mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
8283d036b4
@ -1,47 +1,48 @@
|
||||
PKI 和 密码学中的私钥的角色
|
||||
公钥基础设施和密码学中的私钥的角色
|
||||
======
|
||||
> 了解如何验证某人所声称的身份。
|
||||
|
||||

|
||||
|
||||
在[上一篇文章][1]中,我们概述了密码学并讨论了密码学的核心概念:<ruby>保密性<rt>confidentiality</rt></ruby> (让数据保密),<ruby>完整性<rt>integrity</rt></ruby> (防止数据被篡改)和<ruby>身份认证<rt>authentication</rt></ruby> (确认数据源的<ruby>身份<rt>identity</rt></ruby>)。由于要在存在各种身份混乱的现实世界中完成身份认证,人们逐渐建立起一个复杂的<ruby>技术生态体系<rt>technological ecosystem</rt></ruby>,用于证明某人就是其声称的那个人。在本文中,我们将大致介绍这些体系是如何工作的。
|
||||
在[上一篇文章][1]中,我们概述了密码学并讨论了密码学的核心概念:<ruby>保密性<rt>confidentiality</rt></ruby> (让数据保密)、<ruby>完整性<rt>integrity</rt></ruby> (防止数据被篡改)和<ruby>身份认证<rt>authentication</rt></ruby> (确认数据源的<ruby>身份<rt>identity</rt></ruby>)。由于要在存在各种身份混乱的现实世界中完成身份认证,人们逐渐建立起一个复杂的<ruby>技术生态体系<rt>technological ecosystem</rt></ruby>,用于证明某人就是其声称的那个人。在本文中,我们将大致介绍这些体系是如何工作的。
|
||||
|
||||
### 公钥密码学及数字签名快速回顾
|
||||
### 快速回顾公钥密码学及数字签名
|
||||
|
||||
互联网世界中的身份认证依赖于公钥密码学,其中密钥分为两部分:拥有者需要保密的私钥和可以对外公开的公钥。经过公钥加密过的数据,只能用对应的私钥解密。举个例子,对于希望与[记者][2]建立联系的举报人来说,这个特性非常有用。但就本文介绍的内容而言,私钥更重要的用途是与一个消息一起创建一个<ruby>数字签名<rt>digital signature</rt></ruby>,用于提供完整性和身份认证。
|
||||
|
||||
在实际应用中,我们签名的并不是真实消息,而是经过<ruby>密码学哈希函数<rt>cryptographic hash function</rt></ruby>处理过的消息<ruby>摘要<rt>digest</rt></ruby>。要发送一个包含源代码的压缩文件,发送者会对该压缩文件的 256 比特长度的 [SHA-256][3] 摘要而不是文件本身进行签名,然后用明文发送该压缩包(和签名)。接收者会独立计算收到文件的 SHA-256 摘要,然后结合该摘要、收到的签名及发送者的公钥,使用签名验证算法进行验证。验证过程取决于加密算法,加密算法不同,验证过程也相应不同;而且,由于不断发现微妙的触发条件,签名验证[漏洞][4]依然[层出不穷][5]。如果签名验证通过,说明文件在传输过程中没有被篡改而且来自于发送者,这是因为只有发送者拥有创建签名所需的私钥。
|
||||
在实际应用中,我们签名的并不是真实消息,而是经过<ruby>密码学哈希函数<rt>cryptographic hash function</rt></ruby>处理过的消息<ruby>摘要<rt>digest</rt></ruby>。要发送一个包含源代码的压缩文件,发送者会对该压缩文件的 256 比特长度的 [SHA-256][3] 摘要进行签名,而不是文件本身进行签名,然后用明文发送该压缩包(和签名)。接收者会独立计算收到文件的 SHA-256 摘要,然后结合该摘要、收到的签名及发送者的公钥,使用签名验证算法进行验证。验证过程取决于加密算法,加密算法不同,验证过程也相应不同;而且,很微妙的是签名验证[漏洞][4]依然[层出不穷][5]。如果签名验证通过,说明文件在传输过程中没有被篡改而且来自于发送者,这是因为只有发送者拥有创建签名所需的私钥。
|
||||
|
||||
### 方案中缺失的环节
|
||||
|
||||
上述方案中缺失了一个重要的环节:我们从哪里获得发送者的公钥?发送者可以将公钥与消息一起发送,但除了发送者的自我宣称,我们无法核验其身份。假设你是一名银行柜员,一名顾客走过来向你说,“你好,我是 Jane Doe,我要取一笔钱”。当你要求其证明身份时,她指着衬衫上贴着的姓名标签说道,“看,Jane Doe!”。如果我是这个柜员,我会礼貌的拒绝她的请求。
|
||||
|
||||
如果你认识发送者,你们可以私下见面并彼此交换公钥。如果你并不认识发送者,你们可以私下见面,检查对方的证件,确认真实性后接受对方的公钥。为提高流程效率,你可以举办聚会并邀请一堆人,检查他们的证件,然后接受他们的公钥。此外,如果你认识并信任 Jane Doe (尽管她在银行的表现比较反常),Jane 可以参加聚会,收集大家的公钥然后交给你。事实上,Jane 可以使用她自己的私钥对这些公钥(及对应的身份信息)进行签名,进而你可以从一个[线上密钥库][7]获取公钥(及对应的身份信息)并信任已被 Jane 签名的那部分。如果一个人的公钥被很多你信任的人(即使你并不认识他们)签名,你也可能选择信任这个人。按照这种方式,你可以建立一个[<ruby>信任网络<rt>Web of Trust</rt></ruby>][8]。
|
||||
如果你认识发送者,你们可以私下见面并彼此交换公钥。如果你并不认识发送者,你们可以私下见面,检查对方的证件,确认真实性后接受对方的公钥。为提高流程效率,你可以举办[聚会][6]并邀请一堆人,检查他们的证件,然后接受他们的公钥。此外,如果你认识并信任 Jane Doe(尽管她在银行的表现比较反常),Jane 可以参加聚会,收集大家的公钥然后交给你。事实上,Jane 可以使用她自己的私钥对这些公钥(及对应的身份信息)进行签名,进而你可以从一个[线上密钥库][7]获取公钥(及对应的身份信息)并信任已被 Jane 签名的那部分。如果一个人的公钥被很多你信任的人(即使你并不认识他们)签名,你也可能选择信任这个人。按照这种方式,你可以建立一个<ruby>[信任网络][8]<rt>Web of Trust</rt></ruby>。
|
||||
|
||||
但事情也变得更加复杂:我们需要建立一种标准的编码机制,可以将公钥和其对应的身份信息编码成一个<ruby>数字捆绑<rt>digital bundle</rt></ruby>,以便我们进一步进行签名。更准确的说,这类数字捆绑被称为<ruby>证书<rt>cerificates</rt></ruby>。我们还需要可以创建、使用和管理这些证书的工具链。满足诸如此类的各种需求的方案构成了<ruby>公钥基础设施<rt>public key infrastructure, PKI</rt></ruby>。
|
||||
但事情也变得更加复杂:我们需要建立一种标准的编码机制,可以将公钥和其对应的身份信息编码成一个<ruby>数字捆绑<rt>digital bundle</rt></ruby>,以便我们进一步进行签名。更准确的说,这类数字捆绑被称为<ruby>证书<rt>cerificate</rt></ruby>。我们还需要可以创建、使用和管理这些证书的工具链。满足诸如此类的各种需求的方案构成了<ruby>公钥基础设施<rt>public key infrastructure</rt></ruby>(PKI)。
|
||||
|
||||
### 比信任网络更进一步
|
||||
|
||||
你可以用人际关系网类比信任网络。如果人们之间广泛互信,可以很容易找到(两个人之间的)一条<ruby>短信任链<rt>short path of trust</rt></ruby>:不妨以社交圈为例。基于 [GPG][9] 加密的邮件依赖于信任网络,([理论上][10])只适用于与少量朋友、家庭或同事进行联系的情形。
|
||||
你可以用人际关系网类比信任网络。如果人们之间广泛互信,可以很容易找到(两个人之间的)一条<ruby>短信任链<rt>short path of trust</rt></ruby>:就像一个社交圈。基于 [GPG][9] 加密的邮件依赖于信任网络,([理论上][10])只适用于与少量朋友、家庭或同事进行联系的情形。
|
||||
|
||||
(LCTT 译注:作者提到的“短信任链”应该是暗示“六度空间理论”,即任意两个陌生人之间所间隔的人一般不会超过 6 个。对 GPG 的唱衰,一方面是因为密钥管理的复杂性没有改善,另一方面 Yahoo 和 Google 都提出了更便利的端到端加密方案。)
|
||||
|
||||
在实际应用中,信任网络有一些[<ruby>"硬伤"<rt>significant problems</rt></ruby>][11],主要是在可扩展性方面。当网络规模逐渐增大或者人们之间的连接逐渐降低时,信任网络就会慢慢失效。如果信任链逐渐变长,信任链中某人有意或无意误签证书的几率也会逐渐增大。如果信任链不存在,你不得不自己创建一条信任链;具体而言,你与其它组织建立联系,验证它们的密钥符合你的要求。考虑下面的场景,你和你的朋友要访问一个从未使用过的在线商店。你首先需要核验网站所用的公钥属于其对应的公司而不是伪造者,进而建立安全通信信道,最后完成下订单操作。核验公钥的方法包括去实体店、打电话等,都比较麻烦。这样会导致在线购物变得不那么便利(或者说不那么安全,毕竟很多人会图省事,不去核验密钥)。
|
||||
在实际应用中,信任网络有一些“<ruby>[硬伤][11]<rt>significant problems</rt></ruby>”,主要是在可扩展性方面。当网络规模逐渐增大或者人们之间的连接较少时,信任网络就会慢慢失效。如果信任链逐渐变长,信任链中某人有意或无意误签证书的几率也会逐渐增大。如果信任链不存在,你不得不自己创建一条信任链,与其它组织建立联系,验证它们的密钥以符合你的要求。考虑下面的场景,你和你的朋友要访问一个从未使用过的在线商店。你首先需要核验网站所用的公钥属于其对应的公司而不是伪造者,进而建立安全通信信道,最后完成下订单操作。核验公钥的方法包括去实体店、打电话等,都比较麻烦。这样会导致在线购物变得不那么便利(或者说不那么安全,毕竟很多人会图省事,不去核验密钥)。
|
||||
|
||||
如果世界上有那么几个格外值得信任的人,他们专门负责核验和签发网站证书,情况会怎样呢?你可以只信任他们,那么浏览互联网也会变得更加容易。整体来看,这就是当今互联网的工作方式。那些“格外值得信任的人”就是被称为<ruby>证书颁发机构<rt>cerificate authorities, CAs</rt></ruby>的公司。当网站希望获得公钥签名时,只需向 CA 提交<ruby>证书签名请求<rt>certificate signing request</rt></ruby>。
|
||||
如果世界上有那么几个格外值得信任的人,他们专门负责核验和签发网站证书,情况会怎样呢?你可以只信任他们,那么浏览互联网也会变得更加容易。整体来看,这就是当今互联网的工作方式。那些“格外值得信任的人”就是被称为<ruby>证书颁发机构<rt>cerificate authoritie</rt></ruby>(CA)的公司。当网站希望获得公钥签名时,只需向 CA 提交<ruby>证书签名请求<rt>certificate signing request</rt></ruby>(CSR)。
|
||||
|
||||
CSR 类似于包括公钥和身份信息(在本例中,即服务器的主机名)的<ruby>存根<rt>stub</rt></ruby>证书,但CA 并不会直接对 CSR 本身进行签名。CA 在签名之前会进行一些验证。对于一些证书类型(LCTT 译注:<ruby>DV<rt>Domain Validated</rt></ruby> 类型),CA 只验证申请者的确是 CSR 中列出主机名对应域名的控制者(例如通过邮件验证,让申请者完成指定的域名解析)。[对于另一些证书类型][12] (LCTT 译注:链接中提到<ruby>EV<rt>Extended Validated</rt></ruby> 类型,其实还有 <ruby>OV<rt>Organization Validated</rt></ruby> 类型),CA 还会检查相关法律文书,例如公司营业执照等。一旦验证完成,CA(一般在申请者付费后)会从 CSR 中取出数据(即公钥和身份信息),使用 CA 自己的私钥进行签名,创建一个(签名)证书并发送给申请者。申请者将该证书部署在网站服务器上,当用户使用 HTTPS (或其它基于 [TLS][13] 加密的协议)与服务器通信时,该证书被分发给用户。
|
||||
CSR 类似于包括公钥和身份信息(在本例中,即服务器的主机名)的<ruby>存根<rt>stub</rt></ruby>证书,但 CA 并不会直接对 CSR 本身进行签名。CA 在签名之前会进行一些验证。对于一些证书类型(LCTT 译注:<ruby>域名证实<rt>Domain Validated</rt></ruby>(DV) 类型),CA 只验证申请者的确是 CSR 中列出主机名对应域名的控制者(例如通过邮件验证,让申请者完成指定的域名解析)。[对于另一些证书类型][12] (LCTT 译注:链接中提到<ruby>扩展证实<rt>Extended Validated</rt></ruby>(EV)类型,其实还有 <ruby>OV<rt>Organization Validated</rt></ruby> 类型),CA 还会检查相关法律文书,例如公司营业执照等。一旦验证完成,CA(一般在申请者付费后)会从 CSR 中取出数据(即公钥和身份信息),使用 CA 自己的私钥进行签名,创建一个(签名)证书并发送给申请者。申请者将该证书部署在网站服务器上,当用户使用 HTTPS (或其它基于 [TLS][13] 加密的协议)与服务器通信时,该证书被分发给用户。
|
||||
|
||||
当用户访问该网站时,浏览器获取该证书,接着检查证书中的主机名是否与当前正在连接的网站一致(下文会详细说明),核验 CA 签名有效性。如果其中一步验证不通过,浏览器会给出安全警告并切断与网站的连接。反之,如果验证通过,浏览器会使用证书中的公钥核验服务器发送的签名信息,确认该服务器持有该证书的私钥。有几种算法用于协商后续通信用到的<ruby>共享密钥<rt>shared secret key</rt></ruby>,其中一种也用到了服务器发送的签名信息。<ruby>密钥交换<rt>Key exchange</rt></ruby>算法不在本文的讨论范围,可以参考这个[视频][14],其中仔细说明了一种密钥交换算法。
|
||||
当用户访问该网站时,浏览器获取该证书,接着检查证书中的主机名是否与当前正在连接的网站一致(下文会详细说明),核验 CA 签名有效性。如果其中一步验证不通过,浏览器会给出安全警告并切断与网站的连接。反之,如果验证通过,浏览器会使用证书中的公钥来核验该服务器发送的签名信息,确认该服务器持有该证书的私钥。有几种算法用于协商后续通信用到的<ruby>共享密钥<rt>shared secret key</rt></ruby>,其中一种也用到了服务器发送的签名信息。<ruby>密钥交换<rt>key exchange</rt></ruby>算法不在本文的讨论范围,可以参考这个[视频][14],其中仔细说明了一种密钥交换算法。
|
||||
|
||||
### 建立信任
|
||||
|
||||
你可能会问,“如果 CA 使用其私钥对证书进行签名,也就意味着我们需要使用 CA 的公钥验证证书。那么 CA 的公钥从何而来,谁对其进行签名呢?” 答案是 CA 对自己签名!可以使用证书公钥对应的私钥,对证书本身进行签名!这类签名证书被称为是<ruby>自签名的<rt>self-signed</rt></ruby>;在 PKI 体系下,这意味着对你说“相信我”。(为了表达方便,人们通常说用证书进行了签名,虽然真正用于签名的私钥并不在证书中。)
|
||||
|
||||
通过遵守[浏览器][15]和[操作系统][16]供应商建立的规则,CA 表明自己足够可靠并寻求加入到浏览器或操作系统预装的一组自签名证书中。这些证书被称为“<ruby>信任锚<rt>trust anchors</rt></ruby>”或 <ruby>CA 根证书<rt>root CA certificates</rt></ruby>,被存储在根证书区,我们<ruby>约定<rt>implicitly</rt></ruby>信任该区域内的证书。
|
||||
通过遵守[浏览器][15]和[操作系统][16]供应商建立的规则,CA 表明自己足够可靠并寻求加入到浏览器或操作系统预装的一组自签名证书中。这些证书被称为“<ruby>信任锚<rt>trust anchor</rt></ruby>”或 <ruby>CA 根证书<rt>root CA certificate</rt></ruby>,被存储在根证书区,我们<ruby>约定<rt>implicitly</rt></ruby>信任该区域内的证书。
|
||||
|
||||
CA 也可以签发一种特殊的证书,该证书自身可以作为 CA。在这种情况下,它们可以生成一个证书链。要核验证书链,需要从“信任锚”(也就是 CA 根证书)开始,使用当前证书的公钥核验下一层证书的签名(或其它一些信息)。按照这个方式依次核验下一层证书,直到证书链底部。如果整个核验过程没有问题,信任链也建立完成。当向 CA 付费为网站签发证书时,实际购买的是将证书放置在证书链下的权利。CA 将卖出的证书标记为“不可签发子证书”,这样它们可以在适当的长度终止信任链(防止其继续向下扩展)。
|
||||
|
||||
为何要使用长度超过 2 的信任链呢?毕竟网站的证书可以直接被 CA 根证书签名。在实际应用中,很多因素促使 CA 创建<ruby>中间 CA 证书<rt>intermediate CA certificate</rt></ruby>,最主要是为了方便。由于价值连城,CA 根证书对应的私钥通常被存放在特定的设备中,一种需要多人解锁的<ruby>硬件安全模块<rt>hardware security module, HSM</rt></ruby>,该模块完全离线并被保管在配备监控和报警设备的[地下室][18]中。
|
||||
为何要使用长度超过 2 的信任链呢?毕竟网站的证书可以直接被 CA 根证书签名。在实际应用中,很多因素促使 CA 创建<ruby>中间 CA 证书<rt>intermediate CA certificate</rt></ruby>,最主要是为了方便。由于价值连城,CA 根证书对应的私钥通常被存放在特定的设备中,一种需要多人解锁的<ruby>硬件安全模块<rt>hardware security module</rt></ruby>(HSM),该模块完全离线并被保管在配备监控和报警设备的[地下室][18]中。
|
||||
|
||||
<ruby>CA/浏览器论坛<rt>CAB Forum, CA/Browser Forum</rt></ruby>负责管理 CA,[要求][19]任何与 CA 根证书(LCTT 译注:就像前文提到的那样,这里是指对应的私钥)相关的操作必须由人工完成。设想一下,如果每个证书请求都需要员工将请求内容拷贝到保密介质中、进入地下室、与同事一起解锁 HSM、(使用 CA 根证书对应的私钥)签名证书,最后将签名证书从保密介质中拷贝出来;那么每天为大量网站签发证书是相当繁重乏味的工作。因此,CA 创建内部使用的中间 CA,用于证书签发自动化。
|
||||
|
||||
@ -72,12 +73,12 @@ via: https://opensource.com/article/18/7/private-keys
|
||||
作者:[Alex Wood][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/awood
|
||||
[1]:https://opensource.com/article/18/5/cryptography-pki
|
||||
[1]:https://linux.cn/article-9792-1.html
|
||||
[2]:https://theintercept.com/2014/10/28/smuggling-snowden-secrets/
|
||||
[3]:https://en.wikipedia.org/wiki/SHA-2
|
||||
[4]:https://www.ietf.org/mail-archive/web/openpgp/current/msg00999.html
|
||||
@ -1,26 +1,27 @@
|
||||
如何在 Linux 上使用 tcpdump 命令捕获和分析数据包
|
||||
======
|
||||
tcpdump 是一个有名的命令行**数据包分析**工具。我们可以使用 tcpdump 命令捕获实时 TCP/IP 数据包,这些数据包也可以保存到文件中。之后这些捕获的数据包可以通过 tcpdump 命令进行分析。tcpdump 命令在网络级故障排除时变得非常方便。
|
||||
|
||||
`tcpdump` 是一个有名的命令行**数据包分析**工具。我们可以使用 `tcpdump` 命令捕获实时 TCP/IP 数据包,这些数据包也可以保存到文件中。之后这些捕获的数据包可以通过 `tcpdump` 命令进行分析。`tcpdump` 命令在网络层面进行故障排除时变得非常方便。
|
||||
|
||||

|
||||
|
||||
tcpdump 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux,可以使用 apt 命令安装它
|
||||
`tcpdump` 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux,可以使用 `apt` 命令安装它。
|
||||
|
||||
```
|
||||
# apt install tcpdump -y
|
||||
```
|
||||
|
||||
在基于 RPM 的 Linux 操作系统上,可以使用下面的 yum 命令安装 tcpdump
|
||||
在基于 RPM 的 Linux 操作系统上,可以使用下面的 `yum` 命令安装 `tcpdump`。
|
||||
|
||||
```
|
||||
# yum install tcpdump -y
|
||||
```
|
||||
|
||||
当我们在没用任何选项的情况下运行 tcpdump 命令时,它将捕获所有接口的数据包。因此,要停止或取消 tcpdump 命令,请输入 '**ctrl+c**'。在本教程中,我们将使用不同的实例来讨论如何捕获和分析数据包,
|
||||
当我们在没用任何选项的情况下运行 `tcpdump` 命令时,它将捕获所有接口的数据包。因此,要停止或取消 `tcpdump` 命令,请键入 `ctrl+c`。在本教程中,我们将使用不同的实例来讨论如何捕获和分析数据包。
|
||||
|
||||
### 示例: 1) 从特定接口捕获数据包
|
||||
### 示例:1)从特定接口捕获数据包
|
||||
|
||||
当我们在没用任何选项的情况下运行 tcpdump 命令时,它将捕获所有接口上的数据包,因此,要从特定接口捕获数据包,请使用选项 '**-i**',后跟接口名称。
|
||||
当我们在没用任何选项的情况下运行 `tcpdump` 命令时,它将捕获所有接口上的数据包,因此,要从特定接口捕获数据包,请使用选项 `-i`,后跟接口名称。
|
||||
|
||||
语法:
|
||||
|
||||
@ -28,7 +29,7 @@ tcpdump 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux
|
||||
# tcpdump -i {接口名}
|
||||
```
|
||||
|
||||
假设我想从接口“enp0s3”捕获数据包
|
||||
假设我想从接口 `enp0s3` 捕获数据包。
|
||||
|
||||
输出将如下所示,
|
||||
|
||||
@ -49,21 +50,21 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
|
||||
```
|
||||
|
||||
### 示例: 2) 从特定接口捕获特定数量数据包
|
||||
### 示例:2)从特定接口捕获特定数量数据包
|
||||
|
||||
假设我们想从特定接口(如“enp0s3”)捕获12个数据包,这可以使用选项 '**-c {数量} -I {接口名称}**' 轻松实现
|
||||
假设我们想从特定接口(如 `enp0s3`)捕获 12 个数据包,这可以使用选项 `-c {数量} -I {接口名称}` 轻松实现。
|
||||
|
||||
```
|
||||
root@compute-0-1 ~]# tcpdump -c 12 -i enp0s3
|
||||
```
|
||||
|
||||
上面的命令将生成如下所示的输出
|
||||
上面的命令将生成如下所示的输出,
|
||||
|
||||
[![N-Number-Packsets-tcpdump-interface][1]][2]
|
||||
|
||||
### 示例: 3) 显示 tcpdump 的所有可用接口
|
||||
### 示例:3)显示 tcpdump 的所有可用接口
|
||||
|
||||
使用 '**-D**' 选项显示 tcpdump 命令的所有可用接口,
|
||||
使用 `-D` 选项显示 `tcpdump` 命令的所有可用接口,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -D
|
||||
@ -86,11 +87,11 @@ root@compute-0-1 ~]# tcpdump -c 12 -i enp0s3
|
||||
[[email protected] ~]#
|
||||
```
|
||||
|
||||
我正在我的一个openstack计算节点上运行tcpdump命令,这就是为什么在输出中你会看到数字接口、标签接口、网桥和vxlan接口
|
||||
我正在我的一个 openstack 计算节点上运行 `tcpdump` 命令,这就是为什么在输出中你会看到数字接口、标签接口、网桥和 vxlan 接口
|
||||
|
||||
### 示例: 4) 捕获带有可读时间戳(-tttt 选项)的数据包
|
||||
### 示例:4)捕获带有可读时间戳的数据包(`-tttt` 选项)
|
||||
|
||||
默认情况下,在tcpdump命令输出中,没有显示可读性好的时间戳,如果您想将可读性好的时间戳与每个捕获的数据包相关联,那么使用 '**-tttt**'选项,示例如下所示,
|
||||
默认情况下,在 `tcpdump` 命令输出中,不显示可读性好的时间戳,如果您想将可读性好的时间戳与每个捕获的数据包相关联,那么使用 `-tttt` 选项,示例如下所示,
|
||||
|
||||
```
|
||||
[[email protected] ~]# tcpdump -c 8 -tttt -i enp0s3
|
||||
@ -108,12 +109,11 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
134 packets received by filter
|
||||
69 packets dropped by kernel
|
||||
[[email protected] ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例: 5) 捕获数据包并将其保存到文件( -w 选项)
|
||||
### 示例:5)捕获数据包并将其保存到文件(`-w` 选项)
|
||||
|
||||
使用 tcpdump 命令中的 '**-w**' 选项将捕获的 TCP/IP 数据包保存到一个文件中,以便我们可以在将来分析这些数据包以供进一步分析。
|
||||
使用 `tcpdump` 命令中的 `-w` 选项将捕获的 TCP/IP 数据包保存到一个文件中,以便我们可以在将来分析这些数据包以供进一步分析。
|
||||
|
||||
语法:
|
||||
|
||||
@ -121,9 +121,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
# tcpdump -w 文件名.pcap -i {接口名}
|
||||
```
|
||||
|
||||
注意:文件扩展名必须为 **.pcap**
|
||||
注意:文件扩展名必须为 `.pcap`。
|
||||
|
||||
假设我要把 '**enp0s3**' 接口捕获到的包保存到文件名为 **enp0s3-26082018.pcap**
|
||||
假设我要把 `enp0s3` 接口捕获到的包保存到文件名为 `enp0s3-26082018.pcap`。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018.pcap -i enp0s3
|
||||
@ -140,24 +140,23 @@ tcpdump: listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 b
|
||||
[root@compute-0-1 ~]# ls
|
||||
anaconda-ks.cfg enp0s3-26082018.pcap
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
捕获并保存大小**大于 N 字节**的数据包
|
||||
捕获并保存大小**大于 N 字节**的数据包。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-2.pcap greater 1024
|
||||
```
|
||||
|
||||
捕获并保存大小**小于 N 字节**的数据包
|
||||
捕获并保存大小**小于 N 字节**的数据包。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-3.pcap less 1024
|
||||
```
|
||||
|
||||
### 示例: 6) 从保存的文件中读取数据包( -r 选项)
|
||||
### 示例:6)从保存的文件中读取数据包(`-r` 选项)
|
||||
|
||||
在上面的例子中,我们已经将捕获的数据包保存到文件中,我们可以使用选项 '**-r**' 从文件中读取这些数据包,例子如下所示,
|
||||
在上面的例子中,我们已经将捕获的数据包保存到文件中,我们可以使用选项 `-r` 从文件中读取这些数据包,例子如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -r enp0s3-26082018.pcap
|
||||
@ -183,12 +182,11 @@ p,TS val 81359114 ecr 81350901], length 508
|
||||
2018-08-25 22:03:17.647502 IP controller0.example.com.amqp > compute-0-1.example.com.57788: Flags [.], ack 1956, win 1432, options [nop,nop,TS val 813
|
||||
52753 ecr 81359114], length 0
|
||||
.........................................................................................................................
|
||||
|
||||
```
|
||||
|
||||
### 示例: 7) 仅捕获特定接口上的 IP 地址数据包( -n 选项)
|
||||
### 示例:7)仅捕获特定接口上的 IP 地址数据包(`-n` 选项)
|
||||
|
||||
使用 tcpdump 命令中的 -n 选项,我们能只捕获特定接口上的 IP 地址数据包,示例如下所示,
|
||||
使用 `tcpdump` 命令中的 `-n` 选项,我们能只捕获特定接口上的 IP 地址数据包,示例如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3
|
||||
@ -211,19 +209,18 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:22:28.539595 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 1572, win 9086, options [nop,nop,TS val 20666614 ecr 82510006], length 0
|
||||
22:22:28.539760 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 1572:1912, ack 1, win 291, options [nop,nop,TS val 82510007 ecr 20666614], length 340
|
||||
.........................................................................
|
||||
|
||||
```
|
||||
|
||||
您还可以使用 tcpdump 命令中的 -c 和 -N 选项捕获 N 个 IP 地址包,
|
||||
您还可以使用 `tcpdump` 命令中的 `-c` 和 `-N` 选项捕获 N 个 IP 地址包,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 25 -n -i enp0s3
|
||||
```
|
||||
|
||||
|
||||
### 示例: 8) 仅捕获特定接口上的TCP数据包
|
||||
### 示例:8)仅捕获特定接口上的 TCP 数据包
|
||||
|
||||
在 tcpdump 命令中,我们能使用 '**tcp**' 选项来只捕获TCP数据包,
|
||||
在 `tcpdump` 命令中,我们能使用 `tcp` 选项来只捕获 TCP 数据包,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -i enp0s3 tcp
|
||||
@ -241,9 +238,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
...................................................................................................................................................
|
||||
```
|
||||
|
||||
### 示例: 9) 从特定接口上的特定端口捕获数据包
|
||||
### 示例:9)从特定接口上的特定端口捕获数据包
|
||||
|
||||
使用 tcpdump 命令,我们可以从特定接口 enp0s3 上的特定端口(例如 22 )捕获数据包
|
||||
使用 `tcpdump` 命令,我们可以从特定接口 `enp0s3` 上的特定端口(例如 22)捕获数据包。
|
||||
|
||||
语法:
|
||||
|
||||
@ -262,13 +259,12 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:54:55.038564 IP 169.144.0.1.39406 > compute-0-1.example.com.ssh: Flags [.], ack 940, win 9177, options [nop,nop,TS val 21153238 ecr 84456505], length 0
|
||||
22:54:55.038708 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 940:1304, ack 1, win 291, options [nop,nop,TS val 84456506 ecr 21153238], length 364
|
||||
............................................................................................................................
|
||||
[root@compute-0-1 ~]#
|
||||
```
|
||||
|
||||
|
||||
### 示例: 10) 在特定接口上捕获来自特定来源 IP 的数据包
|
||||
### 示例:10)在特定接口上捕获来自特定来源 IP 的数据包
|
||||
|
||||
在tcpdump命令中,使用 '**src**' 关键字后跟 '**IP 地址**',我们可以捕获来自特定来源 IP 的数据包,
|
||||
在 `tcpdump` 命令中,使用 `src` 关键字后跟 IP 地址,我们可以捕获来自特定来源 IP 的数据包,
|
||||
|
||||
语法:
|
||||
|
||||
@ -296,17 +292,16 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
10 packets captured
|
||||
12 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例: 11) 在特定接口上捕获来自特定目的IP的数据包
|
||||
### 示例:11)在特定接口上捕获来自特定目的 IP 的数据包
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -n -i {接口名} dst {IP 地址}
|
||||
```
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3 dst 169.144.0.1
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
@ -318,42 +313,39 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
23:10:43.522157 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 800:996, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
23:10:43.522346 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 996:1192, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
.........................................................................................
|
||||
|
||||
```
|
||||
|
||||
### 示例: 12) 捕获两台主机之间的 TCP 数据包通信
|
||||
### 示例:12)捕获两台主机之间的 TCP 数据包通信
|
||||
|
||||
假设我想捕获两台主机 169.144.0.1 和 169.144.0.20 之间的 TCP 数据包,示例如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w two-host-tcp-comm.pcap -i enp0s3 tcp and \(host 169.144.0.1 or host 169.144.0.20\)
|
||||
|
||||
```
|
||||
|
||||
使用 tcpdump 命令只捕获两台主机之间的 SSH 数据包流,
|
||||
使用 `tcpdump` 命令只捕获两台主机之间的 SSH 数据包流,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w ssh-comm-two-hosts.pcap -i enp0s3 src 169.144.0.1 and port 22 and dst 169.144.0.20 and port 22
|
||||
|
||||
```
|
||||
|
||||
示例: 13) 捕获两台主机之间的 UDP 网络数据包(来回)
|
||||
### 示例:13)捕获两台主机之间(来回)的 UDP 网络数据包
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -w -s -i udp and \(host and host \)
|
||||
```
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w two-host-comm.pcap -s 1000 -i enp0s3 udp and \(host 169.144.0.10 and host 169.144.0.20\)
|
||||
|
||||
```
|
||||
|
||||
### 示例: 14) 捕获十六进制和ASCII格式的数据包
|
||||
### 示例:14)捕获十六进制和 ASCII 格式的数据包
|
||||
|
||||
使用 tcpdump 命令,我们可以以 ASCII 和十六进制格式捕获 TCP/IP 数据包,
|
||||
使用 `tcpdump` 命令,我们可以以 ASCII 和十六进制格式捕获 TCP/IP 数据包,
|
||||
|
||||
要使用** -A **选项捕获ASCII格式的数据包,示例如下所示:
|
||||
要使用 `-A` 选项捕获 ASCII 格式的数据包,示例如下所示:
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -A -i enp0s3
|
||||
@ -376,7 +368,7 @@ root@compute-0-1 @..........
|
||||
..................................................................................................................................................
|
||||
```
|
||||
|
||||
要同时以十六进制和 ASCII 格式捕获数据包,请使用** -XX **选项
|
||||
要同时以十六进制和 ASCII 格式捕获数据包,请使用 `-XX` 选项。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -XX -i enp0s3
|
||||
@ -406,10 +398,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
0x0030: 3693 7c0e 0000 0101 080a 015a a734 0568 6.|........Z.4.h
|
||||
0x0040: 39af
|
||||
.......................................................................
|
||||
|
||||
```
|
||||
|
||||
这就是本文的全部内容,我希望您能了解如何使用 tcpdump 命令捕获和分析 TCP/IP 数据包。请分享你的反馈和评论。
|
||||
这就是本文的全部内容,我希望您能了解如何使用 `tcpdump` 命令捕获和分析 TCP/IP 数据包。请分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -418,7 +409,7 @@ via: https://www.linuxtechi.com/capture-analyze-packets-tcpdump-command-linux/
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,17 +1,17 @@
|
||||
使用 `top` 命令了解 Fedora 的内存使用情况
|
||||
使用 top 命令了解 Fedora 的内存使用情况
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你使用过 `top` 命令来查看 Fedora 系统中的内存使用情况,你可能会惊讶,显示的数值看起来比系统可用的内存消耗更多。下面会详细介绍内存使用情况以及如何理解这些数据。
|
||||
如果你使用过 `top` 命令来查看 Fedora 系统中的内存使用情况,你可能会惊讶,看起来消耗的数量比系统可用的内存更多。下面会详细介绍内存使用情况以及如何理解这些数据。
|
||||
|
||||
### 内存实际使用情况
|
||||
|
||||
操作系统对内存的使用方式并不是太通俗易懂,而是有很多不为人知的巧妙方式。通过这些方式,可以在无需用户干预的情况下,让操作系统更有效地使用内存。
|
||||
操作系统对内存的使用方式并不是太通俗易懂。事实上,其背后有很多不为人知的巧妙技术在发挥着作用。通过这些方式,可以在无需用户干预的情况下,让操作系统更有效地使用内存。
|
||||
|
||||
大多数应用程序都不是系统自带的,但每个应用程序都依赖于安装在系统中的库中的一些函数集。在 Fedora 中,RPM 包管理系统能够确保在安装应用程序时也会安装所依赖的库。
|
||||
|
||||
当应用程序运行时,操作系统并不需要将它要用到的所有信息都加载到物理内存中。而是会为存放代码的存储构建一个映射,称为虚拟内存。操作系统只把需要的部分加载到内存中,当某一个部分不再需要后,这一部分内存就会被释放掉。
|
||||
当应用程序运行时,操作系统并不需要将它要用到的所有信息都加载到物理内存中。而是会为存放代码的存储空间构建一个映射,称为虚拟内存。操作系统只把需要的部分加载到内存中,当某一个部分不再需要后,这一部分内存就会被释放掉。
|
||||
|
||||
这意味着应用程序可以映射大量的虚拟内存,而使用较少的系统物理内存。特殊情况下,映射的虚拟内存甚至可以比系统实际可用的物理内存更多!而且在操作系统中这种情况也并不少见。
|
||||
|
||||
@ -21,25 +21,25 @@
|
||||
|
||||
### 使用 `top` 命令查看内存使用量
|
||||
|
||||
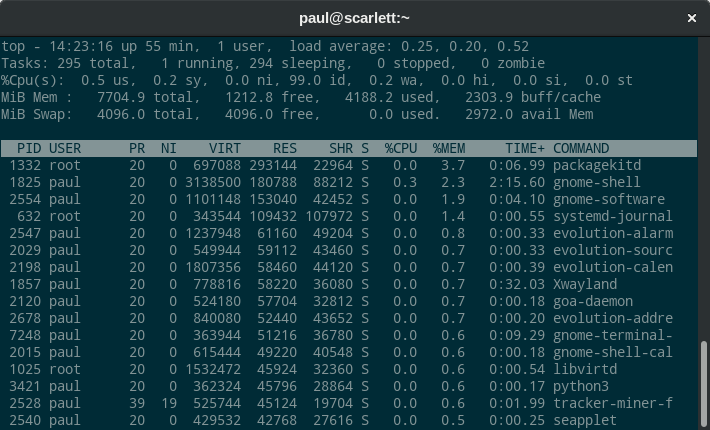
如果你还没有使用过 `top` 命令,可以打开终端直接执行查看。使用 **Shift + M** 可以按照内存使用量来进行排序。下图是在 Fedora Workstation 中执行的结果,在你的机器上显示的结果可能会略有不同:
|
||||
如果你还没有使用过 `top` 命令,可以打开终端直接执行查看。使用 `Shift + M` 可以按照内存使用量来进行排序。下图是在 Fedora Workstation 中执行的结果,在你的机器上显示的结果可能会略有不同:
|
||||
|
||||
|
||||
|
||||
主要通过一下三列来查看内存使用情况:VIRT,RES 和 SHR。目前以 KB 为单位显示相关数值。
|
||||
主要通过以下三列来查看内存使用情况:`VIRT`、`RES` 和 `SHR`。目前以 KB 为单位显示相关数值。
|
||||
|
||||
VIRT 列代表该进程映射的虚拟内存。如上所述,虚拟内存不是实际消耗的物理内存。例如, GNOME Shell 进程 gnome-shell 实际上没有消耗超过 3.1 GB 的物理内存,但它对很多更低或更高级的库都有依赖,系统必须对每个库都进行映射,以确保在有需要时可以加载这些库。
|
||||
`VIRT` 列代表该进程映射的<ruby>虚拟<rt>virtual</rt></ruby>内存。如上所述,虚拟内存不是实际消耗的物理内存。例如, GNOME Shell 进程 `gnome-shell` 实际上没有消耗超过 3.1 GB 的物理内存,但它对很多更低或更高级的库都有依赖,系统必须对每个库都进行映射,以确保在有需要时可以加载这些库。
|
||||
|
||||
RES 列代表应用程序消耗了多少实际(驻留)内存。对于 GNOME Shell 大约是 180788 KB。例子中的系统拥有大约 7704 MB 的物理内存,因此内存使用率显示为 2.3%。
|
||||
`RES` 列代表应用程序消耗了多少实际(<ruby>驻留<rt>resident</rt></ruby>)内存。对于 GNOME Shell 大约是 180788 KB。例子中的系统拥有大约 7704 MB 的物理内存,因此内存使用率显示为 2.3%。
|
||||
|
||||
但根据 SHR 列显示,其中至少有 88212 KB 是共享内存,这部分内存可能是其它应用程序也在使用的库函数。这意味着 GNOME Shell 本身大约有 92 MB 内存不与其他进程共享。需要注意的是,上述例子中的其它程序也共享了很多内存。在某些应用程序中,共享内存在内存使用量中会占很大的比例。
|
||||
但根据 `SHR` 列显示,其中至少有 88212 KB 是<ruby>共享<rt>shared</rt></ruby>内存,这部分内存可能是其它应用程序也在使用的库函数。这意味着 GNOME Shell 本身大约有 92 MB 内存不与其他进程共享。需要注意的是,上述例子中的其它程序也共享了很多内存。在某些应用程序中,共享内存在内存使用量中会占很大的比例。
|
||||
|
||||
值得一提的是,有时进程之间通过内存通信,这些内存也是共享的,但 `top` 工具却不一定能检测到,所以以上的说明也不一定准确。(这一句不太会翻译出来,烦请校对大佬帮忙看看,谢谢)
|
||||
值得一提的是,有时进程之间通过内存通信,这些内存也是共享的,但 `top` 这样的工具却不一定能检测到,所以以上的说明也不一定准确。
|
||||
|
||||
### 关于交换分区
|
||||
|
||||
系统还可以通过交换分区来存储数据(例如硬盘),但读写的速度相对较慢。当物理内存渐渐用满,操作系统就会查找内存中暂时不会使用的部分,将其写出到交换区域等待需要的时候使用。
|
||||
|
||||
因此,如果交换内存的使用量一直偏高,表明系统的物理内存已经供不应求了。尽管错误的内存申请也有可能导致出现这种情况,但如果这种现象经常出现,就需要考虑提升物理内存或者限制某些程序的运行了。
|
||||
因此,如果交换内存的使用量一直偏高,表明系统的物理内存已经供不应求了。有时候一个不正常的应用也有可能导致出现这种情况,但如果这种现象经常出现,就需要考虑提升物理内存或者限制某些程序的运行了。
|
||||
|
||||
感谢 [Stig Nygaard][1] 在 [Flickr][2] 上提供的图片(CC BY 2.0)。
|
||||
|
||||
@ -50,7 +50,7 @@ via: https://fedoramagazine.org/understand-fedora-memory-usage-top/
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,206 +0,0 @@
|
||||
GraveAccent 翻译中 Conditional Rendering in React using Ternaries and Logical AND
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Photo by [Brendan Church][1] on [Unsplash][2]
|
||||
|
||||
There are several ways that your React component can decide what to render. You can use the traditional `if` statement or the `switch` statement. In this article, we’ll explore a few alternatives. But be warned that some come with their own gotchas, if you’re not careful.
|
||||
|
||||
### Ternary vs if/else
|
||||
|
||||
Let’s say we have a component that is passed a `name` prop. If the string is non-empty, we display a greeting. Otherwise we tell the user they need to sign in.
|
||||
|
||||
Here’s a Stateless Function Component (SFC) that does just that.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => {
|
||||
if (name) {
|
||||
return (
|
||||
<div className="hello">
|
||||
Hello {name}
|
||||
</div>
|
||||
);
|
||||
}
|
||||
return (
|
||||
<div className="hello">
|
||||
Please sign in
|
||||
</div>
|
||||
);
|
||||
};
|
||||
```
|
||||
|
||||
Pretty straightforward. But we can do better. Here’s the same component written using a conditional ternary operator.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => (
|
||||
<div className="hello">
|
||||
{name ? `Hello ${name}` : 'Please sign in'}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
Notice how concise this code is compared to the example above.
|
||||
|
||||
A few things to note. Because we are using the single statement form of the arrow function, the `return` statement is implied. Also, using a ternary allowed us to DRY up the duplicate `<div className="hello">` markup. 🎉
|
||||
|
||||
### Ternary vs Logical AND
|
||||
|
||||
As you can see, ternaries are wonderful for `if/else` conditions. But what about simple `if` conditions?
|
||||
|
||||
Let’s look at another example. If `isPro` (a boolean) is `true`, we are to display a trophy emoji. We are also to render the number of stars (if not zero). We could go about it like this.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro ? '🏆' : null}
|
||||
</div>
|
||||
{stars ? (
|
||||
<div>
|
||||
Stars:{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
) : null}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
But notice the “else” conditions return `null`. This is becasue a ternary expects an else condition.
|
||||
|
||||
For simple `if` conditions, we could use something a little more fitting: the logical AND operator. Here’s the same code written using a logical AND.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro && '🏆'}
|
||||
</div>
|
||||
{stars && (
|
||||
<div>
|
||||
Stars:{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
Not too different, but notice how we eliminated the `: null` (i.e. else condition) at the end of each ternary. Everything should render just like it did before.
|
||||
|
||||
|
||||
Hey! What gives with John? There is a `0` when nothing should be rendered. That’s the gotcha that I was referring to above. Here’s why.
|
||||
|
||||
[According to MDN][3], a Logical AND (i.e. `&&`):
|
||||
|
||||
> `expr1 && expr2`
|
||||
|
||||
> Returns `expr1` if it can be converted to `false`; otherwise, returns `expr2`. Thus, when used with Boolean values, `&&` returns `true` if both operands are true; otherwise, returns `false`.
|
||||
|
||||
OK, before you start pulling your hair out, let me break it down for you.
|
||||
|
||||
In our case, `expr1` is the variable `stars`, which has a value of `0`. Because zero is falsey, `0` is returned and rendered. See, that wasn’t too bad.
|
||||
|
||||
I would write this simply.
|
||||
|
||||
> If `expr1` is falsey, returns `expr1`, else returns `expr2`.
|
||||
|
||||
So, when using a logical AND with non-boolean values, we must make the falsey value return something that React won’t render. Say, like a value of `false`.
|
||||
|
||||
There are a few ways that we can accomplish this. Let’s try this instead.
|
||||
|
||||
```
|
||||
{!!stars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
```
|
||||
|
||||
Notice the double bang operator (i.e. `!!`) in front of `stars`. (Well, actually there is no “double bang operator”. We’re just using the bang operator twice.)
|
||||
|
||||
The first bang operator will coerce the value of `stars` into a boolean and then perform a NOT operation. If `stars` is `0`, then `!stars` will produce `true`.
|
||||
|
||||
Then we perform a second NOT operation, so if `stars` is 0, `!!stars` would produce `false`. Exactly what we want.
|
||||
|
||||
If you’re not a fan of `!!`, you can also force a boolean like this (which I find a little wordy).
|
||||
|
||||
```
|
||||
{Boolean(stars) && (
|
||||
```
|
||||
|
||||
Or simply give a comparator that results in a boolean value (which some might say is even more semantic).
|
||||
|
||||
```
|
||||
{stars > 0 && (
|
||||
```
|
||||
|
||||
#### A word on strings
|
||||
|
||||
Empty string values suffer the same issue as numbers. But because a rendered empty string is invisible, it’s not a problem that you will likely have to deal with, or will even notice. However, if you are a perfectionist and don’t want an empty string on your DOM, you should take similar precautions as we did for numbers above.
|
||||
|
||||
### Another solution
|
||||
|
||||
A possible solution, and one that scales to other variables in the future, would be to create a separate `shouldRenderStars` variable. Then you are dealing with boolean values in your logical AND.
|
||||
|
||||
```
|
||||
const shouldRenderStars = stars > 0;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
Then, if in the future, the business rule is that you also need to be logged in, own a dog, and drink light beer, you could change how `shouldRenderStars` is computed, and what is returned would remain unchanged. You could also place this logic elsewhere where it’s testable and keep the rendering explicit.
|
||||
|
||||
```
|
||||
const shouldRenderStars =
|
||||
stars > 0 && loggedIn && pet === 'dog' && beerPref === 'light`;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
I’m of the opinion that you should make best use of the language. And for JavaScript, this means using conditional ternary operators for `if/else`conditions and logical AND operators for simple `if` conditions.
|
||||
|
||||
While we could just retreat back to our safe comfy place where we use the ternary operator everywhere, you now possess the knowledge and power to go forth AND prosper.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Managing Editor at the American Express Engineering Blog http://aexp.io and Director of Engineering @AmericanExpress. MyViews !== ThoseOfMyEmployer.
|
||||
|
||||
----------------
|
||||
|
||||
via: https://medium.freecodecamp.org/conditional-rendering-in-react-using-ternaries-and-logical-and-7807f53b6935
|
||||
|
||||
作者:[Donavon West][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@donavon
|
||||
[1]:https://unsplash.com/photos/pKeF6Tt3c08?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[2]:https://unsplash.com/search/photos/road-sign?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Logical_Operators
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension)
|
||||
======
|
||||
A Unity feature that I miss (it only actually worked for a short while though) is automatically getting player controls in the Ubuntu Sound Indicator when visiting a website like YouTube in a web browser, so you could pause or stop the video directly from the top bar, as well as see the video / song information and a preview.
|
||||
|
||||
@ -1,49 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Force APT Package Manager To Use IPv4 In Ubuntu 16.04
|
||||
======
|
||||
|
||||

|
||||
|
||||
**APT** , short or **A** dvanced **P** ackage **T** ool, is the default package manager for Debian-based systems. Using APT, we can install, update, upgrade and remove applications from the system. Lately, I have been facing a strange error. Whenever I try update my Ubuntu 16.04 box, I get this error – **“0% [Connecting to in.archive.ubuntu.com (2001:67c:1560:8001::14)]”** and the update process gets stuck for a long time. My Internet connection is working well and I can able to ping all websites including Ubuntu official site. After a couple Google searches, I realized that sometimes the Ubuntu mirrors are not reachable over IPv6. This problem is solved after I force APT package manager to use IPv4 in place of IPv6 to access Ubuntu mirrors while updating the system. If you ever encountered with this error, you can solve it as described below.
|
||||
|
||||
### Force APT Package Manager To Use IPv4 In Ubuntu 16.04
|
||||
|
||||
To force APT to use IPv4 in place of IPv6 while updating and upgrading your Ubuntu 16.04 LTS systems, simply use the following commands:
|
||||
|
||||
```
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true update
|
||||
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true upgrade
|
||||
```
|
||||
|
||||
Voila! This time update process run and completed quickly.
|
||||
|
||||
You can also make this persistent for all **apt-get** transactions in the future by adding the following line in **/etc/apt/apt.conf.d/99force-ipv4** file using command:
|
||||
|
||||
```
|
||||
$ echo 'Acquire::ForceIPv4 "true";' | sudo tee /etc/apt/apt.conf.d/99force-ipv4
|
||||
```
|
||||
|
||||
**Disclaimer:**
|
||||
|
||||
I don’t know if anyone is having this issue lately, but I kept getting this error today at least four to five times in my Ubuntu 16.04 LTS virtual machine and I solved it as described above. I am not sure that it is the recommended solution. Go through Ubuntu forums and make sure this method is legitimate. Since mine is just a VM which I use it only for testing and learning purposes, I don’t mind about the authenticity of this method. Use it on your own risk.
|
||||
|
||||
Hope this helps. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-force-apt-package-manager-to-use-ipv4-in-ubuntu-16-04/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,205 @@
|
||||
在 React 条件渲染中使用三元表达式和 “&&”
|
||||
============================================================
|
||||
|
||||

|
||||
Photo by [Brendan Church][1] on [Unsplash][2]
|
||||
|
||||
React 组件可以通过多种方式决定渲染内容。你可以使用传统的 if 语句或 switch 语句。在本文中,我们将探讨一些替代方案。但要注意,如果你不小心,有些方案会带来自己的陷阱。
|
||||
|
||||
### 三元表达式 vs if/else
|
||||
|
||||
假设我们有一个组件被传进来一个 `name` prop。 如果这个字符串非空,我们会显示一个问候语。否则,我们会告诉用户他们需要登录。
|
||||
|
||||
这是一个只实现了如上功能的无状态函数式组件。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => {
|
||||
if (name) {
|
||||
return (
|
||||
<div className="hello">
|
||||
Hello {name}
|
||||
</div>
|
||||
);
|
||||
}
|
||||
return (
|
||||
<div className="hello">
|
||||
Please sign in
|
||||
</div>
|
||||
);
|
||||
};
|
||||
```
|
||||
|
||||
这个很简单但是我们可以做得更好。这是使用三元运算符编写的相同组件。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => (
|
||||
<div className="hello">
|
||||
{name ? `Hello ${name}` : 'Please sign in'}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
请注意这段代码与上面的例子相比是多么简洁。
|
||||
|
||||
有几点需要注意。因为我们使用了箭头函数的单语句形式,所以隐含了return语句。另外,使用三元运算符允许我们省略掉重复的 `<div className="hello">` 标记。🎉
|
||||
|
||||
### 三元表达式 vs &&
|
||||
|
||||
正如您所看到的,三元表达式用于表达 if/else 条件式非常好。但是对于简单的 if 条件式怎么样呢?
|
||||
|
||||
让我们看另一个例子。如果 isPro(一个布尔值)为真,我们将显示一个奖杯表情符号。我们也要渲染星星的数量(如果不是0)。我们可以这样写。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro ? '🏆' : null}
|
||||
</div>
|
||||
{stars ? (
|
||||
<div>
|
||||
Stars:{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
) : null}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
请注意 “else” 条件返回 null 。 这是因为三元表达式要有"否则"条件。
|
||||
|
||||
对于简单的 “if” 条件式,我们可以使用更合适的东西:&& 运算符。这是使用 “&&” 编写的相同代码。
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro && '🏆'}
|
||||
</div>
|
||||
{stars && (
|
||||
<div>
|
||||
Stars:{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
没有太多区别,但是注意我们消除了每个三元表达式最后面的 `: null` (else 条件式)。一切都应该像以前一样渲染。
|
||||
|
||||
|
||||
嘿!约翰得到了什么?当什么都不应该渲染时,只有一个0。这就是我上面提到的陷阱。这里有解释为什么。
|
||||
|
||||
[根据 MDN][3],一个逻辑运算符“和”(也就是`&&`):
|
||||
|
||||
> `expr1 && expr2`
|
||||
|
||||
> 如果 `expr1` 可以被转换成 `false` ,返回 `expr1`;否则返回 `expr2`。 如此,当与布尔值一起使用时,如果两个操作数都是 true,`&&` 返回 `true` ;否则,返回 `false`。
|
||||
|
||||
好的,在你开始拔头发之前,让我为你解释它。
|
||||
|
||||
在我们这个例子里, `expr1` 是变量 `stars`,它的值是 `0`,因为0是 falsey 的值, `0` 会被返回和渲染。看,这还不算太坏。
|
||||
|
||||
我会简单地这么写。
|
||||
|
||||
> 如果 `expr1` 是 falsey,返回 `expr1` ,否则返回 `expr2`
|
||||
|
||||
所以,当对非布尔值使用 “&&” 时,我们必须让 falsy 的值返回 React 无法渲染的东西,比如说,`false` 这个值。
|
||||
|
||||
我们可以通过几种方式实现这一目标。让我们试试吧。
|
||||
|
||||
```
|
||||
{!!stars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
```
|
||||
|
||||
注意 `stars` 前的双感叹操作符( `!!`)(呃,其实没有双感叹操作符。我们只是用了感叹操作符两次)。
|
||||
|
||||
第一个感叹操作符会强迫 `stars` 的值变成布尔值并且进行一次“非”操作。如果 `stars` 是 `0` ,那么 `!stars` 会 是 `true`。
|
||||
|
||||
然后我们执行第二个`非`操作,所以如果 `stars` 是0,`!!stars` 会是 `false`。正好是我们想要的。
|
||||
|
||||
如果你不喜欢 `!!`,那么你也可以强制转换出一个布尔数比如这样(这种方式我觉得有点冗长)。
|
||||
|
||||
```
|
||||
{Boolean(stars) && (
|
||||
```
|
||||
|
||||
或者只是用比较符产生一个布尔值(有些人会说这样甚至更加语义化)。
|
||||
|
||||
```
|
||||
{stars > 0 && (
|
||||
```
|
||||
|
||||
#### 关于字符串
|
||||
|
||||
空字符串与数字有一样的毛病。但是因为渲染后的空字符串是不可见的,所以这不是那种你很可能会去处理的难题,甚至可能不会注意到它。然而,如果你是完美主义者并且不希望DOM上有空字符串,你应采取我们上面对数字采取的预防措施。
|
||||
|
||||
### 其它解决方案
|
||||
|
||||
一种可能的将来可扩展到其他变量的解决方案,是创建一个单独的 `shouldRenderStars` 变量。然后你用“&&”处理布尔值。
|
||||
|
||||
```
|
||||
const shouldRenderStars = stars > 0;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
之后,在将来,如果业务规则要求你还需要已登录,拥有一条狗以及喝淡啤酒,你可以改变 `shouldRenderStars` 的得出方式,而返回的内容保持不变。你还可以把这个逻辑放在其它可测试的地方,并且保持渲染明晰。
|
||||
|
||||
```
|
||||
const shouldRenderStars =
|
||||
stars > 0 && loggedIn && pet === 'dog' && beerPref === 'light`;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
我认为你应该充分利用这种语言。对于 JavaScript,这意味着为 `if/else` 条件式使用三元表达式,以及为 `if` 条件式使用 `&&` 操作符。
|
||||
|
||||
我们可以回到每处都使用三元运算符的舒适区,但你现在消化了这些知识和力量,可以继续前进 && 取得成功了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
美国运通工程博客的执行编辑 http://aexp.io 以及 @AmericanExpress 的工程总监。MyViews !== ThoseOfMyEmployer.
|
||||
|
||||
----------------
|
||||
|
||||
via: https://medium.freecodecamp.org/conditional-rendering-in-react-using-ternaries-and-logical-and-7807f53b6935
|
||||
|
||||
作者:[Donavon West][a]
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@donavon
|
||||
[1]:https://unsplash.com/photos/pKeF6Tt3c08?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[2]:https://unsplash.com/search/photos/road-sign?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Logical_Operators
|
||||
@ -0,0 +1,47 @@
|
||||
如何在 Ubuntu 16.04 强制 APT 包管理器使用 IPv4
|
||||
======
|
||||
|
||||

|
||||
|
||||
**APT**, 是 **A** dvanced **P** ackage **T** ool 的缩写,是基于 Debian 的系统的默认包管理器。我们可以使用 APT 安装、更新、升级和删除应用程序。最近,我一直遇到一个奇怪的错误。每当我尝试更新我的 Ubuntu 16.04 时,我都会收到此错误 - **“0% [Connecting to in.archive.ubuntu.com (2001:67c:1560:8001::14)]”** ,同时更新流程会卡住很长时间。我的网络连接没问题,我可以 ping 通所有网站,包括 Ubuntu 官方网站。在搜索了一番谷歌后,我意识到 Ubuntu 镜像有时无法通过 IPv6 访问。在我强制将 APT 包管理器在更新系统时使用 IPv4 代替 IPv6 访问 Ubuntu 镜像后,此问题得以解决。如果你遇到过此错误,可以按照以下说明解决。
|
||||
|
||||
### 强制 APT 包管理器在 Ubuntu 16.04 中使用 IPv4
|
||||
|
||||
要在更新和升级 Ubuntu 16.04 LTS 系统时强制 APT 使用 IPv4 代替 IPv6,只需使用以下命令:
|
||||
|
||||
```
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true update
|
||||
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true upgrade
|
||||
```
|
||||
|
||||
瞧!这次更新很快就完成了。
|
||||
|
||||
你还可以使用以下命令在 **/etc/apt/apt.conf.d/99force-ipv4** 中添加以下行,以便将来对所有 **apt-get** 事务保持持久性:
|
||||
|
||||
```
|
||||
$ echo 'Acquire::ForceIPv4 "true";' | sudo tee /etc/apt/apt.conf.d/99force-ipv4
|
||||
```
|
||||
|
||||
**免责声明:**
|
||||
|
||||
我不知道最近是否有人遇到这个问题,但我今天在我的 Ubuntu 16.04 LTS 虚拟机中遇到了至少四五次这样的错误,我按照上面的说法解决了这个问题。我不确定这是推荐的解决方案。请浏览 Ubuntu 论坛来确保此方法合法。由于我只是一个 VM,我只将它用于测试和学习目的,我不介意这种方法的真实性。请自行承担使用风险。
|
||||
|
||||
希望这有帮助。还有更多的好东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-force-apt-package-manager-to-use-ipv4-in-ubuntu-16-04/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
Loading…
Reference in New Issue
Block a user