mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge branch 'master' into 20200427
This commit is contained in:
commit
814f08265a
@ -0,0 +1,127 @@
|
||||
GNU 核心实用程序简介
|
||||
======
|
||||
|
||||
> 大多数 Linux 系统管理员需要做的事情都可以在 GNU coreutils 或 util-linux 中找到。
|
||||
|
||||

|
||||
|
||||
许多 Linux 系统管理员最基本和常用的工具主要包括在两套实用程序中:[GNU 核心实用程序(coreutils)][3]和 util-linux。它们的基本功能允许系统管理员执行许多管理 Linux 系统的任务,包括管理和操作文本文件、目录、数据流、存储介质、进程控制、文件系统等等。
|
||||
|
||||
这些工具是不可缺少的,因为没有它们,就不可能在 Unix 或 Linux 计算机上完成任何有用的工作。鉴于它们的重要性,让我们来研究一下它们。
|
||||
|
||||
### GNU coreutils
|
||||
|
||||
要了解 GNU 核心实用程序的起源,我们需要乘坐时光机进行一次短暂的旅行,回到贝尔实验室的 Unix 早期。[编写 Unix][8] 是为了让 Ken Thompson、Dennis Ritchie、Doug McIlroy 和 Joe Ossanna 可以继续他们在大型多任务和多用户计算机项目 [Multics][9] 上的工作:开发一个叫做《太空旅行》游戏的小东西。正如今天一样,推动计算技术发展的似乎总是游戏玩家。这个新的操作系统比 Multics(LCTT 译注:multi- 字头的意思是多数的)的局限性更大,因为一次只能有两个用户登录,所以被称为 Unics(LCTT 译注:uni- 字头的意思是单独的)。后来这个名字被改成了 Unix。
|
||||
|
||||
随着时间的推移,Unix 取得了如此巨大的成功,开始贝尔实验室基本上是将其赠送给大学,后来送给公司也只是收取介质和运输的费用。在那个年代,系统级的软件是在组织和程序员之间共享的,因为在系统管理这个层面,他们努力实现的是共同的目标。
|
||||
|
||||
最终,AT&T 公司的[老板们][10]决定,他们应该在 Unix 上赚钱,并开始使用限制更多的、昂贵的许可证。这发生在软件变得更加专有、受限和封闭的时期,从那时起,与其他用户和组织共享软件变得不可能。
|
||||
|
||||
有些人不喜欢这种情况,于是用自由软件来对抗。Richard M. Stallman(RMS),他带领着一群“反叛者”试图编写一个开放的、自由的可用操作系统,他们称之为 GNU 操作系统。这群人创建了 GNU 实用程序,但并没有产生一个可行的内核。
|
||||
|
||||
当 Linus Torvalds 开始编写和编译 Linux 内核时,他需要一套非常基本的系统实用程序来开始执行一些稍微有用的工作。内核并不提供命令或任何类型的命令 shell,比如 Bash,它本身是没有任何用处的,因此,Linus 使用了免费提供的 GNU 核心实用程序,并为 Linux 重新编译了它们。这让他拥有了一个完整的、即便是相当基本的操作系统。
|
||||
|
||||
你可以通过在终端命令行中输入命令 `info coreutils` 来了解 GNU 核心实用程序的全部内容。下面的核心实用程序列表就是这个信息页面的一部分。这些实用程序按功能进行了分组,以方便查找;在终端中,选择你想了解更多信息的组,然后按回车键。
|
||||
|
||||
```
|
||||
* Output of entire files:: cat tac nl od base32 base64
|
||||
* Formatting file contents:: fmt pr fold
|
||||
* Output of parts of files:: head tail split csplit
|
||||
* Summarizing files:: wc sum cksum b2sum md5sum sha1sum sha2
|
||||
* Operating on sorted files:: sort shuf uniq comm ptx tsort
|
||||
* Operating on fields:: cut paste join
|
||||
* Operating on characters:: tr expand unexpand
|
||||
* Directory listing:: ls dir vdir dircolors
|
||||
* Basic operations:: cp dd install mv rm shred
|
||||
* Special file types:: mkdir rmdir unlink mkfifo mknod ln link readlink
|
||||
* Changing file attributes:: chgrp chmod chown touch
|
||||
* Disk usage:: df du stat sync truncate
|
||||
* Printing text:: echo printf yes
|
||||
* Conditions:: false true test expr
|
||||
* Redirection:: tee
|
||||
* File name manipulation:: dirname basename pathchk mktemp realpath
|
||||
* Working context:: pwd stty printenv tty
|
||||
* User information:: id logname whoami groups users who
|
||||
* System context:: date arch nproc uname hostname hostid uptime
|
||||
* SELinux context:: chcon runcon
|
||||
* Modified command invocation:: chroot env nice nohup stdbuf timeout
|
||||
* Process control:: kill
|
||||
* Delaying:: sleep
|
||||
* Numeric operations:: factor numfmt seq
|
||||
```
|
||||
|
||||
这个列表里有 102 个实用程序。它涵盖了在 Unix 或 Linux 主机上执行基本任务所需的许多功能。但是,很多基本的实用程序都缺失了,例如,`mount` 和 `umount` 命令不在这个列表中。这些命令和其他许多不在 GNU 核心实用程序中的命令可以在 util-linux 中找到。
|
||||
|
||||
### util-linux
|
||||
|
||||
util-linix 实用程序包中包含了许多系统管理员常用的其它命令。这些实用程序是由 Linux 内核组织发布的,这 107 条命令中几乎每一个都来自原本是三个单独的集合 —— fileutils、shellutils 和 textutils,2003 年它们被[合并成一个包][11]:util-linux。
|
||||
|
||||
```
|
||||
agetty fsck.minix mkfs.bfs setpriv
|
||||
blkdiscard fsfreeze mkfs.cramfs setsid
|
||||
blkid fstab mkfs.minix setterm
|
||||
blockdev fstrim mkswap sfdisk
|
||||
cal getopt more su
|
||||
cfdisk hexdump mount sulogin
|
||||
chcpu hwclock mountpoint swaplabel
|
||||
chfn ionice namei swapoff
|
||||
chrt ipcmk newgrp swapon
|
||||
chsh ipcrm nologin switch_root
|
||||
colcrt ipcs nsenter tailf
|
||||
col isosize partx taskset
|
||||
colrm kill pg tunelp
|
||||
column last pivot_root ul
|
||||
ctrlaltdel ldattach prlimit umount
|
||||
ddpart line raw unshare
|
||||
delpart logger readprofile utmpdump
|
||||
dmesg login rename uuidd
|
||||
eject look renice uuidgen
|
||||
fallocate losetup reset vipw
|
||||
fdformat lsblk resizepart wall
|
||||
fdisk lscpu rev wdctl
|
||||
findfs lslocks RTC Alarm whereis
|
||||
findmnt lslogins runuser wipefs
|
||||
flock mcookie script write
|
||||
fsck mesg scriptreplay zramctl
|
||||
fsck.cramfs mkfs setarch
|
||||
```
|
||||
|
||||
这些实用程序中的一些已经被淘汰了,很可能在未来的某个时候会从集合中被踢出去。你应该看看[维基百科的 util-linux 页面][12]来了解其中许多实用程序的信息,而 man 页面也提供了关于这些命令的详细信息。
|
||||
|
||||
### 总结
|
||||
|
||||
这两个 Linux 实用程序的集合,GNU 核心实用程序和 util-linux,共同提供了管理 Linux 系统所需的基本实用程序。在研究这篇文章的过程中,我发现了几个有趣的实用程序,这些实用程序是我从不知道的。这些命令中的很多都是很少需要的,但当你需要的时候,它们是不可缺少的。
|
||||
|
||||
在这两个集合里,有 200 多个 Linux 实用工具。虽然 Linux 的命令还有很多,但这些都是管理一个典型的 Linux 主机的基本功能所需要的。
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/gnu-core-utilities][17]
|
||||
|
||||
作者: [David Both][18] 选题者: [lujun9972][19] 译者: [wxy][20] 校对: [wxy][21]
|
||||
|
||||
本文由 [LCTT][22] 原创编译,[Linux中国][23] 荣誉推出
|
||||
|
||||
[1]: https://pixabay.com/en/tiny-people-core-apple-apple-half-700921/
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.gnu.org/software/coreutils/coreutils.html
|
||||
[4]: https://opensource.com/life/17/10/top-terminal-emulators?intcmp=7016000000127cYAAQ
|
||||
[5]: https://opensource.com/article/17/2/command-line-tools-data-analysis-linux?intcmp=7016000000127cYAAQ
|
||||
[6]: https://opensource.com/downloads/advanced-ssh-cheat-sheet?intcmp=7016000000127cYAAQ
|
||||
[7]: https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=7016000000127cYAAQ
|
||||
[8]: https://en.wikipedia.org/wiki/History_of_Unix
|
||||
[9]: https://en.wikipedia.org/wiki/Multics
|
||||
[10]: https://en.wikipedia.org/wiki/Pointy-haired_Boss
|
||||
[11]: https://en.wikipedia.org/wiki/GNU_Core_Utilities
|
||||
[12]: https://en.wikipedia.org/wiki/Util-linux
|
||||
[13]: https://opensource.com/users/dboth
|
||||
[14]: https://opensource.com/users/dboth
|
||||
[15]: https://opensource.com/users/dboth
|
||||
[16]: https://opensource.com/participate
|
||||
[17]: https://opensource.com/article/18/4/gnu-core-utilities
|
||||
[18]: https://opensource.com/users/dboth
|
||||
[19]: https://github.com/lujun9972
|
||||
[20]: https://github.com/译者ID
|
||||
[21]: https://github.com/校对者ID
|
||||
[22]: https://github.com/LCTT/TranslateProject
|
||||
[23]: https://linux.cn/
|
||||
266
published/20180612 Systemd Services- Reacting to Change.md
Normal file
266
published/20180612 Systemd Services- Reacting to Change.md
Normal file
@ -0,0 +1,266 @@
|
||||
Systemd 服务:响应变化
|
||||
======
|
||||
|
||||

|
||||
|
||||
[我有一个这样的电脑棒][1](图1),我把它用作通用服务器。它很小且安静,由于它是基于 x86 架构的,因此我为我的打印机安装驱动没有任何问题,而且这就是它大多数时候干的事:与客厅的共享打印机和扫描仪通信。
|
||||
|
||||
![ComputeStick][3]
|
||||
|
||||
*一个英特尔电脑棒。欧元硬币大小。*
|
||||
|
||||
大多数时候它都是闲置的,尤其是当我们外出时,因此我认为用它作监视系统是个好主意。该设备没有自带的摄像头,也不需要一直监视。我也不想手动启动图像捕获,因为这样就意味着在出门前必须通过 SSH 登录,并在 shell 中编写命令来启动该进程。
|
||||
|
||||
因此,我以为应该这么做:拿一个 USB 摄像头,然后只需插入它即可自动启动监视系统。如果这个电脑棒重启后发现连接了摄像头也启动监视系统就更加分了。
|
||||
|
||||
在先前的文章中,我们看到 systemd 服务既可以[手动启动或停止][5],也可以[在满足某些条件时启动或停止][6]。这些条件不限于操作系统在启动或关机时序中达到某种状态,还可以在你插入新硬件或文件系统发生变化时进行。你可以通过将 Udev 规则与 systemd 服务结合起来实现。
|
||||
|
||||
### 有 Udev 支持的热插拔
|
||||
|
||||
Udev 规则位于 `/etc/udev/rules` 目录中,通常是由导致一个<ruby>动作<rt>action</rt></ruby>的<ruby>条件<rt>conditions</rt></ruby>和<ruby>赋值<rt>assignments</rt></ruby>的单行语句来描述。
|
||||
|
||||
有点神秘。让我们再解释一次:
|
||||
|
||||
通常,在 Udev 规则中,你会告诉 systemd 当设备连接时需要查看什么信息。例如,你可能想检查刚插入的设备的品牌和型号是否与你让 Udev 等待的设备的品牌和型号相对应。这些就是前面提到的“条件”。
|
||||
|
||||
然后,你可能想要更改一些内容,以便以后可以方便使用该设备。例如,更改设备的读写权限:如果插入 USB 打印机,你会希望用户能够从打印机读取信息(用户的打印应用程序需要知道其模型、制造商,以及是否准备好接受打印作业)并向其写入内容,即发送要打印的内容。更改设备的读写权限是通过你之前阅读的“赋值” 之一完成的。
|
||||
|
||||
最后,你可能希望系统在满足上述条件时执行某些动作,例如在插入某个外部硬盘时启动备份程序以复制重要文件。这就是上面提到的“动作”的例子。
|
||||
|
||||
了解这些之后, 来看看以下几点:
|
||||
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0", ATTRS{idProduct}=="e207",
|
||||
SYMLINK+="mywebcam", TAG+="systemd", MODE="0666", ENV{SYSTEMD_WANTS}="webcam.service"
|
||||
```
|
||||
|
||||
规则的第一部分,
|
||||
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
|
||||
ATTRS{idProduct}=="e207" [etc... ]
|
||||
```
|
||||
|
||||
表明了执行你想让系统执行的其他动作之前设备必须满足的条件。设备必须被添加到(`ACTION=="add"`)机器上,并且必须添加到 `video4linux` 子系统中。为了确保仅在插入正确的设备时才应用该规则,你必须确保 Udev 正确识别设备的制造商(`ATTRS{idVendor}=="03f0"`)和型号(`ATTRS{idProduct}=="e207"`)。
|
||||
|
||||
在本例中,我们讨论的是这个设备(图2):
|
||||
|
||||
![webcam][8]
|
||||
|
||||
*这个试验使用的是 HP 的摄像头。*
|
||||
|
||||
注意怎样用 `==` 来表示这是一个逻辑操作。你应该像这样阅读上面的简要规则:
|
||||
|
||||
> 如果添加了一个设备并且该设备由 video4linux 子系统控制,而且该设备的制造商编码是 03f0,型号是 e207,那么...
|
||||
|
||||
但是,你从哪里获取的这些信息?你在哪里找到触发事件的动作、制造商、型号等?你可要使用多个来源。你可以通过将摄像头插入机器并运行 `lsusb` 来获得 `IdVendor` 和 `idProduct` :
|
||||
|
||||
```
|
||||
lsusb
|
||||
Bus 002 Device 002: ID 8087:0024 Intel Corp. Integrated Rate Matching Hub
|
||||
Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
|
||||
Bus 004 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
|
||||
Bus 003 Device 003: ID 03f0:e207 Hewlett-Packard
|
||||
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
|
||||
Bus 001 Device 003: ID 04f2:b1bb Chicony Electronics Co., Ltd
|
||||
Bus 001 Device 002: ID 8087:0024 Intel Corp. Integrated Rate Matching Hub
|
||||
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
|
||||
```
|
||||
|
||||
我用的摄像头是 HP 的,你在上面的列表中只能看到一个 HP 设备。`ID` 提供了制造商和型号,它们以冒号(`:`)分隔。如果你有同一制造商的多个设备,不确定哪个是哪个设备,请拔下摄像头,再次运行 `lsusb` , 看看少了什么。
|
||||
|
||||
或者...
|
||||
|
||||
拔下摄像头,等待几秒钟,运行命令 `udevadmin monitor --environment` ,然后重新插入摄像头。当你使用的是HP摄像头时,你将看到:
|
||||
|
||||
```
|
||||
udevadmin monitor --environment
|
||||
UDEV [35776.495221] add /devices/pci0000:00/0000:00:1c.3/0000:04:00.0
|
||||
/usb3/3-1/3-1:1.0/input/input21/event11 (input)
|
||||
.MM_USBIFNUM=00
|
||||
ACTION=add
|
||||
BACKSPACE=guess
|
||||
DEVLINKS=/dev/input/by-path/pci-0000:04:00.0-usb-0:1:1.0-event
|
||||
/dev/input/by-id/usb-Hewlett_Packard_HP_Webcam_HD_2300-event-if00
|
||||
DEVNAME=/dev/input/event11
|
||||
DEVPATH=/devices/pci0000:00/0000:00:1c.3/0000:04:00.0/
|
||||
usb3/3-1/3-1:1.0/input/input21/event11
|
||||
ID_BUS=usb
|
||||
ID_INPUT=1
|
||||
ID_INPUT_KEY=1
|
||||
ID_MODEL=HP_Webcam_HD_2300
|
||||
ID_MODEL_ENC=HPx20Webcamx20HDx202300
|
||||
ID_MODEL_ID=e207
|
||||
ID_PATH=pci-0000:04:00.0-usb-0:1:1.0
|
||||
ID_PATH_TAG=pci-0000_04_00_0-usb-0_1_1_0
|
||||
ID_REVISION=1020
|
||||
ID_SERIAL=Hewlett_Packard_HP_Webcam_HD_2300
|
||||
ID_TYPE=video
|
||||
ID_USB_DRIVER=uvcvideo
|
||||
ID_USB_INTERFACES=:0e0100:0e0200:010100:010200:030000:
|
||||
ID_USB_INTERFACE_NUM=00
|
||||
ID_VENDOR=Hewlett_Packard
|
||||
ID_VENDOR_ENC=Hewlettx20Packard
|
||||
ID_VENDOR_ID=03f0
|
||||
LIBINPUT_DEVICE_GROUP=3/3f0/e207:usb-0000:04:00.0-1/button
|
||||
MAJOR=13
|
||||
MINOR=75
|
||||
SEQNUM=3162
|
||||
SUBSYSTEM=input
|
||||
USEC_INITIALIZED=35776495065
|
||||
XKBLAYOUT=es
|
||||
XKBMODEL=pc105
|
||||
XKBOPTIONS=
|
||||
XKBVARIANT=
|
||||
```
|
||||
|
||||
可能看起来有很多信息要处理,但是,看一下这个:列表前面的 `ACTION` 字段, 它告诉你刚刚发生了什么事件,即一个设备被添加到系统中。你还可以在其中几行中看到设备名称的拼写,因此可以非常确定它就是你要找的设备。输出里还显示了制造商的ID(`ID_VENDOR_ID = 03f0`)和型号(`ID_VENDOR_ID = 03f0`)。
|
||||
|
||||
这为你提供了规则条件部分需要的四个值中的三个。你可能也会想到它还给了你第四个,因为还有一行这样写道:
|
||||
|
||||
```
|
||||
SUBSYSTEM=input
|
||||
```
|
||||
|
||||
小心!尽管 USB 摄像头确实是提供输入的设备(键盘和鼠标也是),但它也属于 usb 子系统和其他几个子系统。这意味着你的摄像头被添加到了多个子系统,并且看起来像多个设备。如果你选择了错误的子系统,那么你的规则可能无法按你期望的那样工作,或者根本无法工作。
|
||||
|
||||
因此,第三件事就是检查网络摄像头被添加到的所有子系统,并选择正确的那个。为此,请再次拔下摄像头,然后运行:
|
||||
|
||||
```
|
||||
ls /dev/video*
|
||||
```
|
||||
|
||||
这将向你显示连接到本机的所有视频设备。如果你使用的是笔记本,大多数笔记本都带有内置摄像头,它可能会显示为 `/dev/video0` 。重新插入摄像头,然后再次运行 `ls /dev/video*`。
|
||||
|
||||
现在,你应该看到多一个视频设备(可能是`/dev/video1`)。
|
||||
|
||||
现在,你可以通过运行 `udevadm info -a /dev/video1` 找出它所属的所有子系统:
|
||||
|
||||
```
|
||||
udevadm info -a /dev/video1
|
||||
|
||||
Udevadm info starts with the device specified by the devpath and then
|
||||
walks up the chain of parent devices. It prints for every device
|
||||
found, all possible attributes in the udev rules key format.
|
||||
A rule to match, can be composed by the attributes of the device
|
||||
and the attributes from one single parent device.
|
||||
|
||||
looking at device '/devices/pci0000:00/0000:00:1c.3/0000:04:00.0
|
||||
/usb3/3-1/3-1:1.0/video4linux/video1':
|
||||
KERNEL=="video1"
|
||||
SUBSYSTEM=="video4linux"
|
||||
DRIVER==""
|
||||
ATTR{dev_debug}=="0"
|
||||
ATTR{index}=="0"
|
||||
ATTR{name}=="HP Webcam HD 2300: HP Webcam HD"
|
||||
|
||||
[etc...]
|
||||
```
|
||||
|
||||
输出持续了相当长的时间,但是你感兴趣的只是开头的部分:`SUBSYSTEM =="video4linux"`。你可以将这行文本直接复制粘贴到你的规则中。输出的其余部分(为简洁未显示)为你提供了更多的信息,例如制造商和型号 ID,同样是以你可以复制粘贴到你的规则中的格式。
|
||||
|
||||
现在,你有了识别设备的方式吗,并明确了什么事件应该触发该动作,该对设备进行修改了。
|
||||
|
||||
规则的下一部分,`SYMLINK+="mywebcam", TAG+="systemd", MODE="0666"` 告诉 Udev 做三件事:首先,你要创建设备的符号链接(例如 `/dev/video1` 到 `/dev/mywebcam`。这是因为你无法预测系统默认情况下会把那个设备叫什么。当你拥有内置摄像头并热插拔一个新的时,内置摄像头通常为 `/dev/video0`,而外部摄像头通常为 `/dev/video1`。但是,如果你在插入外部 USB 摄像头的情况下重启计算机,则可能会相反,内部摄像头可能会变成 `/dev/video1` ,而外部摄像头会变成 `/dev/video0`。这想告诉你的是,尽管你的图像捕获脚本(稍后将看到)总是需要指向外部摄像头设备,但是你不能依赖它是 `/dev/video0` 或 `/dev/video1`。为了解决这个问题,你告诉 Udev 创建一个符号链接,该链接在设备被添加到 `video4linux` 子系统的那一刻起就不会再变,你将使你的脚本指向该链接。
|
||||
|
||||
第二件事就是将 `systemd` 添加到与此规则关联的 Udev 标记列表中。这告诉 Udev,该规则触发的动作将由 systemd 管理,即它将是某种 systemd 服务。
|
||||
|
||||
注意在这个两种情况下是如何使用 `+=` 运算符的。这会将值添加到列表中,这意味着你可以向 `SYMLINK` 和 `TAG` 添加多个值。
|
||||
|
||||
另一方面,`MODE` 值只能包含一个值(因此,你可以使用简单的 `=` 赋值运算符)。`MODE` 的作用是告诉 Udev 谁可以读或写该设备。如果你熟悉 `chmod`(你读到此文, 应该会熟悉),你就也会熟悉[如何用数字表示权限][9]。这就是它的含义:`0666` 的含义是 “向所有人授予对设备的读写权限”。
|
||||
|
||||
最后, `ENV{SYSTEMD_WANTS}="webcam.service"` 告诉 Udev 要运行什么 systemd 服务。
|
||||
|
||||
将此规则保存到 `/etc/udev/rules.d` 目录名为 `90-webcam.rules`(或类似的名称)的文件中,你可以通过重启机器或运行以下命令来加载它:
|
||||
|
||||
```
|
||||
sudo udevadm control --reload-rules && udevadm trigger
|
||||
```
|
||||
|
||||
### 最后是服务
|
||||
|
||||
Udev 规则触发的服务非常简单:
|
||||
|
||||
```
|
||||
# webcam.service
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/home/[user name]/bin/checkimage.sh
|
||||
```
|
||||
|
||||
基本上,它只是运行存储在你个人 `bin/` 中的 `checkimage.sh` 脚本并将其放到后台。[这是你在先前的文章中看过的内容][5]。它看起来似乎很小,但那只是因为它是被 Udev 规则调用的,你刚刚创建了一种特殊的 systemd 单元,称为 `device` 单元。 恭喜。
|
||||
|
||||
至于 `webcam.service` 调用的 `checkimage.sh` 脚本,有几种方法从摄像头抓取图像并将其与前一个图像进行比较以检查变化(这是 `checkimage.sh` 所做的事),但这是我的方法:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# This is the checkimage.sh script
|
||||
|
||||
mplayer -vo png -frames 1 tv:// -tv driver=v4l2:width=640:height=480:device=
|
||||
/dev/mywebcam &>/dev/null
|
||||
mv 00000001.png /home/[user name]/monitor/monitor.png
|
||||
|
||||
while true
|
||||
do
|
||||
mplayer -vo png -frames 1 tv:// -tv driver=v4l2:width=640:height=480:device=/dev/mywebcam &>/dev/null
|
||||
mv 00000001.png /home/[user name]/monitor/temp.png
|
||||
|
||||
imagediff=`compare -metric mae /home/[user name]/monitor/monitor.png /home/[user name]
|
||||
/monitor/temp.png /home/[user name]/monitor/diff.png 2>&1 > /dev/null | cut -f 1 -d " "`
|
||||
if [ `echo "$imagediff > 700.0" | bc` -eq 1 ]
|
||||
then
|
||||
mv /home/[user name]/monitor/temp.png /home/[user name]/monitor/monitor.png
|
||||
fi
|
||||
|
||||
sleep 0.5
|
||||
done
|
||||
```
|
||||
|
||||
首先使用[MPlayer][10]从摄像头抓取一帧(`00000001.png`)。注意,我们怎样将 `mplayer` 指向 Udev 规则中创建的 `mywebcam` 符号链接,而不是指向 `video0` 或 `video1`。然后,将图像传输到主目录中的 `monitor/` 目录。然后执行一个无限循环,一次又一次地执行相同的操作,但还使用了[Image Magick 的 compare 工具][11]来查看最后捕获的图像与 `monitor/` 目录中已有的图像之间是否存在差异。
|
||||
|
||||
如果图像不同,则表示摄像头的镜框里某些东西动了。该脚本将新图像覆盖原始图像,并继续比较以等待更多变动。
|
||||
|
||||
### 插线
|
||||
|
||||
所有东西准备好后,当你插入摄像头后,你的 Udev 规则将被触发并启动 `webcam.service`。 `webcam.service` 将在后台执行 `checkimage.sh` ,而 `checkimage.sh` 将开始每半秒拍一次照。你会感觉到,因为摄像头的 LED 在每次拍照时将开始闪。
|
||||
|
||||
与往常一样,如果出现问题,请运行:
|
||||
|
||||
```
|
||||
systemctl status webcam.service
|
||||
```
|
||||
|
||||
检查你的服务和脚本正在做什么。
|
||||
|
||||
### 接下来
|
||||
|
||||
你可能想知道:为什么要覆盖原始图像?当然,系统检测到任何动静,你都想知道发生了什么,对吗?你是对的,但是如你在下一部分中将看到的那样,将它们保持原样,并使用另一种类型的 systemd 单元处理图像将更好,更清晰和更简单。
|
||||
|
||||
请期待下一篇。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[messon007](https://github.com/messon007)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.intel.com/content/www/us/en/products/boards-kits/compute-stick/stk1a32sc.html
|
||||
[2]: https://www.linux.com/files/images/fig01png
|
||||
[3]: https://lcom.static.linuxfound.org/sites/lcom/files/fig01.png
|
||||
[4]: https://www.linux.com/licenses/category/used-permission
|
||||
[5]: https://linux.cn/article-9700-1.html
|
||||
[6]: https://linux.cn/article-9703-1.html
|
||||
[7]: https://www.linux.com/files/images/fig02png
|
||||
[8]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/fig02.png?itok=esFv4BdM (webcam)
|
||||
[9]: https://chmod-calculator.com/
|
||||
[10]: https://mplayerhq.hu/design7/news.html
|
||||
[11]: https://www.imagemagick.org/script/compare.php
|
||||
[12]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,199 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12186-1.html)
|
||||
[#]: subject: (How to Configure SFTP Server with Chroot in Debian 10)
|
||||
[#]: via: (https://www.linuxtechi.com/configure-sftp-chroot-debian10/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
如何在 Debian 10 中配置 Chroot 环境的 SFTP 服务
|
||||
======
|
||||
|
||||
SFTP 意思是“<ruby>安全文件传输协议<rt>Secure File Transfer Protocol</rt></ruby>” 或 “<ruby>SSH 文件传输协议<rt>SSH File Transfer Protocol</rt></ruby>”,它是最常用的用于通过 `ssh` 将文件从本地系统安全地传输到远程服务器的方法,反之亦然。`sftp` 的主要优点是,除 `openssh-server` 之外,我们不需要安装任何额外的软件包,在大多数的 Linux 发行版中,`openssh-server` 软件包是默认安装的一部分。`sftp` 的另外一个好处是,我们可以允许用户使用 `sftp` ,而不允许使用 `ssh` 。
|
||||
|
||||

|
||||
|
||||
当前发布的 Debian 10 代号为 ‘Buster’,在这篇文章中,我们将演示如何在 Debian 10 系统中在 “监狱式的” Chroot 环境中配置 `sftp`。在这里,Chroot 监狱式环境意味着,用户不能超出各自的家目录,或者用户不能从各自的家目录更改目录。下面实验的详细情况:
|
||||
|
||||
* OS = Debian 10
|
||||
* IP 地址 = 192.168.56.151
|
||||
|
||||
让我们跳转到 SFTP 配置步骤,
|
||||
|
||||
### 步骤 1、使用 groupadd 命令给 sftp 创建一个组
|
||||
|
||||
打开终端,使用下面的 `groupadd` 命令创建一个名为的 `sftp_users` 组:
|
||||
|
||||
```
|
||||
root@linuxtechi:~# groupadd sftp_users
|
||||
```
|
||||
|
||||
### 步骤 2、添加用户到组 sftp_users 并设置权限
|
||||
|
||||
假设你想创建新的用户,并且想添加该用户到 `sftp_users` 组中,那么运行下面的命令,
|
||||
|
||||
**语法:**
|
||||
|
||||
```
|
||||
# useradd -m -G sftp_users <用户名>
|
||||
```
|
||||
|
||||
让我们假设用户名是 `jonathan`:
|
||||
|
||||
```
|
||||
root@linuxtechi:~# useradd -m -G sftp_users jonathan
|
||||
```
|
||||
|
||||
使用下面的 `chpasswd` 命令设置密码:
|
||||
|
||||
```
|
||||
root@linuxtechi:~# echo "jonathan:<输入密码>" | chpasswd
|
||||
```
|
||||
|
||||
假设你想添加现有的用户到 `sftp_users` 组中,那么运行下面的 `usermod` 命令,让我们假设已经存在的用户名称是 `chris`:
|
||||
|
||||
```
|
||||
root@linuxtechi:~# usermod -G sftp_users chris
|
||||
```
|
||||
|
||||
现在设置用户所需的权限:
|
||||
|
||||
```
|
||||
root@linuxtechi:~# chown root /home/jonathan /home/chris/
|
||||
```
|
||||
|
||||
在各用户的家目录中都创建一个上传目录,并设置正确地所有权:
|
||||
|
||||
```
|
||||
root@linuxtechi:~# mkdir /home/jonathan/upload
|
||||
root@linuxtechi:~# mkdir /home/chris/upload
|
||||
root@linuxtechi:~# chown jonathan /home/jonathan/upload
|
||||
root@linuxtechi:~# chown chris /home/chris/upload
|
||||
```
|
||||
|
||||
**注意:** 像 Jonathan 和 Chris 之类的用户可以从他们的本地系统上传文件和目录。
|
||||
|
||||
### 步骤 3、编辑 sftp 配置文件 /etc/ssh/sshd_config
|
||||
|
||||
正如我们已经陈述的,`sftp` 操作是通过 `ssh` 完成的,所以它的配置文件是 `/etc/ssh/sshd_config`,在做任何更改前,我建议首先备份文件,然后再编辑该文件,接下来添加下面的内容:
|
||||
|
||||
```
|
||||
root@linuxtechi:~# cp /etc/ssh/sshd_config /etc/ssh/sshd_config-org
|
||||
root@linuxtechi:~# vim /etc/ssh/sshd_config
|
||||
......
|
||||
#Subsystem sftp /usr/lib/openssh/sftp-server
|
||||
Subsystem sftp internal-sftp
|
||||
|
||||
Match Group sftp_users
|
||||
X11Forwarding no
|
||||
AllowTcpForwarding no
|
||||
ChrootDirectory %h
|
||||
ForceCommand internal-sftp
|
||||
......
|
||||
```
|
||||
|
||||
保存并退出文件。
|
||||
|
||||
为使上述更改生效,使用下面的 `systemctl` 命令来重新启动 `ssh` 服务:
|
||||
|
||||
```
|
||||
root@linuxtechi:~# systemctl restart sshd
|
||||
```
|
||||
|
||||
在上面的 `sshd_config` 文件中,我们已经注释掉了以 `Subsystem` 开头的行,并添加了新的条目 `Subsystem sftp internal-sftp` 和新的行。而
|
||||
|
||||
`Match Group sftp_users` –> 它意味着如果用户是 `sftp_users` 组中的一员,那么将应用下面提到的规则到这个条目。
|
||||
|
||||
`ChrootDierctory %h` –> 它意味着用户只能在他们自己各自的家目录中更改目录,而不能超出他们各自的家目录。或者换句话说,我们可以说用户是不允许更改目录的。他们将在他们的目录中获得监狱一样的环境,并且不能访问其他用户的目录和系统的目录。
|
||||
|
||||
`ForceCommand internal-sftp` –> 它意味着用户仅被限制到只能使用 `sftp` 命令。
|
||||
|
||||
### 步骤 4、测试和验证 sftp
|
||||
|
||||
登录到你的 `sftp` 服务器的同一个网络上的任何其它的 Linux 系统,然后通过我们放入 `sftp_users` 组中的用户来尝试 ssh 和 sftp 服务。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ssh root@linuxtechi
|
||||
root@linuxtechi's password:
|
||||
Write failed: Broken pipe
|
||||
[root@linuxtechi ~]# ssh root@linuxtechi
|
||||
root@linuxtechi's password:
|
||||
Write failed: Broken pipe
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
以上操作证实用户不允许 `ssh` ,现在使用下面的命令尝试 `sftp`:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# sftp root@linuxtechi
|
||||
root@linuxtechi's password:
|
||||
Connected to 192.168.56.151.
|
||||
sftp> ls -l
|
||||
drwxr-xr-x 2 root 1001 4096 Sep 14 07:52 debian10-pkgs
|
||||
-rw-r--r-- 1 root 1001 155 Sep 14 07:52 devops-actions.txt
|
||||
drwxr-xr-x 2 1001 1002 4096 Sep 14 08:29 upload
|
||||
```
|
||||
|
||||
让我们使用 sftp 的 `get` 命令来尝试下载一个文件:
|
||||
|
||||
```
|
||||
sftp> get devops-actions.txt
|
||||
Fetching /devops-actions.txt to devops-actions.txt
|
||||
/devops-actions.txt 100% 155 0.2KB/s 00:00
|
||||
sftp>
|
||||
sftp> cd /etc
|
||||
Couldn't stat remote file: No such file or directory
|
||||
sftp> cd /root
|
||||
Couldn't stat remote file: No such file or directory
|
||||
sftp>
|
||||
```
|
||||
|
||||
上面的输出证实我们能从我们的 sftp 服务器下载文件到本地机器,除此之外,我们也必须测试用户不能更改目录。
|
||||
|
||||
让我们在 `upload` 目录下尝试上传一个文件:
|
||||
|
||||
```
|
||||
sftp> cd upload/
|
||||
sftp> put metricbeat-7.3.1-amd64.deb
|
||||
Uploading metricbeat-7.3.1-amd64.deb to /upload/metricbeat-7.3.1-amd64.deb
|
||||
metricbeat-7.3.1-amd64.deb 100% 38MB 38.4MB/s 00:01
|
||||
sftp> ls -l
|
||||
-rw-r--r-- 1 1001 1002 40275654 Sep 14 09:18 metricbeat-7.3.1-amd64.deb
|
||||
sftp>
|
||||
```
|
||||
|
||||
这证实我们已经成功地从我们的本地系统上传一个文件到 sftp 服务中。
|
||||
|
||||
现在使用 winscp 工具来测试 sftp 服务,输入 sftp 服务器 IP 地址和用户的凭证:
|
||||
|
||||
![][3]
|
||||
|
||||
在 “Login” 上单击,然后尝试下载和上传文件:
|
||||
|
||||
![][4]
|
||||
|
||||
现在,在 `upload` 文件夹中尝试上传文件:
|
||||
|
||||
![][5]
|
||||
|
||||
上面的窗口证实上传是完好地工作的,这就是这篇文章的全部。如果这些步骤能帮助你在 Debian 10 中使用 chroot 环境配置 SFTP 服务器s,那么请分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/configure-sftp-chroot-debian10/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Configure-sftp-debian10.jpg
|
||||
[3]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Winscp-sftp-debian10.jpg
|
||||
[4]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Download-file-winscp-debian10-sftp.jpg
|
||||
[5]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Upload-File-using-winscp-Debian10-sftp.jpg
|
||||
@ -0,0 +1,96 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (messon007)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12202-1.html)
|
||||
[#]: subject: (The ins and outs of high-performance computing as a service)
|
||||
[#]: via: (https://www.networkworld.com/article/3534725/the-ins-and-outs-of-high-performance-computing-as-a-service.html)
|
||||
[#]: author: (Josh Fruhlinger https://www.networkworld.com/author/Josh-Fruhlinger/)
|
||||
|
||||
超算即服务:超级计算机如何上云
|
||||
======
|
||||
|
||||
> 高性能计算(HPC)服务可能是一种满足不断增长的超级计算需求的方式,但依赖于使用场景,它们不一定比使用本地超级计算机好。
|
||||
|
||||

|
||||
|
||||
导弹和军用直升机上的电子设备需要工作在极端条件下。美国国防承包商<ruby>麦考密克·史蒂文森公司<rt>McCormick Stevenson Corp.</rt></ruby>在部署任何物理设备之前都会事先模拟它所能承受的真实条件。模拟依赖于像 Ansys 这样的有限元素分析软件,该软件需要强大的算力。
|
||||
|
||||
几年前的一天,它出乎意料地超出了计算极限。
|
||||
|
||||
麦考密克·史蒂文森公司的首席工程师 Mike Krawczyk 说:“我们的一些工作会使办公室的计算机不堪重负。购买机器并安装软件在经济上或计划上都不划算。”相反,他们与 Rescale 签约,该公司销售其超级计算机系统上的处理能力,而这只花费了他们购买新硬件上所需的一小部分。
|
||||
|
||||
麦考密克·史蒂文森公司已成为被称为超级计算即服务或高性能计算即服务(两个紧密相关的术语)市场的早期采用者之一。根据国家计算科学研究所的定义,HPC 是超级计算机在计算复杂问题上的应用,而超级计算机是处理能力最先进的那些计算机。
|
||||
|
||||
无论叫它什么,这些服务都在颠覆传统的超级计算市场,并将 HPC 能力带给以前负担不起的客户。但这不是万能的,而且绝对不是即插即用的,至少现在还不是。
|
||||
|
||||
### HPC 服务实践
|
||||
|
||||
从最终用户的角度来看,HPC 即服务类似于早期大型机时代的批处理模型。 “我们创建一个 Ansys 批处理文件并将其发送过去,运行它,然后将结果文件取下来,然后导入到本地,” Krawczyk 说。
|
||||
|
||||
在 HPC 服务背后,云提供商在其自己的数据中心中运行超级计算基础设施,尽管这不一定意味着当你听到“超级计算机”时你就会看到最先进的硬件。正如 IBM OpenPOWER 计算技术副总裁 Dave Turek 解释的那样,HPC 服务的核心是“相互互连的服务器集合。你可以调用该虚拟计算基础设施,它能够在你提出问题时,使得许多不同的服务器并行工作来解决问题。”
|
||||
|
||||
理论听起来很简单。但都柏林城市大学数字商业教授 Theo Lynn 表示,要使其在实践中可行,需要解决一些技术问题。普通计算与 HPC 的区别在于那些互联互通 —— 高速的、低延时的而且昂贵的 —— 因此需要将这些互连引入云基础设施领域。在 HPC 服务可行之前,至少需要将存储性能和数据传输也提升到与本地 HPC 相同的水平。
|
||||
|
||||
但是 Lynn 说,一些制度创新相比技术更好的帮助了 HPC 服务的起飞。特别是,“我们现在看到越来越多的传统 HPC 应用采用云友好的许可模式 —— 这在过去是阻碍采用的障碍。”
|
||||
|
||||
他说,经济也改变了潜在的客户群。“云服务提供商通过向那些负担不起传统 HPC 所需的投资成本的低端 HPC 买家开放,进一步开放了市场。随着市场的开放,超大规模经济模型变得越来越多,更可行,成本开始下降。”
|
||||
|
||||
### 避免本地资本支出
|
||||
|
||||
HPC 服务对传统超级计算长期以来一直占据主导地位的私营部门客户具有吸引力。这些客户包括严重依赖复杂数学模型的行业,包括麦考密克·史蒂文森公司等国防承包商,以及石油和天然气公司、金融服务公司和生物技术公司。都柏林城市大学的 Lynn 补充说,松耦合的工作负载是一个特别好的用例,这意味着许多早期采用者将其用于 3D 图像渲染和相关应用。
|
||||
|
||||
但是,何时考虑 HPC 服务而不是本地 HPC 才有意义?对于德国的模拟烟雾在建筑物中的蔓延和火灾对建筑物结构部件的破坏的 hhpberlin 公司来说,答案是在它超出了其现有资源时。
|
||||
|
||||
Hpberlin 公司数值模拟的科学负责人 Susanne Kilian 说:“几年来,我们一直在运行自己的小型集群,该集群具有多达 80 个处理器核。……但是,随着应用复杂性的提高,这种架构已经越来越不足以支撑;可用容量并不总是够快速地处理项目。”
|
||||
|
||||
她说:“但是,仅仅花钱买一个新的集群并不是一个理想的解决方案:鉴于我们公司的规模和管理环境,不断地维护这个集群(定期进行软件和硬件升级)是不现实的。另外,需要模拟的项目数量会出现很大的波动,因此集群的利用率并不是真正可预测的。通常,使用率很高的阶段与很少使用或不使用的阶段交替出现。”通过转换为 HPC 服务模式,hhpberlin 释放了过剩的产能,并无需支付升级费用。
|
||||
|
||||
IBM 的 Turek 解释了不同公司在评估其需求时所经历的计算过程。对于拥有 30 名员工的生物科学初创公司来说,“你需要计算,但你真的不可能让 15% 的员工专门负责计算。这就像你可能也会说你不希望有专职的法律代表,所以你也会把它作为一项服务来做。”不过,对于一家较大的公司而言,最终归结为权衡 HPC 服务的运营费用与购买内部超级计算机或 HPC 集群的费用。
|
||||
|
||||
到目前为止,这些都是你采用任何云服务时都会遇到的类似的争论。但是,可以 HPC 市场的某些特殊性将使得衡量运营支出(OPEX)与资本支出(CAPEX)时选择前者。超级计算机不是诸如存储或 x86 服务器之类的商用硬件;它们非常昂贵,技术进步很快会使其过时。正如麦考密克·史蒂文森公司的 Krawczyk 所说,“这就像买车:只要车一开走,它就会开始贬值。”对于许多公司,尤其是规模较大,灵活性较差的公司,购买超级计算机的过程可能会陷入无望的泥潭。IBM 的 Turek 说:“你会被规划问题、建筑问题、施工问题、培训问题所困扰,然后必须执行 RFP。你必须得到 CIO 的支持。你必须与内部客户合作以确保服务的连续性。这是一个非常、非常复杂的过程,并没有很多机构有非常出色的执行力。”
|
||||
|
||||
一旦你选择走 HPC 服务的路线,你会发现你会得到你期望从云服务中得到的许多好处,特别是仅在业务需要时才需付费的能力,从而可以带来资源的高效利用。Gartner 高级总监兼分析师 Chirag Dekate 表示,当你对高性能计算有短期需求时,突发性负载是推动选择 HPC 服务的关键用例。
|
||||
|
||||
他说:“在制造业中,在产品设计阶段前后,HPC 活动往往会达到很高的峰值。但是,一旦产品设计完成,在其余产品开发周期中,HPC 资源的利用率就会降低。” 相比之下,他说:“当你拥有大型的、长期运行的工作时,云计算的经济性才会逐渐减弱。”
|
||||
|
||||
通过巧妙的系统设计,你可以将这些 HPC 服务突发活动与你自己的内部常规计算集成在一起。<ruby>埃森哲<rt>Accenture</rt></ruby>实验室常务董事 Teresa Tung 举了一个例子:“通过 API 访问 HPC 可以与传统计算无缝融合。在模型构建阶段,传统的 AI 流水线可能会在高端超级计算机上进行训练,但是最终经过反复按预期运行的训练好的模型将部署在云端的其他服务上,甚至部署在边缘设备上。”
|
||||
|
||||
### 它并不适合所有的应用场景
|
||||
|
||||
HPC 服务适合批处理和松耦合的场景。这与一个常见的 HPC 缺点有关:数据传输问题。高性能计算本身通常涉及庞大的数据集,而将所有这些信息通过互联网发送到云服务提供商并不容易。IBM 的 Turek 说:“我们与生物技术行业的客户交流,他们每月仅在数据费用上就花费 1000 万美元。”
|
||||
|
||||
而钱并不是唯一的潜在问题。构建一个利用数据的工作流程,可能会对你的工作流程提出挑战,让你绕过数据传输所需的漫长时间。hhpberlin 的 Kilian 说:“当我们拥有自己的 HPC 集群时,当然可以随时访问已经产生的仿真结果,从而进行交互式的临时评估。我们目前正努力达到在仿真的任意时刻都可以更高效地、交互地访问和评估云端生成的数据,而无需下载大量的模拟数据。”
|
||||
|
||||
Mike Krawczyk 提到了另一个绊脚石:合规性问题。国防承包商使用的任何服务都需要遵从《国际武器交易条例》(ITAR),麦考密克·史蒂文森公司之所以选择 Rescale,部分原因是因为这是他们发现的唯一符合的供应商。如今,尽管有更多的公司使用云服务,但任何希望使用云服务的公司都应该意识到使用其他人的基础设施时所涉及的法律和数据保护问题,而且许多 HPC 场景的敏感性使得 HPC 即服务的这个问题更加突出。
|
||||
|
||||
此外,HPC 服务所需的 IT 治理超出了目前的监管范围。例如,你需要跟踪你的软件许可证是否允许云使用 —— 尤其是专门为本地 HPC 群集上运行而编写的软件包。通常,你需要跟踪 HPC 服务的使用方式,它可能是一个诱人的资源,尤其是当你从员工习惯的内部系统过渡到有可用的空闲的 HPC 能力时。例如,Avanade 全球平台高级主管兼 Azure 平台服务全球负责人 Ron Gilpin 建议,将你使用的处理核心的数量回拨给那些对时间不敏感的任务。他说:“如果一项工作只需要用一小时来完成而不需要在十分钟内就完成,那么它可以使用 165 个处理器而不是 1,000 个,从而节省了数千美元。”
|
||||
|
||||
### 对 HPC 技能的要求很高
|
||||
|
||||
一直以来,采用 HPC 的最大障碍之一就是其所需的独特的内部技能,而 HPC 服务并不能神奇使这种障碍消失。Gartner 的 Dekate 表示:“许多 CIO 将许多工作负载迁移到了云上,他们看到了成本的节约、敏捷性和效率的提升,因此相信在 HPC 生态中也可以达成类似的效果。一个普遍的误解是,他们可以通过彻底地免去系统管理员,并聘用能解决其 HPC 工作负载的新的云专家,从而以某种方式优化人力成本。”对于 HPC 即服务来说更是如此。
|
||||
|
||||
“但是 HPC 并不是一个主流的企业环境。” 他说。“你正在处理通过高带宽、低延迟的网络互联的高端计算节点,以及相当复杂的应用和中间件技术栈。许多情况下,甚至连文件系统层也是 HPC 环境所独有的。没有对应的技能可能会破坏稳定性。”
|
||||
|
||||
但是超级计算技能的供给却在减少,Dekate 将其称为劳动力“老龄化”,这是因为这一代开发人员将目光投向了新兴的初创公司,而不是学术界或使用 HPC 的更老套的公司。因此,HPC 服务供应商正在尽其所能地弥补差距。IBM 的 Turek 表示,许多 HPC 老手将总是想运行他们自己精心调整过的代码,并需要专门的调试器和其他工具来帮助他们在云端实现这一目标。但是,即使是 HPC 新手也可以调用供应商构建的代码库,以利用超级计算的并行处理能力。第三方软件提供商出售的交钥匙软件包可以减少 HPC 的许多复杂性。
|
||||
|
||||
埃森哲的 Tung 表示,该行业需要进一步加大投入才能真正繁荣。她说:“HPCaaS 已经创建了具有重大影响力的新功能,但还需要做的是使它易于被数据科学家、企业架构师或软件开发人员使用。这包括易用的 API、文档和示例代码。它包括解答问题的用户支持。仅仅提供 API 是不够的,API 需要适合特定的用途。对于数据科学家而言,这可能是以 Python 形式提供,并容易更换她已经在使用的框架。价值来自于使这些用户能够通过新的效率和性能最终使他们的工作得到改善,只要他们能够访问新的功能就可以了。” 如果供应商能够做到这一点,那么 HPC 服务才能真正将超级计算带给大众。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3534725/the-ins-and-outs-of-high-performance-computing-as-a-service.html
|
||||
|
||||
作者:[Josh Fruhlinger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[messon007](https://github.com/messon007)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Josh-Fruhlinger/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3236875/embargo-10-of-the-worlds-fastest-supercomputers.html
|
||||
[2]: https://www.networkworld.com/blog/itaas-and-the-corporate-storage-technology/?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE22140&utm_content=sidebar (ITAAS and Corporate Storage Strategy)
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,80 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "tinyeyeser"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-12191-1.html"
|
||||
[#]: subject: "How to avoid man-in-the-middle cyber attacks"
|
||||
[#]: via: "https://opensource.com/article/20/4/mitm-attacks"
|
||||
[#]: author: "Jackie Lam https://opensource.com/users/beenverified"
|
||||
|
||||
如何避免中间人攻击(MITM)
|
||||
======
|
||||
|
||||
> 首先搞明白到底什么是中间人攻击(MITM),才能避免成为此类高科技窃听的受害者。
|
||||
|
||||

|
||||
|
||||
当你使用电脑发送数据或与某人在线通话的时候,你一定采取了某种程度的安全隐私手段。
|
||||
|
||||
但如果有第三方在你不知情的情况下窃听,甚至冒充某个你信任的商业伙伴窃取破坏性的信息呢?你的私人数据就这样被放在了危险分子的手中。
|
||||
|
||||
这就是臭名昭著的<ruby>中间人攻击<rt>man-in-the-middle</rt></ruby>(MITM)。
|
||||
|
||||
### 到底什么是中间人攻击?
|
||||
|
||||
黑客潜入到你与受害者或是某个设备间的通信过程中,窃取敏感信息(多数是身份信息)进而从事各种违法行为的过程,就是一次中间人攻击。Scamicide 公司创始人 Steve J. J. Weisman 介绍说:
|
||||
|
||||
> “中间人攻击也可以发生在受害者与某个合法 app 或网页中间。当受害者以为自己面对的是正常 app 或网页时,其实 Ta 正在与一个仿冒的 app 或网页互动,将自己的敏感信息透露给了不法分子。”
|
||||
|
||||
中间人攻击诞生于 1980 年代,是最古老的网络攻击形式之一。但它却更为常见。Weisman 解释道,发生中间人攻击的场景有很多种:
|
||||
|
||||
* **攻陷一个未有效加密的 WiFi 路由器**:该场景多见于人们使用公共 WiFi 的时候。“虽然家用路由器也很脆弱,但黑客攻击公共 WiFi 网络的情况更为常见。”Weisman 说,“黑客的目标就是从毫无戒心的人们那里窃取在线银行账户这样的敏感信息。”
|
||||
* **攻陷银行、金融顾问等机构的电子邮件账户**:“一旦黑客攻陷了这些电子邮件系统,他们就会冒充银行或此类公司给受害者发邮件”,Weisman 说,”他们以紧急情况的名义索要个人信息,诸如用户名和密码。受害者很容易被诱骗交出这些信息。”
|
||||
* **发送钓鱼邮件**:窃贼们还可能冒充成与受害者有合作关系的公司,向其索要个人信息。“在多个案例中,钓鱼邮件会引导受害者访问一个伪造的网页,这个伪造的网页看起来就和受害者常常访问的合法公司网页一模一样。”Weisman 说道。
|
||||
* **在合法网页中嵌入恶意代码**:攻击者还会把恶意代码(通常是 JavaScript)嵌入到一个合法的网页中。“当受害者加载这个合法网页时,恶意代码首先按兵不动,直到用户输入账户登录或是信用卡信息时,恶意代码就会复制这些信息并将其发送至攻击者的服务器。”网络安全专家 Nicholas McBride 介绍说。
|
||||
|
||||
### 有哪些中间人攻击的著名案例?
|
||||
|
||||
联想作为主流的计算机制造厂商,在 2014 到 2015 年售卖的消费级笔记本电脑中预装了一款叫做 VisualDiscovery 的软件,拦截用户的网页浏览行为。当用户的鼠标在某个产品页面经过时,这款软件就会弹出一个来自合作伙伴的类似产品的广告。
|
||||
|
||||
这起中间人攻击事件的关键在于:VisualDiscovery 拥有访问用户所有私人数据的权限,包括身份证号、金融交易信息、医疗信息、登录名和密码等等。所有这些访问行为都是在用户不知情和未获得授权的情况下进行的。联邦交易委员会(FTC)认定此次事件为欺诈与不公平竞争。2019 年,联想同意为此支付 8300 万美元的集体诉讼罚款。
|
||||
|
||||
### 我如何才能避免遭受中间人攻击?
|
||||
|
||||
* **避免使用公共 WiFi**:Weisman 建议,从来都不要使用公开的 WiFi 进行金融交易,除非你安装了可靠的 VPN 客户端并连接至可信任的 VPN 服务器。通过 VPN 连接,你的通信是加密的,信息也就不会失窃。
|
||||
* **时刻注意:**对要求你更新密码或是提供用户名等私人信息的邮件或文本消息要时刻保持警惕。这些手段很可能被用来窃取你的身份信息。
|
||||
|
||||
如果不确定收到的邮件来自于确切哪一方,你可以使用诸如电话反查或是邮件反查等工具。通过电话反查,你可以找出未知发件人的更多身份信息。通过邮件反查,你可以尝试确定谁给你发来了这条消息。
|
||||
|
||||
通常来讲,如果发现某些方面确实有问题,你可以听从公司中某个你认识或是信任的人的意见。或者,你也可以去你的银行、学校或其他某个组织,当面寻求他们的帮助。总之,重要的账户信息绝对不要透露给不认识的“技术人员”。
|
||||
|
||||
* **不要点击邮件中的链接**:如果有人给你发了一封邮件,说你需要登录某个账户,不要点击邮件中的链接。相反,要通过平常习惯的方式自行去访问,并留意是否有告警信息。如果在账户设置中没有看到告警信息,给客服打电话的时候也*不要*联系邮件中留的电话,而是联系站点页面中的联系人信息。
|
||||
* **安装可靠的安全软件**:如果你使用的是 Windows 操作系统,安装开源的杀毒软件,如 [ClamAV][2]。如果使用的是其他平台,要保持你的软件安装有最新的安全补丁。
|
||||
* **认真对待告警信息**:如果你正在访问的页面以 HTTPS 开头,浏览器可能会出现一则告警信息。例如,站点证书的域名与你尝试访问的站点域名不相匹配。千万不要忽视此类告警信息。听从告警建议,迅速关掉页面。确认域名没有输入错误的情况下,如果情况依旧,要立刻联系站点所有者。
|
||||
* **使用广告屏蔽软件**:弹窗广告(也叫广告软件攻击)可被用于窃取个人信息,因此你还可以使用广告屏蔽类软件。对个人用户来说,中间人攻击其实是很难防范的,因为它被设计出来的时候,就是为了让受害者始终蒙在鼓里,意识不到任何异常。有一款不错的开源广告屏蔽软件叫 [uBlock origin][4]。可以同时支持 Firefox 和 Chromium(以及所有基于 Chromium 的浏览器,例如 Chrome、Brave、Vivaldi、Edge 等),甚至还支持 Safari。
|
||||
|
||||
### 保持警惕
|
||||
|
||||
要时刻记住,你并不需要立刻就点击某些链接,你也并不需要听从某个陌生人的建议,无论这些信息看起来有多么紧急。互联网始终都在。你大可以先离开电脑,去证实一下这些人的真实身份,看看这些“无比紧急”的页面到底是真是假。
|
||||
|
||||
尽管任何人都可能遭遇中间人攻击,只要弄明白何为中间人攻击,理解中间人攻击如何发生,并采取有效的防范措施,就可以保护自己避免成为其受害者。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/mitm-attacks
|
||||
|
||||
作者:[Jackie Lam][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[tinyeyeser](https://github.com/tinyeyeser)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/beenverified
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/security_password_chaos_engineer_monster.png?itok=J31aRccu "Security monster"
|
||||
[2]: https://www.clamav.net
|
||||
[3]: https://opensource.com/article/20/1/stop-typosquatting-attacks
|
||||
[4]: https://github.com/gorhill/uBlock
|
||||
[5]: https://www.beenverified.com/crime/what-is-a-man-in-the-middle-attack/
|
||||
[6]: https://creativecommons.org/licenses/by-sa/2.0/
|
||||
185
published/20200417 Create a SDN on Linux with open source.md
Normal file
185
published/20200417 Create a SDN on Linux with open source.md
Normal file
@ -0,0 +1,185 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (messon007)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12199-1.html)
|
||||
[#]: subject: (Create a SDN on Linux with open source)
|
||||
[#]: via: (https://opensource.com/article/20/4/quagga-linux)
|
||||
[#]: author: (M Umer https://opensource.com/users/noisybotnet)
|
||||
|
||||
在 Linux 上使用开源软件创建 SDN
|
||||
======
|
||||
|
||||
> 使用开源路由协议栈 Quagga,使你的 Linux 系统成为一台路由器。
|
||||
|
||||

|
||||
|
||||
网络路由协议分为两大类:内部网关协议和外部网关协议。路由器使用内部网关协议在单个自治系统内共享信息。如果你用的是 Linux,则可以通过开源(GPLv2)路由协议栈 [Quagga][2] 使其表现得像一台路由器。
|
||||
|
||||
### Quagga 是什么?
|
||||
|
||||
Quagga 是一个[路由软件包][3],并且是 [GNU Zebra][4] 的一个分支。它为类 Unix 平台提供了所有主流路由协议的实现,例如开放最短路径优先(OSPF),路由信息协议(RIP),边界网关协议(BGP)和中间系统到中间系统协议(IS-IS)。
|
||||
|
||||
尽管 Quagga 实现了 IPv4 和 IPv6 的路由协议,但它并不是一个完整的路由器。一个真正的路由器不仅实现了所有路由协议,而且还有转发网络流量的能力。 Quagga 仅仅实现了路由协议栈,而转发网络流量的工作由 Linux 内核处理。
|
||||
|
||||
### 架构
|
||||
|
||||
Quagga 通过特定协议的守护程序实现不同的路由协议。守护程序名称与路由协议相同,加了字母“d”作为后缀。Zebra 是核心,也是与协议无关的守护进程,它为内核提供了一个[抽象层][5],并通过 TCP 套接字向 Quagga 客户端提供 Zserv API。每个特定协议的守护程序负责运行相关的协议,并基于交换的信息来建立路由表。
|
||||
|
||||
![Quagga architecture][6]
|
||||
|
||||
### 环境
|
||||
|
||||
本教程通过 Quagga 实现的 OSPF 协议来配置动态路由。该环境包括两个名为 Alpha 和 Beta 的 CentOS 7.7 主机。两台主机共享访问 **192.168.122.0/24** 网络。
|
||||
|
||||
**主机 Alpha:**
|
||||
|
||||
IP:192.168.122.100/24
|
||||
网关:192.168.122.1
|
||||
|
||||
**主机 Beta:**
|
||||
|
||||
IP:192.168.122.50/24
|
||||
网关:192.168.122.1
|
||||
|
||||
### 安装软件包
|
||||
|
||||
首先,在两台主机上安装 Quagga 软件包。它存在于 CentOS 基础仓库中:
|
||||
|
||||
```
|
||||
yum install quagga -y
|
||||
```
|
||||
|
||||
### 启用 IP 转发
|
||||
|
||||
接下来,在两台主机上启用 IP 转发,因为它将由 Linux 内核来执行:
|
||||
|
||||
```
|
||||
sysctl -w net.ipv4.ip_forward = 1
|
||||
sysctl -p
|
||||
```
|
||||
|
||||
### 配置
|
||||
|
||||
现在,进入 `/etc/quagga` 目录并为你的设置创建配置文件。你需要三个文件:
|
||||
|
||||
* `zebra.conf`:Quagga 守护程序的配置文件,你可以在其中定义接口及其 IP 地址和 IP 转发
|
||||
* `ospfd.conf`:协议配置文件,你可以在其中定义将通过 OSPF 协议提供的网络
|
||||
* `daemons`:你将在其中指定需要运行的相关的协议守护程序
|
||||
|
||||
在主机 Alpha 上,
|
||||
|
||||
```
|
||||
[root@alpha]# cat /etc/quagga/zebra.conf
|
||||
interface eth0
|
||||
ip address 192.168.122.100/24
|
||||
ipv6 nd suppress-ra
|
||||
interface eth1
|
||||
ip address 10.12.13.1/24
|
||||
ipv6 nd suppress-ra
|
||||
interface lo
|
||||
ip forwarding
|
||||
line vty
|
||||
|
||||
[root@alpha]# cat /etc/quagga/ospfd.conf
|
||||
interface eth0
|
||||
interface eth1
|
||||
interface lo
|
||||
router ospf
|
||||
network 192.168.122.0/24 area 0.0.0.0
|
||||
network 10.12.13.0/24 area 0.0.0.0
|
||||
line vty
|
||||
|
||||
[root@alphaa ~]# cat /etc/quagga/daemons
|
||||
zebra=yes
|
||||
ospfd=yes
|
||||
```
|
||||
|
||||
在主机 Beta 上,
|
||||
|
||||
```
|
||||
[root@beta quagga]# cat zebra.conf
|
||||
interface eth0
|
||||
ip address 192.168.122.50/24
|
||||
ipv6 nd suppress-ra
|
||||
interface eth1
|
||||
ip address 10.10.10.1/24
|
||||
ipv6 nd suppress-ra
|
||||
interface lo
|
||||
ip forwarding
|
||||
line vty
|
||||
|
||||
[root@beta quagga]# cat ospfd.conf
|
||||
interface eth0
|
||||
interface eth1
|
||||
interface lo
|
||||
router ospf
|
||||
network 192.168.122.0/24 area 0.0.0.0
|
||||
network 10.10.10.0/24 area 0.0.0.0
|
||||
line vty
|
||||
|
||||
[root@beta ~]# cat /etc/quagga/daemons
|
||||
zebra=yes
|
||||
ospfd=yes
|
||||
```
|
||||
|
||||
### 配置防火墙
|
||||
|
||||
要使用 OSPF 协议,必须允许它通过防火墙:
|
||||
|
||||
```
|
||||
firewall-cmd --add-protocol=ospf –permanent
|
||||
|
||||
firewall-cmd –reload
|
||||
```
|
||||
|
||||
现在,启动 `zebra` 和 `ospfd` 守护程序。
|
||||
|
||||
```
|
||||
# systemctl start zebra
|
||||
# systemctl start ospfd
|
||||
```
|
||||
|
||||
用下面命令在两个主机上查看路由表:
|
||||
|
||||
```
|
||||
[root@alpha ~]# ip route show
|
||||
default via 192.168.122.1 dev eth0 proto static metric 100
|
||||
10.10.10.0/24 via 192.168.122.50 dev eth0 proto zebra metric 20
|
||||
10.12.13.0/24 dev eth1 proto kernel scope link src 10.12.13.1
|
||||
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.100 metric 100
|
||||
```
|
||||
|
||||
你可以看到 Alpha 上的路由表包含通过 **192.168.122.50** 到达 **10.10.10.0/24** 的路由项,它是通过协议 zebra 获取的。同样,在主机 Beta 上,该表包含通过 **192.168.122.100** 到达网络 **10.12.13.0/24** 的路由项。
|
||||
|
||||
```
|
||||
[root@beta ~]# ip route show
|
||||
default via 192.168.122.1 dev eth0 proto static metric 100
|
||||
10.10.10.0/24 dev eth1 proto kernel scope link src 10.10.10.1
|
||||
10.12.13.0/24 via 192.168.122.100 dev eth0 proto zebra metric 20
|
||||
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.50 metric 100
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
如你所见,环境和配置相对简单。要增加复杂性,你可以向路由器添加更多网络接口,以为更多网络提供路由。你也可以使用相同的方法来实现 BGP 和 RIP 协议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/quagga-linux
|
||||
|
||||
作者:[M Umer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[messon007](https://github.com/messon007)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/noisybotnet
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
|
||||
[2]: https://www.quagga.net/
|
||||
[3]: https://en.wikipedia.org/wiki/Quagga_(software)
|
||||
[4]: https://www.gnu.org/software/zebra/
|
||||
[5]: https://en.wikipedia.org/wiki/Abstraction_layer
|
||||
[6]: https://opensource.com/sites/default/files/uploads/quagga_arch.png (Quagga architecture)
|
||||
203
published/20200417 How to compress files on Linux 5 ways.md
Normal file
203
published/20200417 How to compress files on Linux 5 ways.md
Normal file
@ -0,0 +1,203 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12190-1.html)
|
||||
[#]: subject: (How to compress files on Linux 5 ways)
|
||||
[#]: via: (https://www.networkworld.com/article/3538471/how-to-compress-files-on-linux-5-ways.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
在 Linux 上压缩文件的 5 种方法
|
||||
======
|
||||
|
||||
> 在 Linux 系统上有很多可以用于压缩文件的工具,但它们的表现并不都是一样的,也不是所有的压缩效果都是一样的。在这篇文章中,我们比较其中的五个工具。
|
||||
|
||||

|
||||
|
||||
在 Linux 上有不少用于压缩文件的命令。最新最有效的一个方法是 `xz`,但是所有的方法都有节省磁盘空间和维护备份文件供以后使用的优点。在这篇文章中,我们将比较这些压缩命令并指出显著的不同。
|
||||
|
||||
### tar
|
||||
|
||||
`tar` 命令不是专门的压缩命令。它通常用于将多个文件拉入一个单个的文件中,以便容易地传输到另一个系统,或者将文件作为一个相关的组进行备份。它也提供压缩的功能,这就很有意义了,附加一个 `z` 压缩选项能够实现压缩文件。
|
||||
|
||||
当使用 `z` 选项为 `tar` 命令附加压缩过程时,`tar` 使用 `gzip` 来进行压缩。
|
||||
|
||||
就像压缩一组文件一样,你可以使用 `tar` 来压缩单个文件,尽管这种操作与直接使用 `gzip` 相比没有特别的优势。要使用 `tar` 这样做,只需要使用 `tar cfz newtarfile filename` 命令来标识要压缩的文件,就像标识一组文件一样,像这样:
|
||||
|
||||
```
|
||||
$ tar cfz bigfile.tgz bigfile
|
||||
^ ^
|
||||
| |
|
||||
+- 新的文件 +- 将被压缩的文件
|
||||
|
||||
$ ls -l bigfile*
|
||||
-rw-rw-r-- 1 shs shs 103270400 Apr 16 16:09 bigfile
|
||||
-rw-rw-r-- 1 shs shs 21608325 Apr 16 16:08 bigfile.tgz
|
||||
```
|
||||
|
||||
注意,文件的大小显著减少了。
|
||||
|
||||
如果你愿意,你可以使用 `tar.gz` 扩展名,这可能会使文件的特征更加明显,但是大多数的 Linux 用户将很可能会意识到与 `tgz` 的意思是一样的 – `tar` 和 `gz` 的组合来显示文件是一个压缩的 tar 文件。在压缩完成后,你将同时得到原始文件和压缩文件。
|
||||
|
||||
要将很多文件收集在一起并在一个命令中压缩出 “tar ball”,使用相同的语法,但要指定要包含的文件为一组,而不是单个文件。这里有一个示例:
|
||||
|
||||
```
|
||||
$ tar cfz bin.tgz bin/*
|
||||
^ ^
|
||||
| +-- 将被包含的文件
|
||||
+ 新的文件
|
||||
```
|
||||
|
||||
### zip
|
||||
|
||||
`zip` 命令创建一个压缩文件,与此同时保留原始文件的完整性。语法像使用 `tar` 一样简单,只是你必需记住,你的原始文件名称应该是命令行上的最后一个参数。
|
||||
|
||||
```
|
||||
$ zip ./bigfile.zip bigfile
|
||||
updating: bigfile (deflated 79%)
|
||||
$ ls -l bigfile bigfile.zip
|
||||
-rw-rw-r-- 1 shs shs 103270400 Apr 16 11:18 bigfile
|
||||
-rw-rw-r-- 1 shs shs 21606889 Apr 16 11:19 bigfile.zip
|
||||
```
|
||||
|
||||
### gzip
|
||||
|
||||
`gzip` 命令非常容易使用。你只需要键入 `gzip`,紧随其后的是你想要压缩的文件名称。不像上述描述的命令,`gzip` 将“就地”加密文件。换句话说,原始文件将被加密文件替换。
|
||||
|
||||
```
|
||||
$ gzip bigfile
|
||||
$ ls -l bigfile*
|
||||
-rw-rw-r-- 1 shs shs 21606751 Apr 15 17:57 bigfile.gz
|
||||
```
|
||||
|
||||
### bzip2
|
||||
|
||||
像使用 `gzip` 命令一样,`bzip2` 将在你选择的文件“就地”压缩,不留下原始文件。
|
||||
|
||||
```
|
||||
$ bzip bigfile
|
||||
$ ls -l bigfile*
|
||||
-rw-rw-r-- 1 shs shs 18115234 Apr 15 17:57 bigfile.bz2
|
||||
```
|
||||
|
||||
### xz
|
||||
|
||||
`xz` 是压缩命令团队中的一个相对较新的成员,在压缩文件的能力方面,它是一个领跑者。像先前的两个命令一样,你只需要将文件名称提供给命令。再强调一次,原始文件被就地压缩。
|
||||
|
||||
```
|
||||
$ xz bigfile
|
||||
$ ls -l bigfile*
|
||||
-rw-rw-r-- 1 shs shs 13427236 Apr 15 17:30 bigfile.xz
|
||||
```
|
||||
|
||||
对于大文件来说,你可能会注意到 `xz` 将比其它的压缩命令花费更多的运行时间,但是压缩的结果却是非常令人赞叹的。
|
||||
|
||||
### 对比
|
||||
|
||||
大多数人都听说过“大小不是一切”。所以,让我们比较一下文件大小以及一些当你计划如何压缩文件时的问题。
|
||||
|
||||
下面显示的统计数据都与压缩单个文件相关,在上面显示的示例中使用 `bigfile`。这个文件是一个大的且相当随机的文本文件。压缩率在一定程度上取决于文件的内容。
|
||||
|
||||
#### 大小减缩率
|
||||
|
||||
当比较时,上面显示的各种压缩命产生下面的结果。百分比表示压缩文件与原始文件的比较效果。
|
||||
|
||||
```
|
||||
-rw-rw-r-- 1 shs shs 103270400 Apr 16 14:01 bigfile
|
||||
------------------------------------------------------
|
||||
-rw-rw-r-- 1 shs shs 18115234 Apr 16 13:59 bigfile.bz2 ~17%
|
||||
-rw-rw-r-- 1 shs shs 21606751 Apr 16 14:00 bigfile.gz ~21%
|
||||
-rw-rw-r-- 1 shs shs 21608322 Apr 16 13:59 bigfile.tgz ~21%
|
||||
-rw-rw-r-- 1 shs shs 13427236 Apr 16 14:00 bigfile.xz ~13%
|
||||
-rw-rw-r-- 1 shs shs 21606889 Apr 16 13:59 bigfile.zip ~21%
|
||||
```
|
||||
|
||||
`xz` 命令获胜,最终只有压缩文件 13% 的大小,但是所有这些压缩命令都相当显著地减少原始文件的大小。
|
||||
|
||||
#### 是否替换原始文件
|
||||
|
||||
`bzip2`、`gzip` 和 `xz` 命令都用压缩文件替换原始文件。`tar` 和 `zip` 命令不替换。
|
||||
|
||||
#### 运行时间
|
||||
|
||||
`xz` 命令似乎比其它命令需要花费更多的时间来加密文件。对于 `bigfile` 来说,大概的时间是:
|
||||
|
||||
```
|
||||
命令 运行时间
|
||||
tar 4.9 秒
|
||||
zip 5.2 秒
|
||||
bzip2 22.8 秒
|
||||
gzip 4.8 秒
|
||||
xz 50.4 秒
|
||||
```
|
||||
|
||||
解压缩文件很可能比压缩时间要短得多。
|
||||
|
||||
#### 文件权限
|
||||
|
||||
不管你对压缩文件设置什么权限,压缩文件的权限将基于你的 `umask` 设置,但 `bzip2` 除外,它保留了原始文件的权限。
|
||||
|
||||
#### 与 Windows 的兼容性
|
||||
|
||||
`zip` 命令创建的文件可以在 Windows 系统以及 Linux 和其他 Unix 系统上使用(即解压),而无需安装其他工具,无论这些工具可能是可用还是不可用的。
|
||||
|
||||
### 解压缩文件
|
||||
|
||||
解压文件的命令与压缩文件的命令类似。在我们运行上述压缩命令后,这些命令用于解压缩 `bigfile`:
|
||||
|
||||
* tar: `tar xf bigfile.tgz`
|
||||
* zip: `unzip bigfile.zip`
|
||||
* gzip: `gunzip bigfile.gz`
|
||||
* bzip2: `bunzip2 bigfile.gz2`
|
||||
* xz: `xz -d bigfile.xz` 或 `unxz bigfile.xz`
|
||||
|
||||
### 自己运行压缩对比
|
||||
|
||||
如果你想自己运行一些测试,抓取一个大的且可以替换的文件,并使用上面显示的每个命令来压缩它 —— 最好使用一个新的子目录。你可能需要先安装 `xz`,如果你想在测试中包含它的话。这个脚本可能更容易地进行压缩,但是可能需要花费几分钟完成。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# 询问用户文件名称
|
||||
echo -n "filename> "
|
||||
read filename
|
||||
|
||||
# 你需要这个,因为一些命令将替换原始文件
|
||||
cp $filename $filename-2
|
||||
|
||||
# 先清理(以免先前的结果仍然可用)
|
||||
rm $filename.*
|
||||
|
||||
tar cvfz ./$filename.tgz $filename > /dev/null
|
||||
zip $filename.zip $filename > /dev/null
|
||||
bzip2 $filename
|
||||
# 恢复原始文件
|
||||
cp $filename-2 $filename
|
||||
gzip $filename
|
||||
# 恢复原始文件
|
||||
cp $filename-2 $filename
|
||||
xz $filename
|
||||
|
||||
# 显示结果
|
||||
ls -l $filename.*
|
||||
|
||||
# 替换原始文件
|
||||
mv $filename-2 $filename
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3538471/how-to-compress-files-on-linux-5-ways.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/blog/itaas-and-the-corporate-storage-technology/?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE22140&utm_content=sidebar (ITAAS and Corporate Storage Strategy)
|
||||
[2]: https://www.facebook.com/NetworkWorld/
|
||||
[3]: https://www.linkedin.com/company/network-world
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12180-1.html)
|
||||
[#]: subject: (4 Git scripts I can't live without)
|
||||
[#]: via: (https://opensource.com/article/20/4/git-extras)
|
||||
[#]: author: (Vince Power https://opensource.com/users/vincepower)
|
||||
@ -12,11 +12,11 @@
|
||||
|
||||
> Git Extras 版本库包含了 60 多个脚本,它们是 Git 基本功能的补充。以下是如何安装、使用和贡献的方法。
|
||||
|
||||
![Person using a laptop][1]
|
||||

|
||||
|
||||
2005 年,[Linus Torvalds][2] 创建了 [Git][3],以取代他之前用于维护 Linux 内核的专有的分布式源码控制管理解决方案。从那时起,Git 已经成为开源和云原生开发团队的主流版本控制解决方案。
|
||||
2005 年,[Linus Torvalds][2] 创建了 [Git][3],以取代他之前用于维护 Linux 内核的分布式源码控制管理的专有解决方案。从那时起,Git 已经成为开源和云原生开发团队的主流版本控制解决方案。
|
||||
|
||||
但即使是像 Git 这样功能丰富的应用程序,也没有人们想要或需要的每个功能,所以人们会花大力气去创建这些功能。就 Git 而言,这个人就是 [TJ Holowaychuk][4]。他的 [Git Extras][5] 项目承载了 60 多个“附加功能”,这些功能扩展了 Git 的基本功能。
|
||||
但即使是像 Git 这样功能丰富的应用程序,也没有人们想要或需要的每个功能,所以会有人花大力气去创建这些缺少的功能。就 Git 而言,这个人就是 [TJ Holowaychuk][4]。他的 [Git Extras][5] 项目承载了 60 多个“附加功能”,这些功能扩展了 Git 的基本功能。
|
||||
|
||||
### 使用 Git 附加功能
|
||||
|
||||
@ -24,9 +24,9 @@
|
||||
|
||||
#### git-ignore
|
||||
|
||||
`git ignore` 是一个方便的附加功能,它可以让你手动添加文件类型和注释到 `.git-ignore` 文件中,而不需要打开文本编辑器。它可以操作你的个人用户帐户的全局忽略文件和单独用于你正在工作的版本库的忽略文件。
|
||||
`git ignore` 是一个方便的附加功能,它可以让你手动添加文件类型和注释到 `.git-ignore` 文件中,而不需要打开文本编辑器。它可以操作你的个人用户帐户的全局忽略文件和单独用于你正在工作的版本库中的忽略文件。
|
||||
|
||||
在没有参数的情况下执行 `git ignore` 会先列出全局忽略文件,然后是本地的忽略文件。
|
||||
在不提供参数的情况下执行 `git ignore` 会先列出全局忽略文件,然后是本地的忽略文件。
|
||||
|
||||
```
|
||||
$ git ignore
|
||||
@ -105,7 +105,7 @@ branch.master.merge=refs/heads/master
|
||||
* `git mr` 检出来自 GitLab 的合并请求。
|
||||
* `git pr` 检出来自 GitHub 的拉取请求。
|
||||
|
||||
无论是哪种情况,你只需要合并请求号、拉取请求号或完整的 URL,它就会抓取远程引用,检出分支,并调整配置,这样 Git 就知道要替换哪个分支了。
|
||||
无论是哪种情况,你只需要合并请求号/拉取请求号或完整的 URL,它就会抓取远程引用,检出分支,并调整配置,这样 Git 就知道要替换哪个分支了。
|
||||
|
||||
```
|
||||
$ git mr 51
|
||||
@ -142,7 +142,7 @@ $ git extras --help
|
||||
$ brew install git-extras
|
||||
```
|
||||
|
||||
在 Linux 上,每个平台的原生包管理器中都有 Git Extras。有时,你需要启用一个额外的仓库,比如在 CentOS 上的 [EPEL][10],然后运行一条命令。
|
||||
在 Linux 上,每个平台原生的包管理器中都包含有 Git Extras。有时,你需要启用额外的仓库,比如在 CentOS 上的 [EPEL][10],然后运行一条命令。
|
||||
|
||||
```
|
||||
$ sudo yum install git-extras
|
||||
@ -152,9 +152,9 @@ $ sudo yum install git-extras
|
||||
|
||||
### 贡献
|
||||
|
||||
你是否你认为 Git 中有缺少的功能,并且已经构建了一个脚本来处理它?为什么不把它作为 Git Extras 发布版的一部分,与全世界分享呢?
|
||||
你是否认为 Git 中有缺少的功能,并且已经构建了一个脚本来处理它?为什么不把它作为 Git Extras 发布版的一部分,与全世界分享呢?
|
||||
|
||||
要做到这一点,请将该功能贡献到 Git Extras 仓库中。更多具体细节请参见仓库中的 [CONTRIBUTING.md][12] 文件,但基本的操作方法很简单。
|
||||
要做到这一点,请将该功能贡献到 Git Extras 仓库中。更多具体细节请参见仓库中的 [CONTRIBUTING.md][12] 文件,但基本的操作方法很简单:
|
||||
|
||||
1. 创建一个处理该功能的 Bash 脚本。
|
||||
2. 创建一个基本的 man 文件,让大家知道如何使用它。
|
||||
@ -171,7 +171,7 @@ via: https://opensource.com/article/20/4/git-extras
|
||||
作者:[Vince Power][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,283 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qfzy1233)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12183-1.html)
|
||||
[#]: subject: (16 Things to do After Installing Ubuntu 20.04)
|
||||
[#]: via: (https://itsfoss.com/things-to-do-after-installing-ubuntu-20-04/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
安装完 Ubuntu 20.04 后要做的 16 件事
|
||||
======
|
||||
|
||||
> 以下是安装 Ubuntu 20.04 之后需要做的一些调整和事项,它将使你获得更流畅、更好的桌面 Linux 体验。
|
||||
|
||||
[Ubuntu 20.04 LTS(长期支持版)带来了许多新的特性][1]和观感上的变化。如果你要安装 Ubuntu 20.04,让我向你展示一些推荐步骤便于你的使用。
|
||||
|
||||
### 安装完 Ubuntu 20.04 LTS “Focal Fossa” 后要做的 16 件事
|
||||
|
||||
![][2]
|
||||
|
||||
我在这里提到的步骤仅是我的建议。如果一些定制或调整不适合你的需要和兴趣,你可以忽略它们。
|
||||
|
||||
同样的,有些步骤看起来很简单,但是对于一个 Ubuntu 新手来说是必要的。
|
||||
|
||||
这里的一些建议适用于启用 GNOME 作为默认桌面 Ubuntu 20.04,所以请检查 [Ubuntu 版本][3]和[桌面环境][4]。
|
||||
|
||||
以下列表便是安装了代号为 Focal Fossa 的 Ubuntu 20.04 LTS 之后要做的事。
|
||||
|
||||
#### 1、通过更新和启用额外的软件仓库来准备你的系统
|
||||
|
||||
安装 Ubuntu 或任何其他 Linux 发行版之后,你应该做的第一件事就是更新它。Linux 的运作是建立在本地的可用软件包数据库上,而这个缓存需要同步以便你能够安装软件。
|
||||
|
||||
升级 Ubuntu 非常简单。你可以运行软件更新从菜单(按 `Super` 键并搜索 “software updater”):
|
||||
|
||||
![Ubuntu 20.04 的软件升级器][5]
|
||||
|
||||
你也可以在终端使用以下命令更新你的系统:
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt upgrade
|
||||
```
|
||||
|
||||
接下来,你应该确保启用了 [universe(宇宙)和 multiverse(多元宇宙)软件仓库][6]。使用这些软件仓库,你可以访问更多的软件。我还推荐阅读关于 [Ubuntu 软件仓库][6]的文章,以了解它背后的基本概念。
|
||||
|
||||
在菜单中搜索 “Software & Updates”:
|
||||
|
||||
![软件及更新设置项][7]
|
||||
|
||||
请务必选中软件仓库前面的勾选框:
|
||||
|
||||
![启用额外的软件仓库][8]
|
||||
|
||||
#### 2、安装媒体解码器来播放 MP3、MPEG4 和其他格式媒体文件
|
||||
|
||||
如果你想播放媒体文件,如 MP3、MPEG4、AVI 等,你需要安装媒体解码器。由于各个国家的版权问题, Ubuntu 在默认情况下不会安装它。
|
||||
|
||||
作为个人,你可以[使用 Ubuntu Restricted Extra 安装包][9]很轻松地安装这些媒体编解码器。这将[在你的 Ubuntu 系统安装][10]媒体编解码器、Adobe Flash 播放器和微软 True Type 字体等。
|
||||
|
||||
你可以通过[点击这个链接][11]来安装它(它会要求在软件中心打开它),或者使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt install ubuntu-restricted-extras
|
||||
```
|
||||
|
||||
如果遇到 EULA 或许可证界面,请记住使用 `tab` 键在选项之间进行选择,然后按回车键确认你的选择。
|
||||
|
||||
![按 tab 键选择 OK 并按回车键][12]
|
||||
|
||||
#### 3、从软件中心或网络上安装软件
|
||||
|
||||
现在已经设置好了软件仓库并更新了软件包缓存,应该开始安装所需的软件了。
|
||||
|
||||
在 Ubuntu 中安装应用程序有几种方法,最简单和正式的方法是使用软件中心。
|
||||
|
||||
![Ubuntu 软件中心][14]
|
||||
|
||||
如果你想要一些关于软件的建议,请参考这个[丰富的各种用途的 Ubuntu 应用程序列表][15]。
|
||||
|
||||
一些软件供应商提供了 .deb 文件来方便地安装他们的应用程序。你可以从他们的网站获得 .deb 文件。例如,要[在 Ubuntu 上安装谷歌 Chrome][16],你可以从它的网站上获得 .deb 文件,双击它开始安装。
|
||||
|
||||
#### 4、享受 Steam Proton 和 GameModeEnjoy 上的游戏
|
||||
|
||||
[在 Linux 上进行游戏][17]已经有了长足的发展。你不再受限于自带的少数游戏。你可以[在 Ubuntu 上安装 Steam][18]并享受许多游戏。
|
||||
|
||||
[Steam 新的 Proton 项目][19]可以让你在 Linux 上玩许多只适用于 Windows 的游戏。除此之外,Ubuntu 20.04 还默认安装了 [Feral Interactive 的 GameMode][20]。
|
||||
|
||||
GameMode 会自动调整 Linux 系统的性能,使游戏具有比其他后台进程更高的优先级。
|
||||
|
||||
这意味着一些支持 GameMode 的游戏(如[古墓丽影·崛起][21])在 Ubuntu 上的性能应该有所提高。
|
||||
|
||||
#### 5、管理自动更新(适用于进阶用户和专家)
|
||||
|
||||
最近,Ubuntu 已经开始自动下载并安装对你的系统至关重要的安全更新。这是一个安全功能,作为一个普通用户,你应该让它保持默认开启。
|
||||
|
||||
但是,如果你喜欢自己进行配置更新,而这个自动更新经常导致你[“无法锁定管理目录”错误][22],也许你可以改变自动更新行为。
|
||||
|
||||
你可以选择“立即显示”,这样一有安全更新就会立即通知你,而不是自动安装。
|
||||
|
||||
![管理自动更新设置][23]
|
||||
|
||||
#### 6、控制电脑的自动挂起和屏幕锁定
|
||||
|
||||
如果你在笔记本电脑上使用 Ubuntu 20.04,那么你可能需要注意一些电源和屏幕锁定设置。
|
||||
|
||||
如果你的笔记本电脑处于电池模式,Ubuntu 会在 20 分钟不活动后休眠系统。这样做是为了节省电池电量。就我个人而言,我不喜欢它,因此我禁用了它。
|
||||
|
||||
类似地,如果你离开系统几分钟,它会自动锁定屏幕。我也不喜欢这种行为,所以我宁愿禁用它。
|
||||
|
||||
![Ubuntu 20.04 的电源设置][24]
|
||||
|
||||
#### 7、享受夜间模式
|
||||
|
||||
[Ubuntu 20.04 中最受关注的特性][25]之一是夜间模式。你可以通过进入设置并在外观部分中选择它来启用夜间模式。
|
||||
|
||||
![开启夜间主题 Ubuntu][26]
|
||||
|
||||
你可能需要做一些[额外的调整来获得完整的 Ubuntu 20.04 夜间模式][27]。
|
||||
|
||||
#### 8、控制桌面图标和启动程序
|
||||
|
||||
如果你想要一个最简的桌面,你可以禁用桌面上的图标。你还可以从左侧禁用启动程序,并在顶部面板中禁用软件状态栏。
|
||||
|
||||
所有这些都可以通过默认的新 GNOME 扩展来控制,该程序默认情况下已经可用。
|
||||
|
||||
![禁用 Ubuntu 20 04 的 Dock][28]
|
||||
|
||||
顺便说一下,你也可以通过“设置”->“外观”来将启动栏的位置改变到底部或者右边。
|
||||
|
||||
#### 9、使用表情符和特殊字符,或从搜索中禁用它
|
||||
|
||||
Ubuntu 提供了一个使用表情符号的简单方法。在默认情况下,有一个专用的应用程序叫做“字符”。它基本上可以为你提供表情符号的 [Unicode][29]。
|
||||
|
||||
不仅是表情符号,你还可以使用它来获得法语、德语、俄语和拉丁语字符的 unicode。单击符号你可以复制 unicode,当你粘贴该代码时,你所选择的符号便被插入。
|
||||
|
||||
![Ubuntu 表情符][30]
|
||||
|
||||
你也能在桌面搜索中找到这些特殊的字符和表情符号。也可以从搜索结果中复制它们。
|
||||
|
||||
![表情符出现在桌面搜索中][31]
|
||||
|
||||
如果你不想在搜索结果中看到它们,你应该禁用搜索功能对它们的访问。下一节将讨论如何做到这一点。
|
||||
|
||||
#### 10、掌握桌面搜索
|
||||
|
||||
GNOME 桌面拥有强大的搜索功能,大多数人使用它来搜索已安装的应用程序,但它不仅限于此。
|
||||
|
||||
按 `Super` 键并搜索一些东西,它将显示与搜索词匹配的任何应用程序,然后是系统设置和软件中心提供的匹配应用程序。
|
||||
|
||||
![桌面搜索][32]
|
||||
|
||||
不仅如此,搜索还可以找到文件中的文本。如果你正在使用日历,它也可以找到你的会议和提醒。你甚至可以在搜索中进行快速计算并复制其结果。
|
||||
|
||||
![Ubuntu搜索的快速计算][33]
|
||||
|
||||
你可以进入“设置”中来控制可以搜索的内容和顺序。
|
||||
|
||||
![][34]
|
||||
|
||||
#### 11、使用夜灯功能,减少夜间眼睛疲劳
|
||||
|
||||
如果你在晚上使用电脑或智能手机,你应该使用夜灯功能来减少眼睛疲劳。我觉得这很有帮助。
|
||||
|
||||
夜灯的特点是在屏幕上增加了一种黄色的色调,比白光少了一些挤压感。
|
||||
|
||||
你可以在“设置”->“显示”切换到夜灯选项卡来开启夜光功能。你可以根据自己的喜好设置“黄度”。
|
||||
|
||||
![夜灯功能][35]
|
||||
|
||||
#### 12、使用 2K/4K 显示器?使用分辨率缩放得到更大的图标和字体
|
||||
|
||||
如果你觉得图标、字体、文件夹在你的高分辨率屏幕上看起来都太小了,你可以利用分辨率缩放。
|
||||
|
||||
启用分辨率缩放可以让你有更多的选项来从 100% 增加到 200%。你可以选择适合自己喜好的缩放尺寸。
|
||||
|
||||
![在设置->显示中启用高分缩放][36]
|
||||
|
||||
#### 13、探索 GNOME 扩展功能以扩展 GNOME 桌面可用性
|
||||
|
||||
GNOME 桌面有称为“扩展”的小插件或附加组件。你应该[学会使用 GNOME 扩展][37]来扩展系统的可用性。
|
||||
|
||||
如下图所示,天气扩展顶部面板中显示了天气信息。不起眼但十分有用。你也可以在这里查看一些[最佳 GNOME 扩展][38]。不需要全部安装,只使用那些对你有用的。
|
||||
|
||||
![天气扩展][39]
|
||||
|
||||
#### 14、启用“勿扰”模式,专注于工作
|
||||
|
||||
如果你想专注于工作,禁用桌面通知会很方便。你可以轻松地启用“勿扰”模式,并静音所有通知。
|
||||
|
||||
![启用“请勿打扰”清除桌面通知][40]
|
||||
|
||||
这些通知仍然会在消息栏中,以便你以后可以阅读它们,但是它们不会在桌面上弹出。
|
||||
|
||||
#### 15、清理你的系统
|
||||
|
||||
这是你安装 Ubuntu 后不需要马上做的事情。但是记住它会对你有帮助。
|
||||
|
||||
随着时间的推移,你的系统将有大量不再需要的包。你可以用这个命令一次性删除它们:
|
||||
|
||||
```
|
||||
sudo apt autoremove
|
||||
```
|
||||
|
||||
还有其他[清理 Ubuntu 以释放磁盘空间的方法][41],但这是最简单和最安全的。
|
||||
|
||||
#### 16、根据你的喜好调整和定制 GNOME 桌面
|
||||
|
||||
我强烈推荐[安装 GNOME 设置工具][42]。这将让你可以通过额外的设置来进行定制。
|
||||
|
||||
![Gnome 设置工具][43]
|
||||
|
||||
比如,你可以[以百分比形式显示电池容量][44]、[修正在触摸板右键问题][45]、改变 Shell 主题、改变鼠标指针速度、显示日期和星期数、改变应用程序窗口行为等。
|
||||
|
||||
定制是没有尽头的,我可能仅使用了它的一小部分功能。这就是为什么我推荐[阅读这些][42]关于[自定义 GNOME 桌面][46]的文章。
|
||||
|
||||
你也可以[在 Ubuntu 中安装新主题][47],不过就我个人而言,我喜欢这个版本的默认主题。这是我第一次在 Ubuntu 发行版中使用默认的图标和主题。
|
||||
|
||||
#### 安装 Ubuntu 之后你会做什么?
|
||||
|
||||
如果你是 Ubuntu 的初学者,我建议你[阅读这一系列 Ubuntu 教程][48]开始学习。
|
||||
|
||||
这就是我的建议。安装 Ubuntu 之后你要做什么?分享你最喜欢的东西,我可能根据你的建议来更新这篇文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/things-to-do-after-installing-ubuntu-20-04/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-12146-1.html
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/things-to-do-after-installing-ubuntu-20-04.jpg?ssl=1
|
||||
[3]: https://linux.cn/article-9872-1.html
|
||||
[4]: https://linux.cn/article-12124-1.html
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/software-updater-ubuntu-20-04.jpg?ssl=1
|
||||
[6]: https://itsfoss.com/ubuntu-repositories/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/software-updates-settings-ubuntu-20-04.jpg?ssl=1
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/extra-repositories-ubuntu-20.jpg?ssl=1
|
||||
[9]: https://linux.cn/article-11906-1.html
|
||||
[10]: https://linux.cn/article-12074-1.html
|
||||
[11]: //ubuntu-restricted-extras/
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/installing_ubuntu_restricted_extras.jpg?ssl=1
|
||||
[13]: https://itsfoss.com/remove-install-software-ubuntu/
|
||||
[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/software-center-ubuntu-20.png?resize=800%2C509&ssl=1
|
||||
[15]: https://itsfoss.com/best-ubuntu-apps/
|
||||
[16]: https://itsfoss.com/install-chrome-ubuntu/
|
||||
[17]: https://linux.cn/article-7316-1.html
|
||||
[18]: https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[19]: https://linux.cn/article-10054-1.html
|
||||
[20]: https://github.com/FeralInteractive/gamemode
|
||||
[21]: https://en.wikipedia.org/wiki/Rise_of_the_Tomb_Raider
|
||||
[22]: https://itsfoss.com/could-not-get-lock-error/
|
||||
[23]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/auto-updates-ubuntu.png?resize=800%2C361&ssl=1
|
||||
[24]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/power-settings-ubuntu-20-04.png?fit=800%2C591&ssl=1
|
||||
[25]: https://www.youtube.com/watch?v=lpq8pm_xkSE
|
||||
[26]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/enable-dark-theme-ubuntu.png?ssl=1
|
||||
[27]: https://linux.cn/article-12098-1.html
|
||||
[28]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/disable-dock-ubuntu-20-04.png?ssl=1
|
||||
[29]: https://en.wikipedia.org/wiki/List_of_Unicode_characters
|
||||
[30]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/emoji-ubuntu.jpg?ssl=1
|
||||
[31]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/emojis-desktop-search-ubuntu.jpg?ssl=1
|
||||
[32]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/ubuntu-desktop-search-1.jpg?ssl=1
|
||||
[33]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/quick-calculations-ubuntu-search.jpg?ssl=1
|
||||
[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/search-settings-control-ubuntu.png?resize=800%2C534&ssl=1
|
||||
[35]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/nightlight-ubuntu-20-04.png?ssl=1
|
||||
[36]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/fractional-scaling-ubuntu.jpg?ssl=1
|
||||
[37]: https://itsfoss.com/gnome-shell-extensions/
|
||||
[38]: https://itsfoss.com/best-gnome-extensions/
|
||||
[39]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/weather-extension-ubuntu.jpg?ssl=1
|
||||
[40]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/03/do-not-distrub-option-ubuntu-20-04.png?ssl=1
|
||||
[41]: https://itsfoss.com/free-up-space-ubuntu-linux/
|
||||
[42]: https://itsfoss.com/gnome-tweak-tool/
|
||||
[43]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/gnome-tweaks-tool-ubuntu-20-04.png?fit=800%2C551&ssl=1
|
||||
[44]: https://itsfoss.com/display-battery-ubuntu/
|
||||
[45]: https://itsfoss.com/fix-right-click-touchpad-ubuntu/
|
||||
[46]: https://itsfoss.com/gnome-tricks-ubuntu/
|
||||
[47]: https://itsfoss.com/install-themes-ubuntu/
|
||||
[48]: https://itsfoss.com/getting-started-with-ubuntu/
|
||||
99
published/20200428 Upgrading Fedora 31 to Fedora 32.md
Normal file
99
published/20200428 Upgrading Fedora 31 to Fedora 32.md
Normal file
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12195-1.html)
|
||||
[#]: subject: (Upgrading Fedora 31 to Fedora 32)
|
||||
[#]: via: (https://fedoramagazine.org/upgrading-fedora-31-to-fedora-32/)
|
||||
[#]: author: (Adam Šamalík https://fedoramagazine.org/author/asamalik/)
|
||||
|
||||
将 Fedora 31 升级到 Fedora 32
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Fedora 32 [已经发布][2]。你可能想升级系统以获得 Fedora 中的最新功能。Fedora Workstation 有图形化的升级方法。另外,Fedora 提供了命令行方法,用于将 Fedora 31 升级到 Fedora 32。
|
||||
|
||||
升级前,请访问 [Fedora 32 个常见 bug 的维基页面][3],查看是否存在可能影响升级的问题。尽管 Fedora 社区试图确保升级正常进行,但是无法为用户可能使用的每种软硬件组合提供保证。
|
||||
|
||||
### 将 Fedora 31 Workstation 升级到 Fedora 32
|
||||
|
||||
在新版本发布不久之后就会出现通知,告诉你有可用的升级。你可以单击该通知启动 “GNOME 软件”。或者,你可以从 GNOME Shell 中选择“软件”。
|
||||
|
||||
在 “GNOME 软件”中选择<ruby>更新<rt>Updates</rt></ruby>选项卡,你会看到一个页面通知你 Fedora 32 现在可用。
|
||||
|
||||
如果你在此页面看不到任何内容,请尝试使用左上方的重新加载按钮。发布后,所有系统可能都需要一段时间才能看到可用的升级。
|
||||
|
||||
选择<ruby>下载<rt>Download</rt></ruby>获取升级包。你可以继续做事直到下载完成。然后使用 “GNOME 软件”重启系统并应用升级。升级需要时间,因此你可能需要喝杯咖啡,稍后再回来。
|
||||
|
||||
### 使用命令行
|
||||
|
||||
如果你是从 Fedora 的先前版本升级的,那么你可能对 `dnf upgrade` 插件很熟悉。这个方法是推荐和受支持的从 Fedora 31 升级到 Fedora 32 的方法。使用此插件将使你轻松地升级到 Fedora 32。
|
||||
|
||||
#### 1、更新软件并备份系统
|
||||
|
||||
在开始升级过程之前,请确保你有 Fedora 31 的最新软件。如果你安装了<ruby>模块化软件<rt>modular software</rt></ruby>,这尤为重要。`dnf` 和 “GNOME 软件”的最新版本对某些模块化流的升级过程进行了改进。要更新软件,请使用 “GNOME 软件” 或在终端中输入以下命令。
|
||||
|
||||
```
|
||||
sudo dnf upgrade --refresh
|
||||
```
|
||||
|
||||
此外,在继续操作之前,请确保备份系统。有关备份的帮助,请参阅 Fedora Magazine 上的[备份系列][4]。
|
||||
|
||||
#### 2、安装 DNF 插件
|
||||
|
||||
接下来,打开终端并输入以下命令安装插件:
|
||||
|
||||
```
|
||||
sudo dnf install dnf-plugin-system-upgrade
|
||||
```
|
||||
|
||||
#### 3、使用 DNF 开始更新
|
||||
|
||||
现在,你的系统已更新、已备份、并且已安装 DNF 插件,你可以在终端中使用以下命令开始升级:
|
||||
|
||||
```
|
||||
sudo dnf system-upgrade download --releasever=32
|
||||
```
|
||||
|
||||
这个命令将开始在本地下载所有的升级包,为升级做准备。如果你在升级的时候因为没有更新的包、依赖关系破损或退役的包而出现问题,请在输入上述命令时添加 `--allowerasing` 标志。这将允许 DNF 移除可能阻碍系统升级的软件包。
|
||||
|
||||
#### 4、重启并升级
|
||||
|
||||
当上一个命令完成了所有升级包的下载,你的系统就可以重新启动了。要将系统引导至升级过程,请在终端中输入以下命令:
|
||||
|
||||
```
|
||||
sudo dnf system-upgrade reboot
|
||||
```
|
||||
|
||||
此后,系统将重启。在许多版本之前,`fedup` 工具会在内核选择/启动页上创建一个新选项。使用 `dnf-plugin-system-upgrade` 包,你的系统会重启进入 Fedora 31 当前安装的内核;这个是正常的。在选择内核之后,你的系统会立即开始升级过程。
|
||||
|
||||
现在可能是喝杯咖啡休息的好时机!完成后,系统将重启,你将能够登录到新升级的 Fedora 32 系统。
|
||||
|
||||
![][5]
|
||||
|
||||
### 解决升级问题
|
||||
|
||||
有时,升级系统时可能会出现意外问题。如果你遇到任何问题,请访问 [DNF 系统升级文档][6],以获取有关故障排除的更多信息。
|
||||
|
||||
如果升级时遇到问题,并且系统上安装了第三方仓库,那么在升级时可能需要禁用这些仓库。对于 Fedora 不提供的仓库的支持,请联系仓库的提供者。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/upgrading-fedora-31-to-fedora-32/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/04/31-32-816x345.png
|
||||
[2]: https://linux.cn/article-12164-1.html
|
||||
[3]: https://fedoraproject.org/wiki/Common_F32_bugs
|
||||
[4]: https://fedoramagazine.org/taking-smart-backups-duplicity/
|
||||
[5]: https://cdn.fedoramagazine.org/wp-content/uploads/2016/06/Screenshot_f23-ws-upgrade-test_2016-06-10_110906-1024x768.png
|
||||
[6]: https://docs.fedoraproject.org/en-US/quick-docs/dnf-system-upgrade/#Resolving_post-upgrade_issues
|
||||
@ -0,0 +1,102 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12198-1.html)
|
||||
[#]: subject: (Using Files and Folders on Desktop Screen in Ubuntu)
|
||||
[#]: via: (https://itsfoss.com/add-files-on-desktop-ubuntu/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
在 Ubuntu 桌面中使用文件和文件夹
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 此初学者教程讨论了 在Ubuntu 桌面上添加文件和文件夹时可能遇到的一些困难。
|
||||
|
||||
我认识一些习惯将所有重要/常用文件放在桌面上以便快速访问的人。
|
||||
|
||||
![][1]
|
||||
|
||||
我不喜欢杂乱的桌面,但是我可以想象它实际上可能对某些人有所帮助。
|
||||
|
||||
在过去的几个版本中,很难在 Ubuntu 的默认 GNOME 桌面上添加文件。这并不是 Ubuntu 的错。
|
||||
|
||||
[GNOME][2] 的开发者认为,桌面上没有图标和文件的存身之地。当你可以在菜单中轻松搜索文件时,无需将文件放在桌面上。这在部分情况下是事实。
|
||||
|
||||
这就是为什么 [GNOME 的文件管理器 Nautilus][3] 的较新版本不能很好地支持桌面上的图标和文件的原因。
|
||||
|
||||
也就是说,在桌面上添加文件和文件夹并非没有可能。让我告诉你如何做。
|
||||
|
||||
### 在 Ubuntu 的桌面上添加文件和文件夹
|
||||
|
||||
![][4]
|
||||
|
||||
我在本教程中使用的是 Ubuntu 20.04。对于其他 Ubuntu 版本,步骤可能会有所不同。
|
||||
|
||||
#### 将文件和文件夹添加到“桌面文件夹”
|
||||
|
||||
如果打开文件管理器,你应该在左侧边栏或文件夹列表中看到一个名为“桌面”的条目。此文件夹(以某种方式)代表你的桌面。
|
||||
|
||||
![Desktop folder can be used to add files to the desktop screen][5]
|
||||
|
||||
你添加到此文件夹的所有内容都会反映在桌面上。
|
||||
|
||||
![Anything added to the Desktop folder will be reflected on the desktop screen][6]
|
||||
|
||||
如果你从“桌面文件夹”中删除文件,那么文件也会从桌面中删除。
|
||||
|
||||
#### 将文件拖放到桌面不起作用
|
||||
|
||||
现在,如果你尝试从文件管理器往桌面上拖放文件,它会不起使用。这不是一个 bug,它是一个使很多人恼火的功能。
|
||||
|
||||
一种临时方案是打开两个文件管理器。在其中一个打开“桌面”文件夹,然后将文件拖放到该文件夹中,它们将被添加到桌面上。
|
||||
|
||||
我知道这并不理想,但是你没有太多选择。
|
||||
|
||||
#### 你不能使用 Ctrl+C 和 Ctrl+V 在桌面上复制粘贴,请使用右键单击菜单
|
||||
|
||||
更恼人的是,你不能使用 `Ctrl+V`(著名的键盘快捷键)将文件粘贴到桌面上。
|
||||
|
||||
但是,你仍然可以使用右键单击,然后选择“粘贴”,将文件复制到桌面上。你甚至可以通过这种方式创建新文件夹。
|
||||
|
||||
![Right click menu can be used for copy-pasting files to desktop][7]
|
||||
|
||||
是否有意义?对我来说不是,但这就是 Ubuntu 20.04 的方式。
|
||||
|
||||
#### 你无法使用 Delete 键删除文件和文件夹,请再次使用右键菜单
|
||||
|
||||
更糟糕的是,你无法使用 `Delete` 键或 `Shift+Delete` 键从桌面上删除文件。但是你仍然可以右键单击文件或文件夹,然后选择“移至回收站”来删除文件。
|
||||
|
||||
![Delete files from desktop using right click][8]
|
||||
|
||||
好了,你现在知道至少有一种方法可以在桌面上添加文件,但有一些限制。不幸的是,这还没有结束。
|
||||
|
||||
你无法在桌面上用名称搜索文件。通常,如果你开始输入 “abc”,那么以 “abc” 开头的文件会高亮显示。但是在这里不行。
|
||||
|
||||
我不知道为什么在桌面上添加文件受到了如此多的限制。值得庆幸的是,我不会经常使用它,否则我会感到非常沮丧。
|
||||
|
||||
如果有兴趣,你也可以阅读[在 Ubuntu 桌面上添加应用快捷方式][9]这篇文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/add-files-on-desktop-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/files-on-desktop-ubuntu.jpg?ssl=1
|
||||
[2]: https://www.gnome.org/
|
||||
[3]: https://wiki.gnome.org/Apps/Files
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/adding-files-desktop-ubuntu.png?ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/desktop-folder-ubuntu.png?ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/adding-files-desktop-screen-ubuntu.jpg?ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/adding-new-files-ubuntu-desktop.jpg?ssl=1
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/delete-files-from-desktop-ubuntu.jpg?ssl=1
|
||||
[9]: https://itsfoss.com/ubuntu-desktop-shortcut/
|
||||
87
published/20200428 What-s new in Fedora 32 Workstation.md
Normal file
87
published/20200428 What-s new in Fedora 32 Workstation.md
Normal file
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12201-1.html)
|
||||
[#]: subject: (What’s new in Fedora 32 Workstation)
|
||||
[#]: via: (https://fedoramagazine.org/whats-new-fedora-32-workstation/)
|
||||
[#]: author: (Ryan Lerch https://fedoramagazine.org/author/ryanlerch/)
|
||||
|
||||
Fedora 32 Workstation 的新功能
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Fedora 32 Workstation 是我们免费的领先操作系统的[最新版本][2]。你现在可以从[官方网站][3]下载它。Fedora 32 Workstation 中有几个新的且值得注意的变化。请阅读下面的详情。
|
||||
|
||||
### GNOME 3.36
|
||||
|
||||
Fedora 32 Workstation 包含了适合所有用户的 GNOME 桌面环境的最新版本。Fedora 32 Workstation 中的 GNOME 3.36 包含了许多更新和改进,包括:
|
||||
|
||||
#### 重新设计的锁屏界面
|
||||
|
||||
Fedora 32 中的锁屏是一种全新的体验。新设计消除了以前版本中使用的“窗口阴影”,并着重于易用性和速度。
|
||||
|
||||
![Unlock screen in Fedora 32][4]
|
||||
|
||||
#### 新的扩展程序
|
||||
|
||||
Fedora 32 有新的“扩展”应用,它可轻松管理你的 GNOME 扩展。过去,扩展是使用“软件”和/或“调整工具”来安装、配置和启用的。
|
||||
|
||||
![The new Extensions application in Fedora 32][5]
|
||||
|
||||
请注意,默认情况下,Fedora 32 上未安装这个“扩展”应用。需要使用“软件”进行搜索和安装,或在终端中使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf install gnome-extensions-app
|
||||
```
|
||||
|
||||
#### 重新组织的设置应用
|
||||
|
||||
敏锐的 Fedora 用户会注意到“设置”应用已重新组织。设置类别的结构更加扁平,因此可以一次看到更多设置。
|
||||
|
||||
此外,“关于”中现在有有关系统的更多信息,包括正在运行的窗口系统(例如 Wayland)。
|
||||
|
||||
![The reorganized settings application in Fedora 32][6]
|
||||
|
||||
#### 重新设计的通知/日历弹出框
|
||||
|
||||
单击桌面顶部的“日期和时间”可切换“通知/日历”弹出窗口,其中有许多小的样式调整项。此外,弹出窗口现在有“请勿打扰”开关,可快速禁用所有通知。这在希望只显示屏幕而不显示个人通知时很有用。
|
||||
|
||||
![The new Notification / Calendar popover in Fedora 32 ][7]
|
||||
|
||||
#### 重新设计的时钟应用
|
||||
|
||||
Fedora 32 完全重新设计了时钟。该设计在较小的窗口中效果更好。
|
||||
|
||||
![The Clocks application in Fedora 32][8]
|
||||
|
||||
GNOME 3.36 还提供了许多其他功能和增强。有关更多信息,请查看 [GNOME 3.36 的发布说明][9]。
|
||||
|
||||
### 改进的内存不足处理
|
||||
|
||||
以前,如果系统内存不足,那么可能会遇到大量使用交换(也称为 [交换抖动][10])–有时会导致 Workstation UI 变慢或在一段时间内无响应。Fedora 32 Workstation 现在默认启用 EarlyOOM。EarlyOOM 可以让用户在低内存的情况下,存在大量使用交换的情况下,更快速地恢复和恢复对系统的控制。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/whats-new-fedora-32-workstation/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/ryanlerch/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/04/fedora32workstation-816x345.jpg
|
||||
[2]: https://linux.cn/article-12164-1.html
|
||||
[3]: https://getfedora.org/workstation
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2020/04/unlock.gif
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2020/04/extensions.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2020/04/settings.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2020/04/donotdisturb.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2020/04/clocks.png
|
||||
[9]: https://help.gnome.org/misc/release-notes/3.36/
|
||||
[10]: https://en.wikipedia.org/wiki/Thrashing_(computer_science)
|
||||
@ -0,0 +1,165 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12193-1.html)
|
||||
[#]: subject: (Drop PNG and JPG for your online images: Use WebP)
|
||||
[#]: via: (https://opensource.com/article/20/4/webp-image-compression)
|
||||
[#]: author: (Jeff Macharyas https://opensource.com/users/jeffmacharyas)
|
||||
|
||||
线上图片请抛弃 PNG 和 JPG:使用 WebP
|
||||
======
|
||||
|
||||
> 了解一下这个开源的图片编辑工具来节省时间和空间。
|
||||
|
||||

|
||||
|
||||
WebP 是 2010 年 Google 开发的一种图片格式,它为网页上的图片提供了卓越的无损和有损压缩。网站开发者们可以使用 WebP 来创建尺寸更小、细节更丰富的图片,以此来提高网站的速度。更快的加载速度对于网站的用户体验和网站的营销效果是至关重要的。
|
||||
|
||||
为了在所有设备和用户中达到最佳加载效果,你网站上的图片文件大小不应该超过 500 KB。
|
||||
|
||||
与 PNG 图片相比,WebP 无损图片通常至少要比 PNG 图片小 25%。在同等的 SSIM(<ruby>结构相似度<rt>structural similarity</rt></ruby>)质量指标下,WebP 有损图片通常比 JPEG 图片小 25% 到 34%。
|
||||
|
||||
无损 WebP 也支持透明度。而在可接受有损 RGB 压缩的情况下,有损 WebP 也支持透明度,通常其大小比 PNG 文件小三倍。
|
||||
|
||||
Google 报告称,把动画 GIF 文件转换为有损 WebP 后文件大小减少了 64%,转换为无损 WebP 后文件大小减少了 19%。
|
||||
|
||||
WebP 文件格式是一种基于 RIFF(<ruby>资源互换文件格式<rt>resource interchange file format</rt></ruby>)的文档格式。你可以用 [hexdump][2] 看到文件的签名是 `52 49 46 46`(RIFF):
|
||||
|
||||
|
||||
```
|
||||
$ hexdump --canonical pixel.webp
|
||||
00000000 52 49 46 46 26 00 00 00 [...] |RIFF&...WEBPVP8 |
|
||||
00000010 1a 00 00 00 30 01 00 9d [...] |....0....*......|
|
||||
00000020 0e 25 a4 00 03 70 00 fe [...] |.%...p...`....|
|
||||
0000002e
|
||||
```
|
||||
|
||||
独立的 libwebp 库作为 WebP 技术规范的参考实现,可以从 Google 的 [Git 仓库][3] 或 tar 包中获得。
|
||||
|
||||
全球在用的 80% 的 web 浏览器兼容 WebP 格式。本文撰写时,Apple 的 Safari 浏览器还不兼容。解决这个问题的方法是将 JPG/PNG 图片与 WebP 图片一起提供,有一些方法和 Wordpress 插件可以做到这一点。
|
||||
|
||||
### 为什么要这样做?
|
||||
|
||||
我的部分工作是设计和维护我们组织的网站。由于网站是个营销工具,而网站的速度是衡量用户体验的重要指标,我一直致力于提高网站速度,通过把图片转换为 WebP 来减少图片大小是一个很好的解决方案。
|
||||
|
||||
我使用了 web.dev 来检测其中一个网页,该工具是由 Lighthouse 提供服务的,遵循 Apache 2.0 许可证,可以在 <https://github.com/GoogleChrome/lighthouse> 找到。
|
||||
|
||||
据其官方描述,“LIghthouse 是一个开源的,旨在提升网页质量的自动化工具。你可以在任何公共的或需要鉴权的网页上运行它。它有性能、可用性、渐进式 web 应用、SEO 等方面的审计。你可以在 Chrome 浏览器的开发工具中运行 Lighthouse,也可以通过命令行或作为 Node 模块运行。你输入一个 URL 给 Lighthouse,它会对这个网页进行一系列的审计,然后生成这个网页的审计结果报告。从报告的失败审计条目中可以知道应该怎么优化网页。每条审计都有对应的文档解释为什么该项目是重要的,以及如何修复它。”
|
||||
|
||||
### 创建更小的 WebP 图片
|
||||
|
||||
我测试的页面返回了三张图片。在它生成的报告中,它提供了推荐和目标。我选择了它报告有 650 KB 的 `app-graphic` 图片。通过把它转换为 WebP 格式,预计可以把图片大小降到 61 KB,节省 589 KB。我在 Photoshop 中把它转换了,用默认的 WebP 设置参数保存它,它的文件大小为 44.9 KB。比预期的还要好!从下面的 Photoshop 截图中可以看出,两张图在视觉质量上完全一样。
|
||||
|
||||
![WebP vs JPG comparison][4]
|
||||
|
||||
*左图:650 KB(实际大小)。右图: 44.9 KB(转换之后的目标大小)。*
|
||||
|
||||
当然,也可以用开源图片编辑工具 [GIMP][5] 把图片导出为 WebP。它提供了几个质量和压缩的参数:
|
||||
|
||||
![GIMP dialog for exporting webp, as a webp][6]
|
||||
|
||||
另一张图放大后:
|
||||
|
||||
![WebP vs PNG comparison][7]
|
||||
|
||||
PNG(左图)和 WebP(右图),都是从 JPG 转换而来,两图对比可以看出 WebP 不仅在文件大小更小,在视觉质量上也更优秀。
|
||||
|
||||
### 把图片转换为 WebP
|
||||
|
||||
你也可以用 Linux 的命令行工具把图片从 JPG/PNG 转换为 WebP:
|
||||
|
||||
在命令行使用 `cwebp` 把 PNG 或 JPG 图片文件转换为 WebP 格式。你可以用下面的命令把 PNG 图片文件转换为质量参数为 80 的 WebP 图片。
|
||||
|
||||
```
|
||||
cwebp -q 80 image.png -o image.webp
|
||||
```
|
||||
|
||||
你还可以用 [Image Magick][8],这个工具可能在你的发行版本软件仓库中可以找到。转换的子命令是 `convert`,它需要的所有参数就是输入和输出文件:
|
||||
|
||||
```
|
||||
convert pixel.png pixel.webp
|
||||
```
|
||||
|
||||
### 使用编辑器把图片转换为 WebP
|
||||
|
||||
要在图片编辑器中来把图片转换为 WebP,可以使用 [GIMP][9]。从 2.10 版本开始,它原生地支持 WebP。
|
||||
|
||||
如果你是 Photoshop 用户,由于 Photoshop 默认不包含 WebP 支持,因此你需要一个转换插件。遵循 Apache License 2.0 许可证发布的 WebPShop 0.2.1 是一个用于打开和保存包括动画图在内的 WebP 图片的 Photoshop 模块,在 <https://github.com/webmproject/WebPShop> 可以找到。
|
||||
|
||||
为了能正常使用它,你需要把它放进 Photoshop 插件目录下的 `bin` 文件夹:
|
||||
|
||||
Windows x64 :`C:\Program Files\Adobe\Adobe Photoshop\Plug-ins\WebPShop.8bi`
|
||||
|
||||
Mac:`Applications/Adobe Photoshop/Plug-ins/WebPShop.plugin`
|
||||
|
||||
### Wordpress 上的 WebP
|
||||
|
||||
很多网站是用 Wordpress 搭建的(我的网站就是)。因此,Wordpress 怎么上传 WebP 图片?本文撰写时,它还不支持。但是,当然已经有插件来满足这种需求,因此你可以在你的网站上同时准备 WebP 和 PNG/JPG 图片(为 Apple 用户)。
|
||||
|
||||
在 [Marius Hosting][11] 有下面的[说明][10]:
|
||||
|
||||
“直接向 Wordpress 上传 WebP 图片会怎样?这很简单。向你的主题 `functions.php` 文件添加几行内容就可以了。Wordpress 默认不支持展示和上传 WebP 文件,但是我会向你介绍一下怎么通过几个简单的步骤来让它支持。登录进你的 Wordpress 管理员界面,进入‘外观/主题编辑器’找到 `functions.php`。复制下面的代码粘贴到该文件最后并保存:
|
||||
|
||||
```
|
||||
//** *Enable upload for webp image files.*/
|
||||
function webp_upload_mimes($existing_mimes) {
|
||||
$existing_mimes['webp'] = 'image/webp';
|
||||
return $existing_mimes;
|
||||
}
|
||||
add_filter('mime_types', 'webp_upload_mimes');
|
||||
```
|
||||
|
||||
如果你想在‘媒体/媒体库’时看到缩略图预览,那么你需要把下面的代码也添加到 `functions.php` 文件。为了找到 `functions.php` 文件,进入‘外观/主题编辑器’并搜索 `functions.php`,然后复制下面的代码粘贴到文件最后并保存:
|
||||
|
||||
```
|
||||
//** * Enable preview / thumbnail for webp image files.*/
|
||||
function webp_is_displayable($result, $path) {
|
||||
if ($result === false) {
|
||||
$displayable_image_types = array( IMAGETYPE_WEBP );
|
||||
$info = @getimagesize( $path );
|
||||
|
||||
if (empty($info)) {
|
||||
$result = false;
|
||||
} elseif (!in_array($info[2], $displayable_image_types)) {
|
||||
$result = false;
|
||||
} else {
|
||||
$result = true;
|
||||
}
|
||||
}
|
||||
|
||||
return $result;
|
||||
}
|
||||
add_filter('file_is_displayable_image', 'webp_is_displayable', 10, 2);
|
||||
```
|
||||
|
||||
”
|
||||
|
||||
### WebP 和未来
|
||||
|
||||
WebP 是一个健壮而优化的格式。它看起来更好,压缩率更高,并具有其他大部分常见图片格式的所有特性。不必再等了,现在就使用它吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/webp-image-compression
|
||||
|
||||
作者:[Jeff Macharyas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jeffmacharyas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/painting_computer_screen_art_design_creative.png?itok=LVAeQx3_ (Painting art on a computer screen)
|
||||
[2]: https://opensource.com/article/19/8/dig-binary-files-hexdump
|
||||
[3]: https://storage.googleapis.com/downloads.webmproject.org/releases/webp/index.html
|
||||
[4]: https://opensource.com/sites/default/files/uploads/webp-vs-jpg-app-graphic.png (WebP vs JPG comparison)
|
||||
[5]: http://gimp.org
|
||||
[6]: https://img.linux.net.cn/data/attachment/album/202005/07/143538plu797s4wmhy9b1p.jpg (GIMP dialog for exporting webp, as a webp)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/xcompare-png-left-webp-right.png (WebP vs PNG comparison)
|
||||
[8]: https://imagemagick.org
|
||||
[9]: https://en.wikipedia.org/wiki/GIMP
|
||||
[10]: https://mariushosting.com/how-to-upload-webp-files-on-wordpress/
|
||||
[11]: https://mariushosting.com/
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12187-1.html)
|
||||
[#]: subject: (10 ways to analyze binary files on Linux)
|
||||
[#]: via: (https://opensource.com/article/20/4/linux-binary-analysis)
|
||||
[#]: author: (Gaurav Kamathe https://opensource.com/users/gkamathe)
|
||||
@ -12,11 +12,11 @@
|
||||
|
||||
> 这些简单的命令和工具可以帮助你轻松完成分析二进制文件的任务。
|
||||
|
||||
![Tux with binary code background][1]
|
||||

|
||||
|
||||
“这个世界上有 10 种人:懂二进制的人和不懂二进制的人。”
|
||||
|
||||
我们每天都在与二进制文件打交道,但我们对二进制文件却知之甚少。我所说的二进制,是指你每天运行的可执行文件,从你的命令行工具到成熟的应用程序都是。
|
||||
我们每天都在与二进制文件打交道,但我们对二进制文件却知之甚少。我所说的二进制,是指你每天运行的可执行文件,从命令行工具到成熟的应用程序都是。
|
||||
|
||||
Linux 提供了一套丰富的工具,让分析二进制文件变得轻而易举。无论你的工作角色是什么,如果你在 Linux 上工作,了解这些工具的基本知识将帮助你更好地理解你的系统。
|
||||
|
||||
@ -26,7 +26,7 @@ Linux 提供了一套丰富的工具,让分析二进制文件变得轻而易
|
||||
|
||||
它的作用:帮助确定文件类型。
|
||||
|
||||
这将是你进行二进制分析的出发点。我们每天都在与文件打交道。并非所有的文件都是可执行类型,除此之外还有各种各样的文件类型。在你开始之前,你需要了解要分析的文件类型。它是二进制文件、库文件、ASCII 文本文件、视频文件、图片文件、PDF、数据文件等等。
|
||||
这将是你进行二进制分析的起点。我们每天都在与文件打交道,并非所有的文件都是可执行类型,除此之外还有各种各样的文件类型。在你开始之前,你需要了解要分析的文件类型。是二进制文件、库文件、ASCII 文本文件、视频文件、图片文件、PDF、数据文件等文件吗?
|
||||
|
||||
`file` 命令将帮助你确定你所处理的文件类型。
|
||||
|
||||
@ -66,11 +66,11 @@ $
|
||||
|
||||
### ltrace
|
||||
|
||||
它的作用:一个库调用跟踪器。
|
||||
它的作用:库调用跟踪器。
|
||||
|
||||
我们现在知道如何使用 `ldd` 命令找到一个可执行程序所依赖的库。然而,一个库可以包含数百个函数。在这几百个函数中,哪些是我们的二进制程序正在使用的实际函数?
|
||||
|
||||
`ltrace` 命令可以显示在运行时从库中调用的所有函数。在下面的例子中,你可以看到被调用的函数名称,以及传递给该函数的参数。你也可以在输出的最右边看到这些函数返回的内容。
|
||||
`ltrace` 命令可以显示运行时从库中调用的所有函数。在下面的例子中,你可以看到被调用的函数名称,以及传递给该函数的参数。你也可以在输出的最右边看到这些函数返回的内容。
|
||||
|
||||
```
|
||||
$ ltrace ls
|
||||
@ -95,7 +95,7 @@ $
|
||||
|
||||
它的作用:以 ASCII、十进制、十六进制或八进制显示文件内容。
|
||||
|
||||
通常情况下,当你用一个应用程序打开一个文件,而它不知道如何处理该文件时,就会出现这种情况。尝试用 `vim` 打开一个可执行文件或视频文件,你会看到的只是屏幕上抛出的乱码。
|
||||
通常情况下,当你用一个应用程序打开一个文件,而它不知道如何处理该文件时,就会出现这种情况。尝试用 `vim` 打开一个可执行文件或视频文件,你屏幕上会看到的只是抛出的乱码。
|
||||
|
||||
在 `hexdump` 中打开未知文件,可以帮助你看到文件的具体内容。你也可以选择使用一些命令行选项来查看用 ASCII 表示的文件数据。这可能会帮助你了解到它是什么类型的文件。
|
||||
|
||||
@ -132,7 +132,7 @@ $ strings /bin/ls
|
||||
|
||||
ELF(<ruby>可执行和可链接文件格式<rt>Executable and Linkable File Format</rt></ruby>)是可执行文件或二进制文件的主流格式,不仅是 Linux 系统,也是各种 UNIX 系统的主流文件格式。如果你已经使用了像 `file` 命令这样的工具,它告诉你文件是 ELF 格式,那么下一步就是使用 `readelf` 命令和它的各种选项来进一步分析文件。
|
||||
|
||||
在使用 `readelf` 命令时,有一个实际的 ELF 规范的参考是非常有用的。你可以在[这里][2]找到规范。
|
||||
在使用 `readelf` 命令时,有一份实际的 ELF 规范的参考是非常有用的。你可以在[这里][2]找到该规范。
|
||||
|
||||
```
|
||||
$ readelf -h /bin/ls
|
||||
@ -163,9 +163,9 @@ $
|
||||
|
||||
它的作用:从对象文件中显示信息。
|
||||
|
||||
二进制文件是通过你编写源码的创建的,这些源码会通过一个叫做编译器的工具进行编译。这个编译器会生成相当于源代码的机器语言指令,然后由 CPU 执行,以执行特定的任务。这些机器语言代码可以通过被称为汇编语言的助记词来解读。汇编语言是一组指令,它可以帮助你理解由程序所进行并最终在 CPU 上执行的操作。
|
||||
二进制文件是通过你编写的源码创建的,这些源码会通过一个叫做编译器的工具进行编译。这个编译器会生成相对于源代码的机器语言指令,然后由 CPU 执行特定的任务。这些机器语言代码可以通过被称为汇编语言的助记词来解读。汇编语言是一组指令,它可以帮助你理解由程序所进行并最终在 CPU 上执行的操作。
|
||||
|
||||
`objdump` 实用程序读取二进制或可执行文件,并将汇编语言指令转储到屏幕上。汇编语言知识对于理解 `objdump` 命令的输出是至关重要的。
|
||||
`objdump` 实用程序读取二进制或可执行文件,并将汇编语言指令转储到屏幕上。汇编语言知识对于理解 `objdump` 命令的输出至关重要。
|
||||
|
||||
请记住:汇编语言是特定于体系结构的。
|
||||
|
||||
@ -174,7 +174,6 @@ $ objdump -d /bin/ls | head
|
||||
|
||||
/bin/ls: file format elf64-x86-64
|
||||
|
||||
|
||||
Disassembly of section .init:
|
||||
|
||||
0000000000402150 <_init@@Base>:
|
||||
@ -219,7 +218,7 @@ $
|
||||
|
||||
它的作用:列出对象文件中的符号。
|
||||
|
||||
如果你所使用的二进制文件没有被剥离,`nm` 命令将为你提供在编译过程中嵌入到二进制文件中的有价值的信息。`nm` 可以帮助你从二进制文件中识别变量和函数。你可以想象一下,如果你无法访问二进制文件的源代码,这将是多么有用。
|
||||
如果你所使用的二进制文件没有被剥离,`nm` 命令将为你提供在编译过程中嵌入到二进制文件中的有价值的信息。`nm` 可以帮助你从二进制文件中识别变量和函数。你可以想象一下,如果你无法访问二进制文件的源代码时,这将是多么有用。
|
||||
|
||||
为了展示 `nm`,我们快速编写了一个小程序,用 `-g` 选项编译,我们会看到这个二进制文件没有被剥离。
|
||||
|
||||
@ -264,7 +263,7 @@ $
|
||||
|
||||
分析这些路径的唯一方法是在运行时环境,在任何给定的位置停止或暂停程序,并能够分析信息,然后再往下执行。
|
||||
|
||||
这就是调试器的作用,在 Linux 上,`gdb` 就是调试器的事实标准。它可以帮助你加载程序,在特定的地方设置断点,分析内存和 CPU 的寄存器,还有更多的功能。它是对上面提到的其他工具的补充,可以让你做更多的运行时分析。
|
||||
这就是调试器的作用,在 Linux 上,`gdb` 就是调试器的事实标准。它可以帮助你加载程序,在特定的地方设置断点,分析内存和 CPU 的寄存器,以及更多的功能。它是对上面提到的其他工具的补充,可以让你做更多的运行时分析。
|
||||
|
||||
有一点需要注意的是,一旦你使用 `gdb` 加载一个程序,你会看到它自己的 `(gdb)` 提示符。所有进一步的命令都将在这个 `gdb` 命令提示符中运行,直到你退出。
|
||||
|
||||
@ -290,7 +289,8 @@ Missing separate debuginfos, use: debuginfo-install glibc-2.17-260.el7_6.6.x86_6
|
||||
Continuing.
|
||||
Hello world![Inferior 1 (process 29620) exited normally]
|
||||
(gdb) q
|
||||
$```
|
||||
$
|
||||
```
|
||||
|
||||
### 结语
|
||||
|
||||
@ -303,7 +303,7 @@ via: https://opensource.com/article/20/4/linux-binary-analysis
|
||||
作者:[Gaurav Kamathe][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,165 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12181-1.html)
|
||||
[#]: subject: (Three Methods Boot CentOS/RHEL 7/8 Systems in Single User Mode)
|
||||
[#]: via: (https://www.2daygeek.com/boot-centos-7-8-rhel-7-8-single-user-mode/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
以单用户模式启动 CentOS/RHEL 7/8 的三种方法
|
||||
======
|
||||
|
||||

|
||||
|
||||
单用户模式,也被称为维护模式,超级用户可以在此模式下恢复/修复系统问题。
|
||||
|
||||
通常情况下,这类问题在多用户环境中修复不了。系统可以启动但功能不能正常运行或者你登录不了系统。
|
||||
|
||||
在基于 [Red Hat][1](RHEL)7/8 的系统中,使用 `runlevel1.target` 或 `rescue.target` 来实现。
|
||||
|
||||
在此模式下,系统会挂载所有的本地文件系统,但不开启网络接口。
|
||||
|
||||
系统仅启动特定的几个服务和修复系统必要的尽可能少的功能。
|
||||
|
||||
当你想运行文件系统一致性检查来修复损坏的文件系统,或忘记 root 密码后重置密码,或要修复系统上的一个挂载点问题时,这个方法会很有用。
|
||||
|
||||
你可以用下面三种方法以单用户模式启动 [CentOS][2]/[RHEL][3] 7/8 系统。
|
||||
|
||||
* 方法 1:通过向内核添加 `rd.break` 参数来以单用户模式启动 CentOS/RHEL 7/8 系统
|
||||
* 方法 2:通过用 `init=/bin/bash` 或 `init=/bin/sh` 替换内核中的 `rhgb quiet` 语句来以单用户模式启动 CentOS/RHEL 7/8 系统
|
||||
* 方法 3:通过用 `rw init=/sysroot/bin/sh` 参数替换内核中的 `ro` 语句以单用户模式启动 CentOS/RHEL 7/8 系统
|
||||
|
||||
### 方法 1
|
||||
|
||||
通过向内核添加 `rd.break` 参数来以单用户模式启动 CentOS/RHEL 7/8 系统。
|
||||
|
||||
重启你的系统,在 GRUB2 启动界面,按下 `e` 键来编辑选中的内核。你需要选中第一行,第一个是最新的内核,然而如果你想用旧的内核启动系统你也可以选择其他的行。
|
||||
|
||||
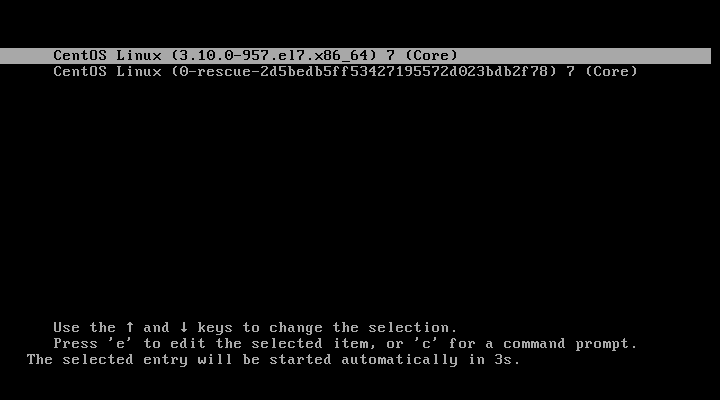
|
||||
|
||||
根据你的 RHEL/CentOS 版本,找到 `linux16` 或 `linux` 语句,按下键盘上的 `End` 键,跳到行末,像下面截图中展示的那样添加关键词 `rd.break`,按下 `Ctrl+x` 或 `F10` 来进入单用户模式。
|
||||
|
||||
如果你的系统是 RHEL/CentOS 7,你需要找 `linux16`,如果你的系统是 RHEL/CentOS 8,那么你需要找 `linux`。
|
||||
|
||||
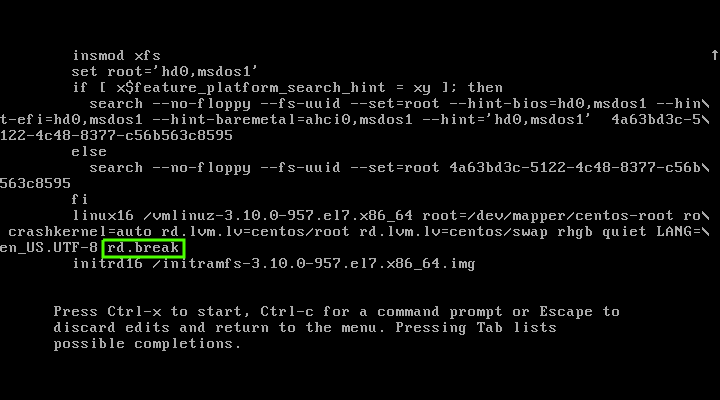
|
||||
|
||||
这个修改会让你的 root 文件系统以 “只读(`ro`)” 模式挂载。你可以用下面的命令来验证下。下面的输出也明确地告诉你当前是在 “<ruby>紧急模式<rt>Emergency Mode</rt></ruby>”。
|
||||
|
||||
```
|
||||
# mount | grep root
|
||||
```
|
||||
|
||||
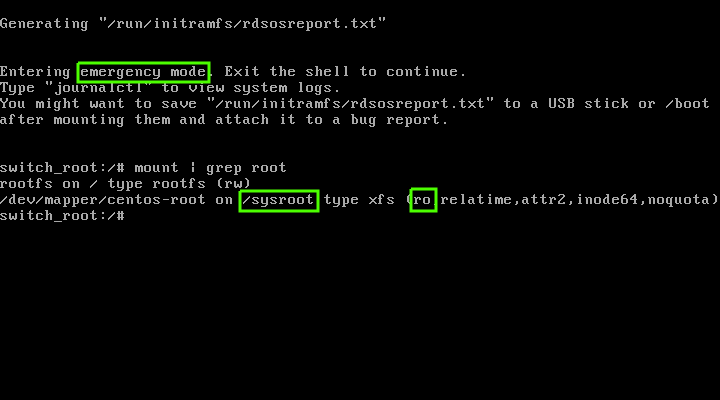
|
||||
|
||||
为了修改 `sysroot` 文件系统,你需要用读写模式(`rw`)重新挂载它。
|
||||
|
||||
```
|
||||
# mount -o remount,rw /sysroot
|
||||
```
|
||||
|
||||
运行下面的命令修改环境,这就是大家熟知的 “监禁目录” 或 “chroot 监狱”。
|
||||
|
||||
```
|
||||
# chroot /sysroot
|
||||
```
|
||||
|
||||
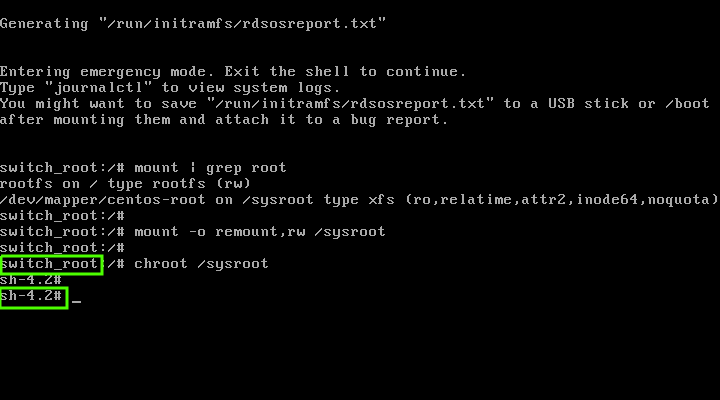
|
||||
|
||||
现在,单用户模式已经完全准备好了。当你修复了你的问题要退出单用户模式时,执行下面的步骤。
|
||||
|
||||
CentOS/RHEL 7/8 默认使用 SELinux,因此创建下面的隐藏文件,这个文件会在下一次启动时重新标记所有文件。
|
||||
|
||||
```
|
||||
# touch /.autorelabel
|
||||
```
|
||||
|
||||
最后,用下面的命令重启系统。你也可以输入两次 `exit` 命令来重启你的系统。
|
||||
|
||||
```
|
||||
# reboot -f
|
||||
```
|
||||
|
||||
### 方法 2
|
||||
|
||||
通过用 `init=/bin/bash` 或 `init=/bin/sh` 替换内核中的 `rhgb quiet` 语句来以单用户模式启动 CentOS/RHEL 7/8 系统。
|
||||
|
||||
重启你的系统,在 GRUB2 启动界面,按下 `e` 键来编辑选中的内核。
|
||||
|
||||

|
||||
|
||||
找到语句 `rhgb quiet`,用 `init=/bin/bash` 或 `init=/bin/sh` 替换它,然后按下 `Ctrl+x` 或 `F10` 来进入单用户模式。
|
||||
|
||||
`init=/bin/bash` 的截图。
|
||||
|
||||
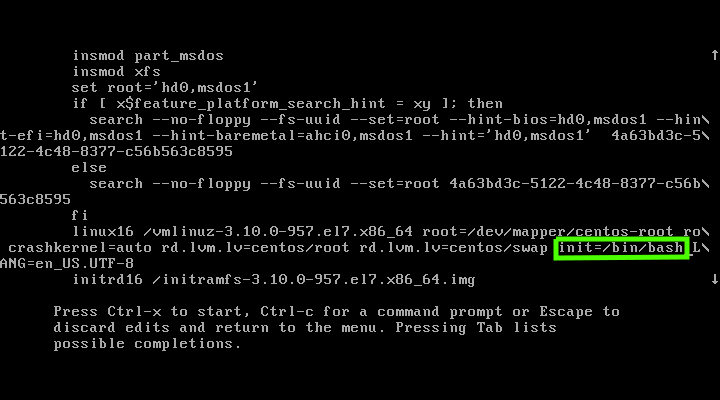
|
||||
|
||||
`init=/bin/sh` 的截图。
|
||||
|
||||
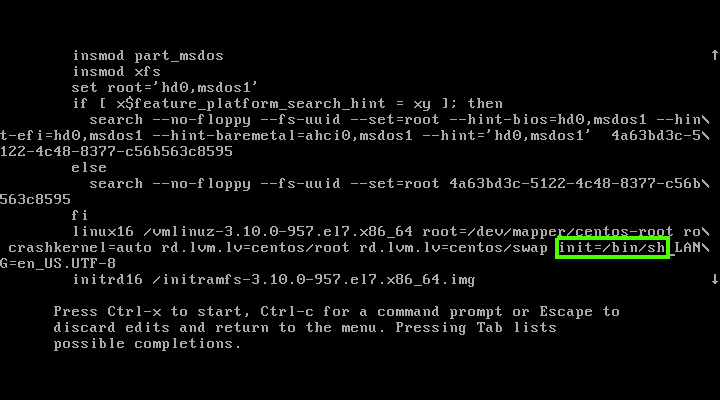
|
||||
|
||||
默认情况下,上面的操作会以只读(`ro`)模式挂载你的 `/` 分区,因此你需要以读写(`rw`)模式重新挂载 `/` 文件系统,这样才能修改它。
|
||||
|
||||
```
|
||||
# mount -o remount,rw /
|
||||
```
|
||||
|
||||
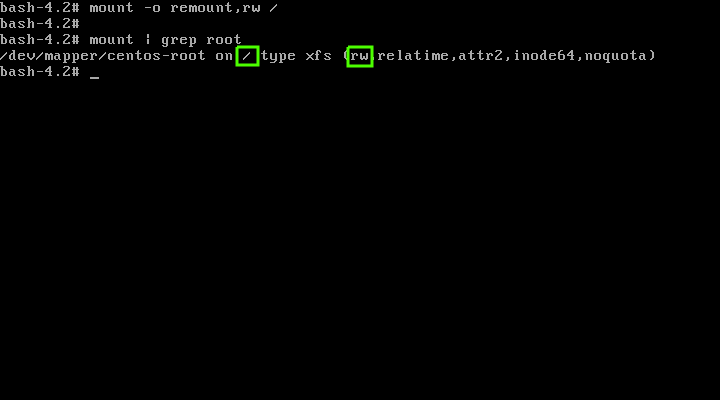
|
||||
|
||||
现在你可以执行你的任务了。当结束时,执行下面的命令来开启重启时的 SELinux 重新标记。
|
||||
|
||||
```
|
||||
# touch /.autorelabel
|
||||
```
|
||||
|
||||
最后,重启系统。
|
||||
|
||||
```
|
||||
# exec /sbin/init 6
|
||||
```
|
||||
|
||||
### 方法 3
|
||||
|
||||
通过用 `rw init=/sysroot/bin/sh` 参数替换内核中的 `ro` 单词,以单用户模式启动 CentOS/RHEL 7/8 系统。
|
||||
|
||||
为了中断自动启动的过程,重启你的系统并在 GRUB2 启动界面按下任意键。
|
||||
|
||||
现在会展示你系统上所有可用的内核,选择最新的内核,按下 `e` 键来编辑选中的内核参数。
|
||||
|
||||
找到以 `linux` 或 `linux16` 开头的语句,用 `rw init=/sysroot/bin/sh` 替换 `ro`。替换完后按下 `Ctrl+x` 或 `F10` 来进入单用户模式。
|
||||
|
||||
运行下面的命令把环境切换为 “chroot 监狱”。
|
||||
|
||||
```
|
||||
# chroot /sysroot
|
||||
```
|
||||
|
||||
如果需要,做出必要的修改。修改完后,执行下面的命令来开启重启时的 SELinux 重新标记。
|
||||
|
||||
```
|
||||
# touch /.autorelabel
|
||||
```
|
||||
|
||||
最后,重启系统。
|
||||
|
||||
```
|
||||
# reboot -f
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/boot-centos-7-8-rhel-7-8-single-user-mode/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/red-hat/
|
||||
[2]: https://www.2daygeek.com/category/centos/
|
||||
[3]: https://www.2daygeek.com/category/rhel/
|
||||
[4]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
@ -0,0 +1,143 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12207-1.html)
|
||||
[#]: subject: (Using mergerfs to increase your virtual storage)
|
||||
[#]: via: (https://fedoramagazine.org/using-mergerfs-to-increase-your-virtual-storage/)
|
||||
[#]: author: (Curt Warfield https://fedoramagazine.org/author/rcurtiswarfield/)
|
||||
|
||||
使用 mergefs 增加虚拟存储
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
如果你想在一个媒体项目中用到了多个磁盘或分区,不想丢失任何现有数据,但又想将所有文件都存放在一个驱动器下,该怎么办?这时,mergefs 就能派上用场!
|
||||
|
||||
[mergerfs][2] 是一个联合文件系统,旨在简化存储和管理众多商业存储设备上的文件。
|
||||
|
||||
你需要从他们的 [GitHub][3] 页面获取最新的 RPM。Fedora 的版本名称中带有 “fc” 和版本号。例如,这是 Fedora 31 的版本: [mergerfs-2.29.0-1.fc31.x86_64.rpm][4]。
|
||||
|
||||
### 安装和配置 mergefs
|
||||
|
||||
使用 `sudo` 安装已下载的 mergefs 软件包:
|
||||
|
||||
```
|
||||
$ sudo dnf install mergerfs-2.29.0-1.fc31.x86_64.rpm
|
||||
```
|
||||
|
||||
现在,你可以将多个磁盘挂载为一个驱动器。如果你有一台媒体服务器,并且希望所有媒体文件都显示在一个地方,这将很方便。如果将新文件上传到系统,那么可以将它们复制到 mergefs 目录,mergefs 会自动将它们复制具有足够可用空间的磁盘上。
|
||||
|
||||
这是使你更容易理解的例子:
|
||||
|
||||
```
|
||||
$ df -hT | grep disk
|
||||
/dev/sdb1 ext4 23M 386K 21M 2% /disk1
|
||||
/dev/sdc1 ext4 44M 1.1M 40M 3% /disk2
|
||||
|
||||
$ ls -l /disk1/Videos/
|
||||
total 1
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Our Wedding.mkv
|
||||
|
||||
$ ls -l /disk2/Videos/
|
||||
total 2
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Baby's first Xmas.mkv
|
||||
-rw-rw-r--. 1 curt curt 0 Mar 8 17:21 Halloween hijinks.mkv
|
||||
```
|
||||
|
||||
在此例中挂载了两块磁盘,分别为 `disk1` 和 `disk2`。两个驱动器都有一个包含文件的 `Videos` 目录。
|
||||
|
||||
现在,我们将使用 mergefs 挂载这些驱动器,使它们看起来像一个更大的驱动器。
|
||||
|
||||
```
|
||||
$ sudo mergerfs -o defaults,allow_other,use_ino,category.create=mfs,moveonenospc=true,minfreespace=1M /disk1:/disk2 /media
|
||||
```
|
||||
|
||||
mergefs 手册页非常庞杂,因此我们将说明上面提到的选项。
|
||||
|
||||
* `defaults`:除非指定,否则将使用默认设置。
|
||||
* `allow_other`:允许 `sudo` 或 `root` 以外的用户查看文件系统。
|
||||
* `use_ino`:让 mergefs 提供文件/目录 inode 而不是 libfuse。虽然不是默认值,但建议你启用它,以便链接的文件共享相同的 inode 值。
|
||||
* `category.create=mfs`:根据可用空间在驱动器间传播文件。
|
||||
* `moveonenospc=true`:如果启用,那么如果写入失败,将进行扫描以查找具有最大可用空间的驱动器。
|
||||
* `minfreespace=1M`:最小使用空间值。
|
||||
* `disk1`:第一块硬盘。
|
||||
* `disk2`:第二块硬盘。
|
||||
* `/media`:挂载驱动器的目录。
|
||||
|
||||
看起来是这样的:
|
||||
|
||||
```
|
||||
$ df -hT | grep disk
|
||||
/dev/sdb1 ext4 23M 386K 21M 2% /disk1
|
||||
/dev/sdc1 ext4 44M 1.1M 40M 3% /disk2
|
||||
|
||||
$ df -hT | grep media
|
||||
1:2 fuse.mergerfs 66M 1.4M 60M 3% /media
|
||||
```
|
||||
|
||||
你可以看到现在 mergefs 挂载显示的总容量为 66M,这是两块硬盘的总容量。
|
||||
|
||||
继续示例:
|
||||
|
||||
有一个叫 `Baby's second Xmas.mkv` 的 30M 视频。让我们将其复制到用 mergerfs 挂载的 `/media` 文件夹中。
|
||||
|
||||
```
|
||||
$ ls -lh "Baby's second Xmas.mkv"
|
||||
-rw-rw-r--. 1 curt curt 30M Apr 20 08:45 Baby's second Xmas.mkv
|
||||
$ cp "Baby's second Xmas.mkv" /media/Videos/
|
||||
```
|
||||
|
||||
这是最终结果:
|
||||
|
||||
```
|
||||
$ df -hT | grep disk
|
||||
/dev/sdb1 ext4 23M 386K 21M 2% /disk1
|
||||
/dev/sdc1 ext4 44M 31M 9.8M 76% /disk2
|
||||
|
||||
$ df -hT | grep media
|
||||
1:2 fuse.mergerfs 66M 31M 30M 51% /media
|
||||
```
|
||||
|
||||
从磁盘空间利用率中可以看到,因为 `disk1` 没有足够的可用空间,所以 mergefs 自动将文件复制到 `disk2`。
|
||||
|
||||
这是所有文件详情:
|
||||
|
||||
```
|
||||
$ ls -l /disk1/Videos/
|
||||
total 1
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Our Wedding.mkv
|
||||
|
||||
$ ls -l /disk2/Videos/
|
||||
total 30003
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Baby's first Xmas.mkv
|
||||
-rw-rw-r--. 1 curt curt 30720000 Apr 20 08:47 Baby's second Xmas.mkv
|
||||
-rw-rw-r--. 1 curt curt 0 Mar 8 17:21 Halloween hijinks.mkv
|
||||
|
||||
$ ls -l /media/Videos/
|
||||
total 30004
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Baby's first Xmas.mkv
|
||||
-rw-rw-r--. 1 curt curt 30720000 Apr 20 08:47 Baby's second Xmas.mkv
|
||||
-rw-rw-r--. 1 curt curt 0 Mar 8 17:21 Halloween hijinks.mkv
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Our Wedding.mkv
|
||||
```
|
||||
|
||||
当你将文件复制到 mergefs 挂载点时,它将始终将文件复制到有足够可用空间的硬盘上。如果池中的所有驱动器都没有足够的可用空间,那么你将无法复制它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/using-mergerfs-to-increase-your-virtual-storage/
|
||||
|
||||
作者:[Curt Warfield][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/rcurtiswarfield/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/04/mergerfs-816x346.png
|
||||
[2]: https://github.com/trapexit/mergerfs
|
||||
[3]: https://github.com/trapexit/mergerfs/releases
|
||||
[4]: https://github.com/trapexit/mergerfs/releases/download/2.29.0/mergerfs-2.29.0-1.fc31.x86_64.rpm
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12184-1.html)
|
||||
[#]: subject: (Mid-stack inlining in Go)
|
||||
[#]: via: (https://dave.cheney.net/2020/05/02/mid-stack-inlining-in-go)
|
||||
[#]: author: (Dave Cheney https://dave.cheney.net/author/davecheney)
|
||||
@ -10,19 +10,21 @@
|
||||
Go 中对栈中函数进行内联
|
||||
======
|
||||
|
||||
[上一篇文章][1]中我论述了叶子内联是怎样让 Go 编译器减少函数调用的开销的,以及延伸出了跨函数边界的优化的机会。本文中,我要论述内联的限制以及叶子与栈中内联的对比。
|
||||

|
||||
|
||||
[上一篇文章][1]中我论述了<ruby>叶子内联<rt>leaf inlining</rt></ruby>是怎样让 Go 编译器减少函数调用的开销的,以及延伸出了跨函数边界的优化的机会。本文中,我要论述内联的限制以及叶子内联与<ruby>栈中内联<rt>mid-stack inlining</rt></ruby>的对比。
|
||||
|
||||
### 内联的限制
|
||||
|
||||
把函数内联到它的调用处消除了调用的开销,为编译器进行其他的优化提供了更好的机会,那么问题来了,既然内联这么好,内联得越多开销就越少,_为什么不尽可能多地内联呢?_
|
||||
把函数内联到它的调用处消除了调用的开销,为编译器进行其他的优化提供了更好的机会,那么问题来了,既然内联这么好,内联得越多开销就越少,*为什么不尽可能多地内联呢?*
|
||||
|
||||
内联用可能的增加程序大小换来了更快的执行时间。限制内联的最主要原因是,创建太多的函数内联的备份会增加编译时间,并且作为边际效应会增加生成的二进制文件的大小。即使把内联带来的进一步的优化机会考虑在内,太激进的内联也可能会增加生成的二进制文件的大小和编译时间。
|
||||
内联可能会以增加程序大小换来更快的执行时间。限制内联的最主要原因是,创建许多函数的内联副本会增加编译时间,并导致生成更大的二进制文件的边际效应。即使把内联带来的进一步的优化机会考虑在内,太激进的内联也可能会增加生成的二进制文件的大小和编译时间。
|
||||
|
||||
内联收益最大的是[小函数][2],相对于调用它们的开销来说,这些函数做很少的工作。随着函数大小的增长,函数内部做的工作与函数调用的开销相比省下的时间越来越少。函数越大通常越复杂,因此对它们内联后进行优化与不内联相比的收益没有(对小函数进行内联)那么大。
|
||||
内联收益最大的是[小函数][2],相对于调用它们的开销来说,这些函数做很少的工作。随着函数大小的增长,函数内部做的工作与函数调用的开销相比省下的时间越来越少。函数越大通常越复杂,因此优化其内联形式相对于原地优化的好处会减少。
|
||||
|
||||
### 内联预算
|
||||
|
||||
在编译过程中,每个函数的内联能力是用_内联预算_计算的。开销的计算过程可以巧妙地内化,像一元和二元等简单操作,在抽象语法数(Abstract Syntax Tree,AST)中通常是每个节点一个单元,更复杂的操作如 `make` 可能单元更多。考虑下面的例子:
|
||||
在编译过程中,每个函数的内联能力是用*内联预算*计算的 [^1]。开销的计算过程可以巧妙地内化,像一元和二元等简单操作,在<ruby>抽象语法数<rt>Abstract Syntax Tree</rt></ruby>(AST)中通常是每个节点一个单位,更复杂的操作如 `make` 可能单位更多。考虑下面的例子:
|
||||
|
||||
```go
|
||||
package main
|
||||
@ -79,28 +81,26 @@ func main() {
|
||||
./inl.go:39:7: inlining call to small func() string { s := "hello, world!"; return s }
|
||||
```
|
||||
|
||||
编译器根据函数 `func small()` 的开销(7)决定可以对它内联,而`func large()` 的开销太大,编译器决定不进行内联。`func main()` 被标记为适合内联的,分配了 68 的开销;其中 `small` 占用 7,调用 `small` 函数占用 57,剩余的(4)是它自己的开销。
|
||||
编译器根据函数 `func small()` 的开销(7)决定可以对它内联,而 `func large()` 的开销太大,编译器决定不进行内联。`func main()` 被标记为适合内联的,分配了 68 的开销;其中 `small` 占用 7,调用 `small` 函数占用 57,剩余的(4)是它自己的开销。
|
||||
|
||||
可以用 `-gcflag=-l` 参数控制内联预算的等级。下面是可使用的值:
|
||||
|
||||
* `-gcflags=-l=0` 默认的内联等级。
|
||||
* `-gcflags=-l` (或 `-gcflags=-l=1`) 取消内联。
|
||||
* `-gcflags=-l=2` 和 `-gcflags=-l=3` 现在已经不使用了。不影响 `-gcflags=-l=0`
|
||||
* `-gcflags=-l=4` 减少非叶子函数和通过接口调用的函数的开销。[2][4]
|
||||
* `-gcflags=-l`(或 `-gcflags=-l=1`)取消内联。
|
||||
* `-gcflags=-l=2` 和 `-gcflags=-l=3` 现在已经不使用了。和 `-gcflags=-l=0` 相比没有区别。
|
||||
* `-gcflags=-l=4` 减少非叶子函数和通过接口调用的函数的开销。[^2]
|
||||
|
||||
#### 不确定语句的优化
|
||||
|
||||
一些函数虽然内联的开销很小,但由于太复杂它们仍不适合进行内联。这就是函数的不确定性,因为一些操作的语义在内联后很难去推导,如 `recover`、`break`。其他的操作,如 `select` 和 `go` 涉及运行时的协调,因此内联后引入的额外的开销不能抵消内联带来的收益。
|
||||
|
||||
#### 难以理解的优化
|
||||
|
||||
一些函数虽然内联的开销很小,但由于太复杂它们仍不适合进行内联。这就是函数的不确定性,因为一些操作的语义在内联后很难去推导,如 `recover`,`break`。其他的操作,如 `select` 和 `go` 涉及运行时的协调,因此内联后引入的额外的开销不能抵消内联带来的收益。
|
||||
|
||||
难理解的语句也包括 `for` 和 `range`,这些语句不一定开销很大,但目前为止还没有对它们进行优化。
|
||||
不确定的语句也包括 `for` 和 `range`,这些语句不一定开销很大,但目前为止还没有对它们进行优化。
|
||||
|
||||
### 栈中函数优化
|
||||
|
||||
在过去,Go 编译器只对叶子函数进行内联 — 只有那些不调用其他函数的函数才有资格。在上一段难以理解的的语句的探讨内容中,一次函数调用会让这个函数失去内联的资格。
|
||||
在过去,Go 编译器只对叶子函数进行内联 —— 只有那些不调用其他函数的函数才有资格。在上一段不确定的语句的探讨内容中,一次函数调用就会让这个函数失去内联的资格。
|
||||
|
||||
进入栈中进行内联,就像它的名字一样,能内联在函数调用栈中间的函数,不需要先让它下面的所有的函数都被标记为有资格内联的。栈中内联是 David Lazar 在 Go 1.9 中引入的,并在随后的版本中做了改进。[这篇文章][5]深入探究保留栈追踪的表现和被深度内联后的代码路径里的 `runtime.Caller` 们的难点。
|
||||
进入栈中进行内联,就像它的名字一样,能内联在函数调用栈中间的函数,不需要先让它下面的所有的函数都被标记为有资格内联的。栈中内联是 David Lazar 在 Go 1.9 中引入的,并在随后的版本中做了改进。[这篇文稿][5]深入探究了保留栈追踪行为和被深度内联后的代码路径里的 `runtime.Callers` 的难点。
|
||||
|
||||
在前面的例子中我们看到了栈中函数内联。内联后,`func main()` 包含了 `func small()` 的函数体和对 `func large()` 的一次调用,因此它被判定为非叶子函数。在过去,这会阻止它被继续内联,虽然它的联合开销小于内联预算。
|
||||
|
||||
@ -134,15 +134,16 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
在这个例子中, `r.Area()` 是个简单的函数,调用了两个函数。`r.Width()` 可以被内联,`r.Height()` 这里用 `//go:noinline` 指令标注了,不能被内联。[3][6]
|
||||
在这个例子中, `r.Area()` 是个简单的函数,调用了两个函数。`r.Width()` 可以被内联,`r.Height()` 这里用 `//go:noinline` 指令标注了,不能被内联。[^3]
|
||||
|
||||
```bash
|
||||
% go build -gcflags='-m=2' square.go
|
||||
% go build -gcflags='-m=2' square.go
|
||||
# command-line-arguments
|
||||
./square.go:12:6: cannot inline (*Rectangle).Height: marked go:noinline
|
||||
./square.go:12:6: cannot inline (*Rectangle).Height: marked go:noinline
|
||||
./square.go:17:6: can inline (*Rectangle).Width with cost 2 as: method(*Rectangle) func() int { return 6 }
|
||||
./square.go:21:6: can inline (*Rectangle).Area with cost 67 as: method(*Rectangle) func() int { return r.Height() * r.Width() } ./square.go:21:61: inlining call to (*Rectangle).Width method(*Rectangle) func() int { return 6 }
|
||||
./square.go:23:6: cannot inline main: function too complex: cost 150 exceeds budget 80
|
||||
./square.go:21:6: can inline (*Rectangle).Area with cost 67 as: method(*Rectangle) func() int { return r.Height() * r.Width() }
|
||||
./square.go:21:61: inlining call to (*Rectangle).Width method(*Rectangle) func() int { return 6 }
|
||||
./square.go:23:6: cannot inline main: function too complex: cost 150 exceeds budget 80
|
||||
./square.go:25:20: inlining call to (*Rectangle).Area method(*Rectangle) func() int { return r.Height() * r.Width() }
|
||||
./square.go:25:20: inlining call to (*Rectangle).Width method(*Rectangle) func() int { return 6 }
|
||||
```
|
||||
@ -151,33 +152,29 @@ func main() {
|
||||
|
||||
#### 快速路径内联
|
||||
|
||||
关于栈中内联的效果最令人吃惊的例子是 2019 年 [Carlo Alberto Ferraris][7] 通过允许把 `sync.Mutex.Lock()` 的快速路径,非竞争的情况,内联到它的调用方来[提升它的性能][7]。在这个修改之前,`sync.Mutex.Lock()` 是个很大的函数,包含很多难以理解的条件,使得它没有资格被内联。即使锁可用时,调用者也要付出调用 `sync.Mutex.Lock()` 的代价。
|
||||
关于栈中内联的效果最令人吃惊的例子是 2019 年 [Carlo Alberto Ferraris][7] 通过允许把 `sync.Mutex.Lock()` 的快速路径(非竞争的情况)内联到它的调用方来[提升它的性能][7]。在这个修改之前,`sync.Mutex.Lock()` 是个很大的函数,包含很多难以理解的条件,使得它没有资格被内联。即使锁可用时,调用者也要付出调用 `sync.Mutex.Lock()` 的代价。
|
||||
|
||||
Carlo 把 `sync.Mutex.Lock()` 分成了两个函数(他自己称为*外联*)。外部的 `sync.Mutex.Lock()` 方法现在调用 `sync/atomic.CompareAndSwapInt32()` 且如果 CAS(Compare and Swap)成功了之后立即返回给调用者。如果 CAS 失败,函数会走到 `sync.Mutex.lockSlow()` 慢速路径,需要对锁进行注册,暂停 goroutine。[4][8]
|
||||
Carlo 把 `sync.Mutex.Lock()` 分成了两个函数(他自己称为<ruby>外联<rt>outlining</rt></ruby>)。外部的 `sync.Mutex.Lock()` 方法现在调用 `sync/atomic.CompareAndSwapInt32()` 且如果 CAS(<ruby>比较并交换<rt>Compare and Swap</rt></ruby>)成功了之后立即返回给调用者。如果 CAS 失败,函数会走到 `sync.Mutex.lockSlow()` 慢速路径,需要对锁进行注册,暂停 goroutine。[^4]
|
||||
|
||||
```bash
|
||||
% go build -gcflags='-m=2 -l=0' sync 2>&1 | grep '(*Mutex).Lock'
|
||||
../go/src/sync/mutex.go:72:6: can inline (*Mutex).Lock with cost 69 as: method(*Mutex) func() { if "sync/atomic".CompareAndSwapInt32(&m.state, 0, mutexLocked) { if race.Enabled { }; return }; m.lockSlow() }
|
||||
../go/src/sync/mutex.go:72:6: can inline (*Mutex).Lock with cost 69 as: method(*Mutex) func() { if "sync/atomic".CompareAndSwapInt32(&m.state, 0, mutexLocked) { if race.Enabled { }; return }; m.lockSlow() }
|
||||
```
|
||||
|
||||
通过把函数分割成一个简单的不能再被分割的外部函数,和(如果没走到外部函数就走到的)一个处理慢速路径的复杂的内部函数,Carlo 组合了栈中函数内联和[编译器对基础操作的支持][9],减少了非竞争锁 14% 的开销。之后他在 `sync.RWMutex.Unlock()` 重复这个技巧,节省了另外 9% 的开销。
|
||||
|
||||
1. 不同发布版本中,在考虑该函数是否适合内联时,Go 编译器对同一函数的预算是不同的。[][10]
|
||||
2. 时刻记着编译器的作者警告过[“更高的内联等级(比 -l 更高)可能导致 bug 或不被支持”][11]。 Caveat emptor。[][12]
|
||||
3. 编译器有足够的能力来内联像 `strconv.ParseInt` 的复杂函数。作为一个实验,你可以尝试去掉 `//go:noinline` 注释,使用 `-gcflags=-m=2` 编译后观察。[][13]
|
||||
4. `race.Enable` 表达式是通过传递给 `go` 工具的 `-race` 参数控制的一个常量。对于普通编译,它的值是 `false`,此时编译器可以完全省略代码路径。[][14]
|
||||
[^1]: 不同发布版本中,在考虑该函数是否适合内联时,Go 编译器对同一函数的预算是不同的。
|
||||
[^2]: 时刻记着编译器的作者警告过[“更高的内联等级(比 -l 更高)可能导致错误或不被支持”][11]。 Caveat emptor。
|
||||
[^3]: 编译器有足够的能力来内联像 `strconv.ParseInt` 的复杂函数。作为一个实验,你可以尝试去掉 `//go:noinline` 注释,使用 `-gcflags=-m=2` 编译后观察。
|
||||
[^4]: `race.Enable` 表达式是通过传递给 `go` 工具的 `-race` 参数控制的一个常量。对于普通编译,它的值是 `false`,此时编译器可以完全省略代码路径。
|
||||
|
||||
|
||||
|
||||
#### 相关文章:
|
||||
### 相关文章:
|
||||
|
||||
1. [Go 中的内联优化][15]
|
||||
2. [goroutine 的栈为什么会无限增长?][16]
|
||||
3. [栈追踪和 errors 包][17]
|
||||
4. [零值是什么,为什么它很有用?][18]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dave.cheney.net/2020/05/02/mid-stack-inlining-in-go
|
||||
@ -185,13 +182,13 @@ via: https://dave.cheney.net/2020/05/02/mid-stack-inlining-in-go
|
||||
作者:[Dave Cheney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://dave.cheney.net/author/davecheney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://dave.cheney.net/2020/04/25/inlining-optimisations-in-go
|
||||
[1]: https://linux.cn/article-12176-1.html
|
||||
[2]: https://medium.com/@joshsaintjacque/small-functions-considered-awesome-c95b3fd1812f
|
||||
[3]: tmp.FyRthF1bbF#easy-footnote-bottom-1-4076 (The budget the Go compiler applies to each function when considering if it is eligible for inlining changes release to release.)
|
||||
[4]: tmp.FyRthF1bbF#easy-footnote-bottom-2-4076 (Keep in mind that the compiler authors warn that “<a href="https://github.com/golang/go/blob/be08e10b3bc07f3a4e7b27f44d53d582e15fd6c7/src/cmd/compile/internal/gc/inl.go#L11">Additional levels of inlining (beyond -l) may be buggy and are not supported”</a>. Caveat emptor.)
|
||||
@ -0,0 +1,124 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12203-1.html)
|
||||
[#]: subject: (Browse the Peer-to-peer Web With Beaker Browser)
|
||||
[#]: via: (https://itsfoss.com/beaker-browser/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
使用 Beaker 浏览器浏览对等 Web
|
||||
======
|
||||
|
||||

|
||||
|
||||
在过去 50 年中,我们所了解的互联网没有什么变化,全球的网民使用他们的设备从遍布在世界各地的服务器上检索数据。
|
||||
|
||||
一群专业的技术专家想改变现状,使互联网变成人们可以连接和直接分享信息的地方,而不是依赖一个中心服务器(去中心化)。
|
||||
|
||||
我们已经在 It’s FOSS 讨论过很多这样的去中心化的服务。[YouTube 竞品:LBRY][1]、[Twitter 竞品:Mastodon][2] 是其中的两个例子。
|
||||
|
||||
今天我将要介绍另一个这样的产品,名为 [Beaker 浏览器][3],它的设计目标是浏览对等 Web。
|
||||
|
||||
![Beaker Browser][4]
|
||||
|
||||
### “对等 Web” 是什么?
|
||||
|
||||
根据 Beaker 浏览器的[开发者之一][5]的描述,“对等 Web 是一项实验性的技术 ……旨在提高我们掌控 Web 的能力。”
|
||||
|
||||
还有,他们说对等 Web 有三个主要原则:任何一点都可以成为服务器;多台计算机可以为同一个网站提供服务;没有后端。
|
||||
|
||||
从这些原则中你可以看出,对等 Web 的思想与 BitTorrent 很像,文件由多个对端做种,这些对端共同承担带宽负载。这减少了一个用户需要提供给他们的网站的总带宽。
|
||||
|
||||
![Beaker Browser Settings][6]
|
||||
|
||||
对等 Web 另一个重要的方面是创作者对于他们自己的想法的控制能力。当今年代,平台都是由庞大的组织控制的,往往拿你的数据为他们所用。Beaker 把数据的控制能力返还给了内容创造者。
|
||||
|
||||
### 使用 Beaker 浏览去中心化的 web
|
||||
|
||||
[Beaker 浏览器][3] 是在 2016 年被创建的。该项目(及其周边技术)由[蓝链实验室][7]的三人团队创建。Beaker 浏览器使用 [Dat 协议][8]在计算机之间共享数据。使用 Dat 协议的网站以 `dat://` 而不是 `http://` 开头。
|
||||
|
||||
Dat 协议的优势如下:
|
||||
|
||||
* 快速 – 档案能立即从多个源同步。
|
||||
* 安全 – 所有的更新都是有签名和经过完整性检查的。
|
||||
* 灵活 – 可以在不修改档案 URL 的情况下迁移主机。
|
||||
* 版本控制 – 每次修改都被写到只能追加的版本日志中。
|
||||
* 去中心化 – 任何设备都可以作为承载档案的主机。
|
||||
|
||||
![Beaker Browser Seeding][9]
|
||||
|
||||
Beaker 浏览器本质上是阉割版的 Chromium,原生支持 `dat://` 地址,也可以访问普通的 `http://` 站点。
|
||||
|
||||
每次访问一个 dat 站点,在你请求时该站点的内容才会下载到你的计算机。例如,在一个站点上的 about 页面中有一张 Linux Torvalds 的图片,只有在你浏览到该站点的这个页面时,才会下载这张图片。
|
||||
|
||||
此外,当你浏览一个 dat 网站时,“[你会短暂性的][10]重新上传或做种你从该网站上下载的所有文件。”你也可以选择为网站(主动)做种来帮助创造者。
|
||||
|
||||
![Beaker Browser Menu][11]
|
||||
|
||||
由于 Beaker 的志向就是创建一个更开放的网络,因此你可以很容易地查看任何网站的源码。不像在大多数浏览器上你只能看到当前浏览的页面的源码那样,使用 Beaker 你能以类似 GitHub 的视图查看整个站点的结构。你甚至可以复刻这个站点,并托管你自己的版本。
|
||||
|
||||
除了浏览基于 dat 的网站外,你还可以创建自己的站点。在 Beaker 浏览器的菜单里,有创建新网站或空项目的选项。如果你选择了创建一个新网站,Beaker 会搭建一个小的演示站点,你可以使用浏览器里自带的编辑器来编辑。
|
||||
|
||||
然而,如果你像我一样更喜欢用 Markdown,你可以选择创建一个空项目。Beaker 会创建一个站点的结构,赋给它一个 `dat://` 地址。你只需要创建一个 `index.md` 文件后就行了。这有个[简短教程][12],你可以看到更多信息。你也可以用创建空项目的方式搭建一个 web 应用。
|
||||
|
||||
![Beaker Browser Website Template][13]
|
||||
|
||||
由于 Beaker 的角色是个 Web 服务器和站点做种者,当你关闭它或关机后你的站点就不可用了。幸运的是,你不必一直开着你的计算机或浏览器。你也可以使用名为 [Hashbase][14] 的做种服务或者你可以搭建一个 [homebase][15] 做种服务器。
|
||||
|
||||
虽然 Beaker [适用于][16] Linux、Windows 和 macOS,但是在使用 Beaker 之前,还是要查阅下[各平台的教程][17]。
|
||||
|
||||
### Beaker 浏览器不是大众可用的,但它有这个意图
|
||||
|
||||
当第一次接触到时,我对 Beaker 浏览器有极高的热情。(但是)如它现在的名字一样(烧杯),Beaker 浏览器仍是非常实验性的。我尝试浏览过的很多 dat 站点还不可用,因为用户并没有为站点做种。当站点恢复可用时 Beaker 确实可以选择通知你。
|
||||
|
||||
![Beaker Browser No Peer][18]
|
||||
|
||||
另一个问题是,Beaker 是真正阉割版的 Chromium。它不能安装扩展或主题。你只能使用白色主题和极少的工具集。我不会把 Beaker 浏览器作为常用浏览器,而且能访问 dat 网站并不是把它留在系统上的充分条件。
|
||||
|
||||
我曾经寻找一个能支持 `dat://` 协议的 Firefox 扩展。我确实找到了这样一款扩展,但它需要安装一系列其他的软件。相比而言,安装 Beaker 比安装那些软件容易点。
|
||||
|
||||
就如它现在的名字一样,Beaker 不适合我。也许在将来更多的人使用 Beaker 或者其他浏览器支持 dat 协议。那时会很有趣。目前而言,聊胜于无。
|
||||
|
||||
在使用 Beaker 的时间里,我用内建的工具创建了一个[网站][19]。不要担心,我已经为它做种了。
|
||||
|
||||
![Beaker Bowser Site Source][20]
|
||||
|
||||
你怎么看 Beaker 浏览器?你怎么看对等 Web?请尽情在下面评论。
|
||||
|
||||
如果你觉得本文有意思,请花点时间把它分享到社交媒体,Hacker News 或 [Reddit][21]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/beaker-browser/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/lbry/
|
||||
[2]: https://itsfoss.com/mastodon-open-source-alternative-twitter/
|
||||
[3]: https://beakerbrowser.com/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/beaker-browser.jpg?resize=800%2C426&ssl=1
|
||||
[5]: https://pfrazee.hashbase.io/blog/what-is-the-p2p-web
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/beaker-bowser-setting.jpg?resize=800%2C573&ssl=1
|
||||
[7]: https://bluelinklabs.com/
|
||||
[8]: https://www.datprotocol.com/
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/beaker-bowser-seedding.jpg?resize=800%2C466&ssl=1
|
||||
[10]: https://beakerbrowser.com/docs/faq/
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/beaker-browser-menu.jpg?ssl=1
|
||||
[12]: https://beakerbrowser.com/docs/guides/create-a-markdown-site
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/beaker-browser-website-template.jpg?resize=800%2C459&ssl=1
|
||||
[14]: https://hashbase.io/
|
||||
[15]: https://github.com/beakerbrowser/homebase
|
||||
[16]: https://beakerbrowser.com/install/
|
||||
[17]: https://beakerbrowser.com/docs/guides/
|
||||
[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/beaker-browser-no-peer.jpg?resize=800%2C424&ssl=1
|
||||
[19]: https://41bfbd06731e8d9c5d5676e8145069c69b254e7a3b710ddda4f6e9804529690c/
|
||||
[20]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/beaker-bowser-source.jpg?resize=800%2C544&ssl=1
|
||||
[21]: https://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,115 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12188-1.html)
|
||||
[#]: subject: (After More Than 3 Years, Inkscape 1.0 is Finally Here With Tons of Feature Improvements)
|
||||
[#]: via: (https://itsfoss.com/inkscape-1-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
经过了 3 年,Inkscape 1.0 终于发布了
|
||||
======
|
||||
|
||||

|
||||
|
||||
虽然我不是这方面的专业人员,但可以肯定地说,Inkscape 是[最好的矢量图形编辑器][1]之一。
|
||||
|
||||
不仅仅因为它是自由开源软件,而且对于数字艺术家来说,它是一个非常有用的应用程序。
|
||||
|
||||
上一次发布(0.92 版本)是在 3 年前。现在,终于,[Inkscape 宣布了它的 1.0 版本][2] —— 增加了很多新的功能和改进。
|
||||
|
||||
### Inkscape 1.0 里的新东西
|
||||
|
||||
![Inkscape 1.0][3]
|
||||
|
||||
在这里,让我重点介绍一下 Inkscape 1.0 版本中重要关键变化。
|
||||
|
||||
#### 首个原生 macOS 应用
|
||||
|
||||
对于像 Inkscape 这样的神奇工具来说,适当的跨平台支持总是好的。在这个最新的版本中,它推出了原生的 macOS 应用。
|
||||
|
||||
请注意,这个 macOS 应用仍然是一个**预览版**,还有很多改进的空间。不过,在无需 [XQuartz][4] 的情况下就做到了更好的系统集成,对于 macOS 用户来说,应该是一个值得期许的进步。
|
||||
|
||||
#### 性能提升
|
||||
|
||||
不管是什么应用程序/工具,都会从显著的性能提升中受益,而 Inkscape 也是如此。
|
||||
|
||||
随着其 1.0 版本的发布,他们提到,当你使用 Inkscape 进行各种创意工作时,你会发现性能更加流畅。
|
||||
|
||||
除了在 macOS 上(仍为“预览版”),Inkscape 在 Linux 和 Windows 上的运行都是很好的。
|
||||
|
||||
#### 改进的 UI 和 HiDPI 支持
|
||||
|
||||
![][5]
|
||||
|
||||
他们在发布说明中提到:
|
||||
|
||||
> ……达成了一个重要的里程碑,使 Inkscape 能够使用最新的软件(即 GTK+3)来构建编辑器的用户界面。拥有 HiDPI(高分辨率)屏幕的用户要感谢 2018 年波士顿黑客节期间的团队合作,让更新后的 GTK 轮子开始运转起来。
|
||||
|
||||
从 GTK+3 的用户界面到高分辨率屏幕的 HiDPI 支持,这都是一次精彩的升级。
|
||||
|
||||
更不要忘了,你还可以获得更多的自定义选项来调整外观和感受。
|
||||
|
||||
#### 新增功能
|
||||
|
||||
![][6]
|
||||
|
||||
即便是从纸面上看,这些列出新功能都看起来不错。根据你的专业知识和你的喜好,这些新增功能应该会派上用场。
|
||||
|
||||
以下是新功能的概述:
|
||||
|
||||
* 新改进过的实时路径效果(LPE)功能。
|
||||
* 新的可搜索的 LPE 选择对话框。
|
||||
* 自由式绘图用户现在可以对画布进行镜像和旋转。
|
||||
* 铅笔工具的新的 PowerPencil 模式提供了压感的宽度,并且终于可以创建封闭路径了。
|
||||
* 包括偏移、PowerClip 和 PowerMask LPE 在内的新路径效果会吸引艺术类用户。
|
||||
* 能够创建复制引导、将网格对齐到页面上、测量工具的路径长度指示器和反向 Y 轴。
|
||||
* 能够导出带有可点击链接和元数据的 PDF 文件。
|
||||
* 新的调色板和网状渐变,可在网页浏览器中使用。
|
||||
|
||||
虽然我已经尝试着整理了这个版本中添加的关键功能列表,但你可以在他们的[发布说明][7]中获得全部细节。
|
||||
|
||||
#### 其他重要变化
|
||||
|
||||
作为重大变化之一,Inkscape 1.0 现在支持 Python 3。而且,随着这一变化,你可能会注意到一些扩展程序无法在最新版本中工作。
|
||||
|
||||
所以,如果你的工作依赖于某个扩展程序的工作流程,我建议你仔细看看他们的[发布说明][7],了解所有的技术细节。
|
||||
|
||||
### 在 Linux 上下载和安装 Inkscape 1.0
|
||||
|
||||
Inkscape 1.0 有用于 Linux 的 AppImage 和 Snap 软件包,你可以从 Inkscape 的网站上下载。
|
||||
|
||||
- [下载 Inkscape 1.0 for Linux][8]
|
||||
|
||||
如果你还不知道,可以查看[如何在 Linux 上使用 AppImage 文件][9]来入门。你也可以参考[这个 Snap 指南][10]。
|
||||
|
||||
Ubuntu 用户可以在 Ubuntu 软件中心找到 Inskcape 1.0 的 Snap 版本。
|
||||
|
||||
我在 [Pop!_OS 20.04][11] 上使用了 AppImage 文件,工作的很好。你可以详细体验所有的功能,看看它的效果如何。
|
||||
|
||||
你试过了吗?请在下面的评论中告诉我你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/inkscape-1-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/vector-graphics-editors-linux/
|
||||
[2]: https://inkscape.org/news/2020/05/04/introducing-inkscape-10/
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/05/inkscape-1-0.jpg?ssl=1
|
||||
[4]: https://en.wikipedia.org/wiki/XQuartz
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/05/inkscape-ui-customization.jpg?ssl=1
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/05/inkscape-live-path-effects.jpg?ssl=1
|
||||
[7]: https://wiki.inkscape.org/wiki/index.php/Release_notes/1.0
|
||||
[8]: https://inkscape.org/release/1.0/gnulinux/
|
||||
[9]: https://itsfoss.com/use-appimage-linux/
|
||||
[10]: https://itsfoss.com/install-snap-linux/
|
||||
[11]: https://itsfoss.com/pop-os-20-04-review/
|
||||
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Good News! You Can Now Buy the De-Googled /e/OS Smartphone from Fairphone)
|
||||
[#]: via: (https://itsfoss.com/fairphone-with-e-os/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Good News! You Can Now Buy the De-Googled /e/OS Smartphone from Fairphone
|
||||
======
|
||||
|
||||
Fairphone is known for its ethical (or fair) approach of making a smartphone.
|
||||
|
||||
Normally, the ethical approach involves that the workers get paid well, the smartphone build materials are safer for the planet, and the phone is durable/sustainable. And, they’ve already done a good job with their [Fairphone 1][1] , [Fairphone 2][2], and [Fairphone 3][3] smartphones.
|
||||
|
||||
Now, to take things up a notch, Fairphone has teamed up with [/e/OS][4] which is a de-googled Android fork, to launch a separate edition of [Fairphone 3][3] (its latest smartphone) that comes with **/e/OS** out of the box.
|
||||
|
||||
In case you didn’t know about the mobile operating system, you can read our [interview with Gael Duval (Founder of /e/OS)][5] to know more about it.
|
||||
|
||||
While we already have some privacy-focused smartphones like [Librem 5][6], Fairphone 3 with /e/OS is something different to its core. In this article, I’ll try highlighting the key things that you need to know before ordering a Fairphone 3 with /e/OS loaded.
|
||||
|
||||
### The First Privacy Conscious & Sustainable Phone
|
||||
|
||||
You may have noticed a privacy-focused smartphone manufactured in some corner of the world, like [Librem 5][7].
|
||||
|
||||
But for the most part, it looks like the Fairphone 3 is the first privacy-conscious sustainable phone to get the spotlight.
|
||||
|
||||
![][8]
|
||||
|
||||
The de-googled operating system /e/OS ensures that the smartphone does not rely on Google services to function among other things. Hence, /e/OS should be a great choice for Fairphone 3 for privacy-focused users.
|
||||
|
||||
Also, to support /e/OS out of the box wasn’t just the decision of the manufacturer – but its community.
|
||||
|
||||
As per their announcement, they’ve mentioned:
|
||||
|
||||
> For many, fairer technology isn’t just about the device and its components, it is also about the software that powers the product; and when Fairphone community members were asked what their preferred alternative operating system (OS) was for the next Fairphone, the Fairphone 3, they voted for /e/OS.
|
||||
|
||||
So, it looks like the users do prefer to have /e/OS on their smartphones.
|
||||
|
||||
### Fairphone 3: Overview
|
||||
|
||||
![][9]
|
||||
|
||||
To tell you what I think about it, let me first share the technical specifications of the phone:
|
||||
|
||||
* Dual Nano-SIM (4G LTE/3G/2G support)
|
||||
* **Display:** 5.65-inch LCD (IPS) with Corning Gorilla Glass 5 protection
|
||||
* **Screen Resolution**: 2160 x 1080
|
||||
* **RAM:** 4 GB
|
||||
* **Chipset**: Qualcomm Snapdragon 632
|
||||
* **Internal Storage:** 64 GB
|
||||
* **Rear Camera:** 12 MP (IMX363 sensor)
|
||||
* **Front Camera:** 8 MP
|
||||
* Bluetooth 5.0
|
||||
* WiFi 802.11a/b/g/n/ac
|
||||
* NFC Supported
|
||||
* USB-C
|
||||
* Expandable Storage supported
|
||||
|
||||
|
||||
|
||||
So, on paper, it sounds like a decent budget smartphone. But, the pricing and availability will be an important factor keeping in mind that it’s a one-of-a-kind smartphone and we don’t really have alternatives to compare to.
|
||||
|
||||
Not just how it’s unique for privacy-focused users, but it is potentially the easiest phone to fix (as suggested by [iFixit’s teardown][10]).
|
||||
|
||||
### Fairphone 3 with /e/OS: Pre-Order, Price & Availability
|
||||
|
||||
![][11]
|
||||
|
||||
As for its availability – the Fairphone 3 with /e/OS is available to pre-order through the [online shop of /e/OS][12] for **€479.90** across Europe.
|
||||
|
||||
If you are an existing Fairphone 3 user, you can also install /e/OS from the [available build here][13].
|
||||
|
||||
You get 2 years of warranty along with a 14-day return policy.
|
||||
|
||||
[Pre-Order Fairphone 3 With /e/OS][12]
|
||||
|
||||
### My Thoughts On Fairphone 3 with /e/OS
|
||||
|
||||
It’s important to consider that the smartphone is targeting a particular group of consumers. So, it’s quite obvious that it isn’t meant for everyone. The specifications on paper may look good – but not necessarily the best bang for the buck.
|
||||
|
||||
Also, looking at the smartphone market right now – the specifications and its value for money matter more than what we privacy-focused users want.
|
||||
|
||||
But it’s definitely something impressive and I believe it’s going to get good attention specially among the privacy-aware people who don’t want their smartphone spying on them.
|
||||
|
||||
With Fairphone 3’s launch with /e/OS, the lesser tech savvy people can now get an out of the box privacy-focused smartphone experience.
|
||||
|
||||
What do you think about the Fairphone 3 with /e/OS? Let me know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/fairphone-with-e-os/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Fairphone_1
|
||||
[2]: https://en.wikipedia.org/wiki/Fairphone_2
|
||||
[3]: https://shop.fairphone.com/en/?ref=header
|
||||
[4]: https://e.foundation/
|
||||
[5]: https://itsfoss.com/gael-duval-interview/
|
||||
[6]: https://itsfoss.com/librem-5-available/
|
||||
[7]: https://itsfoss.com/librem-linux-phone/
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/05/Fairphone-3-battery.png?ssl=1
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/05/fairphone-3.png?ssl=1
|
||||
[10]: https://www.ifixit.com/Teardown/Fairphone+3+Teardown/125573
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/05/fairphone-e-os.png?ssl=1
|
||||
[12]: https://e.foundation/product/e-os-fairphone-3/
|
||||
[13]: https://doc.e.foundation/devices/FP3/
|
||||
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The success of virtual conferences, Retropie comes to Raspberry Pi 4, and other open source news)
|
||||
[#]: via: (https://opensource.com/article/20/5/news-may-9)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
|
||||
The success of virtual conferences, Retropie comes to Raspberry Pi 4, and other open source news
|
||||
======
|
||||
Catch up on the biggest open source headlines from the past two weeks.
|
||||
![][1]
|
||||
|
||||
In this week’s edition of our open source news roundup, we see the success of virtual conferences, continued impact of open source on COVID-19, Retropie adds support for Raspberry Pi 4, and more open source news.
|
||||
|
||||
### Virtual conferences report record attendance
|
||||
|
||||
The technology industry, and non-profits supporting open source software, greatly [depend on conferences][2] to connect their community together. There has been an open question of whether moving to an online alternative would be effective or not. The last two weeks have given us reason to say virtual conferences are a huge success, and there are multiple paths to getting there.
|
||||
|
||||
The first success goes to [Red Hat Summit][3], a conference put on by Red Hat to showcase their technology and interact with the open source community each year. Last year it held at Boston Convention and Exhibition Center in Boston, MA with a record-breaking 8,900 people in attendence. This year, due to COVID-19, Red Hat took it virtual with what they called [Red Hat Summit 2020 Virtual Experience][3]. The final attendance numbers, as [reported by IT World Canada][4], was 80,000 people.
|
||||
|
||||
The explosive growth of online events continued this week with GitHub Satelite [reporting][5] over 40,000 attendees for its multiday event.
|
||||
|
||||
![Example streaming for #DIDevOps][6]
|
||||
|
||||
*Streaming example of [Desert Island DevOps][7] *
|
||||
|
||||
Another success with a different twist came in the shape of 3-D avatars in the popular Animal Crossing game. Desert Island DevOps [reported][8] over 8,500 attendees in a simulated space and received [a lot of praise][9] from attendees and speakers alike.
|
||||
|
||||
### Open source continues to speed COVID-19 response
|
||||
|
||||
Emergency response requires speed and safety to be a top concern, which makes open source licensing and designs even more valuable. In our current battle with COVID-19, there is a need for increasing inventory of medical equipment such as ventilators and PPE as well as the development of treatments and medications. An open source approach is showing to have a major response.
|
||||
|
||||
A recent victory comes in the form of a [ventilator design][10] announced by Nvidia Corporation. Described as "low-cost and easy-to-assemble," the ventilators are expected to cost much less to build than other models on the market, making them a great option for medical professionals who have been working so hard to protect their patients.
|
||||
|
||||
Developing [open source medications][11] may also provide vast benefits. Research and development of vaccines are taking practices perfected in the open source world of the Linux kernel and applying them to how medications are developed. The focus may help merit be more central to the process than profitability. The absence of patent and copyright restrictions are also noted to speed the process of discovery.
|
||||
|
||||
### Retropie announces support for Raspberry Pi 4
|
||||
|
||||
Many of us are passing the time by playing games while we stay at home. If you’re into console gaming and nostalgia, [Retropie][12] gives Raspberry Pi enthusiasts a set of classic games to dig through. Last week the team behind the project is happy to announce [support for the latest Raspberry Pi 4][13] hardware [released 24 June 2019][14].
|
||||
|
||||
#### In other news
|
||||
|
||||
* [Fedora 32 Linux Official Release][15]
|
||||
* [Jitsi open source conferencing gaining interest][16]
|
||||
* [Free Wayland Book Available][17]
|
||||
* [Inkscape 1.0 Released][18]
|
||||
|
||||
|
||||
|
||||
Thanks, as always, to Opensource.com staff members and [Correspondents][19] for their help this week.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/news-may-9
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/weekly_news_roundup_tv.png?itok=tibLvjBd
|
||||
[2]: https://opensource.com/article/20/5/pycon-covid-19
|
||||
[3]: https://www.redhat.com/en/summit
|
||||
[4]: https://www.itworldcanada.com/article/over-80000-people-tune-into-virtual-red-hat-summit-crushing-last-years-record/430090?sc_cid=701f2000000u72aAAA
|
||||
[5]: https://twitter.com/MishManners/status/1258232215814586369
|
||||
[6]: https://opensource.com/sites/default/files/uploads/stream_example.jpg (Example streaming for #DIDevOps)
|
||||
[7]: https://desertedisland.club/about/
|
||||
[8]: https://desertedislanddevops.com/
|
||||
[9]: https://www.vice.com/en_us/article/z3bjga/this-tech-conference-is-being-held-on-an-animal-crossing-island
|
||||
[10]: https://blogs.nvidia.com/blog/2020/05/01/low-cost-open-source-ventilator-nvidia-chief-scientist/
|
||||
[11]: https://www.fastcompany.com/90498448/how-open-source-medicine-could-prepare-us-for-the-next-pandemic
|
||||
[12]: https://opensource.com/article/19/1/retropie
|
||||
[13]: https://retropie.org.uk/2020/04/retropie-4-6-released-with-raspberry-pi-4-support/
|
||||
[14]: https://opensource.com/article/19/6/raspberry-pi-4
|
||||
[15]: https://fedoramagazine.org/announcing-fedora-32/
|
||||
[16]: https://joinup.ec.europa.eu/collection/open-source-observatory-osor/news/open-source-videoconferences
|
||||
[17]: https://www.phoronix.com/scan.php?page=news_item&px=Wayland-Book-Free
|
||||
[18]: https://inkscape.org/news/2020/05/04/introducing-inkscape-10/
|
||||
[19]: https://opensource.com/correspondent-program
|
||||
@ -0,0 +1,96 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (11 DevOps lessons from My Little Pony)
|
||||
[#]: via: (https://opensource.com/article/20/5/devops-lessons)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
11 DevOps lessons from My Little Pony
|
||||
======
|
||||
What you never thought you could learn about DevOps for Twilight Sparkle
|
||||
and her friends.
|
||||
![My Little Pony][1]
|
||||
|
||||
In 2010, the My Little Pony franchise was rebooted with the animated show _My Little Pony: Friendship is Magic_. The combination of accessibility to children with the sophisticated themes the show tackled garnered a following that cut across ages. I was swept up in the wave and discovered there is a lot to learn about DevOps from the show.
|
||||
|
||||
### Discovering technical debt
|
||||
|
||||
The show begins with Twilight Sparkle reading obscure documentation, only to realize that Equestria, where the show is set, is due to suffer a calamity. Though someone named Nightmare Moon has been imprisoned for a thousand years, there is a prophecy she will return.
|
||||
|
||||
#### Lesson 1: Technical debt matters.
|
||||
|
||||
Nightmare Moon is a perfect stand-in for technical debt. Document it. Pay attention to the signs of risk no matter how infrequently they occur. Have a plan to resolve it.
|
||||
|
||||
Twilight Sparkle goes to her manager with the news, only to be told that it is not a current priority. She is sent to Ponyville to prepare for the coming celebration, instead.
|
||||
|
||||
#### Lesson 2: Communication with management is key.
|
||||
|
||||
Twilight Sparkle communicated her priority (the risk of technical debt) but did not convince her management that it was more important than the celebration (of the next release or a new customer).
|
||||
|
||||
We all need to make clear what the business case is for resolving critical issues. It is also not straightforward to explain technical debt in business terms. If management does not agree on the severity, find new ways to communicate the risk, and team up with others who speak that language.
|
||||
|
||||
### When technical debt becomes an outage
|
||||
|
||||
As the prophecy has foreseen, Nightmare Moon returns and declares eternal night. (In this DevOps story, this marks the beginning of a catastrophic outage.) Twilight quickly understands that she cannot resolve the issue by herself, and she recruits the ponies who will become, with her, the "Mane Six." They each stand for a different element of harmony—Applejack stands for Honesty, Fluttershy for Kindness, Pinkie Pie for Laughter, Rarity for Generosity, Rainbow Dash for Loyalty, and Twilight Sparkle herself for Magic. This team-building is full of lessons:
|
||||
|
||||
#### Lesson 3: Few are the issues that can be resolved by one person.
|
||||
|
||||
When facing an outage, reach out to other people with complementary skills who can help you. It is best if they are different than you: different backgrounds leads to differing perspectives, and that can lead to better problem-solving.
|
||||
|
||||
#### Lesson 4: When resolving an outage, honest communication is key.
|
||||
|
||||
Throughout the struggle against the eternal night, the Mane Six have to speak openly and honestly about what's not working. Their [blameless communication][2] is part of problem-solving.
|
||||
|
||||
#### Lesson 5: When resolving an outage, kindness to yourself and to others is crucial.
|
||||
|
||||
Though tempers flare hot in the land of Equestria, we all benefit from coming back to working together.
|
||||
|
||||
#### Lesson 6: Laughter is important.
|
||||
|
||||
Even when everything comes crashing down, remember to take a break, drink a glass of water, and take a deep breath. Stressing out does not help anything.
|
||||
|
||||
#### Lesson 7: Be generous.
|
||||
|
||||
Even if you are not on-call right now, if your help is needed to resolve a problem, help out as you hope your colleagues will do for you.
|
||||
|
||||
#### Lesson 8: Be loyal.
|
||||
|
||||
An outage is not a time to settle rivalries between teams. Focus on how to collaborate and resolve the outage as a team.
|
||||
|
||||
#### Lesson 9: Though people skills are important, you have to understand the technology on a deep level.
|
||||
|
||||
Keep your skills sharp. Expertise is not only the ability to learn; it is knowing when that information is needed. Part of being an expert is practice.
|
||||
|
||||
### Growing into a culture of continual improvement
|
||||
|
||||
After the issue is resolved, Princess Celestia realizes that the Mane Six are crucial to the long-term survival of Equestria, and tells Twilight Sparkle to stay in Ponyville and keep researching the magic of friendship.
|
||||
|
||||
#### Lesson 10: After an outage is resolved, conduct a review, take concrete lessons, and act on them.
|
||||
|
||||
I could go on, episode by episode, detailing lessons relevant for DevOps, but I will wrap up with one of my favorite ones. In the "Winter Wrap-Up" episode, all the ponies in Ponyville help in preparing for the spring. As per tradition, they do not use magic, leaving Twilight Sparkle to wonder how she can contribute. Eventually, she realizes that she can help by making a checklist to make sure everything is done in the right order.
|
||||
|
||||
#### Lesson 11: When automation is impossible or inadvisable, write a solid checklist, and follow it. Do not depend on your memory.
|
||||
|
||||
Twilight Sparkle and the Mane Six overcome great obstacles as a team, and now have a system to improve as a team.
|
||||
|
||||
### A story of DevOps
|
||||
|
||||
This story reflects how many organizations slowly adopt DevOps. The transition from recognizing a fear of technical debt toward addressing it is not simple. With courageous leadership, teamwork, and a willingness to improve, all organizations can come out on the other side with a similar story to Twilight Sparkle and her friends.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/devops-lessons
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/my-little-pony.jpg?itok=X-rwAGuE (My Little Pony)
|
||||
[2]: https://opensource.com/article/19/4/psychology-behind-blameless-retrospective
|
||||
@ -0,0 +1,78 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (IBM rolls Red Hat into edge, AI, hybrid-cloud expansion)
|
||||
[#]: via: (https://www.networkworld.com/article/3542409/ibm-rolls-red-hat-into-edge-ai-hybrid-cloud-expansion.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
IBM rolls Red Hat into edge, AI, hybrid-cloud expansion
|
||||
======
|
||||
Every company will be an AI company new IBM CEO Krishna tells Think! virtual gathering
|
||||
Getty
|
||||
|
||||
Deeply assimilating its Red Hat technology, IBM this week rolled out a set of new platforms and services designed to help customers manage edge-based application workloads and exploit artificial intelligence for infrastructure resiliency.
|
||||
|
||||
The announcements came at IBM’s virtualized Think! 2020 event that also featured the first Big Blue keynote by [the company's new CEO Arvind Krishna][1], during which he told the online audience about challenges of COVID-19: "History will look back on this as the moment when the digital transformation of business and society suddenly accelerated,” but also that [hybrid cloud and AI][2] are the two dominant forces driving digital transformation.
|
||||
|
||||
[Now see how AI can boost data-center availability and efficiency][3]
|
||||
|
||||
“More than 20 years ago, experts predicted every company would become an internet company. I am predicting today that every company will become an AI company, not because they can, but because they must,” he said.
|
||||
|
||||
With that idea in mind the company rolled out [IBM Watson AIOps][4], an application that uses AI to automate how enterprises detect, diagnose and respond to IT anomalies in real time. Watson AIOps works by grouping log anomalies and alerts based on spatial and temporal reasoning as well as similarity to past situations, IBM said. It uses IBM’s natural language processing technology to understand the content in trouble tickets to identify and extract resolution actions automatically.
|
||||
|
||||
Then it provides a pointer to where the problem is and identifies other services that might be affected. “It does this by showing details of the problem based on data from existing tools in the environment, all in the context of the application topology, distilling multiple signals into a succinct report” and eliminating the need for multiple dashboards, IBM stated.
|
||||
|
||||
AI can automate tasks like shifting traffic from one router to another, freeing up space on a drive, or restarting an application. AI systems can also be trained to self-correct, IBM stated.
|
||||
|
||||
“The problem is that many businesses are consumed with fixing problems after they occur, instead of preventing them before they happen. Watson AIOps relies on AI to solve and automate how enterprises self-detect, diagnose and respond to anomalies in real time,” Krishna said.
|
||||
|
||||
AIOps is built on the latest release of Red Hat OpenShift, supports Slack and Box, and can be integrated with IT-monitoring packages from Mattermost and ServiceNow, IBM stated.
|
||||
|
||||
The Kubernetes-based OpenShift Container Platform lets enterprise customers deploy and manage containers on their infrastructure of choice, be it private or public clouds, including AWS, Microsoft Azure, Google Cloud Platform, Alibaba and IBM Cloud. It also integrates with IBM prepackaged Cloud Paks, which include a secured Kubernetes container and containerized IBM middleware designed to let customers quickly spin-up enterprise-ready containers.
|
||||
|
||||
OpenShift is also the underlying package for a new version of its [edge network][5] management application called IBM Edge Application Manager. Based on the open source project [Open Horizon][6], the Edge Application Manager can use AI and analytics to help deploy and manage up to 10,000 edge nodes simultaneously by a single administrator. With the platform customers can remotely add new capabilities to a single-purpose device or automatically direct a device to use a variety of cloud-based resources depending on what resources it needs.
|
||||
|
||||
Cisco said it was working with the IBM Edge Application Manager to deploy apps and analytics models that run on a broad range of Cisco products, such as servers, its industrial portfolio of gateways, routers, switches, SD-WAN, and wireless-connectivity offerings for edge computing.
|
||||
|
||||
“As an example, IBM Edge Application Manager leverages [Cisco HyperFlex Edge][7] and Cisco IC3000 Industrial Compute Gateway servers. The HyperFlex Edge and IC3K platforms are specifically designed to support a number of edge use cases, such as optimizing traffic management, increasing manufacturing productivity, and increasing the safety of oil and gas pipelines,” Cisco [stated][8].
|
||||
|
||||
In addition, Cisco said it has used the capabilities in IBM Edge Application Manager to build an “Edge in a Box proposal,” where customers can deploy remote edge applications that run entirely disconnected from public or private clouds but are also synchronized and managed remotely in controlled connectivity windows. For instance, client edge locations may need to operate in disconnected mode but have the ability to synch up for automated application updates and data exchanges, Cisco stated.
|
||||
|
||||
Other edge-related announcements include:
|
||||
|
||||
* IBM [Edge Ecosystem][9], a group of industry players who will target open technology developments to let customers move data and applications between private data centers, hybrid multicloud environments and the edge. The group includes Cisco, Juniper, Samsung and NVIDIA among others. IBM said a Telco Network Cloud Ecosystem will serve a similar function for their network cloud platforms.
|
||||
* A preview of an upcoming service, called IBM Cloud Satellite. This will extend IBM’s public-cloud service to give customers the ability to use IBM Cloud anywhere – on-premises, in data centers or at the edge – delivered as a service that can be managed from a single pane of glass controlled through the public cloud. It lets customers run applications where it makes sense while utilizing cloud security and ops benefits, IBM stated. Satellite runs on Red Hat OpenShift.
|
||||
* Telco Network Cloud Manager – a telco/service provider offering that runs on Red Hat OpenShift to deliver intelligent automation capabilities to orchestrate virtual and container network functions in minutes. Service providers will have the ability to manage workloads on both Red Hat OpenShift and Red Hat OpenStack platforms, which will be critical as telcos increasingly look to modernize their networks for greater agility and efficiency, and to provide new services as 5G adoption expands, IBM stated.
|
||||
* New capabilities for some of its Cloud Paks including extending the Cloud Pak for Data to include the ability to better automate planning, budgeting and forecasting in [hybrid-cloud][10] environments. IBM upgraded tools for business routing and data capture to the Cloud Pak for Automation as well.
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3542409/ibm-rolls-red-hat-into-edge-ai-hybrid-cloud-expansion.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3536654/ibm-taps-new-leaders-for-hybrid-cloud-battles-ahead.html
|
||||
[2]: https://www.infoworld.com/article/3541825/ibms-new-ceo-lays-out-his-roadmap.html
|
||||
[3]: https://www.networkworld.com/article/3274654/ai-boosts-data-center-availability-efficiency.html
|
||||
[4]: https://www.ibm.com/watson/assets/duo/pdf/WDDE814_IBM_Watson_AIOps_Web.pdf
|
||||
[5]: https://www.networkworld.com/article/3224893/what-is-edge-computing-and-how-it-s-changing-the-network.html
|
||||
[6]: https://developer.ibm.com/blogs/open-horizon-joins-linux-foundation-grow-open-edge-computing-platform/
|
||||
[7]: https://www.cisco.com/c/en/us/products/hyperconverged-infrastructure/index.html?dtid=oblgzzz001087
|
||||
[8]: https://blogs.cisco.com/partner/cisco-and-ibm-teaming-at-the-edge
|
||||
[9]: https://www.ibm.com/blogs/business-partners/join-the-edge-ecosystem/
|
||||
[10]: https://www.networkworld.com/article/3268448/what-is-hybrid-cloud-really-and-whats-the-best-strategy.html
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -1,146 +0,0 @@
|
||||
An introduction to the GNU Core Utilities
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image credits :
|
||||
|
||||
[Bella67][1] via Pixabay. [CC0][2].
|
||||
|
||||
Two sets of utilities—the [GNU Core Utilities][3] and util-linux—comprise many of the Linux system administrator's most basic and regularly used tools. Their basic functions allow sysadmins to perform many of the tasks required to administer a Linux computer, including management and manipulation of text files, directories, data streams, storage media, process controls, filesystems, and much more.
|
||||
|
||||
These tools are indispensable because, without them, it is impossible to accomplish any useful work on a Unix or Linux computer. Given their importance, let's examine them.
|
||||
|
||||
### GNU coreutils
|
||||
|
||||
The Linux Terminal
|
||||
|
||||
* [Top 7 terminal emulators for Linux][4]
|
||||
* [10 command-line tools for data analysis in Linux][5]
|
||||
* [Download Now: SSH cheat sheet][6]
|
||||
* [Advanced Linux commands cheat sheet][7]
|
||||
|
||||
To understand the origins of the GNU Core Utilities, we need to take a short trip in the Wayback machine to the early days of Unix at Bell Labs. [Unix was written][8] so Ken Thompson, Dennis Ritchie, Doug McIlroy, and Joe Ossanna could continue with something they had started while working on a large multi-tasking and multi-user computer project called [Multics][9]. That little something was a game called Space Travel. As remains true today, it always seems to be the gamers who drive forward the technology of computing. This new operating system was much more limited than Multics, as only two users could log in at a time, so it was called Unics. This name was later changed to Unix.
|
||||
|
||||
Over time, Unix turned out to be such a success that Bell Labs began essentially giving it away it to universities and later to companies for the cost of the media and shipping. Back in those days, system-level software was shared between organizations and programmers as they worked to achieve common goals within the context of system administration.
|
||||
|
||||
Eventually, the [PHBs][10] at AT&T decided they should make money on Unix and started using more restrictive—and expensive—licensing. This was taking place at a time when software was becoming more proprietary, restricted, and closed. It was becoming impossible to share software with other users and organizations.
|
||||
|
||||
Some people did not like this and fought it with free software. Richard M. Stallman, aka RMS, led a group of rebels who were trying to write an open and freely available operating system they called the GNU Operating System. This group created the GNU Utilities but didn't produce a viable kernel.
|
||||
|
||||
When Linus Torvalds first wrote and compiled the Linux kernel, he needed a set of very basic system utilities to even begin to perform marginally useful work. The kernel does not provide commands or any type of command shell such as Bash. It is useless by itself. So, Linus used the freely available GNU Core Utilities and recompiled them for Linux. This gave him a complete, if quite basic, operating system.
|
||||
|
||||
You can learn about all the individual programs that comprise the GNU Utilities by entering the command info coreutils at a terminal command line. The following list of the core utilities is part of that info page. The utilities are grouped by function to make specific ones easier to find; in the terminal, highlight the group you want more information on and press the Enter key.
|
||||
|
||||
```
|
||||
* Output of entire files:: cat tac nl od base32 base64
|
||||
* Formatting file contents:: fmt pr fold
|
||||
* Output of parts of files:: head tail split csplit
|
||||
* Summarizing files:: wc sum cksum b2sum md5sum sha1sum sha2
|
||||
* Operating on sorted files:: sort shuf uniq comm ptx tsort
|
||||
* Operating on fields:: cut paste join
|
||||
* Operating on characters:: tr expand unexpand
|
||||
* Directory listing:: ls dir vdir dircolors
|
||||
* Basic operations:: cp dd install mv rm shred
|
||||
* Special file types:: mkdir rmdir unlink mkfifo mknod ln link readlink
|
||||
* Changing file attributes:: chgrp chmod chown touch
|
||||
* Disk usage:: df du stat sync truncate
|
||||
* Printing text:: echo printf yes
|
||||
* Conditions:: false true test expr
|
||||
* Redirection:: tee
|
||||
* File name manipulation:: dirname basename pathchk mktemp realpath
|
||||
* Working context:: pwd stty printenv tty
|
||||
* User information:: id logname whoami groups users who
|
||||
* System context:: date arch nproc uname hostname hostid uptime
|
||||
* SELinux context:: chcon runcon
|
||||
* Modified command invocation:: chroot env nice nohup stdbuf timeout
|
||||
* Process control:: kill
|
||||
* Delaying:: sleep
|
||||
* Numeric operations:: factor numfmt seq
|
||||
```
|
||||
|
||||
There are 102 utilities on this list. It covers many of the functions necessary to perform basic tasks on a Unix or Linux host. However, many basic utilities are missing. For example, the mount and umount commands are not in this list. Those and many of the other commands that are not in the GNU coreutils can be found in the util-linux collection.
|
||||
|
||||
### util-linux
|
||||
|
||||
The util-linix package of utilities contains many of the other common commands that sysadmins use. These utilities are distributed by the Linux Kernel Organization, and virtually every one of these 107 commands were originally three separate collections—fileutils, shellutils, and textutils—which were [combined into the single package][11] util-linux in 2003.
|
||||
|
||||
```
|
||||
agetty fsck.minix mkfs.bfs setpriv
|
||||
blkdiscard fsfreeze mkfs.cramfs setsid
|
||||
blkid fstab mkfs.minix setterm
|
||||
blockdev fstrim mkswap sfdisk
|
||||
cal getopt more su
|
||||
cfdisk hexdump mount sulogin
|
||||
chcpu hwclock mountpoint swaplabel
|
||||
chfn ionice namei swapoff
|
||||
chrt ipcmk newgrp swapon
|
||||
chsh ipcrm nologin switch_root
|
||||
colcrt ipcs nsenter tailf
|
||||
col isosize partx taskset
|
||||
colrm kill pg tunelp
|
||||
column last pivot_root ul
|
||||
ctrlaltdel ldattach prlimit umount
|
||||
ddpart line raw unshare
|
||||
delpart logger readprofile utmpdump
|
||||
dmesg login rename uuidd
|
||||
eject look renice uuidgen
|
||||
fallocate losetup reset vipw
|
||||
fdformat lsblk resizepart wall
|
||||
fdisk lscpu rev wdctl
|
||||
findfs lslocks RTC Alarm whereis
|
||||
findmnt lslogins runuser wipefs
|
||||
flock mcookie script write
|
||||
fsck mesg scriptreplay zramctl
|
||||
fsck.cramfs mkfs setarch
|
||||
```
|
||||
|
||||
Some of these utilities have been deprecated and will likely fall out of the collection at some point in the future. You should check [Wikipedia's util-linux page][12] for information on many of the utilities, and the man pages also provide details on the commands.
|
||||
|
||||
### Summary
|
||||
|
||||
These two collections of Linux utilities, the GNU Core Utilities and util-linux, together provide the basic utilities required to administer a Linux system. As I researched this article, I found several interesting utilities I never knew about. Many of these commands are seldom needed, but when you need them, they are indispensable.
|
||||
|
||||
Between these two collections, there are over 200 Linux utilities. While Linux has many more commands, these are the ones needed to manage the basic functions of a typical Linux host.
|
||||
|
||||
### About the author
|
||||
|
||||
[][13]
|
||||
|
||||
David Both \- David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years. David has written articles for... [more about David Both][14]
|
||||
|
||||
[More about me][15]
|
||||
|
||||
* [Learn how you can contribute][16]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/gnu-core-utilities][17]
|
||||
|
||||
作者: [David Both][18] 选题者: [@lujun9972][19] 译者: [译者ID][20] 校对: [校对者ID][21]
|
||||
|
||||
本文由 [LCTT][22] 原创编译,[Linux中国][23] 荣誉推出
|
||||
|
||||
[1]: https://pixabay.com/en/tiny-people-core-apple-apple-half-700921/
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.gnu.org/software/coreutils/coreutils.html
|
||||
[4]: https://opensource.com/life/17/10/top-terminal-emulators?intcmp=7016000000127cYAAQ
|
||||
[5]: https://opensource.com/article/17/2/command-line-tools-data-analysis-linux?intcmp=7016000000127cYAAQ
|
||||
[6]: https://opensource.com/downloads/advanced-ssh-cheat-sheet?intcmp=7016000000127cYAAQ
|
||||
[7]: https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=7016000000127cYAAQ
|
||||
[8]: https://en.wikipedia.org/wiki/History_of_Unix
|
||||
[9]: https://en.wikipedia.org/wiki/Multics
|
||||
[10]: https://en.wikipedia.org/wiki/Pointy-haired_Boss
|
||||
[11]: https://en.wikipedia.org/wiki/GNU_Core_Utilities
|
||||
[12]: https://en.wikipedia.org/wiki/Util-linux
|
||||
[13]: https://opensource.com/users/dboth
|
||||
[14]: https://opensource.com/users/dboth
|
||||
[15]: https://opensource.com/users/dboth
|
||||
[16]: https://opensource.com/participate
|
||||
[17]: https://opensource.com/article/18/4/gnu-core-utilities
|
||||
[18]: https://opensource.com/users/dboth
|
||||
[19]: https://github.com/lujun9972
|
||||
[20]: https://github.com/译者ID
|
||||
[21]: https://github.com/校对者ID
|
||||
[22]: https://github.com/LCTT/TranslateProject
|
||||
[23]: https://linux.cn/
|
||||
@ -1,276 +0,0 @@
|
||||
//messon007 translating
|
||||
Systemd Services: Reacting to Change
|
||||
======
|
||||
|
||||

|
||||
|
||||
[I have one of these Compute Sticks][1] (Figure 1) and use it as an all-purpose server. It is inconspicuous and silent and, as it is built around an x86 architecture, I don't have problems getting it to work with drivers for my printer, and that’s what it does most days: it interfaces with the shared printer and scanner in my living room.
|
||||
|
||||
![ComputeStick][3]
|
||||
|
||||
An Intel ComputeStick. Euro coin for size.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
Most of the time it is idle, especially when we are out, so I thought it would be good idea to use it as a surveillance system. The device doesn't come with its own camera, and it wouldn't need to be spying all the time. I also didn't want to have to start the image capturing by hand because this would mean having to log into the Stick using SSH and fire up the process by writing commands in the shell before rushing out the door.
|
||||
|
||||
So I thought that the thing to do would be to grab a USB webcam and have the surveillance system fire up automatically just by plugging it in. Bonus points if the surveillance system fired up also after the Stick rebooted, and it found that the camera was connected.
|
||||
|
||||
In prior installments, we saw that [systemd services can be started or stopped by hand][5] or [when certain conditions are met][6]. Those conditions are not limited to when the OS reaches a certain state in the boot up or powerdown sequence but can also be when you plug in new hardware or when things change in the filesystem. You do that by combining a Udev rule with a systemd service.
|
||||
|
||||
### Hotplugging with Udev
|
||||
|
||||
Udev rules live in the _/etc/udev/rules_ directory and are usually a single line containing _conditions_ and _assignments_ that lead to an _action_.
|
||||
|
||||
That was a bit cryptic. Let's try again:
|
||||
|
||||
Typically, in a Udev rule, you tell systemd what to look for when a device is connected. For example, you may want to check if the make and model of a device you just plugged in correspond to the make and model of the device you are telling Udev to wait for. Those are the _conditions_ mentioned earlier.
|
||||
|
||||
Then you may want to change some stuff so you can use the device easily later. An example of that would be to change the read and write permissions to a device: if you plug in a USB printer, you're going to want users to be able to read information from the printer (the user's printing app would want to know the model, make, and whether it is ready to receive print jobs or not) and write to it, that is, send stuff to print. Changing the read and write permissions for a device is done using one of the _assignments_ you read about earlier.
|
||||
|
||||
Finally, you will probably want the system to do something when the conditions mentioned above are met, like start a backup application to copy important files when a certain external hard disk drive is plugged in. That is an example of an _action_ mentioned above.
|
||||
|
||||
With that in mind, ponder this:
|
||||
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0", ATTRS{idProduct}=="e207",
|
||||
SYMLINK+="mywebcam", TAG+="systemd", MODE="0666", ENV{SYSTEMD_WANTS}="webcam.service"
|
||||
```
|
||||
|
||||
The first part of the rule,
|
||||
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
|
||||
ATTRS{idProduct}=="e207" [etc... ]
|
||||
```
|
||||
|
||||
shows the conditions that the device has to meet before doing any of the other stuff you want the system to do. The device has to be added (`ACTION=="add"`) to the machine, it has to be integrated into the `video4linux` subsystem. To make sure the rule is applied only when the correct device is plugged in, you have to make sure Udev correctly identifies the manufacturer (`ATTRS{idVendor}=="03f0"`) and a model (`ATTRS{idProduct}=="e207"`) of the device.
|
||||
|
||||
In this case, we're talking about this device (Figure 2):
|
||||
|
||||
![webcam][8]
|
||||
|
||||
The HP webcam used in this experiment.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
Notice how you use `==` to indicate that these are a logical operation. You would read the above snippet of the rule like this:
|
||||
|
||||
```
|
||||
if the device is added and the device controlled by the video4linux subsystem
|
||||
and the manufacturer of the device is 03f0 and the model is e207, then...
|
||||
```
|
||||
|
||||
But where do you get all this information? Where do you find the action that triggers the event, the manufacturer, model, and so on? You will probably have to use several sources. The `IdVendor` and `idProduct` you can get by plugging the webcam into your machine and running `lsusb`:
|
||||
|
||||
```
|
||||
lsusb
|
||||
Bus 002 Device 002: ID 8087:0024 Intel Corp. Integrated Rate Matching Hub
|
||||
Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
|
||||
Bus 004 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
|
||||
Bus 003 Device 003: ID 03f0:e207 Hewlett-Packard
|
||||
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
|
||||
Bus 001 Device 003: ID 04f2:b1bb Chicony Electronics Co., Ltd
|
||||
Bus 001 Device 002: ID 8087:0024 Intel Corp. Integrated Rate Matching Hub
|
||||
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
|
||||
```
|
||||
|
||||
The webcam I’m using is made by HP, and you can only see one HP device in the list above. The `ID` gives you the manufacturer and the model numbers separated by a colon (`:`). If you have more than one device by the same manufacturer and not sure which is which, unplug the webcam, run `lsusb` again and check what's missing.
|
||||
|
||||
OR...
|
||||
|
||||
Unplug the webcam, wait a few seconds, run the command `udevadmin monitor --environment` and then plug the webcam back in again. When you do that with the HP webcam, you get:
|
||||
|
||||
```
|
||||
udevadmin monitor --environment
|
||||
UDEV [35776.495221] add /devices/pci0000:00/0000:00:1c.3/0000:04:00.0
|
||||
/usb3/3-1/3-1:1.0/input/input21/event11 (input)
|
||||
.MM_USBIFNUM=00
|
||||
ACTION=add
|
||||
BACKSPACE=guess
|
||||
DEVLINKS=/dev/input/by-path/pci-0000:04:00.0-usb-0:1:1.0-event
|
||||
/dev/input/by-id/usb-Hewlett_Packard_HP_Webcam_HD_2300-event-if00
|
||||
DEVNAME=/dev/input/event11
|
||||
DEVPATH=/devices/pci0000:00/0000:00:1c.3/0000:04:00.0/
|
||||
usb3/3-1/3-1:1.0/input/input21/event11
|
||||
ID_BUS=usb
|
||||
ID_INPUT=1
|
||||
ID_INPUT_KEY=1
|
||||
ID_MODEL=HP_Webcam_HD_2300
|
||||
ID_MODEL_ENC=HP\x20Webcam\x20HD\x202300
|
||||
ID_MODEL_ID=e207
|
||||
ID_PATH=pci-0000:04:00.0-usb-0:1:1.0
|
||||
ID_PATH_TAG=pci-0000_04_00_0-usb-0_1_1_0
|
||||
ID_REVISION=1020
|
||||
ID_SERIAL=Hewlett_Packard_HP_Webcam_HD_2300
|
||||
ID_TYPE=video
|
||||
ID_USB_DRIVER=uvcvideo
|
||||
ID_USB_INTERFACES=:0e0100:0e0200:010100:010200:030000:
|
||||
ID_USB_INTERFACE_NUM=00
|
||||
ID_VENDOR=Hewlett_Packard
|
||||
ID_VENDOR_ENC=Hewlett\x20Packard
|
||||
ID_VENDOR_ID=03f0
|
||||
LIBINPUT_DEVICE_GROUP=3/3f0/e207:usb-0000:04:00.0-1/button
|
||||
MAJOR=13
|
||||
MINOR=75
|
||||
SEQNUM=3162
|
||||
SUBSYSTEM=input
|
||||
USEC_INITIALIZED=35776495065
|
||||
XKBLAYOUT=es
|
||||
XKBMODEL=pc105
|
||||
XKBOPTIONS=
|
||||
XKBVARIANT=
|
||||
```
|
||||
|
||||
That may look like a lot to process, but, check this out: the `ACTION` field early in the list tells you what event just happened, i.e., that a device got added to the system. You can also see the name of the device spelled out on several of the lines, so you can be pretty sure that it is the device you are looking for. The output also shows the manufacturer's ID number (`ID_VENDOR_ID=03f0`) and the model number (`ID_VENDOR_ID=03f0`).
|
||||
|
||||
This gives you three of the four values the condition part of the rule needs. You may be tempted to think that it a gives you the fourth, too, because there is also a line that says:
|
||||
|
||||
```
|
||||
SUBSYSTEM=input
|
||||
```
|
||||
|
||||
Be careful! Although it is true that a USB webcam is a device that provides input (as does a keyboard and a mouse), it is also belongs to the _usb_ subsystem, and several others. This means that your webcam gets added to several subsystems and looks like several devices. If you pick the wrong subsystem, your rule may not work as you want it to, or, indeed, at all.
|
||||
|
||||
So, the third thing you have to check is all the subsystems the webcam has got added to and pick the correct one. To do that, unplug your webcam again and run:
|
||||
|
||||
```
|
||||
ls /dev/video*
|
||||
```
|
||||
|
||||
This will show you all the video devices connected to the machine. If you are using a laptop, most come with a built-in webcam and it will probably show up as `/dev/video0`. Plug your webcam back in and run `ls /dev/video*` again.
|
||||
|
||||
Now you should see one more video device (probably `/dev/video1`).
|
||||
|
||||
Now you can find out all the subsystems it belongs to by running `udevadm info -a /dev/video1`:
|
||||
|
||||
```
|
||||
udevadm info -a /dev/video1
|
||||
|
||||
Udevadm info starts with the device specified by the devpath and then
|
||||
walks up the chain of parent devices. It prints for every device
|
||||
found, all possible attributes in the udev rules key format.
|
||||
A rule to match, can be composed by the attributes of the device
|
||||
and the attributes from one single parent device.
|
||||
|
||||
looking at device '/devices/pci0000:00/0000:00:1c.3/0000:04:00.0
|
||||
/usb3/3-1/3-1:1.0/video4linux/video1':
|
||||
KERNEL=="video1"
|
||||
SUBSYSTEM=="video4linux"
|
||||
DRIVER==""
|
||||
ATTR{dev_debug}=="0"
|
||||
ATTR{index}=="0"
|
||||
ATTR{name}=="HP Webcam HD 2300: HP Webcam HD"
|
||||
|
||||
[etc...]
|
||||
```
|
||||
|
||||
The output goes on for quite a while, but what you're interested is right at the beginning: `SUBSYSTEM=="video4linux"`. This is a line you can literally copy and paste right into your rule. The rest of the output (not shown for brevity) gives you a couple more nuggets, like the manufacturer and mode IDs, again in a format you can copy and paste into your rule.
|
||||
|
||||
Now you have a way of identifying the device and what event should trigger the action univocally, it is time to tinker with the device.
|
||||
|
||||
The next section in the rule, `SYMLINK+="mywebcam", TAG+="systemd", MODE="0666"` tells Udev to do three things: First, you want to create symbolic link from the device to (e.g. _/dev/video1_ ) to _/dev/mywebcam_. This is because you cannot predict what the system is going to call the device by default. When you have an in-built webcam and you hotplug a new one, the in-built webcam will usually be _/dev/video0_ while the external one will become _/dev/video1_. However, if you boot your computer with the external USB webcam plugged in, that could be reversed and the internal webcam can become _/dev/video1_ and the external one _/dev/video0_. What this is telling you is that, although your image-capturing script (which you will see later on) always needs to point to the external webcam device, you can't rely on it being _/dev/video0_ or _/dev/video1_. To solve this problem, you tell Udev to create a symbolic link which will never change in the moment the device is added to the _video4linux_ subsystem and you will make your script point to that.
|
||||
|
||||
The second thing you do is add `"systemd"` to the list of Udev tags associated with this rule. This tells Udev that the action that the rule will trigger will be managed by systemd, that is, it will be some sort of systemd service.
|
||||
|
||||
Notice how in both cases you use `+=` operator. This adds the value to a list, which means you can add more than one value to `SYMLINK` and `TAG`.
|
||||
|
||||
The `MODE` values, on the other hand, can only contain one value (hence you use the simple `=` assignment operator). What `MODE` does is tell Udev who can read from or write to the device. If you are familiar with `chmod` (and, if you are reading this, you should be), you will also be familiar of [how you can express permissions using numbers][9]. That is what this is: `0666` means " _give read and write privileges to the device to everybody_ ".
|
||||
|
||||
At last, `ENV{SYSTEMD_WANTS}="webcam.service"` tells Udev what systemd service to run.
|
||||
|
||||
Save this rule into file called _90-webcam.rules_ (or something like that) in _/etc/udev/rules.d_ and you can load it either by rebooting your machine, or by running:
|
||||
|
||||
```
|
||||
sudo udevadm control --reload-rules && udevadm trigger
|
||||
```
|
||||
|
||||
## Service at Last
|
||||
|
||||
The service the Udev rule triggers is ridiculously simple:
|
||||
|
||||
```
|
||||
# webcam.service
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/home/[user name]/bin/checkimage.sh
|
||||
```
|
||||
|
||||
Basically, it just runs the _checkimage.sh_ script stored in your personal _bin/_ and pushes it the background. [This is something you saw how to do in prior installments][5]. It may seem something little, but just because it is called by a Udev rule, you have just created a special kind of systemd unit called a _device_ unit. Congratulations.
|
||||
|
||||
As for the _checkimage.sh_ script _webcam.service_ calls, there are several ways of grabbing an image from a webcam and comparing it to a prior one to check for changes (which is what _checkimage.sh_ does), but this is how I did it:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# This is the checkimage.sh script
|
||||
|
||||
mplayer -vo png -frames 1 tv:// -tv driver=v4l2:width=640:height=480:device=
|
||||
/dev/mywebcam &>/dev/null
|
||||
mv 00000001.png /home/[user name]/monitor/monitor.png
|
||||
|
||||
while true
|
||||
do
|
||||
mplayer -vo png -frames 1 tv:// -tv driver=v4l2:width=640:height=480:device=/dev/mywebcam &>/dev/null
|
||||
mv 00000001.png /home/[user name]/monitor/temp.png
|
||||
|
||||
imagediff=`compare -metric mae /home/[user name]/monitor/monitor.png /home/[user name]
|
||||
/monitor/temp.png /home/[user name]/monitor/diff.png 2>&1 > /dev/null | cut -f 1 -d " "`
|
||||
if [ `echo "$imagediff > 700.0" | bc` -eq 1 ]
|
||||
then
|
||||
mv /home/[user name]/monitor/temp.png /home/[user name]/monitor/monitor.png
|
||||
fi
|
||||
|
||||
sleep 0.5
|
||||
done
|
||||
```
|
||||
|
||||
Start by using [MPlayer][10] to grab a frame ( _00000001.png_ ) from the webcam. Notice how we point `mplayer` to the `mywebcam` symbolic link we created in our Udev rule, instead of to `video0` or `video1`. Then you transfer the image to the _monitor/_ directory in your home directory. Then run an infinite loop that does the same thing again and again, but also uses [Image Magick's _compare_ tool][11] to see if there any differences between the last image captured and the one that is already in the _monitor/_ directory.
|
||||
|
||||
If the images are different, it means something has moved within the webcam's frame. The script overwrites the original image with the new image and continues comparing waiting for some more movement.
|
||||
|
||||
### Plugged
|
||||
|
||||
With all the bits and pieces in place, when you plug your webcam in, your Udev rule will be triggered and will start the _webcam.service_. The _webcam.service_ will execute _checkimage.sh_ in the background, and _checkimage.sh_ will start taking pictures every half a second. You will know because your webcam's LED will start flashing indicating every time it takes a snap.
|
||||
|
||||
As always, if something goes wrong, run
|
||||
|
||||
```
|
||||
systemctl status webcam.service
|
||||
```
|
||||
|
||||
to check what your service and script are up to.
|
||||
|
||||
### Coming up
|
||||
|
||||
You may be wondering: Why overwrite the original image? Surely you would want to see what's going on if the system detects any movement, right? You would be right, but as you will see in the next installment, leaving things as they are and processing the images using yet another type of systemd unit makes things nice, clean and easy.
|
||||
|
||||
Just wait and see.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][12]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.intel.com/content/www/us/en/products/boards-kits/compute-stick/stk1a32sc.html
|
||||
[2]: https://www.linux.com/files/images/fig01png
|
||||
[3]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/fig01.png?itok=cfEHN5f1 (ComputeStick)
|
||||
[4]: https://www.linux.com/licenses/category/used-permission
|
||||
[5]: https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-services-fun-and-profit
|
||||
[6]: https://www.linux.com/blog/learn/2018/5/systemd-services-beyond-starting-and-stopping
|
||||
[7]: https://www.linux.com/files/images/fig02png
|
||||
[8]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/fig02.png?itok=esFv4BdM (webcam)
|
||||
[9]: https://chmod-calculator.com/
|
||||
[10]: https://mplayerhq.hu/design7/news.html
|
||||
[11]: https://www.imagemagick.org/script/compare.php
|
||||
[12]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,296 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Best Raspberry Pi Operating Systems for Various Purposes)
|
||||
[#]: via: (https://itsfoss.com/raspberry-pi-os/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Best Raspberry Pi Operating Systems for Various Purposes
|
||||
======
|
||||
|
||||
[Raspberry Pi][1] is an indispensable single-board computer that comes in handy for a lot of work. Don’t believe me? Just [go through this list of Raspberry Pi projects][2] to get a gist of what this tiny device is capable of.
|
||||
|
||||
Considering how useful a Raspberry Pi is – it is an important task to choose the right operating system for it. Of course, you can do a lot of things with Linux but an OS specially configured for a specific purpose can save you considerable time and effort.
|
||||
|
||||
So, in this article, I will be mentioning some of the popular and useful operating systems tailored for Raspberry Pi.
|
||||
|
||||
### Installing any OS on Raspberry Pi is really easy thanks to the Raspberry Pi Imager tool
|
||||
|
||||
[Installing a Raspberry PI operating system on an SD card][3] is easier than ever before. You can simply get the [Raspberry Pi Imager][4] and get any Raspberry Pi OS installed quickly. Check the official video to see how easy it is.
|
||||
|
||||
You may also utilize [NOOBS][5] (New Out Of the Box Software) to easily install different operating systems on Raspberry Pi. You might also get a pre-installed SD card from the list of their supported retailers mentioned in their [official NOOBS download page][5].
|
||||
|
||||
Feel free to explore more about installing the operating systems in their [official documentation][6].
|
||||
|
||||
[Raspberry Pi OS Download][4]
|
||||
|
||||
Now that you know how to install it (and where to get it from), let me highlight a list of useful Raspberry Pi OS to help you out.
|
||||
|
||||
### Various operating systems for Raspberry Pi
|
||||
|
||||
Please keep in mind that I have taken some effort to list only those Raspberry Pi operating system projects that are being actively maintained. If a project gets discontinued in near future, let me know in the comment section and I’ll update this article.
|
||||
|
||||
Another thing is that I have focused on the latest Raspberry 4 but this should not be considered a list of Raspberry Pi 4 OS. You should be able to use it on Raspberry Pi 3, 3 B+ and other variants as well but please check the official project websites for the exact details.
|
||||
|
||||
**Note:** The list is in no particular order of ranking.
|
||||
|
||||
#### 1\. Raspbian OS: The official Raspberry Pi OS
|
||||
|
||||
![][7]
|
||||
|
||||
Raspbian is the officially supported OS for Raspberry Pi boards. It comes baked in with several tools for education, programming, and general use. Specifically, it includes Python, Scratch, Sonic Pi, Java, and several other important packages.
|
||||
|
||||
Originally, Raspbian is based on Debian and comes pre-installed with loads of useful packages. So, when you get this installed, you probably don’t need to install essentials separately – you should find almost everything pre-installed.
|
||||
|
||||
Raspbian OS is actively maintained and it is one of the most popular Raspberry Pi OS out there. You can install it using [NOOBS][5] or follow the [official documentation][6] to get it installed.
|
||||
|
||||
[Raspbian OS][8]
|
||||
|
||||
#### 2\. Ubuntu MATE: For general purpose computing
|
||||
|
||||
![][9]
|
||||
|
||||
Even though Raspbian is the officially supported OS, it does not feature the latest and greatest packages. So, if you want quicker updates and potentially latest packages, you can try Ubuntu MATE for Raspberry Pi.
|
||||
|
||||
Ubuntu MATE tailored as a Raspberry Pi OS is an incredibly lightweight distribution to have installed. It’s also popularly used on [NVIDIA’s Jetson Nano][10]. In other words, you can utilize it for several use-cases with the Raspberry Pi.
|
||||
|
||||
To help you out, we also have a detailed guide on [how to install Ubuntu MATE on Raspberry Pi][11].
|
||||
|
||||
[Ubuntu MATE for Raspberry Pi][12]
|
||||
|
||||
#### 3\. Ubuntu Server: To use it as a Linux server
|
||||
|
||||
![][13]
|
||||
|
||||
If you’re planning to use your Raspberry Pi as some sort of server for your project, Ubuntu Server can be a great choice to have installed.
|
||||
|
||||
You can find both 32-bit and 64-bit images of the OS. And, depending on what board you have (if it supports 64-bit), you can go ahead and install the same.
|
||||
|
||||
However, it is worth noting that Ubuntu Server isn’t tailored for desktop usage. So, you need to keep in mind that you will have no proper graphical user interface installed by default.
|
||||
|
||||
[Ubuntu Server][14]
|
||||
|
||||
#### 4\. LibreELEC: For media server
|
||||
|
||||
![][15]
|
||||
|
||||
While we already have a list of [media server software available for Linux][16], LibreELEC is one of them.
|
||||
|
||||
It’s a great lightweight OS system capable enough to have [KODI][17] on your Raspberry Pi. You can try installing it using the Raspberry Pi Imager.
|
||||
|
||||
You can easily head to their [official download webpage][18] and find a suitable installer image for your board.
|
||||
|
||||
[LibreELEC][19]
|
||||
|
||||
#### 5\. OSMC: For media server
|
||||
|
||||
![][20]
|
||||
|
||||
OSMC is yet another [popular media server software][16] for Linux. While considering the use of Raspberry Pi boards as media center devices, this is one of the best Raspberry Pi OS that you can recommend to someone.
|
||||
|
||||
Similar to LibreELEC, OSMC also runs KODI to help you manage your media files and enjoy watching the content you already have.
|
||||
|
||||
OSMC does not officially mention the support for **Raspberry Pi 4**. So, if you have Raspberry Pi 3 or lower, you should be good to go.
|
||||
|
||||
[OSMC][21]
|
||||
|
||||
#### 6\. RISC OS: The original ARM OS
|
||||
|
||||
![][22]
|
||||
|
||||
Originally crafted for ARM devices, RISC OS has been around for almost 30 years or so.
|
||||
|
||||
We also have a separate detailed article on [RISC OS][23], if you’re curious to know more about it. Long story short, RISC OS is also tailored for modern ARM-based single-board computers like the Raspberry Pi. It presents a simple user interface with a focus on performance.
|
||||
|
||||
Again, this is not something meant for the Raspberry Pi 4. So, only if you have a Raspberry Pi 3 or lower, you can give it a try.
|
||||
|
||||
[RISC OS][24]
|
||||
|
||||
#### 7\. Mozilla WebThings Gateway: For IoT projects
|
||||
|
||||
![][25]
|
||||
|
||||
As part of Mozilla’s [open-source implementation for IoT devices][26], WebThings Gateway lets you monitor and control all your connected IoT devices.
|
||||
|
||||
You can follow the [official documentation][27] to check the requirements and the instructions to get it installed on a Raspberry Pi. Definitely, one of the most useful Raspberry Pi OS for IoT applications.
|
||||
|
||||
[WebThings Gateway][28]
|
||||
|
||||
#### 8\. Ubuntu Core: For IoT projects
|
||||
|
||||
Yet another Raspberry Pi OS for potential [IoT][29] applications or just to simply test snaps – Ubuntu Core.
|
||||
|
||||
Ubuntu core is specifically tailored for IoT devices or specifically Raspberry Pi, here. I wouldn’t make any claims about it- but Ubuntu Core is a suitable secure OS for Raspberry Pi boards. You can give this a try for yourself!
|
||||
|
||||
[Ubuntu Core][30]
|
||||
|
||||
#### 9\. DietPi: Lightweight Raspberry Pi OS
|
||||
|
||||
![DietPi Screenshot via Distrowatch][31]
|
||||
|
||||
DietPi is a lightweight [Debian][32] operating system that also claims to be lighter than the “Raspbian Lite” OS.
|
||||
|
||||
While considering it as a lightweight Raspberry Pi OS, it offers a lot of features that could come in handy for several use-cases. Ranging from easy installers for software packages to a backup solution, there’s a lot to explore.
|
||||
|
||||
If you’re aiming to get an OS with a low footprint but potentially better performance, you could give this a try.
|
||||
|
||||
[DietPi][33]
|
||||
|
||||
#### 10\. Lakka Linux: Make a retro gaming console
|
||||
|
||||
![][34]
|
||||
|
||||
Looking for a way to turn your Raspberry Pi to a retro gaming console?
|
||||
|
||||
Lakka Linux distribution is originally built on the RetroArch emulator. So, you can have all your retro games on your Raspberry Pi in no time.
|
||||
|
||||
We also have a separate article on [Lakka Linux][35] – if you’re curious to know about it. Or else, just go right ahead and test it out!
|
||||
|
||||
[Lakka][36]
|
||||
|
||||
#### 11\. RetroPie: For retro gaming
|
||||
|
||||
![ ][37]
|
||||
|
||||
RetroPie is yet another popular Raspberry Pi OS that turns it into a retro gaming console. It features several configuration tools so that you can customize the theme or just tweak the emulator to have the best retro games.
|
||||
|
||||
It is worth noting that it does not include any copyrighted games. You can give it a try and see how it works!
|
||||
|
||||
[RetroPie][38]
|
||||
|
||||
#### 12\. Kali Linux: For hacking on budget
|
||||
|
||||
![][39]
|
||||
|
||||
Want to try and learn some ethical hacking skills on your Raspberry Pi? Kali Linux can be a perfect fit for it. And, yes, it usually supports the latest Raspberry Pi as soon as it launches.
|
||||
|
||||
Not just limited to Raspberry Pi, but you can get a long list of other supported devices as well. Try it out and have fun!
|
||||
|
||||
[Kali Linux][40]
|
||||
|
||||
#### 13\. OpenMediaVault: For Network Attached Storage (NAS)
|
||||
|
||||
![][41]
|
||||
|
||||
If you’re trying to set up a [NAS][42] (Network Attached Storage) solution on minimal hardware, Raspberry Pi can help.
|
||||
|
||||
Originally, based on Debian Linux, OpenMediaVault offers a bunch of features that include web-based administration capabilities, plugin support, and more. It does support most of the Raspberry Pi models – so you can try downloading it and get it installed!
|
||||
|
||||
[OpenMediaVault][43]
|
||||
|
||||
#### 14\. ROKOS: For crypto mining
|
||||
|
||||
![][44]
|
||||
|
||||
If you’re someone who’s interested in cryptocurrencies and bitcoins specifically, this could interest you.
|
||||
|
||||
ROKOS is a Debian-based OS that basically lets you turn your Raspberry Pi into a node while having pre-installed drivers and packages for the same. Of course, you need to know how it works before getting it installed. So, I suggest you do some research if you’re not sure what you’re doing.
|
||||
|
||||
[ROKOS][45]
|
||||
|
||||
#### 15\. Alpine Linux: Lightweight security-focused Linux
|
||||
|
||||
Nowadays, a lot of users are usually looking for security-focused and [privacy-focused distributions][46]. And, if you are one of them, you might as well try Alpine Linux for Raspberry Pi.
|
||||
|
||||
It may not be as user-friendly as you’d expect (or beginner-friendly) if you’re just getting started with Raspberry Pi. But, if you want something different to start with, you can try Alpine Linux, which is a security-focused Linux distribution.
|
||||
|
||||
[Alpine Linux][47]
|
||||
|
||||
#### 16\. Kano OS: Operating system for kids’education
|
||||
|
||||
![][48]
|
||||
|
||||
If you’re looking for an open-source OS for Raspberry Pi to make things interesting to learn and educate kids, Kano OS is a good choice.
|
||||
|
||||
It’s being actively maintained and the user experience for the desktop integration on Kano OS is quite simple and fun for someone to play and make kids learn from it.
|
||||
|
||||
[Kano OS][49]
|
||||
|
||||
#### 17\. KDE Plasma Bigscreen: To convert regular TVs into Smart TVs
|
||||
|
||||
![][50]
|
||||
|
||||
This is an under development project from KDE. With [KDE Plasma Bigscreen OS][51] installed on Raspberry Pi, you can use your regular TV like a smart TV.
|
||||
|
||||
You don’t need a special remote to control the TV. You can use the regular remote control.
|
||||
|
||||
Plasma Bigscreen also integrates [MyCroft open source AI][52] for voice control.
|
||||
|
||||
The project is in beta phase so expect some bugs and issues if you are willing to give it a try.
|
||||
|
||||
[Plasma Bigscreen][53]
|
||||
|
||||
#### Wrapping Up
|
||||
|
||||
I’m sure there are a lot of other operating systems tailored for Raspberry Pi – but I’ve tried to list the most popular or the useful ones that are actively maintained.
|
||||
|
||||
If you think I missed one of best suited Raspberry Pi OS, feel free to let me know about it in the comments below!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/raspberry-pi-os/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.raspberrypi.org/
|
||||
[2]: https://itsfoss.com/raspberry-pi-projects/
|
||||
[3]: https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/
|
||||
[4]: https://www.raspberrypi.org/downloads/
|
||||
[5]: https://www.raspberrypi.org/downloads/noobs/
|
||||
[6]: https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/raspbian_home_screen.jpg?resize=800%2C492&ssl=1
|
||||
[8]: https://www.raspbian.org/
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/Desktop-ubuntu.jpg?resize=800%2C600&ssl=1
|
||||
[10]: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-nano/
|
||||
[11]: https://itsfoss.com/ubuntu-mate-raspberry-pi/
|
||||
[12]: https://ubuntu-mate.org/raspberry-pi/
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/03/ubunt-server.png?ssl=1
|
||||
[14]: https://ubuntu.com/download/raspberry-pi
|
||||
[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/libreelec.jpg?resize=800%2C600&ssl=1
|
||||
[16]: https://itsfoss.com/best-linux-media-server/
|
||||
[17]: https://kodi.tv/
|
||||
[18]: https://libreelec.tv/downloads_new/
|
||||
[19]: https://libreelec.tv/
|
||||
[20]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/osmc-server.jpg?resize=800%2C450&ssl=1
|
||||
[21]: https://osmc.tv/
|
||||
[22]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/10/riscos5.1.jpg?resize=800%2C600&ssl=1
|
||||
[23]: https://itsfoss.com/risc-os-is-now-open-source/
|
||||
[24]: https://www.riscosopen.org/content/
|
||||
[25]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/03/web-things-gateway.png?ssl=1
|
||||
[26]: https://iot.mozilla.org/about/
|
||||
[27]: https://iot.mozilla.org/docs/gateway-getting-started-guide.html
|
||||
[28]: https://iot.mozilla.org/gateway/
|
||||
[29]: https://en.wikipedia.org/wiki/Internet_of_things
|
||||
[30]: https://ubuntu.com/download/raspberry-pi-core
|
||||
[31]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/03/diet-pi.jpg?ssl=1
|
||||
[32]: https://www.debian.org/
|
||||
[33]: https://dietpi.com/
|
||||
[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2016/08/lakkaos.jpg?resize=1024%2C640&ssl=1
|
||||
[35]: https://itsfoss.com/lakka-retrogaming-linux/
|
||||
[36]: http://www.lakka.tv/
|
||||
[37]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/03/retro-pie.png?ssl=1
|
||||
[38]: https://retropie.org.uk/
|
||||
[39]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/03/kali-linux-pi.png?ssl=1
|
||||
[40]: https://www.offensive-security.com/kali-linux-arm-images/
|
||||
[41]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/03/openmediavault.jpg?ssl=1
|
||||
[42]: https://en.wikipedia.org/wiki/Network-attached_storage
|
||||
[43]: https://www.openmediavault.org/
|
||||
[44]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/03/rocos-bitcoin-pi.jpg?ssl=1
|
||||
[45]: https://rokos.space/
|
||||
[46]: https://itsfoss.com/privacy-focused-linux-distributions/
|
||||
[47]: https://alpinelinux.org/
|
||||
[48]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/03/kano-os-pi.jpeg?ssl=1
|
||||
[49]: https://kano.me/row/downloadable
|
||||
[50]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/03/plasma-bigscreen-menu.jpg?ssl=1
|
||||
[51]: https://itsfoss.com/kde-plasma-bigscreen/
|
||||
[52]: https://itsfoss.com/mycroft-mark-2/
|
||||
[53]: https://plasma-bigscreen.org/#download-jumpto
|
||||
@ -1,94 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (tinyeyeser )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to avoid man-in-the-middle cyber attacks)
|
||||
[#]: via: (https://opensource.com/article/20/4/mitm-attacks)
|
||||
[#]: author: (Jackie Lam https://opensource.com/users/beenverified)
|
||||
|
||||
How to avoid man-in-the-middle cyber attacks
|
||||
======
|
||||
Understanding MITM attacks is the first step in not being a victim of
|
||||
this high-tech style of eavesdropping.
|
||||
![Security monster][1]
|
||||
|
||||
Whether you're sending data on your computer or talking to someone online, you want to assume some level of security and privacy.
|
||||
|
||||
But what if a third party is eavesdropping online, unbeknownst to you? And worse, what if they're impersonating someone from a business you trust in order to gain damaging information? This could put your personal data into the hands of dangerous, would-be thieves.
|
||||
|
||||
Welcome to what's called a man-in-the-middle (MITM) attack.
|
||||
|
||||
### What are man-in-the-middle attacks?
|
||||
|
||||
A man-in-the-middle attack occurs when a cybercriminal inserts themselves into communications between you, the targeted victim, and a device in order to steal sensitive information that can be used for a variety of criminal purposes—most notably identity theft, says Steve J. J. Weisman, founder of Scamicide.
|
||||
|
||||
"A man-in-the-middle-attack can also occur when the victim believes he or she is communicating with a legitimate app or website," says Weisman, "when the truth is that the victim is communicating with a phony website or app and thereby providing sensitive information to the criminal."
|
||||
|
||||
One of the oldest forms of cyberattacks, MITM attacks have been around since the 1980s. What's more, they're quite common. As Weisman explains, there are a handful of ways a MITM attack can happen:
|
||||
|
||||
* **Attacking a WiFi router that is not properly secured:** This typically occurs when someone is using public WiFi. "While home routers might be vulnerable, it's more common for criminals to attack public WiFi networks," says Weisman. The goal is to spy on unsuspecting people who are handling sensitive information, such as their online bank accounts, he adds.
|
||||
* **Hacking email accounts of banks, financial advisers, and other companies:** "Once [the criminals] have hacked these email systems, they send out emails that appear to come from the legitimate bank or other company," Weisman says. "[They ask] for personal information, such as usernames and passwords, under the guise of an emergency. The targeted victim is lured into providing that information."
|
||||
* **Sending phishing emails:** Thieves might also send emails pretending to be legitimate companies that the targeted victim does business with, asking the recipient for their personal information. "In many instances, the spear-phishing emails will direct the victim to a counterfeit website that appears to be that of a legitimate company with which the victim does business," says Weisman.
|
||||
* **Using malicious code in legitimate websites:** Attackers can also place malicious code—usually JavaScript—into a legitimate website by way of a web application. "When the victim loads the legitimate page, the malicious code just sits in the background until the user enters sensitive information, such as account login or credit card details, which the malicious code then copies and sends to the attackers' servers," says Nicholas McBride, a cybersecurity consultant.
|
||||
|
||||
|
||||
|
||||
### What is an example of an MITM attack?
|
||||
|
||||
The Lenovo case is a well-known example of an MITM attack. In 2014 and 2015, the major computer manufacturer sold consumer laptops with preinstalled software that meddled with how a user's browser communicated with websites. Whenever the user's cursor hovered over a product, this software, called VisualDiscovery, sent pop-up ads from retail partners that sold similar products.
|
||||
|
||||
Here's the kicker: This MITM attack allowed VisualDiscovery to access all of the user's personal data, including social security numbers, info about financial transactions, medical info, and logins and passwords. All without the user knowing or granting permission beforehand. The FTC deemed this a deceptive and unfair online scam. Lenovo agreed to pay $8.3 million in a class-action settlement in 2019.
|
||||
|
||||
### How can I protect myself from an online attack?
|
||||
|
||||
* **Avoid using public WiFi:** Weisman recommends never using public WiFi for financial transactions unless you've installed a reliable virtual private network (VPN) client on your device and have a VPN host you can use and trust. Over a VPN connection, your communications are encrypted, so your information can't be stolen.
|
||||
|
||||
* **Be on the lookout:** Be wary of emails or text messages that ask you to update your password or provide your username or personal information. These methods can be used to steal your identity.
|
||||
|
||||
If you are unsure of the actual identity of the party sending you the email, you can use tools such as a reverse phone or email search. With a reverse phone number lookup, you may be able to find out more about the identity of an unknown texter. And with a reverse email lookup, you can try to determine who might have sent you a message.
|
||||
|
||||
Generally, if something's actually a problem, you'll hear from someone you know and trust within your company, or from someone you can also go and meet, in person, at your bank or school or other organization. Important account information is never the purview of an unknown technician.
|
||||
|
||||
* **Don't click on links contained in emails:** If someone sends you an email telling you that you need to sign into an account, don't click on the link provided in the email. Instead, navigate to the site yourself, log in as you normally would, and look for an alert there. If you don't see an alert message in your account settings, contact a representative by phone using contact information on the site and _not_ from the email.
|
||||
|
||||
* **Install reliable security software:** If you're on Windows, install good open source antivirus like [ClamAV][2]. On all platforms, keep your software up to date with the latest security patches.
|
||||
|
||||
* **Take alerts seriously:** If you're visiting a site that starts with HTTPS, your browser might alert you to an issue, says McBride. For instance, if the domain name on the site's certificate doesn't match the one you're trying to visit. Don't ignore the alert. Heed it and navigate away from the site for now. Verify that you haven't [mistyped it][3], and if the problem persists, contact the site owner if you can.
|
||||
|
||||
* **Use an ad blocker:** Pop-up ads (also known as _adware attacks_) can be used to intercept your personal information, so use an ad blocker. "The truth is, as an individual user, it's hard to protect against a MITM attack," says McBride, "as it is designed to leave the victim in the dark and to prevent them from noticing that there is anything wrong."
|
||||
|
||||
A good open source ad blocker (or "wide-spectrum blocker," in the developer's words) is [uBlock origin][4]. It's available for both Firefox and Chromium (and all Chromium-based browsers, such as Chrome, Brave, Vivaldi, Edge, and so on), and even Safari.
|
||||
|
||||
|
||||
|
||||
|
||||
### Stay alert
|
||||
|
||||
Remember, you don't have to click anything online right away, and you don't have to follow random people's instructions, no matter how urgent they may seem. The internet will still be there after you step away from the computer and verify the identity of a person or site demanding your attention.
|
||||
|
||||
While MITM attacks can happen to anyone, understanding what they are, knowing how they happen, and actively taking steps to prevent them can safeguard you from being a victim.
|
||||
|
||||
* * *
|
||||
|
||||
_This article was originally published on [BeenVerified.com][5] under a [CC BY-SA 2.0][6] license._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/mitm-attacks
|
||||
|
||||
作者:[Jackie Lam][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/beenverified
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/security_password_chaos_engineer_monster.png?itok=J31aRccu (Security monster)
|
||||
[2]: https://www.clamav.net
|
||||
[3]: https://opensource.com/article/20/1/stop-typosquatting-attacks
|
||||
[4]: https://github.com/gorhill/uBlock
|
||||
[5]: https://www.beenverified.com/crime/what-is-a-man-in-the-middle-attack/
|
||||
[6]: https://creativecommons.org/licenses/by-sa/2.0/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (CrazyShipOne)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,166 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LazyWolfLin)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How I containerize a build system)
|
||||
[#]: via: (https://opensource.com/article/20/4/how-containerize-build-system)
|
||||
[#]: author: (Ravi Chandran https://opensource.com/users/ravichandran)
|
||||
|
||||
How I containerize a build system
|
||||
======
|
||||
Building a repeatable structure to deliver applications as containers
|
||||
can be complicated. Here is one way to do it effectively.
|
||||
![Containers on a ship on the ocean][1]
|
||||
|
||||
A build system is comprised of the tools and processes used to transition from source code to a running application. This transition also involves changing the code's audience from the software developer to the end user, whether the end user is a colleague in operations or a deployment system.
|
||||
|
||||
After creating a few build systems using containers, I think I have a decent, repeatable approach that's worth sharing. These build systems were used for generating loadable software images for embedded hardware and compiling machine learning algorithms, but the approach is abstract enough to be used in any container-based build system.
|
||||
|
||||
This approach is about creating or organizing the build system in a way that makes it easy to use and maintain. It's not about the tricks needed to deal with containerizing any particular software compilers or tools. It applies to the common use case of software developers building software to hand off a maintainable image to other technical users (whether they are sysadmins, DevOps engineers, or some other title). The build system is abstracted away from the end users so that they can focus on the software.
|
||||
|
||||
### Why containerize a build system?
|
||||
|
||||
Creating a repeatable, container-based build system can provide a number of benefits to a software team:
|
||||
|
||||
* **Focus:** I want to focus on writing my application. When I call a tool to "build," I want the toolset to deliver a ready-to-use binary. I don't want to spend time troubleshooting the build system. In fact, I'd rather not know or care about the build system.
|
||||
* **Identical build behavior:** Whatever the use case, I want to ensure that the entire team uses the same versions of the toolset and gets the same results when building. Otherwise, I am constantly dealing with the case of "it works on my PC but not yours." Using the same toolset version and getting identical output for a given input source file set is critical in a team project.
|
||||
* **Easy setup and future migration:** Even if a detailed set of instructions is given to everyone to install a toolset for a project, chances are someone will get it wrong. Or there could be issues due to how each person has customized their Linux environment. This can be further compounded by the use of different Linux distributions across the team (or other operating systems). The issues can get uglier quickly when it comes time for moving to the next version of the toolset. Using containers and the guidelines in this article will make migration to newer versions much easier.
|
||||
|
||||
|
||||
|
||||
Containerizing the build systems that I use on my projects has certainly been valuable in my experience, as it has alleviated the problems above. I tend to use Docker for my container tooling, but there can still be issues due to the installation and network configuration being unique environment to environment, especially if you work in a corporate environment involving some complex proxy settings. But at least now I have fewer build system problems to deal with.
|
||||
|
||||
### Walking through a containerized build system
|
||||
|
||||
I created a [tutorial repository][2] you can clone and examine at a later time or follow along through this article. I'll be walking through all the files in the repository. The build system is deliberately trivial (it runs **gcc**) to keep the focus on the build system architecture.
|
||||
|
||||
### Build system requirements
|
||||
|
||||
Two key aspects that I think are desirable in a build system are:
|
||||
|
||||
* **Standard build invocation:** I want to be able to build code by pointing to some work directory whose path is **/path/to/workdir**. I want to invoke the build as: [code]`./build.sh /path/to/workdir`[/code] To keep the example architecture simple (for the sake of explanation), I'll assume that the output is also generated somewhere within **/path/to/workdir**. (Otherwise, it would increase the number of volumes exposed to the container, which is not difficult, but more cumbersome to explain.)
|
||||
* **Custom build invocation via shell:** Sometimes, the toolset needs to be used in unforeseen ways. In addition to the standard **build.sh** to invoke the toolset, some of these could be added as options to **build.sh**, if needed. But I always want to be able to get to a shell where I can invoke toolset commands directly. In this trivial example, say I sometimes want to try out different **gcc** optimization options to see the effects. To achieve this, I want to invoke: [code]`./shell.sh /path/to/workdir`[/code] This should get me to a Bash shell inside the container with access to the toolset and to my **workdir**, so I can experiment as I please with the toolset.
|
||||
|
||||
|
||||
|
||||
### Build system architecture
|
||||
|
||||
To comply with the basic requirements above, here is how I architect the build system:
|
||||
|
||||
![Container build system architecture][3]
|
||||
|
||||
At the bottom, the **workdir** represents any software source code that needs to be built by the software developer end users. Typically, this **workdir** will be a source-code repository. The end users can manipulate this source code repository in any way they want before invoking a build. For example, if they're using **git** for version control, they could **git checkout** the feature branch they are working on and add or modify files. This keeps the build system independent of the **workdir**.
|
||||
|
||||
The three blocks at the top collectively represent the containerized build system. The left-most (yellow) block at the top represents the scripts (**build.sh** and **shell.sh**) that the end user will use to interact with the build system.
|
||||
|
||||
In the middle (the red block) is the Dockerfile and the associated script **build_docker_image.sh**. The development operations people (me, in this case) will typically execute this script and generate the container image. (In fact, I'll execute this many, many times until I get everything working right, but that's another story.) And then I would distribute the image to the end users, such as through a container trusted registry. The end users will need this image. In addition, they will clone the build system repository (i.e., one that is equivalent to the [tutorial repository][2]).
|
||||
|
||||
The **run_build.sh** script on the right is executed inside the container when the end user invokes either **build.sh** or **shell.sh**. I'll explain these scripts in detail next. The key here is that the end user does not need to know anything about the red or blue blocks or how a container works in order to use any of this.
|
||||
|
||||
### Build system details
|
||||
|
||||
The tutorial repository's file structure maps to this architecture. I've used this prototype structure for relatively complex build systems, so its simplicity is not a limitation in any way. Below, I've listed the tree structure of the relevant files from the repository. The **dockerize-tutorial** folder could be replaced with any other name corresponding to a build system. From within this folder, I invoke either **build.sh** or **shell.sh** with the one argument that is the path to the **workdir**.
|
||||
|
||||
|
||||
```
|
||||
dockerize-tutorial/
|
||||
├── build.sh
|
||||
├── shell.sh
|
||||
└── swbuilder
|
||||
├── build_docker_image.sh
|
||||
├── install_swbuilder.dockerfile
|
||||
└── scripts
|
||||
└── run_build.sh
|
||||
```
|
||||
|
||||
Note that I've deliberately excluded the **example_workdir** above, which you'll find in the tutorial repository. Actual source code would typically reside in a separate repository and not be part of the build tool repository; I included it in this repository, so I didn't have to deal with two repositories in the tutorial.
|
||||
|
||||
Doing the tutorial is not necessary if you're only interested in the concepts, as I'll explain all the files. But if you want to follow along (and have Docker installed), first build the container image **swbuilder:v1** with:
|
||||
|
||||
|
||||
```
|
||||
cd dockerize-tutorial/swbuilder/
|
||||
./build_docker_image.sh
|
||||
docker image ls # resulting image will be swbuilder:v1
|
||||
```
|
||||
|
||||
Then invoke **build.sh** as:
|
||||
|
||||
|
||||
```
|
||||
cd dockerize-tutorial
|
||||
./build.sh ~/repos/dockerize-tutorial/example_workdir
|
||||
```
|
||||
|
||||
The code for [build.sh][4] is below. This script instantiates a container from the container image **swbuilder:v1**. It performs two volume mappings: one from the **example_workdir** folder to a volume inside the container at path **/workdir**, and the second from **dockerize-tutorial/swbuilder/scripts** outside the container to **/scripts** inside the container.
|
||||
|
||||
|
||||
```
|
||||
docker container run \
|
||||
--volume $(pwd)/swbuilder/scripts:/scripts \
|
||||
--volume $1:/workdir \
|
||||
--user $(id -u ${USER}):$(id -g ${USER}) \
|
||||
--rm -it --name build_swbuilder swbuilder:v1 \
|
||||
build
|
||||
```
|
||||
|
||||
In addition, the **build.sh** also invokes the container to run with your username (and group, which the tutorial assumes to be the same) so that you will not have issues with file permissions when accessing the generated build output.
|
||||
|
||||
Note that [**shell.sh**][5] is identical except for two things: **build.sh** creates a container named **build_swbuilder** while **shell.sh** creates one named **shell_swbuilder**. This is so that there are no conflicts if either script is invoked while the other one is running.
|
||||
|
||||
The other key difference between the two scripts is the last argument: **build.sh** passes in the argument **build** while **shell.sh** passes in the argument **shell**. If you look at the [Dockerfile][6] that is used to create the container image, the last line contains the following **ENTRYPOINT**. This means that the **docker container run** invocation above will result in executing the **run_build.sh** script with either **build** or **shell** as the sole input argument.
|
||||
|
||||
|
||||
```
|
||||
# run bash script and process the input command
|
||||
ENTRYPOINT [ "/bin/bash", "/scripts/run_build.sh"]
|
||||
```
|
||||
|
||||
[**run_build.sh**][7] uses this input argument to either start the Bash shell or invoke **gcc** to perform the build of the trivial **helloworld.c** project. A real build system would typically invoke a Makefile and not run **gcc** directly.
|
||||
|
||||
|
||||
```
|
||||
cd /workdir
|
||||
|
||||
if [ $1 = "shell" ]; then
|
||||
echo "Starting Bash Shell"
|
||||
/bin/bash
|
||||
elif [ $1 = "build" ]; then
|
||||
echo "Performing SW Build"
|
||||
gcc helloworld.c -o helloworld -Wall
|
||||
fi
|
||||
```
|
||||
|
||||
You could certainly pass more than one argument if your use case demands it. For the build systems I've dealt with, the build is usually for a given project with a specific **make** invocation. In the case of a build system where the build invocation is complex, you can have **run_build.sh** call a specific script inside **workdir** that the end user has to write.
|
||||
|
||||
### A note about the scripts folder
|
||||
|
||||
You may be wondering why the **scripts** folder is located deep in the tree structure rather than at the top level of the repository. Either approach would work, but I didn't want to encourage the end user to poke around and change things there. Placing it deeper is a way to make it more difficult to poke around. Also, I could have added a **.dockerignore** file to ignore the **scripts** folder, as it doesn't need to be part of the container context. But since it's tiny, I didn't bother.
|
||||
|
||||
### Simple yet flexible
|
||||
|
||||
While the approach is simple, I've used it for a few rather different build systems and found it to be quite flexible. The aspects that are going to be relatively stable (e.g., a given toolset that changes only a few times a year) are fixed inside the container image. The aspects that are more fluid are kept outside the container image as scripts. This allows me to easily modify how the toolset is invoked by updating the script and pushing the changes to the build system repository. All the user needs to do is to pull the changes to their local build system repository, which is typically quite fast (unlike updating a Docker image). The structure lends itself to having as many volumes and scripts as are needed while abstracting the complexity away from the end user.
|
||||
|
||||
How will you need to modify your application to optimize it for a containerized environment?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/how-containerize-build-system
|
||||
|
||||
作者:[Ravi Chandran][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ravichandran
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/containers_2015-3-osdc-lead.png?itok=O6aivM_W (Containers on a ship on the ocean)
|
||||
[2]: https://github.com/ravi-chandran/dockerize-tutorial
|
||||
[3]: https://opensource.com/sites/default/files/uploads/build_sys_arch.jpg (Container build system architecture)
|
||||
[4]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/build.sh
|
||||
[5]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/shell.sh
|
||||
[6]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/swbuilder/install_swbuilder.dockerfile
|
||||
[7]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/swbuilder/scripts/run_build.sh
|
||||
@ -1,328 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (messon007)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Learning to love systemd)
|
||||
[#]: via: (https://opensource.com/article/20/4/systemd)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
Learning to love systemd
|
||||
======
|
||||
systemd is the mother of all processes, responsible for bringing the
|
||||
Linux host up to a state where productive work can be done.
|
||||
![Penguin driving a car with a yellow background][1]
|
||||
|
||||
systemd—yes, all lower-case, even at the beginning of a sentence—is the modern replacement for init and SystemV init scripts. It is also much more.
|
||||
|
||||
Like most sysadmins, when I think of the init program and SystemV, I think of Linux startup and shutdown and not really much else, like managing services once they are up and running. Like init, systemd is the mother of all processes, and it is responsible for bringing the Linux host up to a state in which productive work can be done. Some of the functions assumed by systemd, which is far more extensive than the old init program, are to manage many aspects of a running Linux host, including mounting filesystems, managing hardware, handling timers, and starting and managing the system services that are required to have a productive Linux host.
|
||||
|
||||
This series of articles, which is based in part on excerpts from my three-volume Linux training course, [_Using and administering Linux: zero to sysadmin_][2], explores systemd's functions both at startup and beginning after startup finishes.
|
||||
|
||||
### Linux boot
|
||||
|
||||
The complete process that takes a Linux host from an off state to a running state is complex, but it is open and knowable. Before getting into the details, I'll give a quick overview from when the host hardware is turned on until the system is ready for a user to log in. Most of the time, "the boot process" is discussed as a single entity, but that is not accurate. There are, in fact, three major parts to the full boot and startup process:
|
||||
|
||||
* **Hardware boot:** Initializes the system hardware
|
||||
* **Linux boot:** Loads the Linux kernel and then systemd
|
||||
* **Linux startup:** Where systemd prepares the host for productive work
|
||||
|
||||
|
||||
|
||||
The Linux startup sequence begins after the kernel has loaded either init or systemd, depending upon whether the distribution uses the old or new startup, respectively. The init and systemd programs start and manage all the other processes and are both known as the "mother of all processes" on their respective systems.
|
||||
|
||||
It is important to separate the hardware boot from the Linux boot from the Linux startup and to explicitly define the demarcation points between them. Understanding these differences and what part each plays in getting a Linux system to a state where it can be productive makes it possible to manage these processes and better determine where a problem is occurring during what most people refer to as "boot."
|
||||
|
||||
The startup process follows the three-step boot process and brings the Linux computer up to an operational state in which it is usable for productive work. The startup process begins when the kernel transfers control of the host to systemd.
|
||||
|
||||
### systemd controversy
|
||||
|
||||
systemd can evoke a wide range of reactions from sysadmins and others responsible for keeping Linux systems up and running. The fact that systemd is taking over so many tasks in many Linux systems has engendered pushback and discord among certain groups of developers and sysadmins.
|
||||
|
||||
SystemV and systemd are two different methods of performing the Linux startup sequence. SystemV start scripts and the init program are the old methods, and systemd using targets is the new method. Although most modern Linux distributions use the newer systemd for startup, shutdown, and process management, there are still some that do not. One reason is that some distribution maintainers and some sysadmins prefer the older SystemV method over the newer systemd.
|
||||
|
||||
I think both have advantages.
|
||||
|
||||
#### Why I prefer SystemV
|
||||
|
||||
I prefer SystemV because it is more open. Startup is accomplished using Bash scripts. After the kernel starts the init program, which is a compiled binary, init launches the **rc.sysinit** script, which performs many system initialization tasks. After **rc.sysinit** completes, init launches the **/etc/rc.d/rc** script, which in turn starts the various services defined by the SystemV start scripts in the **/etc/rc.d/rcX.d**, where "X" is the number of the runlevel being started.
|
||||
|
||||
Except for the init program itself, all these programs are open and easily knowable scripts. It is possible to read through these scripts and learn exactly what is taking place during the entire startup process, but I don't think many sysadmins actually do that. Each start script is numbered so that it starts its intended service in a specific sequence. Services are started serially, and only one service starts at a time.
|
||||
|
||||
systemd, developed by Red Hat's Lennart Poettering and Kay Sievers, is a complex system of large, compiled binary executables that are not understandable without access to the source code. It is open source, so "access to the source code" isn't hard, just less convenient. systemd appears to represent a significant refutation of multiple tenets of the Linux philosophy. As a binary, systemd is not directly open for the sysadmin to view or make easy changes. systemd tries to do everything, such as managing running services, while providing significantly more status information than SystemV. It also manages hardware, processes, and groups of processes, filesystem mounts, and much more. systemd is present in almost every aspect of the modern Linux host, making it the one-stop tool for system management. All of this is a clear violation of the tenets that programs should be small and that each program should do one thing and do it well.
|
||||
|
||||
#### Why I prefer systemd
|
||||
|
||||
I prefer systemd as my startup mechanism because it starts as many services as possible in parallel, depending upon the current stage in the startup process. This speeds the overall startup and gets the host system to a login screen faster than SystemV.
|
||||
|
||||
systemd manages almost every aspect of a running Linux system. It can manage running services while providing significantly more status information than SystemV. It also manages hardware, processes and groups of processes, filesystem mounts, and much more. systemd is present in almost every aspect of the modern Linux operating system, making it the one-stop tool for system management. (Does this sound familiar?)
|
||||
|
||||
The systemd tools are compiled binaries, but the tool suite is open because all the configuration files are ASCII text files. Startup configuration can be modified through various GUI and command-line tools, as well as adding or modifying various configuration files to suit the needs of the specific local computing environment.
|
||||
|
||||
#### The real issue
|
||||
|
||||
Did you think I could not like both startup systems? I do, and I can work with either one.
|
||||
|
||||
In my opinion, the real issue and the root cause of most of the controversy between SystemV and systemd is that there is [no choice][3] on the sysadmin level. The choice of whether to use SystemV or systemd has already been made by the developers, maintainers, and packagers of the various distributions—but with good reason. Scooping out and replacing an init system, by its extreme, invasive nature, has a lot of consequences that would be hard to tackle outside the distribution design process.
|
||||
|
||||
Despite the fact that this choice is made for me, my Linux hosts boot up and work, which is what I usually care the most about. As an end user and even as a sysadmin, my primary concern is whether I can get my work done, work such as writing my books and this article, installing updates, and writing scripts to automate everything. So long as I can do my work, I don't really care about the start sequence used on my distro.
|
||||
|
||||
I do care when there is a problem during startup or service management. Regardless of which startup system is used on a host, I know enough to follow the sequence of events to find the failure and fix it.
|
||||
|
||||
#### Replacing SystemV
|
||||
|
||||
There have been previous attempts at replacing SystemV with something a bit more modern. For about two releases, Fedora used a thing called Upstart to replace the aging SystemV, but it did not replace init and provided no changes that I noticed. Because Upstart provided no significant changes to the issues surrounding SystemV, efforts in this direction were quickly dropped in favor of systemd.
|
||||
|
||||
Despite the fact that most Linux developers agree that replacing the old SystemV startup is a good idea, many developers and sysadmins dislike systemd for that. Rather than rehash all the so-called issues that people have—or had—with systemd, I will refer you to two good, if somewhat old, articles that should cover most everything. Linus Torvalds, the creator of the Linux kernel, seems disinterested. In a 2014 ZDNet article, _[Linus Torvalds and others on Linux's systemd][4]_, Linus is clear about his feelings.
|
||||
|
||||
> "I don't actually have any particularly strong opinions on systemd itself. I've had issues with some of the core developers that I think are much too cavalier about bugs and compatibility, and I think some of the design details are insane (I dislike the binary logs, for example), but those are details, not big issues."
|
||||
|
||||
In case you don't know much about Linus, I can tell you that if he does not like something, he is very outspoken, explicit, and quite clear about that dislike. He has become more socially acceptable in his manner of addressing his dislike about things.
|
||||
|
||||
In 2013, Poettering wrote a long blog post in which he debunks the [myths about systemd][5] while providing insight into some of the reasons for creating it. This is a very good read, and I highly recommend it.
|
||||
|
||||
### systemd tasks
|
||||
|
||||
Depending upon the options used during the compile process (which are not considered in this series), systemd can have as many as 69 binary executables that perform the following tasks, among others:
|
||||
|
||||
* The systemd program runs as PID 1 and provides system startup of as many services in parallel as possible, which, as a side effect, speeds overall startup times. It also manages the shutdown sequence.
|
||||
* The systemctl program provides a user interface for service management.
|
||||
* Support for SystemV and LSB start scripts is offered for backward compatibility.
|
||||
* Service management and reporting provide more service status data than SystemV.
|
||||
* It includes tools for basic system configuration, such as hostname, date, locale, lists of logged-in users, running containers and virtual machines, system accounts, runtime directories and settings, daemons to manage simple network configuration, network time synchronization, log forwarding, and name resolution.
|
||||
* It offers socket management.
|
||||
* systemd timers provide advanced cron-like capabilities to include running a script at times relative to system boot, systemd startup, the last time the timer was started, and more.
|
||||
* It provides a tool to analyze dates and times used in timer specifications.
|
||||
* Mounting and unmounting of filesystems with hierarchical awareness allows safer cascading of mounted filesystems.
|
||||
* It enables the positive creation and management of temporary files, including deletion.
|
||||
* An interface to D-Bus provides the ability to run scripts when devices are plugged in or removed. This allows all devices, whether pluggable or not, to be treated as plug-and-play, which considerably simplifies device handling.
|
||||
* Its tool to analyze the startup sequence can be used to locate the services that take the most time.
|
||||
* It includes journals for storing system log messages and tools for managing the journals.
|
||||
|
||||
|
||||
|
||||
### Architecture
|
||||
|
||||
Those tasks and more are supported by a number of daemons, control programs, and configuration files. Figure 1 shows many of the components that belong to systemd. This is a simplified diagram designed to provide a high-level overview, so it does not include all of the individual programs or files. Nor does it provide any insight into data flow, which is so complex that it would be a useless exercise in the context of this series of articles.
|
||||
|
||||
![systemd architecture][6]
|
||||
|
||||
A full exposition of systemd would take a book on its own. You do not need to understand the details of how the systemd components in Figure 1 fit together; it's enough to know about the programs and components that enable managing various Linux services and deal with log files and journals. But it's clear that systemd is not the monolithic monstrosity it is purported to be by some of its critics.
|
||||
|
||||
### systemd as PID 1
|
||||
|
||||
systemd is PID 1. Some of its functions, which are far more extensive than the old SystemV3 init program, are to manage many aspects of a running Linux host, including mounting filesystems and starting and managing system services required to have a productive Linux host. Any of systemd's tasks that are not related to the startup sequence are outside the scope of this article (but some will be explored later in this series).
|
||||
|
||||
First, systemd mounts the filesystems defined by **/etc/fstab**, including any swap files or partitions. At this point, it can access the configuration files located in **/etc**, including its own. It uses its configuration link, **/etc/systemd/system/default.target**, to determine which state or target it should boot the host into. The **default.target** file is a symbolic link to the true target file. For a desktop workstation, this is typically going to be the **graphical.target**, which is equivalent to runlevel 5 in SystemV. For a server, the default is more likely to be the **multi-user.target**, which is like runlevel 3 in SystemV. The **emergency.target** is similar to single-user mode. Targets and services are systemd units.
|
||||
|
||||
The table below (Figure 2) compares the systemd targets with the old SystemV startup runlevels. systemd provides the systemd target aliases for backward compatibility. The target aliases allow scripts—and many sysadmins—to use SystemV commands like **init 3** to change runlevels. Of course, the SystemV commands are forwarded to systemd for interpretation and execution.
|
||||
|
||||
**systemd targets** | **SystemV runlevel** | **target aliases** | **Description**
|
||||
---|---|---|---
|
||||
default.target | | | This target is always aliased with a symbolic link to either **multi-user.target** or **graphical.target**. systemd always uses the **default.target** to start the system. The **default.target** should never be aliased to **halt.target**, **poweroff.target**, or **reboot.target**.
|
||||
graphical.target | 5 | runlevel5.target | **Multi-user.target** with a GUI
|
||||
| 4 | runlevel4.target | Unused. Runlevel 4 was identical to runlevel 3 in the SystemV world. This target could be created and customized to start local services without changing the default **multi-user.target**.
|
||||
multi-user.target | 3 | runlevel3.target | All services running, but command-line interface (CLI) only
|
||||
| 2 | runlevel2.target | Multi-user, without NFS, but all other non-GUI services running
|
||||
rescue.target | 1 | runlevel1.target | A basic system, including mounting the filesystems with only the most basic services running and a rescue shell on the main console
|
||||
emergency.target | S | | Single-user mode—no services are running; filesystems are not mounted. This is the most basic level of operation with only an emergency shell running on the main console for the user to interact with the system.
|
||||
halt.target | | | Halts the system without powering it down
|
||||
reboot.target | 6 | runlevel6.target | Reboot
|
||||
poweroff.target | 0 | runlevel0.target | Halts the system and turns the power off
|
||||
|
||||
Each target has a set of dependencies described in its configuration file. systemd starts the required dependencies, which are the services required to run the Linux host at a specific level of functionality. When all the dependencies listed in the target configuration files are loaded and running, the system is running at that target level. In Figure 2, the targets with the most functionality are at the top of the table, with functionality declining towards the bottom of the table.
|
||||
|
||||
systemd also looks at the legacy SystemV init directories to see if any startup files exist there. If so, systemd uses them as configuration files to start the services described by the files. The deprecated network service is a good example of one that still uses SystemV startup files in Fedora.
|
||||
|
||||
Figure 3 (below) is copied directly from the bootup man page. It shows a map of the general sequence of events during systemd startup and the basic ordering requirements to ensure a successful startup.
|
||||
|
||||
|
||||
```
|
||||
cryptsetup-pre.target
|
||||
|
|
||||
(various low-level v
|
||||
API VFS mounts: (various cryptsetup devices...)
|
||||
mqueue, configfs, | |
|
||||
debugfs, ...) v |
|
||||
| cryptsetup.target |
|
||||
| (various swap | | remote-fs-pre.target
|
||||
| devices...) | | | |
|
||||
| | | | | v
|
||||
| v local-fs-pre.target | | | (network file systems)
|
||||
| swap.target | | v v |
|
||||
| | v | remote-cryptsetup.target |
|
||||
| | (various low-level (various mounts and | | |
|
||||
| | services: udevd, fsck services...) | | remote-fs.target
|
||||
| | tmpfiles, random | | | /
|
||||
| | seed, sysctl, ...) v | | /
|
||||
| | | local-fs.target | | /
|
||||
| | | | | | /
|
||||
\\____|______|_______________ ______|___________/ | /
|
||||
\ / | /
|
||||
v | /
|
||||
sysinit.target | /
|
||||
| | /
|
||||
______________________/|\\_____________________ | /
|
||||
/ | | | \ | /
|
||||
| | | | | | /
|
||||
v v | v | | /
|
||||
(various (various | (various | |/
|
||||
timers...) paths...) | sockets...) | |
|
||||
| | | | | |
|
||||
v v | v | |
|
||||
timers.target paths.target | sockets.target | |
|
||||
| | | | v |
|
||||
v \\_______ | _____/ rescue.service |
|
||||
\|/ | |
|
||||
v v |
|
||||
basic.target rescue.target |
|
||||
| |
|
||||
________v____________________ |
|
||||
/ | \ |
|
||||
| | | |
|
||||
v v v |
|
||||
display- (various system (various system |
|
||||
manager.service services services) |
|
||||
| required for | |
|
||||
| graphical UIs) v v
|
||||
| | multi-user.target
|
||||
emergency.service | | |
|
||||
| \\_____________ | _____________/
|
||||
v \|/
|
||||
emergency.target v
|
||||
graphical.target
|
||||
```
|
||||
|
||||
The **sysinit.target** and **basic.target** targets can be considered checkpoints in the startup process. Although one of systemd's design goals is to start system services in parallel, certain services and functional targets must be started before other services and targets can start. These checkpoints cannot be passed until all of the services and targets required by that checkpoint are fulfilled.
|
||||
|
||||
The **sysinit.target** is reached when all of the units it depends on are completed. All of those units, mounting filesystems, setting up swap files, starting udev, setting the random generator seed, initiating low-level services, and setting up cryptographic services (if one or more filesystems are encrypted), must be completed but, within the **sysinit.target**, those tasks can be performed in parallel.
|
||||
|
||||
The **sysinit.target** starts up all of the low-level services and units required for the system to be marginally functional and that are required to enable moving onto the **basic.target**.
|
||||
|
||||
After the **sysinit.target** is fulfilled, systemd then starts all the units required to fulfill the next target. The basic target provides some additional functionality by starting units that are required for all of the next targets. These include setting up things like paths to various executable directories, communication sockets, and timers.
|
||||
|
||||
Finally, the user-level targets, **multi-user.target** or **graphical.target**, can be initialized. The **multi-user.target** must be reached before the graphical target dependencies can be met. The underlined targets in Figure 3 are the usual startup targets. When one of these targets is reached, startup has completed. If the **multi-user.target** is the default, then you should see a text-mode login on the console. If **graphical.target** is the default, then you should see a graphical login; the specific GUI login screen you see depends on your default display manager.
|
||||
|
||||
The bootup man page also describes and provides maps of the boot into the initial RAM disk and the systemd shutdown process.
|
||||
|
||||
systemd also provides a tool that lists dependencies of a complete startup or for a specified unit. A unit is a controllable systemd resource entity that can range from a specific service, such as httpd or sshd, to timers, mounts, sockets, and more. Try the following command and scroll through the results.
|
||||
|
||||
|
||||
```
|
||||
`systemctl list-dependencies graphical.target`
|
||||
```
|
||||
|
||||
Notice that this fully expands the top-level target units list required to bring the system up to the graphical target run mode. Use the **\--all** option to expand all of the other units as well.
|
||||
|
||||
|
||||
```
|
||||
`systemctl list-dependencies --all graphical.target`
|
||||
```
|
||||
|
||||
You can search for strings such as "target," "slice," and "socket" using the search tools of the **less** command.
|
||||
|
||||
So now, try the following.
|
||||
|
||||
|
||||
```
|
||||
`systemctl list-dependencies multi-user.target`
|
||||
```
|
||||
|
||||
and
|
||||
|
||||
|
||||
```
|
||||
`systemctl list-dependencies rescue.target`
|
||||
```
|
||||
|
||||
and
|
||||
|
||||
|
||||
```
|
||||
`systemctl list-dependencies local-fs.target`
|
||||
```
|
||||
|
||||
and
|
||||
|
||||
|
||||
```
|
||||
`systemctl list-dependencies dbus.service`
|
||||
```
|
||||
|
||||
This tool helps me visualize the specifics of the startup dependencies for the host I am working on. Go ahead and spend some time exploring the startup tree for one or more of your Linux hosts. But be careful because the systemctl man page contains this note:
|
||||
|
||||
> _"Note that this command only lists units currently loaded into memory by the service manager. In particular, this command is not suitable to get a comprehensive list at all reverse dependencies on a specific unit, as it won't list the dependencies declared by units currently not loaded."_
|
||||
|
||||
### Final thoughts
|
||||
|
||||
Even before getting very deep into systemd, it's obvious that it is both powerful and complex. It is also apparent that systemd is not a single, huge, monolithic, and unknowable binary file. Rather, it is composed of a number of smaller components and subcommands that are designed to perform specific tasks.
|
||||
|
||||
The next article in this series will explore systemd startup in more detail, as well as systemd configuration files, changing the default target, and how to create a simple service unit.
|
||||
|
||||
### Resources
|
||||
|
||||
There is a great deal of information about systemd available on the internet, but much is terse, obtuse, or even misleading. In addition to the resources mentioned in this article, the following webpages offer more detailed and reliable information about systemd startup.
|
||||
|
||||
* The Fedora Project has a good, practical [guide][7] [to systemd][7]. It has pretty much everything you need to know in order to configure, manage, and maintain a Fedora computer using systemd.
|
||||
* The Fedora Project also has a good [cheat sheet][8] that cross-references the old SystemV commands to comparable systemd ones.
|
||||
* For detailed technical information about systemd and the reasons for creating it, check out [Freedesktop.org][9]'s [description of systemd][10].
|
||||
* [Linux.com][11]'s "More systemd fun" offers more advanced systemd [information and tips][12].
|
||||
|
||||
|
||||
|
||||
There is also a series of deeply technical articles for Linux sysadmins by Lennart Poettering, the designer and primary developer of systemd. These articles were written between April 2010 and September 2011, but they are just as relevant now as they were then. Much of everything else good that has been written about systemd and its ecosystem is based on these papers.
|
||||
|
||||
* [Rethinking PID 1][13]
|
||||
* [systemd for Administrators, Part I][14]
|
||||
* [systemd for Administrators, Part II][15]
|
||||
* [systemd for Administrators, Part III][16]
|
||||
* [systemd for Administrators, Part IV][17]
|
||||
* [systemd for Administrators, Part V][18]
|
||||
* [systemd for Administrators, Part VI][19]
|
||||
* [systemd for Administrators, Part VII][20]
|
||||
* [systemd for Administrators, Part VIII][21]
|
||||
* [systemd for Administrators, Part IX][22]
|
||||
* [systemd for Administrators, Part X][23]
|
||||
* [systemd for Administrators, Part XI][24]
|
||||
|
||||
|
||||
|
||||
Alison Chiaken, a Linux kernel and systems programmer at Mentor Graphics, offers a preview of her...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/systemd
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/car-penguin-drive-linux-yellow.png?itok=twWGlYAc (Penguin driving a car with a yellow background)
|
||||
[2]: http://www.both.org/?page_id=1183
|
||||
[3]: http://www.osnews.com/story/28026/Editorial_Thoughts_on_Systemd_and_the_Freedom_to_Choose
|
||||
[4]: https://www.zdnet.com/article/linus-torvalds-and-others-on-linuxs-systemd/
|
||||
[5]: http://0pointer.de/blog/projects/the-biggest-myths.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/systemd-architecture.png (systemd architecture)
|
||||
[7]: https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html
|
||||
[8]: https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet
|
||||
[9]: http://Freedesktop.org
|
||||
[10]: http://www.freedesktop.org/wiki/Software/systemd
|
||||
[11]: http://Linux.com
|
||||
[12]: https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/
|
||||
[13]: http://0pointer.de/blog/projects/systemd.html
|
||||
[14]: http://0pointer.de/blog/projects/systemd-for-admins-1.html
|
||||
[15]: http://0pointer.de/blog/projects/systemd-for-admins-2.html
|
||||
[16]: http://0pointer.de/blog/projects/systemd-for-admins-3.html
|
||||
[17]: http://0pointer.de/blog/projects/systemd-for-admins-4.html
|
||||
[18]: http://0pointer.de/blog/projects/three-levels-of-off.html
|
||||
[19]: http://0pointer.de/blog/projects/changing-roots
|
||||
[20]: http://0pointer.de/blog/projects/blame-game.html
|
||||
[21]: http://0pointer.de/blog/projects/the-new-configuration-files.html
|
||||
[22]: http://0pointer.de/blog/projects/on-etc-sysinit.html
|
||||
[23]: http://0pointer.de/blog/projects/instances.html
|
||||
[24]: http://0pointer.de/blog/projects/inetd.html
|
||||
@ -1,194 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (messon007)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create a SDN on Linux with open source)
|
||||
[#]: via: (https://opensource.com/article/20/4/quagga-linux)
|
||||
[#]: author: (M Umer https://opensource.com/users/noisybotnet)
|
||||
|
||||
Create a SDN on Linux with open source
|
||||
======
|
||||
Make your Linux system act like a router with the open source routing
|
||||
stack Quagga.
|
||||
![Coding on a computer][1]
|
||||
|
||||
Network routing protocols fall into two main categories: interior gateway protocols and exterior gateway protocols. Interior gateway protocols are used by routers to share information within a single autonomous system. If you are running Linux, you can make your system behave as a router through the open source (GPLv2) routing stack [Quagga][2].
|
||||
|
||||
### What is Quagga?
|
||||
|
||||
Quagga is a [routing software suite][3] and a fork of [GNU Zebra][4]. It provides implementations of all major routing protocols such as Open Shortest Path First (OSPF), Routing Information Protocol (RIP), Border Gateway Protocol (BGP), and Intermediate System to Intermediate System (IS-IS) for Unix-like platforms.
|
||||
|
||||
Although Quagga implements the routing protocols for both IPv4 and IPv6, it doesn't act as a complete router. A true router not only implements all the routing protocols but also has the ability to forward network traffic. Quagga only implements the routing stack, and the job of forwarding network traffic is handled by the Linux kernel.
|
||||
|
||||
### Architecture
|
||||
|
||||
Quagga implements the different routing protocols through protocol-specific daemons. The daemon name is the same as the routing protocol followed by the letter "d." Zebra is the core and a protocol-independent daemon that provides an [abstraction layer][5] to the kernel and presents the Zserv API over TCP sockets to Quagga clients. Each protocol-specific daemon is responsible for running the relevant protocol and building the routing table based on the information exchanged.
|
||||
|
||||
![Quagga architecture][6]
|
||||
|
||||
### Setup
|
||||
|
||||
This tutorial implements the OSPF protocol to configure dynamic routing using Quagga. The setup includes two CentOS 7.7 hosts, named Alpha and Beta. Both hosts share access to the **192.168.122.0/24** network.
|
||||
|
||||
**Host Alpha:**
|
||||
|
||||
IP: 192.168.122.100/24
|
||||
Gateway: 192.168.122.1
|
||||
|
||||
**Host Beta:**
|
||||
|
||||
IP: 192.168.122.50/24
|
||||
Gateway: 192.168.122.1
|
||||
|
||||
### Install the package
|
||||
|
||||
First, install the Quagga package on both hosts. It is available in the CentOS base repo:
|
||||
|
||||
|
||||
```
|
||||
`yum install quagga -y`
|
||||
```
|
||||
|
||||
### Enable IP forwarding
|
||||
|
||||
Next, enable IP forwarding on both hosts since that will performed by the Linux kernel:
|
||||
|
||||
|
||||
```
|
||||
sysctl -w net.ipv4.ip_forward = 1
|
||||
sysctl -p
|
||||
```
|
||||
|
||||
### Configuration
|
||||
|
||||
Now, go into the **/etc/quagga** directory and create the configuration files for your setup. You need three files:
|
||||
|
||||
* **zebra.conf**: Quagga's daemon configuration file, which is where you'll define the interfaces and their IP addresses and IP forwarding
|
||||
* **ospfd.conf**: The protocol configuration file, which is where you'll define the networks that will be offered through the OSPF protocol
|
||||
* **daemons**: Where you'll specify the relevant protocol daemons that are required to run
|
||||
|
||||
|
||||
|
||||
On host Alpha,
|
||||
|
||||
|
||||
```
|
||||
[root@alpha]# cat /etc/quagga/zebra.conf
|
||||
interface eth0
|
||||
ip address 192.168.122.100/24
|
||||
ipv6 nd suppress-ra
|
||||
interface eth1
|
||||
ip address 10.12.13.1/24
|
||||
ipv6 nd suppress-ra
|
||||
interface lo
|
||||
ip forwarding
|
||||
line vty
|
||||
|
||||
[root@alpha]# cat /etc/quagga/ospfd.conf
|
||||
interface eth0
|
||||
interface eth1
|
||||
interface lo
|
||||
router ospf
|
||||
network 192.168.122.0/24 area 0.0.0.0
|
||||
network 10.12.13.0/24 area 0.0.0.0
|
||||
line vty
|
||||
|
||||
[root@alphaa ~]# cat /etc/quagga/daemons
|
||||
zebra=yes
|
||||
ospfd=yes
|
||||
```
|
||||
|
||||
On host Beta,
|
||||
|
||||
|
||||
```
|
||||
[root@beta quagga]# cat zebra.conf
|
||||
interface eth0
|
||||
ip address 192.168.122.50/24
|
||||
ipv6 nd suppress-ra
|
||||
interface eth1
|
||||
ip address 10.10.10.1/24
|
||||
ipv6 nd suppress-ra
|
||||
interface lo
|
||||
ip forwarding
|
||||
line vty
|
||||
|
||||
[root@beta quagga]# cat ospfd.conf
|
||||
interface eth0
|
||||
interface eth1
|
||||
interface lo
|
||||
router ospf
|
||||
network 192.168.122.0/24 area 0.0.0.0
|
||||
network 10.10.10.0/24 area 0.0.0.0
|
||||
line vty
|
||||
|
||||
[root@beta ~]# cat /etc/quagga/daemons
|
||||
zebra=yes
|
||||
ospfd=yes
|
||||
```
|
||||
|
||||
### Configure the firewall
|
||||
|
||||
To use the OSPF protocol, you must allow it in the firewall:
|
||||
|
||||
|
||||
```
|
||||
firewall-cmd --add-protocol=ospf –permanent
|
||||
|
||||
firewall-cmd –reload
|
||||
```
|
||||
|
||||
Now, start the zebra and ospfd daemons.
|
||||
|
||||
|
||||
```
|
||||
# systemctl start zebra
|
||||
# systemctl start ospfd
|
||||
```
|
||||
|
||||
Look at the route table on both hosts using:
|
||||
|
||||
|
||||
```
|
||||
[root@alpha ~]# ip route show
|
||||
default via 192.168.122.1 dev eth0 proto static metric 100
|
||||
10.10.10.0/24 via 192.168.122.50 dev eth0 proto zebra metric 20
|
||||
10.12.13.0/24 dev eth1 proto kernel scope link src 10.12.13.1
|
||||
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.100 metric 100
|
||||
```
|
||||
|
||||
You can see that the routing table on Alpha contains an entry of **10.10.10.0/24** via **192.168.122.50** offered through protocol **zebra**. Similarly, on host Beta, the table contains an entry of network **10.12.13.0/24** via **192.168.122.100**.
|
||||
|
||||
|
||||
```
|
||||
[root@beta ~]# ip route show
|
||||
default via 192.168.122.1 dev eth0 proto static metric 100
|
||||
10.10.10.0/24 dev eth1 proto kernel scope link src 10.10.10.1
|
||||
10.12.13.0/24 via 192.168.122.100 dev eth0 proto zebra metric 20
|
||||
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.50 metric 100
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
As you can see, the setup and configuration are relatively simple. To add complexity, you can add more network interfaces to the router to provide routing for more networks. You can also implement BGP and RIP protocols using the same method.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/quagga-linux
|
||||
|
||||
作者:[M Umer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/noisybotnet
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
|
||||
[2]: https://www.quagga.net/
|
||||
[3]: https://en.wikipedia.org/wiki/Quagga_(software)
|
||||
[4]: https://www.gnu.org/software/zebra/
|
||||
[5]: https://en.wikipedia.org/wiki/Abstraction_layer
|
||||
[6]: https://opensource.com/sites/default/files/uploads/quagga_arch.png (Quagga architecture)
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (qfzy1233)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: ( guevaraya)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,99 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Upgrading Fedora 31 to Fedora 32)
|
||||
[#]: via: (https://fedoramagazine.org/upgrading-fedora-31-to-fedora-32/)
|
||||
[#]: author: (Adam Šamalík https://fedoramagazine.org/author/asamalik/)
|
||||
|
||||
Upgrading Fedora 31 to Fedora 32
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Fedora 32 [is available now][2]. You’ll likely want to upgrade your system to get the latest features available in Fedora. Fedora Workstation has a graphical upgrade method. Alternatively, Fedora offers a command-line method for upgrading Fedora 30 to Fedora 31.
|
||||
|
||||
Before upgrading, visit the [wiki page of common Fedora 32 bugs][3] to see if there’s an issue that might affect your upgrade. Although the Fedora community tries to ensure upgrades work well, there’s no way to guarantee this for every combination of hardware and software that users might have.
|
||||
|
||||
### Upgrading Fedora 31 Workstation to Fedora 32
|
||||
|
||||
Soon after release time, a notification appears to tell you an upgrade is available. You can click the notification to launch the **GNOME Software** app. Or you can choose Software from GNOME Shell.
|
||||
|
||||
Choose the _Updates_ tab in GNOME Software and you should see a screen informing you that Fedora 32 is Now Available.
|
||||
|
||||
If you don’t see anything on this screen, try using the reload button at the top left. It may take some time after release for all systems to be able to see an upgrade available.
|
||||
|
||||
Choose _Download_ to fetch the upgrade packages. You can continue working until you reach a stopping point, and the download is complete. Then use GNOME Software to restart your system and apply the upgrade. Upgrading takes time, so you may want to grab a coffee and come back to the system later.
|
||||
|
||||
### Using the command line
|
||||
|
||||
If you’ve upgraded from past Fedora releases, you are likely familiar with the _dnf upgrade_ plugin. This method is the recommended and supported way to upgrade from Fedora 31 to Fedora 32. Using this plugin will make your upgrade to Fedora 32 simple and easy.
|
||||
|
||||
#### 1\. Update software and back up your system
|
||||
|
||||
Before you do start the upgrade process, make sure you have the latest software for Fedora 31. This is particularly important if you have modular software installed; the latest versions of dnf and GNOME Software include improvements to the upgrade process for some modular streams. To update your software, use _GNOME Software_ or enter the following command in a terminal.
|
||||
|
||||
```
|
||||
sudo dnf upgrade --refresh
|
||||
```
|
||||
|
||||
Additionally, make sure you back up your system before proceeding. For help with taking a backup, see [the backup series][4] on the Fedora Magazine.
|
||||
|
||||
#### 2\. Install the DNF plugin
|
||||
|
||||
Next, open a terminal and type the following command to install the plugin:
|
||||
|
||||
```
|
||||
sudo dnf install dnf-plugin-system-upgrade
|
||||
```
|
||||
|
||||
#### 3\. Start the update with DNF
|
||||
|
||||
Now that your system is up-to-date, backed up, and you have the DNF plugin installed, you can begin the upgrade by using the following command in a terminal:
|
||||
|
||||
```
|
||||
sudo dnf system-upgrade download --releasever=32
|
||||
```
|
||||
|
||||
This command will begin downloading all of the upgrades for your machine locally to prepare for the upgrade. If you have issues when upgrading because of packages without updates, broken dependencies, or retired packages, add the _‐‐allowerasing_ flag when typing the above command. This will allow DNF to remove packages that may be blocking your system upgrade.
|
||||
|
||||
#### 4\. Reboot and upgrade
|
||||
|
||||
Once the previous command finishes downloading all of the upgrades, your system will be ready for rebooting. To boot your system into the upgrade process, type the following command in a terminal:
|
||||
|
||||
```
|
||||
sudo dnf system-upgrade reboot
|
||||
```
|
||||
|
||||
Your system will restart after this. Many releases ago, the _fedup_ tool would create a new option on the kernel selection / boot screen. With the _dnf-plugin-system-upgrade_ package, your system reboots into the current kernel installed for Fedora 31; this is normal. Shortly after the kernel selection screen, your system begins the upgrade process.
|
||||
|
||||
Now might be a good time for a coffee break! Once it finishes, your system will restart and you’ll be able to log in to your newly upgraded Fedora 32 system.
|
||||
|
||||
![][5]
|
||||
|
||||
### Resolving upgrade problems
|
||||
|
||||
On occasion, there may be unexpected issues when you upgrade your system. If you experience any issues, please visit the [DNF system upgrade quick docs][6] for more information on troubleshooting.
|
||||
|
||||
If you are having issues upgrading and have third-party repositories installed on your system, you may need to disable these repositories while you are upgrading. For support with repositories not provided by Fedora, please contact the providers of the repositories.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/upgrading-fedora-31-to-fedora-32/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/04/31-32-816x345.png
|
||||
[2]: https://fedoramagazine.org/announcing-fedora-32/
|
||||
[3]: https://fedoraproject.org/wiki/Common_F32_bugs
|
||||
[4]: https://fedoramagazine.org/taking-smart-backups-duplicity/
|
||||
[5]: https://cdn.fedoramagazine.org/wp-content/uploads/2016/06/Screenshot_f23-ws-upgrade-test_2016-06-10_110906-1024x768.png
|
||||
[6]: https://docs.fedoraproject.org/en-US/quick-docs/dnf-system-upgrade/#Resolving_post-upgrade_issues
|
||||
@ -1,100 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using Files and Folders on Desktop Screen in Ubuntu)
|
||||
[#]: via: (https://itsfoss.com/add-files-on-desktop-ubuntu/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Using Files and Folders on Desktop Screen in Ubuntu
|
||||
======
|
||||
|
||||
_**This beginner tutorial discusses a few difficulties you may face while adding files and folders on the desktop screen on Ubuntu.**_
|
||||
|
||||
I know a few people who are habitual of putting all the important/frequently used files on the desktop screen for quick access.
|
||||
|
||||
![][1]
|
||||
|
||||
I am not a fan of a cluttered desktop screen but I can imagine that it might actually be helpful to some people.
|
||||
|
||||
For the past few releases, it has been difficult to add files on the desktop screen in Ubuntu’s default GNOME desktop. It’s not really Ubuntu’s fault.
|
||||
|
||||
The [GNOME][2] developers thinks that there is no place for icons and files on the desktop screen. There is no need of putting files on the desktop when you can easily search for it in the menu. And that’s part true.
|
||||
|
||||
This is why the newer version of [GNOME’s File Manager Nautilus][3] doesn’t support icons and files on the desktop very well.
|
||||
|
||||
That said, it’s not impossible to add files and folders on the desktop. Let me show you how you can still use it.
|
||||
|
||||
### Adding files and folders on the desktop screen in Ubuntu
|
||||
|
||||
![][4]
|
||||
|
||||
I am using Ubuntu 20.04 in this tutorial. The steps may or may not vary for other Ubuntu versions.
|
||||
|
||||
#### Add the files and folders to the “Desktop folder”
|
||||
|
||||
If you open the file manager, you should see an entry called Desktop in the left sidebar or in the folders list. This folder represents your desktop screen (in a way).
|
||||
|
||||
![Desktop folder can be used to add files to the desktop screen][5]
|
||||
|
||||
Anything you add to this folder will be reflected on the desktop screen.
|
||||
|
||||
![Anything added to the Desktop folder will be reflected on the desktop screen][6]
|
||||
|
||||
If you delete files from this ‘Desktop folder’, it will be removed from the desktop screen as well.
|
||||
|
||||
#### Drag and drop files to desktop screen doesn’t work
|
||||
|
||||
Now, if you try to drag and drop files from the file manager on the desktop, it won’t work. It’s not a bug, it’s a feature that irks a lot of people.
|
||||
|
||||
A workaround would be to open two instances of the file manager. Open Desktop folder in one of them and then drag and drop files to this folder and they will be added on the desktop.
|
||||
|
||||
I know that’s not ideal but you don’t have a lot of choices here.
|
||||
|
||||
#### You cannot use Ctrl+C and Ctrl+V to copy-paste on the desktop, use the right click menu
|
||||
|
||||
To add salt to injury, you cannot use Ctrl+V the famous keyboard shortcut to paste files on the desktop screen.
|
||||
|
||||
But you can still use the right click context menu and select Paste from there to put the copied files on the desktop. You can even create new folders this way.
|
||||
|
||||
![Right click menu can be used for copy-pasting files to desktop][7]
|
||||
|
||||
Does it make sense? Not to me but that’s how it is in Ubuntu 20.04.
|
||||
|
||||
#### You cannot delete files and folder using the Delete key, use the right click menu again
|
||||
|
||||
What’s worse is that you cannot use the delete key or shift delete key to remove files from the desktop screen. But you can still right click on the files or folders and select “Move to trash” to delete the file.
|
||||
|
||||
![Delete files from desktop using right click][8]
|
||||
|
||||
Alright, so now you know that at least there is a way to add files on the desktop with some restrictions. But it doesn’t end here unfortunately.
|
||||
|
||||
You cannot search for files with their names on the desktop screen. Normally, if you start typing ‘abc’, files starting with ‘abc’ are highlighted. You don’t get it here.
|
||||
|
||||
I don’t know why so many restrictions have been put on adding files on the desktop. Thankfully, I don’t use it a lot otherwise I have been way too frustrated.
|
||||
|
||||
If interested, you may read about [adding application shortcut on the desktop in Ubuntu][9] as well.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/add-files-on-desktop-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/files-on-desktop-ubuntu.jpg?ssl=1
|
||||
[2]: https://www.gnome.org/
|
||||
[3]: https://wiki.gnome.org/Apps/Files
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/adding-files-desktop-ubuntu.png?ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/desktop-folder-ubuntu.png?ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/adding-files-desktop-screen-ubuntu.jpg?ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/adding-new-files-ubuntu-desktop.jpg?ssl=1
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/delete-files-from-desktop-ubuntu.jpg?ssl=1
|
||||
[9]: https://itsfoss.com/ubuntu-desktop-shortcut/
|
||||
@ -1,89 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What’s new in Fedora 32 Workstation)
|
||||
[#]: via: (https://fedoramagazine.org/whats-new-fedora-32-workstation/)
|
||||
[#]: author: (Ryan Lerch https://fedoramagazine.org/author/ryanlerch/)
|
||||
|
||||
What’s new in Fedora 32 Workstation
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Fedora 32 Workstation is the [latest release][2] of our free, leading-edge operating system. You can download it from [the official website here][3] right now. There are several new and noteworthy changes in Fedora 32 Workstation. Read more details below.
|
||||
|
||||
### GNOME 3.36
|
||||
|
||||
Fedora 32 Workstation includes the latest release of GNOME Desktop Environment for users of all types. GNOME 3.36 in Fedora 32 Workstation includes many updates and improvements, including:
|
||||
|
||||
#### Redesigned Lock Screen
|
||||
|
||||
The lock screen in Fedora 32 is a totally new experience. The new design removes the “window shade” metaphor used in previous releases, and focuses on ease and speed of use.
|
||||
|
||||
![Unlock screen in Fedora 32][4]
|
||||
|
||||
#### New Extensions Application
|
||||
|
||||
Fedora 32 features the new Extensions application, to easily manage your GNOME Extensions. In the past, extensions were installed, configured, and enabled using either the Software application and / or the Tweak Tool.
|
||||
|
||||
![The new Extensions application in Fedora 32][5]
|
||||
|
||||
Note that the Extensions application is not installed by default on Fedora 32. To either use the Software application to search and install, or use the following command in the terminal:
|
||||
|
||||
```
|
||||
sudo dnf install gnome-extensions-app
|
||||
```
|
||||
|
||||
#### Reorganized Settings
|
||||
|
||||
Eagle-eyed Fedora users will notice that the Settings application has been re-organized. The structure of the settings categories is a lot flatter, resulting in more settings being visible at a glance.
|
||||
|
||||
Additionally, the **About** category now has a more information about your system, including which windowing system you are running (e.g. Wayland)
|
||||
|
||||
![The reorganized settings application in Fedora 32][6]
|
||||
|
||||
#### Redesigned Notifications / Calendar popover
|
||||
|
||||
The Notifications / Calendar popover — toggled by clicking on the Date and Time at the top of your desktop — has had numerous small style tweaks. Additionally, the popover now has a **Do Not Disturb** switch to quickly disable all notifications. This quick access is useful when presenting your screen, and not wanting your personal notifications appearing.
|
||||
|
||||
![The new Notification / Calendar popover in Fedora 32 ][7]
|
||||
|
||||
#### Redesigned Clocks Application
|
||||
|
||||
The Clocks application is totally redesigned in Fedora 32. It features a design that works better on smaller windows.
|
||||
|
||||
![The Clocks application in Fedora 32][8]
|
||||
|
||||
GNOME 3.36 also provides many additional features and enhancements. Check out the [GNOME 3.36 Release Notes][9] for further information
|
||||
|
||||
* * *
|
||||
|
||||
### Improved Out of Memory handling
|
||||
|
||||
Previously, if a system encountered a low-memory situation, it may have encountered heavy swap usage (aka [swap thrashing][10])– sometimes resulting in the Workstation UI slowing down, or becoming unresponsive for periods of time. Fedora 32 Workstation now ships and enables EarlyOOM by default. EarlyOOM enables users to more quickly recover and regain control over their system in low-memory situations with heavy swap usage.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/whats-new-fedora-32-workstation/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/ryanlerch/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/04/fedora32workstation-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/announcing-fedora-32/
|
||||
[3]: https://getfedora.org/workstation
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2020/04/unlock.gif
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2020/04/extensions.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2020/04/settings.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2020/04/donotdisturb.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2020/04/clocks.png
|
||||
[9]: https://help.gnome.org/misc/release-notes/3.36/
|
||||
[10]: https://en.wikipedia.org/wiki/Thrashing_(computer_science)
|
||||
@ -1,144 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Drop PNG and JPG for your online images: Use WebP)
|
||||
[#]: via: (https://opensource.com/article/20/4/webp-image-compression)
|
||||
[#]: author: (Jeff Macharyas https://opensource.com/users/jeffmacharyas)
|
||||
|
||||
Drop PNG and JPG for your online images: Use WebP
|
||||
======
|
||||
Get started with this open source image editing tool to save time and
|
||||
space.
|
||||
![Painting art on a computer screen][1]
|
||||
|
||||
WebP is an image format developed by Google in 2010 that provides superior lossless and lossy compression for images on the web. Using WebP, web developers can create smaller, richer images that improve site speed. A faster loading website is critical to the user experience and for the website's marketing effectiveness.
|
||||
|
||||
For optimal loading across all devices and users, images on your site should not be larger than 500 KB in file size.
|
||||
|
||||
WebP lossless images are often at least 25% smaller in size compared to PNGs. WebP lossy images are often anywhere from 25-34% smaller than comparable JPEG images at equivalent SSIM (structural similarity) quality index.
|
||||
|
||||
Lossless WebP supports transparency, as well. For cases when lossy RGB compression is acceptable, lossy WebP also supports transparency, typically providing three times smaller file sizes compared to PNG.
|
||||
|
||||
Google reports a 64% reduction in file size for images converted from animated GIFs to lossy WebP, and a 19% reduction when converted to lossless WebP.
|
||||
|
||||
The WebP file format is based on the RIFF (resource interchange file format) document format. The file signature is **52 49 46 46** (RIFF), as you can see with [hexdump][2]:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump --canonical pixel.webp
|
||||
00000000 52 49 46 46 26 00 00 00 [...] |RIFF&...WEBPVP8 |
|
||||
00000010 1a 00 00 00 30 01 00 9d [...] |....0....*......|
|
||||
00000020 0e 25 a4 00 03 70 00 fe [...] |.%...p...`....|
|
||||
0000002e
|
||||
```
|
||||
|
||||
The standalone libwebp library serves as a reference implementation for the WebP specification and is available from Google's [Git repository][3] or as a tarball.
|
||||
|
||||
The WebP format is compatible with 80% of the web browsers in use worldwide. At the time of this writing, it is not compatible with Apple's Safari browser. The workaround for this is to serve up a JPG/PNG alongside a WebP, and there are methods and Wordpress plugins to do that.
|
||||
|
||||
### Why does this matter?
|
||||
|
||||
Part of my job is to design and maintain our organization's website. Since the website is a marketing tool and site speed is a critical aspect of the user experience, I have been working to improve the speed, and reducing image sizes by converting them to WebP has been a good solution.
|
||||
|
||||
To test the speed of one of the pages, I turned to **web.dev**, which is powered by Lighthouse, released under the Apache 2.0 license, and can be found at <https://github.com/GoogleChrome/lighthouse>.
|
||||
|
||||
According to its official description, "Lighthouse is an open source, automated tool for improving the quality of web pages. You can run it against any web page—public or requiring authentication. It has audits for performance, accessibility, progressive web apps, SEO, and more. You can run Lighthouse in Chrome DevTools, from the command line, or as a Node module. You give Lighthouse a URL to audit, it runs a series of audits against the page, and then it generates a report on how well the page did. From there, use the failing audits as indicators on how to improve the page. Each audit has a reference doc explaining why the audit is important, as well as how to fix it."
|
||||
|
||||
### Creating a smaller WebP image
|
||||
|
||||
The page I tested returned three images. In the report it generates, it provides recommendations and targets. I chose the "app-graphic" image, which, it reported, is 650 KB. By converting it to WebP, I should save 589 KB, reducing the image to 61 KB. I converted the image in Photoshop and saved it with the default WebP settings, and it returned a file size of 44.9 KB. Better than expected! As the screenshot from Photoshop shows, the images look identical in visual quality.
|
||||
|
||||
![WebP vs JPG comparison][4]
|
||||
|
||||
On the left: 650 KB (actual size). On the right: 589 KB (target size after conversion).
|
||||
|
||||
Of course, the open source image editor [GIMP][5] also supports WebP as an export format. It offers several options for quality and compression profile:
|
||||
|
||||
![GIMP dialog for exporting webp, as a webp][6]
|
||||
|
||||
A zoomed-in look of another image:
|
||||
|
||||
![WebP vs PNG comparison][7]
|
||||
|
||||
PNG (left) and WebP (right), both converted from a JPG, shows the WebP, although smaller in size, is superior in visual quality.
|
||||
|
||||
### Convert to an image to WebP
|
||||
|
||||
To convert images on Linux from JPG/PNG to WebP, you can also use the command-line:
|
||||
|
||||
Use **cwebp** on the command line to convert PNG or JPG image files to WebP format. You can convert a PNG image file to a WebP image with a quality range of 80 with the command:
|
||||
|
||||
|
||||
```
|
||||
`cwebp -q 80 image.png -o image.webp`
|
||||
```
|
||||
|
||||
Alternatively, you can also use [Image Magick][8], which is probably available in your distribution's software repository. The subcommand for conversion is **convert**, and all that's needed is an input and output file:
|
||||
|
||||
|
||||
```
|
||||
`convert pixel.png pixel.webp`
|
||||
```
|
||||
|
||||
### Convert an image to WebP with an editor
|
||||
|
||||
To convert images to WebP with a photo editor, use [GIMP][9]. From version 2.10 on, it supports WebP natively.
|
||||
|
||||
If you're a Photoshop user, you need a plugin to convert the files, as Photoshop does not include it natively. WebPShop 0.2.1, released under the Apache License 2.0 license, is a Photoshop module for opening and saving WebP images, including animations, and can be found at: <https://github.com/webmproject/WebPShop>.
|
||||
|
||||
To use the plugin, put the file found in the **bin** folder inside your Photoshop plugin directory:
|
||||
|
||||
Windows x64—C:\Program Files\Adobe\Adobe Photoshop\Plug-ins\WebPShop.8bi
|
||||
|
||||
Mac—Applications/Adobe Photoshop/Plug-ins/WebPShop.plugin
|
||||
|
||||
### WebP on Wordpress
|
||||
|
||||
Many websites are built using Wordpress (that's what I use). So, how does Wordpress handle uploading WebP images? At the time of this writing, it doesn't. But, there are, of course, plugins to enable it so you can serve up both WebP alongside PNG/JPG images (for the Apple crowd).
|
||||
|
||||
Or there are these [instructions][10] from [Marius Hosting][11]:
|
||||
|
||||
"How about directly uploading WebP images to Wordpress? This is easy. Just add some text line on your theme functions.php file. Wordpress does not natively support viewing and uploading WebP files, but I will explain to you how you can make it work in a few simple steps. Log in to your Wordpress admin area and go to Appearance/Theme Editor and find functions.php. Copy and paste the code below at the end of the file and save it.
|
||||
|
||||
|
||||
```
|
||||
`//** *Enable upload for webp image files.*/ function webp_upload_mimes($existing_mimes) { $existing_mimes['webp'] = 'image/webp'; return $existing_mimes; } add_filter('mime_types', 'webp_upload_mimes');`
|
||||
```
|
||||
|
||||
If you want to see the thumbnail image preview when you go to Media/Library, you have to add the code below in the same functions.php file. To find the functions.php file, go to Appearance/Theme Editor and find functions.php, then copy and paste the code below at the end of the file and save it."
|
||||
|
||||
|
||||
```
|
||||
`//** * Enable preview / thumbnail for webp image files.*/ function webp_is_displayable($result, $path) { if ($result === false) { $displayable_image_types = array( IMAGETYPE_WEBP ); $info = @getimagesize( $path ); if (empty($info)) { $result = false; } elseif (!in_array($info[2], $displayable_image_types)) { $result = false; } else { $result = true; } } return $result; } add_filter('file_is_displayable_image', 'webp_is_displayable', 10, 2);`
|
||||
```
|
||||
|
||||
### WebP and the future
|
||||
|
||||
WebP is a robust and optimized format. It looks better, it has better compression ratio, and it has all the features of most other common image formats. There's no need to wait—start using it now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/webp-image-compression
|
||||
|
||||
作者:[Jeff Macharyas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jeffmacharyas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/painting_computer_screen_art_design_creative.png?itok=LVAeQx3_ (Painting art on a computer screen)
|
||||
[2]: https://opensource.com/article/19/8/dig-binary-files-hexdump
|
||||
[3]: https://storage.googleapis.com/downloads.webmproject.org/releases/webp/index.html
|
||||
[4]: https://opensource.com/sites/default/files/uploads/webp-vs-jpg-app-graphic.png (WebP vs JPG comparison)
|
||||
[5]: http://gimp.org
|
||||
[6]: https://opensource.com/sites/default/files/webp-gimp.webp (GIMP dialog for exporting webp, as a webp)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/xcompare-png-left-webp-right.png (WebP vs PNG comparison)
|
||||
[8]: https://imagemagick.org
|
||||
[9]: https://en.wikipedia.org/wiki/GIMP
|
||||
[10]: https://mariushosting.com/how-to-upload-webp-files-on-wordpress/
|
||||
[11]: https://mariushosting.com/
|
||||
@ -1,80 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The life-changing magic of git rebase -i)
|
||||
[#]: via: (https://opensource.com/article/20/4/git-rebase-i)
|
||||
[#]: author: (Dave Neary https://opensource.com/users/dneary)
|
||||
|
||||
The life-changing magic of git rebase -i
|
||||
======
|
||||
Make everyone think you write perfect code the first time (and make your
|
||||
patches easier to review and merge).
|
||||
![Hands programming][1]
|
||||
|
||||
Software development is messy. So many wrong turns, typos to fix, quick hacks and kludges to correct later, off-by-one errors you find late in the process. With version control, you have a pristine record of every wrong turn and correction made during the process of creating the "perfect" final product—a patch ready to submit upstream. Like the outtakes from movies, they are a little embarrassing and sometimes amusing.
|
||||
|
||||
Wouldn't it be great if you could use version control to save your work regularly at waypoints, and then when you have something you are ready to submit for review, you could hide all of that private drafting work and just submit a single, perfect patch? Meet **git rebase -i**, the perfect way to rewrite history and make everyone think that you produce perfect code the first time!
|
||||
|
||||
### What does git rebase do?
|
||||
|
||||
In case you're not familiar with the intricacies of Git, here is a brief overview. Under the covers, Git associates different versions of your project with a unique identifier, which is made up of a hash of the parent node's unique identifier, and the difference between the new version and its parent node. This creates a tree of revisions, and each person who checks out the project gets their own copy. Different people can take the project in different directions, each starting from potentially different branch points.
|
||||
|
||||
![Master branch vs. private branch][2]
|
||||
|
||||
The master branch in the "origin" repo on the left and the private branch on your personal copy on the right.
|
||||
|
||||
There are two ways to integrate your work back with the master branch in the original repository: one is to use **git merge**, and the other is to use **git rebase**. They work in very different ways.
|
||||
|
||||
When you use **git merge**, a new commit is created on the master branch that includes all of the changes from origin plus all of your local changes. If there are any conflicts (for example, if someone else has changed a file you are also working with), these will be marked, and you have an opportunity to resolve the conflicts before committing this merge commit to your local repository. When you push your changes back to the parent repository, all of your local work will appear as a branch for other users of the Git repository.
|
||||
|
||||
But **git rebase** works differently. It rewinds your commits and replays those commits again from the tip of the master branch. This results in two main changes. First, since your commits are now branching off a different parent node, their hashes will be recalculated, and anyone who has cloned your repository may now have a broken copy of the repository. Second, you do not have a merge commit, so any merge conflicts are identified as your changes are being replayed onto the master branch, and you need to fix them before proceeding with the rebase. When you push your changes now, your work does not appear on a branch, and it looks as though you wrote all of your changes off the very latest commit to the master branch.
|
||||
|
||||
![Merge commits preserve history, and rebase rewrites history.][3]
|
||||
|
||||
Merge commits (left) preserve history, while rebase (right) rewrites history.
|
||||
|
||||
However, both of these options come with a downside: everyone can see all your scribbles and edits as you worked through problems locally before you were ready to share your code. This is where the **\--interactive** (or **-i** for short) flag to **git rebase** comes into the picture.
|
||||
|
||||
### Introducing git rebase -i
|
||||
|
||||
The big advantage of **git rebase** is that it rewrites history. But why stop at just pretending you branched off a later point? There is a way to go even further and rewrite how you arrived at your ready-to-propose code: **git rebase -i**, an interactive **git rebase**.
|
||||
|
||||
This feature is the "magic time machine" function in Git. The flag allows you to make sophisticated changes to revision history while doing a rebase. You can hide your mistakes! Merge many small changes into one pristine feature patch! Reorder how things appear in revision history!
|
||||
|
||||
![output of git rebase -i][4]
|
||||
|
||||
When you run **git rebase -i**, you get an editor session listing all of the commits that are being rebased and a number of options for what you can do to them. The default choice is **pick**.
|
||||
|
||||
* **Pick** maintains the commit in your history.
|
||||
* **Reword** allows you to change a commit message, perhaps to fix a typo or add additional commentary.
|
||||
* **Edit** allows you to make changes to the commit while in the process of replaying the branch.
|
||||
* **Squash** merges multiple commits into one.
|
||||
* You can reorder commits by moving them around in the file.
|
||||
|
||||
|
||||
|
||||
When you are finished, simply save the final result, and the rebase will execute. At each stage where you have chosen to modify a commit (either with **reword**, **edit**, **squash**, or when there is a conflict), the rebase stops and allows you to make the appropriate changes before continuing.
|
||||
|
||||
The example above results in "One-liner bug fix" and "Integrate new header everywhere" being merged into one commit, and "New header for docs website" and "D'oh - typo. Fixed" into another. Like magic, the work that went into the other commits is still there on your branch, but the associated commits have disappeared from your history!
|
||||
|
||||
This makes it easy to submit a clean patch to an upstream project using **git send-email** or by creating a pull request against the parent repository with your newly tidied up patchset. This has a number of advantages, including that it makes your code easier to review, easier to accept, and easier to merge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/git-rebase-i
|
||||
|
||||
作者:[Dave Neary][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dneary
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop.png?itok=pGfEfu2S (Hands programming)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/master-private-branches.png (Master branch vs. private branch)
|
||||
[3]: https://opensource.com/sites/default/files/uploads/merge-commit-vs-rebase.png (Merge commits preserve history, and rebase rewrites history.)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/git-rebase-i.png (output of git rebase -i)
|
||||
@ -1,147 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using mergerfs to increase your virtual storage)
|
||||
[#]: via: (https://fedoramagazine.org/using-mergerfs-to-increase-your-virtual-storage/)
|
||||
[#]: author: (Curt Warfield https://fedoramagazine.org/author/rcurtiswarfield/)
|
||||
|
||||
Using mergerfs to increase your virtual storage
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
What happens if you have multiple disks or partitions that you’d like to use for a media project and you don’t want to lose any of your existing data, but you’d like to have everything located or mounted under one drive. That’s where mergerfs can come to your rescue!
|
||||
|
||||
[mergerfs][2] is a union filesystem geared towards simplifying storage and management of files across numerous commodity storage devices.
|
||||
|
||||
You will need to grab the latest RPM from their github page [here][3]. The releases for Fedora have _**fc**_ and the version number in the name. For example here is the version for Fedora 31:
|
||||
|
||||
[mergerfs-2.29.0-1.fc31.x86_64.rpm][4]
|
||||
|
||||
### Installing and configuring mergerfs
|
||||
|
||||
Install the mergerfs package that you’ve downloaded using sudo:
|
||||
|
||||
```
|
||||
$ sudo dnf install mergerfs-2.29.0-1.fc31.x86_64.rpm
|
||||
```
|
||||
|
||||
You will now be able to mount multiple disks as one drive. This comes in handy if you have a media server and you’d like all of your media files to show up under one location. If you upload new files to your system, you can copy them to your mergerfs directory and mergerfs will automatically copy them to which ever drive has enough free space available.
|
||||
|
||||
Here is an example to make it easier to understand:
|
||||
|
||||
```
|
||||
$ df -hT | grep disk
|
||||
/dev/sdb1 ext4 23M 386K 21M 2% /disk1
|
||||
/dev/sdc1 ext4 44M 1.1M 40M 3% /disk2
|
||||
|
||||
$ ls -l /disk1/Videos/
|
||||
total 1
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Our Wedding.mkv
|
||||
|
||||
$ ls -l /disk2/Videos/
|
||||
total 2
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Baby's first Xmas.mkv
|
||||
-rw-rw-r--. 1 curt curt 0 Mar 8 17:21 Halloween hijinks.mkv
|
||||
```
|
||||
|
||||
In this example there are two disks mounted as _disk1_ and _disk2_. Both drives have a _**Videos**_ directory with existing files.
|
||||
|
||||
Now we’re going to mount those drives using mergerfs to make them appear as one larger drive.
|
||||
|
||||
```
|
||||
$ sudo mergerfs -o defaults,allow_other,use_ino,category.create=mfs,moveonenospc=true,minfreespace=1M /disk1:/disk2 /media
|
||||
```
|
||||
|
||||
The mergerfs man page is quite extensive and complex so we’ll break down the options that were specified.
|
||||
|
||||
* _defaults_: This will use the default settings unless specified.
|
||||
* _allow_other_: allows users besides sudo or root to see the filesystem.
|
||||
* _use_ino_: Causes mergerfs to supply file/directory inodes rather than libfuse. While not a default it is recommended it be enabled so that linked files share the same inode value.
|
||||
* _category.create=mfs_: Spreads files out across your drives based on available space.
|
||||
* _moveonenospc=true_: If enabled, if writing fails, a scan will be done looking for the drive with the most free space.
|
||||
* _minfreespace=1M_: The minimum space value used.
|
||||
* _disk1_: First hard drive.
|
||||
* _disk2_: Second hard drive.
|
||||
* _/media_: The directory folder where the drives are mounted.
|
||||
|
||||
|
||||
|
||||
Here is what it looks like:
|
||||
|
||||
```
|
||||
$ df -hT | grep disk
|
||||
/dev/sdb1 ext4 23M 386K 21M 2% /disk1
|
||||
/dev/sdc1 ext4 44M 1.1M 40M 3% /disk2
|
||||
|
||||
$ df -hT | grep media
|
||||
1:2 fuse.mergerfs 66M 1.4M 60M 3% /media
|
||||
```
|
||||
|
||||
You can see that the mergerfs mount now shows a total capacity of 66M which is the combined total of the two hard drives.
|
||||
|
||||
Continuing with the example:
|
||||
|
||||
There is a 30Mb video called _Baby’s second Xmas.mkv_. Let’s copy it to the _/media_ folder which is the mergerfs mount.
|
||||
|
||||
```
|
||||
$ ls -lh "Baby's second Xmas.mkv"
|
||||
-rw-rw-r--. 1 curt curt 30M Apr 20 08:45 Baby's second Xmas.mkv
|
||||
$ cp "Baby's second Xmas.mkv" /media/Videos/
|
||||
```
|
||||
|
||||
Here is the end result:
|
||||
|
||||
```
|
||||
$ df -hT | grep disk
|
||||
/dev/sdb1 ext4 23M 386K 21M 2% /disk1
|
||||
/dev/sdc1 ext4 44M 31M 9.8M 76% /disk2
|
||||
|
||||
$ df -hT | grep media
|
||||
1:2 fuse.mergerfs 66M 31M 30M 51% /media
|
||||
```
|
||||
|
||||
You can see from the disk space utilization that mergerfs automatically copied the file to disk2 because disk1 did not have enough free space.
|
||||
|
||||
Here is a breakdown of all of the files:
|
||||
|
||||
```
|
||||
$ ls -l /disk1/Videos/
|
||||
total 1
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Our Wedding.mkv
|
||||
|
||||
$ ls -l /disk2/Videos/
|
||||
total 30003
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Baby's first Xmas.mkv
|
||||
-rw-rw-r--. 1 curt curt 30720000 Apr 20 08:47 Baby's second Xmas.mkv
|
||||
-rw-rw-r--. 1 curt curt 0 Mar 8 17:21 Halloween hijinks.mkv
|
||||
|
||||
$ ls -l /media/Videos/
|
||||
total 30004
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Baby's first Xmas.mkv
|
||||
-rw-rw-r--. 1 curt curt 30720000 Apr 20 08:47 Baby's second Xmas.mkv
|
||||
-rw-rw-r--. 1 curt curt 0 Mar 8 17:21 Halloween hijinks.mkv
|
||||
-rw-r--r--. 1 curt curt 0 Mar 8 17:17 Our Wedding.mkv
|
||||
```
|
||||
|
||||
When you copy files to your mergerfs mount, it will always copy the files to the hard disk that has enough free space. If none of the drives in the pool have enough free space, then you won’t be able to copy them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/using-mergerfs-to-increase-your-virtual-storage/
|
||||
|
||||
作者:[Curt Warfield][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/rcurtiswarfield/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/04/mergerfs-816x346.png
|
||||
[2]: https://github.com/trapexit/mergerfs
|
||||
[3]: https://github.com/trapexit/mergerfs/releases
|
||||
[4]: https://github.com/trapexit/mergerfs/releases/download/2.29.0/mergerfs-2.29.0-1.fc31.x86_64.rpm
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (13 tips for getting your talk accepted at a tech conference)
|
||||
[#]: via: (https://opensource.com/article/20/5/tips-conference-proposals)
|
||||
[#]: author: (Todd Lewis https://opensource.com/users/toddlewis)
|
||||
|
||||
13 tips for getting your talk accepted at a tech conference
|
||||
======
|
||||
Before you respond to an event's call for papers, make sure your talk's
|
||||
proposal aligns with these best practices.
|
||||
![All Things Open check-in at registration booth][1]
|
||||
|
||||
As tech conference organizers ramp up for the fall season, you may be seeing calls for papers (CFP) landing in your email box or social media feeds. We at [All Things Open][2] (ATO) have seen a lot of presentation proposals over the years, and we've learned a few things about what makes them successful.
|
||||
|
||||
As we prepare for the eighth annual ATO in October 2020, we thought we'd offer a few best practices for writing successful CFP responses. If you're considering submitting a talk to ATO or another tech event, we hope these tips will help improve the chances that your proposal will be accepted.
|
||||
|
||||
### 1\. Know the event you're submitting a talk to
|
||||
|
||||
This seems like the proverbial _no-brainer_, but some people don't take the time to research an event before they submit a talk. Peruse the conference's website and review the talks, speakers, topics, etc. featured in the last couple of years. You can also find a lot of information simply by googling. The time you invest here will help you avoid a submission that is completely out of context for the event.
|
||||
|
||||
### 2\. Understand what the event is looking for
|
||||
|
||||
Look for information about what the event is looking for and what types of topics or talks it expects will be a good fit. We try to provide as much information as possible about the [ATO conference][3], [why someone would want to speak][4], and [what we're looking for][5] (both general and special interest topics). We also try to make the submission process as easy as possible (no doubt, there is room for improvement), in part because we believe this improves the quality of submissions and makes our review process go more smoothly.
|
||||
|
||||
### 3\. Reach out to the organizer and ask questions
|
||||
|
||||
If you're considering submitting a talk, don't hesitate to reach out and ask the event organizers any questions you have and for guidance specific to the event. If there is no or little response, that should be a red flag. If you have any questions about All Things Open, please reach out directly at [info@allthingsopen.org][6].
|
||||
|
||||
### 4\. Be clear about what attendees will learn from your talk
|
||||
|
||||
This is one of the most common mistakes we see. Only about 25% of the proposals we receive clearly explain the proposed talk's takeaways. One reason you should include this is that nearly every event attendee makes their schedule based on what they will learn if they go to a session. But for organizers and proposal reviewers, having this information clearly stated upfront is pure gold. It simplifies and speeds up the assessment process, which gets you one step closer to being accepted as a speaker. A paragraph titled "Attendee Takeaways" with bullet points is the holy grail for everyone involved.
|
||||
|
||||
### 5\. Keep recommended word counts in mind
|
||||
|
||||
This is another mistake we see a lot. Many talks are submitted with either a single sentence description in the abstract or an extraordinary long volume of text. Neither is a good idea. The only exception we can think of is when a topic is very popular or topical, and that alone is enough to win the day even if the abstract is extremely short (but this is rare). Most abstracts should be between 75 and 250 words, and perhaps more for an extended workshop with prerequisites (e.g., preexisting knowledge or required downloads). Even then, try to keep your proposal as sharp, concise, and on-point as possible.
|
||||
|
||||
Disregard this advice at your own risk; otherwise, there's a high likelihood that your proposal will be met with one of these reactions from reviewers: "They didn't take the time to write any more than this?" or "Sheesh, there's no way I have the time to read all that. I'm going to give it the lowest score and move on."
|
||||
|
||||
### 6\. Choose a good title
|
||||
|
||||
This is a debate we see all the time: Should a talk's title describe what the talk is about, or should it be written to stand out and get attention (e.g., evoking emotion, anchoring to a popular pop culture topic, or asking a compelling question)? There isn't a single correct answer to this question, but we definitely know when a title "works" and when it doesn't. We've seen some very creative titles work well and generate interest, and we've seen very straightforward titles work well, also.
|
||||
|
||||
Here is our rule of thumb: If the talk covers a topic that has been around a while and is not particularly _hot_ right now, try getting creative and spicing it up a bit. If the topic is newer, a more straightforward title describing the talk in plain terms should be good.
|
||||
|
||||
Titles on an event schedule may be the only thing attendees use to decide what talks to attend. So, run your potential talk titles by colleagues and friends, and seek their opinions. Ask: "If you were attending an event and saw this title on the schedule, would it pique your interest?"
|
||||
|
||||
### 7\. Know the basic criteria that reviewers and organizers use to make decisions
|
||||
|
||||
While this isn't a comprehensive list of review criteria, most reviewers and organizers consider one or more of the following when evaluating talk proposals. Therefore, at minimum, consider this list when you're creating a talk and the components that go with it.
|
||||
|
||||
1. **Timeliness of and estimated interest in the topic:** Is the topic applicable to the session's target audience? Will it deliver value? Is it timely?
|
||||
2. **Educational value:** Based on the abstract and speaker, is it clear that attendees will learn something from the talk? As mentioned in item 4 above, including an "Attendee Takeaways" section is really helpful to establish educational value.
|
||||
3. **Technical value:** Is the technology you intend to showcase applicable, unique, or being used in a new and creative way? Is there a live demo or a hands-on component? While some topics don't lend themselves to a demo, most people are visual learners and are better off if a presentation includes one (if it's relevant). For this reason, we place a lot of value on demos and hands-on content.
|
||||
4. **Diversity:** Yes, there are exceptions, but the majority of events, reviewers, and organizers agree that having a diverse speaker lineup is optimal and results in a better overall event in multiple ways. A topic delivered from a different perspective can often lead to creative breakthroughs for attendees, which is a huge value-add. See item 10 below for more on this.
|
||||
5. **Talk difficulty level:** We identify All Things Open talks as introductory, intermediate, or advanced. Having a good mix of talk levels ensures everyone in attendance can access applicable content. See item 9 below for more on this, but in general, it's smart to indicate your talk's level, whether or not the CFP requests it.
|
||||
|
||||
|
||||
|
||||
### 8\. Stay current on the event's industry or sector
|
||||
|
||||
Submitting a proposal on a relevant topic increases the probability your talk will be accepted. But how do you know what topics are of interest, especially if the CFP doesn't spell it out in simple terms? The best way to know what's timely and interesting is to deeply understand the sector the event focuses on.
|
||||
|
||||
Yes, this requires time and effort, and it implies you enjoy the sector enough to stay current on it, but it will pay off. This knowledge will result in a higher _sector IQ_, which will be reflected in your topic, title, and abstract. It will be recognized by reviewers and immediately set you apart from others. At All Things Open, we spend the majority of our time reading about and staying current on the "open" space so that we can feature relevant, substantive, and informed content. Submitting a talk that is relevant, substantive, and informed greatly enhances the chance it will be accepted.
|
||||
|
||||
### 9\. Describe whether the talk is introductory, intermediate, or advanced
|
||||
|
||||
Some CFPs don't ask for this information, but you should offer it anyway. It will make the reviewers and organizer very happy for multiple reasons, including these:
|
||||
|
||||
1. Unless the event targets attendees with a certain skill or experience level (and most do not), organizers must include content that is appealing to a wide audience, including people of all skill, experience, and expertise levels. Even if an event focuses on a specific type of attendee (perhaps people with higher levels of experience or skills), most want to offer something a little different. Listing the talk level makes this much easier for organizers.
|
||||
2. News flash: Reviewers and organizers don't know everything and are not experts in every possible topic area. As a result, reviewers will sometimes look for a few keywords or other criteria, and adding the talk level can "seal the deal" and get your talk confirmed.
|
||||
|
||||
|
||||
|
||||
### 10\. Tell organizers if you're a member of a historically underrepresented group
|
||||
|
||||
A growing number of events are getting better at recognizing the value of diversity and ensuring their speaker lineup reflects it. If you're part of a group that hasn't typically been included in tech events and leadership, look to see if there is a place to indicate that on the submission form. If not, mention it in a conspicuous place somewhere in the abstract. This does not guarantee approval in any way—your proposal must still be well-written and relevant—but it does give reviewers and organizers pertinent information they may value and take into consideration.
|
||||
|
||||
### 11\. Don't be ashamed of your credentials or speaking experience if it is light
|
||||
|
||||
We talk to a lot of people who would like to deliver a presentation and have a lot to offer, but they never submit a talk because they don't feel they're qualified to speak. _Not true._ Some of the best talks we've seen are from first-time speakers or those very early in their speaking careers. Go ahead and submit the talk, and be honest when discussing your background. Most reviewers and organizers will focus on the substance of the submission over your experience and recognize that new ways of approaching and using technology often come from newbies rather than industry veterans.
|
||||
|
||||
One caveat here: It still pays to know yourself. By this, we mean if you absolutely hate public speaking, have no desire to do it, and are only considering submitting a talk due to, for example, pressure from an employer, the talk is not likely to go well. It's better, to be honest, on the frontend than force something you have no desire to do.
|
||||
|
||||
### 12\. Consider panel sessions carefully
|
||||
|
||||
If you've got an idea for a panel session, please consider it carefully. In more than 10 years of hosting events we've seen some really good panel sessions, but we've seen far more that didn't go so well. Perhaps too many people were on the panel and not everyone had a chance to speak, perhaps a single panel member dominated the entire conversation, or perhaps the moderator didn't keep the dialogue and engagement flowing smoothly. Regardless of the issue, panels have the potential to go very wrong.
|
||||
|
||||
That said, panels can still work and deliver a lot of value to attendees. If you do submit a panel session be sure to keep in mind the amount of time allotted for the session and confirm the number of panel members accordingly. Remember, less is always more when it comes to the panel format. Also, be sure the moderator understands the subject matter being discussed and doesn't mind enforcing format parameters and speaking time limits. Finally, let organizers know panel members and the moderator will engage in a pre-conference walk-through/preparation call before the event to ensure a smooth process in front of a live audience. Remember, organizers are well aware panels can be terrific but can also go in the opposite direction and very easily lead to a lot of negative feedback.
|
||||
|
||||
### 13\. This is not an opportunity to sell
|
||||
|
||||
This is a sensitive topic, but one that absolutely must be mentioned. Over the years we've seen literally hundreds of talks "disqualified" by reviewers because they viewed the talk as a sales pitch. Few things evoke such a visceral response. Yes, there are events, tracks, and session slots where a sales pitch is appropriate (and maybe even required by the company paying your costs). However, make it a priority to know when and where this is appropriate and acceptable. And always, and we mean always, err on the side of making substance the focus of the talk rather than a sales angle.
|
||||
|
||||
It might sound like a cliche, but when a talk is delivered effectively with a focus on substance, people will **want** to buy what you're selling. And if you're not selling anything, they'll want to follow you on social media and generally engage with you—because you delivered value to them. Meaning: You gave them something they can apply themselves (education) or because your delivery style was entertaining and engaging. With rare exceptions, always focus any abstract on substance, and the rest will take care of itself.
|
||||
|
||||
### Go for it!
|
||||
|
||||
We greatly admire and respect anyone who submits a talk for consideration—it takes a lot of time, thought, and courage. Therefore, we go to great lengths to thank everyone who goes through the process; we give free event passes to everyone who applies (regardless of approval or rejection), and we make every effort to host Q&A sessions to provide as much guidance as possible on the front end. Again, the more time and consideration speakers put into the submission process, the easier the lives of reviewers and organizers. We need to make all of this as easy as possible.
|
||||
|
||||
While this is not a comprehensive list of best practices, it includes some of the things we think people can benefit from knowing before submitting a talk. There are a lot of people out there with more knowledge and experience, so please share your best tips for submitting conference proposals in the comments, so we can all learn from you.
|
||||
|
||||
* * *
|
||||
|
||||
_[All Things Open][2] is a universe of platforms and events focusing on open source, open tech, and the open web. It hosts the [All Things Open conference][3], the largest open source/tech/web event on the US East Coast. The conference regularly hosts thousands of attendees and many of the world's most influential companies from a wide variety of industries and sectors. In 2019, nearly 5,000 people attended from 41 US states and 24 countries. Please direct inquiries about ATO to the team at [info@allthingsopen.org][6]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/tips-conference-proposals
|
||||
|
||||
作者:[Todd Lewis][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/toddlewis
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/ato2016_checkin_conference.jpg?itok=DJtoSS6t (All Things Open check-in at registration booth)
|
||||
[2]: https://www.allthingsopen.org/
|
||||
[3]: https://2020.allthingsopen.org/
|
||||
[4]: https://2020.allthingsopen.org/call-for-speakers
|
||||
[5]: https://www.allthingsopen.org/what-were-looking-for/
|
||||
[6]: mailto:info@allthingsopen.org
|
||||
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (4 cool new projects to try in COPR for May 2020)
|
||||
[#]: via: (https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-april-2020/)
|
||||
[#]: author: (Dominik Turecek https://fedoramagazine.org/author/dturecek/)
|
||||
|
||||
4 cool new projects to try in COPR for May 2020
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
COPR is a [collection][2] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
This article presents a few new and interesting projects in COPR. If you’re new to using COPR, see the [COPR User Documentation][3] for how to get started.
|
||||
|
||||
### Ytop
|
||||
|
||||
[Ytop][4] is a command-line system monitor similar to _htop_. The main difference between them is that _ytop_, on top of showing processes and their CPU and memory usage, shows graphs of system CPU, memory, and network usage over time. Additionally, _ytop_ shows disk usage and temperatures of the machine. Finally, _ytop_ supports multiple color schemes as well as an option to create new ones.
|
||||
|
||||
![][5]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The [repo][6] currently provides _ytop_ for Fedora 30, 31, 32, and Rawhide, as well as EPEL 7. To install _ytop_, use these commands [with _sudo_][7]:
|
||||
|
||||
```
|
||||
sudo dnf copr enable atim/ytop
|
||||
sudo dnf install ytop
|
||||
```
|
||||
|
||||
### Ctop
|
||||
|
||||
[Ctop][8] is yet another command-line system monitor. However, unlike _htop_ and _ytop_, _ctop_ focuses on showing resource usage of containers. _Ctop_ shows both an overview of CPU, memory, network and disk usage of all containers running on your machine, and more comprehensive information about a single container, including graphs of resource usage over time. Currently, _ctop_ has support for Docker and runc containers.
|
||||
|
||||
![][9]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The [repo][10] currently provides _ctop_ for Fedora 31, 32 and Rawhide, EPEL 7, as well as for other distributions. To install _ctop_, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable fuhrmann/ctop
|
||||
sudo dnf install ctop
|
||||
```
|
||||
|
||||
### Shortwave
|
||||
|
||||
[Shortwave][11] is a program for listening to radio stations. Shortwave uses a community database of radio stations [www.radio-browser.info][12]. In this database, you can discover or search for radio stations, add them to your library, and listen to them. Additionally, Shortwave provides information about currently playing song and can record the songs as well.
|
||||
|
||||
![][13]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The [repo][14] currently provides Shortwave for Fedora 31, 32, and Rawhide. To install Shortwave, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable atim/shortwave
|
||||
sudo dnf install shortwave
|
||||
```
|
||||
|
||||
### Setzer
|
||||
|
||||
[Setzer][15] is a LaTeX editor that can build pdf documents and view them as well. It provides templates for various types of documents, such as articles or presentation slides. Additionally, Setzer has buttons for a lot of special symbols, math symbols and greek letters.
|
||||
|
||||
![][16]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The [repo][17] currently provides Setzer for Fedora 30, 31, 32, and Rawhide. To install Setzer, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable lyessaadi/setzer
|
||||
sudo dnf install setzer
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-april-2020/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/dturecek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2017/08/4-copr-945x400.jpg
|
||||
[2]: https://copr.fedorainfracloud.org/
|
||||
[3]: https://docs.pagure.org/copr.copr/user_documentation.html#
|
||||
[4]: https://github.com/cjbassi/ytop
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2020/04/ytop.png
|
||||
[6]: https://copr.fedorainfracloud.org/coprs/atim/ytop/
|
||||
[7]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[8]: https://github.com/bcicen/ctop
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2020/04/ctop.png
|
||||
[10]: https://copr.fedorainfracloud.org/coprs/fuhrmann/ctop/
|
||||
[11]: https://github.com/ranfdev/shortwave
|
||||
[12]: http://www.radio-browser.info/gui/#!/
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2020/04/shortwave.png
|
||||
[14]: https://copr.fedorainfracloud.org/coprs/atim/shortwave/
|
||||
[15]: https://www.cvfosammmm.org/setzer/
|
||||
[16]: https://fedoramagazine.org/wp-content/uploads/2020/04/setzer.png
|
||||
[17]: https://copr.fedorainfracloud.org/coprs/lyessaadi/setzer/
|
||||
@ -0,0 +1,123 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create interactive learning games for kids with open source)
|
||||
[#]: via: (https://opensource.com/article/20/5/jclic-games-kids)
|
||||
[#]: author: (Peter Cheer https://opensource.com/users/petercheer)
|
||||
|
||||
Create interactive learning games for kids with open source
|
||||
======
|
||||
Help your students learn by creating fun puzzles and games in JClic, an
|
||||
easy Java-based app.
|
||||
![Family learning and reading together at night in a room][1]
|
||||
|
||||
Schools are closed in many countries around the world to slow the spread of COVID-19. This has suddenly thrown many parents and teachers into homeschooling. Fortunately, there are plenty of educational resources on the internet to use or adapt, although their licenses vary. You can try searching for Creative Commons Open Educational Resources, but if you want to create your own materials, there are many options for that to.
|
||||
|
||||
If you want to create digital educational activities with puzzles or tests, two easy-to-use, open source, cross-platform applications that fit the bill are eXeLearning and JClic. My earlier article on [eXeLearning][2] is a good introduction to that program, so here I'll look at [JClic][3]. It is an open source software project for creating various types of interactive activities such as associations, text-based activities, crosswords, and other puzzles with text, graphics, and multimedia elements.
|
||||
|
||||
Although it's been around since the 1990s, JClic never developed a large user base in the English-speaking world. It was created in Catalonia by the [Catalan Educational Telematic Network][4] (XTEC).
|
||||
|
||||
### About JClic
|
||||
|
||||
JClic is a Java-based application that's available in many Linux repositories and can be downloaded from [GitHub][5]. It runs on Linux, macOS, and Windows, but because it is a Java program, you must have a Java runtime environment [installed][6].
|
||||
|
||||
The program's interface has not really changed much over the years, even while features have been added or dropped, such as introducing HTML5 export functionality to replace Java Applet technology for web-based deployment. It hasn't needed to change much, though, because it's very effective at what it does.
|
||||
|
||||
### Creating a JClic project
|
||||
|
||||
Many teachers from many countries have used JClic to create interactive materials for a wide variety of ability levels, subjects, languages, and curricula. Some of these materials have been collected in an [downloadable activities library][7]. Although few activities are in English, you can get a sense of the possibilities JClic offers.
|
||||
|
||||
As JClic has a visual, point-and-click program interface, it is easy enough to learn that a new user can quickly concentrate on content creation. [Documentation][8] is available on GitHub.
|
||||
|
||||
The screenshots below are from one of the JClic projects I created to teach basic Excel skills to learners in Papua New Guinea.
|
||||
|
||||
A JClic project is created in its authoring tool and consists of the following four elements:
|
||||
|
||||
#### 1\. Metadata about the project
|
||||
|
||||
![JClic metadata][9]
|
||||
|
||||
#### 2\. A library of the graphical and other resources it uses
|
||||
|
||||
![JClic media][10]
|
||||
|
||||
#### 3\. A series of one or more activities
|
||||
|
||||
![JClic activities][11]
|
||||
|
||||
JClic can produce seven different activity types:
|
||||
|
||||
* Associations where the user discovers the relationships between two information sets
|
||||
* Memory games where the user discovers pairs of identical elements or relations (which are hidden) between them
|
||||
* Exploration activities involving the identification and information, based on a single Information set
|
||||
* Puzzles where the user reconstructs information that is initially presented in a disordered form; the activity can include graphics, text, sound, or a combination of them
|
||||
* Written-response activities that are solved by writing text, either a single word or a sentence
|
||||
* Text activities that are based on words, phrases, letters, and paragraphs of text that need to be completed, understood, corrected, or ordered; these activities can contain images and windows with active content
|
||||
* Word searches and crosswords
|
||||
|
||||
|
||||
|
||||
Because of variants in the activities, there are 16 possible activity types.
|
||||
|
||||
#### 4\. A timeline to sequence the activities
|
||||
|
||||
![JClic timeline][12]
|
||||
|
||||
### Using JClic content
|
||||
|
||||
Projects can run in JClic's player (part of the Java application you used to create the project), or they can be exported to HTML5 so they can run in a web browser.
|
||||
|
||||
The one thing I don't like about JClic is that its default HTML5 export function assumes you'll be online when running a project. If you want a project to work offline as needed, you must download a compiled and minified HTML5 player from [Github][13], and place it in the same folder as your JClic project.
|
||||
|
||||
Next, open the **index.html** file in a text editor and replace this line:
|
||||
|
||||
|
||||
```
|
||||
`<script type="text/javascript" src="https://clic.xtec.cat/dist/jclic.js/jclic.min.js"></script>`
|
||||
```
|
||||
|
||||
With:
|
||||
|
||||
|
||||
```
|
||||
`<script type="text/javascript" src="jclic.min.js"></script>`
|
||||
```
|
||||
|
||||
Now the HTML5 version of your project runs in a web browser, whether the user is online or not.
|
||||
|
||||
JClic also provides a reports function that can store test scores in an ODBC-compliant database. I have not explored this feature, as my tests and puzzles are mostly used for self-assessment and to prompt reflection by the learner, rather than as part of a formal scheme, so the scores are not very important. If you would like to learn about it, there is [documentation][14] on running JClic Reports Server with Tomcat and MySQL (or [mariaDB][15]).
|
||||
|
||||
### Conclusion
|
||||
|
||||
JClic offers a wide range of activity types that provide plenty of room to be creative in designing content to fit your subject area and type of learner. JClic is a valuable addition for anyone who needs a quick and easy way to develop educational resources.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/jclic-games-kids
|
||||
|
||||
作者:[Peter Cheer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/petercheer
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/family_learning_kids_night_reading.png?itok=6K7sJVb1 (Family learning and reading together at night in a room)
|
||||
[2]: https://opensource.com/article/18/5/exelearning
|
||||
[3]: https://clic.xtec.cat/legacy/en/jclic/index.html
|
||||
[4]: https://clic.xtec.cat/legacy/en/index.html
|
||||
[5]: https://github.com/projectestac/jclic
|
||||
[6]: https://adoptopenjdk.net/installation.html
|
||||
[7]: https://clic.xtec.cat/repo/
|
||||
[8]: https://github.com/projectestac/jclic/wiki/JClic_Guide
|
||||
[9]: https://opensource.com/sites/default/files/uploads/metadata.png (JClic metadata)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/media.png (JClic media)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/activities.png (JClic activities)
|
||||
[12]: https://opensource.com/sites/default/files/uploads/sequence.png (JClic timeline)
|
||||
[13]: http://projectestac.github.io/jclic.js/
|
||||
[14]: https://github.com/projectestac/jclic/wiki/Jclic-Reports-Server-with-Tomcat-and-MySQL-on-Ubuntu
|
||||
[15]: https://mariadb.org/
|
||||
@ -0,0 +1,150 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Define and optimize data partitions in Apache Cassandra)
|
||||
[#]: via: (https://opensource.com/article/20/5/apache-cassandra)
|
||||
[#]: author: (Anil Inamdar https://opensource.com/users/anil-inamdar)
|
||||
|
||||
Define and optimize data partitions in Apache Cassandra
|
||||
======
|
||||
Apache Cassandra is built for speed and scalability; here's how to get
|
||||
the most out of those benefits.
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
Apache Cassandra is a database. But it's not just any database; it's a replicating database designed and tuned for scalability, high availability, low-latency, and performance. Cassandra can help your data survive regional outages, hardware failure, and what many admins would consider excessive amounts of data.
|
||||
|
||||
Having a thorough command of data partitions enables you to achieve superior Cassandra cluster design, performance, and scalability. In this article, I'll examine how to define partitions and how Cassandra uses them, as well as the most critical best practices and known issues you ought to be aware of.
|
||||
|
||||
To set the scene: partitions are chunks of data that serve as the atomic unit for key database-related functions like data distribution, replication, and indexing. Distributed data systems commonly distribute incoming data into these partitions, performing the partitioning with simple mathematical functions such as identity or hashing, and using a "partition key" to group data by partition. For example, consider a case where server logs arrive as incoming data. Using the "identity" partitioning function and the timestamps of each log (rounded to the hour value) for the partition key, we can partition this data such that each partition holds one hour of the logs.
|
||||
|
||||
### Data partitions in Cassandra
|
||||
|
||||
Cassandra operates as a distributed system and adheres to the data partitioning principles described above. With Cassandra, data partitioning relies on an algorithm configured at the cluster level, and a partition key configured at the table level.
|
||||
|
||||
![Cassandra data partition][2]
|
||||
|
||||
Cassandra Query Language (CQL) uses the familiar SQL table, row, and column terminologies. In the example diagram above, the table configuration includes the partition key within its primary key, with the format: Primary Key = Partition Key + [Clustering Columns].
|
||||
|
||||
A primary key in Cassandra represents both a unique data partition and a data arrangement inside a partition. Data arrangement information is provided by optional clustering columns. Each unique partition key represents a set of table rows managed in a server, as well as all servers that manage its replicas.
|
||||
|
||||
### Defining primary keys in CQL
|
||||
|
||||
The following four examples demonstrate how a primary key can be represented in CQL syntax. The sets of rows produced by these definitions are generally considered a partition.
|
||||
|
||||
#### Definition 1 (partition key: log_hour, clustering columns: none)
|
||||
|
||||
|
||||
```
|
||||
CREATE TABLE server_logs(
|
||||
log_hour TIMESTAMP PRIMARYKEY,
|
||||
log_level text,
|
||||
message text,
|
||||
server text
|
||||
)
|
||||
```
|
||||
|
||||
Here, all rows that share a **log_hour** go into the same partition.
|
||||
|
||||
#### Definition 2 (partition key: log_hour, clustering columns: log_level)
|
||||
|
||||
|
||||
```
|
||||
CREATE TABLE server_logs(
|
||||
log_hour TIMESTAMP,
|
||||
log_level text,
|
||||
message text,
|
||||
server text,
|
||||
PRIMARY KEY (log_hour, log_level)
|
||||
)
|
||||
```
|
||||
|
||||
This definition uses the same partition key as Definition 1, but here all rows in each partition are arranged in ascending order by **log_level**.
|
||||
|
||||
#### Definition 3 (partition key: log_hour, server, clustering columns: none)
|
||||
|
||||
|
||||
```
|
||||
CREATE TABLE server_logs(
|
||||
log_hour TIMESTAMP,
|
||||
log_level text,
|
||||
message text,
|
||||
server text,
|
||||
PRIMARY KEY ((log_hour, server))
|
||||
)
|
||||
```
|
||||
|
||||
In this definition, all rows share a **log_hour** for each distinct **server** as a single partition.
|
||||
|
||||
#### Definition 4 (partition key: log_hour, server, clustering columns: log_level)
|
||||
|
||||
|
||||
```
|
||||
CREATE TABLE server_logs(
|
||||
log_hour TIMESTAMP,
|
||||
log_level text,
|
||||
message text,
|
||||
server text,
|
||||
PRIMARY KEY ((log_hour, server),log_level)
|
||||
)WITH CLUSTERING ORDER BY (column3 DESC);
|
||||
```
|
||||
|
||||
This definition uses the same partition as Definition 3 but arranges the rows within a partition in descending order by **log_level**.
|
||||
|
||||
### How Cassandra uses the partition key
|
||||
|
||||
Cassandra relies on the partition key to determine which node to store data on and where to locate data when it's needed. Cassandra performs these read and write operations by looking at a partition key in a table, and using tokens (a long value out of range -2^63 to +2^63-1) for data distribution and indexing. These tokens are mapped to partition keys by using a partitioner, which applies a partitioning function that converts any partition key to a token. Through this token mechanism, every node of a Cassandra cluster owns a set of data partitions. The partition key then enables data indexing on each node.
|
||||
|
||||
![Cassandra cluster with 3 nodes and token-based ownership][3]
|
||||
|
||||
A Cassandra cluster with three nodes and token-based ownership. This is a simplistic representation: the actual implementation uses [Vnodes][4].
|
||||
|
||||
### Data partition impacts on Cassandra clusters
|
||||
|
||||
Careful partition key design is crucial to achieving the ideal partition size for the use case. Getting it right allows for even data distribution and strong I/O performance. Partition size has several impacts on Cassandra clusters you need to be aware of:
|
||||
|
||||
* Read performance—In order to find partitions in SSTables files on disk, Cassandra uses data structures that include caches, indexes, and index summaries. Partitions that are too large reduce the efficiency of maintaining these data structures – and will negatively impact performance as a result. Cassandra releases have made strides in this area: in particular, version 3.6 and above of the Cassandra engine introduce storage improvements that deliver better performance for large partitions and resilience against memory issues and crashes.
|
||||
* Memory usage— Large partitions place greater pressure on the JVM heap, increasing its size while also making the garbage collection mechanism less efficient.
|
||||
* Cassandra repairs—Large partitions make it more difficult for Cassandra to perform its repair maintenance operations, which keep data consistent by comparing data across replicas.
|
||||
* Tombstone eviction—Not as mean as it sounds, Cassandra uses unique markers known as "tombstones" to mark data for deletion. Large partitions can make that deletion process more difficult if there isn't an appropriate data deletion pattern and compaction strategy in place.
|
||||
|
||||
|
||||
|
||||
While these impacts may make it tempting to simply design partition keys that yield especially small partitions, the data access pattern is also highly influential on ideal partition size (for more information, read this in-depth guide to [Cassandra data modeling][5]). The data access pattern can be defined as how a table is queried, including all of the table's **select** queries. Ideally, CQL select queries should have just one partition key in the **where** clause—that is to say, Cassandra is most efficient when queries can get needed data from a single partition, instead of many smaller ones.
|
||||
|
||||
### Best practices for partition key design
|
||||
|
||||
Following best practices for partition key design helps you get to an ideal partition size. As a rule of thumb, the maximum partition size in Cassandra should stay under 100MB. Ideally, it should be under 10MB. While Cassandra versions 3.6 and newer make larger partition sizes more viable, careful testing and benchmarking must be performed for each workload to ensure a partition key design supports desired cluster performance.
|
||||
|
||||
Specifically, these best practices should be considered as part of any partition key design:
|
||||
|
||||
* The goal for a partition key must be to fit an ideal amount of data into each partition for supporting the needs of its access pattern.
|
||||
* A partition key should disallow unbounded partitions: those that may grow indefinitely in size over time. For instance, in the **server_logs** examples above, using the server column as a partition key would create unbounded partitions as the number of server logs continues to increase. In contrast, using **log_hour** limits each partition to an hour of data.
|
||||
* A partition key should also avoid creating a partition skew, in which partitions grow unevenly, and some are able to grow without limit over time. In the **server_logs** examples, using the server column in a scenario where one server generates considerably more logs than others would produce a partition skew. To avoid this, a useful technique is to introduce another attribute from the table to force an even distribution, even if it's necessary to create a dummy column to do so.
|
||||
* It's helpful to partition time-series data with a partition key that uses a time element as well as other attributes. This protects against unbounded partitions, enables access patterns to use the time attribute in querying specific data, and allows for time-bound data deletion. The examples above each demonstrate this by using the **log_hour** time attribute.
|
||||
|
||||
|
||||
|
||||
Several tools are available to help test, analyze, and monitor Cassandra partitions to check that a chosen schema is efficient and effective. By carefully designing partition keys to align well with the data and needs of the solution at hand, and following best practices to optimize partition size, you can utilize data partitions that more fully deliver on the scalability and performance potential of a Cassandra deployment.
|
||||
|
||||
Dani and Jon will give a three hour tutorial at OSCON this year called: Becoming friends with...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/apache-cassandra
|
||||
|
||||
作者:[Anil Inamdar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/anil-inamdar
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/apache_cassandra_1_0.png (Cassandra data partition)
|
||||
[3]: https://opensource.com/sites/default/files/uploads/apache_cassandra_2_0.png (Cassandra cluster with 3 nodes and token-based ownership)
|
||||
[4]: https://www.instaclustr.com/cassandra-vnodes-how-many-should-i-use/
|
||||
[5]: https://www.instaclustr.com/resource/6-step-guide-to-apache-cassandra-data-modelling-white-paper/
|
||||
@ -0,0 +1,445 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Understanding systemd at startup on Linux)
|
||||
[#]: via: (https://opensource.com/article/20/5/systemd-startup)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
Understanding systemd at startup on Linux
|
||||
======
|
||||
systemd's startup provides important clues to help you solve problems
|
||||
when they occur.
|
||||
![People at the start line of a race][1]
|
||||
|
||||
In [_Learning to love systemd_][2], the first article in this series, I looked at systemd's functions and architecture and the controversy around its role as a replacement for the old SystemV init program and startup scripts. In this second article, I'll start exploring the files and tools that manage the Linux startup sequence. I'll explain the systemd startup sequence, how to change the default startup target (runlevel in SystemV terms), and how to manually switch to a different target without going through a reboot.
|
||||
|
||||
I'll also look at two important systemd tools. The first is the **systemctl** command, which is the primary means of interacting with and sending commands to systemd. The second is **journalctl**, which provides access to the systemd journals that contain huge amounts of system history data such as kernel and service messages (both informational and error messages).
|
||||
|
||||
Be sure to use a non-production system for testing and experimentation in this and future articles. Your test system needs to have a GUI desktop (such as Xfce, LXDE, Gnome, KDE, or another) installed.
|
||||
|
||||
I wrote in my previous article that I planned to look at creating a systemd unit and adding it to the startup sequence in this article. Because this article became longer than I anticipated, I will hold that for the next article in this series.
|
||||
|
||||
### Exploring Linux startup with systemd
|
||||
|
||||
Before you can observe the startup sequence, you need to do a couple of things to make the boot and startup sequences open and visible. Normally, most distributions use a startup animation or splash screen to hide the detailed messages that would otherwise be displayed during a Linux host's startup and shutdown. This is called the Plymouth boot screen on Red Hat-based distros. Those hidden messages can provide a great deal of information about startup and shutdown to a sysadmin looking for information to troubleshoot a bug or to just learn about the startup sequence. You can change this using the GRUB (Grand Unified Boot Loader) configuration.
|
||||
|
||||
The main GRUB configuration file is **/boot/grub2/grub.cfg**, but, because this file can be overwritten when the kernel version is updated, you do not want to change it. Instead, modify the **/etc/default/grub** file, which is used to modify the default settings of **grub.cfg**.
|
||||
|
||||
Start by looking at the current, unmodified version of the **/etc/default/grub** file:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# cd /etc/default ; cat grub
|
||||
GRUB_TIMEOUT=5
|
||||
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
|
||||
GRUB_DEFAULT=saved
|
||||
GRUB_DISABLE_SUBMENU=true
|
||||
GRUB_TERMINAL_OUTPUT="console"
|
||||
GRUB_CMDLINE_LINUX="resume=/dev/mapper/fedora_testvm1-swap rd.lvm.
|
||||
lv=fedora_testvm1/root rd.lvm.lv=fedora_testvm1/swap rd.lvm.lv=fedora_
|
||||
testvm1/usr rhgb quiet"
|
||||
GRUB_DISABLE_RECOVERY="true"
|
||||
[root@testvm1 default]#
|
||||
```
|
||||
|
||||
Chapter 6 of the [GRUB documentation][3] contains a list of all the possible entries in the **/etc/default/grub** file, but I focus on the following:
|
||||
|
||||
* I change **GRUB_TIMEOUT**, the number of seconds for the GRUB menu countdown, from five to 10 to give a bit more time to respond to the GRUB menu before the countdown hits zero.
|
||||
* I delete the last two parameters on **GRUB_CMDLINE_LINUX**, which lists the command-line parameters that are passed to the kernel at boot time. One of these parameters, **rhgb** stands for Red Hat Graphical Boot, and it displays the little Fedora icon animation during the kernel initialization instead of showing boot-time messages. The other, the **quiet** parameter, prevents displaying the startup messages that document the progress of the startup and any errors that occur. I delete both **rhgb** and **quiet** because sysadmins need to see these messages. If something goes wrong during boot, the messages displayed on the screen can point to the cause of the problem.
|
||||
|
||||
|
||||
|
||||
After you make these changes, your GRUB file will look like:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 default]# cat grub
|
||||
GRUB_TIMEOUT=10
|
||||
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
|
||||
GRUB_DEFAULT=saved
|
||||
GRUB_DISABLE_SUBMENU=true
|
||||
GRUB_TERMINAL_OUTPUT="console"
|
||||
GRUB_CMDLINE_LINUX="resume=/dev/mapper/fedora_testvm1-swap rd.lvm.
|
||||
lv=fedora_testvm1/root rd.lvm.lv=fedora_testvm1/swap rd.lvm.lv=fedora_
|
||||
testvm1/usr"
|
||||
GRUB_DISABLE_RECOVERY="false"
|
||||
[root@testvm1 default]#
|
||||
```
|
||||
|
||||
The **grub2-mkconfig** program generates the **grub.cfg** configuration file using the contents of the **/etc/default/grub** file to modify some of the default GRUB settings. The **grub2-mkconfig** program sends its output to **STDOUT**. It has a **-o** option that allows you to specify a file to send the datastream to, but it is just as easy to use redirection. Run the following command to update the **/boot/grub2/grub.cfg** configuration file:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 grub2]# grub2-mkconfig > /boot/grub2/grub.cfg
|
||||
Generating grub configuration file ...
|
||||
Found linux image: /boot/vmlinuz-4.18.9-200.fc28.x86_64
|
||||
Found initrd image: /boot/initramfs-4.18.9-200.fc28.x86_64.img
|
||||
Found linux image: /boot/vmlinuz-4.17.14-202.fc28.x86_64
|
||||
Found initrd image: /boot/initramfs-4.17.14-202.fc28.x86_64.img
|
||||
Found linux image: /boot/vmlinuz-4.16.3-301.fc28.x86_64
|
||||
Found initrd image: /boot/initramfs-4.16.3-301.fc28.x86_64.img
|
||||
Found linux image: /boot/vmlinuz-0-rescue-7f12524278bd40e9b10a085bc82dc504
|
||||
Found initrd image: /boot/initramfs-0-rescue-7f12524278bd40e9b10a085bc82dc504.img
|
||||
done
|
||||
[root@testvm1 grub2]#
|
||||
```
|
||||
|
||||
Reboot your test system to view the startup messages that would otherwise be hidden behind the Plymouth boot animation. But what if you need to view the startup messages and have not disabled the Plymouth boot animation? Or you have, but the messages stream by too fast to read? (Which they do.)
|
||||
|
||||
There are a couple of options, and both involve log files and systemd journals—which are your friends. You can use the **less** command to view the contents of the **/var/log/messages** file. This file contains boot and startup messages as well as messages generated by the operating system during normal operation. You can also use the **journalctl** command without any options to view the systemd journal, which contains essentially the same information:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 grub2]# journalctl
|
||||
\-- Logs begin at Sat 2020-01-11 21:48:08 EST, end at Fri 2020-04-03 08:54:30 EDT. --
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: Linux version 5.3.7-301.fc31.x86_64 ([mockbuild@bkernel03.phx2.fedoraproject.org][4]) (gcc version 9.2.1 20190827 (Red Hat 9.2.1-1) (GCC)) #1 SMP Mon Oct >
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: Command line: BOOT_IMAGE=(hd0,msdos1)/vmlinuz-5.3.7-301.fc31.x86_64 root=/dev/mapper/VG01-root ro resume=/dev/mapper/VG01-swap rd.lvm.lv=VG01/root rd>
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers'
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Supporting XSAVE feature 0x002: 'SSE registers'
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Supporting XSAVE feature 0x004: 'AVX registers'
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Enabled xstate features 0x7, context size is 832 bytes, using 'standard' format.
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-provided physical RAM map:
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x000000000009fc00-0x000000000009ffff] reserved
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x0000000000100000-0x00000000dffeffff] usable
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000dfff0000-0x00000000dfffffff] ACPI data
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000fec00000-0x00000000fec00fff] reserved
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000fee00000-0x00000000fee00fff] reserved
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000fffc0000-0x00000000ffffffff] reserved
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x0000000100000000-0x000000041fffffff] usable
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: NX (Execute Disable) protection: active
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: SMBIOS 2.5 present.
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: DMI: innotek GmbH VirtualBox/VirtualBox, BIOS VirtualBox 12/01/2006
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: Hypervisor detected: KVM
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: kvm-clock: Using msrs 4b564d01 and 4b564d00
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: kvm-clock: cpu 0, msr 30ae01001, primary cpu clock
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: kvm-clock: using sched offset of 8250734066 cycles
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: clocksource: kvm-clock: mask: 0xffffffffffffffff max_cycles: 0x1cd42e4dffb, max_idle_ns: 881590591483 ns
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: tsc: Detected 2807.992 MHz processor
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: e820: update [mem 0x00000000-0x00000fff] usable ==> reserved
|
||||
Jan 11 21:48:08 f31vm.both.org kernel: e820: remove [mem 0x000a0000-0x000fffff] usable
|
||||
<snip>
|
||||
```
|
||||
|
||||
I truncated this datastream because it can be hundreds of thousands or even millions of lines long. (The journal listing on my primary workstation is 1,188,482 lines long.) Be sure to try this on your test system. If it has been running for some time—even if it has been rebooted many times—huge amounts of data will be displayed. Explore this journal data because it contains a lot of information that can be very useful when doing problem determination. Knowing what this data looks like for a normal boot and startup can help you locate problems when they occur.
|
||||
|
||||
I will discuss systemd journals, the **journalctl** command, and how to sort through all of that data to find what you want in more detail in a future article in this series.
|
||||
|
||||
After GRUB loads the kernel into memory, it must first extract itself from the compressed version of the file before it can perform any useful work. After the kernel has extracted itself and started running, it loads systemd and turns control over to it.
|
||||
|
||||
This is the end of the boot process. At this point, the Linux kernel and systemd are running but unable to perform any productive tasks for the end user because nothing else is running, there's no shell to provide a command line, no background processes to manage the network or other communication links, and nothing that enables the computer to perform any productive function.
|
||||
|
||||
Systemd can now load the functional units required to bring the system up to a selected target run state.
|
||||
|
||||
### Targets
|
||||
|
||||
A systemd target represents a Linux system's current or desired run state. Much like SystemV start scripts, targets define the services that must be present for the system to run and be active in that state. Figure 1 shows the possible run-state targets of a Linux system using systemd. As seen in the first article of this series and in the systemd bootup man page (man bootup), there are other intermediate targets that are required to enable various necessary services. These can include **swap.target**, **timers.target**, **local-fs.target**, and more. Some targets (like **basic.target**) are used as checkpoints to ensure that all the required services are up and running before moving on to the next-higher level target.
|
||||
|
||||
Unless otherwise changed at boot time in the GRUB menu, systemd always starts the **default.target**. The **default.target** file is a symbolic link to the true target file. For a desktop workstation, this is typically going to be the **graphical.target**, which is equivalent to runlevel 5 in SystemV. For a server, the default is more likely to be the **multi-user.target**, which is like runlevel 3 in SystemV. The **emergency.target** file is similar to single-user mode. Targets and services are systemd units.
|
||||
|
||||
The following table, which I included in the previous article in this series, compares the systemd targets with the old SystemV startup runlevels. The systemd target aliases are provided by systemd for backward compatibility. The target aliases allow scripts—and sysadmins—to use SystemV commands like **init 3** to change runlevels. Of course, the SystemV commands are forwarded to systemd for interpretation and execution.
|
||||
|
||||
**systemd targets** | **SystemV runlevel** | **target aliases** | **Description**
|
||||
---|---|---|---
|
||||
default.target | | | This target is always aliased with a symbolic link to either **multi-user.target** or **graphical.target**. systemd always uses the **default.target** to start the system. The **default.target** should never be aliased to **halt.target**, **poweroff.target**, or **reboot.target**.
|
||||
graphical.target | 5 | runlevel5.target | **Multi-user.target** with a GUI
|
||||
| 4 | runlevel4.target | Unused. Runlevel 4 was identical to runlevel 3 in the SystemV world. This target could be created and customized to start local services without changing the default **multi-user.target**.
|
||||
multi-user.target | 3 | runlevel3.target | All services running, but command-line interface (CLI) only
|
||||
| 2 | runlevel2.target | Multi-user, without NFS, but all other non-GUI services running
|
||||
rescue.target | 1 | runlevel1.target | A basic system, including mounting the filesystems with only the most basic services running and a rescue shell on the main console
|
||||
emergency.target | S | | Single-user mode—no services are running; filesystems are not mounted. This is the most basic level of operation with only an emergency shell running on the main console for the user to interact with the system.
|
||||
halt.target | | | Halts the system without powering it down
|
||||
reboot.target | 6 | runlevel6.target | Reboot
|
||||
poweroff.target | 0 | runlevel0.target | Halts the system and turns the power off
|
||||
|
||||
Each target has a set of dependencies described in its configuration file. systemd starts the required dependencies, which are the services required to run the Linux host at a specific level of functionality. When all of the dependencies listed in the target configuration files are loaded and running, the system is running at that target level. If you want, you can review the systemd startup sequence and runtime targets in the first article in this series, [_Learning to love systemd_][2].
|
||||
|
||||
### Exploring the current target
|
||||
|
||||
Many Linux distributions default to installing a GUI desktop interface so that the installed systems can be used as workstations. I always install from a Fedora Live boot USB drive with an Xfce or LXDE desktop. Even when I'm installing a server or other infrastructure type of host (such as the ones I use for routers and firewalls), I use one of these installations that installs a GUI desktop.
|
||||
|
||||
I could install a server without a desktop (and that would be typical for data centers), but that does not meet my needs. It is not that I need the GUI desktop itself, but the LXDE installation includes many of the other tools I use that are not in a default server installation. This means less work for me after the initial installation.
|
||||
|
||||
But just because I have a GUI desktop does not mean it makes sense to use it. I have a 16-port KVM that I can use to access the KVM interfaces of most of my Linux systems, but the vast majority of my interaction with them is via a remote SSH connection from my primary workstation. This way is more secure and uses fewer system resources to run **multi-user.target** compared to **graphical.target.**
|
||||
|
||||
To begin, check the default target to verify that it is the **graphical.target**:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl get-default
|
||||
graphical.target
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
Now verify the currently running target. It should be the same as the default target. You can still use the old method, which displays the old SystemV runlevels. Note that the previous runlevel is on the left; it is **N** (which means None), indicating that the runlevel has not changed since the host was booted. The number 5 indicates the current target, as defined in the old SystemV terminology:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# runlevel
|
||||
N 5
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
Note that the runlevel man page indicates that runlevels are obsolete and provides a conversion table.
|
||||
|
||||
You can also use the systemd method. There is no one-line answer here, but it does provide the answer in systemd terms:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl list-units --type target
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
basic.target loaded active active Basic System
|
||||
cryptsetup.target loaded active active Local Encrypted Volumes
|
||||
getty.target loaded active active Login Prompts
|
||||
graphical.target loaded active active Graphical Interface
|
||||
local-fs-pre.target loaded active active Local File Systems (Pre)
|
||||
local-fs.target loaded active active Local File Systems
|
||||
multi-user.target loaded active active Multi-User System
|
||||
network-online.target loaded active active Network is Online
|
||||
network.target loaded active active Network
|
||||
nfs-client.target loaded active active NFS client services
|
||||
nss-user-lookup.target loaded active active User and Group Name Lookups
|
||||
paths.target loaded active active Paths
|
||||
remote-fs-pre.target loaded active active Remote File Systems (Pre)
|
||||
remote-fs.target loaded active active Remote File Systems
|
||||
rpc_pipefs.target loaded active active rpc_pipefs.target
|
||||
slices.target loaded active active Slices
|
||||
sockets.target loaded active active Sockets
|
||||
sshd-keygen.target loaded active active sshd-keygen.target
|
||||
swap.target loaded active active Swap
|
||||
sysinit.target loaded active active System Initialization
|
||||
timers.target loaded active active Timers
|
||||
|
||||
LOAD = Reflects whether the unit definition was properly loaded.
|
||||
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
|
||||
SUB = The low-level unit activation state, values depend on unit type.
|
||||
|
||||
21 loaded units listed. Pass --all to see loaded but inactive units, too.
|
||||
To show all installed unit files use 'systemctl list-unit-files'.
|
||||
```
|
||||
|
||||
This shows all of the currently loaded and active targets. You can also see the **graphical.target** and the **multi-user.target**. The **multi-user.target** is required before the **graphical.target** can be loaded. In this example, the **graphical.target** is active.
|
||||
|
||||
### Switching to a different target
|
||||
|
||||
Making the switch to the **multi-user.target** is easy:
|
||||
|
||||
|
||||
```
|
||||
`[root@testvm1 ~]# systemctl isolate multi-user.target`
|
||||
```
|
||||
|
||||
The display should now change from the GUI desktop or login screen to a virtual console. Log in and list the currently active systemd units to verify that **graphical.target** is no longer running:
|
||||
|
||||
|
||||
```
|
||||
`[root@testvm1 ~]# systemctl list-units --type target`
|
||||
```
|
||||
|
||||
Be sure to use the **runlevel** command to verify that it shows both previous and current "runlevels":
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# runlevel
|
||||
5 3
|
||||
```
|
||||
|
||||
### Changing the default target
|
||||
|
||||
Now, change the default target to the **multi-user.target** so that it will always boot into the **multi-user.target** for a console command-line interface rather than a GUI desktop interface. As the root user on your test host, change to the directory where the systemd configuration is maintained and do a quick listing:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# cd /etc/systemd/system/ ; ll
|
||||
drwxr-xr-x. 2 root root 4096 Apr 25 2018 basic.target.wants
|
||||
<snip>
|
||||
lrwxrwxrwx. 1 root root 36 Aug 13 16:23 default.target -> /lib/systemd/system/graphical.target
|
||||
lrwxrwxrwx. 1 root root 39 Apr 25 2018 display-manager.service -> /usr/lib/systemd/system/lightdm.service
|
||||
drwxr-xr-x. 2 root root 4096 Apr 25 2018 getty.target.wants
|
||||
drwxr-xr-x. 2 root root 4096 Aug 18 10:16 graphical.target.wants
|
||||
drwxr-xr-x. 2 root root 4096 Apr 25 2018 local-fs.target.wants
|
||||
drwxr-xr-x. 2 root root 4096 Oct 30 16:54 multi-user.target.wants
|
||||
<snip>
|
||||
[root@testvm1 system]#
|
||||
```
|
||||
|
||||
I shortened this listing to highlight a few important things that will help explain how systemd manages the boot process. You should be able to see the entire list of directories and links on your virtual machine.
|
||||
|
||||
The **default.target** entry is a symbolic link (symlink, soft link) to the directory **/lib/systemd/system/graphical.target**. List that directory to see what else is there:
|
||||
|
||||
|
||||
```
|
||||
`[root@testvm1 system]# ll /lib/systemd/system/ | less`
|
||||
```
|
||||
|
||||
You should see files, directories, and more links in this listing, but look specifically for **multi-user.target** and **graphical.target**. Now display the contents of **default.target**, which is a link to **/lib/systemd/system/graphical.target**:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 system]# cat default.target
|
||||
# SPDX-License-Identifier: LGPL-2.1+
|
||||
#
|
||||
# This file is part of systemd.
|
||||
#
|
||||
# systemd is free software; you can redistribute it and/or modify it
|
||||
# under the terms of the GNU Lesser General Public License as published by
|
||||
# the Free Software Foundation; either version 2.1 of the License, or
|
||||
# (at your option) any later version.
|
||||
|
||||
[Unit]
|
||||
Description=Graphical Interface
|
||||
Documentation=man:systemd.special(7)
|
||||
Requires=multi-user.target
|
||||
Wants=display-manager.service
|
||||
Conflicts=rescue.service rescue.target
|
||||
After=multi-user.target rescue.service rescue.target display-manager.service
|
||||
AllowIsolate=yes
|
||||
[root@testvm1 system]#
|
||||
```
|
||||
|
||||
This link to the **graphical.target** file describes all of the prerequisites and requirements that the graphical user interface requires. I will explore at least some of these options in the next article in this series.
|
||||
|
||||
To enable the host to boot to multi-user mode, you need to delete the existing link and create a new one that points to the correct target. Make the [PWD][5] **/etc/systemd/system**, if it is not already:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 system]# rm -f default.target
|
||||
[root@testvm1 system]# ln -s /lib/systemd/system/multi-user.target default.target
|
||||
```
|
||||
|
||||
List the **default.target** link to verify that it links to the correct file:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 system]# ll default.target
|
||||
lrwxrwxrwx 1 root root 37 Nov 28 16:08 default.target -> /lib/systemd/system/multi-user.target
|
||||
[root@testvm1 system]#
|
||||
```
|
||||
|
||||
If your link does not look exactly like this, delete it and try again. List the content of the **default.target** link:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 system]# cat default.target
|
||||
# SPDX-License-Identifier: LGPL-2.1+
|
||||
#
|
||||
# This file is part of systemd.
|
||||
#
|
||||
# systemd is free software; you can redistribute it and/or modify it
|
||||
# under the terms of the GNU Lesser General Public License as published by
|
||||
# the Free Software Foundation; either version 2.1 of the License, or
|
||||
# (at your option) any later version.
|
||||
|
||||
[Unit]
|
||||
Description=Multi-User System
|
||||
Documentation=man:systemd.special(7)
|
||||
Requires=basic.target
|
||||
Conflicts=rescue.service rescue.target
|
||||
After=basic.target rescue.service rescue.target
|
||||
AllowIsolate=yes
|
||||
[root@testvm1 system]#
|
||||
```
|
||||
|
||||
The **default.target**—which is really a link to the **multi-user.target** at this point—now has different requirements in the **[Unit]** section. It does not require the graphical display manager.
|
||||
|
||||
Reboot. Your virtual machine should boot to the console login for virtual console 1, which is identified on the display as tty1. Now that you know how to change the default target, change it back to the **graphical.target** using a command designed for the purpose.
|
||||
|
||||
First, check the current default target:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl get-default
|
||||
multi-user.target
|
||||
[root@testvm1 ~]# systemctl set-default graphical.target
|
||||
Removed /etc/systemd/system/default.target.
|
||||
Created symlink /etc/systemd/system/default.target → /usr/lib/systemd/system/graphical.target.
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
Enter the following command to go directly to the **graphical.target** and the display manager login page without having to reboot:
|
||||
|
||||
|
||||
```
|
||||
`[root@testvm1 system]# systemctl isolate default.target`
|
||||
```
|
||||
|
||||
I do not know why the term "isolate" was chosen for this sub-command by systemd's developers. My research indicates that it may refer to running the specified target but "isolating" and terminating all other targets that are not required to support the target. However, the effect is to switch targets from one run target to another—in this case, from the multi-user target to the graphical target. The command above is equivalent to the old init 5 command in SystemV start scripts and the init program.
|
||||
|
||||
Log into the GUI desktop, and verify that it is working as it should.
|
||||
|
||||
### Summing up
|
||||
|
||||
This article explored the Linux systemd startup sequence and started to explore two important systemd tools, **systemctl** and **journalctl**. It also explained how to switch from one target to another and to change the default target.
|
||||
|
||||
The next article in this series will create a new systemd unit and configure it to run during startup. It will also look at some of the configuration options that help determine where in the sequence a particular unit will start, for example, after networking is up and running.
|
||||
|
||||
### Resources
|
||||
|
||||
There is a great deal of information about systemd available on the internet, but much is terse, obtuse, or even misleading. In addition to the resources mentioned in this article, the following webpages offer more detailed and reliable information about systemd startup.
|
||||
|
||||
* The Fedora Project has a good, practical [guide][6] [to systemd][6]. It has pretty much everything you need to know in order to configure, manage, and maintain a Fedora computer using systemd.
|
||||
* The Fedora Project also has a good [cheat sheet][7] that cross-references the old SystemV commands to comparable systemd ones.
|
||||
* For detailed technical information about systemd and the reasons for creating it, check out [Freedesktop.org][8]'s [description of systemd][9].
|
||||
* [Linux.com][10]'s "More systemd fun" offers more advanced systemd [information and tips][11].
|
||||
|
||||
|
||||
|
||||
There is also a series of deeply technical articles for Linux sysadmins by Lennart Poettering, the designer and primary developer of systemd. These articles were written between April 2010 and September 2011, but they are just as relevant now as they were then. Much of everything else good that has been written about systemd and its ecosystem is based on these papers.
|
||||
|
||||
* [Rethinking PID 1][12]
|
||||
* [systemd for Administrators, Part I][13]
|
||||
* [systemd for Administrators, Part II][14]
|
||||
* [systemd for Administrators, Part III][15]
|
||||
* [systemd for Administrators, Part IV][16]
|
||||
* [systemd for Administrators, Part V][17]
|
||||
* [systemd for Administrators, Part VI][18]
|
||||
* [systemd for Administrators, Part VII][19]
|
||||
* [systemd for Administrators, Part VIII][20]
|
||||
* [systemd for Administrators, Part IX][21]
|
||||
* [systemd for Administrators, Part X][22]
|
||||
* [systemd for Administrators, Part XI][23]
|
||||
|
||||
|
||||
|
||||
Alison Chiaken, a Linux kernel and systems programmer at Mentor Graphics, offers a preview of her...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/systemd-startup
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/start_line.jpg?itok=9reaaW6m (People at the start line of a race)
|
||||
[2]: https://opensource.com/article/20/4/systemd
|
||||
[3]: http://www.gnu.org/software/grub/manual/grub
|
||||
[4]: mailto:mockbuild@bkernel03.phx2.fedoraproject.org
|
||||
[5]: https://en.wikipedia.org/wiki/Pwd
|
||||
[6]: https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html
|
||||
[7]: https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet
|
||||
[8]: http://Freedesktop.org
|
||||
[9]: http://www.freedesktop.org/wiki/Software/systemd
|
||||
[10]: http://Linux.com
|
||||
[11]: https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/
|
||||
[12]: http://0pointer.de/blog/projects/systemd.html
|
||||
[13]: http://0pointer.de/blog/projects/systemd-for-admins-1.html
|
||||
[14]: http://0pointer.de/blog/projects/systemd-for-admins-2.html
|
||||
[15]: http://0pointer.de/blog/projects/systemd-for-admins-3.html
|
||||
[16]: http://0pointer.de/blog/projects/systemd-for-admins-4.html
|
||||
[17]: http://0pointer.de/blog/projects/three-levels-of-off.html
|
||||
[18]: http://0pointer.de/blog/projects/changing-roots
|
||||
[19]: http://0pointer.de/blog/projects/blame-game.html
|
||||
[20]: http://0pointer.de/blog/projects/the-new-configuration-files.html
|
||||
[21]: http://0pointer.de/blog/projects/on-etc-sysinit.html
|
||||
[22]: http://0pointer.de/blog/projects/instances.html
|
||||
[23]: http://0pointer.de/blog/projects/inetd.html
|
||||
116
sources/tech/20200505 8 open source video games to play.md
Normal file
116
sources/tech/20200505 8 open source video games to play.md
Normal file
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (8 open source video games to play)
|
||||
[#]: via: (https://opensource.com/article/20/5/open-source-fps-games)
|
||||
[#]: author: (Aman Gaur https://opensource.com/users/amangaur)
|
||||
|
||||
8 open source video games to play
|
||||
======
|
||||
These games are fun and free to play, a way to connect with friends, and
|
||||
an opportunity to make an old favorite even better.
|
||||
![Gaming on a grid with penguin pawns][1]
|
||||
|
||||
Video games are a big business. That's great for the industry's longevity—not to mention for all the people working in programming and graphics. But it can take a lot of work, time, and money to keep up with all the latest gaming crazes. If you feel like playing a few quick rounds of a video game without investing in a new console or game franchise, then you'll be happy to know that there are plenty of open source combat games you can download, play, share, and even modify (if you're inclined to programming) for free.
|
||||
|
||||
First-person shooters (FPS) are one of the most popular categories of video games. They are centered around the perspective of the protagonist (the player), and they often offer weapon-based advancement. As you get better at the game, you survive longer, you get better weapons, and you increase your power. FPS games have a distinct look and feel, which is reflected in the category's name: players see everything—their weapons and the game world—in first person, as if they're looking through their player character's eyes.
|
||||
|
||||
If you want to give one a try, check out the following eight great open source FPS games.
|
||||
|
||||
### Xonotic
|
||||
|
||||
![Xonotic][2]
|
||||
|
||||
[Xonotic][3] is a fast-paced, arena-based FPS game. It is a popular game in the open source world. One reason could be the fact that it has never been a mainstream game. It offers a variety of weapons and enemies that are thrown right at you mercilessly from the start. Demanding quick action and response, it is an experience that will keep you on the edge of your seats. The game is available under the GPLv3+ license.
|
||||
|
||||
### Wolfenstein Enemy Territory
|
||||
|
||||
![Wolfenstein Enemy Territory][4]
|
||||
|
||||
Wolfenstein has been a major franchise in gaming for many years. If you are a fan of gore and glory, then you've probably already heard of this game (if not, you'll love it once you try it). [Wolfenstein Enemy Territory][5] is an early iteration of the popular World War II game. It became free to play in 2003, and its [source code][6] is provided under the GPLv3. To play, however, you must own the game data (or recreate it yourself) separately (which remains under its original EULA).
|
||||
|
||||
### Doom
|
||||
|
||||
![Doom][7]
|
||||
|
||||
[Doom][8] is a wildly popular game that was also an early example of games on Linux—way back in 2004. There are many iterations of the game, many of which have been released as open source. The game is about acquiring a teleportation device that's been captured by demons, so the violence, while gory, is low on realism. The source code for the game was provided under the GPL, but many versions require that you own the game for the game assets. There are dozens of ports and adaptations, including [Freedoom][9] (with free assets), [Dhewm3][10], [RBDoom-3-BFG][11], and many more. Try a few and pick your favorite!
|
||||
|
||||
### Smokin' Guns
|
||||
|
||||
![Smokin' Guns][12]
|
||||
|
||||
If you're a fan of the Old West and six-shooters, this FPS is for you. From cowboys to gunslingers and with a captivating background score, [Smokin' Guns][13] has it all. It's a semi-realistic simulation of the old spaghetti western. On your way through the game, you face multiple enemies and get multiple weapons, so there's always the promise of excitement and danger around the corner. The game is free and open source under the terms of the GPLv2.
|
||||
|
||||
### Nexuiz
|
||||
|
||||
![Nexuiz][14]
|
||||
|
||||
[Nexuiz][15] (classic) is another great FPS that's free to play on multiple platforms. The game is based on the Quake engine and has been made open source under the GNU GPLv2. The game offers multiple modes, including online, LAN party, and bot training. The game features sophisticated weapons and fast action. It's brutal and exciting, with an objective: kill as many opponents as possible before they get you.
|
||||
|
||||
Note that the open source version of Nexuiz is not the same as the version built on CryEngine3 that is sold on Steam.
|
||||
|
||||
### .kkrieger
|
||||
|
||||
![kkrieger][16]
|
||||
|
||||
[.Kkrieger][17] was developed in 2004 by .theprodukkt, a German demogroup. The game was developed using an unreleased (at the time) engine known as Werkkzeug. This game might feel a little slow to many, but it still offers an intense experience. The approaching enemies are slow, but their sheer number makes it confusing to know which one to take down first. It's an onslaught, and you have to shoot through layers of enemies before you reach the final boss. It was released in a rather raw form on [GitHub][18] by its creators under a BSD license with some public domain components.
|
||||
|
||||
### Warsow
|
||||
|
||||
![Warsow][19]
|
||||
|
||||
If you've ever played Borderlands 2, then imagine [Warsow][20] as an arena-style Borderlands. The game is built on a modernized Quake II engine, and its plot takes a simple approach: Kill as many opponents as possible. The team with the most number of kills wins. Despite its simplicity, it features amazing weaponry and lots of great trick moves, like circle jumping, bunny hopping, double jumping, ramp sliding, and so on. It makes for an engaging multiplayer session, and it's been recognized by multiple online leagues as a worthy game for their competitions. Get the source code from [GitHub][21] or install the game from your software repository.
|
||||
|
||||
### World of Padman
|
||||
|
||||
![World of Padman][22]
|
||||
|
||||
[The World of Padman][23] may be the last game on this list, but it's one of the most unique. Designed by PadWorld Entertainment, World of Padman takes a different twist graphically and introduces you to quirky and whimsical characters in a colorful (albeit cartoonishly violent) world. It's based on the ioquake3 engine, and its unique style and uproarious gameplay have earned it a featured place in multiple gaming magazines. You can download the source code from [GitHub][24].
|
||||
|
||||
### Give one a shot
|
||||
|
||||
A game that becomes open source can act as a template for something great, whether it's a wholly open source version of an old classic, a remix of a beloved game, or an entirely new platform built on an old reliable engine.
|
||||
|
||||
Open source gaming is important for many reasons: it provides users with a fun diversion, a way to connect with friends, and an opportunity for programmers and designers to hack within an existing framework. If titles like Doom weren't made open source, a little bit of video game history would be lost. Instead, it endures and has the opportunity to grow even more.
|
||||
|
||||
Try an open source game, and watch your six.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/open-source-fps-games
|
||||
|
||||
作者:[Aman Gaur][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/amangaur
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/game_pawn_grid_linux.png?itok=4gERzRkg (Gaming on a grid with penguin pawns)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/xonotic.jpg (Xonotic)
|
||||
[3]: https://www.xonotic.org/download/
|
||||
[4]: https://opensource.com/sites/default/files/uploads/wolfensteinenemyterritory.jpg (Wolfenstein Enemy Territory)
|
||||
[5]: https://www.splashdamage.com/games/wolfenstein-enemy-territory/
|
||||
[6]: https://github.com/id-Software/Enemy-Territory
|
||||
[7]: https://opensource.com/sites/default/files/uploads/doom.jpg (Doom)
|
||||
[8]: https://github.com/id-Software/DOOM
|
||||
[9]: https://freedoom.github.io/
|
||||
[10]: https://dhewm3.org/
|
||||
[11]: https://github.com/RobertBeckebans/RBDOOM-3-BFG/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/smokinguns.jpg (Smokin' Guns)
|
||||
[13]: https://www.smokin-guns.org/downloads
|
||||
[14]: https://opensource.com/sites/default/files/uploads/nexuiz.jpg (Nexuiz)
|
||||
[15]: https://sourceforge.net/projects/nexuiz/
|
||||
[16]: https://opensource.com/sites/default/files/uploads/kkrieger.jpg (kkrieger)
|
||||
[17]: https://web.archive.org/web/20120204065621/http://www.theprodukkt.com/kkrieger
|
||||
[18]: https://github.com/farbrausch/fr_public
|
||||
[19]: https://opensource.com/sites/default/files/uploads/warsow.jpg (Warsow)
|
||||
[20]: https://www.warsow.net/download
|
||||
[21]: https://github.com/Warsow
|
||||
[22]: https://opensource.com/sites/default/files/uploads/padman.jpg (World of Padman)
|
||||
[23]: https://worldofpadman.net/en/
|
||||
[24]: https://github.com/PadWorld-Entertainment
|
||||
@ -0,0 +1,133 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Analyzing data science code with R and Emacs)
|
||||
[#]: via: (https://opensource.com/article/20/5/r-emacs-data-science)
|
||||
[#]: author: (Peter Prevos https://opensource.com/users/danderzei)
|
||||
|
||||
Analyzing data science code with R and Emacs
|
||||
======
|
||||
Emacs' versatility and extensibility bring the editor's full power into
|
||||
play for writing data science code.
|
||||
![metrics and data shown on a computer screen][1]
|
||||
|
||||
Way back in 2012, _Harvard Business Review_ published an article that proclaimed "data scientist" to be the [sexiest job][2] of the 21st century. Interest in data science has exploded since then. Many great open source projects, such as [Python][3] and the [R language][4] for statistical computing, have facilitated the rapid developments in how we analyze data.
|
||||
|
||||
I started my career using pencil and paper and moved to spreadsheets. Now the R language is my weapon of choice when I need to create value from data. Emacs is another one of my favorite tools. This article briefly explains how to use the [Emacs Speaks Statistics][5] (ESS) package to get started with developing R projects in this venerable editor.
|
||||
|
||||
The vast majority of R developers use the [RStudio][6] IDE to manage their projects. RStudio is a powerful open source editor with specialized functionality to develop data science projects. RStudio is a great integrated development environment (IDE), but its editing functions are limited.
|
||||
|
||||
Using Emacs to write data science code means that you have access to the full power of this extensible editor. I prefer using Emacs for my data science projects because I can do many other tasks within the same application, leveraging the multifunctionality of this venerable editor. If you are just getting started with Emacs, then please first read Seth Kenlon's [Emacs getting started][7] article.
|
||||
|
||||
### Setting up Emacs for R
|
||||
|
||||
Emacs is an almost infinitely extensible text editor, which unfortunately means that many things don't work the way you want them to out of the box. Before you can write and execute R scripts, you need to install some packages and configure them. The ESS package provides an interface between Emacs and R. Other packages, such as [Company][8] and [highlight-parentheses][9] help with completion and balancing parentheses.
|
||||
|
||||
Emacs uses a version of Lisp for configuration. The lines of [Emacs Lisp][10] code below install the required extensions and define a minimal configuration to get you started. These lines were tested for GNU Emacs version 26.3.
|
||||
|
||||
Copy these lines and save them in a file named **init.el** in your **.emacs.d** folder. This is the folder that Emacs uses to store configurations, including the [init file][11]. If you already have an init file, then you can append these lines to your config. This minimal configuration is enough to get you started.
|
||||
|
||||
|
||||
```
|
||||
;; Elisp file for R coding with Emacs
|
||||
|
||||
;; Add MELPA repository and initialise the package manager
|
||||
(require 'package)
|
||||
(add-to-list 'package-archives
|
||||
'("melpa" . "<https://melpa.org/packages/>"))
|
||||
(package-initialize)
|
||||
|
||||
;; Install use-package,in case it does not exist yet
|
||||
;; The use-package software will install all other packages as required
|
||||
(unless (package-installed-p 'use-package)
|
||||
(package-refresh-contents)
|
||||
(package-install 'use-package))
|
||||
|
||||
;; ESS configurationEmacs Speaks Statistics
|
||||
(use-package ess
|
||||
:ensure t
|
||||
)
|
||||
|
||||
;; Auto completion
|
||||
(use-package company
|
||||
:ensure t
|
||||
:config
|
||||
(setq company-idle-delay 0)
|
||||
(setq company-minimum-prefix-length 2)
|
||||
(global-company-mode t)
|
||||
)
|
||||
|
||||
; Parentheses
|
||||
(use-package highlight-parentheses
|
||||
:ensure t
|
||||
:config
|
||||
(progn
|
||||
(highlight-parentheses-mode)
|
||||
(global-highlight-parentheses-mode))
|
||||
)
|
||||
```
|
||||
|
||||
### Using the R console
|
||||
|
||||
To start an R console session, press **M-x R** and hit **Enter** (**M** is the Emacs way to denote the **Alt** or **Command** key). ESS will ask you to nominate a working directory, which defaults to the folder of the current buffer. You can use more than one console in the same Emacs session by repeating the R command.
|
||||
|
||||
Emacs opens a new buffer for your new R console. You can also use the **Up** and **Down** arrow keys to go to previous lines and re-run them. Use the **Ctrl** and **Up/Down** arrow keys to recycle old commands.
|
||||
|
||||
The Company ("complete anything") package manages autocompletion in both the console and R scripts. When entering a function, the mini-buffer at the bottom of the screen shows the relevant parameters. When the autocompletion dropdown menu appears, you can press **F1** to view the chosen option's Help file before you select it.
|
||||
|
||||
The [highlight-parentheses][9] package does what its name suggests. Several other Emacs packages are available to help you balance parentheses and other structural elements in your code.
|
||||
|
||||
### Writing R scripts
|
||||
|
||||
Emacs recognizes R mode for any buffer with a **.R** extension (the file extension is case-sensitive). Open or create a new file with the **C-x C-f** shortcut and type the path and file name. You can start writing your code and use all of the powerful editing techniques that Emacs provides.
|
||||
|
||||
Several functions are available to evaluate the code. You can evaluate each line separately with **C-<return>**, while **C-c C-c** will evaluate a contiguous region. Keying **C-c C-b** will evaluate the whole buffer.
|
||||
|
||||
When you evaluate some code, Emacs will use any running console or ask you to open a new console to run the code.
|
||||
|
||||
The output of any plotting functions appears in a window outside of Emacs. If you prefer to view the output within Emacs, then you need to save the output to disk and open the resulting file in a separate buffer.
|
||||
|
||||
![Literate programming in Org mode, the ESS buffer, and graphics output.][12]
|
||||
|
||||
Literate programming in Org mode, the ESS buffer, and graphics output.
|
||||
|
||||
### Advanced use
|
||||
|
||||
This article provides a brief introduction to using R in Emacs. Many parameters can be fine-tuned to make Emacs behave according to your preferences, but it would take too much space to cover them here. The [ESS manual][13] describes these in detail. You can also extend functionality with additional packages.
|
||||
|
||||
Org mode can integrate R code, providing a productive platform for literate programming. If you prefer to use RMarkdown, the [Polymode][14] package has you covered.
|
||||
|
||||
Emacs has various packages to make your editing experience more efficient. The best part of using Emacs to write R code is that the program is more than just an IDE; it is a malleable computer system that you can configure to match your favorite workflow.
|
||||
|
||||
Learning how to configure Emacs can be daunting. The best way to learn quickly is to copy ideas from people who share their configurations. Miles McBain manages a [list of Emacs configurations][15] that could be useful if you want to explore using the R language in Emacs further.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/r-emacs-data-science
|
||||
|
||||
作者:[Peter Prevos][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/danderzei
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
|
||||
[2]: https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century
|
||||
[3]: https://www.python.org/
|
||||
[4]: https://www.r-project.org/
|
||||
[5]: https://ess.r-project.org/
|
||||
[6]: https://opensource.com/article/18/2/getting-started-RStudio-IDE
|
||||
[7]: https://opensource.com/article/20/3/getting-started-emacs
|
||||
[8]: https://company-mode.github.io/
|
||||
[9]: https://github.com/tsdh/highlight-parentheses.el
|
||||
[10]: https://en.wikipedia.org/wiki/Emacs_Lisp
|
||||
[11]: https://www.gnu.org/software/emacs/manual/html_node/emacs/Init-File.html
|
||||
[12]: https://opensource.com/sites/default/files/uploads/r-ess-screenshot.jpg (Literate programming in Org mode, the ESS buffer, and graphics output.)
|
||||
[13]: https://ess.r-project.org/index.php?Section=documentation&subSection=manuals
|
||||
[14]: https://github.com/polymode/polymode
|
||||
[15]: https://github.com/MilesMcBain/esscss
|
||||
@ -0,0 +1,124 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (6 open source alternatives to Wunderlist)
|
||||
[#]: via: (https://opensource.com/article/20/5/alternatives-list)
|
||||
[#]: author: (Jen Wike Huger https://opensource.com/users/jen-wike)
|
||||
|
||||
6 open source alternatives to Wunderlist
|
||||
======
|
||||
Love lists? Check out this handy list of open source apps for managing
|
||||
all your lists!
|
||||
![a checklist for a team][1]
|
||||
|
||||
Wunderlist is an app for lists, loved by many, but gone for good as of May 6, 2020. The website encourages existing users to download and use Microsoft To Do in its place. That's tempting because it makes it easy to import all of those lists you've made over the years. Then again, maybe it's a chance to _Marie Kondo_ those lists and pare things down. Do you really need 30 lists? (Apparently, I've decided that I do, so I won't judge.)
|
||||
|
||||
I have lists for all sorts of things, from "Plants for the garden 2020" to "Gifts for the husband." Some are checklists, some are To Do lists, and some are lists for list's sake.
|
||||
|
||||
For my husband and me, the most useful list is our shared grocery list. We both have the app on our phones, we both add things to the list, we review it together but separately on our phones before he goes shopping (yes, you read that correctly), and he checks things off as he puts them in the cart. It makes the whole thing surprisingly efficient, and I think we save some money because we're into sticking to THE LIST.
|
||||
|
||||
While its users loved it, Wunderlist isn't entirely unique. There are a gazillion list apps out there. With Wunderlist, I've specifically enjoyed its combination of simplicity and design, and that it managed to implement useful features like sharing and collaboration with others, dynamics checkboxes for lists, and a great user experience across both mobile and web interfaces. I've also enjoyed using it for a list that isn't an "active" document: a list I don't review weekly or make regular progress on—like my many lists I've used for brainstorming an idea (including that novel I've been meaning to write...).
|
||||
|
||||
From the many wonderful articles we've published over the years, I've curated a list of open source alternatives to Wunderlist that may work for your needs, from simple task management and to-do lists to complex note-taking and process management. Or, if you are that person scribbling tasks and notes on paper scraps and post-it notes that are lying... er, around somewhere and everywhere... this might be a good time to try one of these digital options out.
|
||||
|
||||
### Tasks—works with OwnCloud
|
||||
|
||||
> Tasks is a free and open source app you can install from [F-droid][2]. Tasks is a mobile-only application, but it's extremely flexible in what it can sync to. You can save your lists to NextCloud or OwnCloud, Google Tasks, Apple Reminders, and just about any CalDAV server you have an account on.
|
||||
>
|
||||
> The default view of Tasks is a daily view, so any task you enter is assumed to be a task from today onward. If you're like me and you want to maintain several unique lists, you can do that with Tags. When you create a tag, you create a category for tasks. You can assign a colour and an icon so each list of tasks is unique.
|
||||
>
|
||||
> It takes a little getting used to, but tagging has many advantages. Because all tasks are tagged, you can view groups of tasks by clicking the tag you want to filter for, but you can also filter by day and even by place. That means that when you go grocery shopping, your grocery list becomes the active default list, and your everyday life list becomes active again when you return home.
|
||||
>
|
||||
> By syncing your data to one of your online accounts, you can share lists with loved ones, collaborators, and colleagues.
|
||||
>
|
||||
> Another great feature is that if you the same tasks every morning when you get to work, or the same 20 items in your weekly grocery list, you can create tasks that repeat on a regular basis.
|
||||
|
||||
Reviewed by Seth Kenlon
|
||||
|
||||
![Screenshot of Tasks interface][3]
|
||||
|
||||
### OpenTasks—best for long lists
|
||||
|
||||
> [OpenTasks][4] is an excellent task management tool for creating individual tasks with a wide variety of settings. It supports a wide range of fields when creating a task, ranging from basic things, such as name and description, to more complex items, such as choosing if the task is private, public, or confidential. The biggest thing that sets OpenTasks apart from the alternatives is its use of tabs on the app's main screen. These tabs quickly allow you to see the tasks due, tasks starting soon, tasks sorted by priority, and tasks sorted by current progress towards completion. Many of the other apps support doing things like these, but OpenTasks quickly easily accesses these lists.
|
||||
|
||||
[Read the full OpenTasks review][5] by Joshua Allen Holm
|
||||
|
||||
![OpenTasks in Google Play store][6]
|
||||
|
||||
### Mirakel—great for nested lists
|
||||
|
||||
> [Mirakel][7] is a task management app with a modern user interface and support for just about every format you might want in such a program. At Mirakel's basic level, it supports multiple lists, which are referred to as "meta lists." Creating an individual task has a plethora of options with deadlines, reminders, progress tracking, tags, notes, sub-tasks, and file attachments, all comprising a part of a task's entry.
|
||||
|
||||
[Read the full Mirakel review][5] by Joshua Allen Holm
|
||||
|
||||
![Screenshot from website of Mirakel app][8]
|
||||
|
||||
### Todo—simple and effective, works anywhere
|
||||
|
||||
> [Todo.txt][9] is one of the two to-do list and task management apps that I keep coming back to over and over again (the other is Org mode). And what keeps me coming back is that it is simple, portable, understandable, and has many great add-ons that don't break it if one machine has them and the others don't. And since it is a Bash shell script, I have never found a system that cannot support it. Read more about [how to install and use Todo.txt][10].
|
||||
|
||||
[Read the full todo.txt review][10] by Kevin Sonney
|
||||
|
||||
![Drop-down menu for Todo.txt][11]
|
||||
|
||||
Drop-down menu for Todo.txt
|
||||
|
||||
### Joplin—best for private lists
|
||||
|
||||
> [Joplin][12] is a NodeJS application that runs and stores information locally, allows you to encrypt your tasks and supports multiple sync methods. Joplin can run as a console or graphical application on Windows, Mac, and Linux. Joplin also has mobile apps for Android and iOS, meaning you can take your notes with you without a major hassle. Joplin even allows you to format your notes with Markdown, HTML, or plain text.
|
||||
|
||||
[Read the full Joplin review][13] by Kevin Sonney
|
||||
|
||||
![Joplin graphical version ][14]
|
||||
|
||||
### CherryTree—great alternative to Evernote / OneNote / Keep
|
||||
|
||||
> [CherryTree][15] is a GPLv3-licensed application that organizes information in nodes. Each node can have child nodes, allowing you to easily organize your lists and thoughts. And, child nodes can have their own children with independent properties.
|
||||
|
||||
[Read the full CherryTree review][16] by Ben Cotton
|
||||
|
||||
![CherryTree's hierarchical note layout][17]
|
||||
|
||||
### Bonus: Wekan—for fans of Kanban
|
||||
|
||||
> Kanban boards are a mainstay of today's agile processes. And many of us (myself included) use them to organize not just our work but also our personal lives. I know several artists who use apps like Trello to keep track of their commission lists as well as what's in progress and what's complete. But these apps are often linked to a work account or a commercial service. Enter [Wekan][18], an open source kanban board you can run locally or on the service of your choice. Wekan offers much of the same functionality as other Kanban apps, such as creating boards, lists, swimlanes, and cards, dragging and dropping between lists, assigning to users, labeling cards, and doing pretty much everything else you'd expect in a modern kanban board.
|
||||
|
||||
[Read the full Wekan review][19]* by Kevin Sonney*
|
||||
|
||||
![Wekan kanban board][20]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/alternatives-list
|
||||
|
||||
作者:[Jen Wike Huger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jen-wike
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/checklist_hands_team_collaboration.png?itok=u82QepPk (a checklist for a team)
|
||||
[2]: https://f-droid.org/en/packages/org.tasks/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/screenshot_tasks_resized.jpg (Screenshot of Tasks interface)
|
||||
[4]: https://play.google.com/store/apps/details?id=org.dmfs.tasks
|
||||
[5]: https://opensource.com/article/17/1/task-management-time-tracking-android
|
||||
[6]: https://opensource.com/sites/default/files/uploads/opentasks_rezied.jpg (OpenTasks in Google Play store)
|
||||
[7]: https://mirakel.azapps.de/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/mirakel_web_resized.jpg (Screenshot from website of Mirakel app)
|
||||
[9]: http://todotxt.org/
|
||||
[10]: https://opensource.com/article/20/1/open-source-to-do-list
|
||||
[11]: https://opensource.com/sites/default/files/uploads/todo.txtmenu_3.png (Drop-down menu for Todo.txt)
|
||||
[12]: https://joplin.cozic.net/
|
||||
[13]: https://opensource.com/article/19/1/productivity-tool-joplin
|
||||
[14]: https://opensource.com/sites/default/files/uploads/joplin-1.png (Joplin graphical version )
|
||||
[15]: https://www.giuspen.com/cherrytree/
|
||||
[16]: https://opensource.com/article/19/5/cherrytree-notetaking
|
||||
[17]: https://opensource.com/sites/default/files/uploads/cherrytree.png (CherryTree's hierarchical note layout)
|
||||
[18]: https://wekan.github.io/
|
||||
[19]: https://opensource.com/article/19/1/productivity-tool-wekan
|
||||
[20]: https://opensource.com/sites/default/files/uploads/wekan-board.png (Wekan kanban board)
|
||||
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Customizing my open source PHP framework for web development)
|
||||
[#]: via: (https://opensource.com/article/20/5/codeigniter)
|
||||
[#]: author: (Wee Ben Sen https://opensource.com/users/bswee14)
|
||||
|
||||
Customizing my open source PHP framework for web development
|
||||
======
|
||||
Codeigniter is a PHP framework that empowers companies to develop
|
||||
high-performance websites with flexibility and ease.
|
||||
![Business woman on laptop sitting in front of window][1]
|
||||
|
||||
PHP Codeigniter is an open source framework providing business applications with the easy-to-use PHP programming language and powerful tools for coding. It also provides business intelligence, server monitoring, development, and application integration facilities. It's a relatively quiet project that you don't hear much about, but it's got a lot going for it that many developers new to it find surprising and refreshing.
|
||||
|
||||
I use [Codeigniter][2] at my job working for an online tuition service provider in Singapore. We offer services that aren't common enough to be the default feature set for templates or existing back-ends, so I need something that provides good, solid, raw materials I can build upon. Initially, I was considering other platforms such as Wordpress for our website; however, I arrived at Codeigniter due to its flexibility and integration of functions needed in the tuition-matching process.
|
||||
|
||||
Here are the points that sold me on Codeigniter:
|
||||
|
||||
* Database integration with MySQL—A major functionality is allowing clients to browse the tutor database and add tutors like a "shopping cart" similar to an e-commerce platform.
|
||||
* Client interface system—Users can log in to manage preferences and edit their particulars, modify subject taught, areas traveled, mobile number, address, etc.
|
||||
* Customized administrator panel—The administrator can access the client's submission with a customized admin panel, which is integrated with a customer service feature so the administrator can follow up individually.
|
||||
* Payment system—The admin panel comes with an invoice and payments gateway, which is integrated with Paypal.
|
||||
* CMS editor interface—The administrator is able to edit text and images in the blog and subject pages, as well as add new pages.
|
||||
|
||||
|
||||
|
||||
The project took around six months to complete and another two months of debugging work. If I'd had to build all of it from scratch or try to rework an existing framework to suit our needs, it would have taken longer, and I probably wouldn't have ended up with what I needed for the demands of our customers.
|
||||
|
||||
### Features and benefits
|
||||
|
||||
There are many more features that draw developers to PHP Codeigniter, including error handling and code formatting, which are useful in every coding situation. It supports templates, which can be used to add functionality to an existing website or to generate new ones. There are many features available for a business that needs to use a web-based system, including the ability to use custom tags. Most can be used by even an average developer who does not have any prior experience in programming.
|
||||
|
||||
The key features of Codeigniter are:
|
||||
|
||||
* XML core services,
|
||||
* HTTP/FTP core services
|
||||
* AppData and PHP sandbox features
|
||||
* XSLT and HTML templates
|
||||
* Encrypted information transfer
|
||||
* PCM Codeigniter server monitoring
|
||||
* Application integration
|
||||
* File Transfer Protocol (FTP)
|
||||
* Help desk support
|
||||
* Apache POI (content management infrastructure used for hosting a website)
|
||||
|
||||
|
||||
|
||||
#### Compatibility
|
||||
|
||||
Codeigniter is compatible with many leading software applications like PHP, MySQL, [MariaDB][3], [phpMyAdmin][4], [Apache][5], OpenBSD, XSLT, [SQLite][6], and more. A number of companies prefer to use Codeigniter products for their website requirements because they are easy to work with and integrate. If you're not comfortable creating your own website, you can find many developers and design agencies that provide custom web development services.
|
||||
|
||||
#### Security
|
||||
|
||||
Codeigniter also provides data security through SSL encryption. The encryption protects the data from external threats such as intruders and firewalls. The data storage facility also allows for security audits of the company's website.
|
||||
|
||||
#### Other features
|
||||
|
||||
A good PHP web development company uses several advanced and third-party technologies such as XML and PHP. It provides organizations with a complete platform to develop professional-looking, useful websites with a business application. Codeigniter makes it easy to use third party technology, and works with common web development software. This allows web agencies to easily create websites with their chosen modules. Most PHP developers offer support and training services for individuals, as well.
|
||||
|
||||
### Using PHP framework Codeigniter
|
||||
|
||||
Codeigniter allows businesses to have a complete package for PHP development that will offer the right combination of power, flexibility, and performance. So far, I am very pleased with our website and I have continuously upgraded and added new features along the way. I look forward to discovering what else I can do with our website using Codeigniter. Could it be right for you too?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/codeigniter
|
||||
|
||||
作者:[Wee Ben Sen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bswee14
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-concentration-focus-windows-office.png?itok=-8E2ihcF (Woman using laptop concentrating)
|
||||
[2]: https://codeigniter.com/
|
||||
[3]: http://mariadb.org/
|
||||
[4]: https://www.phpmyadmin.net/
|
||||
[5]: http://apache.org/
|
||||
[6]: http://sqlite.org/
|
||||
@ -0,0 +1,311 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Speed up administration of Kubernetes clusters with k9s)
|
||||
[#]: via: (https://opensource.com/article/20/5/kubernetes-administration)
|
||||
[#]: author: (Jessica Cherry https://opensource.com/users/cherrybomb)
|
||||
|
||||
Speed up administration of Kubernetes clusters with k9s
|
||||
======
|
||||
Check out this cool terminal UI for Kubernetes administration.
|
||||
![Dogs playing chess][1]
|
||||
|
||||
Usually, my articles about Kubernetes administration are full of kubectl commands for administration for your clusters. Recently, however, someone pointed me to the [k9s][2] project for a fast way to review and resolve day-to-day issues in Kubernetes. It's been a huge improvement to my workflow and I'll show you how to get started in this tutorial.
|
||||
|
||||
Installation can be done on a Mac, in Windows, and Linux. Instructions for each operating system can be found [here][2]. Be sure to complete installation to be able to follow along.
|
||||
|
||||
I will be using Linux and Minikube, which is a lightweight way to run Kubernetes on a personal computer. Install it following [this tutorial][3] or by using the [documentation][4].
|
||||
|
||||
### Setting the k9s configuration file
|
||||
|
||||
Once you've installed the k9s app, it's always good to start with the help command.
|
||||
|
||||
|
||||
```
|
||||
$ k9s help
|
||||
K9s is a CLI to view and manage your Kubernetes clusters.
|
||||
|
||||
Usage:
|
||||
k9s [flags]
|
||||
k9s [command]
|
||||
|
||||
Available Commands:
|
||||
help Help about any command
|
||||
info Print configuration info
|
||||
version Print version/build info
|
||||
|
||||
Flags:
|
||||
-A, --all-namespaces Launch K9s in all namespaces
|
||||
--as string Username to impersonate for the operation
|
||||
--as-group stringArray Group to impersonate for the operation
|
||||
--certificate-authority string Path to a cert file for the certificate authority
|
||||
--client-certificate string Path to a client certificate file for TLS
|
||||
--client-key string Path to a client key file for TLS
|
||||
--cluster string The name of the kubeconfig cluster to use
|
||||
-c, --command string Specify the default command to view when the application launches
|
||||
--context string The name of the kubeconfig context to use
|
||||
--demo Enable demo mode to show keyboard commands
|
||||
--headless Turn K9s header off
|
||||
-h, --help help for k9s
|
||||
--insecure-skip-tls-verify If true, the server's caCertFile will not be checked for validity
|
||||
--kubeconfig string Path to the kubeconfig file to use for CLI requests
|
||||
-l, --logLevel string Specify a log level (info, warn, debug, error, fatal, panic, trace) (default "info")
|
||||
-n, --namespace string If present, the namespace scope for this CLI request
|
||||
--readonly Disable all commands that modify the cluster
|
||||
-r, --refresh int Specify the default refresh rate as an integer (sec) (default 2)
|
||||
--request-timeout string The length of time to wait before giving up on a single server request
|
||||
--token string Bearer token for authentication to the API server
|
||||
--user string The name of the kubeconfig user to use
|
||||
|
||||
Use "k9s [command] --help" for more information about a command.
|
||||
```
|
||||
|
||||
As you can see, there is a lot of functionality we can configure with k9s. The only step we need to take place to get off the ground is to write a configuration file. The **info** command will point us to where the application is looking for it.
|
||||
|
||||
|
||||
```
|
||||
$ k9s info
|
||||
____ __.________
|
||||
| |/ _/ __ \\______
|
||||
| < \\____ / ___/
|
||||
| | \ / /\\___ \
|
||||
|____|__ \ /____//____ >
|
||||
\/ \/
|
||||
|
||||
Configuration: /Users/jess/.k9s/config.yml
|
||||
Logs: /var/folders/5l/c1y1gcw97szdywgf9rk1100m0000gn/T/k9s-jess.log
|
||||
Screen Dumps: /var/folders/5l/c1y1gcw97szdywgf9rk1100m0000gn/T/k9s-screens-jess
|
||||
```
|
||||
|
||||
By default, k9s expects a configuration file and will fail to run without one. The command will return without any message, but if we look at the log file we see an error.
|
||||
|
||||
|
||||
```
|
||||
$ tail -1 /var/folders/5l/c1y1gcw97szdywgf9rk1100m0000gn/T/k9s-mbbroberg.log
|
||||
10:56AM FTL Unable to connect to api server error="Missing or incomplete configuration info. Please point to an existing, complete config file:\n\n 1. Via the command-line flag --kubeconfig\n 2. Via the KUBECONFIG environment variable\n 3. In your home directory as ~/.kube/config\n\nTo view or setup config directly use the 'config' command."
|
||||
```
|
||||
|
||||
To add a file, make the directory if it doesn't already exist and then add one.
|
||||
|
||||
|
||||
```
|
||||
$ mkdir -p ~/.k9s/
|
||||
$ touch ~/.k9s/config.yml
|
||||
```
|
||||
|
||||
For this introduction, we will use the default config.yml recommendations from the k9s repository. The maintainers note that this format is subject to change, so we can [check here][5] for the latest version.
|
||||
|
||||
|
||||
```
|
||||
k9s:
|
||||
refreshRate: 2
|
||||
headless: false
|
||||
readOnly: false
|
||||
noIcons: false
|
||||
logger:
|
||||
tail: 200
|
||||
buffer: 500
|
||||
sinceSeconds: 300
|
||||
fullScreenLogs: false
|
||||
textWrap: false
|
||||
showTime: false
|
||||
currentContext: minikube
|
||||
currentCluster: minikube
|
||||
clusters:
|
||||
minikube:
|
||||
namespace:
|
||||
active: ""
|
||||
favorites:
|
||||
- all
|
||||
- kube-system
|
||||
- default
|
||||
view:
|
||||
active: dp
|
||||
thresholds:
|
||||
cpu:
|
||||
critical: 90
|
||||
warn: 70
|
||||
memory:
|
||||
critical: 90
|
||||
warn: 70
|
||||
```
|
||||
|
||||
We set k9s to look for a local minikube configuration, so I'm going to confirm minikube is online and ready to go.
|
||||
|
||||
|
||||
```
|
||||
$ minikube status
|
||||
host: Running
|
||||
kubelet: Running
|
||||
apiserver: Running
|
||||
kubeconfig: Configured
|
||||
```
|
||||
|
||||
### Running k9s to explore a Kubernetes cluster
|
||||
|
||||
### With a configuration file set and pointing at our local cluster, we can now run the **k9s** command.
|
||||
|
||||
|
||||
```
|
||||
`$ k9s`
|
||||
```
|
||||
|
||||
Once you start it up, the k9s text-based user interface (UI) will pop up. With no flag for a namespace, it will show you the pods in the default namespace.
|
||||
|
||||
![K9s screenshot][6]
|
||||
|
||||
If you run in an environment with a lot of pods, the default view can be overwhelming. Alternatively, we can focus on a given namespace. Exit the application and run **k9s -n <namespace>** where _<namespace>_ is an existing namespace. In the picture below, I ran **k9s -n minecraft,** and it shows my broken pod
|
||||
|
||||
![K9s screenshot][7]
|
||||
|
||||
So once you have k9s up and running, there are a bunch of things you can do quickly.
|
||||
|
||||
Navigating k9s happens through shortcut keys. We can always use arrow keys and the enter key to choose items listed. There are quite a few other universal keystrokes to navigate to different views:
|
||||
|
||||
* **0**—Show all pods in all namespaces
|
||||
|
||||
|
||||
|
||||
![K9s screenshot][8]
|
||||
|
||||
* **d**—Describe the selected pod
|
||||
|
||||
|
||||
|
||||
![K9s screenshot][9]
|
||||
|
||||
* **l**—Show logs for the selected pod pod
|
||||
|
||||
|
||||
|
||||
![Using k9s to show Kubernetes pod logs][10]
|
||||
|
||||
You may notice that k9s is set to use [Vim command keys][11], including moving up and down using **J** and **K** keys. Good luck exiting, emacs users :)
|
||||
|
||||
### Viewing different Kubernetes resources quickly
|
||||
|
||||
Need to get to something that's not a pod? Yea I do too. There are a number of shortcuts that are available when we enter a colon (":") key. From there, you can use the following commands to navigate around there.
|
||||
|
||||
* **:svc**—Jump to a services view.
|
||||
|
||||
|
||||
|
||||
![K9s screenshot][12]
|
||||
|
||||
* **:deploy**—Jump to a deployment view.
|
||||
|
||||
|
||||
|
||||
![K9s screenshot][13]
|
||||
|
||||
* **:rb**—Jump to a Rolebindings view for [role-based access control (RBAC)][14] management.
|
||||
|
||||
|
||||
|
||||
![K9s screenshot][15]
|
||||
|
||||
* **:namespace**—Jump back to the namespaces view.
|
||||
|
||||
|
||||
|
||||
![K9s screenshot][16]
|
||||
|
||||
* **:cj**—Jump to the cronjobs view to see what jobs are scheduled in the cluster.
|
||||
|
||||
|
||||
|
||||
![K9s screenshot][17]
|
||||
|
||||
The most used tool for this application will be the keyboard; to go up or down on any page, use the arrow keys. If you need to quit, remember to use Vim keybindings. Type **:q** and hit enter to leave.
|
||||
|
||||
### Example of troubleshooting Kubernetes with k9s
|
||||
|
||||
How does k9s help when something goes wrong? To walk through an example, I let several pods die due to misconfiguration. Below you can see my terrible hello deployment that's crashing. Once we highlight it, we press **d** to run a _describe_ command to see what is causing the failure.
|
||||
|
||||
![K9s screenshot][18]
|
||||
|
||||
![K9s screenshot][19]
|
||||
|
||||
Skimming the events does not tell us a reason for the failure. Next, I hit the **esc** key and go check the logs by highlighting the pod and entering **<shift-l>**.
|
||||
|
||||
![K9s screenshot][20]
|
||||
|
||||
Unfortunately, the logs don't offer anything helpful either (probably because the deployment was never correctly configured), and the pod will not come up.
|
||||
|
||||
I then **esc** to step back out, and I will see if deleting the pod will take care of this issue. To do so, I highlight the pod and use **<ctrl-d>**. Thankfully, k9s prompts users before deletion.
|
||||
|
||||
![K9s screenshot][21]
|
||||
|
||||
While I did delete the pod, the deployment resource still exists, so a new pod will come back up. It will also continue to restart and crash for whatever reason (we don't know yet).
|
||||
|
||||
Here is the point where I would repeat reviewing logs, describing resources, and use the **e** shortcut to even edit a running pod to troubleshoot the behavior. In this particular case, the failing pod is not configured to run in this environment. So let's delete the deployment to stop crash-then-reboot loop we are in.
|
||||
|
||||
We can get to deployments by typing **:deploy** and clicking enter. From there we highlight and press **<ctrl-d>** to delete.
|
||||
|
||||
![K9s screenshot][22]
|
||||
|
||||
![K9s screenshot][23]
|
||||
|
||||
And poof the deployment is gone! It only took a few keystrokes to clean up this failed deployment.
|
||||
|
||||
### k9s is incredibly customizable
|
||||
|
||||
So this application has a ton of customization options, down to the color scheme of the UI. Here are a few editable options you may be interested in:
|
||||
|
||||
* Adjust where you put the config.yml file (so you can store it in [version control][24])
|
||||
* Add [custom aliases][25] to an **alias.yml** file
|
||||
* Create [custom hotkeys][26] in a **hotkey.yml** file
|
||||
* Explore available [plugins][27] or write your own
|
||||
|
||||
|
||||
|
||||
The entire application is configured in YAML files, so customization will feel familiar to any Kubernetes administrator.
|
||||
|
||||
### Simplify your life with k9s
|
||||
|
||||
I'm prone to administrating over my team's systems in a very manual way, more for brain training than anything else. When I first heard about k9s, I thought, "This is just lazy Kubernetes," so I dismissed it and went back to doing my manual intervention everywhere. I actually started using it daily while working through my backlog, and I was blown away at how much faster it was to use than kubectl alone. Now I'm a convert.
|
||||
|
||||
It's important to know your tools and master the "hard way" of doing something. It is also important to remember, as far as administration goes, it's important to work smarter, not harder. Using k9s is the way I live up to that objective. I guess we can call it lazy Kubernetes administration, and that's okay.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/kubernetes-administration
|
||||
|
||||
作者:[Jessica Cherry][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cherrybomb
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/game-dogs-chess-play-lead.png?itok=NAuhav4Z (Dogs playing chess)
|
||||
[2]: https://github.com/derailed/k9s
|
||||
[3]: https://opensource.com/article/18/10/getting-started-minikube
|
||||
[4]: https://kubernetes.io/docs/tasks/tools/install-minikube/
|
||||
[5]: https://github.com/derailed/k9s#k9s-configuration
|
||||
[6]: https://opensource.com/sites/default/files/uploads/k9s_1.png (K9s screenshot)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/k9s_2.png (K9s screenshot)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/k9s_3.png (K9s screenshot)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/k9s_5_0.png (K9s screenshot)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/k9s-show-logs-opensourcedotcom.png (Using k9s to show Kubernetes pod logs)
|
||||
[11]: https://opensource.com/article/19/3/getting-started-vim
|
||||
[12]: https://opensource.com/sites/default/files/uploads/k9s_5.png (K9s screenshot)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/k9s_6.png (K9s screenshot)
|
||||
[14]: https://kubernetes.io/docs/reference/access-authn-authz/rbac/
|
||||
[15]: https://opensource.com/sites/default/files/uploads/k9s_7.png (K9s screenshot)
|
||||
[16]: https://opensource.com/sites/default/files/uploads/k9s_8.png (K9s screenshot)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/k9s_9.png (K9s screenshot)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/k9s_10.png (K9s screenshot)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/k9s_11.png (K9s screenshot)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/k9s_12.png (K9s screenshot)
|
||||
[21]: https://opensource.com/sites/default/files/uploads/k9s_13.png (K9s screenshot)
|
||||
[22]: https://opensource.com/sites/default/files/uploads/k9s_14.png (K9s screenshot)
|
||||
[23]: https://opensource.com/sites/default/files/uploads/k9s_15.png (K9s screenshot)
|
||||
[24]: https://opensource.com/article/19/3/move-your-dotfiles-version-control
|
||||
[25]: https://k9scli.io/topics/aliases/
|
||||
[26]: https://k9scli.io/topics/hotkeys/
|
||||
[27]: https://github.com/derailed/k9s/tree/master/plugins
|
||||
@ -0,0 +1,143 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Three Methods to Check Uptime of MySQL/MariaDB Database Server on Linux)
|
||||
[#]: via: (https://www.2daygeek.com/check-mysql-mariadb-database-server-uptime-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Three Methods to Check Uptime of MySQL/MariaDB Database Server on Linux
|
||||
======
|
||||
|
||||
We all know the purpose of the uptime command in Linux.
|
||||
|
||||
This is used to check the **[uptime of the Linux system][1]** and how long the system runs without restarting.
|
||||
|
||||
The Linux admin job is to keep the system up and running.
|
||||
|
||||
If you want to check how long other services like **[Apache][2]**, MySQL, MariaDB, sftp, etc., are running on Linux, how do you do that?
|
||||
|
||||
Each service has their own command to check the uptime of service.
|
||||
|
||||
But you can also use other commands for this purpose.
|
||||
|
||||
### Method-1: How to Check the Uptime of a MySQL/MariaDB Database Server on Linux Using the ps Command
|
||||
|
||||
The **[ps command][3]** stands for process status. This is one of the most basic commands that shows the system running processes with details.
|
||||
|
||||
To do so, you first need to find the PID of **[MySQL][4]**/MariaDB using the **[pidof command][5]**.
|
||||
|
||||
```
|
||||
# pidof mysqld | cut -d" " -f1
|
||||
|
||||
2412
|
||||
```
|
||||
|
||||
Once you have the MySQL/[**MariaDB**][6] PID, use the “etime” option with the ps command and get the uptime.
|
||||
|
||||
* **etime:** elapsed time since the process was started, in the form of [[DD-]hh:]mm:ss.
|
||||
|
||||
|
||||
|
||||
```
|
||||
# ps -p 2412 -o etime
|
||||
|
||||
ELAPSED
|
||||
2-08:49:30
|
||||
```
|
||||
|
||||
Alternatively, use the “lstart” option with the ps command to get the uptime of a given PID.
|
||||
|
||||
```
|
||||
# ps -p 2412 -o lstart
|
||||
|
||||
STARTED
|
||||
Sat May 2 03:02:15 2020
|
||||
```
|
||||
|
||||
The MySQL/MariaDB process has been running for 2 days, 03 hours, 02 minutes and 15 seconds.
|
||||
|
||||
### Method-2: How to Check the Uptime of a MySQL/MariaDB Database Server on Linux Using the Systemctl Command
|
||||
|
||||
The **[systemctl command][7]** is used to control the systemd system and service manager.
|
||||
|
||||
systemd is a new init system and system manager, that was adopted by most of Linux distributions now over the traditional SysVinit manager.
|
||||
|
||||
```
|
||||
# systemctl status mariadb
|
||||
or
|
||||
# systemctl status mysql
|
||||
|
||||
● mariadb.service - MariaDB 10.1.44 database server
|
||||
Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled; vendor preset: disabled)
|
||||
Drop-In: /etc/systemd/system/mariadb.service.d
|
||||
└─migrated-from-my.cnf-settings.conf
|
||||
Active: active (running) since Sat 2020-05-02 03:02:18 UTC; 2 days ago
|
||||
Docs: man:mysqld(8)
|
||||
https://mariadb.com/kb/en/library/systemd/
|
||||
Process: 2448 ExecStartPost=/bin/sh -c systemctl unset-environment _WSREP_START_POSITION (code=exited, status=0/SUCCESS)
|
||||
Process: 2388 ExecStartPre=/bin/sh -c [ ! -e /usr/bin/galera_recovery ] && VAR= || VAR=/usr/bin/galera_recovery; [ $? -eq 0 ] && systemctl set-environment _WSREP_START_POSITION=$VAR || exit 1 (code=exited, status=0/SUCCESS)
|
||||
Process: 2386 ExecStartPre=/bin/sh -c systemctl unset-environment _WSREP_START_POSITION (code=exited, status=0/SUCCESS)
|
||||
Main PID: 2412 (mysqld)
|
||||
Status: "Taking your SQL requests now…"
|
||||
CGroup: /system.slice/mariadb.service
|
||||
└─2412 /usr/sbin/mysqld
|
||||
|
||||
May 03 21:41:26 ns2.2daygeek.com mysqld[2412]: 2020-05-03 21:41:26 140328136861440 [Warning] Host name '1.1.1.1' could not be resolved: … not known
|
||||
May 04 02:00:46 ns2.2daygeek.com mysqld[2412]: 2020-05-04 2:00:46 140328436418304 [Warning] IP address '1.1.1.1' has been resolved to the host name '2…ss itself.
|
||||
May 04 03:01:31 ns2.2daygeek.com mysqld[2412]: 2020-05-04 3:01:31 140328436111104 [Warning] IP address '1.1.1.1' could not be resolved: Temporary fai…resolution
|
||||
May 04 04:03:06 ns2.2daygeek.com mysqld[2412]: 2020-05-04 4:03:06 140328136861440 [Warning] IP address '1.1.1.1' could not be resolved: Name or ser… not known
|
||||
May 04 07:23:54 ns2.2daygeek.com mysqld[2412]: 2020-05-04 7:23:54 140328435189504 [Warning] IP address '1.1.1.1' could not be resolved: Name or service not known
|
||||
May 04 08:03:31 ns2.2daygeek.com mysqld[2412]: 2020-05-04 8:03:31 140328436418304 [Warning] IP address '1.1.1.1' could not be resolved: Name or service not known
|
||||
May 04 08:25:56 ns2.2daygeek.com mysqld[2412]: 2020-05-04 8:25:56 140328135325440 [Warning] IP address '1.1.1.1' could not be resolved: Name or service not known
|
||||
Warning: Journal has been rotated since unit was started. Log output is incomplete or unavailable.
|
||||
Hint: Some lines were ellipsized, use -l to show in full.
|
||||
```
|
||||
|
||||
### Method-3: How to Check the Uptime of a MySQL/MariaDB Database Server on Linux Using the MySQLAdmin Command
|
||||
|
||||
**[MySQLAdmin][8]** is a command-line utility for MySQL Server that is installed when installing the MySQL package.
|
||||
|
||||
The MySQLAdmin client allows you to perform some basic administrative functions on the MySQL server.
|
||||
|
||||
It is used to create a database, drop a database, set a root password, change the root password, check MySQL status, verify MySQL functionality, monitor mysql processes, and verify the configuration of the server.
|
||||
|
||||
```
|
||||
# mysqladmin -u root -pPassword version
|
||||
|
||||
mysqladmin Ver 8.42 Distrib 5.7.27, for Linux on x86_64
|
||||
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
|
||||
|
||||
Oracle is a registered trademark of Oracle Corporation and/or its
|
||||
affiliates. Other names may be trademarks of their respective
|
||||
owners.
|
||||
|
||||
Server version 5.7.27
|
||||
Protocol version 10
|
||||
Connection Localhost via UNIX socket
|
||||
UNIX socket /var/lib/mysql/mysql.sock
|
||||
Uptime: 1 day 10 hours 44 min 13 sec
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/check-mysql-mariadb-database-server-uptime-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/linux-system-server-uptime-check/
|
||||
[2]: https://www.2daygeek.com/check-find-apache-httpd-web-server-uptime-linux/
|
||||
[3]: https://www.2daygeek.com/linux-ps-command-find-running-process-monitoring/
|
||||
[4]: https://www.2daygeek.com/category/mysql/
|
||||
[5]: https://www.2daygeek.com/check-find-parent-process-id-pid-ppid-linux/
|
||||
[6]: https://www.2daygeek.com/category/mariadb/
|
||||
[7]: https://www.2daygeek.com/sysvinit-vs-systemd-cheatsheet-systemctl-command-usage/
|
||||
[8]: https://www.2daygeek.com/linux-mysqladmin-command-administrate-mysql-mariadb-server/
|
||||
@ -0,0 +1,30 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to repeat a Linux command until it succeeds)
|
||||
[#]: via: (https://www.linux.com/news/how-to-repeat-a-linux-command-until-it-succeeds/)
|
||||
[#]: author: (Linux.com Editorial Staff https://www.linux.com/author/linuxdotcom/)
|
||||
|
||||
How to repeat a Linux command until it succeeds
|
||||
======
|
||||
|
||||
If you want to run a command on a Linux system until it succeeds, there are some really easy ways to do it that don’t require you to retype the command repeatedly or sit in front of your screen pressing !! Let’s look at the two options available with bash.
|
||||
|
||||
Read More at [Network World][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/how-to-repeat-a-linux-command-until-it-succeeds/
|
||||
|
||||
作者:[Linux.com Editorial Staff][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/linuxdotcom/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3541298/how-to-repeat-a-linux-command-until-it-succeeds.html
|
||||
@ -0,0 +1,157 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Ubuntu Cinnamon Remix 20.04 Review: The Perfect Blend of Ubuntu With Cinnamon)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-cinnamon-remix-review/)
|
||||
[#]: author: (Dimitrios Savvopoulos https://itsfoss.com/author/dimitrios/)
|
||||
|
||||
Ubuntu Cinnamon Remix 20.04 Review: The Perfect Blend of Ubuntu With Cinnamon
|
||||
======
|
||||
|
||||
GNOME 3 was introduced in 2011, and the GNOME Shell immediately generated both positive and negative responses. Many users and developers liked the original GNOME interface enough that a few groups forked it and one of those, Linux Mint team, created the [Cinnamon desktop environment][1].
|
||||
|
||||
The Cinnamon desktop became the identity of Linux Mint. For years, Cinnamon has been synonymous to [Linux Mint][2]. It has changed slightly in the past few years as the popularity for Cinnamon grew. Now other distributions have also started offering Cinnamon desktop environment. [Manjaro][3] is one such example.
|
||||
|
||||
A few months back, we introduced you to a [new Ubuntu flavor that provides an out of the box Cinnamon desktop experience][4]. let’s take a deeper look at [Ubuntu Cinnamon Remix][5] today.
|
||||
|
||||
### Why Ubuntu Cinnamon Remix and not Linux Mint?
|
||||
|
||||
It is true that Linux Mint is based on Ubuntu and Many Linux Mint users will have the question: Does it make any sense to switch over to Ubuntu as Linux Mint is such a mature project and the user experience will remain more or less the same?
|
||||
|
||||
Ubuntu Cinnamon Remix has a number of small differences from Linux Mint, but has has one key difference that a Linux enthusiast can’t ignore.
|
||||
|
||||
Linux Mint is based on “LTS” (Long-Term Support) versions of Ubuntu, meaning it stays behind the Canonical’s 6-month update cadence. Ubuntu Cinnamon Remix benefits from a newer kernel to other 6-month cycle feature upgrade and more recent software.
|
||||
|
||||
Another key difference is that Ubuntu Cinnamon Remix will “inherit” [Snap support][6], and Linux Mint embraces [FlatPak][7]. Ubuntu Cinnamon Remix uses Ubuntu Software Center instead of Mint Software Manager.
|
||||
|
||||
That said, I am a huge fan of Cinnamon. So I chose to review this mix of Ubuntu and Cinnamon and here I share my experience with it.
|
||||
|
||||
### Experiencing Ubuntu Cinnamon Remix
|
||||
|
||||
By any chance given, I will always mention how fast [Calamares installer][8] is and thanks to Ubuntu Cinnamon Remix Team for choosing so.
|
||||
|
||||
![Calamares Installer][9]
|
||||
|
||||
A fresh installation of Ubuntu Cinnamon Remix consumes approximately 750 MB of RAM. This is very similar to Linux Mint Cinnamon.
|
||||
|
||||
![An idle Cinnamon takes 750 MB of RAM][10]
|
||||
|
||||
I was also impressed by the beautiful [Kimmo theme][11] and the orange toned Ubuntu wallpaper which seems to be a result of a very meticulous effort.
|
||||
|
||||
![Ubuntu Cinammon Remix 20.04 Desktop][12]
|
||||
|
||||
#### Enough tools to get you started
|
||||
|
||||
As with any other Ubuntu distribution, Ubuntu Cinnamon Remix is packed with the essential productivity tools, to name a few:
|
||||
|
||||
* Firefox Web Browser
|
||||
* Thunderbird – Email Client
|
||||
* LibreOffice suite
|
||||
* Celluloid – Multimedia player
|
||||
* [GIMP][13] – Image processing software
|
||||
* Synaptic Package Manager
|
||||
* Gnome Software Center
|
||||
* [Gparted][14] – Partition Manager
|
||||
|
||||
|
||||
|
||||
Using Ubuntu Cinnamon Remix as my main runner for a few days, fulfilled my high expectations. Ubuntu is rock-solid stable, very fast and I didn’t face a single issue at my day to day tasks.
|
||||
|
||||
#### Ubuntu for Linux Mint Lovers
|
||||
|
||||
Are you enthusiastic about Ubuntu Cinnamon but got used to Linux Mint theme? Click below to see how you can get a full Linux Mint theme pack and how to configure it to keep the Ubuntu heritage.
|
||||
|
||||
Give Ubuntu Cinnamon Remix the real Mint touch
|
||||
|
||||
Firstly you have to download and unpack the following, easily done via terminal.
|
||||
|
||||
**Get the Linux Mint-X icon pack**
|
||||
|
||||
```
|
||||
wget http://packages.linuxmint.com/pool/main/m/mint-x-icons/mint-x-icons_1.5.5_all.deb
|
||||
```
|
||||
|
||||
**Get the Linux Mint-Y icon pack**
|
||||
|
||||
```
|
||||
wget http://packages.linuxmint.com/pool/main/m/mint-y-icons/mint-y-icons_1.3.9_all.deb
|
||||
```
|
||||
|
||||
**Get the Linux Mint Themes**
|
||||
|
||||
```
|
||||
wget http://packages.linuxmint.com/pool/main/m/mint-themes/mint-themes_1.8.4_all.deb
|
||||
```
|
||||
|
||||
**Install the downloaded content**
|
||||
|
||||
```
|
||||
sudo dpkg -i ./mint-x-icons_1.5.5_all.deb ./mint-y-icons_1.3.9_all.deb ./mint-themes_1.8.4_all.deb
|
||||
```
|
||||
|
||||
When done, click on the Menu button at the bottom left corner and type themes. You can also find themes in system settings.
|
||||
|
||||
![Accessing Themes][15]
|
||||
|
||||
Once opened replace the kimmo icons and theme as shown below. The Linux Mint default “Green” is the plain Mint-Y but the orange colour is a perfect selection for Ubuntu.
|
||||
|
||||
![Linux Mint Theme Settings][16]
|
||||
|
||||
#### A treat for Cinnamon fans
|
||||
|
||||
Let’s accept it, aesthetics are important. Cinnamon has a clean and elegant look, easy to read fonts and nice colour contrast themes. Cinnamon offers an uncluttered desktop with easily configured desktop icons simply by accessing the Desktop menu under System Settings. You can also choose the desktop icons to be shown only on the primary monitor, only on secondary monitor, or on both. This also applies to a beyond two monitor setup.
|
||||
|
||||
![Ubuntu Cinnamon Remix Desklets][17]
|
||||
|
||||
Desklets and applets are small, single-purpose applications that can be added to your desktop or your panel respectively. The most commonly used among the many you can choose are CPU or resources monitor, a weather applet, sticky notes, and calendar.
|
||||
|
||||
The Cinnamon Control Center provides centralized access to many of the desktop configuration options. By accessing the themes section you can choose the desktop basic scheme and icons, window borders, mouse pointers, and controls look. Fonts can have a great impact on the overall desktop look and cinnamon makes the change easier than ever.
|
||||
|
||||
The Cinnamon Control Center makes the configuration simple enough for a new user, compared to KDE Plasma that can lead a new user to confusion, due to the massive number of configuration options.
|
||||
|
||||
![][18]
|
||||
|
||||
The Cinnamon Panel contains the menu used to launch programs, a basic system tray, and an application selector. The panel is easy to configure and adding new program launchers is simply done by locating the program you want to add in the main Menu, right click on the icon and select “Add to panel.” You can also add the launcher icon to the desktop, and to the Cinnamon “Favourites” launcher bar. If you don’t like the order of the icons at your panel, just right click at the panel bar, enter panel’s Edit mode and rearrange the icons.
|
||||
|
||||
#### **Conclusions**
|
||||
|
||||
Whether you decide to “spice” up your desktop or thinking to move from [Windows to Linux][19], the Cinnamon Community has made plenty of spices for you.
|
||||
|
||||
Traditional yet elegant, customizable but simple, Ubuntu Cinnamon Remix is an interesting project with a promising future, and for existing fans of the Cinnamon Desktop who love Ubuntu, this is probably a no-brainer.
|
||||
|
||||
What do you think of Ubuntu Cinnamon Remix? Have you used it already?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-cinnamon-remix-review/
|
||||
|
||||
作者:[Dimitrios Savvopoulos][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/dimitrios/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Cinnamon_(desktop_environment)
|
||||
[2]: https://www.linuxmint.com/
|
||||
[3]: https://manjaro.org/
|
||||
[4]: https://itsfoss.com/ubuntudde/
|
||||
[5]: https://ubuntucinnamon.org/
|
||||
[6]: https://snapcraft.io/
|
||||
[7]: https://flatpak.org/
|
||||
[8]: https://calamares.io/
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/Calamares-Installer.png?resize=800%2C426&ssl=1
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/htop-running-on-Ubuntu-Cinnamon-Remix-20.04.png?ssl=1
|
||||
[11]: https://github.com/Ubuntu-Cinnamon-Remix/kimmo-gtk-theme
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/Ubuntu-Cinammon-Remix-20.04-desktop.png?resize=800%2C450&ssl=1
|
||||
[13]: https://itsfoss.com/gimp-2-10-release/
|
||||
[14]: https://itsfoss.com/gparted/
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/accessing-themes.png?ssl=1
|
||||
[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/Linux-Mint-theme-settings.png?ssl=1
|
||||
[17]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/05/ubuntu-cinnamon-remix-desklets.jpg?fit=800%2C450&ssl=1
|
||||
[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/05/ubuntu-cinnamon-control.jpg?fit=800%2C450&ssl=1
|
||||
[19]: https://itsfoss.com/windows-like-linux-distributions/
|
||||
@ -0,0 +1,618 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using the systemctl command to manage systemd units)
|
||||
[#]: via: (https://opensource.com/article/20/5/systemd-units)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
Using the systemctl command to manage systemd units
|
||||
======
|
||||
Units are the basis of everything in systemd.
|
||||
![woman on laptop sitting at the window][1]
|
||||
|
||||
In the first two articles in this series, I explored the Linux systemd startup sequence. In the [first article][2], I looked at systemd's functions and architecture and the controversy around its role as a replacement for the old SystemV init program and startup scripts. And in the [second article][3], I examined two important systemd tools, systemctl and journalctl, and explained how to switch from one target to another and to change the default target.
|
||||
|
||||
In this third article, I'll look at systemd units in more detail and how to use the systemctl command to explore and manage units. I'll also explain how to stop and disable units and how to create a new systemd mount unit to mount a new filesystem and enable it to initiate during startup.
|
||||
|
||||
### Preparation
|
||||
|
||||
All of the experiments in this article should be done as the root user (unless otherwise specified). Some of the commands that simply list various systemd units can be performed by non-root users, but the commands that make changes cannot. Make sure to do all of these experiments only on non-production hosts or virtual machines (VMs).
|
||||
|
||||
One of these experiments requires the sysstat package, so install it before you move on. For Fedora and other Red Hat-based distributions you can install sysstat with:
|
||||
|
||||
|
||||
```
|
||||
`dnf -y install sysstat`
|
||||
```
|
||||
|
||||
The sysstat RPM installs several statistical tools that can be used for problem determination. One is [System Activity Report][4] (SAR), which records many system performance data points at regular intervals (every 10 minutes by default). Rather than run as a daemon in the background, the sysstat package installs two systemd timers. One timer runs every 10 minutes to collect data, and the other runs once a day to aggregate the daily data. In this article, I will look briefly at these timers but wait to explain how to create a timer in a future article.
|
||||
|
||||
### systemd suite
|
||||
|
||||
The fact is, systemd is more than just one program. It is a large suite of programs all designed to work together to manage nearly every aspect of a running Linux system. A full exposition of systemd would take a book on its own. Most of us do not need to understand all of the details about how all of systemd's components fit together, so I will focus on the programs and components that enable you to manage various Linux services and deal with log files and journals.
|
||||
|
||||
### Practical structure
|
||||
|
||||
The structure of systemd—outside of its executable files—is contained in its many configuration files. Although these files have different names and identifier extensions, they are all called "unit" files. Units are the basis of everything systemd.
|
||||
|
||||
Unit files are ASCII plain-text files that are accessible to and can be created or modified by a sysadmin. There are a number of unit file types, and each has its own man page. Figure 1 lists some of these unit file types by their filename extensions and a short description of each.
|
||||
|
||||
systemd unit | Description
|
||||
---|---
|
||||
.automount | The **.automount** units are used to implement on-demand (i.e., plug and play) and mounting of filesystem units in parallel during startup.
|
||||
.device | The **.device** unit files define hardware and virtual devices that are exposed to the sysadmin in the **/dev/directory**. Not all devices have unit files; typically, block devices such as hard drives, network devices, and some others have unit files.
|
||||
.mount | The **.mount** unit defines a mount point on the Linux filesystem directory structure.
|
||||
.scope | The **.scope** unit defines and manages a set of system processes. This unit is not configured using unit files, rather it is created programmatically. Per the **systemd.scope** man page, “The main purpose of scope units is grouping worker processes of a system service for organization and for managing resources.”
|
||||
.service | The **.service** unit files define processes that are managed by systemd. These include services such as crond cups (Common Unix Printing System), iptables, multiple logical volume management (LVM) services, NetworkManager, and more.
|
||||
.slice | The **.slice** unit defines a “slice,” which is a conceptual division of system resources that are related to a group of processes. You can think of all system resources as a pie and this subset of resources as a “slice” out of that pie.
|
||||
.socket | The **.socket** units define interprocess communication sockets, such as network sockets.
|
||||
.swap | The **.swap** units define swap devices or files.
|
||||
.target | The **.target** units define groups of unit files that define startup synchronization points, runlevels, and services. Target units define the services and other units that must be active in order to start successfully.
|
||||
.timer | The **.timer** unit defines timers that can initiate program execution at specified times.
|
||||
|
||||
### systemctl
|
||||
|
||||
I looked at systemd's startup functions in the [second article][3], and here I'll explore its service management functions a bit further. systemd provides the **systemctl** command that is used to start and stop services, configure them to launch (or not) at system startup, and monitor the current status of running services.
|
||||
|
||||
In a terminal session as the root user, ensure that root's home directory ( **~** ) is the [PWD][5]. To begin looking at units in various ways, list all of the loaded and active systemd units. systemctl automatically pipes its [stdout][6] data stream through the **less** pager, so you don't have to:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
proc-sys-fs-binfmt_misc.automount loaded active running Arbitrary Executable File>
|
||||
sys-devices-pci0000:00-0000:00:01.1-ata7-host6-target6:0:0-6:0:0:0-block-sr0.device loaded a>
|
||||
sys-devices-pci0000:00-0000:00:03.0-net-enp0s3.device loaded active plugged 82540EM Gigabi>
|
||||
sys-devices-pci0000:00-0000:00:05.0-sound-card0.device loaded active plugged 82801AA AC'97>
|
||||
sys-devices-pci0000:00-0000:00:08.0-net-enp0s8.device loaded active plugged 82540EM Gigabi>
|
||||
sys-devices-pci0000:00-0000:00:0d.0-ata1-host0-target0:0:0-0:0:0:0-block-sda-sda1.device loa>
|
||||
sys-devices-pci0000:00-0000:00:0d.0-ata1-host0-target0:0:0-0:0:0:0-block-sda-sda2.device loa>
|
||||
<snip – removed lots of lines of data from here>
|
||||
|
||||
LOAD = Reflects whether the unit definition was properly loaded.
|
||||
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
|
||||
SUB = The low-level unit activation state, values depend on unit type.
|
||||
|
||||
206 loaded units listed. Pass --all to see loaded but inactive units, too.
|
||||
To show all installed unit files use 'systemctl list-unit-files'.
|
||||
```
|
||||
|
||||
As you scroll through the data in your terminal session, look for some specific things. The first section lists devices such as hard drives, sound cards, network interface cards, and TTY devices. Another section shows the filesystem mount points. Other sections include various services and a list of all loaded and active targets.
|
||||
|
||||
The sysstat timers at the bottom of the output are used to collect and generate daily system activity summaries for SAR. SAR is a very useful problem-solving tool. (You can learn more about it in Chapter 13 of my book [_Using and Administering Linux: Volume 1, Zero to SysAdmin: Getting Started_][7].)
|
||||
|
||||
Near the very bottom, three lines describe the meanings of the statuses (loaded, active, and sub). Press **q** to exit the pager.
|
||||
|
||||
Use the following command (as suggested in the last line of the output above) to see all the units that are installed, whether or not they are loaded. I won't reproduce the output here, because you can scroll through it on your own. The systemctl program has an excellent tab-completion facility that makes it easy to enter complex commands without needing to memorize all the options:
|
||||
|
||||
|
||||
```
|
||||
`[root@testvm1 ~]# systemctl list-unit-files`
|
||||
```
|
||||
|
||||
You can see that some units are disabled. Table 1 in the man page for systemctl lists and provides short descriptions of the entries you might see in this listing. Use the **-t** (type) option to view just the timer units:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl list-unit-files -t timer
|
||||
UNIT FILE STATE
|
||||
[chrony-dnssrv@.timer][8] disabled
|
||||
dnf-makecache.timer enabled
|
||||
fstrim.timer disabled
|
||||
logrotate.timer disabled
|
||||
logwatch.timer disabled
|
||||
[mdadm-last-resort@.timer][9] static
|
||||
mlocate-updatedb.timer enabled
|
||||
sysstat-collect.timer enabled
|
||||
sysstat-summary.timer enabled
|
||||
systemd-tmpfiles-clean.timer static
|
||||
unbound-anchor.timer enabled
|
||||
```
|
||||
|
||||
You could do the same thing with this alternative, which provides considerably more detail:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl list-timers
|
||||
Thu 2020-04-16 09:06:20 EDT 3min 59s left n/a n/a systemd-tmpfiles-clean.timer systemd-tmpfiles-clean.service
|
||||
Thu 2020-04-16 10:02:01 EDT 59min left Thu 2020-04-16 09:01:32 EDT 49s ago dnf-makecache.timer dnf-makecache.service
|
||||
Thu 2020-04-16 13:00:00 EDT 3h 57min left n/a n/a sysstat-collect.timer sysstat-collect.service
|
||||
Fri 2020-04-17 00:00:00 EDT 14h left Thu 2020-04-16 12:51:37 EDT 3h 49min left mlocate-updatedb.timer mlocate-updatedb.service
|
||||
Fri 2020-04-17 00:00:00 EDT 14h left Thu 2020-04-16 12:51:37 EDT 3h 49min left unbound-anchor.timer unbound-anchor.service
|
||||
Fri 2020-04-17 00:07:00 EDT 15h left n/a n/a sysstat-summary.timer sysstat-summary.service
|
||||
|
||||
6 timers listed.
|
||||
Pass --all to see loaded but inactive timers, too.
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
Although there is no option to do systemctl list-mounts, you can list the mount point unit files:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl list-unit-files -t mount
|
||||
UNIT FILE STATE
|
||||
-.mount generated
|
||||
boot.mount generated
|
||||
dev-hugepages.mount static
|
||||
dev-mqueue.mount static
|
||||
home.mount generated
|
||||
proc-fs-nfsd.mount static
|
||||
proc-sys-fs-binfmt_misc.mount disabled
|
||||
run-vmblock\x2dfuse.mount disabled
|
||||
sys-fs-fuse-connections.mount static
|
||||
sys-kernel-config.mount static
|
||||
sys-kernel-debug.mount static
|
||||
tmp.mount generated
|
||||
usr.mount generated
|
||||
var-lib-nfs-rpc_pipefs.mount static
|
||||
var.mount generated
|
||||
|
||||
15 unit files listed.
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
The STATE column in this data stream is interesting and requires a bit of explanation. The "generated" states indicate that the mount unit was generated on the fly during startup using the information in **/etc/fstab**. The program that generates these mount units is **/lib/systemd/system-generators/systemd-fstab-generator,** along with other tools that generate a number of other unit types. The "static" mount units are for filesystems like **/proc** and **/sys**, and the files for these are located in the **/usr/lib/systemd/system** directory.
|
||||
|
||||
Now, look at the service units. This command will show all services installed on the host, whether or not they are active:
|
||||
|
||||
|
||||
```
|
||||
`[root@testvm1 ~]# systemctl --all -t service`
|
||||
```
|
||||
|
||||
The bottom of this listing of service units displays 166 as the total number of loaded units on my host. Your number will probably differ.
|
||||
|
||||
Unit files do not have a filename extension (such as **.unit**) to help identify them, so you can generalize that most configuration files that belong to systemd are unit files of one type or another. The few remaining files are mostly **.conf** files located in **/etc/systemd**.
|
||||
|
||||
Unit files are stored in the **/usr/lib/systemd** directory and its subdirectories, while the **/etc/systemd/** directory and its subdirectories contain symbolic links to the unit files necessary to the local configuration of this host.
|
||||
|
||||
To explore this, make **/etc/systemd** the PWD and list its contents. Then make **/etc/systemd/system** the PWD and list its contents, and list the contents of at least a couple of the current PWD's subdirectories.
|
||||
|
||||
Take a look at the **default.target** file, which determines which runlevel target the system will boot to. In the second article in this series, I explained how to change the default target from the GUI (**graphical.target**) to the command-line only (**multi-user.target**) target. The **default.target** file on my test VM is simply a symlink to **/usr/lib/systemd/system/graphical.target**.
|
||||
|
||||
Take a few minutes to examine the contents of the **/etc/systemd/system/default.target** file:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 system]# cat default.target
|
||||
# SPDX-License-Identifier: LGPL-2.1+
|
||||
#
|
||||
# This file is part of systemd.
|
||||
#
|
||||
# systemd is free software; you can redistribute it and/or modify it
|
||||
# under the terms of the GNU Lesser General Public License as published by
|
||||
# the Free Software Foundation; either version 2.1 of the License, or
|
||||
# (at your option) any later version.
|
||||
|
||||
[Unit]
|
||||
Description=Graphical Interface
|
||||
Documentation=man:systemd.special(7)
|
||||
Requires=multi-user.target
|
||||
Wants=display-manager.service
|
||||
Conflicts=rescue.service rescue.target
|
||||
After=multi-user.target rescue.service rescue.target display-manager.service
|
||||
AllowIsolate=yes
|
||||
```
|
||||
|
||||
Note that this requires the **multi-user.target**; the **graphical.target** cannot start if the **multi-user.target** is not already up and running. It also says it "wants" the **display-manager.service** unit. A "want" does not need to be fulfilled in order for the unit to start successfully. If the "want" cannot be fulfilled, it will be ignored by systemd, and the rest of the target will start regardless.
|
||||
|
||||
The subdirectories in **/etc/systemd/system** are lists of wants for various targets. Take a few minutes to explore the files and their contents in the **/etc/systemd/system/graphical.target.wants** directory.
|
||||
|
||||
The **systemd.unit** man page contains a lot of good information about unit files, their structure, the sections they can be divided into, and the options that can be used. It also lists many of the unit types, all of which have their own man pages. If you want to interpret a unit file, this would be a good place to start.
|
||||
|
||||
### Service units
|
||||
|
||||
A Fedora installation usually installs and enables services that particular hosts do not need for normal operation. Conversely, sometimes it doesn't include services that need to be installed, enabled, and started. Services that are not needed for the Linux host to function as desired, but which are installed and possibly running, represent a security risk and should—at minimum—be stopped and disabled and—at best—should be uninstalled.
|
||||
|
||||
The systemctl command is used to manage systemd units, including services, targets, mounts, and more. Take a closer look at the list of services to identify services that will never be used:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl --all -t service
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
<snip>
|
||||
chronyd.service loaded active running NTP client/server
|
||||
crond.service loaded active running Command Scheduler
|
||||
cups.service loaded active running CUPS Scheduler
|
||||
dbus-daemon.service loaded active running D-Bus System Message Bus
|
||||
<snip>
|
||||
● ip6tables.service not-found inactive dead ip6tables.service
|
||||
● ipset.service not-found inactive dead ipset.service
|
||||
● iptables.service not-found inactive dead iptables.service
|
||||
<snip>
|
||||
firewalld.service loaded active running firewalld - dynamic firewall daemon
|
||||
<snip>
|
||||
● ntpd.service not-found inactive dead ntpd.service
|
||||
● ntpdate.service not-found inactive dead ntpdate.service
|
||||
pcscd.service loaded active running PC/SC Smart Card Daemon
|
||||
```
|
||||
|
||||
I have pruned out most of the output from the command to save space. The services that show "loaded active running" are obvious. The "not-found" services are ones that systemd is aware of but are not installed on the Linux host. If you want to run those services, you must install the packages that contain them.
|
||||
|
||||
Note the **pcscd.service** unit. This is the PC/SC smart-card daemon. Its function is to communicate with smart-card readers. Many Linux hosts—including VMs—have no need for this reader nor the service that is loaded and taking up memory and CPU resources. You can stop this service and disable it, so it will not restart on the next boot. First, check its status:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl status pcscd.service
|
||||
● pcscd.service - PC/SC Smart Card Daemon
|
||||
Loaded: loaded (/usr/lib/systemd/system/pcscd.service; indirect; vendor preset: disabled)
|
||||
Active: active (running) since Fri 2019-05-10 11:28:42 EDT; 3 days ago
|
||||
Docs: man:pcscd(8)
|
||||
Main PID: 24706 (pcscd)
|
||||
Tasks: 6 (limit: 4694)
|
||||
Memory: 1.6M
|
||||
CGroup: /system.slice/pcscd.service
|
||||
└─24706 /usr/sbin/pcscd --foreground --auto-exit
|
||||
|
||||
May 10 11:28:42 testvm1 systemd[1]: Started PC/SC Smart Card Daemon.
|
||||
```
|
||||
|
||||
This data illustrates the additional information systemd provides versus SystemV, which only reports whether or not the service is running. Note that specifying the **.service** unit type is optional. Now stop and disable the service, then re-check its status:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl stop pcscd ; systemctl disable pcscd
|
||||
Warning: Stopping pcscd.service, but it can still be activated by:
|
||||
pcscd.socket
|
||||
Removed /etc/systemd/system/sockets.target.wants/pcscd.socket.
|
||||
[root@testvm1 ~]# systemctl status pcscd
|
||||
● pcscd.service - PC/SC Smart Card Daemon
|
||||
Loaded: loaded (/usr/lib/systemd/system/pcscd.service; indirect; vendor preset: disabled)
|
||||
Active: failed (Result: exit-code) since Mon 2019-05-13 15:23:15 EDT; 48s ago
|
||||
Docs: man:pcscd(8)
|
||||
Main PID: 24706 (code=exited, status=1/FAILURE)
|
||||
|
||||
May 10 11:28:42 testvm1 systemd[1]: Started PC/SC Smart Card Daemon.
|
||||
May 13 15:23:15 testvm1 systemd[1]: Stopping PC/SC Smart Card Daemon...
|
||||
May 13 15:23:15 testvm1 systemd[1]: pcscd.service: Main process exited, code=exited, status=1/FAIL>
|
||||
May 13 15:23:15 testvm1 systemd[1]: pcscd.service: Failed with result 'exit-code'.
|
||||
May 13 15:23:15 testvm1 systemd[1]: Stopped PC/SC Smart Card Daemon.
|
||||
```
|
||||
|
||||
The short log entry display for most services prevents having to search through various log files to locate this type of information. Check the status of the system runlevel targets—specifying the "target" unit type is required:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl status multi-user.target
|
||||
● multi-user.target - Multi-User System
|
||||
Loaded: loaded (/usr/lib/systemd/system/multi-user.target; static; vendor preset: disabled)
|
||||
Active: active since Thu 2019-05-09 13:27:22 EDT; 4 days ago
|
||||
Docs: man:systemd.special(7)
|
||||
|
||||
May 09 13:27:22 testvm1 systemd[1]: Reached target Multi-User System.
|
||||
[root@testvm1 ~]# systemctl status graphical.target
|
||||
● graphical.target - Graphical Interface
|
||||
Loaded: loaded (/usr/lib/systemd/system/graphical.target; indirect; vendor preset: disabled)
|
||||
Active: active since Thu 2019-05-09 13:27:22 EDT; 4 days ago
|
||||
Docs: man:systemd.special(7)
|
||||
|
||||
May 09 13:27:22 testvm1 systemd[1]: Reached target Graphical Interface.
|
||||
[root@testvm1 ~]# systemctl status default.target
|
||||
● graphical.target - Graphical Interface
|
||||
Loaded: loaded (/usr/lib/systemd/system/graphical.target; indirect; vendor preset: disabled)
|
||||
Active: active since Thu 2019-05-09 13:27:22 EDT; 4 days ago
|
||||
Docs: man:systemd.special(7)
|
||||
|
||||
May 09 13:27:22 testvm1 systemd[1]: Reached target Graphical Interface.
|
||||
```
|
||||
|
||||
The default target is the graphical target. The status of any unit can be checked in this way.
|
||||
|
||||
### Mounts the old way
|
||||
|
||||
A mount unit defines all of the parameters required to mount a filesystem on a designated mount point. systemd can manage mount units with more flexibility than those using the **/etc/fstab** filesystem configuration file. Despite this, systemd still uses the **/etc/fstab** file for filesystem configuration and mounting purposes. systemd uses the **systemd-fstab-generator** tool to create transient mount units from the data in the **fstab** file.
|
||||
|
||||
I will create a new filesystem and a systemd mount unit to mount it. If you have some available disk space on your test system, you can do it along with me.
|
||||
|
||||
_Note that the volume group and logical volume names may be different on your test system. Be sure to use the names that are pertinent to your system._
|
||||
|
||||
You will need to create a partition or logical volume, then make an EXT4 filesystem on it. Add a label to the filesystem, **TestFS**, and create a directory for a mount point **/TestFS**.
|
||||
|
||||
To try this on your own, first, verify that you have free space on the volume group. Here is what that looks like on my VM where I have some space available on the volume group to create a new logical volume:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# lsblk
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
sda 8:0 0 120G 0 disk
|
||||
├─sda1 8:1 0 4G 0 part /boot
|
||||
└─sda2 8:2 0 116G 0 part
|
||||
├─VG01-root 253:0 0 5G 0 lvm /
|
||||
├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
|
||||
├─VG01-usr 253:2 0 30G 0 lvm /usr
|
||||
├─VG01-home 253:3 0 20G 0 lvm /home
|
||||
├─VG01-var 253:4 0 20G 0 lvm /var
|
||||
└─VG01-tmp 253:5 0 10G 0 lvm /tmp
|
||||
sr0 11:0 1 1024M 0 rom
|
||||
[root@testvm1 ~]# vgs
|
||||
VG #PV #LV #SN Attr VSize VFree
|
||||
VG01 1 6 0 wz--n- <116.00g <23.00g
|
||||
```
|
||||
|
||||
Then create a new volume on **VG01** named **TestFS**. It does not need to be large; 1GB is fine. Then create a filesystem, add the filesystem label, and create the mount point:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# lvcreate -L 1G -n TestFS VG01
|
||||
Logical volume "TestFS" created.
|
||||
[root@testvm1 ~]# mkfs -t ext4 /dev/mapper/VG01-TestFS
|
||||
mke2fs 1.45.3 (14-Jul-2019)
|
||||
Creating filesystem with 262144 4k blocks and 65536 inodes
|
||||
Filesystem UUID: 8718fba9-419f-4915-ab2d-8edf811b5d23
|
||||
Superblock backups stored on blocks:
|
||||
32768, 98304, 163840, 229376
|
||||
|
||||
Allocating group tables: done
|
||||
Writing inode tables: done
|
||||
Creating journal (8192 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
|
||||
[root@testvm1 ~]# e2label /dev/mapper/VG01-TestFS TestFS
|
||||
[root@testvm1 ~]# mkdir /TestFS
|
||||
```
|
||||
|
||||
Now, mount the new filesystem:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# mount /TestFS/
|
||||
mount: /TestFS/: can't find in /etc/fstab.
|
||||
```
|
||||
|
||||
This will not work because you do not have an entry in **/etc/fstab**. You can mount the new filesystem even without the entry in **/etc/fstab** using both the device name (as it appears in **/dev**) and the mount point. Mounting in this manner is simpler than it used to be—it used to require the filesystem type as an argument. The mount command is now smart enough to detect the filesystem type and mount it accordingly.
|
||||
|
||||
Try it again:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# mount /dev/mapper/VG01-TestFS /TestFS/
|
||||
[root@testvm1 ~]# lsblk
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
sda 8:0 0 120G 0 disk
|
||||
├─sda1 8:1 0 4G 0 part /boot
|
||||
└─sda2 8:2 0 116G 0 part
|
||||
├─VG01-root 253:0 0 5G 0 lvm /
|
||||
├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
|
||||
├─VG01-usr 253:2 0 30G 0 lvm /usr
|
||||
├─VG01-home 253:3 0 20G 0 lvm /home
|
||||
├─VG01-var 253:4 0 20G 0 lvm /var
|
||||
├─VG01-tmp 253:5 0 10G 0 lvm /tmp
|
||||
└─VG01-TestFS 253:6 0 1G 0 lvm /TestFS
|
||||
sr0 11:0 1 1024M 0 rom
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
Now the new filesystem is mounted in the proper location. List the mount unit files:
|
||||
|
||||
|
||||
```
|
||||
`[root@testvm1 ~]# systemctl list-unit-files -t mount`
|
||||
```
|
||||
|
||||
This command does not show a file for the **/TestFS** filesystem because no file exists for it. The command **systemctl status TestFS.mount** does not display any information about the new filesystem either. You can try it using wildcards with the **systemctl status** command:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl status *mount
|
||||
● usr.mount - /usr
|
||||
Loaded: loaded (/etc/fstab; generated)
|
||||
Active: active (mounted)
|
||||
Where: /usr
|
||||
What: /dev/mapper/VG01-usr
|
||||
Docs: man:fstab(5)
|
||||
man:systemd-fstab-generator(8)
|
||||
|
||||
<SNIP>
|
||||
● TestFS.mount - /TestFS
|
||||
Loaded: loaded (/proc/self/mountinfo)
|
||||
Active: active (mounted) since Fri 2020-04-17 16:02:26 EDT; 1min 18s ago
|
||||
Where: /TestFS
|
||||
What: /dev/mapper/VG01-TestFS
|
||||
|
||||
● run-user-0.mount - /run/user/0
|
||||
Loaded: loaded (/proc/self/mountinfo)
|
||||
Active: active (mounted) since Thu 2020-04-16 08:52:29 EDT; 1 day 5h ago
|
||||
Where: /run/user/0
|
||||
What: tmpfs
|
||||
|
||||
● var.mount - /var
|
||||
Loaded: loaded (/etc/fstab; generated)
|
||||
Active: active (mounted) since Thu 2020-04-16 12:51:34 EDT; 1 day 1h ago
|
||||
Where: /var
|
||||
What: /dev/mapper/VG01-var
|
||||
Docs: man:fstab(5)
|
||||
man:systemd-fstab-generator(8)
|
||||
Tasks: 0 (limit: 19166)
|
||||
Memory: 212.0K
|
||||
CPU: 5ms
|
||||
CGroup: /system.slice/var.mount
|
||||
```
|
||||
|
||||
This command provides some very interesting information about your system's mounts, and your new filesystem shows up. The **/var** and **/usr** filesystems are identified as being generated from **/etc/fstab**, while your new filesystem simply shows that it is loaded and provides the location of the info file in the **/proc/self/mountinfo** file.
|
||||
|
||||
Next, automate this mount. First, do it the old-fashioned way by adding an entry in **/etc/fstab**. Later, I'll show you how to do it the new way, which will teach you about creating units and integrating them into the startup sequence.
|
||||
|
||||
Unmount **/TestFS** and add the following line to the **/etc/fstab** file:
|
||||
|
||||
|
||||
```
|
||||
`/dev/mapper/VG01-TestFS /TestFS ext4 defaults 1 2`
|
||||
```
|
||||
|
||||
Now, mount the filesystem with the simpler **mount** command and list the mount units again:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# mount /TestFS
|
||||
[root@testvm1 ~]# systemctl status *mount
|
||||
<SNIP>
|
||||
● TestFS.mount - /TestFS
|
||||
Loaded: loaded (/proc/self/mountinfo)
|
||||
Active: active (mounted) since Fri 2020-04-17 16:26:44 EDT; 1min 14s ago
|
||||
Where: /TestFS
|
||||
What: /dev/mapper/VG01-TestFS
|
||||
<SNIP>
|
||||
```
|
||||
|
||||
This did not change the information for this mount because the filesystem was manually mounted. Reboot and run the command again, and this time specify **TestFS.mount** rather than using the wildcard. The results for this mount are now consistent with it being mounted at startup:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl status TestFS.mount
|
||||
● TestFS.mount - /TestFS
|
||||
Loaded: loaded (/etc/fstab; generated)
|
||||
Active: active (mounted) since Fri 2020-04-17 16:30:21 EDT; 1min 38s ago
|
||||
Where: /TestFS
|
||||
What: /dev/mapper/VG01-TestFS
|
||||
Docs: man:fstab(5)
|
||||
man:systemd-fstab-generator(8)
|
||||
Tasks: 0 (limit: 19166)
|
||||
Memory: 72.0K
|
||||
CPU: 6ms
|
||||
CGroup: /system.slice/TestFS.mount
|
||||
|
||||
Apr 17 16:30:21 testvm1 systemd[1]: Mounting /TestFS...
|
||||
Apr 17 16:30:21 testvm1 systemd[1]: Mounted /TestFS.
|
||||
```
|
||||
|
||||
### Creating a mount unit
|
||||
|
||||
Mount units may be configured either with the traditional **/etc/fstab** file or with systemd units. Fedora uses the **fstab** file as it is created during the installation. However, systemd uses the **systemd-fstab-generator** program to translate the **fstab** file into systemd units for each entry in the **fstab** file. Now that you know you can use systemd **.mount** unit files for filesystem mounting, try it out by creating a mount unit for this filesystem.
|
||||
|
||||
First, unmount **/TestFS**. Edit the **/etc/fstab** file and delete or comment out the **TestFS** line. Now, create a new file with the name **TestFS.mount** in the **/etc/systemd/system** directory. Edit it to contain the configuration data below. The unit file name and the name of the mount point _must_ be identical, or the mount will fail:
|
||||
|
||||
|
||||
```
|
||||
# This mount unit is for the TestFS filesystem
|
||||
# By David Both
|
||||
# Licensed under GPL V2
|
||||
# This file should be located in the /etc/systemd/system directory
|
||||
|
||||
[Unit]
|
||||
Description=TestFS Mount
|
||||
|
||||
[Mount]
|
||||
What=/dev/mapper/VG01-TestFS
|
||||
Where=/TestFS
|
||||
Type=ext4
|
||||
Options=defaults
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
|
||||
The **Description** line in the **[Unit]** section is for us humans, and it provides the name that's shown when you list mount units with **systemctl -t mount**. The data in the **[Mount]** section of this file contains essentially the same data that would be found in the **fstab** file.
|
||||
|
||||
Now enable the mount unit:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 etc]# systemctl enable TestFS.mount
|
||||
Created symlink /etc/systemd/system/multi-user.target.wants/TestFS.mount → /etc/systemd/system/TestFS.mount.
|
||||
```
|
||||
|
||||
This creates the symlink in the **/etc/systemd/system** directory, which will cause this mount unit to be mounted on all subsequent boots. The filesystem has not yet been mounted, so you must "start" it:
|
||||
|
||||
|
||||
```
|
||||
`[root@testvm1 ~]# systemctl start TestFS.mount`
|
||||
```
|
||||
|
||||
Verify that the filesystem has been mounted:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl status TestFS.mount
|
||||
● TestFS.mount - TestFS Mount
|
||||
Loaded: loaded (/etc/systemd/system/TestFS.mount; enabled; vendor preset: disabled)
|
||||
Active: active (mounted) since Sat 2020-04-18 09:59:53 EDT; 14s ago
|
||||
Where: /TestFS
|
||||
What: /dev/mapper/VG01-TestFS
|
||||
Tasks: 0 (limit: 19166)
|
||||
Memory: 76.0K
|
||||
CPU: 3ms
|
||||
CGroup: /system.slice/TestFS.mount
|
||||
|
||||
Apr 18 09:59:53 testvm1 systemd[1]: Mounting TestFS Mount...
|
||||
Apr 18 09:59:53 testvm1 systemd[1]: Mounted TestFS Mount.
|
||||
```
|
||||
|
||||
This experiment has been specifically about creating a unit file for a mount, but it can be applied to other types of unit files as well. The details will be different, but the concepts are the same. Yes, I know it is still easier to add a line to the **/etc/fstab** file than it is to create a mount unit. But this is a good example of how to create a unit file because systemd does not have generators for every type of unit.
|
||||
|
||||
### In summary
|
||||
|
||||
This article looked at systemd units in more detail and how to use the systemctl command to explore and manage units. It also showed how to stop and disable units and create a new systemd mount unit to mount a new filesystem and enable it to initiate during startup.
|
||||
|
||||
In the next article in this series, I will take you through a recent problem I had during startup and show you how I circumvented it using systemd.
|
||||
|
||||
### Resources
|
||||
|
||||
There is a great deal of information about systemd available on the internet, but much is terse, obtuse, or even misleading. In addition to the resources mentioned in this article, the following webpages offer more detailed and reliable information about systemd startup.
|
||||
|
||||
* The Fedora Project has a good, practical [guide][10] [to systemd][10]. It has pretty much everything you need to know in order to configure, manage, and maintain a Fedora computer using systemd.
|
||||
* The Fedora Project also has a good [cheat sheet][11] that cross-references the old SystemV commands to comparable systemd ones.
|
||||
* For detailed technical information about systemd and the reasons for creating it, check out [Freedesktop.org][12]'s [description of systemd][13].
|
||||
* [Linux.com][14]'s "More systemd fun" offers more advanced systemd [information and tips][15].
|
||||
|
||||
|
||||
|
||||
There is also a series of deeply technical articles for Linux sysadmins by Lennart Poettering, the designer and primary developer of systemd. These articles were written between April 2010 and September 2011, but they are just as relevant now as they were then. Much of everything else good that has been written about systemd and its ecosystem is based on these papers.
|
||||
|
||||
* [Rethinking PID 1][16]
|
||||
* [systemd for Administrators, Part I][17]
|
||||
* [systemd for Administrators, Part II][18]
|
||||
* [systemd for Administrators, Part III][19]
|
||||
* [systemd for Administrators, Part IV][20]
|
||||
* [systemd for Administrators, Part V][21]
|
||||
* [systemd for Administrators, Part VI][22]
|
||||
* [systemd for Administrators, Part VII][23]
|
||||
* [systemd for Administrators, Part VIII][24]
|
||||
* [systemd for Administrators, Part IX][25]
|
||||
* [systemd for Administrators, Part X][26]
|
||||
* [systemd for Administrators, Part XI][27]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/systemd-units
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-window-focus.png?itok=g0xPm2kD (young woman working on a laptop)
|
||||
[2]: https://opensource.com/article/20/4/systemd
|
||||
[3]: https://opensource.com/article/20/4/systemd-startup
|
||||
[4]: https://en.wikipedia.org/wiki/Sar_%28Unix%29
|
||||
[5]: https://en.wikipedia.org/wiki/Pwd
|
||||
[6]: https://en.wikipedia.org/wiki/Standard_streams#Standard_output_(stdout)
|
||||
[7]: http://www.both.org/?page_id=1183
|
||||
[8]: mailto:chrony-dnssrv@.timer
|
||||
[9]: mailto:mdadm-last-resort@.timer
|
||||
[10]: https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html
|
||||
[11]: https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet
|
||||
[12]: http://Freedesktop.org
|
||||
[13]: http://www.freedesktop.org/wiki/Software/systemd
|
||||
[14]: http://Linux.com
|
||||
[15]: https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/
|
||||
[16]: http://0pointer.de/blog/projects/systemd.html
|
||||
[17]: http://0pointer.de/blog/projects/systemd-for-admins-1.html
|
||||
[18]: http://0pointer.de/blog/projects/systemd-for-admins-2.html
|
||||
[19]: http://0pointer.de/blog/projects/systemd-for-admins-3.html
|
||||
[20]: http://0pointer.de/blog/projects/systemd-for-admins-4.html
|
||||
[21]: http://0pointer.de/blog/projects/three-levels-of-off.html
|
||||
[22]: http://0pointer.de/blog/projects/changing-roots
|
||||
[23]: http://0pointer.de/blog/projects/blame-game.html
|
||||
[24]: http://0pointer.de/blog/projects/the-new-configuration-files.html
|
||||
[25]: http://0pointer.de/blog/projects/on-etc-sysinit.html
|
||||
[26]: http://0pointer.de/blog/projects/instances.html
|
||||
[27]: http://0pointer.de/blog/projects/inetd.html
|
||||
169
sources/tech/20200508 5 ways to split your Linux terminal.md
Normal file
169
sources/tech/20200508 5 ways to split your Linux terminal.md
Normal file
@ -0,0 +1,169 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 ways to split your Linux terminal)
|
||||
[#]: via: (https://opensource.com/article/20/5/split-terminal)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
5 ways to split your Linux terminal
|
||||
======
|
||||
What's your favorite terminal multiplexer? Take our poll. Then read
|
||||
about how Linux offers plenty of ways for you to split your terminal so
|
||||
you can multitask.
|
||||
![4 different color terminal windows with code][1]
|
||||
|
||||
Is there anything better than a warmly flickering Linux terminal?
|
||||
|
||||
Sure there is: two warmly flickering Linux terminals. In fact, the more, the better.
|
||||
|
||||
Long ago, [terminals were physical devices][2], but of course, today, they're just emulated as an application on your computer. If you prefer the terminal as your interface, you probably know that one terminal is rarely enough. Inevitably, you're going to open a new terminal or a new tab so you can work in it while your first is busy compiling or converting or otherwise processing data.
|
||||
|
||||
If you're a sysadmin, then you know you're going to need at least four open windows while you work on several systems at the same time.
|
||||
|
||||
Terminal applications with tabs have existed on Linux for a long time, and luckily, that trend seems to have caught on such that it's an expected feature of a modern terminal. And yet, sometimes it's distracting or inconvenient to flip back and forth between tabs.
|
||||
|
||||
The only answer is a split screen so that two or more terminals can exist at the same time within just one application window. There are many tools in your Linux kit to help you slice and dice your consoles.
|
||||
|
||||
### Shells, terminals, and consoles
|
||||
|
||||
Before you slice and dice screens, you should know the difference between a terminal, a shell, and a "console." To get the full picture, read my article on the subject over on the [Enable Sysadmin][2] blog.
|
||||
|
||||
The short version:
|
||||
|
||||
* A shell is an input and output screen with a prompt. There's technically a shell running somewhere underneath your [POSIX][3] desktop, even when it's not visible (because it's a shell that launched your user session).
|
||||
* A terminal is an application running within a graphics server (such as X11 or Wayland) with a shell loaded into it. A terminal is only running when you have a terminal window launched. It's more or less a "portal" into your shell.
|
||||
* "Console" or "virtual console" is a term usually used to imply a shell running outside of your desktop. You can get to a virtual console by pressing **Alt-Ctrl-F2** (more are usually available from **F3** up to **F7**, with **F1** or **F7** representing your desktop, depending on your distribution).
|
||||
|
||||
|
||||
|
||||
Some applications let you split your shell or console, while others let you split your terminal.
|
||||
|
||||
### tmux
|
||||
|
||||
![tmux terminal][4]
|
||||
|
||||
Arguably the most flexible and capable of screen splitters, [tmux][5] is a keyboard-centric terminal multiplexer, meaning that you can "layer" one console on top of another and then switch between the two. You can also split a console view in half (or thirds or fourths, and so on) so you can see other consoles next to it.
|
||||
|
||||
All controls center around the keyboard, which means you never have to take your hand off the keys in search of a mouse, but also that you must learn some new keyboard combos.
|
||||
|
||||
If you're using tmux primarily for screen splitting, then the only commands you really need are these:
|
||||
|
||||
* **Ctrl-B %** for a vertical split (one shell on the left, one shell on the right)
|
||||
* **Ctrl-B"** for a horizontal split (one shell at the top, one shell at the bottom)
|
||||
* **Ctrl-B O** to make the other shell active
|
||||
* **Ctrl-B ?** for help
|
||||
* **Ctrl-B d** detach from Tmux, leaving it running in the background (use **tmux attach** to reenter)
|
||||
|
||||
|
||||
|
||||
There are many benefits to tmux, including the ability to start a tmux session on one computer, and then join that same session from another computer remotely. It essentially daemonizes your shell.
|
||||
|
||||
It's with tmux running on a Pi, for example, that I can stay logged into IRC on a permanent basis—I start tmux on the Pi, and then log in from whatever computer I happen to be on. When I log out, tmux continues to run, patiently waiting for me to reattach to the session from a different computer.
|
||||
|
||||
### GNU Screen
|
||||
|
||||
![GNU Screen terminal][6]
|
||||
|
||||
Similar to tmux, [GNU Screen][7] is a shell multiplexer. You can detach and reattach from a running session, and you can split the screen both horizontally and vertically.
|
||||
|
||||
Screen is a little clunkier than tmux. Its default key binding is **Ctrl-A**, which also happens to be Bash's keyboard shortcut to go to the beginning of a line. This means that if you have Screen running, you must press **Ctrl-A** twice instead of just once to go to the beginning of the line. Personally, I redefine the trigger key to **Ctrl-J** with this line in **$HOME/.screenrc**:
|
||||
|
||||
|
||||
```
|
||||
`escape ^jJ`
|
||||
```
|
||||
|
||||
Screen's split function works well, but it leaves out a few pleasantries that tmux lacks. For instance, when you split your shell, a new shell does not start in the other panel. You have to navigate to the other space with **Ctrl-A Tab** (or **Ctrl-J** if you redefine your keyboard shortcut as I do) and create a new shell manually with **Ctrl-A C**.
|
||||
|
||||
Unlike tmux, a split doesn't go away when you exit a shell, which is a design feature that's quite nice in some instances but can also sometimes be cumbersome because it forces you to manage your splits manually.
|
||||
|
||||
Still, Screen is a reliable and flexible application that you can run should you find that **tmux** is unavailable to you.
|
||||
|
||||
Here are the basic split commands, using the default keyboard shortcuts:
|
||||
|
||||
* **Ctrl-A |** for a vertical split (one shell on the left, one shell on the right)
|
||||
* **Ctrl-A S** for a horizontal split (one shell at the top, one shell at the bottom)
|
||||
* **Ctrl-A Tab** to make the other shell active
|
||||
* **Ctrl-A ?** for help
|
||||
* **Ctrl-A d** detach from Screen, leaving it running in the background (use **screen -r** to reenter)
|
||||
|
||||
|
||||
|
||||
### Konsole
|
||||
|
||||
![Konsole screen][8]
|
||||
|
||||
[Konsole][9] is the terminal bundled along with the KDE Plasma desktop. Like KDE itself, Konsole is famous for being highly customizable and powerful.
|
||||
|
||||
Among its many features is the ability to split its window, similar to both tmux and GNU Screen. Because Konsole is a graphical terminal, you can control its split-screen feature with your mouse instead of your keyboard.
|
||||
|
||||
Splitting is found in the **View** menu of Konsole. You can split your window horizontally or vertically. To change which panel is active, just click on it. Each panel is a unique terminal, so it can have its own theme and tabs.
|
||||
|
||||
Unlike tmux and GNU Screen, you can't detach and reattach from Konsole. Like most graphical applications, you use Konsole while you're physically in front of it, and you lose access to it when you're away (unless you use remote desktop software).
|
||||
|
||||
### Emacs
|
||||
|
||||
![Emacs rpg][10]
|
||||
|
||||
Emacs isn't exactly a terminal multiplexer, but its interface supports splitting and resizing, and it has a built-in terminal.
|
||||
|
||||
If you're in Emacs on a daily basis anyway, the ability to split your window between essentially different applications means you never have to leave the familiarity and comfort of your favorite text editor. Furthermore, because the Emacs **eshell** module is implemented in eLISP, you can interact with it using the same commands you use in Emacs itself, making it trivial to copy and yank long file paths or command output.
|
||||
|
||||
If you're using Emacs in a graphical window, you can perform some actions with your mouse. It's faster to use keyboard shortcuts, and some are more or less required. For instance, you can change which panel is the active one by clicking into it, and you can resize the proportions of your split screen with your mouse.
|
||||
|
||||
These are the important keyboard shortcuts:
|
||||
|
||||
* **Ctrl-X 3** for a vertical split (one shell on the left, one shell on the right)
|
||||
* **Ctrl-X 2** for a horizontal split (one shell at the top, one shell at the bottom)
|
||||
* **Ctrl-X O** to make the other shell active (you can also do this with the mouse)
|
||||
* **Ctrl-X 0** (that’s a zero) close the current panel
|
||||
|
||||
|
||||
|
||||
Similar to tmux and GNU Screen, you can detach and reattach from Emacs as long as you run **emacs-client**.
|
||||
|
||||
### Window manager
|
||||
|
||||
![Ratpoison split screen][11]
|
||||
|
||||
Should you think a text editor that can split its screen and load a terminal is amazing, imagine your desktop serving the same purpose. There are Linux desktops, like [Ratpoison][12], [Herbsluftwm][13], i3, Awesome, and even the KDE Plasma desktop with specific settings enabled, that present each application window to you as a fixed tile in a desktop grid.
|
||||
|
||||
Instead of windows floating "above" your desktop, they remain in a predictable place so you can change from one to the other. You can open any number of terminals within your grid, emulating a terminal multiplexer. In fact, you could even load a terminal multiplexer in your desktop multiplexer.
|
||||
|
||||
And there's nothing stopping you from loading Emacs with split buffers inside of that. No one knows what happens if you take it further than that, and most Linux users agree it's best not to find out.
|
||||
|
||||
Unlike tmux and GNU Screen, you can't detach and reattach from your desktop unless you count using remote desktop software.
|
||||
|
||||
### Other options
|
||||
|
||||
Believe it or not, these aren't the only options you have to split your screen on Linux. There are other terminal emulators, like [Tilix][14] and Terminator before it, that can split into sections, and applications with embedded terminal components, and much more. Tell us your favorite way of splitting up your workspace in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/split-terminal
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/freedos.png?itok=aOBLy7Ky (4 different color terminal windows with code)
|
||||
[2]: https://www.redhat.com/sysadmin/terminals-shells-consoles
|
||||
[3]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||
[4]: https://opensource.com/sites/default/files/uploads/terminal-split-tmux2.png (tmux terminal)
|
||||
[5]: https://github.com/tmux/tmux
|
||||
[6]: https://opensource.com/sites/default/files/uploads/terminal-split-screen.png (GNU Screen terminal)
|
||||
[7]: https://www.gnu.org/software/screen/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/konsole.jpg (Konsole screen)
|
||||
[9]: https://konsole.kde.org
|
||||
[10]: https://opensource.com/sites/default/files/uploads/emacs-rpg_0.jpg (Emacs rpg)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/advent-ratpoison-split_0.jpg (Ratpoison split screen)
|
||||
[12]: https://opensource.com/article/19/12/ratpoison-linux-desktop
|
||||
[13]: https://opensource.com/article/19/12/herbstluftwm-linux-desktop
|
||||
[14]: https://gnunn1.github.io/tilix-web/
|
||||
@ -0,0 +1,193 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A guide to setting up your Open Source Program Office (OSPO) for success)
|
||||
[#]: via: (https://opensource.com/article/20/5/open-source-program-office)
|
||||
[#]: author: (J. Manrique Lopez de la Fuente https://opensource.com/users/jsmanrique)
|
||||
|
||||
A guide to setting up your Open Source Program Office (OSPO) for success
|
||||
======
|
||||
Learn how to best grow and maintain your open source communities and
|
||||
allies.
|
||||
![community team brainstorming ideas][1]
|
||||
|
||||
Companies create Open Source Program Offices (OSPO) to manage their relationship with the open source ecosystems they depend on. By understanding the company's open source ecosystem, an OSPO is able to maximize the company's return on investment and reduce the risks of consuming, contributing to, and releasing open source software. Additionally, since the company depends on its open source ecosystem, ensuring its health and sustainability shall ensure the company's health, sustainable growth, and evolution.
|
||||
|
||||
### How has OSPO become vital to companies and their open source ecosystem?
|
||||
|
||||
Marc Andreessen has said that "software is eating the world," and more recently, it could be said that open source is eating the software world. But how is that process happening?
|
||||
|
||||
Companies get involved with open source projects in several ways. These projects comprise the company's open source ecosystem, and their relationships and interactions can be seen through Open Source Software's (OSS) inbound and outbound processes.
|
||||
|
||||
From the OSS inbound point of view, companies use it to build their own solutions and their own infrastructure. OSS gets introduced because it's part of the code their technology providers use, or because their own developers add open source components to the company's information technology (IT) infrastructure.
|
||||
|
||||
From the OSS outbound point of view, some companies contribute to OSS projects. That contribution could be part of the company's requirements for their solutions that need certain fixes in upstream projects. For example, Samsung contributes to certain graphics-related projects to ensure its hardware has software support once it gets into the market. In some other cases, contributing to OSS is a mechanism to retain talent by allowing the people to contribute to projects different from their daily work.
|
||||
|
||||
Some companies release their own open source projects as an outbound OSS process. For companies like Red Hat or GitLab, it would be expected. But, there are increasingly more non-software companies releasing a lot of OSS, like Lyft.
|
||||
|
||||
![OSS inbound and outbound processes][2]
|
||||
|
||||
OSS inbound and outbound processes
|
||||
|
||||
Ultimately, all of these projects involved in the inbound and outbound OSS flow are the company's OSS ecosystem. And like any living being, the company's health and sustainability depend on the ecosystem that surrounds it.
|
||||
|
||||
### OSPO responsibilities
|
||||
|
||||
Following the species and their ecosystem, people working in the OSPO team could be seen as the rangers in the organization's OSS ecosystem. They take care of the ecosystem and its relationship with the company, to keep everything healthy and sustainable.
|
||||
|
||||
When the company consumes open source software projects, they need to be aware of licenses and compliance, to check the project's health, to ensure there are no security flaws, and, in some cases, to identify talented community members for potential hiring processes.
|
||||
|
||||
When the company contributes to open source software projects, they need to be sure there are no Intellectual Property (IP) issues, to ensure the company contributions' footprint and its leadership in the projects, and sometimes, also to help talented people stay engaged with the company through their contributions.
|
||||
|
||||
And when the company releases and maintains open source projects, they are responsible for ensuring community engagement and growth, for checking there are no IP issues, that the company maintains its footprint and leadership, and perhaps, to attract new talent to the company.
|
||||
|
||||
Have you realized the whole set of skills required in an OSPO team? When I've asked people working in OSPO about the size of their teams, the number is around 1 to 5 people per 1,000 developers in the company. That's a small team to monitor a lot of people and their potential OSS related activity.
|
||||
|
||||
### How to manage an OSPO
|
||||
|
||||
With all these activities in OSPO people's minds and all the resources they need to worry about, how are they able to manage all of this?
|
||||
|
||||
There are at least a couple of open source communities with valuable knowledge and resources available for them:
|
||||
|
||||
* The [TODO Group][3] is "an open group of companies who want to collaborate on practices, tools, and other ways to run successful and effective open source projects and programs." For example, they have a complete set of [guides][4] with best practices for and from companies running OSPOS.
|
||||
* The [CHAOSS (Community Health Analytics for Open Source Software)][5] community develops metrics, methodologies, and software for managing open source project health and sustainability. (See more on CHAOSS' active communities and working groups below).
|
||||
|
||||
|
||||
|
||||
OSPO managers need to report a lot of information to the rest of the company to answer many questions related to their OSS inbound and outbound processes, i.e., Which projects are we using in our organization? What's the health of those projects? Who are the key people in those projects? Which projects are we contributing to? Which projects are we releasing? How are we dealing with community contributions? Who are the key contributors?
|
||||
|
||||
### Data-driven OSPO
|
||||
|
||||
As William Edwards Deming said, "Without data, you are just a person with an opinion."
|
||||
|
||||
Having opinions is not a bad thing, but having opinions based on data certainly makes it easier to understand, discuss, and determine the processes best suited to your company and its goals. CHAOSS is the recommended community to look to for guidance about metrics strategies and tools.
|
||||
|
||||
Recently, the CHAOSS community has released [a new set of metric definitions][6]. These metrics are only subsets of all the ones being discussed in the focus areas of each working group (WG):
|
||||
|
||||
* [Common WG][7]: Defines the metrics that are used by both working groups or are important for community health, but that do not cleanly fit into one of the other existing working groups. Areas of interest include organizational affiliation, responsiveness, and geographic coverage.
|
||||
* [Diversity and Inclusion WG][8]: Gathers experiences regarding diversity and inclusion in open source projects with the goal of understanding, from a qualitative and quantitative point of view, how diversity and inclusion can be measured.
|
||||
* [Evolution WG][9]: Refines the metrics that inform evolution and works with software implementations.
|
||||
* [Risk WG][10]: Refines the metrics that inform risk and works with software implementations.
|
||||
* [Value WG][11]: Focuses on industry-standard metrics for economic value in open source. Their main goal is to publish trusted industry-standard value metrics—a kind of S&P for software development and an authoritative source for metrics significance and industry norms.
|
||||
|
||||
|
||||
|
||||
On the tooling side, projects like [Augur][12], [Cregit][13], and [GrimoireLab][14] are the reference tools that report these metrics, but also many others related to OSPO activities. They are also the seed for new tools and solutions provided by the OSS community like [Cauldron.io][15], a SaaS open source solution to ease OSS ecosystem analysis.
|
||||
|
||||
![CHAOSS Metrics for 15 years of Unity OSS activity. Source: cauldron.io][16]
|
||||
|
||||
CHAOSS Metrics for 15 years of Unity OSS activity. Source: cauldron.io
|
||||
|
||||
All these metrics and data are useless without a metrics strategy. Usually, the first approach is to try to measure as much as possible, producing overwhelming reports and dashboards full of charts and data. What is the value of that?
|
||||
|
||||
Experience has shown that a very valid approach is the [Goal, Questions, Metrics (GQM)][17] strategy. But how do we put that in practice in an OSPO?
|
||||
|
||||
First of all, we need to understand the company's goals when using, consuming, contributing to, or releasing and maintaining OSS projects. The usual goals are related to market positioning, required upstream features development, and talent attraction or retention. Based on these goals, we should write down related questions that can be answered with numbers, like the following:
|
||||
|
||||
#### Who/how many are the core maintainers of my OSS ecosystem projects?
|
||||
|
||||
![Uber OSS code core, regular, and casual contributors evolution. Source: uber.biterg.io][18]
|
||||
|
||||
Uber OSS code core, regular, and casual contributors evolution. Source: uber.biterg.io
|
||||
|
||||
People contribute through different mechanisms or tools (code, issues, comments, tests, etc.). Measuring the core contributors (those that have done 80% of the contributions), the regular ones (those that have done 15% of the contributions), and the casual ones (those have made 5% of the contributions) can answer questions related to participation over time, but also how people move between the different buckets. Adding affiliation information helps to identify external core contributors.
|
||||
|
||||
#### Where are the contributions happening?
|
||||
|
||||
![Uber OSS activity based on location. Source: uber.biterg.io][19]
|
||||
|
||||
Uber OSS activity based on location. Source: uber.biterg.io
|
||||
|
||||
The growth of OSS ecosystems is also related to OSS projects spread across the world. Understanding that spread helps OSPO, and the company, to manage actions that improve support for people from different countries and regions.
|
||||
|
||||
#### What is the company's OSS network?
|
||||
|
||||
![Uber OSS network. Source: uber.biterg.io][20]
|
||||
|
||||
Uber OSS network. Source: uber.biterg.io
|
||||
|
||||
The company's OSS ecosystem includes those projects that the company's people contribute to. Understanding which projects they contribute to offers insight into which technologies or OSS components are interesting to people, and which companies or organizations the company collaborates with.
|
||||
|
||||
#### How is the company dealing with contributions?
|
||||
|
||||
![Github Pull Requests backlog management index and time to close analysis. Source: uber.biterg.io][21]
|
||||
|
||||
Github Pull Requests backlog management index and time to close analysis. Source: uber.biterg.io
|
||||
|
||||
One of the goals when releasing OSS projects is to grow the community around them. Measuring how the company handles contributions to its projects from outside its boundaries helps to understand how "welcoming" it is and identifies mentors (or bottlenecks) and opportunities to lower the barrier to contribute.
|
||||
|
||||
#### Consumers vs. maintainers
|
||||
|
||||
Over the last months, we have been hearing that corporations are taking OSS for free without contributing back. The typical arguments are that these corporations are making millions of dollars thanks to free work, plus the issue of OSS project maintainer burnout due to users' complaints and requests for free support.
|
||||
|
||||
The system is unbalanced; usually, the number of users exceeds the number of maintainers. Is that good or bad? Having users for our software is (or should be) good. But we need to manage expectations on both sides.
|
||||
|
||||
From the corporation's point of view, consuming OSS without care is very, very risky.
|
||||
|
||||
OSPO can play an important role in educating the company about the risks they are facing, and how to reduce them by contributing back to their OSS ecosystem. Remember, a company's overall sustainability could rely heavily on its ecosystem sustainability.
|
||||
|
||||
A good strategy is to start shifting your company from being pure OSS consumers to becoming contributors to their OSS inbound projects. From just submitting issues and asking questions to help solve issues, answering questions, and even sending patches, contributing helps grow and maintain the project while giving back to the community. It doesn't happen immediately, but over time, the company will be perceived as an OSS ecosystem citizen. Eventually, some people from the company could end up helping to maintain those projects too.
|
||||
|
||||
And what about money? There are plenty of ways to support the OSS ecosystem financially. Some examples:
|
||||
|
||||
* Business initiatives like [Tidelift][22], or [OpenCollective][23]
|
||||
* Foundations and their supporting mechanisms, like [Software Freedom Conservancy][24], or [CommunityBridge][25] from the Linux Foundation
|
||||
* Self-funding programs (like [Indeed][26] and [Salesforce][27] have done)
|
||||
* Emerging gig development approaches like [Github Sponsors][28] or [Patreon][29]
|
||||
|
||||
|
||||
|
||||
Last but not least, companies need to avoid the "not invented here" syndrome. For some OSS projects, there might be companies providing consulting, customization, maintenance, and/or support services. Instead of taking OSS and spending time and people to self-host, self-customize, or try to bring those kinds of services in-house, it might be smarter and more efficient to hire some of those companies to do the thought work.
|
||||
|
||||
As a final remark, I would like to emphasize the importance of an OSPO for a company to succeed and grow in the current market. As shepherds of the company's OSS ecosystem, they are the best people in the organization to understand how the ecosystem works and flows, and they should be empowered to manage, monitor, and make recommendations and decisions to ensure sustainability and growth.
|
||||
|
||||
Does your organization have an OSPO yet?
|
||||
|
||||
Six common traits of successful open source programs, and a look back at how the open source...
|
||||
|
||||
Why would a company not in the business of software development create an open source program...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/open-source-program-office
|
||||
|
||||
作者:[J. Manrique Lopez de la Fuente][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jsmanrique
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/meeting_discussion_brainstorm.png?itok=7_m4CC8S (community team brainstorming ideas)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/ospo_1.png (OSS inbound and outbound processes)
|
||||
[3]: https://todogroup.org/
|
||||
[4]: https://todogroup.org/guides/
|
||||
[5]: https://chaoss.community/
|
||||
[6]: https://chaoss.community/metrics/
|
||||
[7]: https://github.com/chaoss/wg-common
|
||||
[8]: https://github.com/chaoss/wg-diversity-inclusion
|
||||
[9]: https://github.com/chaoss/wg-evolution
|
||||
[10]: https://github.com/chaoss/wg-risk
|
||||
[11]: https://github.com/chaoss/wg-value
|
||||
[12]: https://github.com/chaoss/augur
|
||||
[13]: https://github.com/cregit
|
||||
[14]: https://chaoss.github.io/grimoirelab/
|
||||
[15]: https://cauldron.io/
|
||||
[16]: https://opensource.com/sites/default/files/uploads/ospo_2.png (CHAOSS Metrics for 15 years of Unity OSS activity. Source: cauldron.io)
|
||||
[17]: https://en.wikipedia.org/wiki/GQM
|
||||
[18]: https://opensource.com/sites/default/files/uploads/ospo_3.png (Uber OSS code core, regular, and casual contributors evolution. Source: uber.biterg.io)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/ospo_4.png (Uber OSS activity based on location. Source: uber.biterg.io)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/ospo_5_0.png (Uber OSS network. Source: uber.biterg.io)
|
||||
[21]: https://opensource.com/sites/default/files/uploads/ospo_6.png (Github Pull Requests backlog management index and time to close analysis. Source: uber.biterg.io)
|
||||
[22]: https://tidelift.com/
|
||||
[23]: https://opencollective.com/
|
||||
[24]: https://sfconservancy.org/
|
||||
[25]: https://funding.communitybridge.org/
|
||||
[26]: https://engineering.indeedblog.com/blog/2019/02/sponsoring-osi/
|
||||
[27]: https://sustain.codefund.fm/23
|
||||
[28]: https://help.github.com/en/github/supporting-the-open-source-community-with-github-sponsors
|
||||
[29]: https://www.patreon.com/
|
||||
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with FreeBSD as a desktop operating system)
|
||||
[#]: via: (https://opensource.com/article/20/5/furybsd-linux)
|
||||
[#]: author: (Joshua Allen Holm https://opensource.com/users/holmja)
|
||||
|
||||
Getting started with FreeBSD as a desktop operating system
|
||||
======
|
||||
FuryBSD's live desktop environment lets you try it before committing to
|
||||
it.
|
||||
![web development and design, desktop and browser][1]
|
||||
|
||||
[FreeBSD][2] is a great operating system, but, by design, it does not come with a desktop environment. Without installing additional software from FreeBSD's [ports and packages collection][3], FreeBSD is a command-line only experience. The screenshot below shows what logging into FreeBSD 12.1 looks like when every one of the "optional system components" is selected during installation.
|
||||
|
||||
![FreeBSD][4]
|
||||
|
||||
FreeBSD can be turned into a desktop operating system with any of a wide selection of desktop environments, but it takes time, effort, and [following a lot of written instructions][5]. Using the **desktop-installer** package, which provides the user with options in a text-based menu and helps automate much of the process, is still time-consuming. The biggest problem with either of these methods is that users might find out that their system is not fully compatible with FreeBSD after they have taken all the time to set things up.
|
||||
|
||||
[FuryBSD][6] solves that problem by providing a live desktop image that users can evaluate before installing. Currently, FuryBSD provides an Xfce image and a KDE image. Each of these images provides an installation of FreeBSD that has a desktop environment pre-installed. If users try out the image and find that their hardware works, they can install FuryBSD and have a ready-to-go desktop operating system powered by FreeBSD. For the purposes of this article, I will be using the Xfce image, but the KDE image works the exact same way.
|
||||
|
||||
Getting started with FuryBSD should be a familiar process to anyone who has installed a Linux distribution, any of the BSDs, or any other Unix-like open source operating system. Download the ISO from the FuryBSD website, copy it to a flash drive, and boot a computer from the flash drive. If booting from the flash drive fails, make sure Secure Boot is disabled.
|
||||
|
||||
![FuryBSD Live XFCE Desktop][7]
|
||||
|
||||
After booting from the flash drive, the desktop environment loads automatically. In addition to the Home, File System, and Trash icons, the live desktop has icons for a tool to configure Xorg, getting started instructions, the FuryBSD installer, and a system information utility. Other than these extras and some custom Xfce settings and wallpaper, the desktop environment does not come with much beyond the basic Xfce applications and Firefox.
|
||||
|
||||
![FuryBSD Xorg Tool][8]
|
||||
|
||||
Only basic graphics drivers are loaded at this point, but it is enough to check to see if the system's wired and wireless network interfaces are supported by FuryBSD. If none of the network interfaces is working automatically, the **Getting Started.txt** file contains instructions for attempting to configure network interfaces and other configuration tasks. If at least one of the network interfaces works, the **Configure Xorg** application can be used to install Intel, NVidia, or VirtualBox graphics drivers. The drivers will be downloaded and installed, and Xorg will need to be restarted. If the system does not automatically re-login to the live image user, the password is **furybsd**. Once they are configured, the graphics drivers will carry over to an installed system.
|
||||
|
||||
![FuryBSD Installer - ZFS Configuration][9]
|
||||
|
||||
If everything works well in the live environment, the FuryBSD installer can configure and install FuryBSD onto the computer. This installer runs in a terminal, but it provides the same options found in most other BSD and Linux installers. The user will be asked to set the system's hostname, configure ZFS storage, set the root password, add at least one non-root user, and configure the time and date settings. Once the process is complete, the system can be rebooted into a pre-configured FreeBSD with an Xfce (or KDE) desktop. FuryBSD did all the hard work and even took the extra effort to make the desktop look nice.
|
||||
|
||||
![FuryBSD Post-Install XFCE Desktop][10]
|
||||
|
||||
As noted above, the desktop environment does not come with a lot of pre-installed software, so installing additional packages is almost certainly necessary. The quickest way to do this is by using the **pkg** command in the terminal. This command behaves much like **dnf** and **apt**, so users coming from a Linux distribution that uses one of those should feel right at home when it comes to finding and installing packages. FreeBSD's package collection is large, so most of the big-name open source software packages are available.
|
||||
|
||||
Users trying out FuryBSD without having much FreeBSD experience should consult the [FreeBSD Handbook][11] to learn more about how to do things the FreeBSD way. Users with experience using any Linux distribution or one of the other BSDs should be able to figure out a lot of things, but there are differences that the handbook can help clarify. Another great resource for learning more about the FreeBSD way of doing things is _[Absolute FreeBSD, 3rd Edition][12],_ by Michael W. Lucas.
|
||||
|
||||
A brief overview of PC-BSD and thoughts about the distribution.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/furybsd-linux
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/holmja
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web_browser_desktop_devlopment_design_system_computer.jpg?itok=pfqRrJgh (web development and design, desktop and browser)
|
||||
[2]: https://www.freebsd.org
|
||||
[3]: https://www.freebsd.org/ports/
|
||||
[4]: https://opensource.com/sites/default/files/uploads/freebsd.png (FreeBSD)
|
||||
[5]: https://www.freebsdfoundation.org/freebsd/how-to-guides/installing-a-desktop-environment-on-freebsd/
|
||||
[6]: https://www.furybsd.org
|
||||
[7]: https://opensource.com/sites/default/files/uploads/furybsd_live_xfce_desktop.png (FuryBSD Live XFCE Desktop)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/furybsd_xorg_tool.png (FuryBSD Xorg Tool)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/furybsd_installer_-_zfs_configuration.png (FuryBSD Installer - ZFS Configuration)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/furybsd_post-install_xfce_desktop.png (FuryBSD Post-Install XFCE Desktop)
|
||||
[11]: https://www.freebsd.org/doc/en_US.ISO8859-1/books/handbook/
|
||||
[12]: https://nostarch.com/absfreebsd3
|
||||
@ -0,0 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Open source underpins coronavirus IoT and robotics solutions)
|
||||
[#]: via: (https://opensource.com/article/20/5/robotics-covid19)
|
||||
[#]: author: (Sam Bocetta https://opensource.com/users/sambocetta)
|
||||
|
||||
Open source underpins coronavirus IoT and robotics solutions
|
||||
======
|
||||
From sanitization of equipment and facilities to plotting the spread of
|
||||
the virus, robots are playing an active role in combating COVID-19.
|
||||
![Three giant robots and a person][1]
|
||||
|
||||
The tech sector is quietly having a boom during the COVID-19 pandemic. Open source developers are getting involved with many aspects of the fight against the coronavirus, [using Python to visualize its spread][2] and helping to repurpose data acquisition systems to perform contact tracing.
|
||||
|
||||
However, one of the most exciting areas of current research is the use of robotics to contain the spread of the coronavirus. In the last few weeks, robots have been deployed in critical environments—particularly in hospitals and on airplanes—to help staff sterilize surfaces and objects.
|
||||
|
||||
Most of these robots are produced by tech startups, who have seen an opportunity to prove the worth of their proprietary systems. Many of them, however, rely on [open source cloud and IoT tools][3] that have been developed by the open source community.
|
||||
|
||||
In this article, we'll take a look at how robotics are being used to fight the disease, the IoT infrastructure that underpins these systems, and finally, the security and privacy concerns that their increased use is highlighting.
|
||||
|
||||
### Robots and COVID-19
|
||||
|
||||
Around the world, robots are being deployed to help the fight against COVID-19. The most direct use of robots has been in healthcare facilities, and China has taken the lead when it comes to deploying robots in hospitals.
|
||||
|
||||
For example, a field hospital that recently opened in Wuhan—where the virus originated—is [making extensive use of robots][4] to help healthcare workers care for patients. Some of these robots provide food, drink, and medicine to patients, and others are used to clean parts of the hospital.
|
||||
|
||||
Other companies, such as the Texas startup Xenex Disinfection Services, are using robots and UV light to deactivate viruses, bacteria, and spores on surfaces in airports. Still others, like Dimer UVC Innovations, are focusing on making robots that can [improve aircraft hygiene][5].
|
||||
|
||||
Not all of the "robots" deployed against the disease are anthropomorphic, though. The same field hospital in Wuhan that is using human-like robots is also making extensive use of less obviously "robotic" IoT devices.
|
||||
|
||||
Patients entering the hospital are screened by networked 5G thermometers to alert staff for anyone showing a high fever, and patients wear smart bracelets and rings equipped with sensors. These are synced with CloudMinds' AI platform, and patients' vital signs, including temperature, heart rate, and blood oxygen levels, can be monitored.
|
||||
|
||||
### Robots and the IoT
|
||||
|
||||
Even when these robots appear to be independent entities, they make [extensive use of the IoT][6]. In other words, although patients may feel that they are being cared for by a robot that can make its own decisions, in reality, these robots are controlled by large, distributed sensing and data processing systems.
|
||||
|
||||
Although many of the robots being deployed are the proprietary property of the tech firms who produce their hardware, their functioning is based on an ecosystem of software that is largely open source.
|
||||
|
||||
This observation is an important one because it overturns one of the primary misconceptions about the [way that AI is used today][7][,][7] whether in a healthcare setting or elsewhere. Most research into robotics today does not seek to embed fully intelligent AI systems into robots themselves but, instead, uses centralized AI systems to control a wide variety of far less "smart" IoT devices.
|
||||
|
||||
This observation, in turn, highlights two key points about the robots currently being developed and used to fight COVID-19. One is that they rely on a software ecosystem—much of it open source—that has been developed in a truly collaborative process involving thousands of engineers. The second is that the networked nature of these robots makes them vulnerable to exploitation.
|
||||
|
||||
### Security and privacy
|
||||
|
||||
This vulnerability to cybersecurity threats has led some analysts to raise questions about the wisdom of widespread deployment of IoT-driven robotics, whether in the healthcare system or anywhere else. Spyware in the IoT [remains a huge problem][8], and some fear that by integrating IoT systems into healthcare, we may be exposing more data—and more sensitive data—to intruders.
|
||||
|
||||
Even where developers are careful to build security into these devices, the sheer number of components they rely on makes DevSecOps processes difficult to implement. Especially in this current time of crisis, many software engineers have been forced to accelerate the release of new components, and this could lead to them being vulnerable. If a company is rushing to bring a healthcare robot onto the market in response to COVID-19, it's unlikely that the open source code that these devices run on will be [properly audited][9].
|
||||
|
||||
And even if companies are able to maintain the integrity of their DevSecOps processes while still accelerating development, it's far from certain that patients themselves understand the privacy implications of delegating their care to IoT devices. Many lack the open source privacy tools [necessary to keep their data private][10] when browsing the internet, let alone those that should be deployed to protect sensitive healthcare data.
|
||||
|
||||
### The future
|
||||
|
||||
In short, the deployment of robots in the fight against COVID-19 is highlighting long-standing concerns about the integrity, security, and privacy of IoT systems more generally. Professionals in this field have long argued that [IoT audits][11] and [embedded Linux systems][12] should be the standard for IoT development, but in the current crisis, their warnings are likely to be ignored.
|
||||
|
||||
This is worrying because it's likely that IoT systems will be increasingly used in healthcare in the coming decade. So whilst the COVID-19 pandemic will provide a proof of their utility in this sector, it should also not be used as an excuse to roll out poorly secured, poorly audited IoT software in highly sensitive environments.
|
||||
|
||||
Open source isn’t just changing the way we interact with the world, it’s changing the way the world...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/robotics-covid19
|
||||
|
||||
作者:[Sam Bocetta][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sambocetta
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_robots.png?itok=TOZgajrd (Three giant robots and a person)
|
||||
[2]: https://opensource.com/article/20/4/python-data-covid-19
|
||||
[3]: https://opensource.com/article/18/7/digital-transformation-strategy-think-cloud
|
||||
[4]: https://www.cnbc.com/2020/03/18/how-china-is-using-robots-and-telemedicine-to-combat-the-coronavirus.html
|
||||
[5]: https://www.therobotreport.com/company-offers-germ-killing-robot-to-airports-to-address-coronavirus-outbreak/
|
||||
[6]: https://www.cloudwards.net/what-is-the-internet-of-things/
|
||||
[7]: https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives
|
||||
[8]: https://blog.eccouncil.org/spyware-in-the-iot-what-does-it-mean-for-your-online-privacy/
|
||||
[9]: https://opensource.com/article/17/10/doc-audits
|
||||
[10]: https://privacyaustralia.net/privacy-tools/
|
||||
[11]: https://opensource.com/article/19/11/how-many-iot-devices
|
||||
[12]: https://opensource.com/article/17/3/embedded-linux-iot-ecosystem
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Can’t Install Deb File on Ubuntu 20.04? Here’s What You Need to do!)
|
||||
[#]: via: (https://itsfoss.com/cant-install-deb-file-ubuntu/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Can’t Install Deb File on Ubuntu 20.04? Here’s What You Need to do!
|
||||
======
|
||||
|
||||
_**Brief: Double clicking on the deb file doesn’t install it via the software center in Ubuntu 20.04? You are not the only one facing this issue. This tutorial shows how to fix it.**_
|
||||
|
||||
On the “[things to do after installing Ubuntu 20.04][1]” article, a few readers mentioned that they had trouble [installing software from the Deb file][2].
|
||||
|
||||
I found that strange because installing a program using the deb file is one of the simplest methods. All you have to do is to double click the downloaded file and it opens (by default) with the Software Center program. You click on install, it asks for your password and within a few seconds/minute, the software is installed.
|
||||
|
||||
I had [upgraded to Ubuntu 20.04 from 19.10][3] and hadn’t faced this issue with it until today.
|
||||
|
||||
I downloaded the .deb file for installing [Rocket Chat messenger][4] and when I double clicked on it to install this software, the file was opened with the archive manager. This is not what I expected.
|
||||
|
||||
![DEB files opened with Archive Manager instead of Software Center][5]
|
||||
|
||||
The “fix” is simple and I am going to show it to you in this quick tutorial.
|
||||
|
||||
### Installing deb files in Ubuntu 20.04
|
||||
|
||||
For some reasons, the default software to open the deb file has been set to Archive Manager tool in Ubuntu 20.04. The Archive Manager tool is used for [extract zip][6] and other compressed files.
|
||||
|
||||
The solution for this problem is pretty simple. You [change the default application in Ubuntu][7] for opening DEB files from Archive Manager to Software Install. Let me show you the steps.
|
||||
|
||||
**Step 1:** Right click on the downloaded DEB file and select **Properties**:
|
||||
|
||||
![][8]
|
||||
|
||||
**Step 2:** Go to “**Open With**” tab, select “**Software Install**” app and click on “**Set as default**“.
|
||||
|
||||
![][9]
|
||||
|
||||
This way, all the deb files in the future will be opened with Software Install i.e. the software center applications.
|
||||
|
||||
Confirm it by double clicking the DEB file and see if it open with the software center application or not.
|
||||
|
||||
#### Ignorant bug or stupid feature?
|
||||
|
||||
Why is deb files are supposed to be opened with Archive Manager is beyond comprehension. I do hope that this is a bug, not a weird feature like [not allowing drag and drop files on the desktop in Ubuntu 20.04][10].
|
||||
|
||||
Since we are discussing deb file installation, let me tell you about a nifty tool [gdebi][11]. It’s a lightweight application with the sole purpose of installing DEB file. Not always but some times, it can also handle the dependencies.
|
||||
|
||||
You can learn more about [using gdebi and making it default for installing deb files here][12].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cant-install-deb-file-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/things-to-do-after-installing-ubuntu-20-04/
|
||||
[2]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[3]: https://itsfoss.com/upgrade-ubuntu-version/
|
||||
[4]: https://rocket.chat/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/05/error-opening-deb-file.png?ssl=1
|
||||
[6]: https://itsfoss.com/unzip-linux/
|
||||
[7]: https://itsfoss.com/change-default-applications-ubuntu/
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/05/open-deb-files.png?ssl=1
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/05/deb-file-install-fix-ubuntu.png?fit=800%2C454&ssl=1
|
||||
[10]: https://itsfoss.com/add-files-on-desktop-ubuntu/
|
||||
[11]: https://launchpad.net/gdebi
|
||||
[12]: https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
@ -0,0 +1,144 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How I track my home's energy consumption with open source)
|
||||
[#]: via: (https://opensource.com/article/20/5/energy-monitoring)
|
||||
[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
|
||||
|
||||
How I track my home's energy consumption with open source
|
||||
======
|
||||
These open source components help you find ways to save money and
|
||||
conserve resources.
|
||||
![lightbulb drawing outline][1]
|
||||
|
||||
An important step towards optimizing energy consumption is knowing your actual consumption. My house was built during the oil crisis in the 1970s, and due to the lack of a natural gas connection, the builders decided to use electricity to do all of the heating (water and home heating). This is not unusual for this area of Germany, and it remains an appropriate solution in countries that depend highly on nuclear power.
|
||||
|
||||
Electricity prices here are quite high (around € 0.28/kWh), so I decided to monitor my home's energy consumption to get a feel for areas where I could save some energy.
|
||||
|
||||
I used to work for a company that sold energy-monitoring systems for industrial customers. While this company mostly used proprietary software, you can set up a similar smart monitoring and logging solution for your home based on open source components. This article will show you how.
|
||||
|
||||
In Germany, the grid operator owns the electricity meter. The grid operator is obliged to provide an interface on its metering device to enable the customer to access the meter reading. Here is the metering device on my home:
|
||||
|
||||
![Actaris ACE3000 electricity meter][2]
|
||||
|
||||
Actaris ACE3000 Type 110 (dry contact located behind the marked cover)
|
||||
|
||||
Generally, almost every metering device has at least a [dry contact][3]—as my electricity meter does—that you can use to log metering. As you can see, my electricity meter has two counters: The upper one is for the day tariff (6am to 10pm), and the lower one is for the night tariff (10pm to 6am). The night tariff is a bit cheaper. Two-tariff meters are usually found only in houses with electric heating.
|
||||
|
||||
### Design
|
||||
|
||||
A reliable energy-monitoring solution for private use should meet the following requirements:
|
||||
|
||||
* Logging of metering impulses (dry contact)
|
||||
* 24/7 operation
|
||||
* Energy-saving operation
|
||||
* Visualization of consumption data
|
||||
* Long-term recording of consumption data
|
||||
* Connectivity (e.g., Ethernet, USB, WiFi, etc.)
|
||||
* Affordability
|
||||
|
||||
|
||||
|
||||
I choose the Siemens SIMATIC IOT2020 as my hardware platform. This industrial-proven device is based on an Intel Quark x86 CPU, has programmable interrupts, and is compatible with many Arduino shields.
|
||||
|
||||
![Siemens SIMATIC IOT2020][4]
|
||||
|
||||
Siemens SIMATIC IOT2020
|
||||
|
||||
The Siemens device comes without an SD card and, therefore, without an operating system. Luckily, you can find a current Yocto-based Linux OS image and instructions on how to flash the SD card in the [Siemens forum][5].
|
||||
|
||||
In addition to the hardware platform, you also need some accessories. The following materials list shows the minimum components you need. Each item includes links to the parts I purchased, so you can get a sense of the project's costs.
|
||||
|
||||
#### Materials list
|
||||
|
||||
* [Siemens SIMATIC IoT2020 unit][6]
|
||||
* [Siemens I/O Shield for SIMATIC IoT2000 series][7]
|
||||
* [microSD card][8] (2GB or more)
|
||||
* [CSL 300Mbit USB-WLAN adapter][9]
|
||||
* 24V power supply (I used a 2.1A [TDK-Lambda DRB50-24-1][10], which I already owned). You could use a less expensive power supply with less power: the SIMATIC IOT2020 has a maximum current of 1.4A, and the dry contact needs an additional 0.1A (24V / 220Ω).
|
||||
* 5 terminal blocks ([Weidmueller WDU 2.5mm][11])
|
||||
* 2 terminal cross-connecting bridges ([Weidmueller WQV][12])
|
||||
* [DIN rail][13] (~300 mm)
|
||||
* [220Ω / 3W resistor][14]
|
||||
* Wire
|
||||
|
||||
|
||||
|
||||
Here is the assembled result:
|
||||
|
||||
![Mounted and hooked up energy logger][15]
|
||||
|
||||
Energy logger mounted and hooked up
|
||||
|
||||
Unfortunately, I didn't have enough space at the rear wall of the cabinet; therefore, the DIN rail with the mounted parts lies on the ground.
|
||||
|
||||
The connections between the meter and the Siemens device look like this:
|
||||
|
||||
![Wiring between meter and energy logger][16]
|
||||
|
||||
### How it works
|
||||
|
||||
A dry contact is a current interface. When the electricity meter triggers, a current of 0.1A starts flowing between **s0+** and **s0-**. On **DI0**, the voltage rises to 24V and triggers an interrupt. When the electricity meter disconnects **s0+** and **s0-**, **DI0** is grounded over the resistor.
|
||||
|
||||
On my device, the contact closes 1,000 times per kWh (this value varies between metering devices).
|
||||
|
||||
To count these peaks reliably, I created [a C program][17] that registers an interrupt service routine on the DI0 input and counts upwards in memory. Once a minute, the values from memory are written to an [SQLite][18] database.
|
||||
|
||||
The overall meter reading is also written to a text file and can be preset with a starting value. This acts as a copy of the overall metering value of the meter in the cabinet.
|
||||
|
||||
![Energy logger architecture][19]
|
||||
|
||||
Energy logger architecture
|
||||
|
||||
The data is visualized using [Node-RED][20], and I can access overviews, like the daily consumption dashboard below, over a web-based GUI.
|
||||
|
||||
![Node-RED based GUI][21]
|
||||
|
||||
Daily overview in the Node-RED GUI
|
||||
|
||||
For the daily overview, I calculate the hourly costs based on the consumption data (the large bar chart). On the top-left of the dashboard you can see the actual power; below that is the daily consumption (energy and costs). The water heater for the shower causes the large peak in the bar chart.
|
||||
|
||||
### A reliable system
|
||||
|
||||
Aside from a lost timestamp during a power failure (the real-time clock in the Siemens device is not backed by a battery by default), everything has been working fine for more than one-and-a-half years.
|
||||
|
||||
If you can set up the whole Linux system completely from the command line, you'll get a reliable and flexible system with the ability to link interrupt service routines to the I/O level.
|
||||
|
||||
Because the I/O Shield runs on standard control voltage (24V), you can extend its functionality with the whole range of standardized industrial components (e.g., relays, sensors, actors, etc.). And, due to its open architecture, this system can be extended easily and applied to other applications, like for monitoring gas or water consumption or as a weather station, a simple controller for tasks, and more.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/energy-monitoring
|
||||
|
||||
作者:[Stephan Avenwedde][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/hansic99
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/Collaboration%20for%20health%20innovation.png?itok=s4O5EX2w (lightbulb drawing outline)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/openenergylogger_1_electricity_meter.jpg (Actaris ACE3000 electricity meter)
|
||||
[3]: https://en.wikipedia.org/wiki/Dry_contact
|
||||
[4]: https://opensource.com/sites/default/files/uploads/openenergylogger_2_siemens_device.jpg (Siemens SIMATIC IOT2020)
|
||||
[5]: https://support.industry.siemens.com/tf/ww/en/posts/new-example-image-version-online/189090/?page=0&pageSize=10
|
||||
[6]: https://de.rs-online.com/web/p/products/1244037
|
||||
[7]: https://de.rs-online.com/web/p/products/1354133
|
||||
[8]: https://de.rs-online.com/web/p/micro-sd-karten/7582584/
|
||||
[9]: https://www.amazon.de/300Mbit-WLAN-Adapter-Hochleistungs-Antennen-Dual-Band/dp/B00LLIOT34
|
||||
[10]: https://de.rs-online.com/web/p/products/8153133
|
||||
[11]: https://de.rs-online.com/web/p/din-schienenklemmen-ohne-sicherung/0425190/
|
||||
[12]: https://de.rs-online.com/web/p/din-schienenklemmen-zubehor/0202574/
|
||||
[13]: https://de.rs-online.com/web/p/din-schienen/2835729/
|
||||
[14]: https://de.rs-online.com/web/p/widerstande-durchsteckmontage/2142673/
|
||||
[15]: https://opensource.com/sites/default/files/uploads/openenergylogger_3_assembled_device.jpg (Mounted and hooked up energy logger)
|
||||
[16]: https://opensource.com/sites/default/files/uploads/openenergylogger_4_wiring.png (Wiring between meter and energy logger)
|
||||
[17]: https://github.com/hANSIc99/OpenEnergyLogger
|
||||
[18]: https://www.sqlite.org/index.html
|
||||
[19]: https://opensource.com/sites/default/files/uploads/openenergylogger_5_architecure.png (Energy logger architecture)
|
||||
[20]: https://nodered.org/
|
||||
[21]: https://opensource.com/sites/default/files/uploads/openenergylogger_6_dashboard.png (Node-RED based GUI)
|
||||
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Modify a disk image to create a Raspberry Pi-based homelab)
|
||||
[#]: via: (https://opensource.com/article/20/5/disk-image-raspberry-pi)
|
||||
[#]: author: (Chris Collins https://opensource.com/users/clcollins)
|
||||
|
||||
Modify a disk image to create a Raspberry Pi-based homelab
|
||||
======
|
||||
Create a "private cloud at home" with a Raspberry Pi or other
|
||||
single-board computer.
|
||||
![Science lab with beakers][1]
|
||||
|
||||
Building a [homelab][2] can be a fun way to entertain yourself while learning new concepts and experimenting with new technologies. Thanks to the popularity of single-board computers (SBCs), led by the [Raspberry Pi][3], it is easier than ever to build a multi-computer lab right from the comfort of your home. Creating a "private cloud at home" is also a great way to get exposure to cloud-native technologies for considerably less money than trying to replicate the same setup with a major cloud provider.
|
||||
|
||||
This article explains how to modify a disk image for the Raspberry Pi or another SBC, pre-configure the host for SSH (secure shell), and disable the service that forces interaction for configuration on first boot. This is a great way to make your devices "boot and go," similar to cloud instances. Later, you can do more specialized, in-depth configurations using automated processes over an SSH connection.
|
||||
|
||||
Also, as you add more Pis to your lab, modifying disk images lets you just write the image to an SD card, drop it into the Pi, and go!
|
||||
|
||||
![Multiple Raspberry Pi computers, a switch, and a power bank][4]
|
||||
|
||||
### Decompress and mount the image
|
||||
|
||||
For this project, you need to modify a server disk image. I used the [Fedora Server 31 ARM][5] image during testing. After you download the disk image and [verify its checksum][6], you need to decompress and mount it to a location on the host computer's file system so you can modify it as needed.
|
||||
|
||||
You can use the **[xz][7]** command to decompress the Fedora Server image by using the **\--decompress** argument:
|
||||
|
||||
|
||||
```
|
||||
`xz --decompress Fedora-Server-armhfp-X-y.z-sda.raw.xz`
|
||||
```
|
||||
|
||||
This leaves you with a raw, decompressed disk image (which automatically replaces the **.xz** compressed file). This raw disk image is just what it sounds like: a file containing all the data that would be on a formatted and installed disk. That includes partition information, the boot partition, the root partition, and any other partitions. You need to mount the partition you intend to work in, but to do that, you need information about where that partition starts in the disk image and the size of the sectors on the disk, so you can mount the file at the right sector.
|
||||
|
||||
Luckily, you can use the [**fdisk**][8] command on a disk image just as easily as on a real disk and use the **\--list** or **-l** argument to view the list of partitions and their information:
|
||||
|
||||
|
||||
```
|
||||
# Use fdisk to list the partitions in the raw image:
|
||||
$ fdisk -l Fedora-Server-armhfp-31-1.9-sda.raw
|
||||
Disk Fedora-Server-armhfp-X-y.z-sda.raw: 3.2 GiB, 3242196992 bytes, 6332416 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0xdaad9f57
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
Fedora-Server-armhfp-X-y.z-sda.raw1 8192 163839 155648 76M c W95 F
|
||||
Fedora-Server-armhfp-X-y.z-sda.raw2 * 163840 1163263 999424 488M 83 Linux
|
||||
Fedora-Server-armhfp-X-y.z-sda.raw3 1163264 6047743 4884480 2.3G 83 Linux
|
||||
```
|
||||
|
||||
All the information you need is available in this output. Line 3 indicates the sector size, both logical and physical: (512 bytes / 512 bytes).
|
||||
|
||||
The list of devices shows the partitions inside the raw disk image. The first one, **Fedora-Server-armhfp-X-y.z-sda.raw1** is no doubt the bootloader partition because it is the first, small (only 76MB), and type W95 FAT32 (LBA), as identified by the Id "c," a FAT32 partition for booting off the SD card.
|
||||
|
||||
The second partition is not very large either, just 488MB. This partition is a Linux native-type partition (Id 83), and it probably is the Linux boot partition containing the kernel and [initramfs][9].
|
||||
|
||||
The third partition is what you probably want: it is 2.3GB, so it should have the majority of the distribution on it, and it is a Linux-native partition type, which is expected. This should contain the partition and data you want to modify.
|
||||
|
||||
The third partition starts on sector 1163264 (indicated by the "Start" column in the output of **fdisk**), so your mount offset is **595591168**, calculated by multiplying the sector size (512) by the start sector (1163264) (i.e., **512 * 1163264**). This means you need to mount the file with an offset of 595591168 to be in the right place at the mount point.
|
||||
|
||||
ARMed (see what I did there?) with this information, you can now mount the third partition to a directory in your homedir:
|
||||
|
||||
|
||||
```
|
||||
$ mkdir ~/mnt
|
||||
$ sudo mount -o loop,offset=595591168 Fedora-Server-armhfp-X-y.z-sda.raw ~/mnt
|
||||
$ ls ~/mnt
|
||||
```
|
||||
|
||||
### Work directly within the disk image
|
||||
|
||||
Once the disk image has been decompressed and mounted to a spot on the host computer, it is time to start modifying the image to suit your needs. In my opinion, the easiest way to make changes to the image is to use **chroot** to change the working root of your session to that of the mounted image. There's a tricky bit, though.
|
||||
|
||||
When you change root, your session will use the binaries from the new root. Unless you are doing all of this from an ARM system, the architecture of the decompressed disk image will not be the same as the host system you are using. Even inside the **chroot**, the host system will not be able to make use of binaries with a different architecture. At least, not natively.
|
||||
|
||||
Luckily, there is a solution: **qemu-user-static**. From the [Debian Wiki][10]:
|
||||
|
||||
> "[qemu-user-static] provides the user mode emulation binaries, built statically. In this mode QEMU can launch Linux processes compiled for one CPU on another CPU… If binfmt-support package is installed, qemu-user-static package will register binary formats which the provided emulators can handle, so that it will be possible to run foreign binaries directly."
|
||||
|
||||
This is exactly what you need to be able to work in the non-native architecture inside your chroot. If the host system is Fedora, install the **qemu-user-static** package with DNF, and restart **systemd-binfmt.service**:
|
||||
|
||||
|
||||
```
|
||||
# Enable non-native arch chroot with DNF, adding new binary format information
|
||||
# Output suppressed for brevity
|
||||
$ dnf install qemu-user-static
|
||||
$ systemctl restart systemd-binfmt.service
|
||||
```
|
||||
|
||||
With this, you should be able to change root to the mounted disk image and run the **uname** command to verify that everything is working:
|
||||
|
||||
|
||||
```
|
||||
sudo chroot ~/mnt/ /usr/bin/uname -a -r
|
||||
Linux marvin 5.5.16-200.fc31.x86_64 #1 SMP Wed Apr 8 16:43:33 UTC 2020 armv7l armv7l armv7l GNU/Linux
|
||||
```
|
||||
|
||||
Running **uname** from within the changed root shows **armv7l** in the output—the architecture of the raw disk image—and not the host machine. Everything is working as expected, and you can continue on to modify the image.
|
||||
|
||||
### Modify the disk image
|
||||
|
||||
Now that you can change directly into the ARM-based disk image and work in that environment, you can begin to make changes to the image itself. You want to set up the image so it can be booted and immediately accessed without having to do any additional setup directly on the Raspberry Pi. To do this, you need to install and enable sshd (the OpenSSH daemon) and add the authorized keys for SSH access.
|
||||
|
||||
And to make this behave more like a cloud environment and realize the dream of a private cloud at home, add a local user, give that user **sudo** rights, and (to be just like the cloud heavyweights) allow that user to use **sudo** without a password.
|
||||
|
||||
So, your to-do list is:
|
||||
|
||||
* Install and enable SSHD (SSHD is already installed and enabled in the Fedora ARM image, but you may need to do this manually for your distribution)
|
||||
* Set up a local user
|
||||
* Allow the local user to use sudo (without a password, optional)
|
||||
* Add authorized keys
|
||||
* Allow root to SSH with the authorized keys (optional)
|
||||
|
||||
|
||||
|
||||
I use the GitHub feature that allows you to upload your public SSH keys and make them available at **[https://github.com/<your_github_username>.keys][11]**. I find this to be a convenient way to distribute public keys, although I am paranoid enough that I always check that the downloaded keys match what I am expecting. If you don't want to use this method, you can copy your public keys into the **chroot** directly from your host computer, or you can host your keys on a web server that you control in order to use the same workflow.
|
||||
|
||||
To start modifying the disk image, **chroot** into the mounted disk image again, this time starting a shell so multiple commands can be run:
|
||||
|
||||
|
||||
```
|
||||
# Output of these commands (if any) are omitted for brevity
|
||||
$ sudo chroot ~/mnt /bin/bash
|
||||
|
||||
# Install openssh-server and enable it (already done on Fedora)
|
||||
$ dnf install -y openssh-server
|
||||
$ systemctl enable sshd.service
|
||||
|
||||
# Allow root to SSH with your authorized keys
|
||||
$ mkdir /root/.ssh
|
||||
|
||||
# Download, or otherwise add to the authorized_keys file, your public keys
|
||||
# Replace the URL with the path to your own public keys
|
||||
$ curl <https://github.com/clcollins.keys> -o /root/.ssh/authorized_keys
|
||||
$ chmod 700 /root/.ssh
|
||||
$ chmod 600 /root/.ssh/authorized_keys
|
||||
|
||||
# Add a local user, and put them in the wheel group
|
||||
# Change the group and user to whatever you desire
|
||||
groupadd chris
|
||||
useradd -g chris -G wheel -m -u 1000 chris
|
||||
|
||||
# Download or add your authorized keys
|
||||
# Change the homedir and URL as you've done above
|
||||
mkdir /home/chris/.ssh
|
||||
curl <https://github.com/clcollins.keys> -o /home/chris/.ssh/authorized_keys
|
||||
chmod 700 /home/chris/.ssh
|
||||
chmod 600 /home/chris/.ssh/authorized_keys
|
||||
chown -R chris.chris /home/chris/.ssh/
|
||||
|
||||
# Allow the wheel group (with your local user) to use suso without a password
|
||||
echo "%wheel ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers.d/91-wheel-nopasswd
|
||||
```
|
||||
|
||||
This is all that generally needs to be done to set up SSH into a Raspberry Pi or other single-board computer on first boot. However, each distribution has its own quirks. For example, Rasbian already includes a local user, **pi**, and does not use the **wheel** group. So for Raspbian, it may be better to use the existing user or to delete the **pi** user and replace it with another.
|
||||
|
||||
In the case of Fedora ARM, the image prompts you to finish setup on first boot. This defeats the purpose of the changes you made above, especially since it blocks startup entirely until setup is complete. Your goal is to make the Raspberry Pi function like part of a private cloud infrastructure, and that workflow includes setting up the host remotely via SSH when it starts up. Disable the initial setup, controlled by the service **initial-setup.service**:
|
||||
|
||||
|
||||
```
|
||||
# Disable the initial-setup.service for both the multi-user and graphical targets
|
||||
unlink /etc/systemd/system/multi-user.target.wants/initial-setup.service
|
||||
unlink /etc/systemd/system/graphical.target.wants/initial-setup.service
|
||||
```
|
||||
|
||||
While you are in the change root, you can make any other changes you might want for your systems or just leave it at that and follow the cloud-native workflow of configuration over SSH after first boot.
|
||||
|
||||
### Recompress and install the modified image
|
||||
|
||||
With these changes to your system completed, all that is left is to recompress the disk image and install it on an SD card for your Raspberry Pi.
|
||||
|
||||
Make sure to exit the chroot, then unmount the disk image:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo umount ~/mnt/`
|
||||
```
|
||||
|
||||
Just as you decompressed the image initially, you can use the **xz** command again to compress the image. By using the **\--keep** argument, **xz** will leave the raw image rather than cleaning it up. While this uses more disk space, leaving the uncompressed image allows you to make incremental changes to the images you are working with without needing to decompress them each time. This is great for saving time while testing and tweaking images to your liking:
|
||||
|
||||
|
||||
```
|
||||
# Compress the raw disk image to a .xz file, but keep the raw disk image
|
||||
xz --compress Fedora-Server-armhfp-31-1.9-sda.raw --keep
|
||||
```
|
||||
|
||||
The compression takes a while, so take this time to stand up, stretch, and get your blood flowing again.
|
||||
|
||||
Once the compression is done, the new, modified disk image can be copied to an SD card to use with a Raspberry Pi. The standard **dd** method to copy the image to the SD card works fine, but I like to use Fedora's **arm-image-installer** because of the options it provides when working with unedited images. It also works great for edited images and is a little more user-friendly than the **dd** command.
|
||||
|
||||
Make sure to check which disk the SD card is on and use that for the **\--media** argument:
|
||||
|
||||
|
||||
```
|
||||
# Use arm-image-installer to copy the modified disk image to the SD card
|
||||
arm-image-installer --image=Fedora-Server-armhfp-X-y.z-sda.raw.xz --target=rpi3 --media=/dev/sdc --norootpass --resizefs -y
|
||||
```
|
||||
|
||||
Now you are all set with a new, modified Fedora Server ARM image for Raspberry Pis or other single board computers, ready to boot and immediately SSH into with your modifications. This method can also be used to make other changes, and you can use it with other distributions' raw disk images if you prefer them to Fedora. This is a good base to start building a private-cloud-at-home homelab. In future articles, I will guide you through setting up a homelab using cloud technologies and automation.
|
||||
|
||||
### Further reading
|
||||
|
||||
A lot of research went into learning how to do the things in this article. Two of the most helpful sources I found for learning how to customize disk images and work with non-native architectures are listed below. They were extremely helpful in rounding the corner from "I have no idea what I'm doing" to "OK, I can do this!"
|
||||
|
||||
* [How to modify a raw disk image of your custom Linux distro][12]
|
||||
* [Using DNF wiki][13]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/disk-image-raspberry-pi
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clcollins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/science_experiment_beaker_lab.png?itok=plKWRhlU (Science lab with beakers)
|
||||
[2]: https://opensource.com/article/19/3/home-lab
|
||||
[3]: https://opensource.com/resources/raspberry-pi
|
||||
[4]: https://opensource.com/sites/default/files/uploads/raspberrypi_homelab.jpg (Multiple Raspberry Pi computers, a switch, and a power bank)
|
||||
[5]: https://arm.fedoraproject.org/
|
||||
[6]: https://arm.fedoraproject.org/verify.html
|
||||
[7]: https://tukaani.org/xz/
|
||||
[8]: https://en.wikipedia.org/wiki/Fdisk
|
||||
[9]: https://wiki.debian.org/initramfs
|
||||
[10]: https://wiki.debian.org/RaspberryPi/qemu-user-static
|
||||
[11]: https://github.com/%3Cyour_github_username%3E.keys
|
||||
[12]: https://www.linux.com/news/how-modify-raw-disk-image-your-custom-linux-distro/
|
||||
[13]: https://wiki.mageia.org/en/Using_DNF#Setting_up_a_container_for_a_non-native_architectur
|
||||
@ -0,0 +1,269 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Start using systemd as a troubleshooting tool)
|
||||
[#]: via: (https://opensource.com/article/20/5/systemd-troubleshooting-tool)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
Start using systemd as a troubleshooting tool
|
||||
======
|
||||
While systemd is not really a troubleshooting tool, the information in
|
||||
its output points the way toward solving problems.
|
||||
![Magnifying glass on code][1]
|
||||
|
||||
No one would really consider systemd to be a troubleshooting tool, but when I encountered a problem on my webserver, my growing knowledge of systemd and some of its features helped me locate and circumvent the problem.
|
||||
|
||||
The problem was that my server, yorktown, which provides name services, DHCP, NTP, HTTPD, and SendMail email services for my home office network, failed to start the Apache HTTPD daemon during normal startup. I had to start it manually after I realized that it was not running. The problem had been going on for some time, and I recently got around to trying to fix it.
|
||||
|
||||
Some of you will say that systemd itself is the cause of this problem, and, based on what I know now, I agree with you. However, I had similar types of problems with SystemV. (In the [first article][2] in this series, I looked at the controversy around systemd as a replacement for the old SystemV init program and startup scripts. If you're interested in learning more about systemd, read the [second][3] and [third][4] articles, too.) No software is perfect, and neither systemd nor SystemV is an exception, but systemd provides far more information for problem-solving than SystemV ever offered.
|
||||
|
||||
### Determining the problem
|
||||
|
||||
The first step to finding the source of this problem is to determine the httpd service's status:
|
||||
|
||||
|
||||
```
|
||||
[root@yorktown ~]# systemctl status httpd
|
||||
● httpd.service - The Apache HTTP Server
|
||||
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
|
||||
Active: failed (Result: exit-code) since Thu 2020-04-16 11:54:37 EDT; 15min ago
|
||||
Docs: man:httpd.service(8)
|
||||
Process: 1101 ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND (code=exited, status=1/FAILURE)
|
||||
Main PID: 1101 (code=exited, status=1/FAILURE)
|
||||
Status: "Reading configuration..."
|
||||
CPU: 60ms
|
||||
|
||||
Apr 16 11:54:35 yorktown.both.org systemd[1]: Starting The Apache HTTP Server...
|
||||
Apr 16 11:54:37 yorktown.both.org httpd[1101]: (99)Cannot assign requested address: AH00072: make_sock: could not bind to address 192.168.0.52:80
|
||||
Apr 16 11:54:37 yorktown.both.org httpd[1101]: no listening sockets available, shutting down
|
||||
Apr 16 11:54:37 yorktown.both.org httpd[1101]: AH00015: Unable to open logs
|
||||
Apr 16 11:54:37 yorktown.both.org systemd[1]: httpd.service: Main process exited, code=exited, status=1/FAILURE
|
||||
Apr 16 11:54:37 yorktown.both.org systemd[1]: httpd.service: Failed with result 'exit-code'.
|
||||
Apr 16 11:54:37 yorktown.both.org systemd[1]: Failed to start The Apache HTTP Server.
|
||||
[root@yorktown ~]#
|
||||
```
|
||||
|
||||
This status information is one of the systemd features that I find much more useful than anything SystemV offers. The amount of helpful information here leads me easily to a logical conclusion that takes me in the right direction. All I ever got from the old **chkconfig** command is whether or not the service is running and the process ID (PID) if it is. That is not very helpful.
|
||||
|
||||
The key entry in this status report shows that HTTPD cannot bind to the IP address, which means it cannot accept incoming requests. This indicates that the network is not starting fast enough to be ready for the HTTPD service to bind to the IP address because the IP address has not yet been set. This is not supposed to happen, so I explored my network service systemd startup configuration files; all appeared to be correct with the right "after" and "requires" statements. Here is the **/lib/systemd/system/httpd.service** file from my server:
|
||||
|
||||
|
||||
```
|
||||
# Modifying this file in-place is not recommended, because changes
|
||||
# will be overwritten during package upgrades. To customize the
|
||||
# behaviour, run "systemctl edit httpd" to create an override unit.
|
||||
|
||||
# For example, to pass additional options (such as -D definitions) to
|
||||
# the httpd binary at startup, create an override unit (as is done by
|
||||
# systemctl edit) and enter the following:
|
||||
|
||||
# [Service]
|
||||
# Environment=OPTIONS=-DMY_DEFINE
|
||||
|
||||
[Unit]
|
||||
Description=The Apache HTTP Server
|
||||
Wants=httpd-init.service
|
||||
After=network.target remote-fs.target nss-lookup.target httpd-init.service
|
||||
Documentation=man:httpd.service(8)
|
||||
|
||||
[Service]
|
||||
Type=notify
|
||||
Environment=LANG=C
|
||||
|
||||
ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND
|
||||
ExecReload=/usr/sbin/httpd $OPTIONS -k graceful
|
||||
# Send SIGWINCH for graceful stop
|
||||
KillSignal=SIGWINCH
|
||||
KillMode=mixed
|
||||
PrivateTmp=true
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
|
||||
The **httpd.service** unit file explicitly specifies that it should load after the **network.target** and the **httpd-init.service** (among others). I tried to find all of these services using the **systemctl list-units** command and searching for them in the resulting data stream. All were present and should have ensured that the httpd service did not load before the network IP address was set.
|
||||
|
||||
### First solution
|
||||
|
||||
A bit of searching on the internet confirmed that others had encountered similar problems with httpd and other services. This appears to happen because one of the required services indicates to systemd that it has finished its startup—but it actually spins off a child process that has not finished. After a bit more searching, I came up with a circumvention.
|
||||
|
||||
I could not figure out why the IP address was taking so long to be assigned to the network interface card. So, I thought that if I could delay the start of the HTTPD service by a reasonable amount of time, the IP address would be assigned by that time.
|
||||
|
||||
Fortunately, the **/lib/systemd/system/httpd.service** file above provides some direction. Although it says not to alter it, it does indicate how to proceed: Use the command **systemctl edit httpd**, which automatically creates a new file (**/etc/systemd/system/httpd.service.d/override.conf**) and opens the [GNU Nano][5] editor. (If you are not familiar with Nano, be sure to look at the hints at the bottom of the Nano interface.)
|
||||
|
||||
Add the following text to the new file and save it:
|
||||
|
||||
|
||||
```
|
||||
[root@yorktown ~]# cd /etc/systemd/system/httpd.service.d/
|
||||
[root@yorktown httpd.service.d]# ll
|
||||
total 4
|
||||
-rw-r--r-- 1 root root 243 Apr 16 11:43 override.conf
|
||||
[root@yorktown httpd.service.d]# cat override.conf
|
||||
# Trying to delay the startup of httpd so that the network is
|
||||
# fully up and running so that httpd can bind to the correct
|
||||
# IP address
|
||||
#
|
||||
# By David Both, 2020-04-16
|
||||
|
||||
[Service]
|
||||
ExecStartPre=/bin/sleep 30
|
||||
```
|
||||
|
||||
The **[Service]** section of this override file contains a single line that delays the start of the HTTPD service by 30 seconds. The following status command shows the service status during the wait time:
|
||||
|
||||
|
||||
```
|
||||
[root@yorktown ~]# systemctl status httpd
|
||||
● httpd.service - The Apache HTTP Server
|
||||
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
|
||||
Drop-In: /etc/systemd/system/httpd.service.d
|
||||
└─override.conf
|
||||
/usr/lib/systemd/system/httpd.service.d
|
||||
└─php-fpm.conf
|
||||
Active: activating (start-pre) since Thu 2020-04-16 12:14:29 EDT; 28s ago
|
||||
Docs: man:httpd.service(8)
|
||||
Cntrl PID: 1102 (sleep)
|
||||
Tasks: 1 (limit: 38363)
|
||||
Memory: 260.0K
|
||||
CPU: 2ms
|
||||
CGroup: /system.slice/httpd.service
|
||||
└─1102 /bin/sleep 30
|
||||
|
||||
Apr 16 12:14:29 yorktown.both.org systemd[1]: Starting The Apache HTTP Server...
|
||||
Apr 16 12:15:01 yorktown.both.org systemd[1]: Started The Apache HTTP Server.
|
||||
[root@yorktown ~]#
|
||||
```
|
||||
|
||||
And this command shows the status of the HTTPD service after the 30-second delay expires. The service is up and running correctly:
|
||||
|
||||
|
||||
```
|
||||
[root@yorktown ~]# systemctl status httpd
|
||||
● httpd.service - The Apache HTTP Server
|
||||
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
|
||||
Drop-In: /etc/systemd/system/httpd.service.d
|
||||
└─override.conf
|
||||
/usr/lib/systemd/system/httpd.service.d
|
||||
└─php-fpm.conf
|
||||
Active: active (running) since Thu 2020-04-16 12:15:01 EDT; 1min 18s ago
|
||||
Docs: man:httpd.service(8)
|
||||
Process: 1102 ExecStartPre=/bin/sleep 30 (code=exited, status=0/SUCCESS)
|
||||
Main PID: 1567 (httpd)
|
||||
Status: "Total requests: 0; Idle/Busy workers 100/0;Requests/sec: 0; Bytes served/sec: 0 B/sec"
|
||||
Tasks: 213 (limit: 38363)
|
||||
Memory: 21.8M
|
||||
CPU: 82ms
|
||||
CGroup: /system.slice/httpd.service
|
||||
├─1567 /usr/sbin/httpd -DFOREGROUND
|
||||
├─1569 /usr/sbin/httpd -DFOREGROUND
|
||||
├─1570 /usr/sbin/httpd -DFOREGROUND
|
||||
├─1571 /usr/sbin/httpd -DFOREGROUND
|
||||
└─1572 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
Apr 16 12:14:29 yorktown.both.org systemd[1]: Starting The Apache HTTP Server...
|
||||
Apr 16 12:15:01 yorktown.both.org systemd[1]: Started The Apache HTTP Server.
|
||||
```
|
||||
|
||||
I could have experimented to see if a shorter delay would work as well, but my system is not that critical, so I decided not to. It works reliably as it is, so I am happy.
|
||||
|
||||
Because I gathered all this information, I reported it to Red Hat Bugzilla as Bug [1825554][6]. I believe that it is much more productive to report bugs than it is to complain about them.
|
||||
|
||||
### The better solution
|
||||
|
||||
A couple of days after reporting this as a bug, I received a response indicating that systemd is just the manager, and if httpd needs to be ordered after some requirements are met, it needs to be expressed in the unit file. The response pointed me to the **httpd.service** man page. I wish I had found this earlier because it is a better solution than the one I came up with. This solution is explicitly targeted to the prerequisite target unit rather than a somewhat random delay.
|
||||
|
||||
From the [**httpd.service** man page][7]:
|
||||
|
||||
> **Starting the service at boot time**
|
||||
>
|
||||
> The httpd.service and httpd.socket units are _disabled_ by default. To start the httpd service at boot time, run: **systemctl enable httpd.service**. In the default configuration, the httpd daemon will accept connections on port 80 (and, if mod_ssl is installed, TLS connections on port 443) for any configured IPv4 or IPv6 address.
|
||||
>
|
||||
> If httpd is configured to depend on any specific IP address (for example, with a "Listen" directive) which may only become available during start-up, or if httpd depends on other services (such as a database daemon), the service _must_ be configured to ensure correct start-up ordering.
|
||||
>
|
||||
> For example, to ensure httpd is only running after all configured network interfaces are configured, create a drop-in file (as described above) with the following section:
|
||||
>
|
||||
> [Unit]
|
||||
> After=network-online.target
|
||||
> Wants=network-online.target
|
||||
|
||||
I still think this is a bug because it is quite common—at least in my experience—to use a **Listen** directive in the **httpd.conf** configuration file. I have always used **Listen** directives, even on hosts with only a single IP address, and it is clearly necessary on hosts with multiple network interface cards (NICs) and internet protocol (IP) addresses. Adding the lines above to the **/usr/lib/systemd/system/httpd.service** default file would not cause problems for configurations that do not use a **Listen** directive and would prevent this problem for those that do.
|
||||
|
||||
In the meantime, I will use the suggested solution.
|
||||
|
||||
### Next steps
|
||||
|
||||
This article describes a problem I had with starting the Apache HTTPD service on my server. It leads you through the problem determination steps I took and shows how I used systemd to assist. I also covered the circumvention I implemented using systemd and the better solution that followed from my bug report.
|
||||
|
||||
As I mentioned at the start, it is very likely that this is the result of a problem with systemd, specifically the configuration for httpd startup. Nevertheless, systemd provided me with the tools to locate the likely source of the problem and to formulate and implement a circumvention. Neither solution really resolves the problem to my satisfaction. For now, the root cause of the problem still exists and must be fixed. If that is simply adding the recommended lines to the **/usr/lib/systemd/system/httpd.service** file, that would work for me.
|
||||
|
||||
One of the things I discovered during this is process is that I need to learn more about defining the sequences in which things start. I will explore that in my next article, the fifth in this series.
|
||||
|
||||
### Resources
|
||||
|
||||
There is a great deal of information about systemd available on the internet, but much is terse, obtuse, or even misleading. In addition to the resources mentioned in this article, the following webpages offer more detailed and reliable information about systemd startup.
|
||||
|
||||
* The Fedora Project has a good, practical [guide][8] [to systemd][8]. It has pretty much everything you need to know in order to configure, manage, and maintain a Fedora computer using systemd.
|
||||
* The Fedora Project also has a good [cheat sheet][9] that cross-references the old SystemV commands to comparable systemd ones.
|
||||
* For detailed technical information about systemd and the reasons for creating it, check out [Freedesktop.org][10]'s [description of systemd][11].
|
||||
* [Linux.com][12]'s "More systemd fun" offers more advanced systemd [information and tips][13].
|
||||
|
||||
|
||||
|
||||
There is also a series of deeply technical articles for Linux sysadmins by Lennart Poettering, the designer and primary developer of systemd. These articles were written between April 2010 and September 2011, but they are just as relevant now as they were then. Much of everything else good that has been written about systemd and its ecosystem is based on these papers.
|
||||
|
||||
* [Rethinking PID 1][14]
|
||||
* [systemd for Administrators, Part I][15]
|
||||
* [systemd for Administrators, Part II][16]
|
||||
* [systemd for Administrators, Part III][17]
|
||||
* [systemd for Administrators, Part IV][18]
|
||||
* [systemd for Administrators, Part V][19]
|
||||
* [systemd for Administrators, Part VI][20]
|
||||
* [systemd for Administrators, Part VII][21]
|
||||
* [systemd for Administrators, Part VIII][22]
|
||||
* [systemd for Administrators, Part IX][23]
|
||||
* [systemd for Administrators, Part X][24]
|
||||
* [systemd for Administrators, Part XI][25]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/systemd-troubleshooting-tool
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
|
||||
[2]: https://opensource.com/article/20/4/systemd
|
||||
[3]: https://opensource.com/article/20/4/systemd-startup
|
||||
[4]: https://opensource.com/article/20/4/understanding-and-using-systemd-units
|
||||
[5]: https://www.nano-editor.org/
|
||||
[6]: https://bugzilla.redhat.com/show_bug.cgi?id=1825554
|
||||
[7]: https://www.mankier.com/8/httpd.service#Description-Starting_the_service_at_boot_time
|
||||
[8]: https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html
|
||||
[9]: https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet
|
||||
[10]: http://Freedesktop.org
|
||||
[11]: http://www.freedesktop.org/wiki/Software/systemd
|
||||
[12]: http://Linux.com
|
||||
[13]: https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/
|
||||
[14]: http://0pointer.de/blog/projects/systemd.html
|
||||
[15]: http://0pointer.de/blog/projects/systemd-for-admins-1.html
|
||||
[16]: http://0pointer.de/blog/projects/systemd-for-admins-2.html
|
||||
[17]: http://0pointer.de/blog/projects/systemd-for-admins-3.html
|
||||
[18]: http://0pointer.de/blog/projects/systemd-for-admins-4.html
|
||||
[19]: http://0pointer.de/blog/projects/three-levels-of-off.html
|
||||
[20]: http://0pointer.de/blog/projects/changing-roots
|
||||
[21]: http://0pointer.de/blog/projects/blame-game.html
|
||||
[22]: http://0pointer.de/blog/projects/the-new-configuration-files.html
|
||||
[23]: http://0pointer.de/blog/projects/on-etc-sysinit.html
|
||||
[24]: http://0pointer.de/blog/projects/instances.html
|
||||
[25]: http://0pointer.de/blog/projects/inetd.html
|
||||
@ -0,0 +1,201 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Tips and tricks for optimizing container builds)
|
||||
[#]: via: (https://opensource.com/article/20/5/optimize-container-builds)
|
||||
[#]: author: (Ravi Chandran https://opensource.com/users/ravichandran)
|
||||
|
||||
Tips and tricks for optimizing container builds
|
||||
======
|
||||
Try these techniques to minimize the number and length of your container
|
||||
build iterations.
|
||||
![Toolbox drawing of a container][1]
|
||||
|
||||
How many iterations does it take to get a container configuration just right? And how long does each iteration take? Well, if you answered "too many times and too long," then my experiences are similar to yours. On the surface, creating a configuration file seems like a straightforward exercise: implement the same steps in a configuration file that you would perform if you were installing the system by hand. Unfortunately, I've found that it usually doesn't quite work that way, and a few "tricks" are handy for such DevOps exercises.
|
||||
|
||||
In this article, I'll share some techniques I've found that help minimize the number and length of iterations. In addition, I'll outline a few good practices beyond the [standard ones][2].
|
||||
|
||||
In the [tutorial repository][3] from my previous article about [containerizing build systems][4], I've added a folder called **/tutorial2_docker_tricks** with an example covering some of the tricks that I'll walk through in this post. If you want to follow along and you have Git installed, you can pull it locally with:
|
||||
|
||||
|
||||
```
|
||||
`$ git clone https://github.com/ravi-chandran/dockerize-tutorial`
|
||||
```
|
||||
|
||||
The tutorial has been tested with Docker Desktop Edition, although it should work with any compatible Linux container system (like [Podman][5]).
|
||||
|
||||
### Save time on container image build iterations
|
||||
|
||||
If the Dockerfile involves downloading and installing a 5GB file, each iteration of **docker image build** could take a lot of time even with good network speeds. And forgetting to include one item to be installed can mean rebuilding all the layers after that point.
|
||||
|
||||
One way around that challenge is to use a local HTTP server to avoid downloading large files from the internet multiple times during **docker image build** iterations. To illustrate this by example, say you need to create a container image with Anaconda 3 under Ubuntu 18.04. The Anaconda 3 installer is a ~0.5GB file, so this will be the "large" file for this example.
|
||||
|
||||
Note that you don't want to use the **COPY** instruction, as it creates a new layer. You should also delete the large installer after using it to minimize the container image size. You could use [multi-stage builds][6], but I've found the following approach sufficient and quite effective.
|
||||
|
||||
The basic idea is to use a Python-based HTTP server locally to serve the large file(s) and have the Dockerfile **wget** the large file(s) from this local server. Let's explore the details of how to set this up effectively. As a reminder, you can access the [full example][7].
|
||||
|
||||
The necessary contents of the folder **tutorial2_docker_tricks/** in this example repository are:
|
||||
|
||||
|
||||
```
|
||||
tutorial2_docker_tricks/
|
||||
├── build_docker_image.sh # builds the docker image
|
||||
├── run_container.sh # instantiates a container from the image
|
||||
├── install_anaconda.dockerfile # Dockerfile for creating our target docker image
|
||||
├── .dockerignore # used to ignore contents of the installer/ folder from the docker context
|
||||
├── installer # folder with all our large files required for creating the docker image
|
||||
│ └── Anaconda3-2019.10-Linux-x86_64.sh # from <https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86\_64.sh>
|
||||
└── workdir # example folder used as a volume in the running container
|
||||
```
|
||||
|
||||
The key steps of the approach are:
|
||||
|
||||
* Place the large file(s) in the **installer/** folder. In this example, I have the large Anaconda installer file **Anaconda3-2019.10-Linux-x86_64.sh**. You won't find this file if you clone my [Git repository][8] because only you, as the container image creator, need this source file. The end users of the image don't. [Download the installer][9] to follow along with the example.
|
||||
* Create the **.dockerignore** file and have it ignore the **installer/** folder to avoid Docker copying all the large files into the build context.
|
||||
* In a terminal, **cd** into the **tutorial2_docker_tricks/** folder and execute the build script as **./build_docker_image.sh**.
|
||||
* In **build_docker_image.sh**, start the Python HTTP server to serve any files from the **installer/** folder: [code] cd installer
|
||||
python3 -m http.server --bind 10.0.2.15 8888 &
|
||||
cd ..
|
||||
```
|
||||
* If you're wondering about the strange internet protocol (IP) address, I'm working with a VirtualBox Linux VM, and **10.0.2.15** shows up as the address of the Ethernet adapter when I run **ifconfig**. This IP seems to be the convention used by VirtualBox. If your setup is different, you'll need to update this IP address to match your environment and then update **build_docker_image.sh** and **install_anaconda.dockerfile**. The server's port number is set to **8888** for this example. Note that the IP and port numbers could be passed in as build arguments, but I've hard-coded them for brevity.
|
||||
* Since the HTTP server is set to run in the background, stop the server near the end of the script with the **kill -9** command using an [elegant approach][10] I found: [code]`kill -9 `ps -ef | grep http.server | grep 8888 | awk '{print $2}'`
|
||||
```
|
||||
* Note that this same **kill -9** is also used earlier in the script (before starting the HTTP server). In general, when I iterate on any build script that I might deliberately interrupt, this ensures a clean start of the HTTP server each time.
|
||||
* In the [Dockerfile][11], there is a **RUN wget** instruction that downloads the Anaconda installer from the local HTTP server. It also deletes the installer file and cleans up after the installation. Most importantly, all these actions are performed within the same layer to keep the image size to a minimum: [code] # install Anaconda by downloading the installer via the local http server
|
||||
ARG ANACONDA
|
||||
RUN wget --no-proxy <http://10.0.2.15:8888/${ANACONDA}> -O ~/anaconda.sh \
|
||||
&& /bin/bash ~/anaconda.sh -b -p /opt/conda \
|
||||
&& rm ~/anaconda.sh \
|
||||
&& rm -fr /var/lib/apt/lists/{apt,dpkg,cache,log} /tmp/* /var/tmp/*
|
||||
```
|
||||
* This file runs the wrapper script, **anaconda.sh**, and cleans up large files by removing them with **rm**.
|
||||
* After the build is complete, you should see an image **anaconda_ubuntu1804:v1**. (You can list the images with **docker image ls**.)
|
||||
* You can instantiate a container from this image using **./run_container.sh** at the terminal while in the folder **tutorial2_docker_tricks/**. You can verify that Anaconda is installed with: [code] $ ./run_container.sh
|
||||
$ python --version
|
||||
Python 3.7.5
|
||||
$ conda --version
|
||||
conda 4.8.0
|
||||
$ anaconda --version
|
||||
anaconda Command line client (version 1.7.2)
|
||||
```
|
||||
* You'll note that **run_container.sh** sets up a volume **workdir**. In this example repository, the folder **workdir/** is empty. This is a convention I use to set up a volume where I can have my Python and other scripts that are independent of the container image.
|
||||
|
||||
|
||||
|
||||
### Minimize container image size
|
||||
|
||||
Each **RUN** command is equivalent to executing a new shell, and each **RUN** command creates a layer. The naive approach of mimicking installation instructions with separate **RUN** commands may eventually break at one or more interdependent steps. If it happens to work, it will typically result in a larger image. Chaining multiple installation steps in one **RUN** command and including the **autoremove**, **autoclean**, and **rm** commands (as in the example below) is useful to minimize the size of each layer. Some of these steps may not be needed, depending on what's being installed. However, since these steps take an insignificant amount of time, I always throw them in for good measure at the end of **RUN** commands invoking **apt-get**:
|
||||
|
||||
|
||||
```
|
||||
RUN apt-get update \
|
||||
&& DEBIAN_FRONTEND=noninteractive \
|
||||
apt-get -y --quiet --no-install-recommends install \
|
||||
# list of packages being installed go here \
|
||||
&& apt-get -y autoremove \
|
||||
&& apt-get clean autoclean \
|
||||
&& rm -fr /var/lib/apt/lists/{apt,dpkg,cache,log} /tmp/* /var/tmp/*
|
||||
```
|
||||
|
||||
Also, ensure that you have a **.dockerignore** file in place to ignore items that don't need to be sent to the Docker build context (such as the Anaconda installer file in the earlier example).
|
||||
|
||||
### Organize the build tool I/O
|
||||
|
||||
For software build systems, the build inputs and outputs—all the scripts that configure and invoke the tools—should be outside the image and the eventually running container. The container itself should remain stateless so that different users will have identical results with it. I covered this extensively in my [previous article][4] but wanted to emphasize it because it's been a useful convention for my work. These inputs and outputs are best accessed by setting up container volumes.
|
||||
|
||||
I've had to use a container image that provides data in the form of source code and large pre-built binaries. As a software developer, I was expected to edit the code in the container. This was problematic, because containers are by default stateless: they don't save data within the container, because they're designed to be disposable. But I worked on it, and at the end of each day, I stopped the container and had to be careful not to remove it, because the state had to be maintained so I could continue work the next day. The disadvantage of this approach was that there would be a divergence of development state had there been more than one person working on the project. The value of having identical build systems across developers is somewhat lost with this approach.
|
||||
|
||||
### Generate output as non-root user
|
||||
|
||||
An important aspect of I/O concerns the ownership of the output files generated when running the tools in the container. By default, since Docker runs as **root**, the output files would be owned by **root**, which is unpleasant. You typically want to work as a non-root user. Changing the ownership after the build output is generated can be done with scripts, but it is an additional and unnecessary step. It's best to set the [**USER**][12] argument in the Dockerfile at the earliest point possible:
|
||||
|
||||
|
||||
```
|
||||
ARG USERNAME
|
||||
# other commands...
|
||||
USER ${USERNAME}
|
||||
```
|
||||
|
||||
The **USERNAME** can be passed in as a build argument (**\--build-arg**) when executing the **docker image build**. You can see an example of this in the example [Dockerfile][11] and corresponding [build script][13].
|
||||
|
||||
Some portions of the tools may also need to be installed as a non-root user. So the sequence of installations in the Dockerfile may need to be different from the way it's done if you are installing manually and directly under Linux.
|
||||
|
||||
### Non-interactive installation
|
||||
|
||||
Interactivity is the opposite of container automation. I've found the
|
||||
|
||||
|
||||
```
|
||||
`DEBIAN_FRONTEND=noninteractive apt-get -y --quiet --no-install-recommends`
|
||||
```
|
||||
|
||||
options for the **apt-get install** instruction (as in the example above) necessary to prevent the installer from opening dialog boxes. Note that these options should be used as part of the **RUN** instruction. The **DEBIAN_FRONTEND=noninteractive** should not be set as an environment variable (**ENV**) in the Dockerfile, as this [FAQ explains][14], as it will be inherited by the containers.
|
||||
|
||||
### Log your build and run output
|
||||
|
||||
Debugging why a build failed is a common task, and logs are a great way to do this. Save a TypeScript of everything that happened during the container image build or container run session using the **tee** utility in a Bash script. In other words, add **|& tee $BASH_SOURCE.log** to the end of the **docker image build** and the **docker image run** commands in your scripts. See the examples in the [image build][13] and [container run][15] scripts.
|
||||
|
||||
What this **tee**-ing technique does is generate a file with the same name as the Bash script but with a **.log** extension appended to it so that you know which script it originated from. Everything you see printed to the terminal when running the script will get logged to this file with a similar name.
|
||||
|
||||
This is especially valuable for users of your container images to report issues to you when something doesn't work. You can ask them to send you the log file to help diagnose the issue. Many tools generate so much output that it easily overwhelms the default size of the terminal's buffer. Relying only on the terminal's buffer capacity to copy-paste error messages may not be sufficient for diagnosing issues because earlier errors may have been lost.
|
||||
|
||||
I've found this to be useful, even in the container image-building scripts, especially when using the Python-based HTTP server discussed above. The server generates so many lines during a download that it typically overwhelms the terminal's buffer.
|
||||
|
||||
### Deal with proxies elegantly
|
||||
|
||||
In my work environment, proxies are required to reach the internet for downloading the resources in **RUN apt-get** and **RUN wget** commands. The proxies are typically inferred from the environment variables **http_proxy** or **https_proxy**. While **ENV** commands can be used to hard-code such proxy settings in the Dockerfile, there are multiple issues with using **ENV** for proxies directly.
|
||||
|
||||
If you are the only one who will ever build the container, then perhaps this will work. But the Dockerfile couldn't be used by someone else at a different location with a different proxy setting. Another issue is that the IT department could change the proxy at some point, resulting in a Dockerfile that won't work any longer. Furthermore, the Dockerfile is a precise document specifying a configuration-controlled system, and every change will be scrutinized by quality assurance.
|
||||
|
||||
One simple approach to avoid hard-coding the proxy is to pass your local proxy setting as a build argument in the **docker image build** command:
|
||||
|
||||
|
||||
```
|
||||
docker image build \
|
||||
--build-arg MY_PROXY=<http://my\_local\_proxy.proxy.com:xx>
|
||||
```
|
||||
|
||||
And then, in the Dockerfile, set the environment variables based on the build argument. In the example shown here, you can still set a default proxy value that can be overridden by the build argument above:
|
||||
|
||||
|
||||
```
|
||||
# set a default proxy
|
||||
ARG MY_PROXY=MY_PROXY=<http://my\_default\_proxy.proxy.com:nn/>
|
||||
ENV http_proxy=$MY_PROXY
|
||||
ENV https_proxy=$MY_PROXY
|
||||
```
|
||||
|
||||
### Summary
|
||||
|
||||
These techniques have helped me significantly reduce the time it takes to create container images and debug them when they go wrong. I continue to be on the lookout for additional best practices to add to my list. I hope you find the above techniques useful.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/optimize-container-builds
|
||||
|
||||
作者:[Ravi Chandran][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ravichandran
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/toolbox-learn-draw-container-yearbook.png?itok=xDbwz1pP (Toolbox drawing of a container)
|
||||
[2]: https://docs.docker.com/develop/develop-images/dockerfile_best-practices/
|
||||
[3]: https://github.com/ravi-chandran/dockerize-tutorial
|
||||
[4]: https://opensource.com/article/20/4/how-containerize-build-system
|
||||
[5]: https://podman.io/getting-started/installation
|
||||
[6]: https://docs.docker.com/develop/develop-images/multistage-build/
|
||||
[7]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/tutorial2_docker_tricks/
|
||||
[8]: https://github.com/ravi-chandran/dockerize-tutorial/
|
||||
[9]: https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.sh
|
||||
[10]: https://stackoverflow.com/a/37214138
|
||||
[11]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/tutorial2_docker_tricks/install_anaconda.dockerfile
|
||||
[12]: https://docs.docker.com/engine/reference/builder/#user
|
||||
[13]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/tutorial2_docker_tricks/build_docker_image.sh
|
||||
[14]: https://docs.docker.com/engine/faq/
|
||||
[15]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/tutorial2_docker_tricks/run_container.sh
|
||||
@ -1,101 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (messon007)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The ins and outs of high-performance computing as a service)
|
||||
[#]: via: (https://www.networkworld.com/article/3534725/the-ins-and-outs-of-high-performance-computing-as-a-service.html)
|
||||
[#]: author: (Josh Fruhlinger https://www.networkworld.com/author/Josh-Fruhlinger/)
|
||||
|
||||
高性能计算即服务的来龙去脉
|
||||
======
|
||||
高性能计算(HPC)服务可能是一种满足不断增长的超级计算需求的方式,但依赖于使用场景,它们不一定比使用本地超级计算机好。
|
||||
|
||||
戴尔EMC
|
||||
导弹和军用直升机上的电子设备需要工作在极端条件下。国防承包商麦考密克·史蒂文森公司(McCormick Stevenson Corp.)在部署任何物理设备之前都会事先模拟它所能承受的真实条件。模拟依赖于像Ansys这样的有限元素分析软件,该软件需要强大的算力。
|
||||
|
||||
几年前的一天,它出乎意料地超出了计算极限。
|
||||
[世界上最快的10个超级计算机][1]
|
||||
|
||||
麦考密克·史蒂文森(McCormick Stevenson)的首席工程师迈克·克劳奇奇(Mike Krawczyk)说:“我们的一些工作会使办公室的计算机不堪重负。购买机器并安装软件在经济上或计划上都不划算。” 相反,该公司与Rescale签约,从其购买在超级计算机系统上运行的周期(cycles),而这只花费了他们购买新硬件上所需的一小部分。
|
||||
|
||||
麦考密克·史蒂文森(McCormick Stevenson)已成为被称为超级计算即服务或高性能计算(HPC)即服务(两个紧密相关的术语)市场的早期采用者之一。根据国家计算科学研究所(的定义),HPC是超级计算机在计算复杂问题上的应用,而超级计算机是处理能力最先进的那些计算机。
|
||||
|
||||
无论叫它什么,这些服务都在颠覆传统的超级计算市场,并将HPC能力带给以前买不起的客户。但这不是万能的,而且绝对不是即插即用的,至少现在还不是。
|
||||
|
||||
### HPC服务实践
|
||||
|
||||
从最终用户的角度来看,HPC即服务类似于早期大型机时代的批处理模型。 “我们创建一个Ansys批处理文件并将其发送过去,运行它,然后将结果文件取下来并在本地导入它们,” Krawczyk说。
|
||||
|
||||
在HPC服务背后,云提供商在其自己的数据中心中运行超级计算基础设施,尽管这不一定意味着当您听到“超级计算机”时你就会看到最先进的硬件。正如IBM OpenPOWER计算技术副总裁Dave Turek解释的那样,HPC服务的核心是“相互互连的服务器集合。您可以调用该虚拟计算基础设施,它能够在您提出问题时,使得许多不同的服务器并行工作来解决问题。”
|
||||
[][2]
|
||||
|
||||
理论听起来很简单。但都柏林城市大学数字业务教授西奥·林恩(Theo Lynn)表示,要使其在实践中可行,需要解决一些技术问题。普通计算与HPC的区别在于那些互连-高速的,低延时的而且昂贵的-因此需要将这些互连引入云基础设施领域。在HPC服务可行之前,至少需要将存储性能和数据传输也提升到与本地HPC相同的水平。
|
||||
|
||||
但是林恩说,一些制度创新相比技术更好的帮助了HPC服务的起飞。特别是,“我们现在看到越来越多的传统HPC应用采用云友好的许可模式-过去是采用这种模式的障碍。”
|
||||
|
||||
他说,经济也改变了潜在的客户群。 “云服务提供商通过向那些负担不起传统HPC所需的投资成本的低端HPC买家开放,进一步开放了市场。随着市场的开放,超大规模经济模型变得越来越多,更可行,成本开始下降。”
|
||||
|
||||
避免本地资本支出**
|
||||
**
|
||||
|
||||
HPC服务对有志于传统超级计算长期把持的领域的私营行业客户具有吸引力。这些客户包括严重依赖复杂数学模型的行业,包括麦考密克·史蒂文森(McCormick Stevenson)等国防承包商,以及油气公司,金融服务公司和生物技术公司。都柏林城市大学的Lynn补充说,松耦合的工作负载是一个特别好的用例,这意味着许多早期采用者将其用于3D图像渲染和相关应用。
|
||||
|
||||
但是,何时考虑HPC服务而不是本地HPC才有意义?对于德国的模拟烟雾在建筑物中的蔓延和火灾对建筑物结构部件的破坏的hhpberlin公司来说,答案是在它超出了其现有资源时。
|
||||
|
||||
Hpberlin公司数值模拟的科学负责人Susanne Kilian说:“几年来,我们一直在运行自己的小型集群,该集群具有多达80个处理器核。” “但是,随着应用复杂性的提高,这种架构(constellation)已经越来越不足以支撑;可用容量并不总是够快速地处理项目。”
|
||||
|
||||
她说:“但是,仅仅花钱买一个新的集群并不是一个理想的解决方案:鉴于我们公司的规模和管理环境,强制持续维护该集群(定期进行软件和硬件升级)是不现实的。另外,需要模拟的项目数量会出现很大的波动,因此集群的利用率并不是真正可预测的。通常,使用率很高的阶段与很少使用或不使用的阶段交替出现。”通过转换为HPC服务模式,hhpberlin释放了过剩的容量,并无需支付升级费用。
|
||||
|
||||
IBM的Turek解释了不同公司在评估其需求时所经历的计算过程。对于拥有30名员工的生物科学初创公司来说,“您需要计算,但您实在负担不起15%的员工专门从事它。这就像您可能也说过,您不想拥有在职法律代表,因此您也可以通过服务获得它。”但是,对于一家较大的公司而言,最终归结为权衡HPC服务的运营费用与购买内部超级计算机或HPC集群的费用。
|
||||
|
||||
到目前为止,这些都是您采用任何云服务时都会遇到的类似的争论。但是,可以HPC市场的某些特点将使得衡量运营支出与资本支出时选择前者。超级计算机不是诸如存储或x86服务器之类的商用硬件;它们非常昂贵,技术进步很快会使其过时。正如麦考密克·史蒂文森(McCormick Stevenson)的克拉维奇(Krawczyk)所说,“这就像买车:只要车一开走,它就会开始贬值。”对于许多公司,尤其是规模较大,灵活性较差的公司,购买超级计算机的过程可能会陷入无望的泥潭。 IBM的Turek说:“您陷入了计划问题,建筑问题,施工问题,培训问题,然后必须执行RFP。您必须得到CIO的支持。您必须与内部客户合作以确保服务的连续性。这是一个非常非常复杂的过程,并没有很多机构有非常出色的执行力。”
|
||||
|
||||
一旦您选择了HPC服务的路线后,您会发现您会得到您期望从云服务中得到的许多好处,特别是仅在业务需要时才需付费的能力,从而可以带来资源的高效利用。 Gartner高级总监兼分析师Chirag Dekate表示,当您对高性能计算有短期需求时的突发性负载是推动选择HPC服务的关键用例。
|
||||
|
||||
他说:“在制造业中,在产品设计阶段,HPC活动往往会达到很高的峰值。但是,一旦产品设计完成,在其余产品开发周期中,HPC资源的利用率就会降低。” 相比之下,他说:“当您拥有大量长期运行的工作时,云的经济性就会逐渐减弱。”
|
||||
|
||||
通过巧妙的系统设计,您可以将这些HPC服务突发活动与您自己的内部常规计算集成在一起。 埃森哲(Accenture)实验室常务董事Teresa Tung举了一个例子:“通过API访问HPC可以无缝地与传统计算混合。在模型构建阶段,传统的AI流水线可能会在高端超级计算机上进行训练,但是最终经过反复按预期运行的训练好的模型将部署在云中的其他服务上,甚至部署在边缘设备上。”
|
||||
|
||||
### 它并不适合所有的应用场景 **
|
||||
|
||||
**
|
||||
|
||||
HPC服务适合批处理和松耦合的场景。这与HPC的普遍缺点有关:数据传输问题。高性能计算本身通常涉及庞大的数据集,而将所有这些信息通过Internet发送到云服务提供商并不容易。IBM的Turek说:“我们与生物技术行业的客户交流,他们每月仅在数据费用上就花费1000万美元。”
|
||||
|
||||
钱并不是唯一的潜在问题。已制定的需要使用数据的工作流可能会使您在数据传输所需的时间内无法工作。hhpberlin的Kilian说:“当我们拥有自己的HPC集群时,当然可以随时访问已经产生的仿真结果,从而进行交互式的临时评估。我们目前正努力达到在仿真的任意时刻都可以更高效地,交互地访问和评估云中生成的数据,而无需下载大量的模拟数据。”
|
||||
|
||||
Mike Krawczyk提到了另一个绊脚石:合规性问题。国防承包商使用的任何服务都需要遵从(原文是complaint, 应该是笔误)《国际武器交易条例》(ITAR),麦考密克·史蒂文森(McCormick Stevenson)之所以选择Rescale,部分原因是因为这是他们发现的唯一符合的供应商。如今,尽管有更多的公司(使用云服务),但任何希望使用云服务的公司都应该意识到使用其他人的基础设施时所涉及的法律和数据保护问题,而且许多HPC场景的敏感性使得更HPC即服务的这个问题更加突出。
|
||||
|
||||
此外,HPC服务所需的IT治理超出了目前的监管范围。例如,您需要跟踪您的软件许可证是否允许云使用 –尤其是专门为本地HPC群集上运行而编写的软件包。通常,您需要跟踪HPC服务的使用方式,它可能是一个诱人的资源,尤其是当您从员工习惯的内部系统过渡到有可用的空闲的HPC能力时。例如,Avanade全球平台高级主管兼Azure平台服务全球负责人Ron Gilpin建议,回调您用于时间不敏感任务的处理核心数量。他说:“如果一项工作只需要用一小时来完成而不需要在十分钟内就完成,那么它可以使用165个处理器而不是1,000个,从而节省了数千美元。”
|
||||
|
||||
### 独特的HPC技能**
|
||||
|
||||
**
|
||||
|
||||
一直以来,采用HPC的最大障碍之一就是其所需的独特的内部技能,而HPC服务并不能使这种障碍消失。Gartner的Dekate表示:“许多CIO将许多工作负载迁移到了云上,他们看到了成本的节约,敏捷性和效率的提升,因此相信在HPC生态中也可以达成类似的效果。一个普遍的误解是,他们可以通过彻底地免去系统管理员,并聘用能解决其HPC工作负载的新的云专家,从而以某种方式优化人力成本。”
|
||||
|
||||
“但是HPC并不是一个主流的企业环境。” 他说。“您正在处理通过高带宽,低延迟的网络互联的高端计算节点,以及相当复杂的应用和中间件技术栈。许多情况下,甚至连文件系统层也是HPC环境所独有的。没有对应的技能可能会破坏稳定性。”
|
||||
|
||||
但是超级计算技能的供给却在减少,Dekate将其称为劳动力“灰化”,这是因为一代开发人员将目光投向了新兴的初创公司,而不是学术界或使用HPC的更老套的公司。因此,HPC服务供应商正在尽其所能地弥补差距。 IBM的Turek表示,许多HPC老手将总是想运行他们自己精心调整过的代码,将需要专门的调试器和其他工具来帮助他们在云上实现这一目标。但是,即使是HPC新手也可以调用供应商构建的代码库,以利用超级计算的并行处理能力。第三方软件提供商出售的交钥匙软件包可以减少HPC的许多复杂性。
|
||||
|
||||
埃森哲的Tung表示,该行业需要进一步加大投入才能真正繁荣。她说:“HPCaaS已经创建了具有重大影响力的新功能,但还需要做的是使它易于被数据科学家,企业架构师或软件开发人员使用。这包括易用的API,文档和示例代码。它包括用户支持来解答问题。仅仅提供API是不够的,API需要适合特定的用途。对于数据科学家而言,这可能是以python形式提供,并容易更换她已经在使用的框架。其价值来自使这些用户最综只有在使用新功能时才能够改进效率和性能。” 如果供应商能够做到这一点,那么HPC服务才能真正将超级计算带给大众。
|
||||
|
||||
加入[Facebook][3]和[LinkedIn][4]上的Network World社区,探讨最前沿的话题。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3534725/the-ins-and-outs-of-high-performance-computing-as-a-service.html
|
||||
|
||||
作者:[Josh Fruhlinger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[messon007](https://github.com/messon007)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Josh-Fruhlinger/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3236875/embargo-10-of-the-worlds-fastest-supercomputers.html
|
||||
[2]: https://www.networkworld.com/blog/itaas-and-the-corporate-storage-technology/?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE22140&utm_content=sidebar (ITAAS and Corporate Storage Strategy)
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -1,197 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Configure SFTP Server with Chroot in Debian 10)
|
||||
[#]: via: (https://www.linuxtechi.com/configure-sftp-chroot-debian10/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
如何在 Debian 10 中使用 Chroot 配置 SFTP 服务
|
||||
======
|
||||
|
||||
**SFTP** 代表安全文件传输协议 / SSH 文件传输协议,它是最常用的一个方法,用于通过ssh将文件从本地系统安全地传输到远程服务器,反之亦然。sftp 的主要优点是,除 ‘**openssh-server**’ 之外,我们不需要安装任何额外的软件包,在大多数的 Linux 发行版中,‘openssh-server’ 软件包是默认安装的一部分。sftp 的另外一个好处是,我们可以允许用户使用 sftp ,而不允许使用 ssh 。
|
||||
|
||||
[![配置-sftp-debian10][1]][2]
|
||||
|
||||
当前 Debian 10 ,代号‘Buster’,已经发布,在这篇文章中,我们将演示如何在 Debian 10 系统中使用 Chroot ‘Jail’ 类似的环境配置 sftp 。在这里,Chroot Jail 类似环境意味着,用户不能超出各自的 home 目录,或者用户不能从各自的 home 目录更改目录。下面实验的详细情况:
|
||||
|
||||
* OS = Debian 10
|
||||
* IP 地址 = 192.168.56.151
|
||||
|
||||
|
||||
|
||||
让我们跳转到 SFTP 配置步骤,
|
||||
|
||||
### 步骤:1) 为 sftp 使用 groupadd 命令创建一个组
|
||||
|
||||
打开终端,使用下面的 groupadd 命令创建一个名为的“**sftp_users**”组,
|
||||
|
||||
```
|
||||
root@linuxtechi:~# groupadd sftp_users
|
||||
```
|
||||
|
||||
### 步骤:2) 添加用户到组 ‘sftp_users’ 并设置权限
|
||||
|
||||
假设你想创建新的用户,并且想添加该用户到 ‘sftp_users’ 组中,那么运行下面的命令,
|
||||
|
||||
**语法:** # useradd -m -G sftp_users <user_name>
|
||||
|
||||
让我们假设用户名是 ’Jonathan’
|
||||
|
||||
```
|
||||
root@linuxtechi:~# useradd -m -G sftp_users jonathan
|
||||
```
|
||||
|
||||
使用下面的 chpasswd 命令设置密码,
|
||||
|
||||
```
|
||||
root@linuxtechi:~# echo "jonathan:<enter_password>" | chpasswd
|
||||
```
|
||||
|
||||
假设你想添加现有的用户到 ‘sftp_users’ 组中,那么运行下面的 usermod 命令,让我们假设已经存在的用户名称是 ‘chris’
|
||||
|
||||
```
|
||||
root@linuxtechi:~# usermod -G sftp_users chris
|
||||
```
|
||||
|
||||
现在设置用户所需的权限,
|
||||
|
||||
```
|
||||
root@linuxtechi:~# chown root /home/jonathan /home/chris/
|
||||
```
|
||||
|
||||
在各用户的 home 目录中都创建一个上传目录,并设置正确地所有权,
|
||||
|
||||
```
|
||||
root@linuxtechi:~# mkdir /home/jonathan/upload
|
||||
root@linuxtechi:~# mkdir /home/chris/upload
|
||||
root@linuxtechi:~# chown jonathan /home/jonathan/upload
|
||||
root@linuxtechi:~# chown chris /home/chris/upload
|
||||
```
|
||||
|
||||
**注意:** 像 Jonathan 和 Chris 之类的用户可以从他们的本地系统上传文件和目录。
|
||||
|
||||
### 步骤:3) 编辑 sftp 配置文件 (/etc/ssh/sshd_config)
|
||||
|
||||
正如我们已经陈述的,sftp 操作是通过 ssh 完成的,所以它的配置文件是 “**/etc/ssh/sshd_config**“, 在做任何更改前,我建议首先备份文件,然后再编辑该文件,接下来添加下面的内容,
|
||||
|
||||
```
|
||||
root@linuxtechi:~# cp /etc/ssh/sshd_config /etc/ssh/sshd_config-org
|
||||
root@linuxtechi:~# vim /etc/ssh/sshd_config
|
||||
………
|
||||
#Subsystem sftp /usr/lib/openssh/sftp-server
|
||||
Subsystem sftp internal-sftp
|
||||
|
||||
Match Group sftp_users
|
||||
X11Forwarding no
|
||||
AllowTcpForwarding no
|
||||
ChrootDirectory %h
|
||||
ForceCommand internal-sftp
|
||||
…………
|
||||
```
|
||||
|
||||
保存并退出文件。
|
||||
|
||||
为使上述更改生效,使用下面的 systemctl 命令来重新启动 ssh 服务
|
||||
|
||||
```
|
||||
root@linuxtechi:~# systemctl restart sshd
|
||||
```
|
||||
|
||||
在上面的 ‘sshd_config’ 文件中,我们已经注释掉了以 “Subsystem”开头的行,并添加了新的条目 “Subsystem sftp internal-sftp” 和新的行,像,
|
||||
|
||||
“**Match Group sftp_users”** –> 它意味着如果用户是 ‘sftp_users’ 组中的一员,那么将应用下面提到的规则到这个条目。
|
||||
|
||||
“**ChrootDierctory %h**” –> 它意味着用户只能在他们自己各自的 home 目录中更改目录,而不能超出他们各自的 home 目录。或者换句话说,我们可以说用户是不允许更改目录的。他们将在他们的目录中获得 jai 类似环境,并且不能访问其他用户的目录和系统的目录。
|
||||
|
||||
“**ForceCommand internal-sftp**” –> 它意味着用户仅被限制到 sftp 命令。
|
||||
|
||||
### 步骤:4) 测试和验证 sftp
|
||||
|
||||
登录到你的 sftp 服务器的同一个网络上的任何其它的 Linux 系统,然后通过我们在 ‘sftp_users’ 组中映射的用户来尝试 ssh sftp 服务。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ssh root@linuxtechi
|
||||
root@linuxtechi's password:
|
||||
Write failed: Broken pipe
|
||||
[root@linuxtechi ~]# ssh root@linuxtechi
|
||||
root@linuxtechi's password:
|
||||
Write failed: Broken pipe
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
以上操作证实用户不允许 SSH ,现在使用下面的命令尝试 sftp ,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# sftp root@linuxtechi
|
||||
root@linuxtechi's password:
|
||||
Connected to 192.168.56.151.
|
||||
sftp> ls -l
|
||||
drwxr-xr-x 2 root 1001 4096 Sep 14 07:52 debian10-pkgs
|
||||
-rw-r--r-- 1 root 1001 155 Sep 14 07:52 devops-actions.txt
|
||||
drwxr-xr-x 2 1001 1002 4096 Sep 14 08:29 upload
|
||||
```
|
||||
|
||||
让我们使用 sftp ‘**get**‘ 命令来尝试下载一个文件
|
||||
|
||||
```
|
||||
sftp> get devops-actions.txt
|
||||
Fetching /devops-actions.txt to devops-actions.txt
|
||||
/devops-actions.txt 100% 155 0.2KB/s 00:00
|
||||
sftp>
|
||||
sftp> cd /etc
|
||||
Couldn't stat remote file: No such file or directory
|
||||
sftp> cd /root
|
||||
Couldn't stat remote file: No such file or directory
|
||||
sftp>
|
||||
```
|
||||
|
||||
上面的输出证实我们能从我们的 sftp 服务器下载文件到本地机器,除此之外,我们也必需测试用户不能更改目录。
|
||||
|
||||
让我们在 **upload**”目录下尝试上传一个文件,
|
||||
|
||||
```
|
||||
sftp> cd upload/
|
||||
sftp> put metricbeat-7.3.1-amd64.deb
|
||||
Uploading metricbeat-7.3.1-amd64.deb to /upload/metricbeat-7.3.1-amd64.deb
|
||||
metricbeat-7.3.1-amd64.deb 100% 38MB 38.4MB/s 00:01
|
||||
sftp> ls -l
|
||||
-rw-r--r-- 1 1001 1002 40275654 Sep 14 09:18 metricbeat-7.3.1-amd64.deb
|
||||
sftp>
|
||||
```
|
||||
|
||||
这证实我们已经成功地从我们的本地系统上传一个文件到 sftp 服务中。
|
||||
|
||||
现在使用 winscp 工具来测试 SFTP 服务,输入 sftp 服务器 ip 地址和用户的凭证,
|
||||
|
||||
[![Winscp-sftp-debian10][1]][3]
|
||||
|
||||
在 Login 上单击,然后尝试下载和上传文件
|
||||
|
||||
[![下载-文件-winscp-debian10-sftp][1]][4]
|
||||
|
||||
现在,在 upload 文件夹中尝试上传文件,
|
||||
|
||||
[![使用-winscp-Debian10-sftp-上传-文件][1]][5]
|
||||
|
||||
上面的窗口证实上传是完好地工作的,这就是这篇文章的全部。如果这些步骤能帮助你在 Debian 10 中使用 chroot 环境配置 SFTP 服务器s,那么请分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/configure-sftp-chroot-debian10/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Configure-sftp-debian10.jpg
|
||||
[3]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Winscp-sftp-debian10.jpg
|
||||
[4]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Download-file-winscp-debian10-sftp.jpg
|
||||
[5]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Upload-File-using-winscp-Debian10-sftp.jpg
|
||||
@ -0,0 +1,296 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Best Raspberry Pi Operating Systems for Various Purposes)
|
||||
[#]: via: (https://itsfoss.com/raspberry-pi-os/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
不同需求下各自最适合的树莓派操作系统
|
||||
======
|
||||
|
||||
[树莓派][1] 是一种具有很多功能且使用便捷的不可或缺的卡片式计算机。不相信?那就[浏览下这个树莓派项目列表][2],来领会下这个小设备能做什么。
|
||||
|
||||
考虑到树莓派用途这么多,为它选择一个合适的操作系统就极其重要。当然,你可以用 Linux 做很多事,但是一个为某个目的特意配置的操作系统可以节省你大量的时间和精力。
|
||||
|
||||
因此,本文中我要介绍一些专门为树莓派量身定制的流行和有用的操作系统。
|
||||
|
||||
### 由于有树莓派镜像工具,安装任何操作系统到树莓派上都很容易
|
||||
|
||||
[把树莓派操作系统安装到 SD 卡上][3] 比以前容易得多。你可以很容易地下载[树莓派镜像][4]和很快地安装树莓派操作系统。看一下官方视频,你就知道有多简单。
|
||||
|
||||
你也可以使用 [NOOBS][5](New Out Of the Box Software)来很容易地安装不同的操作系统到树莓派上。你还可以从 [NOOBS官方下载页面][5] 提及的他们支持的零售商那里获取预先安装好系统的 SD 卡。
|
||||
|
||||
尽情去他们的[官方文档][6]里找更多关于安装操作系统的信息吧。
|
||||
|
||||
[下载树莓派操作系统][4]
|
||||
|
||||
现在你知道了怎么安装它(以及从哪儿获取),让我来重点介绍下几个有用的树莓派操作系统来帮助你。
|
||||
|
||||
### 适用于树莓派的不同操作系统
|
||||
|
||||
请注意,我花了一些精力来筛选出那些被积极维护的树莓派操作系统项目。如果某个项目在不久的将来会停止维护,请在评论区告诉我,我会更新本文。
|
||||
|
||||
另一件事是,我关注到现在最新的版本是 Raspberry 4,但是下面的列表不应被认为是适 Raspberry 4 的操作系统列表。这些系统应该能用于树莓派 3、3B+ 和其他各种版本,但是请参照项目的官方网站核对详细信息。
|
||||
|
||||
**注意:** 排名不分先后。
|
||||
|
||||
#### 1\. Raspbian OS:官方的树莓派操作系统
|
||||
|
||||
![][7]
|
||||
|
||||
Raspbian 是官方支持的树莓派板操作系统。它集成了很多工具,用于教育、编程以及其他广泛的用途。特别地,它包含 Python、Scratch、Sonic Pi、Java和一些其他的很重要的包。
|
||||
|
||||
最初,Raspbian 是基于 Debian 的,系统中预安装了很多有用的包。因此,当你安装 Raspbian 后,你可能就不需要特意安装基本工具了 — 你会发现大部分工具已经提前安装好了。
|
||||
|
||||
Raspbian OS 是被积极地维护着的,它也是最流行的树莓派操作系统之一。你可以使用 [NOOBS][5] 或参照[官方文档][6]来安装它。
|
||||
|
||||
[Raspbian OS][8]
|
||||
|
||||
#### 2\. Ubuntu MATE:适合通用计算需求
|
||||
|
||||
![][9]
|
||||
|
||||
虽然 Raspbian 是官方支持的操作系统,但是对于最新和最好的包它往往不能及时支持。因此,如果你想更新得更快并且在将来想用最新的包,你可以试试树莓派版本的 Ubuntu MATE。
|
||||
|
||||
树莓派定制版的 Ubuntu MATE 是很适合安装的不可思议的轻量级发行版本。它还被广泛用于 [NVIDIA 的 Jetson Nano][10]。换言之,你可以在树莓派的很多场景下使用它。
|
||||
|
||||
为了更好地帮助你,我们还有一份详细的教程:[怎样在树莓派上安装 Ubuntu MATE][11]。
|
||||
|
||||
[Ubuntu MATE for Raspberry Pi][12]
|
||||
|
||||
#### 3\. Ubuntu Server:把树莓派作为一台 Linux 服务器来使用
|
||||
|
||||
![][13]
|
||||
|
||||
如果你计划把你的树莓派当作你项目的服务器来使用,那么安装 Ubuntu Server 会是一个不错的选择。
|
||||
|
||||
Ubuntu Server 有 32 位和 64 位的镜像。你可以根据你的板的类型(是否支持 64 位)来选择对应的操作系统。
|
||||
|
||||
然而,值得注意的一点是 Ubuntu Server 不是为桌面用户定制的。因此,你需要留意 Ubuntu Server 默认不会安装图形用户界面。
|
||||
|
||||
[Ubuntu Server][14]
|
||||
|
||||
#### 4\. LibreELEC:适合做媒体服务器
|
||||
|
||||
![][15]
|
||||
|
||||
我们已经有一个 [Linux 下可用的媒体服务器软件][16],LibreELEC 在列表中。
|
||||
|
||||
它是一个伟大的轻量级操作系统,让你可以在树莓派上安装 [KODI][17]。你可以尝试使用 Raspberry Pi Imager 来安装它。
|
||||
|
||||
你可以很容易地找到他们的[官方下载页面][18],并找到适合你板子的安装镜像。
|
||||
|
||||
[LibreELEC][19]
|
||||
|
||||
#### 5\. OSMC:适合做媒体服务器
|
||||
|
||||
![][20]
|
||||
|
||||
OSMC 是另一个 Linux 下[流行的媒体服务器软件][16]。如果要把树莓派板作为媒体中心设备,那么 OSMC 是你可以向他人推荐的操作系统之一。
|
||||
|
||||
类似 LibreELEC,OSMC 也运行 KODI 来帮助你管理你的媒体文件和享受你已有的素材中。
|
||||
|
||||
OSMC 官方没有提及对 **Raspberry Pi 4** 的支持。因此,如果你的树莓派是 Raspberry Pi 3 或更早的版本,那么应该没有问题。
|
||||
|
||||
[OSMC][21]
|
||||
|
||||
#### 6\. RISC OS:传统的 ARM 操作系统
|
||||
|
||||
![][22]
|
||||
|
||||
ARM 设备的原始草稿版,RISC 已经存在了差不多 30 年了。
|
||||
|
||||
如果你想了解,我们也有篇详细介绍 [RISC OS][23] 的文章。简而言之,RISC OS 也是为诸如树莓派的现代基于 ARM 的卡片式计算机定制的。它的用于界面很简单,更专注于性能。
|
||||
|
||||
同样的,这个系统也不支持 Raspberry Pi 4。因此,如果你的树莓派是 Raspberry Pi 3 或更早的版本,你可以试一下。
|
||||
|
||||
[RISC OS][24]
|
||||
|
||||
#### 7\. Mozilla WebThings Gateway:适合 IoT 项目
|
||||
|
||||
![][25]
|
||||
|
||||
作为 Mozilla 的 [IoT 设备的开源实现][26] 的一部分,WebThings Gateway 让你可以监控和控制连接的 IoT 设备。
|
||||
|
||||
你可以参考[官方文档][27]来检查所需的环境,遵照指导把安装到树莓派上。它确实是适合 IoT 应用的最有用的树莓派操作系统之一。
|
||||
|
||||
[WebThings Gateway][28]
|
||||
|
||||
#### 8\. Ubuntu Core:适合 IoT 项目
|
||||
|
||||
另一个适合 [IoT][29] 应用的树莓派操作系统,或者仅仅用来测试一下 — Ubuntu Core。
|
||||
|
||||
Ubuntu Core 是为 IoT 设备或特定的树莓派特意定制。我不会刻意主张大家使用它 — 但是 Ubuntu Core 是适合树莓派板的安全的操作系统。你可以自己尝试一下!
|
||||
|
||||
[Ubuntu Core][30]
|
||||
|
||||
#### 9\. DietPi:轻量级树莓派操作系统
|
||||
|
||||
![DietPi Screenshot via Distrowatch][31]
|
||||
|
||||
DietPi 是一款轻量级的 [Debian][32] 操作系统,它还宣称比 “Raspbian Lite” 操作系统更轻量。
|
||||
|
||||
考虑到它是一款轻量级的树莓派操作系统,它在很多使用场景下以很便捷的方式提供了大量的功能。从简单的软件安装包到备份解决方案,还有很多功能等待发掘。
|
||||
|
||||
如果你想安装一个低内存占用而性能相对更好的操作系统,你可以尝试一下 DietPi。
|
||||
|
||||
[DietPi][33]
|
||||
|
||||
#### 10\. Lakka Linux:打造复古的游戏控制台
|
||||
|
||||
![][34]
|
||||
|
||||
想让你的树莓派变成一个复古的游戏控制台?
|
||||
|
||||
Lakka Linux 发行版本最初是在 RetroArch 模拟器中构建的。因此,你可以立刻在树莓派上获得所有的复古游戏。
|
||||
|
||||
如果你想了解,我们也有一篇介绍 [Lakka Linux][35] 的文章。或者直接上手吧!
|
||||
|
||||
[Lakka][36]
|
||||
|
||||
#### 11\. RetroPie:适合复古游戏
|
||||
|
||||
![ ][37]
|
||||
|
||||
RetroPie 是另一款可以让树莓派变成复古游戏控制台的树莓派操作系统。它提供了很多配置工具,因此你可以自定义主题,或者调整模拟器来找到最好的复古游戏。
|
||||
|
||||
值得注意的是它不包含任何有版权的游戏。你可以试一下,看看它是怎么工作的!
|
||||
|
||||
[RetroPie][38]
|
||||
|
||||
#### 12\. Kali Linux:适合低成本入侵
|
||||
|
||||
![][39]
|
||||
|
||||
想要在你的树莓派上尝试和学习一些渗透测试技巧?Kali Linux 会是最佳选择。是的,Kali Linux 通常会支持最新的树莓派。
|
||||
|
||||
Kali Linux 不仅适合树莓派,它也支持很多其他设备。尝试一下,玩得愉快!
|
||||
|
||||
[Kali Linux][40]
|
||||
|
||||
#### 13\. OpenMediaVault:适合<ruby>网络附加存储<rt>Network Attached Storage</rt></ruby>
|
||||
|
||||
![][41]
|
||||
|
||||
如果你想在最小的硬件上搭建 [NAS][42] 解决方案,树莓派可以帮助你。
|
||||
|
||||
OpenMediaVault 最初是基于 Debian Linux 的,提供了大量功能,如基于 web 的管理员能力、插件支持,等等。它支持大多数树莓派模块,因此你可以尝试下载并安装它!
|
||||
|
||||
[OpenMediaVault][43]
|
||||
|
||||
#### 14\. ROKOS:适合加密挖矿
|
||||
|
||||
![][44]
|
||||
|
||||
如果你对加密货币和比特币很感兴趣,那么 ROKOS 会吸引你。
|
||||
|
||||
ROKOS 是基于 Debian 的操作系统,预安装的驱动和包基本可以让你的树莓派变成一个节点。当然,在安装之前你需要了解它是怎么工作的。因此,如果你对此不太了解,我建议你先调研下。
|
||||
|
||||
[ROKOS][45]
|
||||
|
||||
#### 15\. Alpine Linux:专注于安全的轻量级 Linux
|
||||
|
||||
当今年代,很多用户都在寻找专注于安全和[隐私的发行版本][46]。如果你也是其中一员,你可以试试在树莓派上安装 Alpine Linux。
|
||||
|
||||
如果你是个树莓派新手,它可能不像你想象的那样对用户友好(或对新手友好)。但是,如果你想尝试一些不一样的东西,那么你可以试试 Alpine Linux 这个专注于安全的 Linux 发行版本。
|
||||
|
||||
[Alpine Linux][47]
|
||||
|
||||
#### 16\. Kano OS:适合儿童教育的操作系统
|
||||
|
||||
![][48]
|
||||
|
||||
如果你在寻找一款能让学习变得有趣还能教育儿童的树莓派操作系统,那么 Kano OS 是个不错的选择。
|
||||
|
||||
它是被积极地维护着的,Kano 操作系统上的桌面对于儿童玩和学习的用户体验都是很简单的。
|
||||
|
||||
[Kano OS][49]
|
||||
|
||||
#### 17\. KDE Plasma Bigscreen:适合把普通 TV 转换为智能 TV
|
||||
|
||||
![][50]
|
||||
|
||||
这是 KDE 的子开发项目。在树莓派上安装 [KDE Plasma Bigscreen OS][51] 后,你可以把普通 TV 变成智能 TV。
|
||||
|
||||
你不需要特殊的远程服务器来控制 TV。你可以使用普通的远程控制。
|
||||
|
||||
Plasma Bigscreen 也集成了 [MyCroft open source AI][52] 作为声控。
|
||||
|
||||
这个项目还在内测阶段,所以如果你想尝试,可能会有一些 bug 和问题。
|
||||
|
||||
[Plasma Bigscreen][53]
|
||||
|
||||
#### 结语
|
||||
|
||||
我知道还有很多为树莓派定制的操作系统 — 但是我尽力列出了被积极维护的最流行的或最有用的操作系统。
|
||||
|
||||
如果你觉得我遗漏了最合适的树莓派操作系统,尽情在下面的评论去告诉我吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/raspberry-pi-os/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.raspberrypi.org/
|
||||
[2]: https://itsfoss.com/raspberry-pi-projects/
|
||||
[3]: https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/
|
||||
[4]: https://www.raspberrypi.org/downloads/
|
||||
[5]: https://www.raspberrypi.org/downloads/noobs/
|
||||
[6]: https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/raspbian_home_screen.jpg?resize=800%2C492&ssl=1
|
||||
[8]: https://www.raspbian.org/
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/Desktop-ubuntu.jpg?resize=800%2C600&ssl=1
|
||||
[10]: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-nano/
|
||||
[11]: https://itsfoss.com/ubuntu-mate-raspberry-pi/
|
||||
[12]: https://ubuntu-mate.org/raspberry-pi/
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/03/ubunt-server.png?ssl=1
|
||||
[14]: https://ubuntu.com/download/raspberry-pi
|
||||
[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/libreelec.jpg?resize=800%2C600&ssl=1
|
||||
[16]: https://itsfoss.com/best-linux-media-server/
|
||||
[17]: https://kodi.tv/
|
||||
[18]: https://libreelec.tv/downloads_new/
|
||||
[19]: https://libreelec.tv/
|
||||
[20]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/osmc-server.jpg?resize=800%2C450&ssl=1
|
||||
[21]: https://osmc.tv/
|
||||
[22]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/10/riscos5.1.jpg?resize=800%2C600&ssl=1
|
||||
[23]: https://itsfoss.com/risc-os-is-now-open-source/
|
||||
[24]: https://www.riscosopen.org/content/
|
||||
[25]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/03/web-things-gateway.png?ssl=1
|
||||
[26]: https://iot.mozilla.org/about/
|
||||
[27]: https://iot.mozilla.org/docs/gateway-getting-started-guide.html
|
||||
[28]: https://iot.mozilla.org/gateway/
|
||||
[29]: https://en.wikipedia.org/wiki/Internet_of_things
|
||||
[30]: https://ubuntu.com/download/raspberry-pi-core
|
||||
[31]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/03/diet-pi.jpg?ssl=1
|
||||
[32]: https://www.debian.org/
|
||||
[33]: https://dietpi.com/
|
||||
[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2016/08/lakkaos.jpg?resize=1024%2C640&ssl=1
|
||||
[35]: https://itsfoss.com/lakka-retrogaming-linux/
|
||||
[36]: http://www.lakka.tv/
|
||||
[37]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/03/retro-pie.png?ssl=1
|
||||
[38]: https://retropie.org.uk/
|
||||
[39]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/03/kali-linux-pi.png?ssl=1
|
||||
[40]: https://www.offensive-security.com/kali-linux-arm-images/
|
||||
[41]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/03/openmediavault.jpg?ssl=1
|
||||
[42]: https://en.wikipedia.org/wiki/Network-attached_storage
|
||||
[43]: https://www.openmediavault.org/
|
||||
[44]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/03/rocos-bitcoin-pi.jpg?ssl=1
|
||||
[45]: https://rokos.space/
|
||||
[46]: https://itsfoss.com/privacy-focused-linux-distributions/
|
||||
[47]: https://alpinelinux.org/
|
||||
[48]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/03/kano-os-pi.jpeg?ssl=1
|
||||
[49]: https://kano.me/row/downloadable
|
||||
[50]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/03/plasma-bigscreen-menu.jpg?ssl=1
|
||||
[51]: https://itsfoss.com/kde-plasma-bigscreen/
|
||||
[52]: https://itsfoss.com/mycroft-mark-2/
|
||||
[53]: https://plasma-bigscreen.org/#download-jumpto
|
||||
163
translated/tech/20200414 How I containerize a build system.md
Normal file
163
translated/tech/20200414 How I containerize a build system.md
Normal file
@ -0,0 +1,163 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LazyWolfLin)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How I containerize a build system)
|
||||
[#]: via: (https://opensource.com/article/20/4/how-containerize-build-system)
|
||||
[#]: author: (Ravi Chandran https://opensource.com/users/ravichandran)
|
||||
|
||||
构建系统容器化指南
|
||||
======
|
||||
搭建一个通过容器分发应用的可复用系统可能很复杂,但这儿有个好方法。
|
||||
![Containers on a ship on the ocean][1]
|
||||
|
||||
一个用于将源代码编译成可运行的应用的构建系统是由工具和流程共同组成。在编译过程中还涉及到代码从软件开发者流转到最终用户,无论最终用户是运维的同事还是部署的同事。
|
||||
|
||||
在使用容器搭建了一些构建系统后,我觉得有一个不错的可复用的方法值得分享。虽然这些构建系统被用于编译机器学习算法和为嵌入式硬件生成可加载的软件镜像上,但这个方法足够抽象,可用于任何基于容器的构建系统。
|
||||
|
||||
这个方法是关于通过简单和可维护的方式搭建或组织构建系统,但并不涉及处理特定编译器或工具容器化的技巧。它适用于软件开发人员构建软件并将可维护镜像交给其他技术人员(无论是系统管理员,运维工程师或者其他头衔)的常见情况。由于构建系统对于最终用户是透明的,因此他们能够专注于软件本身。
|
||||
|
||||
### 为什么要容器化构建系统?
|
||||
|
||||
搭建基于容器的可复用构建系统可以为软件团队带来诸多好处:
|
||||
|
||||
* **专注**:我希望专注于应用的开发。当我调用一个名为“build”的工具时,我希望这个工具集能生成一个随时可用的二进制文件。我不想浪费时间在构建系统的查错上。实际上,我宁愿不了解也不关心构建系统。
|
||||
* **一致的构建行为**:无论在哪种使用情况下,我都想确保整个团队使用相同版本的工具集并在构建时得到相同的结果。否则,我就得不断地处理“我这咋就是好的”的麻烦。在团队项目中,使用相同版本的工具集并对给定的输入源文件集产生一致的输出是非常重要。
|
||||
* **易于部署和升级**:即使向每个人都提供一套详细说明来为项目安装工具集,也可能会有人翻车。问题可能是由于每个人对自己的 Linux 环境的个性化修改导致的。在团队中使用不同的 Linux 发行版(或者其他操作系统),情况可能还会变得更复杂。当需要将工具集升级到下一版本时,问题很快就会变得更糟糕。使用容器和本指南将使得新版本升级非常简单。
|
||||
|
||||
我在项目中容器化构建系统的经验显然很有价值,因为它可以缓解上述问题。我倾向于使用 Docker 作为容器工具,虽然在相对特殊的环境中安装和网络配置仍可能出现问题,尤其是当你在一个使用复杂代理的企业环境中工作时。但至少现在我需要解决的构建系统问题已经很少了。
|
||||
|
||||
### 漫步容器化的构建系统
|
||||
|
||||
我创建了一个[教程存储库][2],随后你可以 clone 并检查它,或者按照本文内容进行操作。我将逐个介绍存储库中的文件。这个构建系统非常简单(它使用**gcc**)从而可以专注于构建系统结构上。
|
||||
|
||||
### 构建系统需求
|
||||
|
||||
我认为构建系统中有两个关键点:
|
||||
|
||||
* **标准化构建调用**:我希望能够指定一些形如 **/path/to/workdir** 的工作目录来构建代码。我希望以如下形式调用构建:
|
||||
|
||||
./build.sh /path/to/workdir
|
||||
|
||||
为了使得示例的结构足够简单(以便说明),我将假定输出也在 **/path/to/workdir** 路径下的某处生成。(否则,将增加容器中显示的卷的数量,虽然这并不困难,但解释起来比较麻烦。)
|
||||
* **通过 shell 自定义构建调用**:有时,工具集会以出乎意料的方式被调用。除了标准的工具集调用 **build.sh** 之外,如果需要还可以为 **build.sh** 添加一些选项。但我一直希望能够有一个可以直接调用工具集命令的 shell。在这个简单的示例中,有时我想尝试不同的 **gcc** 优化选项并查看效果。为此,我希望调用:
|
||||
|
||||
./shell.sh /path/to/workdir
|
||||
|
||||
这将让我得到一个容器内部的 Bash shell,并且可以调用工具集和访问我的**工作目录 workdir**,从而我可以根据需要尝试使用这个工具集。
|
||||
|
||||
### 构建系统架构
|
||||
|
||||
为了满足上述基本需求,这是我的构架系统架构:
|
||||
|
||||
![Container build system architecture][3]
|
||||
|
||||
在底部的 **workdir** 代表软件开发者用于构建的任意软件源码。通常,这个 **workdir** 是一个源代码的存储库。在构建之前,最终用户可以通过任何方式来操纵这个存储库。例如,如果他们使用 **git** 作为版本控制工具的话,可以使用 **git checkout** 切换到他们正在工作的功能分支上并添加或修改文件。这样可以使得构建系统独立于 **workdir** 之外。
|
||||
|
||||
顶部的三个模块共同代表了容器化的构建系统。最左边的黄色模块代表最终用户与构建系统交互的脚本(**build.sh** 和 **shell.sh**)。
|
||||
|
||||
在中间的红色模块是 Dockerfile 和相关的脚本 **build_docker_image.sh**。开发者(在这个例子中指我)通常将执行这个脚本并生成容器镜像(事实上我多次执行它直到一切正常为止,但这是另一个故事)。然后我将镜像分发给最终用户,例如通过 container trusted registry 进行分发。最终用户将需要这个镜像。另外,他们将 clone 构建系统存储库(即一个与[教程存储库][2]等效的存储库)。
|
||||
|
||||
当最终用户调用 **build.sh** 或者 **shell.sh** 时,容器内将执行右边的 **run_build.sh** 脚本。接下来我将详细解释这些脚本。这里的关键是最终用户不需要为了使用而去了解任何关于红色或者蓝色模块或者容器工作原理的知识。
|
||||
|
||||
### 构建系统细节
|
||||
|
||||
把教程存储库的文件结构映射到这个系统结构上。我曾将这个原型结构用于相对复杂构建系统,因此它的简单并不会造成任何限制。下面我列出存储库中相关文件的树结构。文件夹 **dockerize-tutorial** 能用构建系统的其他任何名称代替。在这个文件夹下,我用 **workdir** 的路径作参数调用 **build.sh** 或 **shell.sh**。
|
||||
|
||||
```
|
||||
dockerize-tutorial/
|
||||
├── build.sh
|
||||
├── shell.sh
|
||||
└── swbuilder
|
||||
├── build_docker_image.sh
|
||||
├── install_swbuilder.dockerfile
|
||||
└── scripts
|
||||
└── run_build.sh
|
||||
```
|
||||
|
||||
请注意,我上面特意没列出 **example_workdir**,你能在教程存储库中找到。实际的源码通常存放在单独的存储库中,而不是构建工具库中的一部分;本教程为了不必处理两个存储库,所以我将它包含在这个存储库中。
|
||||
|
||||
如果你只对概念感兴趣,本教程并非必须的,因为我将解释所有文件。但是如果你继续本教程(并且已经安装 Docker),首先使用以下命令来构建容器镜像 **swbuilder:v1**:
|
||||
|
||||
```
|
||||
cd dockerize-tutorial/swbuilder/
|
||||
./build_docker_image.sh
|
||||
docker image ls # resulting image will be swbuilder:v1
|
||||
```
|
||||
|
||||
然后调用 **build.sh**:
|
||||
|
||||
```
|
||||
cd dockerize-tutorial
|
||||
./build.sh ~/repos/dockerize-tutorial/example_workdir
|
||||
```
|
||||
|
||||
下面是 [build.sh][4] 的代码。这个脚本从容器镜像 **swbuilder:v1** 实例化一个容器。而这个容器实例映射了两个卷:一个将文件夹 **example_workdir** 挂载到容器内部路径 **/workdir** 上,第二个则将容器外的文件夹 **dockerize-tutorial/swbuilder/scripts** 挂载到容器内部路径 **/scripts** 上。
|
||||
|
||||
```
|
||||
docker container run \
|
||||
--volume $(pwd)/swbuilder/scripts:/scripts \
|
||||
--volume $1:/workdir \
|
||||
--user $(id -u ${USER}):$(id -g ${USER}) \
|
||||
--rm -it --name build_swbuilder swbuilder:v1 \
|
||||
build
|
||||
```
|
||||
|
||||
另外,**build.sh** 还会用你的用户名(以及组,本教程假设两者一致)去运行容器,以便在访问构建输出时不出现文件权限问题。
|
||||
|
||||
请注意,[**shell.sh**][5] 和 **build.sh** 大体上是一致的,除了两点不同:**build.sh** 会创建一个名为 **build_swbuilder** 的容器,而 **shell.sh** 则会创建一个名为 **shell_swbuilder** 的容器。这样一来,当其中一个脚本运行时另一个脚本被调用也不会产生冲突。
|
||||
|
||||
两个脚本之间的另一处关键不同则在于最后一个参数:**build.sh** 传入参数 **build** 而 **shell.sh** 则传入 **shell**。如果你看了用于构建容器镜像的 [Dockerfile][6],就会发现最后一行包含了下面的 **ENTRYPOINT** 语句。这意味着上面的 **docker container run** 调用将使用 **build** 或 **shell** 作为唯一的输入参数来执行 **run_build.sh** 脚本。
|
||||
|
||||
```
|
||||
# run bash script and process the input command
|
||||
ENTRYPOINT [ "/bin/bash", "/scripts/run_build.sh"]
|
||||
```
|
||||
|
||||
[**run_build.sh**][7] 使用这个输入参数来选择启动 Bash shell 还是调用 **gcc** 来构建 **helloworld.c** 项目。一个真正的构建系统通常会使用 Makefile 而非直接运行 **gcc**。
|
||||
|
||||
```
|
||||
cd /workdir
|
||||
|
||||
if [ $1 = "shell" ]; then
|
||||
echo "Starting Bash Shell"
|
||||
/bin/bash
|
||||
elif [ $1 = "build" ]; then
|
||||
echo "Performing SW Build"
|
||||
gcc helloworld.c -o helloworld -Wall
|
||||
fi
|
||||
```
|
||||
|
||||
在使用时,如果你需要传入多个参数,当然也是可以的。我处理过的构建系统,构建通常是对给定的项目调用 **make**。如果一个构建系统有非常复杂的构建调用,则你可以让 **run_build.sh** 调用 **workdir** 下最终用户编写的特定脚本。
|
||||
|
||||
### 关于 scripts 文件夹的说明
|
||||
|
||||
你可能想知道为什么 **scripts** 文件夹位于目录树深处而不是位于存储库的顶层。两种方法都是可行的,但我不想鼓励最终用户到处乱翻并修改里面的脚本。将它放到更深的地方是一个让他们更难乱翻的方法。另外,我也可以添加一个 **.dockerignore** 文件去忽略 **scripts** 文件夹,因为它不是容器必需的部分。但因为它很小,所以我没有这样做。
|
||||
|
||||
### 简单而灵活
|
||||
|
||||
尽管这一方法很简单,但我将其用于某些非常特殊的构建系统时,发现它其实非常灵活。相对稳定的部分(例如,一年仅修改数次的给定工具集)被固定在容器镜像内。较为灵活的部分则以脚本的形式放在镜像外。这使我能够简单地通过修改脚本并将更改推送到构建系统存储库来修改调用工具集的方式。用户所需要做的是将更改拉到本地的构建系统存储库中,这通常是非常快的(与更新 Docker 镜像不同)。这种结构使其能够拥有尽可能多的卷和脚本,同时使最终用户摆脱复杂性。
|
||||
|
||||
你将如何修改你的应用来针对容器化环境进行优化呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/how-containerize-build-system
|
||||
|
||||
作者:[Ravi Chandran][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/LazyWolfLin)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ravichandran
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/containers_2015-3-osdc-lead.png?itok=O6aivM_W (Containers on a ship on the ocean)
|
||||
[2]: https://github.com/ravi-chandran/dockerize-tutorial
|
||||
[3]: https://opensource.com/sites/default/files/uploads/build_sys_arch.jpg (Container build system architecture)
|
||||
[4]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/build.sh
|
||||
[5]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/shell.sh
|
||||
[6]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/swbuilder/install_swbuilder.dockerfile
|
||||
[7]: https://github.com/ravi-chandran/dockerize-tutorial/blob/master/swbuilder/scripts/run_build.sh
|
||||
325
translated/tech/20200416 Learning to love systemd.md
Normal file
325
translated/tech/20200416 Learning to love systemd.md
Normal file
@ -0,0 +1,325 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (messon007)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Learning to love systemd)
|
||||
[#]: via: (https://opensource.com/article/20/4/systemd)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
学会爱上systemd
|
||||
======
|
||||
|
||||
systemd是所有进程的源头,负责将Linux主机启动到可以做生产性任务的状态。
|
||||
![Penguin driving a car with a yellow background][1]
|
||||
|
||||
systemd(是的,全小写,即使在句子开头也是小写),是init和SystemV init脚本的现代替代者。它还有更多功能。
|
||||
|
||||
当我想到init和SystemV时,像大多数系统管理员一样,我想到的是Linux的启动和关闭,而没有太多其他的,例如在服务启动和运行后对其进行管理。像init一样,systemd是所有进程的源头,它负责使Linux主机启动到可以做生产性任务的状态。 systemd设定的一些功能比老的init要广泛得多,它要管理正在运行的Linux主机的许多方面,包括挂载文件系统,管理硬件,处理定时器以及启动和管理生产性主机所需的系统服务。
|
||||
|
||||
本系列文章是基于我的部分三期Linux培训课程[_使用和管理Linux:从零开始进行学习系统管理_][2]的摘录,探讨了systemd在启动和启动完成后的功能。
|
||||
|
||||
### Linux启动
|
||||
|
||||
Linux主机从关机状态到运行状态的完整启动过程很复杂,但它是开放的并且是可知的。在详细介绍之前,我将简要介绍一下从主机硬件被上电到系统准备好用户登录(的过程)。大多数时候,“启动过程”被作为单个概念来讨论,但这是不准确的。实际上,完整的引导和启动过程包含三个主要部分:
|
||||
|
||||
* **硬件引导:** 初始化系统硬件
|
||||
* **Linux引导:** 加载Linux内核和systemd
|
||||
* **Linux启动:** systemd启动, 为生产工作做准备
|
||||
|
||||
|
||||
Linux启动阶段在内核加载了init或systemd(取决于具体发行版使用的是旧的方式还是还是新的方式)之后开始。init和systemd程序启动并管理所有其他进程,他们在各自的系统上都被称为“所有进程之母”。
|
||||
|
||||
将硬件引导与Linux引导及Linux启动区分开,并明确定义它们之间的分界点是很重要的。理解他们的差异以及他们每一个在使Linux系统进入生产准备状态所起的作用,才能够管理这些进程并更好地确定大部分人所谓的“启动”问题出在哪里。
|
||||
|
||||
启动过程按照三步引导流程使Linux计算机进入可进行生产工作的状态。当内核将主机的控制权转移到systemd时,启动环节开始。
|
||||
|
||||
### systemd之争
|
||||
|
||||
systemd引起了系统管理员和其他负责维护Linux系统正常运行人员的广泛回应。systemd正在许多Linux系统中接管大量任务的事实造成了某些开发人群和系统管理员群组之间的阻挠和争议。
|
||||
|
||||
SystemV和systemd是执行Linux启动环节的两种不同的方法。 SystemV启动脚本和init程序是老的方法,而使用目标(targets)的systemd是新方法。尽管大多数现代Linux发行版都使用较新的systemd进行启动,关机和进程管理,但仍有一些发行版未采用。原因之一是某些发行版维护者和系统管理员喜欢老的SystemV方法,而不是新的systemd。
|
||||
|
||||
我认为两者都有其优势。
|
||||
|
||||
#### 为何我更喜欢SystemV
|
||||
|
||||
我更喜欢SystemV,因为它更开放。使用Bash脚本来完成启动。内核启动init程序(编译后的二进制)后,init启动 **rc.sysinit** 脚本,该脚本执行许多系统初始化任务。 **rc.sysinit** 执行完后,init启动 **/etc/rc.d/rc** 脚本,该脚本依次启动 **/etc/rc.d/rcX.d** 中由SystemV启动脚本定义的各种服务。 其中“ X”是待启动的运行级别号。
|
||||
|
||||
除了init程序本身之外,所有这些程序都是开放且易于理解的脚本。可以通读这些脚本并确切了解整个启动过程中发生的事情,但是我不认为有太多系统管理员会实际这样做。每个启动脚本都被编了号,以便按特定顺序启动预期的服务。服务是串行启动的,一次只能启动一个服务。
|
||||
|
||||
由Red Hat的Lennart Poettering和Kay Sievers开发的systemd是一个由大的已编译的二进制可执行文件构成的复杂系统,不访问其源码就无法理解。它是开源的,因此“访问其源代码”并不难,只是不太方便。systemd似乎表现出对Linux哲学多个原则的重大驳斥。作为二进制文件,systemd无法被直接打开供系统管理员查看或进行简单更改。systemd试图做所有事情,例如管理正在运行的服务,同时提供比SystemV更多的状态信息。它还管理硬件,进程,进程组,文件系统挂载等。 systemd几乎涉足于现代Linux主机的每方面,使它成为系统管理的一站式工具。所有这些都明显违反了"程序应该小且每个程序都应该只做一件事并且做好"的原则。
|
||||
|
||||
#### 为何我更喜欢systemd
|
||||
|
||||
我更喜欢用systemd作为启动机制,因为它会根据启动阶段并行地启动尽可能多的服务。这样可以加快整个的启动速度,使得主机系统比SystemV更快地到达登录屏幕。
|
||||
|
||||
systemd几乎可以管理正在运行的Linux系统的各个方面。它可以管理正在运行的服务,同时提供比SystemV多得多的状态信息。它还管理硬件,进程和进程组,文件系统挂载等。 systemd几乎涉足于现代Linux操作系统的每方面,使其成为系统管理的一站式工具。(听起来熟悉吧?)
|
||||
|
||||
systemd工具是编译后的二进制文件,但该工具包是开放的,因为所有配置文件都是ASCII文本文件。可以通过各种GUI和命令行工具来修改启动配置,也可以添加或修改各种配置文件来满足特定的本地计算环境的需求。
|
||||
|
||||
#### 真正的问题
|
||||
|
||||
您认为我不能喜欢两种启动系统吗?我能,我会用它们中的任何一个。
|
||||
|
||||
我认为,SystemV和systemd之间大多数争议的真正问题和根本原因在于,系统管理阶段[没有选择权][3]。使用SystemV还是systemd已经由各种发行版的开发人员,维护人员和打包人员选择了(但有充分的理由)。由于init极端的侵入性, 挖出(scooping out)并替换init系统会带来很多影响,发行版设计过程之外(的环节)很难处理这些影响。
|
||||
|
||||
尽管该选择实际上是为我而选的,我通常最关心的是我的Linux主机仍然可以启动并正常工作。作为最终用户,甚至是系统管理员,我主要关心的是我是否可以完成我的工作,例如写我的书和这篇文章,安装更新以及编写脚本来自动化所有事情。只要我能做我的工作,我就不会真正在意发行版中使用的启动系统。
|
||||
|
||||
在启动或服务管理出现问题时,我会在意。无论主机上使用哪种启动系统,我都足够了解如何沿着事件顺序来查找故障并进行修复。
|
||||
|
||||
#### 替换SystemV
|
||||
|
||||
以前曾有过用更现代的东西替代SystemV的尝试。在大约两个版本中,Fedora使用了一个叫作Upstart的东西来替换老化的SystemV,但是它没有替换init并且没有我能感知到的变化。由于Upstart并未对SystemV的问题进行任何重大更改,因此这个方向的努力很快就被systemd放弃了。
|
||||
|
||||
尽管大部分Linux开发人员都认可替换旧的SystemV启动系统是个好主意,但许多开发人员和系统管理员并不喜欢systemd。与其重新讨论人们在systemd中遇到的或曾经遇到过的所有所谓的问题,不如带您去看两篇好文章,尽管有些陈旧,但它们涵盖了大多数内容。Linux内核的创建者Linus Torvalds对systemd似乎不感兴趣。在2014年ZDNet的文章_[Linus Torvalds和其他人对Linux上的systemd的看法][4]_中,Linus清楚地表达了他的感受。
|
||||
|
||||
>“实际上我对systemd本身没有任何特别强烈的意见。我对一些核心开发人员有一些意见,我认为它们在对待bugs和兼容性方面过于轻率,而且我认为某些设计细节是疯狂的(例如,我不喜欢二进制日志),但这只是细节,不是大问题。”
|
||||
|
||||
如果您对Linus不太了解,我可以告诉您,如果他不喜欢某事,那么他非常直率,坦率,并且非常清楚这种不喜欢。他解决自己对事物不满的方式已经被社会更好地接受了。
|
||||
|
||||
2013年,Poettering写了一篇很长的博客,其中他在揭穿[systemd的神话][5]的同时透露了创建它的一些原因。这是一本很好的读物,我强烈建议您阅读。
|
||||
|
||||
### systemd任务
|
||||
|
||||
根据编译过程中使用的选项(不在本系列中介绍),systemd可以有多达69个二进制可执行文件用于执行任务,其中包括:
|
||||
|
||||
* systemd程序以1号进程(PID 1)运行,并提供使尽可能多服务并行启动的系统启动能力,它额外加快了总体启动时间。它还管理关机顺序。
|
||||
* systemctl程序提供了服务管理的用户接口。
|
||||
* 支持SystemV和LSB启动脚本,以便向后兼容。
|
||||
* 服务管理和报告提供了比SystemV更多的服务状态数据。
|
||||
* 提供基本的系统配置工具,例如主机名,日期,语言环境,已登录用户的列表,正在运行的容器和虚拟机,系统帐户,运行时目录和设置;用于简易网络配置,网络时间同步,日志转发和名称解析的守护程序。
|
||||
* 提供套接字管理。
|
||||
* systemd定时器提供类似cron的高级功能,包括在相对于系统启动,systemd启动,定时器上次启动时刻的某个时间点运行脚本。
|
||||
* 提供了一个工具来分析定时器规格中使用的日期和时间。
|
||||
* 能感知层次的文件系统挂载和卸载可以更安全地级联挂载的文件系统。
|
||||
* 允许主动的创建和管理临时文件,包括删除文件。
|
||||
* D-Bus的接口提供在插入或移除设备时运行脚本的能力。这允许将所有设备(无论是否可插拔)都被视为即插即用,从而大大简化了设备的处理。
|
||||
* 分析启动顺序的工具可用于查找耗时最多的服务。
|
||||
* 包括用于存储系统消息的日志以及管理日志的工具。
|
||||
|
||||
|
||||
### 架构
|
||||
|
||||
这些和更多的任务通过许多守护程序,控制程序和配置文件来支持。图1显示了许多属于systemd的组件。这是一个简化的图,旨在提供概要描述,因此它并不包括所有独立的程序或文件。它也不提供数据流的视角,数据流是如此复杂,因此在本系列文章的背景下没用。
|
||||
|
||||
![系统架构][6]
|
||||
|
||||
完整的systemd讲解就需要一本书。您不需要了解图1中的systemd组件是如何组合在一起的细节。了解支持各种Linux服务管理以及日志文件和日志处理的程序和组件就够了。 但是很明显,systemd并不是某些批评者所说的那样的庞然大物。
|
||||
|
||||
### 作为1号进程的systemd
|
||||
|
||||
systemd是1号进程(PID 1)。它的一些功能(比老的SystemV3 init要广泛得多)用于管理正在运行的Linux主机的许多方面,包括挂载文件系统以及启动和管理Linux生产主机所需的系统服务。与启动顺序无关的任何systemd任务都不在本文讨论范围之内(但本系列后面的一些文章将探讨其中的一些任务)。
|
||||
|
||||
首先,systemd挂载 **/etc/fstab** 所定义的文件系统,包括所有交换文件或分区。此时,它可以访问位于 **/etc** 中的配置文件,包括它自己的配置文件。它使用其配置链接 **/etc/systemd/system/default.target** 来确定将主机引导至哪个状态或目标。 **default.target** 文件是指向真实目标文件的符号链接。对于桌面工作站,通常是 **graphical.target**,它相当于SystemV中的运行级别5。对于服务器,默认值更可能是 **multi-user.target**,相当于SystemV中的运行级别3。 **emergency.target** 类似于单用户模式。目标(targets)和服务(services)是systemd的单位。
|
||||
|
||||
下表(图2)将systemd目标与老的SystemV启动运行级别进行了比较。systemd提供systemd目标别名以便向后兼容。目标别名允许脚本(以及许多系统管理员)使用SystemV命令(如**init 3**)更改运行级别。当然,SystemV命令被转发给systemd进行解释和执行。
|
||||
|
||||
**systemd目标** | **SystemV运行级别** | **目标别名** | **描述**
|
||||
--- | --- | ---- |-
|
||||
default.target | | |此目标总是通过符号连接的方式成为“多用户目标”或“图形化目标”的别名。systemd始终使用 **default.target** 来启动系统。 ** default.target** 绝不应该设为 **halt.target**,**poweroff.target** 或 **reboot.target** 的别名
|
||||
graphic.target | 5 | runlevel5.target |带有GUI的 **Multi-user.target**
|
||||
| 4 | runlevel4.target |未用。在SystemV中运行级别4与运行级别3相同。可以创建并自定义此目标以启动本地服务,而无需更改默认的 **multi-user.target**
|
||||
multi-user.target | 3 | runlevel3.target |所有服务在运行,但仅有命令行界面(CLI)
|
||||
| 2 | runlevel2.target |多用户,没有NFS,其他所有非GUI服务在运行
|
||||
rescue.target | 1 | runlevel1.target |基本系统,包括挂载文件系统,运行最基本的服务和主控制台的恢复shell
|
||||
Emergency.target | S | |单用户模式-没有服务运行;不挂载文件系统。这是最基本的工作级别,只有主控制台上运行的一个紧急Shell供用户与系统交互
|
||||
halt.target | | |在不关电源的情况下停止系统
|
||||
reboot.target | 6 | runlevel6.target |重启
|
||||
poweroff.target | 0 | runlevel0.target |停止系统并关闭电源
|
||||
|
||||
每个目标在其配置文件中都描述了一个依赖集。systemd启动必须的依赖,这些依赖是运行Linux主机到特定功能级别所需的服务。当目标配置文件中列出的所有依赖项被加载并运行后,系统就在该目标级别运行了。 在图2中,功能最多的目标位于表的顶部,从顶向下,功能逐步递减。
|
||||
|
||||
systemd还会检查老的SystemV init目录,以确认是否存在任何启动文件。如果有,systemd会将它们作为配置文件以启动它们描述的服务。网络服务是一个很好的例子,在Fedora中它仍然使用SystemV启动文件。
|
||||
|
||||
图3(如下)是直接从启动手册页复制来的。它显示了systemd启动期间普遍的事件顺序以及确保成功启动的基本顺序要求。
|
||||
|
||||
```
|
||||
cryptsetup-pre.target
|
||||
|
|
||||
(various low-level v
|
||||
API VFS mounts: (various cryptsetup devices...)
|
||||
mqueue, configfs, | |
|
||||
debugfs, ...) v |
|
||||
| cryptsetup.target |
|
||||
| (various swap | | remote-fs-pre.target
|
||||
| devices...) | | | |
|
||||
| | | | | v
|
||||
| v local-fs-pre.target | | | (network file systems)
|
||||
| swap.target | | v v |
|
||||
| | v | remote-cryptsetup.target |
|
||||
| | (various low-level (various mounts and | | |
|
||||
| | services: udevd, fsck services...) | | remote-fs.target
|
||||
| | tmpfiles, random | | | /
|
||||
| | seed, sysctl, ...) v | | /
|
||||
| | | local-fs.target | | /
|
||||
| | | | | | /
|
||||
\\____|______|_______________ ______|___________/ | /
|
||||
\ / | /
|
||||
v | /
|
||||
sysinit.target | /
|
||||
| | /
|
||||
______________________/|\\_____________________ | /
|
||||
/ | | | \ | /
|
||||
| | | | | | /
|
||||
v v | v | | /
|
||||
(various (various | (various | |/
|
||||
timers...) paths...) | sockets...) | |
|
||||
| | | | | |
|
||||
v v | v | |
|
||||
timers.target paths.target | sockets.target | |
|
||||
| | | | v |
|
||||
v \\_______ | _____/ rescue.service |
|
||||
\|/ | |
|
||||
v v |
|
||||
basic.target rescue.target |
|
||||
| |
|
||||
________v____________________ |
|
||||
/ | \ |
|
||||
| | | |
|
||||
v v v |
|
||||
display- (various system (various system |
|
||||
manager.service services services) |
|
||||
| required for | |
|
||||
| graphical UIs) v v
|
||||
| | multi-user.target
|
||||
emergency.service | | |
|
||||
| \\_____________ | _____________/
|
||||
v \|/
|
||||
emergency.target v
|
||||
graphical.target
|
||||
```
|
||||
|
||||
**sysinit.target** 和 **basic.target** 目标可以看作启动过程中的检查点。尽管systemd的设计目标之一是并行启动系统服务,但是某些服务和功能目标必须先启动,然后才能启动其他服务和目标。直到该检查点所需的所有服务和目标被满足后才能通过这些检查点。
|
||||
|
||||
当它依赖的所有单元都完成时,将到达 **sysinit.target**。所有这些单元,挂载文件系统,设置交换文件,启动udev,设置随机数生成器种子,启动低层服务以及配置安全服务(如果一个或多个文件系统是加密的)都必须被完成,但 **sysinit.target** 的这些任务可以并行执行。
|
||||
|
||||
**sysinit.target** 将启动系统接近正常运行所需的所有低层服务和单元,以及转移到 **basic.target** 所需的服务和单元。
|
||||
|
||||
在完成 **sysinit.target** 目标之后,systemd会启动实现下一个目标所需的所有单元。基本目标通过启动所有下一目标所需的单元来提供一些其他功能。包括设置如PATHs为各种可执行程序的路径,设置通信套接字和计时器之类。
|
||||
|
||||
最后,用户级目标 **multi-user.target** 或 **graphical.target** 被初始化。要满足图形目标的依赖必须先达到**multi-user.target**。图3中带下划线的目标是通常的启动目标。当达到这些目标之一时,启动就完成了。如果 **multi-user.target** 是默认设置,那么您应该在控制台上看到文本模式的登录界面。如果 **graphical.target** 是默认设置,那么您应该看到图形的登录界面。您看到的特定的GUI登录界面取决于您默认的显示管理器。
|
||||
|
||||
引导手册页还描述并提供了引导到初始RAM磁盘和systemd关机过程的地图。
|
||||
|
||||
systemd还提供了一个工具,该工具列出了完整启动或指定单元的依赖。单元是可控制的systemd资源实体,其范围从特定服务(例如httpd或sshd)到计时器,挂载,套接字等。尝试以下命令并滚动查看结果。
|
||||
|
||||
```
|
||||
`systemctl list-dependencies graphical.target`
|
||||
```
|
||||
|
||||
注意,这完全展开了使系统进入图形目标运行模式所需的顶层目标单元列表。 也可以使用 **\-all** 选项来展开所有其他单元。
|
||||
|
||||
```
|
||||
`systemctl list-dependencies --all graphical.target`
|
||||
```
|
||||
|
||||
您可以使用 **less** 命令来搜索诸如“target”,“slice”和“ socket”之类的字符串。
|
||||
|
||||
现在尝试下面的方法。
|
||||
|
||||
```
|
||||
`systemctl list-dependencies multi-user.target`
|
||||
```
|
||||
|
||||
和
|
||||
|
||||
|
||||
```
|
||||
`systemctl list-dependencies rescue.target`
|
||||
```
|
||||
|
||||
和
|
||||
|
||||
|
||||
```
|
||||
`systemctl list-dependencies local-fs.target`
|
||||
```
|
||||
|
||||
和
|
||||
|
||||
|
||||
```
|
||||
`systemctl list-dependencies dbus.service`
|
||||
```
|
||||
```
|
||||
`systemctl list-dependencies graphic.target`
|
||||
```
|
||||
|
||||
|
||||
|
||||
这个工具帮助我可视化我正用的主机的启动依赖细节。继续花一些时间探索一个或多个Linux主机的启动树。但是要小心,因为systemctl手册页包含以下注释:
|
||||
|
||||
> _“请注意,此命令仅列出当前被服务管理器加载到内存的单元。尤其是,此命令根本不适合用于获取特定单元的全部反向依赖列表,因为它不会列出被单元声明了但是未加载的依赖项。” _
|
||||
|
||||
### 结尾语
|
||||
|
||||
即使在深入研究systemd之前,很明显能看出它既强大又复杂。显然,systemd不是单一,庞大,整体且不可知的二进制文件。相反,它是由许多较小的组件和旨在执行特定任务的子命令组成。
|
||||
|
||||
本系列的下一篇文章将更详细地探讨systemd的启动,以及systemd的配置文件,更改默认的目标以及如何创建简单服务单元。
|
||||
|
||||
### 资源
|
||||
|
||||
互联网上有大量关于systemd的信息,但是很多都简短,晦涩甚至是误导。除了本文提到的资源外,以下网页还提供了有关systemd启动的更详细和可靠的信息。
|
||||
|
||||
* Fedora项目有一个很好的,实用的[guide to systemd][7]。它有你需要知道的通过systemd来配置,管理和维护Fedora主机所需的几乎所有知识。
|
||||
* Fedora项目还有一个不错的[cheat sheet][8],将老的SystemV命令与对比的systemd命令相互关联。
|
||||
* 有关systemd及其创建原因的详细技术信息,请查看[Freedesktop.org][9]的[systemd描述][10]。
|
||||
* [Linux.com][11]的“systemd的更多乐趣”提供了更高级的systemd [信息和技巧][12]。
|
||||
|
||||
|
||||
还有systemd的设计师和主要开发者Lennart Poettering撰写的针对Linux系统管理员的一系列技术文章。这些文章是在2010年4月至2011年9月之间撰写的,但它们现在和那时一样有用。关于systemd及其生态的其他许多好文都基于这些论文。
|
||||
|
||||
* [重新思考1号进程][13]
|
||||
* [systemd之系统管理员, I][14]
|
||||
* [systemd之系统管理员, II][15]
|
||||
* [systemd之系统管理员, III][16]
|
||||
* [systemd之系统管理员, IV][17]
|
||||
* [systemd之系统管理员, V][18]
|
||||
* [systemd之系统管理员, VI][19]
|
||||
* [systemd之系统管理员, VII][20]
|
||||
* [systemd之系统管理员, VIII][21]
|
||||
* [systemd之系统管理员, IX][22]
|
||||
* [systemd之系统管理员, X][23]
|
||||
* [systemd之系统管理员, XI][24]
|
||||
|
||||
|
||||
|
||||
Mentor Graphics的Linux内核和系统程序员Alison Chiaken预览了此文...
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/systemd
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[messon007](https://github.com/messon007)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/car-penguin-drive-linux-yellow.png?itok=twWGlYAc (Penguin driving a car with a yellow background)
|
||||
[2]: http://www.both.org/?page_id=1183
|
||||
[3]: http://www.osnews.com/story/28026/Editorial_Thoughts_on_Systemd_and_the_Freedom_to_Choose
|
||||
[4]: https://www.zdnet.com/article/linus-torvalds-and-others-on-linuxs-systemd/
|
||||
[5]: http://0pointer.de/blog/projects/the-biggest-myths.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/systemd-architecture.png (systemd architecture)
|
||||
[7]: https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html
|
||||
[8]: https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet
|
||||
[9]: http://Freedesktop.org
|
||||
[10]: http://www.freedesktop.org/wiki/Software/systemd
|
||||
[11]: http://Linux.com
|
||||
[12]: https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/
|
||||
[13]: http://0pointer.de/blog/projects/systemd.html
|
||||
[14]: http://0pointer.de/blog/projects/systemd-for-admins-1.html
|
||||
[15]: http://0pointer.de/blog/projects/systemd-for-admins-2.html
|
||||
[16]: http://0pointer.de/blog/projects/systemd-for-admins-3.html
|
||||
[17]: http://0pointer.de/blog/projects/systemd-for-admins-4.html
|
||||
[18]: http://0pointer.de/blog/projects/three-levels-of-off.html
|
||||
[19]: http://0pointer.de/blog/projects/changing-roots
|
||||
[20]: http://0pointer.de/blog/projects/blame-game.html
|
||||
[21]: http://0pointer.de/blog/projects/the-new-configuration-files.html
|
||||
[22]: http://0pointer.de/blog/projects/on-etc-sysinit.html
|
||||
[23]: http://0pointer.de/blog/projects/instances.html
|
||||
[24]: http://0pointer.de/blog/projects/inetd.html
|
||||
@ -1,207 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to compress files on Linux 5 ways)
|
||||
[#]: via: (https://www.networkworld.com/article/3538471/how-to-compress-files-on-linux-5-ways.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
在 Linux 上压缩文件的 5 种方法
|
||||
======
|
||||
在 Linux 系统上有很多可以用于压缩文件的工具,但是它们表现的行为或产生相同程度的压缩等级并不相同,在这篇文章中,我们比较其中的五个工具。
|
||||
Getty Images
|
||||
|
||||
在 Linux 上有不少用于压缩文件的命令。最新最有效的一个方法是 **xz** ,但是所有的方法都有节省磁盘空间和为后期使用维护备份文件的优点。在这篇文章中,我们将比较压缩命令并指出显著的不同 。
|
||||
|
||||
### tar
|
||||
|
||||
tar 命令不是专门的压缩命令。它通常用于将多个文件拉入一单个文件中,以便容易地传输到另一个系统,或者备份文件为一个相关的组。它也提供压缩作为一个功能,这是很明智的,附加的 **z** 压缩选项能够实现压缩文件。
|
||||
|
||||
当压缩过程被附加到一个使用 **z** 选项的 **tar** 命令时,tar 使用 **gzip** 来进行压缩。
|
||||
|
||||
你可以使用 **tar** 来压缩一个单个文件,就像压缩一个组一样容易,尽管这种操作与直接使用 **gzip** 相比没有特别的优势。为此,要使用 **tar** ,只需要使用一个 “tar cfz newtarfile filename” 命令来像你标识一个组一样标识文件,像这样:
|
||||
|
||||
```
|
||||
$ tar cfz bigfile.tgz bigfile
|
||||
^ ^
|
||||
| |
|
||||
+- 新的文件 +- 将被压缩的文件
|
||||
|
||||
$ ls -l bigfile*
|
||||
-rw-rw-r-- 1 shs shs 103270400 Apr 16 16:09 bigfile
|
||||
-rw-rw-r-- 1 shs shs 21608325 Apr 16 16:08 bigfile.tgz
|
||||
```
|
||||
|
||||
注意,文件的大小显著减少。
|
||||
|
||||
如果你喜欢,你可以使用 **tar.gz** 扩展名,这可能会使文件的特征更加明显,但是大多数的 Linux 用户将很可能会意识到与 **tgz** 的意思是相同的东西 – **tar** 和 **gz** 的组合来显示文件是一个压缩的 tar 文件。在压缩完成后,将留下原始文件和压缩文件。
|
||||
|
||||
为收集很多文件在一起并在一个命令中压缩生成的 “tar ball” ,使用相同的语法,但是要指明将要被包含的文件来作为一个组,而不是单个文件。这里有一个示例:
|
||||
|
||||
[][1]
|
||||
|
||||
```
|
||||
$ tar cfz bin.tgz bin/*
|
||||
^ ^
|
||||
| +-- 将被包含的文件
|
||||
+ 新的文件
|
||||
```
|
||||
|
||||
### zip
|
||||
|
||||
**zip** 命令创建一个压缩文件,与此同时保留原始文件的完整性。语法像使用 **tar** 一样简单,只是你必需记住,你的原始文件名称应该是命令行上的最后一个参数。
|
||||
|
||||
```
|
||||
$ zip ./bigfile.zip bigfile
|
||||
updating: bigfile (deflated 79%)
|
||||
$ ls -l bigfile bigfile.zip
|
||||
-rw-rw-r-- 1 shs shs 103270400 Apr 16 11:18 bigfile
|
||||
-rw-rw-r-- 1 shs shs 21606889 Apr 16 11:19 bigfile.zip
|
||||
```
|
||||
|
||||
### gzip
|
||||
|
||||
**gzip** 命令非常容易使用。你只需要键入 "gzip" ,紧随其后的是你想要压缩的文件名称。不像上述描述的命令,**gzip** 将“就地”加密文件。换句话说,原始文件将被加密文件替换。
|
||||
|
||||
```
|
||||
$ gzip bigfile
|
||||
$ ls -l bigfile*
|
||||
-rw-rw-r-- 1 shs shs 21606751 Apr 15 17:57 bigfile.gz
|
||||
```
|
||||
|
||||
### bzip2
|
||||
|
||||
像使用 **gzip** 命令一样,**bzip2** 将在你选的“合适位置”压缩文件,只留下原始文件保持原样离开。
|
||||
|
||||
```
|
||||
$ bzip bigfile
|
||||
$ ls -l bigfile*
|
||||
-rw-rw-r-- 1 shs shs 18115234 Apr 15 17:57 bigfile.bz2
|
||||
```
|
||||
|
||||
### xz
|
||||
|
||||
压缩命令组中的一个相对较新的成员,**xz** 就如何更好的压缩文件而言是领跑者。像先前的两个命令一样,你只需要将文件名称补给到命令中。再强调一次,原始文件被就地压缩。
|
||||
|
||||
```
|
||||
$ xz bigfile
|
||||
$ ls -l bigfile*
|
||||
-rw-rw-r-- 1 shs shs 13427236 Apr 15 17:30 bigfile.xz
|
||||
```
|
||||
|
||||
对于大文件来说,你可能会注意到 **xz** 将比其它的压缩命令花费更多的运行时间,但是压缩的结果却是非常令人赞叹的。
|
||||
|
||||
### 考虑对比性
|
||||
|
||||
大多数人都听说过 "文件大小不是万能的"。所以,让我们比较一下文件大小以及一些当你计划如何压缩文件时的问题。
|
||||
|
||||
下面显示的统计数据都与压缩单个文件相关,在上面显示的示例中使用 – bigfile – 。这个文件是一个大的且相当随机的文本文件。压缩率在一定程度上取决于文件的内容。
|
||||
|
||||
#### 大小减缩率
|
||||
|
||||
在比较期间,上面显示的各种压缩命产生下面的结果。百分比表示压缩文件对比原始文件。
|
||||
|
||||
```
|
||||
-rw-rw-r-- 1 shs shs 103270400 Apr 16 14:01 bigfile
|
||||
------------------------------------------------------
|
||||
-rw-rw-r-- 1 shs shs 18115234 Apr 16 13:59 bigfile.bz2 ~17%
|
||||
-rw-rw-r-- 1 shs shs 21606751 Apr 16 14:00 bigfile.gz ~21%
|
||||
-rw-rw-r-- 1 shs shs 21608322 Apr 16 13:59 bigfile.tgz ~21%
|
||||
-rw-rw-r-- 1 shs shs 13427236 Apr 16 14:00 bigfile.xz ~13%
|
||||
-rw-rw-r-- 1 shs shs 21606889 Apr 16 13:59 bigfile.zip ~21%
|
||||
```
|
||||
|
||||
**xz** 命令获胜,最终只有压缩文件大小的13%,但是这些所有的压缩命令都相当显著地减少原始文件的大小。
|
||||
|
||||
#### 是否替换原始文件
|
||||
|
||||
**bzip2**,**gzip** 和 **xz** 命令都将使用压缩文件替换原始文件。**tar** 和 **zip** 命令不替换。
|
||||
|
||||
#### 运行时间
|
||||
|
||||
**xz** 命令似乎比其它命令需要花费更多的时间来加密文件。对于 bigfile 来说,近似时间是:
|
||||
|
||||
```
|
||||
命令 运行时间
|
||||
tar 4.9 秒
|
||||
zip 5.2 秒
|
||||
bzip2 22.8 秒
|
||||
gzip 4.8 秒
|
||||
xz 50.4 秒
|
||||
```
|
||||
|
||||
解压缩文件很可能比压缩时间要短得多。
|
||||
|
||||
#### 文件权限
|
||||
|
||||
不管你对压缩文件设置什么权限,压缩文件的权限将基于你的 **umask** 设置,除 **bzip2** 维持原始文件的权限外。
|
||||
|
||||
#### 与 Windows 的兼容性
|
||||
|
||||
**zip** 命令将创建一个可被使用的文件(例如,解压缩),在 Windows 系统上以及 Linux 和其它 Unix 系统上,无需安装其它可能可用或不可用的工具。
|
||||
|
||||
### 解压缩文件
|
||||
|
||||
解压缩文件的命令类似于这些压缩文件的命令。这些命令将在我们运行上述压缩命令后用于解压缩 bigfile 。
|
||||
|
||||
* tar: **tar xf bigfile.tgz**
|
||||
* zip: **unzip bigfile.zip**
|
||||
* gzip: **gunzip bigfile.gz**
|
||||
* bzip2: **bunzip2 bigfile.gz2**
|
||||
* xz: **xz -d bigfile.xz** 或 **unxz bigfile.xz**
|
||||
|
||||
|
||||
|
||||
### 对比你自己运行的压缩
|
||||
|
||||
如果你想自己运行一些测试,抓取一个大的且可以替换的文件,并使用上面显示的每个命令来压缩它 – 最好使用一个新的子目录。你可能必需先安装 **xz** ,如果你想在测试中包含它的话。这个脚本可能更容易地压缩,但是将可能花费几分钟来完成。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# 询问用户文件名称
|
||||
echo -n "filename> "
|
||||
read filename
|
||||
|
||||
# 你需要这个,因为一些命令将替换原始文件
|
||||
cp $filename $filename-2
|
||||
|
||||
# 先清理(以免先前的结果仍然可用)
|
||||
rm $filename.*
|
||||
|
||||
tar cvfz ./$filename.tgz $filename > /dev/null
|
||||
zip $filename.zip $filename > /dev/null
|
||||
bzip2 $filename
|
||||
# 恢复原始文件
|
||||
cp $filename-2 $filename
|
||||
gzip $filename
|
||||
# 恢复原始文件
|
||||
cp $filename-2 $filename
|
||||
xz $filename
|
||||
|
||||
# 显示结果
|
||||
ls -l $filename.*
|
||||
|
||||
# 替换原始文件
|
||||
mv $filename-2 $filename
|
||||
```
|
||||
|
||||
加入 [Facebook][2] 和 [LinkedIn][3] 网络世界社区来评论那些最重要的话题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3538471/how-to-compress-files-on-linux-5-ways.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/blog/itaas-and-the-corporate-storage-technology/?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE22140&utm_content=sidebar (ITAAS and Corporate Storage Strategy)
|
||||
[2]: https://www.facebook.com/NetworkWorld/
|
||||
[3]: https://www.linkedin.com/company/network-world
|
||||
@ -1,283 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qfzy1233)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (16 Things to do After Installing Ubuntu 20.04)
|
||||
[#]: via: (https://itsfoss.com/things-to-do-after-installing-ubuntu-20-04/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
安装完 Ubuntu 20.04 后要做的 16 件事
|
||||
======
|
||||
|
||||
_**以下是安装 Ubuntu 20.04 之后需要做的一些调整和事项,它将使你获得更流畅、更好的桌面 Linux 体验。**_
|
||||
|
||||
[Ubuntu 20.04 LTS (长期支持版)带来了许多新的特性][1] 和观感上的变化。 如果你要安装 Ubuntu 20.04 ,让我向你展示一些推荐步骤便于你的使用。
|
||||
|
||||
### 安装完 Ubuntu 20.04 LTS “Focal Fossa”后要做的 16 件事
|
||||
|
||||
![][2]
|
||||
|
||||
我在这里要提到的步骤仅是我的建议。如果一些定制或调整不适合你的需要和兴趣,你可以忽略它们。
|
||||
|
||||
同样的,有些步骤看起来很简单,但是对于一个 Ubuntu 新手来说是必要的。
|
||||
|
||||
这里的一些建议适用于启用 GNOME 作为默认桌面Ubuntu 20.04。所以请检查[Ubuntu版本][3]和[桌面环境][4]。
|
||||
|
||||
以下列表便是安装了代号为 Focal Fossa 的 Ubuntu 20.04 LTS 之后要做的事。
|
||||
|
||||
#### 1\. 通过更新和启用额外的 repos 来准备您的系统
|
||||
|
||||
安装Ubuntu或任何其他Linux发行版之后,你应该做的第一件事就是更新它。Linux 的可用包数据库工作于本地。这个缓存需要同步以便你能够安装任何软件。
|
||||
|
||||
升级Ubuntu非常简单。你可以运行软件更新从菜单( 按 Win 键并搜索软件更新):
|
||||
|
||||
![Ubuntu 20.04 的软件升级中心][5]
|
||||
|
||||
你也可以在终端使用以下命令更新你的系统:
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt upgrade
|
||||
```
|
||||
|
||||
接下来,您应该确保启用了[universe和multiverse存储库][6]。使用这些存储库,你可以访问更多的软件。我还推荐阅读关于[Ubuntu软件库][6]的书籍,以了解它背后的基本概念。
|
||||
|
||||
搜索软件和放大器;更新菜单:
|
||||
|
||||
![软件及更新设置项][7]
|
||||
|
||||
请务必选中存储库前面的方框:
|
||||
|
||||
![启用额外的存储库][8]
|
||||
|
||||
#### 2\. 安装媒体解码器来播放MP3、MPEG4和其他格式媒体文件
|
||||
|
||||
如果你想播放媒体文件,如MP3, MPEG4, AVI等,你需要安装媒体解码器。由于不同国家的版权问题,Ubuntu在默认情况下不会安装它。
|
||||
|
||||
作为个人,你可以很容易地安装这些媒体编解码器[使用 Ubuntu 额外安装包][9]。这将安装媒体编解码器,Adobe Flash播放器和[微软 True Type 字体在您的Ubuntu系统][10]。
|
||||
|
||||
你可以通过[点击这个链接][11](它将要求打开软件中心)来安装它,或者使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt install ubuntu-restricted-extras
|
||||
```
|
||||
|
||||
如果遇到EULA或许可证界面,请记住使用tab键在选项之间进行选择,然后按enter键确认你的选择。
|
||||
|
||||
![按tab键选择OK并按enter键][12]
|
||||
|
||||
#### 3\. 从软件中心或网络上安装软件
|
||||
|
||||
现在已经设置了存储库并更新了包缓存,应该开始安装所需的软件了。
|
||||
|
||||
有几种方法可以在Ubuntu中安装应用程序。最简单和正式的方法是使用软件中心。
|
||||
|
||||
![Ubuntu 软件中心][14]
|
||||
|
||||
如果你想要一些关于软件的建议,请参考这个扩展的[不同用途的Ubuntu应用程序列表][15]。
|
||||
|
||||
一些软件供应商提供 .deb 文件来方便地安装他们的应用程序。你可以从他们的网站获得 deb 文件。例如,要[在 Ubuntu 上安装谷歌 Chrome ][16],你可以从它的网站上获得 deb 文件,双击它开始安装。
|
||||
|
||||
#### 4\. 享受 Steam Proton 和 GameModeEnjoy 上的游戏
|
||||
|
||||
[ Linux 上的游戏][17] 已经有了长足的发展。你不受限于自带的少数游戏。你可以[在 Ubuntu 上安装 Steam ][18]并享受许多游戏。
|
||||
|
||||
[Steam 新的 Proton 项目][19]可以让你在Linux上玩许多只适用于windows的游戏。除此之外,Ubuntu 20.04还默认安装了[Feral Interactive的游戏][20]。
|
||||
|
||||
游戏模式会自动调整Linux系统的性能,使游戏具有比其他后台进程更高的优先级。
|
||||
|
||||
这意味着一些支持游戏模式的游戏(如[古墓丽影崛起][21])在 Ubuntu 上的性能应该有所提高。
|
||||
|
||||
#### 5\. 管理自动更新(适用于进阶和专家)
|
||||
|
||||
最近,Ubuntu 已经开始自动下载和安装对你的系统至关重要的安全更新。这是一个安全功能,作为一个普通用户,你应该让它保持默认,
|
||||
|
||||
但是,如果你喜欢自己进行配置更新,而这个自动更新经常导致你[“无法锁定管理目录”错误][22],也许你可以改变自动更新行为。
|
||||
|
||||
你可以选择更新是提示,以便它通知你的安全更新是否可用,而不是自动安装。
|
||||
|
||||
![管理自动更新设置][23]
|
||||
|
||||
#### 6\. 控制电脑的自动挂起和屏幕锁定
|
||||
|
||||
如果你在笔记本电脑上使用Ubuntu 20.04,那么你可能需要注意一些电源和屏幕锁定设置。
|
||||
|
||||
如果你的笔记本电脑是电池模式,Ubuntu会在20分钟不工作后休眠系统。这样做是为了节省电池电量。就我个人而言,我不喜欢它,因此我禁用了它。
|
||||
|
||||
类似地,如果您离开系统几分钟,它会自动锁定屏幕。我也不喜欢这种行为,所以我宁愿禁用它。
|
||||
|
||||
![Ubuntu 20.04的电源设置][24]
|
||||
|
||||
#### 7\. 享受夜间模式
|
||||
|
||||
一个[谈论最多的 Ubuntu 20.04 特性][25]是夜间模式。你可以通过进入设置并在外观部分中选择它来启用夜间模式。
|
||||
|
||||
![开启夜间主题 Ubuntu ][26]
|
||||
|
||||
你可能需要做一些额外的调整来启用 Ubuntu 20.04 的深度夜间模式。
|
||||
|
||||
#### 8\. 控制桌面图标和启动程序
|
||||
|
||||
如果你想要一个最简的桌面,你可以禁用桌面上的图标。您还可以从左侧禁用启动程序,并在顶部面板中禁用软件状态栏。
|
||||
|
||||
所有这些都可以通过默认的新 GNOME 扩展来控制。
|
||||
|
||||
![][28]
|
||||
|
||||
顺便说一下,你也可以通过设置-外观来改变启动栏的位置到底部或者右边。
|
||||
|
||||
#### 9\. 使用emojis(表情)和特殊字符,或从搜索中禁用它
|
||||
|
||||
Ubuntu提供了一个使用 emojis 或表情符号的简单方法。在默认情况下,有一个专用的应用程序叫做 Characters。它可以给你基本表情符号的[Unicode][29]码。
|
||||
|
||||
不仅是表情符号,你还可以使用它来获得法语、德语、俄语和拉丁语字符的 unicode 。单击符号你可以复制 unicode ,当你粘贴这段代码时,你所选择的符号便被插入。
|
||||
|
||||
! [Emoji Ubuntu] [30]
|
||||
|
||||
你也能在桌面搜索中找到这些特殊的字符和表情符号。也可以从搜索结果中复制它们。
|
||||
|
||||
![Emojis 出现在桌面搜索中][31]
|
||||
|
||||
如果你不想在搜索结果中看到它们,你应该禁用搜索功能对它们的访问。下一节将讨论如何做到这一点。
|
||||
|
||||
#### 10\. 掌握桌面搜索
|
||||
|
||||
GNOME桌面拥有强大的搜索功能。大多数人使用它来搜索已安装的应用程序,但它不仅限于此。
|
||||
|
||||
按超级键(Win键)并搜索一些东西。它将显示与搜索词匹配的任何应用程序,然后是系统设置和软件中心提供的匹配应用程序。
|
||||
|
||||
![桌面搜索][32]
|
||||
|
||||
不仅如此,搜索还可以找到文件中的文本。如果你正在使用日历,它也可以找到你的会议和提醒。你甚至可以在搜索中进行快速计算并复制其结果。
|
||||
|
||||
![Ubuntu搜索的快速计算][33]
|
||||
|
||||
你可以通过进入设置来控制搜索的内容和顺序。
|
||||
|
||||
![][34]
|
||||
|
||||
#### 11\. 使用夜灯功能,减少夜间眼睛疲劳
|
||||
|
||||
如果你在晚上使用电脑或智能手机,你应该使用夜灯功能来减少眼睛疲劳。我觉得这很有帮助。
|
||||
|
||||
夜灯的特点是在屏幕上增加了一种黄色的色调,比白光少了一些挤压感。
|
||||
|
||||
你可以在设置->显示并切换到夜灯选项卡。你可以根据自己的喜好设置“黄色”。
|
||||
|
||||
![夜灯功能][35]
|
||||
|
||||
#### 12\.使用 2K/4K 显示器? 使用分辨率缩放得到更大的图标和字体
|
||||
|
||||
如果你觉得图标、字体、文件夹在你的高分辨率屏幕上看起来都太小了,你可以利用分辨率缩放。
|
||||
|
||||
启用分级缩放可以让你有更多的选项来从100%增加到200%。你可以选择适合自己喜好的缩放尺寸。
|
||||
|
||||
![启用高分缩放从设置->显示][36]
|
||||
|
||||
#### 13\. 探索GNOME扩展以扩展GNOME桌面的可用性
|
||||
|
||||
GNOME桌面有称为扩展的小插件或附加组件。你应该[学习使用 GNOM E扩展][37]来扩展系统的可用性。
|
||||
|
||||
如下图所示,天气扩展顶部面板中显示了天气信息。不起眼但十分有用。您也可以在这里查看一些[最佳 GNOME 扩展][38]。不要全部安装,只使用那些对你有用的。
|
||||
|
||||
![天气 扩展][39]
|
||||
|
||||
#### 14\.启用“勿扰”模式,专注于工作
|
||||
|
||||
如果你想专注于工作,禁用桌面通知会很方便。你可以轻松地启用“勿扰”模式,并静音所有通知。
|
||||
|
||||
![启用“请勿打扰”清除桌面通知][40]
|
||||
|
||||
这些通知仍然会在消息栏中,以便您以后可以阅读它们,但是它们不会在桌面上弹出。
|
||||
|
||||
#### 15\. 清理你的系统
|
||||
|
||||
这是你安装Ubuntu后不需要马上做的事情。但是记住它会对你有帮助。
|
||||
|
||||
随着时间的推移,你的系统将有大量不再需要的包。你可以用这个命令一次性删除它们:
|
||||
|
||||
```
|
||||
sudo apt autoremove
|
||||
```
|
||||
|
||||
还有其他[清理 Ubuntu 以释放磁盘空间的方法][41],但这是最简单和最安全的。
|
||||
|
||||
#### 16\. 根据您的喜好调整和定制 GNOME 桌面
|
||||
|
||||
我强烈推荐[安装 GNOME 设置工具][42]。这将让你可以通过额外的设置来进行定制。
|
||||
|
||||
![Gnome 设置工具][43]
|
||||
|
||||
比如,你可以[以百分比形式显示电池容量][44],[修正在touchpad中右键问题][45],改变 Shell 主题,改变鼠标指针速度,显示日期和星期数,改变应用程序窗口行为等。
|
||||
|
||||
定制是没有尽头的,我可能仅使用了它的一小部分功能。这就是为什么我推荐[阅读这些文章]关于[自定义GNOME桌面][46]的[42]。
|
||||
|
||||
你也可以[在Ubuntu中安装新主题][47],不过就我个人而言,我喜欢这个版本的默认主题。这是我第一次在Ubuntu发行版中使用默认的图标和主题。
|
||||
|
||||
#### 安装 Ubuntu 之后你会做什么?
|
||||
|
||||
如果你是Ubuntu的初学者,我建议你[阅读这一系列Ubuntu教程][48]开始学习。
|
||||
|
||||
这就是我的建议。安装Ubuntu之后你要做什么?分享你最喜欢的东西,我可能根据你的建议来更新这篇文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/things-to-do-after-installing-ubuntu-20-04/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/ubuntu-20-04-release-features/
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/things-to-do-after-installing-ubuntu-20-04.jpg?ssl=1
|
||||
[3]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[4]: https://itsfoss.com/find-desktop-environment/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/software-updater-ubuntu-20-04.jpg?ssl=1
|
||||
[6]: https://itsfoss.com/ubuntu-repositories/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/software-updates-settings-ubuntu-20-04.jpg?ssl=1
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/extra-repositories-ubuntu-20.jpg?ssl=1
|
||||
[9]: https://itsfoss.com/install-media-codecs-ubuntu/
|
||||
[10]: https://itsfoss.com/install-microsoft-fonts-ubuntu/
|
||||
[11]: https://ubuntu-restricted-extras/
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/installing_ubuntu_restricted_extras.jpg?ssl=1
|
||||
[13]: https://itsfoss.com/remove-install-software-ubuntu/
|
||||
[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/software-center-ubuntu-20.png?resize=800%2C509&ssl=1
|
||||
[15]: https://itsfoss.com/best-ubuntu-apps/
|
||||
[16]: https://itsfoss.com/install-chrome-ubuntu/
|
||||
[17]: https://itsfoss.com/linux-gaming-guide/
|
||||
[18]: https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[19]: https://itsfoss.com/steam-play/
|
||||
[20]: https://github.com/FeralInteractive/gamemode
|
||||
[21]: https://en.wikipedia.org/wiki/Rise_of_the_Tomb_Raider
|
||||
[22]: https://itsfoss.com/could-not-get-lock-error/
|
||||
[23]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/auto-updates-ubuntu.png?resize=800%2C361&ssl=1
|
||||
[24]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/power-settings-ubuntu-20-04.png?fit=800%2C591&ssl=1
|
||||
[25]: https://www.youtube.com/watch?v=lpq8pm_xkSE
|
||||
[26]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/enable-dark-theme-ubuntu.png?ssl=1
|
||||
[27]: https://itsfoss.com/dark-mode-ubuntu/
|
||||
[28]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/disable-dock-ubuntu-20-04.png?ssl=1
|
||||
[29]: https://en.wikipedia.org/wiki/List_of_Unicode_characters
|
||||
[30]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/emoji-ubuntu.jpg?ssl=1
|
||||
[31]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/emojis-desktop-search-ubuntu.jpg?ssl=1
|
||||
[32]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/ubuntu-desktop-search-1.jpg?ssl=1
|
||||
[33]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/quick-calculations-ubuntu-search.jpg?ssl=1
|
||||
[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/search-settings-control-ubuntu.png?resize=800%2C534&ssl=1
|
||||
[35]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/nightlight-ubuntu-20-04.png?ssl=1
|
||||
[36]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/fractional-scaling-ubuntu.jpg?ssl=1
|
||||
[37]: https://itsfoss.com/gnome-shell-extensions/
|
||||
[38]: https://itsfoss.com/best-gnome-extensions/
|
||||
[39]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/weather-extension-ubuntu.jpg?ssl=1
|
||||
[40]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/03/do-not-distrub-option-ubuntu-20-04.png?ssl=1
|
||||
[41]: https://itsfoss.com/free-up-space-ubuntu-linux/
|
||||
[42]: https://itsfoss.com/gnome-tweak-tool/
|
||||
[43]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/gnome-tweaks-tool-ubuntu-20-04.png?fit=800%2C551&ssl=1
|
||||
[44]: https://itsfoss.com/display-battery-ubuntu/
|
||||
[45]: https://itsfoss.com/fix-right-click-touchpad-ubuntu/
|
||||
[46]: https://itsfoss.com/gnome-tricks-ubuntu/
|
||||
[47]: https://itsfoss.com/install-themes-ubuntu/
|
||||
[48]: https://itsfoss.com/getting-started-with-ubuntu/
|
||||
@ -0,0 +1,79 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The life-changing magic of git rebase -i)
|
||||
[#]: via: (https://opensource.com/article/20/4/git-rebase-i)
|
||||
[#]: author: (Dave Neary https://opensource.com/users/dneary)
|
||||
|
||||
完美生活:git rebase -i
|
||||
======
|
||||
|
||||
> 让大家觉得你一次就能写出完美的代码,并让你的补丁更容易审核和合并。
|
||||
|
||||
![Hands programming][1]
|
||||
|
||||
软件开发是混乱的。有很多错误的转折、有需要修复的错别字、有需要修正的错误、有需要稍后纠正临时和粗陋的代码,还有在开发过程中以后发现的错位问题。有了版本控制,在创建“完美”的最终产品(即准备提交给上游的补丁)的过程中,你会有一个记录着每一个错误的转折和修正的原始记录。就像电影中的片段一样,它们有些尴尬,有时还很有趣。就像电影中的花絮一样,它们会让人有点尴尬,有时也会让人觉得好笑。
|
||||
|
||||
如果你能使用版本控制来定期保存你的工作线索,然后当你准备提交审核的东西时,可以隐藏所有这些私人草稿工作,只需提交一份单一的、完美的补丁就可以了,那不是很好吗?`git rebase -i`,是重写历史记录的完美方法,可以让大家觉得你一次就写出了完美的代码。
|
||||
|
||||
### git rebase 的作用是什么?
|
||||
|
||||
如果你不熟悉 Git 的复杂性,这里简单介绍一下。在幕后,Git 将项目的不同版本与唯一标识符关联起来,这个标识符由父节点的唯一标识符的哈希以及新版本与其父节点的差异组成。这样就形成了一棵修订树,每个检出项目的人都会得到自己的副本。不同的人可以把项目往不同的方向发展,每个人的出发点都可能是不同的分支点。
|
||||
|
||||
![Master branch vs. private branch][2]
|
||||
|
||||
*左边是 `origin` 版本库中的主分支,右边是你个人副本中的私有分支。*
|
||||
|
||||
有两种方法可以将你的工作与原始版本库中的主分支整合起来:一种是使用 合并:`git merge`,另一种是使用变基:`git rebase`。它们的工作方式非常不同。
|
||||
|
||||
当你使用 `git merge` 时,会在主分支上创建一个新的提交,其中包括所有来自 `origin` 的修改和所有本地的修改。如果有任何冲突(例如,如果别人修改了你也在修改的文件),则将这些冲突标记出来,并且你有机会在将该“合并提交”提交到本地版本库之前解决这些冲突。当你将更改推送回父版本库时,所有的本地工作都会以分支的形式出现在 Git 仓库的其他用户面前。
|
||||
|
||||
但是 `git rebase` 的工作方式不同。它回滚你的提交,并从主分支的顶端再次重放这些提交。这导致了两个主要的变化。首先,由于你的提交现在从一个不同的父节点分支出来,它们的哈希值会被重新计算,并且任何克隆了你的仓库的人都可能会有一个残破的仓库副本。第二,你没有一个合并提交,所以在将更改重放到主分支上时会识别出任何合并冲突,所以任何合并冲突都会被识别出来,因此,你需要在进行<ruby>变基<rt>rebase</rt></ruby>之前修复它们。当你现在推送你的修改时,你的工作不会出现在分支上,并且看起来像是你把所有的修改都写到了主分支的最新的提交上。
|
||||
|
||||
![Merge commits preserve history, and rebase rewrites history.][3]
|
||||
|
||||
*合并提交(左)保留了历史,而变基(右)重写历史。*
|
||||
|
||||
然而,这两种方式都有一个坏处:在你准备好分享代码之前,每个人都可以看到你在本地处理问题时的所有涂鸦和编辑。这就是 `git rebase` 的 `--interactive`(或简写 `-i`)标志的作用。
|
||||
|
||||
### 介绍 git rebase -i
|
||||
|
||||
`git rebase` 的最大优点是它重写了历史。但是,为什么仅止于假装你从后面的点分支出来呢?有一种更进一步方法可以重写你是如何准备就绪这些代码的:`git rebase -i`,交互式的 `git rebase`。
|
||||
|
||||
这个功能就是 Git 中的 "神奇的时间机器” 功能。这个标志允许你在做变基时对修订历史记录进行复杂的修改。你可以隐藏你的错误! 将许多小的修改合并到一个原始的功能补丁中! 重新排序修改历史记录中的内容
|
||||
|
||||
![output of git rebase -i][4]
|
||||
|
||||
当你运行 `git rebase -i` 时,你会得到一个编辑器会话,其中列出了所有正在被变基的提交,并有一些选项可以对它们做什么。默认的选择是 `pick`。
|
||||
|
||||
* `Pick`:会在你的历史记录中保留该提交。
|
||||
* `Reword`:允许你修改提交信息,可能是修复一个错别字或添加额外的注释。
|
||||
* `Edit`:允许你在重放分支的过程中对提交进行修改。
|
||||
* `Squash`:可以将多个提交合并为一个。
|
||||
* 你可以通过移动文件中的提交来重新排序。
|
||||
|
||||
当你完成后,只需保存最终结果,变基就会执行。在每个阶段,当你选择了修改提交(无论是用 `reword`、`edit`、`squash` 还是有冲突时),变基会停止,并允许你在继续提交之前进行适当的修改。
|
||||
|
||||
上面这个例子的结果是 “One-liner bug fix” 和 “Integate new header everywhere” 被合并到一个提交中,而 “New header for docs website” 和 “D'oh - typo. Fixed” 合并到另一个提交中。就像变魔术一样,其他提交的工作还在你的分支中,但相关的提交已经从你的历史记录中消失了!这样一来,你就可以很容易地提交干净的提交。
|
||||
|
||||
这使得使用 `git send-email` 或者用你新整理好的补丁集在父版本库中创建一个拉取请求来提交一个干净的补丁给上游项目变得很容易。这有很多好处,包括让你的代码更容易审核,更容易接受,也更容易合并。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/git-rebase-i
|
||||
|
||||
作者:[Dave Neary][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dneary
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop.png?itok=pGfEfu2S (Hands programming)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/master-private-branches.png (Master branch vs. private branch)
|
||||
[3]: https://opensource.com/sites/default/files/uploads/merge-commit-vs-rebase.png (Merge commits preserve history, and rebase rewrites history.)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/git-rebase-i.png (output of git rebase -i)
|
||||
@ -1,159 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Three Methods Boot CentOS/RHEL 7/8 Systems in Single User Mode)
|
||||
[#]: via: (https://www.2daygeek.com/boot-centos-7-8-rhel-7-8-single-user-mode/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
在单用户模式下启动 CentOS/RHEL 7/8 的三种方法
|
||||
======
|
||||
|
||||
单用户模式,也被称为维护模式,超级用户可以在此模式下恢复/修复系统问题。
|
||||
|
||||
通常情况下,这些问题在多用户环境中修复不了。系统可以启动但功能不能正常运行或者你登录不了系统。
|
||||
|
||||
在基于 **[Red Hat][1]** (RHEL) 7/8 的系统中,使用 `runlevel1.target` 或 `rescue.target` 来实现。
|
||||
|
||||
在此模式下,系统会挂载所有的本地文件系统,但不开启网络接口。
|
||||
|
||||
系统仅启动特定的几个服务和修复系统必要的尽可能少的功能。
|
||||
|
||||
当你想运行文件系统一致性检查来修复损坏的文件系统,或忘记 root 密码后重置密码,或修复系统上的一个挂载点问题时,这个方法会很有用。
|
||||
|
||||
你可以用下面三种方法以单用户模式启动 **[CentOS][2]**/**[RHEL][3]** 7/8 系统。
|
||||
|
||||
* **方法 1:** 通过向内核添加 “rd.break” 参数来以单用户模式启动 CentOS/RHEL 7/8 系统
|
||||
* **方法 2:** 通过用 “init=/bin/bash“ 或 ”init=/bin/sh” 替换内核中的 “rhgb quiet” 语句来以单用户模式启动 CentOS/RHEL 7/8 系统
|
||||
* **方法 3:** 通过用 “rw init=/sysroot/bin/sh” 参数替换内核中的 “ro” 语句以单用户模式启动 CentOS/RHEL 7/8 系统
|
||||
|
||||
|
||||
|
||||
### 方法 1: 通过向内核添加 “rd.break” 参数来以单用户模式启动 CentOS/RHEL 7/8 系统
|
||||
|
||||
重启你的系统,在 GRUB2 启动界面,按下 `e` 键来编辑选中的内核。你需要选中第一行,第一个是最新的内核,然而如果你想用旧的内核启动系统你也可以选择其他的行。
|
||||
|
||||
![][4]
|
||||
|
||||
根据你的 RHEL/CentOS 版本,找到 **“linux16”** 或 **“linux”** 语句,按下键盘上的 ”End“ 按钮,跳到行末,像下面截图中展示的那样添加关键词 **“rd.break”**,按下 **“Ctrl+x”** 或 **“F10”** 来进入单用户模式。
|
||||
|
||||
如果你的系统是 RHEL/CentOS 7,你需要找 **`linux16`**,如果你的系统是 RHEL/CentOS 8,那么你需要找 **`linux`**。
|
||||
|
||||
![][4]
|
||||
|
||||
这个修改会让你的 root 文件系统以 **“只读 (RO)”** 模式挂载。你可以用下面的命令来验证下。下面的输出也明确地告诉你当前是在 **“紧急模式”**。
|
||||
|
||||
```
|
||||
# mount | grep root
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
为了修改 **“sysroot”** 文件系统,你需要用 RW 模式重新挂载它。
|
||||
|
||||
```
|
||||
# mount -o remount,rw /sysroot
|
||||
```
|
||||
|
||||
运行下面的命令修改环境,这就是大家熟知的 “jailed directory” 或 “chroot jail”。
|
||||
|
||||
```
|
||||
# chroot /sysroot
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
现在,单用户模式的前期准备已经完成了。当你修复了你的问题要退出单用户模式时,执行下面的步骤。
|
||||
|
||||
CentOS/RHEL 7/8 默认使用 SELinux,因此创建下面的隐藏文件,这个文件会在下一次启动时重新确认所有文件。
|
||||
|
||||
```
|
||||
# touch /.autorelabel
|
||||
```
|
||||
|
||||
最后,用下面的命令重启系统。你也可以输入两次 “exit” 命令来重启你的系统。
|
||||
|
||||
```
|
||||
# reboot -f
|
||||
```
|
||||
|
||||
### 方法 2: 通过用 “init=/bin/bash“ 或 ”init=/bin/sh” 替换内核中的 “rhgb quiet” 语句来以单用户模式启动 CentOS/RHEL 7/8 系统
|
||||
|
||||
重启你的系统,在 GRUB2 启动界面,按下 `e` 键来编辑选中的内核。
|
||||
|
||||
![][4]
|
||||
|
||||
找到语句 **“rhgb quiet”**,用 **“init=/bin/bash”** 或 **“init=/bin/sh”** 替换它,然后按下 **“Ctrl+x”** 或 **“F10”** 来进入单用户模式。
|
||||
|
||||
**`init=/bin/bash`** 的截图。
|
||||
|
||||
![][4]
|
||||
|
||||
**`init=/bin/sh`** 的截图。
|
||||
|
||||
![][4]
|
||||
|
||||
默认情况下,上面的操作会以只读(RO)模式挂载你的 “/” 分区,因此你需要以读写(RW)模式重新挂载 “/” 文件系统,这样才能修改它。
|
||||
|
||||
```
|
||||
# mount -o remount,rw /
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
现在你可以执行你的任务了。当结束时,执行下面的命令来开启重启时的 SELinux 重新确认。
|
||||
|
||||
```
|
||||
# touch /.autorelabel
|
||||
```
|
||||
|
||||
最后,重启系统。
|
||||
|
||||
```
|
||||
# exec /sbin/init 6
|
||||
```
|
||||
|
||||
### 方法 3: 通过用 “rw init=/sysroot/bin/sh” 参数替换内核中的 “ro” 语句以单用户模式启动 CentOS/RHEL 7/8 系统
|
||||
|
||||
为了中断自动启动的过程,重启你的系统并在 GRUB2 启动界面按下任意键。
|
||||
|
||||
现在会展示你系统上所有可用的内核,选择最新的内核,按下 `e` 键来编辑选中的内核参数。
|
||||
|
||||
找到以 **“linux”** 或 **“linux16”** 开头的语句,用 **“rw init=/sysroot/bin/sh”** 替换 **“ro”**。替换完后按下 **“Ctrl+x”** 或 **“F10”** 来进入单用户模式。
|
||||
|
||||
运行下面的命令把环境切换为 “chroot jail”。
|
||||
|
||||
```
|
||||
# chroot /sysroot
|
||||
```
|
||||
|
||||
如果需要,做出必要的修改。修改完后,执行下面的命令来开启重启时的 SELinux 重新确认。
|
||||
|
||||
```
|
||||
# touch /.autorelabel
|
||||
```
|
||||
|
||||
最后,重启系统。
|
||||
|
||||
```
|
||||
# reboot -f
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/boot-centos-7-8-rhel-7-8-single-user-mode/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/red-hat/
|
||||
[2]: https://www.2daygeek.com/category/centos/
|
||||
[3]: https://www.2daygeek.com/category/rhel/
|
||||
[4]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
@ -0,0 +1,209 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Managing Git projects with submodules and subtrees)
|
||||
[#]: via: (https://opensource.com/article/20/5/git-submodules-subtrees)
|
||||
[#]: author: (Manaswini Das https://opensource.com/users/manaswinidas)
|
||||
|
||||
使用子模块和子仓库管理 Git 项目
|
||||
======
|
||||
使用子模块和子仓库来帮助你管理多个仓库中共有的子项目。
|
||||
![Digital creative of a browser on the internet][1]
|
||||
|
||||
如果你参与了开源项目的开发,那么你可能会用 Git 来管理你的源码。你可能遇到过有很多依赖和/或子项目的项目。你怎么管理它们?
|
||||
|
||||
对于一个开源组织,社区*和*产品想要实现单一来源文档和依赖管理比较棘手。文档和项目往往会碎片化和变得冗余,这致使它们很难维护。
|
||||
|
||||
### 必要性
|
||||
|
||||
假设你想要在一个仓库中把一个项目作为子项目来用。传统的方法是把该项目复制到父仓库中。但是,如果你想要在多个父项目中用同一个子项目呢?(如果)把子项目复制到所有父项目中,当有更新时,你不得不在每个父项目中都做修改,这是不太可行的。(因为)这会导致父项目中的冗余和数据不一致,也会使更新和维护子项目变得很困难。
|
||||
|
||||
### Git 子模块和子仓库
|
||||
|
||||
如果你可以用一条命令把一个项目放进另一个项目中,会怎样呢?如果你随时可以把一个项目作为子项目添加到任意数目的项目中,并可以同步更新修改呢?Git 提供了这类问题的解决方案:Git 子模块和 Git 子仓库。创建这些工具的目的是以更加模块化的水平来支持共用代码的开发工作流,(创建者)意在消除 Git 仓库<ruby>源码管理<rt>source-code management</rt></ruby>与它下面的子仓库间的障碍。
|
||||
|
||||
![Cherry tree growing on a mulberry tree][2]
|
||||
|
||||
生长在桑树上的樱桃树
|
||||
|
||||
下面是本文要详细介绍的概念的一个真实应用场景。如果你已经很熟悉 tree,这个模型看起来是下面这样:
|
||||
|
||||
![Tree with subtrees][3]
|
||||
|
||||
CC BY-SA opensource.com
|
||||
|
||||
### Git 子模块是什么?
|
||||
|
||||
Git 在它默认的包中提供了子模块,子模块可以把 Git 仓库嵌入到其他仓库中。确切地说,Git 子模块是指向子仓库中的某次提交。下面是我 [Docs-test][4] GitHub 仓库中的 Git 子模块:
|
||||
|
||||
![Git submodules screenshot][5]
|
||||
|
||||
**[文件夹@提交 Id][6]** 格式表明这个仓库是一个子模块,你可以直接点击文件夹进入该子仓库。名为 **.gitmodules** 的配置文件包含所有子模块仓库的详细信息。我的仓库的 **.gitmodules** 文件如下:
|
||||
|
||||
![Screenshot of .gitmodules file][7]
|
||||
|
||||
你可以用下面的命令在你的仓库中使用 Git 子模块:
|
||||
|
||||
#### 克隆一个仓库并加载子模块
|
||||
|
||||
克隆一个含有子模块的仓库:
|
||||
|
||||
|
||||
```
|
||||
`$ git clone --recursive <URL to Git repo>`
|
||||
```
|
||||
|
||||
如果你之前已经克隆了仓库,现在想加载它的子模块:
|
||||
|
||||
|
||||
```
|
||||
`$ git submodule update --init`
|
||||
```
|
||||
|
||||
如果有嵌套的子模块:
|
||||
|
||||
|
||||
```
|
||||
`$ git submodule update --init --recursive`
|
||||
```
|
||||
|
||||
#### 下载子模块
|
||||
|
||||
串行地连续下载多个子模块是很枯燥的工作,所以 **clone** 和 **submodule update** 会支持 **\--jobs** 或 **-j** 参数:
|
||||
|
||||
例如,想一次下载 8 个子模块,使用:
|
||||
|
||||
|
||||
```
|
||||
$ git submodule update --init --recursive -j 8
|
||||
$ git clone --recursive --jobs 8 <URL to Git repo>
|
||||
```
|
||||
|
||||
#### 拉取子模块
|
||||
|
||||
在运行或构建父项目之前,你需要确保依赖的子项目都是最新的。
|
||||
|
||||
拉取子模块的所有修改:
|
||||
|
||||
|
||||
```
|
||||
`$ git submodule update --remote`
|
||||
```
|
||||
|
||||
#### 使用 submodule 创建仓库:
|
||||
|
||||
向一个父仓库添加子仓库:
|
||||
|
||||
|
||||
```
|
||||
`$ git submodule add <URL to Git repo>`
|
||||
```
|
||||
|
||||
初始化一个已存在的 Git 子模块:
|
||||
|
||||
|
||||
```
|
||||
`$ git submodule init`
|
||||
```
|
||||
|
||||
你也可以通过为 **submodule update** 命令添加 **\--update** 参数在子模块中创建分支和追踪提交:
|
||||
|
||||
|
||||
```
|
||||
`$ git submodule update --remote`
|
||||
```
|
||||
|
||||
#### 更新子模块提交
|
||||
|
||||
上面提到过,一个子模块就是一个指向子仓库中某次提交的链接。如果你想更新子模块的提交,不要担心。你不需要显式地指定最新的提交。你只需要使用通用的 **submodule update** 命令:
|
||||
|
||||
|
||||
```
|
||||
`$ git submodule update`
|
||||
```
|
||||
|
||||
就像你平时创建父仓库和把父仓库推送到 GitHub 那样添加和提交就可以了。
|
||||
|
||||
#### 从一个父仓库中删除一个子模块
|
||||
|
||||
仅仅手动删除一个子项目文件夹不会从父项目中移除这个子项目。想要删除名为 **childmodule** 的子模块,使用:
|
||||
|
||||
|
||||
```
|
||||
`$ git rm -f childmodule`
|
||||
```
|
||||
|
||||
虽然 Git 子模块看起来很容易上手,但是对于初学者来说,有一定的使用门槛。
|
||||
|
||||
### Git 子仓库是什么?
|
||||
|
||||
Git 子仓库,是在 Git 1.7.11 引入的,让你可以把任何仓库的副本作为子目录嵌入另一个仓库中。它是 Git 项目可以注入和管理项目依赖的几种方法之一。它在常规的提交中保存了外部依赖信息。Git 子仓库提供了整洁的集成点,因此很容易复原它们。
|
||||
|
||||
如果你参考 [GitHub 提供的子仓库教程][8] 来使用子仓库,那么无论你什么时候添加子仓库,在本地都不会看到 **.gittrees** 配置文件。这让我们很难分辨哪个是子仓库,因为它们看起来很像普通的文件夹,但是它们却是子仓库的副本。默认的 Git 包中不提供带 **.gittrees** 配置文件的 Git 子仓库版本,因此如果你想要带 **.gittrees** 配置文件的 git-subtree,必须从 Git 源码仓库的 [**/contrib/subtree** 文件夹][9] 下载 git-subtree。
|
||||
|
||||
你可以像克隆其他常规的仓库那样克隆任何含有子仓库的仓库,但由于在父仓库中有整个子仓库的副本,因此克隆过程可能会持续很长时间。
|
||||
|
||||
你可以用下面的命令在你的仓库中使用 Git 子仓库。
|
||||
|
||||
#### 向父仓库中添加一个子仓库
|
||||
|
||||
想要向父仓库中添加一个子仓库,首先你需要执行 **remote add**,之后执行 **subtree add** 命令:
|
||||
|
||||
|
||||
```
|
||||
$ git remote add remote-name <URL to Git repo>
|
||||
$ git subtree add --prefix=folder/ remote-name <URL to Git repo> subtree-branchname
|
||||
```
|
||||
|
||||
上面的命令会把整个子项目的提交历史合并到父仓库。
|
||||
|
||||
#### 向子仓库推送修改以及从子仓库拉取修改
|
||||
|
||||
|
||||
```
|
||||
`$ git subtree push-all`
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
|
||||
```
|
||||
`$ git subtree pull-all`
|
||||
```
|
||||
|
||||
### 你应该使用哪个?
|
||||
|
||||
任何工具都有优缺点。下面是一些可能会帮助你决定哪种最适合你的特性:
|
||||
|
||||
* Git 子模块的仓库占用空间更小,因为它们只是指向子项目的某次提交的链接,而 Git 子仓库保存了整个子项目及其提交历史。
|
||||
* Git 子模块需要在服务器中可访问,但子仓库是去中心化的。
|
||||
* Git 子模块大量用于基于组件的开发,而 Git 子仓库多用于基于系统的开发。
|
||||
|
||||
Git 子仓库并不是 Git 子模块的直接可替代项。有明确的说明来指导我们该使用哪种。如果有一个归属于你的外部仓库,使用场景是向它回推代码,那么就使用 Git 子模块,因为推送代码更容易。如果你有第三方代码,且不会向它推送代码,那么使用 Git 子仓库,因为拉取代码更容易。
|
||||
|
||||
自己尝试使用 Git 子仓库和子模块,然后在评论中留下你的使用感想。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/git-submodules-subtrees
|
||||
|
||||
作者:[Manaswini Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/manaswinidas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_web_internet_website.png?itok=g5B_Bw62 (Digital creative of a browser on the internet)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/640px-bialbero_di_casorzo.jpg (Cherry tree growing on a mulberry tree)
|
||||
[3]: https://opensource.com/sites/default/files/subtree_0.png (Tree with subtrees)
|
||||
[4]: https://github.com/manaswinidas/Docs-test/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/git-submodules_github.png (Git submodules screenshot)
|
||||
[6]: mailto:folder@commitId
|
||||
[7]: https://opensource.com/sites/default/files/uploads/gitmodules.png (Screenshot of .gitmodules file)
|
||||
[8]: https://help.github.com/en/github/using-git/about-git-subtree-merges
|
||||
[9]: https://github.com/git/git/tree/master/contrib/subtree
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Ubuntu Studio To Replace Xfce With KDE Plasma Desktop Environment)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-studio-opts-for-kde/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Ubuntu Studio 将用 KDE Plasma 桌面环境替换 Xfce
|
||||
======
|
||||
|
||||
[Ubuntu Studio][1] 是一个流行的 [Ubuntu 官方变种][2],它是为从事音频制作、视频、图形、摄影和书籍出版的创意内容创建者量身定制的。它提供了许多拥有良好体验的开箱即用的多媒体内容创建应用。
|
||||
|
||||
在最近的 20.04 LTS 版本发布之后,Ubuntu Studio 团队在其[官方公告][3]中强调了一些非常重要的内容。而且,也许不是每个人都注意到关键信息,即 Ubuntu Studio 的未来。
|
||||
|
||||
Ubuntu Studio 20.04 将是带有 [Xfce 桌面环境][4]的最后一个版本。将来的所有发行版都将改用 [KDE Plasma][5]。
|
||||
|
||||
### 为什么 Ubuntu Studio 放弃 XFCE?
|
||||
|
||||
![][6]
|
||||
|
||||
据他们的澄清,Ubuntu Studio 并不致力于任何特定的外观,而是致力于提供最佳的用户体验。同时,KDE 被证明是一个更好的选择。
|
||||
|
||||
> Plasma 已被证明为图形艺术家和摄影师提供了更好的工具,例如在 Gwenview、Krita 甚至文件管理器 Dolphin 中都可以看到。此外,它对 Wacom 平板的支持比其他任何桌面环境都更好。
|
||||
|
||||
> 它已经变得不错,以至于大多数 Ubuntu Studio 团队现在都使用 Kubuntu,并通过 Ubuntu Studio Installer 将 Ubuntu Studio 作为日常附加驱动使用。由于我们中的许多人都在使用 Plasma,因此在我们的下一个版本中过渡到 Plasma 的时机似乎是正确的。
|
||||
|
||||
当然,每个桌面环境都针对不同的内容进行了量身定制。他们认为 KDE Plasma 将是取代 XFCE 的最适合的桌面环境,从而为所有用户提供更好的用户体验。
|
||||
|
||||
尽管我不确定用户对此会有何反应,因为每个用户都有不同的偏好。如果现有用户对 KDE 没有问题,那就没什么大不了的。
|
||||
|
||||
值得注意的是,Ubuntu Studio 还提到了为什么 KDE 可能是它们的更好选择:
|
||||
|
||||
>在没有 Akonadi 的情况下,Plasma 桌面环境的资源使用与 Xfce 一样轻,甚至更轻。Fedora Jam 和 KXStudio 等其他以音频为重点的 Linux 发行版在历史上一直使用 KDE Plasma 桌面环境,并且在音频方面做得很好。
|
||||
|
||||
此外,他们还强调了[福布斯杂志中 Jason Evangelho 的文章][7],其中一些基准测试表明 KDE 几乎与 Xfce 一样轻。即使这是一个好征兆,我们仍然必须等待用户测试 KDE 驱动的 Ubuntu Studio。只有这样,我们才能观察 Ubuntu Studio 放弃 XFCE 桌面环境的决定是否正确。
|
||||
|
||||
### 更改后,Ubuntu Studio 用户将发生什么变化?
|
||||
|
||||
在带 KDE 的 Ubuntu Studio 20.10 及更高版本上可能会影响(或改进)整个工作流程。
|
||||
|
||||
但是,升级过程(从 20.04 到 20.10)将导致系统损坏。因此,全新安装 Ubuntu Studio 20.10 或更高版本将是唯一的方法。
|
||||
|
||||
他们还提到,他们将不断评估与预安装的应用是否存在重复。因此,我相信在接下来的几天中将会有更多细节。
|
||||
|
||||
Ubuntu Studio 是最近第二个切换它主要桌面环境的发行版。先前,[Lubuntu] [8] 从 LXDE 切换到 LXQt。
|
||||
|
||||
你如何看待这种变化?欢迎在下面的评论中分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-studio-opts-for-kde/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://ubuntustudio.org/
|
||||
[2]: https://itsfoss.com/which-ubuntu-install/
|
||||
[3]: https://ubuntustudio.org/2020/04/ubuntu-studio-20-04-lts-released/
|
||||
[4]: https://xfce.org
|
||||
[5]: https://kde.org/plasma-desktop
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/05/ubuntu-studio-kde-xfce.jpg?ssl=1
|
||||
[7]: https://www.forbes.com/sites/jasonevangelho/2019/10/23/bold-prediction-kde-will-steal-the-lightweight-linux-desktop-crown-in-2020
|
||||
[8]: https://itsfoss.com/lubuntu-20-04-review/
|
||||
@ -0,0 +1,112 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Fixing “Unable to parse package file /var/lib/apt/lists” Error in Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/unable-to-parse-package-file/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
修复 Ubuntu 和其他 Linux 发行版中的 “Unable to parse package file /var/lib/apt/lists” 错误
|
||||
======
|
||||
|
||||
过去,我已经讨论了许多 [Ubuntu 更新错误][1]。如果你[使用命令行更新 Ubuntu][2],那可能会遇到一些“错误”。
|
||||
|
||||
其中一些“错误”基本上是内置功能,可防止对系统进行不必要的更改。在本教程中,我不会涉及那些细节。
|
||||
|
||||
在本文中,我将向你展示如何解决在更新系统或安装新软件时可能遇到的以下错误:
|
||||
|
||||
**Reading package lists… Error!
|
||||
E: Unable to parse package file /var/lib/apt/lists/archive.ubuntu.com_ubuntu_dists_bionic_InRelease
|
||||
E: The package lists or status file could not be parsed or opened.**
|
||||
|
||||
在 Debian 中可能会遇到类似的错误:
|
||||
|
||||
**E: Unable to parse package file /var/lib/apt/extended_states (1)**
|
||||
|
||||
即使遇到 “**The package cache file is corrupted**” 也完全不必惊慌。这真的很容易“修复”。
|
||||
|
||||
### 在基于 Ubuntu 和 Debian 的 Linux 发行版中处理 “Unable to parse package file” 错误
|
||||
|
||||
![][3]
|
||||
|
||||
以下是你需要做的。仔细查看 [Ubuntu][4] 报错文件的名称和路径。
|
||||
|
||||
Reading package lists… Error!
|
||||
**E: Unable to parse package file /var/lib/apt/lists/archive.ubuntu.com_ubuntu_dists_bionic_InRelease**
|
||||
E: The package lists or status file could not be parsed or opened.
|
||||
|
||||
例如,上面的错误是在报 /var/lib/apt/lists/archive.ubuntu.com_ubuntu_dists_bionic_InRelease 文件错误。
|
||||
|
||||
这让你想到这个文件不正确。现在,你需要做的就是删除该文件并重新生成缓存。
|
||||
|
||||
```
|
||||
sudo rm <file_that_is_not_parsed>
|
||||
```
|
||||
|
||||
因此,这里我可以使用以下命令:**sudo rm /var/lib/apt/lists/archive.ubuntu.com_ubuntu_dists_bionic_InRelease**,然后使用 sudo apt update 命令重建缓存。
|
||||
|
||||
#### 给初学者的分步指导
|
||||
|
||||
如果你熟悉 Linux 命令,那么可能知道如何使用绝对路径删除文件。对于新手用户,让我指导你安全删除文件。
|
||||
|
||||
首先,你应该进入文件目录:
|
||||
|
||||
```
|
||||
cd /var/lib/apt/lists/
|
||||
```
|
||||
|
||||
现在删除无法解析的文件:
|
||||
|
||||
```
|
||||
sudo rm archive.ubuntu.com_ubuntu_dists_bionic_InRelease
|
||||
```
|
||||
|
||||
现在,如果你再次运行更新,将重新生成 apt 缓存。
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
#### 有很多文件无法解析?
|
||||
|
||||
如果你在更新系统时有一个或两个文件无法解析,那么问题不大。但是,如果系统报错有十个或二十个此类文件,那么一一删除它们就太累了。
|
||||
|
||||
在这种情况下,你可以执行以下操作来删除整个缓存,然后再次生成它:
|
||||
|
||||
```
|
||||
sudo rm -r /var/lib/apt/lists/*
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
#### 解释这为何能解决问题
|
||||
|
||||
/var/lib/apt 是与 apt 软件包管理器相关的文件和数据的存储目录。/var/lib/apt/lists 是用于保存系统 source.list 中指定的每个软件包资源信息的目录。
|
||||
|
||||
简单点来说,/var/lib/apt/lists 保存软件包信息缓存。当你要安装或更新程序时,系统会在此目录中检查该软件包中的信息。如果找到了该包的详细信息,那么它将进入远程仓库并实际下载程序或其更新。
|
||||
|
||||
当你运行 “sudo apt update” 时,它将构建缓存。这就是为什么即使删除 /var/lib/apt/lists 目录中的所有内容,运行更新也会建立新的缓存的原因。
|
||||
|
||||
这就是处理文件无法解析问题的方式。你的系统报某个软件包或仓库信息以某种方式损坏(下载失败或手动更改 sources.list)。删除该文件(或所有文件)并重建缓存即可解决此问题。
|
||||
|
||||
#### 仍然有错误?
|
||||
|
||||
这应该能解决你的问题。但是,如果问题仍然存在,或者你还有其他相关问题,请在评论栏告诉我,我将尽力帮助你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/unable-to-parse-package-file/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/ubuntu-update-error/
|
||||
[2]: https://itsfoss.com/update-ubuntu/
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/05/Unable-to-parse-package-file.png?ssl=1
|
||||
[4]: https://ubuntu.com/
|
||||
@ -0,0 +1,164 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Ensmallening Go binaries by prohibiting comparisons)
|
||||
[#]: via: (https://dave.cheney.net/2020/05/09/ensmallening-go-binaries-by-prohibiting-comparisons)
|
||||
[#]: author: (Dave Cheney https://dave.cheney.net/author/davecheney)
|
||||
|
||||
通过禁止比较让 Go 二进制文件变小
|
||||
======
|
||||
|
||||
大家常规的认知是,Go 程序中声明的类型越多,生成的二进制文件就越大。这个符合直觉,毕竟如果你写的代码不去操作定义的类型,那么定义一堆类型就没有意义了。然而,链接器的部分工作就是检测程序没有引用的函数,比如仅仅有某个功能的子功能使用的库中的某些函数,然后把他们从最后的编译产出中删除。常言道,“类型越多,二进制文件越大“,对于多数 Go 程序还是正确的。
|
||||
|
||||
本文中我会深入讲解在 Go 程序的上下文中相等的意义,以及为什么[像这样][1]的修改会对 Go 程序的大小有重大的影响。
|
||||
|
||||
### 定义两个值相等
|
||||
|
||||
Go 的语法定义了赋值和相等的概念。赋值是把一个值赋给一个标识符的行为。并不是所有声明的标识符都可以被赋值,如常量和函数就不可以。相等是通过检查标识符的内容是否相等来比较两个标识符的行为。
|
||||
|
||||
作为强类型语言,“相同”的概念从根源上被植入标识符的类型中。两个标识符只有是相同类型的前提下,才有可能相同。除此之外,值的类型定义了如何比较该类型的两个值。
|
||||
|
||||
例如,整型是用算数方法进行比较的。对于指针类型,是否相等是指他们指向的地址是否相同。map 和 channel 等引用类型,跟指针类似,如果它们有相同的地址,那么就认为它们是相同的。
|
||||
|
||||
上面都是按位比较相等的例子,即值占用的位模式内存是相同的,那么这些值就相等。这个就是 memcmp,全称为 memory comparison,相等是通过比较两个内存区域的内容来定义的。
|
||||
|
||||
记住这个思路,我会很快回来的。
|
||||
|
||||
### 结构体相等
|
||||
|
||||
除了整型、浮点型和指针等标量类型,还有复合类型;结构体。所有的结构体以程序中的顺序被排列在内存中。因此下面这个声明
|
||||
|
||||
```
|
||||
type S struct {
|
||||
a, b, c, d int64
|
||||
}
|
||||
```
|
||||
|
||||
会占用 32 字节的内存空间;`a` 占用 8 个字节,`b` 占用 8 个字节,以此类推。Go 的规则说如果结构体所有的字段都是可以比较的,那么结构体的值就是可以比较的。因此如果两个结构体所有的字段都相等,那么它们就相等。
|
||||
|
||||
```
|
||||
a := S{1, 2, 3, 4}
|
||||
b := S{1, 2, 3, 4}
|
||||
fmt.Println(a == b) // prints true
|
||||
```
|
||||
|
||||
编译器在底层使用 memcmp 来比较 `a` 的 32 个字节和 `b` 的 32 个字节。
|
||||
|
||||
### 填充和对齐
|
||||
|
||||
然而,在下面的场景下过分简单化的按位比较的策略会返回错误的结果:
|
||||
|
||||
```
|
||||
type S struct {
|
||||
a byte
|
||||
b uint64
|
||||
c int16
|
||||
d uint32
|
||||
}
|
||||
|
||||
func main()
|
||||
a := S{1, 2, 3, 4}
|
||||
b := S{1, 2, 3, 4}
|
||||
fmt.Println(a == b) // prints true
|
||||
}
|
||||
```
|
||||
|
||||
编译代码后,这个比较表达式的结果还是 true,但是编译器在底层并不能仅依赖比较 `a` 和 `b` 的位模式,因为结构体有*填充*。
|
||||
|
||||
Go 要求结构体的所有字段都对齐。2 字节的值必须从偶数地址开始,4 字节的值必须从 4 的倍数地址开始,以此类推[1][2]。编译器根据字段的类型和底层平台加入了填充来确保字段都*对齐*。在填充之后,编译器实际上看到的是[2][3]:
|
||||
|
||||
```
|
||||
type S struct {
|
||||
a byte
|
||||
_ [7]byte // padding
|
||||
b uint64
|
||||
c int16
|
||||
_ [2]int16 // padding
|
||||
d uint32
|
||||
}
|
||||
```
|
||||
|
||||
填充的存在保证了字段正确对齐,而填充确实占用了内存空间,但是填充字节的内容是未知的。你可能会认为在 Go 中 填充字节都是 0,但实际上并不是 — 填充字节的内容是未定义的。由于它们并不是被定义为某个确定的值,因此按位比较会因为分布在 `s` 的 24 字节中的 9 个填充字节不一样而返回错误结果。
|
||||
|
||||
Go 通过生成相等函数来解决这个问题。在这个例子中,`s` 的相等函数只比较函数中的字段略过填充部分,这样就能正确比较类型 `s` 的两个值。
|
||||
|
||||
### 类型算法
|
||||
|
||||
嚄,需要做很多准备工作才能解释原因,对于 Go 程序中定义的每种类型,编译器都会生成几个支持它的函数,编译器内部把它们识别为类型的算法。如果类型是一个 map 的 key,那么除相等函数外,编译器还会生成一个哈希函数。为了维持稳定,哈希函数在计算结果时也会像相等函数一样考虑诸如填充等因素。
|
||||
|
||||
凭直觉判断编译器什么时候生成这些函数实际上很难,有时并不明显,(因为)这超出了你的预期,而且链接器也很难消除没有被使用的类型,因为反射往往导致链接器在裁剪类型时变得更保守。
|
||||
|
||||
### 通过禁止比较来减小二进制文件的大小
|
||||
|
||||
现在,我们能解释 Brad 的修改了。向类型添加一个不可比较的字段[3][4],结构体也随之变成不可比较的,从而强制编译器不再生成相等和哈希算法、规避了链接器对那些类型的消除、在实际应用中减小了生成的二进制文件的大小。作为这项技术的一个例子,下面的程序:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
type t struct {
|
||||
// _ [0][]byte uncomment to prevent comparison
|
||||
a byte
|
||||
b uint16
|
||||
c int32
|
||||
d uint64
|
||||
}
|
||||
var a t
|
||||
fmt.Println(a)
|
||||
}
|
||||
```
|
||||
|
||||
用 Go 1.14.2(darwin/amd64)编译,大小从 2174088 降到了 2174056,节省了 32 字节。单独看节省的这 32 字节似乎微不足道,但是考虑到你的程序中每个类型及其传递闭包都会生成相等和哈希函数,还有他们的依赖,这些函数的大小随类型大小和复杂度的不同而不同,禁止它们会大大减小最终的二进制文件的大小,效果比之前使用 `-ldflags="-s -w"` 还要好。
|
||||
|
||||
最后总结一下,如果你不想把类型定义为可比较的,像这样的入侵可以在源码层级强制实现,而且会使生成的二进制文件变小。
|
||||
|
||||
* * *
|
||||
|
||||
附录:在 Brad 的推动下,[Cherry Zhang][5] 和 [Keith Randall][6] 已经在 Go 1.15 做了大量的改进来修复最恶名昭彰的消除无用相等和哈希函数失败(虽然我猜想这也是为了避免这类 CL 的扩散)。
|
||||
|
||||
1. 在 32 位平台上 `int64` 和 `unit64` 的值可能不是按 8 字节对齐的,因为平台原生的是以 4 字节对齐的。查看 [issue 599][7] 了解内部详细信息[][8]。
|
||||
2. 32 位平台会在 `a` 和 `b` 的声明中填充 `_ [3]byte`。查看前面的内容[][9]。
|
||||
3. Brad 使用的是`[0]func()`,但是所有能限制和禁止比较的类型都可以。添加了一个有 0 个元素的数组的声明后,结构体的大小和对齐不会受影响。[][10]
|
||||
|
||||
|
||||
|
||||
#### 相关文章:
|
||||
|
||||
1. [Go 运行时如何高效地实现 map(不使用泛型)][11]
|
||||
2. [空结构体][12]
|
||||
3. [填充很难][13]
|
||||
4. [Go 中有类型的 nil 2][14]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dave.cheney.net/2020/05/09/ensmallening-go-binaries-by-prohibiting-comparisons
|
||||
|
||||
作者:[Dave Cheney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://dave.cheney.net/author/davecheney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/golang/net/commit/e0ff5e5a1de5b859e2d48a2830d7933b3ab5b75f
|
||||
[2]: tmp.uBLyaVR1Hm#easy-footnote-bottom-1-4116 (On 32bit platforms <code>int64</code> and <code>uint64</code> values may not be 8 byte aligned as the natural alignment of the platform is 4 bytes. See <a href="https://github.com/golang/go/issues/599">issue 599</a> for the gory details.)
|
||||
[3]: tmp.uBLyaVR1Hm#easy-footnote-bottom-2-4116 (32 bit platforms would see <code>_ [3]byte</code> padding between the declaration of <code>a</code> and <code>b</code>. See previous.)
|
||||
[4]: tmp.uBLyaVR1Hm#easy-footnote-bottom-3-4116 (Brad used <code>[0]func()</code>, but any type that the spec limits or prohibits comparisons on will do. By declaring the array has zero elements the type has no impact on the size or alignment of the struct.)
|
||||
[5]: https://go-review.googlesource.com/c/go/+/231397
|
||||
[6]: https://go-review.googlesource.com/c/go/+/191198
|
||||
[7]: https://github.com/golang/go/issues/599
|
||||
[8]: tmp.uBLyaVR1Hm#easy-footnote-1-4116
|
||||
[9]: tmp.uBLyaVR1Hm#easy-footnote-2-4116
|
||||
[10]: tmp.uBLyaVR1Hm#easy-footnote-3-4116
|
||||
[11]: https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics (How the Go runtime implements maps efficiently (without generics))
|
||||
[12]: https://dave.cheney.net/2014/03/25/the-empty-struct (The empty struct)
|
||||
[13]: https://dave.cheney.net/2015/10/09/padding-is-hard (Padding is hard)
|
||||
[14]: https://dave.cheney.net/2017/08/09/typed-nils-in-go-2 (Typed nils in Go 2)
|
||||
Loading…
Reference in New Issue
Block a user