mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
8014124601
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oska874)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10530-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 5 OK05)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
计算机实验室之树莓派:课程 5 OK05
|
||||
======
|
||||
|
||||
OK05 课程构建于课程 OK04 的基础,使用它来闪烁摩尔斯电码的 SOS 序列(`...---...`)。这里假设你已经有了 [课程 4:OK04][1] 操作系统的代码作为基础。
|
||||
|
||||
### 1、数据
|
||||
|
||||
到目前为止,我们与操作系统有关的所有内容提供的都是指令。然而有时候,指令只是完成了一半的工作。我们的操作系统可能还需要数据。
|
||||
|
||||
> 一些早期的操作系统确实只允许特定文件中的特定类型的数据,但是这通常被认为限制太多了。现代方法确实可以使程序变得复杂的多。
|
||||
|
||||
通常,数据就是些很重要的值。你可能接受过培训,认为数据就是某种类型的,比如,文本文件包含文本,图像文件包含图片,等等。说实话,这只是你的想法而已。计算机上的全部数据都是二进制数字,重要的是我们选择用什么来解释这些数据。在这个例子中,我们会用一个闪灯序列作为数据保存下来。
|
||||
|
||||
在 `main.s` 结束处复制下面的代码:
|
||||
|
||||
```
|
||||
.section .data %定义 .data 段
|
||||
.align 2 %对齐
|
||||
pattern: %定义整形变量
|
||||
.int 0b11111111101010100010001000101010
|
||||
```
|
||||
|
||||
> `.align num` 确保下一行代码的地址是 2^num 的整数倍。
|
||||
|
||||
> `.int val` 输出数值 `val`。
|
||||
|
||||
要区分数据和代码,我们将数据都放在 `.data` 区域。我已经将该区域包含在操作系统的内存布局图。我选择将数据放到代码后面。将我们的指令和数据分开保存的原因是,如果最后我们在自己的操作系统上实现一些安全措施,我们就需要知道代码的那些部分是可以执行的,而那些部分是不行的。
|
||||
|
||||
我在这里使用了两个新命令 `.align` 和 `.int`。`.align` 保证接下来的数据是按照 2 的乘方对齐的。在这个里,我使用 `.align 2` ,意味着数据最终存放的地址是 2^2=4 的整数倍。这个操作是很重要的,因为我们用来读取内存的指令 `ldr` 要求内存地址是 4 的倍数。
|
||||
|
||||
命令 `.int` 直接复制它后面的常量到输出。这意味着 11111111101010100010001000101010<sub>2</sub> 将会被存放到输出,所以该标签模式实际是将这段数据标识为模式。
|
||||
|
||||
> 关于数据的一个挑战是寻找一个高效和有用的展示形式。这种保存一个开、关的时间单元的序列的方式,运行起来很容易,但是将很难编辑,因为摩尔斯电码的 `-` 或 `.` 样式丢失了。
|
||||
|
||||
如我提到的,数据可以代表你想要的所有东西。在这里我编码了摩尔斯电码的 SOS 序列,对于不熟悉的人,就是 `...---...`。我使用 0 表示一个时间单元的 LED 灭灯,而 1 表示一个时间单元的 LED 亮。这样,我们可以像这样编写一些代码在数据中显示一个序列,然后要显示不同序列,我们所有需要做的就是修改这段数据。下面是一个非常简单的例子,操作系统必须一直执行这段程序,解释和展示数据。
|
||||
|
||||
复制下面几行到 `main.s` 中的标记 `loop$` 之前。
|
||||
|
||||
```
|
||||
ptrn .req r4 %重命名 r4 为 ptrn
|
||||
ldr ptrn,=pattern %加载 pattern 的地址到 ptrn
|
||||
ldr ptrn,[ptrn] %加载地址 ptrn 所在内存的值
|
||||
seq .req r5 %重命名 r5 为 seq
|
||||
mov seq,#0 %seq 赋值为 0
|
||||
```
|
||||
|
||||
这段代码加载 `pattrern` 到寄存器 `r4`,并加载 0 到寄存器 `r5`。`r5` 将是我们的序列位置,所以我们可以追踪我们已经展示了多少个 `pattern`。
|
||||
|
||||
如果 `pattern` 的当前位置是 1 且仅有一个 1,下面的代码将非零值放入 `r1`。
|
||||
|
||||
```
|
||||
mov r1,#1 %加载1到 r1
|
||||
lsl r1,seq %对r1 的值逻辑左移 seq 次
|
||||
and r1,ptrn %按位与
|
||||
```
|
||||
|
||||
这段代码对你调用 `SetGpio` 很有用,它必须有一个非零值来关掉 LED,而一个 0 值会打开 LED。
|
||||
|
||||
现在修改 `main.s` 中你的全部代码,这样代码中每次循环会根据当前的序列数设置 LED,等待 250000 毫秒(或者其他合适的延时),然后增加序列数。当这个序列数到达 32 就需要返回 0。看看你是否能实现这个功能,作为额外的挑战,也可以试着只使用一条指令。
|
||||
|
||||
### 2、当你玩得开心时,时间过得很快
|
||||
|
||||
你现在准备好在树莓派上实验。应该闪烁一串包含 3 个短脉冲,3 个长脉冲,然后 3 个短脉冲的序列。在一次延时之后,这种模式应该重复。如果这不工作,请查看我们的问题页。
|
||||
|
||||
一旦它工作,祝贺你已经抵达 OK 系列教程的结束点。
|
||||
|
||||
在这个系列我们学习了汇编代码,GPIO 控制器和系统定时器。我们已经学习了函数和 ABI,以及几个基础的操作系统原理,已经关于数据的知识。
|
||||
|
||||
你现在已经可以准备学习下面几个更高级的课程的某一个。
|
||||
|
||||
* [Screen][2] 系列是接下来的,会教你如何通过汇编代码使用屏幕。
|
||||
* [Input][3] 系列教授你如何使用键盘和鼠标。
|
||||
|
||||
到现在,你已经有了足够的信息来制作操作系统,用其它方法和 GPIO 交互。如果你有任何机器人工具,你可能会想尝试编写一个通过 GPIO 管脚控制的机器人操作系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10526-1.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
@ -1,26 +1,26 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (bestony)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10532-1.html)
|
||||
[#]: subject: (PyGame Zero: Games without boilerplate)
|
||||
[#]: via: (https://opensource.com/article/19/1/pygame-zero)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
PyGame Zero: 从 0 开始的游戏
|
||||
PyGame Zero: 无需模板的游戏开发
|
||||
======
|
||||
|
||||
在你的游戏开发过程中有了 PyGame Zero,和枯燥的模板说再见吧。
|
||||
> 在你的游戏开发过程中有了 PyGame Zero,和枯燥的模板说再见吧。
|
||||
|
||||

|
||||
|
||||
Python 说一个很好的入门编程语言。并且,游戏是一个很好的入门项目:它们是可视化的,自驱动的,并且可以很愉快的与朋友和家人分享。虽然,绝大多数的 Python 写就的库,比如 [PyGame][1] ,会让初学者因为忘记微小的细节很容易导致什么都没渲染而感到困扰
|
||||
Python 是一个很好的入门级编程语言。并且,游戏是一个很好的入门项目:它们是可视化的,自驱动的,并且可以很愉快的与朋友和家人分享。虽然,绝大多数的 Python 写就的库,比如 [PyGame][1] ,会让初学者因为忘记微小的细节很容易导致什么都没渲染而感到困扰。
|
||||
|
||||
在人们理解所有部分的原因前,他们将其中的许多部分都视为“无意识的样板文件”——需要复制和粘贴到程序中才能使其工作的神奇段落。
|
||||
在理解所有部分的作用之前,他们会将其中的许多部分都视为“无意识的模板文件”——需要复制和粘贴到程序中才能使其工作的神奇段落。
|
||||
|
||||
[PyGame Zero][2] 试图通过在 PyGame 上放置一个抽象的层来弥合这一差距,因此它实际上并不需要模板。
|
||||
[PyGame Zero][2] 试图通过在 PyGame 上放置一个抽象层来弥合这一差距,因此它字面上并不需要模板。
|
||||
|
||||
我们在字面上说的,就是我们的意思
|
||||
我们在说的“字面”,就是在指字面。
|
||||
|
||||
这是一个合格的 PyGame Zero 文件:
|
||||
|
||||
@ -28,17 +28,17 @@ Python 说一个很好的入门编程语言。并且,游戏是一个很好的
|
||||
# This comment is here for clarity reasons
|
||||
```
|
||||
|
||||
我们可以将它放在一个 **game.py** 文件里,并运行:
|
||||
我们可以将它放在一个 `game.py` 文件里,并运行:
|
||||
|
||||
```
|
||||
$ pgzrun game.py
|
||||
```
|
||||
|
||||
这将会展示一个可以通过关闭窗口或按下**CTRL-C**中断的窗口,并在后台运行一个游戏循环 ,
|
||||
这将会展示一个窗口,并运行一个可以通过关闭窗口或按下 `CTRL-C` 中断的游戏循环。
|
||||
|
||||
遗憾的是,这将是一场无聊的游戏。什么都没发生。
|
||||
|
||||
为了让他更有趣一点,我们可以画一个不同的背景:
|
||||
为了让它更有趣一点,我们可以画一个不同的背景:
|
||||
|
||||
```
|
||||
def draw():
|
||||
@ -59,10 +59,9 @@ def update():
|
||||
|
||||
这将会让窗口从黑色开始,逐渐变亮,直到变为亮红色,再返回黑色,一遍一遍循环。
|
||||
|
||||
**update** 函数更新了 **draw** 渲染这个游戏所需的这些参数的值。
|
||||
`update` 函数更新了参数的值,而 `draw` 基于这些参数渲染这个游戏。
|
||||
|
||||
即使是这样,这里也没有任何方式给玩家与这个游戏的交互的方式。
|
||||
让我们试试其他一些事情:
|
||||
即使是这样,这里也没有任何方式给玩家与这个游戏的交互的方式。让我们试试其他一些事情:
|
||||
|
||||
```
|
||||
colors = [0, 0, 0]
|
||||
@ -77,7 +76,7 @@ def on_key_down(key, mod, unicode):
|
||||
colors[1] = (colors[1] + 1) % 256
|
||||
```
|
||||
|
||||
现在,按下按钮来提升亮度。
|
||||
现在,按下按键来提升亮度。
|
||||
|
||||
这些包括游戏循环的三个重要部分:响应用户输入,更新参数和重新渲染屏幕。
|
||||
|
||||
@ -92,7 +91,7 @@ via: https://opensource.com/article/19/1/pygame-zero
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,23 +1,24 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( dianbanjiu )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (dianbanjiu)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10531-1.html)
|
||||
[#]: subject: (Using more to view text files at the Linux command line)
|
||||
[#]: via: (https://opensource.com/article/19/1/more-text-files-linux)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
在 Linux 命令行使用 more 查看文本文件
|
||||
======
|
||||
文本文件和 Linux 一直是携手并进的。或者说看起来如此。那你又是依靠哪些让你使用起来很舒服的工具来查看这些文本文件的呢?
|
||||
|
||||
> 文本文件和 Linux 一直是携手并进的。或者说看起来如此。那你又是依靠哪些让你使用起来很舒服的工具来查看这些文本文件的呢?
|
||||
|
||||

|
||||
|
||||
Linux 下有很多实用工具可以让你在终端界面查看文本文件。其中一个就是 [**more**][1]。
|
||||
Linux 下有很多实用工具可以让你在终端界面查看文本文件。其中一个就是 [more][1]。
|
||||
|
||||
**more** 跟我之前另一篇文章里写到的工具 —— **[less][2]** 很相似。它们之间的主要不同点在于 **more** 只允许你向前查看文件。
|
||||
`more` 跟我之前另一篇文章里写到的工具 —— [less][2] 很相似。它们之间的主要不同点在于 `more` 只允许你向前查看文件。
|
||||
|
||||
尽管它能提供的功能看起来很有限,不过它依旧有很多有用的特性值得你去了解。下面让我们来快速浏览一下 **more** 可以做什么,以及如何使用它吧。
|
||||
尽管它能提供的功能看起来很有限,不过它依旧有很多有用的特性值得你去了解。下面让我们来快速浏览一下 `more` 可以做什么,以及如何使用它吧。
|
||||
|
||||
### 基础使用
|
||||
|
||||
@ -35,9 +36,9 @@ $ more jekyll-article.md
|
||||
|
||||
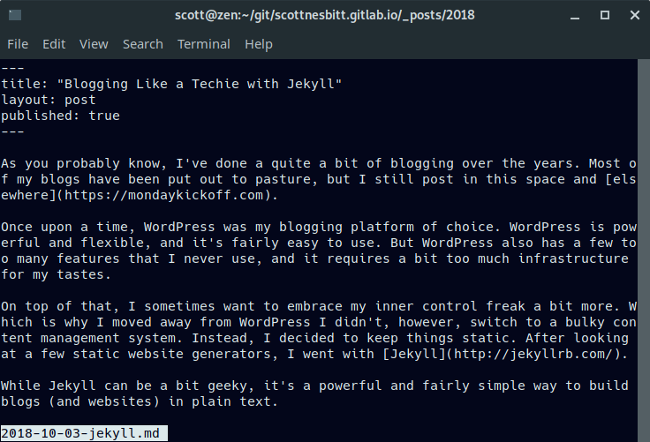
|
||||
|
||||
使用空格键可以向下翻页,输入 **q** 可以退出。
|
||||
使用空格键可以向下翻页,输入 `q` 可以退出。
|
||||
|
||||
如果你想在这个文件中搜索一些文本,输入 **/** 字符并在其后加上你想要查找的文字。例如你要查看的字段是 terminal,只需输入:
|
||||
如果你想在这个文件中搜索一些文本,输入 `/` 字符并在其后加上你想要查找的文字。例如你要查看的字段是 “terminal”,只需输入:
|
||||
|
||||
```
|
||||
/terminal
|
||||
@ -45,12 +46,13 @@ $ more jekyll-article.md
|
||||
|
||||
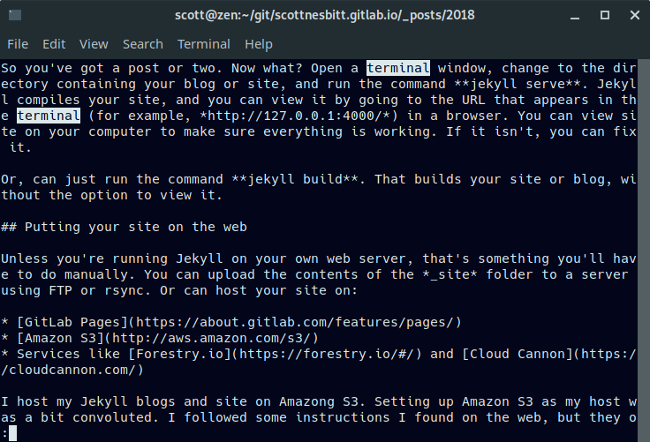
|
||||
|
||||
搜索的内容是区分大小写的,所以输入 /terminal 跟 /Terminal 会出现不同的结果。
|
||||
搜索的内容是区分大小写的,所以输入 `/terminal` 跟 `/Terminal` 会出现不同的结果。
|
||||
|
||||
### 和其他实用工具组合使用
|
||||
你可以通过管道将其他命令行工具得到的文本传输到 **more**。你问为什么这样做?因为有时这些工具获取的文本会超过终端一页可以显示的限度。
|
||||
|
||||
想要做到这个,先输入你想要使用的完整命令,后面跟上管道符(**|**),管道符后跟 **more**。假设现在有一个有很多文件的目录。你就可以组合 **more** 跟 **ls** 命令完整查看这个目录当中的内容。
|
||||
你可以通过管道将其他命令行工具得到的文本传输到 `more`。你问为什么这样做?因为有时这些工具获取的文本会超过终端一页可以显示的限度。
|
||||
|
||||
想要做到这个,先输入你想要使用的完整命令,后面跟上管道符(`|`),管道符后跟 `more`。假设现在有一个有很多文件的目录。你就可以组合 `more` 跟 `ls` 命令完整查看这个目录当中的内容。
|
||||
|
||||
```shell
|
||||
$ ls | more
|
||||
@ -58,7 +60,7 @@ $ ls | more
|
||||
|
||||
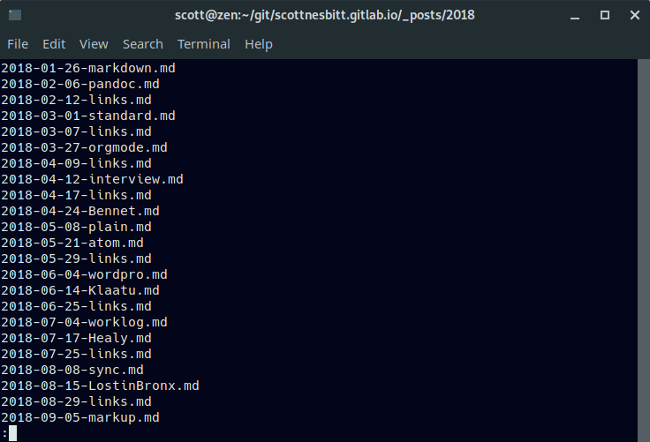
|
||||
|
||||
你可以组合 **more** 和 **grep** 命令,从而实现在多个文件中找到指定的文本。下面是我在多篇文章的源文件中查找 productivity 的例子。
|
||||
你可以组合 `more` 和 `grep` 命令,从而实现在多个文件中找到指定的文本。下面是我在多篇文章的源文件中查找 “productivity” 的例子。
|
||||
|
||||
```shell
|
||||
$ grep ‘productivity’ core.md Dict.md lctt2014.md lctt2016.md lctt2018.md README.md | more
|
||||
@ -66,17 +68,17 @@ $ grep ‘productivity’ core.md Dict.md lctt2014.md lctt2016.md lctt2018.md RE
|
||||
|
||||
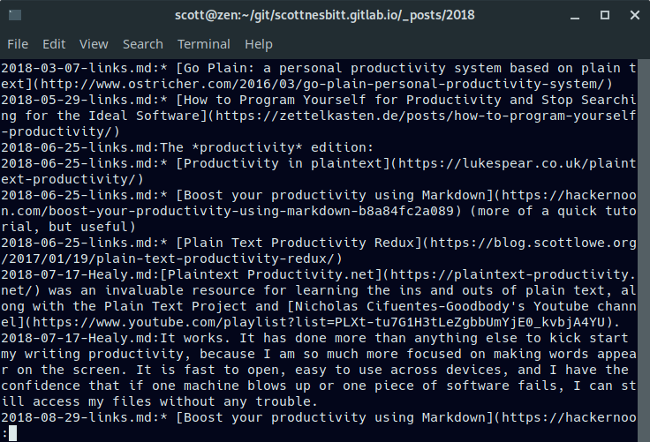
|
||||
|
||||
另外一个可以和 **more** 组合的实用工具是 **ps**(列出你系统上正在运行的进程)。当你的系统上运行了很多的进程,你现在想要查看他们的时候,这个组合将会派上用场。例如你想找到一个你需要杀死的进程,只需输入下面的命令:
|
||||
另外一个可以和 `more` 组合的实用工具是 `ps`(列出你系统上正在运行的进程)。当你的系统上运行了很多的进程,你现在想要查看他们的时候,这个组合将会派上用场。例如你想找到一个你需要杀死的进程,只需输入下面的命令:
|
||||
|
||||
```shell
|
||||
$ ps -u scott | more
|
||||
```
|
||||
|
||||
注意用你的用户名替换掉 scott。
|
||||
注意用你的用户名替换掉 “scott”。
|
||||
|
||||
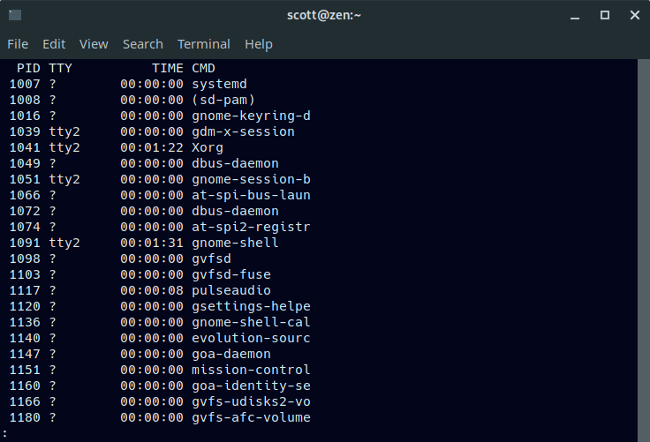
|
||||
|
||||
就像我文章开篇提到的, **more** 很容易使用。尽管不如它的双胞胎兄弟 **less** 那般灵活,但是仍然值得了解一下。
|
||||
就像我文章开篇提到的, `more` 很容易使用。尽管不如它的双胞胎兄弟 `less` 那般灵活,但是仍然值得了解一下。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -85,7 +87,7 @@ via: https://opensource.com/article/19/1/more-text-files-linux
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,15 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10529-1.html)
|
||||
[#]: subject: (More About Angle Brackets in Bash)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/1/more-about-angle-brackets-bash)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Bash 中尖括号的更多用法
|
||||
======
|
||||
> 在这篇文章,我们继续来深入探讨尖括号的更多其它用法。
|
||||
|
||||

|
||||
|
||||
@ -22,19 +23,20 @@ Bash 中尖括号的更多用法
|
||||
diff <(ls /original/dir/) <(ls /backup/dir/)
|
||||
```
|
||||
|
||||
[`diff`][2] 命令是一个逐行比较两个文件之间差异的工具。在上面的例子中,就使用了 `<` 让 `diff` 认为两个 `ls` 命令输出的结果都是文件,从而能够比较它们之间的差异。
|
||||
[diff][2] 命令是一个逐行比较两个文件之间差异的工具。在上面的例子中,就使用了 `<` 让 `diff` 认为两个 `ls` 命令输出的结果都是文件,从而能够比较它们之间的差异。
|
||||
|
||||
要注意,在 `<` 和 `(...)` 之间是没有空格的。
|
||||
|
||||
我尝试在我的图片目录和它的备份目录执行上面的命令,输出的是以下结果:
|
||||
|
||||
```
|
||||
diff <(ls /My/Pictures/) <(ls /My/backup/Pictures/) 5d4 < Dv7bIIeUUAAD1Fc.jpg:large.jpg
|
||||
diff <(ls /My/Pictures/) <(ls /My/backup/Pictures/)
|
||||
5d4 < Dv7bIIeUUAAD1Fc.jpg:large.jpg
|
||||
```
|
||||
|
||||
输出结果中的 `<` 表示 `Dv7bIIeUUAAD1Fc.jpg:large.jpg` 这个文件存在于左边的目录(`/My/Pictures`)但不存在于右边的目录(`/My/backup/Pictures`)中。也就是说,在备份过程中可能发生了问题,导致这个文件没有被成功备份。如果 `diff` 没有显示出任何输出结果,就表明两个目录中的文件是一致的。
|
||||
|
||||
看到这里你可能会想到,既然可以通过 `<` 将一些命令行的输出内容作为一个文件,提供给一个需要接受文件格式的命令,那么在上一篇文章的“最喜欢的演员排序”例子中,就可以省去中间的一些步骤,直接对输出内容执行 `sort` 操作了。
|
||||
看到这里你可能会想到,既然可以通过 `<` 将一些命令行的输出内容作为一个文件提供给一个需要接受文件格式的命令,那么在上一篇文章的“最喜欢的演员排序”例子中,就可以省去中间的一些步骤,直接对输出内容执行 `sort` 操作了。
|
||||
|
||||
确实如此,这个例子可以简化成这样:
|
||||
|
||||
@ -42,7 +44,7 @@ diff <(ls /My/Pictures/) <(ls /My/backup/Pictures/) 5d4 < Dv7bIIeUUAAD1Fc.jpg:la
|
||||
sort -r <(while read -r name surname films;do echo $films $name $surname ; done < CBactors)
|
||||
```
|
||||
|
||||
### Here string
|
||||
### Here 字符串
|
||||
|
||||
除此以外,尖括号的重定向功能还有另一种使用方式。
|
||||
|
||||
@ -52,9 +54,9 @@ sort -r <(while read -r name surname films;do echo $films $name $surname ; done
|
||||
myvar="Hello World" echo $myvar | tr '[:lower:]' '[:upper:]' HELLO WORLD
|
||||
```
|
||||
|
||||
[`tr`][3] 命令可以将一个字符串转换为某种格式。在上面的例子中,就使用了 `tr` 将字符串中的所有小写字母都转换为大写字母。
|
||||
[tr][3] 命令可以将一个字符串转换为某种格式。在上面的例子中,就使用了 `tr` 将字符串中的所有小写字母都转换为大写字母。
|
||||
|
||||
要理解的是,这个传递过程的重点不是变量,而是变量的值,也就是字符串 `Hello World`。这样的字符串叫做 here string,含义是“这就是我们要处理的字符串”。但对于上面的例子,还可以用更直观的方式的处理,就像下面这样:
|
||||
要理解的是,这个传递过程的重点不是变量,而是变量的值,也就是字符串 `Hello World`。这样的字符串叫做 HERE 字符串,含义是“这就是我们要处理的字符串”。但对于上面的例子,还可以用更直观的方式的处理,就像下面这样:
|
||||
|
||||
```
|
||||
tr '[:lower:]' '[:upper:]' <<< $myvar
|
||||
@ -75,13 +77,13 @@ via: https://www.linux.com/blog/learn/2019/1/more-about-angle-brackets-bash
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash
|
||||
[1]: https://linux.cn/article-10502-1.html
|
||||
[2]: https://linux.die.net/man/1/diff
|
||||
[3]: https://linux.die.net/man/1/tr
|
||||
|
||||
@ -1,63 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (jdh8383)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Toyota Motors and its Linux Journey)
|
||||
[#]: via: (https://itsfoss.com/toyota-motors-linux-journey)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
丰田汽车的Linux之旅
|
||||
======
|
||||
|
||||
I spoke with Brian R Lyons of TMNA Toyota Motor Corp North America about the implementation of Linux in Toyota and Lexus infotainment systems. I came to find out there is an Automotive Grade Linux (AGL) being used by several autmobile manufacturers.
|
||||
我之前跟丰田汽车北美分公司的Brian.R.Lyons聊过天,话题是关于Linux在丰田和雷克萨斯汽车的信息娱乐系统上的实施方案。我发现一些汽车制造商使用了Automotive Grade Linux (AGL)。
|
||||
|
||||
I put together a short article comprising of my discussion with Brian about Toyota and its tryst with Linux. I hope that Linux enthusiasts will like this quick little chat.
|
||||
|
||||
All [Toyota vehicles and Lexus vehicles are going to use Automotive Grade Linux][1] (AGL) majorly for the infotainment system. This is instrumental in Toyota Motor Corp because as per Mr. Lyons “As a technology leader, Toyota realized that adopting open source development methodology is the best way to keep up with the rapid pace of new technologies”.
|
||||
|
||||
Toyota among other automotive companies thought, going with a Linux based operating system might be cheaper and quicker when it comes to updates, and upgrades compared to using proprietary software.
|
||||
|
||||
Wow! Finally Linux in a vehicle. I use Linux every day on my desktop; what a great way to expand the use of this awesome software to a completely different industry.
|
||||
|
||||
I was curious when Toyota decided to use the [Automotive Grade Linux][2] (AGL). According to Mr. Lyons, it goes back to 2011.
|
||||
|
||||
> “Toyota has been an active member and contributor to AGL since its launch more than five years ago, collaborating with other OEMs, Tier 1s and suppliers to develop a robust, Linux-based platform with increased security and capabilities”
|
||||
|
||||
![Toyota Infotainment][3]
|
||||
|
||||
In 2011, [Toyota joined the Linux Foundation][4] and started discussions about IVI (In-Vehicle Infotainment) software with other car OEMs and software companies. As a result, in 2012, Automotive Grade Linux working group was formed in the Linux Foundation.
|
||||
|
||||
What Toyota did at first in AGL group was to take “code first” approach as normal as in the open source domains, and then start the conversation about the initial direction by specifying requirement specifications which had been discussed among car OEMs, IVI Tier-1 companies, software companies, and so on.
|
||||
|
||||
Toyota had already realized that sharing the software code among Tier1 companies was going to essential at the time when it joined the Linux Foundation. This was because the cost of maintaining such a huge software was very costly and was no longer differentiation by Tier1 companies. Toyota and its Tier1 supplier companies wanted to spend more resources n new functions and new user experiences rather than maintaining conventional code all by themselves.
|
||||
|
||||
This is a huge thing as automotive companies have gone in together to further their cooperation. Many companies have adopted this after finding proprietary software to be expensive.
|
||||
|
||||
Today, AGL is used for all Toyota and Lexus vehicles and is used in all markets where vehicles are sold.
|
||||
|
||||
As someone who has sold cars for Lexus, I think this is a huge step forward. I and other sales associates had many customers who would come back to speak with a technology specialist to learn about the full capabilities of their infotainment system.
|
||||
|
||||
I see this as a huge step forward for the Linux community, and users. The operating system we use on a daily basis is being put to use right in front of us albeit in a modified form but is there none-the-less.
|
||||
|
||||
Where does this lead? Hopefully a better user-friendly and less glitchy experience for consumers.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/toyota-motors-linux-journey
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linuxfoundation.org/press-release/2018/01/automotive-grade-linux-hits-road-globally-toyota-amazon-alexa-joins-agl-support-voice-recognition/
|
||||
[2]: https://www.automotivelinux.org/
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/toyota-interiors.jpg?resize=800%2C450&ssl=1
|
||||
[4]: https://www.linuxfoundation.org/press-release/2011/07/toyota-joins-linux-foundation/
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Introducing kids to computational thinking with Python)
|
||||
[#]: via: (https://opensource.com/article/19/2/break-down-stereotypes-python)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
Introducing kids to computational thinking with Python
|
||||
======
|
||||
Coding program gives low-income students the skills, confidence, and knowledge to break free from economic and societal disadvantages.
|
||||
|
||||

|
||||
|
||||
When the [Parkman Branch][1] of the Detroit Public Library was flooded with bored children taking up all the computers during summer break, the library saw it not as a problem, rather an opportunity. They started a coding club, the [Parkman Coders][2], led by [Qumisha Goss][3], a librarian who is leveraging the power of Python to introduce disadvantaged children to computational thinking.
|
||||
|
||||
When she started the Parkman Coders program about four years ago, "Q" (as she is known) didn't know much about coding. Since then, she's become a specialist in library instruction and technology and a certified Raspberry Pi instructor.
|
||||
|
||||
The program began by using [Scratch][4], but the students got bored with the block coding interface, which they regarded as "baby stuff." She says, "I knew we need to make a change to something that was still beginner friendly, but that would be more challenging for them to continue to hold their attention." At this point, she started teaching them Python.
|
||||
|
||||
Q first saw Python while playing a game with dungeons and skeleton monsters on [Code.org][5]. She began to learn Python by reading books like [Python Programming: An Introduction to Computer Science][6] and [Python for Kids][7]. She also recommends [Automate the Boring Stuff with Python][8] and [Lauren Ipsum: A Story about Computer Science and Other Improbable Things][9].
|
||||
|
||||
### Setting up a Raspberry Pi makerspace
|
||||
|
||||
Q decided to use [Raspberry Pi][10] computers to avoid the possibility that the students might be able to hack into the library system's computers, which weren't arranged in a way conducive to a makerspace anyway. The Pi's affordability, plus its flexibility and the included free software, lent more credibility to her decision.
|
||||
|
||||
While the coder program was the library's effort keep the peace and create a learning space that would engage the children, it quickly grew so popular that it ran out of space, computers, and adequate electrical outlets in a building built in 1921. They started with 10 Raspberry Pi computers shared among 20 children, but the library obtained funding from individuals, companies including Microsoft, the 4H, and the Detroit Public Library Foundation to get more equipment and expand the program.
|
||||
|
||||
Currently, about 40 children participate in each session and they have enough Raspberry Pi's for one device per child and some to give away. Many of the Parkman Coders come from low socio-economic backgrounds and don't have a computer at home, so the library provides them with donated Chromebooks.
|
||||
|
||||
Q says, "when kids demonstrate that they have a good understanding of how to use a Raspberry Pi or a [Microbit][11] and have been coming to programs regularly, we give them equipment to take home with them. This process is very challenging, however, because [they may not] have internet access at home [or] all the peripheral things they need like monitors, keyboards, and mice."
|
||||
|
||||
### Learning life skills and breaking stereotypes with Python
|
||||
|
||||
Q says, "I believe that the mainstays of learning computer science are learning critical thinking and problem-solving skills. My hope is that these lessons will stay with the kids as they grow and pursue futures in whatever field they choose. In addition, I'm hoping to inspire some pride in creatorship. It's a very powerful feeling to know 'I made this thing,' and once they've had these successes early, I hope they will approach new challenges with zeal."
|
||||
|
||||
She also says, "in learning to program, you have to learn to be hyper-vigilant about spelling and capitalization, and for some of our kids, reading is an issue. To make sure that the program is inclusive, we spell aloud during our lessons, and we encourage kids to speak up if they don't know a word or can't spell it correctly."
|
||||
|
||||
Q also tries to give extra attention to children who need it. She says, "if I recognize that someone has a more severe problem, we try to get them paired with a tutor at our library outside of program time, but still allow them to come to the program. We want to help them without discouraging them from participating."
|
||||
|
||||
Most importantly, the Parkman Coders program seeks to help every child realize that each has a unique skill set and abilities. Most of the children are African-American and half are girls. Q says, "we live in a world where we grow up with societal stigmas that frequently limit our own belief of what we can accomplish." She believes that children need a nonjudgmental space where "they can try new things, mess up, and discover."
|
||||
|
||||
The environment Q and the Parkman Coders program creates helps the participants break away from economic and societal disadvantages. She says that the secret sauce is to "make sure you have a welcoming space so anyone can come and that your space is forgiving and understanding. Let people come as they are, and be prepared to teach and to learn; when people feel comfortable and engaged, they want to stay."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/break-down-stereotypes-python
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://detroitpubliclibrary.org/locations/parkman
|
||||
[2]: https://www.dplfound.org/single-post/2016/05/15/Parkman-Branch-Coders
|
||||
[3]: https://www.linkedin.com/in/qumisha-goss-b3bb5470
|
||||
[4]: https://scratch.mit.edu/
|
||||
[5]: http://Code.org
|
||||
[6]: https://www.amazon.com/Python-Programming-Introduction-Computer-Science/dp/1887902996
|
||||
[7]: https://nostarch.com/pythonforkids
|
||||
[8]: https://automatetheboringstuff.com/
|
||||
[9]: https://nostarch.com/laurenipsum
|
||||
[10]: https://www.raspberrypi.org/
|
||||
[11]: https://microbit.org/guide/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (Guevaraya)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
172
sources/tech/20190205 5 Streaming Audio Players for Linux.md
Normal file
172
sources/tech/20190205 5 Streaming Audio Players for Linux.md
Normal file
@ -0,0 +1,172 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 Streaming Audio Players for Linux)
|
||||
[#]: via: (https://www.linux.com/blog/2019/2/5-streaming-audio-players-linux)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
|
||||
5 Streaming Audio Players for Linux
|
||||
======
|
||||

|
||||
|
||||
As I work, throughout the day, music is always playing in the background. Most often, that music is in the form of vinyl spinning on a turntable. But when I’m not in purist mode, I’ll opt to listen to audio by way of a streaming app. Naturally, I’m on the Linux platform, so the only tools I have at my disposal are those that play well on my operating system of choice. Fortunately, plenty of options exist for those who want to stream audio to their Linux desktops.
|
||||
|
||||
In fact, Linux offers a number of solid offerings for music streaming, and I’ll highlight five of my favorite tools for this task. A word of warning, not all of these players are open source. But if you’re okay running a proprietary app on your open source desktop, you have some really powerful options. Let’s take a look at what’s available.
|
||||
|
||||
### Spotify
|
||||
|
||||
Spotify for Linux isn’t some dumb-downed, half-baked app that crashes every other time you open it, and doesn’t offer the full-range of features found on the macOS and Windows equivalent. In fact, the Linux version of Spotify is exactly the same as you’ll find on other platforms. With the Spotify streaming client you can listen to music and podcasts, create playlists, discover new artists, and so much more. And the Spotify interface (Figure 1) is quite easy to navigate and use.
|
||||
|
||||
![Spotify][2]
|
||||
|
||||
Figure 1: The Spotify interface makes it easy to find new music and old favorites.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
You can install Spotify either using snap (with the command sudo snap install spotify), or from the official repository, with the following commands:
|
||||
|
||||
* sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 931FF8E79F0876134EDDBDCCA87FF9DF48BF1C90
|
||||
|
||||
* sudo echo deb <http://repository.spotify.com> stable non-free | sudo tee /etc/apt/sources.list.d/spotify.list
|
||||
|
||||
* sudo apt-get update
|
||||
|
||||
* sudo apt-get install spotify-client
|
||||
|
||||
|
||||
|
||||
|
||||
Once installed, you’ll want to log into your Spotify account, so you can start streaming all of the great music to help motivate you to get your work done. If you have Spotify installed on other devices (and logged into the same account), you can dictate to which device the music should stream (by clicking the Devices Available icon near the bottom right corner of the Spotify window).
|
||||
|
||||
### Clementine
|
||||
|
||||
Clementine one of the best music players available to the Linux platform. Clementine not only allows user to play locally stored music, but to connect to numerous streaming audio services, such as:
|
||||
|
||||
* Amazon Cloud Drive
|
||||
|
||||
* Box
|
||||
|
||||
* Dropbox
|
||||
|
||||
* Icecast
|
||||
|
||||
* Jamendo
|
||||
|
||||
* Magnatune
|
||||
|
||||
* RockRadio.com
|
||||
|
||||
* Radiotunes.com
|
||||
|
||||
* SomaFM
|
||||
|
||||
* SoundCloud
|
||||
|
||||
* Spotify
|
||||
|
||||
* Subsonic
|
||||
|
||||
* Vk.com
|
||||
|
||||
* Or internet radio streams
|
||||
|
||||
|
||||
|
||||
|
||||
There are two caveats to using Clementine. The first is you must be using the most recent version (as the build available in some repositories is out of date and won’t install the necessary streaming plugins). Second, even with the most recent build, some streaming services won’t function as expected. For example, with Spotify, you’ll only have available to you the Top Tracks (and not your playlist … or the ability to search for songs).
|
||||
|
||||
With Clementine Internet radio streaming, you’ll find musicians and bands you’ve never heard of (Figure 2), and plenty of them to tune into.
|
||||
|
||||
![Clementine][5]
|
||||
|
||||
Figure 2: Clementine Internet radio is a great way to find new music.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
### Odio
|
||||
|
||||
Odio is a cross-platform, proprietary app (available for Linux, MacOS, and Windows) that allows you to stream internet music stations of all genres. Radio stations are curated from [www.radio-browser.info][6] and the app itself does an incredible job of presenting the streams for you (Figure 3).
|
||||
|
||||
|
||||
![Odio][8]
|
||||
|
||||
Figure 3: The Odio interface is one of the best you’ll find.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
Odio makes it very easy to find unique Internet radio stations and even add those you find and enjoy to your library. Currently, the only way to install Odio on Linux is via Snap. If your distribution supports snap packages, install this streaming app with the command:
|
||||
|
||||
sudo snap install odio
|
||||
|
||||
Once installed, you can open the app and start using it. There is no need to log into (or create) an account. Odio is very limited in its settings. In fact, it only offers the choice between a dark or light theme in the settings window. However, as limited as it might be, Odio is one of your best bets for playing Internet radio on Linux.
|
||||
|
||||
Streamtuner2 is an outstanding Internet radio station GUI tool. With it you can stream music from the likes of:
|
||||
|
||||
* Internet radio stations
|
||||
|
||||
* Jameno
|
||||
|
||||
* MyOggRadio
|
||||
|
||||
* Shoutcast.com
|
||||
|
||||
* SurfMusic
|
||||
|
||||
* TuneIn
|
||||
|
||||
* Xiph.org
|
||||
|
||||
* YouTube
|
||||
|
||||
|
||||
### StreamTuner2
|
||||
|
||||
Streamtuner2 offers a nice (if not slightly outdated) interface, that makes it quite easy to find and stream your favorite music. The one caveat with StreamTuner2 is that it’s really just a GUI for finding the streams you want to hear. When you find a station, double-click on it to open the app associated with the stream. That means you must have the necessary apps installed, in order for the streams to play. If you don’t have the proper apps, you can’t play the streams. Because of this, you’ll spend a good amount of time figuring out what apps to install for certain streams (Figure 4).
|
||||
|
||||
![Streamtuner2][10]
|
||||
|
||||
Figure 4: Configuring Streamtuner2 isn’t for the faint of heart.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
### VLC
|
||||
|
||||
VLC has been, for a very long time, dubbed the best media playback tool for Linux. That’s with good reason, as it can play just about anything you throw at it. Included in that list is streaming radio stations. Although you won’t find VLC connecting to the likes of Spotify, you can head over to Internet-Radio, click on a playlist and have VLC open it without a problem. And considering how many internet radio stations are available at the moment, you won’t have any problem finding music to suit your tastes. VLC also includes tools like visualizers, equalizers (Figure 5), and more.
|
||||
|
||||
![VLC ][12]
|
||||
|
||||
Figure 5: The VLC visualizer and equalizer features in action.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
The only caveat to VLC is that you do have to have a URL for the Internet Radio you wish you hear, as the tool itself doesn’t curate. But with those links in hand, you won’t find a better media player than VLC.
|
||||
|
||||
### Always More Where That Came From
|
||||
|
||||
If one of these five tools doesn’t fit your needs, I suggest you open your distribution’s app store and search for one that will. There are plenty of tools to make streaming music, podcasts, and more not only possible on Linux, but easy.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][13] course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2019/2/5-streaming-audio-players-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[2]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/spotify_0.jpg?itok=8-Ym-R61 (Spotify)
|
||||
[3]: https://www.linux.com/licenses/category/used-permission
|
||||
[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/clementine_0.jpg?itok=5oODJO3b (Clementine)
|
||||
[6]: http://www.radio-browser.info
|
||||
[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/odio.jpg?itok=sNPTSS3c (Odio)
|
||||
[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/streamtuner2.jpg?itok=1MSbafWj (Streamtuner2)
|
||||
[12]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/vlc_0.jpg?itok=QEOsq7Ii (VLC )
|
||||
[13]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,192 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Remove/Delete The Empty Lines In A File In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/remove-delete-empty-lines-in-a-file-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Remove/Delete The Empty Lines In A File In Linux
|
||||
======
|
||||
|
||||
Some times you may wants to remove or delete the empty lines in a file in Linux.
|
||||
|
||||
If so, you can use the one of the below method to achieve it.
|
||||
|
||||
It can be done in many ways but i have listed simple methods in the article.
|
||||
|
||||
You may aware of that grep, awk and sed commands are specialized for textual data manipulation.
|
||||
|
||||
Navigate to the following URL, if you would like to read more about these kind of topics. For **[creating a file in specific size in Linux][1]** multiple ways, for **[creating a file in Linux][2]** multiple ways and for **[removing a matching string from a file in Linux][3]**.
|
||||
|
||||
These are fall in advanced commands category because these are used in most of the shell script to do required things.
|
||||
|
||||
It can be done using the following 5 methods.
|
||||
|
||||
* **`sed Command:`** Stream editor for filtering and transforming text.
|
||||
* **`grep Command:`** Print lines that match patterns.
|
||||
* **`cat Command:`** It concatenate files and print on the standard output.
|
||||
* **`tr Command:`** Translate or delete characters.
|
||||
* **`awk Command:`** The awk utility shall execute programs written in the awk programming language, which is specialized for textual data manipulation.
|
||||
* **`perl Command:`** Perl is a programming language specially designed for text editing.
|
||||
|
||||
|
||||
|
||||
To test this, i had already created the file called `2daygeek.txt` with some texts and empty lines. The details are below.
|
||||
|
||||
```
|
||||
$ cat 2daygeek.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
|
||||
It's FIVE years old blog.
|
||||
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
|
||||
He got two GIRL babys.
|
||||
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
Now everything is ready and i’m going to test this in multiple ways.
|
||||
|
||||
### How To Remove/Delete The Empty Lines In A File In Linux Using sed Command?
|
||||
|
||||
Sed is a stream editor. A stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline).
|
||||
|
||||
```
|
||||
$ sed '/^$/d' 2daygeek.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
It's FIVE years old blog.
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
He got two GIRL babes.
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
Details are follow:
|
||||
|
||||
* **`sed:`** It’s a command
|
||||
* **`//:`** It holds the searching string.
|
||||
* **`^:`** Matches start of string.
|
||||
* **`$:`** Matches end of string.
|
||||
* **`d:`** Delete the matched string.
|
||||
* **`2daygeek.txt:`** Source file name.
|
||||
|
||||
|
||||
|
||||
### How To Remove/Delete The Empty Lines In A File In Linux Using grep Command?
|
||||
|
||||
grep searches for PATTERNS in each FILE. PATTERNS is one or patterns separated by newline characters, and grep prints each line that matches a pattern.
|
||||
|
||||
```
|
||||
$ grep . 2daygeek.txt
|
||||
or
|
||||
$ grep -Ev "^$" 2daygeek.txt
|
||||
or
|
||||
$ grep -v -e '^$' 2daygeek.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
It's FIVE years old blog.
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
He got two GIRL babes.
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
Details are follow:
|
||||
|
||||
* **`grep:`** It’s a command
|
||||
* **`.:`** Replaces any character.
|
||||
* **`^:`** matches start of string.
|
||||
* **`$:`** matches end of string.
|
||||
* **`E:`** For extended regular expressions pattern matching.
|
||||
* **`e:`** For regular expressions pattern matching.
|
||||
* **`v:`** To select non-matching lines from the file.
|
||||
* **`2daygeek.txt:`** Source file name.
|
||||
|
||||
|
||||
|
||||
### How To Remove/Delete The Empty Lines In A File In Linux Using awk Command?
|
||||
|
||||
The awk utility shall execute programs written in the awk programming language, which is specialized for textual data manipulation. An awk program is a sequence of patterns and corresponding actions.
|
||||
|
||||
```
|
||||
$ awk NF 2daygeek.txt
|
||||
or
|
||||
$ awk '!/^$/' 2daygeek.txt
|
||||
or
|
||||
$ awk '/./' 2daygeek.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
It's FIVE years old blog.
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
He got two GIRL babes.
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
Details are follow:
|
||||
|
||||
* **`awk:`** It’s a command
|
||||
* **`//:`** It holds the searching string.
|
||||
* **`^:`** matches start of string.
|
||||
* **`$:`** matches end of string.
|
||||
* **`.:`** Replaces any character.
|
||||
* **`!:`** Delete the matched string.
|
||||
* **`2daygeek.txt:`** Source file name.
|
||||
|
||||
|
||||
|
||||
### How To Delete The Empty Lines In A File In Linux using Combination of cat And tr Command?
|
||||
|
||||
cat stands for concatenate. It is very frequently used in Linux to reads data from a file.
|
||||
|
||||
cat is one of the most frequently used commands on Unix-like operating systems. It’s offer three functions which is related to text file such as display content of a file, combine multiple files into the single output and create a new file.
|
||||
|
||||
Translate, squeeze, and/or delete characters from standard input, writing to standard output.
|
||||
|
||||
```
|
||||
$ cat 2daygeek.txt | tr -s '\n'
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
It's FIVE years old blog.
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
He got two GIRL babes.
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
Details are follow:
|
||||
|
||||
* **`cat:`** It’s a command
|
||||
* **`tr:`** It’s a command
|
||||
* **`|:`** Pipe symbol. It pass first command output as a input to another command.
|
||||
* **`s:`** Replace each sequence of a repeated character that is listed in the last specified SET.
|
||||
* **`\n:`** To add a new line.
|
||||
* **`2daygeek.txt:`** Source file name.
|
||||
|
||||
|
||||
|
||||
### How To Remove/Delete The Empty Lines In A File In Linux Using perl Command?
|
||||
|
||||
Perl stands in for “Practical Extraction and Reporting Language”. Perl is a programming language specially designed for text editing. It is now widely used for a variety of purposes including Linux system administration, network programming, web development, etc.
|
||||
|
||||
```
|
||||
$ perl -ne 'print if /\S/' 2daygeek.txt
|
||||
2daygeek.com is a best Linux blog to learn Linux.
|
||||
It's FIVE years old blog.
|
||||
This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
|
||||
He got two GIRL babes.
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/remove-delete-empty-lines-in-a-file-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/create-a-file-in-specific-certain-size-linux/
|
||||
[2]: https://www.2daygeek.com/linux-command-to-create-a-file/
|
||||
[3]: https://www.2daygeek.com/empty-a-file-delete-contents-lines-from-a-file-remove-matching-string-from-a-file-remove-empty-blank-lines-from-a-file/
|
||||
107
sources/tech/20190211 How does rootless Podman work.md
Normal file
107
sources/tech/20190211 How does rootless Podman work.md
Normal file
@ -0,0 +1,107 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How does rootless Podman work?)
|
||||
[#]: via: (https://opensource.com/article/19/2/how-does-rootless-podman-work)
|
||||
[#]: author: (Daniel J Walsh https://opensource.com/users/rhatdan)
|
||||
|
||||
How does rootless Podman work?
|
||||
======
|
||||
Learn how Podman takes advantage of user namespaces to run in rootless mode.
|
||||

|
||||
|
||||
In my [previous article][1] on user namespace and [Podman][2], I discussed how you can use Podman commands to launch different containers with different user namespaces giving you better separation between containers. Podman also takes advantage of user namespaces to be able to run in rootless mode. Basically, when a non-privileged user runs Podman, the tool sets up and joins a user namespace. After Podman becomes root inside of the user namespace, Podman is allowed to mount certain filesystems and set up the container. Note there is no privilege escalation here other then additional UIDs available to the user, explained below.
|
||||
|
||||
### How does Podman create the user namespace?
|
||||
|
||||
#### shadow-utils
|
||||
|
||||
Most current Linux distributions include a version of shadow-utils that uses the **/etc/subuid** and **/etc/subgid** files to determine what UIDs and GIDs are available for a user in a user namespace.
|
||||
|
||||
```
|
||||
$ cat /etc/subuid
|
||||
dwalsh:100000:65536
|
||||
test:165536:65536
|
||||
$ cat /etc/subgid
|
||||
dwalsh:100000:65536
|
||||
test:165536:65536
|
||||
```
|
||||
|
||||
The useradd program automatically allocates 65536 UIDs for each user added to the system. If you have existing users on a system, you would need to allocate the UIDs yourself. The format of these files is **username:STARTUID:TOTALUIDS**. Meaning in my case, dwalsh is allocated UIDs 100000 through 165535 along with my default UID, which happens to be 3265 defined in /etc/passwd. You need to be careful when allocating these UID ranges that they don't overlap with any **real** UID on the system. If you had a user listed as UID 100001, now I (dwalsh) would be able to become this UID and potentially read/write/execute files owned by the UID.
|
||||
|
||||
Shadow-utils also adds two setuid programs (or setfilecap). On Fedora I have:
|
||||
|
||||
```
|
||||
$ getcap /usr/bin/newuidmap
|
||||
/usr/bin/newuidmap = cap_setuid+ep
|
||||
$ getcap /usr/bin/newgidmap
|
||||
/usr/bin/newgidmap = cap_setgid+ep
|
||||
```
|
||||
|
||||
Podman executes these files to set up the user namespace. You can see the mappings by examining /proc/self/uid_map and /proc/self/gid_map from inside of the rootless container.
|
||||
|
||||
```
|
||||
$ podman run alpine cat /proc/self/uid_map /proc/self/gid_map
|
||||
0 3267 1
|
||||
1 100000 65536
|
||||
0 3267 1
|
||||
1 100000 65536
|
||||
```
|
||||
|
||||
As seen above, Podman defaults to mapping root in the container to your current UID (3267) and then maps ranges of allocated UIDs/GIDs in /etc/subuid and /etc/subgid starting at 1. Meaning in my example, UID=1 in the container is UID 100000, UID=2 is UID 100001, all the way up to 65536, which is 165535.
|
||||
|
||||
Any item from outside of the user namespace that is owned by a UID or GID that is not mapped into the user namespace appears to belong to the user configured in the **kernel.overflowuid** sysctl, which by default is 35534, which my /etc/passwd file says has the name **nobody**. Since your process can't run as an ID that isn't mapped, the owner and group permissions don't apply, so you can only access these files based on their "other" permissions. This includes all files owned by **real** root on the system running the container, since root is not mapped into the user namespace.
|
||||
|
||||
The [Buildah][3] command has a cool feature, [**buildah unshare**][4]. This puts you in the same user namespace that Podman runs in, but without entering the container's filesystem, so you can list the contents of your home directory.
|
||||
|
||||
```
|
||||
$ ls -ild /home/dwalsh
|
||||
8193 drwx--x--x. 290 dwalsh dwalsh 20480 Jan 29 07:58 /home/dwalsh
|
||||
$ buildah unshare ls -ld /home/dwalsh
|
||||
drwx--x--x. 290 root root 20480 Jan 29 07:58 /home/dwalsh
|
||||
```
|
||||
|
||||
Notice that when listing the home dir attributes outside the user namespace, the kernel reports the ownership as dwalsh, while inside the user namespace it reports the directory as owned by root. This is because the home directory is owned by 3267, and inside the user namespace we are treating that UID as root.
|
||||
|
||||
### What happens next in Podman after the user namespace is set up?
|
||||
|
||||
Podman uses [containers/storage][5] to pull the container image, and containers/storage is smart enough to map all files owned by root in the image to the root of the user namespace, and any other files owned by different UIDs to their user namespace UIDs. By default, this content gets written to ~/.local/share/containers/storage. Container storage works in rootless mode with either the vfs mode or with Overlay. Note: Overlay is supported only if the [fuse-overlayfs][6] executable is installed.
|
||||
|
||||
The kernel only allows user namespace root to mount certain types of filesystems; at this time it allows mounting of procfs, sysfs, tmpfs, fusefs, and bind mounts (as long as the source and destination are owned by the user running Podman. OverlayFS is not supported yet, although the kernel teams are working on allowing it).
|
||||
|
||||
Podman then mounts the container's storage if it is using fuse-overlayfs; if the storage driver is using vfs, then no mounting is required. Podman on vfs requires a lot of space though, since each container copies the entire underlying filesystem.
|
||||
|
||||
Podman then mounts /proc and /sys along with a few tmpfs and creates the devices in the container.
|
||||
|
||||
In order to use networking other than the host networking, Podman uses the [slirp4netns][7] program to set up **User mode networking for unprivileged network namespace**. Slirp4netns allows Podman to expose ports within the container to the host. Note that the kernel still will not allow a non-privileged process to bind to ports less than 1024. Podman-1.1 or later is required for binding to ports.
|
||||
|
||||
Rootless Podman can use user namespace for container separation, but you only have access to the UIDs defined in the /etc/subuid file.
|
||||
|
||||
### Conclusion
|
||||
|
||||
The Podman tool is enabling people to build and use containers without sacrificing the security of the system; you can give your developers the access they need without giving them root.
|
||||
|
||||
And when you put your containers into production, you can take advantage of the extra security provided by the user namespace to keep the workloads isolated from each other.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/how-does-rootless-podman-work
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rhatdan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/12/podman-and-user-namespaces
|
||||
[2]: https://podman.io/
|
||||
[3]: https://buildah.io/
|
||||
[4]: https://github.com/containers/buildah/blob/master/docs/buildah-unshare.md
|
||||
[5]: https://github.com/containers/storage
|
||||
[6]: https://github.com/containers/fuse-overlayfs
|
||||
[7]: https://github.com/rootless-containers/slirp4netns
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What's the right amount of swap space for a modern Linux system?)
|
||||
[#]: via: (https://opensource.com/article/19/2/swap-space-poll)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
What's the right amount of swap space for a modern Linux system?
|
||||
======
|
||||
Complete our survey and voice your opinion on how much swap space to allocate.
|
||||

|
||||
|
||||
Swap space is one of those things that everyone seems to have an idea about, and I am no exception. All my sysadmin friends have their opinions, and most distributions make recommendations too.
|
||||
|
||||
Many years ago, the rule of thumb for the amount of swap space that should be allocated was 2X the amount of RAM installed in the computer. Of course that was when a typical computer's RAM was measured in KB or MB. So if a computer had 64KB of RAM, a swap partition of 128KB would be an optimum size.
|
||||
|
||||
This took into account the fact that RAM memory sizes were typically quite small, and allocating more than 2X RAM for swap space did not improve performance. With more than twice RAM for swap, most systems spent more time thrashing than performing useful work.
|
||||
|
||||
RAM memory has become quite inexpensive and many computers now have RAM in the tens of gigabytes. Most of my newer computers have at least 4GB or 8GB of RAM, two have 32GB, and my main workstation has 64GB. When dealing with computers with huge amounts of RAM, the limiting performance factor for swap space is far lower than the 2X multiplier. As a consequence, recommended swap space is considered a function of system memory workload, not system memory.
|
||||
|
||||
Table 1 provides the Fedora Project's recommended size for a swap partition, depending on the amount of RAM in your system and whether you want enough memory for your system to hibernate. To allow for hibernation, you need to edit the swap space in the custom partitioning stage. The "recommended" swap partition size is established automatically during a default installation, but I usually find it's either too large or too small for my needs.
|
||||
|
||||
The [Fedora 28 Installation Guide][1] defines current thinking about swap space allocation. Note that other versions of Fedora and other Linux distributions may differ slightly, but this is the same table Red Hat Enterprise Linux uses for its recommendations. These recommendations have not changed since Fedora 19.
|
||||
|
||||
| Amount of RAM installed in system | Recommended swap space | Recommended swap space with hibernation |
|
||||
| --------------------------------- | ---------------------- | --------------------------------------- |
|
||||
| ≤ 2GB | 2X RAM | 3X RAM |
|
||||
| 2GB – 8GB | = RAM | 2X RAM |
|
||||
| 8GB – 64GB | 4G to 0.5X RAM | 1.5X RAM |
|
||||
| >64GB | Minimum 4GB | Hibernation not recommended |
|
||||
|
||||
Table 1: Recommended system swap space in Fedora 28's documentation.
|
||||
|
||||
Table 2 contains my recommendations based on my experiences in multiple environments over the years.
|
||||
| Amount of RAM installed in system | Recommended swap space |
|
||||
| --------------------------------- | ---------------------- |
|
||||
| ≤ 2GB | 2X RAM |
|
||||
| 2GB – 8GB | = RAM |
|
||||
| > 8GB | 8GB |
|
||||
|
||||
Table 2: My recommended system swap space.
|
||||
|
||||
It's possible that neither of these tables will work for your environment, but they will give you a place to start. The main consideration is that as the amount of RAM increases, adding more swap space simply leads to thrashing well before the swap space comes close to being filled. If you have too little virtual memory, you should add more RAM, if possible, rather than more swap space.
|
||||
|
||||
In order to test the Fedora (and RHEL) swap space recommendations, I used its recommendation of **0.5*RAM** on my two largest systems (the ones with 32GB and 64GB of RAM). Even when running four or five VMs, multiple documents in LibreOffice, Thunderbird, the Chrome web browser, several terminal emulator sessions, the Xfe file manager, and a number of other background applications, the only time I see any use of swap is during backups I have scheduled for every morning at about 2am. Even then, swap usage is no more than 16MB—yes megabytes. These results are for my system with my loads and do not necessarily apply to your real-world environment.
|
||||
|
||||
I recently had a conversation about swap space with some of the other Community Moderators here at [Opensource.com][2], and Chris Short, one of my friends in that illustrious and talented group, pointed me to an old [article][3] where he recommended using 1GB for swap space. This article was written in 2003, and he told me later that he now recommends zero swap space.
|
||||
|
||||
So, we wondered, what you think? What do you recommend or use on your systems for swap space?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/swap-space-poll
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://docs.fedoraproject.org/en-US/fedora/f28/install-guide/
|
||||
[2]: http://Opensource.com
|
||||
[3]: https://chrisshort.net/moving-to-linux-partitioning/
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (jdh8383)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Toyota Motors and its Linux Journey)
|
||||
[#]: via: (https://itsfoss.com/toyota-motors-linux-journey)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
丰田汽车的Linux之旅
|
||||
======
|
||||
|
||||
**这篇文章来自 It's FOSS 的读者 Malcolm Dean的投递。**
|
||||
|
||||
我之前跟丰田汽车北美分公司的 Brian.R.Lyons(丰田发言人)聊了聊,话题是关于Linux在丰田和雷克萨斯汽车的信息娱乐系统上的实施方案。我了解到一些汽车制造商使用了 Automotive Grade Linux (AGL)。
|
||||
|
||||
然后我写了一篇短文,记录了我和 Brian 的讨论内容,就是丰田和 Linux 的一些渊源。希望 Linux 的狂热粉丝们能够喜欢这次对话。
|
||||
|
||||
全部[丰田和雷克萨斯汽车都将会使用 Automotive Grade Linux][1] (AGL),主要是用于车载信息娱乐系统。这项措施对于丰田集团来说是至关重要的,因为据 Lyons 先生所说:“作为技术的引领者之一,丰田认识到,赶上科技快速进步最好的方法就是拥抱开源理念”。
|
||||
|
||||
丰田和众多汽车制造公司都认为,与使用非自由软件相比,采用基于 Linux 的操作系统在更新和升级方面会更加廉价和快捷。
|
||||
|
||||
这简直太棒了! Linux 终于跟汽车结合起来了。我每天都在电脑上使用 Linux;能看到这个优秀的软件在一个完全不同的产业领域里大展拳脚真是太好了。
|
||||
|
||||
我很好奇丰田是什么时候开始使用 [Automotive Grade Linux][2] (AGL) 的。按照 Lyons 先生的说法,这要追溯到 2011 年。
|
||||
|
||||
>“自 AGL 项目在五年前启动之始,作为活跃的会员和贡献者,丰田与其他顶级制造商和供应商展开合作,着手开发一个基于 Linux 的强大平台,并不断地增强其功能和安全性。”
|
||||
|
||||
![丰田信息娱乐系统][3]
|
||||
|
||||
[丰田于2011年加入了 Linux 基金会][4],与其他汽车制造商和软件公司就 IVI(车内信息娱乐系统)展开讨论,最终在 2012 年,Linux 基金会内部成立了 Automotive Grade Linux 工作组。
|
||||
|
||||
丰田在 AGL 工作组里首先提出了“代码优先”的策略,这在开源领域是很常见的做法。然后丰田和其他汽车制造商、IVI 一线厂家,软件公司等各方展开对话,根据各方的技术需求详细制定了初始方向。
|
||||
|
||||
在加入 Linux 基金会的时候,丰田就已经意识到,在一线公司之间共享软件代码将会是至关重要的。因为要维护如此复杂的软件系统,对于任何一家顶级厂商都是一笔不小的开销。丰田和它的一级供货商想把更多的资源用在开发新功能和新的用户体验上,而不是用在维护各自的代码上。
|
||||
|
||||
各个汽车公司联合起来深入合作是一件大事。许多公司都达成了这样的共识,因为他们都发现开发维护私有软件其实更费钱。
|
||||
|
||||
今天,在全球市场上,丰田和雷克萨斯的全部车型都使用了 AGL。
|
||||
|
||||
身为雷克萨斯的销售人员,我认为这是一大进步。我和其他销售顾问都曾接待过很多回来找技术专员的客户,他们想更多的了解自己车上的信息娱乐系统到底都能做些什么。
|
||||
|
||||
这件事本身对于 Linux 社区和用户是个重大利好。虽然那个我们每天都在使用的操作系统变了模样,被推到了更广阔的舞台上,但它仍然是那个 Linux,简单、包容而强大。
|
||||
|
||||
未来将会如何发展呢?我希望它能少出差错,为消费者带来更佳的用户体验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/toyota-motors-linux-journey
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[jdh8383](https://github.com/jdh8383)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linuxfoundation.org/press-release/2018/01/automotive-grade-linux-hits-road-globally-toyota-amazon-alexa-joins-agl-support-voice-recognition/
|
||||
[2]: https://www.automotivelinux.org/
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/toyota-interiors.jpg?resize=800%2C450&ssl=1
|
||||
[4]: https://www.linuxfoundation.org/press-release/2011/07/toyota-joins-linux-foundation/
|
||||
@ -1,103 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oska874)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 5 OK05)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
translating by ezio
|
||||
|
||||
树莓派计算机实验室 课程 5 OK05
|
||||
======
|
||||
|
||||
OK05 课程构建于课程 OK04 的基础,使用更多代码方式烧、保存写莫尔斯码的 SOS 序列(`...---...`)。这里假设你已经有了 [课程 4: OK04][1] 操作系统的代码基础。
|
||||
|
||||
### 1 数据
|
||||
|
||||
到目前为止,我们与操作系统有关的所有内容都提供了遵循的说明。然而有时候,说明只是一半。我们的操作系统可能需要数据
|
||||
|
||||
> 一些早期的操作系统确实只允许特定文件中的特定类型的数据,但是这通常被认为太严格了。现代方法确实使程序变得复杂的多。
|
||||
|
||||
通常,只是数据的值很重要。你可能经过训练,认为数据是指定类型,比如,一个文本文件包含文章,一个图像文件包含一幅图片,等等。说实话,这只是一个理想罢了。计算机上的全部数据都是二进制数字,重要的是我们选择用什么来解释这些数据。在这个例子中,我们会将一个闪灯序列作为数据保存下来。
|
||||
|
||||
在 `main.s` 结束处复制下面的代码:
|
||||
|
||||
```
|
||||
.section .data %定义 .data 段
|
||||
.align 2 %对齐
|
||||
pattern: %定义整形变量
|
||||
.int 0b11111111101010100010001000101010
|
||||
```
|
||||
|
||||
>`.align num` 保证下一行代码的地址是 `2^num` 的整数倍。
|
||||
|
||||
>`.int val` 输出数值 `val`。
|
||||
|
||||
要区分数据和代码,我们将数据都放在 `.data` 区域。我已经将该区域包含在操作系统的内存布局图。我已经选择将数据放到代码后面。将我们的指令和数据分开保存的原因是,如果最后我们在自己的操作系统上实现一些安全措施,我们就需要知道代码的那些部分是可以执行的,而那些部分是不行的。
|
||||
|
||||
我在这里使用了两个新命令 `.align` 和 `.int`。`.align` 保证下来的数据是按照 2 的乘方对齐的。在这个里,我使用 `.align 2` ,意味着数据最终存放的地址是 `2^2=4` 的整数倍。这个操作是很重要的,因为我们用来读取内寸的指令 `ldr` 要求内存地址是 4 的倍数。
|
||||
|
||||
The .int command copies the constant after it into the output directly. That means that 111111111010101000100010001010102 will be placed into the output, and so the label pattern actually labels this piece of data as pattern.
|
||||
|
||||
命令 `.int` 直接复制它后面的常量到输出。这意味着 `11111111101010100010001000101010`(二进制数) 将会被存放到输出,所以标签模式实际将标记这段数据作为模式。
|
||||
|
||||
> 关于数据的一个挑战是寻找一个高效和有用的展示形式。这种保存一个开、关的时间单元的序列的方式,运行起来很容易,但是将很难编辑,因为摩尔斯的原理 `-` 或 `.` 丢失了。
|
||||
|
||||
如我提到的,数据可以意味这你想要的所有东西。在这里我编码了摩尔斯代码 SOS 序列,对于不熟悉的人,就是 `...---...`。我使用 0 表示一个时间单元的 LED 灭灯,而 1 表示一个时间单元的 LED 亮。这样,我们可以像这样编写一些代码在数据中显示一个序列,然后要显示不同序列,我们所有需要做的就是修改这段数据。下面是一个非常简单的例子,操作系统必须一直执行这段程序,解释和展示数据。
|
||||
|
||||
复制下面几行到 `main.s` 中的标记 `loop$` 之前。
|
||||
|
||||
```
|
||||
ptrn .req r4 %重命名 r4 为 ptrn
|
||||
ldr ptrn,=pattern %加载 pattern 的地址到 ptrn
|
||||
ldr ptrn,[ptrn] %加载地址 ptrn 所在内存的值
|
||||
seq .req r5 %重命名 r5 为 seq
|
||||
mov seq,#0 %seq 赋值为 0
|
||||
```
|
||||
|
||||
这段代码加载 `pattrern` 到寄存器 `r4`,并加载 0 到寄存器 `r5`。`r5` 将是我们的序列位置,所以我们可以追踪有多少 `pattern` 我们已经展示了。
|
||||
|
||||
下面的代码将非零值放入 `r1` ,如果仅仅是如果,这里有个 1 在当前位置的 `pattern`。
|
||||
|
||||
```
|
||||
mov r1,#1 %加载1到 r1
|
||||
lsl r1,seq %对r1 的值逻辑左移 seq 次
|
||||
and r1,ptrn %按位与
|
||||
```
|
||||
|
||||
这段代码对你调用 `SetGpio` 很有用,它必须有一个非零值来关掉 LED,而一个0值会打开 LED。
|
||||
|
||||
现在修改 `main.s` 中全部你的代码,这样代码中每次循环会根据当前的序列数设置 LED,等待 250000 毫秒(或者其他合适的延时),然后增加序列数。当这个序列数到达 32 就需要返回 0.看看你是否能实现这个功能,作为额外的挑战,也可以试着只使用一条指令。
|
||||
|
||||
### 2 Time Flies When You're Having Fun... 当你玩得开心时,过得很快
|
||||
|
||||
你现在准备好在树莓派上实验。应该闪烁一串包含 3 个短脉冲,3 个长脉冲,然后 3 个更短脉冲的序列。在一次延时之后,这种模式应该重复。如果这部工作,请查看我们的问题页。
|
||||
|
||||
一旦它工作,祝贺你已经达到 OK 系列教程的结束。
|
||||
|
||||
在这个谢列我们学习了汇编代码,GPIO 控制器和系统定时器。我们已经学习了函数和 ABI,以及几个基础的操作系统原理,和关于数据的知识。
|
||||
|
||||
你现在已经准备好下面几个更高级的课程的某一个。
|
||||
* [Screen][2] 系列是接下来的,会教你如何通过汇编代码使用屏幕。
|
||||
* [Input][3] 系列教授你如何使用键盘和鼠标。
|
||||
|
||||
到现在,你已经有了足够的信息来制作操作系统,用其它方法和 GPIO 交互。如果你有任何机器人工具,你可能会想尝试编写一个通过 GPIO 管教控制的机器人操作系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
Loading…
Reference in New Issue
Block a user