mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
commit
80687b3576
@ -5,7 +5,7 @@ LCTT 是“Linux中国”([https://linux.cn/](https://linux.cn/))的翻译
|
||||
|
||||
LCTT 已经拥有几百名活跃成员,并欢迎更多的Linux志愿者加入我们的团队。
|
||||
|
||||

|
||||

|
||||
|
||||
LCTT 的组成
|
||||
-------------------------------
|
||||
|
||||
@ -0,0 +1,66 @@
|
||||
一个老奶奶的唠叨:当年我玩 Linux 时……
|
||||
=====================
|
||||
|
||||

|
||||
|
||||
在很久以前,那时还没有 Linux 系统。真的没有!之前也从未存在过。不像现在,Linux 系统随处可见。那时有各种流派的 Unix 系统、有苹果的操作系统、有微软的 Windows 操作系统。
|
||||
|
||||
比如说 Windows,它的很多东西都改变了,但是依然保持不变的东西的更多。尽管它已经增加了 20GB 以上的鬼知道是什么的东西,但是 Windows 还是大体保持不变(除了不能在 DOS 的提示下实际做些什么了)。嘿,谁还记得 Gorilla.bas 那个出现在 DOS 系统里的炸香蕉的游戏吗?多么美好的时光啊!不过互联网却不会忘记,你可以在 Kongregate.com 这个网站玩这个游戏的 Flash版本。
|
||||
|
||||
苹果系统也改变了,从一个鼓励你 hack 的友善系统变成了一个漂亮而密实的、根本不让你打开的小盒子,而且还限制了你使用的硬件接口。1998 年:软盘没了。2012 年:光驱没了。而 12 英寸的 MacBook 只有一个单一的 USB Type-C 接口,提供了电源、蓝牙、无线网卡、外部存储、视频输出和其它的一些配件的接口。而你要是想一次连接多个外设就不得不背着一堆转接器,这真是太令人抓狂了!然后就轮到耳机插孔了,没错,这唯一一个苹果世界里留着的非专有的标准硬件接口了,也注定要消失了。(LCTT 译注:还好,虽然最新的 IPhone 7 上没有耳机插孔了,但是新发布的 Macbook 上还有)
|
||||
|
||||
还有一大堆其它的操作系统,比如:Amiga、BeOS、OS/2 ,如果你愿意的话,你能找到几十个操作系统。我建议你去找找看,太容易找到了。Amiga、 BeOS 和 OS/2 这些系统都值得关注,因为它们有强大的功能,比如 32 位的多任务和高级图形处理能力。但是市场的影响击败了强大的系统性能,因此技术上并不出众的 Apple 和 Windows 操作系统统治了市场的主导地位,而那些曾经的系统也逐渐销声匿迹了。
|
||||
|
||||
然后 Linux 系统出现了,世界也因此改变了。
|
||||
|
||||
### 第一款电脑
|
||||
|
||||
我曾经使用过的第一款电脑是 Apple IIc ,大概在 1994年左右,而那个时候 Linux 系统刚出来 3 年。这是我从一个朋友那里借来的,用起来各方面都还不错,但是很不方便。所以我自己花了将近 500 美元买了一台二手的 Tandy 牌的电脑。这对于卖电脑的人来说是一件很伤心的事,因为新电脑要花费双倍的价钱。那个时候,电脑贬值的速度非常快。这个电脑当时看起来强劲得像是个怪物:一个英特尔 386SX 的 CPU,4MB的内存,一个 107MB 的硬盘,14 英寸的彩色 CRT 显示器,运行 MS-DOS 5 和 Windows 3.1 系统。
|
||||
|
||||
我曾无数次的拆开那个可怜的怪物,并且多次重新安装 Windows 和 DOS 系统。因为 Windows 桌面用的比较少,所以我的大部分工作都是在 DOS 下完成的。我喜欢玩血腥暴力的视频游戏,包括 Doom、Duke Nukem、Quake 和 Heretic。啊!那些美好的,让人心动的 8 位图像!
|
||||
|
||||
那个时候硬件的发展一直落后于软件,因此我经常升级硬件。现在我们能买到满足我们需求的任何配置的电脑。我已经好多年都没有再更新我的任何电脑硬件了。
|
||||
|
||||
### 《比特杂志(Computer bits)》
|
||||
|
||||
回到那些曾经辉煌的年代,电脑商店布满大街小巷,找到本地的一家网络服务提供商(ISP)也不用走遍整个街区。ISP 那个时候真的非比寻常,它们不是那种冷冰冰的令人讨论的超级大公司,而是像美国电信运营商和有线电视公司这样的好朋友。他们都非常友好,并且提供各种各样的像 BBS、文件下载、MUD (多玩家在线游戏)等的额外服务。
|
||||
|
||||
我花了很多的时间在电脑商店购买配件,但是很多时候我一个女人家去那里会让店里的员工感到吃惊,我真的很无语了,这怎么就会让一些人看不惯了。我现成已经是一位 58 岁的老家伙了,但是他们还是一样的看不惯我。我希望我这个女电脑迷在我死之前能被他们所接受。
|
||||
|
||||
那些商店的书架上摆满了《比特杂志(Computer bits)》。有关《比特杂志》的[历史刊物](https://web.archive.org/web/20020122193349/http://computerbits.com/)可以在互联网档案库(Internet Archive)中查到。《比特杂志》是当地一家免费报纸,有很多关于计算机方面的优秀的文章和大量的广告。可惜当时的广告没有网络版,因此大家不能再看到那些很有价值的关于计算机方面的详细信息了。你知道现在的广告商们有多么的抓狂吗?他们埋怨那些安装广告过滤器的人,致使科技新闻变成了伪装的广告。他们应该学习一下过去的广告模式,那时候的广告里有很多有价值的信息,大家都喜欢阅读。我从《比特杂志》和其它的电脑杂志的广告中学到了所有关于计算机硬件的知识。《电脑购买者杂志(Computer Shopper)》更是非常好的学习资料,其中有上百页的广告和很多高质量的文章。
|
||||
|
||||

|
||||
|
||||
《比特杂志》的出版人 Paul Harwood 开启了我的写作生涯。我的第一篇计算机专业性质的文章就是在《比特杂志》发表的。 Paul,仿佛你一直都在我的身旁,谢谢你。
|
||||
|
||||
在互联网档案库中,关于《比特杂志》的分类广告信息已经几乎查询不到了。分类广告模式曾经给出版商带来巨大的收入。免费的分类广告网站 Craigslist 在这个领域独占鳌头,同时也扼杀了像《比特杂志》这种以传统的报纸和出版为主的杂志行业。
|
||||
|
||||
其中有一些让我最难以忘怀的记忆就是一个 12 岁左右的吊儿郎当的小屁孩,他脸上挂满了对我这种光鲜亮丽的女人所做工作的不屑和不理解的表情,他在我钟爱的电脑店里走动,递给我一本《比特杂志》,当成给初学者的一本好书。我翻开杂志,指着其中一篇我写的关于 Linux 系统的文章给他看,他说“哦,我明白了”。他尴尬的脸变成了那种正常生理上都不可能呈现的颜色,然后很仓促地夹着尾巴溜走了。(不是的,我亲爱的、诚实的读者们,他不是真的只有 12 岁,而应该是 20 来岁。他现在应该比以前更成熟懂事一些了吧!)
|
||||
|
||||
### 发现 Linux
|
||||
|
||||
我第一次了解到 Linux 系统是在《比特杂志》上,大概在 1997 年左右。我一开始用的一些 Linux操作系统版本是 Red Hat 5 和 Mandrake Linux(曼德拉草)。 Mandrake 真是太棒了,它是第一款易安装型的 Linux 系统,并且还附带图形界面和声卡驱动,因此我马上就可以玩 Tux Racer 游戏了。不像那时候大多数的 Linux 迷们,因为我之前没接触过 Unix系统,所以我学习起来比较难。但是一切都还顺利吧,因为我学到的东西都很有用。相对于我在 Windows 中的体验,我在 Windows 中学习的大部分东西都是徒劳,最终只能放弃返回到 DOS 下。
|
||||
|
||||
玩转电脑真是充满了太多的乐趣,后来我转行成为计算机自由顾问,去帮助一些小型公司的 IT 部门把数据迁移到 Linux 服务器上,这让 Windows 系统或多或少的失去一些用武之地。通常情况下我们都是在背地里偷偷地做这些工作的,因为那段时期微软把 Linux 称为毒瘤,诬蔑 Linux 系统是一种共产主义,用来削弱和吞噬我们身体里的珍贵血液的阴谋。
|
||||
|
||||
### Linux 赢了
|
||||
|
||||
我持续做了很多年的顾问工作,也做其它一些相关的工作,比如:电脑硬件修理和升级、布线、系统和网络管理,还有运行包括 Apple、Windows、Linux 系统在内的混合网络。Apple 和 Windows 系统故意不兼容对方,因此这两个系统真的是最头疼,也最难整合到同一网络中。但是在 Linux 系统和其它开源软件中最有趣的一件事是总有一些人能够处理这些厂商之间的兼容性问题。
|
||||
|
||||
现在已经大不同了。在系统间的互操作方面一直存在一些兼容性问题,而且也没有桌面 Linux 系统的 1 级 OEM 厂商。我觉得这是因为微软和苹果公司在零售行业在大力垄断造成的。也许他们这样做反而帮了我们帮大忙,因为我们可以从 ZaReason 和 System76 这样独立的 Linux 系统开发商得到更好的服务和更高性能的系统。他们对 Linux 系统都很专业,也特别欢迎我们这样的用户。
|
||||
|
||||
Linux 除了在零售行业的桌面版系统占有一席之地以外,从嵌入式系统到超级计算机以及分布式计算系统等各个方面都占据着主要地位。开源技术掌握着软件行业的发展方向,所有的软件行业的前沿技术,比如容器、集群以及人工智能的发展都离不开开源技术的支持。从我的第一台老式的 386SX 电脑到现在,Linux 和开源技术都取得了巨大的进步。
|
||||
|
||||
如果没有 Linux 系统和开源,这一切都不可能发生。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/my-linux-story-carla-schroder
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/carlaschroder
|
||||
@ -0,0 +1,217 @@
|
||||
如何在 Ubuntu 上使用 Grafana 监控 Docker
|
||||
=========
|
||||
|
||||
Grafana 是一个有着丰富指标的开源控制面板。在可视化大规模测量数据的时候是非常有用的。根据不同的指标数据,它提供了一个强大、优雅的来创建、分享和浏览数据的方式。
|
||||
|
||||
它提供了丰富多样、灵活的图形选项。此外,针对数据源(Data Source),它支持许多不同的存储后端。每个数据源都有针对特定数据源的特性和功能所定制的查询编辑器。Grafana 提供了对下述数据源的正式支持:Graphite、InfluxDB、OpenTSDB、 Prometheus、Elasticsearch 和 Cloudwatch。
|
||||
|
||||
每个数据源的查询语言和能力显然是不同的,你可以将来自多个数据源的数据混合到一个单一的仪表盘上,但每个面板(Panel)被绑定到属于一个特定组织(Organization)的特定数据源上。它支持验证登录和基于角色的访问控制方案。它是作为一个独立软件部署,使用 Go 和 JavaScript 编写的。
|
||||
|
||||
在这篇文章,我将讲解如何在 Ubuntu 16.04 上安装 Grafana 并使用这个软件配置 Docker 监控。
|
||||
|
||||
### 先决条件
|
||||
|
||||
- 安装好 Docker 的服务器
|
||||
|
||||
### 安装 Grafana
|
||||
|
||||
我们可以在 Docker 中构建我们的 Grafana。 有一个官方提供的 Grafana Docker 镜像。请运行下述命令来构建Grafana 容器。
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -i -p 3000:3000 grafana/grafana
|
||||
|
||||
Unable to find image 'grafana/grafana:latest' locally
|
||||
latest: Pulling from grafana/grafana
|
||||
5c90d4a2d1a8: Pull complete
|
||||
b1a9a0b6158e: Pull complete
|
||||
acb23b0d58de: Pull complete
|
||||
Digest: sha256:34ca2f9c7986cb2d115eea373083f7150a2b9b753210546d14477e2276074ae1
|
||||
Status: Downloaded newer image for grafana/grafana:latest
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Starting Grafana" logger=main version=3.1.0 commit=v3.1.0 compiled=2016-07-12T06:42:28+0000
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config loaded from" logger=settings file=/usr/share/grafana/conf/defaults.ini
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config loaded from" logger=settings file=/etc/grafana/grafana.ini
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.data=/var/lib/grafana"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.logs=/var/log/grafana"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.plugins=/var/lib/grafana/plugins"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Home" logger=settings path=/usr/share/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Data" logger=settings path=/var/lib/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Logs" logger=settings path=/var/log/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Plugins" logger=settings path=/var/lib/grafana/plugins
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Initializing DB" logger=sqlstore dbtype=sqlite3
|
||||
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create playlist table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create playlist item table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="drop preferences table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="drop preferences table v3"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create preferences table v3"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Created default admin user: [admin]"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Starting plugin search" logger=plugins
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Server Listening" logger=server address=0.0.0.0:3000 protocol=http subUrl=
|
||||
```
|
||||
|
||||
我们可以通过运行此命令确认 Grafana 容器的工作状态 `docker ps -a` 或通过这个URL访问 `http://Docker IP:3000`。
|
||||
|
||||
所有的 Grafana 配置设置都使用环境变量定义,在使用容器技术时这个是非常有用的。Grafana 配置文件路径为 `/etc/grafana/grafana.ini`。
|
||||
|
||||
### 理解配置项
|
||||
|
||||
Grafana 可以在它的 ini 配置文件中指定几个配置选项,或可以使用前面提到的环境变量来指定。
|
||||
|
||||
#### 配置文件位置
|
||||
|
||||
通常配置文件路径:
|
||||
|
||||
- 默认配置文件路径 : `$WORKING_DIR/conf/defaults.ini`
|
||||
- 自定义配置文件路径 : `$WORKING_DIR/conf/custom.ini`
|
||||
|
||||
PS:当你使用 deb、rpm 或 docker 镜像安装 Grafana 时,你的配置文件在 `/etc/grafana/grafana.ini`。
|
||||
|
||||
#### 理解配置变量
|
||||
|
||||
现在我们看一些配置文件中的变量:
|
||||
|
||||
- `instance_name`:这是 Grafana 服务器实例的名字。默认值从 `${HOSTNAME}` 获取,其值是环境变量` HOSTNAME`,如果该变量为空或不存在,Grafana 将会尝试使用系统调用来获取机器名。
|
||||
- `[paths]`:这些路径通常都是在 init.d 脚本或 systemd service 文件中通过命令行指定。
|
||||
- `data`:这个是 Grafana 存储 sqlite3 数据库(如果使用)、基于文件的会话(如果使用),和其他数据的路径。
|
||||
- `logs`:这个是 Grafana 存储日志的路径。
|
||||
- `[server]`
|
||||
- `http_addr`:应用监听的 IP 地址,如果为空,则监听所有的接口。
|
||||
- `http_port`:应用监听的端口,默认是 3000,你可以使用下面的命令将你的 80 端口重定向到 3000 端口:`$iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 3000`
|
||||
- `root_url` : 这个 URL 用于从浏览器访问 Grafana 。
|
||||
- `cert_file` : 证书文件的路径(如果协议是 HTTPS)。
|
||||
- `cert_key` : 证书密钥文件的路径(如果协议是 HTTPS)。
|
||||
- `[database]`:Grafana 使用数据库来存储用户和仪表盘以及其他信息,默认配置为使用内嵌在 Grafana 主二进制文件中的 SQLite3。
|
||||
- `type`:你可以根据你的需求选择 MySQL、Postgres、SQLite3。
|
||||
- `path`:仅用于选择 SQLite3 数据库时,这个是数据库所存储的路径。
|
||||
- `host`:仅适用 MySQL 或者 Postgres。它包括 IP 地址或主机名以及端口。例如,Grafana 和 MySQL 运行在同一台主机上设置如: `host = 127.0.0.1:3306`。
|
||||
- `name`:Grafana 数据库的名称,把它设置为 Grafana 或其它名称。
|
||||
- `user`:数据库用户(不适用于 SQLite3)。
|
||||
- `password`:数据库用户密码(不适用于 SQLite3)。
|
||||
- `ssl_mode`:对于 Postgres,使用 `disable`,`require`,或 `verify-full` 等值。对于 MySQL,使用 `true`,`false`,或 `skip-verify`。
|
||||
- `ca_cert_path`:(只适用于 MySQL)CA 证书文件路径,在多数 Linux 系统中,证书可以在 `/etc/ssl/certs` 找到。
|
||||
- `client_key_path`:(只适用于 MySQL)客户端密钥的路径,只在服务端需要用户端验证时使用。
|
||||
- `client_cert_path`:(只适用于 MySQL)客户端证书的路径,只在服务端需要用户端验证时使用。
|
||||
- `server_cert_name`:(只适用于 MySQL)MySQL 服务端使用的证书的通用名称字段。如果 `ssl_mode` 设置为 `skip-verify` 时可以不设置。
|
||||
- `[security]`
|
||||
- `admin_user`:这个是 Grafana 默认的管理员用户的用户名,默认设置为 admin。
|
||||
- `admin_password`:这个是 Grafana 默认的管理员用户的密码,在第一次运行时设置,默认为 admin。
|
||||
- `login_remember_days`:保持登录/记住我的持续天数。
|
||||
- `secret_key`:用于保持登录/记住我的 cookies 的签名。
|
||||
|
||||
### 设置监控的重要组件
|
||||
|
||||
我们可以使用下面的组件来创建我们的 Docker 监控系统。
|
||||
|
||||
- `cAdvisor`:它被称为 Container Advisor。它给用户提供了一个资源利用和性能特征的解读。它会收集、聚合、处理、导出运行中的容器的信息。你可以通过[这个文档](https://github.com/google/cadvisor)了解更多。
|
||||
- `InfluxDB`:这是一个包含了时间序列、度量和分析数据库。我们使用这个数据源来设置我们的监控。cAdvisor 只展示实时信息,并不保存这些度量信息。Influx Db 帮助保存 cAdvisor 提供的监控数据,以展示非某一时段的数据。
|
||||
- `Grafana Dashboard`:它可以帮助我们在视觉上整合所有的信息。这个强大的仪表盘使我们能够针对 InfluxDB 数据存储进行查询并将他们放在一个布局合理好看的图表中。
|
||||
|
||||
### Docker 监控的安装
|
||||
|
||||
我们需要一步一步的在我们的 Docker 系统中安装以下每一个组件:
|
||||
|
||||
#### 安装 InfluxDB
|
||||
|
||||
我们可以使用这个命令来拉取 InfluxDB 镜像,并部署了 influxDB 容器。
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -d -p 8083:8083 -p 8086:8086 --expose 8090 --expose 8099 -e PRE_CREATE_DB=cadvisor --name influxsrv tutum/influxdb:0.8.8
|
||||
Unable to find image 'tutum/influxdb:0.8.8' locally
|
||||
0.8.8: Pulling from tutum/influxdb
|
||||
a3ed95caeb02: Already exists
|
||||
23efb549476f: Already exists
|
||||
aa2f8df21433: Already exists
|
||||
ef072d3c9b41: Already exists
|
||||
c9f371853f28: Already exists
|
||||
a248b0871c3c: Already exists
|
||||
749db6d368d0: Already exists
|
||||
7d7c7d923e63: Pull complete
|
||||
e47cc7808961: Pull complete
|
||||
1743b6eeb23f: Pull complete
|
||||
Digest: sha256:8494b31289b4dbc1d5b444e344ab1dda3e18b07f80517c3f9aae7d18133c0c42
|
||||
Status: Downloaded newer image for tutum/influxdb:0.8.8
|
||||
d3b6f7789e0d1d01fa4e0aacdb636c221421107d1df96808ecbe8e241ceb1823
|
||||
|
||||
-p 8083:8083 : user interface, log in with username-admin, pass-admin
|
||||
-p 8086:8086 : interaction with other application
|
||||
--name influxsrv : container have name influxsrv, use to cAdvisor link it.
|
||||
```
|
||||
|
||||
你可以测试 InfluxDB 是否安装好,通过访问这个 URL `http://你的 IP 地址:8083`,用户名和密码都是 ”root“。
|
||||
|
||||

|
||||
|
||||
我们可以在这个界面上创建我们所需的数据库。
|
||||
|
||||

|
||||
|
||||
#### 安装 cAdvisor
|
||||
|
||||
我们的下一个步骤是安装 cAdvisor 容器,并将其链接到 InfluxDB 容器。你可以使用此命令来创建它。
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8080:8080 --detach=true --link influxsrv:influxsrv --name=cadvisor google/cadvisor:latest -storage_driver_db=cadvisor -storage_driver_host=influxsrv:8086
|
||||
Unable to find image 'google/cadvisor:latest' locally
|
||||
latest: Pulling from google/cadvisor
|
||||
09d0220f4043: Pull complete
|
||||
151807d34af9: Pull complete
|
||||
14cd28dce332: Pull complete
|
||||
Digest: sha256:8364c7ab7f56a087b757a304f9376c3527c8c60c848f82b66dd728980222bd2f
|
||||
Status: Downloaded newer image for google/cadvisor:latest
|
||||
3bfdf7fdc83872485acb06666a686719983a1172ac49895cd2a260deb1cdde29
|
||||
root@ubuntu:~#
|
||||
|
||||
--publish=8080:8080 : user interface
|
||||
--link=influxsrv:influxsrv: link to container influxsrv
|
||||
-storage_driver=influxdb: set the storage driver as InfluxDB
|
||||
Specify what InfluxDB instance to push data to:
|
||||
-storage_driver_host=influxsrv:8086: The ip:port of the database. Default is ‘localhost:8086’
|
||||
-storage_driver_db=cadvisor: database name. Uses db ‘cadvisor’ by default
|
||||
```
|
||||
|
||||
你可以通过访问这个地址来测试安装 cAdvisor 是否正常 `http://你的 IP 地址:8080`。 这将为你的 Docker 主机和容器提供统计信息。
|
||||
|
||||

|
||||
|
||||
#### 安装 Grafana 控制面板
|
||||
|
||||
最后,我们需要安装 Grafana 仪表板并连接到 InfluxDB,你可以执行下面的命令来设置它。
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -d -p 3000:3000 -e INFLUXDB_HOST=localhost -e INFLUXDB_PORT=8086 -e INFLUXDB_NAME=cadvisor -e INFLUXDB_USER=root -e INFLUXDB_PASS=root --link influxsrv:influxsrv --name grafana grafana/grafana
|
||||
f3b7598529202b110e4e6b998dca6b6e60e8608d75dcfe0d2b09ae408f43684a
|
||||
```
|
||||
|
||||
现在我们可以登录 Grafana 来配置数据源. 访问 `http://你的 IP 地址:3000` 或 `http://你的 IP 地址`(如果你在前面做了端口映射的话):
|
||||
|
||||
- 用户名 - admin
|
||||
- 密码 - admin
|
||||
|
||||
一旦我们安装好了 Grafana,我们可以连接 InfluxDB。登录到仪表盘并且点击面板左上方角落的 Grafana 图标(那个火球)。点击数据源(Data Sources)来配置。
|
||||
|
||||

|
||||
|
||||
现在你可以添加新的图形(Graph)到我们默认的数据源 InfluxDB。
|
||||
|
||||

|
||||
|
||||
我们可以通过在测量(Metric)页面编辑和调整我们的查询以调整我们的图形。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
关于 Docker 监控,你可用[从此了解][1]更多信息。 感谢你的阅读。我希望你可以留下有价值的建议和评论。希望你有个美好的一天。
|
||||
|
||||
------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/monitor-docker-containers-grafana-ubuntu/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linoxide.com/author/saheethas/
|
||||
[1]: https://github.com/vegasbrianc/docker-monitoring
|
||||
410
published/20160820 Protocol Buffer Basics C++.md
Normal file
410
published/20160820 Protocol Buffer Basics C++.md
Normal file
@ -0,0 +1,410 @@
|
||||
C++ 程序员 Protocol Buffers 基础指南
|
||||
============================
|
||||
|
||||
这篇教程提供了一个面向 C++ 程序员关于 protocol buffers 的基础介绍。通过创建一个简单的示例应用程序,它将向我们展示:
|
||||
|
||||
* 在 `.proto` 文件中定义消息格式
|
||||
* 使用 protocol buffer 编译器
|
||||
* 使用 C++ protocol buffer API 读写消息
|
||||
|
||||
这不是一个关于在 C++ 中使用 protocol buffers 的全面指南。要获取更详细的信息,请参考 [Protocol Buffer Language Guide][1] 和 [Encoding Reference][2]。
|
||||
|
||||
### 为什么使用 Protocol Buffers
|
||||
|
||||
我们接下来要使用的例子是一个非常简单的"地址簿"应用程序,它能从文件中读取联系人详细信息。地址簿中的每一个人都有一个名字、ID、邮件地址和联系电话。
|
||||
|
||||
如何序列化和获取结构化的数据?这里有几种解决方案:
|
||||
|
||||
* 以二进制形式发送/接收原生的内存数据结构。通常,这是一种脆弱的方法,因为接收/读取代码必须基于完全相同的内存布局、大小端等环境进行编译。同时,当文件增加时,原始格式数据会随着与该格式相关的软件而迅速扩散,这将导致很难扩展文件格式。
|
||||
* 你可以创造一种 ad-hoc 方法,将数据项编码为一个字符串——比如将 4 个整数编码为 `12:3:-23:67`。虽然它需要编写一次性的编码和解码代码且解码需要耗费一点运行时成本,但这是一种简单灵活的方法。这最适合编码非常简单的数据。
|
||||
* 序列化数据为 XML。这种方法是非常吸引人的,因为 XML 是一种适合人阅读的格式,并且有为许多语言开发的库。如果你想与其他程序和项目共享数据,这可能是一种不错的选择。然而,众所周知,XML 是空间密集型的,且在编码和解码时,它对程序会造成巨大的性能损失。同时,使用 XML DOM 树被认为比操作一个类的简单字段更加复杂。
|
||||
|
||||
Protocol buffers 是针对这个问题的一种灵活、高效、自动化的解决方案。使用 Protocol buffers,你需要写一个 `.proto` 说明,用于描述你所希望存储的数据结构。利用 `.proto` 文件,protocol buffer 编译器可以创建一个类,用于实现对高效的二进制格式的 protocol buffer 数据的自动化编码和解码。产生的类提供了构造 protocol buffer 的字段的 getters 和 setters,并且作为一个单元来处理读写 protocol buffer 的细节。重要的是,protocol buffer 格式支持格式的扩展,代码仍然可以读取以旧格式编码的数据。
|
||||
|
||||
### 在哪可以找到示例代码
|
||||
|
||||
示例代码被包含于源代码包,位于“examples”文件夹。可在[这里][4]下载代码。
|
||||
|
||||
### 定义你的协议格式
|
||||
|
||||
为了创建自己的地址簿应用程序,你需要从 `.proto` 开始。`.proto` 文件中的定义很简单:为你所需要序列化的每个数据结构添加一个消息(message),然后为消息中的每一个字段指定一个名字和类型。这里是定义你消息的 `.proto` 文件 `addressbook.proto`。
|
||||
|
||||
```
|
||||
package tutorial;
|
||||
|
||||
message Person {
|
||||
required string name = 1;
|
||||
required int32 id = 2;
|
||||
optional string email = 3;
|
||||
|
||||
enum PhoneType {
|
||||
MOBILE = 0;
|
||||
HOME = 1;
|
||||
WORK = 2;
|
||||
}
|
||||
|
||||
message PhoneNumber {
|
||||
required string number = 1;
|
||||
optional PhoneType type = 2 [default = HOME];
|
||||
}
|
||||
|
||||
repeated PhoneNumber phone = 4;
|
||||
}
|
||||
|
||||
message AddressBook {
|
||||
repeated Person person = 1;
|
||||
}
|
||||
```
|
||||
|
||||
如你所见,其语法类似于 C++ 或 Java。我们开始看看文件的每一部分内容做了什么。
|
||||
|
||||
`.proto` 文件以一个 package 声明开始,这可以避免不同项目的命名冲突。在 C++,你生成的类会被置于与 package 名字一样的命名空间。
|
||||
|
||||
下一步,你需要定义消息(message)。消息只是一个包含一系列类型字段的集合。大多标准的简单数据类型是可以作为字段类型的,包括 `bool`、`int32`、`float`、`double` 和 `string`。你也可以通过使用其他消息类型作为字段类型,将更多的数据结构添加到你的消息中——在以上的示例,`Person` 消息包含了 `PhoneNumber` 消息,同时 `AddressBook` 消息包含 `Person` 消息。你甚至可以定义嵌套在其他消息内的消息类型——如你所见,`PhoneNumber` 类型定义于 `Person` 内部。如果你想要其中某一个字段的值是预定义值列表中的某个值,你也可以定义 `enum` 类型——这儿你可以指定一个电话号码是 `MOBILE`、`HOME` 或 `WORK` 中的某一个。
|
||||
|
||||
每一个元素上的 `= 1`、`= 2` 标记确定了用于二进制编码的唯一“标签”(tag)。标签数字 1-15 的编码比更大的数字少需要一个字节,因此作为一种优化,你可以将这些标签用于经常使用的元素或 repeated 元素,剩下 16 以及更高的标签用于非经常使用的元素或 `optional` 元素。每一个 `repeated` 字段的元素需要重新编码标签数字,因此 `repeated` 字段适合于使用这种优化手段。
|
||||
|
||||
每一个字段必须使用下面的修饰符加以标注:
|
||||
|
||||
* `required`:必须提供该字段的值,否则消息会被认为是 “未初始化的”(uninitialized)。如果 `libprotobuf` 以调试模式编译,序列化未初始化的消息将引起一个断言失败。以优化形式构建,将会跳过检查,并且无论如何都会写入该消息。然而,解析未初始化的消息总是会失败(通过 parse 方法返回 `false`)。除此之外,一个 `required` 字段的表现与 `optional` 字段完全一样。
|
||||
* `optional`:字段可能会被设置,也可能不会。如果一个 `optional` 字段没被设置,它将使用默认值。对于简单类型,你可以指定你自己的默认值,正如例子中我们对电话号码的 `type` 一样,否则使用系统默认值:数字类型为 0、字符串为空字符串、布尔值为 false。对于嵌套消息,默认值总为消息的“默认实例”或“原型”,它的所有字段都没被设置。调用 accessor 来获取一个没有显式设置的 `optional`(或 `required`) 字段的值总是返回字段的默认值。
|
||||
* `repeated`:字段可以重复任意次数(包括 0 次)。`repeated` 值的顺序会被保存于 protocol buffer。可以将 repeated 字段想象为动态大小的数组。
|
||||
|
||||
你可以查找关于编写 `.proto` 文件的完整指导——包括所有可能的字段类型——在 [Protocol Buffer Language Guide][6] 里面。不要在这里面查找与类继承相似的特性,因为 protocol buffers 不会做这些。
|
||||
|
||||
> **`required` 是永久性的**
|
||||
|
||||
>在把一个字段标识为 `required` 的时候,你应该特别小心。如果在某些情况下你不想写入或者发送一个 `required` 的字段,那么将该字段更改为 `optional` 可能会遇到问题——旧版本的读者(LCTT 译注:即读取、解析旧版本 Protocol Buffer 消息的一方)会认为不含该字段的消息是不完整的,从而有可能会拒绝解析。在这种情况下,你应该考虑编写特别针对于应用程序的、自定义的消息校验函数。Google 的一些工程师得出了一个结论:使用 `required` 弊多于利;他们更愿意使用 `optional` 和 `repeated` 而不是 `required`。当然,这个观点并不具有普遍性。
|
||||
|
||||
### 编译你的 Protocol Buffers
|
||||
|
||||
既然你有了一个 `.proto`,那你需要做的下一件事就是生成一个将用于读写 `AddressBook` 消息的类(从而包括 `Person` 和 `PhoneNumber`)。为了做到这样,你需要在你的 `.proto` 上运行 protocol buffer 编译器 `protoc`:
|
||||
|
||||
1. 如果你没有安装编译器,请[下载这个包][4],并按照 README 中的指令进行安装。
|
||||
2. 现在运行编译器,指定源目录(你的应用程序源代码位于哪里——如果你没有提供任何值,将使用当前目录)、目标目录(你想要生成的代码放在哪里;常与 `$SRC_DIR` 相同),以及你的 `.proto` 路径。在此示例中:
|
||||
|
||||
```
|
||||
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/addressbook.proto
|
||||
```
|
||||
|
||||
因为你想要 C++ 的类,所以你使用了 `--cpp_out` 选项——也为其他支持的语言提供了类似选项。
|
||||
|
||||
在你指定的目标文件夹,将生成以下的文件:
|
||||
|
||||
* `addressbook.pb.h`,声明你生成类的头文件。
|
||||
* `addressbook.pb.cc`,包含你的类的实现。
|
||||
|
||||
### Protocol Buffer API
|
||||
|
||||
让我们看看生成的一些代码,了解一下编译器为你创建了什么类和函数。如果你查看 `addressbook.pb.h`,你可以看到有一个在 `addressbook.proto` 中指定所有消息的类。关注 `Person` 类,可以看到编译器为每个字段生成了读写函数(accessors)。例如,对于 `name`、`id`、`email` 和 `phone` 字段,有下面这些方法:(LCTT 译注:此处原文所指文件名有误,径该之。)
|
||||
|
||||
```c++
|
||||
// name
|
||||
inline bool has_name() const;
|
||||
inline void clear_name();
|
||||
inline const ::std::string& name() const;
|
||||
inline void set_name(const ::std::string& value);
|
||||
inline void set_name(const char* value);
|
||||
inline ::std::string* mutable_name();
|
||||
|
||||
// id
|
||||
inline bool has_id() const;
|
||||
inline void clear_id();
|
||||
inline int32_t id() const;
|
||||
inline void set_id(int32_t value);
|
||||
|
||||
// email
|
||||
inline bool has_email() const;
|
||||
inline void clear_email();
|
||||
inline const ::std::string& email() const;
|
||||
inline void set_email(const ::std::string& value);
|
||||
inline void set_email(const char* value);
|
||||
inline ::std::string* mutable_email();
|
||||
|
||||
// phone
|
||||
inline int phone_size() const;
|
||||
inline void clear_phone();
|
||||
inline const ::google::protobuf::RepeatedPtrField< ::tutorial::Person_PhoneNumber >& phone() const;
|
||||
inline ::google::protobuf::RepeatedPtrField< ::tutorial::Person_PhoneNumber >* mutable_phone();
|
||||
inline const ::tutorial::Person_PhoneNumber& phone(int index) const;
|
||||
inline ::tutorial::Person_PhoneNumber* mutable_phone(int index);
|
||||
inline ::tutorial::Person_PhoneNumber* add_phone();
|
||||
```
|
||||
|
||||
正如你所见到,getters 的名字与字段的小写名字完全一样,并且 setter 方法以 set_ 开头。同时每个单一(singular)(`required` 或 `optional`)字段都有 `has_` 方法,该方法在字段被设置了值的情况下返回 true。最后,所有字段都有一个 `clear_` 方法,用以清除字段到空(empty)状态。
|
||||
|
||||
数字型的 `id` 字段仅有上述的基本读写函数集合(accessors),而 `name` 和 `email` 字段有两个额外的方法,因为它们是字符串——一个是可以获得字符串直接指针的`mutable_` 的 getter ,另一个为额外的 setter。注意,尽管 `email` 还没被设置(set),你也可以调用 `mutable_email`;因为 `email` 会被自动地初始化为空字符串。在本例中,如果你有一个单一的(`required` 或 `optional`)消息字段,它会有一个 `mutable_` 方法,而没有 `set_` 方法。
|
||||
|
||||
`repeated` 字段也有一些特殊的方法——如果你看看 `repeated` 的 `phone` 字段的方法,你可以看到:
|
||||
|
||||
* 检查 `repeated` 字段的 `_size`(也就是说,与 `Person` 相关的电话号码的个数)
|
||||
* 使用下标取得特定的电话号码
|
||||
* 更新特定下标的电话号码
|
||||
* 添加新的电话号码到消息中,之后你便可以编辑。(`repeated` 标量类型有一个 `add_` 方法,用于传入新的值)
|
||||
|
||||
为了获取 protocol 编译器为所有字段定义生成的方法的信息,可以查看 [C++ generated code reference][5]。
|
||||
|
||||
#### 枚举和嵌套类
|
||||
|
||||
与 `.proto` 的枚举相对应,生成的代码包含了一个 `PhoneType` 枚举。你可以通过 `Person::PhoneType` 引用这个类型,通过 `Person::MOBILE`、`Person::HOME` 和 `Person::WORK` 引用它的值。(实现细节有点复杂,但是你无须了解它们而可以直接使用)
|
||||
|
||||
编译器也生成了一个 `Person::PhoneNumber` 的嵌套类。如果你查看代码,你可以发现真正的类型为 `Person_PhoneNumber`,但它通过在 `Person` 内部使用 `typedef` 定义,使你可以把 `Person_PhoneNumber` 当成嵌套类。唯一产生影响的一个例子是,如果你想要在其他文件前置声明该类——在 C++ 中你不能前置声明嵌套类,但是你可以前置声明 `Person_PhoneNumber`。
|
||||
|
||||
#### 标准的消息方法
|
||||
|
||||
所有的消息方法都包含了许多别的方法,用于检查和操作整个消息,包括:
|
||||
|
||||
* `bool IsInitialized() const;` :检查是否所有 `required` 字段已经被设置。
|
||||
* `string DebugString() const;` :返回人类可读的消息表示,对调试特别有用。
|
||||
* `void CopyFrom(const Person& from);`:使用给定的值重写消息。
|
||||
* `void Clear();`:清除所有元素为空(empty)的状态。
|
||||
|
||||
上面这些方法以及下一节要讲的 I/O 方法实现了被所有 C++ protocol buffer 类共享的消息(Message)接口。为了获取更多信息,请查看 [complete API documentation for Message][7]。
|
||||
|
||||
#### 解析和序列化
|
||||
|
||||
最后,所有 protocol buffer 类都有读写你选定类型消息的方法,这些方法使用了特定的 protocol buffer [二进制格式][8]。这些方法包括:
|
||||
|
||||
* `bool SerializeToString(string* output) const;`:序列化消息并将消息字节数据存储在给定的字符串中。注意,字节数据是二进制格式的,而不是文本格式;我们只使用 `string` 类作为合适的容器。
|
||||
* `bool ParseFromString(const string& data);`:从给定的字符创解析消息。
|
||||
* `bool SerializeToOstream(ostream* output) const;`:将消息写到给定的 C++ `ostream`。
|
||||
* `bool ParseFromIstream(istream* input);`:从给定的 C++ `istream` 解析消息。
|
||||
|
||||
这些只是两个用于解析和序列化的选择。再次说明,可以查看 `Message API reference` 完整的列表。
|
||||
|
||||
> **Protocol Buffers 和面向对象设计**
|
||||
|
||||
> Protocol buffer 类通常只是纯粹的数据存储器(像 C++ 中的结构体);它们在对象模型中并不是一等公民。如果你想向生成的 protocol buffer 类中添加更丰富的行为,最好的方法就是在应用程序中对它进行封装。如果你无权控制 `.proto` 文件的设计的话,封装 protocol buffers 也是一个好主意(例如,你从另一个项目中重用一个 `.proto` 文件)。在那种情况下,你可以用封装类来设计接口,以更好地适应你的应用程序的特定环境:隐藏一些数据和方法,暴露一些便于使用的函数,等等。**但是你绝对不要通过继承生成的类来添加行为。**这样做的话,会破坏其内部机制,并且不是一个好的面向对象的实践。
|
||||
|
||||
### 写消息
|
||||
|
||||
现在我们尝试使用 protocol buffer 类。你的地址簿程序想要做的第一件事是将个人详细信息写入到地址簿文件。为了做到这一点,你需要创建、填充 protocol buffer 类实例,并且将它们写入到一个输出流(output stream)。
|
||||
|
||||
这里的程序可以从文件读取 `AddressBook`,根据用户输入,将新 `Person` 添加到 `AddressBook`,并且再次将新的 `AddressBook` 写回文件。这部分直接调用或引用 protocol buffer 类的代码会以“// pb”标出。
|
||||
|
||||
```c++
|
||||
#include <iostream>
|
||||
#include <fstream>
|
||||
#include <string>
|
||||
#include "addressbook.pb.h" // pb
|
||||
using namespace std;
|
||||
|
||||
// This function fills in a Person message based on user input.
|
||||
void PromptForAddress(tutorial::Person* person) {
|
||||
cout << "Enter person ID number: ";
|
||||
int id;
|
||||
cin >> id;
|
||||
person->set_id(id); // pb
|
||||
cin.ignore(256, '\n');
|
||||
|
||||
cout << "Enter name: ";
|
||||
getline(cin, *person->mutable_name()); // pb
|
||||
|
||||
cout << "Enter email address (blank for none): ";
|
||||
string email;
|
||||
getline(cin, email);
|
||||
if (!email.empty()) { // pb
|
||||
person->set_email(email); // pb
|
||||
}
|
||||
|
||||
while (true) {
|
||||
cout << "Enter a phone number (or leave blank to finish): ";
|
||||
string number;
|
||||
getline(cin, number);
|
||||
if (number.empty()) {
|
||||
break;
|
||||
}
|
||||
|
||||
tutorial::Person::PhoneNumber* phone_number = person->add_phone(); //pb
|
||||
phone_number->set_number(number); // pb
|
||||
|
||||
cout << "Is this a mobile, home, or work phone? ";
|
||||
string type;
|
||||
getline(cin, type);
|
||||
if (type == "mobile") {
|
||||
phone_number->set_type(tutorial::Person::MOBILE); // pb
|
||||
} else if (type == "home") {
|
||||
phone_number->set_type(tutorial::Person::HOME); // pb
|
||||
} else if (type == "work") {
|
||||
phone_number->set_type(tutorial::Person::WORK); // pb
|
||||
} else {
|
||||
cout << "Unknown phone type. Using default." << endl;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Main function: Reads the entire address book from a file,
|
||||
// adds one person based on user input, then writes it back out to the same
|
||||
// file.
|
||||
int main(int argc, char* argv[]) {
|
||||
// Verify that the version of the library that we linked against is
|
||||
// compatible with the version of the headers we compiled against.
|
||||
GOOGLE_PROTOBUF_VERIFY_VERSION; // pb
|
||||
|
||||
if (argc != 2) {
|
||||
cerr << "Usage: " << argv[0] << " ADDRESS_BOOK_FILE" << endl;
|
||||
return -1;
|
||||
}
|
||||
|
||||
tutorial::AddressBook address_book; // pb
|
||||
|
||||
{
|
||||
// Read the existing address book.
|
||||
fstream input(argv[1], ios::in | ios::binary);
|
||||
if (!input) {
|
||||
cout << argv[1] << ": File not found. Creating a new file." << endl;
|
||||
} else if (!address_book.ParseFromIstream(&input)) { // pb
|
||||
cerr << "Failed to parse address book." << endl;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
// Add an address.
|
||||
PromptForAddress(address_book.add_person()); // pb
|
||||
|
||||
{
|
||||
// Write the new address book back to disk.
|
||||
fstream output(argv[1], ios::out | ios::trunc | ios::binary);
|
||||
if (!address_book.SerializeToOstream(&output)) { // pb
|
||||
cerr << "Failed to write address book." << endl;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
// Optional: Delete all global objects allocated by libprotobuf.
|
||||
google::protobuf::ShutdownProtobufLibrary(); // pb
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
注意 `GOOGLE_PROTOBUF_VERIFY_VERSION` 宏。它是一种好的实践——虽然不是严格必须的——在使用 C++ Protocol Buffer 库之前执行该宏。它可以保证避免不小心链接到一个与编译的头文件版本不兼容的库版本。如果被检查出来版本不匹配,程序将会终止。注意,每个 `.pb.cc` 文件在初始化时会自动调用这个宏。
|
||||
|
||||
同时注意在程序最后调用 `ShutdownProtobufLibrary()`。它用于释放 Protocol Buffer 库申请的所有全局对象。对大部分程序,这不是必须的,因为虽然程序只是简单退出,但是 OS 会处理释放程序的所有内存。然而,如果你使用了内存泄漏检测工具,工具要求全部对象都要释放,或者你正在写一个 Protocol Buffer 库,该库可能会被一个进程多次加载和卸载,那么你可能需要强制 Protocol Buffer 清除所有东西。
|
||||
|
||||
### 读取消息
|
||||
|
||||
当然,如果你无法从它获取任何信息,那么这个地址簿没多大用处!这个示例读取上面例子创建的文件,并打印文件里的所有内容。
|
||||
|
||||
```c++
|
||||
#include <iostream>
|
||||
#include <fstream>
|
||||
#include <string>
|
||||
#include "addressbook.pb.h" // pb
|
||||
using namespace std;
|
||||
|
||||
// Iterates though all people in the AddressBook and prints info about them.
|
||||
void ListPeople(const tutorial::AddressBook& address_book) { // pb
|
||||
for (int i = 0; i < address_book.person_size(); i++) { // pb
|
||||
const tutorial::Person& person = address_book.person(i); // pb
|
||||
|
||||
cout << "Person ID: " << person.id() << endl; // pb
|
||||
cout << " Name: " << person.name() << endl; // pb
|
||||
if (person.has_email()) { // pb
|
||||
cout << " E-mail address: " << person.email() << endl; // pb
|
||||
}
|
||||
|
||||
for (int j = 0; j < person.phone_size(); j++) { // pb
|
||||
const tutorial::Person::PhoneNumber& phone_number = person.phone(j); // pb
|
||||
|
||||
switch (phone_number.type()) { // pb
|
||||
case tutorial::Person::MOBILE: // pb
|
||||
cout << " Mobile phone #: ";
|
||||
break;
|
||||
case tutorial::Person::HOME: // pb
|
||||
cout << " Home phone #: ";
|
||||
break;
|
||||
case tutorial::Person::WORK: // pb
|
||||
cout << " Work phone #: ";
|
||||
break;
|
||||
}
|
||||
cout << phone_number.number() << endl; // ob
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Main function: Reads the entire address book from a file and prints all
|
||||
// the information inside.
|
||||
int main(int argc, char* argv[]) {
|
||||
// Verify that the version of the library that we linked against is
|
||||
// compatible with the version of the headers we compiled against.
|
||||
GOOGLE_PROTOBUF_VERIFY_VERSION; // pb
|
||||
|
||||
if (argc != 2) {
|
||||
cerr << "Usage: " << argv[0] << " ADDRESS_BOOK_FILE" << endl;
|
||||
return -1;
|
||||
}
|
||||
|
||||
tutorial::AddressBook address_book; // pb
|
||||
|
||||
{
|
||||
// Read the existing address book.
|
||||
fstream input(argv[1], ios::in | ios::binary);
|
||||
if (!address_book.ParseFromIstream(&input)) { // pb
|
||||
cerr << "Failed to parse address book." << endl;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
ListPeople(address_book);
|
||||
|
||||
// Optional: Delete all global objects allocated by libprotobuf.
|
||||
google::protobuf::ShutdownProtobufLibrary(); // pb
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
### 扩展 Protocol Buffer
|
||||
|
||||
或早或晚在你发布了使用 protocol buffer 的代码之后,毫无疑问,你会想要 "改善"
|
||||
protocol buffer 的定义。如果你想要新的 buffers 向后兼容,并且老的 buffers 向前兼容——几乎可以肯定你很渴望这个——这里有一些规则,你需要遵守。在新的 protocol buffer 版本:
|
||||
|
||||
* 你绝不可以修改任何已存在字段的标签数字
|
||||
* 你绝不可以添加或删除任何 `required` 字段
|
||||
* 你可以删除 `optional` 或 `repeated` 字段
|
||||
* 你可以添加新的 `optional` 或 `repeated` 字段,但是你必须使用新的标签数字(也就是说,标签数字在 protocol buffer 中从未使用过,甚至不能是已删除字段的标签数字)。
|
||||
|
||||
(对于上面规则有一些[例外情况][9],但它们很少用到。)
|
||||
|
||||
如果你能遵守这些规则,旧代码则可以欢快地读取新的消息,并且简单地忽略所有新的字段。对于旧代码来说,被删除的 `optional` 字段将会简单地赋予默认值,被删除的 `repeated` 字段会为空。新代码显然可以读取旧消息。然而,请记住新的 `optional` 字段不会呈现在旧消息中,因此你需要显式地使用 `has_` 检查它们是否被设置或者在 `.proto` 文件在标签数字后使用 `[default = value]` 提供一个合理的默认值。如果一个 `optional` 元素没有指定默认值,它将会使用类型特定的默认值:对于字符串,默认值为空字符串;对于布尔值,默认值为 false;对于数字类型,默认类型为 0。注意,如果你添加一个新的 `repeated` 字段,新代码将无法辨别它被留空(left empty)(被新代码)或者从没被设置(被旧代码),因为 `repeated` 字段没有 `has_` 标志。
|
||||
|
||||
### 优化技巧
|
||||
|
||||
C++ Protocol Buffer 库已极度优化过了。但是,恰当的用法能够更多地提高性能。这里是一些技巧,可以帮你从库中挤压出最后一点速度:
|
||||
|
||||
* 尽可能复用消息对象。即使它们被清除掉,消息也会尽量保存所有被分配来重用的内存。因此,如果我们正在处理许多相同类型或一系列相似结构的消息,一个好的办法是重用相同的消息对象,从而减少内存分配的负担。但是,随着时间的流逝,对象可能会膨胀变大,尤其是当你的消息尺寸(LCTT 译注:各消息内容不同,有些消息内容多一些,有些消息内容少一些)不同的时候,或者你偶尔创建了一个比平常大很多的消息的时候。你应该自己通过调用 [SpaceUsed][10] 方法监测消息对象的大小,并在它太大的时候删除它。
|
||||
* 对于在多线程中分配大量小对象的情况,你的操作系统内存分配器可能优化得不够好。你可以尝试使用 google 的 [tcmalloc][11]。
|
||||
|
||||
### 高级用法
|
||||
|
||||
Protocol Buffers 绝不仅用于简单的数据存取以及序列化。请阅读 [C++ API reference][12] 来看看你还能用它来做什么。
|
||||
|
||||
protocol 消息类所提供的一个关键特性就是反射(reflection)。你不需要针对一个特殊的消息类型编写代码,就可以遍历一个消息的字段并操作它们的值。一个使用反射的有用方法是 protocol 消息与其他编码互相转换,比如 XML 或 JSON。反射的一个更高级的用法可能就是可以找出两个相同类型的消息之间的区别,或者开发某种“协议消息的正则表达式”,利用正则表达式,你可以对某种消息内容进行匹配。只要你发挥你的想像力,就有可能将 Protocol Buffers 应用到一个更广泛的、你可能一开始就期望解决的问题范围上。
|
||||
|
||||
反射是由 [Message::Reflection interface][13] 提供的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://developers.google.com/protocol-buffers/docs/cpptutorial
|
||||
|
||||
作者:[Google][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://developers.google.com/protocol-buffers/docs/cpptutorial
|
||||
[1]: https://developers.google.com/protocol-buffers/docs/proto
|
||||
[2]: https://developers.google.com/protocol-buffers/docs/encoding
|
||||
[3]: https://developers.google.com/protocol-buffers/docs/downloads
|
||||
[4]: https://developers.google.com/protocol-buffers/docs/downloads.html
|
||||
[5]: https://developers.google.com/protocol-buffers/docs/reference/cpp-generated
|
||||
[6]: https://developers.google.com/protocol-buffers/docs/proto
|
||||
[7]: https://developers.google.com/protocol-buffers/docs/reference/cpp/google.protobuf.message.html#Message
|
||||
[8]: https://developers.google.com/protocol-buffers/docs/encoding
|
||||
[9]: https://developers.google.com/protocol-buffers/docs/proto#updating
|
||||
[10]: https://developers.google.com/protocol-buffers/docs/reference/cpp/google.protobuf.message.html#Message.SpaceUsed.details
|
||||
[11]: http://code.google.com/p/google-perftools/
|
||||
[12]: https://developers.google.com/protocol-buffers/docs/reference/cpp/index.html
|
||||
[13]: https://developers.google.com/protocol-buffers/docs/reference/cpp/google.protobuf.message.html#Message.Reflection
|
||||
@ -0,0 +1,447 @@
|
||||
新手指南 - 通过 Docker 在 Linux 上托管 .NET Core
|
||||
=====
|
||||
|
||||
这篇文章基于我之前的文章 [.NET Core 入门][1]。首先,我把 RESTful API 从 .NET Core RC1 升级到了 .NET Core 1.0,然后,我增加了对 Docker 的支持并描述了如何在 Linux 生产环境里托管它。
|
||||
|
||||

|
||||
|
||||
我是首次接触 Docker 并且距离成为一名 Linux 高手还有很远的一段路程。因此,这里的很多想法是来自一个新手。
|
||||
|
||||
### 安装
|
||||
|
||||
按照 https://www.microsoft.com/net/core 上的介绍在你的电脑上安装 .NET Core 。这将会同时在 Windows 上安装 dotnet 命令行工具以及最新的 Visual Studio 工具。
|
||||
|
||||
### 源代码
|
||||
|
||||
你可以直接到 [GitHub](https://github.com/niksoper/aspnet5-books/tree/blog-docker) 上找最到最新完整的源代码。
|
||||
|
||||
### 转换到 .NET CORE 1.0
|
||||
|
||||
自然地,当我考虑如何把 API 从 .NET Core RC1 升级到 .NET Core 1.0 时想到的第一个求助的地方就是谷歌搜索。我是按照下面这两条非常全面的指导来进行升级的:
|
||||
|
||||
- [从 DNX 迁移到 .NET Core CLI][2]
|
||||
- [从 ASP.NET 5 RC1 迁移到 ASP.NET Core 1.0][3]
|
||||
|
||||
当你迁移代码的时候,我建议仔细阅读这两篇指导,因为我在没有阅读第一篇指导的情况下又尝试浏览第二篇,结果感到非常迷惑和沮丧。
|
||||
|
||||
我不想描述细节上的改变因为你可以看 GitHub 上的[提交](https://github.com/niksoper/aspnet5-books/commit/b41ad38794c69a70a572be3ffad051fd2d7c53c0)。这儿是我所作改变的总结:
|
||||
|
||||
- 更新 `global.json` 和 `project.json` 上的版本号
|
||||
- 删除 `project.json` 上的废弃章节
|
||||
- 使用轻型 `ControllerBase` 而不是 `Controller`, 因为我不需要与 MVC 视图相关的方法(这是一个可选的改变)。
|
||||
- 从辅助方法中去掉 `Http` 前缀,比如:`HttpNotFound` -> `NotFound`
|
||||
- `LogVerbose` -> `LogTrace`
|
||||
- 名字空间改变: `Microsoft.AspNetCore.*`
|
||||
- 在 `Startup` 中使用 `SetBasePath`(没有它 `appsettings.json` 将不会被发现)
|
||||
- 通过 `WebHostBuilder` 来运行而不是通过 `WebApplication.Run` 来运行
|
||||
- 删除 Serilog(在写文章的时候,它不支持 .NET Core 1.0)
|
||||
|
||||
唯一令我真正头疼的事是需要移动 Serilog。我本可以实现自己的文件记录器,但是我删除了文件记录功能,因为我不想为了这次操作在这件事情上花费精力。
|
||||
|
||||
不幸的是,将有大量的第三方开发者扮演追赶 .NET Core 1.0 的角色,我非常同情他们,因为他们通常在休息时间还坚持工作但却依旧根本无法接近靠拢微软的可用资源。我建议阅读 Travis Illig 的文章 [.NET Core 1.0 发布了,但 Autofac 在哪儿][4]?这是一篇关于第三方开发者观点的文章。
|
||||
|
||||
做了这些改变以后,我可以从 `project.json` 目录恢复、构建并运行 dotnet,可以看到 API 又像以前一样工作了。
|
||||
|
||||
### 通过 Docker 运行
|
||||
|
||||
在我写这篇文章的时候, Docker 只能够在 Linux 系统上工作。在 [Windows](https://docs.docker.com/engine/installation/windows/#/docker-for-windows) 系统和 [OS X](https://docs.docker.com/engine/installation/mac/) 上有 beta 支持 Docker,但是它们都必须依赖于虚拟化技术,因此,我选择把 Ubuntu 14.04 当作虚拟机来运行。如果你还没有安装过 Docker,请按照[指导](https://docs.docker.com/engine/installation/linux/ubuntulinux/)来安装。
|
||||
|
||||
我最近阅读了一些关于 Docker 的东西,但我直到现在还没有真正用它来干任何事。我假设读者还没有关于 Docker 的知识,因此我会解释我所使用的所有命令。
|
||||
|
||||
#### HELLO DOCKER
|
||||
|
||||
在 Ubuntu 上安装好 Docker 之后,我所进行的下一步就是按照 https://www.microsoft.com/net/core#docker 上的介绍来开始运行 .NET Core 和 Docker。
|
||||
|
||||
首先启动一个已安装有 .NET Core 的容器。
|
||||
|
||||
```
|
||||
docker run -it microsoft/dotnet:latest
|
||||
```
|
||||
|
||||
`-it` 选项表示交互,所以你执行这条命令之后,你就处于容器之内了,可以如你所希望的那样执行任何 bash 命令。
|
||||
|
||||
然后我们可以执行下面这五条命令来在 Docker 内部运行起来微软 .NET Core 控制台应用程序示例。
|
||||
|
||||
```
|
||||
mkdir hwapp
|
||||
cd hwapp
|
||||
dotnet new
|
||||
dotnet restore
|
||||
dotnet run
|
||||
```
|
||||
|
||||
你可以通过运行 `exit` 来离开容器,然后运行 `Docker ps -a` 命令,这会显示你创建的那个已经退出的容器。你可以通过上运行命令 `Docker rm <container_name>` 来清除容器。
|
||||
|
||||
#### 挂载源代码
|
||||
|
||||
我的下一步骤是使用和上面相同的 microsoft/dotnet 镜像,但是将为我们的应用程序以[数据卷](https://docs.docker.com/engine/tutorials/dockervolumes/1)的方式挂载上源代码。
|
||||
|
||||
首先签出有相关提交的仓库:
|
||||
|
||||
```
|
||||
git clone https://github.com/niksoper/aspnet5-books.git
|
||||
cd aspnet5-books/src/MvcLibrary
|
||||
git checkout dotnet-core-1.0
|
||||
```
|
||||
|
||||
现在启动一个容器来运行 .NET Core 1.0,并将源代码放在 `/book` 下。注意更改 `/path/to/repo` 这部分文件来匹配你的电脑:
|
||||
|
||||
```
|
||||
docker run -it \
|
||||
-v /path/to/repo/aspnet5-books/src/MvcLibrary:/books \
|
||||
microsoft/dotnet:latest
|
||||
```
|
||||
|
||||
现在你可以在容器中运行应用程序了!
|
||||
|
||||
```
|
||||
cd /books
|
||||
dotnet restore
|
||||
dotnet run
|
||||
```
|
||||
|
||||
作为一个概念性展示这的确很棒,但是我们可不想每次运行一个程序都要考虑如何把源代码安装到容器里。
|
||||
|
||||
#### 增加一个 DOCKERFILE
|
||||
|
||||
我的下一步骤是引入一个 Dockerfile,这可以让应用程序很容易在自己的容器内启动。
|
||||
|
||||
我的 Dockerfile 和 `project.json` 一样位于 `src/MvcLibrary` 目录下,看起来像下面这样:
|
||||
|
||||
|
||||
```
|
||||
FROM microsoft/dotnet:latest
|
||||
|
||||
# 为应用程序源代码创建目录
|
||||
RUN mkdir -p /usr/src/books
|
||||
WORKDIR /usr/src/books
|
||||
|
||||
# 复制源代码并恢复依赖关系
|
||||
|
||||
COPY . /usr/src/books
|
||||
RUN dotnet restore
|
||||
|
||||
# 暴露端口并运行应用程序
|
||||
EXPOSE 5000
|
||||
CMD [ "dotnet", "run" ]
|
||||
```
|
||||
|
||||
严格来说,`RUN mkdir -p /usr/src/books` 命令是不需要的,因为 `COPY` 会自动创建丢失的目录。
|
||||
|
||||
Docker 镜像是按层建立的,我们从包含 .NET Core 的镜像开始,添加另一个从源代码生成应用程序,然后运行这个应用程序的层。
|
||||
|
||||
添加了 Dockerfile 以后,我通过运行下面的命令来生成一个镜像,并使用生成的镜像启动一个容器(确保在和 Dockerfile 相同的目录下进行操作,并且你应该使用自己的用户名)。
|
||||
|
||||
```
|
||||
docker build -t niksoper/netcore-books .
|
||||
docker run -it niksoper/netcore-books
|
||||
```
|
||||
|
||||
你应该看到程序能够和之前一样的运行,不过这一次我们不需要像之前那样安装源代码,因为源代码已经包含在 docker 镜像里面了。
|
||||
|
||||
#### 暴露并发布端口
|
||||
|
||||
这个 API 并不是特别有用,除非我们需要从容器外面和它进行通信。 Docker 已经有了暴露和发布端口的概念,但这是两件完全不同的事。
|
||||
|
||||
据 Docker [官方文档](https://docs.docker.com/engine/reference/builder/#/expose):
|
||||
|
||||
> `EXPOSE` 指令通知 Docker 容器在运行时监听特定的网络端口。`EXPOSE` 指令不能够让容器的端口可被主机访问。要使可被访问,你必须通过 `-p` 标志来发布一个端口范围或者使用 `-P` 标志来发布所有暴露的端口
|
||||
|
||||
`EXPOSE` 指令只是将元数据添加到镜像上,所以你可以如文档中说的认为它是镜像消费者。从技术上讲,我本应该忽略 `EXPOSE 5000` 这行指令,因为我知道 API 正在监听的端口,但把它们留下很有用的,并且值得推荐。
|
||||
|
||||
在这个阶段,我想直接从主机访问这个 API ,因此我需要通过 `-p` 指令来发布这个端口,这将允许请求从主机上的端口 5000 转发到容器上的端口 5000,无论这个端口是不是之前通过 Dockerfile 暴露的。
|
||||
|
||||
```
|
||||
docker run -d -p 5000:5000 niksoper/netcore-books
|
||||
```
|
||||
|
||||
通过 `-d` 指令告诉 docker 在分离模式下运行容器,因此我们不能看到它的输出,但是它依旧会运行并监听端口 5000。你可以通过 `docker ps` 来证实这件事。
|
||||
|
||||
因此,接下来我准备从主机向容器发起一个请求来庆祝一下:
|
||||
|
||||
```
|
||||
curl http://localhost:5000/api/books
|
||||
```
|
||||
|
||||
它不工作。
|
||||
|
||||
重复进行相同 `curl` 请求,我看到了两个错误:要么是 `curl: (56) Recv failure: Connection reset by peer`,要么是 `curl: (52) Empty reply from server`。
|
||||
|
||||
我返回去看 docker run 的[文档](https://docs.docker.com/engine/reference/run/#/expose-incoming-ports),然后再次检查我所使用的 `-p` 选项以及 Dockerfile 中的 `EXPOSE` 指令是否正确。我没有发现任何问题,这让我开始有些沮丧。
|
||||
|
||||
重新振作起来以后,我决定去咨询当地的一个 Scott Logic DevOps 大师 - Dave Wybourn(也在[这篇 Docker Swarm 的文章](http://blog.scottlogic.com/2016/08/30/docker-1-12-swarm-mode-round-robin.html)里提到过),他的团队也曾遇到这个实际问题。这个问题是我没有配置过 [Kestral](https://docs.asp.net/en/latest/fundamentals/servers.html#kestrel),这是一个全新的轻量级、跨平台 web 服务器,用于 .NET Core 。
|
||||
|
||||
默认情况下, Kestrel 会监听 http://localhost:5000。但问题是,这儿的 `localhost` 是一个回路接口。
|
||||
|
||||
据[维基百科](https://en.wikipedia.org/wiki/Localhost):
|
||||
|
||||
> 在计算机网络中,localhost 是一个代表本机的主机名。本地主机可以通过网络回路接口访问在主机上运行的网络服务。通过使用回路接口可以绕过任何硬件网络接口。
|
||||
|
||||
当运行在容器内时这是一个问题,因为 `localhost` 只能够在容器内访问。解决方法是更新 `Startup.cs` 里的 `Main` 方法来配置 Kestral 监听的 URL:
|
||||
|
||||
```
|
||||
public static void Main(string[] args)
|
||||
{
|
||||
var host = new WebHostBuilder()
|
||||
.UseKestrel()
|
||||
.UseContentRoot(Directory.GetCurrentDirectory())
|
||||
.UseUrls("http://*:5000") // 在所有网络接口上监听端口 5000
|
||||
.UseIISIntegration()
|
||||
.UseStartup<Startup>()
|
||||
.Build();
|
||||
|
||||
host.Run();
|
||||
}
|
||||
```
|
||||
|
||||
通过这些额外的配置,我可以重建镜像,并在容器中运行应用程序,它将能够接收来自主机的请求:
|
||||
|
||||
```
|
||||
docker build -t niksoper/netcore-books .
|
||||
docker run -d -p 5000:5000 niksoper/netcore-books
|
||||
curl -i http://localhost:5000/api/books
|
||||
```
|
||||
|
||||
我现在得到下面这些相应:
|
||||
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
Date: Tue, 30 Aug 2016 15:25:43 GMT
|
||||
Transfer-Encoding: chunked
|
||||
Content-Type: application/json; charset=utf-8
|
||||
Server: Kestrel
|
||||
|
||||
[{"id":"1","title":"RESTful API with ASP.NET Core MVC 1.0","author":"Nick Soper"}]
|
||||
```
|
||||
|
||||
### 在产品环境中运行 KESTREL
|
||||
|
||||
[微软的介绍](https://docs.asp.net/en/latest/publishing/linuxproduction.html#why-use-a-reverse-proxy-server):
|
||||
|
||||
> Kestrel 可以很好的处理来自 ASP.NET 的动态内容,然而,网络服务部分的特性没有如 IIS,Apache 或者 Nginx 那样的全特性服务器那么好。反向代理服务器可以让你不用去做像处理静态内容、缓存请求、压缩请求、SSL 端点这样的来自 HTTP 服务器的工作。
|
||||
|
||||
因此我需要在我的 Linux 机器上把 Nginx 设置成一个反向代理服务器。微软介绍了如何[发布到 Linux 生产环境下](https://docs.asp.net/en/latest/publishing/linuxproduction.html)的指导教程。我把说明总结在这儿:
|
||||
|
||||
1. 通过 `dotnet publish` 来给应用程序产生一个自包含包。
|
||||
2. 把已发布的应用程序复制到服务器上
|
||||
3. 安装并配置 Nginx(作为反向代理服务器)
|
||||
4. 安装并配置 [supervisor](http://supervisord.org/)(用于确保 Nginx 服务器处于运行状态中)
|
||||
5. 安装并配置 [AppArmor](https://wiki.ubuntu.com/AppArmor)(用于限制应用的资源使用)
|
||||
6. 配置服务器防火墙
|
||||
7. 安全加固 Nginx(从源代码构建和配置 SSL)
|
||||
|
||||
这些内容已经超出了本文的范围,因此我将侧重于如何把 Nginx 配置成一个反向代理服务器。自然地,我通过 Docker 来完成这件事。
|
||||
|
||||
### 在另一个容器中运行 NGINX
|
||||
|
||||
我的目标是在第二个 Docker 容器中运行 Nginx 并把它配置成我们的应用程序容器的反向代理服务器。
|
||||
|
||||
我使用的是[来自 Docker Hub 的官方 Nginx 镜像](https://hub.docker.com/_/nginx/)。首先我尝试这样做:
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 --name web nginx
|
||||
```
|
||||
|
||||
这启动了一个运行 Nginx 的容器并把主机上的 8080 端口映射到了容器的 80 端口上。现在在浏览器中打开网址 `http://localhost:8080` 会显示出 Nginx 的默认登录页面。
|
||||
|
||||
现在我们证实了运行 Nginx 是多么的简单,我们可以关闭这个容器。
|
||||
|
||||
```
|
||||
docker rm -f web
|
||||
```
|
||||
|
||||
### 把 NGINX 配置成一个反向代理服务器
|
||||
|
||||
可以通过像下面这样编辑位于 `/etc/nginx/conf.d/default.conf` 的配置文件,把 Nginx 配置成一个反向代理服务器:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:6666;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
通过上面的配置可以让 Nginx 将所有对根目录的访问请求代理到 `http://localhost:6666`。记住这里的 `localhost` 指的是运行 Nginx 的容器。我们可以在 Nginx容器内部利用卷来使用我们自己的配置文件:
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 \
|
||||
-v /path/to/my.conf:/etc/nginx/conf.d/default.conf \
|
||||
nginx
|
||||
```
|
||||
|
||||
注意:这把一个单一文件从主机映射到容器中,而不是一个完整目录。
|
||||
|
||||
### 在容器间进行通信
|
||||
|
||||
Docker 允许内部容器通过共享虚拟网络进行通信。默认情况下,所有通过 Docker 守护进程启动的容器都可以访问一种叫做“桥”的虚拟网络。这使得一个容器可以被另一个容器在相同的网络上通过 IP 地址和端口来引用。
|
||||
|
||||
你可以通过监测(inspect)容器来找到它的 IP 地址。我将从之前创建的 `niksoper/netcore-books` 镜像中启动一个容器并监测(inspect)它:
|
||||
|
||||
```
|
||||
docker run -d -p 5000:5000 --name books niksoper/netcore-books
|
||||
docker inspect books
|
||||
```
|
||||
|
||||
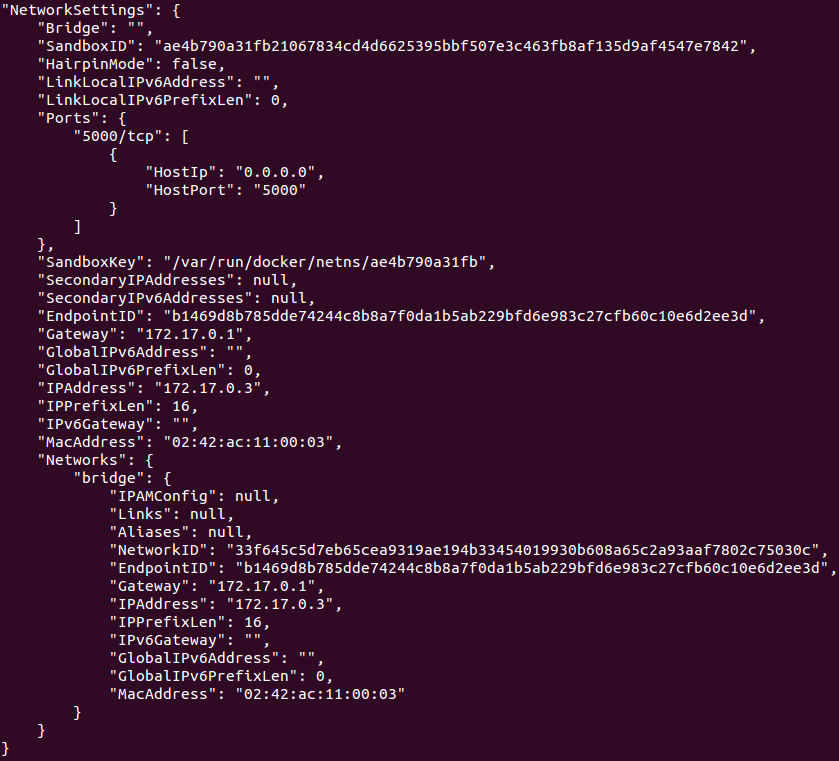
|
||||
|
||||
我们可以看到这个容器的 IP 地址是 `"IPAddress": "172.17.0.3"`。
|
||||
|
||||
所以现在如果我创建下面的 Nginx 配置文件,并使用这个文件启动一个 Nginx容器, 它将代理请求到我的 API :
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
location / {
|
||||
proxy_pass http://172.17.0.3:5000;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
现在我可以使用这个配置文件启动一个 Nginx 容器(注意我把主机上的 8080 端口映射到了 Nginx 容器上的 80 端口):
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 \
|
||||
-v ~/dev/nginx/my.nginx.conf:/etc/nginx/conf.d/default.conf \
|
||||
nginx
|
||||
```
|
||||
|
||||
一个到 `http://localhost:8080` 的请求将被代理到应用上。注意下面 `curl` 响应的 `Server` 响应头:
|
||||
|
||||
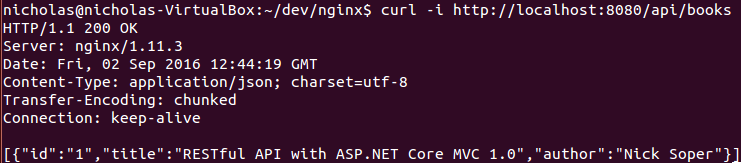
|
||||
|
||||
### DOCKER COMPOSE
|
||||
|
||||
在这个地方,我为自己的进步而感到高兴,但我认为一定还有更好的方法来配置 Nginx,可以不需要知道应用程序容器的确切 IP 地址。另一个当地的 Scott Logic DevOps 大师 Jason Ebbin 在这个地方进行了改进,并建议使用 [Docker Compose](https://docs.docker.com/compose/)。
|
||||
|
||||
概况描述一下,Docker Compose 使得一组通过声明式语法互相连接的容器很容易启动。我不想再细说 Docker Compose 是如何工作的,因为你可以在[之前的文章](http://blog.scottlogic.com/2016/01/25/playing-with-docker-compose-and-erlang.html)中找到。
|
||||
|
||||
我将通过一个我所使用的 `docker-compose.yml` 文件来启动:
|
||||
|
||||
```
|
||||
version: '2'
|
||||
services:
|
||||
books-service:
|
||||
container_name: books-api
|
||||
build: .
|
||||
|
||||
reverse-proxy:
|
||||
container_name: reverse-proxy
|
||||
image: nginx
|
||||
ports:
|
||||
- "9090:8080"
|
||||
volumes:
|
||||
- ./proxy.conf:/etc/nginx/conf.d/default.conf
|
||||
```
|
||||
|
||||
*这是版本 2 语法,所以为了能够正常工作,你至少需要 1.6 版本的 Docker Compose。*
|
||||
|
||||
这个文件告诉 Docker 创建两个服务:一个是给应用的,另一个是给 Nginx 反向代理服务器的。
|
||||
|
||||
### BOOKS-SERVICE
|
||||
|
||||
这个与 docker-compose.yml 相同目录下的 Dockerfile 构建的容器叫做 `books-api`。注意这个容器不需要发布任何端口,因为只要能够从反向代理服务器访问它就可以,而不需要从主机操作系统访问它。
|
||||
|
||||
### REVERSE-PROXY
|
||||
|
||||
这将基于 nginx 镜像启动一个叫做 `reverse-proxy` 的容器,并将位于当前目录下的 `proxy.conf` 文件挂载为配置。它把主机上的 9090 端口映射到容器中的 8080 端口,这将允许我们在 `http://localhost:9090` 上通过主机访问容器。
|
||||
|
||||
`proxy.conf` 文件看起来像下面这样:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 8080;
|
||||
|
||||
location / {
|
||||
proxy_pass http://books-service:5000;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这儿的关键点是我们现在可以通过名字引用 `books-service`,因此我们不需要知道 `books-api` 这个容器的 IP 地址!
|
||||
|
||||
现在我们可以通过一个运行着的反向代理启动两个容器(`-d` 意味着这是独立的,因此我们不能看到来自容器的输出):
|
||||
|
||||
```
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
验证我们所创建的容器:
|
||||
|
||||
```
|
||||
docker ps
|
||||
```
|
||||
|
||||
最后来验证我们可以通过反向代理来控制该 API :
|
||||
|
||||
```
|
||||
curl -i http://localhost:9090/api/books
|
||||
```
|
||||
|
||||
### 怎么做到的?
|
||||
|
||||
Docker Compose 通过创建一个新的叫做 `mvclibrary_default` 的虚拟网络来实现这件事,这个虚拟网络同时用于 `books-api` 和 `reverse-proxy` 容器(名字是基于 `docker-compose.yml` 文件的父目录)。
|
||||
|
||||
通过 `docker network ls` 来验证网络已经存在:
|
||||
|
||||

|
||||
|
||||
你可以使用 `docker network inspect mvclibrary_default` 来看到新的网络的细节:
|
||||
|
||||
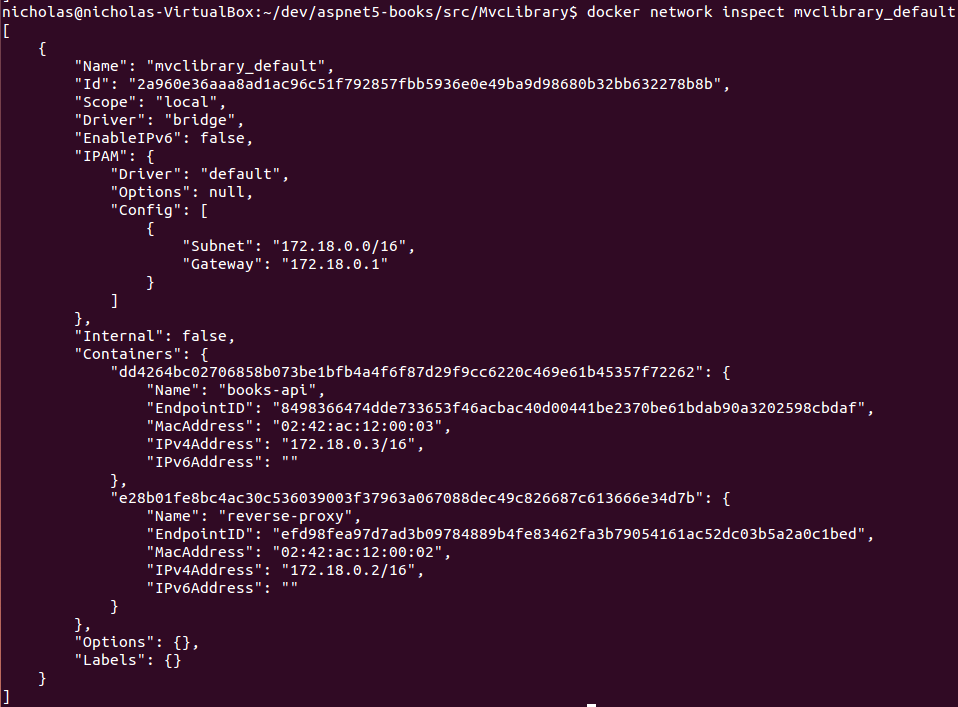
|
||||
|
||||
注意 Docker 已经给网络分配了子网:`"Subnet": "172.18.0.0/16"`。/16 部分是无类域内路由选择(CIDR),完整的解释已经超出了本文的范围,但 CIDR 只是表示 IP 地址范围。运行 `docker network inspect bridge` 显示子网:`"Subnet": "172.17.0.0/16"`,因此这两个网络是不重叠的。
|
||||
|
||||
现在用 `docker inspect books-api` 来确认应用程序的容器正在使用该网络:
|
||||
|
||||
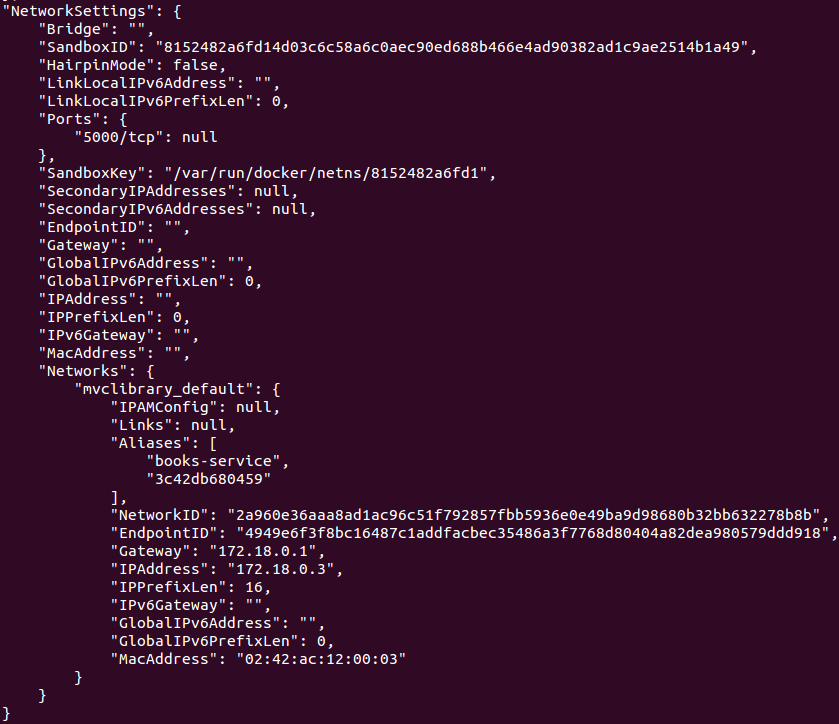
|
||||
|
||||
注意容器的两个别名(`"Aliases"`)是容器标识符(`3c42db680459`)和由 `docker-compose.yml` 给出的服务名(`books-service`)。我们通过 `books-service` 别名在自定义 Nginx 配置文件中来引用应用程序的容器。这本可以通过 `docker network create` 手动创建,但是我喜欢用 Docker Compose,因为它可以干净简洁地将容器创建和依存捆绑在一起。
|
||||
|
||||
### 结论
|
||||
|
||||
所以现在我可以通过几个简单的步骤在 Linux 系统上用 Nginx 运行应用程序,不需要对主机操作系统做任何长期的改变:
|
||||
|
||||
```
|
||||
git clone https://github.com/niksoper/aspnet5-books.git
|
||||
cd aspnet5-books/src/MvcLibrary
|
||||
git checkout blog-docker
|
||||
docker-compose up -d
|
||||
curl -i http://localhost:9090/api/books
|
||||
```
|
||||
|
||||
我知道我在这篇文章中所写的内容不是一个真正的生产环境就绪的设备,因为我没有写任何有关下面这些的内容,绝大多数下面的这些主题都需要用单独一篇完整的文章来叙述。
|
||||
|
||||
- 安全考虑比如防火墙和 SSL 配置
|
||||
- 如何确保应用程序保持运行状态
|
||||
- 如何选择需要包含的 Docker 镜像(我把所有的都放入了 Dockerfile 中)
|
||||
- 数据库 - 如何在容器中管理它们
|
||||
|
||||
对我来说这是一个非常有趣的学习经历,因为有一段时间我对探索 ASP.NET Core 的跨平台支持非常好奇,使用 “Configuratin as Code” 的 Docker Compose 方法来探索一下 DevOps 的世界也是非常愉快并且很有教育意义的。
|
||||
|
||||
如果你对 Docker 很好奇,那么我鼓励你来尝试学习它 或许这会让你离开舒适区,不过,有可能你会喜欢它?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.scottlogic.com/2016/09/05/hosting-netcore-on-linux-with-docker.html
|
||||
|
||||
作者:[Nick Soper][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://blog.scottlogic.com/nsoper
|
||||
[1]: http://blog.scottlogic.com/2016/01/20/restful-api-with-aspnet50.html
|
||||
[2]: https://docs.microsoft.com/en-us/dotnet/articles/core/migrating-from-dnx
|
||||
[3]: https://docs.asp.net/en/latest/migration/rc1-to-rtm.html
|
||||
[4]: http://www.paraesthesia.com/archive/2016/06/29/netcore-rtm-where-is-autofac/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
92
published/20160914 Down and dirty with Windows Nano Server 2016.md
Executable file
92
published/20160914 Down and dirty with Windows Nano Server 2016.md
Executable file
@ -0,0 +1,92 @@
|
||||
一起来看看 Windows Nano Server 2016
|
||||
====
|
||||
|
||||

|
||||
|
||||
> 对于远程 Windows 服务器管理,Nano Server 是快速的功能强大的工具,但是你需要知道你在做的是什么。
|
||||
|
||||
下面谈论[即将到来的 Windows Server 2016 的 Nano 版本][1],带远程管理和命令行设计,考虑到了私有云和数据中心。但是,谈论它和动手用它区别还是很大的,让我们深入看下去。
|
||||
|
||||
没有本地登录,且所有的程序、工具和代理都是 64 位,安装升级快捷,只需要非常少的时间就能重启。它非常适合做计算节点(无论在不在集群)、存储主机、DNS 服务器、IIS web 服务器,以及在容器中提供主机服务或者虚拟化的客户操作系统。
|
||||
|
||||
Nano 服务器也并不是太好玩的,你必须知道你要完成什么。你会看着远程的 PowerShell 的连接而不知所措,但如果你知道你要做什么的话,那它就非常方便和强大。
|
||||
|
||||
微软为设置 Nano 服务器提供了一个[快速入门手册][2] ,在这我给大家具体展示一下。
|
||||
|
||||
首先,你必须创建一个 .vhd 格式的虚拟磁盘文件。在步骤一中,我有几个文件不在正确的位置的小问题,Powershell 总是提示不匹配,所以我不得不反复查找文件的位置方便我可以用 ISO 信息(需要把它拷贝粘贴到你要创建 .vhd 文件的服务器上)。当你所有的东西都位置正确了,你可以开始创建 .vhd 文件的步骤了。
|
||||
|
||||

|
||||
|
||||
*步骤一:尝试运行 New-NanoServerImage 脚本时,很多文件路径错误,我把文件位置的问题搞定后,就能进行下去创建 .vhd 文件了(如图所示)*
|
||||
|
||||
接下来,你可以用创建 VM 向导在 Hyper-V 里面创建 VM 虚拟机,你需要指定一个存在的虚拟磁盘同时指向你新创建的 .vhd 文件。(步骤二)
|
||||
|
||||

|
||||
|
||||
*步骤二:连接虚拟磁盘(一开始创建的)*
|
||||
|
||||
当你启动 Nano 服务器的时候,你或许会发现有内存错误,提示你已经分配了多少内存,如果你还有其他 VM 虚拟机的话, Hyper-V 服务器剩余了多少内存。我已经关闭了一些虚机以增加可用内存,因为微软说 Nano 服务器最少需要 512M 内存,但是它又推荐你至少 800M,最后我分配了 8G 内存因为我给它 1G 的时候根本不能用,为了方便,我也没有尝试其他的内存配置。
|
||||
|
||||
最后我终于到达登录界面,到达 Nano Server Recovery Console 界面(步骤三),Nano 服务器的基本命令界面。
|
||||
|
||||

|
||||
|
||||
*步骤三:Nano 服务器的恢复窗口*
|
||||
|
||||
本来我以为进到这里会很美好,但是当我弄明白几个细节(如何加入域,弹出个磁盘,添加用户),我明白一些配置的细节,用几个参数运行 New-NanoServerImage cmdlet 会变得很简单。
|
||||
|
||||
然而,当你的服务器运行时,也有办法确认它的状态,就像步骤四所示,这一切都始于一个远程 PowerShell 连接。
|
||||
|
||||

|
||||
|
||||
*步骤四:从 Nano 服务器恢复窗口得到的信息,你可以从远程运行一个 Powershell 连接。*
|
||||
|
||||
微软展示了如何创建连接,但是尝试了四个不同的方法,我发现 [MSDN][4] 提供的是最好的方式,步骤五展示。
|
||||
|
||||

|
||||
|
||||
*步骤五:创建到 Nano 服务器的 PowerShell 远程连接*
|
||||
|
||||
提示:创建远程连接,你可以用下面这条命令:
|
||||
|
||||
```
|
||||
Enter-PSSession –ComputerName "192.168.0.100"-Credential ~\Administrator.
|
||||
```
|
||||
|
||||
如果你提前知道这台服务器将要做 DNS 服务器或者集群中的一个计算节点,可以事先在 .vhd 文件中加入一些角色和特定的软件包。如果不太清楚,你可以先建立 PowerShell 连接,然后安装 NanoServerPackage 并导入它,你就可以用 Find-NanoServerPackage 命令来查找你要部署的软件包了(步骤六)。
|
||||
|
||||

|
||||
|
||||
*步骤六:你安装完并导入 NanoServerPackage 后,你可以找到你需要启动服务器的工具以及设置的用户和你需要的一些其他功能包。*
|
||||
|
||||
我测试了安装 DNS 安装包,用 `Install-NanoServerPackage –Name Microsoft-NanoServer-DNS-Package` 这个命令。安装好后,我用 `Enable-WindowsOptionalFeature –Online –FeatureName DNS-Server-Full-Role` 命令启用它。
|
||||
|
||||
之前我并不知道这些命令,之前也从来没运行过,也没有弄过 DNS,但是现在稍微研究一下我就能用 Nano 服务器建立一个 DNS 服务并且运行它。
|
||||
|
||||
接下来是用 PowerShell 来配置 DNS 服务器。这个复杂一些,需要网上研究一下。但是它也不是那么复杂,当你学习了使用 cmdlet ,就可以用 `Add-DNSServerPrimaryZone` 添加 zone,用 `Add-DNSServerResourceRecordA` 命令在 zone 中添加记录。
|
||||
|
||||
做完这些命令行的工作,你可能需要验证是否起效。你可以快速浏览一下 PowerShell 命令,没有太多的 DNS 命令(使用 `Get-Command` 命令)。
|
||||
|
||||
如果你需要一个图形化的配置,你可以从一个图形化的主机上用图形管理器打开 Nano 服务器的 IP 地址。右击需要管理的服务器,提供你的验证信息,你连接好后,在图形管理器中右击然后选择 Add Roles and Features,它会显示你安装好的 DNS 服务,如步骤七所示。
|
||||
|
||||

|
||||
|
||||
*步骤七:通过图形化界面验证 DNS 已经安装*
|
||||
|
||||
不用麻烦登录服务器的远程桌面,你可以用服务器管理工具来进行操作。当然你能验证 DNS 角色不代表你能够通过 GUI 添加新的角色和特性,它有命令行就足够了。你现在可以用 Nano 服务器做一些需要的调整了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3119770/windows-server/down-and-dirty-with-windows-nano-server-2016.html
|
||||
|
||||
作者:[J. Peter Bruzzese][a]
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.infoworld.com/author/J.-Peter-Bruzzese/
|
||||
[1]: http://www.infoworld.com/article/3049191/windows-server/nano-server-a-slimmer-slicker-windows-server-core.html
|
||||
[2]: https://technet.microsoft.com/en-us/windows-server-docs/compute/nano-server/getting-started-with-nano-server
|
||||
[3]: https://technet.microsoft.com/en-us/windows-server-docs/get-started/system-requirements--and-installation
|
||||
[4]: https://msdn.microsoft.com/en-us/library/mt708805(v=vs.85).aspx
|
||||
@ -3,31 +3,30 @@
|
||||
|
||||

|
||||
|
||||
|
||||
我自认为自己是个奥迪亚的维基人。我通过写文章和纠正错误的文章贡献[奥迪亚][1]知识(在印度的[奥里萨邦][2]的主要的语言 )给很多维基项目,像维基百科和维基文库,我也为用印地语和英语写的维基文章做贡献。
|
||||
我自认为自己是个奥迪亚的维基人。我通过写文章和纠正文章错误给很多维基项目贡献了[奥迪亚(Odia)][1]知识(这是在印度的[奥里萨邦][2]的主要语言),比如维基百科和维基文库,我也为用印地语和英语写的维基文章做贡献。
|
||||
|
||||

|
||||
|
||||
我对维基的爱从我第 10 次考试(像在美国的 10 年级学生的年级考试)之后看到的英文维基文章[孟加拉解放战争][3]开始。一不小心我打开了印度维基文章的链接,,并且开始阅读它. 在文章左边有用奥迪亚语写的东西, 所以我点击了一下, 打开了一篇在奥迪亚维基上的 [????/Bhārat][4] 文章. 发现了用母语写的维基让我很激动!
|
||||
我对维基的爱从我第 10 次考试(像在美国的 10 年级学生的年级考试)之后看到的英文维基文章[孟加拉解放战争][3]开始。一不小心我打开了印度维基文章的链接,并且开始阅读它。在文章左边有用奥迪亚语写的东西,所以我点击了一下, 打开了一篇在奥迪亚维基上的 [ଭାରତ/Bhārat][4] 文章。发现了用母语写的维基让我很激动!
|
||||
|
||||

|
||||
|
||||
一个邀请读者参加 2014 年 4 月 1 日第二次布巴内斯瓦尔的研讨会的标语引起了我的好奇。我过去从来没有为维基做过贡献, 只用它搜索过, 我并不熟悉开源和社区贡献流程。加上,我只有 15 岁。我注册了。在研讨会上有很多语言爱好者,我是中间最年轻的一个。尽管我害怕我父亲还是鼓励我去参与。他起了非常重要的作用—他不是一个维基媒体人,和我不一样,但是他的鼓励给了我改变奥迪亚维基的动力和参加社区活动的勇气。
|
||||
一个邀请读者参加 2014 年 4 月 1 日召开的第二届布巴内斯瓦尔研讨会的旗帜广告引起了我的好奇。我过去从来没有为维基做过贡献,只用它做过研究,我并不熟悉开源和社区贡献流程。再加上,当时我只有 15 岁。我注册了,在研讨会上有很多语言爱好者,他们全比我大。尽管我害怕,我父亲还是鼓励我去参与。他起了非常重要的作用—他不是一个维基媒体人,和我不一样,但是他的鼓励给了我改变奥迪亚维基的动力和参加社区活动的勇气。
|
||||
|
||||
我相信奥迪亚语言和文学需要改进很多错误的想法和知识缺口所以,我帮助组织关于奥迪亚维基的活动和和研讨会,我完成了如下列表:
|
||||
我觉得关于奥迪亚语言和文学的知识很多需要改进,有很多错误的观念和知识缺口,所以,我帮助组织关于奥迪亚维基的活动和和研讨会,我完成了如下列表:
|
||||
|
||||
* 发起3次主要的 edit-a-thons 在奥迪亚维基:2015 年妇女节,2016年妇女节, abd [Nabakalebara edit-a-thon 2015][5]
|
||||
* 在奥迪亚维基发起 3 次主要的 edit-a-thons :2015 年妇女节、2016年妇女节、abd [Nabakalebara edit-a-thon 2015][5]
|
||||
* 在全印度发起了征集[檀车节][6]图片的比赛
|
||||
* 在谷歌的两大事件([谷歌I/O大会扩展][7]和谷歌开发节)中代表奥迪亚维基
|
||||
* 在2015[Perception][8]和第一次[Open Access India][9]会议
|
||||
* 在2015 [Perception][8] 和第一次 [Open Access India][9] 会议
|
||||
|
||||

|
||||
|
||||
我只编辑维基项目到了去年,在 2015 年一月,当我出席[孟加拉语维基百科的十周年会议][10]和[毗瑟挐][11]活动时,[互联网和社会中心][12]主任,邀请我参加[培训培训师][13] 计划。我的灵感始于扩展奥迪亚维基,为[华丽][14]的活动举办的聚会和培训新的维基人。这些经验告诉我作为一个贡献者该如何为社区工作。
|
||||
我在维基项目当编辑直到去年( 2015 年 1 月)为止,当我出席[孟加拉语维基百科的十周年会议][10]和[毗瑟挐][11]活动时,[互联网和社会中心][12]主任,邀请我参加[培训师培训计划][13]。我的开始超越奥迪亚维基,为[GLAM][14]的活动举办聚会和培训新的维基人。这些经验告诉我作为一个贡献者该如何为社区工作。
|
||||
|
||||
[Ravi][15],在当时维基的主任,在我的旅程也发挥了重要作用。他非常相信我让我参与到了[Wiki Loves Food][16],维基共享中的公共摄影比赛,组织方是[2016 印度维基会议][17]。在2015的 Loves Food 活动期间,我的团队在维基共享中加入了 10,000+ 有 CC BY-SA 协议的图片。Ravi 进一步巩固了我的承诺,和我分享很多关于维基媒体运动的信息,和他自己在 [奥迪亚维基百科13周年][18]的经历。
|
||||
[Ravi][15],在当时印度维基的总监,在我的旅程也发挥了重要作用。他非常相信我,让我参与到了 [Wiki Loves Food][16],维基共享中的公共摄影比赛,组织方是 [2016 印度维基会议][17]。在 2015 的 Loves Food 活动期间,我的团队在维基共享中加入了 10000+ 采用 CC BY-SA 协议的图片。Ravi 进一步坚定了我的信心,和我分享了很多关于维基媒体运动的信息,以及他自己在 [奥迪亚维基百科 13 周年][18]的经历。
|
||||
|
||||
不到一年后,在 2015 年十二月,我成为了网络与社会中心的[获取知识的程序][19]的项目助理( CIS-A2K 运动)。我自豪的时刻之一是在普里的研讨会,我们从印度带了 20 个新的维基人来编辑奥迪亚维基媒体社区。现在,我的指导者在一个普里非正式聚会被叫作[WikiTungi][20]。我和这个小组一起工作,把 wikiquotes 变成一个真实的计划项目。在奥迪亚维基我也致力于缩小性别差距。[八个女编辑][21]也正帮助组织聚会和研讨会,参加 [Women's History month edit-a-thon][22]。
|
||||
不到一年后,在 2015 年十二月,我成为了网络与社会中心的[获取知识计划][19]的项目助理( CIS-A2K 运动)。我自豪的时刻之一是在印度普里的研讨会,我们给奥迪亚维基媒体社区带来了 20 个新的维基人。现在,我在一个名为 [WikiTungi][20] 普里的非正式聚会上指导着维基人。我和这个小组一起工作,把奥迪亚 Wikiquotes 变成一个真实的计划项目。在奥迪亚维基我也致力于缩小性别差距。[八个女编辑][21]也正帮助组织聚会和研讨会,参加 [Women's History month edit-a-thon][22]。
|
||||
|
||||
在我四年短暂而令人激动的旅行之中,我也参与到 [维基百科的教育项目][23],[通讯团队][24],两个全球的 edit-a-thons: [Art and Feminsim][25] 和 [Menu Challenge][26]。我期待着更多的到来!
|
||||
|
||||
@ -38,8 +37,8 @@
|
||||
via: https://opensource.com/life/16/4/my-open-source-story-sailesh-patnaik
|
||||
|
||||
作者:[Sailesh Patnaik][a]
|
||||
译者:[译者ID](https://github.com/hkurj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[hkurj](https://github.com/hkurj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,38 @@
|
||||
有理想,有追求的系统管理员会在 Linux 中成长
|
||||
===============================================
|
||||
|
||||

|
||||
|
||||
我第一次看到运行着的 Linux 操作系统是在我的首份工作时,大约是在 2001 年。当时我在澳大利亚的一家汽车业供应商担任客户经理,和公司的 IT 工程师共用一间办公室。他做了一台 CD 刻录工作站(一个可以同时刻录好几张 CD 的巨大的东西),然后我们可以把汽车零配件目录刻录到 CD 并送给客户。刻录工作站最初是为 Windows 设计的,但是他一直没能让刻录机正常工作。最终他放弃在 Windows 上使用的念头并且换成在 Linux 上使用,刻录机完美工作了。
|
||||
|
||||
对我来说,Linux 的一切都是晦涩难懂的。大部分工作都在看起来像 DOS(LCTT 译注:磁盘操作系统,早期的个人电脑操作系统) 的命令行下完成,但它更加强大(后来我才认识到这一点)。我从 1993 年就开始使用 Mac 电脑,在那个时候,在我看来命令行界面有点过时了。
|
||||
|
||||
直到几年后——我记得是 2009 年,我才真正的认识 Linux。那时我已经移民荷兰并且在一家零售供应商那里找到了工作。那是一个只有 20 人的小公司,我除了做一个关键客户经理的正常工作,还无意间成了个一线 IT 技术支持。只要东西有了故障,他们总是会在花大价钱请外部 IT 顾问之前先来询问我。
|
||||
|
||||
我的一个同事因为点击了一封似乎来自 DHL(LCTT 译注:全球著名的邮递和物流集团 Deutsche Post DHL 旗下公司) 的电子邮件所附带的一个 .exe 文件而受到了一次网络钓鱼攻击。(是的,这的确发生了。)他的电脑被完全入侵了,他什么事都做不了。甚至完全格式化电脑都不起作用,好像病毒只靠它丑陋的脑袋就能活下来。我在后来才了解到这种情况可能是病毒被复制到了 MBR(主引导记录)里。而此时,为了节约成本,公司已经终止了和外部 IT 顾问的合同。
|
||||
|
||||
于是我帮助同事安装了 Ubuntu 操作系统让他继续工作,这的确很有效。他的电脑再次嗡嗡的运转了,而且我找到了他们工作必需的所有应用。我承认,从某些方面来说这不是最优雅的解决方案,不过他(包括我)喜欢这个操作系统的流畅度和稳定性。
|
||||
|
||||
然而我的同事在 Windows 世界形成的观念根深蒂固,他无法习惯新的使用方式,开始不停的抱怨。(很耳熟吧?)
|
||||
|
||||
虽然我的同事不能忍受新的使用方式,但我发现到这对我这个 Mac 用户已经不是一个问题。它们之间有很多相似点,我被迷住了。所以我在我工作用的笔记本电脑上又安装了一个 Ubuntu 组成双系统,我的工作效率提高了,让机器做我想做的事也变得更容易。从那时起我有规律的使用了几个 Linux 发行版,但我最喜欢 Ubuntu 和 Elementary。
|
||||
|
||||
当时我失业了,因此我有大量的时间给自己充电。由于我一直对 IT 行业很感兴趣,所以我致力于研究对 Linux 操作系统的管理。但是目前得到一个展示学识的机会太难了,因为我多年来所学的 95% 都不能简单的通过邮寄一份简历展示出来。我需要一个入职面试来展示我所知道的东西,所以我进行了 Linux 认证得到证书,希望能给我一些帮助。
|
||||
|
||||
我对开源做贡献已经有好一阵子了。刚开始时是为 xTuple ERP(LCTT 译注:世界领先的开源 ERP 软件)做翻译工作(英语译德语),现在已经转为在 Twitter 上做 Mozilla 的“客户服务”,提交 bug 报告等。我为自由和开源软件做推广宣传(取得了不同程度的成功)并且尽我所能在财政方面支持一些 FOSS(LCTT 译注:自由及开源软件)倡导组织(DuckDuckGo、bof.nl、EFF、GIMP、LibreCAD、维基百科以及其他)。目前我也在准备设立一个本地的隐私咖啡馆(LCTT 译注:这是荷兰的一个旨在强化网上个人隐私安全的咖啡馆/志愿者组织,参见: https://privacycafe.bof.nl/)。
|
||||
|
||||
除此之外,我已经开始写我的第一本书。这应该是一本涉及计算机隐私和安全领域的简易实用手册,适用于普通计算机用户,我希望它能在今年年底自主出版。(这本书遵循知识共享许可协议 CC。)至于这本书的内容,正如你预料的那样我会详细解释为什么隐私如此重要,以及“我没有什么需要隐藏“这种思想错的有多么离谱。但是最主要的部分还是指导读者如何避免让人讨厌的广告追踪,加密你的硬盘和邮件,通过 OTR(LCTT 译注:一种安全协议,为即时通讯提供加密保护)网上聊天,如何使用 TOR(LCTT 译注:第二代洋葱路由,可以在因特网上进行匿名交流)等等。虽然起初说这是一个手册,但我尽量会使用随和的语调来叙述,并且会根据精彩的我亲身经历的故事让它更加通俗易懂。
|
||||
|
||||
我依然爱着我所有的 Mac,只要买得起(主要因为它那伟大的构造),我还会使用它们,但是我的 Linux 一直在虚拟机里完成我的几乎所有的日常工作。没有什么不可思议的,不是自夸:文档编辑(LibreOffice 和 Scribus),建立我的网页和博客(Wordpress 和 Jekyll),编辑图片(Shotwell 和 Gimp),听音乐(Rhythmbox),以及几乎其他任何工作。
|
||||
|
||||
不论我最后怎么找到工作,Linux 永远都是我必用的操作系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/5/my-linux-story-rene-raggl
|
||||
|
||||
作者:[Rene Raggl][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
[a]: https://opensource.com/users/rraggl
|
||||
@ -0,0 +1,61 @@
|
||||
4 个你需要了解的容器网络工具
|
||||
===========
|
||||
|
||||

|
||||
|
||||
> [Creative Commons Zero][1]
|
||||
|
||||
有如此之多的各种新的云计算技术、工具和技术需要我们跟进,到底从哪里开始学习是一个艰难的决定。这一系列[下一代云计算技术][2]的文章旨在让你快速了解新兴和快速变化领域的重大项目和产品,比如软件定义网络(SDN)、容器,以及其交叉领域:容器网络。
|
||||
|
||||
对于企业容器部署,容器和网络之间的关系仍然是一个挑战。容器需要网络功能来连接分布式应用程序。根据一篇最新的[企业网络星球][3]的文章,一部分的挑战是“以隔离的方式部署容器,在提供隔离自己容器内数据的所需功能的同时,保持有效的连接性”。
|
||||
|
||||
流行的容器平台 [Docker][4],使用了软件定义虚拟网络来连接容器与本地网络。此外,它使用 Linux 的桥接功能和虚拟可扩展局域网(VXLAN)技术,可以在同一 Swarm 或容器集群内互相沟通。Docker 的插件架构也支持其他网络管理工具来管理容器网络,比如下面的提到的工具。
|
||||
|
||||
容器网络上的创新使得容器可以跨主机连接到其他容器上。这使开发人员可以在开发环境中,在一个主机上部署一个容器来运行一个应用,然后可以过渡到测试环境中,进而到生产环境中,使应用可以持续集成,敏捷开发,快速部署。
|
||||
|
||||
容器网络工具有助于实现容器网络的可扩展性,主要是通过:
|
||||
|
||||
1. 使复杂的,多主机系统能够跨多个容器主机进行分发。
|
||||
2. 允许构建跨越多个公有云和私有云平台上的大量主机的容器系统。
|
||||
|
||||

|
||||
|
||||
*John Willis speaking 在 Open Networking Summit 2016.*
|
||||
|
||||
要获取更多信息,查看 [Docker 网络教程][5],是由 Brent Salisbury 和 John Willis 在最近的 [Open Networking Summit (ONS)][6]讲演的。更多关于 ONS 的演讲内容可以在[这里][7]找到。
|
||||
|
||||
你应该知道的容器网络工具和项目包括下述:
|
||||
|
||||
- [Calico][8] -- Calico 项目(源自 [Metaswitch][9])利用边界网关协议(BGP)和集成的云编排系统来保证虚拟机和容器之间的 IP 通信安全。
|
||||
- [Flannel][10] -- Flannel (之前叫 rudder) 源自 [CoreOS][11],它提供了一个覆盖网络,可以作为一个现有的 SDN 解决方案的替代品。
|
||||
- [Weaveworks][12] -- Weaveworks 项目管理容器的工具包括 [Weave Net][13]、Weave Scope、Weave Flux。Weave Net 是一种用于构建和部署 Docker 容器的网络工具。
|
||||
- [Canal][14] -- 就在本周,CoreOS 和 Tigera 宣布了新的开源项目 Canal 的信息。据其声明,Canal 项目旨在结合部分 Calico 和 Flannel,“构造网络安全策略到网络架构和云管理平台之中”。
|
||||
|
||||
你可以通过 Linux 基金会的免费“云基础设施技术”课程来了解更多关于容器管理、软件定义网络和其他下一代云技术,这是一个在 edX 上提供的大规模公开在线课程。[课程注册目前已经开放][15],课程内容于 6 月开放。
|
||||
|
||||
------
|
||||
|
||||
via: https://www.linux.com/news/4-container-networking-tools-know
|
||||
|
||||
作者:[AMBER ANKERHOLZ][a]
|
||||
译者:[Bestony](https://github.com/Bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/aankerholz
|
||||
[1]: https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]: https://www.linux.com/news/5-next-gen-cloud-technologies-you-should-know
|
||||
[3]: http://www.enterprisenetworkingplanet.com/datacenter/datacenter-blog/container-networking-challenges-for-the-enterprise.html
|
||||
[4]: https://docs.docker.com/engine/userguide/networking/dockernetworks/
|
||||
[5]: https://youtu.be/Le0bEg4taak
|
||||
[6]: http://events.linuxfoundation.org/events/open-networking-summit
|
||||
[7]: https://www.linux.com/watch-videos-from-ons2016
|
||||
[8]: https://www.projectcalico.org/
|
||||
[9]: http://www.metaswitch.com/cloud-network-virtualization
|
||||
[10]: https://coreos.com/blog/introducing-rudder/
|
||||
[11]: https://coreos.com/
|
||||
[12]: https://www.weave.works/
|
||||
[13]: https://www.weave.works/products/weave-net/
|
||||
[14]: https://github.com/tigera/canal
|
||||
[15]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-cloud-infrastructure-technologies?utm_source=linuxcom&utm_medium=article&utm_campaign=cloud%20mooc%20article%201
|
||||
@ -0,0 +1,176 @@
|
||||
Python 单元测试:assertTrue 是真值,assertFalse 是假值
|
||||
===========================
|
||||
|
||||
在这篇文章中,我们将介绍单元测试的布尔断言方法 `assertTrue` 和 `assertFalse` 与身份断言 `assertIs` 之间的区别。
|
||||
|
||||
### 定义
|
||||
|
||||
下面是目前[单元测试模块文档][1]中关于 `assertTrue` 和 `assertFalse` 的说明,代码进行了高亮:
|
||||
|
||||
|
||||
> `assertTrue(expr, msg=None)`
|
||||
|
||||
> `assertFalse(expr, msg=None)`
|
||||
|
||||
>> 测试该*表达式*是真值(或假值)。
|
||||
|
||||
>> 注:这等价于
|
||||
|
||||
>> `bool(expr) is True`
|
||||
|
||||
>> 而不等价于
|
||||
|
||||
>> `expr is True`
|
||||
|
||||
>> (后一种情况请使用 `assertIs(expr, True)`)。
|
||||
|
||||
[Mozilla 开发者网络中定义 `真值`][2] 如下:
|
||||
|
||||
> 在一个布尔值的上下文环境中能变成“真”的值
|
||||
|
||||
在 Python 中等价于:
|
||||
|
||||
```
|
||||
bool(expr) is True
|
||||
```
|
||||
|
||||
这个和 `assertTrue` 的测试目的完全匹配。
|
||||
|
||||
因此该文档中已经指出 `assertTrue` 返回真值,`assertFalse` 返回假值。这些断言方法从接受到的值构造出一个布尔值,然后判断它。同样文档中也建议我们根本不应该使用 `assertTrue` 和 `assertFalse`。
|
||||
|
||||
### 在实践中怎么理解?
|
||||
|
||||
我们使用一个非常简单的例子 - 一个名称为 `always_true` 的函数,它返回 `True`。我们为它写一些测试用例,然后改变代码,看看测试用例的表现。
|
||||
|
||||
作为开始,我们先写两个测试用例。一个是“宽松的”:使用 `assertTrue` 来测试真值。另外一个是“严格的”:使用文档中建议的 `assertIs` 函数。
|
||||
|
||||
```
|
||||
import unittest
|
||||
|
||||
from func import always_true
|
||||
|
||||
|
||||
class TestAlwaysTrue(unittest.TestCase):
|
||||
|
||||
def test_assertTrue(self):
|
||||
"""
|
||||
always_true returns a truthy value
|
||||
"""
|
||||
result = always_true()
|
||||
|
||||
self.assertTrue(result)
|
||||
|
||||
def test_assertIs(self):
|
||||
"""
|
||||
always_true returns True
|
||||
"""
|
||||
result = always_true()
|
||||
|
||||
self.assertIs(result, True)
|
||||
```
|
||||
|
||||
下面是 `func.py` 中的非常简单的函数代码:
|
||||
|
||||
```
|
||||
def always_true():
|
||||
"""
|
||||
I'm always True.
|
||||
|
||||
Returns:
|
||||
bool: True
|
||||
"""
|
||||
return True
|
||||
```
|
||||
|
||||
当你运行时,所有测试都通过了:
|
||||
|
||||
```
|
||||
always_true returns True ... ok
|
||||
always_true returns a truthy value ... ok
|
||||
|
||||
----------------------------------------------------------------------
|
||||
Ran 2 tests in 0.004s
|
||||
|
||||
OK
|
||||
```
|
||||
|
||||
开心ing~
|
||||
|
||||
现在,某个人将 `always_true` 函数改变成下面这样:
|
||||
|
||||
```
|
||||
def always_true():
|
||||
"""
|
||||
I'm always True.
|
||||
|
||||
Returns:
|
||||
bool: True
|
||||
"""
|
||||
return 'True'
|
||||
```
|
||||
|
||||
它现在是用返回字符串 `"True"` 来替代之前反馈的 `True` (布尔值)。(当然,那个“某人”并没有更新文档 - 后面我们会增加难度。)
|
||||
|
||||
这次结果并不如开心了:
|
||||
|
||||
```
|
||||
always_true returns True ... FAIL
|
||||
always_true returns a truthy value ... ok
|
||||
|
||||
======================================================================
|
||||
FAIL: always_true returns True
|
||||
----------------------------------------------------------------------
|
||||
Traceback (most recent call last):
|
||||
File "/tmp/assertttt/test.py", line 22, in test_is_true
|
||||
self.assertIs(result, True)
|
||||
AssertionError: 'True' is not True
|
||||
|
||||
----------------------------------------------------------------------
|
||||
Ran 2 tests in 0.004s
|
||||
|
||||
FAILED (failures=1)
|
||||
```
|
||||
|
||||
只有一个测试用例失败了!这意味着 `assertTrue` 给了我们一个误判(false-positive)。在它不应该通过测试时,它通过了。很幸运的是我们第二个测试是使用 `assertIs` 来写的。
|
||||
|
||||
因此,跟手册上了解到的信息一样,为了保证 `always_true` 的功能和更严格测试的结果保持一致,应该使用 `assertIs` 而不是 `assertTrue`。
|
||||
|
||||
### 使用断言的辅助方法
|
||||
|
||||
使用 `assertIs` 来测试返回 `True` 和 `False` 来冗长了。因此,如果你有个项目需要经常检查是否是返回了 `True` 或者 `False`,那们你可以自己编写一些断言的辅助方法。
|
||||
|
||||
这好像并没有节省大量的代码,但是我个人觉得提高了代码的可读性。
|
||||
|
||||
```
|
||||
def assertIsTrue(self, value):
|
||||
self.assertIs(value, True)
|
||||
|
||||
def assertIsFalse(self, value):
|
||||
self.assertIs(value, False)
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
一般来说,我的建议是让测试越严格越好。如果你想测试 `True` 或者 `False`,听从[文档][3]的建议,使用 `assertIs`。除非不得已,否则不要使用 `assertTrue` 和 `assertFalse`。
|
||||
|
||||
如果你面对的是一个可以返回多种类型的函数,例如,有时候返回布尔值,有时候返回整形,那么考虑重构它。这是代码的异味。在 Python 中,抛出一个异常比使用 `False` 表示错误更好。
|
||||
|
||||
此外,如果你确实想使用断言来判断函数的返回值是否是真,可能还存在第二个代码异味 - 代码是正确封装了吗?如果 `assertTrue` 和 `assertFalse` 是根据正确的 `if` 语句来执行,那么值得检查下你是否把所有你想要的东西都封装在合适的位置。也许这些 `if` 语句应该封装在测试的函数中。
|
||||
|
||||
测试开心!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jamescooke.info/python-unittest-asserttrue-is-truthy-assertfalse-is-falsy.html
|
||||
|
||||
作者:[James Cooke][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://jamescooke.info/pages/hello-my-name-is-james.html
|
||||
[1]:https://docs.python.org/3/library/unittest.html#unittest.TestCase.assertTrue
|
||||
[2]:https://developer.mozilla.org/en-US/docs/Glossary/Truthy
|
||||
[3]:https://docs.python.org/3/library/unittest.html#unittest.TestCase.assertTrue
|
||||
317
published/201610/20160604 How to Build Your First Slack Bot with Python.md
Executable file
317
published/201610/20160604 How to Build Your First Slack Bot with Python.md
Executable file
@ -0,0 +1,317 @@
|
||||
如何运用 Python 建立你的第一个 Slack 聊天机器人?
|
||||
============
|
||||
|
||||
[聊天机器人(Bot)](https://www.fullstackpython.com/bots.html) 是一种像 [Slack](https://slack.com/) 一样的实用的互动聊天服务方式。如果你之前从来没有建立过聊天机器人,那么这篇文章提供了一个简单的入门指南,告诉你如何用 Python 结合 [Slack API](https://api.slack.com/) 建立你第一个聊天机器人。
|
||||
|
||||
我们通过搭建你的开发环境, 获得一个 Slack API 的聊天机器人令牌,并用 Pyhon 开发一个简单聊天机器人。
|
||||
|
||||
### 我们所需的工具
|
||||
|
||||
我们的聊天机器人我们将它称作为“StarterBot”,它需要 Python 和 Slack API。要运行我们的 Python 代码,我们需要:
|
||||
|
||||
* [Python 2 或者 Python 3](https://www.fullstackpython.com/python-2-or-3.html)
|
||||
* [pip](https://pip.pypa.io/en/stable/) 和 [virtualenv](https://virtualenv.pypa.io/en/stable/) 来处理 Python [应用程序依赖关系](https://www.fullstackpython.com/application-dependencies.html)
|
||||
* 一个可以访问 API 的[免费 Slack 账号](https://slack.com/),或者你可以注册一个 [Slack Developer Hangout team](http://dev4slack.xoxco.com/)。
|
||||
* 通过 Slack 团队建立的官方 Python [Slack 客户端](https://github.com/slackhq/python-slackclient)代码库
|
||||
* [Slack API 测试令牌](https://api.slack.com/tokens)
|
||||
|
||||
当你在本教程中进行构建时,[Slack API 文档](https://api.slack.com/) 是很有用的。
|
||||
|
||||
本教程中所有的代码都放在 [slack-starterbot](https://github.com/mattmakai/slack-starterbot) 公共库里,并以 MIT 许可证开源。
|
||||
|
||||
### 搭建我们的环境
|
||||
|
||||
我们现在已经知道我们的项目需要什么样的工具,因此让我们来搭建我们所的开发环境吧。首先到终端上(或者 Windows 上的命令提示符)并且切换到你想要存储这个项目的目录。在那个目录里,创建一个新的 virtualenv 以便和其他的 Python 项目相隔离我们的应用程序依赖关系。
|
||||
|
||||
```
|
||||
virtualenv starterbot
|
||||
|
||||
```
|
||||
|
||||
激活 virtualenv:
|
||||
|
||||
```
|
||||
source starterbot/bin/activate
|
||||
|
||||
```
|
||||
|
||||
你的提示符现在应该看起来如截图:
|
||||
|
||||

|
||||
|
||||
这个官方的 slack 客户端 API 帮助库是由 Slack 建立的,它可以通过 Slack 通道发送和接收消息。通过这个 `pip` 命令安装 slackclient 库:
|
||||
|
||||
```
|
||||
pip install slackclient
|
||||
|
||||
```
|
||||
|
||||
当 `pip` 命令完成时,你应该看到类似这样的输出,并返回提示符。
|
||||
|
||||

|
||||
|
||||
我们也需要为我们的 Slack 项目获得一个访问令牌,以便我们的聊天机器人可以用它来连接到 Slack API。
|
||||
|
||||
### Slack 实时消息传递(RTM)API
|
||||
|
||||
Slack 允许程序通过一个 [Web API](https://www.fullstackpython.com/application-programming-interfaces.html) 来访问他们的消息传递通道。去这个 [Slack Web API 页面](https://api.slack.com/) 注册建立你自己的 Slack 项目。你也可以登录一个你拥有管理权限的已有账号。
|
||||
|
||||

|
||||
|
||||
登录后你会到达 [聊天机器人用户页面](https://api.slack.com/bot-users)。
|
||||
|
||||

|
||||
|
||||
给你的聊天机器人起名为“starterbot”然后点击 “Add bot integration” 按钮。
|
||||
|
||||

|
||||
|
||||
这个页面将重新加载,你将看到一个新生成的访问令牌。你还可以将标志改成你自己设计的。例如我给的这个“Full Stack Python”标志。
|
||||
|
||||

|
||||
|
||||
在页面底部点击“Save Integration”按钮。你的聊天机器人现在已经准备好连接 Slack API。
|
||||
|
||||
Python 开发人员的一个常见的做法是以环境变量输出秘密令牌。输出的 Slack 令牌名字为`SLACK_BOT_TOKEN`:
|
||||
|
||||
```
|
||||
export SLACK_BOT_TOKEN='你的 slack 令牌粘帖在这里'
|
||||
|
||||
```
|
||||
|
||||
好了,我们现在得到了将这个 Slack API 用作聊天机器人的授权。
|
||||
|
||||
我们建立聊天机器人还需要更多信息:我们的聊天机器人的 ID。接下来我们将会写一个简短的脚本,从 Slack API 获得该 ID。
|
||||
|
||||
### 获得我们聊天机器人的 ID
|
||||
|
||||
这是最后写一些 Python 代码的时候了! 我们编写一个简短的 Python 脚本获得 StarterBot 的 ID 来热身一下。这个 ID 基于 Slack 项目而不同。
|
||||
|
||||
我们需要该 ID,当解析从 Slack RTM 上发给 StarterBot 的消息时,它用于对我们的应用验明正身。我们的脚本也会测试我们 `SLACK_BOT_TOKEN` 环境变量是否设置正确。
|
||||
|
||||
建立一个命名为 print_bot_id.py 的新文件,并且填入下面的代码:
|
||||
|
||||
```
|
||||
import os
|
||||
from slackclient import SlackClient
|
||||
|
||||
|
||||
BOT_NAME = 'starterbot'
|
||||
|
||||
slack_client = SlackClient(os.environ.get('SLACK_BOT_TOKEN'))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
api_call = slack_client.api_call("users.list")
|
||||
if api_call.get('ok'):
|
||||
# retrieve all users so we can find our bot
|
||||
users = api_call.get('members')
|
||||
for user in users:
|
||||
if 'name' in user and user.get('name') == BOT_NAME:
|
||||
print("Bot ID for '" + user['name'] + "' is " + user.get('id'))
|
||||
else:
|
||||
print("could not find bot user with the name " + BOT_NAME)
|
||||
|
||||
```
|
||||
|
||||
我们的代码导入 SlackClient,并用我们设置的环境变量 `SLACK_BOT_TOKEN` 实例化它。 当该脚本通过 python 命令执行时,我们通过会访问 Slack API 列出所有的 Slack 用户并且获得匹配一个名字为“satrterbot”的 ID。
|
||||
|
||||
这个获得聊天机器人的 ID 的脚本我们仅需要运行一次。
|
||||
|
||||
```
|
||||
python print_bot_id.py
|
||||
|
||||
```
|
||||
|
||||
当它运行为我们提供了聊天机器人的 ID 时,脚本会打印出简单的一行输出。
|
||||
|
||||

|
||||
|
||||
复制这个脚本打印出的唯一 ID。并将该 ID 作为一个环境变量 `BOT_ID` 输出。
|
||||
|
||||
```
|
||||
(starterbot)$ export BOT_ID='bot id returned by script'
|
||||
|
||||
```
|
||||
|
||||
这个脚本仅仅需要运行一次来获得聊天机器人的 ID。 我们现在可以在我们的运行 StarterBot 的 Python应用程序中使用这个 ID 。
|
||||
|
||||
### 编码我们的 StarterBot
|
||||
|
||||
现在我们拥有了写我们的 StarterBot 代码所需的一切。 创建一个新文件命名为 starterbot.py ,它包括以下代码。
|
||||
|
||||
```
|
||||
import os
|
||||
import time
|
||||
from slackclient import SlackClient
|
||||
|
||||
```
|
||||
|
||||
对 `os` 和 `SlackClient` 的导入我们看起来很熟悉,因为我们已经在 theprint_bot_id.py 中用过它们了。
|
||||
|
||||
通过我们导入的依赖包,我们可以使用它们获得环境变量值,并实例化 Slack 客户端。
|
||||
|
||||
```
|
||||
# starterbot 的 ID 作为一个环境变量
|
||||
BOT_ID = os.environ.get("BOT_ID")
|
||||
|
||||
# 常量
|
||||
AT_BOT = "<@" + BOT_ID + ">:"
|
||||
EXAMPLE_COMMAND = "do"
|
||||
|
||||
# 实例化 Slack 和 Twilio 客户端
|
||||
slack_client = SlackClient(os.environ.get('SLACK_BOT_TOKEN'))
|
||||
|
||||
```
|
||||
|
||||
该代码通过我们以输出的环境变量 `SLACK_BOT_TOKEN 实例化 `SlackClient` 客户端。
|
||||
|
||||
```
|
||||
if __name__ == "__main__":
|
||||
READ_WEBSOCKET_DELAY = 1 # 1 从 firehose 读取延迟 1 秒
|
||||
if slack_client.rtm_connect():
|
||||
print("StarterBot connected and running!")
|
||||
while True:
|
||||
command, channel = parse_slack_output(slack_client.rtm_read())
|
||||
if command and channel:
|
||||
handle_command(command, channel)
|
||||
time.sleep(READ_WEBSOCKET_DELAY)
|
||||
else:
|
||||
print("Connection failed. Invalid Slack token or bot ID?")
|
||||
|
||||
```
|
||||
|
||||
Slack 客户端会连接到 Slack RTM API WebSocket,然后当解析来自 firehose 的消息时会不断循环。如果有任何发给 StarterBot 的消息,那么一个被称作 `handle_command` 的函数会决定做什么。
|
||||
|
||||
接下来添加两个函数来解析 Slack 的输出并处理命令。
|
||||
|
||||
```
|
||||
def handle_command(command, channel):
|
||||
"""
|
||||
Receives commands directed at the bot and determines if they
|
||||
are valid commands. If so, then acts on the commands. If not,
|
||||
returns back what it needs for clarification.
|
||||
"""
|
||||
response = "Not sure what you mean. Use the *" + EXAMPLE_COMMAND + \
|
||||
"* command with numbers, delimited by spaces."
|
||||
if command.startswith(EXAMPLE_COMMAND):
|
||||
response = "Sure...write some more code then I can do that!"
|
||||
slack_client.api_call("chat.postMessage", channel=channel,
|
||||
text=response, as_user=True)
|
||||
|
||||
def parse_slack_output(slack_rtm_output):
|
||||
"""
|
||||
The Slack Real Time Messaging API is an events firehose.
|
||||
this parsing function returns None unless a message is
|
||||
directed at the Bot, based on its ID.
|
||||
"""
|
||||
output_list = slack_rtm_output
|
||||
if output_list and len(output_list) > 0:
|
||||
for output in output_list:
|
||||
if output and 'text' in output and AT_BOT in output['text']:
|
||||
# 返回 @ 之后的文本,删除空格
|
||||
return output['text'].split(AT_BOT)[1].strip().lower(), \
|
||||
output['channel']
|
||||
return None, None
|
||||
|
||||
```
|
||||
|
||||
`parse_slack_output` 函数从 Slack 接受信息,并且如果它们是发给我们的 StarterBot 时会作出判断。消息以一个给我们的聊天机器人 ID 的直接命令开始,然后交由我们的代码处理。目前只是通过 Slack 管道发布一个消息回去告诉用户去多写一些 Python 代码!
|
||||
|
||||
这是整个程序组合在一起的样子 (你也可以 [在 GitHub 中查看该文件](https://github.com/mattmakai/slack-starterbot/blob/master/starterbot.py)):
|
||||
|
||||
```
|
||||
import os
|
||||
import time
|
||||
from slackclient import SlackClient
|
||||
|
||||
# starterbot 的 ID 作为一个环境变量
|
||||
BOT_ID = os.environ.get("BOT_ID")
|
||||
|
||||
# 常量
|
||||
AT_BOT = "<@" + BOT_ID + ">:"
|
||||
EXAMPLE_COMMAND = "do"
|
||||
|
||||
# 实例化 Slack 和 Twilio 客户端
|
||||
slack_client = SlackClient(os.environ.get('SLACK_BOT_TOKEN'))
|
||||
|
||||
def handle_command(command, channel):
|
||||
"""
|
||||
Receives commands directed at the bot and determines if they
|
||||
are valid commands. If so, then acts on the commands. If not,
|
||||
returns back what it needs for clarification.
|
||||
"""
|
||||
response = "Not sure what you mean. Use the *" + EXAMPLE_COMMAND + \
|
||||
"* command with numbers, delimited by spaces."
|
||||
if command.startswith(EXAMPLE_COMMAND):
|
||||
response = "Sure...write some more code then I can do that!"
|
||||
slack_client.api_call("chat.postMessage", channel=channel,
|
||||
text=response, as_user=True)
|
||||
|
||||
def parse_slack_output(slack_rtm_output):
|
||||
"""
|
||||
The Slack Real Time Messaging API is an events firehose.
|
||||
this parsing function returns None unless a message is
|
||||
directed at the Bot, based on its ID.
|
||||
"""
|
||||
output_list = slack_rtm_output
|
||||
if output_list and len(output_list) > 0:
|
||||
for output in output_list:
|
||||
if output and 'text' in output and AT_BOT in output['text']:
|
||||
# 返回 @ 之后的文本,删除空格
|
||||
return output['text'].split(AT_BOT)[1].strip().lower(), \
|
||||
output['channel']
|
||||
return None, None
|
||||
|
||||
if __name__ == "__main__":
|
||||
READ_WEBSOCKET_DELAY = 1 # 1 second delay between reading from firehose
|
||||
if slack_client.rtm_connect():
|
||||
print("StarterBot connected and running!")
|
||||
while True:
|
||||
command, channel = parse_slack_output(slack_client.rtm_read())
|
||||
if command and channel:
|
||||
handle_command(command, channel)
|
||||
time.sleep(READ_WEBSOCKET_DELAY)
|
||||
else:
|
||||
print("Connection failed. Invalid Slack token or bot ID?")
|
||||
|
||||
```
|
||||
|
||||
现在我们的代码已经有了,我们可以通过 `python starterbot.py` 来运行我们 StarterBot 的代码了。
|
||||
|
||||

|
||||
|
||||
在 Slack 中创建新通道,并且把 StarterBot 邀请进来,或者把 StarterBot 邀请进一个已经存在的通道中。
|
||||
|
||||

|
||||
|
||||
现在在你的通道中给 StarterBot 发命令。
|
||||
|
||||

|
||||
|
||||
如果你从聊天机器人得到的响应中遇见问题,你可能需要做一个修改。正如上面所写的这个教程,其中一行 `AT_BOT = "<@" + BOT_ID + ">:"`,在“@starter”(你给你自己的聊天机器人起的名字)后需要一个冒号。从`AT_BOT` 字符串后面移除`:`。Slack 似乎需要在 `@` 一个人名后加一个冒号,但这好像是有些不协调的。
|
||||
|
||||
### 结束
|
||||
|
||||
好吧,你现在已经获得一个简易的聊天机器人,你可以在代码中很多地方加入你想要创建的任何特性。
|
||||
|
||||
我们能够使用 Slack RTM API 和 Python 完成很多功能。看看通过这些文章你还可以学习到什么:
|
||||
|
||||
* 附加一个持久的[关系数据库](https://www.fullstackpython.com/databases.html) 或者 [NoSQL 后端](https://www.fullstackpython.com/no-sql-datastore.html) 比如 [PostgreSQL](https://www.fullstackpython.com/postgresql.html)、[MySQL](https://www.fullstackpython.com/mysql.html) 或者 [SQLite](https://www.fullstackpython.com/sqlite.html) ,来保存和检索用户数据
|
||||
* 添加另外一个与聊天机器人互动的通道,比如 [短信](https://www.twilio.com/blog/2016/05/build-sms-slack-bot-python.html) 或者[电话呼叫](https://www.twilio.com/blog/2016/05/add-phone-calling-slack-python.html)
|
||||
* [集成其它的 web API](https://www.fullstackpython.com/api-integration.html),比如 [GitHub](https://developer.github.com/v3/)、[Twilio](https://www.twilio.com/docs) 或者 [api.ai](https://docs.api.ai/)
|
||||
|
||||
有问题? 通过 Twitter 联系我 [@fullstackpython](https://twitter.com/fullstackpython) 或 [@mattmakai](https://twitter.com/mattmakai)。 我在 GitHub 上的用户名是 [mattmakai](https://github.com/mattmakai)。
|
||||
|
||||
这篇文章感兴趣? Fork 这个 [GitHub 上的页面](https://github.com/mattmakai/fullstackpython.com/blob/gh-pages/source/content/posts/160604-build-first-slack-bot-python.markdown)吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://www.fullstackpython.com/blog/build-first-slack-bot-python.html
|
||||
|
||||
作者:[Matt Makai][a]
|
||||
译者:[jiajia9llinuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出aa
|
||||
|
||||
[a]: https://www.fullstackpython.com/about-author.html
|
||||
@ -0,0 +1,133 @@
|
||||
科学音频处理(三):如何使用 Octave 的高级数学技术处理音频文件
|
||||
=====
|
||||
|
||||
我们的数字音频处理技术第三部分涵盖了信号调制内容,将解释如何进行调幅(Amplitude Modulation)、颤音效果(Tremolo Effect)和频率变化(Frequency Variation)。
|
||||
|
||||
### 调制
|
||||
|
||||
#### 调幅
|
||||
|
||||
正如它的名字暗示的那样, 影响正弦信号的振幅变化依据传递的信息而不断改变。正弦波因为承载着大量的信息被称作载波(carrier)。这种调制技术被用于许多的商业广播和市民信息传输波段(AM)。
|
||||
|
||||
#### 为何要使用调幅技术?
|
||||
|
||||
**调制发射**
|
||||
|
||||
假设信道是免费资源,有天线就可以发射和接收信号。这要求有效的电磁信号发射天线,它的大小和要被发射的信号的波长应该是同一数量级。很多信号,包括音频成分,通常在 100 赫兹或更低。对于这些信号,如果直接发射,我们就需要建立长达 300 公里的天线。如果通过信号调制将信息加载到 100MHz 的高频载波中,那么天线仅仅需要 1 米(横向长度)。
|
||||
|
||||
**集中调制与多通道**
|
||||
|
||||
假设多个信号占用一个通道,调制可以将不同的信号不同频域位置,以便接收者选择该特定信号。使用集中调制(“复用”)的应用有遥感探测数据、立体声调频收音机和长途电话等。
|
||||
|
||||
**克服设备限制的调制**
|
||||
|
||||
信号处理设备,比如过滤器、放大器,以及可以用它们简单组成的设备,它们的性能依赖于信号在频域中的境况以及高频率和低频信号的关系。调制可以用于传递信号到频域中的更容易满足设计需求的位置。调制也可以将“宽带信号“(高频和低频的比例很大的信号)转换成”窄带“信号。
|
||||
|
||||
**音频特效**
|
||||
|
||||
许多音频特效由于引人注目和处理信号的便捷性使用了调幅技术。我们可以说出很多,比如颤音、合唱、镶边等等。这种实用性就是我们关注它的原因。
|
||||
|
||||
### 颤音效果
|
||||
|
||||
颤音效果是调幅最简单的应用,为实现这样的效果,我们会用周期信号改变(乘)音频信号,使用正弦或其他。
|
||||
|
||||
```
|
||||
>> tremolo='tremolo.ogg';
|
||||
>> fs=44100;
|
||||
>> t=0:1/fs:10;
|
||||
>> wo=2*pi*440*t;
|
||||
>> wa=2*pi*1.2*t;
|
||||
>> audiowrite(tremolo, cos(wa).*cos(wo),fs);
|
||||
```
|
||||
|
||||
|
||||
|
||||
这将创造一个正弦形状的信号,它的效果就像‘颤音’。
|
||||
|
||||
|
||||
|
||||
### 在真实音频文件中的颤音
|
||||
|
||||
现在我们将展示真实世界中的颤音效果。首先,我们使用之前记录过男性发声 ‘A’ 的音频文件。这个信号图就像下面这样:
|
||||
|
||||
```
|
||||
>> [y,fs]=audioread('A.ogg');
|
||||
>> plot(y);
|
||||
```
|
||||
|
||||
|
||||
|
||||
现在我们将创建一个完整的正弦信号,使用如下的参数:
|
||||
|
||||
- 增幅 = 1
|
||||
- 频率= 1.5Hz
|
||||
- 相位 = 0
|
||||
|
||||
```
|
||||
>> t=0:1/fs:4.99999999;
|
||||
>> t=t(:);
|
||||
>> w=2*pi*1.5*t;
|
||||
>> q=cos(w);
|
||||
>> plot(q);
|
||||
```
|
||||
|
||||
注意: 当我们创建一组时间值时,默认情况下,它是以列的格式呈现,如, 1x220500 的值。为了乘以这样的值,必须将其变成行的形式(220500x1)。这就是 `t=t(:)` 命令的作用。
|
||||
|
||||
|
||||
|
||||
我们将创建第二份 ogg 音频格式的文件,它包含了如下的调制信号:
|
||||
|
||||
```
|
||||
>> tremolo='tremolo.ogg';
|
||||
>> audiowrite(tremolo, q.*y,fs);
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 频率变化
|
||||
|
||||
我们可以改变频率实现一些有趣的音效,比如原音变形,电影音效,多人比赛。
|
||||
|
||||
#### 正弦频率调制的影响
|
||||
|
||||
这是正弦调制频率变化的演示代码,根据方程:
|
||||
|
||||
```
|
||||
Y=Ac*Cos(wo*Cos(wo/k))
|
||||
```
|
||||
|
||||
这里:
|
||||
|
||||
- Ac = 增幅
|
||||
- wo = 基频
|
||||
- k = 标量除数
|
||||
|
||||
```
|
||||
>> fm='fm.ogg';
|
||||
>> fs=44100;
|
||||
>> t=0:1/fs:10;
|
||||
>> w=2*pi*442*t;
|
||||
>> audiowrite(fm, cos(cos(w/1500).*w), fs);
|
||||
>> [y,fs]=audioread('fm.ogg');
|
||||
>> figure (); plot (y);
|
||||
```
|
||||
|
||||
信号图:
|
||||
|
||||
|
||||
|
||||
你可以使用几乎任何类型的周期函数频率调制。本例中,我们仅仅用了一个正弦函数。请大胆的改变函数频率,用复合函数,甚至改变函数的类型。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/ubuntu-octave-audio-processing-part-3/
|
||||
|
||||
作者:[David Duarte][a]
|
||||
译者:[theArcticOcean](https://github.com/theArcticOcean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/ubuntu-octave-audio-processing-part-3/
|
||||
@ -0,0 +1,41 @@
|
||||
Canonical 正考虑移除 Ubuntu 的 32 位支持
|
||||
========================================================
|
||||
|
||||

|
||||
|
||||
之前,[Dimitri John Ledkov][1] 在 [Ubuntu 邮件列表][2] 发送了一则消息,称将在 Ubuntu 18.10 中取消 32 位支持。他说越来越多的软件已经有了 64 位支持,而且为古老的 32 位架构提供安全支持将变得更加困难。
|
||||
|
||||
Ledkov 同时表示,构建 32 位镜像并不是没有成本的,而要耗费 Canonical 不少的资源。
|
||||
|
||||
> 构建 32 位镜像并不是“免费的”,它的代价就是占用了我们的构建服务器资源、QA 和校验时间。尽管我我们有可扩展的构建环境,但 32 位支持还需要为所有包进行构建和自动测试,而且 ISO 也需要在我们的各种架构上进行测试。同时这还会占据大量的镜像空间和带宽。
|
||||
|
||||
Ledkov 计划着,Ubuntu 16.10、17.04、17.10 还会继续提供 32 位内核、网络安装器和云镜像,但移除桌面版和服务器版的 32 位 ISO 镜像。18.04 LTS 将会移除 32 位内核、网络安装器和云镜像,但在 64 位架构中兼容运行 32 位程序。然后在 18.10 中结束 32 位支持,并将传统的 32 位应用放在 snap、容器和虚拟机中。
|
||||
|
||||
但是,Ledkov 的这份计划还未被大家接受,但它表明了 32 位支持迟早要被遗弃。(LCTT 译注:我们已经知道 16.10 依旧有 32 为支持。)
|
||||
|
||||
### 好消息
|
||||
|
||||
当然,使用 32 位系统的用户也不必伤心。这个并不会影响用于拯救老式电脑的发行版。[Ubuntu MATE][4] 的创建者 [Martin Wimpress][3] 在 Googl+ 的讨论中透露,这些改变这是影响着主线上的 Ubuntu 而已。
|
||||
|
||||
>18.04 将继续存在 32 位架构支持,分支版本可以继续选择构建 32 位镜像。但还是会存在安全隐患,一些大型应用,如 Firefox、Chromium、LibreOffice,已经凸显了在一些旧版的 LTS 的更新安全问题。所以,这些分支版本需要注意其 32 位支持期限。
|
||||
|
||||
### 思考
|
||||
|
||||
从安全的角度,我可以理解他们为什么要移除 32 位支持,但是这可能会导致一部分人离开主线 Ubuntu 而投入另一个喜爱的发行版或者另一种架构的怀抱。值得庆幸的是,我们还可以选择 [轻量级 Linux 发行版][5]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-32-bit-support-drop/
|
||||
|
||||
作者:[John Paul][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]: https://plus.google.com/+DimitriJohnLedkov
|
||||
[2]: https://lists.ubuntu.com/archives/ubuntu-devel-discuss/2016-June/016661.html
|
||||
[3]: https://twitter.com/m_wimpress
|
||||
[4]: http://ubuntu-mate.org/
|
||||
[5]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
@ -0,0 +1,84 @@
|
||||
Terminator:一款一个窗口包含多个终端的 Linux 终端仿真器
|
||||
=============================================================================
|
||||
|
||||

|
||||
|
||||
为了通过命令行和系统互动,每一款 Linux 发行版都有一款默认的终端仿真器。但是,默认的终端应用可能不适合你。为了大幅提升你工作的速度,有好多款终端应用提供了更多的功能,可以同时执行更多的任务。这些有用的终端仿真器就包括 Terminator,这是一款 Linux 系统下支持多窗口的自由开源的终端仿真器。
|
||||
|
||||
### 什么是 Linux 终端仿真器
|
||||
|
||||
Linux 终端仿真器是一个让你和 shell 交互的程序。所有的 Linux 发行版都会自带一款 Linux 终端应用让你向 shell 传递命令。
|
||||
|
||||
### Terminator,一款自由开源的 Linux 终端应用
|
||||
|
||||
Terminator 是一款 Linux 终端模拟器,提供了你的默认的终端应用不支持的多个特性。它提供了在一个窗口创建多个终端的功能,以加快你的工作速度。除了多窗口外,它也允许你修改其它特性,例如字体、字体颜色、背景色等等。让我们看看我们如何安装它,并且如何在不同的 Linux 发行版下使用 Terminator。
|
||||
|
||||
### 如何在 Linux 下安装 Terminator?
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Terminator
|
||||
|
||||
Terminator 在默认的 Ubuntu 仓库就可以使用。所以你不需要添加额外的 PPA。只需要使用 APT 或者“软件应用”在 Ubuntu 下直接安装。
|
||||
|
||||
```
|
||||
sudo apt-get install terminator
|
||||
```
|
||||
|
||||
假如你的默认的仓库中 Terminator 不可用,只需要使用源码编译 Terminator 即可。
|
||||
|
||||
- [下载源码][1]
|
||||
|
||||
下载 Terminator 源码并且解压到你的桌面。现在打开你的默认的终端,然后 `cd` 到解压的目录。
|
||||
|
||||
现在就可以使用下面的命令来安装 Terminator 了:
|
||||
|
||||
```
|
||||
sudo ./setup.py install
|
||||
```
|
||||
|
||||
#### 在 Fedora 及衍生的操作系统上安装 Terminator
|
||||
|
||||
```
|
||||
dnf install terminator
|
||||
```
|
||||
|
||||
#### 在 OpenSuse 上安装 Terminator
|
||||
|
||||
参见此文:[在 OPENSUSE 上安装][2]。
|
||||
|
||||
### 如何在一个窗口使用多个终端?
|
||||
|
||||
安装好 Terminator 之后,你可以简单的在一个窗口打开多个终端。只需要右键点击并切分。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
只要你愿意,你可以创建尽可能多的终端,只要你能管理得过来。
|
||||
|
||||

|
||||
|
||||
### 定制终端
|
||||
|
||||
右键点击终端,并单击属性。现在你可以定制字体、字体颜色、标题颜色和背景,还有终端字体颜色和背景。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 结论:什么是你最喜欢的终端模拟器
|
||||
|
||||
Terminator 是一款先进的终端模拟器,它可以让你自定义界面。如果你还没有从你默认的终端模拟器中切换过来的话,你可以尝试一下它。我知道你将会喜欢上它。如果你正在使用其他的自由开源的终端模拟器的话,请让我们知道你最喜欢的那一款。不要忘了和你的朋友分享这篇文章。或许你的朋友正在寻找类似的东西。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/terminator-a-linux-terminal-emulator-with-multiple-terminals-in-one-window
|
||||
|
||||
作者:[author][a]
|
||||
译者:[yangmingming](https://github.com/yangmingming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxandubuntu.com/home/terminator-a-linux-terminal-emulator-with-multiple-terminals-in-one-window
|
||||
[1]: https://launchpad.net/terminator/+download
|
||||
[2]: http://software.opensuse.org/download.html?project=home%3AKorbi123&package=terminator
|
||||
459
published/201610/20160729 Best Password Manager all platform.md
Normal file
459
published/201610/20160729 Best Password Manager all platform.md
Normal file
@ -0,0 +1,459 @@
|
||||
全平台最佳密码管理工具大全:支持 Windows、Linux、Mac、Android、iOS 以及企业应用
|
||||
===============
|
||||
|
||||

|
||||
|
||||
当谈到你的网络安全的防护时,从各种网络威胁的角度来看,仅安装一个防病毒软件或运行一个[安全的 Linux 操作系统][1],并不意味你就是足够安全的。
|
||||
|
||||
今天大多数网络用户都容易受到网络攻击,并不是因为他们没有使用最好的防病毒软件或其他安全措施,而是因为他们使用了[弱密码][2]来保护他们自己的网上帐号。
|
||||
|
||||
密码是你抵御网络威胁的最后一道防线。只要回顾一下最近的一些数据泄露和网络攻击,包括大众关注的 [OPM(美国联邦人事管理局)][3]和婚外情网站 [Ashley Madison][4] 的数据泄露,都导致成千上万的记录的网上曝光。
|
||||
|
||||
虽然你不能控制数据泄露,但创建强壮的、可以抵御字典和[暴力破解][5]的密码仍然是重要的。
|
||||
|
||||
你知道,你的密码越长,它越难破解。
|
||||
|
||||
### 如何保证在线服务的安全?
|
||||
|
||||
安全研究人员喋喋不休地劝说在线用户为他们的各种网上账户创建长的、复杂和各异的密码。这样,如果一个网站被攻破,你在其他网站上的帐户是安全的,不会被黑客攻击。
|
||||
|
||||
理想的情况下,你的密码必须至少16个字符长,应该包含数字、符号、大写字母和小写字母,而最重要的是,甚至你都不知道的密码才是最安全的密码。
|
||||
|
||||
密码应该不重复,而且不包含任何字典中的词汇、代词,你的用户名或 ID 号,以及任何其它预定义的字母或数字序列。
|
||||
|
||||
我知道记住这样的复杂的密码字符串是一个实在痛苦的过程,除非我们是一个人型超级计算机,为不同的在线账户记住不同的密码并不是一个轻松的任务。
|
||||
|
||||
问题是,现在人们注册了大量的在线网站和服务,为每一个帐户创建和记住不同的密码通常是很难的。
|
||||
|
||||
不过,幸运的是,我们可以让这个事情变得很轻松,不断涌现的面向桌面计算机和智能电话的口令管理器可以显著地降低你密码记忆难度,从而治愈你设置弱密码的坏毛病。
|
||||
|
||||
### 密码管理器是什么?
|
||||
|
||||
|
||||
|
||||
在过去的几年里,密码管理软件已经取得了长足的进展,它是一个很好的系统,不但可以让你为不同的网站创建复杂的密码,而且能让你记住它们。
|
||||
|
||||
密码管理器是一个为你的个人电脑、网站,应用程序和网络创建、存储和整理密码的软件。
|
||||
|
||||
密码管理器可以生成密码,也可以作为表单填充器,它可以自动在网站的登录表单中输入你的用户名和密码。
|
||||
|
||||
所以,如果你想为你的多个在线帐户设置超级安全的密码,但你又不想全部记住它们,密码管理器是你最好的选择。
|
||||
|
||||
### 密码管理器如何工作?
|
||||
|
||||
通常,密码管理器可以为您生成冗长、复杂,而且更重要的是唯一的密码字符串,然后以加密形式存储它们,以保护该机密数据免受黑客对您的 PC 或移动设备的物理访问。
|
||||
|
||||
加密的文件只能通过“主密码”访问。因此,所有你需要做的只是记住一个“主密码”,用来打开你的密码管理器或保险库,从而解锁你所有的其他密码。
|
||||
|
||||
然而,你需要确保你的主密码是超级安全的,至少 16 个字符。
|
||||
|
||||
### 哪个是最好的密码管理器?如何选择?
|
||||
|
||||
我一直在推荐密码管理器,但大多数读者总是问:
|
||||
|
||||
- 哪个密码管理器最好?
|
||||
- 哪个密码管理器最安全?帮帮我!
|
||||
|
||||
所以,今天我要介绍给你一些最好的密码管理器,它们可在 Windows、Mac、Linux、Android、iOS 和企业中使用。
|
||||
|
||||
在为你的设备选择一个好的密码管理器之前,你应该检查以下功能:
|
||||
|
||||
- 跨平台应用
|
||||
- 零知识模型
|
||||
- 提供双因素认证(或者多因素身份验证)
|
||||
|
||||
注意:一旦采用,就要按照密码管理器的方式来用,因为如果你仍然为你的重要在线帐户使用弱密码的话,没有人可以从恶意黑客那里拯救你。
|
||||
|
||||
### Windows 最佳密码管理工具
|
||||
|
||||

|
||||
|
||||
Windows 用户最容易受到网络攻击,因为 Windows 操作系统一直是黑客最喜欢的目标。所以,对于 Windows 用户来说,使用一个好的密码管理器是重要的。
|
||||
|
||||
除了下述以外,Windows 其它的密码管理器还有:Password Safe、LockCrypt、1Password。
|
||||
|
||||
#### 1. Keeper 密码管理器(跨平台)
|
||||
|
||||
|
||||
|
||||
Keeper 是一个安全、易用而稳健的密码管理器,支持 Windows、Mac、iPhone、iPad 和 iPod 设备。
|
||||
|
||||
通过使用军事级 256 位 AES 加密技术,Keeper 密码管理器可以让您的数据安全在窥探之下保持安全。
|
||||
|
||||
它的安全的数字保险柜,用于保护和管理您的密码,以及其他秘密信息。Keeper 密码管理器应用程序支持双因素身份验证,可用于各大主流操作系统。
|
||||
|
||||
它还有一个称为“自毁”的重要的安全功能,启用后,如果不正确的错误地输入主密码达五次以上,它将删除设备中的所有记录!
|
||||
|
||||
但您不必担心,因为此操作不会删除存储在 Keeper 上的云安全保险柜上的备份记录。
|
||||
|
||||
下载 Keeper 密码管理器: [Windows、Linux 和 Mac][6] | [iOS][7] | [Android][8] | [Kindle][9]
|
||||
|
||||
#### 2. Dashlane 密码管理器(跨平台)
|
||||
|
||||
|
||||
|
||||
DashLane 密码管理器有点新,但它几乎为每个平台提供了极棒的功能。
|
||||
|
||||
DashLane 密码管理器通过在本地计算机上使用 AES-256 加密技术来加密您的个人信息和帐户密码,然后将其同步到其在线服务器,以便您可以从任何地方访问您的帐户数据库。
|
||||
|
||||
DashLane 最好的一点是它有一个自动密码更改器,可以自动更改您的帐户的密码,而不必自己处理。
|
||||
|
||||
DashLane 密码管理器 Android 版为您的 Android 手机提供了安全的密码管理工具:密码保险库和在线商店及其他网站的表单自动填充器。
|
||||
|
||||
Android 的 DashLane 密码管理器在单个设备上使用完全免费,如要在多个设备上访问,您可以购买该应用的收费的高级版本。
|
||||
|
||||
下载 DashLane 密码管理器: [Windows][10] 和 [Mac][11] | [iOS][12] | [Android][13]
|
||||
|
||||
#### 3. LastPass 密码管理器(跨平台)
|
||||
|
||||

|
||||
|
||||
LastPass 是 Windows 用户最好的密码管理器之一,它可以通过扩展插件、移动应用程序,甚至桌面应用程序支持所有的浏览器和操作系统。
|
||||
|
||||
LastPass 是一个非常强大的基于云的密码管理器软件,它使用 AES-256 加密技术来加密您的个人信息和帐户密码,甚至提供各种双因素身份验证选项,以确保没有其他人可以登录您的密码保险柜中。
|
||||
|
||||
LastPass 密码管理器是免费的,收费的高级版本支持指纹读取器。
|
||||
|
||||
下载 LastPass 密码管理器: [Windows、Mac 和 Linux][14] | [iOS][15] | [Android][16]
|
||||
|
||||
### Mac OS X 最佳密码管理器
|
||||
|
||||

|
||||
|
||||
人们经常说,Mac 电脑比 Windows 更安全,“Mac 没有病毒”,但它是不完全正确的。
|
||||
|
||||
作为证据,你可以阅读我们以前的关于对 Mac 和 iOS 用户进行网络攻击的文章,然后自己决定需要不需要一个密码管理器。
|
||||
|
||||
除了下述以外,Mac OS X 其它的密码管理器还有:1Password,Dashlane,LastPass,OneSafe,PwSafe。
|
||||
|
||||
#### 1. LogMeOnce 密码管理器(跨平台)
|
||||
|
||||

|
||||
|
||||
LogMeOnce 密码管理套件是 Mac OS X 上的最佳密码管理器之一,并且可以在 Windows,iOS 和 Android 设备上同步您的密码。
|
||||
|
||||
LogMeOnce 是最好的收费的企业密码管理软件之一,提供各种功能和选项,包括 Mugshot(嫌犯照片)功能。
|
||||
|
||||
如果您的手机被盗,LogMeOnce Mugshot 功能可以跟踪小偷的位置,并秘密拍摄试图在未经许可访问您的帐户的入侵者的照片。
|
||||
|
||||
LogmeOnce 使用军用级 AES-256 加密技术保护您的密码,并提供双因素身份验证,以确保即使掌握了主密码,窃贼也无法窃取您的帐户。
|
||||
|
||||
下载 LogMeOnce 密码管理器: [Windows and Mac][17] | [iOS][18] | [Android][19]
|
||||
|
||||
#### 2. KeePass 密码管理器(跨平台)
|
||||
|
||||
|
||||
|
||||
虽然 LastPass 是最好的密码管理器之一,有些人不喜欢基于云的密码管理器。
|
||||
|
||||
KeePass 是一个流行的 Windows 密码管理器应用程序,但也有浏览器扩展和 KeePass 的移动应用程序。
|
||||
|
||||
用于 Windows 的 KeePass 密码管理器将您的帐户密码存储在您的 PC 上,因此您仍然可以控制它们,也可以放在 Dropbox 上,因此您可以使用多个设备访问它。
|
||||
|
||||
KeePass 使用当前已知的最安全的加密技术加密您的密码和登录信息:默认情况下为 AES 256 位加密,或可选地用 Twofish 256 位加密技术。
|
||||
|
||||
KeePass 不仅仅是免费的,它也是开源的,这意味着它的代码和完整性可以被任何人检查,从而赢得了更多的信任度。
|
||||
|
||||
下载 KeePass 密码管理器: [Windows 和 Linux][20] | [Mac][21] | [iOS][22] | [Android][23]
|
||||
|
||||
#### 3. 苹果 iCloud 钥匙串
|
||||
|
||||
|
||||
|
||||
苹果推出了 iCloud 钥匙串密码管理系统,提供了一种方便的、可以在您获准的 Apple 设备(包括 Mac OS X、iPhone 和 iPad)上安全地存储和自动同步所有登录凭据、Wi-Fi 密码和信用卡号码的方式。
|
||||
|
||||
您的钥匙串中的密码数据使用 256 位 AES 加密技术进行加密,并使用椭圆曲线非对称加密和密钥封装。
|
||||
|
||||
此外,iCloud 钥匙串还会生成新的、独特的和强大的密码,用于保护您的计算机和帐户。
|
||||
|
||||
主要限制:钥匙串不能与 Apple Safari 之外的其他浏览器一起使用。
|
||||
|
||||
参阅:[如何设置 iCloud 钥匙串?][24]
|
||||
|
||||
### Linux 最佳密码管理器
|
||||
|
||||
|
||||
|
||||
毫无疑问,一些 Linux 发行版是地球上最安全的操作系统,但正如我上面所说,采用 Linux 不能完全保护您的在线帐户免受黑客攻击。
|
||||
|
||||
有许多跨平台密码管理器可用于在所有设备上同步所有帐户的密码,例如 LastPass、KeePass、RoboForm 密码管理器。
|
||||
|
||||
下面我列出了两个 Linux 上流行和安全的开源密码管理器:
|
||||
|
||||
#### 1. SpiderOak 加密密码管理器(跨平台)
|
||||
|
||||

|
||||
|
||||
爱德华·斯诺登推荐的由 SpiderOak 开发的 Encryptr 密码管理器是一个零知识的基于云的密码管理器,使用 Crypton JavaScript 框架加密保护您的密码。
|
||||
|
||||
它是一个跨平台、开源和免费的密码管理器,使用端到端加密,可以完美地工作于 Ubuntu、Debian Linux Mint 和其它 Linux 发行版。
|
||||
|
||||
Encryptr 密码管理器应用程序本身非常简单,带有一些基本功能。
|
||||
|
||||
Encryptr 软件允许您加密三种类型的内容:密码、信用卡号码和常规的键值对。
|
||||
|
||||
下载 Encryptr 密码管理器: [Windows、Linux 和 Mac][25] | [iOS][26] | [Android][27]
|
||||
|
||||
#### 2. EnPass 密码管理器(跨平台)
|
||||
|
||||
|
||||
|
||||
Enpass 是一个优秀的安全导向的 Linux 密码管理器,在其它平台也能很好地工作。
|
||||
|
||||
Enpass 可让您使用第三方云服务(包括 Google 云端硬盘、Dropbox、OneDrive 或 OwnCloud)备份和恢复存储的密码。
|
||||
|
||||
它确保提供高级别的安全性,并通过主密码保护您的数据,在将备份上传到云上之前,使用开源加密引擎 SQLCipher 的 256 位 AES 加密技术进行加密。
|
||||
|
||||
> “我们不会在我们的服务器上托管您的 Enpass 数据,因此,我们不需要注册,您的数据只存储在您的设备上,”Enpass 说。
|
||||
|
||||
此外,默认情况下,当您离开计算机时,Enpass 会锁定自己,并且每隔 30 秒清除剪贴板内存,以防止您的密码被任何其他恶意软件窃取。
|
||||
|
||||
下载 EnPass 密码管理器: [Windows][28]、[Linux][29] | [Mac][30] | [iOS][31] | [Android][32]
|
||||
|
||||
#### 3. RoboForm 密码管理器(跨平台)
|
||||
|
||||
|
||||
|
||||
你可以很容易地在 Windows 操作系统上找到好的密码管理器,但 RoboForm 免费密码管理器软件不止于此。
|
||||
|
||||
除了创建复杂的密码并记住它们,RoboForm 还提供了一个智能表单填充功能,以节省您在浏览网络的时间。
|
||||
|
||||
RoboForm 使用军用级 AES 加密技术来加密您的登录信息和帐户密码,密钥是通过您的 RoboForm 主密码获得的。
|
||||
|
||||
RoboForm 适用于 IE、Chrome 和 Firefox 等浏览器,以及适用于 iOS、Android 和 Windows Phone 等移动平台。
|
||||
|
||||
下载 RoboForm 密码管理器: [Windows 和 Mac][33] | [Linux][34] | [iOS][35] | [Android][36]
|
||||
|
||||
### Android 最佳密码管理器
|
||||
|
||||

|
||||
|
||||
目前全球有超过一半的人使用 Android 设备,因此 Android 用户保护他们的在线帐户、避免黑客总是试图访问这些设备成为一种必要。
|
||||
|
||||
Android 上一些最好的密码管理器应用程序包括 1Password、Keeper、DashLane、EnPass、OneSafe、mSecure 和 SplashID Safe。
|
||||
|
||||
#### 1. 1Password 密码管理器(跨平台)
|
||||
|
||||

|
||||
|
||||
1Password 密码管理器 Anroid 版是管理你的所有账户密码的最佳应用程序之一。
|
||||
|
||||
1Password 密码管理器为每个帐号创建强大、独特和安全的密码,并为你全部记住,你只需要轻轻一点即可登录。
|
||||
|
||||
1Password 密码管理器软件通过 AES-256 加密技术保护您的登录名和密码,并通过您的 Dropbox 帐户将其同步到所有设备,或者存储在本地,你可以用任何其他应用程序来进行同步。
|
||||
|
||||
最近,Android 版本的 1Password 密码管理器应用程序了添加指纹支持来解锁所有的密码,而不是使用您的主密码。
|
||||
|
||||
下载 1Password 密码管理器: [Windows 和 Mac][37] | [iOS][38] | [Android][39]
|
||||
|
||||
#### 2. mSecure密码管理器(跨平台)
|
||||
|
||||
|
||||
|
||||
就像其他流行的密码管理器解决方案,Android 下的 mSecure 密码管理器自动生成安全密码,并使用 256 位Blowfish 加密技术存储它们。
|
||||
|
||||
令人印象深刻的独特功能是 mSecure 密码管理器软件提供了在输入 5、10 或 20 次错误的密码后(根据您的设置)自毁数据库的功能。
|
||||
|
||||
您还可以使用 Dropbox 或通过专用 Wi-Fi 网络同步所有设备。不管什么情况下,无论您的云帐户的安全性如何,您的所有数据都会在设备之间安全而加密地传输。
|
||||
|
||||
下载 mSecure 密码管理软件: [Windows 和 Mac][40] | [iOS][41] | [Android][42]
|
||||
|
||||
### iOS 最佳密码管理器
|
||||
|
||||

|
||||
|
||||
正如我所说,苹果的 iOS 也很容易发生网络攻击,所以你可以使用一些 iOS 下最好的密码管理器应用程序来保护你的在线帐户,它们包括 Keeper、OneSafe、Enpass、mSecure、LastPass、RoboForm、SplashID Safe 和 LoginBox Pro 。
|
||||
|
||||
#### 1. OneSafe 密码管理器(跨平台)
|
||||
|
||||
|
||||
|
||||
OneSafe 是 iOS 设备最好的密码管理器应用程序之一,它不仅可以存储您的帐户密码,还可以存储敏感文档、信用卡详细信息、照片等。
|
||||
|
||||
iOS 的 OneSafe 密码管理器应用程序使用 AES-256 加密技术(移动设备上可用的最高级别)和 Touch ID 将您的数据用主密码加密。 你还可以为给定文件夹设置附加密码。
|
||||
|
||||
iOS 的 OneSafe 密码管理器还提供了一个支持自动填充登录的应用内浏览器,因此您无需每次都输入登录详细信息。
|
||||
|
||||
除此之外,OneSafe 还为您的帐户的密码提供了高级安全功能,如自动锁定、入侵检测、自毁模式、诱饵安全和双重保护。
|
||||
|
||||
下载 OneSafe 密码管理器:[iOS][43] | [Mac][44] | [Android][45] | [Windows][46]
|
||||
|
||||
#### 2. SplashID 安全密码管理器(跨平台)
|
||||
|
||||
|
||||
|
||||
SplashID Safe 是 iOS 中最古老、最好的密码管理工具之一,它允许用户将其登录数据和其他敏感信息安全地存储在加密记录中。
|
||||
|
||||
您的所有信息,包括网站登录信息、信用卡和社会保障数据、照片和文件附件,都受到 256 位的加密保护。
|
||||
|
||||
用于 iOS 的 SplashID Safe 密码管理器还提供了网络自动填充选项,这意味着您不必在登录时复制粘贴密码。
|
||||
|
||||
免费版本的 SplashID Safe 具有基本的记录存储功能,但您可以选择收费版本,提供跨设备同步以及其它收费功能。
|
||||
|
||||
下载 SplashID 安全密码管理器:[Windows 和 Mac][47] | [iOS][48] | [Android][49]
|
||||
|
||||
#### 3. LoginBox Pro 密码管理器
|
||||
|
||||
|
||||
|
||||
LoginBox Pro 是另一个 iOS 设备上极棒的密码管理器应用程序。该应用程序提供了一个单击登录到你访问的任何网站的功能,使密码管理器应用程序成为登录密码保护的互联网网站的最安全和最快的方式。
|
||||
|
||||
iOS 的 LoginBox 密码管理器应用程序的把密码管理器和浏览器结合到一起。
|
||||
|
||||
从您下载那一刻起,所有登录操作(包括输入信息、点击按钮、复选框或回答安全提问)都会通过 LoginBox 密码管理器自动完成。
|
||||
|
||||
为了安全起见,LoginBox 密码管理器使用硬件加速的 AES 加密技术和密码来加密您的数据并将其保存在您的设备上。
|
||||
|
||||
下载 LoginBox 密码管理器:[iOS][50] | [Android][51]
|
||||
|
||||
### 最佳在线密码管理器
|
||||
|
||||
使用在线密码管理器工具是保护你的个人和私人信息安全,免于黑客和心怀恶意的人攻击的最简单方法。
|
||||
|
||||
在这里,我列出了一些最好的在线密码管理器,你可以依靠它们保持自己的线上安全:
|
||||
|
||||
#### 1. Google 在线密码管理器
|
||||
|
||||
|
||||
|
||||
你知道 Google 有自己的专用密码管理器吗?
|
||||
|
||||
Google Chrome 有一个内置的密码管理器工具,当你使用 Chrome 登录网站或网络服务时,你可以选择用它保存密码。
|
||||
|
||||
你所储存的所有帐户密码都会与你的 Google 帐户同步,方便你通过同一个 Google 帐户在所有装置上使用。
|
||||
|
||||
Chrome 密码管理器可让你通过网络管理你的所有帐户的密码。
|
||||
|
||||
因此,如果您喜欢使用其他浏览器,例如 Windows 10 上的 Microsoft Edge 或 iPhone 上的 Safari,只需访问[passwords.google.com][52],您就会看到一个列表,其中包含您保存在 Chrome 之中所有密码。Google 的双重身份验证会保护此列表。
|
||||
|
||||
#### 2. Clipperz 在线密码管理器
|
||||
|
||||
|
||||
|
||||
Clipperz 是一个免费的跨平台最佳在线密码管理器,不需要你下载任何软件。Clipperz 在线密码管理器使用书签栏或侧栏来直接登录。
|
||||
|
||||
Clipperz 还提供了其软件的密码管理器的离线版本,允许你将密码下载到一个[加密的磁盘][53]或 USB 盘里面,以便你在旅行时可以随身携带,并在离线时访问你的帐户密码。
|
||||
|
||||
Clipperz 在线密码管理器的一些功能还包括密码强度指示器、应用程序锁定、SSL 安全连接、一次性密码和密码生成器。
|
||||
|
||||
Clipperz 在线密码管理器可以在任何支持 JavaScript 的浏览器上工作。
|
||||
|
||||
#### 3. Passpack 在线密码管理器
|
||||
|
||||
|
||||
|
||||
Passpack 是一个优秀的在线密码管理器,拥有一套极具竞争力的功能,可为你的不同在线帐户创建、存储和管理密码。
|
||||
|
||||
PassPack 在线密码管理器还允许你与你的家人或同事安全地共享你的密码,以轻松管理多个项目、团队成员、客户和员工。
|
||||
|
||||
你的各个帐户的用户名和密码使用 PassPack 服务器上的 AES-256 加密技术进行加密,即使黑客访问其服务器也无法读取你的登录信息。
|
||||
|
||||
将 PassPack 在线密码管理器工具栏下载到 Web 浏览器并正常浏览 Web。每当你登录任何受密码保护的网站时,PassPack 会保存你的登录数据,以便你不必在其网站上手动保存你的用户名和密码。
|
||||
|
||||
### 最佳企业密码管理器
|
||||
|
||||
在过去 12 个月的过程中,我们看到了互联网历史上最大的数据泄露,而且这种情况年复一年的增多。
|
||||
|
||||
据统计,大多数员工甚至不知道如何在线保护他们自己,这导致公司的业务处于风险之中。
|
||||
|
||||
为了在组织中保持密码共享机制安全,有一些专门为企业使用而设计的密码管理工具,例如 Vaultier、CommonKey、Meldium、PassWork 和 Zoho Vault。
|
||||
|
||||
#### 1. Meldium 企业密码管理软件
|
||||
|
||||
|
||||
|
||||
LogMeIn 的 [Meldium 密码管理工具][54]附带一个一键式单点登录解决方案,可帮助企业安全快速地访问网络应用。
|
||||
|
||||
它会自动将用户记录到应用和网站中,而无需输入用户名和密码,也可以跟踪组织内的密码使用情况。
|
||||
|
||||
Meldium 密码管理器非常适合在您的团队成员内共享帐户,而无需共享实际密码,这有助于组织保护自己免受网络钓鱼攻击。
|
||||
|
||||
#### 2. Zoho Vault 密码管理软件
|
||||
|
||||
|
||||
|
||||
[Zoho Vault][55] 是企业用户最好的密码管理器之一,可帮助您的团队快速、安全地共享密码和其他敏感信息,同时监控每个用户的使用情况。
|
||||
|
||||
您所有的团队成员需要下载 Zoho 浏览器扩展。 Zoho Vault 密码管理器将自动填充您团队存储在共享保险柜中的密码。
|
||||
|
||||
Zoho Vault 还提供了一些功能,可让您监控团队的密码使用情况和安全级别,以便您可以知道谁在使用哪个登录。
|
||||
|
||||
Zoho Vault 企业级软件包甚至会在更改或访问密码时发出警告。
|
||||
|
||||
### 更多安全性,请使用双重身份验证
|
||||
|
||||

|
||||
|
||||
无论你的密码有多强大,黑客仍然有可能找到一些或其他方式侵入你的帐户。
|
||||
|
||||
双因素身份验证旨在解决这个问题。对一个密码取而代之的是,它要求你输入第二个口令,这会通过短信发送到你的手机上,或通过电子邮件发送到你的电子邮件地址上。
|
||||
|
||||
因此,我建议你启用[双因素身份验证][56],并使用密码管理器软件来保护你的在线帐户和敏感信息免受黑客攻击。
|
||||
|
||||
------
|
||||
|
||||
via: https://thehackernews.com/2016/07/best-password-manager.html
|
||||
|
||||
作者:[Swati Khandelwal][a]
|
||||
译者:[Bestony](https://github.com/Bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://thehackernews.com/2016/07/best-password-manager.html#author-info
|
||||
[1]: http://thehackernews.com/2016/03/subgraph-secure-operating-system.html
|
||||
[2]: http://thehackernews.com/2016/01/password-security-manager.html
|
||||
[3]: http://thehackernews.com/2015/09/opm-hack-fingerprint.html
|
||||
[4]: http://thehackernews.com/2015/08/ashley-madison-accounts-leaked-online.html
|
||||
[5]: http://thehackernews.com/2013/05/cracking-16-character-strong-passwords.html
|
||||
[6]: https://keepersecurity.com/download.html
|
||||
[7]: https://itunes.apple.com/us/app/keeper-password-manager-digital/id287170072?mt=8
|
||||
[8]: https://play.google.com/store/apps/details?id=com.callpod.android_apps.keeper
|
||||
[9]: http://www.amazon.com/gp/mas/dl/android?p=com.callpod.android_apps.keeper
|
||||
[10]: https://www.dashlane.com/download
|
||||
[11]: https://www.dashlane.com/passwordmanager/mac-password-manager
|
||||
[12]: https://itunes.apple.com/in/app/dashlane-free-secure-password/id517914548?mt=8
|
||||
[13]: https://play.google.com/store/apps/details?id=com.dashlane&hl=en
|
||||
[14]: https://lastpass.com/misc_download2.php
|
||||
[15]: https://itunes.apple.com/us/app/lastpass-for-premium-customers/id324613447?mt=8&ign-mpt=uo%3D4
|
||||
[16]: https://play.google.com/store/apps/details?id=com.lastpass.lpandroid
|
||||
[17]: https://www.logmeonce.com/download/
|
||||
[18]: https://itunes.apple.com/us/app/logmeonce-free-password-manager/id972000703?ls=1&mt=8
|
||||
[19]: https://play.google.com/store/apps/details?id=log.me.once
|
||||
[20]: http://keepass.info/download.html
|
||||
[21]: https://itunes.apple.com/us/app/kypass-companion/id555293879?ls=1&mt=12
|
||||
[22]: https://itunes.apple.com/de/app/ikeepass/id299697688?mt=8
|
||||
[23]: https://play.google.com/store/apps/details?id=keepass2android.keepass2android
|
||||
[24]: https://support.apple.com/en-in/HT204085
|
||||
[25]: https://spideroak.com/opendownload
|
||||
[26]: https://itunes.apple.com/us/app/spideroak/id360584371?mt=8
|
||||
[27]: https://play.google.com/store/apps/details?id=com.spideroak.android
|
||||
[28]: https://www.enpass.io/download-enpass-for-windows/
|
||||
[29]: https://www.enpass.io/download-enpass-linux/
|
||||
[30]: https://itunes.apple.com/app/enpass-password-manager-best/id732710998?mt=12
|
||||
[31]: https://itunes.apple.com/us/app/enpass-password-manager/id455566716?mt=8
|
||||
[32]: https://play.google.com/store/apps/details?id=io.enpass.app&hl=en
|
||||
[33]: http://www.roboform.com/download
|
||||
[34]: http://www.roboform.com/for-linux
|
||||
[35]: https://itunes.apple.com/WebObjects/MZStore.woa/wa/viewSoftware?id=331787573&mt=8
|
||||
[36]: https://play.google.com/store/apps/details?id=com.siber.roboform
|
||||
[37]: https://1password.com/downloads/
|
||||
[38]: https://itunes.apple.com/in/app/1password-password-manager/id568903335?mt=8
|
||||
[39]: https://play.google.com/store/apps/details?id=com.agilebits.onepassword&hl=en
|
||||
[40]: https://www.msecure.com/desktop-app/
|
||||
[41]: https://itunes.apple.com/in/app/msecure-password-manager/id292411902?mt=8
|
||||
[42]: https://play.google.com/store/apps/details?id=com.mseven.msecure&hl=en
|
||||
[43]: https://itunes.apple.com/us/app/onesafe/id455190486?ls=1&mt=8
|
||||
[44]: https://itunes.apple.com/us/app/onesafe-secure-password-manager/id595543758?ls=1&mt=12
|
||||
[45]: https://play.google.com/store/apps/details?id=com.lunabee.onesafe
|
||||
[46]: https://www.microsoft.com/en-us/store/apps/onesafe/9wzdncrddtx9
|
||||
[47]: https://splashid.com/downloads.php
|
||||
[48]: https://itunes.apple.com/app/splashid-safe-password-manager/id284334840?mt=8
|
||||
[49]: https://play.google.com/store/apps/details?id=com.splashidandroid&hl=en
|
||||
[50]: https://itunes.apple.com/app/loginbox-pro/id579954762?mt=8
|
||||
[51]: https://play.google.com/store/apps/details?id=com.mygosoftware.android.loginbox
|
||||
[52]: https://passwords.google.com/
|
||||
[53]: http://thehackernews.com/2014/01/Kali-linux-Self-Destruct-nuke-password.html
|
||||
[54]: https://www.meldium.com/
|
||||
[55]: https://www.zoho.com/vault/password-management-tools.html
|
||||
[56]: http://thehackernews.com/2016/07/two-factor-authentication.html
|
||||
36
published/201610/20160805 Introducing React Native Ubuntu.md
Normal file
36
published/201610/20160805 Introducing React Native Ubuntu.md
Normal file
@ -0,0 +1,36 @@
|
||||
React Native Ubuntu 简介
|
||||
=====================
|
||||
|
||||
在 Canonical 的 Webapps 团队,我们总在寻找可以为开发者所用的 web 和 web 相关技术。我们想让每个人生活更轻松,让 web 开发者更加熟悉工具的使用,并且在 Ubuntu 上提供一个使用它们的简单途径。
|
||||
|
||||
我们提供对 web 应用以及创建和打包 Cordova 应用的支持,这使得在 Ubuntu 上使用任意 web 框架来创造美妙的应用体验成为可能。
|
||||
|
||||
其中一个可以在这些情景中使用的主流框架就是 React.js。React.js 是一个拥有声明式编程模型和强大的组件系统的 UI 框架,它主要侧重于 UI 的构建,所以你可以在你喜欢的任何地方用上它。
|
||||
|
||||
然而这些应用场景太广泛了,有时候你可能需要更高的性能,或者能够直接用原生 UI 组件来开发,但是在一个不太熟悉的场景中使用它可能不合时宜。如果你熟悉 React.js,那么通过 React Native 来开发可以毫不费力地将你所有现有的知识和工具迁移到完全的原生组件开发中。React Native 是 React.js 的姐妹项目,你可以用同样的方式和代码来创建一个直接使用原生组件并且拥有原生级别性能的应用,而且这就和你期待的一样轻松快捷。
|
||||
|
||||

|
||||
|
||||
我们很高兴地宣布随着我们对 HTML5 应用的支持,现在可以在 Ubuntu 平台上开发 React Native 应用了。你可以移植你现有的 iOS 或 Android 版本的 React Native 应用,或者利用你的 web 开发技能来创建一个新的应用。
|
||||
|
||||
你可以在 [这里][1] 找到 React Native Ubuntu 的源代码,要开始使用时,跟随 [README-ubuntu.md][2] 的指导,并创建你的第一个应用吧。
|
||||
|
||||
Ubuntu 的支持包括生成软件包的功能。通过 React Native CLI,构建一个 snap 软件包只需要简单执行 `react-native package-ubuntu --snap` 这样的命令。还可以为 Ubuntu 设备构建一个 click 包,这意味着 React Native Ubuntu 应用从一开始就可以放到 Ubuntu 商店了。
|
||||
|
||||
在不久的将来会有很多关于在 Ubuntu 上开发一个 React Native 应用你所需要了解的东西的博文,例如创建应用、开发流程以及打包并发布到商店等等。还会有一些关于怎样开发新型的可复用的模块的信息,这些模块可以给运行时环境增加额外的功能,并且可以发布为 npm 模块。
|
||||
|
||||
赶快去实践一下吧,看看你能创造出些什么来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://developer.ubuntu.com/en/blog/2016/08/05/introducing-react-native-ubuntu/
|
||||
|
||||
作者:[Justin McPherson][a]
|
||||
译者:[Mars Wong](https://github.com/OneNewLife)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://developer.ubuntu.com/en/blog/authors/justinmcp/
|
||||
[1]: https://github.com/CanonicalLtd/react-native
|
||||
[2]: https://github.com/CanonicalLtd/react-native/blob/ubuntu/README-ubuntu.md
|
||||
@ -0,0 +1,241 @@
|
||||
通过 AWS 的 Lambda 和 API Gateway 走向 Serverless
|
||||
============================
|
||||
|
||||
近来,在计算领域出现了很多关于 serverless 的讨论。serverless 是一个概念,它允许你提供代码或可执行程序给某个服务,由服务来为你执行它们,而你无需自己管理服务器。这就是所谓的执行即服务(execution-as-a-service),它带来了很多机会,同时也遇到了它独有的挑战。
|
||||
|
||||
### 简短回忆下计算领域的发展
|
||||
|
||||
早期,出现了……好吧,这有点复杂。很早的时候,出现了机械计算机,后来又有了埃尼阿克 ENIAC(Electronic Numerical Integrator And Computer,很早的电子计算机),但是都没有规模生产。直到大型机出现后,计算领域才快速发展。
|
||||
|
||||
- 上世纪 50 年代 - 大型机
|
||||
- 上世纪 60 年代 - 微型机
|
||||
- 1994 - 机架服务器
|
||||
- 2001 - 刀片服务器
|
||||
- 本世纪初 - 虚拟服务器
|
||||
- 2006 - 服务器云化
|
||||
- 2013 - 容器化
|
||||
- 2014 - serverless(计算资源服务化)
|
||||
|
||||
> 这些日期是大概的发布或者流行日期,无需和我争论时间的准确性。
|
||||
|
||||
计算领域的演进趋势是执行的功能单元越来越小。每一次演进通常都意味着运维负担的减小和运维灵活性的增加。
|
||||
|
||||
### 发展前景
|
||||
|
||||
喔,Serverless!但是,serverless 能给我们带来什么好处? 我们将面临什么挑战呢?
|
||||
|
||||
**未执行代码时无需付费。**我认为,这是个巨大的卖点。当无人访问你的站点或用你的 API 时,你无需付钱。没有持续支出的基础设施成本,仅仅支付你需要的部分。换句话说,这履行了云计算的承诺:“仅仅支付你真正用的资源”。
|
||||
|
||||
**无需维护服务器,也无需考虑服务器安全。**服务器的维护和安全将由你的服务提供商来处理(当然,你也可以架设自己的 serverless 主机,只是这似乎是在向错误的方向前进)。由于你的执行时间也是受限的,安全补丁也被简化了,因为完全不需要重启。这些都应该由你的服务提供商无缝地处理。
|
||||
|
||||
**无限的可扩展性。**这是又一个大的好处。假设你又开发了一个 Pokemon Go, 与其频繁地把站点下线维护升级,不如用 serverless 来不断地扩展。当然,这也是个双刃剑,大量的账单也会随之而来。如果你的业务的利润强依赖于站点上线率的话,serverless 确实能帮上忙。
|
||||
|
||||
**强制的微服务架构。**这也有两面性,一方面,微服务似乎是一种好的构建灵活可扩展的、容错的架构的方式。另一方面,如果你的业务没有按照这种方式设计,你将很难在已有的架构中引入 serverless。
|
||||
|
||||
### 但是现在你被限制在**他们的**平台上
|
||||
|
||||
**受限的环境。**你只能用服务提供商提供的环境,你想在 Rust 中用 serverless?你可能不会太幸运。
|
||||
|
||||
**受限的预装包。**你只有提供商预装的包。但是你或许能够提供你自己的包。
|
||||
|
||||
**受限的执行时间。**你的 Function 只可以运行这么长时间。如果你必须处理 1TB 的文件,你可能需要有一个解决办法或者用其他方案。
|
||||
|
||||
**强制的微服务架构。**参考上面的描述。
|
||||
|
||||
**受限的监视和诊断能力。**例如,你的代码**在**干什么? 在 serverless 中,基本不可能在调试器中设置断点和跟踪流程。你仍然可以像往常一样记录日志并发出统计度量,但是这带来的帮助很有限,无法定位在 serverless 环境中发生的难点问题。
|
||||
|
||||
### 竞争领域
|
||||
|
||||
自从 2014 年出现 AWS Lambda 以后,serverless 的提供商已经增加了一些。下面是一些主流的服务提供商:
|
||||
|
||||
- AWS Lambda - 起步最早的
|
||||
- OpenWhisk - 在 IBM 的 Bluemix 云上可用
|
||||
- Google Cloud Functions
|
||||
- Azure Functions
|
||||
|
||||
这些平台都有它们的相对优势和劣势(例如,Azure 支持 C#,或者紧密集成在其他提供商的平台上)。这里面最大的玩家是 AWS。
|
||||
|
||||
### 通过 AWS 的 Lambda 和 API Gateway 构建你的第一个 API
|
||||
|
||||
我们来试一试 serverless。我们将用 AWS Lambda 和 API Gateway 来构建一个能返回 [Jimmy][2] 所说的“Guru Meditations”的 API。
|
||||
|
||||
所有代码在 [GitHub][1] 上可以找到。
|
||||
|
||||
API文档:
|
||||
|
||||
```
|
||||
POST /
|
||||
{
|
||||
"status": "success",
|
||||
"meditation": "did u mention banana cognac shower"
|
||||
}
|
||||
```
|
||||
|
||||
### 怎样组织工程文件
|
||||
|
||||
文件结构树:
|
||||
|
||||
```
|
||||
.
|
||||
├── LICENSE
|
||||
├── README.md
|
||||
├── server
|
||||
│ ├── __init__.py
|
||||
│ ├── meditate.py
|
||||
│ └── swagger.json
|
||||
├── setup.py
|
||||
├── tests
|
||||
│ └── test_server
|
||||
│ └── test_meditate.py
|
||||
└── tools
|
||||
├── deploy.py
|
||||
├── serve.py
|
||||
├── serve.sh
|
||||
├── setup.sh
|
||||
└── zip.sh
|
||||
```
|
||||
|
||||
AWS 中的信息(想了解这里究竟在做什么的详细信息,可查看源码 `tools/deploy.py`)。
|
||||
|
||||
- **API。**实际构建的对象。它在 AWS 中表示为一个单独的对象。
|
||||
- **执行角色。**在 AWS 中,每个 Function 作为一个单独的角色执行。在这里就是 meditations。
|
||||
- **角色策略。**每个 Function 作为一个角色执行,每个角色需要权限来干活。我们的 Lambda Function 不干太多活,故我们只添加一些日志记录权限。
|
||||
- **Lambda Function。**运行我们的代码的地方。
|
||||
- **Swagger。** Swagger 是 API 的规范。API Gateway 支持解析 swagger 的定义来为 API 配置大部分资源。
|
||||
- **部署。**API Gateway 提供部署的概念。我们只需要为我们的 API 用一个就行(例如,所有的都用生产或者 yolo等),但是得知道它们是存在的,并且对于真正的产品级服务,你可能想用开发和暂存环境。
|
||||
- **监控。**在我们的业务崩溃的情况下(或者因为使用产生大量账单时),我们想以云告警查看方式为这些错误和费用添加一些监控。注意你应该修改 `tools/deploy.py` 来正确地设置你的 email。
|
||||
|
||||
### 代码
|
||||
|
||||
Lambda Function 将从一个硬编码列表中随机选择一个并返回 guru meditations,非常简单:
|
||||
|
||||
```
|
||||
import logging
|
||||
import random
|
||||
|
||||
|
||||
logger = logging.getLogger()
|
||||
logger.setLevel(logging.INFO)
|
||||
|
||||
|
||||
def handler(event, context):
|
||||
|
||||
logger.info(u"received request with id '{}'".format(context.aws_request_id))
|
||||
|
||||
meditations = [
|
||||
"off to a regex/",
|
||||
"the count of machines abides",
|
||||
"you wouldn't fax a bat",
|
||||
"HAZARDOUS CHEMICALS + RKELLY",
|
||||
"your solution requires a blood eagle",
|
||||
"testing is broken because I'm lazy",
|
||||
"did u mention banana cognac shower",
|
||||
]
|
||||
|
||||
meditation = random.choice(meditations)
|
||||
|
||||
return {
|
||||
"status": "success",
|
||||
"meditation": meditation,
|
||||
}
|
||||
```
|
||||
|
||||
### deploy.py 脚本
|
||||
|
||||
这个脚本相当长,我没法贴在这里。它基本只是遍历上述“AWS 中的信息”下的项目,确保每项都存在。
|
||||
|
||||
### 我们来部署这个脚本
|
||||
|
||||
只需运行 `./tools/deploy.py`。
|
||||
|
||||
基本完成了。不过似乎在权限申请上有些问题,由于 API Gateway 没有权限去执行你的 Function,所以你的 Lambda Function 将不能执行,报错应该是“Execution failed due to configuration error: Invalid permissions on Lambda function”。我不知道怎么用 botocore 添加权限。你可以通过 AWS console 来解决这个问题,找到你的 API, 进到 `/POST` 端点,进到“integration request”,点击“Lambda Function”旁边的编辑图标,修改它,然后保存。此时将弹出一个窗口提示“You are about to give API Gateway permission to invoke your Lambda function”, 点击“OK”。
|
||||
|
||||
当你完成后,记录下 `./tools/deploy.py` 打印出的 URL,像下面这样调用它,然后查看你的新 API 的行为:
|
||||
|
||||
```
|
||||
$ curl -X POST https://a1b2c3d4.execute-api.us-east-1.amazonaws.com/prod/
|
||||
{"status": "success", "meditation": "the count of machines abides"}
|
||||
```
|
||||
|
||||
### 本地运行
|
||||
|
||||
不幸的是,AWS Lambda 没有好的方法能在本地运行你的代码。在这个例子里,我们将用一个简单的 flask 服务器来在本地托管合适的端点,并调用 handler 函数。
|
||||
|
||||
```
|
||||
from __future__ import absolute_import
|
||||
|
||||
from flask import Flask, jsonify
|
||||
|
||||
from server.meditate import handler
|
||||
|
||||
|
||||
app = Flask(__name__)
|
||||
|
||||
@app.route("/", methods=["POST"])
|
||||
def index():
|
||||
|
||||
class FakeContext(object):
|
||||
aws_request_id = "XXX"
|
||||
|
||||
return jsonify(**handler(None, FakeContext()))
|
||||
|
||||
app.run(host="0.0.0.0")
|
||||
```
|
||||
|
||||
你可以在仓库中用 `./tools/serve.sh` 运行它,像这样调用:
|
||||
|
||||
```
|
||||
$ curl -X POST http://localhost:5000/
|
||||
{
|
||||
"meditation": "your solution requires a blood eagle",
|
||||
"status": "success"
|
||||
}
|
||||
```
|
||||
|
||||
### 测试
|
||||
|
||||
你总是应该测试你的代码。我们的测试方法是导入并运行我们的 handler 函数。这是最基本的 python 测试方法:
|
||||
|
||||
```
|
||||
from __future__ import absolute_import
|
||||
|
||||
import unittest
|
||||
|
||||
from server.meditate import handler
|
||||
|
||||
|
||||
class SubmitTestCase(unittest.TestCase):
|
||||
|
||||
def test_submit(self):
|
||||
|
||||
class FakeContext(object):
|
||||
|
||||
aws_request_id = "XXX"
|
||||
|
||||
response = handler(None, FakeContext())
|
||||
|
||||
self.assertEquals(response["status"], "success")
|
||||
self.assertTrue("meditation" in response)
|
||||
```
|
||||
|
||||
你可以在仓库里通过 nose2 运行这个测试代码。
|
||||
|
||||
### 更多前景
|
||||
|
||||
- **和 AWS 服务的无缝集成。**通过 boto,你可以完美地轻易连接到任何其他的 AWS 服务。你可以轻易地让你的执行角色用 IAM 访问这些服务。你可以从 S3 取文件或放文件到 S3,连接到 Dynamo DB,调用其他 Lambda Function,等等。
|
||||
- **访问数据库。**你也可以轻易地访问远程数据库。在你的 Lambda handler 模块的最上面连接数据库,并在handler 函数中执行查询。你很可能必须从它的安装位置上传相关的包内容才能使它正常工作。可能你也需要静态编译某些库。
|
||||
- **调用其他 webservices。**API Gateway 也是一种把 webservices 的输出从一个格式转换成另一个格式的方法。你可以充分利用这个特点通过不同的 webservices 来代理调用,或者当业务变更时提供后向兼容能力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.ryankelly.us/2016/08/07/going-serverless-with-aws-lambda-and-api-gateway.html
|
||||
|
||||
作者:[Ryan Kelly][a]
|
||||
译者:[messon007](https://github.com/messon007)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/f0rk/blog.ryankelly.us/
|
||||
[1]: https://github.com/f0rk/meditations
|
||||
[2]: http://blog.ryankelly.us/2016/07/11/jimmy.html
|
||||
@ -1,13 +1,13 @@
|
||||
translating by StdioA
|
||||
|
||||
搭个 Web 服务器(三)
|
||||
=====================================
|
||||
|
||||
>“当我们必须创造时,才能够学到更多。” ——伯爵
|
||||
>“当我们必须创造时,才能够学到更多。” ——皮亚杰
|
||||
|
||||
在本系列的第二部分中,你创造了一个可以处理基本 HTTP GET 请求的、朴素的 WSGI 服务器。当时我问了一个问题:“你该如何让你的服务器在同一时间处理多个请求呢?”在这篇文章中,你会找到答案。系好安全带,我们要认真起来,全速前进了!你将会体验到一段非常快速的旅程。准备好你的 Linux,Mac OS X(或者其他 *nix 系统),还有你的 Python. 本文中所有源代码均可在 [GitHub][1] 上找到。
|
||||
在本系列的[第二部分](https://linux.cn/article-7685-1.html)中,你创造了一个可以处理基本 HTTP GET 请求的、朴素的 WSGI 服务器。当时我问了一个问题:“你该如何让你的服务器在同一时间处理多个请求呢?”在这篇文章中,你会找到答案。系好安全带,我们要认真起来,全速前进了!你将会体验到一段非常快速的旅程。准备好你的 Linux、Mac OS X(或者其他 *nix 系统),还有你的 Python。本文中所有源代码均可在 [GitHub][1] 上找到。
|
||||
|
||||
首先,我们来回顾一下 Web 服务器的基本结构,以及服务器处理来自客户端的请求时,所需的必要步骤。你在第一及第二部分中创建的轮询服务器只能够在同一时间内处理一个请求。在处理完当前请求之前,它不能够打开一个新的客户端连接。所有请求为了等待服务都需要排队,在服务繁忙时,这个队伍可能会排的很长,一些客户端可能会感到不开心。
|
||||
### 服务器的基本结构及如何处理请求
|
||||
|
||||
首先,我们来回顾一下 Web 服务器的基本结构,以及服务器处理来自客户端的请求时,所需的必要步骤。你在[第一部分](https://linux.cn/article-7662-1.html)及[第二部分](https://linux.cn/article-7685-1.html)中创建的轮询服务器只能够一次处理一个请求。在处理完当前请求之前,它不能够接受新的客户端连接。所有请求为了等待服务都需要排队,在服务繁忙时,这个队伍可能会排的很长,一些客户端可能会感到不开心。
|
||||
|
||||
|
||||
|
||||
@ -53,7 +53,7 @@ if __name__ == '__main__':
|
||||
serve_forever()
|
||||
```
|
||||
|
||||
为了观察到你的服务器在同一时间只能处理一个请求,我们对服务器的代码做一点点修改:在将响应发送至客户端之后,将程序阻塞 60 秒。这个修改只需要一行代码,来告诉服务器进程暂停 60 秒钟。
|
||||
为了观察到你的服务器在同一时间只能处理一个请求的行为,我们对服务器的代码做一点点修改:在将响应发送至客户端之后,将程序阻塞 60 秒。这个修改只需要一行代码,来告诉服务器进程暂停 60 秒钟。
|
||||
|
||||
|
||||
|
||||
@ -84,7 +84,7 @@ HTTP/1.1 200 OK
|
||||
Hello, World!
|
||||
"""
|
||||
client_connection.sendall(http_response)
|
||||
time.sleep(60) # 睡眠语句,阻塞该进程 60 秒
|
||||
time.sleep(60) ### 睡眠语句,阻塞该进程 60 秒
|
||||
|
||||
|
||||
def serve_forever():
|
||||
@ -126,88 +126,85 @@ $ curl http://localhost:8888/hello
|
||||
|
||||
|
||||
|
||||
当你等待足够长的时间(60 秒以上)后,你会看到第一个 `curl` 程序完成,而第二个 `curl` 在屏幕上输出了“Hello, World!”,然后休眠 60 秒,进而停止运行。
|
||||
当你等待足够长的时间(60 秒以上)后,你会看到第一个 `curl` 程序完成,而第二个 `curl` 在屏幕上输出了“Hello, World!”,然后休眠 60 秒,进而终止。
|
||||
|
||||
|
||||
|
||||
这两个程序这样运行,是因为在服务器在处理完第一个来自 `curl` 的请求之后,只有等待 60 秒才能开始处理第二个请求。这个处理请求的过程按顺序进行(也可以说,迭代进行),一步一步进行,在我们刚刚给出的例子中,在同一时间内只能处理一个请求。
|
||||
这样运行的原因是因为在服务器在处理完第一个来自 `curl` 的请求之后,只有等待 60 秒才能开始处理第二个请求。这个处理请求的过程按顺序进行(也可以说,迭代进行),一步一步进行,在我们刚刚给出的例子中,在同一时间内只能处理一个请求。
|
||||
|
||||
现在,我们来简单讨论一下客户端与服务器的交流过程。为了让两个程序在网络中互相交流,它们必须使用套接字。你应当在本系列的前两部分中见过它几次了。但是,套接字是什么?
|
||||
|
||||
|
||||
|
||||
套接字是一个交互通道的端点的抽象形式,它可以让你的程序通过文件描述符来与其它程序进行交流。在这篇文章中,我只会单独讨论 Linux 或 Mac OS X 中的 TCP/IP 套接字。这里有一个重点概念需要你去理解:TCP 套接字对。
|
||||
套接字(socket)是一个通讯通道端点(endpoint)的抽象描述,它可以让你的程序通过文件描述符来与其它程序进行交流。在这篇文章中,我只会单独讨论 Linux 或 Mac OS X 中的 TCP/IP 套接字。这里有一个重点概念需要你去理解:TCP 套接字对(socket pair)。
|
||||
|
||||
> TCP 连接使用的套接字对是一个由 4 个元素组成的元组,它确定了 TCP 连接的两端:本地 IP 地址、本地端口、远端 IP 地址及远端端口。一个套接字对独一无二地确定了网络中的每一个 TCP 连接。在连接一端的两个值:一个 IP 地址和一个端口,通常被称作一个套接字。[1][4]
|
||||
> TCP 连接使用的套接字对是一个由 4 个元素组成的元组,它确定了 TCP 连接的两端:本地 IP 地址、本地端口、远端 IP 地址及远端端口。一个套接字对唯一地确定了网络中的每一个 TCP 连接。在连接一端的两个值:一个 IP 地址和一个端口,通常被称作一个套接字。(引自[《UNIX 网络编程 卷1:套接字联网 API (第3版)》][4])
|
||||
|
||||
|
||||
|
||||
所以,元组 {10.10.10.2:49152, 12.12.12.3:8888} 就是一个能够在客户端确定 TCP 连接两端的套接字对,而元组 {12.12.12.3:8888, 10.10.10.2:49152} 则是在服务端确定 TCP 连接两端的套接字对。在这个例子中,确定 TCP 服务端的两个值(IP 地址 `12.12.12.3` 及端口 `8888`),代表一个套接字;另外两个值则代表客户端的套接字。
|
||||
所以,元组 `{10.10.10.2:49152, 12.12.12.3:8888}` 就是一个能够在客户端确定 TCP 连接两端的套接字对,而元组 `{12.12.12.3:8888, 10.10.10.2:49152}` 则是在服务端确定 TCP 连接两端的套接字对。在这个例子中,确定 TCP 服务端的两个值(IP 地址 `12.12.12.3` 及端口 `8888`),代表一个套接字;另外两个值则代表客户端的套接字。
|
||||
|
||||
一个服务器创建一个套接字并开始建立连接的基本工作流程如下:
|
||||
|
||||
|
||||
|
||||
1. 服务器创建一个 TCP/IP 套接字。我们可以用下面那条 Python 语句来创建:
|
||||
1. 服务器创建一个 TCP/IP 套接字。我们可以用这条 Python 语句来创建:
|
||||
|
||||
```
|
||||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
```
|
||||
```
|
||||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
```
|
||||
2. 服务器可能会设定一些套接字选项(这个步骤是可选的,但是你可以看到上面的服务器代码做了设定,这样才能够在重启服务器时多次复用同一地址):
|
||||
|
||||
2. 服务器可能会设定一些套接字选项(这个步骤是可选的,但是你可以看到上面的服务器代码做了设定,这样才能够在重启服务器时多次复用同一地址)。
|
||||
|
||||
```
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
```
|
||||
|
||||
3. 然后,服务器绑定一个地址。绑定函数可以将一个本地协议地址赋给套接字。若使用 TCP 协议,调用绑定函数时,需要指定一个端口号,一个 IP 地址,或两者兼有,或两者兼无。[1][4]
|
||||
|
||||
```
|
||||
listen_socket.bind(SERVER_ADDRESS)
|
||||
```
|
||||
```
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
```
|
||||
3. 然后,服务器绑定一个地址。绑定函数 `bind` 可以将一个本地协议地址赋给套接字。若使用 TCP 协议,调用绑定函数 `bind` 时,需要指定一个端口号,一个 IP 地址,或两者兼有,或两者全无。(引自[《UNIX网络编程 卷1:套接字联网 API (第3版)》][4])
|
||||
|
||||
```
|
||||
listen_socket.bind(SERVER_ADDRESS)
|
||||
```
|
||||
4. 然后,服务器开启套接字的监听模式。
|
||||
|
||||
```
|
||||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||||
```
|
||||
```
|
||||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||||
```
|
||||
|
||||
监听函数只应在服务端调用。它会通知操作系统内核,标明它会接受所有向该套接字发送请求的链接。
|
||||
监听函数 `listen` 只应在服务端调用。它会通知操作系统内核,表明它会接受所有向该套接字发送的入站连接请求。
|
||||
|
||||
以上四步完成后,服务器将循环接收来自客户端的连接,一次循环处理一条。当有连接可用时,`accept` 函数将会返回一个已连接的客户端套接字。然后,服务器从客户端套接字中读取请求数据,将它在标准输出流中打印出来,并向客户端回送一条消息。然后,服务器会关闭这个客户端连接,并准备接收一个新的客户端连接。
|
||||
以上四步完成后,服务器将循环接收来自客户端的连接,一次循环处理一条。当有连接可用时,接受请求函数 `accept` 将会返回一个已连接的客户端套接字。然后,服务器从这个已连接的客户端套接字中读取请求数据,将数据在其标准输出流中输出出来,并向客户端回送一条消息。然后,服务器会关闭这个客户端连接,并准备接收一个新的客户端连接。
|
||||
|
||||
这是客户端使用 TCP/IP 协议与服务器通信的必要步骤:
|
||||
|
||||
|
||||
|
||||
下面是一段示例代码,使用这段代码,客户端可以连接你的服务器,发送一个请求,并打印响应内容:
|
||||
下面是一段示例代码,使用这段代码,客户端可以连接你的服务器,发送一个请求,并输出响应内容:
|
||||
|
||||
```
|
||||
import socket
|
||||
|
||||
# 创建一个套接字,并连接值服务器
|
||||
### 创建一个套接字,并连接值服务器
|
||||
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
sock.connect(('localhost', 8888))
|
||||
|
||||
# 发送一段数据,并接收响应数据
|
||||
### 发送一段数据,并接收响应数据
|
||||
sock.sendall(b'test')
|
||||
data = sock.recv(1024)
|
||||
print(data.decode())
|
||||
```
|
||||
|
||||
在创建套接字后,客户端需要连接至服务器。我们可以调用 `connect` 函数来完成这个操作:
|
||||
在创建套接字后,客户端需要连接至服务器。我们可以调用连接函数 `connect` 来完成这个操作:
|
||||
|
||||
```
|
||||
sock.connect(('localhost', 8888))
|
||||
```
|
||||
|
||||
客户端只需提供待连接服务器的 IP 地址(或主机名),及端口号,即可连接至远端服务器。
|
||||
客户端只需提供待连接的远程服务器的 IP 地址(或主机名),及端口号,即可连接至远端服务器。
|
||||
|
||||
你可能已经注意到了,客户端不需要调用 `bind` 及 `accept` 函数,就可以与服务器建立连接。客户端不需要调用 `bind` 函数是因为客户端不需要关注本地 IP 地址及端口号。操作系统内核中的 TCP/IP 协议栈会在客户端调用 `connect` 函数时,自动为套接字分配本地 IP 地址及本地端口号。这个本地端口被称为临时端口,也就是一个短暂开放的端口。
|
||||
你可能已经注意到了,客户端不需要调用 `bind` 及 `accept` 函数,就可以与服务器建立连接。客户端不需要调用 `bind` 函数是因为客户端不需要关注本地 IP 地址及端口号。操作系统内核中的 TCP/IP 协议栈会在客户端调用 `connect` 函数时,自动为套接字分配本地 IP 地址及本地端口号。这个本地端口被称为临时端口(ephemeral port),即一个短暂开放的端口。
|
||||
|
||||

|
||||
|
||||
服务器中有一些端口被用于承载一些众所周知的服务,它们被称作通用端口:如 80 端口用于 HTTP 服务,22 端口用于 SSH 服务。打开你的 Python shell,与你在本地运行的服务器建立一个连接,来看看内核给你的客户端套接字分配了哪个临时端口(在尝试这个例子之前,你需要运行服务器程序 `webserver3a.py` 或 `webserver3b.py`):
|
||||
服务器中有一些端口被用于承载一些众所周知的服务,它们被称作通用(well-known)端口:如 80 端口用于 HTTP 服务,22 端口用于 SSH 服务。打开你的 Python shell,与你在本地运行的服务器建立一个连接,来看看内核给你的客户端套接字分配了哪个临时端口(在尝试这个例子之前,你需要运行服务器程序 `webserver3a.py` 或 `webserver3b.py`):
|
||||
|
||||
```
|
||||
>>> import socket
|
||||
@ -222,12 +219,11 @@ sock.connect(('localhost', 8888))
|
||||
|
||||
在我开始回答我在第二部分中提出的问题之前,我还需要快速讲解一些概念。你很快就会明白这些概念为什么非常重要。这两个概念,一个是进程,另外一个是文件描述符。
|
||||
|
||||
什么是进程?进程就是一个程序执行的实体。举个例子:当你的服务器代码被执行时,它会被载入内存,而内存中表现此次程序运行的实体就叫做进程。内核记录了进程的一系列有关信息——比如进程 ID——来追踪它的运行情况。当你在执行轮询服务器 `webserver3a.py` 或 `webserver3b.py` 时,你只启动了一个进程。
|
||||
什么是进程?进程就是一个程序执行的实体。举个例子:当你的服务器代码被执行时,它会被载入内存,而内存中表现此次程序运行的实体就叫做进程。内核记录了进程的一系列有关信息——比如进程 ID——来追踪它的运行情况。当你在执行轮询服务器 `webserver3a.py` 或 `webserver3b.py` 时,你其实只是启动了一个进程。
|
||||
|
||||
|
||||
|
||||
我们在终端窗口中运行 `webserver3b.py`:
|
||||
Start the server webserver3b.py in a terminal window:
|
||||
|
||||
```
|
||||
$ python webserver3b.py
|
||||
@ -240,7 +236,7 @@ $ ps | grep webserver3b | grep -v grep
|
||||
7182 ttys003 0:00.04 python webserver3b.py
|
||||
```
|
||||
|
||||
`ps` 命令显示,我们刚刚只运行了一个 Python 进程 `webserver3b`。当一个进程被创建时,内核会为其分配一个进程 ID,也就是 PID。在 UNIX 中,所有用户进程都有一个父进程;当然,这个父进程也有进程 ID,叫做父进程 ID,缩写为 PPID。假设你默认使用 BASH shell,那当你启动服务器时,一个新的进程会被启动,同时被赋予一个 PID,而它的父进程 PID 会被设为 BASH shell 的 PID。
|
||||
`ps` 命令显示,我们刚刚只运行了一个 Python 进程 `webserver3b.py`。当一个进程被创建时,内核会为其分配一个进程 ID,也就是 PID。在 UNIX 中,所有用户进程都有一个父进程;当然,这个父进程也有进程 ID,叫做父进程 ID,缩写为 PPID。假设你默认使用 BASH shell,那当你启动服务器时,就会启动一个新的进程,同时被赋予一个 PID,而它的父进程 PID 会被设为 BASH shell 的 PID。
|
||||
|
||||
|
||||
|
||||
@ -248,11 +244,11 @@ $ ps | grep webserver3b | grep -v grep
|
||||
|
||||
|
||||
|
||||
另外一个需要了解的概念,就是文件描述符。什么是文件描述符?文件描述符是一个非负整数,当进程打开一个现有文件、创建新文件或创建一个新的套接字时,内核会将这个数返回给进程。你以前可能听说过,在 UNIX 中,一切皆是文件。内核会根据一个文件描述符来为一个进程打开一个文件。当你需要读取文件或向文件写入时,我们同样通过文件描述符来定位这个文件。Python 提供了高层次的文件(或套接字)对象,所以你不需要直接通过文件描述符来定位文件。但是,在高层对象之下,我们就是用它来在 UNIX 中定位文件及套接字:整形的文件描述符。
|
||||
另外一个需要了解的概念,就是文件描述符。什么是文件描述符?文件描述符是一个非负整数,当进程打开一个现有文件、创建新文件或创建一个新的套接字时,内核会将这个数返回给进程。你以前可能听说过,在 UNIX 中,一切皆是文件。内核会按文件描述符来找到一个进程所打开的文件。当你需要读取文件或向文件写入时,我们同样通过文件描述符来定位这个文件。Python 提供了高层次的操作文件(或套接字)的对象,所以你不需要直接通过文件描述符来定位文件。但是,在高层对象之下,我们就是用它来在 UNIX 中定位文件及套接字,通过这个整数的文件描述符。
|
||||
|
||||
|
||||
|
||||
一般情况下,UNIX shell 会将一个进程的标准输入流的文件描述符设为 0,标准输出流设为 1,而标准错误打印的文件描述符会被设为 2。
|
||||
一般情况下,UNIX shell 会将一个进程的标准输入流(STDIN)的文件描述符设为 0,标准输出流(STDOUT)设为 1,而标准错误打印(STDERR)的文件描述符会被设为 2。
|
||||
|
||||
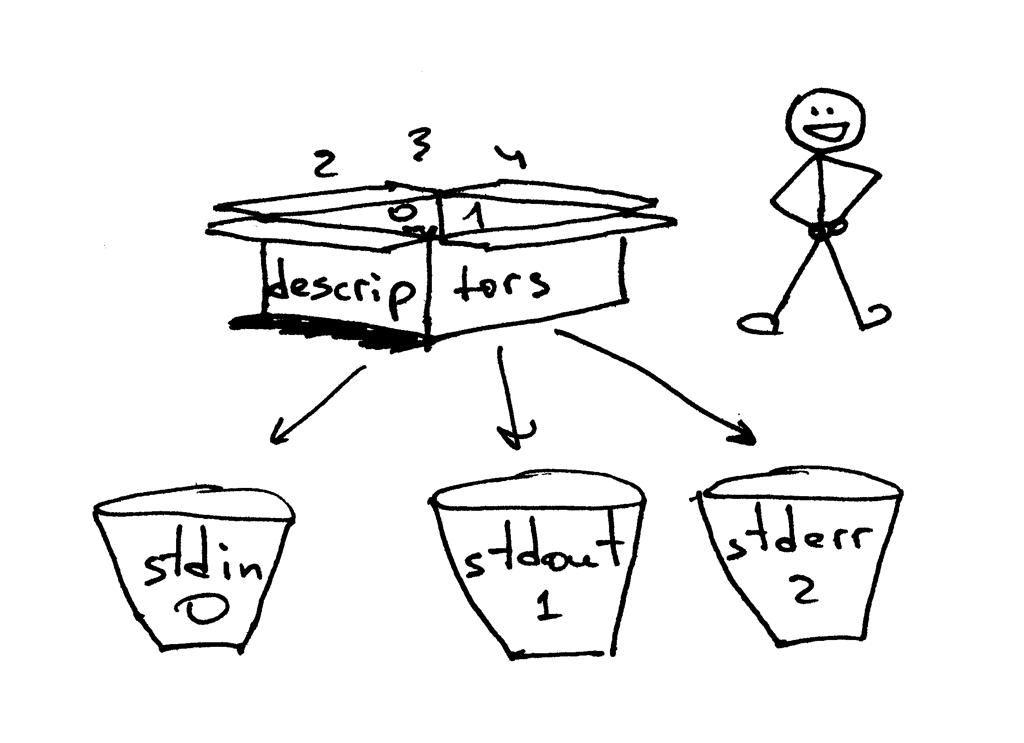
|
||||
|
||||
@ -289,7 +285,7 @@ hello
|
||||
3
|
||||
```
|
||||
|
||||
我还想再提一件事:不知道你有没有注意到,在我们的第二个轮询服务器 `webserver3b.py` 中,当你的服务器休眠 60 秒的过程中,你仍然可以通过第二个 `curl` 命令连接至服务器。当然 `curl` 命令并没有立刻输出任何内容而是挂在哪里,但是既然服务器没有接受连接,那它为什么不立即拒绝掉连接,而让它还能够继续与服务器建立连接呢?这个问题的答案是:当我在调用套接字对象的 `listen` 方法时,我为该方法提供了一个 `BACKLOG` 参数,在代码中用 `REQUEST_QUEUE_SIZE` 变量来表示。`BACKLOG` 参数决定了在内核中为存放即将到来的连接请求所创建的队列的大小。当服务器 `webserver3b.py` 被挂起的时候,你运行的第二个 `curl` 命令依然能够连接至服务器,因为内核中用来存放即将接收的连接请求的队列依然拥有足够大的可用空间。
|
||||
我还想再提一件事:不知道你有没有注意到,在我们的第二个轮询服务器 `webserver3b.py` 中,当你的服务器休眠 60 秒的过程中,你仍然可以通过第二个 `curl` 命令连接至服务器。当然 `curl` 命令并没有立刻输出任何内容而是挂在哪里,但是既然服务器没有接受连接,那它为什么不立即拒绝掉连接,而让它还能够继续与服务器建立连接呢?这个问题的答案是:当我在调用套接字对象的 `listen` 方法时,我为该方法提供了一个 `BACKLOG` 参数,在代码中用 `REQUEST_QUEUE_SIZE` 常量来表示。`BACKLOG` 参数决定了在内核中为存放即将到来的连接请求所创建的队列的大小。当服务器 `webserver3b.py` 在睡眠的时候,你运行的第二个 `curl` 命令依然能够连接至服务器,因为内核中用来存放即将接收的连接请求的队列依然拥有足够大的可用空间。
|
||||
|
||||
尽管增大 `BACKLOG` 参数并不能神奇地使你的服务器同时处理多个请求,但当你的服务器很繁忙时,将它设置为一个较大的值还是相当重要的。这样,在你的服务器调用 `accept` 方法时,不需要再等待一个新的连接建立,而可以立刻直接抓取队列中的第一个客户端连接,并不加停顿地立刻处理它。
|
||||
|
||||
@ -297,7 +293,7 @@ hello
|
||||
|
||||

|
||||
|
||||
- 迭代服务器
|
||||
- 轮询服务器
|
||||
- 服务端套接字创建流程(创建套接字,绑定,监听及接受)
|
||||
- 客户端连接创建流程(创建套接字,连接)
|
||||
- 套接字对
|
||||
@ -308,6 +304,8 @@ hello
|
||||
- 文件描述符
|
||||
- 套接字的 `listen` 方法中,`BACKLOG` 参数的含义
|
||||
|
||||
### 如何并发处理多个请求
|
||||
|
||||
现在,我可以开始回答第二部分中的那个问题了:“你该如何让你的服务器在同一时间处理多个请求呢?”或者换一种说法:“如何编写一个并发服务器?”
|
||||
|
||||
|
||||
@ -368,13 +366,13 @@ def serve_forever():
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中复制的套接字对象
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中复制的套接字对象
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0) # 子进程在这里退出
|
||||
else: # 父进程
|
||||
client_connection.close() # 关闭父进程中的客户端连接对象,并循环执行
|
||||
os._exit(0) ### 子进程在这里退出
|
||||
else: ### 父进程
|
||||
client_connection.close() ### 关闭父进程中的客户端连接对象,并循环执行
|
||||
|
||||
if __name__ == '__main__':
|
||||
serve_forever()
|
||||
@ -386,13 +384,13 @@ if __name__ == '__main__':
|
||||
$ python webserver3c.py
|
||||
```
|
||||
|
||||
然后,像我们之前测试轮询服务器那样,运行两个 `curl` 命令,来看看这次的效果。现在你可以看到,即使子进程在处理客户端请求后会休眠 60 秒,但它并不会影响其它客户端连接,因为他们都是由完全独立的进程来处理的。你应该看到你的 `curl` 命令立即输出了“Hello, World!”然后挂起 60 秒。你可以按照你的想法运行尽可能多的 `curl` 命令(好吧,并不能运行特别特别多 ^_^),所有的命令都会立刻输出来自服务器的响应“Hello, World!”,并不会出现任何可被察觉到的延迟行为。试试看吧。
|
||||
然后,像我们之前测试轮询服务器那样,运行两个 `curl` 命令,来看看这次的效果。现在你可以看到,即使子进程在处理客户端请求后会休眠 60 秒,但它并不会影响其它客户端连接,因为他们都是由完全独立的进程来处理的。你应该看到你的 `curl` 命令立即输出了“Hello, World!”然后挂起 60 秒。你可以按照你的想法运行尽可能多的 `curl` 命令(好吧,并不能运行特别特别多 `^_^`),所有的命令都会立刻输出来自服务器的响应 “Hello, World!”,并不会出现任何可被察觉到的延迟行为。试试看吧。
|
||||
|
||||
如果你要理解 `fork()`,那最重要的一点是:你调用了它一次,但是它会返回两次:一次在父进程中,另一次是在子进程中。当你创建了一个新进程,那么 `fork()` 在子进程中的返回值是 0。如果是在父进程中,那 `fork()` 函数会返回子进程的 PID。
|
||||
如果你要理解 `fork()`,那最重要的一点是:**你调用了它一次,但是它会返回两次** —— 一次在父进程中,另一次是在子进程中。当你创建了一个新进程,那么 `fork()` 在子进程中的返回值是 0。如果是在父进程中,那 `fork()` 函数会返回子进程的 PID。
|
||||
|
||||
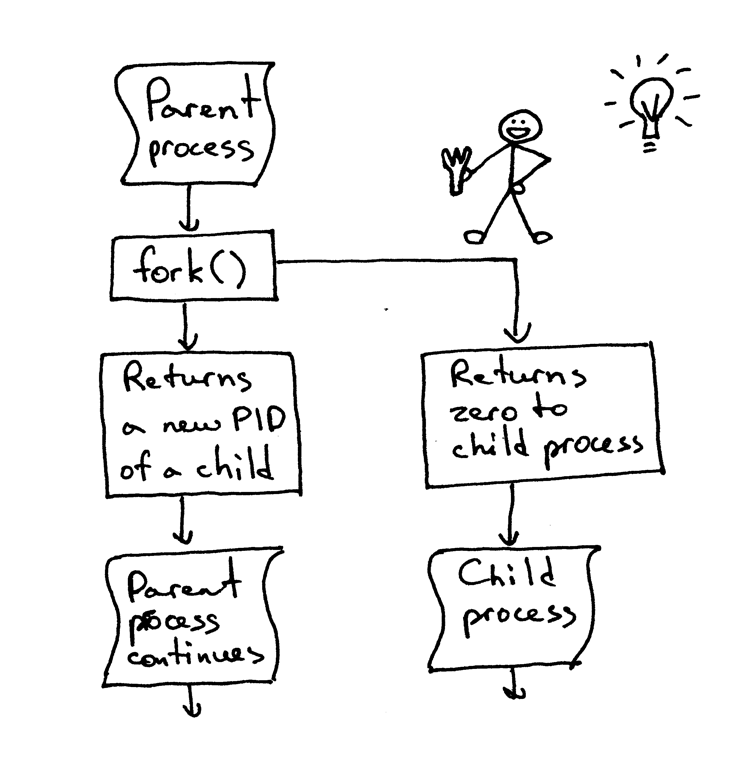
|
||||
|
||||
我依然记得在第一次看到它并尝试使用 `fork()` 的时候,我是多么的入迷。它在我眼里就像是魔法一样。这就好像我在读一段顺序执行的代码,然后“砰”地一声,代码变成了两份,然后出现了两个实体,同时并行地运行相同的代码。讲真,那个时候我觉得它真的跟魔法一样神奇。
|
||||
我依然记得在第一次看到它并尝试使用 `fork()` 的时候,我是多么的入迷。它在我眼里就像是魔法一样。这就好像我在读一段顺序执行的代码,然后“砰!”地一声,代码变成了两份,然后出现了两个实体,同时并行地运行相同的代码。讲真,那个时候我觉得它真的跟魔法一样神奇。
|
||||
|
||||
当父进程创建出一个新的子进程时,子进程会复制从父进程中复制一份文件描述符:
|
||||
|
||||
@ -401,38 +399,39 @@ $ python webserver3c.py
|
||||
你可能注意到,在上面的代码中,父进程关闭了客户端连接:
|
||||
|
||||
```
|
||||
else: # parent
|
||||
else: ### parent
|
||||
client_connection.close() # close parent copy and loop over
|
||||
```
|
||||
|
||||
不过,既然父进程关闭了这个套接字,那为什么子进程仍然能够从来自客户端的套接字中读取数据呢?答案就在上面的图片中。内核会使用描述符引用计数器来决定是否要关闭一个套接字。当你的服务器创建一个子进程时,子进程会复制父进程的所有文件描述符,内核中改描述符的引用计数也会增加。如果只有一个父进程及一个子进程,那客户端套接字的文件描述符引用数应为 2;当父进程关闭客户端连接的套接字时,内核只会减少它的引用计数,将其变为 1,但这仍然不会使内核关闭该套接字。子进程也关闭了父进程中 `listen_socket` 的复制实体,因为子进程不需要关注新的客户端连接,而只需要处理已建立的客户端连接中的请求。
|
||||
不过,既然父进程关闭了这个套接字,那为什么子进程仍然能够从来自客户端的套接字中读取数据呢?答案就在上面的图片中。内核会使用描述符引用计数器来决定是否要关闭一个套接字。当你的服务器创建一个子进程时,子进程会复制父进程的所有文件描述符,内核中该描述符的引用计数也会增加。如果只有一个父进程及一个子进程,那客户端套接字的文件描述符引用数应为 2;当父进程关闭客户端连接的套接字时,内核只会减少它的引用计数,将其变为 1,但这仍然不会使内核关闭该套接字。子进程也关闭了父进程中 `listen_socket` 的复制实体,因为子进程不需要关注新的客户端连接,而只需要处理已建立的客户端连接中的请求。
|
||||
|
||||
```
|
||||
listen_socket.close() # 关闭子进程中的复制实体
|
||||
listen_socket.close() ### 关闭子进程中的复制实体
|
||||
```
|
||||
|
||||
我们将会在后文中讨论,如果你不关闭那些重复的描述符,会发生什么。
|
||||
|
||||
你可以从你的并发服务器源码看到,父进程的主要职责为:接受一个新的客户端连接,复制出一个子进程来处理这个连接,然后继续循环来接受另外的客户端连接,仅此而已。服务器父进程并不会处理客户端连接——子进程才会做这件事。
|
||||
你可以从你的并发服务器源码中看到,父进程的主要职责为:接受一个新的客户端连接,复制出一个子进程来处理这个连接,然后继续循环来接受另外的客户端连接,仅此而已。服务器父进程并不会处理客户端连接——子进程才会做这件事。
|
||||
|
||||
打个岔:当我们说两个事件并发执行时,我们在说什么?
|
||||
A little aside. What does it mean when we say that two events are concurrent?
|
||||
打个岔:当我们说两个事件并发执行时,我们所要表达的意思是什么?
|
||||
|
||||
|
||||
|
||||
当我们说“两个事件并发执行”时,它通常意味着这两个事件同时发生。简单来讲,这个定义没问题,但你应该记住它的严格定义:
|
||||
|
||||
> 如果你阅读代码时,无法判断两个事件的发生顺序,那这两个事件就是并发执行的。[2][5]
|
||||
> 如果你不能在代码中判断两个事件的发生顺序,那这两个事件就是并发执行的。(引自[《信号系统简明手册 (第二版): 并发控制深入浅出及常见错误》][5])
|
||||
|
||||
好的,现在你又该回顾一下你刚刚学过的知识点了。
|
||||
|
||||

|
||||
|
||||
- 在 Unix 中,编写一个并发服务器的最简单的方式——使用 `fork()` 系统调用;
|
||||
- 当一个进程复制出另一个进程时,它会变成刚刚复制出的进程的父进程;
|
||||
- 当一个进程分叉(`fork`)出另一个进程时,它会变成刚刚分叉出的进程的父进程;
|
||||
- 在进行 `fork` 调用后,父进程和子进程共享相同的文件描述符;
|
||||
- 系统内核通过描述符引用计数来决定是否要关闭该描述符对应的文件或套接字;
|
||||
- 服务器父进程的主要职责:现在它做的只是从客户端接受一个新的连接,复制出子进程来处理这个客户端连接,然后开始下一轮循环,去接收新的客户端连接。
|
||||
- 系统内核通过描述符的引用计数来决定是否要关闭该描述符对应的文件或套接字;
|
||||
- 服务器父进程的主要职责:现在它做的只是从客户端接受一个新的连接,分叉出子进程来处理这个客户端连接,然后开始下一轮循环,去接收新的客户端连接。
|
||||
|
||||
### 进程分叉后不关闭重复的套接字会发生什么?
|
||||
|
||||
我们来看看,如果我们不在父进程与子进程中关闭重复的套接字描述符会发生什么。下面是刚才的并发服务器代码的修改版本,这段代码(`webserver3d.py` 中,服务器不会关闭重复的描述符):
|
||||
|
||||
@ -470,15 +469,15 @@ def serve_forever():
|
||||
clients = []
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
# 将引用存储起来,否则在下一轮循环时,他们会被垃圾回收机制销毁
|
||||
### 将引用存储起来,否则在下一轮循环时,他们会被垃圾回收机制销毁
|
||||
clients.append(client_connection)
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的套接字
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的套接字
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0) # 子进程在这里结束
|
||||
else: # 父进程
|
||||
os._exit(0) ### 子进程在这里结束
|
||||
else: ### 父进程
|
||||
# client_connection.close()
|
||||
print(len(clients))
|
||||
|
||||
@ -503,7 +502,7 @@ Hello, World!
|
||||
|
||||
|
||||
|
||||
所以,为什么 `curl` 不终止呢?原因就在于多余的文件描述符。当子进程关闭客户端连接时,系统内核会减少客户端套接字的引用计数,将其变为 1。服务器子进程退出了,但客户端套接字并没有被内核关闭,因为该套接字的描述符引用计数并没有变为 0,所以,这就导致了连接终止包(在 TCP/IP 协议中称作 `FIN`)不会被发送到客户端,所以客户端会一直保持连接。这里就会出现另一个问题:如果你的服务器在长时间运行,并且不关闭重复的文件描述符,那么可用的文件描述符会被消耗殆尽:
|
||||
所以,为什么 `curl` 不终止呢?原因就在于文件描述符的副本。当子进程关闭客户端连接时,系统内核会减少客户端套接字的引用计数,将其变为 1。服务器子进程退出了,但客户端套接字并没有被内核关闭,因为该套接字的描述符引用计数并没有变为 0,所以,这就导致了连接终止包(在 TCP/IP 协议中称作 `FIN`)不会被发送到客户端,所以客户端会一直保持连接。这里也会出现另一个问题:如果你的服务器长时间运行,并且不关闭文件描述符的副本,那么可用的文件描述符会被消耗殆尽:
|
||||
|
||||
|
||||
|
||||
@ -529,7 +528,7 @@ virtual memory (kbytes, -v) unlimited
|
||||
file locks (-x) unlimited
|
||||
```
|
||||
|
||||
你可以从上面的结果看到,在我的 Ubuntu box 中,系统为我的服务器进程分配的最大可用文件描述符(文件打开)数为 1024。
|
||||
你可以从上面的结果看到,在我的 Ubuntu 机器中,系统为我的服务器进程分配的最大可用文件描述符(文件打开)数为 1024。
|
||||
|
||||
现在我们来看一看,如果你的服务器不关闭重复的描述符,它会如何消耗可用的文件描述符。在一个已有的或新建的终端窗口中,将你的服务器进程的最大可用文件描述符设为 256:
|
||||
|
||||
@ -607,15 +606,18 @@ if __name__ == '__main__':
|
||||
$ python client3.py --max-clients=300
|
||||
```
|
||||
|
||||
过一会,你的服务器就该爆炸了。这是我的环境中出现的异常截图:
|
||||
过一会,你的服务器进程就该爆了。这是我的环境中出现的异常截图:
|
||||
|
||||
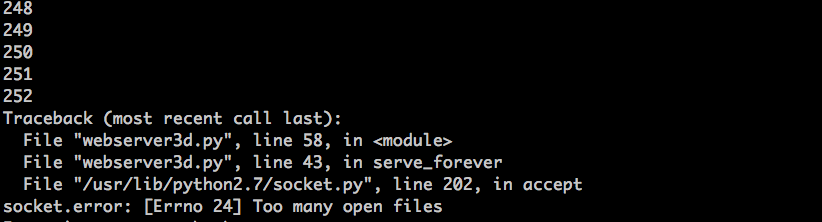
|
||||
|
||||
这个例子很明显——你的服务器应该关闭重复的描述符。但是,即使你关闭了多余的描述符,你依然没有摆脱险境,因为你的服务器还有一个问题,这个问题在于“僵尸”!
|
||||
这个例子很明显——你的服务器应该关闭描述符副本。
|
||||
|
||||
#### 僵尸进程
|
||||
|
||||
但是,即使你关闭了描述符副本,你依然没有摆脱险境,因为你的服务器还有一个问题,这个问题在于“僵尸(zombies)”!
|
||||
|
||||
|
||||
|
||||
|
||||
没错,这个服务器代码确实在制造僵尸进程。我们来看看怎么回事。重新运行你的服务器:
|
||||
|
||||
```
|
||||
@ -636,13 +638,13 @@ vagrant 9099 0.0 1.2 31804 6256 pts/0 S+ 16:33 0:00 python webserve
|
||||
vagrant 9102 0.0 0.0 0 0 pts/0 Z+ 16:33 0:00 [python] <defunct>
|
||||
```
|
||||
|
||||
你看到第二行中,pid 为 9102,状态为 Z+,名字里面有个 `<defunct>` 的进程了吗?那就是我们的僵尸进程。这个僵尸进程的问题在于:你无法将它杀掉。
|
||||
你看到第二行中,pid 为 9102,状态为 `Z+`,名字里面有个 `<defunct>` 的进程了吗?那就是我们的僵尸进程。这个僵尸进程的问题在于:你无法将它杀掉!
|
||||
|
||||
|
||||
|
||||
就算你尝试使用 `kill -9` 来杀死僵尸进程,它们仍旧会存活。自己试试看,看看结果。
|
||||
|
||||
这个僵尸到底是什么,为什么我们的服务器会造出它们呢?一个僵尸进程是一个已经结束的进程,但它的父进程并没有等待它结束,并且也没有收到它的终结状态。如果一个进程在父进程退出之前退出,系统内核会把它变为一个僵尸进程,存储它的部分信息,以便父进程读取。内核保存的进程信息通常包括进程 ID,进程终止状态,以及进程的资源占用情况。OK,所以僵尸进程确实有存在的意义,但如果服务器不管这些僵尸进程,你的系统调用将会被阻塞。我们来看看这个要如何发生。首先,关闭你的服务器;然后,在一个新的终端窗口中,使用 `ulimit` 命令将最大用户进程数设为 400(同时,要确保你的最大可用描述符数大于这个数字,我们在这里设为 500):
|
||||
这个僵尸到底是什么,为什么我们的服务器会造出它们呢?一个僵尸进程(zombie)是一个已经结束的进程,但它的父进程并没有等待(`waited`)它结束,并且也没有收到它的终结状态。如果一个进程在父进程退出之前退出,系统内核会把它变为一个僵尸进程,存储它的部分信息,以便父进程读取。内核保存的进程信息通常包括进程 ID、进程终止状态,以及进程的资源占用情况。OK,所以僵尸进程确实有存在的意义,但如果服务器不管这些僵尸进程,你的系统将会被壅塞。我们来看看这个会如何发生。首先,关闭你运行的服务器;然后,在一个新的终端窗口中,使用 `ulimit` 命令将最大用户进程数设为 400(同时,要确保你的最大可用描述符数大于这个数字,我们在这里设为 500):
|
||||
|
||||
```
|
||||
$ ulimit -u 400
|
||||
@ -661,33 +663,35 @@ $ python webserver3d.py
|
||||
$ python client3.py --max-clients=500
|
||||
```
|
||||
|
||||
然后,过一会,你的服务器应该会再次爆炸,它会在创建新进程时抛出一个 `OSError: 资源暂时不可用` 异常。但它并没有达到系统允许的最大进程数。这是我的环境中输出的异常信息截图:
|
||||
然后,过一会,你的服务器进程应该会再次爆了,它会在创建新进程时抛出一个 `OSError: 资源暂时不可用` 的异常。但它并没有达到系统允许的最大进程数。这是我的环境中输出的异常信息截图:
|
||||
|
||||
|
||||
|
||||
你可以看到,如果服务器不管僵尸进程,它们会引发问题。我会简单探讨一下僵尸进程问题的解决方案。
|
||||
你可以看到,如果服务器不管僵尸进程,它们会引发问题。接下来我会简单探讨一下僵尸进程问题的解决方案。
|
||||
|
||||
我们来回顾一下你刚刚掌握的知识点:
|
||||
|
||||

|
||||
|
||||
- 如果你不关闭重复的描述符,客户端就不会在请求处理完成后终止,因为客户端连接没有被关闭;
|
||||
- 如果你不关闭重复的描述符,长久运行的服务器最终会把可用的文件描述符(最大文件打开数)消耗殆尽;
|
||||
- 当你创建一个新进程,而父进程不等待子进程,也不在子进程结束后收集它的终止状态,它会变为一个僵尸进程;
|
||||
- 僵尸通常都会吃东西,在我们的例子中,僵尸进程会占用资源。如果你的服务器不管僵尸进程,它最终会消耗掉所有的可用进程(最大用户进程数);
|
||||
- 你不能杀死僵尸进程,你需要等待它。
|
||||
- 如果你不关闭文件描述符副本,客户端就不会在请求处理完成后终止,因为客户端连接没有被关闭;
|
||||
- 如果你不关闭文件描述符副本,长久运行的服务器最终会把可用的文件描述符(最大文件打开数)消耗殆尽;
|
||||
- 当你创建一个新进程,而父进程不等待(`wait`)子进程,也不在子进程结束后收集它的终止状态,它会变为一个僵尸进程;
|
||||
- 僵尸通常都会吃东西,在我们的例子中,僵尸进程会吃掉资源。如果你的服务器不管僵尸进程,它最终会消耗掉所有的可用进程(最大用户进程数);
|
||||
- 你不能杀死(`kill`)僵尸进程,你需要等待(`wait`)它。
|
||||
|
||||
所以,你需要做什么来处理僵尸进程呢?你需要修改你的服务器代码,来等待僵尸进程,并收集它们的终止信息。你可以在代码中使用系统调用 `wait` 来完成这个任务。不幸的是,这个方法里理想目标还很远,因为在没有终止的子进程存在的情况下调用 `wait` 会导致程序阻塞,这会阻碍你的服务器处理新的客户端连接请求。那么,我们有其他选择吗?嗯,有的,其中一个解决方案需要结合信号处理以及 `wait` 系统调用。
|
||||
### 如何处理僵尸进程?
|
||||
|
||||
所以,你需要做什么来处理僵尸进程呢?你需要修改你的服务器代码,来等待(`wait`)僵尸进程,并收集它们的终止信息。你可以在代码中使用系统调用 `wait` 来完成这个任务。不幸的是,这个方法离理想目标还很远,因为在没有终止的子进程存在的情况下调用 `wait` 会导致服务器进程阻塞,这会阻碍你的服务器处理新的客户端连接请求。那么,我们有其他选择吗?嗯,有的,其中一个解决方案需要结合信号处理以及 `wait` 系统调用。
|
||||
|
||||

|
||||
|
||||
这是它的工作流程。当一个子进程退出时,内核会发送 `SIGCHLD` 信号。父进程可以设置一个信号处理器,它可以异步响应 `SIGCHLD` 信号,并在信号响应函数中等待子进程收集终止信息,从而阻止了僵尸进程的存在。
|
||||
这是它的工作流程。当一个子进程退出时,内核会发送 `SIGCHLD` 信号。父进程可以设置一个信号处理器,它可以异步响应 `SIGCHLD` 信号,并在信号响应函数中等待(`wait`)子进程收集终止信息,从而阻止了僵尸进程的存在。
|
||||
|
||||
|
||||
|
||||
顺便,异步事件意味着父进程无法提前知道事件的发生时间。
|
||||
顺便说一下,异步事件意味着父进程无法提前知道事件的发生时间。
|
||||
|
||||
修改你的服务器代码,设置一个 `SIGCHLD` 信号处理器,在信号处理器中等待终止的子进程。修改后的代码如下(webserver3e.py):
|
||||
修改你的服务器代码,设置一个 `SIGCHLD` 信号处理器,在信号处理器中等待(`wait`)终止的子进程。修改后的代码如下(webserver3e.py):
|
||||
|
||||
```
|
||||
#######################################################
|
||||
@ -722,7 +726,7 @@ HTTP/1.1 200 OK
|
||||
Hello, World!
|
||||
"""
|
||||
client_connection.sendall(http_response)
|
||||
# 挂起进程,来允许父进程完成循环,并在 "accept" 处阻塞
|
||||
### 挂起进程,来允许父进程完成循环,并在 "accept" 处阻塞
|
||||
time.sleep(3)
|
||||
|
||||
|
||||
@ -738,12 +742,12 @@ def serve_forever():
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的套接字
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的套接字
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0)
|
||||
else: # 父进程
|
||||
else: ### 父进程
|
||||
client_connection.close()
|
||||
|
||||
if __name__ == '__main__':
|
||||
@ -766,7 +770,7 @@ $ curl http://localhost:8888/hello
|
||||
|
||||
|
||||
|
||||
刚刚发生了什么?`accept` 调用失败了,错误信息为 `EINTR`
|
||||
刚刚发生了什么?`accept` 调用失败了,错误信息为 `EINTR`。
|
||||
|
||||

|
||||
|
||||
@ -822,20 +826,20 @@ def serve_forever():
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
except IOError as e:
|
||||
code, msg = e.args
|
||||
# 若 'accept' 被打断,那么重启它
|
||||
### 若 'accept' 被打断,那么重启它
|
||||
if code == errno.EINTR:
|
||||
continue
|
||||
else:
|
||||
raise
|
||||
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的描述符
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的描述符
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0)
|
||||
else: # 父进程
|
||||
client_connection.close() # 关闭父进程中多余的描述符,继续下一轮循环
|
||||
else: ### 父进程
|
||||
client_connection.close() ### 关闭父进程中多余的描述符,继续下一轮循环
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
@ -854,7 +858,7 @@ $ python webserver3f.py
|
||||
$ curl http://localhost:8888/hello
|
||||
```
|
||||
|
||||
看到了吗?没有 EINTR 异常出现了。现在检查一下,确保没有僵尸进程存活,调用 `wait` 函数的 `SIGCHLD` 信号处理器能够正常处理被终止的子进程。我们只需使用 `ps` 命令,然后看看现在没有处于 Z+ 状态(或名字包含 `<defunct>` )的 Python 进程就好了。很棒!僵尸进程没有了,我们很安心。
|
||||
看到了吗?没有 EINTR 异常出现了。现在检查一下,确保没有僵尸进程存活,调用 `wait` 函数的 `SIGCHLD` 信号处理器能够正常处理被终止的子进程。我们只需使用 `ps` 命令,然后看看现在没有处于 `Z+` 状态(或名字包含 `<defunct>` )的 Python 进程就好了。很棒!僵尸进程没有了,我们很安心。
|
||||
|
||||

|
||||
|
||||
@ -862,6 +866,8 @@ $ curl http://localhost:8888/hello
|
||||
- 使用 `SIGCHLD` 信号处理器可以异步地等待子进程终止,并收集其终止状态;
|
||||
- 当使用事件处理器时,你需要牢记,系统调用可能会被打断,所以你需要处理这种情况发生时带来的异常。
|
||||
|
||||
#### 正确处理 SIGCHLD 信号
|
||||
|
||||
好的,一切顺利。是不是没问题了?额,几乎是。重新尝试运行 `webserver3f.py` 但我们这次不会只发送一个请求,而是同步创建 128 个连接:
|
||||
|
||||
```
|
||||
@ -882,7 +888,7 @@ $ ps auxw | grep -i python | grep -v grep
|
||||
|
||||
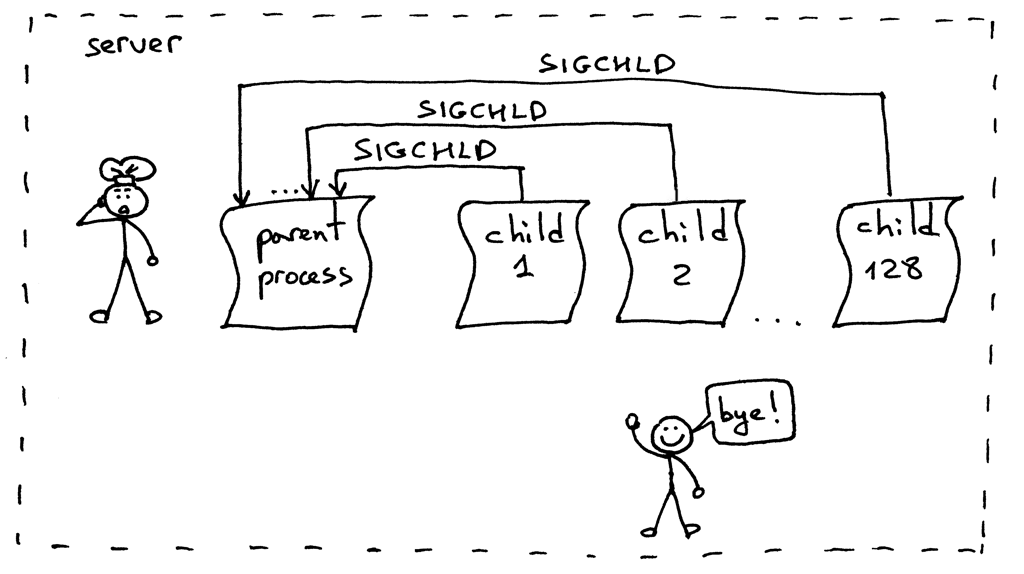
|
||||
|
||||
这个问题的解决方案依然是设置 `SIGCHLD` 事件处理器。但我们这次将会用 `WNOHANG` 参数循环调用 `waitpid`,来保证所有处于终止状态的子进程都会被处理。下面是修改后的代码,`webserver3g.py`:
|
||||
这个问题的解决方案依然是设置 `SIGCHLD` 事件处理器。但我们这次将会用 `WNOHANG` 参数循环调用 `waitpid` 来替代 `wait`,以保证所有处于终止状态的子进程都会被处理。下面是修改后的代码,`webserver3g.py`:
|
||||
|
||||
```
|
||||
#######################################################
|
||||
@ -904,13 +910,13 @@ def grim_reaper(signum, frame):
|
||||
while True:
|
||||
try:
|
||||
pid, status = os.waitpid(
|
||||
-1, # 等待所有子进程
|
||||
os.WNOHANG # 无终止进程时,不阻塞进程,并抛出 EWOULDBLOCK 错误
|
||||
-1, ### 等待所有子进程
|
||||
os.WNOHANG ### 无终止进程时,不阻塞进程,并抛出 EWOULDBLOCK 错误
|
||||
)
|
||||
except OSError:
|
||||
return
|
||||
|
||||
if pid == 0: # 没有僵尸进程存在了
|
||||
if pid == 0: ### 没有僵尸进程存在了
|
||||
return
|
||||
|
||||
|
||||
@ -939,20 +945,20 @@ def serve_forever():
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
except IOError as e:
|
||||
code, msg = e.args
|
||||
# 若 'accept' 被打断,那么重启它
|
||||
### 若 'accept' 被打断,那么重启它
|
||||
if code == errno.EINTR:
|
||||
continue
|
||||
else:
|
||||
raise
|
||||
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的描述符
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的描述符
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0)
|
||||
else: # 父进程
|
||||
client_connection.close() # 关闭父进程中多余的描述符,继续下一轮循环
|
||||
else: ### 父进程
|
||||
client_connection.close() ### 关闭父进程中多余的描述符,继续下一轮循环
|
||||
|
||||
if __name__ == '__main__':
|
||||
serve_forever()
|
||||
@ -970,17 +976,19 @@ $ python webserver3g.py
|
||||
$ python client3.py --max-clients 128
|
||||
```
|
||||
|
||||
现在来查看一下,确保没有僵尸进程存在。耶!没有僵尸的生活真美好 ^_^
|
||||
现在来查看一下,确保没有僵尸进程存在。耶!没有僵尸的生活真美好 `^_^`。
|
||||
|
||||

|
||||
|
||||
恭喜!你刚刚经历了一段很长的旅程,我希望你能够喜欢它。现在你拥有了自己的建议并发服务器,并且这段代码能够为你在继续研究生产级 Web 服务器的路上奠定基础。
|
||||
### 大功告成
|
||||
|
||||
我将会留一个作业:你需要将第二部分中的 WSGI 服务器升级,将它改造为一个并发服务器。你可以在[这里][12]找到更改后的代码。但是,当你实现了自己的版本之后,你才应该来看我的代码。你已经拥有了实现这个服务器所需的所有信息。所以,快去实现它吧 ^_^
|
||||
恭喜!你刚刚经历了一段很长的旅程,我希望你能够喜欢它。现在你拥有了自己的简易并发服务器,并且这段代码能够为你在继续研究生产级 Web 服务器的路上奠定基础。
|
||||
|
||||
我将会留一个作业:你需要将第二部分中的 WSGI 服务器升级,将它改造为一个并发服务器。你可以在[这里][12]找到更改后的代码。但是,当你实现了自己的版本之后,你才应该来看我的代码。你已经拥有了实现这个服务器所需的所有信息。所以,快去实现它吧 `^_^`。
|
||||
|
||||
然后要做什么呢?乔希·比林斯说过:
|
||||
|
||||
> “我们应该做一枚邮票——专注于一件事,不达目的不罢休。”
|
||||
> “就像一枚邮票一样——专注于一件事,不达目的不罢休。”
|
||||
|
||||
开始学习基本知识。回顾你已经学过的知识。然后一步一步深入。
|
||||
|
||||
@ -990,13 +998,13 @@ $ python client3.py --max-clients 128
|
||||
|
||||
下面是一份书单,我从这些书中提炼出了这篇文章所需的素材。他们能助你在我刚刚所述的几个方面中发掘出兼具深度和广度的知识。我极力推荐你们去搞到这几本书看看:从你的朋友那里借,在当地的图书馆中阅读,或者直接在亚马逊上把它买回来。下面是我的典藏秘籍:
|
||||
|
||||
1. [UNIX网络编程 (卷1):套接字联网API (第3版)][6]
|
||||
2. [UNIX环境高级编程 (第3版)][7]
|
||||
3. [Linux/UNIX系统编程手册][8]
|
||||
4. [TCP/IP详解 (卷1):协议 (第2版) (爱迪生-韦斯莱专业编程系列)][9]
|
||||
5. [信号系统简明手册 (第二版): 并发控制深入浅出及常见错误][10]. 这本书也可以从[作者的个人网站][11]中买到。
|
||||
1. [《UNIX 网络编程 卷1:套接字联网 API (第3版)》][6]
|
||||
2. [《UNIX 环境高级编程(第3版)》][7]
|
||||
3. [《Linux/UNIX 系统编程手册》][8]
|
||||
4. [《TCP/IP 详解 卷1:协议(第2版)][9]
|
||||
5. [《信号系统简明手册 (第二版): 并发控制深入浅出及常见错误》][10],这本书也可以从[作者的个人网站][11]中免费下载到。
|
||||
|
||||
顺便,我在撰写一本名为《搭个 Web 服务器:从头开始》的书。这本书讲解了如何从头开始编写一个基本的 Web 服务器,里面包含本文中没有的更多细节。订阅邮件列表,你就可以获取到这本书的最新进展,以及发布日期。
|
||||
顺便,我在撰写一本名为《搭个 Web 服务器:从头开始》的书。这本书讲解了如何从头开始编写一个基本的 Web 服务器,里面包含本文中没有的更多细节。订阅[原文下方的邮件列表][13],你就可以获取到这本书的最新进展,以及发布日期。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1004,7 +1012,7 @@ via: https://ruslanspivak.com/lsbaws-part3/
|
||||
|
||||
作者:[Ruslan][a]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1013,12 +1021,13 @@ via: https://ruslanspivak.com/lsbaws-part3/
|
||||
[1]: https://github.com/rspivak/lsbaws/blob/master/part3/
|
||||
[2]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3a.py
|
||||
[3]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3b.py
|
||||
[4]: https://ruslanspivak.com/lsbaws-part3/#fn:1
|
||||
[5]: https://ruslanspivak.com/lsbaws-part3/#fn:2
|
||||
[6]: http://www.amazon.com/gp/product/0131411551/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0131411551&linkCode=as2&tag=russblo0b-20&linkId=2F4NYRBND566JJQL
|
||||
[7]: http://www.amazon.com/gp/product/0321637739/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0321637739&linkCode=as2&tag=russblo0b-20&linkId=3ZYAKB537G6TM22J
|
||||
[8]: http://www.amazon.com/gp/product/1593272200/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1593272200&linkCode=as2&tag=russblo0b-20&linkId=CHFOMNYXN35I2MON
|
||||
[9]: http://www.amazon.com/gp/product/0321336313/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0321336313&linkCode=as2&tag=russblo0b-20&linkId=K467DRFYMXJ5RWAY
|
||||
[4]: http://www.epubit.com.cn/book/details/1692
|
||||
[5]: http://www.amazon.com/gp/product/1441418687/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1441418687&linkCode=as2&tag=russblo0b-20&linkId=QFOAWARN62OWTWUG
|
||||
[6]: http://www.epubit.com.cn/book/details/1692
|
||||
[7]: http://www.epubit.com.cn/book/details/1625
|
||||
[8]: http://www.epubit.com.cn/book/details/1432
|
||||
[9]: http://www.epubit.com.cn/book/details/4232
|
||||
[10]: http://www.amazon.com/gp/product/1441418687/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1441418687&linkCode=as2&tag=russblo0b-20&linkId=QFOAWARN62OWTWUG
|
||||
[11]: http://greenteapress.com/semaphores/
|
||||
[12]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3h.py
|
||||
[13]: https://ruslanspivak.com/lsbaws-part1/
|
||||
103
published/201610/20160811 5 best linux init system.md
Normal file
103
published/201610/20160811 5 best linux init system.md
Normal file
@ -0,0 +1,103 @@
|
||||
现代 Linux 的五大初始化系统(1992-2015)
|
||||
============================================
|
||||
|
||||
在 Linux 和其他类 Uniux 系统中,init(初始化)进程是系统启动时由内核执行的第一个进程,其进程 ID(PID)为 1,并静默运行在后台,直到系统关闭。
|
||||
|
||||
init 进程负责启动其他所有的进程,比如守护进程、服务和其他后台进程,因此,它是系统中其它所有进程之母(偏偏叫做“父进程”)。某个进程可以启动许多个子进程,但在这个过程中,某个子进程的父进程结束之后,该子进程的父进程会变成 init 进程。
|
||||
|
||||

|
||||
|
||||
这么多年过去了,许多的初始化系统在主流 Linux 脱颖而出,和本文中,我将你来看看在 Linux 操作系统最好的初始化系统。
|
||||
|
||||
### 1. System V Init
|
||||
|
||||
System V (SysV) 是一个在类 Unix 系统中最为成熟而且大受欢迎的初始化方案,是 Unix/Linux 系统中所有进程的父进程。SysV 是第一个商业 Unix 系统设计的初始化方案。
|
||||
|
||||
除了 Gentoo 使用自主的初始化系统、Slackware 使用 BSD 风格的初始化方案外,几乎所有的 Linux 发行版都率先使用 SysV 作为初始化方案。
|
||||
|
||||
随着时间的推移,由于一些设计上的缺陷,有几个 SysV 初始化替换方案已经开发出来,用以为 Linux 创建更加高效和完美的初始化系统。
|
||||
|
||||
尽管这些替代方案都超越了 SysV 并提供了更多新特性,但它们仍然和原始 SysV 初始化脚本保持兼容。
|
||||
|
||||
### 2. SystemD
|
||||
|
||||
SystemD 是一个 Linux 平台中相对较新的初始化方案。它由 Fedora 15 引入,集成了各类工具以便更好的管理系统。主要目的是:系统初始化、管理和跟踪引导进程中和系统运行时所有的系统进程。
|
||||
|
||||
Systemd 全面有别于其他传统的 Unix 初始化系统,特别是在启动系统和服务管理方面。它同样兼容 SysV 和 LBS 初始化脚本。
|
||||
|
||||
其中较为突出的特性如下:
|
||||
|
||||
- 纯粹、简单、高效的设计
|
||||
- 启动时的并发和并行处理
|
||||
- 更好的 API
|
||||
- 开启可选进程的移除功能
|
||||
- 使用 journald 来支持事件日志
|
||||
- 使用 systemd calender timers 来支持任务计划
|
||||
- 以二进制文件存储日志
|
||||
- 保存 systemd 的状态以待今后查看
|
||||
- 与 GNOME 更好整合实现等
|
||||
|
||||
查看 Systemd 初始化系统简介:<https://fedoraproject.org/wiki/Systemd>
|
||||
|
||||
### 3. Upstart
|
||||
|
||||
Upstart 是一个基于事件的初始化系统,由 Ubuntu 的制作团队开发的,用以替代 SysV。它可以启动不同的系统任务和进程、在系统运行时校验进程并在系统关闭时结束进程。
|
||||
|
||||
它是一个使用 SysV 和 Systemd 启动脚本的混合初始化系统,Upstart 中值得一提的特性如下:
|
||||
|
||||
- Ubuntu 的原生初始化系统,但可以运行在其他所有的发行版中
|
||||
- 基于事件启动/结束的任务和服务
|
||||
- 启动/结束任务和服务时生成事件
|
||||
- 可以由其他系统进程发送事件
|
||||
- 使用 D-Bus 和 init 进程通信
|
||||
- 用户可以启动/结束其各自的进程
|
||||
- 可以再现崩溃的进程等
|
||||
|
||||
访问 Upstart 主页:<http://upstart.ubuntu.com/index.html>
|
||||
|
||||
### 4. OpenRC
|
||||
|
||||
OpenRC 是一个基于依赖关系的类 Unix 系统初始化方案,兼容 SysV。基本可以说是 SysV 的升级版,但必须要清楚记住的是:OpenRC 并非只是完全替代 /sbin/init 文件。
|
||||
|
||||
它所提供的出色特性如下:
|
||||
|
||||
- 可运行在包括 Gentoo 和 BSD 在内的多数 Linux 系统之中
|
||||
- 支持硬件触发的初始化脚本(LCTT 译注:如硬件热插拔所触发的)
|
||||
- 支持单个配置文件
|
||||
- 不支持单个服务配置文件
|
||||
- 以守护进程的方式运行
|
||||
- 并行服务启动等
|
||||
|
||||
访问 OpenRC 主页:<https://wiki.gentoo.org/wiki/OpenRC>
|
||||
|
||||
### 5. runit
|
||||
|
||||
runit 同样是一个跨平台初始化系统,可以运行在 GNU/Linux、Solaris、BSD 和 Mac OS X 中,用替代 SysV,同时提供服务监控。
|
||||
|
||||
相比于 SysV 和其他 Linux 初始化系统,它提供了一些好用和卓越的组件,如下:
|
||||
|
||||
- 服务监控:每个服务都关联一个服务目录
|
||||
- 清理进程状态,以保证每个进程处于干净状态
|
||||
- 可靠的日志机制
|
||||
- 快速的系统启动和关闭
|
||||
- 可移植
|
||||
- 打包方便
|
||||
- 代码体积小等
|
||||
|
||||
访问 runit 主页:<http://smarden.org/runit/>
|
||||
|
||||
正如我之前所说的,Linux 中的初始化系统负责启动和管理所有的进程。此外,SysV 是 Linux 系统中主要的初始化系统,但由于一些性能缺陷,系统开发者已经开发出几个替代品。
|
||||
|
||||
在这里,我已经介绍了几个可用的替代方案,但你可能觉得有一些其他的初始化系统值得在此提及。请在下方的评论区将你的想法告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/best-linux-init-systems/
|
||||
|
||||
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/)
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,147 @@
|
||||
如何使用 SSHFS 通过 SSH 挂载远程的 Linux 文件系统或者目录
|
||||
============================
|
||||
|
||||
写这篇文章的主要目的就是提供一步一步的指导,关于如何使用 SSHFS 通过 SSH 挂载远程的 Linux 文件系统或目录。
|
||||
|
||||
这篇文章对于那些无论出于什么目的,希望在他们本地的系统中挂载远程的文件系统的用户或者系统管理员有帮助。我们通过 Linux 系统中的一个安装了 SSHFS 客户端进行实际测试,并且成功的挂载了远程的文件系统。
|
||||
|
||||
在我们进一步安装之前,让我们了解一下 SSHFS 的相关内容,以及它是如何工作的。
|
||||
|
||||
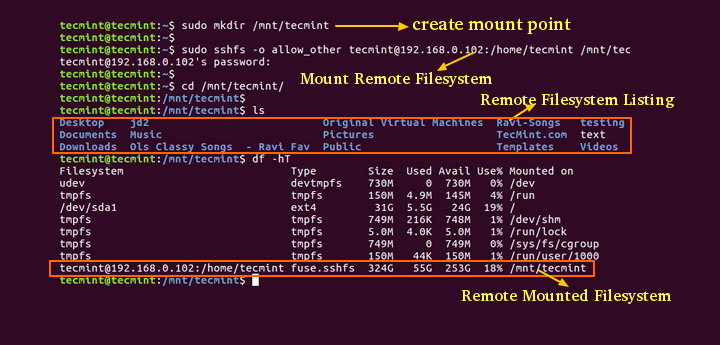
|
||||
*Sshfs 挂载远程的 Linux 文件系统或者目录*
|
||||
|
||||
### 什么是 SSHFS?
|
||||
|
||||
SSHFS(Secure SHell FileSystem)是一个客户端,可以让我们通过 SSH 文件传输协议(SFTP)挂载远程的文件系统并且在本地机器上和远程的目录和文件进行交互。
|
||||
|
||||
SFTP 是一种通过 SSH 协议提供文件访问、文件传输和文件管理功能的安全文件传输协议。因为 SSH 在网络中从一台电脑到另一台电脑传输文件的时候使用数据加密通道,并且 SSHFS 内置在 FUSE(用户空间的文件系统)内核模块,允许任何非特权用户在不修改内核代码的情况下创建他们自己的文件系统。
|
||||
|
||||
在这篇文章中,我们将会向你展示在任意 Linux 发行版上如何安装并且使用 SSHFS 客户端,在本地 Linux 机器上挂载远程的 Linux 文件系统或者目录。
|
||||
|
||||
#### 步骤1:在 Linux 系统上安装 SSHFS
|
||||
|
||||
默认情况下,sshfs 包不存在所有的主流 Linux 发行版中,你需要在你的 Linux 系统中启用 [epel 仓库][1],在 Yum 命令行的帮助下安装 SSHFS 及其依赖。
|
||||
|
||||
```
|
||||
# yum install sshfs
|
||||
# dnf install sshfs 【在 Fedora 22+ 发行版上】
|
||||
$ sudo apt-get install sshfs 【基于 Debian/Ubuntu 的系统】
|
||||
```
|
||||
|
||||
#### 步骤2:创建 SSHFS 挂载目录
|
||||
|
||||
当你安装 SSHFS 包之后,你需要创建一个挂载点目录,在这儿你将要挂载你的远程文件系统。例如,我们在 /mnt/tecmint 下创建挂载目录。
|
||||
|
||||
```
|
||||
# mkdir /mnt/tecmint
|
||||
$ sudo mkdir /mnt/tecmint 【基于 Debian/Ubuntu 的系统】
|
||||
```
|
||||
|
||||
### 步骤 3:使用 SSHFS 挂载远程的文件系统
|
||||
|
||||
当你已经创建你的挂载点目录之后,现在使用 root 用户运行下面的命令行,在 /mnt/tecmint 目录下挂载远程的文件系统。视你的情况挂载目录可以是任何目录。
|
||||
|
||||
下面的命令行将会在本地的 /mnt/tecmint 目录下挂载一个叫远程的一个 /home/tecmint 目录。(不要忘了使用你的 IP 地址和挂载点替换 x.x.x.x)。
|
||||
|
||||
```
|
||||
# sshfs tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint
|
||||
$ sudo sshfs -o allow_other tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint 【基于 Debian/Ubuntu 的系统】
|
||||
```
|
||||
|
||||
如果你的 Linux 服务器配置为基于 SSH 密钥授权,那么你将需要使用如下所示的命令行指定你的公共密钥的路径。
|
||||
|
||||
```
|
||||
# sshfs -o IdentityFile=~/.ssh/id_rsa tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint
|
||||
$ sudo sshfs -o allow_other,IdentityFile=~/.ssh/id_rsa tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint 【基于 Debian/Ubuntu 的系统】
|
||||
```
|
||||
|
||||
#### 步骤 4:验证远程的文件系统挂载成功
|
||||
|
||||
如果你已经成功的运行了上面的命令并且没有任何错误,你将会看到挂载在 /mnt/tecmint 目录下的远程的文件和目录的列表
|
||||
|
||||
```
|
||||
# cd /mnt/tecmint
|
||||
# ls
|
||||
[root@ tecmint]# ls
|
||||
12345.jpg ffmpeg-php-0.6.0.tbz2 Linux news-closeup.xsl s3.jpg
|
||||
cmslogs gmd-latest.sql.tar.bz2 Malware newsletter1.html sshdallow
|
||||
epel-release-6-5.noarch.rpm json-1.2.1 movies_list.php pollbeta.sql
|
||||
ffmpeg-php-0.6.0 json-1.2.1.tgz my_next_artical_v2.php pollbeta.tar.bz2
|
||||
```
|
||||
|
||||
#### 步骤 5:使用 df -hT 命令检查挂载点
|
||||
|
||||
如果你运行 df -hT命令,你将会看到远程文件系统的挂载点。
|
||||
|
||||
```
|
||||
# df -hT
|
||||
```
|
||||
|
||||
样本输出:
|
||||
|
||||
```
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
udev devtmpfs 730M 0 730M 0% /dev
|
||||
tmpfs tmpfs 150M 4.9M 145M 4% /run
|
||||
/dev/sda1 ext4 31G 5.5G 24G 19% /
|
||||
tmpfs tmpfs 749M 216K 748M 1% /dev/shm
|
||||
tmpfs tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs tmpfs 749M 0 749M 0% /sys/fs/cgroup
|
||||
tmpfs tmpfs 150M 44K 150M 1% /run/user/1000
|
||||
tecmint@192.168.0.102:/home/tecmint fuse.sshfs 324G 55G 253G 18% /mnt/tecmint
|
||||
```
|
||||
|
||||
#### 步骤 6:永久挂载远程文件系统
|
||||
|
||||
为了永久的挂载远程的文件系统,你需要修改一个叫 `/etc/fstab` 的文件。照着做,使用你最喜欢的编辑器打开文件。
|
||||
|
||||
```
|
||||
# vi /etc/fstab
|
||||
$ sudo vi /etc/fstab 【基于 Debian/Ubuntu 的系统】
|
||||
```
|
||||
|
||||
移动到文件的底部并且添加下面的一行,保存文件并退出。下面条目表示使用默认的设置挂载远程的文件系统。
|
||||
|
||||
```
|
||||
sshfs#tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint fuse.sshfs defaults 0 0
|
||||
```
|
||||
|
||||
确保服务器之间允许 [SSH 无密码登录][2],这样系统重启之后才能自动挂载文件系统。
|
||||
|
||||
如果你的服务器配置为基于 SSH 密钥的认证方式,请加入如下行:
|
||||
|
||||
```
|
||||
sshfs#tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint fuse.sshfs IdentityFile=~/.ssh/id_rsa defaults 0 0
|
||||
```
|
||||
|
||||
接下来,你需要更新 fstab 文件使修改生效。
|
||||
|
||||
```
|
||||
# mount -a
|
||||
$ sudo mount -a 【基于 Debian/Ubuntu 的系统】
|
||||
```
|
||||
|
||||
#### 步骤 7:卸载远程的文件系统
|
||||
|
||||
为了卸载远程的文件系统,只需要发出以下的命令即可。
|
||||
|
||||
```
|
||||
# umount /mnt/tecmint
|
||||
```
|
||||
|
||||
目前为止就这样了,如果你在挂载远程文件系统的时候遇到任何问题或者需要任何帮助,请通过评论联系我们,如果你感觉这篇文章非常有用,请分享给你的朋友们。
|
||||
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sshfs-mount-remote-linux-filesystem-directory-using-ssh/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[yangmingming](https://github.com/yangmingming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/admin/
|
||||
[1]: https://linux.cn/article-2324-1.html
|
||||
[2]: https://linux.cn/article-5444-1.html
|
||||
754
published/201610/20160820 Building your first Atom plugin.md
Normal file
754
published/201610/20160820 Building your first Atom plugin.md
Normal file
@ -0,0 +1,754 @@
|
||||
制作你的第一个 Atom 文本编辑器插件
|
||||
===========
|
||||
|
||||
这篇教程将会教你怎么制作你的第一个 Atom 文本编辑器的插件。我们将会制作一个山寨版的 [Sourcerer][2],这是一个从 StackOverflow 查询并使用代码片段的插件。到教程结束时,你将会制作好一个将编程问题(用英语描述的)转换成获取自 StackOverflow 的代码片段的插件,像这样:
|
||||
|
||||

|
||||
|
||||
#### 教程须知
|
||||
|
||||
Atom 文本编辑器是用 web 技术创造出来的。我们将完全使用 JavaScript 的 EcmaScript 6 规范来制作插件。你需要熟悉以下内容:
|
||||
|
||||
- 使用命令行
|
||||
- JavaScript 编程
|
||||
- [Promises][14]
|
||||
- [HTTP][16]
|
||||
|
||||
#### 教程的仓库
|
||||
|
||||
你可以跟着教程一步一步走,或者看看 [放在 GitHub 上的仓库][3],这里有插件的源代码。这个仓库的历史提交记录包含了这里每一个标题。
|
||||
|
||||
### 开始
|
||||
|
||||
#### 安装 Atom
|
||||
|
||||
根据 [Atom 官网][16] 的说明来下载 Atom。我们同时还要安装上 `apm`(Atom 包管理器的命令行工具)。你可以打开 Atom 并在应用菜单中导航到 `Atom > Install Shell Commands` 来安装。打开你的命令行终端,运行 `apm -v` 来检查 `apm` 是否已经正确安装好,安装成功的话打印出来的工具版本和相关环境信息应该是像这样的:
|
||||
|
||||
```
|
||||
apm -v
|
||||
> apm 1.9.2
|
||||
> npm 2.13.3
|
||||
> node 0.10.40
|
||||
> python 2.7.10
|
||||
> git 2.7.4
|
||||
```
|
||||
|
||||
#### 生成骨架代码
|
||||
|
||||
让我们使用 Atom 提供的一个实用工具创建一个新的 **package**(软件包)来开始这篇教程。
|
||||
|
||||
- 启动编辑器,按下 `Cmd+Shift+P`(MacOS)或者 `Ctrl+Shift+P`(Windows/Linux)来打开命令面板(Command Palette)。
|
||||
- 搜索“Package Generator: Generate Package”并点击列表中正确的条目,你会看到一个输入提示,输入软件包的名称:“sourcefetch”。
|
||||
- 按下回车键来生成这个骨架代码包,它会自动在 Atom 中打开。
|
||||
|
||||
如果你在侧边栏没有看到软件包的文件,依次按下 `Cmd+K` `Cmd+B`(MacOS)或者 `Ctrl+K` `Ctrl+B`(Windows/Linux)。
|
||||
|
||||

|
||||
|
||||
> 命令面板(Command Palette)可以让你通过模糊搜索来找到并运行软件包。这是一个执行命令比较方便的途径,你不用去找导航菜单,也不用刻意去记快捷键。我们将会在整篇教程中使用这个方法。
|
||||
|
||||
#### 运行骨架代码包
|
||||
|
||||
在开始编程前让我们来试用一下这个骨架代码包。我们首先需要重启 Atom,这样它才可以识别我们新增的软件包。再次打开命令面板,执行 `Window: Reload` 命令。
|
||||
|
||||
重新加载当前窗口以确保 Atom 执行的是我们最新的源代码。每当需要测试我们对软件包的改动的时候,就需要运行这条命令。
|
||||
|
||||
通过导航到编辑器菜单的 `Packages > sourcefetch > Toggle` 或者在命令面板执行 `sourcefetch:toggle` 来运行软件包的 `toggle` 命令。你应该会看到屏幕的顶部出现了一个小黑窗。再次运行这条命令就可以隐藏它。
|
||||
|
||||

|
||||
|
||||
#### “toggle”命令
|
||||
|
||||
打开 `lib/sourcefetch.js`,这个文件包含有软件包的逻辑和 `toggle` 命令的定义。
|
||||
|
||||
```
|
||||
toggle() {
|
||||
console.log('Sourcefetch was toggled!');
|
||||
return (
|
||||
this.modalPanel.isVisible() ?
|
||||
this.modalPanel.hide() :
|
||||
this.modalPanel.show()
|
||||
);
|
||||
}
|
||||
```
|
||||
|
||||
`toggle` 是这个模块导出的一个函数。根据模态面板的可见性,它通过一个[三目运算符][17] 来调用 `show` 和 `hide` 方法。`modalPanel` 是 [Panel][18](一个由 Atom API 提供的 UI 元素) 的一个实例。我们需要在 `export default` 内部声明 `modalPanel` 才可以让我们通过一个实例变量 `this` 来访问它。
|
||||
|
||||
```
|
||||
this.subscriptions.add(atom.commands.add('atom-workspace', {
|
||||
'sourcefetch:toggle': () => this.toggle()
|
||||
}));
|
||||
```
|
||||
|
||||
上面的语句让 Atom 在用户运行 `sourcefetch:toggle` 的时候执行 `toggle` 方法。我们指定了一个 [匿名函数][19] `() => this.toggle()`,每次执行这条命令的时候都会执行这个函数。这是[事件驱动编程][20](一种常用的 JavaScript 模式)的一个范例。
|
||||
|
||||
#### Atom 命令
|
||||
|
||||
命令只是用户触发事件时使用的一些字符串标识符,它定义在软件包的命名空间内。我们已经用过的命令有:
|
||||
|
||||
- `package-generator:generate-package`
|
||||
- `Window:reload`
|
||||
- `sourcefetch:toggle`
|
||||
|
||||
软件包对应到命令,以执行代码来响应事件。
|
||||
|
||||
### 进行你的第一次代码更改
|
||||
|
||||
让我们来进行第一次代码更改——我们将通过改变 `toggle` 函数来实现逆转用户选中文本的功能。
|
||||
|
||||
#### 改变 “toggle” 函数
|
||||
|
||||
如下更改 `toggle` 函数。
|
||||
|
||||
```
|
||||
toggle() {
|
||||
let editor
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let selection = editor.getSelectedText()
|
||||
let reversed = selection.split('').reverse().join('')
|
||||
editor.insertText(reversed)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 测试你的改动
|
||||
|
||||
- 通过在命令面板运行 `Window: Reload` 来重新加载 Atom。
|
||||
- 通过导航到 `File > New` 来创建一个新文件,随便写点什么并通过光标选中它。
|
||||
- 通过命令面板、Atom 菜单或者右击文本然后选中 `Toggle sourcefetch` 来运行 `sourcefetch:toggle` 命令。
|
||||
|
||||
更新后的命令将会改变选中文本的顺序:
|
||||
|
||||

|
||||
|
||||
在 [sourcefetch 教程仓库][4] 查看这一步的全部代码更改。
|
||||
|
||||
### Atom 编辑器 API
|
||||
|
||||
我们添加的代码通过用 [TextEditor API][21] 来访问编辑器内的文本并进行操作。让我们来仔细看看。
|
||||
|
||||
```
|
||||
let editor
|
||||
if (editor = atom.workspace.getActiveTextEditor()) { /* ... */ }
|
||||
```
|
||||
|
||||
头两行代码获取了 [TextEditor][5] 实例的一个引用。变量的赋值和后面的代码被包在一个条件结构里,这是为了处理没有可用的编辑器实例的情况,例如,当用户在设置菜单中运行该命令时。
|
||||
|
||||
```
|
||||
let selection = editor.getSelectedText()
|
||||
```
|
||||
|
||||
调用 `getSelectedText` 方法可以让我们访问到用户选中的文本。如果当前没有文本被选中,函数将返回一个空字符串。
|
||||
|
||||
```
|
||||
let reversed = selection.split('').reverse().join('')
|
||||
editor.insertText(reversed)
|
||||
```
|
||||
|
||||
我们选中的文本通过一个 [JavaScript 字符串方法][6] 来逆转。最后,我们调用 `insertText` 方法来将选中的文本替换为逆转后的文本副本。通过阅读 [Atom API 文档][5],你可以学到更多关于 TextEditor 的不同的方法。
|
||||
|
||||
### 浏览骨架代码
|
||||
|
||||
现在我们已经完成第一次代码更改了,让我们浏览骨架代码包的代码来深入了解一下 Atom 的软件包是怎样构成的。
|
||||
|
||||
#### 主文件
|
||||
|
||||
主文件是 Atom 软件包的入口文件。Atom 通过 `package.json` 里的条目设置来找到主文件的位置:
|
||||
|
||||
```
|
||||
"main": "./lib/sourcefetch",
|
||||
```
|
||||
|
||||
这个文件导出一个带有生命周期函数(Atom 在特定的事件发生时调用的处理函数)的对象。
|
||||
|
||||
- **activate** 会在 Atom 初次加载软件包的时候调用。这个函数用来初始化一些诸如软件包所需的用户界面元素的对象,以及订阅软件包命令的处理函数。
|
||||
- **deactivate** 会在软件包停用的时候调用,例如,当用户关闭或者刷新编辑器的时候。
|
||||
- **serialize** Atom 调用它在使用软件包的过程中保存软件包的当前状态。它的返回值会在 Atom 下一次加载软件包的时候作为一个参数传递给 `activate`。
|
||||
|
||||
我们将会重命名我们的软件包命令为 `fetch`,并移除一些我们不再需要的用户界面元素。按照如下更改主文件:
|
||||
|
||||
```
|
||||
'use babel';
|
||||
|
||||
import { CompositeDisposable } from 'atom'
|
||||
|
||||
export default {
|
||||
|
||||
subscriptions: null,
|
||||
|
||||
activate() {
|
||||
this.subscriptions = new CompositeDisposable()
|
||||
|
||||
this.subscriptions.add(atom.commands.add('atom-workspace', {
|
||||
'sourcefetch:fetch': () => this.fetch()
|
||||
}))
|
||||
},
|
||||
|
||||
deactivate() {
|
||||
this.subscriptions.dispose()
|
||||
},
|
||||
|
||||
fetch() {
|
||||
let editor
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let selection = editor.getSelectedText()
|
||||
selection = selection.split('').reverse().join('')
|
||||
editor.insertText(selection)
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
### “启用”命令
|
||||
|
||||
为了提升性能,Atom 软件包可以用时加载。我们可以让 Atom 在用户执行特定的命令的时候才加载我们的软件包。这些命令被称为 **启用命令**,它们在 `package.json` 中定义:
|
||||
|
||||
```
|
||||
"activationCommands": {
|
||||
"atom-workspace": "sourcefetch:toggle"
|
||||
},
|
||||
```
|
||||
|
||||
更新一下这个条目设置,让 `fetch` 成为一个启用命令。
|
||||
|
||||
```
|
||||
"activationCommands": {
|
||||
"atom-workspace": "sourcefetch:fetch"
|
||||
},
|
||||
```
|
||||
|
||||
有一些软件包需要在 Atom 启动的时候被加载,例如那些改变 Atom 外观的软件包。在那样的情况下,`activationCommands` 会被完全忽略。
|
||||
|
||||
### “触发”命令
|
||||
|
||||
#### 菜单项
|
||||
|
||||
`menus` 目录下的 JSON 文件指定了哪些菜单项是为我们的软件包而建的。让我们看看 `menus/sourcefetch.json`:
|
||||
|
||||
```
|
||||
"context-menu": {
|
||||
"atom-text-editor": [
|
||||
{
|
||||
"label": "Toggle sourcefetch",
|
||||
"command": "sourcefetch:toggle"
|
||||
}
|
||||
]
|
||||
},
|
||||
```
|
||||
|
||||
这个 `context-menu` 对象可以让我们定义右击菜单的一些新条目。每一个条目都是通过一个显示在菜单的 `label` 属性和一个点击后执行的命令的 `command` 属性来定义的。
|
||||
|
||||
```
|
||||
"context-menu": {
|
||||
"atom-text-editor": [
|
||||
{
|
||||
"label": "Fetch code",
|
||||
"command": "sourcefetch:fetch"
|
||||
}
|
||||
]
|
||||
},
|
||||
```
|
||||
|
||||
同一个文件中的这个 `menu` 对象用来定义插件的自定义应用菜单。我们如下重命名它的条目:
|
||||
|
||||
```
|
||||
"menu": [
|
||||
{
|
||||
"label": "Packages",
|
||||
"submenu": [
|
||||
{
|
||||
"label": "sourcefetch",
|
||||
"submenu": [
|
||||
{
|
||||
"label": "Fetch code",
|
||||
"command": "sourcefetch:fetch"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
#### 键盘快捷键
|
||||
|
||||
命令还可以通过键盘快捷键来触发。快捷键通过 `keymaps` 目录的 JSON 文件来定义:
|
||||
|
||||
```
|
||||
{
|
||||
"atom-workspace": {
|
||||
"ctrl-alt-o": "sourcefetch:toggle"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
以上代码可以让用户通过 `Ctrl+Alt+O`(Windows/Linux) 或 `Cmd+Alt+O`(MacOS) 来触发 `toggle` 命令。
|
||||
|
||||
重命名引用的命令为 `fetch`:
|
||||
|
||||
```
|
||||
"ctrl-alt-o": "sourcefetch:fetch"
|
||||
```
|
||||
|
||||
通过执行 `Window: Reload` 命令来重启 Atom。你应该会看到 Atom 的右击菜单更新了,并且逆转文本的功能应该还可以像之前一样使用。
|
||||
|
||||
在 [sourcefetch 教程仓库][7] 查看这一步所有的代码更改。
|
||||
|
||||
### 使用 NodeJS 模块
|
||||
|
||||
现在我们已经完成了第一次代码更改并且了解了 Atom 软件包的结构,让我们介绍一下 [Node 包管理器(npm)][22] 中的第一个依赖项模块。我们将使用 **request** 模块发起 HTTP 请求来下载网站的 HTML 文件。稍后将会用到这个功能来扒 StackOverflow 的页面。
|
||||
|
||||
#### 安装依赖
|
||||
|
||||
打开你的命令行工具,切换到你的软件包的根目录并运行:
|
||||
|
||||
```
|
||||
npm install --save request@2.73.0
|
||||
apm install
|
||||
```
|
||||
|
||||
这两条命令将 `request` 模块添加到我们软件包的依赖列表并将模块安装到 `node_modules` 目录。你应该会在 `package.json` 看到一个新条目。`@` 符号的作用是让 npm 安装我们这篇教程需要用到的特定版本的模块。运行 `apm install` 是为了让 Atom 知道使用我们新安装的模块。
|
||||
|
||||
```
|
||||
"dependencies": {
|
||||
"request": "^2.73.0"
|
||||
}
|
||||
```
|
||||
|
||||
#### 下载 HTML 并将记录打印在开发者控制台
|
||||
|
||||
通过在 `lib/sourcefetch.js` 的顶部添加一条引用语句引入 `request` 模块到我们的主文件:
|
||||
|
||||
```
|
||||
import { CompositeDisposable } from 'atom'
|
||||
import request from 'request'
|
||||
```
|
||||
|
||||
现在,在 `fetch` 函数下面添加一个新函数 `download` 作为模块的导出项:
|
||||
|
||||
```
|
||||
export default {
|
||||
|
||||
/* subscriptions, activate(), deactivate() */
|
||||
|
||||
fetch() {
|
||||
...
|
||||
},
|
||||
|
||||
download(url) {
|
||||
request(url, (error, response, body) => {
|
||||
if (!error && response.statusCode == 200) {
|
||||
console.log(body)
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这个函数用 `request` 模块来下载一个页面的内容并将记录输出到控制台。当 HTTP 请求完成之后,我们的[回调函数][23]会将响应体作为参数来被调用。
|
||||
|
||||
最后一步是更新 `fetch` 函数以调用 `download` 函数:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
let editor
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let selection = editor.getSelectedText()
|
||||
this.download(selection)
|
||||
}
|
||||
},
|
||||
```
|
||||
|
||||
`fetch` 函数现在的功能是将 selection 当作一个 URL 传递给 `download` 函数,而不再是逆转选中的文本了。让我们来看看这次的更改:
|
||||
|
||||
- 通过执行 `Window: Reload` 命令来重新加载 Atom。
|
||||
- 打开开发者工具。为此,导航到菜单中的 `View > Developer > Toggle Developer Tools`。
|
||||
- 新建一个文件,导航到 `File > New`。
|
||||
- 输入一个 URL 并选中它,例如:`http://www.atom.io`。
|
||||
- 用上述的任意一种方法执行我们软件包的命令:
|
||||
|
||||

|
||||
|
||||
> **开发者工具**让 Atom 软件包的调试更轻松。每个 `console.log` 语句都可以将信息打印到交互控制台,你还可以使用 `Elements` 选项卡来浏览整个应用的可视化结构——即 HTML 的[文本对象模型(DOM)][8]。
|
||||
|
||||
在 [sourcefetch 教程仓库][9] 查看这一步所有的代码更改。
|
||||
|
||||
### 用 Promises 来将下载好的 HTML 插入到编辑器中
|
||||
|
||||
理想情况下,我们希望 `download` 函数可以将 HTML 作为一个字符串来返回,而不仅仅是将页面的内容打印到控制台。然而,返回文本内容是无法实现的,因为我们要在回调函数里面访问内容而不是在 `download` 函数那里。
|
||||
|
||||
我们会通过返回一个 [Promise][24] 来解决这个问题,而不再是返回一个值。让我们改动 `download` 函数来返回一个 Promise:
|
||||
|
||||
```
|
||||
download(url) {
|
||||
return new Promise((resolve, reject) => {
|
||||
request(url, (error, response, body) => {
|
||||
if (!error && response.statusCode == 200) {
|
||||
resolve(body)
|
||||
} else {
|
||||
reject({
|
||||
reason: 'Unable to download page'
|
||||
})
|
||||
}
|
||||
})
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
Promises 允许我们通过将异步逻辑封装在一个提供两个回调方法的函数里来返回获得的值(`resolve` 用来处理请求成功的返回值,`reject` 用来向使用者报错)。如果请求返回了错误我们就调用 `reject`,否则就用 `resolve` 来处理 HTML。
|
||||
|
||||
让我们更改 `fetch` 函数来使用 `download` 返回的 Promise:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
let editor
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let selection = editor.getSelectedText()
|
||||
this.download(selection).then((html) => {
|
||||
editor.insertText(html)
|
||||
}).catch((error) => {
|
||||
atom.notifications.addWarning(error.reason)
|
||||
})
|
||||
}
|
||||
},
|
||||
```
|
||||
|
||||
在我们新版的 `fetch` 函数里,我们通过在 `download` 返回的 Promise 调用 `then` 方法来对 HTML 进行操作。这会将 HTML 插入到编辑器中。我们同样会通过调用 `catch` 方法来接收并处理所有的错误。我们通过用 [Atom Notification API][25] 来显示警告的形式来处理错误。
|
||||
|
||||
看看发生了什么变化。重新加载 Atom 并在一个选中的 URL 上执行软件包命令:
|
||||
|
||||

|
||||
|
||||
如果这个 URL 是无效的,一个警告通知将会弹出来:
|
||||
|
||||

|
||||
|
||||
在 [sourcefetch 教程仓库][10] 查看这一步所有的代码更改。
|
||||
|
||||
#### 编写一个爬虫来提取 StackOverflow 页面的代码片段
|
||||
|
||||
下一步涉及用我们前面扒到的 StackOverflow 的页面的 HTML 来提取代码片段。我们尤其关注那些来自采纳答案(提问者选择的一个正确答案)的代码。我们可以在假设这类答案都是相关且正确的前提下大大简化我们这个软件包的实现。
|
||||
|
||||
#### 使用 jQuery 和 Chrome 开发者工具来构建查询
|
||||
|
||||
这一部分假设你使用的是 [Chrome][26] 浏览器。你接下来可以使用其它浏览器,但是提示可能会不一样。
|
||||
|
||||
让我们先看看一张典型的包含采纳答案和代码片段的 StackOverflow 页面。我们将会使用 Chrome 开发者工具来浏览 HTML:
|
||||
|
||||
- 打开 Chrome 并跳到任意一个带有采纳答案和代码的 StackOverflow 页面,比如像这个用 Python 写的 [hello world][27] 的例子或者这个关于 [用 `C` 来读取文本内容的问题][28]。
|
||||
- 滚动窗口到采纳答案的位置并选中一部分代码。
|
||||
- 右击选中文本并选择 `检查`。
|
||||
- 使用元素侦察器来检查代码片段在 HTML 中的位置。
|
||||
|
||||
注意文本结构应该是这样的:
|
||||
|
||||
```
|
||||
<div class="accepted-answer">
|
||||
...
|
||||
...
|
||||
<pre>
|
||||
<code>
|
||||
...snippet elements...
|
||||
</code>
|
||||
</pre>
|
||||
...
|
||||
...
|
||||
</div>
|
||||
```
|
||||
|
||||
- 采纳的答案通过一个 class 为 `accepted-answer` 的 `div` 来表示
|
||||
- 代码块位于 `pre` 元素的内部
|
||||
- 呈现代码片段的元素就是里面那一对 `code` 标签
|
||||
|
||||

|
||||
|
||||
现在让我们写一些 `jQuery` 代码来提取代码片段:
|
||||
|
||||
- 在开发者工具那里点击 **Console** 选项卡来访问 Javascript 控制台。
|
||||
- 在控制台中输入 `$('div.accepted-answer pre code').text()` 并按下回车键。
|
||||
|
||||
你应该会看到控制台中打印出采纳答案的代码片段。我们刚刚运行的代码使用了一个 jQuery 提供的特别的 `$` 函数。`$` 接收要选择的**查询字符串**并返回网站中的某些 HTML 元素。让我们通过思考几个查询案例看看这段代码的工作原理:
|
||||
|
||||
```
|
||||
$('div.accepted-answer')
|
||||
> [<div id="answer-1077349" class="answer accepted-answer" ... ></div>]
|
||||
```
|
||||
|
||||
上面的查询会匹配所有 class 为 `accepted-answer` 的 `<div>` 元素,在我们的案例中只有一个 div。
|
||||
|
||||
```
|
||||
$('div.accepted-answer pre code')
|
||||
> [<code>...</code>]
|
||||
```
|
||||
|
||||
在前面的基础上改造了一下,这个查询会匹配所有在之前匹配的 `<div>` 内部的 `<pre>` 元素内部的 `<code>` 元素。
|
||||
|
||||
```
|
||||
$('div.accepted-answer pre code').text()
|
||||
> "print("Hello World!")"
|
||||
```
|
||||
|
||||
`text` 函数提取并连接原本将由上一个查询返回的元素列表中的所有文本。这也从代码中去除了用来使语法高亮的元素。
|
||||
|
||||
### 介绍 Cheerio
|
||||
|
||||
我们的下一步涉及使用我们创建好的查询结合 [Cheerio][29](一个服务器端实现的 jQuery)来实现扒页面的功能。
|
||||
|
||||
#### 安装 Cheerio
|
||||
|
||||
打开你的命令行工具,切换到你的软件包的根目录并执行:
|
||||
|
||||
```
|
||||
npm install --save cheerio@0.20.0
|
||||
apm install
|
||||
```
|
||||
|
||||
#### 实现扒页面的功能
|
||||
|
||||
在 `lib/sourcefetch.js` 为 `cheerio` 添加一条引用语句:
|
||||
|
||||
```
|
||||
import { CompositeDisposable } from 'atom'
|
||||
import request from 'request'
|
||||
import cheerio from 'cheerio'
|
||||
```
|
||||
|
||||
现在创建一个新函数 `scrape`,它用来提取 StackOverflow HTML 里面的代码片段:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
...
|
||||
},
|
||||
|
||||
scrape(html) {
|
||||
$ = cheerio.load(html)
|
||||
return $('div.accepted-answer pre code').text()
|
||||
},
|
||||
|
||||
download(url) {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
最后,让我们更改 `fetch` 函数以传递下载好的 HTML 给 `scrape` 而不是将其插入到编辑器:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
let editor
|
||||
let self = this
|
||||
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let selection = editor.getSelectedText()
|
||||
this.download(selection).then((html) => {
|
||||
let answer = self.scrape(html)
|
||||
if (answer === '') {
|
||||
atom.notifications.addWarning('No answer found :(')
|
||||
} else {
|
||||
editor.insertText(answer)
|
||||
}
|
||||
}).catch((error) => {
|
||||
console.log(error)
|
||||
atom.notifications.addWarning(error.reason)
|
||||
})
|
||||
}
|
||||
},
|
||||
```
|
||||
|
||||
我们扒取页面的功能仅仅用两行代码就实现了,因为 cheerio 已经替我们做好了所有的工作!我们通过调用 `load` 方法加载 HTML 字符串来创建一个 `$` 函数,然后用这个函数来执行 jQuery 语句并返回结果。你可以在官方 [开发者文档][30] 查看完整的 `Cheerio API`。
|
||||
|
||||
### 测试更新后的软件包
|
||||
|
||||
重新加载 Atom 并在一个选中的 StackOverflow URL 上运行 `soucefetch:fetch` 以查看到目前为止的进度。
|
||||
|
||||
如果我们在一个有采纳答案的页面上运行这条命令,代码片段将会被插入到编辑器中:
|
||||
|
||||

|
||||
|
||||
如果我们在一个没有采纳答案的页面上运行这条命令,将会弹出一个警告通知:
|
||||
|
||||

|
||||
|
||||
我们最新的 `fetch` 函数给我们提供了一个 StackOverflow 页面的代码片段而不再是整个 HTML 内容。要注意我们更新的 `fetch` 函数会检查有没有答案并显示通知以提醒用户。
|
||||
|
||||
在 [sourcefetch 教程仓库][11] 查看这一步所有的代码更改。
|
||||
|
||||
### 实现用来查找相关的 StackOverflow URL 的谷歌搜索功能
|
||||
|
||||
现在我们已经将 StackOverflow 的 URL 转化为代码片段了,让我们来实现最后一个函数——`search`,它应该要返回一个相关的 URL 并附加一些像“hello world”或者“快速排序”这样的描述。我们会通过一个非官方的 `google` npm 模块来使用谷歌搜索功能,这样可以让我们以编程的方式来搜索。
|
||||
|
||||
#### 安装这个 Google npm 模块
|
||||
|
||||
通过在软件包的根目录打开命令行工具并执行命令来安装 `google` 模块:
|
||||
|
||||
```
|
||||
npm install --save google@2.0.0
|
||||
apm install
|
||||
```
|
||||
|
||||
#### 引入并配置模块
|
||||
|
||||
在 `lib/sourcefetch.js` 的顶部为 `google` 模块添加一条引用语句:
|
||||
|
||||
```
|
||||
import google from "google"
|
||||
```
|
||||
|
||||
我们将配置一下 `google` 以限制搜索期间返回的结果数。将下面这行代码添加到引用语句下面以限制搜索返回最热门的那个结果。
|
||||
|
||||
```
|
||||
google.resultsPerPage = 1
|
||||
```
|
||||
|
||||
#### 实现 search 函数
|
||||
|
||||
接下来让我们来实现我们的 `search` 函数:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
...
|
||||
},
|
||||
|
||||
search(query, language) {
|
||||
return new Promise((resolve, reject) => {
|
||||
let searchString = `${query} in ${language} site:stackoverflow.com`
|
||||
|
||||
google(searchString, (err, res) => {
|
||||
if (err) {
|
||||
reject({
|
||||
reason: 'A search error has occured :('
|
||||
})
|
||||
} else if (res.links.length === 0) {
|
||||
reject({
|
||||
reason: 'No results found :('
|
||||
})
|
||||
} else {
|
||||
resolve(res.links[0].href)
|
||||
}
|
||||
})
|
||||
})
|
||||
},
|
||||
|
||||
scrape() {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
以上代码通过谷歌来搜索一个和指定的关键词以及编程语言相关的 StackOverflow 页面,并返回一个最热门的 URL。让我们看看这是怎样来实现的:
|
||||
|
||||
```
|
||||
let searchString = `${query} in ${language} site:stackoverflow.com`
|
||||
```
|
||||
|
||||
我们使用用户输入的查询和当前所选的语言来构造搜索字符串。比方说,当用户在写 Python 的时候输入“hello world”,查询语句就会变成 `hello world in python site:stackoverflow.com`。字符串的最后一部分是谷歌搜索提供的一个过滤器,它让我们可以将搜索结果的来源限制为 StackOverflow。
|
||||
|
||||
```
|
||||
google(searchString, (err, res) => {
|
||||
if (err) {
|
||||
reject({
|
||||
reason: 'A search error has occured :('
|
||||
})
|
||||
} else if (res.links.length === 0) {
|
||||
reject({
|
||||
reason: 'No results found :('
|
||||
})
|
||||
} else {
|
||||
resolve(res.links[0].href)
|
||||
}
|
||||
})
|
||||
```
|
||||
|
||||
我们将 `google` 方法放在一个 `Promise` 里面,这样我们可以异步地返回我们的 URL。我们会传递由 `google` 返回的所有错误并且会在没有可用的搜索结果的时候返回一个错误。否则我们将通过 `resolve` 来解析最热门结果的 URL。
|
||||
|
||||
### 更新 fetch 来使用 search
|
||||
|
||||
我们的最后一步是更新 `fetch` 函数来使用 `search` 函数:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
let editor
|
||||
let self = this
|
||||
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let query = editor.getSelectedText()
|
||||
let language = editor.getGrammar().name
|
||||
|
||||
self.search(query, language).then((url) => {
|
||||
atom.notifications.addSuccess('Found google results!')
|
||||
return self.download(url)
|
||||
}).then((html) => {
|
||||
let answer = self.scrape(html)
|
||||
if (answer === '') {
|
||||
atom.notifications.addWarning('No answer found :(')
|
||||
} else {
|
||||
atom.notifications.addSuccess('Found snippet!')
|
||||
editor.insertText(answer)
|
||||
}
|
||||
}).catch((error) => {
|
||||
atom.notifications.addWarning(error.reason)
|
||||
})
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
让我们看看发生了什么变化:
|
||||
|
||||
- 我们选中的文本现在变成了用户输入的 `query`
|
||||
- 我们使用 [TextEditor API][21] 来获取当前编辑器选项卡使用的 `language`
|
||||
- 我们调用 `search` 方法来获取一个 URL,然后通过在得到的 Promise 上调用 `then` 方法来访问这个 URL
|
||||
|
||||
我们不在 `download` 返回的 Promise 上调用 `then` 方法,而是在前面 `search` 方法本身链式调用的另一个 `then` 方法返回的 Promise 上面接着调用 `then` 方法。这样可以帮助我们避免[回调地狱][31]
|
||||
|
||||
在 [sourcefetch 教程仓库][12] 查看这一步所有的代码更改。
|
||||
|
||||
### 测试最终的插件
|
||||
|
||||
大功告成了!重新加载 Atom,对一个“问题描述”运行软件包的命令来看看我们最终的插件是否工作,不要忘了在编辑器右下角选择一种语言。
|
||||
|
||||

|
||||
|
||||
### 下一步
|
||||
|
||||
现在你知道怎么去 “hack” Atom 的基本原理了,通过 [分叉 sourcefetch 这个仓库并添加你的特性][13] 来随心所欲地实践你所学到的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/2231-building-your-first-atom-plugin
|
||||
|
||||
作者:[NickTikhonov][a]
|
||||
译者:[OneNewLife](https://github.com/OneNewLife)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/NickTikhonov
|
||||
[1]: https://education.github.com/experts
|
||||
[2]: https://github.com/NickTikhonov/sourcerer
|
||||
[3]: https://github.com/NickTikhonov/sourcefetch-guide
|
||||
[4]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/89e174ab6ec6e270938338b34905f75bb74dbede
|
||||
[5]: https://atom.io/docs/api/latest/TextEditor
|
||||
[6]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String
|
||||
[7]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/aa3ec5585b0aa049393351a30be14590df09c29a
|
||||
[8]: https://www.wikipedia.com/en/Document_Object_Model
|
||||
[9]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/85992043e57c802ca71ff6e8a4f9c477fbfd13db
|
||||
[10]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/896d160dca711f4a53ff5b182018b39cf78d2774
|
||||
[11]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/039a1e1e976d029f7d6b061b4c0dac3eb4a3b5d2
|
||||
[12]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/aa9d0b5fc4811a70292869730e0f60ddf0bcf2aa
|
||||
[13]: https://github.com/NickTikhonov/sourcefetch-tutorial
|
||||
[14]: https://developers.google.com/web/fundamentals/getting-started/primers/promises
|
||||
[15]: https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
|
||||
[16]: https://atom.io/
|
||||
[17]: https://en.wikipedia.org/wiki/%3F:
|
||||
[18]: https://atom.io/docs/api/v1.9.4/Panel
|
||||
[19]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/Arrow_functions
|
||||
[20]: https://en.wikipedia.org/wiki/Event-driven_programming
|
||||
[21]: https://atom.io/docs/api/v1.11.1/TextEditor
|
||||
[22]: https://www.npmjs.com/
|
||||
[23]: http://recurial.com/programming/understanding-callback-functions-in-javascript/
|
||||
[24]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise
|
||||
[25]: https://atom.io/docs/api/v1.11.1/NotificationManager
|
||||
[26]: https://www.google.com/chrome/
|
||||
[27]: http://stackoverflow.com/questions/1077347/hello-world-in-python
|
||||
[28]: http://stackoverflow.com/questions/3463426/in-c-how-should-i-read-a-text-file-and-print-all-strings
|
||||
[29]: https://www.npmjs.com/package/cheerio
|
||||
[30]: https://github.com/cheeriojs/cheerio
|
||||
[31]: http://callbackhell.com/
|
||||
@ -1,26 +1,26 @@
|
||||
Twitter背后的基础设施:效率与优化
|
||||
揭秘 Twitter 背后的基础设施:效率与优化篇
|
||||
===========
|
||||
|
||||
过去我们曾经发布过一些关于 [Finagle](https://twitter.github.io/finagle/) , [Manhattan](https://blog.twitter.com/2014/manhattan-our-real-time-multi-tenant-distributed-database-for-twitter-scale) 这些项目的文章,还写过一些针对大型事件活动的架构优化的文章,例如天空之城,超级碗, 2014 世界杯,全球新年夜庆祝活动等。在这篇基础设施系列文章中,我主要聚焦于 Twitter 的一些关键设施和组件。我也会写一些我们在系统的扩展性,可靠性,效率性方面的做过的改进,例如我们基础设施的历史,遇到过的挑战,学到的教训,做过的升级,以及我们现在前进的方向等等。
|
||||
过去我们曾经发布过一些关于 [Finagle](https://twitter.github.io/finagle/) 、[Manhattan](https://blog.twitter.com/2014/manhattan-our-real-time-multi-tenant-distributed-database-for-twitter-scale) 这些项目的文章,还写过一些针对大型事件活动的[架构优化](https://blog.twitter.com/2013/new-tweets-per-second-record-and-how)的文章,例如天空之城、超级碗、2014 世界杯、全球新年夜庆祝活动等。在这篇基础设施系列文章中,我主要聚焦于 Twitter 的一些关键设施和组件。我也会写一些我们在系统的扩展性、可靠性、效率方面的做过的改进,例如我们基础设施的历史,遇到过的挑战,学到的教训,做过的升级,以及我们现在前进的方向等等。
|
||||
|
||||
> 天空之城:2013年8月2日,宫崎骏的《天空之城》在NTV迎来其第14次电视重播,剧情发展到高潮之时,Twitter的TPS(Tweets Per Second)也被推上了新的高度——143,199 TPS,是平均值的25倍,这个记录保持至今 -- 译者注。
|
||||
> 天空之城:2013 年 8 月 2 日,宫崎骏的《天空之城(Castle in the Sky)》在 NTV 迎来其第 14 次电视重播,剧情发展到高潮之时,Twitter 的 TPS(Tweets Per Second)也被推上了新的高度——143,199 TPS,是平均值的 25 倍,这个记录保持至今。-- LCTT 译注
|
||||
|
||||
### 数据中心的效率优化
|
||||
|
||||
#### 历史
|
||||
|
||||
当前Twitter硬件和数据中心的规模已经超过大多数公司。但达到这样的规模不是一蹴而就的,系统是随着软硬件的升级优化一步步成熟起来的,过程中我们也曾经犯过很多错误。
|
||||
当前 Twitter 硬件和数据中心的规模已经超过大多数公司。但达到这样的规模不是一蹴而就的,系统是随着软硬件的升级优化一步步成熟起来的,过程中我们也曾经犯过很多错误。
|
||||
|
||||
有个一时期我们的系统故障不断。软件问题,硬件问题,甚至底层设备问题不断爆发,常常导致系统运营中断。随着 Twitter 在客户、服务、媒体上的影响力不断扩大,构建一个高效、可靠的系统来提供服务成为我们的战略诉求。
|
||||
有个一时期我们的系统故障不断。软件问题、硬件问题,甚至底层设备问题不断爆发,常常导致系统运营中断。出现故障的地方存在于各个方面,必须综合考虑才能确定其风险和受到影响的服务。随着 Twitter 在客户、服务、媒体上的影响力不断扩大,构建一个高效、可靠的系统来提供服务成为我们的战略诉求。
|
||||
|
||||
> Twitter系统故障的界面被称为失败鲸(Fail Whale),如下图 -- 译者注
|
||||

|
||||
> Twitter系统故障的界面被称为失败鲸(Fail Whale),如下图 -- LCTT 译注
|
||||
> 
|
||||
|
||||
#### 挑战
|
||||
|
||||
一开始,我们的软件是直接安装在服务器,这意味着软件可靠性依赖硬件,电源、网络以及其他的环境因素都是威胁。这种情况下,如果要增加容错能力,就需要统筹考虑物理设备和在上面运行的服务。
|
||||
一开始,我们的软件是直接安装在服务器,这意味着软件可靠性依赖硬件,电源、网络以及其他的环境因素都是威胁。这种情况下,如果要增加容错能力,就需要统筹考虑这些互不关联的物理设备因素及在上面运行的服务。
|
||||
|
||||
最早采购数据中心方案的时候,我们都还是菜鸟,对于站点选择、运营和设计都非常不专业。我们先直接租用主机,业务增长后我们改用主机托管。早期遇到的问题主要是因为设备故障、数据中心设计问题、维护问题以及人为操作失误。我们也在持续迭代我们的硬件设计,从而增强硬件和数据中心的容错性。
|
||||
最早采购数据中心方案的时候,我们都还是菜鸟,对于站点选择、运营和设计都非常不专业。我们先直接托管主机,业务增长后我们改用租赁机房。早期遇到的问题主要是因为设备故障、数据中心设计问题、维护问题以及人为操作失误。我们也在持续迭代我们的硬件设计,从而增强硬件和数据中心的容错性。
|
||||
|
||||
服务中断的原因有很多,其中硬件故障常发生在服务器、机架交换机、核心交换机这地方。举一个我们曾经犯过的错误,硬件团队最初在设计服务器的时候,认为双路电源对减少供电问题的意义不大 -- 他们真的就移除了一块电源。然而数据中心一般给机架提供两路供电来提高冗余性,防止电网故障传导到服务器,而这需要两块电源。最终我们不得不在机架上增加了一个 ATS 单元(AC transfer switch 交流切换开关)来接入第二路供电。
|
||||
|
||||
@ -28,9 +28,9 @@ Twitter背后的基础设施:效率与优化
|
||||
|
||||
#### 我们学到的教训以及技术的升级、迁移和选型
|
||||
|
||||
我们学到的第一个教训就是要先建模,将可能出故障的地方(例如建筑的供电和冷却系统、硬件、光线网络等)和运行在上面的服务之间的依赖关系弄清楚,这样才能更好地分析,从而优化设计提升容错能力。
|
||||
我们学到的第一个教训就是要先建模,将可能出故障的地方(例如建筑的供电和冷却系统、硬件、光纤网络等)和运行在上面的服务之间的依赖关系弄清楚,这样才能更好地分析,从而优化设计提升容错能力。
|
||||
|
||||
我们增加了更多的数据中心提升地理容灾能力,减少自然灾害的影响。而且这种站点隔离也降低了软件的风险,减少了例如软件部署升级和系统故障的风险。这种多活的数据中心架构提供了代码灰度发布的能力,减少代码首次上线时候的影响。
|
||||
我们增加了更多的数据中心提升地理容灾能力,减少自然灾害的影响。而且这种站点隔离也降低了软件的风险,减少了例如软件部署升级和系统故障的风险。这种多活的数据中心架构提供了代码灰度发布(staged code deployment)的能力,减少代码首次上线时候的影响。
|
||||
|
||||
我们设计新硬件使之能够在更高温度下正常运行,数据中心的能源效率因此有所提升。
|
||||
|
||||
@ -46,9 +46,9 @@ Twitter背后的基础设施:效率与优化
|
||||
|
||||
Twitter 是一个很大的公司,它对硬件的要求对任何团队来说都是一个不小的挑战。为了满足整个公司的需求,我们的首要工作是能检测并保证购买的硬件的品质。团队重点关注的是性能和可靠性这两部分。对于硬件我们会做系统性的测试来保证其性能可预测,保证尽量不引入新的问题。
|
||||
|
||||
随着我们一些关键组件的负荷越来越大(如 Mesos , Hadoop , Manhattan , MySQL 等),市面上的产品已经无法满足我们的需求。同时供应商提供的一些高级服务器功能,例如 Raid 管理或者电源热切换等,可靠性提升很小,反而会拖累系统性能而且价格高昂,例如一些 Raid 控制器价格高达系统总报价的三分之一,还拖累了 SSD 的性能。
|
||||
随着我们一些关键组件的负荷越来越大(如 Mesos、Hadoop、Manhattan、MySQL 等),市面上的产品已经无法满足我们的需求。同时供应商提供的一些高级服务器功能,例如 Raid 管理或者电源热切换等,可靠性提升很小,反而会拖累系统性能而且价格高昂,例如一些 Raid 控制器价格高达系统总报价的三分之一,还拖累了 SSD 的性能。
|
||||
|
||||
那时,我们也是 MySQL 数据库的一个大型用户。SAS(Serial Attached SCSI,串行连接 SCSI )设备的供应和性能都有很大的问题。我们大量使用 1 u 的服务器,它的驱动器和回写缓存一起也只能支撑每秒 2000 次顺序 IO。为了获得更好的效果,我们只得不断增加 CPU 核心数并加强磁盘能力。我们那时候找不到更节省成本的方案。
|
||||
那时,我们也是 MySQL 数据库的一个大型用户。SAS(Serial Attached SCSI,串行连接 SCSI )设备的供应和性能都有很大的问题。我们大量使用 1U 规格的服务器,它的磁盘和回写缓存一起也只能支撑每秒 2000 次的顺序 IO。为了获得更好的效果,我们只得不断增加 CPU 核心数并加强磁盘能力。我们那时候找不到更节省成本的方案。
|
||||
|
||||
后来随着我们对硬件需求越来越大,我们可以成立了一个硬件团队,从而自己来设计更便宜更高效的硬件。
|
||||
|
||||
@ -58,62 +58,59 @@ Twitter 是一个很大的公司,它对硬件的要求对任何团队来说都
|
||||
|
||||
- 2012 - 采用 SSD 作为我们 MySQL 和 Key-Value 数据库的主要存储。
|
||||
- 2013 - 我们开发了第一个定制版 Hadoop 工作站,它现在是我们主要的大容量存储方案。
|
||||
- 2013 - 我们定制的解决方案应用在 Mesos 、 TFE( Twitter Front-End )以及缓存设备上。
|
||||
- 2013 - 我们定制的解决方案应用在 Mesos、TFE( Twitter Front-End )以及缓存设备上。
|
||||
- 2014 - 我们定制的 SSD Key-Value 服务器完成开发。
|
||||
- 2015 - 我们定制的数据库解决方案完成开发。
|
||||
- 2016 - 我们开发了一个 GPU 系统来做模糊推理和训练机器学习。
|
||||
|
||||
#### 学到的教训
|
||||
|
||||
硬件团队的工作本质是通过做取舍来优化TCO(总体拥有成本),最终达到达到降低 CAPEX(资本支出)和 OPEX(运营支出)的目的。概括来说,服务器降成本就是:
|
||||
硬件团队的工作本质是通过做取舍来优化 TCO(总体拥有成本),最终达到达到降低 CAPEX(资本支出)和 OPEX(运营支出)的目的。概括来说,服务器降成本就是:
|
||||
|
||||
1. 删除无用的功能和组件
|
||||
2. 提升利用率
|
||||
|
||||
Twitter 的设备总体来说有这四大类:存储设备、计算设备、数据库和 GPU 。 Twitter 对每一类都定义了详细的需求,让硬件工程师更针对性地设计产品,从而优化掉那些用不到或者极少用的冗余部分。例如,我们的存储设备就专门为 Hadoop 优化,设备的购买和运营成本相比于 OEM 产品降低了 20% 。同时,这样做减法还提高了设备的性能和可靠性。同样的,对于计算设备,硬件工程师们也通过移除无用的特性获得了效率提升。
|
||||
Twitter 的设备总体来说有这四大类:存储设备、计算设备、数据库和 GPU 。 Twitter 对每一类都定义了详细的需求,让硬件工程师更针对性地设计产品,从而优化掉那些用不到或者极少用的冗余部分。例如,我们的存储设备就专门为 Hadoop 优化过,设备的购买和运营成本相比于 OEM 产品降低了 20% 。同时,这样做减法还提高了设备的性能和可靠性。同样的,对于计算设备,硬件工程师们也通过移除无用的特性获得了效率提升。
|
||||
|
||||
一个服务器可以移除的组件总是有限的,我们很快就把能移除的都扔掉了。于是我们想出了其他办法,例如在存储设备里,我们认为降低成本最好的办法是用一个节点替换多个节点,并通过 Aurora/Mesos 来管理任务负载。这就是我们现在正在做的东西。
|
||||
|
||||
对于这个我们自己新设计的服务器,首先要通过一系列的标准测试,然后会再做一系列负载测试,我们的目标是一台新设备至少能替换两台旧设备。大多数的提升都比较简单,例如增加 CPU 的进程数,同时我们的测试也比较出新 CPU 的 单线程能力提高了 20~50% ,对应能耗降低了 25% ,这都是我们测试环节需要做的工作。
|
||||
对于这个我们自己新设计的服务器,首先要通过一系列的标准测试,然后会再做一系列负载测试,我们的目标是一台新设备至少能替换两台旧设备。最大的性能提升来自增加 CPU 的线程数,我们的测试结果表示新 CPU 的 单线程能力提高了 20~50% 。同时由于整个服务器的线程数增加,我们看到单线程能效提升了 25%。
|
||||
|
||||
这个新设备首次部署的时候,监控发现新设备只能替换 1.5 台旧设备,这比我们的目标低了很多。对性能数据检查后发现,我们之前新硬件的部分指标是错的,而这正是我们在做性能测试需要发现的问题。
|
||||
这个新设备首次部署的时候,监控发现新设备只能替换 1.5 台旧设备,这比我们的目标低了很多。对性能数据检查后发现,我们之前对负载特性的一些假定是有问题的,而这正是我们在做性能测试需要发现的问题。
|
||||
|
||||
对此我们硬件团队开发了一个模型,用来预测在不同的硬件配置下当前 Aurora 任务的打包效率。这个模型正确的预测了新旧硬件的性能比例。模型还指出了我们一开始没有考虑到的存储需求,并因此建议我们增加 CPU 核心数。另外,它还预测,如果我们修改内存的配置,那系统的性能还会有较大提高。
|
||||
对此我们硬件团队开发了一个模型,用来预测在不同的硬件配置下当前 Aurora 任务的填充效率。这个模型正确的预测了新旧硬件的性能比例。模型还指出了我们一开始没有考虑到的存储需求,并因此建议我们增加 CPU 核心数。另外,它还预测,如果我们修改内存的配置,那系统的性能还会有较大提高。
|
||||
|
||||
硬件配置的改变都需要花时间去操作,所以我们的硬件工程师们就首先找出几个关键痛点。例如我们和站点工程团队一起调整任务顺序来降低存储需求,这种修改很简单也很有效,新设备可以代替 1.85 个旧设备了。
|
||||
硬件配置的改变都需要花时间去操作,所以我们的硬件工程师们就首先找出几个关键痛点。例如我们和 SRE(Site Reliability Engineer,网站可靠性工程师)团队一起调整任务顺序来降低存储需求,这种修改很简单也很有效,新设备可以代替 1.85 个旧设备了。
|
||||
|
||||
为了更好的优化效率,我们对新硬件的配置做了修改,扩大了内存和磁盘容量就将 CPU 利用率提高了20% ,而这只增加了非常小的成本。同时我们的硬件工程师也和生产的伙伴一起优化发货顺序来降低货运成本。后续的观察发现我们的自己的新设备实际上可以代替 2.4 台旧设备,这个超出了预定的目标。
|
||||
为了更好的优化效率,我们对新硬件的配置做了修改,只是扩大了内存和磁盘容量就将 CPU 利用率提高了20% ,而这只增加了非常小的成本。同时我们的硬件工程师也和合作生产厂商一起为那些服务器的最初出货调整了物料清单。后续的观察发现我们的自己的新设备实际上可以代替 2.4 台旧设备,这个超出了预定的目标。
|
||||
|
||||
### 从裸设备迁移到 mesos 集群
|
||||
|
||||
直到2012年为止,软件团队在 Twitter 开通一个新服务还需要自己操心硬件:配置硬件的规格需求,研究机架尺寸,开发部署脚本以及处理硬件故障。同时,系统中没有所谓的“服务发现”机制,当一个服务需要调用一个另一个服务时候,需要读取一个 YAML 配置文件,这个配置文件中有目标服务对应的主机 IP 和端口信息(端口信息是由一个公共 wiki 页面维护的)。随着硬件的替换和更新,YAML 配置文件里的内容也会不断的编辑更新。每次更新都需要花几个小时甚至几天来重启在各个服务,从而将新配置刷新到所有服务的缓存里,所以我们只能尽量一次增加多个配置并且按次序分别重启。我们经常遇到重启过程中 cache 不一致导致的问题,因为有的主机在使用旧的配置有的主机在用新的。有时候一台主机的异常(例如它正在重启)会导致整个站点都无法正常工作。
|
||||
直到 2012 年为止,软件团队在 Twitter 开通一个新服务还需要自己操心硬件:配置硬件的规格需求,研究机架尺寸,开发部署脚本以及处理硬件故障。同时,系统中没有所谓的“服务发现”机制,当一个服务需要调用一个另一个服务时候,需要读取一个 YAML 配置文件,这个配置文件中有目标服务对应的主机 IP 和端口信息(预留的端口信息是由一个公共 wiki 页面维护的)。随着硬件的替换和更新,YAML 配置文件里的内容也会不断的编辑更新。在缓存层做修改意味着我们可以按小时或按天做很多次部署,每次添加少量主机并按阶段部署。我们经常遇到在部署过程中 cache 不一致导致的问题,因为有的主机在使用旧的配置有的主机在用新的。有时候一台主机的异常(例如在部署过程中它临时宕机了)会导致整个站点都无法正常工作。
|
||||
|
||||
在 2012/2013 年的时候,Twitter 开始尝试两个新事物:服务发现(来自 ZooKeeper 集群和 Finagle 核心模块中的一个库)和 Mesos(包括基于 Mesos 的一个自研的计划任务框架 Aurora ,它现在也是 Apache 基金会的一个项目)。
|
||||
在 2012/2013 年的时候,Twitter 开始尝试两个新事物:服务发现(来自 ZooKeeper 集群和 [Finagle](https://twitter.github.io/finagle/) 核心模块中的一个库)和 [Mesos](http://mesos.apache.org/)(包括基于 Mesos 的一个自研的计划任务框架 Aurora ,它现在也是 Apache 基金会的一个项目)。
|
||||
|
||||
服务发现功能意味着不需要再维护一个静态 YAML 主机列表了。服务或者在启动后主动注册,或者自动被 mesos 接入到一个“服务集”(就是一个 ZooKeeper 中的 znode 列表,包含角色、环境和服务名信息)中。任何想要访问这个服务的组件都只需要监控这个路径就可以实时获取到一个正在工作的服务列表。
|
||||
|
||||
现在我们通过 Mesos/Aurora ,而不是使用脚本(我们曾经是 Capistrano 的重度用户)来获取一个主机列表、分发代码并规划重启任务。现在软件团队如果想部署一个新服务,只需要将软件包上传到一个叫 Packer 的工具上(它是一个基于 HDFS 的服务),再在 Aurora 配置上描述文件(需要多少 CPU ,多少内存,多少个实例,启动的命令行代码),然后 Aurora 就会自动完成整个部署过程。 Aurora 先找到可用的主机,从 Packer 下载代码,注册到“服务发现”,最后启动这个服务。如果整个过程中遇到失败(硬件故障、网络中断等等), Mesos/Aurora 会自动重选一个新主机并将服务部署上去。
|
||||
现在我们通过 Mesos/Aurora ,而不是使用脚本(我们曾经是 [Capistrano](https://github.com/capistrano/capistrano) 的重度用户)来获取一个主机列表、分发代码并规划重启任务。现在软件团队如果想部署一个新服务,只需要将软件包上传到一个叫 Packer 的工具上(它是一个基于 HDFS 的服务),再在 Aurora 配置上描述文件(需要多少 CPU ,多少内存,多少个实例,启动的命令行代码),然后 Aurora 就会自动完成整个部署过程。 Aurora 先找到可用的主机,从 Packer 下载代码,注册到“服务发现”,最后启动这个服务。如果整个过程中遇到失败(硬件故障、网络中断等等), Mesos/Aurora 会自动重选一个新主机并将服务部署上去。
|
||||
|
||||
#### Twitter 的私有 PaaS 云平台
|
||||
|
||||
Mesos/Aurora 和服务发现这两个功能给我们带了革命性的变化。虽然在接下来几年里,我们碰到了无数 bug ,伤透了无数脑筋,学到了分布式系统里的无数教训,但是这套架还是非常赞的。以前大家一直忙于处理硬件搭配和管理,而现在,大家只需要考虑如何优化业务以及需要多少系统能力就可以了。同时,我们也从根本上解决了 CPU 利用率低的问题,以前服务直接安装在服务器上,这种方式无法充分利用服务器资源,任务协调能力也很差。现在 Mesos 允许我们把多个服务打包成一个服务包,增加一个新服务只需要修改硬件配额,再改一行配置就可以了。
|
||||
Mesos/Aurora 和服务发现这两个功能给我们带了革命性的变化。虽然在接下来几年里,我们碰到了无数 bug ,伤透了无数脑筋,学到了分布式系统里的无数教训,但是这套架还是非常赞的。以前大家一直忙于处理硬件搭配和管理,而现在,大家只需要考虑如何优化业务以及需要多少系统能力就可以了。同时,我们也从根本上解决了 Twitter 之前经历过的 CPU 利用率低的问题,以前服务直接安装在服务器上,这种方式无法充分利用服务器资源,任务协调能力也很差。现在 Mesos 允许我们把多个服务打包成一个服务包,增加一个新服务只需要修改配额,再改一行配置就可以了。
|
||||
|
||||
在两年时间里,多数“无状态”服务迁移到了 Mesos 平台。一些大型且重要的服务(包括我们的用户服务和广告服务)是最先迁移上去的。因为它们的体量巨大,所以他们从这些服务里获得的好处也最多。
|
||||
在两年时间里,多数“无状态”服务迁移到了 Mesos 平台。一些大型且重要的服务(包括我们的用户服务和广告服务系统)是最先迁移上去的。因为它们的体量巨大,所以它们从这些服务里获得的好处也最多,这也降低了它们的服务压力。
|
||||
|
||||
我们一直在不断追求效率提升和架构优化的最佳实践。我们会定期去测试公有云的产品,和我们自己产品的 TCO 以及性能做对比。我们也拥抱公有云的服务,事实上我们现在正在使用公有云产品。最后,这个系列的下一篇将会主要聚焦于我们基础设施的体量方面。
|
||||
|
||||
特别感谢 Jennifer Fraser, David Barr, Geoff Papilion, Matt Singer, Lam Dong 对这篇文章的贡献。
|
||||
|
||||
|
||||
|
||||
特别感谢 [Jennifer Fraser][1]、[David Barr][2]、[Geoff Papilion][3]、 [Matt Singer][4]、[Lam Dong][5] 对这篇文章的贡献。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.twitter.com/2016/the-infrastructure-behind-twitter-efficiency-and-optimization?utm_source=webopsweekly&utm_medium=email
|
||||
via: https://blog.twitter.com/2016/the-infrastructure-behind-twitter-efficiency-and-optimization
|
||||
|
||||
作者:[mazdakh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[eriwoon](https://github.com/eriwoon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -121,9 +118,5 @@ via: https://blog.twitter.com/2016/the-infrastructure-behind-twitter-efficiency-
|
||||
[1]: https://twitter.com/jenniferfraser
|
||||
[2]: https://twitter.com/davebarr
|
||||
[3]: https://twitter.com/gpapilion
|
||||
[4]: https://twitter.com/lamdong
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[4]: https://twitter.com/mattbytes
|
||||
[5]: https://twitter.com/lamdong
|
||||
@ -0,0 +1,74 @@
|
||||
8 个构建容器应用的最佳实践
|
||||
====
|
||||
|
||||

|
||||
|
||||
容器是未来在共有云和私有云进行应用开发的主要趋势,但是容器到底是什么,为什么它们成为了一种广受欢迎的部署机制,而且你需要怎样来修改你的应用来为容器化的环境优化它?
|
||||
|
||||
### 什么是容器?
|
||||
|
||||
容器技术的历史始于 2000 年的 SELinux 和 2005 年的 Solaris zones。今天,容器是由包括 SELinux、Linux 命名空间和控制组(cgroup)等几项内核特性构成,提供了用户进程、网络空间和文件系统空间的隔离。
|
||||
|
||||
### 为什么它们如此流行?
|
||||
|
||||
最近容器技术大规模的应用在很大程度上是由于旨在使容器更加易于使用的标准的发展,例如 Docker 镜像格式和分布模型,这个标准使用不可变镜像(immutable image),这正是容器运行时环境的起点,不可变镜像可以保证开发团队发布的镜像就是经过测试的,和部署到生产环境中的镜像是同样的镜像。
|
||||
|
||||
容器所提供的轻量级隔离为一个应用组件提供了一个更好的抽象。在容器中运行的组件将不会干扰其它可能直接运行在虚拟机上的应用。它们可以避免对系统资源的争夺,而且除非它们共享一个持久卷,否则不会阻止对同一个文件的写请求。容器使得日志和指标采集的实践得以标准化,而且它们可以在物理机和虚拟机上支持更大的用户密度,所有的这些优点将导致更低的部署成本。
|
||||
|
||||
### 我们应该如何构建一个基于容器的应用呢?
|
||||
|
||||
将应用改为运行在容器中并不是什么很高的要求。主要的 Linux 发行版都有提供了基础镜像,任何可以在虚拟机上运行的程序都可以在上面运行。但是容器化应用的趋势是遵循如下最佳实践:
|
||||
|
||||
#### 1. 实例是一次性的
|
||||
|
||||
你的应用的任何实例都不需要小心地保持运行。如果你的一个运行了许多容器的系统崩溃了,你还能够转移到其它可用的系统去创建新的容器。
|
||||
|
||||
#### 2. 重试而不是崩溃
|
||||
|
||||
当你的应用的一个服务依赖于另一个服务的时候,在另一个服务不可用的时候它应该不会崩溃。例如,你的 API 服务正在启动而且监测到数据库不能连接。你应该设计它使得其不断重试连接,而不是运行失败和拒绝启动。当数据库连接断开的时候 API 可以返回 503 状态码,告诉客户端服务现在不可用。应用应该已经遵守了这个实践,但是如果你正在一个一次性实例的容器环境中工作,那么对这个实践的需要会更加明显。
|
||||
|
||||
#### 3. 持久性数据是特殊的
|
||||
|
||||
容器是基于共享镜像启动,它使用了写时复制(COW)文件系统。如果容器的进程选择写入文件,那么这些写的内容只有在直到容器存在时才存在。当容器被删除的时候,写时复制文件系统中的那一层会被删除。提供给容器一个挂载的文件系统目录,使之在容器存活之外也能持久保存,这需要另外的配置,而且会额外消耗物理存储。明确的抽象定义了什么存储是持久的,催生出了实例是一次性的观点。拥有一个抽象层也使得容器编制引擎可以处理挂载和卸载持久卷的复杂请求,以便这些持久卷可以用于容器。
|
||||
|
||||
#### 4. 使用 stdout 而不是日志文件
|
||||
|
||||
现在你或许会思考,如果持久的数据是特殊的,那么我用日志文件来做什么事情?容器运行时环境和编制引擎项目所采用的方法是进程应该[写入 stdout/stderr][1],而且具有归档和维护[容器日志][2]的基础设施。
|
||||
|
||||
#### 5. 敏感信息(以及其它配置信息)也是特殊的
|
||||
|
||||
你绝不应该将敏感信息例如密码、密钥和证书硬编码到你的镜像中。通常在你的应用与开发服务、测试服务,或者生产服务相交互时,这些敏感信息通常都是不同的。大多数开发者并没有访问生产环境的敏感信息的权限,所以如果敏感信息被打包到镜像中,那么必须创建一个新的镜像层来覆盖这个开发服务的敏感信息。基于这一点来看,你再也不能使用与你们开发团队所创建的和质量测试所测试的相同的镜像了,而且也失去了不可修改的镜像的好处。相反的,这些值应该被存储在环境变量中文件中,它们会在容器启动时导入。
|
||||
|
||||
#### 6. 不要假设服务的协同定位
|
||||
|
||||
在一个编排好的容器环境中,你会希望让编排器将你的容器发送到任何最适合的节点。最适合意味着很多事情:它应该基于那个节点现在拥有最多的空间、容器所需的服务质量、容器是否需要持久卷,等等。这可能意味这你的前端、API 和数据库容器最终都会放在不同的节点。尽管给每个节点强制分配一个 API 容器是可以做到的(参考 Kubernetes 的 [DaemonSets][3]),但这种方式应该留给执行监控节点自身这类任务的容器。
|
||||
|
||||
#### 7. 冗余/高可用计划
|
||||
|
||||
即使你没有那么多负载需要高可用性的配置,你也不应该以单路方式编写服务,否则会阻止它运行多份拷贝。这将会允许你运用滚动式部署,使得将负载从一个节点移动到另外一个节点非常容易,或者将服务从一个版本更新到下一个版本而不需要下线。
|
||||
|
||||
#### 8. 实现就绪检查和灵活性检查
|
||||
|
||||
应用在响应请求之前会有一定的启动时间是一件很正常的事情,例如,一个 API 服务器需要填充内存数据缓存。容器编排引擎需要一种方法来检测你的容器是否准备好服务用户请求。为一个新的容器提供就绪检查可以允许我们进行滚动式部署,使得旧容器可以继续运行直到不再需要它,这可以防止服务宕机。类似的,一个存活检查也是一种容器编排引擎持续检查容器是否在健康可用状态的方法。决定容器健康或者说“存活”应该由容器应用的创建者说了算。一个不再存活的容器将会被结束,而且一个新的容器会被创建来替代它。
|
||||
|
||||
### 想查找更多资料?
|
||||
|
||||
我将会出席十月份的格雷丝霍普计算机女性峰会(Grace Hopper Celebration of Women in Computing),你可以在这里来看一下关于我的访谈:[应用的容器化:是什么,为什么,和如何实现][4]。今年不去 GHC 吗?那你可以在 [OpenShift][5] 和 [Kubernetes][6] 的项目站点来了解关于容器、编排和应用的相关内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/9/8-best-practices-building-containerized-applications
|
||||
|
||||
作者:[Jessica Forrester][a]
|
||||
译者:[LinuxBars](https://github.com/LinuxBars)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jwforres
|
||||
[1]: https://docs.docker.com/engine/reference/commandline/logs/
|
||||
[2]: http://kubernetes.io/docs/getting-started-guides/logging/
|
||||
[3]: http://kubernetes.io/docs/admin/daemons/
|
||||
[4]: https://www.eiseverywhere.com/ehome/index.php?eventid=153076&tabid=351462&cid=1350690&sessionid=11443135&sessionchoice=1&
|
||||
[5]: https://www.openshift.org/
|
||||
[6]: http://kubernetes.io/
|
||||
@ -0,0 +1,231 @@
|
||||
内容安全策略(CSP),防御 XSS 攻击的好助手
|
||||
=====
|
||||
|
||||
很久之前,我的个人网站被攻击了。我不知道它是如何发生的,但它确实发生了。幸运的是,攻击带来的破坏是很小的:一小段 JavaScript 被注入到了某些页面的底部。我更新了 FTP 和其它的口令,清理了一些文件,事情就这样结束了。
|
||||
|
||||
有一点使我很恼火:在当时,还没有一种简便的方案能够使我知道那里有问题,更重要的是能够保护网站的访客不被这段恼人的代码所扰。
|
||||
|
||||
现在有一种方案出现了,这种技术在上述两方面都十分的成功。它就是内容安全策略(content security policy,CSP)。
|
||||
|
||||
### 什么是 CSP?
|
||||
|
||||
其核心思想十分简单:网站通过发送一个 CSP 头部,来告诉浏览器什么是被授权执行的与什么是需要被禁止的。
|
||||
|
||||
这里有一个 PHP 的例子:
|
||||
|
||||
```
|
||||
<?php
|
||||
header("Content-Security-Policy: <your directives>");
|
||||
?>
|
||||
```
|
||||
|
||||
#### 一些指令
|
||||
|
||||
你可以定义一些全局规则或者定义一些涉及某一类资源的规则:
|
||||
|
||||
```
|
||||
default-src 'self' ;
|
||||
# self = 同端口,同域名,同协议 => 允许
|
||||
```
|
||||
|
||||
基础参数是 `default-src`:如果没有为某一类资源设置指令规则,那么浏览器就会使用这个默认参数值。
|
||||
|
||||
```
|
||||
script-src 'self' www.google-analytics.com ;
|
||||
# 来自这些域名的 JS 文件 => 允许
|
||||
```
|
||||
|
||||
在这个例子中,我们已经授权了 www.google-analytics.com 这个域名来源的 JavaScript 文件使用到我们的网站上。我们也添加了 `'self'` 这个关键词;如果我们通过 `script-src` 来重新设置其它的规则指令,它将会覆盖 `default-src` 规则。
|
||||
|
||||
如果没有指明协议(scheme)或端口,它就会强制选择与当前页面相同的协议或端口。这样做防止了混合内容(LCTT 译注:混合内容指 HTTPS 页面中也有非 HTTPS 资源,可参见: https://developer.mozilla.org/zh-CN/docs/Security/MixedContent )。如果页面是 https://example.com,那么你将无法加载 http://www.google-analytics.com/file.js 因为它已经被禁止了(协议不匹配)。然而,有一个例外就是协议的提升是被允许的。如果 http://example.com 尝试加载 https://www.google-analytics.com/file.js,接着协议或端口允许被更改以便协议的提升。
|
||||
|
||||
```
|
||||
style-src 'self' data: ;
|
||||
# Data-Uri 嵌入 CSS => 允许
|
||||
```
|
||||
|
||||
在这个例子中,关键词 `data:` 授权了在 CSS 文件中 data 内嵌内容。
|
||||
|
||||
在 CSP 1 规范下,你也可以设置如下规则:
|
||||
|
||||
- `img-src` 有效的图片来源
|
||||
- `connect-src` 应用于 XMLHttpRequest(AJAX),WebSocket 或 EventSource
|
||||
- `font-src` 有效的字体来源
|
||||
- `object-src` 有效的插件来源(例如,`<object>`,`<embed>`,`<applet>`)
|
||||
- `media-src` 有效的 `<audio>` 和 `<video>` 来源
|
||||
|
||||
CSP 2 规范包含了如下规则:
|
||||
|
||||
- `child-src` 有效的 web workers 和 元素来源,如 `<frame>` 和 `<iframe>` (这个指令用来替代 CSP 1 中废弃了的 `frame-src` 指令)
|
||||
- `form-action` 可以作为 HTML `<form>` 的 action 的有效来源
|
||||
- `frame-ancestors` 使用 `<frame>`,`<iframe>`,`<object>`,`<embed>` 或 `<applet>` 内嵌资源的有效来源
|
||||
- `upgrade-insecure-requests` 命令用户代理来重写 URL 协议,将 HTTP 改到 HTTPS (为一些需要重写大量陈旧 URL 的网站提供了方便)。
|
||||
|
||||
为了更好的向后兼容一些废弃的属性,你可以简单的复制当前指令的内容同时为那个废弃的指令创建一个相同的副本。例如,你可以复制 `child-src` 的内容同时在 `frame-src` 中添加一份相同的副本。
|
||||
|
||||
CSP 2 允许你添加路径到白名单中(CSP 1 只允许域名被添加到白名单中)。因此,相较于将整个 www.foo.com 域添加到白名单,你可以通过添加 www.foo.com/some/folder 这样的路径到白名单中来作更多的限制。这个需要浏览器中 CSP 2 的支持,但它很明显更安全。
|
||||
|
||||
#### 一个例子
|
||||
|
||||
我为 Web 2015 巴黎大会上我的演讲 “[CSP in Action][1]”制作了一个简单的例子。
|
||||
|
||||
在没有 CSP 的情况下,页面展示如下图所示:
|
||||
|
||||

|
||||
|
||||
不是十分优美。要是我们启用了如下的 CSP 指令又会怎样呢?
|
||||
|
||||
```
|
||||
<?php
|
||||
header("Content-Security-Policy:
|
||||
default-src 'self' ;
|
||||
script-src 'self' www.google-analytics.com stats.g.doubleclick.net ;
|
||||
style-src 'self' data: ;
|
||||
img-src 'self' www.google-analytics.com stats.g.doubleclick.net data: ;
|
||||
frame-src 'self' ;");
|
||||
?>
|
||||
```
|
||||
|
||||
浏览器将会作什么呢?它会(非常严格的)在 CSP 基础规则之下应用这些指令,这意味着**任何没有在 CSP 指令中被授权允许的都将会被禁止**(“blocked” 指的是不被执行、不被显示并且不被使用在网站中)。
|
||||
|
||||
在 CSP 的默认设置中,内联脚本和样式是不被授权的,意味着每一个 `<script>`,`onclick` 事件属性或 `style` 属性都将会被禁止。你可以使用 `style-src 'unsafe-inline' ;` 指令来授权使用内联 CSS。
|
||||
|
||||
在一个支持 CSP 的现代浏览器中,上述示例看起来如下图:
|
||||
|
||||

|
||||
|
||||
发生了什么?浏览器应用了指令并且拒绝了所有没有被授权的内容。它在浏览器调试终端中发送了这些通知:
|
||||
|
||||

|
||||
|
||||
如果你依然不确定 CSP 的价值,请看一下 Aaron Gustafson 文章 “[More Proof We Don't Control Our Web Pages][2]”。
|
||||
|
||||
当然,你可以使用比我们在示例中提供的更严格的指令:
|
||||
|
||||
- 设置 `default-src` 为 'none'
|
||||
- 为每条规则指定你的设置
|
||||
- 为请求的文件指定它的绝对路径
|
||||
- 等
|
||||
|
||||
### 更多关于 CSP 的信息
|
||||
|
||||
#### 支持
|
||||
|
||||
CSP 不是一个需要复杂的配置才能正常工作的每日构建特性。CSP 1 和 2 是候选推荐标准![浏览器可以非常完美的支持 CSP 1][3]。
|
||||
|
||||

|
||||
|
||||
[CSP 2 是较新的规范][4],因此对它的支持会少那么一点。
|
||||
|
||||

|
||||
|
||||
现在 CSP 3 还是一个早期草案,因此还没有被支持,但是你依然可以使用 CSP 1 和 2 来做一些重大的事。
|
||||
|
||||
#### 其他需要考虑的因素
|
||||
|
||||
CSP 被设计用来降低跨站脚本攻击(XSS)的风险,这就是不建议开启内联脚本和 `script-src` 指令的原因。Firefox 对这个问题做了很好的说明:在浏览器中,敲击 `Shift + F2` 并且键入 `security csp`,它就会向你展示指令和对应的建议。这里有一个在 Twitter 网站中应用的例子:
|
||||
|
||||

|
||||
|
||||
如果你确实需要使用内联脚本和样式的话,另一种可能就是生成一份散列值。例如,我们假定你需要使用如下的内联脚本:
|
||||
|
||||
```
|
||||
<script>alert('Hello, world.');</script>
|
||||
```
|
||||
|
||||
你应该在 `script-src` 指令中添加 `sha256-qznLcsROx4GACP2dm0UCKCzCG-HiZ1guq6ZZDob_Tng=` 作为有效来源。这个散列值用下面的 PHP 脚本执行获得的结果:
|
||||
|
||||
```
|
||||
<?php
|
||||
echo base64_encode(hash('sha256', "alert('Hello, world.');", true));
|
||||
?>
|
||||
```
|
||||
|
||||
我在前文中说过 CSP 被设计用来降低 XSS 风险,我还得加上“……与降低未经请求内容的风险。”伴随着 CSP 的使用,你必须**知道你内容的来源是哪里**与**它们在你的前端都作了些什么**(内联样式,等)。CSP 同时可以帮助你让贡献者、开发人员和其他人员来遵循你内容来源的规则!
|
||||
|
||||
现在你的问题就只是,“不错,这很好,但是我们如何在生产环境中使用它呢?”
|
||||
|
||||
### 如何在现实世界中使用它
|
||||
|
||||
想要在第一次使用 CSP 之后就失望透顶的方法就是在生产环境中测试。不要想当然的认为,“这会很简单。我的代码是完美并且相当清晰的。”不要这样作。我这样干过。相信我,这相当的蠢。
|
||||
|
||||
正如我之前说明的,CSP 指令由 CSP 头部来激活,这中间没有过渡阶段。你恰恰就是其中的薄弱环节。你可能会忘记授权某些东西或者遗忘了你网站中的一小段代码。CSP 不会饶恕你的疏忽。然而,CSP 的两个特性将这个问题变得相当的简单。
|
||||
|
||||
#### report-uri
|
||||
|
||||
还记得 CSP 发送到终端中的那些通知么?`report-uri` 指令可以被用来告诉浏览器发送那些通知到指定的地址。报告以 JSON 格式送出。
|
||||
|
||||
```
|
||||
report-uri /csp-parser.php ;
|
||||
```
|
||||
|
||||
因此,我们可以在 csp-parser.php 文件中处理有浏览器送出的数据。这里有一个由 PHP 实现的最基础的例子:
|
||||
|
||||
```
|
||||
$data = file_get_contents('php://input');
|
||||
|
||||
if ($data = json_decode($data, true)) {
|
||||
$data = json_encode(
|
||||
$data,
|
||||
JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES
|
||||
);
|
||||
mail(EMAIL, SUBJECT, $data);
|
||||
}
|
||||
```
|
||||
|
||||
这个通知将会被转换成为一封邮件。在开发过程中,你可能不会需要比这更复杂的其它东西。
|
||||
|
||||
对于一个生产环境(或者是一个有较多访问的开发环境),你应该使用一种比邮件更好的收集信息的方式,因为这种方式在节点上没有验证和速率限制,并且 CSP 可能变得乱哄哄的。只需想像一个会产生 100 个 CSP 通知(例如,一个从未授权来源展示图片的脚本)并且每天会被浏览 100 次的页面,那你就会每天收到 10000 个通知啊!
|
||||
|
||||
例如 [report-uri.io](https://report-uri.io/) 这样的服务可以用来简化你的通知管理。你也可以在 GitHub上看一些另外的使用 `report-uri` (与数据库搭配,添加一些优化,等)的简单例子。
|
||||
|
||||
### report-only
|
||||
|
||||
正如我们所见的,最大的问题就是在使用和不使用 CSP 之间没有中间地带。然而,一个名为 `report-only` 的特性会发送一个稍有不同的头部:
|
||||
|
||||
```
|
||||
<?php
|
||||
header("Content-Security-Policy-Report-Only: <your directives>");
|
||||
?>
|
||||
```
|
||||
|
||||
总的来说,这个头部就是告诉浏览器,“表现得似乎所有的 CSP 指令都被应用了,但是不禁止任何东西。只是发送通知给自己。”这是一种相当棒的测试指令的方式,避免了任何有价值的东西被禁止的风险。
|
||||
|
||||
在 `report-only` 和 `report-uri` 的帮助下你可以毫无风险的测试 CSP 指令,并且可以实时的监控网站上一切与 CSP 相关的内容。这两个特性对部署和维护 CSP 来说真是相当的有用!
|
||||
|
||||
### 结论
|
||||
|
||||
#### 为什么 CSP 很酷
|
||||
|
||||
CSP 对你的用户来说是尤其重要的:他们在你的网站上不再需要遭受任何的未经请求的脚本,内容或 XSS 的威胁了。
|
||||
|
||||
对于网站维护者来说 CSP 最重要的优势就是可感知。如果你对图片来源设置了严格的规则,这时一个脚本小子尝试在你的网站上插入一张未授权来源的图片,那么这张图片就会被禁止,并且你会在第一时间收到提醒。
|
||||
|
||||
开发者也需要确切的知道他们的前端代码都在做些什么,CSP 可以帮助他们掌控一切。会促使他们去重构他们代码中的某些部分(避免内联函数和样式,等)并且促使他们遵循最佳实践。
|
||||
|
||||
#### 如何让 CSP 变得更酷
|
||||
|
||||
讽刺的是,CSP 在一些浏览器中过分的高效了,在和书签栏小程序一起使用时会产生一些 bug。因此,不要更新你的 CSP 指令来允许书签栏小程序。我们无法单独的责备任何一个浏览器;它们都有些问题:
|
||||
|
||||
- Firefox
|
||||
- Chrome (Blink)
|
||||
- WebKit
|
||||
|
||||
大多数情况下,这些 bug 都是禁止通知中的误报。所有的浏览器提供者都在努力解决这些问题,因此我们可以期待很快就会被解决。无论怎样,这都不会成为你使用 CSP 的绊脚石。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.smashingmagazine.com/2016/09/content-security-policy-your-future-best-friend/
|
||||
|
||||
作者:[Nicolas Hoffmann][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.smashingmagazine.com/author/nicolashoffmann/
|
||||
[1]: https://rocssti.net/en/example-csp-paris-web2015
|
||||
[2]: https://www.aaron-gustafson.com/notebook/more-proof-we-dont-control-our-web-pages/
|
||||
[3]: http://caniuse.com/#feat=contentsecuritypolicy
|
||||
[4]: http://caniuse.com/#feat=contentsecuritypolicy2
|
||||
|
||||
@ -0,0 +1,476 @@
|
||||
使用 Elasticsearch 和 cAdvisor 监控 Docker 容器
|
||||
=======
|
||||
|
||||
如果你正在运行 Swarm 模式的集群,或者只运行单台 Docker,你都会有下面的疑问:
|
||||
|
||||
> 我如何才能监控到它们都在干些什么?
|
||||
|
||||
这个问题的答案是“很不容易”。
|
||||
|
||||
你需要监控下面的参数:
|
||||
|
||||
1. 容器的数量和状态。
|
||||
2. 一台容器是否已经移到另一个节点了,如果是,那是在什么时候,移动到哪个节点?
|
||||
3. 给定节点上运行着的容器数量。
|
||||
4. 一段时间内的通信峰值。
|
||||
5. 孤儿卷和网络(LCTT 译注:孤儿卷就是当你删除容器时忘记删除它的卷,这个卷就不会再被使用,但会一直占用资源)。
|
||||
6. 可用磁盘空间、可用 inode 数。
|
||||
7. 容器数量与连接在 `docker0` 和 `docker_gwbridge` 上的虚拟网卡数量不一致(LCTT 译注:当 docker 启动时,它会在宿主机器上创建一个名为 docker0 的虚拟网络接口)。
|
||||
8. 开启和关闭 Swarm 节点。
|
||||
9. 收集并集中处理日志。
|
||||
|
||||
本文的目标是介绍 [Elasticsearch][1] + [Kibana][2] + [cAdvisor][3] 的用法,使用它们来收集 Docker 容器的参数,分析数据并产生可视化报表。
|
||||
|
||||
阅读本文后你可以发现有一个监控仪表盘能够部分解决上述列出的问题。但如果只是使用 cAdvisor,有些参数就无法显示出来,比如 Swarm 模式的节点。
|
||||
|
||||
如果你有一些 cAdvisor 或其他工具无法解决的特殊需求,我建议你开发自己的数据收集器和数据处理器(比如 [Beats][4]),请注意我不会演示如何使用 Elasticsearch 来集中收集 Docker 容器的日志。
|
||||
|
||||
> [“你要如何才能监控到 Swarm 模式集群里面发生了什么事情?要做到这点很不容易。” —— @fntlnz][5]
|
||||
|
||||
### 我们为什么要监控容器?
|
||||
|
||||
想象一下这个经典场景:你在管理一台或多台虚拟机,你把 tmux 工具用得很溜,用各种 session 事先设定好了所有基础的东西,包括监控。然后生产环境出问题了,你使用 `top`、`htop`、`iotop`、`jnettop` 各种 top 来排查,然后你准备好修复故障。
|
||||
|
||||
现在重新想象一下你有 3 个节点,包含 50 台容器,你需要在一个地方查看整洁的历史数据,这样你知道问题出在哪个地方,而不是把你的生命浪费在那些字符界面来赌你可以找到问题点。
|
||||
|
||||
### 什么是 Elastic Stack ?
|
||||
|
||||
Elastic Stack 就一个工具集,包括以下工具:
|
||||
|
||||
- Elasticsearch
|
||||
- Kibana
|
||||
- Logstash
|
||||
- Beats
|
||||
|
||||
我们会使用其中一部分工具,比如使用 Elasticsearch 来分析基于 JSON 格式的文本,以及使用 Kibana 来可视化数据并产生报表。
|
||||
|
||||
另一个重要的工具是 [Beats][4],但在本文中我们还是把精力放在容器上,官方的 Beats 工具不支持 Docker,所以我们选择原生兼容 Elasticsearch 的 cAdvisor。
|
||||
|
||||
[cAdvisor][3] 工具负责收集、整合正在运行的容器数据,并导出报表。在本文中,这些报表被到入到 Elasticsearch 中。
|
||||
|
||||
cAdvisor 有两个比较酷的特性:
|
||||
|
||||
- 它不只局限于 Docker 容器。
|
||||
- 它有自己的 Web 服务器,可以简单地显示当前节点的可视化报表。
|
||||
|
||||
### 设置测试集群,或搭建自己的基础架构
|
||||
|
||||
和我[以前的文章][9]一样,我习惯提供一个简单的脚本,让读者不用花很多时间就能部署好和我一样的测试环境。你可以使用以下(非生产环境使用的)脚本来搭建一个 Swarm 模式的集群,其中一个容器运行着 Elasticsearch。
|
||||
|
||||
> 如果你有充足的时间和经验,你可以搭建自己的基础架构 (Bring Your Own Infrastructure,BYOI)。
|
||||
|
||||
如果要继续阅读本文,你需要:
|
||||
|
||||
- 运行 Docker 进程的一个或多个节点(docker 版本号大于等于 1.12)。
|
||||
- 至少有一个独立运行的 Elasticsearch 节点(版本号 2.4.X)。
|
||||
|
||||
重申一下,此 Elasticsearch 集群环境不能放在生产环境中使用。生产环境也不推荐使用单节点集群,所以如果你计划安装一个生产环境,请参考 [Elastic 指南][6]。
|
||||
|
||||
### 对喜欢尝鲜的用户的友情提示
|
||||
|
||||
我就是一个喜欢尝鲜的人(当然我也已经在生产环境中使用了最新的 alpha 版本),但是在本文中,我不会使用最新的 Elasticsearch 5.0.0 alpha 版本,我还不是很清楚这个版本的功能,所以我不想成为那个引导你们出错的关键。
|
||||
|
||||
所以本文中涉及的 Elasticsearch 版本为最新稳定版 2.4.0。
|
||||
|
||||
### 测试集群部署脚本
|
||||
|
||||
前面已经说过,我提供这个脚本给你们,让你们不必费神去部署 Swarm 集群和 Elasticsearch,当然你也可以跳过这一步,用你自己的 Swarm 模式引擎和你自己的 Elasticserch 节点。
|
||||
|
||||
执行这段脚本之前,你需要:
|
||||
|
||||
- [Docker Machine][7] – 最终版:在 DigitalOcean 中提供 Docker 引擎。
|
||||
- [DigitalOcean API Token][8]: 让 docker 机器按照你的意思来启动节点。
|
||||
|
||||

|
||||
|
||||
### 创建集群的脚本
|
||||
|
||||
现在万事俱备,你可以把下面的代码拷到 create-cluster.sh 文件中:
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
#
|
||||
# Create a Swarm Mode cluster with a single master and a configurable number of workers
|
||||
|
||||
workers=${WORKERS:-"worker1 worker2"}
|
||||
|
||||
#######################################
|
||||
# Creates a machine on Digital Ocean
|
||||
# Globals:
|
||||
# DO_ACCESS_TOKEN The token needed to access DigitalOcean's API
|
||||
# Arguments:
|
||||
# $1 the actual name to give to the machine
|
||||
#######################################
|
||||
create_machine() {
|
||||
docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token=$DO_ACCESS_TOKEN \
|
||||
--digitalocean-size 2gb \
|
||||
$1
|
||||
}
|
||||
|
||||
#######################################
|
||||
# Executes a command on the specified machine
|
||||
# Arguments:
|
||||
# $1 The machine on which to run the command
|
||||
# $2..$n The command to execute on that machine
|
||||
#######################################
|
||||
machine_do() {
|
||||
docker-machine ssh $@
|
||||
}
|
||||
|
||||
main() {
|
||||
|
||||
if [ -z "$DO_ACCESS_TOKEN" ]; then
|
||||
echo "Please export a DigitalOcean Access token: https://cloud.digitalocean.com/settings/api/tokens/new"
|
||||
echo "export DO_ACCESS_TOKEN=<yourtokenhere>"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ -z "$WORKERS" ]; then
|
||||
echo "You haven't provided your workers by setting the \$WORKERS environment variable, using the default ones: $workers"
|
||||
fi
|
||||
|
||||
# Create the first and only master
|
||||
echo "Creating the master"
|
||||
|
||||
create_machine master1
|
||||
|
||||
master_ip=$(docker-machine ip master1)
|
||||
|
||||
# Initialize the swarm mode on it
|
||||
echo "Initializing the swarm mode"
|
||||
machine_do master1 docker swarm init --advertise-addr $master_ip
|
||||
|
||||
# Obtain the token to allow workers to join
|
||||
worker_tkn=$(machine_do master1 docker swarm join-token -q worker)
|
||||
echo "Worker token: ${worker_tkn}"
|
||||
|
||||
# Create and join the workers
|
||||
for worker in $workers; do
|
||||
echo "Creating worker ${worker}"
|
||||
create_machine $worker
|
||||
machine_do $worker docker swarm join --token $worker_tkn $master_ip:2377
|
||||
done
|
||||
}
|
||||
|
||||
main $@
|
||||
```
|
||||
|
||||
赋予它可执行权限:
|
||||
|
||||
```
|
||||
chmod +x create-cluster.sh
|
||||
```
|
||||
|
||||
### 创建集群
|
||||
|
||||
如文件名所示,我们可以用它来创建集群。默认情况下这个脚本会创建一个 master 和两个 worker,如果你想修改 worker 个数,可以设置环境变量 WORKERS。
|
||||
|
||||
现在就来创建集群吧。
|
||||
|
||||
```
|
||||
./create-cluster.sh
|
||||
```
|
||||
|
||||
你可以出去喝杯咖啡,因为这需要花点时间。
|
||||
|
||||
最后集群部署好了。
|
||||
|
||||

|
||||
|
||||
现在为了验证 Swarm 模式集群已经正常运行,我们可以通过 ssh 登录进 master:
|
||||
|
||||
```
|
||||
docker-machine ssh master1
|
||||
```
|
||||
|
||||
然后列出集群的节点:
|
||||
|
||||
```
|
||||
docker node ls
|
||||
```
|
||||
|
||||
```
|
||||
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
|
||||
26fi3wiqr8lsidkjy69k031w2 * master1 Ready Active Leader
|
||||
dyluxpq8sztj7kmwlzs51u4id worker2 Ready Active
|
||||
epglndegvixag0jztarn2lte8 worker1 Ready Active
|
||||
```
|
||||
|
||||
### 安装 Elasticsearch 和 Kibana
|
||||
|
||||
> 注意,从现在开始所有的命令都运行在主节点 master1 上。
|
||||
|
||||
在生产环境中,你可能会把 Elasticsearch 和 Kibana 安装在一个单独的、[大小合适][14]的实例集合中。但是在我们的实验中,我们还是把它们和 Swarm 模式集群安装在一起。
|
||||
|
||||
为了将 Elasticsearch 和 cAdvisor 连通,我们需要创建一个自定义的网络,因为我们使用了集群,并且容器可能会分布在不同的节点上,我们需要使用 [overlay][10] 网络(LCTT 译注:overlay 网络是指在不改变现有网络基础设施的前提下,通过某种约定通信协议,把二层报文封装在 IP 报文之上的新的数据格式,是目前最主流的容器跨节点数据传输和路由方案)。
|
||||
|
||||
也许你会问,“为什么还要网络?我们不是可以用 link 吗?” 请考虑一下,自从引入*用户定义网络*后,link 机制就已经过时了。
|
||||
|
||||
以下内容摘自[ Docker 文档][11]:
|
||||
|
||||
> 在 Docker network 特性出来以前,你可以使用 Docker link 特性实现容器互相发现、安全通信。而在 network 特性出来以后,你还可以使用 link,但是当容器处于默认桥接网络或用户自定义网络时,它们的表现是不一样的。
|
||||
|
||||
现在创建 overlay 网络,名称为 monitoring:
|
||||
|
||||
```
|
||||
docker network create monitoring -d overlay
|
||||
```
|
||||
|
||||
### Elasticsearch 容器
|
||||
|
||||
```
|
||||
docker service create --network=monitoring \
|
||||
--mount type=volume,target=/usr/share/elasticsearch/data \
|
||||
--constraint node.hostname==worker1 \
|
||||
--name elasticsearch elasticsearch:2.4.0
|
||||
```
|
||||
|
||||
注意 Elasticsearch 容器被限定在 worker1 节点,这是因为它运行时需要依赖 worker1 节点上挂载的卷。
|
||||
|
||||
### Kibana 容器
|
||||
|
||||
```
|
||||
docker service create --network=monitoring --name kibana -e ELASTICSEARCH_URL="http://elasticsearch:9200" -p 5601:5601 kibana:4.6.0
|
||||
```
|
||||
|
||||
如你所见,我们启动这两个容器时,都让它们加入 monitoring 网络,这样一来它们可以通过名称(如 Kibana)被相同网络的其他服务访问。
|
||||
|
||||
现在,通过 [routing mesh][12] 机制,我们可以使用浏览器访问服务器的 IP 地址来查看 Kibana 报表界面。
|
||||
|
||||
获取 master1 实例的公共 IP 地址:
|
||||
|
||||
```
|
||||
docker-machine ip master1
|
||||
```
|
||||
|
||||
打开浏览器输入地址:`http://[master1 的 ip 地址]:5601/status`
|
||||
|
||||
所有项目都应该是绿色:
|
||||
|
||||

|
||||
|
||||
让我们接下来开始收集数据!
|
||||
|
||||
### 收集容器的运行数据
|
||||
|
||||
收集数据之前,我们需要创建一个服务,以全局模式运行 cAdvisor,为每个有效节点设置一个定时任务。
|
||||
|
||||
这个服务与 Elasticsearch 处于相同的网络,以便于 cAdvisor 可以推送数据给 Elasticsearch。
|
||||
|
||||
```
|
||||
docker service create --network=monitoring --mode global --name cadvisor \
|
||||
--mount type=bind,source=/,target=/rootfs,readonly=true \
|
||||
--mount type=bind,source=/var/run,target=/var/run,readonly=false \
|
||||
--mount type=bind,source=/sys,target=/sys,readonly=true \
|
||||
--mount type=bind,source=/var/lib/docker/,target=/var/lib/docker,readonly=true \
|
||||
google/cadvisor:latest \
|
||||
-storage_driver=elasticsearch \
|
||||
-storage_driver_es_host="http://elasticsearch:9200"
|
||||
```
|
||||
|
||||
> 注意:如果你想配置 cAdvisor 选项,参考[这里][13]。
|
||||
|
||||
现在 cAdvisor 在发送数据给 Elasticsearch,我们通过定义一个索引模型来检索 Kibana 中的数据。有两种方式可以做到这一点:通过 Kibana 或者通过 API。在这里我们使用 API 方式实现。
|
||||
|
||||
我们需要在一个连接到 monitoring 网络的正在运行的容器中运行索引创建命令,你可以在 cAdvisor 容器中拿到 shell,不幸的是 Swarm 模式在开启服务时会在容器名称后面附加一个唯一的 ID 号,所以你需要手动指定 cAdvisor 容器的名称。
|
||||
|
||||
拿到 shell:
|
||||
|
||||
```
|
||||
docker exec -ti <cadvisor-container-name> sh
|
||||
```
|
||||
|
||||
创建索引:
|
||||
|
||||
```
|
||||
curl -XPUT http://elasticsearch:9200/.kibana/index-pattern/cadvisor -d '{"title" : "cadvisor*", "timeFieldName": "container_stats.timestamp"}'
|
||||
```
|
||||
|
||||
如果你够懒,可以只执行下面这一句:
|
||||
|
||||
```
|
||||
docker exec $(docker ps | grep cadvisor | awk '{print $1}' | head -1) curl -XPUT http://elasticsearch:9200/.kibana/index-pattern/cadvisor -d '{"title" : "cadvisor*", "timeFieldName": "container_stats.timestamp"}'
|
||||
```
|
||||
|
||||
### 把数据汇总成报表
|
||||
|
||||
你现在可以使用 Kibana 来创建一份美观的报表了。但是不要着急,我为你们建了一份报表和一些图形界面来方便你们入门。
|
||||
|
||||

|
||||
|
||||
访问 Kibana 界面 => Setting => Objects => Import,然后选择包含以下内容的 JSON 文件,就可以导入我的配置信息了:
|
||||
|
||||
```
|
||||
[
|
||||
{
|
||||
"_id": "cAdvisor",
|
||||
"_type": "dashboard",
|
||||
"_source": {
|
||||
"title": "cAdvisor",
|
||||
"hits": 0,
|
||||
"description": "",
|
||||
"panelsJSON": "[{\"id\":\"Filesystem-usage\",\"type\":\"visualization\",\"panelIndex\":1,\"size_x\":6,\"size_y\":3,\"col\":1,\"row\":1},{\"id\":\"Memory-[Node-equal->Container]\",\"type\":\"visualization\",\"panelIndex\":2,\"size_x\":6,\"size_y\":4,\"col\":7,\"row\":4},{\"id\":\"memory-usage-by-machine\",\"type\":\"visualization\",\"panelIndex\":3,\"size_x\":6,\"size_y\":6,\"col\":1,\"row\":4},{\"id\":\"CPU-Total-Usage\",\"type\":\"visualization\",\"panelIndex\":4,\"size_x\":6,\"size_y\":5,\"col\":7,\"row\":8},{\"id\":\"Network-RX-TX\",\"type\":\"visualization\",\"panelIndex\":5,\"size_x\":6,\"size_y\":3,\"col\":7,\"row\":1}]",
|
||||
"optionsJSON": "{\"darkTheme\":false}",
|
||||
"uiStateJSON": "{}",
|
||||
"version": 1,
|
||||
"timeRestore": false,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"filter\":[{\"query\":{\"query_string\":{\"query\":\"*\",\"analyze_wildcard\":true}}}]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "Network",
|
||||
"_type": "search",
|
||||
"_source": {
|
||||
"title": "Network",
|
||||
"description": "",
|
||||
"hits": 0,
|
||||
"columns": [
|
||||
"machine_name",
|
||||
"container_Name",
|
||||
"container_stats.network.name",
|
||||
"container_stats.network.interfaces",
|
||||
"container_stats.network.rx_bytes",
|
||||
"container_stats.network.rx_packets",
|
||||
"container_stats.network.rx_dropped",
|
||||
"container_stats.network.rx_errors",
|
||||
"container_stats.network.tx_packets",
|
||||
"container_stats.network.tx_bytes",
|
||||
"container_stats.network.tx_dropped",
|
||||
"container_stats.network.tx_errors"
|
||||
],
|
||||
"sort": [
|
||||
"container_stats.timestamp",
|
||||
"desc"
|
||||
],
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"analyze_wildcard\":true,\"query\":\"*\"}},\"highlight\":{\"pre_tags\":[\"@kibana-highlighted-field@\"],\"post_tags\":[\"@/kibana-highlighted-field@\"],\"fields\":{\"*\":{}},\"fragment_size\":2147483647},\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "Filesystem-usage",
|
||||
"_type": "visualization",
|
||||
"_source": {
|
||||
"title": "Filesystem usage",
|
||||
"visState": "{\"title\":\"Filesystem usage\",\"type\":\"histogram\",\"params\":{\"addLegend\":true,\"addTimeMarker\":false,\"addTooltip\":true,\"defaultYExtents\":false,\"mode\":\"stacked\",\"scale\":\"linear\",\"setYExtents\":false,\"shareYAxis\":true,\"times\":[],\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.filesystem.usage\",\"customLabel\":\"USED\"}},{\"id\":\"2\",\"type\":\"terms\",\"schema\":\"split\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\",\"row\":false}},{\"id\":\"3\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.filesystem.capacity\",\"customLabel\":\"AVAIL\"}},{\"id\":\"4\",\"type\":\"terms\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.filesystem.device\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}}],\"listeners\":{}}",
|
||||
"uiStateJSON": "{\"vis\":{\"colors\":{\"Average container_stats.filesystem.available\":\"#E24D42\",\"Average container_stats.filesystem.base_usage\":\"#890F02\",\"Average container_stats.filesystem.capacity\":\"#3F6833\",\"Average container_stats.filesystem.usage\":\"#E24D42\",\"USED\":\"#BF1B00\",\"AVAIL\":\"#508642\"}}}",
|
||||
"description": "",
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"analyze_wildcard\":true,\"query\":\"*\"}},\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "CPU-Total-Usage",
|
||||
"_type": "visualization",
|
||||
"_source": {
|
||||
"title": "CPU Total Usage",
|
||||
"visState": "{\"title\":\"CPU Total Usage\",\"type\":\"area\",\"params\":{\"shareYAxis\":true,\"addTooltip\":true,\"addLegend\":true,\"smoothLines\":false,\"scale\":\"linear\",\"interpolate\":\"linear\",\"mode\":\"stacked\",\"times\":[],\"addTimeMarker\":false,\"defaultYExtents\":false,\"setYExtents\":false,\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.cpu.usage.total\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"terms\",\"schema\":\"group\",\"params\":{\"field\":\"container_Name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}},{\"id\":\"4\",\"type\":\"terms\",\"schema\":\"split\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\",\"row\":true}}],\"listeners\":{}}",
|
||||
"uiStateJSON": "{}",
|
||||
"description": "",
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"query\":\"*\",\"analyze_wildcard\":true}},\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "memory-usage-by-machine",
|
||||
"_type": "visualization",
|
||||
"_source": {
|
||||
"title": "Memory [Node]",
|
||||
"visState": "{\"title\":\"Memory [Node]\",\"type\":\"area\",\"params\":{\"shareYAxis\":true,\"addTooltip\":true,\"addLegend\":true,\"smoothLines\":false,\"scale\":\"linear\",\"interpolate\":\"linear\",\"mode\":\"stacked\",\"times\":[],\"addTimeMarker\":false,\"defaultYExtents\":false,\"setYExtents\":false,\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.memory.usage\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"terms\",\"schema\":\"group\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}}],\"listeners\":{}}",
|
||||
"uiStateJSON": "{}",
|
||||
"description": "",
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"query\":\"*\",\"analyze_wildcard\":true}},\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "Network-RX-TX",
|
||||
"_type": "visualization",
|
||||
"_source": {
|
||||
"title": "Network RX TX",
|
||||
"visState": "{\"title\":\"Network RX TX\",\"type\":\"histogram\",\"params\":{\"addLegend\":true,\"addTimeMarker\":true,\"addTooltip\":true,\"defaultYExtents\":false,\"mode\":\"stacked\",\"scale\":\"linear\",\"setYExtents\":false,\"shareYAxis\":true,\"times\":[],\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.network.rx_bytes\",\"customLabel\":\"RX\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"s\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.network.tx_bytes\",\"customLabel\":\"TX\"}}],\"listeners\":{}}",
|
||||
"uiStateJSON": "{\"vis\":{\"colors\":{\"RX\":\"#EAB839\",\"TX\":\"#BF1B00\"}}}",
|
||||
"description": "",
|
||||
"savedSearchId": "Network",
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "Memory-[Node-equal->Container]",
|
||||
"_type": "visualization",
|
||||
"_source": {
|
||||
"title": "Memory [Node=>Container]",
|
||||
"visState": "{\"title\":\"Memory [Node=>Container]\",\"type\":\"area\",\"params\":{\"shareYAxis\":true,\"addTooltip\":true,\"addLegend\":true,\"smoothLines\":false,\"scale\":\"linear\",\"interpolate\":\"linear\",\"mode\":\"stacked\",\"times\":[],\"addTimeMarker\":false,\"defaultYExtents\":false,\"setYExtents\":false,\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.memory.usage\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"terms\",\"schema\":\"group\",\"params\":{\"field\":\"container_Name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}},{\"id\":\"4\",\"type\":\"terms\",\"schema\":\"split\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\",\"row\":true}}],\"listeners\":{}}",
|
||||
"uiStateJSON": "{}",
|
||||
"description": "",
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"query\":\"* NOT container_Name.raw: \\\\\\\"/\\\\\\\" AND NOT container_Name.raw: \\\\\\\"/docker\\\\\\\"\",\"analyze_wildcard\":true}},\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
这里还有很多东西可以玩,你也许想自定义报表界面,比如添加内存页错误状态,或者收发包的丢包数。如果你能实现开头列表处我没能实现的项目,那也是很好的。
|
||||
|
||||
### 总结
|
||||
|
||||
正确监控需要大量时间和精力,容器的 CPU、内存、IO、网络和磁盘,监控的这些参数还只是整个监控项目中的沧海一粟而已。
|
||||
|
||||
我不知道你做到了哪一阶段,但接下来的任务也许是:
|
||||
|
||||
- 收集运行中的容器的日志
|
||||
- 收集应用的日志
|
||||
- 监控应用的性能
|
||||
- 报警
|
||||
- 监控健康状态
|
||||
|
||||
如果你有意见或建议,请留言。祝你玩得开心。
|
||||
|
||||
现在你可以关掉这些测试系统了:
|
||||
|
||||
```
|
||||
docker-machine rm master1 worker{1,2}
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
|
||||
|
||||
作者:[Lorenzo Fontana][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.codeship.com/author/lorenzofontana/
|
||||
|
||||
[1]: https://github.com/elastic/elasticsearch
|
||||
[2]: https://github.com/elastic/kibana
|
||||
[3]: https://github.com/google/cadvisor
|
||||
[4]: https://github.com/elastic/beats
|
||||
[5]: https://twitter.com/share?text=%22How+do+you+keep+track+of+all+that%27s+happening+in+a+Swarm+Mode+cluster%3F+Not+easily.%22+via+%40fntlnz&url=https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
|
||||
[6]: https://www.elastic.co/guide/en/elasticsearch/guide/2.x/deploy.html
|
||||
[7]: https://docs.docker.com/machine/install-machine/
|
||||
[8]: https://cloud.digitalocean.com/settings/api/tokens/new
|
||||
[9]: https://blog.codeship.com/nginx-reverse-proxy-docker-swarm-clusters/
|
||||
[10]: https://docs.docker.com/engine/userguide/networking/get-started-overlay/
|
||||
[11]: https://docs.docker.com/engine/userguide/networking/default_network/dockerlinks/
|
||||
[12]: https://docs.docker.com/engine/swarm/ingress/
|
||||
[13]: https://github.com/google/cadvisor/blob/master/docs/runtime_options.md
|
||||
[14]: https://www.elastic.co/blog/found-sizing-elasticsearch
|
||||
@ -0,0 +1,66 @@
|
||||
Ryver:你应该使用它替代 Slack
|
||||
===============
|
||||
|
||||

|
||||
|
||||
貌似每个人都听说过 [Slack][1],它是一款跨平台的,可以使你时刻保持与他人同步的团队沟通应用。它革新了用户讨论和规划项目的方式,显而易见,它升级了 email 的沟通功能。
|
||||
|
||||
我在一个非常小的写作团队工作,不管是通过手机还是电脑,我从未在使用 Slack 过程中遇到过沟通问题。若想与任何规模的团队保持同步,继续使用 Slack 仍然不失为不错的方式。
|
||||
|
||||
既然如此,为什么我们还要讨论今天的话题?Ryver 被人们认为是下一个热点,相比 Slack,Ryver 提供了升级版的服务。Ryver 完全免费,它的团队正在奋力争取更大的市场份额。
|
||||
|
||||
是否 Ryver 已经强大到可以扮演 Slack 杀手的角色?这两种旗鼓相当的消息应用究竟有何不同?
|
||||
|
||||
欲知详情,请阅读下文。
|
||||
|
||||
### 为什么用 Ryver ?
|
||||
|
||||

|
||||
|
||||
既然 Slack 能用为什么还要折腾呢?Ryver 的开发者对 Slack 的功能滚瓜烂熟,他们希望 Ryver 改进的服务足以让你移情别恋。他们承诺 Ryver 提供完全免费的团队沟通服务,并且不会在任何一个环节隐形收费。
|
||||
|
||||
谢天谢地,他们用高质量产品兑现了自己的承诺。
|
||||
|
||||
额外的内容是关键所在,他们承诺去掉一些你在 Slack 免费账号上面遇到的限制。无限的存储空间是一个加分点,除此之外,在许多其他方面 Ryver 也更加开放。如果存储空间限制对你来说是个痛点,不防试试 Ryver。
|
||||
|
||||
这是一个简单易用的系统,所有的功能都可以一键搞定。这种设计哲学使 Apple 大获成功。当你开始使用它之后,也不会遭遇成长的烦恼。
|
||||
|
||||

|
||||
|
||||
会话分为私聊和公示,这意味着团队平台和私人用途有明确的界限。它应该有助于避免将任何尴尬的广而告之给你的同事,这些问题我在使用 Slack 期间都遇到过。
|
||||
|
||||
Ryver 支持与大量现成的 App 的集成,并在大多数平台上有原生应用程序。
|
||||
|
||||
在需要时,你可以添加访客而无需增加费用,如果你经常和外部客户打交道,这将是一个非常有用的功能。访客可以增加更多的访客,这种流动性的元素是无法从其他更流行的消息应用中看到的。
|
||||
|
||||
考虑到 Ryver 是一个为迎合不同需求而产生的完全不同的服务。如果你需要一个账户来处理几个客户,Ryver 值得一试。
|
||||
|
||||
问题是它是如何做到免费的呢? 简单的答案是高级用户将为你的使用付了费。 就像 Spotify 和其他应用一样,有一小部分人为我们其他人支付了费用。 这里有一个[直接链接][2]到他们的下载页面的地址,如果有兴趣就去试一试吧。
|
||||
|
||||
### 你应该切换到 Ryver 吗?
|
||||
|
||||

|
||||
|
||||
像我一样在小团队使用 Slack 的体验还是非常棒,但是 Ryver 可以给予的更多。一个完全免费的团队沟通应用的想法不可谓不宏伟,更何况它工作的十分完美。
|
||||
|
||||
同时使用这两种消息应用也无可厚非,但是如果你不愿意为一个白金 Slack 账户付费,一定要尝试一下竞争对手的服务。你可能会发现,两者各擅胜场,这取决于你需要什么。
|
||||
|
||||
最重要的是,Ryver 是一个极棒的免费替代品,它不仅仅是一个 Slack 克隆。他们清楚地知道他们想要实现什么,他们有一个可以在拥挤不堪的市场提供不同的东西的不错的产品。
|
||||
|
||||
但是,如果将来持续缺乏资金,Ryver 有可能消失。 它可能会让你的团队和讨论陷入混乱。 目前一切还好,但是如果你计划把更大的业务委托给这个新贵还是需要三思而行。
|
||||
|
||||
如果你厌倦了 Slack 对免费帐户的限制,你会对 Ryver 印象深刻。 要了解更多,请访问其网站以获取有关服务的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/why-use-ryver-instead-of-slack/
|
||||
|
||||
作者:[James Milin-Ashmore][a]
|
||||
译者:[firstadream](https://github.com/firstadream)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/james-ashmore/
|
||||
[1]: https://www.maketecheasier.com/new-slack-features/
|
||||
[2]: http://www.ryver.com/downloads/
|
||||
@ -0,0 +1,97 @@
|
||||
NitroShare:内网多操作系统间快捷文件共享工具
|
||||
====
|
||||
|
||||
网络的最重要用途之一就是实现文件共享的目的。现在,虽然有多种方式可以让在同一网络中的 Linux 和 Windows 以及 MacOS X 用户之间共享文件,但这篇文章,我们只打算介绍 Nitroshare。这是一款跨平台、开源以及易于使用的应用软件,可以在本地网络(内网)中共享文件。
|
||||
|
||||
Nitroshare 大大简化了本地网络的文件共享操作,一旦安装上,它就会与操作系统无缝集成。Ubuntu 系统中,从应用程序显示面板中可以简单的打开,在 Windows 系统中,在系统托盘中可以找到它。
|
||||
|
||||
此外,在装有 Nirtroshare 的机器上,它会自动检测在同一网段的其它安装了它的设备,用户只需选择好需要传输到的设备,就可以直接向其传输文件。
|
||||
|
||||
Nitroshare 的特性如下:
|
||||
|
||||
- 跨平台,即可以运行于 Linux, Windows 和 MacOS X 系统
|
||||
- 设置容易,无需配置
|
||||
- 易于使用
|
||||
- 支持在本地网络上自动发现运行着 Nitroshare 设备的能力
|
||||
- 安全性上支持可选的 TLS (Transport Layer Security,传输层安全协议) 编码传输方式
|
||||
- 支持网络高速传输功能
|
||||
- 支持文件和目录(Windows 上的文件夹)传输
|
||||
- 支持对发送文件、连接设备等这些的桌面通知功能
|
||||
|
||||
最新版本的 Nitroshare 是使用 Qt5 开发的,它做了一些重大的改进,例如:
|
||||
|
||||
- 用户界面焕然一新
|
||||
- 简化设备发现过程
|
||||
- 移除不同版本传输文件大小的限制
|
||||
- 为了使用方便,已经去除配置向导
|
||||
|
||||
### Linux 系统中安装 Nitroshare
|
||||
|
||||
NitroShare 可运行于各种各样的现代 Linux 发行版和桌面环境。
|
||||
|
||||
#### Debian Sid 和 Ubuntu 16.04+
|
||||
|
||||
NitroShare 已经包含在 Debian 和 Ubuntu 的软件源仓库中,所以可以很容易的就安装上,使用如下命令:
|
||||
|
||||
```
|
||||
$ sudo apt-get install nitroshare
|
||||
```
|
||||
|
||||
但安装的版本可能已经过期了。要安装最新的版本的话,可按照如下的命令添加最新的 PPA。
|
||||
|
||||
```
|
||||
$ sudo apt-add-repository ppa:george-edison55/nitroshare
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install nitroshare
|
||||
```
|
||||
|
||||
#### Fedora 24-23
|
||||
|
||||
最近,NitroShare 已经包含在 Fedora 源仓库中了,可以按如下命令安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install nitroshare
|
||||
```
|
||||
|
||||
#### Arch Linux
|
||||
|
||||
在 Arch Linux 系统中,NitroShare 包在 AUR 上已经可用了,可以用如下命令来构建/安装:
|
||||
|
||||
```
|
||||
# wget https://aur.archlinux.org/cgit/aur.git/snapshot/nitroshare.tar.gz
|
||||
# tar xf nitroshare.tar.gz
|
||||
# cd nitroshare
|
||||
# makepkg -sri
|
||||
```
|
||||
|
||||
### Linux 中使用 NitroShare
|
||||
|
||||
注意:如我前面所述,在本地网络中,您想要共享文件的其它机器设备都需要安装上 Nitroshare 并运行起来。
|
||||
|
||||
在成功安装后,在系统 dash 面板里或系统菜单里搜索 Nitroshare,然后启动。Nitroshare 非常容易使用,你可从该应用或托盘图标上找到“发送文件”、“发送目录”、“查看传输”等选项。
|
||||
|
||||
|
||||
|
||||
选择文件后,点击“打开”继续选择目标设备,如下图所示。如果在本地网络有设备正的运行 Nitroshare 的话,选择相应的设备然后点击“确定”。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
如果需要,在 NitroShare 的配置 -- 通用标签页里,您可以增加设备的名字,设置默认文件下载位置,在高级设置里您能设置端口、缓存、超时时间等等。
|
||||
|
||||
主页:<https://nitroshare.net/index.html>
|
||||
|
||||
这就是所要介绍的,如果您有关于 Nitroshare 的任何问题,可以在下面的评论区给我们分享。您也可以给我们提供一些建议,告诉一些可能我们不知道的很不错的跨平台文件共享应用程序。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/nitroshare-share-files-between-linux-ubuntu-windows/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
@ -0,0 +1,50 @@
|
||||
一个漂亮的 Linux 桌面 REST 客户端:Insomnia 3.0
|
||||
=====
|
||||
|
||||
|
||||
|
||||
正在为 Linux 桌面端找一个免费的 REST 客户端? 别睡不着觉了!试试 [Insomnia][1]。
|
||||
|
||||
这个应用是跨平台的,可以工作在 Linux、macOS、Windows。开发者 Gregory Schier 告诉我们他创造这个应用是为了“帮助开发者处理和 [REST API][2] 的通信”
|
||||
|
||||
他还说,Insomnia 已经有大约10000 个活跃用户,9% 使用着 Linux.
|
||||
|
||||
“目前来说,Linux用户的反馈是非常积极的,因为类似的应用(反正不怎么样)通常不支持 Linux。”
|
||||
|
||||
Insomnia 的目标是“加速你的 API 测试工作流”,通过一个简洁的接口让你组织、运行、调试 HTTP 请求。
|
||||
|
||||
这款应用还包含一些其他的高级功能比如 Cookie 管理、全局环境、SSL 验证和代码段生成。
|
||||
|
||||
由于我不是一个开发者,没有办法第一时间的评价这款应用,也没办法告诉你的它的特性或指出任何比较重大的不足之处。
|
||||
|
||||
但是,我将这款应用告诉你,让你自己决定它,如果你正在寻找一个有着顺滑的用户界面的替代命令行工具,比如HTTPie,它可能是值得一试的。
|
||||
|
||||
### 下载 Linux 版 Insomnia 3.0
|
||||
|
||||
Insomnia 3.0 现在可以用在 Windows、macOS、Linux 上(不要和只能在 Chrome 上使用的 Insomnia v2.0 混淆)。
|
||||
|
||||
- [下载 Insomnia 3.0][4]
|
||||
|
||||
对于 Ubuntu 14.04 LTS 或更高版本,有一个安装包,它是一个跨发行版的安装包:
|
||||
|
||||
- [下载 Insomnia 3.0 (.AppImage)][5]
|
||||
|
||||
如果你想跟进这个应用的步伐,你可以在 [Twitter][6] 上关注它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2016/09/insomnia-3-is-free-rest-client-for-linux
|
||||
|
||||
作者:[JOEY-ELIJAH SNEDDON][a]
|
||||
译者:[Bestony](https://github.com/Bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]: http://insomnia.rest/
|
||||
[2]: https://en.wikipedia.org/wiki/Representational_state_transfer
|
||||
[3]: https://github.com/jkbrzt/httpie
|
||||
[4]: https://insomnia.rest/download/
|
||||
[5]: https://builds.insomnia.rest/downloads/linux/latest
|
||||
[6]: https://twitter.com/GetInsomnia
|
||||
@ -0,0 +1,159 @@
|
||||
用 Ansible 来交付 Vagrant 实例
|
||||
====
|
||||
|
||||

|
||||
|
||||
Ansible 是一款系统管理员进行自动化运维的强大工具。Ansible 让配置、交付、管理各种容器,软件部署[变得非常简单][1]。基于轻量级模块的架构非常适合系统管理,一个优点就是如果某个节点没有被 Ansible 管理的话,它的资源就不会被使用。
|
||||
|
||||
这篇文章介绍用 Ansible 来配置 [Vagrant 实例][2],它是一个配置好的基础虚拟机映像,包含了开发环境中需要用到的工具。你可以用它来部署开发环境,然后和其他成员协同工作。用 Ansible,你可以用你的开发包自动化交付 Vagrant 实例。
|
||||
|
||||
我们用 Fedora 24 做主机,用 [CentOS][3] 7 来作 Vagrant 实例。
|
||||
|
||||
### 设置工作环境
|
||||
|
||||
在用 Ansible 配置 Vagrant 实例时,你需要做几件准备的事情。首先在宿主机上安装 Ansible 和 Vagrant,在你的主机上运行下面的命令来安装:
|
||||
|
||||
```
|
||||
sudo dnf install ansible vagrant vagrant-libvirt
|
||||
```
|
||||
|
||||
上面的命令将 Ansible 和 Vagrant 在你的宿主机上,以及包括 Vagrant 的 libvirt 接口。Vagrant 并没有提供托管你的虚拟机的功能,需要第三方工具比如:libirt、VirtualBox、VMWare 等等。这些工具可以直接与你的 Fedora 系统上的 libvirt 和 KVM 协同工作。
|
||||
|
||||
接着确认你的账户在正确的 wheel 用户组当中,确保你可以运行系统管理员命令。如果你的账号在安装过程中就创建为管理员,那么你就肯定在这个用户组里。运行下面的命令查看:
|
||||
|
||||
```
|
||||
id | grep wheel
|
||||
```
|
||||
|
||||
如果你能看到输出,那么你的账户就在这个组里,可以进行下一步。如果没有的话,你需要运行下面的命令,这一步需要你提供 root 账户的密码,将 \<username> 换成你的用户名:
|
||||
|
||||
```
|
||||
su -c 'usermod -a -G wheel <username>'
|
||||
```
|
||||
|
||||
然后,你需要注销然后重新登录,确保在用户组里。
|
||||
|
||||
现在要建立你的第一个 Vagrant 实例了,你需要用 Ansible 来配置它。
|
||||
|
||||
### 设置 Vagrant 实例
|
||||
|
||||
配置一个镜像实例之前,你需要先创建它。创建一个目录,存放 Vagrant 实例 相关的文件,并且将它作为当前工作目录,用下面这条命令:
|
||||
|
||||
```
|
||||
mkdir -p ~/lampbox && cd ~/lampbox
|
||||
```
|
||||
|
||||
在创建镜像实例之前,你需要搞清楚目的,这个镜像实例是一个运行 CentOS 7 基础系统,模板包括 Apache 的 Web 服务,MariaDB(MySQL 原开发者创建的一个流行的开源数据库)数据库和 PHP 服务。
|
||||
|
||||
初始化 Vagrant 实例,用 `vagrant init` 命令:
|
||||
|
||||
```
|
||||
vagrant init centos/7
|
||||
```
|
||||
|
||||
这个命令初始化 Vagrant 实例,并创建一个名为 Vagrantfile 的文件,包含一些预先配置的变量。打开并编辑它,下面的命令显示了用于这次配置的基本镜像实例。
|
||||
|
||||
```
|
||||
config.vm.box = "centos/7"
|
||||
```
|
||||
|
||||
现在设置端口转发,以便你配置完毕 Vagrant 实例并让它运行起来之后可以测试它。将下述配置加入到 Vagrantfile 的最终的 `end` 语句之前:
|
||||
|
||||
```
|
||||
config.vm.network "forwarded_port", guest: 80, host: 8080
|
||||
```
|
||||
|
||||
这个命令将 Vagrant 实例 的 80 端口映射为主机的 8080 端口。
|
||||
|
||||
下一步是设置 Ansible 作为配置 Vagrant 实例的工具,将下述配置加入到 Vagrantfile 的 `end` 语句之前,将 Ansible 作为配置工具(provisioning provider):
|
||||
|
||||
```
|
||||
config.vm.provision :ansible do |ansible|
|
||||
ansible.playbook = "lamp.yml"
|
||||
end
|
||||
```
|
||||
|
||||
(必须将这三行在最后的 `end` 语句之前加入)注意 `ansible.playbook = "lamp.yml"` 这一句定义了配置镜像实例的 Ansible playbook 的名字。
|
||||
|
||||
### 创建 Ansible playbook
|
||||
|
||||
在 Ansible 之中,playbook 是指在你的远端节点执行的策略,换句话说,它管理远端节点的配置和部署。详细的说,playbook 是一个 Yaml 文件,在里面写入你要在远端节点上将要执行的任务。所以,你需要创建一个名为 lamp.yml 的 playbook 来配置镜像实例。
|
||||
|
||||
在 Vagrantfile 相同的目录里创建一个 lamp.yml 文件,将下面的内容粘贴到文件当中:
|
||||
|
||||
```
|
||||
---
|
||||
- hosts: all
|
||||
become: yes
|
||||
become_user: root
|
||||
tasks:
|
||||
- name: Install Apache
|
||||
yum: name=httpd state=latest
|
||||
- name: Install MariaDB
|
||||
yum: name=mariadb-server state=latest
|
||||
- name: Install PHP5
|
||||
yum: name=php state=latest
|
||||
- name: Start the Apache server
|
||||
service: name=httpd state=started
|
||||
- name: Install firewalld
|
||||
yum: name=firewalld state=latest
|
||||
- name: Start firewalld
|
||||
service: name=firewalld state=started
|
||||
- name: Open firewall
|
||||
command: firewall-cmd --add-service=http --permanent
|
||||
```
|
||||
|
||||
每一行代表的意思:
|
||||
|
||||
- `hosts: all` 指定该 playbook 需要在 Ansible 配置文件中定义的所有主机上都执行,因为还没定义主机, playbook 将只在本地运行。
|
||||
- `sudo: true` 表明该任务需要用 root 权限运行。(LCTT 译注:此语句上述配置中缺失。)
|
||||
- `tasks:` 指定当 playbook 运行是需要执行的任务,在这一节之下:
|
||||
- `name: ...` 描述任务的名字
|
||||
- `yum: ...` 描述该任务应该由 yum 模块执行,可选的 key=value 键值对将由 yum 模块所使用。
|
||||
|
||||
当 playbook 运行时,它会安装最新的 Apache Web 服务(http),MariaDB 和 PHP。当安装完毕并启动防火墙 firewalld,给 Apache 打开一个端口。你可以通过编写 playbook 来完成这些。现在可以配置它了。
|
||||
|
||||
### 配置镜像 实例
|
||||
|
||||
用 Ansible 配置 Vagrant 实例只需要以下几步了:
|
||||
|
||||
```
|
||||
vagrant up --provider libvirt
|
||||
```
|
||||
|
||||
上面的命令运行 Vagrant 实例,将实例的基础镜像下载到宿主机当中(如果还没下载的话),然后运行 lamp.yml 来进行配置。
|
||||
|
||||
如果一切正常,输出应该和下面的例子类似:
|
||||
|
||||

|
||||
|
||||
这个输出显示镜像实例已经被配置好了,现在检查服务是否可用,在宿主机上打开浏览器,输入 `http://localhost:8080`,记住本地主机的 8080 端口是 Vagrant 实例映射过来的 80 端口。你应该可以看到如下的 Apache 的欢迎界面。
|
||||
|
||||

|
||||
|
||||
要修改你的 Vagrant 实例,你可以修改 lamp.yml,你能从 Ansible 的[官网][4]上找到很多文章。然后运行下面的命令来重新配置:
|
||||
|
||||
```
|
||||
vagrant provision
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
现在我们知道怎么用 Ansible 来配置 Vagrant 实例了。这只是一个基本的例子,但是你可以用这些工具来实现不同的例子。比如你可以用所需工具的最新版本来部署一个完整的应用。现在你可以用 Ansible 来配置你自己的远端服务器和容器了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/using-ansible-provision-vagrant-boxes/
|
||||
|
||||
作者:[Saurabh Badhwar][a]
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://h4xr.id.fedoraproject.org/
|
||||
[1]: https://ansible.com/
|
||||
[2]: https://www.vagrantup.com/
|
||||
[3]: https://centos.org/
|
||||
[4]: http://docs.ansible.com/ansible/index.html
|
||||
68
published/201610/20160921 Rust meets Fedora.md
Normal file
68
published/201610/20160921 Rust meets Fedora.md
Normal file
@ -0,0 +1,68 @@
|
||||
当 Rust 遇上 Fedora
|
||||
=============
|
||||
|
||||

|
||||
|
||||
### Rust 是什么?
|
||||
|
||||
Rust 是一种系统编程语言,它运行速度惊人,并且可以避免几乎所有的崩溃、[内存区块错误](https://wikipedia.org/wiki/Segmentation_fault) 以及数据竞争。你也许会质疑为什么我们还需要又一种这样的语言,因为已经有很多同类的语言了。这篇文章将会告诉你为什么。
|
||||
|
||||
### 安全性 vs. 控制权
|
||||
|
||||

|
||||
|
||||
你也许见过上面的图谱。一边是 C/C++,对运行的硬件拥有更多的控制权,因此它可以让开发者通过对所生成的机器代码进行更精细的控制来优化性能。然而这不是很安全,这很容易造成内存区块错误以及像 [心血漏洞](https://fedoramagazine.org/update-on-cve-2014-0160-aka-heartbleed/) 这样的安全漏洞。
|
||||
|
||||
另一边是像 Python、Ruby 和 JavaScript 这种没有给予开发者多少控制权但是可以创建出更安全的代码的语言。虽然这些代码可以生成相当安全并且可控的异常,但是它们不会造成内存区块错误。
|
||||
|
||||
在图谱中间的区域是 Java 和一些其它混合了这些特性的语言。它们提供对运行的硬件部分控制权,并且尝试尽量减少漏洞的出现。
|
||||
|
||||
Rust 有点不太一样,它并没有出现在这个图谱上。它同时提供给开发者安全性和控制权。
|
||||
|
||||
### Rust 的特性
|
||||
|
||||
Rust 是一种像 C/C++ 一样的系统编程语言,除此之外它还给予开发者对内存分配细粒度的控制。它不需要垃圾回收器。它的运行环境(runtime)很小,运行速度接近于在裸机上的运行。它为开发者提供了代码性能更大的保证。此外,任何了解 C/C++ 的人都能读懂以及编写 Rust 的代码。
|
||||
|
||||
Rust 的运行速度非常快,因为它是一种编译语言。它使用 LLVM 作为编译器的后端,并且还可以利用一大堆优化。在许多领域,它的性能都要高于 C/C++。它像 JavaScript、Ruby 和 Python 一样,与生俱来就是安全的,这意味着它们不会造成内存区块错误、野指针(dangling pointers)或者空指针(null pointers)。
|
||||
|
||||
另外一个很重要的特性就是消除数据竞争。如今,大多数计算机都具有多个核心,许多线程并发运行。然而,开发者很难编写好的并行代码,因此这个特性除去了他们的后顾之忧。Rust 使用两个关键概念来消除数据竞争:
|
||||
|
||||
* 所有权(Ownership)。每一个变量都被移动到一个新的位置,并防止通过先前的位置来引用它。每一个数据块只有一个所有者。
|
||||
* 借用(Borrowing)。被拥有的值可以借用,以允许在一段时间内使用。
|
||||
|
||||
### 在 Fedora 24 和 25 上使用 Rust
|
||||
|
||||
若要开始使用,只需安装软件包:
|
||||
|
||||
```
|
||||
sudo dnf install rust
|
||||
```
|
||||
|
||||
```
|
||||
fn main() {
|
||||
println!("Hello, Rust is running on Fedora 25 Alpha!");
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
rustc helloworld.rs
|
||||
./helloworld
|
||||
```
|
||||
|
||||
在 Fedora 上执行以下命令来安装最新的测试版本:
|
||||
|
||||
```
|
||||
sudo dnf --enablerepo=updates-testing --refresh --best install rust
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/rust-meets-fedora/
|
||||
|
||||
作者:[Sumantro Mukherjee][a]
|
||||
译者:[OneNewLife](https://github.com/OneNewLife)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/sumantrom/
|
||||
@ -0,0 +1,78 @@
|
||||
在电脑和安卓设备之间使用 FTP 传输文件
|
||||
====
|
||||
|
||||
[](https://itsfoss.com/wp-content/uploads/2016/09/linux-ftp-android.jpg)
|
||||
|
||||
每一个使用安卓设备的人都知道可以[使用 USB 线连接电脑来传输文件](https://itsfoss.com/how-to-connect-kindle-fire-hd-with-ubuntu-12-10/),但是不是所有人都知道可以使用自由开源软件(FOSS 软件)通过无线连接到安卓设备。
|
||||
|
||||
我知道,这并非最简易的方式,但这样做的确很有趣而且感觉很极客。所有,如果你有一些 DIY 精神,让我为你展示如何在 Linux 和 安卓设备之间使用 FTP 来传输文件。
|
||||
|
||||
### 第一步:安装必要的软件
|
||||
|
||||
为了连接你的安卓设备,至少需要:一个 FTP 服务器和一个 FTP 客户端。这两者都有不少的选择,个人比较推荐 [Filezilla](https://filezilla-project.org/) 作为客户端,因为它是开源的,而且支持多种平台。
|
||||
|
||||
我最喜欢的 FOSS 安卓应用商店就是 [F-Droid](https://f-droid.org/)。F-Droid 有两个非常棒的 FTP 服务端应用:[primitive ftpd](https://f-droid.org/repository/browse/?fdfilter=ftp&fdid=org.primftpd) 和 [FTP Server (Free)](https://f-droid.org/repository/browse/?fdfilter=ftp&fdid=be.ppareit.swiftp_free)。这两者都只能运行在安卓 4.0 或者更高的版本中。本文我会集中介绍 primitive ftpd,如果使用 FTP Sever (free) 也是一样的步骤。
|
||||
|
||||
### 第二步:熟悉 FTP 服务器
|
||||
|
||||
安装好 FTP 客户端和服务端之后,就是设置两者之间的连接了。先从安卓设备的 FTP 服务端开始,首先,通过应用启动器打开 primitive ftpd。
|
||||
|
||||
[](https://itsfoss.com/wp-content/uploads/2016/09/android-1.png)
|
||||
|
||||
打开应用之后,你将看到一大串的数字。不用紧张,你可以看到服务端已经分配到一个 IP 地址 (本文是 192.168.1.131)。往下看,将看到 FTP 和 SFTP 服务 (SFTP 是一个截然不同的协议,它通过 SSH 进行连接) 都是还未运行的。再往下就是用户名,本文设置为 user。
|
||||
|
||||
在屏幕顶端有两个按钮,一个用于开启 FTP 服务,另一个则是设置 FTP 服务。启动服务是不言自明的。
|
||||
|
||||
[](https://itsfoss.com/wp-content/uploads/2016/09/android-2.png)
|
||||
|
||||
在设置菜单中,可以改变服务器的用户名、访问密码以及所使用的端口。并且你可以设置当服务器激活是阻止待机、服务开机自启或者变更主题。
|
||||
|
||||

|
||||
|
||||
### 第三步:使用 Filezilla
|
||||
|
||||
现在打开对应你所用系统的 Filezilla。使用 Filezilla 有两种方法:在需要传输文件时输入 IP、用户名、密码和端口,或者在 Filezilla 中预先保存这些信息(值得注意的是:基本上,每次你打开 FTP 服务时,IP 都会不同的,所用需要更新保存在 Filezilla 中信息)。我会展示这两种方法。
|
||||
|
||||
如果你想要手动输入,直接在 Filezilla 窗口上方输入必要的信息然后点击“快速连接”即可。
|
||||
|
||||

|
||||
|
||||
需要预先存储信息的话,点击文件菜单下方的按钮,这会打开“站点管理器”对话框,填写你想要保存的信息即可。通常,我设置“登录类型”为“询问密码”,安全为上。如果使用的是 FTP,保存默认选项即可;但如果使用的是 SFTP,必须在协议下拉选项框中进行协议的选择。
|
||||
|
||||

|
||||
|
||||
点击连接,输入密码即可。你会看到一个连接新主机的警告,这是可以在此验证屏幕上显示的“指纹信息”是否与 Primitive FTPD 上的一致。如果一致 (也应该是一致的),点击确认添加都已知主机列表,之后就不会出现该警告了。
|
||||
|
||||

|
||||
|
||||
### 第四步:传输文件
|
||||
|
||||
现在,你会看到两个框,一个是“本地站点”,一个是“远程站点”,对应的呈现了你电脑和安装设备上的目录和文件信息。然后你就可以在电脑端浏览和传输文件到你的安卓设备上了。个人建议上传文件到你的 Download 文件夹,以便于文件跟踪管理。你可以右击某个文件,在弹出的菜单中选择上传或者下载以及移动操作,或者简单双击也行。
|
||||
|
||||

|
||||
|
||||
### 第五步:停止服务
|
||||
|
||||
当你完成文件的传输之后,你需要做得就是停止安卓设备上的 FTP 服务和关闭 Filezilla,如此简单,不是吗?
|
||||
|
||||
### 结论
|
||||
|
||||
我相信会有人指出,FTP 并不安全。而我认为,本例不需要考虑这个问题,因为连接时间一般很短。并且多数情况下,都是在家庭私有网络环境中进行操作。
|
||||
|
||||
这就是我在 Linux 和安卓设备间最喜欢使用的方法。
|
||||
|
||||
觉得有用吗?或有又没觉得推荐的相似软件?请在评论中告诉我们。
|
||||
|
||||
如果觉得此文有用,清花几分钟分享到你常用的社交站点中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/use-ftp-linux-android/
|
||||
|
||||
作者:[John Paul][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
@ -0,0 +1,52 @@
|
||||
Windows 的 Linux 子系统之 Archlinux
|
||||
====
|
||||
|
||||

|
||||
|
||||
Ubuntu 的制造商 [Canonical](http://www.canonical.com/) 早已和微软进行合作,让我们体验了极具争议的 [Bash on Windows](https://itsfoss.com/bash-on-windows/)。外界对此也是褒贬不一,许多 Linux 重度用户则是质疑其是否有用,以及更进一步认为 [Bash on Windows 是一个安全隐患](https://itsfoss.com/linux-bash-windows-security/)。
|
||||
|
||||
Unix 的 Bash 是通过 WSL (Windows Subsystem for Linux,Windows 的 Linux 子系统) 特性移植到了 Windows 中。早先,我们已经展示过 [安装 Bash 到 Windows](https://itsfoss.com/install-bash-on-windows/)。
|
||||
|
||||
Canonical 和微软合作的 Bash on Windows 也仅仅是 Ubuntu 的命令行而已,并非是正规的图形用户界面。
|
||||
|
||||
不过,有个好现象是 Linux 爱好者开始在上面投入时间和精力,他们在 WSL 做到的成绩甚至让最初的开发者都吃惊,“等等,这真的可以吗?”。
|
||||
|
||||
这个正在逐步实现之中。
|
||||
|
||||

|
||||
|
||||
没错,上图所示就是运行在 Windows 中的 Ubuntu Unity 桌面。一位名为 Pablo Gonzalez (GitHub ID 为 [Guerra24](https://github.com/Guerra24) )的程序员将这个完美实现了。随着这个实现,他向我们展示了 WSL 已经超越了当初构想之时的功能。
|
||||
|
||||
如果现在可以在 Windows 子系统之中运行 Ubuntu Unity,那么运行其他的 Linux 发行版还会远吗?
|
||||
|
||||
### Arch Linux 版的 Bash on Windows
|
||||
|
||||
在 WSL 本地运行完整的 Linux发行版,迟早是要实现的。而我最希望的就是 [Arch Linux](https://www.archlinux.org/) ([Antergos](https://itsfoss.com/tag/antergos/) 爱好者点击此处)。
|
||||
|
||||

|
||||
|
||||
Hold 住,Hold 住,该项目目前还在测试中。它由“mintxomat”在 GitHub 上开发的,最新为 0.6 版本。第一个稳定版将在今年的 12 月底发布。
|
||||
|
||||
那么,该项目的出台会有什么不同呢?
|
||||
|
||||
你可能早就知道,WSL 仅在 Windows 10 中可用。但是 Windows 的 Linux 子系统之 Arch Linux (AWSL) 早已成功的运行在 Windows 7、Windows 8、Windows 8.1 和 Windows Server 2012(R2),当然还有 Windows 10。
|
||||
|
||||
我靠,他们是怎么做到的?!
|
||||
|
||||
其开发者曾说,AWSL 协议抽象归纳了不同 Windows 版本的各种框架。所以,当 AWSL 发布 1.0 应该会取得更大的成绩。如我们之前提到的移植性,该项目会先向所有 Windows 版本推出 Bash on Windows。
|
||||
|
||||
该项目很有雄心,并且很有看头。如果等不及 12 月底的稳定版,你可以先行尝试其测试版。但要记住,目前还是开发者预览版,此刻并不稳定。但是,我们什么时候停止过折腾的脚步?
|
||||
|
||||
你也可到 GitHub 查看此项目的进度:[Arch on Windows Subsystem](https://github.com/turbo/alwsl)
|
||||
|
||||
分享本文,以便大家都知道 Arch Linux 即将登陆 Windows 子系统。同时,也告诉我们,你希望 WSL 中有什么发行版。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/arch-linux-windows-subsystem/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,56 @@
|
||||
解决 Linux 内核代码审查人员短缺问题
|
||||
====
|
||||
|
||||
操作系统安全是[现在最重要的事情](http://www.infoworld.com/article/3124432/linux/is-the-linux-kernel-a-security-problem.html),而 Linux 则是一个主要被讨论的部分。首先要解决的问题之一就是:我们如何确定提交到上游的补丁已经进行了代码审核?
|
||||
|
||||
Wolfram Sang 从 2008 年开始成为一名 Linux 内核开发者,他经常在各地召开的 Linux 峰会上发表讲话,比如在 [2016 年柏林 Linux 峰会](https://linuxconcontainerconeurope2016.sched.org/event/7oA4/kernel-development-i-still-think-we-have-a-scaling-problem-wolfram-sang-consultant),他提出了如何提高内核开发实践的想法。
|
||||
|
||||
让我们来看看他的观点。
|
||||
|
||||

|
||||
|
||||
**在 2013 年的时候,你曾在爱丁堡(Edinburgh)提醒 ELCE 委员会,如果不作出改变,那么子系统的潜在问题和其他争议问题将会逐渐扩大。他们做出改变了吗?你所提及的那些事件发生了吗?**
|
||||
|
||||
是的,在某些程度上来说。当然了,Linux 内核是一个很多部分组成的项目,所以给以 Linux 各个子系统更多关注应该放在一个更重要的位置。然而,有太多的子系统“只是拼图中的一块”,所以通常来说,这些子系统的潜在问题还未被解决。
|
||||
|
||||
**你曾指出代码审核人数是一个大问题。为何你觉得 Linux 内核开发社区没有足够的代码审核人员呢?**
|
||||
|
||||
理由之一就是,大多数开发者实际上只是编写代码,而读代码并不多。这本是没有什么错,但却说明了并非每个人都是代码审核人员,所以我们真的应该鼓励每个人都进行代码审核。
|
||||
|
||||
我所看到另一件事就是,但我们要请人员加入我们的社区时,最重要的考核就是补丁贡献数量。我个人认为这是很正常的,并且在初期总贡献量少的时候是非常好的做法。但是随着越来越多的人员,特别是公司的加入,我们就碰到源码审核的问题。但是别误解了,有着数量可观的贡献是很棒的。但目前需要指出的是,参与社区有着更多内涵,比方说如何为下一步发展负责。有些部分在改善,但是还不够。
|
||||
|
||||
**你认为更多的代码审核人员培训或者审核激励措施是否会有帮助?**
|
||||
|
||||
我最主要的观点就是要指出,现今仍存在问题。是的,目前为止我们做到很好,但不意味着全都做的很好。我们也有类似扩张方面的问题。让人们了解事实,是希望能够让一些团体对此感兴趣并参与其中。尽管,我并不认为我们需要特殊的训练。我所熟悉的一些代码审核人员都非常棒或者很有天赋,只是这类人太少或者他们的空闲时间太少。
|
||||
|
||||
首先就是需要有这种内在动力,至于其它的,边做边学就非常好了。这又是我想要指出的优势之一:审核补丁能够使你成为更出色的代码开发者。
|
||||
|
||||
**依你之见,是否有那么一个受欢迎的大项目在扩张这方面做的很好,可以供我们借鉴?**
|
||||
|
||||
我还真不知道有这么一个项目,如果有的话随时借鉴。
|
||||
|
||||
我很专注于 Linux 内核,所以可能会存在一些偏见。然而在我看来,Linux 内核项目在规模大小、贡献数量和多样性方面真的很特别。所以当我想要找另一个项目来寻找灵感以便改善工作流是很正常的想法,目前我们的扩张问题真的比较特别。而且我发现,看看其他子系统在内核中做了什么是一个很有的方法。
|
||||
|
||||
**你曾说安全问题是我们每个人都该想到的事情,那用户应该做些什么来避免或者改善安全问题的危险?**
|
||||
|
||||
在今年(2016年)柏林 Linux 峰会我的谈话是针对开发层面的。安全隐患可能来自于没有正确审核的补丁中。我并不想要用户亲自解决这种问题,我更希望这些安全问题永远不会出现。当然这是不可能的,但这仍然是我处理问题所首选的方法。
|
||||
|
||||
**我很好奇这个庞大社区如何改善这些问题。是否有你希望用户定期以文件形式提交的某些类型的错误报告?需要定期检查的区域却因为某些原因没有注意到的?**
|
||||
|
||||
我们并不缺少错误报告。我所担心的是:由于代码审核人员的短缺造成补丁不完整,从而导致更多的错误报告。所以,到时候不仅需要处理大量的贡献,还需要处理更多错误或者进行版本回退。
|
||||
|
||||
**你是否还有什么事情希望我们读者知道,以了解你所在的努力?**
|
||||
|
||||
Linux 内核的特殊性,常常让我牢记着,在底层它就是代码而已。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/10/linux-kernel-review
|
||||
|
||||
作者:[Deb Nicholson][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/eximious
|
||||
@ -0,0 +1,85 @@
|
||||
又一顶帽子:适用于初学者的 FEDORA —— CHAPEAU LINUX 24 已发布
|
||||
===================
|
||||
|
||||

|
||||
|
||||
[Chapeau][23] 是专注于初学者的[一个基于 Fedora 的 Linux 发行版][22]。 Chapeau Linux 最近发布了新的 24 版本。
|
||||
|
||||
正如名字所暗示的,Chapeau 24 基于 Fedora 24。所以,你可以在 Chapeau 24 中找到大多数(如果不是全部)的[Fedora 24 特性][21]。
|
||||
|
||||
我在这儿增加一个细节。你可能已经知道 [Fedora 是一种帽子][20]。我认为因为 [Fedora][19] 是来自[红帽][18]的一个社区项目,所以他们命名它为另一种帽子。有趣的是,[Chapeau 也是一种帽子][17],一种法国帽子。现在,这些名字变得有意义了,不是吗?如果你对这样的细节性事实感兴趣,可以去了解一下其它 [Linux 发行版命令习惯][16]的背后的逻辑。
|
||||
|
||||
### CHAPEAU 24 特性
|
||||
|
||||
Chapeau 24 的特性几乎和 Fedora 24 提供的特性一样。它仍然运行在 GNOME 3.20 上,这是可以理解的,因为[GNOME 3.22][15] 最近才刚发布。Chapeau 24 发行版一些主要的新亮点是:
|
||||
|
||||
* [Gnome][10] 3.20 桌面环境
|
||||
* LibreOffice 5
|
||||
* [PlayOnLinux][9] 和 [Wine][8]
|
||||
* [Steam][7]
|
||||
* [VLC][6]
|
||||
* [Mozilla 火狐浏览器][5],带有 [Adobe Flash][4]
|
||||
* [硬件帮助工具(hht)][3](在 [Chapeau 23][2] 中引入,这个工具能够帮助你找到硬件的驱动程序)
|
||||
* 预配置了 [RPMFusion][1] 软件源
|
||||
* 媒体解码和 DVD 回放支持
|
||||
* Gnome Boxes
|
||||
* KVM 虚拟化
|
||||
* Dropbox 集成
|
||||
* UI 改善
|
||||
* 博通(Broadcom)无线芯片硬件
|
||||
* 针对佳能打印机的 CUPS 后端
|
||||
* Linux 4.7 内核
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 应该使用 CHAPEAU 24 吗?
|
||||
|
||||
这是一个很难回答的问题。看,在 Linux 的世界里,我们有超过 300 种活跃的 Linux 发行版。这些系统大量是针对桌面用户的。
|
||||
|
||||
这取决于个人更偏爱什么样的系统。你可以完整的安装 Fedora 24 和它所伴有的各种工具,然后你不需要再到其他地方寻找这些工具。但是你可能也知道 Fedora 对专有硬件支持非常“吝啬”。
|
||||
|
||||
总之, Chapeau 是一个很好的 Linux 版本,使用它能够不像使用 Fedora 那么“头疼”。如果你喜欢 GNOME,那么 Chapeau Linux 会是你的菜。
|
||||
|
||||
你可以从 SourceForge 下载 Chapeau 24:
|
||||
|
||||
- [下载 Chapeau 24][12]
|
||||
|
||||
你已经尝试使用 Chapeau 24 了吗?你的使用体验是什么样的?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/chapeau-linux-24-released/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:http://rpmfusion.org/
|
||||
[2]:https://itsfoss.com/chapeau-23-armstrong-released/
|
||||
[3]:http://chapeaulinux.org/hardware-helper-tool
|
||||
[4]:http://www.adobe.com/products/flashplayer.html
|
||||
[5]:https://www.mozilla.org/en-US/firefox/desktop
|
||||
[6]:http://www.videolan.org/
|
||||
[7]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[8]:https://itsfoss.com/use-windows-applications-linux/
|
||||
[9]:http://www.playonlinux.com/
|
||||
[10]:http://www.gnome.org/
|
||||
[12]:https://sourceforge.net/projects/chapeau/files/releases/Chapeau_24_x86-64.iso/download
|
||||
[13]:https://itsfoss.com/wp-content/uploads/2016/09/chapeau-24_desktop_wine.jpg
|
||||
[14]:https://itsfoss.com/wp-content/uploads/2016/09/chapeau-24-desktop-1.jpg
|
||||
[15]:https://itsfoss.com/gnome-3-22-new-features/
|
||||
[16]:https://itsfoss.com/linux-code-names/
|
||||
[17]:https://en.wikipedia.org/wiki/Chapeau
|
||||
[18]:https://www.redhat.com/en
|
||||
[19]:https://getfedora.org/
|
||||
[20]:https://en.wikipedia.org/wiki/Fedora
|
||||
[21]:https://itsfoss.com/fedora-24-released/
|
||||
[22]:https://itsfoss.com/best-fedora-linux-distributions/
|
||||
[23]:http://chapeaulinux.org/
|
||||
[24]:https://itsfoss.com/wp-content/uploads/2016/09/chapeau-24-release.jpg
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
使用原子主机(Atomic Host)、Ansible 和 Cockpit 部署容器
|
||||
==============
|
||||
|
||||

|
||||
|
||||
我在[红帽](https://www.redhat.com/)工作的期间,每天在 [Fedora Atomic host](https://getfedora.org/en/cloud/download/atomic.html) 上使用 [Docker](https://www.docker.com/) 容器。 来自 [原子项目(Project Atomic)](http://www.projectatomic.io/)的原子主机(Atomic Host)是一个轻量级容器操作系统,可以以 Docker 格式运行 Linux 容器。它专门为提高效率而定制,使其成为用于云环境的 Docker 运行时系统的理想选择。
|
||||
|
||||
幸运的是,我发现一个很好的方式来管理在主机上运行的容器:[Cockpit](http://cockpit-project.org/)。 它是一个具有漂亮的 Web 界面的 GNU/Linux 服务器远程管理工具。它可以帮我管理在主机上运行的服务器和容器。你可以在从之前发布在这里的[这篇概述](https://fedoramagazine.org/cockpit-overview/)中了解 Cockpit 的更多信息。不过,我也希望在主机上可以自动运行容器,我可以使用 [Ansible](https://www.ansible.com/) 来完成这个工作。
|
||||
|
||||
请注意,我们不能在原子主机上使用 dnf 命令。原子主机并没有设计为通用操作系统,而是更适合容器和其他用途。但在原子主机上设置应用程序和服务仍然非常容易。这篇文章向您展示了如何自动化和简化这个过程。
|
||||
|
||||
### 设置组件
|
||||
|
||||
开始之前,请确保你的系统上安装了 Ansible。
|
||||
|
||||
```
|
||||
sudo dnf -y install ansible
|
||||
```
|
||||
|
||||
首先,我们需要在原子主机上运行 cockpit 容器。在你的机器上从 https://github.com/trishnaguha/fedora-cloud-ansible 下载它的源代码。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/trishnaguha/fedora-cloud-ansible.git
|
||||
```
|
||||
|
||||
现在切换到 `cockpit` 的目录,并如下编辑 `inventory` 文件:
|
||||
```
|
||||
$ cd fedora-cloud-ansible
|
||||
$ cd cockpit
|
||||
$ vim inventory
|
||||
```
|
||||
|
||||
完成如下修改:
|
||||
|
||||
1. 使用你的原子主机的 IP 替换掉 `IP_ADDRESS_OF_HOST`。
|
||||
2. 用您的 SSH 私钥文件的路径替换 `ansible_ssh_private_key_file ='PRIVATE_KEY_FILE'` 行中的`PRIVATE_KEY_FILE`。
|
||||
|
||||
然后保存并退出 `inventory` 文件编辑。
|
||||
|
||||
接下来,编辑 ansible 配置文件:
|
||||
|
||||
```
|
||||
$ vim ansible.cfg
|
||||
```
|
||||
|
||||
替换 `remote_user=User` 中 `User` 为你的原子主机上的远程用户名。然后保存并退出文件编辑。
|
||||
|
||||
### 结合起来
|
||||
|
||||
现在是运行 Ansible 的 PlayBook 的时候了。此命令开始运行原子主机上的 Cockpit 容器:
|
||||
|
||||
```
|
||||
$ ansible-playbook cockpit.yml
|
||||
```
|
||||
|
||||
Cockpit 现在运行在原子主机上了。使用浏览器去访问你的实例的公网 IP 的 9090 端口——这是 Cockpit 的默认端口。举个例子,如果该实例的 IP 地址是 192.168.1.4,就去访问 192.168.1.4:9090,你将会看到如下的 Web 界面:
|
||||
|
||||

|
||||
|
||||
### 管理你的容器
|
||||
|
||||
使用原子主机的登录信息或以 root 用户身份登录。然后访问 Cockpit 管理器上的 Containers 部分来查看原子主机上运行的容器。在下面的示例中,您会看到我还设置了其他容器,如 [httpd](https://github.com/trishnaguha/fedora-cloud-ansible/tree/master/httpd) 和 [redis](https://github.com/trishnaguha/fedora-cloud-ansible/tree/master/redis):
|
||||
|
||||

|
||||
|
||||
注意,该界面允许您直接在 Cockpit 管理器中使用 Run 和 Stop 按钮启动和停止容器。您还可以使用 Cockpit 管理器管理您的原子主机。转到 Tools -> Terminals,在这里里你可以使用原子主机的终端:
|
||||
|
||||

|
||||
|
||||
如果您打算在原子主机上部署容器化的应用程序,则可以简单地为其编写一个 PlayBook。然后,您可以使用 `ansible-playbook` 命令进行部署,并使用 Cockpit 来管理容器。
|
||||
|
||||

|
||||
|
||||
欢迎你对这个[仓库](https://github.com/trishnaguha/fedora-cloud-ansible)进行分支或添加容器的 PlayBook。
|
||||
|
||||
------
|
||||
|
||||
via: https://fedoramagazine.org/deploy-containers-atomic-host-ansible-cockpit/
|
||||
|
||||
作者:[trishnag][a]
|
||||
译者:[Bestony](https://github.com/Bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/trishnag/
|
||||
@ -0,0 +1,30 @@
|
||||
概览最有前景的下一代嵌入式 Linux 软件更新机制
|
||||
===============
|
||||
|
||||

|
||||
|
||||
随着像 APT 和 Yum 等传统包管理解决方案渐渐老去,并且不适用于嵌入式和 IoT 等 Linux 的大量新兴领域,新一代的基于原子化的 Linux 软件升级方案应运而生。Konsulko Group 的 Matt Porter 在本周的 2016 年欧洲嵌入式 Linux 峰会(LCTT 译注:于 2016 年 10 月 11-13 日在德国柏林召开)为大家对比了这些新技术的不同点。
|
||||
|
||||
目前已有多个 Linux 软件商使用增量原子更新方式来传递更可靠的发行版更新,通过二进制差异实现更小体积的更新,假如出现意外状况也运行回退。这些新的发行版升级机制包含了 SWUpdate、Mender、OSTree 和 swupd。但有趣的是,幻灯片之中并没有提及 Ubuntu 的 Snappy。
|
||||
|
||||
SWUpdate 一种单/双镜像的模块化升级框架,支持镜像签名、可以使用 Kconfig 来进行配置、能够处理本地或者远程升级等。[SWUpdate](https://github.com/sbabic/swupdate) 简直就是为嵌入式系统设计的。
|
||||
|
||||
而 [Mender](https://github.com/mendersoftware/mender) 则是以无线传输进行升级位目标的升级方案。它是用 Go 编程语言编写的双镜像升级框架。
|
||||
|
||||
[OSTree](https://github.com/ostreedev/ostree) 是此次增量原子升级方案演示中最有名气的,它类似于 Git。Fedora 和 RedHat 都有它的身影,甚至 Gnome 的 Flatpak 容器系统也使用了 OSTree。
|
||||
|
||||
Swupd 是最后展示的一个升级系统,是由 Intel 的 Clear Linux 发行版率先使用的升级方案。它的代码放在 [GitHub](https://github.com/clearlinux/swupd-client),而它的客户端和服务端则由 Clear Linux 托管。Swupd 与 OSTree 相似,但它不必重启就可以启用更新。
|
||||
|
||||
而那些在本次柏林召开的欧洲嵌入式 Linux 峰会中没有提及的,你也可以访问 [这些 PDF 讲演稿](http://events.linuxfoundation.org/sites/events/files/slides/Comparison%20of%20Linux%20Software%20Update%20Technologies.pdf) 来了解这些专注于嵌入式 Linux 的软件更新机制。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://phoronix.com/scan.php?page=news_item&px=ELC2016-Software-Updates
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.michaellarabel.com/
|
||||
@ -0,0 +1,142 @@
|
||||
Antergos:基于 Arch 发行版,想要尝试 Arch 的绝对值得一试
|
||||
=====
|
||||
|
||||
### 介绍
|
||||
|
||||
众所周知,Arch Linux 是最好的 Linux 发行版之一,我们可以随心所欲的进行定制。我们可以滚动式更新最新的软件,但它的安装和配置的过程对于初学者则相对困难。现在就让我来为你展示如何安装 Antergos,这个基于 Arch 的、给新手的最好发行版,要尝试 Arch 的用户可以试一试,我保证绝对值得一试。
|
||||
|
||||
Antergos 是一个滚动式更新的发行版,基于 Arch Linux 提供桌面环境,是集现代化、高雅和高效率于一体的操作系统。想要挑战一下安装 Arch Linux 的用户,都可以先试一试 Antergos。
|
||||
|
||||
由于是滚动式更新,当上游发布更新,你的整个系统 (包括系统组件和你已安装的应用) 就会升级到最新的滚动版本,仅仅稍微延期一点时间以确保系统的稳定。
|
||||
|
||||
Antergos 有多个语言版本,包括英语、西班牙语等版本,在安装时你可以在语言栏选择预置语言。默认的配置确保了开箱即用,不需要安装额外的软件就可以直接浏览网页、听音乐、看视频以及做任何你想做的事情。
|
||||
|
||||
Antergos 项目最初名字是 Cinnarch,并且只提供一个桌面环境。现在它有多个桌面环境(包括 Cinnamon、Gnome、KDE、MATE、Openbox 和 Xfce)以供用户在安装之时进行选择。同时,它还默认包含了著名的 Numix GTK 主题和 Icon 主题。
|
||||
|
||||
### 安装
|
||||
|
||||
#### 下载 Antergos Linux
|
||||
|
||||
访问 [Antergos][1] 下载页面,然后下载最新的 Live ISO 镜像。任何人都可以免费获取 Antergos 镜像,烧录到 CD/DVD 或者写到 USB 设备,开始 Antergos 之旅。
|
||||
|
||||
#### 创建可启动 USB
|
||||
|
||||
下载好最新的 Antergos Live ISO 镜像之后,你需要使用命令行或者图形界面的方法来制作一个可启动介质。
|
||||
|
||||
#### 使用 Antergos 安装介质来启动电脑
|
||||
|
||||
使用 Antergos 安装介质来启动电脑。成功启动到 Live ISO 之后,你会看到与下图相似的界面。
|
||||
|
||||

|
||||
|
||||
点击 Install It 按钮开始 Angergos 的安装过程。
|
||||
|
||||

|
||||
|
||||
#### 选择语系
|
||||
|
||||
Antergos 的易于使用的图形安装器非常不错。此处选择你需要选用的语系并点击 Next 按钮继续下一步。
|
||||
|
||||

|
||||
|
||||
#### 系统检测
|
||||
|
||||
请确保你有足够的磁盘空间,连接好电源以及连接到网络,点击 Next 按钮继续下一步。
|
||||
|
||||

|
||||
|
||||
#### 选择地点
|
||||
|
||||
选择地点可以帮助决定系统所使用的本地化信息(locale)。通常是选择你所属的国家即可。这里有一个基于你选择的语言的位置的简短列表。点击 Next 按钮继续下一步。
|
||||
|
||||

|
||||
|
||||
#### 选择时区
|
||||
|
||||
选择使用的时区,然后点击 Next 按钮继续下一步。
|
||||
|
||||

|
||||
|
||||
#### 选择键盘布局
|
||||
|
||||
选择你选用的键盘布局,然后点击 Next 按钮继续下一步。
|
||||
|
||||

|
||||
|
||||
#### 选择桌面环境
|
||||
|
||||
Antergos 提供了多个选择(包括 Cinnamon、Gnome、KDE、MATE、Openbox 和 Xfce),根据你的喜好进行选择即可。然后点击 Next 按钮继续下一步。
|
||||
|
||||

|
||||
|
||||
#### Gnome – 特性选择
|
||||
|
||||
这里我选择了默认的 Gnome 桌面环境,此处你可以选择需要额外安装的软件以及正确的驱动程序。然后点击 Next 按钮继续下一步。
|
||||
|
||||

|
||||
|
||||
#### 安装类型
|
||||
|
||||
初次安装可以选择第一个选项( Erase disk and install Antergos )。然后点击 Next 按钮继续下一步。(LCTT 译注,但是要注意这个选项会擦除你的整个硬盘数据,如果你是全新安装,则可以使用该选项。)
|
||||
|
||||

|
||||
|
||||
#### 自动安装模式
|
||||
|
||||
这里会有一个檫除硬盘的警告,并选择安装 Grub 启动器,然后点击 Next 按钮继续下一步。
|
||||
|
||||
> WARNING ! This will overwrite everything currently on your drive !
|
||||
|
||||

|
||||
|
||||
#### 安装设置综述
|
||||
|
||||
确认最后的安装设置概览,如地点、时区、键盘布局、桌面环境和特性,然后点击 Next 按钮继续下一步。
|
||||
|
||||

|
||||
|
||||
#### 创建你的用户名
|
||||
|
||||
此时需要为你的系统创建一个新用户名和对应的密码,然后点击 Next 按钮继续下一步。
|
||||
|
||||
- 你的昵称
|
||||
- 电脑名称
|
||||
- 用户名
|
||||
- 设置密码
|
||||
- 密码二次确认
|
||||
- 选择“登录系统需要密码”
|
||||
|
||||

|
||||
|
||||
#### 安装进程
|
||||
|
||||
此时就是等待 Antergos 安装完成。安装好之后,移除安装介质在点击“立刻重启”按钮。
|
||||
|
||||

|
||||
|
||||
#### 输入用户名和密码
|
||||
|
||||
这是欢迎界面,输入密码即可登录:
|
||||
|
||||

|
||||
|
||||
发行信息截图:
|
||||
|
||||

|
||||
|
||||
我们还会提供了一些列循序渐进的 Linux 系统管理的相关文章。如果本文对你有用,请花费几分钟分享你得想法到评论区。
|
||||
|
||||
请于我们保持联系,祝君好运!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/how-to-install-antergos-linux/
|
||||
|
||||
作者:[MAGESH MARUTHAMUTHU][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.2daygeek.com/author/magesh/
|
||||
[1]: https://antergos.com/try-it/
|
||||
@ -0,0 +1,64 @@
|
||||
为何 Linux 之父 Linus Torvalds 在 ARM 会议上说他喜欢 x86
|
||||
=============
|
||||
|
||||
**Torvalds 因为 x86 的基础架构和生态系统而对其宠爱有加**
|
||||
|
||||

|
||||
|
||||
*Linus Torvalds 于 1999 年 8 月 10 日在加州圣何塞举行的 LinuxWorld 节目中给挤满礼堂的 Linux 发烧友们作演讲。 ——出自:James Niccolai*
|
||||
|
||||
Linux 领袖 Linus Torvalds 是一个直率的人——他总是心口如一。比方说最近在 Linux 内核 4.8 的 [事故][1] 中,他没有文过饰非,而是承认了自己的过失。
|
||||
|
||||
不过他在上周的 Linaro Connect 会议上倒是[让人瞠目结舌][2]。当他被问到最喜欢的芯片架构的时候,他不假思索地说 x86,而不是 ARM。
|
||||
|
||||
或许是 x86 电脑悠久的历史让他得出这个答案。x86 没有多少碎片化的软件和硬件,它几乎仅仅是用来工作的。
|
||||
|
||||
Torvalds 说,人们总是痴迷于指令集和 CPU 核心,但事实是围绕架构的生态系统更为重要。
|
||||
|
||||
“重要的是围绕指令集的所有基础设施,而 x86 拥有大量的不同级别的基础设施”,Torvalds 说。“它在走一条与众不同的路。”
|
||||
|
||||
许多应用都是在英特尔或者 AMD 的 x86 机器上开发的。兼容性对于 x86 芯片和电脑来说是重要的,x86 平台有统一的硬件、开发模式以及其它的基础设施。
|
||||
|
||||
而 ARM 则迥然不同。从硬件供应商的角度来看,它引领着一个碎片化的市场,Torvalds 说。
|
||||
|
||||
“x86 的生态系统一向都秉承着兼容为先的理念,而 ARM 则不以为然,”Torvalds 在与 ARM 开发者进行的一场炉边闲谈时如是说。
|
||||
|
||||
ARM 主导了移动设备的市场,有大量的设备都是使用基于 Linux 内核的安卓操作系统的。但是 ARM 的生态系统太过于碎片化了,这导致了很多支持和设备的问题。
|
||||
|
||||
问题之一:由于硬件的配置不同,在所有移动设备上部署同一个版本的 Android 是不可能的。硬件制造商会调整 Android 系统以兼容他们设备的芯片组。不像 Windows 更新到 PC,一个 Android 更新无法推送到所有的移动设备。
|
||||
|
||||
英特尔尝试过将 x86 芯片放在智能手机上,但是现在已经放弃了。英特尔的其中一个目标就是推送可以在所有 x86 手机上下载并安装成功的[安卓更新][3]。
|
||||
|
||||
还有 ARM 服务器软件的开发问题。每个芯片组的架构、网络和 I/O 特性不同,必须编写软件才能利用这些特性。这大大减慢了服务器中采用 ARM 的速度。x86 不存在适配的问题,它将继续主导服务器市场。
|
||||
|
||||
“我对于 ARM 作为一个硬件平台而不是一个指令集感到非常失望,虽然我也有我的问题,”Torvalds 说。“作为一个硬件平台,它始终不太好对付。”
|
||||
|
||||
Torvalds 小时候在一台装配有 8 位的 6502 处理器的微机上编程,他很喜欢这种架构,因为它的指令是流式的,当时还没有其它硬件可以与之媲美。这种架构为芯片提供了更高的性能。
|
||||
|
||||
“我那时想升级的是一台 Acorn Archimedes,呃,ARM 就是因该公司而命名的,“Torvalds说,“那曾经是我梦寐以求的机器。”
|
||||
|
||||
[Archimedes][4] 是第一台基于 Acorn 电脑公司的 ARM RISC 芯片的个人电脑。ARM 作为 Acorn 的一个分支而成立。(LCTT 译注:ARM 的缩写来自于 Acorn RISC Machine。——引自[维基百科](https://en.wikipedia.org/wiki/Acorn_Archimedes)。)
|
||||
|
||||
Torvalds 喜欢 Archimedes,因为它搭载了像 6502 一样的流式指令和 RAM 芯片以获得高性能。不尽人意的是,他找不到那台电脑。
|
||||
|
||||
他尝试过一台“古怪的英式电脑”,[Sinclair QL][5],这是一台比 Acorn Archimedes 还要失败的机器,Torvalds 说。
|
||||
|
||||
“那时的芬兰不是宇宙的中心,”Torvalds 说。“在那之后我吸取教训了——再也没有去买没有基础设施(生态)的机器。”
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.pcworld.com/article/3129300/linux/why-linux-pioneer-linus-torvalds-prefers-x86-over-arm.html
|
||||
|
||||
作者:[Agam Shah][a]
|
||||
译者:[OneNewLife](https://github.com/OneNewLife)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.pcworld.com/author/Agam-Shah/
|
||||
[1]: http://www.theregister.co.uk/2016/10/05/linus_torvalds_admits_buggy_crap_made_it_into_linux_48/
|
||||
[2]: https://www.youtube.com/watch?v=fuAebQvFnRI
|
||||
[3]: http://www.infoworld.com/article/2908072/android/google-and-intel-vow-to-speed-up-delivery-of-android-updates-to-devices.html
|
||||
[4]: http://www.pcworld.com/article/3097427/hardware/how-arm-set-itself-up-for-a-32-billion-acquisition.html
|
||||
[5]: http://oldcomputers.net/ql.html
|
||||
@ -0,0 +1,52 @@
|
||||
ORWL:能够删除被篡改数据的小型开源计算机
|
||||
===========
|
||||
|
||||

|
||||
|
||||
在当今这个信息时代,安全是最重要的。恐怕没有人会希望自己的重要数据落入到坏人的手里。但是即便是无安全防护的硬件同样面临不少威胁,而大多数时候人们还只是对软件采取安全防护措施。ORWL 就是来改变这件事的。
|
||||
|
||||
### [ORWL 是什么?](http://www.design-shift.com/orwl/)
|
||||
|
||||
ORWL 宣称是社区里“造得最安全的家用电脑”。 它是一台小型的飞碟形计算机,在设计上全面考虑了物理安全性。物理安全很重要,因为一旦有人获得了从物理上访问你的计算机的途径,那么就 Game Over 了,这是信息安全专业人员中的一个老生常谈。
|
||||
|
||||

|
||||
|
||||
ORWL 的基本规格包括英特尔 Skylake M3 处理器、USB-C 和微型 HDMI 接口、8GB 内存、120G 固态硬盘、蓝牙、Wifi 和 NFC 技术。目前它支持的操作系统有 Ubuntu 16.04、Qubes OS,以及 Windows 10 等,开箱即用。你只需要有一个显示器,键盘和鼠标就可以开始使用它了。
|
||||
|
||||
### ORWL 是开源的
|
||||
|
||||
ORWL 是**完全**开源的。这意味着,如果有人想设计一台自己的计算机或者对 ORWL 作出改进的话,原理图和设计文件、软件、固件、所有东西都是可以获取的。
|
||||
|
||||

|
||||
|
||||
### ORWL 是如何工作的?
|
||||
|
||||
ORWL 使用自加密固态硬盘(SSD)。一个安全微控制器集成到其主板上来产生和存储加密密匙。一旦核实了系统的完整性和已验证用户,它就使用密匙来解密固态硬盘(SSD)。无论对 ORWL 进行任何类型的篡改,密匙都会立即删除固态硬盘(SSD)上的无用数据
|
||||
|
||||
为了完成身份验证,ORWL 有一个使用和智能卡类似技术的密匙卡。它使用 NFC 技术来验证用户,同时使用蓝牙来检测用户是否在当前使用范围内。如果用户不在附近(不在使用范围内),ORWL 将会自动锁定。
|
||||
|
||||

|
||||
|
||||
整个 ORWL 系统被包裹在一个到处伴有压力开关的活动翻盖网格里。安全微控制器持续监控专用惯性测量部件,活动翻盖网格,内部温度和电源输入电压,以用于检测篡改。这将防止访问内部组件,比如试图破坏翻盖将会触发安全微控制器从而删除加密密匙。此外,出于安全考虑,动态随机存储器(DRAM)也焊有外壳。
|
||||
|
||||
这并不是全部安全防护措施,ORWL 还有更多详细的措施来确保设备绝对的物理安全性,包括冷启动防护,直接存储器访问(DMA)攻击防御等。
|
||||
|
||||
更多信息可以在 [ORWL 引导页](https://www.orwl.org/)找到。这儿是一个关于它如何工作的快速视频。
|
||||
|
||||
### ORWL 是信息安全的最终答案吗?
|
||||
|
||||
令人沮丧的是,ORWL 并不是信息安全的最终答案。ORWL 只能为计算机提供物理安全,尽管这很强大并且看起来极酷(totally ninja),但是还有许多来自其他方面的攻击会损坏你的系统。然而,ORWL 确实从整体上提高了计算机的安全性。
|
||||
|
||||
你认为 ORWL 怎么样?通过评论让我们知道你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/orwl-physically-secure-computer/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/munif/
|
||||
120
published/201610/20161012 7 Mistakes New Linux Users Make.md
Normal file
120
published/201610/20161012 7 Mistakes New Linux Users Make.md
Normal file
@ -0,0 +1,120 @@
|
||||
7 个 Linux 新手容易犯的错误
|
||||
===================
|
||||
|
||||
换操作系统对每个人来说都是一件大事——尤其是许多用户根本不清楚操作系统是什么。
|
||||
|
||||
然而,从 Windows 切换到 Linux 特别地困难。这两个操作系统有着不同的前提和优先级,以及不同的处理方式。结果导致 Linux 新手容易混淆,因为他们在 Windows 上面得到经验不再适用。
|
||||
|
||||
例如,这里有 7 个 Windows “难民”开始使用 Linux 的时候会犯的错误(没有先后顺序):
|
||||
|
||||
### 7. 选择错误的 Linux 发行版
|
||||
|
||||
Linux 有几百个不同的版本,或者按他们的称呼叫做发行版(distributions)。其中许多是专门针对不同的版本或用户的。选择了错误的版本,你与 Linux 的第一次亲密体验将很快变成一个噩梦。
|
||||
|
||||
如果你是在朋友的帮助下切换的话,确认他们的建议是适合你,而不是他们。有大量的文章可以帮助到你,你只需要关注前 20 名左右的或者列在 [Distrowatch][46] 的即可,就不太可能会搞错。
|
||||
|
||||
更好的做法是,在你安装某个发行版之前先试试它的 [Live DVD][45]。Live DVD 是在外设上运行发行版的,这样可以允许你在不对硬盘做任何改动的情况下对其进行测试。事实上,除非你知道怎么让硬盘在 Linux 下可访问,否则你是不会看到你的硬盘的。
|
||||
|
||||
### 6. 期待什么都是一样的
|
||||
|
||||
由于经验有限,许多 Windows 用户不知道新的操作系统意味着新的程序和新的处理方式。事实上你的 Windows 程序是无法在 Linux 上运行的,除非你用 [WINE][44] 或者 Windows 虚拟机。而且你还不能用 MS Office 或者 PhotoShop —— 你必须要学会使用 LibreOffice 和 Krita。经过这些年,这些应用可能会有和 Windows 上的应用类似的功能,但它们的功能可能具有不同的名称,并且会从不同的菜单或工具栏获得。
|
||||
|
||||
就连很多想当然的都不一样了。Windows 用户会特别容易因为他们有多个桌面环境可以选择而大吃一惊——至少有一个主要的和很多次要的桌面环境。
|
||||
|
||||
### 5. 安装软件的时候不知所措
|
||||
|
||||
在 Windows 上,新软件是作为一个完全独立的程序来安装的。通常它囊括了其它所需的依赖库。
|
||||
|
||||
有两种叫做 [Flatpak][43] 和 [Snap][42] 的软件包服务目前正在 Linux 上引进类似的安装系统,但是它们对于移动设备和嵌入式设备来说太大了。更多情况下,Linux 依赖于包管理系统,它会根据已安装的包来判断软件的依赖包是否是必需的,从而提供其它所需的依赖包。
|
||||
|
||||
笔记本和工作站上的包管理本质上相当于手机或平板电脑上的 Google Play:它速度很快,并且不需要用于安装的物理介质。不仅如此,它还可以节省 20%-35% 的硬盘空间,因为依赖包不会重复安装。
|
||||
|
||||
### 4. 假想软件会自动更新好
|
||||
|
||||
Linux 用户认为控制权很重要。Linux 提供更新服务,不过默认需要用户手动运行。例如,大多数发行版会让你知道有可用的软件更新,但是你需要选择安装这些更新。
|
||||
|
||||
如果你选择更新的话,你甚至可以单独决定每一个更新。例如,你可能不想更新到新的内核,因为你安装了一些东西需要使用当前的内核。又或者你想要安装所有的安全性更新,但不想把发行版更新到一个新的版本。一切都由你来选择。
|
||||
|
||||
### 3. 忘记密码
|
||||
|
||||
许多 Windows 用户因为登录不方便而忘记密码。又或者为了方便起见,经常运行一个管理账户。
|
||||
|
||||
在 Linux 上这两种做法都不容易。许多发行版使用 [sudo][41] 来避免以 root 登录,特别是那些基于 Ubuntu 的发行版,而其它发行版大多数是安装为禁止 root 运行图形界面。但是,如果你在 Linux 上成功绕开了这些限制,请注意你的大部分 Linux 安全性优势都会无效(其实在 Windows 上也不推荐这样做)。
|
||||
|
||||
对了,你是不是在安装程序上看到一个自动登录的选项?那是在不常用的情景下使用的,例如不包含隐私信息的虚拟机。
|
||||
|
||||
### 2. 担心没有碎片整理和杀毒软件
|
||||
|
||||
Linux 偶尔需要进行碎片整理,不过只有在恢复分区或者分区差不多满了的时候。并且由于固态硬盘越来越火,碎片整理正在变成过去时,尽管固态硬盘确实需要在任何操作系统上定期运行 [trim][40]。
|
||||
|
||||
同样地,只有当你安装的 Linux 经常传输文件给 Windows 机器的时候,杀毒软件才是一个主要问题。很少有 Linux 病毒或恶意软件存在,并且日常使用非 root 用户、使用强密码、经常备份当前文件就已经足够阻止病毒了。
|
||||
|
||||
### 1. 认为自己没有软件可用
|
||||
|
||||
Windows 上的软件是收费的,大多数类别由一家公司独占——例如,办公套装 MS Office 以及图形和设计的 Adobe。这些条件鼓励用户坚持使用相同的应用程序,尽管它们错漏百出。
|
||||
|
||||
在 Linux 上,故事情节不一样了。只有少数高端程序是收费的,而且几乎每一类软件都有两三个替代品,所有这些可用的软件都可以在 10 分钟或者更短的时间内下载好。如果一个替代品不合你口味,你可以删掉它然后毫不费力就可以再装一个其它的。在 Linux 上,你几乎总会有选择。
|
||||
|
||||
### 过渡期
|
||||
|
||||
可能没有那么多建议可以让 Windows 用户充分准备好切换到 Linux。即使说新用户应该保持开放的心态也是没什么用的,因为他们的期望总是太高,以至于许多用户都没有意识到自己有如此高的期望。
|
||||
|
||||
Linux 新手可以做的最好的事情就是调整心态,并且花一点时间来适应它们。过渡期会需要一些功夫,不过,从长远来看,你的多次尝试终会得到回报。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/7-mistakes-new-linux-users-make.html
|
||||
|
||||
作者:[Bruce Byfield][a]
|
||||
译者:[OneNewLife](https://github.com/OneNewLife)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.datamation.com/author/Bruce-Byfield-6030.html
|
||||
[1]: https://www.youtube.com/channel/UCOfXyFkINXf_e9XNosTJZDw
|
||||
[2]: https://www.youtube.com/user/desainew
|
||||
[3]: https://www.youtube.com/channel/UCEQXp_fcqwPcqrzNtWJ1w9w
|
||||
[4]: http://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Ffreedompenguin.com%2Farticles%2Fopinion%2Fopen-source-design-thing%2F
|
||||
[5]: http://twitter.com/intent/tweet/?text=Is+Open+Source+Design+a+Thing%3F&url=https%3A%2F%2Ffreedompenguin.com%2Farticles%2Fopinion%2Fopen-source-design-thing%2F
|
||||
[6]: https://plus.google.com/share?url=https%3A%2F%2Ffreedompenguin.com%2Farticles%2Fopinion%2Fopen-source-design-thing%2F
|
||||
[7]: https://atom.io/
|
||||
[8]: http://froont.com/
|
||||
[9]: https://webflow.com/
|
||||
[10]: https://gravit.io/
|
||||
[11]: http://getbootstrap.com/
|
||||
[12]: https://inkscape.org/en/
|
||||
[13]: https://www.gimp.org/
|
||||
[14]: https://en.wikipedia.org/wiki/Free_and_open-source_software
|
||||
[15]: https://medium.com/dawn-capital/why-leverage-the-power-of-open-source-to-build-a-successful-software-business-8aba6f665bc4#.ggmn2ojxp
|
||||
[16]: https://github.com/majutsushi/tagbar
|
||||
[17]: http://ctags.sourceforge.net/
|
||||
[18]: https://github.com/majutsushi/tagbar/zipball/70fix
|
||||
[19]: https://raw.githubusercontent.com/tpope/vim-pathogen/master/autoload/pathogen.vim
|
||||
[20]: http://www.vim.org/scripts/script.php?script_id=2332
|
||||
[21]: https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-2-syntastic/
|
||||
[22]: https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-delimitmate-help.png
|
||||
[23]: https://github.com/Raimondi/delimitMate
|
||||
[24]: https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-tagbar-visibility.png
|
||||
[25]: https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-tagbar-ex2.png
|
||||
[26]: https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-tagbar-example.png
|
||||
[27]: http://www.tldp.org/LDP/intro-linux/html/sect_06_02.html
|
||||
[28]: http://majutsushi.github.io/tagbar/
|
||||
[29]: http://vi.stackexchange.com/questions/388/what-is-the-difference-between-the-vim-plugin-managers
|
||||
[30]: https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-vimrc.png
|
||||
[31]: http://www.vim.org/
|
||||
[32]: https://github.com/scrooloose/syntastic
|
||||
[33]: https://github.com/scrooloose/syntastic/blob/master/doc/syntastic.txt
|
||||
[34]: https://www.howtoforge.com/images/3337/big/syntastic-error-all-descr.png
|
||||
[35]: https://www.howtoforge.com/images/3337/big/syntastic-error-descr.png
|
||||
[36]: https://www.howtoforge.com/images/3337/big/syntastic-error-highlight.png
|
||||
[37]: https://github.com/scrooloose/syntastic
|
||||
[38]: http://www.vim.org/
|
||||
[39]: https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers/
|
||||
[40]: https://en.wikipedia.org/wiki/Trim_%28computing%29
|
||||
[41]: https://en.wikipedia.org/wiki/Sudo
|
||||
[42]: http://snapcraft.io/
|
||||
[43]: http://flatpak.org/
|
||||
[44]: https://en.wikipedia.org/wiki/Wine_%28software%29
|
||||
[45]: https://en.wikipedia.org/wiki/Live_CD
|
||||
[46]: http://distrowatch.com/
|
||||
@ -0,0 +1,148 @@
|
||||
开发者的实用 Vim 插件(一)
|
||||
============
|
||||
|
||||
作为 Vi 的升级版,[Vim][31] 毫无争议是 Linux 中最受欢迎的命令行编辑器之一。除了是一个多功能编辑器外,世界各地的软件开发者将 Vim 当做 IDE(Integrated Development Environment,集成开发环境)来使用。
|
||||
|
||||
事实上,因为 Vim 可以通过插件来扩展其自身功能才使得它如此功能强大。不用说,肯定有那么几个 Vim 插件是旨在提高用户的编程体验的。
|
||||
|
||||
特别是对于刚刚使用 Vim 或者使用 Vim 做开发的的软件开发者来说,我们将在本教程中讨论一些非常有用的 Vim 插件,具体请看例示。
|
||||
|
||||
请注意:本教程中列举的所有例示、命令和说明都是在 Ubuntu 16.04 环境下进行测试的,并且,我们使用的 Vim 版本是 7.4。
|
||||
|
||||
### 插件安装设置
|
||||
|
||||
这是为新用户准备的,假设他们不知道如何安装 Vim 插件。所以,首先,就是给出一些完成安装设置的步骤。
|
||||
|
||||
* 在你的家目录下创建 `.vim` 目录,并在其中创建子目录 `autoload` 和 `bundle`。
|
||||
* 然后,在 `autoload` 放置 [pathogen.vim][20] 文件,这个文件可以从[此处][19] 下载。
|
||||
* 最后,在你的家目录创建 `.vimrc` 文件,并添加以下内容。
|
||||
|
||||
```
|
||||
call pathogen#infect()
|
||||
```
|
||||
|
||||
|
||||
|
||||
至此,你已完成了 Vim 插件安装的准备工作。
|
||||
|
||||
注意:我们已经讨论了使用 Pathogen 管理 Vim 插件。当然还有其他的插件管理工具——欲了解,请访问[此处][29]。
|
||||
|
||||
现在已经全部设置完毕,就让我们来讨论两个好用的 Vim 插件吧。
|
||||
|
||||
### Vim 标签侧边栏(Tagbar)插件
|
||||
|
||||
首先就是标签侧边栏(Tagbar)插件。该插件能够让你浏览源文件包含的标签,从而提供该源文件的结构简览。[其官网的插件说明][28]是这样说的:“它通过创建侧边栏,然后以一定顺序展示从当前文件以 ctags 提取的标签来完成这一功能。这意味着,比如,C++ 中的方法将展示在其自身所定义在的类里边。”
|
||||
|
||||
听起来很酷,不是吗?让我们来看看该怎么安装它。
|
||||
|
||||
标签侧边栏(Tagbar)的安装过程是相当容易的——你只需要运行下列命令:
|
||||
|
||||
```
|
||||
cd ~/.vim/bundle/
|
||||
|
||||
git clone git://github.com/majutsushi/tagbar
|
||||
```
|
||||
安装完之后就可以使用了,你可以在 Vim 中打开一个 .cpp 文件来测试它:进入[命令模式][27],然后运行 `:TagbarOpen` 命令。以下是运行 `:TagbarOpen` 命令之后出现侧边栏(右侧) 的效果图。
|
||||
|
||||
[][26]
|
||||
|
||||
使用 `:TagbarClose` 可以关闭侧边栏。值得一提的是,可以使用 `:TagbarOpen fj` 命令打开侧边栏来打开它的跳转(shift control)功能。也就是说,你可以很方便的浏览当前文件包含的标签——在对应的标签上按下 Enter 键,然后在左侧的源代码窗口跳转到对应的位置。
|
||||
|
||||
|
||||
|
||||
假如你想要反复地开关侧边栏,你可以使用 `:TagbarToggle` 命令,而不用交替的使用 `:TagbarOpen` 和 `:TagbarClose` 命令。
|
||||
|
||||
如果你觉得输入这些命令很费时间,你可以为 `:TagbarToggle` 命令创建快捷键。比如,添加以下内容到 `.vimrc` 文件中:
|
||||
|
||||
```
|
||||
nmap <F8> :TagbarToggle<CR>
|
||||
```
|
||||
这样,你就可以用 F8 来切换标签侧边栏(Tagbar)了。
|
||||
|
||||
更进一步,有时候你可能会注意到某个标签前边有一个 `+`、`-` 或者 `#` 符号。比如,以下截图(取自该插件的官网)展示了一些前边有 `+` 号的标签。
|
||||
|
||||
|
||||
|
||||
这些符号基本是用来表明一个特定标签的可见性信息。特别是 `+` 表示该类是 public 的,而 `-` 表示一个 private 类。`#` 则是表示一个 protected 类。
|
||||
|
||||
以下是使用标签侧边栏(Tagbar)的一些注意事项:
|
||||
|
||||
* 该插件的官网早就有说明:“标签侧边栏(Tagbar)并非是管理标签(tags)文件而设计,它只是在内存中动态创建所需的标签,而非创建任何文件。标签(tags)文件的管理有其他插件提供支持。”
|
||||
* 低于 7.0.167 版本的 Vim 和标签侧边栏(Tagbar)插件存在着一个兼容性问题。根据官网:“如果你受到此问题的影响,请使用代替版:[下载 zip 压缩包][18]。这对应到 2.2 版本,但由于大量的依赖变更,它可能不会再升级。”
|
||||
* 如果你在加载该插件时遇到这样的错误:未找到 ctags!(Tagbar: Exuberant ctags not found!)。你可以从 [此处][17]下载并安装 ctags 来修复错误。
|
||||
* 获取更多信息请访问 [这里][16]。
|
||||
|
||||
### Vim 界定符自动补齐(delimitMate)插件
|
||||
|
||||
下一个要介绍的插件就是界定符自动补齐(delimitMate)。该插件在 Vim 插入模式下提供引号、圆括号和方括号等界定符自动补齐功能。
|
||||
|
||||
[该插件官网][23]说:“它同时也提供一些相关的特性让你在输入模式下变得更加便捷,比如语法纠错(在注释区或者其他的可配置区不会自动插入结束界定符)、回车和空格填充(默认关闭)等。”
|
||||
|
||||
安装步骤与之前介绍的相似:
|
||||
|
||||
```
|
||||
cd ~/.vim/bundle/
|
||||
|
||||
git clone git://github.com/Raimondi/delimitMate.git
|
||||
```
|
||||
|
||||
一旦你成功安装这个插件(即上述命令执行成功),你就不需要进行任何配置了——当 Vim 启动时会自动加载这个插件。
|
||||
|
||||
至此,在你使用 Vim 的任何时候,只要你输入一个双引号、单引号、单号、圆括号、方括号,它们都会自动补齐。
|
||||
|
||||
你可以自己配置界定符自动补齐(delimitMate)。比如,你可以添加需要自动补齐的符号列表,阻止自动加载该插件,对指定类型文件关闭该插件等。想了解如何配置这些(或者其他更多的配置),请阅读该插件的详细文档——运行 `:help delimitMate` 即可。
|
||||
|
||||
上述命令会将你的 Vim 窗口水平分割成两个,上边一个包含我们所说的文档。
|
||||
|
||||
|
||||
|
||||
### 结论
|
||||
|
||||
本文之中提到的两个插件,Tagbar 需要花费较多时间来适应——你应该会同样这个说法。但只要正确设置好它(这意味着你像是有了快捷键一样方便),就容易使用了。至于 delimitMate,不需要任何要求就可以上手。
|
||||
|
||||
本教程就是向你展示 Vim 如何高效能的想法。除了本文中提及的,仍然还有许多开发者可用的插件,我们将在下一个部分进行讨论。假如你正在使用一个关于开发的 Vim 插件,并希望广为人知,请在下方留下评论。
|
||||
|
||||
我们将在本教程的第二部分讲到 [语法高亮插件:Syntastic][21]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers/
|
||||
[1]:https://www.youtube.com/channel/UCOfXyFkINXf_e9XNosTJZDw
|
||||
[2]:https://www.youtube.com/user/desainew
|
||||
[3]:https://www.youtube.com/channel/UCEQXp_fcqwPcqrzNtWJ1w9w
|
||||
[4]:http://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Ffreedompenguin.com%2Farticles%2Fopinion%2Fopen-source-design-thing%2F
|
||||
[5]:http://twitter.com/intent/tweet/?text=Is+Open+Source+Design+a+Thing%3F&url=https%3A%2F%2Ffreedompenguin.com%2Farticles%2Fopinion%2Fopen-source-design-thing%2F
|
||||
[6]:https://plus.google.com/share?url=https%3A%2F%2Ffreedompenguin.com%2Farticles%2Fopinion%2Fopen-source-design-thing%2F
|
||||
[7]:https://atom.io/
|
||||
[8]:http://froont.com/
|
||||
[9]:https://webflow.com/
|
||||
[10]:https://gravit.io/
|
||||
[11]:http://getbootstrap.com/
|
||||
[12]:https://inkscape.org/en/
|
||||
[13]:https://www.gimp.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Free_and_open-source_software
|
||||
[15]:https://medium.com/dawn-capital/why-leverage-the-power-of-open-source-to-build-a-successful-software-business-8aba6f665bc4#.ggmn2ojxp
|
||||
[16]:https://github.com/majutsushi/tagbar
|
||||
[17]:http://ctags.sourceforge.net/
|
||||
[18]:https://github.com/majutsushi/tagbar/zipball/70fix
|
||||
[19]:https://raw.githubusercontent.com/tpope/vim-pathogen/master/autoload/pathogen.vim
|
||||
[20]:http://www.vim.org/scripts/script.php?script_id=2332
|
||||
[21]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-2-syntastic/
|
||||
[22]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-delimitmate-help.png
|
||||
[23]:https://github.com/Raimondi/delimitMate
|
||||
[24]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-tagbar-visibility.png
|
||||
[25]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-tagbar-ex2.png
|
||||
[26]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-tagbar-example.png
|
||||
[27]:http://www.tldp.org/LDP/intro-linux/html/sect_06_02.html
|
||||
[28]:http://majutsushi.github.io/tagbar/
|
||||
[29]:http://vi.stackexchange.com/questions/388/what-is-the-difference-between-the-vim-plugin-managers
|
||||
[30]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-vimrc.png
|
||||
[31]:http://www.vim.org/
|
||||
@ -0,0 +1,121 @@
|
||||
开发者的实用 Vim 插件(二)
|
||||
============
|
||||
|
||||
毫无疑问,Vim 是一个开箱即用并能够胜任编程任务的编辑器,但实际上是该编辑器中的插件帮你实现这些方便的功能。在 [开发者的实用 Vim 插件(一)][39],我们已经讨论两个编程相关的 Vim 插件——标签侧边栏(Tagbar)和定界符自动补齐(delimitMate)。作为相同系列,我们在本文讨论另一个非常有用、专门为软件开发正定制的插件——语法高亮插件。
|
||||
|
||||
请注意:本教程中列举的所有例示、命令和说明都是在 Ubuntu 16.04 环境下进行测试的,并且,我们使用的 Vim 版本是 7.4。
|
||||
|
||||
### 语法高亮(Syntastic)插件
|
||||
|
||||
假如你的软件开发工作涉及到 C/C++ 语言,毫无疑问的说,遇到编译错误也是你每天工作中的一部分。很多时候,编译错误是由源代码之中的语法不正确造成的,因为开发者在浏览源码的时候很少能够一眼就看出所有这些错误。
|
||||
|
||||
那么 Vim 中是否存在一种插件可以让你不经编译源码就可以显示出语法错误呢?当然是有这样一种插件的,其名字就是 Syntastic。
|
||||
|
||||
“Syntastic 是 Vim 用来检验语法的插件,通过外部语法校验器校验文件并将错误呈现给用户。该过程可以在需要时进行,或者在文件保存的时候自动进行。”该插件 [官方文档][37] 如是说。“如果检测到语法错误就会提示用户,因为不用编译代码或者执行脚本就可以知道语法错误,用户也就乐享与此了。”
|
||||
|
||||
安装过程和第一部分提到的方法类似,你只需要运行下列命令即可:
|
||||
|
||||
```
|
||||
cd ~/.vim/bundle/
|
||||
|
||||
git clone https://github.com/scrooloose/syntastic.git
|
||||
```
|
||||
一旦你成功安装这个插件(即上述命令执行成功),你就不需要进行任何配置了——当 Vim 启动时会自动加载这个插件。
|
||||
|
||||
现在,打开一个源码文件并用 `:w` Vim 命令保存即可使用这个插件了。等待片刻之后,如果在源码中有语法错误的好,就会高亮显示出来。比如,看看一下截图你就会明白该插件是如何高亮显示语法错误的:
|
||||
|
||||
|
||||
|
||||
在每行之前的 `>>` 表示该行中有语法错误。了解确切的错误或者想知道是什么东西错了,将光标移到该行——错误描述就会展示在 Vim 窗口的最底下。
|
||||
|
||||
[][35]
|
||||
|
||||
这样,不用进行编译你就能够修复大多数语法相关的错误。
|
||||
|
||||
再往下,如果你运行 `:Errors` 命令,就会展现当前源文件中所有语法相关错误的描述。比如,我运行 `:Errors` 命令就是下图的效果:
|
||||
|
||||
[][34]
|
||||
|
||||
请记住,`:Errors` 展现的语法错误是不会自动更新的,这意味着在你修复错误之后,你需要重新运行 `:Errors` 命令,编辑器底部的错误描述才会消除。
|
||||
|
||||
值得一提的是,还有 [许多配置选项][33] 能够使得 Syntastic 插件使用起来更加友好。比如,你可以在你的 `.vimrc` 中添加下列内容,然后 `:Errors` 就可以在修复错误之后自动更新它的底部描述。
|
||||
|
||||
```
|
||||
let g:syntastic_always_populate_loc_list = 1
|
||||
```
|
||||
添加以下内容,以确保在你打开文件时 Syntastic 插件自动高亮显示错误。
|
||||
|
||||
```
|
||||
let g:syntastic_check_on_open = 1
|
||||
```
|
||||
类似的,你也可以在保存或打开文件时让光标跳转到检测到的第一个问题处,将下列行放到你的 `.vimrc` 文件之中:
|
||||
```
|
||||
let g:syntastic_auto_jump = 1
|
||||
```
|
||||
这个值也可以指定为其它两个值: 2 和 3,其官方文档的解释如下:
|
||||
|
||||
“如果设置为 2 的话,光标就会跳到检测到的第一个问题,当然,只有这个问题是一个错误的时候才跳转;设置为 3 的话,如果存在错误,则会跳到第一个错误。所有检测到的问题都会有警告,但光标不会跳转。”
|
||||
|
||||
以下信息可能对你有帮助:
|
||||
|
||||
“使用 `:SyntasticCheck` 来手动检测错误。使用 `:Errors` 打开错误位置列表并使用 `:lclose` 来关闭。使用 `:SyntasticReset` 可以清除掉错误列表,使用 `:SyntasticToggleMode` 来切换激活(在写到 buffer 时检测)和被动(即手动检测)检测错误。”
|
||||
|
||||
注意:Syntastic 并不局限于 C/C++ 所写的代码,它同时也支持很多的编程语言——点击 [此处][32] 了解更多相关信息。
|
||||
|
||||
### 结论
|
||||
|
||||
毫无疑问的,Syntastic 是一个非常有用的 Vim 插件,因为在出现语法相关错误时候,它至少能够让免去频繁编译的麻烦,而且不用说,同时也节约了你不少的时间。
|
||||
|
||||
正如你所看到的一样,配置好几个主要选项之后,Syntastic 变得非常好用了。为了帮助你了解这些设置,官方文档中包含了一份“推荐设置”——跟着文档进行设置即可。加入你遇到一些错误、有些疑问或者问题,你也可以查询一下 FAQ。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-2-syntastic/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-2-syntastic/
|
||||
[1]:https://www.youtube.com/channel/UCOfXyFkINXf_e9XNosTJZDw
|
||||
[2]:https://www.youtube.com/user/desainew
|
||||
[3]:https://www.youtube.com/channel/UCEQXp_fcqwPcqrzNtWJ1w9w
|
||||
[4]:http://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Ffreedompenguin.com%2Farticles%2Fopinion%2Fopen-source-design-thing%2F
|
||||
[5]:http://twitter.com/intent/tweet/?text=Is+Open+Source+Design+a+Thing%3F&url=https%3A%2F%2Ffreedompenguin.com%2Farticles%2Fopinion%2Fopen-source-design-thing%2F
|
||||
[6]:https://plus.google.com/share?url=https%3A%2F%2Ffreedompenguin.com%2Farticles%2Fopinion%2Fopen-source-design-thing%2F
|
||||
[7]:https://atom.io/
|
||||
[8]:http://froont.com/
|
||||
[9]:https://webflow.com/
|
||||
[10]:https://gravit.io/
|
||||
[11]:http://getbootstrap.com/
|
||||
[12]:https://inkscape.org/en/
|
||||
[13]:https://www.gimp.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Free_and_open-source_software
|
||||
[15]:https://medium.com/dawn-capital/why-leverage-the-power-of-open-source-to-build-a-successful-software-business-8aba6f665bc4#.ggmn2ojxp
|
||||
[16]:https://github.com/majutsushi/tagbar
|
||||
[17]:http://ctags.sourceforge.net/
|
||||
[18]:https://github.com/majutsushi/tagbar/zipball/70fix
|
||||
[19]:https://raw.githubusercontent.com/tpope/vim-pathogen/master/autoload/pathogen.vim
|
||||
[20]:http://www.vim.org/scripts/script.php?script_id=2332
|
||||
[21]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-2-syntastic/
|
||||
[22]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-delimitmate-help.png
|
||||
[23]:https://github.com/Raimondi/delimitMate
|
||||
[24]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-tagbar-visibility.png
|
||||
[25]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-tagbar-ex2.png
|
||||
[26]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-tagbar-example.png
|
||||
[27]:http://www.tldp.org/LDP/intro-linux/html/sect_06_02.html
|
||||
[28]:http://majutsushi.github.io/tagbar/
|
||||
[29]:http://vi.stackexchange.com/questions/388/what-is-the-difference-between-the-vim-plugin-managers
|
||||
[30]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers/big/vimplugins-vimrc.png
|
||||
[31]:http://www.vim.org/
|
||||
[32]:https://github.com/scrooloose/syntastic
|
||||
[33]:https://github.com/scrooloose/syntastic/blob/master/doc/syntastic.txt
|
||||
[34]:https://www.howtoforge.com/images/3337/big/syntastic-error-all-descr.png
|
||||
[35]:https://www.howtoforge.com/images/3337/big/syntastic-error-descr.png
|
||||
[36]:https://www.howtoforge.com/images/3337/big/syntastic-error-highlight.png
|
||||
[37]:https://github.com/scrooloose/syntastic
|
||||
[38]:http://www.vim.org/
|
||||
[39]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers/
|
||||
|
||||
@ -0,0 +1,27 @@
|
||||
白宫开源聊天机器人代码
|
||||
===================
|
||||
|
||||
争先部署那种可以响应用户请求的机器人的潮流也步入到了奥巴马总统的家——美国白宫。白宫在 10 月 14 号宣布开源其机器人代码,目的是为了使增加更加开放的合作与交流。
|
||||
|
||||

|
||||
|
||||
“具体地说,我们开源了一个 Drupal 模块,只需要一些简单的步骤和样板化代码就可以搞定,” 白宫首席数码执行官 Jason Goldman 在他的博客的[文章][1]中这样写到,“这可以让 Drupal 8 开发者迅速推出 Facebook Messenger 机器人。”
|
||||
|
||||
白宫早在 2009 年就率先用开源的 Drupal 内容管理系统(CMS)[部署][2]了它自己的网站。从那时起白宫就已经成为了 Drupal 的积极贡献者,并以许多不同的方式做着贡献,包括将用在其网站上的代码以开源方式发布。在白宫过去发布的那些项目中有完整的 Drupal 主题,被称作“fourtyfour”,目前用于 WhiteHouse.gov 网站。
|
||||
|
||||
现在,白宫新发布 Facebook Messenger 机器人的完整代码可以从 [GitHub][3] 上获取,包括完整的安装指导和项目蓝图。在蓝图中最大的项目(列在 ‘Enhancements and hopes’ 一节下面)是切实使项目更加独立,通过重构代码使项目模块化,从而让它在 Drupal 内容管理系统(CMS)之外也可以使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.internetnews.com/blog/skerner/white-house-open-sources-bot-code.html
|
||||
|
||||
作者:[Michael Kerner][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.internetnews.com/blog/skerner/white-house-open-sources-bot-code.html
|
||||
[1]:https://www.whitehouse.gov/blog/2016/10/13/removing-barriers-constituent-conversations
|
||||
[2]:http://www.internetnews.com/skerner/2009/10/white-house-goes-open-source-w.html
|
||||
[3]: https://github.com/WhiteHouse/fb_messenger_bot
|
||||
@ -0,0 +1,849 @@
|
||||
构建你的数据科学作品集:机器学习项目
|
||||
===========================================================
|
||||
|
||||
> 这是[这个系列][3]发布的第三篇关于如何构建数据科学作品集(Data Science Portfolio)的文章。如果你喜欢这个系列并且想继续关注,你可以在订阅页面的底部找到[链接][1]。
|
||||
|
||||
数据科学公司在决定雇佣时越来越关注你在数据科学方面的作品集(Portfolio)。这其中的一个原因是,这样的作品集是判断某人的实际技能的最好的方法。好消息是构建这样的作品集完全要看你自己。只要你在这方面付出了努力,你一定可以取得让这些公司钦佩的作品集。
|
||||
|
||||
构建高质量的作品集的第一步就是知道需要什么技能。公司想要在数据科学方面拥有的、他们希望你能够运用的主要技能有:
|
||||
|
||||
- 沟通能力
|
||||
- 协作能力
|
||||
- 技术能力
|
||||
- 数据推理能力
|
||||
- 动机和主动性
|
||||
|
||||
任何好的作品集都由多个项目表现出来,其中每个都能够表现出以上一到两点。这是本系列的第三篇,本系列我们主要讲包括如何打造面面俱到的数据科学作品集。在这一篇中,我们主要涵盖了如何构建组成你的作品集的第二个项目,以及如何创建一个端对端的机器学习项目。在最后,我们将拥有一个展示你的数据推理能力和技术能力的项目。如果你想看一下的话,[这里][2]有一个完整的例子。
|
||||
|
||||
### 一个端到端的项目
|
||||
|
||||
作为一个数据科学家,有时候你会拿到一个数据集并被问如何[用它来讲故事][3]。在这个时候,沟通就是非常重要的,你需要用它来完成这个事情。像我们在前一篇文章中用过的,类似 Jupyter notebook 这样的工具,将对你非常有帮助。在这里你能找到一些可以用的报告或者总结文档。
|
||||
|
||||
不管怎样,有时候你会被要求创建一个具有操作价值的项目。具有操作价值的项目将直接影响到公司的日常业务,它会使用不止一次,经常是许多人使用。这个任务可能像这样 “创建一个算法来预测周转率”或者“创建一个模型来自动对我们的文章打标签”。在这种情况下,技术能力比讲故事更重要。你必须能够得到一个数据集,并且理解它,然后创建脚本处理该数据。这个脚本要运行的很快,占用系统资源很小。通常它可能要运行很多次,脚本的可使用性也很重要,并不仅仅是一个演示版。可使用性是指整合进操作流程,并且甚至是是面向用户的。
|
||||
|
||||
端对端项目的主要组成部分:
|
||||
|
||||
- 理解背景
|
||||
- 浏览数据并找出细微差别
|
||||
- 创建结构化项目,那样比较容易整合进操作流程
|
||||
- 运行速度快、占用系统资源小的高性能代码
|
||||
- 写好安装和使用文档以便其他人用
|
||||
|
||||
为了有效的创建这种类型的项目,我们可能需要处理多个文件。强烈推荐使用 [Atom][4] 这样的文本编辑器或者 [PyCharm][5] 这样的 IDE。这些工具允许你在文件间跳转,编辑不同类型的文件,例如 markdown 文件,Python 文件,和 csv 文件等等。结构化你的项目还利于版本控制,并上传一个类似 [Github][6] 这样的协作开发工具上也很有用。
|
||||
|
||||

|
||||
|
||||
*Github 上的这个项目*
|
||||
|
||||
在这一节中我们将使用 [Pandas][7] 和 [scikit-learn][8] 这样的库,我们还将大量用到 Pandas [DataFrames][9],它使得 python 读取和处理表格数据更加方便。
|
||||
|
||||
### 找到好的数据集
|
||||
|
||||
为一个端到端的作品集项目的找到好的数据集很难。在内存和性能的限制下,数据集需要尽量的大。它还需要是实际有用的。例如,[这个数据集][10],它包含有美国院校的录取标准、毕业率以及毕业以后的收入,是个很好的可以讲故事的数据集。但是,不管你如何看待这个数据,很显然它不适合创建端到端的项目。比如,你能告诉人们他们去了这些大学以后的未来收入,但是这个快速检索却并不足够呈现出你的技术能力。你还能找出院校的招生标准和更高的收入相关,但是这更像是常理而不是你的技术结论。
|
||||
|
||||
这里还有内存和性能约束的问题,比如你有几千兆的数据,而且当你需要找到一些差异时,就需要对数据集一遍遍运行算法。
|
||||
|
||||
一个好的可操作的数据集可以让你构建一系列脚本来转换数据、动态地回答问题。一个很好的例子是股票价格数据集,当股市关闭时,就会给算法提供新的数据。这可以让你预测明天的股价,甚至预测收益。这不是讲故事,它带来的是真金白银。
|
||||
|
||||
一些找到数据集的好地方:
|
||||
|
||||
- [/r/datasets][11] – 有上百的有趣数据的 subreddit(Reddit 是国外一个社交新闻站点,subreddit 指该论坛下的各不同版块)。
|
||||
- [Google Public Datasets][12] – 通过 Google BigQuery 使用的公开数据集。
|
||||
- [Awesome datasets][13] – 一个数据集列表,放在 Github 上。
|
||||
|
||||
当你查看这些数据集时,想一下人们想要在这些数据集中得到什么答案,哪怕这些问题只想过一次(“房价是如何与标准普尔 500 指数关联的?”),或者更进一步(“你能预测股市吗?”)。这里的关键是更进一步地找出问题,并且用相同的代码在不同输入(不同的数据)上运行多次。
|
||||
|
||||
对于本文的目标,我们来看一下 [房利美(Fannie Mae)贷款数据][14]。房利美是一家在美国的政府赞助的企业抵押贷款公司,它从其他银行购买按揭贷款,然后捆绑这些贷款为贷款证券来转卖它们。这使得贷款机构可以提供更多的抵押贷款,在市场上创造更多的流动性。这在理论上会带来更多的住房和更好的贷款期限。从借款人的角度来说,它们大体上差不多,话虽这样说。
|
||||
|
||||
房利美发布了两种类型的数据 – 它获得的贷款的数据,和贷款偿还情况的数据。在理想的情况下,有人向贷款人借钱,然后还款直到还清。不管怎样,有些人多次不还,从而丧失了抵押品赎回权。抵押品赎回权是指没钱还了被银行把房子给收走了。房利美会追踪谁没还钱,并且哪个贷款需要收回抵押的房屋(取消赎回权)。每个季度会发布此数据,发布的是滞后一年的数据。当前可用是 2015 年第一季度数据。
|
||||
|
||||
“贷款数据”是由房利美发布的贷款发放的数据,它包含借款人的信息、信用评分,和他们的家庭贷款信息。“执行数据”,贷款发放后的每一个季度公布,包含借贷人的还款信息和是否丧失抵押品赎回权的状态,一个“贷款数据”的“执行数据”可能有十几行。可以这样理解,“贷款数据”告诉你房利美所控制的贷款,“执行数据”包含该贷款一系列的状态更新。其中一个状态更新可以告诉我们一笔贷款在某个季度被取消赎回权了。
|
||||
|
||||

|
||||
|
||||
*一个没有及时还贷的房子就这样的被卖了*
|
||||
|
||||
### 选择一个角度
|
||||
|
||||
这里有几个我们可以去分析房利美数据集的方向。我们可以:
|
||||
|
||||
- 预测房屋的销售价格。
|
||||
- 预测借款人还款历史。
|
||||
- 在获得贷款时为每一笔贷款打分。
|
||||
|
||||
最重要的事情是坚持单一的角度。同时关注太多的事情很难做出效果。选择一个有着足够细节的角度也很重要。下面的角度就没有太多细节:
|
||||
|
||||
- 找出哪些银行将贷款出售给房利美的多数被取消赎回权。
|
||||
- 计算贷款人的信用评分趋势。
|
||||
- 找到哪些类型的家庭没有偿还贷款的能力。
|
||||
- 找到贷款金额和抵押品价格之间的关系。
|
||||
|
||||
上面的想法非常有趣,如果我们关注于讲故事,那是一个不错的角度,但是不是很适合一个操作性项目。
|
||||
|
||||
在房利美数据集中,我们将仅使用申请贷款时有的那些信息来预测贷款是否将来会被取消赎回权。实际上, 我们将为每一笔贷款建立“分数”来告诉房利美买还是不买。这将给我们打下良好的基础,并将组成这个漂亮的作品集的一部分。
|
||||
|
||||
### 理解数据
|
||||
|
||||
我们来简单看一下原始数据文件。下面是 2012 年 1 季度前几行的贷款数据:
|
||||
|
||||
```
|
||||
100000853384|R|OTHER|4.625|280000|360|02/2012|04/2012|31|31|1|23|801|N|C|SF|1|I|CA|945||FRM|
|
||||
100003735682|R|SUNTRUST MORTGAGE INC.|3.99|466000|360|01/2012|03/2012|80|80|2|30|794|N|P|SF|1|P|MD|208||FRM|788
|
||||
100006367485|C|PHH MORTGAGE CORPORATION|4|229000|360|02/2012|04/2012|67|67|2|36|802|N|R|SF|1|P|CA|959||FRM|794
|
||||
```
|
||||
|
||||
下面是 2012 年 1 季度的前几行执行数据:
|
||||
|
||||
```
|
||||
100000853384|03/01/2012|OTHER|4.625||0|360|359|03/2042|41860|0|N||||||||||||||||
|
||||
100000853384|04/01/2012||4.625||1|359|358|03/2042|41860|0|N||||||||||||||||
|
||||
100000853384|05/01/2012||4.625||2|358|357|03/2042|41860|0|N||||||||||||||||
|
||||
```
|
||||
|
||||
在开始编码之前,花些时间真正理解数据是值得的。这对于操作性项目优为重要,因为我们没有交互式探索数据,将很难察觉到细微的差别,除非我们在前期发现他们。在这种情况下,第一个步骤是阅读房利美站点的资料:
|
||||
|
||||
- [概述][15]
|
||||
- [有用的术语表][16]
|
||||
- [常见问答][17]
|
||||
- [贷款和执行文件中的列][18]
|
||||
- [贷款数据文件样本][19]
|
||||
- [执行数据文件样本][20]
|
||||
|
||||
在看完这些文件后后,我们了解到一些能帮助我们的关键点:
|
||||
|
||||
- 从 2000 年到现在,每季度都有一个贷款和执行文件,因数据是滞后一年的,所以到目前为止最新数据是 2015 年的。
|
||||
- 这些文件是文本格式的,采用管道符号`|`进行分割。
|
||||
- 这些文件是没有表头的,但我们有个文件列明了各列的名称。
|
||||
- 所有一起,文件包含 2200 万个贷款的数据。
|
||||
- 由于执行数据的文件包含过去几年获得的贷款的信息,在早些年获得的贷款将有更多的执行数据(即在 2014 获得的贷款没有多少历史执行数据)。
|
||||
|
||||
这些小小的信息将会为我们节省很多时间,因为这样我们就知道如何构造我们的项目和利用这些数据了。
|
||||
|
||||
### 构造项目
|
||||
|
||||
在我们开始下载和探索数据之前,先想一想将如何构造项目是很重要的。当建立端到端项目时,我们的主要目标是:
|
||||
|
||||
- 创建一个可行解决方案
|
||||
- 有一个快速运行且占用最小资源的解决方案
|
||||
- 容易可扩展
|
||||
- 写容易理解的代码
|
||||
- 写尽量少的代码
|
||||
|
||||
为了实现这些目标,需要对我们的项目进行良好的构造。一个结构良好的项目遵循几个原则:
|
||||
|
||||
- 分离数据文件和代码文件
|
||||
- 从原始数据中分离生成的数据。
|
||||
- 有一个 `README.md` 文件帮助人们安装和使用该项目。
|
||||
- 有一个 `requirements.txt` 文件列明项目运行所需的所有包。
|
||||
- 有一个单独的 `settings.py` 文件列明其它文件中使用的所有的设置
|
||||
- 例如,如果从多个 `Python` 脚本读取同一个文件,让它们全部 `import` 设置并从一个集中的地方获得文件名是有用的。
|
||||
- 有一个 `.gitignore` 文件,防止大的或密码文件被提交。
|
||||
- 分解任务中每一步可以单独执行的步骤到单独的文件中。
|
||||
- 例如,我们将有一个文件用于读取数据,一个用于创建特征,一个用于做出预测。
|
||||
- 保存中间结果,例如,一个脚本可以输出下一个脚本可读取的文件。
|
||||
- 这使我们无需重新计算就可以在数据处理流程中进行更改。
|
||||
|
||||
|
||||
我们的文件结构大体如下:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
├── processed
|
||||
├── .gitignore
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### 创建初始文件
|
||||
|
||||
首先,我们需要创建一个 `loan-prediction` 文件夹,在此文件夹下面,再创建一个 `data` 文件夹和一个 `processed` 文件夹。`data` 文件夹存放原始数据,`processed` 文件夹存放所有的中间计算结果。
|
||||
|
||||
其次,创建 `.gitignore` 文件,`.gitignore` 文件将保证某些文件被 git 忽略而不会被推送至 GitHub。关于这个文件的一个好的例子是由 OSX 在每一个文件夹都会创建的 `.DS_Store` 文件,`.gitignore` 文件一个很好的范本在[这里](https://github.com/github/gitignore/blob/master/Python.gitignore)。我们还想忽略数据文件,因为它们实在是太大了,同时房利美的条文禁止我们重新分发该数据文件,所以我们应该在我们的文件后面添加以下 2 行:
|
||||
|
||||
```
|
||||
data
|
||||
processed
|
||||
```
|
||||
|
||||
[这里](https://github.com/dataquestio/loan-prediction/blob/master/.gitignore)是该项目的一个关于 .gitignore 文件的例子。
|
||||
|
||||
再次,我们需要创建 `README.md` 文件,它将帮助人们理解该项目。后缀 .md 表示这个文件采用 markdown 格式。Markdown 使你能够写纯文本文件,同时还可以添加你想要的神奇的格式。[这里](https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet)是关于 markdown 的导引。如果你上传一个叫 `README.md` 的文件至 Github,Github 会自动处理该 markdown,同时展示给浏览该项目的人。例子在[这里](https://github.com/dataquestio/loan-prediction)。
|
||||
|
||||
至此,我们仅需在 `README.md` 文件中添加简单的描述:
|
||||
|
||||
```
|
||||
Loan Prediction
|
||||
-----------------------
|
||||
|
||||
Predict whether or not loans acquired by Fannie Mae will go into foreclosure. Fannie Mae acquires loans from other lenders as a way of inducing them to lend more. Fannie Mae releases data on the loans it has acquired and their performance afterwards [here](http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html).
|
||||
```
|
||||
|
||||
现在,我们可以创建 `requirements.txt` 文件了。这会帮助其它人可以很方便地安装我们的项目。我们还不知道我们将会具体用到哪些库,但是以下几个库是需要的:
|
||||
|
||||
```
|
||||
pandas
|
||||
matplotlib
|
||||
scikit-learn
|
||||
numpy
|
||||
ipython
|
||||
scipy
|
||||
```
|
||||
|
||||
以上几个是在 python 数据分析任务中最常用到的库。可以认为我们将会用到大部分这些库。[这里][24]是该项目 `requirements.txt` 文件的一个例子。
|
||||
|
||||
创建 `requirements.txt` 文件之后,你应该安装这些包了。我们将会使用 python3。如果你没有安装 python,你应该考虑使用 [Anaconda][25],它是一个 python 安装程序,同时安装了上面列出的所有包。
|
||||
|
||||
最后,我们可以建立一个空白的 `settings.py` 文件,因为我们的项目还没有任何设置。
|
||||
|
||||
### 获取数据
|
||||
|
||||
一旦我们有了项目的基本架构,我们就可以去获得原始数据。
|
||||
|
||||
房利美对获取数据有一些限制,所以你需要去注册一个账户。在创建完账户之后,你可以找到[在这里][26]的下载页面,你可以按照你所需要的下载或多或少的贷款数据文件。文件格式是 zip,在解压后当然是非常大的。
|
||||
|
||||
为了达到我们这个文章的目的,我们将要下载从 2012 年 1 季度到 2015 年 1 季度的所有数据。接着我们需要解压所有的文件。解压过后,删掉原来的 .zip 格式的文件。最后,loan-prediction 文件夹看起来应该像下面的一样:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
├── .gitignore
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
在下载完数据后,你可以在 shell 命令行中使用 `head` 和 `tail` 命令去查看文件中的行数据,你看到任何的不需要的数据列了吗?在做这件事的同时查阅[列名称的 pdf 文件][27]可能有帮助。
|
||||
|
||||
### 读入数据
|
||||
|
||||
有两个问题让我们的数据难以现在就使用:
|
||||
|
||||
- 贷款数据和执行数据被分割在多个文件中
|
||||
- 每个文件都缺少列名标题
|
||||
|
||||
在我们开始使用数据之前,我们需要首先明白我们要在哪里去存一个贷款数据的文件,同时到哪里去存储一个执行数据的文件。每个文件仅仅需要包括我们关注的那些数据列,同时拥有正确的列名标题。这里有一个小问题是执行数据非常大,因此我们需要尝试去修剪一些数据列。
|
||||
|
||||
第一步是向 `settings.py` 文件中增加一些变量,这个文件中同时也包括了我们原始数据的存放路径和处理出的数据存放路径。我们同时也将添加其他一些可能在接下来会用到的设置数据:
|
||||
|
||||
```
|
||||
DATA_DIR = "data"
|
||||
PROCESSED_DIR = "processed"
|
||||
MINIMUM_TRACKING_QUARTERS = 4
|
||||
TARGET = "foreclosure_status"
|
||||
NON_PREDICTORS = [TARGET, "id"]
|
||||
CV_FOLDS = 3
|
||||
```
|
||||
|
||||
把路径设置在 `settings.py` 中使它们放在一个集中的地方,同时使其修改更加的容易。当在多个文件中用到相同的变量时,你想改变它的话,把他们放在一个地方比分散放在每一个文件时更加容易。[这里的][28]是一个这个工程的示例 `settings.py` 文件
|
||||
|
||||
第二步是创建一个文件名为 `assemble.py`,它将所有的数据分为 2 个文件。当我们运行 `Python assemble.py`,我们在处理数据文件的目录会获得 2 个数据文件。
|
||||
|
||||
接下来我们开始写 `assemble.py` 文件中的代码。首先我们需要为每个文件定义相应的列名标题,因此我们需要查看[列名称的 pdf 文件][29],同时创建在每一个贷款数据和执行数据的文件的数据列的列表:
|
||||
|
||||
```
|
||||
HEADERS = {
|
||||
"Acquisition": [
|
||||
"id",
|
||||
"channel",
|
||||
"seller",
|
||||
"interest_rate",
|
||||
"balance",
|
||||
"loan_term",
|
||||
"origination_date",
|
||||
"first_payment_date",
|
||||
"ltv",
|
||||
"cltv",
|
||||
"borrower_count",
|
||||
"dti",
|
||||
"borrower_credit_score",
|
||||
"first_time_homebuyer",
|
||||
"loan_purpose",
|
||||
"property_type",
|
||||
"unit_count",
|
||||
"occupancy_status",
|
||||
"property_state",
|
||||
"zip",
|
||||
"insurance_percentage",
|
||||
"product_type",
|
||||
"co_borrower_credit_score"
|
||||
],
|
||||
"Performance": [
|
||||
"id",
|
||||
"reporting_period",
|
||||
"servicer_name",
|
||||
"interest_rate",
|
||||
"balance",
|
||||
"loan_age",
|
||||
"months_to_maturity",
|
||||
"maturity_date",
|
||||
"msa",
|
||||
"delinquency_status",
|
||||
"modification_flag",
|
||||
"zero_balance_code",
|
||||
"zero_balance_date",
|
||||
"last_paid_installment_date",
|
||||
"foreclosure_date",
|
||||
"disposition_date",
|
||||
"foreclosure_costs",
|
||||
"property_repair_costs",
|
||||
"recovery_costs",
|
||||
"misc_costs",
|
||||
"tax_costs",
|
||||
"sale_proceeds",
|
||||
"credit_enhancement_proceeds",
|
||||
"repurchase_proceeds",
|
||||
"other_foreclosure_proceeds",
|
||||
"non_interest_bearing_balance",
|
||||
"principal_forgiveness_balance"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
接下来一步是定义我们想要保留的数据列。因为我们要预测一个贷款是否会被撤回,我们可以丢弃执行数据中的许多列。我们将需要保留贷款数据中的所有数据列,因为我们需要尽量多的了解贷款发放时的信息(毕竟我们是在预测贷款发放时这笔贷款将来是否会被撤回)。丢弃数据列将会使我们节省下内存和硬盘空间,同时也会加速我们的代码。
|
||||
|
||||
```
|
||||
SELECT = {
|
||||
"Acquisition": HEADERS["Acquisition"],
|
||||
"Performance": [
|
||||
"id",
|
||||
"foreclosure_date"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
下一步,我们将编写一个函数来连接数据集。下面的代码将:
|
||||
|
||||
- 引用一些需要的库,包括 `settings`。
|
||||
- 定义一个函数 `concatenate`,目的是:
|
||||
- 获取到所有 `data` 目录中的文件名。
|
||||
- 遍历每个文件。
|
||||
- 如果文件不是正确的格式 (不是以我们需要的格式作为开头),我们将忽略它。
|
||||
- 通过使用 Pandas 的 [read_csv][31]函数及正确的设置把文件读入一个[数据帧][30]。
|
||||
- 设置分隔符为`|`,以便所有的字段能被正确读出。
|
||||
- 数据没有标题行,因此设置 `header` 为 `None` 来进行标示。
|
||||
- 从 `HEADERS` 字典中设置正确的标题名称 – 这将会是我们的数据帧中的数据列名称。
|
||||
- 仅选择我们加在 `SELECT` 中的数据帧的列。
|
||||
- 把所有的数据帧共同连接在一起。
|
||||
- 把已经连接好的数据帧写回一个文件。
|
||||
|
||||
```
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
|
||||
def concatenate(prefix="Acquisition"):
|
||||
files = os.listdir(settings.DATA_DIR)
|
||||
full = []
|
||||
for f in files:
|
||||
if not f.startswith(prefix):
|
||||
continue
|
||||
|
||||
data = pd.read_csv(os.path.join(settings.DATA_DIR, f), sep="|", header=None, names=HEADERS[prefix], index_col=False)
|
||||
data = data[SELECT[prefix]]
|
||||
full.append(data)
|
||||
|
||||
full = pd.concat(full, axis=0)
|
||||
|
||||
full.to_csv(os.path.join(settings.PROCESSED_DIR, "{}.txt".format(prefix)), sep="|", header=SELECT[prefix], index=False)
|
||||
```
|
||||
|
||||
我们可以通过调用上面的函数,通过传递的参数 `Acquisition` 和 `Performance` 两次以将所有的贷款和执行文件连接在一起。下面的代码将:
|
||||
|
||||
- 仅在命令行中运行 `python assemble.py` 时执行。
|
||||
- 将所有的数据连接在一起,并且产生 2 个文件:
|
||||
- `processed/Acquisition.txt`
|
||||
- `processed/Performance.txt`
|
||||
|
||||
```
|
||||
if __name__ == "__main__":
|
||||
concatenate("Acquisition")
|
||||
concatenate("Performance")
|
||||
```
|
||||
|
||||
我们现在拥有了一个漂亮的,划分过的 `assemble.py` 文件,它很容易执行,也容易建立。通过像这样把问题分解为一块一块的,我们构建工程就会变的容易许多。不用一个可以做所有工作的凌乱脚本,我们定义的数据将会在多个脚本间传递,同时使脚本间完全的彼此隔离。当你正在一个大的项目中工作时,这样做是一个好的想法,因为这样可以更加容易修改其中的某一部分而不会引起其他项目中不关联部分产生预料之外的结果。
|
||||
|
||||
一旦我们完成 `assemble.py` 脚本文件,我们可以运行 `python assemble.py` 命令。你可以[在这里][32]查看完整的 `assemble.py` 文件。
|
||||
|
||||
这将会在 `processed` 目录下产生 2 个文件:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
├── .gitignore
|
||||
├── assemble.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
|
||||
### 计算来自执行数据的值
|
||||
|
||||
接下来我们会计算来自 `processed/Performance.txt` 中的值。我们要做的就是推测这些资产是否被取消赎回权。如果能够计算出来,我们只要看一下关联到贷款的执行数据的参数 `foreclosure_date` 就可以了。如果这个参数的值是 `None`,那么这些资产肯定没有收回。为了避免我们的样例中只有少量的执行数据,我们会为每个贷款计算出执行数据文件中的行数。这样我们就能够从我们的训练数据中筛选出贷款数据,排除了一些执行数据。
|
||||
|
||||
下面是我认为贷款数据和执行数据的关系:
|
||||
|
||||

|
||||
|
||||
在上面的表格中,贷款数据中的每一行数据都关联到执行数据中的多行数据。在执行数据中,在取消赎回权的时候 `foreclosure_date` 就会出现在该季度,而之前它是空的。一些贷款还没有被取消赎回权,所以与执行数据中的贷款数据有关的行在 `foreclosure_date` 列都是空格。
|
||||
|
||||
我们需要计算 `foreclosure_status` 的值,它的值是布尔类型,可以表示一个特殊的贷款数据 `id` 是否被取消赎回权过,还有一个参数 `performance_count` ,它记录了执行数据中每个贷款 `id` 出现的行数。
|
||||
|
||||
计算这些行数有多种不同的方法:
|
||||
|
||||
- 我们能够读取所有的执行数据,然后我们用 Pandas 的 [groupby](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.groupby.html) 方法在 DataFrame 中计算出与每个贷款 `id` 有关的行的行数,然后就可以查看贷款 `id` 的 `foreclosure_date` 值是否为 `None` 。
|
||||
- 这种方法的优点是从语法上来说容易执行。
|
||||
- 它的缺点需要读取所有的 129236094 行数据,这样就会占用大量内存,并且运行起来极慢。
|
||||
- 我们可以读取所有的执行数据,然后在贷款 DataFrame 上使用 [apply](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.apply.html) 去计算每个贷款 `id` 出现的次数。
|
||||
- 这种方法的优点是容易理解。
|
||||
- 缺点是需要读取所有的 129236094 行数据。这样会占用大量内存,并且运行起来极慢。
|
||||
- 我们可以在迭代访问执行数据中的每一行数据,而且会建立一个单独的计数字典。
|
||||
- 这种方法的优点是数据不需要被加载到内存中,所以运行起来会很快且不需要占用内存。
|
||||
- 缺点是这样的话理解和执行上可能有点耗费时间,我们需要对每一行数据进行语法分析。
|
||||
|
||||
加载所有的数据会非常耗费内存,所以我们采用第三种方法。我们要做的就是迭代执行数据中的每一行数据,然后为每一个贷款 `id` 在字典中保留一个计数。在这个字典中,我们会计算出贷款 `id` 在执行数据中出现的次数,而且看看 `foreclosure_date` 是否是 `None` 。我们可以查看 `foreclosure_status` 和 `performance_count` 的值 。
|
||||
|
||||
我们会新建一个 `annotate.py` 文件,文件中的代码可以计算这些值。我们会使用下面的代码:
|
||||
|
||||
- 导入需要的库
|
||||
- 定义一个函数 `count_performance_rows` 。
|
||||
- 打开 `processed/Performance.txt` 文件。这不是在内存中读取文件而是打开了一个文件标识符,这个标识符可以用来以行为单位读取文件。
|
||||
- 迭代文件的每一行数据。
|
||||
- 使用分隔符`|`分开每行的不同数据。
|
||||
- 检查 `loan_id` 是否在计数字典中。
|
||||
- 如果不存在,把它加进去。
|
||||
- `loan_id` 的 `performance_count` 参数自增 1 次,因为我们这次迭代也包含其中。
|
||||
- 如果 `date` 不是 `None ,我们就会知道贷款被取消赎回权了,然后为 `foreclosure_status` 设置合适的值。
|
||||
|
||||
```
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
|
||||
def count_performance_rows():
|
||||
counts = {}
|
||||
with open(os.path.join(settings.PROCESSED_DIR, "Performance.txt"), 'r') as f:
|
||||
for i, line in enumerate(f):
|
||||
if i == 0:
|
||||
# Skip header row
|
||||
continue
|
||||
loan_id, date = line.split("|")
|
||||
loan_id = int(loan_id)
|
||||
if loan_id not in counts:
|
||||
counts[loan_id] = {
|
||||
"foreclosure_status": False,
|
||||
"performance_count": 0
|
||||
}
|
||||
counts[loan_id]["performance_count"] += 1
|
||||
if len(date.strip()) > 0:
|
||||
counts[loan_id]["foreclosure_status"] = True
|
||||
return counts
|
||||
```
|
||||
|
||||
### 获取值
|
||||
|
||||
只要我们创建了计数字典,我们就可以使用一个函数通过一个 `loan_id` 和一个 `key` 从字典中提取到需要的参数的值:
|
||||
|
||||
```
|
||||
def get_performance_summary_value(loan_id, key, counts):
|
||||
value = counts.get(loan_id, {
|
||||
"foreclosure_status": False,
|
||||
"performance_count": 0
|
||||
})
|
||||
return value[key]
|
||||
```
|
||||
|
||||
上面的函数会从 `counts` 字典中返回合适的值,我们也能够为贷款数据中的每一行赋一个 `foreclosure_status` 值和一个 `performance_count` 值。如果键不存在,字典的 [get][33] 方法会返回一个默认值,所以在字典中不存在键的时候我们就可以得到一个可知的默认值。
|
||||
|
||||
### 转换数据
|
||||
|
||||
我们已经在 `annotate.py` 中添加了一些功能,现在我们来看一看数据文件。我们需要将贷款到的数据转换到训练数据集来进行机器学习算法的训练。这涉及到以下几件事情:
|
||||
|
||||
- 转换所有列为数字。
|
||||
- 填充缺失值。
|
||||
- 为每一行分配 `performance_count` 和 `foreclosure_status`。
|
||||
- 移除出现执行数据很少的行(`performance_count` 计数低)。
|
||||
|
||||
我们有几个列是文本类型的,看起来对于机器学习算法来说并不是很有用。然而,它们实际上是分类变量,其中有很多不同的类别代码,例如 `R`,`S` 等等. 我们可以把这些类别标签转换为数值:
|
||||
|
||||

|
||||
|
||||
通过这种方法转换的列我们可以应用到机器学习算法中。
|
||||
|
||||
还有一些包含日期的列 (`first_payment_date` 和 `origination_date`)。我们可以将这些日期放到两个列中:
|
||||
|
||||

|
||||
|
||||
在下面的代码中,我们将转换贷款数据。我们将定义一个函数如下:
|
||||
|
||||
- 在 `acquisition` 中创建 `foreclosure_status` 列,并从 `counts` 字典中得到值。
|
||||
- 在 `acquisition` 中创建 `performance_count` 列,并从 `counts` 字典中得到值。
|
||||
- 将下面的列从字符串转换为整数:
|
||||
- `channel`
|
||||
- `seller`
|
||||
- `first_time_homebuyer`
|
||||
- `loan_purpose`
|
||||
- `property_type`
|
||||
- `occupancy_status`
|
||||
- `property_state`
|
||||
- `product_type`
|
||||
- 将 `first_payment_date` 和 `origination_date` 分别转换为两列:
|
||||
- 通过斜杠分离列。
|
||||
- 将第一部分分离成 `month` 列。
|
||||
- 将第二部分分离成 `year` 列。
|
||||
- 删除该列。
|
||||
- 最后,我们得到 `first_payment_month`、`first_payment_year`、`rigination_month` 和 `origination_year`。
|
||||
- 所有缺失值填充为 `-1`。
|
||||
|
||||
```
|
||||
def annotate(acquisition, counts):
|
||||
acquisition["foreclosure_status"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "foreclosure_status", counts))
|
||||
acquisition["performance_count"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "performance_count", counts))
|
||||
for column in [
|
||||
"channel",
|
||||
"seller",
|
||||
"first_time_homebuyer",
|
||||
"loan_purpose",
|
||||
"property_type",
|
||||
"occupancy_status",
|
||||
"property_state",
|
||||
"product_type"
|
||||
]:
|
||||
acquisition[column] = acquisition[column].astype('category').cat.codes
|
||||
|
||||
for start in ["first_payment", "origination"]:
|
||||
column = "{}_date".format(start)
|
||||
acquisition["{}_year".format(start)] = pd.to_numeric(acquisition[column].str.split('/').str.get(1))
|
||||
acquisition["{}_month".format(start)] = pd.to_numeric(acquisition[column].str.split('/').str.get(0))
|
||||
del acquisition[column]
|
||||
|
||||
acquisition = acquisition.fillna(-1)
|
||||
acquisition = acquisition[acquisition["performance_count"] > settings.MINIMUM_TRACKING_QUARTERS]
|
||||
return acquisition
|
||||
```
|
||||
|
||||
### 聚合到一起
|
||||
|
||||
我们差不多准备就绪了,我们只需要再在 `annotate.py` 添加一点点代码。在下面代码中,我们将:
|
||||
|
||||
- 定义一个函数来读取贷款的数据。
|
||||
- 定义一个函数来写入处理过的数据到 `processed/train.csv`。
|
||||
- 如果该文件在命令行以 `python annotate.py` 的方式运行:
|
||||
- 读取贷款数据。
|
||||
- 计算执行数据的计数,并将其赋予 `counts`。
|
||||
- 转换 `acquisition` DataFrame。
|
||||
- 将` acquisition` DataFrame 写入到 `train.csv`。
|
||||
|
||||
```
|
||||
def read():
|
||||
acquisition = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "Acquisition.txt"), sep="|")
|
||||
return acquisition
|
||||
|
||||
def write(acquisition):
|
||||
acquisition.to_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"), index=False)
|
||||
|
||||
if __name__ == "__main__":
|
||||
acquisition = read()
|
||||
counts = count_performance_rows()
|
||||
acquisition = annotate(acquisition, counts)
|
||||
write(acquisition)
|
||||
```
|
||||
|
||||
修改完成以后,确保运行 `python annotate.py` 来生成 `train.csv` 文件。 你可以在[这里][34]找到完整的 `annotate.py` 文件。
|
||||
|
||||
现在文件夹看起来应该像这样:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
│ ├── train.csv
|
||||
├── .gitignore
|
||||
├── annotate.py
|
||||
├── assemble.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### 找到误差标准
|
||||
|
||||
我们已经完成了训练数据表的生成,现在我们需要最后一步,生成预测。我们需要找到误差的标准,以及该如何评估我们的数据。在这种情况下,因为有很多的贷款没有被取消赎回权,所以根本不可能做到精确的计算。
|
||||
|
||||
我们需要读取训练数据,并且计算 `foreclosure_status` 列的计数,我们将得到如下信息:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
import settings
|
||||
|
||||
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
|
||||
train["foreclosure_status"].value_counts()
|
||||
```
|
||||
|
||||
```
|
||||
False 4635982
|
||||
True 1585
|
||||
Name: foreclosure_status, dtype: int64
|
||||
```
|
||||
|
||||
因为只有很少的贷款被取消赎回权,只需要检查正确预测的标签的百分比就意味着我们可以创建一个机器学习模型,来为每一行预测 `False`,并能取得很高的精确度。相反,我们想要使用一个度量来考虑分类的不平衡,确保我们可以准确预测。我们要避免太多的误报率(预测贷款被取消赎回权,但是实际没有),也要避免太多的漏报率(预测贷款没有别取消赎回权,但是实际被取消了)。对于这两个来说,漏报率对于房利美来说成本更高,因为他们买的贷款可能是他们无法收回投资的贷款。
|
||||
|
||||
所以我们将定义一个漏报率,就是模型预测没有取消赎回权但是实际上取消了,这个数除以总的取消赎回权数。这是“缺失的”实际取消赎回权百分比的模型。下面看这个图表:
|
||||
|
||||

|
||||
|
||||
通过上面的图表,有 1 个贷款预测不会取消赎回权,但是实际上取消了。如果我们将这个数除以实际取消赎回权的总数 2,我们将得到漏报率 50%。 我们将使用这个误差标准,因此我们可以评估一下模型的行为。
|
||||
|
||||
### 设置机器学习分类器
|
||||
|
||||
我们使用交叉验证预测。通过交叉验证法,我们将数据分为3组。按照下面的方法来做:
|
||||
|
||||
- 用组 1 和组 2 训练模型,然后用该模型来预测组 3
|
||||
- 用组 1 和组 3 训练模型,然后用该模型来预测组 2
|
||||
- 用组 2 和组 3 训练模型,然后用该模型来预测组 1
|
||||
|
||||
将它们分割到不同的组,这意味着我们永远不会用相同的数据来为其预测训练模型。这样就避免了过拟合。如果过拟合,我们将错误地拉低了漏报率,这使得我们难以改进算法或者应用到现实生活中。
|
||||
|
||||
[Scikit-learn][35] 有一个叫做 [cross_val_predict][36] ,它可以帮助我们理解交叉算法.
|
||||
|
||||
我们还需要一种算法来帮我们预测。我们还需要一个分类器来做[二元分类][37]。目标变量 `foreclosure_status` 只有两个值, `True` 和 `False`。
|
||||
|
||||
这里我们用 [逻辑回归算法][38],因为它能很好的进行二元分类,并且运行很快,占用内存很小。我们来说一下它是如何工作的:不使用像随机森林一样多树结构,也不像支持向量机一样做复杂的转换,逻辑回归算法涉及更少的步骤和更少的矩阵。
|
||||
|
||||
我们可以使用 scikit-learn 实现的[逻辑回归分类器][39]算法。我们唯一需要注意的是每个类的权重。如果我们使用等权重的类,算法将会预测每行都为 `false`,因为它总是试图最小化误差。不管怎样,我们重视有多少贷款要被取消赎回权而不是有多少不能被取消。因此,我们给[逻辑回归][40]类的 `class_weight` 关键字传递 `balanced` 参数,让算法可以为不同 counts 的每个类考虑不同的取消赎回权的权重。这将使我们的算法不会为每一行都预测 `false`,而是两个类的误差水平一致。
|
||||
|
||||
### 做出预测
|
||||
|
||||
既然完成了前期准备,我们可以开始准备做出预测了。我将创建一个名为 `predict.py` 的新文件,它会使用我们在最后一步创建的 `train.csv` 文件。下面的代码:
|
||||
|
||||
- 导入所需的库
|
||||
- 创建一个名为 `cross_validate` 的函数:
|
||||
- 使用正确的关键词参数创建逻辑回归分类器
|
||||
- 创建用于训练模型的数据列的列表,移除 `id` 和 `foreclosure_status` 列
|
||||
- 交叉验证 `train` DataFrame
|
||||
- 返回预测结果
|
||||
|
||||
```python
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
from sklearn import cross_validation
|
||||
from sklearn.linear_model import LogisticRegression
|
||||
from sklearn import metrics
|
||||
|
||||
def cross_validate(train):
|
||||
clf = LogisticRegression(random_state=1, class_weight="balanced")
|
||||
|
||||
predictors = train.columns.tolist()
|
||||
predictors = [p for p in predictors if p not in settings.NON_PREDICTORS]
|
||||
|
||||
predictions = cross_validation.cross_val_predict(clf, train[predictors], train[settings.TARGET], cv=settings.CV_FOLDS)
|
||||
return predictions
|
||||
```
|
||||
|
||||
### 预测误差
|
||||
|
||||
现在,我们仅仅需要写一些函数来计算误差。下面的代码:
|
||||
|
||||
- 创建函数 `compute_error`:
|
||||
- 使用 scikit-learn 计算一个简单的精确分数(与实际 `foreclosure_status` 值匹配的预测百分比)
|
||||
- 创建函数 `compute_false_negatives`:
|
||||
- 为了方便,将目标和预测结果合并到一个 DataFrame
|
||||
- 查找漏报率
|
||||
- 找到原本应被预测模型取消赎回权,但实际没有取消的贷款数目
|
||||
- 除以没被取消赎回权的贷款总数目
|
||||
|
||||
```python
|
||||
def compute_error(target, predictions):
|
||||
return metrics.accuracy_score(target, predictions)
|
||||
|
||||
def compute_false_negatives(target, predictions):
|
||||
df = pd.DataFrame({"target": target, "predictions": predictions})
|
||||
return df[(df["target"] == 1) & (df["predictions"] == 0)].shape[0] / (df[(df["target"] == 1)].shape[0] + 1)
|
||||
|
||||
def compute_false_positives(target, predictions):
|
||||
df = pd.DataFrame({"target": target, "predictions": predictions})
|
||||
return df[(df["target"] == 0) & (df["predictions"] == 1)].shape[0] / (df[(df["target"] == 0)].shape[0] + 1)
|
||||
```
|
||||
|
||||
### 聚合到一起
|
||||
|
||||
现在,我们可以把函数都放在 `predict.py`。下面的代码:
|
||||
|
||||
- 读取数据集
|
||||
- 计算交叉验证预测
|
||||
- 计算上面的 3 个误差
|
||||
- 打印误差
|
||||
|
||||
```python
|
||||
def read():
|
||||
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
|
||||
return train
|
||||
|
||||
if __name__ == "__main__":
|
||||
train = read()
|
||||
predictions = cross_validate(train)
|
||||
error = compute_error(train[settings.TARGET], predictions)
|
||||
fn = compute_false_negatives(train[settings.TARGET], predictions)
|
||||
fp = compute_false_positives(train[settings.TARGET], predictions)
|
||||
print("Accuracy Score: {}".format(error))
|
||||
print("False Negatives: {}".format(fn))
|
||||
print("False Positives: {}".format(fp))
|
||||
```
|
||||
|
||||
一旦你添加完代码,你可以运行 `python predict.py` 来产生预测结果。运行结果向我们展示漏报率为 `.26`,这意味着我们没能预测 `26%` 的取消贷款。这是一个好的开始,但仍有很多改善的地方!
|
||||
|
||||
你可以在[这里][41]找到完整的 `predict.py` 文件。
|
||||
|
||||
你的文件树现在看起来像下面这样:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
│ ├── train.csv
|
||||
├── .gitignore
|
||||
├── annotate.py
|
||||
├── assemble.py
|
||||
├── predict.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### 撰写 README
|
||||
|
||||
既然我们完成了端到端的项目,那么我们可以撰写 `README.md` 文件了,这样其他人便可以知道我们做的事,以及如何复制它。一个项目典型的 `README.md` 应该包括这些部分:
|
||||
|
||||
- 一个高水准的项目概览,并介绍项目目的
|
||||
- 任何必需的数据和材料的下载地址
|
||||
- 安装命令
|
||||
- 如何安装要求依赖
|
||||
- 使用命令
|
||||
- 如何运行项目
|
||||
- 每一步之后会看到的结果
|
||||
- 如何为这个项目作贡献
|
||||
- 扩展项目的下一步计划
|
||||
|
||||
[这里][42] 是这个项目的一个 `README.md` 样例。
|
||||
|
||||
### 下一步
|
||||
|
||||
恭喜你完成了端到端的机器学习项目!你可以在[这里][43]找到一个完整的示例项目。一旦你完成了项目,把它上传到 [Github][44] 是一个不错的主意,这样其他人也可以看到你的文件夹的部分项目。
|
||||
|
||||
这里仍有一些留待探索数据的角度。总的来说,我们可以把它们分割为 3 类: 扩展这个项目并使它更加精确,发现其他可以预测的列,并探索数据。这是其中一些想法:
|
||||
|
||||
- 在 `annotate.py` 中生成更多的特性
|
||||
- 切换 `predict.py` 中的算法
|
||||
- 尝试使用比我们发表在这里的更多的房利美数据
|
||||
- 添加对未来数据进行预测的方法。如果我们添加更多数据,我们所写的代码仍然可以起作用,这样我们可以添加更多过去和未来的数据。
|
||||
- 尝试看看是否你能预测一个银行原本是否应该发放贷款(相对地,房利美是否应该获得贷款)
|
||||
- 移除 `train` 中银行在发放贷款时间的不知道的任何列
|
||||
- 当房利美购买贷款时,一些列是已知的,但之前是不知道的
|
||||
- 做出预测
|
||||
- 探索是否你可以预测除了 `foreclosure_status` 的其他列
|
||||
- 你可以预测在销售时资产值是多少?
|
||||
- 探索探索执行数据更新之间的细微差别
|
||||
- 你能否预测借款人会逾期还款多少次?
|
||||
- 你能否标出的典型贷款周期?
|
||||
- 将数据按州或邮政编码标出
|
||||
- 你看到一些有趣的模式了吗?
|
||||
|
||||
如果你建立了任何有趣的东西,请在评论中让我们知道!
|
||||
|
||||
如果你喜欢这篇文章,或许你也会喜欢阅读“构建你的数据科学作品集”系列的其他文章:
|
||||
|
||||
- [用数据讲故事][45]
|
||||
- [如何搭建一个数据科学博客][46]
|
||||
- [构建一个可以帮你找到工作的数据科学作品集的关键][47]
|
||||
- [找到数据科学用的数据集的 17 个地方][48]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.dataquest.io/blog/data-science-portfolio-machine-learning/
|
||||
|
||||
作者:[Vik Paruchuri][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves), [zky001](https://github.com/zky001), [vim-kakali](https://github.com/vim-kakali), [cposture](https://github.com/cposture), [ideas4u](https://github.com/ideas4u)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.dataquest.io/blog
|
||||
[1]: https://www.dataquest.io/blog/data-science-portfolio-machine-learning/#email-signup
|
||||
[2]: https://github.com/dataquestio/loan-prediction
|
||||
[3]: https://www.dataquest.io/blog/data-science-portfolio-project/
|
||||
[4]: https://atom.io/
|
||||
[5]: https://www.jetbrains.com/pycharm/
|
||||
[6]: https://github.com/
|
||||
[7]: http://pandas.pydata.org/
|
||||
[8]: http://scikit-learn.org/
|
||||
[9]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
|
||||
[10]: https://collegescorecard.ed.gov/data/
|
||||
[11]: https://reddit.com/r/datasets
|
||||
[12]: https://cloud.google.com/bigquery/public-data/#usa-names
|
||||
[13]: https://github.com/caesar0301/awesome-public-datasets
|
||||
[14]: http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html
|
||||
[15]: http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html
|
||||
[16]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_glossary.pdf
|
||||
[17]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_faq.pdf
|
||||
[18]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[19]: https://loanperformancedata.fanniemae.com/lppub-docs/acquisition-sample-file.txt
|
||||
[20]: https://loanperformancedata.fanniemae.com/lppub-docs/performance-sample-file.txt
|
||||
[21]: https://github.com/dataquestio/loan-prediction/blob/master/.gitignore
|
||||
[22]: https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet
|
||||
[23]: https://github.com/dataquestio/loan-prediction
|
||||
[24]: https://github.com/dataquestio/loan-prediction/blob/master/requirements.txt
|
||||
[25]: https://www.continuum.io/downloads
|
||||
[26]: https://loanperformancedata.fanniemae.com/lppub/index.html
|
||||
[27]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[28]: https://github.com/dataquestio/loan-prediction/blob/master/settings.py
|
||||
[29]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[30]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
|
||||
[31]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html
|
||||
[32]: https://github.com/dataquestio/loan-prediction/blob/master/assemble.py
|
||||
[33]: https://docs.python.org/3/library/stdtypes.html#dict.get
|
||||
[34]: https://github.com/dataquestio/loan-prediction/blob/master/annotate.py
|
||||
[35]: http://scikit-learn.org/
|
||||
[36]: http://scikit-learn.org/stable/modules/generated/sklearn.cross_validation.cross_val_predict.html
|
||||
[37]: https://en.wikipedia.org/wiki/Binary_classification
|
||||
[38]: https://en.wikipedia.org/wiki/Logistic_regression
|
||||
[39]: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
|
||||
[40]: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
|
||||
[41]: https://github.com/dataquestio/loan-prediction/blob/master/predict.py
|
||||
[42]: https://github.com/dataquestio/loan-prediction/blob/master/README.md
|
||||
[43]: https://github.com/dataquestio/loan-prediction
|
||||
[44]: https://www.github.com/
|
||||
[45]: https://www.dataquest.io/blog/data-science-portfolio-project/
|
||||
[46]: https://www.dataquest.io/blog/how-to-setup-a-data-science-blog/
|
||||
[47]: https://www.dataquest.io/blog/build-a-data-science-portfolio/
|
||||
[48]: https://www.dataquest.io/blog/free-datasets-for-projects
|
||||
@ -0,0 +1,119 @@
|
||||
如何在后台运行 Linux 命令并且将进程脱离终端
|
||||
=================
|
||||
|
||||
在本指南中,我们将会阐明一个在 [Linux 系统中进程管理][8]的简单但是重要的概念,那就是如何从它的控制终端完全脱离一个进程。
|
||||
|
||||
当一个进程与终端关联在一起时,可能会出现两种问题:
|
||||
|
||||
1. 你的控制终端充满了很多输出数据或者错误及诊断信息
|
||||
2. 如果发生终端关闭的情况,进程连同它的子进程都将会终止
|
||||
|
||||
为了解决上面两个问题,你需要从一个控制终端完全脱离一个进程。在我们实际上解决这个问题之前,让我们先简要的介绍一下,如何在后台运行一个进程。
|
||||
|
||||
### 如何在后台开始一个 Linux 进程或者命令行
|
||||
|
||||
如果一个进程已经运行,例如下面的 [tar 命令行的例子][7],简单的按下 `Ctrl+Z` 就可以停止它(LCTT 译注:这里说的“停止”,不是终止,而是“暂停”的意思),然后输入命令 `bg` 就可以继续以一个任务在后台运行了。
|
||||
|
||||
你可以通过输入 `jobs` 查看所有的后台任务。但是,标准输入(STDIN)、标准输出(STDOUT)和标准错误(STDERR)依旧掺杂到控制台中。
|
||||
|
||||
```
|
||||
$ tar -czf home.tar.gz .
|
||||
$ bg
|
||||
$ jobs
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
*在后台运行 Linux 命令*
|
||||
|
||||
你也可以直接使用符号 `&` 在后台运行一个进程:
|
||||
|
||||
```
|
||||
$ tar -czf home.tar.gz . &
|
||||
$ jobs
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
*在后台开始一个 Linux 进程*
|
||||
|
||||
看一下下面的这个例子,虽然 [tar 命令][4]是作为一个后台任务开始的,但是错误信息依旧发送到终端,这表示,进程依旧和控制终端关联在一起。
|
||||
|
||||
```
|
||||
$ tar -czf home.tar.gz . &
|
||||
$ jobs
|
||||
|
||||
```
|
||||
|
||||
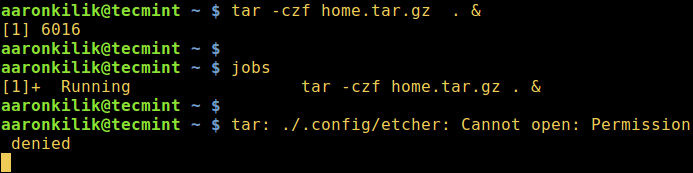
|
||||
|
||||
*运行在后台的 Linux 进程信息*
|
||||
|
||||
### 退出控制台之后,保持 Linux 进程的运行
|
||||
|
||||
我们将使用 `disown` 命令,它在一个进程已经运行并且被放在后台之后使用,它的作用是从 shell 的活动任务列表中移走一个 shell 任务,因此,对于该任务,你将再也不能使用 `fg` 、 `bg` 命令了。
|
||||
|
||||
而且,当你关闭控制控制终端,这个任务将不会挂起(暂停)或者向任何一个子任务发送 SIGHUP 信号。
|
||||
|
||||
让我们看一下先下面的这个使用 bash 中内置命令 `disown` 的例子。
|
||||
|
||||
```
|
||||
$ sudo rsync Templates/* /var/www/html/files/ &
|
||||
$ jobs
|
||||
$ disown -h %1
|
||||
$ jobs
|
||||
|
||||
```
|
||||
|
||||
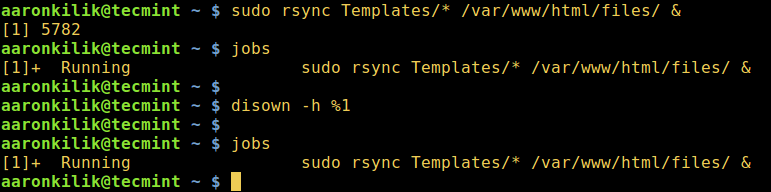
|
||||
|
||||
*关闭终端之后,保持 Linux 进程运行*
|
||||
|
||||
你也可以使用 `nohup` 命令,这个命令也可以在用户退出 shell 之后保证进程在后台继续运行。
|
||||
|
||||
```
|
||||
$ nohup tar -czf iso.tar.gz Templates/* &
|
||||
$ jobs
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
*关闭 shell 之后把 Linux 进程置于后台*
|
||||
|
||||
### 从控制终端脱离一个 Linux 进程
|
||||
|
||||
因此,为了彻底从控制终端脱离一个程序,对于图形用户界面 (GUI) 的程序例如 firefox 来说,使用下面的命令行格式会更有效:
|
||||
|
||||
```
|
||||
$ firefox </dev/null &>/dev/null &
|
||||
|
||||
```
|
||||
|
||||
在 Linux 上,/dev/null 是一个特殊的文件设备,它会忽略所有的写在它上面的数据,上述命令,输入来源和输出发送目标都是 /dev/null。
|
||||
|
||||
作为结束陈述,运行一个连接到控制终端的进程,作为用户你将会在你的终端上看到这个进程数据的许多行的输出,也包含错误信息。同样,当你关闭一个控制终端,你的进程和子进程都将会终止。
|
||||
|
||||
重要的是,对于这个主题任何的问题或者观点,通过下面的评论联系我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/run-linux-command-process-in-background-detach-process/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[yangmingming](https://github.com/yangmingming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2016/10/Put-Linux-Process-in-Background.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/10/Keep-Linux-Processes-Running.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/10/Linux-Process-Running-in-Background-Message.png
|
||||
[4]:https://linux.cn/article-7802-1.html
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/10/Start-Linux-Process-in-Background.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2016/10/Run-Linux-Command-in-Background.png
|
||||
[7]:https://linux.cn/article-7802-1.html
|
||||
[8]:http://www.tecmint.com/monitor-linux-processes-and-set-process-limits-per-user/
|
||||
@ -0,0 +1,73 @@
|
||||
苹果新的文件系统 APFS 比 HFS+ 强在哪里?
|
||||
===============
|
||||
|
||||

|
||||
|
||||
如果你一直关注苹果最新版的 macOS 的消息,你可能已经注意到苹果文件系统 APFS。这是不太让人感冒的话题之一。然而,它是支撑了操作系统用户体验的核心结构。APFS 将在 2017 年之前完成,不过你现在可以在 Sierra(最新版的 macOS) 上面体验一番开发者预览版。
|
||||
|
||||
### 特色与改进
|
||||
|
||||
先快速科普一下,**文件系统**是操作系统用于存储和检索数据的基本结构,不同的文件系统采用不同的方式来实现这个任务。随着计算机变得越来越快,新生代的文件系统已经从计算机速度的提升中获益,以提供新功能和适应现代存储需求。
|
||||
|
||||
HFS+,作为今天新一代 Mac 的附带文件系统,已经 18 岁了。它的祖先 HFS 比 Tom Cruise 的兄弟情影片“壮志凌云”还要老。它有点像一辆老丰田。它仍然可以工作(也许惊人的好),但是它不再得到人们的嘉奖。
|
||||
|
||||
APFS 不完全是 HFS+ 的升级版,因为相对现在而言,它是一个大幅度的飞跃。虽然这对苹果用户来说是一个重大的升级,但似乎这看起来更像是苹果赶上了其它系统,而不是超越了它们。然而,更新还进展得非常慢。
|
||||
|
||||
### 克隆和数据完整性
|
||||
|
||||

|
||||
|
||||
APFS 使用称为写时复制(copy-on-write)的方案来生成重复文件的即时克隆。在 HFS+ 下,当用户复制文件的时候,每一个比特(二进制中的“位”)都会被复制。而 APFS 则通过操作元数据并分配磁盘空间来创建克隆。但是,在修改复制的文件之前都不会复制任何比特。当克隆体与原始副本分离的时候,那些改动(并且只有那些改动)才会被保存。
|
||||
|
||||
写时复制还提高了数据的完整性。在其它系统下,如果你卸载卷导致覆写操作挂起的话,你可能会发现你的文件系统有一部分与其它部分不同步。写时复制则通过将改动写入到可用的磁盘空间而不是覆盖旧文件来避免这个问题。直到写入操作成功完成前,旧文件都是正式版本。只有当新文件被成功复制时,旧文件才会被清除。
|
||||
|
||||
### 系统快照
|
||||
|
||||

|
||||
|
||||
快照是写时复制架构给你带来的一个主要的升级。快照是文件系统在某个时间点的一个只读的可装载映像。随着文件系统发生改动,只有改动的比特会被更改。这可以让备份更简单,更可靠。考虑到时间机器(一个苹果出品的备份工具)已经成为硬链接的痛点,这可能是一个重大的升级。
|
||||
|
||||
### 输入/输出的服务质量(QoS)
|
||||
|
||||
你可能已经在你的路由器说明书看到了服务质量(QoS)这个名词。QoS 优先分配带宽使用以避免降低优先任务的速度。在你的路由器上,它采用用户定义的规则来为指定任务提供最大的带宽。据报道,苹果的 QoS 会优先考虑用户操作,例如活跃窗口。而诸如时间机器备份这些后台任务将会被降级。所以,这意味着更少的闲暇时光了?
|
||||
|
||||
### 本地加密
|
||||
|
||||

|
||||
|
||||
在后斯诺登时代,加密成为众所关注的了。越来越多的苹果产品正在强调其系统安全性。内置强大的加密机制并不让人感到意外。包括 APFS 在内,苹果正在采用更加细致入微的加密方案,要么不加密,要么就将加密进行到底。用户可以使用单个密钥来为所有数据加密,或者使用多个加密密钥分别锁定单个文件和文件夹。当然,你也可以不加密,只要你对坏蛋无所忌惮。
|
||||
|
||||
### 固态硬盘和闪存优化
|
||||
|
||||

|
||||
|
||||
闪存优化已经被列为 APFS 的一个亮点功能,不过它的实现并没有那么振奋人心。苹果选择将一些典型的固态硬盘芯片的处理功能迁移到操作系统,而没有深度系统集成的优势。这更像是让文件系统感知固态硬盘,而不是为它们做优化。
|
||||
|
||||
### 动态分区调整
|
||||
|
||||

|
||||
|
||||
APFS 驱动器的逻辑分区可以动态调整自身大小。用户只需指定所需分区的数量,然后文件系统会在运行时进行磁盘分配。每个分区只占用其用于存储文件的磁盘空间。剩余的磁盘空间会由任何分区获取。这种设计很整洁,不过比起其它文件系统,这更像是元文件夹。
|
||||
|
||||
### 结论
|
||||
|
||||
这是否重要?对于开发者和高级用户来说真是棒极了。对于一般的 Mac 用户应该没有太多的外部差异。虽然升级是重大的举措,但仍然存在一些缺失的部分。本地压缩显然还没有,对用户数据进行的校验也没有。当然,2017 年还没到,一切皆有可能,让我们拭目以待。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/apple-file-system-better-than-hfs/
|
||||
|
||||
作者:[Alexander Fox][a]
|
||||
译者:[OneNewLife](https://github.com/OneNewLife)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/alexfox-2-2-2/
|
||||
[1]:https://www.maketecheasier.com/apple-file-system-better-than-hfs/#respond
|
||||
[3]:https://www.maketecheasier.com/schedule-windows-empty-recycle-bin/
|
||||
[4]:https://www.maketecheasier.com/manage-automatic-wordpress-updates/
|
||||
[5]:mailto:?subject=What%20is%20Apple%20File%20System%20and%20Why%20is%20it%20Better%20than%20HFS+?&body=https%3A%2F%2Fwww.maketecheasier.com%2Fapple-file-system-better-than-hfs%2F
|
||||
[6]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fapple-file-system-better-than-hfs%2F&text=What+is+Apple+File+System+and+Why+is+it+Better+than+HFS%2B%3F
|
||||
[7]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fapple-file-system-better-than-hfs%2F
|
||||
[8]:https://www.maketecheasier.com/category/mac-tips/
|
||||
64
published/20161026 2 free desktop recording tools to try.md
Normal file
64
published/20161026 2 free desktop recording tools to try.md
Normal file
@ -0,0 +1,64 @@
|
||||
两款免费的 Linux 桌面录制工具:SimpleScreenRecorder 和 Kazam
|
||||
====
|
||||
|
||||
> 桌面录制工具可以帮做我们快速高效的制作教学视频和在线示范。
|
||||
|
||||

|
||||
|
||||
一图胜千言,但一段视频演示则可以让你不用大费口舌。我是一个“视觉学习者”,亲眼目睹一件事情的发生对我的学习大有裨益。我也曾观察发现,如果学生实际看到应用程序的设置流程或者代码的编写过程,他们就能从中受益良多。所以,录屏工具是制作教学视频的绝佳工具。在本文中我将介绍一下两款开源桌面录制工具: [SimpleScreenRecorder][4] 和 [Kazam][3]。
|
||||
|
||||
### SimpleScreenRecorder
|
||||
|
||||
使用 SimpleScreenRecorder 能够轻松录制桌面动作,它拥有直观的用户界面以及多样的编码方式,如 MP4、OGG、[Matroska][2] 或 [WebM][1] 格式。 SimpleScreenRecorder 遵从 GPL 协议发行,运行在 Linux 上。
|
||||
|
||||
在安装运行 SimpleScreenRecorder 后,你可以轻松选择录制整个桌面、指定窗口或者一个自定义的区域。我比较偏爱最后这种方式,因为这样我可以使我的学生把注意力集中在我想让他们注意的地方。你还可以在设置中选择是否隐藏光标、调整录制帧率(默认帧率为 30fps)、视频压缩比例或者调整音频后端(如 ALSA、JACK 或 PusleAudio)。
|
||||
|
||||
由于 SimpleScreenRecorder 使用了 libav/ffmpeg 库进行编码,故而支持多种文件格式和视频编码方式。可以使用不同的配置文件(编码更快的配置文件意味着更大的体积),包括 YouTube 和 1000kbps – 3000kbps 的 LiveStream。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
配置完毕后,单击“开始录制”按钮或者使用自定义的快捷键就可以轻松开始录制屏幕啦~
|
||||
|
||||
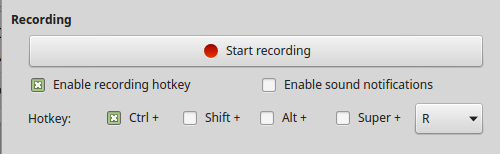
|
||||
|
||||
你还能在设置中开启提示音功能,它会开始录制和录制结束时给你声音的提示。屏幕录制完成后,你可以对视频文件进行编辑或者直接上传到 YouTube、Vimeo 等视频网站上。
|
||||
|
||||
SimpleScreenRecorder 的[官方网站][4]上还有大量说明文档,其中包括设置、录制、上传等方面的帮助手册和针对多种Linux发行版的安装说明。
|
||||
|
||||
### Kazam
|
||||
|
||||
Kazam 桌面录制工具同样是遵循 GPL 协议的软件。同时和 SimpleScreenRecorder 一样,Kazam 易于上手,界面直观。安装运行 Kazam 之后,你可以设置选择录制整个桌面、指定窗口或是一个自定义的区域。(LCTT 译注:关于自定义区域录制一部分的内容与 SimpleScreenRecorder 介绍中的内容基本相似,略过) ,你还可以选择记录鼠标的移动轨迹。我最中意 Kazam 的一点是延时录制的功能,这在制作视频教程的时候必不可少。
|
||||
|
||||
在“文件|设置”菜单下可以轻松对 Kazam 进行个性化设置,比如可以选择扬声器或是麦克风中的音源、关闭倒计时提示等等。
|
||||
|
||||
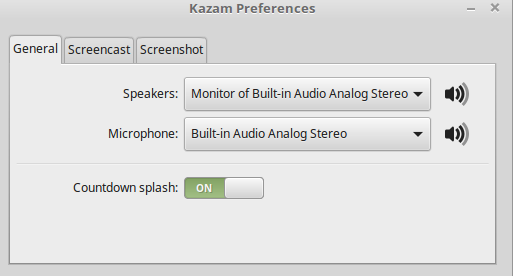
|
||||
|
||||
在设置页的第二个选项卡中可以进行视频录制设置。Kazam 默认录制帧率为 15fps,编码格式为 H264(MP4)。其它可供选择的格式有 VP8(WEBM)、HUFFYUV、Lossless JPEG 以及 RAW AVI。录制好的文件会以附加一个预设的前缀来命名,并自动保存在默认目录下,你可以随时修改这些设置。
|
||||
|
||||
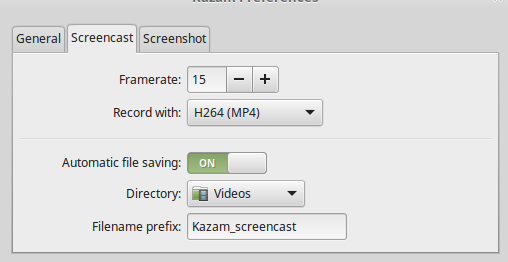
|
||||
|
||||
设置屏幕截图同样很简单。你可以选择 Nikon D80 或 Canon 7D 的快门音效,也可以干脆关掉他们。截图文件是自动存放的。除非你关闭这一功能。
|
||||
|
||||
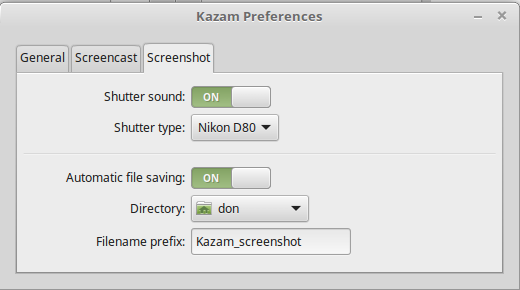
|
||||
|
||||
录制好的视频将会存储在你选定的目录下,随时可以上传到你喜欢的视频分享网站或是教程网站上。
|
||||
|
||||
是时候利用 Linux 和录屏工具让你的课堂焕然一新了!如果你还有其他的屏幕录制工具或是使用技巧,记得在评论里与我交流哦~
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/education/16/10/simplescreenrecorder-and-kazam
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[HaohongWANG](https://github.com/HaohongWANG)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[1]:https://www.webmproject.org/
|
||||
[2]:https://www.matroska.org/technical/whatis/index.html
|
||||
[3]:https://launchpad.net/kazam
|
||||
[4]:http://www.maartenbaert.be/simplescreenrecorder/
|
||||
@ -0,0 +1,70 @@
|
||||
7-Zip vs WinRAR vs WinZIP: 最好的文件压缩工具对比
|
||||
==================
|
||||
|
||||

|
||||
|
||||
在拳击界里有阿里、弗雷泽和福尔曼。在游戏机界里有任天堂、索尼和微软,在 PC 压缩软件领域里有7-Zip、WinRAR 和 WinZIP。我要发动这个软件的对决吗?也许,不管怎么说它一直是一个重要的软件。
|
||||
|
||||
这三个程序有同样的功能,你可以获取一堆你电脑上的文件然后打包压缩它们到一个归档,压缩它们的文件大小,直到有人决定取出它们。它们都易于使用,但是哪个做的更好?我拿它们做了一个测试来找出答案。
|
||||
|
||||
注意:虽然还有很多其它的压缩格式,但 Winzip、7Zip 和 WinRAR 是三个 Windows 上最流行的压缩工具。那就是为什么我们只对比这三个工具。
|
||||
|
||||
注意:为了测试,我压缩了一堆未压缩的视频文件,总计占用 1.3GB 的空间。我还使用最好的压缩设置来测试它们而不是默认的设置。对于每个项目,我描述了如何使这些设置。
|
||||
|
||||
### 7-Zip 出了免费这一大招
|
||||
|
||||
值得一说的是,开源的 7-Zip 是免费的,没有附加条件的这一块已经拥有优势。WinRAR 本质上是免费的,除了你必须忍受每次打开它时恼人的提示告诉你试用过期了。(你付款主要是为了摆脱这个提示。)而另一方面,WinZip 在试用期结束后会锁定你。
|
||||
|
||||
### WinZip
|
||||
|
||||
在今天的世界里,我们莫名其妙地期望的一切与软件相关的都是免费的,与我们的预期相悖,WinZip 大胆的在试用期后收费 £25.95。不过,也许是因为它比竞争对手做得更好,才让其标上这么大胆的价格标签?让我们来看看。
|
||||
|
||||
WinZip 有一个选项可以把文件压缩成 .zipx 格式,它生成拥有比 .zip 和其它竞争者更高的压缩比。要做到这一点,选择并右键单击要压缩文件,然后单击“WinZip - >添加到压缩”文件。当 WinZip 打开后,选择“压缩类型”下的“.Zipx”,然后开始压缩。
|
||||
|
||||
这里是我们使用两种 WinZip 压缩方法的结果:
|
||||
|
||||
* .Zip: 855MB (34% 压缩)
|
||||
* .Zipx: 744MB (43% 压缩)
|
||||
|
||||

|
||||
|
||||
### WinRAR
|
||||
|
||||
WinRAR 压缩的文件是 RAR 格式(这是它自己独有的名字),也有一些技巧可以获得最大的压缩。
|
||||
|
||||
一旦你选择要压缩文件,右击它们,请单击“添加到压缩文件”,然后勾选“创建可靠的归档”复选框。下一步,单击“压缩方式”的下拉列表,将其更改为“最佳”。WinRAR 的还有一个叫做 RAR5 的明显增强的压缩方法,所以我测试了这一点,以及标准的压缩方法。下面是我们得到的:
|
||||
|
||||
* .rar: 780MB (40% 压缩)
|
||||
* .rar5: 778MB (40% 压缩)
|
||||
|
||||

|
||||
|
||||
### 7-Zip
|
||||
|
||||
它没有评估版或付费版,但是随之而来的压缩质量如何?要正确测试它,选择要压缩文件,右击它们,选择“添加到压缩文件”,然后选择7-Zip。
|
||||
|
||||
在新的窗口中更改压缩方法 LZMA2(如果你有一个 4 核或更强的 CPU),压缩级别设置为极端,然后压缩!这里的结果:
|
||||
|
||||
* .7z: 758MB (42% 压缩)
|
||||
|
||||

|
||||
|
||||
### 结论
|
||||
|
||||
基于以上结果,我将继续坚持使用 7-zip。和技术上的“赢家” WinZip 比,这 1% 差别的压缩水平不足以为此花钱。
|
||||
|
||||

|
||||
|
||||
或许你并不想下载任何第三方软件,在这种情况下,你可以使用 Windows 的内置压缩工具。要使用它,只需右键单击任何你想压缩的文件,选择“发送到”,然后“压缩文件夹”。它只把文件压缩到 892 MB的水平(31%),但它更便捷快速,而且是免费和内置的,所以我们还有抱怨吗?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/7-zip-vs-winrar-vs-winzip/
|
||||
|
||||
作者:[Robert Zak][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/robzak/
|
||||
@ -0,0 +1,122 @@
|
||||
如何在 Ubuntu 命令行下管理浏览器书签
|
||||
=======
|
||||
|
||||

|
||||
|
||||
浏览器书签虽然不常被提及,但是作为互联网浏览的一部分。没有好的书签功能,网站链接可能会丢失,下次再不能访问。这就是为什么一个好的书签管理器很重要。
|
||||
|
||||
所有的现代浏览器都提供了一些形式的管理工具,虽然它们严格上来讲功能较少。如果你已经厌倦了这些内置在浏览器中的主流工具,你或许想要寻找一个替代品。这里介绍 **Buku**:一个命令行下的书签管理器。它不仅可以管理你的书签,还可以给它们加密,将它们保存在一个数据库中等等。下面是如何安装它。
|
||||
|
||||
### 安装
|
||||
|
||||

|
||||
|
||||
Buku 不是非常流行。因此,用户需要自己编译它。然而,在 Ubuntu 上安装实际上很简单。打开终端并且使用 apt 安装`git` 和 `python3`,这两个工具在构建中很关键。
|
||||
|
||||
```
|
||||
sudo apt python3-cryptography python3-bs4
|
||||
```
|
||||
|
||||
装完所需的工具后,就可以拉取源码了。
|
||||
|
||||
```
|
||||
git clone https://github.com/jarun/Buku/.
|
||||
cd Buku
|
||||
```
|
||||
|
||||
最后要安装它,只需要运行 `make` 命令。在这之后就可以在终端中输入 `buku`来运行 Buku 了。
|
||||
|
||||
```
|
||||
sudo make install
|
||||
```
|
||||
|
||||
**注意**:虽然这份指导针对的是 Ubuntu,但是 Buku 可以在任何 Linux 发行版中用相似的方法安装。
|
||||
|
||||
### 导入书签
|
||||
|
||||

|
||||
|
||||
要将书签直接导入 Buku 中,首先从浏览器中将书签导出成一个 html 文件。接着,输入下面的命令:
|
||||
|
||||
```
|
||||
buku -i bookmarks.html
|
||||
```
|
||||
|
||||
最后,导入的书签会添加到 Buku 的数据库中。
|
||||
|
||||
### 导出书签
|
||||
|
||||

|
||||
|
||||
导出书签和导入一样简单。要导出所有的书签,使用下面的命令:
|
||||
|
||||
```
|
||||
buku -e bookmarks.html
|
||||
```
|
||||
|
||||
它会和其他书签管理器一样,将数据库中所有的书签导出成一个 html 文件。之后就可以用它做你任何要做的事情了!
|
||||
|
||||
### 打开书签
|
||||
|
||||

|
||||
|
||||
要打开一个书签,首先要搜索。这需要用 `-s` 选项。运行下面的命令来搜索:
|
||||
|
||||
```
|
||||
buku -s searchterm
|
||||
```
|
||||
|
||||
接着一旦找到匹配的结果,输入旁边的数字,书签将会在默认的浏览器中打开了。
|
||||
|
||||
### 加密
|
||||
|
||||
不像其他的书签管理器,Buku 可以加密你的数据。这对拥有“敏感”书签的用户而言很有用的功能。要加密数据库,使用 `-l` 标志来创建一个密码。
|
||||
|
||||
```
|
||||
buku -l
|
||||
```
|
||||
|
||||

|
||||
|
||||
数据库加锁后,没有输入密码将不能打开书签。要解密它,使用 `-k` 选项。
|
||||
|
||||
```
|
||||
buku -k
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 其他功能
|
||||
|
||||
这个书签管理器有许多不同的功能。要了解其他的功能,使用 `--help` 选项。当使用这个选项后,所有的选项以及每个功能详细内容都会列出来。这个非常有用,由于用户经常忘记东西,并且有时可以打开一个备忘单也不错。
|
||||
|
||||
```
|
||||
buku --help
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 总结
|
||||
|
||||
即使这个工具不是浏览器的一部分,它的功能比任何现在管理器提供的功能多。尽管事实是它在命令行中运行,但是也有很好的竞争力。书签对大部分人来言并不重要,但是哪些不喜欢现有选择以及喜欢 Linux 命令行的应该看一下 Buku。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/manage-browser-bookmarks-ubuntu-command-line/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/derrikdiener/
|
||||
[1]:https://www.maketecheasier.com/manage-browser-bookmarks-ubuntu-command-line/#comments
|
||||
[2]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[3]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[4]:https://www.maketecheasier.com/hidden-google-games/
|
||||
[5]:https://www.maketecheasier.com/change-app-permissions-windows10/
|
||||
[6]:mailto:?subject=How%20to%20Manage%20Browser%20Bookmarks%20from%20the%20Ubuntu%20Command%20Line&body=https%3A%2F%2Fwww.maketecheasier.com%2Fmanage-browser-bookmarks-ubuntu-command-line%2F
|
||||
[7]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fmanage-browser-bookmarks-ubuntu-command-line%2F&text=How+to+Manage+Browser+Bookmarks+from+the+Ubuntu+Command+Line
|
||||
[8]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fmanage-browser-bookmarks-ubuntu-command-line%2F
|
||||
[9]:https://www.maketecheasier.com/category/linux-tips/
|
||||
@ -1,192 +0,0 @@
|
||||
GHLandy Translating
|
||||
|
||||
Linux vs. Windows device driver model : architecture, APIs and build environment comparison
|
||||
============================================================================================
|
||||
|
||||
Device drivers are parts of the operating system that facilitate usage of hardware devices via certain programming interface so that software applications can control and operate the devices. As each driver is specific to a particular operating system, you need separate Linux, Windows, or Unix device drivers to enable the use of your device on different computers. This is why when hiring a driver developer or choosing an R&D service provider, it is important to look at their experience of developing drivers for various operating system platforms.
|
||||
|
||||
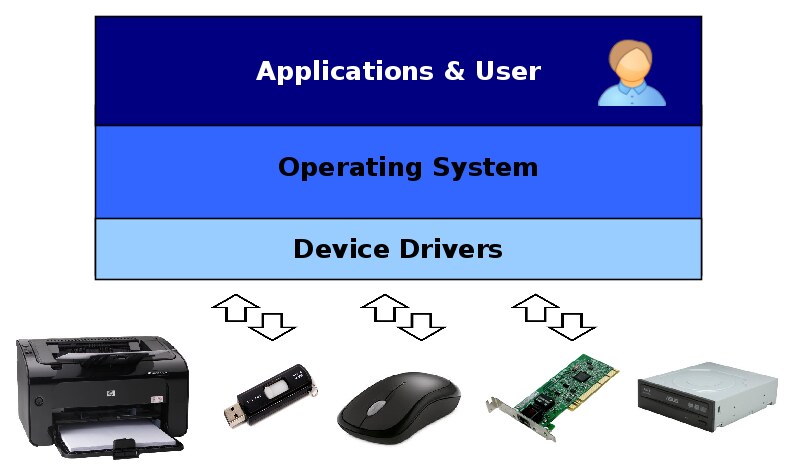
|
||||
|
||||
The first step in driver development is to understand the differences in the way each operating system handles its drivers, underlying driver model and architecture it uses, as well as available development tools. For example, Linux driver model is very different from the Windows one. While Windows facilitates separation of the driver development and OS development and combines drivers and OS via a set of ABI calls, Linux device driver development does not rely on any stable ABI or API, with the driver code instead being incorporated into the kernel. Each of these models has its own set of advantages and drawbacks, but it is important to know them all if you want to provide a comprehensive support for your device.
|
||||
|
||||
In this article we will compare Windows and Linux device drivers and explore the differences in terms of their architecture, APIs, build development, and distribution, in hopes of providing you with an insight on how to start writing device drivers for each of these operating systems.
|
||||
|
||||
### 1. Device Driver Architecture
|
||||
|
||||
Windows device driver architecture is different from the one used in Linux drivers, with either of them having their own pros and cons. Differences are mainly influenced by the fact that Windows is a closed-source OS while Linux is open-source. Comparison of the Linux and Windows device driver architectures will help us understand the core differences behind Windows and Linux drivers.
|
||||
|
||||
#### 1.1. Windows driver architecture
|
||||
|
||||
While Linux kernel is distributed with drivers themselves, Windows kernel does not include device drivers. Instead, modern Windows device drivers are written using the Windows Driver Model (WDM) which fully supports plug-and-play and power management so that the drivers can be loaded and unloaded as necessary.
|
||||
|
||||
Requests from applications are handled by a part of Windows kernel called IO manager which transforms them into IO Request Packets (IRPs) which are used to identify the request and convey data between driver layers.
|
||||
|
||||
WDM provides three kinds of drivers, which form three layers:
|
||||
|
||||
- Filter drivers provide optional additional processing of IRPs.
|
||||
- Function drivers are the main drivers that implement interfaces to individual devices.
|
||||
- Bus drivers service various adapters and bus controllers that host devices.
|
||||
|
||||
An IRP passes these layers as it travels from the IO manager down to the hardware. Each layer can handle an IRP by itself and send it back to the IO manager. At the bottom there is Hardware Abstraction Layer (HAL) which provides a common interface to physical devices.
|
||||
|
||||
#### 1.2. Linux driver architecture
|
||||
|
||||
The core difference in Linux device driver architecture as compared to the Windows one is that Linux does not have a standard driver model or a clean separation into layers. Each device driver is usually implemented as a module that can be loaded and unloaded into the kernel dynamically. Linux provides means for plug-and-play support and power management so that drivers can use them to manage devices correctly, but this is not a requirement.
|
||||
|
||||
Modules export functions they provide and communicate by calling these functions and passing around arbitrary data structures. Requests from user applications come from the filesystem or networking level, and are converted into data structures as necessary. Modules can be stacked into layers, processing requests one after another, with some modules providing a common interface to a device family such as USB devices.
|
||||
|
||||
Linux device drivers support three kinds of devices:
|
||||
|
||||
- Character devices which implement a byte stream interface.
|
||||
- Block devices which host filesystems and perform IO with multibyte blocks of data.
|
||||
- Network interfaces which are used for transferring data packets through the network.
|
||||
|
||||
Linux also has a Hardware Abstraction Layer that acts as an interface to the actual hardware for the device drivers.
|
||||
|
||||
### 2. Device Driver APIs
|
||||
|
||||
Both Linux and Windows driver APIs are event-driven: the driver code executes only when some event happens: either when user applications want something from the device, or when the device has something to tell to the OS.
|
||||
|
||||
#### 2.1. Initialization
|
||||
|
||||
On Windows, drivers are represented by a DriverObject structure which is initialized during the execution of the DriverEntry function. This entry point also registers a number of callbacks to react to device addition and removal, driver unloading, and handling the incoming IRPs. Windows creates a device object when a device is connected, and this device object handles all application requests on behalf of the device driver.
|
||||
|
||||
As compared to Windows, Linux device driver lifetime is managed by kernel module's module_init and module_exit functions, which are called when the module is loaded or unloaded. They are responsible for registering the module to handle device requests using the internal kernel interfaces. The module has to create a device file (or a network interface), specify a numerical identifier of the device it wishes to manage, and register a number of callbacks to be called when the user interacts with the device file.
|
||||
|
||||
#### 2.2. Naming and claiming devices
|
||||
|
||||
##### **Registering devices on Windows**
|
||||
|
||||
Windows device driver is notified about newly connected devices in its AddDevice callback. It then proceeds to create a device object used to identify this particular driver instance for the device. Depending on the driver kind, device object can be a Physical Device Object (PDO), Function Device Object (FDO), or a Filter Device Object (FIDO). Device objects can be stacked, with a PDO in the bottom.
|
||||
|
||||
Device objects exist for the whole time the device is connected to the computer. DeviceExtension structure can be used to associate global data with a device object.
|
||||
|
||||
Device objects can have names of the form **\Device\DeviceName**, which are used by the system to identify and locate them. An application opens a file with such name using CreateFile API function, obtaining a handle, which then can be used to interact with the device.
|
||||
|
||||
However, usually only PDOs have distinct names. Unnamed devices can be accessed via device class interfaces. The device driver registers one or more interfaces identified by 128-bit globally unique identifiers (GUIDs). User applications can then obtain a handle to such device using known GUIDs.
|
||||
|
||||
##### **Registering devices on Linux**
|
||||
|
||||
On Linux user applications access the devices via file system entries, usually located in the /dev directory. The module creates all necessary entries during module initialization by calling kernel functions like register_chrdev. An application issues an open system call to obtain a file descriptor, which is then used to interact with the device. This call (and further system calls with the returned descriptor like read, write, or close) are then dispatched to callback functions installed by the module into structures like file_operations or block_device_operations.
|
||||
|
||||
The device driver module is responsible for allocating and maintaining any data structures necessary for its operation. A file structure passed into the file system callbacks has a private_data field, which can be used to store a pointer to driver-specific data. The block device and network interface APIs also provide similar fields.
|
||||
|
||||
While applications use file system nodes to locate devices, Linux uses a concept of major and minor numbers to identify devices and their drivers internally. A major number is used to identify device drivers, while a minor number is used by the driver to identify devices managed by it. The driver has to register itself in order to manage one or more fixed major numbers, or ask the system to allocate some unused number for it.
|
||||
|
||||
Currently, Linux uses 32-bit values for major-minor pairs, with 12 bits allocated for the major number allowing up to 4096 distinct drivers. The major-minor pairs are distinct for character and block devices, so a character device and a block device can use the same pair without conflicts. Network interfaces are identified by symbolic names like eth0, which are again distinct from major-minor numbers of both character and block devices.
|
||||
|
||||
#### 2.3. Exchanging data
|
||||
|
||||
Both Linux and Windows support three ways of transferring data between user-level applications and kernel-level drivers:
|
||||
|
||||
- **Buffered Input-Output** which uses buffers managed by the kernel. For write operations the kernel copies data from a user-space buffer into a kernel-allocated buffer, and passes it to the device driver. Reads are the same, with kernel copying data from a kernel buffer into the buffer provided by the application.
|
||||
- **Direct Input-Output** which does not involve copying. Instead, the kernel pins a user-allocated buffer in physical memory so that it remains there without being swapped out while data transfer is in progress.
|
||||
- **Memory mapping** can also be arranged by the kernel so that the kernel and user space applications can access the same pages of memory using distinct addresses.
|
||||
|
||||
##### **Driver IO modes on Windows**
|
||||
|
||||
Support for Buffered IO is a built-in feature of WDM. The buffer is accessible to the device driver via the AssociatedIrp.SystemBuffer field of the IRP structure. The driver simply reads from or writes to this buffer when it needs to communicate with the userspace.
|
||||
|
||||
Direct IO on Windows is mediated by memory descriptor lists (MDLs). These are semi-opaque structures accessible via MdlAddress field of the IRP. They are used to locate the physical address of the buffer allocated by the user application and pinned for the duration of the IO request.
|
||||
|
||||
The third option for data transfer on Windows is called METHOD_NEITHER. In this case the kernel simply passes the virtual addresses of user-space input and output buffers to the driver, without validating them or ensuring that they are mapped into physical memory accessible by the device driver. The device driver is responsible for handling the details of the data transfer.
|
||||
|
||||
##### **Driver IO modes on Linux**
|
||||
|
||||
Linux provides a number of functions like clear_user, copy_to_user, strncpy_from_user, and some others to perform buffered data transfers between the kernel and user memory. These functions validate pointers to data buffers and handle all details of the data transfer by safely copying the data buffer between memory regions.
|
||||
|
||||
However, drivers for block devices operate on entire data blocks of known size, which can be simply moved between the kernel and user address spaces without copying them. This case is automatically handled by Linux kernel for all block device drivers. The block request queue takes care of transferring data blocks without excess copying, and Linux system call interface takes care of converting file system requests into block requests.
|
||||
|
||||
Finally, the device driver can allocate some memory pages from kernel address space (which is non-swappable) and then use the remap_pfn_range function to map the pages directly into the address space of the user process. The application can then obtain the virtual address of this buffer and use it to communicate with the device driver.
|
||||
|
||||
### 3. Device Driver Development Environment
|
||||
|
||||
#### 3.1. Device driver frameworks
|
||||
|
||||
##### **Windows Driver Kit**
|
||||
|
||||
Windows is a closed-source operating system. Microsoft provides a Windows Driver Kit to facilitate Windows device driver development by non-Microsoft vendors. The kit contains all that is necessary to build, debug, verify, and package device drivers for Windows.
|
||||
|
||||
Windows Driver Model defines a clean interface framework for device drivers. Windows maintains source and binary compatibility of these interfaces. Compiled WDM drivers are generally forward-compatible: that is, an older driver can run on a newer system as is, without being recompiled, but of course it will not have access to the new features provided by the OS. However, drivers are not guaranteed to be backward-compatible.
|
||||
|
||||
##### **Linux source code**
|
||||
|
||||
In comparison to Windows, Linux is an open-source operating system, thus the entire source code of Linux is the SDK for driver development. There is no formal framework for device drivers, but Linux kernel includes numerous subsystems that provide common services like driver registration. The interfaces to these subsystems are described in kernel header files.
|
||||
|
||||
While Linux does have defined interfaces, these interfaces are not stable by design. Linux does not provide any guarantees about forward or backward compatibility. Device drivers are required to be recompiled to work with different kernel versions. No stability guarantees allow rapid development of Linux kernel as developers do not have to support older interfaces and can use the best approach to solve the problems at hand.
|
||||
|
||||
Such ever-changing environment does not pose any problems when writing in-tree drivers for Linux, as they are a part of the kernel source, because they are updated along with the kernel itself. However, closed-source drivers must be developed separately, out-of-tree, and they must be maintained to support different kernel versions. Thus Linux encourages device driver developers to maintain their drivers in-tree.
|
||||
|
||||
#### 3.2. Build system for device drivers
|
||||
|
||||
Windows Driver Kit adds driver development support for Microsoft Visual Studio, and includes a compiler used to build the driver code. Developing Windows device drivers is not much different from developing a user-space application in an IDE. Microsoft also provides an Enterprise Windows Driver Kit, which enables command-line build environment similar to the one of Linux.
|
||||
|
||||
Linux uses Makefiles as a build system for both in-tree and out-of-tree device drivers. Linux build system is quite developed and usually a device driver needs no more than a handful of lines to produce a working binary. Developers can use any [IDE][5] as long as it can handle Linux source code base and run make, or they can easily compile drivers manually from terminal.
|
||||
|
||||
#### 3.3. Documentation support
|
||||
|
||||
Windows has excellent documentation support for driver development. Windows Driver Kit includes documentation and sample driver code, abundant information about kernel interfaces is available via MSDN, and there exist numerous reference and guide books on driver development and Windows internals.
|
||||
|
||||
Linux documentation is not as descriptive, but this is alleviated with the whole source code of Linux being available to driver developers. The Documentation directory in the source tree documents some of the Linux subsystems, but there are [multiple books][4] concerning Linux device driver development and Linux kernel overviews, which are much more elaborate.
|
||||
|
||||
Linux does not provide designated samples of device drivers, but the source code of existing production drivers is available and can be used as a reference for developing new device drivers.
|
||||
|
||||
#### 3.4. Debugging support
|
||||
|
||||
Both Linux and Windows have logging facilities that can be used to trace-debug driver code. On Windows one would use DbgPrint function for this, while on Linux the function is called printk. However, not every problem can be resolved by using only logging and source code. Sometimes breakpoints are more useful as they allow to examine the dynamic behavior of the driver code. Interactive debugging is also essential for studying the reasons of crashes.
|
||||
|
||||
Windows supports interactive debugging via its kernel-level debugger WinDbg. This requires two machines connected via a serial port: a computer to run the debugged kernel, and another one to run the debugger and control the operating system being debugged. Windows Driver Kit includes debugging symbols for Windows kernel so Windows data structures will be partially visible in the debugger.
|
||||
|
||||
Linux also supports interactive debugging by means of KDB and KGDB. Debugging support can be built into the kernel and enabled at boot time. After that one can either debug the system directly via a physical keyboard, or connect to it from another machine via a serial port. KDB offers a simple command-line interface and it is the only way to debug the kernel on the same machine. However, KDB lacks source-level debugging support. KGDB provides a more complex interface via a serial port. It enables usage of standard application debuggers like GDB for debugging Linux kernel just like any other userspace application.
|
||||
|
||||
### 4. Distributing Device Drivers
|
||||
|
||||
##### 4.1. Installing device drivers
|
||||
|
||||
On Windows installed drivers are described by text files called INF files, which are typically stored in C:\Windows\INF directory. These files are provided by the driver vendor and define which devices are serviced by the driver, where to find the driver binaries, the version of the driver, etc.
|
||||
|
||||
When a new device is plugged into the computer, Windows looks though
|
||||
installed drivers and loads an appropriate one. The driver will be automatically unloaded as soon as the device is removed.
|
||||
|
||||
On Linux some drivers are built into the kernel and stay permanently loaded. Non-essential ones are built as kernel modules, which are usually stored in the /lib/modules/kernel-version directory. This directory also contains various configuration files, like modules.dep describing dependencies between kernel modules.
|
||||
|
||||
While Linux kernel can load some of the modules at boot time itself, generally module loading is supervised by user-space applications. For example, init process may load some modules during system initialization, and the udev daemon is responsible for tracking the newly plugged devices and loading appropriate modules for them.
|
||||
|
||||
#### 4.2. Updating device drivers
|
||||
|
||||
Windows provides a stable binary interface for device drivers so in some cases it is not necessary to update driver binaries together with the system. Any necessary updates are handled by the Windows Update service, which is responsible for locating, downloading, and installing up-to-date versions of drivers appropriate for the system.
|
||||
|
||||
However, Linux does not provide a stable binary interface so it is necessary to recompile and update all necessary device drivers with each kernel update. Obviously, device drivers, which are built into the kernel are updated automatically, but out-of-tree modules pose a slight problem. The task of maintaining up-to-date module binaries is usually solved with [DKMS][3]: a service that automatically rebuilds all registered kernel modules when a new kernel version is installed.
|
||||
|
||||
#### 4.3. Security considerations
|
||||
|
||||
All Windows device drivers must be digitally signed before Windows loads them. It is okay to use self-signed certificates during development, but driver packages distributed to end users must be signed with valid certificates trusted by Microsoft. Vendors can obtain a Software Publisher Certificate from any trusted certificate authority authorized by Microsoft. This certificate is then cross-signed by Microsoft and the resulting cross-certificate is used to sign driver packages before the release.
|
||||
|
||||
Linux kernel can also be configured to verify signatures of kernel modules being loaded and disallow untrusted ones. The set of public keys trusted by the kernel is fixed at the build time and is fully configurable. The strictness of checks performed by the kernel is also configurable at build time and ranges from simply issuing warnings for untrusted modules to refusing to load anything with doubtful validity.
|
||||
|
||||
### 5. Conclusion
|
||||
|
||||
As shown above, Windows and Linux device driver infrastructure have some things in common, such as approaches to API, but many more details are rather different. The most prominent differences stem from the fact that Windows is a closed-source operating system developed by a commercial corporation. This is what makes good, documented, stable driver ABI and formal frameworks a requirement for Windows while on Linux it would be more of a nice addition to the source code. Documentation support is also much more developed in Windows environment as Microsoft has resources necessary to maintain it.
|
||||
|
||||
On the other hand, Linux does not constrain device driver developers with frameworks and the source code of the kernel and production device drivers can be just as helpful in the right hands. The lack of interface stability also has an implications as it means that up-to-date device drivers are always using the latest interfaces and the kernel itself carries lesser burden of backwards compatibility, which results in even cleaner code.
|
||||
|
||||
Knowing these differences as well as specifics for each system is a crucial first step in providing effective driver development and support for your devices. We hope that this Windows and Linux device driver development comparison was helpful in understanding them, and will serve as a great starting point in your study of device driver development process.
|
||||
|
||||
Download this article as ad-free PDF (made possible by [your kind donation][2]): [Download PDF][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/linux-vs-windows-device-driver-model.html
|
||||
|
||||
作者:[Dennis Turpitka][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://xmodulo.com/author/dennis
|
||||
[1]: http://xmodulo.com/linux-vs-windows-device-driver-model.html?format=pdf
|
||||
[2]: https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=PBHS9R4MB9RX4
|
||||
[3]: http://xmodulo.com/build-kernel-module-dkms-linux.html
|
||||
[4]: http://xmodulo.com/go/linux_device_driver_books
|
||||
[5]: http://xmodulo.com/good-ide-for-c-cpp-linux.html
|
||||
@ -1,109 +0,0 @@
|
||||
chenxinlong translating
|
||||
Who needs a GUI? How to live in a Linux terminal
|
||||
=================================================
|
||||
|
||||

|
||||
|
||||
### The best Linux shell apps for handling common functions
|
||||
|
||||
Ever consider the idea of living entirely in a Linux terminal? No graphical desktop. No modern GUI software. Just text—and nothing but text—inside a Linux shell. It may not be easy, but it’s absolutely doable. [I recently tried living completely in a Linux shell for 30 days][1]. What follows are my favorite shell applications for handling some of the most common bits of computer functionality (web browsing, word processing, etc.). With a few obvious holes. Because being text-only is hard.
|
||||
|
||||
|
||||
|
||||
### Emailing within a Linux terminal
|
||||
|
||||
For emailing in a terminal, we are spoiled for choice. Many people recommend mutt and notmuch. Both of those are powerful and excellent, but I prefer alpine. Why? Not only does it work well, but it’s also much more of a familiar interface if you are used to GUI email software like Thunderbird.
|
||||
|
||||

|
||||
|
||||
### Web browsing within a Linux terminal
|
||||
|
||||
I have one word for you: [w3m][5]. Well, I suppose that’s not even really a word. But w3m is definitely my terminal web browser of choice. It tenders things fairly well and is powerful enough to even let you post to sites such as Google Plus (albeit, not in a terribly fun way). Lynx may be the de facto text-based web browser, but w3m is my favorite.
|
||||
|
||||

|
||||
|
||||
### Text editing within a Linux terminal
|
||||
|
||||
For editing simple text files, I have one application that I straight-up love. No, not emacs. Also, definitely not vim. For editing of a text file or jotting down some notes, I like nano. Yes, nano. It’s simple, easy to learn and pleasant to use. Are there pieces of software with more features? Sure. But nano is just delightful.
|
||||
|
||||

|
||||
|
||||
### Word processing within a Linux terminal
|
||||
|
||||
In a shell—with nothing but text—there really isn’t a huge difference between a “text editor” and a “word processor.” But being as I do a lot of writing, having a piece of software built specifically for long-form writing is a definite must. My favorite is wordgrinder. It has just enough tools to make me happy, a nice menu-driven interface (with hot-keys), and it supports multiple file types, including OpenDocument, HTML and a bunch of other ones.
|
||||
|
||||

|
||||
|
||||
### Music playing within a Linux terminal
|
||||
|
||||
When it comes to playing music (mp3, Ogg, etc.) from a shell, one piece of software is king: [cmus][7]. It supports every conceivable file format. It’s super easy to use and incredibly fast and light on system resource usage. So clean. So streamlined. This is what a good music player should be like.
|
||||
|
||||

|
||||
|
||||
### Instant messaging within a Linux terminal
|
||||
|
||||
When I realized how will I could instant message from the terminal, my head exploded. You know Pidgin, the multi-protocol IM client? Well, it has a version for the terminal, called “[finch][8],” that allows you to connect to multiple networks and chat with multiple people at once. The interface is even similar to Pidgin. Just amazing. Use Google Hangouts? Try [hangups][9]. It has a nice tabbed interface and works amazingly well. Seriously. Other than needing perhaps some emoji and inline pictures, instant messaging from the shell is a great experience.
|
||||
|
||||

|
||||
|
||||
### Tweeting within a Linux terminal
|
||||
|
||||
No joke. Twitter, in your terminal, thanks to [rainbowstream][10]. I hit a few bugs here and there, but overall, it works rather well. Not as well as the website itself—and not as well as the official mobile clients—but, come on, this is Twitter in a shell. Even if it has one or two rough edges, this is pretty stinkin’ cool.
|
||||
|
||||

|
||||
|
||||
### Reddit-ing within a Linux terminal
|
||||
|
||||
Spending time on Reddit from the comforts of the command line feels right somehow. And with rtv, it’s a rather pleasant experience. Reading. Commenting. Voting. It all works. The experience isn’t actually all that different than the website itself.
|
||||
|
||||

|
||||
|
||||
### Process managing within a Linux terminal
|
||||
|
||||
Use [htop][12]. It’s like top—only better and prettier. Sometimes I just leave htop up and running all the time. Just because. In that regard, it’s like a music visualizer—only for RAM and CPU usage.
|
||||
|
||||
|
||||
|
||||
### File managing within a Linux terminal
|
||||
|
||||
Just because you’re in a text-based shell doesn’t mean you don’t enjoy the finer things in life. Like having a nice file browser and manager. In that regard, [Midnight Commander][13] is a pretty doggone great one.
|
||||
|
||||
|
||||
|
||||
### Terminal managing within a Linux terminal
|
||||
|
||||
If you spend much time in the shell, you’re going to need a terminal multiplexer. Basically it’s a piece of software that lets you split up your terminal session into a customizable grid, allowing you to use and see multiple terminal applications at the same time. It’s a tiled window manager for your shell. My favorite is [tmux][14]. But [GNU Screen][15] is also quite nice. It might take a few minutes to learn how to use it, but once you do, you’ll be glad you did.
|
||||
|
||||

|
||||
|
||||
### Presentation-ing within a Linux terminal
|
||||
|
||||
LibreOffice, Google Slides or, gasp, PowerPoint. I spend a lot of time in presentation software. The fact that one exists for the shell pleases me greatly. It’s called, appropriately, “[text presentation program][16].” There are no images (obviously), just a simple program for displaying slides put together in a simple markup language. It may not let you embed pictures of cats, but you’ll earn some serious nerd-cred for doing an entire presentation from the terminal.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/3091139/linux/who-needs-a-gui-how-to-live-in-a-linux-terminal.html#slide1
|
||||
|
||||
作者:[Bryan Lunduke][a]
|
||||
译者:[译者ID](https://github.com/chenxinlong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.networkworld.com/author/Bryan-Lunduke/
|
||||
[1]: http://www.networkworld.com/article/3083268/linux/30-days-in-a-terminal-day-0-the-adventure-begins.html
|
||||
[2]: https://en.wikipedia.org/wiki/Mutt_(email_client)
|
||||
[3]: https://notmuchmail.org/
|
||||
[4]: https://en.wikipedia.org/wiki/Alpine_(email_client)
|
||||
[5]: https://en.wikipedia.org/wiki/W3m
|
||||
[6]: http://cowlark.com/wordgrinder/index.html
|
||||
[7]: https://en.wikipedia.org/wiki/Cmus
|
||||
[8]: https://developer.pidgin.im/wiki/Using%20Finch
|
||||
[9]: https://github.com/tdryer/hangups
|
||||
[10]: http://www.rainbowstream.org/
|
||||
[11]: https://github.com/michael-lazar/rtv
|
||||
[12]: http://hisham.hm/htop/
|
||||
[13]: https://en.wikipedia.org/wiki/Midnight_Commander
|
||||
[14]: https://tmux.github.io/
|
||||
[15]: https://en.wikipedia.org/wiki/GNU_Screen
|
||||
[16]: http://www.ngolde.de/tpp.html
|
||||
@ -1,5 +1,3 @@
|
||||
rusking 翻译中
|
||||
|
||||
What is open source
|
||||
===========================
|
||||
|
||||
|
||||
@ -0,0 +1,288 @@
|
||||
# Forget Technical Debt —Here'sHowtoBuild Technical Wealth
|
||||
|
||||
[Andrea Goulet][58] and her business partner sat in her living room, casually reviewing their strategic plan, when an episode of This Old House came on television. It was one of those moments where ideas collide to create something new. They’d been looking for a way to communicate their value proposition — cleaning up legacy code and technical debt for other companies. And here they were, face to face with the perfect analogy.
|
||||
|
||||
“We realized that what we were doing transcended clearing out old code, we were actually remodeling software the way you would remodel a house to make it last longer, run better, do more,” says Goulet. “It got me thinking about how companies have to invest in mending their code to get more productivity. Just like you have to put a new roof on a house to make it more valuable. It’s not sexy, but it’s vital, and too many people are doing it wrong.”
|
||||
|
||||
Today, she’s CEO of [Corgibytes][57] — a consulting firm that re-architects and modernizes apps. She’s seen all varieties of broken systems, legacy code, and cases of technical debt so extreme it’s basically digital hoarding. Here, Goulet argues that startups need to shift their mindset away from paying down debt toward building technical wealth, and away from tearing down old code toward deliberately remodeling it. She explains this new approach, and how you can do the impossible — actually recruit amazing engineers to tackle this work.
|
||||
|
||||
### RETHINKING LEGACY CODE
|
||||
|
||||
#
|
||||
|
||||
The most popular definition of legacy code comes from Michael Feathers, author of the aptly titled [Working Effectively with Legacy Code][56][][55]: It's code without test coverage. That’s better than what most people assume — that the term only applies only to really old, archaic systems. But neither definition goes far enough, according to Goulet. “Legacy code has nothing to do with the age of the software. A two year-old app can already be in a legacy state,” she says. “It’s all about how difficult that software is to improve.”
|
||||
|
||||
This means code that isn’t written cleanly, that lacks explanation, that contains zero artifacts of your ideas and decision-making processes. A unit test is one type of artifact, but so is any documentation of the rationale and reasoning used to create that code. If there’s no way to tell what the developer was thinking when you go to improve it — that’s legacy code.
|
||||
|
||||
> Legacy code isn't a technical problem. It's a communication problem.
|
||||
|
||||

|
||||
|
||||
If you linger around in legacy code circles like Goulet does, you’ll find that one particular, and rather obscure adage dubbed [Conway’s Law][54] will make it’s way into nearly every conversation.
|
||||
|
||||
“It’s the law that says your codebase will mirror the communication structures across your organization,” Goulet says. “If you want to fix your legacy code, you can’t do it without also addressing operations, too. That’s the missing link that so many people miss.”
|
||||
|
||||
Goulet and her team dive into a legacy project much like an archaeologist would. They look for artifacts left behind that give them clues into what past developers were thinking. All of these artifacts together provide context to make new decisions.
|
||||
|
||||
The most important artifact? Well organized, intention-revealing, clean code. For example, if you name a variable with generic terms like “foo” or “bar,” you might come back six months later and have no idea what that variable is for.
|
||||
|
||||
If the code isn’t easy to read, a useful artifact is the source control system, because it provides a history of changes to the code and gives developers an opportunity to write about the changes they’re making.
|
||||
|
||||
“A friend of mine says that for commit messages, every summary should be the size of half a tweet, with the description as long as a blog post, if necessary,” says Goulet. “You have the chance to tightly couple your rationale with the code that’s being changed. It doesn’t take a lot of extra time and gives tons of information to people working on the project later, but surprisingly few people do it. It’s common to hear developers get so frustrated about working with a piece of code they run ‘git blame’ in a fit of rage to figure out who wrote that mess, only to find it was themselves.”
|
||||
|
||||
Automated tests are also fertile ground for rationale. “There’s a reason that so many people like Michael Feathers’ definition of legacy code,” Goulet explains. “Test suites, especially when used along with [Behavior Driven Development][53] practices like writing out scenarios, are incredibly useful tools for understanding a developer’s intention.”
|
||||
|
||||
The lesson here is simple: If you want to limit your legacy code down the line, pay attention to the details that will make it easier to understand and work with in the future. Write and run unit, acceptance, approval, and integration tests. Explain your commits. Make it easy for future you (and others) to read your mind.
|
||||
|
||||
That said, legacy code will happen no matter what. For reasons both obvious and unexpected.
|
||||
|
||||
Early on at a startup, there’s usually a heavy push to get features out the door. Developers are under enormous pressure to deliver, and testing falls by the wayside. The Corgibytes team has encountered many companies that simply couldn’t be bothered with testing as they grew — for years.
|
||||
|
||||
Sure, it might not make sense to test compulsively when you’re pushing toward a prototype. But once you have a product and users, you need to start investing in maintenance and incremental improvements. “Too many people say, ‘Don’t worry about the maintenance, the cool things are the features!’” says Goulet. “If you do this, you’re guaranteed to hit a point where you cannot scale. You cannot compete.”
|
||||
|
||||
As it turns out, the second law of thermodynamics applies to code too: You’ll always be hurtling toward entropy. You need to constantly battle the chaos of technical debt. And legacy code is simply one type of debt you’ll accrue over time.
|
||||
|
||||
“Again the house metaphor applies. You have to keep putting away dishes, vacuuming, taking out the trash,” she says. “if you don’t, it’s going to get harder, until eventually you have to call in the HazMat team.”
|
||||
|
||||
Corgibytes gets a lot of calls from CEOs like this one, who said: “Features used to take two weeks to push three years ago. Now they’re taking 12 weeks. My developers are super unproductive.”
|
||||
|
||||
> Technical debt always reflects an operations problem.
|
||||
|
||||
A lot of CTOs will see the problem coming, but it’s hard to convince their colleagues that it’s worth spending money to fix what already exists. It seems like backtracking, with no exciting or new outputs. A lot of companies don’t move to address technical debt until it starts crippling day-to-day productivity, and by then it can be very expensive to pay down.
|
||||
|
||||
### FORGET DEBT, BUILD TECHNICAL WEALTH
|
||||
|
||||
# Recommended Article
|
||||
|
||||
You’re much more likely to get your CEO, investors and other stakeholders on board if you [reframe your technical debt][52] as an opportunity to accumulate technical wealth — [a term recently coined by agile development coach Declan Whelan][51].
|
||||
|
||||
“We need to stop thinking about debt as evil. Technical debt can be very useful when you’re in the early-stage trenches of designing and building your product,” says Goulet. “And when you resolve some debt, you’re giving yourself momentum. When you install new windows in your home, yes you’re spending a bunch of money, but then you save a hundred dollars a month on your electric bill. The same thing happens with code. Only instead of efficiency, you gain productivity that compounds over time.”
|
||||
|
||||
As soon as you see your team not being as productive, you want to identify the technical debt that's holding them back.
|
||||
|
||||
“I talk to so many startups that are killing themselves to acquire talent — they’re hiring so many high-paid engineers just to get more work done,” she says. “Instead, they should have looked at how to make each of their existing engineers more productive. What debt could you have paid off to get that extra productivity?”
|
||||
|
||||
If you change your perspective and focus on wealth building, you’ll end up with a productivity surplus, which can then be reinvested in fixing even more debt and legacy code in a virtuous cycle. Your product will be cruising and getting better all the time.
|
||||
|
||||
> Stop thinking about your software as a project. Start thinking about it as a house you will live in for a long time.
|
||||
|
||||
This is a critical mindset shift, says Goulet. It will take you out of short-term thinking and make you care about maintenance more than you ever have.
|
||||
|
||||
Just like with a house, modernization and upkeep happens in two ways: small, superficial changes (“I bought a new rug!”) and big, costly investments that will pay off over time (“I guess we’ll replace the plumbing...”). You have to think about both to keep your product current and your team running smoothly.
|
||||
|
||||
This also requires budgeting ahead — if you don’t, those bigger purchases are going to hurt. Regular upkeep is the expected cost of home ownership. Shockingly, many companies don’t anticipate maintenance as the cost of doing business.
|
||||
|
||||
This is how Goulet coined the term ‘software remodeling.’ When something in your house breaks, you don’t bulldoze parts of it and rebuild from scratch. Likewise, when you have old, broken code, reaching for a re-write isn’t usually the best option.
|
||||
|
||||
Here are some of the things Corgibytes does when they’re called in to ‘remodel’ a codebase:
|
||||
|
||||
* Break monolithic apps into micro-services that are lighter weight and more easily maintained.
|
||||
* Decouple features from each other to make them more extensible.
|
||||
* Refresh branding and look and feel of the front-end.
|
||||
* Establish automated testing so that code validates itself.
|
||||
* Refactor, or edit, codebases to make them easier to work with.
|
||||
|
||||
Remodeling also gets into DevOps territory. For example, Corgibytes often introduces new clients to [Docker][50], making it much easier and faster to set up new developer environments. When you have 30 engineers on your team, cutting the initial setup time from 10 hours to 10 minutes gives you massive leverage to accomplish more tasks. This type of effort can’t just be about the software itself, it also has to change how it’s built.
|
||||
|
||||
If you know which of these activities will make your code easier to handle and create efficiencies, you should build them into your annual or quarterly roadmap. Don’t expect them to happen on their own. But don’t put pressure on yourself to implement them all right away either. Goulet sees just as many startups hobbled by their obsession with having 100% test coverage from the very beginning.
|
||||
|
||||
To get more specific, there are three types of remodeling work every company should plan on:
|
||||
|
||||
* Automated testing
|
||||
* Continuous delivery
|
||||
* Cultural upgrades
|
||||
|
||||
Let’s take a closer look at each of these.
|
||||
|
||||
Automated Testing
|
||||
|
||||
“One of our clients was going into their Series B and told us they couldn’t hire talent fast enough. We helped them introduce an automated testing framework, and it doubled the productivity of their team in under 3 months,” says Goulet. “They were able to go to their investors and say, ‘We’re getting more with a lean team than we would have if we’d doubled the team.'”
|
||||
|
||||
Automated testing is basically a combination of individual tests. You have unit tests which double-check single lines of code. You have integration tests that make sure different parts of the system are playing nice. And you have acceptance tests that ensure features are working as you envisioned. When you write these tests as automated scripts, you can essentially push a button and have your system validate itself rather than having to comb through and manually click through everything.
|
||||
|
||||
Instituting this before hitting product-market fit is probably premature. But as soon as you have a product you’re happy with, and that users who depend on it, it’s more than worth it to put this framework in place.
|
||||
|
||||
Continuous Delivery
|
||||
|
||||
This is the automation of delivery related tasks that used to be manual. The goal is to be able to deploy a small change as soon as it’s done and make the feedback loop as short as possible. This can give companies a big competitive advantage over their competition, especially in customer service.
|
||||
|
||||
“Let’s say every time you deploy, it’s this big gnarly mess. Entropy is out of control,” says Goulet. “We’ve seen deployments take 12 hours or more because it’s such a cluster. And when this happens, you’re not going to deploy as often. You’re going to postpone shipping features because it’s too painful. You’re going to fall behind and lose to the competition.”
|
||||
|
||||
Other tasks commonly automated during continuous improvement include:
|
||||
|
||||
* Checking for breaks in the build when commits are made.
|
||||
* Rolling back in the event of a failure.
|
||||
* Automated code reviews that check for code quality.
|
||||
* Scaling computing resources up or down based on demand.
|
||||
* Making it easy to set up development, testing, and production environments.
|
||||
|
||||
As a simple example, let’s say a customer sends in a bug report. The more efficient the developer is in fixing that bug and getting it out, the better. The challenge with bug fixes isn’t that making the change is all that difficult, it’s that the system isn’t set up well and the developer wastes a lot of time doing things other than solving problems, which is what they’re best at.
|
||||
|
||||
With continuous improvement, you would become ruthless about determining which tasks are best for the computer and which are best for the human. If a computer is better at it, you automate it. This leaves the developer gleefully solving challenging problems. Customers are happier because their complaints are addressed and fixed quickly. Your backlog of fixes narrows and you’re able to spend more time on new creative ways to improve your app even more. This is the kind of change that generates technical wealth. Because that developer can ship new code as soon as they fix a bug in one step, they have time and bandwidth to do so much more frequently.
|
||||
|
||||
“You have to constantly ask, ‘How can I improve this for my users? How can I make this better? How can I make this more efficient?’ But don’t stop there,” says Goulet. “As soon as you have answers to these questions, you have to ask yourself how you can automate that improvement or efficiency.”
|
||||
|
||||
Cultural Upgrades
|
||||
|
||||
Every day, Corgibytes sees the same problem: A startup that's built an environment that makes it impossible for its developers to be impactful. The CEO looms over their shoulders wondering why they aren’t shipping more often. And the truth is that the culture of the company is working against them. To empower your engineers, you have to look at their environment holistically.
|
||||
|
||||
To make this point, Goulet quotes author Robert Henri:
|
||||
|
||||
> The object isn't to make art, it's to be in that wonderful state which makes art inevitable.
|
||||
|
||||
“That’s how you need to start thinking about your software,” she says. “Your culture can be that state. Your goal should always be to create an environment where art just happens, and that art is clean code, awesome customer service, happy developers, good product-market fit, profitability, etc. It’s all connected.”
|
||||
|
||||
This is a culture that prioritizes the resolution of technical debt and legacy code. That’s what will truly clear the path for your developers to make impact. And that’s what will give you the surplus to build cooler things in the future. You can’t remodel your product without making over the environment it’s developed in. Changing the overall attitude toward investing in maintenance and modernization is the place to start, ideally at the top with the CEO.
|
||||
|
||||
Here are some of Goulet's suggestions for establishing that flow-state culture:
|
||||
|
||||
* Resist the urge to reward “heroes” who work late nights. Praise effectiveness over effort.
|
||||
* Get curious about collaboration techniques, such as Woody Zuill’s [Mob Programming][44][][43].
|
||||
* Follow the four [Modern Agile][42] principles: make users awesome, experiment and learn rapidly, make safety a prerequisite, and deliver value continuously.
|
||||
* Give developers time outside of projects each week for professional development.
|
||||
* Practice [daily shared journals][41] as a way to enable your team to solve problems proactively.
|
||||
* Put empathy at the center of everything you do. At Corgibytes, [Brene Brown’s CourageWorks][40] training has been invaluable.
|
||||
|
||||
If execs and investors balk at this upgrade, frame it in terms of customer service, Goulet says. Tell them how the end product of this change will be a better experience for the people who matter most to them. It’s the most compelling argument you can make.
|
||||
|
||||
### FINDING THE MOST TALENTED REMODELERS
|
||||
|
||||
#
|
||||
|
||||
It’s an industry-wide assumption that badass engineers don’t want to work on legacy code. They want to build slick new features. Sticking them in the maintenance department would be a waste, people say.
|
||||
|
||||
These are misconceptions. You can find incredibly skilled engineers to work on your thorniest debt if you know where and how to look — and how to make them happy when you’ve got them.
|
||||
|
||||
“Whenever we speak at conferences, we poll the audience and ask 'Who loves working on legacy code?' It's pretty consistent that less than 10% of any crowd will raise their hands.” says Goulet. “But when I talked to these people, I found out they were the engineers who liked the most challenging problems.”
|
||||
|
||||
She has clients coming to her with homegrown databases, zero documentation, and no conceivable way to parse out structure. This is the bread and butter of a class of engineers she calls “menders.” Now she has a team of them working for her at Corgibytes who like nothing more than diving into binary files to see what’s really going on.
|
||||
|
||||

|
||||
|
||||
So, how can you find these elite forces? Goulet has tried a lot of things — and a few have worked wonders.
|
||||
|
||||
She launched a community website at [legacycode.rocks][49] that touts the following manifesto: “For too long, those of us who enjoy refactoring legacy code have been treated as second class developers... If you’re proud to work on legacy code, welcome!”
|
||||
|
||||
“I started getting all these emails from people saying, ‘Oh my god, me too!’” she says. “Just getting out there and spreading this message about how valuable this work is drew in the right people.”
|
||||
|
||||
Recommended Article
|
||||
|
||||
She’s also used continuous delivery practices in her recruiting to give these type of developers what they want: Loads of detail and explicit instructions. “It started because I hated repeating myself. If I got more than a few emails asking the same question, I’d put it up on the website, much like I would if I was writing documentation.”
|
||||
|
||||
But over time, she noticed that she could refine the application process even further to help her identify good candidates earlier in the process. For example, her application instructions read, “The CEO is going to review your resume, so make sure to address your cover letter to the CEO” without providing a gender. All letters starting with “Dear Sir,” or "Mr." are immediately trashed. And this is just the beginning of her recruiting gauntlet.
|
||||
|
||||
“This started because I was annoyed at how many times people assumed that because I’m the CEO of a software company, I must be a man,” Goulet said. “So one day, I thought I’d put it on the website as an instruction for applicants to see who was paying attention. To my surprise, it didn’t just muffle the less serious candidates. It amplified the folks who had the particular skills for working with legacy code.”
|
||||
|
||||
Goulet recalls how one candidate emailed her to say, “I inspected the code on your website (I like the site and hey, it’s what I do). There’s a weird artifact that seems to be written in PHP but it appears you’re running Jekyll which is in Ruby. I was really curious what that’s about.”
|
||||
|
||||
It turned out that there was a leftover PHP class name in the HTML, CSS, and JavaScript that Goulet got from her designer that she’d been meaning to getting around to but hadn’t had a chance. Her response: “Are you looking for a job?”
|
||||
|
||||
Another candidate noticed that she had used the term CTO in an instruction, but that title didn’t exist on her team (her business partner is the Chief Code Whisperer). Again, the attention to detail, the curiosity, and the initiative to make it better caught her eye.
|
||||
|
||||
> Menders aren't just detail-oriented, they're compelled by attention to detail.
|
||||
|
||||
Surprisingly, Goulet hasn't been plagued with the recruiting challenges of most tech companies. “Most people apply directly through our website, but when we want to cast a wider net, we use [PowerToFly][48] and [WeWorkRemotely][47]. I really don’t have a need for recruiters at the moment. They have a tough time understanding the nuance of what makes menders different.”
|
||||
|
||||
If they make it through an initial round, Goulet has a candidate read an article called “[Naming is a Process][46]” by Arlo Belshee. It delves into the very granular specifics of working with indebted code. Her only directions: “Read it and tell me what you think.”
|
||||
|
||||
She’s looking for understanding of subtleties in their responses, and also the willingness to take a point of view. It’s been really helpful in separating deep thinkers with conviction from candidates who just want to get hired. She highly recommends choosing a piece of writing that matters to your operations and will demonstrate how passionate, opinionated, and analytical people are.
|
||||
|
||||
Lastly, she’ll have a current team member pair program with the candidate using [Exercism.io][45]. It’s an open-source project that allows developers to learn how to code in different languages with a range of test driven development exercises. The first part of the pair programming session allows the candidate to choose a language to build in. For the next exercise, the interviewer gets to pick the language. They get to see how the person deals with surprise, how flexible they are, and whether they’re willing to admit they don’t know something.
|
||||
|
||||
“When someone has truly transitioned from a practitioner to a master, they freely admit what they don’t know,” says Goulet.
|
||||
|
||||
Having someone code in a language they aren’t that familiar with also gauges their stick-to-it-iveness. “We want someone who will say, ‘I’m going to hammer on this problem until it’s done.’ Maybe they’ll even come to us the next day and say, ‘I kept at it until I figured it out.’ That’s the type of behavior that’s very indicative of success as a mender.”
|
||||
|
||||
> Makers are so lionized in our industry that everyone wants to have them do maintenance too. That's a mistake. The best menders are never the best makers.
|
||||
|
||||
Once she has talented menders in the door, Goulet knows how to set them up for success. Here’s what you can do to make this type of developer happy and productive:
|
||||
|
||||
* Give them a generous amount of autonomy. Hand them assignments where you explain the problem, sure, but never dictate how they should solve it.
|
||||
* If they ask for upgrades to their computers and tooling, do it. They know what they need to maximize efficiency.
|
||||
* Help them [limit their context-switching][39]. They like to focus until something’s done.
|
||||
|
||||
Altogether, this approach has helped Corgibytes build a waiting list of over 20 qualified developers passionate about legacy code.
|
||||
|
||||
### STABILITY IS NOT A DIRTY WORD
|
||||
|
||||
#
|
||||
|
||||
Most startups don’t think past their growth phase. Some may even believe growth should never end. And it doesn’t have to, even when you enter the next stage: Stability. All stability means is that you have the people and processes you need to build technical wealth and spend it on the right priorities.
|
||||
|
||||
“There’s this inflection point between growth and stability where menders must surge, and you start to balance them more equally against the makers focused on new features,” says Goulet. “You have your systems. Now you need them to work better.”
|
||||
|
||||
This means allocating more of your organization’s budget to maintenance and modernization. “You can’t afford to think of maintenance as just another line item,” she says. “It has to become innate to your culture — something important that will yield greater success in the future.”
|
||||
|
||||
Ultimately, the technical wealth you build with these efforts will give rise to a whole new class of developers on your team: scouts that have the time and resources to explore new territory, customer bases and opportunities. When you have the bandwidth to tap into new markets and continuously get better at what you already do — that’s when you’re truly thriving.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://firstround.com/review/forget-technical-debt-heres-how-to-build-technical-wealth/
|
||||
|
||||
作者:[http://firstround.com/][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://firstround.com/
|
||||
[1]:http://corgibytes.com/blog/2016/04/15/inception-layers/
|
||||
[2]:http://www.courageworks.com/
|
||||
[3]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
|
||||
[4]:https://www.industriallogic.com/blog/modern-agile/
|
||||
[5]:http://mobprogramming.org/
|
||||
[6]:http://exercism.io/
|
||||
[7]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
|
||||
[8]:https://weworkremotely.com/
|
||||
[9]:https://www.powertofly.com/
|
||||
[10]:http://legacycode.rocks/
|
||||
[11]:https://www.docker.com/
|
||||
[12]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
|
||||
[13]:https://www.agilealliance.org/resources/initiatives/technical-debt/
|
||||
[14]:https://en.wikipedia.org/wiki/Behavior-driven_development
|
||||
[15]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
[16]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[17]:http://corgibytes.com/
|
||||
[18]:https://www.linkedin.com/in/andreamgoulet
|
||||
[19]:http://corgibytes.com/blog/2016/04/15/inception-layers/
|
||||
[20]:http://www.courageworks.com/
|
||||
[21]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
|
||||
[22]:https://www.industriallogic.com/blog/modern-agile/
|
||||
[23]:http://mobprogramming.org/
|
||||
[24]:http://mobprogramming.org/
|
||||
[25]:http://exercism.io/
|
||||
[26]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
|
||||
[27]:https://weworkremotely.com/
|
||||
[28]:https://www.powertofly.com/
|
||||
[29]:http://legacycode.rocks/
|
||||
[30]:https://www.docker.com/
|
||||
[31]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
|
||||
[32]:https://www.agilealliance.org/resources/initiatives/technical-debt/
|
||||
[33]:https://en.wikipedia.org/wiki/Behavior-driven_development
|
||||
[34]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
[35]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[36]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[37]:http://corgibytes.com/
|
||||
[38]:https://www.linkedin.com/in/andreamgoulet
|
||||
[39]:http://corgibytes.com/blog/2016/04/15/inception-layers/
|
||||
[40]:http://www.courageworks.com/
|
||||
[41]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
|
||||
[42]:https://www.industriallogic.com/blog/modern-agile/
|
||||
[43]:http://mobprogramming.org/
|
||||
[44]:http://mobprogramming.org/
|
||||
[45]:http://exercism.io/
|
||||
[46]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
|
||||
[47]:https://weworkremotely.com/
|
||||
[48]:https://www.powertofly.com/
|
||||
[49]:http://legacycode.rocks/
|
||||
[50]:https://www.docker.com/
|
||||
[51]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
|
||||
[52]:https://www.agilealliance.org/resources/initiatives/technical-debt/
|
||||
[53]:https://en.wikipedia.org/wiki/Behavior-driven_development
|
||||
[54]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
[55]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[56]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[57]:http://corgibytes.com/
|
||||
[58]:https://www.linkedin.com/in/andreamgoulet
|
||||
@ -1,61 +0,0 @@
|
||||
Translating by WangYueScream
|
||||
============================================================================
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Should Smartphones Do Away with the Headphone Jack? Here Are Our Thoughts
|
||||
====
|
||||
|
||||

|
||||
|
||||
Even though Apple removing the headphone jack from the iPhone 7 has been long-rumored, after the official announcement last week confirming the news, it has still become a hot topic.
|
||||
|
||||
For those not in the know on this latest news, Apple has removed the headphone jack from the phone, and the headphones will now plug into the lightning port. Those that want to still use their existing headphones may, as there is an adapter that ships with the phone along with the lightning headphones. They are also selling a new product: AirPods. These are wireless and are inserted into your ear. The biggest advantage is that by eliminating the jack they were able to make the phone dust and water-resistant.
|
||||
|
||||
Being it’s such a big story right now, we asked our writers, “What are your thoughts on Smartphones doing away with the headphone jack?”
|
||||
|
||||
### Our Opinion
|
||||
|
||||
Derrik believes that “Apple’s way of doing it is a play to push more expensive peripherals that do not comply to an open standard.” He also doesn’t want to have to charge something every five hours, meaning the AirPods. While he understands that the 3.5mm jack is aging, as an “audiophile” he would love a new, open standard, but “proprietary pushes” worry him about device freedom.
|
||||
|
||||

|
||||
|
||||
Damien doesn’t really even use the headphone jack these days as he has Bluetooth headphones. He hates that wire anyway, so feels “this is a good move.” Yet he also understands Derrik’s point about the wireless headphones running out of battery, leaving him with “nothing to fall back on.”
|
||||
|
||||
Trevor is very upfront in saying he thought it was “dumb” until he heard you couldn’t charge the phone and use the headphones at the same time and realized it was “dumb X 2.” He uses the headphones/headphone jack all the time in a work van without Bluetooth and listens to audio or podcasts. He uses the plug-in style as Bluetooth drains his battery.
|
||||
|
||||
Simon is not a big fan. He hasn’t seen much reasoning past it leaving more room within the device. He figures “it will then come down to whether or not consumers favor wireless headphones, an adapter, and water-resistance over not being locked into AirPods, lightning, or an adapter”. He fears it might be “too early to jump into removing ports” and likes a “one pair fits all” standard.
|
||||
|
||||
James believes that wireless technology is progressive, so he sees it as a good move “especially for Apple in terms of hardware sales.” He happens to use expensive headphones, so personally he’s “yet to be convinced,” noting his Xperia is waterproof and has a jack.
|
||||
|
||||
Jeffry points out that “almost every transition attempt in the tech world always starts with strong opposition from those who won’t benefit from the changes.” He remembers the flak Apple received when they removed the floppy disk drive and decided not to support Flash, and now both are industry standards. He believes everything is evolving for the better, removing the audio jack is “just the first step toward the future,” and Apple is just the one who is “brave enough to lead the way (and make a few bucks in doing so).”
|
||||
|
||||

|
||||
|
||||
Vamsi doesn’t mind the removal of the headphone jack as long as there is a “better solution applicable to all the users that use different headphones and other gadgets.” He doesn’t feel using headphones via a lightning port is a good solution as it renders nearly all other headphones obsolete. Regarding Bluetooth headphones, he just doesn’t want to deal with another gadget. Additionally, he doesn’t get the argument of it being good for water resistance since there are existing devices with headphone jacks that are water resistant.
|
||||
|
||||
Mahesh prefers a phone with a jack because many times he is charging his phone and listening to music simultaneously. He believes we’ll get to see how it affects the public in the next few months.
|
||||
|
||||
Derrik chimed back in to say that by “removing open standard ports and using a proprietary connection too.,” you can be technical and say there are adapters, but Thunderbolt is also closed, and Apple can stop selling those adapters at any time. He also notes that the AirPods won’t be Bluetooth.
|
||||
|
||||

|
||||
|
||||
As for me, I’m always up for two things: New technology and anything Apple. I’ve been using iPhones since a few weeks past the very first model being introduced, yet I haven’t updated since 2012 and the iPhone 5, so I was overdue. I’ll be among the first to get my hands on the iPhone 7. I hate that stupid white wire being in my face, so I just might be opting for AirPods at some point. I am very appreciative of the phone becoming water-resistant. As for charging vs. listening, the charge on new iPhones lasts so long that I don’t expect it to be much of a problem. Even my old iPhone 5 usually lasts about twenty hours on a good day and twelve hours on a bad day. So I don’t expect that to be a problem.
|
||||
|
||||
### Your Opinion
|
||||
|
||||
Our writers have given you a lot to think about. What are your thoughts on Smartphones doing away with the headphone jack? Will you miss it? Is it a deal breaker for you? Or do you relish the upgrade in technology? Will you be trying the iPhone 5 or the AirPods? Let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/should-smartphones-do-away-with-the-headphone-jack/?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+maketecheasier
|
||||
|
||||
作者:[Laura Tucker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/lauratucker/
|
||||
@ -1,59 +0,0 @@
|
||||
willcoderwang 正在翻译
|
||||
|
||||
What the rise of permissive open source licenses means
|
||||
====
|
||||
|
||||
Why restrictive licenses such as the GNU GPL are steadily falling out of favor.
|
||||
|
||||
"If you use any open source software, you have to make the rest of your software open source." That's what former Microsoft CEO Steve Ballmer said back in 2001, and while his statement was never true, it must have spread some FUD (fear, uncertainty and doubt) about free software. Probably that was the intention.
|
||||
|
||||
This FUD about open source software is mainly about open source licensing. There are many different licenses, some more restrictive (some people use the term "protective") than others. Restrictive licenses such as the GNU General Public License (GPL) use the concept of copyleft, which grants people the right to freely distribute copies and modified versions of a piece of software as long as the same rights are preserved in derivative works. The GPL (v3) is used by open source projects such as bash and GIMP. There's also the Affero GPL, which provides copyleft to software that is offered over a network (for example as a web service.)
|
||||
|
||||
What this means is that if you take code that is licensed in this way and you modify it by adding some of your own proprietary code, then in some circumstances the whole new body of code, including your code, becomes subject to the restrictive open source license. It was this type of license that Ballmer was probably referring to when he made his statement.
|
||||
|
||||
But permissive licenses are a different animal. The MIT License, for example, lets anyone take open source code and do what they want with it — including modifying and selling it — as long as they provide attribution and don't hold the developer liable. Another popular permissive open source license, the Apache License 2.0, also provides an express grant of patent rights from contributors to users. JQuery, the .NET Core and Rails are licensed using the MIT license, while the Apache 2.0 license is used by software including Android, Apache and Swift.
|
||||
|
||||
Ultimately both license types are intended to make software more useful. Restrictive licenses aim to foster the open source ideals of participation and sharing so everyone gets the maximum benefit from software. And permissive licenses aim to ensure that people can get the maximum benefit from software by allowing them to do what they want with it — even if that means they take the code, modify it and keep it for themselves or even sell the resulting work as proprietary software without contributing anything back.
|
||||
|
||||
Figures compiled by open source license management company Black Duck Software show that the restrictive GPL 2.0 was the most commonly used open source license last year with about 25 percent of the market. The permissive MIT and Apache 2.0 licenses were next with about 18 percent and 16 percent respectively, followed by the GPL 3.0 with about 10 percent. That's almost evenly split at 35 percent restrictive and 34 percent permissive.
|
||||
|
||||
But this snapshot misses the trend. Black Duck's data shows that in the six years from 2009 to 2015 the MIT license's share of the market has gone up 15.7 percent and Apache's share has gone up 12.4 percent. GPL v2 and v3's share during the same period has dropped by a staggering 21.4 percent. In other words there was a significant move away from restrictive licenses and towards permissive ones during that period.
|
||||
|
||||
And the trend is continuing. Black Duck's [latest figures][1] show that MIT is now at 26 percent, GPL v2 21 percent, Apache 2 16 percent, and GPL v3 9 percent. That's 30 percent restrictive, 42 percent permissive — a huge swing from last year’s 35 percent restrictive and 34 percent permissive. Separate [research][2] of the licenses used on GitHub appears to confirm this shift. It shows that MIT is overwhelmingly the most popular license with a 45 percent share, compared to GLP v2 with just 13 percent and Apache with 11 percent.
|
||||
|
||||

|
||||
|
||||
### Driving the trend
|
||||
|
||||
What’s behind this mass move from restrictive to permissive licenses? Do companies fear that if they let restrictive software into the house they will lose control of their proprietary software, as Ballmer warned? In fact, that may well be the case. Google, for example, has [banned Affero GPL software][3] from its operations.
|
||||
|
||||
Jim Farmer, chairman of [Instructional Media + Magic][4], a developer of open source technology for education, believes that many companies avoid restrictive licenses to avoid legal difficulties. "The problem is really about complexity. The more complexity in a license, the more chance there is that someone has a cause of action to bring you to court. Complexity makes litigation more likely," he says.
|
||||
|
||||
He adds that fear of restrictive licenses is being driven by lawyers, many of whom recommend that clients use software that is licensed with the MIT or Apache 2.0 licenses, and who specifically warn against the Affero license.
|
||||
|
||||
This has a knock-on effect with software developers, he says, because if companies avoid software with restrictive licenses then developers have more incentive to license their new software with permissive ones if they want it to get used.
|
||||
|
||||
But Greg Soper, CEO of SalesAgility, the company behind the open source SuiteCRM, believes that the move towards permissive licenses is also being driven by some developers. "Look at an application like Rocket.Chat. The developers could have licensed that with GPL 2.0 or Affero but they chose a permissive license," he says. "That gives the app the widest possible opportunity, because a proprietary vendor can take it and not harm their product or expose it to an open source license. So if a developer wants an application to be used inside a third-party application it makes sense to use a permissive license."
|
||||
|
||||
Soper points out that restrictive licenses are designed to help an open source project succeed by stopping developers from taking other people's code, working on it, and then not sharing the results back with the community. "The Affero license is critical to the health of our product because if people could make a fork that was better than ours and not give the code back that would kill our product," he says. "For Rocket.Chat it's different because if it used Affero then it would pollute companies' IP and so it wouldn't get used. Different licenses have different use cases."
|
||||
|
||||
Michael Meeks, an open source developer who has worked on Gnome, OpenOffice and now LibreOffice, agrees with Jim Farmer that many companies do choose to use software with permissive licenses for fear of legal action. "There are risks with copyleft licenses, but there are also huge benefits. Unfortunately people listen to lawyers, and lawyers talk about risk but they never tell you that something is safe."
|
||||
|
||||
Fifteen years after Ballmer made his inaccurate statement it seems that the FUD it generated it is still having an effect — even if the move from restrictive licenses to permissive ones is not quite the effect he intended.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cio.com/article/3120235/open-source-tools/what-the-rise-of-permissive-open-source-licenses-means.html
|
||||
|
||||
作者:[Paul Rubens ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cio.com/author/Paul-Rubens/
|
||||
[1]: https://www.blackducksoftware.com/top-open-source-licenses
|
||||
[2]: https://github.com/blog/1964-open-source-license-usage-on-github-com
|
||||
[3]: http://www.theregister.co.uk/2011/03/31/google_on_open_source_licenses/
|
||||
[4]: http://immagic.com/
|
||||
|
||||
@ -0,0 +1,68 @@
|
||||
/*翻译中 WangYueScream LemonDemo*/
|
||||
|
||||
|
||||
Fedora-powered computer lab at our university
|
||||
==========
|
||||
|
||||

|
||||
|
||||
At the [University of Novi Sad in Serbia, Faculty of Sciences, Department of Mathematics and Informatics][5], we teach our students a lot of things. From an introduction to programming to machine learning, all the courses make them think like great developers and software engineers. The pace is fast and there are many students, so we must have a setup on which we can rely on. We decided to switch our computer lab to Fedora.
|
||||
|
||||
### Previous setup
|
||||
|
||||
Our previous solution was keeping our development software in Windows [virtual machines][4] installed on Ubuntu Linux. This seemed like a good idea at the time. However, there were a couple of drawbacks. Firstly, there were serious performance losses because of running virtual machines. Performance and speed of the operating system was impacted because of this. Also, sometimes virtual machines ran concurrently in another user’s session. This led to serious slowdowns. We were losing precious time on booting the machines and then booting the virtual machines. Lastly, we realized that most of our software was Linux-compatible. Virtual machines weren’t necessary. We had to find a better solution.
|
||||
|
||||
### Enter Fedora!
|
||||
|
||||

|
||||
|
||||
Picture of a computer lab running Fedora Workstation by default
|
||||
|
||||
We thought about replacing the virtual machines with a “bare bones” installation for a while. We decided to go for Fedora for several reasons.
|
||||
|
||||
#### Cutting edge of development
|
||||
|
||||
In our courses, we use many different development tools. Therefore, it is crucial that we always use the latest and greatest development tools available. In Fedora, we found 95% of the tools we needed in the official software repositories! For a few tools, we had to do a manual installation. This was easy in Fedora because you have almost all development tools available out of the box.
|
||||
|
||||
What we realized in this process was that we used a lot of free and open source software and tools. Having all that software always up to date was always going to be a lot of work – but not with Fedora.
|
||||
|
||||
#### Hardware compatibility
|
||||
|
||||
The second reason for choosing Fedora in our computer lab was hardware compatibility. The computers in the lab are new. In the past, there were some problems with older kernel versions. In Fedora, we knew that we would always have a recent kernel. As we expected, everything worked out of the box without any issues.
|
||||
|
||||
We decided that we would go for the [Workstation edition][3] of Fedora with [GNOME desktop environment][2]. Students found it easy, intuitive, and fast to navigate through the operating system. It was important for us that students have an easy environment where they could focus on the tasks at hand and the course itself rather than a complicated or slow user interface.
|
||||
|
||||
#### Powered by freedom
|
||||
|
||||
Lastly, in our department, we value free and open source software greatly. By utilizing such software, students are able to use it freely even when they graduate and start working. In the process, they also learn about Fedora and free and open source software in general.
|
||||
|
||||
### Switching the computer lab
|
||||
|
||||
We took one of the computers and fully set it up manually. That included preparing all the needed scripts and software, setting up remote access, and other important components. We also made one user account per course so students could easily store their files.
|
||||
|
||||
After that one computer was ready, we used a great, free and open source tool called [CloneZilla][1]. CloneZilla let us make a hard drive image for restoration. The image size was around 11GB. We used some fast USB 3.0 flash drives to restore the disk image to the remaining computers. We managed to fully provision and setup twenty-four computers in one hour and fifteen minutes, with just a couple of flash drives.
|
||||
|
||||
### Future work
|
||||
|
||||
All the computers in our computer lab are now exclusively using Fedora (with no virtual machines). The remaining work is to set up some administration scripts for remotely installing software, turning computers on and off, and so forth.
|
||||
|
||||
We would like to thank all Fedora maintainers, packagers, and other contributors. We hope our work encourages other schools and universities to make a switch similar to ours. We happily confirm that Fedora works great for us, and we can also vouch that it would work great for you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/fedora-computer-lab-university/
|
||||
|
||||
作者:[Nemanja Milošević][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/nmilosev/
|
||||
[1]:http://clonezilla.org/
|
||||
[2]:https://www.gnome.org/
|
||||
[3]:https://getfedora.org/workstation/
|
||||
[4]:https://en.wikipedia.org/wiki/Virtual_machine
|
||||
[5]:http://www.dmi.rs/
|
||||
@ -0,0 +1,57 @@
|
||||
willcoderwang translating
|
||||
|
||||
# Would You Consider Riding in a Driverless Car?
|
||||
|
||||

|
||||
|
||||
Technology goes through major movements. The last one we entered into was the wearables phase with the Apple Watch and clones, FitBits, and Google Glass. It seems like the next phase they’ve been working on for quite a while is the driverless car.
|
||||
|
||||
|
||||
These cars, sometimes called autonomous cars, self-driving cars, or robotic cars, would literally drive themselves thanks to technology. They detect their surroundings, such as obstacles and signs, and use GPS to find their way. But would they be safe to drive in? We asked our technology-minded writers, “Would you consider riding in a driverless car?
|
||||
|
||||
### Our Opinion
|
||||
|
||||
**Derrik** reports that he would ride in a driver-less car because “_the technology is there and a lot of smart people have been working on it for a long time._” He admits there are issues with them, but for the most part he believes a lot of the accidents happen when a human does get involved. But if you take humans out of the equation, he thinks riding in a driverless car “_would be incredibly safe_.”
|
||||
|
||||
For **Phil**, these cars give him “the willies,” yet he admits that’s only in the abstract as he’s never ridden in one. He agrees with Derrik that the tech is well developed and knows how it works, but then sees himself as “a_ tough sell being a bit of a luddite at heart._” He admits to even rarely using cruise control. Yet he agrees that a driver relying on it too much would be what would make him feel unsafe.
|
||||
|
||||

|
||||
|
||||
**Robert** agrees that “_the concept is a little freaky,_” but in principle he doesn’t see why cars shouldn’t go in that direction. He notes that planes have gone that route and become much safer, and he believes the accidents we see are mainly “_caused by human error due to over-relying on the technology then not knowing what to do when it fails._”
|
||||
|
||||
He’s a bit of an “anxious passenger” as it is, preferring to have control over the situation, so for him much of it would have to do with where he car is being driven. He’d be okay with it if it was driving in the city at slow speeds but definitely not on “motorways of weaving English country roads with barely enough room for two cars to drive past each other.” He and Phil both see English roads as much different than American ones. He suggests letting others be the guinea pigs and joining in after it’s known to be safe.
|
||||
|
||||
For **Mahesh**, he would definitely ride in a driverless car, as he knows that the companies with these cars “_have robust technology and would never put their customers at risk._” He agrees that it depends on the roads that the cars are being driven on.
|
||||
|
||||
My opinion kind of floats in the middle of all the others. While I’m normally one to jump readily into new technology, putting my life at risk makes it different. I agree that the cars have been in development so long they’re bound to be safe. And frankly there are many drivers on the road that are much more dangerous than driverless cars. But like Robert, I think I’ll let others be the guinea pigs and will welcome the technology once it becomes a bit more commonplace.
|
||||
|
||||
### Your Opinion
|
||||
|
||||
Where do you sit with this issue? Do you trust this emerging technology? Or would you be a nervous nelly in one of these cars? Would you consider driving in a driverless car? Jump into the discussion below in the comments.
|
||||
|
||||
<small style="box-sizing: inherit; font-size: 16px;">Image Credit: [Steve Jurvetson][4] and [Steve Jurvetson at Wikimedia Commons][3]</small>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/riding-driverless-car/?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+maketecheasier
|
||||
|
||||
作者:[Laura Tucker][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/lauratucker/
|
||||
[1]:https://www.maketecheasier.com/riding-driverless-car/#comments
|
||||
[2]:https://www.maketecheasier.com/author/lauratucker/
|
||||
[3]:https://commons.m.wikimedia.org/wiki/File:Inside_the_Google_RoboCar_today_with_PlanetLabs.jpg
|
||||
[4]:https://commons.m.wikimedia.org/wiki/File:Jurvetson_Google_driverless_car_trimmed.jpg
|
||||
[5]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[6]:https://www.maketecheasier.com/best-wordpress-video-plugins/
|
||||
[7]:https://www.maketecheasier.com/hidden-google-games/
|
||||
[8]:mailto:?subject=Would%20You%20Consider%20Riding%20in%20a%20Driverless%20Car?&body=https%3A%2F%2Fwww.maketecheasier.com%2Friding-driverless-car%2F
|
||||
[9]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Friding-driverless-car%2F&text=Would+You+Consider+Riding+in+a+Driverless+Car%3F
|
||||
[10]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Friding-driverless-car%2F
|
||||
[11]:https://www.maketecheasier.com/category/opinion/
|
||||
@ -0,0 +1,56 @@
|
||||
# Arch Linux: In a world of polish, DIY never felt so good
|
||||
|
||||

|
||||
|
||||
Dig through the annals of Linux journalism and you'll find a surprising amount of coverage of some pretty obscure distros. Flashy new distros like Elementary OS and Solus garner attention for their slick interfaces, and anything shipping with a MATE desktop gets coverage by simple virtue of using MATE.
|
||||
|
||||
Thanks to television shows like _Mr Robot_, I fully expect coverage of even Kali Linux to be on the uptick soon.
|
||||
|
||||
In all that coverage, though, there's one very widely used distro that's almost totally ignored: Arch Linux.
|
||||
|
||||
Arch gets very little coverage for a several reasons, not the least of which is that it's somewhat difficult to install and requires you feel comfortable with the command line to get it working. Worse, from the point of view of anyone trying to appeal to mainstream users, that difficulty is by design - nothing keeps the noobs out like a daunting install process.
|
||||
|
||||
It's a shame, though, because once the installation is complete, Arch is actually - in my experience - far easier to use than any other Linux distro I've tried.
|
||||
|
||||
But yes, installation is a pain. Hand-partitioning, hand-mounting and generating your own `fstab` files takes more time and effort than clicking "install" and merrily heading off to do something else. But the process of installing Arch teaches you a lot. It pulls back the curtain so you can see what's behind it. In fact it makes the curtain disappear entirely. In Arch, _you_ are the person behind the curtain.
|
||||
|
||||
In addition to its reputation for being difficult to install, Arch is justly revered for its customizability, though this is somewhat misunderstood. There is no "default" desktop in Arch. What you want installed on top of the base set of Arch packages is entirely up to you.
|
||||
|
||||
|
||||
|
||||
While you can see this as infinite customizability, you can also see it as totally lacking in customization. For example, unlike - say - Ubuntu there is almost no patching or customization happening in Arch. Arch developers simply pass on what upstream developers have released, end of story. For some this good; you can run "pure" GNOME, for instance. But in other cases, some custom patching can take care of bugs that upstream devs might not prioritize.
|
||||
|
||||
The lack of a default set of applications and desktop system also does not make for tidy reviews - or reviews at all really, since what I install will no doubt be different to what you choose. I happened to select a very minimal setup of bare Openbox, tint2 and dmenu. You might prefer the latest release of GNOME. We'd both be running Arch, but our experiences of it would be totally different. This is of course true of any distro, but most others have a default desktop at least.
|
||||
|
||||
Still there are common elements that together can make the basis of an Arch review. There is, for example, the primary reason I switched - Arch is a rolling release distro. This means two things. First, the latest kernels are delivered as soon as they're available and reasonably stable. This means I can test things that are difficult to test with other distros. The other big win for a rolling distro is that all updates are delivered when they're ready. Not only does this mean newer software sooner, it means there's no massive system updates that might break things.
|
||||
|
||||
Many people feel that Arch is less stable because it's rolling, but in my experience over the last nine months I would argue the opposite.
|
||||
|
||||
I have yet to break anything with an update. I did once have to rollback because my /boot partition wasn't mounted when I updated and changes weren't written, but that was pure user error. Bugs that do surface (like some regressions related to the trackpad on a Dell XPS laptop I was testing) are fixed and updates are available much faster than they would be with a non-rolling distro. In short, I've found Arch's rolling release updates to be far more stable than anything else I've been using along side it. The only caveat I have to add to that is read the wiki and pay close attention to what you're updating.
|
||||
|
||||
This brings us to the main reason I suspect that Arch's appeal is limited - you have to pay attention to what you're doing. Blindly updating Arch is risky - but it's risky with any distro; you've just been conditioned to think it's not because you have no choice.
|
||||
|
||||
All of which leads me to the other major reason I embraced Arch - the [Arch Philosophy][1]. The part in particular that I find appealing is this bit: "[Arch] is targeted at the proficient GNU/Linux user, or anyone with a do-it-yourself attitude who is willing to read the documentation, and solve their own problems."
|
||||
|
||||
As Linux moves further into the mainstream developers seem to feel a greater need to smooth over all the rough areas - as if mirroring the opaque user experience of proprietary software were somehow the apex of functionality.
|
||||
|
||||
Strange though it sounds in this day and age, there are many of us who actually prefer to configure things ourselves. In this sense Arch may well be the last refuge of the DIY Linux user. ®
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theregister.co.uk/2016/11/02/arch_linux_taster/
|
||||
|
||||
作者:[Scott Gilbertson][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theregister.co.uk/Author/1785
|
||||
[1]:https://wiki.archlinux.org/index.php/Arch_Linux
|
||||
[2]:http://www.theregister.co.uk/Author/1785
|
||||
[3]:https://www.linkedin.com/shareArticle?mini=true&url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&title=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good&summary=Last%20refuge%20for%20purists
|
||||
[4]:http://twitter.com/share?text=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good&url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&via=theregister
|
||||
[5]:http://www.reddit.com/submit?url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&title=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good
|
||||
87
sources/talk/20161104 Open Source Vs Closed Source.md
Normal file
87
sources/talk/20161104 Open Source Vs Closed Source.md
Normal file
@ -0,0 +1,87 @@
|
||||
[
|
||||

|
||||
][2]There are many differences between **open source operating system** and **closed source operating system**. Here we have written few of them.
|
||||
|
||||
### What Is Open Source? It's Freedom!
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
This is the most important thing that a user should possess. I may or may not be modifying the code but someone who wants to modify the code for good purposes should not be restricted. And a user should be allowed to share the software if he likes it. And this is all possible with **open source** software.
|
||||
|
||||
The **closed source** operating systems have really scaring license terms. Moreover do all the people read the license terms?, Nope, most of them just click ‘Accept’.
|
||||
|
||||
* * *
|
||||
|
||||
### Cost
|
||||
|
||||
Nearly all of the open source operating systems are free of cost. People only donate voluntarily. And a single installation **CD/DVD or USB** can be used to install the OS in as many computers as possible.
|
||||
|
||||
Closed source operating systems are very costly when compared with open source OSs and if you are building a PC, it may cost you at least $100 per PC.
|
||||
|
||||
We could use the money that we may spend on closed source software to buy better.
|
||||
|
||||
### Choice
|
||||
|
||||
There are numerous open source operating systems out there. So if you don’t like a distro then you can try others and at least a single operating system will be suitable for you.
|
||||
|
||||
Distros like Ubuntu studio, Bio Linux, Edubuntu, Kali Linux, Qubes, SteamOS are some of the distros that are created for the particular type of users.
|
||||
|
||||
Is there anything called choice in closed source operating systems? I don’t think so.
|
||||
|
||||
### Privacy
|
||||
|
||||
There is no need for **Open source operating systems** to collect user data. They are not going show any personalized ads or sell your data to third parties. If the developers need money they will ask for donations or display ads on their website. ADs will always be related to Linux, so it also helps us.
|
||||
|
||||
You might have known how a major closed source operating system(you know what its name is) is said to be collecting users data which caused many people to turn down their free upgrade offer. Many users of that OS had even turned off updates to avoid any upgrade, it means they preferred security risk to free upgrade.
|
||||
|
||||
### Security
|
||||
|
||||
Open source software are mostly secure. They are not secure because of less market share but the way they are made. Qubes Os is one of the most secure OS that isolates the running software from one another.
|
||||
|
||||
Closed source operating systems compromise security for usability making them more vulnerable.
|
||||
|
||||
### Hardware support
|
||||
|
||||
Many of us might have an old PC that we don’t want to throw away and at that situation lightweight distros that are capable of giving a new life to them. Here is a list of lightweight operating systems you can try these distros [5 Lightweight Linux for old computers][3]. Linux based OSs comes with drivers for almost all devices, so there won’t be any need to search and install drivers.
|
||||
|
||||
Many a time closed source operating systems scrap support for older hardware forcing the user to buy new hardware. We may have to search and install drivers ourself.
|
||||
|
||||
### Community Support
|
||||
|
||||
Nearly all of the **open source OSes** have user forums where you can ask questions and get answers from other users. People share tips and tricks and help each other. Experienced Linux users love to help newbies, so they always try their best to help them.
|
||||
|
||||
**Closed source OSes **community is not even comparable to open source OS community. Questions asked might even go unanswered.
|
||||
|
||||
### Monetisation
|
||||
|
||||
Making many out of OSes will be tough. Developers accept donations from users and get some money from ads that are displayed on their website. Most of the donations are used to pay hosting bills and developers’ salary.
|
||||
|
||||
Many of the closed source OSes not only make money from licensing their software but also through targeted ads.
|
||||
|
||||
### Crapware
|
||||
|
||||
I accept some of the open source operating systems provide some software that we may not use in our lifetime and some people consider them as crapware. But there are distros that provide the minimal installation that contain no unwanted software. So, crapware is not really a problem.
|
||||
|
||||
All the closed source operating systems contain crapware installed by the manufacturer and will force as to do a clean installation.
|
||||
|
||||
Open source software is more like a philosophy . It’s a way of sharing and learning. It’s even good for the economy.
|
||||
So, we have listed things that we know. If you think we have missed some points, then please do comment and let us know.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/open-source-vs-closed-source
|
||||
|
||||
作者:[Mohd Sohail][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/mohdsohail
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/what-is-open-source_orig.jpg?250
|
||||
[2]:http://www.linuxandubuntu.com/home/open-source-vs-closed-source
|
||||
[3]:http://www.linuxandubuntu.com/home/5-lightweight-linux-for-old-computers
|
||||
@ -0,0 +1,54 @@
|
||||
# Build Strong Real-Time Streaming Apps with Apache Calcite
|
||||
|
||||
|
||||

|
||||
Calcite is a data framework that lets you to build custom database functionality, explains Microsoft developer Atri Sharma in this preview to his upcoming talk at Apache: Big Data Europe, Nov. 14-16 in Seville, Spain.[Creative Commons Zero][2]Wikimedia Commons: Parent Géry
|
||||
|
||||
The [Apache Calcite][7] data management framework contains many pieces of a typical database management system but omits others, such as storage of data and algorithms to process data. In his talk at the upcoming [Apache: Big Data][6] conference in Seville, Spain, Atri Sharma, a Software Engineer for Azure Data Lake at Microsoft, will talk about developing applications using [Apache Calcite][5]'s advanced query planning capabilities. We spoke with Sharma to learn more about Calcite and how existing applications can take advantage of its functionality.
|
||||
|
||||

|
||||
|
||||
Atri Sharma, Software Engineer, Azure Data Lake, Microsoft[Used with permission][1]
|
||||
|
||||
**Linux.com: Can you provide some background on Apache Calcite? What does it do?**
|
||||
|
||||
Atri Sharma: Calcite is a framework that is the basis of many database kernels. Calcite empowers you to build your custom database functionality and use the required resources from Calcite. For example, Hive uses Calcite for cost-based query optimization, Drill and Kylin use Calcite for SQL parsing and optimization, and Apex uses Calcite for streaming SQL.
|
||||
|
||||
**Linux.com: What are some features that make Apache Calcite different from other frameworks?**
|
||||
|
||||
Atri: Calcite is unique in the sense that it allows you to build your own data platform. Calcite does not manage your data directly but rather allows you to use Calcite's libraries to define your own components. For eg, instead of providing a generic query optimizer, it allows defining custom query optimizers using the Planners available in Calcite.
|
||||
|
||||
**Linux.com: Apache Calcite itself does not store or process data. How does that affect application development?**
|
||||
|
||||
Atri: Calcite is a dependency in the kernel of your database. It is targeted for data management platforms that wish to extend their functionalities without writing a lot of functionality from scratch.
|
||||
|
||||
**Linux.com: Who should be using it? Can you give some examples?**
|
||||
|
||||
Atri: Any data management platform looking to extend their functionalities should use Calcite. We are the foundation of your next high-performance database!
|
||||
|
||||
Specifically, I think the biggest examples would be Hive using Calcite for query optimization and Flink for parsing and streaming SQL processing. Hive and Flink are full-fledged data management engines, and they use Calcite for highly specialized purposes. This is a good case study for applications of Calcite to further strengthen the core of a data management platform.
|
||||
|
||||
**Linux.com: What are some new features that you’re looking forward to?**
|
||||
|
||||
Atri: Streaming SQL enhancements are something I am very excited about. These features are exciting because they will enable users of Calcite to develop real-time streaming applications much faster, and the strength and capabilities of these applications will be manifold. Streaming applications are the new de facto, and the strength to have query optimization in streaming SQL will be very useful for a large crowd. Also, there is discussion ongoing about temporal tables, so watch out for more!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/build-strong-real-time-streaming-apps-apache-calcite
|
||||
|
||||
作者:[AMBER ANKERHOLZ][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/aankerholz
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/atri-sharmajpg
|
||||
[4]:https://www.linux.com/files/images/calcitejpg
|
||||
[5]:https://calcite.apache.org/
|
||||
[6]:http://events.linuxfoundation.org/events/apache-big-data-europe
|
||||
[7]:https://calcite.apache.org/
|
||||
@ -0,0 +1,34 @@
|
||||
# The iconic text editor Vim celebrates 25 years
|
||||
|
||||

|
||||
>Image by [Oscar Cortez][8]. Modified by Opensource.com. [CC BY-SA 2.0][7].
|
||||
|
||||
Turn back the dial of time a bit. No, keep turning... a little more... there! Over 25 years ago, when some of your professional colleagues were still toddlers, Bram Moolenaar started working on a text editor for his Amiga. He was a user of vi on Unix, but the Amiga didn't have anything quite like it. On November 2, 1991, after three years in development, he released the first version of the "Vi IMitation" editor, or [Vim][6].
|
||||
|
||||
Two years later, with the 2.0 release, Vim's feature set had exceeded that of vi, so the acronym was changed to "Vi IMproved," Today, having just marked its 25th birthday, Vim is available on a wide array of platforms—Windows, OS/2, OpenVMS, BSD, Android, iOS—and it comes shipped standard with OS X and many Linux distros. It is praised by many, reviled by many, and is a central player in the ongoing conflicts between groups of developers. Interview questions have even been asked: "Emacs or Vim?" Vim is licensed freely, under a [charityware license][5] compatible with the GPL.
|
||||
|
||||
Vim is a flexible, extensible text editor with a powerful plugin system, rock-solid integration with many development tools, and support for hundreds of programming languages and file formats. Twenty-five years after its creation, Bram Moolenaar still leads development and maintenance of the project—a feat in itself! Vim had been chugging along in maintenance mode for more than a decade, but in September 2016 version 8.0 was released, adding new features to the editor of use to modern programmers. For many years now, sales of T-shirts and other Vim logo gear on the website has supported [ICCF][4], a Dutch charity that supports children in Uganda. It's a favorite project of Moolenaar, who has made trips to Uganda to volunteer at the children's center in Kibaale.
|
||||
|
||||
Vim is one of the interesting tidbits of open source history: a project that, for 25 years, has kept the same core contributor and is used by vast numbers of people, many without ever knowing its history. If you'd like to learn a little more about Vim, [check out the website][3], or you can read [some tips for getting started with Vim][2]or [the story of a Vim convert][1] right here on Opensource.com.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/11/happy-birthday-vim-25
|
||||
|
||||
作者:[D Ruth Bavousett][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/druthb
|
||||
[1]:https://opensource.com/business/16/8/7-reasons-love-vim
|
||||
[2]:https://opensource.com/life/16/7/tips-getting-started-vim
|
||||
[3]:http://www.vim.org/
|
||||
[4]:http://iccf-holland.org/
|
||||
[5]:http://vimdoc.sourceforge.net/htmldoc/uganda.html#license
|
||||
[6]:http://www.vim.org/
|
||||
[7]:https://creativecommons.org/licenses/by-sa/2.0/
|
||||
[8]:https://www.flickr.com/photos/drastudio/7161064915/in/photolist-bUNk7t-d1eWDm-7X6nmx-7AUchG-7AQpe8-9ob1yW-YZfUi-5LqxMi-9rye8j-7xptiR-9AE5Pe-duq1Wu-7DvLFt-7Mt7TN-7xRZHa-e19sFi-7uc6u3-dV7YuK-9DRH37-6oQE3u-9u3TG9-9jbg3J-7ELgDS-5Sgp87-8NXn1u-7ZSBk7-9kytY5-7f1cMC-3sdkMh-8SWLRX-8ebBMm-pfRPHJ-9wsSQW-8iZj4Z-pCaSMa-ejZLDj-7NnKCZ-9PjXb1-92hxHD-7LbXSZ-7cAZuB-7eJgiE-7VKc9d-8Yuun8-9tZReM-dxp7r8-9NH1R4-7QfoWB-7RGWtU-7NCPf9
|
||||
@ -1,54 +0,0 @@
|
||||
After a nasty computer virus, sys admin looks to Linux
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
My first brush with open source came while I was working for my university as a part-time system administrator in 2001. I was part of a small group that created business case studies for teaching not just in the university, but elsewhere in academia.
|
||||
|
||||
As the team grew, the need for a robust LAN setup with file serving, intranet applications, domain logons, etc. emerged. Our IT infrastructure consisted mostly of bootstrapped Windows 98 computers that had become too old for the university's IT labs and were reassigned to our department.
|
||||
|
||||
### Discovering Linux
|
||||
|
||||
One day, as part of the university's IT procurement plan, our department received an IBM server. We planned to use it as an Internet gateway, domain controller, file and backup server, and intranet application host.
|
||||
|
||||
Upon unboxing, we noticed that it came with Red Hat Linux CDs. No one on our 22-person team (including me) knew anything about Linux. After a few days of research, I met a friend of a friend who did Linux RTOS programming for a living. I asked him for some help installing it.
|
||||
|
||||
It was heady stuff as I watched the friend load up the CD drive with the first of the installation CDs and boot into the Anaconda install system. In about an hour we had completed the basic installation, but still had no working internet connection.
|
||||
|
||||
Another hour of tinkering got us connected to the Internet, but we still weren't anywhere near domain logons or Internet gateway functionality. After another weekend of tinkering, we were able to instruct our Windows 98 terminals to accept the IP of the the Linux PC as the proxy so that we had a working shared Internet connection. But domain logons were still some time away.
|
||||
|
||||
We downloaded [Samba][1] over our awfully slow phone modem connection and hand configured it to serve as the domain controller. File services were also enabled via NFS Kernel Server and creating user directories and making the necessary adjustments and configurations on Windows 98 in Network Neighborhood.
|
||||
|
||||
This setup ran flawlessly for quite some time, and we eventually decided to get started with Intranet applications for timesheet management and some other things. By this time, I was leaving the organization and had handed over most of the sys admin stuff to someone who replaced me.
|
||||
|
||||
### A second Linux experience
|
||||
|
||||
In 2004, I got into Linux once again. My wife ran an independent staff placement business that used data from services like Monster.com to connect clients with job seekers.
|
||||
|
||||
Being the more computer literate of the two of us, it was my job to set things right with the computer or Internet when things went wrong. We also needed to experiment with a lot of tools for sifting through the mountains of resumes and CVs she had to go through on a daily basis.
|
||||
|
||||
Windows [BSoDs][2] were a routine affair, but that was tolerable as long as the data we paid for was safe. I had to spend a few hours each week creating backups.
|
||||
|
||||
One day, we had a virus that simply would not go away. Little did we know what was happening to the data on the slave disk. When it finally failed, we plugged in the week-old slave backup and it failed a week later. Our second backup simply refused to boot up. It was time for professional help, so we took our PC to a reputable repair shop. After two days, we learned that some malware or virus had wiped certain file types, including our paid data, clean.
|
||||
|
||||
This was a body blow to my wife's business plans and meant lost contracts and delayed invoice payments. I had in the interim travelled abroad on business and purchased my first laptop computer from [Computex 2004][3] in Taiwan. It had Windows XP pre-installed, but I wanted to replace it with Linux. I had read that Linux was ready for the desktop and that [Mandrake Linux][4] was a good choice. My first attempt at installation went without a glitch. Everything worked beautifully. I used [OpenOffice][5] for my writing, presentation, and spreadsheet needs.
|
||||
|
||||
We got new hard drives for our computer and installed Mandrake Linux on them. OpenOffice replaced Microsoft Office. We relied on webmail for mailing needs, and [Mozilla Firefox][6] was a welcome change in November 2004. My wife saw the benefits immediately, as there were no crashes or virus/malware infections. More importantly, we bade goodbye to the frequent crashes that plagued Windows 98 and XP. She continued to use the same distribution.
|
||||
|
||||
I, on the other hand, started playing around with other distributions. I love distro-hopping and trying out new ones every once in a while. I also regularly try and test out web applications like Drupal, Joomla, and WordPress on Apache and NGINX stacks. And now our son, who was born in 2006, grew up on Linux. He's very happy with Tux Paint, Gcompris, and SMPlayer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/my-linux-story-soumya-sarkar
|
||||
|
||||
作者:[Soumya Sarkar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/ssarkarhyd
|
||||
[1]: https://www.samba.org/
|
||||
[2]: https://en.wikipedia.org/wiki/Blue_Screen_of_Death
|
||||
[3]: https://en.wikipedia.org/wiki/Computex_Taipei
|
||||
[4]: https://en.wikipedia.org/wiki/Mandriva_Linux
|
||||
[5]: http://www.openoffice.org/
|
||||
[6]: https://www.mozilla.org/en-US/firefox/new/
|
||||
@ -1,38 +0,0 @@
|
||||
Aspiring sys admin works his way up in Linux
|
||||
===============================================
|
||||
|
||||

|
||||
|
||||
I first saw Linux in action around 2001 at my first job. I was as an account manager for an Austrian automotive industry supplier and shared an office with our IT guy. He was creating a CD burning station (one of those huge things that can burn and print several CDs simultaneously) so that we could create and send CDs of our car parts catalogue to customers. While the burning station was originally designed for Windows, he just could not get it to work. He eventually gave up on Windows and turned to Linux, and it worked flawlessly.
|
||||
|
||||
For me, it was all kind of arcane. Most of the work was done on the command line, which looked like DOS but was much more powerful (even back then, I recognized this). I had been a Mac user since 1993, and a CLI (command line interface) seemed a bit old fashioned to me at the time.
|
||||
|
||||
It was not until years later—I believe around 2009—that I really discovered Linux for myself. By then, I had moved to the Netherlands and found a job working for a retail supplier. It was a small company (about 20 people) where, aside from my normal job as a key account manager, I had involuntarily become the first line of IT support. Whenever something didn't work, people first came to me before calling the expensive external IT consultant.
|
||||
|
||||
One of my colleagues had fallen for a phishing attack and clicked on an .exe file in an email that appeared to be from DHL. (Yes, it does happen.) His computer got completely taken over and he could not do anything. Even a complete reformat wouldn't help, as the virus kept rearing it's ugly head. I only later learned that it probably had written itself to the MBR (Master Boot Record). By this time, the contract with the external IT consultant had been terminated due to cost savings.
|
||||
|
||||
I turned to Ubuntu to get my colleague to work again. And work it did—like a charm. The computer was humming along again, and I got all the important applications to work like they should. In some ways it wasn't the most elegant solution, I'll admit, yet he (and I) liked the speed and stability of the system.
|
||||
|
||||
However, my colleague was so entrenched in the Windows world that he just couldn't get used to the fact that some things were done differently. He just kept complaining. (Sound familiar?)
|
||||
|
||||
While my colleague couldn't bear that things were done differently, I noticed that this was much less of an issue for me as a Mac user. There were more similarities. I was intrigued. So, I installed a dual boot with Ubuntu on my work laptop and found that I got much more work done in less time and it was much easier to get the machine to do what I wanted. Ever since then I've been regularly using several Linux distros, with Ubuntu and Elementary being my personal favorites.
|
||||
|
||||
At the moment, I am unemployed and hence have a lot of time to educate myself. Because I've always had an interest in IT, I am working to get into Linux systems administration. But is awfully hard to get a chance to show your knowledge nowadays because 95% of what I have learned over the years can't be shown on a paper with a stamp on it. Interviews are the place for me to have a conversation about what I know. So, I signed up for Linux certifications that I hope give me the boost I need.
|
||||
|
||||
I have also been contributing to open source for some time. I started by doing translations (English to German) for the xTuple ERP and have since moved on to doing Mozilla "customer service" on Twitter, filing bug reports, etc. I evangelize for free and open software (with varying degrees of success) and financially support several FOSS advocate organizations (DuckDuckGo, bof.nl, EFF, GIMP, LibreCAD, Wikipedia, and many others) whenever I can. I am also currently working to set up a regional privacy cafe.
|
||||
|
||||
Aside from that, I have started working on my first book. It's supposed to be a lighthearted field manual for normal people about computer privacy and security, which I hope to self-publish by the end of the year. (The book will be licensed under Creative Commons.) As for content, you can expect that I will explain in detail why privacy is important and what is wrong with the whole "I have nothing to hide" mentality. But the biggest part will be instructions how to get rid of pesky ad-trackers, encrypting your hard disk and mail, chat OTR, how to use TOR, etc. While it's a manual first, I aim for a tone that is casual and easy to understand spiced up with stories of personal experiences.
|
||||
|
||||
I still love my Macs and will use them whenever I can afford it (mainly because of the great construction), but Linux is always there in a VM and is used for most of my daily work. Nothing fancy here, though: word processing (LibreOffice and Scribus), working on my website and blog (Wordpress and Jekyll), editing some pictures (Shotwell and Gimp), listening to music (Rhythmbox), and pretty much every other task that comes along.
|
||||
|
||||
Whichever way my job hunt turns out, I know that Linux will always be my go-to system.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/5/my-linux-story-rene-raggl
|
||||
|
||||
作者:[Rene Raggl][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/rraggl
|
||||
@ -1,837 +0,0 @@
|
||||
Building a data science portfolio: Machine learning project
|
||||
===========================================================
|
||||
|
||||
>这是这个系列的第三次发布关于如何建立科学的投资数据. 如果你喜欢这个系列并且想继续关注, 你可以在订阅页面的底部找到链接[subscribe at the bottom of the page][1].
|
||||
|
||||
数据科学公司越来越关注投资组合问题. 这其中的一个原因是,投资组合是最好的判断人们生活技能的方法. 好消息是投资组合是完全在你的控制之下的. 只要你做些投资方面的工作,就可以做出很棒的投资组合.
|
||||
|
||||
高质量投资组合的第一步就是知道需要什么技能. 客户想要将这些初级技能应用到数据科学, 因此这些投资技能显示如下:
|
||||
|
||||
- 沟通能力
|
||||
- 协作能力
|
||||
- 技术能力
|
||||
- 数据推理能力
|
||||
- 主动性
|
||||
|
||||
任何好的投资组合都由多个能力组成,其中必然包含以上一到两点. 这里我们主要讲第三点如何做好科学的数据投资组合. 在这一节, 我们主要讲第二项以及如何创建一个端对端的机器学习项目. 在最后, 在最后我们将拥有一个项目它将显示你的能力和技术水平. [Here’s][2]如果你想看一下这里有一个完整的例子.
|
||||
|
||||
### 一个端到端的项目
|
||||
|
||||
作为一个数据科学家, 有时候你会拿到一个数据集并被问到是 [如何产生的][3]. 在这个时候, 交流是非常重要的, 走一遍流程. 用用Jupyter notebook, 看一看以前的例子,这对你非常有帮助. 在这里你能找到一些可以用的报告或者文档.
|
||||
|
||||
不管怎样, 有时候你会被要求创建一个具有操作价值的项目. 一个直接影响公司业务的项目, 不止一次的, 许多人用的项目. 这个任务可能像这样 “创建一个算法来预测波动率”或者 “创建一个模型来自动标签我们的文章”. 在这种情况下, 技术能力比说评书更重要. 你必须能够创建一个数据集, 并且理解它, 然后创建脚本处理该数据. 还有很重要的脚本要运行的很快, 占用系统资源很小. 它可能要运行很多次, 脚本的可使用性也很重要,并不仅仅是一个演示版. 可使用性是指整合操作流程, 因为他很有可能是面向用户的.
|
||||
|
||||
端对端项目的主要组成部分:
|
||||
|
||||
- 理解背景
|
||||
- 浏览数据并找出细微差别
|
||||
- 创建结构化项目, 那样比较容易整合操作流程
|
||||
- 运行速度快占用系统资源小的代码
|
||||
- 写好文档以便其他人用
|
||||
|
||||
为类有效的创建这种类型的项目, 我们可能需要处理多个文件. 强烈推荐使用 [Atom][4]或者[PyCharm][5] . 这些工具允许你在文件间跳转, 编辑不同类型的文件, 例如 markdown 文件, Python 文件, 和csv 文件. 结构化你的项目还利于版本控制 [Github][6] 也很有用.
|
||||
|
||||

|
||||
>Github上的这个项目.
|
||||
|
||||
在这一节中我们将使用 [Pandas][7] 和 [scikit-learn][8]扩展包 . 我们还将用到Pandas [DataFrames][9], 它使得python读取和处理表格数据更加方便.
|
||||
|
||||
### 找到好的数据集
|
||||
|
||||
找到一个好的端到端投资项目数据集很难. [The dataset][10]数据集需要足够大但是内存和性能限制了它. 它还需要实际有用的. 例如, 这个数据集, 它包含有美国院校的录取标准, 毕业率以及毕业以后的收入是个很好的数据集了. 不管怎样, 不管你如何想这个数据, 很显然它不适合创建端到端的项目. 比如, 你能告诉人们他们去了这些大学以后的未来收益, 但是却没有足够的细微差别. 你还能找出院校招生标准收入更高, 但是却没有告诉你如何实际操作.
|
||||
|
||||
这里还有内存和性能约束的问题比如你有几千兆的数据或者有一些细微差别需要你去预测或者运行什么样的算法数据集等.
|
||||
|
||||
一个好的数据集包括你可以动态的转换数组, 并且回答动态的问题. 一个很好的例子是股票价格数据集. 你可以预测明天的价格, 持续的添加数据在算法中. 它将有助于你预测利润. 这不是讲故事这是真实的.
|
||||
|
||||
一些找到数据集的好地方:
|
||||
|
||||
- [/r/datasets][11] – subreddit(Reddit是国外一个社交新闻站点,subreddit指该论坛下的各不同板块).
|
||||
- [Google Public Datasets][12] – 通过Google BigQuery发布的可用数据集.
|
||||
- [Awesome datasets][13] – Github上的数据集.
|
||||
|
||||
当你查看这些数据集, 想一下人们想要在这些数据集中得到什么答案, 哪怕这些问题只想过一次 (“放假是如何S&P 500关联的?”), 或者更进一步(“你能预测股市吗?”). 这里的关键是更进一步找出问题, 并且多次运行不同的数据相同的代码.
|
||||
|
||||
为了这个目标, 我们来看一下[Fannie Mae 贷款数据][14]. Fannie Mae 是一家政府赞助的企业抵押贷款公司它从其他银行购买按揭贷款. 然后捆绑这些贷款为抵押贷款来倒卖证券. 这使得贷款机构可以提供更多的抵押贷款, 在市场上创造更多的流动性. 这在理论上会导致更多的住房和更好的贷款条件. 从借款人的角度来说,他们大体上差不多, 话虽这样说.
|
||||
|
||||
Fannie Mae 发布了两种类型的数据 – 它获得的贷款, 随着时间的推移这些贷款是否被偿还.在理想的情况下, 有人向贷款人借钱, 然后还清贷款. 不管怎样, 有些人没还的起钱, 丧失了抵押品赎回权. Foreclosure 是说没钱还了被银行把房子给回收了. Fannie Mae 追踪谁没还钱, 并且需要收回房屋抵押权. 每个季度会发布此数据, 并滞后一年. 当前可用是2015年第一季度数据.
|
||||
|
||||
采集数据是由Fannie Mae发布的贷款数据, 它包含借款人的信息, 信用评分, 和他们的家庭贷款信息. 性能数据, 贷款回收后的每一个季度公布, 包含借贷人所支付款项信息和丧失抵押品赎回状态, 收回贷款的性能数据可能有十几行.一个很好的思路是这样的采集数据告诉你Fannie Mae所控制的贷款, 性能数据包含几个属性来更新贷款. 其中一个属性告诉我们每个季度的贷款赎回权.
|
||||
|
||||

|
||||
>一个没有及时还贷的房子就这样的被卖了.
|
||||
|
||||
### 选择一个角度
|
||||
|
||||
这里有几个方向我们可以去分析 Fannie Mae 数据集. 我们可以:
|
||||
|
||||
- 预测房屋的销售价格.
|
||||
- 预测借款人还款历史.
|
||||
- 在收购时为每一笔贷款打分.
|
||||
|
||||
最重要的事情是坚持单一的角度. 关注太多的事情很难做出效果. 选择一个有着足够细节的角度也很重要. 下面的理解就没有太多差别:
|
||||
|
||||
- 找出哪些银行将贷款出售给Fannie Mae.
|
||||
- 计算贷款人的信用评分趋势.
|
||||
- 搜索哪些类型的家庭没有偿还贷款的能力.
|
||||
- 搜索贷款金额和抵押品价格之间的关系
|
||||
|
||||
上面的想法非常有趣, 它会告诉我们很多有意思的事情, 但是不是一个很适合操作的项目。
|
||||
|
||||
在Fannie Mae数据集中, 我们将预测贷款是否能被偿还. 实际上, 我们将建立一个抵押贷款的分数来告诉 Fannie Mae买还是不买. 这将给我提供很好的基础.
|
||||
|
||||
------------
|
||||
|
||||
### 理解数据
|
||||
我们来简单看一下原始数据文件。下面是2012年1季度前几行的采集数据。
|
||||
```
|
||||
100000853384|R|OTHER|4.625|280000|360|02/2012|04/2012|31|31|1|23|801|N|C|SF|1|I|CA|945||FRM|
|
||||
100003735682|R|SUNTRUST MORTGAGE INC.|3.99|466000|360|01/2012|03/2012|80|80|2|30|794|N|P|SF|1|P|MD|208||FRM|788
|
||||
100006367485|C|PHH MORTGAGE CORPORATION|4|229000|360|02/2012|04/2012|67|67|2|36|802|N|R|SF|1|P|CA|959||FRM|794
|
||||
```
|
||||
|
||||
下面是2012年1季度的前几行执行数据
|
||||
```
|
||||
100000853384|03/01/2012|OTHER|4.625||0|360|359|03/2042|41860|0|N||||||||||||||||
|
||||
100000853384|04/01/2012||4.625||1|359|358|03/2042|41860|0|N||||||||||||||||
|
||||
100000853384|05/01/2012||4.625||2|358|357|03/2042|41860|0|N||||||||||||||||
|
||||
```
|
||||
在开始编码之前,花些时间真正理解数据是值得的。这对于操作项目优为重要,因为我们没有交互式探索数据,将很难察觉到细微的差别除非我们在前期发现他们。在这种情况下,第一个步骤是阅读房利美站点的资料:
|
||||
- [概述][15]
|
||||
- [有用的术语表][16]
|
||||
- [问答][17]
|
||||
- [采集和执行文件中的列][18]
|
||||
- [采集数据文件样本][19]
|
||||
- [执行数据文件样本][20]
|
||||
|
||||
在看完这些文件后后,我们了解到一些能帮助我们的关键点:
|
||||
- 从2000年到现在,每季度都有一个采集和执行文件,因数据是滞后一年的,所以到目前为止最新数据是2015年的。
|
||||
- 这些文件是文本格式的,采用管道符号“|”进行分割。
|
||||
- 这些文件是没有表头的,但我们有文件列明各列的名称。
|
||||
- 所有一起,文件包含2200万个贷款的数据。
|
||||
由于执行文件包含过去几年获得的贷款的信息,在早些年获得的贷款将有更多的执行数据(即在2014获得的贷款没有多少历史执行数据)。
|
||||
这些小小的信息将会为我们节省很多时间,因为我们知道如何构造我们的项目和利用这些数据。
|
||||
|
||||
### 构造项目
|
||||
在我们开始下载和探索数据之前,先想一想将如何构造项目是很重要的。当建立端到端项目时,我们的主要目标是:
|
||||
- 创建一个可行解决方案
|
||||
- 有一个快速运行且占用最小资源的解决方案
|
||||
- 容易可扩展
|
||||
- 写容易理解的代码
|
||||
- 写尽量少的代码
|
||||
|
||||
为了实现这些目标,需要对我们的项目进行良好的构造。一个结构良好的项目遵循几个原则:
|
||||
- 分离数据文件和代码文件
|
||||
- 从原始数据中分离生成的数据。
|
||||
- 有一个README.md文件帮助人们安装和使用该项目。
|
||||
- 有一个requirements.txt文件列明项目运行所需的所有包。
|
||||
- 有一个单独的settings.py 文件列明其它文件中使用的所有的设置
|
||||
- 例如,如果从多个Python脚本读取相同的文件,把它们全部import设置和从一个集中的地方获得文件名是有用的。
|
||||
- 有一个.gitignore文件,防止大的或秘密文件被提交。
|
||||
- 分解任务中每一步可以单独执行的步骤到单独的文件中。
|
||||
- 例如,我们将有一个文件用于读取数据,一个用于创建特征,一个用于做出预测。
|
||||
- 保存中间结果,例如,一个脚本可输出下一个脚本可读取的文件。
|
||||
|
||||
- 这使我们无需重新计算就可以在数据处理流程中进行更改。
|
||||
|
||||
|
||||
我们的文件结构大体如下:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
├── processed
|
||||
├── .gitignore
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### 创建初始文件
|
||||
首先,我们需要创建一个loan-prediction文件夹,在此文件夹下面,再创建一个data文件夹和一个processed文件夹。data文件夹存放原始数据,processed文件夹存放所有的中间计算结果。
|
||||
其次,创建.gitignore文件,.gitignore文件将保证某些文件被git忽略而不会被推送至github。关于这个文件的一个好的例子是由OSX在每一个文件夹都会创建的.DS_Store文件,.gitignore文件一个很好的起点就是在这了。我们还想忽略数据文件因为他们实在是太大了,同时房利美的条文禁止我们重新分发该数据文件,所以我们应该在我们的文件后面添加以下2行:
|
||||
```
|
||||
data
|
||||
processed
|
||||
```
|
||||
|
||||
这是该项目的一个关于.gitignore文件的例子。
|
||||
再次,我们需要创建README.md文件,它将帮助人们理解该项目。后缀.md表示这个文件采用markdown格式。Markdown使你能够写纯文本文件,同时还可以添加你想要的梦幻格式。这是关于markdown的导引。如果你上传一个叫README.md的文件至Github,Github会自动处理该markdown,同时展示给浏览该项目的人。
|
||||
至此,我们仅需在README.md文件中添加简单的描述:
|
||||
```
|
||||
Loan Prediction
|
||||
-----------------------
|
||||
|
||||
Predict whether or not loans acquired by Fannie Mae will go into foreclosure. Fannie Mae acquires loans from other lenders as a way of inducing them to lend more. Fannie Mae releases data on the loans it has acquired and their performance afterwards [here](http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html).
|
||||
```
|
||||
|
||||
现在,我们可以创建requirements.txt文件了。这会唯其它人可以很方便地安装我们的项目。我们还不知道我们将会具体用到哪些库,但是以下几个库是一个很好的开始:
|
||||
```
|
||||
pandas
|
||||
matplotlib
|
||||
scikit-learn
|
||||
numpy
|
||||
ipython
|
||||
scipy
|
||||
```
|
||||
|
||||
以上几个是在python数据分析任务中最常用到的库。可以认为我们将会用到大部分这些库。这里是【24】该项目requirements文件的一个例子。
|
||||
创建requirements.txt文件之后,你应该安装包了。我们将会使用python3.如果你没有安装python,你应该考虑使用 [Anaconda][25],一个python安装程序,同时安装了上面列出的所有包。
|
||||
最后,我们可以建立一个空白的settings.py文件,因为我们的项目还没有任何设置。
|
||||
|
||||
|
||||
----------------
|
||||
|
||||
### 获取数据
|
||||
|
||||
一旦我们拥有项目的基本架构,我们就可以去获得原始数据
|
||||
|
||||
Fannie Mae 对获取数据有一些限制,所有你需要去注册一个账户。在创建完账户之后,你可以找到下载页面[在这里][26],你可以按照你所需要的下载非常少量或者很多的借款数据文件。文件格式是zip,在解压后当然是非常大的。
|
||||
|
||||
为了达到我们这个博客文章的目的,我们将要下载从2012年1季度到2015
|
||||
年1季度的所有数据。接着我们需要解压所有的文件。解压过后,删掉原来的.zip格式的文件。最后,借款预测文件夹看起来应该像下面的一样:
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
├── .gitignore
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
在下载完数据后,你可以在shell命令行中使用head和tail命令去查看文件中的行数据,你看到任何的不需要的列数据了吗?在做这件事的同时查阅[列名称的pdf文件][27]可能是有用的事情。
|
||||
### 读入数据
|
||||
|
||||
有两个问题让我们的数据难以现在就使用:
|
||||
- 收购数据和业绩数据被分割在多个文件中
|
||||
- 每个文件都缺少标题
|
||||
|
||||
在我们开始使用数据之前,我们需要首先明白我们要在哪里去存一个收购数据的文件,同时到哪里去存储一个业绩数据的文件。每个文件仅仅需要包括我们关注的那些数据列,同时拥有正确的标题。这里有一个小问题是业绩数据非常大,因此我们需要尝试去修剪一些数据列。
|
||||
|
||||
第一步是向settings.py文件中增加一些变量,这个文件中同时也包括了我们原始数据的存放路径和处理出的数据存放路径。我们同时也将添加其他一些可能在接下来会用到的设置数据:
|
||||
```
|
||||
DATA_DIR = "data"
|
||||
PROCESSED_DIR = "processed"
|
||||
MINIMUM_TRACKING_QUARTERS = 4
|
||||
TARGET = "foreclosure_status"
|
||||
NON_PREDICTORS = [TARGET, "id"]
|
||||
CV_FOLDS = 3
|
||||
```
|
||||
|
||||
把路径设置在settings.py中将使它们放在一个集中的地方,同时使其修改更加的容易。当提到在多个文件中的相同的变量时,你想改变它的话,把他们放在一个地方比分散放在每一个文件时更加容易。[这里的][28]是一个这个工程的示例settings.py文件
|
||||
|
||||
第二步是创建一个文件名为assemble.py,它将所有的数据分为2个文件。当我们运行Python assemble.py,我们在处理数据文件的目录会获得2个数据文件。
|
||||
|
||||
接下来我们开始写assemble.py文件中的代码。首先我们需要为每个文件定义相应的标题,因此我们需要查看[列名称的pdf文件][29]同时创建在每一个收购数据和业绩数据的文件的列数据的列表:
|
||||
```
|
||||
HEADERS = {
|
||||
"Acquisition": [
|
||||
"id",
|
||||
"channel",
|
||||
"seller",
|
||||
"interest_rate",
|
||||
"balance",
|
||||
"loan_term",
|
||||
"origination_date",
|
||||
"first_payment_date",
|
||||
"ltv",
|
||||
"cltv",
|
||||
"borrower_count",
|
||||
"dti",
|
||||
"borrower_credit_score",
|
||||
"first_time_homebuyer",
|
||||
"loan_purpose",
|
||||
"property_type",
|
||||
"unit_count",
|
||||
"occupancy_status",
|
||||
"property_state",
|
||||
"zip",
|
||||
"insurance_percentage",
|
||||
"product_type",
|
||||
"co_borrower_credit_score"
|
||||
],
|
||||
"Performance": [
|
||||
"id",
|
||||
"reporting_period",
|
||||
"servicer_name",
|
||||
"interest_rate",
|
||||
"balance",
|
||||
"loan_age",
|
||||
"months_to_maturity",
|
||||
"maturity_date",
|
||||
"msa",
|
||||
"delinquency_status",
|
||||
"modification_flag",
|
||||
"zero_balance_code",
|
||||
"zero_balance_date",
|
||||
"last_paid_installment_date",
|
||||
"foreclosure_date",
|
||||
"disposition_date",
|
||||
"foreclosure_costs",
|
||||
"property_repair_costs",
|
||||
"recovery_costs",
|
||||
"misc_costs",
|
||||
"tax_costs",
|
||||
"sale_proceeds",
|
||||
"credit_enhancement_proceeds",
|
||||
"repurchase_proceeds",
|
||||
"other_foreclosure_proceeds",
|
||||
"non_interest_bearing_balance",
|
||||
"principal_forgiveness_balance"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
接下来一步是定义我们想要保持的数据列。我们将需要保留收购数据中的所有列数据,丢弃列数据将会使我们节省下内存和硬盘空间,同时也会加速我们的代码。
|
||||
```
|
||||
SELECT = {
|
||||
"Acquisition": HEADERS["Acquisition"],
|
||||
"Performance": [
|
||||
"id",
|
||||
"foreclosure_date"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
下一步,我们将编写一个函数来连接数据集。下面的代码将:
|
||||
- 引用一些需要的库,包括设置。
|
||||
- 定义一个函数concatenate, 目的是:
|
||||
- 获取到所有数据目录中的文件名.
|
||||
- 在每个文件中循环.
|
||||
- 如果文件不是正确的格式 (不是以我们需要的格式作为开头), 我们将忽略它.
|
||||
- 把文件读入一个[数据帧][30] 伴随着正确的设置通过使用Pandas [读取csv][31]函数.
|
||||
- 在|处设置分隔符以便所有的字段能被正确读出.
|
||||
- 数据没有标题行,因此设置标题为None来进行标示.
|
||||
- 从HEADERS字典中设置正确的标题名称 – 这将会是我们数据帧中的数据列名称.
|
||||
- 通过SELECT来选择我们加入数据的数据帧中的列.
|
||||
- 把所有的数据帧共同连接在一起.
|
||||
- 把已经连接好的数据帧写回一个文件.
|
||||
|
||||
```
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
|
||||
def concatenate(prefix="Acquisition"):
|
||||
files = os.listdir(settings.DATA_DIR)
|
||||
full = []
|
||||
for f in files:
|
||||
if not f.startswith(prefix):
|
||||
continue
|
||||
|
||||
data = pd.read_csv(os.path.join(settings.DATA_DIR, f), sep="|", header=None, names=HEADERS[prefix], index_col=False)
|
||||
data = data[SELECT[prefix]]
|
||||
full.append(data)
|
||||
|
||||
full = pd.concat(full, axis=0)
|
||||
|
||||
full.to_csv(os.path.join(settings.PROCESSED_DIR, "{}.txt".format(prefix)), sep="|", header=SELECT[prefix], index=False)
|
||||
```
|
||||
|
||||
我们可以通过调用上面的函数,通过传递的参数收购和业绩两次以将所有收购和业绩文件连接在一起。下面的代码将:
|
||||
- 仅仅在脚本被在命令行中通过python assemble.py被唤起而执行.
|
||||
- 将所有的数据连接在一起,并且产生2个文件:
|
||||
- `processed/Acquisition.txt`
|
||||
- `processed/Performance.txt`
|
||||
|
||||
```
|
||||
if __name__ == "__main__":
|
||||
concatenate("Acquisition")
|
||||
concatenate("Performance")
|
||||
```
|
||||
|
||||
我们现在拥有了一个漂亮的,划分过的assemble.py文件,它很容易执行,也容易被建立。通过像这样把问题分解为一块一块的,我们构建工程就会变的容易许多。不用一个可以做所有的凌乱的脚本,我们定义的数据将会在多个脚本间传递,同时使脚本间完全的0耦合。当你正在一个大的项目中工作,这样做是一个好的想法,因为这样可以更佳容易的修改其中的某一部分而不会引起其他项目中不关联部分产生超出预期的结果。
|
||||
|
||||
一旦我们完成assemble.py脚本文件, 我们可以运行python assemble.py命令. 你可以查看完整的assemble.py文件[在这里][32].
|
||||
|
||||
这将会在处理结果目录下产生2个文件:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
├── .gitignore
|
||||
├── assemble.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
|
||||
--------------
|
||||
|
||||
|
||||
### 计算运用数据中的值
|
||||
|
||||
接下来我们会计算过程数据或运用数据中的值。我们要做的就是推测这些数据代表的贷款是否被收回。如果能够计算出来,我们只要看一下包含贷款的运用数据的参数 foreclosure_date 就可以了。如果这个参数的值是 None ,那么这些贷款肯定没有收回。为了避免我们的样例中存在少量的运用数据,我们会计算出运用数据中有贷款数据的行的行数。这样我们就能够从我们的训练数据中筛选出贷款数据,排除了一些运用数据。
|
||||
|
||||
下面是一种区分贷款数据和运用数据的方法:
|
||||
|
||||

|
||||
|
||||
|
||||
在上面的表格中,采集数据中的每一行数据都与运用数据中的多行数据有联系。在运用数据中,在收回贷款的时候 foreclosure_date 就会以季度的的形式显示出收回时间,而且它会在该行数据的最前面显示一个空格。一些贷款没有收回,所以与运用数据中的贷款数据有关的行都会在前面出现一个表示 foreclosure_date 的空格。
|
||||
|
||||
我们需要计算 foreclosure_status 的值,它的值是布尔类型,可以表示一个特殊的贷款数据 id 是否被收回过,还有一个参数 performance_count ,它记录了运用数据中每个贷款 id 出现的行数。
|
||||
|
||||
计算这些行数有多种不同的方法:
|
||||
|
||||
- 我们能够读取所有的运用数据,然后我们用 Pandas 的 groupby 方法在数据框中计算出与每个贷款 id 有关的行的行数,然后就可以查看贷款 id 的 foreclosure_date 值是否为 None 。
|
||||
- 这种方法的优点是从语法上来说容易执行。
|
||||
- 它的缺点需要读取所有的 129236094 行数据,这样就会占用大量内存,并且运行起来极慢。
|
||||
- 我们可以读取所有的运用数据,然后使用采集到的数据框去计算每个贷款 id 出现的次数。
|
||||
- 这种方法的优点是容易理解。
|
||||
- 缺点是需要读取所有的 129236094 行数据。这样会占用大量内存,并且运行起来极慢。
|
||||
- 我们可以在迭代访问运用数据中的每一行数据,而且会建立一个区分开的计数字典。
|
||||
- 这种方法的优点是数据不需要被加载到内存中,所以运行起来会很快且不需要占用内存。
|
||||
- 缺点是这样的话理解和执行上可能有点耗费时间,我们需要对每一行数据进行语法分析。
|
||||
|
||||
加载所有的数据会非常耗费内存,所以我们采用第三种方法。我们要做的就是迭代运用数据中的每一行数据,然后为每一个贷款 id 生成一个字典值。在这个字典中,我们会计算出贷款 id 在运用数据中出现的次数,而且如果 foreclosure_date 不是 Nnoe 。我们可以查看 foreclosure_status 和 performance_count 的值 。
|
||||
|
||||
我们会新建一个 annotate.py 文件,文件中的代码可以计算这些值。我们会使用下面的代码:
|
||||
|
||||
- 导入需要的库
|
||||
- 定义一个函数 count_performance_rows 。
|
||||
- 打开 processed/Performance.txt 文件。这不是在内存中读取文件而是打开了一个文件标识符,这个标识符可以用来以行为单位读取文件。
|
||||
- 迭代文件的每一行数据。
|
||||
- 使用分隔符(|)分开每行的不同数据。
|
||||
- 检查 loan_id 是否在计数字典中。
|
||||
- 如果不存在,进行一次计数。
|
||||
- loan_id 的 performance_count 参数自增 1 次,因为我们这次迭代也包含其中。
|
||||
- 如果日期是 None ,我们就会知道贷款被收回了,然后为foreclosure_status 设置合适的值。
|
||||
|
||||
```
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
|
||||
def count_performance_rows():
|
||||
counts = {}
|
||||
with open(os.path.join(settings.PROCESSED_DIR, "Performance.txt"), 'r') as f:
|
||||
for i, line in enumerate(f):
|
||||
if i == 0:
|
||||
# Skip header row
|
||||
continue
|
||||
loan_id, date = line.split("|")
|
||||
loan_id = int(loan_id)
|
||||
if loan_id not in counts:
|
||||
counts[loan_id] = {
|
||||
"foreclosure_status": False,
|
||||
"performance_count": 0
|
||||
}
|
||||
counts[loan_id]["performance_count"] += 1
|
||||
if len(date.strip()) > 0:
|
||||
counts[loan_id]["foreclosure_status"] = True
|
||||
return counts
|
||||
```
|
||||
|
||||
### 获取值
|
||||
|
||||
只要我们创建了计数字典,我们就可以使用一个函数通过一个 loan_id 和一个 key 从字典中提取到需要的参数的值:
|
||||
|
||||
```
|
||||
def get_performance_summary_value(loan_id, key, counts):
|
||||
value = counts.get(loan_id, {
|
||||
"foreclosure_status": False,
|
||||
"performance_count": 0
|
||||
})
|
||||
return value[key]
|
||||
```
|
||||
|
||||
|
||||
上面的函数会从计数字典中返回合适的值,我们也能够为采集数据中的每一行赋一个 foreclosure_status 值和一个 performance_count 值。如果键不存在,字典的 [get][33] 方法会返回一个默认值,所以在字典中不存在键的时候我们就可以得到一个可知的默认值。
|
||||
|
||||
|
||||
|
||||
------------------
|
||||
|
||||
|
||||
### 注解数据
|
||||
|
||||
我们已经在annotate.py中添加了一些功能, 现在我们来看一看数据文件. 我们需要将采集到的数据转换到训练数据表来进行机器学习的训练. 这涉及到以下几件事情:
|
||||
|
||||
- 转换所以列数字.
|
||||
- 填充缺失值.
|
||||
- 分配 performance_count 和 foreclosure_status.
|
||||
- 移除出现次数很少的行(performance_count 计数低).
|
||||
|
||||
我们有几个列是文本类型的, 看起来对于机器学习算法来说并不是很有用. 然而, 他们实际上是分类变量, 其中有很多不同的类别代码, 例如R,S等等. 我们可以把这些类别标签转换为数值:
|
||||
|
||||

|
||||
|
||||
通过这种方法转换的列我们可以应用到机器学习算法中.
|
||||
|
||||
还有一些包含日期的列 (first_payment_date 和 origination_date). 我们可以将这些日期放到两个列中:
|
||||
|
||||

|
||||
在下面的代码中, 我们将转换采集到的数据. 我们将定义一个函数如下:
|
||||
|
||||
- 在采集到的数据中创建foreclosure_status列 .
|
||||
- 在采集到的数据中创建performance_count列.
|
||||
- 将下面的string列转换为integer列:
|
||||
- channel
|
||||
- seller
|
||||
- first_time_homebuyer
|
||||
- loan_purpose
|
||||
- property_type
|
||||
- occupancy_status
|
||||
- property_state
|
||||
- product_type
|
||||
- 转换first_payment_date 和 origination_date 为两列:
|
||||
- 通过斜杠分离列.
|
||||
- 将第一部分分离成月清单.
|
||||
- 将第二部分分离成年清单.
|
||||
- 删除这一列.
|
||||
- 最后, 我们得到 first_payment_month, first_payment_year, origination_month, and origination_year.
|
||||
- 所有缺失值填充为-1.
|
||||
|
||||
```
|
||||
def annotate(acquisition, counts):
|
||||
acquisition["foreclosure_status"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "foreclosure_status", counts))
|
||||
acquisition["performance_count"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "performance_count", counts))
|
||||
for column in [
|
||||
"channel",
|
||||
"seller",
|
||||
"first_time_homebuyer",
|
||||
"loan_purpose",
|
||||
"property_type",
|
||||
"occupancy_status",
|
||||
"property_state",
|
||||
"product_type"
|
||||
]:
|
||||
acquisition[column] = acquisition[column].astype('category').cat.codes
|
||||
|
||||
for start in ["first_payment", "origination"]:
|
||||
column = "{}_date".format(start)
|
||||
acquisition["{}_year".format(start)] = pd.to_numeric(acquisition[column].str.split('/').str.get(1))
|
||||
acquisition["{}_month".format(start)] = pd.to_numeric(acquisition[column].str.split('/').str.get(0))
|
||||
del acquisition[column]
|
||||
|
||||
acquisition = acquisition.fillna(-1)
|
||||
acquisition = acquisition[acquisition["performance_count"] > settings.MINIMUM_TRACKING_QUARTERS]
|
||||
return acquisition
|
||||
```
|
||||
|
||||
### 聚合到一起
|
||||
|
||||
我们差不多准备就绪了, 我们只需要再在annotate.py添加一点点代码. 在下面代码中, 我们将:
|
||||
|
||||
- 定义一个函数来读取采集的数据.
|
||||
- 定义一个函数来写入数据到/train.csv
|
||||
- 如果我们在命令行运行annotate.py来读取更新过的数据文件,它将做如下事情:
|
||||
- 读取采集到的数据.
|
||||
- 计算数据性能.
|
||||
- 注解数据.
|
||||
- 将注解数据写入到train.csv.
|
||||
|
||||
```
|
||||
def read():
|
||||
acquisition = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "Acquisition.txt"), sep="|")
|
||||
return acquisition
|
||||
|
||||
def write(acquisition):
|
||||
acquisition.to_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"), index=False)
|
||||
|
||||
if __name__ == "__main__":
|
||||
acquisition = read()
|
||||
counts = count_performance_rows()
|
||||
acquisition = annotate(acquisition, counts)
|
||||
write(acquisition)
|
||||
```
|
||||
|
||||
修改完成以后为了确保annotate.py能够生成train.csv文件. 你可以在这里找到完整的 annotate.py file [here][34].
|
||||
|
||||
文件夹结果应该像这样:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
│ ├── train.csv
|
||||
├── .gitignore
|
||||
├── annotate.py
|
||||
├── assemble.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### 找到标准
|
||||
|
||||
我们已经完成了训练数据表的生成, 现在我们需要最后一步, 生成预测. 我们需要找到错误的标准, 以及该如何评估我们的数据. 在这种情况下, 因为有很多的贷款没有收回, 所以根本不可能做到精确的计算.
|
||||
|
||||
我们需要读取数据, 并且计算foreclosure_status列, 我们将得到如下信息:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
import settings
|
||||
|
||||
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
|
||||
train["foreclosure_status"].value_counts()
|
||||
```
|
||||
|
||||
```
|
||||
False 4635982
|
||||
True 1585
|
||||
Name: foreclosure_status, dtype: int64
|
||||
```
|
||||
|
||||
因为只有一点点贷款收回, 通过百分比标签来建立的机器学习模型会把每行都设置为Fasle, 所以我们在这里要考虑每个样本的不平衡性,确保我们做出的预测是准确的. 我们不想要这么多假的false, 我们将预计贷款收回但是它并没有收回, 我们预计贷款不会回收但是却回收了. 通过以上两点, Fannie Mae的false太多了, 因此显示他们可能无法收回投资.
|
||||
|
||||
所以我们将定义一个百分比,就是模型预测没有收回但是实际上收回了, 这个数除以总的负债回收总数. 这个负债回收百分比模型实际上是“没有的”. 下面看这个图表:
|
||||
|
||||

|
||||
|
||||
通过上面的图表, 1个负债预计不会回收, 也确实没有回收. 如果我们将这个数除以总数, 2, 我们将得到false的概率为50%. 我们将使用这个标准, 因此我们可以评估一下模型的性能.
|
||||
|
||||
### 设置机器学习分类器
|
||||
|
||||
我们使用交叉验证预测. 通过交叉验证法, 我们将数据分为3组. 按照下面的方法来做:
|
||||
|
||||
- Train a model on groups 1 and 2, and use the model to make predictions for group 3.
|
||||
- Train a model on groups 1 and 3, and use the model to make predictions for group 2.
|
||||
- Train a model on groups 2 and 3, and use the model to make predictions for group 1.
|
||||
|
||||
将它们分割到不同的组 ,这意味着我们永远不会用相同的数据来为预测训练模型. 这样就避免了overfitting(过拟合). 如果我们overfit(过拟合), 我们将得到很低的false概率, 这使得我们难以改进算法或者应用到现实生活中.
|
||||
|
||||
[Scikit-learn][35] 有一个叫做 [cross_val_predict][36] 他可以帮助我们理解交叉算法.
|
||||
|
||||
我们还需要一种算法来帮我们预测. 我们还需要一个分类器 [binary classification][37](二元分类). 目标变量foreclosure_status 只有两个值, True 和 False.
|
||||
|
||||
我们用[logistic regression][38](回归算法), 因为它能很好的进行binary classification(二元分类), 并且运行很快, 占用内存很小. 我们来说一下它是如何工作的 – 取代许多树状结构, 更像随机森林, 进行转换, 更像一个向量机, 逻辑回归涉及更少的步骤和更少的矩阵.
|
||||
|
||||
我们可以使用[logistic regression classifier][39](逻辑回归分类器)算法 来实现scikit-learn. 我们唯一需要注意的是每个类的标准. 如果我们使用同样标准的类, 算法将会预测每行都为false, 因为它总是试图最小化误差.不管怎样, 我们关注有多少贷款能够回收而不是有多少不能回收. 因此, 我们通过 [LogisticRegression][40](逻辑回归)来平衡标准参数, 并计算回收贷款的标准. 这将使我们的算法不会认为每一行都为false.
|
||||
|
||||
|
||||
----------------------
|
||||
|
||||
### 做出预测
|
||||
|
||||
既然完成了前期准备,我们可以开始准备做出预测了。我将创建一个名为 predict.py 的新文件,它会使用我们在最后一步创建的 train.csv 文件。下面的代码:
|
||||
|
||||
- 导入所需的库
|
||||
- 创建一个名为 `cross_validate` 的函数:
|
||||
- 使用正确的关键词参数创建逻辑回归分类器(logistic regression classifier)
|
||||
- 创建移除了 `id` 和 `foreclosure_status` 属性的用于训练模型的列
|
||||
- 跨 `train` 数据帧使用交叉验证
|
||||
- 返回预测结果
|
||||
|
||||
```python
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
from sklearn import cross_validation
|
||||
from sklearn.linear_model import LogisticRegression
|
||||
from sklearn import metrics
|
||||
|
||||
def cross_validate(train):
|
||||
clf = LogisticRegression(random_state=1, class_weight="balanced")
|
||||
|
||||
predictors = train.columns.tolist()
|
||||
predictors = [p for p in predictors if p not in settings.NON_PREDICTORS]
|
||||
|
||||
predictions = cross_validation.cross_val_predict(clf, train[predictors], train[settings.TARGET], cv=settings.CV_FOLDS)
|
||||
return predictions
|
||||
```
|
||||
|
||||
### 预测误差
|
||||
|
||||
现在,我们仅仅需要写一些函数来计算误差。下面的代码:
|
||||
|
||||
- 创建函数 `compute_error`:
|
||||
- 使用 scikit-learn 计算一个简单的精确分数(与实际 `foreclosure_status` 值匹配的预测百分比)
|
||||
- 创建函数 `compute_false_negatives`:
|
||||
- 为了方便,将目标和预测结果合并到一个数据帧
|
||||
- 查找漏报率
|
||||
- 找到原本应被预测模型取消但没有取消的贷款数目
|
||||
- 除以没被取消的贷款总数目
|
||||
|
||||
```python
|
||||
def compute_error(target, predictions):
|
||||
return metrics.accuracy_score(target, predictions)
|
||||
|
||||
def compute_false_negatives(target, predictions):
|
||||
df = pd.DataFrame({"target": target, "predictions": predictions})
|
||||
return df[(df["target"] == 1) & (df["predictions"] == 0)].shape[0] / (df[(df["target"] == 1)].shape[0] + 1)
|
||||
|
||||
def compute_false_positives(target, predictions):
|
||||
df = pd.DataFrame({"target": target, "predictions": predictions})
|
||||
return df[(df["target"] == 0) & (df["predictions"] == 1)].shape[0] / (df[(df["target"] == 0)].shape[0] + 1)
|
||||
```
|
||||
|
||||
### 聚合到一起
|
||||
|
||||
现在,我们可以把函数都放在 `predict.py`。下面的代码:
|
||||
|
||||
- 读取数据集
|
||||
- 计算交叉验证预测
|
||||
- 计算上面的 3 个误差
|
||||
- 打印误差
|
||||
|
||||
```python
|
||||
def read():
|
||||
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
|
||||
return train
|
||||
|
||||
if __name__ == "__main__":
|
||||
train = read()
|
||||
predictions = cross_validate(train)
|
||||
error = compute_error(train[settings.TARGET], predictions)
|
||||
fn = compute_false_negatives(train[settings.TARGET], predictions)
|
||||
fp = compute_false_positives(train[settings.TARGET], predictions)
|
||||
print("Accuracy Score: {}".format(error))
|
||||
print("False Negatives: {}".format(fn))
|
||||
print("False Positives: {}".format(fp))
|
||||
```
|
||||
|
||||
一旦你添加完代码,你可以运行 `python predict.py` 来产生预测结果。运行结果向我们展示漏报率为 `.26`,这意味着我们没能预测 `26%` 的取消贷款。这是一个好的开始,但仍有很多改善的地方!
|
||||
|
||||
你可以在[这里][41]找到完整的 `predict.py` 文件
|
||||
|
||||
你的文件树现在看起来像下面这样:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
│ ├── train.csv
|
||||
├── .gitignore
|
||||
├── annotate.py
|
||||
├── assemble.py
|
||||
├── predict.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### 撰写 README
|
||||
|
||||
既然我们完成了端到端的项目,那么我们可以撰写 README.md 文件了,这样其他人便可以知道我们做的事,以及如何复制它。一个项目典型的 README.md 应该包括这些部分:
|
||||
|
||||
- 一个高水准的项目概览,并介绍项目目的
|
||||
- 任何必需的数据和材料的下载地址
|
||||
- 安装命令
|
||||
- 如何安装要求依赖
|
||||
- 使用命令
|
||||
- 如何运行项目
|
||||
- 每一步之后会看到的结果
|
||||
- 如何为这个项目作贡献
|
||||
- 扩展项目的下一步计划
|
||||
|
||||
[这里][42] 是这个项目的一个 README.md 样例。
|
||||
|
||||
### 下一步
|
||||
|
||||
恭喜你完成了端到端的机器学习项目!你可以在[这里][43]找到一个完整的示例项目。一旦你完成了项目,把它上传到 [Github][44] 是一个不错的主意,这样其他人也可以看到你的文件夹的部分项目。
|
||||
|
||||
这里仍有一些留待探索数据的角度。总的来说,我们可以把它们分割为 3 类 - 扩展这个项目并使它更加精确,发现预测其他列并探索数据。这是其中一些想法:
|
||||
|
||||
- 在 `annotate.py` 中生成更多的特性
|
||||
- 切换 `predict.py` 中的算法
|
||||
- 尝试使用比我们发表在这里的更多的来自 `Fannie Mae` 的数据
|
||||
- 添加对未来数据进行预测的方法。如果我们添加更多数据,我们所写的代码仍然可以起作用,这样我们可以添加更多过去和未来的数据。
|
||||
- 尝试看看是否你能预测一个银行是否应该发放贷款(相对地,`Fannie Mae` 是否应该获得贷款)
|
||||
- 移除 train 中银行不知道发放贷款的时间的任何列
|
||||
- 当 Fannie Mae 购买贷款时,一些列是已知的,但不是之前
|
||||
- 做出预测
|
||||
- 探索是否你可以预测除了 foreclosure_status 的其他列
|
||||
- 你可以预测在销售时财产值多少?
|
||||
- 探索探索性能更新之间的细微差别
|
||||
- 你能否预测借款人会逾期还款多少次?
|
||||
- 你能否标出的典型贷款周期?
|
||||
- 标出一个州到州或邮政编码到邮政级水平的数据
|
||||
- 你看到一些有趣的模式了吗?
|
||||
|
||||
如果你建立了任何有趣的东西,请在评论中让我们知道!
|
||||
|
||||
如果你喜欢这个,你可能会喜欢阅读 ‘Build a Data Science Porfolio’ 系列的其他文章:
|
||||
|
||||
- [Storytelling with data][45].
|
||||
- [How to setup up a data science blog][46].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.dataquest.io/blog/data-science-portfolio-machine-learning/
|
||||
|
||||
作者:[Vik Paruchuri][a]
|
||||
译者:[kokialoves](https://github.com/译者ID),[zky001](https://github.com/译者ID),[vim-kakali](https://github.com/译者ID),[cposture](https://github.com/译者ID),[ideas4u](https://github.com/译者ID)
|
||||
校对:[校对ID](https://github.com/校对ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.dataquest.io/blog
|
||||
[1]: https://www.dataquest.io/blog/data-science-portfolio-machine-learning/#email-signup
|
||||
[2]: https://github.com/dataquestio/loan-prediction
|
||||
[3]: https://www.dataquest.io/blog/data-science-portfolio-project/
|
||||
[4]: https://atom.io/
|
||||
[5]: https://www.jetbrains.com/pycharm/
|
||||
[6]: https://github.com/
|
||||
[7]: http://pandas.pydata.org/
|
||||
[8]: http://scikit-learn.org/
|
||||
[9]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
|
||||
[10]: https://collegescorecard.ed.gov/data/
|
||||
[11]: https://reddit.com/r/datasets
|
||||
[12]: https://cloud.google.com/bigquery/public-data/#usa-names
|
||||
[13]: https://github.com/caesar0301/awesome-public-datasets
|
||||
[14]: http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html
|
||||
[15]: http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html
|
||||
[16]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_glossary.pdf
|
||||
[17]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_faq.pdf
|
||||
[18]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[19]: https://loanperformancedata.fanniemae.com/lppub-docs/acquisition-sample-file.txt
|
||||
[20]: https://loanperformancedata.fanniemae.com/lppub-docs/performance-sample-file.txt
|
||||
[21]: https://github.com/dataquestio/loan-prediction/blob/master/.gitignore
|
||||
[22]: https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet
|
||||
[23]: https://github.com/dataquestio/loan-prediction
|
||||
[24]: https://github.com/dataquestio/loan-prediction/blob/master/requirements.txt
|
||||
[25]: https://www.continuum.io/downloads
|
||||
[26]: https://loanperformancedata.fanniemae.com/lppub/index.html
|
||||
[27]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[28]: https://github.com/dataquestio/loan-prediction/blob/master/settings.py
|
||||
[29]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[30]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
|
||||
[31]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html
|
||||
[32]: https://github.com/dataquestio/loan-prediction/blob/master/assemble.py
|
||||
[33]: https://docs.python.org/3/library/stdtypes.html#dict.get
|
||||
[34]: https://github.com/dataquestio/loan-prediction/blob/master/annotate.py
|
||||
[35]: http://scikit-learn.org/
|
||||
[36]: http://scikit-learn.org/stable/modules/generated/sklearn.cross_validation.cross_val_predict.html
|
||||
[37]: https://en.wikipedia.org/wiki/Binary_classification
|
||||
[38]: https://en.wikipedia.org/wiki/Logistic_regression
|
||||
[39]: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
|
||||
[40]: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
|
||||
[41]: https://github.com/dataquestio/loan-prediction/blob/master/predict.py
|
||||
[42]: https://github.com/dataquestio/loan-prediction/blob/master/README.md
|
||||
[43]: https://github.com/dataquestio/loan-prediction
|
||||
[44]: https://www.github.com/
|
||||
[45]: https://www.dataquest.io/blog/data-science-portfolio-project/
|
||||
[46]: https://www.dataquest.io/blog/how-to-setup-a-data-science-blog/
|
||||
@ -1,268 +0,0 @@
|
||||
lujianbo
|
||||
|
||||
How to Setup Pfsense Firewall and Basic Configuration
|
||||
================================================================================
|
||||
In this article our focus is Pfsense setup, basic configuration and overview of features available in the security distribution of FreeBSD. In this tutorial we will run network wizard for basic setting of firewall and detailed overview of services. After the [installation process][1] following snapshot shows the IP addresses of WAN/LAN and different options for the management of Pfsense firewall.
|
||||
|
||||

|
||||
|
||||
After setup , following window appear which shows the url for configuration of Pfsense.
|
||||
|
||||

|
||||
|
||||
Open above given URL in the browser and login with username **admin** and password **pfsense**
|
||||
|
||||

|
||||
|
||||
After successful login, following wizard appears for the basic setting of Pfsense firewall. However setup wizard option can be bypassed and user can run it from the **System** menu from the web interface.
|
||||
|
||||
Click on the **Next** button to start basic configuration process on Pfsense firewall.
|
||||
|
||||

|
||||
|
||||
Setting hostname, domain and DNS addresses is shown in the following figure.
|
||||
|
||||

|
||||
|
||||
Setting time zone is shown in the below given snapshot.
|
||||
|
||||

|
||||
|
||||
Next window shows setting for the WAN interface. By defaults Pfsense firewall block bogus and private networks.
|
||||
|
||||

|
||||
|
||||
Setting LAN IP address which is used to access the Pfsense web interface for further configuration.
|
||||
|
||||

|
||||
|
||||
By default password for web interface is "pfsense". Enter new password for admin user on the following window to access the web interface for further configuration.
|
||||
|
||||

|
||||
|
||||
Click on the "reload" button which is shown below. It applies the setting and redirect firewall user to main dashboard of Pfsense.
|
||||
|
||||
 and status of ethernet/wireless interfaces etc.
|
||||
|
||||

|
||||
|
||||
### Menu detail ###
|
||||
|
||||
PFsense consist of System, interfaces, firewall,services,vpn,status,diagnostics and help menus.
|
||||
|
||||

|
||||
|
||||
### System Menu ###
|
||||
|
||||
Sub menus of **System** is given below.
|
||||
|
||||

|
||||
|
||||
In the **Advanced** sub menu user can perform following operations.
|
||||
|
||||
1. Configuration of web interface
|
||||
1. Firewall/Nat setting
|
||||
1. Networking setting
|
||||
1. System tuneables setting
|
||||
1. Notification setting
|
||||
|
||||

|
||||
|
||||
In the **Cert manager** sub menu, firewall administrator generates certificates for CA and users.
|
||||
|
||||

|
||||
|
||||
In the **Firmware** sub menu, user can update Pfsense firmware manually/automatically. User can take full backup of Pfsense configurations.
|
||||
|
||||

|
||||
|
||||
In the **General Setup** sub menu, user can change basic setting such as hostname and domain etc.
|
||||
|
||||

|
||||
|
||||
As menu title indicates, user can enable/disable high availability feature from this sub menu.
|
||||
|
||||

|
||||
|
||||
Packages sub menu provides package manager facility in the web interface for Pfsense .
|
||||
|
||||

|
||||
|
||||
User can perform gateway and route management using **Routing** sub menu.
|
||||
|
||||

|
||||
|
||||
**Setup Wizard** sub menu opens following window which start basic configuration of Pfsense.
|
||||
|
||||

|
||||
|
||||
Management of user can be done from the **User manager** sub menu.
|
||||
|
||||

|
||||
|
||||
### Interfaces Menu ###
|
||||
|
||||
This menu is used for the assignment of interfaces (LAN/WAN), VLAN setting,wireless and GRE configuration etc.
|
||||
|
||||

|
||||
|
||||
### Firewall Menu ###
|
||||
|
||||
Firewall is the main and core part of Pfsense distribution and it provides following features.
|
||||
|
||||

|
||||
|
||||
**Aliases**
|
||||
|
||||
Aliases are defined for real hosts, networks or ports and they can be used to minimize the number of changes.
|
||||
|
||||

|
||||
|
||||
**NAT (Network Address Translation)**
|
||||
|
||||
NAT binds a specific internal address to a specific external address. Incoming traffic from the Internet to the specified IP will be directed toward the associated internal IP.
|
||||
|
||||

|
||||
|
||||
**Firewall Rules**
|
||||
|
||||
Firewall rules control what traffic is allowed to enter an interface on the firewall. After traffic is passed on the interface, it enters an entry in the state table is created.
|
||||
|
||||

|
||||
|
||||
**Schedules**
|
||||
|
||||
Firewall rules can be scheduled so that they are only active at certain times of day or on certain specific days or days of the week.
|
||||
|
||||

|
||||
|
||||
**Traffic Shaper**
|
||||
|
||||
Traffic shaping is the control of computer network traffic in order to optimize performance and lower latency.
|
||||
|
||||

|
||||
|
||||
**Virtual IPs**
|
||||
|
||||
Virtual IPs add knowledge of additional IP addresses to the firewall that are different from the firewall's real interface addresses.
|
||||
|
||||

|
||||
|
||||
### Services Menu ###
|
||||
|
||||
Services menu shows services which are provided by the Pfsense distribution along firewall.
|
||||
|
||||

|
||||
|
||||
New program/software installed for some specific service is also shown in this menu such as snort. By default following services are listed in services menu.
|
||||
|
||||
**Captive portal**
|
||||
|
||||
The captive portal functionality in Pfsense allows securing a network by requiring a username and password entered on a portal page.
|
||||
|
||||

|
||||
|
||||
**DHCP Relay**
|
||||
|
||||
The DHCP Relay daemon will relay DHCP requests between broadcast domains for IPv4 DHCP.
|
||||
|
||||

|
||||
|
||||
**DHCP Server**
|
||||
|
||||
User can run DHCP service on the firewall for the network devices.
|
||||
|
||||

|
||||
|
||||
**DNS Forwarder/Resolver/Dynamic DNS**
|
||||
|
||||
DNS different services can be configured on the Pfsense firewall.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**IGMP Proxy**
|
||||
|
||||
User can configure IGMP on the Pfsense firewall from services menu.
|
||||
|
||||

|
||||
|
||||
**Load Balancer**
|
||||
|
||||
Load Balancing is one of the important feature which is also supported by the Pfsense firewall.
|
||||
|
||||

|
||||
|
||||
**SNMP (Simple Network Management Protocol)**
|
||||
|
||||
Pfsense supports all versions of snmp for remote management of firewall.
|
||||
|
||||

|
||||
|
||||
**Wake on Lan**
|
||||
|
||||
Using this feature packet sent to a workstation on a locally connected network which will power on a workstation.
|
||||
|
||||

|
||||
|
||||
### VPN Menu ###
|
||||
|
||||
It is one of the most important feature of Pfsense. Its supports following types of vpn configuration.
|
||||
|
||||
**VPN IPsec**
|
||||
|
||||
IPsec is a standard for providing security to IP protocols via encryption and/or authentication.
|
||||
|
||||

|
||||
|
||||
**L2TP IPsec**
|
||||
|
||||
L2TP/IPsec is a common VPN type that wraps L2TP, an insecure tunneling protocol, inside a secure channel built using transport mode IPsec.
|
||||
|
||||

|
||||
|
||||
**OpenVPN**
|
||||
|
||||
OpenVPN is an Open Source VPN server and client that is supported on pfSense.
|
||||
|
||||

|
||||
|
||||
**Status Menu**
|
||||
|
||||
It shows the status of services provided by Pfsense such as dhcp server, ipsec and load balancer etc.
|
||||
|
||||

|
||||
|
||||
**Diagnostic Menu**
|
||||
|
||||
This menu helps administrator/user for the rectification of Pfsense issues or problems.
|
||||
|
||||

|
||||
|
||||
**Help Menu**
|
||||
|
||||
This menu provides links for different useful resources such as FreeBSD handbook,developer wiki, paid support and pfsense book.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article our focus was on the basic configuration and features set of Pfsense distribution. It is based on FreeBSD distribution and widely used due to security and stability features. In our future articles on Pfsense, our focus will be on the basic firewall rules setting, snort (IDS/IPS) and IPSEC VPN configuration.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/firewall/pfsense-setup-basic-configuration/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:http://linoxide.com/firewall/install-pfsense-firewall/
|
||||
@ -0,0 +1,248 @@
|
||||
# dpkg commands to manage packages on Debian Based Systems
|
||||
|
||||
[dpkg][7] stands for Debian package manager (dpkg). dpkg is a command-line tool to install, build, remove and manage Debian packages. dpkg uses Aptitude (primary and more user-friendly) as a front-end to perform all the actions.
|
||||
|
||||
Other utility such as dpkg-deb and dpkg-query uses dpkg as a front-end to perform some action.
|
||||
|
||||
Now a days most of the administrator using Apt, [Apt-Get][6] & Aptitude to manage packages easily without headache and its robust management too.
|
||||
|
||||
Even though still we need to use dpkg to perform some software installation where it’s necessary. Some other package manger utilities which are being used widely in Linux are [yum][5], [dnf][4], [apt-get][3], dpkg, [rpm][2], [Zypper][1], pacman, urpmi, etc.,
|
||||
|
||||
Now, i’m going to play on our Ubuntu 15.10 box to explain and cover mostly used dpkg commands with examples.
|
||||
|
||||
#### 1) Common syntax/file location for dpkg
|
||||
|
||||
See below for common syntax/ file location of dpkg which will help you if you want to check more about it.
|
||||
|
||||
<iframe marginwidth="0" marginheight="0" scrolling="no" frameborder="0" height="90" width="728" id="_mN_gpt_827143833" style="border-width: 0px; border-style: initial; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: inherit; vertical-align: baseline;"></iframe>
|
||||
```
|
||||
[General syntax for dpkg]
|
||||
$ dpkg -[command] [.deb package name]
|
||||
|
||||
$ dpkg -[command] [package name]
|
||||
|
||||
[dpkg releated files location]
|
||||
$ /var/lib/dpkg
|
||||
|
||||
[This file contain modified package info by dpkg command like (install, remove, etc..,)]
|
||||
$ /var/lib/dpkg/status
|
||||
|
||||
[This file contain available package list]
|
||||
$ /var/lib/dpkg/status
|
||||
|
||||
```
|
||||
|
||||
#### 2) Install/Upgrade the package
|
||||
|
||||
Use the below command to install/upgrade .deb packge on Debian based systems such as Debian, Mint, Ubuntu & elementryOS, etc..,. Here i’m going to install Atom through atom-amd64.deb file. It will upgrade if it’s installed other wise install a fresh one.
|
||||
|
||||
```
|
||||
[Install/Upgrade dpkg packages]
|
||||
$ sudo dpkg -i atom-amd64.deb
|
||||
Selecting previously unselected package atom.
|
||||
(Reading database ... 426102 files and directories currently installed.)
|
||||
Preparing to unpack atom-amd64.deb ...
|
||||
Unpacking atom (1.5.3) over (1.5.3) ...
|
||||
Setting up atom (1.5.3) ...
|
||||
Processing triggers for gnome-menus (3.13.3-6ubuntu1) ...
|
||||
Processing triggers for bamfdaemon (0.5.2~bzr0+15.10.20150627.1-0ubuntu1) ...
|
||||
Rebuilding /usr/share/applications/bamf-2.index...
|
||||
Processing triggers for desktop-file-utils (0.22-1ubuntu3) ...
|
||||
Processing triggers for mime-support (3.58ubuntu1) ...
|
||||
|
||||
```
|
||||
|
||||
#### 3) Install a package from folder
|
||||
|
||||
Use the below command to install the packages recursively from directory on Debian based systems such as Debian, Mint, Ubuntu & elementryOS, etc,. This will install all the *.deb packages under the /opt/software directory.
|
||||
|
||||
```
|
||||
$ sudo dpkg -iR /opt/software
|
||||
Selecting previously unselected package atom.
|
||||
(Reading database ... 423303 files and directories currently installed.)
|
||||
Preparing to unpack /opt/software/atom-amd64.deb ...
|
||||
Unpacking atom (1.5.3) ...
|
||||
Setting up atom (1.5.3) ...
|
||||
Processing triggers for gnome-menus (3.13.3-6ubuntu1) ...
|
||||
Processing triggers for bamfdaemon (0.5.2~bzr0+15.10.20150627.1-0ubuntu1) ...
|
||||
Rebuilding /usr/share/applications/bamf-2.index...
|
||||
Processing triggers for desktop-file-utils (0.22-1ubuntu3) ...
|
||||
Processing triggers for mime-support (3.58ubuntu1) ...
|
||||
```
|
||||
|
||||
#### 4) Print the Installed packages list
|
||||
|
||||
Use the below command to List all installed packages, along with package version and description on Debian based systems such as Debian, Mint, Ubuntu & elementryOS, etc..,.
|
||||
|
||||
```
|
||||
$ dpkg -l
|
||||
Desired=Unknown/Install/Remove/Purge/Hold
|
||||
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|
||||
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
|
||||
||/ Name Version Architecture Description
|
||||
+++-===========================-==================================-============-================================================================
|
||||
ii account-plugin-aim 3.12.10-0ubuntu2 amd64 Messaging account plugin for AIM
|
||||
ii account-plugin-facebook 0.12+15.10.20150723-0ubuntu1 all GNOME Control Center account plugin for single signon - facebook
|
||||
ii account-plugin-flickr 0.12+15.10.20150723-0ubuntu1 all GNOME Control Center account plugin for single signon - flickr
|
||||
ii account-plugin-google 0.12+15.10.20150723-0ubuntu1 all GNOME Control Center account plugin for single signon
|
||||
ii account-plugin-jabber 3.12.10-0ubuntu2 amd64 Messaging account plugin for Jabber/XMPP
|
||||
ii account-plugin-salut 3.12.10-0ubuntu2 amd64 Messaging account plugin for Local XMPP (Salut)
|
||||
.
|
||||
.
|
||||
|
||||
```
|
||||
|
||||
#### 5) Check particular Installed package
|
||||
|
||||
Use the below command to List individual installed package, along with package version and description on Debian based systems such as Debian, Mint, Ubuntu & elementryOS, etc..,.
|
||||
|
||||
<iframe marginwidth="0" marginheight="0" scrolling="no" frameborder="0" height="90" width="728" id="_mN_gpt_827143833" style="border-width: 0px; border-style: initial; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: inherit; vertical-align: baseline;"></iframe>
|
||||
```
|
||||
$ dpkg -l atom
|
||||
Desired=Unknown/Install/Remove/Purge/Hold
|
||||
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|
||||
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
|
||||
||/ Name Version Architecture Description
|
||||
+++-==========-=========-===================-============================================
|
||||
ii atom 1.5.3 amd64 A hackable text editor for the 21st Century.
|
||||
|
||||
```
|
||||
|
||||
#### 6) Check package Installed Location
|
||||
|
||||
Use the below command to Check package Installed Location on Debian based systems such as Debian, Mint, Ubuntu & elementryOS, etc..,.
|
||||
|
||||
```
|
||||
$ dpkg -L atom
|
||||
/.
|
||||
/usr
|
||||
/usr/bin
|
||||
/usr/bin/atom
|
||||
/usr/share
|
||||
/usr/share/lintian
|
||||
/usr/share/lintian/overrides
|
||||
/usr/share/lintian/overrides/atom
|
||||
/usr/share/pixmaps
|
||||
/usr/share/pixmaps/atom.png
|
||||
/usr/share/doc
|
||||
|
||||
```
|
||||
|
||||
#### 7) View deb package content
|
||||
|
||||
Use the below command to View deb package content, It will show list of files on inside .deb package.
|
||||
|
||||
```
|
||||
$ dpkg -c atom-amd64.deb
|
||||
drwxr-xr-x root/root 0 2016-02-13 02:13 ./
|
||||
drwxr-xr-x root/root 0 2016-02-13 02:13 ./usr/
|
||||
drwxr-xr-x root/root 0 2016-02-13 02:13 ./usr/bin/
|
||||
-rwxr-xr-x root/root 3067 2016-02-13 02:13 ./usr/bin/atom
|
||||
drwxr-xr-x root/root 0 2016-02-13 02:13 ./usr/share/
|
||||
drwxr-xr-x root/root 0 2016-02-13 02:13 ./usr/share/lintian/
|
||||
drwxr-xr-x root/root 0 2016-02-13 02:13 ./usr/share/lintian/overrides/
|
||||
-rw-r--r-- root/root 299 2016-02-13 02:13 ./usr/share/lintian/overrides/atom
|
||||
drwxr-xr-x root/root 0 2016-02-13 02:13 ./usr/share/pixmaps/
|
||||
-rw-r--r-- root/root 643183 2016-02-13 02:13 ./usr/share/pixmaps/atom.png
|
||||
drwxr-xr-x root/root 0 2016-02-13 02:13 ./usr/share/doc/
|
||||
.
|
||||
.
|
||||
```
|
||||
|
||||
#### 8) Display details about package
|
||||
|
||||
Use the below command to Display detailed information about package, package group, version, maintainer, Architecture, display depends packages, description, etc.,.
|
||||
|
||||
```
|
||||
$ dpkg -s atom
|
||||
Package: atom
|
||||
Status: install ok installed
|
||||
Priority: optional
|
||||
Section: devel
|
||||
Installed-Size: 213496
|
||||
Maintainer: GitHub <atom@github.com>Architecture: amd64
|
||||
Version: 1.5.3
|
||||
Depends: git, gconf2, gconf-service, libgtk2.0-0, libudev0 | libudev1, libgcrypt11 | libgcrypt20, libnotify4, libxtst6, libnss3, python, gvfs-bin, xdg-utils, libcap2
|
||||
Recommends: lsb-release
|
||||
Suggests: libgnome-keyring0, gir1.2-gnomekeyring-1.0
|
||||
Description: A hackable text editor for the 21st Century.
|
||||
Atom is a free and open source text editor that is modern, approachable, and hackable to the core.</atom@github.com>
|
||||
```
|
||||
|
||||
#### 9) Find what package owns the file
|
||||
|
||||
Use the below command to find out what package does file belong.
|
||||
|
||||
```
|
||||
$ dpkg -S /usr/bin/atom
|
||||
atom: /usr/bin/atom
|
||||
|
||||
```
|
||||
|
||||
#### 10) Remove/Delete package
|
||||
|
||||
Use the below command to Remove/Delete an installed package except configuration files.
|
||||
|
||||
<iframe marginwidth="0" marginheight="0" scrolling="no" frameborder="0" height="90" width="728" id="_mN_gpt_827143833" style="border-width: 0px; border-style: initial; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: inherit; vertical-align: baseline;"></iframe>
|
||||
```
|
||||
$ sudo dpkg -r atom
|
||||
(Reading database ... 426404 files and directories currently installed.)
|
||||
Removing atom (1.5.3) ...
|
||||
Processing triggers for gnome-menus (3.13.3-6ubuntu1) ...
|
||||
Processing triggers for bamfdaemon (0.5.2~bzr0+15.10.20150627.1-0ubuntu1) ...
|
||||
Rebuilding /usr/share/applications/bamf-2.index...
|
||||
Processing triggers for desktop-file-utils (0.22-1ubuntu3) ...
|
||||
Processing triggers for mime-support (3.58ubuntu1) ...
|
||||
|
||||
```
|
||||
|
||||
#### 11) Purge package
|
||||
|
||||
Use the below command to Remove/Delete everything including configuration files.
|
||||
|
||||
```
|
||||
$ sudo dpkg -P atom
|
||||
(Reading database ... 426404 files and directories currently installed.)
|
||||
Removing atom (1.5.3) ...
|
||||
Processing triggers for gnome-menus (3.13.3-6ubuntu1) ...
|
||||
Processing triggers for bamfdaemon (0.5.2~bzr0+15.10.20150627.1-0ubuntu1) ...
|
||||
Rebuilding /usr/share/applications/bamf-2.index...
|
||||
Processing triggers for desktop-file-utils (0.22-1ubuntu3) ...
|
||||
Processing triggers for mime-support (3.58ubuntu1) ...
|
||||
|
||||
```
|
||||
|
||||
#### 12) Read more about dpkg
|
||||
|
||||
Use the below commands to read more about dpkg command information.
|
||||
|
||||
```
|
||||
$ dpkg -help
|
||||
or
|
||||
$ man dpkg
|
||||
|
||||
```
|
||||
|
||||
Enjoy….)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/dpkg-command-examples/
|
||||
|
||||
作者:[MAGESH MARUTHAMUTHU ][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:http://www.2daygeek.com/zypper-command-examples/
|
||||
[2]:http://www.2daygeek.com/rpm-command-examples/
|
||||
[3]:http://www.2daygeek.com/apt-get-apt-cache-command-examples/
|
||||
[4]:http://www.2daygeek.com/dnf-command-examples/
|
||||
[5]:http://www.2daygeek.com/yum-command-examples/
|
||||
[6]:http://www.2daygeek.com/apt-get-apt-cache-command-examples/
|
||||
[7]:https://wiki.debian.org/Teams/Dpkg
|
||||
[8]:http://www.2daygeek.com/author/magesh/
|
||||
@ -1,64 +0,0 @@
|
||||
[Translating by itsang]
|
||||
4 Container Networking Tools to Know
|
||||
=======================================
|
||||
|
||||

|
||||
>[Creative Commons Zero][1]
|
||||
|
||||
With so many new cloud computing technologies, tools, and techniques to keep track of, it can be hard to know where to start learning new skills. This series on [next-gen cloud technologies][2] aims to help you get up to speed on the important projects and products in emerging and rapidly changing areas such as software-defined networking (SDN) , containers, and the space where they coincide: container networking.
|
||||
|
||||
The relationship between containers and networks remains challenging for enterprise container deployment. Containers need networking functionality to connect distributed applications. Part of the challenge, according to a recent [Enterprise Networking Planet][3] article, is “to deploy containers in a way that provides the isolation they need to function as their own self-contained data environments while still maintaining effective connectivity.”
|
||||
|
||||
[Docker][4], the popular container platform, uses software-defined virtual networks to connect containers with the local network. Additionally, it uses Linux bridging features and virtual extensible LAN (VXLAN) technology so containers can communicate with each other in the same Swarm, or cluster. Docker’s plug-in architecture also allows other network management tools, such as those listed below, to control containers.
|
||||
|
||||
Innovation in container networking has enabled containers to connect with other containers across hosts. This enables developers to start an application in a container on a host in a development environment and transition it across testing and then into a production environment enabling continuous integration, agility, and rapid deployment.
|
||||
|
||||
Container networking tools help accomplish container networking scalability, mainly by:
|
||||
|
||||
1) enabling complex, multi-host systems to be distributed across multiple container hosts.
|
||||
|
||||
2) enabling orchestration for container systems spanning a tremendous number of hosts across multiple public and private cloud platforms.
|
||||
|
||||

|
||||
>John Willis speaking at Open Networking Summit 2016.
|
||||
|
||||
For more information, check out the [Docker Networking Tutorial][5] video, which was presented by Brent Salisbury and John Willis at the recent [Open Networking Summit (ONS)][6]. This and many other ONS keynotes and presentations can be found [here][7].
|
||||
|
||||
Container networking tools and projects you should know about include:
|
||||
|
||||
[Calico][8] -- The Calico project (from [Metaswitch][9]) leverages Border Gateway Protocol (BGP) and integrates with cloud orchestration systems for secure IP communication between virtual machines and containers.
|
||||
|
||||
[Flannel][10] -- Flannel (previously called rudder) from [CoreOS][11] provides an overlay network that can be used as an alternative to existing SDN solutions.
|
||||
|
||||
[Weaveworks][12] -- The Weaveworks projects for managing containers include [Weave Net][13], Weave Scope, and Weave Flux. Weave Net is a tool for building and deploying Docker container networks.
|
||||
|
||||
[Canal][14] -- Just this week, CoreOS and Tigera announced the formation of a new open source project called Canal. According to the announcement, the Canal project aims to combine aspects of Calico and Flannel, "weaving security policy into both the network fabric and the cloud orchestrator."
|
||||
|
||||
You can learn more about container management, software-defined networking, and other next-gen cloud technologies through The Linux Foundation’s free “Cloud Infrastructure Technologies” course -- a massively open online course being offered through edX. [Registration for this course is open now][15], and course content will be available in June.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/4-container-networking-tools-know
|
||||
|
||||
作者:[AMBER ANKERHOLZ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/aankerholz
|
||||
[1]: https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]: https://www.linux.com/news/5-next-gen-cloud-technologies-you-should-know
|
||||
[3]: http://www.enterprisenetworkingplanet.com/datacenter/datacenter-blog/container-networking-challenges-for-the-enterprise.html
|
||||
[4]: https://docs.docker.com/engine/userguide/networking/dockernetworks/
|
||||
[5]: https://youtu.be/Le0bEg4taak
|
||||
[6]: http://events.linuxfoundation.org/events/open-networking-summit
|
||||
[7]: https://www.linux.com/watch-videos-from-ons2016
|
||||
[8]: https://www.projectcalico.org/
|
||||
[9]: http://www.metaswitch.com/cloud-network-virtualization
|
||||
[10]: https://coreos.com/blog/introducing-rudder/
|
||||
[11]: https://coreos.com/
|
||||
[12]: https://www.weave.works/
|
||||
[13]: https://www.weave.works/products/weave-net/
|
||||
[14]: https://github.com/tigera/canal
|
||||
[15]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-cloud-infrastructure-technologies?utm_source=linuxcom&utm_medium=article&utm_campaign=cloud%20mooc%20article%201
|
||||
@ -1,4 +1,6 @@
|
||||
|
||||
Translating by Firstadream
|
||||
|
||||
Rapid prototyping with docker-compose
|
||||
========================================
|
||||
|
||||
|
||||
@ -1,177 +0,0 @@
|
||||
Translating by cposture
|
||||
Python unittest: assertTrue is truthy, assertFalse is falsy
|
||||
===========================
|
||||
|
||||
In this post, I explore the differences between the unittest boolean assert methods assertTrue and assertFalse and the assertIs identity assertion.
|
||||
|
||||
### Definitions
|
||||
|
||||
Here’s what the [unittest module documentation][1] currently notes about assertTrue and assertFalse, with the appropriate code highlighted:
|
||||
|
||||
|
||||
>assertTrue(expr, msg=None)
|
||||
|
||||
>assertFalse(expr, msg=None)
|
||||
|
||||
>>Test that expr is true (or false).
|
||||
|
||||
>>Note that this is equivalent to
|
||||
|
||||
>>bool(expr) is True
|
||||
|
||||
>>and not to
|
||||
|
||||
>>expr is True
|
||||
|
||||
>>(use assertIs(expr, True) for the latter).
|
||||
|
||||
[Mozilla Developer Network defines truthy][2] as:
|
||||
|
||||
> A value that translates to true when evaluated in a Boolean context.
|
||||
In Python this is equivalent to:
|
||||
|
||||
```
|
||||
bool(expr) is True
|
||||
```
|
||||
|
||||
Which exactly matches what assertTrue is testing for.
|
||||
|
||||
Therefore the documentation already indicates assertTrue is truthy and assertFalse is falsy. These assertion methods are creating a bool from the received value and then evaluating it. It also suggests that we really shouldn’t use assertTrue or assertFalse for very much at all.
|
||||
|
||||
### What does this mean in practice?
|
||||
|
||||
Let’s use a very simple example - a function called always_true that returns True. We’ll write the tests for it and then make changes to the code and see how the tests perform.
|
||||
|
||||
Starting with the tests, we’ll have two tests. One is “loose”, using assertTrue to test for a truthy value. The other is “strict” using assertIs as recommended by the documentation:
|
||||
|
||||
```
|
||||
import unittest
|
||||
|
||||
from func import always_true
|
||||
|
||||
|
||||
class TestAlwaysTrue(unittest.TestCase):
|
||||
|
||||
def test_assertTrue(self):
|
||||
"""
|
||||
always_true returns a truthy value
|
||||
"""
|
||||
result = always_true()
|
||||
|
||||
self.assertTrue(result)
|
||||
|
||||
def test_assertIs(self):
|
||||
"""
|
||||
always_true returns True
|
||||
"""
|
||||
result = always_true()
|
||||
|
||||
self.assertIs(result, True)
|
||||
```
|
||||
|
||||
Here’s the code for our simple function in func.py:
|
||||
|
||||
```
|
||||
def always_true():
|
||||
"""
|
||||
I'm always True.
|
||||
|
||||
Returns:
|
||||
bool: True
|
||||
"""
|
||||
return True
|
||||
```
|
||||
|
||||
When run, everything passes:
|
||||
|
||||
```
|
||||
always_true returns True ... ok
|
||||
always_true returns a truthy value ... ok
|
||||
|
||||
----------------------------------------------------------------------
|
||||
Ran 2 tests in 0.004s
|
||||
|
||||
OK
|
||||
```
|
||||
|
||||
Happy days!
|
||||
|
||||
Now, “someone” changes always_true to the following:
|
||||
|
||||
```
|
||||
def always_true():
|
||||
"""
|
||||
I'm always True.
|
||||
|
||||
Returns:
|
||||
bool: True
|
||||
"""
|
||||
return 'True'
|
||||
```
|
||||
|
||||
Instead of returning True (boolean), it’s now returning string 'True'. (Of course this “someone” hasn’t updated the docstring - we’ll raise a ticket later.)
|
||||
|
||||
This time the result is not so happy:
|
||||
|
||||
```
|
||||
always_true returns True ... FAIL
|
||||
always_true returns a truthy value ... ok
|
||||
|
||||
======================================================================
|
||||
FAIL: always_true returns True
|
||||
----------------------------------------------------------------------
|
||||
Traceback (most recent call last):
|
||||
File "/tmp/assertttt/test.py", line 22, in test_is_true
|
||||
self.assertIs(result, True)
|
||||
AssertionError: 'True' is not True
|
||||
|
||||
----------------------------------------------------------------------
|
||||
Ran 2 tests in 0.004s
|
||||
|
||||
FAILED (failures=1)
|
||||
```
|
||||
|
||||
Only one test failed! This means assertTrue gave us a false-positive. It passed when it shouldn’t have. It’s lucky we wrote the second test with assertIs.
|
||||
|
||||
Therefore, just as we learned from the manual, to keep the functionality of always_true pinned tightly the stricter assertIs should be used rather than assertTrue.
|
||||
|
||||
### Use assertion helpers
|
||||
|
||||
Writing out assertIs to test for True and False values is not too lengthy. However, if you have a project in which you often need to check that values are exactly True or exactly False, then you can make yourself the assertIsTrue and assertIsFalse assertion helpers.
|
||||
|
||||
This doesn’t save a particularly large amount of code, but it does improve readability in my opinion.
|
||||
|
||||
```
|
||||
def assertIsTrue(self, value):
|
||||
self.assertIs(value, True)
|
||||
|
||||
def assertIsFalse(self, value):
|
||||
self.assertIs(value, False)
|
||||
```
|
||||
|
||||
### Summary
|
||||
|
||||
In general, my recommendation is to keep tests as tight as possible. If you mean to test for the exact value True or False, then follow the [documentation][3] and use assertIs. Do not use assertTrue or assertFalse unless you really have to.
|
||||
|
||||
If you are looking at a function that can return various types, for example, sometimes bool sometimes int, then consider refactoring. This is a code smell and in Python, that False value for an error would probably be better raised as an exception.
|
||||
|
||||
In addition, if you really need to assert the return value from a function under test is truthy, there might be a second code smell - is your code correctly encapsulated? If assertTrue and assertFalse are asserting that function return values will trigger if statements correctly, then it might be worth sense-checking you’ve encapsulated everything you intended in the appropriate place. Maybe those if statements should be encapsulated within the function under test.
|
||||
|
||||
Happy testing!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jamescooke.info/python-unittest-asserttrue-is-truthy-assertfalse-is-falsy.html
|
||||
|
||||
作者:[James Cooke][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://jamescooke.info/pages/hello-my-name-is-james.html
|
||||
[1]:https://docs.python.org/3/library/unittest.html#unittest.TestCase.assertTrue
|
||||
[2]:https://developer.mozilla.org/en-US/docs/Glossary/Truthy
|
||||
[3]:https://docs.python.org/3/library/unittest.html#unittest.TestCase.assertTrue
|
||||
@ -0,0 +1,282 @@
|
||||
# aria2 (Command Line Downloader) command examples
|
||||
|
||||
[aria2][4] is a Free, open source, lightweight multi-protocol & multi-source command-line download utility. It supports HTTP/HTTPS, FTP, SFTP, BitTorrent and Metalink. aria2 can be manipulated via built-in JSON-RPC and XML-RPC interfaces. aria2 automatically validates chunks of data while downloading a file. It can download a file from multiple sources/protocols and tries to utilize your maximum download bandwidth. By default all the Linux Distribution included aria2, so we can install easily from official repository. some of the GUI download manager using aria2 as a plugin to improve the download speed like [uget][3].
|
||||
|
||||
#### Aria2 Features
|
||||
|
||||
* HTTP/HTTPS GET support
|
||||
* HTTP Proxy support
|
||||
* HTTP BASIC authentication support
|
||||
* HTTP Proxy authentication support
|
||||
* FTP support(active, passive mode)
|
||||
* FTP through HTTP proxy(GET command or tunneling)
|
||||
* Segmented download
|
||||
* Cookie support
|
||||
* It can run as a daemon process.
|
||||
* BitTorrent protocol support with fast extension.
|
||||
* Selective download in multi-file torrent
|
||||
* Metalink version 3.0 support(HTTP/FTP/BitTorrent).
|
||||
* Limiting download/upload speed
|
||||
|
||||
#### 1) Install aria2 on Linux
|
||||
|
||||
We can easily install aria2 command line downloader to all the Linux Distribution such as Debian, Ubuntu, Mint, RHEL, CentOS, Fedora, suse, openSUSE, Arch Linux, Manjaro, Mageia, etc.. Just fire the below command to install. For CentOS, RHEL systems we need to enable [uget][2] or [RPMForge][1] repository.
|
||||
|
||||
```
|
||||
[For Debian, Ubuntu & Mint]
|
||||
$ sudo apt-get install aria2
|
||||
|
||||
[For CentOS, RHEL, Fedora 21 and older Systems]
|
||||
# yum install aria2
|
||||
|
||||
[Fedora 22 and later systems]
|
||||
# dnf install aria2
|
||||
|
||||
[For suse & openSUSE]
|
||||
# zypper install wget
|
||||
|
||||
[Mageia]
|
||||
# urpmi aria2
|
||||
|
||||
[For Debian, Ubuntu & Mint]
|
||||
$ sudo pacman -S aria2
|
||||
|
||||
```
|
||||
|
||||
#### 2) Download Single File
|
||||
|
||||
The below command will download the file from given URL and stores in current directory, while downloading the file we can see the (date, time, download speed & download progress) of file.
|
||||
|
||||
```
|
||||
# aria2c https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
[#986c80 19MiB/21MiB(90%) CN:1 DL:3.0MiB]
|
||||
03/22 09:49:13 [NOTICE] Download complete: /opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Download Results:
|
||||
gid |stat|avg speed |path/URI
|
||||
======+====+===========+=======================================================
|
||||
986c80|OK | 3.0MiB/s|/opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Status Legend:
|
||||
(OK):download completed.
|
||||
|
||||
```
|
||||
|
||||
#### 3) Save the file with different name
|
||||
|
||||
We can save the file with different name & format while initiate downloading, using -o (lowercase) option. Here we are going to save the filename with owncloud.zip.
|
||||
|
||||
```
|
||||
# aria2c -o owncloud.zip https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
[#d31304 16MiB/21MiB(74%) CN:1 DL:6.2MiB]
|
||||
03/22 09:51:02 [NOTICE] Download complete: /opt/owncloud.zip
|
||||
|
||||
Download Results:
|
||||
gid |stat|avg speed |path/URI
|
||||
======+====+===========+=======================================================
|
||||
d31304|OK | 7.3MiB/s|/opt/owncloud.zip
|
||||
|
||||
Status Legend:
|
||||
(OK):download completed.
|
||||
|
||||
```
|
||||
|
||||
#### 4) Limit download speed
|
||||
|
||||
By default aria2 utilize full bandwidth for downloading file and we can’t use anything on server before download completion (Which will affect other service accessing bandwidth). So better use –max-download-limit option to avoid further issue while downloading big size file.
|
||||
|
||||
```
|
||||
# aria2c --max-download-limit=500k https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
[#7f9fbf 21MiB/21MiB(99%) CN:1 DL:466KiB]
|
||||
03/22 09:54:51 [NOTICE] Download complete: /opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Download Results:
|
||||
gid |stat|avg speed |path/URI
|
||||
======+====+===========+=======================================================
|
||||
7f9fbf|OK | 462KiB/s|/opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Status Legend:
|
||||
(OK):download completed.
|
||||
|
||||
```
|
||||
|
||||
#### 5) Download Multiple Files
|
||||
|
||||
The below command will download more then on file from the location and stores in current directory, while downloading the file we can see the (date, time, download speed & download progress) of file.
|
||||
|
||||
```
|
||||
# aria2c -Z https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2 ftp://ftp.gnu.org/gnu/wget/wget-1.17.tar.gz
|
||||
[DL:1.7MiB][#53533c 272KiB/21MiB(1%)][#b52bb1 768KiB/3.6MiB(20%)]
|
||||
03/22 10:25:54 [NOTICE] Download complete: /opt/wget-1.17.tar.gz
|
||||
[#53533c 18MiB/21MiB(86%) CN:1 DL:3.2MiB]
|
||||
03/22 10:25:59 [NOTICE] Download complete: /opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Download Results:
|
||||
gid |stat|avg speed |path/URI
|
||||
======+====+===========+=======================================================
|
||||
b52bb1|OK | 2.8MiB/s|/opt/wget-1.17.tar.gz
|
||||
53533c|OK | 3.4MiB/s|/opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Status Legend:
|
||||
(OK):download completed.
|
||||
|
||||
```
|
||||
|
||||
#### 6) Resume Incomplete download
|
||||
|
||||
Make sure, whenever going to download big size of file (eg: ISO Images), i advise you to use -c option which will help us to resume the existing incomplete download from the state and complete as usual when we are facing any network connectivity issue or system problems. Otherwise when you are download again, it will initiate the fresh download and store to different file name (append .1 to the filename automatically). Note: If any interrupt happen, aria2 save file with .aria2 extension.
|
||||
|
||||
<iframe marginwidth="0" marginheight="0" scrolling="no" frameborder="0" height="90" width="728" id="_mN_gpt_827143833" style="border-width: 0px; border-style: initial; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: inherit; vertical-align: baseline;"></iframe>
|
||||
```
|
||||
# aria2c -c https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
[#db0b08 8.2MiB/21MiB(38%) CN:1 DL:3.1MiB ETA:4s]^C
|
||||
03/22 10:09:26 [NOTICE] Shutdown sequence commencing... Press Ctrl-C again for emergency shutdown.
|
||||
|
||||
03/22 10:09:26 [NOTICE] Download GID#db0b08bf55d5908d not complete: /opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Download Results:
|
||||
gid |stat|avg speed |path/URI
|
||||
======+====+===========+=======================================================
|
||||
db0b08|INPR| 3.3MiB/s|/opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Status Legend:
|
||||
(INPR):download in-progress.
|
||||
|
||||
aria2 will resume download if the transfer is restarted.
|
||||
|
||||
# aria2c -c https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
[#873d08 21MiB/21MiB(98%) CN:1 DL:2.7MiB]
|
||||
03/22 10:09:57 [NOTICE] Download complete: /opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Download Results:
|
||||
gid |stat|avg speed |path/URI
|
||||
======+====+===========+=======================================================
|
||||
873d08|OK | 1.9MiB/s|/opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Status Legend:
|
||||
(OK):download completed.
|
||||
|
||||
```
|
||||
|
||||
#### 7) Get the input from file
|
||||
|
||||
Alternatively wget can get the list of input URL’s from file and start downloading. We need to create a file and store each URL in separate line. Add -i option with aria2 command to perform this action.
|
||||
|
||||
```
|
||||
# aria2c -i test-aria2.txt
|
||||
[DL:3.9MiB][#b97984 192KiB/21MiB(0%)][#673c8e 2.5MiB/3.6MiB(69%)]
|
||||
03/22 10:14:22 [NOTICE] Download complete: /opt/wget-1.17.tar.gz
|
||||
[#b97984 19MiB/21MiB(90%) CN:1 DL:2.5MiB]
|
||||
03/22 10:14:30 [NOTICE] Download complete: /opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Download Results:
|
||||
gid |stat|avg speed |path/URI
|
||||
======+====+===========+=======================================================
|
||||
673c8e|OK | 4.3MiB/s|/opt/wget-1.17.tar.gz
|
||||
b97984|OK | 2.5MiB/s|/opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Status Legend:
|
||||
(OK):download completed.
|
||||
|
||||
```
|
||||
|
||||
#### 8) Download using 2 connections per host
|
||||
|
||||
The maximum number of connections to one server for each download. By default this will establish one connection to each host. We can establish more then one connection to each host to speedup download by adding -x2 (2 means, two connection) option with aria2 command
|
||||
|
||||
```
|
||||
# aria2c -x2 https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
[#ddd4cd 18MiB/21MiB(83%) CN:1 DL:5.0MiB]
|
||||
03/22 10:16:27 [NOTICE] Download complete: /opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Download Results:
|
||||
gid |stat|avg speed |path/URI
|
||||
======+====+===========+=======================================================
|
||||
ddd4cd|OK | 5.5MiB/s|/opt/owncloud-9.0.0.tar.bz2
|
||||
|
||||
Status Legend:
|
||||
(OK):download completed.
|
||||
|
||||
```
|
||||
|
||||
#### 9) Download Torrent Files
|
||||
|
||||
We can directly download a Torrent files using aria2 command.
|
||||
|
||||
```
|
||||
# aria2c https://torcache.net/torrent/C86F4E743253E0EBF3090CCFFCC9B56FA38451A3.torrent?title=[kat.cr]irudhi.suttru.2015.official.teaser.full.hd.1080p.pathi.team.sr
|
||||
[#388321 0B/0B CN:1 DL:0B]
|
||||
03/22 20:06:14 [NOTICE] Download complete: /opt/[kat.cr]irudhi.suttru.2015.official.teaser.full.hd.1080p.pathi.team.sr.torrent
|
||||
|
||||
03/22 20:06:14 [ERROR] Exception caught
|
||||
Exception: [BtPostDownloadHandler.cc:98] errorCode=25 Could not parse BitTorrent metainfo
|
||||
|
||||
Download Results:
|
||||
gid |stat|avg speed |path/URI
|
||||
======+====+===========+=======================================================
|
||||
388321|OK | 11MiB/s|/opt/[kat.cr]irudhi.suttru.2015.official.teaser.full.hd.1080p.pathi.team.sr.torrent
|
||||
|
||||
Status Legend:
|
||||
(OK):download completed.
|
||||
|
||||
```
|
||||
|
||||
#### 10) Download BitTorrent Magnet URI
|
||||
|
||||
Also we can directly download a Torrent files through BitTorrent Magnet URI using aria2 command.
|
||||
|
||||
```
|
||||
# aria2c 'magnet:?xt=urn:btih:248D0A1CD08284299DE78D5C1ED359BB46717D8C'
|
||||
|
||||
```
|
||||
|
||||
#### 11) Download BitTorrent Metalink
|
||||
|
||||
Also we can directly download a Metalink file using aria2 command.
|
||||
|
||||
```
|
||||
# aria2c https://curl.haxx.se/metalink.cgi?curl=tar.bz2
|
||||
|
||||
```
|
||||
|
||||
#### 12) Download a file from password protected site
|
||||
|
||||
Alternatively we can download a file from password protected site. The below command will download the file from password protected site.
|
||||
|
||||
```
|
||||
# aria2c --http-user=xxx --http-password=xxx https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
|
||||
# aria2c --ftp-user=xxx --ftp-password=xxx ftp://ftp.gnu.org/gnu/wget/wget-1.17.tar.gz
|
||||
|
||||
```
|
||||
|
||||
#### 13) Read more about aria2
|
||||
|
||||
If you want to know more option which is available for wget, you can grep the details on your terminal itself by firing below commands..
|
||||
|
||||
```
|
||||
# man aria2c
|
||||
or
|
||||
# aria2c --help
|
||||
|
||||
```
|
||||
|
||||
Enjoy…)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/aria2-command-line-download-utility-tool/
|
||||
|
||||
作者:[MAGESH MARUTHAMUTHU][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:http://www.2daygeek.com/aria2-command-line-download-utility-tool/
|
||||
[2]:http://www.2daygeek.com/aria2-command-line-download-utility-tool/
|
||||
[3]:http://www.2daygeek.com/install-uget-download-manager-on-ubuntu-centos-debian-fedora-mint-rhel-opensuse/
|
||||
[4]:https://aria2.github.io/
|
||||
File diff suppressed because one or more lines are too long
@ -1,68 +0,0 @@
|
||||
Translating by ivo-wang
|
||||
Microfluidic cooling may prevent the demise of Moore's Law
|
||||
============================================================
|
||||
|
||||

|
||||
>Image: iStock/agsandrew
|
||||
|
||||
Existing technology's inability to keep microchips cool is fast becoming the number one reason why [Moore's Law][1] may soon meet its demise.
|
||||
|
||||
In the ongoing need for digital speed, scientists and engineers are working hard to squeeze more transistors and support circuitry onto an already-crowded piece of silicon. However, as complex as that seems, it pales in comparison to the [problem of heat buildup][2].
|
||||
|
||||
"Right now, we're limited in the power we can put into microchips," says John Ditri, principal investigator at Lockheed Martin in [this press release][3]. "One of the biggest challenges is managing the heat. If you can manage the heat, you can use fewer chips, and that means using less material, which results in cost savings as well as reduced system size and weight. If you manage the heat and use the same number of chips, you'll get even greater performance in your system."
|
||||
|
||||
Resistance to the flow of electrons through silicon causes the heat, and packing so many transistors in such a small space creates enough heat to destroy components. One way to eliminate heat buildup is to reduce the flow of electrons by [using photonics at the chip level][4]. However, photonic technology is not without its set of problems.
|
||||
|
||||
SEE: [Silicon photonics will revolutionize data centers in 2015][5]
|
||||
|
||||
### Microfluid cooling might be the answer
|
||||
|
||||
To seek out other solutions, the Defense Advanced Research Projects Agency (DARPA) has initiated a program called [ICECool Applications][6] (Intra/Interchip Enhanced Cooling). "ICECool is exploring disruptive thermal technologies that will mitigate thermal limitations on the operation of military electronic systems while significantly reducing the size, weight, and power consumption," explains the [GSA website FedBizOpps.gov][7].
|
||||
|
||||
What is unique about this method of cooling is the push to use a combination of intra- and/or inter-chip microfluidic cooling and on-chip thermal interconnects.
|
||||
|
||||

|
||||
>MicroCooling 1 Image: DARPA
|
||||
|
||||
The [DARPA ICECool Application announcement][8] notes, "Such miniature intra- and/or inter-chip passages (see right) may take the form of axial micro-channels, radial passages, and/or cross-flow passages, and may involve micro-pores and manifolded structures to distribute and re-direct liquid flow, including in the form of localized liquid jets, in the most favorable manner to meet the specified heat flux and heat density metrics."
|
||||
|
||||
Using the above technology, engineers at Lockheed Martin have experimentally demonstrated how on-chip cooling is a significant improvement. "Phase I of the ICECool program verified the effectiveness of Lockheed's embedded microfluidic cooling approach by showing a four-times reduction in thermal resistance while cooling a thermal demonstration die dissipating 1 kW/cm2 die-level heat flux with multiple local 30 kW/cm2 hot spots," mentions the Lockheed Martin press release.
|
||||
|
||||
In phase II of the Lockheed Martin project, the engineers focused on RF amplifiers. The press release continues, "Utilizing its ICECool technology, the team has been able to demonstrate greater than six times increase in RF output power from a given amplifier while still running cooler than its conventionally cooled counterpart."
|
||||
|
||||
### Moving to production
|
||||
|
||||
Confident of the technology, Lockheed Martin is already designing and building a functional microfluidic cooled transmit antenna. Lockheed Martin is also collaborating with Qorvo to integrate its thermal solution with Qorvo's high-performance [GaN process][9].
|
||||
|
||||
The authors of the research paper [DARPA's Intra/Interchip Enhanced Cooling (ICECool) Program][10] suggest ICECool Applications will produce a paradigm shift in the thermal management of electronic systems. "ICECool Apps performers will define and demonstrate intra-chip and inter-chip thermal management approaches that are tailored to specific applications and this approach will be consistent with the materials sets, fabrication processes, and operating environment of the intended application."
|
||||
|
||||
If this microfluidic technology is as successful as scientists and engineers suggest, it seems Moore's Law does have a fighting chance.
|
||||
|
||||
For more about networking, subscribe to our Data Centers newsletter.
|
||||
|
||||
[SUBSCRIBE](https://secure.techrepublic.com/user/login/?regSource=newsletter-button&position=newsletter-button&appId=true&redirectUrl=http%3A%2F%2Fwww.techrepublic.com%2Farticle%2Fmicrofluidic-cooling-may-prevent-the-demise-of-moores-law%2F&)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techrepublic.com/article/microfluidic-cooling-may-prevent-the-demise-of-moores-law/
|
||||
|
||||
作者:[Michael Kassner][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.techrepublic.com/search/?a=michael+kassner
|
||||
[1]: http://www.intel.com/content/www/us/en/history/museum-gordon-moore-law.html
|
||||
[2]: https://books.google.com/books?id=mfec2Zw_b7wC&pg=PA154&lpg=PA154&dq=does+heat+destroy+transistors&source=bl&ots=-aNdbMD7FD&sig=XUUiaYG_6rcxHncx4cI4Cqe3t20&hl=en&sa=X&ved=0ahUKEwif4M_Yu_PMAhVL7oMKHW3GC3cQ6AEITTAH#v=onepage&q=does%20heat%20destroy%20transis
|
||||
[3]: http://www.lockheedmartin.com/us/news/press-releases/2016/march/160308-mst-cool-technology-turns-down-the-heat-on-high-tech-equipment.html
|
||||
[4]: http://www.techrepublic.com/article/silicon-photonics-will-revolutionize-data-centers-in-2015/
|
||||
[5]: http://www.techrepublic.com/article/silicon-photonics-will-revolutionize-data-centers-in-2015/
|
||||
[6]: https://www.fbo.gov/index?s=opportunity&mode=form&id=0be99f61fbac0501828a9d3160883b97&tab=core&_cview=1
|
||||
[7]: https://www.fbo.gov/index?s=opportunity&mode=form&id=0be99f61fbac0501828a9d3160883b97&tab=core&_cview=1
|
||||
[8]: https://www.fbo.gov/index?s=opportunity&mode=form&id=0be99f61fbac0501828a9d3160883b97&tab=core&_cview=1
|
||||
[9]: http://electronicdesign.com/communications/what-s-difference-between-gaas-and-gan-rf-power-amplifiers
|
||||
[10]: http://www.csmantech.org/Digests/2013/papers/050.pdf
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,232 @@
|
||||
Setting Up Real-Time Monitoring with ‘Ganglia’ for Grids and Clusters of Linux Servers
|
||||
===========
|
||||
|
||||
|
||||
Ever since system administrators have been in charge of managing servers and groups of machines, tools like monitoring applications have been their best friends. You will probably be familiar with tools like [Nagios][11], [Zabbix][10], [Icinga][9], and Centreon. While those are the heavyweights of monitoring, setting them up and fully taking advantage of their features may be somewhat difficult for new users.
|
||||
|
||||
In this article we will introduce you to Ganglia, a monitoring system that is easily scalable and allows to view a wide variety of system metrics of Linux servers and clusters (plus graphs) in real time.
|
||||
|
||||
[][8]
|
||||
|
||||
Install Gangila Monitoring in Linux
|
||||
|
||||
Ganglia lets you set up grids (locations) and clusters (groups of servers) for better organization.
|
||||
|
||||
Thus, you can create a grid composed of all the machines in a remote environment, and then group those machines into smaller sets based on other criteria.
|
||||
|
||||
In addition, Ganglia’s web interface is optimized for mobile devices, and also allows you to export data en `.csv`and `.json` formats.
|
||||
|
||||
Our test environment will consist of a central CentOS 7 server (IP address 192.168.0.29) where we will install Ganglia, and an Ubuntu 14.04 machine (192.168.0.32), the box that we want to monitor through Ganglia’s web interface.
|
||||
|
||||
Throughout this guide we will refer to the CentOS 7 system as the master node, and to the Ubuntu box as the monitored machine.
|
||||
|
||||
### Installing and Configuring Ganglia
|
||||
|
||||
To install the monitoring utilities in the the master node, follow these steps:
|
||||
|
||||
#### 1. Enable the [EPEL repository][7] and then install Ganglia and related utilities from there:
|
||||
```
|
||||
# yum update && yum install epel-release
|
||||
# yum install ganglia rrdtool ganglia-gmetad ganglia-gmond ganglia-web
|
||||
```
|
||||
|
||||
The packages installed in the step above along with ganglia, the application itself, perform the following functions:
|
||||
|
||||
1. `rrdtool`, the Round-Robin Database, is a tool that’s used to store and display the variation of data over time using graphs.
|
||||
2. `ganglia-gmetad` is the daemon that collects monitoring data from the hosts that you want to monitor. In those hosts and in the master node it is also necessary to install ganglia-gmond (the monitoring daemon itself):
|
||||
3. `ganglia-web` provides the web frontend where we will view the historical graphs and data about the monitored systems.
|
||||
|
||||
#### 2. Set up authentication for the Ganglia web interface (/usr/share/ganglia). We will use basic authentication as provided by Apache.
|
||||
|
||||
If you want to explore more advanced security mechanisms, refer to the [Authorization and Authentication][6]section of the Apache docs.
|
||||
|
||||
To accomplish this goal, create a username and assign a password to access a resource protected by Apache. In this example, we will create a username called `adminganglia` and assign a password of our choosing, which will be stored in /etc/httpd/auth.basic (feel free to choose another directory and / or file name – as long as Apache has read permissions on those resources, you will be fine):
|
||||
|
||||
```
|
||||
# htpasswd -c /etc/httpd/auth.basic adminganglia
|
||||
|
||||
```
|
||||
|
||||
Enter the password for adminganglia twice before proceeding.
|
||||
|
||||
#### 3. Modify /etc/httpd/conf.d/ganglia.conf as follows:
|
||||
|
||||
```
|
||||
Alias /ganglia /usr/share/ganglia
|
||||
<Location /ganglia>
|
||||
AuthType basic
|
||||
AuthName "Ganglia web UI"
|
||||
AuthBasicProvider file
|
||||
AuthUserFile "/etc/httpd/auth.basic"
|
||||
Require user adminganglia
|
||||
</Location>
|
||||
|
||||
```
|
||||
|
||||
#### 4. Edit /etc/ganglia/gmetad.conf:
|
||||
|
||||
First, use the gridname directive followed by a descriptive name for the grid you’re setting up:
|
||||
|
||||
```
|
||||
gridname "Home office"
|
||||
|
||||
```
|
||||
|
||||
Then, use data_source followed by a descriptive name for the cluster (group of servers), a polling interval in seconds and the IP address of the master and monitored nodes:
|
||||
|
||||
```
|
||||
data_source "Labs" 60 192.168.0.29:8649 # Master node
|
||||
data_source "Labs" 60 192.168.0.32 # Monitored node
|
||||
|
||||
```
|
||||
|
||||
#### 5. Edit /etc/ganglia/gmond.conf.
|
||||
|
||||
a) Make sure the cluster block looks as follows:
|
||||
|
||||
```
|
||||
cluster {
|
||||
name = "Labs" # The name in the data_source directive in gmetad.conf
|
||||
owner = "unspecified"
|
||||
latlong = "unspecified"
|
||||
url = "unspecified"
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
b) In the udp_send_chanel block, comment out the mcast_join directive:
|
||||
|
||||
```
|
||||
udp_send_channel {
|
||||
#mcast_join = 239.2.11.71
|
||||
host = localhost
|
||||
port = 8649
|
||||
ttl = 1
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
c) Finally, comment out the mcast_join and bind directives in the udp_recv_channel block:
|
||||
|
||||
```
|
||||
udp_recv_channel {
|
||||
#mcast_join = 239.2.11.71 ## comment out
|
||||
port = 8649
|
||||
#bind = 239.2.11.71 ## comment out
|
||||
}
|
||||
```
|
||||
|
||||
Save the changes and exit.
|
||||
|
||||
#### 6. Open port 8649/udp and allow PHP scripts (run via Apache) to connect to the network using the necessary SELinux boolean:
|
||||
|
||||
```
|
||||
# firewall-cmd --add-port=8649/udp
|
||||
# firewall-cmd --add-port=8649/udp --permanent
|
||||
# setsebool -P httpd_can_network_connect 1
|
||||
|
||||
```
|
||||
|
||||
#### 7. Restart Apache, gmetad, and gmond. Also, make sure they are enabled to start on boot:
|
||||
|
||||
```
|
||||
# systemctl restart httpd gmetad gmond
|
||||
# systemctl enable httpd gmetad httpd
|
||||
|
||||
```
|
||||
|
||||
At this point, you should be able to open the Ganglia web interface at `http://192.168.0.29/ganglia` and login with the credentials from #Step 2.
|
||||
|
||||
[][5]
|
||||
|
||||
Gangila Web Interface
|
||||
|
||||
#### 8. In the Ubuntu host, we will only install ganglia-monitor, the equivalent of ganglia-gmond in CentOS:
|
||||
|
||||
```
|
||||
$ sudo aptitude update && aptitude install ganglia-monitor
|
||||
|
||||
```
|
||||
|
||||
#### 9. Edit the /etc/ganglia/gmond.conf file in the monitored box. This should be identical to the same file in the master node except that the commented out lines in the cluster, udp_send_channel, and udp_recv_channelshould be enabled:
|
||||
|
||||
```
|
||||
cluster {
|
||||
name = "Labs" # The name in the data_source directive in gmetad.conf
|
||||
owner = "unspecified"
|
||||
latlong = "unspecified"
|
||||
url = "unspecified"
|
||||
}
|
||||
udp_send_channel {
|
||||
mcast_join = 239.2.11.71
|
||||
host = localhost
|
||||
port = 8649
|
||||
ttl = 1
|
||||
}
|
||||
udp_recv_channel {
|
||||
mcast_join = 239.2.11.71 ## comment out
|
||||
port = 8649
|
||||
bind = 239.2.11.71 ## comment out
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Then, restart the service:
|
||||
|
||||
```
|
||||
$ sudo service ganglia-monitor restart
|
||||
|
||||
```
|
||||
|
||||
#### 10. Refresh the web interface and you should be able to view the statistics and graphs for both hosts inside the Home office grid / Labs cluster (use the dropdown menu next to to Home office grid to choose a cluster, Labsin our case):
|
||||
|
||||
[][4]
|
||||
|
||||
Ganglia Home Office Grid Report
|
||||
|
||||
Using the menu tabs (highlighted above) you can access lots of interesting information about each server individually and in groups. You can even compare the stats of all the servers in a cluster side by side using the Compare Hosts tab.
|
||||
|
||||
Simply choose a group of servers using a regular expression and you will be able to see a quick comparison of how they are performing:
|
||||
|
||||
[][3]
|
||||
|
||||
Ganglia Host Server Information
|
||||
|
||||
One of the features I personally find most appealing is the mobile-friendly summary, which you can access using the Mobile tab. Choose the cluster you’re interested in and then the individual host:
|
||||
|
||||
[][2]
|
||||
|
||||
Ganglia Mobile Friendly Summary View
|
||||
|
||||
### Summary
|
||||
|
||||
In this article we have introduced Ganglia, a powerful and scalable monitoring solution for grids and clusters of servers. Feel free to install, explore, and play around with Ganglia as much as you like (by the way, you can even try out Ganglia in a demo provided in the project’s [official website][1].
|
||||
|
||||
While you’re at it, you will also discover that several well-known companies both in the IT world or not use Ganglia. There are plenty of good reasons for that besides the ones we have shared in this article, with easiness of use and graphs along with stats (it’s nice to put a face to the name, isn’t it?) probably being at the top.
|
||||
|
||||
But don’t just take our word for it, try it out yourself and don’t hesitate to drop us a line using the comment form below if you have any questions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-configure-ganglia-monitoring-centos-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://ganglia.info/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/06/Ganglia-Mobile-View.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/06/Ganglia-Server-Information.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/06/Ganglia-Home-Office-Grid-Report.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/06/Gangila-Web-Interface.png
|
||||
[6]:http://httpd.apache.org/docs/current/howto/auth.html
|
||||
[7]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/06/Install-Gangila-Monitoring-in-Linux.png
|
||||
[9]:http://www.tecmint.com/install-icinga-in-centos-7/
|
||||
[10]:http://www.tecmint.com/install-and-configure-zabbix-monitoring-on-debian-centos-rhel/
|
||||
[11]:http://www.tecmint.com/install-nagios-in-linux/
|
||||
@ -1,139 +0,0 @@
|
||||
translated by pspkforever
|
||||
DOCKER DATACENTER IN AWS AND AZURE IN A FEW CLICKS
|
||||
===================================================
|
||||
|
||||
Introducing Docker Datacenter AWS Quickstart and Azure Marketplace Templates production-ready, high availability deployments in just a few clicks.
|
||||
|
||||
The Docker Datacenter AWS Quickstart uses a CloudFormation templates and pre-built templates on Azure Marketplace to make it easier than ever to deploy an enterprise CaaS Docker environment on public cloud infrastructures.
|
||||
|
||||
The Docker Datacenter Container as a Service (CaaS) platform for agile application development provides container and cluster orchestration and management that is simple, secure and scalable for enterprises of any size. With our new cloud templates pre-built for Docker Datacenter, developers and IT operations can frictionlessly move dockerized applications to an Amazon EC2 or Microsoft Azure environment without any code changes. Now businesses can quickly realize greater efficiency of computing and operations resources and Docker supported container management and orchestration in just a few steps.
|
||||
|
||||
### What is Docker Datacenter?
|
||||
|
||||
Docker Datacenter includes Docker Universal Control Plane, Docker Trusted Registry (DTR), CS Docker Engine with commercial support & subscription to align to your application SLAs:
|
||||
|
||||
- Docker Universal Control Plane (UCP), an enterprise-grade cluster management solution that helps you manage your whole cluster from a single pane of glass
|
||||
- Docker Trusted Registry (DTR), an image storage solution that helps securely store and manage the Docker images.
|
||||
- Commercially Supported (CS) Docker Engines
|
||||
|
||||
|
||||
|
||||
### Deploy on AWS in a single click with the Docker Datacenter AWS Quick Start
|
||||
|
||||
With AWS Quick Start reference deployments you can rapidly deploy Docker containers on the AWS cloud, adhering to Docker and AWS best practices. The Docker Datacenter Quick Start uses CloudFormation templates that are modular and customizable so you can layer additional functionality on top or modify them for your own Docker deployments.
|
||||
|
||||
[Docker Datacenter for AWS Quickstart](https://youtu.be/aUx7ZdFSkXU)
|
||||
|
||||
#### Architecture
|
||||
|
||||
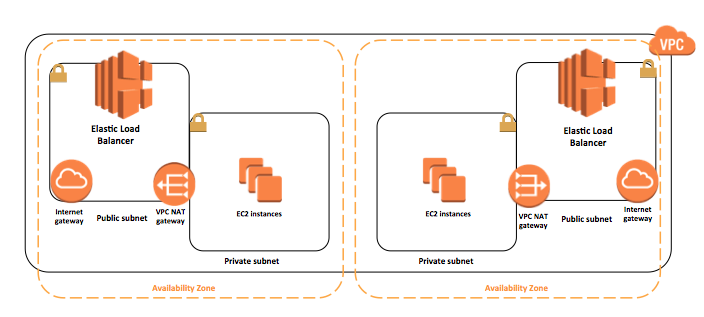
|
||||
|
||||
The AWS Cloudformation starts the installation process by creating all the required AWS resources such as the VPC, security groups, public and private subnets, internet gateways, NAT gateways, and S3 bucket.
|
||||
|
||||
It then launches the first UCP controller instances and goes through the installation process of Docker engine and UCP containers. It backs the Root CAs created by the first UCP controllers to S3. Once the first UCP controller is up and running, the process of creating the other UCP controllers, the UCP cluster nodes, and the first DTR replica is triggered. Similar to the first UCP controller node, all other nodes are started by installing Docker Commercially Supported engine, followed by running the UCP and DTR containers to join the cluster. Two ELBs, one for UCP and one for DTR, are launched and automatically configured to provide resilient load balancing across the two AZs.
|
||||
|
||||
Additionally, UCP controllers and nodes are launched in an ASG to provide scaling functionality if needed. This architecture ensures that both UCP and DTR instances are spread across both AZs to ensure resiliency and high-availability. Route53 is used to dynamically register and configure UCP and DTR in your private or public HostedZone.
|
||||
|
||||
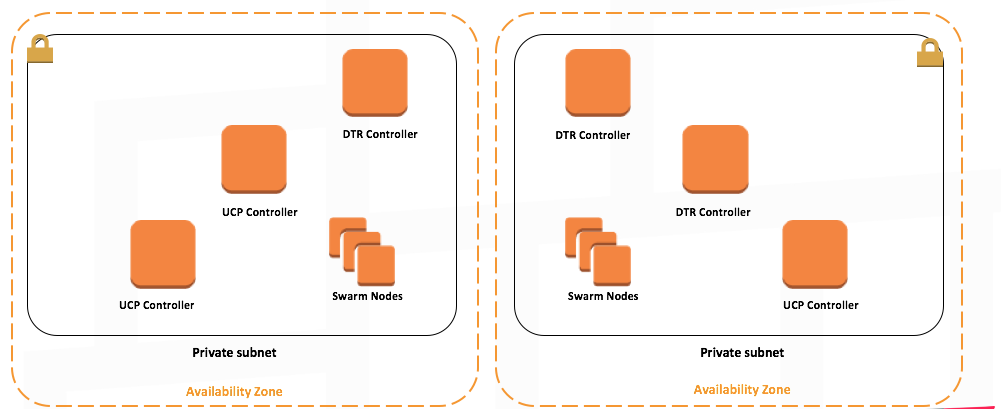
|
||||
|
||||
### Key functionality of this Quickstart templates includes the following:
|
||||
|
||||
- Creates a New VPC, Private and Public Subnets in different AZs, ELBs, NAT Gateways, Internet Gateways, AutoScaling Groups- all based on AWS best practices
|
||||
- Creates an S3 bucket for DDC to be used for cert backup and DTR image storage ( requires additional configuration in DTR )
|
||||
- Deploys 3 UCP Controllers across multiple AZs within your VPC
|
||||
- Creates a UCP ELB with preconfigured health checks
|
||||
- Creates a DNS record and attaches it to UCP ELB
|
||||
- Deploys a scalable cluster of UCP nodes
|
||||
- Backs up UCP Root CAs to S3
|
||||
- Create a 3 DTR Replicas across multiple AZs within your VPC
|
||||
- Creates a DTR with preconfigured health checks
|
||||
- Creates a DNS record and attaches it to DTR ELB
|
||||
|
||||
[Download the AWS Quick Start Guide to Learn More](https://s3.amazonaws.com/quickstart-reference/docker/latest/doc/docker-datacenter-on-the-aws-cloud.pdf)
|
||||
|
||||
### Getting Started with Docker Datacenter for AWS
|
||||
|
||||
1. Go to [Docker Store][1] to get your [30 day free trial][2] or [contact sales][4].
|
||||
2. At confirmation, you’ll be prompted to “Launch Stack” and you’ll be directed to the AWS Cloudformation portal.
|
||||
3. Confirm your AWS Region that you’d like to launch this stack in
|
||||
4. Provide the required parameters
|
||||
5. Confirm and Launch.
|
||||
6. Once complete, click on outputs tab to see the URLs of UCP/DTR, default username, and password, and S3 bucket name.
|
||||
|
||||
[Request up to $2000 AWS credit for Docker Datacenter](https://aws.amazon.com/mp/contactdocker/)
|
||||
|
||||
### Deploy on Azure with pre-built templates on Azure Marketplace
|
||||
|
||||
Docker Datacenter is available as pre-built template on Azure Marketplace for you to run instantly on Azure across various datacenters globally. Customers can choose to deploy Docker Datacenter from various VM choices offered on Azure as it fits their needs.
|
||||
|
||||
#### Architecture
|
||||
|
||||
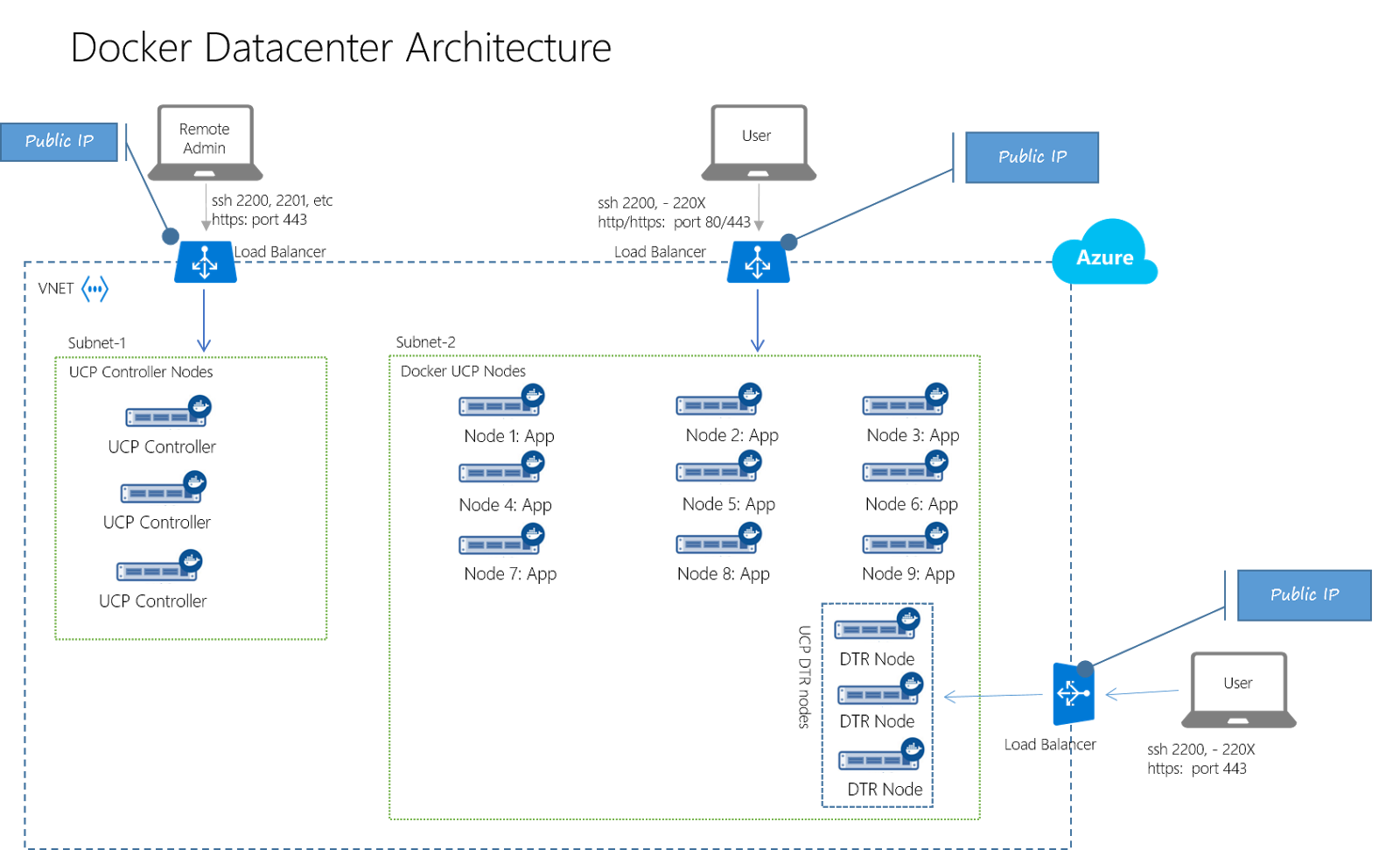
|
||||
|
||||
The Azure deployment process begins by entering some basic information about the user including, the admin username for ssh-ing into all the nodes (OS level admin user) and the name of the resource group. You can think of the resource group as a collection of resources that has a lifecycle and deployment boundary. You can read more about resource groups here: <azure.microsoft.com/en-us/documentation/articles/resource-group-overview/>
|
||||
|
||||
Next you will enter the details of the cluster, including: VM size for UCP controllers, Number of Controllers (default is 3), VM size for UCP nodes, Number of UCP nodes (default is 1, max of 10), VM size for DTR nodes, Number of DTR nodes (default is 3), Virtual Network Name and Address (ex. 10.0.0.1/19). Regarding networking, you will have 2 subnets: the first subnet is for the UCP controller nodes and the second subnet is for the DTR and UCP nodes.
|
||||
|
||||
Lastly you will click OK to complete deployment. Provisioning should take about 15-19 minutes for small clusters with a few additional minutes for larger ones.
|
||||
|
||||
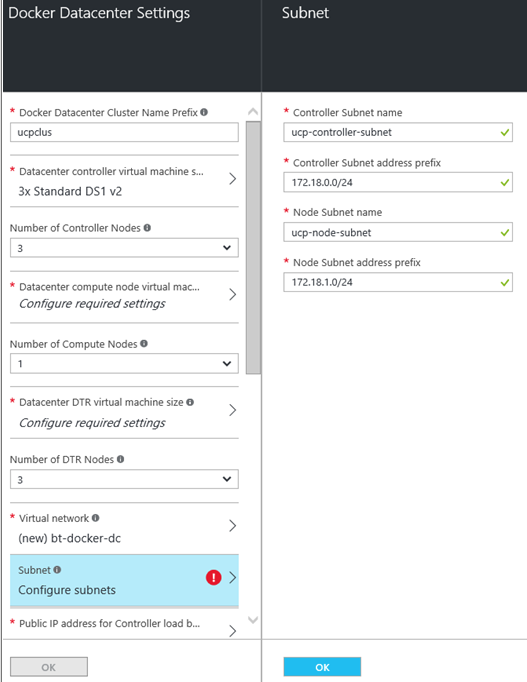
|
||||
|
||||
|
||||
|
||||
#### How to Deploy in Azure
|
||||
|
||||
1. Register for [a 30 day free trial][5] license of Docker Datacenter or [contact sales][6].
|
||||
2. [Go to Docker Datacenter on the Microsoft Azure Marketplace][7]
|
||||
3. [Review Deployment Documents][8]
|
||||
|
||||
Get Started by registering for a Docker Datacenter license and you’ll be prompted with the ability to launch either the AWS or Azure templates.
|
||||
|
||||
- [Get a 30 day trial license][9]
|
||||
- [Understand Docker Datacenter architecture with this video][10]
|
||||
- [Watch demo videos][11]
|
||||
- [Get $75 AWS credit torwards your deployment][12]
|
||||
|
||||
### Learn More about Docker
|
||||
|
||||
- New to Docker? Try our 10 min [online tutorial][20]
|
||||
- Share images, automate builds, and more with [a free Docker Hub account][21]
|
||||
- Read the Docker [1.12 Release Notes][22]
|
||||
- Subscribe to [Docker Weekly][23]
|
||||
- Sign up for upcoming [Docker Online Meetups][24]
|
||||
- Attend upcoming [Docker Meetups][25]
|
||||
- Watch [DockerCon EU 2015 videos][26]
|
||||
- Start [contributing to Docker][27]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2016/06/docker-datacenter-aws-azure-cloud/
|
||||
|
||||
作者:[Trisha McCanna][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.docker.com/author/trisha/
|
||||
[1]: https://store.docker.com/login?next=%2Fbundles%2Fdocker-datacenter%2Fpurchase?plan=free-trial
|
||||
[2]: https://store.docker.com/login?next=%2Fbundles%2Fdocker-datacenter%2Fpurchase?plan=free-trial
|
||||
[4]: https://goto.docker.com/contact-us.html
|
||||
[5]: https://store.docker.com/login?next=%2Fbundles%2Fdocker-datacenter%2Fpurchase?plan=free-trial
|
||||
[6]: https://goto.docker.com/contact-us.html
|
||||
[7]: https://azure.microsoft.com/en-us/marketplace/partners/docker/dockerdatacenterdocker-datacenter/
|
||||
[8]: https://success.docker.com/Datacenter/Apply/Docker_Datacenter_on_Azure
|
||||
[9]: http://www.docker.com/trial
|
||||
[10]: https://www.youtube.com/playlist?list=PLkA60AVN3hh8tFH7xzI5Y-vP48wUiuXfH
|
||||
[11]: https://www.youtube.com/playlist?list=PLkA60AVN3hh8a8JaIOA5Q757KiqEjPKWr
|
||||
[12]: https://aws.amazon.com/quickstart/promo/
|
||||
[20]: https://docs.docker.com/engine/understanding-docker/
|
||||
[21]: https://hub.docker.com/
|
||||
[22]: https://docs.docker.com/release-notes/
|
||||
[23]: https://www.docker.com/subscribe_newsletter/
|
||||
[24]: http://www.meetup.com/Docker-Online-Meetup/
|
||||
[25]: https://www.docker.com/community/meetup-groups
|
||||
[26]: https://www.youtube.com/playlist?list=PLkA60AVN3hh87OoVra6MHf2L4UR9xwJkv
|
||||
[27]: https://docs.docker.com/contributing/contributing/
|
||||
|
||||
@ -1,139 +0,0 @@
|
||||
translating by theArcticOcean.
|
||||
|
||||
Part III - How to apply Advanced Mathematical Processing Effects on Audio files with Octave 4.0 on Ubuntu
|
||||
=====
|
||||
|
||||
The third part of our Digital Audio processing tutorial series covers the signal Modulation, we explain how to apply Amplitude Modulation, Tremolo Effect, and Frequency Variation.
|
||||
|
||||
### Modulation
|
||||
|
||||
#### Amplitude Modulation
|
||||
|
||||
As its name implies, this effect varies the amplitude of a sinusoid according to the message to be transmitted. A sine wave is called a carrier because it carries the information. This type of modulation is used in some commercial broadcasting and transmission citizen bands (AM).
|
||||
|
||||
#### Why use the Amplitude Modulation?
|
||||
|
||||
**Modulation Radiation.**
|
||||
|
||||
If the communication channel is a free space, then antennas are required to radiate and receive the signal. It requires an efficient electromagnetic radiation antenna whose dimensions are of the same order of magnitude as the wavelength of the signal being radiated. Many signals, including audio components, have often 100 Hz or less. For these signals, it would be necessary to build antennas about 300 km in length if the signal were to be radiated directly. If signal modulation is used to print the message on a high-frequency carrier, let's say 100 MHz, then the antenna needs to have a length of over a meter (transverse length) only.
|
||||
|
||||
**Concentration modulation or multi-channeling.**
|
||||
|
||||
If more than one signal uses a single channel, modulation can be used for transferring different signals to different spectral positions allowing the receiver to select the desired signal. Applications that use concentration ("multiplexing") include telemetry data, stereo FM radio and long-distance telephony.
|
||||
|
||||
**Modulation to Overcome Limitations on equipment.**
|
||||
|
||||
The performance of signal processing devices such as filters and amplifiers, and the ease with which these devices can be constructed, depends on the situation of the signal in the frequency domain and the relationship between the higher frequency and low signal. Modulation can be used to transfer the signal to a position in the frequency domain where design requirements are met easier. The modulation can also be used to convert a "broadband signal" (a signal for which the ratio between the highest and lowest frequency is large) into a sign of "narrow band".
|
||||
|
||||
**Audio Effects**
|
||||
|
||||
Many audio effects use amplitude modulation due to the striking and ease with which it can handle such signals. We can name a few such as tremolo, chorus, flanger, etc. This utility is where we focus in this tutorial series.
|
||||
|
||||
### Tremolo effect
|
||||
|
||||
The tremolo effect is one of the simplest applications of amplitude modulation, to achieve this effect, we have to vary (multiply) the audio signal by a periodic signal, either sinusoidal or otherwise.
|
||||
|
||||
```
|
||||
>> tremolo='tremolo.ogg';
|
||||
>> fs=44100;
|
||||
>> t=0:1/fs:10;
|
||||
>> wo=2*pi*440*t;
|
||||
>> wa=2*pi*1.2*t;
|
||||
>> audiowrite(tremolo, cos(wa).*cos(wo),fs);
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremolo.png)
|
||||
|
||||
This will generate a sinusoid-shaped signal which effect is like a 'tremolo'.
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremoloshape.png)
|
||||
|
||||
### Tremolo on real Audio Files
|
||||
|
||||
Now we will show the tremolo effect in the real world, First, we use a file previously recorded by a male voice saying 'A'. The plot for this signal is the following:
|
||||
|
||||
```
|
||||
>> [y,fs]=audioread('A.ogg');
|
||||
>> plot(y);
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/avocalmale.png)
|
||||
|
||||
Now we have to create an enveloping sinusoidal signal with the following parameters:
|
||||
|
||||
```
|
||||
Amplitude = 1
|
||||
Frequency= 1.5Hz
|
||||
Phase = 0
|
||||
```
|
||||
|
||||
```
|
||||
>> t=0:1/fs:4.99999999;
|
||||
>> t=t(:);
|
||||
>> w=2*pi*1.5*t;
|
||||
>> q=cos(w);
|
||||
>> plot(q);
|
||||
```
|
||||
|
||||
Note: when we create an array of values of the time, by default, this is created in the form of columns, ie, 1x220500 values. To multiply this set of values must transpose it in rows (220500x1). This is the t=t(:) command
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/sinusoidal.png)
|
||||
|
||||
We will create a second ogg file which contains the resulting modulated signal:
|
||||
|
||||
```
|
||||
>> tremolo='tremolo.ogg';
|
||||
>> audiowrite(tremolo, q.*y,fs);
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremsignal1.png)[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremolsignal1.png)
|
||||
|
||||
### Frequency Variation
|
||||
|
||||
We can vary the frequency to obtain quite interesting musical effects such as distortion, sound effects for movies and games among others.
|
||||
|
||||
#### Effect of sinusoidal frequency modulation
|
||||
|
||||
This is the code where the sinusoidal modulation frequency is shown, according to equation:
|
||||
|
||||
```
|
||||
Y=Ac*Cos(wo*Cos(wo/k))
|
||||
```
|
||||
|
||||
Where:
|
||||
|
||||
```
|
||||
Ac = Amplitude
|
||||
|
||||
wo = fundamental frequency
|
||||
|
||||
k = scalar divisor
|
||||
```
|
||||
|
||||
```
|
||||
>> fm='fm.ogg';
|
||||
>> fs=44100;
|
||||
>> t=0:1/fs:10;
|
||||
>> w=2*pi*442*t;
|
||||
>> audiowrite(fm, cos(cos(w/1500).*w), fs);
|
||||
>> [y,fs]=audioread('fm.ogg');
|
||||
>> figure (); plot (y);
|
||||
```
|
||||
|
||||
The plot of the signal is:
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/fmod.png)
|
||||
|
||||
You can use almost any type of periodic function as the frequency modulator. For this example, we only used a sine function here. Please feel free to experiment with changing the frequencies of the functions, mixing with other functions or change, even, the type of function.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/ubuntu-octave-audio-processing-part-3/
|
||||
|
||||
作者:[David Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/ubuntu-octave-audio-processing-part-3/
|
||||
@ -1,6 +1,3 @@
|
||||
vim-kakali translating
|
||||
|
||||
|
||||
TOP 5 BEST VIDEO EDITING SOFTWARE FOR LINUX IN 2016
|
||||
=====================================================
|
||||
|
||||
|
||||
@ -1,43 +0,0 @@
|
||||
(翻译中 by runningwater)
|
||||
CANONICAL CONSIDERING TO DROP 32 BIT SUPPORT IN UBUNTU
|
||||
========================================================
|
||||
|
||||

|
||||
|
||||
Yesterday, developer [Dimitri John Ledkov][1] wrote a message on the [Ubuntu Mailing list][2] calling for the end of i386 support by Ubuntu 18.10. Ledkov argues that more software is being developed with 64-bit support. He is also concerned that it will be difficult to provide security support for the aging i386 architecture.
|
||||
|
||||
Ledkov also argues that building i386 images is not free, but takes quite a bit of Canonical’s resources.
|
||||
|
||||
>Building i386 images is not “for free”, it comes at the cost of utilizing our build farm, QA and validation time. Whilst we have scalable build-farms, i386 still requires all packages, autopackage tests, and ISOs to be revalidated across our infrastructure. As well as take up mirror space & bandwidth.
|
||||
|
||||
Ledkov offers a plan where the 16.10, 17.04, and 17.10 versions of Ubuntu will continue to have i386 kernels, netboot installers, and cloud images, but drop i386 ISO for desktop and server. The 18.04 LTS would then drop support for i386 kernels, netboot installers, and cloud images, but still provide the ability for i386 programs to run on 64-bit architecture. Then, 18.10 would end the i386 port and limit legacy 32-bit applications to snaps, containers, and virtual machines.
|
||||
|
||||
Ledkov’s plan had not been accepted yet, but it shows a definite push toward eliminating 32-bit support.
|
||||
|
||||
### GOOD NEWS
|
||||
|
||||
Don’t despair yet. this will not affect the distros used to resurrect your old system. [Martin Wimpress][3], the creator of [Ubuntu MATE][4], revealed during a discussion on Googl+ that these changes will only affect mainline Ubuntu.
|
||||
|
||||
>The i386 archive will continue to exist into 18.04 and flavours can continue to elect to build i386 isos. There is however a security concern, in that some larger applications (Firefox, Chromium, LibreOffice) are already presenting challenges in terms of applying some security patches to older LTS releases. So flavours are being asked to be mindful of the support period they can reasonably be expected to support i386 versions for.
|
||||
|
||||
### THOUGHTS
|
||||
|
||||
I understand why they need to make this move from a security standpoint, but it’s going to make people move away from mainline Ubuntu to either one of the flavors or a different architecture. Thankfully, we have alternative [lightweight Linux distributions][5].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-32-bit-support-drop/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[John Paul][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]: https://plus.google.com/+DimitriJohnLedkov
|
||||
[2]: https://lists.ubuntu.com/archives/ubuntu-devel-discuss/2016-June/016661.html
|
||||
[3]: https://twitter.com/m_wimpress
|
||||
[4]: http://ubuntu-mate.org/
|
||||
[5]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
@ -1,850 +0,0 @@
|
||||
Translating by wikiios
|
||||
Building a data science portfolio: Machine learning project
|
||||
构建一个数据科学投资:机器学习项目
|
||||
===========================================================
|
||||
|
||||
>This is the third in a series of posts on how to build a Data Science Portfolio. If you like this and want to know when the next post in the series is released, you can [subscribe at the bottom of the page][1].
|
||||
>这是如何构建一个数据科学投资系列文章的第三弹。如果你喜欢本文并且想知道本系列下一篇文章发布的时间,你可以订阅本文底[邮箱][1]。
|
||||
|
||||
Data science companies are increasingly looking at portfolios when making hiring decisions. One of the reasons for this is that a portfolio is the best way to judge someone’s real-world skills. The good news for you is that a portfolio is entirely within your control. If you put some work in, you can make a great portfolio that companies are impressed by.
|
||||
数据科学公司越来越多地研究投资并同时作出雇佣决定。原因之一就是一个投资是评判某人真实能力最好的方式。对你来说好消息是一个投资是完全在你掌控之中。如果你花些心思在其中,你就可以做出一个令公司印象深刻的投资。
|
||||
|
||||
The first step in making a high-quality portfolio is to know what skills to demonstrate. The primary skills that companies want in data scientists, and thus the primary skills they want a portfolio to demonstrate, are:
|
||||
做出高质量投资的第一步是了解应该展示哪些技能,
|
||||
|
||||
- Ability to communicate
|
||||
- Ability to collaborate with others
|
||||
- Technical competence
|
||||
- Ability to reason about data
|
||||
- Motivation and ability to take initiative
|
||||
|
||||
Any good portfolio will be composed of multiple projects, each of which may demonstrate 1-2 of the above points. This is the third post in a series that will cover how to make a well-rounded data science portfolio. In this post, we’ll cover how to make the second project in your portfolio, and how to build an end to end machine learning project. At the end, you’ll have a project that shows your ability to reason about data, and your technical competence. [Here’s][2] the completed project if you want to take a look.
|
||||
|
||||
### An end to end project
|
||||
|
||||
As a data scientist, there are times when you’ll be asked to take a dataset and figure out how to [tell a story with it][3]. In times like this, it’s important to communicate very well, and walk through your process. Tools like Jupyter notebook, which we used in a previous post, are very good at helping you do this. The expectation here is that the deliverable is a presentation or document summarizing your findings.
|
||||
|
||||
However, there are other times when you’ll be asked to create a project that has operational value. A project with operational value directly impacts the day-to-day operations of a company, and will be used more than once, and often by multiple people. A task like this might be “create an algorithm to forecast our churn rate”, or “create a model that can automatically tag our articles”. In cases like this, storytelling is less important than technical competence. You need to be able to take a dataset, understand it, then create a set of scripts that can process that data. It’s often important that these scripts run quickly, and use minimal system resources like memory. It’s very common that these scripts will be run several times, so the deliverable becomes the scripts themselves, not a presentation. The deliverable is often integrated into operational flows, and may even be user-facing.
|
||||
|
||||
The main components of building an end to end project are:
|
||||
|
||||
- Understanding the context
|
||||
- Exploring the data and figuring out the nuances
|
||||
- Creating a well-structured project, so its easy to integrate into operational flows
|
||||
- Writing high-performance code that runs quickly and uses minimal system resources
|
||||
- Documenting the installation and usage of your code well, so others can use it
|
||||
|
||||
In order to effectively create a project of this kind, we’ll need to work with multiple files. Using a text editor like [Atom][4], or an IDE like [PyCharm][5] is highly recommended. These tools will allow you to jump between files, and edit files of different types, like markdown files, Python files, and csv files. Structuring your project so it’s easy to version control and upload to collaborative coding tools like [Github][6] is also useful.
|
||||
|
||||

|
||||
>This project on Github.
|
||||
|
||||
We’ll use our editing tools along with libraries like [Pandas][7] and [scikit-learn][8] in this post. We’ll make extensive use of Pandas [DataFrames][9], which make it easy to read in and work with tabular data in Python.
|
||||
|
||||
### Finding good datasets
|
||||
|
||||
A good dataset for an end to end portfolio project can be hard to find. [The dataset][10] needs to be sufficiently large that memory and performance constraints come into play. It also needs to potentially be operationally useful. For instance, this dataset, which contains data on the admission criteria, graduation rates, and graduate future earnings for US colleges would be a great dataset to use to tell a story. However, as you think about the dataset, it becomes clear that there isn’t enough nuance to build a good end to end project with it. For example, you could tell someone their potential future earnings if they went to a specific college, but that would be a quick lookup without enough nuance to demonstrate technical competence. You could also figure out if colleges with higher admissions standards tend to have graduates who earn more, but that would be more storytelling than operational.
|
||||
|
||||
These memory and performance constraints tend to come into play when you have more than a gigabyte of data, and when you have some nuance to what you want to predict, which involves running algorithms over the dataset.
|
||||
|
||||
A good operational dataset enables you to build a set of scripts that transform the data, and answer dynamic questions. A good example would be a dataset of stock prices. You would be able to predict the prices for the next day, and keep feeding new data to the algorithm as the markets closed. This would enable you to make trades, and potentially even profit. This wouldn’t be telling a story – it would be adding direct value.
|
||||
|
||||
Some good places to find datasets like this are:
|
||||
|
||||
- [/r/datasets][11] – a subreddit that has hundreds of interesting datasets.
|
||||
- [Google Public Datasets][12] – public datasets available through Google BigQuery.
|
||||
- [Awesome datasets][13] – a list of datasets, hosted on Github.
|
||||
|
||||
As you look through these datasets, think about what questions someone might want answered with the dataset, and think if those questions are one-time (“how did housing prices correlate with the S&P 500?”), or ongoing (“can you predict the stock market?”). The key here is to find questions that are ongoing, and require the same code to be run multiple times with different inputs (different data).
|
||||
|
||||
For the purposes of this post, we’ll look at [Fannie Mae Loan Data][14]. Fannie Mae is a government sponsored enterprise in the US that buys mortgage loans from other lenders. It then bundles these loans up into mortgage-backed securities and resells them. This enables lenders to make more mortgage loans, and creates more liquidity in the market. This theoretically leads to more homeownership, and better loan terms. From a borrowers perspective, things stay largely the same, though.
|
||||
|
||||
Fannie Mae releases two types of data – data on loans it acquires, and data on how those loans perform over time. In the ideal case, someone borrows money from a lender, then repays the loan until the balance is zero. However, some borrowers miss multiple payments, which can cause foreclosure. Foreclosure is when the house is seized by the bank because mortgage payments cannot be made. Fannie Mae tracks which loans have missed payments on them, and which loans needed to be foreclosed on. This data is published quarterly, and lags the current date by 1 year. As of this writing, the most recent dataset that’s available is from the first quarter of 2015.
|
||||
|
||||
Acquisition data, which is published when the loan is acquired by Fannie Mae, contains information on the borrower, including credit score, and information on their loan and home. Performance data, which is published every quarter after the loan is acquired, contains information on the payments being made by the borrower, and the foreclosure status, if any. A loan that is acquired may have dozens of rows in the performance data. A good way to think of this is that the acquisition data tells you that Fannie Mae now controls the loan, and the performance data contains a series of status updates on the loan. One of the status updates may tell us that the loan was foreclosed on during a certain quarter.
|
||||
|
||||

|
||||
>A foreclosed home being sold.
|
||||
|
||||
### Picking an angle
|
||||
|
||||
There are a few directions we could go in with the Fannie Mae dataset. We could:
|
||||
|
||||
- Try to predict the sale price of a house after it’s foreclosed on.
|
||||
- Predict the payment history of a borrower.
|
||||
- Figure out a score for each loan at acquisition time.
|
||||
|
||||
The important thing is to stick to a single angle. Trying to focus on too many things at once will make it hard to make an effective project. It’s also important to pick an angle that has sufficient nuance. Here are examples of angles without much nuance:
|
||||
|
||||
- Figuring out which banks sold loans to Fannie Mae that were foreclosed on the most.
|
||||
- Figuring out trends in borrower credit scores.
|
||||
- Exploring which types of homes are foreclosed on most often.
|
||||
- Exploring the relationship between loan amounts and foreclosure sale prices
|
||||
|
||||
All of the above angles are interesting, and would be great if we were focused on storytelling, but aren’t great fits for an operational project.
|
||||
|
||||
With the Fannie Mae dataset, we’ll try to predict whether a loan will be foreclosed on in the future by only using information that was available when the loan was acquired. In effect, we’ll create a “score” for any mortgage that will tell us if Fannie Mae should buy it or not. This will give us a nice foundation to build on, and will be a great portfolio piece.
|
||||
|
||||
### Understanding the data
|
||||
|
||||
Let’s take a quick look at the raw data files. Here are the first few rows of the acquisition data from quarter 1 of 2012:
|
||||
|
||||
```
|
||||
100000853384|R|OTHER|4.625|280000|360|02/2012|04/2012|31|31|1|23|801|N|C|SF|1|I|CA|945||FRM|
|
||||
100003735682|R|SUNTRUST MORTGAGE INC.|3.99|466000|360|01/2012|03/2012|80|80|2|30|794|N|P|SF|1|P|MD|208||FRM|788
|
||||
100006367485|C|PHH MORTGAGE CORPORATION|4|229000|360|02/2012|04/2012|67|67|2|36|802|N|R|SF|1|P|CA|959||FRM|794
|
||||
```
|
||||
|
||||
Here are the first few rows of the performance data from quarter 1 of 2012:
|
||||
|
||||
```
|
||||
100000853384|03/01/2012|OTHER|4.625||0|360|359|03/2042|41860|0|N||||||||||||||||
|
||||
100000853384|04/01/2012||4.625||1|359|358|03/2042|41860|0|N||||||||||||||||
|
||||
100000853384|05/01/2012||4.625||2|358|357|03/2042|41860|0|N||||||||||||||||
|
||||
```
|
||||
|
||||
Before proceeding too far into coding, it’s useful to take some time and really understand the data. This is more critical in operational projects – because we aren’t interactively exploring the data, it can be harder to spot certain nuances unless we find them upfront. In this case, the first step is to read the materials on the Fannie Mae site:
|
||||
|
||||
- [Overview][15]
|
||||
- [Glossary of useful terms][16]
|
||||
- [FAQs][17]
|
||||
- [Columns in the Acquisition and Performance files][18]
|
||||
- [Sample Acquisition data file][19]
|
||||
- [Sample Performance data file][20]
|
||||
|
||||
After reading through these files, we know some key facts that will help us:
|
||||
|
||||
- There’s an Acquisition file and a Performance file for each quarter, starting from the year 2000 to present. There’s a 1 year lag in the data, so the most recent data is from 2015 as of this writing.
|
||||
- The files are in text format, with a pipe (|) as a delimiter.
|
||||
- The files don’t have headers, but we have a list of what each column is.
|
||||
- All together, the files contain data on 22 million loans.
|
||||
- Because the Performance files contain information on loans acquired in previous years, there will be more performance data for loans acquired in earlier years (ie loans acquired in 2014 won’t have much performance history).
|
||||
|
||||
These small bits of information will save us a ton of time as we figure out how to structure our project and work with the data.
|
||||
|
||||
### Structuring the project
|
||||
|
||||
Before we start downloading and exploring the data, it’s important to think about how we’ll structure the project. When building an end-to-end project, our primary goals are:
|
||||
|
||||
- Creating a solution that works
|
||||
- Having a solution that runs quickly and uses minimal resources
|
||||
- Enabling others to easily extend our work
|
||||
- Making it easy for others to understand our code
|
||||
- Writing as little code as possible
|
||||
|
||||
In order to achieve these goals, we’ll need to structure our project well. A well structured project follows a few principles:
|
||||
|
||||
- Separates data files and code files.
|
||||
- Separates raw data from generated data.
|
||||
- Has a README.md file that walks people through installing and using the project.
|
||||
- Has a requirements.txt file that contains all the packages needed to run the project.
|
||||
- Has a single settings.py file that contains any settings that are used in other files.
|
||||
- For example, if you are reading the same file from multiple Python scripts, it’s useful to have them all import settings and get the file name from a centralized place.
|
||||
- Has a .gitignore file that prevents large or secret files from being committed.
|
||||
- Breaks each step in our task into a separate file that can be executed separately.
|
||||
- For example, we may have one file for reading in the data, one for creating features, and one for making predictions.
|
||||
- Stores intermediate values. For example, one script may output a file that the next script can read.
|
||||
- This enables us to make changes in our data processing flow without recalculating everything.
|
||||
|
||||
Our file structure will look something like this shortly:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
├── processed
|
||||
├── .gitignore
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### Creating the initial files
|
||||
|
||||
To start with, we’ll need to create a loan-prediction folder. Inside that folder, we’ll need to make a data folder and a processed folder. The first will store our raw data, and the second will store any intermediate calculated values.
|
||||
|
||||
Next, we’ll make a .gitignore file. A .gitignore file will make sure certain files are ignored by git and not pushed to Github. One good example of such a file is the .DS_Store file created by OSX in every folder. A good starting point for a .gitignore file is here. We’ll also want to ignore the data files because they are very large, and the Fannie Mae terms prevent us from redistributing them, so we should add two lines to the end of our file:
|
||||
|
||||
```
|
||||
data
|
||||
processed
|
||||
```
|
||||
|
||||
[Here’s][21] an example .gitignore file for this project.
|
||||
|
||||
Next, we’ll need to create README.md, which will help people understand the project. .md indicates that the file is in markdown format. Markdown enables you write plain text, but also add some fancy formatting if you want. [Here’s][22] a guide on markdown. If you upload a file called README.md to Github, Github will automatically process the markdown, and show it to anyone who views the project. [Here’s][23] an example.
|
||||
|
||||
For now, we just need to put a simple description in README.md:
|
||||
|
||||
```
|
||||
Loan Prediction
|
||||
-----------------------
|
||||
|
||||
Predict whether or not loans acquired by Fannie Mae will go into foreclosure. Fannie Mae acquires loans from other lenders as a way of inducing them to lend more. Fannie Mae releases data on the loans it has acquired and their performance afterwards [here](http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html).
|
||||
```
|
||||
|
||||
Now, we can create a requirements.txt file. This will make it easy for other people to install our project. We don’t know exactly what libraries we’ll be using yet, but here’s a good starting point:
|
||||
|
||||
```
|
||||
pandas
|
||||
matplotlib
|
||||
scikit-learn
|
||||
numpy
|
||||
ipython
|
||||
scipy
|
||||
```
|
||||
|
||||
The above libraries are the most commonly used for data analysis tasks in Python, and its fair to assume that we’ll be using most of them. [Here’s][24] an example requirements file for this project.
|
||||
|
||||
After creating requirements.txt, you should install the packages. For this post, we’ll be using Python 3. If you don’t have Python installed, you should look into using [Anaconda][25], a Python installer that also installs all the packages listed above.
|
||||
|
||||
Finally, we can just make a blank settings.py file, since we don’t have any settings for our project yet.
|
||||
|
||||
### Acquiring the data
|
||||
|
||||
Once we have the skeleton of our project, we can get the raw data.
|
||||
|
||||
Fannie Mae has some restrictions around acquiring the data, so you’ll need to sign up for an account. You can find the download page [here][26]. After creating an account, you’ll be able to download as few or as many loan data files as you want. The files are in zip format, and are reasonably large after decompression.
|
||||
|
||||
For the purposes of this blog post, we’ll download everything from Q1 2012 to Q1 2015, inclusive. We’ll then need to unzip all of the files. After unzipping the files, remove the original .zip files. At the end, the loan-prediction folder should look something like this:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
├── .gitignore
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
After downloading the data, you can use the head and tail shell commands to look at the lines in the files. Do you see any columns that aren’t needed? It might be useful to consult the [pdf of column names][27] while doing this.
|
||||
|
||||
### Reading in the data
|
||||
|
||||
There are two issues that make our data hard to work with right now:
|
||||
|
||||
- The acquisition and performance datasets are segmented across multiple files.
|
||||
- Each file is missing headers.
|
||||
|
||||
Before we can get started on working with the data, we’ll need to get to the point where we have one file for the acquisition data, and one file for the performance data. Each of the files will need to contain only the columns we care about, and have the proper headers. One wrinkle here is that the performance data is quite large, so we should try to trim some of the columns if we can.
|
||||
|
||||
The first step is to add some variables to settings.py, which will contain the paths to our raw data and our processed data. We’ll also add a few other settings that will be useful later on:
|
||||
|
||||
```
|
||||
DATA_DIR = "data"
|
||||
PROCESSED_DIR = "processed"
|
||||
MINIMUM_TRACKING_QUARTERS = 4
|
||||
TARGET = "foreclosure_status"
|
||||
NON_PREDICTORS = [TARGET, "id"]
|
||||
CV_FOLDS = 3
|
||||
```
|
||||
|
||||
Putting the paths in settings.py will put them in a centralized place and make them easy to change down the line. When referring to the same variables in multiple files, it’s easier to put them in a central place than edit them in every file when you want to change them. [Here’s][28] an example settings.py file for this project.
|
||||
|
||||
The second step is to create a file called assemble.py that will assemble all the pieces into 2 files. When we run python assemble.py, we’ll get 2 data files in the processed directory.
|
||||
|
||||
We’ll then start writing code in assemble.py. We’ll first need to define the headers for each file, so we’ll need to look at [pdf of column names][29] and create lists of the columns in each Acquisition and Performance file:
|
||||
|
||||
```
|
||||
HEADERS = {
|
||||
"Acquisition": [
|
||||
"id",
|
||||
"channel",
|
||||
"seller",
|
||||
"interest_rate",
|
||||
"balance",
|
||||
"loan_term",
|
||||
"origination_date",
|
||||
"first_payment_date",
|
||||
"ltv",
|
||||
"cltv",
|
||||
"borrower_count",
|
||||
"dti",
|
||||
"borrower_credit_score",
|
||||
"first_time_homebuyer",
|
||||
"loan_purpose",
|
||||
"property_type",
|
||||
"unit_count",
|
||||
"occupancy_status",
|
||||
"property_state",
|
||||
"zip",
|
||||
"insurance_percentage",
|
||||
"product_type",
|
||||
"co_borrower_credit_score"
|
||||
],
|
||||
"Performance": [
|
||||
"id",
|
||||
"reporting_period",
|
||||
"servicer_name",
|
||||
"interest_rate",
|
||||
"balance",
|
||||
"loan_age",
|
||||
"months_to_maturity",
|
||||
"maturity_date",
|
||||
"msa",
|
||||
"delinquency_status",
|
||||
"modification_flag",
|
||||
"zero_balance_code",
|
||||
"zero_balance_date",
|
||||
"last_paid_installment_date",
|
||||
"foreclosure_date",
|
||||
"disposition_date",
|
||||
"foreclosure_costs",
|
||||
"property_repair_costs",
|
||||
"recovery_costs",
|
||||
"misc_costs",
|
||||
"tax_costs",
|
||||
"sale_proceeds",
|
||||
"credit_enhancement_proceeds",
|
||||
"repurchase_proceeds",
|
||||
"other_foreclosure_proceeds",
|
||||
"non_interest_bearing_balance",
|
||||
"principal_forgiveness_balance"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
The next step is to define the columns we want to keep. Since all we’re measuring on an ongoing basis about the loan is whether or not it was ever foreclosed on, we can discard many of the columns in the performance data. We’ll need to keep all the columns in the acquisition data, though, because we want to maximize the information we have about when the loan was acquired (after all, we’re predicting if the loan will ever be foreclosed or not at the point it’s acquired). Discarding columns will enable us to save disk space and memory, while also speeding up our code.
|
||||
|
||||
```
|
||||
SELECT = {
|
||||
"Acquisition": HEADERS["Acquisition"],
|
||||
"Performance": [
|
||||
"id",
|
||||
"foreclosure_date"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Next, we’ll write a function to concatenate the data sets. The below code will:
|
||||
|
||||
- Import a few needed libraries, including settings.
|
||||
- Define a function concatenate, that:
|
||||
- Gets the names of all the files in the data directory.
|
||||
- Loops through each file.
|
||||
- If the file isn’t the right type (doesn’t start with the prefix we want), we ignore it.
|
||||
- Reads the file into a [DataFrame][30] with the right settings using the Pandas [read_csv][31] function.
|
||||
- Sets the separator to | so the fields are read in correctly.
|
||||
- The data has no header row, so sets header to None to indicate this.
|
||||
- Sets names to the right value from the HEADERS dictionary – these will be the column names of our DataFrame.
|
||||
- Picks only the columns from the DataFrame that we added in SELECT.
|
||||
- Concatenates all the DataFrames together.
|
||||
- Writes the concatenated DataFrame back to a file.
|
||||
|
||||
```
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
|
||||
def concatenate(prefix="Acquisition"):
|
||||
files = os.listdir(settings.DATA_DIR)
|
||||
full = []
|
||||
for f in files:
|
||||
if not f.startswith(prefix):
|
||||
continue
|
||||
|
||||
data = pd.read_csv(os.path.join(settings.DATA_DIR, f), sep="|", header=None, names=HEADERS[prefix], index_col=False)
|
||||
data = data[SELECT[prefix]]
|
||||
full.append(data)
|
||||
|
||||
full = pd.concat(full, axis=0)
|
||||
|
||||
full.to_csv(os.path.join(settings.PROCESSED_DIR, "{}.txt".format(prefix)), sep="|", header=SELECT[prefix], index=False)
|
||||
```
|
||||
|
||||
We can call the above function twice with the arguments Acquisition and Performance to concatenate all the acquisition and performance files together. The below code will:
|
||||
|
||||
- Only execute if the script is called from the command line with python assemble.py.
|
||||
- Concatenate all the files, and result in two files:
|
||||
- `processed/Acquisition.txt`
|
||||
- `processed/Performance.txt`
|
||||
|
||||
```
|
||||
if __name__ == "__main__":
|
||||
concatenate("Acquisition")
|
||||
concatenate("Performance")
|
||||
```
|
||||
|
||||
We now have a nice, compartmentalized assemble.py that’s easy to execute, and easy to build off of. By decomposing the problem into pieces like this, we make it easy to build our project. Instead of one messy script that does everything, we define the data that will pass between the scripts, and make them completely separate from each other. When you’re working on larger projects, it’s a good idea to do this, because it makes it much easier to change individual pieces without having unexpected consequences on unrelated pieces of the project.
|
||||
|
||||
Once we finish the assemble.py script, we can run python assemble.py. You can find the complete assemble.py file [here][32].
|
||||
|
||||
This will result in two files in the processed directory:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
├── .gitignore
|
||||
├── assemble.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### Computing values from the performance data
|
||||
|
||||
The next step we’ll take is to calculate some values from processed/Performance.txt. All we want to do is to predict whether or not a property is foreclosed on. To figure this out, we just need to check if the performance data associated with a loan ever has a foreclosure_date. If foreclosure_date is None, then the property was never foreclosed on. In order to avoid including loans with little performance history in our sample, we’ll also want to count up how many rows exist in the performance file for each loan. This will let us filter loans without much performance history from our training data.
|
||||
|
||||
One way to think of the loan data and the performance data is like this:
|
||||
|
||||

|
||||
|
||||
As you can see above, each row in the Acquisition data can be related to multiple rows in the Performance data. In the Performance data, foreclosure_date will appear in the quarter when the foreclosure happened, so it should be blank prior to that. Some loans are never foreclosed on, so all the rows related to them in the Performance data have foreclosure_date blank.
|
||||
|
||||
We need to compute foreclosure_status, which is a Boolean that indicates whether a particular loan id was ever foreclosed on, and performance_count, which is the number of rows in the performance data for each loan id.
|
||||
|
||||
There are a few different ways to compute the counts we want:
|
||||
|
||||
- We could read in all the performance data, then use the Pandas groupby method on the DataFrame to figure out the number of rows associated with each loan id, and also if the foreclosure_date is ever not None for the id.
|
||||
- The upside of this method is that it’s easy to implement from a syntax perspective.
|
||||
- The downside is that reading in all 129236094 lines in the data will take a lot of memory, and be extremely slow.
|
||||
- We could read in all the performance data, then use apply on the acquisition DataFrame to find the counts for each id.
|
||||
- The upside is that it’s easy to conceptualize.
|
||||
- The downside is that reading in all 129236094 lines in the data will take a lot of memory, and be extremely slow.
|
||||
- We could iterate over each row in the performance dataset, and keep a separate dictionary of counts.
|
||||
- The upside is that the dataset doesn’t need to be loaded into memory, so it’s extremely fast and memory-efficient.
|
||||
- The downside is that it will take slightly longer to conceptualize and implement, and we need to parse the rows manually.
|
||||
|
||||
Loading in all the data will take quite a bit of memory, so let’s go with the third option above. All we need to do is to iterate through all the rows in the Performance data, while keeping a dictionary of counts per loan id. In the dictionary, we’ll keep track of how many times the id appears in the performance data, as well as if foreclosure_date is ever not None. This will give us foreclosure_status and performance_count.
|
||||
|
||||
We’ll create a new file called annotate.py, and add in code that will enable us to compute these values. In the below code, we’ll:
|
||||
|
||||
- Import needed libraries.
|
||||
- Define a function called count_performance_rows.
|
||||
- Open processed/Performance.txt. This doesn’t read the file into memory, but instead opens a file handler that can be used to read in the file line by line.
|
||||
- Loop through each line in the file.
|
||||
- Split the line on the delimiter (|)
|
||||
- Check if the loan_id is not in the counts dictionary.
|
||||
- If not, add it to counts.
|
||||
- Increment performance_count for the given loan_id because we’re on a row that contains it.
|
||||
- If date is not None, then we know that the loan was foreclosed on, so set foreclosure_status appropriately.
|
||||
|
||||
```
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
|
||||
def count_performance_rows():
|
||||
counts = {}
|
||||
with open(os.path.join(settings.PROCESSED_DIR, "Performance.txt"), 'r') as f:
|
||||
for i, line in enumerate(f):
|
||||
if i == 0:
|
||||
# Skip header row
|
||||
continue
|
||||
loan_id, date = line.split("|")
|
||||
loan_id = int(loan_id)
|
||||
if loan_id not in counts:
|
||||
counts[loan_id] = {
|
||||
"foreclosure_status": False,
|
||||
"performance_count": 0
|
||||
}
|
||||
counts[loan_id]["performance_count"] += 1
|
||||
if len(date.strip()) > 0:
|
||||
counts[loan_id]["foreclosure_status"] = True
|
||||
return counts
|
||||
```
|
||||
|
||||
### Getting the values
|
||||
|
||||
Once we create our counts dictionary, we can make a function that will extract values from the dictionary if a loan_id and a key are passed in:
|
||||
|
||||
```
|
||||
def get_performance_summary_value(loan_id, key, counts):
|
||||
value = counts.get(loan_id, {
|
||||
"foreclosure_status": False,
|
||||
"performance_count": 0
|
||||
})
|
||||
return value[key]
|
||||
```
|
||||
|
||||
The above function will return the appropriate value from the counts dictionary, and will enable us to assign a foreclosure_status value and a performance_count value to each row in the Acquisition data. The [get][33] method on dictionaries returns a default value if a key isn’t found, so this enables us to return sensible default values if a key isn’t found in the counts dictionary.
|
||||
|
||||
### Annotating the data
|
||||
|
||||
We’ve already added a few functions to annotate.py, but now we can get into the meat of the file. We’ll need to convert the acquisition data into a training dataset that can be used in a machine learning algorithm. This involves a few things:
|
||||
|
||||
- Converting all columns to numeric.
|
||||
- Filling in any missing values.
|
||||
- Assigning a performance_count and a foreclosure_status to each row.
|
||||
- Removing any rows that don’t have a lot of performance history (where performance_count is low).
|
||||
|
||||
Several of our columns are strings, which aren’t useful to a machine learning algorithm. However, they are actually categorical variables, where there are a few different category codes, like R, S, and so on. We can convert these columns to numeric by assigning a number to each category label:
|
||||
|
||||

|
||||
|
||||
Converting the columns this way will allow us to use them in our machine learning algorithm.
|
||||
|
||||
Some of the columns also contain dates (first_payment_date and origination_date). We can split these dates into 2 columns each:
|
||||
|
||||

|
||||
In the below code, we’ll transform the Acquisition data. We’ll define a function that:
|
||||
|
||||
- Creates a foreclosure_status column in acquisition by getting the values from the counts dictionary.
|
||||
- Creates a performance_count column in acquisition by getting the values from the counts dictionary.
|
||||
- Converts each of the following columns from a string column to an integer column:
|
||||
- channel
|
||||
- seller
|
||||
- first_time_homebuyer
|
||||
- loan_purpose
|
||||
- property_type
|
||||
- occupancy_status
|
||||
- property_state
|
||||
- product_type
|
||||
- Converts first_payment_date and origination_date to 2 columns each:
|
||||
- Splits the column on the forward slash.
|
||||
- Assigns the first part of the split list to a month column.
|
||||
- Assigns the second part of the split list to a year column.
|
||||
- Deletes the column.
|
||||
- At the end, we’ll have first_payment_month, first_payment_year, origination_month, and origination_year.
|
||||
- Fills any missing values in acquisition with -1.
|
||||
|
||||
```
|
||||
def annotate(acquisition, counts):
|
||||
acquisition["foreclosure_status"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "foreclosure_status", counts))
|
||||
acquisition["performance_count"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "performance_count", counts))
|
||||
for column in [
|
||||
"channel",
|
||||
"seller",
|
||||
"first_time_homebuyer",
|
||||
"loan_purpose",
|
||||
"property_type",
|
||||
"occupancy_status",
|
||||
"property_state",
|
||||
"product_type"
|
||||
]:
|
||||
acquisition[column] = acquisition[column].astype('category').cat.codes
|
||||
|
||||
for start in ["first_payment", "origination"]:
|
||||
column = "{}_date".format(start)
|
||||
acquisition["{}_year".format(start)] = pd.to_numeric(acquisition[column].str.split('/').str.get(1))
|
||||
acquisition["{}_month".format(start)] = pd.to_numeric(acquisition[column].str.split('/').str.get(0))
|
||||
del acquisition[column]
|
||||
|
||||
acquisition = acquisition.fillna(-1)
|
||||
acquisition = acquisition[acquisition["performance_count"] > settings.MINIMUM_TRACKING_QUARTERS]
|
||||
return acquisition
|
||||
```
|
||||
|
||||
### Pulling everything together
|
||||
|
||||
We’re almost ready to pull everything together, we just need to add a bit more code to annotate.py. In the below code, we:
|
||||
|
||||
- Define a function to read in the acquisition data.
|
||||
- Define a function to write the processed data to processed/train.csv
|
||||
- If this file is called from the command line, like python annotate.py:
|
||||
- Read in the acquisition data.
|
||||
- Compute the counts for the performance data, and assign them to counts.
|
||||
- Annotate the acquisition DataFrame.
|
||||
- Write the acquisition DataFrame to train.csv.
|
||||
|
||||
```
|
||||
def read():
|
||||
acquisition = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "Acquisition.txt"), sep="|")
|
||||
return acquisition
|
||||
|
||||
def write(acquisition):
|
||||
acquisition.to_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"), index=False)
|
||||
|
||||
if __name__ == "__main__":
|
||||
acquisition = read()
|
||||
counts = count_performance_rows()
|
||||
acquisition = annotate(acquisition, counts)
|
||||
write(acquisition)
|
||||
```
|
||||
|
||||
Once you’re done updating the file, make sure to run it with python annotate.py, to generate the train.csv file. You can find the complete annotate.py file [here][34].
|
||||
|
||||
The folder should now look like this:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
│ ├── train.csv
|
||||
├── .gitignore
|
||||
├── annotate.py
|
||||
├── assemble.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### Finding an error metric
|
||||
|
||||
We’re done with generating our training dataset, and now we’ll just need to do the final step, generating predictions. We’ll need to figure out an error metric, as well as how we want to evaluate our data. In this case, there are many more loans that aren’t foreclosed on than are, so typical accuracy measures don’t make much sense.
|
||||
|
||||
If we read in the training data, and check the counts in the foreclosure_status column, here’s what we get:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
import settings
|
||||
|
||||
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
|
||||
train["foreclosure_status"].value_counts()
|
||||
```
|
||||
|
||||
```
|
||||
False 4635982
|
||||
True 1585
|
||||
Name: foreclosure_status, dtype: int64
|
||||
```
|
||||
|
||||
Since so few of the loans were foreclosed on, just checking the percentage of labels that were correctly predicted will mean that we can make a machine learning model that predicts False for every row, and still gets a very high accuracy. Instead, we’ll want to use a metric that takes the class imbalance into account, and ensures that we predict foreclosures accurately. We don’t want too many false positives, where we make predict that a loan will be foreclosed on even though it won’t, or too many false negatives, where we predict that a loan won’t be foreclosed on, but it is. Of these two, false negatives are more costly for Fannie Mae, because they’re buying loans where they may not be able to recoup their investment.
|
||||
|
||||
We’ll define false negative rate as the number of loans where the model predicts no foreclosure but the the loan was actually foreclosed on, divided by the number of total loans that were actually foreclosed on. This is the percentage of actual foreclosures that the model “Missed”. Here’s a diagram:
|
||||
|
||||

|
||||
|
||||
In the diagram above, 1 loan was predicted as not being foreclosed on, but it actually was. If we divide this by the number of loans that were actually foreclosed on, 2, we get the false negative rate, 50%. We’ll use this as our error metric, so we can evaluate our model’s performance.
|
||||
|
||||
### Setting up the classifier for machine learning
|
||||
|
||||
We’ll use cross validation to make predictions. With cross validation, we’ll divide our data into 3 groups. Then we’ll do the following:
|
||||
|
||||
- Train a model on groups 1 and 2, and use the model to make predictions for group 3.
|
||||
- Train a model on groups 1 and 3, and use the model to make predictions for group 2.
|
||||
- Train a model on groups 2 and 3, and use the model to make predictions for group 1.
|
||||
|
||||
Splitting it up into groups this way means that we never train a model using the same data we’re making predictions for. This avoids overfitting. If we overfit, we’ll get a falsely low false negative rate, which makes it hard to improve our algorithm or use it in the real world.
|
||||
|
||||
[Scikit-learn][35] has a function called [cross_val_predict][36] which will make it easy to perform cross validation.
|
||||
|
||||
We’ll also need to pick an algorithm to use to make predictions. We need a classifier that can do [binary classification][37]. The target variable, foreclosure_status only has two values, True and False.
|
||||
|
||||
We’ll use [logistic regression][38], because it works well for binary classification, runs extremely quickly, and uses little memory. This is due to how the algorithm works – instead of constructing dozens of trees, like a random forest, or doing expensive transformations, like a support vector machine, logistic regression has far fewer steps involving fewer matrix operations.
|
||||
|
||||
We can use the [logistic regression classifier][39] algorithm that’s implemented in scikit-learn. The only thing we need to pay attention to is the weights of each class. If we weight the classes equally, the algorithm will predict False for every row, because it is trying to minimize errors. However, we care much more about foreclosures than we do about loans that aren’t foreclosed on. Thus, we’ll pass balanced to the class_weight keyword argument of the [LogisticRegression][40] class, to get the algorithm to weight the foreclosures more to account for the difference in the counts of each class. This will ensure that the algorithm doesn’t predict False for every row, and instead is penalized equally for making errors in predicting either class.
|
||||
|
||||
### Making predictions
|
||||
|
||||
Now that we have the preliminaries out of the way, we’re ready to make predictions. We’ll create a new file called predict.py that will use the train.csv file we created in the last step. The below code will:
|
||||
|
||||
- Import needed libraries.
|
||||
- Create a function called cross_validate that:
|
||||
- Creates a logistic regression classifier with the right keyword arguments.
|
||||
- Creates a list of columns that we want to use to train the model, removing id and foreclosure_status.
|
||||
- Run cross validation across the train DataFrame.
|
||||
- Return the predictions.
|
||||
|
||||
|
||||
```
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
from sklearn import cross_validation
|
||||
from sklearn.linear_model import LogisticRegression
|
||||
from sklearn import metrics
|
||||
|
||||
def cross_validate(train):
|
||||
clf = LogisticRegression(random_state=1, class_weight="balanced")
|
||||
|
||||
predictors = train.columns.tolist()
|
||||
predictors = [p for p in predictors if p not in settings.NON_PREDICTORS]
|
||||
|
||||
predictions = cross_validation.cross_val_predict(clf, train[predictors], train[settings.TARGET], cv=settings.CV_FOLDS)
|
||||
return predictions
|
||||
```
|
||||
|
||||
### Predicting error
|
||||
|
||||
Now, we just need to write a few functions to compute error. The below code will:
|
||||
|
||||
- Create a function called compute_error that:
|
||||
- Uses scikit-learn to compute a simple accuracy score (the percentage of predictions that matched the actual foreclosure_status values).
|
||||
- Create a function called compute_false_negatives that:
|
||||
- Combines the target and the predictions into a DataFrame for convenience.
|
||||
- Finds the false negative rate.
|
||||
- Create a function called compute_false_positives that:
|
||||
- Combines the target and the predictions into a DataFrame for convenience.
|
||||
- Finds the false positive rate.
|
||||
- Finds the number of loans that weren’t foreclosed on that the model predicted would be foreclosed on.
|
||||
- Divide by the total number of loans that weren’t foreclosed on.
|
||||
|
||||
```
|
||||
def compute_error(target, predictions):
|
||||
return metrics.accuracy_score(target, predictions)
|
||||
|
||||
def compute_false_negatives(target, predictions):
|
||||
df = pd.DataFrame({"target": target, "predictions": predictions})
|
||||
return df[(df["target"] == 1) & (df["predictions"] == 0)].shape[0] / (df[(df["target"] == 1)].shape[0] + 1)
|
||||
|
||||
def compute_false_positives(target, predictions):
|
||||
df = pd.DataFrame({"target": target, "predictions": predictions})
|
||||
return df[(df["target"] == 0) & (df["predictions"] == 1)].shape[0] / (df[(df["target"] == 0)].shape[0] + 1)
|
||||
```
|
||||
|
||||
### Putting it all together
|
||||
|
||||
Now, we just have to put the functions together in predict.py. The below code will:
|
||||
|
||||
- Read in the dataset.
|
||||
- Compute cross validated predictions.
|
||||
- Compute the 3 error metrics above.
|
||||
- Print the error metrics.
|
||||
|
||||
```
|
||||
def read():
|
||||
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
|
||||
return train
|
||||
|
||||
if __name__ == "__main__":
|
||||
train = read()
|
||||
predictions = cross_validate(train)
|
||||
error = compute_error(train[settings.TARGET], predictions)
|
||||
fn = compute_false_negatives(train[settings.TARGET], predictions)
|
||||
fp = compute_false_positives(train[settings.TARGET], predictions)
|
||||
print("Accuracy Score: {}".format(error))
|
||||
print("False Negatives: {}".format(fn))
|
||||
print("False Positives: {}".format(fp))
|
||||
```
|
||||
|
||||
Once you’ve added the code, you can run python predict.py to generate predictions. Running everything shows that our false negative rate is .26, which means that of the foreclosed loans, we missed predicting 26% of them. This is a good start, but can use a lot of improvement!
|
||||
|
||||
You can find the complete predict.py file [here][41].
|
||||
|
||||
Your file tree should now look like this:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
│ ├── train.csv
|
||||
├── .gitignore
|
||||
├── annotate.py
|
||||
├── assemble.py
|
||||
├── predict.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### Writing up a README
|
||||
|
||||
Now that we’ve finished our end to end project, we just have to write up a README.md file so that other people know what we did, and how to replicate it. A typical README.md for a project should include these sections:
|
||||
|
||||
- A high level overview of the project, and what the goals are.
|
||||
- Where to download any needed data or materials.
|
||||
- Installation instructions.
|
||||
- How to install the requirements.
|
||||
- Usage instructions.
|
||||
- How to run the project.
|
||||
- What you should see after each step.
|
||||
- How to contribute to the project.
|
||||
- Good next steps for extending the project.
|
||||
|
||||
[Here’s][42] a sample README.md for this project.
|
||||
|
||||
### Next steps
|
||||
|
||||
Congratulations, you’re done making an end to end machine learning project! You can find a complete example project [here][43]. It’s a good idea to upload your project to [Github][44] once you’ve finished it, so others can see it as part of your portfolio.
|
||||
|
||||
There are still quite a few angles left to explore with this data. Broadly, we can split them up into 3 categories – extending this project and making it more accurate, finding other columns to predict, and exploring the data. Here are some ideas:
|
||||
|
||||
- Generate more features in annotate.py.
|
||||
- Switch algorithms in predict.py.
|
||||
- Try using more data from Fannie Mae than we used in this post.
|
||||
- Add in a way to make predictions on future data. The code we wrote will still work if we add more data, so we can add more past or future data.
|
||||
- Try seeing if you can predict if a bank should have issued the loan originally (vs if Fannie Mae should have acquired the loan).
|
||||
- Remove any columns from train that the bank wouldn’t have known at the time of issuing the loan.
|
||||
- Some columns are known when Fannie Mae bought the loan, but not before.
|
||||
- Make predictions.
|
||||
- Explore seeing if you can predict columns other than foreclosure_status.
|
||||
- Can you predict how much the property will be worth at sale time?
|
||||
- Explore the nuances between performance updates.
|
||||
- Can you predict how many times the borrower will be late on payments?
|
||||
- Can you map out the typical loan lifecycle?
|
||||
- Map out data on a state by state or zip code by zip code level.
|
||||
- Do you see any interesting patterns?
|
||||
|
||||
If you build anything interesting, please let us know in the comments!
|
||||
|
||||
If you liked this, you might like to read the other posts in our ‘Build a Data Science Porfolio’ series:
|
||||
|
||||
- [Storytelling with data][45].
|
||||
- [How to setup up a data science blog][46].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.dataquest.io/blog/data-science-portfolio-machine-learning/
|
||||
|
||||
作者:[Vik Paruchuri][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对ID](https://github.com/校对ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.dataquest.io/blog
|
||||
[1]: https://www.dataquest.io/blog/data-science-portfolio-machine-learning/#email-signup
|
||||
[2]: https://github.com/dataquestio/loan-prediction
|
||||
[3]: https://www.dataquest.io/blog/data-science-portfolio-project/
|
||||
[4]: https://atom.io/
|
||||
[5]: https://www.jetbrains.com/pycharm/
|
||||
[6]: https://github.com/
|
||||
[7]: http://pandas.pydata.org/
|
||||
[8]: http://scikit-learn.org/
|
||||
[9]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
|
||||
[10]: https://collegescorecard.ed.gov/data/
|
||||
[11]: https://reddit.com/r/datasets
|
||||
[12]: https://cloud.google.com/bigquery/public-data/#usa-names
|
||||
[13]: https://github.com/caesar0301/awesome-public-datasets
|
||||
[14]: http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html
|
||||
[15]: http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html
|
||||
[16]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_glossary.pdf
|
||||
[17]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_faq.pdf
|
||||
[18]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[19]: https://loanperformancedata.fanniemae.com/lppub-docs/acquisition-sample-file.txt
|
||||
[20]: https://loanperformancedata.fanniemae.com/lppub-docs/performance-sample-file.txt
|
||||
[21]: https://github.com/dataquestio/loan-prediction/blob/master/.gitignore
|
||||
[22]: https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet
|
||||
[23]: https://github.com/dataquestio/loan-prediction
|
||||
[24]: https://github.com/dataquestio/loan-prediction/blob/master/requirements.txt
|
||||
[25]: https://www.continuum.io/downloads
|
||||
[26]: https://loanperformancedata.fanniemae.com/lppub/index.html
|
||||
[27]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[28]: https://github.com/dataquestio/loan-prediction/blob/master/settings.py
|
||||
[29]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[30]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
|
||||
[31]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html
|
||||
[32]: https://github.com/dataquestio/loan-prediction/blob/master/assemble.py
|
||||
[33]: https://docs.python.org/3/library/stdtypes.html#dict.get
|
||||
[34]: https://github.com/dataquestio/loan-prediction/blob/master/annotate.py
|
||||
[35]: http://scikit-learn.org/
|
||||
[36]: http://scikit-learn.org/stable/modules/generated/sklearn.cross_validation.cross_val_predict.html
|
||||
[37]: https://en.wikipedia.org/wiki/Binary_classification
|
||||
[38]: https://en.wikipedia.org/wiki/Logistic_regression
|
||||
[39]: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
|
||||
[40]: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
|
||||
[41]: https://github.com/dataquestio/loan-prediction/blob/master/predict.py
|
||||
[42]: https://github.com/dataquestio/loan-prediction/blob/master/README.md
|
||||
[43]: https://github.com/dataquestio/loan-prediction
|
||||
[44]: https://www.github.com/
|
||||
[45]: https://www.dataquest.io/blog/data-science-portfolio-project/
|
||||
[46]: https://www.dataquest.io/blog/how-to-setup-a-data-science-blog/
|
||||
@ -1,86 +0,0 @@
|
||||
sevenot translating
|
||||
Terminator A Linux Terminal Emulator With Multiple Terminals In One Window
|
||||
=============================================================================
|
||||
|
||||

|
||||
|
||||
Each Linux distribution has a default terminal emulator for interacting with system through commands. But the default terminal app might not be perfect for you. There are so many terminal apps that will provide you more functionalities to perform more tasks simultaneously to sky-rocket speed of your work. Such useful terminal emulators include Terminator, a multi-windows supported free terminal emulator for your Linux system.
|
||||
|
||||
### What Is Linux Terminal Emulator?
|
||||
|
||||
A Linux terminal emulator is a program that lets you interact with the shell. All Linux distributions come with a default Linux terminal app that let you pass commands to the shell.
|
||||
|
||||
### Terminator, A Free Linux Terminal App
|
||||
|
||||
Terminator is a Linux terminal emulator that provides several features that your default terminal app does not support. It provides the ability to create multiple terminals in one window and faster your work progress. Other than multiple windows, it allows you to change other properties such as, terminal fonts, fonts colour, background colour and so on. Let's see how we can install and use Terminator in different Linux distributions.
|
||||
|
||||
### How To Install Terminator In Linux?
|
||||
|
||||
#### Install Terminator In Ubuntu Based Distributions
|
||||
|
||||
Terminator is available in the default Ubuntu repository. So you don't require to add any additional PPA. Just use APT or Software App to install it in Ubuntu.
|
||||
|
||||
```
|
||||
sudo apt-get install terminator
|
||||
```
|
||||
|
||||
In case Terminator is not available in your default repository, just compile Terminator from source code.
|
||||
|
||||
[DOWNLOAD SOURCE CODE][1]
|
||||
|
||||
Download Terminator source code and extract it on your desktop. Now open your default terminal & cd into the extracted folder.
|
||||
|
||||
Now use the following command to install Terminator -
|
||||
|
||||
```
|
||||
sudo ./setup.py install
|
||||
```
|
||||
|
||||
#### Install Terminator In Fedora & Other Derivatives
|
||||
|
||||
```
|
||||
dnf install terminator
|
||||
```
|
||||
|
||||
#### Install Terminator In OpenSuse
|
||||
|
||||
[INSTALL IN OPENSUSE][2]
|
||||
|
||||
### How To Use Multiple Terminals In One Window?
|
||||
|
||||
After you have installed Terminator, simply open multiple terminals in one window. Simply right click and divide.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
You can create as many terminals as you want, if you can manage them.
|
||||
|
||||

|
||||
|
||||
### Customise Terminals
|
||||
|
||||
Right click the terminal and click Properties. Now you can customise fonts, fonts colour, title colour & background and terminal fonts colour & background.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Conclusion & What Is Your Favorite Terminal Emulator?
|
||||
|
||||
Terminator is an advanced terminal emulator and it also let you customize the interface. If you have not yet switched from your default terminal emulator then just try this one. I know you'll like it. If you're using any other free terminal emulator, then let us know your favorite terminal emulator. Also don't forget to share this article with your friends. Perhaps your friends are searching for something like this.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
||||
|
||||
作者:[author][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxandubuntu.com/home/terminator-a-linux-terminal-emulator-with-multiple-terminals-in-one-window
|
||||
[1]: https://launchpad.net/terminator/+download
|
||||
[2]: http://software.opensuse.org/download.html?project=home%3AKorbi123&package=terminator
|
||||
@ -1,460 +0,0 @@
|
||||
Translating by Flowsnow!
|
||||
Best Password Manager — For Windows, Linux, Mac, Android, iOS and Enterprise
|
||||
==============================
|
||||
|
||||

|
||||
|
||||
When it comes to safeguarding your Internet security, installing an antivirus software or running a [Secure Linux OS][1] on your system does not mean you are safe enough from all kinds of cyber-threats.
|
||||
|
||||
Today majority of Internet users are vulnerable to cyber attacks, not because they aren't using any best antivirus software or other security measures, but because they are using [weak passwords][2] to secure their online accounts.
|
||||
|
||||
Passwords are your last lines of defense against online threats. Just look back to some recent data breaches and cyber attacks, including high-profile [data breach at OPM][3] (United States Office of Personnel Management) and the extra-marital affair site [Ashley Madison][4], that led to the exposure of hundreds of millions of records online.
|
||||
|
||||
Although you can not control data breaches, it is still important to create strong passwords that can withstand dictionary and [brute-force attacks][5].
|
||||
|
||||
You see, the longer and more complex your password is, the much harder it is crack.
|
||||
|
||||
### How to Stay Secure Online?
|
||||
|
||||
Security researchers have always advised online users to create long, complex and different passwords for their various online accounts. So, if one site is breached, your other accounts on other websites are secure enough from being hacked.
|
||||
|
||||
Ideally, your strong password should be at least 16 characters long, should contain a combination of digits, symbols, uppercase letters and lowercase letters and most importantly the most secure password is one you don't even know.
|
||||
|
||||
The password should be free of repetition and not contain any dictionary word, pronoun, your username or ID, and any other predefined letter or number sequences.
|
||||
|
||||
I know this is a real pain to memorize such complex password strings and unless we are human supercomputers, remembering different passwords for several online accounts is not an easy task.
|
||||
|
||||
The issue is that today people subscribe to a lot of online sites and services, and it's usually hard to create and remember different passwords for every single account.
|
||||
|
||||
But, Luckily to make this whole process easy, there's a growing market for password managers for PCs and phones that can significantly reduce your password memorizing problem, along with the cure for your bad habit of setting weak passwords.
|
||||
|
||||
### What is Password Manager?
|
||||
|
||||

|
||||
|
||||
Password Manager software has come a very long way in the past few years and is an excellent system that both allows you to create complex passwords for different sites and remember them.
|
||||
|
||||
A password manager is just software that creates, stores and organizes all your passwords for your computers, websites, applications and networks.
|
||||
|
||||
Password managers that generate passwords and double as a form filler are also available in the market, which has the ability to enter your username and password automatically into login forms on websites.
|
||||
|
||||
So, if you want super secure passwords for your multiple online accounts, but you do not want to memorize them all, Password Manager is the way to go.
|
||||
|
||||
### How does a Password Manager work?
|
||||
|
||||
Typically, Password Manager software works by generating long, complex, and, most importantly, unique password strings for you, and then stores them in encrypted form to protect the confidential data from hackers with physical access to your PC or mobile device.
|
||||
|
||||
The encrypted file is accessible only through a master password. So, all you need to do is remember just one master password to open your password manager or vault and unlock all your other passwords.
|
||||
|
||||
?
|
||||
|
||||
However, you need to make sure your master password is extra-secure of at least 16 characters long.
|
||||
|
||||
### Which is the Best Password Manager? How to Choose?
|
||||
|
||||
I've long recommended password managers, but most of our readers always ask:
|
||||
|
||||
- Which password manager is best?
|
||||
- Which password manager is the most secure? Help!
|
||||
|
||||
So, today I'm introducing you some of the best Password Manager currently available in the market for Windows, Linux, Mac, Android, iOS and Enterprise.
|
||||
|
||||
Before choosing a good password manager for your devices, you should check these following features:
|
||||
|
||||
- Cross-Platform Application
|
||||
- Works with zero-knowledge model
|
||||
- Offers two-factor authentication (multi-factor authentication)
|
||||
|
||||
Note: Once adopted, start relying on your password manager because if you are still using weak passwords for your important online accounts, nobody can save you from malicious hackers.
|
||||
|
||||
### Best Password Managers for Windows
|
||||
|
||||

|
||||
|
||||
Windows users are most vulnerable to cyber attacks because Windows operating system has always been the favorite target of hackers. So, it is important for Windows users to make use of a good password manager.
|
||||
|
||||
Some other best password manager for windows: Keeper, Password Safe, LockCrypt, 1Password, and Dashlane.
|
||||
|
||||
- 1. Keeper Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
Keeper is a secure, easy-to-use and robust password manager for your Windows, Mac, iPhone, iPad, and iPod devices.
|
||||
|
||||
Using military-grade 256-bit AES encryption, Keeper password manager keeps your data safe from prying eyes.
|
||||
|
||||
It has a secure digital vault for protecting and managing your passwords, as well as other secret information. Keeper password manager application supports Two-factor authentication and available for every major operating system.
|
||||
|
||||
There is also an important security feature, called Self-destruct, which if enabled, will delete all records from your device if the incorrect master password is entered more than five times incorrectly.
|
||||
|
||||
But you don't need worry, as this action will not delete the backup records stored on Keeper's Cloud Security Vault.
|
||||
|
||||
Download Keeper Password Manager: [Windows, Linux and Mac][6] | [iOS][7] | [Android][8] | [Kindle][9]
|
||||
|
||||
- 2. Dashlane Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
DashLane Password Manager software is a little newer, but it offers great features for almost every platform.
|
||||
|
||||
DashLane password manager works by encrypting your personal info and accounts' passwords with AES-256 encryption on a local machine, and then syncs your details with its online server, so that you can access your accounts database from anywhere.
|
||||
|
||||
The best part of DashLane is that it has an automatic password changer that can change your accounts' passwords for you without having to deal with it yourself.
|
||||
|
||||
DashLane Password Manager app for Android gives you the secure password management tools right to your Android phone: your password vault and form auto-filler for online stores and other sites.
|
||||
|
||||
DashLane Password Manager app for Android is completely free to use on a single device and for accessing multiple devices, you can buy a premium version of the app.
|
||||
|
||||
Download DashLane Password Manager: [Windows][10] and [Mac][11] | [iOS][12] | [Android][13]
|
||||
|
||||
- 3. LastPass Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
LastPass is one of the best Password Manager for Windows users, though it comes with the extension, mobile app, and even desktop app support for all the browsers and operating systems.
|
||||
|
||||
LastPass is an incredibly powerful cloud-based password manager software that encrypts your personal info and accounts' passwords with AES-256 bit encryption and even offers a variety of two-factor authentication options in order to ensure no one else can log into your password vault.
|
||||
|
||||
LastPass Password Manager comes for free as well as a premium with a fingerprint reader support.
|
||||
|
||||
Download LastPass Password Manager: [Windows, Mac, and Linux][14] | [iOS][15] | [Android][16]
|
||||
|
||||
### Best Password Manager for Mac OS X
|
||||
|
||||

|
||||
|
||||
People often say that Mac computers are more secure than Windows and that "Macs don't get viruses," but it is not entirely correct.
|
||||
|
||||
As proof, you can read our previous articles on cyber attacks against Mac and iOs users, and then decide yourself that you need a password manager or not.
|
||||
|
||||
Some other best password manager for Mac OS X: 1Password, Dashlane, LastPass, OneSafe, PwSafe.
|
||||
|
||||
- 1. LogMeOnce Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
LogMeOnce Password Management Suite is one of the best password manager for Mac OS X, as well as syncs your passwords across Windows, iOS, and Android devices.
|
||||
|
||||
LogMeOnce is one of the best Premium and Enterprise Password Management Software that offers a wide variety of features and options, including Mugshot feature.
|
||||
|
||||
If your phone is ever stolen, LogMeOnce Mugshot feature tracks the location of the thief and also secretly takes a photo of the intruder when trying to gain access to your account without permission.
|
||||
|
||||
LogmeOnce protects your passwords with military-grade AES-256 encryption technology and offers Two-factor authentication to ensure that even with the master password in hand, a thief hacks your account.
|
||||
|
||||
Download LogMeOnce Password Manager: [Windows and Mac][17] | [iOS][18] | [Android][19]
|
||||
|
||||
- 2. KeePass Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
Although LastPass is one of the best password manager, some people are not comfortable with a cloud-based password manager.
|
||||
|
||||
KeePass is a popular password manager application for Windows, but there are browser extensions and mobile apps for KeePass as well.
|
||||
|
||||
KeePass password manager for Windows stores your accounts' passwords on your PC, so you remain in control of them, and also on Dropbox, so you can access it using multiple devices.
|
||||
|
||||
KeePass encrypts your passwords and login info using the most secure encryption algorithms currently known: AES 256-bit encryption by default, or optional, Twofish 256-bit encryption.
|
||||
|
||||
KeePass is not just free, but it is also open source, which means its code and integrity can be examined by anyone, adding a degree of confidence.
|
||||
|
||||
Download KeePass Password Manager: [Windows and Linux][20] | [Mac][21] | [iOS][22] | [Android][23]
|
||||
3. Apple iCloud Keychain
|
||||
|
||||

|
||||
|
||||
Apple introduced the iCloud Keychain password management system as a convenient way to store and automatically sync all your login credentials, Wi-Fi passwords, and credit card numbers securely across your approved Apple devices, including Mac OS X, iPhone, and iPad.
|
||||
|
||||
Your Secret Data in Keychain is encrypted with 256-bit AES (Advanced Encryption Standard) and secured with elliptic curve asymmetric cryptography and key wrapping.
|
||||
|
||||
Also, iCloud Keychain generates new, unique and strong passwords for you to use to protect your computer and accounts.
|
||||
|
||||
Major limitation: Keychain doesn't work with other browsers other than Apple Safari.
|
||||
|
||||
Also Read: [How to Setup iCloud Keychain][24]?
|
||||
Best Password Manager for Linux
|
||||
|
||||

|
||||
|
||||
No doubt, some Linux distributions are the safest operating systems exist on the earth, but as I said above that adopting Linux doesn't completely protect your online accounts from hackers.
|
||||
|
||||
There are a number of cross-platform password managers available that sync all your accounts' passwords across all your devices, such as LastPass, KeePass, RoboForm password managers.
|
||||
|
||||
Here below I have listed two popular and secure open source password managers for Linux:
|
||||
|
||||
- 1. SpiderOak Encryptr Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
SpiderOak's Encryptr Password Manager is a zero-knowledge cloud-based password manager that encrypts protect your passwords using Crypton JavaScript framework, developed by SpiderOak and recommended by Edward Snowden.
|
||||
|
||||
It is a cross-platform, open-Source and free password manager that uses end-to-end encryption and works perfectly for Ubuntu, Debian Linux Mint, and other Linux distributions.
|
||||
|
||||
Encryptr Password Manager application itself is very simple and comes with some basic features.
|
||||
|
||||
Encryptr software lets you encrypt three types of files: Passwords, Credit Card numbers and general any text/keys.
|
||||
|
||||
Download Encryptr Password Manager: [Windows, Linux and Mac][25] | [iOS][26] | [Android][27]
|
||||
|
||||
2. EnPass Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
Enpass is an excellent security oriented Linux password manager that works perfectly with other platforms too. Enpass offers you to backup and restores stored passwords with third-party cloud services, including Google Drive, Dropbox, OneDrive, or OwnCloud.
|
||||
|
||||
It makes sure to provide the high levels of security and protects your data by a master password and encrypted it with 256-bit AES using open-source encryption engine SQLCipher, before uploading backup onto the cloud.
|
||||
"We do not host your Enpass data on our servers. So, no signup is required for us. Your data is only stored on your device," EnPass says.
|
||||
Additionally, by default, Enpass locks itself every minute when you leave your computer unattended and clears clipboard memory every 30 seconds to prevent your passwords from being stolen by any other malicious software.
|
||||
|
||||
Download EnPass Password Manager: [Windows][28], [Linux][29] | [Mac][30] | [iOS][31] | [Android][32]
|
||||
|
||||
3. RoboForm Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
You can easily find good password managers for Windows OS, but RoboForm Free Password Manager software goes a step further.
|
||||
|
||||
Besides creating complex passwords and remembering them for you, RoboForm also offers a smart form filler feature to save your time while browsing the Web.
|
||||
|
||||
RoboForm encrypts your login info and accounts' passwords using military grade AES encryption with the key that is obtained from your RoboForm Master Password.
|
||||
|
||||
RoboForm is available for browsers like Internet Explorer, Chrome, and Firefox as well as mobile platforms with apps available for iOS, Android, and Windows Phone.
|
||||
|
||||
Download RoboForm Password Manager: [Windows and Mac][33] | [Linux][34] | [iOS][35] | [Android][36]
|
||||
|
||||
### Best Password Manager for Android
|
||||
|
||||

|
||||
|
||||
More than half of the world's population today is using Android devices, so it becomes necessary for Android users to secure their online accounts from hackers who are always seeking access to these devices.
|
||||
|
||||
Some of the best Password Manager apps for Android include 1Password, Keeper, DashLane, EnPass, OneSafe, mSecure and SplashID Safe.
|
||||
|
||||
- 1. 1Password Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
1Password Password Manager app for Android is one of the best apps for managing all your accounts' passwords.
|
||||
|
||||
1Password password manager app creates strong, unique and secure passwords for every account, remembers them all for you, and logs you in with just a single tap.
|
||||
|
||||
1Password password manager software secures your logins and passwords with AES-256 bit encryption, and syncs them to all of your devices via your Dropbox account or stores locally for any other application to sync if you choose.
|
||||
|
||||
Recently, the Android version of 1Password password manager app has added Fingerprint support for unlocking all of your passwords instead of using your master password.
|
||||
|
||||
Download 1Password Password Manager: [Windows and Mac][37] | [iOS][38] | [Android][39]
|
||||
|
||||
- 2. mSecure Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
Like other popular password manager solutions, mSecure Password Manager for Android automatically generates secure passwords for you and stores them using 256-bit Blowfish encryption.
|
||||
|
||||
The catchy and unique feature mSecure Password Manager software provides its ability to self-destruct database after 5, 10, or 20 failed attempts (as per your preference) to input the right password.
|
||||
|
||||
You can also sync all of your devices with Dropbox, or via a private Wi-Fi network. In either case, all your data is transmitted safely and securely between devices regardless of the security of your cloud account.
|
||||
|
||||
Download mSecure Password Manager software: [Windows and Mac][40] | [iOS][41] | [Android][42]
|
||||
|
||||
### Best Password Manager for iOS
|
||||
|
||||

|
||||
|
||||
As I said, Apple's iOS is also prone to cyber attacks, so you can use some of the best password manager apps for iOS to secure your online accounts, including Keeper, OneSafe, Enpass, mSecure, LastPass, RoboForm, SplashID Safe and LoginBox Pro.
|
||||
|
||||
- 1. OneSafe Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
OneSafe is one of the best Password Manager apps for iOS devices that lets you store not only your accounts' passwords but also sensitive documents, credit card details, photos, and more.
|
||||
|
||||
OneSafe password manager app for iOS encrypts your data behind a master password, with AES-256 encryption — the highest level available on mobile — and Touch ID. There is also an option for additional passwords for given folders.
|
||||
|
||||
OneSafe password manager for iOS also offers an in-app browser that supports autofill of logins, so that you don't need to enter your login details every time.
|
||||
|
||||
Besides this, OneSafe also provides advanced security for your accounts' passwords with features like auto-lock, intrusion detection, self-destruct mode, decoy safe and double protection.
|
||||
|
||||
Download OneSafe Password Manager: [iOS][43] | [Mac][44] | [Android][45] | [Windows][46]
|
||||
|
||||
- 2. SplashID Safe Password Manager (Cross-Platform)
|
||||
|
||||

|
||||
|
||||
SplashID Safe is one of the oldest and best password manager tools for iOS that allows users to securely store their login data and other sensitive information in an encrypted record.
|
||||
|
||||
All your information, including website logins, credit card and social security data, photos and file attachments, are protected with 256-bit encryption.
|
||||
|
||||
SplashID Safe Password Manager app for iOS also provides web autofill option, meaning you will not have to bother copy-pasting your passwords in login.
|
||||
|
||||
The free version of SplashID Safe app comes with basic record storage functionality, though you can opt for premium subscriptions that provide cross-device syncing among other premium features.
|
||||
|
||||
Download SplashID Safe Password Manager: [Windows and Mac][47] | [iOS][48] | [Android][49]
|
||||
|
||||
3. LoginBox Pro Password Manager
|
||||
|
||||

|
||||
|
||||
LoginBox Pro is another great password manager app for iOS devices. The app provides a single tap login to any website you visit, making the password manager app as the safest and fastest way to sign in to password-protected internet sites.
|
||||
|
||||
LoginBox Password Manager app for iOS combines a password manager as well as a browser.
|
||||
|
||||
From the moment you download it, all your login actions, including entering information, tapping buttons, checking boxes, or answering security questions, automatically completes by the LoginBox Password Manager app.
|
||||
|
||||
For security, LoginBox Password Manager app uses hardware-accelerated AES encryption and passcode to encrypt your data and save it on your device itself.
|
||||
|
||||
Download LoginBox Password Manager: [iOS][50] | [Android][51]
|
||||
|
||||
### Best Online Password Managers
|
||||
|
||||
Using an online password manager tool is the easiest way to keep your personal and private information safe and secure from hackers and people with malicious intents.
|
||||
|
||||
Here I have listed some of the best online password managers that you can rely on to keep yourself safe online:
|
||||
|
||||
- 1. Google Online Password Manager
|
||||
|
||||

|
||||
|
||||
Did you know Google has its homebrew dedicated password manager?
|
||||
|
||||
Google Chrome has a built-in password manager tool that offers you an option to save your password whenever you sign in to a website or web service using Chrome.
|
||||
|
||||
All of your stored accounts' passwords are synced with your Google Account, making them available across all of your devices using the same Google Account.
|
||||
|
||||
Chrome password manager lets you manage all your accounts' passwords from the Web.
|
||||
|
||||
So, if you prefer using a different browser, like Microsoft Edge on Windows 10 or Safari on iPhone, just visit [passwords.google.com][52], and you'll see a list of all your passwords you have saved with Chrome. Google's two-factor authentication protects this list.
|
||||
|
||||
- 2. Clipperz Online Password Manager
|
||||
|
||||

|
||||
|
||||
Clipperz is a free, cross-platform best online password manager that does not require you to download any software. Clipperz online password manager uses a bookmarklet or sidebar to create and use direct logins.
|
||||
|
||||
Clipperz also offers an offline password manager version of its software that allows you to download your passwords to an [encrypted disk][53] or a USB drive so you can take them with you while traveling and access your accounts' passwords when you are offline.
|
||||
|
||||
Some features of Clipperz online password manager also includes password strength indicator, application locking, SSL secure connection, one-time password and a password generator.
|
||||
|
||||
Clipperz online password manager can work on any computer that runs a browser with a JavaScript browser.
|
||||
|
||||
- 3. Passpack Online Password Manager
|
||||
|
||||

|
||||
|
||||
Passpack is an excellent online password manager with a competitive collection of features that creates, stores and manages passwords for your different online accounts.
|
||||
|
||||
PassPack online password manager also allows you to share your passwords safely with your family or coworkers for managing multiple projects, team members, clients, and employees easily.
|
||||
|
||||
Your usernames and passwords for different accounts are encrypted with AES-256 Encryption on PassPack's servers that even hackers access to its server can not read your login information.
|
||||
|
||||
Download the PassPack online password manager toolbar to your web browser and navigate the web normally. Whenever you log into any password-protected site, PassPack saves your login data so that you do not have to save your username and password manually on its site.
|
||||
|
||||
### Best Enterprise Password Manager
|
||||
|
||||
Over the course of last 12 months, we've seen some of the biggest data breaches in the history of the Internet and year-over-year the growth is heating up.
|
||||
|
||||
According to statistics, a majority of employees even don't know how to protect themselves online, which led company’s business at risk.
|
||||
|
||||
To keep password sharing mechanism secure in an organization, there exist some password management tools specially designed for enterprises use, such as Vaultier, CommonKey, Meldium, PassWork, and Zoho Vault.
|
||||
|
||||
- 1. Meldium Enterprise Password Manager Software
|
||||
|
||||

|
||||
|
||||
LogMeIn's Meldium password management tool comes with a one-click single sign-on solution that helps businesses access to web apps securely and quickly.
|
||||
|
||||
It automatically logs users into apps and websites without typing usernames and passwords and also tracks password usage within your organization.
|
||||
|
||||
Meldium password manager is perfect for sharing accounts within your team member without sharing the actual password, which helps organizations to protect themselves from phishing attacks.
|
||||
|
||||
- 2. Zoho Vault Password Management Software
|
||||
|
||||

|
||||
|
||||
Zoho Vault is one of the best Password Manager for Enterprise users that helps your team share passwords and other sensitive information fast and securely while monitoring each user's usage.
|
||||
|
||||
All your team members need to download is the Zoho browser extension. Zoho Vault password manager will automatically fill passwords from your team's shared vault.
|
||||
|
||||
Zoho Vault also provides features that let you monitor your team's password usage and security level so that you can know who is using which login.
|
||||
|
||||
The Zoho Vault enterprise-level package even alerts you whenever a password is changed or accessed.
|
||||
|
||||
### For Extra Security, Use 2-Factor Authentication
|
||||
|
||||

|
||||
|
||||
No matter how strong your password is, there still remains a possibility for hackers to find some or the other way to hack into your account.
|
||||
|
||||
Two-factor authentication is designed to fight this issue. Instead of just one password, it requires you to enter the second passcode which is sent either to your mobile number via an SMS or to your email address via an email.
|
||||
|
||||
So, I recommend you to enable two-factor authentication now along with using a password manager software to secure your online accounts and sensitive information from hackers.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://thehackernews.com/2016/07/best-password-manager.html
|
||||
|
||||
作者:[Swati Khandelwal][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://thehackernews.com/2016/07/best-password-manager.html#author-info
|
||||
|
||||
[1]: http://thehackernews.com/2016/03/subgraph-secure-operating-system.html
|
||||
[2]: http://thehackernews.com/2016/01/password-security-manager.html
|
||||
[3]: http://thehackernews.com/2015/09/opm-hack-fingerprint.html
|
||||
[4]: http://thehackernews.com/2015/08/ashley-madison-accounts-leaked-online.html
|
||||
[5]: http://thehackernews.com/2013/05/cracking-16-character-strong-passwords.html
|
||||
[6]: https://keepersecurity.com/download.html
|
||||
[7]: https://itunes.apple.com/us/app/keeper-password-manager-digital/id287170072?mt=8
|
||||
[8]: https://play.google.com/store/apps/details?id=com.callpod.android_apps.keeper
|
||||
[9]: http://www.amazon.com/gp/mas/dl/android?p=com.callpod.android_apps.keeper
|
||||
[10]: https://www.dashlane.com/download
|
||||
[11]: https://www.dashlane.com/passwordmanager/mac-password-manager
|
||||
[12]: https://itunes.apple.com/in/app/dashlane-free-secure-password/id517914548?mt=8
|
||||
[13]: https://play.google.com/store/apps/details?id=com.dashlane&hl=en
|
||||
[14]: https://lastpass.com/misc_download2.php
|
||||
[15]: https://itunes.apple.com/us/app/lastpass-for-premium-customers/id324613447?mt=8&ign-mpt=uo%3D4
|
||||
[16]: https://play.google.com/store/apps/details?id=com.lastpass.lpandroid
|
||||
[17]: https://www.logmeonce.com/download/
|
||||
[18]: https://itunes.apple.com/us/app/logmeonce-free-password-manager/id972000703?ls=1&mt=8
|
||||
[19]: https://play.google.com/store/apps/details?id=log.me.once
|
||||
|
||||
[20]: http://keepass.info/download.html
|
||||
[21]: https://itunes.apple.com/us/app/kypass-companion/id555293879?ls=1&mt=12
|
||||
[22]: https://itunes.apple.com/de/app/ikeepass/id299697688?mt=8
|
||||
[23]: https://play.google.com/store/apps/details?id=keepass2android.keepass2android
|
||||
[24]: https://support.apple.com/en-in/HT204085
|
||||
[25]: https://spideroak.com/opendownload
|
||||
[26]: https://itunes.apple.com/us/app/spideroak/id360584371?mt=8
|
||||
[27]: https://play.google.com/store/apps/details?id=com.spideroak.android
|
||||
[28]: https://www.enpass.io/download-enpass-for-windows/
|
||||
[29]: https://www.enpass.io/download-enpass-linux/
|
||||
[30]: https://itunes.apple.com/app/enpass-password-manager-best/id732710998?mt=12
|
||||
[31]: https://itunes.apple.com/us/app/enpass-password-manager/id455566716?mt=8
|
||||
[32]: https://play.google.com/store/apps/details?id=io.enpass.app&hl=en
|
||||
[33]: http://www.roboform.com/download
|
||||
[34]: http://www.roboform.com/for-linux
|
||||
[35]: https://itunes.apple.com/WebObjects/MZStore.woa/wa/viewSoftware?id=331787573&mt=8
|
||||
[36]: https://play.google.com/store/apps/details?id=com.siber.roboform
|
||||
[37]: https://1password.com/downloads/
|
||||
[38]: https://itunes.apple.com/in/app/1password-password-manager/id568903335?mt=8
|
||||
[39]: https://play.google.com/store/apps/details?id=com.agilebits.onepassword&hl=en
|
||||
[40]: https://www.msecure.com/desktop-app/
|
||||
[41]: https://itunes.apple.com/in/app/msecure-password-manager/id292411902?mt=8
|
||||
[42]: https://play.google.com/store/apps/details?id=com.mseven.msecure&hl=en
|
||||
[43]: https://itunes.apple.com/us/app/onesafe/id455190486?ls=1&mt=8
|
||||
[44]: https://itunes.apple.com/us/app/onesafe-secure-password-manager/id595543758?ls=1&mt=12
|
||||
[45]: https://play.google.com/store/apps/details?id=com.lunabee.onesafe
|
||||
[46]: https://www.microsoft.com/en-us/store/apps/onesafe/9wzdncrddtx9
|
||||
[47]: https://splashid.com/downloads.php
|
||||
[48]: https://itunes.apple.com/app/splashid-safe-password-manager/id284334840?mt=8
|
||||
[49]: https://play.google.com/store/apps/details?id=com.splashidandroid&hl=en
|
||||
[50]: https://itunes.apple.com/app/loginbox-pro/id579954762?mt=8
|
||||
[51]: https://play.google.com/store/apps/details?id=com.mygosoftware.android.loginbox
|
||||
[52]: https://passwords.google.com/
|
||||
[53]: http://thehackernews.com/2014/01/Kali-linux-Self-Destruct-nuke-password.html
|
||||
|
||||
@ -1,40 +0,0 @@
|
||||
ch_cn translating
|
||||
Introducing React Native Ubuntu
|
||||
=====================
|
||||
|
||||
In the Webapps team at Canonical, we are always looking to make sure that web and near-web technologies are available to developers. We want to make everyone's life easier, enable the use of tools that are familiar to web developers and provide an easy path to using them on the Ubuntu platform.
|
||||
|
||||
We have support for web applications and creating and packaging Cordova applications, both of these enable any web framework to be used in creating great application experiences on the Ubuntu platform.
|
||||
|
||||
One popular web framework that can be used in these environments is React.js; React.js is a UI framework with a declarative programming model and strong component system, which focuses primarily on the composition of the UI, so you can use what you like elsewhere.
|
||||
|
||||
While these environments are great, sometimes you need just that bit more performance, or to be able to work with native UI components directly, but working in a less familiar environment might not be a good use of time. If you are familiar with React.js, it's easy to move into full native development with all your existing knowledge and tools by developing with React Native. React Native is the sister to React.js, you can use the same style and code to create an application that works directly with native components with native levels of performance, but with the ease of and rapid development you would expect.
|
||||
|
||||
|
||||

|
||||
|
||||
We are happy to announce that along with our HTML5 application support, it is now possible to develop React Native applications on the Ubuntu platform. You can port existing iOS or Android React Native applications, or you can start a new application leveraging your web-dev skills.
|
||||
|
||||
You can find the source code for React Native Ubuntu [here][1],
|
||||
|
||||
To get started, follow the instructions in [README-ubuntu.md][2] and create your first application.
|
||||
|
||||
The Ubuntu support includes the ability to generate packages. Managed by the React Native CLI, building a snap is as easy as 'react-native package-ubuntu --snap'. It's also possible to build a click package for Ubuntu devices; meaning React Native Ubuntu apps are store ready from the start.
|
||||
|
||||
Over the next little while there will be blogs posts on everything you need to know about developing a React Native Application for the Ubuntu platform; creating the app, the development process, packaging and releasing to the store. There will also be some information on how to develop new reusable modules, that can add extra functionality to the runtime and be distributed as Node Package Manager (npm) modules.
|
||||
|
||||
Go and experiment, and see what you can create.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://developer.ubuntu.com/en/blog/2016/08/05/introducing-react-native-ubuntu/?utm_source=javascriptweekly&utm_medium=email
|
||||
|
||||
作者:[Justin McPherson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://developer.ubuntu.com/en/blog/authors/justinmcp/
|
||||
[1]: https://github.com/CanonicalLtd/react-native
|
||||
[2]: https://github.com/CanonicalLtd/react-native/blob/ubuntu/README-ubuntu.md
|
||||
@ -1,244 +0,0 @@
|
||||
Going Serverless with AWS Lambda and API Gateway
|
||||
============================
|
||||
|
||||
Lately, there's been a lot of buzz in the computing world about "serverless". Serverless is a concept wherein you don't manage any servers yourself but instead provide your code or executables to a service that executes them for you. This is execution-as-a-service. It introduces many opportunities and also presents its own unique set of challenges.
|
||||
|
||||
A brief digression on computing
|
||||
|
||||
In the beginning, there was... well. It's a little complicated. At the very beginning, we had mechanical computers. Then along came ENIAC. Things really don't start to get "mass production", however, until the advent of mainframes.
|
||||
|
||||
```
|
||||
1950s - Mainframes
|
||||
1960s - Minicomputers
|
||||
1994 - Rack servers
|
||||
2001 - Blade servers
|
||||
2000s - Virtual servers
|
||||
2006 - Cloud servers
|
||||
2013 - Containers
|
||||
2014 - Serverless
|
||||
```
|
||||
|
||||
>These are rough release/popularity dates. Argue amongst yourselves about the timeline.
|
||||
|
||||
The progression here seems to be a trend toward executing smaller and smaller units of functionality. Each step down generally represents a decrease in the operational overhead and an increase in the operational flexibility.
|
||||
|
||||
### The possibilities
|
||||
|
||||
Yay! Serverless! But. What advantages do we gain by going serverless? And what challenges do we face?
|
||||
|
||||
No billing when there is no execution. In my mind, this is a huge selling point. When no one is using your site or your API, you aren't paying for. No ongoing infrastructure costs. Pay only for what you need. In some ways, this is the fulfillment of the cloud computing promise "pay only for what you use".
|
||||
|
||||
No servers to maintain or secure. Server maintenance and security is handled by your vendor (you could, of course, host serverless yourself, but in some ways this seems like a step in the wrong direction). Since your execution times are also limited, the patching of security issues is also simplified since there is nothing to restart. This should all be handled seamlessly by your vendor.
|
||||
|
||||
Unlimited scalability. This is another big one. Let's say you write the next Pokémon Go. Instead of your site being down every couple of days, serverless lets you just keep growing and growing. A double-edged sword, for sure (with great scalability comes great... bills), but if your service's profitability depends on being up, then serverless can help enable that.
|
||||
|
||||
Forced microservices architecture. This one really goes both ways. Microservices seem to be a good way to build flexible, scalable, and fault-tolerant architectures. On the other hand, if your business' services aren't designed this way, you're going to have difficulty adding serverless into your existing architecture.
|
||||
|
||||
### But now your stuck on their platform
|
||||
|
||||
Limited range of environments. You get what the vendor gives. You want to go serverless in Rust? You're probably out of luck.
|
||||
|
||||
Limited preinstalled packages. You get what the vendor pre-installs. But you may be able to supply your own.
|
||||
|
||||
Limited execution time. Your function can only run for so long. If you have to process a 1TB file you will likely need to 1) use a work around or 2) use something else.
|
||||
|
||||
Forced microservices architecture. See above.
|
||||
|
||||
Limited insight and ability to instrument. Just what is your code doing? With serverless, it is basically impossible to drop in a debugger and ride along. You still have the ability to log and emit metrics the usual way but these generally can only take you so far. Some of the most difficult problems may be out of reach when the occur in a serverless environment.
|
||||
|
||||
### The playing field
|
||||
|
||||
Since the introduction of AWS Lambda in 2014, the number of offerings has expanded quite a bit. Here are a few popular ones:
|
||||
|
||||
- AWS Lambda - The Original
|
||||
- OpenWhisk - Available on IBM's Bluemix cloud
|
||||
- Google Cloud Functions
|
||||
- Azure Functions
|
||||
|
||||
While all of these have their relative strengths and weaknesses (like, C# support on Azure or tight integration on any vendor's platform) the biggest player here is AWS.
|
||||
|
||||
### Building your first API with AWS Lambda and API Gateway
|
||||
|
||||
Let's give serverless a whirl, shall we? We'll be using AWS Lambda and API Gateway offerings to build an API that returns "Guru Meditations" as spoken by Jimmy.
|
||||
|
||||
All of the code is available on [GitHub][1].
|
||||
|
||||
API Documentation:
|
||||
|
||||
```
|
||||
POST /
|
||||
{
|
||||
"status": "success",
|
||||
"meditation": "did u mention banana cognac shower"
|
||||
}
|
||||
```
|
||||
|
||||
### How we'll structure things
|
||||
|
||||
The layout:
|
||||
|
||||
```
|
||||
.
|
||||
├── LICENSE
|
||||
├── README.md
|
||||
├── server
|
||||
│ ├── __init__.py
|
||||
│ ├── meditate.py
|
||||
│ └── swagger.json
|
||||
├── setup.py
|
||||
├── tests
|
||||
│ └── test_server
|
||||
│ └── test_meditate.py
|
||||
└── tools
|
||||
├── deploy.py
|
||||
├── serve.py
|
||||
├── serve.sh
|
||||
├── setup.sh
|
||||
└── zip.sh
|
||||
```
|
||||
|
||||
Things in AWS (for a more detailed view as to what is happening here, consult the source of tools/deploy.py):
|
||||
|
||||
- API. The thing that were actually building. It is represented as a separate object in AWS.
|
||||
- Execution Role. Every function executes as a particular role in AWS. Ours will be meditations.
|
||||
- Role Policy. Every function executes as a role, and every role needs permission to do things. Our lambda function doesn't do much, so we'll just add some logging permissions.
|
||||
- Lambda Function. The thing that runs our code.
|
||||
- Swagger. Swagger is a specification of an API. API Gateway supports consuming a swagger definition to configure most resources for that API.
|
||||
- Deployments. API Gateway provides for the notion of deployments. We won't be using more than one of these for our API here (i.e., everything is production, yolo, etc.), but know that they exist and for a real production-ready service you will probably want to use development and staging environments.
|
||||
- Monitoring. In case our service crashes (or begins to accumulate a hefty bill from usage) we'll want to add some monitoring in the form of cloudwatch alarms for errors and billing. Note that you should modify tools/deploy.py to set your email correctly.
|
||||
|
||||
### the codes
|
||||
|
||||
The lambda function itself will be returning guru meditations at random from a hardcoded list and is very simple:
|
||||
|
||||
```
|
||||
import logging
|
||||
import random
|
||||
|
||||
|
||||
logger = logging.getLogger()
|
||||
logger.setLevel(logging.INFO)
|
||||
|
||||
|
||||
def handler(event, context):
|
||||
|
||||
logger.info(u"received request with id '{}'".format(context.aws_request_id))
|
||||
|
||||
meditations = [
|
||||
"off to a regex/",
|
||||
"the count of machines abides",
|
||||
"you wouldn't fax a bat",
|
||||
"HAZARDOUS CHEMICALS + RKELLY",
|
||||
"your solution requires a blood eagle",
|
||||
"testing is broken because I'm lazy",
|
||||
"did u mention banana cognac shower",
|
||||
]
|
||||
|
||||
meditation = random.choice(meditations)
|
||||
|
||||
return {
|
||||
"status": "success",
|
||||
"meditation": meditation,
|
||||
}
|
||||
```
|
||||
|
||||
### The deploy.py script
|
||||
|
||||
This one is rather long (sadly) and I won't be including it here. It basically goes through each of the items under "Things in AWS" and ensures each item exists.
|
||||
|
||||
Let's deploy this shit
|
||||
|
||||
Just run `./tools/deploy.py`.
|
||||
|
||||
Well. Almost. There seems to be some issue applying privileges that I can't seem to figure out. Your lambda function will fail to execute because API Gateway does not have permissions to execute your function. The specific error should be "Execution failed due to configuration error: Invalid permissions on Lambda function". I am not sure how to add these using botocore. You can work around this issue by going to the AWS console (sadness), locating your API, going to the / POST endpoint, going to integration request, clicking the pencil icon next to "Lambda Function" to edit it, and then saving it. You'll get a popup stating "You are about to give API Gateway permission to invoke your Lambda function". Click "OK".
|
||||
|
||||
When you're finished with that, take the URL that ./tools/deploy.py printed and call it like so to see your new API in action:
|
||||
|
||||
```
|
||||
$ curl -X POST https://a1b2c3d4.execute-api.us-east-1.amazonaws.com/prod/
|
||||
{"status": "success", "meditation": "the count of machines abides"}
|
||||
```
|
||||
|
||||
### Running Locally
|
||||
|
||||
One unfortunate thing about AWS Lambda is that there isn't really a good way to run your code locally. In our case, we will use a simple flask server to host the appropriate endpoint locally and handle calling our handler function:
|
||||
|
||||
```
|
||||
from __future__ import absolute_import
|
||||
|
||||
from flask import Flask, jsonify
|
||||
|
||||
from server.meditate import handler
|
||||
|
||||
|
||||
app = Flask(__name__)
|
||||
|
||||
@app.route("/", methods=["POST"])
|
||||
def index():
|
||||
|
||||
class FakeContext(object):
|
||||
aws_request_id = "XXX"
|
||||
|
||||
return jsonify(**handler(None, FakeContext()))
|
||||
|
||||
app.run(host="0.0.0.0")
|
||||
```
|
||||
|
||||
You can run this in the repo with ./tools/serve.sh. Invoke like:
|
||||
|
||||
```
|
||||
$ curl -X POST http://localhost:5000/
|
||||
{
|
||||
"meditation": "your solution requires a blood eagle",
|
||||
"status": "success"
|
||||
}
|
||||
```
|
||||
|
||||
### Testing
|
||||
|
||||
You should always test your code. The way we'll be doing this is importing and running our handler function. This is really just plain vanilla python testing:
|
||||
|
||||
```
|
||||
from __future__ import absolute_import
|
||||
|
||||
import unittest
|
||||
|
||||
from server.meditate import handler
|
||||
|
||||
|
||||
class SubmitTestCase(unittest.TestCase):
|
||||
|
||||
def test_submit(self):
|
||||
|
||||
class FakeContext(object):
|
||||
|
||||
aws_request_id = "XXX"
|
||||
|
||||
response = handler(None, FakeContext())
|
||||
|
||||
self.assertEquals(response["status"], "success")
|
||||
self.assertTrue("meditation" in response)
|
||||
```
|
||||
|
||||
You can run the tests in the repo with nose2.
|
||||
|
||||
### Other possibilities
|
||||
|
||||
Seamless integration with AWS services. Using boto, you can pretty simply connect to any of AWS other services. You simply allow your execution role access to these services using IAM and you're on your way. You can get/put files from S3, connect to Dynamo DB, invoke other lambda functions, etc. etc. The list goes on.
|
||||
|
||||
Accessing a database. You can easily access remote databases as well. Connect to the database at the top of your lambda handler's module. Execute queries on the connection from within the handler function itself. You will (very likely) have to upload the associated package contents from where it is installed locally for this to work. You may also need to statically compile certain libraries.
|
||||
|
||||
Calling other webservices. API Gateway is also a way to translate the output from one web service into a different form. You can take advantage of this to proxy calls through to a different webservice or provide backwards compatibility when a service changes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.ryankelly.us/2016/08/07/going-serverless-with-aws-lambda-and-api-gateway.html?utm_source=webopsweekly&utm_medium=email
|
||||
|
||||
作者:[Ryan Kelly][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/f0rk/blog.ryankelly.us/
|
||||
[1]: https://github.com/f0rk/meditations
|
||||
@ -1,265 +0,0 @@
|
||||
Being translated by ChrisLeeGit
|
||||
How to Monitor Docker Containers using Grafana on Ubuntu
|
||||
================================================================================
|
||||
|
||||
Grafana is an open source feature rich metrics dashboard. It is very useful for visualizing large-scale measurement data. It provides a powerful and elegant way to create, share, and explore data and dashboards from your disparate metric databases.
|
||||
|
||||
It supports a wide variety of graphing options for ultimate flexibility. Furthermore, it supports many different storage backends for your Data Source. Each Data Source has a specific Query Editor that is customized for the features and capabilities that the particular Data Source exposes. The following datasources are officially supported by Grafana: Graphite, InfluxDB, OpenTSDB, Prometheus, Elasticsearch and Cloudwatch
|
||||
|
||||
The query language and capabilities of each Data Source are obviously very different. You can combine data from multiple Data Sources onto a single Dashboard, but each Panel is tied to a specific Data Source that belongs to a particular Organization. It supports authenticated login and a basic role based access control implementation. It is deployed as a single software installation which is written in Go and Javascript.
|
||||
|
||||
In this article, I'll explain on how to install Grafana on a docker container in Ubuntu 16.04 and configure docker monitoring using this software.
|
||||
|
||||
### Pre-requisites ###
|
||||
|
||||
- Docker installed server
|
||||
|
||||
### Installing Grafana ###
|
||||
|
||||
We can build our Grafana in a docker container. There is an official docker image available for building Grafana. Please run this command to build a Grafana container.
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -i -p 3000:3000 grafana/grafana
|
||||
|
||||
Unable to find image 'grafana/grafana:latest' locally
|
||||
latest: Pulling from grafana/grafana
|
||||
5c90d4a2d1a8: Pull complete
|
||||
b1a9a0b6158e: Pull complete
|
||||
acb23b0d58de: Pull complete
|
||||
Digest: sha256:34ca2f9c7986cb2d115eea373083f7150a2b9b753210546d14477e2276074ae1
|
||||
Status: Downloaded newer image for grafana/grafana:latest
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Starting Grafana" logger=main version=3.1.0 commit=v3.1.0 compiled=2016-07-12T06:42:28+0000
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config loaded from" logger=settings file=/usr/share/grafana/conf/defaults.ini
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config loaded from" logger=settings file=/etc/grafana/grafana.ini
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.data=/var/lib/grafana"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.logs=/var/log/grafana"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.plugins=/var/lib/grafana/plugins"
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Home" logger=settings path=/usr/share/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Data" logger=settings path=/var/lib/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Logs" logger=settings path=/var/log/grafana
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Plugins" logger=settings path=/var/lib/grafana/plugins
|
||||
t=2016-07-27T15:20:19+0000 lvl=info msg="Initializing DB" logger=sqlstore dbtype=sqlite3
|
||||
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create playlist table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create playlist item table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="drop preferences table v2"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="drop preferences table v3"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create preferences table v3"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Created default admin user: [admin]"
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Starting plugin search" logger=plugins
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Server Listening" logger=server address=0.0.0.0:3000 protocol=http subUrl=
|
||||
```
|
||||
|
||||
We can confirm the working of the Grafana container by running this command `docker ps -a` or by accessing it by URL `http://Docker IP:3000`
|
||||
|
||||
All Grafana configuration settings are defined using environment variables, this is much useful when using container technology. The Grafana configuration file is located at /etc/grafana/grafana.ini.
|
||||
|
||||
### Understanding the Configuration ###
|
||||
|
||||
The Grafana has number of configuration options that can be specified in its configuration file as .ini file or can be specified using environment variables as mentioned before.
|
||||
|
||||
#### Config file locations ####
|
||||
|
||||
Normal config file locations.
|
||||
|
||||
- Default configuration from : $WORKING_DIR/conf/defaults.ini
|
||||
- Custom configuration from : $WORKING_DIR/conf/custom.ini
|
||||
|
||||
PS : When you install Grafana using the deb or rpm packages or docker images, then your configuration file is located at /etc/grafana/grafana.ini
|
||||
|
||||
#### Understanding the config variables ####
|
||||
|
||||
Let's see some of the variables in the configuration file below:
|
||||
|
||||
`instance_name` : It's the name of the grafana server instance. It default value is fetched from ${HOSTNAME}, which will be replaced with environment variable HOSTNAME, if that is empty or does not exist Grafana will try to use system calls to get the machine name.
|
||||
|
||||
`[paths]`
|
||||
|
||||
`data` : It's the path where Grafana stores the sqlite3 database (when used), file based sessions (when used), and other data.
|
||||
|
||||
`logs` : It's where Grafana stores the logs.
|
||||
|
||||
Both these paths are usually specified via command line in the init.d scripts or the systemd service file.
|
||||
|
||||
`[server]`
|
||||
|
||||
`http_addr` : The IP address to bind the application. If it's left empty it will bind to all interfaces.
|
||||
|
||||
`http_port` : The port to which the application is bind to, defaults is 3000. You can redirect your 80 port to 3000 using the below command.
|
||||
|
||||
```
|
||||
$iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 3000
|
||||
```
|
||||
|
||||
`root_url` : This is the URL used to access Grafana from a web browser.
|
||||
|
||||
`cert_file` : Path to the certificate file (if protocol is set to https).
|
||||
|
||||
`cert_key` : Path to the certificate key file (if protocol is set to https).
|
||||
|
||||
`[database]`
|
||||
|
||||
Grafana uses a database to store its users and dashboards and other informations. By default it is configured to use sqlite3 which is an embedded database included in the main Grafana binary.
|
||||
|
||||
`type`
|
||||
You can choose mysql, postgres or sqlite3 as per our requirement.
|
||||
|
||||
`path`
|
||||
It's applicable only for sqlite3 database. The file path where the database will be stored.
|
||||
|
||||
`host`
|
||||
It's applicable only to MySQL or Postgres. it includes IP or hostname and port. For example, for MySQL running on the same host as Grafana: host = 127.0.0.1:3306
|
||||
|
||||
`name`
|
||||
The name of the Grafana database. Leave it set to grafana or some other name.
|
||||
|
||||
`user`
|
||||
The database user (not applicable for sqlite3).
|
||||
|
||||
`password`
|
||||
The database user's password (not applicable for sqlite3).
|
||||
|
||||
`ssl_mode`
|
||||
For Postgres, use either disable, require or verify-full. For MySQL, use either true, false, or skip-verify.
|
||||
|
||||
`ca_cert_path`
|
||||
(MySQL only) The path to the CA certificate to use. On many linux systems, certs can be found in /etc/ssl/certs.
|
||||
|
||||
`client_key_path`
|
||||
(MySQL only) The path to the client key. Only if server requires client authentication.
|
||||
|
||||
`client_cert_path`
|
||||
(MySQL only) The path to the client cert. Only if server requires client authentication.
|
||||
|
||||
`server_cert_name`
|
||||
(MySQL only) The common name field of the certificate used by the mysql server. Not necessary if ssl_mode is set to skip-verify.
|
||||
|
||||
`[security]`
|
||||
|
||||
`admin_user` : It is the name of the default Grafana admin user. The default name set is admin.
|
||||
|
||||
`admin_password` : It is the password of the default Grafana admin. It is set on first-run. The default password is admin.
|
||||
|
||||
`login_remember_days` : The number of days the keep me logged in / remember me cookie lasts.
|
||||
|
||||
`secret_key` : It is used for signing keep me logged in / remember me cookies.
|
||||
|
||||
### Essentials components for setting up Monitoring ###
|
||||
|
||||
We use the below components to create our Docker Monitoring system.
|
||||
|
||||
`cAdvisor` : It is otherwise called Container Advisor. It provides its users an understanding of the resource usage and performance characteristics. It collects, aggregates, processes and exports information about the running containers. You can go through this documentation for more information about this.
|
||||
|
||||
`InfluxDB` : It is a time series, metrics, and analytic database. We use this datasource for setting up our monitoring. cAdvisor displays only real time information and doesn’t store the metrics. Influx Db helps to store the monitoring information which cAdvisor provides in order to display a time range other than real time.
|
||||
|
||||
`Grafana Dashboard` : It allows us to combine all the pieces of information together visually. This powerful Dashboard allows us to run queries against the data store InfluxDB and chart them accordingly in beautiful layout.
|
||||
|
||||
### Installation of Docker Monitoring ###
|
||||
|
||||
We need to install each of these components one by one in our docker system.
|
||||
|
||||
#### Installing InfluxDB ####
|
||||
|
||||
We can use this command to pull InfluxDB image and setuup a influxDB container.
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -d -p 8083:8083 -p 8086:8086 --expose 8090 --expose 8099 -e PRE_CREATE_DB=cadvisor --name influxsrv tutum/influxdb:0.8.8
|
||||
Unable to find image 'tutum/influxdb:0.8.8' locally
|
||||
0.8.8: Pulling from tutum/influxdb
|
||||
a3ed95caeb02: Already exists
|
||||
23efb549476f: Already exists
|
||||
aa2f8df21433: Already exists
|
||||
ef072d3c9b41: Already exists
|
||||
c9f371853f28: Already exists
|
||||
a248b0871c3c: Already exists
|
||||
749db6d368d0: Already exists
|
||||
7d7c7d923e63: Pull complete
|
||||
e47cc7808961: Pull complete
|
||||
1743b6eeb23f: Pull complete
|
||||
Digest: sha256:8494b31289b4dbc1d5b444e344ab1dda3e18b07f80517c3f9aae7d18133c0c42
|
||||
Status: Downloaded newer image for tutum/influxdb:0.8.8
|
||||
d3b6f7789e0d1d01fa4e0aacdb636c221421107d1df96808ecbe8e241ceb1823
|
||||
|
||||
-p 8083:8083 : user interface, log in with username-admin, pass-admin
|
||||
-p 8086:8086 : interaction with other application
|
||||
--name influxsrv : container have name influxsrv, use to cAdvisor link it.
|
||||
```
|
||||
|
||||
You can test your InfluxDB installation by calling this URL >>http://45.79.148.234:8083 and login with user/password as "root".
|
||||
|
||||

|
||||
|
||||
We can create our required databases from this tab.
|
||||
|
||||

|
||||
|
||||
#### Installing cAdvisor ####
|
||||
|
||||
Our next step is to install cAdvisor container and link it to the InfluxDB container. You can use this command to create it.
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8080:8080 --detach=true --link influxsrv:influxsrv --name=cadvisor google/cadvisor:latest -storage_driver_db=cadvisor -storage_driver_host=influxsrv:8086
|
||||
Unable to find image 'google/cadvisor:latest' locally
|
||||
latest: Pulling from google/cadvisor
|
||||
09d0220f4043: Pull complete
|
||||
151807d34af9: Pull complete
|
||||
14cd28dce332: Pull complete
|
||||
Digest: sha256:8364c7ab7f56a087b757a304f9376c3527c8c60c848f82b66dd728980222bd2f
|
||||
Status: Downloaded newer image for google/cadvisor:latest
|
||||
3bfdf7fdc83872485acb06666a686719983a1172ac49895cd2a260deb1cdde29
|
||||
root@ubuntu:~#
|
||||
|
||||
--publish=8080:8080 : user interface
|
||||
--link=influxsrv:influxsrv: link to container influxsrv
|
||||
-storage_driver=influxdb: set the storage driver as InfluxDB
|
||||
Specify what InfluxDB instance to push data to:
|
||||
-storage_driver_host=influxsrv:8086: The ip:port of the database. Default is ‘localhost:8086’
|
||||
-storage_driver_db=cadvisor: database name. Uses db ‘cadvisor’ by default
|
||||
```
|
||||
|
||||
You can test our cAdvisor installation by calling this URL >>http://45.79.148.234:8080. This will provide you the statistics of your Docker host and containers.
|
||||
|
||||

|
||||
|
||||
#### Installing the Grafana Dashboard ####
|
||||
|
||||
Finally, we need to install the Grafana Dashboard and link to the InfluxDB. You can run this command to setup that.
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -d -p 3000:3000 -e INFLUXDB_HOST=localhost -e INFLUXDB_PORT=8086 -e INFLUXDB_NAME=cadvisor -e INFLUXDB_USER=root -e INFLUXDB_PASS=root --link influxsrv:influxsrv --name grafana grafana/grafana
|
||||
f3b7598529202b110e4e6b998dca6b6e60e8608d75dcfe0d2b09ae408f43684a
|
||||
```
|
||||
|
||||
Now we can login to Grafana and configure the Data Sources. Navigate to http://45.79.148.234:3000 or just http://45.79.148.234:
|
||||
|
||||
Username - admin
|
||||
Password - admin
|
||||
|
||||
Once we've installed Grafana, we can connect the InfluxDB. Login on the Dashboard and click on the Grafana icon(Fireball) in the upper left hand corner of the panel. Click on Data Sources to configure.
|
||||
|
||||

|
||||
|
||||
Now you can add our new Graph to our default Datasource InfluxDB.
|
||||
|
||||

|
||||
|
||||
We can edit and modify our query by adjusting our graph at Metric tab.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
You can get [more information][1] on docker monitoring here. Thank you for reading this. I would suggest your valuable comments and suggestions on this. Hope you'd a wonderful day!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/monitor-docker-containers-grafana-ubuntu/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/saheethas/
|
||||
[1]:https://github.com/vegasbrianc/docker-monitoring
|
||||
@ -1,104 +0,0 @@
|
||||
hkurj translating
|
||||
I Best Modern Linux ‘init’ Systems (1992-2015)
|
||||
============================================
|
||||
|
||||
In Linux and other Unix-like operating systems, the init (initialization) process is the first process executed by the kernel at boot time. It has a process ID (PID) of 1, it is executed in the background until the system is shut down.
|
||||
|
||||
The init process starts all other processes, that is daemons, services and other background processes, therefore, it is the mother of all other processes on the system. A process can start many other child processes on the system, but in the event that a parent process dies, init becomes the parent of the orphan process.
|
||||
|
||||

|
||||
|
||||
Over the years, many init systems have emerged in major Linux distributions and in this guide, we shall take a look at some of the best init systems you can work with on the Linux operating system.
|
||||
|
||||
### 1. System V Init
|
||||
|
||||
System V (SysV) is a mature and popular init scheme on Unix-like operating systems, it is the parent of all processes on a Unix/Linux system. SysV is the first commercial Unix operating system designed.
|
||||
|
||||
Almost all Linux distributions first used SysV init scheme except Gentoo which has a custom init and Slackware using BSD-style init scheme.
|
||||
|
||||
As years have passed by, due to some imperfections, several SysV init replacements have been developed in quests to create more efficient and perfect init systems for Linux.
|
||||
|
||||
Although these alternatives seek to improve SysV and probably offer new features, they are still compatible with original SysV init scripts.
|
||||
|
||||
### 2. SystemD
|
||||
|
||||
SystemD is a relatively new init scheme on the Linux platform. Introduced in Fedora 15, its is an assortment of tools for easy system management. The main purpose is to initialize, manage and keep track of all system processes in the boot process and while the system is running.
|
||||
|
||||
Systemd init is comprehensively distinct from other traditional Unix init systems, in the way it practically approaches system and services management. It is also compatible with SysV and LBS init scripts.
|
||||
|
||||
It has some of the following eminent features:
|
||||
|
||||
- Clean, straightforward and efficient design
|
||||
- Concurrent and parallel processing at bootup
|
||||
- Better APIv
|
||||
- Enables removal of optional processes
|
||||
- Supports event logging using journald
|
||||
- Supports job scheduling using systemd calender timers
|
||||
- Storage of logs in binary files
|
||||
- Preservation of systemd state for future reference
|
||||
- Better integration with GNOME plus many more
|
||||
|
||||
Read the Systemd init Overview: <https://fedoraproject.org/wiki/Systemd>
|
||||
|
||||
### 3. Upstart
|
||||
|
||||
Upstart is an event-based init system developed by makers of Ubuntu as a replacement for SysV init system. It starts different system tasks and processes, inspects them while the system is running and stops them during system shut down.
|
||||
|
||||
It is a hybrid init system which uses both SysV startup scripts and also Systemd scripts, some of the notable features of Upstart init system include:
|
||||
|
||||
- Originally developed for Ubuntu Linux but can run on all other distributions
|
||||
- Event-based starting and stopping of tasks and services
|
||||
- Events are generated during starting and stopping of tasks and services
|
||||
- Events can be sent by other system processes
|
||||
- Communication with init process through D-Bus
|
||||
- Users can start and stop their own processes
|
||||
- Re-spawning of services that die abruptly and many more
|
||||
|
||||
Visit Homepage: <http://upstart.ubuntu.com/index.html>
|
||||
|
||||
### 4. OpenRC
|
||||
|
||||
OpenRC is a dependency-based init scheme for Unix-like operating systems, it is compatible with SysV init. As much as it brings some improvements to Sys V, you must keep in mind that OpenRC is not an absolute replacement for /sbin/init file.
|
||||
|
||||
It offers some illustrious features and these include:
|
||||
|
||||
- It can run on other many Linux distributions including Gentoo and also on BSD
|
||||
- Supports hardware initiated init scripts
|
||||
- Supports a single configuration file
|
||||
- No per-service configurations supported
|
||||
- Runs as a daemon
|
||||
- Parallel services startup and many more
|
||||
|
||||
Visit Homepage: <https://wiki.gentoo.org/wiki/OpenRC>
|
||||
|
||||
### 5. runit
|
||||
|
||||
runit is also a cross-platform init system that can run on GNU/Linux, Solaris, *BSD and Mac OS X and it is an alternative for SysV init, that offers service supervision.
|
||||
|
||||
It comes with some benefits and remarkable components not found in SysV init and possibly other init systems in Linux and these include:
|
||||
|
||||
Service supervision, where each service is associated with a service directory
|
||||
Clean process state, it guarantees each process a clean state
|
||||
It has a reliable logging facility
|
||||
Fast system boot up and shutdown
|
||||
It is also portable
|
||||
Packaging friendly
|
||||
Small code size and many more
|
||||
Visit Homepage: <http://smarden.org/runit/>
|
||||
|
||||
As I had earlier on mentioned, the init system starts and manages all other processes on a Linux system. Additionally, SysV is the primary init scheme on Linux operating systems, but due to some performance weaknesses, system programmers have developed several replacements for it.
|
||||
|
||||
And here, we looked at a few of those replacements, but there could be other init systems that you think are worth mentioning in this list. You can let us know of them via the comment section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/best-linux-init-systems/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
@ -1,146 +0,0 @@
|
||||
Translating by cposture
|
||||
How to Mount Remote Linux Filesystem or Directory Using SSHFS Over SSH
|
||||
============================
|
||||
|
||||
The main purpose of writing this article is to provide a step-by-step guide on how to mount remote Linux file system using SSHFS client over SSH.
|
||||
|
||||
This article is useful for those users and system administrators who want to mount remote file system on their local systems for whatever purposes. We have practically tested by installing SSHFS client on one of our Linux system and successfully mounted remote file systems.
|
||||
|
||||
Before we go further installation let’s understand about SSHFS and how it works.
|
||||
|
||||

|
||||
>Sshfs Mount Remote Linux Filesystem or Directory
|
||||
|
||||
### What Is SSHFS?
|
||||
|
||||
SSHFS stands for (Secure SHell FileSystem) client that enable us to mount remote filesystem and interact with remote directories and files on a local machine using SSH File Transfer Protocol (SFTP).
|
||||
|
||||
SFTP is a secure file transfer protocol that provides file access, file transfer and file management features over Secure Shell protocol. Because SSH uses encryption while transferring files over the network from one computer to another computer and SSHFS comes with built-in FUSE (Filesystem in Userspace) kernel module that allows any non-privileged users to create their file system without modifying kernel code.
|
||||
|
||||
In this article, we will show you how to install and use SSHFS client on any Linux distribution to mount remote Linux filesystem or directory on a local Linux machine.
|
||||
|
||||
#### Step 1: Install SSHFS Client in Linux Systems
|
||||
|
||||
By default sshfs packages does not exists on all major Linux distributions, you need to enable [epel repository][1] under your Linux systems to install sshfs with the help of Yum command with their dependencies.
|
||||
|
||||
```
|
||||
# yum install sshfs
|
||||
# dnf install sshfs [On Fedora 22+ releases]
|
||||
$ sudo apt-get install sshfs [On Debian/Ubuntu based systems]
|
||||
```
|
||||
|
||||
#### Step 2: Creating SSHFS Mount Directory
|
||||
|
||||
Once the sshfs package installed, you need to create a mount point directory where you will mount your remote file system. For example, we have created mount directory under /mnt/tecmint.
|
||||
|
||||
```
|
||||
# mkdir /mnt/tecmint
|
||||
$ sudo mkdir /mnt/tecmint [On Debian/Ubuntu based systems]
|
||||
```
|
||||
|
||||
### Step 3: Mounting Remote Filesystem with SSHFS
|
||||
|
||||
Once you have created your mount point directory, now run the following command as a root user to mount remote file system under /mnt/tecmint. In your case the mount directory would be anything.
|
||||
|
||||
The following command will mount remote directory called /home/tecmint under /mnt/tecmint in local system. (Don’t forget replace x.x.x.x with your IP Address and mount point).
|
||||
|
||||
```
|
||||
# sshfs tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint
|
||||
$ sudo sshfs -o allow_other tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint [On Debian/Ubuntu based systems]
|
||||
```
|
||||
|
||||
If your Linux server is configured with SSH key based authorization, then you will need to specify the path to your public keys as shown in the following command.
|
||||
|
||||
```
|
||||
# sshfs -o IdentityFile=~/.ssh/id_rsa tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint
|
||||
$ sudo sshfs -o allow_other,IdentityFile=~/.ssh/id_rsa tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint [On Debian/Ubuntu based systems]
|
||||
```
|
||||
|
||||
#### Step 4: Verifying Remote Filesystem is Mounted
|
||||
|
||||
If you have run the above command successfully without any errors, you will see the list of remote files and directories mounted under /mnt/tecmint.
|
||||
|
||||
```
|
||||
# cd /mnt/tecmint
|
||||
# ls
|
||||
[root@ tecmint]# ls
|
||||
12345.jpg ffmpeg-php-0.6.0.tbz2 Linux news-closeup.xsl s3.jpg
|
||||
cmslogs gmd-latest.sql.tar.bz2 Malware newsletter1.html sshdallow
|
||||
epel-release-6-5.noarch.rpm json-1.2.1 movies_list.php pollbeta.sql
|
||||
ffmpeg-php-0.6.0 json-1.2.1.tgz my_next_artical_v2.php pollbeta.tar.bz2
|
||||
```
|
||||
|
||||
#### Step 5: Checking Mount Point with df -hT Command
|
||||
|
||||
If you run df -hT command you will see the remote file system mount point.
|
||||
|
||||
```
|
||||
# df -hT
|
||||
```
|
||||
|
||||
Sample Output
|
||||
|
||||
```
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
udev devtmpfs 730M 0 730M 0% /dev
|
||||
tmpfs tmpfs 150M 4.9M 145M 4% /run
|
||||
/dev/sda1 ext4 31G 5.5G 24G 19% /
|
||||
tmpfs tmpfs 749M 216K 748M 1% /dev/shm
|
||||
tmpfs tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs tmpfs 749M 0 749M 0% /sys/fs/cgroup
|
||||
tmpfs tmpfs 150M 44K 150M 1% /run/user/1000
|
||||
tecmint@192.168.0.102:/home/tecmint fuse.sshfs 324G 55G 253G 18% /mnt/tecmint
|
||||
```
|
||||
|
||||
#### Step 6: Mounting Remote Filesystem Permanently
|
||||
|
||||
To mount remote filesystem permanently, you need to edit the file called /etc/fstab. To do, open the file with your favorite editor.
|
||||
|
||||
```
|
||||
# vi /etc/fstab
|
||||
$ sudo vi /etc/fstab [On Debian/Ubuntu based systems]
|
||||
```
|
||||
|
||||
Go to the bottom of the file and add the following line to it and save the file and exit. The below entry mount remote server file system with default settings.
|
||||
|
||||
```
|
||||
sshfs#tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint fuse.sshfs defaults 0 0
|
||||
```
|
||||
|
||||
Make sure you’ve [SSH Passwordless Login][2] in place between servers to auto mount filesystem during system reboots..
|
||||
|
||||
```
|
||||
sshfs#tecmint@x.x.x.x:/home/tecmint/ /mnt/tecmint fuse.sshfs IdentityFile=~/.ssh/id_rsa defaults 0 0
|
||||
```
|
||||
|
||||
Next, you need to update the fstab file to reflect the changes.
|
||||
|
||||
```
|
||||
# mount -a
|
||||
$ sudo mount -a [On Debian/Ubuntu based systems]
|
||||
```
|
||||
|
||||
#### Step 7: Unmounting Remote Filesystem
|
||||
|
||||
To unmount remote filesystem, jun issue the following command it will unmount the remote file system.
|
||||
|
||||
```
|
||||
# umount /mnt/tecmint
|
||||
```
|
||||
|
||||
That’s all for now, if you’re facing any difficulties or need any help in mounting remote file system, please contact us via comments and if you feel this article is much useful then share it with your friends.
|
||||
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sshfs-mount-remote-linux-filesystem-directory-using-ssh/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/admin/
|
||||
[1]: http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]: http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
@ -1,5 +1,4 @@
|
||||
icecoobe translating
|
||||
|
||||
(翻译中 by runningwater)
|
||||
part 7 - How to manage binary blobs with Git
|
||||
=====================
|
||||
|
||||
@ -127,7 +126,7 @@ Git is a powerful and extensible system, and by now there is really no excuse fo
|
||||
via: https://opensource.com/life/16/8/how-manage-binary-blobs-git-part-7
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,222 +0,0 @@
|
||||
Translating by Yinr
|
||||
|
||||
The cost of small modules
|
||||
====
|
||||
|
||||
About a year ago I was refactoring a large JavaScript codebase into smaller modules, when I discovered a depressing fact about Browserify and Webpack:
|
||||
|
||||
> “The more I modularize my code, the bigger it gets. ”– Nolan Lawson
|
||||
|
||||
Later on, Sam Saccone published some excellent research on [Tumblr](https://docs.google.com/document/d/1E2w0UQ4RhId5cMYsDcdcNwsgL0gP_S6SDv27yi1mCEY/edit) and [Imgur](https://github.com/perfs/audits/issues/1)‘s page load performance, in which he noted:
|
||||
|
||||
> “Over 400ms is being spent simply walking the Browserify tree.”– Sam Saccone
|
||||
|
||||
In this post, I’d like to demonstrate that small modules can have a surprisingly high performance cost depending on your choice of bundler and module system. Furthermore, I’ll explain why this applies not only to the modules in your own codebase, but also to the modules within dependencies, which is a rarely-discussed aspect of the cost of third-party code.
|
||||
|
||||
### Web perf 101
|
||||
|
||||
The more JavaScript included on a page, the slower that page tends to be. Large JavaScript bundles cause the browser to spend more time downloading, parsing, and executing the script, all of which lead to slower load times.
|
||||
|
||||
Even when breaking up the code into multiple bundles – Webpack [code splitting](https://webpack.github.io/docs/code-splitting.html), Browserify[factor bundles](https://github.com/substack/factor-bundle), etc. – the cost is merely delayed until later in the page lifecycle. Sooner or later, the JavaScript piper must be paid.
|
||||
|
||||
Furthermore, because JavaScript is a dynamic language, and because the prevailing[CommonJS](http://www.commonjs.org/) module system is also dynamic, it’s fiendishly difficult to extract unused code from the final payload that gets shipped to users. You might only need jQuery’s $.ajax, but by including jQuery, you pay the cost of the entire library.
|
||||
|
||||
The JavaScript community has responded to this problem by advocating the use of [small modules](http://substack.net/how_I_write_modules). Small modules have a lot of [aesthetic and practical benefits](http://dailyjs.com/2015/07/02/small-modules-complexity-over-size/) – easier to maintain, easier to comprehend, easier to plug together – but they also solve the jQuery problem by promoting the inclusion of small bits of functionality rather than big “kitchen sink” libraries.
|
||||
|
||||
So in the “small modules” world, instead of doing:
|
||||
|
||||
```
|
||||
var _ = require('lodash')
|
||||
_.uniq([1,2,2,3])
|
||||
```
|
||||
|
||||
You might do:
|
||||
|
||||
```
|
||||
var uniq = require('lodash.uniq')
|
||||
uniq([1,2,2,3])
|
||||
```
|
||||
|
||||
### Packages vs modules
|
||||
|
||||
It’s important to note that, when I say “modules,” I’m not talking about “packages” in the npm sense. When you install a package from npm, it might only expose a single module in its public API, but under the hood it could actually be a conglomeration of many modules.
|
||||
|
||||
For instance, consider a package like [is-array](https://www.npmjs.com/package/is-array). It has no dependencies and only contains[one JavaScript file](https://github.com/retrofox/is-array/blob/d79f1c90c824416b60517c04f0568b5cd3f8271d/index.js#L6-L33), so it has one module. Simple enough.
|
||||
|
||||
Now consider a slightly more complex package like [once](https://www.npmjs.com/package/once), which has exactly one dependency:[wrappy](https://www.npmjs.com/package/wrappy). [Both](https://github.com/isaacs/once/blob/2ad558657e17fafd24803217ba854762842e4178/once.js#L1-L21) [packages](https://github.com/npm/wrappy/blob/71d91b6dc5bdeac37e218c2cf03f9ab55b60d214/wrappy.js#L6-L33) contain one module, so the total module count is 2\. So far, so good.
|
||||
|
||||
Now let’s consider a more deceptive example: [qs](https://www.npmjs.com/package/qs). Since it has zero dependencies, you might assume it only has one module. But in fact, it has four!
|
||||
|
||||
You can confirm this by using a tool I wrote called [browserify-count-modules](https://www.npmjs.com/package/browserify-count-modules), which simply counts the total number of modules in a Browserify bundle:
|
||||
|
||||
```
|
||||
$ npm install qs
|
||||
$ browserify node_modules/qs | browserify-count-modules
|
||||
4
|
||||
```
|
||||
|
||||
This means that a given package can actually contain one or more modules. These modules can also depend on other packages, which might bring in their own packages and modules. The only thing you can be sure of is that each package contains at least one module.
|
||||
|
||||
### Module bloat
|
||||
|
||||
How many modules are in a typical web application? Well, I ran browserify-count-moduleson a few popular Browserify-using sites, and came up with these numbers:
|
||||
|
||||
* [requirebin.com](http://requirebin.com/): 91 modules
|
||||
* [keybase.io](https://keybase.io/): 365 modules
|
||||
* [m.reddit.com](http://m.reddit.com/): 1050 modules
|
||||
* [Apple.com](http://images.apple.com/ipad-air-2/): 1060 modules (Added. [Thanks, Max!](https://twitter.com/denormalize/status/765300194078437376))
|
||||
|
||||
For the record, my own [Pokedex.org](https://pokedex.org/) (the largest open-source site I’ve built) contains 311 modules across four bundle files.
|
||||
|
||||
Ignoring for a moment the raw size of those JavaScript bundles, I think it’s interesting to explore the cost of the number of modules themselves. Sam Saccone has already blown this story wide open in [“The cost of transpiling es2015 in 2016”](https://github.com/samccone/The-cost-of-transpiling-es2015-in-2016#the-cost-of-transpiling-es2015-in-2016), but I don’t think his findings have gotten nearly enough press, so let’s dig a little deeper.
|
||||
|
||||
### Benchmark time!
|
||||
|
||||
I put together [a small benchmark](https://github.com/nolanlawson/cost-of-small-modules) that constructs a JavaScript module importing 100, 1000, and 5000 other modules, each of which merely exports a number. The parent module just sums the numbers together and logs the result:
|
||||
|
||||
```
|
||||
// index.js
|
||||
var total = 0
|
||||
total += require('./module_0')
|
||||
total += require('./module_1')
|
||||
total += require('./module_2')
|
||||
// etc.
|
||||
console.log(total)
|
||||
|
||||
|
||||
// module_1.js
|
||||
module.exports = 1
|
||||
```
|
||||
|
||||
I tested five bundling methods: Browserify, Browserify with the [bundle-collapser](https://www.npmjs.com/package/bundle-collapser) plugin, Webpack, Rollup, and Closure Compiler. For Rollup and Closure Compiler I used ES6 modules, whereas for Browserify and Webpack I used CommonJS, so as not to unfairly disadvantage them (since they would need a transpiler like Babel, which adds its own overhead).
|
||||
|
||||
In order to best simulate a production environment, I used Uglify with the --mangle and--compress settings for all bundles, and served them gzipped over HTTPS using GitHub Pages. For each bundle, I downloaded and executed it 15 times and took the median, noting the (uncached) load time and execution time using performance.now().
|
||||
|
||||
### Bundle sizes
|
||||
|
||||
Before we get into the benchmark results, it’s worth taking a look at the bundle files themselves. Here are the byte sizes (minified but ungzipped) for each bundle ([chart view](https://nolanwlawson.files.wordpress.com/2016/08/min.png)):
|
||||
|
||||
| | 100 modules | 1000 modules | 5000 modules |
|
||||
| --- | --- | --- | --- |
|
||||
| browserify | 7982 | 79987 | 419985 |
|
||||
| browserify-collapsed | 5786 | 57991 | 309982 |
|
||||
| webpack | 3954 | 39055 | 203052 |
|
||||
| rollup | 671 | 6971 | 38968 |
|
||||
| closure | 758 | 7958 | 43955 |
|
||||
|
||||
| | 100 modules | 1000 modules | 5000 modules |
|
||||
| --- | --- | --- | --- |
|
||||
| browserify | 1649 | 13800 | 64513 |
|
||||
| browserify-collapsed | 1464 | 11903 | 56335 |
|
||||
| webpack | 693 | 5027 | 26363 |
|
||||
| rollup | 300 | 2145 | 11510 |
|
||||
| closure | 302 | 2140 | 11789 |
|
||||
|
||||
The way Browserify and Webpack work is by isolating each module into its own function scope, and then declaring a top-level runtime loader that locates the proper module whenever require() is called. Here’s what our Browserify bundle looks like:
|
||||
|
||||
```
|
||||
(function e(t,n,r){function s(o,u){if(!n[o]){if(!t[o]){var a=typeof require=="function"&&require;if(!u&&a)return a(o,!0);if(i)return i(o,!0);var f=new Error("Cannot find module '"+o+"'");throw f.code="MODULE_NOT_FOUND",f}var l=n[o]={exports:{}};t[o][0].call(l.exports,function(e){var n=t[o][1][e];return s(n?n:e)},l,l.exports,e,t,n,r)}return n[o].exports}var i=typeof require=="function"&&require;for(var o=0;o
|
||||
```
|
||||
|
||||
Whereas the Rollup and Closure bundles look more like what you might hand-author if you were just writing one big module. Here’s Rollup:
|
||||
|
||||
```
|
||||
(function () {
|
||||
'use strict';
|
||||
var total = 0
|
||||
total += 0
|
||||
total += 1
|
||||
total += 2
|
||||
// etc.
|
||||
```
|
||||
|
||||
If you understand the inherent cost of functions-within-functions in JavaScript, and of looking up a value in an associative array, then you’ll be in a good position to understand the following benchmark results.
|
||||
|
||||
### Results
|
||||
|
||||
I ran this benchmark on a Nexus 5 with Android 5.1.1 and Chrome 52 (to represent a low- to mid-range device) as well as an iPod Touch 6th generation running iOS 9 (to represent a high-end device).
|
||||
|
||||
Here are the results for the Nexus 5 ([tabular results](https://gist.github.com/nolanlawson/e84ad060a20f0cb7a7c32308b6b46abe)):
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_nexus_5.png)
|
||||
|
||||
And here are the results for the iPod Touch ([tabular results](https://gist.github.com/nolanlawson/45ed2c7fa53da035dfc1e153763b9f93)):
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_ipod.png)
|
||||
|
||||
At 100 modules, the variance between all the bundlers is pretty negligible, but once we get up to 1000 or 5000 modules, the difference becomes severe. The iPod Touch is hurt the least by the choice of bundler, but the Nexus 5, being an aging Android phone, suffers a lot under Browserify and Webpack.
|
||||
|
||||
I also find it interesting that both Rollup and Closure’s execution cost is essentially free for the iPod, regardless of the number of modules. And in the case of the Nexus 5, the runtime costs aren’t free, but they’re still much cheaper for Rollup/Closure than for Browserify/Webpack, the latter of which chew up the main thread for several frames if not hundreds of milliseconds, meaning that the UI is frozen just waiting for the module loader to finish running.
|
||||
|
||||
Note that both of these tests were run on a fast Gigabit connection, so in terms of network costs, it’s really a best-case scenario. Using the Chrome Dev Tools, we can manually throttle that Nexus 5 down to 3G and see the impact ([tabular results](https://gist.github.com/nolanlawson/6269d304c970174c21164288808392ea)):
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_nexus_53g.png)
|
||||
|
||||
Once we take slow networks into account, the difference between Browserify/Webpack and Rollup/Closure is even more stark. In the case of 1000 modules (which is close to Reddit’s count of 1050), Browserify takes about 400 milliseconds longer than Rollup. And that 400ms is no small potatoes, since Google and Bing have both noted that sub-second delays have an[appreciable impact on user engagement](http://radar.oreilly.com/2009/06/bing-and-google-agree-slow-pag.html).
|
||||
|
||||
One thing to note is that this benchmark doesn’t measure the precise execution cost of 100, 1000, or 5000 modules per se, since that will depend on your usage of require(). Inside of these bundles, I’m calling require() once per module, but if you are calling require()multiple times per module (which is the norm in most codebases) or if you are callingrequire() multiple times on-the-fly (i.e. require() within a sub-function), then you could see severe performance degradations.
|
||||
|
||||
Reddit’s mobile site is a good example of this. Even though they have 1050 modules, I clocked their real-world Browserify execution time as much worse than the “1000 modules” benchmark. When profiling on that same Nexus 5 running Chrome, I measured 2.14 seconds for Reddit’s Browserify require() function, and 197 milliseconds for the equivalent function in the “1000 modules” script. (In desktop Chrome on an i7 Surface Book, I also measured it at 559ms vs 37ms, which is pretty astonishing given we’re talking desktop.)
|
||||
|
||||
This suggests that it may be worthwhile to run the benchmark again with multiplerequire()s per module, although in my opinion it wouldn’t be a fair fight for Browserify/Webpack, since Rollup/Closure both resolve duplicate ES6 imports into a single hoisted variable declaration, and it’s also impossible to import from anywhere but the top-level scope. So in essence, the cost of a single import for Rollup/Closure is the same as the cost of n imports, whereas for Browserify/Webpack, the execution cost will increase linearly with n require()s.
|
||||
|
||||
For the purposes of this analysis, though, I think it’s best to just assume that the number of modules is only a lower bound for the performance hit you might feel. In reality, the “5000 modules” benchmark may be a better yardstick for “5000 require() calls.”
|
||||
|
||||
### Conclusions
|
||||
|
||||
First off, the bundle-collapser plugin seems to be a valuable addition to Browserify. If you’re not using it in production, then your bundle will be a bit larger and slower than it would be otherwise (although I must admit the difference is slight). Alternatively, you could switch to Webpack and get an even faster bundle without any extra configuration. (Note that it pains me to say this, since I’m a diehard Browserify fanboy.)
|
||||
|
||||
However, these results clearly show that Webpack and Browserify both underperform compared to Rollup and Closure Compiler, and that the gap widens the more modules you add. Unfortunately I’m not sure [Webpack 2](https://gist.github.com/sokra/27b24881210b56bbaff7) will solve any of these problems, because although they’ll be [borrowing some ideas from Rollup](http://www.2ality.com/2015/12/webpack-tree-shaking.html), they seem to be more focused on the[tree-shaking aspects](http://www.2ality.com/2015/12/bundling-modules-future.html) and not the scope-hoisting aspects. (Update: a better name is “inlining,” and the Webpack team is [working on it](https://github.com/webpack/webpack/issues/2873#issuecomment-240067865).)
|
||||
|
||||
Given these results, I’m surprised Closure Compiler and Rollup aren’t getting much traction in the JavaScript community. I’m guessing it’s due to the fact that (in the case of the former) it has a Java dependency, and (in the case of the latter) it’s still fairly immature and doesn’t quite work out-of-the-box yet (see [Calvin’s Metcalf’s comments](https://github.com/rollup/rollup/issues/552) for a good summary).
|
||||
|
||||
Even without the average JavaScript developer jumping on the Rollup/Closure bandwagon, though, I think npm package authors are already in a good position to help solve this problem. If you npm install lodash, you’ll notice that the main export is one giant JavaScript module, rather than what you might expect given Lodash’s hyper-modular nature (require('lodash/uniq'), require('lodash.uniq'), etc.). For PouchDB, we made a similar decision to [use Rollup as a prepublish step](http://pouchdb.com/2016/01/13/pouchdb-5.2.0-a-better-build-system-with-rollup.html), which produces the smallest possible bundle in a way that’s invisible to users.
|
||||
|
||||
I also created [rollupify](https://github.com/nolanlawson/rollupify) to try to make this pattern a bit easier to just drop-in to existing Browserify projects. The basic idea is to use imports and exports within your own project ([cjs-to-es6](https://github.com/nolanlawson/cjs-to-es6) can help migrate), and then use require() for third-party packages. That way, you still have all the benefits of modularity within your own codebase, while exposing more-or-less one big module to your users. Unfortunately, you still pay the costs for third-party modules, but I’ve found that this is a good compromise given the current state of the npm ecosystem.
|
||||
|
||||
So there you have it: one horse-sized JavaScript duck is faster than a hundred duck-sized JavaScript horses. Despite this fact, though, I hope that our community will eventually realize the pickle we’re in – advocating for a “small modules” philosophy that’s good for developers but bad for users – and improve our tools, so that we can have the best of both worlds.
|
||||
|
||||
### Bonus round! Three desktop browsers
|
||||
|
||||
Normally I like to run performance tests on mobile devices, since that’s where you see the clearest differences. But out of curiosity, I also ran this benchmark on Chrome 52, Edge 14, and Firefox 48 on an i7 Surface Book using Windows 10 RS1\. Here are the results:
|
||||
|
||||
Chrome 52 ([tabular results](https://gist.github.com/nolanlawson/4f79258dc05bbd2c14b85cf2196c6ef0))
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_chrome.png)
|
||||
|
||||
Edge 14 ([tabular results](https://gist.github.com/nolanlawson/726fa47e0723b45e4ee9ecf0cf2fcddb))
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_edge.png)
|
||||
|
||||
Firefox 48 ([tabular results](https://gist.github.com/nolanlawson/7eed17e6ffa18752bf99a9d4bff2941f))
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_firefox.png)
|
||||
|
||||
The only interesting tidbits I’ll call out in these results are:
|
||||
|
||||
1. bundle-collapser is definitely not a slam-dunk in all cases.
|
||||
2. The ratio of network-to-execution time is always extremely high for Rollup and Closure; their runtime costs are basically zilch. ChakraCore and SpiderMonkey eat them up for breakfast, and V8 is not far behind.
|
||||
|
||||
This latter point could be extremely important if your JavaScript is largely lazy-loaded, because if you can afford to wait on the network, then using Rollup and Closure will have the additional benefit of not clogging up the UI thread, i.e. they’ll introduce less jank than Browserify or Webpack.
|
||||
|
||||
Update: in response to this post, JDD has [opened an issue on Webpack](https://github.com/webpack/webpack/issues/2873). There’s also [one on Browserify](https://github.com/substack/node-browserify/issues/1379).
|
||||
|
||||
Update 2: [Ryan Fitzer](https://github.com/nolanlawson/cost-of-small-modules/pull/5) has generously added RequireJS and RequireJS with [Almond](https://github.com/requirejs/almond) to the benchmark, both of which use AMD instead of CommonJS or ES6.
|
||||
|
||||
Testing shows that RequireJS has [the largest bundle sizes](https://gist.github.com/nolanlawson/511e0ce09fed29fed040bb8673777ec5) but surprisingly its runtime costs are [very close to Rollup and Closure](https://gist.github.com/nolanlawson/4e725df00cd1bc9673b25ef72b831c8b). Here are the results for a Nexus 5 running Chrome 52 throttled to 3G:
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/2016-08-20-14_45_29-small_modules3-xlsx-excel.png)
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nolanlawson.com/2016/08/15/the-cost-of-small-modules/?utm_source=javascriptweekly&utm_medium=email
|
||||
|
||||
作者:[Nolan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nolanlawson.com/
|
||||
@ -1,201 +0,0 @@
|
||||
JianhuanZhuo
|
||||
|
||||
Building a Real-Time Recommendation Engine with Data Science
|
||||
======================
|
||||
|
||||
Editor’s Note: This presentation was given by Nicole White at GraphConnect Europe in April 2016. Here’s a quick review of what she covered:
|
||||
- [Basic graph-powered recommendations][1]
|
||||
- [Social recommendations][2]
|
||||
- [Similarity recommendations][3]
|
||||
- [Cluster recommendations][4]
|
||||
|
||||
What we’re going to be talking about today is data science and graph recommendations:
|
||||
|
||||
I’ve been with Neo4j for two years now, but have been working with Neo4j and Cypher for three. I discovered this particular graph database when I was a grad student at the University of Texas Austin studying for a masters in statistics with a focus on social networks.
|
||||
|
||||
[Real-time recommendation engines][5] are one of the most common use cases for Neo4j, and one of the things that makes it so powerful and easy to use. To explore this, I’ll explain how to incorporate statistical methods into these recommendations by using example datasets.
|
||||
|
||||
The first will be simple – entirely in Cypher with a focus on social recommendations. Next we’ll look at the similarity recommendation, which involves similarity metrics that can be calculated, and finally a clustering recommendation.
|
||||
|
||||
### Basic Graph-Powered Recommendations
|
||||
|
||||
The following dataset includes food and drink places in the Dallas Fort Worth International Airport, one of the major airport hubs in the United States:
|
||||
|
||||

|
||||
|
||||
We have place nodes in yellow and are modeling their location in terms of gate and terminal. And we are also categorizing the place in terms of major categories for food and drink. Some include Mexican food, sandwiches, bars and barbecue.
|
||||
|
||||
Let’s do a simple recommendation. We want to find a specific type of food in a certain location in the airport, and the curled brackets represent user inputs which are being entered into our hypothetical app:
|
||||
|
||||

|
||||
|
||||
This English sentence maps really well as a Cypher query:
|
||||
|
||||

|
||||
|
||||
This is going to pull all the places in the category, terminal and gate the user has requested. Then we get the absolute distance of the place to gate where the user is, and return the results in ascending order. Again, a very simple Cypher recommendation to a user based just on their location in the airport.
|
||||
|
||||
### Social Recommendations
|
||||
|
||||
Let’s look at a social recommendation. In our hypothetical app, we have users who can log in and “like” places in a way similar to Facebook and can also check into places:
|
||||
|
||||

|
||||
|
||||
Consider this data model on top of the first model that we explored, and now let’s find food and drink places in the following categories closest to some gate in whatever terminal that user’s friends like:
|
||||
|
||||

|
||||
|
||||
The MATCH clause is very similar to the MATCH clause of our first Cypher query, except now we are matching on likes and friends:
|
||||
|
||||

|
||||
|
||||
The first three lines are the same, but for the user in question – the user that’s “logged in” – we want to find their friends through the :FRIENDS_WITH relationship along with the places those friends liked. With just a few added lines of Cypher, we are now taking a social aspect into account for our recommendation engine.
|
||||
|
||||
Again, we’re only showing categories that the user explicitly asked for that are in the same terminals the user is in. And, of course, we want to filter this by the user who is logged in and making this request, and it returns the name of the place along with its location and category. We are also accounting for how many friends have liked that place and the absolute value of the distance of the place from the gate, all returned in the RETURN clause.
|
||||
|
||||
### Similarity Recommendation
|
||||
|
||||
Now let’s take a look at a similarity recommendation engine:
|
||||
|
||||

|
||||
|
||||
Similarly to our earlier data model, we have users who can like places, but this time they can also rate places with an integer between one and 10. This is easily modeled in Neo4j by adding a property to the relationship.
|
||||
|
||||
This allows us to find other similar users, like in the example of Greta and Alice. We’ve queried the places they’ve mutually liked, and for each of those places, we can see the weights they have assigned. Presumably, we can use these numbers to determine how similar they are to each other:
|
||||
|
||||
|
||||
|
||||
Now we have two vectors:
|
||||
|
||||

|
||||
|
||||
And now let’s apply Euclidean distance to find the distance between those two vectors:
|
||||
|
||||

|
||||
|
||||
And when we plug in all the numbers, we get the following similarity metric, which is really the distance metric between the two users:
|
||||
|
||||

|
||||
|
||||
You can do this between two specific users easily in Cypher, especially if they’ve only mutually liked a small subset of places. Again, here we’re matching on two users, Alice and Greta, and are trying to find places they’ve mutually liked:
|
||||
|
||||

|
||||
|
||||
They both have to have a :LIKES relationship to the place for it to be found in this result, and then we can easily calculate the Euclidean distance between them with the square root of the sum of their squared differences in Cypher.
|
||||
|
||||
While this may work in an example with two specific people, it doesn’t necessarily work in real time when you’re trying to infer similar users from another user on the fly, by comparing them against every other user in the database in real time. Needless to say, this doesn’t work very well.
|
||||
|
||||
To find a way around this, we pre-compute this calculation and store it in an actual relationship:
|
||||
|
||||

|
||||
|
||||
While in large datasets we would do this in batches, in this small example dataset, we can match on a Cartesian product of all the users and places they’ve mutually liked. When we use WHERE id(u1) < id(u2) as part of our Cypher query, this is just a trick to ensure we’re not finding the same pair twice on both the left and the right.
|
||||
|
||||
Then with their Euclidean distance and themselves, we’re going to create a relationship between them called :DISTANCE and set a Euclidean property called euclidean. In theory, we could also store other similarity metrics on some relationship between users to capture different similarity metrics, since some might be more useful than others in certain contexts.
|
||||
|
||||
And it’s really this ability to model properties on relationships in Neo4j that makes things like this incredibly easy. However, in practice you don’t want to store every single relationship that can possibly exist because you’ll only want to return the top few people of their neighbors.
|
||||
|
||||
So you can just store the top in according to some threshold so you don’t have this fully connected graph. This allows you to perform graph database queries like the below in real time, because we’ve pre-computed it and stored it on the relationship, and in Cypher we’ll be able to grab that very quickly:
|
||||
|
||||

|
||||
|
||||
In this query, we’re matching on places and categories:
|
||||
|
||||

|
||||
|
||||
Again, the first three lines are the same, except that for the logged-in user, we’re getting users who have a :DISTANCE relationship to them. This is where what we went over earlier comes into play – in practice you should only store the top :DISTANCE relationships to users who are similar to them so you’re not grabbing a huge volume of users in this MATCH clause. Instead, we’re grabbing users who have a :DISTANCE relationship to them where those users like that place.
|
||||
|
||||
This has allowed us to express a somewhat complicated pattern in just a few lines. We’re also grabbing the :LIKES relationship and putting it on a variable because we’re going to use those weights later to apply a rating.
|
||||
|
||||
What’s important here is that we’re ordering those users by their distance ascending, because it is a distance metric, and we want the lowest distances because that indicates they are the most similar.
|
||||
|
||||
With those other users ordered by the Euclidean distance, we’re going to collect the top three users’ ratings and use those as our average score to recommend these places. In other words, we’ve taken an active user, found users who are most similar to them based on the places they’ve liked, and then averaged the scores those similar users have given to rank those places in a result set.
|
||||
|
||||
We’re essentially taking an average here by adding it up and dividing by the number of elements in the collection, and we’re ordering by that average ascending. Then secondarily, we’re ordering by the gate distance. Hypothetically, there could be ties I suppose, and then you order by the gate distance and then returning the name, category, gate and terminal.
|
||||
|
||||
### Cluster Recommendations
|
||||
|
||||
Our final example is going to be a cluster recommendation, which can be thought of as a workflow of offline computing that may be required as a workaround in Cypher. This may now be obsolete based on the new procedures announced at GraphConnect Europe, but sometimes you have to do certain algorithmic approaches that Cypher version 2.3 doesn’t expose.
|
||||
|
||||
This is where you can use some form of statistical software, pull data out of Neo4j into a software such as Apache Spark, R or Python. Below is an example of R code for pulling data out of Neo4j, running an algorithm, and then – if appropriate – writing the results of that algorithm back into Neo4j as either a property, node, relationship or a new label.
|
||||
|
||||
By persisting the results of that algorithm into the graph, you can use it in real-time with queries similar to the ones we just went over:
|
||||
|
||||

|
||||
|
||||
Below is some example code for how you do this in R, but you can easily do the same thing with whatever software you’re most comfortable with, such as Python or Spark. All you have to do is log in and connect to the graph.
|
||||
|
||||
In the following example, I’ve clustered users together based on their similarities. Each user is represented as an observation, and I want to get the average rating that they’ve given each category:
|
||||
|
||||
|
||||
|
||||
Presumably, users who rate the bar category in similar ways are similar in general. Here I’m grabbing the names of users who like places in the same category, the category name, and the average weight of the “likes” relationships, as average weight, and that’s going to give me a table like this:
|
||||
|
||||
|
||||
|
||||
Because we want each user to be an observation, we will have to manipulate the data where each feature is the average weight rating they’ve given restaurants within that category, per category. We’ll then use this to determine how similar they are, and I’m going to use a clustering algorithm to determine users being in different clusters.
|
||||
|
||||
In R this is very straightforward:
|
||||
|
||||

|
||||
|
||||
For this demonstration we are using k-means, which allows you to easily grab cluster assignments. In summary, I ran a clustering algorithm and now for each user I have a cluster assignment.
|
||||
|
||||
Bob and David are in the same cluster – they’re in cluster two – and now I’ll be able to see in real time which users have been determined to be in the same cluster.
|
||||
|
||||
Next we write it into a CSV, which we then load into the graph:
|
||||
|
||||

|
||||
|
||||
We have users and cluster assignments, so the CSV will only have two columns. LOAD CSV is a syntax that’s built into Cypher that allows you to call a CSV from some file path or URL and alias it as something. Then we’ll match on the users that already exist in the graph, grab the user column out of that CSV, and merge on the cluster.
|
||||
|
||||
Here we’re creating a new labeled node in the graph, the Cluster ID, which was given by k-means. Next we create relationships between the user and the cluster, which allows us to easily query when we get to the actual recommendation users who are in the same cluster.
|
||||
|
||||
Now we have a new label cluster where users who are in the same cluster have a relationship to that cluster. Below is what our new data model looks like, which is on top of the other data models we explored:
|
||||
|
||||

|
||||
|
||||
Now let’s consider the following query:
|
||||
|
||||

|
||||
|
||||
With this Cypher query, we’re going beyond similar users to users in the same cluster. At this point we’ve also deleted those distance relationships:
|
||||
|
||||

|
||||
|
||||
In this query, we’ve taken the user who’s logged in, finding their cluster based on the user-cluster relationship, and finding their neighbors who are in that same cluster.
|
||||
|
||||
We’ve assigned that to some variable cl, and we’re getting other users – which I’ve aliased as a neighbor variable – who have a user-cluster relationship to that same cluster, and then we’re getting the places that neighbor has liked. Again, we’re putting the “likes” on a variable, r, because we’re going want to grab weights off of the relationship to order our results.
|
||||
|
||||
All we’ve changed in the query is that instead of using the similarity distance, we’re grabbing users in the same cluster, asserting categories, asserting the terminal and asserting that we’re only grabbing the user who is logged in. We’re collecting all those weights of the :LIKES relationships from their neighbors liking places, getting the category, the absolute value of the distance, ordering that in descending order, and returning those results.
|
||||
|
||||
In these examples we’ve been able to take a pretty involved process and persist it in the graph, and then used the results of that algorithm – the results of the clustering algorithm and the clustering assignments – in real time.
|
||||
|
||||
Our preferred workflow is to update these clustering assignments however frequently you see fit — for example, nightly or hourly. And, of course, you can use intuition to figure out how often is acceptable to be updating these cluster assignments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[Nicole White][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://neo4j.com/blog/contributor/nicole-white/
|
||||
[1]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#basic-graph-recommendations
|
||||
[2]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#social-recommendations
|
||||
[3]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#similarity-recommendations
|
||||
[4]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#cluster-recommendations
|
||||
[5]: https://neo4j.com/use-cases/real-time-recommendation-engine/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,758 +0,0 @@
|
||||
Tranlating by lengmi.
|
||||
Building your first Atom plugin
|
||||
=====
|
||||
|
||||
>Authored by [GitHub Campus Expert][1] @NickTikhonov.
|
||||
|
||||
This tutorial will teach you how to write your first package for the Atom text editor. We'll be building a clone of [Sourcerer][2], a plugin for finding and using code snippets from StackOverflow. By the end of this tutorial you will have written a plugin that converts programming problems written in English into code snippets pulled from StackOverflow:
|
||||
|
||||

|
||||
|
||||
### What you need to know
|
||||
|
||||
Atom is written using web technologies. Our package will be built entirely using the EcmaScript 6 standard for JavaScript. You will need to be familiar with:
|
||||
|
||||
- Using the command line
|
||||
- JavaScript programming
|
||||
- Promises
|
||||
- HTTP
|
||||
|
||||
### Tutorial repository
|
||||
|
||||
You can follow this tutorial step-by-step or check out the [supplementary repository on GitHub][3], which contains the plugin source code. The repository history contains one commit for each step outlined here.
|
||||
|
||||
### Getting Started
|
||||
|
||||
#### Installing Atom
|
||||
|
||||
Download Atom by following the instructions on the [Atom website][4]. We will also need to install apm, the Atom Package Manager command line tool. You can do this by opening Atom and navigating to Atom > Install Shell Commands in the application menu. Check that apm was installed correctly by opening your command line terminal and running apm -v, which should print the version of the tool and related environments:
|
||||
|
||||
```
|
||||
apm -v
|
||||
> apm 1.9.2
|
||||
> npm 2.13.3
|
||||
> node 0.10.40
|
||||
> python 2.7.10
|
||||
> git 2.7.4
|
||||
```
|
||||
|
||||
#### Generating starter code
|
||||
|
||||
Let's begin by creating a new package using a utility provided by Atom.
|
||||
|
||||
- Launch the editor and press Cmd+Shift+P (on MacOS) or Ctrl+Shift+P (on Windows/Linux) to open the Command Palette.
|
||||
|
||||
- Search for "Package Generator: Generate Package" and click the corresponding item on the list. You will see a prompt where you can enter the name of the package - "sourcefetch".
|
||||
|
||||
- Press enter to generate the starter package, which should automatically be opened in Atom.
|
||||
|
||||
If you don't see package files appear in the sidebar, press Cmd+K Cmd+B (on MacOS) or Ctrl+K Ctrl+B (on Windows/Linux).
|
||||
|
||||

|
||||
|
||||
The Command Palette lets you find and run package commands using fuzzy search. This is a convenient way to run commands without navigating menus or remembering shortcuts. We will be using it throughout this tutorial.
|
||||
|
||||
#### Running the starter code
|
||||
|
||||
Let's try out the starter package before diving into the code itself. We will first need to reload Atom to make it aware of the new package that was added. Open the Command Palette again and run the "Window: Reload" command.
|
||||
|
||||
Reloading the current window ensures that Atom runs the latest version of our source code. We will be running this command every time we want to test the changes we make to our package.
|
||||
|
||||
Run the package toggle command by navigating to Packages > sourcefetch > Toggle using the editor menu, or run sourcefetch: Toggle using the Command Palette. You should see a black box appear at the top of the screen. Hide it by running the command again.
|
||||
|
||||

|
||||
|
||||
#### The "toggle" command
|
||||
|
||||
Let's open lib/sourcefetch.js, which contains the package logic and defines the toggle command.
|
||||
|
||||
```
|
||||
toggle() {
|
||||
console.log('Sourcefetch was toggled!');
|
||||
return (
|
||||
this.modalPanel.isVisible() ?
|
||||
this.modalPanel.hide() :
|
||||
this.modalPanel.show()
|
||||
);
|
||||
}
|
||||
```
|
||||
|
||||
toggle is a function exported by the module. It uses a ternary operator to call show and hide on the modal panel based on its visibility. modalPanel is an instance of Panel, a UI element provided by the Atom API. We declare modalPanel inside export default, which lets us access it as an instance variable with this.
|
||||
|
||||
```
|
||||
this.subscriptions.add(atom.commands.add('atom-workspace', {
|
||||
'sourcefetch:toggle': () => this.toggle()
|
||||
}));
|
||||
```
|
||||
|
||||
The above statement tells Atom to execute toggle every time the user runs sourcefetch:toggle. We subscribe an anonymous function, () => this.toggle(), to be called every time the command is run. This is an example of event-driven programming, a common paradigm in JavaScript.
|
||||
|
||||
#### Atom Commands
|
||||
|
||||
Commands are nothing more than string identifiers for events triggered by the user, defined within a package namespace. We've already used:
|
||||
|
||||
- package-generator:generate-package
|
||||
- window:reload
|
||||
- sourcefetch:toggle
|
||||
|
||||
Packages subscribe to commands in order to execute code in response to these events.
|
||||
|
||||
### Making your first code change
|
||||
|
||||
Let's make our first code change—we're going to change toggle to reverse text selected by the user.
|
||||
|
||||
#### Change "toggle"
|
||||
|
||||
- Change the toggle function to match the snippet below.
|
||||
|
||||
```
|
||||
toggle() {
|
||||
let editor
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let selection = editor.getSelectedText()
|
||||
let reversed = selection.split('').reverse().join('')
|
||||
editor.insertText(reversed)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Test your changes
|
||||
|
||||
- Reload Atom by running Window: Reload in the Command Palette
|
||||
|
||||
- Navigate to File > New to create a new file, type anything you like and select it with the cursor.
|
||||
|
||||
- Run the sourcefetch:toggle command using the Command Palette, Atom menu, or by right clicking and selecting "Toggle sourcefetch"
|
||||
|
||||
The updated command will toggle the order of the selected text:
|
||||
|
||||

|
||||
|
||||
See all code changes for this step in the [sourcefetch tutorial repository][4].
|
||||
|
||||
### The Atom Editor API
|
||||
|
||||
The code we added uses the TextEditor API to access and manipulate the text inside the editor. Let's take a closer look.
|
||||
|
||||
```
|
||||
let editor
|
||||
if (editor = atom.workspace.getActiveTextEditor()) { /* ... */ }
|
||||
```
|
||||
|
||||
The first two lines obtain a reference to a TextEditor instance. The variable assignment and following code is wrapped in a conditional to handle the case where there is no text editor instance available, for example, if the command was run while the user was in the settings menu.
|
||||
|
||||
```
|
||||
let selection = editor.getSelectedText()
|
||||
```
|
||||
|
||||
Calling getSelectedText gives us access to text selected by the user. If no text is currently selected, the function returns an empty string.
|
||||
|
||||
```
|
||||
let reversed = selection.split('').reverse().join('')
|
||||
editor.insertText(reversed)
|
||||
```
|
||||
|
||||
Our selected text is reversed using [JavaScript String methods][6] . Finally, we call insertText to replace the selected text with the reversed counterpart. You can learn more about the different TextEditor methods available by reading the [Atom API documentation][5].
|
||||
|
||||
### Exploring the starter package
|
||||
|
||||
Now that we've made our first code change, let's take a closer look at how an Atom package is organized by exploring the starter code.
|
||||
|
||||
#### The main file
|
||||
|
||||
The main file is the entry-point to an Atom package. Atom knows where to find the main file from an entry in package.json:
|
||||
|
||||
```
|
||||
"main": "./lib/sourcefetch",
|
||||
```
|
||||
|
||||
The file exports an object with lifecycle functions which Atom calls on certain events.
|
||||
|
||||
- activate is called when the package is initially loaded by Atom. This function is used to initialize objects such as user interface elements needed by the package, and to subscribe handler functions to package commands.
|
||||
|
||||
- deactivate is called when the package is deactivated, for example, when the editor is closed or refreshed by the user.
|
||||
|
||||
- serialize is called by Atom to allow you to save the state of the package between uses. The returned value is passed as an argument to activate when the package is next loaded by Atom.
|
||||
|
||||
We are going to rename our package command to fetch, and remove user interface elements we won't be using. Update the file to match the version below:
|
||||
|
||||
```
|
||||
'use babel';
|
||||
|
||||
import { CompositeDisposable } from 'atom'
|
||||
|
||||
export default {
|
||||
|
||||
subscriptions: null,
|
||||
|
||||
activate() {
|
||||
this.subscriptions = new CompositeDisposable()
|
||||
|
||||
this.subscriptions.add(atom.commands.add('atom-workspace', {
|
||||
'sourcefetch:fetch': () => this.fetch()
|
||||
}))
|
||||
},
|
||||
|
||||
deactivate() {
|
||||
this.subscriptions.dispose()
|
||||
},
|
||||
|
||||
fetch() {
|
||||
let editor
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let selection = editor.getSelectedText()
|
||||
selection = selection.split('').reverse().join('')
|
||||
editor.insertText(selection)
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
### Activation commands
|
||||
|
||||
To improve performance, Atom packages can be lazy loading. We can tell Atom to load our package only when certain commands are run by the user. These commands are called activation commands and are defined in package.json:
|
||||
|
||||
```
|
||||
"activationCommands": {
|
||||
"atom-workspace": "sourcefetch:toggle"
|
||||
},
|
||||
```
|
||||
|
||||
Update this entry to make fetch an activation command.
|
||||
|
||||
```
|
||||
"activationCommands": {
|
||||
"atom-workspace": "sourcefetch:fetch"
|
||||
},
|
||||
```
|
||||
|
||||
Some packages, such as those which modify Atom's appearance need to be loaded on startup. In those cases, activationCommands can be omitted entirely.
|
||||
|
||||
### Triggering commands
|
||||
|
||||
#### Menu items
|
||||
|
||||
JSON files inside the menus folder specify which menu items are created for our package. Let's take a look at `menus/sourcefetch.json`:
|
||||
|
||||
```
|
||||
"context-menu": {
|
||||
"atom-text-editor": [
|
||||
{
|
||||
"label": "Toggle sourcefetch",
|
||||
"command": "sourcefetch:toggle"
|
||||
}
|
||||
]
|
||||
},
|
||||
```
|
||||
|
||||
The context-menu object lets us define new items in the right-click menu. Each item is defined by a label to be displayed in the menu and a command to run when the item is clicked.
|
||||
|
||||
```
|
||||
"context-menu": {
|
||||
"atom-text-editor": [
|
||||
{
|
||||
"label": "Fetch code",
|
||||
"command": "sourcefetch:fetch"
|
||||
}
|
||||
]
|
||||
},
|
||||
```
|
||||
|
||||
The menu object in the same file defines custom application menu items created for the package. We're going to rename this entry as well:
|
||||
|
||||
```
|
||||
"menu": [
|
||||
{
|
||||
"label": "Packages",
|
||||
"submenu": [
|
||||
{
|
||||
"label": "sourcefetch",
|
||||
"submenu": [
|
||||
{
|
||||
"label": "Fetch code",
|
||||
"command": "sourcefetch:fetch"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
#### Keyboard shortcuts
|
||||
|
||||
Commands can also be triggered with keyboard shortcuts, defined with JSON files in the keymaps directory:
|
||||
|
||||
```
|
||||
{
|
||||
"atom-workspace": {
|
||||
"ctrl-alt-o": "sourcefetch:toggle"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The above lets package users call toggle with Ctrl+Alt+O on Windows/Linux or Cmd+Alt+O on MacOS.
|
||||
|
||||
Rename the referenced command to fetch:
|
||||
|
||||
```
|
||||
"ctrl-alt-o": "sourcefetch:fetch"
|
||||
```
|
||||
|
||||
Reload Atom by running the Window: Reload command. You should see that the application and right-click menus are updated, and the reverse functionality should work as before.
|
||||
|
||||
See all code changes for this step in the [sourcefetch tutorial repository][7].
|
||||
|
||||
### Using NodeJS modules
|
||||
|
||||
Now that we've made our first code change and learned about Atom package structure, let's introduce our first dependency—a module from Node Package Manager (npm). We will use the request module to make HTTP requests and download the HTML of a website. This functionality will be needed later, to scrape StackOverflow pages.
|
||||
|
||||
#### Installing dependencies
|
||||
|
||||
Open your command line application, navigate to your package root directory and run:
|
||||
|
||||
```
|
||||
npm install --save request@2.73.0
|
||||
apm install
|
||||
```
|
||||
|
||||
These commands add the request Node module to our dependencies list and install the module into the node_modules directory. You should see a new entry in package.json. The @ symbol tells npm to install the specific version we will be using for this tutorial. Running apm install lets Atom know to use our newly installed module.
|
||||
|
||||
```
|
||||
"dependencies": {
|
||||
"request": "^2.73.0"
|
||||
}
|
||||
```
|
||||
|
||||
#### Downloading and logging HTML to the Developer Console
|
||||
|
||||
Import request into our main file by adding an import statement to the top of lib/sourcefetch.js:
|
||||
|
||||
```
|
||||
import { CompositeDisposable } from 'atom'
|
||||
import request from 'request'
|
||||
```
|
||||
|
||||
Now, add a new function, download to the module's exports, below fetch:
|
||||
|
||||
```
|
||||
export default {
|
||||
|
||||
/* subscriptions, activate(), deactivate() */
|
||||
|
||||
fetch() {
|
||||
...
|
||||
},
|
||||
|
||||
download(url) {
|
||||
request(url, (error, response, body) => {
|
||||
if (!error && response.statusCode == 200) {
|
||||
console.log(body)
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This function uses request to download the contents of a web page and logs the output to the Developer Console. When the HTTP request completes, our callback function will be called with the response as an argument.
|
||||
|
||||
The final step is to update fetch so that it calls download:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
let editor
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let selection = editor.getSelectedText()
|
||||
this.download(selection)
|
||||
}
|
||||
},
|
||||
```
|
||||
|
||||
Instead of reversing the selected text, fetch now treats the selection as a URL, passing it to download. Let's see our changes in action:
|
||||
|
||||
- Reload Atom by running the Window: Reload command.
|
||||
|
||||
- Open the Developer Tools. To do this, navigate to View > Developer > Toggle Developer Tools in the menu.
|
||||
|
||||
- Create a new file, navigate to File > New.
|
||||
|
||||
- Enter and select a URL, for example, http://www.atom.io.
|
||||
|
||||
- Run our package command in any of the three ways previously described:
|
||||
|
||||

|
||||
|
||||
>Developer Tools make it easy to debug Atom packages. Any console.log statement will print to the interactive console, and you can use the Elements tab to explore the visual structure of the whole applicatio—which is just an HTML [Document Object Model (DOM)][8].
|
||||
|
||||
See all code changes for this step in the [sourcefetch tutorial repository][9].
|
||||
|
||||
### Using Promises to insert downloaded HTML into the editor
|
||||
|
||||
Ideally, we would like our download function to return the HTML as a string instead of just printing page contents into the console. Returning body won't work, however, since we get access to body inside of the callback rather than download itself.
|
||||
|
||||
We will solve this problem by returning a Promise rather than the value itself. Let's change download to return a Promise:
|
||||
|
||||
```
|
||||
download(url) {
|
||||
return new Promise((resolve, reject) => {
|
||||
request(url, (error, response, body) => {
|
||||
if (!error && response.statusCode == 200) {
|
||||
resolve(body)
|
||||
} else {
|
||||
reject({
|
||||
reason: 'Unable to download page'
|
||||
})
|
||||
}
|
||||
})
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
Promises allow us to return values obtained asynchronously by wrapping asynchronous logic in a function that provides two callbacks— resolve for returning a value successfully, and reject for notifying the caller of an error. We call reject if an error is returned by request, and resolve the HTML otherwise.
|
||||
|
||||
Let's change fetch to work with the Promise returned by download:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
let editor
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let selection = editor.getSelectedText()
|
||||
this.download(selection).then((html) => {
|
||||
editor.insertText(html)
|
||||
}).catch((error) => {
|
||||
atom.notifications.addWarning(error.reason)
|
||||
})
|
||||
}
|
||||
},
|
||||
```
|
||||
|
||||
In our new version of fetch, we get access to the HTML by calling then on the Promise returned by download. This lets us insert the HTML into the editor. We also accept and handle any errors returned by calling catch. We handle errors by displaying a warning notification using the Atom Notification API.
|
||||
|
||||
Let's see what changed. Reload Atom and run the package command on a selected URL:
|
||||
|
||||

|
||||
|
||||
If the command is run on an invalid URL, a warning notification will be displayed:
|
||||
|
||||

|
||||
|
||||
See all code changes for this step in the [sourcefetch tutorial repository][10].
|
||||
|
||||
#### Building a scraper to extract code snippets from StackOverflow HTML
|
||||
|
||||
The next step involves extracting code snippets from the HTML of a StackOverflow page we obtained in the previous step. In particular, we're interested in code from the accepted answer—an answer chosen to be correct by the question author. We can greatly simplify our package implementation by assuming any such answer to be relevant and correct.
|
||||
|
||||
#### Constructing a query using jQuery and Chrome Developer Tools
|
||||
|
||||
This section assumes you are using the Chrome web browser. You may be able to follow along using another browser, but instructions may change.
|
||||
|
||||
Let's take a look at a typical StackOverflow page that contains an accepted answer with a code snippet. We are going to explore the HTML using Chrome Developer Tools:
|
||||
|
||||
- Open Chrome and navigate to any StackOverflow page containing an accepted answer with code, such as this hello world example in Python or this question about reading text from a file in C.
|
||||
|
||||
- Scroll down to the accepted answer and highlight a section of the code snippet.
|
||||
|
||||
- Right click and select Inspect
|
||||
|
||||
- Inspect the location of the code snippet within the HTML code using the Elements browser.
|
||||
|
||||
Note that the document has the following structure:
|
||||
|
||||
```
|
||||
<div class="accepted-answer">
|
||||
...
|
||||
...
|
||||
<pre>
|
||||
<code>
|
||||
...snippet elements...
|
||||
</code>
|
||||
</pre>
|
||||
...
|
||||
...
|
||||
</div>
|
||||
```
|
||||
|
||||
- The accepted answer is denoted by a div with class accepted-answer
|
||||
|
||||
- Block code snippets are located inside a pre element
|
||||
|
||||
- Elements that render the code snippet itself sit inside a code tag
|
||||
|
||||

|
||||
|
||||
Now let's construct a jQuery statement for extracting code snippets:
|
||||
|
||||
- Click the Console tab within Developer Tools to access the JavaScript console.
|
||||
|
||||
- Type $('div.accepted-answer pre code').text() into the console and press Enter.
|
||||
|
||||
You should see the accepted answer code snippets printed out in the console. The code we just ran uses a special $ function provided by jQuery. $ accepts a query string to select and return certain HTML elements from the website. Let's take a look at how this code works by considering a couple of intermediate example queries:
|
||||
|
||||
```
|
||||
$('div.accepted-answer')
|
||||
> [<div id="answer-1077349" class="answer accepted-answer" ... ></div>]
|
||||
```
|
||||
|
||||
The above query will match all <div> elements that contain the class accepted-answer, in our case - just one div.
|
||||
|
||||
```
|
||||
$('div.accepted-answer pre code')
|
||||
> [<code>...</code>]
|
||||
```
|
||||
|
||||
Building upon the previous, this query will match any `<code>` element that is inside a `<pre>` element contained within the previously matched `<div>`.
|
||||
|
||||
```
|
||||
$('div.accepted-answer pre code').text()
|
||||
> "print("Hello World!")"
|
||||
```
|
||||
|
||||
The text function extracts and concatenates all text from the list of elements that would otherwise be returned by the previous query. This also strips out elements used for syntax highlighting purposes from the code.
|
||||
|
||||
### Introducing Cheerio
|
||||
|
||||
Our next step involves using the query we created to implement a scraping function using Cheerio, a jQuery implementation for server-side applications.
|
||||
|
||||
#### Install Cheerio
|
||||
|
||||
Open your command line application, navigate to your package root directory and run:
|
||||
|
||||
```
|
||||
npm install --save cheerio@0.20.0
|
||||
apm install
|
||||
```
|
||||
|
||||
#### Implement the scraping function
|
||||
|
||||
- Add an import statement for cheerio in lib/sourcefetch.js:
|
||||
|
||||
```
|
||||
import { CompositeDisposable } from 'atom'
|
||||
import request from 'request'
|
||||
import cheerio from 'cheerio'
|
||||
```
|
||||
|
||||
- Now create a new function that extracts code snippets given StackOverflow HTML, called scrape:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
...
|
||||
},
|
||||
|
||||
scrape(html) {
|
||||
$ = cheerio.load(html)
|
||||
return $('div.accepted-answer pre code').text()
|
||||
},
|
||||
|
||||
download(url) {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
- Finally, let's change fetch to pass downloaded HTML to scrape instead of inserting it into the editor:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
let editor
|
||||
let self = this
|
||||
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let selection = editor.getSelectedText()
|
||||
this.download(selection).then((html) => {
|
||||
let answer = self.scrape(html)
|
||||
if (answer === '') {
|
||||
atom.notifications.addWarning('No answer found :(')
|
||||
} else {
|
||||
editor.insertText(answer)
|
||||
}
|
||||
}).catch((error) => {
|
||||
console.log(error)
|
||||
atom.notifications.addWarning(error.reason)
|
||||
})
|
||||
}
|
||||
},
|
||||
```
|
||||
|
||||
Our scraping function is implemented in just two lines because cheerio does all of the work for us! We create a $ function by calling load with our HTML string, and use this function to run our jQuery statement and return the results. You can explore the entire Cheerio API in their developer documentation.
|
||||
|
||||
### Testing the updated package
|
||||
|
||||
- Reload Atom and run soucefetch:fetch on a selected StackOverflow URL to see the progress so far.
|
||||
|
||||
If we run the command on a page with an accepted answer, it will be inserted into the editor:
|
||||
|
||||

|
||||
|
||||
If we run the command on a page with no accepted answer, a warning notification will be displayed instead:
|
||||
|
||||
|
||||

|
||||
|
||||
Our new iteration of fetch gives us the code snippet within a StackOverflow page instead of the entire HTML contents. Note that our updated fetch function checks for the absence of an answer and displays a notification to alert the user.
|
||||
|
||||
See all code changes for this step in the [sourcefetch tutorial repository][11].
|
||||
|
||||
### Implementing Google search to find relevant StackOverflow URLs
|
||||
|
||||
Now that we can turn StackOverflow URLs into code snippets, let's implement our final function, search, which will return a relevant URL given the description of a snippet, such as "hello world" or "quicksort". We will be using Google search via the unofficial google npm module, which allows us to search programmatically.
|
||||
|
||||
#### Installing the Google npm module
|
||||
|
||||
- Install google by opening your command line application at the package root directory, and run:
|
||||
|
||||
```
|
||||
npm install --save google@2.0.0
|
||||
apm install
|
||||
```
|
||||
|
||||
#### Importing and configuring the module
|
||||
|
||||
Add an import statement for google at the top of lib/sourcefetch.js:
|
||||
|
||||
```
|
||||
import google from "google"
|
||||
```
|
||||
|
||||
We will configure the library to limit the number of results returned during search. Add the following line below the import statement to limit returned results to just the top one.
|
||||
|
||||
```
|
||||
google.resultsPerPage = 1
|
||||
```
|
||||
|
||||
#### Implementing the search function
|
||||
|
||||
Next, let's implement our search function itself:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
...
|
||||
},
|
||||
|
||||
search(query, language) {
|
||||
return new Promise((resolve, reject) => {
|
||||
let searchString = `${query} in ${language} site:stackoverflow.com`
|
||||
|
||||
google(searchString, (err, res) => {
|
||||
if (err) {
|
||||
reject({
|
||||
reason: 'A search error has occured :('
|
||||
})
|
||||
} else if (res.links.length === 0) {
|
||||
reject({
|
||||
reason: 'No results found :('
|
||||
})
|
||||
} else {
|
||||
resolve(res.links[0].href)
|
||||
}
|
||||
})
|
||||
})
|
||||
},
|
||||
|
||||
scrape() {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
The code above searches Google for a StackOverflow page relevant to the given query and programming language, returning the URL of the top result. Let's take a look at how it works:
|
||||
|
||||
```
|
||||
let searchString = `${query} in ${language} site:stackoverflow.com`
|
||||
```
|
||||
|
||||
We construct the search string using the query entered by the user and the current language selected. For example, if the user types "hello world" while editing Python, the query will be hello world in python site:stackoverflow.com. The final part of the string is a filter provided by Google Search that lets us limit results to those linked to StackOverflow.
|
||||
|
||||
```
|
||||
google(searchString, (err, res) => {
|
||||
if (err) {
|
||||
reject({
|
||||
reason: 'A search error has occured :('
|
||||
})
|
||||
} else if (res.links.length === 0) {
|
||||
reject({
|
||||
reason: 'No results found :('
|
||||
})
|
||||
} else {
|
||||
resolve(res.links[0].href)
|
||||
}
|
||||
})
|
||||
```
|
||||
|
||||
We wrap the call to google inside a Promise so that we can return our URL asynchronously. We propagate any errors returned by the library, also returning an error when there are no results available. We resolve the URL of the top result otherwise.
|
||||
|
||||
### Updating fetch to use search
|
||||
|
||||
Our final step is to update fetch to use search:
|
||||
|
||||
```
|
||||
fetch() {
|
||||
let editor
|
||||
let self = this
|
||||
|
||||
if (editor = atom.workspace.getActiveTextEditor()) {
|
||||
let query = editor.getSelectedText()
|
||||
let language = editor.getGrammar().name
|
||||
|
||||
self.search(query, language).then((url) => {
|
||||
atom.notifications.addSuccess('Found google results!')
|
||||
return self.download(url)
|
||||
}).then((html) => {
|
||||
let answer = self.scrape(html)
|
||||
if (answer === '') {
|
||||
atom.notifications.addWarning('No answer found :(')
|
||||
} else {
|
||||
atom.notifications.addSuccess('Found snippet!')
|
||||
editor.insertText(answer)
|
||||
}
|
||||
}).catch((error) => {
|
||||
atom.notifications.addWarning(error.reason)
|
||||
})
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Let's take a look at what changed:
|
||||
|
||||
- Our selected text is now treated as the query entered by the user.
|
||||
|
||||
- We obtain the language of the current editor tab using the TextEditor API
|
||||
|
||||
- We call search to obtain a URL, which we access by calling then on the resulting Promise
|
||||
|
||||
Instead of calling then on the Promise returned by download, we instead return the Promise itself and chain another then call onto the original call. This helps us avoid callback hell
|
||||
|
||||
See all code changes for this step in the [sourcefetch tutorial repository][12].
|
||||
|
||||
### Testing the final plugin
|
||||
|
||||
And we're done! See the final plugin in action by reloading Atom and running our package command on a problem description, and don't forget to select a language in the bottom-right corner.
|
||||
|
||||

|
||||
|
||||
### Next steps
|
||||
|
||||
Now that you know the basics of hacking Atom, feel free to practice what you've learned [by forking the sourcefetch repository and adding your own features][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/2231-building-your-first-atom-plugin
|
||||
|
||||
作者:[NickTikhonov][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/NickTikhonov
|
||||
[1]: https://education.github.com/experts
|
||||
[2]: https://github.com/NickTikhonov/sourcerer
|
||||
[3]: https://github.com/NickTikhonov/sourcefetch-guide
|
||||
[4]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/89e174ab6ec6e270938338b34905f75bb74dbede
|
||||
[5]: https://atom.io/docs/api/latest/TextEditor
|
||||
[6]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String
|
||||
[7]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/aa3ec5585b0aa049393351a30be14590df09c29a
|
||||
[8]: https://www.wikipedia.com/en/Document_Object_Model
|
||||
[9]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/85992043e57c802ca71ff6e8a4f9c477fbfd13db
|
||||
[10]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/896d160dca711f4a53ff5b182018b39cf78d2774
|
||||
[11]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/039a1e1e976d029f7d6b061b4c0dac3eb4a3b5d2
|
||||
[12]: https://github.com/NickTikhonov/sourcefetch-tutorial/commit/aa9d0b5fc4811a70292869730e0f60ddf0bcf2aa
|
||||
[13]: https://github.com/NickTikhonov/sourcefetch-tutorial
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user