewriteLock, SSLMutex, SSLStaplingMutex 和 WatchdogMutexPath 等指令。你需要做的是估计一下这些被替代的指令在2.2中的使用情况,来决定是否删除或者使用Mutex来替代。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/apache-migration-2-2-to-2-4-ubuntu-14-04/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:http://httpd.apache.org/docs/2.4/
|
||||
@ -1,17 +1,16 @@
|
||||
translating by mtunique
|
||||
Linux FAQs with Answers--How to check disk space on Linux with df command
|
||||
在 Linux 下你所不知道的 df 命令的那些功能
|
||||
================================================================================
|
||||
> **Question**: I know I can use df command to check a file system's disk space usage on Linux. Can you show me practical examples of the df command so that I can make the most out of it?
|
||||
> **问题**: 我知道在Linux上我可以用df命令来查看磁盘使用空间。你能告诉我df命令的实际例子使我可以最大限度得利用它吗?
|
||||
|
||||
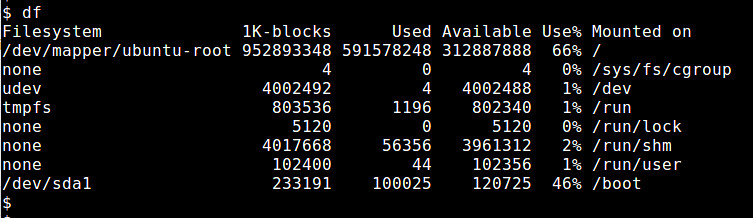
As far as disk storage is concerned, there are many command-line or GUI-based tools that can tell you about current disk space usage. These tools report on detailed disk utilization in various human-readable formats, such as easy-to-understand summary, detailed statistics, or [intuitive visualization][1]. If you simply want to know how much free disk space is available for different file systems, then df command is probably all you need.
|
||||
对于磁盘存储方面,有很多命令行或基于GUI的工具,它可以告诉你关于当前磁盘空间的使用情况。这些工具用各种人们可读的格式展示磁盘利用率的详细信息,比如易于理解的总结,详细的统计信息或直观的[可视化报告][1]。如果你只想知道不同文件系统有多少空闲的磁盘空间,那么df命令可能是你所需要的。
|
||||
|
||||
|
||||
|
||||
The df command can report on disk utilization of any "mounted" file system. There are different ways this command can be invoked. Here are some **useful** df **command examples**.
|
||||
df命令可以展示任何“mounted”文件系统的磁盘利用率。该命令可以用不同的方式调用。这里有一些**有用的** df **命令例子**.
|
||||
|
||||
### Display in Human-Readable Format ###
|
||||
### 用人们可读的方式展示 ###
|
||||
|
||||
By default, the df command reports disk space in 1K blocks, which is not easily interpretable. The "-h" parameter will make df print disk space in a more human-readable format (e.g., 100K, 200M, 3G).
|
||||
默认情况下,df命令用1K为块来展示磁盘空间,这看起来不是很直观。“-h”参数使df用更可读的方式打印磁盘空间(例如 100K,200M,3G)。
|
||||
|
||||
$ df -h
|
||||
|
||||
@ -27,9 +26,9 @@ By default, the df command reports disk space in 1K blocks, which is not easily
|
||||
none 100M 48K 100M 1% /run/user
|
||||
/dev/sda1 228M 98M 118M 46% /boot
|
||||
|
||||
### Display Inode Usage ###
|
||||
### 展示Inode使用情况 ###
|
||||
|
||||
When you monitor disk usage, you must watch out for not only disk space, but also "inode" usage. In Linux, inode is a data structure used to store metadata of a particular file, and when a file system is created, a pre-defined number of inodes are allocated. This means that a file system can run out of space not only because big files use up all available space, but also because many small files use up all available inodes. To display inode usage, use "-i" option.
|
||||
当你监视磁盘使用情况时,你必须注意的不仅仅是磁盘空间还有“inode”的使用情况。在Linux中,inode是用来存储特定文件的元数据的一种数据结构,在创建一个文件系统时,inode的预先定义数量将被分配。这意味着,**一个文件系统可能耗尽空间不只是因为大文件用完了所有可用空间,也可能是因为很多小文件用完了所有可能的inode**。用“-i”选项展示inode使用情况。
|
||||
|
||||
$ df -i
|
||||
|
||||
@ -45,9 +44,9 @@ When you monitor disk usage, you must watch out for not only disk space, but als
|
||||
none 1004417 28 1004389 1% /run/user
|
||||
/dev/sda1 124496 346 124150 1% /boot
|
||||
|
||||
### Display Disk Usage Grant Total ###
|
||||
### 展示磁盘总利用率 ###
|
||||
|
||||
By default, the df command shows disk utilization of individual file systems. If you want to know the total disk usage over all existing file systems, add "--total" option.
|
||||
默认情况下, df命令显示磁盘的单个文件系统的利用率。如果你想知道的所有文件系统的总磁盘使用量,增加“ --total ”选项(见最下面的汇总行)。
|
||||
|
||||
$ df -h --total
|
||||
|
||||
@ -64,9 +63,9 @@ By default, the df command shows disk utilization of individual file systems. If
|
||||
/dev/sda1 228M 98M 118M 46% /boot
|
||||
total 918G 565G 307G 65% -
|
||||
|
||||
### Display File System Types ###
|
||||
### 展示文件系统类型 ###
|
||||
|
||||
By default, the df command does not show file system type information. Use "-T" option to add file system types to the output.
|
||||
默认情况下,df命令不显示文件系统类型信息。用“-T”选项来添加文件系统信息到输出中。
|
||||
|
||||
$ df -T
|
||||
|
||||
@ -82,9 +81,9 @@ By default, the df command does not show file system type information. Use "-T"
|
||||
none tmpfs 102400 48 102352 1% /run/user
|
||||
/dev/sda1 ext2 233191 100025 120725 46% /boot
|
||||
|
||||
### Include or Exclude a Specific File System Type ###
|
||||
### 包含或排除特定的文件系统类型 ###
|
||||
|
||||
If you want to know free space of a specific file system type, use "-t <type>" option. You can use this option multiple times to include more than one file system types.
|
||||
如果你想知道特定文件系统类型的剩余空间,用“-t <type>”选项。你可以多次使用这个选项来包含更多的文件系统类型。
|
||||
|
||||
$ df -t ext2 -t ext4
|
||||
|
||||
@ -94,13 +93,13 @@ If you want to know free space of a specific file system type, use "-t <type>" o
|
||||
/dev/mapper/ubuntu-root 952893348 591583380 312882756 66% /
|
||||
/dev/sda1 233191 100025 120725 46% /boot
|
||||
|
||||
To exclude a specific file system type, use "-x <type>" option. You can use this option multiple times as well.
|
||||
排除特定的文件系统类型,用“-x <type>”选项。同样,你可以用这个选项多次来排除多种文件系统类型。
|
||||
|
||||
$ df -x tmpfs
|
||||
|
||||
### Display Disk Usage of a Specific Mount Point ###
|
||||
### 显示一个具体的挂载点磁盘使用情况 ###
|
||||
|
||||
If you specify a mount point with df, it will report disk usage of the file system mounted at that location. If you specify a regular file (or a directory) instead of a mount point, df will display disk utilization of the file system which contains the file (or the directory).
|
||||
如果你用df指定一个挂载点,它将报告挂载在那个地方的文件系统的磁盘使用情况。如果你指定一个普通文件(或一个目录)而不是一个挂载点,df将显示包含这个文件(或目录)的文件系统的磁盘利用率。
|
||||
|
||||
$ df /
|
||||
|
||||
@ -118,9 +117,9 @@ If you specify a mount point with df, it will report disk usage of the file syst
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/ubuntu-root 952893348 591583528 312882608 66% /
|
||||
|
||||
### Display Information about Dummy File Systems ###
|
||||
### 显示虚拟文件系统的信息 ###
|
||||
|
||||
If you want to display disk space information for all existing file systems including dummy file systems, use "-a" option. Here, dummy file systems refer to pseudo file systems which do not have corresponding physical devices, e.g., tmpfs, cgroup virtual file system or FUSE file systems. These dummy filesystems have size of 0, and are not reported by df without "-a" option.
|
||||
如果你想显示所有已经存在的文件系统(包括虚拟文件系统)的磁盘空间信息,用“-a”选项。这里,虚拟文件系统是指没有相对应的物理设备的假文件系统,例如,tmpfs,cgroup虚拟文件系统或FUSE文件安系统。这些虚拟文件系统大小为0,不用“-a”选项将不会被报告出来。
|
||||
|
||||
$ df -a
|
||||
|
||||
@ -150,8 +149,8 @@ If you want to display disk space information for all existing file systems incl
|
||||
|
||||
via: http://ask.xmodulo.com/check-disk-space-linux-df-command.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
78
published/20150127 Install Jetty Web Server On CentOS 7.md
Normal file
78
published/20150127 Install Jetty Web Server On CentOS 7.md
Normal file
@ -0,0 +1,78 @@
|
||||
在CentOS 7中安装Jetty服务器
|
||||
================================================================================
|
||||
[Jetty][1] 是一款纯Java的HTTP **(Web) 服务器**和Java Servlet容器。 通常在更大的网络框架中,Jetty经常用于设备间的通信,而其他Web服务器通常给“人类”传递文件 :D。Jetty是一个Eclipse基金会的免费开源项目。这个Web服务器用于如Apache ActiveMQ、 Alfresco、 Apache Geronimo、 Apache Maven、 Apache Spark、Google App Engine、 Eclipse、 FUSE、 Twitter的 Streaming API 和 Zimbra中。
|
||||
|
||||
这篇文章会介绍‘如何在CentOS服务器中安装Jetty服务器’。
|
||||
|
||||
**首先我们要用下面的命令安装JDK:**
|
||||
|
||||
yum -y install java-1.7.0-openjdk wget
|
||||
|
||||
**JDK安装之后,我们就可以下载最新版本的Jetty了:**
|
||||
|
||||
wget http://download.eclipse.org/jetty/stable-9/dist/jetty-distribution-9.2.5.v20141112.tar.gz
|
||||
|
||||
**解压并移动下载的包到/opt:**
|
||||
|
||||
tar zxvf jetty-distribution-9.2.5.v20141112.tar.gz -C /opt/
|
||||
|
||||
**重命名文件夹名为jetty:**
|
||||
|
||||
mv /opt/jetty-distribution-9.2.5.v20141112/ /opt/jetty
|
||||
|
||||
**创建一个jetty用户:**
|
||||
|
||||
useradd -m jetty
|
||||
|
||||
**改变jetty文件夹的所属用户:**
|
||||
|
||||
chown -R jetty:jetty /opt/jetty/
|
||||
|
||||
**为jetty.sh创建一个软链接到 /etc/init.d directory 来创建一个启动脚本文件:**
|
||||
|
||||
ln -s /opt/jetty/bin/jetty.sh /etc/init.d/jetty
|
||||
|
||||
**添加脚本:**
|
||||
|
||||
chkconfig --add jetty
|
||||
|
||||
**是jetty在系统启动时启动:**
|
||||
|
||||
chkconfig --level 345 jetty on
|
||||
|
||||
**使用你最喜欢的文本编辑器打开 /etc/default/jetty 并修改端口和监听地址:**
|
||||
|
||||
vi /etc/default/jetty
|
||||
|
||||
----------
|
||||
|
||||
JETTY_HOME=/opt/jetty
|
||||
JETTY_USER=jetty
|
||||
JETTY_PORT=8080
|
||||
JETTY_HOST=50.116.24.78
|
||||
JETTY_LOGS=/opt/jetty/logs/
|
||||
|
||||
**我们完成了安装,现在可以启动jetty服务了 **
|
||||
|
||||
service jetty start
|
||||
|
||||
完成了!
|
||||
|
||||
现在你可以在 **http://\<你的 IP 地址>:8080** 中访问了
|
||||
|
||||
就是这样。
|
||||
|
||||
干杯!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-jetty-web-server-centos-7/
|
||||
|
||||
作者:[Jijo][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/jijo/
|
||||
[1]:http://eclipse.org/jetty/
|
||||
@ -1,50 +0,0 @@
|
||||
Data of 20 Million Users Stolen from Dating Website
|
||||
----------
|
||||
*Info includes Gmail, Hotmail and Yahoo emails*
|
||||
|
||||

|
||||
|
||||
#A database containing details of more than 20 million users of an online dating website has been allegedly stolen by a hacker.
|
||||
|
||||
It is unclear at the moment if the information has been dumped into the public domain, but someone using the online alias “Mastermind” claims to have it, according to a post on an undisclosed paste site.
|
||||
|
||||
#List contains hundreds of domains from all over the world
|
||||
|
||||
The individual claims that the details are 100% valid and Daniel Ingevaldson, Chief Technology Officer at Easy Solutions, said in a blog post on Sunday that the list included email addresses from Hotmail, Yahoo and Gmail.
|
||||
|
||||
Easy Solutions is a US-based company that provides security products for detecting and preventing cyber fraud across different computer platforms.
|
||||
|
||||
According to Ingevaldson, the list contains over 7 million credentials from Hotmail, 2.5 million from Yahoo, and 2.2 million from Gmail.com.
|
||||
|
||||
It is unclear if “credentials” refers to usernames and passwords that can be used to access the email accounts or the account of the dating website. Also, it is unknown whether the database stored the passwords in a secure manner or if they were available in plain text.
|
||||
|
||||
An email address is often used as the username for an online service, to which the user can log in with a unique password. However, password recycling is a common practice for many users and the same string could be used to sign in to multiple online accounts.
|
||||
|
||||
“The list appears to be international in nature with hundreds of domains listed from all over the world. Hackers and fraudsters are likely to leverage stolen credentials to commit fraud not on the original hacked site, but to use them to exploit password re-use to automatically scan and compromise other sites including banking, travel and email providers,” [says Ingevaldson](1).
|
||||
|
||||
#More information is expected to emerge
|
||||
|
||||
According to our sources, the affected website is Topface, an online dating location that touts over 90 million users. The business is headquartered in Sankt Petersburg, Russia, and it advertises that more than 50% of its users are from outside Russia.
|
||||
|
||||
We contacted Topface to confirm or deny whether they suffered a breach recently that could have resulted in exposing a database this big; we are yet to receive an answer from the company.
|
||||
|
||||
The credentials could have been stolen without perpetrators needing to gain unauthorized access, as Easy Solutions draws attention to the fact that email phishing may also have been used to get the info straight from the clients of the website.
|
||||
|
||||
Easy Solutions could not be contacted through the online form available on its website, but we tried alternative communication and are currently waiting for more details.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Data-of-20-Million-Users-Stolen-from-Dating-Website-471179.shtml
|
||||
|
||||
本文发布时间:26 Jan 2015, 10:20 GMT
|
||||
|
||||
作者:[Ionut Ilascu][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/ionut-ilascu
|
||||
[1]:http://newblog.easysol.net/dating-site-breached/
|
||||
@ -1,33 +0,0 @@
|
||||
Ubuntu 15.04 to Integrate Linux Kernel 3.19 Branch Soon
|
||||
----
|
||||
*A new kernel branch is being tracked by Ubuntu*
|
||||
|
||||
|
||||
|
||||
#The Linux kernel is one of the most important components in a distribution and Ubuntu users are interested to know what will be used in the stable edition for the 15.04 branch, which is scheduled to arrive in a couple of months.
|
||||
|
||||
The Ubuntu and the Linux kernel development cycles are not in sync and it's hard to anticipate what version will eventually land in Ubuntu 15.04. For now, Ubuntu 15.04 (Vivid Vervet) is using Linux kernel 3.18, but the developers are already looking to implement the 3.19 branch.
|
||||
|
||||
"Our Vivid kernel remains based on the v3.18.2 upstream stable kernel, but we'll be rebasing to v3.18.3 shortly. We'll also be re-basing our unstable branch to v3.19-rc5 and get that uploaded to our team PPA soon," [said](1) Canonical's Joseph Salisbury.
|
||||
|
||||
Linux kernel 3.19 is still under development and it will take a few weeks to see a stable version, but it's enough time to implement it in Ubuntu and test it properly. It won't be possible to get the 3.20 branch, for example, even if it launches before the April 23.
|
||||
|
||||
You can [download Ubuntu 15.04](2) right now from Softpedia and give it a spin. It's a daily build and it contains all the improvements made so far to the distribution.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Data-of-20-Million-Users-Stolen-from-Dating-Website-471179.shtml
|
||||
|
||||
本文发布时间:25 Jan 2015, 20:39 GMT
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://lists.ubuntu.com/archives/ubuntu-devel/2015-January/038644.html
|
||||
[2]:http://linux.softpedia.com/get/Linux-Distributions/Ubuntu-Vivid-Vervet-103651.shtml
|
||||
@ -0,0 +1,38 @@
|
||||
LibreOffice 4.4 Released as the Most Beautiful LibreOffice Ever
|
||||
----
|
||||
*The developer has made a lot of UI improvements*
|
||||
|
||||

|
||||
|
||||
The Document Foundation has just announced that a new major update has been released for LibreOffice and it brings important UI improvements, enough for them to call this the most beautiful version ever.
|
||||
|
||||
The Document Foundation doesn't usually make the UI the main focus of an update, but now the developers are saying that this is the most beautiful release made so far and that says a lot. Fortunately, this version is not just about interface fixes and there are plenty of other major improvements that should really provide a very good reason to get LibreOffice 4.4.
|
||||
|
||||
LibreOffice has been gaining quite a lot of fans and users, and the past couple of years have been very successful. The office suite is implemented by default in most of the important Linux distributions out there and it was adopted by numerous administrations and companies across the world. LibreOffice is proving to be a difficult adversary for Microsoft's Office and each new version makes it even better.
|
||||
LibreOffice 4.4 brings a lot of new features
|
||||
|
||||
If we move aside all the improvements made to the interface, we're still left with a ton of fixes and changes. The Document Foundation takes its job very seriously and all upgrades really improve the users' experience tremendously.
|
||||
|
||||
"LibreOffice 4.4 has got a lot of UX and design love, and in my opinion is the most beautiful ever. We have completed the dialog conversion, redesigned menu bars, context menus, toolbars, status bars and rulers to make them much more useful. The Sifr monochrome icon theme is extended and now the default on OS X. We also developed a new Color Selector, improved the Sidebar to integrate more smoothly with menus, and reworked many user interface details to follow today’s UX trends," [says Jan "Kendy" Holesovsky](1), a member of the Membership Committee and the leader of the design team.
|
||||
|
||||
Some of the other improvements include much better support for OOXML file formats, the source code has been "groomed" and cleaned after a Coverity Scan analysis, digital signatures for exported PDF files, improved import filters for Microsoft Visio, Microsoft Publisher and AbiWord files, and Microsoft Works spreadsheets, and much more.
|
||||
|
||||
For now, the PPA doesn't have the latest version, but that should change soon. For the time being, you can download the [LibreOffice 4.4](2) source packages from Softpedia, if you want to compile them yourself.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/LibreOffice-4-4-Releases-As-the-Most-Beautiful-LibreOffice-Ever-471575.shtml
|
||||
|
||||
本文发布时间:29 Jan 2015, 14:16 GMT
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://blog.documentfoundation.org/2015/01/29/libreoffice-4-4-the-most-beautiful-libreoffice-ever/
|
||||
[2]:http://linux.softpedia.com/get/Office/Office-Suites/LibreOffice-60713.shtml
|
||||
@ -0,0 +1,33 @@
|
||||
OpenJDK 7 Vulnerabilities Closed in Ubuntu 14.04 and Ubuntu 14.10
|
||||
----
|
||||
*Users have been advised to upgrade as soon as possible*
|
||||
|
||||
##Canonical published details about a new OpenJDK 7 version has been pushed to the Ubuntu 14.04 LTS and Ubuntu 14.10 repositories. This update fixes a number of problems and various vulnerabilities.
|
||||
|
||||
The Ubuntu maintainers have upgraded the OpenJDK packages in the repositories and numerous fixes have been implemented. This is an important update and it covers a few libraries.
|
||||
|
||||
"Several vulnerabilities were discovered in the OpenJDK JRE related to information disclosure, data integrity and availability. An attacker could
|
||||
exploit these to cause a denial of service or expose sensitive data over the network,” reads the security notice.
|
||||
|
||||
Also, "a vulnerability was discovered in the OpenJDK JRE related to information disclosure and integrity. An attacker could exploit this to
|
||||
expose sensitive data over the network."
|
||||
|
||||
These are just a couple of the vulnerabilities identified and corrected by the developer and implemented by the maintainers/., and for a more detailed description of the problems, you can see Canonical's security notification. Users have been advised to upgrade their systems as soon as possible.
|
||||
|
||||
The flaws can be fixed if you upgrade your system to the latest openjdk-7-related packages specific to each distribution. To apply the patch, users will have to run the Update Manager application. In general, a standard system update will make all the necessary changes. All Java-related applications will have to be restarted.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://linux.softpedia.com/blog/OpenJDK-7-Vulnerabilities-Closed-in-Ubuntu-14-04-and-Ubuntu-14-10-471605.shtml
|
||||
|
||||
本文发布时间:29 Jan 2015, 16:53 GMT
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
@ -0,0 +1,49 @@
|
||||
WordPress Can Be Used to Leverage Critical Ghost Flaw in Linux
|
||||
-----
|
||||
*Users are advised to apply available patches immediately*
|
||||
|
||||

|
||||
|
||||
**The vulnerability revealed this week by security researchers at Qualys, who dubbed it [Ghost](1), could be taken advantage of through WordPress or other PHP applications to compromise web servers.**
|
||||
|
||||
The glitch is a buffer overflow that can be triggered by an attacker to gain command execution privileges on a Linux machine. It is present in the glibc’s “__nss_hostname_digits_dots()” function that can be used by the “gethostbyname()” function.
|
||||
|
||||
##PHP applications can be used to exploit the glitch
|
||||
|
||||
Marc-Alexandre Montpas at Sucuri says that the problem is significant because these functions are used in plenty of software and server-level mechanism.
|
||||
|
||||
“An example of where this could be a big issue is within WordPress itself: it uses a function named wp_http_validate_url() to validate every pingback’s post URL,” which is carried out through the “gethostbyname()” function wrapper used by PHP applications, he writes in a blog post on Wednesday.
|
||||
|
||||
An attacker could use this method to introduce a malicious URL designed to trigger the vulnerability on the server side and thus obtain access to the machine.
|
||||
|
||||
In fact, security researchers at Trustwave created [proof-of-concept](2) code that would cause the buffer overflow using the pingback feature in WordPress.
|
||||
|
||||
##Multiple Linux distributions are affected
|
||||
|
||||
Ghost is present in glibc versions up to 2.17, which was made available in May 21, 2013. The latest version of glibc is 2.20, available since September 2014.
|
||||
|
||||
However, at that time it was not promoted as a security fix and was not included in many Linux distributions, those offering long-term support (LTS) in particular.
|
||||
|
||||
Among the impacted operating systems are Debian 7 (wheezy), Red Hat Enterprise Linux 6 and 7, CentOS 6 and 7, Ubuntu 12.04. Luckily, Linux vendors have started to distribute updates with the fix that mitigates the risk. Users are advised to waste no time downloading and applying them.
|
||||
|
||||
In order to demonstrate the flaw, Qualys has created an exploit that allowed them remote code execution through the Exim email server. The security company said that it would not release the exploit until the glitch reached its half-life, meaning that the number of the affected systems has been reduced by 50%.
|
||||
|
||||
Vulnerable application in Linux are clockdiff, ping and arping (under certain conditions), procmail, pppd, and Exim mail server.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/WordPress-Can-Be-Used-to-Leverage-Critical-Ghost-Flaw-in-Linux-471730.shtml
|
||||
|
||||
本文发布时间:30 Jan 2015, 17:36 GMT
|
||||
|
||||
作者:[Ionut Ilascu][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/ionut-ilascu
|
||||
[1]:http://news.softpedia.com/news/Linux-Systems-Affected-by-14-year-old-Vulnerability-in-Core-Component-471428.shtml
|
||||
[2]:http://blog.spiderlabs.com/2015/01/ghost-gethostbyname-heap-overflow-in-glibc-cve-2015-0235.html
|
||||
38
sources/news/20150202 The Pirate Bay Is Now Back Online.md
Normal file
38
sources/news/20150202 The Pirate Bay Is Now Back Online.md
Normal file
@ -0,0 +1,38 @@
|
||||
The Pirate Bay Is Now Back Online
|
||||
------
|
||||
*The website was closed for about seven weeks*
|
||||

|
||||
##After being [raided](1) by the police almost two months ago, (in)famous torrent website The Pirate Bay is now back online. Those who thought the website will never return will be either disappointed or happy given that The Pirate Bay seems to live once again.
|
||||
|
||||
In order to celebrate its coming back, The Pirate Bay admins have posted a Phoenix bird on the front page, which signifies the fact that the website can't be killed only damaged.
|
||||
|
||||
About two weeks after The Pirate Bay was raided the domain miraculously came back to life. Soon after a countdown appeared on the temporary homepage of The Pirate Bay indicating that the website is almost ready for a comeback.
|
||||
|
||||
The countdown hinted to February 1, as the possible date for The Pirate Bay's comeback, but it looks like those who manage the website manage to pull it out one day earlier.
|
||||
|
||||
Beginning today, those who have accounts on The Pirate Bay can start downloading the torrents they want. Other than the Phoenix on the front page there are no other messages that might point to the resurrection The Pirate Bay except for the fact that it's now operational.
|
||||
|
||||
Admins of the website said a few weeks ago they will find ways to manage and optimize The Pirate Bay, so that there will be minimal chances for the website to be closed once again. Let's see how it lasts this time.
|
||||
|
||||
##Another version of The Pirate Bay may be launched soon
|
||||
|
||||
In related news, one of the members of the original staff was dissatisfied with the decisions made by the majority regarding some of the changes made in the way admins interact with the website.
|
||||
|
||||
He told [Torrentfreak](2) earlier this week that he, along with a few others, will open his version of The Pirate Bay, which they claim will be the "real" one.
|
||||
|
||||
------
|
||||
via:http://news.softpedia.com/news/The-Pirate-Bay-Is-Now-Back-Online-471802.shtml
|
||||
|
||||
本文发布时间:31 Jan 2015, 22:49 GMT
|
||||
|
||||
作者:[Cosmin Vasile][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/cosmin-vasile
|
||||
[1]:http://news.softpedia.com/news/The-Pirate-Bay-Is-Down-December-9-2014-466987.shtml
|
||||
[2]:http://torrentfreak.com/pirate-bay-back-online-150131/
|
||||
@ -1,86 +0,0 @@
|
||||
4 Best Modern Open Source Code Editors For Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Looking for **best programming editors in Linux**? If you ask the old school Linux users, their answer would be Vi, Vim, Emacs, Nano etc. But I am not talking about them. I am going to talk about new age, cutting edge, great looking, sleek and yet powerful, feature rich **best open source code editors for Linux** that would enhance your programming experience.
|
||||
|
||||
### Best modern Open Source editors for Linux ###
|
||||
|
||||
I use Ubuntu as my main desktop and hence I have provided installation instructions for Ubuntu based distributions. But this doesn’t make this list as **best text editors for Ubuntu** because the list is apt for any Linux distribution. Just to add, the list is not in any particular priority order.
|
||||
|
||||
#### Brackets ####
|
||||
|
||||

|
||||
|
||||
[Brackets][1] is an open source code editor from [Adobe][2]. Brackets focuses exclusively on the needs of web designers with built in support for HTML, CSS and Java Script. It’s light weight and yet powerful. It provides you with inline editing and live preview. There are plenty of plugins available to further enhance your experience with Brackets.
|
||||
|
||||
To [install Brackets in Ubuntu][3] and Ubuntu based distributions such as Linux Mint, you can use this unofficial PPA:
|
||||
|
||||
sudo add-apt-repository ppa:webupd8team/brackets
|
||||
sudo apt-get update
|
||||
sudo apt-get install brackets
|
||||
|
||||
For other Linux distributions, you can get the source code as well as binaries for Linux, OS X and Windows on its website.
|
||||
|
||||
- [Download Brackets Source Code and Binaries][5]
|
||||
|
||||
#### Atom ####
|
||||
|
||||

|
||||
|
||||
[Atom][5] is another modern and sleek looking open source editor for programmers. Atom is developed by Github and promoted as a “hackable text editor for the 21st century”. The looks of Atom resembles a lot like Sublime Text editor, a hugely popular but closed source text editors among programmers.
|
||||
|
||||
Atom has recently released .deb and .rpm packages so that one can easily install Atom in Debian and Fedora based Linux distributions. Of course, its source code is available as well.
|
||||
|
||||
- [Download Atom .deb][6]
|
||||
- [Download Atom .rpm][7]
|
||||
- [Get Atom source code][8]
|
||||
|
||||
#### Lime Text ####
|
||||
|
||||

|
||||
|
||||
So you like Sublime Text editor but you are not comfortable with the fact that it is not open source. No worries. We have an [open source clone of Sublime Text][9], called [Lime Text][10]. It is built on Go, HTML and QT. The reason behind cloning of Sublime Text is that there are numerous bugs in Sublime Text 2 and Sublime Text 3 is in beta since forever. There are no transparency in its development, on whether the bugs are being fixed or not.
|
||||
|
||||
So open source lovers, rejoice and get the source code of Lime Text from the link below:
|
||||
|
||||
- [Get Lime Text Source Code][11]
|
||||
|
||||
#### Light Table ####
|
||||
|
||||

|
||||
|
||||
Flaunted as “the next generation code editor”, [Light Table][12] is another modern looking, feature rich open source editor which is more of an IDE than a mere text editor. There are numerous extensions available to enhance its capabilities. Inline evaluation is what you would love in it. You have to use it to believe how useful Light Table actually is.
|
||||
|
||||
- [Get Light Table Source Code][13]
|
||||
|
||||
### What’s your pick? ###
|
||||
|
||||
No, we are not limited to just four code editors in Linux. The list was about modern editors for programmers. Of course you have plenty of other options such as [Notepad++ alternative Notepadqq][14] or [SciTE][15] and many more. So, among these four, which one is your favorite code editor for Linux?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://brackets.io/
|
||||
[2]:http://www.adobe.com/
|
||||
[3]:http://itsfoss.com/install-brackets-ubuntu/
|
||||
[4]:https://github.com/adobe/brackets/releases
|
||||
[5]:https://atom.io/
|
||||
[6]:https://atom.io/download/deb
|
||||
[7]:https://atom.io/download/rpm
|
||||
[8]:https://github.com/atom/atom/blob/master/docs/build-instructions/linux.md
|
||||
[9]:http://itsfoss.com/lime-text-open-source-alternative/
|
||||
[10]:http://limetext.org/
|
||||
[11]:https://github.com/limetext/lime
|
||||
[12]:http://lighttable.com/
|
||||
[13]:https://github.com/LightTable/LightTable
|
||||
[14]:http://itsfoss.com/notepadqq-notepad-for-linux/
|
||||
[15]:http://itsfoss.com/scite-the-notepad-for-linux/
|
||||
@ -0,0 +1,60 @@
|
||||
Meet Vivaldi — A New Web Browser Built for Power Users
|
||||
================================================================================
|
||||
|
||||
|
||||
**A brand new web browser has arrived this week that aims to meet the needs of power users — and it’s already available for Linux.**
|
||||
|
||||
Vivaldi is the name of this new browser and it has been launched as a tech preview (read: a beta without the responsibility) for 64-bit Linux machines, Windows and Mac. It is built — shock — on the tried-and-tested open-source frameworks of Chromium, Blink and Google’s open-source V8 JavaScript engine (among other projects).
|
||||
|
||||
Does the world really want another browser? Vivaldi, the brain child of former Opera Software CEO Jon von Tetzchner, is less concerned about want and more about need.
|
||||
|
||||
Vivaldi is being built with the sort of features that keyboard preferring tab addicts need. It is not being pitched at users who find Firefox perplexing or whose sole criticism of Chrome is that it moved the bookmarks button.
|
||||
|
||||
That’s not tacky marketing spiel either. Despite the ‘technical preview’ badge it comes with, Vivaldi is already packed with features that demonstrate its power user slant.
|
||||
|
||||
Plenty of folks feel left behind and underserved by the simplified, paired back offerings other software companies are producing. Vivaldi, even at this early juncture, looks well placed to succeed in winning them over.
|
||||
|
||||
### Vivaldi Features ###
|
||||
|
||||
A few of Vivaldi’s key features already present include:
|
||||
|
||||

|
||||
|
||||
**Quick Commands** (Ctrl + Q) is an in-app HUD that lets you quickly filter through settings, options and features, be it opening a bookmark or hiding the status bar, using your keyboard. No clicks needed.
|
||||
|
||||
**Tab Stacks** let you clean up your workspace by grouping separate tabs into one, and then using a keyboard command or the tab preview picker to switch between them.
|
||||
|
||||

|
||||
|
||||
A collapsible **side panel** that houses extra features (just like old Opera) including a (not yet working) mail client, contacts, bookmarks browser and note taking section that lets you take and annotate screenshots.
|
||||
|
||||
A bunch of other features are on offer too, including customizable keyboard shortcuts, a tabs bar that can be set on any edge of the browser (or hidden entirely), privacy options and a speed dial with folders.
|
||||
|
||||
### Opera Mark II ###
|
||||
|
||||
|
||||
|
||||
It’s not a leap to see Vivaldi as the true successor to Opera post-Presto (Opera’s old, proprietary rendering engine). Opera (which also pushed out a minor new update today) has split out many of its “power user” features as it chases a lighter, more manageable set of features.
|
||||
|
||||
Vivaldi wants to pick up the baggage Opera has been so keen to offload. And while that might not help it grab marketshare it will see it grab the attention of power users, many of whom will no doubt already be using Linux.
|
||||
|
||||
### Download ###
|
||||
|
||||
Interested in taking it for a spin? You can. Vivaldi is available to download for Windows, Mac and 64-bit Linux distributions. On the latter you have a choice of Debian or RPM installer.
|
||||
|
||||
Bear in mind that it’s not finished and that more features (including extensions, sync and more) are planned for future builds.
|
||||
|
||||
- [Download Vivaldi Tech Preview for Linux][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/vivaldi-web-browser-linux-download-power-users
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://vivaldi.com/#Download
|
||||
@ -1,144 +0,0 @@
|
||||
Translating by ZTinoZ
|
||||
20 Linux Commands Interview Questions & Answers
|
||||
================================================================================
|
||||
**Q:1 How to check current run level of a linux server ?**
|
||||
|
||||
Ans: ‘who -r’ & ‘runlevel’ commands are used to check the current runlevel of a linux box.
|
||||
|
||||
**Q:2 How to check the default gatway in linux ?**
|
||||
|
||||
Ans: Using the commands “route -n” and “netstat -nr” , we can check default gateway. Apart from the default gateway info , these commands also display the current routing tables .
|
||||
|
||||
**Q:3 How to rebuild initrd image file on Linux ?**
|
||||
|
||||
Ans: In case of CentOS 5.X / RHEL 5.X , mkinitrd command is used to create initrd file , example is shown below :
|
||||
|
||||
# mkinitrd -f -v /boot/initrd-$(uname -r).img $(uname -r)
|
||||
|
||||
If you want to create initrd for a specific kernel version , then replace ‘uname -r’ with desired kernel
|
||||
|
||||
In Case of CentOS 6.X / RHEL 6.X , dracut command is used to create initrd file example is shown below :
|
||||
|
||||
# dracut -f
|
||||
|
||||
Above command will create the initrd file for the current version. To rebuild the initrd file for a specific kernel , use below command :
|
||||
|
||||
# dracut -f initramfs-2.x.xx-xx.el6.x86_64.img 2.x.xx-xx.el6.x86_64
|
||||
|
||||
**Q:4 What is cpio command ?**
|
||||
|
||||
Ans: cpio stands for Copy in and copy out. Cpio copies files, lists and extract files to and from a archive ( or a single file).
|
||||
|
||||
**Q:5 What is patch command and where to use it ?**
|
||||
|
||||
Ans: As the name suggest patch command is used to apply changes ( or patches) to the text file. Patch command generally accept output from the diff and convert older version of files into newer versions. For example Linux kernel source code consists of number of files with millions of lines , so whenever any contributor contribute the changes , then he/she will be send the only changes instead of sending the whole source code. Then the receiver will apply the changes with patch command to its original source code.
|
||||
|
||||
Create a diff file for use with patch,
|
||||
|
||||
# diff -Naur old_file new_file > diff_file
|
||||
|
||||
Where old_file and new_file are either single files or directories containing files. The r option supports recursion of a directory tree.
|
||||
|
||||
Once the diff file has been created, we can apply it to patch the old file into the new file:
|
||||
|
||||
# patch < diff_file
|
||||
|
||||
**Q:6 What is use of aspell ?**
|
||||
|
||||
Ans: As the name suggest aspell is an interactive spelling checker in linux operating system. The aspell command is the successor to an earlier program named ispell, and can be used, for the most part, as a drop-in replacement. While the aspell program is mostly used by other programs that require spell-checking capability, it can also be used very effectively as a stand-alone tool from the command line.
|
||||
|
||||
**Q:7 How to check the SPF record of domain from command line ?**
|
||||
|
||||
Ans: We can check SPF record of a domain using dig command. Example is shown below :
|
||||
|
||||
linuxtechi@localhost:~$ dig -t TXT google.com
|
||||
|
||||
**Q:8 How to identify which package the specified file (/etc/fstab) is associated with in linux ?**
|
||||
|
||||
Ans: # rpm -qf /etc/fstab
|
||||
|
||||
Above command will list the package which provides file “/etc/fstab”
|
||||
|
||||
**Q:9 Which command is used to check the status of bond0 ?**
|
||||
|
||||
Ans: cat /proc/net/bonding/bond0
|
||||
|
||||
**Q:10 What is the use of /proc file system in linux ?**
|
||||
|
||||
Ans: The /proc file system is a RAM based file system which maintains information about the current state of the running kernel including details on CPU, memory, partitioning, interrupts, I/O addresses, DMA channels, and running processes. This file system is represented by various files which do not actually store the information, they point to the information in the memory. The /proc file system is maintained automatically by the system.
|
||||
|
||||
**Q:11 How to find files larger than 10MB in size in /usr directory ?**
|
||||
|
||||
Ans: # find /usr -size +10M
|
||||
|
||||
**Q:12 How to find files in the /home directory that were modified more than 120 days ago ?**
|
||||
|
||||
Ans: # find /home -mtime +l20
|
||||
|
||||
**Q:13 How to find files in the /var directory that have not been accessed in the last 90 days ?**
|
||||
|
||||
Ans: # find /var -atime -90
|
||||
|
||||
**Q:14 Search for core files in the entire directory tree and delete them as found without prompting for confirmation**
|
||||
|
||||
Ans: # find / -name core -exec rm {} \;
|
||||
|
||||
**Q:15 What is the purpose of strings command ?**
|
||||
|
||||
Ans: The strings command is used to extract and display the legible contents of a non-text file.
|
||||
|
||||
**Q:16 What is the use tee filter ?**
|
||||
|
||||
Ans: The tee filter is used to send an output to more than one destination. It can send one copy of the output to a file and another to the screen (or some other program) if used with pipe.
|
||||
|
||||
linuxtechi@localhost:~$ ll /etc | nl | tee /tmp/ll.out
|
||||
|
||||
In the above example, the output from ll is numbered and captured in /tmp/ll.out file. The output is also displayed on the screen.
|
||||
|
||||
**Q:17 What would the command export PS1 = ”$LOGNAME@`hostname`:\$PWD: do ?**
|
||||
|
||||
Ans: The export command provided will change the login prompt to display username, hostname, and the current working directory.
|
||||
|
||||
**Q:18 What would the command ll | awk ‘{print $3,”owns”,$9}’ do ?**
|
||||
|
||||
Ans: The ll command provided will display file names and their owners.
|
||||
|
||||
**Q:19 What is the use of at command in linux ?**
|
||||
|
||||
Ans: The at command is used to schedule a one-time execution of a program in the future. All submitted jobs are spooled in the /var/spool/at directory and executed by the atd daemon when the scheduled time arrives.
|
||||
|
||||
**Q:20 What is the role of lspci command in linux ?**
|
||||
|
||||
Ans: The lspci command displays information about PCI buses and the devices attached to your system. Specify -v, -vv, or -vvv for detailed output. With the -m option, the command produces more legible output.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/20-linux-commands-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
[1]:
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,82 +0,0 @@
|
||||
[Translating by Stevearzh]
|
||||
Why Mac users don’t switch to Linux
|
||||
================================================================================
|
||||
Linux and Mac users share at least one common thing: they prefer not to use Windows. But after that the two groups part company and tend to go their separate ways. But why don’t more Mac users switch to Linux? Is there something that prevents Mac users from making the jump?
|
||||
|
||||
[Datamation took a look at these questions][1] and tried to answer them. Datamation’s conclusion was that it’s really about the applications and workflow, not the operating system:
|
||||
|
||||
> …there are some instances where replacing existing applications with new options isn’t terribly practical – both in workflow and in overall functionality. This is an area where, sadly, Apple has excelled in. So while it’s hardly “impossible” to get around these issues, they are definitely a large enough challenge that it will give the typical Mac enthusiast pause.
|
||||
>
|
||||
> But outside of Web developers, honestly, I don’t see Mac users “en masse,” seeking to disrupt their workflows for the mere idea of avoiding the upgrade to OS X Yosemite. Granted, having seen Yosemite up close – Mac users who are considered power users will absolutely find this change-up to be hideous. However, despite poor OS X UI changes, the core workflow for existing Mac users will remain largely unchanged and unchallenged.
|
||||
>
|
||||
> No, I believe Linux adoption will continue to be sporadic and random. Ever-growing, but not something that is easily measured or accurately calculated.
|
||||
|
||||
I agree to a certain extent with Datamation’s take on the importance of applications and workflows, both things are important and matter in the choice of a desktop operating system. But I think there’s something more going on with Mac users than just that. I believe that there’s a different mentality that exists between Linux and Mac users, and I think that’s the real reason why many Mac users don’t switch to Linux.
|
||||
|
||||

|
||||
|
||||
### It’s all about control for Linux users ###
|
||||
|
||||
Linux users tend to want control over their computing experience, they want to be able to change things to make them the way that they want them. One simply cannot do that in the same way with OS X or any other Apple products. With Apple you get what they give you for the most part.
|
||||
|
||||
For Mac (and iOS) users this is fine, they seem mostly content to stay within Apple’s walled garden and live according to whatever standards and options Apple gives them. But this is totally unacceptable to most Linux users. People who move to Linux usually come from Windows, and it’s there that they develop their loathing for someone else trying to define or control their computing experiences.
|
||||
|
||||
And once someone like that has tasted the freedom that Linux offers, it’s almost impossible for them to want to go back to living under the thumb of Apple, Microsoft or anyone else. You’d have to pry Linux from their cold, dead fingers before they’d accept the computing experience created for them Apple or Microsoft.
|
||||
|
||||
But you won’t find that same determination to have control among most Mac users. For them it’s mostly about getting the most out of whatever Apple has done with OS X in its latest update. They tend to adjust fairly quickly to new versions of OS X and even when unhappy with Apple’s changes they seem content to continue living within Apple’s walled garden.
|
||||
|
||||
So the need for control is a huge difference between Mac and Linux users. I don’t see it as a problem though since it just reflects the reality of two very different attitudes toward using computers.
|
||||
|
||||
### Mac users need Apple’s support mechanisms ###
|
||||
|
||||
Linux users are also different in the sense that they don’t mind getting their hands dirty by getting “under the hood” of their computers. Along with control comes the personal responsibility of making sure that their Linux systems work well and efficiently, and digging into the operating system is something that many Linux users have no problem doing.
|
||||
|
||||
When a Linux user needs to fix something, chances are they will attempt to do so immediately themselves. If that doesn’t work then they’ll seek additional information online from other Linux users and work through the problem until it has been resolved.
|
||||
|
||||
But Mac users are most likely not going to do that to the same extent. That is probably one of the reasons why Apple stores are so popular and why so many Mac users opt to buy Apple Care when they get a new Mac. A Mac user can simply take his or her computer to the Apple store and ask someone to fix it for them. There they can belly up to the Genius Bar and have their computer looked at by someone Apple has paid to fix it.
|
||||
|
||||
Most Linux users would blanche at the thought of doing such a thing. Who wants some guy you don’t even know to lay hands on your computer and start trying to fix it for you? Some Linux users would shudder at the very idea of such a thing happening.
|
||||
|
||||
So it would be hard for a Mac user to switch to Linux and suddenly be bereft of the support from Apple that he or she was used to getting in the past. Some Mac users might feel very vulnerable and uncertain if they were cut off from the Apple mothership in terms of support.
|
||||
|
||||
### Mac users love Apple’s hardware ###
|
||||
|
||||
The Datamation article focused on software, but I believe that hardware also matters to Mac users. Most Apple customers tend to love Apple’s hardware. When they buy a Mac, they aren’t just buying it for OS X. They are also buying Apple’s industrial design expertise and that can be an important differentiator for Mac users. Mac users are willing to pay more because they perceive that the overall value they are getting from Apple for a Mac is worth it.
|
||||
|
||||
Linux users, on the other hand, seem less concerned by such things. I think they tend to focus more on cost and less on the looks or design of their computer hardware. For them it’s probably about getting the most value from the hardware at the lowest cost. They aren’t in love with the way their computer hardware looks in the same way that some Mac users probably are, and so they don’t make buying decisions based on it.
|
||||
|
||||
I think both points of view on hardware are equally valid. It ultimately gets down to the needs of the individual user and what matters to them when they choose to buy or, in the case of some Linux users, build their computer. Value is the key for both groups, and each has its own perceptions of what constitutes real value in a computer.
|
||||
|
||||
Of course it is [possible to run Linux on a Mac][2], directly or indirectly via virtual machine. So a user that really liked Apple’s hardware does have the option of keeping their Mac but installing Linux on it.
|
||||
|
||||
### Too many Linux distros to choose from? ###
|
||||
|
||||
Another reason that might make it hard for a Mac user to move to Linux is the sheer number of distributions to choose from in the world of Linux. While most Linux users probably welcome the huge diversity of distros available, it could also be very confusing for a Mac user who hasn’t learned to navigate those choices.
|
||||
|
||||
Over time I think a Mac user would learn and adjust by figuring out which distribution worked best for him or her. But in the short term it might be a very daunting hurdle to overcome after being used to OS X for a long period of time. I don’t think it’s insurmountable, but it’s definitely something that is worth mentioning here.
|
||||
|
||||
Of course we do have helpful resources like [DistroWatch][3] and even my own [Desktop Linux Reviews][4] blog that can help people find the right Linux distribution. Plus there are many articles available about “the best Linux distro” and that sort of thing that Mac users can use as resources when trying to figure out the distribution they want to use.
|
||||
|
||||
But one of the reasons why Apple customers buy Macs is the simplicity and all-in-one solution that they offer in terms of the hardware and software being unified by Apple. So I am not sure how many Mac users would really want to spend the time trying to find the right Linux distribution. It might be something that puts them off really considering the switch to Linux.
|
||||
|
||||
### Mac users are apples and Linux users are oranges ###
|
||||
|
||||
I see nothing wrong with Mac and Linux users going their separate ways. I think we’re just talking about two very different groups of people, and it’s a good thing that both groups can find and use the operating system and software that they prefer. Let Mac users enjoy OS X and let Linux users enjoy Linux, and hopefully both groups will be happy and content with their computers.
|
||||
|
||||
Every once in a while a Mac user might stray over to Linux or vice versa, but for the most part I think the two groups live in different worlds and mostly prefer to stay separate and apart from one another. I generally don’t compare the two because when you get right down to it, it’s really just a case of apples and oranges.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jimlynch.com/linux-articles/why-mac-users-dont-switch-to-linux/
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://jimlynch.com/author/Jim/
|
||||
[1]:http://www.datamation.com/open-source/why-linux-isnt-winning-over-mac-users-1.html
|
||||
[2]:http://www.howtogeek.com/187410/how-to-install-and-dual-boot-linux-on-a-mac/
|
||||
[3]:http://distrowatch.com/
|
||||
[4]:http://desktoplinuxreviews.com/
|
||||
@ -1,96 +0,0 @@
|
||||
KayGuoWhu translating
|
||||
If a 32-bit integer overflows, can we use a 40-bit structure instead of a 64-bit long one?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
If, say, a 32-bit integer is overflowing, instead of upgrading int to long, can we make use of some 40-bit type if we need a range only within 240, so that we save 24 (64-40) bits for every integer?
|
||||
|
||||
If so, how?
|
||||
|
||||
I have to deal with billions and space is a bigger constraint.
|
||||
|
||||
#A:
|
||||
|
||||
##Yes, but...
|
||||
|
||||
It is certainly possible, but it is usually nonsensical (for any program that doesn't use billions of these numbers):
|
||||
|
||||
```C
|
||||
#include <stdint.h> // don't want to rely on something like long long
|
||||
struct bad_idea
|
||||
{
|
||||
uint64_t var : 40;
|
||||
};
|
||||
```
|
||||
|
||||
Here, var will indeed have a width of 40 bits at the expense of much less efficient code generated (it turns out that "much" is very much wrong -- the measured overhead is a mere 1-2%, see timings below), and usually to no avail. Unless you have need for another 24-bit value (or an 8 and 16 bit value) which you wish to pack into the same structure, alignment will forfeit anything that you may gain.
|
||||
|
||||
In any case, unless you have billions of these, the effective difference in memory consumption will not be noticeable (but the extra code needed to manage the bit field will be noticeable!).
|
||||
|
||||
###Note:
|
||||
|
||||
The question has in the mean time been updated to reflect that indeed billions of numbers are needed, so this may be a viable thing to do, presumed that you take measures not to lose the gains due to structure alignment and padding, i.e. either by storing something else in the remaining 24 bits or by storing your 40-bit values in structures of 8 each or multiples thereof).
|
||||
Saving three bytes a billion times is worthwhile as it will require noticeably fewer memory pages and thus cause fewer cache and TLB misses, and above all page faults (a single page fault weighting tens of millions instructions).
|
||||
|
||||
While the above snippet does not make use of the remaining 24 bits (it merely demonstrates the "use 40 bits" part), something akin to the following will be necessary to really make the approach useful in a sense of preserving memory -- presumed that you indeed have other "useful" data to put in the holes:
|
||||
|
||||
```C
|
||||
struct using_gaps
|
||||
{
|
||||
uint64_t var : 40;
|
||||
uint64_t useful_uint16 : 16;
|
||||
uint64_t char_or_bool : 8;
|
||||
};
|
||||
```
|
||||
|
||||
Structure size and alignment will be equal to a 64 bit integer, so nothing is wasted if you make e.g. an array of a billion such structures (even without using compiler-specific extensions). If you don't have use for an 8-bit value, you could also use an 48-bit and a 16-bit value (giving a bigger overflow margin).
|
||||
Alternatively you could, at the expense of usability, put 8 40-bit values into a structure (least common multiple of 40 and 64 being 320 = 8*40). Of course then your code which accesses elements in the array of structures will become much more complicated (though one could probably implement an operator[] that restores the linear array functionality and hides the structure complexity).
|
||||
|
||||
Update:
|
||||
Wrote a quick test suite, just to see what overhead the bitfields (and operator overloading with bitfield refs) would have. Posted code (due to length) at gcc.godbolt.org, test output from my Win7-64 machine is:
|
||||
|
||||
```TXT
|
||||
Running test for array size = 1048576
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 2 1 35 35 1
|
||||
uint64_t 0 3 3 35 35 1
|
||||
bad40_t 0 5 3 35 35 1
|
||||
packed40_t 0 7 4 48 49 1
|
||||
|
||||
|
||||
Running test for array size = 16777216
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 38 14 560 555 8
|
||||
uint64_t 0 81 22 565 554 17
|
||||
bad40_t 0 85 25 565 561 16
|
||||
packed40_t 0 151 75 765 774 16
|
||||
|
||||
|
||||
Running test for array size = 134217728
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 312 100 4480 4441 65
|
||||
uint64_t 0 648 172 4482 4490 130
|
||||
bad40_t 0 682 193 4573 4492 130
|
||||
packed40_t 0 1164 552 6181 6176 130
|
||||
```
|
||||
|
||||
What one can see is that the extra overhead of bitfields is neglegible, but the operator overloading with bitfield reference as a convenience thing is rather drastic (about 3x increase) when accessing data linearly in a cache-friendly manner. On the other hand, on random access it barely even matters.
|
||||
|
||||
These timings suggest that simply using 64-bit integers would be better since they are still faster overall than bitfields (despite touching more memory), but of course they do not take into account the cost of page faults with much bigger datasets. It might look very different once you run out of physical RAM (I didn't test that).
|
||||
|
||||
------
|
||||
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/27705409/if-a-32-bit-integer-overflows-can-we-use-a-40-bit-structure-instead-of-a-64-bit/27705562#27705562)
|
||||
|
||||
作者:[Damon][a][Michael Kohne][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/572743/damon
|
||||
[b]:http://stackoverflow.com/users/5801/michael-kohne
|
||||
31
sources/talk/20150127 Windows 10 versus Linux.md
Normal file
31
sources/talk/20150127 Windows 10 versus Linux.md
Normal file
@ -0,0 +1,31 @@
|
||||
Windows 10 versus Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Windows 10 seemed to dominate the headlines today, even in many Linux circles. Leading the pack is Brian Fagioli at betanews.com saying Windows 10 is ringing the death knell for Linux desktops. Microsoft announced today that Windows 10 will be free for loyal Windows users and Steven J. Vaughan-Nichols said it's the newest Open Source company. Then Matt Hartley compares Windows 10 to Ubuntu and Jesse Smith reviews Windows 10 from a Linux user's perspective.
|
||||
|
||||
**Windows 10** was the talk around water coolers today with Microsoft's [announcement][1] that it would be free for Windows 7 and up users. Here in Linuxland, that didn't go unnoticed. Brian Fagioli at betanews.com, a self-proclaimed Linux fan, said today, "Windows 10 closes the door entirely. The year of the Linux desktop will never happen. Rest in peace." [Fagioli explained][2] that Microsoft listened to user complaints and not only addressed them but improved way beyond that. He said Linux missed the boat by failing to capitalize on the Windows 8 unpopularity and ultimate failure. Then he concluded that we on the fringe must accept our "shattered dreams" thanks to Windows 10.
|
||||
|
||||
**H**owever, Jesse Smith, of Distrowatch.com fame, said Microsoft isn't making it easy to find the download, but it is possible and he did it. The installer was simple enough except for the partitioner, which was quite limited and almost scary. After finally getting into Windows 10, Smith said the layout was "sparce" without a lot of the distractions folks hated about 7. The menu is back and the start screen is gone. A new package manager looks a lot like Ubuntu's and Android's according to Smith, but requires an online Microsoft account to use. [Smith concludes][3] in part, "Windows 10 feels like a beta for an early version of Android, a consumer operating system that is designed to be on-line all the time. It does not feel like an operating system I would use to get work done."
|
||||
|
||||
**S**mith's [full article][4] compares Windows 10 to Linux quite a bit, but Matt Hartley today posted an actual Windows 10 vs Linux report. [He said][5] both installers were straightforward and easy Windows still doesn't dual boot easily and Windows provides encryption by default but Ubuntu offers it as an option. At the desktop Hartley said Windows 10 "is struggling to let go of its Windows 8 roots." He thought the Windows Store looks more polished than Ubuntu's but didn't really like the "tile everything" approach to newly installed apps. In conclusion, Hartley said, "The first issue is that it's going to be a free upgrade for a lot of Windows users. This means the barrier to entry and upgrade is largely removed. Second, it seems this time Microsoft has really buckled down on listening to what their users want."
|
||||
|
||||
**S**teven J. Vaughan-Nichols today said that Microsoft is the newest Open Source company; not because it's going to be releasing Windows 10 as a free upgrade but because Microsoft is changing itself from a software company to a software as a service company. And, according to Vaughan-Nichols, Microsoft needs Open Source to do it. They've been working on it for years beginning with Novell/SUSE. Not only that, they've been releasing software as Open Source as well (whatever the motives). [Vaughan-Nichols concluded][6], "Most people won't see it, but Microsoft -- yes Microsoft -- has become an open-source company."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/windows-10-versus-linux
|
||||
|
||||
作者:[Susan Linton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/susan-linton
|
||||
[1]:https://news.google.com/news/section?q=microsoft+windows+10+free&ie=UTF-8&oe=UTF-8
|
||||
[2]:http://betanews.com/2015/01/25/windows-10-is-the-final-nail-in-the-coffin-for-the-linux-desktop/
|
||||
[3]:http://blowingupbits.com/2015/01/an-outsiders-perspective-on-windows-10-preview/
|
||||
[4]:http://blowingupbits.com/2015/01/an-outsiders-perspective-on-windows-10-preview/
|
||||
[5]:http://www.datamation.com/open-source/windows-vs-linux-the-2015-version-1.html
|
||||
[6]:http://www.zdnet.com/article/microsoft-the-open-source-company/
|
||||
@ -0,0 +1,86 @@
|
||||
7 communities driving open source development
|
||||
================================================================================
|
||||
Not so long ago, the open source model was the rebellious kid on the block, viewed with suspicion by established industry players. Today, open initiatives and foundations are flourishing with long lists of vendor committers who see the model as a key to innovation.
|
||||
|
||||

|
||||
|
||||
### Open Development of Tech Drives Innovation ###
|
||||
|
||||
Over the past two decades, open development of technology has come to be seen as a key to driving innovation. Even companies that once saw open source as a threat have come around — Microsoft, for example, is now active in a number of open source initiatives. To date, most open development has focused on software. But even that is changing as communities have begun to coalesce around open hardware initiatives. Here are seven organizations that are successfully promoting and developing open technologies, both hardware and software.
|
||||
|
||||
### OpenPOWER Foundation ###
|
||||
|
||||

|
||||
|
||||
The [OpenPOWER Foundation][2] was founded by IBM, Google, Mellanox, Tyan and NVIDIA in 2013 to drive open collaboration hardware development in the same spirit as the open source software development which has found fertile ground in the past two decades.
|
||||
|
||||
IBM seeded the foundation by opening up its Power-based hardware and software technologies, offering licenses to use Power IP in independent hardware products. More than 70 members now work together to create custom open servers, components and software for Linux-based data centers.
|
||||
|
||||
In April, OpenPOWER unveiled a technology roadmap based on new POWER8 process-based servers capable of analyzing data 50 times faster than the latest x86-based systems. In July, IBM and Google released a firmware stack. October saw the availability of NVIDIA GPU accelerated POWER8 systems and the first OpenPOWER reference server from Tyan.
|
||||
|
||||
### The Linux Foundation ###
|
||||
|
||||

|
||||
|
||||
Founded in 2000, [The Linux Foundation][2] is now the host for the largest open source, collaborative development effort in history, with more than 180 corporate members and many individual and student members. It sponsors the work of key Linux developers and promotes, protects and advances the Linux operating system and collaborative software development.
|
||||
|
||||
Some of its most successful collaborative projects include Code Aurora Forum (a consortium of companies with projects serving the mobile wireless industry), MeeGo (a project to build a Linux kernel-based operating system for mobile devices and IVI) and the Open Virtualization Alliance (which fosters the adoption of free and open source software virtualization solutions).
|
||||
|
||||
### Open Virtualization Alliance ###
|
||||
|
||||

|
||||
|
||||
The [Open Virtualization Alliance (OVA)][3] exists to foster the adoption of free and open source software virtualization solutions like Kernel-based Virtual Machine (KVM) through use cases and support for the development of interoperable common interfaces and APIs. KVM turns the Linux kernel into a hypervisor.
|
||||
|
||||
Today, KVM is the most commonly used hypervisor with OpenStack.
|
||||
|
||||
### The OpenStack Foundation ###
|
||||
|
||||

|
||||
|
||||
Originally launched as an Infrastructure-as-a-Service (IaaS) product by NASA and Rackspace hosting in 2010, the [OpenStack Foundation][4] has become the home for one of the biggest open source projects around. It boasts more than 200 member companies, including AT&T, AMD, Avaya, Canonical, Cisco, Dell and HP.
|
||||
|
||||
Organized around a six-month release cycle, the foundation's OpenStack projects are developed to control pools of processing, storage and networking resources through a data center — all managed or provisioned through a Web-based dashboard, command-line tools or a RESTful API. So far, the collaborative development supported by the foundation has resulted in the creation of OpenStack components including OpenStack Compute (a cloud computing fabric controller that is the main part of an IaaS system), OpenStack Networking (a system for managing networks and IP addresses) and OpenStack Object Storage (a scalable redundant storage system).
|
||||
|
||||
### OpenDaylight ###
|
||||
|
||||

|
||||
|
||||
Another collaborative project to come out of the Linux Foundation, [OpenDaylight][5] is a joint initiative of industry vendors, like Dell, HP, Oracle and Avaya founded in April 2013. Its mandate is the creation of a community-led, open, industry-supported framework consisting of code and blueprints for Software-Defined Networking (SDN). The idea is to provide a fully functional SDN platform that can be deployed directly, without requiring other components, though vendors can offer add-ons and enhancements.
|
||||
|
||||
### Apache Software Foundation ###
|
||||
|
||||

|
||||
|
||||
The [Apache Software Foundation (ASF)][7] is home to nearly 150 top level projects ranging from open source enterprise automation software to a whole ecosystem of distributed computing projects related to Apache Hadoop. These projects deliver enterprise-grade, freely available software products, while the Apache License is intended to make it easy for users, whether commercial or individual, to deploy Apache products.
|
||||
|
||||
ASF was incorporated in 1999 as a membership-based, not-for-profit corporation with meritocracy at its heart — to become a member you must first be actively contributing to one or more of the foundation's collaborative projects.
|
||||
|
||||
### Open Compute Project ###
|
||||
|
||||

|
||||
|
||||
An outgrowth of Facebook's redesign of its Oregon data center, the [Open Compute Project (OCP)][7] aims to develop open hardware solutions for data centers. The OCP is an initiative made up of cheap, vanity-free servers, modular I/O storage for Open Rack (a rack standard designed for data centers to integrate the rack into the data center infrastructure) and a relatively "green" data center design.
|
||||
|
||||
OCP board members include representatives from Facebook, Intel, Goldman Sachs, Rackspace and Microsoft.
|
||||
|
||||
OCP recently announced two options for licensing: an Apache 2.0-like license that allows for derivative works and a more prescriptive license that encourages changes to be rolled back into the original software.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2866074/opensource-subnet/7-communities-driving-open-source-development.html
|
||||
|
||||
作者:[Thor Olavsrud][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Thor-Olavsrud/
|
||||
[1]:http://openpowerfoundation.org/
|
||||
[2]:http://www.linuxfoundation.org/
|
||||
[3]:https://openvirtualizationalliance.org/
|
||||
[4]:http://www.openstack.org/foundation/
|
||||
[5]:http://www.opendaylight.org/
|
||||
[6]:http://www.apache.org/
|
||||
[7]:http://www.opencompute.org/
|
||||
153
sources/talk/20150128 The top 10 rookie open source projects.md
Normal file
153
sources/talk/20150128 The top 10 rookie open source projects.md
Normal file
@ -0,0 +1,153 @@
|
||||
The top 10 rookie open source projects
|
||||
================================================================================
|
||||
Black Duck presents its Open Source Rookies of the Year -- the 10 most exciting, active new projects germinated by the global open source community
|
||||
|
||||

|
||||
|
||||
### Open Source Rookies of the Year ###
|
||||
|
||||
Each year sees the start of thousands of new open source projects. Only a handful gets real traction. Some projects gain momentum by building on existing, well-known technologies; others truly break new ground. Many projects are created to solve a simple development problem, while others begin with loftier intentions shared by like-minded developers around the world.
|
||||
|
||||
Since 2009, the open source software logistics company Black Duck has identified the [Open Source Rookies of the Year][1], based on activity tracked by its [Open Hub][2] (formerly Ohloh) site. This year, we're delighted to present 10 winners and two honorable mentions for 2015, selected from thousands of open source projects. Using a weighted scoring system, points were awarded based on project activity, the pace of commits, and several other factors.
|
||||
|
||||
Open source has become the industry's engine of innovation. This year, for example, growth in projects related to Docker containerization trumped every other rookie area -- and not coincidentally reflected the most exciting area of enterprise technology overall. At the very least, the projects described here provide a window on what the global open source developer community is thinking, which is fast becoming a good indicator of where we're headed.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: DebOps ###
|
||||
|
||||

|
||||
|
||||
[DebOps][3] is a collection of [Ansible][4] playbooks and roles, scalable from one container to an entire data center. Founder Maciej Delmanowski open-sourced DebOps to ensure his work outlived his current work environment and could grow in strength and depth from outside contributors.
|
||||
|
||||
DebOps began at a small university in Poland that ran its own data center, where everything was configured by hand. Crashes sometimes led to days of downtime -- and Delmanowski realized that a configuration management system was needed. Starting with a Debian base, DebOps is a group of Ansible playbooks that configure an entire data infrastructure. The project has been implemented in many different working environments, and the founders plan to continue supporting and improving it as time goes on.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Code Combat ###
|
||||
|
||||

|
||||
|
||||
The traditional pen-and-paper way of learning falls short for technical subjects. Games, however, are all about engagement -- which is why the founders of [CodeCombat][5] went about creating a multiplayer programming game to teach people how to code.
|
||||
|
||||
At its inception, CodeCombat was an idea for a startup, but the founders decided to create an open source project instead. The idea blossomed within the community, and the project gained contributors at a steady rate. A mere two months after its launch, the game was accepted into Google’s Summer of Code. The game reaches a broad audience and is available in 45 languages. CodeCombat hopes to become the standard for people who want to learn to code and have fun at the same time.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Storj ###
|
||||
|
||||

|
||||
|
||||
[Storj][6] is a peer-to-peer cloud storage network that implements end-to-end encryption, enabling users to transfer and share data without reliance on a third party. Based on bitcoin blockchain technology and peer-to-peer protocols, Storj provides secure, private, and encrypted cloud storage.
|
||||
|
||||
Opponents of cloud-based data storage worry about cost efficiencies and vulnerability to attack. Intended to address both concerns, Storj is a private cloud storage marketplace where space is purchased and traded via Storjcoin X (SJCX). Files uploaded to Storj are shredded, encrypted, and stored across the community. File owners are the sole individuals who possess keys to the encrypted information.
|
||||
|
||||
The proof of concept for this decentralized cloud storage marketplace was first presented at the Texas Bitcoin Conference Hackathon in 2014. After winning first place in the hackathon, the project founders and leaders used open forums, Reddit, bitcoin forums, and social media to grow an active community, now an essential part of the Storj decision-making process.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Neovim ###
|
||||
|
||||

|
||||
|
||||
Since its inception in 1991, Vim has been a beloved text editor adopted by millions of software developers. [Neovim][6] is the next generation.
|
||||
|
||||
The software development ecosystem has experienced exponential growth and innovation over the past 23 years. Neovim founder Thiago de Arruda knew that Vim was lacking in modern-day features and development speed. Although determined to preserve the signature features of Vim, the community behind Neovim seeks to improve and evolve the technology of its favorite text editor. Crowdfunding initially enabled de Arruda to focus six uninterrupted months on launching this endeavor. He credits the Neovim community for supporting the project and for inspiring him to continue contributing.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: CockroachDB ###
|
||||
|
||||

|
||||
|
||||
Former Googlers are bringing a big-company data solution to open source in the form of [CockroachDB][8], a scalable, geo-replicated, transactional data store.
|
||||
|
||||
To maintain the terabytes of data transacted over its global online properties, Google developed Spanner. This powerful tool provides Google with scalability, survivability, and transactionality -- qualities that the team behind CockroachDB is serving up to the open source community. Like an actual cockroach, CockroachDB can survive without its head, tolerating the failure of any node. This open source project has a devoted community of experienced contributors, actively cultivated by the founders via social media, GitHub, networking, conferences, and meet-ups.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Kubernetes ###
|
||||
|
||||

|
||||
|
||||
In introducing containerized software development to the open source community, [Docker][9] has become the backbone of a strong, innovative set of tools and technologies. [Kubernetes][10], which Google introduced last June, is an open source container management tool used to accelerate development and simplify operations.
|
||||
|
||||
Google has been using containers for years in its internal operations. At the summer 2014 DockerCon, the Internet giant open-sourced Kubernetes, which was developed to meet the needs of the exponentially growing Docker ecosystem. Through collaborations with other organizations and projects, such as Red Hat and CoreOS, Kubernetes project managers have grown their project to be the No. 1 downloaded tool on the Docker Hub. The Kubernetes team hopes to expand the project and grow the community, so software developers can spend less time managing infrastructure and more time building the apps they want.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Open Bazaar ###
|
||||
|
||||

|
||||
|
||||
[OpenBazaar][11] is a decentralized marketplace for trading with anyone using bitcoin. The proof of concept for OpenBazaar was born at a hackathon, where its founders combined BitTorent, bitcoin, and traditional financial server methodologies to create a censorship-resistant trading platform. The OpenBazaar team sought new members, and before long they were able to expand the OpenBazaar community immensely. The table stakes of OpenBazaar -- transparency and a common goal to revolutionize trade and commerce -- are helping founders and contributors work toward a real-world, uncontrolled, and decentralized marketplace.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: IPFS ###
|
||||
|
||||

|
||||
|
||||
[IPFS (InterPlanetary File System)][12] is a global, versioned, peer-to-peer file system.It synthesizes many of the ideas behind Git, BitTorrent, and HTTP to bring a new data and data structure transport protocol to the open Web.
|
||||
|
||||
Open source is known for developing simple solutions to complex problems that result in many innovations, but these powerful projects represent only one slice of the open source community. IFPS belong to a more radical group whose proof of concept seems daring, outrageous, and even unattainable -- in this case, a peer-to-peer distributed file system that seeks to connect all computing devices. This possible HTTP replacement maintains a community through multiple mediums, including the Git community and an IRC channel that has more than 100 current contributors. This “crazy” idea will be available for alpha testing in 2015.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: cAdvisor ###
|
||||
|
||||

|
||||
|
||||
[cAdvisor (Container Advisor)][13] is a daemon that collects, aggregates, processes, and exports information about running containers, providing container users with an understanding of resource usage and performance characteristics. For each container, cAdvisor keeps resource isolation parameters, historical resource usage, histograms of complete historical resource usage, and network statistics. This data is exported by container and across machines.
|
||||
|
||||
cAdvisor can run on most Linux distros and supports many container types, including Docker. It has become the de facto monitoring agent for containers, has been integrated into many systems, and is one of the most downloaded images on the Docker Hub. The team hopes to grow cAdvisor to understand application performance more deeply and to integrate this information into clusterwide systems.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Terraform ###
|
||||
|
||||

|
||||
|
||||
[Terraform][14] provides a common configuration to launch infrastructure, from physical and virtual servers to email and DNS providers. The idea is to encompass everything from custom in-house solutions to services offered by public cloud platforms. Once launched, Terraform enables ops to change infrastructure safely and efficiently as the configuration evolves.
|
||||
|
||||
Working at a devops company, Terraform.io's founders identified a pain point in codifying the knowledge required to build a complete data center, from plugged-in servers to a fully networked and functional data center. Infrastructure is described using a high-level configuration syntax, which allows a blueprint of your data center to be versioned and treated as you would any other code. Sponsorship from the well-respected open source company HashiCorp helped launch the project.
|
||||
|
||||
### Honorable mention: Docker Fig ###
|
||||
|
||||

|
||||
|
||||
[Fig][15] provides fast, isolated development environments using [Docker][16]. It moves the configuration required to orchestrate Docker into a simple fig.yml file. It handles all the work of building and running containers and forwarding their ports, as well as sharing volumes and linking them.
|
||||
|
||||
Orchard formed Fig last year to create a new system of tools to make Docker work. It was developed as a way of setting up development environments with Docker, enabling users to define the exact environment for their apps, while also running databases and caches inside Docker. Fig solved a major pain point for developers. Docker fully supports this open source project and [recently purchased Orchard][17] to expand the reach of Fig.
|
||||
|
||||
### Honorable mention: Drone ###
|
||||
|
||||

|
||||
|
||||
[Drone][18] is a Continuous Integration platform built on Docker and [written in Go][19]. The Drone project grew out of frustration with existing available technologies and processes for setting up development environments.
|
||||
|
||||
Drone provides a simple approach to automated testing and continuous delivery: Simply pick a Docker image tailored to your needs, connect GitHub, and commit. Drone uses Docker containers to provision isolated testing environments, giving every project complete control over its stack without the burden of traditional server administration. The community behind Drone is 100 contributors strong and hopes to bring this project to the enterprise and to mobile app development.
|
||||
|
||||
### Open source rookies ###
|
||||
|
||||

|
||||
|
||||
- [Open Source Rookies of the 2014 Year][20]
|
||||
- [InfoWorld's 2015 Technology of the Year Award winners][21]
|
||||
- [Bossies: The Best of Open Source Software Awards][22]
|
||||
- [15 essential open source tools for Windows admins][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2875439/open-source-software/the-top-10-rookie-open-source-projects.html
|
||||
|
||||
作者:[Black Duck Software][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Black-Duck-Software/
|
||||
[1]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[2]:https://www.openhub.net/
|
||||
[3]:https://github.com/debops/debops
|
||||
[4]:http://www.infoworld.com/article/2612397/data-center/review--ansible-orchestration-is-a-veteran-unix-admin-s-dream.html
|
||||
[5]:https://codecombat.com/
|
||||
[6]:http://storj.io/
|
||||
[7]:http://neovim.org/
|
||||
[8]:https://github.com/cockroachdb/cockroach
|
||||
[9]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[10]:http://kubernetes.io/
|
||||
[11]:https://openbazaar.org/
|
||||
[12]:http://ipfs.io/
|
||||
[13]:https://github.com/google/cadvisor
|
||||
[14]:https://www.terraform.io/
|
||||
[15]:http://www.fig.sh/
|
||||
[16]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[17]:http://www.infoworld.com/article/2608546/application-virtualization/docker-acquires-orchard-in-a-sign-of-rising-ambitions.html
|
||||
[18]:https://drone.io/
|
||||
[19]:http://www.infoworld.com/article/2683845/google-go/164121-Fast-guide-to-Go-programming.html
|
||||
[20]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[21]:http://www.infoworld.com/article/2871935/application-development/infoworlds-2015-technology-of-the-year-award-winners.html
|
||||
[22]:http://www.infoworld.com/article/2688104/open-source-software/article.html
|
||||
[23]:http://www.infoworld.com/article/2854954/microsoft-windows/15-essential-open-source-tools-for-windows-admins.html
|
||||
@ -0,0 +1,82 @@
|
||||
9 Best IDEs and Code Editors for JavaScript Users
|
||||
================================================================================
|
||||
Web designing and developing is one of the trending sectors in the recent times, where more and more peoples started to search for their career opportunities. But, Getting the right opportunity as a web developer or graphic designer is not just a piece of cake for everyone, It certainly requires a strong mind presence as well as right skills to find the find the right job. There are a lot of websites available today which can help you to get the right job description according to your knowledge. But still if you want to achieve something in this sector you must have some excellent skills like working with different platforms, IDEs and various other tools too.
|
||||
|
||||
Talking about the different platforms and IDEs used for various languages for different purposes, gone is the time when we learn just one IDE and get the optimum solutions for our web design projects easily. Today we are living in the modern lifestyle where competition is getting more and more tough on every single day. Same is the case with the IDEs, IDE is basically a powerful client application for creating and deploying applications. Today we are going to share some best javascript IDE for web designers and developers.
|
||||
|
||||
Please visit this list of best code editors for javascript user and share your thought with us.
|
||||
|
||||
### 1) [Spket][1] ###
|
||||
|
||||
**Spket IDE** is powerful toolkit for JavaScript and XML development. The powerful editor for JavaScript, XUL/XBL and Yahoo! Widget development. The JavaScript editor provides features like code completion, syntax highlighting and content outline that helps developers productively create efficient JavaScript code.
|
||||
|
||||

|
||||
|
||||
### 2) [Ixedit][2] ###
|
||||
|
||||
IxEdit is a JavaScript-based interaction design tool for the web. With IxEdit, designers can practice DOM-scripting without coding to change, add, move, or transform elements dynamically on your web pages.
|
||||
|
||||

|
||||
|
||||
### 3) [Komodo Edit][3] ###
|
||||
|
||||
Komode is free and powerful code editor for Javascript and other programming languages.
|
||||
|
||||

|
||||
|
||||
### 4) [EpicEditor][4] ###
|
||||
|
||||
EpicEditor is an embeddable JavaScript Markdown editor with split fullscreen editing, live previewing, automatic draft saving, offline support, and more. For developers, it offers a robust API, can be easily themed, and allows you to swap out the bundled Markdown parser with anything you throw at it.
|
||||
|
||||

|
||||
|
||||
### 5) [codepress][5] ###
|
||||
|
||||
CodePress is web-based source code editor with syntax highlighting written in JavaScript that colors text in real time while it’s being typed in the browser.
|
||||
|
||||

|
||||
|
||||
### 6) [ACe][6] ###
|
||||
|
||||
Ace is an embeddable code editor written in JavaScript. It matches the features and performance of native editors such as Sublime, Vim and TextMate. It can be easily embedded in any web page and JavaScript application.
|
||||
|
||||

|
||||
|
||||
### 7) [scripted][7] ###
|
||||
|
||||
Scripted is a fast and lightweight code editor with an initial focus on JavaScript editing. Scripted is a browser based editor and the editor itself is served from a locally running Node.js server instance.
|
||||
|
||||

|
||||
|
||||
### 8) [Netbeans][8] ###
|
||||
|
||||
This is another more impressive and useful code editors for javascript and other programming languages.
|
||||
|
||||

|
||||
|
||||
### 9) [Webstorm][9] ###
|
||||
|
||||
This is the smartest ID for javascript. WebStorm is a lightweight yet powerful IDE, perfectly equipped for complex client-side development and server-side development with Node.js.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://devzum.com/2015/01/31/9-best-ides-and-code-editors-for-javascript-users/
|
||||
|
||||
作者:[vikas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://devzum.com/author/vikas/
|
||||
[1]:http://spket.com/
|
||||
[2]:http://www.ixedit.com/
|
||||
[3]:http://komodoide.com/komodo-edit/
|
||||
[4]:http://oscargodson.github.io/EpicEditor/
|
||||
[5]:http://codepress.sourceforge.net/
|
||||
[6]:http://ace.c9.io/#nav=about
|
||||
[7]:https://github.com/scripted-editor/scripted
|
||||
[8]:https://netbeans.org/
|
||||
[9]:http://www.jetbrains.com/webstorm/
|
||||
@ -1,75 +0,0 @@
|
||||
Test drive Linux with nothing but a flash drive
|
||||
================================================================================
|
||||

|
||||
Image by : Opensource.com
|
||||
|
||||
Maybe you’ve heard about Linux and are intrigued by it. So intrigued that you want to give it a try. But you might not know where to begin.
|
||||
|
||||
You’ve probably done a bit of research online and have run across terms like dual booting and virtualization. Those terms might mean nothing to you, and you’re definitely not ready to sacrifice the operating system that you’re currently using to give Linux a try. So what can you do?
|
||||
|
||||
If you have a USB flash drive lying around, you can test drive Linux by creating a live USB. It’s a USB flash drive that contains an operating system that can start from the flash drive. It doesn’t take much technical ability to create one. Let’s take a look at how to do that and how to run Linux using a live USB.
|
||||
|
||||
### What you’ll need ###
|
||||
|
||||
Aside from a desktop or laptop computer, you’ll need:
|
||||
|
||||
- A blank USB flash drive—preferably one that has a capacity of 4 GB or more.
|
||||
- An [ISO image][1] (an archive of the contents of a hard disk) of the Linux distribution that you want to try. More about this in a moment.
|
||||
- An application called [Unetbootin][2], an open source tool, cross platform tool that creates a live USB. You don’t need to be running Linux to use it. In the instructions that below, I’m running Unetbootin on a MacBook.
|
||||
|
||||
### Getting to work ###
|
||||
|
||||
Plug your flash drive into a USB port on your computer and then fire up Unetbootin. You’ll be asked for the password that you use to log into your computer.
|
||||
|
||||

|
||||
|
||||
Remember the ISO image that was mentioned a few moments ago? There are two ways you can get one: either by downloading it from the website of the Linux distribution that you want to try, or by having Unetbootin download it for you. To do that latter, click **Select Distribution** at the top of the window, choose the distribution that you want to download, and then click **Select Version** to select the version of the distribution that you want to try.
|
||||
|
||||

|
||||
|
||||
Or, you can download the distribution yourself. Usually, the Linux distributions that I want to try aren’t in the list. If you go the second route, click **Disk image** and then click the button to search for the .iso file that you downloaded.
|
||||
|
||||
Notice the **Space used to preserve files across reboots (Ubuntu only)** option? If you’re testing Ubuntu or one of its derivatives (like Lubuntu or Xubuntu), you can set aside a few megabytes of space on your flash drive to save files like web browser bookmarks or documents that you create. When you load Ubuntu from the flash drive again, you can reuse those files.
|
||||
|
||||

|
||||
|
||||
Once the ISO image is loaded, click **OK**. It takes anywhere from a couple of minutes to 10 minutes for Unetbootin to create the live USB.
|
||||
|
||||

|
||||
|
||||
### Testing out the live USB ###
|
||||
|
||||
This is the point where you have to embrace your inner geek a bit. Not too much, but you will be taking a peek into the innards of your computer by going into the [BIOS][3]. Your computer’s BIOS starts various bits of hardware and controls where the computer’s operating system starts, or boots, from.
|
||||
|
||||
The BIOS usually looks for the operating system in this order (or something like it): hard drive, then CD-ROM or DVD drive, and then an external drive. You’ll want to change that order so that the external drive (in this case, your live USB) is the one that the BIOS checks first.
|
||||
|
||||
To do that, restart your computer with the flash drive plugged into a USB port. When you see the message **Press F2 to enter setup**, do just that. On some computers, the key might be F10.
|
||||
|
||||
In the BIOS, use the right arrow key on your keyboard to navigate to the **Boot** menu. You’ll see a list of drives on your computer. Use the down arrow key on your keyboard to navigate to the item labeled **USB HDD** and then press **F6** to move that item to the top of the list.
|
||||
|
||||
Once you’ve done that, press **F10** to save the changes. You’ll be kicked out of the BIOS and your computer will start up. After a short amount of time, you’ll be presented with a menu listing the options for starting the Linux distribution you’re trying out. Select **Run without installing** (or the menu item closest to it).
|
||||
|
||||
Once the desktop loads, you can connect to a wireless or wired network, browse the web, and give the pre-installed software a whirl. You can also check to see if, for example, your printer or scanner works with the Linux distribution you’re testing. If you really, really want to you can also fiddle at the command line.
|
||||
|
||||
### What to expect ###
|
||||
|
||||
Depending on the Linux distribution you’re testing and the speed of the flash drive you’re using, the operating system might take longer to load and it might run a bit slower than it would if it was installed on your hard drive.
|
||||
|
||||
As well, you’ll only have the basic software that the Linux distribution packs out of the box. You generally get a web browser, a word processor, a text editor, a media player, an image viewer, and a set of utilities. That should be enough to give you a feel for what it’s like to use Linux.
|
||||
|
||||
If you decide that you like using Linux, you can install it from the flash drive by double clicking on the installer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/14/10/test-drive-linux-nothing-flash-drive
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:http://en.wikipedia.org/wiki/ISO_image
|
||||
[2]:http://unetbootin.sourceforge.net/
|
||||
[3]:http://en.wikipedia.org/wiki/BIOS
|
||||
@ -1,98 +0,0 @@
|
||||
dupeGuru – Find And Remove Duplicate Files Instantly From Hard Drive
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
|
||||
Disk full is one of the big trouble for us. No matter how we’re careful, sometimes we might copy the same file to multiple locations, or download the same file twice unknowingly. Therefore, sooner or later we will end up with disk full error message, which is worst when we really need some space to store important data. If you believe your system has multiple duplicate files, then **dupeGuru** might help you.
|
||||
|
||||
dupeGuru team have also developed applications called **dupeGuru Music Edition** to remove duplicate music files, and **dupeGuru Picture Edition** to remove duplicate pictures.
|
||||
|
||||
### 1. dupeGuru (Standard Edition) ###
|
||||
|
||||
For those who don’t know about [dupeGuru][1], It is a free, open source, cross-platform application that can used to find and remove the duplicate files in your system. It will run under Linux, Windows, and Mac OS X platforms. It uses a quick fuzzy matching algorithm to find the duplicate files in minutes. Also, you can tweak dupeGuru to find exactly what kind of duplicate files you want to, and eliminate what kind of files from deletion. It supports English, French, German, Chinese (Simplified), Czech, Italian, Armenian, Russian, Ukrainian, Brazilian, and Vietnamese.
|
||||
|
||||
#### Install dupeGuru On Ubuntu 14.10/14.04/13.10/13.04/12.04 ####
|
||||
|
||||
dupeGuru developers have created a Ubuntu PPA to ease the installation. To install dupeGuru, enter the following commands one by one in your Terminal.
|
||||
|
||||
sudo apt-add-repository ppa:hsoft/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install dupeguru-se
|
||||
|
||||
#### Usage ####
|
||||
|
||||
Usage is very simple. Launch dupeGuru either from Unity Dash or Menu.
|
||||
|
||||

|
||||
|
||||
Click + button on the bottom, and add the folder you want to scan. Click Scan button to start finding the duplicate files.
|
||||
|
||||

|
||||
|
||||
If the selected folder contains any duplicate files, it will display them. As you in the below screen shot, I have a duplicate file in the Downloads directory.
|
||||
|
||||

|
||||
|
||||
Now, you can decide what to do. You can either delete the duplicate file, or rename it, or copy/move it to another location. To do that select the duplicate files, or check the box that says “**Dupes only**” on the Menu bar. If you selected the Dupes only option, the duplicates files will only visible. So you can select and delete them easily. Click on the **Actions** drop-down box. Finally, select the action you want to perform. Here, I just want to delete the duplicate file, so I selected the option: **Send marked to Recycle bin**.
|
||||
|
||||

|
||||
|
||||
Then, click **Proceed** to delete the duplicate files.
|
||||
|
||||

|
||||
|
||||
### 2. dupeGuru Music Edition ###
|
||||
|
||||
[dupeGuru Music Edition][2] or dupeGuru ME in short, is just like dupeGuru. It does everything dupeGuru does, but it has more information columns (such as bitrate, duration, tags, etc..) and more scan types (filename with fields, tags and audio content). Like dupeGuru, dupeGuru ME also runs on Linux, Windows, and Mac OS X.
|
||||
|
||||
It supports variety of formats such as MP3, WMA, AAC (iTunes format), OGG, FLAC, loss-less AAC and loss-less WMA etc,
|
||||
|
||||
#### Install dupeGuru ME On Ubuntu 14.10/14.04/13.10/13.04/12.04 ####
|
||||
|
||||
Now, we don’t have to add any PPA, because already the added in the previous steps. So, enter the following command to install from your Terminal.
|
||||
|
||||
sudo apt-get install dupeguru-me
|
||||
|
||||
#### Usage ####
|
||||
|
||||
Launch it either from Unity dash or Menu. The usage, interface, and look of dupeGuru ME is similar to normal dupeGuru. Add the folder you to scan and select the action you want to perform. The duplicate music files will be deleted.
|
||||
|
||||

|
||||
|
||||
### 3. dupeGuru Picture Edition ###
|
||||
|
||||
[dupeGuru Picture Edition][3], or duepGuru PE in short, is a tool to find duplicate pictures on your computer. It is as like as dupeGuru, but is specialized for duplicate pictures matching. dupeGuru PE runs on Linux, Windows, and Mac OS X.
|
||||
|
||||
dupeGuru PE supports JPG, PNG, TIFF, GIF and BMP formats. All these formats can be compared together. The Mac OS X version of dupeGuru PE also supports PSD and RAW (CR2 and NEF) formats.
|
||||
|
||||
#### Install dupeGuru PE On Ubuntu 14.10/14.04/13.10/13.04/12.04 ####
|
||||
|
||||
As we have already added the PPA, We don’t need to add PPA for dupeGuru either. Just, run the following command to install it.
|
||||
|
||||
sudo apt-get install dupeguru-pe
|
||||
|
||||
#### Usage ####
|
||||
|
||||
It’s also look like dupeGuru, and dupeGuru ME in terms of usage, interface, and look.I wonder why the developer have created there separate versions for each category. It would be better, a single application has all of the above three features combined.
|
||||
|
||||
Launch it, add the folder you want to scan, and select the action you want to perform. That’s it. you duplicated files will be gone.
|
||||
|
||||

|
||||
|
||||
If you can’t remove them in case of any security problems, note down the location of the files, and manually delete them either from Terminal or File manager.
|
||||
|
||||
Cheers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/dupeguru-find-remove-duplicate-files-instantly-hard-drive/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://www.hardcoded.net/dupeguru/
|
||||
[2]:http://www.hardcoded.net/dupeguru_me/
|
||||
[3]:http://www.hardcoded.net/dupeguru_pe/
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by shipsw
|
||||
|
||||
|
||||
Auditd - Tool for Security Auditing on Linux Server
|
||||
================================================================================
|
||||
First of all , we wish all our readers **Happy & Prosperous New YEAR 2015** from our Linoxide team. So lets start this new year explaining about Auditd tool.
|
||||
@ -200,4 +203,4 @@ via: http://linoxide.com/how-tos/auditd-tool-security-auditing/
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/pungki/
|
||||
[1]:http://linoxide.com/tools/wajig-package-management-debian/
|
||||
[1]:http://linoxide.com/tools/wajig-package-management-debian/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
[bazz2222222]
|
||||
How to Configure Chroot Environment in Ubuntu 14.04
|
||||
================================================================================
|
||||
There are many instances when you may wish to isolate certain applications, user, or environments within a Linux system. Different operating systems have different methods of achieving isolation, and in Linux, a classic way is through a `chroot` environment.
|
||||
@ -143,4 +144,4 @@ via: http://linoxide.com/ubuntu-how-to/configure-chroot-environment-ubuntu-14-04
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://launchpad.net/ubuntu/+archivemirrors
|
||||
[1]:https://launchpad.net/ubuntu/+archivemirrors
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by ZTinoZ
|
||||
Linux FAQs with Answers--How to check CPU info on Linux
|
||||
================================================================================
|
||||
> **Question**: I would like to know detailed information about the CPU processor of my computer. What are the available methods to check CPU information on Linux?
|
||||
@ -112,4 +113,4 @@ via: http://ask.xmodulo.com/check-cpu-info-linux.html
|
||||
[1]:http://xmodulo.com/how-to-find-number-of-cpu-cores-on.html
|
||||
[2]:http://en.wikipedia.org/wiki/CPUID
|
||||
[3]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
[4]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
[4]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
|
||||
@ -1,113 +0,0 @@
|
||||
Ping Translating
|
||||
|
||||
Linux FAQs with Answers--How to check memory usage on Linux
|
||||
================================================================================
|
||||
> **Question**: I would like to monitor memory usage on my Linux system. What are the available GUI-based or command-line tools for checking current memory usage of Linux?
|
||||
|
||||
When it comes to optimizing the performance of a Linux system, physical memory is the single most important factor. Naturally, Linux offers a wealth of options to monitor the usage of the precious memory resource. Different tools vary in terms of their monitoring granularity (e.g., system-wide, per-process, per-user), interface (e.g., GUI, command-line, ncurses) or running mode (e.g., interactive, batch mode).
|
||||
|
||||
Here is a non-exhaustive list of GUI or command-line tools to choose from to check used and free memory on Linux platform.
|
||||
|
||||
### 1. /proc/meminfo ###
|
||||
|
||||
The simpliest method to check RAM usage is via /proc/meminfo. This dynamically updated virtual file is actually the source of information displayed by many other memory related tools such as free, top and ps tools. From the amount of available/free physical memory to the amount of buffer waiting to be or being written back to disk, /proc/meminfo has everything you want to know about system memory usage. Process-specific memory information is also available from /proc/<pid>/statm and /proc/<pid>/status
|
||||
|
||||
$ cat /proc/meminfo
|
||||
|
||||
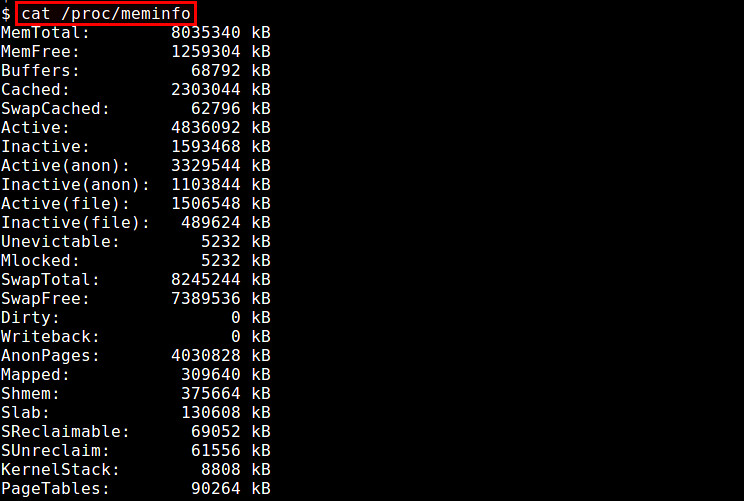
|
||||
|
||||
### 2. atop ###
|
||||
|
||||
The atop command is an ncurses-based interactive system and process monitor for terminal environments. It shows a dynamically-updated summary of system resources (CPU, memory, network, I/O, kernel), with colorized warnings in case of high system load. It also offers a top-like view of processes (or users) along with their resource usage, so that system admin can tell which processes or users are responsible for system load. Reported memory statistics include total/free memory, cached/buffer memory and committed virtual memory.
|
||||
|
||||
$ sudo atop
|
||||
|
||||
|
||||
|
||||
### 3. free ###
|
||||
|
||||
The free command is a quick and easy way to get an overview of memory usage gleaned from /proc/meminfo. It shows a snapshot of total/free physical memory and swap space of the system, as well as used/free buffer space in the kernel.
|
||||
|
||||
$ free -h
|
||||

|
||||
|
||||
### 4. GNOME System Monitor ###
|
||||
|
||||
GNOME System Monitor is a GUI application that shows a short history of system resource utilization for CPU, memory, swap space and network. It also offers a process view of CPU and memory usage.
|
||||
|
||||
$ gnome-system-monitor
|
||||
|
||||
|
||||
|
||||
### 5. htop ###
|
||||
|
||||
The htop command is an ncurses-based interactive processor viewer which shows per-process memory usage in real time. It can report resident memory size (RSS), total program size in memory, library size, shared page size, and dirty page size for all running processes. You can scroll the (sorted) list of processes horizontally or vertically.
|
||||
|
||||
$ htop
|
||||
|
||||
|
||||
|
||||
### 6. KDE System Monitor ###
|
||||
|
||||
While GNOME desktop has GNOME System Monitor, KDE desktop has its own counterpart: KDE System Monitor. Its functionality is mostly similar to GNOME version, i.e., showing a real-time history of system resource usage, as well as a process list along with per-process CPU/memory consumption.
|
||||
|
||||
$ ksysguard
|
||||
|
||||
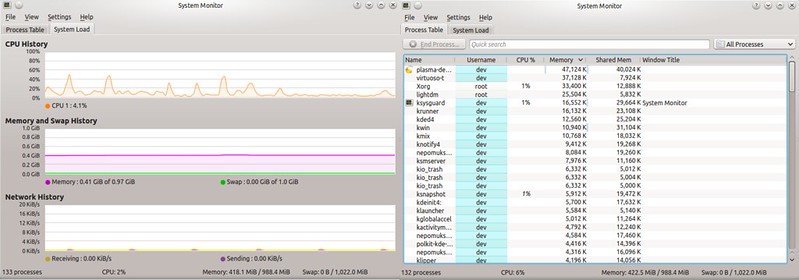
|
||||
|
||||
### 7. memstat ###
|
||||
|
||||
The memstat utility is useful to identify which executable(s), process(es) and shared libraries are consuming virtual memory. Given a process ID, memstat identifies how much virtual memory is used by the process' associated executable, data, and shared libraries.
|
||||
|
||||
$ memstat -p <PID>
|
||||
|
||||
|
||||
|
||||
### 8. nmon ###
|
||||
|
||||
The nmon utility is an ncurses-based system benchmark tool which can monitor CPU, memory, disk I/O, kernel, filesystem and network resources in interactive mode. As for memory usage, it can show information such as total/free memory, swap space, buffer/cached memory, virtual memory page in/out statistics, all in real time.
|
||||
|
||||
$ nmon
|
||||
|
||||
|
||||
|
||||
### 9. ps ###
|
||||
|
||||
The ps command can show per-process memory usage in real-time. Reported memory usage information includes %MEM (percent of physical memory used), VSZ (total amount of virtual memory used), and RSS (total amount of physical memory used). You can sort the process list by using "--sort" option. For example, to sort in the decreasing order of RSS:
|
||||
|
||||
$ ps aux --sort -rss
|
||||
|
||||
|
||||
|
||||
### 10. smem ###
|
||||
|
||||
The [smem][1] command allows you to measure physical memory usage by different processes and users based on information available from /proc. It utilizes proportional set size (PSS) metric to accurately quantify effective memory usage of Linux processes. Memory usage analysis can be exported to graphical charts such as bar and pie graphs.
|
||||
|
||||
$ sudo smem --pie name -c "pss"
|
||||
|
||||
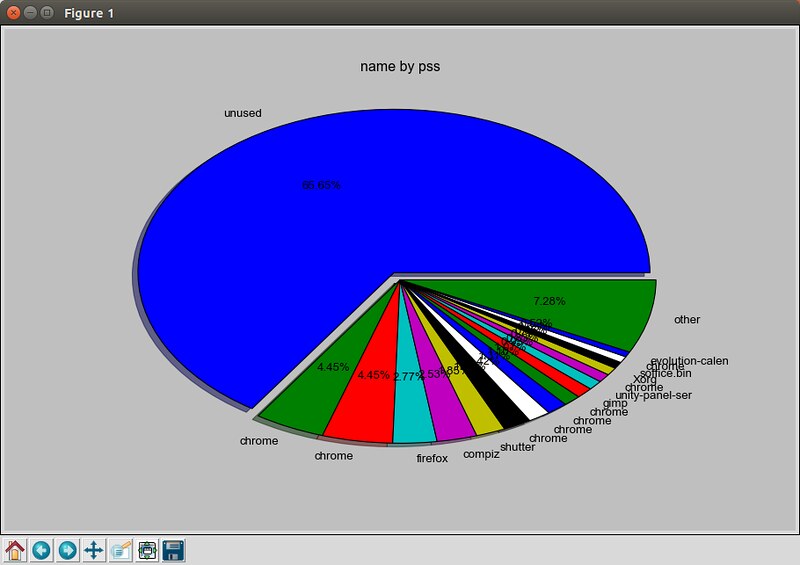
|
||||
|
||||
### 11. top ###
|
||||
|
||||
The top command offers a real-time view of running processes, along with various process-specific resource usage statistics. Memory related information includes %MEM (memory utilization percentage), VIRT (total amount of virtual memory used), SWAP (amount of swapped-out virtual memory), CODE (amount of physical memory allocated for code execution), DATA (amount of physical memory allocated to non-executable data), RES (total amount of physical memory used; CODE+DATA), and SHR (amount of memory potentially shared with other processes). You can sort the process list based on memory usage or size.
|
||||
|
||||
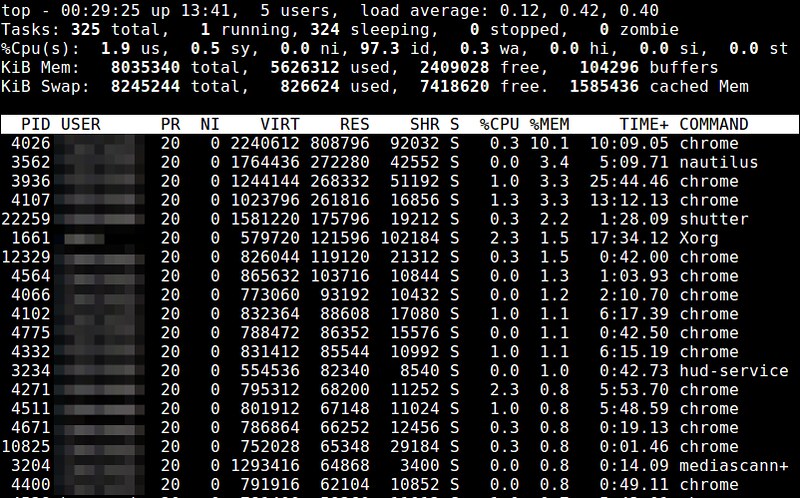
|
||||
|
||||
### 12. vmstat ###
|
||||
|
||||
The vmstat command-line utility displays instantaneous and average statistics of various system activities covering CPU, memory, interrupts, and disk I/O. As for memory information, the command shows not only physical memory usage (e.g., tota/used memory and buffer/cache memory), but also virtual memory statistics (e.g., memory paged in/out, swapped in/out).
|
||||
|
||||
$ vmstat -s
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-memory-usage-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/visualize-memory-usage-linux.html
|
||||
@ -1,78 +0,0 @@
|
||||
How to Boot Linux ISO Images Directly From Your Hard Drive
|
||||
================================================================================
|
||||
Hi all, today we'll teach you an awesome interesting stuff related with the Operating System Disk Image and Booting. Now, try many OS you like without installing them in your Physical Hard Drive and without burning DVDs or USBs.
|
||||
|
||||
We can boot Linux ISO files directly from your hard drive with Linux’s GRUB2 boot loader. We can boot any Linux Distribution's using this method without creating bootable USBs, Burn DVDs, etc but the changes made will be temporary.
|
||||
|
||||

|
||||
|
||||
### 1. Get the ISO of the Linux Distributions: ###
|
||||
|
||||
Here, we're gonna create Menu of Ubuntu 14.04 LTS "Trusty" and Linux Mint 17.1 LTS "Rebecca" so, we downloaded them from their official site:
|
||||
|
||||
Ubuntu from : [http://ubuntu.com/][1] And Linux Mint from: [http://linuxmint.com/][2]
|
||||
|
||||
You can download ISO files of required linux distributions from their respective websites. If you have mirror of the iso files hosted near your area or country, it is recommended if you have no sufficient internet download speed.
|
||||
|
||||
### 2. Determine the Hard Drive Partition’s Path ###
|
||||
|
||||
GRUB uses a different “device name” scheme than Linux does. On a Linux system, /dev/sda0 is the first partition on the first hard disk — **a** means the first hard disk and **0** means its first partition. In GRUB, (hd0,1) is equivalent to /dev/sda0. The **0** means the first hard disk, while **1** means the first partition on it. In other words, in a GRUB device name, the disk numbers start counting at 0 and the partition numbers start counting at 1. For example, (hd3,6) refers to the sixth partition on the fourth hard disk.
|
||||
|
||||
You can use the **fdisk -l** command to view this information. On Ubuntu, open a Terminal and run the following command:
|
||||
|
||||
$ sudo fdisk -l
|
||||
|
||||

|
||||
|
||||
You’ll see a list of Linux device paths, which you can convert to GRUB device names on your own. For example, below we can see the system partition is /dev/sda1 — so that’s (hd0,1) for GRUB.
|
||||
|
||||
### 3. Adding boot menu to Grub2 ###
|
||||
|
||||
The easiest way to add a custom boot entry is to edit the /etc/grub.d/40_custom script. This file is designed for user-added custom boot entries. After editing the file, the contents of your /etc/defaults/grub file and the /etc/grub.d/ scripts will be combined to create a /boot/grub/grub.cfg file. You shouldn't edit this file by hand. It’s designed to be automatically generated from settings you specify in other files.
|
||||
|
||||
So we’ll need to open the /etc/grub.d/40_custom file for editing with root privileges. On Ubuntu, you can do this by opening a Terminal window and running the following command:
|
||||
|
||||
$ sudo nano /etc/grub.d/40_custom
|
||||
|
||||
Unless we’ve added other custom boot entries, we should see a mostly empty file. We'll need to add one or more ISO-booting sections to the file below the commented lines.
|
||||
|
||||
=====
|
||||
menuentry “Ubuntu 14.04 ISO” {
|
||||
set isofile=”/home/linoxide/Downloads/ubuntu-14.04.1-desktop-amd64.iso”
|
||||
loopback loop (hd0,1)$isofile
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
initrd (loop)/casper/initrd.lz
|
||||
}
|
||||
menuentry "Linux Mint 17.1 Cinnamon ISO" {
|
||||
set isofile=”/home/linoxide/Downloads/mint-17.1-desktop-amd64.iso”
|
||||
loopback loop (hd0,1)$isofile
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
initrd (loop)/casper/initrd.lz
|
||||
}
|
||||
|
||||

|
||||
|
||||
**Important Note**: Different Linux distributions require different boot entries with different boot options. The GRUB Live ISO Multiboot project offers a variety of [menu entries for different Linux distributions][3]. You should be able to adapt these example menu entries for the ISO file you want to boot. You can also just perform a web search for the name and release number of the Linux distribution you want to boot along with “boot from ISO in GRUB” to find more information.
|
||||
|
||||
### 4. Updating Grub2 ###
|
||||
|
||||
To make the custom menu entries active, we'll run "sudo update-grub"
|
||||
|
||||
sudo update-grub
|
||||
|
||||
Hurray, we have successfully added our brand new linux distribution's ISO to our GRUB Menu. Now, we'll be able to boot them and enjoy trying them. You can add many distributions and try them all. Note that the changes made in those OS will don't be kept preserved, which means you'll loose changes made in that distros after the restart.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/boot-linux-iso-images-directly-hard-drive/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://ubuntu.com/
|
||||
[2]:http://linuxmint.com/
|
||||
[3]:http://git.marmotte.net/git/glim/tree/grub2
|
||||
@ -1,120 +0,0 @@
|
||||
4 lvcreate Command Examples on Linux
|
||||
================================================================================
|
||||
Logical volume management (LVM) is a widely-used technique and extremely flexible disk management scheme. It basically contain three basic command :
|
||||
|
||||
a. Creates the physical volumes using **pvcreate**
|
||||
b. Create the volume group and add partition into volume group using **vgcreate**
|
||||
c. Create a new logical volume using **lvcreate**
|
||||
|
||||

|
||||
|
||||
The following examples focus on the command to create a logical volume in an existing volume group, **lvcreate**. **lvcreate** is the command do allocating logical extents from the free physical extent pool of that volume group. Normally logical volumes use up any space available on the underlying physical volumes on a next-free basis. Modifying the logical volume will frees and reallocates space in the physical volumes. The following **lvcreate** command has been tested on linux CentOS 5, CentOS 6, CentOS 7, RHEL 5, RHEl 6 and RHEL 7 version.
|
||||
|
||||
### 4 lvcreate Command Examples on Linux : ###
|
||||
|
||||
1. The following command creates a logical volume 15 gigabytes in size in the volume group vg_newlvm :
|
||||
|
||||
[root@centos7 ~]# lvcreate -L 15G vg_newlvm
|
||||
|
||||
2. The following command creates a 2500 MB linear logical volume named centos7_newvol in the volume group
|
||||
vg_newlvm, creating the block device /dev/vg_newlvm/centos7_newvol :
|
||||
|
||||
[root@centos7 ~]# lvcreate -L 2500 -n centos7_newvol vg_newlvm
|
||||
|
||||
3. You can use the -l argument of the **lvcreate** command to specify the size of the logical volume in extents. You can also use this argument to specify the percentage of the volume group to use for the logical volume. The following command creates a logical volume called centos7_newvol that uses 50% of the total space in volume group vg_newlvm :
|
||||
|
||||
[root@centos7 ~]# lvcreate -l 50%VG -n centos7_newvol vg_newlvm
|
||||
|
||||
4. The following command creates a logical volume called centos7_newvol that uses all of the unallocated space in the volume group vg_newlvm :
|
||||
|
||||
[root@centos7 ~]# lvcreate --name centos7_newvol -l 100%FREE vg_newlvm
|
||||
|
||||
To see more **lvcreate** command options, issue the following command :
|
||||
|
||||
[root@centos7 ~]# lvcreate --help
|
||||
|
||||
----------
|
||||
|
||||
lvcreate: Create a logical volume
|
||||
|
||||
lvcreate
|
||||
[-A|--autobackup {y|n}]
|
||||
[-a|--activate [a|e|l]{y|n}]
|
||||
[--addtag Tag]
|
||||
[--alloc AllocationPolicy]
|
||||
[--cachemode CacheMode]
|
||||
[-C|--contiguous {y|n}]
|
||||
[-d|--debug]
|
||||
[-h|-?|--help]
|
||||
[--ignoremonitoring]
|
||||
[--monitor {y|n}]
|
||||
[-i|--stripes Stripes [-I|--stripesize StripeSize]]
|
||||
[-k|--setactivationskip {y|n}]
|
||||
[-K|--ignoreactivationskip]
|
||||
{-l|--extents LogicalExtentsNumber[%{VG|PVS|FREE}] |
|
||||
-L|--size LogicalVolumeSize[bBsSkKmMgGtTpPeE]}
|
||||
[-M|--persistent {y|n}] [--major major] [--minor minor]
|
||||
[-m|--mirrors Mirrors [--nosync] [{--mirrorlog {disk|core|mirrored}|--corelog}]]
|
||||
[-n|--name LogicalVolumeName]
|
||||
[--noudevsync]
|
||||
[-p|--permission {r|rw}]
|
||||
[--[raid]minrecoveryrate Rate]
|
||||
[--[raid]maxrecoveryrate Rate]
|
||||
[-r|--readahead ReadAheadSectors|auto|none]
|
||||
[-R|--regionsize MirrorLogRegionSize]
|
||||
[-T|--thin [-c|--chunksize ChunkSize]
|
||||
[--discards {ignore|nopassdown|passdown}]
|
||||
[--poolmetadatasize MetadataSize[bBsSkKmMgG]]]
|
||||
[--poolmetadataspare {y|n}]
|
||||
[--thinpool ThinPoolLogicalVolume{Name|Path}]
|
||||
[-t|--test]
|
||||
[--type VolumeType]
|
||||
[-v|--verbose]
|
||||
[-W|--wipesignatures {y|n}]
|
||||
[-Z|--zero {y|n}]
|
||||
[--version]
|
||||
VolumeGroupName [PhysicalVolumePath...]
|
||||
|
||||
lvcreate
|
||||
{ {-s|--snapshot} OriginalLogicalVolume[Path] |
|
||||
[-s|--snapshot] VolumeGroupName[Path] -V|--virtualsize VirtualSize}
|
||||
{-T|--thin} VolumeGroupName[Path][/PoolLogicalVolume]
|
||||
-V|--virtualsize VirtualSize}
|
||||
[-c|--chunksize]
|
||||
[-A|--autobackup {y|n}]
|
||||
[--addtag Tag]
|
||||
[--alloc AllocationPolicy]
|
||||
[-C|--contiguous {y|n}]
|
||||
[-d|--debug]
|
||||
[--discards {ignore|nopassdown|passdown}]
|
||||
[-h|-?|--help]
|
||||
[--ignoremonitoring]
|
||||
[--monitor {y|n}]
|
||||
[-i|--stripes Stripes [-I|--stripesize StripeSize]]
|
||||
[-k|--setactivationskip {y|n}]
|
||||
[-K|--ignoreactivationskip]
|
||||
{-l|--extents LogicalExtentsNumber[%{VG|FREE|ORIGIN}] |
|
||||
-L|--size LogicalVolumeSize[bBsSkKmMgGtTpPeE]}
|
||||
[--poolmetadatasize MetadataVolumeSize[bBsSkKmMgG]]
|
||||
[-M|--persistent {y|n}] [--major major] [--minor minor]
|
||||
[-n|--name LogicalVolumeName]
|
||||
[--noudevsync]
|
||||
[-p|--permission {r|rw}]
|
||||
[-r|--readahead ReadAheadSectors|auto|none]
|
||||
[-t|--test]
|
||||
[--thinpool ThinPoolLogicalVolume[Path]]
|
||||
[-v|--verbose]
|
||||
[--version]
|
||||
[PhysicalVolumePath...]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ehowstuff.com/4-lvcreate-command-examples-on-linux/
|
||||
|
||||
作者:[skytech][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ehowstuff.com/author/mhstar/
|
||||
@ -1,165 +0,0 @@
|
||||
FSSLC Translating !
|
||||
|
||||
Cleaning up Ubuntu 14.10,14.04,13.10 system
|
||||
================================================================================
|
||||
We have already discussed [Cleaning up a Ubuntu GNU/Linux system][1] and this tutorial is updated with new ubuntu versions and more tools added.
|
||||
|
||||
If you want to clean your ubuntu machine you need to follow these simple steps to remove all unnecessary junk files.
|
||||
|
||||
### Remove partial packages ###
|
||||
|
||||
This is yet another built-in feature, but this time it is not used in Synaptic Package Manager. It is used in the Terminal. Now, in the Terminal, key in the following command
|
||||
|
||||
sudo apt-get autoclean
|
||||
|
||||
Then enact the package clean command. What this commnad does is to clean remove .deb packages that apt caches when you install/update programs. To use the clean command type the following in a terminal window:
|
||||
|
||||
sudo apt-get clean
|
||||
|
||||
You can then use the autoremove command. What the autoremove command does is to remove packages installed as dependencies after the original package is removed from the system. To use autoremove tye the following in a terminal window:
|
||||
|
||||
sudo apt-get autoremove
|
||||
|
||||
### Remove unnecessary locale data ###
|
||||
|
||||
For this we need to install localepurge.Automagically remove unnecessary locale data.This is just a simple script to recover diskspace wasted for unneeded locale files and localized man pages. It will automagically be invoked upon completion of any apt installation run.
|
||||
|
||||
Install localepurge in Ubuntu
|
||||
|
||||
sudo apt-get install localepurge
|
||||
|
||||
After installing anything with apt-get install, localepurge will remove all translation files and translated man pages in languages you cannot read.
|
||||
|
||||
If you want to configure localepurge you need to edit /etc/locale.nopurge
|
||||
|
||||
This can save you several megabytes of disk space, depending on the packages you have installed.
|
||||
|
||||
Example:-
|
||||
|
||||
I am trying to install dicus using apt-get
|
||||
|
||||
sudo apt-get install discus
|
||||
|
||||
after end of this installation you can see something like below
|
||||
|
||||
localepurge: Disk space freed in /usr/share/locale: 41860K
|
||||
|
||||
### Remove "orphaned" packages ###
|
||||
|
||||
If you want to remove orphaned packages you need to install deborphan package.
|
||||
|
||||
Install deborphan in Ubuntu
|
||||
|
||||
sudo apt-get install deborphan
|
||||
|
||||
### Using deborphan ###
|
||||
|
||||
Open Your terminal and enter the following command
|
||||
|
||||
sudo deborphan | xargs sudo apt-get -y remove --purge
|
||||
|
||||
### Remove "orphaned" packages Using GtkOrphan ###
|
||||
|
||||
GtkOrphan (a Perl/Gtk2 application for debian systems) is a graphical tool which analyzes the status of your installations, looking for orphaned libraries. It implements a GUI front-end for deborphan, adding the package-removal capability.
|
||||
|
||||
### Install GtkOrphan in Ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install gtkorphan
|
||||
|
||||
#### Screenshot ####
|
||||
|
||||

|
||||
|
||||
### Remove Orphan packages using Wajig ###
|
||||
|
||||
simplified Debian package management front end.Wajig is a single commandline wrapper around apt, apt-cache, dpkg,/etc/init.d scripts and more, intended to be easy to use and providing extensive documentation for all of its functions.
|
||||
|
||||
With a suitable sudo configuration, most (if not all) package installation as well as creation tasks can be done from a user shell. Wajig is also suitable for general system administration.A Gnome GUI command ‘gjig' is also included in the package.
|
||||
|
||||
### Install Wajig in Ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install wajig
|
||||
|
||||
### Debfoster --- Keep track of what you did install ###
|
||||
|
||||
debfoster maintains a list of installed packages that were explicitly requested rather than installed as a dependency. Arguments are entirely optional, debfoster can be invoked per se after each run of dpkg and/or apt-get.
|
||||
|
||||
Alternatively you can use debfoster to install and remove packages by specifying the packages on the command line. Packages suffixed with a --- are removed while packages without a suffix are installed.
|
||||
|
||||
If a new package is encountered or if debfoster notices that a package that used to be a dependency is now an orphan, it will ask you what to do with it. If you decide to keep it, debfoster will just take note and continue. If you decide that this package is not interesting enough it will be removed as soon as debfoster is done asking questions. If your choices cause other packages to become orphaned more questions will ensue.
|
||||
|
||||
### Install debfoster in Ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install debfoster
|
||||
|
||||
### Using debfoster ###
|
||||
|
||||
to create the initial keepers file use the following command
|
||||
|
||||
sudo debfoster -q
|
||||
|
||||
you can always edit the file /var/lib/debfosterkeepers which defines the packages you want to remain on your system.
|
||||
|
||||
to edit the keepers file type
|
||||
|
||||
sudo vi /var/lib/debfoster/keepers
|
||||
|
||||
To force debfoster to remove all packages that aren't listed in this list or dependencies of packages that are listed in this list.It will also add all packages in this list that aren't installed. So it makes your system comply with this list. Do this
|
||||
|
||||
sudo debfoster -f
|
||||
|
||||
To keep track of what you installed additionally do once in a while :
|
||||
|
||||
sudo debfoster
|
||||
|
||||
### xdiskusage -- Check where the space on your hard drive goes ###
|
||||
|
||||
Displays a graphic of your disk usage with du.xdiskusage is a user-friendly program to show you what is using up all your disk space. It is based on the design of the "xdu" program written by Phillip C. Dykstra. Changes have been made so it runs "du" for you, and can display the free space left on the disk, and produce a PostScript version of the display.xdiskusage is nice if you want to easily see where the space on your hard drive goes.
|
||||
|
||||
### Install xdiskusage in Ubuntu ###
|
||||
|
||||
sudo apt-get install xdiskusage
|
||||
|
||||
If you want to open this application you need to use the following command
|
||||
|
||||
sudo xdiskusage
|
||||
|
||||

|
||||
|
||||
Once it opens you should see similar to the following screen
|
||||
|
||||
### Bleachbit ###
|
||||
|
||||
BleachBit quickly frees disk space and tirelessly guards your privacy. Free cache, delete cookies, clear Internet history, shred temporary files, delete logs, and discard junk you didn't know was there. Designed for Linux and Windows systems, it wipes clean a thousand applications including Firefox, Internet Explorer, Adobe Flash, Google Chrome, Opera, Safari,and more. Beyond simply deleting files, BleachBit includes advanced features such as shredding files to prevent recovery, wiping free disk space to hide traces of files deleted by other applications, and vacuuming Firefox to make it faster. Better than free, BleachBit is open source.
|
||||
|
||||
### Install Bleachbit in ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install bleachbit
|
||||
|
||||

|
||||
|
||||
### Using Ubuntu-Tweak ###
|
||||
|
||||
You can also Use [Ubuntu-Tweak][2] To clean up your system
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/cleaning-up-a-ubuntu-gnulinux-system-updated-with-ubuntu-14-10-and-more-tools-added.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.ubuntugeek.com/cleaning-up-all-unnecessary-junk-files-in-ubuntu.html
|
||||
[2]:http://www.ubuntugeek.com/www.ubuntugeek.com/install-ubuntu-tweak-on-ubuntu-14-10.html
|
||||
@ -1,3 +1,5 @@
|
||||
Ping -- Translating
|
||||
|
||||
iptraf: A TCP/UDP Network Monitoring Utility
|
||||
================================================================================
|
||||
[iptraf][1] is an ncurses-based IP LAN monitor that generates various network statistics including TCP info, UDP counts, ICMP and OSPF information, Ethernet load info, node stats, IP checksum errors, and others.
|
||||
@ -61,4 +63,4 @@ via: http://www.unixmen.com/iptraf-tcpudp-network-monitoring-utility/
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/seth/
|
||||
[1]:http://iptraf.seul.org/about.html
|
||||
[1]:http://iptraf.seul.org/about.html
|
||||
|
||||
@ -0,0 +1,422 @@
|
||||
25 Useful Apache ‘.htaccess’ Tricks to Secure and Customize Websites
|
||||
================================================================================
|
||||
Websites are important parts of our lives. They serve the means to expand businesses, share knowledge and lots more. Earlier restricted to providing only static contents, with introduction of dynamic client and server side scripting languages and continued advancement of existing static language like html to html5, adding every bit of dynamicity is possible to the websites and what left is expected to follow soon in near future.
|
||||
|
||||
With websites, comes the need of a unit that can display these websites to a huge set of audience all over the globe. This need is fulfilled by the servers that provide means to host a website. This includes a list of servers like: Apache HTTP Server, Joomla, and WordPress that allow one to host their websites.
|
||||
|
||||

|
||||
25 htaccess Tricks
|
||||
|
||||
One who wants to host a website can create a local server of his own or can contact any of above mentioned or any another server administrator to host his website. But the actual issue starts from this point. Performance of a website depends mainly on following factors:
|
||||
|
||||
- Bandwidth consumed by the website.
|
||||
- How secure is the website against hackers.
|
||||
- Optimism when it comes to data search through the database
|
||||
- User-friendliness when it comes to displaying navigation menus and providing more UI features.
|
||||
|
||||
Alongside this, various factors that govern success of servers in hosting websites are:
|
||||
|
||||
- Amount of data compression achieved for a particular website.
|
||||
- Ability to simultaneously serve multiple clients asking for a same or different website.
|
||||
- Securing the confidential data entered on the websites like: emails, credit card details and so on.
|
||||
- Allowing more and more options to enhance dynamicity to a website.
|
||||
|
||||
This article deals with one such feature provided by the servers that help enhance performance of websites along with securing them from bad bots, hotlinks etc. i.e. ‘.htaccess‘ file.
|
||||
|
||||
### What is .htaccess? ###
|
||||
|
||||
htaccess (or hypertext access) are the files that provide options for website owners to control the server environment variables and other parameters to enhance functionality of their websites. These files can reside in any and every directory in the directory tree of the website and provide features to the directory and the files and folders inside it.
|
||||
|
||||
What are these features? Well these are the server directives i.e. the lines that instruct server to perform a specific task, and these directives apply only to the files and folders inside the folder in which this file is placed. These files are hidden by default as all Operating System and the web servers are configured to ignore them by default but making the hidden files visible can make you see this very special file. What type of parameters can be controlled is the topic of discussion of subsequent sections.
|
||||
|
||||
Note: If .htaccess file is placed in /apache/home/www/Gunjit/ directory then it will provide directives for all the files and folders in that directory, but if this directory contains another folder namely: /Gunjit/images/ which again has another .htaccess file then the directives in this folder will override those provided by the master .htaccess file (or file in the folder up in hierarchy).
|
||||
|
||||
### Apache Server and .htaccess files ###
|
||||
|
||||
Apache HTTP Server colloquially called Apache was named after a Native American Tribe Apache to respect its superior skills in warfare strategy. Build on C/C++ and XML it is cross-platform web server which is based on NCSA HTTPd server and has a key role in growth and advancement of World Wide Web.
|
||||
|
||||
Most commonly used on UNIX, Apache is available for wide variety of platforms including FreeBSD, Linux, Windows, Mac OS, Novel Netware etc. In 2009, Apache became the first server to serve more than 100 million websites.
|
||||
|
||||
Apache server has one .htaccess file per user in www/ directory. Although these files are hidden but can be made visible if required. In www/ directory there are a number of folders each pertaining to a website named on user’s or owner’s name. Apart from this you can have one .htaccess file in each folder which configured files in that folder as stated above.
|
||||
|
||||
How to configure htaccess file on Apache server is as follows…
|
||||
|
||||
### Configuration on Apache Server ###
|
||||
|
||||
There can be two cases:
|
||||
|
||||
#### Hosting website on own server ####
|
||||
|
||||
In this case, if .htaccess files are not enabled, you can enable .htaccess files by simply going to httpd.conf (Default configuration file for Apache HTTP Daemon) and finding the <Directories> section.
|
||||
|
||||
<Directory "/var/www/htdocs">
|
||||
|
||||
And locate the line that says…
|
||||
|
||||
AllowOverride None
|
||||
|
||||
And correct it to.
|
||||
|
||||
AllowOverride All
|
||||
|
||||
Now, on restarting Apache, .htaccess will work.
|
||||
|
||||
#### Hosting website on different hosting provider server ####
|
||||
|
||||
In this case it is better to consult the hosting admin, if they allow access to .htaccess files.
|
||||
|
||||
### 25 ‘.htaccess’ Tricks of Apache Web Server for Websites ###
|
||||
|
||||
#### 1. How to enable mod_rewrite in .htaccess file ####
|
||||
|
||||
mod_rewrite option allows you to use redirections and hiding your true URL with redirecting to some other URL. This option can prove very useful allowing you to replace the lengthy and long URL’s to short and easy to remember ones.
|
||||
|
||||
To allow mod_rewrite just have a practice to add the following line as the first line of your .htaccess file.
|
||||
|
||||
Options +FollowSymLinks
|
||||
|
||||
This option allows you to follow symbolic links and thus enable the mod_rewrite option on the website. Replacing the URL with short and crispy one is presented later on.
|
||||
|
||||
#### 2. How to Allow or Deny Access to Websites ####
|
||||
|
||||
htaccess file can allow or deny access of website or a folder or files in the directory in which it is placed by using order, allow and deny keywords.
|
||||
|
||||
**Allowing access to only 192.168.3.1 IP**
|
||||
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
Allow from 192.168.3.1
|
||||
|
||||
OR
|
||||
|
||||
Order Allow, Deny
|
||||
Allow from 192.168.3.1
|
||||
|
||||
Order keyword here specifies the order in which allow, deny access would be processed. For the above ‘Order’ statement, the Allow statements would be processed first and then the deny statements would be processed.
|
||||
|
||||
**Denying access to only one IP Address**
|
||||
|
||||
The below lines provide the means to allow access of the website to all the users accept one with IP Address: 192.168.3.1.
|
||||
|
||||
rder Allow, Deny
|
||||
Deny from 192.168.3.1
|
||||
Allow from All
|
||||
|
||||
OR
|
||||
|
||||
|
||||
Order Deny, Allow
|
||||
Deny from 192.168.3.1
|
||||
|
||||
#### 3. Generate Apache Error documents for different error codes. ####
|
||||
|
||||
Using some simple lines, we can fix the error document that run on different error codes generated by the server when user/client requests a page not available on the website like most of us would have seen the ‘404 Page not found’ page in their web browser. ‘.htaccess’ files specify what action to take in case of such error conditions.
|
||||
|
||||
To do this, the following lines are needed to be added to the ‘.htaccess’ files:
|
||||
|
||||
ErrorDocument <error-code> <path-of-document/string-representing-html-file-content>
|
||||
|
||||
‘ErrorDocument’ is a keyword, error-code can be any of 401, 403, 404, 500 or any valid error representing code and lastly, ‘path-of-document’ represents the path on the local machine (in case you are using your own local server) or on the server (in case you are using any other’s server to host your website).
|
||||
|
||||
**Example:**
|
||||
|
||||
ErrorDocument 404 /error-docs/error-404.html
|
||||
|
||||
The above line sets the document ‘error-404.html’ placed in error-docs folder to be displayed in case the 404 error is reported by the server for any invalid request for a page by the client.
|
||||
|
||||
rrorDocument 404 "<html><head><title>404 Page not found</title></head><body><p>The page you request is not present. Check the URL you have typed</p></body></html>"
|
||||
|
||||
The above representation is also correct which places the string representing a usual html file.
|
||||
|
||||
#### 4. Setting/Unsetting Apache server environment variables ####
|
||||
|
||||
In .htaccess file you can set or unset the global environment variables that server allow to be modified by the hosters of the websites. For setting or unsetting the environment variables you need to add the following lines to your .htaccess files.
|
||||
|
||||
**Setting the Environment variables**
|
||||
|
||||
SetEnv OWNER “Gunjit Khera”
|
||||
|
||||
Unsetting the Environment variables
|
||||
|
||||
UnsetEnv OWNER
|
||||
|
||||
#### 5. Defining different MIME types for files ####
|
||||
|
||||
MIME (Multipurpose Internet Multimedia Extensions) are the types that are recognized by the browser by default when running any web page. You can define MIME types for your website in .htaccess files, so that different types of files as defined by you can be recognized and run by the server.
|
||||
|
||||
<IfModule mod_mime.c>
|
||||
AddType application/javascript js
|
||||
AddType application/x-font-ttf ttf ttc
|
||||
</IfModule>
|
||||
|
||||
Here, mod_mime.c is the module for controlling definitions of different MIME types and if you have this module installed on your system then you can use this module to define different MIME types for different extensions used in your website so that server can understand them.
|
||||
|
||||
#### 6. How to Limit the size of Uploads and Downloads in Apache ####
|
||||
|
||||
.htaccess files allow you the feature to control the amount of data being uploaded or downloaded by a particular client from your website. For this you just need to append the following lines to your .htaccess file:
|
||||
|
||||
php_value upload_max_filesize 20M
|
||||
php_value post_max_size 20M
|
||||
php_value max_execution_time 200
|
||||
php_value max_input_time 200
|
||||
|
||||
The above lines set maximum upload size, maximum size of data being posted, maximum execution time i.e. the maximum time the a user is allowed to execute a website on his local machine, maximum time constrain within on the input time.
|
||||
|
||||
#### 7. Making Users to download .mp3 and other files before playing on your website. ####
|
||||
|
||||
Mostly, people play songs on websites before downloading them to check the song quality etc. Being a smart seller you can add a feature that can come in very handy for you which will not let any user play songs or videos online and users have to download them for playing. This is very useful as online playing of songs and videos consumes a lot of bandwidth.
|
||||
|
||||
Following lines are needed to be added to be added to your .htaccess file:
|
||||
|
||||
AddType application/octet-stream .mp3 .zip
|
||||
|
||||
#### 8. Setting Directory Index for Website ####
|
||||
|
||||
Most of website developers would already know that the first page that is displayed i.e. the home page of a website is named as ‘index.html’ .Many of us would have seen this also. But how is this set?
|
||||
|
||||
.htaccess file provides a way to list a set of pages which would be scanned in order when a client requests to visit home page of the website and accordingly any one of the listed set of pages if found would be listed as the home page of the website and displayed to the user.
|
||||
|
||||
Following line is needed to be added to produce the desired effect.
|
||||
|
||||
DirectoryIndex index.html index.php yourpage.php
|
||||
|
||||
The above line specifies that if any request for visiting the home page comes by any visitor then the above listed pages will be searched in order in the directory firstly: index.html which if found will be displayed as the sites home page, otherwise list will proceed to the next page i.e. index.php and so on till the last page you have entered in the list.
|
||||
|
||||
#### 9. How to enable GZip compression for Files to save site’s bandwidth. ####
|
||||
|
||||
This is a common observation that heavy sites generally run bit slowly than light weight sites that take less amount of space. This is just because for a heavy site it takes time to load the huge script files and images before displaying them on the client’s web browser.
|
||||
|
||||
This is a common mechanism that when a browser requests a web page, server provides the browser with that webpage and now to locally display that web page, the browser has to download that page and then run the script inside that page.
|
||||
|
||||
What GZip compression does here is saving the time required to serve a single customer thus increasing the bandwidth. The source files of the website on the server are kept in compressed form and when the request comes from a user then these files are transferred in compressed form which are then uncompressed and executed on the server. This improves the bandwidth constrain.
|
||||
|
||||
Following lines can allow you to compress the source files of your website but this requires mod_deflate.c module to be installed on your server.
|
||||
|
||||
<IfModule mod_deflate.c>
|
||||
AddOutputFilterByType DEFLATE text/plain
|
||||
AddOutputFilterByType DEFLATE text/html
|
||||
AddOutputFilterByType DEFLATE text/xml
|
||||
AddOutputFilterByType DEFLATE application/html
|
||||
AddOutputFilterByType DEFLATE application/javascript
|
||||
AddOutputFilterByType DEFLATE application/x-javascript
|
||||
</IfModule>
|
||||
|
||||
#### 10. Playing with the File types. ####
|
||||
|
||||
There are certain conditions that the server assumes by default. Like: .php files are run on the server, similarly .txt files say for example are meant to be displayed. Like this we can make some executable cgi-scripts or files to be simply displayed as the source code on our website instead of being executed.
|
||||
|
||||
To do this observe the following lines from a .htaccess file.
|
||||
|
||||
RemoveHandler cgi-script .php .pl .py
|
||||
AddType text/plain .php .pl .py
|
||||
|
||||
These lines tell the server that .pl (perl script), .php (PHP file) and .py (Python file) are meant to just be displayed and not executed as cgi-scripts.
|
||||
|
||||
#### 11. Setting the Time Zone for Apache server ####
|
||||
|
||||
The power and importance of .htaccess files can be seen by the fact that this can be used to set the Time Zone of the server accordingly. This can be done by setting a global Environment variable ‘TZ’ of the list of global environment variables that are provided by the server to each of the hosted website for modification.
|
||||
|
||||
Due to this reason only, we can see time on the websites (that display it) according to our time zone. May be some other person hosting his website on the server would have the timezone set according to the location where he lives.
|
||||
|
||||
Following lines set the Time Zone of the Server.
|
||||
|
||||
SetEnv TZ India/Kolkata
|
||||
|
||||
#### 12. How to enable Cache Control on Website ####
|
||||
|
||||
A very interesting feature of browser, most have observed is that on opening one website simultaneously more than one time, the latter one opens fast as compared to the first time. But how is this possible? Well in this case, the browser stores some frequently visited pages in its cache for faster access later on.
|
||||
|
||||
But for how long? Well this answer depends on you i.e. on the time you set in your .htaccess file for Cache control. The .htaccess file can specify the amount of time for which the pages of website can stay in the browser’s cache and after expiration of time, it must revalidate i.e. pages would be deleted from the Cache and recreated the next time user visits the site.
|
||||
|
||||
Following lines implement Cache Control for your website.
|
||||
|
||||
<FilesMatch "\.(ico|png|jpeg|svg|ttf)$">
|
||||
Header Set Cache-Control "max-age=3600, public"
|
||||
</FilesMatch>
|
||||
<FilesMatch "\.(js|css)$">
|
||||
Header Set Cache-Control "public"
|
||||
Header Set Expires "Sat, 24 Jan 2015 16:00:00 GMT"
|
||||
</FilesMatch>
|
||||
|
||||
The above lines allow caching of the pages which are inside the directory in which .htaccess files are placed for 1 hour.
|
||||
|
||||
#### 13. Configuring a single file, the <files> option. ####
|
||||
|
||||
Usually the content in .htaccess files apply to all the files and folders inside the directory in which the file is placed, but you can also provide some special permissions to a special file, like denying access to that file only or so on.
|
||||
|
||||
For this you need to add <File> tag to your file in a way like this:
|
||||
|
||||
<files conf.html="">
|
||||
Order allow, deny
|
||||
Deny from 188.100.100.0
|
||||
</files>
|
||||
|
||||
This is a simple case of denying a file ‘conf.html’ from access by IP 188.100.100.0, but you can add any or every feature described for .htaccess file till now including the features yet to be described to the file like: Cache-control, GZip compression.
|
||||
|
||||
This feature is used by most of the servers to secure .htaccess files which is the reason why we are not able to see the .htaccess files on the browsers. How the files are authenticated is demonstrated in subsequent heading.
|
||||
|
||||
#### 14. Enabling CGI scripts to run outside of cgi-bin folder. ####
|
||||
|
||||
Usually servers run CGI scripts that are located inside the cgi-bin folder but, you can enable running of CGI scripts located in your desired folder but just adding following lines to .htaccess file located in the desired folder and if not, then creating one, appending following lines:
|
||||
|
||||
AddHandler cgi-script .cgi
|
||||
Options +ExecCGI
|
||||
|
||||
#### 15. How to enable SSI on Website with .htaccess ####
|
||||
|
||||
Server side includes as the name suggests would be related to something included at the server side. But what? Generally when we have many pages in our website and we have a navigation menu on our home page that displays links to other pages then, we can enable SSI (Server Size Includes) option that allows all the pages displayed in the navigation menu to be included with the home page completely.
|
||||
|
||||
The SSI allows inclusion of multiple pages as if content they contain is a part of a single page so that any editing needed to be done is done in one file only which saves a lot of disk space. This option is by default enabled on servers but for .shtml files.
|
||||
|
||||
In case you want to enable it for .html files you need to add following lines:
|
||||
|
||||
AddHandler server-parsed .html
|
||||
|
||||
After this following in the html file would lead to SSI.
|
||||
|
||||
<!--#inlcude virtual= “gk/document.html”-->
|
||||
|
||||
#### 16. How to Prevent website Directory Listing ####
|
||||
|
||||
To prevent any client being able to list the directories of the website on the server at his local machine add following lines to the file inside the directory you don’t want to get listed.
|
||||
|
||||
Options -Indexes
|
||||
|
||||
#### 17. Changing Default charset and language headers. ####
|
||||
|
||||
.htaccess files allow you to modify the character set used i.e. ASCII or UNICODE, UTF-8 etc. for your website along with the default language used for the display of content.
|
||||
|
||||
Following server’s global environment variables allow you to achieve above feature.
|
||||
|
||||
AddDefaultCharset UTF-8
|
||||
DefaultLanguage en-US
|
||||
|
||||
**Re-writing URL’s: Redirection Rules**
|
||||
|
||||
Re-writing feature simply means replacing the long and un-rememberable URL’s with short and easy to remember ones. But, before going into this topic there are some rules and some conventions for special symbols used later on in this article.
|
||||
|
||||
**Special Symbols:**
|
||||
|
||||
Symbol Meaning
|
||||
^ - Start of the string
|
||||
$ - End of the String
|
||||
| - Or [a|b] – a or b
|
||||
[a-z] - Any of the letter between a to z
|
||||
+ - One or more occurrence of previous letter
|
||||
* - Zero or more occurrence of previous letter
|
||||
? - Zero or one occurrence of previous letter
|
||||
|
||||
**Constants and their meaning:**
|
||||
|
||||
Constant Meaning
|
||||
NC - No-case or case sensitive
|
||||
L - Last rule – stop processing further rules
|
||||
R - Temporary redirect to new URL
|
||||
R=301 - Permanent redirect to new URL
|
||||
F - Forbidden, send 403 header to the user
|
||||
P - Proxy – grab remote content in substitution section and return it
|
||||
G - Gone, no longer exists
|
||||
S=x - Skip next x rules
|
||||
T=mime-type - Force specified MIME type
|
||||
E=var:value - Set environment variable var to value
|
||||
H=handler - Set handler
|
||||
PT - Pass through – in case of URL’s with additional headers.
|
||||
QSA - Append query string from requested to substituted URL
|
||||
|
||||
#### 18. Redirecting a non-www URL to a www URL. ####
|
||||
|
||||
Before starting with the explanation, lets first see the lines that are needed to be added to .htaccess file to enable this feature.
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_HOST} ^abc\.net$
|
||||
RewriteRule (.*) http://www.abc.net/$1 [R=301,L]
|
||||
|
||||
The above lines enable the Rewrite Engine and then in second line check all those URL’s that pertain to host abc.net or have the HTTP_HOST environment variable set to “abc.net”.
|
||||
|
||||
For all such URL’s the code permanently redirects them (as R=301 rule is enabled) to the new URL http://www.abc.net/$1 where $1 is the non-www URL having host as abc.net. The non-www URL is the one in bracket and is referred by $1.
|
||||
|
||||
#### 19. Redirecting entire website to https. ####
|
||||
|
||||
Following lines will help you transfer entire website to https:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTPS} !on
|
||||
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
|
||||
|
||||
The above lines enable the re-write engine and then check the value of HTTPS environment variable. If it is on then re-write the entire pages of the website to https.
|
||||
|
||||
#### 20. A custom redirection example ####
|
||||
|
||||
For example, redirect url ‘http://www.abc.net?p=100&q=20 ‘ to ‘http://www.abc.net/10020pq’.
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteRule ^http://www.abc.net/([0-9]+)([0-9]+)pq$ ^http://www.abc.net?p=$1&q=$2
|
||||
|
||||
In above lines, $1 represents the first bracket and $2 represents the second bracket.
|
||||
|
||||
#### 21. Renaming the htaccess file ####
|
||||
|
||||
For preventing the .htaccess file from the intruders and other people from viewing those files you can rename that file so that it is not accessed by client’s browser. The line that does this is:
|
||||
|
||||
AccessFileName htac.cess
|
||||
|
||||
#### 22. How to Prevent Image Hotlinking for your Website ####
|
||||
|
||||
Another problem that is major factor of large bandwidth consumption by the websites is the problem of hot links which are links to your websites by other websites for display of images mostly of your website which consumes your bandwidth. This problem is also called as ‘bandwidth theft’.
|
||||
|
||||
A common observation is when a site displays the image contained in some other site due to this hot-linking your site needs to be loaded and at the stake of your site’s bandwidth, the other site’s images are displayed. To prevent this for like: images such as: .gif, .jpeg etc. following lines of code would help:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_REFERER} !^$
|
||||
RewriteCond %{HTTP_REFERERER} !^http://(www\.)?mydomain.com/.*$ [NC]
|
||||
RewriteRule \.(gif|jpeg|png)$ - [F].
|
||||
|
||||
The above lines check if the HTTP_REFERER is not set to blank or not set to any of the links in your websites. If this is happening then all the images in your page are replaced by 403 forbidden.
|
||||
|
||||
#### 23. How to Redirect Users to Maintenance Page. ####
|
||||
|
||||
In case your website is down for maintenance and you want to notify all your clients that need to access your websites about this then for such cases you can add following lines to your .htaccess websites that allow only admin access and replace the site pages having links to any .jpg, .css, .gif, .js etc.
|
||||
|
||||
RewriteCond %{REQUEST_URI} !^/admin/ [NC]
|
||||
RewriteCond %{REQUEST_URI} !^((.*).css|(.*).js|(.*).png|(.*).jpg) [NC]
|
||||
RewriteRule ^(.*)$ /ErrorDocs/Maintainence_Page.html
|
||||
[NC,L,U,QSA]
|
||||
|
||||
These lines check if the Requested URL contains any request for any admin page i.e. one starting with ‘/admin/’ or any request to ‘.png, .jpg, .js, .css’ pages and for any such requests it replaces that page to ‘ErrorDocs/Maintainence_Page.html’.
|
||||
|
||||
#### 24. Mapping IP Address to Domain Name ####
|
||||
|
||||
Name servers are the servers that convert a specific IP Address to a domain name. This mapping can also be specified in the .htaccess files in the following manner.
|
||||
|
||||
For Mapping L.M.N.O address to a domain name www.hellovisit.com
|
||||
RewriteCond %{HTTP_HOST} ^L\.M\.N\.O$ [NC]
|
||||
RewriteRule ^(.*)$ http://www.hellovisit.com/$1 [L,R=301]
|
||||
|
||||
The above lines check if the host for any page is having the IP Address as: L.M.N.O and if so the page is mapped to the domain name http://www.hellovisit.com by the third line by permanent redirection.
|
||||
|
||||
#### 25. FilesMatch Tag ####
|
||||
|
||||
Like <files> tag that is used to apply conditions to a single file, <FilesMatch> can be used to match to a group of files and apply some conditions to the group of files as below:
|
||||
|
||||
<FilesMatch “\.(png|jpg)$”>
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
</FilesMatch>
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The list of tricks that can be done with .htaccess files is much more. Thus, this gives us an idea how powerful this file is and how much security and dynamicity and other features it can give to your website.
|
||||
|
||||
We’ve tried our best to cover as much as htaccess tricks in this article, but incase if we’ve missed any important trick, or you most welcome to post your htaccess ideas and tricks that you know via comments section below – we will include those in our article too…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/apache-htaccess-tricks/
|
||||
|
||||
作者:[Gunjit Khera][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gunjitk94/
|
||||
@ -0,0 +1,92 @@
|
||||
[Translating] by FSSlc
|
||||
|
||||
How to limit network bandwidth on Linux
|
||||
================================================================================
|
||||
If you often run multiple networking applications on your Linux desktop, or share bandwidth among multiple computers at home, you will want to have a better control over bandwidth usage. Otherwise, when you are downloading a big file with a downloader, your interactive SSH session may become sluggish to the point where it's unusable. Or when you sync a big folder over Dropbox, your roommate may complain that video streaming at her computer gets choppy.
|
||||
|
||||
In this tutorial, I am going to describe two different ways to rate limit network traffic on Linux.
|
||||
|
||||
### Rate Limit an Application on Linux ###
|
||||
|
||||
One way to rate limit network traffic is via a command-line tool called [trickle][1]. The trickle command allows you to shape the traffic of any particular program by "pre-loading" a rate-limited socket library at run-time. A nice thing about trickle is that it runs purely in user-space, meaning you don't need root privilege to restrict the bandwidth usage of a program. To be compatible with trickle, the program must use socket interface with no statically linked library. trickle can be handy when you want to rate limit a program which does not have a built-in bandwidth control functionality.
|
||||
|
||||
To install trickle on Ubuntu, Debian and their derivatives:
|
||||
|
||||
$ sudo apt-get install trickle
|
||||
|
||||
To install trickle on Fedora or CentOS/RHEL (with [EPEL repository][2]):
|
||||
|
||||
$ sudo yum install trickle
|
||||
|
||||
Basic usage of trickle is as follows. Simply put, you prepend trickle (with rate) in front of the command you are trying to run.
|
||||
|
||||
$ trickle -d <download-rate> -u <upload-rate> <command>
|
||||
|
||||
This will limit the download and upload rate of <command> to specified values (in KBytes/s).
|
||||
|
||||
For example, set the maximum upload bandwidth of your scp session to 100 KB/s:
|
||||
|
||||
$ trickle -u 100 scp backup.tgz alice@remote_host.com:
|
||||
|
||||
If you want, you can set the maximum download speed (e.g., 300 KB/s) of your Firefox browser by creating a [custom launcher][3] with the following command.
|
||||
|
||||
trickle -d 300 firefox %u
|
||||
|
||||
Finally, trickle can run in a daemon mode, where it can restrict the "aggregate" bandwidth usage of all running programs launched via trickle. To launch trickle as a daemon (i.e., trickled):
|
||||
|
||||
$ sudo trickled -d 1000
|
||||
|
||||
Once the trickled daemon is running in the background, you can launch other programs via trickle. If you launch one program with trickle, its maximum download rate is 1000 KB/s. If you launch another program with trickle, each of them will be rate limited to 500 KB/s, etc.
|
||||
|
||||
### Rate Limit a Network Interface on Linux ###
|
||||
|
||||
Another way to control your bandwidth resource is to enforce bandwidth limit on a per-interface basis. This is useful when you are sharing your upstream Internet connection with someone else. Like anything else, Linux has a tool for you. [wondershaper][4] exactly does that: rate-limit a network interface.
|
||||
|
||||
wondershaper is in fact a shell script which uses [tc][5] to define traffic shaping and QoS for a specific network interface. Outgoing traffic is shaped by being placed in queues with different priorities, while incoming traffic is rate-limited by packet dropping.
|
||||
|
||||
In fact, the stated goal of wondershaper is much more than just adding bandwidth cap to an interface. wondershaper tries to maintain low latency for interactive sessions such as SSH while bulk download or upload is going on. Also, it makes sure that bulk upload (e.g., Dropbox sync) does not suffocate download, and vice versa.
|
||||
|
||||
To install wondershaper on Ubuntu, Debian and their derivatives:
|
||||
|
||||
$ sudo apt-get install wondershaper
|
||||
|
||||
To install wondershaper on Fedora or CentOS/RHEL (with [EPEL repository][6]):
|
||||
|
||||
$ sudo yum install wondershaper
|
||||
|
||||
Basic usage of wondershaper is as follows.
|
||||
|
||||
$ sudo wondershaper <interface> <download-rate> <upload-rate>
|
||||
|
||||
For example, to set the maximum download/upload bandwidth for eth0 to 1000Kbit/s and 500Kbit/s, respectively:
|
||||
|
||||
$ sudo wondershaper eth0 1000 500
|
||||
|
||||
You can remove the rate limit by running:
|
||||
|
||||
$ sudo wondershaper clear eth0
|
||||
|
||||
If you are interested in how wondershaper works, you can read its shell script (/sbin/wondershaper).
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I introduced two different ways to control your bandwidth usages on Linux desktop, on per-application or per-interface basis. Both tools are extremely user-friendly, offering you a quick and easy way to shape otherwise unconstrained traffic. For those of you who want to know more about rate control on Linux, refer to [the Linux bible][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/limit-network-bandwidth-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://monkey.org/~marius/trickle
|
||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[3]:http://xmodulo.com/create-desktop-shortcut-launcher-linux.html
|
||||
[4]:http://lartc.org/wondershaper/
|
||||
[5]:http://lartc.org/manpages/tc.txt
|
||||
[6]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[7]:http://www.lartc.org/lartc.html
|
||||
82
sources/tech/20150128 Docker-1 Moving to Docker.md
Normal file
82
sources/tech/20150128 Docker-1 Moving to Docker.md
Normal file
@ -0,0 +1,82 @@
|
||||
Translating by mtunique
|
||||
Moving to Docker
|
||||
================================================================================
|
||||

|
||||
|
||||
[TL;DR] This is the first post in a series of 3 on how my company moved its infrastructure from PaaS to Docker based deployment. If you want, you can skip the intro (this post) and head directly to the technical topics (links at the bottom of the page).
|
||||
|
||||
----------
|
||||
|
||||
In the last month I've been strggling with devops. This is my very personal story and experience in trying to streamline a deployment process of a Raila app with Docker.
|
||||
|
||||
When I started my company – [Touchware][1] – in 2012 I was a lone developer. Things were small, uncomplicated, they didn't require a lot of maintenance, nor they needed to scale all that much. During the course of last year though, we grew quite a lot (we are now a team of 10 people) and our server-side applications and API grew both in terms of scope and scale.
|
||||
|
||||
### Step 1 - Heroku ###
|
||||
|
||||
We still are a very small team and we need to make things going and run as smoothly as possible. When we looked for possible solutions, we decided to stick with something that would have removed from our shoulders the burden of managing hardware. Since we develop mainly Rails based applications and Heroku has a great support for RoR and various kind of DBs and cached (Postgres / Mongo / Redis etc.), the smartest choice seemed to be going with [Heroku][2]. And that's what we did.
|
||||
|
||||
Heroku has a great support and great documentation and deploying apps is just so snappy! Only problem is, when you start growing, you need to have piles of cash around to pay the bills. Not the best deal, really.
|
||||
|
||||
### Step 2 - Dokku ###
|
||||
|
||||
In a rush to try and cut the costs, we decided to try with Dokku. [Dokku][3], quoting the Github repo is a
|
||||
|
||||
> Docker powered mini-Heroku in around 100 lines of Bash
|
||||
|
||||
We launched some instances on [DigitalOcean][4] with Dokku pre-installed and we gave it spin. Dokku is very much like Heroku, but when you have complex applications for whom you need to twear params, or where you need certain dependencies, it's just not gonna work out. We had an app where we needed to apply multiple transformations on images and we couldn't find a way to install the correct version of imagemagick into the dokku-based Docker container that was hosting our Rails app. We still have a couple of very simple apps that are running on Dokku, but we had to move some of them back to Heroku.
|
||||
|
||||
### Step 3 - Docker ###
|
||||
|
||||
A couple of months ago, since the problem of devops and managing production apps was resurfacing, I decided to try out [Docker][5]. Docker, in simple terms, allows developers to containerize applications and to ease the deployment. Since a Docker container basically has all the dependencies it needs to run your app, if everything runs fine on your laptop, you can be sure it'll also run like a champ in production on a remote server, be it an AWS E2C instance or a VPS on DigitalOcean.
|
||||
|
||||
Docker IMHO is particularly interesting for the following reasons:
|
||||
|
||||
- it promotes modularization and separation of concerns: you need to start thinking about your apps in terms of logical components (load balancer: 1 container, DB: 1 container, webapp: 1 container etc.);
|
||||
- it's very flexible in terms of deployment options: containers can be deployed to a wide variety of HW and can be easily redeployed to different servers / providers;
|
||||
- it allows for a very fine grained tuning of your app environment: you build the images your containers runs from, so you have plenty of options for configuring your environment exactly as you would like to.
|
||||
|
||||
There are howerver some downsides:
|
||||
|
||||
- the learning curve is quite steep (this is probably a very personal problem, but I'm talking as a software dev and not as a skilled operations professional);
|
||||
- setup is not simple, especially if you want to have a private registry / repository (more about this later).
|
||||
|
||||
Following are some tips I put together during the course of the last week with the findings of someone that is new to the game.
|
||||
|
||||
----------
|
||||
|
||||
In the following articles we'll see how to setup a semi-automated Docker based deployment system.
|
||||
|
||||
- [Setting up a private Docker registry][6]
|
||||
- [Configuring a Rails app for semi-automated deployment][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://cocoahunter.com/2015/01/23/docker-1/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://cocoahunter.com/author/michelangelo/
|
||||
[1]:http://www.touchwa.re/
|
||||
[2]:http://cocoahunter.com/2015/01/23/docker-1/www.heroku.com
|
||||
[3]:https://github.com/progrium/dokku
|
||||
[4]:http://cocoahunter.com/2015/01/23/docker-1/www.digitalocean.com
|
||||
[5]:http://www.docker.com/
|
||||
[6]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
[7]:http://cocoahunter.com/2015/01/23/docker-3/
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -0,0 +1,241 @@
|
||||
Setting up a private Docker registry
|
||||
================================================================================
|
||||

|
||||
|
||||
[TL;DR] This is the second post in a series of 3 on how my company moved its infrastructure from PaaS to Docker based deployment.
|
||||
|
||||
- [First part][1]: where I talk about the process we went thru before approaching Docker;
|
||||
- [Third pard][2]: where I show how to automate the entire process of building images and deploying a Rails app with Docker.
|
||||
|
||||
----------
|
||||
|
||||
Why would ouy want ot set up a provate registry? Well, for starters, Docker Hub only allows you to have one free private repo. Other companies are beginning to offer similar services, but they are all not very cheap. In addition, if you need to deploy production ready applications built with Docker, you might not want to publish those images on the public Docker Hub.
|
||||
|
||||
This is a very pragmatic approach to dealing with the intricacies of setting up a private Docker registry. For the tutorial we will be using a small 512MB instance on DigitalOcean (from now on DO). I also assume you already know the basics of Docker since I will be concentrating on some more complicated stuff.
|
||||
|
||||
### Local set up ###
|
||||
|
||||
First of all you need to install **boot2docker** and docker CLI. If you already have your basic Docker environment up and running, you can just skip to the next section.
|
||||
|
||||
From the terminal run the following command[1][3]:
|
||||
|
||||
brew install boot2docker docker
|
||||
|
||||
If everything is ok[2][4], you will now be able to start the VM inside which Docker will run with the following command:
|
||||
|
||||
boot2docker up
|
||||
|
||||
Follow the instructions, copy and paste the export commands that boot2docker will print in the terminal. If you now run `docker ps` you should be greeted by the following line
|
||||
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
|
||||
Ok, Docker is ready to go. This will be enough for the moment. Let's go back to setting up the registry.
|
||||
|
||||
### Creating the server ###
|
||||
|
||||
Log into you DO account and create a new Droplet by selecting an image with Docker pre-installed[^n].
|
||||
|
||||

|
||||
|
||||
You should receive your root credentials via email. Log into your instance and run `docker ps` to see if eveything is ok.
|
||||
|
||||
### Setting up AWS S3 ###
|
||||
|
||||
We are going to use Amazon Simple Storage Service (S3) as the storage layer for our registry / repository. We will need to create a bucket and user credentials to allow our docker container accessoing it.
|
||||
|
||||
Login into your AWS account (if you don't have one you can set one up at [http://aws.amazon.com/][5]) and from the console select S3 (Simple Storage Service).
|
||||
|
||||

|
||||
|
||||
Click on **Create Bucket**, enter a unique name for your bucket (and write it down, we're gonna need it later), then click on **Create**.
|
||||
|
||||

|
||||
|
||||
That's it! We're done setting up the storage part.
|
||||
|
||||
### Setup AWS access credentials ###
|
||||
|
||||
We are now going to create a new user. Go back to your AWS console and select IAM (Identity & Access Management).
|
||||
|
||||

|
||||
|
||||
In the dashboard, on the left side of the webpage, you should click on Users. Then select **Create New Users**.
|
||||
|
||||
You should be presented with the following screen:
|
||||
|
||||

|
||||
|
||||
Enter a name for your user (e.g. docker-registry) and click on Create. Write down (or download the csv file with) your Access Key and Secret Access Key that we'll need when running the Docker container. Go back to your users list and select the one you just created.
|
||||
|
||||
Under the Permission section, click on Attach User Policy. In the next screen, you will be presented with multiple choices: select Custom Policy.
|
||||
|
||||

|
||||
|
||||
Here's the content of the custom policy:
|
||||
|
||||
{
|
||||
"Version": "2012-10-17",
|
||||
"Statement": [
|
||||
{
|
||||
"Sid": "SomeStatement",
|
||||
"Effect": "Allow",
|
||||
"Action": [
|
||||
"s3:*"
|
||||
],
|
||||
"Resource": [
|
||||
"arn:aws:s3:::docker-registry-bucket-name/*",
|
||||
"arn:aws:s3:::docker-registry-bucket-name"
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
This will allow the user (i.e. the registry) to manage (read/write) content on the bucket (make sure to use the bucket name you previously defined when setting up AWS S3). To sum it up: when you'll be pushing Docker images from your local machine to your repository, the server will be able to upload them to S3.
|
||||
|
||||
### Installing the registry ###
|
||||
|
||||
Now let's head back to our DO server and SSH into it. We are going to use[^n] one of the [official Docker registry images][6].
|
||||
|
||||
Let's start our registry with the following command:
|
||||
|
||||
docker run \
|
||||
-e SETTINGS_FLAVOR=s3 \
|
||||
-e AWS_BUCKET=bucket-name \
|
||||
-e STORAGE_PATH=/registry \
|
||||
-e AWS_KEY=your_aws_key \
|
||||
-e AWS_SECRET=your_aws_secret \
|
||||
-e SEARCH_BACKEND=sqlalchemy \
|
||||
-p 5000:5000 \
|
||||
--name registry \
|
||||
-d \
|
||||
registry
|
||||
|
||||
Docker should pull the required fs layers from the Docker Hub and eventually start the daemonised container.
|
||||
|
||||
### Testing the registry ###
|
||||
|
||||
If everything worked out, you should now be able to test the registry by pinging it and by searching its content (though for the time being it's still empty).
|
||||
|
||||
Our registry is very basic and it does not provide any means of authentication. Since there are no easy ways of adding authentication (at least none that I'm aware of that are easy enough to implment in order to justify the effort), I've decided that the easiest way of querying / pulling / pushing the registry is an unsecure (over HTTP) connection tunneled thru SSH.
|
||||
|
||||
Opening an SSH tunnel from your local machine is straightforward:
|
||||
|
||||
ssh -N -L 5000:localhost:5000 root@your_registry.com
|
||||
|
||||
The command is tunnelling connections over SSH from port 5000 of the registry server (which is the one we exposed with the `docker run` command in the previous paragraph) to port 5000 on the localhost.
|
||||
|
||||
If you now browse to the following address [http://localhost:5000/v1/_ping][7] you should get the following very simple response
|
||||
|
||||
{}
|
||||
|
||||
This just means that the registry is working correctly. You can also list the whole content of the registry by browsing to [http://localhost:5000/v1/search][8] that will get you a similar response:
|
||||
|
||||
{
|
||||
"num_results": 2,
|
||||
"query": "",
|
||||
"results": [
|
||||
{
|
||||
"description": "",
|
||||
"name": "username/first-repo"
|
||||
},
|
||||
{
|
||||
"description": "",
|
||||
"name": "username/second-repo"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
### Building an image ###
|
||||
|
||||
Let's now try and build a very simple Docker image to test our newly installed registry. On your local machine, create a Dockerfile with the following content[^n]:
|
||||
|
||||
# Base image with ruby 2.2.0
|
||||
FROM ruby:2.2.0
|
||||
|
||||
MAINTAINER Michelangelo Chasseur <michelangelo.chasseur@touchwa.re>
|
||||
|
||||
...and build it:
|
||||
|
||||
docker build -t localhost:5000/username/repo-name .
|
||||
|
||||
The `localhost:5000` part is especially important: the first part of the name of a Docker image will tell the `docker push` command the endpoint towards which we are trying to push our image. In our case, since we are connecting to our remote private registry via an SSH tunnel, `localhost:5000` represents exactly the reference to our registry.
|
||||
|
||||
If everything works as expected, when the command returns, you should be able to list your newly created image with the `docker images` command. Run it and see it for yourself.
|
||||
|
||||
### Pushing to the registry ###
|
||||
|
||||
Now comes the trickier part. It took a me a while to realize what I'm about to describe, so just be patient if you don't get it the first time you read and try to follow along. I know that all this stuff will seem pretty complicated (and it would be if you didn't automate the process), but I promise in the end it will all make sense. In the next post I will show a couple of shell scripts and Rake tasks that will automate the whole process and will let you deploy a Rails to your registry app with a single easy command.
|
||||
|
||||
The docker command you are running from your terminal is actually using the boot2docker VM to run the containers and do all the magic stuff. So when we run a command like `docker push some_repo` what is actually happening is that it's the boot2docker VM that is reacing out for the registry, not our localhost.
|
||||
|
||||
This is an extremely important point to understand: in order to push the Docker image to the remote private registry, the SSH tunnel needs to be established from the boot2docker VM and not from your local machine.
|
||||
|
||||
There are a couple of ways to go with it. I will show you the shortest one (which is not probably the easiest to understand, but it's the one that will let us automate the process with shell scripts).
|
||||
|
||||
First of all though we need to sort one last thing with SSH.
|
||||
|
||||
### Setting up SSH ###
|
||||
|
||||
Let's add our boot2docker SSH key to our remote server (registry) known hosts. We can do so using the ssh-copy-id utility that you can install with the following command shouldn't you already have it:
|
||||
|
||||
brew install ssh-copy-id
|
||||
|
||||
Then run:
|
||||
|
||||
ssh-copy-id -i /Users/username/.ssh/id_boot2docker root@your-registry.com
|
||||
|
||||
Make sure to substitute `/Users/username/.ssh/id_boot2docker` with the correct path of your ssh key.
|
||||
|
||||
This will allow us to connect via SSH to our remote registry without being prompted for the password.
|
||||
|
||||
Finally let's test it out:
|
||||
|
||||
boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/michelangelo/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@registry.touchwa.re &" &
|
||||
|
||||
To break things out a little bit:
|
||||
|
||||
- `boot2docker ssh` lets you pass a command as a parameter that will be executed by the boot2docker VM;
|
||||
- the final `&` indicates that we want our command to be executed in the background;
|
||||
- `ssh -o 'StrictHostKeyChecking no' -i /Users/michelangelo/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@registry.touchwa.re &` is the actual command our boot2docker VM will run;
|
||||
- the `-o 'StrictHostKeyChecking no'` will make sure that we are not prompted with security questions;
|
||||
- the `-i /Users/michelangelo/.ssh/id_boot2docker` indicates which SSH key we want our VM to use for authentication purposes (note that this should be the key you added to your remote registry in the previous step);
|
||||
- finally we are opening a tunnel on mapping port 5000 to localhost:5000.
|
||||
|
||||
### Pulling from another server ###
|
||||
|
||||
You should now be able to push your image to the remote registry by simply issuing the following command:
|
||||
|
||||
docker push localhost:5000/username/repo_name
|
||||
|
||||
In the [next post][9] we'll se how to automate some of this stuff and we'll containerize a real Rails application. Stay tuned!
|
||||
|
||||
P.S. Please use the comments to let me know of any inconsistencies or fallacies in my tutorial. Hope you enjoyed it!
|
||||
|
||||
1. I'm also assuming you are running on OS X.
|
||||
1. For a complete list of instructions to set up your docker environment and requirements, please visit [http://boot2docker.io/][10]
|
||||
1. Select Image > Applications > Docker 1.4.1 on 14.04 at the time of this writing.
|
||||
1. [https://github.com/docker/docker-registry/][11]
|
||||
1. This is just a stub, in the next post I will show you how to bundle a Rails application into a Docker container.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://cocoahunter.com/2015/01/23/docker-2/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://cocoahunter.com/author/michelangelo/
|
||||
[1]:http://cocoahunter.com/2015/01/23/docker-1/
|
||||
[2]:http://cocoahunter.com/2015/01/23/docker-3/
|
||||
[3]:http://cocoahunter.com/2015/01/23/docker-2/#fn:1
|
||||
[4]:http://cocoahunter.com/2015/01/23/docker-2/#fn:2
|
||||
[5]:http://aws.amazon.com/
|
||||
[6]:https://registry.hub.docker.com/_/registry/
|
||||
[7]:http://localhost:5000/v1/_ping
|
||||
[8]:http://localhost:5000/v1/search
|
||||
[9]:http://cocoahunter.com/2015/01/23/docker-3/
|
||||
[10]:http://boot2docker.io/
|
||||
[11]:https://github.com/docker/docker-registry/
|
||||
@ -0,0 +1,253 @@
|
||||
Automated Docker-based Rails deployments
|
||||
================================================================================
|
||||

|
||||
|
||||
[TL;DR] This is the third post in a series of 3 on how my company moved its infrastructure from PaaS to Docker based deployment.
|
||||
|
||||
- [First part][1]: where I talk about the process we went thru before approaching Docker;
|
||||
- [Second part][2]: where I explain how setting up a private registry for in house secure deployments.
|
||||
|
||||
----------
|
||||
|
||||
In this final part we will see how to automate the whole deployment process with a real world (though very basic) example.
|
||||
|
||||
### Basic Rails app ###
|
||||
|
||||
Let's dive into the topic right away and bootstrap a basic Rails app. For the purpose of this demonstration I'm going to use Ruby 2.2.0 and Rails 4.1.1
|
||||
|
||||
From the terminal run:
|
||||
|
||||
$ rvm use 2.2.0
|
||||
$ rails new && cd docker-test
|
||||
|
||||
Let's create a basic controller:
|
||||
|
||||
$ rails g controller welcome index
|
||||
|
||||
...and edit `routes.rb` so that the root of the project will point to our newly created welcome#index method:
|
||||
|
||||
root 'welcome#index'
|
||||
|
||||
Running `rails s` from the terminal and browsing to [http://localhost:3000][3] should bring you to the index page. We're not going to make anything fancier to the app, it's just a basic example to prove that when we'll build and deploy the container everything is working.
|
||||
|
||||
### Setup the webserver ###
|
||||
|
||||
We are going to use Unicorn as our webserver. Add `gem 'unicorn'` and `gem 'foreman'` to the Gemfile and bundle it up (run `bundle install` from the command line).
|
||||
|
||||
Unicorn needs to be configured when the Rails app launches, so let's put a **unicorn.rb** file inside the **config** directory. [Here is an example][4] of a Unicorn configuration file. You can just copy & paste the content of the Gist.
|
||||
|
||||
Let's also add a Procfile with the following content inside the root of the project so that we will be able to start the app with foreman:
|
||||
|
||||
web: bundle exec unicorn -p $PORT -c ./config/unicorn.rb
|
||||
|
||||
If you now try to run the app with **foreman start** everything should work as expected and you should have a running app on [http://localhost:5000][5]
|
||||
|
||||
### Building a Docker image ###
|
||||
|
||||
Now let's build the image inside which our app is going to live. In the root of our Rails project, create a file named **Dockerfile** and paste in it the following:
|
||||
|
||||
# Base image with ruby 2.2.0
|
||||
FROM ruby:2.2.0
|
||||
|
||||
# Install required libraries and dependencies
|
||||
RUN apt-get update && apt-get install -qy nodejs postgresql-client sqlite3 --no-install-recommends && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# Set Rails version
|
||||
ENV RAILS_VERSION 4.1.1
|
||||
|
||||
# Install Rails
|
||||
RUN gem install rails --version "$RAILS_VERSION"
|
||||
|
||||
# Create directory from where the code will run
|
||||
RUN mkdir -p /usr/src/app
|
||||
WORKDIR /usr/src/app
|
||||
|
||||
# Make webserver reachable to the outside world
|
||||
EXPOSE 3000
|
||||
|
||||
# Set ENV variables
|
||||
ENV PORT=3000
|
||||
|
||||
# Start the web app
|
||||
CMD ["foreman","start"]
|
||||
|
||||
# Install the necessary gems
|
||||
ADD Gemfile /usr/src/app/Gemfile
|
||||
ADD Gemfile.lock /usr/src/app/Gemfile.lock
|
||||
RUN bundle install --without development test
|
||||
|
||||
# Add rails project (from same dir as Dockerfile) to project directory
|
||||
ADD ./ /usr/src/app
|
||||
|
||||
# Run rake tasks
|
||||
RUN RAILS_ENV=production rake db:create db:migrate
|
||||
|
||||
Using the provided Dockerfile, let's try and build an image with the following command[1][7]:
|
||||
|
||||
$ docker build -t localhost:5000/your_username/docker-test .
|
||||
|
||||
And again, if everything worked out correctly, the last line of the long log output should read something like:
|
||||
|
||||
Successfully built 82e48769506c
|
||||
$ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
|
||||
localhost:5000/your_username/docker-test latest 82e48769506c About a minute ago 884.2 MB
|
||||
|
||||
Let's try and run the container!
|
||||
|
||||
$ docker run -d -p 3000:3000 --name docker-test localhost:5000/your_username/docker-test
|
||||
|
||||
You should be able to reach your Rails app running inside the Docker container at port 3000 of your boot2docker VM[2][8] (in my case [http://192.168.59.103:3000][6]).
|
||||
|
||||
### Automating with shell scripts ###
|
||||
|
||||
Since you should already know from the previous post3 how to push your newly created image to a private regisitry and deploy it on a server, let's skip this part and go straight to automating the process.
|
||||
|
||||
We are going to define 3 shell scripts and finally tie it all together with rake.
|
||||
|
||||
### Clean ###
|
||||
|
||||
Every time we build our image and deploy we are better off always clean everything. That means the following:
|
||||
|
||||
- stop (if running) and restart boot2docker;
|
||||
- remove orphaned Docker images (images that are without tags and that are no longer used by your containers).
|
||||
|
||||
Put the following into a **clean.sh** file in the root of your project.
|
||||
|
||||
echo Restarting boot2docker...
|
||||
boot2docker down
|
||||
boot2docker up
|
||||
|
||||
echo Exporting Docker variables...
|
||||
sleep 1
|
||||
export DOCKER_HOST=tcp://192.168.59.103:2376
|
||||
export DOCKER_CERT_PATH=/Users/user/.boot2docker/certs/boot2docker-vm
|
||||
export DOCKER_TLS_VERIFY=1
|
||||
|
||||
sleep 1
|
||||
echo Removing orphaned images without tags...
|
||||
docker images | grep "<none>" | awk '{print $3}' | xargs docker rmi
|
||||
|
||||
Also make sure to make the script executable:
|
||||
|
||||
$ chmod +x clean.sh
|
||||
|
||||
### Build ###
|
||||
|
||||
The build process basically consists in reproducing what we just did before (docker build). Create a **build.sh** script at the root of your project with the following content:
|
||||
|
||||
docker build -t localhost:5000/your_username/docker-test .
|
||||
|
||||
Make the script executable.
|
||||
|
||||
### Deploy ###
|
||||
|
||||
Finally, create a **deploy.sh** script with this content:
|
||||
|
||||
# Open SSH connection from boot2docker to private registry
|
||||
boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/username/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@your-registry.com &" &
|
||||
|
||||
# Wait to make sure the SSH tunnel is open before pushing...
|
||||
echo Waiting 5 seconds before pushing image.
|
||||
|
||||
echo 5...
|
||||
sleep 1
|
||||
echo 4...
|
||||
sleep 1
|
||||
echo 3...
|
||||
sleep 1
|
||||
echo 2...
|
||||
sleep 1
|
||||
echo 1...
|
||||
sleep 1
|
||||
|
||||
# Push image onto remote registry / repo
|
||||
echo Starting push!
|
||||
docker push localhost:5000/username/docker-test
|
||||
|
||||
If you don't understand what's going on here, please make sure you've read thoroughfully [part 2][9] of this series of posts.
|
||||
|
||||
Make the script executable.
|
||||
|
||||
### Tying it all together with rake ###
|
||||
|
||||
Having 3 scripts would now require you to run them individually each time you decide to deploy your app:
|
||||
|
||||
1. clean
|
||||
1. build
|
||||
1. deploy / push
|
||||
|
||||
That wouldn't be much of an effort, if it weren't for the fact that developers are lazy! And lazy be it, then!
|
||||
|
||||
The final step to wrap things up, is tying the 3 parts together with rake.
|
||||
|
||||
To make things even simpler you can just append a bunch of lines of code to the end of the already present Rakefile in the root of your project. Open the Rakefile file - pun intended :) - and paste the following:
|
||||
|
||||
namespace :docker do
|
||||
desc "Remove docker container"
|
||||
task :clean do
|
||||
sh './clean.sh'
|
||||
end
|
||||
|
||||
desc "Build Docker image"
|
||||
task :build => [:clean] do
|
||||
sh './build.sh'
|
||||
end
|
||||
|
||||
desc "Deploy Docker image"
|
||||
task :deploy => [:build] do
|
||||
sh './deploy.sh'
|
||||
end
|
||||
end
|
||||
|
||||
Even if you don't know rake syntax (which you should, because it's pretty awesome!), it's pretty obvious what we are doing. We have declared 3 tasks inside a namespace (docker).
|
||||
|
||||
This will create the following 3 tasks:
|
||||
|
||||
- rake docker:clean
|
||||
- rake docker:build
|
||||
- rake docker:deploy
|
||||
|
||||
Deploy is dependent on build, build is dependent on clean. So every time we run from the command line
|
||||
|
||||
$ rake docker:deploy
|
||||
|
||||
All the script will be executed in the required order.
|
||||
|
||||
### Test it ###
|
||||
|
||||
To see if everything is working, you just need to make a small change in the code of your app and run
|
||||
|
||||
$ rake docker:deploy
|
||||
|
||||
and see the magic happening. Once the image has been uploaded (and the first time it could take quite a while), you can ssh into your production server and pull (thru an SSH tunnel) the docker image onto the server and run. It's that easy!
|
||||
|
||||
Well, maybe it takes a while to get accustomed to how everything works, but once it does, it's almost (almost) as easy as deploying with Heroku.
|
||||
|
||||
P.S. As always, please let me have your ideas. I'm not sure this is the best, or the fastest, or the safest way of doing devops with Docker, but it certainly worked out for us.
|
||||
|
||||
- make sure to have **boot2docker** up and running.
|
||||
- If you don't know your boot2docker VM address, just run `$ boot2docker ip`
|
||||
- if you don't, you can read it [here][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://cocoahunter.com/2015/01/23/docker-3/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://cocoahunter.com/author/michelangelo/
|
||||
[1]:http://cocoahunter.com/docker-1
|
||||
[2]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
[3]:http://localhost:3000/
|
||||
[4]:https://gist.github.com/chasseurmic/0dad4d692ff499761b20
|
||||
[5]:http://localhost:5000/
|
||||
[6]:http://192.168.59.103:3000/
|
||||
[7]:http://cocoahunter.com/2015/01/23/docker-3/#fn:1
|
||||
[8]:http://cocoahunter.com/2015/01/23/docker-3/#fn:2
|
||||
[9]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
[10]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
@ -0,0 +1,79 @@
|
||||
How to Bind Apache Tomcat to IPv4 in Centos / Redhat
|
||||
================================================================================
|
||||
Hi all, today we'll learn how to bind tomcat to ipv4 in CentOS 7 Linux Distribution.
|
||||
|
||||
**Apache Tomcat** is an open source web server and servlet container developed by the [Apache Software Foundation][1]. It implements the Java Servlet, JavaServer Pages (JSP), Java Unified Expression Language and Java WebSocket specifications from Sun Microsystems and provides a web server environment for Java code to run in.
|
||||
|
||||
Binding Tomcat to IPv4 is necessary if we have our server not working due to the default binding of our tomcat server to IPv6. As we know IPv6 is the modern way of assigning IP address to a device and is not in complete practice these days but may come into practice in soon future. So, currently we don't need to switch our tomcat server to IPv6 due to no use and we should bind it to IPv4.
|
||||
|
||||
Before thinking to bind to IPv4, we should make sure that we've got tomcat installed in our CentOS 7. Here's is a quick tutorial on [how to install tomcat 8 in CentOS 7.0 Server][2].
|
||||
|
||||
### 1. Switching to user tomcat ###
|
||||
|
||||
First of all, we'll gonna switch user to **tomcat** user. We can do that by running **su - tomcat** in a shell or terminal.
|
||||
|
||||
# su - tomcat
|
||||
|
||||

|
||||
|
||||
### 2. Finding Catalina.sh ###
|
||||
|
||||
Now, we'll First Go to bin directory inside the directory of Apache Tomcat installation which is usually under **/usr/share/apache-tomcat-8.0.x/bin/** where x is sub version of the Apache Tomcat Release. In my case, its **/usr/share/apache-tomcat-8.0.18/bin/** as I have version 8.0.18 installed in my CentOS 7 Server.
|
||||
|
||||
$ cd /usr/share/apache-tomcat-8.0.18/bin
|
||||
|
||||
**Note: Please replace 8.0.18 to the version of Apache Tomcat installed in your system. **
|
||||
|
||||
Inside the bin folder, there is a script file named catalina.sh . Thats the script file which we'll gonna edit and add a line of configuration which will bind tomcat to IPv4 . You can see that file by running **ls** into a terminal or shell.
|
||||
|
||||
$ ls
|
||||
|
||||

|
||||
|
||||
### 3. Configuring Catalina.sh ###
|
||||
|
||||
Now, we'll add **JAVA_OPTS= "$JAVA_OPTS -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Addresses"** to that scripting file catalina.sh at the end of the file as shown in the figure below. We can edit the file using our favorite text editing software like nano, vim, etc. Here, we'll gonna use nano.
|
||||
|
||||
$ nano catalina.sh
|
||||
|
||||

|
||||
|
||||
Then, add to the file as shown below:
|
||||
|
||||
**JAVA_OPTS= "$JAVA_OPTS -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Addresses"**
|
||||
|
||||

|
||||
|
||||
Now, as we've added the configuration to the file, we'll now save and exit nano.
|
||||
|
||||
### 4. Restarting ###
|
||||
|
||||
Now, we'll restart our tomcat server to get our configuration working. We'll need to first execute shutdown.sh and then startup.sh .
|
||||
|
||||
$ ./shutdown.sh
|
||||
|
||||
Now, well run execute startup.sh as:
|
||||
|
||||
$ ./startup.sh
|
||||
|
||||

|
||||
|
||||
This will restart our tomcat server and the configuration will be loaded which will ultimately bind the server to IPv4.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Hurray, finally we'have got our tomcat server bind to IPv4 running in our CentOS 7 Linux Distribution. Binding to IPv4 is easy and is necessary if your Tomcat server is bind to IPv6 which will infact will make your tomcat server not working as IPv6 is not used these days and may come into practice in coming future. If you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/bind-apache-tomcat-ipv4-centos/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.apache.org/
|
||||
[2]:http://linoxide.com/linux-how-to/install-tomcat-8-centos-7/
|
||||
@ -0,0 +1,186 @@
|
||||
How to create and show a presentation from the command line on Linux
|
||||
================================================================================
|
||||
When you prepare a talk for audience, the first thing that will probably come to your mind is shiny presentation charts filled with fancy diagrams, graphics and animation effects. Fine. No one can deny the power of visually charming presentation. However, not all presentations need to be Ted talk quality. Often times, the purpose of a presentation is to convey specific information, which can easily be done with textual messages. In such cases, your time can be better spent on gathering information and checking facts, rather than searching for good-looking graphics from Google Image.
|
||||
|
||||
In the world of Linux, you can do presentation in several different ways, e.g., Impress for multimedia-rich content, [Impress.js][1] for stunning visualization, Beamer for hardcore LaTex users, and so on. If you are looking for a simple means to create and show a textual presentation, look no further. [mdp][2] can get the job done for you.
|
||||
|
||||
### What is Mdp? ###
|
||||
|
||||
mdp is an ncurses-based command-line presentation tool for Linux. What I like about mdp is its [markdown][3] support, which makes it easy to create slides with familiar markdown format. Naturally, it becomes painless to publish the slides in HTML format as well. Another plus is its support for UTF-8 character encoding, which comes in handy when showing non-English characters (e.g., Greek or Cyrillic alphabets).
|
||||
|
||||
### Install Mdp on Linux ###
|
||||
|
||||
Installation of mdp is mostly painless due to its light dependency requirement (i.e., ncursesw).
|
||||
|
||||
#### Debian, Ubuntu or their derivatives ####
|
||||
|
||||
$ sudo apt-get install git gcc make libncursesw5-dev
|
||||
$ git clone https://github.com/visit1985/mdp.git
|
||||
$ cd mdp
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
#### Fedora or CentOS/RHEL ####
|
||||
|
||||
$ sudo yum install git gcc make ncurses-devel
|
||||
$ git clone https://github.com/visit1985/mdp.git
|
||||
$ cd mdp
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
#### Arch Linux ####
|
||||
|
||||
On Arch Linux, you can easily install mdp from [AUR][4].
|
||||
|
||||
### Create a Presentation from the Command Line ###
|
||||
|
||||
Once you installed mdp, you can easily create a presentation by using your favorite text editor. If you are familiar with markdown, it will take no time to master mdp. For those of you who are not familiar with markdown, starting with an example is the best way to learn mdp.
|
||||
|
||||
Here is a 6-page sample presentation for your reference.
|
||||
|
||||
%title: Sample Presentation made with mdp (Xmodulo.com)
|
||||
%author: Dan Nanni
|
||||
%date: 2015-01-28
|
||||
|
||||
-> This is a slide title <-
|
||||
=========
|
||||
|
||||
-> mdp is a command-line based presentation tool with markdown support. <-
|
||||
|
||||
*_Features_*
|
||||
|
||||
* Multi-level headers
|
||||
* Code block formatting
|
||||
* Nested quotes
|
||||
* Nested list
|
||||
* Text highlight and underline
|
||||
* Citation
|
||||
* UTF-8 special characters
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of nested list <-
|
||||
|
||||
This is an example of multi-level headers and a nested list.
|
||||
|
||||
# first-level title
|
||||
|
||||
second-level
|
||||
------------
|
||||
|
||||
- *item 1*
|
||||
- sub-item 1
|
||||
- sub-sub-item 1
|
||||
- sub-sub-item 2
|
||||
- sub-sub-item 3
|
||||
- sub-item 2
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of code block formatting <-
|
||||
|
||||
This example shows how to format a code snippet.
|
||||
|
||||
1 /* Hello World program */
|
||||
2
|
||||
3 #include <stdio.h>
|
||||
4
|
||||
5 int main()
|
||||
6 {
|
||||
7 printf("Hello World");
|
||||
8 return 0;
|
||||
9 }
|
||||
|
||||
This example shows inline code: `sudo reboot`
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of nested quotes <-
|
||||
|
||||
This is an example of nested quotes.
|
||||
|
||||
# three-level nested quotes
|
||||
|
||||
> This is the first-level quote.
|
||||
>> This is the second-level quote
|
||||
>> and continues.
|
||||
>>> *This is the third-level quote, and so on.*
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of citations <-
|
||||
|
||||
This example shows how to place a citation inside a presentation.
|
||||
|
||||
This tutorial is published at [Xmodulo](http://xmodulo.com)
|
||||
|
||||
You are welcome to connect with me at [LinkedIn](http://www.linkedin.com/in/xmodulo)
|
||||
|
||||
Pretty cool, huh?
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of UTF-8 special characters <-
|
||||
|
||||
This example shows UTF-8 special characters.
|
||||
|
||||
ae = ä, oe = ö, ue = ü, ss = ß
|
||||
alpha = ?, beta = ?, upsilon = ?, phi = ?
|
||||
Omega = ?, Delta = ?, Sigma = ?
|
||||
|
||||
???????????
|
||||
?rectangle?
|
||||
???????????
|
||||
|
||||
### Show a Presentation from the Command Line ###
|
||||
|
||||
Once you save the above code as slide.md text file, you can show the presentation by simply running:
|
||||
|
||||
$ mdp slide.md
|
||||
|
||||
You can navigate the presentation by pressing Enter/Space/Page-Down/Down-Arrow (next slide), Backspace/Page-Up/Up-Arrow (previous slide), Home (first slide), End (last slide), or numeric-N (N-th slide).
|
||||
|
||||
The title of the presentation appears on top of each slide, and your name and page number are shown at the bottom.
|
||||
|
||||
|
||||
|
||||
This is an example of a nested list and multi-level headers.
|
||||
|
||||
|
||||
|
||||
This is an example of a code snippet and inline code.
|
||||
|
||||
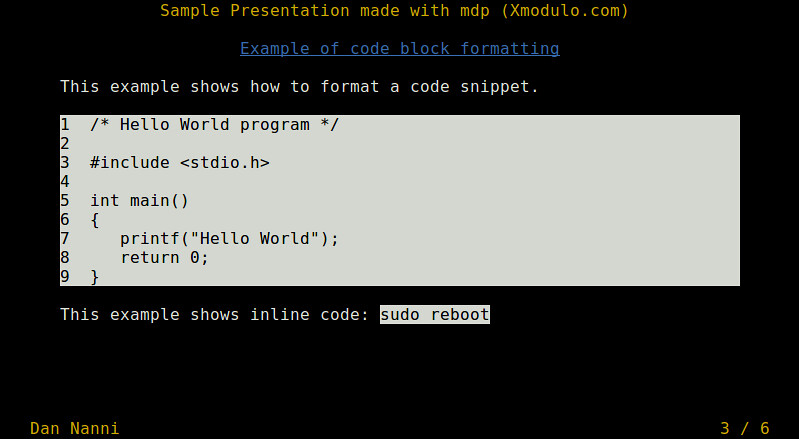
|
||||
|
||||
This is an example of nested quotes.
|
||||
|
||||
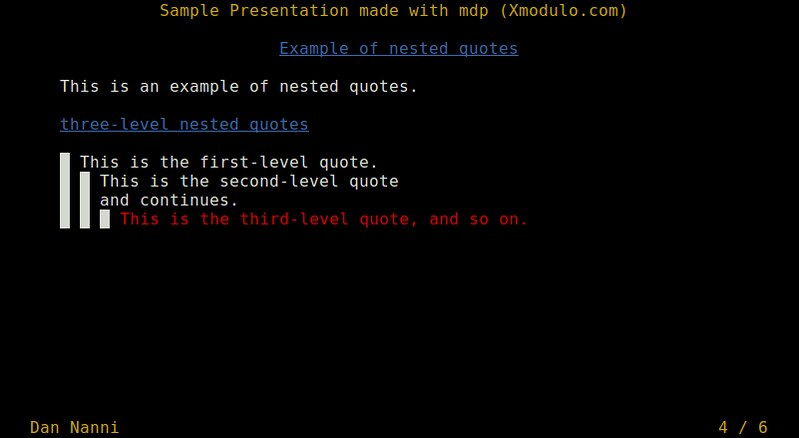
|
||||
|
||||
This is an example of placing citations.
|
||||
|
||||
|
||||
|
||||
This is an example of UTF-8 special characters.
|
||||
|
||||
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this tutorial, I showed you how to use mdp to create and show a presentation from the command line. Its markdown compatibility saves us the trouble and hassle of having to learn any new formatting, which is an advantage compared to [tpp][5], another command-line presentation tool. Due to its limitations, mdp may not qualify as your default presentation tool, but there should be definitely a use case for that. What do you think of mdp? Do you prefer something else?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/presentation-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://bartaz.github.io/impress.js/
|
||||
[2]:https://github.com/visit1985/mdp
|
||||
[3]:http://daringfireball.net/projects/markdown/
|
||||
[4]:https://aur.archlinux.org/packages/mdp-git/
|
||||
[5]:http://www.ngolde.de/tpp.html
|
||||
@ -0,0 +1,201 @@
|
||||
How to filter BGP routes in Quagga BGP router
|
||||
================================================================================
|
||||
In the [previous tutorial][1], we demonstrated how to turn a CentOS box into a BGP router using Quagga. We also covered basic BGP peering and prefix exchange setup. In this tutorial, we will focus on how we can control incoming and outgoing BGP prefixes by using **prefix-list** and **route-map**.
|
||||
|
||||
As described in earlier tutorials, BGP routing decisions are made based on the prefixes received/advertised. To ensure error-free routing, it is recommended that you use some sort of filtering mechanism to control these incoming and outgoing prefixes. For example, if one of your BGP neighbors starts advertising prefixes which do not belong to them, and you accept such bogus prefixes by mistake, your traffic can be sent to that wrong neighbor, and end up going nowhere (so-called "getting blackholed"). To make sure that such prefixes are not received or advertised to any neighbor, you can use prefix-list and route-map. The former is a prefix-based filtering mechanism, while the latter is a more general prefix-based policy mechanism used to fine-tune actions.
|
||||
|
||||
We will show you how to use prefix-list and route-map in Quagga.
|
||||
|
||||
### Topology and Requirement ###
|
||||
|
||||
In this tutorial, we assume the following topology.
|
||||
|
||||

|
||||
|
||||
Service provider A has already established an eBGP peering with service provider B, and they are exchanging routing information between them. The AS and prefix details are as stated below.
|
||||
|
||||
- **Peering block**: 192.168.1.0/24
|
||||
- **Service provider A**: AS 100, prefix 10.10.0.0/16
|
||||
- **Service provider B**: AS 200, prefix 10.20.0.0/16
|
||||
|
||||
In this scenario, service provider B wants to receive only prefixes 10.10.10.0/23, 10.10.10.0/24 and 10.10.11.0/24 from provider A.
|
||||
|
||||
### Quagga Installation and BGP Peering ###
|
||||
|
||||
In the [previous tutorial][1], we have already covered the method of installing Quagga and setting up BGP peering. So we will not go through the details here. Nonetheless, I am providing a summary of BGP configuration and prefix advertisements:
|
||||
|
||||

|
||||
|
||||
The above output indicates that the BGP peering is up. Router-A is advertising multiple prefixes towards router-B. Router-B, on the other hand, is advertising a single prefix 10.20.0.0/16 to router-A. Both routers are receiving the prefixes without any problems.
|
||||
|
||||
### Creating Prefix-List ###
|
||||
|
||||
In a router, a prefix can be blocked with either an ACL or prefix-list. Using prefix-list is often preferred to ACLs since prefix-list is less processor intensive than ACLs. Also, prefix-list is easier to create and maintain.
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 192.168.0.0/23
|
||||
|
||||
The above command creates prefix-list called 'DEMO-FRFX' that allows only 192.168.0.0/23.
|
||||
|
||||
Another great feature of prefix-list is that we can specify a range of subnet mask(s). Take a look at the following example:
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 192.168.0.0/23 le 24
|
||||
|
||||
The above command creates prefix-list called 'DEMO-PRFX' that permits prefixes between 192.168.0.0/23 and /24, which are 192.168.0.0/23, 192.168.0.0/24 and 192.168.1.0/24. The 'le' operator means less than or equal to. You can also use 'ge' operator for greater than or equal to.
|
||||
|
||||
A single prefix-list statement can have multiple permit/deny actions. Each statement is assigned a sequence number which can be determined automatically or specified manually.
|
||||
|
||||
Multiple prefix-list statements are parsed one by one in the increasing order of sequence numbers. When configuring prefix-list, we should keep in mind that there is always an **implicit deny** at the end of all prefix-list statements. This means that anything that is not explicitly allowed will be denied.
|
||||
|
||||
To allow everything, we can use the following prefix-list statement which allows any prefix starting from 0.0.0.0/0 up to anything with subnet mask /32.
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 0.0.0.0/0 le 32
|
||||
|
||||
Now that we know how to create prefix-list statements, we will create prefix-list called 'PRFX-LST' that will allow prefixes required in our scenario.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# ip prefix-list PRFX-LST permit 10.10.10.0/23 le 24
|
||||
|
||||
### Creating Route-Map ###
|
||||
|
||||
Besides prefix-list and ACLs, there is yet another mechanism called route-map, which can control prefixes in a BGP router. In fact, route-map can fine-tune possible actions more flexibly on the prefixes matched with an ACL or prefix-list.
|
||||
|
||||
Similar to prefix-list, a route-map statement specifies permit or deny action, followed by a sequence number. Each route-map statement can have multiple permit/deny actions with it. For example:
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
|
||||
The above statement creates route-map called 'DEMO-RMAP', and adds permit action with sequence 10. Now we will use match command under sequence 10.
|
||||
|
||||
router-a(config-route-map)# match (press ? in the keyboard)
|
||||
|
||||
----------
|
||||
|
||||
as-path Match BGP AS path list
|
||||
community Match BGP community list
|
||||
extcommunity Match BGP/VPN extended community list
|
||||
interface match first hop interface of route
|
||||
ip IP information
|
||||
ipv6 IPv6 information
|
||||
metric Match metric of route
|
||||
origin BGP origin code
|
||||
peer Match peer address
|
||||
probability Match portion of routes defined by percentage value
|
||||
tag Match tag of route
|
||||
|
||||
As we can see, route-map can match many attributes. We will match a prefix in this tutorial.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
|
||||
The match command will match the IP addresses permitted by the prefix-list 'DEMO-PRFX' created earlier (i.e., prefixes 192.168.0.0/23, 192.168.0.0/24 and 192.168.1.0/24).
|
||||
|
||||
Next, we can modify the attributes by using the set command. The following example shows possible use cases of set.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set (press ? in keyboard)
|
||||
|
||||
----------
|
||||
|
||||
aggregator BGP aggregator attribute
|
||||
as-path Transform BGP AS-path attribute
|
||||
atomic-aggregate BGP atomic aggregate attribute
|
||||
comm-list set BGP community list (for deletion)
|
||||
community BGP community attribute
|
||||
extcommunity BGP extended community attribute
|
||||
forwarding-address Forwarding Address
|
||||
ip IP information
|
||||
ipv6 IPv6 information
|
||||
local-preference BGP local preference path attribute
|
||||
metric Metric value for destination routing protocol
|
||||
metric-type Type of metric
|
||||
origin BGP origin code
|
||||
originator-id BGP originator ID attribute
|
||||
src src address for route
|
||||
tag Tag value for routing protocol
|
||||
vpnv4 VPNv4 information
|
||||
weight BGP weight for routing table
|
||||
|
||||
As we can see, the set command can be used to change many attributes. For a demonstration purpose, we will set BGP local preference.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set local-preference 500
|
||||
|
||||
Just like prefix-list, there is an implicit deny at the end of all route-map statements. So we will add another permit statement in sequence number 20 to permit everything.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set local-preference 500
|
||||
!
|
||||
route-map DEMO-RMAP permit 20
|
||||
|
||||
The sequence number 20 does not have a specific match command, so it will, by default, match everything. Since the decision is permit, everything will be permitted by this route-map statement.
|
||||
|
||||
If you recall, our requirement is to only allow/deny some prefixes. So in our scenario, the set command is not necessary. We will just use one permit statement as follows.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# route-map RMAP permit 10
|
||||
router-b(config-route-map)# match ip address prefix-list PRFX-LST
|
||||
|
||||
This route-map statement should do the trick.
|
||||
|
||||
### Applying Route-Map ###
|
||||
|
||||
Keep in mind that ACLs, prefix-list and route-map are not effective unless they are applied to an interface or a BGP neighbor. Just like ACLs or prefix-list, a single route-map statement can be used with any number of interfaces or neighbors. However, any one interface or a neighbor can support only one route-map statement for inbound, and one for outbound traffic.
|
||||
|
||||
We will apply the created route-map to the BGP configuration of router-B for neighbor 192.168.1.1 with incoming prefix advertisement.
|
||||
|
||||
router-b# conf terminal
|
||||
router-b(config)# router bgp 200
|
||||
router-b(config-router)# neighbor 192.168.1.1 route-map RMAP in
|
||||
|
||||
Now, we check the routes advertised and received by using the following commands.
|
||||
|
||||
For advertised routes:
|
||||
|
||||
show ip bgp neighbor-IP advertised-routes
|
||||
|
||||
For received routes:
|
||||
|
||||
show ip bgp neighbor-IP routes
|
||||
|
||||

|
||||
|
||||
You can see that while router-A is advertising four prefixes towards router-B, router-B is accepting only three prefixes. If we check the range, we can see that only the prefixes that are allowed by route-map are visible on router-B. All other prefixes are discarded.
|
||||
|
||||
**Tip**: If there is no change in the received prefixes, try resetting the BGP session using the command: "clear ip bgp neighbor-IP". In our case:
|
||||
|
||||
clear ip bgp 192.168.1.1
|
||||
|
||||
As we can see, the requirement has been met. We can create similar prefix-list and route-map statements in routers A and B to further control inbound and outbound prefixes.
|
||||
|
||||
I am summarizing the configuration in one place so you can see it all at a glance.
|
||||
|
||||
router bgp 200
|
||||
network 10.20.0.0/16
|
||||
neighbor 192.168.1.1 remote-as 100
|
||||
neighbor 192.168.1.1 route-map RMAP in
|
||||
!
|
||||
ip prefix-list PRFX-LST seq 5 permit 10.10.10.0/23 le 24
|
||||
!
|
||||
route-map RMAP permit 10
|
||||
match ip address prefix-list PRFX-LST
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this tutorial, we showed how we can filter BGP routes in Quagga by defining prefix-list and route-map. We also demonstrated how we can combine prefix-list with route-map to fine-control incoming prefixes. You can create your own prefix-list and route-map in a similar way to match your network requirements. These tools are one of the most effective ways to protect the production network from route poisoning and advertisement of bogon routes.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
@ -0,0 +1,60 @@
|
||||
How To Install KDE Plasma 5.2 In Ubuntu 14.10
|
||||
================================================================================
|
||||

|
||||
|
||||
[KDE][1] Plasma 5.2 has been [released][2] and in this post we shall see how to install KDE Plasma 5.2 in Ubuntu 14.10.
|
||||
|
||||
Ubuntu’s default desktop environment Unity is beautiful and packs quite some feature. But if you ask any experienced Linux user about desktop customization, his answer will be KDE. KDE is boss when it comes to customization and its popularity can be guessed that Ubuntu has an official KDE flavor, known as [Kubuntu][3].
|
||||
|
||||
A good thing about Ubuntu (or any other Linux OS for that matter) is that it doesn’t bind you with one particular desktop environment. You can always install additional desktop environments and choose to switch between them while keeping several desktop environments at the same time. Earlier, we have seen the installation of following desktop environments:
|
||||
|
||||
- [How to install Mate desktop in Ubuntu 14.04][4]
|
||||
- [How to install Cinnamon in Ubuntu 14.04][5]
|
||||
- [How to install Budgie desktop in Ubuntu 14.04][6]
|
||||
- [How to install GNOME Shell in Ubuntu 14.04][7]
|
||||
|
||||
And today we shall see how to install KDE Plasma in Ubuntu 14.10.
|
||||
|
||||
### Install KDE Plasma 5.2 in Ubuntu 14.04 ###
|
||||
|
||||
Before you go on installing Plasma on Ubuntu 14.10, you should know that it will download around one GB of data. So consider your network speed and data package (if any) before opting for KDE installation. The PPA we are going to use for installing Plasma is the official PPA provided by the KDE community. Use the commands below in terminal:
|
||||
|
||||
sudo apt-add-repository ppa:kubuntu-ppa/next-backports
|
||||
sudo apt-get update
|
||||
sudo apt-get dist-upgrade
|
||||
sudo apt-get install kubuntu-plasma5-desktop plasma-workspace-wallpapers
|
||||
|
||||
During the installation, it will as you to choose the default display manager. I chose the default LightDM. Once installed, restart the system. At the login, click on the Ubuntu symbol beside the login field. In here, select Plasma.
|
||||
|
||||

|
||||
|
||||
You’ll be logged in to KDE Plasma now. Here is a quick screenshot of how KDE Plasma 5.2 looks like in Ubuntu 14.10:
|
||||
|
||||

|
||||
|
||||
### Remove KDE Plasma from Ubuntu ###
|
||||
|
||||
If you want to revert the changes, use the following commands to get rid of KDE Plasma from Ubuntu 14.10.
|
||||
|
||||
sudo apt-get install ppa-purge
|
||||
sudo apt-get remove kubuntu-plasma5-desktop
|
||||
sudo ppa-purge ppa:kubuntu-ppa/next
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-kde-plasma-ubuntu-1410/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:https://www.kde.org/
|
||||
[2]:https://dot.kde.org/2015/01/27/plasma-52-beautiful-and-featureful
|
||||
[3]:http://www.kubuntu.org/
|
||||
[4]:http://itsfoss.com/install-mate-desktop-ubuntu-14-04/
|
||||
[5]:http://itsfoss.com/install-cinnamon-24-ubuntu-1404/
|
||||
[6]:http://itsfoss.com/install-budgie-desktop-ubuntu-1404/
|
||||
[7]:http://itsfoss.com/how-to-install-gnome-in-ubuntu-14-04/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user